Repository: 1051727403/SHU-CS-Source-Share
Branch: main
Commit: 48793a1642ad
Files: 41
Total size: 180.0 KB
Directory structure:
gitextract_gzz3lvdu/
├── .gitattributes
├── .gitignore
├── README.md
├── 学习资料(非电子书)/
│ ├── C语言/
│ │ └── README.md
│ ├── JAVA程序设计/
│ │ └── README.md
│ ├── Web开发计算A/
│ │ └── README.md
│ ├── 人工智能/
│ │ └── README.md
│ ├── 其他/
│ │ └── README.md
│ ├── 大学物理/
│ │ └── README.md
│ ├── 大数据从理论到实践A/
│ │ └── README.md
│ ├── 实用计算机英语/
│ │ └── README.md
│ ├── 微积分/
│ │ └── README.md
│ ├── 操作系统/
│ │ └── README.md
│ ├── 数字逻辑/
│ │ └── README.md
│ ├── 数据分析与智能计算/
│ │ └── README.md
│ ├── 数据库/
│ │ └── README.md
│ ├── 数据结构/
│ │ └── README.md
│ ├── 概率论/
│ │ └── README.md
│ ├── 汇编语言/
│ │ └── README.md
│ ├── 离散数学/
│ │ └── README.md
│ ├── 算法设计与分析课程/
│ │ └── README.md
│ ├── 线性代数/
│ │ └── README.md
│ ├── 组合数学/
│ │ └── README.md
│ ├── 编译原理/
│ │ └── README.md
│ ├── 脑认知/
│ │ ├── README.md
│ │ └── cxy-脑认知复习/
│ │ └── 脑认知复习.md
│ ├── 计算机体系结构/
│ │ └── README.md
│ ├── 计算机最新进展研讨/
│ │ └── README.md
│ ├── 计算机研究前沿/
│ │ └── README.md
│ ├── 计算机组成原理/
│ │ └── README.md
│ ├── 计算机编程实训/
│ │ └── README.md
│ ├── 计算机网络/
│ │ └── README.md
│ ├── 语义网络与知识图谱/
│ │ └── README.md
│ ├── 软件工程/
│ │ └── README.md
│ └── 面向对象/
│ └── README.MD
├── 就业相关/
│ ├── 八股笔记/
│ │ └── 个人珍藏八股笔记,看缘分更新.md
│ ├── 简历/
│ │ └── 简历攻略.md
│ └── 面经/
│ ├── Nvidia-Internship.md
│ ├── Shanghai-AI-Lab-Internship.md
│ └── 一些面经.md
└── 电子书/
└── README.md
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitattributes
================================================
* text=auto eol=lf
================================================
FILE: .gitignore
================================================
================================================
FILE: README.md
================================================
# 🖥️[SHU-CS-Source-Share](https://github.com/1051727403/SHU-CS-Source-Share)
## [❤️](https://github.com/makeplane/plane#️-community)SHU-上大计算机资料分享汇总
注:本项目旨在通过汇总学习资料的方式帮助上大计算机同学更好地进行学习,无任何不良引导。
资料来源:学长学姐分享以及网络上搜索
所有资料地址均经过鉴定,为免费资源,质量有保障,部分敏感资源没有。
**如果有侵权情况,麻烦您发送必要的信息至ldw@foxmail.com,带来不便还请您谅解**
**🔥关于如何分享提交资料请移动至页面最底部**
**PS:若想要的资料不在项目内,也可以私信我,我会尽量去完善(\*\^▽\^\*)**
# 🔥资料地址汇总
~~电子书可以直接在本项目中找到,资料地址一般是实验、报告、PPT、复习资料等类型的~~
-------------------分割线-------------------
#### 🎉最新更新时间:2024-06-18
#### 👉最新更新内容:NVIDIA和SH-AiLab的面经
🤗PS:感谢同学分享以及提交PR!祝大家考试顺利!
-------------------分割线-------------------
## 🔥本项目内资料快速跳转
#### 同学们可以通过该表格快速跳转查找资料
| 🔥课程名称🔥 | 类别 | 学习资料、报告等 | 电子书 |
| :----------------------- | ---- | :----------------------------------------------------------: | :----------------------------------------------------------: |
| SHU-数据结构 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84) | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E7%94%B5%E5%AD%90%E4%B9%A6/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84) |
| SHU-计算机网络 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C) | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E7%94%B5%E5%AD%90%E4%B9%A6/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C) |
| SHU-操作系统 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F) | 暂无资料 |
| SHU-计算机组成原理 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86) | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E7%94%B5%E5%AD%90%E4%B9%A6/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86) |
| SHU-数据库 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E6%95%B0%E6%8D%AE%E5%BA%93) | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E7%94%B5%E5%AD%90%E4%B9%A6/%E6%95%B0%E6%8D%AE%E5%BA%93) |
| SHU-编译原理 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E7%BC%96%E8%AF%91%E5%8E%9F%E7%90%86) | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E7%94%B5%E5%AD%90%E4%B9%A6/%E7%BC%96%E8%AF%91%E5%8E%9F%E7%90%86) |
| SHU-计算机体系结构 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E8%AE%A1%E7%AE%97%E6%9C%BA%E4%BD%93%E7%B3%BB%E7%BB%93%E6%9E%84) | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E7%94%B5%E5%AD%90%E4%B9%A6/%E8%AE%A1%E7%AE%97%E6%9C%BA%E4%BD%93%E7%B3%BB%E7%BB%93%E6%9E%84) |
| SHU-数字逻辑 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E6%95%B0%E5%AD%97%E9%80%BB%E8%BE%91) | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E7%94%B5%E5%AD%90%E4%B9%A6/%E6%95%B0%E5%AD%97%E9%80%BB%E8%BE%91) |
| SHU-软件工程 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E8%BD%AF%E4%BB%B6%E5%B7%A5%E7%A8%8B) | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E7%94%B5%E5%AD%90%E4%B9%A6/%E8%BD%AF%E4%BB%B6%E5%B7%A5%E7%A8%8B) |
| SHU-C语言 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/C%E8%AF%AD%E8%A8%80) | 暂无资料 |
| SHU-面向对象 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E9%9D%A2%E5%90%91%E5%AF%B9%E8%B1%A1) | 暂无资料 |
| SHU-计算机研究前沿 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%A0%94%E7%A9%B6%E5%89%8D%E6%B2%BF) | 暂无资料 |
| SHU-计算机编程实训 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BC%96%E7%A8%8B%E5%AE%9E%E8%AE%AD) | 暂无资料 |
| SHU-夏季硬件大作业 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/SummerProject) | 暂无资料 |
| SHU-大学物理 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E5%A4%A7%E5%AD%A6%E7%89%A9%E7%90%86) | 暂无资料 |
| SHU-微积分 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E5%BE%AE%E7%A7%AF%E5%88%86) | 暂无资料 |
| SHU-概率论 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E6%A6%82%E7%8E%87%E8%AE%BA) | 暂无资料 |
| SHU-离散数学 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E7%A6%BB%E6%95%A3%E6%95%B0%E5%AD%A6) | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E7%94%B5%E5%AD%90%E4%B9%A6/%E7%A6%BB%E6%95%A3%E6%95%B0%E5%AD%A6) |
| SHU-线性代数 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E7%BA%BF%E6%80%A7%E4%BB%A3%E6%95%B0) | 暂无资料 |
| SHU-计算机最新进展研讨 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E8%AE%A1%E7%AE%97%E6%9C%BA%E6%9C%80%E6%96%B0%E8%BF%9B%E5%B1%95%E7%A0%94%E8%AE%A8) | 资料内有 |
| SHU-人工智能与脑认知 | 必修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E8%84%91%E8%AE%A4%E7%9F%A5) | 暂无资料 |
| SHU-算法设计与分析课程 | 选修 | [点击跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E7%AE%97%E6%B3%95%E8%AE%BE%E8%AE%A1%E4%B8%8E%E5%88%86%E6%9E%90%E8%AF%BE%E7%A8%8B) | 暂无资料 |
| SHU-数据分析与智能计算 | 选修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E4%B8%8E%E6%99%BA%E8%83%BD%E8%AE%A1%E7%AE%97) | 暂无资料 |
| SHU-组合数学 | 选修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E7%BB%84%E5%90%88%E6%95%B0%E5%AD%A6) | 暂无资料 |
| SHU-汇编语言 | 选修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E6%B1%87%E7%BC%96%E8%AF%AD%E8%A8%80) | 暂无资料 |
| SHU-JAVA程序设计 | 选修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/JAVA%E7%A8%8B%E5%BA%8F%E8%AE%BE%E8%AE%A1) | 暂无资料 |
| SHU-语义网络与知识图谱 | 选修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E8%AF%AD%E4%B9%89%E7%BD%91%E7%BB%9C%E4%B8%8E%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1) | 暂无资料 |
| SHU-Web开发技术A | 选修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/Web%E5%BC%80%E5%8F%91%E8%AE%A1%E7%AE%97A) | 暂无资料 |
| SHU-大数据从理论到实践A | 选修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%BB%8E%E7%90%86%E8%AE%BA%E5%88%B0%E5%AE%9E%E8%B7%B5A) | 暂无资料 |
| SHU-实用计算机英语 | 选修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E5%AE%9E%E7%94%A8%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%8B%B1%E8%AF%AD) | 暂无资料 |
| SHU-人工智能(计科选修) | 选修 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD) | 暂无资料 |
| SHU-其他 | 其他 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E5%85%B6%E4%BB%96) | 暂无资料 |
| SHU-ACM算法知识&模板 | 其他 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99%EF%BC%88%E9%9D%9E%E7%94%B5%E5%AD%90%E4%B9%A6%EF%BC%89/%E5%85%B6%E4%BB%96/ACM%E7%AE%97%E6%B3%95%E7%9F%A5%E8%AF%86%26%E6%A8%A1%E6%9D%BF) | 暂无资料 |
## ❤️就业专题
| ❤️名称❤️ | 类别 | 快速跳转 |
| :----------- | ---- | :----------------------------------------------------------: |
| SHU-简历相关 | 就业 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%B0%B1%E4%B8%9A%E7%9B%B8%E5%85%B3/%E7%AE%80%E5%8E%86) |
| SHU-面经 | 就业 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%B0%B1%E4%B8%9A%E7%9B%B8%E5%85%B3/%E9%9D%A2%E7%BB%8F) |
| SHU-八股笔记 | 就业 | [点此跳转](https://github.com/1051727403/SHU-CS-Source-Share/tree/main/%E5%B0%B1%E4%B8%9A%E7%9B%B8%E5%85%B3/%E5%85%AB%E8%82%A1%E7%AC%94%E8%AE%B0) |
| | | |
## 🔥非本项目内资料
#### 该处存放无实体的资料,例如别人的仓库链接、博客、第三方平台上的笔记等,需要外链跳转
### SHU-计算机网络
1、[❤️](https://github.com/makeplane/plane#%EF%B8%8F-community)[SHU-计网实验分享](https://github.com/1051727403/SHU-NetWork-report)
### SHU-操作系统
1、[❤️](https://github.com/makeplane/plane#%EF%B8%8F-community)[SHU-操作系统(1-2)实验全报告](https://github.com/1051727403/SHU-OS-Report)
### SHU-编译原理
1、[❤️](https://github.com/makeplane/plane#%EF%B8%8F-community)[编译原理考点和概念全集](https://icy-roadway-527.notion.site/96c5082078494e85994fd6c2e05c1893)
2、❤️[编译原理实验全集](https://github.com/Blbrw/SHU--CompilationPrinciples)
### SHU-计算机体系结构
1、[上海大学计算机体系结构实验四 HPL安装和测试(虚拟机centos7.6环境下保姆级教程!)](https://blog.csdn.net/qq_51413628/article/details/130628390?spm=1001.2014.3001.5501)
### SHU-法设计与分析课程
1、[❤️](https://github.com/makeplane/plane#%EF%B8%8F-community)[SHU算法设计与分析课程实验(含代码实现与报告)](https://github.com/RuoShui66/algorithm):罗神出品,品质有保障!
### SHU-汇编语言程序设计
1、[❤️](https://github.com/makeplane/plane#%EF%B8%8F-community)[2023秋季汇编语言程序设计课程实验、作业与复习资料](https://github.com/30Hzzh/SHUOS-Assembly-Language)
### SHU-计算思维实训
1、[❤️](https://github.com/makeplane/plane#%EF%B8%8F-community)[2023计算思维实训-无尺度网络建模及其各项特性的研究、分析、可视化](https://github.com/drewjin/drew_Scale-Free_Network)
### **SHU-ACM模板**
1、[❤️ACM模板](https://github.com/whoamizx/banzi):新手算法模板,持续更新到2025年
# 🕵️友情链接
#### 该板块存放其他学长创建的类似资料合集仓库,若本项目内寻找不到想要的资料,可以跳转到其他资料仓库寻找。
-------------------分割线-------------------
**🔥1、[历年试卷、作业答案、心得体会笔记等](https://github.com/shuosc/libshu)**
**🔥2、[学校课内课程的笔记,电子书,复习资料、包括自己写的一些专业课历年卷的解答等](https://github.com/Amadeus-1048/Course-Review)**
**🔥3、[上海大学网络空间安全专业指南](https://github.com/shu-cake1salie/SHU-Cyberspace-Security-101)**:主要是网安专业的内容,包括信息安全技术等专业课相关内容
[👉该项目配套网站](https://shu-cake1salie.github.io/SHU-Cyberspace-Security-101):上面项目的成品网站,点击查看具体内容,很nice
**🔥4、[hcy的个人仓库(已全部分类完毕,涵盖各科内容),包括课程资料、个人作业、历年卷、笔记、代码等等](https://github.com/caiyuhu-backup/SHU-CS-Assignments-and-Resources/tree/main)**
👉**概述**:这个仓库包含了在上海大学计算机科学与技术专业本科期间的课程资源以及个人作业。希望这些内容能为同学们学习专业课提供参考,帮助大家节省时间,避免将宝贵的时间浪费在课程上。
# 📈贡献者
 # 🔔加入我们&分享资料
注:分享内容可以是你的项目地址、博客地址,也可以是一个word文件、PDF、电子书等等
## 🔥如何分享提交资料?
如果你希望贡献此仓库, 请先确保自己下载了 git, 并且能够成功 clone GitHub 中的远程仓库.
如果对 git 有疑问, 请参考 [How to Use Git](https://github.com/1051727403/SHU-CS-Source-Share/wiki/How-to-Use-Git).
具体贡献的方式, 请参考 [How to Contribute](https://github.com/1051727403/SHU-CS-Source-Share/wiki/How-to-Contribute).
-------------------分割线-------------------
**鸣谢:**
感谢所有愿意维护该项目以及分享资源的同学,欢迎大家提交PR或是直接QQ联系我,我会及时更新资料。
若想要参与项目维护可以QQ私信我
QQ:1051727403
================================================
FILE: 学习资料(非电子书)/C语言/README.md
================================================
# C语言
资料链接: [[百度网盘](https://pan.baidu.com/s/1OdaHrgdZVbCh7VBgRB_mlg?pwd=1lsd)]
1. C语言复习题合辑包
- C语言课后习题答案截图
- 第[2-7]章答案
- 校内历年卷
- [2000-2011]
- 编程题评分参考
- ...
- 练习题
- ...
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/JAVA程序设计/README.md
================================================
# JAVA程序设计
资料链接: [[百度网盘](https://pan.baidu.com/s/1t5PjPaSYis2fiBxVt4omZg?pwd=1ewn)]
1. lv课后作业源码
- 1-9周课后作业.zip
- README.md
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/Web开发计算A/README.md
================================================
# Web开发计算A
资料链接: [[百度网盘](https://pan.baidu.com/s/1CmV87La7qNJyA17kq72HAQ?pwd=daca)]
1. 实验
- 实验三.docx
- 实验四.docx
- 实验五.docx
- 实验六.docx
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/人工智能/README.md
================================================
# 人工智能
资料链接: [[百度网盘](https://pan.baidu.com/s/1kS8tlxhvzHbuFZ0_EaYTAg?pwd=e02y)]
1. JIN人工智能复习大纲 [[百度网盘](https://pan.baidu.com/s/1v1XZQJ09833MzEQmeWOkKg?pwd=pbhp)]
- Assets
- AI复习大纲2023冬.pdf
- README.md
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/其他/README.md
================================================
# 其他
资料链接: [[百度网盘](https://pan.baidu.com/s/1ORPhnqPtd88EQwYhpIqHyA?pwd=v4no)]
1. ACM算法知识&模板
- 【算法知识整理】无图版.md
- 【算法知识整理】有图版.pdf
- ACM算法模板-纯模板无图片.pdf
- README.md
2. PPT通用模板
- 学府红.pptx
- 上大蓝.pptx
- 江南绿.pptx
- 银杏黄.pptx
- 玉兰白.pptx
- 锦鲤红.pptx
- 海派蓝.pptx
- 芳菲紫.pptx
- 星空灰.pptx
3. PS教程 [[GitHub](https://github.com/1051727403/PS-Tutorial)]
4. 阿里巴巴JAVA开发规范
- Java开发手册(黄山版).pdf
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/大学物理/README.md
================================================
# 大学物理
资料链接: [[百度网盘](https://pan.baidu.com/s/1IS8pAVRmw20hFBKhiZTyQA?pwd=69ta)]
1. 大学物理实验
- 【大物实验】填空题爆炸秒杀.xls
- 大物实验基础课ppt.pdf
- 物理实验题库.xlsx
- 碰撞实验.xlsx
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/大数据从理论到实践A/README.md
================================================
# 大数据从理论到实践A
资料链接: [[百度网盘](https://pan.baidu.com/s/1dpzsmXZMuKs1P1RfUwCjMA?pwd=c9f0)]
1. 课程论文
- lv课程论文.docx
- 论文模板.docx
2. 参考资料
- README.md
- 如何实现机器学习算法.pdf
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/实用计算机英语/README.md
================================================
# 实用计算机英语
简介:这门课作为一门4分的选修课,是在第十周提前考的,考试方式为闭卷
优点:不需要制作项目,分值高,管得不严,适合划水
缺点:课后作业习题较多(当前目录下仅为其中的一小部分),最后个人感觉很难给高分
总结:如果不对绩点有高需求,又想划水,又想给分多,并且自身有一定英语水平的可以考虑选
---
资料链接: [[百度网盘](https://pan.baidu.com/s/1Hb-sMekvp7vEsEa5fzlI6w?pwd=r7j0)]
1. 历年卷
- 2021 ~ 2022实用计算机英语历年卷.doc
2. 教材
- Computing Essentials 2021 .pdf
3. 课后作业
- 第一周词汇.docx
- 第二章词汇.docx
- 第三章词汇.docx
- 第四章词汇.docx
- 第五章词汇.docx
- 第六章词汇.docx
- 第七章词汇.docx
- 第七章词汇.docx
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/微积分/README.md
================================================
# 微积分
资料链接: [[百度网盘](https://pan.baidu.com/s/1N6JaIQlP_rIbcomwLm6-Cg?pwd=xkf8)]
1. 试卷
- 2023年微积分1练习题(理工).pdf
- 2023年微积分1练习题(理工)参考答案.docx
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/操作系统/README.md
================================================
# 操作系统
资料链接: [[百度网盘](https://pan.baidu.com/s/1WFoMo53BeIQHaQ7zg0DeRg?pwd=vb58)]
1. 操作系统(1)
- 哲学家问题模拟源代码.docx
2. 操作系统(2)
- 试卷
- 操作系统(二)试卷.pdf
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/数字逻辑/README.md
================================================
# 数字逻辑
资料链接: [[百度网盘](https://pan.baidu.com/s/1SQBZLEHqmKIJcYHwtq5bxg?pwd=vh5a)]
本文件夹下存放了数字逻辑实验相关的内容,其中,以不同前缀命名的实验报告:“jk报告”“lv报告”分别代表两个不同的人的报告,感谢大家分享!
---
1. jk报告
- 实验[1-5].doc
2. lv报告
- 实验[1-6].doc
3. 复习资料
- 2019秋数字逻辑复习汇总.pptx
4. 数字逻辑实验PPT_20201109
- 数字逻辑实验[1-7].ppt
5. 数字逻辑实验指导书_20201030
- ...
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/数据分析与智能计算/README.md
================================================
# 数据分析与智能计算
资料链接: [[百度网盘](https://pan.baidu.com/s/1Pfb_NbInGLS-oznu4hdVmQ?pwd=tm0i)]
1. 复习资料
- 复习大纲.md
- 库函数快速索引表.xlsx
- 数据分析复习.pptx
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/数据库/README.md
================================================
# 数据库
资料链接: [[百度网盘](https://pan.baidu.com/s/1iV616CU8FSVyB5nU7FmETw?pwd=a005)]
1. 数据库(1)
- 《数据库原理一》复习、习题分析.ppt
- README.md
- 数据库原理(一)--复习课2024版.ppt
- 课后习题参考答案.pdf
2. 数据库(1)实验
- 2022冬-数据库1-研讨和实验安排(更.docx
- 李晓强1-5周.docx
3. 数据库(2)
- 第...章.ppt
4. 数据库(2)实验-ly
- 实验1 在云服务器上部署mysql.md
- 实验2 Hadoop&Hive部署.md
- 实验3 在Docker中部署Redis.md
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/数据结构/README.md
================================================
# 数据结构
资料链接: [[百度网盘](https://pan.baidu.com/s/1HtkEoSB2ui0bxrQZK-qzlw?pwd=fx7m)]
1. ycshao21-CourseProject [[GitHub](https://github.com/ycshao21/DataStructure-ZNJ-SHU)]
2. 数据结构(2)
- PPT课件
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/概率论/README.md
================================================
# 概率论
资料链接: [[百度网盘](https://pan.baidu.com/s/1UYKbE4YdS5a2E0grD6vnAg?pwd=qsdg)]
1. 历年卷
- 12-13秋概率论与数理统计A试题(A卷).doc
2. 复习
- 复习提纲_概率统计.pdf
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/汇编语言/README.md
================================================
# 汇编语言
资料链接: [[百度网盘](https://pan.baidu.com/s/1lYX3JYTSGQiuCHHSD8Tecw?pwd=6lw6)]
1. HighVorz-assembly
- experiment
- exp[2-7].asm
- report.md
- func
- *.asm
- assembly.md
- HelloWorld.asm
- method.jpg
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/离散数学/README.md
================================================
# 离散数学
资料链接: [[百度网盘](https://pan.baidu.com/s/1qpt52Mw-4pdXpMGucdylng?pwd=9us1)]
1. 历年卷
- 2012~2013学年秋季离散数学.pdf
2. 复习
- 图论:几种特殊的图.jpg
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/算法设计与分析课程/README.md
================================================
# 算法设计与分析
资料链接: [[百度网盘](https://pan.baidu.com/s/1rCpVy_rKS7kPVF2gpVtKkw?pwd=ju84)]
1. jk-实验题目与源码解析
- 实验[1-7]
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/线性代数/README.md
================================================
# 线性代数
资料链接: [[百度网盘](https://pan.baidu.com/s/12H7BrmmLMdV28Dfe0dATGA?pwd=2rn7)]
1. 复习、历年真题
- [2009-2018]
2. 笔记
- 手写复习笔记.pdf
- 线性代数笔记zzr.pdf
3. 课件PPT
- ...
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/组合数学/README.md
================================================
# 组合数学
资料链接: [[百度网盘](https://pan.baidu.com/s/1OhdZ02D7MCh98f_MYdgcOg?pwd=n12o)]
1. 习题
- lv-八种球盒问题.docx
- 经典考题1.png
- 经典考题2.png
2. 课件
- Chapter[1-6].pdf
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/编译原理/README.md
================================================
# 编译原理
资料链接: [[百度网盘](https://pan.baidu.com/s/1BgMNHwcAUQQiwFXEgIHEAA?pwd=15o7)]
1. 实验指导书和模板
- 《编译原理》课程实验报告撰写提纲.docx
- 《编译原理》课程实验指导书.pdf
2. 课程项目: PrettyLazy0 [[Github](git@github.com:jamesnulliu/PrettyLazy0.git)]
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/脑认知/README.md
================================================
# 脑认知
1. cxy-脑认知复习
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/脑认知/cxy-脑认知复习/脑认知复习.md
================================================
# 人工智能与脑认知
> :heavy_exclamation_mark: 考前预测的重点
> ==xx==考到的部分小题和几乎所有简答题,大题
## Chapter 1 人工智能与脑科学
### 人工智能与智能
#### 史观
- 亚里士多德 三段论 前提真 结论真;培根 归纳法 前提真,结论不一定真
- Godel的这两条定理,指出了把人的思维形式化和机械化的某种**极限**,在理论上证明了**有些事情是做不到的**
- 诺伯特·维纳认为所有人类智力的结果都是一种**反馈**的结果;**反馈机制**是有可能用机器模拟的
- 图灵测试使实验研究智能行为成为可能
#### 相关定义:heavy_exclamation_mark:
##### 人工智能
1. **基于能力行为的定义**:智能机器所执行的通常与人类智能有关的智能行为 ,如判断、推理、证明、识别、感知、理解、通信、设计、思考、规划、学习和问题求解等思维活动 。
1. **学科的定义**:计算机科学中涉及研究、设计和应用智能机器的一个分支 。它的近期目标在于研究用机器来模仿和执行人脑的某些功能,并开发相关理论和技术。
##### 知识
==人们通过体验、学习或联想而知晓的对客观世界规律性的认识,包括事实、条件、过程、规则、关系和规律等==
##### 智能
两种定义方式:
人类在认识和改造世界的活动中,由脑力劳动表现出来的能力。包括感知、理解、抽象、分析、推理、判断、学习和对变化环境的适应等等。
一种应用知识对一定环境或问题进行**处理**的能力或者进行**抽象思考**的能力。
##### 智能机器
能够在各类环境中**自主地或交互地**执行各种拟人任务的机器。
##### 生物智能
生物智能是个体有目的的行为、合理的思维, 以及有效的适应环境的综合能力
#### 人类思维的主要形态
==**感知,形象,抽象,灵感**==
1. 感知是思维的**初级形态**,来源**客观的,丰富的**
2. 形象思维主要是典型化的方法进行概括,用形象材料来思维,高等生物共有。
3. **形象思维**处理外部感知,进一步进行抽象思维
#### 人工智能的五个基本问题
1. **知识与概念化**是否是人工智能的核心?
2. **认知能力**能否与**载体**分开来研究?
3. **认知的轨迹**是否可用**类自然语言**来描述?
4. **学习能力**能否与**认知**分开来研究?
5. 所有的认知是否有一种**统一的结构**?
#### 人工智能的研究目标
* 根本目标是要求计算机不仅能模拟而且可以延伸、扩展人的智能, 达到甚至超过人类智能的水平。
* 近期目标是使现有的计算机不仅能做一般的数值计算及非数值信息的数据处理,而且能运用知识处理问题,能模拟人类的部分智能行为。
* 作为工程技术学科,人工智能的目标是提出建造人工智能系统的新技术、新方法和新理论,并在此基础上研制出具有智能行为的计算机系统。
* 作为理论研究学科,人工智能的目标是提出能够描述和解释智能行为的概念与理论,为建立人工智能系统提供理论依据。
#### 人工智能分类 :heavy_exclamation_mark:
> 听王昊的意思必考?草结果没考,至少a卷没考
类人思维方法 理性思维系统
类人行为方法 理性行为系统
### 人脑工程
#### 人类脑计划
人类脑计划的核心:***神经信息学***,指**神经科学**和**信息科学**相互结合的研究领域。
目标:**认识脑,保护脑,创造脑** :heavy_exclamation_mark:
### 选择题
#### 人脑的特点
1. 大脑重量占人体的2%,能耗却达到正常消耗的20%,是人体能量消耗最大的器官之一。
2. 大脑的神经细胞超过1000亿个,具有一定的自我修复、学习和功能强化能力。
3. 大脑具有计算机所不能达到的逻辑思维、情感思维和模糊分析能力。
4. 脑死亡状态下,脑部**仍产生生物电流**,脑神经元若未完全死亡还有脑电。
#### 人脑的智能特点 :heavy_exclamation_mark:
1. 能感知客观世界的信息 **(感知能力)**
2. 能对通过思维获得的知识进行加工处理 **(记忆与思维能力)**
3. 能通过学习积累知识增长才干和适应环境变化 **(归纳与演绎)**
4. 能对外界的刺激作出反应传递信息 **(学习能力以及行为能力)**
#### 人工智能与人的自然智能 :heavy_exclamation_mark:
1. 人工智能是人类智能的延申与扩展
2. 人的自然智能能够结合外部环境进行合理的判断,而人工智能可以根据外界的输入(即外界环境的变化)进行分析输出,两者具有相似性,但是不具备可替代性。
3. 在所有人工智能的定义以及人工智能的基本问题中,人工智能的目的是为了代替人的某些单调的或是复杂的体力和脑力活动,从而让人具有更多的精力来完成更加复杂的工作。
4. 人工智能技术实质上是一种类人行为和思维方法。
#### 人工智能的描述
1. 人工智能的研究注意智能系统的效果而不是单纯的对人的智能行为的模拟。
2. 人工智能研究者主要从智能行为的过程与表现入手。
3. 人工智能的目标是提出建造人工智能系统的新技术、新方法和新理论,并在此基础上研制出具有智能行为的计算机系统。
4. 人工智能的目标是提出能够描述和解释智能行为的概念与理论,为建立人工智能系统提供理论依据。
## Chapter 2-a 认知科学概述
### 认知神经科学
#### 定义
认知神经科学是认知活动的**心理过程**和**脑机制**的科学。
心理学由认知心理学进入到认知神经科学的新时代。认知神经科学并不是认知心理学的分支
#### 研究模式
将**行为、认知过程、脑机制**三者结合起来
#### 常用研究方法
1. **无创性脑功能(认知)成像技术**
- 脑代谢功能成像
- 生理功能成像
2. **清醒动物认知生理心理学研究方法**
- 包括单细胞记录
- 多细胞记录
- 多维(阵列)电极记录法
- 其他生理心理学方法(手术法、冷却法、药物法等)
3. 脑事件相关电位、脑磁图和高分辨率脑成像等生理学电位方法
#### 具体研究方法
- 脑整体活动层次
- 不同脑区活动层次
- 神经细胞和亚细胞层次
- 分子活动层次
#### 认知活动测量工具
脑活动测量工具:
- 脑电波(Electroencephalogram, EEG)
- fNIR近红外光学脑成像系统
- 脑磁共振
其他生理设备:眼动仪、皮电、肌电、血电容积等
#### 神经系统
神经系统分为:**中枢神经系统**和**周围神经系统**
### 认知心理学
#### 核心 :heavy_exclamation_mark:
输入和输出之间发生的内部心理过程
#### 研究对象
1. 人的高级心理过程,主要是认知过程
2. 信息加工心理学
#### 研究内容
1. 人们如何获得外部世界信息
2. 信息在人脑内如何表示并转化为知识
3. 知识怎样存储又如何用来指导人们的注意和行为
4. 从认知神经生理基础、感知觉基本过程、认知行为脑机制到认知心理应 用多个层面探索心智奥秘
5. 从基因-神经-心理-行为层面出发,开展个体-群体-组织-社会等多个水平 的基础研究和应用研究
### 脑结构与功能
#### 神经细胞的组成
细胞体,轴突,树突
#### 脑的结构
**大脑、间脑、小脑、中脑、脑桥及延髓**等六个部分
#### 大脑皮质
- 三个面:上外侧面、内侧面、下面
- 三个沟:中央沟、外侧沟、顶枕沟
- ==**五个叶:额叶、顶叶、枕叶、颞叶、岛叶** :heavy_exclamation_mark:==
大脑皮质中,**额叶**部分负责高级思维相关,**枕叶**部分被认为是视觉初级感受区,**颞叶**主要是听觉初级区域所在的位置。

#### 左右脑
:heavy_exclamation_mark: 左右脑的协同主要依赖**胼胝体**
> 选填?
##### 对比
左半脑主要具有语言、分析、计算、抽象、逻辑、对时间感觉等思维功能;右半脑具有表象、综合、直观、音乐、对空间知觉和理解等思维功能。在思考方式上,左半球是垂直的、连续的、因果式的;右半球是并行的、发散的、整体式的。
##### 联系
大脑左右半球的分工并不是那么泾渭分明,功能的单侧化只具有相对的意义,左右半球既有相对的分工,又有密切的协作,人的许多重要的心理功能都需要左右半球的密切协作才能完成。
#### 脑的联络区
大脑中除了一些具有特定功能的中枢外,还存在着广泛的脑区,它们不局限于某种功能,而是对各种信息进行加工和整合,完成高级的神经精神活动,称为联络区。
#### 大脑认知功能模块:heavy_exclamation_mark:
**加扎尼加**提出脑认知功能模块论
#### 无法说话 :heavy_exclamation_mark:
原因是**运动型语言中枢**出问题
## Chapter 2-b 认知科学详细
### 认知科学
认知科学是研究人类感知和思维信息处理过程的科学,**(研究方向)** 包括从感觉的输入到复杂问题求解, 从人类个体到人类社会的智能活动, 以及人类智能和机器智能的性质。
#### 研究层次(认知科学or认知神经科学)
分子、细胞、脑组织区和全脑
#### 四个焦点问题 *(可能多选)*
1. 知觉和认知
2. 运动和行为
3. 记忆和学习
4. 语言和思考
#### 认知的三个方面
==***适应、结构、过程***==
#### hoston等对认知的看法
1. 认知是信息的处理过程;
2. 认知是心理上的符号运算;
3. 认知是问题求解;
4. 认知是思维;
5. 认知是一组相关的活动,如知觉、记忆、思维、判断、推理、问题求解、学习、想象、概念形成、语言使用等
#### 认知的分类
**经验认知**和**思维认知**
#### 感知和认知的定义及关系 :heavy_exclamation_mark:
> 感觉得背
感知:即通过人体器官和组织进行人与外部世界的信息的交流和传递
认知:人们在进行日常活动时发生于头脑中的事情,它涉及思维、记忆、学习、幻想、决策、看、读、写和交谈等
关系:感知是认知的基础,认知是将感知获取的信息综合应用
### 感知
#### 种类
视,听,嗅,味,触
#### 视觉
##### 一些性质
- 与外界联系最重要的通道 **80%信息来源**
- 视觉感知的两个阶段:接受信息和解释信息
##### 特点
- 一方面,物理特性决定了人类无法看到一些事物
- 另一方面,解释处理信息时可对不完全的信息发挥一定想象力
##### 视敏度
指**人眼对细节的感知能力**,通常用被辨别物体最小间距所对应的视角的倒数表示。
##### 图像识别
> 只考一题?
两种理论:**模板匹配**和**原型匹配(格式塔心理学)**
###### 格式塔
格式塔即任何分离的整体,认为整体比局部更优先被感知
##### 阅读 :heavy_exclamation_mark:
> 很重要;感觉会考?
三个阶段
1. 页面上文字的形状被人眼感知
2. 文字被编码成相关的内部语言表示
3. 语言在人脑中被解释成有语法和语义的单词或句
##### 颜色模型
> 顶多一道选择题?
- RGB(加性原色系统)
- CMYK(减色原色系统)
- HSV(色调、饱和度、亮度)
#### 信息表示方法
> 小概率?
信息的显示方式对于人们能否快速捕捉到所需的信息片断有很大的影响。**分类显示**的信息就比较便于人们查找
### 识别
:heavy_exclamation_mark:人的***识别能力大于回忆能力***
> 重复过,感觉会考
#### 人脸识别 :heavy_exclamation_mark:
在人脸的感知中,全局特征一般是用来**进行粗略的匹配**,局部特征一般是用来提供更为**精细的确认**
脸部的识别为整体优先,物体的识别为局部优先
##### 对于人脸的识别下面说法正确的是
- 人脸的上半区域的识别的重要性要高于下半区域。
- 个性化特征可以用于更加精确的识别。
- 特殊脸比大众脸型更容易被记住和识别。
#### 记忆
三个环节:**识记,保持,再认和回忆**
#### 交互设计
1. 应考虑用户的记忆能力,勿使用过于复杂的任务执行步骤。
2. 由于用户长于“识别”而短于“回忆”,所以在设计界面时,应使用菜单、图标,且它们的位置应保持一致。
3. 为用户提供多种电子信息(如文件、邮件、图像)的编码方式,并且通过颜色、标志、时间戳、图标等,帮助用户记住它们的存放位置
### 场依存性与场独立性:heavy_exclamation_mark::heavy_exclamation_mark::heavy_exclamation_mark:
> wh说必考,猛猛背 考个鸡脖,a卷无
场依存性的人:
1. 独立性差,并且容易受暗示;比较容易受当时环境中的其它事物(包括知觉者本身的状况)的影响,很难离析出知觉单元。
2. 倾向于以外在参照(客观事物)作为信息加工的依据。
场独立性的人
1. 有较大的独立性,并且不易受暗示;比较少受知觉当时的情境影响,比较易于离析出知觉单元。
2. 倾向于更多地利用内在参照(主体感觉)。
### 认知概念框架
四种框架
1. 思维模型
2. 信息处理模型
3. 外部认知模型
4. 分布式认知模型
### 信息处理模型
> wh提了

## Chapter 3 事件相关电位概述
### 脑活动测量方法 :heavy_exclamation_mark:
- **脑电图(EEG)——时间分辨率最高**
- 脑磁图(MEG)
- 功能性磁共振成像(fMRI)
- **功能性近红外成像(fNIR)——空间分辨率最高**
- 正电子发射断层扫描(PET)
- 功能性经颅多普勒超声(fTCD)
### 脑神经活动特点及脑电产生原理
脑电首次发现**贝鲁加**
>wh提到了
#### 脑的工作原理
人的感觉、情感、动作、包括不能意识和控制得体内活动都是由**电化学、生物活动**左右
##### 突触结构
突触的结构包括**突触前膜(突触小泡)、突触间隙、突触后膜(受体)**
#### 脑电(EEG)产生原理
1. 活的人脑一直会不断放电,产生脑电波
2. 是由大脑大量的神经组织的活动产生的
3. 是由皮质中的神经组织突触后点位同步总和而成的
#### 脑电测量的基准 :heavy_exclamation_mark:
CZ
##### 电极名称
Fp=额极(frontal pole);
F=额(frontal);
C=中央(central);
P=顶(parietal);
O=枕(occipital)
T=颞(temporal)
#### 脑电节律
1. alpha波:8-13Hz
2. beta波:13-30Hz
3. Theta波:4-8Hz
4. Delta波:0.5-4Hz
### 事件相关电位(ERP)的概念及特点 :heavy_exclamation_mark:
>大概率会考
#### ERP的定义 :heavy_exclamation_mark::heavy_exclamation_mark:
事件相关电位是由外加的一种**特定刺激**,作用于**感觉系统**或**脑**的某一部位,再**给予**刺激或**撤销**刺激时,在脑区所引起的**电位**变化。被认为是**心理行为**的一种客观表现形式。
#### ERP的特点
1. **潜伏期恒定**
2. **波形恒定**
#### ERP的优点和缺点
优点:
1. 优异的时间分辨率
2. 推断受实验调控影响的认知过程
3. 识别多个认知神经过程
4. 认知过程的内隐性测量
5. 可以作为一些医疗应用的生物标志物
缺点:
1. 仅仅是脑活动的外在反应,无法提供实际的脑活动机制(这在大部分的测量系统里都存在);
2. 代表了许多潜在成分的总和(即为多个成分的叠加),**无法判断这些潜在成分的神经元活动位置;**
3. 有些心理或神经过程可能并不存在对应的ERP。必须满足特殊的生物物理学条件时,ERP才是可记录的;
4. ERP相对噪声水平来说时很小的,需要多次测量才能够得到;噪声产生的来源非常广泛;
5. 时间跨度不能特别长
#### 相较于其他生理测量手段
1. 无创伤性,但是干扰明显。
2. 时间分辨率高(ms级),但是空间分辨率不足(大脑表层);
3. 价格便宜
#### ERP的起源
##### 神经元细胞的主要电活动
- 动作电位
- 突触后电位
**ERP 几乎都是起源于突触后电位**
**仅有小部分的大脑活动能够引发头皮表面的ERPs**
1. 头皮上的ERP通常并不是由动作电位引发的(除刺激后几十毫秒内出现的听觉响应外)。
2. 数以千计的且有类似朝向的神经元引发的电偶极子相互叠加时,才能够在头皮表面观察到。
3. 头皮上记录到的ERPs几乎总是反应了锥体细胞(皮层中主要的输入-输出细胞)的神经传导。
##### ERP为什么总是反应了锥体细胞的神经传导? :heavy_exclamation_mark::heavy_exclamation_mark:
锥体细胞是皮层中主要的输入-输出细胞,它们的朝向与皮层表面垂直,所以他们的偶极子会相互叠加,而不是抵消。
#### 影响ERPs成分的极性的因素
四个因素
- 突触后电位是兴奋性还是抑制性
- 突触后电位是发生于尖端树突,还是发生于基底树突和细胞体;
- 所形成的偶极子相对于活动记录电极的位置朝向;
- 参考电极的位置
#### 获取ERP的生理条件
- 大量神经元必须同时活动;
- 神经元个体之间必修具有大致相同的朝向;
- 大部分神经元中的突触后电位必须来自于神经元中的同一部位(尖端树突或者细胞体和基底树突)
- 大部分神经元必须具有相同的电流方向,以避免相互抵消
#### ERPs数据获取
获取到的ERP数据是给定电极的电压和频率所有的潜在成分的**加权总和**,但是,人们感兴趣的是**单个成分**。
##### ICA:heavy_exclamation_mark::heavy_exclamation_mark::heavy_exclamation_mark:
>wh说必考
独立成分分析(Independent Component Analysis,简称ICA)是一种用于多维信号分离的统计方法,旨在将多个混合信号分解为独立的成分。
==**目的**:==
1. ==从混合信号中提取出各独立的信号分量。==
2. ==滤除伪迹。==
### 脑电特征
#### 脑电基线
每一个波上下偏移时都会依据自己的中心点,将连续脑电波的每一个中心点连接起来,就会成为一个近似的直线,该线被称为基线。
基线平稳:中心轴线为一条直线或近似直线
基线不平稳:若形成一条波幅高于25μV,时间大于1000ms缓慢移动的曲线
基线欠稳:波幅小于25μV。则成为基线欠稳
##### 基线矫正的目的 :heavy_exclamation_mark:
消除由于时间或其他外部因素造成的信号偏移,从而使信号能够准确地反映实际的情况。
==根据时间的不一样,脑电的活动不一样,脑电波形是有偏移的,这是一个外部问题,所以要将它从偏移上拉下来,做一个近似直线。这样才能很好的观察到波形的存在==
> 考的基线移除?反正不会随便写上去了
#### 伪迹
生物伪迹
- 眼伪迹
- 心电伪迹
- 肌电伪迹
- 舌动伪迹
- 皮点伪迹
##### 几种伪迹图 :heavy_exclamation_mark:
> 分辨伪迹



## Chapter 4 ERP成分
### 概述
#### ERP的成分的定义
1. 概念性的定义:一个ERP的成分是当大脑执行某个特定的计算信号时,产生于某个特定的神经解剖学模块,并且可以在头皮上记录到的神经信号。**(ERP的本质)**
2. 实用性的定义:一个成分为一些电位的变化,它们符合单一的神经产生源位置,并且在不同的实验条件、时间段、个体等等之间出现系统性的变化。
**即:一个ERP成分是一个ERP数据集内具有系统性和稳定性的变异源。**
3. 习惯性的定义:如果结构简单、且对应与一个单偶极子(或者一对在左右半球间呈镜像堆成的偶极子)相符,我们可以暂且认为它是个单一成分。
#### ERP成分分类
ERP有多种分类,主要的有根据**刺激成分、感觉通路及潜伏期**三种分类方法
##### 根据潜伏期分类
- 早
- 中
- 晚成
- 慢波

##### 根据刺激成分分类
- 由刺激呈现而强制性诱发的**外源性感官成分**
- 完全反应任务相关神经过程的**内源性成分**
- 伴随运动准备和执行过程的**运动成分**
##### 根据感觉通路分类
- 听觉诱发电位
- 视觉诱发电位
- 体感诱发电位
#### ==ERP成分解释时避免歧义的方法==
>一道多选题
1. **聚焦于单个成分**;一个实验仅仅关注一个或两个ERP成分,尽量使其他所有成分在不同的条件之间保持不变。
2. **聚焦于较大的成分**;当感兴趣的成分远大于其它成分时,它在观测波形中占据主导,此时对该成分的测量,相对来说不太容易受到来自其它成份的干扰。
3. **从其它领域中劫持有用的成分**;利用与实验主题本不明显相关的成分来进行解释。
4. **采用经过充分研究的实验操作**;考察一个已被研究过的ERP成分,且尽可能保持实验条件与先前该成分研究时的条件类似。
5. **利用差异波**;差异波有助于分离特定的ERP成分,但是解释的时候需要小心。这也是目前应用的越来越多的方法。
6. **聚焦容易分离的成分**;利用某个成分研究其之前发生的加工过程,不同条件之间出现的差异在逻辑上意味着某些过程已经发生了。
7. **利用某个成分研究其之前发生的加工过程**;不同条件之间出现的差异在逻辑上意味着某些过程已经发生了。
8. **与成分无关的实验设计**;利用许多已有策略都聚焦于可以分离出特定的ERP成分,完全回避这些特定成分的识别问题,也能够有效的解释需要注意的成分。
### 听觉和视觉诱发电位 :heavy_exclamation_mark::heavy_exclamation_mark:
>wh说视觉,听觉必考一个
#### 视觉诱发电位(VEP):heavy_exclamation_mark::heavy_exclamation_mark:

:heavy_exclamation_mark: **研究枕叶皮层对视觉刺激产生的电活动**
##### C1成分 :heavy_exclamation_mark:
> 比较重要
1. 通常发生在P1之前(不一定会出现);
2. 在头皮后部中线处的电极上;
3. 下视野的刺激诱发的C1为正性,上视野的刺激诱发的是负性。
***C1的产生极性出现不同的原因是什么?***
在实验中,如果诱发的成分产生区域为距状裂上方的区域,由于其负责编码下方的视野,则产生的为正性。如果刺激诱发的是距状裂下方的区域,由于其负责编码上方的视野,则产生的C1为负性。
##### P1 成分 :heavy_exclamation_mark:
> 比较重要
***特性***
1. 第一个主要的视觉成分;
2. 通常起始于刺激后60-90ms,并于100-300ms达到峰值;
3. **潜伏期受刺激对比度**的影响非常大;
4. 对**刺激参数敏感**,受**选择性注意**和受试者**觉醒状态控制**;
5. 振幅对于刺激是否与任务下的**靶刺激类别匹配不敏感**
***位置***
- 最大幅值位于侧向枕叶电极;
- **早期成分产生于背侧纹外皮层,晚期成分产生于梭状回的腹侧部分**
##### N1 成分 :heavy_exclamation_mark:
> 比较重要
**N1对注意力敏感**
1. 紧随在P1后面;
2. 包含多个子成分;
- 这些子成分在功能上不一定关联,被称为子成分的原因是因为它们共同构成了波形中的一个显著偏转。
- 最早的子成分峰值出现在刺激后100-150ms,位于前部头皮电极位置;
- 在后部电极位置,至少有2个N1成分的峰值出现在刺激后150-200ms,一个来自顶叶皮层,另一个来自外侧枕叶皮层;
3. 具有高度的不应性;如果短时间内接连出现两个刺激,那么第二个刺激诱发的响应会减少许多
##### P2 成分 (我赌它不考)
#### ==听觉诱发电位(AEP) :heavy_exclamation_mark::heavy_exclamation_mark:==
> 背吧感觉会考,果然考了,明年感觉还会考

这是一个简单听觉(嘀嗒声)诱发的脑电。
0-10ms: 体现了来自耳蜗的信息经过脑干传递到丘脑的过程;这些听觉脑干响应,通常用罗马数字进行标记。 这些响应是高度自动的,可以用来评估听觉通道的完整性。
10-50ms:中潜伏期响应,至少部分来自内次膝状体和初级听觉皮层。注意力对该部分有调控作用。
50ms-:长潜伏期响应。(通常顺序为P50(P1),N100(N1)和P160(P2))这个潜伏期比高级认知成分低,但从听觉器官的特性来说,100ms相对比较晚了。受到高级认知的影响,如注意力、觉醒度等。
### 主要成分 :heavy_exclamation_mark::heavy_exclamation_mark:
#### 关联性负变(CNV)
**标志着现代ERP研究的正式开始**
> 考了一道填空
> 说不定明年就考到上面这句话了
>
==CNV被认为主要与***心理因素***有关。比如期待、意动、朝向反应、觉醒、注意、动机等,可以认为它基本上是一个**综合**的心理准备状态的反映,处于**紧张或应急状态**的反映。==
#### N2
N2a是一个由听觉刺激匹配条件自动诱发的效应,甚至当刺激与任务无关的时候也会被诱发。这一效应通常被称为**失匹配负波**(mismatch negativity,MMN)
#### 失匹配负波(MMN)
产生于**额叶和颞叶**
由于MMN具有**高度的自动性**,对于无法容易做出行为反应的人群进行研究就会非常有用:如不会说话的婴儿、处于昏迷状态的人
##### 差异波
**目的**:是去除相同的内容,得到较为纯粹的成分
**前提**:两种条件的心理活动或者机制的差异是清楚的,不包含其他成分
#### N2pc
“N”——负波,“2”——200ms左右出现,“pc”——posterior contralateral,即对侧脑后区域。
N2pc 是一种与**空间选择性注意**密切相关的ERP 成分, 反映了对当前任务相关刺激所进行的空间选择加工
##### N2pc相关结论
1. N2pc对研究注意是否已被隐性的转移至特定物体,以及注意转移的时间过程时非常有用;
2. N2pc能够被用来判断注意是否会自动地被明显但无关的物体所捕获;
3. N2pc可以证明被遮掩的阈下物体仍然能够吸引注意。
4. 与奖赏有关的物体可以诱发更快的注意转移;
5. 注意力在某些视觉搜索任务下是以串行方式在物体间转移的;
6. 精神分裂症患者在某些条件下的注意转约速度和正常人一样快。
##### N2pc产生区域
- 视觉皮层V4区
- 外侧枕叶皮层复合体位置
#### P300
##### P300的特点 :heavy_exclamation_mark::heavy_exclamation_mark:
**振幅**:P300波幅与概率成**反比**,靶与非靶皆然
**潜伏期**:P300的潜伏期随任务**难度的增加而增加**
判断同义词的任务较难,潜伏期较长
#### N400
##### 诱发N400
- 阅读中的歧义信息
- 特殊的图片特征
- 面孔识别
## Chapter 5 实验范式
典型范式
- Oddball范式
- Go-Nogo范式
- 特定认知领域实验研究范式
### 靶刺激
- 靶刺激是需要被测做出反应的⽬标刺激;
- 在Oddball实验中,通常将偏差刺激作为靶刺激。
- 根据实验需求,靶刺激可以是偏差刺激,也可以是新异刺激。
### Oddball实验范式
==经典Oddball范式也被称为**基于概率的实验范式**,是在一项实验中随机呈现**同一种感觉通道**的两种刺激,两种刺激的概率相差很大,大概率者即经常出现者称为**标准刺激**,小概率者即偶然出现者称为**偏差刺激**。==
> 典,我赌明年继续考
>
将**偏差刺激作为靶刺激**
***可用来获取P300成分,MMN成分***
### Go-Nogo实验范式
#### 与Oddball范式的区别
- 取消标准刺激与偏差刺激之间的概率差别;
- 需要被试者反应的刺激为Go刺激,不需要反应的为Nogo刺激。
### 知觉和意识研究的实验范式
#### 视觉的局部优先与整体优先 :heavy_exclamation_mark:
> 一道填空题
>
==物体认知:局部优先,物体的识别常常被表征为各部件的外形==
==脸部认知:整体优先,脸部常常被表征为一个整体==
#### 视运动知觉启动范式
##### 理论基础
>草 多选改大题,md没背下来
1. ==视觉感知是可以被诱导的(或者被启动的);==
2. ==视觉运动知觉的启动是一种非意识加工的脑机制;==
##### 相关论述
1. ==某一特定运动方向的视觉刺激,即使是非意识的也能使视觉运动知觉偏向它们的方向。==
2. ==视运动知觉启动可以提供一种非意识加工脑机制的研究方向。==
### 视觉注意研究的实验范式(空间注意提示范式)
> wh和题目都只有空间注意提示范式,前面的早期实验就没管了
:heavy_exclamation_mark:在经典视觉注意实验中,当有效刺激诱发的 **P1** 和 **N1** 成分比无效、中性刺激诱发的明显增大。
#### 概述 :heavy_exclamation_mark:
##### 基本范式
注视点 —— 提示 —— 靶
##### 特点
1. 搜索时的心理活动主要是注意的选择;
2. 搜索到靶后对靶的属性进行分辨,分辨过程的心理活动中含有注意的集中;
3. 可以改变提示信息的有效性、提示与靶的间隔、提示范围大小等来研究各种视觉空间注意的脑机制。
#### 有效提示与无效提示
提示的有效与无效,指的是提示信息对指定的任务所起到的作用真实与否,即**提示信息能否正确反应靶刺激的情况**。
#### 符号性提示又称内源性提示
#### 周围提示
更容易诱发 **P1**和**N1**
#### 提示与靶的间隔
##### 注意的分类
- 随意注意
- 非随意注意
##### 提示与靶的间隔对注意的影响
**原因**:随意注意和非随意注意的***来源、性质、功能以及脑内加工的机制不同***
- 随意注意:又被称为内源性注意,提示与靶的间隔长(大于500ms)、提示有效率高(大于70%)
- 非随意注意:又被称为外源性注意,提示与靶的间隔短(小于300ms)、提示有效率低(小于50%)
#### 上、下视野提示
下视野为优势视野
#### 结论
- 三种刺激诱发的N2pc在潜伏期和头皮分布上相同;
- 运动靶的N2pc虽然稍大,但系运动靶会比颜色靶、方向靶自动吸引更多注意资源所致;
- **颜色、方向与运动的搜索动用的是同一个注意系统。**
### 记忆研究的实验范式
#### 工作记忆实验范式 :heavy_exclamation_mark::heavy_exclamation_mark:
##### 工作记忆分类 :heavy_exclamation_mark:
*三个子系统*
- 中央执行系统
- 语音回路
- 视觉空间存储
##### ==认知加工的三个阶段==
> 听wh说的感觉会考,考了
使用**样本延迟匹配**范式(任务)对其进行研究

