[
{
"path": "LICENSE",
"content": "The MIT License (MIT)\n\n\nCopyright (c) 2017 Microsoft Corporation\n\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof this software and associated documentation files (the \"Software\"), to deal\nin the Software without restriction, including without limitation the rights\nto use, copy, modify, merge, publish, distribute, sublicense, and/or sell\ncopies of the Software, and to permit persons to whom the Software is\nfurnished to do so, subject to the following conditions:\n\n\nThe above copyright notice and this permission notice shall be included in all\ncopies or substantial portions of the Software.\n\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\nIMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\nFITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\nAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\nLIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\nOUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\nSOFTWARE.\n"
},
{
"path": "README.md",
"content": "# Deep Feature Flow for Video Recognition\n\n\n## Introduction\n\n\n**Deep Feature Flow** is initially described in a [CVPR 2017 paper]\n\nIt provides a simple, fast, accurate, and end-to-end framework for video recognition (e.g., object detection and semantic segmentation in videos). It is worth noting that:\n\n* Deep Feature Flow significantly speeds up video recognition by applying the heavy-weight image recognition network (e.g., ResNet-101) on sparse key frames, and propagating the recognition outputs (feature maps) to the other frames by the light-weight flow network (e.g., [FlowNet].\n* The entire system is end-to-end trained for the task of video recognition, which is vital for improving the recognition accuracy. Directly adopting state-of-the-art flow estimation methods without end-to-end training would deliver noticable worse results.\n* Deep Feature Flow can easily make use of sparsely annotated video recognition datasets, where only a small portion of the frames are annotated with ground-truth labels.\n\n***Click image to watch our demo video***\n\n[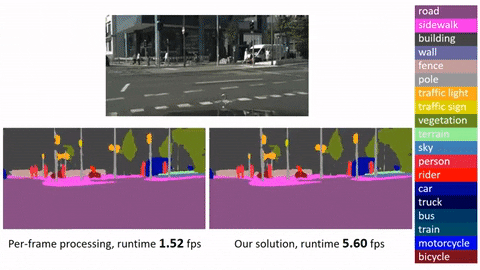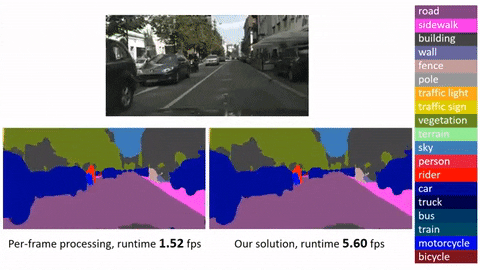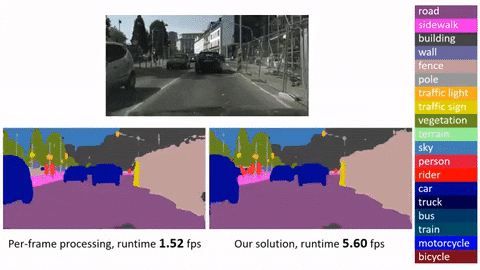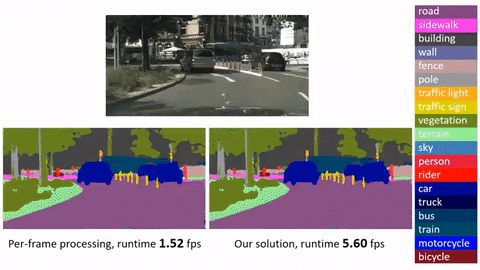]\n\n[] \n\n## Disclaimer\n\nThis is an official implementation for [Deep Feature Flow for Video Recognition](https://arxiv.org/abs/1611.07715) (DFF) based on MXNet. It is worth noticing that:\n\n * The original implementation is based on our internal Caffe version on Windows. There are slight differences in the final accuracy and running time due to the plenty details in platform switch.\n \n\n\n\n## License\n\n© Microsoft, 2018. Licensed under the [MIT](LICENSE) License.\n\n## Citing Deep Feature Flow\n\nIf you find Deep Feature Flow useful in your research, please consider citing:\n```\n@inproceedings{zhu17dff,\n Author = {Xizhou Zhu, Yuwen Xiong, Jifeng Dai, Lu Yuan, Yichen Wei},\n Title = {Deep Feature Flow for Video Recognition},\n Conference = {CVPR},\n Year = {2017}\n}\n\n@inproceedings{dai16rfcn,\n Author = {Jifeng Dai, Yi Li, Kaiming He, Jian Sun},\n Title = {{R-FCN}: Object Detection via Region-based Fully Convolutional Networks},\n Conference = {NIPS},\n Year = {2016}\n}\n```\n\n## Main Results\n\n\n| | training data | testing data | mAP@0.5 | time/image (Tesla K40) | time/image(Maxwell Titan X) |\n|---------------------------------|-------------------|--------------|---------|---------|--------|\n| Frame baseline(R-FCN, ResNet-v1-101) | ImageNet DET train + VID train | ImageNet VID validation | 74.1 | 0.271s | 0.133s |\n| Deep Feature Flow(R-FCN, ResNet-v1-101, FlowNet) | ImageNet DET train + VID train | ImageNet VID validation | 73.0 | 0.073s | 0.034s |\n\n*Running time is counted on a single GPU (mini-batch size is 1 in inference, key-frame duration length for Deep Feature Flow is 10).*\n\n*The runtime of the light-weight FlowNet seems to be a bit slower on MXNet than that on Caffe.*\n\n## Requirements: Software\n\n1. MXNet from \n Due to the rapid development of MXNet, it is recommended to checkout this version if you encounter any issues. We may maintain this repository periodically if MXNet adds important feature in future release.\n\n2. Python 2.7. We recommend using Anaconda2 as it already includes many common packages. We do not suppoort Python 3 yet, if you want to use Python 3 you need to modify the code to make it work.\n\n3. Python packages might missing: cython, opencv-python >= 3.2.0, easydict. If `pip` is set up on your system, those packages should be able to be fetched and installed by running\n\t```\n\tpip install Cython\n\tpip install opencv-python==3.2.0.6\n\tpip install easydict==1.6\n\t```\n4. For Windows users, Visual Studio 2015 is needed to compile cython module.\n\n\n## Requirements: Hardware\n\nAny NVIDIA GPUs with at least 6GB memory should be OK\n\n## Installation\n\n1. Clone the Deep Feature Flow repository, and we'll call the directory that you cloned Deep-Feature-Flow as ${DFF_ROOT}. \n\n~~~\ngit clone https://github.com/msracver/Deep-Feature-Flow.git\n~~~\n2. For Windows users, run ``cmd .\\init.bat``. For Linux user, run `sh ./init.sh`. The scripts will build cython module automatically and create some folders.\n\n3. Install MXNet:\n\n\t3.1 Clone MXNet and checkout to [MXNet@(commit 62ecb60)] by\n\t```\n\tgit clone --recursive https://github.com/dmlc/mxnet.git\n\tgit checkout 62ecb60\n\tgit submodule update\n\t```\n\t3.2 Copy operators in `$(DFF_ROOT)/dff_rfcn/operator_cxx` or `$(DFF_ROOT)/rfcn/operator_cxx` to `$(YOUR_MXNET_FOLDER)/src/operator/contrib` by\n\t```\n\tcp -r $(DFF_ROOT)/dff_rfcn/operator_cxx/* $(MXNET_ROOT)/src/operator/contrib/\n\t```\n\t3.3 Compile MXNet\n\t```\n\tcd ${MXNET_ROOT}\n\tmake -j4\n\t```\n\t3.4 Install the MXNet Python binding by\n\t\n\t***Note: If you will actively switch between different versions of MXNet, please follow 3.5 instead of 3.4***\n\t```\n\tcd python\n\tsudo python setup.py install\n\t```\n\t3.5 For advanced users, you may put your Python packge into `./external/mxnet/$(YOUR_MXNET_PACKAGE)`, and modify `MXNET_VERSION` in `./experiments/dff_rfcn/cfgs/*.yaml` to `$(YOUR_MXNET_PACKAGE)`. Thus you can switch among different versions of MXNet quickly.\n\n\n## Demo\n\n\n1. To run the demo with our trained model (on ImageNet DET + VID train), please download the model manually from [OneDrive](for users from Mainland China, please try [Baidu Yun]), and put it under folder `model/`.\n\n\tMake sure it looks like this:\n\t```\n\t./model/rfcn_vid-0000.params\n\t./model/rfcn_dff_flownet_vid-0000.params\n\t```\n2. Run (inference batch size = 1)\n\t```\n\tpython ./rfcn/demo.py\n\tpython ./dff_rfcn/demo.py\n\t```\n\tor run (inference batch size = 10)\n\t```\n\tpython ./rfcn/demo_batch.py\n\tpython ./dff_rfcn/demo_batch.py\n\t```\n\n## Preparation for Training & Testing\n\n1. Please download ILSVRC2015 DET and ILSVRC2015 VID dataset, and make sure it looks like this:\n\n\t```\n\t./data/ILSVRC2015/\n\t./data/ILSVRC2015/Annotations/DET\n\t./data/ILSVRC2015/Annotations/VID\n\t./data/ILSVRC2015/Data/DET\n\t./data/ILSVRC2015/Data/VID\n\t./data/ILSVRC2015/ImageSets\n\t```\n\n## FAQ\n\nQ: It says `AttributeError: 'module' object has no attribute 'MultiProposal'`.\n\nA: This is because either\n - you forget to copy the operators to your MXNet folder\n - or you copy to the wrong path\n - or you forget to re-compile and install\n - or you install the wrong MXNet\n\n Please print `mxnet.__path__` to make sure you use correct MXNet\n\n
\nQ: I encounter `segment fault` at the beginning.\n\nA: A compatibility issue has been identified between MXNet and opencv-python 3.0+. We suggest that you always `import cv2` first before `import mxnet` in the entry script. \n\n
\nQ: I find the training speed becomes slower when training for a long time.\n\nA: It has been identified that MXNet on Windows has this problem. So we recommend to run this program on Linux. You could also stop it and resume the training process to regain the training speed if you encounter this problem.\n\n
\nQ: Can you share your caffe implementation?\n\nA: Due to several reasons (code is based on a old, internal Caffe, port to public Caffe needs extra work, time limit, etc.). We do not plan to release our Caffe code. Since a warping layer is easy to implement, anyone who wish to do it is welcome to make a pull request.\n"
},
{
"path": "ThirdPartyNotices.txt",
"content": "Deep Feature Flow\n\nTHIRD-PARTY SOFTWARE NOTICES AND INFORMATION\n\nThis project incorporates components from the projects listed below. The original copyright notices and the licenses under which Microsoft received such components are set forth below. Microsoft reserves all rights not expressly granted herein, whether by implication, estoppel or otherwise.\n\n1. MXNet (https://github.com/apache/incubator-mxnet)\n2. Fast R-CNN (https://github.com/rbgirshick/fast-rcnn)\n3. Faster R-CNN (https://github.com/rbgirshick/py-faster-rcnn)\n4. MS COCO API (https://github.com/cocodataset/cocoapi)\n\n\nMXNet\n\nCopyright (c) 2015-2016 by Contributors\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.\n\n\nFast R-CNN\n\nCopyright (c) Microsoft Corporation\n\nAll rights reserved.\n\nMIT License\n\nPermission is hereby granted, free of charge, to any person obtaining a\ncopy of this software and associated documentation files (the \"Software\"),\nto deal in the Software without restriction, including without limitation\nthe rights to use, copy, modify, merge, publish, distribute, sublicense,\nand/or sell copies of the Software, and to permit persons to whom the\nSoftware is furnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included\nin all copies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED *AS IS*, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\nIMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\nFITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL\nTHE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\nOTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE,\nARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR\nOTHER DEALINGS IN THE SOFTWARE.\n\n\nFaster R-CNN\n\nThe MIT License (MIT)\n\nCopyright (c) 2015 Microsoft Corporation\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof this software and associated documentation files (the \"Software\"), to deal\nin the Software without restriction, including without limitation the rights\nto use, copy, modify, merge, publish, distribute, sublicense, and/or sell\ncopies of the Software, and to permit persons to whom the Software is\nfurnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in\nall copies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\nIMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\nFITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\nAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\nLIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\nOUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN\nTHE SOFTWARE.\n\n\nMS COCO API\n\nCopyright (c) 2014, Piotr Dollar and Tsung-Yi Lin\nAll rights reserved.\n\nRedistribution and use in source and binary forms, with or without\nmodification, are permitted provided that the following conditions are met:\n\n1. Redistributions of source code must retain the above copyright notice, this\n list of conditions and the following disclaimer.\n2. Redistributions in binary form must reproduce the above copyright notice,\n this list of conditions and the following disclaimer in the documentation\n and/or other materials provided with the distribution.\n\nTHIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\" AND\nANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED\nWARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\nDISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR\nANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES\n(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\nLOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND\nON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT\n(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS\nSOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nThe views and conclusions contained in the software and documentation are those\nof the authors and should not be interpreted as representing official policies,\neither expressed or implied, of the FreeBSD Project.\n"
},
{
"path": "dff_rfcn/__init__.py",
"content": ""
},
{
"path": "dff_rfcn/_init_paths.py",
"content": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed under The MIT License [see LICENSE for details]\n# Written by Yuwen Xiong\n# --------------------------------------------------------\n\nimport os.path as osp\nimport sys\n\ndef add_path(path):\n if path not in sys.path:\n sys.path.insert(0, path)\n\nthis_dir = osp.dirname(__file__)\n\nlib_path = osp.join(this_dir, '..', 'lib')\nadd_path(lib_path)\n"
},
{
"path": "dff_rfcn/config/__init__.py",
"content": ""
},
{
"path": "dff_rfcn/config/config.py",
"content": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed under The MIT License [see LICENSE for details]\n# Modified by Xizhou Zhu, Yuwen Xiong, Bin Xiao\n# --------------------------------------------------------\n# Based on:\n# MX-RCNN\n# Copyright (c) 2016 by Contributors\n# Licence under The Apache 2.0 License\n# https://github.com/ijkguo/mx-rcnn/\n# --------------------------------------------------------\n\nimport yaml\nimport numpy as np\nfrom easydict import EasyDict as edict\n\nconfig = edict()\n\nconfig.MXNET_VERSION = ''\nconfig.output_path = ''\nconfig.symbol = ''\nconfig.gpus = ''\nconfig.CLASS_AGNOSTIC = True\nconfig.SCALES = [(600, 1000)] # first is scale (the shorter side); second is max size\n\n# default training\nconfig.default = edict()\nconfig.default.frequent = 20\nconfig.default.kvstore = 'device'\n\n# network related params\nconfig.network = edict()\nconfig.network.pretrained = ''\nconfig.network.pretrained_flow = ''\nconfig.network.pretrained_epoch = 0\nconfig.network.PIXEL_MEANS = np.array([0, 0, 0])\nconfig.network.IMAGE_STRIDE = 0\nconfig.network.RPN_FEAT_STRIDE = 16\nconfig.network.RCNN_FEAT_STRIDE = 16\nconfig.network.FIXED_PARAMS = ['gamma', 'beta']\nconfig.network.ANCHOR_SCALES = (8, 16, 32)\nconfig.network.ANCHOR_RATIOS = (0.5, 1, 2)\nconfig.network.NORMALIZE_RPN = True\nconfig.network.ANCHOR_MEANS = (0.0, 0.0, 0.0, 0.0)\nconfig.network.ANCHOR_STDS = (0.1, 0.1, 0.4, 0.4)\nconfig.network.NUM_ANCHORS = len(config.network.ANCHOR_SCALES) * len(config.network.ANCHOR_RATIOS)\nconfig.network.DFF_FEAT_DIM = 1024\n\n# dataset related params\nconfig.dataset = edict()\nconfig.dataset.dataset = 'ImageNetVID'\nconfig.dataset.image_set = 'DET_train_30classes+VID_train_15frames'\nconfig.dataset.test_image_set = 'VID_val_videos'\nconfig.dataset.root_path = './data'\nconfig.dataset.dataset_path = './data/ILSVRC2015'\nconfig.dataset.NUM_CLASSES = 31\n\n\nconfig.TRAIN = edict()\n\nconfig.TRAIN.lr = 0\nconfig.TRAIN.lr_step = ''\nconfig.TRAIN.lr_factor = 0.1\nconfig.TRAIN.warmup = False\nconfig.TRAIN.warmup_lr = 0\nconfig.TRAIN.warmup_step = 0\nconfig.TRAIN.momentum = 0.9\nconfig.TRAIN.wd = 0.0005\nconfig.TRAIN.begin_epoch = 0\nconfig.TRAIN.end_epoch = 0\nconfig.TRAIN.model_prefix = ''\n\n# whether resume training\nconfig.TRAIN.RESUME = False\n# whether flip image\nconfig.TRAIN.FLIP = True\n# whether shuffle image\nconfig.TRAIN.SHUFFLE = True\n# whether use OHEM\nconfig.TRAIN.ENABLE_OHEM = False\n# size of images for each device, 2 for rcnn, 1 for rpn and e2e\nconfig.TRAIN.BATCH_IMAGES = 2\n# e2e changes behavior of anchor loader and metric\nconfig.TRAIN.END2END = False\n# group images with similar aspect ratio\nconfig.TRAIN.ASPECT_GROUPING = True\n\n# R-CNN\n# rcnn rois batch size\nconfig.TRAIN.BATCH_ROIS = 128\nconfig.TRAIN.BATCH_ROIS_OHEM = 128\n# rcnn rois sampling params\nconfig.TRAIN.FG_FRACTION = 0.25\nconfig.TRAIN.FG_THRESH = 0.5\nconfig.TRAIN.BG_THRESH_HI = 0.5\nconfig.TRAIN.BG_THRESH_LO = 0.0\n# rcnn bounding box regression params\nconfig.TRAIN.BBOX_REGRESSION_THRESH = 0.5\nconfig.TRAIN.BBOX_WEIGHTS = np.array([1.0, 1.0, 1.0, 1.0])\n\n# RPN anchor loader\n# rpn anchors batch size\nconfig.TRAIN.RPN_BATCH_SIZE = 256\n# rpn anchors sampling params\nconfig.TRAIN.RPN_FG_FRACTION = 0.5\nconfig.TRAIN.RPN_POSITIVE_OVERLAP = 0.7\nconfig.TRAIN.RPN_NEGATIVE_OVERLAP = 0.3\nconfig.TRAIN.RPN_CLOBBER_POSITIVES = False\n# rpn bounding box regression params\nconfig.TRAIN.RPN_BBOX_WEIGHTS = (1.0, 1.0, 1.0, 1.0)\nconfig.TRAIN.RPN_POSITIVE_WEIGHT = -1.0\n\n# used for end2end training\n# RPN proposal\nconfig.TRAIN.CXX_PROPOSAL = True\nconfig.TRAIN.RPN_NMS_THRESH = 0.7\nconfig.TRAIN.RPN_PRE_NMS_TOP_N = 12000\nconfig.TRAIN.RPN_POST_NMS_TOP_N = 2000\nconfig.TRAIN.RPN_MIN_SIZE = config.network.RPN_FEAT_STRIDE\n# approximate bounding box regression\nconfig.TRAIN.BBOX_NORMALIZATION_PRECOMPUTED = True\nconfig.TRAIN.BBOX_MEANS = (0.0, 0.0, 0.0, 0.0)\nconfig.TRAIN.BBOX_STDS = (0.1, 0.1, 0.2, 0.2)\n\n# DFF, trained image sampled from [min_offset, max_offset]\nconfig.TRAIN.MIN_OFFSET = -9\nconfig.TRAIN.MAX_OFFSET = 0\n\nconfig.TEST = edict()\n\n# R-CNN testing\n# use rpn to generate proposal\nconfig.TEST.HAS_RPN = False\n# size of images for each device\nconfig.TEST.BATCH_IMAGES = 1\n\n# RPN proposal\nconfig.TEST.CXX_PROPOSAL = True\nconfig.TEST.RPN_NMS_THRESH = 0.7\nconfig.TEST.RPN_PRE_NMS_TOP_N = 6000\nconfig.TEST.RPN_POST_NMS_TOP_N = 300\nconfig.TEST.RPN_MIN_SIZE = config.network.RPN_FEAT_STRIDE\n\n# RCNN nms\nconfig.TEST.NMS = 0.3\n\n# DFF\nconfig.TEST.KEY_FRAME_INTERVAL = 10\n\nconfig.TEST.max_per_image = 300\n\n# Test Model Epoch\nconfig.TEST.test_epoch = 0\n\n\ndef update_config(config_file):\n exp_config = None\n with open(config_file) as f:\n exp_config = edict(yaml.load(f))\n for k, v in exp_config.items():\n if k in config:\n if isinstance(v, dict):\n if k == 'TRAIN':\n if 'BBOX_WEIGHTS' in v:\n v['BBOX_WEIGHTS'] = np.array(v['BBOX_WEIGHTS'])\n elif k == 'network':\n if 'PIXEL_MEANS' in v:\n v['PIXEL_MEANS'] = np.array(v['PIXEL_MEANS'])\n for vk, vv in v.items():\n config[k][vk] = vv\n else:\n if k == 'SCALES':\n config[k][0] = (tuple(v))\n else:\n config[k] = v\n else:\n raise ValueError(\"key must exist in config.py\")\n"