- ==样本阶段 —— 信息编码输入==
- ==延迟阶段 —— 信息复述保持==
- ==靶阶段 —— 信息提取匹配==
##### n-back任务
n-back任务是让被试浏览一系列逐个呈现的项目,然后要求被试从第n个项目起判断每一个出现的项目是否与前面刚呈现过的倒数第n个项目匹配。
***特点:能够通过控制n的大小来操纵工作记忆的负荷,从而考察不同记忆负荷下工作记忆的加工机制***
#### 学习——再认实验范式
> wh说没怎么考,考了个多选
**发现的新效应**
- ==相继记忆效应==
- ==重复效应==
- ==新旧效应==
- ==内隐记忆效应==
#### 语言文字研究的实验范式(N400)
其重要意义不仅在于发现了N400的成分,主要是它成功的将**ERP**运用到了**语言心理学**中
##### 研究N400的实验
- 句尾畸义词,N400经典范式;
- 相关词与无关词,词性不同、反义词、无关词产生明显的N400;**近义词不产生**
- 新词与旧词,首次出现的新词与重复出现的旧词,新词可以诱发更正的N400;
- 文字与非文字符号;
- 图片命名,图片内容和名称的匹配
##### 哪些刺激诱发N400
- 阅读中的歧义信息。
- 特殊的图片特征
- 面孔识别
### 情绪与认知相互关系研究的实验范式
#### 需要注意的因素
1. 情绪的快速可变性
2. 影响情绪的因素很多
3. 情绪往往具有延迟性,会影响到我们设计的实验中情绪的测量。
#### 一些结论
- 一个人的情绪能够被外来的图片刺激、声音刺激、气味等所感染,诱发**杏仁核**的活动
- 然情绪能够被**外界**所诱发,但是从心理学、生理学角度来说,情绪是一种**无意识**的诱发。
- 情绪活动常伴随一系列生理活动的变化,通过**自主神经系统**和**内分泌系统活动**的改变引起的
- 研究发现,焦虑情绪会选择性的**干扰空间工作记忆任务**,但**未影响词语工作记忆**,因此,情绪对认知的影响**不是全脑水平的**,其交互作用更为复杂。
#### 无意识诱发
本能的防御反应:发怒,恐惧,逃避
## Chapter 6 脑机接口与fNIRs
### 脑机接口
#### 定义
脑机接口是在人或动物脑(或者脑细胞的培养物)与外部设备间建立的直接连接通路。
#### 信号采集方法
脑机接口用到的信号采集方法有侵入式、半侵入式和脑外(非侵入式)。
#### 研究方向
- 人机互交
- 心理认知学
- 心理疾病评估
- 神经疾病诊断与康复
#### 过程
> 作业题有,wh也提了
>
>
脑机接口技术中,使用**信号分析与特征提取方法**,在预处理过程过,将EEG信号分为**5个有用的频带部分**,作为**模式识别**的特征。
#### ==为什么现在很多BCI(脑机接口)的研究都无法做到直接用大脑控制机器人,必须借助于外界的刺激?==
> 考了,但我没背的很详细,小寄
>
因为大脑的思维或反应在相关的(或不相关的)加工过程中涉及到的多个脑分区,很难通过自发的方式产生高度单一的成分,因此也很难从ERP实验中分离出高度特异的心理或神经过程。目前,借助外界的刺激,可以加强(增强)某一类ERP响应成分,从而达到控制机器人的目的。
### fNIRs
#### 原理
FNIRs成像主要测量大脑活动中,**血氧**的浓度变化
#### ==对比EEG==
> 一道大题
fNIRS
优点:
- 安全、非侵入性
- 造价相对便宜,维护成本低
- 时间、空间分辨率相对较高
- 被尝试友好度高
- 生态效率高
- 兼容性高
缺点:
- 外皮层记录
- 被试间脑区解剖位置差异
- 信噪比较低
EEG
优点:
- 时间分辨率极高:EEG的时间分辨率非常高,能够捕捉到快速的脑电活动变化。
- 成本相对较低:相对于fNIRS,EEG的设备和维护成本更低。
- 广泛的临床应用:EEG在临床诊断(如癫痫)中有着长期而广泛的应用。
- 便于重复测量:EEG设备相对轻便,便于进行长时间或重复的测量。
缺点:
- 空间分辨率低:EEG的空间分辨率较低,难以精确确定脑活动的具体位置。
- 信号可能受到伪影的干扰:头发、肌肉活动、眼动等都可能对EEG信号产生干扰。
- 实验设置和电极放置要求严格:EEG需要精确的电极放置和常常较长的准备时间。
## Chapter 7 眼动
> 压根没考
### 常用指标
- 访问时长
- 首次注视时间
- 访问次数
- 访问百分比
**眼跳潜伏期:** 刺激呈现到第一个眼跳开始的时间。潜伏期越短,表明当前目标的加工越简单。
================================================
FILE: 学习资料(非电子书)/计算机体系结构/README.md
================================================
# 计算机体系结构
资料链接: [[百度网盘](https://pan.baidu.com/s/1cWcpP6JG2uz-bfXeROKlHw?pwd=wxy2)]
1. PPT
- 第[1-6]章
2. 习题答案
- ...
3. 实验: SHU-Computer-Architecture-Experiments [[GitHub](https://github.com/SHUSCT/SHU-Computer-Architecture-Experiments)]
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/计算机最新进展研讨/README.md
================================================
# 计算机最新进展研讨
资料链接: [[百度网盘](https://pan.baidu.com/s/15FWenseWqKsxLoLgFk2UKA?pwd=hj5q)]
1. 2021-2022 lv卷积神经网络综述(PPT+报告)
- ...
2. 相关文献
- 机器学习-5 深度学习的昨天、今天和明天.pdf
- 机器学习-6 7 卷积神经网络研究综述(2人).pdf
- 机器学习-8 迁移学习-回顾与进展.pdf
3. 2021-2022 研讨主题.ppt
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/计算机研究前沿/README.md
================================================
# 计算机研究前沿
资料链接: [[百度网盘](https://pan.baidu.com/s/1vihd36RRKujxbF2gSgRM3g?pwd=yxuk)]
1. lv流行病传播过程仿真实验
- netlogo仿真
- Untitled.nlogo
- 计算机研究前沿-第.pptx
- 计算机研究前沿.docx
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/计算机组成原理/README.md
================================================
# 计算机组成原理
资料链接: [[百度网盘](https://pan.baidu.com/s/1VzCASGZnF4WvSFRHO3QKMw?pwd=cce1)]
1. 原理(1)
- lv实验报告分享
- ...
- 实验指导书、PPT等
- ...
2. 原理(2)
- lv实验报告分享
- ...
- 实验指导书、PPT等
- ...
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/计算机编程实训/README.md
================================================
# 计算机编程实训
资料链接: [[百度网盘](https://pan.baidu.com/s/1jGWtNyteTXXXTVmv-X4Gfw?pwd=i663)]
1. 2020-2021夏季学期《计算机编程实训》
- lv计算机编程实训源代码+小论文
- ...
- 相关资料
- ...
- 2020-2021夏季学期《计算机编程实训》课程方案20210613.docx
- README.md
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/计算机网络/README.md
================================================
# 计算机网络
资料链接: [[百度网盘](https://pan.baidu.com/s/1cwl4r1YdL6AI_FGp4Z67jg?pwd=sy8e)]
1. 实验
- 使用GNS3完成
- GNS3+cisco 动态路由实验.md
- GNS3静态路由实验.md
- 使用GNS3完成实验指南
- GNS3+cisco 动态路由实验.md
- GNS3静态路由实验.md
- 实验辅助资料
- 《网络与通信》实验指导书(V1.0).pdf
- 706network.jpg
- Network_01.doc
- Network_02.doc
- Network_03.doc
- 静态路由及RIP和OSPF实验帮助.pdf
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/语义网络与知识图谱/README.md
================================================
# 语义网络与知识图谱
资料链接: [[百度网盘](https://pan.baidu.com/s/1zh12BQugZXsyzASwds1nig?pwd=d7ky)]
1. 2021实验手册
- 2021语义网与知识图谱实验手册-[1-6].docx
2. 2021课件
- 2020语义网与知识图谱-第[1-8]讲.pdf
3. 实验工具及资料
- logic4cs-script.pdf
- Protégé 使用方法.pdf
4. 扩展研讨PPT
- ...
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/软件工程/README.md
================================================
# 软件工程
资料链接: [[百度网盘](https://pan.baidu.com/s/1h90VNRS5yqJUjcr99AONjA?pwd=lwx5)]
1. lv实验
- README.md
- 实验[1-8].docx
2. 2019冬软工总复习.ppt
3. 上海大学2021-2022软件工程主观题考卷(A).pdf
4. 复习.ppt
5. 软件设计师2017至2019年试题分析与解答.pdf
6. 软工考试类型.doc
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/面向对象/README.MD
================================================
# 面向对象资料
资料链接: [[百度网盘](https://pan.baidu.com/s/1X_mEVtk_Rz5fIPK29kBFlQ?pwd=ni3b)]
1. 面向对象复习笔记 [[GitHub](https://github.com/Amadeus-1048/Course-Review/blob/main/%E9%9D%A2%E5%90%91%E5%AF%B9%E8%B1%A1%E7%A8%8B%E5%BA%8F%E8%AE%BE%E8%AE%A1/%E9%9D%A2%E5%90%91%E5%AF%B9%E8%B1%A1%E5%A4%8D%E4%B9%A0%E7%AC%94%E8%AE%B0.md)]
2. 历年试题
- 2004-2020
3. 课程小项目
- 单向链表类模板应用---音乐资料库
- ...
- 向量类模板实现
- ...
- 封装C-字符串
- ...
- 抽象向量类模板及其派生类
- ...
---
Last update: Jun 28, 2024
================================================
FILE: 就业相关/八股笔记/个人珍藏八股笔记,看缘分更新.md
================================================
# 笔记
# ==408==
## 一、TCP
seq代表从对方的何处开始发消息:我把数据从你的seq处开始发(你的上一次的ack所要求的)
ack代表对方从我的何处发消息:你下一次发送消息到我的ack处开始发
因此回复的ack=seq+len
初始连接时SYN占据一个字节,相当于发送len=1的包,所以ack=x+1
结束时FIN同理
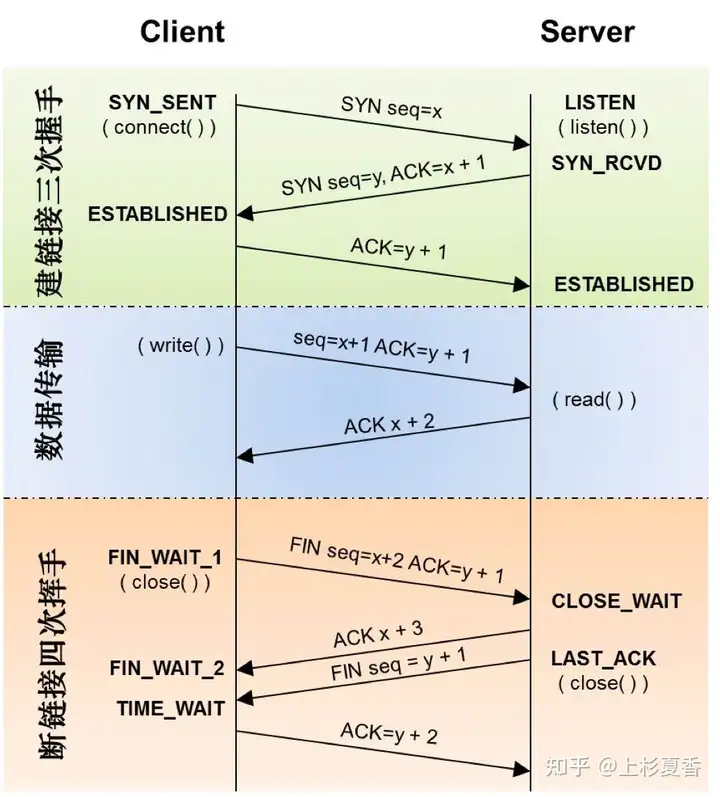
TCP 协议保证数据传输可靠性的方式主要有:
- **校验和**:TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
- **序列号**:TCP 传输时将每个字节的数据都进行了编号,这就是序列号。(为了应对延时抵达和排序混乱)。每个连接都会选择一个初始序列号,初始序列号(视为一个 32 位计数器),会随时间而改变(每 4 微秒加 1)。因此,每一个连接都拥有不同的序列号。序列号的作用不仅仅是应答的作用,有了序列号能够将接收到的数据根据序列号排序,并且去掉重复序列号的数据。这也是 TCP 传输可靠性的保证之一。
- **确认应答**:TCP 传输的过程中,每次接收方收到数据后,都会对传输方进行确认应答。也就是发送 ACK 报文。这个 ACK 报文当中带有对应的确认序列号,告诉发送方,接收到了哪些数据,下一次的数据从哪里发。
- **超时重传**:超时重传机制。简单理解就是发送方在发送完数据后等待一个时间,时间到达没有接收到 ACK 报文,那么对刚才发送的数据进行重新发送。如果是刚才第一个原因,接收方收到二次重发的数据后,便进行 ACK 应答。如果是第二个原因,接收方发现接收的数据已存在(判断存在的根据就是序列号,所以上面说序列号还有去除重复数据的作用),那么直接丢弃,仍旧发送 ACK 应答。那么发送方发送完毕后等待的时间是多少呢?如果这个等待的时间过长,那么会影响 TCP 传输的整体效率,如果等待时间过短,又会导致频繁的发送重复的包。如何权衡?由于 TCP 传输时保证能够在任何环境下都有一个高性能的通信,因此这个最大超时时间(也就是等待的时间)是动态计算的。
- **连接管理**:说白了就是三次握手四次挥手。
- **流量控制**:当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。
- **拥塞控制**:拥塞控制是 TCP 在传输时尽可能快的将数据传输,并且避免拥塞造成的一系列问题。是可靠性的保证,同时也是维护了传输的高效性。
为什么第四次挥手客户端需要等待 2*MSL(报文段最长寿命)时间后才进入 CLOSED 状态?
第四次挥手时,客户端发送给服务器的 ACK 有可能丢失,如果服务端因为某些原因而没有收到 ACK 的话,服务端就会重发 FIN,如果客户端在 2*MSL 的时间内收到了 FIN,就会重新发送 ACK 并再次等待 2MSL,防止 Server 没有收到 ACK 而不断重发 FIN。
> **MSL(Maximum Segment Lifetime)** : 一个片段在网络中最大的存活时间,2MSL 就是一个发送和一个回复所需的最大时间。如果直到 2MSL,Client 都没有再次收到 FIN,那么 Client 推断 ACK 已经被成功接收,则结束 TCP 连接。
## 二、死锁
**一、死锁的定义**
[死锁](https://so.csdn.net/so/search?q=死锁&spm=1001.2101.3001.7020)是指,有两个或两个以上的线程在执行的过程中,由于竞争的资源或者彼此通信而造成的一种阻塞状态,若无外力作用,他们将都无法进行下去,从而形成一直阻塞的状态叫死锁。
**二、产生死锁的必要条件**
- 互斥条件
一个资源只能被一个线程所拥有的,若一个线程已经拥有了该资源,那么其他想获取该资源的线程就需要阻塞等待。
- 不可剥夺条件
当一个资源被线程获取了之后,如果该线程不主动释放该资源,那么该资源一直被占有,其他想获取该资源的线程就要一直进行等待。
- 请求并持有条件
一个线程已经拥有了一个资源,还要请求新的资源。
- 循环等待条件
产生死锁一定是发生了环路等待,形成线程资源环形链。
以上是产生死锁的四个必要条件,缺一不可,产生死锁的时候这四个条件一定是都满足的,那么就表示,要想避免死锁,破坏其中一个条件即可。
死锁实现
```java
public class DeadLockCSDN {
public static void main(String[] args) {
//资源A和B
Object A = new Object();
Object B = new Object();
//第一个线程
Thread t1 = new Thread(() -> {
//先得到资源A
synchronized (A){
System.out.println("线程1已经获得资源A");
try {
//这里线程休眠两秒是为了保证线程1拿到A
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//拿到A之后再去获取B资源
synchronized (B){
System.out.println("线程1已经获得资源B");
}
}
});
//第二个线程
Thread t2 = new Thread(() -> {
//先获得资源B
synchronized (B){
System.out.println("线程2已经获得资源B");
try {
//保证线程2 获得资源B
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//再去请求获得A资源
synchronized (A){
System.out.println("线程2已经获得资源A");
}
}
});
t1.start();
t2.start();
}
}
```
## 三、线程上下文切换
什么是线程上下文切换
多线程的上下文切换:是指 CPU 控制权由一个已经正在运行的线程切换到另外一个就绪并等待获取 CPU 执行权的线程的过程。CPU给每个线程分配CPU时间片(机会),多线程创建并切完到另一个线程的过程,就是上下文切换。
时间片:是指 CPU分配给每个线程的执行时间段。
CPU为了能够执行多个线程,需要不停的切换执行的线程,这样才能使所有线程在一段时间内都有被执行的机会。CPU通过时间片分配算法来循环执行任务,当前任务执行一个时间片后切换到下一个任务。但是,在切换前会保存上一个任务的状态,以便下次切换回这个任务时,可以再加载这个任务的状态。所以任务从保存到再加载的过程就是一次上下文切换。
线程上下文切换的原因
当前执行任务(线程)的时间片用完之后,系统CPU正常调度下一个任务中断处理,在中断处理中,其他程序”打断”了当前正在运行的程序。当CPU接收到中断请求时,会在正在运行的程序和发起中断请求的程序之间进行一次上下文切换。中断分为硬件中断和软件中断,软件中断包括因为IO阻塞、未抢到资源或者用户代码等原因,线程被挂起。
用户态切换,对于一些操作系统,当进行用户态切换时也会进行一次上下文切换,虽然这不是必须的。
多个任务抢占锁资源,在多任务处理中,CPU会在不同程序之间来回切换,每个程序都有相应的处理时间片,CPU在两个时间片的间隔中进行上下文切换。
理解:每个线程根据算法(优先、高响应比、多级队列反馈、时间片轮转)执行完了自己的时间片后,即使该线程还没有执行完毕,为了兼顾到密集型和长期作业,CPU也需要中断,然后将就绪态的下一个线程执行。
Linux系统下可以使用vmst[at命令](https://so.csdn.net/so/search?q=at命令&spm=1001.2101.3001.7020)来查看上下文切换的次数, 其中cs列就是指上下文切换的数目(一般情况下, 空闲系统的上下文切换每秒大概在1500以下)。
线程上下文切换存在的问题
上下文切换会导致额外的开销,常常表现为高并发执行时速度会慢串行,因此减少上下文切换次数便可以提高多线程程序的运行效率。
直接消耗:指的是CPU寄存器需要保存和加载, 系统调度器的代码需要执行, TLB实例需要重新加载, CPU 的pipeline需要刷掉。
间接消耗:指的是多核的cache之间得共享数据, 间接消耗对于程序的影响要看线程工作区操作数据的大小。
线程上下文切换优化
1、无锁并发编程:多线程处理数据时,可以用一些办法来避免使用锁,如将数据的ID按照Hash取模分段,不同的线程处理不同段的数据。
2、CAS算法:Java的Atomic包使用CAS算法来更新数据,而不需要加锁。
3、使用最少线程:避免创建不必要的线程,比如,任务量很小,使用多线程处理,就容易造成线程等待。
4、协程:单线程里实现多任务的调度,并在单线程里维持多个任务间的切换。
**合理设置线程数目既可以最大化利用CPU,又可以减少线程切换的开销。**
- 高并发,低耗时的情况,建议少线程。
- 低并发,高耗时的情况:建议多线程。
- 高并发高耗时,要分析任务类型、增加排队、加大线程数。
## 四、IO多路复用
介绍:IO 多路复用是一种同步 IO 模型,实现一个线程可以监视多个文件句柄。一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;没有文件句柄就绪时会阻塞应用程序,交出 cpu。IO 是指网络 IO,多路指多个TCP连接(即 socket 或者 channel),复用指复用一个或几个线程。
意思说一个或一组线程处理多个 TCP 连接。最大优势是减少系统开销小,不必创建过多的进程/线程,也不必维护这些进程/线程。IO 多路复用的三种实现方式:select、poll、epoll。
1、select机制(NIO)
> 优点:适用性好,全平台可用
>
> 缺点:采用轮询的方式全盘扫描,会随着文件描述符 FD 数量增多而性能下降。
> 每次调用 select(),都需要把 fd 集合从用户态拷贝到内核态,并进行遍历(消息传递都是从内核到用户空间)。
> 单个进程打开的 FD 是有限制(通过FD_SETSIZE设置)的,默认是 1024 个,可修改宏定义,但是效率仍然慢。
2、poll(NIO)
> 和select机制相同,只是底层使用链表实现,没有最大数量限制
3、epoll(AIO)
> epoll有EPOLLLT和EPOLLET两种触发模式,LT是默认的模式,ET是“高速”模式。LT模式下,只要这个fd还有数据可读,每次 epoll_wait都会返回它的事件,提醒用户程序去操作,而在ET(边缘触发)模式中,它只会提示一次,直到下次再有数据流入之前都不会再提示了,无 论fd中是否还有数据可读。所以在ET模式下,read一个fd的时候一定要把它的buffer读光,也就是说一直读到read的返回值小于请求值,或者 遇到EAGAIN错误。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
==epoll的好处==
epoll为什么要有EPOLLET触发模式?
如果采用EPOLLLT模式的话,系统中一旦有大量你不需要读写的就绪文件描述符,它们每次调用epoll_wait都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率.。而采用EPOLLET这种边沿触发模式的话,当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符
epoll的优点:
1、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口);
2、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;
即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
3、 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
### 总结
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
## 五、进程和线程
1、根本区别
==进程和线程的根本区别是进程是操作系统(OS)资源分配的基本单位,而线程是处理器(CPU)任务调度和执行的基本单位。==
2、资源开销:
每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
3、包含关系:
如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线
同完成的;线程是进程的一部分,所行过程不是一条线的,而是多条线(线耗)其被称为轻权进程或者轻量级进程。
4、内存分配:
同一进程的线程共享本进程的内存空间和资源,而进程之间的地址空间和资源是相互独立的。
5、影响关系:
一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
6、执行过程:
每个独立的进程有程序运行的入口、顺序执行序列和程序出口。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,两者均可并发执行。
### 5.1 进程、线程、协程的概念
进程:是并发执行的程序在执行过程中分配和管理资源的基本单位,是一个动态概念,竞争计算机系统资源的基本单位。
线程:是进程的一个执行单元,是进程内科调度实体。比进程更小的独立运行的基本单位。线程也被称为轻量级进程。
协程:是一种比线程更加轻量级的存在。一个线程也可以拥有多个协程。其执行过程更类似于子例程,或者说不带返回值的函数调用。
### 5.2 线程间的同步的方式有哪些?
线程同步是两个或多个共享关键资源的线程的并发执行。应该同步线程以避免关键的资源使用冲突。
下面是几种常见的线程同步的方式:
1. **互斥锁(Mutex)**:采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。比如 Java 中的 `synchronized` 关键词和各种 `Lock` 都是这种机制。
2. **读写锁(Read-Write Lock)**:允许多个线程同时读取共享资源,但只有一个线程可以对共享资源进行写操作。
3. **信号量(Semaphore)**:它允许同一时刻多个线程访问同一资源,但是需要控制同一时刻访问此资源的最大线程数量。
4. **屏障(Barrier)**:屏障是一种同步原语,用于等待多个线程到达某个点再一起继续执行。当一个线程到达屏障时,它会停止执行并等待其他线程到达屏障,直到所有线程都到达屏障后,它们才会一起继续执行。比如 Java 中的 `CyclicBarrier` 是这种机制。
5. **事件(Event)** :Wait/Notify:通过通知操作的方式来保持多线程同步,还可以方便的实现多线程优先级的比较操作。
### 5.3 进程间的通信方式有哪些?
**管道/匿名管道(Pipes)**:用于具有亲缘关系的父子进程间或者兄弟进程之间的通信。
**有名管道(Named Pipes)** : 匿名管道由于没有名字,只能用于亲缘关系的进程间通信。为了克服这个缺点,提出了有名管道。有名管道严格遵循 **先进先出(First In First Out)** 。有名管道以磁盘文件的方式存在,可以实现本机任意两个进程通信。
**信号(Signal)**:信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生;
**消息队列(Message Queuing)**:消息队列是消息的链表,具有特定的格式,存放在内存中并由消息队列标识符标识。管道和消息队列的通信数据都是先进先出的原则。与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即,操作系统重启)或者显式地删除一个消息队列时,该消息队列才会被真正的删除。消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取.比 FIFO 更有优势。**消息队列克服了信号承载信息量少,管道只能承载无格式字 节流以及缓冲区大小受限等缺点。**
**信号量(Semaphores)**:信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。这种通信方式主要用于解决与同步相关的问题并避免竞争条件。
**共享内存(Shared memory)**:使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。可以说这是最有用的进程间通信方式。
**套接字(Sockets)** : 此方法主要用于在客户端和服务器之间通过网络进行通信。套接字是支持 TCP/IP 的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点,简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。
### 5.4 JAVA中线程同步方式
线程同步主要包括四种方式:
- 互斥量`pthread_mutex_`
- 读写锁`pthread_rwlock_`
- 条件变量`pthread_cond_`
- 信号量`sem_`
> 1、synchronized 关键字
>
> 2、Lock 接口
>
> 3、volatile
>
> 4、使用重入锁实现线程同步ReenreantLock类
>
> 5、使用局部变量实现线程同步 如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,
>
> 6、使用阻塞队列实现线程同步LinkedBlockingQueue 类
>
> 7、使用原子变量实现线程同步AtomicInteger类
## 六、HTTP和HTTPS的区别
**1、加密**
加密是 HTTP 和 HTTPS 之间的主要区别之一。HTTPS 使用 SSL 或 TLS 来加密数据,使其比 HTTP 安全得多。当通过 HTTPS 传输时,数据在通过 Internet 发送之前被加密。这种加密有助于防止未经授权访问敏感数据,例如信用卡号和密码。
**2、证书认证**
证书认证是 HTTP 和 HTTPS 的另一个区别。当 Web 浏览器通过 HTTPS 连接到 Web 服务器时,服务器会向浏览器发送数字证书。该证书包含特定于服务器的信息,包括服务器的公钥。浏览器随后使用此证书与服务器建立安全连接。
**3、端口号**
HTTP 使用端口 80,而 HTTPS 使用端口 443。这意味着当您通过 HTTP 访问网站时,URL 以 开头http://,而通过 HTTPS 的 URL 以 开头https://。
**4、表现**
由于加密和解密数据的额外开销,HTTPS 通常比 HTTP 慢。然而,SSL 和 TLS 协议的进步显着降低了这种开销,使 HTTPS 比以前快得多。
## 七、HTTP 1.0/1.1/2.0/3.0
==**HTTP/1.0** 默认是短连接,可以强制开启,HTTP/1.1 默认长连接,HTTP/2.0 采用**多路复用**,HTTP/3.0基于UDP==
**HTTP/1.0**
- 默认使用**短连接**,每次请求都需要建立一个 TCP 连接。它可以设置`Connection: keep-alive` 这个字段,强制开启长连接。
**HTTP/1.1**
- 引入了持久连接,即 TCP 连接默认不关闭,可以被多个请求复用。
- 分块传输编码,即服务端每产生一块数据,就发送一块,用” 流模式” 取代” 缓存模式”。
- 管道机制,即在同一个 TCP 连接里面,客户端可以同时发送多个请求。
**HTTP/2.0**
- 二进制协议,1.1 版本的头信息是文本(ASCII 编码),数据体可以是文本或者二进制;2.0 中,头信息和数据体都是二进制。
- 完全多路复用,在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,而且不用按照顺序一一对应。
- 报头压缩,HTTP 协议不带有状态,每次请求都必须附上所有信息。Http/2.0 引入了头信息压缩机制,使用 gzip 或 compress 压缩后再发送。
- 服务端推送,允许服务器未经请求,主动向客户端发送资源。
### [#](https://tobebetterjavaer.com/sidebar/sanfene/network.html#_16-http-3-了解吗)16.HTTP/3 了解吗?
HTTP/3 主要有两大变化,**传输层基于 UDP**、使用**QUIC 保证 UDP 可靠性**。
HTTP/2 存在的一些问题,比如重传等等,都是由于 TCP 本身的特性导致的,所以 HTTP/3 在 QUIC 的基础上进行发展而来,QUIC(Quick UDP Connections)直译为快速 UDP 网络连接,底层使用 UDP 进行数据传输。
HTTP/3 主要有这些特点:
- 使用 UDP 作为传输层进行通信
- 在 UDP 的基础上 QUIC 协议保证了 HTTP/3 的安全性,在传输的过程中就完成了 TLS 加密握手
- HTTPS 要建⽴⼀个连接,要花费 6 次交互,先是建⽴三次握⼿,然后是 TLS/1.3 的三次握⼿。QUIC 直接把以往的 TCP 和 TLS/1.3 的 6 次交互合并成了 **3** 次,减少了交互次数。
- QUIC 有⾃⼰的⼀套机制可以保证传输的可靠性的。当某个流发⽣丢包时,只会阻塞这个流,其他流不会受到影响。
# ==数据库相关==
## **一、数据库基本操作**
- 创建数据库MySQL命令:
```sql
create database 数据库名称;
```
- 删除数据库MySQL命令:
```sql
drop database 数据库名称;
```
- 查询出MySQL中所有的数据库MySQL命令:
```sql
show databases;
```
- 将数据库的字符集修改为gbk MySQL命令:
```sql
alter database db1 character set gbk;
```
- 查看当前使用的数据库 MySQL命令:
```sql
select database();
```
- 创建表
```sql
create table 表名(
字段1 字段类型,
字段2 字段类型,
…
字段n 字段类型
);
```
- 查看当前数据库中所有表 MySQL命令:
```sql
show tables;
```
- 查看表的字段信息 MySQL命令:
```sql
desc 数据库名称;
```
- 修改表名 MySQL命令:
```sql
alter table student rename to stu;
```
- 修改字段数据类型 MySQL命令:
```sql
alter table stu modify sname int;
```
- 增加字段 MySQL命令:
```sql
alter table stu add address varchar(50);
```
- 删除字段 MySQL命令:
```sql
alter table stu drop address;
```
- 删除数据表 MySQL命令:
```sql
drop table 表名;
```
- 外键约束即FOREIGN KEY常用于多张表之间的约束。基本语法如下:
```sql
-- 在创建数据表时语法如下:
CONSTRAINT 外键名 FOREIGN KEY (从表外键字段) REFERENCES 主表 (主键字段)
-- 将创建数据表创号后语法如下:
ALTER TABLE 从表名 ADD CONSTRAINT 外键名 FOREIGN KEY (从表外键字段) REFERENCES 主表 (主键字段);
```
- 删除外键 MySQL命令:
```sql
alter table 从表名 drop foreign key 外键名;
```
## 二、数据库疑难
mybitis中foreach使用需要让服务器允许执行多条sql。

## 三、**数据库连接、重启相关**
**==一、启动、停止、重启==**
一、启动
1、使用 service 启动:service mysqld start
2、使用 mysqld 脚本启动:/etc/inint.d/mysqld start
3、使用 safe_mysqld 启动:safe_mysqld&
二、停止
1、使用 service 启动:service mysqld stop
2、使用 mysqld 脚本启动:/etc/inint.d/mysqld stop
3、mysqladmin shutdown
三、重启
1、使用 service 启动:service mysqld restart
2、使用 mysqld 脚本启动:/etc/inint.d/mysqld restart 展开
## **四、数据库原理**
### 1、索引
#### 1.1 索引结构


#### 1.2 ==B+tree的好处:==

#### 1.3 索引查询过程
二级索引可以多个,自己设置,聚集索引默认为主键,若无通过自动创建。
过程:
- 先按照索引在B+树中查询到对应的聚集索引。
- 再通过聚集索引查询到该行的数据。

#### 1.4 索引创建&删除
- 创建
```sql
//创建唯一(聚集)索引,unique关键字
create unique index idx_xxx on user(xxx);(表名+字段名)
//创建二级索引,无unique关键字即可
create index idx_xxx on user(xxx);(表名+字段名)
```
- 删除
```sql
drop index xxx on xxx;
```
#### 1.5 查询某一张表的索引
```sql
show index from xxx;
```
## 五、数据库杂语句
```sql
-- 查看服务器语句使用量
show GLOBAL STATUS LIKE 'Com_______';
```
- 结果大致样子

## 六、数据库八股
### 1、快照读和当前读
快照读就是普通的读操作,而当前读包括了 **加锁的读取** 和 **DML**(DML只是对表内部的数据操作,不涉及表的定义,结构的修改。主要包括insert、update、deletet) 操作。
当B事务修改了内容时,快照读不能获取修改的内容,相当于还是读取CPU中而不是内存中,而当前读则是直接读取内存中的最新的值,能够获取到B事务修改的内容。
当前读就是读取最新数据,而不是历史版本的数据。加锁的 SELECT,或者对数据进行增删改都会进行当前读。这有点像是 Java 中的 volatile 关键字,被 volatile 修饰的变量,进行修改时,JVM 会强制将其写回内存,而不是放在 CPU 缓存中,进行读取时,JVM 会强制从内存读取,而不是放在 CPU 缓存中。这样就能保证其可见行,保证每次读取到的都是最新的值。如果没有用 volatile 关键字修饰,变量的值可能会被放在 CPU 缓存中,这就导致读取到的值可能是某次修改的值,不能保证是最新的值。
### 2、幻读和不可重复读
**幻读 VS 不可重复读**
- 幻读重点在于数据是否存在。原本不存在的数据却真实的存在了,这便是幻读。在同一个事务中,第一次读取到结果集和第二次读取到的结果集不同。(对比上面的例子,当B事务INSERT以后,A事务中再进行插入,此次插入相当于一次隐式查询)。引起幻读的原因在于另一个事务进行了INSERT操作。
幻读是增加或删除了一些东西
- 不可重复读重点在于数据是否被改变了。在一个事务中对同一条记录进行查询,第一次读取到的数据和第二次读取到的数据不一致,这便是不可重复读。引起不可重复读的原因在于另一个事务进行了UPDATE或者是DELETE操作。
不可重复读是修改了已有的东西被读到了
**简单来说:幻读是说数据的条数发生了变化,原本不存在的数据存在了。不可重复读是说数据的内容发生了变化,原本存在的数据的内容发生了改变。**
==幻读的解决方法之一是加上间隙锁==

在一行行扫描的过程中,不仅将给行加上了行锁,还给行两边的空隙,也加上了间隙锁。MySQL将行锁 + 间隙锁组合统称为 next-key lock,通过 next-key lock 解决了幻读问题。
### 3、事务的隔离级别
1、READ UNCOMMITTED:读未提交,也叫未提交读,该隔离级别的事务可以看到其他事务中未提交的数据。该隔离级别因为可以读取到其他事务中未提交的数据,⽽未提交的数据可能会发⽣回滚, 因此我们把该级别读取到的数据称之为脏数据,把这个问题称之为脏读。
2、READ COMMITTED:读已提交,也叫提交读,该隔离级别的事务能读取到已经提交事务的数据, 因此它不会有脏读问题。但由于在事务的执⾏中可以读取到其他事务提交的结果,所以在不同时间 的相同 SQL 查询中,可能会得到不同的结果,这种现象叫做不可重复读。
3、REPEATABLE READ:可重复读,是 MySQL 的默认事务隔离级别,它能确保同⼀事务多次查询的结果⼀致。但也会有新的问题,⽐如此级别的事务正在执⾏时,另⼀个事务成功的插⼊了某条数据,但因为它每次查询的结果都是⼀样的,所以会导致查询不到这条数据,⾃⼰重复插⼊时⼜失败(因为唯⼀约束的原因)。明明在事务中查询不到这条信息,但⾃⼰就是插⼊不进去,这就叫幻读(Phantom Read)。
4、SERIALIZABLE:串行化(序列化),事务最⾼隔离级别,它会强制事务排序,使之不会发⽣冲突,从⽽解决 了脏读、不可重复读和幻读问题,但因为执⾏效率低,所以真正使⽤的场景并不多。
### 4、MVCC
==定义:==
MVCC是多版本并发控制 Multi-Version Concurrent Contrl。
它是MySQL中的提高性能的一种方式,配合Undo log 和版本链,替代锁,让不同事物的读-写、写-读操作可以并发的执行,从而提升系统的性能。
MVCC 在 MySQL InnoDB 中的实现主要是为了提高数据库并发性能。一般是在使用读已提交(PEAD COMMITTED)和可重复读(REPEATABLE READ)隔离级别的事务中实现。
用自己的话说就是:
多版本意思是指数据库中一条数据有多个版本同时存在,在某个事务对其进行具体操作的时候,是需要查看这一条记录的隐藏列事务版本的id,比对事务id并根据事物的隔离级别从而去判断是哪个版本的数据。
==准确的说,MVCC多版本并发控制指的是 “维持一个数据的多个版本,使得读写操作没有冲突” 这么一个概念。==
==MVCC的优点==
- MVCC在MySQL InnoDB中的实现主要是为了提高数据库的并发性能,用更好的方式去处理读-写或写-读之间的冲突,也能做到不加锁,非阻塞并发读,提高了数据库并发读写的性能。
- MVCC还可以解决脏读,幻读,不可重复读等事务隔离问题。但它还不能解决更新丢失的问题。
所以MVCC能够解决读-写之间的并发控制,但它不能解决写-写之间的的并发控制
==**基本原理**==
因为MVCC的目的就是控制并发控制的,在数据库中的实现,为了解决读写的冲突问题。
*它的实现原理主要依赖3个模块:隐藏字段、undo日志、Read View来实现的。*
==隐藏字段==
对于使用 InnoDB 存储引擎的表来说,它的聚簇索引记录中都包含两个必要的隐藏列。
● trx_id:每次对某条聚簇索引记录进行改动的时候,都会把对应的事务id赋值给trx_id进行记录的隐藏列。
● roll_pointer:在每次对某条聚簇索引记录进行改动的时候,都会把旧版本写入undo日志当中,然后这个隐藏列就相当于一个指针的作用,我们可以通过roll_pointer来找到该记录修改之前的信息。
==undo日志==
undo log主要分为两种:
insert undo log:
代表事务在insert新记录时产生的undo log,只在事务回滚时需要,并且在事务提交后就立即删除。
update undo log:
事务在进行update或delete时产生的undo log;不仅在事务回滚的时需要,在快照时也需要;所以不能随便删除,只有在快速读或事务回滚不涉及该日志时,对应的日志才会被purge线程统一清除。
==Read View(读视图)==
对于使用READ UNCOMMITTED(读未提交)隔离级别的事务来说,直接读取记录的最新版本就好了,对于使用SERIALIZABLE(串行化)隔离级别的事务来说,使用加锁的方式来访问记录。
所以在InnoDB引擎中设计了一个ReadView的概念。
Read View就是事务进行快照读操作的时候产生的读视图(Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的ID(当每个事务开启时,都会分配一个ID,这个ID是自增的,所以最新的事务,ID越大)。
在MySQL当中,READ COMMITTED和REPEATABLE READ 隔离级别的一个非常大的区别就是它们生成的Read View 的时机不同。
● READ COMMITTED:每次读取数据前都生成一个ReadView;
● REPEATABLE READ:在第一个读取数据时生成一个ReadView;

### 5、为什么MySQL使用B+树

==简洁版==
`先看原因:`
1.B+树减少了IO次数,效率更高
(这里这么理解:-----就是减少了磁盘的访问次数,毕竟内存速度要比磁盘快的多)
2.B+树查询跟稳定,因为所有数据放在叶子节点
3.B+树范围查询更好,因为叶子节点指向下一个叶子结点
==详细:==
```java
1、在B树的基础上每个节点存储的关键字数更多,树的层级更少所以查询数据更快。
2、所有关键字指针都存在叶⼦节点,所以每次查找的次数都相同所以查询速度更稳定。
3、除此之外,B+树的叶⼦节点是跟后序节点相连接的,这对范围查找是⾮常有⽤的。
看到没B+树的⾮叶⼦节点是主键,主键占⽤的空间越⼩,每个节点能放的主键就能更多,这就是为什么我们的主键 ⼀般不设置太⼤的原因。主键占⽤的空间⼩,能降低树⾼,减少IO次数
```
1、B+树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据。之所以这么做是因为在数据库中页的大小是固定的,innodb中页的默认大小是16KB。如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少,数据查询的效率也会更快。另外,B+树的阶数是等于键值的数量的,如果我们的B+树一个节点可以存储1000个键值,那么3层B+树可以存储1000×1000×1000=10亿个数据。一般根节点是常驻内存的,所以一般我们查找10亿数据,只需要2次磁盘IO。
2、因为B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。而B树因为数据分散在各个节点,要实现这一点是很不容易的。
#### 5.1、为什么不用平衡二叉树?
> **为什么不用普通二叉树?**
普通二叉树存在退化的情况,如果它退化成链表,相当于全表扫描。平衡二叉树相比于二叉查找树来说,查找效率更稳定,总体的查找速度也更快。
> **为什么不用平衡二叉树呢?**
读取数据的时候,是从磁盘读到内存。如果树这种数据结构作为索引,那每查找一次数据就需要从磁盘中读取一个节点,也就是一个磁盘块,但是平衡二叉树可是每个节点只存储一个键值和数据的,如果是 B+ 树,可以存储更多的节点数据,树的高度也会降低,因此读取磁盘的次数就降下来啦,查询效率就快。
### 6、索引
MySQL的索引包括普通索引、唯一性索引、全文索引、单列索引和空间索引等。
从功能逻辑上说,索引主要有4类,分别是普通索引、唯一索引、主键索引、全文索引。
按照物理实现方式,索引可以分为2种:聚簇索引和非聚簇索引。
按照作用字段个数进行划分,分成单列索引和联合索引。
1. 普通索引(还有前缀索引)
在创建普通索引时,不附加任何限制条件,只是用于提高查询效率。这类索引可以创建在任何数据类型中,其值是否唯一和非空,要由字段本身的完整性约束条件决定。建立索引以后,可以通过索引进行查询。例如,在表 student 的字段 name 上建立一个普通索引,查询记录时就可以根据该索引进行查询。
2. 唯一性索引
使用 UNIQUE 参数可以设置索引为唯一性索引,在创建唯一性索引时,限制该索引的值必须是唯一的,但允许有空值。在一张数据表里可以有多个唯一索引。
例如,在表 student 的字段 email 中创建唯一性索引,那么字段 email 的值就必须是唯一的。通过唯一性索引,可以更快速地确定某条记录。
3. 主键索引
主键索引就是一种特殊的唯一性索引,在唯一索引的基础上增加了不为空的约束,也就是 NOT NULL + UNIQUE,一张表里最多只有一个主键索引。
Why?这是由主键索引的物理实现方式决定的,因为数据存储在文件中只能按照一种顺序进行存储。
4. 单列索引
在表的单个字段上创建索引。单列索引只根据该字段进行索引。单列索引可以是普通索引,也可以是唯一性索引,还可以是全文索引。只要保证该索引只对应一个字段即可。一个表可以有多个单列索引。
5. 多列(组合、联合)索引
多列索引是在表的多个字段组合上创建一个索引。该索引指向创建时对应的多个字段,可以通过这几个字段进行查询,但是只有查询条件中使用了这些字段的第一个字段时才会被使用。例如,在表的字段 id、name 和 gender 上建立一个多列索引 idx_id_name_gender ,只有在查询条件中使用了字段 id 时该索引才会被使用。使用组合索引时遵循最左前缀集合。
6. 全文索引
全文索引(也称全文检索)是目前搜索引擎使用的一种关键技术。它能够利用【分词技术】等多种算法智能分析出文本文字中关键词的频率和重要性,然后按照一定的算法规则智能地筛选出我们想要的搜索结果。全文索引非常适合大型数据集,对于小的数据集,它的用处比较小。
使用参数 FULLTEXT 可以设置索引为全文索引。在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引只能创建在 CHAR、VARCHAR 或 TEXT 类型及其系列类型的字段上,查询数据量较大的字符串类型的字段时,使用全文索引可以提高查询速度。例如,表 student 的字段 infomation 是 TEXT 类型,该字段包含了很多文字信息。在字段 information 上建立全文索引后,可以提高查询字段 information 的速度。
全文索引典型的有两种类型:自然语言的全文索引和布尔全文索引。
自然语言搜索引擎将计算每一个文档对象和查询的相关度。这里,相关度是基于匹配的关键词的个数,以及关键词在文档中出现的次数。在整个索引中出现次数越少的词语,匹配时的相关度就越高。相反,非常常见的单词将不会被搜索,如果一个词语在超过50%的记录中都出现了,那么自然语言的搜索将不会搜索这类词语。
随着大数据时代的到来,关系型数据库应对全文索引的需求已力不从心,逐渐被 solr、ElasticSearch 等专门的搜索引擎所替代。
7、空间索引
#### 6.1、什么时候需要 / 不需要创建索引?
索引最大的好处是提高查询速度,但是索引也是有缺点的,比如:
- 需要占用物理空间,数量越大,占用空间越大;
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增大;
- 会降低表的增删改的效率,因为每次增删改索引,B+ 树为了维护索引有序性,都需要进行动态维护。
所以,索引不是万能钥匙,它也是根据场景来使用的。
[#](https://www.xiaolincoding.com/mysql/index/index_interview.html#什么时候适用索引)什么时候适用索引?
- 字段有唯一性限制的,比如商品编码;
- 经常用于 `WHERE` 查询条件的字段,这样能够提高整个表的查询速度,如果查询条件不是一个字段,可以建立联合索引。
- 经常用于 `GROUP BY` 和 `ORDER BY` 的字段,这样在查询的时候就不需要再去做一次排序了,因为我们都已经知道了建立索引之后在 B+Tree 中的记录都是排序好的。
[#](https://www.xiaolincoding.com/mysql/index/index_interview.html#什么时候不需要创建索引)什么时候不需要创建索引?
- `WHERE` 条件,`GROUP BY`,`ORDER BY` 里用不到的字段,索引的价值是快速定位,如果起不到定位的字段通常是不需要创建索引的,因为索引是会占用物理空间的。
- 字段中存在大量重复数据,不需要创建索引,比如性别字段,只有男女,如果数据库表中,男女的记录分布均匀,那么无论搜索哪个值都可能得到一半的数据。在这些情况下,还不如不要索引,因为 MySQL 还有一个查询优化器,查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。
- 表数据太少的时候,不需要创建索引;
- 经常更新的字段不用创建索引,比如不要对电商项目的用户余额建立索引,因为索引字段频繁修改,由于要维护 B+Tree的有序性,那么就需要频繁的重建索引,这个过程是会影响数据库性能的。
#### 6.2、索引失效的情况
- 查询条件包含 or,可能导致索引失效
- 如果字段类型是字符串,where 时一定用引号括起来,否则会因为隐式类型转换,索引失效
- like 通配符可能导致索引失效。
- 联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。
- 在索引列上使用 mysql 的内置函数,索引失效。
- 对索引列运算(如,+、-、*、/),索引失效。
- 索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。
- 索引字段上使用 is null, is not null,可能导致索引失效。
- 左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效。
- MySQL 优化器估计使用全表扫描要比使用索引快,则不使用索引。
### 7、AUTO-INC锁
==**在插入数据时,会加一个表级别的 AUTO-INC 锁**==
- 当 innodb_autoinc_lock_mode = 0,就采用 AUTO-INC 锁,语句执行结束后才释放锁;
- 当 innodb_autoinc_lock_mode = 2,就采用轻量级锁,申请自增主键后就释放锁,并不需要等语句执行后才释放。
- 当 innodb_autoinc_lock_mode = 1:
- 普通 insert 语句,自增锁在申请之后就马上释放;
- 类似 insert … select 这样的批量插入数据的语句,自增锁还是要等语句结束后才被释放;
当 innodb_autoinc_lock_mode = 2 是性能最高的方式,但是当搭配 binlog 的日志格式是 statement 一起使用的时候,在「主从复制的场景」中会发生**数据不一致的问题**。
如果 innodb_autoinc_lock_mode = 2,意味着「==申请自增主键后就释放锁,不必等插入语句执行完==」。那么就可能出现这样的情况:
- session B 先插入了两个记录,(1,1,1)、(2,2,2);
- 然后,session A 来申请自增 id 得到 id=3,插入了(3,5,5);
- 之后,session B 继续执行,插入两条记录 (4,3,3)、 (5,4,4)。
可以看到,**session B 的 insert 语句,生成的 id 不连续**。
当「主库」发生了这种情况,binlog 面对 t2 表的更新只会记录这两个 session 的 insert 语句,如果 binlog_format=statement,记录的语句就是原始语句。记录的顺序要么先记 session A 的 insert 语句,要么先记 session B 的 insert 语句。
但不论是哪一种,这个 binlog 拿去「从库」执行,这时从库是按「顺序」执行语句的,只有当执行完一条 SQL 语句后,才会执行下一条 SQL。因此,在**从库上「不会」发生像主库那样两个 session 「同时」执行向表 t2 中插入数据的场景。所以,在备库上执行了 session B 的 insert 语句,生成的结果里面,id 都是连续的。这时,主从库就发生了数据不一致**。
要解决这问题,binlog 日志格式要设置为 row,这样在 binlog 里面记录的是主库分配的自增值,到备库执行的时候,主库的自增值是什么,从库的自增值就是什么。
==所以,**当 innodb_autoinc_lock_mode = 2 时,并且 binlog_format = row,既能提升并发性,又不会出现数据一致性问题**。==
### 8、锁相关
#### 8.1 幻读解决以及死锁问题
**Innodb 引擎为了解决「可重复读」隔离级别下的幻读问题,就引出了 next-key 锁**,它是记录锁和间隙锁的组合。
- Record Lock,记录锁,锁的是记录本身;
- Gap Lock,间隙锁,锁的就是两个值之间的空隙,以防止其他事务在这个空隙间插入新的数据,从而避免幻读现象。
普通的 select 语句是不会对记录加锁的,因为它是通过 MVCC 的机制实现的快照读,如果要在查询时对记录加行锁,可以使用下面这两个方式:
```sql
begin;
//对读取的记录加共享锁
select ... lock in share mode;
commit; //锁释放
begin;
//对读取的记录加排他锁
select ... for update;
commit; //锁释放
```
死锁原因:两个事务都持有相同的间隙锁,**而插入意向锁与间隙锁是冲突的,所以当其它事务持有该间隙的间隙锁时,需要等待其它事务释放间隙锁之后,才能获取到插入意向锁**,而只有等待对方的间隙锁释放后才能执行接下来的步骤,导致互等,死锁。
临键锁就是记录锁(Record Locks)和间隙锁(Gap Locks)的结合,即除了锁住记录本身,还要再锁住索引之间的间隙。当我们使用范围查询,并且命中了部分`record`记录,此时锁住的就是临键区间。注意,临键锁锁住的区间会包含最后一个 record 的右边的临键区间。例如`select * from t where id > 5 and id <= 7 for update;`会锁住(4,7]、(7,+∞)。mysql 默认行锁类型就是`临键锁(Next-Key Locks)`。当使用唯一性索引,等值查询匹配到一条记录的时候,临键锁(Next-Key Locks)会退化成记录锁;没有匹配到任何记录的时候,退化成间隙锁。
> `间隙锁(Gap Locks)`和`临键锁(Next-Key Locks)`都是用来解决幻读问题的,在`已提交读(READ COMMITTED)`隔离级别下,`间隙锁(Gap Locks)`和`临键锁(Next-Key Locks)`都会失效!
#### 8.2、什么时候使用表锁和行锁
1. 对于表级锁而言,当执行 DDL 语句去修改表结构时,会使用表级锁。
> 其他:主键自增的情况下插入数据会使用**AUTO-INC 锁**(表锁),AUTO-INC 锁是特殊的表锁机制,锁**不是再一个事务提交后才释放,而是再执行完插入语句后就会立即释放**。
2. 对于行级锁而言,一般情况下都会默认使用行级锁,貌似是需要有索引匹配到才行。
#### 8.3、意向锁的作用
意向锁是表级锁,某一行加锁时需要先加意向锁,假如没有意向锁,那么我们就得遍历表中所有数据行来判断有没有行锁;有了意向锁这个表级锁之后,则我们直接判断一次就知道表中是否有数据行被锁定了。
### 9、索引下推
**图一:不使用ICP技术(过程使用数字符号标示,如①②③等)**

**图二:使用ICP技术(过程使用数字符号标示,如①②③等)**

理解:相当于原本是回表查出所有的数据后再进行筛选,使用索引下推后变为回表前就先使用where对联合索引中的其他字段进行筛选,回表后再进行第二次筛选,这样减少了回表的次数。
### 10、分库分表
==分库==
**垂直分库** 就是把单一数据库按照业务进行划分,不同的业务使用不同的数据库,进而将一个数据库的压力分担到多个数据库。

**水平分库** 是把同一个表按一定规则拆分到不同的数据库中,每个库可以位于不同的服务器上,这样就实现了水平扩展,解决了单表的存储和性能瓶颈的问题。

垂直分库分担数据库压力,水平分库增加存储空间
==分表==
**分表** 就是对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分。
**垂直分表** 是对数据表列的拆分,把一张列比较多的表拆分为多张表。
举个例子:我们可以将用户信息表中的一些列单独抽出来作为一个表。
**水平分表** 是对数据表行的拆分,把一张行比较多的表拆分为多张表,可以解决单一表数据量过大的问题。
举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
水平拆分只能解决单表数据量大的问题,为了提升性能,我们通常会选择将拆分后的多张表放在不同的数据库中。也就是说,水平分表通常和水平分库同时出现。

#### 10.1、什么情况下需要分库分表?
遇到下面几种场景可以考虑分库分表:
- 单表的数据达到千万级别以上,数据库读写速度比较缓慢。
- 数据库中的数据占用的空间越来越大,备份时间越来越长。
- 应用的并发量太大。
#### 10.2、常见的分片算法有哪些?
分片算法主要解决了数据被水平分片之后,数据究竟该存放在哪个表的问题。
- **哈希分片**:求指定 key(比如 id) 的哈希,然后根据哈希值确定数据应被放置在哪个表中。哈希分片比较适合随机读写的场景,不太适合经常需要范围查询的场景。
- **范围分片**:按照特性的范围区间(比如时间区间、ID 区间)来分配数据,比如 将 `id` 为 `1~299999` 的记录分到第一个库, `300000~599999` 的分到第二个库。范围分片适合需要经常进行范围查找的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。
- **地理位置分片**:很多 NewSQL 数据库都支持地理位置分片算法,也就是根据地理位置(如城市、地域)来分配数据。
- **融合算法**:灵活组合多种分片算法,比如将哈希分片和范围分片组合。
#### 10.3 、分库分表存在的问题
1、原本的事务不能保证原子性,需要使用分布式事务(2PC两阶段提交、3PC、TCC、可靠消息最终一致性)
2、跨库无法使用JOIN,只能通过`业务代码关联`、`增添冗余字段`、`数据异构通过ES查询`的方式解决
3、聚合函数等只能通过业务逻辑或者中间件实现而不能使用order by
4、主键ID问题,需要使用分布式ID(UUID、雪花算法、redisID、zookeeper生成唯一ID)
5、需要考虑数据库容量、迁移、扩容的问题
#### 10.4、总结
- 读写分离主要是为了将对数据库的读写操作分散到不同的数据库节点上。 这样的话,就能够小幅提升写性能,大幅提升读性能。
- 读写分离基于主从复制,MySQL 主从复制是依赖于 binlog 。
- **分库** 就是将数据库中的数据分散到不同的数据库上。**分表** 就是对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分。
- 引入分库分表之后,需要系统解决事务、分布式 id、无法 join 操作问题。
- ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理等功能。另外,ShardingSphere 的生态体系完善,社区活跃,文档完善,更新和发布比较频繁。
### 11、并发操作数据库需要注意什么
在并发操作数据库时,有一些重要的注意事项需要考虑,以确保数据的一致性、完整性和可靠性。以下是一些需要注意的方面:
1. **事务处理**:使用数据库事务来维护数据的一致性和完整性。事务是一组操作,要么全部成功执行,要么全部回滚。这可以防止在并发情况下数据损坏或不一致。
2. **锁机制**:数据库通常提供了锁机制来管理并发访问。锁可以分为共享锁(读取操作)和排他锁(写入操作)。合理地使用锁可以避免多个并发事务同时修改同一数据造成的问题,如死锁、锁竞争等。
3. **并发控制**:数据库管理系统通常具有并发控制机制,如多版本并发控制(MVCC),用于处理同时读取和写入操作。这可以防止读取脏数据(未提交的数据)和写入丢失等问题。
4. **隔离级别**:数据库提供了不同的隔离级别,用于控制并发事务之间的可见性和影响范围。常见的隔离级别包括读未提交、读提交、可重复读和串行化。选择适当的隔离级别可以平衡一致性和性能。
5. **死锁处理**:死锁是多个事务相互等待对方释放资源而无法继续执行的情况。数据库管理系统应该具备死锁检测和解除机制,以避免持续的死锁问题。
6. **并发测试**:在开发和测试阶段,需要进行并发测试,模拟多个用户同时访问数据库并执行操作。这有助于发现潜在的并发问题和性能瓶颈。
7. **连接池管理**:使用连接池来管理数据库连接,以避免频繁地打开和关闭连接,从而提高性能并减少资源消耗。
8. **优化查询**:并发操作时,数据库查询可能会成为性能瓶颈。确保你的查询经过优化,使用合适的索引和查询语句,以减少查询时间和资源消耗。
9. **错误处理和回滚**:在并发操作中,可能会发生错误。正确处理错误,并在必要时回滚事务,可以保护数据的完整性和一致性。
10. **监控和调优**:定期监控数据库的性能指标,如响应时间、并发连接数等。根据监控结果进行调优,以保持数据库的高性能和稳定性。
总之,处理并发操作数据库需要综合考虑事务管理、锁机制、并发控制、隔离级别、死锁处理等多个方面,以确保数据的可靠性和一致性。
### 12、日志相关
- **undo log(回滚日志)**:是 Innodb 存储引擎层生成的日志,实现了事务中的**原子性**,主要**用于事务回滚和 MVCC**。
- **redo log(重做日志)**:是 Innodb 存储引擎层生成的日志,实现了事务中的**持久性**,主要**用于掉电等故障恢复**;
- **binlog (归档日志)**:是 Server 层生成的日志,主要**用于数据备份和主从复制**;
### 13、为什么Redis Zset使用跳表?
1、**简单实现**
2、**更好的内存效率**,每个节点只需要记录下一层节点的指针,跳表在内存中的存储布局相对紧凑,不需要像平衡树那样维护大量的指针和额外的数据结构,因此可以在相对较少的内存中存储大量元素。
3、**高效的插入和删除操作**,跳表允许在平均情况下以O(log n)的时间复杂度执行插入、删除和查找操作。这对于有序集合来说是非常重要的,因为有序集合需要保持元素的有序性,并且需要高效地进行元素的插入和删除。
4、**可读性和维护性:** 跳表的实现相对直观,容易理解和调试。这对于Redis的开发团队和其他开发人员来说都是有益的。
缺点:
1、分层结构,当层数过高时相对于红黑树,空间消耗增加。
2、跳表并没有一个现成的实现,所以在开发中,如果你想使用跳表,必须要自己实现。
原因:**分层结构:** 跳表的核心思想是分层结构,每个层级都有一定数量的节点。这些层级在内存中占用了一定的空间。==红黑树虽然也有层级结构,但是它的高度相对较低==,而且不需要为每个节点都维护多个层级,因此在某些情况下可以在整体高度上占用更少的空间。
### 14、SQL优化
尽量避免使用子查询
用IN来替换OR
读取适当的记录LIMIT M,N,而不要读多余的记录
禁止不必要的Order By排序
总和查询可以禁止排重用union all
避免随机取记录
将多次插入换成批量Insert插入
只返回必要的列,用具体的字段列表代替 select * 语句
区分in和exists
优化Group By语句
尽量使用数字型字段
优化Join语句
#### 14.1、分页查询优化
分页优化
在数据量比较大,分页比较深的情况下,需要考虑分页的优化。
例如:
```text
select * from table where type = 2 and level = 9 order by id asc limit 190289,10;
```
优化方案:
- **延迟关联**
**操作:**查询条件放到子查询中,子查询只查主键ID,然后使用子查询中确定的主键关联查询其他的属性字段;
例如:
```text
select a.* from table a,
(select id from table where type = 2 and level = 9 order by id asc limit 190289,10 ) b
where a.id = b.id
```
说明: MySQL并不是挑过offeset行,而是取offset+N行,然后返回放弃前offset行,返回N行,那当offset特别大的时候,效率就非常的底下,要么控制返回的总页数,要么对超过特定阈值的页数进行SQL改写。
==理解:原本的SQL需要走一次二级索引通过最左前缀找到id后回表,回表后需要对所有行进行排序以及筛选(2次),而延迟关联优化先通过子查询获取主键id,再进行内连接(2次),第二种只需要在子查询中对id进行排序,这样可以减少查询的数据量,不需要对行进行排序,因此快很多==
一句话:第一种需要检索行,第二种只要检索id
**方案二:**
select * from user limit 10000,100;
select * from user where id>= (select id from user limit 10000,1) limit 100;
先定位筛选出起始点,再读取后面的100条信息
详细解释:
1、https://zhuanlan.zhihu.com/p/626142956?utm_id=0
2、https://blog.csdn.net/HongZeng_CSDN/article/details/130045243
### 15、事务ACID
**原子性**(`Atomicity`):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
**一致性**(`Consistency`):执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
**隔离性**(`Isolation`):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
**持久性**(`Durability`):一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
### 16、两阶段提交
**什么是两阶段提交**
当有数据修改时,会先将修改redo log cache和binlog cache然后在刷入到磁盘形成redo log file,当redo log file全都刷入到磁盘时(prepare 状态)和提交成功后才能将binlog cache刷入磁盘,当binlog全部刷新到磁盘后会记录一个xid,然后在relo log file上打上commit标志(commit阶段)。
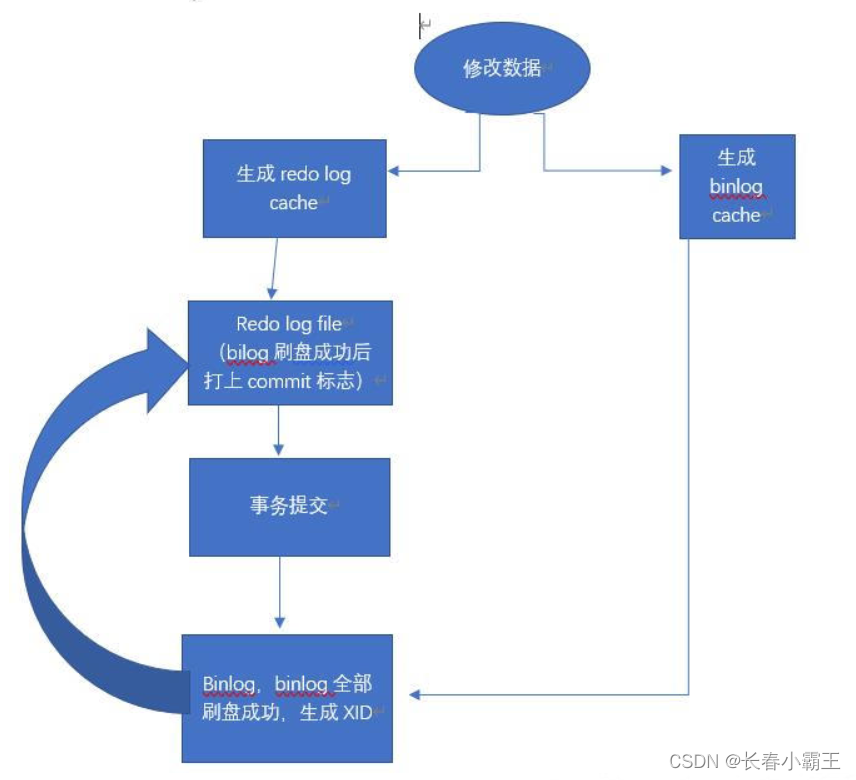
为什么要两阶段提交呢?直接提交不行吗?
我们可以假设不采用两阶段提交的方式,而是采用“单阶段”进行提交,即要么先写入 redo log,后写入 binlog;要么先写入 binlog,后写入 redo log。这两种方式的提交都会导致原先数据库的状态和被恢复后的数据库的状态不一致
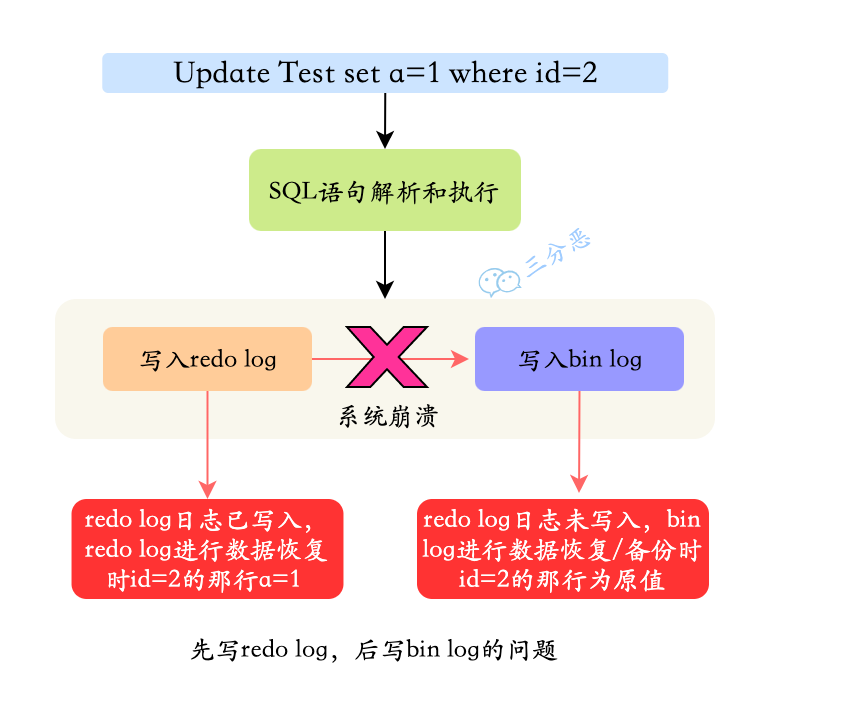
**先写入 redo log,后写入 binlog:**
在写完 redo log 之后,数据此时具有`crash-safe`能力,因此系统崩溃,数据会恢复成事务开始之前的状态。但是,若在 redo log 写完时候,binlog 写入之前,系统发生了宕机。此时 binlog 没有对上面的更新语句进行保存,导致当使用 binlog 进行数据库的备份或者恢复时,就少了上述的更新语句。从而使得`id=2`这一行的数据没有被更新。
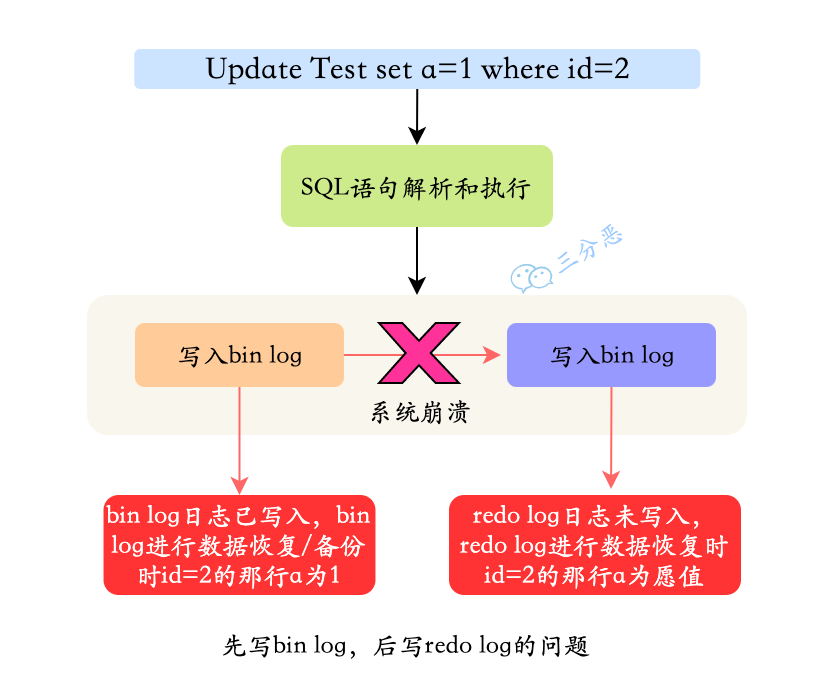
**先写入 binlog,后写入 redo log:**
写完 binlog 之后,所有的语句都被保存,所以通过 binlog 复制或恢复出来的数据库中 id=2 这一行的数据会被更新为 a=1。但是如果在 redo log 写入之前,系统崩溃,那么 redo log 中记录的这个事务会无效,导致实际数据库中`id=2`这一行的数据并没有更新。
## 七、数据库sql题目
### 1、查找每个班级分数最高的前三名

答案:
```sql
select class, name,score
FROM test_score a
WHERE (
SELECT COUNT(score) from test_score b WHERE b.class=a.class AND a.score60)
```
### 3、查询学过课程ID为‘301’和‘302’的学生的学号、姓名
```sql
select student.student_id,student.student_name
from student
where student.student_id IN(
select a.student_id
from (select student_id from score where course_id=301) as a
INNER JOIN (select student_id from score where course_id=302) as b
on a.student_id=b.student_id
);
```
### 4、查询学过学号为1005同学所有课程的同学的学号
```sql
select student.student_id,student.student_name,score.course_id
FROM student,score
where student.student_id=score.student_id and score.course_id = (select score.course_id
FROM student,score
where student.student_id=score.student_id and student.student_id=1005) AND student.student_id!=1005;
```
=代表course_id中的每一个都和1005同学学的所有课程相同
### 5、查询至少有一门课与学号为“1001”的学生所学课程相同的学生的学号和姓名
```sql
select student.student_id,student.student_name,score.course_id
from student,score
where student.student_id=score.student_id and score.course_id in (select score.course_id
from score
where score.student_id=1001);
```
in代表只要有一门相同就取出
### 6、查询比例
```sql
SELECT
SUM(CASE WHEN is_activity = 1 THEN 1 ELSE 0 END) AS successful_count,
COUNT(*) AS total_count,
(SUM(CASE WHEN is_activity = 1 THEN 1 ELSE 0 END) * 1.0 / COUNT(*)) AS success_rate
FROM announcement;
```

# ==Redis知识点==
## 1、redis的五种核心数据结构
string、hash、list、set、zset

## 2、Hash
用于电商购物车、只改变部分关键属性的情况


## 3、List
推送、信息流,可以模拟栈,每个人一个信息流栈空间,使得取出的数据自带时间顺序排序。粉丝量较大时可以后台缓慢推送(不同用户之间收到信息时间可能不同)

## 4、SET
用于点赞收藏的场景。


后端
http://localhost:8080/
前端
http://localhost:1024/
```c++
yarn serve
```
## 5、启动redis
```c++
//启动
redis-server.exe redis.windows.conf
//在开一个cmd
redis-cli.exe
//查看密码
config get requirepass
//设置密码
config set requirepass 123456Aa
```
127.0.0.1:6379
登录命令:auth 123456Aa

## 6、Redis实现分布式锁
Redis 的 SET 命令有个 NX 参数可以实现「key不存在才插入」,所以可以用它来实现分布式锁:
- 如果 key 不存在,则显示插入成功,可以用来表示加锁成功;
- 如果 key 存在,则会显示插入失败,可以用来表示加锁失败。
基于 Redis 节点实现分布式锁时,对于加锁操作,我们需要满足三个条件。
- 加锁包括了读取锁变量、检查锁变量值和设置锁变量值三个操作,但需要以原子操作的方式完成,所以,我们使用 SET 命令带上 NX 选项来实现加锁;
- 锁变量需要设置过期时间,以免客户端拿到锁后发生异常,导致锁一直无法释放,所以,我们在 SET 命令执行时加上 EX/PX 选项,设置其过期时间;
- 锁变量的值需要能区分来自不同客户端的加锁操作,以免在释放锁时,出现误释放操作,所以,我们使用 SET 命令设置锁变量值时,每个客户端设置的值是一个唯一值,用于标识客户端;
满足这三个条件的分布式命令如下:
```c
SET lock_key unique_value NX PX 10000
```
- lock_key 就是 key 键;
- unique_value 是客户端生成的唯一的标识,区分来自不同客户端的锁操作;
- NX 代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;
- PX 10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。
而解锁的过程就是将 lock_key 键删除(del lock_key),但不能乱删,要保证执行操作的客户端就是加锁的客户端。所以,解锁的时候,我们要先判断锁的 unique_value 是否为加锁客户端,是的话,才将 lock_key 键删除。
可以看到,解锁是有两个操作,这时就需要 Lua 脚本来保证解锁的原子性,因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,保证了锁释放操作的原子性。
```c
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
```
这样一来,就通过使用 SET 命令和 Lua 脚本在 Redis 单节点上完成了分布式锁的加锁和解锁。
> 基于 Redis 实现分布式锁有什么优缺点?
基于 Redis 实现分布式锁的**优点**:
1. 性能高效(这是选择缓存实现分布式锁最核心的出发点)。
2. 实现方便。很多研发工程师选择使用 Redis 来实现分布式锁,很大成分上是因为 Redis 提供了 setnx 方法,实现分布式锁很方便。
3. 避免单点故障(因为 Redis 是跨集群部署的,自然就避免了单点故障)。
基于 Redis 实现分布式锁的**缺点**:
- 超时时间不好设置
。如果锁的超时时间设置过长,会影响性能,如果设置的超时时间过短会保护不到共享资源。比如在有些场景中,一个线程 A 获取到了锁之后,由于业务代码执行时间可能比较长,导致超过了锁的超时时间,自动失效,注意 A 线程没执行完,后续线程 B 又意外的持有了锁,意味着可以操作共享资源,那么两个线程之间的共享资源就没办法进行保护了。
- **那么如何合理设置超时时间呢?** 我们可以基于续约的方式设置超时时间:先给锁设置一个超时时间,然后启动一个守护线程,让守护线程在一段时间后,重新设置这个锁的超时时间。实现方式就是:写一个守护线程,然后去判断锁的情况,当锁快失效的时候,再次进行续约加锁,当主线程执行完成后,销毁续约锁即可,不过这种方式实现起来相对复杂。
- **Redis 主从复制模式中的数据是异步复制的,这样导致分布式锁的不可靠性**。如果在 Redis 主节点获取到锁后,在没有同步到其他节点时,Redis 主节点宕机了,此时新的 Redis 主节点依然可以获取锁,所以多个应用服务就可以同时获取到锁。
## 7、执行LUA 脚本
4.2 执行 Lua 脚本文件
执行命令: redis-cli -a 密码 --eval Lua 脚本路径 key [key ...] , arg [arg ...] 。
脚本路径后紧跟 key [key …] ,相比命令行模式,少了 numkeys 这个 key 的数量值。key [key …] 和 arg [arg …] 之间的英文逗号前后必须有空格,否则报错。
```
[testuser@vm-10-211-42-26 ~] redis-cli -a 123456 --eval /home/testuser/compareAndSwap.lua testkey1 , value1 120 value2
OK
[testuser@vm-10-211-42-26 ~]redis-cli -a 123456 --eval /home/testuser/compareAndSwap.lua testkey1 , value2 120 value3
OK
[testuser@vm-10-211-42-26 ~]$ redis-cli -a 123456 --eval /home/testuser/compareAndSwap.lua testkey1 , value2 120 value3
0
```
redis-cli --eval Lua脚本路径 key [key …] , arg [arg …]
# Redis八股
## 1、Redis模式有哪些?
### 1、单机模式
单机模式就是在一台服务器上安装redis,然后启动,所有业务都调用这一台redis服务器。
优点:
1、部署简单,只需要在一台服务器上安装并启动redis就行。
2、成本低,没有备用节点,不需要其他的开支。
3、高性能,单机不需要同步数据,数据天然一致性。
缺点:
1、可靠性较弱,一旦服务器宕机,所有业务都无法使用redis服务。
2、单机模式redis性能受限于CPU的处理能力。
### 2、主从模式
主从模式是指有多台redis服务器,其中一台主要负责写入客户端请求数据,称为主节点(master),其他服务专门负责处理客户端的读取数据的请求,不负责写入数据,称为从节点(slave)。主节点写入的数据会复制的各个从节点上,并且数据复制的方向是单向的,只能从主节点复制到从节点。
具体工作机制:
1、slave启动后,向master发送SYNC命令,master接收到SYNC命令后通过bgsave将当前主节点的全量数据以rdb的方式2、保存快照,同时使用缓冲区记录后续主节点执行的增量数据。
3、master将保存的快照文件发送给slave。
4、slave接收到快照文件后,加载快照文件,载入数据。
5、当slave节点复制完全量数据后,主节点在将后续的增量数据同步给slave节点,slave接收命令并执行,完成复制初始化。
6、此后master每次执行一个写命令都会同步发送给slave,保持master与slave之间数据的一致性。
优点:
1、读写分离:master写,slave读,同时可以根据访问需求大小来添加slave节点数量。
2、负载均衡:通过读写分离的方式来分但服务器负载,主节点负责写入数据,多个从节点负责读取数据,缓解单个服务器访问的压力,提高读的吞吐量。
3、数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
4、高可用性:提高了服务的可用性,多个节点同时提供服务,当前其中一台节点宕机后,其他节点仍然可以提供服务。
5、故障恢复:master宕机后,快速升级slave为master。
缺点:
1、master宕机后,slave节点升级成新的master节点后,需要手动切换主机,同时会有部分数据不能及时同步从服务器,造成数据不一致。
2、slave宕机后,多个slave恢复后,大量的SYNC同步会造成master IO压力倍增。
3、主从模式只要一个maste节点,所以master节点的写数据的能力会受到单机的限制。
### 3、哨兵模式(sentinel)
哨兵模式主要是在主从复制模式基础上,增加了自动化的故障恢复功能。因为主从复制模式下,当master节点宕机后,虽然slave节点会升级成新的master节点,但是升级后的slave节点的ip顺其自然的就称为了新的master节点ip,原先其他的slave节点配置的master节点的ip也是需要变更的,在主从复制模式下,这种变更是需要人工手动去修改配置文件的。而哨兵模式则完美的解决了这一缺陷,实现了快速的自动恢复,不再需要人工修改。
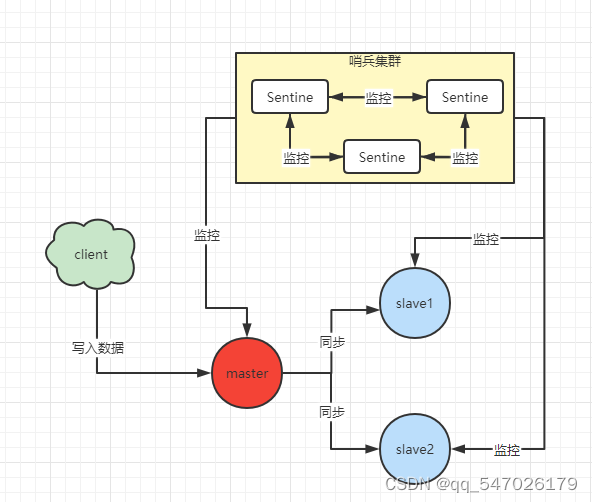
需要注意到是每个哨兵都是一个独立的redis服务,只是不提供数据的读取服务。一般哨兵模式都是以集群的方式部署,每个哨兵都部署在不同的服务器上,且每个哨兵的配置文件除了ip和端口不一样,其他基本都是一样。一般集群中包含的哨兵数目都为奇数。
哨兵的主要功能:
- 集群监控:负责监控 master 和 slave 进程是否正常工作。
- 消息通知:如果某个 Redis 实例宕机,那么哨兵负责向(哨兵间,客户端)发送消息。
- 自动故障转移:当master宕机后,由哨兵负责重新在slave节点中选举出新的master节点,并将其他slave连接到新的master,以及告知客户端新的服务器地址。更好的为客户端提供高可用服务。
哨兵模式的缺点:
- 哨兵的部署会占用额外的服务器资源,且不提供数据的读取服务。哨兵模式除了解决了主从模式手动切换主从节点的问题外,其他主从模式存在的问题,哨兵模式基本也都存在。
### 4、集群模式(类似于RabbitMQ到Kafka的转变)(Cluster)
==redis集群解决了哪些问题?==
主从模式实现了数据的热备份,哨兵模式实现了redis的高可用。但是这两种模式存在两个问题:
(1)写并发:这两种都只能有一个master节点负责写操作,在高并发的写操作场景,master节点就会成为性能瓶颈。而redis集群则可以实现多个节点同时提供写操作,redis集群模式采用无中心结构,每个节点都可以看做是一个主从模式,节点之间互相连接从而知道整个集群状态。
(2)海量数据的存储压力:无论是哨兵模式还是主从模式,每台机器上存储的数据都是一样的,都是从主节点上复制过去的,本质上只有一台Master作为存储。所以无论增加多少slave节点都无法解决单台机器存储的上限问题。但是集群模式就解决了这以问题,因为Redis Cluster是一种服务器 Sharding 技术,采用数据分片的方式,将不同的数据存储在不同的master节点上面,因为我们可以通过不断的增加集群中的节点,从而达到存储海量数据。
==redis集群的实现原理?==
Redis集群采用去中心化的思想,没有中心节点的说法,对于客户端来说,整个集群可以看成一个整体,可以连接任意一个节点进行操作,就像操作单一Redis实例一样,不需要任何代理中间件,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node。 Redis也内置了高可用机制,支持N个master节点,每个master节点都可以挂载多个slave节点,当master节点挂掉时,集群会提升它的某个slave节点作为新的master节点。Redis集群可以看成多个主从架构组合起来的,每一个主从架构可以看成一个节点(其中,只有master节点具有处理请求的能力,slave节点主要是用于节点的高可用)。
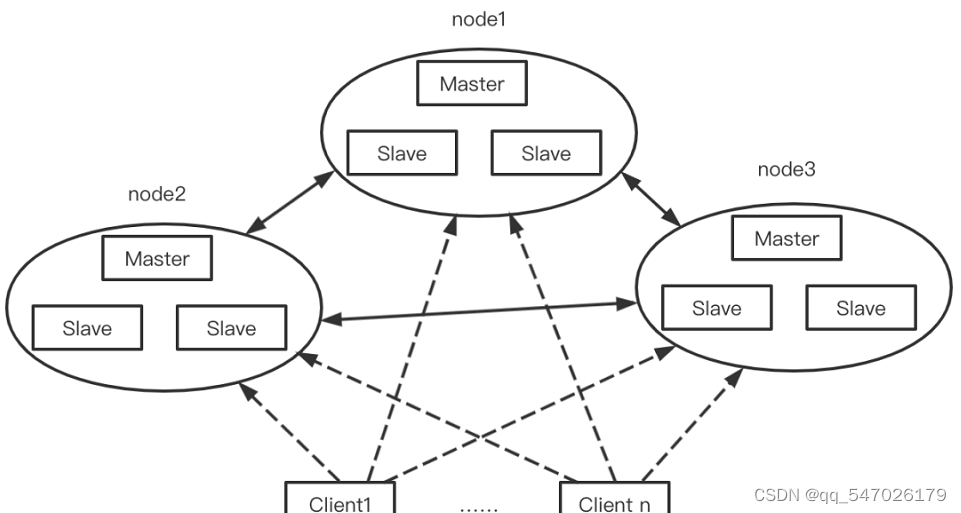
点间的内部通信机制
redis cluster节点间采取gossip协议进行通信,跟集中式不同,不是将集群元数据(节点信息,故障,等等)集中存储在某个节点上,而是互相之间不断通信,保持整个集群所有节点的数据是完整的。
集中式:的好处在于节点信息的更新和读取时效性非常好,所有节点的元数据信息都集中式的存储在一起,一旦某个节点元数据出现了变更,立即就更新到集中式的存储中。不好在于,所有的元数据的跟新压力全部集中在一个地方,可能会导致元数据的存储有压力。
gossip:好处在于,将元数据的更新分散到各个节点上,不再集中在一个地方处理,降低了集中式处理的压力,但是有一定的延时,可能导致集群的一些操作会有一些滞后。且gossip 协议对服务器时间的要求较高,时间戳不准确会影响节点判断消息的有效性。随着节点数量增多后的节点间频繁的通信会导致网络开销增加,同时结点数太多,意味着达到最终一致性的时间也相对变长,因此官方推荐最大节点数为1000左右。
通信端口
每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如8011,那么用于节点间通信的就是18011端口。
交换的信息
节点间的通信主要有:故障信息,节点的增加和移除,hash slot信息,等等。
gossip常见协议类型
gossip协议常见的消息类型包含: ping、pong、meet、fail等等。
(1)meet: 某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信。
(2)ping:用于交换节点的元数据。每个节点每秒会向集群中其他节点发送 ping 消息,消息中封装了自身节点状态还有其他部分节点的状态数据,也包括自身所管理的槽信息等等。
(3)pong:ping和meet消息的响应,同样包含了自身节点的状态和集群元数据信息。
(4)fail:某个节点判断另一个节点 fail 之后,向集群所有节点广播该节点挂掉的消息,其他节点收到消息后标记已下线。
# 服务器相关
### 1、导出Dump文件排查问题
跳转到JDK的bin目录下
```
cd /usr/local/btjdk/jdk8/bin
```
TOP查看JAVA的实际使用情况,按下大写H可以查看每个线程的CPU占用情况
```
top -p PID
```
查看JAVA文件的PID
```
ps -ef|grep java
```
使用宝塔代理,所以需要切换到对应的用户www才可以执行命令,
```
Ubuntu:
sudo su - www -s /bin/bash
Linux:
su -s /bin/bash -c "ls" www
或者直接使用www用户来执行命令
sudo -u www command
```
使用jmap导出
```
./jmap -dump:file=/tmp/xdx_dump.bin PID
```
导入到VisualVM中进行查看


### 2、jstart查看GC
==首先需要和之前一样切换到www用户==
```
sudo su - www -s /bin/bash
```
跳转到JDK的bin目录下
```
cd /usr/local/btjdk/jdk8/bin
```
查看GC情况
```
jstat -gcutil PID
```

参数表示有:
S0C:第一个幸存区的大小
S1C:第二个幸存区的大小
S0U:第一个幸存区的使用大小
S1U:第二个幸存区的使用大小
EC:伊甸园区的大小
EU:伊甸园区的使用大小
OC:老年代大小
OU:老年代使用大小
MC:方法区大小
MU:方法区使用大小
CCSC:压缩类空间大小
CCSU:压缩类空间使用大小
YGC:年轻代垃圾回收次数
YGCT:年轻代垃圾回收消耗时间
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间
# ==场景题==
## 1、网站统计PV、UV
1.1、使用位图进行统计
将每一个ip映射为一个hash值,然后再次映射到到对应位图的位置,最后统计数量
1.2使用Redis的HyperLogLog进行基数统计
HyperLogLog采用随机的hash函数,误差率低,但不能判断一个元素是否存在,只能统计数量。
**HLL 具有以下几个特点:**
- `能够使用极少的内存来统计巨量的数据,它只需要 12K 空间就能统计 2^64 的数据;`
- `统计存在一定的误差,误差率整体较低,标准误差为 0.81%;`
- `误差可以被设置辅助计算因子进行降低。`
==HyperLogLog和布隆过滤器的区别==
- 布隆过滤器主要用来判断,某个数据存不存在
> 布隆过滤器采用固定的几个hash函数来进行散列,导致误差率相比于HyperLogLog较高,但他能够判断元素是否存在
- HyperLogLog用来做 **统计** , 没法确认某个数据在不在
> HyperLogLog采用随机的hash函数,误差率低,但不能判断一个元素是否存在,只能统计数量。
# ==JAVA==
## 1、GET请求
@RequestBody
RequestBody -- Map / Object
GET请求中不可以使用@RequestBody
@RequestParam
(@RequestParam Map map)
在url中的?后面添加参数即可使用
(@RequestParam String waterEleId,@RequestParam String enterpriseName)
在url中的?后面添加参数即可使用
(@RequestParam Object object)
GET请求中不可以使用
## 2、为什么重写 equals() 时必须重写 hashCode() 方法?
**那为什么 JDK 还要同时提供这两个方法呢?**
这是因为在一些容器(比如 `HashMap`、`HashSet`)中,有了 `hashCode()` 之后,判断元素是否在对应容器中的效率会更高(参考添加元素进`HashSet`的过程)!
我们在前面也提到了添加元素进`HashSet`的过程,如果 `HashSet` 在对比的时候,同样的 `hashCode` 有多个对象,它会继续使用 `equals()` 来判断是否真的相同。也就是说 `hashCode` 帮助我们大大缩小了查找成本。
**那为什么不只提供 `hashCode()` 方法呢?**
这是因为两个对象的`hashCode` 值相等并不代表两个对象就相等。
**那为什么两个对象有相同的 `hashCode` 值,它们也不一定是相等的?**
因为 `hashCode()` 所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。越糟糕的哈希算法越容易碰撞,但这也与数据值域分布的特性有关(所谓哈希碰撞也就是指的是不同的对象得到相同的 `hashCode` )。
总结下来就是:
- 如果两个对象的`hashCode` 值相等,那这两个对象不一定相等(哈希碰撞)。
- 如果两个对象的`hashCode` 值相等并且`equals()`方法也返回 `true`,我们才认为这两个对象相等。
- 如果两个对象的`hashCode` 值不相等,我们就可以直接认为这两个对象不相等
因为两个相等的对象的 `hashCode` 值必须是相等。也就是说如果 `equals` 方法判断两个对象是相等的,那这两个对象的 `hashCode` 值也要相等。
如果重写 `equals()` 时没有重写 `hashCode()` 方法的话就可能会导致 `equals` 方法判断是相等的两个对象,`hashCode` 值却不相等。
**思考**:重写 `equals()` 时没有重写 `hashCode()` 方法的话,使用 `HashMap` 可能会出现什么问题。
答:不重写hashCode()会导致当加入到hashSet或hashMap中时两个内容一致的东西会被识别为不同的,导致出现两个对象,这是因为在内部调用判断是否相等时,hashmap先判断hashcode再判断equal,
1)、如果两个对象相等,那么它们的hashCode()值一定相同。
这里的相等是指,通过equals()比较两个对象时返回true。
2)、如果两个对象hashCode()相等,它们并不一定相等。
因为在散列表中,hashCode()相等,即两个键值对的哈希值相等。然而哈希值相等,并不一定能得出键值对相等。补充说一句:“两个不同的键值对,哈希值相等”,这就是哈希冲突。
此外,在这种情况下。若要判断两个对象是否相等,除了要覆盖equals()之外,也要覆盖hashCode()函数。否则,equals()无效。
例如,创建Person类的HashSet集合,必须同时覆盖Person类的equals() 和 hashCode()方法。
如果单单只是覆盖equals()方法。我们会发现,equals()方法没有达到我们想要的效果,会出现两个重复的值。
**参考代码:**
```java
import java.util.*;
import java.lang.Comparable;
/**
* @desc 比较equals() 返回true 以及 返回false时, hashCode()的值。
*
* @author skywang
* @emai kuiwu-wang@163.com
*/
public class ConflictHashCodeTest2{
public static void main(String[] args) {
// 新建Person对象,
Person p1 = new Person("eee", 100);
Person p2 = new Person("eee", 100);
Person p3 = new Person("aaa", 200);
Person p4 = new Person("EEE", 100);
// 新建HashSet对象
HashSet set = new HashSet();
set.add(p1);
set.add(p2);
set.add(p3);
// 比较p1 和 p2, 并打印它们的hashCode()
System.out.printf("p1.equals(p2) : %s; p1(%d) p2(%d)\n", p1.equals(p2), p1.hashCode(), p2.hashCode());
// 比较p1 和 p4, 并打印它们的hashCode()
System.out.printf("p1.equals(p4) : %s; p1(%d) p4(%d)\n", p1.equals(p4), p1.hashCode(), p4.hashCode());
// 打印set
System.out.printf("set:%s\n", set);
}
/**
* @desc Person类。
*/
private static class Person {
int age;
String name;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return name + " - " +age;
}
/**
* @desc重写hashCode
*/
@Override
public int hashCode(){
int nameHash = name.toUpperCase().hashCode();
return nameHash ^ age;
}
/**
* @desc 覆盖equals方法
*/
@Override
public boolean equals(Object obj){
if(obj == null){
return false;
}
//如果是同一个对象返回true,反之返回false
if(this == obj){
return true;
}
//判断是否类型相同
if(this.getClass() != obj.getClass()){
return false;
}
Person person = (Person)obj;
return name.equals(person.name) && age==person.age;
}
}
}
```
**运行结果**:
```
p1.equals(p2) : true; p1(68545) p2(68545)
p1.equals(p4) : false; p1(68545) p4(68545)
set:[aaa - 200, eee - 100]
```
## 3、String
[#](#string、stringbuffer、stringbuilder-的区别) String、StringBuffer、StringBuilder 的区别?
**可变性**
`String` 是不可变的(后面会详细分析原因)。
`StringBuilder` 与 `StringBuffer` 都继承自 `AbstractStringBuilder` 类,在 `AbstractStringBuilder` 中也是使用字符数组保存字符串,不过没有使用 `final` 和 `private` 关键字修饰,最关键的是这个 `AbstractStringBuilder` 类还提供了很多修改字符串的方法比如 `append` 方法。
```java
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
//...
}
```
**线程安全性**
`String` 中的对象是不可变的,也就可以理解为常量,线程安全。`AbstractStringBuilder` 是 `StringBuilder` 与 `StringBuffer` 的公共父类,定义了一些字符串的基本操作,如 `expandCapacity`、`append`、`insert`、`indexOf` 等公共方法。`StringBuffer` 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。`StringBuilder` 并没有对方法进行加同步锁,所以是非线程安全的。
**性能**
每次对 `String` 类型进行改变的时候,都会生成一个新的 `String` 对象,然后将指针指向新的 `String` 对象。`StringBuffer` 每次都会对 `StringBuffer` 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 `StringBuilder` 相比使用 `StringBuffer` 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
**对于三者使用的总结:**
1. 操作少量的数据: 适用 `String`
2. 单线程操作字符串缓冲区下操作大量数据: 适用 `StringBuilder`
3. 多线程操作字符串缓冲区下操作大量数据: 适用 `StringBuffer`
## 4、int类型排序问题
1、使用Arrays的sort函数
```java
//正序排序
Arrays.sort(num);
//逆序排序
Arrays.sort(nums, new Comparator() {
@Override
public int compare(Integer o1, Integer o2) {
//return若为正数o1放前面,负数放后面
return o2-o1;
}
});
```
## 5、List自定义排序问题
总结:自己比传入的大,那么return小于0,自己排在前面,大于0排在后面

1:利用集合框架提供的Collections.sort实现排序,其中User需要实现比较器Comparable接口,并且实现其中compareTo接口,返回的时当前入参的学生和当前这个学生的年龄差,负数,0,正数表示当前入参比本身小,相等和大,调用Collections.sort(temp);返回的排序方式为自然排序,结果如下:
```java
@Data
@AllArgsConstructor
public class User implements Comparable{
private int age;
private String sex;
private int grade;
@Override
public int compareTo(User o) {
return o.getAge()-this.getAge();
}
}
```

2.Collections.sort还提供了两个参数的方法,第二个参数为为比价器,如下:
return 负数则将o1放在前面升序排序,正数则将o1放在后面,降序排序
```java
Collections.sort(temp, new Comparator() {
@Override
public int compare(User o1, User o2) {
return -o1.getAge()+o2.getAge();
}
});
```

3.如果jdk版本为Java8或者更高的版本,则可以利用java8的新特性的stream流实现排序,而且user对象无需实现compare接口,代码如下:
```java
//3.利用Java8的stream流和Comparator实现集合排序
temp = temp.stream().sorted(Comparator.comparing(User::getAge)).collect(Collectors.toList());
```

现在如果排序要求更复杂,排序要求:先按学生年龄降序排序,年龄相等的话,则按年级升级排序!则可以利用java8的stream流实现,如下:
```java
temp = temp.stream().sorted(Comparator.comparing(User::getAge)
.reversed()
.thenComparing(Comparator.comparing(User::getGrade))
).collect(Collectors.toList());
```

## 6、ArrayList转int[]
## 7、使用Stream流转换
```java
ArrayList arrList = new ArrayList<>();
arrList.add(7);
arrList.add(8);
arrList.add(9);
int[] ints = arrList.stream().mapToInt(i -> (int)i).toArray(); // 关键代码,使用到了Stream转换
//int[] ints = arrList.stream().mapToInt(i -> i.intValue()).toArray(); // 这种写法也可以
System.out.println("结果是" + ints); // 结果是[I@7cca494b, 打印的是int[]的地址
System.out.println("结果内容是" + Arrays.toString(ints)); // 结果内容是[7, 8, 9]
```
## 8、Queue使用方法
LinkedList类实现了Queue接口,因此我们可以把LinkedList当成Queue来用。
在Java的标准库中,队列接口Queue定义了以下几个方法:
int size():获取队列长度;
boolean add(E)/boolean offer(E):添加元素到队尾;
E remove()/E poll():获取队首元素并从队列中删除;
E element()/E peek():获取队首元素但并不从队列中删除。
| | throw Exception | 返回false或null |
| ------------------ | --------------- | ------------------ |
| 添加元素到队尾 | add(E e) | boolean offer(E e) |
| 取队首元素并删除 | E remove() | E poll() |
| 取队首元素但不删除 | E element() | E peek() |
根据是否需要抛出异常来确定使用的方法
## 9、Spring 中的事务隔离级别
Spring 中的事务隔离级别比 MySQL 中的事务隔离级别多了一种,它包含的 5 种隔离级别分别是
Isolation.DEFAULT:默认的事务隔离级别,以连接的数据库的事务隔离级别为准。
Isolation.READ_UNCOMMITTED:读未提交,可以读取到未提交的事务,存在脏读。
Isolation.READ_COMMITTED:读已提交,只能读取到已经提交的事务,解决了脏读,存在不可重复读。
Isolation.REPEATABLE_READ:可重复读,解决了不可重复读,但存在幻读(MySQL 数据库默认的事务隔离级别)。
Isolation.SERIALIZABLE:串行化,可以解决所有并发问题,但性能太低。
Spring 中的事务传播机制
1.事务传播机制
事务特点: 事务是恢复和并发控制的基本单位,事务具有4个属性:原子性,一致性,隔离性,持久性,这4个属性通常也叫做ACID特性.
原子性(Atomicity):事务是一个原子操作,由一系列动作组成。事务的原子性确保动作要么全部完成,要么完全不起作用。
一致性(Consistency):一旦事务完成(不管成功还是失败),系统必须确保它所建模的业务处于一致的状态,而不会是部分完成部分失败。在现实中的数据不应该被破坏。
隔离性(Isolation):可能有许多事务会同时处理相同的数据,因此每个事务都应该与其他事务隔离开来,防止数据损坏。
持久性(Durability):一旦事务完成,无论发生什么系统错误,它的结果都不应该受到影响,这样就能从任何系统崩溃中恢复过来。通常情况下,事务的结果被写到持久化存储器中。
2.事务的传播机制
事务的传播性一般用在事务嵌套的场景,比如一个事务方法里面调用了另外一个事务方法,那么两个方法是各自作为独立的方法提交还是内层的事务合并到外层的事务一起提交,这就是需要事务传播机制的配置来确定怎么样执行。
常用的事务传播机制如下:

3.数据库事务隔离级别

脏读(Dirty read)
脏读发生在一个事务读取了被另一个事务改写但尚未提交的数据时。如果这些改变在稍后被回滚了,那么第一个事务读取的数据就会是无效的。
不可重复读(Nonrepeatable read)
不可重复读发生在一个事务执行相同的查询两次或两次以上,但每次查询结果都不相同时。这通常是由于另一个并发事务在两次查询之间更新了数据。
不可重复读重点在修改。
幻读(Phantom reads)
幻读和不可重复读相似。当一个事务(T1)读取几行记录后,另一个并发事务(T2)插入了一些记录时,幻读就发生了。在后来的查询中,第一个事务(T1)就会发现一些原来没有的额外记录。
事务的隔离级别越高越能保证数据的完整性和一致性,mysql InnoDB事务默认隔离级别是Repeatabled-Read
## 10、乐观锁悲观锁(CAS)
一、基本概念
乐观锁和悲观锁是两种思想,用于解决并发场景下的数据竞争问题。
- 乐观锁:乐观锁在操作数据时非常乐观,认为别人不会同时修改数据。因此乐观锁不会上锁,只是在执行更新的时候判断一下在此期间别人是否修改了数据:如果别人修改了数据则放弃操作,否则执行操作。
- 悲观锁:悲观锁在操作数据时比较悲观,认为别人会同时修改数据。因此操作数据时直接把数据锁住,直到操作完成后才会释放锁;上锁期间其他人不能修改数据。
悲观锁的实现方式是加锁,加锁既可以是对代码块加锁(如Java的synchronized关键字),也可以是对数据加锁(如MySQL中的排它锁)。
乐观锁的实现方式主要有两种:CAS机制和版本号机制。
1、CAS(Compare And Swap)
CAS操作包括了3个操作数:
- 需要读写的内存位置(V)
- 进行比较的预期值(A)
- 拟写入的新值(B)
CAS操作逻辑如下:如果内存位置V的值等于预期的A值,则将该位置更新为新值B,否则不进行任何操作。许多CAS的操作是自旋的:如果操作不成功,会一直重试,直到操作成功为止。
下面以Java中的自增操作(i++)为例,看一下悲观锁和CAS分别是如何保证线程安全的。我们知道,在Java中自增操作不是原子操作,它实际上包含三个独立的操作:(1)读取i值;(2)加1;(3)将新值写回i
因此,如果并发执行自增操作,可能导致计算结果的不准确。在下面的代码示例中:value1没有进行任何线程安全方面的保护,value2使用了乐观锁(CAS),value3使用了悲观锁(synchronized)。运行程序,使用1000个线程同时对value1、value2和value3进行自增操作,可以发现:value2和value3的值总是等于1000,而value1的值常常小于1000。
AtomicInteger是java.util.concurrent.atomic包提供的原子类,利用CPU提供的CAS操作来保证原子性;除了AtomicInteger外,还有AtomicBoolean、AtomicLong、AtomicReference等众多原子类。
public class CAS {
//value1:线程不安全
private static int value1 = 0;
//value2:使用乐观锁
private static AtomicInteger value2 = new AtomicInteger(0);
//value3:使用悲观锁
private static int value3 = 0;
private static synchronized void increaseValue3(){
value3++;
}
public static void main(String[] args) throws InterruptedException {
//开启1000个线程,并执行自增操作
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
value1++;
value2.getAndIncrement();
increaseValue3();
}
}).start();
}
//打印结果
Thread.sleep(1000);
System.out.println("线程不安全:" + value1);
System.out.println("乐观锁(AtomicInteger):" + value2);
System.out.println("悲观锁(synchronized):" + value3);
}
}
**三、优缺点与适用场景**
1、功能限制
与悲观锁相比,乐观锁适用的场景受到了更多的限制,无论是CAS还是版本号机制。
例如,CAS只能保证单个变量操作的原子性,当涉及到多个变量时,CAS是无能为力的,而synchronized则可以通过对整个代码块加锁来处理。再比如版本号机制,如果query的时候是针对表1,而update的时候是针对表2,也很难通过简单的版本号来实现乐观锁。
2、竞争激烈程度
如果悲观锁和乐观锁都可以使用,那么选择就要考虑竞争的激烈程度:
==当竞争不激烈 (出现并发冲突的概率小)时,乐观锁更有优势,因为悲观锁会锁住代码块或数据,其他线程无法同时访问,影响并发,而且加锁和释放锁都需要消耗额外的资源。==
==当竞争激烈(出现并发冲突的概率大)时,悲观锁更有优势,因为乐观锁在执行更新时频繁失败,需要不断重试,浪费CPU资源。==
**四、面试官追问:乐观锁加锁吗?**
笔者在面试时,曾遇到面试官如此追问。下面是我对这个问题的理解:
(1)乐观锁本身是不加锁的,只是在更新时判断一下数据是否被其他线程更新了;AtomicInteger便是一个例子。
(2)有时乐观锁可能与加锁操作合作,例如,在前述updateCoins()的例子中,MySQL在执行update时会加排它锁。但这只是乐观锁与加锁操作合作的例子,不能改变“乐观锁本身不加锁”这一事实。
**五、CAS有哪些缺点?**
**1、ABA问题**
假设有两个线程——线程1和线程2,两个线程按照顺序进行以下操作:
(1)线程1读取内存中数据为A;
(2)线程2将该数据修改为B;
(3)线程2将该数据修改为A;
(4)线程1对数据进行CAS操作
在第(4)步中,由于内存中数据仍然为A,因此CAS操作成功,但实际上该数据已经被线程2修改过了。这就是ABA问题。
在AtomicInteger的例子中,ABA似乎没有什么危害。但是在某些场景下,ABA却会带来隐患,例如栈顶问题:一个栈的栈顶经过两次(或多次)变化又恢复了原值,但是栈可能已发生了变化。
对于ABA问题,比较有效的方案是引入版本号,内存中的值每发生一次变化,版本号都+1;在进行CAS操作时,不仅比较内存中的值,也会比较版本号,只有当二者都没有变化时,CAS才能执行成功。Java中的AtomicStampedReference类便是使用版本号来解决ABA问题的。
**2、高竞争下的开销问题**
在并发冲突概率大的高竞争环境下,如果CAS一直失败,会一直重试,CPU开销较大。针对这个问题的一个思路是引入退出机制,如重试次数超过一定阈值后失败退出。当然,更重要的是避免在高竞争环境下使用乐观锁。
**3、功能限制**
CAS的功能是比较受限的,例如CAS只能保证单个变量(或者说单个内存值)操作的原子性,这意味着:(1)原子性不一定能保证线程安全,例如在Java中需要与volatile配合来保证线程安全;(2)当涉及到多个变量(内存值)时,CAS也无能为力。
除此之外,CAS的实现需要硬件层面处理器的支持,在Java中普通用户无法直接使用,只能借助atomic包下的原子类使用,灵活性受到限制。
## 11、AOP
理解AOP
什么是AOP
AOP(Aspect Oriented Programming),面向切面思想,是Spring的三大核心思想之一(两外两个:IOC-控制反转、DI-依赖注入)。
那么AOP为何那么重要呢?在我们的程序中,经常存在一些系统性的需求,比如权限校验、日志记录、统计等,这些代码会散落穿插在各个业务逻辑中,非常冗余且不利于维护。例如下面这个示意图:
有多少业务操作,就要写多少重复的校验和日志记录代码,这显然是无法接受的。当然,用面向对象的思想,我们可以把这些重复的代码抽离出来,写成公共方法,就是下面这样:
这样,代码冗余和可维护性的问题得到了解决,但每个业务方法中依然要依次手动调用这些公共方法,也是略显繁琐。有没有更好的方式呢?有的,那就是AOP,AOP将权限校验、日志记录等非业务代码完全提取出来,与业务代码分离,并寻找节点切入业务代码中:
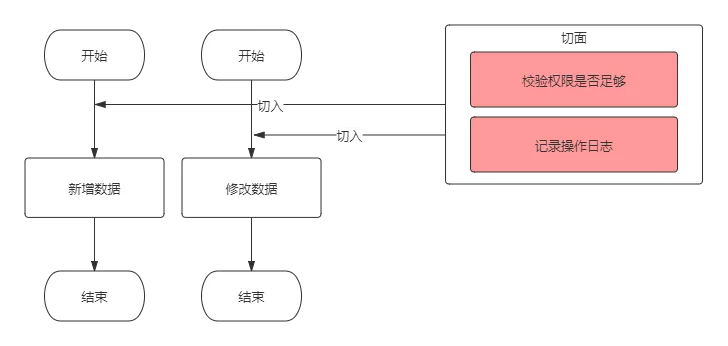
AOP体系与概念
> 简单地去理解,其实AOP要做三类事:
- 在哪里切入,也就是权限校验等非业务操作在哪些业务代码中执行。
- 在什么时候切入,是业务代码执行前还是执行后。
- 切入后做什么事,比如做权限校验、日志记录等。
**因此,AOP的体系可以梳理为下图**:
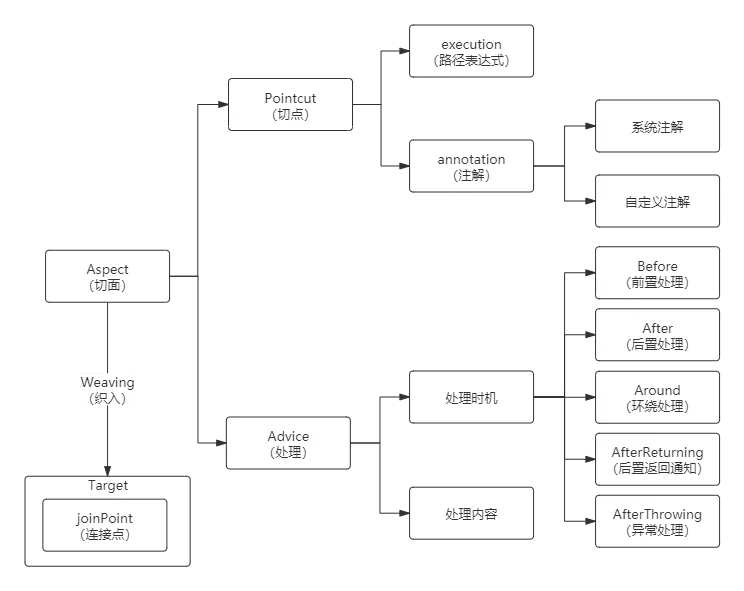
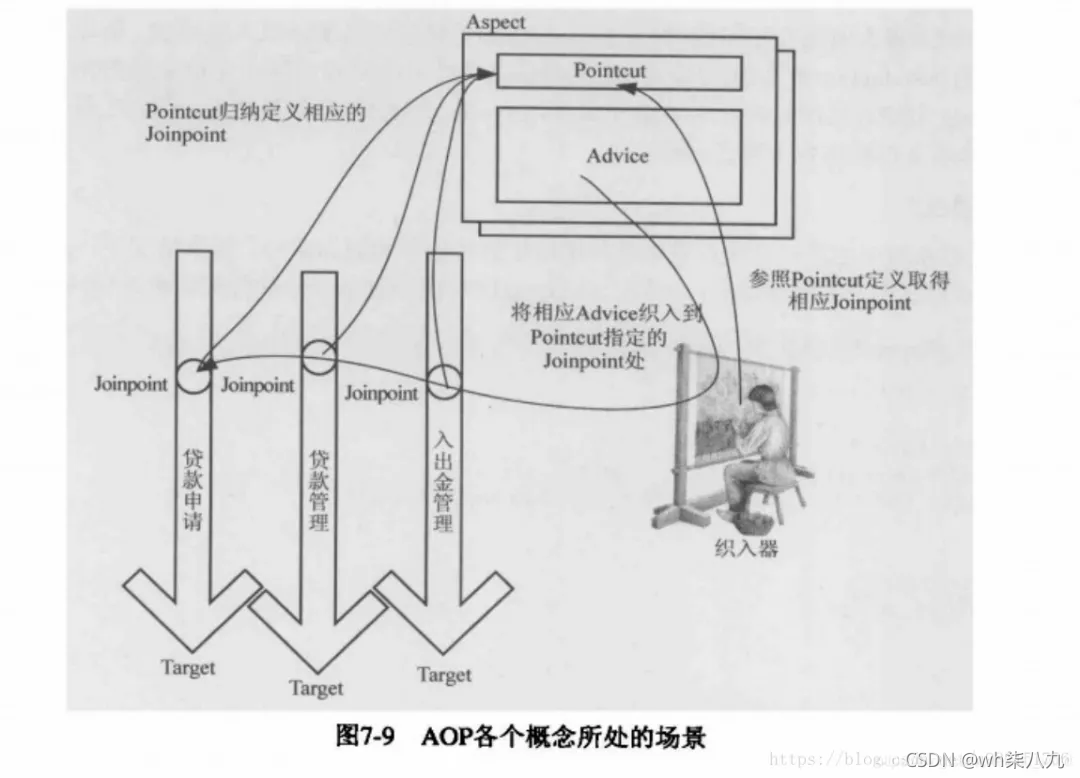
**具体实现:**
实践出真知,接下来我们就撸代码来实现一下AOP。使用 AOP,首先需要引入 AOP 的依赖。参数校验:这么写参数校验(validator)就不会被劝退了。
org.springframework.boot
spring-boot-starter-aop
接下来,我们先看一个极简的例子:所有的get请求被调用前在控制台输出一句"get请求的advice触发了"。
创建一个AOP切面类,只要在类上加个 @Aspect 注解即可。@Aspect 注解用来描述一个切面类,定义切面类的时候需要打上这个注解。@Component 注解将该类交给 Spring 来管理。在这个类里实现advice:
```java
package cn.wideth.aop;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.stereotype.Component;
@Aspect
@Component
public class LogAdvice {
// 定义一个切点:所有被GetMapping注解修饰的方法会织入advice
@Pointcut("@annotation(org.springframework.web.bind.annotation.GetMapping)")
private void logAdvicePointcut() {}
// Before表示logAdvice将在目标方法执行前执行
@Before("logAdvicePointcut()")
public void logAdvice(){
// 这里只是一个示例,你可以写任何处理逻辑
System.out.println("get请求的advice触发了");
}
}
```
### 11.1、Spring AOP 和 AspectJ AOP 有什么区别?
**Spring AOP 属于运行时增强,而 AspectJ 是编译时增强。** Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作(Bytecode Manipulation)
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择 AspectJ ,它比 Spring AOP 快很多。
### ==11.2 总结AOP静/动态代理==
AOP代理实现有两种方式
1、静态代理(AspectJ)
> AspectJ编译时(AOP框架会在编译阶段生成AOP代理类)增强,基于==字节码==,切面多时性能好,每个目标类都要创建一个代理类,AspectJ**相比于**SpringAOP更加强大允许更加高级的操作,可以允许在字段上使用切面
2、动态代理(SpringAOP)
> SpringAOP运行时增强,==内存中==生成一个对象去代理原对象,调用其方法。
>
> SpringAOP有两种实现方式:
>
> - ==JDK动态代理==:只能代理实现了接口的类,通过==反射方式==
> - ==CGLIB动态代理==:可以代理没有实现接口的类,通过==继承方式==,因此不能代理Final的类
**Spring AOP**
Spring AOP 属于`运行时增强`,主要具有如下特点:
1. 基于动态代理来实现,默认如果使用接口的,用 JDK 提供的动态代理实现,如果是方法则使用 CGLIB 实现
2. Spring AOP 需要依赖 IOC 容器来管理,并且只能作用于 Spring 容器,使用纯 Java 代码实现
3. 在性能上,由于 Spring AOP 是基于**动态代理**来实现的,在容器启动时需要生成代理实例,在方法调用上也会增加栈的深度,使得 Spring AOP 的性能不如 AspectJ 的那么好。
4. Spring AOP 致力于解决企业级开发中最普遍的 AOP(方法织入)。
**AspectJ**
AspectJ 是一个易用的功能强大的 AOP 框架,属于`编译时增强`, 可以单独使用,也可以整合到其它框架中,是 AOP 编程的完全解决方案。AspectJ 需要用到单独的编译器 ajc。
AspectJ 属于**静态织入**,通过修改代码来实现,在实际运行之前就完成了织入,所以说它生成的类是没有额外运行时开销的,一般有如下几个织入的时机:
1. 编译期织入(Compile-time weaving):如类 A 使用 AspectJ 添加了一个属性,类 B 引用了它,这个场景就需要编译期的时候就进行织入,否则没法编译类 B。
2. 编译后织入(Post-compile weaving):也就是已经生成了 .class 文件,或已经打成 jar 包了,这种情况我们需要增强处理的话,就要用到编译后织入。
3. 类加载后织入(Load-time weaving):指的是在加载类的时候进行织入,要实现这个时期的织入,有几种常见的方法
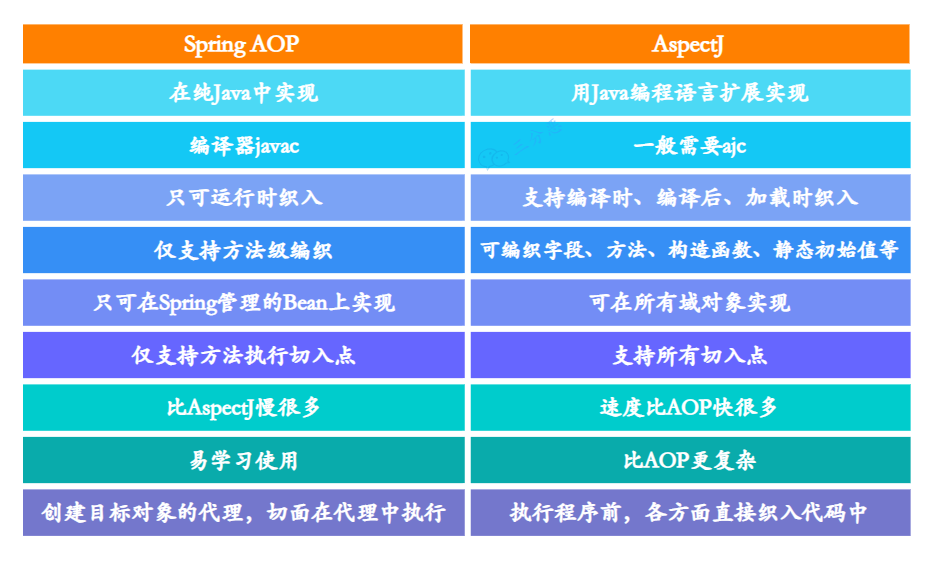
## 12、分布式dubbo
当系统不断的迭代,访问量逐渐增大单一应用无法满足需求,此时为了应对更高的并发和业务需求,我们根据业务功能对系统进行拆分:
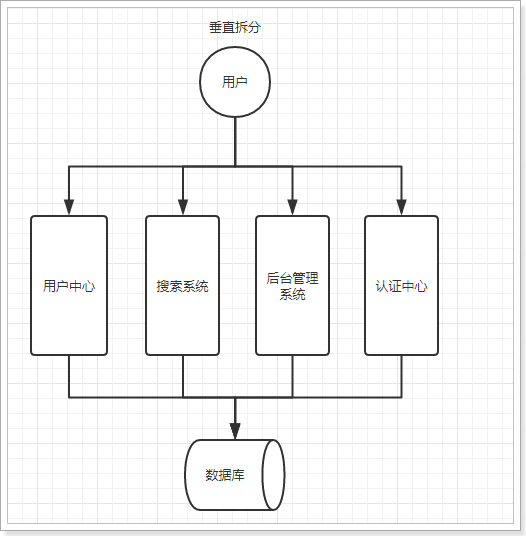
优点:
- 系统拆分实现了流量分担,解决了并发问题
- 可以针对不同模块进行优化
- 方便水平扩展,负载均衡,容错率提高
缺点:
- 系统间相互独立,会有很多重复开发工作,影响开发效率
分布式项目的诞生
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的分布式调用是关键。