},
{
"path": "dff_rfcn/core/DataParallelExecutorGroup.py",
"content": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed under The MIT License [see LICENSE for details]\n# Modified by Yuwen Xiong\n# --------------------------------------------------------\n# Based on:\n# MX-RCNN\n# Copyright (c) 2016 by Contributors\n# Licence under The Apache 2.0 License\n# https://github.com/ijkguo/mx-rcnn/\n# --------------------------------------------------------\n\nimport logging\nimport numpy as np\n\nfrom mxnet import context as ctx\nfrom mxnet import ndarray as nd\nfrom mxnet.io import DataDesc\nfrom mxnet.executor_manager import _split_input_slice\n\n\n\ndef _load_general(data, targets, major_axis):\n \"\"\"Load a list of arrays into a list of arrays specified by slices\"\"\"\n for d_src, d_targets in zip(data, targets):\n if isinstance(d_targets, nd.NDArray):\n d_src.copyto(d_targets)\n elif isinstance(d_src, (list, tuple)):\n for src, dst in zip(d_src, d_targets):\n src.copyto(dst)\n else:\n raise NotImplementedError\n\n\n\ndef _load_data(batch, targets, major_axis):\n \"\"\"Load data into sliced arrays\"\"\"\n _load_general(batch.data, targets, major_axis)\n\n\ndef _load_label(batch, targets, major_axis):\n \"\"\"Load label into sliced arrays\"\"\"\n _load_general(batch.label, targets, major_axis)\n\n\ndef _merge_multi_context(outputs, major_axis):\n \"\"\"Merge outputs that lives on multiple context into one, so that they look\n like living on one context.\n \"\"\"\n rets = []\n for tensors, axis in zip(outputs, major_axis):\n if axis >= 0:\n rets.append(nd.concatenate(tensors, axis=axis, always_copy=False))\n else:\n # negative axis means the there is no batch_size axis, and all the\n # results should be the same on each device. We simply take the\n # first one, without checking they are actually the same\n rets.append(tensors[0])\n return rets\n\n\n\nclass DataParallelExecutorGroup(object):\n \"\"\"DataParallelExecutorGroup is a group of executors that lives on a group of devices.\n This is a helper class used to implement data parallelization. Each mini-batch will\n be split and run on the devices.\n\n Parameters\n ----------\n symbol : Symbol\n The common symbolic computation graph for all executors.\n contexts : list\n A list of contexts.\n workload : list\n If not `None`, could be a list of numbers that specify the workload to be assigned\n to different context. Larger number indicate heavier workload.\n data_shapes : list\n Should be a list of (name, shape) tuples, for the shapes of data. Note the order is\n important and should be the same as the order that the `DataIter` provide the data.\n label_shapes : list\n Should be a list of (name, shape) tuples, for the shapes of label. Note the order is\n important and should be the same as the order that the `DataIter` provide the label.\n param_names : list\n A list of strings, indicating the names of parameters (e.g. weights, filters, etc.)\n in the computation graph.\n for_training : bool\n Indicate whether the executors should be bind for training. When not doing training,\n the memory for gradients will not be allocated.\n inputs_need_grad : bool\n Indicate whether the gradients for the input data should be computed. This is currently\n not used. It will be useful for implementing composition of modules.\n shared_group : DataParallelExecutorGroup\n Default is `None`. This is used in bucketing. When not `None`, it should be a executor\n group corresponding to a different bucket. In other words, it will correspond to a different\n symbol but with the same set of parameters (e.g. unrolled RNNs with different lengths).\n In this case, many memory will be shared.\n logger : Logger\n Default is `logging`.\n fixed_param_names: list of str\n Indicate parameters to be fixed during training. Parameters in this list will not allocate\n space for gradient, nor do gradient calculation.\n grad_req : str, list of str, dict of str to str\n Requirement for gradient accumulation. Can be 'write', 'add', or 'null'\n (default to 'write').\n Can be specified globally (str) or for each argument (list, dict).\n \"\"\"\n def __init__(self, symbol, contexts, workload, data_shapes, label_shapes, param_names,\n for_training, inputs_need_grad, shared_group=None, logger=logging,\n fixed_param_names=None, grad_req='write', state_names=None):\n self.param_names = param_names\n self.arg_names = symbol.list_arguments()\n self.aux_names = symbol.list_auxiliary_states()\n\n self.symbol = symbol\n self.contexts = contexts\n self.workload = workload\n\n self.for_training = for_training\n self.inputs_need_grad = inputs_need_grad\n\n self.logger = logger\n #In the future we should have a better way to profile memory per device (haibin)\n # self._total_exec_bytes = 0\n self.fixed_param_names = fixed_param_names\n if self.fixed_param_names is None:\n self.fixed_param_names = []\n\n self.state_names = state_names\n if self.state_names is None:\n self.state_names = []\n\n if not for_training:\n grad_req = 'null'\n\n # data_shapes = [x if isinstance(x, DataDesc) else DataDesc(*x) for x in data_shapes]\n # if label_shapes is not None:\n # label_shapes = [x if isinstance(x, DataDesc) else DataDesc(*x) for x in label_shapes]\n\n data_names = [x.name for x in data_shapes[0]]\n\n if isinstance(grad_req, str):\n self.grad_req = {}\n for k in self.arg_names:\n if k in self.param_names:\n self.grad_req[k] = 'null' if k in self.fixed_param_names else grad_req\n elif k in data_names:\n self.grad_req[k] = grad_req if self.inputs_need_grad else 'null'\n else:\n self.grad_req[k] = 'null'\n elif isinstance(grad_req, (list, tuple)):\n assert len(grad_req) == len(self.arg_names)\n self.grad_req = dict(zip(self.arg_names, grad_req))\n elif isinstance(grad_req, dict):\n self.grad_req = {}\n for k in self.arg_names:\n if k in self.param_names:\n self.grad_req[k] = 'null' if k in self.fixed_param_names else 'write'\n elif k in data_names:\n self.grad_req[k] = 'write' if self.inputs_need_grad else 'null'\n else:\n self.grad_req[k] = 'null'\n self.grad_req.update(grad_req)\n else:\n raise ValueError(\"grad_req must be one of str, list, tuple, or dict.\")\n\n if shared_group is not None:\n self.shared_data_arrays = shared_group.shared_data_arrays\n else:\n self.shared_data_arrays = [{} for _ in contexts]\n\n # initialize some instance variables\n self.batch_size = len(data_shapes)\n self.slices = None\n self.execs = []\n self._default_execs = None\n self.data_arrays = None\n self.label_arrays = None\n self.param_arrays = None\n self.state_arrays = None\n self.grad_arrays = None\n self.aux_arrays = None\n self.input_grad_arrays = None\n\n self.data_shapes = None\n self.label_shapes = None\n self.data_layouts = None\n self.label_layouts = None\n self.output_layouts = [DataDesc.get_batch_axis(self.symbol[name].attr('__layout__'))\n for name in self.symbol.list_outputs()]\n self.bind_exec(data_shapes, label_shapes, shared_group)\n\n def decide_slices(self, data_shapes):\n \"\"\"Decide the slices for each context according to the workload.\n\n Parameters\n ----------\n data_shapes : list\n list of (name, shape) specifying the shapes for the input data or label.\n \"\"\"\n assert len(data_shapes) > 0\n major_axis = [DataDesc.get_batch_axis(x.layout) for x in data_shapes]\n\n for (name, shape), axis in zip(data_shapes, major_axis):\n if axis == -1:\n continue\n\n batch_size = shape[axis]\n if self.batch_size is not None:\n assert batch_size == self.batch_size, (\"all data must have the same batch size: \"\n + (\"batch_size = %d, but \" % self.batch_size)\n + (\"%s has shape %s\" % (name, shape)))\n else:\n self.batch_size = batch_size\n self.slices = _split_input_slice(self.batch_size, self.workload)\n\n return major_axis\n\n def _collect_arrays(self):\n \"\"\"Collect internal arrays from executors.\"\"\"\n # convenient data structures\n self.data_arrays = [[e.arg_dict[name] for name, _ in self.data_shapes[0]] for e in self.execs]\n\n self.state_arrays = [[e.arg_dict[name] for e in self.execs]\n for name in self.state_names]\n\n if self.label_shapes is not None:\n self.label_arrays = [[e.arg_dict[name] for name, _ in self.label_shapes[0]] for e in self.execs]\n else:\n self.label_arrays = None\n\n self.param_arrays = [[exec_.arg_arrays[i] for exec_ in self.execs]\n for i, name in enumerate(self.arg_names)\n if name in self.param_names]\n if self.for_training:\n self.grad_arrays = [[exec_.grad_arrays[i] for exec_ in self.execs]\n for i, name in enumerate(self.arg_names)\n if name in self.param_names]\n else:\n self.grad_arrays = None\n\n data_names = [x[0] for x in self.data_shapes]\n if self.inputs_need_grad:\n self.input_grad_arrays = [[exec_.grad_arrays[i] for exec_ in self.execs]\n for i, name in enumerate(self.arg_names)\n if name in data_names]\n else:\n self.input_grad_arrays = None\n\n self.aux_arrays = [[exec_.aux_arrays[i] for exec_ in self.execs]\n for i in range(len(self.aux_names))]\n\n def bind_exec(self, data_shapes, label_shapes, shared_group=None, reshape=False):\n \"\"\"Bind executors on their respective devices.\n\n Parameters\n ----------\n data_shapes : list\n label_shapes : list\n shared_group : DataParallelExecutorGroup\n reshape : bool\n \"\"\"\n assert reshape or not self.execs\n\n for i in range(len(self.contexts)):\n data_shapes_i = data_shapes[i]\n if label_shapes is not None:\n label_shapes_i = label_shapes[i]\n else:\n label_shapes_i = []\n\n if reshape:\n self.execs[i] = self._default_execs[i].reshape(\n allow_up_sizing=True, **dict(data_shapes_i + label_shapes_i))\n else:\n self.execs.append(self._bind_ith_exec(i, data_shapes_i, label_shapes_i,\n shared_group))\n\n self.data_shapes = data_shapes\n self.label_shapes = label_shapes\n self._collect_arrays()\n\n def reshape(self, data_shapes, label_shapes):\n \"\"\"Reshape executors.\n\n Parameters\n ----------\n data_shapes : list\n label_shapes : list\n \"\"\"\n if self._default_execs is None:\n self._default_execs = [i for i in self.execs]\n for i in range(len(self.contexts)):\n self.execs[i] = self._default_execs[i].reshape(\n allow_up_sizing=True, **dict(data_shapes[i] + (label_shapes[i] if label_shapes is not None else []))\n )\n self.data_shapes = data_shapes\n self.label_shapes = label_shapes\n self._collect_arrays()\n\n\n def set_params(self, arg_params, aux_params):\n \"\"\"Assign, i.e. copy parameters to all the executors.\n\n Parameters\n ----------\n arg_params : dict\n A dictionary of name to `NDArray` parameter mapping.\n aux_params : dict\n A dictionary of name to `NDArray` auxiliary variable mapping.\n \"\"\"\n for exec_ in self.execs:\n exec_.copy_params_from(arg_params, aux_params)\n\n def get_params(self, arg_params, aux_params):\n \"\"\" Copy data from each executor to `arg_params` and `aux_params`.\n\n Parameters\n ----------\n arg_params : list of NDArray\n target parameter arrays\n aux_params : list of NDArray\n target aux arrays\n\n Notes\n -----\n - This function will inplace update the NDArrays in arg_params and aux_params.\n \"\"\"\n for name, block in zip(self.param_names, self.param_arrays):\n weight = sum(w.copyto(ctx.cpu()) for w in block) / len(block)\n weight.astype(arg_params[name].dtype).copyto(arg_params[name])\n for name, block in zip(self.aux_names, self.aux_arrays):\n weight = sum(w.copyto(ctx.cpu()) for w in block) / len(block)\n weight.astype(aux_params[name].dtype).copyto(aux_params[name])\n\n def forward(self, data_batch, is_train=None):\n \"\"\"Split `data_batch` according to workload and run forward on each devices.\n\n Parameters\n ----------\n data_batch : DataBatch\n Or could be any object implementing similar interface.\n is_train : bool\n The hint for the backend, indicating whether we are during training phase.\n Default is `None`, then the value `self.for_training` will be used.\n Returns\n -------\n\n \"\"\"\n _load_data(data_batch, self.data_arrays, self.data_layouts)\n if is_train is None:\n is_train = self.for_training\n\n if self.label_arrays is not None:\n assert not is_train or data_batch.label\n if data_batch.label:\n _load_label(data_batch, self.label_arrays, self.label_layouts)\n\n for exec_ in self.execs:\n exec_.forward(is_train=is_train)\n\n\n def get_outputs(self, merge_multi_context=True):\n \"\"\"Get outputs of the previous forward computation.\n\n Parameters\n ----------\n merge_multi_context : bool\n Default is `True`. In the case when data-parallelism is used, the outputs\n will be collected from multiple devices. A `True` value indicate that we\n should merge the collected results so that they look like from a single\n executor.\n\n Returns\n -------\n If `merge_multi_context` is `True`, it is like `[out1, out2]`. Otherwise, it\n is like `[[out1_dev1, out1_dev2], [out2_dev1, out2_dev2]]`. All the output\n elements are `NDArray`.\n \"\"\"\n outputs = [[exec_.outputs[i] for exec_ in self.execs]\n for i in range(len(self.execs[0].outputs))]\n if merge_multi_context:\n outputs = _merge_multi_context(outputs, self.output_layouts)\n return outputs\n\n def get_states(self, merge_multi_context=True):\n \"\"\"Get states from all devices\n\n Parameters\n ----------\n merge_multi_context : bool\n Default is `True`. In the case when data-parallelism is used, the states\n will be collected from multiple devices. A `True` value indicate that we\n should merge the collected results so that they look like from a single\n executor.\n\n Returns\n -------\n If `merge_multi_context` is `True`, it is like `[out1, out2]`. Otherwise, it\n is like `[[out1_dev1, out1_dev2], [out2_dev1, out2_dev2]]`. All the output\n elements are `NDArray`.\n \"\"\"\n assert not merge_multi_context, \\\n \"merge_multi_context=True is not supported for get_states yet.\"\n return self.state_arrays\n\n def set_states(self, states=None, value=None):\n \"\"\"Set value for states. Only one of states & value can be specified.\n\n Parameters\n ----------\n states : list of list of NDArrays\n source states arrays formatted like [[state1_dev1, state1_dev2],\n [state2_dev1, state2_dev2]].\n value : number\n a single scalar value for all state arrays.\n \"\"\"\n if states is not None:\n assert value is None, \"Only one of states & value can be specified.\"\n _load_general(states, self.state_arrays, (0,)*len(states))\n else:\n assert value is not None, \"At least one of states & value must be specified.\"\n assert states is None, \"Only one of states & value can be specified.\"\n for d_dst in self.state_arrays:\n for dst in d_dst:\n dst[:] = value\n\n def get_input_grads(self, merge_multi_context=True):\n \"\"\"Get the gradients with respect to the inputs of the module.\n\n Parameters\n ----------\n merge_multi_context : bool\n Default is `True`. In the case when data-parallelism is used, the outputs\n will be collected from multiple devices. A `True` value indicate that we\n should merge the collected results so that they look like from a single\n executor.\n\n Returns\n -------\n If `merge_multi_context` is `True`, it is like `[grad1, grad2]`. Otherwise, it\n is like `[[grad1_dev1, grad1_dev2], [grad2_dev1, grad2_dev2]]`. All the output\n elements are `NDArray`.\n \"\"\"\n assert self.inputs_need_grad\n if merge_multi_context:\n return _merge_multi_context(self.input_grad_arrays, self.data_layouts)\n return self.input_grad_arrays\n\n def backward(self, out_grads=None):\n \"\"\"Run backward on all devices. A backward should be called after\n a call to the forward function. Backward cannot be called unless\n `self.for_training` is `True`.\n\n Parameters\n ----------\n out_grads : NDArray or list of NDArray, optional\n Gradient on the outputs to be propagated back.\n This parameter is only needed when bind is called\n on outputs that are not a loss function.\n \"\"\"\n assert self.for_training, 're-bind with for_training=True to run backward'\n if out_grads is None:\n out_grads = []\n\n for i, exec_ in enumerate(self.execs):\n out_grads_slice = []\n exec_.backward(out_grads=out_grads_slice)\n\n def update_metric(self, eval_metric, labels):\n \"\"\"Accumulate the performance according to `eval_metric` on all devices.\n\n Parameters\n ----------\n eval_metric : EvalMetric\n The metric used for evaluation.\n labels : list of NDArray\n Typically comes from `label` of a `DataBatch`.\n \"\"\"\n for texec, labels in zip(self.execs, labels):\n eval_metric.update(labels, texec.outputs)\n\n def _bind_ith_exec(self, i, data_shapes, label_shapes, shared_group):\n \"\"\"Internal utility function to bind the i-th executor.\n \"\"\"\n shared_exec = None if shared_group is None else shared_group.execs[i]\n context = self.contexts[i]\n shared_data_arrays = self.shared_data_arrays[i]\n\n input_shapes = dict(data_shapes)\n if label_shapes is not None:\n input_shapes.update(dict(label_shapes))\n\n arg_shapes, _, aux_shapes = self.symbol.infer_shape(**input_shapes)\n assert arg_shapes is not None, \"shape inference failed\"\n\n input_types = {x.name: x.dtype for x in data_shapes}\n if label_shapes is not None:\n input_types.update({x.name: x.dtype for x in label_shapes})\n arg_types, _, aux_types = self.symbol.infer_type(**input_types)\n assert arg_types is not None, \"type inference failed\"\n\n arg_arrays = []\n grad_arrays = {} if self.for_training else None\n\n def _get_or_reshape(name, shared_data_arrays, arg_shape, arg_type, context, logger):\n \"\"\"Internal helper to get a memory block or re-use by re-shaping\"\"\"\n if name in shared_data_arrays:\n arg_arr = shared_data_arrays[name]\n\n if np.prod(arg_arr.shape) >= np.prod(arg_shape):\n # nice, we can directly re-use this data blob\n assert arg_arr.dtype == arg_type\n arg_arr = arg_arr.reshape(arg_shape)\n else:\n logger.warning(('bucketing: data \"%s\" has a shape %s' % (name, arg_shape)) +\n (', which is larger than already allocated ') +\n ('shape %s' % (arg_arr.shape,)) +\n ('. Need to re-allocate. Consider putting ') +\n ('default_bucket_key to') +\n (' be the bucket taking the largest input for better ') +\n ('memory sharing.'))\n arg_arr = nd.zeros(arg_shape, context, dtype=arg_type)\n\n # replace existing shared array because the new one is bigger\n shared_data_arrays[name] = arg_arr\n else:\n arg_arr = nd.zeros(arg_shape, context, dtype=arg_type)\n shared_data_arrays[name] = arg_arr\n\n return arg_arr\n\n # create or borrow arguments and gradients\n for j in range(len(self.arg_names)):\n name = self.arg_names[j]\n if name in self.param_names: # model parameters\n if shared_exec is None:\n arg_arr = nd.zeros(arg_shapes[j], context, dtype=arg_types[j])\n if self.grad_req[name] != 'null':\n grad_arr = nd.zeros(arg_shapes[j], context, dtype=arg_types[j])\n grad_arrays[name] = grad_arr\n else:\n arg_arr = shared_exec.arg_dict[name]\n assert arg_arr.shape == arg_shapes[j]\n assert arg_arr.dtype == arg_types[j]\n if self.grad_req[name] != 'null':\n grad_arrays[name] = shared_exec.grad_dict[name]\n else: # data, label, or states\n arg_arr = _get_or_reshape(name, shared_data_arrays, arg_shapes[j], arg_types[j],\n context, self.logger)\n\n # data might also need grad if inputs_need_grad is True\n if self.grad_req[name] != 'null':\n grad_arrays[name] = _get_or_reshape('grad of ' + name, shared_data_arrays,\n arg_shapes[j], arg_types[j], context,\n self.logger)\n\n arg_arrays.append(arg_arr)\n\n # create or borrow aux variables\n if shared_exec is None:\n aux_arrays = [nd.zeros(s, context, dtype=t) for s, t in zip(aux_shapes, aux_types)]\n else:\n for j, arr in enumerate(shared_exec.aux_arrays):\n assert aux_shapes[j] == arr.shape\n assert aux_types[j] == arr.dtype\n aux_arrays = shared_exec.aux_arrays[:]\n\n executor = self.symbol.bind(ctx=context, args=arg_arrays,\n args_grad=grad_arrays, aux_states=aux_arrays,\n grad_req=self.grad_req, shared_exec=shared_exec)\n # Get the total bytes allocated for this executor\n return executor\n\n def _sliced_shape(self, shapes, i, major_axis):\n \"\"\"Get the sliced shapes for the i-th executor.\n\n Parameters\n ----------\n shapes : list of (str, tuple)\n The original (name, shape) pairs.\n i : int\n Which executor we are dealing with.\n \"\"\"\n sliced_shapes = []\n for desc, axis in zip(shapes, major_axis):\n shape = list(desc.shape)\n if axis >= 0:\n shape[axis] = self.slices[i].stop - self.slices[i].start\n sliced_shapes.append(DataDesc(desc.name, tuple(shape), desc.dtype, desc.layout))\n return sliced_shapes\n\n def install_monitor(self, mon):\n \"\"\"Install monitor on all executors\"\"\"\n for exe in self.execs:\n mon.install(exe)\n"
},
{
"path": "dff_rfcn/core/__init__.py",
"content": ""
},
{
"path": "dff_rfcn/core/callback.py",
"content": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed under The MIT License [see LICENSE for details]\n# Modified by Yuwen Xiong\n# --------------------------------------------------------\n# Based on:\n# MX-RCNN\n# Copyright (c) 2016 by Contributors\n# Licence under The Apache 2.0 License\n# https://github.com/ijkguo/mx-rcnn/\n# --------------------------------------------------------\n\nimport time\nimport logging\nimport mxnet as mx\n\n\nclass Speedometer(object):\n def __init__(self, batch_size, frequent=50):\n self.batch_size = batch_size\n self.frequent = frequent\n self.init = False\n self.tic = 0\n self.last_count = 0\n\n def __call__(self, param):\n \"\"\"Callback to Show speed.\"\"\"\n count = param.nbatch\n if self.last_count > count:\n self.init = False\n self.last_count = count\n\n if self.init:\n if count % self.frequent == 0:\n speed = self.frequent * self.batch_size / (time.time() - self.tic)\n s = ''\n if param.eval_metric is not None:\n name, value = param.eval_metric.get()\n s = \"Epoch[%d] Batch [%d]\\tSpeed: %.2f samples/sec\\tTrain-\" % (param.epoch, count, speed)\n for n, v in zip(name, value):\n s += \"%s=%f,\\t\" % (n, v)\n else:\n s = \"Iter[%d] Batch [%d]\\tSpeed: %.2f samples/sec\" % (param.epoch, count, speed)\n\n logging.info(s)\n print(s)\n self.tic = time.time()\n else:\n self.init = True\n self.tic = time.time()\n\n\ndef do_checkpoint(prefix, means, stds):\n def _callback(iter_no, sym, arg, aux):\n weight = arg['rfcn_bbox_weight']\n bias = arg['rfcn_bbox_bias']\n repeat = bias.shape[0] / means.shape[0]\n\n arg['rfcn_bbox_weight_test'] = weight * mx.nd.repeat(mx.nd.array(stds), repeats=repeat).reshape((bias.shape[0], 1, 1, 1))\n arg['rfcn_bbox_bias_test'] = arg['rfcn_bbox_bias'] * mx.nd.repeat(mx.nd.array(stds), repeats=repeat) + mx.nd.repeat(mx.nd.array(means), repeats=repeat)\n mx.model.save_checkpoint(prefix, iter_no + 1, sym, arg, aux)\n arg.pop('rfcn_bbox_weight_test')\n arg.pop('rfcn_bbox_bias_test')\n return _callback"
},
{
"path": "dff_rfcn/core/loader.py",
"content": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed under The MIT License [see LICENSE for details]\n# Modified by Xizhou Zhu, Yuwen Xiong\n# --------------------------------------------------------\n# Based on:\n# MX-RCNN\n# Copyright (c) 2016 by Contributors\n# Licence under The Apache 2.0 License\n# https://github.com/ijkguo/mx-rcnn/\n# --------------------------------------------------------\n\nimport numpy as np\nimport mxnet as mx\nfrom mxnet.executor_manager import _split_input_slice\n\nfrom config.config import config\nfrom utils.image import tensor_vstack\nfrom rpn.rpn import get_rpn_testbatch, get_rpn_pair_batch, assign_anchor\nfrom rcnn import get_rcnn_testbatch, get_rcnn_batch\n\nclass TestLoader(mx.io.DataIter):\n def __init__(self, roidb, config, batch_size=1, shuffle=False,\n has_rpn=False):\n super(TestLoader, self).__init__()\n\n # save parameters as properties\n self.cfg = config\n self.roidb = roidb\n self.batch_size = batch_size\n self.shuffle = shuffle\n self.has_rpn = has_rpn\n\n # infer properties from roidb\n self.size = np.sum([x['frame_seg_len'] for x in self.roidb])\n self.index = np.arange(self.size)\n\n # decide data and label names (only for training)\n self.data_name = ['data', 'im_info', 'data_key', 'feat_key']\n self.label_name = None\n\n #\n self.cur_roidb_index = 0\n self.cur_frameid = 0\n self.data_key = None\n self.key_frameid = 0\n self.cur_seg_len = 0\n self.key_frame_flag = -1\n\n # status variable for synchronization between get_data and get_label\n self.cur = 0\n self.data = None\n self.label = []\n self.im_info = None\n\n # get first batch to fill in provide_data and provide_label\n self.reset()\n self.get_batch()\n\n @property\n def provide_data(self):\n return [[(k, v.shape) for k, v in zip(self.data_name, idata)] for idata in self.data]\n\n @property\n def provide_label(self):\n return [None for _ in range(len(self.data))]\n\n @property\n def provide_data_single(self):\n return [(k, v.shape) for k, v in zip(self.data_name, self.data[0])]\n\n @property\n def provide_label_single(self):\n return None\n\n def reset(self):\n self.cur = 0\n if self.shuffle:\n np.random.shuffle(self.index)\n\n def iter_next(self):\n return self.cur < self.size\n\n def next(self):\n if self.iter_next():\n self.get_batch()\n self.cur += self.batch_size\n self.cur_frameid += 1\n if self.cur_frameid == self.cur_seg_len:\n self.cur_roidb_index += 1\n self.cur_frameid = 0\n self.key_frameid = 0\n elif self.cur_frameid - self.key_frameid == self.cfg.TEST.KEY_FRAME_INTERVAL:\n self.key_frameid = self.cur_frameid\n return self.im_info, self.key_frame_flag, mx.io.DataBatch(data=self.data, label=self.label,\n pad=self.getpad(), index=self.getindex(),\n provide_data=self.provide_data, provide_label=self.provide_label)\n else:\n raise StopIteration\n\n def getindex(self):\n return self.cur / self.batch_size\n\n def getpad(self):\n if self.cur + self.batch_size > self.size:\n return self.cur + self.batch_size - self.size\n else:\n return 0\n\n def get_batch(self):\n cur_roidb = self.roidb[self.cur_roidb_index].copy()\n cur_roidb['image'] = cur_roidb['pattern'] % self.cur_frameid\n self.cur_seg_len = cur_roidb['frame_seg_len']\n data, label, im_info = get_rpn_testbatch([cur_roidb], self.cfg)\n if self.key_frameid == self.cur_frameid: # key frame\n self.data_key = data[0]['data'].copy()\n if self.key_frameid == 0:\n self.key_frame_flag = 0\n else:\n self.key_frame_flag = 1\n else:\n self.key_frame_flag = 2\n extend_data = [{'data': data[0]['data'],\n 'im_info': data[0]['im_info'],\n 'data_key': self.data_key,\n 'feat_key': np.zeros((1,self.cfg.network.DFF_FEAT_DIM,1,1))}]\n self.data = [[mx.nd.array(extend_data[i][name]) for name in self.data_name] for i in xrange(len(data))]\n self.im_info = im_info\n\nclass AnchorLoader(mx.io.DataIter):\n\n def __init__(self, feat_sym, roidb, cfg, batch_size=1, shuffle=False, ctx=None, work_load_list=None,\n feat_stride=16, anchor_scales=(8, 16, 32), anchor_ratios=(0.5, 1, 2), allowed_border=0,\n aspect_grouping=False, normalize_target=False, bbox_mean=(0.0, 0.0, 0.0, 0.0),\n bbox_std=(0.1, 0.1, 0.4, 0.4)):\n \"\"\"\n This Iter will provide roi data to Fast R-CNN network\n :param feat_sym: to infer shape of assign_output\n :param roidb: must be preprocessed\n :param batch_size: must divide BATCH_SIZE(128)\n :param shuffle: bool\n :param ctx: list of contexts\n :param work_load_list: list of work load\n :param aspect_grouping: group images with similar aspects\n :param normalize_target: normalize rpn target\n :param bbox_mean: anchor target mean\n :param bbox_std: anchor target std\n :return: AnchorLoader\n \"\"\"\n super(AnchorLoader, self).__init__()\n\n # save parameters as properties\n self.feat_sym = feat_sym\n self.roidb = roidb\n self.cfg = cfg\n self.batch_size = batch_size\n self.shuffle = shuffle\n self.ctx = ctx\n if self.ctx is None:\n self.ctx = [mx.cpu()]\n self.work_load_list = work_load_list\n self.feat_stride = feat_stride\n self.anchor_scales = anchor_scales\n self.anchor_ratios = anchor_ratios\n self.allowed_border = allowed_border\n self.aspect_grouping = aspect_grouping\n self.normalize_target = normalize_target\n self.bbox_mean = bbox_mean\n self.bbox_std = bbox_std\n\n # infer properties from roidb\n self.size = len(roidb)\n self.index = np.arange(self.size)\n\n # decide data and label names\n if config.TRAIN.END2END:\n self.data_name = ['data', 'data_ref', 'eq_flag', 'im_info', 'gt_boxes']\n else:\n self.data_name = ['data']\n self.label_name = ['label', 'bbox_target', 'bbox_weight']\n\n # status variable for synchronization between get_data and get_label\n self.cur = 0\n self.batch = None\n self.data = None\n self.label = None\n\n # get first batch to fill in provide_data and provide_label\n self.reset()\n self.get_batch_individual()\n\n @property\n def provide_data(self):\n return [[(k, v.shape) for k, v in zip(self.data_name, self.data[i])] for i in xrange(len(self.data))]\n\n @property\n def provide_label(self):\n return [[(k, v.shape) for k, v in zip(self.label_name, self.label[i])] for i in xrange(len(self.data))]\n\n @property\n def provide_data_single(self):\n return [(k, v.shape) for k, v in zip(self.data_name, self.data[0])]\n\n @property\n def provide_label_single(self):\n return [(k, v.shape) for k, v in zip(self.label_name, self.label[0])]\n\n def reset(self):\n self.cur = 0\n if self.shuffle:\n if self.aspect_grouping:\n widths = np.array([r['width'] for r in self.roidb])\n heights = np.array([r['height'] for r in self.roidb])\n horz = (widths >= heights)\n vert = np.logical_not(horz)\n horz_inds = np.where(horz)[0]\n vert_inds = np.where(vert)[0]\n inds = np.hstack((np.random.permutation(horz_inds), np.random.permutation(vert_inds)))\n extra = inds.shape[0] % self.batch_size\n inds_ = np.reshape(inds[:-extra], (-1, self.batch_size))\n row_perm = np.random.permutation(np.arange(inds_.shape[0]))\n inds[:-extra] = np.reshape(inds_[row_perm, :], (-1,))\n self.index = inds\n else:\n np.random.shuffle(self.index)\n\n def iter_next(self):\n return self.cur + self.batch_size <= self.size\n\n def next(self):\n if self.iter_next():\n self.get_batch_individual()\n self.cur += self.batch_size\n return mx.io.DataBatch(data=self.data, label=self.label,\n pad=self.getpad(), index=self.getindex(),\n provide_data=self.provide_data, provide_label=self.provide_label)\n else:\n raise StopIteration\n\n def getindex(self):\n return self.cur / self.batch_size\n\n def getpad(self):\n if self.cur + self.batch_size > self.size:\n return self.cur + self.batch_size - self.size\n else:\n return 0\n\n def infer_shape(self, max_data_shape=None, max_label_shape=None):\n \"\"\" Return maximum data and label shape for single gpu \"\"\"\n if max_data_shape is None:\n max_data_shape = []\n if max_label_shape is None:\n max_label_shape = []\n max_shapes = dict(max_data_shape + max_label_shape)\n input_batch_size = max_shapes['data'][0]\n im_info = [[max_shapes['data'][2], max_shapes['data'][3], 1.0]]\n _, feat_shape, _ = self.feat_sym.infer_shape(**max_shapes)\n label = assign_anchor(feat_shape[0], np.zeros((0, 5)), im_info, self.cfg,\n self.feat_stride, self.anchor_scales, self.anchor_ratios, self.allowed_border,\n self.normalize_target, self.bbox_mean, self.bbox_std)\n label = [label[k] for k in self.label_name]\n label_shape = [(k, tuple([input_batch_size] + list(v.shape[1:]))) for k, v in zip(self.label_name, label)]\n return max_data_shape, label_shape\n\n def get_batch(self):\n # slice roidb\n cur_from = self.cur\n cur_to = min(cur_from + self.batch_size, self.size)\n roidb = [self.roidb[self.index[i]] for i in range(cur_from, cur_to)]\n\n # decide multi device slice\n work_load_list = self.work_load_list\n ctx = self.ctx\n if work_load_list is None:\n work_load_list = [1] * len(ctx)\n assert isinstance(work_load_list, list) and len(work_load_list) == len(ctx), \\\n \"Invalid settings for work load. \"\n slices = _split_input_slice(self.batch_size, work_load_list)\n\n # get testing data for multigpu\n data_list = []\n label_list = []\n for islice in slices:\n iroidb = [roidb[i] for i in range(islice.start, islice.stop)]\n data, label = get_rpn_pair_batch(iroidb, self.cfg)\n data_list.append(data)\n label_list.append(label)\n\n # pad data first and then assign anchor (read label)\n data_tensor = tensor_vstack([batch['data'] for batch in data_list])\n for data, data_pad in zip(data_list, data_tensor):\n data['data'] = data_pad[np.newaxis, :]\n\n new_label_list = []\n for data, label in zip(data_list, label_list):\n # infer label shape\n data_shape = {k: v.shape for k, v in data.items()}\n del data_shape['im_info']\n _, feat_shape, _ = self.feat_sym.infer_shape(**data_shape)\n feat_shape = [int(i) for i in feat_shape[0]]\n\n # add gt_boxes to data for e2e\n data['gt_boxes'] = label['gt_boxes'][np.newaxis, :, :]\n\n # assign anchor for label\n label = assign_anchor(feat_shape, label['gt_boxes'], data['im_info'], self.cfg,\n self.feat_stride, self.anchor_scales,\n self.anchor_ratios, self.allowed_border,\n self.normalize_target, self.bbox_mean, self.bbox_std)\n new_label_list.append(label)\n\n all_data = dict()\n for key in self.data_name:\n all_data[key] = tensor_vstack([batch[key] for batch in data_list])\n\n all_label = dict()\n for key in self.label_name:\n pad = -1 if key == 'label' else 0\n all_label[key] = tensor_vstack([batch[key] for batch in new_label_list], pad=pad)\n\n self.data = [mx.nd.array(all_data[key]) for key in self.data_name]\n self.label = [mx.nd.array(all_label[key]) for key in self.label_name]\n\n def get_batch_individual(self):\n cur_from = self.cur\n cur_to = min(cur_from + self.batch_size, self.size)\n roidb = [self.roidb[self.index[i]] for i in range(cur_from, cur_to)]\n # decide multi device slice\n work_load_list = self.work_load_list\n ctx = self.ctx\n if work_load_list is None:\n work_load_list = [1] * len(ctx)\n assert isinstance(work_load_list, list) and len(work_load_list) == len(ctx), \\\n \"Invalid settings for work load. \"\n slices = _split_input_slice(self.batch_size, work_load_list)\n rst = []\n for idx, islice in enumerate(slices):\n iroidb = [roidb[i] for i in range(islice.start, islice.stop)]\n rst.append(self.parfetch(iroidb))\n all_data = [_['data'] for _ in rst]\n all_label = [_['label'] for _ in rst]\n self.data = [[mx.nd.array(data[key]) for key in self.data_name] for data in all_data]\n self.label = [[mx.nd.array(label[key]) for key in self.label_name] for label in all_label]\n\n def parfetch(self, iroidb):\n # get testing data for multigpu\n data, label = get_rpn_pair_batch(iroidb, self.cfg)\n data_shape = {k: v.shape for k, v in data.items()}\n del data_shape['im_info']\n _, feat_shape, _ = self.feat_sym.infer_shape(**data_shape)\n feat_shape = [int(i) for i in feat_shape[0]]\n\n # add gt_boxes to data for e2e\n data['gt_boxes'] = label['gt_boxes'][np.newaxis, :, :]\n\n # assign anchor for label\n label = assign_anchor(feat_shape, label['gt_boxes'], data['im_info'], self.cfg,\n self.feat_stride, self.anchor_scales,\n self.anchor_ratios, self.allowed_border,\n self.normalize_target, self.bbox_mean, self.bbox_std)\n return {'data': data, 'label': label}\n\n"
},
{
"path": "dff_rfcn/core/metric.py",