优点:
- 将基础服务进行了抽取,系统间相互调用,提高了代码复用和开发效率
缺点:
- 系统间调用关系错综复杂,难以维护
==服务治理(SOA)和微服务==
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)是关键。
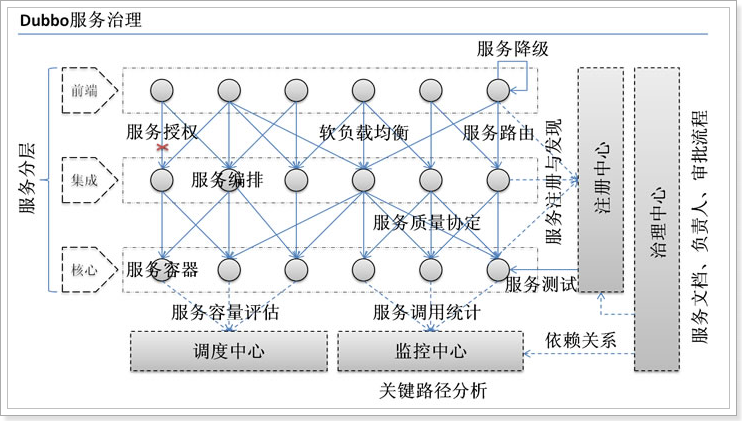
以前出现了什么问题?
服务越来越多,需要管理每个服务的地址
调用关系错综复杂,难以理清依赖关系
服务过多,服务状态难以管理,无法根据服务情况动态管理
服务治理要做什么?
服务注册中心,实现服务自动注册和发现,无需人为记录服务地址
服务自动订阅,服务列表自动推送,服务调用透明化,无需关心依赖关系
动态监控服务状态监控报告,人为控制服务状态
缺点:
服务间会有依赖关系,一旦某个环节出错会影响较大
服务关系复杂,运维、测试部署困难,不符合DevOps思想
微服务:
在SOA思想的基础上,再把项目细分,将其‘微小独立化’就成了微服务项目。微服务(或微服务架构)是一种[云原生](https://baike.baidu.com/item/云原生/53770166?fromModule=lemma_inlink)架构方法,其中单个应用程序由许多松散耦合且可独立部署的较小组件或服务组成。
微服务的特点:
单一职责:微服务中每一个服务都对应唯一的业务能力,做到单一职责。
微:微服务的服务拆分粒度很小,例如一个用户管理就可以作为一个服务。每个服务虽小,但“五脏俱全”。
面向服务:面向服务是说每个服务都要对外暴露服务接口API。并不关心服务的技术实现,做到与平台和语言无关,也不限定用什么技术实现,只要提供Rest的接口即可。
自治:自治是说服务间互相独立,互不干扰。
团队独立:每个服务都是一个独立的开发团队,人数不能过多。
技术独立:因为是面向服务,提供Rest接口,使用什么技术没有别人干涉。
前后端分离:采用前后端分离开发,提供统一Rest接口,后端不用再为PC、移动端开发不同接口。
数据库分离:每个服务都使用自己的数据源部署独立,服务间虽然有调用,但要做到服务重启不影响其它服务。有利于持续集成和持续交付。每个服务都是独立的组件,可复用,可替换,降低耦合,易维护。
RPC架构
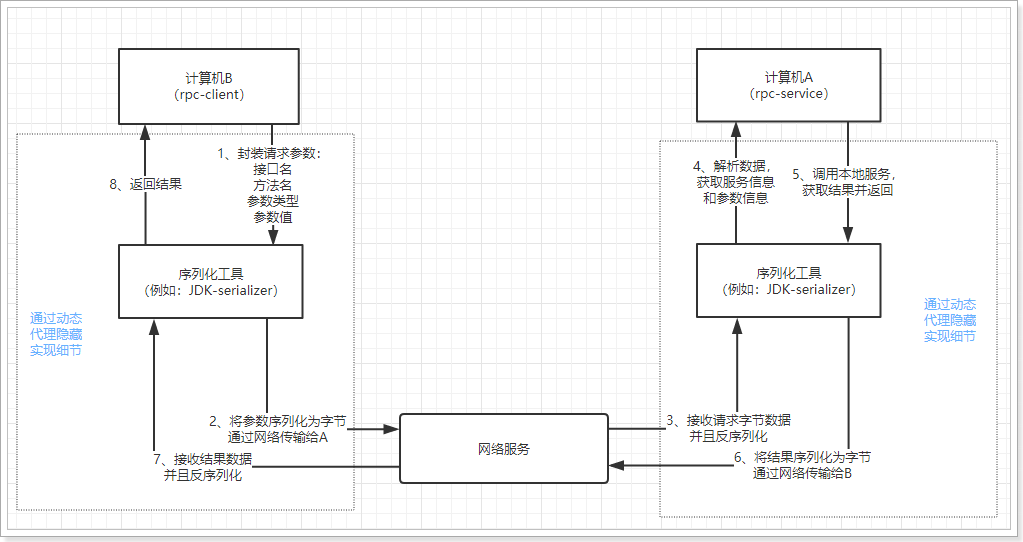
1、客户端(Client):服务调用方(服务消费者)
2、客户端存根(Client Stub):存放服务端地址信息,将客户端的请求参数数据信息打包成网络消息,再通过网络传输发送给服务端
3、服务端存根(Server Stub):接收客户端发送过来的请求消息并进行解包,然后再调用本地服务进行处理
4、服务端(Server):服务的真正提供者
RPC调用顺序
服务消费者(client客户端)通过调用本地服务的方式调用需要消费的服务;
客户端存根(client stub)接收到调用请求后负责将方法、入参等信息序列化(组装)成能够进行网络传输的消息体;
客户端存根(client stub)找到远程的服务地址,并且将消息通过网络发送给服务端;
服务端存根(server stub)收到消息后进行解码(反序列化操作);
服务端存根(server stub)根据解码结果调用本地的服务进行相关处理;
本地服务执行具体业务逻辑并将处理结果返回给服务端存根(server stub);
服务端存根(server stub)将返回结果重新打包成消息(序列化)并通过网络发送至消费方;
客户端存根(client stub)接收到消息,并进行解码(反序列化);
服务消费方得到最终结果;
而RPC框架的实现目标则是将上面的第2-10步完好地封装起来,也就是把调用、编码/解码的过程给封装起来,让用户感觉上像调用本地服务一样的调用远程服务。
RPC框架用到了哪些技术
1、动态代理
生成Client Stub(客户端存根)和Server Stub(服务端存根)的时候需要用到Java动态代理技术,可以使用JDK提供的原生的动态代理机制,也可以使用开源的:CGLib代理,Javassist字节码生成技术。
2、序列化和反序列化
在网络中,所有的数据都将会被转化为字节进行传送,所以为了能够使参数对象在网络中进行传输,需要对这些参数进行序列化和反序列化操作。
序列化:把对象转换为字节序列的过程称为对象的序列化,也就是编码的过程。
反序列化:把字节序列恢复为对象的过程称为对象的反序列化,也就是解码的过程。
目前比较高效的开源序列化框架:如Kryo、FastJson和Protobuf等。
3、NIO通信
出于并发性能的考虑,传统的阻塞式 IO 显然不太合适,因此我们需要异步的 IO,即 NIO。Java 提供了 NIO 的解决方案,Java 7 也提供了更优秀的 NIO.2 支持。可以选择Netty或者MINA来解决NIO数据传输的问题。
4、服务注册中心
可选:Redis、Zookeeper、Consul 、Etcd。一般使用ZooKeeper提供服务注册与发现功能,解决单点故障以及分布式部署的问题(注册中心)。
==Apache Dubbo 是一款易用、高性能的 WEB 和 RPC 框架,同时为构建企业级微服务提供服务发现、流量治理、可观测、认证鉴权等能力、工具与最佳实践。==
## 13、静态代理和动态代理
[#](#_4-静态代理和动态代理的对比) 4. 静态代理和动态代理的对比
1. **灵活性**:动态代理更加灵活,不需要必须实现接口,可以直接代理实现类,并且可以不需要针对每个目标类都创建一个代理类。另外,静态代理中,接口一旦新增加方法,目标对象和代理对象都要进行修改,这是非常麻烦的!
2. **JVM 层面**:静态代理在编译时就将接口、实现类、代理类这些都变成了一个个实际的 class 文件。而动态代理是在运行时动态生成类字节码,并加载到 JVM 中的。
3.3. JDK 动态代理和 CGLIB 动态代理对比
1. **JDK 动态代理只能代理实现了接口的类或者直接代理接口,而 CGLIB 可以代理未实现任何接口的类。** 另外, CGLIB 动态代理是通过生成一个被代理类的子类来拦截被代理类的方法调用,因此不能代理声明为 final 类型的类和方法。
2. 就二者的效率来说,大部分情况都是 JDK 动态代理更优秀,随着 JDK 版本的升级,这个优势更加明显
**JDK 动态代理有一个最致命的问题是其只能代理实现了接口的类。**
**为了解决这个问题,我们可以用 CGLIB 动态代理机制来避免。**
[CGLIBopen in new window](https://github.com/cglib/cglib)(*Code Generation Library*)是一个基于[ASMopen in new window](http://www.baeldung.com/java-asm)的字节码生成库,它允许我们在运行时对字节码进行修改和动态生成。CGLIB 通过继承方式实现代理。很多知名的开源框架都使用到了[CGLIBopen in new window](https://github.com/cglib/cglib), 例如 Spring 中的 AOP 模块中:如果目标对象实现了接口,则默认采用 JDK 动态代理,否则采用 CGLIB 动态代理。
**在 CGLIB 动态代理机制中 `MethodInterceptor` 接口和 `Enhancer` 类是核心。**
你需要自定义 `MethodInterceptor` 并重写 `intercept` 方法,`intercept` 用于拦截增强被代理类的方法。
```java
public interface MethodInterceptor
extends Callback{
// 拦截被代理类中的方法
public Object intercept(Object obj, java.lang.reflect.Method method, Object[] args,MethodProxy proxy) throws Throwable;
}
```
## 14、HashMap
### 14.1、HashMap 的长度为什么是 2 的幂次方
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ `(n - 1) & hash`”。(n 代表数组长度)。这也就解释了 HashMap 的长度为什么是 2 的幂次方。
**这个算法应该如何设计呢?**
我们首先可能会想到采用%取余的操作来实现。但是,重点来了:**“取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;)。”** 并且 **采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方**
### 14.2 ConcurrentHashMap
线程安全,在HashMap的基础上对各个segment进行加锁,保证了线程安全,但避免不了影响性能
ConcurrentHashMap比HashTable效率高
要点:
- 扩容时会使用多线程并发扩容,对原结构分片后每个线程负责各自分片的数据迁移工作。
- 当调用完`put`方法后,ConcurrentHashMap必须会增加当前元素的个数,方便在`size()`方法中获得存储的数据大小。代码的实现如下。元素个数累加时,使用了多线程并发来优化,当前程并发不激烈时,直接使用CAS来实现元素累加,当竞争激烈时,通过构建一个`CounterCell`数组,默认长度是2,当需要增加时随机从数组中选取一个使用CAS进行增加,实现了负载均衡,降低了锁的竞争。

Java7 中 `ConcurrentHashMap` 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 `Segment` 都是一个类似 `HashMap` 数组的结构,它可以扩容,它的冲突会转化为链表。但是 `Segment` 的个数一但初始化就不能改变。
Java8 中的 `ConcurrentHashMap` 使用的 `Synchronized` 锁加 CAS 的机制。结构也由 Java7 中的 **`Segment` 数组 + `HashEntry` 数组 + 链表** 进化成了 **Node 数组 + 链表 / 红黑树**,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
### 14.3、HashMap链表成环问题
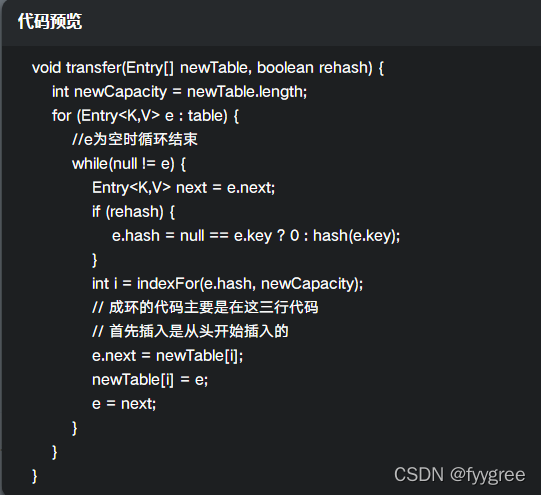
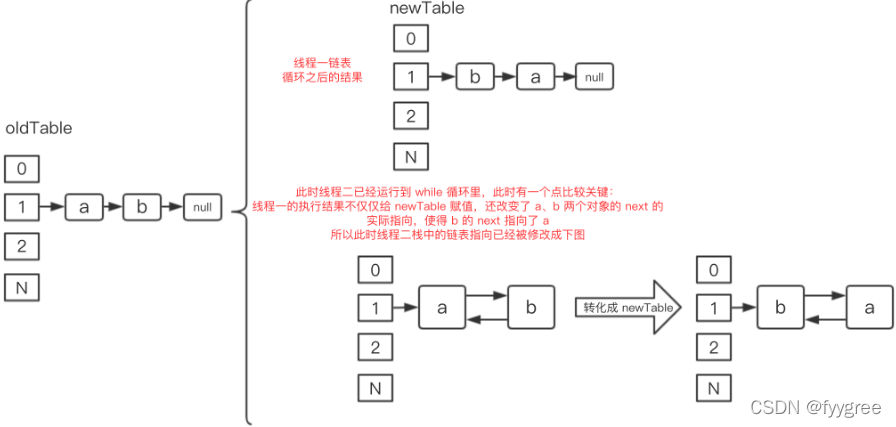
```java
// java 7 是在 while 循环里面,单个计算好数组索引位置后,单个的插入数组中,在多线程情况下,会有成环问题
// java 8 是等链表整个 while 循环结束后,才给数组赋值,所以多线程情况下,也不会成环
JDK8 是等链表整个 while 循环结束后,才给数组赋值,此时使用局部变量 loHead 和 hiHead 来保存链表的值,因为是局部变量,所以多线程的情况下,肯定是没有问题的。
```
==JAVA8中其实也没有真正解决链表成环的问题==
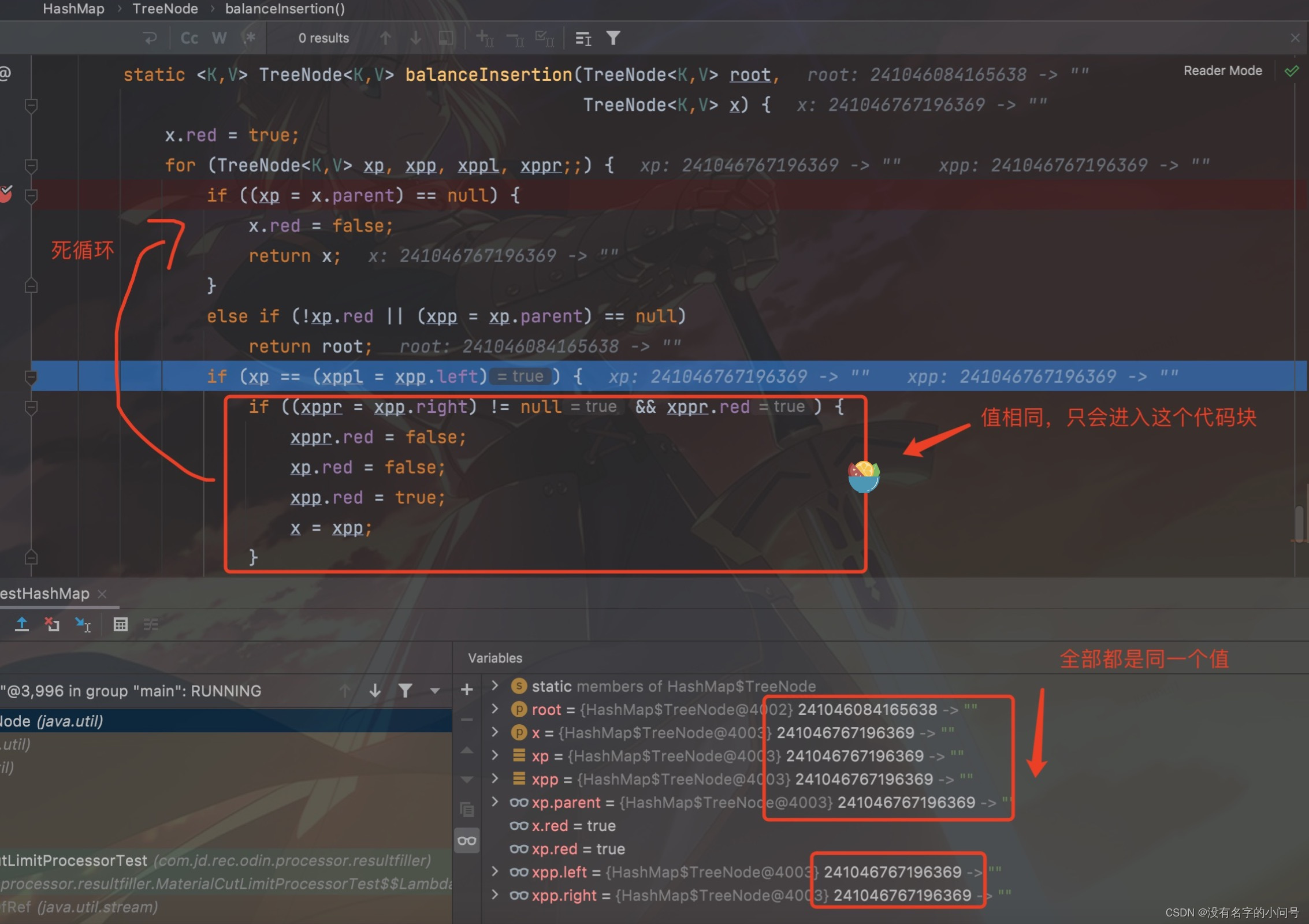
```java
//死循环复现代码
public void testHashMap() {
List storeInfos = TestObjectUtil.createStoreInfoList(500000);
Map testMap = Maps.newHashMap();
storeInfos.parallelStream().forEach(storeInfo -> {
testMap.put(storeInfo.getId(), storeInfo.getName()); //并发往map中添加50万store信息
});
}
```
假如此时有两个线程,线程1刚好构建好了树,树的左(或右)子节点为当前节点x,那么刚好线程2又刚好走到当前节点并进行判断,那么p = p.left or right = x != null, 则线程2进入下次循环后,x.parent = xp = p = x,出现自我引用,则继续执行balanceInsertion,必将进入如图9所示死循环。至此可以得出结论:jdk1.8的HashMap虽然在扩容、数据结构等多方面进行了优化,但仍旧会出现死循环的问题
另外除了balanceInsertion代码会出现问题,下面代码也可能存在相互引用导致的死循环风险,线上代码排查过程中也已经发现该问题方法,但最终并未复现,因此先放在这里提醒自己:
```java
final TreeNode root() {
for (TreeNode r = this, p;;) {
if ((p = r.parent) == null) //相互引用不为null
return r;
r = p;
}
}
```
## 15、分布式和微服务
微服务架构
1、面向服务架构。以业务服务的角度和服务总线的方式,一般是webservice与ESB,考虑系统架构和企业IT治理;
2、分布式服务架构。基于去中心化的分布式服务框架与技术,考虑系统架构和服务治理;
3、微服务架构。微服务架构可以看作是面向服务架构和分布式服务架构的拓展,使用更细粒度的服务和一组设计准则来考虑大规模的复杂系统架构设计。
==分布式:分散的是压力。==
不同模块部署在不同的服务器上,解决网站高并发带来的问题
==微服务:分散的是能力。==
从概念理解,分布式服务架构强调的是服务化以及服务的分散化,微服务则更强调服务的专业化和精细分工;
从实践的角度来看,微服务架构通常是分布式服务架构,反之则未必成立。所以,选择微服务通常意味着需要解决分布式架构的各种难题。
==微服务重在解耦合,使每个模块都独立。分布式重在资源共享与加快计算机计算速度。==
微服务的设计是为了不因为某个模块的升级和BUG影响现有的系统业务。
微服务与分布式的细微差别是,微服务的应用不一定是分散在多个服务器上,他也可以是同一个服务器。
## 16、RabbitMQ和Kafka比较选择
RabbitMQ架构
RabbitMQ是一个[分布式系统](https://so.csdn.net/so/search?q=分布式系统&spm=1001.2101.3001.7020),这里面有几个抽象概念。
- broker:每个节点运行的服务程序,功能为维护该节点的队列的增删以及转发队列操作请求。
- master queue:每个队列都分为一个主队列和若干个镜像队列。
- mirror queue:镜像队列,作为master queue的备份。在master queue所在节点挂掉之后,系统把mirror queue提升为master queue,负责处理客户端队列操作请求。注意,mirror queue只做镜像,设计目的不是为了承担客户端读写压力。

[Kafka](https://so.csdn.net/so/search?q=Kafka&spm=1001.2101.3001.7020)
Kafka我觉得就是看到了RabbitMQ这个缺陷才设计出的一个改进版,改进的点就是:把一个队列的单一master变成多个master,即一台机器扛不住qps,那么我就用多台机器扛qps,把一个队列的流量均匀分散在多台机器上不就可以了么?注意,多个master之间的数据没有交集,即一条消息要么发送到这个master queue,要么发送到另外一个master queue。
这里面的每个master queue 在Kafka中叫做Partition,即一个分片。一个队列有多个主分片,每个主分片又有若干副分片做备份,同步机制类似于RabbitMQ。
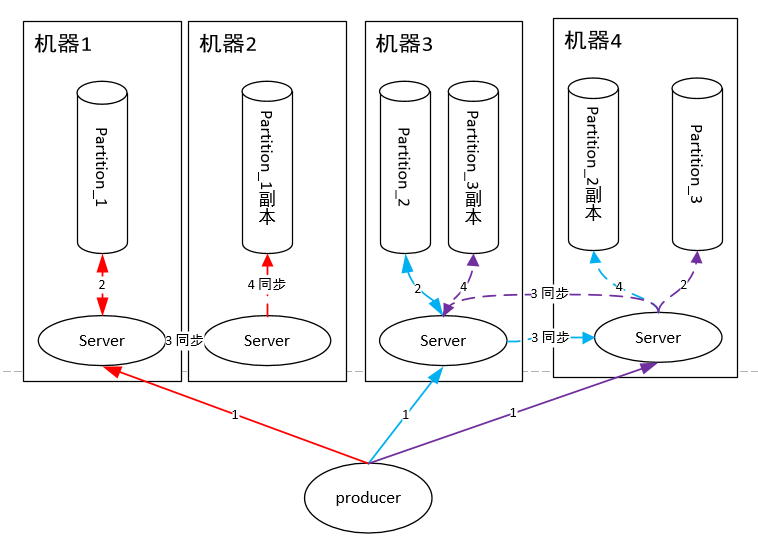
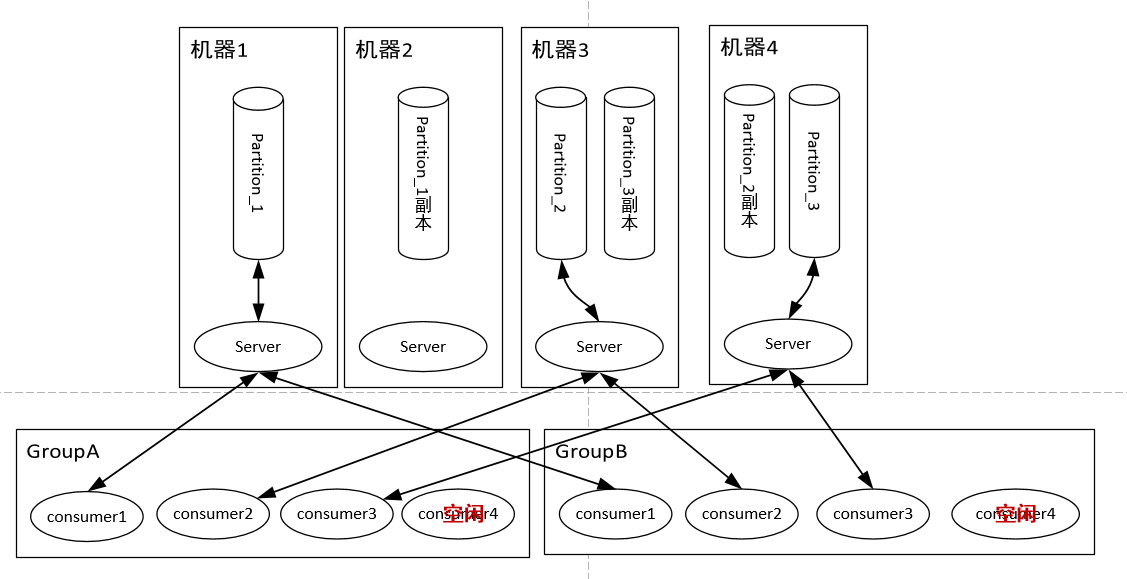
队列读取的时候虚拟出一个Group的概念,一个Topic内部的消息,只会路由到同Group内的一个consumer上,同一个Group中的consumer消费的消息是不一样的;Group之间共享一个Topic,看起来就是一个队列的多个拷贝。所以,为了达到多个Group共享一个Topic数据,Kafka并不会像RabbitMQ那样消息消费完毕立马删除,而是必须在后台配置保存日期,即只保存最近一段时间的消息,超过这个时间的消息就会从磁盘删除,这样就保证了在一个时间段内,Topic数据对所有Group可见(这个特性使得Kafka非常适合做一个公司的数据总线)。队列读同样是读主分片,并且为了优化性能,消费者与主分片有一一的对应关系,如果消费者数目大于分片数,则存在某些消费者得不到消息。
由此可见,Kafka绝对是为了高吞吐量设计的,比如设置分片数为100,那么就有100台机器去扛一个Topic的流量,当然比RabbitMQ的单机性能好。
## 17、线程池
线程池参数
/**
* 用给定的初始参数创建一个新的ThreadPoolExecutor。
*/
public ThreadPoolExecutor(int corePoolSize,//线程池的核心线程数量
int maximumPoolSize,//线程池的最大线程数
long keepAliveTime,//当线程数大于核心线程数时,多余的空闲线程存活的最长时间
TimeUnit unit,//时间单位
BlockingQueue workQueue,//任务队列,用来储存等待执行任务的队列
ThreadFactory threadFactory,//线程工厂,用来创建线程,一般默认即可
RejectedExecutionHandler handler//拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
**`ThreadPoolExecutor` 3 个最重要的参数:**
- **`corePoolSize` :** 任务队列未达到队列容量时,最大可以同时运行的线程数量。
- **`maximumPoolSize` :** 任务队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
- **`workQueue`:** 新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
`ThreadPoolExecutor`其他常见参数 :
- **`keepAliveTime`**:线程池中的线程数量大于 `corePoolSize` 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 `keepAliveTime`才会被回收销毁。
- **`unit`** : `keepAliveTime` 参数的时间单位。
- **`threadFactory`** :executor 创建新线程的时候会用到。
- **`handler`** :拒绝策略,当核心线程数。等于最大线程数并且阻塞队列已满的时候使用。
**拒绝策略:**
> 1、AbortPolicy:这种拒绝战略在拒绝任务时,直接提出RejectedExecutionexception类型的Runtimeeexception,觉任务被拒绝,可以根据业务逻辑重试或放弃提交
>
> 2、DiscardPolicy:新任务提交后被直接丢弃,没有任何通知,有一定的风险,有可能丢失数据。
>
> 3、DiscardOldestPolicy:新任务提交后,将丢弃生存时间最长的任务,同样也有丢失数据的风险。
>
> 4、CallerRunsPolicy:新任务提交后,该任务提交给提交任务的线程,即谁提交任务,谁负责任务。这样做主要有两点好处。
>
> 第一,新提交的任务不会被抛弃,不会造成业务损失。
>
> 第二,由于谁提交任务谁负责任务,提交任务的路线必须负责任务,执行任务需要时间,在此期间,提交任务的路线被占有,不提交新任务,任务提交速度变慢,相当于负面反馈。在此期间,线程池的线程也可以充分利用这个时间执行一部分任务,腾出一定的空间,相当于给线程池一定的缓冲期。
>
> 当线程池无法接受新任务时,任务会被退回给调用execute方法的线程运行。这样可以确保任务总是能够被执行,避免任务被丢弃。
>
> ==缺点:使用CallerRunsPolicy拒绝策略可能会导致任务运行时间较长,且有可能会影响整体性能。若任务提交速度远大于任务执行速度,可能会使调用execute方法的线程滞留在任务执行中,影响其他任务的提交和执行。因此,在选择拒绝策略时,需要根据具体业务场景和需求进行合理选择。==

线程池创建以及各参数设置
```java
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolExecutorDemo {
private static final int CORE_POOL_SIZE = 5;
private static final int MAX_POOL_SIZE = 10;
private static final int QUEUE_CAPACITY = 100;
private static final Long KEEP_ALIVE_TIME = 1L;
public static void main(String[] args) {
//使用阿里巴巴推荐的创建线程池的方式
//通过ThreadPoolExecutor构造函数自定义参数创建
ThreadPoolExecutor executor = new ThreadPoolExecutor(
CORE_POOL_SIZE,
MAX_POOL_SIZE,
KEEP_ALIVE_TIME,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(QUEUE_CAPACITY),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < 10; i++) {
//创建WorkerThread对象(WorkerThread类实现了Runnable 接口)
Runnable worker = new MyRunnable("" + i);
//执行Runnable
executor.execute(worker);
}
//终止线程池
executor.shutdown();
while (!executor.isTerminated()) {
}
System.out.println("Finished all threads");
}
}
```
线程池线程进入以及运行过程
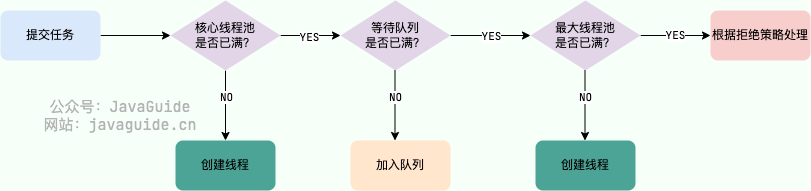
FixedThreadPool(固定线程数量)
```java
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
```
### 17.1 为什么需要二次检查线程池的运行状态,当前工作线程数量为0,尝试创建一个非核心线程并且传入的任务对象为null?
线程池源码解析:https://www.throwx.cn/2020/08/23/java-concurrency-thread-pool-executor/
先看源码:
```java
// 执行命令,其中命令(下面称任务)对象是Runnable的实例
public void execute(Runnable command) {
// 判断命令(任务)对象非空
if (command == null)
throw new NullPointerException();
// 获取ctl的值
int c = ctl.get();
// 判断如果当前工作线程数小于核心线程数,则创建新的核心线程并且执行传入的任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
// 如果创建新的核心线程成功则直接返回
return;
// 这里说明创建核心线程失败,需要更新ctl的临时变量c
c = ctl.get();
}
// 走到这里说明创建新的核心线程失败,也就是当前工作线程数大于等于corePoolSize
// 判断线程池是否处于运行中状态,同时尝试用非阻塞方法向任务队列放入任务(放入任务失败返回false)
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 这里是向任务队列投放任务成功,对线程池的运行中状态做二次检查
// 如果线程池二次检查状态是非运行中状态,则从任务队列移除当前的任务调用拒绝策略处理之(也就是移除前面成功入队的任务实例)
if (! isRunning(recheck) && remove(command))
// 调用拒绝策略处理任务 - 返回
reject(command);
// 走到下面的else if分支,说明有以下的前提:
// 0、待执行的任务已经成功加入任务队列
// 1、线程池可能是RUNNING状态
// 2、传入的任务可能从任务队列中移除失败(移除失败的唯一可能就是任务已经被执行了)
// 如果当前工作线程数量为0,则创建一个非核心线程并且传入的任务对象为null - 返回
// 也就是创建的非核心线程不会马上运行,而是等待获取任务队列的任务去执行
// 如果前工作线程数量不为0,原来应该是最后的else分支,但是可以什么也不做,因为任务已经成功入队列,总会有合适的时机分配其他空闲线程去执行它
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 走到这里说明有以下的前提:
// 0、线程池中的工作线程总数已经大于等于corePoolSize(简单来说就是核心线程已经全部懒创建完毕)
// 1、线程池可能不是RUNNING状态
// 2、线程池可能是RUNNING状态同时任务队列已经满了
// 如果向任务队列投放任务失败,则会尝试创建非核心线程传入任务执行
// 创建非核心线程失败,此时需要拒绝执行任务
else if (!addWorker(command, false))
// 调用拒绝策略处理任务 - 返回
reject(command);
}
```
这里是一个疑惑点:为什么需要二次检查线程池的运行状态,当前工作线程数量为0,尝试创建一个非核心线程并且传入的任务对象为null?这个可以看API注释:
如果一个任务成功加入任务队列,我们依然需要二次检查是否需要添加一个工作线程(因为所有存活的工作线程有可能在最后一次检查之后已经终结)或者执行当前方法的时候线程池是否已经shutdown了。所以我们需要二次检查线程池的状态,必须时把任务从任务队列中移除或者在没有可用的工作线程的前提下新建一个工作线程。
总结:
1、==为什么需要二次检查线程池的运行状态==:可能在执行道加入阻塞队列(步骤耗时)后核心线程有空闲,导致其已经被执行,或者是在加入到阻塞队列后线程池被关闭了,导致需要执行拒绝策略。
2、==当前工作线程数量为0,尝试创建一个非核心线程并且传入的任务对象为null:==因为如果二次检查后没有问题,这说明其被放入到了阻塞队列中,而若是线程池中一个工作线程也没有`核心线程数=0的特殊情况下,新增一个任务会被放到阻塞队列中,导致没有开辟线程,没有线程工作,只有等阻塞队列满了才会开一个线程,造成资源浪费,因此为了避免这种情况`,则需要判断当工作线程为0的时候为其开一个null(从阻塞队列中拿,不主动放)线程。
## **18、双重校验锁实现对象单例(线程安全)**:
```java
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
//先判断对象是否已经实例过,没有实例化过才进入加锁代码
if (uniqueInstance == null) {
//类对象加锁
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
```
`uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要的, `uniqueInstance = new Singleton();` 这段代码其实是分为三步执行:
1. 为 `uniqueInstance` 分配内存空间
2. 初始化 `uniqueInstance`
3. 将 `uniqueInstance` 指向分配的内存地址
但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 `getUniqueInstance`() 后发现 `uniqueInstance` 不为空,因此返回 `uniqueInstance`,但此时 `uniqueInstance` 还未被初始化。
## 19、JVM
### 19.1 JVM内存模型
JVM内存模型可以分为两个部分,如下图所示,堆和方法区是所有线程共有的,而虚拟机栈,本地方法栈和程序计数器则是线程私有的。

堆(Heap)
在 Java 中,堆被划分成两个不同的区域:新生代 ( Young )、老年代 ( Old ),新生代 ( Young ) 又被划分为三个区域:Eden、From Survivor、To Survivor。
下图中的Perm代表的是永久代,但是注意永久代并不属于堆内存中的一部分,同时jdk1.8之后永久代也将被移除。

堆是java虚拟机所管理的内存中最大的一块内存区域,也是被各个线程共享的内存区域,该内存区域存放了对象实例及数组(但不是所有的对象实例都在堆中)。
其大小通过-Xms(最小值)和-Xmx(最大值)参数设置(最大最小值都要小于1G),前者为启动时申请的最小内存,默认为操作系统物理内存的1/64,后者为JVM可申请的最大内存,默认为物理内存的1/4,默认当空余堆内存小于40%时,JVM会增大堆内存到-Xmx指定的大小,可通过-XX:MinHeapFreeRation=来指定这个比列。
当空余堆内存大于70%时,JVM会减小堆内存的大小到-Xms指定的大小,可通过XX:MaxHeapFreeRation=来指定这个比列,当然为了避免在运行时频繁调整Heap的大小,通常-Xms与-Xmx的值设成一样。堆内存 = 新生代+老生代+持久代。
在我们垃圾回收的时候,我们往往将堆内存分成新生代和老生代(大小比例1:2),新生代中由Eden和Survivor0,Survivor1组成,三者的比例是8:1:1,新生代的回收机制采用复制算法,在Minor GC的时候,我们都留一个存活区用来存放存活的对象,真正进行的区域是Eden+其中一个存活区,当我们的对象时长超过一定年龄时(默认15,可以通过参数设置),将会把对象放入老生代,当然大的对象会直接进入老生代,老生代采用的回收算法是标记整理算法。
GC原理及调优(9张图)