"content": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed under The MIT License [see LICENSE for details]\n# Modified by Yuwen Xiong\n# --------------------------------------------------------\n# Based on:\n# MX-RCNN\n# Copyright (c) 2016 by Contributors\n# Licence under The Apache 2.0 License\n# https://github.com/ijkguo/mx-rcnn/\n# --------------------------------------------------------\n\nimport mxnet as mx\nimport numpy as np\n\n\ndef get_rpn_names():\n pred = ['rpn_cls_prob', 'rpn_bbox_loss']\n label = ['rpn_label', 'rpn_bbox_target', 'rpn_bbox_weight']\n return pred, label\n\n\ndef get_rcnn_names(cfg):\n pred = ['rcnn_cls_prob', 'rcnn_bbox_loss']\n label = ['rcnn_label', 'rcnn_bbox_target', 'rcnn_bbox_weight']\n if cfg.TRAIN.ENABLE_OHEM or cfg.TRAIN.END2END:\n pred.append('rcnn_label')\n if cfg.TRAIN.END2END:\n rpn_pred, rpn_label = get_rpn_names()\n pred = rpn_pred + pred\n label = rpn_label\n return pred, label\n\n\nclass RPNAccMetric(mx.metric.EvalMetric):\n def __init__(self):\n super(RPNAccMetric, self).__init__('RPNAcc')\n self.pred, self.label = get_rpn_names()\n\n def update(self, labels, preds):\n pred = preds[self.pred.index('rpn_cls_prob')]\n label = labels[self.label.index('rpn_label')]\n\n # pred (b, c, p) or (b, c, h, w)\n pred_label = mx.ndarray.argmax_channel(pred).asnumpy().astype('int32')\n pred_label = pred_label.reshape((pred_label.shape[0], -1))\n # label (b, p)\n label = label.asnumpy().astype('int32')\n\n # filter with keep_inds\n keep_inds = np.where(label != -1)\n pred_label = pred_label[keep_inds]\n label = label[keep_inds]\n\n self.sum_metric += np.sum(pred_label.flat == label.flat)\n self.num_inst += len(pred_label.flat)\n\n\nclass RCNNAccMetric(mx.metric.EvalMetric):\n def __init__(self, cfg):\n super(RCNNAccMetric, self).__init__('RCNNAcc')\n self.e2e = cfg.TRAIN.END2END\n self.ohem = cfg.TRAIN.ENABLE_OHEM\n self.pred, self.label = get_rcnn_names(cfg)\n\n def update(self, labels, preds):\n pred = preds[self.pred.index('rcnn_cls_prob')]\n if self.ohem or self.e2e:\n label = preds[self.pred.index('rcnn_label')]\n else:\n label = labels[self.label.index('rcnn_label')]\n\n last_dim = pred.shape[-1]\n pred_label = pred.asnumpy().reshape(-1, last_dim).argmax(axis=1).astype('int32')\n label = label.asnumpy().reshape(-1,).astype('int32')\n\n # filter with keep_inds\n keep_inds = np.where(label != -1)\n pred_label = pred_label[keep_inds]\n label = label[keep_inds]\n\n self.sum_metric += np.sum(pred_label.flat == label.flat)\n self.num_inst += len(pred_label.flat)\n\n\nclass RPNLogLossMetric(mx.metric.EvalMetric):\n def __init__(self):\n super(RPNLogLossMetric, self).__init__('RPNLogLoss')\n self.pred, self.label = get_rpn_names()\n\n def update(self, labels, preds):\n pred = preds[self.pred.index('rpn_cls_prob')]\n label = labels[self.label.index('rpn_label')]\n\n # label (b, p)\n label = label.asnumpy().astype('int32').reshape((-1))\n # pred (b, c, p) or (b, c, h, w) --> (b, p, c) --> (b*p, c)\n pred = pred.asnumpy().reshape((pred.shape[0], pred.shape[1], -1)).transpose((0, 2, 1))\n pred = pred.reshape((label.shape[0], -1))\n\n # filter with keep_inds\n keep_inds = np.where(label != -1)[0]\n label = label[keep_inds]\n cls = pred[keep_inds, label]\n\n cls += 1e-14\n cls_loss = -1 * np.log(cls)\n cls_loss = np.sum(cls_loss)\n self.sum_metric += cls_loss\n self.num_inst += label.shape[0]\n\n\nclass RCNNLogLossMetric(mx.metric.EvalMetric):\n def __init__(self, cfg):\n super(RCNNLogLossMetric, self).__init__('RCNNLogLoss')\n self.e2e = cfg.TRAIN.END2END\n self.ohem = cfg.TRAIN.ENABLE_OHEM\n self.pred, self.label = get_rcnn_names(cfg)\n\n def update(self, labels, preds):\n pred = preds[self.pred.index('rcnn_cls_prob')]\n if self.ohem or self.e2e:\n label = preds[self.pred.index('rcnn_label')]\n else:\n label = labels[self.label.index('rcnn_label')]\n\n last_dim = pred.shape[-1]\n pred = pred.asnumpy().reshape(-1, last_dim)\n label = label.asnumpy().reshape(-1,).astype('int32')\n\n # filter with keep_inds\n keep_inds = np.where(label != -1)[0]\n label = label[keep_inds]\n cls = pred[keep_inds, label]\n\n cls += 1e-14\n cls_loss = -1 * np.log(cls)\n cls_loss = np.sum(cls_loss)\n self.sum_metric += cls_loss\n self.num_inst += label.shape[0]\n\n\nclass RPNL1LossMetric(mx.metric.EvalMetric):\n def __init__(self):\n super(RPNL1LossMetric, self).__init__('RPNL1Loss')\n self.pred, self.label = get_rpn_names()\n\n def update(self, labels, preds):\n bbox_loss = preds[self.pred.index('rpn_bbox_loss')].asnumpy()\n\n # calculate num_inst (average on those kept anchors)\n label = labels[self.label.index('rpn_label')].asnumpy()\n num_inst = np.sum(label != -1)\n\n self.sum_metric += np.sum(bbox_loss)\n self.num_inst += num_inst\n\n\nclass RCNNL1LossMetric(mx.metric.EvalMetric):\n def __init__(self, cfg):\n super(RCNNL1LossMetric, self).__init__('RCNNL1Loss')\n self.e2e = cfg.TRAIN.END2END\n self.ohem = cfg.TRAIN.ENABLE_OHEM\n self.pred, self.label = get_rcnn_names(cfg)\n\n def update(self, labels, preds):\n bbox_loss = preds[self.pred.index('rcnn_bbox_loss')].asnumpy()\n if self.ohem:\n label = preds[self.pred.index('rcnn_label')].asnumpy()\n else:\n if self.e2e:\n label = preds[self.pred.index('rcnn_label')].asnumpy()\n else:\n label = labels[self.label.index('rcnn_label')].asnumpy()\n\n # calculate num_inst (average on those kept anchors)\n num_inst = np.sum(label != -1)\n\n self.sum_metric += np.sum(bbox_loss)\n self.num_inst += num_inst\n"
},
{
"path": "dff_rfcn/core/module.py",
"content": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed under The MIT License [see LICENSE for details]\n# Modified by Yuwen Xiong\n# --------------------------------------------------------\n# Based on:\n# MX-RCNN\n# Copyright (c) 2016 by Contributors\n# Licence under The Apache 2.0 License\n# https://github.com/ijkguo/mx-rcnn/\n# --------------------------------------------------------\n\n\n\"\"\"A `MutableModule` implement the `BaseModule` API, and allows input shape\nvarying with training iterations. If shapes vary, executors will rebind,\nusing shared arrays from the initial module binded with maximum shape.\n\"\"\"\n\nimport time\nimport logging\nimport warnings\n\nfrom mxnet import context as ctx\nfrom mxnet.initializer import Uniform, InitDesc\nfrom mxnet.module.base_module import BaseModule, _check_input_names, _parse_data_desc, _as_list\nfrom mxnet.model import _create_kvstore, _initialize_kvstore, _update_params, _update_params_on_kvstore, load_checkpoint, BatchEndParam\nfrom mxnet import metric\n\nfrom .DataParallelExecutorGroup import DataParallelExecutorGroup\nfrom mxnet import ndarray as nd\nfrom mxnet import optimizer as opt\n\n\nclass Module(BaseModule):\n \"\"\"Module is a basic module that wrap a `Symbol`. It is functionally the same\n as the `FeedForward` model, except under the module API.\n\n Parameters\n ----------\n symbol : Symbol\n data_names : list of str\n Default is `('data')` for a typical model used in image classification.\n label_names : list of str\n Default is `('softmax_label')` for a typical model used in image\n classification.\n logger : Logger\n Default is `logging`.\n context : Context or list of Context\n Default is `cpu()`.\n work_load_list : list of number\n Default `None`, indicating uniform workload.\n fixed_param_names: list of str\n Default `None`, indicating no network parameters are fixed.\n state_names : list of str\n states are similar to data and label, but not provided by data iterator.\n Instead they are initialized to 0 and can be set by set_states()\n \"\"\"\n def __init__(self, symbol, data_names=('data',), label_names=('softmax_label',),\n logger=logging, context=ctx.cpu(), work_load_list=None,\n fixed_param_names=None, state_names=None):\n super(Module, self).__init__(logger=logger)\n\n if isinstance(context, ctx.Context):\n context = [context]\n self._context = context\n if work_load_list is None:\n work_load_list = [1] * len(self._context)\n assert len(work_load_list) == len(self._context)\n self._work_load_list = work_load_list\n\n self._symbol = symbol\n\n data_names = list(data_names) if data_names is not None else []\n label_names = list(label_names) if label_names is not None else []\n state_names = list(state_names) if state_names is not None else []\n fixed_param_names = list(fixed_param_names) if fixed_param_names is not None else []\n\n _check_input_names(symbol, data_names, \"data\", True)\n _check_input_names(symbol, label_names, \"label\", False)\n _check_input_names(symbol, state_names, \"state\", True)\n _check_input_names(symbol, fixed_param_names, \"fixed_param\", True)\n\n arg_names = symbol.list_arguments()\n input_names = data_names + label_names + state_names\n self._param_names = [x for x in arg_names if x not in input_names]\n self._fixed_param_names = fixed_param_names\n self._aux_names = symbol.list_auxiliary_states()\n self._data_names = data_names\n self._label_names = label_names\n self._state_names = state_names\n self._output_names = symbol.list_outputs()\n\n self._arg_params = None\n self._aux_params = None\n self._params_dirty = False\n\n self._optimizer = None\n self._kvstore = None\n self._update_on_kvstore = None\n self._updater = None\n self._preload_opt_states = None\n self._grad_req = None\n\n self._exec_group = None\n self._data_shapes = None\n self._label_shapes = None\n\n @staticmethod\n def load(prefix, epoch, load_optimizer_states=False, **kwargs):\n \"\"\"Create a model from previously saved checkpoint.\n\n Parameters\n ----------\n prefix : str\n path prefix of saved model files. You should have\n \"prefix-symbol.json\", \"prefix-xxxx.params\", and\n optionally \"prefix-xxxx.states\", where xxxx is the\n epoch number.\n epoch : int\n epoch to load.\n load_optimizer_states : bool\n whether to load optimizer states. Checkpoint needs\n to have been made with save_optimizer_states=True.\n data_names : list of str\n Default is `('data')` for a typical model used in image classification.\n label_names : list of str\n Default is `('softmax_label')` for a typical model used in image\n classification.\n logger : Logger\n Default is `logging`.\n context : Context or list of Context\n Default is `cpu()`.\n work_load_list : list of number\n Default `None`, indicating uniform workload.\n fixed_param_names: list of str\n Default `None`, indicating no network parameters are fixed.\n \"\"\"\n sym, args, auxs = load_checkpoint(prefix, epoch)\n mod = Module(symbol=sym, **kwargs)\n mod._arg_params = args\n mod._aux_params = auxs\n mod.params_initialized = True\n if load_optimizer_states:\n mod._preload_opt_states = '%s-%04d.states'%(prefix, epoch)\n return mod\n\n def save_checkpoint(self, prefix, epoch, save_optimizer_states=False):\n \"\"\"Save current progress to checkpoint.\n Use mx.callback.module_checkpoint as epoch_end_callback to save during training.\n\n Parameters\n ----------\n prefix : str\n The file prefix to checkpoint to\n epoch : int\n The current epoch number\n save_optimizer_states : bool\n Whether to save optimizer states for continue training\n \"\"\"\n self._symbol.save('%s-symbol.json'%prefix)\n param_name = '%s-%04d.params' % (prefix, epoch)\n self.save_params(param_name)\n logging.info('Saved checkpoint to \\\"%s\\\"', param_name)\n if save_optimizer_states:\n state_name = '%s-%04d.states' % (prefix, epoch)\n self.save_optimizer_states(state_name)\n logging.info('Saved optimizer state to \\\"%s\\\"', state_name)\n\n def _reset_bind(self):\n \"\"\"Internal function to reset binded state.\"\"\"\n self.binded = False\n self._exec_group = None\n self._data_shapes = None\n self._label_shapes = None\n\n @property\n def data_names(self):\n \"\"\"A list of names for data required by this module.\"\"\"\n return self._data_names\n\n @property\n def label_names(self):\n \"\"\"A list of names for labels required by this module.\"\"\"\n return self._label_names\n\n @property\n def output_names(self):\n \"\"\"A list of names for the outputs of this module.\"\"\"\n return self._output_names\n\n @property\n def data_shapes(self):\n \"\"\"Get data shapes.\n Returns\n -------\n A list of `(name, shape)` pairs.\n \"\"\"\n assert self.binded\n return self._data_shapes\n\n @property\n def label_shapes(self):\n \"\"\"Get label shapes.\n Returns\n -------\n A list of `(name, shape)` pairs. The return value could be `None` if\n the module does not need labels, or if the module is not binded for\n training (in this case, label information is not available).\n \"\"\"\n assert self.binded\n return self._label_shapes\n\n @property\n def output_shapes(self):\n \"\"\"Get output shapes.\n Returns\n -------\n A list of `(name, shape)` pairs.\n \"\"\"\n assert self.binded\n return self._exec_group.get_output_shapes()\n\n def get_params(self):\n \"\"\"Get current parameters.\n Returns\n -------\n `(arg_params, aux_params)`, each a dictionary of name to parameters (in\n `NDArray`) mapping.\n \"\"\"\n assert self.binded and self.params_initialized\n\n if self._params_dirty:\n self._sync_params_from_devices()\n return (self._arg_params, self._aux_params)\n\n def init_params(self, initializer=Uniform(0.01), arg_params=None, aux_params=None,\n allow_missing=False, force_init=False):\n \"\"\"Initialize the parameters and auxiliary states.\n\n Parameters\n ----------\n initializer : Initializer\n Called to initialize parameters if needed.\n arg_params : dict\n If not None, should be a dictionary of existing arg_params. Initialization\n will be copied from that.\n aux_params : dict\n If not None, should be a dictionary of existing aux_params. Initialization\n will be copied from that.\n allow_missing : bool\n If true, params could contain missing values, and the initializer will be\n called to fill those missing params.\n force_init : bool\n If true, will force re-initialize even if already initialized.\n \"\"\"\n if self.params_initialized and not force_init:\n warnings.warn(\"Parameters already initialized and force_init=False. \"\n \"init_params call ignored.\", stacklevel=2)\n return\n assert self.binded, 'call bind before initializing the parameters'\n\n def _impl(name, arr, cache):\n \"\"\"Internal helper for parameter initialization\"\"\"\n if cache is not None:\n if name in cache:\n cache_arr = cache[name]\n\n # just in case the cached array is just the target itself\n if cache_arr is not arr:\n cache_arr.copyto(arr)\n else:\n if not allow_missing:\n raise RuntimeError(\"%s is not presented\" % name)\n if initializer != None:\n initializer(name, arr)\n else:\n initializer(name, arr)\n\n attrs = self._symbol.attr_dict()\n for name, arr in self._arg_params.items():\n desc = InitDesc(name, attrs.get(name, None))\n _impl(desc, arr, arg_params)\n\n for name, arr in self._aux_params.items():\n desc = InitDesc(name, attrs.get(name, None))\n _impl(desc, arr, aux_params)\n\n self.params_initialized = True\n self._params_dirty = False\n\n # copy the initialized parameters to devices\n self._exec_group.set_params(self._arg_params, self._aux_params)\n\n def set_params(self, arg_params, aux_params, allow_missing=False, force_init=True):\n \"\"\"Assign parameter and aux state values.\n\n Parameters\n ----------\n arg_params : dict\n Dictionary of name to value (`NDArray`) mapping.\n aux_params : dict\n Dictionary of name to value (`NDArray`) mapping.\n allow_missing : bool\n If true, params could contain missing values, and the initializer will be\n called to fill those missing params.\n force_init : bool\n If true, will force re-initialize even if already initialized.\n\n Examples\n --------\n An example of setting module parameters::\n >>> sym, arg_params, aux_params = \\\n >>> mx.model.load_checkpoint(model_prefix, n_epoch_load)\n >>> mod.set_params(arg_params=arg_params, aux_params=aux_params)\n \"\"\"\n if not allow_missing:\n self.init_params(initializer=None, arg_params=arg_params, aux_params=aux_params,\n allow_missing=allow_missing, force_init=force_init)\n return\n\n if self.params_initialized and not force_init:\n warnings.warn(\"Parameters already initialized and force_init=False. \"\n \"set_params call ignored.\", stacklevel=2)\n return\n\n self._exec_group.set_params(arg_params, aux_params)\n\n # because we didn't update self._arg_params, they are dirty now.\n self._params_dirty = True\n self.params_initialized = True\n\n def bind(self, data_shapes, label_shapes=None, for_training=True,\n inputs_need_grad=False, force_rebind=False, shared_module=None,\n grad_req='write'):\n \"\"\"Bind the symbols to construct executors. This is necessary before one\n can perform computation with the module.\n\n Parameters\n ----------\n data_shapes : list of (str, tuple)\n Typically is `data_iter.provide_data`.\n label_shapes : list of (str, tuple)\n Typically is `data_iter.provide_label`.\n for_training : bool\n Default is `True`. Whether the executors should be bind for training.\n inputs_need_grad : bool\n Default is `False`. Whether the gradients to the input data need to be computed.\n Typically this is not needed. But this might be needed when implementing composition\n of modules.\n force_rebind : bool\n Default is `False`. This function does nothing if the executors are already\n binded. But with this `True`, the executors will be forced to rebind.\n shared_module : Module\n Default is `None`. This is used in bucketing. When not `None`, the shared module\n essentially corresponds to a different bucket -- a module with different symbol\n but with the same sets of parameters (e.g. unrolled RNNs with different lengths).\n \"\"\"\n # force rebinding is typically used when one want to switch from\n # training to prediction phase.\n if force_rebind:\n self._reset_bind()\n\n if self.binded:\n self.logger.warning('Already binded, ignoring bind()')\n return\n\n self.for_training = for_training\n self.inputs_need_grad = inputs_need_grad\n self.binded = True\n self._grad_req = grad_req\n\n if not for_training:\n assert not inputs_need_grad\n else:\n pass\n # this is not True, as some module might not contains a loss function\n # that consumes the labels\n # assert label_shapes is not None\n\n # self._data_shapes, self._label_shapes = _parse_data_desc(\n # self.data_names, self.label_names, data_shapes, label_shapes)\n self._data_shapes, self._label_shapes = zip(*[_parse_data_desc(self.data_names, self.label_names, data_shape, label_shape)\n for data_shape, label_shape in zip(data_shapes, label_shapes)])\n if self._label_shapes.count(None) == len(self._label_shapes):\n self._label_shapes = None\n\n if shared_module is not None:\n assert isinstance(shared_module, Module) and \\\n shared_module.binded and shared_module.params_initialized\n shared_group = shared_module._exec_group\n else:\n shared_group = None\n\n self._exec_group = DataParallelExecutorGroup(self._symbol, self._context,\n self._work_load_list, self._data_shapes,\n self._label_shapes, self._param_names,\n for_training, inputs_need_grad,\n shared_group, logger=self.logger,\n fixed_param_names=self._fixed_param_names,\n grad_req=grad_req,\n state_names=self._state_names)\n # self._total_exec_bytes = self._exec_group._total_exec_bytes\n if shared_module is not None:\n self.params_initialized = True\n self._arg_params = shared_module._arg_params\n self._aux_params = shared_module._aux_params\n elif self.params_initialized:\n # if the parameters are already initialized, we are re-binding\n # so automatically copy the already initialized params\n self._exec_group.set_params(self._arg_params, self._aux_params)\n else:\n assert self._arg_params is None and self._aux_params is None\n param_arrays = [\n nd.zeros(x[0].shape, dtype=x[0].dtype)\n for x in self._exec_group.param_arrays\n ]\n self._arg_params = {name:arr for name, arr in zip(self._param_names, param_arrays)}\n\n aux_arrays = [\n nd.zeros(x[0].shape, dtype=x[0].dtype)\n for x in self._exec_group.aux_arrays\n ]\n self._aux_params = {name:arr for name, arr in zip(self._aux_names, aux_arrays)}\n\n if shared_module is not None and shared_module.optimizer_initialized:\n self.borrow_optimizer(shared_module)\n\n\n def reshape(self, data_shapes, label_shapes=None):\n \"\"\"Reshape the module for new input shapes.\n\n Parameters\n ----------\n data_shapes : list of (str, tuple)\n Typically is `data_iter.provide_data`.\n label_shapes : list of (str, tuple)\n Typically is `data_iter.provide_label`.\n \"\"\"\n assert self.binded\n # self._data_shapes, self._label_shapes = _parse_data_desc(\n # self.data_names, self.label_names, data_shapes, label_shapes)\n self._data_shapes, self._label_shapes = zip(*[_parse_data_desc(self.data_names, self.label_names, data_shape, label_shape)\n for data_shape, label_shape in zip(data_shapes, label_shapes)])\n\n self._exec_group.reshape(self._data_shapes, self._label_shapes)\n\n\n def init_optimizer(self, kvstore='local', optimizer='sgd',\n optimizer_params=(('learning_rate', 0.01),), force_init=False):\n \"\"\"Install and initialize optimizers.\n\n Parameters\n ----------\n kvstore : str or KVStore\n Default `'local'`.\n optimizer : str or Optimizer\n Default `'sgd'`\n optimizer_params : dict\n Default `(('learning_rate', 0.01),)`. The default value is not a dictionary,\n just to avoid pylint warning of dangerous default values.\n force_init : bool\n Default `False`, indicating whether we should force re-initializing the\n optimizer in the case an optimizer is already installed.\n \"\"\"\n assert self.binded and self.params_initialized\n\n if self.optimizer_initialized and not force_init:\n self.logger.warning('optimizer already initialized, ignoring...')\n return\n\n (kvstore, update_on_kvstore) = \\\n _create_kvstore(kvstore, len(self._context), self._arg_params)\n\n batch_size = self._exec_group.batch_size\n if kvstore and 'dist' in kvstore.type and '_sync' in kvstore.type:\n batch_size *= kvstore.num_workers\n rescale_grad = 1.0/batch_size\n\n if isinstance(optimizer, str):\n idx2name = {}\n if update_on_kvstore:\n idx2name.update(enumerate(self._exec_group.param_names))\n else:\n for k in range(len(self._context)):\n idx2name.update({i*len(self._context)+k: n\n for i, n in enumerate(self._exec_group.param_names)})\n optimizer_params = dict(optimizer_params)\n if 'rescale_grad' not in optimizer_params:\n optimizer_params['rescale_grad'] = rescale_grad\n optimizer = opt.create(optimizer,\n sym=self.symbol, param_idx2name=idx2name,\n **optimizer_params)\n else:\n assert isinstance(optimizer, opt.Optimizer)\n if optimizer.rescale_grad != rescale_grad:\n #pylint: disable=no-member\n warnings.warn(\n \"Optimizer created manually outside Module but rescale_grad \" +\n \"is not normalized to 1.0/batch_size/num_workers (%s vs. %s). \"%(\n optimizer.rescale_grad, rescale_grad) +\n \"Is this intended?\", stacklevel=2)\n\n self._optimizer = optimizer\n self._kvstore = kvstore\n self._update_on_kvstore = update_on_kvstore\n self._updater = None\n\n if kvstore:\n # copy initialized local parameters to kvstore\n _initialize_kvstore(kvstore=kvstore,\n param_arrays=self._exec_group.param_arrays,\n arg_params=self._arg_params,\n param_names=self._param_names,\n update_on_kvstore=update_on_kvstore)\n if update_on_kvstore:\n kvstore.set_optimizer(self._optimizer)\n else:\n self._updater = opt.get_updater(optimizer)\n\n self.optimizer_initialized = True\n\n if self._preload_opt_states is not None:\n self.load_optimizer_states(self._preload_opt_states)\n self._preload_opt_states = None\n\n def borrow_optimizer(self, shared_module):\n \"\"\"Borrow optimizer from a shared module. Used in bucketing, where exactly the same\n optimizer (esp. kvstore) is used.\n\n Parameters\n ----------\n shared_module : Module\n \"\"\"\n assert shared_module.optimizer_initialized\n self._optimizer = shared_module._optimizer\n self._kvstore = shared_module._kvstore\n self._update_on_kvstore = shared_module._update_on_kvstore\n self._updater = shared_module._updater\n self.optimizer_initialized = True\n\n def forward(self, data_batch, is_train=None):\n \"\"\"Forward computation.\n\n Parameters\n ----------\n data_batch : DataBatch\n Could be anything with similar API implemented.\n is_train : bool\n Default is `None`, which means `is_train` takes the value of `self.for_training`.\n \"\"\"\n assert self.binded and self.params_initialized\n self._exec_group.forward(data_batch, is_train)\n\n def backward(self, out_grads=None):\n \"\"\"Backward computation.\n\n Parameters\n ----------\n out_grads : NDArray or list of NDArray, optional\n Gradient on the outputs to be propagated back.\n This parameter is only needed when bind is called\n on outputs that are not a loss function.\n \"\"\"\n assert self.binded and self.params_initialized\n self._exec_group.backward(out_grads=out_grads)\n\n def update(self):\n \"\"\"Update parameters according to the installed optimizer and the gradients computed\n in the previous forward-backward batch.\n \"\"\"\n assert self.binded and self.params_initialized and self.optimizer_initialized\n\n self._params_dirty = True\n if self._update_on_kvstore:\n _update_params_on_kvstore(self._exec_group.param_arrays,\n self._exec_group.grad_arrays,\n self._kvstore)\n else:\n _update_params(self._exec_group.param_arrays,\n self._exec_group.grad_arrays,\n updater=self._updater,\n num_device=len(self._context),\n kvstore=self._kvstore)\n\n def get_outputs(self, merge_multi_context=True):\n \"\"\"Get outputs of the previous forward computation.\n\n Parameters\n ----------\n merge_multi_context : bool\n Default is `True`. In the case when data-parallelism is used, the outputs\n will be collected from multiple devices. A `True` value indicate that we\n should merge the collected results so that they look like from a single\n executor.\n\n Returns\n -------\n If `merge_multi_context` is `True`, it is like `[out1, out2]`. Otherwise, it\n is like `[[out1_dev1, out1_dev2], [out2_dev1, out2_dev2]]`. All the output\n elements are `NDArray`.\n \"\"\"\n assert self.binded and self.params_initialized\n return self._exec_group.get_outputs(merge_multi_context=merge_multi_context)\n\n def get_input_grads(self, merge_multi_context=True):\n \"\"\"Get the gradients with respect to the inputs of the module.\n\n Parameters\n ----------\n merge_multi_context : bool\n Default is `True`. In the case when data-parallelism is used, the outputs\n will be collected from multiple devices. A `True` value indicate that we\n should merge the collected results so that they look like from a single\n executor.\n\n Returns\n -------\n If `merge_multi_context` is `True`, it is like `[grad1, grad2]`. Otherwise, it\n is like `[[grad1_dev1, grad1_dev2], [grad2_dev1, grad2_dev2]]`. All the output\n elements are `NDArray`.\n \"\"\"\n assert self.binded and self.params_initialized and self.inputs_need_grad\n return self._exec_group.get_input_grads(merge_multi_context=merge_multi_context)\n\n def get_states(self, merge_multi_context=True):\n \"\"\"Get states from all devices\n\n Parameters\n ----------\n merge_multi_context : bool\n Default is `True`. In the case when data-parallelism is used, the states\n will be collected from multiple devices. A `True` value indicate that we\n should merge the collected results so that they look like from a single\n executor.\n\n Returns\n -------\n If `merge_multi_context` is `True`, it is like `[out1, out2]`. Otherwise, it\n is like `[[out1_dev1, out1_dev2], [out2_dev1, out2_dev2]]`. All the output\n elements are `NDArray`.\n \"\"\"\n assert self.binded and self.params_initialized\n return self._exec_group.get_states(merge_multi_context=merge_multi_context)\n\n def set_states(self, states=None, value=None):\n \"\"\"Set value for states. Only one of states & value can be specified.\n\n Parameters\n ----------\n states : list of list of NDArrays\n source states arrays formatted like [[state1_dev1, state1_dev2],\n [state2_dev1, state2_dev2]].\n value : number\n a single scalar value for all state arrays.\n \"\"\"\n assert self.binded and self.params_initialized\n self._exec_group.set_states(states, value)\n\n def update_metric(self, eval_metric, labels):\n \"\"\"Evaluate and accumulate evaluation metric on outputs of the last forward computation.\n\n Parameters\n ----------\n eval_metric : EvalMetric\n labels : list of NDArray\n Typically `data_batch.label`.\n \"\"\"\n self._exec_group.update_metric(eval_metric, labels)\n\n def _sync_params_from_devices(self):\n \"\"\"Synchronize parameters from devices to CPU. This function should be called after\n calling `update` that updates the parameters on the devices, before one can read the\n latest parameters from `self._arg_params` and `self._aux_params`.\n \"\"\"\n self._exec_group.get_params(self._arg_params, self._aux_params)\n self._params_dirty = False\n\n def save_optimizer_states(self, fname):\n \"\"\"Save optimizer (updater) state to file\n\n Parameters\n ----------\n fname : str\n Path to output states file.\n \"\"\"\n assert self.optimizer_initialized\n\n if self._update_on_kvstore:\n self._kvstore.save_optimizer_states(fname)\n else:\n with open(fname, 'wb') as fout:\n fout.write(self._updater.get_states())\n\n def load_optimizer_states(self, fname):\n \"\"\"Load optimizer (updater) state from file\n\n Parameters\n ----------\n fname : str\n Path to input states file.\n \"\"\"\n assert self.optimizer_initialized\n\n if self._update_on_kvstore:\n self._kvstore.load_optimizer_states(fname)\n else:\n self._updater.set_states(open(fname, 'rb').read())\n\n def install_monitor(self, mon):\n \"\"\" Install monitor on all executors \"\"\"\n assert self.binded\n self._exec_group.install_monitor(mon)\n\n\nclass MutableModule(BaseModule):\n \"\"\"A mutable module is a module that supports variable input data.\n\n Parameters\n ----------\n symbol : Symbol\n data_names : list of str\n label_names : list of str\n logger : Logger\n context : Context or list of Context\n work_load_list : list of number\n max_data_shapes : list of (name, shape) tuple, designating inputs whose shape vary\n max_label_shapes : list of (name, shape) tuple, designating inputs whose shape vary\n fixed_param_prefix : list of str, indicating fixed parameters\n \"\"\"\n def __init__(self, symbol, data_names, label_names,\n logger=logging, context=ctx.cpu(), work_load_list=None,\n max_data_shapes=None, max_label_shapes=None, fixed_param_prefix=None):\n super(MutableModule, self).__init__(logger=logger)\n self._symbol = symbol\n self._data_names = data_names\n self._label_names = label_names\n self._context = context\n self._work_load_list = work_load_list\n\n self._curr_module = None\n self._max_data_shapes = max_data_shapes\n self._max_label_shapes = max_label_shapes\n self._fixed_param_prefix = fixed_param_prefix\n\n fixed_param_names = list()\n if fixed_param_prefix is not None:\n for name in self._symbol.list_arguments():\n for prefix in self._fixed_param_prefix:\n if name.startswith(prefix):\n fixed_param_names.append(name)\n self._fixed_param_names = fixed_param_names\n self._preload_opt_states = None\n\n def _reset_bind(self):\n self.binded = False\n self._curr_module = None\n\n @property\n def data_names(self):\n return self._data_names\n\n @property\n def output_names(self):\n return self._symbol.list_outputs()\n\n @property\n def data_shapes(self):\n assert self.binded\n return self._curr_module.data_shapes\n\n @property\n def label_shapes(self):\n assert self.binded\n return self._curr_module.label_shapes\n\n @property\n def output_shapes(self):\n assert self.binded\n return self._curr_module.output_shapes\n\n def get_params(self):\n assert self.binded and self.params_initialized\n return self._curr_module.get_params()\n\n def init_params(self, initializer=Uniform(0.01), arg_params=None, aux_params=None,\n allow_missing=False, force_init=False):\n if self.params_initialized and not force_init:\n return\n assert self.binded, 'call bind before initializing the parameters'\n self._curr_module.init_params(initializer=initializer, arg_params=arg_params,\n aux_params=aux_params, allow_missing=allow_missing,\n force_init=force_init)\n self.params_initialized = True\n\n def bind(self, data_shapes, label_shapes=None, for_training=True,\n inputs_need_grad=False, force_rebind=False, shared_module=None, grad_req='write'):\n # in case we already initialized params, keep it\n if self.params_initialized:\n arg_params, aux_params = self.get_params()\n\n # force rebinding is typically used when one want to switch from\n # training to prediction phase.\n if force_rebind:\n self._reset_bind()\n\n if self.binded:\n self.logger.warning('Already binded, ignoring bind()')\n return\n\n assert shared_module is None, 'shared_module for MutableModule is not supported'\n\n self.for_training = for_training\n self.inputs_need_grad = inputs_need_grad\n self.binded = True\n\n max_shapes_dict = dict()\n if self._max_data_shapes is not None:\n max_shapes_dict.update(dict(self._max_data_shapes[0]))\n if self._max_label_shapes is not None:\n max_shapes_dict.update(dict(self._max_label_shapes[0]))\n\n max_data_shapes = list()\n for name, shape in data_shapes[0]:\n if name in max_shapes_dict:\n max_data_shapes.append((name, max_shapes_dict[name]))\n else:\n max_data_shapes.append((name, shape))\n\n max_label_shapes = list()\n if not label_shapes.count(None) == len(label_shapes):\n for name, shape in label_shapes[0]:\n if name in max_shapes_dict:\n max_label_shapes.append((name, max_shapes_dict[name]))\n else:\n max_label_shapes.append((name, shape))\n\n if len(max_label_shapes) == 0:\n max_label_shapes = None\n\n module = Module(self._symbol, self._data_names, self._label_names, logger=self.logger,\n context=self._context, work_load_list=self._work_load_list,\n fixed_param_names=self._fixed_param_names)\n module.bind([max_data_shapes for _ in xrange(len(self._context))], [max_label_shapes for _ in xrange(len(self._context))],\n for_training, inputs_need_grad, force_rebind=False, shared_module=None)\n self._curr_module = module\n\n # copy back saved params, if already initialized\n if self.params_initialized:\n self.set_params(arg_params, aux_params)\n\n def save_checkpoint(self, prefix, epoch, save_optimizer_states=False):\n \"\"\"Save current progress to checkpoint.\n Use mx.callback.module_checkpoint as epoch_end_callback to save during training.\n\n Parameters\n ----------\n prefix : str\n The file prefix to checkpoint to\n epoch : int\n The current epoch number\n save_optimizer_states : bool\n Whether to save optimizer states for continue training\n \"\"\"\n self._curr_module.save_checkpoint(prefix, epoch, save_optimizer_states)\n\n def init_optimizer(self, kvstore='local', optimizer='sgd',\n optimizer_params=(('learning_rate', 0.01),), force_init=False):\n assert self.binded and self.params_initialized\n if self.optimizer_initialized and not force_init:\n self.logger.warning('optimizer already initialized, ignoring.')\n return\n\n self._curr_module._preload_opt_states = self._preload_opt_states\n self._curr_module.init_optimizer(kvstore, optimizer, optimizer_params,\n force_init=force_init)\n self.optimizer_initialized = True\n\n def fit(self, train_data, eval_data=None, eval_metric='acc',\n epoch_end_callback=None, batch_end_callback=None, kvstore='local',\n optimizer='sgd', optimizer_params=(('learning_rate', 0.01),),\n eval_end_callback=None,\n eval_batch_end_callback=None, initializer=Uniform(0.01),\n arg_params=None, aux_params=None, allow_missing=False,\n force_rebind=False, force_init=False, begin_epoch=0, num_epoch=None,\n validation_metric=None, monitor=None, prefix=None):\n \"\"\"Train the module parameters.\n\n Parameters\n ----------\n train_data : DataIter\n eval_data : DataIter\n If not `None`, will be used as validation set and evaluate the performance\n after each epoch.\n eval_metric : str or EvalMetric\n Default `'acc'`. The performance measure used to display during training.\n epoch_end_callback : function or list of function\n Each callback will be called with the current `epoch`, `symbol`, `arg_params`\n and `aux_params`.\n batch_end_callback : function or list of function\n Each callback will be called with a `BatchEndParam`.\n kvstore : str or KVStore\n Default `'local'`.\n optimizer : str or Optimizer\n Default `'sgd'`\n optimizer_params : dict\n Default `(('learning_rate', 0.01),)`. The parameters for the optimizer constructor.\n The default value is not a `dict`, just to avoid pylint warning on dangerous\n default values.\n eval_end_callback : function or list of function\n These will be called at the end of each full evaluation, with the metrics over\n the entire evaluation set.\n eval_batch_end_callback : function or list of function\n These will be called at the end of each minibatch during evaluation\n initializer : Initializer\n Will be called to initialize the module parameters if not already initialized.\n arg_params : dict\n Default `None`, if not `None`, should be existing parameters from a trained\n model or loaded from a checkpoint (previously saved model). In this case,\n the value here will be used to initialize the module parameters, unless they\n are already initialized by the user via a call to `init_params` or `fit`.\n `arg_params` has higher priority to `initializer`.\n aux_params : dict\n Default `None`. Similar to `arg_params`, except for auxiliary states.\n allow_missing : bool\n Default `False`. Indicate whether we allow missing parameters when `arg_params`\n and `aux_params` are not `None`. If this is `True`, then the missing parameters\n will be initialized via the `initializer`.\n force_rebind : bool\n Default `False`. Whether to force rebinding the executors if already binded.\n force_init : bool\n Default `False`. Indicate whether we should force initialization even if the\n parameters are already initialized.\n begin_epoch : int\n Default `0`. Indicate the starting epoch. Usually, if we are resuming from a\n checkpoint saved at a previous training phase at epoch N, then we should specify\n this value as N+1.\n num_epoch : int\n Number of epochs to run training.\n\n Examples\n --------\n An example of using fit for training::\n >>> #Assume training dataIter and validation dataIter are ready\n >>> mod.fit(train_data=train_dataiter, eval_data=val_dataiter,\n optimizer_params={'learning_rate':0.01, 'momentum': 0.9},\n num_epoch=10)\n \"\"\"\n assert num_epoch is not None, 'please specify number of epochs'\n\n self.bind(data_shapes=train_data.provide_data, label_shapes=train_data.provide_label,\n for_training=True, force_rebind=force_rebind)\n if monitor is not None:\n self.install_monitor(monitor)\n self.init_params(initializer=initializer, arg_params=arg_params, aux_params=aux_params,\n allow_missing=allow_missing, force_init=force_init)\n self.init_optimizer(kvstore=kvstore, optimizer=optimizer,\n optimizer_params=optimizer_params)\n\n if validation_metric is None:\n validation_metric = eval_metric\n if not isinstance(eval_metric, metric.EvalMetric):\n eval_metric = metric.create(eval_metric)\n\n ################################################################################\n # training loop\n ################################################################################\n for epoch in range(begin_epoch, num_epoch):\n tic = time.time()\n eval_metric.reset()\n for nbatch, data_batch in enumerate(train_data):\n if monitor is not None:\n monitor.tic()\n self.forward_backward(data_batch)\n self.update()\n self.update_metric(eval_metric, data_batch.label)\n\n if monitor is not None:\n monitor.toc_print()\n\n if batch_end_callback is not None:\n batch_end_params = BatchEndParam(epoch=epoch, nbatch=nbatch,\n eval_metric=eval_metric,\n locals=locals())\n for callback in _as_list(batch_end_callback):\n callback(batch_end_params)\n\n # one epoch of training is finished\n for name, val in eval_metric.get_name_value():\n self.logger.info('Epoch[%d] Train-%s=%f', epoch, name, val)\n toc = time.time()\n self.logger.info('Epoch[%d] Time cost=%.3f', epoch, (toc-tic))\n\n # sync aux params across devices\n arg_params, aux_params = self.get_params()\n self.set_params(arg_params, aux_params)\n\n if epoch_end_callback is not None:\n for callback in _as_list(epoch_end_callback):\n callback(epoch, self.symbol, arg_params, aux_params)\n\n #----------------------------------------\n # evaluation on validation set\n if eval_data:\n res = self.score(eval_data, validation_metric,\n score_end_callback=eval_end_callback,\n batch_end_callback=eval_batch_end_callback, epoch=epoch)\n #TODO: pull this into default\n for name, val in res:\n self.logger.info('Epoch[%d] Validation-%s=%f', epoch, name, val)\n\n # end of 1 epoch, reset the data-iter for another epoch\n train_data.reset()\n\n\n def forward(self, data_batch, is_train=None):\n assert self.binded and self.params_initialized\n\n # get current_shapes\n if self._curr_module.label_shapes is not None:\n current_shapes = [dict(self._curr_module.data_shapes[i] + self._curr_module.label_shapes[i]) for i in xrange(len(self._context))]\n else:\n current_shapes = [dict(self._curr_module.data_shapes[i]) for i in xrange(len(self._context))]\n\n # get input_shapes\n if is_train:\n input_shapes = [dict(data_batch.provide_data[i] + data_batch.provide_label[i]) for i in xrange(len(self._context))]\n else:\n input_shapes = [dict(data_batch.provide_data[i]) for i in xrange(len(data_batch.provide_data))]\n\n # decide if shape changed\n shape_changed = len(current_shapes) != len(input_shapes)\n for pre, cur in zip(current_shapes, input_shapes):\n for k, v in pre.items():\n if v != cur[k]:\n shape_changed = True\n\n if shape_changed:\n # self._curr_module.reshape(data_batch.provide_data, data_batch.provide_label)\n module = Module(self._symbol, self._data_names, self._label_names,\n logger=self.logger, context=[self._context[i] for i in xrange(len(data_batch.provide_data))],\n work_load_list=self._work_load_list,\n fixed_param_names=self._fixed_param_names)\n module.bind(data_batch.provide_data, data_batch.provide_label, self._curr_module.for_training,\n self._curr_module.inputs_need_grad, force_rebind=False,\n shared_module=self._curr_module)\n self._curr_module = module\n\n self._curr_module.forward(data_batch, is_train=is_train)\n\n def backward(self, out_grads=None):\n assert self.binded and self.params_initialized\n self._curr_module.backward(out_grads=out_grads)\n\n def update(self):\n assert self.binded and self.params_initialized and self.optimizer_initialized\n self._curr_module.update()\n\n def get_outputs(self, merge_multi_context=True):\n assert self.binded and self.params_initialized\n return self._curr_module.get_outputs(merge_multi_context=merge_multi_context)\n def get_input_grads(self, merge_multi_context=True):\n assert self.binded and self.params_initialized and self.inputs_need_grad\n return self._curr_module.get_input_grads(merge_multi_context=merge_multi_context)\n\n def update_metric(self, eval_metric, labels):\n assert self.binded and self.params_initialized\n self._curr_module.update_metric(eval_metric, labels)\n\n def install_monitor(self, mon):\n \"\"\" Install monitor on all executors \"\"\"\n assert self.binded\n self._curr_module.install_monitor(mon)\n"
},
{
"path": "dff_rfcn/core/rcnn.py",
"content": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed under The MIT License [see LICENSE for details]\n# Modified by Yuwen Xiong\n# --------------------------------------------------------\n# Based on:\n# MX-RCNN\n# Copyright (c) 2016 by Contributors\n# Licence under The Apache 2.0 License\n# https://github.com/ijkguo/mx-rcnn/\n# --------------------------------------------------------\n\n\"\"\"\nFast R-CNN:\ndata =\n {'data': [num_images, c, h, w],\n 'rois': [num_rois, 5]}\nlabel =\n {'label': [num_rois],\n 'bbox_target': [num_rois, 4 * num_classes],\n 'bbox_weight': [num_rois, 4 * num_classes]}\nroidb extended format [image_index]\n ['image', 'height', 'width', 'flipped',\n 'boxes', 'gt_classes', 'gt_overlaps', 'max_classes', 'max_overlaps', 'bbox_targets']\n\"\"\"\n\nimport numpy as np\nimport numpy.random as npr\n\nfrom utils.image import get_image, tensor_vstack\nfrom bbox.bbox_transform import bbox_overlaps, bbox_transform\nfrom bbox.bbox_regression import expand_bbox_regression_targets\n\n\ndef get_rcnn_testbatch(roidb, cfg):\n \"\"\"\n return a dict of testbatch\n :param roidb: ['image', 'flipped'] + ['boxes']\n :return: data, label, im_info\n \"\"\"\n # assert len(roidb) == 1, 'Single batch only'\n imgs, roidb = get_image(roidb, cfg)\n im_array = imgs\n im_info = [np.array([roidb[i]['im_info']], dtype=np.float32) for i in range(len(roidb))]\n\n im_rois = [roidb[i]['boxes'] for i in range(len(roidb))]\n rois = im_rois\n rois_array = [np.hstack((0 * np.ones((rois[i].shape[0], 1)), rois[i])) for i in range(len(rois))]\n\n data = [{'data': im_array[i],\n 'rois': rois_array[i]} for i in range(len(roidb))]\n label = {}\n\n return data, label, im_info\n\n\ndef get_rcnn_batch(roidb, cfg):\n \"\"\"\n return a dict of multiple images\n :param roidb: a list of dict, whose length controls batch size\n ['images', 'flipped'] + ['gt_boxes', 'boxes', 'gt_overlap'] => ['bbox_targets']\n :return: data, label\n \"\"\"\n num_images = len(roidb)\n imgs, roidb = get_image(roidb, cfg)\n im_array = tensor_vstack(imgs)\n\n assert cfg.TRAIN.BATCH_ROIS == -1 or cfg.TRAIN.BATCH_ROIS % cfg.TRAIN.BATCH_IMAGES == 0, \\\n 'BATCHIMAGES {} must divide BATCH_ROIS {}'.format(cfg.TRAIN.BATCH_IMAGES, cfg.TRAIN.BATCH_ROIS)\n\n if cfg.TRAIN.BATCH_ROIS == -1:\n rois_per_image = np.sum([iroidb['boxes'].shape[0] for iroidb in roidb])\n fg_rois_per_image = rois_per_image\n else:\n rois_per_image = cfg.TRAIN.BATCH_ROIS / cfg.TRAIN.BATCH_IMAGES\n fg_rois_per_image = np.round(cfg.TRAIN.FG_FRACTION * rois_per_image).astype(int)\n\n rois_array = list()\n labels_array = list()\n bbox_targets_array = list()\n bbox_weights_array = list()\n\n for im_i in range(num_images):\n roi_rec = roidb[im_i]\n\n # infer num_classes from gt_overlaps\n num_classes = roi_rec['gt_overlaps'].shape[1]\n\n # label = class RoI has max overlap with\n rois = roi_rec['boxes']\n labels = roi_rec['max_classes']\n overlaps = roi_rec['max_overlaps']\n bbox_targets = roi_rec['bbox_targets']\n\n im_rois, labels, bbox_targets, bbox_weights = \\\n sample_rois(rois, fg_rois_per_image, rois_per_image, num_classes, cfg,\n labels, overlaps, bbox_targets)\n\n # project im_rois\n # do not round roi\n rois = im_rois\n batch_index = im_i * np.ones((rois.shape[0], 1))\n rois_array_this_image = np.hstack((batch_index, rois))\n rois_array.append(rois_array_this_image)\n\n # add labels\n labels_array.append(labels)\n bbox_targets_array.append(bbox_targets)\n bbox_weights_array.append(bbox_weights)\n\n rois_array = np.array(rois_array)\n labels_array = np.array(labels_array)\n bbox_targets_array = np.array(bbox_targets_array)\n bbox_weights_array = np.array(bbox_weights_array)\n\n data = {'data': im_array,\n 'rois': rois_array}\n label = {'label': labels_array,\n 'bbox_target': bbox_targets_array,\n 'bbox_weight': bbox_weights_array}\n\n return data, label\n\n\ndef sample_rois(rois, fg_rois_per_image, rois_per_image, num_classes, cfg,\n labels=None, overlaps=None, bbox_targets=None, gt_boxes=None):\n \"\"\"\n generate random sample of ROIs comprising foreground and background examples\n :param rois: all_rois [n, 4]; e2e: [n, 5] with batch_index\n :param fg_rois_per_image: foreground roi number\n :param rois_per_image: total roi number\n :param num_classes: number of classes\n :param labels: maybe precomputed\n :param overlaps: maybe precomputed (max_overlaps)\n :param bbox_targets: maybe precomputed\n :param gt_boxes: optional for e2e [n, 5] (x1, y1, x2, y2, cls)\n :return: (labels, rois, bbox_targets, bbox_weights)\n \"\"\"\n if labels is None:\n overlaps = bbox_overlaps(rois[:, 1:].astype(np.float), gt_boxes[:, :4].astype(np.float))\n gt_assignment = overlaps.argmax(axis=1)\n overlaps = overlaps.max(axis=1)\n labels = gt_boxes[gt_assignment, 4]\n\n # foreground RoI with FG_THRESH overlap\n fg_indexes = np.where(overlaps >= cfg.TRAIN.FG_THRESH)[0]\n # guard against the case when an image has fewer than fg_rois_per_image foreground RoIs\n fg_rois_per_this_image = np.minimum(fg_rois_per_image, fg_indexes.size)\n # Sample foreground regions without replacement\n if len(fg_indexes) > fg_rois_per_this_image:\n fg_indexes = npr.choice(fg_indexes, size=fg_rois_per_this_image, replace=False)\n\n # Select background RoIs as those within [BG_THRESH_LO, BG_THRESH_HI)\n bg_indexes = np.where((overlaps < cfg.TRAIN.BG_THRESH_HI) & (overlaps >= cfg.TRAIN.BG_THRESH_LO))[0]\n # Compute number of background RoIs to take from this image (guarding against there being fewer than desired)\n bg_rois_per_this_image = rois_per_image - fg_rois_per_this_image\n bg_rois_per_this_image = np.minimum(bg_rois_per_this_image, bg_indexes.size)\n # Sample foreground regions without replacement\n if len(bg_indexes) > bg_rois_per_this_image:\n bg_indexes = npr.choice(bg_indexes, size=bg_rois_per_this_image, replace=False)\n\n # indexes selected\n keep_indexes = np.append(fg_indexes, bg_indexes)\n\n # pad more to ensure a fixed minibatch size\n while keep_indexes.shape[0] < rois_per_image:\n gap = np.minimum(len(rois), rois_per_image - keep_indexes.shape[0])\n gap_indexes = npr.choice(range(len(rois)), size=gap, replace=False)\n keep_indexes = np.append(keep_indexes, gap_indexes)\n\n # select labels\n labels = labels[keep_indexes]\n # set labels of bg_rois to be 0\n labels[fg_rois_per_this_image:] = 0\n rois = rois[keep_indexes]\n\n # load or compute bbox_target\n if bbox_targets is not None:\n bbox_target_data = bbox_targets[keep_indexes, :]\n else:\n targets = bbox_transform(rois[:, 1:], gt_boxes[gt_assignment[keep_indexes], :4])\n if cfg.TRAIN.BBOX_NORMALIZATION_PRECOMPUTED:\n targets = ((targets - np.array(cfg.TRAIN.BBOX_MEANS))\n / np.array(cfg.TRAIN.BBOX_STDS))\n bbox_target_data = np.hstack((labels[:, np.newaxis], targets))\n\n bbox_targets, bbox_weights = \\\n expand_bbox_regression_targets(bbox_target_data, num_classes, cfg)\n\n return rois, labels, bbox_targets, bbox_weights\n\n"
},
{
"path": "dff_rfcn/core/tester.py",
"content": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed under The MIT License [see LICENSE for details]\n# Modified by Xizhou Zhu, Yuwen Xiong\n# --------------------------------------------------------\n# Based on:\n# MX-RCNN\n# Copyright (c) 2016 by Contributors\n# Licence under The Apache 2.0 License\n# https://github.com/ijkguo/mx-rcnn/\n# --------------------------------------------------------\n\nfrom multiprocessing.pool import ThreadPool as Pool\nimport cPickle\nimport os\nimport time\nimport mxnet as mx\nimport numpy as np\n\nfrom module import MutableModule\nfrom utils import image\nfrom bbox.bbox_transform import bbox_pred, clip_boxes\nfrom nms.nms import py_nms_wrapper, cpu_nms_wrapper, gpu_nms_wrapper\nfrom utils.PrefetchingIter import PrefetchingIter\n\n\nclass Predictor(object):\n def __init__(self, symbol, data_names, label_names,\n context=mx.cpu(), max_data_shapes=None,\n provide_data=None, provide_label=None,\n arg_params=None, aux_params=None):\n self._mod = MutableModule(symbol, data_names, label_names,\n context=context, max_data_shapes=max_data_shapes)\n self._mod.bind(provide_data, provide_label, for_training=False)\n self._mod.init_params(arg_params=arg_params, aux_params=aux_params)\n\n def predict(self, data_batch):\n self._mod.forward(data_batch)\n # [dict(zip(self._mod.output_names, _)) for _ in zip(*self._mod.get_outputs(merge_multi_context=False))]\n return [dict(zip(self._mod.output_names, _)) for _ in zip(*self._mod.get_outputs(merge_multi_context=False))]\n\n\ndef im_proposal(predictor, data_batch, data_names, scales):\n output_all = predictor.predict(data_batch)\n\n data_dict_all = [dict(zip(data_names, data_batch.data[i])) for i in xrange(len(data_batch.data))]\n scores_all = []\n boxes_all = []\n\n for output, data_dict, scale in zip(output_all, data_dict_all, scales):\n # drop the batch index\n boxes = output['rois_output'].asnumpy()[:, 1:]\n scores = output['rois_score'].asnumpy()\n\n # transform to original scale\n boxes = boxes / scale\n scores_all.append(scores)\n boxes_all.append(boxes)\n\n return scores_all, boxes_all, data_dict_all\n\n\ndef generate_proposals(predictor, test_data, imdb, cfg, vis=False, thresh=0.):\n \"\"\"\n Generate detections results using RPN.\n :param predictor: Predictor\n :param test_data: data iterator, must be non-shuffled\n :param imdb: image database\n :param vis: controls visualization\n :param thresh: thresh for valid detections\n :return: list of detected boxes\n \"\"\"\n assert vis or not test_data.shuffle\n data_names = [k[0] for k in test_data.provide_data[0]]\n\n if not isinstance(test_data, PrefetchingIter):\n test_data = PrefetchingIter(test_data)\n\n idx = 0\n t = time.time()\n imdb_boxes = list()\n original_boxes = list()\n for im_info, data_batch in test_data:\n t1 = time.time() - t\n t = time.time()\n\n scales = [iim_info[0, 2] for iim_info in im_info]\n scores_all, boxes_all, data_dict_all = im_proposal(predictor, data_batch, data_names, scales)\n t2 = time.time() - t\n t = time.time()\n for delta, (scores, boxes, data_dict, scale) in enumerate(zip(scores_all, boxes_all, data_dict_all, scales)):\n # assemble proposals\n dets = np.hstack((boxes, scores))\n original_boxes.append(dets)\n\n # filter proposals\n keep = np.where(dets[:, 4:] > thresh)[0]\n dets = dets[keep, :]\n imdb_boxes.append(dets)\n\n if vis:\n vis_all_detection(data_dict['data'].asnumpy(), [dets], ['obj'], scale, cfg)\n\n print 'generating %d/%d' % (idx + 1, imdb.num_images), 'proposal %d' % (dets.shape[0]), \\\n 'data %.4fs net %.4fs' % (t1, t2 / test_data.batch_size)\n idx += 1\n\n\n assert len(imdb_boxes) == imdb.num_images, 'calculations not complete'\n\n # save results\n rpn_folder = os.path.join(imdb.result_path, 'rpn_data')\n if not os.path.exists(rpn_folder):\n os.mkdir(rpn_folder)\n\n rpn_file = os.path.join(rpn_folder, imdb.name + '_rpn.pkl')\n with open(rpn_file, 'wb') as f:\n cPickle.dump(imdb_boxes, f, cPickle.HIGHEST_PROTOCOL)\n\n if thresh > 0:\n full_rpn_file = os.path.join(rpn_folder, imdb.name + '_full_rpn.pkl')\n with open(full_rpn_file, 'wb') as f:\n cPickle.dump(original_boxes, f, cPickle.HIGHEST_PROTOCOL)\n\n print 'wrote rpn proposals to {}'.format(rpn_file)\n return imdb_boxes\n\n\ndef im_detect(predictor, data_batch, data_names, scales, cfg):\n output_all = predictor.predict(data_batch)\n\n data_dict_all = [dict(zip(data_names, data_batch.data[i])) for i in xrange(len(data_batch.data))]\n scores_all = []\n pred_boxes_all = []\n for output, data_dict, scale in zip(output_all, data_dict_all, scales):\n if cfg.TEST.HAS_RPN:\n rois = output['rois_output'].asnumpy()[:, 1:]\n else:\n rois = data_dict['rois'].asnumpy().reshape((-1, 5))[:, 1:]\n im_shape = data_dict['data'].shape\n\n # save output\n scores = output['cls_prob_reshape_output'].asnumpy()[0]\n bbox_deltas = output['bbox_pred_reshape_output'].asnumpy()[0]\n\n # post processing\n pred_boxes = bbox_pred(rois, bbox_deltas)\n pred_boxes = clip_boxes(pred_boxes, im_shape[-2:])\n\n # we used scaled image & roi to train, so it is necessary to transform them back\n pred_boxes = pred_boxes / scale\n\n scores_all.append(scores)\n pred_boxes_all.append(pred_boxes)\n\n if output_all[0].has_key('feat_conv_3x3_relu_output'):\n feat = output_all[0]['feat_conv_3x3_relu_output']\n else:\n feat = None\n return scores_all, pred_boxes_all, data_dict_all, feat\n\n\ndef im_batch_detect(predictor, data_batch, data_names, scales, cfg):\n output_all = predictor.predict(data_batch)\n\n data_dict_all = [dict(zip(data_names, data_batch.data[i])) for i in xrange(len(data_batch.data))]\n scores_all = []\n pred_boxes_all = []\n for output, data_dict, scale in zip(output_all, data_dict_all, scales):\n im_infos = data_dict['im_info'].asnumpy()\n # save output\n scores = output['cls_prob_reshape_output'].asnumpy()[0]\n bbox_deltas = output['bbox_pred_reshape_output'].asnumpy()[0]\n rois = output['rois_output'].asnumpy()\n for im_idx in xrange(im_infos.shape[0]):\n bb_idxs = np.where(rois[:,0] == im_idx)[0]\n im_shape = im_infos[im_idx, :2].astype(np.int)\n\n # post processing\n pred_boxes = bbox_pred(rois[bb_idxs, 1:], bbox_deltas[bb_idxs, :])\n pred_boxes = clip_boxes(pred_boxes, im_shape)\n\n # we used scaled image & roi to train, so it is necessary to transform them back\n pred_boxes = pred_boxes / scale[im_idx]\n\n scores_all.append(scores[bb_idxs, :])\n pred_boxes_all.append(pred_boxes)\n\n return scores_all, pred_boxes_all, data_dict_all\n\n\ndef pred_eval(gpu_id, key_predictor, cur_predictor, test_data, imdb, cfg, vis=False, thresh=1e-4, logger=None, ignore_cache=True):\n \"\"\"\n wrapper for calculating offline validation for faster data analysis\n in this example, all threshold are set by hand\n :param predictor: Predictor\n :param test_data: data iterator, must be non-shuffle\n :param imdb: image database\n :param vis: controls visualization\n :param thresh: valid detection threshold\n :return:\n \"\"\"\n\n det_file = os.path.join(imdb.result_path, imdb.name + '_'+ str(gpu_id) + '_detections.pkl')\n if os.path.exists(det_file) and not ignore_cache:\n with open(det_file, 'rb') as fid:\n all_boxes, frame_ids = cPickle.load(fid)\n return all_boxes, frame_ids\n\n assert vis or not test_data.shuffle\n data_names = [k[0] for k in test_data.provide_data[0]]\n num_images = test_data.size\n roidb_frame_ids = [x['frame_id'] for x in test_data.roidb]\n\n if not isinstance(test_data, PrefetchingIter):\n test_data = PrefetchingIter(test_data)\n\n nms = py_nms_wrapper(cfg.TEST.NMS)\n\n # limit detections to max_per_image over all classes\n max_per_image = cfg.TEST.max_per_image\n\n # all detections are collected into:\n # all_boxes[cls][image] = N x 5 array of detections in\n # (x1, y1, x2, y2, score)\n all_boxes = [[[] for _ in range(num_images)]\n for _ in range(imdb.num_classes)]\n frame_ids = np.zeros(num_images, dtype=np.int)\n\n roidb_idx = -1\n roidb_offset = -1\n idx = 0\n data_time, net_time, post_time = 0.0, 0.0, 0.0\n t = time.time()\n for im_info, key_frame_flag, data_batch in test_data:\n t1 = time.time() - t\n t = time.time()\n\n scales = [iim_info[0, 2] for iim_info in im_info]\n if key_frame_flag != 2:\n scores_all, boxes_all, data_dict_all, feat = im_detect(key_predictor, data_batch, data_names, scales, cfg)\n else:\n data_batch.data[0][-1] = feat\n data_batch.provide_data[0][-1] = ('feat_key', feat.shape)\n scores_all, boxes_all, data_dict_all, _ = im_detect(cur_predictor, data_batch, data_names, scales, cfg)\n\n if key_frame_flag == 0:\n roidb_idx += 1\n roidb_offset = 0\n else:\n roidb_offset += 1\n\n frame_ids[idx] = roidb_frame_ids[roidb_idx] + roidb_offset\n\n t2 = time.time() - t\n t = time.time()\n for delta, (scores, boxes, data_dict) in enumerate(zip(scores_all, boxes_all, data_dict_all)):\n for j in range(1, imdb.num_classes):\n indexes = np.where(scores[:, j] > thresh)[0]\n cls_scores = scores[indexes, j, np.newaxis]\n cls_boxes = boxes[indexes, 4:8] if cfg.CLASS_AGNOSTIC else boxes[indexes, j * 4:(j + 1) * 4]\n cls_dets = np.hstack((cls_boxes, cls_scores))\n keep = nms(cls_dets)\n all_boxes[j][idx+delta] = cls_dets[keep, :]\n\n if max_per_image > 0:\n image_scores = np.hstack([all_boxes[j][idx+delta][:, -1]\n for j in range(1, imdb.num_classes)])\n if len(image_scores) > max_per_image:\n image_thresh = np.sort(image_scores)[-max_per_image]\n for j in range(1, imdb.num_classes):\n keep = np.where(all_boxes[j][idx+delta][:, -1] >= image_thresh)[0]\n all_boxes[j][idx+delta] = all_boxes[j][idx+delta][keep, :]\n\n if vis:\n boxes_this_image = [[]] + [all_boxes[j][idx+delta] for j in range(1, imdb.num_classes)]\n vis_all_detection(data_dict['data'].asnumpy(), boxes_this_image, imdb.classes, scales[delta], cfg)\n\n idx += test_data.batch_size\n t3 = time.time() - t\n t = time.time()\n data_time += t1\n net_time += t2\n post_time += t3\n print 'testing {}/{} data {:.4f}s net {:.4f}s post {:.4f}s'.format(idx, num_images, data_time / idx * test_data.batch_size, net_time / idx * test_data.batch_size, post_time / idx * test_data.batch_size)\n if logger:\n logger.info('testing {}/{} data {:.4f}s net {:.4f}s post {:.4f}s'.format(idx, num_images, data_time / idx * test_data.batch_size, net_time / idx * test_data.batch_size, post_time / idx * test_data.batch_size))\n\n with open(det_file, 'wb') as f:\n cPickle.dump((all_boxes, frame_ids), f, protocol=cPickle.HIGHEST_PROTOCOL)\n\n return all_boxes, frame_ids\n\ndef pred_eval_multiprocess(gpu_num, key_predictors, cur_predictors, test_datas, imdb, cfg, vis=False, thresh=1e-4, logger=None, ignore_cache=True):\n if gpu_num == 1:\n res = [pred_eval(0, key_predictors[0], cur_predictors[0], test_datas[0], imdb, cfg, vis, thresh, logger, ignore_cache),]\n else:\n pool = Pool(processes=gpu_num)\n multiple_results = [pool.apply_async(pred_eval,args=(i, key_predictors[i], cur_predictors[i], test_datas[i], imdb, cfg, vis, thresh, logger, ignore_cache)) for i in range(gpu_num)]\n pool.close()\n pool.join()\n res = [res.get() for res in multiple_results]\n info_str = imdb.evaluate_detections_multiprocess(res)\n if logger:\n logger.info('evaluate detections: \\n{}'.format(info_str))\n\ndef vis_all_detection(im_array, detections, class_names, scale, cfg, threshold=1e-4):\n \"\"\"\n visualize all detections in one image\n :param im_array: [b=1 c h w] in rgb\n :param detections: [ numpy.ndarray([[x1 y1 x2 y2 score]]) for j in classes ]\n :param class_names: list of names in imdb\n :param scale: visualize the scaled image\n :return:\n \"\"\"\n import matplotlib.pyplot as plt\n import random\n im = image.transform_inverse(im_array, cfg.network.PIXEL_MEANS)\n plt.imshow(im)\n for j, name in enumerate(class_names):\n if name == '__background__':\n continue\n color = (random.random(), random.random(), random.random()) # generate a random color\n dets = detections[j]\n for det in dets:\n bbox = det[:4] * scale\n score = det[-1]\n if score < threshold:\n continue\n rect = plt.Rectangle((bbox[0], bbox[1]),\n bbox[2] - bbox[0],\n bbox[3] - bbox[1], fill=False,\n edgecolor=color, linewidth=3.5)\n plt.gca().add_patch(rect)\n plt.gca().text(bbox[0], bbox[1] - 2,\n '{:s} {:.3f}'.format(name, score),\n bbox=dict(facecolor=color, alpha=0.5), fontsize=12, color='white')\n plt.show()\n\n\ndef draw_all_detection(im_array, detections, class_names, scale, cfg, threshold=1e-1):\n \"\"\"\n visualize all detections in one image\n :param im_array: [b=1 c h w] in rgb\n :param detections: [ numpy.ndarray([[x1 y1 x2 y2 score]]) for j in classes ]\n :param class_names: list of names in imdb\n :param scale: visualize the scaled image\n :return:\n \"\"\"\n import cv2\n import random\n color_white = (255, 255, 255)\n im = image.transform_inverse(im_array, cfg.network.PIXEL_MEANS)\n # change to bgr\n im = cv2.cvtColor(im, cv2.COLOR_RGB2BGR)\n for j, name in enumerate(class_names):\n if name == '__background__':\n continue\n color = (random.randint(0, 256), random.randint(0, 256), random.randint(0, 256)) # generate a random color\n dets = detections[j]\n for det in dets:\n bbox = det[:4] * scale\n score = det[-1]\n if score < threshold:\n continue\n bbox = map(int, bbox)\n cv2.rectangle(im, (bbox[0], bbox[1]), (bbox[2], bbox[3]), color=color, thickness=2)\n cv2.putText(im, '%s %.3f' % (class_names[j], score), (bbox[0], bbox[1] + 10),\n color=color_white, fontFace=cv2.FONT_HERSHEY_COMPLEX, fontScale=0.5)\n return im\n"
},
{
"path": "dff_rfcn/demo.py",
"content": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed under The MIT License [see LICENSE for details]\n# Written by Xizhou Zhu, Yi Li, Haochen Zhang\n# --------------------------------------------------------\n\nimport _init_paths\n\nimport argparse\nimport os\nimport glob\nimport sys\nimport logging\nimport pprint\nimport cv2\nfrom config.config import config, update_config\nfrom utils.image import resize, transform\nimport numpy as np\n# get config\nos.environ['PYTHONUNBUFFERED'] = '1'\nos.environ['MXNET_CUDNN_AUTOTUNE_DEFAULT'] = '0'\nos.environ['MXNET_ENABLE_GPU_P2P'] = '0'\ncur_path = os.path.abspath(os.path.dirname(__file__))\nupdate_config(cur_path + '/../experiments/dff_rfcn/cfgs/dff_rfcn_vid_demo.yaml')\n\nsys.path.insert(0, os.path.join(cur_path, '../external/mxnet', config.MXNET_VERSION))\nimport mxnet as mx\nfrom core.tester import im_detect, Predictor\nfrom symbols import *\nfrom utils.load_model import load_param\nfrom utils.show_boxes import show_boxes, draw_boxes\nfrom utils.tictoc import tic, toc\nfrom nms.nms import py_nms_wrapper, cpu_nms_wrapper, gpu_nms_wrapper\n\ndef parse_args():\n parser = argparse.ArgumentParser(description='Show Deep Feature Flow demo')\n args = parser.parse_args()\n return args\n\nargs = parse_args()\n\ndef main():\n # get symbol\n pprint.pprint(config)\n config.symbol = 'resnet_v1_101_flownet_rfcn'\n model = '/../model/rfcn_dff_flownet_vid'\n sym_instance = eval(config.symbol + '.' + config.symbol)()\n key_sym = sym_instance.get_key_test_symbol(config)\n cur_sym = sym_instance.get_cur_test_symbol(config)\n\n # set up class names\n num_classes = 31\n classes = ['airplane', 'antelope', 'bear', 'bicycle',\n 'bird', 'bus', 'car', 'cattle',\n 'dog', 'domestic_cat', 'elephant', 'fox',\n 'giant_panda', 'hamster', 'horse', 'lion',\n 'lizard', 'monkey', 'motorcycle', 'rabbit',\n 'red_panda', 'sheep', 'snake', 'squirrel',\n 'tiger', 'train', 'turtle', 'watercraft',\n 'whale', 'zebra']\n\n # load demo data\n image_names = glob.glob(cur_path + '/../demo/ILSVRC2015_val_00007010/*.JPEG')\n output_dir = cur_path + '/../demo/rfcn_dff/'\n if not os.path.exists(output_dir):\n os.makedirs(output_dir)\n key_frame_interval = 10\n\n #\n\n data = []\n key_im_tensor = None\n for idx, im_name in enumerate(image_names):\n assert os.path.exists(im_name), ('%s does not exist'.format(im_name))\n im = cv2.imread(im_name, cv2.IMREAD_COLOR | cv2.IMREAD_IGNORE_ORIENTATION)\n target_size = config.SCALES[0][0]\n max_size = config.SCALES[0][1]\n im, im_scale = resize(im, target_size, max_size, stride=config.network.IMAGE_STRIDE)\n im_tensor = transform(im, config.network.PIXEL_MEANS)\n im_info = np.array([[im_tensor.shape[2], im_tensor.shape[3], im_scale]], dtype=np.float32)\n if idx % key_frame_interval == 0:\n key_im_tensor = im_tensor\n data.append({'data': im_tensor, 'im_info': im_info, 'data_key': key_im_tensor, 'feat_key': np.zeros((1,config.network.DFF_FEAT_DIM,1,1))})\n\n\n # get predictor\n data_names = ['data', 'im_info', 'data_key', 'feat_key']\n label_names = []\n data = [[mx.nd.array(data[i][name]) for name in data_names] for i in xrange(len(data))]\n max_data_shape = [[('data', (1, 3, max([v[0] for v in config.SCALES]), max([v[1] for v in config.SCALES]))),\n ('data_key', (1, 3, max([v[0] for v in config.SCALES]), max([v[1] for v in config.SCALES]))),]]\n provide_data = [[(k, v.shape) for k, v in zip(data_names, data[i])] for i in xrange(len(data))]\n provide_label = [None for i in xrange(len(data))]\n arg_params, aux_params = load_param(cur_path + model, 0, process=True)\n key_predictor = Predictor(key_sym, data_names, label_names,\n context=[mx.gpu(0)], max_data_shapes=max_data_shape,\n provide_data=provide_data, provide_label=provide_label,\n arg_params=arg_params, aux_params=aux_params)\n cur_predictor = Predictor(cur_sym, data_names, label_names,\n context=[mx.gpu(0)], max_data_shapes=max_data_shape,\n provide_data=provide_data, provide_label=provide_label,\n arg_params=arg_params, aux_params=aux_params)\n nms = gpu_nms_wrapper(config.TEST.NMS, 0)\n\n # warm up\n for j in xrange(2):\n data_batch = mx.io.DataBatch(data=[data[j]], label=[], pad=0, index=0,\n provide_data=[[(k, v.shape) for k, v in zip(data_names, data[j])]],\n provide_label=[None])\n scales = [data_batch.data[i][1].asnumpy()[0, 2] for i in xrange(len(data_batch.data))]\n if j % key_frame_interval == 0:\n scores, boxes, data_dict, feat = im_detect(key_predictor, data_batch, data_names, scales, config)\n else:\n data_batch.data[0][-1] = feat\n data_batch.provide_data[0][-1] = ('feat_key', feat.shape)\n scores, boxes, data_dict, _ = im_detect(cur_predictor, data_batch, data_names, scales, config)\n\n print \"warmup done\"\n # test\n time = 0\n count = 0\n for idx, im_name in enumerate(image_names):\n data_batch = mx.io.DataBatch(data=[data[idx]], label=[], pad=0, index=idx,\n provide_data=[[(k, v.shape) for k, v in zip(data_names, data[idx])]],\n provide_label=[None])\n scales = [data_batch.data[i][1].asnumpy()[0, 2] for i in xrange(len(data_batch.data))]\n\n tic()\n if idx % key_frame_interval == 0:\n scores, boxes, data_dict, feat = im_detect(key_predictor, data_batch, data_names, scales, config)\n else:\n data_batch.data[0][-1] = feat\n data_batch.provide_data[0][-1] = ('feat_key', feat.shape)\n scores, boxes, data_dict, _ = im_detect(cur_predictor, data_batch, data_names, scales, config)\n time += toc()\n count += 1\n print 'testing {} {:.4f}s'.format(im_name, time/count)\n\n boxes = boxes[0].astype('f')\n scores = scores[0].astype('f')\n dets_nms = []\n for j in range(1, scores.shape[1]):\n cls_scores = scores[:, j, np.newaxis]\n cls_boxes = boxes[:, 4:8] if config.CLASS_AGNOSTIC else boxes[:, j * 4:(j + 1) * 4]\n cls_dets = np.hstack((cls_boxes, cls_scores))\n keep = nms(cls_dets)\n cls_dets = cls_dets[keep, :]\n cls_dets = cls_dets[cls_dets[:, -1] > 0.7, :]\n dets_nms.append(cls_dets)\n # visualize\n im = cv2.imread(im_name)\n im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)\n # show_boxes(im, dets_nms, classes, 1)\n out_im = draw_boxes(im, dets_nms, classes, 1)\n _, filename = os.path.split(im_name)\n cv2.imwrite(output_dir + filename,out_im)\n\n print 'done'\n\nif __name__ == '__main__':\n main()\n"
},
{
"path": "dff_rfcn/demo_batch.py",
"content": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed under The MIT License [see LICENSE for details]\n# Written by Xizhou Zhu, Yi Li, Haochen Zhang\n# --------------------------------------------------------\n\nimport _init_paths\n\nimport argparse\nimport os\nimport glob\nimport sys\nimport logging\nimport pprint\nimport cv2\nfrom config.config import config, update_config\nfrom utils.image import resize, transform\nimport numpy as np\n# get config\nos.environ['PYTHONUNBUFFERED'] = '1'\nos.environ['MXNET_CUDNN_AUTOTUNE_DEFAULT'] = '0'\nos.environ['MXNET_ENABLE_GPU_P2P'] = '0'\ncur_path = os.path.abspath(os.path.dirname(__file__))\nupdate_config(cur_path + '/../experiments/dff_rfcn/cfgs/dff_rfcn_vid_demo.yaml')\n\nsys.path.insert(0, os.path.join(cur_path, '../external/mxnet', config.MXNET_VERSION))\nimport mxnet as mx\nfrom core.tester import im_batch_detect, Predictor\nfrom symbols import *\nfrom utils.load_model import load_param\nfrom utils.show_boxes import show_boxes, draw_boxes\nfrom utils.tictoc import tic, toc\nfrom nms.nms import py_nms_wrapper, cpu_nms_wrapper, gpu_nms_wrapper\n\ndef parse_args():\n parser = argparse.ArgumentParser(description='Show Deep Feature Flow demo')\n args = parser.parse_args()\n return args\n\nargs = parse_args()\n\ndef main():\n # get symbol\n pprint.pprint(config)\n config.symbol = 'resnet_v1_101_flownet_rfcn'\n model = '/../model/rfcn_dff_flownet_vid'\n sym_instance = eval(config.symbol + '.' + config.symbol)()\n sym = sym_instance.get_batch_test_symbol(config)\n\n # set up class names\n num_classes = 31\n classes = ['airplane', 'antelope', 'bear', 'bicycle',\n 'bird', 'bus', 'car', 'cattle',\n 'dog', 'domestic_cat', 'elephant', 'fox',\n 'giant_panda', 'hamster', 'horse', 'lion',\n 'lizard', 'monkey', 'motorcycle', 'rabbit',\n 'red_panda', 'sheep', 'snake', 'squirrel',\n 'tiger', 'train', 'turtle', 'watercraft',\n 'whale', 'zebra']\n\n # load demo data\n image_names = glob.glob(cur_path + '/../demo/ILSVRC2015_val_00007010/*.JPEG')\n output_dir = cur_path + '/../demo/rfcn_dff_batch/'\n if not os.path.exists(output_dir):\n os.makedirs(output_dir)\n key_frame_interval = 10\n\n #\n\n data = []\n key_im_tensor = None\n cur_im_tensor = []\n im_info_tensor = []\n image_names_list = []\n image_names_batch = []\n for idx, im_name in enumerate(image_names):\n assert os.path.exists(im_name), ('%s does not exist'.format(im_name))\n im = cv2.imread(im_name, cv2.IMREAD_COLOR | cv2.IMREAD_IGNORE_ORIENTATION)\n target_size = config.SCALES[0][0]\n max_size = config.SCALES[0][1]\n im, im_scale = resize(im, target_size, max_size, stride=config.network.IMAGE_STRIDE)\n im_tensor = transform(im, config.network.PIXEL_MEANS)\n im_info = np.array([[im_tensor.shape[2], im_tensor.shape[3], im_scale]], dtype=np.float32)\n if idx % key_frame_interval == 0:\n key_im_tensor = im_tensor\n else:\n cur_im_tensor.append(im_tensor)\n im_info_tensor.append(im_info)\n image_names_batch.append(im_name)\n if (idx+1) % key_frame_interval == 0 or idx == len(image_names) - 1:\n data.append({'data_other': np.concatenate(cur_im_tensor), 'im_info': np.concatenate(im_info_tensor), 'data_key': key_im_tensor})\n key_im_tensor = None\n cur_im_tensor = []\n im_info_tensor = []\n image_names_list.append(image_names_batch)\n image_names_batch = []\n\n # get predictor\n data_names = ['data_other', 'im_info', 'data_key']\n label_names = []\n data = [[mx.nd.array(data[i][name]) for name in data_names] for i in xrange(len(data))]\n max_data_shape = [[('data_other', (key_frame_interval-1, 3, max([v[0] for v in config.SCALES]), max([v[1] for v in config.SCALES]))),\n ('data_key', (1, 3, max([v[0] for v in config.SCALES]), max([v[1] for v in config.SCALES]))),]]\n provide_data = [[(k, v.shape) for k, v in zip(data_names, data[i])] for i in xrange(len(data))]\n provide_label = [None for i in xrange(len(data))]\n arg_params, aux_params = load_param(cur_path + model, 0, process=True)\n predictor = Predictor(sym, data_names, label_names,\n context=[mx.gpu(0)], max_data_shapes=max_data_shape,\n provide_data=provide_data, provide_label=provide_label,\n arg_params=arg_params, aux_params=aux_params)\n nms = gpu_nms_wrapper(config.TEST.NMS, 0)\n\n # warm up\n for j in xrange(1):\n data_batch = mx.io.DataBatch(data=[data[j]], label=[], pad=0, index=0,\n provide_data=[[(k, v.shape) for k, v in zip(data_names, data[j])]],\n provide_label=[None])\n scales = [data_batch.data[i][1].asnumpy()[:, 2] for i in xrange(len(data_batch.data))]\n scores_all, boxes_all, data_dict = im_batch_detect(predictor, data_batch, data_names, scales, config)\n\n print \"warmup done\"\n # test\n time = 0\n count = 0\n for idx, im_names in enumerate(image_names_list):\n data_batch = mx.io.DataBatch(data=[data[idx]], label=[], pad=0, index=idx,\n provide_data=[[(k, v.shape) for k, v in zip(data_names, data[idx])]],\n provide_label=[None])\n scales = [data_batch.data[i][1].asnumpy()[:, 2] for i in xrange(len(data_batch.data))]\n\n tic()\n scores_all, boxes_all, data_dict = im_batch_detect(predictor, data_batch, data_names, scales, config)\n time += toc()\n count += len(scores_all)\n print 'testing {} {:.4f}s x {:d}'.format(im_names[0], time/count, len(scores_all))\n\n for batch_idx in xrange(len(scores_all)):\n boxes = boxes_all[batch_idx].astype('f')\n scores = scores_all[batch_idx].astype('f')\n dets_nms = []\n for j in range(1, scores.shape[1]):\n cls_scores = scores[:, j, np.newaxis]\n cls_boxes = boxes[:, 4:8] if config.CLASS_AGNOSTIC else boxes[:, j * 4:(j + 1) * 4]\n cls_dets = np.hstack((cls_boxes, cls_scores))\n keep = nms(cls_dets)\n cls_dets = cls_dets[keep, :]\n cls_dets = cls_dets[cls_dets[:, -1] > 0.7, :]\n dets_nms.append(cls_dets)\n # visualize\n im = cv2.imread(im_names[batch_idx])\n im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)\n # show_boxes(im, dets_nms, classes, 1)\n out_im = draw_boxes(im, dets_nms, classes, 1)\n _, filename = os.path.split(im_names[batch_idx])\n cv2.imwrite(output_dir + filename,out_im)\n\n\n print 'done'\n\nif __name__ == '__main__':\n main()\n"
},
{
"path": "dff_rfcn/function/__init__.py",
"content": ""
},
{
"path": "dff_rfcn/function/test_rcnn.py",
"content": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed under The MIT License [see LICENSE for details]\n# Modified by Yuwen Xiong\n# --------------------------------------------------------\n# Based on:\n# MX-RCNN\n# Copyright (c) 2016 by Contributors\n# Licence under The Apache 2.0 License\n# https://github.com/ijkguo/mx-rcnn/\n# --------------------------------------------------------\n\nimport argparse\nimport pprint\nimport logging\nimport time\nimport os\nimport numpy as np\nimport mxnet as mx\n\nfrom symbols import *\nfrom dataset import *\nfrom core.loader import TestLoader\nfrom core.tester import Predictor, pred_eval, pred_eval_multiprocess\nfrom utils.load_model import load_param\n\ndef get_predictor(sym, sym_instance, cfg, arg_params, aux_params, test_data, ctx):\n # infer shape\n data_shape_dict = dict(test_data.provide_data_single)\n sym_instance.infer_shape(data_shape_dict)\n sym_instance.check_parameter_shapes(arg_params, aux_params, data_shape_dict, is_train=False)\n\n # decide maximum shape\n data_names = [k[0] for k in test_data.provide_data_single]\n label_names = None\n max_data_shape = [[('data', (1, 3, max([v[0] for v in cfg.SCALES]), max([v[1] for v in cfg.SCALES]))),\n ('data_key', (1, 3, max([v[0] for v in cfg.SCALES]), max([v[1] for v in cfg.SCALES]))),]]\n\n # create predictor\n predictor = Predictor(sym, data_names, label_names,\n context=ctx, max_data_shapes=max_data_shape,\n provide_data=test_data.provide_data, provide_label=test_data.provide_label,\n arg_params=arg_params, aux_params=aux_params)\n return predictor\n\ndef test_rcnn(cfg, dataset, image_set, root_path, dataset_path,\n ctx, prefix, epoch,\n vis, ignore_cache, shuffle, has_rpn, proposal, thresh, logger=None, output_path=None):\n if not logger:\n assert False, 'require a logger'\n\n # print cfg\n pprint.pprint(cfg)\n logger.info('testing cfg:{}\\n'.format(pprint.pformat(cfg)))\n\n # load symbol and testing data\n key_sym_instance = eval(cfg.symbol + '.' + cfg.symbol)()\n cur_sym_instance = eval(cfg.symbol + '.' + cfg.symbol)()\n key_sym = key_sym_instance.get_key_test_symbol(cfg)\n cur_sym = cur_sym_instance.get_cur_test_symbol(cfg)\n imdb = eval(dataset)(image_set, root_path, dataset_path, result_path=output_path)\n roidb = imdb.gt_roidb()\n\n # get test data iter\n # split roidbs\n gpu_num = len(ctx)\n roidbs = [[] for x in range(gpu_num)]\n roidbs_seg_lens = np.zeros(gpu_num, dtype=np.int)\n for x in roidb:\n gpu_id = np.argmin(roidbs_seg_lens)\n roidbs[gpu_id].append(x)\n roidbs_seg_lens[gpu_id] += x['frame_seg_len']\n\n # get test data iter\n test_datas = [TestLoader(x, cfg, batch_size=1, shuffle=shuffle, has_rpn=has_rpn) for x in roidbs]\n\n # load model\n arg_params, aux_params = load_param(prefix, epoch, process=True)\n\n # create predictor\n key_predictors = [get_predictor(key_sym, key_sym_instance, cfg, arg_params, aux_params, test_datas[i], [ctx[i]]) for i in range(gpu_num)]\n cur_predictors = [get_predictor(cur_sym, cur_sym_instance, cfg, arg_params, aux_params, test_datas[i], [ctx[i]]) for i in range(gpu_num)]\n\n # start detection\n #pred_eval(0, key_predictors[0], cur_predictors[0], test_datas[0], imdb, cfg, vis=vis, ignore_cache=ignore_cache, thresh=thresh, logger=logger)\n pred_eval_multiprocess(gpu_num, key_predictors, cur_predictors, test_datas, imdb, cfg, vis=vis, ignore_cache=ignore_cache, thresh=thresh, logger=logger)\n"
},
{
"path": "dff_rfcn/function/test_rpn.py",
"content": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed under The MIT License [see LICENSE for details]\n# Modified by Yuwen Xiong\n# --------------------------------------------------------\n# Based on:\n# MX-RCNN\n# Copyright (c) 2016 by Contributors\n# Licence under The Apache 2.0 License\n# https://github.com/ijkguo/mx-rcnn/\n# --------------------------------------------------------\n\nimport argparse\nimport pprint\nimport logging\nimport mxnet as mx\n\nfrom symbols import *\nfrom dataset import *\nfrom core.loader import TestLoader\nfrom core.tester import Predictor, generate_proposals\nfrom utils.load_model import load_param\n\n\ndef test_rpn(cfg, dataset, image_set, root_path, dataset_path,\n ctx, prefix, epoch,\n vis, shuffle, thresh, logger=None, output_path=None):\n # set up logger\n if not logger:\n logging.basicConfig()\n logger = logging.getLogger()\n logger.setLevel(logging.INFO)\n\n # rpn generate proposal cfg\n cfg.TEST.HAS_RPN = True\n\n # print cfg\n pprint.pprint(cfg)\n logger.info('testing rpn cfg:{}\\n'.format(pprint.pformat(cfg)))\n\n # load symbol\n sym_instance = eval(cfg.symbol + '.' + cfg.symbol)()\n sym = sym_instance.get_symbol_rpn(cfg, is_train=False)\n\n # load dataset and prepare imdb for training\n imdb = eval(dataset)(image_set, root_path, dataset_path, result_path=output_path)\n roidb = imdb.gt_roidb()\n test_data = TestLoader(roidb, cfg, batch_size=len(ctx), shuffle=shuffle, has_rpn=True)\n\n # load model\n arg_params, aux_params = load_param(prefix, epoch)\n\n # infer shape\n data_shape_dict = dict(test_data.provide_data_single)\n sym_instance.infer_shape(data_shape_dict)\n\n # check parameters\n sym_instance.check_parameter_shapes(arg_params, aux_params, data_shape_dict, is_train=False)\n\n # decide maximum shape\n data_names = [k[0] for k in test_data.provide_data[0]]\n label_names = None if test_data.provide_label[0] is None else [k[0] for k in test_data.provide_label[0]]\n max_data_shape = [[('data', (1, 3, max([v[0] for v in cfg.SCALES]), max([v[1] for v in cfg.SCALES])))]]\n\n # create predictor\n predictor = Predictor(sym, data_names, label_names,\n context=ctx, max_data_shapes=max_data_shape,\n provide_data=test_data.provide_data, provide_label=test_data.provide_label,\n arg_params=arg_params, aux_params=aux_params)\n\n # start testing\n imdb_boxes = generate_proposals(predictor, test_data, imdb, cfg, vis=vis, thresh=thresh)\n\n all_log_info = imdb.evaluate_recall(roidb, candidate_boxes=imdb_boxes)\n logger.info(all_log_info)\n"
},
{
"path": "dff_rfcn/function/train_rcnn.py",
"content": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed under The MIT License [see LICENSE for details]\n# Modified by Yuwen Xiong\n# --------------------------------------------------------\n# Based on:\n# MX-RCNN\n# Copyright (c) 2016 by Contributors\n# Licence under The Apache 2.0 License\n# https://github.com/ijkguo/mx-rcnn/\n# --------------------------------------------------------\n\nimport argparse\nimport logging\nimport pprint\nimport os\nimport mxnet as mx\n\nfrom symbols import *\nfrom core import callback, metric\nfrom core.loader import ROIIter\nfrom core.module import MutableModule\nfrom bbox.bbox_regression import add_bbox_regression_targets\nfrom utils.load_data import load_proposal_roidb, merge_roidb, filter_roidb\nfrom utils.load_model import load_param\nfrom utils.PrefetchingIter import PrefetchingIter\nfrom utils.lr_scheduler import WarmupMultiFactorScheduler\n\n\ndef train_rcnn(cfg, dataset, image_set, root_path, dataset_path,\n frequent, kvstore, flip, shuffle, resume,\n ctx, pretrained, epoch, prefix, begin_epoch, end_epoch,\n train_shared, lr, lr_step, proposal, logger=None, output_path=None):\n # set up logger\n if not logger:\n logging.basicConfig()\n logger = logging.getLogger()\n logger.setLevel(logging.INFO)\n\n # load symbol\n sym_instance = eval(cfg.symbol + '.' + cfg.symbol)()\n sym = sym_instance.get_symbol_rfcn(cfg, is_train=True)\n\n # setup multi-gpu\n batch_size = len(ctx)\n input_batch_size = cfg.TRAIN.BATCH_IMAGES * batch_size\n\n # print cfg\n pprint.pprint(cfg)\n logger.info('training rcnn cfg:{}\\n'.format(pprint.pformat(cfg)))\n\n # load dataset and prepare imdb for training\n image_sets = [iset for iset in image_set.split('+')]\n roidbs = [load_proposal_roidb(dataset, image_set, root_path, dataset_path,\n proposal=proposal, append_gt=True, flip=flip, result_path=output_path)\n for image_set in image_sets]\n roidb = merge_roidb(roidbs)\n roidb = filter_roidb(roidb, cfg)\n means, stds = add_bbox_regression_targets(roidb, cfg)\n\n # load training data\n train_data = ROIIter(roidb, cfg, batch_size=input_batch_size, shuffle=shuffle,\n ctx=ctx, aspect_grouping=cfg.TRAIN.ASPECT_GROUPING)\n\n # infer max shape\n max_data_shape = [('data', (cfg.TRAIN.BATCH_IMAGES, 3, max([v[0] for v in cfg.SCALES]), max([v[1] for v in cfg.SCALES])))]\n\n # infer shape\n data_shape_dict = dict(train_data.provide_data_single + train_data.provide_label_single)\n sym_instance.infer_shape(data_shape_dict)\n\n # load and initialize params\n if resume:\n print('continue training from ', begin_epoch)\n arg_params, aux_params = load_param(prefix, begin_epoch, convert=True)\n else:\n arg_params, aux_params = load_param(pretrained, epoch, convert=True)\n sym_instance.init_weight_rfcn(cfg, arg_params, aux_params)\n\n # check parameter shapes\n sym_instance.check_parameter_shapes(arg_params, aux_params, data_shape_dict)\n\n # prepare training\n # create solver\n data_names = [k[0] for k in train_data.provide_data_single]\n label_names = [k[0] for k in train_data.provide_label_single]\n if train_shared:\n fixed_param_prefix = cfg.network.FIXED_PARAMS_SHARED\n else:\n fixed_param_prefix = cfg.network.FIXED_PARAMS\n mod = MutableModule(sym, data_names=data_names, label_names=label_names,\n logger=logger, context=ctx,\n max_data_shapes=[max_data_shape for _ in range(batch_size)], fixed_param_prefix=fixed_param_prefix)\n\n if cfg.TRAIN.RESUME:\n mod._preload_opt_states = '%s-%04d.states'%(prefix, begin_epoch)\n\n\n # decide training params\n # metric\n eval_metric = metric.RCNNAccMetric(cfg)\n cls_metric = metric.RCNNLogLossMetric(cfg)\n bbox_metric = metric.RCNNL1LossMetric(cfg)\n eval_metrics = mx.metric.CompositeEvalMetric()\n for child_metric in [eval_metric, cls_metric, bbox_metric]:\n eval_metrics.add(child_metric)\n # callback\n batch_end_callback = callback.Speedometer(train_data.batch_size, frequent=frequent)\n epoch_end_callback = [mx.callback.module_checkpoint(mod, prefix, period=1, save_optimizer_states=True),\n callback.do_checkpoint(prefix, means, stds)]\n # decide learning rate\n base_lr = lr\n lr_factor = cfg.TRAIN.lr_factor\n lr_epoch = [float(epoch) for epoch in lr_step.split(',')]\n lr_epoch_diff = [epoch - begin_epoch for epoch in lr_epoch if epoch > begin_epoch]\n lr = base_lr * (lr_factor ** (len(lr_epoch) - len(lr_epoch_diff)))\n lr_iters = [int(epoch * len(roidb) / batch_size) for epoch in lr_epoch_diff]\n print('lr', lr, 'lr_epoch_diff', lr_epoch_diff, 'lr_iters', lr_iters)\n lr_scheduler = WarmupMultiFactorScheduler(lr_iters, lr_factor, cfg.TRAIN.warmup, cfg.TRAIN.warmup_lr, cfg.TRAIN.warmup_step)\n # optimizer\n optimizer_params = {'momentum': cfg.TRAIN.momentum,\n 'wd': cfg.TRAIN.wd,\n 'learning_rate': lr,\n 'lr_scheduler': lr_scheduler,\n 'rescale_grad': 1.0,\n 'clip_gradient': None}\n\n # train\n\n if not isinstance(train_data, PrefetchingIter):\n train_data = PrefetchingIter(train_data)\n\n mod.fit(train_data, eval_metric=eval_metrics, epoch_end_callback=epoch_end_callback,\n batch_end_callback=batch_end_callback, kvstore=kvstore,\n optimizer='sgd', optimizer_params=optimizer_params,\n arg_params=arg_params, aux_params=aux_params, begin_epoch=begin_epoch, num_epoch=end_epoch)\n\n"
},
{
"path": "dff_rfcn/function/train_rpn.py",
"content": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed under The MIT License [see LICENSE for details]\n# Modified by Yuwen Xiong\n# --------------------------------------------------------\n# Based on:\n# MX-RCNN\n# Copyright (c) 2016 by Contributors\n# Licence under The Apache 2.0 License\n# https://github.com/ijkguo/mx-rcnn/\n# --------------------------------------------------------\n\nimport argparse\nimport logging\nimport pprint\nimport mxnet as mx\n\nfrom symbols import *\nfrom core import callback, metric\nfrom core.loader import AnchorLoader\nfrom core.module import MutableModule\nfrom utils.load_data import load_gt_roidb, merge_roidb, filter_roidb\nfrom utils.load_model import load_param\nfrom utils.PrefetchingIter import PrefetchingIter\nfrom utils.lr_scheduler import WarmupMultiFactorScheduler\n\n\ndef train_rpn(cfg, dataset, image_set, root_path, dataset_path,\n frequent, kvstore, flip, shuffle, resume,\n ctx, pretrained, epoch, prefix, begin_epoch, end_epoch,\n train_shared, lr, lr_step, logger=None, output_path=None):\n # set up logger\n if not logger:\n logging.basicConfig()\n logger = logging.getLogger()\n logger.setLevel(logging.INFO)\n\n # set up config\n cfg.TRAIN.BATCH_IMAGES = cfg.TRAIN.ALTERNATE.RPN_BATCH_IMAGES\n\n # load symbol\n sym_instance = eval(cfg.symbol + '.' + cfg.symbol)()\n sym = sym_instance.get_symbol_rpn(cfg, is_train=True)\n feat_sym = sym.get_internals()['rpn_cls_score_output']\n\n # setup multi-gpu\n batch_size = len(ctx)\n input_batch_size = cfg.TRAIN.BATCH_IMAGES * batch_size\n\n # print cfg\n pprint.pprint(cfg)\n logger.info('training rpn cfg:{}\\n'.format(pprint.pformat(cfg)))\n\n # load dataset and prepare imdb for training\n image_sets = [iset for iset in image_set.split('+')]\n roidbs = [load_gt_roidb(dataset, image_set, root_path, dataset_path, result_path=output_path,\n flip=flip)\n for image_set in image_sets]\n roidb = merge_roidb(roidbs)\n roidb = filter_roidb(roidb, cfg)\n\n # load training data\n train_data = AnchorLoader(feat_sym, roidb, cfg, batch_size=input_batch_size, shuffle=shuffle,\n ctx=ctx, feat_stride=cfg.network.RPN_FEAT_STRIDE, anchor_scales=cfg.network.ANCHOR_SCALES,\n anchor_ratios=cfg.network.ANCHOR_RATIOS, aspect_grouping=cfg.TRAIN.ASPECT_GROUPING)\n\n # infer max shape\n max_data_shape = [('data', (cfg.TRAIN.BATCH_IMAGES, 3, max([v[0] for v in cfg.SCALES]), max([v[1] for v in cfg.SCALES])))]\n max_data_shape, max_label_shape = train_data.infer_shape(max_data_shape)\n print('providing maximum shape', max_data_shape, max_label_shape)\n\n # infer shape\n data_shape_dict = dict(train_data.provide_data_single + train_data.provide_label_single)\n sym_instance.infer_shape(data_shape_dict)\n\n # load and initialize params\n if resume:\n print('continue training from ', begin_epoch)\n arg_params, aux_params = load_param(prefix, begin_epoch, convert=True)\n else:\n arg_params, aux_params = load_param(pretrained, epoch, convert=True)\n sym_instance.init_weight_rpn(cfg, arg_params, aux_params)\n\n # check parameter shapes\n sym_instance.check_parameter_shapes(arg_params, aux_params, data_shape_dict)\n\n # create solver\n data_names = [k[0] for k in train_data.provide_data_single]\n label_names = [k[0] for k in train_data.provide_label_single]\n if train_shared:\n fixed_param_prefix = cfg.network.FIXED_PARAMS_SHARED\n else:\n fixed_param_prefix = cfg.network.FIXED_PARAMS\n mod = MutableModule(sym, data_names=data_names, label_names=label_names,\n logger=logger, context=ctx, max_data_shapes=[max_data_shape for _ in xrange(batch_size)],\n max_label_shapes=[max_label_shape for _ in xrange(batch_size)], fixed_param_prefix=fixed_param_prefix)\n\n # decide training params\n # metric\n eval_metric = metric.RPNAccMetric()\n cls_metric = metric.RPNLogLossMetric()\n bbox_metric = metric.RPNL1LossMetric()\n eval_metrics = mx.metric.CompositeEvalMetric()\n for child_metric in [eval_metric, cls_metric, bbox_metric]:\n eval_metrics.add(child_metric)\n # callback\n batch_end_callback = callback.Speedometer(train_data.batch_size, frequent=frequent)\n # epoch_end_callback = mx.callback.do_checkpoint(prefix)\n epoch_end_callback = mx.callback.module_checkpoint(mod, prefix, period=1, save_optimizer_states=True)\n # decide learning rate\n base_lr = lr\n lr_factor = cfg.TRAIN.lr_factor\n lr_epoch = [int(epoch) for epoch in lr_step.split(',')]\n lr_epoch_diff = [epoch - begin_epoch for epoch in lr_epoch if epoch > begin_epoch]\n lr = base_lr * (lr_factor ** (len(lr_epoch) - len(lr_epoch_diff)))\n lr_iters = [int(epoch * len(roidb) / batch_size) for epoch in lr_epoch_diff]\n print('lr', lr, 'lr_epoch_diff', lr_epoch_diff, 'lr_iters', lr_iters)\n lr_scheduler = WarmupMultiFactorScheduler(lr_iters, lr_factor, cfg.TRAIN.warmup, cfg.TRAIN.warmup_lr, cfg.TRAIN.warmup_step)\n # optimizer\n optimizer_params = {'momentum': cfg.TRAIN.momentum,\n 'wd': cfg.TRAIN.wd,\n 'learning_rate': lr,\n 'lr_scheduler': lr_scheduler,\n 'rescale_grad': 1.0,\n 'clip_gradient': None}\n\n if not isinstance(train_data, PrefetchingIter):\n train_data = PrefetchingIter(train_data)\n\n # train\n mod.fit(train_data, eval_metric=eval_metrics, epoch_end_callback=epoch_end_callback,\n batch_end_callback=batch_end_callback, kvstore=kvstore,\n optimizer='sgd', optimizer_params=optimizer_params,\n arg_params=arg_params, aux_params=aux_params, begin_epoch=begin_epoch, num_epoch=end_epoch)\n\n"
},
{
"path": "dff_rfcn/operator_cxx/multi_proposal-inl.h",
"content": "/*!\n * Copyright (c) 2015 by Contributors\n * Copyright (c) 2017 Microsoft\n * Licensed under The MIT License [see LICENSE for details]\n * \\file multi_proposal-inl.h\n * \\brief MultiProposal Operator\n * \\author Piotr Teterwak, Bing Xu, Jian Guo, Xizhou Zhu\n*/\n#ifndef MXNET_OPERATOR_CONTRIB_PROPOSAL_INL_H_\n#define MXNET_OPERATOR_CONTRIB_PROPOSAL_INL_H_\n\n#include \n#include \n#include \n#include