面试如何回答:
1、先表态,回答在合理的JVM参数下不需要进行调优。
2、说明部分场景需要调优,对JVM的部分核心指标配置告警,通过分析告警日志判断是否需要调优以及调优的方向。
3、举一个实际的例子
==启动java应用时,可以加以下参数来开启jvm垃圾回收日志。==
-XX:+PrintGC:打印最基本的回收信息
-XX:+PrintGCDetails:可以打印详细GC信息至控制台
-XX:+PrintGCDateStamps 可以记录GC发生的详细时间
JVM调优例子
1、metaspace导致频繁FGC,反射调用创建了大量的类加载器,占用了较大的内存,而内存是以整块进行分配的,每一块都只存放一个类加载器,导致内存碎片化严重。出现FGC。
通过mat分析heapdump,发现`DelegatingClassLoader`(类加载器)有几千个,查看源码后发现是类加载器,继续跟踪发现是mybatis的Reflector应用了这些对象。最终发现Method在调用过程会创建一个MethodAccessor并将MehtodAccessor作为存在一个叫做methodAccessor的field中,java为了提高反射调用的性能,用了一种膨胀(inflation)的方式(从jni调用转换成classbytes调用),通过参数-Dsun.reflect.inflationThreshold进行控制默认15,在小于这个次数时会使用native的方式对方法进行调用,如果method的调用次数超过指定次数就会使用字节码的方式生成方法调用,如果使用字节码的方式最终会为每一个方法都生成类DelegatingClassLoader加载器
使用BeanUtils.copyProperties模拟origin和Aim均为700成员变量且均可以getset,BeanUtils.copyProperties使用了反射机制get属性,大量调用会导致频繁FGC,频繁FGC导致CPU占用率高,卡顿。超过15次调用相同的类,会使用膨胀机制使用字节码为每一个get set方法创建一个类加载器,而模拟中类的get set方法有700个
```
import java.lang.reflect.Method;
import java.util.ArrayList;
import java.util.List;
public class ReflectionTest {
public static void main(String[] args) {
try {
List origins = new ArrayList<>();
List aims = new ArrayList<>();
// Create a large number of objects
for (int i = 0; i < 1e5; i++) {
Origin origin = new Origin();
origin.setTest1("111");
origins.add(origin);
Aim aim = new Aim();
aims.add(aim);
}
// Let's perform copying in a loop to generate garbage
for (int i = 0; i < 1000; i++) {
BeanUtils.copyProperties(origins.get(i), aims.get(i));
}
// Now, set the lists to null to release references and trigger garbage collection
origins = null;
aims = null;
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
### 19.2 GC相关
#### 如何判断一个类是无用的类?
方法区主要回收的是无用的类,那么如何判断一个类是无用的类的呢?
判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面 3 个条件才能算是 **“无用的类”**:
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的 `ClassLoader` 已经被回收。
- 该类对应的 `java.lang.Class` 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述 3 个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收
#### 如何判断一个常量是废弃常量?
运行时常量池主要回收的是废弃的常量。那么,我们如何判断一个常量是废弃常量呢?
**JDK1.7 及之后版本的 JVM 已经将运行时常量池从方法区中移了出来,在 Java 堆(Heap)中开辟了一块区域存放运行时常量池。**
> **🐛 修正(参见:[issue747open in new window](https://github.com/Snailclimb/JavaGuide/issues/747),[referenceopen in new window](https://blog.csdn.net/q5706503/article/details/84640762))**:
>
> 1. **JDK1.7 之前运行时常量池逻辑包含字符串常量池存放在方法区, 此时 hotspot 虚拟机对方法区的实现为永久代**
> 2. **JDK1.7 字符串常量池被从方法区拿到了堆中, 这里没有提到运行时常量池,也就是说字符串常量池被单独拿到堆,运行时常量池剩下的东西还在方法区, 也就是 hotspot 中的永久代** 。
> 3. **JDK1.8 hotspot 移除了永久代用元空间(Metaspace)取而代之, 这时候字符串常量池还在堆, 运行时常量池还在方法区, 只不过方法区的实现从永久代变成了元空间(Metaspace)**
假如在字符串常量池中存在字符串 "abc",如果当前没有任何 String 对象引用该字符串常量的话,就说明常量 "abc" 就是废弃常量,如果这时发生内存回收的话而且有必要的话,"abc" 就会被系统清理出常量池了。
## 20、字符串常量池
字符串常量池位置
Jdk1.6及之前: 有永久代, 运行时常量池在永久代,运行时常量池包含字符串常量池
Jdk1.7:有永久代,但已经逐步“去永久代”,字符串常量池从永久代里的运行时常量池分离到堆里
Jdk1.8及之后: 无永久代,运行时常量池在元空间,字符串常量池里依然在堆里
举例1
```java
public class StringDemo03 {
public static void main(String[] args) {
String s0="abc";
String s1="abc";
String s2="ab" + "c"; //编译期会进行优化 ,
//放入常量池 “abc”是一个字面量(静态链接,编译的时候吧符号引用转换成直接引用---静态链接)
System.out.println( s0==s1 ); //true
System.out.println( s0==s2 ); //true
}
}
```
举例2
```java
public class StringDemo04 {
public static void main(String[] args) {
String s0 = "abcd";
String s1 = new String("ab"); //运行时创建的新对象”abcd”的引用
//new String 会在堆中创建对象,并且把引用进行返回,不会把创建的字符串放入常量池
String s2 = "ab" + new String("cd");
System.out.println(s0 == s1);// false
System.out.println(s0 == s2);// false
System.out.println(s1 == s2);// false
}
}
```
分析:用new String()创建的字符串不是常量,不能在编译期就确定,所以new String() 创建的字符串不放入常量池中,它们有自己的地址空间。s0还是常量池 中"abcd”的引用,s1因为无法在编译期确定,所以是运行时创建的新对象”abcd”的引用,s2因为有后半部分 new String(”cd”)所以也无法在编译期确定,所以也是一个新创建对象”abcd”的引用.
S1S2运行时确定,存放在元空间metaspace中
## 21、阻塞队列
Java 中常用的阻塞队列实现类有以下几种:
1. `ArrayBlockingQueue`:使用数组实现的有界阻塞队列。在创建时需要指定容量大小,并支持公平和非公平两种方式的锁访问机制。
2. `LinkedBlockingQueue`:使用单向链表实现的可选有界阻塞队列。在创建时可以指定容量大小,如果不指定则默认为`Integer.MAX_VALUE`。和`ArrayBlockingQueue`类似, 它也支持公平和非公平的锁访问机制。
3. `PriorityBlockingQueue`:支持优先级排序的无界阻塞队列。元素必须实现`Comparable`接口或者在构造函数中传入`Comparator`对象,并且不能插入 null 元素。
4. `SynchronousQueue`:同步队列,是一种不存储元素的阻塞队列。每个插入操作都必须等待对应的删除操作,反之删除操作也必须等待插入操作。因此,`SynchronousQueue`通常用于线程之间的直接传递数据。
5. `DelayQueue`:延迟队列,其中的元素只有到了其指定的延迟时间,才能够从队列中出队。
具体实现


首先检查是否为空,从这个方法中我们可以看到,首先检查队列是否为空,然后获取锁,判断当前元素个数是否等于数组的长度,如果相等,则调用notFull.await()进行等待,如果捕获到中断异常,则唤醒线程并抛出异常。当被其他线程唤醒时,通过enqueue(e)方法插入元素,最后解锁。
我们按照这个源码来看,真正实现插入操作的是enqueue,我们跟进去看看:

就几行代码,就是一个正常的移动数组插入的过程,不过最后还要再通知一下队列,插入了元素,此时的队列就不为空了。
## 22、工厂模式、单例模式等
### 22.1、==工厂模式==
工厂模式(Factory Pattern)是 Java 中最常用的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
工厂模式提供了一种将对象的实例化过程封装在工厂类中的方式。通过使用工厂模式,可以将对象的创建与使用代码分离,提供一种统一的接口来创建不同类型的对象。
在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。
介绍
**意图:**定义一个创建对象的接口,让其子类自己决定实例化哪一个工厂类,工厂模式使其创建过程延迟到子类进行。
**主要解决:**主要解决接口选择的问题。
**何时使用:**我们明确地计划不同条件下创建不同实例时。
**如何解决:**让其子类实现工厂接口,返回的也是一个抽象的产品。
**关键代码:**创建过程在其子类执行。
**应用实例:** 1、您需要一辆汽车,可以直接从工厂里面提货,而不用去管这辆汽车是怎么做出来的,以及这个汽车里面的具体实现。 2、Hibernate 换数据库只需换方言和驱动就可以。
**优点:** 1、一个调用者想创建一个对象,只要知道其名称就可以了。 2、扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。 3、屏蔽产品的具体实现,调用者只关心产品的接口。
**缺点:**每次增加一个产品时,都需要增加一个具体类和对象实现工厂,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,同时也增加了系统具体类的依赖。这并不是什么好事。
**使用场景:** 1、日志记录器:记录可能记录到本地硬盘、系统事件、远程服务器等,用户可以选择记录日志到什么地方。 2、数据库访问,当用户不知道最后系统采用哪一类数据库,以及数据库可能有变化时。 3、设计一个连接服务器的框架,需要三个协议,"POP3"、"IMAP"、"HTTP",可以把这三个作为产品类,共同实现一个接口。
**注意事项:**作为一种创建类模式,在任何需要生成复杂对象的地方,都可以使用工厂方法模式。有一点需要注意的地方就是复杂对象适合使用工厂模式,而简单对象,特别是只需要通过 new 就可以完成创建的对象,无需使用工厂模式。如果使用工厂模式,就需要引入一个工厂类,会增加系统的复杂度。
**工厂模式包含以下几个核心角色:**
- 抽象产品(Abstract Product):定义了产品的共同接口或抽象类。它可以是具体产品类的父类或接口,规定了产品对象的共同方法。
- 具体产品(Concrete Product):实现了抽象产品接口,定义了具体产品的特定行为和属性。
- 抽象工厂(Abstract Factory):声明了创建产品的抽象方法,可以是接口或抽象类。它可以有多个方法用于创建不同类型的产品。
- 具体工厂(Concrete Factory):实现了抽象工厂接口,负责实际创建具体产品的对象。
### 22.2、==单例模式==
单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
单例模式是一种创建型设计模式,它确保一个类只有一个实例,并提供了一个全局访问点来访问该实例。
**注意:**
- 1、单例类只能有一个实例。
- 2、单例类必须自己创建自己的唯一实例。
- 3、单例类必须给所有其他对象提供这一实例。
介绍
**意图:**保证一个类仅有一个实例,并提供一个访问它的全局访问点。
**主要解决:**一个全局使用的类频繁地创建与销毁。
**何时使用:**当您想控制实例数目,节省系统资源的时候。
**如何解决:**判断系统是否已经有这个单例,如果有则返回,如果没有则创建。
**关键代码:**构造函数是私有的。
**应用实例:**
- 1、一个班级只有一个班主任。
- 2、Windows 是多进程多线程的,在操作一个文件的时候,就不可避免地出现多个进程或线程同时操作一个文件的现象,所以所有文件的处理必须通过唯一的实例来进行。
- 3、一些设备管理器常常设计为单例模式,比如一个电脑有两台打印机,在输出的时候就要处理不能两台打印机打印同一个文件。
**优点:**
- 1、在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。
- 2、避免对资源的多重占用(比如写文件操作)。
**缺点:**没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
==**Spring 中 bean 的默认作用域就是 singleton(单例)的。** 除了 singleton 作用域,Spring 中 bean 还有下面几种作用域:==
- **prototype** : 每次获取都会创建一个新的 bean 实例。也就是说,连续 `getBean()` 两次,得到的是不同的 Bean 实例。
- **request** (仅 Web 应用可用): 每一次 HTTP 请求都会产生一个新的 bean(请求 bean),该 bean 仅在当前 HTTP request 内有效。
- **session** (仅 Web 应用可用) : 每一次来自新 session 的 HTTP 请求都会产生一个新的 bean(会话 bean),该 bean 仅在当前 HTTP session 内有效。
- **application/global-session** (仅 Web 应用可用):每个 Web 应用在启动时创建一个 Bean(应用 Bean),,该 bean 仅在当前应用启动时间内有效。
- **websocket** (仅 Web 应用可用):每一次 WebSocket 会话产生一个新的 bean.
**使用场景:**
- 1、要求生产唯一序列号。
- 2、WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。
- 3、创建的一个对象需要消耗的资源过多,比如 I/O 与数据库的连接等。
**单例 Bean 存在线程安全问题吗?**
大部分时候我们并没有在项目中使用多线程,所以很少有人会关注这个问题。单例 Bean 存在线程问题,主要是因为当多个线程操作同一个对象的时候是存在资源竞争的。
常见的有两种解决办法:
1. 在 Bean 中尽量避免定义可变的成员变量。
2. 在类中定义一个 `ThreadLocal` 成员变量,将需要的可变成员变量保存在 `ThreadLocal` 中(推荐的一种方式)。
不过,大部分 Bean 实际都是无状态(没有实例变量)的(比如 Dao、Service),这种情况下, Bean 是线程安全的。
### 22.3、==代理模式==
在代理模式(Proxy Pattern)中,一个类代表另一个类的功能。这种类型的设计模式属于结构型模式。
在代理模式中,我们创建具有现有对象的对象,以便向外界提供功能接口。
介绍
**意图:**为其他对象提供一种代理以控制对这个对象的访问。
**主要解决:**在直接访问对象时带来的问题,比如说:要访问的对象在远程的机器上。在面向对象系统中,有些对象由于某些原因(比如对象创建开销很大,或者某些操作需要安全控制,或者需要进程外的访问),直接访问会给使用者或者系统结构带来很多麻烦,我们可以在访问此对象时加上一个对此对象的访问层。
**何时使用:**想在访问一个类时做一些控制。
**如何解决:**增加中间层。
**关键代码:**实现与被代理类组合。
**应用实例:** 1、Windows 里面的快捷方式。 2、猪八戒去找高翠兰结果是孙悟空变的,可以这样理解:把高翠兰的外貌抽象出来,高翠兰本人和孙悟空都实现了这个接口,猪八戒访问高翠兰的时候看不出来这个是孙悟空,所以说孙悟空是高翠兰代理类。 3、买火车票不一定在火车站买,也可以去代售点。 4、一张支票或银行存单是账户中资金的代理。支票在市场交易中用来代替现金,并提供对签发人账号上资金的控制。 5、spring aop。
**优点:** 1、职责清晰。 2、高扩展性。 3、智能化。
**缺点:** 1、由于在客户端和真实主题之间增加了代理对象,因此有些类型的代理模式可能会造成请求的处理速度变慢。 2、实现代理模式需要额外的工作,有些代理模式的实现非常复杂。
**使用场景:**按职责来划分,通常有以下使用场景: 1、远程代理。 2、虚拟代理。 3、Copy-on-Write 代理。 4、保护(Protect or Access)代理。 5、Cache代理。 6、防火墙(Firewall)代理。 7、同步化(Synchronization)代理。 8、智能引用(Smart Reference)代理。
**注意事项:** 1、和适配器模式的区别:适配器模式主要改变所考虑对象的接口,而代理模式不能改变所代理类的接口。 2、和装饰器模式的区别:装饰器模式为了增强功能,而代理模式是为了加以控制。
### 22.4、==观察者模式==(NIO轮询)
观察者模式是一种行为型设计模式,它定义了一种一对多的依赖关系,当一个对象的状态发生改变时,其所有依赖者都会收到通知并自动更新。
当对象间存在一对多关系时,则使用观察者模式(Observer Pattern)。比如,当一个对象被修改时,则会自动通知依赖它的对象。观察者模式属于行为型模式。
介绍
**意图:**定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
**主要解决:**一个对象状态改变给其他对象通知的问题,而且要考虑到易用和低耦合,保证高度的协作。
**何时使用:**一个对象(目标对象)的状态发生改变,所有的依赖对象(观察者对象)都将得到通知,进行广播通知。
**如何解决:**使用面向对象技术,可以将这种依赖关系弱化。
**关键代码:**在抽象类里有一个 ArrayList 存放观察者们。
**应用实例:** 1、拍卖的时候,拍卖师观察最高标价,然后通知给其他竞价者竞价。 2、西游记里面悟空请求菩萨降服红孩儿,菩萨洒了一地水招来一个老乌龟,这个乌龟就是观察者,他观察菩萨洒水这个动作。
**优点:** 1、观察者和被观察者是抽象耦合的。 2、建立一套触发机制。
**缺点:** 1、如果一个被观察者对象有很多的直接和间接的观察者的话,将所有的观察者都通知到会花费很多时间。 2、如果在观察者和观察目标之间有循环依赖的话,观察目标会触发它们之间进行循环调用,可能导致系统崩溃。 3、观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。
**使用场景:**
- 一个抽象模型有两个方面,其中一个方面依赖于另一个方面。将这些方面封装在独立的对象中使它们可以各自独立地改变和复用。
- 一个对象的改变将导致其他一个或多个对象也发生改变,而不知道具体有多少对象将发生改变,可以降低对象之间的耦合度。
- 一个对象必须通知其他对象,而并不知道这些对象是谁。
- 需要在系统中创建一个触发链,A对象的行为将影响B对象,B对象的行为将影响C对象……,可以使用观察者模式创建一种链式触发机制。
**注意事项:** 1、JAVA 中已经有了对观察者模式的支持类。 2、避免循环引用。 3、如果顺序执行,某一观察者错误会导致系统卡壳,一般采用异步方式。
**观察者模式包含以下几个核心角色:**
- 主题(Subject):也称为被观察者或可观察者,它是具有状态的对象,并维护着一个观察者列表。主题提供了添加、删除和通知观察者的方法。
- 观察者(Observer):观察者是接收主题通知的对象。观察者需要实现一个更新方法,当收到主题的通知时,调用该方法进行更新操作。
- 具体主题(Concrete Subject):具体主题是主题的具体实现类。它维护着观察者列表,并在状态发生改变时通知观察者。
- 具体观察者(Concrete Observer):具体观察者是观察者的具体实现类。它实现了更新方法,定义了在收到主题通知时需要执行的具体操作。
观察者模式通过将主题和观察者解耦,实现了对象之间的松耦合。当主题的状态发生改变时,所有依赖于它的观察者都会收到通知并进行相应的更新。
### 22.5、MVC 模式
MVC 模式代表 Model-View-Controller(模型-视图-控制器) 模式。这种模式用于应用程序的分层开发。
- **Model(模型)** - 模型代表一个存取数据的对象或 JAVA POJO。它也可以带有逻辑,在数据变化时更新控制器。
- **View(视图)** - 视图代表模型包含的数据的可视化。
- **Controller(控制器)** - 控制器作用于模型和视图上。它控制数据流向模型对象,并在数据变化时更新视图。它使视图与模型分离开。
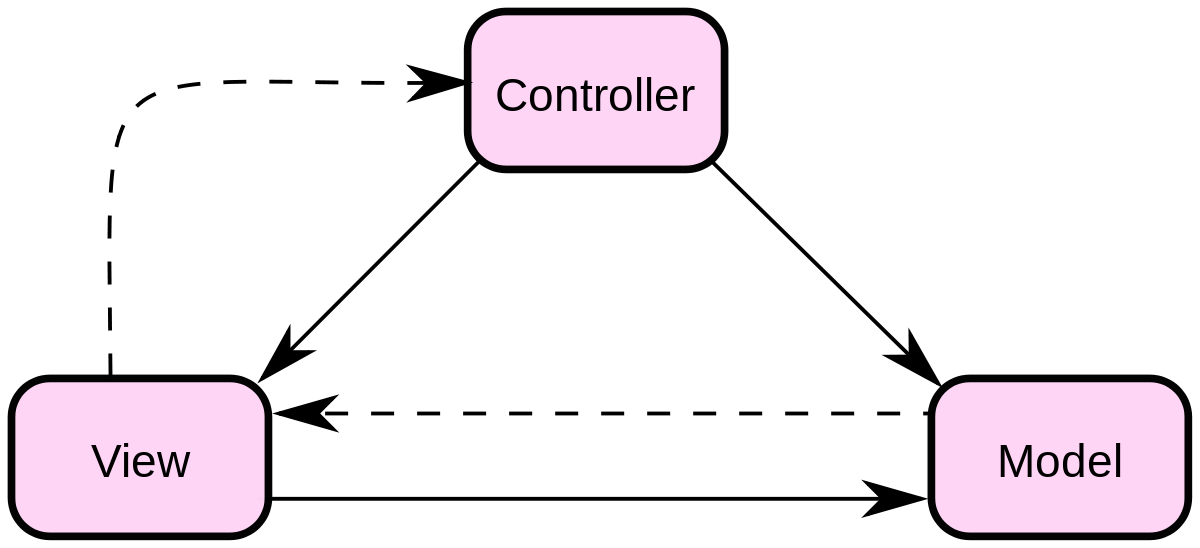
### 22.6、装饰器模式和代理模式的区别
理解:装饰器模式是增强了自身的功能,例如IO流中`bufferedInputStream`(字节缓冲输入流)、`DataInputStream` 等等都是`FilterInputStream` 的子类,我们可以通过 `BufferedInputStream`(字节缓冲输入流)来增强 `FileInputStream` 的功能。
```java
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("input.txt"))) {
int content;
long skip = bis.skip(2);
while ((content = bis.read()) != -1) {
System.out.print((char) content);
}
} catch (IOException e) {
e.printStackTrace();
}
```
而代理模式注重增加了额外的功能,比如AOP编程中使用代理模式的思想在接口前后增加了缓存双删的功能,比如在写入数据库前进行验证。
代理注重控制,控制不易二次扩展;装饰注重增强,且通过上层装饰进行增强,易于扩展。装饰是特殊的代理,特殊的地方就在于其代理角色proxy 是一个抽象的Decorator,所以才易于扩展
1、装饰器模式强调的是增强自身,在被装饰之后你能够在被增强的类上使用增强后的功能。增强后你还是你,只不过能力更强了而已;代理模式强调要让别人帮你去做一些本身与你业务没有太多关系的职责(记录日志、设置缓存)。代理模式是为了实现对象的控制,因为被代理的对象往往难以直接获得或者是其内部不想暴露出来。
2、装饰模式是以对客户端透明的方式扩展对象的功能,是继承方案的一个替代方案;代理模式则是给一个对象提供一个代理对象,并由代理对象来控制对原有对象的引用;
3、装饰模式是为装饰的对象增强功能;而代理模式对代理的对象施加控制,但不对对象本身的功能进行增强;
## 23、CompletableFuture
completableFuture继承于java.util.concurrent.Future,它本身具备Future的所有特性,并且基于JDK1.8的流式编程以及Lambda表达式等实现一元操作符、异步性以及事件驱动编程模型,可以用来实现多线程的串行关系,并行关系,聚合关系。它的灵活性和更强大的功能是Future无法比拟的。
举例:
1、使用自定义线程池
```java
ThreadPoolExecutor pool = new ThreadPoolExecutor(2, 4, 3,
TimeUnit.SECONDS, new ArrayBlockingQueue(3),
new ThreadPoolExecutor.DiscardOldestPolicy());
CompletableFuture.runAsync(() -> System.out.println("Hello World!"), pool);
```
2、allOf等待所有异步操作结束
```java
Random rand = new Random();
CompletableFuture future1 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1000 + rand.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println("future1 done...");
}
return "abc";
});
CompletableFuture future2 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1000 + rand.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println("future2 done...");
}
return "efg";
});
//主线程
//allof需要全部完成,anyOf() 方法不会等待所有的 CompletableFuture 都运行完成之后再返回,只要有一个执行完成即可!
CompletableFuture completableFuture = CompletableFuture.allOf(future1, future2);
completableFuture.join();
assertTrue(completableFuture.isDone());
System.out.println("all futures done...");
//结果
future1 done...
future2 done...
all futures done...
```
## 25、控制反转IOC
使用之前:

使用IOC思想之后

理解:IOC采用注入的方式,类似于零件组装,不new一个类,而是先类似于深度遍历所有组件,然后new出全部的零件,最后进行注入,传给上层,这样当需要修改某个组件的属性时,只需要修改某个组件自身,而不需要在最上层的类中new的时候就传入相关的属性。
## 26、cglib代理和jdk动态代理的区别
cglib代理和jdk动态代理的区别在于,JDK动态代理基于接口来创建被代理对象的代理实例,而Cglib代理基于继承的方式对被代理类生成子类。
1、JDK 动态代理:
- 基于接口来创建被代理对象的代理实例。当对象要被代理时,它必须实现一个或多个接口并依赖JDK库。JDK动态代理利用反射机制生成一个包含被代理对象的所有接口的代理类,并覆盖接口中的所有方法,可以对目标对象进行代理。
- 优点:无需引用第三方库,在JRE运行环境中就可以运行,生成代理对象更加简单、快捷;缺点:==仅支持基于接口进行代理==,无法对类进行代理,所以它的作用有限。
2.、Cglib 代理:
- 基于继承的方式对被代理类生成子类,从而添加代理逻辑。因为它是继承了被代理类,所以它会受到final类、private、static等不可继承属性的影响。
- 优点:Cglib支持对类进行代理,即使没有接口,也可通过设置回调接口间接地实现。性能比JDK动态代理更高,==能够代理那些没有实现任何接口的目标对象==。
Cglib在生成代理类的过程中,采用动态生成字节码的方式,在被代理类加载之前就完成了代理类的创建并缓存到内存中,以后每次调用时,都直接使用缓存的代理类。在大多数情况下,Cglib代理比JDK动态代理更适合于大规模的方法拦截和增强等场景。
3.3. JDK 动态代理和 CGLIB 动态代理对比
1. **JDK 动态代理只能代理实现了接口的类或者直接代理接口,而 CGLIB 可以代理未实现任何接口的类。** 另外, CGLIB 动态代理是通过生成一个被代理类的子类来拦截被代理类的方法调用,因此不能代理声明为 final 类型的类和方法。
2. 就二者的效率来说,大部分情况都是 JDK 动态代理更优秀,随着 JDK 版本的升级,这个优势更加明显
## 27、缓存中间件有哪些?
Redis、消息队列MQ、Nginx、Netty、Mycat、
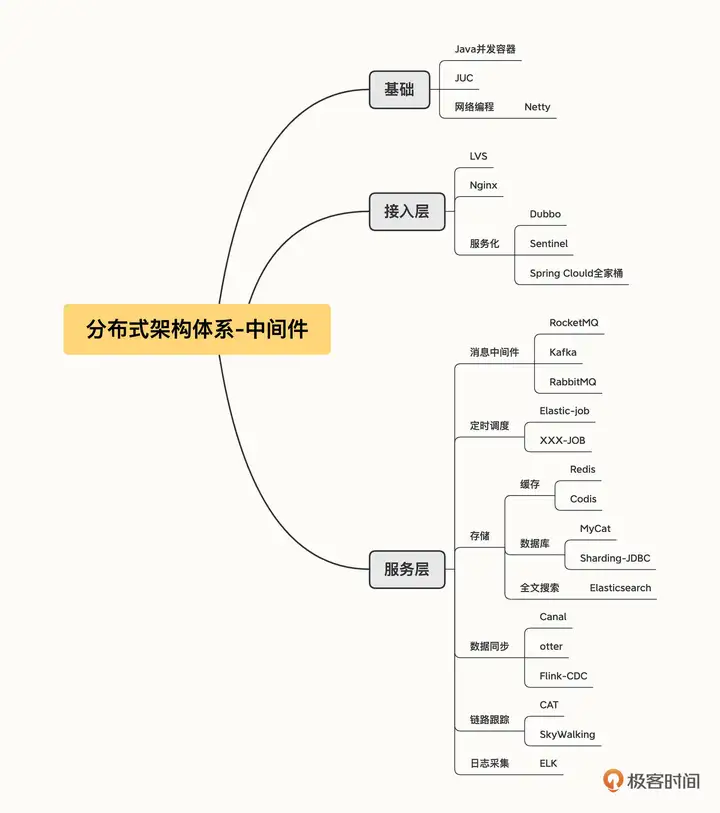
## 28、Synchronize锁升级过程
一、锁升级基础
1)偏向锁
只有一个线程争抢锁资源的时候.将线程拥有者标识为当前线程。引入了偏向锁目的是来尽可能减少无竞争情况下的同步操作开销。当一个线程访问同步块并获取对象的锁时,会将锁的标记记录在线程的栈帧中,并将对象头中的Thread ID设置为当前线程的ID。此后,当这个线程再次请求相同对象的锁时,虚拟机会使用已经记录的锁标记,而不需要再次进入同步块。
2)轻量级锁(自旋锁)
一个或多个线程通过CAS去争抢锁,如果抢不到则一直自旋。虚拟机会将对象的Mark Word复制到线程的栈帧中作为锁记录,并尝试使用CAS(Compare and Set)操作尝试获取锁。如果CAS成功,则表示线程获取了轻量级锁,并继续执行同步块。如果CAS失败,说明有竞争,虚拟机会通过自旋(spinning)等待其他线程释放锁
3)重量级锁
如果自旋等待不成功(类似出现死锁),虚拟机会将轻量级锁升级为重量级锁。在这种状态下,虚拟机会将线程阻塞,并使用操作系统的互斥量来实现锁的释放和获取。
需要注意的是,锁的升级是逐级升级的过程,而不会存在降级。换句话说,一旦锁升级到更高级别,就不会再回到低级别。
二、为什么要有锁升级过程?
锁的升级过程是为了提供更好的性能和吞吐量,并减少多线程竞争产生的开销。下面是锁的升级过程的一些原因:
1)减少无竞争情况下的同步操作开销
在多线程环境下,如果没有竞争,每个线程都可以安全地访问共享资源,无需进行同步操作。锁的升级过程中的第一阶段偏向锁(Biased Locking)就是为了在无竞争的情况下减少同步操作的开销。它通过记录线程ID来避免对锁的加锁和解锁操作,提高了单线程访问同步代码块时的性能。
2)尽量避免线程切换的开销
锁的升级过程中的第二阶段轻量级锁(Lightweight Locking)是为了减少线程切换的开销。它使用CAS(Compare and Set)操作来尝试获取锁,如果成功则可以继续执行同步块,无需线程切换;如果失败,则会进行自旋操作等待锁的释放。自旋操作避免了线程挂起和切换的开销,提高了多线程竞争时的性能。
3)降低内存消耗
锁的升级过程中的第二阶段轻量级锁使用对象头中的一部分位来存储线程ID和锁标记,不需要额外的内存存储锁的状态。相对于传统的重量级锁,它能够节省内存消耗。
4)提高系统吞吐量
锁的升级过程可以使多个线程在无竞争情况下快速获取锁,避免了线程阻塞和等待的开销。这样,系统的吞吐量会更高,因为更多的线程可以并发地执行任务。
总而言之,锁的升级过程是为了提高多线程环境下的性能和吞吐量,减少同步操作的开销,并尽量避免线程切换的开销。Java虚拟机根据线程竞争的情况和锁的使用情况自动进行锁的升级和降级,以优化多线程程序的性能。
三、==锁升级过程==
1)当只有一个线程去争抢锁的时候,会先使用偏向锁,就是给一个标识,说明现在这个锁被线程a占有.
2)后来又来了线程b,线程c,说凭什么你占有锁,需要公平的竞争,于是将标识去掉,也就是撤销偏向锁,升级为轻量级锁,三个线程通过CAS自旋进行锁的争抢(其实这个抢锁过程还是偏向于原来的持有偏向锁的线程).
3)现在线程a占有了锁,线程b,线程c一直在循环尝试获取锁,后来又来了十个线程,一直在自旋,那这样等着也是干耗费CPU资源,所以就将锁升级为重量级锁,向内核申请资源,直接将等待的线程进行阻塞.

## 29、为什么HashMap底层使用红黑树而不是平衡二叉树?
HashMap使用红黑树是因为红黑树相对于平衡二叉树有更好的性能表现。
首先,红黑树的平衡性能比平衡二叉树更好。红黑树的平衡性能是通过对节点进行颜色标记和旋转操作来实现的,而平衡二叉树只能通过旋转操作来实现平衡。因此,红黑树的平衡性能更好,可以更快地进行插入、删除和查找操作。
其次,红黑树的空间利用率比平衡二叉树更高。红黑树的节点结构比平衡二叉树的节点结构更紧凑,因此在存储大量数据时,红黑树的空间利用率更高。
最后,红黑树的实现比平衡二叉树更简单。红黑树的实现比平衡二叉树的实现更简单,因为红黑树的平衡性能是通过颜色标记和旋转操作来实现的,而平衡二叉树需要更复杂的平衡算法来实现平衡。
因此,HashMap使用红黑树来实现内部的数据结构,以提高性能和空间利用率。
作者:月下瑶台
链接:https://www.nowcoder.com/
来源:牛客网
## 30、接口和抽象类的异同
**区别1:定义关键字不同**
接口使用关键字 interface 来定义。 抽象类使用关键字 abstract 来定义。
**区别2:继承或实现的关键字不同**
接口使用 implements 关键字定义其具体实现。 抽象类使用 extends 关键字实现继承。
**区别3:子类扩展的数量不同**
在 Java 语言中,一个类只能继承一个父类(单继承),但可以实现多个接口。
**区别4:属性访问控制符不同**
接口中属性的访问控制符只能是 public,如下图所示:
> 接口中的属性默认是 public static final 修饰的。
>
抽象类中的属性访问控制符无限制,可为任意控制符
**区别5:方法控制符不同**
接口中方法的默认控制符是 public,并且不能定义为其他控制符,如下图所示:
**区别6:方法实现不同**
接口中普通方法不能有具体的方法实现,在 JDK 8 之后 static 和 default 方法必须有方法实现
==普通不能实现,其他必须实现==
抽象类中的普通方法如果没有方法实现就会报错,而抽象方法如果有方法实现则会报错。
==普通需要实现,抽象不能实现==
**区别7:静态代码块使用不同**
接口中不能使用静态代码块,如下代码所示:
抽象类中可以使用静态代码块,如下代码所示:
## 31、在并发量特别高的情况下是使用 synchronized 还是 ReentrantLock
在并发量特别高的情况下,一般推荐使用 ReentrantLock,原因如下:
1. **更高的性能**:在Java 1.6之前,**synchronized** 的性能一般比 **ReentrantLock** 差一些。虽然在 Java 1.6 及之后的版本中,synchronized进行了一些优化,如偏向锁、轻量级锁等,但在高并发情况下,ReentrantLock 的性能通常会优于 synchronized。
2. **更大的灵活性**:`ReentrantLock` 比 `synchronized` 有更多的功能。例如,`ReentrantLoc`k 可以实现**公平锁和非公平锁**(synchronized只能实现非公平锁);ReentrantLock 提供了一个 **Condition** 类,可以分组唤醒需要唤醒的线程(synchronized 要么随机唤醒一个线程,要么唤醒所有线程);ReentrantLock 提供了 `tryLock` 方法,可以尝试获取锁,如果获取不到立即返回,不会像synchronized 那样阻塞。
3. **更好的可控制性**:ReentrantLock可以中断等待锁的线程(synchronized无法响应中断),也可以获取等待锁的线程列表,这在调试并发问题时非常有用。
但是,虽然 ReentrantLock 在功能上比 synchronized 更强大,但也更复杂,使用不当容易造成死锁。**而 synchronized 由 JVM 直接支持,使用更简单,不容易出错**。所以,在并发量不高,对性能要求不高的情况下,也可以考虑使用 synchronized。
## 32、CAP分布式三原则
CAP理论的核心是:一个[分布式系统](https://so.csdn.net/so/search?q=分布式系统&spm=1001.2101.3001.7020)不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
## 33、线程相关
### 33.1 创建线程的方式
1. **继承Thread类**:这是创建线程的最基本方法。我们可以创建一个新的类,继承自 Thread 类,然后重写其 run() 方法,将我们的任务代码写在 run() 方法中。然后创建该类的对象并调用其 start() 方法来启动线程。
2. 实**现Runnable接口**:我们也可以创建一个新的类,实现 Runnable 接口,然后将我们的任务代码写在 run() 方法中。然后创建该类的对象,将其作为参数传递给 Thread 类的构造器,创建 Thread 类的对象并调用其 start() 方法来启动线程。
3. **实现Callable接口和FutureTask类**:Callable 接口与 Runnable 接口类似,但是它可以返回一个结果,或者抛出一个异常。我们可以创建一个新的类,实现 Callable 接口,然后将我们的任务代码写在 call() 方法中。然后创建该类的对象,将其作为参数传递给FutureTask 类的构造器,创建 FutureTask 类的对象。最后,将FutureTask类的对象作为参数传递给 Thread 类的构造器,创建Thread 类的对象并调用其 start() 方法来启动线程。
4. **使用线程池**:Java 提供了线程池 API(Executor框架),我们可以通过 Executors 类的一些静态工厂方法来创建线程池,然后调用其 execute() 或 submit() 方法来启动线程。线程池可以有效地管理和控制线程,避免大量线程的创建和销毁带来的性能开销。
以上四种方式,前两种是最基本的创建线程的方式,但是在实际开发中,我们通常会选择使用**线程池**,因为它可以提供更好的性能和更易于管理的线程生命周期。
### 33.2 一个线程池中的线程异常了,那么线程池会怎么处理这个线程?
> 1.抛出堆栈异常 (execute会抛出,submit不会,而是会封装在future中,主动调用才会显示)
>
> 2.不影响其他线程任务
>
> 3.这个线程会被直接从线程池中移除

当使用execute时会直接抛出异常,当submit时,会返回为Future,需要使用get方法拿到异常信息
### 33.3 Java 创建多线程时要注意哪些问题?
1. 线程安全问题:多个线程同时访问共享资源时可能会出现数据竞争、死锁等问题,需要使用同步机制来保证线程安全。
2. 上下文切换问题:线程切换会消耗系统资源,如果线程数量过多,会导致系统性能下降。
3. 线程间通信问题:多个线程之间需要进行通信,需要使用合适的方式进行线程间通信,如wait/notify、Lock/Condition等。
4. 线程优先级问题:线程优先级高的线程会优先执行,但是过度依赖线程优先级可能会导致线程饥饿问题。
5. 线程生命周期问题:线程的生命周期包括创建、运行、阻塞、唤醒和销毁等阶段,需要合理控制线程的生命周期。
6. 线程池问题:线程池可以有效地管理线程,但是线程池的大小、任务队列的大小等需要根据实际情况进行调整。
7. 异常处理问题:多线程程序中可能会出现异常,需要合理处理异常,避免程序崩溃。
### 33.4 线程同步方式
线程同步主要包括四种方式:
- 互斥量`pthread_mutex_`
- 读写锁`pthread_rwlock_`
- 条件变量`pthread_cond_`
- 信号量`sem_`
> 1、synchronized 关键字
>
> 2、Lock 接口
>
> 3、volatile
>
> 4、使用重入锁实现线程同步ReenreantLock类
>
> 5、使用局部变量实现线程同步 如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,
>
> 6、使用阻塞队列实现线程同步LinkedBlockingQueue 类
>
> 7、使用原子变量实现线程同步AtomicInteger类
### 33.5 ThreadLocal

### ThreadLocal源码简介
- 每个Thread对象中都持有一个ThreadLocalMap类型的成员变量。key是ThreadLocal的引用。一个Thread里只有一个ThreadLocalMap,一个ThreadLocalMap里有很多的ThreadLocal
- ThreadLocalMap中的key和value都保存在线程Thread类中的,而不是保存在ThreadLocal中
- getMap(Thread t):返回threadLocals,threadLocals是线程的一个成员变量。获取到当前线程内的ThreadLocalMap对象,每个线程都有ThreadLocalMap对象,而这个对象的名字就叫做threadLocals,初始值为null
- set(T value):把想要存储的value给保存进去。this:是把当前ThreadLocal的引用,在ThreadLocalMap中,它的key的类型是ThreadLocal;value:可以把这个键值对保存到ThreadLocalMap中去
- entry:把entry理解为一个map,它是一个WeakReference的引用,其键为当前的ThreadLocal,值为实际需要存储的变量
每个线程Thread持有一个ThreadLocalMap类型的实例threadLocals,结合此处的构造方法可以理解成每个线程Thread都持有一个Entry型的数组table,而一切的读取过程都是通过操作这个数组table完成的。
多个ThreadLocal
//在某一线程声明了ABC三种类型的ThreadLocal
ThreadLocal sThreadLocalA = new ThreadLocal();
ThreadLocal sThreadLocalB = new ThreadLocal();
ThreadLocal sThreadLocalC = new ThreadLocal();
对于一个Thread来说只有持有一个ThreadLocalMap,所以多个ThreadLocal对应同一个ThreadLocalMap对象。为了管理多个ThreadLocal,于是将他们存储在一个数组的不同位置,而这个数组就是上面提到的Entry型的数组table。
#### ThreadLocal 内存泄露问题是怎么导致的?
`ThreadLocalMap` 中使用的 key 为 `ThreadLocal` 的弱引用,而 value 是强引用。所以,如果 `ThreadLocal` 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。
这样一来,`ThreadLocalMap` 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。`ThreadLocalMap` 实现中已经考虑了这种情况,在调用 `set()`、`get()`、`remove()` 方法的时候,会清理掉 key 为 null 的记录。使用完 `ThreadLocal`方法后最好手动调用`remove()`方法
```java
static class Entry extends WeakReference> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
}
```
## 34、RocketMQ消息队列相关
### 34.1、RocketMQ 如何实现分布式事务?
在 `RocketMQ` 中使用的是 **事务消息加上事务反查机制** 来解决分布式事务问题的。我画了张图,大家可以对照着图进行理解。
在第一步发送的 half 消息 ,它的意思是 **在事务提交之前,对于消费者来说,这个消息是不可见的** 。
> 那么,如何做到写入消息但是对用户不可见呢?RocketMQ 事务消息的做法是:如果消息是 half 消息,将备份原消息的主题与消息消费队列,然后 **改变主题** 为 RMQ_SYS_TRANS_HALF_TOPIC。由于消费组未订阅该主题,故消费端无法消费 half 类型的消息,**然后 RocketMQ 会开启一个定时任务,从 Topic 为 RMQ_SYS_TRANS_HALF_TOPIC 中拉取消息进行消费**,根据生产者组获取一个服务提供者发送回查事务状态请求,根据事务状态来决定是提交或回滚消息。
你可以试想一下,如果没有从第 5 步开始的 **事务反查机制** ,如果出现网路波动第 4 步没有发送成功,这样就会产生 MQ 不知道是不是需要给消费者消费的问题,他就像一个无头苍蝇一样。在 `RocketMQ` 中就是使用的上述的事务反查来解决的,而在 `Kafka` 中通常是直接抛出一个异常让用户来自行解决。
### 34.2 顺序消费

根据上图可以,上面的方法可以实现==一组消息被顺序的存放,不同组的消息之间的顺序无法保证==,这就是部分顺序。
另外,顺序消息必须使用同步发送的方式才能保证生产者发送的消息有序。
实际上,采用队列选择器的方法不能保证消息的严格顺序,我们的目的是将消息发送到同一个队列中,如果某个broker挂了,那么队列就会减少一部分,如果采用取余的方式投递,将可能导致同一个业务中的不同消息被发送到不同的队列中,导致同一个业务的不同消息被存入不同的队列中,短暂的造成部分消息无序。同样的,如果增加了服务器,那么也会造成==短暂的造成部分消息无序。==
其实很简单,我们需要处理的仅仅是将同一语义下的消息放入同一个队列(比如这里是同一个订单),那我们就可以使用 **Hash 取模法** 来保证同一个订单在同一个队列中就行了。
### 34.3 重复消费
**幂等**
那么如何给业务实现幂等呢?这个还是需要结合具体的业务的。你可以使用 **写入 `Redis`** 来保证,因为 `Redis` 的 `key` 和 `value` 就是天然支持幂等的。当然还有使用 **数据库插入法** ,基于数据库的唯一键来保证重复数据不会被插入多条。
## 35、select、poll、epoll的区别
select==>时间复杂度O(n)(BIO)
它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
poll==>时间复杂度O(n)(BIO)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的.
epoll==>时间复杂度O(1)(NIO)
类似于回调
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
epoll跟select都能提供多路I/O复用的解决方案。在现在的Linux内核里有都能够支持,其中epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现
epoll的优点:
1、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口);
2、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;
即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
3、 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
==消息传递==
**select**
内核需要将消息传递到用户空间,都需要内核拷贝动作
**poll**
同上
**epoll**
epoll通过内核和用户空间共享一块内存来实现的。
## 36、AQS抽象队列同步器
AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 **CLH 队列锁** 实现的,即将暂时获取不到锁的线程加入到队列中。
CLH(Craig,Landin,and Hagersten) 队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配。在 CLH 同步队列中,一个节点表示一个线程,它保存着线程的引用(thread)、 当前节点在队列中的状态(waitStatus)、前驱节点(prev)、后继节点(next)。
CLH 队列结构如下图所示:
AQS(`AbstractQueuedSynchronizer`)的核心原理图(图源[Java 并发之 AQS 详解open in new window](https://www.cnblogs.com/waterystone/p/4920797.html))如下:

## 37、ReentrantLock和Synchronize的区别
==`ReentrantLock` 的底层就是由 AQS 来实现的,AQS基于CLH队列实现,是一个虚拟的双向队列,原版是通过自旋实现的,后来修改后变为使用阻塞等待操作替换了自旋,可以很好地处理超时和取消(等待可中断)==
两者都是可重入锁
**可重入锁** 也叫递归锁,指的是线程可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果是不可重入锁的话,就会造成死锁。
synchronized 依赖于 JVM(JVM虚拟机monitorenter和monitorexit) 而 ReentrantLock 依赖于 API
`ReentrantLock` 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成
ReentrantLock 比 synchronized 增加了一些高级功能
相比`synchronized`,`ReentrantLock`增加了一些高级功能。主要来说主要有三点:
- **等待可中断** : `ReentrantLock`提供了一种能够中断等待锁的线程的机制,通过 `lock.lockInterruptibly()` 来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
- **可实现公平锁** : `ReentrantLock`可以指定是公平锁还是非公平锁。而`synchronized`只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。`ReentrantLock`默认情况是非公平的,可以通过 `ReentrantLock`类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
- **可实现选择性通知(锁可以绑定多个条件)**: `synchronized`关键字与`wait()`和`notify()`/`notifyAll()`方法相结合可以实现等待/通知机制。`ReentrantLock`类当然也可以实现,但是需要借助于`Condition`接口与`newCondition()`方法。
## 38、volatile相关
不能保证原子性(线程并发时会被多个线程同时修改,导致最终答案错误,比如两个线程同时对变量+1,结果出来还是1而不是2),可以保证可见性。
`volatile`定义:
- 当对volatile变量执行写操作后,JMM会把工作内存中的最新变量值强制刷新到主内存
- 写操作会导致其他线程中的缓存无效
这样,其他线程使用缓存时,发现本地工作内存中此变量无效,便从主内存中获取,这样获取到的变量便是最新的值,实现了线程的可见性。
1. volatile修饰符适用于以下场景:某个属性被多个线程共享,其中有一个线程修改了此属性,其他线程可以立即得到修改后的值,比如booleanflag;或者作为触发器,实现轻量级同步。
2. volatile属性的读写操作都是无锁的,它不能替代synchronized,因为它没有提供原子性和互斥性。因为无锁,不需要花费时间在获取锁和释放锁_上,所以说它是低成本的。
3. volatile只能作用于属性,我们用volatile修饰属性,这样compilers就不会对这个属性做指令重排序。
4. volatile提供了可见性,任何一个线程对其的修改将立马对其他线程可见,volatile属性不会被线程缓存,始终从主 存中读取。
5. volatile提供了happens-before保证,对volatile变量v的写入happens-before所有其他线程后续对v的读操作。
6. volatile可以使得long和double的赋值是原子的。
7. volatile可以在单例双重检查中实现可见性和禁止指令重排序,从而保证安全性
volatile 是一种 Java 关键字,它的作用是保证变量的可见性和禁止指令重排序。
在 Java 中,线程之间的通信通常是通过共享变量进行的。但是由于线程之间的工作内存是相互独立的,因此一个线程对共享变量的修改可能并不会立即被其他线程看到,这就会导致可见性问题。使用 volatile 关键字可以解决这个问题,因为它能够保证对 volatile 变量的读写操作都是在主内存中进行的,而不是在工作内存中进行的。
此外,编译器和处理器在优化代码时可能会进行指令重排序,这可能会导致程序出现意想不到的行为。使用 volatile 关键字可以禁止编译器和处理器对指令进行重排序,从而保证程序的正确性。
需要注意的是,volatile 关键字并不能保证原子性,因此在需要保证原子性的场合,需要使用其他的同步机制,如 synchronized 关键字或者使用原子类。
> 可见性能举个例子说明一下吗
好的,下面举个例子说明一下可见性的问题:
假设有两个线程 A 和 B,它们共享一个变量 flag,初始值为 false。线程 A 执行了以下代码:
arduino
```arduino
flag = true;
```
线程 B 执行了以下代码:
```perl
while (!flag) {
// do something
}
```
线程 B 的代码是一个循环,只要 flag 的值为 false,它就会一直循环下去。如果 flag 的值被线程 A 修改为 true,那么线程 B 就能够跳出循环。但是如果线程 A 修改 flag 的值后,线程 B 并没有看到 flag 的最新值,那么它就会一直在循环中阻塞,这就是可见性问题。
使用 volatile 关键字可以解决这个问题,因为它能够保证对 volatile 变量的读写操作都是在主内存中进行的,而不是在工作内存中进行的。因此,如果将 flag 声明为 volatile 变量,那么线程 B 就能够看到线程 A 对 flag 的修改,从而跳出循环。
## 39、SPI和API
API是你实现好了接口,我拿来用。服务方写接口,实现接口,我直接拿来用(实现方确定规则)。==先有供给,后有需求==
SPI是我写接口,多个服务方实现功能,我挑一个用(调用方确定规则)。==先有需求,后有供给,竞标==
SLF4J (Simple Logging Facade for Java)是 Java 的一个日志门面(接口),其具体实现有几种,比如:Logback、Log4j、Log4j2 等等,而且还可以切换,在切换日志具体实现的时候我们是不需要更改项目代码的,只需要在 Maven 依赖里面修改一些 pom 依赖就好了。

## 40、@Async注解有什么问题?
机制:
- **异常处理**:使用 Async 注解时,异常处理可能会变得更加复杂。由于异步操作是在另一个线程中执行的,因此如果异步操作抛出了异常,这个异常可能不会被捕获。为了解决这个问题,开发者需要使用 CompletableFuture 的异常处理机制来捕获异步操作抛出的异常。
- **内存占用**:使用 Async 注解时,由于每个异步操作都会在一个新的线程中执行,因此可能会导致大量的线程被创建。这可能会导致内存占用过高,从而导致应用程序性能下降。
- **阻塞操作**:使用 Async 注解时,如果异步操作中包含了阻塞操作,这可能会导致线程池中的线程被阻塞,从而导致应用程序性能下降。
问题:
- **可能会导致性能问题**:由于 Async 注解会创建新的线程来执行异步操作,因此如果使用不当,可能会导致线程池中的线程被过度消耗,从而导致性能问题。
- **可能会导致内存泄漏问题**:如果使用 Async 注解时没有正确地管理线程池,可能会导致内存泄漏问题。例如,如果不正确地配置线程池大小,可能会导致线程池中的线程无法回收,从而导致内存泄漏。
- **可能会导致死锁问题**:如果异步操作中包含了阻塞操作,可能会导致线程池中的线程被阻塞,从而导致死锁问题。
## 41、Redis延迟双删
延迟双删策略
为什么会存在延迟双删呢,普通的双删时,假设B请求获取到了旧数据,准备填充到缓存,A请求刚刚更新完数据库,立刻删除了缓存,在删除完成后B请求才把旧数据的缓存去填充,这样依然会出现缓存与数据库不一致的情况(即缓存内数据错误)。
延迟双删就是A请求更新完数据库之后,延迟那么一会再去删除缓存,这样的目的也很明显,就是为了让B请求(以及其他很多相近时间的请求)已经拿旧数据填充过缓存了,并且已经走完这一段逻辑了,后续不会去尝试覆盖缓存了。这个时候再去删除缓存,下一次去填充缓存的时候就拿到的是A请求更新好的正确的数据了。
## 42、Bean的生命周期和AOP
Bean的生命周期:
第一阶段 createBeanInstance()方法实例化bean
顺便提一下 为了解决==循环依赖问题(见43)==向缓存暴露bean工厂
第二阶段 populateBean() 属性注入
第三阶段 initializeBean() 方法 进入初始化阶段
第四阶段 销毁
初始化阶段执行Aware接口 和 后置处理器方法 执行初始化方法
==AOP发生在初始化方法执行后==
**initializeBean()源码**
```java
protected Object initializeBean(String beanName, Object bean, @Nullable RootBeanDefinition mbd) {
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction
# 🔔加入我们&分享资料
注:分享内容可以是你的项目地址、博客地址,也可以是一个word文件、PDF、电子书等等
## 🔥如何分享提交资料?
如果你希望贡献此仓库, 请先确保自己下载了 git, 并且能够成功 clone GitHub 中的远程仓库.
如果对 git 有疑问, 请参考 [How to Use Git](https://github.com/1051727403/SHU-CS-Source-Share/wiki/How-to-Use-Git).
具体贡献的方式, 请参考 [How to Contribute](https://github.com/1051727403/SHU-CS-Source-Share/wiki/How-to-Contribute).
-------------------分割线-------------------
**鸣谢:**
感谢所有愿意维护该项目以及分享资源的同学,欢迎大家提交PR或是直接QQ联系我,我会及时更新资料。
若想要参与项目维护可以QQ私信我
QQ:1051727403
================================================
FILE: 学习资料(非电子书)/C语言/README.md
================================================
# C语言
资料链接: [[百度网盘](https://pan.baidu.com/s/1OdaHrgdZVbCh7VBgRB_mlg?pwd=1lsd)]
1. C语言复习题合辑包
- C语言课后习题答案截图
- 第[2-7]章答案
- 校内历年卷
- [2000-2011]
- 编程题评分参考
- ...
- 练习题
- ...
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/JAVA程序设计/README.md
================================================
# JAVA程序设计
资料链接: [[百度网盘](https://pan.baidu.com/s/1t5PjPaSYis2fiBxVt4omZg?pwd=1ewn)]
1. lv课后作业源码
- 1-9周课后作业.zip
- README.md
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/Web开发计算A/README.md
================================================
# Web开发计算A
资料链接: [[百度网盘](https://pan.baidu.com/s/1CmV87La7qNJyA17kq72HAQ?pwd=daca)]
1. 实验
- 实验三.docx
- 实验四.docx
- 实验五.docx
- 实验六.docx
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/人工智能/README.md
================================================
# 人工智能
资料链接: [[百度网盘](https://pan.baidu.com/s/1kS8tlxhvzHbuFZ0_EaYTAg?pwd=e02y)]
1. JIN人工智能复习大纲 [[百度网盘](https://pan.baidu.com/s/1v1XZQJ09833MzEQmeWOkKg?pwd=pbhp)]
- Assets
- AI复习大纲2023冬.pdf
- README.md
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/其他/README.md
================================================
# 其他
资料链接: [[百度网盘](https://pan.baidu.com/s/1ORPhnqPtd88EQwYhpIqHyA?pwd=v4no)]
1. ACM算法知识&模板
- 【算法知识整理】无图版.md
- 【算法知识整理】有图版.pdf
- ACM算法模板-纯模板无图片.pdf
- README.md
2. PPT通用模板
- 学府红.pptx
- 上大蓝.pptx
- 江南绿.pptx
- 银杏黄.pptx
- 玉兰白.pptx
- 锦鲤红.pptx
- 海派蓝.pptx
- 芳菲紫.pptx
- 星空灰.pptx
3. PS教程 [[GitHub](https://github.com/1051727403/PS-Tutorial)]
4. 阿里巴巴JAVA开发规范
- Java开发手册(黄山版).pdf
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/大学物理/README.md
================================================
# 大学物理
资料链接: [[百度网盘](https://pan.baidu.com/s/1IS8pAVRmw20hFBKhiZTyQA?pwd=69ta)]
1. 大学物理实验
- 【大物实验】填空题爆炸秒杀.xls
- 大物实验基础课ppt.pdf
- 物理实验题库.xlsx
- 碰撞实验.xlsx
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/大数据从理论到实践A/README.md
================================================
# 大数据从理论到实践A
资料链接: [[百度网盘](https://pan.baidu.com/s/1dpzsmXZMuKs1P1RfUwCjMA?pwd=c9f0)]
1. 课程论文
- lv课程论文.docx
- 论文模板.docx
2. 参考资料
- README.md
- 如何实现机器学习算法.pdf
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/实用计算机英语/README.md
================================================
# 实用计算机英语
简介:这门课作为一门4分的选修课,是在第十周提前考的,考试方式为闭卷
优点:不需要制作项目,分值高,管得不严,适合划水
缺点:课后作业习题较多(当前目录下仅为其中的一小部分),最后个人感觉很难给高分
总结:如果不对绩点有高需求,又想划水,又想给分多,并且自身有一定英语水平的可以考虑选
---
资料链接: [[百度网盘](https://pan.baidu.com/s/1Hb-sMekvp7vEsEa5fzlI6w?pwd=r7j0)]
1. 历年卷
- 2021 ~ 2022实用计算机英语历年卷.doc
2. 教材
- Computing Essentials 2021 .pdf
3. 课后作业
- 第一周词汇.docx
- 第二章词汇.docx
- 第三章词汇.docx
- 第四章词汇.docx
- 第五章词汇.docx
- 第六章词汇.docx
- 第七章词汇.docx
- 第七章词汇.docx
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/微积分/README.md
================================================
# 微积分
资料链接: [[百度网盘](https://pan.baidu.com/s/1N6JaIQlP_rIbcomwLm6-Cg?pwd=xkf8)]
1. 试卷
- 2023年微积分1练习题(理工).pdf
- 2023年微积分1练习题(理工)参考答案.docx
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/操作系统/README.md
================================================
# 操作系统
资料链接: [[百度网盘](https://pan.baidu.com/s/1WFoMo53BeIQHaQ7zg0DeRg?pwd=vb58)]
1. 操作系统(1)
- 哲学家问题模拟源代码.docx
2. 操作系统(2)
- 试卷
- 操作系统(二)试卷.pdf
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/数字逻辑/README.md
================================================
# 数字逻辑
资料链接: [[百度网盘](https://pan.baidu.com/s/1SQBZLEHqmKIJcYHwtq5bxg?pwd=vh5a)]
本文件夹下存放了数字逻辑实验相关的内容,其中,以不同前缀命名的实验报告:“jk报告”“lv报告”分别代表两个不同的人的报告,感谢大家分享!
---
1. jk报告
- 实验[1-5].doc
2. lv报告
- 实验[1-6].doc
3. 复习资料
- 2019秋数字逻辑复习汇总.pptx
4. 数字逻辑实验PPT_20201109
- 数字逻辑实验[1-7].ppt
5. 数字逻辑实验指导书_20201030
- ...
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/数据分析与智能计算/README.md
================================================
# 数据分析与智能计算
资料链接: [[百度网盘](https://pan.baidu.com/s/1Pfb_NbInGLS-oznu4hdVmQ?pwd=tm0i)]
1. 复习资料
- 复习大纲.md
- 库函数快速索引表.xlsx
- 数据分析复习.pptx
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/数据库/README.md
================================================
# 数据库
资料链接: [[百度网盘](https://pan.baidu.com/s/1iV616CU8FSVyB5nU7FmETw?pwd=a005)]
1. 数据库(1)
- 《数据库原理一》复习、习题分析.ppt
- README.md
- 数据库原理(一)--复习课2024版.ppt
- 课后习题参考答案.pdf
2. 数据库(1)实验
- 2022冬-数据库1-研讨和实验安排(更.docx
- 李晓强1-5周.docx
3. 数据库(2)
- 第...章.ppt
4. 数据库(2)实验-ly
- 实验1 在云服务器上部署mysql.md
- 实验2 Hadoop&Hive部署.md
- 实验3 在Docker中部署Redis.md
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/数据结构/README.md
================================================
# 数据结构
资料链接: [[百度网盘](https://pan.baidu.com/s/1HtkEoSB2ui0bxrQZK-qzlw?pwd=fx7m)]
1. ycshao21-CourseProject [[GitHub](https://github.com/ycshao21/DataStructure-ZNJ-SHU)]
2. 数据结构(2)
- PPT课件
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/概率论/README.md
================================================
# 概率论
资料链接: [[百度网盘](https://pan.baidu.com/s/1UYKbE4YdS5a2E0grD6vnAg?pwd=qsdg)]
1. 历年卷
- 12-13秋概率论与数理统计A试题(A卷).doc
2. 复习
- 复习提纲_概率统计.pdf
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/汇编语言/README.md
================================================
# 汇编语言
资料链接: [[百度网盘](https://pan.baidu.com/s/1lYX3JYTSGQiuCHHSD8Tecw?pwd=6lw6)]
1. HighVorz-assembly
- experiment
- exp[2-7].asm
- report.md
- func
- *.asm
- assembly.md
- HelloWorld.asm
- method.jpg
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/离散数学/README.md
================================================
# 离散数学
资料链接: [[百度网盘](https://pan.baidu.com/s/1qpt52Mw-4pdXpMGucdylng?pwd=9us1)]
1. 历年卷
- 2012~2013学年秋季离散数学.pdf
2. 复习
- 图论:几种特殊的图.jpg
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/算法设计与分析课程/README.md
================================================
# 算法设计与分析
资料链接: [[百度网盘](https://pan.baidu.com/s/1rCpVy_rKS7kPVF2gpVtKkw?pwd=ju84)]
1. jk-实验题目与源码解析
- 实验[1-7]
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/线性代数/README.md
================================================
# 线性代数
资料链接: [[百度网盘](https://pan.baidu.com/s/12H7BrmmLMdV28Dfe0dATGA?pwd=2rn7)]
1. 复习、历年真题
- [2009-2018]
2. 笔记
- 手写复习笔记.pdf
- 线性代数笔记zzr.pdf
3. 课件PPT
- ...
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/组合数学/README.md
================================================
# 组合数学
资料链接: [[百度网盘](https://pan.baidu.com/s/1OhdZ02D7MCh98f_MYdgcOg?pwd=n12o)]
1. 习题
- lv-八种球盒问题.docx
- 经典考题1.png
- 经典考题2.png
2. 课件
- Chapter[1-6].pdf
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/编译原理/README.md
================================================
# 编译原理
资料链接: [[百度网盘](https://pan.baidu.com/s/1BgMNHwcAUQQiwFXEgIHEAA?pwd=15o7)]
1. 实验指导书和模板
- 《编译原理》课程实验报告撰写提纲.docx
- 《编译原理》课程实验指导书.pdf
2. 课程项目: PrettyLazy0 [[Github](git@github.com:jamesnulliu/PrettyLazy0.git)]
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/脑认知/README.md
================================================
# 脑认知
1. cxy-脑认知复习
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/脑认知/cxy-脑认知复习/脑认知复习.md
================================================
# 人工智能与脑认知
> :heavy_exclamation_mark: 考前预测的重点
> ==xx==考到的部分小题和几乎所有简答题,大题
## Chapter 1 人工智能与脑科学
### 人工智能与智能
#### 史观
- 亚里士多德 三段论 前提真 结论真;培根 归纳法 前提真,结论不一定真
- Godel的这两条定理,指出了把人的思维形式化和机械化的某种**极限**,在理论上证明了**有些事情是做不到的**
- 诺伯特·维纳认为所有人类智力的结果都是一种**反馈**的结果;**反馈机制**是有可能用机器模拟的
- 图灵测试使实验研究智能行为成为可能
#### 相关定义:heavy_exclamation_mark:
##### 人工智能
1. **基于能力行为的定义**:智能机器所执行的通常与人类智能有关的智能行为 ,如判断、推理、证明、识别、感知、理解、通信、设计、思考、规划、学习和问题求解等思维活动 。
1. **学科的定义**:计算机科学中涉及研究、设计和应用智能机器的一个分支 。它的近期目标在于研究用机器来模仿和执行人脑的某些功能,并开发相关理论和技术。
##### 知识
==人们通过体验、学习或联想而知晓的对客观世界规律性的认识,包括事实、条件、过程、规则、关系和规律等==
##### 智能
两种定义方式:
人类在认识和改造世界的活动中,由脑力劳动表现出来的能力。包括感知、理解、抽象、分析、推理、判断、学习和对变化环境的适应等等。
一种应用知识对一定环境或问题进行**处理**的能力或者进行**抽象思考**的能力。
##### 智能机器
能够在各类环境中**自主地或交互地**执行各种拟人任务的机器。
##### 生物智能
生物智能是个体有目的的行为、合理的思维, 以及有效的适应环境的综合能力
#### 人类思维的主要形态
==**感知,形象,抽象,灵感**==
1. 感知是思维的**初级形态**,来源**客观的,丰富的**
2. 形象思维主要是典型化的方法进行概括,用形象材料来思维,高等生物共有。
3. **形象思维**处理外部感知,进一步进行抽象思维
#### 人工智能的五个基本问题
1. **知识与概念化**是否是人工智能的核心?
2. **认知能力**能否与**载体**分开来研究?
3. **认知的轨迹**是否可用**类自然语言**来描述?
4. **学习能力**能否与**认知**分开来研究?
5. 所有的认知是否有一种**统一的结构**?
#### 人工智能的研究目标
* 根本目标是要求计算机不仅能模拟而且可以延伸、扩展人的智能, 达到甚至超过人类智能的水平。
* 近期目标是使现有的计算机不仅能做一般的数值计算及非数值信息的数据处理,而且能运用知识处理问题,能模拟人类的部分智能行为。
* 作为工程技术学科,人工智能的目标是提出建造人工智能系统的新技术、新方法和新理论,并在此基础上研制出具有智能行为的计算机系统。
* 作为理论研究学科,人工智能的目标是提出能够描述和解释智能行为的概念与理论,为建立人工智能系统提供理论依据。
#### 人工智能分类 :heavy_exclamation_mark:
> 听王昊的意思必考?草结果没考,至少a卷没考
类人思维方法 理性思维系统
类人行为方法 理性行为系统
### 人脑工程
#### 人类脑计划
人类脑计划的核心:***神经信息学***,指**神经科学**和**信息科学**相互结合的研究领域。
目标:**认识脑,保护脑,创造脑** :heavy_exclamation_mark:
### 选择题
#### 人脑的特点
1. 大脑重量占人体的2%,能耗却达到正常消耗的20%,是人体能量消耗最大的器官之一。
2. 大脑的神经细胞超过1000亿个,具有一定的自我修复、学习和功能强化能力。
3. 大脑具有计算机所不能达到的逻辑思维、情感思维和模糊分析能力。
4. 脑死亡状态下,脑部**仍产生生物电流**,脑神经元若未完全死亡还有脑电。
#### 人脑的智能特点 :heavy_exclamation_mark:
1. 能感知客观世界的信息 **(感知能力)**
2. 能对通过思维获得的知识进行加工处理 **(记忆与思维能力)**
3. 能通过学习积累知识增长才干和适应环境变化 **(归纳与演绎)**
4. 能对外界的刺激作出反应传递信息 **(学习能力以及行为能力)**
#### 人工智能与人的自然智能 :heavy_exclamation_mark:
1. 人工智能是人类智能的延申与扩展
2. 人的自然智能能够结合外部环境进行合理的判断,而人工智能可以根据外界的输入(即外界环境的变化)进行分析输出,两者具有相似性,但是不具备可替代性。
3. 在所有人工智能的定义以及人工智能的基本问题中,人工智能的目的是为了代替人的某些单调的或是复杂的体力和脑力活动,从而让人具有更多的精力来完成更加复杂的工作。
4. 人工智能技术实质上是一种类人行为和思维方法。
#### 人工智能的描述
1. 人工智能的研究注意智能系统的效果而不是单纯的对人的智能行为的模拟。
2. 人工智能研究者主要从智能行为的过程与表现入手。
3. 人工智能的目标是提出建造人工智能系统的新技术、新方法和新理论,并在此基础上研制出具有智能行为的计算机系统。
4. 人工智能的目标是提出能够描述和解释智能行为的概念与理论,为建立人工智能系统提供理论依据。
## Chapter 2-a 认知科学概述
### 认知神经科学
#### 定义
认知神经科学是认知活动的**心理过程**和**脑机制**的科学。
心理学由认知心理学进入到认知神经科学的新时代。认知神经科学并不是认知心理学的分支
#### 研究模式
将**行为、认知过程、脑机制**三者结合起来
#### 常用研究方法
1. **无创性脑功能(认知)成像技术**
- 脑代谢功能成像
- 生理功能成像
2. **清醒动物认知生理心理学研究方法**
- 包括单细胞记录
- 多细胞记录
- 多维(阵列)电极记录法
- 其他生理心理学方法(手术法、冷却法、药物法等)
3. 脑事件相关电位、脑磁图和高分辨率脑成像等生理学电位方法
#### 具体研究方法
- 脑整体活动层次
- 不同脑区活动层次
- 神经细胞和亚细胞层次
- 分子活动层次
#### 认知活动测量工具
脑活动测量工具:
- 脑电波(Electroencephalogram, EEG)
- fNIR近红外光学脑成像系统
- 脑磁共振
其他生理设备:眼动仪、皮电、肌电、血电容积等
#### 神经系统
神经系统分为:**中枢神经系统**和**周围神经系统**
### 认知心理学
#### 核心 :heavy_exclamation_mark:
输入和输出之间发生的内部心理过程
#### 研究对象
1. 人的高级心理过程,主要是认知过程
2. 信息加工心理学
#### 研究内容
1. 人们如何获得外部世界信息
2. 信息在人脑内如何表示并转化为知识
3. 知识怎样存储又如何用来指导人们的注意和行为
4. 从认知神经生理基础、感知觉基本过程、认知行为脑机制到认知心理应 用多个层面探索心智奥秘
5. 从基因-神经-心理-行为层面出发,开展个体-群体-组织-社会等多个水平 的基础研究和应用研究
### 脑结构与功能
#### 神经细胞的组成
细胞体,轴突,树突
#### 脑的结构
**大脑、间脑、小脑、中脑、脑桥及延髓**等六个部分
#### 大脑皮质
- 三个面:上外侧面、内侧面、下面
- 三个沟:中央沟、外侧沟、顶枕沟
- ==**五个叶:额叶、顶叶、枕叶、颞叶、岛叶** :heavy_exclamation_mark:==
大脑皮质中,**额叶**部分负责高级思维相关,**枕叶**部分被认为是视觉初级感受区,**颞叶**主要是听觉初级区域所在的位置。

#### 左右脑
:heavy_exclamation_mark: 左右脑的协同主要依赖**胼胝体**
> 选填?
##### 对比
左半脑主要具有语言、分析、计算、抽象、逻辑、对时间感觉等思维功能;右半脑具有表象、综合、直观、音乐、对空间知觉和理解等思维功能。在思考方式上,左半球是垂直的、连续的、因果式的;右半球是并行的、发散的、整体式的。
##### 联系
大脑左右半球的分工并不是那么泾渭分明,功能的单侧化只具有相对的意义,左右半球既有相对的分工,又有密切的协作,人的许多重要的心理功能都需要左右半球的密切协作才能完成。
#### 脑的联络区
大脑中除了一些具有特定功能的中枢外,还存在着广泛的脑区,它们不局限于某种功能,而是对各种信息进行加工和整合,完成高级的神经精神活动,称为联络区。
#### 大脑认知功能模块:heavy_exclamation_mark:
**加扎尼加**提出脑认知功能模块论
#### 无法说话 :heavy_exclamation_mark:
原因是**运动型语言中枢**出问题
## Chapter 2-b 认知科学详细
### 认知科学
认知科学是研究人类感知和思维信息处理过程的科学,**(研究方向)** 包括从感觉的输入到复杂问题求解, 从人类个体到人类社会的智能活动, 以及人类智能和机器智能的性质。
#### 研究层次(认知科学or认知神经科学)
分子、细胞、脑组织区和全脑
#### 四个焦点问题 *(可能多选)*
1. 知觉和认知
2. 运动和行为
3. 记忆和学习
4. 语言和思考
#### 认知的三个方面
==***适应、结构、过程***==
#### hoston等对认知的看法
1. 认知是信息的处理过程;
2. 认知是心理上的符号运算;
3. 认知是问题求解;
4. 认知是思维;
5. 认知是一组相关的活动,如知觉、记忆、思维、判断、推理、问题求解、学习、想象、概念形成、语言使用等
#### 认知的分类
**经验认知**和**思维认知**
#### 感知和认知的定义及关系 :heavy_exclamation_mark:
> 感觉得背
感知:即通过人体器官和组织进行人与外部世界的信息的交流和传递
认知:人们在进行日常活动时发生于头脑中的事情,它涉及思维、记忆、学习、幻想、决策、看、读、写和交谈等
关系:感知是认知的基础,认知是将感知获取的信息综合应用
### 感知
#### 种类
视,听,嗅,味,触
#### 视觉
##### 一些性质
- 与外界联系最重要的通道 **80%信息来源**
- 视觉感知的两个阶段:接受信息和解释信息
##### 特点
- 一方面,物理特性决定了人类无法看到一些事物
- 另一方面,解释处理信息时可对不完全的信息发挥一定想象力
##### 视敏度
指**人眼对细节的感知能力**,通常用被辨别物体最小间距所对应的视角的倒数表示。
##### 图像识别
> 只考一题?
两种理论:**模板匹配**和**原型匹配(格式塔心理学)**
###### 格式塔
格式塔即任何分离的整体,认为整体比局部更优先被感知
##### 阅读 :heavy_exclamation_mark:
> 很重要;感觉会考?
三个阶段
1. 页面上文字的形状被人眼感知
2. 文字被编码成相关的内部语言表示
3. 语言在人脑中被解释成有语法和语义的单词或句
##### 颜色模型
> 顶多一道选择题?
- RGB(加性原色系统)
- CMYK(减色原色系统)
- HSV(色调、饱和度、亮度)
#### 信息表示方法
> 小概率?
信息的显示方式对于人们能否快速捕捉到所需的信息片断有很大的影响。**分类显示**的信息就比较便于人们查找
### 识别
:heavy_exclamation_mark:人的***识别能力大于回忆能力***
> 重复过,感觉会考
#### 人脸识别 :heavy_exclamation_mark:
在人脸的感知中,全局特征一般是用来**进行粗略的匹配**,局部特征一般是用来提供更为**精细的确认**
脸部的识别为整体优先,物体的识别为局部优先
##### 对于人脸的识别下面说法正确的是
- 人脸的上半区域的识别的重要性要高于下半区域。
- 个性化特征可以用于更加精确的识别。
- 特殊脸比大众脸型更容易被记住和识别。
#### 记忆
三个环节:**识记,保持,再认和回忆**
#### 交互设计
1. 应考虑用户的记忆能力,勿使用过于复杂的任务执行步骤。
2. 由于用户长于“识别”而短于“回忆”,所以在设计界面时,应使用菜单、图标,且它们的位置应保持一致。
3. 为用户提供多种电子信息(如文件、邮件、图像)的编码方式,并且通过颜色、标志、时间戳、图标等,帮助用户记住它们的存放位置
### 场依存性与场独立性:heavy_exclamation_mark::heavy_exclamation_mark::heavy_exclamation_mark:
> wh说必考,猛猛背 考个鸡脖,a卷无
场依存性的人:
1. 独立性差,并且容易受暗示;比较容易受当时环境中的其它事物(包括知觉者本身的状况)的影响,很难离析出知觉单元。
2. 倾向于以外在参照(客观事物)作为信息加工的依据。
场独立性的人
1. 有较大的独立性,并且不易受暗示;比较少受知觉当时的情境影响,比较易于离析出知觉单元。
2. 倾向于更多地利用内在参照(主体感觉)。
### 认知概念框架
四种框架
1. 思维模型
2. 信息处理模型
3. 外部认知模型
4. 分布式认知模型
### 信息处理模型
> wh提了

## Chapter 3 事件相关电位概述
### 脑活动测量方法 :heavy_exclamation_mark:
- **脑电图(EEG)——时间分辨率最高**
- 脑磁图(MEG)
- 功能性磁共振成像(fMRI)
- **功能性近红外成像(fNIR)——空间分辨率最高**
- 正电子发射断层扫描(PET)
- 功能性经颅多普勒超声(fTCD)
### 脑神经活动特点及脑电产生原理
脑电首次发现**贝鲁加**
>wh提到了
#### 脑的工作原理
人的感觉、情感、动作、包括不能意识和控制得体内活动都是由**电化学、生物活动**左右
##### 突触结构
突触的结构包括**突触前膜(突触小泡)、突触间隙、突触后膜(受体)**
#### 脑电(EEG)产生原理
1. 活的人脑一直会不断放电,产生脑电波
2. 是由大脑大量的神经组织的活动产生的
3. 是由皮质中的神经组织突触后点位同步总和而成的
#### 脑电测量的基准 :heavy_exclamation_mark:
CZ
##### 电极名称
Fp=额极(frontal pole);
F=额(frontal);
C=中央(central);
P=顶(parietal);
O=枕(occipital)
T=颞(temporal)
#### 脑电节律
1. alpha波:8-13Hz
2. beta波:13-30Hz
3. Theta波:4-8Hz
4. Delta波:0.5-4Hz
### 事件相关电位(ERP)的概念及特点 :heavy_exclamation_mark:
>大概率会考
#### ERP的定义 :heavy_exclamation_mark::heavy_exclamation_mark:
事件相关电位是由外加的一种**特定刺激**,作用于**感觉系统**或**脑**的某一部位,再**给予**刺激或**撤销**刺激时,在脑区所引起的**电位**变化。被认为是**心理行为**的一种客观表现形式。
#### ERP的特点
1. **潜伏期恒定**
2. **波形恒定**
#### ERP的优点和缺点
优点:
1. 优异的时间分辨率
2. 推断受实验调控影响的认知过程
3. 识别多个认知神经过程
4. 认知过程的内隐性测量
5. 可以作为一些医疗应用的生物标志物
缺点:
1. 仅仅是脑活动的外在反应,无法提供实际的脑活动机制(这在大部分的测量系统里都存在);
2. 代表了许多潜在成分的总和(即为多个成分的叠加),**无法判断这些潜在成分的神经元活动位置;**
3. 有些心理或神经过程可能并不存在对应的ERP。必须满足特殊的生物物理学条件时,ERP才是可记录的;
4. ERP相对噪声水平来说时很小的,需要多次测量才能够得到;噪声产生的来源非常广泛;
5. 时间跨度不能特别长
#### 相较于其他生理测量手段
1. 无创伤性,但是干扰明显。
2. 时间分辨率高(ms级),但是空间分辨率不足(大脑表层);
3. 价格便宜
#### ERP的起源
##### 神经元细胞的主要电活动
- 动作电位
- 突触后电位
**ERP 几乎都是起源于突触后电位**
**仅有小部分的大脑活动能够引发头皮表面的ERPs**
1. 头皮上的ERP通常并不是由动作电位引发的(除刺激后几十毫秒内出现的听觉响应外)。
2. 数以千计的且有类似朝向的神经元引发的电偶极子相互叠加时,才能够在头皮表面观察到。
3. 头皮上记录到的ERPs几乎总是反应了锥体细胞(皮层中主要的输入-输出细胞)的神经传导。
##### ERP为什么总是反应了锥体细胞的神经传导? :heavy_exclamation_mark::heavy_exclamation_mark:
锥体细胞是皮层中主要的输入-输出细胞,它们的朝向与皮层表面垂直,所以他们的偶极子会相互叠加,而不是抵消。
#### 影响ERPs成分的极性的因素
四个因素
- 突触后电位是兴奋性还是抑制性
- 突触后电位是发生于尖端树突,还是发生于基底树突和细胞体;
- 所形成的偶极子相对于活动记录电极的位置朝向;
- 参考电极的位置
#### 获取ERP的生理条件
- 大量神经元必须同时活动;
- 神经元个体之间必修具有大致相同的朝向;
- 大部分神经元中的突触后电位必须来自于神经元中的同一部位(尖端树突或者细胞体和基底树突)
- 大部分神经元必须具有相同的电流方向,以避免相互抵消
#### ERPs数据获取
获取到的ERP数据是给定电极的电压和频率所有的潜在成分的**加权总和**,但是,人们感兴趣的是**单个成分**。
##### ICA:heavy_exclamation_mark::heavy_exclamation_mark::heavy_exclamation_mark:
>wh说必考
独立成分分析(Independent Component Analysis,简称ICA)是一种用于多维信号分离的统计方法,旨在将多个混合信号分解为独立的成分。
==**目的**:==
1. ==从混合信号中提取出各独立的信号分量。==
2. ==滤除伪迹。==
### 脑电特征
#### 脑电基线
每一个波上下偏移时都会依据自己的中心点,将连续脑电波的每一个中心点连接起来,就会成为一个近似的直线,该线被称为基线。
基线平稳:中心轴线为一条直线或近似直线
基线不平稳:若形成一条波幅高于25μV,时间大于1000ms缓慢移动的曲线
基线欠稳:波幅小于25μV。则成为基线欠稳
##### 基线矫正的目的 :heavy_exclamation_mark:
消除由于时间或其他外部因素造成的信号偏移,从而使信号能够准确地反映实际的情况。
==根据时间的不一样,脑电的活动不一样,脑电波形是有偏移的,这是一个外部问题,所以要将它从偏移上拉下来,做一个近似直线。这样才能很好的观察到波形的存在==
> 考的基线移除?反正不会随便写上去了
#### 伪迹
生物伪迹
- 眼伪迹
- 心电伪迹
- 肌电伪迹
- 舌动伪迹
- 皮点伪迹
##### 几种伪迹图 :heavy_exclamation_mark:
> 分辨伪迹



## Chapter 4 ERP成分
### 概述
#### ERP的成分的定义
1. 概念性的定义:一个ERP的成分是当大脑执行某个特定的计算信号时,产生于某个特定的神经解剖学模块,并且可以在头皮上记录到的神经信号。**(ERP的本质)**
2. 实用性的定义:一个成分为一些电位的变化,它们符合单一的神经产生源位置,并且在不同的实验条件、时间段、个体等等之间出现系统性的变化。
**即:一个ERP成分是一个ERP数据集内具有系统性和稳定性的变异源。**
3. 习惯性的定义:如果结构简单、且对应与一个单偶极子(或者一对在左右半球间呈镜像堆成的偶极子)相符,我们可以暂且认为它是个单一成分。
#### ERP成分分类
ERP有多种分类,主要的有根据**刺激成分、感觉通路及潜伏期**三种分类方法
##### 根据潜伏期分类
- 早
- 中
- 晚成
- 慢波

##### 根据刺激成分分类
- 由刺激呈现而强制性诱发的**外源性感官成分**
- 完全反应任务相关神经过程的**内源性成分**
- 伴随运动准备和执行过程的**运动成分**
##### 根据感觉通路分类
- 听觉诱发电位
- 视觉诱发电位
- 体感诱发电位
#### ==ERP成分解释时避免歧义的方法==
>一道多选题
1. **聚焦于单个成分**;一个实验仅仅关注一个或两个ERP成分,尽量使其他所有成分在不同的条件之间保持不变。
2. **聚焦于较大的成分**;当感兴趣的成分远大于其它成分时,它在观测波形中占据主导,此时对该成分的测量,相对来说不太容易受到来自其它成份的干扰。
3. **从其它领域中劫持有用的成分**;利用与实验主题本不明显相关的成分来进行解释。
4. **采用经过充分研究的实验操作**;考察一个已被研究过的ERP成分,且尽可能保持实验条件与先前该成分研究时的条件类似。
5. **利用差异波**;差异波有助于分离特定的ERP成分,但是解释的时候需要小心。这也是目前应用的越来越多的方法。
6. **聚焦容易分离的成分**;利用某个成分研究其之前发生的加工过程,不同条件之间出现的差异在逻辑上意味着某些过程已经发生了。
7. **利用某个成分研究其之前发生的加工过程**;不同条件之间出现的差异在逻辑上意味着某些过程已经发生了。
8. **与成分无关的实验设计**;利用许多已有策略都聚焦于可以分离出特定的ERP成分,完全回避这些特定成分的识别问题,也能够有效的解释需要注意的成分。
### 听觉和视觉诱发电位 :heavy_exclamation_mark::heavy_exclamation_mark:
>wh说视觉,听觉必考一个
#### 视觉诱发电位(VEP):heavy_exclamation_mark::heavy_exclamation_mark:

:heavy_exclamation_mark: **研究枕叶皮层对视觉刺激产生的电活动**
##### C1成分 :heavy_exclamation_mark:
> 比较重要
1. 通常发生在P1之前(不一定会出现);
2. 在头皮后部中线处的电极上;
3. 下视野的刺激诱发的C1为正性,上视野的刺激诱发的是负性。
***C1的产生极性出现不同的原因是什么?***
在实验中,如果诱发的成分产生区域为距状裂上方的区域,由于其负责编码下方的视野,则产生的为正性。如果刺激诱发的是距状裂下方的区域,由于其负责编码上方的视野,则产生的C1为负性。
##### P1 成分 :heavy_exclamation_mark:
> 比较重要
***特性***
1. 第一个主要的视觉成分;
2. 通常起始于刺激后60-90ms,并于100-300ms达到峰值;
3. **潜伏期受刺激对比度**的影响非常大;
4. 对**刺激参数敏感**,受**选择性注意**和受试者**觉醒状态控制**;
5. 振幅对于刺激是否与任务下的**靶刺激类别匹配不敏感**
***位置***
- 最大幅值位于侧向枕叶电极;
- **早期成分产生于背侧纹外皮层,晚期成分产生于梭状回的腹侧部分**
##### N1 成分 :heavy_exclamation_mark:
> 比较重要
**N1对注意力敏感**
1. 紧随在P1后面;
2. 包含多个子成分;
- 这些子成分在功能上不一定关联,被称为子成分的原因是因为它们共同构成了波形中的一个显著偏转。
- 最早的子成分峰值出现在刺激后100-150ms,位于前部头皮电极位置;
- 在后部电极位置,至少有2个N1成分的峰值出现在刺激后150-200ms,一个来自顶叶皮层,另一个来自外侧枕叶皮层;
3. 具有高度的不应性;如果短时间内接连出现两个刺激,那么第二个刺激诱发的响应会减少许多
##### P2 成分 (我赌它不考)
#### ==听觉诱发电位(AEP) :heavy_exclamation_mark::heavy_exclamation_mark:==
> 背吧感觉会考,果然考了,明年感觉还会考

这是一个简单听觉(嘀嗒声)诱发的脑电。
0-10ms: 体现了来自耳蜗的信息经过脑干传递到丘脑的过程;这些听觉脑干响应,通常用罗马数字进行标记。 这些响应是高度自动的,可以用来评估听觉通道的完整性。
10-50ms:中潜伏期响应,至少部分来自内次膝状体和初级听觉皮层。注意力对该部分有调控作用。
50ms-:长潜伏期响应。(通常顺序为P50(P1),N100(N1)和P160(P2))这个潜伏期比高级认知成分低,但从听觉器官的特性来说,100ms相对比较晚了。受到高级认知的影响,如注意力、觉醒度等。
### 主要成分 :heavy_exclamation_mark::heavy_exclamation_mark:
#### 关联性负变(CNV)
**标志着现代ERP研究的正式开始**
> 考了一道填空
> 说不定明年就考到上面这句话了
>
==CNV被认为主要与***心理因素***有关。比如期待、意动、朝向反应、觉醒、注意、动机等,可以认为它基本上是一个**综合**的心理准备状态的反映,处于**紧张或应急状态**的反映。==
#### N2
N2a是一个由听觉刺激匹配条件自动诱发的效应,甚至当刺激与任务无关的时候也会被诱发。这一效应通常被称为**失匹配负波**(mismatch negativity,MMN)
#### 失匹配负波(MMN)
产生于**额叶和颞叶**
由于MMN具有**高度的自动性**,对于无法容易做出行为反应的人群进行研究就会非常有用:如不会说话的婴儿、处于昏迷状态的人
##### 差异波
**目的**:是去除相同的内容,得到较为纯粹的成分
**前提**:两种条件的心理活动或者机制的差异是清楚的,不包含其他成分
#### N2pc
“N”——负波,“2”——200ms左右出现,“pc”——posterior contralateral,即对侧脑后区域。
N2pc 是一种与**空间选择性注意**密切相关的ERP 成分, 反映了对当前任务相关刺激所进行的空间选择加工
##### N2pc相关结论
1. N2pc对研究注意是否已被隐性的转移至特定物体,以及注意转移的时间过程时非常有用;
2. N2pc能够被用来判断注意是否会自动地被明显但无关的物体所捕获;
3. N2pc可以证明被遮掩的阈下物体仍然能够吸引注意。
4. 与奖赏有关的物体可以诱发更快的注意转移;
5. 注意力在某些视觉搜索任务下是以串行方式在物体间转移的;
6. 精神分裂症患者在某些条件下的注意转约速度和正常人一样快。
##### N2pc产生区域
- 视觉皮层V4区
- 外侧枕叶皮层复合体位置
#### P300
##### P300的特点 :heavy_exclamation_mark::heavy_exclamation_mark:
**振幅**:P300波幅与概率成**反比**,靶与非靶皆然
**潜伏期**:P300的潜伏期随任务**难度的增加而增加**
判断同义词的任务较难,潜伏期较长
#### N400
##### 诱发N400
- 阅读中的歧义信息
- 特殊的图片特征
- 面孔识别
## Chapter 5 实验范式
典型范式
- Oddball范式
- Go-Nogo范式
- 特定认知领域实验研究范式
### 靶刺激
- 靶刺激是需要被测做出反应的⽬标刺激;
- 在Oddball实验中,通常将偏差刺激作为靶刺激。
- 根据实验需求,靶刺激可以是偏差刺激,也可以是新异刺激。
### Oddball实验范式
==经典Oddball范式也被称为**基于概率的实验范式**,是在一项实验中随机呈现**同一种感觉通道**的两种刺激,两种刺激的概率相差很大,大概率者即经常出现者称为**标准刺激**,小概率者即偶然出现者称为**偏差刺激**。==
> 典,我赌明年继续考
>
将**偏差刺激作为靶刺激**
***可用来获取P300成分,MMN成分***
### Go-Nogo实验范式
#### 与Oddball范式的区别
- 取消标准刺激与偏差刺激之间的概率差别;
- 需要被试者反应的刺激为Go刺激,不需要反应的为Nogo刺激。
### 知觉和意识研究的实验范式
#### 视觉的局部优先与整体优先 :heavy_exclamation_mark:
> 一道填空题
>
==物体认知:局部优先,物体的识别常常被表征为各部件的外形==
==脸部认知:整体优先,脸部常常被表征为一个整体==
#### 视运动知觉启动范式
##### 理论基础
>草 多选改大题,md没背下来
1. ==视觉感知是可以被诱导的(或者被启动的);==
2. ==视觉运动知觉的启动是一种非意识加工的脑机制;==
##### 相关论述
1. ==某一特定运动方向的视觉刺激,即使是非意识的也能使视觉运动知觉偏向它们的方向。==
2. ==视运动知觉启动可以提供一种非意识加工脑机制的研究方向。==
### 视觉注意研究的实验范式(空间注意提示范式)
> wh和题目都只有空间注意提示范式,前面的早期实验就没管了
:heavy_exclamation_mark:在经典视觉注意实验中,当有效刺激诱发的 **P1** 和 **N1** 成分比无效、中性刺激诱发的明显增大。
#### 概述 :heavy_exclamation_mark:
##### 基本范式
注视点 —— 提示 —— 靶
##### 特点
1. 搜索时的心理活动主要是注意的选择;
2. 搜索到靶后对靶的属性进行分辨,分辨过程的心理活动中含有注意的集中;
3. 可以改变提示信息的有效性、提示与靶的间隔、提示范围大小等来研究各种视觉空间注意的脑机制。
#### 有效提示与无效提示
提示的有效与无效,指的是提示信息对指定的任务所起到的作用真实与否,即**提示信息能否正确反应靶刺激的情况**。
#### 符号性提示又称内源性提示
#### 周围提示
更容易诱发 **P1**和**N1**
#### 提示与靶的间隔
##### 注意的分类
- 随意注意
- 非随意注意
##### 提示与靶的间隔对注意的影响
**原因**:随意注意和非随意注意的***来源、性质、功能以及脑内加工的机制不同***
- 随意注意:又被称为内源性注意,提示与靶的间隔长(大于500ms)、提示有效率高(大于70%)
- 非随意注意:又被称为外源性注意,提示与靶的间隔短(小于300ms)、提示有效率低(小于50%)
#### 上、下视野提示
下视野为优势视野
#### 结论
- 三种刺激诱发的N2pc在潜伏期和头皮分布上相同;
- 运动靶的N2pc虽然稍大,但系运动靶会比颜色靶、方向靶自动吸引更多注意资源所致;
- **颜色、方向与运动的搜索动用的是同一个注意系统。**
### 记忆研究的实验范式
#### 工作记忆实验范式 :heavy_exclamation_mark::heavy_exclamation_mark:
##### 工作记忆分类 :heavy_exclamation_mark:
*三个子系统*
- 中央执行系统
- 语音回路
- 视觉空间存储
##### ==认知加工的三个阶段==
> 听wh说的感觉会考,考了
使用**样本延迟匹配**范式(任务)对其进行研究

- ==样本阶段 —— 信息编码输入==
- ==延迟阶段 —— 信息复述保持==
- ==靶阶段 —— 信息提取匹配==
##### n-back任务
n-back任务是让被试浏览一系列逐个呈现的项目,然后要求被试从第n个项目起判断每一个出现的项目是否与前面刚呈现过的倒数第n个项目匹配。
***特点:能够通过控制n的大小来操纵工作记忆的负荷,从而考察不同记忆负荷下工作记忆的加工机制***
#### 学习——再认实验范式
> wh说没怎么考,考了个多选
**发现的新效应**
- ==相继记忆效应==
- ==重复效应==
- ==新旧效应==
- ==内隐记忆效应==
#### 语言文字研究的实验范式(N400)
其重要意义不仅在于发现了N400的成分,主要是它成功的将**ERP**运用到了**语言心理学**中
##### 研究N400的实验
- 句尾畸义词,N400经典范式;
- 相关词与无关词,词性不同、反义词、无关词产生明显的N400;**近义词不产生**
- 新词与旧词,首次出现的新词与重复出现的旧词,新词可以诱发更正的N400;
- 文字与非文字符号;
- 图片命名,图片内容和名称的匹配
##### 哪些刺激诱发N400
- 阅读中的歧义信息。
- 特殊的图片特征
- 面孔识别
### 情绪与认知相互关系研究的实验范式
#### 需要注意的因素
1. 情绪的快速可变性
2. 影响情绪的因素很多
3. 情绪往往具有延迟性,会影响到我们设计的实验中情绪的测量。
#### 一些结论
- 一个人的情绪能够被外来的图片刺激、声音刺激、气味等所感染,诱发**杏仁核**的活动
- 然情绪能够被**外界**所诱发,但是从心理学、生理学角度来说,情绪是一种**无意识**的诱发。
- 情绪活动常伴随一系列生理活动的变化,通过**自主神经系统**和**内分泌系统活动**的改变引起的
- 研究发现,焦虑情绪会选择性的**干扰空间工作记忆任务**,但**未影响词语工作记忆**,因此,情绪对认知的影响**不是全脑水平的**,其交互作用更为复杂。
#### 无意识诱发
本能的防御反应:发怒,恐惧,逃避
## Chapter 6 脑机接口与fNIRs
### 脑机接口
#### 定义
脑机接口是在人或动物脑(或者脑细胞的培养物)与外部设备间建立的直接连接通路。
#### 信号采集方法
脑机接口用到的信号采集方法有侵入式、半侵入式和脑外(非侵入式)。
#### 研究方向
- 人机互交
- 心理认知学
- 心理疾病评估
- 神经疾病诊断与康复
#### 过程
> 作业题有,wh也提了
>
>
脑机接口技术中,使用**信号分析与特征提取方法**,在预处理过程过,将EEG信号分为**5个有用的频带部分**,作为**模式识别**的特征。
#### ==为什么现在很多BCI(脑机接口)的研究都无法做到直接用大脑控制机器人,必须借助于外界的刺激?==
> 考了,但我没背的很详细,小寄
>
因为大脑的思维或反应在相关的(或不相关的)加工过程中涉及到的多个脑分区,很难通过自发的方式产生高度单一的成分,因此也很难从ERP实验中分离出高度特异的心理或神经过程。目前,借助外界的刺激,可以加强(增强)某一类ERP响应成分,从而达到控制机器人的目的。
### fNIRs
#### 原理
FNIRs成像主要测量大脑活动中,**血氧**的浓度变化
#### ==对比EEG==
> 一道大题
fNIRS
优点:
- 安全、非侵入性
- 造价相对便宜,维护成本低
- 时间、空间分辨率相对较高
- 被尝试友好度高
- 生态效率高
- 兼容性高
缺点:
- 外皮层记录
- 被试间脑区解剖位置差异
- 信噪比较低
EEG
优点:
- 时间分辨率极高:EEG的时间分辨率非常高,能够捕捉到快速的脑电活动变化。
- 成本相对较低:相对于fNIRS,EEG的设备和维护成本更低。
- 广泛的临床应用:EEG在临床诊断(如癫痫)中有着长期而广泛的应用。
- 便于重复测量:EEG设备相对轻便,便于进行长时间或重复的测量。
缺点:
- 空间分辨率低:EEG的空间分辨率较低,难以精确确定脑活动的具体位置。
- 信号可能受到伪影的干扰:头发、肌肉活动、眼动等都可能对EEG信号产生干扰。
- 实验设置和电极放置要求严格:EEG需要精确的电极放置和常常较长的准备时间。
## Chapter 7 眼动
> 压根没考
### 常用指标
- 访问时长
- 首次注视时间
- 访问次数
- 访问百分比
**眼跳潜伏期:** 刺激呈现到第一个眼跳开始的时间。潜伏期越短,表明当前目标的加工越简单。
================================================
FILE: 学习资料(非电子书)/计算机体系结构/README.md
================================================
# 计算机体系结构
资料链接: [[百度网盘](https://pan.baidu.com/s/1cWcpP6JG2uz-bfXeROKlHw?pwd=wxy2)]
1. PPT
- 第[1-6]章
2. 习题答案
- ...
3. 实验: SHU-Computer-Architecture-Experiments [[GitHub](https://github.com/SHUSCT/SHU-Computer-Architecture-Experiments)]
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/计算机最新进展研讨/README.md
================================================
# 计算机最新进展研讨
资料链接: [[百度网盘](https://pan.baidu.com/s/15FWenseWqKsxLoLgFk2UKA?pwd=hj5q)]
1. 2021-2022 lv卷积神经网络综述(PPT+报告)
- ...
2. 相关文献
- 机器学习-5 深度学习的昨天、今天和明天.pdf
- 机器学习-6 7 卷积神经网络研究综述(2人).pdf
- 机器学习-8 迁移学习-回顾与进展.pdf
3. 2021-2022 研讨主题.ppt
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/计算机研究前沿/README.md
================================================
# 计算机研究前沿
资料链接: [[百度网盘](https://pan.baidu.com/s/1vihd36RRKujxbF2gSgRM3g?pwd=yxuk)]
1. lv流行病传播过程仿真实验
- netlogo仿真
- Untitled.nlogo
- 计算机研究前沿-第.pptx
- 计算机研究前沿.docx
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/计算机组成原理/README.md
================================================
# 计算机组成原理
资料链接: [[百度网盘](https://pan.baidu.com/s/1VzCASGZnF4WvSFRHO3QKMw?pwd=cce1)]
1. 原理(1)
- lv实验报告分享
- ...
- 实验指导书、PPT等
- ...
2. 原理(2)
- lv实验报告分享
- ...
- 实验指导书、PPT等
- ...
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/计算机编程实训/README.md
================================================
# 计算机编程实训
资料链接: [[百度网盘](https://pan.baidu.com/s/1jGWtNyteTXXXTVmv-X4Gfw?pwd=i663)]
1. 2020-2021夏季学期《计算机编程实训》
- lv计算机编程实训源代码+小论文
- ...
- 相关资料
- ...
- 2020-2021夏季学期《计算机编程实训》课程方案20210613.docx
- README.md
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/计算机网络/README.md
================================================
# 计算机网络
资料链接: [[百度网盘](https://pan.baidu.com/s/1cwl4r1YdL6AI_FGp4Z67jg?pwd=sy8e)]
1. 实验
- 使用GNS3完成
- GNS3+cisco 动态路由实验.md
- GNS3静态路由实验.md
- 使用GNS3完成实验指南
- GNS3+cisco 动态路由实验.md
- GNS3静态路由实验.md
- 实验辅助资料
- 《网络与通信》实验指导书(V1.0).pdf
- 706network.jpg
- Network_01.doc
- Network_02.doc
- Network_03.doc
- 静态路由及RIP和OSPF实验帮助.pdf
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/语义网络与知识图谱/README.md
================================================
# 语义网络与知识图谱
资料链接: [[百度网盘](https://pan.baidu.com/s/1zh12BQugZXsyzASwds1nig?pwd=d7ky)]
1. 2021实验手册
- 2021语义网与知识图谱实验手册-[1-6].docx
2. 2021课件
- 2020语义网与知识图谱-第[1-8]讲.pdf
3. 实验工具及资料
- logic4cs-script.pdf
- Protégé 使用方法.pdf
4. 扩展研讨PPT
- ...
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/软件工程/README.md
================================================
# 软件工程
资料链接: [[百度网盘](https://pan.baidu.com/s/1h90VNRS5yqJUjcr99AONjA?pwd=lwx5)]
1. lv实验
- README.md
- 实验[1-8].docx
2. 2019冬软工总复习.ppt
3. 上海大学2021-2022软件工程主观题考卷(A).pdf
4. 复习.ppt
5. 软件设计师2017至2019年试题分析与解答.pdf
6. 软工考试类型.doc
---
Last update: Jun 28, 2024
================================================
FILE: 学习资料(非电子书)/面向对象/README.MD
================================================
# 面向对象资料
资料链接: [[百度网盘](https://pan.baidu.com/s/1X_mEVtk_Rz5fIPK29kBFlQ?pwd=ni3b)]
1. 面向对象复习笔记 [[GitHub](https://github.com/Amadeus-1048/Course-Review/blob/main/%E9%9D%A2%E5%90%91%E5%AF%B9%E8%B1%A1%E7%A8%8B%E5%BA%8F%E8%AE%BE%E8%AE%A1/%E9%9D%A2%E5%90%91%E5%AF%B9%E8%B1%A1%E5%A4%8D%E4%B9%A0%E7%AC%94%E8%AE%B0.md)]
2. 历年试题
- 2004-2020
3. 课程小项目
- 单向链表类模板应用---音乐资料库
- ...
- 向量类模板实现
- ...
- 封装C-字符串
- ...
- 抽象向量类模板及其派生类
- ...
---
Last update: Jun 28, 2024
================================================
FILE: 就业相关/八股笔记/个人珍藏八股笔记,看缘分更新.md
================================================
# 笔记
# ==408==
## 一、TCP
seq代表从对方的何处开始发消息:我把数据从你的seq处开始发(你的上一次的ack所要求的)
ack代表对方从我的何处发消息:你下一次发送消息到我的ack处开始发
因此回复的ack=seq+len
初始连接时SYN占据一个字节,相当于发送len=1的包,所以ack=x+1
结束时FIN同理

TCP 协议保证数据传输可靠性的方式主要有:
- **校验和**:TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
- **序列号**:TCP 传输时将每个字节的数据都进行了编号,这就是序列号。(为了应对延时抵达和排序混乱)。每个连接都会选择一个初始序列号,初始序列号(视为一个 32 位计数器),会随时间而改变(每 4 微秒加 1)。因此,每一个连接都拥有不同的序列号。序列号的作用不仅仅是应答的作用,有了序列号能够将接收到的数据根据序列号排序,并且去掉重复序列号的数据。这也是 TCP 传输可靠性的保证之一。
- **确认应答**:TCP 传输的过程中,每次接收方收到数据后,都会对传输方进行确认应答。也就是发送 ACK 报文。这个 ACK 报文当中带有对应的确认序列号,告诉发送方,接收到了哪些数据,下一次的数据从哪里发。
- **超时重传**:超时重传机制。简单理解就是发送方在发送完数据后等待一个时间,时间到达没有接收到 ACK 报文,那么对刚才发送的数据进行重新发送。如果是刚才第一个原因,接收方收到二次重发的数据后,便进行 ACK 应答。如果是第二个原因,接收方发现接收的数据已存在(判断存在的根据就是序列号,所以上面说序列号还有去除重复数据的作用),那么直接丢弃,仍旧发送 ACK 应答。那么发送方发送完毕后等待的时间是多少呢?如果这个等待的时间过长,那么会影响 TCP 传输的整体效率,如果等待时间过短,又会导致频繁的发送重复的包。如何权衡?由于 TCP 传输时保证能够在任何环境下都有一个高性能的通信,因此这个最大超时时间(也就是等待的时间)是动态计算的。
- **连接管理**:说白了就是三次握手四次挥手。
- **流量控制**:当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。
- **拥塞控制**:拥塞控制是 TCP 在传输时尽可能快的将数据传输,并且避免拥塞造成的一系列问题。是可靠性的保证,同时也是维护了传输的高效性。
为什么第四次挥手客户端需要等待 2*MSL(报文段最长寿命)时间后才进入 CLOSED 状态?
第四次挥手时,客户端发送给服务器的 ACK 有可能丢失,如果服务端因为某些原因而没有收到 ACK 的话,服务端就会重发 FIN,如果客户端在 2*MSL 的时间内收到了 FIN,就会重新发送 ACK 并再次等待 2MSL,防止 Server 没有收到 ACK 而不断重发 FIN。
> **MSL(Maximum Segment Lifetime)** : 一个片段在网络中最大的存活时间,2MSL 就是一个发送和一个回复所需的最大时间。如果直到 2MSL,Client 都没有再次收到 FIN,那么 Client 推断 ACK 已经被成功接收,则结束 TCP 连接。
## 二、死锁
**一、死锁的定义**
[死锁](https://so.csdn.net/so/search?q=死锁&spm=1001.2101.3001.7020)是指,有两个或两个以上的线程在执行的过程中,由于竞争的资源或者彼此通信而造成的一种阻塞状态,若无外力作用,他们将都无法进行下去,从而形成一直阻塞的状态叫死锁。
**二、产生死锁的必要条件**
- 互斥条件
一个资源只能被一个线程所拥有的,若一个线程已经拥有了该资源,那么其他想获取该资源的线程就需要阻塞等待。
- 不可剥夺条件
当一个资源被线程获取了之后,如果该线程不主动释放该资源,那么该资源一直被占有,其他想获取该资源的线程就要一直进行等待。
- 请求并持有条件
一个线程已经拥有了一个资源,还要请求新的资源。
- 循环等待条件
产生死锁一定是发生了环路等待,形成线程资源环形链。
以上是产生死锁的四个必要条件,缺一不可,产生死锁的时候这四个条件一定是都满足的,那么就表示,要想避免死锁,破坏其中一个条件即可。
死锁实现
```java
public class DeadLockCSDN {
public static void main(String[] args) {
//资源A和B
Object A = new Object();
Object B = new Object();
//第一个线程
Thread t1 = new Thread(() -> {
//先得到资源A
synchronized (A){
System.out.println("线程1已经获得资源A");
try {
//这里线程休眠两秒是为了保证线程1拿到A
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//拿到A之后再去获取B资源
synchronized (B){
System.out.println("线程1已经获得资源B");
}
}
});
//第二个线程
Thread t2 = new Thread(() -> {
//先获得资源B
synchronized (B){
System.out.println("线程2已经获得资源B");
try {
//保证线程2 获得资源B
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//再去请求获得A资源
synchronized (A){
System.out.println("线程2已经获得资源A");
}
}
});
t1.start();
t2.start();
}
}
```
## 三、线程上下文切换
什么是线程上下文切换
多线程的上下文切换:是指 CPU 控制权由一个已经正在运行的线程切换到另外一个就绪并等待获取 CPU 执行权的线程的过程。CPU给每个线程分配CPU时间片(机会),多线程创建并切完到另一个线程的过程,就是上下文切换。
时间片:是指 CPU分配给每个线程的执行时间段。
CPU为了能够执行多个线程,需要不停的切换执行的线程,这样才能使所有线程在一段时间内都有被执行的机会。CPU通过时间片分配算法来循环执行任务,当前任务执行一个时间片后切换到下一个任务。但是,在切换前会保存上一个任务的状态,以便下次切换回这个任务时,可以再加载这个任务的状态。所以任务从保存到再加载的过程就是一次上下文切换。
线程上下文切换的原因
当前执行任务(线程)的时间片用完之后,系统CPU正常调度下一个任务中断处理,在中断处理中,其他程序”打断”了当前正在运行的程序。当CPU接收到中断请求时,会在正在运行的程序和发起中断请求的程序之间进行一次上下文切换。中断分为硬件中断和软件中断,软件中断包括因为IO阻塞、未抢到资源或者用户代码等原因,线程被挂起。
用户态切换,对于一些操作系统,当进行用户态切换时也会进行一次上下文切换,虽然这不是必须的。
多个任务抢占锁资源,在多任务处理中,CPU会在不同程序之间来回切换,每个程序都有相应的处理时间片,CPU在两个时间片的间隔中进行上下文切换。
理解:每个线程根据算法(优先、高响应比、多级队列反馈、时间片轮转)执行完了自己的时间片后,即使该线程还没有执行完毕,为了兼顾到密集型和长期作业,CPU也需要中断,然后将就绪态的下一个线程执行。
Linux系统下可以使用vmst[at命令](https://so.csdn.net/so/search?q=at命令&spm=1001.2101.3001.7020)来查看上下文切换的次数, 其中cs列就是指上下文切换的数目(一般情况下, 空闲系统的上下文切换每秒大概在1500以下)。
线程上下文切换存在的问题
上下文切换会导致额外的开销,常常表现为高并发执行时速度会慢串行,因此减少上下文切换次数便可以提高多线程程序的运行效率。
直接消耗:指的是CPU寄存器需要保存和加载, 系统调度器的代码需要执行, TLB实例需要重新加载, CPU 的pipeline需要刷掉。
间接消耗:指的是多核的cache之间得共享数据, 间接消耗对于程序的影响要看线程工作区操作数据的大小。
线程上下文切换优化
1、无锁并发编程:多线程处理数据时,可以用一些办法来避免使用锁,如将数据的ID按照Hash取模分段,不同的线程处理不同段的数据。
2、CAS算法:Java的Atomic包使用CAS算法来更新数据,而不需要加锁。
3、使用最少线程:避免创建不必要的线程,比如,任务量很小,使用多线程处理,就容易造成线程等待。
4、协程:单线程里实现多任务的调度,并在单线程里维持多个任务间的切换。
**合理设置线程数目既可以最大化利用CPU,又可以减少线程切换的开销。**
- 高并发,低耗时的情况,建议少线程。
- 低并发,高耗时的情况:建议多线程。
- 高并发高耗时,要分析任务类型、增加排队、加大线程数。
## 四、IO多路复用
介绍:IO 多路复用是一种同步 IO 模型,实现一个线程可以监视多个文件句柄。一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;没有文件句柄就绪时会阻塞应用程序,交出 cpu。IO 是指网络 IO,多路指多个TCP连接(即 socket 或者 channel),复用指复用一个或几个线程。
意思说一个或一组线程处理多个 TCP 连接。最大优势是减少系统开销小,不必创建过多的进程/线程,也不必维护这些进程/线程。IO 多路复用的三种实现方式:select、poll、epoll。
1、select机制(NIO)
> 优点:适用性好,全平台可用
>
> 缺点:采用轮询的方式全盘扫描,会随着文件描述符 FD 数量增多而性能下降。
> 每次调用 select(),都需要把 fd 集合从用户态拷贝到内核态,并进行遍历(消息传递都是从内核到用户空间)。
> 单个进程打开的 FD 是有限制(通过FD_SETSIZE设置)的,默认是 1024 个,可修改宏定义,但是效率仍然慢。
2、poll(NIO)
> 和select机制相同,只是底层使用链表实现,没有最大数量限制
3、epoll(AIO)
> epoll有EPOLLLT和EPOLLET两种触发模式,LT是默认的模式,ET是“高速”模式。LT模式下,只要这个fd还有数据可读,每次 epoll_wait都会返回它的事件,提醒用户程序去操作,而在ET(边缘触发)模式中,它只会提示一次,直到下次再有数据流入之前都不会再提示了,无 论fd中是否还有数据可读。所以在ET模式下,read一个fd的时候一定要把它的buffer读光,也就是说一直读到read的返回值小于请求值,或者 遇到EAGAIN错误。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
==epoll的好处==
epoll为什么要有EPOLLET触发模式?
如果采用EPOLLLT模式的话,系统中一旦有大量你不需要读写的就绪文件描述符,它们每次调用epoll_wait都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率.。而采用EPOLLET这种边沿触发模式的话,当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符
epoll的优点:
1、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口);
2、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;
即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
3、 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
### 总结
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
## 五、进程和线程
1、根本区别
==进程和线程的根本区别是进程是操作系统(OS)资源分配的基本单位,而线程是处理器(CPU)任务调度和执行的基本单位。==
2、资源开销:
每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
3、包含关系:
如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线
同完成的;线程是进程的一部分,所行过程不是一条线的,而是多条线(线耗)其被称为轻权进程或者轻量级进程。
4、内存分配:
同一进程的线程共享本进程的内存空间和资源,而进程之间的地址空间和资源是相互独立的。
5、影响关系:
一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
6、执行过程:
每个独立的进程有程序运行的入口、顺序执行序列和程序出口。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,两者均可并发执行。
### 5.1 进程、线程、协程的概念
进程:是并发执行的程序在执行过程中分配和管理资源的基本单位,是一个动态概念,竞争计算机系统资源的基本单位。
线程:是进程的一个执行单元,是进程内科调度实体。比进程更小的独立运行的基本单位。线程也被称为轻量级进程。
协程:是一种比线程更加轻量级的存在。一个线程也可以拥有多个协程。其执行过程更类似于子例程,或者说不带返回值的函数调用。
### 5.2 线程间的同步的方式有哪些?
线程同步是两个或多个共享关键资源的线程的并发执行。应该同步线程以避免关键的资源使用冲突。
下面是几种常见的线程同步的方式:
1. **互斥锁(Mutex)**:采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。比如 Java 中的 `synchronized` 关键词和各种 `Lock` 都是这种机制。
2. **读写锁(Read-Write Lock)**:允许多个线程同时读取共享资源,但只有一个线程可以对共享资源进行写操作。
3. **信号量(Semaphore)**:它允许同一时刻多个线程访问同一资源,但是需要控制同一时刻访问此资源的最大线程数量。
4. **屏障(Barrier)**:屏障是一种同步原语,用于等待多个线程到达某个点再一起继续执行。当一个线程到达屏障时,它会停止执行并等待其他线程到达屏障,直到所有线程都到达屏障后,它们才会一起继续执行。比如 Java 中的 `CyclicBarrier` 是这种机制。
5. **事件(Event)** :Wait/Notify:通过通知操作的方式来保持多线程同步,还可以方便的实现多线程优先级的比较操作。
### 5.3 进程间的通信方式有哪些?
**管道/匿名管道(Pipes)**:用于具有亲缘关系的父子进程间或者兄弟进程之间的通信。
**有名管道(Named Pipes)** : 匿名管道由于没有名字,只能用于亲缘关系的进程间通信。为了克服这个缺点,提出了有名管道。有名管道严格遵循 **先进先出(First In First Out)** 。有名管道以磁盘文件的方式存在,可以实现本机任意两个进程通信。
**信号(Signal)**:信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生;
**消息队列(Message Queuing)**:消息队列是消息的链表,具有特定的格式,存放在内存中并由消息队列标识符标识。管道和消息队列的通信数据都是先进先出的原则。与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即,操作系统重启)或者显式地删除一个消息队列时,该消息队列才会被真正的删除。消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取.比 FIFO 更有优势。**消息队列克服了信号承载信息量少,管道只能承载无格式字 节流以及缓冲区大小受限等缺点。**
**信号量(Semaphores)**:信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。这种通信方式主要用于解决与同步相关的问题并避免竞争条件。
**共享内存(Shared memory)**:使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。可以说这是最有用的进程间通信方式。
**套接字(Sockets)** : 此方法主要用于在客户端和服务器之间通过网络进行通信。套接字是支持 TCP/IP 的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点,简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。
### 5.4 JAVA中线程同步方式
线程同步主要包括四种方式:
- 互斥量`pthread_mutex_`
- 读写锁`pthread_rwlock_`
- 条件变量`pthread_cond_`
- 信号量`sem_`
> 1、synchronized 关键字
>
> 2、Lock 接口
>
> 3、volatile
>
> 4、使用重入锁实现线程同步ReenreantLock类
>
> 5、使用局部变量实现线程同步 如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,
>
> 6、使用阻塞队列实现线程同步LinkedBlockingQueue 类
>
> 7、使用原子变量实现线程同步AtomicInteger类
## 六、HTTP和HTTPS的区别
**1、加密**
加密是 HTTP 和 HTTPS 之间的主要区别之一。HTTPS 使用 SSL 或 TLS 来加密数据,使其比 HTTP 安全得多。当通过 HTTPS 传输时,数据在通过 Internet 发送之前被加密。这种加密有助于防止未经授权访问敏感数据,例如信用卡号和密码。
**2、证书认证**
证书认证是 HTTP 和 HTTPS 的另一个区别。当 Web 浏览器通过 HTTPS 连接到 Web 服务器时,服务器会向浏览器发送数字证书。该证书包含特定于服务器的信息,包括服务器的公钥。浏览器随后使用此证书与服务器建立安全连接。
**3、端口号**
HTTP 使用端口 80,而 HTTPS 使用端口 443。这意味着当您通过 HTTP 访问网站时,URL 以 开头http://,而通过 HTTPS 的 URL 以 开头https://。
**4、表现**
由于加密和解密数据的额外开销,HTTPS 通常比 HTTP 慢。然而,SSL 和 TLS 协议的进步显着降低了这种开销,使 HTTPS 比以前快得多。
## 七、HTTP 1.0/1.1/2.0/3.0
==**HTTP/1.0** 默认是短连接,可以强制开启,HTTP/1.1 默认长连接,HTTP/2.0 采用**多路复用**,HTTP/3.0基于UDP==
**HTTP/1.0**
- 默认使用**短连接**,每次请求都需要建立一个 TCP 连接。它可以设置`Connection: keep-alive` 这个字段,强制开启长连接。
**HTTP/1.1**
- 引入了持久连接,即 TCP 连接默认不关闭,可以被多个请求复用。
- 分块传输编码,即服务端每产生一块数据,就发送一块,用” 流模式” 取代” 缓存模式”。
- 管道机制,即在同一个 TCP 连接里面,客户端可以同时发送多个请求。
**HTTP/2.0**
- 二进制协议,1.1 版本的头信息是文本(ASCII 编码),数据体可以是文本或者二进制;2.0 中,头信息和数据体都是二进制。
- 完全多路复用,在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,而且不用按照顺序一一对应。
- 报头压缩,HTTP 协议不带有状态,每次请求都必须附上所有信息。Http/2.0 引入了头信息压缩机制,使用 gzip 或 compress 压缩后再发送。
- 服务端推送,允许服务器未经请求,主动向客户端发送资源。
### [#](https://tobebetterjavaer.com/sidebar/sanfene/network.html#_16-http-3-了解吗)16.HTTP/3 了解吗?
HTTP/3 主要有两大变化,**传输层基于 UDP**、使用**QUIC 保证 UDP 可靠性**。
HTTP/2 存在的一些问题,比如重传等等,都是由于 TCP 本身的特性导致的,所以 HTTP/3 在 QUIC 的基础上进行发展而来,QUIC(Quick UDP Connections)直译为快速 UDP 网络连接,底层使用 UDP 进行数据传输。
HTTP/3 主要有这些特点:
- 使用 UDP 作为传输层进行通信
- 在 UDP 的基础上 QUIC 协议保证了 HTTP/3 的安全性,在传输的过程中就完成了 TLS 加密握手
- HTTPS 要建⽴⼀个连接,要花费 6 次交互,先是建⽴三次握⼿,然后是 TLS/1.3 的三次握⼿。QUIC 直接把以往的 TCP 和 TLS/1.3 的 6 次交互合并成了 **3** 次,减少了交互次数。
- QUIC 有⾃⼰的⼀套机制可以保证传输的可靠性的。当某个流发⽣丢包时,只会阻塞这个流,其他流不会受到影响。
# ==数据库相关==
## **一、数据库基本操作**
- 创建数据库MySQL命令:
```sql
create database 数据库名称;
```
- 删除数据库MySQL命令:
```sql
drop database 数据库名称;
```
- 查询出MySQL中所有的数据库MySQL命令:
```sql
show databases;
```
- 将数据库的字符集修改为gbk MySQL命令:
```sql
alter database db1 character set gbk;
```
- 查看当前使用的数据库 MySQL命令:
```sql
select database();
```
- 创建表
```sql
create table 表名(
字段1 字段类型,
字段2 字段类型,
…
字段n 字段类型
);
```
- 查看当前数据库中所有表 MySQL命令:
```sql
show tables;
```
- 查看表的字段信息 MySQL命令:
```sql
desc 数据库名称;
```
- 修改表名 MySQL命令:
```sql
alter table student rename to stu;
```
- 修改字段数据类型 MySQL命令:
```sql
alter table stu modify sname int;
```
- 增加字段 MySQL命令:
```sql
alter table stu add address varchar(50);
```
- 删除字段 MySQL命令:
```sql
alter table stu drop address;
```
- 删除数据表 MySQL命令:
```sql
drop table 表名;
```
- 外键约束即FOREIGN KEY常用于多张表之间的约束。基本语法如下:
```sql
-- 在创建数据表时语法如下:
CONSTRAINT 外键名 FOREIGN KEY (从表外键字段) REFERENCES 主表 (主键字段)
-- 将创建数据表创号后语法如下:
ALTER TABLE 从表名 ADD CONSTRAINT 外键名 FOREIGN KEY (从表外键字段) REFERENCES 主表 (主键字段);
```
- 删除外键 MySQL命令:
```sql
alter table 从表名 drop foreign key 外键名;
```
## 二、数据库疑难
mybitis中foreach使用需要让服务器允许执行多条sql。

## 三、**数据库连接、重启相关**
**==一、启动、停止、重启==**
一、启动
1、使用 service 启动:service mysqld start
2、使用 mysqld 脚本启动:/etc/inint.d/mysqld start
3、使用 safe_mysqld 启动:safe_mysqld&
二、停止
1、使用 service 启动:service mysqld stop
2、使用 mysqld 脚本启动:/etc/inint.d/mysqld stop
3、mysqladmin shutdown
三、重启
1、使用 service 启动:service mysqld restart
2、使用 mysqld 脚本启动:/etc/inint.d/mysqld restart 展开
## **四、数据库原理**
### 1、索引
#### 1.1 索引结构


#### 1.2 ==B+tree的好处:==

#### 1.3 索引查询过程
二级索引可以多个,自己设置,聚集索引默认为主键,若无通过自动创建。
过程:
- 先按照索引在B+树中查询到对应的聚集索引。
- 再通过聚集索引查询到该行的数据。

#### 1.4 索引创建&删除
- 创建
```sql
//创建唯一(聚集)索引,unique关键字
create unique index idx_xxx on user(xxx);(表名+字段名)
//创建二级索引,无unique关键字即可
create index idx_xxx on user(xxx);(表名+字段名)
```
- 删除
```sql
drop index xxx on xxx;
```
#### 1.5 查询某一张表的索引
```sql
show index from xxx;
```
## 五、数据库杂语句
```sql
-- 查看服务器语句使用量
show GLOBAL STATUS LIKE 'Com_______';
```
- 结果大致样子

## 六、数据库八股
### 1、快照读和当前读
快照读就是普通的读操作,而当前读包括了 **加锁的读取** 和 **DML**(DML只是对表内部的数据操作,不涉及表的定义,结构的修改。主要包括insert、update、deletet) 操作。
当B事务修改了内容时,快照读不能获取修改的内容,相当于还是读取CPU中而不是内存中,而当前读则是直接读取内存中的最新的值,能够获取到B事务修改的内容。
当前读就是读取最新数据,而不是历史版本的数据。加锁的 SELECT,或者对数据进行增删改都会进行当前读。这有点像是 Java 中的 volatile 关键字,被 volatile 修饰的变量,进行修改时,JVM 会强制将其写回内存,而不是放在 CPU 缓存中,进行读取时,JVM 会强制从内存读取,而不是放在 CPU 缓存中。这样就能保证其可见行,保证每次读取到的都是最新的值。如果没有用 volatile 关键字修饰,变量的值可能会被放在 CPU 缓存中,这就导致读取到的值可能是某次修改的值,不能保证是最新的值。

### 2、幻读和不可重复读
**幻读 VS 不可重复读**
- 幻读重点在于数据是否存在。原本不存在的数据却真实的存在了,这便是幻读。在同一个事务中,第一次读取到结果集和第二次读取到的结果集不同。(对比上面的例子,当B事务INSERT以后,A事务中再进行插入,此次插入相当于一次隐式查询)。引起幻读的原因在于另一个事务进行了INSERT操作。
幻读是增加或删除了一些东西
- 不可重复读重点在于数据是否被改变了。在一个事务中对同一条记录进行查询,第一次读取到的数据和第二次读取到的数据不一致,这便是不可重复读。引起不可重复读的原因在于另一个事务进行了UPDATE或者是DELETE操作。
不可重复读是修改了已有的东西被读到了
**简单来说:幻读是说数据的条数发生了变化,原本不存在的数据存在了。不可重复读是说数据的内容发生了变化,原本存在的数据的内容发生了改变。**
==幻读的解决方法之一是加上间隙锁==

在一行行扫描的过程中,不仅将给行加上了行锁,还给行两边的空隙,也加上了间隙锁。MySQL将行锁 + 间隙锁组合统称为 next-key lock,通过 next-key lock 解决了幻读问题。
### 3、事务的隔离级别
1、READ UNCOMMITTED:读未提交,也叫未提交读,该隔离级别的事务可以看到其他事务中未提交的数据。该隔离级别因为可以读取到其他事务中未提交的数据,⽽未提交的数据可能会发⽣回滚, 因此我们把该级别读取到的数据称之为脏数据,把这个问题称之为脏读。
2、READ COMMITTED:读已提交,也叫提交读,该隔离级别的事务能读取到已经提交事务的数据, 因此它不会有脏读问题。但由于在事务的执⾏中可以读取到其他事务提交的结果,所以在不同时间 的相同 SQL 查询中,可能会得到不同的结果,这种现象叫做不可重复读。
3、REPEATABLE READ:可重复读,是 MySQL 的默认事务隔离级别,它能确保同⼀事务多次查询的结果⼀致。但也会有新的问题,⽐如此级别的事务正在执⾏时,另⼀个事务成功的插⼊了某条数据,但因为它每次查询的结果都是⼀样的,所以会导致查询不到这条数据,⾃⼰重复插⼊时⼜失败(因为唯⼀约束的原因)。明明在事务中查询不到这条信息,但⾃⼰就是插⼊不进去,这就叫幻读(Phantom Read)。
4、SERIALIZABLE:串行化(序列化),事务最⾼隔离级别,它会强制事务排序,使之不会发⽣冲突,从⽽解决 了脏读、不可重复读和幻读问题,但因为执⾏效率低,所以真正使⽤的场景并不多。
### 4、MVCC
==定义:==
MVCC是多版本并发控制 Multi-Version Concurrent Contrl。
它是MySQL中的提高性能的一种方式,配合Undo log 和版本链,替代锁,让不同事物的读-写、写-读操作可以并发的执行,从而提升系统的性能。
MVCC 在 MySQL InnoDB 中的实现主要是为了提高数据库并发性能。一般是在使用读已提交(PEAD COMMITTED)和可重复读(REPEATABLE READ)隔离级别的事务中实现。
用自己的话说就是:
多版本意思是指数据库中一条数据有多个版本同时存在,在某个事务对其进行具体操作的时候,是需要查看这一条记录的隐藏列事务版本的id,比对事务id并根据事物的隔离级别从而去判断是哪个版本的数据。
==准确的说,MVCC多版本并发控制指的是 “维持一个数据的多个版本,使得读写操作没有冲突” 这么一个概念。==
==MVCC的优点==
- MVCC在MySQL InnoDB中的实现主要是为了提高数据库的并发性能,用更好的方式去处理读-写或写-读之间的冲突,也能做到不加锁,非阻塞并发读,提高了数据库并发读写的性能。
- MVCC还可以解决脏读,幻读,不可重复读等事务隔离问题。但它还不能解决更新丢失的问题。
所以MVCC能够解决读-写之间的并发控制,但它不能解决写-写之间的的并发控制
==**基本原理**==
因为MVCC的目的就是控制并发控制的,在数据库中的实现,为了解决读写的冲突问题。
*它的实现原理主要依赖3个模块:隐藏字段、undo日志、Read View来实现的。*
==隐藏字段==
对于使用 InnoDB 存储引擎的表来说,它的聚簇索引记录中都包含两个必要的隐藏列。
● trx_id:每次对某条聚簇索引记录进行改动的时候,都会把对应的事务id赋值给trx_id进行记录的隐藏列。
● roll_pointer:在每次对某条聚簇索引记录进行改动的时候,都会把旧版本写入undo日志当中,然后这个隐藏列就相当于一个指针的作用,我们可以通过roll_pointer来找到该记录修改之前的信息。
==undo日志==
undo log主要分为两种:
insert undo log:
代表事务在insert新记录时产生的undo log,只在事务回滚时需要,并且在事务提交后就立即删除。
update undo log:
事务在进行update或delete时产生的undo log;不仅在事务回滚的时需要,在快照时也需要;所以不能随便删除,只有在快速读或事务回滚不涉及该日志时,对应的日志才会被purge线程统一清除。
==Read View(读视图)==
对于使用READ UNCOMMITTED(读未提交)隔离级别的事务来说,直接读取记录的最新版本就好了,对于使用SERIALIZABLE(串行化)隔离级别的事务来说,使用加锁的方式来访问记录。
所以在InnoDB引擎中设计了一个ReadView的概念。
Read View就是事务进行快照读操作的时候产生的读视图(Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的ID(当每个事务开启时,都会分配一个ID,这个ID是自增的,所以最新的事务,ID越大)。
在MySQL当中,READ COMMITTED和REPEATABLE READ 隔离级别的一个非常大的区别就是它们生成的Read View 的时机不同。
● READ COMMITTED:每次读取数据前都生成一个ReadView;
● REPEATABLE READ:在第一个读取数据时生成一个ReadView;

### 5、为什么MySQL使用B+树

==简洁版==
`先看原因:`
1.B+树减少了IO次数,效率更高
(这里这么理解:-----就是减少了磁盘的访问次数,毕竟内存速度要比磁盘快的多)
2.B+树查询跟稳定,因为所有数据放在叶子节点
3.B+树范围查询更好,因为叶子节点指向下一个叶子结点
==详细:==
```java
1、在B树的基础上每个节点存储的关键字数更多,树的层级更少所以查询数据更快。
2、所有关键字指针都存在叶⼦节点,所以每次查找的次数都相同所以查询速度更稳定。
3、除此之外,B+树的叶⼦节点是跟后序节点相连接的,这对范围查找是⾮常有⽤的。
看到没B+树的⾮叶⼦节点是主键,主键占⽤的空间越⼩,每个节点能放的主键就能更多,这就是为什么我们的主键 ⼀般不设置太⼤的原因。主键占⽤的空间⼩,能降低树⾼,减少IO次数
```
1、B+树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据。之所以这么做是因为在数据库中页的大小是固定的,innodb中页的默认大小是16KB。如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少,数据查询的效率也会更快。另外,B+树的阶数是等于键值的数量的,如果我们的B+树一个节点可以存储1000个键值,那么3层B+树可以存储1000×1000×1000=10亿个数据。一般根节点是常驻内存的,所以一般我们查找10亿数据,只需要2次磁盘IO。
2、因为B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。而B树因为数据分散在各个节点,要实现这一点是很不容易的。
#### 5.1、为什么不用平衡二叉树?
> **为什么不用普通二叉树?**
普通二叉树存在退化的情况,如果它退化成链表,相当于全表扫描。平衡二叉树相比于二叉查找树来说,查找效率更稳定,总体的查找速度也更快。
> **为什么不用平衡二叉树呢?**
读取数据的时候,是从磁盘读到内存。如果树这种数据结构作为索引,那每查找一次数据就需要从磁盘中读取一个节点,也就是一个磁盘块,但是平衡二叉树可是每个节点只存储一个键值和数据的,如果是 B+ 树,可以存储更多的节点数据,树的高度也会降低,因此读取磁盘的次数就降下来啦,查询效率就快。
### 6、索引
MySQL的索引包括普通索引、唯一性索引、全文索引、单列索引和空间索引等。
从功能逻辑上说,索引主要有4类,分别是普通索引、唯一索引、主键索引、全文索引。
按照物理实现方式,索引可以分为2种:聚簇索引和非聚簇索引。
按照作用字段个数进行划分,分成单列索引和联合索引。
1. 普通索引(还有前缀索引)
在创建普通索引时,不附加任何限制条件,只是用于提高查询效率。这类索引可以创建在任何数据类型中,其值是否唯一和非空,要由字段本身的完整性约束条件决定。建立索引以后,可以通过索引进行查询。例如,在表 student 的字段 name 上建立一个普通索引,查询记录时就可以根据该索引进行查询。
2. 唯一性索引
使用 UNIQUE 参数可以设置索引为唯一性索引,在创建唯一性索引时,限制该索引的值必须是唯一的,但允许有空值。在一张数据表里可以有多个唯一索引。
例如,在表 student 的字段 email 中创建唯一性索引,那么字段 email 的值就必须是唯一的。通过唯一性索引,可以更快速地确定某条记录。
3. 主键索引
主键索引就是一种特殊的唯一性索引,在唯一索引的基础上增加了不为空的约束,也就是 NOT NULL + UNIQUE,一张表里最多只有一个主键索引。
Why?这是由主键索引的物理实现方式决定的,因为数据存储在文件中只能按照一种顺序进行存储。
4. 单列索引
在表的单个字段上创建索引。单列索引只根据该字段进行索引。单列索引可以是普通索引,也可以是唯一性索引,还可以是全文索引。只要保证该索引只对应一个字段即可。一个表可以有多个单列索引。
5. 多列(组合、联合)索引
多列索引是在表的多个字段组合上创建一个索引。该索引指向创建时对应的多个字段,可以通过这几个字段进行查询,但是只有查询条件中使用了这些字段的第一个字段时才会被使用。例如,在表的字段 id、name 和 gender 上建立一个多列索引 idx_id_name_gender ,只有在查询条件中使用了字段 id 时该索引才会被使用。使用组合索引时遵循最左前缀集合。
6. 全文索引
全文索引(也称全文检索)是目前搜索引擎使用的一种关键技术。它能够利用【分词技术】等多种算法智能分析出文本文字中关键词的频率和重要性,然后按照一定的算法规则智能地筛选出我们想要的搜索结果。全文索引非常适合大型数据集,对于小的数据集,它的用处比较小。
使用参数 FULLTEXT 可以设置索引为全文索引。在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引只能创建在 CHAR、VARCHAR 或 TEXT 类型及其系列类型的字段上,查询数据量较大的字符串类型的字段时,使用全文索引可以提高查询速度。例如,表 student 的字段 infomation 是 TEXT 类型,该字段包含了很多文字信息。在字段 information 上建立全文索引后,可以提高查询字段 information 的速度。
全文索引典型的有两种类型:自然语言的全文索引和布尔全文索引。
自然语言搜索引擎将计算每一个文档对象和查询的相关度。这里,相关度是基于匹配的关键词的个数,以及关键词在文档中出现的次数。在整个索引中出现次数越少的词语,匹配时的相关度就越高。相反,非常常见的单词将不会被搜索,如果一个词语在超过50%的记录中都出现了,那么自然语言的搜索将不会搜索这类词语。
随着大数据时代的到来,关系型数据库应对全文索引的需求已力不从心,逐渐被 solr、ElasticSearch 等专门的搜索引擎所替代。
7、空间索引
#### 6.1、什么时候需要 / 不需要创建索引?
索引最大的好处是提高查询速度,但是索引也是有缺点的,比如:
- 需要占用物理空间,数量越大,占用空间越大;
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增大;
- 会降低表的增删改的效率,因为每次增删改索引,B+ 树为了维护索引有序性,都需要进行动态维护。
所以,索引不是万能钥匙,它也是根据场景来使用的。
[#](https://www.xiaolincoding.com/mysql/index/index_interview.html#什么时候适用索引)什么时候适用索引?
- 字段有唯一性限制的,比如商品编码;
- 经常用于 `WHERE` 查询条件的字段,这样能够提高整个表的查询速度,如果查询条件不是一个字段,可以建立联合索引。
- 经常用于 `GROUP BY` 和 `ORDER BY` 的字段,这样在查询的时候就不需要再去做一次排序了,因为我们都已经知道了建立索引之后在 B+Tree 中的记录都是排序好的。
[#](https://www.xiaolincoding.com/mysql/index/index_interview.html#什么时候不需要创建索引)什么时候不需要创建索引?
- `WHERE` 条件,`GROUP BY`,`ORDER BY` 里用不到的字段,索引的价值是快速定位,如果起不到定位的字段通常是不需要创建索引的,因为索引是会占用物理空间的。
- 字段中存在大量重复数据,不需要创建索引,比如性别字段,只有男女,如果数据库表中,男女的记录分布均匀,那么无论搜索哪个值都可能得到一半的数据。在这些情况下,还不如不要索引,因为 MySQL 还有一个查询优化器,查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。
- 表数据太少的时候,不需要创建索引;
- 经常更新的字段不用创建索引,比如不要对电商项目的用户余额建立索引,因为索引字段频繁修改,由于要维护 B+Tree的有序性,那么就需要频繁的重建索引,这个过程是会影响数据库性能的。
#### 6.2、索引失效的情况
- 查询条件包含 or,可能导致索引失效
- 如果字段类型是字符串,where 时一定用引号括起来,否则会因为隐式类型转换,索引失效
- like 通配符可能导致索引失效。
- 联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。
- 在索引列上使用 mysql 的内置函数,索引失效。
- 对索引列运算(如,+、-、*、/),索引失效。
- 索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。
- 索引字段上使用 is null, is not null,可能导致索引失效。
- 左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效。
- MySQL 优化器估计使用全表扫描要比使用索引快,则不使用索引。
### 7、AUTO-INC锁
==**在插入数据时,会加一个表级别的 AUTO-INC 锁**==
- 当 innodb_autoinc_lock_mode = 0,就采用 AUTO-INC 锁,语句执行结束后才释放锁;
- 当 innodb_autoinc_lock_mode = 2,就采用轻量级锁,申请自增主键后就释放锁,并不需要等语句执行后才释放。
- 当 innodb_autoinc_lock_mode = 1:
- 普通 insert 语句,自增锁在申请之后就马上释放;
- 类似 insert … select 这样的批量插入数据的语句,自增锁还是要等语句结束后才被释放;
当 innodb_autoinc_lock_mode = 2 是性能最高的方式,但是当搭配 binlog 的日志格式是 statement 一起使用的时候,在「主从复制的场景」中会发生**数据不一致的问题**。
如果 innodb_autoinc_lock_mode = 2,意味着「==申请自增主键后就释放锁,不必等插入语句执行完==」。那么就可能出现这样的情况:
- session B 先插入了两个记录,(1,1,1)、(2,2,2);
- 然后,session A 来申请自增 id 得到 id=3,插入了(3,5,5);
- 之后,session B 继续执行,插入两条记录 (4,3,3)、 (5,4,4)。
可以看到,**session B 的 insert 语句,生成的 id 不连续**。
当「主库」发生了这种情况,binlog 面对 t2 表的更新只会记录这两个 session 的 insert 语句,如果 binlog_format=statement,记录的语句就是原始语句。记录的顺序要么先记 session A 的 insert 语句,要么先记 session B 的 insert 语句。
但不论是哪一种,这个 binlog 拿去「从库」执行,这时从库是按「顺序」执行语句的,只有当执行完一条 SQL 语句后,才会执行下一条 SQL。因此,在**从库上「不会」发生像主库那样两个 session 「同时」执行向表 t2 中插入数据的场景。所以,在备库上执行了 session B 的 insert 语句,生成的结果里面,id 都是连续的。这时,主从库就发生了数据不一致**。
要解决这问题,binlog 日志格式要设置为 row,这样在 binlog 里面记录的是主库分配的自增值,到备库执行的时候,主库的自增值是什么,从库的自增值就是什么。
==所以,**当 innodb_autoinc_lock_mode = 2 时,并且 binlog_format = row,既能提升并发性,又不会出现数据一致性问题**。==
### 8、锁相关
#### 8.1 幻读解决以及死锁问题
**Innodb 引擎为了解决「可重复读」隔离级别下的幻读问题,就引出了 next-key 锁**,它是记录锁和间隙锁的组合。
- Record Lock,记录锁,锁的是记录本身;
- Gap Lock,间隙锁,锁的就是两个值之间的空隙,以防止其他事务在这个空隙间插入新的数据,从而避免幻读现象。
普通的 select 语句是不会对记录加锁的,因为它是通过 MVCC 的机制实现的快照读,如果要在查询时对记录加行锁,可以使用下面这两个方式:
```sql
begin;
//对读取的记录加共享锁
select ... lock in share mode;
commit; //锁释放
begin;
//对读取的记录加排他锁
select ... for update;
commit; //锁释放
```
死锁原因:两个事务都持有相同的间隙锁,**而插入意向锁与间隙锁是冲突的,所以当其它事务持有该间隙的间隙锁时,需要等待其它事务释放间隙锁之后,才能获取到插入意向锁**,而只有等待对方的间隙锁释放后才能执行接下来的步骤,导致互等,死锁。
临键锁就是记录锁(Record Locks)和间隙锁(Gap Locks)的结合,即除了锁住记录本身,还要再锁住索引之间的间隙。当我们使用范围查询,并且命中了部分`record`记录,此时锁住的就是临键区间。注意,临键锁锁住的区间会包含最后一个 record 的右边的临键区间。例如`select * from t where id > 5 and id <= 7 for update;`会锁住(4,7]、(7,+∞)。mysql 默认行锁类型就是`临键锁(Next-Key Locks)`。当使用唯一性索引,等值查询匹配到一条记录的时候,临键锁(Next-Key Locks)会退化成记录锁;没有匹配到任何记录的时候,退化成间隙锁。
> `间隙锁(Gap Locks)`和`临键锁(Next-Key Locks)`都是用来解决幻读问题的,在`已提交读(READ COMMITTED)`隔离级别下,`间隙锁(Gap Locks)`和`临键锁(Next-Key Locks)`都会失效!
#### 8.2、什么时候使用表锁和行锁
1. 对于表级锁而言,当执行 DDL 语句去修改表结构时,会使用表级锁。
> 其他:主键自增的情况下插入数据会使用**AUTO-INC 锁**(表锁),AUTO-INC 锁是特殊的表锁机制,锁**不是再一个事务提交后才释放,而是再执行完插入语句后就会立即释放**。
2. 对于行级锁而言,一般情况下都会默认使用行级锁,貌似是需要有索引匹配到才行。
#### 8.3、意向锁的作用
意向锁是表级锁,某一行加锁时需要先加意向锁,假如没有意向锁,那么我们就得遍历表中所有数据行来判断有没有行锁;有了意向锁这个表级锁之后,则我们直接判断一次就知道表中是否有数据行被锁定了。
### 9、索引下推
**图一:不使用ICP技术(过程使用数字符号标示,如①②③等)**

**图二:使用ICP技术(过程使用数字符号标示,如①②③等)**

理解:相当于原本是回表查出所有的数据后再进行筛选,使用索引下推后变为回表前就先使用where对联合索引中的其他字段进行筛选,回表后再进行第二次筛选,这样减少了回表的次数。
### 10、分库分表
==分库==
**垂直分库** 就是把单一数据库按照业务进行划分,不同的业务使用不同的数据库,进而将一个数据库的压力分担到多个数据库。

**水平分库** 是把同一个表按一定规则拆分到不同的数据库中,每个库可以位于不同的服务器上,这样就实现了水平扩展,解决了单表的存储和性能瓶颈的问题。

垂直分库分担数据库压力,水平分库增加存储空间
==分表==
**分表** 就是对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分。
**垂直分表** 是对数据表列的拆分,把一张列比较多的表拆分为多张表。
举个例子:我们可以将用户信息表中的一些列单独抽出来作为一个表。
**水平分表** 是对数据表行的拆分,把一张行比较多的表拆分为多张表,可以解决单一表数据量过大的问题。
举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
水平拆分只能解决单表数据量大的问题,为了提升性能,我们通常会选择将拆分后的多张表放在不同的数据库中。也就是说,水平分表通常和水平分库同时出现。

#### 10.1、什么情况下需要分库分表?
遇到下面几种场景可以考虑分库分表:
- 单表的数据达到千万级别以上,数据库读写速度比较缓慢。
- 数据库中的数据占用的空间越来越大,备份时间越来越长。
- 应用的并发量太大。
#### 10.2、常见的分片算法有哪些?
分片算法主要解决了数据被水平分片之后,数据究竟该存放在哪个表的问题。
- **哈希分片**:求指定 key(比如 id) 的哈希,然后根据哈希值确定数据应被放置在哪个表中。哈希分片比较适合随机读写的场景,不太适合经常需要范围查询的场景。
- **范围分片**:按照特性的范围区间(比如时间区间、ID 区间)来分配数据,比如 将 `id` 为 `1~299999` 的记录分到第一个库, `300000~599999` 的分到第二个库。范围分片适合需要经常进行范围查找的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。
- **地理位置分片**:很多 NewSQL 数据库都支持地理位置分片算法,也就是根据地理位置(如城市、地域)来分配数据。
- **融合算法**:灵活组合多种分片算法,比如将哈希分片和范围分片组合。
#### 10.3 、分库分表存在的问题
1、原本的事务不能保证原子性,需要使用分布式事务(2PC两阶段提交、3PC、TCC、可靠消息最终一致性)
2、跨库无法使用JOIN,只能通过`业务代码关联`、`增添冗余字段`、`数据异构通过ES查询`的方式解决
3、聚合函数等只能通过业务逻辑或者中间件实现而不能使用order by
4、主键ID问题,需要使用分布式ID(UUID、雪花算法、redisID、zookeeper生成唯一ID)
5、需要考虑数据库容量、迁移、扩容的问题
#### 10.4、总结
- 读写分离主要是为了将对数据库的读写操作分散到不同的数据库节点上。 这样的话,就能够小幅提升写性能,大幅提升读性能。
- 读写分离基于主从复制,MySQL 主从复制是依赖于 binlog 。
- **分库** 就是将数据库中的数据分散到不同的数据库上。**分表** 就是对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分。
- 引入分库分表之后,需要系统解决事务、分布式 id、无法 join 操作问题。
- ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理等功能。另外,ShardingSphere 的生态体系完善,社区活跃,文档完善,更新和发布比较频繁。
### 11、并发操作数据库需要注意什么
在并发操作数据库时,有一些重要的注意事项需要考虑,以确保数据的一致性、完整性和可靠性。以下是一些需要注意的方面:
1. **事务处理**:使用数据库事务来维护数据的一致性和完整性。事务是一组操作,要么全部成功执行,要么全部回滚。这可以防止在并发情况下数据损坏或不一致。
2. **锁机制**:数据库通常提供了锁机制来管理并发访问。锁可以分为共享锁(读取操作)和排他锁(写入操作)。合理地使用锁可以避免多个并发事务同时修改同一数据造成的问题,如死锁、锁竞争等。
3. **并发控制**:数据库管理系统通常具有并发控制机制,如多版本并发控制(MVCC),用于处理同时读取和写入操作。这可以防止读取脏数据(未提交的数据)和写入丢失等问题。
4. **隔离级别**:数据库提供了不同的隔离级别,用于控制并发事务之间的可见性和影响范围。常见的隔离级别包括读未提交、读提交、可重复读和串行化。选择适当的隔离级别可以平衡一致性和性能。
5. **死锁处理**:死锁是多个事务相互等待对方释放资源而无法继续执行的情况。数据库管理系统应该具备死锁检测和解除机制,以避免持续的死锁问题。
6. **并发测试**:在开发和测试阶段,需要进行并发测试,模拟多个用户同时访问数据库并执行操作。这有助于发现潜在的并发问题和性能瓶颈。
7. **连接池管理**:使用连接池来管理数据库连接,以避免频繁地打开和关闭连接,从而提高性能并减少资源消耗。
8. **优化查询**:并发操作时,数据库查询可能会成为性能瓶颈。确保你的查询经过优化,使用合适的索引和查询语句,以减少查询时间和资源消耗。
9. **错误处理和回滚**:在并发操作中,可能会发生错误。正确处理错误,并在必要时回滚事务,可以保护数据的完整性和一致性。
10. **监控和调优**:定期监控数据库的性能指标,如响应时间、并发连接数等。根据监控结果进行调优,以保持数据库的高性能和稳定性。
总之,处理并发操作数据库需要综合考虑事务管理、锁机制、并发控制、隔离级别、死锁处理等多个方面,以确保数据的可靠性和一致性。
### 12、日志相关
- **undo log(回滚日志)**:是 Innodb 存储引擎层生成的日志,实现了事务中的**原子性**,主要**用于事务回滚和 MVCC**。
- **redo log(重做日志)**:是 Innodb 存储引擎层生成的日志,实现了事务中的**持久性**,主要**用于掉电等故障恢复**;
- **binlog (归档日志)**:是 Server 层生成的日志,主要**用于数据备份和主从复制**;
### 13、为什么Redis Zset使用跳表?
1、**简单实现**
2、**更好的内存效率**,每个节点只需要记录下一层节点的指针,跳表在内存中的存储布局相对紧凑,不需要像平衡树那样维护大量的指针和额外的数据结构,因此可以在相对较少的内存中存储大量元素。
3、**高效的插入和删除操作**,跳表允许在平均情况下以O(log n)的时间复杂度执行插入、删除和查找操作。这对于有序集合来说是非常重要的,因为有序集合需要保持元素的有序性,并且需要高效地进行元素的插入和删除。
4、**可读性和维护性:** 跳表的实现相对直观,容易理解和调试。这对于Redis的开发团队和其他开发人员来说都是有益的。
缺点:
1、分层结构,当层数过高时相对于红黑树,空间消耗增加。
2、跳表并没有一个现成的实现,所以在开发中,如果你想使用跳表,必须要自己实现。
原因:**分层结构:** 跳表的核心思想是分层结构,每个层级都有一定数量的节点。这些层级在内存中占用了一定的空间。==红黑树虽然也有层级结构,但是它的高度相对较低==,而且不需要为每个节点都维护多个层级,因此在某些情况下可以在整体高度上占用更少的空间。
### 14、SQL优化
尽量避免使用子查询
用IN来替换OR
读取适当的记录LIMIT M,N,而不要读多余的记录
禁止不必要的Order By排序
总和查询可以禁止排重用union all
避免随机取记录
将多次插入换成批量Insert插入
只返回必要的列,用具体的字段列表代替 select * 语句
区分in和exists
优化Group By语句
尽量使用数字型字段
优化Join语句

#### 14.1、分页查询优化
分页优化
在数据量比较大,分页比较深的情况下,需要考虑分页的优化。
例如:
```text
select * from table where type = 2 and level = 9 order by id asc limit 190289,10;
```
优化方案:
- **延迟关联**
**操作:**查询条件放到子查询中,子查询只查主键ID,然后使用子查询中确定的主键关联查询其他的属性字段;
例如:
```text
select a.* from table a,
(select id from table where type = 2 and level = 9 order by id asc limit 190289,10 ) b
where a.id = b.id
```
说明: MySQL并不是挑过offeset行,而是取offset+N行,然后返回放弃前offset行,返回N行,那当offset特别大的时候,效率就非常的底下,要么控制返回的总页数,要么对超过特定阈值的页数进行SQL改写。
==理解:原本的SQL需要走一次二级索引通过最左前缀找到id后回表,回表后需要对所有行进行排序以及筛选(2次),而延迟关联优化先通过子查询获取主键id,再进行内连接(2次),第二种只需要在子查询中对id进行排序,这样可以减少查询的数据量,不需要对行进行排序,因此快很多==
一句话:第一种需要检索行,第二种只要检索id
**方案二:**
select * from user limit 10000,100;
select * from user where id>= (select id from user limit 10000,1) limit 100;
先定位筛选出起始点,再读取后面的100条信息
详细解释:
1、https://zhuanlan.zhihu.com/p/626142956?utm_id=0
2、https://blog.csdn.net/HongZeng_CSDN/article/details/130045243
### 15、事务ACID
**原子性**(`Atomicity`):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
**一致性**(`Consistency`):执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
**隔离性**(`Isolation`):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
**持久性**(`Durability`):一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
### 16、两阶段提交
**什么是两阶段提交**
当有数据修改时,会先将修改redo log cache和binlog cache然后在刷入到磁盘形成redo log file,当redo log file全都刷入到磁盘时(prepare 状态)和提交成功后才能将binlog cache刷入磁盘,当binlog全部刷新到磁盘后会记录一个xid,然后在relo log file上打上commit标志(commit阶段)。

为什么要两阶段提交呢?直接提交不行吗?
我们可以假设不采用两阶段提交的方式,而是采用“单阶段”进行提交,即要么先写入 redo log,后写入 binlog;要么先写入 binlog,后写入 redo log。这两种方式的提交都会导致原先数据库的状态和被恢复后的数据库的状态不一致
**先写入 redo log,后写入 binlog:**
在写完 redo log 之后,数据此时具有`crash-safe`能力,因此系统崩溃,数据会恢复成事务开始之前的状态。但是,若在 redo log 写完时候,binlog 写入之前,系统发生了宕机。此时 binlog 没有对上面的更新语句进行保存,导致当使用 binlog 进行数据库的备份或者恢复时,就少了上述的更新语句。从而使得`id=2`这一行的数据没有被更新。

**先写入 binlog,后写入 redo log:**
写完 binlog 之后,所有的语句都被保存,所以通过 binlog 复制或恢复出来的数据库中 id=2 这一行的数据会被更新为 a=1。但是如果在 redo log 写入之前,系统崩溃,那么 redo log 中记录的这个事务会无效,导致实际数据库中`id=2`这一行的数据并没有更新。

## 七、数据库sql题目
### 1、查找每个班级分数最高的前三名

答案:
```sql
select class, name,score
FROM test_score a
WHERE (
SELECT COUNT(score) from test_score b WHERE b.class=a.class AND a.score60)
```
### 3、查询学过课程ID为‘301’和‘302’的学生的学号、姓名
```sql
select student.student_id,student.student_name
from student
where student.student_id IN(
select a.student_id
from (select student_id from score where course_id=301) as a
INNER JOIN (select student_id from score where course_id=302) as b
on a.student_id=b.student_id
);
```
### 4、查询学过学号为1005同学所有课程的同学的学号
```sql
select student.student_id,student.student_name,score.course_id
FROM student,score
where student.student_id=score.student_id and score.course_id = (select score.course_id
FROM student,score
where student.student_id=score.student_id and student.student_id=1005) AND student.student_id!=1005;
```
=代表course_id中的每一个都和1005同学学的所有课程相同
### 5、查询至少有一门课与学号为“1001”的学生所学课程相同的学生的学号和姓名
```sql
select student.student_id,student.student_name,score.course_id
from student,score
where student.student_id=score.student_id and score.course_id in (select score.course_id
from score
where score.student_id=1001);
```
in代表只要有一门相同就取出
### 6、查询比例
```sql
SELECT
SUM(CASE WHEN is_activity = 1 THEN 1 ELSE 0 END) AS successful_count,
COUNT(*) AS total_count,
(SUM(CASE WHEN is_activity = 1 THEN 1 ELSE 0 END) * 1.0 / COUNT(*)) AS success_rate
FROM announcement;
```

# ==Redis知识点==
## 1、redis的五种核心数据结构
string、hash、list、set、zset

## 2、Hash
用于电商购物车、只改变部分关键属性的情况


## 3、List
推送、信息流,可以模拟栈,每个人一个信息流栈空间,使得取出的数据自带时间顺序排序。粉丝量较大时可以后台缓慢推送(不同用户之间收到信息时间可能不同)

## 4、SET
用于点赞收藏的场景。


后端
http://localhost:8080/
前端
http://localhost:1024/
```c++
yarn serve
```
## 5、启动redis
```c++
//启动
redis-server.exe redis.windows.conf
//在开一个cmd
redis-cli.exe
//查看密码
config get requirepass
//设置密码
config set requirepass 123456Aa
```
127.0.0.1:6379
登录命令:auth 123456Aa

## 6、Redis实现分布式锁
Redis 的 SET 命令有个 NX 参数可以实现「key不存在才插入」,所以可以用它来实现分布式锁:
- 如果 key 不存在,则显示插入成功,可以用来表示加锁成功;
- 如果 key 存在,则会显示插入失败,可以用来表示加锁失败。
基于 Redis 节点实现分布式锁时,对于加锁操作,我们需要满足三个条件。
- 加锁包括了读取锁变量、检查锁变量值和设置锁变量值三个操作,但需要以原子操作的方式完成,所以,我们使用 SET 命令带上 NX 选项来实现加锁;
- 锁变量需要设置过期时间,以免客户端拿到锁后发生异常,导致锁一直无法释放,所以,我们在 SET 命令执行时加上 EX/PX 选项,设置其过期时间;
- 锁变量的值需要能区分来自不同客户端的加锁操作,以免在释放锁时,出现误释放操作,所以,我们使用 SET 命令设置锁变量值时,每个客户端设置的值是一个唯一值,用于标识客户端;
满足这三个条件的分布式命令如下:
```c
SET lock_key unique_value NX PX 10000
```
- lock_key 就是 key 键;
- unique_value 是客户端生成的唯一的标识,区分来自不同客户端的锁操作;
- NX 代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;
- PX 10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。
而解锁的过程就是将 lock_key 键删除(del lock_key),但不能乱删,要保证执行操作的客户端就是加锁的客户端。所以,解锁的时候,我们要先判断锁的 unique_value 是否为加锁客户端,是的话,才将 lock_key 键删除。
可以看到,解锁是有两个操作,这时就需要 Lua 脚本来保证解锁的原子性,因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,保证了锁释放操作的原子性。
```c
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
```
这样一来,就通过使用 SET 命令和 Lua 脚本在 Redis 单节点上完成了分布式锁的加锁和解锁。
> 基于 Redis 实现分布式锁有什么优缺点?
基于 Redis 实现分布式锁的**优点**:
1. 性能高效(这是选择缓存实现分布式锁最核心的出发点)。
2. 实现方便。很多研发工程师选择使用 Redis 来实现分布式锁,很大成分上是因为 Redis 提供了 setnx 方法,实现分布式锁很方便。
3. 避免单点故障(因为 Redis 是跨集群部署的,自然就避免了单点故障)。
基于 Redis 实现分布式锁的**缺点**:
- 超时时间不好设置
。如果锁的超时时间设置过长,会影响性能,如果设置的超时时间过短会保护不到共享资源。比如在有些场景中,一个线程 A 获取到了锁之后,由于业务代码执行时间可能比较长,导致超过了锁的超时时间,自动失效,注意 A 线程没执行完,后续线程 B 又意外的持有了锁,意味着可以操作共享资源,那么两个线程之间的共享资源就没办法进行保护了。
- **那么如何合理设置超时时间呢?** 我们可以基于续约的方式设置超时时间:先给锁设置一个超时时间,然后启动一个守护线程,让守护线程在一段时间后,重新设置这个锁的超时时间。实现方式就是:写一个守护线程,然后去判断锁的情况,当锁快失效的时候,再次进行续约加锁,当主线程执行完成后,销毁续约锁即可,不过这种方式实现起来相对复杂。
- **Redis 主从复制模式中的数据是异步复制的,这样导致分布式锁的不可靠性**。如果在 Redis 主节点获取到锁后,在没有同步到其他节点时,Redis 主节点宕机了,此时新的 Redis 主节点依然可以获取锁,所以多个应用服务就可以同时获取到锁。
## 7、执行LUA 脚本
4.2 执行 Lua 脚本文件
执行命令: redis-cli -a 密码 --eval Lua 脚本路径 key [key ...] , arg [arg ...] 。
脚本路径后紧跟 key [key …] ,相比命令行模式,少了 numkeys 这个 key 的数量值。key [key …] 和 arg [arg …] 之间的英文逗号前后必须有空格,否则报错。
```
[testuser@vm-10-211-42-26 ~] redis-cli -a 123456 --eval /home/testuser/compareAndSwap.lua testkey1 , value1 120 value2
OK
[testuser@vm-10-211-42-26 ~]redis-cli -a 123456 --eval /home/testuser/compareAndSwap.lua testkey1 , value2 120 value3
OK
[testuser@vm-10-211-42-26 ~]$ redis-cli -a 123456 --eval /home/testuser/compareAndSwap.lua testkey1 , value2 120 value3
0
```
redis-cli --eval Lua脚本路径 key [key …] , arg [arg …]
# Redis八股
## 1、Redis模式有哪些?
### 1、单机模式
单机模式就是在一台服务器上安装redis,然后启动,所有业务都调用这一台redis服务器。

优点:
1、部署简单,只需要在一台服务器上安装并启动redis就行。
2、成本低,没有备用节点,不需要其他的开支。
3、高性能,单机不需要同步数据,数据天然一致性。
缺点:
1、可靠性较弱,一旦服务器宕机,所有业务都无法使用redis服务。
2、单机模式redis性能受限于CPU的处理能力。
### 2、主从模式
主从模式是指有多台redis服务器,其中一台主要负责写入客户端请求数据,称为主节点(master),其他服务专门负责处理客户端的读取数据的请求,不负责写入数据,称为从节点(slave)。主节点写入的数据会复制的各个从节点上,并且数据复制的方向是单向的,只能从主节点复制到从节点。

具体工作机制:
1、slave启动后,向master发送SYNC命令,master接收到SYNC命令后通过bgsave将当前主节点的全量数据以rdb的方式2、保存快照,同时使用缓冲区记录后续主节点执行的增量数据。
3、master将保存的快照文件发送给slave。
4、slave接收到快照文件后,加载快照文件,载入数据。
5、当slave节点复制完全量数据后,主节点在将后续的增量数据同步给slave节点,slave接收命令并执行,完成复制初始化。
6、此后master每次执行一个写命令都会同步发送给slave,保持master与slave之间数据的一致性。
优点:
1、读写分离:master写,slave读,同时可以根据访问需求大小来添加slave节点数量。
2、负载均衡:通过读写分离的方式来分但服务器负载,主节点负责写入数据,多个从节点负责读取数据,缓解单个服务器访问的压力,提高读的吞吐量。
3、数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
4、高可用性:提高了服务的可用性,多个节点同时提供服务,当前其中一台节点宕机后,其他节点仍然可以提供服务。
5、故障恢复:master宕机后,快速升级slave为master。
缺点:
1、master宕机后,slave节点升级成新的master节点后,需要手动切换主机,同时会有部分数据不能及时同步从服务器,造成数据不一致。
2、slave宕机后,多个slave恢复后,大量的SYNC同步会造成master IO压力倍增。
3、主从模式只要一个maste节点,所以master节点的写数据的能力会受到单机的限制。
### 3、哨兵模式(sentinel)
哨兵模式主要是在主从复制模式基础上,增加了自动化的故障恢复功能。因为主从复制模式下,当master节点宕机后,虽然slave节点会升级成新的master节点,但是升级后的slave节点的ip顺其自然的就称为了新的master节点ip,原先其他的slave节点配置的master节点的ip也是需要变更的,在主从复制模式下,这种变更是需要人工手动去修改配置文件的。而哨兵模式则完美的解决了这一缺陷,实现了快速的自动恢复,不再需要人工修改。

需要注意到是每个哨兵都是一个独立的redis服务,只是不提供数据的读取服务。一般哨兵模式都是以集群的方式部署,每个哨兵都部署在不同的服务器上,且每个哨兵的配置文件除了ip和端口不一样,其他基本都是一样。一般集群中包含的哨兵数目都为奇数。
哨兵的主要功能:
- 集群监控:负责监控 master 和 slave 进程是否正常工作。
- 消息通知:如果某个 Redis 实例宕机,那么哨兵负责向(哨兵间,客户端)发送消息。
- 自动故障转移:当master宕机后,由哨兵负责重新在slave节点中选举出新的master节点,并将其他slave连接到新的master,以及告知客户端新的服务器地址。更好的为客户端提供高可用服务。
哨兵模式的缺点:
- 哨兵的部署会占用额外的服务器资源,且不提供数据的读取服务。哨兵模式除了解决了主从模式手动切换主从节点的问题外,其他主从模式存在的问题,哨兵模式基本也都存在。
### 4、集群模式(类似于RabbitMQ到Kafka的转变)(Cluster)
==redis集群解决了哪些问题?==
主从模式实现了数据的热备份,哨兵模式实现了redis的高可用。但是这两种模式存在两个问题:
(1)写并发:这两种都只能有一个master节点负责写操作,在高并发的写操作场景,master节点就会成为性能瓶颈。而redis集群则可以实现多个节点同时提供写操作,redis集群模式采用无中心结构,每个节点都可以看做是一个主从模式,节点之间互相连接从而知道整个集群状态。
(2)海量数据的存储压力:无论是哨兵模式还是主从模式,每台机器上存储的数据都是一样的,都是从主节点上复制过去的,本质上只有一台Master作为存储。所以无论增加多少slave节点都无法解决单台机器存储的上限问题。但是集群模式就解决了这以问题,因为Redis Cluster是一种服务器 Sharding 技术,采用数据分片的方式,将不同的数据存储在不同的master节点上面,因为我们可以通过不断的增加集群中的节点,从而达到存储海量数据。
==redis集群的实现原理?==
Redis集群采用去中心化的思想,没有中心节点的说法,对于客户端来说,整个集群可以看成一个整体,可以连接任意一个节点进行操作,就像操作单一Redis实例一样,不需要任何代理中间件,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node。 Redis也内置了高可用机制,支持N个master节点,每个master节点都可以挂载多个slave节点,当master节点挂掉时,集群会提升它的某个slave节点作为新的master节点。Redis集群可以看成多个主从架构组合起来的,每一个主从架构可以看成一个节点(其中,只有master节点具有处理请求的能力,slave节点主要是用于节点的高可用)。

点间的内部通信机制
redis cluster节点间采取gossip协议进行通信,跟集中式不同,不是将集群元数据(节点信息,故障,等等)集中存储在某个节点上,而是互相之间不断通信,保持整个集群所有节点的数据是完整的。
集中式:的好处在于节点信息的更新和读取时效性非常好,所有节点的元数据信息都集中式的存储在一起,一旦某个节点元数据出现了变更,立即就更新到集中式的存储中。不好在于,所有的元数据的跟新压力全部集中在一个地方,可能会导致元数据的存储有压力。
gossip:好处在于,将元数据的更新分散到各个节点上,不再集中在一个地方处理,降低了集中式处理的压力,但是有一定的延时,可能导致集群的一些操作会有一些滞后。且gossip 协议对服务器时间的要求较高,时间戳不准确会影响节点判断消息的有效性。随着节点数量增多后的节点间频繁的通信会导致网络开销增加,同时结点数太多,意味着达到最终一致性的时间也相对变长,因此官方推荐最大节点数为1000左右。
通信端口
每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如8011,那么用于节点间通信的就是18011端口。
交换的信息
节点间的通信主要有:故障信息,节点的增加和移除,hash slot信息,等等。
gossip常见协议类型
gossip协议常见的消息类型包含: ping、pong、meet、fail等等。
(1)meet: 某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信。
(2)ping:用于交换节点的元数据。每个节点每秒会向集群中其他节点发送 ping 消息,消息中封装了自身节点状态还有其他部分节点的状态数据,也包括自身所管理的槽信息等等。
(3)pong:ping和meet消息的响应,同样包含了自身节点的状态和集群元数据信息。
(4)fail:某个节点判断另一个节点 fail 之后,向集群所有节点广播该节点挂掉的消息,其他节点收到消息后标记已下线。
# 服务器相关
### 1、导出Dump文件排查问题
跳转到JDK的bin目录下
```
cd /usr/local/btjdk/jdk8/bin
```
TOP查看JAVA的实际使用情况,按下大写H可以查看每个线程的CPU占用情况
```
top -p PID
```
查看JAVA文件的PID
```
ps -ef|grep java
```
使用宝塔代理,所以需要切换到对应的用户www才可以执行命令,
```
Ubuntu:
sudo su - www -s /bin/bash
Linux:
su -s /bin/bash -c "ls" www
或者直接使用www用户来执行命令
sudo -u www command
```
使用jmap导出
```
./jmap -dump:file=/tmp/xdx_dump.bin PID
```
导入到VisualVM中进行查看


### 2、jstart查看GC
==首先需要和之前一样切换到www用户==
```
sudo su - www -s /bin/bash
```
跳转到JDK的bin目录下
```
cd /usr/local/btjdk/jdk8/bin
```
查看GC情况
```
jstat -gcutil PID
```

参数表示有:
S0C:第一个幸存区的大小
S1C:第二个幸存区的大小
S0U:第一个幸存区的使用大小
S1U:第二个幸存区的使用大小
EC:伊甸园区的大小
EU:伊甸园区的使用大小
OC:老年代大小
OU:老年代使用大小
MC:方法区大小
MU:方法区使用大小
CCSC:压缩类空间大小
CCSU:压缩类空间使用大小
YGC:年轻代垃圾回收次数
YGCT:年轻代垃圾回收消耗时间
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间
# ==场景题==
## 1、网站统计PV、UV
1.1、使用位图进行统计
将每一个ip映射为一个hash值,然后再次映射到到对应位图的位置,最后统计数量
1.2使用Redis的HyperLogLog进行基数统计
HyperLogLog采用随机的hash函数,误差率低,但不能判断一个元素是否存在,只能统计数量。
**HLL 具有以下几个特点:**
- `能够使用极少的内存来统计巨量的数据,它只需要 12K 空间就能统计 2^64 的数据;`
- `统计存在一定的误差,误差率整体较低,标准误差为 0.81%;`
- `误差可以被设置辅助计算因子进行降低。`
==HyperLogLog和布隆过滤器的区别==
- 布隆过滤器主要用来判断,某个数据存不存在
> 布隆过滤器采用固定的几个hash函数来进行散列,导致误差率相比于HyperLogLog较高,但他能够判断元素是否存在
- HyperLogLog用来做 **统计** , 没法确认某个数据在不在
> HyperLogLog采用随机的hash函数,误差率低,但不能判断一个元素是否存在,只能统计数量。
# ==JAVA==
## 1、GET请求
@RequestBody
RequestBody -- Map / Object
GET请求中不可以使用@RequestBody
@RequestParam
(@RequestParam Map map)
在url中的?后面添加参数即可使用
(@RequestParam String waterEleId,@RequestParam String enterpriseName)
在url中的?后面添加参数即可使用
(@RequestParam Object object)
GET请求中不可以使用
## 2、为什么重写 equals() 时必须重写 hashCode() 方法?
**那为什么 JDK 还要同时提供这两个方法呢?**
这是因为在一些容器(比如 `HashMap`、`HashSet`)中,有了 `hashCode()` 之后,判断元素是否在对应容器中的效率会更高(参考添加元素进`HashSet`的过程)!
我们在前面也提到了添加元素进`HashSet`的过程,如果 `HashSet` 在对比的时候,同样的 `hashCode` 有多个对象,它会继续使用 `equals()` 来判断是否真的相同。也就是说 `hashCode` 帮助我们大大缩小了查找成本。
**那为什么不只提供 `hashCode()` 方法呢?**
这是因为两个对象的`hashCode` 值相等并不代表两个对象就相等。
**那为什么两个对象有相同的 `hashCode` 值,它们也不一定是相等的?**
因为 `hashCode()` 所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。越糟糕的哈希算法越容易碰撞,但这也与数据值域分布的特性有关(所谓哈希碰撞也就是指的是不同的对象得到相同的 `hashCode` )。
总结下来就是:
- 如果两个对象的`hashCode` 值相等,那这两个对象不一定相等(哈希碰撞)。
- 如果两个对象的`hashCode` 值相等并且`equals()`方法也返回 `true`,我们才认为这两个对象相等。
- 如果两个对象的`hashCode` 值不相等,我们就可以直接认为这两个对象不相等
因为两个相等的对象的 `hashCode` 值必须是相等。也就是说如果 `equals` 方法判断两个对象是相等的,那这两个对象的 `hashCode` 值也要相等。
如果重写 `equals()` 时没有重写 `hashCode()` 方法的话就可能会导致 `equals` 方法判断是相等的两个对象,`hashCode` 值却不相等。
**思考**:重写 `equals()` 时没有重写 `hashCode()` 方法的话,使用 `HashMap` 可能会出现什么问题。
答:不重写hashCode()会导致当加入到hashSet或hashMap中时两个内容一致的东西会被识别为不同的,导致出现两个对象,这是因为在内部调用判断是否相等时,hashmap先判断hashcode再判断equal,
1)、如果两个对象相等,那么它们的hashCode()值一定相同。
这里的相等是指,通过equals()比较两个对象时返回true。
2)、如果两个对象hashCode()相等,它们并不一定相等。
因为在散列表中,hashCode()相等,即两个键值对的哈希值相等。然而哈希值相等,并不一定能得出键值对相等。补充说一句:“两个不同的键值对,哈希值相等”,这就是哈希冲突。
此外,在这种情况下。若要判断两个对象是否相等,除了要覆盖equals()之外,也要覆盖hashCode()函数。否则,equals()无效。
例如,创建Person类的HashSet集合,必须同时覆盖Person类的equals() 和 hashCode()方法。
如果单单只是覆盖equals()方法。我们会发现,equals()方法没有达到我们想要的效果,会出现两个重复的值。
**参考代码:**
```java
import java.util.*;
import java.lang.Comparable;
/**
* @desc 比较equals() 返回true 以及 返回false时, hashCode()的值。
*
* @author skywang
* @emai kuiwu-wang@163.com
*/
public class ConflictHashCodeTest2{
public static void main(String[] args) {
// 新建Person对象,
Person p1 = new Person("eee", 100);
Person p2 = new Person("eee", 100);
Person p3 = new Person("aaa", 200);
Person p4 = new Person("EEE", 100);
// 新建HashSet对象
HashSet set = new HashSet();
set.add(p1);
set.add(p2);
set.add(p3);
// 比较p1 和 p2, 并打印它们的hashCode()
System.out.printf("p1.equals(p2) : %s; p1(%d) p2(%d)\n", p1.equals(p2), p1.hashCode(), p2.hashCode());
// 比较p1 和 p4, 并打印它们的hashCode()
System.out.printf("p1.equals(p4) : %s; p1(%d) p4(%d)\n", p1.equals(p4), p1.hashCode(), p4.hashCode());
// 打印set
System.out.printf("set:%s\n", set);
}
/**
* @desc Person类。
*/
private static class Person {
int age;
String name;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return name + " - " +age;
}
/**
* @desc重写hashCode
*/
@Override
public int hashCode(){
int nameHash = name.toUpperCase().hashCode();
return nameHash ^ age;
}
/**
* @desc 覆盖equals方法
*/
@Override
public boolean equals(Object obj){
if(obj == null){
return false;
}
//如果是同一个对象返回true,反之返回false
if(this == obj){
return true;
}
//判断是否类型相同
if(this.getClass() != obj.getClass()){
return false;
}
Person person = (Person)obj;
return name.equals(person.name) && age==person.age;
}
}
}
```
**运行结果**:
```
p1.equals(p2) : true; p1(68545) p2(68545)
p1.equals(p4) : false; p1(68545) p4(68545)
set:[aaa - 200, eee - 100]
```
## 3、String
[#](#string、stringbuffer、stringbuilder-的区别) String、StringBuffer、StringBuilder 的区别?
**可变性**
`String` 是不可变的(后面会详细分析原因)。
`StringBuilder` 与 `StringBuffer` 都继承自 `AbstractStringBuilder` 类,在 `AbstractStringBuilder` 中也是使用字符数组保存字符串,不过没有使用 `final` 和 `private` 关键字修饰,最关键的是这个 `AbstractStringBuilder` 类还提供了很多修改字符串的方法比如 `append` 方法。
```java
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
//...
}
```
**线程安全性**
`String` 中的对象是不可变的,也就可以理解为常量,线程安全。`AbstractStringBuilder` 是 `StringBuilder` 与 `StringBuffer` 的公共父类,定义了一些字符串的基本操作,如 `expandCapacity`、`append`、`insert`、`indexOf` 等公共方法。`StringBuffer` 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。`StringBuilder` 并没有对方法进行加同步锁,所以是非线程安全的。
**性能**
每次对 `String` 类型进行改变的时候,都会生成一个新的 `String` 对象,然后将指针指向新的 `String` 对象。`StringBuffer` 每次都会对 `StringBuffer` 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 `StringBuilder` 相比使用 `StringBuffer` 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
**对于三者使用的总结:**
1. 操作少量的数据: 适用 `String`
2. 单线程操作字符串缓冲区下操作大量数据: 适用 `StringBuilder`
3. 多线程操作字符串缓冲区下操作大量数据: 适用 `StringBuffer`
## 4、int类型排序问题
1、使用Arrays的sort函数
```java
//正序排序
Arrays.sort(num);
//逆序排序
Arrays.sort(nums, new Comparator() {
@Override
public int compare(Integer o1, Integer o2) {
//return若为正数o1放前面,负数放后面
return o2-o1;
}
});
```
## 5、List自定义排序问题
总结:自己比传入的大,那么return小于0,自己排在前面,大于0排在后面

1:利用集合框架提供的Collections.sort实现排序,其中User需要实现比较器Comparable接口,并且实现其中compareTo接口,返回的时当前入参的学生和当前这个学生的年龄差,负数,0,正数表示当前入参比本身小,相等和大,调用Collections.sort(temp);返回的排序方式为自然排序,结果如下:
```java
@Data
@AllArgsConstructor
public class User implements Comparable{
private int age;
private String sex;
private int grade;
@Override
public int compareTo(User o) {
return o.getAge()-this.getAge();
}
}
```

2.Collections.sort还提供了两个参数的方法,第二个参数为为比价器,如下:
return 负数则将o1放在前面升序排序,正数则将o1放在后面,降序排序
```java
Collections.sort(temp, new Comparator() {
@Override
public int compare(User o1, User o2) {
return -o1.getAge()+o2.getAge();
}
});
```

3.如果jdk版本为Java8或者更高的版本,则可以利用java8的新特性的stream流实现排序,而且user对象无需实现compare接口,代码如下:
```java
//3.利用Java8的stream流和Comparator实现集合排序
temp = temp.stream().sorted(Comparator.comparing(User::getAge)).collect(Collectors.toList());
```

现在如果排序要求更复杂,排序要求:先按学生年龄降序排序,年龄相等的话,则按年级升级排序!则可以利用java8的stream流实现,如下:
```java
temp = temp.stream().sorted(Comparator.comparing(User::getAge)
.reversed()
.thenComparing(Comparator.comparing(User::getGrade))
).collect(Collectors.toList());
```

## 6、ArrayList转int[]
## 7、使用Stream流转换
```java
ArrayList arrList = new ArrayList<>();
arrList.add(7);
arrList.add(8);
arrList.add(9);
int[] ints = arrList.stream().mapToInt(i -> (int)i).toArray(); // 关键代码,使用到了Stream转换
//int[] ints = arrList.stream().mapToInt(i -> i.intValue()).toArray(); // 这种写法也可以
System.out.println("结果是" + ints); // 结果是[I@7cca494b, 打印的是int[]的地址
System.out.println("结果内容是" + Arrays.toString(ints)); // 结果内容是[7, 8, 9]
```
## 8、Queue使用方法
LinkedList类实现了Queue接口,因此我们可以把LinkedList当成Queue来用。
在Java的标准库中,队列接口Queue定义了以下几个方法:
int size():获取队列长度;
boolean add(E)/boolean offer(E):添加元素到队尾;
E remove()/E poll():获取队首元素并从队列中删除;
E element()/E peek():获取队首元素但并不从队列中删除。
| | throw Exception | 返回false或null |
| ------------------ | --------------- | ------------------ |
| 添加元素到队尾 | add(E e) | boolean offer(E e) |
| 取队首元素并删除 | E remove() | E poll() |
| 取队首元素但不删除 | E element() | E peek() |
根据是否需要抛出异常来确定使用的方法
## 9、Spring 中的事务隔离级别
Spring 中的事务隔离级别比 MySQL 中的事务隔离级别多了一种,它包含的 5 种隔离级别分别是
Isolation.DEFAULT:默认的事务隔离级别,以连接的数据库的事务隔离级别为准。
Isolation.READ_UNCOMMITTED:读未提交,可以读取到未提交的事务,存在脏读。
Isolation.READ_COMMITTED:读已提交,只能读取到已经提交的事务,解决了脏读,存在不可重复读。
Isolation.REPEATABLE_READ:可重复读,解决了不可重复读,但存在幻读(MySQL 数据库默认的事务隔离级别)。
Isolation.SERIALIZABLE:串行化,可以解决所有并发问题,但性能太低。
Spring 中的事务传播机制
1.事务传播机制
事务特点: 事务是恢复和并发控制的基本单位,事务具有4个属性:原子性,一致性,隔离性,持久性,这4个属性通常也叫做ACID特性.
原子性(Atomicity):事务是一个原子操作,由一系列动作组成。事务的原子性确保动作要么全部完成,要么完全不起作用。
一致性(Consistency):一旦事务完成(不管成功还是失败),系统必须确保它所建模的业务处于一致的状态,而不会是部分完成部分失败。在现实中的数据不应该被破坏。
隔离性(Isolation):可能有许多事务会同时处理相同的数据,因此每个事务都应该与其他事务隔离开来,防止数据损坏。
持久性(Durability):一旦事务完成,无论发生什么系统错误,它的结果都不应该受到影响,这样就能从任何系统崩溃中恢复过来。通常情况下,事务的结果被写到持久化存储器中。
2.事务的传播机制
事务的传播性一般用在事务嵌套的场景,比如一个事务方法里面调用了另外一个事务方法,那么两个方法是各自作为独立的方法提交还是内层的事务合并到外层的事务一起提交,这就是需要事务传播机制的配置来确定怎么样执行。
常用的事务传播机制如下:

3.数据库事务隔离级别

脏读(Dirty read)
脏读发生在一个事务读取了被另一个事务改写但尚未提交的数据时。如果这些改变在稍后被回滚了,那么第一个事务读取的数据就会是无效的。
不可重复读(Nonrepeatable read)
不可重复读发生在一个事务执行相同的查询两次或两次以上,但每次查询结果都不相同时。这通常是由于另一个并发事务在两次查询之间更新了数据。
不可重复读重点在修改。
幻读(Phantom reads)
幻读和不可重复读相似。当一个事务(T1)读取几行记录后,另一个并发事务(T2)插入了一些记录时,幻读就发生了。在后来的查询中,第一个事务(T1)就会发现一些原来没有的额外记录。
事务的隔离级别越高越能保证数据的完整性和一致性,mysql InnoDB事务默认隔离级别是Repeatabled-Read
## 10、乐观锁悲观锁(CAS)
一、基本概念
乐观锁和悲观锁是两种思想,用于解决并发场景下的数据竞争问题。
- 乐观锁:乐观锁在操作数据时非常乐观,认为别人不会同时修改数据。因此乐观锁不会上锁,只是在执行更新的时候判断一下在此期间别人是否修改了数据:如果别人修改了数据则放弃操作,否则执行操作。
- 悲观锁:悲观锁在操作数据时比较悲观,认为别人会同时修改数据。因此操作数据时直接把数据锁住,直到操作完成后才会释放锁;上锁期间其他人不能修改数据。
悲观锁的实现方式是加锁,加锁既可以是对代码块加锁(如Java的synchronized关键字),也可以是对数据加锁(如MySQL中的排它锁)。
乐观锁的实现方式主要有两种:CAS机制和版本号机制。
1、CAS(Compare And Swap)
CAS操作包括了3个操作数:
- 需要读写的内存位置(V)
- 进行比较的预期值(A)
- 拟写入的新值(B)
CAS操作逻辑如下:如果内存位置V的值等于预期的A值,则将该位置更新为新值B,否则不进行任何操作。许多CAS的操作是自旋的:如果操作不成功,会一直重试,直到操作成功为止。
下面以Java中的自增操作(i++)为例,看一下悲观锁和CAS分别是如何保证线程安全的。我们知道,在Java中自增操作不是原子操作,它实际上包含三个独立的操作:(1)读取i值;(2)加1;(3)将新值写回i
因此,如果并发执行自增操作,可能导致计算结果的不准确。在下面的代码示例中:value1没有进行任何线程安全方面的保护,value2使用了乐观锁(CAS),value3使用了悲观锁(synchronized)。运行程序,使用1000个线程同时对value1、value2和value3进行自增操作,可以发现:value2和value3的值总是等于1000,而value1的值常常小于1000。
AtomicInteger是java.util.concurrent.atomic包提供的原子类,利用CPU提供的CAS操作来保证原子性;除了AtomicInteger外,还有AtomicBoolean、AtomicLong、AtomicReference等众多原子类。
public class CAS {
//value1:线程不安全
private static int value1 = 0;
//value2:使用乐观锁
private static AtomicInteger value2 = new AtomicInteger(0);
//value3:使用悲观锁
private static int value3 = 0;
private static synchronized void increaseValue3(){
value3++;
}
public static void main(String[] args) throws InterruptedException {
//开启1000个线程,并执行自增操作
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
value1++;
value2.getAndIncrement();
increaseValue3();
}
}).start();
}
//打印结果
Thread.sleep(1000);
System.out.println("线程不安全:" + value1);
System.out.println("乐观锁(AtomicInteger):" + value2);
System.out.println("悲观锁(synchronized):" + value3);
}
}
**三、优缺点与适用场景**
1、功能限制
与悲观锁相比,乐观锁适用的场景受到了更多的限制,无论是CAS还是版本号机制。
例如,CAS只能保证单个变量操作的原子性,当涉及到多个变量时,CAS是无能为力的,而synchronized则可以通过对整个代码块加锁来处理。再比如版本号机制,如果query的时候是针对表1,而update的时候是针对表2,也很难通过简单的版本号来实现乐观锁。
2、竞争激烈程度
如果悲观锁和乐观锁都可以使用,那么选择就要考虑竞争的激烈程度:
==当竞争不激烈 (出现并发冲突的概率小)时,乐观锁更有优势,因为悲观锁会锁住代码块或数据,其他线程无法同时访问,影响并发,而且加锁和释放锁都需要消耗额外的资源。==
==当竞争激烈(出现并发冲突的概率大)时,悲观锁更有优势,因为乐观锁在执行更新时频繁失败,需要不断重试,浪费CPU资源。==
**四、面试官追问:乐观锁加锁吗?**
笔者在面试时,曾遇到面试官如此追问。下面是我对这个问题的理解:
(1)乐观锁本身是不加锁的,只是在更新时判断一下数据是否被其他线程更新了;AtomicInteger便是一个例子。
(2)有时乐观锁可能与加锁操作合作,例如,在前述updateCoins()的例子中,MySQL在执行update时会加排它锁。但这只是乐观锁与加锁操作合作的例子,不能改变“乐观锁本身不加锁”这一事实。
**五、CAS有哪些缺点?**
**1、ABA问题**
假设有两个线程——线程1和线程2,两个线程按照顺序进行以下操作:
(1)线程1读取内存中数据为A;
(2)线程2将该数据修改为B;
(3)线程2将该数据修改为A;
(4)线程1对数据进行CAS操作
在第(4)步中,由于内存中数据仍然为A,因此CAS操作成功,但实际上该数据已经被线程2修改过了。这就是ABA问题。
在AtomicInteger的例子中,ABA似乎没有什么危害。但是在某些场景下,ABA却会带来隐患,例如栈顶问题:一个栈的栈顶经过两次(或多次)变化又恢复了原值,但是栈可能已发生了变化。
对于ABA问题,比较有效的方案是引入版本号,内存中的值每发生一次变化,版本号都+1;在进行CAS操作时,不仅比较内存中的值,也会比较版本号,只有当二者都没有变化时,CAS才能执行成功。Java中的AtomicStampedReference类便是使用版本号来解决ABA问题的。
**2、高竞争下的开销问题**
在并发冲突概率大的高竞争环境下,如果CAS一直失败,会一直重试,CPU开销较大。针对这个问题的一个思路是引入退出机制,如重试次数超过一定阈值后失败退出。当然,更重要的是避免在高竞争环境下使用乐观锁。
**3、功能限制**
CAS的功能是比较受限的,例如CAS只能保证单个变量(或者说单个内存值)操作的原子性,这意味着:(1)原子性不一定能保证线程安全,例如在Java中需要与volatile配合来保证线程安全;(2)当涉及到多个变量(内存值)时,CAS也无能为力。
除此之外,CAS的实现需要硬件层面处理器的支持,在Java中普通用户无法直接使用,只能借助atomic包下的原子类使用,灵活性受到限制。
## 11、AOP
理解AOP
什么是AOP
AOP(Aspect Oriented Programming),面向切面思想,是Spring的三大核心思想之一(两外两个:IOC-控制反转、DI-依赖注入)。
那么AOP为何那么重要呢?在我们的程序中,经常存在一些系统性的需求,比如权限校验、日志记录、统计等,这些代码会散落穿插在各个业务逻辑中,非常冗余且不利于维护。例如下面这个示意图:

有多少业务操作,就要写多少重复的校验和日志记录代码,这显然是无法接受的。当然,用面向对象的思想,我们可以把这些重复的代码抽离出来,写成公共方法,就是下面这样:

这样,代码冗余和可维护性的问题得到了解决,但每个业务方法中依然要依次手动调用这些公共方法,也是略显繁琐。有没有更好的方式呢?有的,那就是AOP,AOP将权限校验、日志记录等非业务代码完全提取出来,与业务代码分离,并寻找节点切入业务代码中:

AOP体系与概念
> 简单地去理解,其实AOP要做三类事:
- 在哪里切入,也就是权限校验等非业务操作在哪些业务代码中执行。
- 在什么时候切入,是业务代码执行前还是执行后。
- 切入后做什么事,比如做权限校验、日志记录等。
**因此,AOP的体系可以梳理为下图**:


**具体实现:**
实践出真知,接下来我们就撸代码来实现一下AOP。使用 AOP,首先需要引入 AOP 的依赖。参数校验:这么写参数校验(validator)就不会被劝退了。
org.springframework.boot
spring-boot-starter-aop
接下来,我们先看一个极简的例子:所有的get请求被调用前在控制台输出一句"get请求的advice触发了"。
创建一个AOP切面类,只要在类上加个 @Aspect 注解即可。@Aspect 注解用来描述一个切面类,定义切面类的时候需要打上这个注解。@Component 注解将该类交给 Spring 来管理。在这个类里实现advice:
```java
package cn.wideth.aop;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.stereotype.Component;
@Aspect
@Component
public class LogAdvice {
// 定义一个切点:所有被GetMapping注解修饰的方法会织入advice
@Pointcut("@annotation(org.springframework.web.bind.annotation.GetMapping)")
private void logAdvicePointcut() {}
// Before表示logAdvice将在目标方法执行前执行
@Before("logAdvicePointcut()")
public void logAdvice(){
// 这里只是一个示例,你可以写任何处理逻辑
System.out.println("get请求的advice触发了");
}
}
```
### 11.1、Spring AOP 和 AspectJ AOP 有什么区别?
**Spring AOP 属于运行时增强,而 AspectJ 是编译时增强。** Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作(Bytecode Manipulation)
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择 AspectJ ,它比 Spring AOP 快很多。
### ==11.2 总结AOP静/动态代理==
AOP代理实现有两种方式
1、静态代理(AspectJ)
> AspectJ编译时(AOP框架会在编译阶段生成AOP代理类)增强,基于==字节码==,切面多时性能好,每个目标类都要创建一个代理类,AspectJ**相比于**SpringAOP更加强大允许更加高级的操作,可以允许在字段上使用切面
2、动态代理(SpringAOP)
> SpringAOP运行时增强,==内存中==生成一个对象去代理原对象,调用其方法。
>
> SpringAOP有两种实现方式:
>
> - ==JDK动态代理==:只能代理实现了接口的类,通过==反射方式==
> - ==CGLIB动态代理==:可以代理没有实现接口的类,通过==继承方式==,因此不能代理Final的类
**Spring AOP**
Spring AOP 属于`运行时增强`,主要具有如下特点:
1. 基于动态代理来实现,默认如果使用接口的,用 JDK 提供的动态代理实现,如果是方法则使用 CGLIB 实现
2. Spring AOP 需要依赖 IOC 容器来管理,并且只能作用于 Spring 容器,使用纯 Java 代码实现
3. 在性能上,由于 Spring AOP 是基于**动态代理**来实现的,在容器启动时需要生成代理实例,在方法调用上也会增加栈的深度,使得 Spring AOP 的性能不如 AspectJ 的那么好。
4. Spring AOP 致力于解决企业级开发中最普遍的 AOP(方法织入)。
**AspectJ**
AspectJ 是一个易用的功能强大的 AOP 框架,属于`编译时增强`, 可以单独使用,也可以整合到其它框架中,是 AOP 编程的完全解决方案。AspectJ 需要用到单独的编译器 ajc。
AspectJ 属于**静态织入**,通过修改代码来实现,在实际运行之前就完成了织入,所以说它生成的类是没有额外运行时开销的,一般有如下几个织入的时机:
1. 编译期织入(Compile-time weaving):如类 A 使用 AspectJ 添加了一个属性,类 B 引用了它,这个场景就需要编译期的时候就进行织入,否则没法编译类 B。
2. 编译后织入(Post-compile weaving):也就是已经生成了 .class 文件,或已经打成 jar 包了,这种情况我们需要增强处理的话,就要用到编译后织入。
3. 类加载后织入(Load-time weaving):指的是在加载类的时候进行织入,要实现这个时期的织入,有几种常见的方法

## 12、分布式dubbo
当系统不断的迭代,访问量逐渐增大单一应用无法满足需求,此时为了应对更高的并发和业务需求,我们根据业务功能对系统进行拆分:

优点:
- 系统拆分实现了流量分担,解决了并发问题
- 可以针对不同模块进行优化
- 方便水平扩展,负载均衡,容错率提高
缺点:
- 系统间相互独立,会有很多重复开发工作,影响开发效率
分布式项目的诞生
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的分布式调用是关键。

优点:
- 将基础服务进行了抽取,系统间相互调用,提高了代码复用和开发效率
缺点:
- 系统间调用关系错综复杂,难以维护
==服务治理(SOA)和微服务==
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)是关键。

以前出现了什么问题?
服务越来越多,需要管理每个服务的地址
调用关系错综复杂,难以理清依赖关系
服务过多,服务状态难以管理,无法根据服务情况动态管理
服务治理要做什么?
服务注册中心,实现服务自动注册和发现,无需人为记录服务地址
服务自动订阅,服务列表自动推送,服务调用透明化,无需关心依赖关系
动态监控服务状态监控报告,人为控制服务状态
缺点:
服务间会有依赖关系,一旦某个环节出错会影响较大
服务关系复杂,运维、测试部署困难,不符合DevOps思想
微服务:
在SOA思想的基础上,再把项目细分,将其‘微小独立化’就成了微服务项目。微服务(或微服务架构)是一种[云原生](https://baike.baidu.com/item/云原生/53770166?fromModule=lemma_inlink)架构方法,其中单个应用程序由许多松散耦合且可独立部署的较小组件或服务组成。
微服务的特点:
单一职责:微服务中每一个服务都对应唯一的业务能力,做到单一职责。
微:微服务的服务拆分粒度很小,例如一个用户管理就可以作为一个服务。每个服务虽小,但“五脏俱全”。
面向服务:面向服务是说每个服务都要对外暴露服务接口API。并不关心服务的技术实现,做到与平台和语言无关,也不限定用什么技术实现,只要提供Rest的接口即可。
自治:自治是说服务间互相独立,互不干扰。
团队独立:每个服务都是一个独立的开发团队,人数不能过多。
技术独立:因为是面向服务,提供Rest接口,使用什么技术没有别人干涉。
前后端分离:采用前后端分离开发,提供统一Rest接口,后端不用再为PC、移动端开发不同接口。
数据库分离:每个服务都使用自己的数据源部署独立,服务间虽然有调用,但要做到服务重启不影响其它服务。有利于持续集成和持续交付。每个服务都是独立的组件,可复用,可替换,降低耦合,易维护。
RPC架构

1、客户端(Client):服务调用方(服务消费者)
2、客户端存根(Client Stub):存放服务端地址信息,将客户端的请求参数数据信息打包成网络消息,再通过网络传输发送给服务端
3、服务端存根(Server Stub):接收客户端发送过来的请求消息并进行解包,然后再调用本地服务进行处理
4、服务端(Server):服务的真正提供者
RPC调用顺序
服务消费者(client客户端)通过调用本地服务的方式调用需要消费的服务;
客户端存根(client stub)接收到调用请求后负责将方法、入参等信息序列化(组装)成能够进行网络传输的消息体;
客户端存根(client stub)找到远程的服务地址,并且将消息通过网络发送给服务端;
服务端存根(server stub)收到消息后进行解码(反序列化操作);
服务端存根(server stub)根据解码结果调用本地的服务进行相关处理;
本地服务执行具体业务逻辑并将处理结果返回给服务端存根(server stub);
服务端存根(server stub)将返回结果重新打包成消息(序列化)并通过网络发送至消费方;
客户端存根(client stub)接收到消息,并进行解码(反序列化);
服务消费方得到最终结果;
而RPC框架的实现目标则是将上面的第2-10步完好地封装起来,也就是把调用、编码/解码的过程给封装起来,让用户感觉上像调用本地服务一样的调用远程服务。
RPC框架用到了哪些技术
1、动态代理
生成Client Stub(客户端存根)和Server Stub(服务端存根)的时候需要用到Java动态代理技术,可以使用JDK提供的原生的动态代理机制,也可以使用开源的:CGLib代理,Javassist字节码生成技术。
2、序列化和反序列化
在网络中,所有的数据都将会被转化为字节进行传送,所以为了能够使参数对象在网络中进行传输,需要对这些参数进行序列化和反序列化操作。
序列化:把对象转换为字节序列的过程称为对象的序列化,也就是编码的过程。
反序列化:把字节序列恢复为对象的过程称为对象的反序列化,也就是解码的过程。
目前比较高效的开源序列化框架:如Kryo、FastJson和Protobuf等。
3、NIO通信
出于并发性能的考虑,传统的阻塞式 IO 显然不太合适,因此我们需要异步的 IO,即 NIO。Java 提供了 NIO 的解决方案,Java 7 也提供了更优秀的 NIO.2 支持。可以选择Netty或者MINA来解决NIO数据传输的问题。
4、服务注册中心
可选:Redis、Zookeeper、Consul 、Etcd。一般使用ZooKeeper提供服务注册与发现功能,解决单点故障以及分布式部署的问题(注册中心)。
==Apache Dubbo 是一款易用、高性能的 WEB 和 RPC 框架,同时为构建企业级微服务提供服务发现、流量治理、可观测、认证鉴权等能力、工具与最佳实践。==
## 13、静态代理和动态代理
[#](#_4-静态代理和动态代理的对比) 4. 静态代理和动态代理的对比
1. **灵活性**:动态代理更加灵活,不需要必须实现接口,可以直接代理实现类,并且可以不需要针对每个目标类都创建一个代理类。另外,静态代理中,接口一旦新增加方法,目标对象和代理对象都要进行修改,这是非常麻烦的!
2. **JVM 层面**:静态代理在编译时就将接口、实现类、代理类这些都变成了一个个实际的 class 文件。而动态代理是在运行时动态生成类字节码,并加载到 JVM 中的。
3.3. JDK 动态代理和 CGLIB 动态代理对比
1. **JDK 动态代理只能代理实现了接口的类或者直接代理接口,而 CGLIB 可以代理未实现任何接口的类。** 另外, CGLIB 动态代理是通过生成一个被代理类的子类来拦截被代理类的方法调用,因此不能代理声明为 final 类型的类和方法。
2. 就二者的效率来说,大部分情况都是 JDK 动态代理更优秀,随着 JDK 版本的升级,这个优势更加明显
**JDK 动态代理有一个最致命的问题是其只能代理实现了接口的类。**
**为了解决这个问题,我们可以用 CGLIB 动态代理机制来避免。**
[CGLIBopen in new window](https://github.com/cglib/cglib)(*Code Generation Library*)是一个基于[ASMopen in new window](http://www.baeldung.com/java-asm)的字节码生成库,它允许我们在运行时对字节码进行修改和动态生成。CGLIB 通过继承方式实现代理。很多知名的开源框架都使用到了[CGLIBopen in new window](https://github.com/cglib/cglib), 例如 Spring 中的 AOP 模块中:如果目标对象实现了接口,则默认采用 JDK 动态代理,否则采用 CGLIB 动态代理。
**在 CGLIB 动态代理机制中 `MethodInterceptor` 接口和 `Enhancer` 类是核心。**
你需要自定义 `MethodInterceptor` 并重写 `intercept` 方法,`intercept` 用于拦截增强被代理类的方法。
```java
public interface MethodInterceptor
extends Callback{
// 拦截被代理类中的方法
public Object intercept(Object obj, java.lang.reflect.Method method, Object[] args,MethodProxy proxy) throws Throwable;
}
```
## 14、HashMap
### 14.1、HashMap 的长度为什么是 2 的幂次方
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ `(n - 1) & hash`”。(n 代表数组长度)。这也就解释了 HashMap 的长度为什么是 2 的幂次方。
**这个算法应该如何设计呢?**
我们首先可能会想到采用%取余的操作来实现。但是,重点来了:**“取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;)。”** 并且 **采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方**
### 14.2 ConcurrentHashMap
线程安全,在HashMap的基础上对各个segment进行加锁,保证了线程安全,但避免不了影响性能
ConcurrentHashMap比HashTable效率高
要点:
- 扩容时会使用多线程并发扩容,对原结构分片后每个线程负责各自分片的数据迁移工作。
- 当调用完`put`方法后,ConcurrentHashMap必须会增加当前元素的个数,方便在`size()`方法中获得存储的数据大小。代码的实现如下。元素个数累加时,使用了多线程并发来优化,当前程并发不激烈时,直接使用CAS来实现元素累加,当竞争激烈时,通过构建一个`CounterCell`数组,默认长度是2,当需要增加时随机从数组中选取一个使用CAS进行增加,实现了负载均衡,降低了锁的竞争。

Java7 中 `ConcurrentHashMap` 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 `Segment` 都是一个类似 `HashMap` 数组的结构,它可以扩容,它的冲突会转化为链表。但是 `Segment` 的个数一但初始化就不能改变。
Java8 中的 `ConcurrentHashMap` 使用的 `Synchronized` 锁加 CAS 的机制。结构也由 Java7 中的 **`Segment` 数组 + `HashEntry` 数组 + 链表** 进化成了 **Node 数组 + 链表 / 红黑树**,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
### 14.3、HashMap链表成环问题


```java
// java 7 是在 while 循环里面,单个计算好数组索引位置后,单个的插入数组中,在多线程情况下,会有成环问题
// java 8 是等链表整个 while 循环结束后,才给数组赋值,所以多线程情况下,也不会成环
JDK8 是等链表整个 while 循环结束后,才给数组赋值,此时使用局部变量 loHead 和 hiHead 来保存链表的值,因为是局部变量,所以多线程的情况下,肯定是没有问题的。
```
==JAVA8中其实也没有真正解决链表成环的问题==

```java
//死循环复现代码
public void testHashMap() {
List storeInfos = TestObjectUtil.createStoreInfoList(500000);
Map testMap = Maps.newHashMap();
storeInfos.parallelStream().forEach(storeInfo -> {
testMap.put(storeInfo.getId(), storeInfo.getName()); //并发往map中添加50万store信息
});
}
```
假如此时有两个线程,线程1刚好构建好了树,树的左(或右)子节点为当前节点x,那么刚好线程2又刚好走到当前节点并进行判断,那么p = p.left or right = x != null, 则线程2进入下次循环后,x.parent = xp = p = x,出现自我引用,则继续执行balanceInsertion,必将进入如图9所示死循环。至此可以得出结论:jdk1.8的HashMap虽然在扩容、数据结构等多方面进行了优化,但仍旧会出现死循环的问题
另外除了balanceInsertion代码会出现问题,下面代码也可能存在相互引用导致的死循环风险,线上代码排查过程中也已经发现该问题方法,但最终并未复现,因此先放在这里提醒自己:
```java
final TreeNode root() {
for (TreeNode r = this, p;;) {
if ((p = r.parent) == null) //相互引用不为null
return r;
r = p;
}
}
```
## 15、分布式和微服务
微服务架构
1、面向服务架构。以业务服务的角度和服务总线的方式,一般是webservice与ESB,考虑系统架构和企业IT治理;
2、分布式服务架构。基于去中心化的分布式服务框架与技术,考虑系统架构和服务治理;
3、微服务架构。微服务架构可以看作是面向服务架构和分布式服务架构的拓展,使用更细粒度的服务和一组设计准则来考虑大规模的复杂系统架构设计。
==分布式:分散的是压力。==
不同模块部署在不同的服务器上,解决网站高并发带来的问题
==微服务:分散的是能力。==
从概念理解,分布式服务架构强调的是服务化以及服务的分散化,微服务则更强调服务的专业化和精细分工;
从实践的角度来看,微服务架构通常是分布式服务架构,反之则未必成立。所以,选择微服务通常意味着需要解决分布式架构的各种难题。
==微服务重在解耦合,使每个模块都独立。分布式重在资源共享与加快计算机计算速度。==
微服务的设计是为了不因为某个模块的升级和BUG影响现有的系统业务。
微服务与分布式的细微差别是,微服务的应用不一定是分散在多个服务器上,他也可以是同一个服务器。
## 16、RabbitMQ和Kafka比较选择
RabbitMQ架构
RabbitMQ是一个[分布式系统](https://so.csdn.net/so/search?q=分布式系统&spm=1001.2101.3001.7020),这里面有几个抽象概念。
- broker:每个节点运行的服务程序,功能为维护该节点的队列的增删以及转发队列操作请求。
- master queue:每个队列都分为一个主队列和若干个镜像队列。
- mirror queue:镜像队列,作为master queue的备份。在master queue所在节点挂掉之后,系统把mirror queue提升为master queue,负责处理客户端队列操作请求。注意,mirror queue只做镜像,设计目的不是为了承担客户端读写压力。

[Kafka](https://so.csdn.net/so/search?q=Kafka&spm=1001.2101.3001.7020)
Kafka我觉得就是看到了RabbitMQ这个缺陷才设计出的一个改进版,改进的点就是:把一个队列的单一master变成多个master,即一台机器扛不住qps,那么我就用多台机器扛qps,把一个队列的流量均匀分散在多台机器上不就可以了么?注意,多个master之间的数据没有交集,即一条消息要么发送到这个master queue,要么发送到另外一个master queue。
这里面的每个master queue 在Kafka中叫做Partition,即一个分片。一个队列有多个主分片,每个主分片又有若干副分片做备份,同步机制类似于RabbitMQ。


队列读取的时候虚拟出一个Group的概念,一个Topic内部的消息,只会路由到同Group内的一个consumer上,同一个Group中的consumer消费的消息是不一样的;Group之间共享一个Topic,看起来就是一个队列的多个拷贝。所以,为了达到多个Group共享一个Topic数据,Kafka并不会像RabbitMQ那样消息消费完毕立马删除,而是必须在后台配置保存日期,即只保存最近一段时间的消息,超过这个时间的消息就会从磁盘删除,这样就保证了在一个时间段内,Topic数据对所有Group可见(这个特性使得Kafka非常适合做一个公司的数据总线)。队列读同样是读主分片,并且为了优化性能,消费者与主分片有一一的对应关系,如果消费者数目大于分片数,则存在某些消费者得不到消息。
由此可见,Kafka绝对是为了高吞吐量设计的,比如设置分片数为100,那么就有100台机器去扛一个Topic的流量,当然比RabbitMQ的单机性能好。
## 17、线程池
线程池参数
/**
* 用给定的初始参数创建一个新的ThreadPoolExecutor。
*/
public ThreadPoolExecutor(int corePoolSize,//线程池的核心线程数量
int maximumPoolSize,//线程池的最大线程数
long keepAliveTime,//当线程数大于核心线程数时,多余的空闲线程存活的最长时间
TimeUnit unit,//时间单位
BlockingQueue workQueue,//任务队列,用来储存等待执行任务的队列
ThreadFactory threadFactory,//线程工厂,用来创建线程,一般默认即可
RejectedExecutionHandler handler//拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
**`ThreadPoolExecutor` 3 个最重要的参数:**
- **`corePoolSize` :** 任务队列未达到队列容量时,最大可以同时运行的线程数量。
- **`maximumPoolSize` :** 任务队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
- **`workQueue`:** 新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
`ThreadPoolExecutor`其他常见参数 :
- **`keepAliveTime`**:线程池中的线程数量大于 `corePoolSize` 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 `keepAliveTime`才会被回收销毁。
- **`unit`** : `keepAliveTime` 参数的时间单位。
- **`threadFactory`** :executor 创建新线程的时候会用到。
- **`handler`** :拒绝策略,当核心线程数。等于最大线程数并且阻塞队列已满的时候使用。
**拒绝策略:**
> 1、AbortPolicy:这种拒绝战略在拒绝任务时,直接提出RejectedExecutionexception类型的Runtimeeexception,觉任务被拒绝,可以根据业务逻辑重试或放弃提交
>
> 2、DiscardPolicy:新任务提交后被直接丢弃,没有任何通知,有一定的风险,有可能丢失数据。
>
> 3、DiscardOldestPolicy:新任务提交后,将丢弃生存时间最长的任务,同样也有丢失数据的风险。
>
> 4、CallerRunsPolicy:新任务提交后,该任务提交给提交任务的线程,即谁提交任务,谁负责任务。这样做主要有两点好处。
>
> 第一,新提交的任务不会被抛弃,不会造成业务损失。
>
> 第二,由于谁提交任务谁负责任务,提交任务的路线必须负责任务,执行任务需要时间,在此期间,提交任务的路线被占有,不提交新任务,任务提交速度变慢,相当于负面反馈。在此期间,线程池的线程也可以充分利用这个时间执行一部分任务,腾出一定的空间,相当于给线程池一定的缓冲期。
>
> 当线程池无法接受新任务时,任务会被退回给调用execute方法的线程运行。这样可以确保任务总是能够被执行,避免任务被丢弃。
>
> ==缺点:使用CallerRunsPolicy拒绝策略可能会导致任务运行时间较长,且有可能会影响整体性能。若任务提交速度远大于任务执行速度,可能会使调用execute方法的线程滞留在任务执行中,影响其他任务的提交和执行。因此,在选择拒绝策略时,需要根据具体业务场景和需求进行合理选择。==

线程池创建以及各参数设置
```java
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolExecutorDemo {
private static final int CORE_POOL_SIZE = 5;
private static final int MAX_POOL_SIZE = 10;
private static final int QUEUE_CAPACITY = 100;
private static final Long KEEP_ALIVE_TIME = 1L;
public static void main(String[] args) {
//使用阿里巴巴推荐的创建线程池的方式
//通过ThreadPoolExecutor构造函数自定义参数创建
ThreadPoolExecutor executor = new ThreadPoolExecutor(
CORE_POOL_SIZE,
MAX_POOL_SIZE,
KEEP_ALIVE_TIME,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(QUEUE_CAPACITY),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < 10; i++) {
//创建WorkerThread对象(WorkerThread类实现了Runnable 接口)
Runnable worker = new MyRunnable("" + i);
//执行Runnable
executor.execute(worker);
}
//终止线程池
executor.shutdown();
while (!executor.isTerminated()) {
}
System.out.println("Finished all threads");
}
}
```
线程池线程进入以及运行过程

FixedThreadPool(固定线程数量)
```java
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
```
### 17.1 为什么需要二次检查线程池的运行状态,当前工作线程数量为0,尝试创建一个非核心线程并且传入的任务对象为null?
线程池源码解析:https://www.throwx.cn/2020/08/23/java-concurrency-thread-pool-executor/
先看源码:
```java
// 执行命令,其中命令(下面称任务)对象是Runnable的实例
public void execute(Runnable command) {
// 判断命令(任务)对象非空
if (command == null)
throw new NullPointerException();
// 获取ctl的值
int c = ctl.get();
// 判断如果当前工作线程数小于核心线程数,则创建新的核心线程并且执行传入的任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
// 如果创建新的核心线程成功则直接返回
return;
// 这里说明创建核心线程失败,需要更新ctl的临时变量c
c = ctl.get();
}
// 走到这里说明创建新的核心线程失败,也就是当前工作线程数大于等于corePoolSize
// 判断线程池是否处于运行中状态,同时尝试用非阻塞方法向任务队列放入任务(放入任务失败返回false)
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 这里是向任务队列投放任务成功,对线程池的运行中状态做二次检查
// 如果线程池二次检查状态是非运行中状态,则从任务队列移除当前的任务调用拒绝策略处理之(也就是移除前面成功入队的任务实例)
if (! isRunning(recheck) && remove(command))
// 调用拒绝策略处理任务 - 返回
reject(command);
// 走到下面的else if分支,说明有以下的前提:
// 0、待执行的任务已经成功加入任务队列
// 1、线程池可能是RUNNING状态
// 2、传入的任务可能从任务队列中移除失败(移除失败的唯一可能就是任务已经被执行了)
// 如果当前工作线程数量为0,则创建一个非核心线程并且传入的任务对象为null - 返回
// 也就是创建的非核心线程不会马上运行,而是等待获取任务队列的任务去执行
// 如果前工作线程数量不为0,原来应该是最后的else分支,但是可以什么也不做,因为任务已经成功入队列,总会有合适的时机分配其他空闲线程去执行它
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 走到这里说明有以下的前提:
// 0、线程池中的工作线程总数已经大于等于corePoolSize(简单来说就是核心线程已经全部懒创建完毕)
// 1、线程池可能不是RUNNING状态
// 2、线程池可能是RUNNING状态同时任务队列已经满了
// 如果向任务队列投放任务失败,则会尝试创建非核心线程传入任务执行
// 创建非核心线程失败,此时需要拒绝执行任务
else if (!addWorker(command, false))
// 调用拒绝策略处理任务 - 返回
reject(command);
}
```
这里是一个疑惑点:为什么需要二次检查线程池的运行状态,当前工作线程数量为0,尝试创建一个非核心线程并且传入的任务对象为null?这个可以看API注释:
如果一个任务成功加入任务队列,我们依然需要二次检查是否需要添加一个工作线程(因为所有存活的工作线程有可能在最后一次检查之后已经终结)或者执行当前方法的时候线程池是否已经shutdown了。所以我们需要二次检查线程池的状态,必须时把任务从任务队列中移除或者在没有可用的工作线程的前提下新建一个工作线程。
总结:
1、==为什么需要二次检查线程池的运行状态==:可能在执行道加入阻塞队列(步骤耗时)后核心线程有空闲,导致其已经被执行,或者是在加入到阻塞队列后线程池被关闭了,导致需要执行拒绝策略。
2、==当前工作线程数量为0,尝试创建一个非核心线程并且传入的任务对象为null:==因为如果二次检查后没有问题,这说明其被放入到了阻塞队列中,而若是线程池中一个工作线程也没有`核心线程数=0的特殊情况下,新增一个任务会被放到阻塞队列中,导致没有开辟线程,没有线程工作,只有等阻塞队列满了才会开一个线程,造成资源浪费,因此为了避免这种情况`,则需要判断当工作线程为0的时候为其开一个null(从阻塞队列中拿,不主动放)线程。
## **18、双重校验锁实现对象单例(线程安全)**:
```java
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
//先判断对象是否已经实例过,没有实例化过才进入加锁代码
if (uniqueInstance == null) {
//类对象加锁
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
```
`uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要的, `uniqueInstance = new Singleton();` 这段代码其实是分为三步执行:
1. 为 `uniqueInstance` 分配内存空间
2. 初始化 `uniqueInstance`
3. 将 `uniqueInstance` 指向分配的内存地址
但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 `getUniqueInstance`() 后发现 `uniqueInstance` 不为空,因此返回 `uniqueInstance`,但此时 `uniqueInstance` 还未被初始化。
## 19、JVM
### 19.1 JVM内存模型
JVM内存模型可以分为两个部分,如下图所示,堆和方法区是所有线程共有的,而虚拟机栈,本地方法栈和程序计数器则是线程私有的。

堆(Heap)
在 Java 中,堆被划分成两个不同的区域:新生代 ( Young )、老年代 ( Old ),新生代 ( Young ) 又被划分为三个区域:Eden、From Survivor、To Survivor。
下图中的Perm代表的是永久代,但是注意永久代并不属于堆内存中的一部分,同时jdk1.8之后永久代也将被移除。

堆是java虚拟机所管理的内存中最大的一块内存区域,也是被各个线程共享的内存区域,该内存区域存放了对象实例及数组(但不是所有的对象实例都在堆中)。
其大小通过-Xms(最小值)和-Xmx(最大值)参数设置(最大最小值都要小于1G),前者为启动时申请的最小内存,默认为操作系统物理内存的1/64,后者为JVM可申请的最大内存,默认为物理内存的1/4,默认当空余堆内存小于40%时,JVM会增大堆内存到-Xmx指定的大小,可通过-XX:MinHeapFreeRation=来指定这个比列。
当空余堆内存大于70%时,JVM会减小堆内存的大小到-Xms指定的大小,可通过XX:MaxHeapFreeRation=来指定这个比列,当然为了避免在运行时频繁调整Heap的大小,通常-Xms与-Xmx的值设成一样。堆内存 = 新生代+老生代+持久代。
在我们垃圾回收的时候,我们往往将堆内存分成新生代和老生代(大小比例1:2),新生代中由Eden和Survivor0,Survivor1组成,三者的比例是8:1:1,新生代的回收机制采用复制算法,在Minor GC的时候,我们都留一个存活区用来存放存活的对象,真正进行的区域是Eden+其中一个存活区,当我们的对象时长超过一定年龄时(默认15,可以通过参数设置),将会把对象放入老生代,当然大的对象会直接进入老生代,老生代采用的回收算法是标记整理算法。
GC原理及调优(9张图)









面试如何回答:
1、先表态,回答在合理的JVM参数下不需要进行调优。
2、说明部分场景需要调优,对JVM的部分核心指标配置告警,通过分析告警日志判断是否需要调优以及调优的方向。
3、举一个实际的例子
==启动java应用时,可以加以下参数来开启jvm垃圾回收日志。==
-XX:+PrintGC:打印最基本的回收信息
-XX:+PrintGCDetails:可以打印详细GC信息至控制台
-XX:+PrintGCDateStamps 可以记录GC发生的详细时间
JVM调优例子
1、metaspace导致频繁FGC,反射调用创建了大量的类加载器,占用了较大的内存,而内存是以整块进行分配的,每一块都只存放一个类加载器,导致内存碎片化严重。出现FGC。
通过mat分析heapdump,发现`DelegatingClassLoader`(类加载器)有几千个,查看源码后发现是类加载器,继续跟踪发现是mybatis的Reflector应用了这些对象。最终发现Method在调用过程会创建一个MethodAccessor并将MehtodAccessor作为存在一个叫做methodAccessor的field中,java为了提高反射调用的性能,用了一种膨胀(inflation)的方式(从jni调用转换成classbytes调用),通过参数-Dsun.reflect.inflationThreshold进行控制默认15,在小于这个次数时会使用native的方式对方法进行调用,如果method的调用次数超过指定次数就会使用字节码的方式生成方法调用,如果使用字节码的方式最终会为每一个方法都生成类DelegatingClassLoader加载器
使用BeanUtils.copyProperties模拟origin和Aim均为700成员变量且均可以getset,BeanUtils.copyProperties使用了反射机制get属性,大量调用会导致频繁FGC,频繁FGC导致CPU占用率高,卡顿。超过15次调用相同的类,会使用膨胀机制使用字节码为每一个get set方法创建一个类加载器,而模拟中类的get set方法有700个
```
import java.lang.reflect.Method;
import java.util.ArrayList;
import java.util.List;
public class ReflectionTest {
public static void main(String[] args) {
try {
List origins = new ArrayList<>();
List aims = new ArrayList<>();
// Create a large number of objects
for (int i = 0; i < 1e5; i++) {
Origin origin = new Origin();
origin.setTest1("111");
origins.add(origin);
Aim aim = new Aim();
aims.add(aim);
}
// Let's perform copying in a loop to generate garbage
for (int i = 0; i < 1000; i++) {
BeanUtils.copyProperties(origins.get(i), aims.get(i));
}
// Now, set the lists to null to release references and trigger garbage collection
origins = null;
aims = null;
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
### 19.2 GC相关
#### 如何判断一个类是无用的类?
方法区主要回收的是无用的类,那么如何判断一个类是无用的类的呢?
判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面 3 个条件才能算是 **“无用的类”**:
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的 `ClassLoader` 已经被回收。
- 该类对应的 `java.lang.Class` 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述 3 个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收
#### 如何判断一个常量是废弃常量?
运行时常量池主要回收的是废弃的常量。那么,我们如何判断一个常量是废弃常量呢?
**JDK1.7 及之后版本的 JVM 已经将运行时常量池从方法区中移了出来,在 Java 堆(Heap)中开辟了一块区域存放运行时常量池。**
> **🐛 修正(参见:[issue747open in new window](https://github.com/Snailclimb/JavaGuide/issues/747),[referenceopen in new window](https://blog.csdn.net/q5706503/article/details/84640762))**:
>
> 1. **JDK1.7 之前运行时常量池逻辑包含字符串常量池存放在方法区, 此时 hotspot 虚拟机对方法区的实现为永久代**
> 2. **JDK1.7 字符串常量池被从方法区拿到了堆中, 这里没有提到运行时常量池,也就是说字符串常量池被单独拿到堆,运行时常量池剩下的东西还在方法区, 也就是 hotspot 中的永久代** 。
> 3. **JDK1.8 hotspot 移除了永久代用元空间(Metaspace)取而代之, 这时候字符串常量池还在堆, 运行时常量池还在方法区, 只不过方法区的实现从永久代变成了元空间(Metaspace)**
假如在字符串常量池中存在字符串 "abc",如果当前没有任何 String 对象引用该字符串常量的话,就说明常量 "abc" 就是废弃常量,如果这时发生内存回收的话而且有必要的话,"abc" 就会被系统清理出常量池了。
## 20、字符串常量池
字符串常量池位置
Jdk1.6及之前: 有永久代, 运行时常量池在永久代,运行时常量池包含字符串常量池
Jdk1.7:有永久代,但已经逐步“去永久代”,字符串常量池从永久代里的运行时常量池分离到堆里
Jdk1.8及之后: 无永久代,运行时常量池在元空间,字符串常量池里依然在堆里
举例1
```java
public class StringDemo03 {
public static void main(String[] args) {
String s0="abc";
String s1="abc";
String s2="ab" + "c"; //编译期会进行优化 ,
//放入常量池 “abc”是一个字面量(静态链接,编译的时候吧符号引用转换成直接引用---静态链接)
System.out.println( s0==s1 ); //true
System.out.println( s0==s2 ); //true
}
}
```
举例2
```java
public class StringDemo04 {
public static void main(String[] args) {
String s0 = "abcd";
String s1 = new String("ab"); //运行时创建的新对象”abcd”的引用
//new String 会在堆中创建对象,并且把引用进行返回,不会把创建的字符串放入常量池
String s2 = "ab" + new String("cd");
System.out.println(s0 == s1);// false
System.out.println(s0 == s2);// false
System.out.println(s1 == s2);// false
}
}
```
分析:用new String()创建的字符串不是常量,不能在编译期就确定,所以new String() 创建的字符串不放入常量池中,它们有自己的地址空间。s0还是常量池 中"abcd”的引用,s1因为无法在编译期确定,所以是运行时创建的新对象”abcd”的引用,s2因为有后半部分 new String(”cd”)所以也无法在编译期确定,所以也是一个新创建对象”abcd”的引用.
S1S2运行时确定,存放在元空间metaspace中
## 21、阻塞队列
Java 中常用的阻塞队列实现类有以下几种:
1. `ArrayBlockingQueue`:使用数组实现的有界阻塞队列。在创建时需要指定容量大小,并支持公平和非公平两种方式的锁访问机制。
2. `LinkedBlockingQueue`:使用单向链表实现的可选有界阻塞队列。在创建时可以指定容量大小,如果不指定则默认为`Integer.MAX_VALUE`。和`ArrayBlockingQueue`类似, 它也支持公平和非公平的锁访问机制。
3. `PriorityBlockingQueue`:支持优先级排序的无界阻塞队列。元素必须实现`Comparable`接口或者在构造函数中传入`Comparator`对象,并且不能插入 null 元素。
4. `SynchronousQueue`:同步队列,是一种不存储元素的阻塞队列。每个插入操作都必须等待对应的删除操作,反之删除操作也必须等待插入操作。因此,`SynchronousQueue`通常用于线程之间的直接传递数据。
5. `DelayQueue`:延迟队列,其中的元素只有到了其指定的延迟时间,才能够从队列中出队。
具体实现


首先检查是否为空,从这个方法中我们可以看到,首先检查队列是否为空,然后获取锁,判断当前元素个数是否等于数组的长度,如果相等,则调用notFull.await()进行等待,如果捕获到中断异常,则唤醒线程并抛出异常。当被其他线程唤醒时,通过enqueue(e)方法插入元素,最后解锁。
我们按照这个源码来看,真正实现插入操作的是enqueue,我们跟进去看看:

就几行代码,就是一个正常的移动数组插入的过程,不过最后还要再通知一下队列,插入了元素,此时的队列就不为空了。
## 22、工厂模式、单例模式等
### 22.1、==工厂模式==
工厂模式(Factory Pattern)是 Java 中最常用的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
工厂模式提供了一种将对象的实例化过程封装在工厂类中的方式。通过使用工厂模式,可以将对象的创建与使用代码分离,提供一种统一的接口来创建不同类型的对象。
在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。
介绍
**意图:**定义一个创建对象的接口,让其子类自己决定实例化哪一个工厂类,工厂模式使其创建过程延迟到子类进行。
**主要解决:**主要解决接口选择的问题。
**何时使用:**我们明确地计划不同条件下创建不同实例时。
**如何解决:**让其子类实现工厂接口,返回的也是一个抽象的产品。
**关键代码:**创建过程在其子类执行。
**应用实例:** 1、您需要一辆汽车,可以直接从工厂里面提货,而不用去管这辆汽车是怎么做出来的,以及这个汽车里面的具体实现。 2、Hibernate 换数据库只需换方言和驱动就可以。
**优点:** 1、一个调用者想创建一个对象,只要知道其名称就可以了。 2、扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。 3、屏蔽产品的具体实现,调用者只关心产品的接口。
**缺点:**每次增加一个产品时,都需要增加一个具体类和对象实现工厂,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,同时也增加了系统具体类的依赖。这并不是什么好事。
**使用场景:** 1、日志记录器:记录可能记录到本地硬盘、系统事件、远程服务器等,用户可以选择记录日志到什么地方。 2、数据库访问,当用户不知道最后系统采用哪一类数据库,以及数据库可能有变化时。 3、设计一个连接服务器的框架,需要三个协议,"POP3"、"IMAP"、"HTTP",可以把这三个作为产品类,共同实现一个接口。
**注意事项:**作为一种创建类模式,在任何需要生成复杂对象的地方,都可以使用工厂方法模式。有一点需要注意的地方就是复杂对象适合使用工厂模式,而简单对象,特别是只需要通过 new 就可以完成创建的对象,无需使用工厂模式。如果使用工厂模式,就需要引入一个工厂类,会增加系统的复杂度。
**工厂模式包含以下几个核心角色:**
- 抽象产品(Abstract Product):定义了产品的共同接口或抽象类。它可以是具体产品类的父类或接口,规定了产品对象的共同方法。
- 具体产品(Concrete Product):实现了抽象产品接口,定义了具体产品的特定行为和属性。
- 抽象工厂(Abstract Factory):声明了创建产品的抽象方法,可以是接口或抽象类。它可以有多个方法用于创建不同类型的产品。
- 具体工厂(Concrete Factory):实现了抽象工厂接口,负责实际创建具体产品的对象。
### 22.2、==单例模式==
单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
单例模式是一种创建型设计模式,它确保一个类只有一个实例,并提供了一个全局访问点来访问该实例。
**注意:**
- 1、单例类只能有一个实例。
- 2、单例类必须自己创建自己的唯一实例。
- 3、单例类必须给所有其他对象提供这一实例。
介绍
**意图:**保证一个类仅有一个实例,并提供一个访问它的全局访问点。
**主要解决:**一个全局使用的类频繁地创建与销毁。
**何时使用:**当您想控制实例数目,节省系统资源的时候。
**如何解决:**判断系统是否已经有这个单例,如果有则返回,如果没有则创建。
**关键代码:**构造函数是私有的。
**应用实例:**
- 1、一个班级只有一个班主任。
- 2、Windows 是多进程多线程的,在操作一个文件的时候,就不可避免地出现多个进程或线程同时操作一个文件的现象,所以所有文件的处理必须通过唯一的实例来进行。
- 3、一些设备管理器常常设计为单例模式,比如一个电脑有两台打印机,在输出的时候就要处理不能两台打印机打印同一个文件。
**优点:**
- 1、在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。
- 2、避免对资源的多重占用(比如写文件操作)。
**缺点:**没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
==**Spring 中 bean 的默认作用域就是 singleton(单例)的。** 除了 singleton 作用域,Spring 中 bean 还有下面几种作用域:==
- **prototype** : 每次获取都会创建一个新的 bean 实例。也就是说,连续 `getBean()` 两次,得到的是不同的 Bean 实例。
- **request** (仅 Web 应用可用): 每一次 HTTP 请求都会产生一个新的 bean(请求 bean),该 bean 仅在当前 HTTP request 内有效。
- **session** (仅 Web 应用可用) : 每一次来自新 session 的 HTTP 请求都会产生一个新的 bean(会话 bean),该 bean 仅在当前 HTTP session 内有效。
- **application/global-session** (仅 Web 应用可用):每个 Web 应用在启动时创建一个 Bean(应用 Bean),,该 bean 仅在当前应用启动时间内有效。
- **websocket** (仅 Web 应用可用):每一次 WebSocket 会话产生一个新的 bean.
**使用场景:**
- 1、要求生产唯一序列号。
- 2、WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。
- 3、创建的一个对象需要消耗的资源过多,比如 I/O 与数据库的连接等。
**单例 Bean 存在线程安全问题吗?**
大部分时候我们并没有在项目中使用多线程,所以很少有人会关注这个问题。单例 Bean 存在线程问题,主要是因为当多个线程操作同一个对象的时候是存在资源竞争的。
常见的有两种解决办法:
1. 在 Bean 中尽量避免定义可变的成员变量。
2. 在类中定义一个 `ThreadLocal` 成员变量,将需要的可变成员变量保存在 `ThreadLocal` 中(推荐的一种方式)。
不过,大部分 Bean 实际都是无状态(没有实例变量)的(比如 Dao、Service),这种情况下, Bean 是线程安全的。
### 22.3、==代理模式==
在代理模式(Proxy Pattern)中,一个类代表另一个类的功能。这种类型的设计模式属于结构型模式。
在代理模式中,我们创建具有现有对象的对象,以便向外界提供功能接口。
介绍
**意图:**为其他对象提供一种代理以控制对这个对象的访问。
**主要解决:**在直接访问对象时带来的问题,比如说:要访问的对象在远程的机器上。在面向对象系统中,有些对象由于某些原因(比如对象创建开销很大,或者某些操作需要安全控制,或者需要进程外的访问),直接访问会给使用者或者系统结构带来很多麻烦,我们可以在访问此对象时加上一个对此对象的访问层。
**何时使用:**想在访问一个类时做一些控制。
**如何解决:**增加中间层。
**关键代码:**实现与被代理类组合。
**应用实例:** 1、Windows 里面的快捷方式。 2、猪八戒去找高翠兰结果是孙悟空变的,可以这样理解:把高翠兰的外貌抽象出来,高翠兰本人和孙悟空都实现了这个接口,猪八戒访问高翠兰的时候看不出来这个是孙悟空,所以说孙悟空是高翠兰代理类。 3、买火车票不一定在火车站买,也可以去代售点。 4、一张支票或银行存单是账户中资金的代理。支票在市场交易中用来代替现金,并提供对签发人账号上资金的控制。 5、spring aop。
**优点:** 1、职责清晰。 2、高扩展性。 3、智能化。
**缺点:** 1、由于在客户端和真实主题之间增加了代理对象,因此有些类型的代理模式可能会造成请求的处理速度变慢。 2、实现代理模式需要额外的工作,有些代理模式的实现非常复杂。
**使用场景:**按职责来划分,通常有以下使用场景: 1、远程代理。 2、虚拟代理。 3、Copy-on-Write 代理。 4、保护(Protect or Access)代理。 5、Cache代理。 6、防火墙(Firewall)代理。 7、同步化(Synchronization)代理。 8、智能引用(Smart Reference)代理。
**注意事项:** 1、和适配器模式的区别:适配器模式主要改变所考虑对象的接口,而代理模式不能改变所代理类的接口。 2、和装饰器模式的区别:装饰器模式为了增强功能,而代理模式是为了加以控制。
### 22.4、==观察者模式==(NIO轮询)
观察者模式是一种行为型设计模式,它定义了一种一对多的依赖关系,当一个对象的状态发生改变时,其所有依赖者都会收到通知并自动更新。
当对象间存在一对多关系时,则使用观察者模式(Observer Pattern)。比如,当一个对象被修改时,则会自动通知依赖它的对象。观察者模式属于行为型模式。
介绍
**意图:**定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
**主要解决:**一个对象状态改变给其他对象通知的问题,而且要考虑到易用和低耦合,保证高度的协作。
**何时使用:**一个对象(目标对象)的状态发生改变,所有的依赖对象(观察者对象)都将得到通知,进行广播通知。
**如何解决:**使用面向对象技术,可以将这种依赖关系弱化。
**关键代码:**在抽象类里有一个 ArrayList 存放观察者们。
**应用实例:** 1、拍卖的时候,拍卖师观察最高标价,然后通知给其他竞价者竞价。 2、西游记里面悟空请求菩萨降服红孩儿,菩萨洒了一地水招来一个老乌龟,这个乌龟就是观察者,他观察菩萨洒水这个动作。
**优点:** 1、观察者和被观察者是抽象耦合的。 2、建立一套触发机制。
**缺点:** 1、如果一个被观察者对象有很多的直接和间接的观察者的话,将所有的观察者都通知到会花费很多时间。 2、如果在观察者和观察目标之间有循环依赖的话,观察目标会触发它们之间进行循环调用,可能导致系统崩溃。 3、观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。
**使用场景:**
- 一个抽象模型有两个方面,其中一个方面依赖于另一个方面。将这些方面封装在独立的对象中使它们可以各自独立地改变和复用。
- 一个对象的改变将导致其他一个或多个对象也发生改变,而不知道具体有多少对象将发生改变,可以降低对象之间的耦合度。
- 一个对象必须通知其他对象,而并不知道这些对象是谁。
- 需要在系统中创建一个触发链,A对象的行为将影响B对象,B对象的行为将影响C对象……,可以使用观察者模式创建一种链式触发机制。
**注意事项:** 1、JAVA 中已经有了对观察者模式的支持类。 2、避免循环引用。 3、如果顺序执行,某一观察者错误会导致系统卡壳,一般采用异步方式。
**观察者模式包含以下几个核心角色:**
- 主题(Subject):也称为被观察者或可观察者,它是具有状态的对象,并维护着一个观察者列表。主题提供了添加、删除和通知观察者的方法。
- 观察者(Observer):观察者是接收主题通知的对象。观察者需要实现一个更新方法,当收到主题的通知时,调用该方法进行更新操作。
- 具体主题(Concrete Subject):具体主题是主题的具体实现类。它维护着观察者列表,并在状态发生改变时通知观察者。
- 具体观察者(Concrete Observer):具体观察者是观察者的具体实现类。它实现了更新方法,定义了在收到主题通知时需要执行的具体操作。
观察者模式通过将主题和观察者解耦,实现了对象之间的松耦合。当主题的状态发生改变时,所有依赖于它的观察者都会收到通知并进行相应的更新。
### 22.5、MVC 模式
MVC 模式代表 Model-View-Controller(模型-视图-控制器) 模式。这种模式用于应用程序的分层开发。
- **Model(模型)** - 模型代表一个存取数据的对象或 JAVA POJO。它也可以带有逻辑,在数据变化时更新控制器。
- **View(视图)** - 视图代表模型包含的数据的可视化。
- **Controller(控制器)** - 控制器作用于模型和视图上。它控制数据流向模型对象,并在数据变化时更新视图。它使视图与模型分离开。

### 22.6、装饰器模式和代理模式的区别
理解:装饰器模式是增强了自身的功能,例如IO流中`bufferedInputStream`(字节缓冲输入流)、`DataInputStream` 等等都是`FilterInputStream` 的子类,我们可以通过 `BufferedInputStream`(字节缓冲输入流)来增强 `FileInputStream` 的功能。
```java
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("input.txt"))) {
int content;
long skip = bis.skip(2);
while ((content = bis.read()) != -1) {
System.out.print((char) content);
}
} catch (IOException e) {
e.printStackTrace();
}
```
而代理模式注重增加了额外的功能,比如AOP编程中使用代理模式的思想在接口前后增加了缓存双删的功能,比如在写入数据库前进行验证。
代理注重控制,控制不易二次扩展;装饰注重增强,且通过上层装饰进行增强,易于扩展。装饰是特殊的代理,特殊的地方就在于其代理角色proxy 是一个抽象的Decorator,所以才易于扩展
1、装饰器模式强调的是增强自身,在被装饰之后你能够在被增强的类上使用增强后的功能。增强后你还是你,只不过能力更强了而已;代理模式强调要让别人帮你去做一些本身与你业务没有太多关系的职责(记录日志、设置缓存)。代理模式是为了实现对象的控制,因为被代理的对象往往难以直接获得或者是其内部不想暴露出来。
2、装饰模式是以对客户端透明的方式扩展对象的功能,是继承方案的一个替代方案;代理模式则是给一个对象提供一个代理对象,并由代理对象来控制对原有对象的引用;
3、装饰模式是为装饰的对象增强功能;而代理模式对代理的对象施加控制,但不对对象本身的功能进行增强;
## 23、CompletableFuture
completableFuture继承于java.util.concurrent.Future,它本身具备Future的所有特性,并且基于JDK1.8的流式编程以及Lambda表达式等实现一元操作符、异步性以及事件驱动编程模型,可以用来实现多线程的串行关系,并行关系,聚合关系。它的灵活性和更强大的功能是Future无法比拟的。
举例:
1、使用自定义线程池
```java
ThreadPoolExecutor pool = new ThreadPoolExecutor(2, 4, 3,
TimeUnit.SECONDS, new ArrayBlockingQueue(3),
new ThreadPoolExecutor.DiscardOldestPolicy());
CompletableFuture.runAsync(() -> System.out.println("Hello World!"), pool);
```
2、allOf等待所有异步操作结束
```java
Random rand = new Random();
CompletableFuture future1 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1000 + rand.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println("future1 done...");
}
return "abc";
});
CompletableFuture future2 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1000 + rand.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println("future2 done...");
}
return "efg";
});
//主线程
//allof需要全部完成,anyOf() 方法不会等待所有的 CompletableFuture 都运行完成之后再返回,只要有一个执行完成即可!
CompletableFuture completableFuture = CompletableFuture.allOf(future1, future2);
completableFuture.join();
assertTrue(completableFuture.isDone());
System.out.println("all futures done...");
//结果
future1 done...
future2 done...
all futures done...
```
## 25、控制反转IOC
使用之前:

使用IOC思想之后

理解:IOC采用注入的方式,类似于零件组装,不new一个类,而是先类似于深度遍历所有组件,然后new出全部的零件,最后进行注入,传给上层,这样当需要修改某个组件的属性时,只需要修改某个组件自身,而不需要在最上层的类中new的时候就传入相关的属性。
## 26、cglib代理和jdk动态代理的区别
cglib代理和jdk动态代理的区别在于,JDK动态代理基于接口来创建被代理对象的代理实例,而Cglib代理基于继承的方式对被代理类生成子类。
1、JDK 动态代理:
- 基于接口来创建被代理对象的代理实例。当对象要被代理时,它必须实现一个或多个接口并依赖JDK库。JDK动态代理利用反射机制生成一个包含被代理对象的所有接口的代理类,并覆盖接口中的所有方法,可以对目标对象进行代理。
- 优点:无需引用第三方库,在JRE运行环境中就可以运行,生成代理对象更加简单、快捷;缺点:==仅支持基于接口进行代理==,无法对类进行代理,所以它的作用有限。
2.、Cglib 代理:
- 基于继承的方式对被代理类生成子类,从而添加代理逻辑。因为它是继承了被代理类,所以它会受到final类、private、static等不可继承属性的影响。
- 优点:Cglib支持对类进行代理,即使没有接口,也可通过设置回调接口间接地实现。性能比JDK动态代理更高,==能够代理那些没有实现任何接口的目标对象==。
Cglib在生成代理类的过程中,采用动态生成字节码的方式,在被代理类加载之前就完成了代理类的创建并缓存到内存中,以后每次调用时,都直接使用缓存的代理类。在大多数情况下,Cglib代理比JDK动态代理更适合于大规模的方法拦截和增强等场景。
3.3. JDK 动态代理和 CGLIB 动态代理对比
1. **JDK 动态代理只能代理实现了接口的类或者直接代理接口,而 CGLIB 可以代理未实现任何接口的类。** 另外, CGLIB 动态代理是通过生成一个被代理类的子类来拦截被代理类的方法调用,因此不能代理声明为 final 类型的类和方法。
2. 就二者的效率来说,大部分情况都是 JDK 动态代理更优秀,随着 JDK 版本的升级,这个优势更加明显
## 27、缓存中间件有哪些?
Redis、消息队列MQ、Nginx、Netty、Mycat、

## 28、Synchronize锁升级过程
一、锁升级基础
1)偏向锁
只有一个线程争抢锁资源的时候.将线程拥有者标识为当前线程。引入了偏向锁目的是来尽可能减少无竞争情况下的同步操作开销。当一个线程访问同步块并获取对象的锁时,会将锁的标记记录在线程的栈帧中,并将对象头中的Thread ID设置为当前线程的ID。此后,当这个线程再次请求相同对象的锁时,虚拟机会使用已经记录的锁标记,而不需要再次进入同步块。
2)轻量级锁(自旋锁)
一个或多个线程通过CAS去争抢锁,如果抢不到则一直自旋。虚拟机会将对象的Mark Word复制到线程的栈帧中作为锁记录,并尝试使用CAS(Compare and Set)操作尝试获取锁。如果CAS成功,则表示线程获取了轻量级锁,并继续执行同步块。如果CAS失败,说明有竞争,虚拟机会通过自旋(spinning)等待其他线程释放锁
3)重量级锁
如果自旋等待不成功(类似出现死锁),虚拟机会将轻量级锁升级为重量级锁。在这种状态下,虚拟机会将线程阻塞,并使用操作系统的互斥量来实现锁的释放和获取。
需要注意的是,锁的升级是逐级升级的过程,而不会存在降级。换句话说,一旦锁升级到更高级别,就不会再回到低级别。
二、为什么要有锁升级过程?
锁的升级过程是为了提供更好的性能和吞吐量,并减少多线程竞争产生的开销。下面是锁的升级过程的一些原因:
1)减少无竞争情况下的同步操作开销
在多线程环境下,如果没有竞争,每个线程都可以安全地访问共享资源,无需进行同步操作。锁的升级过程中的第一阶段偏向锁(Biased Locking)就是为了在无竞争的情况下减少同步操作的开销。它通过记录线程ID来避免对锁的加锁和解锁操作,提高了单线程访问同步代码块时的性能。
2)尽量避免线程切换的开销
锁的升级过程中的第二阶段轻量级锁(Lightweight Locking)是为了减少线程切换的开销。它使用CAS(Compare and Set)操作来尝试获取锁,如果成功则可以继续执行同步块,无需线程切换;如果失败,则会进行自旋操作等待锁的释放。自旋操作避免了线程挂起和切换的开销,提高了多线程竞争时的性能。
3)降低内存消耗
锁的升级过程中的第二阶段轻量级锁使用对象头中的一部分位来存储线程ID和锁标记,不需要额外的内存存储锁的状态。相对于传统的重量级锁,它能够节省内存消耗。
4)提高系统吞吐量
锁的升级过程可以使多个线程在无竞争情况下快速获取锁,避免了线程阻塞和等待的开销。这样,系统的吞吐量会更高,因为更多的线程可以并发地执行任务。
总而言之,锁的升级过程是为了提高多线程环境下的性能和吞吐量,减少同步操作的开销,并尽量避免线程切换的开销。Java虚拟机根据线程竞争的情况和锁的使用情况自动进行锁的升级和降级,以优化多线程程序的性能。
三、==锁升级过程==
1)当只有一个线程去争抢锁的时候,会先使用偏向锁,就是给一个标识,说明现在这个锁被线程a占有.
2)后来又来了线程b,线程c,说凭什么你占有锁,需要公平的竞争,于是将标识去掉,也就是撤销偏向锁,升级为轻量级锁,三个线程通过CAS自旋进行锁的争抢(其实这个抢锁过程还是偏向于原来的持有偏向锁的线程).
3)现在线程a占有了锁,线程b,线程c一直在循环尝试获取锁,后来又来了十个线程,一直在自旋,那这样等着也是干耗费CPU资源,所以就将锁升级为重量级锁,向内核申请资源,直接将等待的线程进行阻塞.

## 29、为什么HashMap底层使用红黑树而不是平衡二叉树?
HashMap使用红黑树是因为红黑树相对于平衡二叉树有更好的性能表现。
首先,红黑树的平衡性能比平衡二叉树更好。红黑树的平衡性能是通过对节点进行颜色标记和旋转操作来实现的,而平衡二叉树只能通过旋转操作来实现平衡。因此,红黑树的平衡性能更好,可以更快地进行插入、删除和查找操作。
其次,红黑树的空间利用率比平衡二叉树更高。红黑树的节点结构比平衡二叉树的节点结构更紧凑,因此在存储大量数据时,红黑树的空间利用率更高。
最后,红黑树的实现比平衡二叉树更简单。红黑树的实现比平衡二叉树的实现更简单,因为红黑树的平衡性能是通过颜色标记和旋转操作来实现的,而平衡二叉树需要更复杂的平衡算法来实现平衡。
因此,HashMap使用红黑树来实现内部的数据结构,以提高性能和空间利用率。
作者:月下瑶台
链接:https://www.nowcoder.com/
来源:牛客网
## 30、接口和抽象类的异同
**区别1:定义关键字不同**
接口使用关键字 interface 来定义。 抽象类使用关键字 abstract 来定义。
**区别2:继承或实现的关键字不同**
接口使用 implements 关键字定义其具体实现。 抽象类使用 extends 关键字实现继承。
**区别3:子类扩展的数量不同**
在 Java 语言中,一个类只能继承一个父类(单继承),但可以实现多个接口。
**区别4:属性访问控制符不同**
接口中属性的访问控制符只能是 public,如下图所示:
> 接口中的属性默认是 public static final 修饰的。
>
抽象类中的属性访问控制符无限制,可为任意控制符
**区别5:方法控制符不同**
接口中方法的默认控制符是 public,并且不能定义为其他控制符,如下图所示:
**区别6:方法实现不同**
接口中普通方法不能有具体的方法实现,在 JDK 8 之后 static 和 default 方法必须有方法实现
==普通不能实现,其他必须实现==
抽象类中的普通方法如果没有方法实现就会报错,而抽象方法如果有方法实现则会报错。
==普通需要实现,抽象不能实现==
**区别7:静态代码块使用不同**
接口中不能使用静态代码块,如下代码所示:

抽象类中可以使用静态代码块,如下代码所示:

## 31、在并发量特别高的情况下是使用 synchronized 还是 ReentrantLock
在并发量特别高的情况下,一般推荐使用 ReentrantLock,原因如下:
1. **更高的性能**:在Java 1.6之前,**synchronized** 的性能一般比 **ReentrantLock** 差一些。虽然在 Java 1.6 及之后的版本中,synchronized进行了一些优化,如偏向锁、轻量级锁等,但在高并发情况下,ReentrantLock 的性能通常会优于 synchronized。
2. **更大的灵活性**:`ReentrantLock` 比 `synchronized` 有更多的功能。例如,`ReentrantLoc`k 可以实现**公平锁和非公平锁**(synchronized只能实现非公平锁);ReentrantLock 提供了一个 **Condition** 类,可以分组唤醒需要唤醒的线程(synchronized 要么随机唤醒一个线程,要么唤醒所有线程);ReentrantLock 提供了 `tryLock` 方法,可以尝试获取锁,如果获取不到立即返回,不会像synchronized 那样阻塞。
3. **更好的可控制性**:ReentrantLock可以中断等待锁的线程(synchronized无法响应中断),也可以获取等待锁的线程列表,这在调试并发问题时非常有用。
但是,虽然 ReentrantLock 在功能上比 synchronized 更强大,但也更复杂,使用不当容易造成死锁。**而 synchronized 由 JVM 直接支持,使用更简单,不容易出错**。所以,在并发量不高,对性能要求不高的情况下,也可以考虑使用 synchronized。
## 32、CAP分布式三原则
CAP理论的核心是:一个[分布式系统](https://so.csdn.net/so/search?q=分布式系统&spm=1001.2101.3001.7020)不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
## 33、线程相关
### 33.1 创建线程的方式
1. **继承Thread类**:这是创建线程的最基本方法。我们可以创建一个新的类,继承自 Thread 类,然后重写其 run() 方法,将我们的任务代码写在 run() 方法中。然后创建该类的对象并调用其 start() 方法来启动线程。
2. 实**现Runnable接口**:我们也可以创建一个新的类,实现 Runnable 接口,然后将我们的任务代码写在 run() 方法中。然后创建该类的对象,将其作为参数传递给 Thread 类的构造器,创建 Thread 类的对象并调用其 start() 方法来启动线程。
3. **实现Callable接口和FutureTask类**:Callable 接口与 Runnable 接口类似,但是它可以返回一个结果,或者抛出一个异常。我们可以创建一个新的类,实现 Callable 接口,然后将我们的任务代码写在 call() 方法中。然后创建该类的对象,将其作为参数传递给FutureTask 类的构造器,创建 FutureTask 类的对象。最后,将FutureTask类的对象作为参数传递给 Thread 类的构造器,创建Thread 类的对象并调用其 start() 方法来启动线程。
4. **使用线程池**:Java 提供了线程池 API(Executor框架),我们可以通过 Executors 类的一些静态工厂方法来创建线程池,然后调用其 execute() 或 submit() 方法来启动线程。线程池可以有效地管理和控制线程,避免大量线程的创建和销毁带来的性能开销。
以上四种方式,前两种是最基本的创建线程的方式,但是在实际开发中,我们通常会选择使用**线程池**,因为它可以提供更好的性能和更易于管理的线程生命周期。
### 33.2 一个线程池中的线程异常了,那么线程池会怎么处理这个线程?
> 1.抛出堆栈异常 (execute会抛出,submit不会,而是会封装在future中,主动调用才会显示)
>
> 2.不影响其他线程任务
>
> 3.这个线程会被直接从线程池中移除

当使用execute时会直接抛出异常,当submit时,会返回为Future,需要使用get方法拿到异常信息
### 33.3 Java 创建多线程时要注意哪些问题?
1. 线程安全问题:多个线程同时访问共享资源时可能会出现数据竞争、死锁等问题,需要使用同步机制来保证线程安全。
2. 上下文切换问题:线程切换会消耗系统资源,如果线程数量过多,会导致系统性能下降。
3. 线程间通信问题:多个线程之间需要进行通信,需要使用合适的方式进行线程间通信,如wait/notify、Lock/Condition等。
4. 线程优先级问题:线程优先级高的线程会优先执行,但是过度依赖线程优先级可能会导致线程饥饿问题。
5. 线程生命周期问题:线程的生命周期包括创建、运行、阻塞、唤醒和销毁等阶段,需要合理控制线程的生命周期。
6. 线程池问题:线程池可以有效地管理线程,但是线程池的大小、任务队列的大小等需要根据实际情况进行调整。
7. 异常处理问题:多线程程序中可能会出现异常,需要合理处理异常,避免程序崩溃。
### 33.4 线程同步方式
线程同步主要包括四种方式:
- 互斥量`pthread_mutex_`
- 读写锁`pthread_rwlock_`
- 条件变量`pthread_cond_`
- 信号量`sem_`
> 1、synchronized 关键字
>
> 2、Lock 接口
>
> 3、volatile
>
> 4、使用重入锁实现线程同步ReenreantLock类
>
> 5、使用局部变量实现线程同步 如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,
>
> 6、使用阻塞队列实现线程同步LinkedBlockingQueue 类
>
> 7、使用原子变量实现线程同步AtomicInteger类
### 33.5 ThreadLocal


### ThreadLocal源码简介
- 每个Thread对象中都持有一个ThreadLocalMap类型的成员变量。key是ThreadLocal的引用。一个Thread里只有一个ThreadLocalMap,一个ThreadLocalMap里有很多的ThreadLocal
- ThreadLocalMap中的key和value都保存在线程Thread类中的,而不是保存在ThreadLocal中
- getMap(Thread t):返回threadLocals,threadLocals是线程的一个成员变量。获取到当前线程内的ThreadLocalMap对象,每个线程都有ThreadLocalMap对象,而这个对象的名字就叫做threadLocals,初始值为null
- set(T value):把想要存储的value给保存进去。this:是把当前ThreadLocal的引用,在ThreadLocalMap中,它的key的类型是ThreadLocal;value:可以把这个键值对保存到ThreadLocalMap中去
- entry:把entry理解为一个map,它是一个WeakReference的引用,其键为当前的ThreadLocal,值为实际需要存储的变量
每个线程Thread持有一个ThreadLocalMap类型的实例threadLocals,结合此处的构造方法可以理解成每个线程Thread都持有一个Entry型的数组table,而一切的读取过程都是通过操作这个数组table完成的。
多个ThreadLocal
//在某一线程声明了ABC三种类型的ThreadLocal
ThreadLocal sThreadLocalA = new ThreadLocal();
ThreadLocal sThreadLocalB = new ThreadLocal();
ThreadLocal sThreadLocalC = new ThreadLocal();
对于一个Thread来说只有持有一个ThreadLocalMap,所以多个ThreadLocal对应同一个ThreadLocalMap对象。为了管理多个ThreadLocal,于是将他们存储在一个数组的不同位置,而这个数组就是上面提到的Entry型的数组table。
#### ThreadLocal 内存泄露问题是怎么导致的?
`ThreadLocalMap` 中使用的 key 为 `ThreadLocal` 的弱引用,而 value 是强引用。所以,如果 `ThreadLocal` 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。
这样一来,`ThreadLocalMap` 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。`ThreadLocalMap` 实现中已经考虑了这种情况,在调用 `set()`、`get()`、`remove()` 方法的时候,会清理掉 key 为 null 的记录。使用完 `ThreadLocal`方法后最好手动调用`remove()`方法
```java
static class Entry extends WeakReference> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
}
```
## 34、RocketMQ消息队列相关
### 34.1、RocketMQ 如何实现分布式事务?
在 `RocketMQ` 中使用的是 **事务消息加上事务反查机制** 来解决分布式事务问题的。我画了张图,大家可以对照着图进行理解。

在第一步发送的 half 消息 ,它的意思是 **在事务提交之前,对于消费者来说,这个消息是不可见的** 。
> 那么,如何做到写入消息但是对用户不可见呢?RocketMQ 事务消息的做法是:如果消息是 half 消息,将备份原消息的主题与消息消费队列,然后 **改变主题** 为 RMQ_SYS_TRANS_HALF_TOPIC。由于消费组未订阅该主题,故消费端无法消费 half 类型的消息,**然后 RocketMQ 会开启一个定时任务,从 Topic 为 RMQ_SYS_TRANS_HALF_TOPIC 中拉取消息进行消费**,根据生产者组获取一个服务提供者发送回查事务状态请求,根据事务状态来决定是提交或回滚消息。
你可以试想一下,如果没有从第 5 步开始的 **事务反查机制** ,如果出现网路波动第 4 步没有发送成功,这样就会产生 MQ 不知道是不是需要给消费者消费的问题,他就像一个无头苍蝇一样。在 `RocketMQ` 中就是使用的上述的事务反查来解决的,而在 `Kafka` 中通常是直接抛出一个异常让用户来自行解决。
### 34.2 顺序消费

根据上图可以,上面的方法可以实现==一组消息被顺序的存放,不同组的消息之间的顺序无法保证==,这就是部分顺序。
另外,顺序消息必须使用同步发送的方式才能保证生产者发送的消息有序。
实际上,采用队列选择器的方法不能保证消息的严格顺序,我们的目的是将消息发送到同一个队列中,如果某个broker挂了,那么队列就会减少一部分,如果采用取余的方式投递,将可能导致同一个业务中的不同消息被发送到不同的队列中,导致同一个业务的不同消息被存入不同的队列中,短暂的造成部分消息无序。同样的,如果增加了服务器,那么也会造成==短暂的造成部分消息无序。==
其实很简单,我们需要处理的仅仅是将同一语义下的消息放入同一个队列(比如这里是同一个订单),那我们就可以使用 **Hash 取模法** 来保证同一个订单在同一个队列中就行了。
### 34.3 重复消费
**幂等**
那么如何给业务实现幂等呢?这个还是需要结合具体的业务的。你可以使用 **写入 `Redis`** 来保证,因为 `Redis` 的 `key` 和 `value` 就是天然支持幂等的。当然还有使用 **数据库插入法** ,基于数据库的唯一键来保证重复数据不会被插入多条。
## 35、select、poll、epoll的区别
select==>时间复杂度O(n)(BIO)
它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
poll==>时间复杂度O(n)(BIO)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的.
epoll==>时间复杂度O(1)(NIO)
类似于回调
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
epoll跟select都能提供多路I/O复用的解决方案。在现在的Linux内核里有都能够支持,其中epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现
epoll的优点:
1、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口);
2、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;
即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
3、 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
==消息传递==
**select**
内核需要将消息传递到用户空间,都需要内核拷贝动作
**poll**
同上
**epoll**
epoll通过内核和用户空间共享一块内存来实现的。
## 36、AQS抽象队列同步器
AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 **CLH 队列锁** 实现的,即将暂时获取不到锁的线程加入到队列中。
CLH(Craig,Landin,and Hagersten) 队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配。在 CLH 同步队列中,一个节点表示一个线程,它保存着线程的引用(thread)、 当前节点在队列中的状态(waitStatus)、前驱节点(prev)、后继节点(next)。
CLH 队列结构如下图所示:

AQS(`AbstractQueuedSynchronizer`)的核心原理图(图源[Java 并发之 AQS 详解open in new window](https://www.cnblogs.com/waterystone/p/4920797.html))如下:

## 37、ReentrantLock和Synchronize的区别
==`ReentrantLock` 的底层就是由 AQS 来实现的,AQS基于CLH队列实现,是一个虚拟的双向队列,原版是通过自旋实现的,后来修改后变为使用阻塞等待操作替换了自旋,可以很好地处理超时和取消(等待可中断)==
两者都是可重入锁
**可重入锁** 也叫递归锁,指的是线程可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果是不可重入锁的话,就会造成死锁。
synchronized 依赖于 JVM(JVM虚拟机monitorenter和monitorexit) 而 ReentrantLock 依赖于 API
`ReentrantLock` 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成
ReentrantLock 比 synchronized 增加了一些高级功能
相比`synchronized`,`ReentrantLock`增加了一些高级功能。主要来说主要有三点:
- **等待可中断** : `ReentrantLock`提供了一种能够中断等待锁的线程的机制,通过 `lock.lockInterruptibly()` 来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
- **可实现公平锁** : `ReentrantLock`可以指定是公平锁还是非公平锁。而`synchronized`只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。`ReentrantLock`默认情况是非公平的,可以通过 `ReentrantLock`类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
- **可实现选择性通知(锁可以绑定多个条件)**: `synchronized`关键字与`wait()`和`notify()`/`notifyAll()`方法相结合可以实现等待/通知机制。`ReentrantLock`类当然也可以实现,但是需要借助于`Condition`接口与`newCondition()`方法。
## 38、volatile相关
不能保证原子性(线程并发时会被多个线程同时修改,导致最终答案错误,比如两个线程同时对变量+1,结果出来还是1而不是2),可以保证可见性。
`volatile`定义:
- 当对volatile变量执行写操作后,JMM会把工作内存中的最新变量值强制刷新到主内存
- 写操作会导致其他线程中的缓存无效
这样,其他线程使用缓存时,发现本地工作内存中此变量无效,便从主内存中获取,这样获取到的变量便是最新的值,实现了线程的可见性。
1. volatile修饰符适用于以下场景:某个属性被多个线程共享,其中有一个线程修改了此属性,其他线程可以立即得到修改后的值,比如booleanflag;或者作为触发器,实现轻量级同步。
2. volatile属性的读写操作都是无锁的,它不能替代synchronized,因为它没有提供原子性和互斥性。因为无锁,不需要花费时间在获取锁和释放锁_上,所以说它是低成本的。
3. volatile只能作用于属性,我们用volatile修饰属性,这样compilers就不会对这个属性做指令重排序。
4. volatile提供了可见性,任何一个线程对其的修改将立马对其他线程可见,volatile属性不会被线程缓存,始终从主 存中读取。
5. volatile提供了happens-before保证,对volatile变量v的写入happens-before所有其他线程后续对v的读操作。
6. volatile可以使得long和double的赋值是原子的。
7. volatile可以在单例双重检查中实现可见性和禁止指令重排序,从而保证安全性
volatile 是一种 Java 关键字,它的作用是保证变量的可见性和禁止指令重排序。
在 Java 中,线程之间的通信通常是通过共享变量进行的。但是由于线程之间的工作内存是相互独立的,因此一个线程对共享变量的修改可能并不会立即被其他线程看到,这就会导致可见性问题。使用 volatile 关键字可以解决这个问题,因为它能够保证对 volatile 变量的读写操作都是在主内存中进行的,而不是在工作内存中进行的。
此外,编译器和处理器在优化代码时可能会进行指令重排序,这可能会导致程序出现意想不到的行为。使用 volatile 关键字可以禁止编译器和处理器对指令进行重排序,从而保证程序的正确性。
需要注意的是,volatile 关键字并不能保证原子性,因此在需要保证原子性的场合,需要使用其他的同步机制,如 synchronized 关键字或者使用原子类。
> 可见性能举个例子说明一下吗
好的,下面举个例子说明一下可见性的问题:
假设有两个线程 A 和 B,它们共享一个变量 flag,初始值为 false。线程 A 执行了以下代码:
arduino
```arduino
flag = true;
```
线程 B 执行了以下代码:
```perl
while (!flag) {
// do something
}
```
线程 B 的代码是一个循环,只要 flag 的值为 false,它就会一直循环下去。如果 flag 的值被线程 A 修改为 true,那么线程 B 就能够跳出循环。但是如果线程 A 修改 flag 的值后,线程 B 并没有看到 flag 的最新值,那么它就会一直在循环中阻塞,这就是可见性问题。
使用 volatile 关键字可以解决这个问题,因为它能够保证对 volatile 变量的读写操作都是在主内存中进行的,而不是在工作内存中进行的。因此,如果将 flag 声明为 volatile 变量,那么线程 B 就能够看到线程 A 对 flag 的修改,从而跳出循环。
## 39、SPI和API
API是你实现好了接口,我拿来用。服务方写接口,实现接口,我直接拿来用(实现方确定规则)。==先有供给,后有需求==
SPI是我写接口,多个服务方实现功能,我挑一个用(调用方确定规则)。==先有需求,后有供给,竞标==
SLF4J (Simple Logging Facade for Java)是 Java 的一个日志门面(接口),其具体实现有几种,比如:Logback、Log4j、Log4j2 等等,而且还可以切换,在切换日志具体实现的时候我们是不需要更改项目代码的,只需要在 Maven 依赖里面修改一些 pom 依赖就好了。

## 40、@Async注解有什么问题?
机制:
- **异常处理**:使用 Async 注解时,异常处理可能会变得更加复杂。由于异步操作是在另一个线程中执行的,因此如果异步操作抛出了异常,这个异常可能不会被捕获。为了解决这个问题,开发者需要使用 CompletableFuture 的异常处理机制来捕获异步操作抛出的异常。
- **内存占用**:使用 Async 注解时,由于每个异步操作都会在一个新的线程中执行,因此可能会导致大量的线程被创建。这可能会导致内存占用过高,从而导致应用程序性能下降。
- **阻塞操作**:使用 Async 注解时,如果异步操作中包含了阻塞操作,这可能会导致线程池中的线程被阻塞,从而导致应用程序性能下降。
问题:
- **可能会导致性能问题**:由于 Async 注解会创建新的线程来执行异步操作,因此如果使用不当,可能会导致线程池中的线程被过度消耗,从而导致性能问题。
- **可能会导致内存泄漏问题**:如果使用 Async 注解时没有正确地管理线程池,可能会导致内存泄漏问题。例如,如果不正确地配置线程池大小,可能会导致线程池中的线程无法回收,从而导致内存泄漏。
- **可能会导致死锁问题**:如果异步操作中包含了阻塞操作,可能会导致线程池中的线程被阻塞,从而导致死锁问题。
## 41、Redis延迟双删
延迟双删策略
为什么会存在延迟双删呢,普通的双删时,假设B请求获取到了旧数据,准备填充到缓存,A请求刚刚更新完数据库,立刻删除了缓存,在删除完成后B请求才把旧数据的缓存去填充,这样依然会出现缓存与数据库不一致的情况(即缓存内数据错误)。
延迟双删就是A请求更新完数据库之后,延迟那么一会再去删除缓存,这样的目的也很明显,就是为了让B请求(以及其他很多相近时间的请求)已经拿旧数据填充过缓存了,并且已经走完这一段逻辑了,后续不会去尝试覆盖缓存了。这个时候再去删除缓存,下一次去填充缓存的时候就拿到的是A请求更新好的正确的数据了。
## 42、Bean的生命周期和AOP
Bean的生命周期:
第一阶段 createBeanInstance()方法实例化bean
顺便提一下 为了解决==循环依赖问题(见43)==向缓存暴露bean工厂
第二阶段 populateBean() 属性注入
第三阶段 initializeBean() 方法 进入初始化阶段
第四阶段 销毁
初始化阶段执行Aware接口 和 后置处理器方法 执行初始化方法
==AOP发生在初始化方法执行后==
**initializeBean()源码**
```java
protected Object initializeBean(String beanName, Object bean, @Nullable RootBeanDefinition mbd) {
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction