Repository: BrainCog-X/Brain-Cog
Branch: main
Commit: f9b879f75da2
Files: 685
Total size: 4.5 MB
Directory structure:
gitextract_qe2qoke6/
├── .gitignore
├── LICENSE
├── README.md
├── braincog/
│ ├── __init__.py
│ ├── base/
│ │ ├── __init__.py
│ │ ├── brainarea/
│ │ │ ├── BrainArea.py
│ │ │ ├── IPL.py
│ │ │ ├── Insula.py
│ │ │ ├── PFC.py
│ │ │ ├── __init__.py
│ │ │ ├── basalganglia.py
│ │ │ └── dACC.py
│ │ ├── connection/
│ │ │ ├── CustomLinear.py
│ │ │ ├── __init__.py
│ │ │ └── layer.py
│ │ ├── conversion/
│ │ │ ├── __init__.py
│ │ │ ├── convertor.py
│ │ │ ├── merge.py
│ │ │ └── spicalib.py
│ │ ├── encoder/
│ │ │ ├── __init__.py
│ │ │ ├── encoder.py
│ │ │ ├── population_coding.py
│ │ │ └── qs_coding.py
│ │ ├── learningrule/
│ │ │ ├── BCM.py
│ │ │ ├── Hebb.py
│ │ │ ├── RSTDP.py
│ │ │ ├── STDP.py
│ │ │ ├── STP.py
│ │ │ └── __init__.py
│ │ ├── node/
│ │ │ ├── __init__.py
│ │ │ └── node.py
│ │ ├── strategy/
│ │ │ ├── LateralInhibition.py
│ │ │ ├── __init__.py
│ │ │ └── surrogate.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ ├── criterions.py
│ │ └── visualization.py
│ ├── datasets/
│ │ ├── CUB2002011.py
│ │ ├── ESimagenet/
│ │ │ ├── ES_imagenet.py
│ │ │ ├── __init__.py
│ │ │ └── reconstructed_ES_imagenet.py
│ │ ├── NOmniglot/
│ │ │ ├── NOmniglot.py
│ │ │ ├── __init__.py
│ │ │ ├── nomniglot_full.py
│ │ │ ├── nomniglot_nw_ks.py
│ │ │ ├── nomniglot_pair.py
│ │ │ └── utils.py
│ │ ├── StanfordDogs.py
│ │ ├── TinyImageNet.py
│ │ ├── __init__.py
│ │ ├── bullying10k/
│ │ │ ├── __init__.py
│ │ │ └── bullying10k.py
│ │ ├── cut_mix.py
│ │ ├── datasets.py
│ │ ├── gen_input_signal.py
│ │ ├── hmdb_dvs/
│ │ │ ├── __init__.py
│ │ │ └── hmdb_dvs.py
│ │ ├── ncaltech101/
│ │ │ ├── __init__.py
│ │ │ └── ncaltech101.py
│ │ ├── rand_aug.py
│ │ ├── scripts/
│ │ │ ├── testlist01.txt
│ │ │ └── ucf101_dvs_preprocessing.py
│ │ ├── ucf101_dvs/
│ │ │ ├── __init__.py
│ │ │ └── ucf101_dvs.py
│ │ └── utils.py
│ ├── model_zoo/
│ │ ├── NeuEvo/
│ │ │ ├── __init__.py
│ │ │ ├── architect.py
│ │ │ ├── genotypes.py
│ │ │ ├── model.py
│ │ │ ├── model_search.py
│ │ │ ├── operations.py
│ │ │ └── others.py
│ │ ├── __init__.py
│ │ ├── backeinet.py
│ │ ├── base_module.py
│ │ ├── bdmsnn.py
│ │ ├── convnet.py
│ │ ├── fc_snn.py
│ │ ├── glsnn.py
│ │ ├── linearNet.py
│ │ ├── nonlinearNet.py
│ │ ├── qsnn.py
│ │ ├── resnet.py
│ │ ├── resnet19_snn.py
│ │ ├── rsnn.py
│ │ ├── sew_resnet.py
│ │ └── vgg_snn.py
│ └── utils.py
├── docs/
│ ├── Makefile
│ ├── make.bat
│ └── source/
│ ├── conf.py
│ ├── examples/
│ │ ├── Brain_Cognitive_Function_Simulation/
│ │ │ ├── drosophila.md
│ │ │ └── index.rst
│ │ ├── Decision_Making/
│ │ │ ├── BDM_SNN.md
│ │ │ ├── RL.md
│ │ │ └── index.rst
│ │ ├── Knowledge_Representation_and_Reasoning/
│ │ │ ├── CKRGSNN.md
│ │ │ ├── CRSNN.md
│ │ │ ├── SPSNN.md
│ │ │ ├── index.rst
│ │ │ └── musicMemory.md
│ │ ├── Multi-scale_Brain_Structure_Simulation/
│ │ │ ├── Corticothalamic_minicolumn.md
│ │ │ ├── HumanBrain.md
│ │ │ ├── Human_PFC.md
│ │ │ ├── MacaqueBrain.md
│ │ │ ├── index.rst
│ │ │ └── mouse_brain.md
│ │ ├── Perception_and_Learning/
│ │ │ ├── Conversion.md
│ │ │ ├── MultisensoryIntegration.md
│ │ │ ├── QSNN.md
│ │ │ ├── UnsupervisedSTDP.md
│ │ │ ├── img_cls/
│ │ │ │ ├── bp.md
│ │ │ │ ├── glsnn.md
│ │ │ │ └── index.rst
│ │ │ └── index.rst
│ │ ├── Social_Cognition/
│ │ │ ├── Mirror_Test.md
│ │ │ ├── ToM.md
│ │ │ └── index.rst
│ │ └── index.rst
│ ├── index.rst
│ ├── modules.rst
│ └── setup.rst
├── docs.md
├── documents/
│ ├── Data_engine.md
│ ├── Lectures.md
│ ├── Pub_brain_inspired_AI.md
│ ├── Pub_brain_simulation.md
│ ├── Pub_sh_codesign.md
│ ├── Publication.md
│ └── Tutorial.md
├── examples/
│ ├── Brain_Cognitive_Function_Simulation/
│ │ └── drosophila/
│ │ ├── README.md
│ │ └── drosophila.py
│ ├── Embodied_Cognition/
│ │ └── RHI/
│ │ ├── RHI_Test.py
│ │ ├── RHI_Train.py
│ │ └── ReadMe.md
│ ├── Hardware_acceleration/
│ │ ├── README.md
│ │ ├── firefly_v1_schedule_on_pynq.py
│ │ ├── standalone_utils.py
│ │ ├── ultra96_test.py
│ │ └── zcu104_test.py
│ ├── Knowledge_Representation_and_Reasoning/
│ │ ├── CKRGSNN/
│ │ │ ├── README.md
│ │ │ ├── main.py
│ │ │ └── sub_Conceptnet.csv
│ │ ├── CRSNN/
│ │ │ ├── README.md
│ │ │ └── main.py
│ │ ├── SPSNN/
│ │ │ ├── README.md
│ │ │ └── main.py
│ │ └── musicMemory/
│ │ ├── Areas/
│ │ │ ├── apac.py
│ │ │ ├── cortex.py
│ │ │ ├── pac.py
│ │ │ └── pfc.py
│ │ ├── Modal/
│ │ │ ├── PAC.py
│ │ │ ├── cluster.py
│ │ │ ├── composercluster.py
│ │ │ ├── composerlayer.py
│ │ │ ├── composerlifneuron.py
│ │ │ ├── genrecluster.py
│ │ │ ├── genrelayer.py
│ │ │ ├── genrelifneuron.py
│ │ │ ├── izhikevichneuron.py
│ │ │ ├── layer.py
│ │ │ ├── lifneuron.py
│ │ │ ├── note.py
│ │ │ ├── notecluster.py
│ │ │ ├── notelifneuron.py
│ │ │ ├── notesequencelayer.py
│ │ │ ├── pitch.py
│ │ │ ├── sequencelayer.py
│ │ │ ├── sequencememory.py
│ │ │ ├── synapse.py
│ │ │ ├── tempocluster.py
│ │ │ ├── tempolifneuron.py
│ │ │ ├── temposequencelayer.py
│ │ │ ├── titlecluster.py
│ │ │ ├── titlelayer.py
│ │ │ └── titlelifneuron.py
│ │ ├── README.md
│ │ ├── api/
│ │ │ └── music_engine_api.py
│ │ ├── conf/
│ │ │ ├── GenreData.txt
│ │ │ ├── MIDIData.txt
│ │ │ └── conf.py
│ │ ├── inputs/
│ │ │ ├── 1.txt
│ │ │ ├── Data.txt
│ │ │ ├── GenreData.txt
│ │ │ ├── MIDIData.txt
│ │ │ ├── chords.csv
│ │ │ ├── chords.xlsx
│ │ │ ├── information.csv
│ │ │ ├── keyIndex.csv
│ │ │ ├── keys.csv
│ │ │ ├── keys.xlsx
│ │ │ ├── modeindex.csv
│ │ │ ├── modeindex.xlsx
│ │ │ ├── pitch2midi.csv
│ │ │ └── tones2.csv
│ │ ├── result_output/
│ │ │ └── tone learning/
│ │ │ ├── C major_20241121155522.mid
│ │ │ ├── C major_20241122093822.mid
│ │ │ ├── C major_20241122094000.mid
│ │ │ ├── C major_20241122094419.mid
│ │ │ └── C major_20241122094736.mid
│ │ ├── task/
│ │ │ ├── Bach_generated.mid
│ │ │ ├── Classical_generated.mid
│ │ │ ├── Sonate C Major.Mid_recall.mid
│ │ │ ├── melody_generated.mid
│ │ │ ├── mode-conditioned learning.py
│ │ │ ├── musicGeneration.py
│ │ │ └── musicMemory.py
│ │ ├── testData/
│ │ │ ├── Bach/
│ │ │ │ └── prelude C major.mid
│ │ │ ├── JayZhou/
│ │ │ │ └── rainbow.mid
│ │ │ └── Mozart/
│ │ │ └── Sonate C major.mid
│ │ └── tools/
│ │ ├── __init__.py
│ │ ├── generateData.py
│ │ ├── hamonydataset_test.py
│ │ ├── msg.py
│ │ ├── msgq.py
│ │ ├── oscillations.py
│ │ ├── position.txt
│ │ ├── readjson.py
│ │ ├── testSound.py
│ │ ├── testmusic21.py
│ │ ├── testopengl.py
│ │ ├── testwave.py
│ │ └── xmlParser.py
│ ├── MotorControl/
│ │ └── experimental/
│ │ ├── README.md
│ │ ├── brain_area.py
│ │ ├── main.py
│ │ └── model.py
│ ├── Multiscale_Brain_Structure_Simulation/
│ │ ├── CorticothalamicColumn/
│ │ │ ├── README.md
│ │ │ ├── data/
│ │ │ │ ├── __init__.py
│ │ │ │ └── globaldata.py
│ │ │ ├── main.py
│ │ │ ├── model/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── cortex.py
│ │ │ │ ├── cortex_thalamus.py
│ │ │ │ ├── dendrite.py
│ │ │ │ ├── fire.csv
│ │ │ │ ├── layer.py
│ │ │ │ ├── synapse.py
│ │ │ │ └── thalamus.py
│ │ │ └── tools/
│ │ │ ├── __init__.py
│ │ │ ├── cortical.csv
│ │ │ ├── exdata.py
│ │ │ ├── layer.csv
│ │ │ ├── neuron.csv
│ │ │ └── synapse.csv
│ │ ├── Corticothalamic_Brain_Model/
│ │ │ ├── Bioinformatics_propofol_circle.py
│ │ │ ├── Readme.md
│ │ │ └── spectrogram.py
│ │ ├── HumanBrain/
│ │ │ ├── README.md
│ │ │ ├── human_brain.py
│ │ │ └── human_multi.py
│ │ ├── Human_Brain_Model/
│ │ │ ├── NA.py
│ │ │ ├── Readme.md
│ │ │ ├── gc.py
│ │ │ ├── main_246.py
│ │ │ ├── main_84.py
│ │ │ ├── pci.py
│ │ │ ├── pci_246.py
│ │ │ └── spectrogram.py
│ │ ├── Human_PFC_Model/
│ │ │ ├── README.md
│ │ │ └── Six_Layer_PFC.py
│ │ ├── MacaqueBrain/
│ │ │ ├── README.md
│ │ │ └── macaque_brain.py
│ │ └── MouseBrain/
│ │ ├── README.md
│ │ └── mouse_brain.py
│ ├── Perception_and_Learning/
│ │ ├── Conversion/
│ │ │ ├── burst_conversion/
│ │ │ │ ├── CIFAR10_VGG16.py
│ │ │ │ ├── README.md
│ │ │ │ └── converted_CIFAR10.py
│ │ │ └── msat_conversion/
│ │ │ ├── CIFAR10_VGG16.py
│ │ │ ├── README.md
│ │ │ ├── converted_CIFAR10.py
│ │ │ └── convertor.py
│ │ ├── IllusionPerception/
│ │ │ └── AbuttingGratingIllusion/
│ │ │ ├── distortion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── abutting_grating_illusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── abutting_grating_distortion.py
│ │ │ └── main.py
│ │ ├── MultisensoryIntegration/
│ │ │ ├── README.md
│ │ │ └── code/
│ │ │ ├── MultisensoryIntegrationDEMO_AM.py
│ │ │ ├── MultisensoryIntegrationDEMO_IM.py
│ │ │ └── measure_and_visualization.py
│ │ ├── NeuEvo/
│ │ │ ├── auto_augment.py
│ │ │ ├── main.py
│ │ │ ├── separate_loss.py
│ │ │ ├── train.py
│ │ │ ├── train_search.py
│ │ │ └── utils.py
│ │ ├── QSNN/
│ │ │ ├── README.md
│ │ │ └── main.py
│ │ ├── UnsupervisedSTDP/
│ │ │ ├── Readme.md
│ │ │ └── codef.py
│ │ └── img_cls/
│ │ ├── bp/
│ │ │ ├── README.md
│ │ │ ├── main.py
│ │ │ ├── main_backei.py
│ │ │ └── main_simplified.py
│ │ ├── glsnn/
│ │ │ ├── README.md
│ │ │ └── cls_glsnn.py
│ │ ├── spiking_capsnet/
│ │ │ ├── README.md
│ │ │ └── spikingcaps.py
│ │ └── transfer_for_dvs/
│ │ ├── GradCAM_visualization.py
│ │ ├── README.md
│ │ ├── datasets.py
│ │ ├── main.py
│ │ ├── main_transfer.py
│ │ └── main_visual_losslandscape.py
│ ├── Snn_safety/
│ │ ├── DPSNN/
│ │ │ ├── Readme.txt
│ │ │ ├── load_data.py
│ │ │ ├── main_dpsnn.py
│ │ │ └── model.py
│ │ └── RandHet-SNN/
│ │ ├── README.md
│ │ ├── evaluate.py
│ │ ├── my_node.py
│ │ ├── sew_resnet.py
│ │ ├── train.py
│ │ └── utils.py
│ ├── Social_Cognition/
│ │ ├── FOToM/
│ │ │ ├── algorithms/
│ │ │ │ ├── ToM_class.py
│ │ │ │ ├── __init__.py
│ │ │ │ ├── maddpg.py
│ │ │ │ └── tom11.py
│ │ │ ├── common/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── distributions.py
│ │ │ │ ├── tile_images.py
│ │ │ │ └── vec_env/
│ │ │ │ ├── __init__.py
│ │ │ │ └── vec_env.py
│ │ │ ├── evaluate.py
│ │ │ ├── main.py
│ │ │ ├── multiagent/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── core.py
│ │ │ │ ├── environment.py
│ │ │ │ ├── multi_discrete.py
│ │ │ │ ├── policy.py
│ │ │ │ ├── rendering.py
│ │ │ │ ├── scenario.py
│ │ │ │ └── scenarios/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── hetero_spread.py
│ │ │ │ ├── simple.py
│ │ │ │ ├── simple_adversary.py
│ │ │ │ ├── simple_crypto.py
│ │ │ │ ├── simple_push.py
│ │ │ │ ├── simple_reference.py
│ │ │ │ ├── simple_speaker_listener.py
│ │ │ │ ├── simple_spread.py
│ │ │ │ ├── simple_tag.py
│ │ │ │ └── simple_world_comm.py
│ │ │ ├── readme.md
│ │ │ └── utils/
│ │ │ ├── __init__.py
│ │ │ ├── agents.py
│ │ │ ├── buffer.py
│ │ │ ├── env_wrappers.py
│ │ │ ├── make_env.py
│ │ │ ├── misc.py
│ │ │ ├── multiprocessing.py
│ │ │ ├── networks.py
│ │ │ └── noise.py
│ │ ├── Intention_Prediction/
│ │ │ └── Intention_Prediction.py
│ │ ├── MAToM-SNN/
│ │ │ ├── LICENSE
│ │ │ ├── MPE/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── agents/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── agents.py
│ │ │ │ ├── common/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── distributions.py
│ │ │ │ │ ├── tile_images.py
│ │ │ │ │ └── vec_env/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── vec_env.py
│ │ │ │ ├── main.py
│ │ │ │ ├── multiagent/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── scenarios/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── simple.py
│ │ │ │ │ ├── simple_crypto.py
│ │ │ │ │ ├── simple_push.py
│ │ │ │ │ ├── simple_reference.py
│ │ │ │ │ ├── simple_speaker_listener.py
│ │ │ │ │ ├── simple_spread.py
│ │ │ │ │ └── simple_world_comm.py
│ │ │ │ ├── policy/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── maddpg.py
│ │ │ │ └── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── buffer.py
│ │ │ │ ├── env_wrappers.py
│ │ │ │ ├── make_env.py
│ │ │ │ ├── misc.py
│ │ │ │ ├── multiprocessing.py
│ │ │ │ ├── networks.py
│ │ │ │ └── noise.py
│ │ │ ├── README.md
│ │ │ └── STAG/
│ │ │ ├── agents/
│ │ │ │ ├── __init__.py
│ │ │ │ └── sagent.py
│ │ │ ├── common_sr/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── arguments.py
│ │ │ │ ├── dummy_vec_env.py
│ │ │ │ ├── multiprocessing_env.py
│ │ │ │ ├── replay_buffer.py
│ │ │ │ └── srollout.py
│ │ │ ├── envs/
│ │ │ │ ├── Stag_Hunt_env.py
│ │ │ │ ├── __init__.py
│ │ │ │ ├── abstract.py
│ │ │ │ └── constants.py
│ │ │ ├── main_spiking.py
│ │ │ ├── network/
│ │ │ │ ├── __init__.py
│ │ │ │ └── spiking_net.py
│ │ │ ├── policy/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── dqn.py
│ │ │ │ ├── stomvdn.py
│ │ │ │ └── svdn.py
│ │ │ ├── preprocessoing/
│ │ │ │ ├── __init__.py
│ │ │ │ └── common.py
│ │ │ └── runner.py
│ │ ├── ReadMe.md
│ │ ├── SmashVat/
│ │ │ ├── dqn.py
│ │ │ ├── environment.py
│ │ │ ├── main.py
│ │ │ ├── manual_control.py
│ │ │ ├── qnets.py
│ │ │ ├── side_effect_eval.py
│ │ │ └── window.py
│ │ ├── ToCM/
│ │ │ ├── README.md
│ │ │ ├── agent/
│ │ │ │ ├── controllers/
│ │ │ │ │ └── ToCMController.py
│ │ │ │ ├── learners/
│ │ │ │ │ └── ToCMLearner.py
│ │ │ │ ├── memory/
│ │ │ │ │ └── ToCMMemory.py
│ │ │ │ ├── models/
│ │ │ │ │ └── ToCMModel.py
│ │ │ │ ├── optim/
│ │ │ │ │ ├── loss.py
│ │ │ │ │ └── utils.py
│ │ │ │ ├── runners/
│ │ │ │ │ └── ToCMRunner.py
│ │ │ │ ├── utils/
│ │ │ │ │ └── params.py
│ │ │ │ └── workers/
│ │ │ │ └── ToCMWorker.py
│ │ │ ├── configs/
│ │ │ │ ├── Config.py
│ │ │ │ ├── EnvConfigs.py
│ │ │ │ ├── Experiment.py
│ │ │ │ ├── ToCM/
│ │ │ │ │ ├── ToCMAgentConfig.py
│ │ │ │ │ ├── ToCMControllerConfig.py
│ │ │ │ │ ├── ToCMLearnerConfig.py
│ │ │ │ │ └── optimal/
│ │ │ │ │ └── starcraft/
│ │ │ │ │ ├── AgentConfig.py
│ │ │ │ │ └── LearnerConfig.py
│ │ │ │ └── __init__.py
│ │ │ ├── env/
│ │ │ │ ├── mpe/
│ │ │ │ │ └── MPE.py
│ │ │ │ └── starcraft/
│ │ │ │ └── StarCraft.py
│ │ │ ├── environments.py
│ │ │ ├── mpe/
│ │ │ │ ├── MPE_Env.py
│ │ │ │ ├── __init__.py
│ │ │ │ ├── core.py
│ │ │ │ ├── environment.py
│ │ │ │ ├── multi_discrete.py
│ │ │ │ ├── rendering.py
│ │ │ │ ├── scenario.py
│ │ │ │ └── scenarios/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── hetero_spread.py
│ │ │ │ ├── simple_adversary.py
│ │ │ │ ├── simple_crypto.py
│ │ │ │ ├── simple_crypto_display.py
│ │ │ │ ├── simple_push.py
│ │ │ │ ├── simple_reference.py
│ │ │ │ ├── simple_speaker_listener.py
│ │ │ │ ├── simple_spread.py
│ │ │ │ ├── simple_tag.py
│ │ │ │ └── simple_world_comm.py
│ │ │ ├── networks/
│ │ │ │ ├── ToCM/
│ │ │ │ │ ├── action.py
│ │ │ │ │ ├── critic.py
│ │ │ │ │ ├── dense.py
│ │ │ │ │ ├── rnns.py
│ │ │ │ │ ├── utils.py
│ │ │ │ │ └── vae.py
│ │ │ │ └── transformer/
│ │ │ │ └── layers.py
│ │ │ ├── requirements.txt
│ │ │ ├── run.sh
│ │ │ ├── smac/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── bin/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── map_list.py
│ │ │ │ ├── env/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── multiagentenv.py
│ │ │ │ │ ├── pettingzoo/
│ │ │ │ │ │ ├── StarCraft2PZEnv.py
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ └── test/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── all_test.py
│ │ │ │ │ │ └── smac_pettingzoo_test.py
│ │ │ │ │ └── starcraft2/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── maps/
│ │ │ │ │ │ ├── SMAC_Maps/
│ │ │ │ │ │ │ └── 2s_vs_1sc.SC2Map
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ └── smac_maps.py
│ │ │ │ │ ├── render.py
│ │ │ │ │ └── starcraft2.py
│ │ │ │ └── examples/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pettingzoo/
│ │ │ │ │ ├── README.rst
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── pettingzoo_demo.py
│ │ │ │ ├── random_agents.py
│ │ │ │ └── rllib/
│ │ │ │ ├── README.rst
│ │ │ │ ├── __init__.py
│ │ │ │ ├── env.py
│ │ │ │ ├── model.py
│ │ │ │ ├── run_ppo.py
│ │ │ │ └── run_qmix.py
│ │ │ ├── train.py
│ │ │ └── utils/
│ │ │ ├── __init__.py
│ │ │ ├── mlp_buffer.py
│ │ │ ├── mlp_nstep_buffer.py
│ │ │ ├── popart.py
│ │ │ ├── rec_buffer.py
│ │ │ ├── segment_tree.py
│ │ │ └── util.py
│ │ ├── ToM/
│ │ │ ├── BrainArea/
│ │ │ │ ├── PFC_ToM.py
│ │ │ │ ├── TPJ.py
│ │ │ │ ├── __init__.py
│ │ │ │ ├── dACC.py
│ │ │ │ ├── one_hot.py
│ │ │ │ └── test.py
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── data/
│ │ │ │ ├── NPC_assessment.csv
│ │ │ │ ├── agent_assessment.csv
│ │ │ │ ├── injury_memory.txt
│ │ │ │ ├── injury_value.txt
│ │ │ │ └── one_hot.py
│ │ │ ├── env/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── env.py
│ │ │ │ ├── env3_train_env00.py
│ │ │ │ └── env3_train_env01.py
│ │ │ ├── main_ToM.py
│ │ │ ├── main_both.py
│ │ │ ├── rulebasedpolicy/
│ │ │ │ ├── Find_a_way.py
│ │ │ │ ├── __init__.py
│ │ │ │ ├── a_star.py
│ │ │ │ ├── load_statedata.py
│ │ │ │ ├── point.py
│ │ │ │ ├── random_map.py
│ │ │ │ ├── statedata_pre.py
│ │ │ │ ├── train.txt
│ │ │ │ └── world_model.py
│ │ │ └── utils/
│ │ │ ├── Encoder.py
│ │ │ └── one_hot.py
│ │ ├── affective_empathy/
│ │ │ ├── BAE-SNN/
│ │ │ │ ├── BAESNN.py
│ │ │ │ ├── README.md
│ │ │ │ ├── env_poly.py
│ │ │ │ └── env_two_poly.py
│ │ │ ├── BEEAD-SNN/
│ │ │ │ ├── BEEAD-SNN.py
│ │ │ │ ├── README.md
│ │ │ │ ├── RL_Brain.py
│ │ │ │ ├── env.py
│ │ │ │ ├── env_poly_SNN.py
│ │ │ │ ├── rsnn.py
│ │ │ │ ├── sd_env.py
│ │ │ │ └── snowdrift_main.py
│ │ │ └── BRP-SNN/
│ │ │ ├── BRP-SNN.py
│ │ │ ├── README.md
│ │ │ ├── env_poly_SNN.py
│ │ │ └── env_two_poly_SNN.py
│ │ └── mirror_test/
│ │ ├── README.md
│ │ └── mirror_test.py
│ ├── Spiking-Transformers/
│ │ ├── LIFNode.py
│ │ ├── README.md
│ │ ├── datasets.py
│ │ ├── main.py
│ │ └── models/
│ │ ├── spike_driven_transformer.py
│ │ ├── spike_driven_transformer_dvs.py
│ │ ├── spike_driven_transformer_v2.py
│ │ ├── spike_driven_transformer_v2_dvs.py
│ │ ├── spikformer.py
│ │ └── spikformer_dvs.py
│ ├── Structural_Development/
│ │ ├── DPAP/
│ │ │ ├── README.md
│ │ │ ├── mask_model.py
│ │ │ ├── prun_main.py
│ │ │ └── utils.py
│ │ ├── DSD-SNN/
│ │ │ ├── README.md
│ │ │ └── cifar100/
│ │ │ ├── available.py
│ │ │ ├── main_simplified.py
│ │ │ ├── manipulate.py
│ │ │ ├── maskcl2.py
│ │ │ └── vgg_snn.py
│ │ ├── ELSM/
│ │ │ ├── evolve.py
│ │ │ ├── lsm.py
│ │ │ ├── model.py
│ │ │ ├── nsganet.py
│ │ │ └── spikes.py
│ │ ├── SCA-SNN/
│ │ │ ├── README.md
│ │ │ ├── configs/
│ │ │ │ └── train.yaml
│ │ │ ├── inclearn/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── convnet/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── classifier.py
│ │ │ │ │ ├── imbalance.py
│ │ │ │ │ ├── maskcl2.py
│ │ │ │ │ ├── network.py
│ │ │ │ │ ├── resnet.py
│ │ │ │ │ ├── sew_resnet.py
│ │ │ │ │ └── utils.py
│ │ │ │ ├── datasets/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── data.py
│ │ │ │ │ └── dataset.py
│ │ │ │ ├── models/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── base.py
│ │ │ │ │ └── incmodel.py
│ │ │ │ └── tools/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── autoaugment_extra.py
│ │ │ │ ├── cutout.py
│ │ │ │ ├── data_utils.py
│ │ │ │ ├── factory.py
│ │ │ │ ├── memory.py
│ │ │ │ ├── metrics.py
│ │ │ │ ├── results_utils.py
│ │ │ │ ├── scheduler.py
│ │ │ │ ├── similar.py
│ │ │ │ └── utils.py
│ │ │ └── main.py
│ │ └── SD-SNN/
│ │ ├── README.md
│ │ ├── main.py
│ │ ├── prun_and_generation.py
│ │ ├── snn_model.py
│ │ └── utils.py
│ ├── Structure_Evolution/
│ │ ├── Adaptive_lsm/
│ │ │ ├── BrainCog-Version/
│ │ │ │ ├── README.md
│ │ │ │ ├── brid.py
│ │ │ │ ├── lsmmodel.py
│ │ │ │ ├── maze.py
│ │ │ │ └── tools/
│ │ │ │ ├── EnuGlobalNetwork.py
│ │ │ │ ├── ExperimentEnvGlobalNetworkSurvival.py
│ │ │ │ ├── MazeTurnEnvVec.py
│ │ │ │ └── nsganet.py
│ │ │ └── raw/
│ │ │ ├── BCM.py
│ │ │ ├── README.md
│ │ │ ├── lstm.py
│ │ │ ├── main.py
│ │ │ ├── pltbcm.py
│ │ │ ├── pltrank.py
│ │ │ ├── q_l.py
│ │ │ └── tools/
│ │ │ ├── EnuGlobalNetwork.py
│ │ │ ├── ExperimentEnvGlobalNetworkSurvival.py
│ │ │ └── MazeTurnEnvVec.py
│ │ ├── EB-NAS/
│ │ │ ├── acc_predictor/
│ │ │ │ ├── adaptive_switching.py
│ │ │ │ ├── carts.py
│ │ │ │ ├── factory.py
│ │ │ │ ├── gp.py
│ │ │ │ ├── mlp.py
│ │ │ │ └── rbf.py
│ │ │ ├── cellmodel.py
│ │ │ ├── ebnas.py
│ │ │ ├── micro_encoding.py
│ │ │ ├── motifs.py
│ │ │ ├── nsganet.py
│ │ │ ├── operations.py
│ │ │ ├── readme.md
│ │ │ ├── single_genome.py
│ │ │ └── tm.py
│ │ ├── ELSM/
│ │ │ ├── README.md
│ │ │ ├── evolve.py
│ │ │ ├── lsm.py
│ │ │ ├── model.py
│ │ │ ├── nsganet.py
│ │ │ └── spikes.py
│ │ └── MSE-NAS/
│ │ ├── auto_augment.py
│ │ ├── cellmodel.py
│ │ ├── evolution.py
│ │ ├── loss_f.py
│ │ ├── micro_encoding.py
│ │ ├── motifs.py
│ │ ├── nsganet.py
│ │ ├── obj.py
│ │ ├── operations.py
│ │ ├── readme.md
│ │ ├── tm.py
│ │ └── utils.py
│ ├── TIM/
│ │ ├── README.md
│ │ ├── main.py
│ │ ├── models/
│ │ │ ├── TIM.py
│ │ │ ├── spikformer_braincog_DVS.py
│ │ │ └── spikformer_braincog_SHD.py
│ │ └── utils/
│ │ ├── MyGrad.py
│ │ ├── MyNode.py
│ │ └── datasets.py
│ └── decision_making/
│ ├── BDM-SNN/
│ │ ├── BDM-SNN-UAV.py
│ │ ├── BDM-SNN-hh.py
│ │ ├── BDM-SNN.py
│ │ ├── README.md
│ │ └── decisionmaking.py
│ ├── RL/
│ │ ├── README.md
│ │ ├── atari/
│ │ │ ├── __init__.py
│ │ │ └── atari_wrapper.py
│ │ ├── mcs-fqf/
│ │ │ ├── discrete.py
│ │ │ ├── main.py
│ │ │ ├── network.py
│ │ │ └── policy.py
│ │ ├── requirements.txt
│ │ ├── sdqn/
│ │ │ ├── main.py
│ │ │ └── network.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ └── normalization.py
│ └── swarm/
│ ├── Collision-Avoidance.py
│ └── README.md
├── requirements.txt
└── setup.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
.idea
*.egg-info/
eggs/
.eggs/
*.exe
*.pyc
/.vscode/
*.code-workspace
__pycache__
# Sphinx documentation
docs/_build/
docs/build/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
.python-version
# event data
*.bin
*.dat
*.pt
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: README.md
================================================
# BrainCog
---
BrainCog is an open source spiking neural network based brain-inspired
cognitive intelligence engine for Brain-inspired Artificial Intelligence, Brain-inspired Embodied AI, and brain simulation. More information on BrainCog can be found on its homepage http://www.brain-cog.network/
The current version of BrainCog contains at least 50 functional spiking neural network algorithms (including but not limited to perception and learning, decision making, knowledge representation and reasoning, motor control, social cognition, etc.) built based on BrainCog infrastructures, and BrainCog also provide brain simulations to drosophila, rodent, monkey, and human brains at multiple scales based on spiking neural networks at multiple scales. More detail in http://www.brain-cog.network/docs/
BrainCog is a community based effort for spiking neural network based artificial intelligence, and we welcome any forms of contributions, from contributing to the development of core components, to contributing for applications.
 BrainCog provides essential and fundamental components to model biological and artificial intelligence.
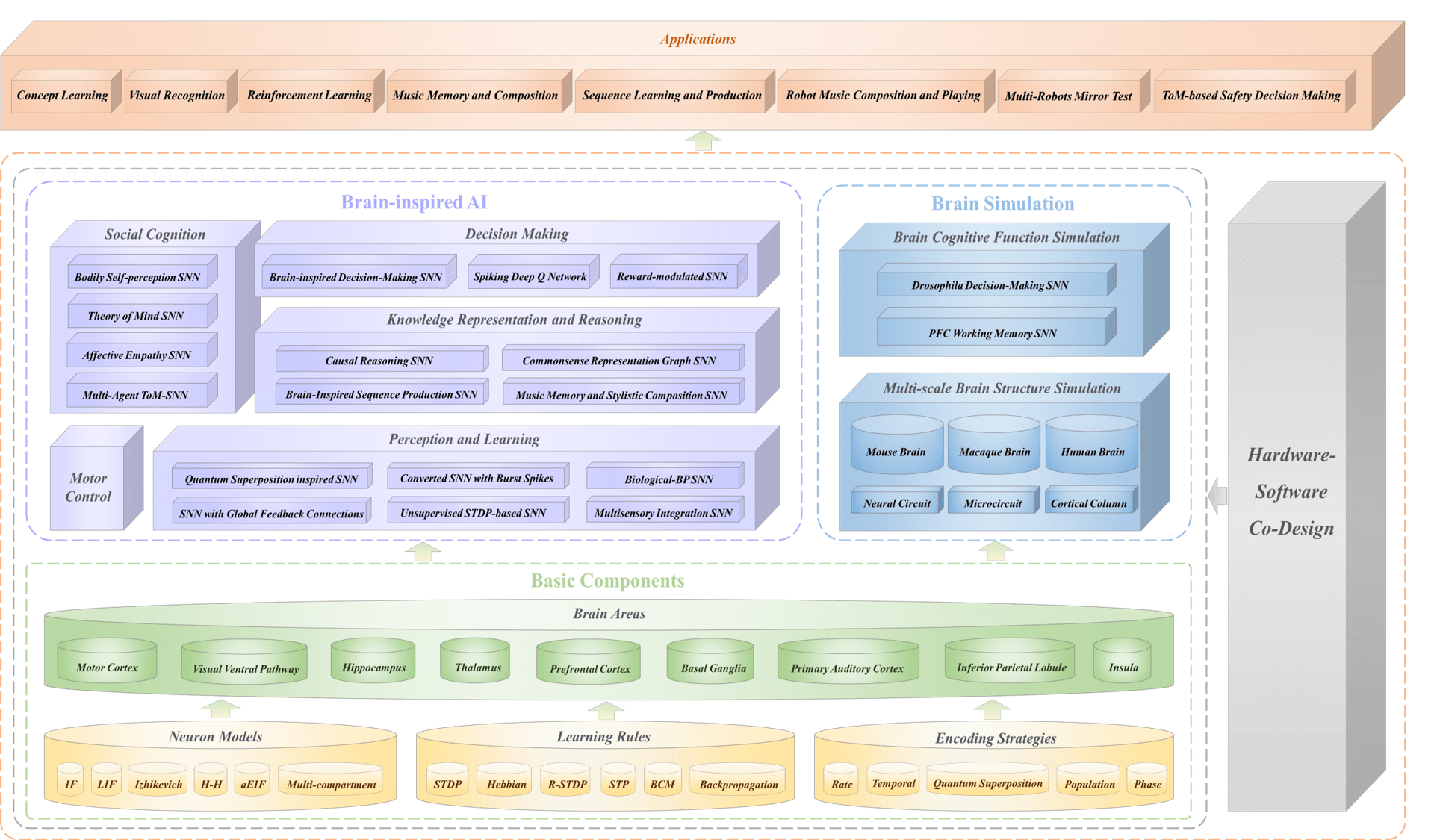
Our paper is published in [Patterns](https://www.cell.com/patterns/fulltext/S2666-3899(23)00144-7?_returnURL=https%3A%2F%2Flinkinghub.elsevier.com%2Fretrieve%2Fpii%2FS2666389923001447%3Fshowall%3Dtrue). If you use BrainCog in your research, the following paper can be cited as the source for BrainCog.
```bib
@article{Zeng2023,
doi = {10.1016/j.patter.2023.100789},
url = {https://doi.org/10.1016/j.patter.2023.100789},
year = {2023},
month = jul,
publisher = {Cell Press},
pages = {100789},
author = {Yi Zeng and Dongcheng Zhao and Feifei Zhao and Guobin Shen and Yiting Dong and Enmeng Lu and Qian Zhang and Yinqian Sun and Qian Liang and Yuxuan Zhao and Zhuoya Zhao and Hongjian Fang and Yuwei Wang and Yang Li and Xin Liu and Chengcheng Du and Qingqun Kong and Zizhe Ruan and Weida Bi},
title = {{BrainCog}: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired {AI} and brain simulation},
journal = {Patterns}
}
```
## Brain-Inspired AI
BrainCog currently provides cognitive functions components that can be classified
into five categories:
* Perception and Learning
* Knowledge Representation and Reasoning
* Decision Making
* Motor Control
* Social Cognition
* Development and Evolution
* Safety and Security
BrainCog provides essential and fundamental components to model biological and artificial intelligence.

Our paper is published in [Patterns](https://www.cell.com/patterns/fulltext/S2666-3899(23)00144-7?_returnURL=https%3A%2F%2Flinkinghub.elsevier.com%2Fretrieve%2Fpii%2FS2666389923001447%3Fshowall%3Dtrue). If you use BrainCog in your research, the following paper can be cited as the source for BrainCog.
```bib
@article{Zeng2023,
doi = {10.1016/j.patter.2023.100789},
url = {https://doi.org/10.1016/j.patter.2023.100789},
year = {2023},
month = jul,
publisher = {Cell Press},
pages = {100789},
author = {Yi Zeng and Dongcheng Zhao and Feifei Zhao and Guobin Shen and Yiting Dong and Enmeng Lu and Qian Zhang and Yinqian Sun and Qian Liang and Yuxuan Zhao and Zhuoya Zhao and Hongjian Fang and Yuwei Wang and Yang Li and Xin Liu and Chengcheng Du and Qingqun Kong and Zizhe Ruan and Weida Bi},
title = {{BrainCog}: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired {AI} and brain simulation},
journal = {Patterns}
}
```
## Brain-Inspired AI
BrainCog currently provides cognitive functions components that can be classified
into five categories:
* Perception and Learning
* Knowledge Representation and Reasoning
* Decision Making
* Motor Control
* Social Cognition
* Development and Evolution
* Safety and Security

 ## Brain Simulation
BrainCog currently include two parts for brain simulation:
* Brain Cognitive Function Simulation
* Multi-scale Brain Structure Simulation
## Brain Simulation
BrainCog currently include two parts for brain simulation:
* Brain Cognitive Function Simulation
* Multi-scale Brain Structure Simulation
 The anatomical and imaging data is used to support our simulation from various aspects.
## Software-Hardware Codesign (BrainCog Firefly)
The anatomical and imaging data is used to support our simulation from various aspects.
## Software-Hardware Codesign (BrainCog Firefly)
 BrainCog currently provides `hardware acceleration` for spiking neural network based brain-inspired AI.
BrainCog currently provides `hardware acceleration` for spiking neural network based brain-inspired AI.
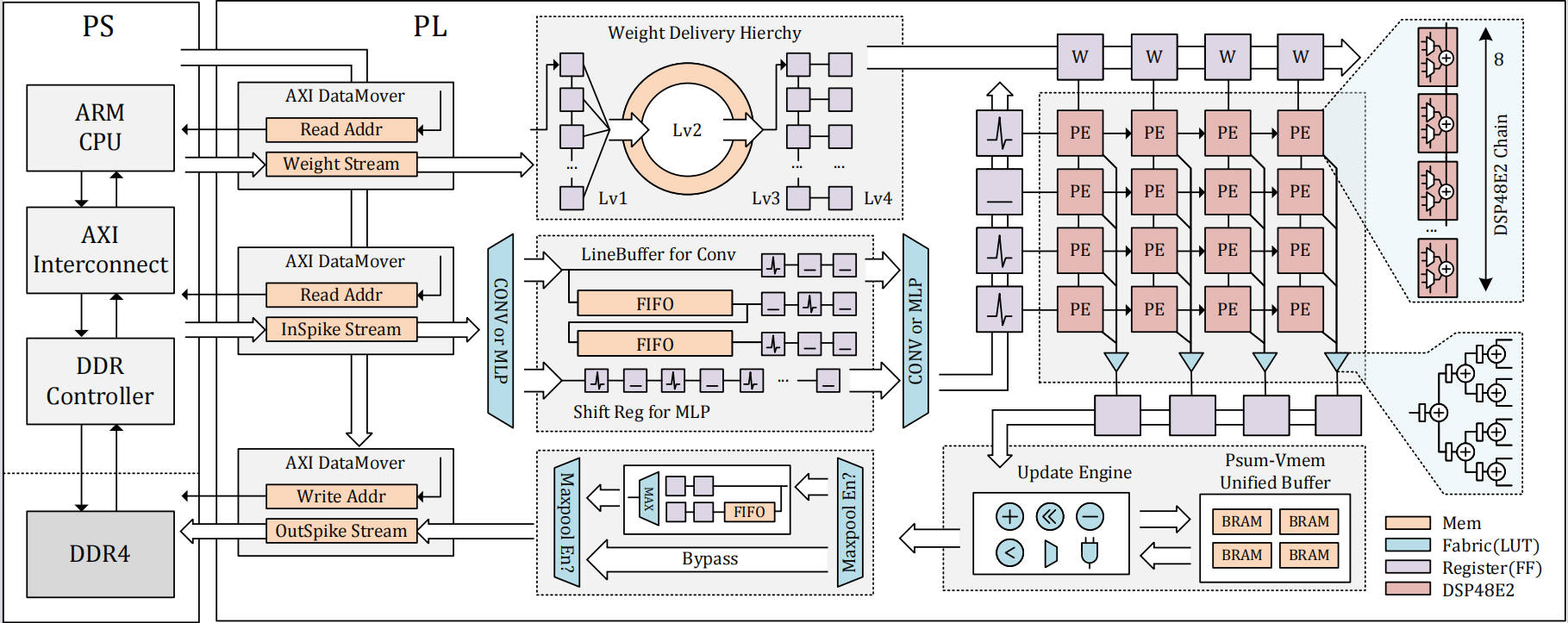 The following papers are most recent advancement of BrainCog Firefly series for Software-Hardware Codesign for Brain-inspired AI.
* Tenglong Li, Jindong Li, Guobin Shen, Dongcheng Zhao, Qian Zhang, Yi Zeng. FireFly-S: Exploiting Dual-Side Sparsity for Spiking Neural Networks Acceleration With Reconfigurable Spatial Architecture. IEEE Transactions on Circuits and Systems I (TCAS-I), 2024.(https://doi.org/10.1109/TCSI.2024.3496554)
* Jindong Li, Guobin Shen, Dongcheng Zhao, Qian Zhang, Yi Zeng. Firefly v2: Advancing hardware support for high-performance spiking neural network with a spatiotemporal fpga accelerator. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2024. (https://ieeexplore.ieee.org/abstract/document/10478105/)
* Jindong Li, Guobin Shen, Dongcheng Zhao, Qian Zhang, Yi Zeng. FireFly: A High-Throughput Hardware Accelerator for Spiking Neural Networks With Efficient DSP and Memory Optimization. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2023. (https://ieeexplore.ieee.org/document/10143752)
## Embodied AI and Robotics (BrainCog Embot)
The following papers are most recent advancement of BrainCog Firefly series for Software-Hardware Codesign for Brain-inspired AI.
* Tenglong Li, Jindong Li, Guobin Shen, Dongcheng Zhao, Qian Zhang, Yi Zeng. FireFly-S: Exploiting Dual-Side Sparsity for Spiking Neural Networks Acceleration With Reconfigurable Spatial Architecture. IEEE Transactions on Circuits and Systems I (TCAS-I), 2024.(https://doi.org/10.1109/TCSI.2024.3496554)
* Jindong Li, Guobin Shen, Dongcheng Zhao, Qian Zhang, Yi Zeng. Firefly v2: Advancing hardware support for high-performance spiking neural network with a spatiotemporal fpga accelerator. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2024. (https://ieeexplore.ieee.org/abstract/document/10478105/)
* Jindong Li, Guobin Shen, Dongcheng Zhao, Qian Zhang, Yi Zeng. FireFly: A High-Throughput Hardware Accelerator for Spiking Neural Networks With Efficient DSP and Memory Optimization. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2023. (https://ieeexplore.ieee.org/document/10143752)
## Embodied AI and Robotics (BrainCog Embot)






 BrainCog Embot is an Embodied AI platform under the Brain-inspired Cognitive Intelligence Engine (BrainCog) framework, which is an open-source Brain-inspired AI platform based on Spiking Neural Network.
The following papers are most recent advancement of BrainCog Embot:
* Qianhao Wang, Yinqian Sun, Enmeng Lu, Qian Zhang, Yi Zeng. Brain-Inspired Action Generation with Spiking Transformer Diffusion Policy Model. Advances in Brain Inspired Cognitive Systems (BICS), 2024.(https://link.springer.com/chapter/10.1007/978-981-96-2882-7_23)
* Yinqian Sun, Feifei Zhao, Mingyang Lv, Yi Zeng. Implementing Spiking World Model with Multi-Compartment Neurons for Model-based Reinforcement Learning, 2025. (https://arxiv.org/abs/2503.00713)
* Qianhao Wang, Yinqian Sun, Enmeng Lu, Qian Zhang, Yi Zeng. MTDP: Modulated Transformer Diffusion Policy Model, 2025. (https://arxiv.org/abs/2502.09029)
## Resources
### [[Lectures]](https://github.com/BrainCog-X/Brain-Cog/blob/main/documents/Lectures.md) | [[Tutorial]](https://github.com/BrainCog-X/Brain-Cog/blob/main/documents/Tutorial.md)
## Publications using BrainCog
### [[Brain Inspired AI]](https://github.com/BrainCog-X/Brain-Cog/blob/main/documents/Publication.md) | [[Brain Simulation]](https://github.com/BrainCog-X/Brain-Cog/blob/main/documents/Pub_brain_simulation.md) | [[Software-Hardware Co-design]](https://github.com/BrainCog-X/Brain-Cog/blob/main/documents/Pub_sh_codesign.md)
## BrainCog Data Engine
### [BrainCog Data Engine](https://github.com/BrainCog-X/Brain-Cog/blob/main/documents/Data_engine.md)
## Requirements:
* numpy
* scipy
* h5py
* torch
* torchvision
* torchaudio
* timm == 0.6.13
* scikit-learn
* einops
* thop
* pyyaml
* matplotlib
* seaborn
* pygame
* dv
* tensorboard
* tonic
## Install
### Install Online
1. You can install braincog by running:
> `pip install braincog`
2. Also, install from github by running:
> `pip install git+https://github.com/braincog-X/Brain-Cog.git`
### Install locally
1. If you are a developer, it is recommanded to download or clone
braincog from github.
> `git clone https://github.com/braincog-X/Brain-Cog.git`
2. Enter the folder of braincog
> `cd Brain-Cog`
3. Install braincog locally
> `pip install -e .`
## Example
1. Examples for Image Classification
```shell
cd ./examples/Perception_and_Learning/img_cls/bp
python main.py --model cifar_convnet --dataset cifar10 --node-type LIFNode --step 8 --device 0
```
2. Examples for Event Classification
```shell
cd ./examples/Perception_and_Learning/img_cls/bp
python main.py --model dvs_convnet --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0
```
Other BrainCog features and tutorials can be found at http://www.brain-cog.network/docs/
## BrainCog Assistant
Please add our BrainCog Assitant via wechat and we will invite you to our wechat developer group.

## Maintenance
This project is led by
**1.Brain-inspired Cognitive Intelligence Lab, Institute of Automation, Chinese Academy of Sciences http://www.braincog.ai/**
**2.Center for Long-term Artificial Intelligence (CLAI) http://long-term-ai.center/**
================================================
FILE: braincog/__init__.py
================================================
# __all__ = ['base', 'datasets', 'model_zoo', 'utils']
#
# from . import (
# base,
# datasets,
# model_zoo,
# utils
# )
================================================
FILE: braincog/base/__init__.py
================================================
__all__ = ['node', 'connection', 'learningrule', 'brainarea', 'encoder', 'utils', 'conversion']
from . import (
node,
strategy,
connection,
conversion,
learningrule,
brainarea,
utils,
encoder
)
================================================
FILE: braincog/base/brainarea/BrainArea.py
================================================
import numpy as np
import torch, os, sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
from braincog.base.node.node import *
from braincog.base.learningrule.STDP import *
from braincog.base.connection.CustomLinear import *
class BrainArea(nn.Module, abc.ABC):
"""
脑区基类
"""
@abc.abstractmethod
def __init__(self):
"""
"""
super().__init__()
@abc.abstractmethod
def forward(self, x):
"""
计算前向传播过程
:return:x是脉冲
"""
return x
def reset(self):
"""
计算前向传播过程
:return:x是脉冲
"""
pass
class ThreePointForward(BrainArea):
"""
三点前馈脑区
"""
def __init__(self, w1, w2, w3):
"""
"""
super().__init__()
self.node = [IFNode(), IFNode(), IFNode()]
self.connection = [CustomLinear(w1), CustomLinear(w2), CustomLinear(w3)]
self.stdp = []
self.stdp.append(STDP(self.node[0], self.connection[0]))
self.stdp.append(STDP(self.node[1], self.connection[1]))
self.stdp.append(STDP(self.node[2], self.connection[2]))
def forward(self, x):
"""
计算前向传播过程
:return:x是脉冲
"""
x, dw1 = self.stdp[0](x)
x, dw2 = self.stdp[1](x)
x, dw3 = self.stdp[2](x)
return x, (*dw1, *dw2, *dw3)
class Feedback(BrainArea):
"""
反馈网络
"""
def __init__(self, w1, w2, w3):
"""
"""
super().__init__()
self.node = [IFNode(), IFNode()]
self.connection = [CustomLinear(w1), CustomLinear(w2), CustomLinear(w3)]
self.stdp = []
self.stdp.append(MutliInputSTDP(self.node[0], [self.connection[0], self.connection[2]]))
self.stdp.append(STDP(self.node[1], self.connection[1]))
self.x1 = torch.zeros(1, w3.shape[0])
def forward(self, x):
"""
计算前向传播过程
:return:x是脉冲
"""
x, dw1 = self.stdp[0](x, self.x1)
self.x1, dw2 = self.stdp[1](x)
return self.x1, (*dw1, *dw2)
def reset(self):
self.x1 *= 0
class TwoInOneOut(BrainArea):
"""
反馈网络
"""
def __init__(self, w1, w2):
"""
"""
super().__init__()
self.node = [IFNode()]
self.connection = [CustomLinear(w1), CustomLinear(w2)]
self.stdp = []
self.stdp.append(MutliInputSTDP(self.node[0], [self.connection[0], self.connection[1]]))
def forward(self, x1, x2):
"""
计算前向传播过程
:return:x是脉冲
"""
x, dw1 = self.stdp[0](x1, x2)
return x, dw1
class SelfConnectionArea(BrainArea):
"""
反馈网络
"""
def __init__(self, w1, w2 ):
"""
"""
super().__init__()
self.node = [IFNode() ]
self.connection = [CustomLinear(w1), CustomLinear(w2) ]
self.stdp = []
self.stdp.append(MutliInputSTDP(self.node[0], [self.connection[0], self.connection[1]]))
self.x1 = torch.zeros(1, w2.shape[0])
def forward(self, x):
"""
计算前向传播过程
:return:x是脉冲
"""
self.x1, dw1 = self.stdp[0](x, self.x1)
return self.x1, dw1
def reset(self):
self.x1 *= 0
if __name__ == "__main__":
T = 20
w1 = torch.tensor([[1., 1], [1, 1]])
w2 = torch.tensor([[1., 1], [1, 1]])
w3 = torch.tensor([[0.4, 0.4], [0.4, 0.4]])
ba = TwoInOneOut(w1, w2)
for i in range(T):
x = ba(torch.tensor([[0.1, 0.1]]), torch.tensor([[0.1, 0.1]]))
print(x[0])
================================================
FILE: braincog/base/brainarea/IPL.py
================================================
from braincog.base.learningrule.STDP import *
from braincog.base.node.node import *
from braincog.base.connection.CustomLinear import *
import random
import numpy as np
import torch
import os
import sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
import matplotlib.pyplot as plt
from braincog.base.strategy.surrogate import *
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
class IPLNet(nn.Module):
"""
inferior parietal lobule (IPL)
"""
def __init__(self, connection):
"""
Setting the network structure of IPL
"""
super().__init__()
# IPLM, IPLV
self.num_subMB = 2
self.node = [IzhNodeMU(threshold=30., a=0.02, b=0.2, c=-65., d=6., mem=-70.) for i in range(self.num_subMB)]
self.connection = connection
self.learning_rule = []
self.learning_rule.append(STDP(self.node[0], self.connection[0])) # vPMC_input-IPLM
self.learning_rule.append(MutliInputSTDP(self.node[1], [self.connection[1], self.connection[2]])) # STS_input-IPLV, IPLM-IPLV
self.out_IPLM = torch.zeros((self.connection[0].weight.shape[1]), dtype=torch.float)
self.out_IPLV = torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float)
def forward(self, input1, input2): # input from vPMC and STS
"""
Calculate the output of IPLv and the weight update between IPLm and IPLv
:param input1: input from vPMC
:param input2: input from STS
:return: output of IPLv, weight update between IPLm and IPLv
"""
self.out_IPLM = self.node[0](self.connection[0](input1))
self.out_IPLV, dw_IPLv = self.learning_rule[1](input2, self.out_IPLM)
if sum(sum(self.out_IPLV)) == 1:
dw_IPLv = dw_IPLv[0][torch.nonzero(dw_IPLv[1])[0][1]][torch.nonzero(dw_IPLv[1])[0][1]] * dw_IPLv[1]
else:
dw_IPLv = dw_IPLv[0]
return self.out_IPLV, dw_IPLv
def UpdateWeight(self, i, dw):
"""
Update the weight
:param i: index of the connection to update
:param dw: weight update
:return: None
"""
self.connection[i].update(dw)
def reset(self):
"""
reset the network
:return: None
"""
for i in range(self.num_subMB):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
"""
Get the connection and weight in IPL
:return: connection
"""
return self.connection
================================================
FILE: braincog/base/brainarea/Insula.py
================================================
import numpy as np
import torch,os,sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
import matplotlib.pyplot as plt
from braincog.base.strategy.surrogate import *
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import random
from braincog.base.connection.CustomLinear import *
from braincog.base.node.node import *
from braincog.base.learningrule.STDP import *
class InsulaNet(nn.Module):
"""
Insula
"""
def __init__(self,connection):
"""
Setting the network structure of Insula
"""
super().__init__()
# Insula
self.num_subMB = 1
self.node = [IzhNodeMU(threshold=30., a=0.02, b=0.2, c=-65., d=6., mem=-70.) for i in range(self.num_subMB)]
self.connection = connection
self.learning_rule = []
self.learning_rule.append(MutliInputSTDP(self.node[0], [self.connection[0],self.connection[1]]))# IPLv-Insula, STS-Insula
self.Insula=torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float)
def forward(self, input1, input2): # input from IPLv and STS
"""
Calculate the output of Insula
:param input1: input from IPLv
:param input2: input from STS
:return: output of Insula, weight update (unused)
"""
self.out_Insula, dw_Insula = self.learning_rule[0](input1, input2)
return self.out_Insula
def UpdateWeight(self,i,dw):
"""
Update the weight
:param i: index of the connection to update
:param dw: weight update
:return: None
"""
self.connection[i].update(dw)
def reset(self):
"""
reset the network
:return: None
"""
for i in range(self.num_subMB):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
"""
Get the connection and weight in Insula
:return: connection
"""
return self.connection
================================================
FILE: braincog/base/brainarea/PFC.py
================================================
import torch
from torch import nn
from braincog.base.brainarea import BrainArea
from braincog.model_zoo.base_module import BaseLinearModule, BaseModule
class PFC:
"""
PFC
"""
def __init__(self):
"""
"""
super().__init__()
def forward(self, x):
"""
:return:x
"""
return x
def reset(self):
"""
:return:x
"""
pass
class dlPFC(BaseModule, PFC):
"""
SNNLinear
"""
def __init__(self,
step,
encode_type,
in_features:int,
out_features:int,
bias,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.bias = bias
self.in_features = in_features
self.out_features = out_features
self.fc = self._create_fc()
self.c = self._rest_c()
def _rest_c(self):
c = torch.rand((self.out_features, self.in_features)) # eligibility trace
return c
def _create_fc(self):
"""
the connection of the SNN linear
@return: nn.Linear
"""
fc = nn.Linear(in_features=self.in_features,
out_features=self.out_features, bias=self.bias)
return fc
================================================
FILE: braincog/base/brainarea/__init__.py
================================================
from .basalganglia import basalganglia
from .BrainArea import BrainArea, ThreePointForward, Feedback, TwoInOneOut, SelfConnectionArea
from .Insula import InsulaNet
from .IPL import IPLNet
from .PFC import PFC, dlPFC
__all__ = [
'basalganglia',
'BrainArea', 'ThreePointForward', 'Feedback', 'TwoInOneOut', 'SelfConnectionArea',
'InsulaNet',
'IPLNet',
'PFC', 'dlPFC'
]
================================================
FILE: braincog/base/brainarea/basalganglia.py
================================================
import numpy as np
import torch
import os
import sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
import torch.nn.functional as F
from braincog.base.strategy.surrogate import *
from braincog.base.node.node import IFNode, SimHHNode
from braincog.base.learningrule.STDP import STDP, MutliInputSTDP
from braincog.base.connection.CustomLinear import CustomLinear
class basalganglia(nn.Module):
"""
Basal Ganglia
"""
def __init__(self, ns, na, we, wi, node_type):
super().__init__()
"""
:param ns: 状态个数
:param na:动作个数
:param we:兴奋性连接权重
:param wi:抑制性连接权重
"""
num_state = ns
num_action = na
num_STN = 2
weight_exc = we
weight_inh = wi
# connetions: 0DLPFC-StrD1 1DLPFC-StrD2 2DLPFC-STN 3StrD1-GPi 4StrD2-GPe 5Gpe-Gpi 6STN-Gpi 7STN-Gpe 8Gpe-STN
bg_connection = []
bg_con_mask = []
# DLPFC-StrD1
con_matrix1 = torch.zeros((num_state, num_state * num_action), dtype=torch.float)
for i in range(num_state):
for j in range(num_action):
con_matrix1[i, i * num_action + j] = 1
bg_con_mask.append(con_matrix1)
bg_connection.append(CustomLinear(weight_exc * con_matrix1, con_matrix1))
# DLPFC-StrD2
bg_connection.append(CustomLinear(weight_exc * con_matrix1, con_matrix1))
bg_con_mask.append(con_matrix1)
# DLPFC-STN
con_matrix3 = torch.ones((num_state, num_STN), dtype=torch.float)
bg_con_mask.append(con_matrix3)
bg_connection.append(CustomLinear(weight_exc * con_matrix3, con_matrix3))
# StrD1-GPi
con_matrix4 = torch.zeros((num_state * num_action, num_action), dtype=torch.float)
for i in range(num_state):
for j in range(num_action):
con_matrix4[i * num_action + j, j] = 1
bg_con_mask.append(con_matrix4)
bg_connection.append(CustomLinear(weight_inh * con_matrix4, con_matrix4))
# StrD2-GPe
bg_con_mask.append(con_matrix4)
bg_connection.append(CustomLinear(weight_inh * con_matrix4, con_matrix4))
# Gpe-Gpi
con_matrix5 = torch.eye((num_action), dtype=torch.float)
bg_con_mask.append(con_matrix5)
bg_connection.append(CustomLinear(weight_inh * con_matrix5, con_matrix5))
# STN-Gpi
con_matrix6 = torch.ones((num_STN, num_action), dtype=torch.float)
bg_con_mask.append(con_matrix6)
bg_connection.append(CustomLinear(0.5 * weight_exc * con_matrix6, con_matrix6))
# STN-Gpe
bg_con_mask.append(con_matrix6)
bg_connection.append(CustomLinear(0.5 * weight_exc * con_matrix6, con_matrix6))
# Gpe-STN
con_matrix7 = torch.ones((num_action, num_STN), dtype=torch.float)
bg_con_mask.append(con_matrix7)
bg_connection.append(CustomLinear(0.5 * weight_inh * con_matrix7, con_matrix7))
self.num_subBG = 5
self.node_type = node_type
if self.node_type == "hh":
self.node = [SimHHNode() for i in range(self.num_subBG)]
if self.node_type == "lif":
self.node = [IFNode() for i in range(self.num_subBG)]
self.connection = bg_connection
self.mask = bg_con_mask
self.learning_rule = []
trace_stdp = 0.99
self.learning_rule.append(STDP(self.node[0], self.connection[0], trace_stdp)) # DLPFC-StrD1
self.learning_rule.append(STDP(self.node[1], self.connection[1], trace_stdp)) # DLPFC-StrD2
self.learning_rule.append(MutliInputSTDP(self.node[2], [self.connection[2], self.connection[8]])) # DLPFC-STN
self.learning_rule.append(MutliInputSTDP(self.node[3], [self.connection[4], self.connection[7]])) # StrD2-GPe STN-Gpe
self.learning_rule.append(MutliInputSTDP(self.node[4], [self.connection[3], self.connection[5], self.connection[6]])) # StrD1-GPi Gpe-Gpi STN-Gpi
self.out_StrD1 = torch.zeros((self.connection[0].weight.shape[1]), dtype=torch.float)
self.out_StrD2 = torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float)
self.out_STN = torch.zeros((self.connection[2].weight.shape[1]), dtype=torch.float)
self.out_Gpi = torch.zeros((self.connection[3].weight.shape[1]), dtype=torch.float)
self.out_Gpe = torch.zeros((self.connection[4].weight.shape[1]), dtype=torch.float)
def forward(self, input):
"""
计算由当前输入基底节网络的输出
:param input: 输入电流
:return: 输出脉冲
"""
self.out_StrD1, dw_strd1 = self.learning_rule[0](input)
self.out_StrD2, dw_strd2 = self.learning_rule[1](input)
self.out_STN, dw_stn = self.learning_rule[2](input, self.out_Gpe)
self.out_Gpe, dw_gpe = self.learning_rule[3](self.out_StrD2, self.out_STN)
self.out_Gpi, dw_gpi = self.learning_rule[4](self.out_StrD1, self.out_Gpe, self.out_STN)
return self.out_Gpi
def UpdateWeight(self, i, dw):
"""
更新基底节内第i组连接的权重 根据传入的dw值
:param i: 要更新的连接的索引
:param dw: 更新的量
:return: None
"""
self.connection[i].update(dw)
self.connection[i].weight.data = F.normalize(self.connection[i].weight.data.float(), p=1, dim=1)
def reset(self):
"""
reset神经元或学习法则的中间量
:return: None
"""
for i in range(self.num_subMB):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
"""
获取基底节网络的连接(包括权值等)
:return: 基底节网络的连接
"""
return self.connection
def getmask(self):
"""
获取基底节网络的连接(仅连接矩阵)
:return: 基底节网络的连接矩阵
"""
return self.mask
if __name__ == "__main__":
BG = basalganglia(4, 2, 0.2, -4)
con = BG.getweight()
print(con)
================================================
FILE: braincog/base/brainarea/dACC.py
================================================
import torch
import matplotlib.pyplot as plt
import numpy as np
np.set_printoptions(threshold=np.inf)
from utils.one_hot import *
import os
import time
import sys
from tqdm import tqdm
from braincog.base.encoder.population_coding import *
from braincog.model_zoo.base_module import BaseLinearModule, BaseModule
from braincog.base.learningrule.STDP import *
import sys
sys.path.append("..")
class dACC(BaseModule):
"""
SNNLinear
"""
def __init__(self,
step,
encode_type,
in_features:int,
out_features:int,
bias,
node,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.bias = bias
self.in_features = in_features
self.out_features = out_features
self.node1 = node(threshold=0.5, tau=2.)
self.node_name1 = node
self.node2 = node(threshold=0.1, tau=2.)
self.node_name2 = node
self.fc = self._create_fc()
self.c = self._rest_c()
def _rest_c(self):
c = torch.rand((self.out_features, self.in_features)) # eligibility trace
return c
def _create_fc(self):
"""
the connection of the SNN linear
@return: nn.Linear
"""
fc = nn.Linear(in_features=self.in_features,
out_features=self.out_features, bias=self.bias)
return fc
def update_c(self, c, STDP, tau_c=0.2):
"""
update the trace of eligibility
@param c: a tensor to record eligibility
@param STDP: the results of STDP
@param tau_c: the parameter of trace decay
@return: a update tensor to record eligibility
Equation:
delta_c = (-(c / tau_c) + STDP) * dela_t
c = c + delta_c
reference:
"""
c = c + tau_c * STDP
return c
def forward(self, inputs, epoch):
"""
decision
@param inputs: state
@return: action
"""
output = []
stdp = STDP(self.node2, self.fc, decay=0.80)
self.c = self._rest_c()
# stdp.connection.weight.data = torch.rand((self.out_features, self.in_features))
for i in range(inputs.shape[0]):
for t in range(self.step):
l1_in = torch.tensor(inputs[i, :])
l1_out = self.node1(l1_in).unsqueeze(0) #pre : l1_out
l2_out, dw = stdp(l1_out) #dw -- STDP
self.c = self.update_c(self.c, dw[0])
output.append(torch.min(l2_out))
# output.append((l2_out.any() == 0).cpu().detach().numpy().tolist())
return output
# if __name__ == '__main__':
# np.random.seed(6)
# T = 5
# num_popneurons = 2
# safety = 2
# epoch = 50
# file_name = "/home/zhaozhuoya/braincog/examples/ToM/data/injury_value.txt"
# state = []
# with open(file_name) as f:
# data = []
# data_split = f.readlines() #
# for i in data_split:
# state.append(one_hot(int(i[0])))
#
# output = np.array(state)
# train_y = output
# test_y = output[79:82]#output[12].reshape(1,2)
#
# file_name = "/home/zhaozhuoya/braincog/examples/ToM/data/injury_memory.txt"
# state = []
# with open(file_name) as f:
# data_split = f.readlines()
# for i in data_split:
# data = []
# data.append(int(bool(abs(int(i[2]) - int(i[18]))))*10)
# data.append(int(bool(abs(int(i[5]) - int(i[21]))))*10)
# state.append(data)
# input = np.array(state)
# train_x = input
# test_x = input[79:82]
# dACC_net = dACC(step=T, encode_type='rate', bias=True,
# in_features=num_popneurons, out_features=safety,
# node=node.LIFNode)
# dACC_net.fc.weight.data = torch.rand((safety, num_popneurons))
# dACC_net.load_state_dict(torch.load('./checkpoint/dACC_net.pth')['dacc'])
# output = dACC_net(inputs=train_x, epoch=50)
# for i in range(len(output)):
# print(output[i], train_x[i])
# torch.save({'dacc': dACC_net.state_dict()}, os.path.join('./checkpoint', 'dACC_net.pth'))
# dACC_net.load_state_dict(torch.load('./checkpoint/dACC_net.pth')['dacc'])
# output = dACC_net(inputs=test_x, epoch=50)
# for i in range(len(test_x)):
#
# print(output[i],test_x[i])
================================================
FILE: braincog/base/connection/CustomLinear.py
================================================
import os
import sys
import numpy as np
import torch
from torch import nn
from torch import einsum
import torch.nn.functional as F
class CustomLinear(nn.Module):
"""
用户自定义连接 通常stdp的计算
"""
def __init__(self, weight, mask=None):
super().__init__()
self.weight = nn.Parameter(weight, requires_grad=True)
self.mask = mask
def forward(self, x: torch.Tensor):
"""
:param x:输入 x.shape = [N ]
"""
#
# ret.shape = [C]
return x.matmul(self.weight)
def update(self, dw):
"""
:param dw:权重更新量
"""
with torch.no_grad():
if self.mask is not None:
dw *= self.mask
self.weight.data += dw
================================================
FILE: braincog/base/connection/__init__.py
================================================
from .CustomLinear import CustomLinear
from .layer import VotingLayer, WTALayer, NDropout, ThresholdDependentBatchNorm2d, LayerNorm, SMaxPool, LIPool
__all__ = [
'CustomLinear',
'VotingLayer', 'WTALayer', 'NDropout', 'ThresholdDependentBatchNorm2d', 'LayerNorm', 'SMaxPool', 'LIPool'
]
================================================
FILE: braincog/base/connection/layer.py
================================================
import warnings
import math
import numpy as np
import torch
from torch import nn
from torch import einsum
from torch.nn.modules.batchnorm import _BatchNorm
import torch.nn.functional as F
from torch.nn import Parameter
from einops import rearrange
class VotingLayer(nn.Module):
"""
用于SNNs的输出层, 几个神经元投票选出最终的类
:param voter_num: 投票的神经元的数量, 例如 ``voter_num = 10``, 则表明会对这10个神经元取平均
"""
def __init__(self, voter_num: int):
super().__init__()
self.voting = nn.AvgPool1d(voter_num, voter_num)
def forward(self, x: torch.Tensor):
# x.shape = [N, voter_num * C]
# ret.shape = [N, C]
return self.voting(x.unsqueeze(1)).squeeze(1)
class WTALayer(nn.Module):
"""
winner take all用于SNNs的每层后,将随机选取一个或者多个输出
:param k: X选取的输出数目 k默认等于1
"""
def __init__(self, k=1):
super().__init__()
self.k = k
def forward(self, x: torch.Tensor):
# x.shape = [N, C,W,H]
# ret.shape = [N, C,W,H]
pos = x * torch.rand(x.shape, device=x.device)
if self.k > 1:
x = x * (pos >= pos.topk(self.k, dim=1)[0][:, -1:]).float()
else:
x = x * (pos >= pos.max(1, True)[0]).float()
return x
class NDropout(nn.Module):
"""
与Drop功能相同, 但是会保证同一个样本不同时刻的mask相同.
"""
def __init__(self, p):
super(NDropout, self).__init__()
self.p = p
self.mask = None
def n_reset(self):
"""
重置, 能够生成新的mask
:return:
"""
self.mask = None
def create_mask(self, x):
"""
生成新的mask
:param x: 输入Tensor, 生成与之形状相同的mask
:return:
"""
self.mask = F.dropout(torch.ones_like(x.data), self.p, training=True)
def forward(self, x):
if self.training:
if self.mask is None:
self.create_mask(x)
return self.mask * x
else:
return x
class WSConv2d(nn.Conv2d):
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, groups=1, bias=True, gain=True):
super(WSConv2d, self).__init__(in_channels, out_channels, kernel_size, stride,
padding, dilation, groups, bias)
if gain:
self.gain = nn.Parameter(torch.ones(self.out_channels, 1, 1, 1))
else:
self.gain = 1.
def forward(self, x):
weight = self.weight
weight_mean = weight.mean(dim=1, keepdim=True).mean(dim=2,
keepdim=True).mean(dim=3, keepdim=True)
weight = weight - weight_mean
std = weight.view(weight.size(0), -1).std(dim=1).view(-1, 1, 1, 1) + 1e-5
weight = self.gain * weight / std.expand_as(weight)
return F.conv2d(x, weight, self.bias, self.stride,
self.padding, self.dilation, self.groups)
class ThresholdDependentBatchNorm2d(_BatchNorm):
"""
tdBN
https://ojs.aaai.org/index.php/AAAI/article/view/17320
"""
def __init__(self, num_features, alpha: float, threshold: float = .5, layer_by_layer: bool = True, affine: bool = True,**kwargs):
self.alpha = alpha
self.threshold = threshold
super().__init__(num_features=num_features, affine=affine)
assert layer_by_layer, \
'tdBN may works in step-by-step mode, which will not take temporal dimension into batch norm'
assert self.affine, 'ThresholdDependentBatchNorm needs to set `affine = True`!'
torch.nn.init.constant_(self.weight, alpha * threshold)
def _check_input_dim(self, input):
if input.dim() != 4:
raise ValueError("expected 4D input (got {}D input)".format(input.dim()))
def forward(self, input):
# input = rearrange(input, '(t b) c w h -> b (t c) w h', t=self.step)
output = super().forward(input)
return output
# return rearrange(output, 'b (t c) w h -> (t b) c w h', t=self.step)
class TEBN(nn.Module):
def __init__(self, num_features,step, eps=1e-5, momentum=0.1,**kwargs):
super(TEBN, self).__init__()
self.bn = nn.BatchNorm3d(num_features)
self.p = nn.Parameter(torch.ones(4, 1, 1, 1, 1))
self.step=step
def forward(self, input):
#y = input.transpose(1, 2).contiguous() # N T C H W , N C T H W
y = rearrange(input,"(t b) c w h -> t c b w h",t=self.step)
y = self.bn(y)
# y = y.contiguous().transpose(1, 2)
# y = y.transpose(0, 1).contiguous() # NTCHW TNCHW
y = rearrange(y,"t c b w h -> t b c w h")
y = y * self.p
#y = y.contiguous().transpose(0, 1) # TNCHW NTCHW
y = rearrange(y, "t b c w h -> (t b) c w h")
return y
class LayerNorm(nn.Module):
""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape,)
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class SMaxPool(nn.Module):
"""用于转换方法的最大池化层的常规替换
选用具有最大脉冲发放率的神经元的脉冲通过,能够满足一般性最大池化层的需要
Reference:
https://arxiv.org/abs/1612.04052
"""
def __init__(self, child):
super(SMaxPool, self).__init__()
self.opration = child
self.sumspike = 0
def forward(self, x):
self.sumspike += x
single = self.opration(self.sumspike * 1000)
sum_plus_spike = self.opration(x + self.sumspike * 1000)
return sum_plus_spike - single
def reset(self):
self.sumspike = 0
class LIPool(nn.Module):
r"""用于转换方法的最大池化层的精准替换
LIPooling通过引入侧向抑制机制保证在转换后的SNN中输出的最大值与期望值相同。
Reference:
https://arxiv.org/abs/2204.13271
"""
def __init__(self, child=None):
super(LIPool, self).__init__()
if child is None:
raise NotImplementedError("child should be Pooling operation with torch.")
self.opration = child
self.sumspike = 0
def forward(self, x):
self.sumspike += x
out = self.opration(self.sumspike)
self.sumspike -= F.interpolate(out, scale_factor=2, mode='nearest')
return out
def reset(self):
self.sumspike = 0
class CustomLinear(nn.Module):
def __init__(self, in_channels, out_channels, bias=True):
super(CustomLinear, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
# self.weight = Parameter(torch.tensor([
# [1., .5, .25, .125],
# [0., 1., .5, .25],
# [0., 0., 1., .5],
# [0., 0., 0., 1.]
# ]), requires_grad=True)
self.weight = Parameter(torch.diag(torch.ones(self.in_channels)), requires_grad=True)
# self.weight = Parameter(torch.randn(self.in_channels, self.in_channels))
mask = torch.tril(torch.ones(self.in_channels, self.in_channels), diagonal=0)
self.register_buffer('mask', mask)
if bias:
self.bias = Parameter(torch.zeros(out_channels), requires_grad=True)
else:
self.register_parameter('bias', None)
def forward(self, inputs):
weight = self.mask * self.weight
return F.linear(inputs, weight, self.bias)
================================================
FILE: braincog/base/conversion/__init__.py
================================================
from .convertor import HookScale, Hookoutput, Scale, Convertor, SNode
from .merge import mergeConvBN, merge
__all__ = [
'Hookoutput', 'HookScale', 'Scale', 'Convertor', 'SNode',
'merge', 'mergeConvBN'
]
================================================
FILE: braincog/base/conversion/convertor.py
================================================
import torch
import torch.nn as nn
from braincog.base.connection.layer import SMaxPool, LIPool
from .merge import mergeConvBN
from .spicalib import SpiCalib
import types
class HookScale(nn.Module):
""" 在每个ReLU层后记录该层的百分位最大值
For channelnorm: 获取最大值时使用了torch.quantile
For layernorm: 使用sort,然后手动取百分比,因为quantile在计算单个通道时有上限,batch较大时易出错
"""
def __init__(self,
p: float = 0.9995,
channelnorm: bool = False,
gamma: float = 0.999,
):
super().__init__()
if channelnorm:
self.register_buffer('scale', torch.tensor(0.0))
else:
self.register_buffer('scale', torch.tensor(0.0))
self.p = p
self.channelnorm = channelnorm
self.gamma = gamma
def forward(self, x):
x = torch.where(x.detach() < self.gamma, x.detach(),
torch.tensor(self.gamma, dtype=x.dtype, device=x.device))
if len(x.shape) == 4 and self.channelnorm:
num_channel = x.shape[1]
tmp = torch.quantile(x.permute(1, 0, 2, 3).reshape(num_channel, -1), self.p, dim=1,
interpolation='lower') + 1e-10
self.scale = torch.max(tmp, self.scale)
else:
sort, _ = torch.sort(x.view(-1))
self.scale = torch.max(sort[int(sort.shape[0] * self.p) - 1], self.scale)
return x
class Hookoutput(nn.Module):
"""
在伪转换中为ReLU和ClipQuan提供包装,用于监控其输出
"""
def __init__(self, module):
super(Hookoutput, self).__init__()
self.activation = 0.
self.operation = module
def forward(self, x):
output = self.operation(x)
self.activation = output.detach()
return output
class Scale(nn.Module):
"""
对前向过程的值进行缩放
"""
def __init__(self, scale: float = 1.0):
super().__init__()
self.register_buffer('scale', scale)
def forward(self, x):
if len(self.scale.shape) == 1:
return self.scale.unsqueeze(0).unsqueeze(2).unsqueeze(3).expand_as(x) * x
else:
return self.scale * x
def reset(self):
"""
转换的网络来自ANN,需要将新附加上的脉冲module进行reset
判断module名称并调用各自节点的reset方法
"""
children = list(self.named_children())
for i, (name, child) in enumerate(children):
if isinstance(child, (SNode, LIPool, SMaxPool)):
child.reset()
else:
reset(child)
class Convertor(nn.Module):
"""ANN2SNN转换器
用于转换完整的pytorch模型,使用dataloader中部分数据进行最大值计算,通过p控制获取第p百分比最大值
channlenorm: https://arxiv.org/abs/1903.06530
channelnorm可以对每个通道获取最大值并进行权重归一化
gamma: https://arxiv.org/abs/2204.13271
gamma可以控制burst spikes的脉冲数,burst spike可以提高神经元的脉冲发放能力,减小信息残留
lipool: https://arxiv.org/abs/2204.13271
lipool用于使用侧向抑制机制进行最大池化,LIPooling能够对SNN中的最大池化进行有效的转换
soft_mode: https://arxiv.org/abs/1612.04052
soft_mode被称为软重置,可以减小重置过程神经元的信息损失,有效提高转换的性能
merge用于是否对网络中相邻的卷积和BN层进行融合
batch_norm控制对dataloader的数据集的用量
"""
def __init__(self,
dataloader,
device=None,
p=0.9995,
channelnorm=False,
lipool=True,
gamma=1,
soft_mode=True,
merge=True,
batch_num=1,
spicalib=0
):
super(Convertor, self).__init__()
self.dataloader = dataloader
self.device = device
self.p = p
self.channelnorm = channelnorm
self.lipool = lipool
self.gamma = gamma
self.soft_mode = soft_mode
self.merge = merge
self.batch_num = batch_num
self.spicalib = spicalib
def forward(self, model):
model.eval()
model = Convertor.register_hook(model, self.p, self.channelnorm, self.gamma)
model = Convertor.get_percentile(model, self.dataloader, self.device, batch_num=self.batch_num)
model = mergeConvBN(model) if self.merge else model
model = Convertor.replace_for_spike(model, self.lipool, self.soft_mode, self.gamma, self.spicalib)
model.reset = types.MethodType(reset, model)
return model
@staticmethod
def register_hook(model, p=0.99, channelnorm=False, gamma=0.999):
""" Reference: https://github.com/fangwei123456/spikingjelly
将网络的每一层后注册一个HookScale类
该方法在仿真上等效于与对权重进行归一化操作,且易扩展到任意结构的网络中
"""
children = list(model.named_children())
for _, (name, child) in enumerate(children):
if isinstance(child, nn.ReLU):
model._modules[name] = nn.Sequential(nn.ReLU(), HookScale(p, channelnorm, gamma))
else:
Convertor.register_hook(child, p, channelnorm, gamma)
return model
@staticmethod
def get_percentile(model, dataloader, device, batch_num=1):
"""
该函数需与具有HookScale层的网络配合使用
"""
for idx, (data, _) in enumerate(dataloader):
data = data.to(device)
if idx >= batch_num:
break
model(data)
return model
@staticmethod
def replace_for_spike(model, lipool=True, soft_mode=True, gamma=1, spicalib=0):
"""
该函数用于将定义好的ANN模型转换为SNN模型
ReLU单元将被替换为脉冲神经元,
如果模型中使用了最大池化,lipool参数将定义使用常规模型还是LIPooling方法
"""
children = list(model.named_children())
for _, (name, child) in enumerate(children):
if isinstance(child, nn.Sequential) and len(child) == 2 and isinstance(child[0], nn.ReLU) and isinstance(child[1], HookScale):
model._modules[name] = nn.Sequential(
Scale(1.0 / child[1].scale),
SNode(soft_mode, gamma),
SpiCalib(spicalib),
Scale(child[1].scale)
)
if isinstance(child, nn.MaxPool2d):
model._modules[name] = LIPool(child) if lipool else SMaxPool(child)
else:
Convertor.replace_for_spike(child, lipool, soft_mode, gamma)
return model
class SNode(nn.Module):
"""
用于转换后的SNN的神经元模型
IF神经元模型由gamma=1确定,当gamma为其他大于1的值时,即为使用burst神经元模型
soft_mode用于定义神经元的重置方法,soft重置能够极大地减少神经元在重置过程的信息损失
"""
def __init__(self, soft_mode=False, gamma=5):
super(SNode, self).__init__()
self.threshold = 1.0
self.soft_mode = soft_mode
self.gamma = gamma
self.mem = 0
self.spike = 0
def forward(self, x):
self.mem = self.mem + x
self.spike = (self.mem / self.threshold).floor().clamp(min=0, max=self.gamma)
self.soft_reset() if self.soft_mode else self.hard_reset
out = self.spike
return out
def hard_reset(self):
"""
硬重置后神经元的膜电势被重置为0
"""
self.mem = self.mem * (1 - self.spike.detach())
def soft_reset(self):
"""
软重置后神经元的膜电势为神经元当前膜电势减去阈值
"""
self.mem = self.mem - self.threshold * self.spike.detach()
def reset(self):
self.mem = 0
self.spike = 0
================================================
FILE: braincog/base/conversion/merge.py
================================================
import torch
import torch.nn as nn
def mergeConvBN(m):
"""
合并网络模块中的卷积与BN层
"""
children = list(m.named_children())
c, cn = None, None
for i, (name, child) in enumerate(children):
if isinstance(child, nn.BatchNorm2d):
bc = merge(c, child)
m._modules[cn] = bc
m._modules[name] = torch.nn.Identity()
c = None
elif isinstance(child, nn.Conv2d):
c = child
cn = name
else:
mergeConvBN(child)
return m
def merge(conv, bn):
"""
conv: 卷积层实例
bn: BN层实例
"""
w = conv.weight
mean, var_sqrt, beta, gamma = bn.running_mean, torch.sqrt(bn.running_var + bn.eps), bn.weight, bn.bias
b = conv.bias if conv.bias is not None else mean.new_zeros(mean.shape)
w = w * (beta / var_sqrt).reshape([conv.out_channels, 1, 1, 1])
b = (b - mean) / var_sqrt * beta + gamma
fused_conv = nn.Conv2d(conv.in_channels, conv.out_channels, conv.kernel_size, conv.stride, conv.padding, bias=True)
fused_conv.weight = nn.Parameter(w)
fused_conv.bias = nn.Parameter(b)
return fused_conv
================================================
FILE: braincog/base/conversion/spicalib.py
================================================
import torch
import torch.nn as nn
class SpiCalib(nn.Module):
def __init__(self, allowance):
super(SpiCalib, self).__init__()
self.allowance = allowance
self.sumspike = 0
self.t = 0
def forward(self, x):
if self.allowance == 0:
return x
if self.t == 0:
self.last_spike = torch.zeros_like(x)
self.avg_time = torch.zeros_like(x)
self.num_spike = torch.zeros_like(x)
SPIKE_MASK = x > 0
self.num_spike[SPIKE_MASK] += 1
self.avg_time[SPIKE_MASK] = (self.t - self.last_spike + self.avg_time * (self.num_spike - 1))[SPIKE_MASK] / \
self.num_spike[SPIKE_MASK]
self.last_spike[SPIKE_MASK] = self.t
SIN_MASK = self.t - self.last_spike > self.avg_time + self.allowance
x[SIN_MASK] -= 1.0
self.sumspike += x
x[self.sumspike <= -1] = 0
self.t += 1
return x
def reset(self):
self.sumspike = 0
self.t = 0
================================================
FILE: braincog/base/encoder/__init__.py
================================================
from .encoder import Encoder
from .population_coding import PEncoder
from.qs_coding import QSEncoder
__all__ = [
'Encoder',
'PEncoder',
'QSEncoder'
]
================================================
FILE: braincog/base/encoder/encoder.py
================================================
import torch
import torch.nn as nn
from einops import rearrange, repeat
from braincog.base.strategy.surrogate import GateGrad
class AutoEncoder(nn.Module):
def __init__(self, step, spike_output=True):
super(AutoEncoder, self).__init__()
self.step = step
self.spike_output = spike_output
# self.gru = nn.GRU(input_size=1, hidden_size=1, num_layers=3)
self.sigmoid = nn.Sigmoid()
self.fc1 = nn.Linear(1, self.step)
self.fc2 = nn.Linear(self.step, self.step)
self.relu = nn.ReLU()
#
self.act_fun = GateGrad()
def forward(self, x):
shape = x.shape
x = self.fc1(x.view(-1, 1))
x = self.relu(x)
x = self.fc2(x).transpose_(1, 0)
# x = x.view(1, -1, 1).repeat(self.step, 1, 1)
# x, _ = self.gru(x)
x = self.sigmoid(x)
if not self.spike_output:
return x.view(self.step, *shape)
else:
return self.act_fun(x).view(self.step, *shape)
# class TransEncoder(nn.Module):
# def __init__(self, step):
# super(TransEncoder, self).__init__()
# self.step = step
# self.trans = Transformer(dim=128, depth=3, heads=8, dim_head=, mlp_dim, dropout=0.)
class Encoder(nn.Module):
'''
将static image编码
:param step: 仿真步长
:param encode_type: 编码方式, 可选 ``direct``, ``ttfs``, ``rate``, ``phase``
:param temporal_flatten: 直接将temporal维度concat到channel维度
:param layer_by_layer: 是否使用计算每一层的所有的输出的方式进行推理
:param
(step, batch_size, )
'''
def __init__(self, step, encode_type='ttfs', *args, **kwargs):
super(Encoder, self).__init__()
self.step = step
self.fun = getattr(self, encode_type)
self.encode_type = encode_type
self.temporal_flatten = kwargs['temporal_flatten'] if 'temporal_flatten' in kwargs else False
self.layer_by_layer = kwargs['layer_by_layer'] if 'layer_by_layer' in kwargs else False
self.no_encode = kwargs['adaptive_node'] if 'adaptive_node' in kwargs else False
self.groups = kwargs['n_groups'] if 'n_groups' in kwargs else 1
# if encode_type == 'auto':
# self.fun = AutoEncoder(self.step, spike_output=False)
def forward(self, inputs, deletion_prob=None, shift_var=None):
if len(inputs.shape) == 5: # DVS data
outputs = inputs.permute(1, 0, 2, 3, 4).contiguous() # t, b, c, w, h
elif len(inputs.shape) == 3: # DAS data
outputs = inputs.permute(1, 0, 2).contiguous() # t, b, c
else:
if self.encode_type == 'auto':
if self.fun.device != inputs.device:
self.fun.to(inputs.device)
outputs = self.fun(inputs)
if deletion_prob:
outputs = self.delete(outputs, deletion_prob)
if shift_var:
outputs = self.shift(outputs, shift_var)
if self.temporal_flatten or self.no_encode:
outputs = rearrange(outputs, 't b c w h -> 1 b (t c) w h')
elif self.groups != 1:
outputs = rearrange(outputs, 't b c w h -> b (c t) w h')
elif self.layer_by_layer:
if len(inputs.shape) == 3:
outputs = rearrange(outputs, 't b c-> (t b) c')
else:
outputs = rearrange(outputs, 't b c w h -> (t b) c w h')
return outputs
@torch.no_grad()
def direct(self, inputs):
"""
直接编码
:param inputs: 形状(b, c, w, h)
:return: (t, b, c, w, h)
"""
outputs = repeat(inputs, 'b c w h -> t b c w h', t=self.step)
# outputs = inputs.unsqueeze(0).repeat(self.step, *([1] * len(shape)))
return outputs
def auto(self, inputs):
# TODO: Calc loss for firing-rate
shape = inputs.shape
outputs = self.fun(inputs)
print(outputs.shape)
return outputs
@torch.no_grad()
def ttfs(self, inputs):
"""
Time-to-First-Spike Encoder
:param inputs: static data
:return: Encoded data
"""
# print("ttfs")
shape = (self.step,) + inputs.shape
outputs = torch.zeros(shape, device=self.device)
for i in range(self.step):
mask = (inputs * self.step <= (self.step - i)
) & (inputs * self.step > (self.step - i - 1))
outputs[i, mask] = 1 / (i + 1)
return outputs
@torch.no_grad()
def rate(self, inputs):
"""
Rate Coding
:param inputs:
:return:
"""
shape = (self.step,) + inputs.shape
return (inputs > torch.rand(shape, device=inputs.device)).float()
@torch.no_grad()
def phase(self, inputs):
"""
Phase Coding
相位编码
:param inputs: static data
:return: encoded data
"""
shape = (self.step,) + inputs.shape
outputs = torch.zeros(shape, device=self.device)
inputs = (inputs * 256).long()
val = 1.
for i in range(self.step):
if i < 8:
mask = (inputs >> (8 - i - 1)) & 1 != 0
outputs[i, mask] = val
val /= 2.
else:
outputs[i] = outputs[i % 8]
return outputs
@torch.no_grad()
def delete(self, inputs, prob):
"""
在Coding 过程中随机删除脉冲
:param inputs: encoded data
:param prob: 删除脉冲的概率
:return: 随机删除脉冲之后的数据
"""
mask = (inputs >= 0) & (torch.randn_like(
inputs, device=self.device) < prob)
inputs[mask] = 0.
return inputs
@torch.no_grad()
def shift(self, inputs, var):
"""
对数据进行随机平移, 添加噪声
:param inputs: encoded data
:param var: 随机平移的方差
:return: shifted data
"""
# TODO: Real-time shift
outputs = torch.zeros_like(inputs)
for step in range(self.step):
shift = (var * torch.randn(1)).round_() + step
shift.clamp_(min=0, max=self.step - 1)
outputs[step] += inputs[int(shift)]
return outputs
================================================
FILE: braincog/base/encoder/population_coding.py
================================================
import torch
import torch.nn as nn
import torchvision.utils
class PEncoder(nn.Module):
"""
Population coding
:param step: time steps
:param encode_type: encoder type (str)
"""
def __init__(self, step, encode_type):
super().__init__()
self.step = step
self.fun = getattr(self, encode_type)
def forward(self, inputs, num_popneurons, *args, **kwargs):
outputs = self.fun(inputs, num_popneurons, *args, **kwargs)
return outputs
@torch.no_grad()
def population_time(self, inputs, m):
"""
one feature will be encoded into gauss_neurons
the center of i-th neuron is: gauss --
.. math::
\\mu u_i = I_min + (2i-3)/2(I_max-I_min)/(m -2)
the width of i-th neuron is : gauss --
.. math::
\\sigma sigma_i = \\frac{1}{1.5}\\frac{(I_max-I_min)}{m - 2}
:param inputs: (N_num, N_feature) array
:param m: the number of the gaussian neurons
i : the i_th gauss_neuron
1.5: experience value
popneurons_spike_t: gauss -- function
I_min = min(inputs)
I_max = max(inputs)
:return: (step, num_gauss_neuron)
"""
# m = self.step
I_min, I_max = torch.min(inputs), torch.max(inputs)
mu = [i for i in range(0, m)]
mu = torch.ones((1, m)) * I_min + ((2 * torch.tensor(mu) - 3) / 2) * ((I_max-I_min) / (m -2))
sigma = (1 / 1.5) * ((I_max-I_min) / (m -2))
# shape = (self.step,) + inputs.shape
shape = (self.step,m)
popneurons_spike_t = torch.zeros(((m,) + inputs.shape))
for i in range(m):
popneurons_spike_t[i, :] = torch.exp(-(inputs - mu[0, i]) ** 2 / (2 * sigma * sigma))
spike_time = (self.step * popneurons_spike_t).type(torch.int)
spikes = torch.zeros(shape)
for spike_time_k in range(self.step):
if torch.where(spike_time == spike_time_k)[1].numel() != 0:
spikes[spike_time_k][torch.where(spike_time == spike_time_k)[0]] = 1
return spikes
@torch.no_grad()
def population_voltage(self, inputs, m, VTH):
'''
The more similar the input is to the mean,
the more sensitive the neuron corresponding to the mean is to the input.
You can change the maen.
:param inputs: (N_num, N_feature) array
:param m : the number of the gaussian neurons
:param VTH : threshold voltage
i : the i_th gauss_neuron
one feature will be encoded into gauss_neurons
the center of i-th neuron is: gauss -- \mu u_i = I_min + (2i-3)/2(I_max-I_min)/(m -2)
the width of i-th neuron is : gauss -- \sigma sigma_i = 1/1.5(I_max-I_min)/(m -2) 1.5: experience value
popneuron_v: gauss -- function
I_min = min(inputs)
I_max = max(inputs)
:return: (step, num_gauss_neuron, dim_inputs)
'''
ENCODER_REGULAR_VTH = VTH
I_min, I_max = torch.min(inputs), torch.max(inputs)
mu = [i for i in range(0, m)]
mu = torch.ones((1, m)) * I_min + ((2 * torch.tensor(mu) - 3) / 2) * ((I_max-I_min) / (m -2))
sigma = (1 / 1.5) * ((I_max-I_min) / (m -2))
popneuron_v = torch.zeros(((m,) + inputs.shape))
delta_v = torch.zeros(((m,) + inputs.shape))
for i in range(m):
delta_v[i] = torch.exp(-(inputs - mu[0, i]) ** 2 / (2 * sigma * sigma))
spikes = torch.zeros((self.step,) + ((m,) + inputs.shape))
for spike_time_k in range(self.step):
popneuron_v = popneuron_v + delta_v
spikes[spike_time_k][torch.where(popneuron_v.ge(ENCODER_REGULAR_VTH))] = 1
popneuron_v = popneuron_v - spikes[spike_time_k] * ENCODER_REGULAR_VTH
popneuron_rate = torch.sum(spikes, dim=0)/self.step
return spikes, popneuron_rate
## test
# if __name__ == '__main__':
# a = (torch.rand((2,4))*10).type(torch.int)
# print(a)
# pencoder = PEncoder(10, 'population_time')
# spikes=pencoder(inputs=a, num_popneurons=3)
# print(spikes, spikes.shape)
# pencoder = PEncoder(10, 'population_voltage')
# spikes, popneuron_rate = pencoder(inputs=a, num_popneurons=5, VTH=0.99)
# print(spikes, spikes.shape)
================================================
FILE: braincog/base/encoder/qs_coding.py
================================================
from signal import signal
from subprocess import call
import numpy as np
import random
import copy
class QSEncoder:
"""
QS Encoding.
:param lambda_max: 最大发放率
:param steps: 脉冲发放周期长度 T
:param sig_len: 脉冲发放窗口
:param shift: 是否反转背景
:param noise: 是否增加噪声
:param noise_rate: 噪声比例
:param eps: 防止溢出参数
"""
def __init__(self,
lambda_max,
steps,
sig_len,
shift=False,
noise=None,
noise_rate=None,
eps=1e-6
) -> None:
self._lambda_max = lambda_max
self._steps = steps
self._sig_len = sig_len
self._shift = shift
self._noise = noise
self._noise_rate = noise_rate
self._eps = eps
def __call__(self, image, image_delta, image_ori, image_ori_delta):
"""
将图片转换为脉冲。
:param image: 背景反转图片
:param image_delta: 扰动图片,用于计算相位
:param image_ori: 原始图片
:param image_ori_delta: 原始扰动图片
"""
if self._noise:
signals = self.noise_trans(image, image_ori, image_ori_delta)
elif self._shift:
signals = self.shift_trans(image, image_delta, image_ori, image_ori_delta)
else:
signals = np.zeros((self.steps, image.shape[0]))
signal_possion = np.random.poisson(image, (self._sig_len, image.shape[0]))
signals[:self._sig_len] = signal_possion[:]
return signal.T
def shift_trans(self, image, image_delta, image_ori, image_ori_delta):
"""
背景翻转图片转脉冲序列。
:param image: 背景反转图片
:param image_delta: 扰动图片,用于计算相位
:param image_ori: 原始图片
:param image_ori_delta: 原始扰动图片
"""
signal = np.zeros((self._steps, image.shape[0]))
assert image_ori is not None
assert self.noise is False
assert image_delta is not None
assert image_ori_delta is not None
image_ori_reverse = self._lambda_max - image_ori
image_ori_delta_reverse = self._lambda_max - image_ori_delta
zeta = image / (image_ori**2 + image_ori_reverse**2) ** 0.5
zeta_delta = image_delta / (image_ori_delta**2 + image_ori_delta_reverse**2)**0.5
idx_left = zeta < zeta_delta
phi = np.arctan(image_ori / (image_ori_reverse + self._eps))
zeta = np.clip(zeta, -1, 1)
zeta = np.arcsin(zeta)
theta1 = zeta - phi
theta2 = np.pi - zeta - phi
theta = np.zeros(theta1.shape)
theta[idx_left] = theta1[idx_left]
theta[~idx_left] = theta2[~idx_left]
theta = np.mean(theta)
cos_theta = np.cos(theta)
sin_theta = np.sin(theta)
spike_rate = np.abs((self._lambda_max * sin_theta - image) / (sin_theta - cos_theta + self._eps))
signal_possion = np.random.poisson(spike_rate, (self._sig_len, spike_rate.shape[0]))
shift_step = np.rint(np.clip(2 * theta / np.pi, a_min=0, a_max=1.0) * (self._steps - self._sig_len))
shift_step = shift_step.astype(np.int)
signal[shift_step:shift_step + self._sig_len] = signal_possion[:]
def noise_trans(self, image, image_ori, image_ori_delta):
"""
噪声图片转脉冲序列
:param image: 背景反转图片
:param image_ori: 原始图片
:param image_ori_delta: 原始扰动图片
"""
signal = np.zeros((self._steps, image.shape[0]))
assert image_ori is not None
assert self._shift is False
assert self._noise_rate is not None
image_ori_delta = copy.deepcopy(image_ori)
idx = image_ori_delta < (self._lambda_max - 0.001)
image_ori_delta[idx] += 0.001
image_ori_reverse = self._lambda_max - image_ori
image_ori_delta_reverse = self._lambda_max - image_ori_delta
image_noise, image_delta_noise = self.reverse_pixels(image_ori, image_ori_delta, noise_rate=self._noise_rate)
zeta = image_noise / (image_ori**2 + image_ori_reverse**2)**0.5
zeta_delta = image_delta_noise / (image_ori_delta**2 + image_ori_delta_reverse**2)**0.5
idx_left = zeta < zeta_delta
phi = np.arctan(image_ori / (image_ori_reverse + self._eps))
zeta = np.clip(zeta, -1, 1)
zeta = np.arcsin(zeta)
theta1 = zeta - phi
theta2 = np.pi - zeta - phi
theta = np.zeros(theta1.shape)
theta[idx_left] = theta1[idx_left]
theta[~idx_left] = theta2[~idx_left]
theta = np.mean(theta)
cos_theta = np.cos(theta)
sin_theta = np.sin(theta)
spike_rate = np.abs((self._lambda_max * sin_theta - image_noise) / (sin_theta - cos_theta + self._eps))
signal_possion = np.random.poisson(spike_rate, (self._sig_len, spike_rate.shape[0]))
shift_step = np.rint(np.clip(2 * theta / np.pi, a_min=0, a_max=1.0) * (self._steps - self._sig_len))
shift_step = shift_step.astype(np.int)
signal[shift_step:shift_step + self._sig_len] = signal_possion[:]
return signal
def reverse_pixels(self, image, image_delta, noise_rate, flip_bits=None):
"""
反转图片像素
"""
if flip_bits is None:
N = int(noise_rate * image.shape[0])
flip_bits = random.sample(range(image.shape[0]), N)
img = copy.copy(image)
img_delta = copy.copy(image_delta)
img[flip_bits] = self._lambda_max - img[flip_bits]
img_delta[flip_bits] = self._lambda_max - img_delta[flip_bits]
return img, img_delta
================================================
FILE: braincog/base/learningrule/BCM.py
================================================
import numpy as np
import torch
import os
import sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
from braincog.base.node import *
class BCM(nn.Module):
"""
BCM learning rule 多组神经元输入到该节点
"""
def __init__(self, node, connection, cfunc=None, weightdecay=0.99, tau=10):
"""
:param node:node神经元类型实例如IFNode LIFNode
:param connection:连接 类的实例列表 里面只能有一个操作
:param cfunc:BCM的频率函数 默认y(y-th)
:param weightdecay:权重衰减系数 默认0.99
:param tau: 频率更新时间常数
"""
super().__init__()
self.node = node
self.connection = connection
if not isinstance(connection, list):
self.connection = [self.connection]
self.weightdecay = weightdecay
self.tau = tau
self.threshold = 0
def forward(self, *x):
"""
计算前向传播过程
:return:s是脉冲 dw更新量
"""
i = 0
x = [xi.clone().detach() for xi in x]
for xi, coni in zip(x, self.connection):
i += coni(xi)
with torch.no_grad():
s = self.node(i)
i.data += self.cfunc(s) - i.data
dw = torch.autograd.grad(outputs=i, inputs=[i.weight for i in self.connection], grad_outputs=i)
for dwi, i in zip(dw, self.connection):
dwi -= (1 - self.weightdecay) * i.weight
return s, dw
def cfunc(self, s):
self.threshold = ((self.tau - 1) * self.threshold + s) / self.tau
return (s * (s - self.threshold)).detach()
def reset(self):
"""
重置
"""
self.threshold = 0
pass
================================================
FILE: braincog/base/learningrule/Hebb.py
================================================
import numpy as np
import torch
import os
import sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
from braincog.base.node.node import *
class Hebb(nn.Module):
"""
Hebb learning rule 多组神经元输入到该节点
"""
def __init__(self, node, connection):
"""
:param node:node神经元类型实例如IFNode LIFNode
:param connection:连接 类的实例列表 里面只能有一个操作
"""
super().__init__()
self.node = node
self.connection = connection
self.trace = [None for i in self.connection]
def forward(self, *x):
"""
计算前向传播过程
:return:s是脉冲 dw更新量
"""
i = 0
x = [xi.clone().detach() for xi in x]
for xi, coni in zip(x, self.connection):
i += coni(xi)
with torch.no_grad():
s = self.node(i)
i.data += s - i.data
dw = torch.autograd.grad(outputs=i, inputs=[i.weight for i in self.connection], grad_outputs=i)
return s, dw
def reset(self):
"""
重置
"""
self.trace = [None for i in self.connection]
if __name__ == "__main__":
node = IFNode()
linear1 = nn.Linear(2, 2, bias=False)
linear2 = nn.Linear(2, 2, bias=False)
linear1.weight.data = torch.tensor([[1., 1], [1, 1]], requires_grad=True)
linear2.weight.data = torch.tensor([[1., 1], [1, 1]], requires_grad=True)
hebb = Hebb(node, [linear1, linear2])
for i in range(10):
x, dw1 = hebb(torch.tensor([1.1, 1.1]), torch.tensor([1.1, 1.1]))
print(dw1)
================================================
FILE: braincog/base/learningrule/RSTDP.py
================================================
import numpy as np
import torch
import os
import sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
from braincog.base.node import *
class RSTDP(nn.Module):
"""
RSTDP算法
"""
def __init__(self, node, connection, decay=0.99, reward_decay=0.5):
"""
:param node:node神经元类型实例如IFNode LIFNode
:param connection:连接 类的实例列表 里面只能有一个操作
"""
super().__init__()
self.node = node
self.connection = connection
if not isinstance(connection, list):
self.connection = [self.connection]
self.trace = [None for i in self.connection]
self.decay = decay
self.reward_decay = reward_decay
self.stdp = STDP(self.node, self.node, self.decay)
def forward(self, *x, r):
"""
计算前向传播过程
:return:s是脉冲 dw更新量
"""
s, dw = self.stdp(x)
trace = self.cal_trace(r)
return s, dw * trace
def cal_trace(self, x):
"""
计算trace
"""
for i in range(len(x)):
if self.trace[i] is None:
self.trace[i] = Parameter(x[i].clone().detach(), requires_grad=False)
else:
self.trace[i] *= self.decay
self.trace[i] += x[i].detach()
return self.trace
def reset(self):
self.trace = [None for i in self.connection]
================================================
FILE: braincog/base/learningrule/STDP.py
================================================
import numpy as np
import torch
import os
import sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
from braincog.base.node.node import *
class STDP(nn.Module):
"""
STDP learning rule
"""
def __init__(self, node, connection, decay=0.99):
"""
:param node:node神经元类型实例如IFNode LIFNode
:param connection:连接 类的实例 里面只能有一个操作
"""
super().__init__()
self.node = node
self.connection = connection
self.trace = None
self.decay = decay
def forward(self, x):
"""
计算前向传播过程
:return:s是脉冲 dw更新量
"""
x = x.clone().detach()
i = self.connection(x)
with torch.no_grad():
s = self.node(i)
i.data += s - i.data
trace = self.cal_trace(x)
x.data += trace - x.data
dw = torch.autograd.grad(outputs=i, inputs=self.connection.weight, grad_outputs=i)
return s, dw
def cal_trace(self, x):
"""
计算trace
"""
if self.trace is None:
self.trace = Parameter(x.clone().detach(), requires_grad=False)
else:
self.trace *= self.decay
self.trace += x
return self.trace.detach()
def reset(self):
"""
重置
"""
self.trace = None
class MutliInputSTDP(nn.Module):
"""
STDP learning rule 多组神经元输入到该节点
"""
def __init__(self, node, connection, decay=0.99):
"""
:param node:node神经元类型实例如IFNode LIFNode
:param connection:连接 类的实例列表 里面只能有一个操作
"""
super().__init__()
self.node = node
self.connection = connection
self.trace = [None for i in self.connection]
self.decay = decay
def forward(self, *x):
"""
计算前向传播过程
:return:s是脉冲 dw更新量
"""
i = 0
x = [xi.clone().detach() for xi in x]
for xi, coni in zip(x, self.connection):
i += coni(xi)
with torch.no_grad():
s = self.node(i)
i.data += s - i.data
trace = self.cal_trace(x)
for xi, ti in zip(x, trace):
xi.data += ti - xi.data
dw = torch.autograd.grad(outputs=i, inputs=[i.weight for i in self.connection], grad_outputs=i)
return s, dw
def cal_trace(self, x):
"""
计算trace
"""
for i in range(len(x)):
if self.trace[i] is None:
self.trace[i] = Parameter(x[i].clone().detach(), requires_grad=False)
else:
self.trace[i] *= self.decay
self.trace[i] += x[i].detach()
return self.trace
def reset(self):
"""
重置
"""
self.trace = [None for i in self.connection]
class LTP(MutliInputSTDP):
"""
STDP learning rule 多组神经元输入到该节点
"""
pass
class LTD(nn.Module):
"""
STDP learning rule 多组神经元输入到该节点
"""
def __init__(self, node, connection, decay=0.99):
"""
:param node:node神经元类型实例如IFNode LIFNode
:param connection:连接 类的实例列表 里面只能有一个操作
"""
super().__init__()
self.node = node
self.connection = connection
self.trace = None
self.decay = decay
def forward(self, *x):
"""
计算前向传播过程
:return:s是脉冲 dw更新量
"""
i = 0
x = [xi.clone().detach() for xi in x]
for xi, coni in zip(x, self.connection):
i += coni(xi)
with torch.no_grad():
s = self.node(i)
trace = self.cal_trace(s)
i.data += trace - i.data
dw = torch.autograd.grad(outputs=i, inputs=[i.weight for i in self.connection], grad_outputs=i)
return s, dw
def cal_trace(self, x):
"""
计算trace
"""
if self.trace is None:
self.trace = Parameter(torch.zeros_like(x), requires_grad=False)
else:
self.trace *= self.decay
trace = self.trace.clone().detach()
self.trace += x
return trace
def reset(self):
"""
重置
"""
self.trace = None
class FullSTDP(nn.Module):
"""
STDP learning rule 多组神经元输入到该节点
"""
def __init__(self, node, connection, decay=0.99, decay2=0.99):
"""
:param node:node神经元类型实例如IFNode LIFNode
:param connection:连接 类的实例列表 里面只能有一个操作
"""
super().__init__()
self.node = node
self.connection = connection
self.tracein = [None for i in self.connection]
self.traceout = None
self.decay = decay
self.decay2 = decay2
def forward(self, *x):
"""
计算前向传播过程
:return:s是脉冲 dw更新量
"""
i = 0
x = [xi.clone().detach() for xi in x]
for xi, coni in zip(x, self.connection):
i += coni(xi)
with torch.no_grad():
s = self.node(i)
traceout = self.cal_traceout(s)
i.data += traceout - i.data
dw1 = torch.autograd.grad(outputs=i, inputs=[i.weight for i in self.connection], retain_graph=True,
grad_outputs=i)
with torch.no_grad():
i.data += s - i.data
tracein = self.cal_tracein(x)
for xi, ti in zip(x, tracein):
xi.data += ti - xi.data
dw2 = torch.autograd.grad(outputs=i, inputs=[i.weight for i in self.connection], grad_outputs=i)
return s, dw2, dw1
def cal_tracein(self, x):
"""
计算trace
"""
for i in range(len(x)):
if self.tracein[i] is None:
self.tracein[i] = Parameter(x[i].clone().detach(), requires_grad=False)
else:
self.tracein[i] *= self.decay
self.tracein[i] += x[i].detach()
return self.tracein
def cal_traceout(self, x):
"""
计算trace
"""
if self.traceout is None:
self.traceout = Parameter(torch.zeros_like(x), requires_grad=False)
else:
self.traceout *= self.decay2
trace = self.traceout.clone().detach()
self.traceout += x
return trace
def reset(self):
"""
重置
"""
self.traceout = [None for i in self.connection]
self.tracein = None
if __name__ == "__main__":
node = IFNode()
linear1 = nn.Linear(2, 2, bias=False)
linear2 = nn.Linear(2, 2, bias=False)
linear1.weight.data = torch.tensor([[1., 1], [1, 1]], requires_grad=True)
linear2.weight.data = torch.tensor([[1., 1], [1, 1]], requires_grad=True)
stdp = LTD(node, [linear1, linear2])
for i in range(10):
x, dw1 = stdp(torch.tensor([1.1, 1.1]), torch.tensor([1.1, 1.1]))
print(dw1)
================================================
FILE: braincog/base/learningrule/STP.py
================================================
import math
class short_time():
"""
计算短期突触可塑性的变量详见Tsodyks和Markram 1997
:param Syn:突出可塑性结构体
:param ISI:棘突间期
:param Nsp:突触前棘波
"""
def __init__(self, SizeHistOutput):
super().__init__()
self.SizeHistOutput = SizeHistOutput
def syndepr(self, Syn=None, ISI=None, Nsp=None):
"""
短期突触可塑性计算
"""
SizeHistOutput = self.SizeHistOutput
qu = Syn.uprev[Nsp] * math.exp(-ISI / Syn.tc_fac)
qR = math.exp(-ISI / Syn.tc_rec)
u = qu + Syn.use * (1.0 - qu)
R = Syn.Rprev[Nsp] * (1.0 - Syn.uprev[Nsp]) * qR + 1.0 - qR
Syn.uprev[(Nsp + 1) % SizeHistOutput] = u
Syn.Rprev[(Nsp + 1) % SizeHistOutput] = R
return R * u
def set_gsyn(self, np=None, dt=None, v=None, NoiseSyn=None):
"""
突触电流参数计算
"""
Isyn = 0
gsyn_AN = 0
gsyn_G = 0
for j in range(np.NumSynType):
syn = np.STList[j]
sgate = 1.0
if (syn.Mg_gate > 0.0):
sgate = syn.Mg_gate / (1.0 + syn.Mg_fac * math.exp(syn.Mg_slope * (syn.Mg_half - v[0])))
Isyn += sgate * (
np.gfOFFsyn[j] * math.exp(-dt / syn.tc_off) - np.gfONsyn[j] * math.exp(-dt / syn.tc_on)) * (
syn.Erev - v[0])
if (syn.Erev == 0.0):
gsyn_AN = gsyn_AN + sgate * (
np.gfOFFsyn[j] * math.exp(-dt / syn.tc_off) - np.gfONsyn[j] * math.exp(-dt / syn.tc_on))
else:
gsyn_G = gsyn_G + sgate * (
np.gfOFFsyn[j] * math.exp(-dt / syn.tc_off) - np.gfONsyn[j] * math.exp(-dt / syn.tc_on))
for j in range(NoiseSyn.NumSyn):
syn = NoiseSyn.Syn[j].STPtr
sgate = 1.0
if (syn.Mg_gate > 0.0):
sgate = syn.Mg_gate / (1.0 + syn.Mg_fac * math.exp(syn.Mg_slope * (syn.Mg_half - v)))
Isyn += sgate * (
np.gfOFFnoise[j] * math.exp(-dt / syn.tc_off) - np.gfONnoise[j] * math.exp(-dt / syn.tc_on)) * (
syn.Erev - v)
if (syn.Erev == 0.0):
gsyn_AN = gsyn_AN + sgate * (
np.gfOFFnoise[j] * math.exp(-dt / syn.tc_off) - np.gfONnoise[j] * math.exp(-dt / syn.tc_on))
else:
gsyn_G = gsyn_G + sgate * (
np.gfOFFnoise[j] * math.exp(-dt / syn.tc_off) - np.gfONnoise[j] * math.exp(-dt / syn.tc_on))
I_tot = Isyn + np.Iinj
return gsyn_AN, I_tot, gsyn_G
def IDderiv(self, np=None, v=None, dt=None, dv=None, NoiseSyn=None, flag_dv=None):
"""
定义模型的常微分方程计算单个神经元常微分方程
:param np:神经元参数
:param v:当前变量
:param dt:时间步长
"""
Isyn = 0
gsyn_G = 0
gsyn_AN = 0
for j in range(np.NumSynType):
syn = np.STList[j]
sgate = 1.0
if (syn.Mg_gate > 0.0):
sgate = syn.Mg_gate / (1.0 + syn.Mg_fac * math.exp(syn.Mg_slope * (syn.Mg_half - v[0])))
Isyn += sgate * (
np.gfOFFsyn[j] * math.exp(-dt / syn.tc_off) - np.gfONsyn[j] * math.exp(-dt / syn.tc_on)) * (
syn.Erev - v[0])
if (syn.Erev == 0.0):
gsyn_AN = gsyn_AN + sgate * (
np.gfOFFsyn[j] * math.exp(-dt / syn.tc_off) - np.gfONsyn[j] * math.exp(-dt / syn.tc_on))
else:
gsyn_G = gsyn_G + sgate * (
np.gfOFFsyn[j] * math.exp(-dt / syn.tc_off) - np.gfONsyn[j] * math.exp(-dt / syn.tc_on))
for j in range(NoiseSyn.NumSyn):
syn = NoiseSyn.Syn[j].STPtr
sgate = 1.0
if (syn.Mg_gate > 0.0):
sgate = syn.Mg_gate / (1.0 + syn.Mg_fac * math.exp(syn.Mg_slope * (syn.Mg_half - v[0])))
Isyn += sgate * (
np.gfOFFnoise[j] * math.exp(-dt / syn.tc_off) - np.gfONnoise[j] * math.exp(-dt / syn.tc_on)) * (
syn.Erev - v[0])
if (syn.Erev == 0.0):
gsyn_AN = gsyn_AN + sgate * (
np.gfOFFnoise[j] * math.exp(-dt / syn.tc_off) - np.gfONnoise[j] * math.exp(-dt / syn.tc_on))
else:
gsyn_G = gsyn_G + sgate * (
np.gfOFFnoise[j] * math.exp(-dt / syn.tc_off) - np.gfONnoise[j] * math.exp(-dt / syn.tc_on))
I_ex = np.gL * np.sf * math.exp((v[0] - np.Vth) / np.sf)
wV = np.Iinj + Isyn - np.gL * (v[0] - np.EL) + I_ex
D0 = (np.Cm / np.gL) * wV
if ((
np.Iinj + Isyn) >= np.I_ref and flag_dv == 0):
dv[0] = -(np.gL / np.Cm) * (v[0] - np.v_dep)
flag_regime_osc = 0
else:
dv[0] = (np.Iinj - np.gL * (v[0] - np.EL) - v[1] + I_ex + Isyn) / np.Cm
flag_regime_osc = 1
dD0 = np.Cm * (math.exp((v[0] - np.Vth) / np.sf) - 1)
if ((v[1] > wV - D0 / np.tcw) and (v[1] < wV + D0 / np.tcw) and v[0] <= np.Vth and (
np.Iinj + Isyn) < np.I_ref):
dv[1] = -(np.gL * (1 - math.exp((v[0] - np.Vth) / np.sf)) + dD0 / np.tcw) * dv[0]
else:
dv[1] = 0
I_tot = Isyn + np.Iinj
return wV, D0, gsyn_AN, gsyn_G, I_tot, dv
def update(self, np=None, dt=None, NoiseSyn=None, flag_dv=None):
"""
用二阶显式龙格-库塔法积分常微分方程
:param np:神经元参数
:param dt:时间步长
"""
nvar = 2
v = [0] * 2
dv1 = [0] * 2
dv2 = [0] * 2
for i in range(nvar):
v[i] = np.v[i]
wV, D0, gsyn_AN, gsyn_G, I_tot, dv1 = short_time(self.SizeHistOutput).IDderiv(np, v, 0.0, dv1, NoiseSyn, flag_dv)
for i in range(nvar):
v[i] += dt * dv1[i]
wV, D0, gsyn_AN, gsyn_G, I_tot, dv2 = short_time(self.SizeHistOutput).IDderiv(np, v, 0.0, dv2, NoiseSyn, flag_dv)
for i in range(nvar):
np.v[i] += dt / 2.0 * (dv1[i] + dv2[i])
np.dv[i] = dt / 2.0 * (dv1[i] + dv2[i])
if ((np.v[1] > wV - D0 / np.tcw) and (np.v[1] < wV + D0 / np.tcw) and np.v[0] <= np.Vth):
np.v[1] = wV - (D0 / np.tcw)
return np, gsyn_AN, gsyn_G, I_tot
================================================
FILE: braincog/base/learningrule/__init__.py
================================================
from .BCM import BCM
from .Hebb import Hebb
from .RSTDP import RSTDP
from .STDP import STDP, MutliInputSTDP, LTP, LTD, FullSTDP
from .STP import short_time
__all__ = [
'BCM',
"Hebb",
'RSTDP',
'STDP', 'MutliInputSTDP', 'LTP', 'LTD', 'FullSTDP',
'short_time'
]
================================================
FILE: braincog/base/node/__init__.py
================================================
from .node import *
================================================
FILE: braincog/base/node/node.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/4/10 18:46
# User : Floyed
# Product : PyCharm
# Project : braincog
# File : node.py
# explain : 神经元节点类型
import abc
import math
from abc import ABC
import numpy as np
import random
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
from einops import rearrange, repeat
from braincog.base.connection.layer import CustomLinear
from braincog.base.strategy.surrogate import *
class BaseNode(nn.Module, abc.ABC):
"""
神经元模型的基类
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param mem_detach: 是否将上一时刻的膜电位在计算图中截断
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self,
threshold=.5,
v_reset=0.,
dt=1.,
step=8,
requires_thres_grad=False,
sigmoid_thres=False,
requires_fp=False,
layer_by_layer=False,
n_groups=1,
*args,
**kwargs):
super(BaseNode, self).__init__()
self.threshold = Parameter(torch.tensor(threshold), requires_grad=requires_thres_grad)
self.sigmoid_thres = sigmoid_thres
self.mem = 0.
self.spike = 0.
self.dt = dt
self.feature_map = []
self.mem_collect = []
self.requires_fp = requires_fp
self.v_reset = v_reset
self.step = step
self.layer_by_layer = layer_by_layer
self.groups = n_groups
self.mem_detach = kwargs['mem_detach'] if 'mem_detach' in kwargs else False
self.requires_mem = kwargs['requires_mem'] if 'requires_mem' in kwargs else False
@abc.abstractmethod
def calc_spike(self):
"""
通过当前的mem计算是否发放脉冲,并reset
:return: None
"""
pass
def integral(self, inputs):
"""
计算由当前inputs对于膜电势的累积
:param inputs: 当前突触输入电流
:type inputs: torch.tensor
:return: None
"""
pass
def get_thres(self):
return self.threshold if not self.sigmoid_thres else self.threshold.sigmoid()
def rearrange2node(self, inputs):
if self.groups != 1:
if len(inputs.shape) == 4:
outputs = rearrange(inputs, 'b (c t) w h -> t b c w h', t=self.step)
elif len(inputs.shape) == 2:
outputs = rearrange(inputs, 'b (c t) -> t b c', t=self.step)
else:
raise NotImplementedError
elif self.layer_by_layer:
if len(inputs.shape) == 4:
outputs = rearrange(inputs, '(t b) c w h -> t b c w h', t=self.step)
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, '(t b) n c -> t b n c', t=self.step)
elif len(inputs.shape) == 2:
outputs = rearrange(inputs, '(t b) c -> t b c', t=self.step)
else:
raise NotImplementedError
else:
outputs = inputs
return outputs
def rearrange2op(self, inputs):
if self.groups != 1:
if len(inputs.shape) == 5:
outputs = rearrange(inputs, 't b c w h -> b (c t) w h')
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, ' t b c -> b (c t)')
else:
raise NotImplementedError
elif self.layer_by_layer:
if len(inputs.shape) == 5:
outputs = rearrange(inputs, 't b c w h -> (t b) c w h')
elif len(inputs.shape) == 4:
outputs = rearrange(inputs, ' t b n c -> (t b) n c')
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, ' t b c -> (t b) c')
else:
raise NotImplementedError
else:
outputs = inputs
return outputs
def forward(self, inputs):
"""
torch.nn.Module 默认调用的函数,用于计算膜电位的输入和脉冲的输出
在```self.requires_fp is True``` 的情况下,可以使得```self.feature_map```用于记录trace
:param inputs: 当前输入的膜电位
:return: 输出的脉冲
"""
if hasattr(self, 'parallel') and self.parallel is True:
inputs = self.rearrange2node(inputs)
if self.mem_detach and hasattr(self.mem, 'detach'):
self.mem = self.mem.detach()
self.spike = self.spike.detach()
self.integral(inputs)
self.calc_spike()
if self.requires_fp is True:
self.feature_map.append(self.spike)
if self.requires_mem is True:
self.mem_collect.append(self.mem)
return self.rearrange2op(self.spike)
elif self.layer_by_layer or self.groups != 1:
inputs = self.rearrange2node(inputs)
outputs = []
for i in range(self.step):
if self.mem_detach and hasattr(self.mem, 'detach'):
self.mem = self.mem.detach()
self.spike = self.spike.detach()
self.integral(inputs[i])
self.calc_spike()
if self.requires_fp is True:
self.feature_map.append(self.spike)
if self.requires_mem is True:
self.mem_collect.append(self.mem)
outputs.append(self.spike)
outputs = torch.stack(outputs)
outputs = self.rearrange2op(outputs)
return outputs
else:
if self.mem_detach and hasattr(self.mem, 'detach'):
self.mem = self.mem.detach()
self.spike = self.spike.detach()
self.integral(inputs)
self.calc_spike()
if self.requires_fp is True:
self.feature_map.append(self.spike)
if self.requires_mem is True:
self.mem_collect.append(self.mem)
return self.spike
def n_reset(self):
"""
神经元重置,用于模型接受两个不相关输入之间,重置神经元所有的状态
:return: None
"""
self.mem = self.v_reset
self.spike = 0.
self.feature_map = []
self.mem_collect = []
def get_n_attr(self, attr):
if hasattr(self, attr):
return getattr(self, attr)
else:
return None
def set_n_warm_up(self, flag):
"""
一些训练策略会在初始的一些epoch,将神经元视作ANN的激活函数训练,此为设置是否使用该方法训练
:param flag: True:神经元变为激活函数, False:不变
:return: None
"""
self.warm_up = flag
def set_n_threshold(self, thresh):
"""
动态设置神经元的阈值
:param thresh: 阈值
:return:
"""
self.threshold = Parameter(torch.tensor(thresh, dtype=torch.float), requires_grad=False)
def set_n_tau(self, tau):
"""
动态设置神经元的衰减系数,用于带Leaky的神经元
:param tau: 衰减系数
:return:
"""
if hasattr(self, 'tau'):
self.tau = Parameter(torch.tensor(tau, dtype=torch.float), requires_grad=False)
else:
raise NotImplementedError
#============================================================================
# node的基类
class BaseMCNode(nn.Module, abc.ABC):
"""
多房室神经元模型的基类
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param comps: 神经元不同房室, 例如["apical", "basal", "soma"]
"""
def __init__(self,
threshold=1.0,
v_reset=0.,
comps=[]):
super().__init__()
self.threshold = Parameter(torch.tensor(threshold), requires_grad=False)
# self.decay = Parameter(torch.tensor(decay), requires_grad=False)
self.v_reset = v_reset
assert len(comps) != 0
self.mems = dict()
for c in comps:
self.mems[c] = None
self.spike = None
self.warm_up = False
@abc.abstractmethod
def calc_spike(self):
pass
@abc.abstractmethod
def integral(self, inputs):
pass
def forward(self, inputs: dict):
'''
Params:
inputs dict: Inputs for every compartments of neuron
'''
if self.warm_up:
return inputs
else:
self.integral(**inputs)
self.calc_spike()
return self.spike
def n_reset(self):
for c in self.mems.keys():
self.mems[c] = self.v_reset
self.spike = 0.0
def get_n_fire_rate(self):
if self.spike is None:
return 0.
return float((self.spike.detach() >= self.threshold).sum()) / float(np.product(self.spike.shape))
def set_n_warm_up(self, flag):
self.warm_up = flag
def set_n_threshold(self, thresh):
self.threshold = Parameter(torch.tensor(thresh, dtype=torch.float), requires_grad=False)
class ThreeCompNode(BaseMCNode):
"""
三房室神经元模型
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param tau: 胞体膜电位时间常数, 用于控制胞体膜电位衰减
:param tau_basal: 基底树突膜电位时间常数, 用于控制基地树突胞体膜电位衰减
:param tau_apical: 远端树突膜电位时间常数, 用于控制远端树突胞体膜电位衰减
:param comps: 神经元不同房室, 例如["apical", "basal", "soma"]
:param act_fun: 脉冲梯度代理函数
"""
def __init__(self,
threshold=1.0,
tau=2.0,
tau_basal=2.0,
tau_apical=2.0,
v_reset=0.0,
comps=['basal', 'apical', 'soma'],
act_fun=AtanGrad):
g_B = 0.6
g_L = 0.05
super().__init__(threshold, v_reset, comps)
self.tau = tau
self.tau_basal = tau_basal
self.tau_apical = tau_apical
self.act_fun = act_fun(alpha=tau, requires_grad=False)
def integral(self, basal_inputs, apical_inputs):
'''
Params:
inputs torch.Tensor: Inputs for basal dendrite
'''
self.mems['basal'] = (self.mems['basal'] + basal_inputs) / self.tau_basal
self.mems['apical'] = (self.mems['apical'] + apical_inputs) / self.tau_apical
self.mems['soma'] = self.mems['soma'] + (self.mems['apical'] + self.mems['basal'] - self.mems['soma']) / self.tau
def calc_spike(self):
self.spike = self.act_fun(self.mems['soma'] - self.threshold)
self.mems['soma'] = self.mems['soma'] * (1. - self.spike.detach())
self.mems['basal'] = self.mems['basal'] * (1. - self.spike.detach())
self.mems['apical'] = self.mems['apical'] * (1. - self.spike.detach())
#============================================================================
# 用于静态测试 使用ANN的情况 不累积电位
class ReLUNode(BaseNode):
"""
用于相同连接的ANN的测试
"""
def __init__(self,
*args,
**kwargs):
super().__init__(requires_fp=False, *args, **kwargs)
self.act_fun = nn.ReLU()
def forward(self, x):
"""
参考```BaseNode```
:param x:
:return:
"""
self.spike = self.act_fun(x)
if self.requires_fp is True:
self.feature_map.append(self.spike)
if self.requires_mem is True:
self.mem_collect.append(self.mem)
return self.spike
def calc_spike(self):
pass
class BiasReLUNode(BaseNode):
"""
用于相同连接的ANN的测试, 会在每个时刻注入恒定电流, 使得神经元更容易激发
"""
def __init__(self,
*args,
**kwargs):
super().__init__(*args, **kwargs)
self.act_fun = nn.ReLU()
def forward(self, x):
self.spike = self.act_fun(x + 0.1)
if self.requires_fp is True:
self.feature_map += self.spike
return self.spike
def calc_spike(self):
pass
# ============================================================================
# 用于SNN的node
class IFNode(BaseNode):
"""
Integrate and Fire Neuron
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=.5, act_fun=AtanGrad, *args, **kwargs):
"""
:param threshold:
:param act_fun:
:param args:
:param kwargs:
"""
super().__init__(threshold, *args, **kwargs)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
def integral(self, inputs):
self.mem = self.mem + inputs * self.dt
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.get_thres())
self.mem = self.mem * (1 - self.spike.detach())
class LIFNode(BaseNode):
"""
Leaky Integrate and Fire
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=0.5, tau=2., act_fun=QGateGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
# self.threshold = threshold
# print(threshold)
# print(tau)
def integral(self, inputs):
self.mem = self.mem + (inputs - self.mem) / self.tau
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
self.mem = self.mem * (1 - self.spike.detach())
class BurstLIFNode(LIFNode):
def __init__(self, threshold=.5, tau=2., act_fun=RoundGrad, *args, **kwargs):
super().__init__(threshold=threshold, tau=tau, act_fun=act_fun, *args, **kwargs)
self.burst_factor = 1.5
def calc_spike(self):
LIFNode.calc_spike(self)
self.spike = torch.where(self.spike > 1., self.burst_factor * self.spike, self.spike)
class BackEINode(BaseNode):
"""
BackEINode with self feedback connection and excitatory and inhibitory neurons
Reference:https://www.sciencedirect.com/science/article/pii/S0893608022002520
:param threshold: 神经元发放脉冲需要达到的阈值
:param if_back whether to use self feedback
:param if_ei whether to use excitotory and inhibitory neurons
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=0.5, decay=0.2, act_fun=BackEIGateGrad, th_fun=EIGrad, channel=40, if_back=True,
if_ei=True, cfg_backei=2, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.decay = decay
if isinstance(act_fun, str):
act_fun = eval(act_fun)
if isinstance(th_fun, str):
th_fun = eval(th_fun)
self.act_fun = act_fun()
self.th_fun = th_fun()
self.channel = channel
self.if_back = if_back
if self.if_back:
self.back = nn.Conv2d(channel, channel, kernel_size=2 * cfg_backei+1, stride=1, padding=cfg_backei)
self.if_ei = if_ei
if self.if_ei:
self.ei = nn.Conv2d(channel, channel, kernel_size=2 * cfg_backei+1, stride=1, padding=cfg_backei)
def integral(self, inputs):
if self.mem is None:
self.mem = torch.zeros_like(inputs)
self.spike = torch.zeros_like(inputs)
self.mem = self.decay * self.mem
if self.if_back:
self.mem += F.sigmoid(self.back(self.spike)) * inputs
else:
self.mem += inputs
def calc_spike(self):
if self.if_ei:
ei_gate = self.th_fun(self.ei(self.mem))
self.spike = self.act_fun(self.mem-self.threshold)
self.mem = self.mem * (1 - self.spike)
self.spike = ei_gate * self.spike
else:
self.spike = self.act_fun(self.mem-self.threshold)
self.mem = self.mem * (1 - self.spike)
def n_reset(self):
self.mem = None
self.spike = None
self.feature_map = []
self.mem_collect = []
class NoiseLIFNode(LIFNode):
"""
Noisy Leaky Integrate and Fire
在神经元中注入噪声, 默认的噪声分布为 ``Beta(log(2), log(6))``
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param log_alpha: 控制 beta 分布的参数 ``a``
:param log_beta: 控制 beta 分布的参数 ``b``
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self,
threshold=1,
tau=2.,
act_fun=GateGrad,
log_alpha=np.log(2),
log_beta=np.log(6),
*args,
**kwargs):
super().__init__(threshold=threshold, tau=tau, act_fun=act_fun, *args, **kwargs)
self.log_alpha = Parameter(torch.as_tensor(log_alpha), requires_grad=True)
self.log_beta = Parameter(torch.as_tensor(log_beta), requires_grad=True)
# self.fc = nn.Sequential(
# nn.Linear(1, 5),
# nn.ReLU(),
# nn.Linear(5, 5),
# nn.ReLU(),
# nn.Linear(5, 2)
# )
def integral(self, inputs): # b, c, w, h / b, c
# self.mu, self.log_var = self.fc(inputs.mean().unsqueeze(0)).split(1)
alpha, beta = torch.exp(self.log_alpha), torch.exp(self.log_beta)
mu = alpha / (alpha + beta)
var = ((alpha + 1) * alpha) / ((alpha + beta + 1) * (alpha + beta))
noise = torch.distributions.beta.Beta(alpha, beta).sample(inputs.shape) * self.get_thres()
noise = noise * var / var.detach() + mu - mu.detach()
self.mem = self.mem + ((inputs - self.mem) / self.tau + noise) * self.dt
class BiasLIFNode(BaseNode):
"""
带有恒定电流输入Bias的LIF神经元,用于带有抑制性/反馈链接的网络的测试
Noisy Leaky Integrate and Fire
在神经元中注入噪声, 默认的噪声分布为 ``Beta(log(2), log(6))``
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
def integral(self, inputs):
self.mem = self.mem + ((inputs - self.mem) / self.tau) * self.dt + 0.1
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.get_thres())
self.mem = self.mem * (1 - self.spike.detach())
class LIFSTDPNode(BaseNode):
"""
用于执行STDP运算时使用的节点 decay的方式是膜电位乘以decay并直接加上输入电流
"""
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
def integral(self, inputs):
self.mem = self.mem * self.tau + inputs
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
# print(( self.threshold).max())
self.mem = self.mem * (1 - self.spike.detach())
def requires_activation(self):
return False
class PLIFNode(BaseNode):
"""
Parametric LIF, 其中的 ```tau``` 会被backward过程影响
Reference:https://arxiv.org/abs/2007.05785
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = -math.log(tau - 1.)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=True)
self.w = nn.Parameter(torch.as_tensor(init_w))
def integral(self, inputs):
self.mem = self.mem + ((inputs - self.mem) * self.w.sigmoid()) * self.dt
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.get_thres())
self.mem = self.mem * (1 - self.spike.detach())
class PSU(BaseNode):
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = -math.log(tau - 1.)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.parallel = True
self.act_fun = act_fun(alpha=2., requires_grad=True)
T = self.step
m1, m2 = generate_matrix(T, tau)
self.register_buffer('m1', m1)
self.register_buffer('m2', m2)
self.m2 *= self.threshold
def integral(self, inputs):
d1 = self.m1 @ inputs.flatten(1)
self.mem = (d1 + self.m2 @ d1.sigmoid()).view(inputs.shape)
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
class IPSU(BaseNode):
def masked_weight(self):
return self.fc.weight * self.mask0
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = -math.log(tau - 1.)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.parallel = True
self.act_fun = act_fun(alpha=2., requires_grad=True)
T = self.step
matrix, matrix2 = generate_matrix(T, tau)
self.register_buffer('m1', matrix)
self.register_buffer('m2', matrix2)
# self.m2 *= self.threshold
self.fc = nn.Linear(T, T)
nn.init.constant_(self.fc.bias, 0.)
nn.init.kaiming_normal_(self.fc.weight, mode='fan_out', nonlinearity='relu')
mask0 = torch.tril(torch.ones([T, T]))
self.register_buffer('mask0', mask0)
def integral(self, inputs):
d1 = torch.addmm(self.fc.bias.unsqueeze(1), self.masked_weight(), inputs.flatten((1)))
self.mem = (d1 + self.m2 @ inputs.flatten(1)).view(inputs.shape)
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
class RPSU(BaseNode):
def masked_weight(self):
return self.fc.weight * self.mask0
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = -math.log(tau - 1.)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.parallel = True
self.act_fun = act_fun(alpha=2., requires_grad=True)
T = self.step
matrix, matrix2 = generate_matrix(T, tau)
self.register_buffer('m1', matrix)
self.register_buffer('m2', matrix2)
# self.m2 *= self.threshold
self.fc = nn.Linear(T, T)
nn.init.constant_(self.fc.bias, 0.)
nn.init.kaiming_normal_(self.fc.weight, mode='fan_out', nonlinearity='relu')
mask0 = torch.tril(torch.ones([T, T]))
self.register_buffer('mask0', mask0)
def integral(self, inputs):
d1 = self.m1 @ inputs.flatten(1)
d2 = torch.addmm(self.fc.bias.unsqueeze(1), self.masked_weight(), inputs.flatten((1)))
self.mem = (d1 + self.m2 @ d2.sigmoid()).view(inputs.shape)
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
class SPSN(BaseNode):
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = -math.log(tau - 1.)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.parallel = True
self.act_fun = act_fun(alpha=2., requires_grad=True)
m1, m2 = generate_matrix(self.step, tau)
self.register_buffer('m1', m1)
def integral(self, inputs):
self.mem = (self.m1 @ inputs.flatten(1)).sigmoid().view(inputs.shape)
def calc_spike(self):
self.spike = torch.bernoulli(self.mem)
class NoisePLIFNode(PLIFNode):
"""
Noisy Parametric Leaky Integrate and Fire
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self,
threshold=1,
tau=2.,
act_fun=GateGrad,
*args,
**kwargs):
super().__init__(threshold=threshold, tau=tau, act_fun=act_fun, *args, **kwargs)
log_alpha = kwargs['log_alpha'] if 'log_alpha' in kwargs else np.log(2)
log_beta = kwargs['log_beta'] if 'log_beta' in kwargs else np.log(6)
self.log_alpha = Parameter(torch.as_tensor(log_alpha), requires_grad=True)
self.log_beta = Parameter(torch.as_tensor(log_beta), requires_grad=True)
# self.fc = nn.Sequential(
# nn.Linear(1, 5),
# nn.ReLU(),
# nn.Linear(5, 5),
# nn.ReLU(),
# nn.Linear(5, 2)
# )
def integral(self, inputs): # b, c, w, h / b, c
# self.mu, self.log_var = self.fc(inputs.mean().unsqueeze(0)).split(1)
alpha, beta = torch.exp(self.log_alpha), torch.exp(self.log_beta)
mu = alpha / (alpha + beta)
var = ((alpha + 1) * alpha) / ((alpha + beta + 1) * (alpha + beta))
noise = torch.distributions.beta.Beta(alpha, beta).sample(inputs.shape) * self.get_thres()
noise = noise * var / var.detach() + mu - mu.detach()
self.mem = self.mem + ((inputs - self.mem) * self.w.sigmoid() + noise) * self.dt
class BiasPLIFNode(BaseNode):
"""
Parametric LIF with bias
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = -math.log(tau - 1.)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=True)
self.w = nn.Parameter(torch.as_tensor(init_w))
def integral(self, inputs):
self.mem = self.mem + ((inputs - self.mem) * self.w.sigmoid() + 0.1) * self.dt
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.get_thres())
self.mem = self.mem * (1 - self.spike.detach())
class DoubleSidePLIFNode(LIFNode):
"""
能够输入正负脉冲的 PLIF
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self,
threshold=.5,
tau=2.,
act_fun=AtanGrad,
*args,
**kwargs):
super().__init__(threshold, tau, act_fun, *args, **kwargs)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=True)
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.get_thres()) - self.act_fun(self.get_thres - self.mem)
self.mem = self.mem * (1. - torch.abs(self.spike.detach()))
class IzhNode(BaseNode):
"""
Izhikevich 脉冲神经元
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.a = kwargs['a'] if 'a' in kwargs else 0.02
self.b = kwargs['b'] if 'b' in kwargs else 0.2
self.c = kwargs['c'] if 'c' in kwargs else -55.
self.d = kwargs['d'] if 'd' in kwargs else -2.
'''
v' = 0.04v^2 + 5v + 140 -u + I
u' = a(bv-u)
下面是将Izh离散化的写法
if v>= thresh:
v = c
u = u + d
'''
# 初始化膜电势 以及 对应的U
self.mem = 0.
self.u = 0.
self.dt = kwargs['dt'] if 'dt' in kwargs else 1.
def integral(self, inputs):
self.mem = self.mem + self.dt * (0.04 * self.mem * self.mem + 5 * self.mem - self.u + 140 + inputs)
self.u = self.u + self.dt * (self.a * self.b * self.mem - self.a * self.u)
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.get_thres()) # 大于阈值释放脉冲
self.mem = self.mem * (1 - self.spike.detach()) + self.spike.detach() * self.c
self.u = self.u + self.spike.detach() * self.d
def n_reset(self):
self.mem = 0.
self.u = 0.
self.spike = 0.
class IzhNodeMU(BaseNode):
"""
Izhikevich 脉冲神经元多参数版
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.a = kwargs['a'] if 'a' in kwargs else 0.02
self.b = kwargs['b'] if 'b' in kwargs else 0.2
self.c = kwargs['c'] if 'c' in kwargs else -55.
self.d = kwargs['d'] if 'd' in kwargs else -2.
self.mem = kwargs['mem'] if 'mem' in kwargs else 0.
self.u = kwargs['u'] if 'u' in kwargs else 0.
self.dt = kwargs['dt'] if 'dt' in kwargs else 1.
def integral(self, inputs):
self.mem = self.mem + self.dt * (0.04 * self.mem * self.mem + 5 * self.mem - self.u + 140 + inputs)
self.u = self.u + self.dt * (self.a * self.b * self.mem - self.a * self.u)
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
self.mem = self.mem * (1 - self.spike.detach()) + self.spike.detach() * self.c
self.u = self.u + self.spike.detach() * self.d
def n_reset(self):
self.mem = -70.
self.u = 0.
self.spike = 0.
def requires_activation(self):
return False
class DGLIFNode(BaseNode):
"""
Reference: https://arxiv.org/abs/2110.08858
:param threshold: 神经元的脉冲发放阈值
:param tau: 神经元的膜常数, 控制膜电位衰减
"""
def __init__(self, threshold=.5, tau=2., *args, **kwargs):
super().__init__(threshold, tau, *args, **kwargs)
self.act = nn.ReLU()
self.tau = tau
def integral(self, inputs):
inputs = self.act(inputs)
self.mem = self.mem + ((inputs - self.mem) / self.tau) * self.dt
def calc_spike(self):
spike = self.mem.clone()
spike[(spike < self.get_thres())] = 0.
# self.spike = spike / (self.mem.detach().clone() + 1e-12)
self.spike = spike - spike.detach() + \
torch.where(spike.detach() > self.get_thres(), torch.ones_like(spike), torch.zeros_like(spike))
self.spike = spike
self.mem = torch.where(self.mem >= self.get_thres(), torch.zeros_like(self.mem), self.mem)
class HTDGLIFNode(IFNode):
"""
Reference: https://arxiv.org/abs/2110.08858
:param threshold: 神经元的脉冲发放阈值
:param tau: 神经元的膜常数, 控制膜电位衰减
"""
def __init__(self, threshold=.5, tau=2., *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.warm_up = False
def calc_spike(self):
spike = self.mem.clone()
spike[(spike < self.get_thres())] = 0.
# self.spike = spike / (self.mem.detach().clone() + 1e-12)
self.spike = spike - spike.detach() + \
torch.where(spike.detach() > self.get_thres(), torch.ones_like(spike), torch.zeros_like(spike))
self.spike = spike
self.mem = torch.where(self.mem >= self.get_thres(), torch.zeros_like(self.mem), self.mem)
# self.mem[[(spike > self.get_thres())]] = self.mem[[(spike > self.get_thres())]] - self.get_thres()
self.mem = (self.mem + 0.2 * self.spike - 0.2 * self.spike.detach()) * self.dt
def forward(self, inputs):
if self.warm_up:
return F.relu(inputs)
else:
return super(IFNode, self).forward(F.relu(inputs))
class SimHHNode(BaseNode):
"""
简单版本的HH模型
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=50., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
'''
I = Cm dV/dt + g_k*n^4*(V_m-V_k) + g_Na*m^3*h*(V_m-V_Na) + g_l*(V_m - V_L)
'''
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.g_Na, self.g_K, self.g_l = torch.tensor(120.), torch.tensor(120), torch.tensor(0.3) # k 36
self.V_Na, self.V_K, self.V_l = torch.tensor(120.), torch.tensor(-120.), torch.tensor(10.6) # k -12
self.m, self.n, self.h = torch.tensor(0), torch.tensor(0), torch.tensor(0)
self.mem = 0
self.dt = 0.01
def integral(self, inputs):
self.I_Na = torch.pow(self.m, 3) * self.g_Na * self.h * (self.mem - self.V_Na)
self.I_K = torch.pow(self.n, 4) * self.g_K * (self.mem - self.V_K)
self.I_L = self.g_l * (self.mem - self.V_l)
self.mem = self.mem + self.dt * (inputs - self.I_Na - self.I_K - self.I_L) / 0.02
# non Na
# self.mem = self.mem + 0.01 * (inputs - self.I_K - self.I_L) / 0.02 #decayed
# NON k
# self.mem = self.mem + 0.01 * (inputs - self.I_Na - self.I_L) / 0.02 #increase
self.alpha_n = 0.01 * (self.mem + 10.0) / (1 - torch.exp(-(self.mem + 10.0) / 10))
self.beta_n = 0.125 * torch.exp(-(self.mem) / 80)
self.alpha_m = 0.1 * (self.mem + 25) / (1 - torch.exp(-(self.mem + 25) / 10))
self.beta_m = 4 * torch.exp(-(self.mem) / 18)
self.alpha_h = 0.07 * torch.exp(-(self.mem) / 20)
self.beta_h = 1 / (1 + torch.exp(-(self.mem + 30) / 10))
self.n = self.n + self.dt * (self.alpha_n * (1 - self.n) - self.beta_n * self.n)
self.m = self.m + self.dt * (self.alpha_m * (1 - self.m) - self.beta_m * self.m)
self.h = self.h + self.dt * (self.alpha_h * (1 - self.h) - self.beta_h * self.h)
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
self.mem = self.mem * (1 - self.spike.detach())
def forward(self, inputs):
self.integral(inputs)
self.calc_spike()
return self.spike
def n_reset(self):
self.mem = 0.
self.spike = 0.
self.m, self.n, self.h = torch.tensor(0), torch.tensor(0), torch.tensor(0)
def requires_activation(self):
return False
class CTIzhNode(IzhNode):
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, tau, act_fun, *args, **kwargs)
self.name = kwargs['name'] if 'name' in kwargs else ''
self.excitability = kwargs['excitability'] if 'excitability' in kwargs else 'TRUE'
self.spikepattern = kwargs['spikepattern'] if 'spikepattern' in kwargs else 'RS'
self.synnum = kwargs['synnum'] if 'synnum' in kwargs else 0
self.locationlayer = kwargs['locationlayer'] if 'locationlayer' in kwargs else ''
self.adjneuronlist = {}
self.proximal_dendrites = []
self.distal_dendrites = []
self.totalindex = kwargs['totalindex'] if 'totalindex' in kwargs else 0
self.colindex = 0
self.state = 'inactive'
self.Gup = kwargs['Gup'] if 'Gup' in kwargs else 0.0
self.Gdown = kwargs['Gdown'] if 'Gdown' in kwargs else 0.0
self.Vr = kwargs['Vr'] if 'Vr' in kwargs else 0.0
self.Vt = kwargs['Vt'] if 'Vt' in kwargs else 0.0
self.Vpeak = kwargs['Vpeak'] if 'Vpeak' in kwargs else 0.0
self.capicitance = kwargs['capacitance'] if 'capacitance' in kwargs else 0.0
self.k = kwargs['k'] if 'k' in kwargs else 0.0
self.mem = -65
self.vtmp = -65
self.u = -13.0
self.spike = 0
self.dc = 0
def integral(self, inputs):
self.mem += self.dt * (
self.k * (self.mem - self.Vr) * (self.mem - self.Vt) - self.u + inputs) / self.capicitance
self.u += self.dt * (self.a * (self.b * (self.mem - self.Vr) - self.u))
def calc_spike(self):
if self.mem >= self.Vpeak:
self.mem = self.c
self.u = self.u + self.d
self.spike = 1
self.spreadMarkPostNeurons()
def spreadMarkPostNeurons(self):
for post, list in self.adjneuronlist.items():
if self.excitability == "TRUE":
post.dc = random.randint(140, 160)
else:
post.dc = random.randint(-160, -140)
class adth(BaseNode):
"""
The adaptive Exponential Integrate-and-Fire model (aEIF)
:param args: Other parameters
:param kwargs: Other parameters
"""
def __init__(self, *args, **kwargs):
super().__init__(requires_fp=False, *args, **kwargs)
def adthNode(self, v, dt, c_m, g_m, alpha_w, ad, Ieff, Ichem, Igap, tau_ad, beta_ad, vt, vm1):
"""
Calculate the neurons that discharge after the current threshold is reached
:param v: Current neuron voltage
:param dt: time step
:param ad:Adaptive variable
:param vv:Spike, if the voltage exceeds the threshold from below
"""
v = v + dt / c_m * (-g_m * v + alpha_w * ad + Ieff + Ichem + Igap)
ad = ad + dt / tau_ad * (-ad + beta_ad * v)
vv = (v >= vt).astype(int) * (vm1 < vt).astype(int)
vm1 = v
return v, ad, vv, vm1
def calc_spike(self):
pass
class HHNode(BaseNode):
"""
用于脑模拟的HH模型
p: [threshold, g_Na, g_K, g_l, V_Na, V_K, V_l, C]
"""
def __init__(self, p, dt, device, act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold=p[0], *args, **kwargs)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
'''
I = Cm dV/dt + g_k*n^4*(V_m-V_k) + g_Na*m^3*h*(V_m-V_Na) + g_l*(V_m - V_L)
'''
self.neuron_num = len(p[0])
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.tau_I = 3
self.g_Na = torch.tensor(p[1])
self.g_K = torch.tensor(p[2])
self.g_l = torch.tensor(p[3])
self.V_Na = torch.tensor(p[4])
self.V_K = torch.tensor(p[5])
self.V_l = torch.tensor(p[6])
self.C = torch.tensor(p[7])
self.m = 0.05 * torch.ones(self.neuron_num, device=device, requires_grad=False)
self.n = 0.31 * torch.ones(self.neuron_num, device=device, requires_grad=False)
self.h = 0.59 * torch.ones(self.neuron_num, device=device, requires_grad=False)
self.v_reset = 0
self.dt = dt
self.dt_over_tau = self.dt / self.tau_I
self.sqrt_coeff = math.sqrt(1 / (2 * (1 / self.dt_over_tau)))
self.mu = 10
self.sig = 12
self.mem = torch.tensor(self.v_reset, device=device, requires_grad=False)
self.mem_p = self.mem
self.spike = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.Iback = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.Ieff = torch.zeros(self.neuron_num, device=device, requires_grad=False)
def integral(self, inputs):
self.alpha_n = (0.1 - 0.01 * self.mem) / (torch.exp(1 - 0.1 * self.mem) - 1)
self.alpha_m = (2.5 - 0.1 * self.mem) / (torch.exp(2.5 - 0.1 * self.mem) - 1)
self.alpha_h = 0.07 * torch.exp(-self.mem / 20.0)
self.beta_n = 0.125 * torch.exp(-self.mem / 80.0)
self.beta_m = 4.0 * torch.exp(-self.mem / 18.0)
self.beta_h = 1 / (torch.exp(3 - 0.1 * self.mem) + 1)
self.n = self.n + self.dt * (self.alpha_n * (1 - self.n) - self.beta_n * self.n)
self.m = self.m + self.dt * (self.alpha_m * (1 - self.m) - self.beta_m * self.m)
self.h = self.h + self.dt * (self.alpha_h * (1 - self.h) - self.beta_h * self.h)
self.I_Na = torch.pow(self.m, 3) * self.g_Na * self.h * (self.mem - self.V_Na)
self.I_K = torch.pow(self.n, 4) * self.g_K * (self.mem - self.V_K)
self.I_L = self.g_l * (self.mem - self.V_l)
self.mem_p = self.mem
self.mem = self.mem + self.dt * (inputs - self.I_Na - self.I_K - self.I_L) / self.C
def calc_spike(self):
self.spike = (self.threshold > self.mem_p).float() * (self.mem > self.threshold).float()
def forward(self, inputs):
self.integral(inputs)
self.calc_spike()
return self.spike, self.mem
def requires_activation(self):
return False
class aEIF(BaseNode):
"""
The adaptive Exponential Integrate-and-Fire model (aEIF)
This class define the membrane, spike, current and parameters of a neuron group of a specific type
:param args: Other parameters
:param kwargs: Other parameters
"""
def __init__(self, p, dt, device, *args, **kwargs):
"""
p:[threshold, v_reset, c_m, tao_w, alpha_ad, beta_ad]
"""
super().__init__(threshold=p[0], requires_fp=False, *args, **kwargs)
self.neuron_num = len(p[0])
self.g_m = 0.1 # neuron conduction
self.dt = dt
self.tau_I = 3 # Time constant to filter the synaptic inputs
self.Delta_T = 0.5 # parameter
self.v_reset = p[1] # membrane potential reset to v_reset after fire spike
self.c_m = p[2]
self.tau_w = p[3] # Time constant of adaption coupling
self.alpha_ad = p[4]
self.beta_ad = p[5]
self.refrac = 5 / self.dt # refractory period
self.dt_over_tau = self.dt / self.tau_I
self.sqrt_coeff = math.sqrt(1 / (2 * (1 / self.dt_over_tau)))
self.mem = self.v_reset
self.spike = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.ad = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.ref = torch.randint(0, int(self.refrac + 1), (1, self.neuron_num), device=device, requires_grad=False).squeeze(
0) # refractory counter
self.ref = self.ref.float()
self.mu = 10
self.sig = 12
self.Iback = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.Ieff = torch.zeros(self.neuron_num, device=device, requires_grad=False)
def integral(self, inputs):
self.mem = self.mem + (self.ref > self.refrac) * self.dt / self.c_m * \
(-self.g_m * (self.mem - self.v_reset) + self.g_m * self.Delta_T *
torch.exp((self.mem - self.threshold) / self.Delta_T) +
self.alpha_ad * self.ad + inputs)
self.ad = self.ad + (self.ref > self.refrac) * self.dt / self.tau_w * \
(-self.ad + self.beta_ad * (self.mem - self.v_reset))
def calc_spike(self):
self.spike = (self.mem > self.threshold).float()
self.ref = self.ref * (1 - self.spike) + 1
self.ad = self.ad + self.spike * 30
self.mem = self.spike * self.v_reset + (1 - self.spike.detach()) * self.mem
def forward(self, inputs):
# aeifnode_cuda.forward(self.threshold, self.c_m, self.alpha_w, self.beta_ad, inputs, self.ref, self.ad, self.mem, self.spike)
self.integral(inputs)
self.calc_spike()
return self.spike, self.mem
class LIAFNode(BaseNode):
"""
Leaky Integrate and Analog Fire (LIAF), Reference: https://ieeexplore.ieee.org/abstract/document/9429228
与LIF相同, 但前传的是膜电势, 更新沿用阈值和膜电势
:param act_fun: 前传使用的激活函数 [ReLU, SeLU, LeakyReLU]
:param threshold_related: 阈值依赖模式,若为"True"则 self.spike = act_fun(mem-threshold)
:note that BaseNode return self.spike, and here self.spike is analog value.
"""
def __init__(self, spike_act=BackEIGateGrad(), act_fun="SELU", threshold=0.5, tau=2., threshold_related=True, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
if isinstance(act_fun, str):
act_fun = eval("nn." + act_fun + "()")
self.tau = tau
self.act_fun = act_fun
self.spike_act = spike_act
self.threshold_related = threshold_related
def integral(self, inputs):
self.mem = self.mem + (inputs - self.mem) / self.tau
def calc_spike(self):
if self.threshold_related:
spike_tmp = self.act_fun(self.mem - self.threshold)
else:
spike_tmp = self.act_fun(self.mem)
self.spike = self.spike_act(self.mem - self.threshold)
self.mem = self.mem * (1 - self.spike)
self.spike = spike_tmp
class OnlineLIFNode(BaseNode):
"""
Online-update Leaky Integrate and Fire
与LIF模型相同,但是时序信息在反传时从计算图剥离,因此可以实现在线的更新;模型占用显存固定,不随仿真步step线性提升。
使用此神经元需要修改: 1. 将模型中t次forward从model_zoo写到main.py中
2. 在Conv层与OnelineLIFNode层中加入Replace函数,即时序前传都是detach的,但仍计算该层空间梯度信息。
3. 网络结构不适用BN层,使用weight standardization
注意该神经元不同于OTTT,而是将时序信息全部扔弃。对应这篇文章:https://arxiv.org/abs/2302.14311
若需保留时序,需要对self.rate_tracking进行计算。实现可参考https://github.com/pkuxmq/OTTT-SNN
"""
def __init__(self, threshold=0.5, tau=2., act_fun=QGateGrad, init=False, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.rate_tracking = None
self.init = True
def integral(self, inputs):
if self.init is True:
self.mem = torch.zeros_like(inputs)
self.init = False
self.mem = self.mem.detach() + (inputs - self.mem.detach()) / self.tau
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
self.mem = self.mem * (1 - self.spike.detach())
with torch.no_grad():
if self.rate_tracking == None:
self.rate_tracking = self.spike.clone().detach()
self.spike = torch.cat((self.spike, self.rate_tracking), dim=0)
class AdaptiveNode(LIFNode):
def __init__(self, threshold=1., act_fun=QGateGrad, step=10, spike_output=True, *args, **kwargs):
super().__init__(threshold=threshold, step=step, **kwargs)
self.n_encode_type = kwargs['n_encode_type'] if 'n_encode_type' in kwargs else 'linear'
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
# self.act_fun = BinaryActivation()
print(self.n_encode_type)
if self.n_encode_type == 'linear':
self.encoder = nn.Sequential(
CustomLinear(self.step, self.step)
)
elif self.n_encode_type == 'mlp':
# Direct
self.encoder = nn.Sequential(
CustomLinear(self.step, self.step),
nn.ReLU(),
CustomLinear(self.step, self.step),
nn.ReLU(),
CustomLinear(self.step, self.step),
nn.ReLU(),
CustomLinear(self.step, self.step),
)
elif self.n_encode_type == 'att':
# -> SE block
self.encoder = nn.Sequential(
nn.Linear(self.step, self.step),
nn.ReLU(),
nn.Linear(self.step, self.step),
nn.ReLU(),
nn.Linear(self.step, self.step),
nn.Sigmoid()
)
elif self.n_encode_type == 'conv':
self.encoder = nn.Sequential(
nn.Linear(self.step, self.step),
nn.ReLU(),
nn.Linear(self.step, self.step),
)
# self.init_weight()
else:
raise NotImplementedError('Unrecognizable categories {}.'.format(self.n_encode_type))
self.saved_mem = 0.
def init_weight(self):
for mod in self.encoder.modules():
if isinstance(mod, nn.Conv1d):
mod.weight.data[:, :, 4] = 1. / mod.weight.shape[0]
mod.weight.data[:, :, [0, 1, 2, 3, 5, 6, 7, 8]] = 0.
mod.bias.data[:] = 0.
def forward(self, inputs): # (t b) c w h
if self.n_encode_type != 'conv':
x = rearrange(inputs, '(t b) ... -> b ... t', t=self.step)
else:
c, w, h = inputs.shape[1:]
x = rearrange(inputs, '(t b) c w h -> (b c w h) 1 t', t=self.step)
if self.n_encode_type != 'att':
x = self.encoder(x) # Direct
else:
x = x * self.encoder(x) # SE Block
if self.n_encode_type != 'conv':
x = rearrange(x, 'b ... t -> (t b) ...')
else:
x = rearrange(x, '(b c w h) 1 t -> (t b) c w h', c=c, w=w, h=h)
# self.spike = self.act_fun(x - 0.5)
# # print(self.spike.mean())
# # print(self.requires_fp)
# if self.requires_fp:
# spike = rearrange(self.spike, '(t b) c w h -> t b c w h', t=self.step)
# for t in range(self.step):
# # print(t, float(spike[t].mean()), float(spike[t].std()))
# self.feature_map.append(spike[t])
# self.saved_mem = x
# return self.spike
return super().forward(x)
# def get_thres(self):
# mem_relu = F.relu(self.mem.detach())
# return mem_relu[mem_relu > 0.].median()
def n_reset(self):
super().n_reset()
self.saved_mem = 0.
================================================
FILE: braincog/base/strategy/LateralInhibition.py
================================================
import warnings
import torch
from torch import nn
import torch.nn.functional as F
class LateralInhibition(nn.Module):
"""
侧抑制 用于发放脉冲的神经元抑制其他同层神经元 在膜电位上作用
"""
def __init__(self, node, inh, mode="constant"):
super().__init__()
self.inh = inh
self.node = node
self.mode = mode
def forward(self, x: torch.Tensor, xori=None):
# x.shape = [N, C,W,H]
# ret.shape = [N, C,W,H]
if self.mode == "constant":
self.node.mem = self.node.mem - self.inh * (x.max(1, True)[0] - x)
elif self.mode == "max":
self.node.mem = self.node.mem - self.inh * xori.max(1, True)[0] .detach() * (x.max(1, True)[0] - x)
elif self.mode == "threshold":
self.node.mem = self.node.mem - self.inh * self.node.threshold * (x.max(1, True)[0] - x)
else:
pass
return x
================================================
FILE: braincog/base/strategy/__init__.py
================================================
__all__ = ['surrogate', 'LateralInhibition']
from . import (
surrogate,
LateralInhibition
)
================================================
FILE: braincog/base/strategy/surrogate.py
================================================
import math
import torch
from torch import nn
from torch.nn import functional as F
def heaviside(x):
return (x >= 0.).to(x.dtype)
class SurrogateFunctionBase(nn.Module):
"""
Surrogate Function 的基类
:param alpha: 为一些能够调控函数形状的代理函数提供参数.
:param requires_grad: 参数 ``alpha`` 是否需要计算梯度, 默认为 ``False``
"""
def __init__(self, alpha, requires_grad=True):
super().__init__()
self.alpha = nn.Parameter(
torch.tensor(alpha, dtype=torch.float),
requires_grad=requires_grad)
@staticmethod
def act_fun(x, alpha):
"""
:param x: 膜电位的输入
:param alpha: 控制代理梯度形状的变量, 可以为 ``NoneType``
:return: 激发之后的spike, 取值为 ``[0, 1]``
"""
raise NotImplementedError
def forward(self, x):
"""
:param x: 膜电位输入
:return: 激发之后的spike
"""
return self.act_fun(x, self.alpha)
'''
sigmoid surrogate function.
'''
class sigmoid(torch.autograd.Function):
"""
使用 sigmoid 作为代理梯度函数
对应的原函数为:
.. math::
g(x) = \\mathrm{sigmoid}(\\alpha x) = \\frac{1}{1+e^{-\\alpha x}}
反向传播的函数为:
.. math::
g'(x) = \\alpha * (1 - \\mathrm{sigmoid} (\\alpha x)) \\mathrm{sigmoid} (\\alpha x)
"""
@staticmethod
def forward(ctx, x, alpha):
if x.requires_grad:
ctx.save_for_backward(x)
ctx.alpha = alpha
return heaviside(x)
@staticmethod
def backward(ctx, grad_output):
grad_x = None
if ctx.needs_input_grad[0]:
s_x = torch.sigmoid(ctx.alpha * ctx.saved_tensors[0])
grad_x = grad_output * s_x * (1 - s_x) * ctx.alpha
return grad_x, None
class SigmoidGrad(SurrogateFunctionBase):
def __init__(self, alpha=1., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return sigmoid.apply(x, alpha)
'''
atan surrogate function.
'''
class atan(torch.autograd.Function):
"""
使用 Atan 作为代理梯度函数
对应的原函数为:
.. math::
g(x) = \\frac{1}{\\pi} \\arctan(\\frac{\\pi}{2}\\alpha x) + \\frac{1}{2}
反向传播的函数为:
.. math::
g'(x) = \\frac{\\alpha}{2(1 + (\\frac{\\pi}{2}\\alpha x)^2)}
"""
@staticmethod
def forward(ctx, inputs, alpha):
ctx.save_for_backward(inputs, alpha)
return inputs.gt(0.).float()
@staticmethod
def backward(ctx, grad_output):
grad_x = None
grad_alpha = None
shared_c = grad_output / \
(1 + (ctx.saved_tensors[1] * math.pi /
2 * ctx.saved_tensors[0]).square())
if ctx.needs_input_grad[0]:
grad_x = ctx.saved_tensors[1] / 2 * shared_c
if ctx.needs_input_grad[1]:
grad_alpha = (ctx.saved_tensors[0] / 2 * shared_c).sum()
return grad_x, grad_alpha
class AtanGrad(SurrogateFunctionBase):
def __init__(self, alpha=2., requires_grad=True):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return atan.apply(x, alpha)
'''
gate surrogate fucntion.
'''
class gate(torch.autograd.Function):
"""
使用 gate 作为代理梯度函数
对应的原函数为:
.. math::
g(x) = \\mathrm{NonzeroSign}(x) \\log (|\\alpha x| + 1)
反向传播的函数为:
.. math::
g'(x) = \\frac{\\alpha}{1 + |\\alpha x|} = \\frac{1}{\\frac{1}{\\alpha} + |x|}
"""
@staticmethod
def forward(ctx, x, alpha):
if x.requires_grad:
grad_x = torch.where(x.abs() < 1. / alpha, torch.ones_like(x), torch.zeros_like(x))
ctx.save_for_backward(grad_x)
return x.gt(0).float()
@staticmethod
def backward(ctx, grad_output):
grad_x = None
if ctx.needs_input_grad[0]:
grad_x = grad_output * ctx.saved_tensors[0]
return grad_x, None
class GateGrad(SurrogateFunctionBase):
def __init__(self, alpha=2., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return gate.apply(x, alpha)
'''
gatquadratic_gate surrogate function.
'''
class quadratic_gate(torch.autograd.Function):
"""
使用 quadratic_gate 作为代理梯度函数
对应的原函数为:
.. math::
g(x) =
\\begin{cases}
0, & x < -\\frac{1}{\\alpha} \\\\
-\\frac{1}{2}\\alpha^2|x|x + \\alpha x + \\frac{1}{2}, & |x| \\leq \\frac{1}{\\alpha} \\\\
1, & x > \\frac{1}{\\alpha} \\\\
\\end{cases}
反向传播的函数为:
.. math::
g'(x) =
\\begin{cases}
0, & |x| > \\frac{1}{\\alpha} \\\\
-\\alpha^2|x|+\\alpha, & |x| \\leq \\frac{1}{\\alpha}
\\end{cases}
"""
@staticmethod
def forward(ctx, x, alpha):
if x.requires_grad:
mask_zero = (x.abs() > 1 / alpha)
grad_x = -alpha * alpha * x.abs() + alpha
grad_x.masked_fill_(mask_zero, 0)
ctx.save_for_backward(grad_x)
return x.gt(0.).float()
@staticmethod
def backward(ctx, grad_output):
grad_x = None
if ctx.needs_input_grad[0]:
grad_x = grad_output * ctx.saved_tensors[0]
return grad_x, None
class QGateGrad(SurrogateFunctionBase):
def __init__(self, alpha=2., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return quadratic_gate.apply(x, alpha)
class relu_like(torch.autograd.Function):
@staticmethod
def forward(ctx, x, alpha):
if x.requires_grad:
ctx.save_for_backward(x, alpha)
return heaviside(x)
@staticmethod
def backward(ctx, grad_output):
grad_x, grad_alpha = None, None
x, alpha = ctx.saved_tensors
if ctx.needs_input_grad[0]:
grad_x = grad_output * x.gt(0.).float() * alpha
if ctx.needs_input_grad[1]:
grad_alpha = (grad_output * F.relu(x)).sum()
return grad_x, grad_alpha
class RoundGrad(nn.Module):
def __init__(self, **kwargs):
super(RoundGrad, self).__init__()
self.act = nn.Hardtanh(-.5, 4.5)
def forward(self, x):
x = self.act(x)
return x.ceil() + x - x.detach()
class ReLUGrad(SurrogateFunctionBase):
"""
使用ReLU作为代替梯度函数, 主要用为相同结构的ANN的测试
"""
def __init__(self, alpha=2., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return relu_like.apply(x, alpha)
'''
Straight-Through (ST) Estimator
'''
class straight_through_estimator(torch.autograd.Function):
"""
使用直通估计器作为代理梯度函数
http://arxiv.org/abs/1308.3432
"""
@staticmethod
def forward(ctx, inputs):
outputs = heaviside(inputs)
ctx.save_for_backward(outputs)
return outputs
@staticmethod
def backward(ctx, grad_output):
grad_x = None
if ctx.needs_input_grad[0]:
grad_x = grad_output
return grad_x
class stdp(torch.autograd.Function):
@staticmethod
def forward(ctx, inputs):
outputs = inputs.gt(0.).float()
ctx.save_for_backward(outputs)
return outputs
@staticmethod
def backward(ctx, grad_output):
inputs, = ctx.saved_tensors
return inputs * grad_output
class STDPGrad(SurrogateFunctionBase):
def __init__(self, alpha=2., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return stdp.apply(x)
class backeigate(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
return input.gt(0.).float()
@staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
grad_input = grad_output.clone()
temp = abs(input) < 0.5
return grad_input * temp.float()
class BackEIGateGrad(SurrogateFunctionBase):
def __init__(self, alpha=2., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return backeigate.apply(x)
class ei(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
return torch.sign(input).float()
@staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
grad_input = grad_output.clone()
temp = abs(input) < 0.5
return grad_input * temp.float()
class EIGrad(SurrogateFunctionBase):
def __init__(self, alpha=2., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return ei.apply(x)
================================================
FILE: braincog/base/utils/__init__.py
================================================
from .criterions import UnilateralMse, MixLoss
from .visualization import plot_tsne, plot_tsne_3d, plot_confusion_matrix
from torch.autograd import Variable
import torch
__all__ = [
'UnilateralMse', 'MixLoss',
'plot_tsne', 'plot_tsne_3d', 'plot_confusion_matrix', 'drop_path'
]
def drop_path(x, drop_prob):
if drop_prob > 0.:
keep_prob = 1. - drop_prob
mask = Variable(torch.cuda.FloatTensor(
x.size(0), 1, 1, 1).bernoulli_(keep_prob))
x.div_(keep_prob)
x.mul_(mask)
return x
================================================
FILE: braincog/base/utils/criterions.py
================================================
import numpy as np
import torch
import torch.nn.functional as F
class UnilateralMse(torch.nn.Module):
"""
扩展单边的MSE损失, 用于控制输出层的期望fire-rate 高于 thresh
:param thresh: 输出层的期望输出频率
"""
def __init__(self, thresh=1.):
super(UnilateralMse, self).__init__()
self.thresh = thresh
self.loss = torch.nn.MSELoss()
def forward(self, x, target):
# x = nn.functional.softmax(x, dim=1)
torch.clip(x, max=self.thresh)
if x.shape == target.shape:
return self.loss(x, target)
return self.loss(x, torch.zeros_like(x).scatter_(1, target.view(-1, 1), self.thresh))
class MixLoss(torch.nn.Module):
"""
混合损失函数, 可以将任意的损失函数与UnilateralMse损失混合
:param ce_loss: 任意的损失函数
"""
def __init__(self, ce_loss):
super(MixLoss, self).__init__()
self.ce = ce_loss
self.mse = UnilateralMse(1.)
def forward(self, x, target):
return 0.1 * self.ce(x, target) + self.mse(x, target)
class TetLoss(torch.nn.Module):
def __init__(self, loss_fn):
super(TetLoss, self).__init__()
self.loss_fn = loss_fn
def forward(self, x, target):
loss = 0.
for logit in x:
loss += self.loss_fn(logit, target)
return loss / x.shape[0]
class OnehotMse(torch.nn.Module):
"""
将类别转换为onehot进行mse损失计算, 用于带vote的SNN中
"""
def __init__(self, num_class):
super(OnehotMse, self).__init__()
self.num_class = num_class
self.loss_fn = torch.nn.MSELoss()
def forward(self, x, target):
target = F.one_hot(target.to(torch.int64), self.num_class).float()
loss = self.loss_fn(x, target)
return loss
================================================
FILE: braincog/base/utils/visualization.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/7/1 11:10
# User : Floyed
# Product : PyCharm
# Project : braincog
# File : visualization.py
# explain : add t-SNE
import os
import numpy as np
import sklearn
from sklearn.manifold import TSNE
from sklearn.metrics import confusion_matrix
import torch
import torch.nn.functional as F
from einops import rearrange
import matplotlib.pyplot as plt
import matplotlib.patheffects as PathEffects
import matplotlib
from mpl_toolkits.mplot3d import Axes3D
from mpl_toolkits.mplot3d import proj3d
import seaborn as sns
# Random state.
RS = 20150101
def spike_rate_vis_1d(data, output_dir=''):
assert len(data.shape) == 2, 'Shape should be (t, c).'
data = rearrange(data, 'i j -> j i')
if isinstance(data, torch.Tensor):
data = data.to('cpu').numpy()
plt.figure(figsize=(8, 8))
sns.heatmap(data, annot=None, cmap='YlGnBu')
# plt.ylim(0, _max + 1)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
def spike_rate_vis(data, output_dir=''):
assert len(data.shape) == 3, 'Shape should be (t, r, c).'
data = data.mean(axis=0)
if isinstance(data, torch.Tensor):
data = data.to('cpu').numpy()
plt.figure(figsize=(8, 8))
sns.heatmap(data, annot=None, cmap='YlGnBu')
# plt.ylim(0, _max + 1)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
def plot_mem_distribution(data,
output_dir='',
legend='',
xlabel='Membrane Potential',
ylabel='Density',
**kwargs):
# print(type(data), len(data))
if isinstance(data, torch.Tensor):
data = data.reshape(-1).to('cpu').numpy()
mean = data.mean()
std = data.std()
idx = np.argwhere(data < mean - 3 * std)
data = np.delete(data, idx)
idx = np.argwhere(data > mean + 3 * std)
data = np.delete(data, idx)
sns.set_style('darkgrid')
# sns.set_palette('deep', desat=.6)
sns.set_context("notebook", font_scale=1.5,
rc={"lines.linewidth": 2.5})
# fig = plt.figure(figsize=(8, 8))
# ax = fig.add_subplot(111, aspect='equal')
# sns.distplot(data, bins=int(np.sqrt(data.shape[0])),
# hist=True, kde=False, hist_kws={'histtype': 'stepfilled'}, **kwargs)
# print('hist begin')
print(len(data))
n, bins, patches = plt.hist(data,
density=True,
histtype='stepfilled',
alpha=0.618,
bins=int(np.sqrt(data.shape[0])),
**kwargs)
# print('hist finished')
# sns.kdeplot(data, color='#5294c3')
# print('kde finished')
plt.xlabel(xlabel)
plt.ylabel(ylabel)
# if legend != '':
# plt.legend(legend)
# ax.axis('tight')
if output_dir != '':
plt.savefig(output_dir, bbox_inches='tight')
print('{} saved'.format(output_dir))
# plt.show()
def plot_tsne(x, colors,output_dir="", num_classes=None):
if isinstance(x, torch.Tensor):
x = x.to('cpu').numpy()
if isinstance(colors, torch.Tensor):
colors = colors.to('cpu').numpy()
if num_classes is None:
num_classes=colors.max()+1
x = TSNE(random_state=RS, n_components=2).fit_transform(x)
sns.set_style('darkgrid')
sns.set_palette('muted')
sns.set_context("notebook", font_scale=1.5,
rc={"lines.linewidth": 2.5})
palette = np.array(sns.color_palette("hls", num_classes))
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, aspect='equal')
sc = ax.scatter(x[:, 0], x[:, 1], lw=0, s=25,
c=palette[colors.astype(np.int)])
# plt.xlim(-25, 25)
# plt.ylim(-25, 25)
# ax.axis('off')
ax.axis('tight')
# plt.grid('off')
plt.savefig(output_dir, facecolor=fig.get_facecolor(), bbox_inches='tight')
#plt.show()
def plot_tsne_3d(x, colors,output_dir="", num_classes=None):
"""
绘制3D t-SNE聚类图, 直接将图片保存到输出路径
:param x: 输入的feature map / spike
:param colors: predicted labels 作为不同类别的颜色
:param output_dir: 图片输出的路径(包括图片名及后缀)
:return: None
"""
if isinstance(x, torch.Tensor):
x = x.to('cpu').numpy()
if isinstance(colors, torch.Tensor):
colors = colors.to('cpu').numpy()
if num_classes is None:
num_classes=colors.max()+1
x = TSNE(random_state=RS, n_components=3, perplexity=30).fit_transform(x)
# sns.set_style('darkgrid')
sns.set_palette('muted')
sns.set_context("notebook", font_scale=1.5,
rc={"lines.linewidth": 2.5})
fig = plt.figure(figsize=(8, 8))
palette = np.array(sns.color_palette("hls", num_classes))
ax = fig.add_subplot(111, projection='3d')
sc = ax.scatter(x[:, 0], x[:, 1], x[:, 2], lw=0, s=20, alpha=0.8,
c=palette[colors.astype(np.int)])
# ax.set_xlabel('X')
# ax.set_ylabel('Y')
# ax.set_zlabel('Z')
# ax.view_init(20, -120)
ax.axis('tight')
plt.savefig(output_dir, facecolor=fig.get_facecolor(), bbox_inches='tight')
#plt.show()
def plot_confusion_matrix(logits, labels, output_dir):
"""
绘制混淆矩阵图
:param logits: predicted labels
:param labels: true labels
:param output_dir: 输出路径, 需要包括文件名以及后缀
:return: None
"""
sns.set_style('darkgrid')
sns.set_palette('Blues_r')
sns.set_context("notebook", font_scale=1.,
rc={"lines.linewidth": 2.})
logits = logits.argmax(dim=1).cpu()
labels = labels.cpu()
_max = labels.max()
if _max > 10:
annot = False
else:
annot = True
# print(labels.shape, logits.shape)
conf_matrix = confusion_matrix(labels, logits)
con_mat_norm = conf_matrix.astype('float') / conf_matrix.sum(axis=1)[:, np.newaxis] # 归一化
con_mat_norm = np.around(con_mat_norm, decimals=2)
plt.figure(figsize=(8, 8))
sns.heatmap(con_mat_norm, annot=annot, cmap='Blues')
plt.ylim(0, _max + 1)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.savefig(output_dir, bbox_inches='tight')
#plt.show()
if __name__ == '__main__':
# Test for T-SNE
# x = torch.randn((100, 100))
# y = torch.randint(low=0, high=10, size=[100])
# plot_tsne_3d(x, y, output_dir='./t-sne.eps')
# Test for confusion matrix
# x = torch.rand(5012, 100)
# y = torch.randint(0, 100, (5012,))
# plot_confusion_matrix(x, y, '')
# Test for Mem Distribution
x = torch.randn(100000)
plot_mem_distribution(x, legend=['test'])
================================================
FILE: braincog/datasets/CUB2002011.py
================================================
import os
import pandas as pd
from torchvision.datasets import VisionDataset
from torchvision.datasets.folder import default_loader
from torchvision.datasets.utils import download_file_from_google_drive
class CUB2002011(VisionDataset):
"""`CUB-200-2011 `_ Dataset.
Args:
root (string): Root directory of the dataset.
train (bool, optional): If True, creates dataset from training set, otherwise
creates from test set.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
download (bool, optional): If true, downloads the dataset from the internet and
puts it in root directory. If dataset is already downloaded, it is not
downloaded again.
"""
base_folder = 'CUB_200_2011/images'
# url = 'http://www.vision.caltech.edu/visipedia-data/CUB-200-2011/CUB_200_2011.tgz'
file_id = '1hbzc_P1FuxMkcabkgn9ZKinBwW683j45'
filename = 'CUB_200_2011.tgz'
tgz_md5 = '97eceeb196236b17998738112f37df78'
def __init__(self, root, train=True, transform=None, target_transform=None, download=False):
super(CUB2002011, self).__init__(root, transform=transform, target_transform=target_transform)
self.loader = default_loader
self.train = train
if download:
self._download()
if not self._check_integrity():
raise RuntimeError('Dataset not found or corrupted. You can use download=True to download it')
def _load_metadata(self):
images = pd.read_csv(os.path.join(self.root, 'CUB_200_2011', 'images.txt'), sep=' ',
names=['img_id', 'filepath'])
image_class_labels = pd.read_csv(os.path.join(self.root, 'CUB_200_2011', 'image_class_labels.txt'),
sep=' ', names=['img_id', 'target'])
train_test_split = pd.read_csv(os.path.join(self.root, 'CUB_200_2011', 'train_test_split.txt'),
sep=' ', names=['img_id', 'is_training_img'])
data = images.merge(image_class_labels, on='img_id')
self.data = data.merge(train_test_split, on='img_id')
class_names = pd.read_csv(os.path.join(self.root, 'CUB_200_2011', 'classes.txt'),
sep=' ', names=['class_name'], usecols=[1])
self.class_names = class_names['class_name'].to_list()
if self.train:
self.data = self.data[self.data.is_training_img == 1]
else:
self.data = self.data[self.data.is_training_img == 0]
def _check_integrity(self):
try:
self._load_metadata()
except Exception:
return False
for index, row in self.data.iterrows():
filepath = os.path.join(self.root, self.base_folder, row.filepath)
if not os.path.isfile(filepath):
print(filepath)
return False
return True
def _download(self):
import tarfile
if self._check_integrity():
print('Files already downloaded and verified')
return
download_file_from_google_drive(self.file_id, self.root, self.filename, self.tgz_md5)
with tarfile.open(os.path.join(self.root, self.filename), "r:gz") as tar:
tar.extractall(path=self.root)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
sample = self.data.iloc[idx]
path = os.path.join(self.root, self.base_folder, sample.filepath)
target = sample.target - 1 # Targets start at 1 by default, so shift to 0
img = self.loader(path)
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
if __name__ == '__main__':
train_dataset = CUB2002011('./cub2011', train=True, download=False)
test_dataset = CUB2002011('./cub2011', train=False, download=False)
================================================
FILE: braincog/datasets/ESimagenet/ES_imagenet.py
================================================
# -*- coding: utf-8 -*-
# Time : 2022/11/1 11:06
# Author : Regulus
# FileName: ES_imagenet.py
# Explain:
# Software: PyCharm
import numpy as np
import torch
import linecache
import torch.utils.data as data
class ESImagenet_Dataset(data.Dataset):
def __init__(self, mode, data_set_path='/data/dvsimagenet/', transform=None):
super().__init__()
self.mode = mode
self.filenames = []
self.trainpath = data_set_path + 'train'
self.testpath = data_set_path + 'val'
self.traininfotxt = data_set_path + 'trainlabel.txt'
self.testinfotxt = data_set_path + 'vallabel.txt'
self.formats = '.npz'
self.transform = transform
if mode == 'train':
self.path = self.trainpath
trainfile = open(self.traininfotxt, 'r')
for line in trainfile:
filename, classnum, a, b = line.split()
realname, sub = filename.split('.')
self.filenames.append(realname + self.formats)
else:
self.path = self.testpath
testfile = open(self.testinfotxt, 'r')
for line in testfile:
filename, classnum, a, b = line.split()
realname, sub = filename.split('.')
self.filenames.append(realname + self.formats)
def __getitem__(self, index):
if self.mode == 'train':
info = linecache.getline(self.traininfotxt, index + 1)
else:
info = linecache.getline(self.testinfotxt, index + 1)
filename, classnum, a, b = info.split()
realname, sub = filename.split('.')
filename = realname + self.formats
filename = self.path + r'/' + filename
classnum = int(classnum)
a = int(a)
b = int(b)
datapos = np.load(filename)['pos'].astype(np.float64)
dataneg = np.load(filename)['neg'].astype(np.float64)
dy = (254 - b) // 2
dx = (254 - a) // 2
input = torch.zeros([2, 8, 256, 256])
x = datapos[:, 0] + dx
y = datapos[:, 1] + dy
t = datapos[:, 2] - 1
input[0, t, x, y] = 1
x = dataneg[:, 0] + dx
y = dataneg[:, 1] + dy
t = dataneg[:, 2] - 1
input[1, t, x, y] = 1
reshape = input[:, :, 16:240, 16:240].permute(0, 1, 2, 3).contiguous()
if self.transform is not None:
reshape = self.transform(reshape)
label = torch.tensor([classnum])
return reshape, label
def __len__(self):
return len(self.filenames)
================================================
FILE: braincog/datasets/ESimagenet/__init__.py
================================================
# -*- coding: utf-8 -*-
# Time : 2022/11/1 11:05
# Author : Regulus
# FileName: __init__.py.py
# Explain:
# Software: PyCharm
"""
from: https://github.com/lyh983012/ES-imagenet-master
"""
__all__ = ['ES_imagenet', 'reconstructed_ES_imagenet']
from . import (
ES_imagenet,
reconstructed_ES_imagenet
)
================================================
FILE: braincog/datasets/ESimagenet/reconstructed_ES_imagenet.py
================================================
# -*- coding: utf-8 -*-
# Time : 2022/11/1 11:06
# Author : Regulus
# FileName: reconstructed_ES_imagenet.py
# Explain:
# Software: PyCharm
import numpy as np
import torch
import linecache
import torch.utils.data as data
from tqdm import tqdm
class ESImagenet2D_Dataset(data.Dataset):
def __init__(self, mode, data_set_path='/data/ESimagenet-0.18/', transform=None):
super().__init__()
self.mode = mode
self.filenames = []
self.trainpath = data_set_path + 'train'
self.testpath = data_set_path + 'val'
self.traininfotxt = data_set_path + 'trainlabel.txt'
self.testinfotxt = data_set_path + 'vallabel.txt'
self.formats = '.npz'
self.transform = transform
if mode == 'train':
self.path = self.trainpath
trainfile = open(self.traininfotxt, 'r')
for line in trainfile:
filename, classnum, a, b = line.split()
realname, sub = filename.split('.')
self.filenames.append(realname + self.formats)
trainfile = open(self.traininfotxt, 'r')
self.infolist = trainfile.readlines()
else:
self.path = self.testpath
testfile = open(self.testinfotxt, 'r')
for line in testfile:
filename, classnum, a, b = line.split()
realname, sub = filename.split('.')
self.filenames.append(realname + self.formats)
testfile = open(self.testinfotxt, 'r')
self.infolist = testfile.readlines()
def __getitem__(self, index):
info = self.infolist[index]
filename, classnum, a, b = info.split()
realname, sub = filename.split('.')
filename = realname + self.formats
filename = self.path + r'/' + filename
classnum = int(classnum)
a = int(a)
b = int(b)
with open(filename, "rb") as f:
data = np.load(f)
datapos = data['pos'].astype(np.float64)
dataneg = data['neg'].astype(np.float64)
tracex = [0, 2, 1, 0, 2, 1, 1, 2]
tracey = [2, 1, 0, 1, 2, 0, 1, 1]
dy = (254 - b) // 2
dx = (254 - a) // 2
input = torch.zeros([2, 8, 256, 256])
x = datapos[:, 0] + dx
y = datapos[:, 1] + dy
t = datapos[:, 2] - 1
input[0, t, x, y] += 1
x = dataneg[:, 0] + dx
y = dataneg[:, 1] + dy
t = dataneg[:, 2] - 1
input[1, t, x, y] += 1
sum_gary_data = torch.zeros([1, 1, 256, 256])
reshape = input[:, :, 16:240, 16:240]
H = 224
W = 224
for t in range(8):
dx = tracex[t]
dy = tracey[t]
sum_gary_data[0, 0, 2 - dx:2 - dx + H, 2 - dy:2 - dy + W] += reshape[0, t, :, :]
sum_gary_data[0, 0, 2 - dx:2 - dx + H, 2 - dy:2 - dy + W] -= reshape[1, t, :, :]
sum_gary_data = sum_gary_data[:, :, 1:225, 1:225]
# if self.transform is not None:
# sum_gary_data = self.transform(sum_gary_data)
label = classnum
return sum_gary_data, label
def __len__(self):
return len(self.filenames)
================================================
FILE: braincog/datasets/NOmniglot/NOmniglot.py
================================================
from torch.utils.data import Dataset
from braincog.datasets.NOmniglot.utils import *
class NOmniglot(Dataset):
def __init__(self, root='data/', frames_num=12, train=True, data_type='event',
transform=None, target_transform=None, use_npz=False, crop=True, create=True, thread_num=16):
super().__init__()
self.crop = crop
self.data_type = data_type
self.use_npz = use_npz
self.transform = transform
self.target_transform = target_transform
events_npy_root = os.path.join(root, 'events_npy', 'background' if train else "evaluation")
frames_root = os.path.join(root, f'fnum_{frames_num}_dtype_{data_type}_npz_{use_npz}',
'background' if train else "evaluation")
if not os.path.exists(frames_root) and create:
if not os.path.exists(events_npy_root) and create:
os.makedirs(events_npy_root)
print('creating event data..')
convert_aedat4_dir_to_events_dir(root, train)
else:
print(f'npy format events data root {events_npy_root}, already exists')
os.makedirs(frames_root)
print('creating frames data..')
convert_events_dir_to_frames_dir(events_npy_root, frames_root, '.npy', frames_num, data_type,
thread_num=thread_num, compress=use_npz)
else:
print(f'frames data root {frames_root} already exists.')
self.datadict, self.num_classes = list_class_files(events_npy_root, frames_root, True, use_npz=use_npz)
self.datalist = []
for i in self.datadict:
self.datalist.extend([(j, i) for j in self.datadict[i]])
def __len__(self):
return len(self.datalist)
def __getitem__(self, index):
image, label = self.datalist[index]
image, label = self.readimage(image, label)
return image, label
def readimage(self, image, label):
if self.use_npz:
image = torch.tensor(np.load(image)['arr_0']).float()
else:
image = torch.tensor(np.load(image)).float()
if self.crop:
image = image[:, :, 4:254, 54:304]
if self.transform is not None: image = self.transform(image)
if self.target_transform is not None: label = self.target_transform(label)
return image, label
================================================
FILE: braincog/datasets/NOmniglot/__init__.py
================================================
__all__ = ['NOmniglot', 'nomniglot_full', 'nomniglot_nw_ks','nomniglot_pair','utils']
from . import (
NOmniglot,
nomniglot_full,
nomniglot_nw_ks,
nomniglot_pair,
utils
)
================================================
FILE: braincog/datasets/NOmniglot/nomniglot_full.py
================================================
import torch
from torch.utils.data import Dataset, DataLoader
from braincog.datasets.NOmniglot.NOmniglot import NOmniglot
class NOmniglotfull(Dataset):
'''
solve few-shot learning as general classification problem,
We combine the original training set with the test set and take 3/4 as the training set
'''
def __init__(self, root='data/', train=True, frames_num=4, data_type='event',
transform=None, target_transform=None, use_npz=False, crop=True, create=True):
super().__init__()
trainSet = NOmniglot(root=root, train=True, frames_num=frames_num, data_type=data_type,
transform=transform, target_transform=target_transform,
use_npz=use_npz, crop=crop, create=create)
testSet = NOmniglot(root=root, train=False, frames_num=frames_num, data_type=data_type,
transform=transform, target_transform=lambda x: x + 964,
use_npz=use_npz, crop=crop, create=create)
self.data = torch.utils.data.ConcatDataset([trainSet, testSet])
if train:
self.id = [j for j in range(len(self.data)) if j % 20 in [i for i in range(15)]]
else:
self.id = [j for j in range(len(self.data)) if j % 20 in [i for i in range(15, 20)]]
def __len__(self):
return len(self.id)
def __getitem__(self, index):
image, label = self.data[self.id[index]]
return image, label
if __name__ == '__main__':
db_train = NOmniglotfull('../../data/', train=True, frames_num=4, data_type='event')
dataloadertrain = DataLoader(db_train, batch_size=16, shuffle=True, num_workers=16, pin_memory=True)
for x_spt, y_spt, x_qry, y_qry in dataloadertrain:
print(x_spt.shape)
================================================
FILE: braincog/datasets/NOmniglot/nomniglot_nw_ks.py
================================================
import torch
import torchvision
import numpy as np
from torch.utils.data import Dataset, DataLoader
from braincog.datasets.NOmniglot.NOmniglot import NOmniglot
class NOmniglotNWayKShot(Dataset):
'''
get n-wway k-shot data as meta learning
We set the sampling times of each epoch as "len(self.dataSet) // (self.n_way * (self.k_shot + self.k_query))"
you can increase or decrease the number of epochs to determine the total training times
'''
def __init__(self, root, n_way, k_shot, k_query, train=True, frames_num=12, data_type='event',
transform=torchvision.transforms.Resize((28, 28))):
self.dataSet = NOmniglot(root=root, train=train,
frames_num=frames_num, data_type=data_type, transform=transform)
self.n_way = n_way # n way
self.k_shot = k_shot # k shot
self.k_query = k_query # k query
assert (k_shot + k_query) <= 20
self.length = 256
self.data_cache = self.load_data_cache(self.dataSet.datadict, self.length)
def load_data_cache(self, data_dict, length):
'''
The dataset is sampled randomly length times, and the address is saved to obtain
'''
data_cache = []
for i in range(length):
selected_cls = np.random.choice(len(data_dict), self.n_way, False)
x_spts, y_spts, x_qrys, y_qrys = [], [], [], []
for j, cur_class in enumerate(selected_cls):
selected_img = np.random.choice(20, self.k_shot + self.k_query, False)
x_spts.append(np.array(data_dict[cur_class])[selected_img[:self.k_shot]])
x_qrys.append(np.array(data_dict[cur_class])[selected_img[self.k_shot:]])
y_spts.append([j for _ in range(self.k_shot)])
y_qrys.append([j for _ in range(self.k_query)])
shufflespt = np.random.choice(self.n_way * self.k_shot, self.n_way * self.k_shot, False)
shuffleqry = np.random.choice(self.n_way * self.k_query, self.n_way * self.k_query, False)
temp = [np.array(x_spts).reshape(-1)[shufflespt], np.array(y_spts).reshape(-1)[shufflespt],
np.array(x_qrys).reshape(-1)[shuffleqry], np.array(y_qrys).reshape(-1)[shuffleqry]]
data_cache.append(temp)
return data_cache
def __getitem__(self, index):
x_spts, y_spts, x_qrys, y_qrys = self.data_cache[index]
x_sptst, y_sptst, x_qryst, y_qryst = [], [], [], []
for i, j in zip(x_spts, y_spts):
i, j = self.dataSet.readimage(i, j)
x_sptst.append(i.unsqueeze(0))
y_sptst.append(j)
for i, j in zip(x_qrys, y_qrys):
i, j = self.dataSet.readimage(i, j)
x_qryst.append(i.unsqueeze(0))
y_qryst.append(j)
return torch.cat(x_sptst, dim=0), np.array(y_sptst), torch.cat(x_qryst, dim=0), np.array(y_qryst)
def reset(self):
self.data_cache = self.load_data_cache(self.dataSet.datadict, self.length)
def __len__(self):
return len(self.data_cache)
if __name__ == "__main__":
db_train = NOmniglotNWayKShot('./data/', n_way=5, k_shot=1, k_query=15,
frames_num=4, data_type='frequency', train=True)
dataloadertrain = DataLoader(db_train, batch_size=16, shuffle=True, num_workers=16, pin_memory=True)
for x_spt, y_spt, x_qry, y_qry in dataloadertrain:
print(x_spt.shape)
db_train.resampling()
================================================
FILE: braincog/datasets/NOmniglot/nomniglot_pair.py
================================================
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np
from numpy.random import choice as npc
import random
import torch.nn.functional as F
from braincog.datasets.NOmniglot import NOmniglot
class NOmniglotTrainSet(Dataset):
'''
Dataloader for Siamese Net
The pairs of similar samples are labeled as 1, and those of different samples are labeled as 0
'''
def __init__(self, root='data/', use_frame=True, frames_num=10, data_type='event', use_npz=False, resize=None):
super(NOmniglotTrainSet, self).__init__()
self.resize = resize
self.data_type = data_type
self.use_frame = use_frame
self.dataSet = NOmniglot(root=root, train=True, frames_num=frames_num, data_type=data_type, use_npz=use_npz)
self.datas, self.num_classes = self.dataSet.datadict, self.dataSet.num_classes
np.random.seed(0)
def __len__(self):
'''
Sampling upper limit, you can set the maximum sampling times when using to terminate
'''
return 21000000
def __getitem__(self, index):
# get image from same class
if index % 2 == 1:
label = 1.0
idx1 = random.randint(0, self.num_classes - 1)
image1 = random.choice(self.datas[idx1])
image2 = random.choice(self.datas[idx1])
# get image from different class
else:
label = 0.0
idx1 = random.randint(0, self.num_classes - 1)
idx2 = random.randint(0, self.num_classes - 1)
while idx1 == idx2:
idx2 = random.randint(0, self.num_classes - 1)
image1 = random.choice(self.datas[idx1])
image2 = random.choice(self.datas[idx2])
if self.use_frame:
if self.data_type == 'event':
image1 = torch.tensor(np.load(image1)['arr_0']).float()
image2 = torch.tensor(np.load(image2)['arr_0']).float()
elif self.data_type == 'frequency':
image1 = torch.tensor(np.load(image1)['arr_0']).float()
image2 = torch.tensor(np.load(image2)['arr_0']).float()
else:
raise NotImplementedError
if self.resize is not None:
image1 = image1[:, :, 4:254, 54:304]
image1 = F.interpolate(image1, size=(self.resize, self.resize))
image2 = image2[:, :, 4:254, 54:304]
image2 = F.interpolate(image2, size=(self.resize, self.resize))
return image1, image2, torch.from_numpy(np.array([label], dtype=np.float32))
class NOmniglotTestSet(Dataset):
'''
Dataloader for Siamese Net
'''
def __init__(self, root='data/', time=1000, way=20, shot=1, query=1, use_frame=True, frames_num=10, data_type='event', use_npz=True, resize=None):
super(NOmniglotTestSet, self).__init__()
self.resize = resize
self.use_frame = use_frame
self.time = time # Sampling times
self.way = way
self.shot = shot
self.query = query
self.img1 = None # Fix test sample while sampling support set
self.c1 = None # Fixed categories when sampling multiple samples
self.c2 = None
self.select_class = [] # selected classes
self.select_sample = [] # selected samples
self.data_type = data_type
np.random.seed(0)
self.dataSet = NOmniglot(root=root, train=False, frames_num=frames_num, data_type=data_type, use_npz=use_npz)
self.datas, self.num_classes = self.dataSet.datadict, self.dataSet.num_classes
def __len__(self):
'''
In general, the total number of test tasks is 1000.
Since one test sample is collected at a time, way * shot support samples are used for each test
'''
return self.time * self.way * self.shot
def __getitem__(self, index):
'''
The 0th sample of each way*shot is used for query and recorded in the selected sample
to achieve the effect of selecting K +1
'''
idx = index % (self.way * self.shot)
# generate image pair from same class
if idx == 0: #
self.select_class = []
self.c1 = random.randint(0, self.num_classes - 1)
self.c2 = self.c1
sind = random.randint(0, len(self.datas[self.c1]) - 1)
self.select_sample.append(sind)
self.img1 = self.datas[self.c1][sind]
sind = random.randint(0, len(self.datas[self.c2]) - 1)
while sind in self.select_sample:
sind = random.randint(0, len(self.datas[self.c2]) - 1)
img2 = self.datas[self.c1][sind]
self.select_sample.append(sind)
self.select_class.append(self.c1)
# generate image pair from different class
else:
if index % self.shot == 0:
self.c2 = random.randint(0, self.num_classes - 1)
while self.c2 in self.select_class: # self.c1 == c2:
self.c2 = random.randint(0, self.num_classes - 1)
self.select_class.append(self.c2)
self.select_sample = []
sind = random.randint(0, len(self.datas[self.c2]) - 1)
while sind in self.select_sample:
sind = random.randint(0, len(self.datas[self.c2]) - 1)
img2 = self.datas[self.c2][sind]
self.select_sample.append(sind)
if self.use_frame:
if self.data_type == 'event':
img1 = torch.tensor(np.load(self.img1)['arr_0']).float()
img2 = torch.tensor(np.load(img2)['arr_0']).float()
elif self.data_type == 'frequency':
img1 = torch.tensor(np.load(self.img1)['arr_0']).float()
img2 = torch.tensor(np.load(img2)['arr_0']).float()
else:
raise NotImplementedError
if self.resize is not None:
img1 = img1[:, :, 4:254, 54:304]
img1 = F.interpolate(img1, size=(self.resize, self.resize))
img2 = img2[:, :, 4:254, 54:304]
img2 = F.interpolate(img2, size=(self.resize, self.resize))
return img1, img2
if __name__ == '__main__':
data_type = 'frequency'
T = 4
trainSet = NOmniglotTrainSet(root='data/', use_frame=True, frames_num=T, data_type=data_type, use_npz=True, resize=105)
testSet = NOmniglotTestSet(root='data/', time=1000, way=5, shot=1, use_frame=True, frames_num=T,
data_type=data_type, use_npz=True, resize=105)
trainLoader = DataLoader(trainSet, batch_size=48, shuffle=False, num_workers=4)
testLoader = DataLoader(testSet, batch_size=5 * 1, shuffle=False, num_workers=4)
for batch_id, (img1, img2) in enumerate(testLoader, 1):
# img1.shape [batch, T, 2, H, W]
print(batch_id)
break
for batch_id, (img1, img2, label) in enumerate(trainLoader, 1):
# img1.shape [batch, T, 2, H, W]
print(batch_id)
break
================================================
FILE: braincog/datasets/NOmniglot/utils.py
================================================
import torch
import threading
import numpy as np
import pandas
import os
from dv import AedatFile
class FunctionThread(threading.Thread):
def __init__(self, f, *args, **kwargs):
super().__init__()
self.f = f
self.args = args
self.kwargs = kwargs
def run(self):
self.f(*self.args, **self.kwargs)
def integrate_events_to_frames(events, height, width, frames_num=10, data_type='event'):
frames = np.zeros(shape=[frames_num, 2, height * width])
# create j_{l}和j_{r}
j_l = np.zeros(shape=[frames_num], dtype=int)
j_r = np.zeros(shape=[frames_num], dtype=int)
# split by time
events['t'] -= events['t'][0] # start with 0 timestamp
assert events['t'][-1] > frames_num
dt = events['t'][-1] // frames_num # get length of each frame
idx = np.arange(events['t'].size)
for i in range(frames_num):
t_l = dt * i
t_r = t_l + dt
mask = np.logical_and(events['t'] >= t_l, events['t'] < t_r)
idx_masked = idx[mask]
if len(idx_masked) == 0:
j_l[i] = -1
j_r[i] = -1
else:
j_l[i] = idx_masked[0]
j_r[i] = idx_masked[-1] + 1 if i < frames_num - 1 else events['t'].size
for i in range(frames_num):
if j_l[i] >= 0:
x = events['x'][j_l[i]:j_r[i]]
y = events['y'][j_l[i]:j_r[i]]
p = events['p'][j_l[i]:j_r[i]]
mask = []
mask.append(p == 0)
mask.append(np.logical_not(mask[0]))
for j in range(2):
position = y[mask[j]] * width + x[mask[j]]
events_number_per_pos = np.bincount(position)
frames[i][j][np.arange(events_number_per_pos.size)] += events_number_per_pos
if data_type == 'frequency':
if i < frames_num - 1:
frames[i] /= dt
else:
frames[i] /= (dt + events['t'][-1] % frames_num)
frames = frames.astype(np.float16)
if data_type == 'event':
frames = (frames > 0).astype(np.bool)
else:
frames = normalize_frame(frames, 'max')
return frames.reshape((frames_num, 2, height, width))
def normalize_frame(frames: np.ndarray or torch.Tensor, normalization: str):
eps = 1e-5
for i in range(frames.shape[0]):
if normalization == 'max':
frames[i][0] = frames[i][0] / max(frames[i][0].max(), eps)
frames[i][1] = frames[i][1] / max(frames[i][1].max(), eps)
elif normalization == 'norm':
frames[i][0] = (frames[i][0] - frames[i][0].mean()) / np.sqrt(max(frames[i][0].var(), eps))
frames[i][1] = (frames[i][1] - frames[i][1].mean()) / np.sqrt(max(frames[i][1].var(), eps))
elif normalization == 'sum':
frames[i][0] = frames[i][0] / max(frames[i][0].sum(), eps)
frames[i][1] = frames[i][1] / max(frames[i][1].sum(), eps)
else:
raise NotImplementedError
return frames
def convert_events_dir_to_frames_dir(events_data_dir, frames_data_dir, suffix,
frames_num=12, result_type='event', thread_num=1,
compress=True):
"""
Iterate through all event data in eventS_date_DIR and generate frame data files in frames_data_DIR
"""
def read_function(file_name):
return np.load(file_name, allow_pickle=True).item()
def cvt_fun(events_file_list):
for events_file in events_file_list:
print(events_file)
frames = integrate_events_to_frames(read_function(events_file), 260, 346, frames_num, result_type )
if compress:
frames_file = os.path.join(frames_data_dir,
os.path.basename(events_file)[0: -suffix.__len__()] + '.npz')
np.savez_compressed(frames_file, frames)
else:
frames_file = os.path.join(frames_data_dir,
os.path.basename(events_file)[0: -suffix.__len__()] + '.npy')
np.save(frames_file, frames)
# Obtain the path of the all files
events_file_list = list_all_files(events_data_dir, '.npy')
if thread_num == 1:
cvt_fun(events_file_list)
else:
# Multithreading acceleration
thread_list = []
block = events_file_list.__len__() // thread_num
for i in range(thread_num - 1):
thread_list.append(FunctionThread(cvt_fun, events_file_list[i * block: (i + 1) * block]))
thread_list[-1].start()
print(f'thread {i} start, processing files index: {i * block} : {(i + 1) * block}.')
thread_list.append(FunctionThread(cvt_fun, events_file_list[(thread_num - 1) * block:]))
thread_list[-1].start()
print(
f'thread {thread_num} start, processing files index: {(thread_num - 1) * block} : {events_file_list.__len__()}.')
for i in range(thread_num):
thread_list[i].join()
print(f'thread {i} finished.')
def convert_aedat4_dir_to_events_dir(root, train):
kind = 'background' if train else "evaluation"
originroot = root
root = root + '/dvs_' + kind + '/'
alphabet_names = [a for a in os.listdir(root) if a[0] != '.'] # get folder names
for a in range(len(alphabet_names)):
alpha_name = alphabet_names[a]
for b in range(len(os.listdir(os.path.join(root, alpha_name)))):
character_id = b + 1
character_path = alpha_name + '/character' + num2str(character_id)
print('Parsing %s \\ character%s ...' % (alpha_name, num2str(character_id)))
file_path = os.path.join(root, character_path)
aedat4_name = [a for a in os.listdir(file_path) if a[-4:] == 'dat4' and len(a) == 11][0]
csv_name = [a for a in os.listdir(file_path) if a[-4:] == '.csv' and len(a) == 8][0]
number = csv_name[:4]
new_path = originroot + '/events_npy/' + kind + '/' + alpha_name + '/character' + num2str(character_id)
if not os.path.exists(new_path):
os.makedirs(new_path)
start_end_timestamp = pandas.read_csv(os.path.join(file_path, csv_name)).values
a_timestamp, a_polarity, a_x, a_y = [], [], [], []
with AedatFile(os.path.join(file_path, aedat4_name)) as f: # read aedat4
for e in f['events']:
a_timestamp.append(e.timestamp)
a_polarity.append(e.polarity)
a_x.append(e.x)
a_y.append(e.y)
for ii in range(20): # each file has 20 samples
name = str(number) + '_' + num2str(ii + 1) + '.npy'
start_index = a_timestamp.index(start_end_timestamp[ii][1])
end_index = a_timestamp.index(start_end_timestamp[ii][2])
tmp = {'t': np.array(a_timestamp[start_index:end_index]),
'x': np.array(a_x[start_index:end_index]),
'y': np.array(a_y[start_index:end_index]),
'p': np.array(a_polarity[start_index:end_index])}
np.save(os.path.join(new_path, name), tmp)
def num2str(idx):
if idx < 10:
return '0' + str(idx)
return str(idx)
def list_all_files(root, suffix, getlen=False):
'''
List the path of all files under root, output a list
'''
file_list = []
alphabet_names = [a for a in os.listdir(root) if a[0] != '.'] # get folder names
idx = 0
for a in range(len(alphabet_names)):
alpha_name = alphabet_names[a]
for b in range(len(os.listdir(os.path.join(root, alpha_name)))):
character_id = b + 1
character_path = os.path.join(root, alpha_name, 'character' + num2str(character_id))
idx += 1
for c in range(len(os.listdir(character_path))):
fn_example = os.listdir(character_path)[c]
if fn_example[-4:] == suffix:
file_list.append(os.path.join(character_path, fn_example))
if getlen:
return file_list, idx
else:
return file_list
def list_class_files(root, frames_kind_root, getlen=False, use_npz=False):
'''
index the generated samples,
get dictionaries according to categories, each corresponding to a list,
the list contain the address of the new file in fnum_x_dtype_x_npz_True
'''
file_list = {}
alphabet_names = [a for a in os.listdir(root) if a[0] != '.'] # get folder names
idx = 0
for a in range(len(alphabet_names)):
alpha_name = alphabet_names[a]
for b in range(len(os.listdir(os.path.join(root, alpha_name)))):
character_id = b + 1
character_path = os.path.join(root, alpha_name, 'character' + num2str(character_id))
file_list[idx] = []
for c in range(len(os.listdir(character_path))):
fn_example = os.listdir(character_path)[c]
if use_npz:
fn_example = fn_example[:-1] + 'z'
file_list[idx].append(os.path.join(frames_kind_root, fn_example))
idx += 1
if getlen:
return file_list, idx
else:
return file_list
================================================
FILE: braincog/datasets/StanfordDogs.py
================================================
import os
import scipy.io
from os.path import join
from torchvision.datasets import VisionDataset
from torchvision.datasets.folder import default_loader
from torchvision.datasets.utils import download_url, list_dir
class StanfordDogs(VisionDataset):
"""`Stanford Dogs `_ Dataset.
Args:
root (string): Root directory of the dataset.
train (bool, optional): If True, creates dataset from training set, otherwise
creates from test set.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
download (bool, optional): If true, downloads the dataset from the internet and
puts it in root directory. If dataset is already downloaded, it is not
downloaded again.
"""
download_url_prefix = 'http://vision.stanford.edu/aditya86/ImageNetDogs'
def __init__(self, root, train=True, transform=None, target_transform=None, download=False):
super(StanfordDogs, self).__init__(root, transform=transform, target_transform=target_transform)
self.loader = default_loader
self.train = train
if download:
self.download()
split = self.load_split()
self.images_folder = join(self.root, 'Images')
self.annotations_folder = join(self.root, 'Annotation')
self._breeds = list_dir(self.images_folder)
self._breed_images = [(annotation + '.jpg', idx) for annotation, idx in split]
self._flat_breed_images = self._breed_images
def __len__(self):
return len(self._flat_breed_images)
def __getitem__(self, index):
image_name, target = self._flat_breed_images[index]
image_path = join(self.images_folder, image_name)
image = self.loader(image_path)
if self.transform is not None:
image = self.transform(image)
if self.target_transform is not None:
target = self.target_transform(target)
return image, target
def download(self):
import tarfile
if os.path.exists(join(self.root, 'Images')) and os.path.exists(join(self.root, 'Annotation')):
if len(os.listdir(join(self.root, 'Images'))) == len(os.listdir(join(self.root, 'Annotation'))) == 120:
print('Files already downloaded and verified')
return
for filename in ['images', 'annotation', 'lists']:
tar_filename = filename + '.tar'
url = self.download_url_prefix + '/' + tar_filename
download_url(url, self.root, tar_filename, None)
print('Extracting downloaded file: ' + join(self.root, tar_filename))
with tarfile.open(join(self.root, tar_filename), 'r') as tar_file:
tar_file.extractall(self.root)
os.remove(join(self.root, tar_filename))
def load_split(self):
if self.train:
split = scipy.io.loadmat(join(self.root, 'train_list.mat'))['annotation_list']
labels = scipy.io.loadmat(join(self.root, 'train_list.mat'))['labels']
else:
split = scipy.io.loadmat(join(self.root, 'test_list.mat'))['annotation_list']
labels = scipy.io.loadmat(join(self.root, 'test_list.mat'))['labels']
split = [item[0][0] for item in split]
labels = [item[0] - 1 for item in labels]
return list(zip(split, labels))
def stats(self):
counts = {}
for index in range(len(self._flat_breed_images)):
image_name, target_class = self._flat_breed_images[index]
if target_class not in counts.keys():
counts[target_class] = 1
else:
counts[target_class] += 1
print("%d samples spanning %d classes (avg %f per class)" % (len(self._flat_breed_images), len(counts.keys()),
float(len(self._flat_breed_images)) / float(
len(counts.keys()))))
return counts
if __name__ == '__main__':
train_dataset = Dogs('./dogs', train=True, download=False)
test_dataset = Dogs('./dogs', train=False, download=False)
================================================
FILE: braincog/datasets/TinyImageNet.py
================================================
import os
import os
import pandas as pd
import warnings
from torchvision.datasets import ImageFolder
from torchvision.datasets import VisionDataset
from torchvision.datasets.folder import default_loader
from torchvision.datasets.folder import default_loader
from torchvision.datasets.utils import extract_archive, check_integrity, download_url, verify_str_arg
class TinyImageNet(VisionDataset):
"""`tiny-imageNet `_ Dataset.
Args:
root (string): Root directory of the dataset.
split (string, optional): The dataset split, supports ``train``, or ``val``.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
download (bool, optional): If true, downloads the dataset from the internet and
puts it in root directory. If dataset is already downloaded, it is not
downloaded again.
"""
base_folder = 'tiny-imagenet-200/'
url = 'http://cs231n.stanford.edu/tiny-imagenet-200.zip'
filename = 'tiny-imagenet-200.zip'
md5 = '90528d7ca1a48142e341f4ef8d21d0de'
def __init__(self, root, split='train', transform=None, target_transform=None, download=False):
super(TinyImageNet, self).__init__(root, transform=transform, target_transform=target_transform)
self.dataset_path = os.path.join(root, self.base_folder)
self.loader = default_loader
self.split = verify_str_arg(split, "split", ("train", "val",))
if self._check_integrity():
print('Files already downloaded and verified.')
elif download:
self._download()
else:
raise RuntimeError(
'Dataset not found. You can use download=True to download it.')
if not os.path.isdir(self.dataset_path):
print('Extracting...')
extract_archive(os.path.join(root, self.filename))
_, class_to_idx = find_classes(os.path.join(self.dataset_path, 'wnids.txt'))
self.data = make_dataset(self.root, self.base_folder, self.split, class_to_idx)
def _download(self):
print('Downloading...')
download_url(self.url, root=self.root, filename=self.filename)
print('Extracting...')
extract_archive(os.path.join(self.root, self.filename))
def _check_integrity(self):
return check_integrity(os.path.join(self.root, self.filename), self.md5)
def __getitem__(self, index):
img_path, target = self.data[index]
image = self.loader(img_path)
if self.transform is not None:
image = self.transform(image)
if self.target_transform is not None:
target = self.target_transform(target)
return image, target
def __len__(self):
return len(self.data)
def find_classes(class_file):
with open(class_file) as r:
classes = list(map(lambda s: s.strip(), r.readlines()))
classes.sort()
class_to_idx = {classes[i]: i for i in range(len(classes))}
return classes, class_to_idx
def make_dataset(root, base_folder, dirname, class_to_idx):
images = []
dir_path = os.path.join(root, base_folder, dirname)
if dirname == 'train':
for fname in sorted(os.listdir(dir_path)):
cls_fpath = os.path.join(dir_path, fname)
if os.path.isdir(cls_fpath):
cls_imgs_path = os.path.join(cls_fpath, 'images')
for imgname in sorted(os.listdir(cls_imgs_path)):
path = os.path.join(cls_imgs_path, imgname)
item = (path, class_to_idx[fname])
images.append(item)
else:
imgs_path = os.path.join(dir_path, 'images')
imgs_annotations = os.path.join(dir_path, 'val_annotations.txt')
with open(imgs_annotations) as r:
data_info = map(lambda s: s.split('\t'), r.readlines())
cls_map = {line_data[0]: line_data[1] for line_data in data_info}
for imgname in sorted(os.listdir(imgs_path)):
path = os.path.join(imgs_path, imgname)
item = (path, class_to_idx[cls_map[imgname]])
images.append(item)
return images
if __name__ == '__main__':
train_dataset = TinyImageNet('./tiny-imagenet', split='train', download=False)
test_dataset = TinyImageNet('./tiny-imagenet', split='val', download=False)
================================================
FILE: braincog/datasets/__init__.py
================================================
from .datasets import build_transform, build_dataset, get_mnist_data, get_fashion_data, \
get_cifar10_data, get_cifar100_data, get_imnet_data, get_dvsg_data, get_dvsc10_data, \
get_NCALTECH101_data, get_NCARS_data, get_nomni_data, get_bullyingdvs_data
from .utils import rescale, dvs_channel_check_expend
from .hmdb_dvs import HMDBDVS
from .ucf101_dvs import ucf101_dvs
from .ncaltech101 import NCALTECH101
from .bullying10k import BULLYINGDVS
__all__ = [
'build_transform', 'build_dataset',
'get_mnist_data', 'get_fashion_data', 'get_cifar10_data', 'get_cifar100_data', 'get_imnet_data',
'get_dvsg_data', 'get_dvsc10_data', 'get_NCALTECH101_data', 'get_NCARS_data', 'get_nomni_data',
'rescale', 'dvs_channel_check_expend', 'get_bullyingdvs_data'
]
dvs_data = [
'dvsg',
'dvsc10',
'ncaltech101',
'ncars',
'dvsg',
'ucf101dvs',
'hmdbdvs',
'shd',
'ntidigits',
'nmnist'
]
def is_dvs_data(dataset):
if dataset.lower() in dvs_data:
return True
else:
return False
================================================
FILE: braincog/datasets/bullying10k/__init__.py
================================================
from .bullying10k import BULLYINGDVS
================================================
FILE: braincog/datasets/bullying10k/bullying10k.py
================================================
import os
import numpy as np
from numpy.lib import recfunctions
import scipy.io as scio
from typing import Tuple, Any, Optional
from tonic.dataset import Dataset
from tonic.download_utils import extract_archive
import dv
class BULLYINGDVS(Dataset):
classes = ["fingerguess", "greeting", "hairgrabs", "handshake", "kicking",
"punching", "pushing", "slapping", "strangling", "walking"]
class_dict = {cls: idx for idx, cls in enumerate(classes)}
sensor_size = (346, 260, 2)
dtype = np.dtype([("t", int), ("x", int), ("y", int), ("p", int)])
ordering = dtype.names
def __init__(self, save_to, transform=None, target_transform=None):
super(BULLYINGDVS, self).__init__(
save_to, transform=transform, target_transform=target_transform
)
self.aedat4 = True
for path, dirs, files in os.walk(self.location_on_system):
dirs.sort()
files.sort()
for file in files:
if file.endswith("aedat4"):
self.data.append(path + "/" + file)
self.targets.append(self.class_dict[path.split('/')[-2]])
if file.endswith("npy"):
self.aedat4 = False
self.data.append(path + "/" + file)
self.targets.append(self.class_dict[path.split('/')[-2]])
def __getitem__(self, index: int) -> Tuple[Any, Any]:
"""
Returns:
(events, target) where target is index of the target class.
"""
if self.aedat4:
events, target = dv.AedatFile(self.data[index])['events'], self.targets[index]
events = np.concatenate([event for event in events.numpy()])
else:
events = np.concatenate(np.load(self.data[index], allow_pickle=True))
events = np.column_stack(
[
events['timestamp'] - events['timestamp'][0],
events['x'],
events['y'],
events['polarity']
]
)
events = np.lib.recfunctions.unstructured_to_structured(events, self.dtype)
if self.transform is not None:
events = self.transform(events)
if self.target_transform is not None:
target = self.target_transform(target)
return events, target
def __len__(self):
return len(self.data)
def _check_exists(self):
return True
================================================
FILE: braincog/datasets/cut_mix.py
================================================
import math
import numpy as np
import random
from torch.utils.data.dataset import Dataset
from braincog.datasets.rand_aug import SaltAndPepperNoise
import numpy as np
import torch
from torch.nn import functional as F
def event_difference(x1, x2, kernel_size=3):
padding = kernel_size // 2
x1 = F.avg_pool2d(x1, kernel_size=kernel_size, stride=1, padding=padding)
x2 = F.avg_pool2d(x2, kernel_size=kernel_size, stride=1, padding=padding)
return F.mse_loss(x1, x2)
def onehot(size, target):
vec = torch.zeros(size, dtype=torch.float32)
vec[target] = 1.
return vec
def rand_bbox_time(size, rat):
if len(size) == 4: # step, channel, height, width
step = size[0]
else:
raise Exception
cut_t = np.int(step * rat)
ct = np.random.randint(step)
bbt1 = np.clip(ct - cut_t // 2, 0, step)
bbt2 = np.clip(ct + cut_t // 2, 0, step)
return bbt1, bbt2
def rand_bbox(size, rat):
if len(size) == 4:
W = size[2]
H = size[3]
else:
raise Exception
cut_rat = np.sqrt(rat)
cut_w = np.int(W * cut_rat)
cut_h = np.int(H * cut_rat)
# uniform
cx = np.random.randint(W)
cy = np.random.randint(H)
bbx1 = np.clip(cx - cut_w // 2, 0, W)
bby1 = np.clip(cy - cut_h // 2, 0, H)
bbx2 = np.clip(cx + cut_w // 2, 0, W)
bby2 = np.clip(cy + cut_h // 2, 0, H)
return bbx1, bby1, bbx2, bby2
def calc_lam(x1, x2, bbt1, bbt2, bbx1, bbx2, bby1, bby2):
tot_x1 = x1.sum()
tot_x2 = x2.sum()
tot_bb1 = x1[bbt1:bbt2, :, bbx1:bbx2, bby1:bby2].sum()
tot_bb2 = x2[bbt1:bbt2, :, bbx1:bbx2, bby1:bby2].sum()
x1_rat = tot_bb1 / tot_x1
x2_rat = tot_bb2 / tot_x2
lam = 1. - (x2_rat / (1. - x1_rat + x2_rat))
return lam
def rand_bbox_st(size, rat):
temporal_rat = np.random.uniform(rat, 1.)
wh_rat = rat / temporal_rat
bbt1, bbt2 = rand_bbox_time(size, temporal_rat)
bbx1, bby1, bbx2, bby2 = rand_bbox(size, wh_rat)
return bbt1, bbt2, bbx1, bby1, bbx2, bby2
def spatio_mask(size, rat):
t = size[0]
x = torch.rand(2, 2)
y = torch.rand(2, 2)
f = torch.zeros(*size[-2:], dtype=torch.complex64)
# f[0:2, 0:2] = x + y * 0.j
f[[[0, -1], [-1, -1]], [[0, -1], [0, -1]]] = x + y * 1.j
mask = torch.fft.ifftn(f).real
idx = int(np.prod(size[-2:]) * rat)
val = mask.flatten().sort()[0][idx]
return (mask < val).unsqueeze(0).unsqueeze(0).repeat(t, 2, 1, 1)
def temporal_mask(size, rat):
bbt1, bbt2 = rand_bbox_time(size, rat)
mask = torch.zeros(*size, dtype=torch.bool)
mask[bbt1:bbt2] = True
return mask
def st_mask(size, rat):
t = size[0]
temporal_rat = np.random.uniform(rat, 1.)
wh_rat = rat / temporal_rat
bbt1, bbt2 = rand_bbox_time(size, temporal_rat)
mask = spatio_mask(size, wh_rat)
mask[0:bbt1] = False
mask[bbt2:t] = False
return mask
def GMM_mask_clip(size, rat):
t = size[0]
temporal_rat = np.random.uniform(rat, 1.)
wh_rat = rat / temporal_rat
bbt1, bbt2 = rand_bbox_time(size, temporal_rat)
mask = GMM_mask(size, wh_rat)
mask[0:bbt1] = False
mask[bbt2:t] = False
return mask
def GMM_mask(size, rat, n=None):
if n is None:
n = np.random.randint(2, 5)
pi = torch.tensor(np.random.rand(n))
# pi = torch.ones(n) / n
mask = torch.zeros((size[0], size[2], size[3]))
t = torch.tensor(list(range(size[0])))
x = torch.tensor(list(range(size[2])))
y = torch.tensor(list(range(size[3])))
t, x, y = torch.meshgrid(t, x, y, indexing='ij')
for p in pi:
mt = np.random.randint(0, size[0])
mx = np.random.randint(0, size[2])
my = np.random.randint(0, size[3])
# print(mt, mx, my)
st = max(np.random.rand(), 0.1) * size[0] * 0.5
sx = max(np.random.rand(), 0.1) * size[2] * .5
sy = max(np.random.rand(), 0.1) * size[3] * .5
# st, sx, sy = size[0], 0000.5 * size[2], 0000.5 * size[3]
# print(st, sx, sy)
tt = t - mt
xx = x - mx
yy = y - my
tmp = -((tt ** 2) / (st ** 2) + (xx ** 2) / (sx ** 2) + (yy ** 2) / (sy ** 2)) / 2
mask += p * tmp.exp()
idx = int(np.prod(mask.shape) * rat)
val = mask.flatten().sort()[0][idx - 1]
return (mask > val).unsqueeze(1).repeat(1, 2, 1, 1)
# return mask.unsqueeze(1).repeat(1, 2, 1, 1)
# FOR EVENT VIS
# def spatio_mask(size, rat):
# t = size[0]
# x = torch.rand(2, 2)
# y = torch.rand(2, 2)
# f = torch.zeros(*size[-2:], dtype=torch.complex64)
# # f[0:2, 0:2] = x + y * 0.j
# f[[[0, -1], [-1, -1]], [[0, -1], [0, -1]]] = x + y * 1.j
#
# f = f.unsqueeze(0).repeat(t, 1, 1)
# f[1:-2, :, :] = 0
#
# mask = torch.fft.ifftn(f).real
# # print(mask.shape)
# idx = int(np.prod(mask.shape) * 0.6)
# # print(idx)
# val = mask.flatten().sort()[0][idx]
# print(mask.unsqueeze(1).repeat(1, 2, 1, 1).shape)
# return (mask < val).unsqueeze(1).repeat(1, 2, 1, 1)
#
# def st_mask(size, rat):
# # t = size[0]
# # temporal_rat = np.random.uniform(rat, 1.)
# # wh_rat = rat / temporal_rat
# wh_rat = rat
# # bbt1, bbt2 = rand_bbox_time(size, temporal_rat)
# mask = spatio_mask(size, wh_rat)
# # mask[0:bbt1] = False
# # mask[bbt2:t] = False
# return mask
def calc_masked_lam(x1, x2, mask):
tot_x1 = x1.sum()
tot_x2 = x2.sum()
tot_mask1 = x1[mask].sum()
tot_mask2 = x2[mask].sum()
x1_rat = tot_mask1 / tot_x1
x2_rat = tot_mask2 / tot_x2
lam = 1. - (x2_rat / (1. - x1_rat + x2_rat))
# print(tot_x1, tot_x2, tot_mask1, tot_mask2)
return lam
def calc_masked_lam_with_difference(x1, x2, mix, kernel_size=3):
s1 = event_difference(x1, mix, kernel_size=kernel_size)
s2 = event_difference(x2, mix, kernel_size=kernel_size)
return (s2 * s2) / (s1 * s1 + s2 * s2)
class MixUp(Dataset):
def __init__(self, dataset, num_class, num_mix=1, beta=1., prob=1.0, indices=None, noise=0.0, vis=False, **kwargs):
self.dataset = dataset
self.num_class = num_class
self.num_mix = num_mix
self.beta = beta
self.prob = prob
self.indices = indices
self.noise = noise
self.vis = vis
def __getitem__(self, index):
img, lb = self.dataset[index]
lb_onehot = onehot(self.num_class, lb)
if self.vis:
origin = img.clone()
for _ in range(self.num_mix):
r = np.random.rand(1)
if self.beta <= 0 or r > self.prob:
continue
# generate mixed sample
lam = np.random.beta(self.beta, self.beta)
if self.indices is None:
rand_index = random.choice(range(len(self)))
else:
rand_index = random.choice(self.indices)
img2, lb2 = self.dataset[rand_index]
lb2_onehot = onehot(self.num_class, lb2)
img = img * lam + img2 * (1. - lam)
lb_onehot = lb_onehot * lam + lb2_onehot * (1. - lam)
if self.noise != 0.:
img = SaltAndPepperNoise(img, self.noise)
if self.vis:
return origin, img, img2
else:
return img, lb_onehot
def __len__(self):
return len(self.dataset)
class CutMix(Dataset):
# 81.45161290322581 (epoch 584) /data/floyed/BrainCog/train/20220413-050658-resnet34-dvsc10-10-cut_mix before lam
def __init__(self, dataset, num_class, num_mix=1, beta=1., prob=1.0, indices=None, noise=0.0, vis=False, **kwargs):
self.dataset = dataset
self.num_class = num_class
self.num_mix = num_mix
self.beta = beta
self.prob = prob
self.indices = indices
self.noise = noise
self.vis = vis
def __getitem__(self, index):
img, lb = self.dataset[index]
lb_onehot = onehot(self.num_class, lb)
if self.vis:
origin = img.clone()
for _ in range(self.num_mix):
r = np.random.rand(1)
if self.beta <= 0 or r > self.prob:
continue
# generate mixed sample
lam = np.random.beta(self.beta, self.beta)
if self.indices is None:
rand_index = random.choice(range(len(self)))
else:
rand_index = random.choice(self.indices)
img2, lb2 = self.dataset[rand_index]
lb2_onehot = onehot(self.num_class, lb2)
# shape: step, channel, height, width
# alpha = np.random.rand()
# if alpha < 0.333:
bbx1, bby1, bbx2, bby2 = rand_bbox(img.shape, 1. - lam)
# bbx1, bby1, bbx2, bby2 = 32, 0, 48, 16
lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (img.shape[-1] * img.shape[-2])) # area
# lam = calc_lam(img, img2, 0, shape[0], bbx1, bbx2, bby1, bby2) # count
# distance
# mask = torch.zeros_like(img, dtype=torch.bool)
# mask[:, :, bbx1:bbx2, bby1:bby2] = True
# mix = img.clone()
# mix[mask] = img2[mask]
# lam = calc_masked_lam_with_difference(img, img2, mix, kernel_size=3)
if self.vis:
img[:, :, bbx1:bbx2, bby1:bby2] = -img2[:, :, bbx1:bbx2, bby1:bby2]
img2 = -img2
else:
img[:, :, bbx1:bbx2, bby1:bby2] = img2[:, :, bbx1:bbx2, bby1:bby2]
# elif alpha > 0.667:
# bbt1, bbt2 = rand_bbox_time(img.shape, 1. - lam)
# lam = calc_lam(img, img2, bbt1, bbt2, 0, shape[2], 0, shape[3])
# img[:, bbt1:bbt2, :, :] = img2[:, bbt1:bbt2, :, :]
# # lam = 1 - (bbt2 - bbt1) / (img.shape[-4])
# else:
# bbt1, bbt2, bbx1, bby1, bbx2, bby2 = rand_bbox_st(img.shape, 1. - lam)
# lam = calc_lam(img, img2, bbt1, bbt2, bbx1, bbx2, bby1, bby2)
# img[:, bbt1:bbt2, bbx1:bbx2, bby1:bby2] = img2[:, bbt1:bbt2, bbx1:bbx2, bby1:bby2]
# # lam = 1 - ((bbt2 - bbt1) * (bbx2 - bbx1) * (bby2 - bby1) / (img.shape[-1] * img.shape[-2] * img.shape[-4]))
if self.noise != 0.:
img = SaltAndPepperNoise(img, self.noise)
lb_onehot = lb_onehot * lam + lb2_onehot * (1. - lam)
if self.vis:
mask = torch.zeros_like(img)
mask[:, :, bbx1:bbx2, bby1:bby2] = 1.
return origin, img, img2, mask
else:
return img, lb_onehot
def __len__(self):
return len(self.dataset)
class EventMix(Dataset):
# 82.15725806451613 (epoch 554) /data/floyed/BrainCog/train/20220413-014843-resnet34-dvsc10-10-masked
def __init__(self,
dataset,
num_class,
num_mix=1,
beta=1.,
prob=1.0,
indices=None,
noise=0.1,
vis=False,
gaussian_n=None,
**kwargs):
self.dataset = dataset
self.num_class = num_class
self.num_mix = num_mix
self.beta = beta
self.prob = prob
self.indices = indices
self.noise = noise
self.vis = vis
self.gaussian_n = gaussian_n
print(self.prob, self.gaussian_n, self.beta)
def __getitem__(self, index):
img, lb = self.dataset[index]
lb_onehot = onehot(self.num_class, lb)
shape = img.shape
if self.vis:
origin = img.clone()
for _ in range(self.num_mix):
r = np.random.rand(1)
if self.beta <= 0 or r > self.prob:
continue
# generate mixed sample
lam = np.random.beta(self.beta, self.beta) # lam -> remain ratio
if self.indices is None:
rand_index = random.choice(range(len(self)))
else:
rand_index = random.choice(self.indices)
img2, lb2 = self.dataset[rand_index]
lb2_onehot = onehot(self.num_class, lb2)
# shape: step, channel, height, width
# alpha = np.random.rand()
# if alpha < 0.333:
# mask = spatio_mask(shape, 1. - lam)
# elif alpha > 0.667:
# mask = temporal_mask(shape, 1. - lam)
# else:
# mask = st_mask(shape, 1. - lam)
mask = GMM_mask(shape, 1. - lam, self.gaussian_n)
# mask = GMM_mask_clip(shape, 1. - lam)
# mask = torch.logical_not(mask)
# lam = 1 - (mask.sum() / np.prod(img.shape)) # area
lam = calc_masked_lam(img, img2, mask) # count
img[mask] = img2[mask] # count && mask required
# distance
# mix = torch.clone(img)
# if self.vis:
# mix[mask] = -img2[mask]
# img2 = -img2
# else:
# mix[mask] = img2[mask]
# lam = calc_masked_lam_with_difference(img, img2, mix, kernel_size=3)
# img = mix
if self.noise != 0.:
img = SaltAndPepperNoise(img, self.noise)
lb_onehot = lb_onehot * lam + lb2_onehot * (1. - lam)
if self.vis:
return origin, img, img2, mask
else:
return img, lb_onehot
def __len__(self):
return len(self.dataset)
if __name__ == '__main__':
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from mpl_toolkits.mplot3d import proj3d
def get_proj(self):
"""
Create the projection matrix from the current viewing position.
elev stores the elevation angle in the z plane
azim stores the azimuth angle in the (x, y) plane
dist is the distance of the eye viewing point from the object point.
"""
# chosen for similarity with the initial view before gh-8896
relev, razim = np.pi * self.elev / 180, np.pi * self.azim / 180
# EDITED TO HAVE SCALED AXIS
xmin, xmax = np.divide(self.get_xlim3d(), self.pbaspect[0])
ymin, ymax = np.divide(self.get_ylim3d(), self.pbaspect[1])
zmin, zmax = np.divide(self.get_zlim3d(), self.pbaspect[2])
# transform to uniform world coordinates 0-1, 0-1, 0-1
worldM = proj3d.world_transformation(xmin, xmax,
ymin, ymax,
zmin, zmax)
# look into the middle of the new coordinates
R = self.pbaspect / 2
xp = R[0] + np.cos(razim) * np.cos(relev) * self.dist
yp = R[1] + np.sin(razim) * np.cos(relev) * self.dist
zp = R[2] + np.sin(relev) * self.dist
E = np.array((xp, yp, zp))
self.eye = E
self.vvec = R - E
self.vvec = self.vvec / np.linalg.norm(self.vvec)
if abs(relev) > np.pi / 2:
# upside down
V = np.array((0, 0, -1))
else:
V = np.array((0, 0, 1))
zfront, zback = -self.dist, self.dist
viewM = proj3d.view_transformation(E, R, V)
projM = self._projection(zfront, zback)
M0 = np.dot(viewM, worldM)
M = np.dot(projM, M0)
return M
Axes3D.get_proj = get_proj
size = (100, 2, 48, 48)
mask = GMM_mask(size, 0.3)
print(mask.shape)
# for i in range(100):
# plt.figure()
# plt.imshow(mask[i, 0])
# plt.show()
pos_idx1 = []
neg_idx1 = []
for t in range(100):
for r in range(48):
for c in range(48):
if mask[t, 0, r, c] > 0:
pos_idx1.append((t, r, c))
if mask[t, 1, r, c] > 0:
neg_idx1.append((t, r, c))
pos_t1, pos_x1, pos_y1 = np.split(np.array(pos_idx1), 3, axis=1)
neg_t1, neg_x1, neg_y1 = np.split(np.array(neg_idx1), 3, axis=1)
fig = plt.figure(figsize=plt.figaspect(0.5) * 1.5)
ax = Axes3D(fig)
ax.pbaspect = np.array([1, 1, 1]) # np.array([2.0, 1.0, 0.5])
ax.view_init(elev=10, azim=-75)
# ax.axis('off')
ax.scatter(pos_t1[:, 0], pos_y1[:, 0], 48 - pos_x1[:, 0], color='red', alpha=0.1, s=2.)
ax.scatter(neg_t1[:, 0], neg_y1[:, 0], 48 - neg_x1[:, 0], color='blue', alpha=0.1, s=2.)
plt.show()
================================================
FILE: braincog/datasets/datasets.py
================================================
import os, warnings
import tonic
from tonic import DiskCachedDataset
import torch
import torch.nn.functional as F
import torch.utils
import torchvision.datasets as datasets
from timm.data import ImageDataset, create_loader, Mixup, FastCollateMixup, AugMixDataset
from timm.data import create_transform
from torchvision import transforms
from typing import Any, Dict, Optional, Sequence, Tuple, Union
import braincog
from braincog.datasets.NOmniglot.nomniglot_full import NOmniglotfull
from braincog.datasets.NOmniglot.nomniglot_nw_ks import NOmniglotNWayKShot
from braincog.datasets.NOmniglot.nomniglot_pair import NOmniglotTrainSet, NOmniglotTestSet
from braincog.datasets.ESimagenet.ES_imagenet import ESImagenet_Dataset
from braincog.datasets.ESimagenet.reconstructed_ES_imagenet import ESImagenet2D_Dataset
from braincog.datasets.CUB2002011 import CUB2002011
from braincog.datasets.TinyImageNet import TinyImageNet
from braincog.datasets.StanfordDogs import StanfordDogs
from braincog.datasets.bullying10k import BULLYINGDVS
from .cut_mix import CutMix, EventMix, MixUp
from .rand_aug import *
from .utils import dvs_channel_check_expend, rescale
DVSCIFAR10_MEAN_16 = [0.3290, 0.4507]
DVSCIFAR10_STD_16 = [1.8398, 1.6549]
DATA_DIR = '/data/datasets'
DEFAULT_CROP_PCT = 0.875
IMAGENET_DEFAULT_MEAN = (0.485, 0.456, 0.406)
IMAGENET_DEFAULT_STD = (0.229, 0.224, 0.225)
IMAGENET_INCEPTION_MEAN = (0.5, 0.5, 0.5)
IMAGENET_INCEPTION_STD = (0.5, 0.5, 0.5)
IMAGENET_DPN_MEAN = (124 / 255, 117 / 255, 104 / 255)
IMAGENET_DPN_STD = tuple([1 / (.0167 * 255)] * 3)
CIFAR10_DEFAULT_MEAN = (0.4914, 0.4822, 0.4465)
CIFAR10_DEFAULT_STD = (0.2023, 0.1994, 0.2010)
def unpack_mix_param(args):
mix_up = args['mix_up'] if 'mix_up' in args else False
cut_mix = args['cut_mix'] if 'cut_mix' in args else False
event_mix = args['event_mix'] if 'event_mix' in args else False
beta = args['beta'] if 'beta' in args else 1.
prob = args['prob'] if 'prob' in args else .5
num = args['num'] if 'num' in args else 1
num_classes = args['num_classes'] if 'num_classes' in args else 10
noise = args['noise'] if 'noise' in args else 0.
gaussian_n = args['gaussian_n'] if 'gaussian_n' in args else None
return mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n
def build_transform(is_train, img_size):
"""
构建数据增强, 适用于static data
:param is_train: 是否训练集
:param img_size: 输出的图像尺寸
:return: 数据增强策略
"""
resize_im = img_size > 32
if is_train:
# this should always dispatch to transforms_imagenet_train
transform = create_transform(
input_size=img_size,
is_training=True,
color_jitter=0.4,
auto_augment='rand-m9-mstd0.5-inc1',
interpolation='bicubic',
re_prob=0.25,
re_mode='pixel',
re_count=1,
)
if not resize_im:
# replace RandomResizedCropAndInterpolation with
# RandomCrop
transform.transforms[0] = transforms.RandomCrop(
img_size, padding=4)
return transform
t = []
if resize_im:
size = int((256 / 224) * img_size)
t.append(
# to maintain same ratio w.r.t. 224 images
transforms.Resize(size, interpolation=3),
)
t.append(transforms.CenterCrop(img_size))
t.append(transforms.ToTensor())
if img_size > 32:
t.append(transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD))
else:
t.append(transforms.Normalize(CIFAR10_DEFAULT_MEAN, CIFAR10_DEFAULT_STD))
return transforms.Compose(t)
def build_dataset(is_train, img_size, dataset, path, same_da=False):
"""
构建带有增强策略的数据集
:param is_train: 是否训练集
:param img_size: 输出图像尺寸
:param dataset: 数据集名称
:param path: 数据集路径
:param same_da: 为训练集使用测试集的增广方法
:return: 增强后的数据集
"""
transform = build_transform(False, img_size) if same_da else build_transform(is_train, img_size)
if dataset == 'CIFAR10':
dataset = datasets.CIFAR10(
path, train=is_train, transform=transform, download=True)
nb_classes = 10
elif dataset == 'CIFAR100':
dataset = datasets.CIFAR100(
path, train=is_train, transform=transform, download=True)
nb_classes = 100
else:
raise NotImplementedError
return dataset, nb_classes
class MNISTData(object):
"""
Load MNIST datesets.
"""
def __init__(self,
data_path: str,
batch_size: int,
train_trans: Sequence[torch.nn.Module] = None,
test_trans: Sequence[torch.nn.Module] = None,
pin_memory: bool = True,
drop_last: bool = True,
shuffle: bool = True,
) -> None:
self._data_path = data_path
self._batch_size = batch_size
self._pin_memory = pin_memory
self._drop_last = drop_last
self._shuffle = shuffle
self._train_transform = transforms.Compose(train_trans) if train_trans else None
self._test_transform = transforms.Compose(test_trans) if test_trans else None
def get_data_loaders(self):
print('Batch size: ', self._batch_size)
train_datasets = datasets.MNIST(root=self._data_path, train=True, transform=self._train_transform, download=True)
test_datasets = datasets.MNIST(root=self._data_path, train=False, transform=self._test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=self._drop_last, shuffle=self._shuffle
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=False
)
return train_loader, test_loader
def get_standard_data(self):
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
self._train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
self._test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
return self.get_data_loaders()
def get_mnist_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, **kwargs):
"""
获取MNIST数据
http://data.pymvpa.org/datasets/mnist/
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
if 'root' in kwargs:root=kwargs["root"]
if 'skip_norm' in kwargs and kwargs['skip_norm'] is True:
train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
else:
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
# transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
train_datasets = datasets.MNIST(
root=root, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.MNIST(
root=root, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_fashion_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, **kwargs):
"""
获取fashion MNIST数据
http://arxiv.org/abs/1708.07747
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor()])
test_transform = transforms.Compose([transforms.ToTensor()])
train_datasets = datasets.FashionMNIST(
root=root, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.FashionMNIST(
root=root, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_cifar10_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, **kwargs):
"""
获取CIFAR10数据
https://www.cs.toronto.edu/~kriz/cifar.html
:param batch_size: batch size
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_datasets, _ = build_dataset(True, 32, 'CIFAR10', root, same_da)
test_datasets, _ = build_dataset(False, 32, 'CIFAR10', root, same_da)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True,
num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False,
num_workers=num_workers
)
return train_loader, test_loader, None, None
def get_cifar100_data(batch_size, num_workers=8, same_data=False,root=DATA_DIR, *args, **kwargs):
"""
获取CIFAR100数据
https://www.cs.toronto.edu/~kriz/cifar.html
:param batch_size: batch size
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_datasets, _ = build_dataset(True, 32, 'CIFAR100', root, same_data)
test_datasets, _ = build_dataset(False, 32, 'CIFAR100', root, same_data)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_TinyImageNet_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, *args, **kwargs):
size=kwargs["size"] if "size" in kwargs else 224
train_transform = transforms.Compose([
transforms.RandomResizedCrop(size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(size*8//7),
transforms.CenterCrop(size),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(root, 'TinyImageNet')
train_datasets = TinyImageNet(
root=root, split="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = TinyImageNet(
root=root, split="val", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_imnet_data(args, _logger, data_config, num_aug_splits,root=DATA_DIR, **kwargs):
"""
获取ImageNet数据集
http://arxiv.org/abs/1409.0575
:param args: 其他的参数
:param _logger: 日志路径
:param data_config: 增强策略
:param num_aug_splits: 不同增强策略的数量
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_dir = os.path.join(root, 'ILSVRC2012/train')
if not os.path.exists(train_dir):
_logger.error(
'Training folder does not exist at: {}'.format(train_dir))
exit(1)
dataset_train = ImageDataset(train_dir)
# collate_fn = None
# mixup_fn = None
# mixup_active = args.mixup > 0 or args.cutmix > 0. or args.cutmix_minmax is not None
# if mixup_active:
# mixup_args = dict(
# mixup_alpha=args.mixup, cutmix_alpha=args.cutmix, cutmix_minmax=args.cutmix_minmax,
# prob=args.mixup_prob, switch_prob=args.mixup_switch_prob, mode=args.mixup_mode,
# label_smoothing=args.smoothing, num_classes=args.num_classes)
# if args.prefetcher:
# # collate conflict (need to support deinterleaving in collate mixup)
# assert not num_aug_splits
# collate_fn = FastCollateMixup(**mixup_args)
# else:
# mixup_fn = Mixup(**mixup_args)
# if num_aug_splits > 1:
# dataset_train = AugMixDataset(dataset_train, num_splits=num_aug_splits)
train_interpolation = args.train_interpolation
if args.no_aug or not train_interpolation:
train_interpolation = data_config['interpolation']
loader_train = create_loader(
dataset_train,
input_size=data_config['input_size'],
batch_size=args.batch_size,
is_training=True,
use_prefetcher=args.prefetcher,
no_aug=args.no_aug,
# re_prob=args.reprob,
# re_mode=args.remode,
# re_count=args.recount,
# re_split=args.resplit,
scale=args.scale,
ratio=args.ratio,
hflip=args.hflip,
# vflip=arg,
color_jitter=args.color_jitter,
#auto_augment=args.aa,
num_aug_splits=num_aug_splits,
interpolation=train_interpolation,
mean=data_config['mean'],
std=data_config['std'],
num_workers=args.workers,
distributed=args.distributed,
#collate_fn=collate_fn,
pin_memory=args.pin_mem,
use_multi_epochs_loader=args.use_multi_epochs_loader)
eval_dir = os.path.join(root, 'ILSVRC2012/val')
if not os.path.isdir(eval_dir):
eval_dir = os.path.join(root, 'ILSVRC2012/validation')
if not os.path.isdir(eval_dir):
_logger.error(
'Validation folder does not exist at: {}'.format(eval_dir))
exit(1)
dataset_eval = ImageDataset(eval_dir)
loader_eval = create_loader(
dataset_eval,
input_size=data_config['input_size'],
batch_size=args.validation_batch_size_multiplier * args.batch_size,
is_training=False,
use_prefetcher=args.prefetcher,
interpolation=data_config['interpolation'],
mean=data_config['mean'],
std=data_config['std'],
num_workers=args.workers,
distributed=args.distributed,
crop_pct=data_config['crop_pct'],
pin_memory=args.pin_mem,
)
return loader_train, loader_eval, False, None
def get_dvsg_data(batch_size, step,root=DATA_DIR, **kwargs):
"""
获取DVS Gesture数据
DOI: 10.1109/CVPR.2017.781
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.DVSGesture.sensor_size
size = kwargs['size'] if 'size' in kwargs else 48
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
train_dataset = tonic.datasets.DVSGesture(os.path.join(root, 'DVS/DVSGesture'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.DVSGesture(os.path.join(root, 'DVS/DVSGesture'),
transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(root, 'DVS/DVSGesture/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(root, 'DVS/DVSGesture/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, mixup_active, None
def get_bullyingdvs_data(batch_size, step, root=DATA_DIR, **kwargs):
"""
获取Bullying10K数据
NeurIPS 2023
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return:
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = BULLYINGDVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = BULLYINGDVS('/data/datasets/Bullying10k_processed', transform=train_transform)
# train_dataset = BULLYINGDVS(os.path.join(root, 'DVS/BULLYINGDVS'), transform=train_transform)
test_dataset = BULLYINGDVS(os.path.join(root, 'DVS/BULLYINGDVS'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(root, 'DVS/BULLYINGDVS/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(root, 'DVS/BULLYINGDVS/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_train),
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_test),
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_dvsc10_data(batch_size, step, root=DATA_DIR, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = tonic.datasets.CIFAR10DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.CIFAR10DVS(os.path.join(root, 'DVS/DVS_Cifar10'), transform=train_transform)
test_dataset = tonic.datasets.CIFAR10DVS(os.path.join(root, 'DVS/DVS_Cifar10'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(root, 'DVS/DVS_Cifar10/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(root, 'DVS/DVS_Cifar10/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_train),
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_test),
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_NCALTECH101_data(batch_size, step,root=DATA_DIR, **kwargs):
"""
获取NCaltech101数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.NCALTECH101.sensor_size
cls_count = tonic.datasets.NCALTECH101.cls_count
dataset_length = tonic.datasets.NCALTECH101.length
portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += train_sample
train_sample_weight.extend(
[sample_weight] * train_sample
)
train_sample_weight.extend(
[0.] * test_sample
)
train_sample_index.extend(
list((range(idx_begin, idx_begin + train_sample)))
)
test_sample_index.extend(
list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.NCALTECH101(os.path.join(root, 'DVS/NCALTECH101'), transform=train_transform)
test_dataset = tonic.datasets.NCALTECH101(os.path.join(root, 'DVS/NCALTECH101'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: print(x.shape),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
#transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: temporal_flatten(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(root, 'DVS/NCALTECH101/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(root, 'DVS/NCALTECH101/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=train_sampler,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_NCARS_data(batch_size, step,root=DATA_DIR, **kwargs):
"""
获取N-Cars数据
https://ieeexplore.ieee.org/document/8578284/
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.NCARS.sensor_size
size = kwargs['size'] if 'size' in kwargs else 48
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
])
train_dataset = tonic.datasets.NCARS(os.path.join(root, 'DVS/NCARS'), transform=train_transform, train=True)
test_dataset = tonic.datasets.NCARS(os.path.join(root, 'DVS/NCARS'), transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(root, 'DVS/NCARS/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(root, 'DVS/NCARS/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, mixup_active, None
def get_nomni_data(batch_size, train_portion=1.,root=DATA_DIR, **kwargs):
"""
获取N-Omniglot数据
:param batch_size:batch的大小
:param data_mode:一共full nkks pair三种模式
:param frames_num:一个样本帧的个数
:param data_type:event frequency两种模式
"""
data_mode = kwargs["data_mode"] if "data_mode" in kwargs else "full"
frames_num = kwargs["frames_num"] if "frames_num" in kwargs else 4
data_type = kwargs["data_type"] if "data_type" in kwargs else "event"
train_transform = transforms.Compose([
transforms.Resize((28, 28))])
test_transform = transforms.Compose([
transforms.Resize((28, 28))])
if data_mode == "full":
train_datasets = NOmniglotfull(root=os.path.join(root, 'DVS/NOmniglot'), train=True, frames_num=frames_num,
data_type=data_type,
transform=train_transform)
test_datasets = NOmniglotfull(root=os.path.join(root, 'DVS/NOmniglot'), train=False, frames_num=frames_num,
data_type=data_type,
transform=test_transform)
elif data_mode == "nkks":
train_datasets = NOmniglotNWayKShot(os.path.join(root, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=True,
frames_num=frames_num,
data_type=data_type,
transform=train_transform)
test_datasets = NOmniglotNWayKShot(os.path.join(root, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=False,
frames_num=frames_num,
data_type=data_type,
transform=test_transform)
elif data_mode == "pair":
train_datasets = NOmniglotTrainSet(root=os.path.join(root, 'DVS/NOmniglot'), use_frame=True,
frames_num=frames_num, data_type=data_type,
use_npz=False, resize=105)
test_datasets = NOmniglotTestSet(root=os.path.join(root, 'DVS/NOmniglot'), time=2000, way=kwargs["n_way"],
shot=kwargs["k_shot"], use_frame=True,
frames_num=frames_num, data_type=data_type, use_npz=False, resize=105)
else:
pass
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size, num_workers=12,
pin_memory=True, drop_last=True, shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size, num_workers=12,
pin_memory=True, drop_last=False
)
return train_loader, test_loader, None, None
def get_esimnet_data(batch_size, step,root=DATA_DIR, **kwargs):
"""
获取ES imagenet数据
DOI: 10.3389/fnins.2021.726582
:param batch_size: batch size
:param step: 仿真步长,固定为8
:param reconstruct: 重构则时间步为1, 否则为8
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
:note: 没有自动下载, 下载及md5请参考spikingjelly, sampler默认为DistributedSampler
"""
reconstruct = kwargs["reconstruct"] if "reconstruct" in kwargs else False
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: dvs_channel_check_expend(x),
])
if reconstruct:
assert step == 1
train_dataset = ESImagenet2D_Dataset(mode='train',
data_set_path=os.path.join(root, 'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=train_transform)
test_dataset = ESImagenet2D_Dataset(mode='test',
data_set_path=os.path.join(root, 'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=test_transform)
else:
assert step == 8
train_dataset = ESImagenet_Dataset(mode='train',
data_set_path=os.path.join(root,
'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=train_transform)
test_dataset = ESImagenet_Dataset(mode='test',
data_set_path=os.path.join(root,
'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=test_transform)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
test_sampler = torch.utils.data.distributed.DistributedSampler(test_dataset)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=False, sampler=train_sampler
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=1,
shuffle=False, sampler=test_sampler
)
return train_loader, test_loader, mixup_active, None
def get_nmnist_data(batch_size, step, **kwargs):
"""
获取N-MNIST数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.NMNIST.sensor_size
size = kwargs['size'] if 'size' in kwargs else 34
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
train_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/N-MNIST'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/N-MNIST'),
transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
# transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/N-MNIST/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/N-MNIST/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, mixup_active, None
def get_ntidigits_data(batch_size, step, **kwargs):
"""
获取N-TIDIGITS数据 (tonic 新版本中的下载链接可能挂了,可以参考0.4.0的版本)
https://www.frontiersin.org/articles/10.3389/fnins.2018.00023/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
:format: (b,t,c,len) 不同于vision, audio中c为1, 并且没有h,w; 只有len=64
"""
sensor_size = tonic.datasets.NTIDIGITS.sensor_size
train_transform = transforms.Compose([
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: x.squeeze(1)
])
test_transform = transforms.Compose([
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: x.squeeze(1)
])
train_dataset = tonic.datasets.NTIDIGITS(os.path.join(DATA_DIR, 'DVS/NTIDIGITS'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.NTIDIGITS(os.path.join(DATA_DIR, 'DVS/NTIDIGITS'),
transform=test_transform, train=False)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, None, None
def get_shd_data(batch_size, step, **kwargs):
"""
获取SHD数据
https://ieeexplore.ieee.org/abstract/document/9311226
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
:format: (b,t,c,len) 不同于vision, audio中c为1, 并且没有h,w; 只有len=700. Transform后变为(b, t, len)
"""
sensor_size = tonic.datasets.SHD.sensor_size
train_transform = transforms.Compose([
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step)
])
test_transform = transforms.Compose([
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step)
])
train_dataset = tonic.datasets.SHD(os.path.join(DATA_DIR, 'DVS/SHD'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.SHD(os.path.join(DATA_DIR, 'DVS/SHD'),
transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: x.squeeze(1)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: x.squeeze(1)
])
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/SHD/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/SHD/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, None, None
def get_CUB2002011_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(root, 'CUB2002011')
train_datasets = CUB2002011(
root=root, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = CUB2002011(
root=root, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_StanfordCars_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(root, 'StanfordCars')
train_datasets = datasets.StanfordCars(
root=root, split ="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.StanfordCars(
root=root, split ="test", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_StanfordDogs_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(root, 'StanfordDogs')
train_datasets = StanfordDogs(
root=root, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = StanfordDogs(
root=root, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_FGVCAircraft_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(root, 'FGVCAircraft')
train_datasets = datasets.FGVCAircraft(
root=root, split="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.FGVCAircraft(
root=root, split="test", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_Flowers102_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(root, 'Flowers102')
train_datasets = datasets.Flowers102(
root=root, split="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.Flowers102(
root=root, split="test", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_UCF101DVS_data(batch_size, step, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = braincog.datasets.ucf101_dvs.UCF101DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.ucf101_dvs.UCF101DVS(os.path.join(DATA_DIR, 'UCF101DVS'), train=True, transform=train_transform)
test_dataset = braincog.datasets.ucf101_dvs.UCF101DVS(os.path.join(DATA_DIR, 'UCF101DVS'), train=False, transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
# transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'UCF101DVS/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'UCF101DVS/test_cache_{}'.format(step)),
transform=test_transform)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size, shuffle=False,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_HMDBDVS_data(batch_size, step, **kwargs):
sensor_size = braincog.datasets.hmdb_dvs.HMDBDVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.hmdb_dvs.HMDBDVS(os.path.join(DATA_DIR, 'HMDBDVS'), transform=train_transform)
test_dataset = braincog.datasets.hmdb_dvs.HMDBDVS(os.path.join(DATA_DIR, 'HMDBDVS'), transform=test_transform)
cls_count = train_dataset.cls_count
dataset_length = train_dataset.length
portion = .5
# portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += train_sample
train_sample_weight.extend(
[sample_weight] * train_sample
)
train_sample_weight.extend(
[0.] * test_sample
)
lst = list(range(idx_begin, idx_begin + train_sample + test_sample))
random.seed(0)
random.shuffle(lst)
train_sample_index.extend(
lst[:train_sample]
# list((range(idx_begin, idx_begin + train_sample)))
)
test_sample_index.extend(
lst[train_sample:train_sample + test_sample]
# list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: print(x.shape),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: temporal_flatten(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'HMDBDVS/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'HMDBDVS/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=train_sampler,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
================================================
FILE: braincog/datasets/gen_input_signal.py
================================================
import numpy as np
import random
import copy
dt = 1.0 # ms
lambda_max = 0.25 * dt # maximum spike rate (spikes per time step)
================================================
FILE: braincog/datasets/hmdb_dvs/__init__.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2023/1/30 20:54
# User : yu
# Product : PyCharm
# Project : BrainCog
# File : __init__.py
# explain :
from .hmdb_dvs import HMDBDVS
__all__ = [
'HMDBDVS'
]
================================================
FILE: braincog/datasets/hmdb_dvs/hmdb_dvs.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2023/1/30 20:54
# User : yu
# Product : PyCharm
# Project : BrainCog
# File : hmdb_dvs.py
# explain :
import os
import numpy as np
from numpy.lib import recfunctions
import scipy.io as scio
from typing import Tuple, Any, Optional
from tonic.dataset import Dataset
from tonic.download_utils import extract_archive
class HMDBDVS(Dataset):
"""ASL-DVS dataset . Events have (txyp) ordering.
::
@inproceedings{bi2019graph,
title={Graph-based Object Classification for Neuromorphic Vision Sensing},
author={Bi, Y and Chadha, A and Abbas, A and and Bourtsoulatze, E and Andreopoulos, Y},
booktitle={2019 IEEE International Conference on Computer Vision (ICCV)},
year={2019},
organization={IEEE}
}
Parameters:
save_to (string): Location to save files to on disk.
transform (callable, optional): A callable of transforms to apply to the data.
target_transform (callable, optional): A callable of transforms to apply to the targets/labels.
"""
sensor_size = (240, 180, 2)
dtype = np.dtype([("t", int), ("x", int), ("y", int), ("p", int)])
ordering = dtype.names
def __init__(self, save_to, transform=None, target_transform=None):
super(HMDBDVS, self).__init__(
save_to, transform=transform, target_transform=target_transform
)
if not self._check_exists():
raise NotImplementedError(
'Please manually download the dataset from'
' https://www.dropbox.com/sh/ie75dn246cacf6n/AACoU-_zkGOAwj51lSCM0JhGa?dl=0 '
'and extract it to {}'.format(self.location_on_system))
classes = os.listdir(self.location_on_system)
self.int_classes = dict(zip(classes, range(len(classes))))
for path, dirs, files in os.walk(self.location_on_system):
dirs.sort()
files.sort()
for file in files:
if file.endswith("mat"):
fsize = os.path.getsize(path + '/' + file) / float(1024)
if fsize < 1:
# print('{} size {} K'.format(file, fsize))
continue
self.data.append(path + "/" + file)
self.targets.append(self.int_classes[path.split('/')[-1]])
self.length = self.__len__()
self.cls_count = np.bincount(self.targets)
def __getitem__(self, index: int) -> Tuple[Any, Any]:
"""
Returns:
(events, target) where target is index of the target class.
"""
events, target = scio.loadmat(self.data[index]), self.targets[index]
events = np.column_stack(
[
events["ts"],
events["x"],
self.sensor_size[1] - 1 - events["y"],
events["pol"],
]
)
events = np.lib.recfunctions.unstructured_to_structured(events, self.dtype)
if self.transform is not None:
events = self.transform(events)
if self.target_transform is not None:
target = self.target_transform(target)
return events, target
def __len__(self):
return len(self.data)
def _check_exists(self):
return self._folder_contains_at_least_n_files_of_type(
6765, ".mat"
)
================================================
FILE: braincog/datasets/ncaltech101/__init__.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2023/1/30 21:26
# User : yu
# Product : PyCharm
# Project : BrainCog
# File : __init__.py.py
# explain :
from .ncaltech101 import NCALTECH101
__all__ = [
'NCALTECH101'
]
================================================
FILE: braincog/datasets/ncaltech101/ncaltech101.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2023/1/30 21:28
# User : yu
# Product : PyCharm
# Project : BrainCog
# File : ncaltech101.py
# explain :
import os
import numpy as np
from tonic.io import read_mnist_file
from tonic.dataset import Dataset
from tonic.download_utils import extract_archive
class NCALTECH101(Dataset):
"""N-CALTECH101 dataset . Events have (xytp) ordering.
::
@article{orchard2015converting,
title={Converting static image datasets to spiking neuromorphic datasets using saccades},
author={Orchard, Garrick and Jayawant, Ajinkya and Cohen, Gregory K and Thakor, Nitish},
journal={Frontiers in neuroscience},
volume={9},
pages={437},
year={2015},
publisher={Frontiers}
}
Parameters:
save_to (string): Location to save files to on disk.
transform (callable, optional): A callable of transforms to apply to the data.
target_transform (callable, optional): A callable of transforms to apply to the targets/labels.
"""
url = "https://data.mendeley.com/public-files/datasets/cy6cvx3ryv/files/36b5c52a-b49d-4853-addb-a836a8883e49/file_downloaded"
filename = "N-Caltech101-archive.zip"
file_md5 = "66201824eabb0239c7ab992480b50ba3"
data_filename = "N-Caltech101-archive.zip"
folder_name = "Caltech101"
cls_count = [467,
435, 200, 798, 55, 800, 42, 42, 47, 54, 46,
33, 128, 98, 43, 85, 91, 50, 43, 123, 47,
59, 62, 107, 47, 69, 73, 70, 50, 51, 57,
67, 52, 65, 68, 75, 64, 53, 64, 85, 67,
67, 45, 34, 34, 51, 99, 100, 42, 54, 88,
80, 31, 64, 86, 114, 61, 81, 78, 41, 66,
43, 40, 87, 32, 76, 55, 35, 39, 47, 38,
45, 53, 34, 57, 82, 59, 49, 40, 63, 39,
84, 57, 35, 64, 45, 86, 59, 64, 35, 85,
49, 86, 75, 239, 37, 59, 34, 56, 39, 60]
# length = 8242
length = 8709
sensor_size = None # all recordings are of different size
dtype = np.dtype([("x", int), ("y", int), ("t", int), ("p", int)])
ordering = dtype.names
def __init__(self, save_to, transform=None, target_transform=None):
super(NCALTECH101, self).__init__(
save_to, transform=transform, target_transform=target_transform
)
classes = {
'BACKGROUND_Google': 0,
'Faces_easy': 1,
'Leopards': 2,
'Motorbikes': 3,
'accordion': 4,
'airplanes': 5,
'anchor': 6,
'ant': 7,
'barrel': 8,
'bass': 9,
'beaver': 10,
'binocular': 11,
'bonsai': 12,
'brain': 13,
'brontosaurus': 14,
'buddha': 15,
'butterfly': 16,
'camera': 17,
'cannon': 18,
'car_side': 19,
'ceiling_fan': 20,
'cellphone': 21,
'chair': 22,
'chandelier': 23,
'cougar_body': 24,
'cougar_face': 25,
'crab': 26,
'crayfish': 27,
'crocodile': 28,
'crocodile_head': 29,
'cup': 30,
'dalmatian': 31,
'dollar_bill': 32,
'dolphin': 33,
'dragonfly': 34,
'electric_guitar': 35,
'elephant': 36,
'emu': 37,
'euphonium': 38,
'ewer': 39,
'ferry': 40,
'flamingo': 41,
'flamingo_head': 42,
'garfield': 43,
'gerenuk': 44,
'gramophone': 45,
'grand_piano': 46,
'hawksbill': 47,
'headphone': 48,
'hedgehog': 49,
'helicopter': 50,
'ibis': 51,
'inline_skate': 52,
'joshua_tree': 53,
'kangaroo': 54,
'ketch': 55,
'lamp': 56,
'laptop': 57,
'llama': 58,
'lobster': 59,
'lotus': 60,
'mandolin': 61,
'mayfly': 62,
'menorah': 63,
'metronome': 64,
'minaret': 65,
'nautilus': 66,
'octopus': 67,
'okapi': 68,
'pagoda': 69,
'panda': 70,
'pigeon': 71,
'pizza': 72,
'platypus': 73,
'pyramid': 74,
'revolver': 75,
'rhino': 76,
'rooster': 77,
'saxophone': 78,
'schooner': 79,
'scissors': 80,
'scorpion': 81,
'sea_horse': 82,
'snoopy': 83,
'soccer_ball': 84,
'stapler': 85,
'starfish': 86,
'stegosaurus': 87,
'stop_sign': 88,
'strawberry': 89,
'sunflower': 90,
'tick': 91,
'trilobite': 92,
'umbrella': 93,
'watch': 94,
'water_lilly': 95,
'wheelchair': 96,
'wild_cat': 97,
'windsor_chair': 98,
'wrench': 99,
'yin_yang': 100,
}
# if not self._check_exists():
# self.download()
# extract_archive(os.path.join(self.location_on_system, self.data_filename))
file_path = os.path.join(self.location_on_system, self.folder_name)
for path, dirs, files in os.walk(file_path):
dirs.sort()
# if 'BACKGROUND_Google' in path:
# continue
for file in files:
if file.endswith("bin"):
self.data.append(path + "/" + file)
label_name = os.path.basename(path)
if isinstance(label_name, bytes):
label_name = label_name.decode()
self.targets.append(classes[label_name])
def __getitem__(self, index):
"""
Returns:
a tuple of (events, target) where target is the index of the target class.
"""
events = read_mnist_file(self.data[index], dtype=self.dtype)
target = self.targets[index]
events["x"] -= events["x"].min()
events["y"] -= events["y"].min()
if self.transform is not None:
events = self.transform(events)
if self.target_transform is not None:
target = self.target_transform(target)
return events, target
def __len__(self):
return len(self.data)
def _check_exists(self):
return self._is_file_present() and self._folder_contains_at_least_n_files_of_type(
8709, ".bin"
)
================================================
FILE: braincog/datasets/rand_aug.py
================================================
import random
import numpy as np
import torch
from torchvision import transforms
from torchvision.transforms import functional
from torchvision.transforms import InterpolationMode
def ShearX(x, v): # [-0.3, 0.3]
assert 0 <= v <= 30
v = np.random.uniform(0, v)
if random.random() > 0.5:
v = -v
return functional.affine(x, angle=0, translate=[0, 0], scale=1., shear=[v, 0])
def ShearY(x, v): # [-0.3, 0.3]
assert 0 <= v <= 30
v = np.random.uniform(0, v)
if random.random() > 0.5:
v = -v
return functional.affine(x, angle=0, translate=[0, 0], scale=1., shear=[0, v])
def TranslateX(x, v):
assert 0 <= v <= 0.45
v = np.random.uniform(0, v)
w, h = x.shape[-2::]
v = round(w * v)
if random.random() > 0.5:
v = -v
return functional.affine(x, angle=0, translate=[0, v], scale=1., shear=[0, 0])
def TranslateY(x, v):
assert 0 <= v <= 0.45
v = np.random.uniform(0, v)
w, h = x.shape[-2::]
v = round(w * v)
if random.random() > 0.5:
v = -v
return functional.affine(x, angle=0, translate=[v, 0], scale=1., shear=[0, 0])
def Rotate(x, v): # [-30, 30]
assert 0 <= v <= 30
v = np.random.uniform(0, v)
if random.random() > 0.5:
v = -v
return functional.affine(x, angle=v, translate=[0, 0], scale=1., shear=[0, 0])
def CutoutAbs(x, v): # [0, 60] => percentage: [0, 0.2]
assert 0 <= v <= 0.5
w, h = x.shape[-2::]
v = round(v * w)
x0 = np.random.uniform(w)
y0 = np.random.uniform(h)
x0 = round(max(0, x0 - v / 2.))
y0 = round(max(0, y0 - v / 2.))
x1 = min(w, x0 + v)
y1 = min(h, y0 + v)
x[:, :, y0:y1, x0:x1] = 0.
return x
def CutoutTemporal(x, v):
assert 0 <= v <= 0.5
v = np.random.uniform(0, v)
step = x.shape[0]
v = round(v * step)
t0 = np.random.randint(step)
t1 = min(step, t0 + v)
x[t0:t1, :, :, :] = 0.
return x
def TemporalShift(x, v):
# TODO: Maybe shift too mach than origin has
assert 0 <= v <= 0.2
v = v / 2.
shape = x.shape
# p = torch.zeros(2 * (shape[0] - 1), *shape[-3:], device=x.device)
shift = []
for i in range(x.shape[0] - 1):
spike = x[i].clone()
_max = int(spike.max())
sft = torch.zeros(shape[-3:], device=x.device)
for j in range(_max):
p = torch.rand_like(sft)
sft[torch.logical_and(p < v, spike > 0.)] += 1.
spike -= 1
shift.append(sft)
spike = x[i + 1].clone()
_max = int(spike.max())
sft = torch.zeros(shape[-3:], device=x.device)
for j in range(_max):
p = torch.rand_like(sft)
sft[torch.logical_and(p < v, spike > 0.)] += 1.
shift.append(sft)
for i in range(shape[0] - 1):
sft_next = shift[i * 2]
sft_pre = shift[i * 2 + 1]
x[i + 1] = torch.clip(x[i + 1] + sft_next - sft_pre, 0.)
x[i] = torch.clip(x[i] - sft_next + sft_pre, 0.)
return x
def SpatioShift(x, v):
# assert 0 <= v <= 0.1
w, h = x.shape[-2::]
shift_x = round(random.uniform(-v, v) * w)
shift_y = round(random.uniform(-v, v) * h)
output = []
step = x.shape[0]
for t in range(step):
output.append(functional.affine(x[t],
angle=0,
translate=[
round(shift_x * t / step),
round(shift_y * t / step)],
scale=1.,
shear=[0, 0]))
return torch.stack(output, dim=0)
def drop(x, v):
assert 0 <= v <= 0.5
v = np.random.uniform(0, v)
_max = int(torch.max(x))
p = torch.rand((_max, *x.shape), device=x.device)
for i in range(_max):
p[i, x > 0] += 1.
x -= 1.
p = torch.where(p > 1. + v, 1., 0.)
return torch.sum(p, dim=0)
def GaussianBlur(x, v):
assert 0.1 <= v <= 1.
v = np.random.uniform(0.1, v)
return functional.gaussian_blur(x, kernel_size=[5, 5], sigma=v)
def SaltAndPepperNoise(x, v):
assert 0 <= v <= 0.3
v = np.random.uniform(0, v)
p = torch.rand_like(x)
p = torch.where(p > v, 0., 1.)
return x + p
def Identity(x, v):
return x
# DVSC10 NCAL
augment_list = [ # normal: 79.44 77.57
# (ShearX, 0, 20), # 75.71
# (ShearY, 0, 20),
# (TranslateX, 0, 0.25), # 77.52
# (TranslateY, 0, 0.25),
# (Rotate, 0, 30), # 77.02
(CutoutAbs, 0, 0.5), # 79.13
(CutoutTemporal, 0, 0.5), # 80.65
# (TemporalShift, 0, 0.2), # 75.30
# (SpatioShift, 0, 0.1), # 78.43
(GaussianBlur, 0, 1.), # 79.83
# (drop, 0, 0.5), # 74.00
(SaltAndPepperNoise, 0, 0.3), # 79.64
# cutmix_normal_aug: 90.02 86.52
]
class RandAugment:
def __init__(self, n, m):
self.n = n
self.m = m # [0, 30]
self.augment_list = augment_list
def __call__(self, x):
ops = random.choices(self.augment_list, k=self.n)
for op, minvalue, maxvalue in ops:
val = (float(self.m) / 30) * float(maxvalue - minvalue) + minvalue
x = op(x, val)
return x
================================================
FILE: braincog/datasets/scripts/testlist01.txt
================================================
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c01.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c02.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c03.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c04.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c05.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c06.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g02_c01.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g02_c02.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g02_c03.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g02_c04.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g03_c01.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g03_c02.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g03_c03.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g03_c04.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g03_c05.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g03_c06.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g04_c01.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g04_c02.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g04_c03.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g04_c04.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g04_c05.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g04_c06.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g04_c07.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g05_c01.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g05_c02.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g05_c03.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g05_c04.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g05_c05.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g05_c06.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g05_c07.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g06_c01.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g06_c02.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g06_c03.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g06_c04.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g06_c05.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g06_c06.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g06_c07.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c01.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c02.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c03.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c04.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c05.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c06.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c07.avi
ApplyLipstick/v_ApplyLipstick_g01_c01.avi
ApplyLipstick/v_ApplyLipstick_g01_c02.avi
ApplyLipstick/v_ApplyLipstick_g01_c03.avi
ApplyLipstick/v_ApplyLipstick_g01_c04.avi
ApplyLipstick/v_ApplyLipstick_g01_c05.avi
ApplyLipstick/v_ApplyLipstick_g02_c01.avi
ApplyLipstick/v_ApplyLipstick_g02_c02.avi
ApplyLipstick/v_ApplyLipstick_g02_c03.avi
ApplyLipstick/v_ApplyLipstick_g02_c04.avi
ApplyLipstick/v_ApplyLipstick_g03_c01.avi
ApplyLipstick/v_ApplyLipstick_g03_c02.avi
ApplyLipstick/v_ApplyLipstick_g03_c03.avi
ApplyLipstick/v_ApplyLipstick_g03_c04.avi
ApplyLipstick/v_ApplyLipstick_g04_c01.avi
ApplyLipstick/v_ApplyLipstick_g04_c02.avi
ApplyLipstick/v_ApplyLipstick_g04_c03.avi
ApplyLipstick/v_ApplyLipstick_g04_c04.avi
ApplyLipstick/v_ApplyLipstick_g04_c05.avi
ApplyLipstick/v_ApplyLipstick_g05_c01.avi
ApplyLipstick/v_ApplyLipstick_g05_c02.avi
ApplyLipstick/v_ApplyLipstick_g05_c03.avi
ApplyLipstick/v_ApplyLipstick_g05_c04.avi
ApplyLipstick/v_ApplyLipstick_g05_c05.avi
ApplyLipstick/v_ApplyLipstick_g06_c01.avi
ApplyLipstick/v_ApplyLipstick_g06_c02.avi
ApplyLipstick/v_ApplyLipstick_g06_c03.avi
ApplyLipstick/v_ApplyLipstick_g06_c04.avi
ApplyLipstick/v_ApplyLipstick_g06_c05.avi
ApplyLipstick/v_ApplyLipstick_g07_c01.avi
ApplyLipstick/v_ApplyLipstick_g07_c02.avi
ApplyLipstick/v_ApplyLipstick_g07_c03.avi
ApplyLipstick/v_ApplyLipstick_g07_c04.avi
Archery/v_Archery_g01_c01.avi
Archery/v_Archery_g01_c02.avi
Archery/v_Archery_g01_c03.avi
Archery/v_Archery_g01_c04.avi
Archery/v_Archery_g01_c05.avi
Archery/v_Archery_g01_c06.avi
Archery/v_Archery_g01_c07.avi
Archery/v_Archery_g02_c01.avi
Archery/v_Archery_g02_c02.avi
Archery/v_Archery_g02_c03.avi
Archery/v_Archery_g02_c04.avi
Archery/v_Archery_g02_c05.avi
Archery/v_Archery_g02_c06.avi
Archery/v_Archery_g02_c07.avi
Archery/v_Archery_g03_c01.avi
Archery/v_Archery_g03_c02.avi
Archery/v_Archery_g03_c03.avi
Archery/v_Archery_g03_c04.avi
Archery/v_Archery_g03_c05.avi
Archery/v_Archery_g04_c01.avi
Archery/v_Archery_g04_c02.avi
Archery/v_Archery_g04_c03.avi
Archery/v_Archery_g04_c04.avi
Archery/v_Archery_g04_c05.avi
Archery/v_Archery_g05_c01.avi
Archery/v_Archery_g05_c02.avi
Archery/v_Archery_g05_c03.avi
Archery/v_Archery_g05_c04.avi
Archery/v_Archery_g05_c05.avi
Archery/v_Archery_g06_c01.avi
Archery/v_Archery_g06_c02.avi
Archery/v_Archery_g06_c03.avi
Archery/v_Archery_g06_c04.avi
Archery/v_Archery_g06_c05.avi
Archery/v_Archery_g06_c06.avi
Archery/v_Archery_g07_c01.avi
Archery/v_Archery_g07_c02.avi
Archery/v_Archery_g07_c03.avi
Archery/v_Archery_g07_c04.avi
Archery/v_Archery_g07_c05.avi
Archery/v_Archery_g07_c06.avi
BabyCrawling/v_BabyCrawling_g01_c01.avi
BabyCrawling/v_BabyCrawling_g01_c02.avi
BabyCrawling/v_BabyCrawling_g01_c03.avi
BabyCrawling/v_BabyCrawling_g01_c04.avi
BabyCrawling/v_BabyCrawling_g02_c01.avi
BabyCrawling/v_BabyCrawling_g02_c02.avi
BabyCrawling/v_BabyCrawling_g02_c03.avi
BabyCrawling/v_BabyCrawling_g02_c04.avi
BabyCrawling/v_BabyCrawling_g02_c05.avi
BabyCrawling/v_BabyCrawling_g02_c06.avi
BabyCrawling/v_BabyCrawling_g03_c01.avi
BabyCrawling/v_BabyCrawling_g03_c02.avi
BabyCrawling/v_BabyCrawling_g03_c03.avi
BabyCrawling/v_BabyCrawling_g03_c04.avi
BabyCrawling/v_BabyCrawling_g04_c01.avi
BabyCrawling/v_BabyCrawling_g04_c02.avi
BabyCrawling/v_BabyCrawling_g04_c03.avi
BabyCrawling/v_BabyCrawling_g04_c04.avi
BabyCrawling/v_BabyCrawling_g05_c01.avi
BabyCrawling/v_BabyCrawling_g05_c02.avi
BabyCrawling/v_BabyCrawling_g05_c03.avi
BabyCrawling/v_BabyCrawling_g05_c04.avi
BabyCrawling/v_BabyCrawling_g05_c05.avi
BabyCrawling/v_BabyCrawling_g06_c01.avi
BabyCrawling/v_BabyCrawling_g06_c02.avi
BabyCrawling/v_BabyCrawling_g06_c03.avi
BabyCrawling/v_BabyCrawling_g06_c04.avi
BabyCrawling/v_BabyCrawling_g06_c05.avi
BabyCrawling/v_BabyCrawling_g06_c06.avi
BabyCrawling/v_BabyCrawling_g07_c01.avi
BabyCrawling/v_BabyCrawling_g07_c02.avi
BabyCrawling/v_BabyCrawling_g07_c03.avi
BabyCrawling/v_BabyCrawling_g07_c04.avi
BabyCrawling/v_BabyCrawling_g07_c05.avi
BabyCrawling/v_BabyCrawling_g07_c06.avi
BalanceBeam/v_BalanceBeam_g01_c01.avi
BalanceBeam/v_BalanceBeam_g01_c02.avi
BalanceBeam/v_BalanceBeam_g01_c03.avi
BalanceBeam/v_BalanceBeam_g01_c04.avi
BalanceBeam/v_BalanceBeam_g02_c01.avi
BalanceBeam/v_BalanceBeam_g02_c02.avi
BalanceBeam/v_BalanceBeam_g02_c03.avi
BalanceBeam/v_BalanceBeam_g02_c04.avi
BalanceBeam/v_BalanceBeam_g03_c01.avi
BalanceBeam/v_BalanceBeam_g03_c02.avi
BalanceBeam/v_BalanceBeam_g03_c03.avi
BalanceBeam/v_BalanceBeam_g03_c04.avi
BalanceBeam/v_BalanceBeam_g04_c01.avi
BalanceBeam/v_BalanceBeam_g04_c02.avi
BalanceBeam/v_BalanceBeam_g04_c03.avi
BalanceBeam/v_BalanceBeam_g04_c04.avi
BalanceBeam/v_BalanceBeam_g05_c01.avi
BalanceBeam/v_BalanceBeam_g05_c02.avi
BalanceBeam/v_BalanceBeam_g05_c03.avi
BalanceBeam/v_BalanceBeam_g05_c04.avi
BalanceBeam/v_BalanceBeam_g06_c01.avi
BalanceBeam/v_BalanceBeam_g06_c02.avi
BalanceBeam/v_BalanceBeam_g06_c03.avi
BalanceBeam/v_BalanceBeam_g06_c04.avi
BalanceBeam/v_BalanceBeam_g06_c05.avi
BalanceBeam/v_BalanceBeam_g06_c06.avi
BalanceBeam/v_BalanceBeam_g06_c07.avi
BalanceBeam/v_BalanceBeam_g07_c01.avi
BalanceBeam/v_BalanceBeam_g07_c02.avi
BalanceBeam/v_BalanceBeam_g07_c03.avi
BalanceBeam/v_BalanceBeam_g07_c04.avi
BandMarching/v_BandMarching_g01_c01.avi
BandMarching/v_BandMarching_g01_c02.avi
BandMarching/v_BandMarching_g01_c03.avi
BandMarching/v_BandMarching_g01_c04.avi
BandMarching/v_BandMarching_g01_c05.avi
BandMarching/v_BandMarching_g01_c06.avi
BandMarching/v_BandMarching_g01_c07.avi
BandMarching/v_BandMarching_g02_c01.avi
BandMarching/v_BandMarching_g02_c02.avi
BandMarching/v_BandMarching_g02_c03.avi
BandMarching/v_BandMarching_g02_c04.avi
BandMarching/v_BandMarching_g02_c05.avi
BandMarching/v_BandMarching_g02_c06.avi
BandMarching/v_BandMarching_g02_c07.avi
BandMarching/v_BandMarching_g03_c01.avi
BandMarching/v_BandMarching_g03_c02.avi
BandMarching/v_BandMarching_g03_c03.avi
BandMarching/v_BandMarching_g03_c04.avi
BandMarching/v_BandMarching_g03_c05.avi
BandMarching/v_BandMarching_g03_c06.avi
BandMarching/v_BandMarching_g03_c07.avi
BandMarching/v_BandMarching_g04_c01.avi
BandMarching/v_BandMarching_g04_c02.avi
BandMarching/v_BandMarching_g04_c03.avi
BandMarching/v_BandMarching_g04_c04.avi
BandMarching/v_BandMarching_g05_c01.avi
BandMarching/v_BandMarching_g05_c02.avi
BandMarching/v_BandMarching_g05_c03.avi
BandMarching/v_BandMarching_g05_c04.avi
BandMarching/v_BandMarching_g05_c05.avi
BandMarching/v_BandMarching_g05_c06.avi
BandMarching/v_BandMarching_g05_c07.avi
BandMarching/v_BandMarching_g06_c01.avi
BandMarching/v_BandMarching_g06_c02.avi
BandMarching/v_BandMarching_g06_c03.avi
BandMarching/v_BandMarching_g06_c04.avi
BandMarching/v_BandMarching_g07_c01.avi
BandMarching/v_BandMarching_g07_c02.avi
BandMarching/v_BandMarching_g07_c03.avi
BandMarching/v_BandMarching_g07_c04.avi
BandMarching/v_BandMarching_g07_c05.avi
BandMarching/v_BandMarching_g07_c06.avi
BandMarching/v_BandMarching_g07_c07.avi
BaseballPitch/v_BaseballPitch_g01_c01.avi
BaseballPitch/v_BaseballPitch_g01_c02.avi
BaseballPitch/v_BaseballPitch_g01_c03.avi
BaseballPitch/v_BaseballPitch_g01_c04.avi
BaseballPitch/v_BaseballPitch_g01_c05.avi
BaseballPitch/v_BaseballPitch_g01_c06.avi
BaseballPitch/v_BaseballPitch_g02_c01.avi
BaseballPitch/v_BaseballPitch_g02_c02.avi
BaseballPitch/v_BaseballPitch_g02_c03.avi
BaseballPitch/v_BaseballPitch_g02_c04.avi
BaseballPitch/v_BaseballPitch_g03_c01.avi
BaseballPitch/v_BaseballPitch_g03_c02.avi
BaseballPitch/v_BaseballPitch_g03_c03.avi
BaseballPitch/v_BaseballPitch_g03_c04.avi
BaseballPitch/v_BaseballPitch_g03_c05.avi
BaseballPitch/v_BaseballPitch_g03_c06.avi
BaseballPitch/v_BaseballPitch_g03_c07.avi
BaseballPitch/v_BaseballPitch_g04_c01.avi
BaseballPitch/v_BaseballPitch_g04_c02.avi
BaseballPitch/v_BaseballPitch_g04_c03.avi
BaseballPitch/v_BaseballPitch_g04_c04.avi
BaseballPitch/v_BaseballPitch_g04_c05.avi
BaseballPitch/v_BaseballPitch_g05_c01.avi
BaseballPitch/v_BaseballPitch_g05_c02.avi
BaseballPitch/v_BaseballPitch_g05_c03.avi
BaseballPitch/v_BaseballPitch_g05_c04.avi
BaseballPitch/v_BaseballPitch_g05_c05.avi
BaseballPitch/v_BaseballPitch_g05_c06.avi
BaseballPitch/v_BaseballPitch_g05_c07.avi
BaseballPitch/v_BaseballPitch_g06_c01.avi
BaseballPitch/v_BaseballPitch_g06_c02.avi
BaseballPitch/v_BaseballPitch_g06_c03.avi
BaseballPitch/v_BaseballPitch_g06_c04.avi
BaseballPitch/v_BaseballPitch_g06_c05.avi
BaseballPitch/v_BaseballPitch_g06_c06.avi
BaseballPitch/v_BaseballPitch_g06_c07.avi
BaseballPitch/v_BaseballPitch_g07_c01.avi
BaseballPitch/v_BaseballPitch_g07_c02.avi
BaseballPitch/v_BaseballPitch_g07_c03.avi
BaseballPitch/v_BaseballPitch_g07_c04.avi
BaseballPitch/v_BaseballPitch_g07_c05.avi
BaseballPitch/v_BaseballPitch_g07_c06.avi
BaseballPitch/v_BaseballPitch_g07_c07.avi
Basketball/v_Basketball_g01_c01.avi
Basketball/v_Basketball_g01_c02.avi
Basketball/v_Basketball_g01_c03.avi
Basketball/v_Basketball_g01_c04.avi
Basketball/v_Basketball_g01_c05.avi
Basketball/v_Basketball_g01_c06.avi
Basketball/v_Basketball_g01_c07.avi
Basketball/v_Basketball_g02_c01.avi
Basketball/v_Basketball_g02_c02.avi
Basketball/v_Basketball_g02_c03.avi
Basketball/v_Basketball_g02_c04.avi
Basketball/v_Basketball_g02_c05.avi
Basketball/v_Basketball_g02_c06.avi
Basketball/v_Basketball_g03_c01.avi
Basketball/v_Basketball_g03_c02.avi
Basketball/v_Basketball_g03_c03.avi
Basketball/v_Basketball_g03_c04.avi
Basketball/v_Basketball_g03_c05.avi
Basketball/v_Basketball_g03_c06.avi
Basketball/v_Basketball_g04_c01.avi
Basketball/v_Basketball_g04_c02.avi
Basketball/v_Basketball_g04_c03.avi
Basketball/v_Basketball_g04_c04.avi
Basketball/v_Basketball_g05_c01.avi
Basketball/v_Basketball_g05_c02.avi
Basketball/v_Basketball_g05_c03.avi
Basketball/v_Basketball_g05_c04.avi
Basketball/v_Basketball_g06_c01.avi
Basketball/v_Basketball_g06_c02.avi
Basketball/v_Basketball_g06_c03.avi
Basketball/v_Basketball_g06_c04.avi
Basketball/v_Basketball_g07_c01.avi
Basketball/v_Basketball_g07_c02.avi
Basketball/v_Basketball_g07_c03.avi
Basketball/v_Basketball_g07_c04.avi
BasketballDunk/v_BasketballDunk_g01_c01.avi
BasketballDunk/v_BasketballDunk_g01_c02.avi
BasketballDunk/v_BasketballDunk_g01_c03.avi
BasketballDunk/v_BasketballDunk_g01_c04.avi
BasketballDunk/v_BasketballDunk_g01_c05.avi
BasketballDunk/v_BasketballDunk_g01_c06.avi
BasketballDunk/v_BasketballDunk_g01_c07.avi
BasketballDunk/v_BasketballDunk_g02_c01.avi
BasketballDunk/v_BasketballDunk_g02_c02.avi
BasketballDunk/v_BasketballDunk_g02_c03.avi
BasketballDunk/v_BasketballDunk_g02_c04.avi
BasketballDunk/v_BasketballDunk_g03_c01.avi
BasketballDunk/v_BasketballDunk_g03_c02.avi
BasketballDunk/v_BasketballDunk_g03_c03.avi
BasketballDunk/v_BasketballDunk_g03_c04.avi
BasketballDunk/v_BasketballDunk_g03_c05.avi
BasketballDunk/v_BasketballDunk_g03_c06.avi
BasketballDunk/v_BasketballDunk_g04_c01.avi
BasketballDunk/v_BasketballDunk_g04_c02.avi
BasketballDunk/v_BasketballDunk_g04_c03.avi
BasketballDunk/v_BasketballDunk_g04_c04.avi
BasketballDunk/v_BasketballDunk_g05_c01.avi
BasketballDunk/v_BasketballDunk_g05_c02.avi
BasketballDunk/v_BasketballDunk_g05_c03.avi
BasketballDunk/v_BasketballDunk_g05_c04.avi
BasketballDunk/v_BasketballDunk_g05_c05.avi
BasketballDunk/v_BasketballDunk_g05_c06.avi
BasketballDunk/v_BasketballDunk_g06_c01.avi
BasketballDunk/v_BasketballDunk_g06_c02.avi
BasketballDunk/v_BasketballDunk_g06_c03.avi
BasketballDunk/v_BasketballDunk_g06_c04.avi
BasketballDunk/v_BasketballDunk_g07_c01.avi
BasketballDunk/v_BasketballDunk_g07_c02.avi
BasketballDunk/v_BasketballDunk_g07_c03.avi
BasketballDunk/v_BasketballDunk_g07_c04.avi
BasketballDunk/v_BasketballDunk_g07_c05.avi
BasketballDunk/v_BasketballDunk_g07_c06.avi
BenchPress/v_BenchPress_g01_c01.avi
BenchPress/v_BenchPress_g01_c02.avi
BenchPress/v_BenchPress_g01_c03.avi
BenchPress/v_BenchPress_g01_c04.avi
BenchPress/v_BenchPress_g01_c05.avi
BenchPress/v_BenchPress_g01_c06.avi
BenchPress/v_BenchPress_g02_c01.avi
BenchPress/v_BenchPress_g02_c02.avi
BenchPress/v_BenchPress_g02_c03.avi
BenchPress/v_BenchPress_g02_c04.avi
BenchPress/v_BenchPress_g02_c05.avi
BenchPress/v_BenchPress_g02_c06.avi
BenchPress/v_BenchPress_g02_c07.avi
BenchPress/v_BenchPress_g03_c01.avi
BenchPress/v_BenchPress_g03_c02.avi
BenchPress/v_BenchPress_g03_c03.avi
BenchPress/v_BenchPress_g03_c04.avi
BenchPress/v_BenchPress_g03_c05.avi
BenchPress/v_BenchPress_g03_c06.avi
BenchPress/v_BenchPress_g03_c07.avi
BenchPress/v_BenchPress_g04_c01.avi
BenchPress/v_BenchPress_g04_c02.avi
BenchPress/v_BenchPress_g04_c03.avi
BenchPress/v_BenchPress_g04_c04.avi
BenchPress/v_BenchPress_g04_c05.avi
BenchPress/v_BenchPress_g04_c06.avi
BenchPress/v_BenchPress_g04_c07.avi
BenchPress/v_BenchPress_g05_c01.avi
BenchPress/v_BenchPress_g05_c02.avi
BenchPress/v_BenchPress_g05_c03.avi
BenchPress/v_BenchPress_g05_c04.avi
BenchPress/v_BenchPress_g05_c05.avi
BenchPress/v_BenchPress_g05_c06.avi
BenchPress/v_BenchPress_g05_c07.avi
BenchPress/v_BenchPress_g06_c01.avi
BenchPress/v_BenchPress_g06_c02.avi
BenchPress/v_BenchPress_g06_c03.avi
BenchPress/v_BenchPress_g06_c04.avi
BenchPress/v_BenchPress_g06_c05.avi
BenchPress/v_BenchPress_g06_c06.avi
BenchPress/v_BenchPress_g06_c07.avi
BenchPress/v_BenchPress_g07_c01.avi
BenchPress/v_BenchPress_g07_c02.avi
BenchPress/v_BenchPress_g07_c03.avi
BenchPress/v_BenchPress_g07_c04.avi
BenchPress/v_BenchPress_g07_c05.avi
BenchPress/v_BenchPress_g07_c06.avi
BenchPress/v_BenchPress_g07_c07.avi
Biking/v_Biking_g01_c01.avi
Biking/v_Biking_g01_c02.avi
Biking/v_Biking_g01_c03.avi
Biking/v_Biking_g01_c04.avi
Biking/v_Biking_g02_c01.avi
Biking/v_Biking_g02_c02.avi
Biking/v_Biking_g02_c03.avi
Biking/v_Biking_g02_c04.avi
Biking/v_Biking_g02_c05.avi
Biking/v_Biking_g02_c06.avi
Biking/v_Biking_g02_c07.avi
Biking/v_Biking_g03_c01.avi
Biking/v_Biking_g03_c02.avi
Biking/v_Biking_g03_c03.avi
Biking/v_Biking_g03_c04.avi
Biking/v_Biking_g04_c01.avi
Biking/v_Biking_g04_c02.avi
Biking/v_Biking_g04_c03.avi
Biking/v_Biking_g04_c04.avi
Biking/v_Biking_g04_c05.avi
Biking/v_Biking_g05_c01.avi
Biking/v_Biking_g05_c02.avi
Biking/v_Biking_g05_c03.avi
Biking/v_Biking_g05_c04.avi
Biking/v_Biking_g05_c05.avi
Biking/v_Biking_g05_c06.avi
Biking/v_Biking_g05_c07.avi
Biking/v_Biking_g06_c01.avi
Biking/v_Biking_g06_c02.avi
Biking/v_Biking_g06_c03.avi
Biking/v_Biking_g06_c04.avi
Biking/v_Biking_g06_c05.avi
Biking/v_Biking_g07_c01.avi
Biking/v_Biking_g07_c02.avi
Biking/v_Biking_g07_c03.avi
Biking/v_Biking_g07_c04.avi
Biking/v_Biking_g07_c05.avi
Biking/v_Biking_g07_c06.avi
Billiards/v_Billiards_g01_c01.avi
Billiards/v_Billiards_g01_c02.avi
Billiards/v_Billiards_g01_c03.avi
Billiards/v_Billiards_g01_c04.avi
Billiards/v_Billiards_g01_c05.avi
Billiards/v_Billiards_g01_c06.avi
Billiards/v_Billiards_g02_c01.avi
Billiards/v_Billiards_g02_c02.avi
Billiards/v_Billiards_g02_c03.avi
Billiards/v_Billiards_g02_c04.avi
Billiards/v_Billiards_g02_c05.avi
Billiards/v_Billiards_g02_c06.avi
Billiards/v_Billiards_g02_c07.avi
Billiards/v_Billiards_g03_c01.avi
Billiards/v_Billiards_g03_c02.avi
Billiards/v_Billiards_g03_c03.avi
Billiards/v_Billiards_g03_c04.avi
Billiards/v_Billiards_g03_c05.avi
Billiards/v_Billiards_g04_c01.avi
Billiards/v_Billiards_g04_c02.avi
Billiards/v_Billiards_g04_c03.avi
Billiards/v_Billiards_g04_c04.avi
Billiards/v_Billiards_g04_c05.avi
Billiards/v_Billiards_g04_c06.avi
Billiards/v_Billiards_g04_c07.avi
Billiards/v_Billiards_g05_c01.avi
Billiards/v_Billiards_g05_c02.avi
Billiards/v_Billiards_g05_c03.avi
Billiards/v_Billiards_g05_c04.avi
Billiards/v_Billiards_g05_c05.avi
Billiards/v_Billiards_g05_c06.avi
Billiards/v_Billiards_g06_c01.avi
Billiards/v_Billiards_g06_c02.avi
Billiards/v_Billiards_g06_c03.avi
Billiards/v_Billiards_g06_c04.avi
Billiards/v_Billiards_g06_c05.avi
Billiards/v_Billiards_g07_c01.avi
Billiards/v_Billiards_g07_c02.avi
Billiards/v_Billiards_g07_c03.avi
Billiards/v_Billiards_g07_c04.avi
BlowDryHair/v_BlowDryHair_g01_c01.avi
BlowDryHair/v_BlowDryHair_g01_c02.avi
BlowDryHair/v_BlowDryHair_g01_c03.avi
BlowDryHair/v_BlowDryHair_g01_c04.avi
BlowDryHair/v_BlowDryHair_g02_c01.avi
BlowDryHair/v_BlowDryHair_g02_c02.avi
BlowDryHair/v_BlowDryHair_g02_c03.avi
BlowDryHair/v_BlowDryHair_g02_c04.avi
BlowDryHair/v_BlowDryHair_g02_c05.avi
BlowDryHair/v_BlowDryHair_g03_c01.avi
BlowDryHair/v_BlowDryHair_g03_c02.avi
BlowDryHair/v_BlowDryHair_g03_c03.avi
BlowDryHair/v_BlowDryHair_g03_c04.avi
BlowDryHair/v_BlowDryHair_g03_c05.avi
BlowDryHair/v_BlowDryHair_g04_c01.avi
BlowDryHair/v_BlowDryHair_g04_c02.avi
BlowDryHair/v_BlowDryHair_g04_c03.avi
BlowDryHair/v_BlowDryHair_g04_c04.avi
BlowDryHair/v_BlowDryHair_g04_c05.avi
BlowDryHair/v_BlowDryHair_g05_c01.avi
BlowDryHair/v_BlowDryHair_g05_c02.avi
BlowDryHair/v_BlowDryHair_g05_c03.avi
BlowDryHair/v_BlowDryHair_g05_c04.avi
BlowDryHair/v_BlowDryHair_g05_c05.avi
BlowDryHair/v_BlowDryHair_g06_c01.avi
BlowDryHair/v_BlowDryHair_g06_c02.avi
BlowDryHair/v_BlowDryHair_g06_c03.avi
BlowDryHair/v_BlowDryHair_g06_c04.avi
BlowDryHair/v_BlowDryHair_g06_c05.avi
BlowDryHair/v_BlowDryHair_g06_c06.avi
BlowDryHair/v_BlowDryHair_g06_c07.avi
BlowDryHair/v_BlowDryHair_g07_c01.avi
BlowDryHair/v_BlowDryHair_g07_c02.avi
BlowDryHair/v_BlowDryHair_g07_c03.avi
BlowDryHair/v_BlowDryHair_g07_c04.avi
BlowDryHair/v_BlowDryHair_g07_c05.avi
BlowDryHair/v_BlowDryHair_g07_c06.avi
BlowDryHair/v_BlowDryHair_g07_c07.avi
BlowingCandles/v_BlowingCandles_g01_c01.avi
BlowingCandles/v_BlowingCandles_g01_c02.avi
BlowingCandles/v_BlowingCandles_g01_c03.avi
BlowingCandles/v_BlowingCandles_g01_c04.avi
BlowingCandles/v_BlowingCandles_g02_c01.avi
BlowingCandles/v_BlowingCandles_g02_c02.avi
BlowingCandles/v_BlowingCandles_g02_c03.avi
BlowingCandles/v_BlowingCandles_g02_c04.avi
BlowingCandles/v_BlowingCandles_g03_c01.avi
BlowingCandles/v_BlowingCandles_g03_c02.avi
BlowingCandles/v_BlowingCandles_g03_c03.avi
BlowingCandles/v_BlowingCandles_g03_c04.avi
BlowingCandles/v_BlowingCandles_g04_c01.avi
BlowingCandles/v_BlowingCandles_g04_c02.avi
BlowingCandles/v_BlowingCandles_g04_c03.avi
BlowingCandles/v_BlowingCandles_g04_c04.avi
BlowingCandles/v_BlowingCandles_g04_c05.avi
BlowingCandles/v_BlowingCandles_g05_c01.avi
BlowingCandles/v_BlowingCandles_g05_c02.avi
BlowingCandles/v_BlowingCandles_g05_c03.avi
BlowingCandles/v_BlowingCandles_g05_c04.avi
BlowingCandles/v_BlowingCandles_g05_c05.avi
BlowingCandles/v_BlowingCandles_g06_c01.avi
BlowingCandles/v_BlowingCandles_g06_c02.avi
BlowingCandles/v_BlowingCandles_g06_c03.avi
BlowingCandles/v_BlowingCandles_g06_c04.avi
BlowingCandles/v_BlowingCandles_g06_c05.avi
BlowingCandles/v_BlowingCandles_g06_c06.avi
BlowingCandles/v_BlowingCandles_g06_c07.avi
BlowingCandles/v_BlowingCandles_g07_c01.avi
BlowingCandles/v_BlowingCandles_g07_c02.avi
BlowingCandles/v_BlowingCandles_g07_c03.avi
BlowingCandles/v_BlowingCandles_g07_c04.avi
BodyWeightSquats/v_BodyWeightSquats_g01_c01.avi
BodyWeightSquats/v_BodyWeightSquats_g01_c02.avi
BodyWeightSquats/v_BodyWeightSquats_g01_c03.avi
BodyWeightSquats/v_BodyWeightSquats_g01_c04.avi
BodyWeightSquats/v_BodyWeightSquats_g02_c01.avi
BodyWeightSquats/v_BodyWeightSquats_g02_c02.avi
BodyWeightSquats/v_BodyWeightSquats_g02_c03.avi
BodyWeightSquats/v_BodyWeightSquats_g02_c04.avi
BodyWeightSquats/v_BodyWeightSquats_g03_c01.avi
BodyWeightSquats/v_BodyWeightSquats_g03_c02.avi
BodyWeightSquats/v_BodyWeightSquats_g03_c03.avi
BodyWeightSquats/v_BodyWeightSquats_g03_c04.avi
BodyWeightSquats/v_BodyWeightSquats_g03_c05.avi
BodyWeightSquats/v_BodyWeightSquats_g04_c01.avi
BodyWeightSquats/v_BodyWeightSquats_g04_c02.avi
BodyWeightSquats/v_BodyWeightSquats_g04_c03.avi
BodyWeightSquats/v_BodyWeightSquats_g04_c04.avi
BodyWeightSquats/v_BodyWeightSquats_g05_c01.avi
BodyWeightSquats/v_BodyWeightSquats_g05_c02.avi
BodyWeightSquats/v_BodyWeightSquats_g05_c03.avi
BodyWeightSquats/v_BodyWeightSquats_g05_c04.avi
BodyWeightSquats/v_BodyWeightSquats_g06_c01.avi
BodyWeightSquats/v_BodyWeightSquats_g06_c02.avi
BodyWeightSquats/v_BodyWeightSquats_g06_c03.avi
BodyWeightSquats/v_BodyWeightSquats_g06_c04.avi
BodyWeightSquats/v_BodyWeightSquats_g06_c05.avi
BodyWeightSquats/v_BodyWeightSquats_g07_c01.avi
BodyWeightSquats/v_BodyWeightSquats_g07_c02.avi
BodyWeightSquats/v_BodyWeightSquats_g07_c03.avi
BodyWeightSquats/v_BodyWeightSquats_g07_c04.avi
Bowling/v_Bowling_g01_c01.avi
Bowling/v_Bowling_g01_c02.avi
Bowling/v_Bowling_g01_c03.avi
Bowling/v_Bowling_g01_c04.avi
Bowling/v_Bowling_g01_c05.avi
Bowling/v_Bowling_g01_c06.avi
Bowling/v_Bowling_g01_c07.avi
Bowling/v_Bowling_g02_c01.avi
Bowling/v_Bowling_g02_c02.avi
Bowling/v_Bowling_g02_c03.avi
Bowling/v_Bowling_g02_c04.avi
Bowling/v_Bowling_g03_c01.avi
Bowling/v_Bowling_g03_c02.avi
Bowling/v_Bowling_g03_c03.avi
Bowling/v_Bowling_g03_c04.avi
Bowling/v_Bowling_g03_c05.avi
Bowling/v_Bowling_g03_c06.avi
Bowling/v_Bowling_g03_c07.avi
Bowling/v_Bowling_g04_c01.avi
Bowling/v_Bowling_g04_c02.avi
Bowling/v_Bowling_g04_c03.avi
Bowling/v_Bowling_g04_c04.avi
Bowling/v_Bowling_g05_c01.avi
Bowling/v_Bowling_g05_c02.avi
Bowling/v_Bowling_g05_c03.avi
Bowling/v_Bowling_g05_c04.avi
Bowling/v_Bowling_g05_c05.avi
Bowling/v_Bowling_g05_c06.avi
Bowling/v_Bowling_g05_c07.avi
Bowling/v_Bowling_g06_c01.avi
Bowling/v_Bowling_g06_c02.avi
Bowling/v_Bowling_g06_c03.avi
Bowling/v_Bowling_g06_c04.avi
Bowling/v_Bowling_g06_c05.avi
Bowling/v_Bowling_g06_c06.avi
Bowling/v_Bowling_g06_c07.avi
Bowling/v_Bowling_g07_c01.avi
Bowling/v_Bowling_g07_c02.avi
Bowling/v_Bowling_g07_c03.avi
Bowling/v_Bowling_g07_c04.avi
Bowling/v_Bowling_g07_c05.avi
Bowling/v_Bowling_g07_c06.avi
Bowling/v_Bowling_g07_c07.avi
BoxingPunchingBag/v_BoxingPunchingBag_g01_c01.avi
BoxingPunchingBag/v_BoxingPunchingBag_g01_c02.avi
BoxingPunchingBag/v_BoxingPunchingBag_g01_c03.avi
BoxingPunchingBag/v_BoxingPunchingBag_g01_c04.avi
BoxingPunchingBag/v_BoxingPunchingBag_g01_c05.avi
BoxingPunchingBag/v_BoxingPunchingBag_g01_c06.avi
BoxingPunchingBag/v_BoxingPunchingBag_g01_c07.avi
BoxingPunchingBag/v_BoxingPunchingBag_g02_c01.avi
BoxingPunchingBag/v_BoxingPunchingBag_g02_c02.avi
BoxingPunchingBag/v_BoxingPunchingBag_g02_c03.avi
BoxingPunchingBag/v_BoxingPunchingBag_g02_c04.avi
BoxingPunchingBag/v_BoxingPunchingBag_g02_c05.avi
BoxingPunchingBag/v_BoxingPunchingBag_g02_c06.avi
BoxingPunchingBag/v_BoxingPunchingBag_g02_c07.avi
BoxingPunchingBag/v_BoxingPunchingBag_g03_c01.avi
BoxingPunchingBag/v_BoxingPunchingBag_g03_c02.avi
BoxingPunchingBag/v_BoxingPunchingBag_g03_c03.avi
BoxingPunchingBag/v_BoxingPunchingBag_g03_c04.avi
BoxingPunchingBag/v_BoxingPunchingBag_g03_c05.avi
BoxingPunchingBag/v_BoxingPunchingBag_g03_c06.avi
BoxingPunchingBag/v_BoxingPunchingBag_g03_c07.avi
BoxingPunchingBag/v_BoxingPunchingBag_g04_c01.avi
BoxingPunchingBag/v_BoxingPunchingBag_g04_c02.avi
BoxingPunchingBag/v_BoxingPunchingBag_g04_c03.avi
BoxingPunchingBag/v_BoxingPunchingBag_g04_c04.avi
BoxingPunchingBag/v_BoxingPunchingBag_g04_c05.avi
BoxingPunchingBag/v_BoxingPunchingBag_g04_c06.avi
BoxingPunchingBag/v_BoxingPunchingBag_g04_c07.avi
BoxingPunchingBag/v_BoxingPunchingBag_g05_c01.avi
BoxingPunchingBag/v_BoxingPunchingBag_g05_c02.avi
BoxingPunchingBag/v_BoxingPunchingBag_g05_c03.avi
BoxingPunchingBag/v_BoxingPunchingBag_g05_c04.avi
BoxingPunchingBag/v_BoxingPunchingBag_g05_c05.avi
BoxingPunchingBag/v_BoxingPunchingBag_g05_c06.avi
BoxingPunchingBag/v_BoxingPunchingBag_g05_c07.avi
BoxingPunchingBag/v_BoxingPunchingBag_g06_c01.avi
BoxingPunchingBag/v_BoxingPunchingBag_g06_c02.avi
BoxingPunchingBag/v_BoxingPunchingBag_g06_c03.avi
BoxingPunchingBag/v_BoxingPunchingBag_g06_c04.avi
BoxingPunchingBag/v_BoxingPunchingBag_g06_c05.avi
BoxingPunchingBag/v_BoxingPunchingBag_g06_c06.avi
BoxingPunchingBag/v_BoxingPunchingBag_g06_c07.avi
BoxingPunchingBag/v_BoxingPunchingBag_g07_c01.avi
BoxingPunchingBag/v_BoxingPunchingBag_g07_c02.avi
BoxingPunchingBag/v_BoxingPunchingBag_g07_c03.avi
BoxingPunchingBag/v_BoxingPunchingBag_g07_c04.avi
BoxingPunchingBag/v_BoxingPunchingBag_g07_c05.avi
BoxingPunchingBag/v_BoxingPunchingBag_g07_c06.avi
BoxingPunchingBag/v_BoxingPunchingBag_g07_c07.avi
BoxingSpeedBag/v_BoxingSpeedBag_g01_c01.avi
BoxingSpeedBag/v_BoxingSpeedBag_g01_c02.avi
BoxingSpeedBag/v_BoxingSpeedBag_g01_c03.avi
BoxingSpeedBag/v_BoxingSpeedBag_g01_c04.avi
BoxingSpeedBag/v_BoxingSpeedBag_g02_c01.avi
BoxingSpeedBag/v_BoxingSpeedBag_g02_c02.avi
BoxingSpeedBag/v_BoxingSpeedBag_g02_c03.avi
BoxingSpeedBag/v_BoxingSpeedBag_g02_c04.avi
BoxingSpeedBag/v_BoxingSpeedBag_g03_c01.avi
BoxingSpeedBag/v_BoxingSpeedBag_g03_c02.avi
BoxingSpeedBag/v_BoxingSpeedBag_g03_c03.avi
BoxingSpeedBag/v_BoxingSpeedBag_g03_c04.avi
BoxingSpeedBag/v_BoxingSpeedBag_g03_c05.avi
BoxingSpeedBag/v_BoxingSpeedBag_g04_c01.avi
BoxingSpeedBag/v_BoxingSpeedBag_g04_c02.avi
BoxingSpeedBag/v_BoxingSpeedBag_g04_c03.avi
BoxingSpeedBag/v_BoxingSpeedBag_g04_c04.avi
BoxingSpeedBag/v_BoxingSpeedBag_g04_c05.avi
BoxingSpeedBag/v_BoxingSpeedBag_g04_c06.avi
BoxingSpeedBag/v_BoxingSpeedBag_g04_c07.avi
BoxingSpeedBag/v_BoxingSpeedBag_g05_c01.avi
BoxingSpeedBag/v_BoxingSpeedBag_g05_c02.avi
BoxingSpeedBag/v_BoxingSpeedBag_g05_c03.avi
BoxingSpeedBag/v_BoxingSpeedBag_g05_c04.avi
BoxingSpeedBag/v_BoxingSpeedBag_g05_c05.avi
BoxingSpeedBag/v_BoxingSpeedBag_g06_c01.avi
BoxingSpeedBag/v_BoxingSpeedBag_g06_c02.avi
BoxingSpeedBag/v_BoxingSpeedBag_g06_c03.avi
BoxingSpeedBag/v_BoxingSpeedBag_g06_c04.avi
BoxingSpeedBag/v_BoxingSpeedBag_g06_c05.avi
BoxingSpeedBag/v_BoxingSpeedBag_g07_c01.avi
BoxingSpeedBag/v_BoxingSpeedBag_g07_c02.avi
BoxingSpeedBag/v_BoxingSpeedBag_g07_c03.avi
BoxingSpeedBag/v_BoxingSpeedBag_g07_c04.avi
BoxingSpeedBag/v_BoxingSpeedBag_g07_c05.avi
BoxingSpeedBag/v_BoxingSpeedBag_g07_c06.avi
BoxingSpeedBag/v_BoxingSpeedBag_g07_c07.avi
BreastStroke/v_BreastStroke_g01_c01.avi
BreastStroke/v_BreastStroke_g01_c02.avi
BreastStroke/v_BreastStroke_g01_c03.avi
BreastStroke/v_BreastStroke_g01_c04.avi
BreastStroke/v_BreastStroke_g02_c01.avi
BreastStroke/v_BreastStroke_g02_c02.avi
BreastStroke/v_BreastStroke_g02_c03.avi
BreastStroke/v_BreastStroke_g02_c04.avi
BreastStroke/v_BreastStroke_g03_c01.avi
BreastStroke/v_BreastStroke_g03_c02.avi
BreastStroke/v_BreastStroke_g03_c03.avi
BreastStroke/v_BreastStroke_g03_c04.avi
BreastStroke/v_BreastStroke_g04_c01.avi
BreastStroke/v_BreastStroke_g04_c02.avi
BreastStroke/v_BreastStroke_g04_c03.avi
BreastStroke/v_BreastStroke_g04_c04.avi
BreastStroke/v_BreastStroke_g05_c01.avi
BreastStroke/v_BreastStroke_g05_c02.avi
BreastStroke/v_BreastStroke_g05_c03.avi
BreastStroke/v_BreastStroke_g05_c04.avi
BreastStroke/v_BreastStroke_g06_c01.avi
BreastStroke/v_BreastStroke_g06_c02.avi
BreastStroke/v_BreastStroke_g06_c03.avi
BreastStroke/v_BreastStroke_g06_c04.avi
BreastStroke/v_BreastStroke_g07_c01.avi
BreastStroke/v_BreastStroke_g07_c02.avi
BreastStroke/v_BreastStroke_g07_c03.avi
BreastStroke/v_BreastStroke_g07_c04.avi
BrushingTeeth/v_BrushingTeeth_g01_c01.avi
BrushingTeeth/v_BrushingTeeth_g01_c02.avi
BrushingTeeth/v_BrushingTeeth_g01_c03.avi
BrushingTeeth/v_BrushingTeeth_g01_c04.avi
BrushingTeeth/v_BrushingTeeth_g02_c01.avi
BrushingTeeth/v_BrushingTeeth_g02_c02.avi
BrushingTeeth/v_BrushingTeeth_g02_c03.avi
BrushingTeeth/v_BrushingTeeth_g02_c04.avi
BrushingTeeth/v_BrushingTeeth_g02_c05.avi
BrushingTeeth/v_BrushingTeeth_g02_c06.avi
BrushingTeeth/v_BrushingTeeth_g02_c07.avi
BrushingTeeth/v_BrushingTeeth_g03_c01.avi
BrushingTeeth/v_BrushingTeeth_g03_c02.avi
BrushingTeeth/v_BrushingTeeth_g03_c03.avi
BrushingTeeth/v_BrushingTeeth_g03_c04.avi
BrushingTeeth/v_BrushingTeeth_g03_c05.avi
BrushingTeeth/v_BrushingTeeth_g04_c01.avi
BrushingTeeth/v_BrushingTeeth_g04_c02.avi
BrushingTeeth/v_BrushingTeeth_g04_c03.avi
BrushingTeeth/v_BrushingTeeth_g04_c04.avi
BrushingTeeth/v_BrushingTeeth_g05_c01.avi
BrushingTeeth/v_BrushingTeeth_g05_c02.avi
BrushingTeeth/v_BrushingTeeth_g05_c03.avi
BrushingTeeth/v_BrushingTeeth_g05_c04.avi
BrushingTeeth/v_BrushingTeeth_g05_c05.avi
BrushingTeeth/v_BrushingTeeth_g06_c01.avi
BrushingTeeth/v_BrushingTeeth_g06_c02.avi
BrushingTeeth/v_BrushingTeeth_g06_c03.avi
BrushingTeeth/v_BrushingTeeth_g06_c04.avi
BrushingTeeth/v_BrushingTeeth_g06_c05.avi
BrushingTeeth/v_BrushingTeeth_g07_c01.avi
BrushingTeeth/v_BrushingTeeth_g07_c02.avi
BrushingTeeth/v_BrushingTeeth_g07_c03.avi
BrushingTeeth/v_BrushingTeeth_g07_c04.avi
BrushingTeeth/v_BrushingTeeth_g07_c05.avi
BrushingTeeth/v_BrushingTeeth_g07_c06.avi
CleanAndJerk/v_CleanAndJerk_g01_c01.avi
CleanAndJerk/v_CleanAndJerk_g01_c02.avi
CleanAndJerk/v_CleanAndJerk_g01_c03.avi
CleanAndJerk/v_CleanAndJerk_g01_c04.avi
CleanAndJerk/v_CleanAndJerk_g01_c05.avi
CleanAndJerk/v_CleanAndJerk_g02_c01.avi
CleanAndJerk/v_CleanAndJerk_g02_c02.avi
CleanAndJerk/v_CleanAndJerk_g02_c03.avi
CleanAndJerk/v_CleanAndJerk_g02_c04.avi
CleanAndJerk/v_CleanAndJerk_g03_c01.avi
CleanAndJerk/v_CleanAndJerk_g03_c02.avi
CleanAndJerk/v_CleanAndJerk_g03_c03.avi
CleanAndJerk/v_CleanAndJerk_g03_c04.avi
CleanAndJerk/v_CleanAndJerk_g03_c05.avi
CleanAndJerk/v_CleanAndJerk_g03_c06.avi
CleanAndJerk/v_CleanAndJerk_g04_c01.avi
CleanAndJerk/v_CleanAndJerk_g04_c02.avi
CleanAndJerk/v_CleanAndJerk_g04_c03.avi
CleanAndJerk/v_CleanAndJerk_g04_c04.avi
CleanAndJerk/v_CleanAndJerk_g04_c05.avi
CleanAndJerk/v_CleanAndJerk_g05_c01.avi
CleanAndJerk/v_CleanAndJerk_g05_c02.avi
CleanAndJerk/v_CleanAndJerk_g05_c03.avi
CleanAndJerk/v_CleanAndJerk_g05_c04.avi
CleanAndJerk/v_CleanAndJerk_g06_c01.avi
CleanAndJerk/v_CleanAndJerk_g06_c02.avi
CleanAndJerk/v_CleanAndJerk_g06_c03.avi
CleanAndJerk/v_CleanAndJerk_g06_c04.avi
CleanAndJerk/v_CleanAndJerk_g07_c01.avi
CleanAndJerk/v_CleanAndJerk_g07_c02.avi
CleanAndJerk/v_CleanAndJerk_g07_c03.avi
CleanAndJerk/v_CleanAndJerk_g07_c04.avi
CleanAndJerk/v_CleanAndJerk_g07_c05.avi
CliffDiving/v_CliffDiving_g01_c01.avi
CliffDiving/v_CliffDiving_g01_c02.avi
CliffDiving/v_CliffDiving_g01_c03.avi
CliffDiving/v_CliffDiving_g01_c04.avi
CliffDiving/v_CliffDiving_g01_c05.avi
CliffDiving/v_CliffDiving_g01_c06.avi
CliffDiving/v_CliffDiving_g02_c01.avi
CliffDiving/v_CliffDiving_g02_c02.avi
CliffDiving/v_CliffDiving_g02_c03.avi
CliffDiving/v_CliffDiving_g02_c04.avi
CliffDiving/v_CliffDiving_g03_c01.avi
CliffDiving/v_CliffDiving_g03_c02.avi
CliffDiving/v_CliffDiving_g03_c03.avi
CliffDiving/v_CliffDiving_g03_c04.avi
CliffDiving/v_CliffDiving_g03_c05.avi
CliffDiving/v_CliffDiving_g04_c01.avi
CliffDiving/v_CliffDiving_g04_c02.avi
CliffDiving/v_CliffDiving_g04_c03.avi
CliffDiving/v_CliffDiving_g04_c04.avi
CliffDiving/v_CliffDiving_g05_c01.avi
CliffDiving/v_CliffDiving_g05_c02.avi
CliffDiving/v_CliffDiving_g05_c03.avi
CliffDiving/v_CliffDiving_g05_c04.avi
CliffDiving/v_CliffDiving_g05_c05.avi
CliffDiving/v_CliffDiving_g05_c06.avi
CliffDiving/v_CliffDiving_g05_c07.avi
CliffDiving/v_CliffDiving_g06_c01.avi
CliffDiving/v_CliffDiving_g06_c02.avi
CliffDiving/v_CliffDiving_g06_c03.avi
CliffDiving/v_CliffDiving_g06_c04.avi
CliffDiving/v_CliffDiving_g06_c05.avi
CliffDiving/v_CliffDiving_g06_c06.avi
CliffDiving/v_CliffDiving_g06_c07.avi
CliffDiving/v_CliffDiving_g07_c01.avi
CliffDiving/v_CliffDiving_g07_c02.avi
CliffDiving/v_CliffDiving_g07_c03.avi
CliffDiving/v_CliffDiving_g07_c04.avi
CliffDiving/v_CliffDiving_g07_c05.avi
CliffDiving/v_CliffDiving_g07_c06.avi
CricketBowling/v_CricketBowling_g01_c01.avi
CricketBowling/v_CricketBowling_g01_c02.avi
CricketBowling/v_CricketBowling_g01_c03.avi
CricketBowling/v_CricketBowling_g01_c04.avi
CricketBowling/v_CricketBowling_g01_c05.avi
CricketBowling/v_CricketBowling_g01_c06.avi
CricketBowling/v_CricketBowling_g01_c07.avi
CricketBowling/v_CricketBowling_g02_c01.avi
CricketBowling/v_CricketBowling_g02_c02.avi
CricketBowling/v_CricketBowling_g02_c03.avi
CricketBowling/v_CricketBowling_g02_c04.avi
CricketBowling/v_CricketBowling_g02_c05.avi
CricketBowling/v_CricketBowling_g02_c06.avi
CricketBowling/v_CricketBowling_g02_c07.avi
CricketBowling/v_CricketBowling_g03_c01.avi
CricketBowling/v_CricketBowling_g03_c02.avi
CricketBowling/v_CricketBowling_g03_c03.avi
CricketBowling/v_CricketBowling_g03_c04.avi
CricketBowling/v_CricketBowling_g04_c01.avi
CricketBowling/v_CricketBowling_g04_c02.avi
CricketBowling/v_CricketBowling_g04_c03.avi
CricketBowling/v_CricketBowling_g04_c04.avi
CricketBowling/v_CricketBowling_g04_c05.avi
CricketBowling/v_CricketBowling_g05_c01.avi
CricketBowling/v_CricketBowling_g05_c02.avi
CricketBowling/v_CricketBowling_g05_c03.avi
CricketBowling/v_CricketBowling_g05_c04.avi
CricketBowling/v_CricketBowling_g06_c01.avi
CricketBowling/v_CricketBowling_g06_c02.avi
CricketBowling/v_CricketBowling_g06_c03.avi
CricketBowling/v_CricketBowling_g06_c04.avi
CricketBowling/v_CricketBowling_g06_c05.avi
CricketBowling/v_CricketBowling_g07_c01.avi
CricketBowling/v_CricketBowling_g07_c02.avi
CricketBowling/v_CricketBowling_g07_c03.avi
CricketBowling/v_CricketBowling_g07_c04.avi
CricketShot/v_CricketShot_g01_c01.avi
CricketShot/v_CricketShot_g01_c02.avi
CricketShot/v_CricketShot_g01_c03.avi
CricketShot/v_CricketShot_g01_c04.avi
CricketShot/v_CricketShot_g01_c05.avi
CricketShot/v_CricketShot_g01_c06.avi
CricketShot/v_CricketShot_g01_c07.avi
CricketShot/v_CricketShot_g02_c01.avi
CricketShot/v_CricketShot_g02_c02.avi
CricketShot/v_CricketShot_g02_c03.avi
CricketShot/v_CricketShot_g02_c04.avi
CricketShot/v_CricketShot_g02_c05.avi
CricketShot/v_CricketShot_g02_c06.avi
CricketShot/v_CricketShot_g02_c07.avi
CricketShot/v_CricketShot_g03_c01.avi
CricketShot/v_CricketShot_g03_c02.avi
CricketShot/v_CricketShot_g03_c03.avi
CricketShot/v_CricketShot_g03_c04.avi
CricketShot/v_CricketShot_g03_c05.avi
CricketShot/v_CricketShot_g03_c06.avi
CricketShot/v_CricketShot_g03_c07.avi
CricketShot/v_CricketShot_g04_c01.avi
CricketShot/v_CricketShot_g04_c02.avi
CricketShot/v_CricketShot_g04_c03.avi
CricketShot/v_CricketShot_g04_c04.avi
CricketShot/v_CricketShot_g04_c05.avi
CricketShot/v_CricketShot_g04_c06.avi
CricketShot/v_CricketShot_g04_c07.avi
CricketShot/v_CricketShot_g05_c01.avi
CricketShot/v_CricketShot_g05_c02.avi
CricketShot/v_CricketShot_g05_c03.avi
CricketShot/v_CricketShot_g05_c04.avi
CricketShot/v_CricketShot_g05_c05.avi
CricketShot/v_CricketShot_g05_c06.avi
CricketShot/v_CricketShot_g05_c07.avi
CricketShot/v_CricketShot_g06_c01.avi
CricketShot/v_CricketShot_g06_c02.avi
CricketShot/v_CricketShot_g06_c03.avi
CricketShot/v_CricketShot_g06_c04.avi
CricketShot/v_CricketShot_g06_c05.avi
CricketShot/v_CricketShot_g06_c06.avi
CricketShot/v_CricketShot_g06_c07.avi
CricketShot/v_CricketShot_g07_c01.avi
CricketShot/v_CricketShot_g07_c02.avi
CricketShot/v_CricketShot_g07_c03.avi
CricketShot/v_CricketShot_g07_c04.avi
CricketShot/v_CricketShot_g07_c05.avi
CricketShot/v_CricketShot_g07_c06.avi
CricketShot/v_CricketShot_g07_c07.avi
CuttingInKitchen/v_CuttingInKitchen_g01_c01.avi
CuttingInKitchen/v_CuttingInKitchen_g01_c02.avi
CuttingInKitchen/v_CuttingInKitchen_g01_c03.avi
CuttingInKitchen/v_CuttingInKitchen_g01_c04.avi
CuttingInKitchen/v_CuttingInKitchen_g01_c05.avi
CuttingInKitchen/v_CuttingInKitchen_g02_c01.avi
CuttingInKitchen/v_CuttingInKitchen_g02_c02.avi
CuttingInKitchen/v_CuttingInKitchen_g02_c03.avi
CuttingInKitchen/v_CuttingInKitchen_g02_c04.avi
CuttingInKitchen/v_CuttingInKitchen_g03_c01.avi
CuttingInKitchen/v_CuttingInKitchen_g03_c02.avi
CuttingInKitchen/v_CuttingInKitchen_g03_c03.avi
CuttingInKitchen/v_CuttingInKitchen_g03_c04.avi
CuttingInKitchen/v_CuttingInKitchen_g04_c01.avi
CuttingInKitchen/v_CuttingInKitchen_g04_c02.avi
CuttingInKitchen/v_CuttingInKitchen_g04_c03.avi
CuttingInKitchen/v_CuttingInKitchen_g04_c04.avi
CuttingInKitchen/v_CuttingInKitchen_g04_c05.avi
CuttingInKitchen/v_CuttingInKitchen_g05_c01.avi
CuttingInKitchen/v_CuttingInKitchen_g05_c02.avi
CuttingInKitchen/v_CuttingInKitchen_g05_c03.avi
CuttingInKitchen/v_CuttingInKitchen_g05_c04.avi
CuttingInKitchen/v_CuttingInKitchen_g05_c05.avi
CuttingInKitchen/v_CuttingInKitchen_g05_c06.avi
CuttingInKitchen/v_CuttingInKitchen_g06_c01.avi
CuttingInKitchen/v_CuttingInKitchen_g06_c02.avi
CuttingInKitchen/v_CuttingInKitchen_g06_c03.avi
CuttingInKitchen/v_CuttingInKitchen_g06_c04.avi
CuttingInKitchen/v_CuttingInKitchen_g06_c05.avi
CuttingInKitchen/v_CuttingInKitchen_g07_c01.avi
CuttingInKitchen/v_CuttingInKitchen_g07_c02.avi
CuttingInKitchen/v_CuttingInKitchen_g07_c03.avi
CuttingInKitchen/v_CuttingInKitchen_g07_c04.avi
Diving/v_Diving_g01_c01.avi
Diving/v_Diving_g01_c02.avi
Diving/v_Diving_g01_c03.avi
Diving/v_Diving_g01_c04.avi
Diving/v_Diving_g01_c05.avi
Diving/v_Diving_g01_c06.avi
Diving/v_Diving_g01_c07.avi
Diving/v_Diving_g02_c01.avi
Diving/v_Diving_g02_c02.avi
Diving/v_Diving_g02_c03.avi
Diving/v_Diving_g02_c04.avi
Diving/v_Diving_g02_c05.avi
Diving/v_Diving_g02_c06.avi
Diving/v_Diving_g02_c07.avi
Diving/v_Diving_g03_c01.avi
Diving/v_Diving_g03_c02.avi
Diving/v_Diving_g03_c03.avi
Diving/v_Diving_g03_c04.avi
Diving/v_Diving_g03_c05.avi
Diving/v_Diving_g03_c06.avi
Diving/v_Diving_g03_c07.avi
Diving/v_Diving_g04_c01.avi
Diving/v_Diving_g04_c02.avi
Diving/v_Diving_g04_c03.avi
Diving/v_Diving_g04_c04.avi
Diving/v_Diving_g04_c05.avi
Diving/v_Diving_g04_c06.avi
Diving/v_Diving_g04_c07.avi
Diving/v_Diving_g05_c01.avi
Diving/v_Diving_g05_c02.avi
Diving/v_Diving_g05_c03.avi
Diving/v_Diving_g05_c04.avi
Diving/v_Diving_g05_c05.avi
Diving/v_Diving_g05_c06.avi
Diving/v_Diving_g06_c01.avi
Diving/v_Diving_g06_c02.avi
Diving/v_Diving_g06_c03.avi
Diving/v_Diving_g06_c04.avi
Diving/v_Diving_g06_c05.avi
Diving/v_Diving_g06_c06.avi
Diving/v_Diving_g06_c07.avi
Diving/v_Diving_g07_c01.avi
Diving/v_Diving_g07_c02.avi
Diving/v_Diving_g07_c03.avi
Diving/v_Diving_g07_c04.avi
Drumming/v_Drumming_g01_c01.avi
Drumming/v_Drumming_g01_c02.avi
Drumming/v_Drumming_g01_c03.avi
Drumming/v_Drumming_g01_c04.avi
Drumming/v_Drumming_g01_c05.avi
Drumming/v_Drumming_g01_c06.avi
Drumming/v_Drumming_g01_c07.avi
Drumming/v_Drumming_g02_c01.avi
Drumming/v_Drumming_g02_c02.avi
Drumming/v_Drumming_g02_c03.avi
Drumming/v_Drumming_g02_c04.avi
Drumming/v_Drumming_g02_c05.avi
Drumming/v_Drumming_g02_c06.avi
Drumming/v_Drumming_g02_c07.avi
Drumming/v_Drumming_g03_c01.avi
Drumming/v_Drumming_g03_c02.avi
Drumming/v_Drumming_g03_c03.avi
Drumming/v_Drumming_g03_c04.avi
Drumming/v_Drumming_g03_c05.avi
Drumming/v_Drumming_g04_c01.avi
Drumming/v_Drumming_g04_c02.avi
Drumming/v_Drumming_g04_c03.avi
Drumming/v_Drumming_g04_c04.avi
Drumming/v_Drumming_g04_c05.avi
Drumming/v_Drumming_g04_c06.avi
Drumming/v_Drumming_g04_c07.avi
Drumming/v_Drumming_g05_c01.avi
Drumming/v_Drumming_g05_c02.avi
Drumming/v_Drumming_g05_c03.avi
Drumming/v_Drumming_g05_c04.avi
Drumming/v_Drumming_g05_c05.avi
Drumming/v_Drumming_g05_c06.avi
Drumming/v_Drumming_g06_c01.avi
Drumming/v_Drumming_g06_c02.avi
Drumming/v_Drumming_g06_c03.avi
Drumming/v_Drumming_g06_c04.avi
Drumming/v_Drumming_g06_c05.avi
Drumming/v_Drumming_g06_c06.avi
Drumming/v_Drumming_g07_c01.avi
Drumming/v_Drumming_g07_c02.avi
Drumming/v_Drumming_g07_c03.avi
Drumming/v_Drumming_g07_c04.avi
Drumming/v_Drumming_g07_c05.avi
Drumming/v_Drumming_g07_c06.avi
Drumming/v_Drumming_g07_c07.avi
Fencing/v_Fencing_g01_c01.avi
Fencing/v_Fencing_g01_c02.avi
Fencing/v_Fencing_g01_c03.avi
Fencing/v_Fencing_g01_c04.avi
Fencing/v_Fencing_g01_c05.avi
Fencing/v_Fencing_g01_c06.avi
Fencing/v_Fencing_g02_c01.avi
Fencing/v_Fencing_g02_c02.avi
Fencing/v_Fencing_g02_c03.avi
Fencing/v_Fencing_g02_c04.avi
Fencing/v_Fencing_g02_c05.avi
Fencing/v_Fencing_g03_c01.avi
Fencing/v_Fencing_g03_c02.avi
Fencing/v_Fencing_g03_c03.avi
Fencing/v_Fencing_g03_c04.avi
Fencing/v_Fencing_g03_c05.avi
Fencing/v_Fencing_g04_c01.avi
Fencing/v_Fencing_g04_c02.avi
Fencing/v_Fencing_g04_c03.avi
Fencing/v_Fencing_g04_c04.avi
Fencing/v_Fencing_g04_c05.avi
Fencing/v_Fencing_g05_c01.avi
Fencing/v_Fencing_g05_c02.avi
Fencing/v_Fencing_g05_c03.avi
Fencing/v_Fencing_g05_c04.avi
Fencing/v_Fencing_g05_c05.avi
Fencing/v_Fencing_g06_c01.avi
Fencing/v_Fencing_g06_c02.avi
Fencing/v_Fencing_g06_c03.avi
Fencing/v_Fencing_g06_c04.avi
Fencing/v_Fencing_g07_c01.avi
Fencing/v_Fencing_g07_c02.avi
Fencing/v_Fencing_g07_c03.avi
Fencing/v_Fencing_g07_c04.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g01_c01.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g01_c02.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g01_c03.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g01_c04.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g01_c05.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g02_c01.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g02_c02.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g02_c03.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g02_c04.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g02_c05.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g02_c06.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g03_c01.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g03_c02.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g03_c03.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g03_c04.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g04_c01.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g04_c02.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g04_c03.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g04_c04.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g04_c05.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g04_c06.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g04_c07.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g05_c01.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g05_c02.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g05_c03.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g05_c04.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g05_c05.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g05_c06.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g05_c07.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g06_c01.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g06_c02.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g06_c03.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g06_c04.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g06_c05.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g06_c06.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g06_c07.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g07_c01.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g07_c02.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g07_c03.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g07_c04.avi
FloorGymnastics/v_FloorGymnastics_g01_c01.avi
FloorGymnastics/v_FloorGymnastics_g01_c02.avi
FloorGymnastics/v_FloorGymnastics_g01_c03.avi
FloorGymnastics/v_FloorGymnastics_g01_c04.avi
FloorGymnastics/v_FloorGymnastics_g01_c05.avi
FloorGymnastics/v_FloorGymnastics_g02_c01.avi
FloorGymnastics/v_FloorGymnastics_g02_c02.avi
FloorGymnastics/v_FloorGymnastics_g02_c03.avi
FloorGymnastics/v_FloorGymnastics_g02_c04.avi
FloorGymnastics/v_FloorGymnastics_g03_c01.avi
FloorGymnastics/v_FloorGymnastics_g03_c02.avi
FloorGymnastics/v_FloorGymnastics_g03_c03.avi
FloorGymnastics/v_FloorGymnastics_g03_c04.avi
FloorGymnastics/v_FloorGymnastics_g04_c01.avi
FloorGymnastics/v_FloorGymnastics_g04_c02.avi
FloorGymnastics/v_FloorGymnastics_g04_c03.avi
FloorGymnastics/v_FloorGymnastics_g04_c04.avi
FloorGymnastics/v_FloorGymnastics_g04_c05.avi
FloorGymnastics/v_FloorGymnastics_g05_c01.avi
FloorGymnastics/v_FloorGymnastics_g05_c02.avi
FloorGymnastics/v_FloorGymnastics_g05_c03.avi
FloorGymnastics/v_FloorGymnastics_g05_c04.avi
FloorGymnastics/v_FloorGymnastics_g06_c01.avi
FloorGymnastics/v_FloorGymnastics_g06_c02.avi
FloorGymnastics/v_FloorGymnastics_g06_c03.avi
FloorGymnastics/v_FloorGymnastics_g06_c04.avi
FloorGymnastics/v_FloorGymnastics_g06_c05.avi
FloorGymnastics/v_FloorGymnastics_g06_c06.avi
FloorGymnastics/v_FloorGymnastics_g06_c07.avi
FloorGymnastics/v_FloorGymnastics_g07_c01.avi
FloorGymnastics/v_FloorGymnastics_g07_c02.avi
FloorGymnastics/v_FloorGymnastics_g07_c03.avi
FloorGymnastics/v_FloorGymnastics_g07_c04.avi
FloorGymnastics/v_FloorGymnastics_g07_c05.avi
FloorGymnastics/v_FloorGymnastics_g07_c06.avi
FloorGymnastics/v_FloorGymnastics_g07_c07.avi
FrisbeeCatch/v_FrisbeeCatch_g01_c01.avi
FrisbeeCatch/v_FrisbeeCatch_g01_c02.avi
FrisbeeCatch/v_FrisbeeCatch_g01_c03.avi
FrisbeeCatch/v_FrisbeeCatch_g01_c04.avi
FrisbeeCatch/v_FrisbeeCatch_g01_c05.avi
FrisbeeCatch/v_FrisbeeCatch_g01_c06.avi
FrisbeeCatch/v_FrisbeeCatch_g02_c01.avi
FrisbeeCatch/v_FrisbeeCatch_g02_c02.avi
FrisbeeCatch/v_FrisbeeCatch_g02_c03.avi
FrisbeeCatch/v_FrisbeeCatch_g02_c04.avi
FrisbeeCatch/v_FrisbeeCatch_g02_c05.avi
FrisbeeCatch/v_FrisbeeCatch_g03_c01.avi
FrisbeeCatch/v_FrisbeeCatch_g03_c02.avi
FrisbeeCatch/v_FrisbeeCatch_g03_c03.avi
FrisbeeCatch/v_FrisbeeCatch_g03_c04.avi
FrisbeeCatch/v_FrisbeeCatch_g03_c05.avi
FrisbeeCatch/v_FrisbeeCatch_g04_c01.avi
FrisbeeCatch/v_FrisbeeCatch_g04_c02.avi
FrisbeeCatch/v_FrisbeeCatch_g04_c03.avi
FrisbeeCatch/v_FrisbeeCatch_g04_c04.avi
FrisbeeCatch/v_FrisbeeCatch_g04_c05.avi
FrisbeeCatch/v_FrisbeeCatch_g05_c01.avi
FrisbeeCatch/v_FrisbeeCatch_g05_c02.avi
FrisbeeCatch/v_FrisbeeCatch_g05_c03.avi
FrisbeeCatch/v_FrisbeeCatch_g05_c04.avi
FrisbeeCatch/v_FrisbeeCatch_g05_c05.avi
FrisbeeCatch/v_FrisbeeCatch_g06_c01.avi
FrisbeeCatch/v_FrisbeeCatch_g06_c02.avi
FrisbeeCatch/v_FrisbeeCatch_g06_c03.avi
FrisbeeCatch/v_FrisbeeCatch_g06_c04.avi
FrisbeeCatch/v_FrisbeeCatch_g06_c05.avi
FrisbeeCatch/v_FrisbeeCatch_g07_c01.avi
FrisbeeCatch/v_FrisbeeCatch_g07_c02.avi
FrisbeeCatch/v_FrisbeeCatch_g07_c03.avi
FrisbeeCatch/v_FrisbeeCatch_g07_c04.avi
FrisbeeCatch/v_FrisbeeCatch_g07_c05.avi
FrisbeeCatch/v_FrisbeeCatch_g07_c06.avi
FrontCrawl/v_FrontCrawl_g01_c01.avi
FrontCrawl/v_FrontCrawl_g01_c02.avi
FrontCrawl/v_FrontCrawl_g01_c03.avi
FrontCrawl/v_FrontCrawl_g01_c04.avi
FrontCrawl/v_FrontCrawl_g02_c01.avi
FrontCrawl/v_FrontCrawl_g02_c02.avi
FrontCrawl/v_FrontCrawl_g02_c03.avi
FrontCrawl/v_FrontCrawl_g02_c04.avi
FrontCrawl/v_FrontCrawl_g03_c01.avi
FrontCrawl/v_FrontCrawl_g03_c02.avi
FrontCrawl/v_FrontCrawl_g03_c03.avi
FrontCrawl/v_FrontCrawl_g03_c04.avi
FrontCrawl/v_FrontCrawl_g03_c05.avi
FrontCrawl/v_FrontCrawl_g03_c06.avi
FrontCrawl/v_FrontCrawl_g04_c01.avi
FrontCrawl/v_FrontCrawl_g04_c02.avi
FrontCrawl/v_FrontCrawl_g04_c03.avi
FrontCrawl/v_FrontCrawl_g04_c04.avi
FrontCrawl/v_FrontCrawl_g04_c05.avi
FrontCrawl/v_FrontCrawl_g04_c06.avi
FrontCrawl/v_FrontCrawl_g04_c07.avi
FrontCrawl/v_FrontCrawl_g05_c01.avi
FrontCrawl/v_FrontCrawl_g05_c02.avi
FrontCrawl/v_FrontCrawl_g05_c03.avi
FrontCrawl/v_FrontCrawl_g05_c04.avi
FrontCrawl/v_FrontCrawl_g06_c01.avi
FrontCrawl/v_FrontCrawl_g06_c02.avi
FrontCrawl/v_FrontCrawl_g06_c03.avi
FrontCrawl/v_FrontCrawl_g06_c04.avi
FrontCrawl/v_FrontCrawl_g06_c05.avi
FrontCrawl/v_FrontCrawl_g07_c01.avi
FrontCrawl/v_FrontCrawl_g07_c02.avi
FrontCrawl/v_FrontCrawl_g07_c03.avi
FrontCrawl/v_FrontCrawl_g07_c04.avi
FrontCrawl/v_FrontCrawl_g07_c05.avi
FrontCrawl/v_FrontCrawl_g07_c06.avi
FrontCrawl/v_FrontCrawl_g07_c07.avi
GolfSwing/v_GolfSwing_g01_c01.avi
GolfSwing/v_GolfSwing_g01_c02.avi
GolfSwing/v_GolfSwing_g01_c03.avi
GolfSwing/v_GolfSwing_g01_c04.avi
GolfSwing/v_GolfSwing_g01_c05.avi
GolfSwing/v_GolfSwing_g01_c06.avi
GolfSwing/v_GolfSwing_g02_c01.avi
GolfSwing/v_GolfSwing_g02_c02.avi
GolfSwing/v_GolfSwing_g02_c03.avi
GolfSwing/v_GolfSwing_g02_c04.avi
GolfSwing/v_GolfSwing_g03_c01.avi
GolfSwing/v_GolfSwing_g03_c02.avi
GolfSwing/v_GolfSwing_g03_c03.avi
GolfSwing/v_GolfSwing_g03_c04.avi
GolfSwing/v_GolfSwing_g03_c05.avi
GolfSwing/v_GolfSwing_g03_c06.avi
GolfSwing/v_GolfSwing_g03_c07.avi
GolfSwing/v_GolfSwing_g04_c01.avi
GolfSwing/v_GolfSwing_g04_c02.avi
GolfSwing/v_GolfSwing_g04_c03.avi
GolfSwing/v_GolfSwing_g04_c04.avi
GolfSwing/v_GolfSwing_g04_c05.avi
GolfSwing/v_GolfSwing_g04_c06.avi
GolfSwing/v_GolfSwing_g05_c01.avi
GolfSwing/v_GolfSwing_g05_c02.avi
GolfSwing/v_GolfSwing_g05_c03.avi
GolfSwing/v_GolfSwing_g05_c04.avi
GolfSwing/v_GolfSwing_g05_c05.avi
GolfSwing/v_GolfSwing_g05_c06.avi
GolfSwing/v_GolfSwing_g05_c07.avi
GolfSwing/v_GolfSwing_g06_c01.avi
GolfSwing/v_GolfSwing_g06_c02.avi
GolfSwing/v_GolfSwing_g06_c03.avi
GolfSwing/v_GolfSwing_g06_c04.avi
GolfSwing/v_GolfSwing_g07_c01.avi
GolfSwing/v_GolfSwing_g07_c02.avi
GolfSwing/v_GolfSwing_g07_c03.avi
GolfSwing/v_GolfSwing_g07_c04.avi
GolfSwing/v_GolfSwing_g07_c05.avi
Haircut/v_Haircut_g01_c01.avi
Haircut/v_Haircut_g01_c02.avi
Haircut/v_Haircut_g01_c03.avi
Haircut/v_Haircut_g01_c04.avi
Haircut/v_Haircut_g02_c01.avi
Haircut/v_Haircut_g02_c02.avi
Haircut/v_Haircut_g02_c03.avi
Haircut/v_Haircut_g02_c04.avi
Haircut/v_Haircut_g03_c01.avi
Haircut/v_Haircut_g03_c02.avi
Haircut/v_Haircut_g03_c03.avi
Haircut/v_Haircut_g03_c04.avi
Haircut/v_Haircut_g03_c05.avi
Haircut/v_Haircut_g03_c06.avi
Haircut/v_Haircut_g04_c01.avi
Haircut/v_Haircut_g04_c02.avi
Haircut/v_Haircut_g04_c03.avi
Haircut/v_Haircut_g04_c04.avi
Haircut/v_Haircut_g04_c05.avi
Haircut/v_Haircut_g05_c01.avi
Haircut/v_Haircut_g05_c02.avi
Haircut/v_Haircut_g05_c03.avi
Haircut/v_Haircut_g05_c04.avi
Haircut/v_Haircut_g06_c01.avi
Haircut/v_Haircut_g06_c02.avi
Haircut/v_Haircut_g06_c03.avi
Haircut/v_Haircut_g06_c04.avi
Haircut/v_Haircut_g07_c01.avi
Haircut/v_Haircut_g07_c02.avi
Haircut/v_Haircut_g07_c03.avi
Haircut/v_Haircut_g07_c04.avi
Haircut/v_Haircut_g07_c05.avi
Haircut/v_Haircut_g07_c06.avi
Hammering/v_Hammering_g01_c01.avi
Hammering/v_Hammering_g01_c02.avi
Hammering/v_Hammering_g01_c03.avi
Hammering/v_Hammering_g01_c04.avi
Hammering/v_Hammering_g02_c01.avi
Hammering/v_Hammering_g02_c02.avi
Hammering/v_Hammering_g02_c03.avi
Hammering/v_Hammering_g02_c04.avi
Hammering/v_Hammering_g03_c01.avi
Hammering/v_Hammering_g03_c02.avi
Hammering/v_Hammering_g03_c03.avi
Hammering/v_Hammering_g03_c04.avi
Hammering/v_Hammering_g03_c05.avi
Hammering/v_Hammering_g04_c01.avi
Hammering/v_Hammering_g04_c02.avi
Hammering/v_Hammering_g04_c03.avi
Hammering/v_Hammering_g04_c04.avi
Hammering/v_Hammering_g04_c05.avi
Hammering/v_Hammering_g05_c01.avi
Hammering/v_Hammering_g05_c02.avi
Hammering/v_Hammering_g05_c03.avi
Hammering/v_Hammering_g05_c04.avi
Hammering/v_Hammering_g06_c01.avi
Hammering/v_Hammering_g06_c02.avi
Hammering/v_Hammering_g06_c03.avi
Hammering/v_Hammering_g06_c04.avi
Hammering/v_Hammering_g06_c05.avi
Hammering/v_Hammering_g06_c06.avi
Hammering/v_Hammering_g07_c01.avi
Hammering/v_Hammering_g07_c02.avi
Hammering/v_Hammering_g07_c03.avi
Hammering/v_Hammering_g07_c04.avi
Hammering/v_Hammering_g07_c05.avi
HammerThrow/v_HammerThrow_g01_c01.avi
HammerThrow/v_HammerThrow_g01_c02.avi
HammerThrow/v_HammerThrow_g01_c03.avi
HammerThrow/v_HammerThrow_g01_c04.avi
HammerThrow/v_HammerThrow_g01_c05.avi
HammerThrow/v_HammerThrow_g01_c06.avi
HammerThrow/v_HammerThrow_g02_c01.avi
HammerThrow/v_HammerThrow_g02_c02.avi
HammerThrow/v_HammerThrow_g02_c03.avi
HammerThrow/v_HammerThrow_g02_c04.avi
HammerThrow/v_HammerThrow_g02_c05.avi
HammerThrow/v_HammerThrow_g02_c06.avi
HammerThrow/v_HammerThrow_g02_c07.avi
HammerThrow/v_HammerThrow_g03_c01.avi
HammerThrow/v_HammerThrow_g03_c02.avi
HammerThrow/v_HammerThrow_g03_c03.avi
HammerThrow/v_HammerThrow_g03_c04.avi
HammerThrow/v_HammerThrow_g03_c05.avi
HammerThrow/v_HammerThrow_g03_c06.avi
HammerThrow/v_HammerThrow_g03_c07.avi
HammerThrow/v_HammerThrow_g04_c01.avi
HammerThrow/v_HammerThrow_g04_c02.avi
HammerThrow/v_HammerThrow_g04_c03.avi
HammerThrow/v_HammerThrow_g04_c04.avi
HammerThrow/v_HammerThrow_g04_c05.avi
HammerThrow/v_HammerThrow_g04_c06.avi
HammerThrow/v_HammerThrow_g04_c07.avi
HammerThrow/v_HammerThrow_g05_c01.avi
HammerThrow/v_HammerThrow_g05_c02.avi
HammerThrow/v_HammerThrow_g05_c03.avi
HammerThrow/v_HammerThrow_g05_c04.avi
HammerThrow/v_HammerThrow_g05_c05.avi
HammerThrow/v_HammerThrow_g05_c06.avi
HammerThrow/v_HammerThrow_g06_c01.avi
HammerThrow/v_HammerThrow_g06_c02.avi
HammerThrow/v_HammerThrow_g06_c03.avi
HammerThrow/v_HammerThrow_g06_c04.avi
HammerThrow/v_HammerThrow_g06_c05.avi
HammerThrow/v_HammerThrow_g06_c06.avi
HammerThrow/v_HammerThrow_g06_c07.avi
HammerThrow/v_HammerThrow_g07_c01.avi
HammerThrow/v_HammerThrow_g07_c02.avi
HammerThrow/v_HammerThrow_g07_c03.avi
HammerThrow/v_HammerThrow_g07_c04.avi
HammerThrow/v_HammerThrow_g07_c05.avi
HandstandPushups/v_HandStandPushups_g01_c01.avi
HandstandPushups/v_HandStandPushups_g01_c02.avi
HandstandPushups/v_HandStandPushups_g01_c03.avi
HandstandPushups/v_HandStandPushups_g01_c04.avi
HandstandPushups/v_HandStandPushups_g02_c01.avi
HandstandPushups/v_HandStandPushups_g02_c02.avi
HandstandPushups/v_HandStandPushups_g02_c03.avi
HandstandPushups/v_HandStandPushups_g02_c04.avi
HandstandPushups/v_HandStandPushups_g03_c01.avi
HandstandPushups/v_HandStandPushups_g03_c02.avi
HandstandPushups/v_HandStandPushups_g03_c03.avi
HandstandPushups/v_HandStandPushups_g03_c04.avi
HandstandPushups/v_HandStandPushups_g04_c01.avi
HandstandPushups/v_HandStandPushups_g04_c02.avi
HandstandPushups/v_HandStandPushups_g04_c03.avi
HandstandPushups/v_HandStandPushups_g04_c04.avi
HandstandPushups/v_HandStandPushups_g05_c01.avi
HandstandPushups/v_HandStandPushups_g05_c02.avi
HandstandPushups/v_HandStandPushups_g05_c03.avi
HandstandPushups/v_HandStandPushups_g05_c04.avi
HandstandPushups/v_HandStandPushups_g06_c01.avi
HandstandPushups/v_HandStandPushups_g06_c02.avi
HandstandPushups/v_HandStandPushups_g06_c03.avi
HandstandPushups/v_HandStandPushups_g06_c04.avi
HandstandPushups/v_HandStandPushups_g07_c01.avi
HandstandPushups/v_HandStandPushups_g07_c02.avi
HandstandPushups/v_HandStandPushups_g07_c03.avi
HandstandPushups/v_HandStandPushups_g07_c04.avi
HandstandWalking/v_HandstandWalking_g01_c01.avi
HandstandWalking/v_HandstandWalking_g01_c02.avi
HandstandWalking/v_HandstandWalking_g01_c03.avi
HandstandWalking/v_HandstandWalking_g01_c04.avi
HandstandWalking/v_HandstandWalking_g02_c01.avi
HandstandWalking/v_HandstandWalking_g02_c02.avi
HandstandWalking/v_HandstandWalking_g02_c03.avi
HandstandWalking/v_HandstandWalking_g02_c04.avi
HandstandWalking/v_HandstandWalking_g03_c01.avi
HandstandWalking/v_HandstandWalking_g03_c02.avi
HandstandWalking/v_HandstandWalking_g03_c03.avi
HandstandWalking/v_HandstandWalking_g03_c04.avi
HandstandWalking/v_HandstandWalking_g04_c01.avi
HandstandWalking/v_HandstandWalking_g04_c02.avi
HandstandWalking/v_HandstandWalking_g04_c03.avi
HandstandWalking/v_HandstandWalking_g04_c04.avi
HandstandWalking/v_HandstandWalking_g04_c05.avi
HandstandWalking/v_HandstandWalking_g05_c01.avi
HandstandWalking/v_HandstandWalking_g05_c02.avi
HandstandWalking/v_HandstandWalking_g05_c03.avi
HandstandWalking/v_HandstandWalking_g05_c04.avi
HandstandWalking/v_HandstandWalking_g05_c05.avi
HandstandWalking/v_HandstandWalking_g05_c06.avi
HandstandWalking/v_HandstandWalking_g05_c07.avi
HandstandWalking/v_HandstandWalking_g06_c01.avi
HandstandWalking/v_HandstandWalking_g06_c02.avi
HandstandWalking/v_HandstandWalking_g06_c03.avi
HandstandWalking/v_HandstandWalking_g06_c04.avi
HandstandWalking/v_HandstandWalking_g07_c01.avi
HandstandWalking/v_HandstandWalking_g07_c02.avi
HandstandWalking/v_HandstandWalking_g07_c03.avi
HandstandWalking/v_HandstandWalking_g07_c04.avi
HandstandWalking/v_HandstandWalking_g07_c05.avi
HandstandWalking/v_HandstandWalking_g07_c06.avi
HeadMassage/v_HeadMassage_g01_c01.avi
HeadMassage/v_HeadMassage_g01_c02.avi
HeadMassage/v_HeadMassage_g01_c03.avi
HeadMassage/v_HeadMassage_g01_c04.avi
HeadMassage/v_HeadMassage_g01_c05.avi
HeadMassage/v_HeadMassage_g02_c01.avi
HeadMassage/v_HeadMassage_g02_c02.avi
HeadMassage/v_HeadMassage_g02_c03.avi
HeadMassage/v_HeadMassage_g02_c04.avi
HeadMassage/v_HeadMassage_g02_c05.avi
HeadMassage/v_HeadMassage_g02_c06.avi
HeadMassage/v_HeadMassage_g02_c07.avi
HeadMassage/v_HeadMassage_g03_c01.avi
HeadMassage/v_HeadMassage_g03_c02.avi
HeadMassage/v_HeadMassage_g03_c03.avi
HeadMassage/v_HeadMassage_g03_c04.avi
HeadMassage/v_HeadMassage_g03_c05.avi
HeadMassage/v_HeadMassage_g03_c06.avi
HeadMassage/v_HeadMassage_g03_c07.avi
HeadMassage/v_HeadMassage_g04_c01.avi
HeadMassage/v_HeadMassage_g04_c02.avi
HeadMassage/v_HeadMassage_g04_c03.avi
HeadMassage/v_HeadMassage_g04_c04.avi
HeadMassage/v_HeadMassage_g05_c01.avi
HeadMassage/v_HeadMassage_g05_c02.avi
HeadMassage/v_HeadMassage_g05_c03.avi
HeadMassage/v_HeadMassage_g05_c04.avi
HeadMassage/v_HeadMassage_g05_c05.avi
HeadMassage/v_HeadMassage_g05_c06.avi
HeadMassage/v_HeadMassage_g06_c01.avi
HeadMassage/v_HeadMassage_g06_c02.avi
HeadMassage/v_HeadMassage_g06_c03.avi
HeadMassage/v_HeadMassage_g06_c04.avi
HeadMassage/v_HeadMassage_g06_c05.avi
HeadMassage/v_HeadMassage_g06_c06.avi
HeadMassage/v_HeadMassage_g06_c07.avi
HeadMassage/v_HeadMassage_g07_c01.avi
HeadMassage/v_HeadMassage_g07_c02.avi
HeadMassage/v_HeadMassage_g07_c03.avi
HeadMassage/v_HeadMassage_g07_c04.avi
HeadMassage/v_HeadMassage_g07_c05.avi
HighJump/v_HighJump_g01_c01.avi
HighJump/v_HighJump_g01_c02.avi
HighJump/v_HighJump_g01_c03.avi
HighJump/v_HighJump_g01_c04.avi
HighJump/v_HighJump_g01_c05.avi
HighJump/v_HighJump_g02_c01.avi
HighJump/v_HighJump_g02_c02.avi
HighJump/v_HighJump_g02_c03.avi
HighJump/v_HighJump_g02_c04.avi
HighJump/v_HighJump_g02_c05.avi
HighJump/v_HighJump_g02_c06.avi
HighJump/v_HighJump_g02_c07.avi
HighJump/v_HighJump_g03_c01.avi
HighJump/v_HighJump_g03_c02.avi
HighJump/v_HighJump_g03_c03.avi
HighJump/v_HighJump_g03_c04.avi
HighJump/v_HighJump_g04_c01.avi
HighJump/v_HighJump_g04_c02.avi
HighJump/v_HighJump_g04_c03.avi
HighJump/v_HighJump_g04_c04.avi
HighJump/v_HighJump_g04_c05.avi
HighJump/v_HighJump_g04_c06.avi
HighJump/v_HighJump_g05_c01.avi
HighJump/v_HighJump_g05_c02.avi
HighJump/v_HighJump_g05_c03.avi
HighJump/v_HighJump_g05_c04.avi
HighJump/v_HighJump_g05_c05.avi
HighJump/v_HighJump_g06_c01.avi
HighJump/v_HighJump_g06_c02.avi
HighJump/v_HighJump_g06_c03.avi
HighJump/v_HighJump_g06_c04.avi
HighJump/v_HighJump_g07_c01.avi
HighJump/v_HighJump_g07_c02.avi
HighJump/v_HighJump_g07_c03.avi
HighJump/v_HighJump_g07_c04.avi
HighJump/v_HighJump_g07_c05.avi
HighJump/v_HighJump_g07_c06.avi
HorseRace/v_HorseRace_g01_c01.avi
HorseRace/v_HorseRace_g01_c02.avi
HorseRace/v_HorseRace_g01_c03.avi
HorseRace/v_HorseRace_g01_c04.avi
HorseRace/v_HorseRace_g02_c01.avi
HorseRace/v_HorseRace_g02_c02.avi
HorseRace/v_HorseRace_g02_c03.avi
HorseRace/v_HorseRace_g02_c04.avi
HorseRace/v_HorseRace_g03_c01.avi
HorseRace/v_HorseRace_g03_c02.avi
HorseRace/v_HorseRace_g03_c03.avi
HorseRace/v_HorseRace_g03_c04.avi
HorseRace/v_HorseRace_g03_c05.avi
HorseRace/v_HorseRace_g04_c01.avi
HorseRace/v_HorseRace_g04_c02.avi
HorseRace/v_HorseRace_g04_c03.avi
HorseRace/v_HorseRace_g04_c04.avi
HorseRace/v_HorseRace_g04_c05.avi
HorseRace/v_HorseRace_g04_c06.avi
HorseRace/v_HorseRace_g05_c01.avi
HorseRace/v_HorseRace_g05_c02.avi
HorseRace/v_HorseRace_g05_c03.avi
HorseRace/v_HorseRace_g05_c04.avi
HorseRace/v_HorseRace_g06_c01.avi
HorseRace/v_HorseRace_g06_c02.avi
HorseRace/v_HorseRace_g06_c03.avi
HorseRace/v_HorseRace_g06_c04.avi
HorseRace/v_HorseRace_g06_c05.avi
HorseRace/v_HorseRace_g06_c06.avi
HorseRace/v_HorseRace_g07_c01.avi
HorseRace/v_HorseRace_g07_c02.avi
HorseRace/v_HorseRace_g07_c03.avi
HorseRace/v_HorseRace_g07_c04.avi
HorseRace/v_HorseRace_g07_c05.avi
HorseRace/v_HorseRace_g07_c06.avi
HorseRiding/v_HorseRiding_g01_c01.avi
HorseRiding/v_HorseRiding_g01_c02.avi
HorseRiding/v_HorseRiding_g01_c03.avi
HorseRiding/v_HorseRiding_g01_c04.avi
HorseRiding/v_HorseRiding_g01_c05.avi
HorseRiding/v_HorseRiding_g01_c06.avi
HorseRiding/v_HorseRiding_g01_c07.avi
HorseRiding/v_HorseRiding_g02_c01.avi
HorseRiding/v_HorseRiding_g02_c02.avi
HorseRiding/v_HorseRiding_g02_c03.avi
HorseRiding/v_HorseRiding_g02_c04.avi
HorseRiding/v_HorseRiding_g02_c05.avi
HorseRiding/v_HorseRiding_g02_c06.avi
HorseRiding/v_HorseRiding_g02_c07.avi
HorseRiding/v_HorseRiding_g03_c01.avi
HorseRiding/v_HorseRiding_g03_c02.avi
HorseRiding/v_HorseRiding_g03_c03.avi
HorseRiding/v_HorseRiding_g03_c04.avi
HorseRiding/v_HorseRiding_g03_c05.avi
HorseRiding/v_HorseRiding_g03_c06.avi
HorseRiding/v_HorseRiding_g03_c07.avi
HorseRiding/v_HorseRiding_g04_c01.avi
HorseRiding/v_HorseRiding_g04_c02.avi
HorseRiding/v_HorseRiding_g04_c03.avi
HorseRiding/v_HorseRiding_g04_c04.avi
HorseRiding/v_HorseRiding_g04_c05.avi
HorseRiding/v_HorseRiding_g04_c06.avi
HorseRiding/v_HorseRiding_g04_c07.avi
HorseRiding/v_HorseRiding_g05_c01.avi
HorseRiding/v_HorseRiding_g05_c02.avi
HorseRiding/v_HorseRiding_g05_c03.avi
HorseRiding/v_HorseRiding_g05_c04.avi
HorseRiding/v_HorseRiding_g05_c05.avi
HorseRiding/v_HorseRiding_g05_c06.avi
HorseRiding/v_HorseRiding_g05_c07.avi
HorseRiding/v_HorseRiding_g06_c01.avi
HorseRiding/v_HorseRiding_g06_c02.avi
HorseRiding/v_HorseRiding_g06_c03.avi
HorseRiding/v_HorseRiding_g06_c04.avi
HorseRiding/v_HorseRiding_g06_c05.avi
HorseRiding/v_HorseRiding_g06_c06.avi
HorseRiding/v_HorseRiding_g06_c07.avi
HorseRiding/v_HorseRiding_g07_c01.avi
HorseRiding/v_HorseRiding_g07_c02.avi
HorseRiding/v_HorseRiding_g07_c03.avi
HorseRiding/v_HorseRiding_g07_c04.avi
HorseRiding/v_HorseRiding_g07_c05.avi
HorseRiding/v_HorseRiding_g07_c06.avi
HorseRiding/v_HorseRiding_g07_c07.avi
HulaHoop/v_HulaHoop_g01_c01.avi
HulaHoop/v_HulaHoop_g01_c02.avi
HulaHoop/v_HulaHoop_g01_c03.avi
HulaHoop/v_HulaHoop_g01_c04.avi
HulaHoop/v_HulaHoop_g01_c05.avi
HulaHoop/v_HulaHoop_g01_c06.avi
HulaHoop/v_HulaHoop_g01_c07.avi
HulaHoop/v_HulaHoop_g02_c01.avi
HulaHoop/v_HulaHoop_g02_c02.avi
HulaHoop/v_HulaHoop_g02_c03.avi
HulaHoop/v_HulaHoop_g02_c04.avi
HulaHoop/v_HulaHoop_g03_c01.avi
HulaHoop/v_HulaHoop_g03_c02.avi
HulaHoop/v_HulaHoop_g03_c03.avi
HulaHoop/v_HulaHoop_g03_c04.avi
HulaHoop/v_HulaHoop_g03_c05.avi
HulaHoop/v_HulaHoop_g04_c01.avi
HulaHoop/v_HulaHoop_g04_c02.avi
HulaHoop/v_HulaHoop_g04_c03.avi
HulaHoop/v_HulaHoop_g04_c04.avi
HulaHoop/v_HulaHoop_g04_c05.avi
HulaHoop/v_HulaHoop_g05_c01.avi
HulaHoop/v_HulaHoop_g05_c02.avi
HulaHoop/v_HulaHoop_g05_c03.avi
HulaHoop/v_HulaHoop_g05_c04.avi
HulaHoop/v_HulaHoop_g06_c01.avi
HulaHoop/v_HulaHoop_g06_c02.avi
HulaHoop/v_HulaHoop_g06_c03.avi
HulaHoop/v_HulaHoop_g06_c04.avi
HulaHoop/v_HulaHoop_g07_c01.avi
HulaHoop/v_HulaHoop_g07_c02.avi
HulaHoop/v_HulaHoop_g07_c03.avi
HulaHoop/v_HulaHoop_g07_c04.avi
HulaHoop/v_HulaHoop_g07_c05.avi
IceDancing/v_IceDancing_g01_c01.avi
IceDancing/v_IceDancing_g01_c02.avi
IceDancing/v_IceDancing_g01_c03.avi
IceDancing/v_IceDancing_g01_c04.avi
IceDancing/v_IceDancing_g01_c05.avi
IceDancing/v_IceDancing_g01_c06.avi
IceDancing/v_IceDancing_g01_c07.avi
IceDancing/v_IceDancing_g02_c01.avi
IceDancing/v_IceDancing_g02_c02.avi
IceDancing/v_IceDancing_g02_c03.avi
IceDancing/v_IceDancing_g02_c04.avi
IceDancing/v_IceDancing_g02_c05.avi
IceDancing/v_IceDancing_g02_c06.avi
IceDancing/v_IceDancing_g02_c07.avi
IceDancing/v_IceDancing_g03_c01.avi
IceDancing/v_IceDancing_g03_c02.avi
IceDancing/v_IceDancing_g03_c03.avi
IceDancing/v_IceDancing_g03_c04.avi
IceDancing/v_IceDancing_g03_c05.avi
IceDancing/v_IceDancing_g03_c06.avi
IceDancing/v_IceDancing_g04_c01.avi
IceDancing/v_IceDancing_g04_c02.avi
IceDancing/v_IceDancing_g04_c03.avi
IceDancing/v_IceDancing_g04_c04.avi
IceDancing/v_IceDancing_g04_c05.avi
IceDancing/v_IceDancing_g04_c06.avi
IceDancing/v_IceDancing_g04_c07.avi
IceDancing/v_IceDancing_g05_c01.avi
IceDancing/v_IceDancing_g05_c02.avi
IceDancing/v_IceDancing_g05_c03.avi
IceDancing/v_IceDancing_g05_c04.avi
IceDancing/v_IceDancing_g05_c05.avi
IceDancing/v_IceDancing_g05_c06.avi
IceDancing/v_IceDancing_g06_c01.avi
IceDancing/v_IceDancing_g06_c02.avi
IceDancing/v_IceDancing_g06_c03.avi
IceDancing/v_IceDancing_g06_c04.avi
IceDancing/v_IceDancing_g06_c05.avi
IceDancing/v_IceDancing_g06_c06.avi
IceDancing/v_IceDancing_g07_c01.avi
IceDancing/v_IceDancing_g07_c02.avi
IceDancing/v_IceDancing_g07_c03.avi
IceDancing/v_IceDancing_g07_c04.avi
IceDancing/v_IceDancing_g07_c05.avi
IceDancing/v_IceDancing_g07_c06.avi
IceDancing/v_IceDancing_g07_c07.avi
JavelinThrow/v_JavelinThrow_g01_c01.avi
JavelinThrow/v_JavelinThrow_g01_c02.avi
JavelinThrow/v_JavelinThrow_g01_c03.avi
JavelinThrow/v_JavelinThrow_g01_c04.avi
JavelinThrow/v_JavelinThrow_g02_c01.avi
JavelinThrow/v_JavelinThrow_g02_c02.avi
JavelinThrow/v_JavelinThrow_g02_c03.avi
JavelinThrow/v_JavelinThrow_g02_c04.avi
JavelinThrow/v_JavelinThrow_g03_c01.avi
JavelinThrow/v_JavelinThrow_g03_c02.avi
JavelinThrow/v_JavelinThrow_g03_c03.avi
JavelinThrow/v_JavelinThrow_g03_c04.avi
JavelinThrow/v_JavelinThrow_g04_c01.avi
JavelinThrow/v_JavelinThrow_g04_c02.avi
JavelinThrow/v_JavelinThrow_g04_c03.avi
JavelinThrow/v_JavelinThrow_g04_c04.avi
JavelinThrow/v_JavelinThrow_g05_c01.avi
JavelinThrow/v_JavelinThrow_g05_c02.avi
JavelinThrow/v_JavelinThrow_g05_c03.avi
JavelinThrow/v_JavelinThrow_g05_c04.avi
JavelinThrow/v_JavelinThrow_g05_c05.avi
JavelinThrow/v_JavelinThrow_g05_c06.avi
JavelinThrow/v_JavelinThrow_g06_c01.avi
JavelinThrow/v_JavelinThrow_g06_c02.avi
JavelinThrow/v_JavelinThrow_g06_c03.avi
JavelinThrow/v_JavelinThrow_g06_c04.avi
JavelinThrow/v_JavelinThrow_g07_c01.avi
JavelinThrow/v_JavelinThrow_g07_c02.avi
JavelinThrow/v_JavelinThrow_g07_c03.avi
JavelinThrow/v_JavelinThrow_g07_c04.avi
JavelinThrow/v_JavelinThrow_g07_c05.avi
JugglingBalls/v_JugglingBalls_g01_c01.avi
JugglingBalls/v_JugglingBalls_g01_c02.avi
JugglingBalls/v_JugglingBalls_g01_c03.avi
JugglingBalls/v_JugglingBalls_g01_c04.avi
JugglingBalls/v_JugglingBalls_g02_c01.avi
JugglingBalls/v_JugglingBalls_g02_c02.avi
JugglingBalls/v_JugglingBalls_g02_c03.avi
JugglingBalls/v_JugglingBalls_g02_c04.avi
JugglingBalls/v_JugglingBalls_g02_c05.avi
JugglingBalls/v_JugglingBalls_g02_c06.avi
JugglingBalls/v_JugglingBalls_g03_c01.avi
JugglingBalls/v_JugglingBalls_g03_c02.avi
JugglingBalls/v_JugglingBalls_g03_c03.avi
JugglingBalls/v_JugglingBalls_g03_c04.avi
JugglingBalls/v_JugglingBalls_g03_c05.avi
JugglingBalls/v_JugglingBalls_g03_c06.avi
JugglingBalls/v_JugglingBalls_g03_c07.avi
JugglingBalls/v_JugglingBalls_g04_c01.avi
JugglingBalls/v_JugglingBalls_g04_c02.avi
JugglingBalls/v_JugglingBalls_g04_c03.avi
JugglingBalls/v_JugglingBalls_g04_c04.avi
JugglingBalls/v_JugglingBalls_g04_c05.avi
JugglingBalls/v_JugglingBalls_g05_c01.avi
JugglingBalls/v_JugglingBalls_g05_c02.avi
JugglingBalls/v_JugglingBalls_g05_c03.avi
JugglingBalls/v_JugglingBalls_g05_c04.avi
JugglingBalls/v_JugglingBalls_g05_c05.avi
JugglingBalls/v_JugglingBalls_g06_c01.avi
JugglingBalls/v_JugglingBalls_g06_c02.avi
JugglingBalls/v_JugglingBalls_g06_c03.avi
JugglingBalls/v_JugglingBalls_g06_c04.avi
JugglingBalls/v_JugglingBalls_g06_c05.avi
JugglingBalls/v_JugglingBalls_g06_c06.avi
JugglingBalls/v_JugglingBalls_g07_c01.avi
JugglingBalls/v_JugglingBalls_g07_c02.avi
JugglingBalls/v_JugglingBalls_g07_c03.avi
JugglingBalls/v_JugglingBalls_g07_c04.avi
JugglingBalls/v_JugglingBalls_g07_c05.avi
JugglingBalls/v_JugglingBalls_g07_c06.avi
JugglingBalls/v_JugglingBalls_g07_c07.avi
JumpingJack/v_JumpingJack_g01_c01.avi
JumpingJack/v_JumpingJack_g01_c02.avi
JumpingJack/v_JumpingJack_g01_c03.avi
JumpingJack/v_JumpingJack_g01_c04.avi
JumpingJack/v_JumpingJack_g01_c05.avi
JumpingJack/v_JumpingJack_g01_c06.avi
JumpingJack/v_JumpingJack_g01_c07.avi
JumpingJack/v_JumpingJack_g02_c01.avi
JumpingJack/v_JumpingJack_g02_c02.avi
JumpingJack/v_JumpingJack_g02_c03.avi
JumpingJack/v_JumpingJack_g02_c04.avi
JumpingJack/v_JumpingJack_g03_c01.avi
JumpingJack/v_JumpingJack_g03_c02.avi
JumpingJack/v_JumpingJack_g03_c03.avi
JumpingJack/v_JumpingJack_g03_c04.avi
JumpingJack/v_JumpingJack_g04_c01.avi
JumpingJack/v_JumpingJack_g04_c02.avi
JumpingJack/v_JumpingJack_g04_c03.avi
JumpingJack/v_JumpingJack_g04_c04.avi
JumpingJack/v_JumpingJack_g05_c01.avi
JumpingJack/v_JumpingJack_g05_c02.avi
JumpingJack/v_JumpingJack_g05_c03.avi
JumpingJack/v_JumpingJack_g05_c04.avi
JumpingJack/v_JumpingJack_g05_c05.avi
JumpingJack/v_JumpingJack_g05_c06.avi
JumpingJack/v_JumpingJack_g06_c01.avi
JumpingJack/v_JumpingJack_g06_c02.avi
JumpingJack/v_JumpingJack_g06_c03.avi
JumpingJack/v_JumpingJack_g06_c04.avi
JumpingJack/v_JumpingJack_g06_c05.avi
JumpingJack/v_JumpingJack_g06_c06.avi
JumpingJack/v_JumpingJack_g06_c07.avi
JumpingJack/v_JumpingJack_g07_c01.avi
JumpingJack/v_JumpingJack_g07_c02.avi
JumpingJack/v_JumpingJack_g07_c03.avi
JumpingJack/v_JumpingJack_g07_c04.avi
JumpingJack/v_JumpingJack_g07_c05.avi
JumpRope/v_JumpRope_g01_c01.avi
JumpRope/v_JumpRope_g01_c02.avi
JumpRope/v_JumpRope_g01_c03.avi
JumpRope/v_JumpRope_g01_c04.avi
JumpRope/v_JumpRope_g02_c01.avi
JumpRope/v_JumpRope_g02_c02.avi
JumpRope/v_JumpRope_g02_c03.avi
JumpRope/v_JumpRope_g02_c04.avi
JumpRope/v_JumpRope_g02_c05.avi
JumpRope/v_JumpRope_g02_c06.avi
JumpRope/v_JumpRope_g02_c07.avi
JumpRope/v_JumpRope_g03_c01.avi
JumpRope/v_JumpRope_g03_c02.avi
JumpRope/v_JumpRope_g03_c03.avi
JumpRope/v_JumpRope_g03_c04.avi
JumpRope/v_JumpRope_g04_c01.avi
JumpRope/v_JumpRope_g04_c02.avi
JumpRope/v_JumpRope_g04_c03.avi
JumpRope/v_JumpRope_g04_c04.avi
JumpRope/v_JumpRope_g04_c05.avi
JumpRope/v_JumpRope_g04_c06.avi
JumpRope/v_JumpRope_g04_c07.avi
JumpRope/v_JumpRope_g05_c01.avi
JumpRope/v_JumpRope_g05_c02.avi
JumpRope/v_JumpRope_g05_c03.avi
JumpRope/v_JumpRope_g05_c04.avi
JumpRope/v_JumpRope_g05_c05.avi
JumpRope/v_JumpRope_g06_c01.avi
JumpRope/v_JumpRope_g06_c02.avi
JumpRope/v_JumpRope_g06_c03.avi
JumpRope/v_JumpRope_g06_c04.avi
JumpRope/v_JumpRope_g06_c05.avi
JumpRope/v_JumpRope_g07_c01.avi
JumpRope/v_JumpRope_g07_c02.avi
JumpRope/v_JumpRope_g07_c03.avi
JumpRope/v_JumpRope_g07_c04.avi
JumpRope/v_JumpRope_g07_c05.avi
JumpRope/v_JumpRope_g07_c06.avi
Kayaking/v_Kayaking_g01_c01.avi
Kayaking/v_Kayaking_g01_c02.avi
Kayaking/v_Kayaking_g01_c03.avi
Kayaking/v_Kayaking_g01_c04.avi
Kayaking/v_Kayaking_g01_c05.avi
Kayaking/v_Kayaking_g01_c06.avi
Kayaking/v_Kayaking_g02_c01.avi
Kayaking/v_Kayaking_g02_c02.avi
Kayaking/v_Kayaking_g02_c03.avi
Kayaking/v_Kayaking_g02_c04.avi
Kayaking/v_Kayaking_g03_c01.avi
Kayaking/v_Kayaking_g03_c02.avi
Kayaking/v_Kayaking_g03_c03.avi
Kayaking/v_Kayaking_g03_c04.avi
Kayaking/v_Kayaking_g04_c01.avi
Kayaking/v_Kayaking_g04_c02.avi
Kayaking/v_Kayaking_g04_c03.avi
Kayaking/v_Kayaking_g04_c04.avi
Kayaking/v_Kayaking_g04_c05.avi
Kayaking/v_Kayaking_g04_c06.avi
Kayaking/v_Kayaking_g04_c07.avi
Kayaking/v_Kayaking_g05_c01.avi
Kayaking/v_Kayaking_g05_c02.avi
Kayaking/v_Kayaking_g05_c03.avi
Kayaking/v_Kayaking_g05_c04.avi
Kayaking/v_Kayaking_g06_c01.avi
Kayaking/v_Kayaking_g06_c02.avi
Kayaking/v_Kayaking_g06_c03.avi
Kayaking/v_Kayaking_g06_c04.avi
Kayaking/v_Kayaking_g06_c05.avi
Kayaking/v_Kayaking_g06_c06.avi
Kayaking/v_Kayaking_g06_c07.avi
Kayaking/v_Kayaking_g07_c01.avi
Kayaking/v_Kayaking_g07_c02.avi
Kayaking/v_Kayaking_g07_c03.avi
Kayaking/v_Kayaking_g07_c04.avi
Knitting/v_Knitting_g01_c01.avi
Knitting/v_Knitting_g01_c02.avi
Knitting/v_Knitting_g01_c03.avi
Knitting/v_Knitting_g01_c04.avi
Knitting/v_Knitting_g02_c01.avi
Knitting/v_Knitting_g02_c02.avi
Knitting/v_Knitting_g02_c03.avi
Knitting/v_Knitting_g02_c04.avi
Knitting/v_Knitting_g02_c05.avi
Knitting/v_Knitting_g03_c01.avi
Knitting/v_Knitting_g03_c02.avi
Knitting/v_Knitting_g03_c03.avi
Knitting/v_Knitting_g03_c04.avi
Knitting/v_Knitting_g03_c05.avi
Knitting/v_Knitting_g04_c01.avi
Knitting/v_Knitting_g04_c02.avi
Knitting/v_Knitting_g04_c03.avi
Knitting/v_Knitting_g04_c04.avi
Knitting/v_Knitting_g04_c05.avi
Knitting/v_Knitting_g04_c06.avi
Knitting/v_Knitting_g05_c01.avi
Knitting/v_Knitting_g05_c02.avi
Knitting/v_Knitting_g05_c03.avi
Knitting/v_Knitting_g05_c04.avi
Knitting/v_Knitting_g05_c05.avi
Knitting/v_Knitting_g06_c01.avi
Knitting/v_Knitting_g06_c02.avi
Knitting/v_Knitting_g06_c03.avi
Knitting/v_Knitting_g06_c04.avi
Knitting/v_Knitting_g07_c01.avi
Knitting/v_Knitting_g07_c02.avi
Knitting/v_Knitting_g07_c03.avi
Knitting/v_Knitting_g07_c04.avi
Knitting/v_Knitting_g07_c05.avi
LongJump/v_LongJump_g01_c01.avi
LongJump/v_LongJump_g01_c02.avi
LongJump/v_LongJump_g01_c03.avi
LongJump/v_LongJump_g01_c04.avi
LongJump/v_LongJump_g01_c05.avi
LongJump/v_LongJump_g01_c06.avi
LongJump/v_LongJump_g01_c07.avi
LongJump/v_LongJump_g02_c01.avi
LongJump/v_LongJump_g02_c02.avi
LongJump/v_LongJump_g02_c03.avi
LongJump/v_LongJump_g02_c04.avi
LongJump/v_LongJump_g02_c05.avi
LongJump/v_LongJump_g03_c01.avi
LongJump/v_LongJump_g03_c02.avi
LongJump/v_LongJump_g03_c03.avi
LongJump/v_LongJump_g03_c04.avi
LongJump/v_LongJump_g03_c05.avi
LongJump/v_LongJump_g03_c06.avi
LongJump/v_LongJump_g04_c01.avi
LongJump/v_LongJump_g04_c02.avi
LongJump/v_LongJump_g04_c03.avi
LongJump/v_LongJump_g04_c04.avi
LongJump/v_LongJump_g04_c05.avi
LongJump/v_LongJump_g04_c06.avi
LongJump/v_LongJump_g04_c07.avi
LongJump/v_LongJump_g05_c01.avi
LongJump/v_LongJump_g05_c02.avi
LongJump/v_LongJump_g05_c03.avi
LongJump/v_LongJump_g05_c04.avi
LongJump/v_LongJump_g05_c05.avi
LongJump/v_LongJump_g06_c01.avi
LongJump/v_LongJump_g06_c02.avi
LongJump/v_LongJump_g06_c03.avi
LongJump/v_LongJump_g06_c04.avi
LongJump/v_LongJump_g07_c01.avi
LongJump/v_LongJump_g07_c02.avi
LongJump/v_LongJump_g07_c03.avi
LongJump/v_LongJump_g07_c04.avi
LongJump/v_LongJump_g07_c05.avi
Lunges/v_Lunges_g01_c01.avi
Lunges/v_Lunges_g01_c02.avi
Lunges/v_Lunges_g01_c03.avi
Lunges/v_Lunges_g01_c04.avi
Lunges/v_Lunges_g01_c05.avi
Lunges/v_Lunges_g01_c06.avi
Lunges/v_Lunges_g01_c07.avi
Lunges/v_Lunges_g02_c01.avi
Lunges/v_Lunges_g02_c02.avi
Lunges/v_Lunges_g02_c03.avi
Lunges/v_Lunges_g02_c04.avi
Lunges/v_Lunges_g03_c01.avi
Lunges/v_Lunges_g03_c02.avi
Lunges/v_Lunges_g03_c03.avi
Lunges/v_Lunges_g03_c04.avi
Lunges/v_Lunges_g04_c01.avi
Lunges/v_Lunges_g04_c02.avi
Lunges/v_Lunges_g04_c03.avi
Lunges/v_Lunges_g04_c04.avi
Lunges/v_Lunges_g05_c01.avi
Lunges/v_Lunges_g05_c02.avi
Lunges/v_Lunges_g05_c03.avi
Lunges/v_Lunges_g05_c04.avi
Lunges/v_Lunges_g06_c01.avi
Lunges/v_Lunges_g06_c02.avi
Lunges/v_Lunges_g06_c03.avi
Lunges/v_Lunges_g06_c04.avi
Lunges/v_Lunges_g06_c05.avi
Lunges/v_Lunges_g06_c06.avi
Lunges/v_Lunges_g06_c07.avi
Lunges/v_Lunges_g07_c01.avi
Lunges/v_Lunges_g07_c02.avi
Lunges/v_Lunges_g07_c03.avi
Lunges/v_Lunges_g07_c04.avi
Lunges/v_Lunges_g07_c05.avi
Lunges/v_Lunges_g07_c06.avi
Lunges/v_Lunges_g07_c07.avi
MilitaryParade/v_MilitaryParade_g01_c01.avi
MilitaryParade/v_MilitaryParade_g01_c02.avi
MilitaryParade/v_MilitaryParade_g01_c03.avi
MilitaryParade/v_MilitaryParade_g01_c04.avi
MilitaryParade/v_MilitaryParade_g01_c05.avi
MilitaryParade/v_MilitaryParade_g01_c06.avi
MilitaryParade/v_MilitaryParade_g01_c07.avi
MilitaryParade/v_MilitaryParade_g02_c01.avi
MilitaryParade/v_MilitaryParade_g02_c02.avi
MilitaryParade/v_MilitaryParade_g02_c03.avi
MilitaryParade/v_MilitaryParade_g02_c04.avi
MilitaryParade/v_MilitaryParade_g03_c01.avi
MilitaryParade/v_MilitaryParade_g03_c02.avi
MilitaryParade/v_MilitaryParade_g03_c03.avi
MilitaryParade/v_MilitaryParade_g03_c04.avi
MilitaryParade/v_MilitaryParade_g04_c01.avi
MilitaryParade/v_MilitaryParade_g04_c02.avi
MilitaryParade/v_MilitaryParade_g04_c03.avi
MilitaryParade/v_MilitaryParade_g04_c04.avi
MilitaryParade/v_MilitaryParade_g05_c01.avi
MilitaryParade/v_MilitaryParade_g05_c02.avi
MilitaryParade/v_MilitaryParade_g05_c03.avi
MilitaryParade/v_MilitaryParade_g05_c04.avi
MilitaryParade/v_MilitaryParade_g06_c01.avi
MilitaryParade/v_MilitaryParade_g06_c02.avi
MilitaryParade/v_MilitaryParade_g06_c03.avi
MilitaryParade/v_MilitaryParade_g06_c04.avi
MilitaryParade/v_MilitaryParade_g07_c01.avi
MilitaryParade/v_MilitaryParade_g07_c02.avi
MilitaryParade/v_MilitaryParade_g07_c03.avi
MilitaryParade/v_MilitaryParade_g07_c04.avi
MilitaryParade/v_MilitaryParade_g07_c05.avi
MilitaryParade/v_MilitaryParade_g07_c06.avi
Mixing/v_Mixing_g01_c01.avi
Mixing/v_Mixing_g01_c02.avi
Mixing/v_Mixing_g01_c03.avi
Mixing/v_Mixing_g01_c04.avi
Mixing/v_Mixing_g01_c05.avi
Mixing/v_Mixing_g01_c06.avi
Mixing/v_Mixing_g01_c07.avi
Mixing/v_Mixing_g02_c01.avi
Mixing/v_Mixing_g02_c02.avi
Mixing/v_Mixing_g02_c03.avi
Mixing/v_Mixing_g02_c04.avi
Mixing/v_Mixing_g02_c05.avi
Mixing/v_Mixing_g02_c06.avi
Mixing/v_Mixing_g03_c01.avi
Mixing/v_Mixing_g03_c02.avi
Mixing/v_Mixing_g03_c03.avi
Mixing/v_Mixing_g03_c04.avi
Mixing/v_Mixing_g03_c05.avi
Mixing/v_Mixing_g03_c06.avi
Mixing/v_Mixing_g03_c07.avi
Mixing/v_Mixing_g04_c01.avi
Mixing/v_Mixing_g04_c02.avi
Mixing/v_Mixing_g04_c03.avi
Mixing/v_Mixing_g04_c04.avi
Mixing/v_Mixing_g04_c05.avi
Mixing/v_Mixing_g04_c06.avi
Mixing/v_Mixing_g04_c07.avi
Mixing/v_Mixing_g05_c01.avi
Mixing/v_Mixing_g05_c02.avi
Mixing/v_Mixing_g05_c03.avi
Mixing/v_Mixing_g05_c04.avi
Mixing/v_Mixing_g05_c05.avi
Mixing/v_Mixing_g05_c06.avi
Mixing/v_Mixing_g05_c07.avi
Mixing/v_Mixing_g06_c01.avi
Mixing/v_Mixing_g06_c02.avi
Mixing/v_Mixing_g06_c03.avi
Mixing/v_Mixing_g06_c04.avi
Mixing/v_Mixing_g06_c05.avi
Mixing/v_Mixing_g06_c06.avi
Mixing/v_Mixing_g07_c01.avi
Mixing/v_Mixing_g07_c02.avi
Mixing/v_Mixing_g07_c03.avi
Mixing/v_Mixing_g07_c04.avi
Mixing/v_Mixing_g07_c05.avi
MoppingFloor/v_MoppingFloor_g01_c01.avi
MoppingFloor/v_MoppingFloor_g01_c02.avi
MoppingFloor/v_MoppingFloor_g01_c03.avi
MoppingFloor/v_MoppingFloor_g01_c04.avi
MoppingFloor/v_MoppingFloor_g02_c01.avi
MoppingFloor/v_MoppingFloor_g02_c02.avi
MoppingFloor/v_MoppingFloor_g02_c03.avi
MoppingFloor/v_MoppingFloor_g02_c04.avi
MoppingFloor/v_MoppingFloor_g02_c05.avi
MoppingFloor/v_MoppingFloor_g02_c06.avi
MoppingFloor/v_MoppingFloor_g03_c01.avi
MoppingFloor/v_MoppingFloor_g03_c02.avi
MoppingFloor/v_MoppingFloor_g03_c03.avi
MoppingFloor/v_MoppingFloor_g03_c04.avi
MoppingFloor/v_MoppingFloor_g04_c01.avi
MoppingFloor/v_MoppingFloor_g04_c02.avi
MoppingFloor/v_MoppingFloor_g04_c03.avi
MoppingFloor/v_MoppingFloor_g04_c04.avi
MoppingFloor/v_MoppingFloor_g04_c05.avi
MoppingFloor/v_MoppingFloor_g04_c06.avi
MoppingFloor/v_MoppingFloor_g05_c01.avi
MoppingFloor/v_MoppingFloor_g05_c02.avi
MoppingFloor/v_MoppingFloor_g05_c03.avi
MoppingFloor/v_MoppingFloor_g05_c04.avi
MoppingFloor/v_MoppingFloor_g05_c05.avi
MoppingFloor/v_MoppingFloor_g06_c01.avi
MoppingFloor/v_MoppingFloor_g06_c02.avi
MoppingFloor/v_MoppingFloor_g06_c03.avi
MoppingFloor/v_MoppingFloor_g06_c04.avi
MoppingFloor/v_MoppingFloor_g07_c01.avi
MoppingFloor/v_MoppingFloor_g07_c02.avi
MoppingFloor/v_MoppingFloor_g07_c03.avi
MoppingFloor/v_MoppingFloor_g07_c04.avi
MoppingFloor/v_MoppingFloor_g07_c05.avi
Nunchucks/v_Nunchucks_g01_c01.avi
Nunchucks/v_Nunchucks_g01_c02.avi
Nunchucks/v_Nunchucks_g01_c03.avi
Nunchucks/v_Nunchucks_g01_c04.avi
Nunchucks/v_Nunchucks_g02_c01.avi
Nunchucks/v_Nunchucks_g02_c02.avi
Nunchucks/v_Nunchucks_g02_c03.avi
Nunchucks/v_Nunchucks_g02_c04.avi
Nunchucks/v_Nunchucks_g02_c05.avi
Nunchucks/v_Nunchucks_g02_c06.avi
Nunchucks/v_Nunchucks_g03_c01.avi
Nunchucks/v_Nunchucks_g03_c02.avi
Nunchucks/v_Nunchucks_g03_c03.avi
Nunchucks/v_Nunchucks_g03_c04.avi
Nunchucks/v_Nunchucks_g03_c05.avi
Nunchucks/v_Nunchucks_g03_c06.avi
Nunchucks/v_Nunchucks_g03_c07.avi
Nunchucks/v_Nunchucks_g04_c01.avi
Nunchucks/v_Nunchucks_g04_c02.avi
Nunchucks/v_Nunchucks_g04_c03.avi
Nunchucks/v_Nunchucks_g04_c04.avi
Nunchucks/v_Nunchucks_g04_c05.avi
Nunchucks/v_Nunchucks_g04_c06.avi
Nunchucks/v_Nunchucks_g05_c01.avi
Nunchucks/v_Nunchucks_g05_c02.avi
Nunchucks/v_Nunchucks_g05_c03.avi
Nunchucks/v_Nunchucks_g05_c04.avi
Nunchucks/v_Nunchucks_g06_c01.avi
Nunchucks/v_Nunchucks_g06_c02.avi
Nunchucks/v_Nunchucks_g06_c03.avi
Nunchucks/v_Nunchucks_g06_c04.avi
Nunchucks/v_Nunchucks_g07_c01.avi
Nunchucks/v_Nunchucks_g07_c02.avi
Nunchucks/v_Nunchucks_g07_c03.avi
Nunchucks/v_Nunchucks_g07_c04.avi
ParallelBars/v_ParallelBars_g01_c01.avi
ParallelBars/v_ParallelBars_g01_c02.avi
ParallelBars/v_ParallelBars_g01_c03.avi
ParallelBars/v_ParallelBars_g01_c04.avi
ParallelBars/v_ParallelBars_g02_c01.avi
ParallelBars/v_ParallelBars_g02_c02.avi
ParallelBars/v_ParallelBars_g02_c03.avi
ParallelBars/v_ParallelBars_g02_c04.avi
ParallelBars/v_ParallelBars_g03_c01.avi
ParallelBars/v_ParallelBars_g03_c02.avi
ParallelBars/v_ParallelBars_g03_c03.avi
ParallelBars/v_ParallelBars_g03_c04.avi
ParallelBars/v_ParallelBars_g04_c01.avi
ParallelBars/v_ParallelBars_g04_c02.avi
ParallelBars/v_ParallelBars_g04_c03.avi
ParallelBars/v_ParallelBars_g04_c04.avi
ParallelBars/v_ParallelBars_g04_c05.avi
ParallelBars/v_ParallelBars_g04_c06.avi
ParallelBars/v_ParallelBars_g04_c07.avi
ParallelBars/v_ParallelBars_g05_c01.avi
ParallelBars/v_ParallelBars_g05_c02.avi
ParallelBars/v_ParallelBars_g05_c03.avi
ParallelBars/v_ParallelBars_g05_c04.avi
ParallelBars/v_ParallelBars_g05_c05.avi
ParallelBars/v_ParallelBars_g06_c01.avi
ParallelBars/v_ParallelBars_g06_c02.avi
ParallelBars/v_ParallelBars_g06_c03.avi
ParallelBars/v_ParallelBars_g06_c04.avi
ParallelBars/v_ParallelBars_g06_c05.avi
ParallelBars/v_ParallelBars_g06_c06.avi
ParallelBars/v_ParallelBars_g06_c07.avi
ParallelBars/v_ParallelBars_g07_c01.avi
ParallelBars/v_ParallelBars_g07_c02.avi
ParallelBars/v_ParallelBars_g07_c03.avi
ParallelBars/v_ParallelBars_g07_c04.avi
ParallelBars/v_ParallelBars_g07_c05.avi
ParallelBars/v_ParallelBars_g07_c06.avi
PizzaTossing/v_PizzaTossing_g01_c01.avi
PizzaTossing/v_PizzaTossing_g01_c02.avi
PizzaTossing/v_PizzaTossing_g01_c03.avi
PizzaTossing/v_PizzaTossing_g01_c04.avi
PizzaTossing/v_PizzaTossing_g02_c01.avi
PizzaTossing/v_PizzaTossing_g02_c02.avi
PizzaTossing/v_PizzaTossing_g02_c03.avi
PizzaTossing/v_PizzaTossing_g02_c04.avi
PizzaTossing/v_PizzaTossing_g02_c05.avi
PizzaTossing/v_PizzaTossing_g03_c01.avi
PizzaTossing/v_PizzaTossing_g03_c02.avi
PizzaTossing/v_PizzaTossing_g03_c03.avi
PizzaTossing/v_PizzaTossing_g03_c04.avi
PizzaTossing/v_PizzaTossing_g04_c01.avi
PizzaTossing/v_PizzaTossing_g04_c02.avi
PizzaTossing/v_PizzaTossing_g04_c03.avi
PizzaTossing/v_PizzaTossing_g04_c04.avi
PizzaTossing/v_PizzaTossing_g04_c05.avi
PizzaTossing/v_PizzaTossing_g04_c06.avi
PizzaTossing/v_PizzaTossing_g04_c07.avi
PizzaTossing/v_PizzaTossing_g05_c01.avi
PizzaTossing/v_PizzaTossing_g05_c02.avi
PizzaTossing/v_PizzaTossing_g05_c03.avi
PizzaTossing/v_PizzaTossing_g05_c04.avi
PizzaTossing/v_PizzaTossing_g06_c01.avi
PizzaTossing/v_PizzaTossing_g06_c02.avi
PizzaTossing/v_PizzaTossing_g06_c03.avi
PizzaTossing/v_PizzaTossing_g06_c04.avi
PizzaTossing/v_PizzaTossing_g06_c05.avi
PizzaTossing/v_PizzaTossing_g07_c01.avi
PizzaTossing/v_PizzaTossing_g07_c02.avi
PizzaTossing/v_PizzaTossing_g07_c03.avi
PizzaTossing/v_PizzaTossing_g07_c04.avi
PlayingCello/v_PlayingCello_g01_c01.avi
PlayingCello/v_PlayingCello_g01_c02.avi
PlayingCello/v_PlayingCello_g01_c03.avi
PlayingCello/v_PlayingCello_g01_c04.avi
PlayingCello/v_PlayingCello_g01_c05.avi
PlayingCello/v_PlayingCello_g01_c06.avi
PlayingCello/v_PlayingCello_g01_c07.avi
PlayingCello/v_PlayingCello_g02_c01.avi
PlayingCello/v_PlayingCello_g02_c02.avi
PlayingCello/v_PlayingCello_g02_c03.avi
PlayingCello/v_PlayingCello_g02_c04.avi
PlayingCello/v_PlayingCello_g02_c05.avi
PlayingCello/v_PlayingCello_g02_c06.avi
PlayingCello/v_PlayingCello_g02_c07.avi
PlayingCello/v_PlayingCello_g03_c01.avi
PlayingCello/v_PlayingCello_g03_c02.avi
PlayingCello/v_PlayingCello_g03_c03.avi
PlayingCello/v_PlayingCello_g03_c04.avi
PlayingCello/v_PlayingCello_g04_c01.avi
PlayingCello/v_PlayingCello_g04_c02.avi
PlayingCello/v_PlayingCello_g04_c03.avi
PlayingCello/v_PlayingCello_g04_c04.avi
PlayingCello/v_PlayingCello_g04_c05.avi
PlayingCello/v_PlayingCello_g04_c06.avi
PlayingCello/v_PlayingCello_g04_c07.avi
PlayingCello/v_PlayingCello_g05_c01.avi
PlayingCello/v_PlayingCello_g05_c02.avi
PlayingCello/v_PlayingCello_g05_c03.avi
PlayingCello/v_PlayingCello_g05_c04.avi
PlayingCello/v_PlayingCello_g05_c05.avi
PlayingCello/v_PlayingCello_g05_c06.avi
PlayingCello/v_PlayingCello_g05_c07.avi
PlayingCello/v_PlayingCello_g06_c01.avi
PlayingCello/v_PlayingCello_g06_c02.avi
PlayingCello/v_PlayingCello_g06_c03.avi
PlayingCello/v_PlayingCello_g06_c04.avi
PlayingCello/v_PlayingCello_g06_c05.avi
PlayingCello/v_PlayingCello_g06_c06.avi
PlayingCello/v_PlayingCello_g06_c07.avi
PlayingCello/v_PlayingCello_g07_c01.avi
PlayingCello/v_PlayingCello_g07_c02.avi
PlayingCello/v_PlayingCello_g07_c03.avi
PlayingCello/v_PlayingCello_g07_c04.avi
PlayingCello/v_PlayingCello_g07_c05.avi
PlayingDaf/v_PlayingDaf_g01_c01.avi
PlayingDaf/v_PlayingDaf_g01_c02.avi
PlayingDaf/v_PlayingDaf_g01_c03.avi
PlayingDaf/v_PlayingDaf_g01_c04.avi
PlayingDaf/v_PlayingDaf_g02_c01.avi
PlayingDaf/v_PlayingDaf_g02_c02.avi
PlayingDaf/v_PlayingDaf_g02_c03.avi
PlayingDaf/v_PlayingDaf_g02_c04.avi
PlayingDaf/v_PlayingDaf_g02_c05.avi
PlayingDaf/v_PlayingDaf_g02_c06.avi
PlayingDaf/v_PlayingDaf_g02_c07.avi
PlayingDaf/v_PlayingDaf_g03_c01.avi
PlayingDaf/v_PlayingDaf_g03_c02.avi
PlayingDaf/v_PlayingDaf_g03_c03.avi
PlayingDaf/v_PlayingDaf_g03_c04.avi
PlayingDaf/v_PlayingDaf_g04_c01.avi
PlayingDaf/v_PlayingDaf_g04_c02.avi
PlayingDaf/v_PlayingDaf_g04_c03.avi
PlayingDaf/v_PlayingDaf_g04_c04.avi
PlayingDaf/v_PlayingDaf_g04_c05.avi
PlayingDaf/v_PlayingDaf_g04_c06.avi
PlayingDaf/v_PlayingDaf_g04_c07.avi
PlayingDaf/v_PlayingDaf_g05_c01.avi
PlayingDaf/v_PlayingDaf_g05_c02.avi
PlayingDaf/v_PlayingDaf_g05_c03.avi
PlayingDaf/v_PlayingDaf_g05_c04.avi
PlayingDaf/v_PlayingDaf_g05_c05.avi
PlayingDaf/v_PlayingDaf_g05_c06.avi
PlayingDaf/v_PlayingDaf_g05_c07.avi
PlayingDaf/v_PlayingDaf_g06_c01.avi
PlayingDaf/v_PlayingDaf_g06_c02.avi
PlayingDaf/v_PlayingDaf_g06_c03.avi
PlayingDaf/v_PlayingDaf_g06_c04.avi
PlayingDaf/v_PlayingDaf_g06_c05.avi
PlayingDaf/v_PlayingDaf_g06_c06.avi
PlayingDaf/v_PlayingDaf_g06_c07.avi
PlayingDaf/v_PlayingDaf_g07_c01.avi
PlayingDaf/v_PlayingDaf_g07_c02.avi
PlayingDaf/v_PlayingDaf_g07_c03.avi
PlayingDaf/v_PlayingDaf_g07_c04.avi
PlayingDaf/v_PlayingDaf_g07_c05.avi
PlayingDhol/v_PlayingDhol_g01_c01.avi
PlayingDhol/v_PlayingDhol_g01_c02.avi
PlayingDhol/v_PlayingDhol_g01_c03.avi
PlayingDhol/v_PlayingDhol_g01_c04.avi
PlayingDhol/v_PlayingDhol_g01_c05.avi
PlayingDhol/v_PlayingDhol_g01_c06.avi
PlayingDhol/v_PlayingDhol_g01_c07.avi
PlayingDhol/v_PlayingDhol_g02_c01.avi
PlayingDhol/v_PlayingDhol_g02_c02.avi
PlayingDhol/v_PlayingDhol_g02_c03.avi
PlayingDhol/v_PlayingDhol_g02_c04.avi
PlayingDhol/v_PlayingDhol_g02_c05.avi
PlayingDhol/v_PlayingDhol_g02_c06.avi
PlayingDhol/v_PlayingDhol_g02_c07.avi
PlayingDhol/v_PlayingDhol_g03_c01.avi
PlayingDhol/v_PlayingDhol_g03_c02.avi
PlayingDhol/v_PlayingDhol_g03_c03.avi
PlayingDhol/v_PlayingDhol_g03_c04.avi
PlayingDhol/v_PlayingDhol_g03_c05.avi
PlayingDhol/v_PlayingDhol_g03_c06.avi
PlayingDhol/v_PlayingDhol_g03_c07.avi
PlayingDhol/v_PlayingDhol_g04_c01.avi
PlayingDhol/v_PlayingDhol_g04_c02.avi
PlayingDhol/v_PlayingDhol_g04_c03.avi
PlayingDhol/v_PlayingDhol_g04_c04.avi
PlayingDhol/v_PlayingDhol_g04_c05.avi
PlayingDhol/v_PlayingDhol_g04_c06.avi
PlayingDhol/v_PlayingDhol_g04_c07.avi
PlayingDhol/v_PlayingDhol_g05_c01.avi
PlayingDhol/v_PlayingDhol_g05_c02.avi
PlayingDhol/v_PlayingDhol_g05_c03.avi
PlayingDhol/v_PlayingDhol_g05_c04.avi
PlayingDhol/v_PlayingDhol_g05_c05.avi
PlayingDhol/v_PlayingDhol_g05_c06.avi
PlayingDhol/v_PlayingDhol_g05_c07.avi
PlayingDhol/v_PlayingDhol_g06_c01.avi
PlayingDhol/v_PlayingDhol_g06_c02.avi
PlayingDhol/v_PlayingDhol_g06_c03.avi
PlayingDhol/v_PlayingDhol_g06_c04.avi
PlayingDhol/v_PlayingDhol_g06_c05.avi
PlayingDhol/v_PlayingDhol_g06_c06.avi
PlayingDhol/v_PlayingDhol_g06_c07.avi
PlayingDhol/v_PlayingDhol_g07_c01.avi
PlayingDhol/v_PlayingDhol_g07_c02.avi
PlayingDhol/v_PlayingDhol_g07_c03.avi
PlayingDhol/v_PlayingDhol_g07_c04.avi
PlayingDhol/v_PlayingDhol_g07_c05.avi
PlayingDhol/v_PlayingDhol_g07_c06.avi
PlayingDhol/v_PlayingDhol_g07_c07.avi
PlayingFlute/v_PlayingFlute_g01_c01.avi
PlayingFlute/v_PlayingFlute_g01_c02.avi
PlayingFlute/v_PlayingFlute_g01_c03.avi
PlayingFlute/v_PlayingFlute_g01_c04.avi
PlayingFlute/v_PlayingFlute_g01_c05.avi
PlayingFlute/v_PlayingFlute_g01_c06.avi
PlayingFlute/v_PlayingFlute_g01_c07.avi
PlayingFlute/v_PlayingFlute_g02_c01.avi
PlayingFlute/v_PlayingFlute_g02_c02.avi
PlayingFlute/v_PlayingFlute_g02_c03.avi
PlayingFlute/v_PlayingFlute_g02_c04.avi
PlayingFlute/v_PlayingFlute_g02_c05.avi
PlayingFlute/v_PlayingFlute_g02_c06.avi
PlayingFlute/v_PlayingFlute_g02_c07.avi
PlayingFlute/v_PlayingFlute_g03_c01.avi
PlayingFlute/v_PlayingFlute_g03_c02.avi
PlayingFlute/v_PlayingFlute_g03_c03.avi
PlayingFlute/v_PlayingFlute_g03_c04.avi
PlayingFlute/v_PlayingFlute_g03_c05.avi
PlayingFlute/v_PlayingFlute_g03_c06.avi
PlayingFlute/v_PlayingFlute_g03_c07.avi
PlayingFlute/v_PlayingFlute_g04_c01.avi
PlayingFlute/v_PlayingFlute_g04_c02.avi
PlayingFlute/v_PlayingFlute_g04_c03.avi
PlayingFlute/v_PlayingFlute_g04_c04.avi
PlayingFlute/v_PlayingFlute_g04_c05.avi
PlayingFlute/v_PlayingFlute_g04_c06.avi
PlayingFlute/v_PlayingFlute_g04_c07.avi
PlayingFlute/v_PlayingFlute_g05_c01.avi
PlayingFlute/v_PlayingFlute_g05_c02.avi
PlayingFlute/v_PlayingFlute_g05_c03.avi
PlayingFlute/v_PlayingFlute_g05_c04.avi
PlayingFlute/v_PlayingFlute_g05_c05.avi
PlayingFlute/v_PlayingFlute_g05_c06.avi
PlayingFlute/v_PlayingFlute_g05_c07.avi
PlayingFlute/v_PlayingFlute_g06_c01.avi
PlayingFlute/v_PlayingFlute_g06_c02.avi
PlayingFlute/v_PlayingFlute_g06_c03.avi
PlayingFlute/v_PlayingFlute_g06_c04.avi
PlayingFlute/v_PlayingFlute_g06_c05.avi
PlayingFlute/v_PlayingFlute_g06_c06.avi
PlayingFlute/v_PlayingFlute_g07_c01.avi
PlayingFlute/v_PlayingFlute_g07_c02.avi
PlayingFlute/v_PlayingFlute_g07_c03.avi
PlayingFlute/v_PlayingFlute_g07_c04.avi
PlayingFlute/v_PlayingFlute_g07_c05.avi
PlayingFlute/v_PlayingFlute_g07_c06.avi
PlayingFlute/v_PlayingFlute_g07_c07.avi
PlayingGuitar/v_PlayingGuitar_g01_c01.avi
PlayingGuitar/v_PlayingGuitar_g01_c02.avi
PlayingGuitar/v_PlayingGuitar_g01_c03.avi
PlayingGuitar/v_PlayingGuitar_g01_c04.avi
PlayingGuitar/v_PlayingGuitar_g01_c05.avi
PlayingGuitar/v_PlayingGuitar_g01_c06.avi
PlayingGuitar/v_PlayingGuitar_g02_c01.avi
PlayingGuitar/v_PlayingGuitar_g02_c02.avi
PlayingGuitar/v_PlayingGuitar_g02_c03.avi
PlayingGuitar/v_PlayingGuitar_g02_c04.avi
PlayingGuitar/v_PlayingGuitar_g03_c01.avi
PlayingGuitar/v_PlayingGuitar_g03_c02.avi
PlayingGuitar/v_PlayingGuitar_g03_c03.avi
PlayingGuitar/v_PlayingGuitar_g03_c04.avi
PlayingGuitar/v_PlayingGuitar_g03_c05.avi
PlayingGuitar/v_PlayingGuitar_g03_c06.avi
PlayingGuitar/v_PlayingGuitar_g03_c07.avi
PlayingGuitar/v_PlayingGuitar_g04_c01.avi
PlayingGuitar/v_PlayingGuitar_g04_c02.avi
PlayingGuitar/v_PlayingGuitar_g04_c03.avi
PlayingGuitar/v_PlayingGuitar_g04_c04.avi
PlayingGuitar/v_PlayingGuitar_g04_c05.avi
PlayingGuitar/v_PlayingGuitar_g04_c06.avi
PlayingGuitar/v_PlayingGuitar_g04_c07.avi
PlayingGuitar/v_PlayingGuitar_g05_c01.avi
PlayingGuitar/v_PlayingGuitar_g05_c02.avi
PlayingGuitar/v_PlayingGuitar_g05_c03.avi
PlayingGuitar/v_PlayingGuitar_g05_c04.avi
PlayingGuitar/v_PlayingGuitar_g05_c05.avi
PlayingGuitar/v_PlayingGuitar_g06_c01.avi
PlayingGuitar/v_PlayingGuitar_g06_c02.avi
PlayingGuitar/v_PlayingGuitar_g06_c03.avi
PlayingGuitar/v_PlayingGuitar_g06_c04.avi
PlayingGuitar/v_PlayingGuitar_g06_c05.avi
PlayingGuitar/v_PlayingGuitar_g06_c06.avi
PlayingGuitar/v_PlayingGuitar_g06_c07.avi
PlayingGuitar/v_PlayingGuitar_g07_c01.avi
PlayingGuitar/v_PlayingGuitar_g07_c02.avi
PlayingGuitar/v_PlayingGuitar_g07_c03.avi
PlayingGuitar/v_PlayingGuitar_g07_c04.avi
PlayingGuitar/v_PlayingGuitar_g07_c05.avi
PlayingGuitar/v_PlayingGuitar_g07_c06.avi
PlayingGuitar/v_PlayingGuitar_g07_c07.avi
PlayingPiano/v_PlayingPiano_g01_c01.avi
PlayingPiano/v_PlayingPiano_g01_c02.avi
PlayingPiano/v_PlayingPiano_g01_c03.avi
PlayingPiano/v_PlayingPiano_g01_c04.avi
PlayingPiano/v_PlayingPiano_g02_c01.avi
PlayingPiano/v_PlayingPiano_g02_c02.avi
PlayingPiano/v_PlayingPiano_g02_c03.avi
PlayingPiano/v_PlayingPiano_g02_c04.avi
PlayingPiano/v_PlayingPiano_g03_c01.avi
PlayingPiano/v_PlayingPiano_g03_c02.avi
PlayingPiano/v_PlayingPiano_g03_c03.avi
PlayingPiano/v_PlayingPiano_g03_c04.avi
PlayingPiano/v_PlayingPiano_g04_c01.avi
PlayingPiano/v_PlayingPiano_g04_c02.avi
PlayingPiano/v_PlayingPiano_g04_c03.avi
PlayingPiano/v_PlayingPiano_g04_c04.avi
PlayingPiano/v_PlayingPiano_g05_c01.avi
PlayingPiano/v_PlayingPiano_g05_c02.avi
PlayingPiano/v_PlayingPiano_g05_c03.avi
PlayingPiano/v_PlayingPiano_g05_c04.avi
PlayingPiano/v_PlayingPiano_g06_c01.avi
PlayingPiano/v_PlayingPiano_g06_c02.avi
PlayingPiano/v_PlayingPiano_g06_c03.avi
PlayingPiano/v_PlayingPiano_g06_c04.avi
PlayingPiano/v_PlayingPiano_g07_c01.avi
PlayingPiano/v_PlayingPiano_g07_c02.avi
PlayingPiano/v_PlayingPiano_g07_c03.avi
PlayingPiano/v_PlayingPiano_g07_c04.avi
PlayingSitar/v_PlayingSitar_g01_c01.avi
PlayingSitar/v_PlayingSitar_g01_c02.avi
PlayingSitar/v_PlayingSitar_g01_c03.avi
PlayingSitar/v_PlayingSitar_g01_c04.avi
PlayingSitar/v_PlayingSitar_g02_c01.avi
PlayingSitar/v_PlayingSitar_g02_c02.avi
PlayingSitar/v_PlayingSitar_g02_c03.avi
PlayingSitar/v_PlayingSitar_g02_c04.avi
PlayingSitar/v_PlayingSitar_g02_c05.avi
PlayingSitar/v_PlayingSitar_g02_c06.avi
PlayingSitar/v_PlayingSitar_g03_c01.avi
PlayingSitar/v_PlayingSitar_g03_c02.avi
PlayingSitar/v_PlayingSitar_g03_c03.avi
PlayingSitar/v_PlayingSitar_g03_c04.avi
PlayingSitar/v_PlayingSitar_g03_c05.avi
PlayingSitar/v_PlayingSitar_g03_c06.avi
PlayingSitar/v_PlayingSitar_g03_c07.avi
PlayingSitar/v_PlayingSitar_g04_c01.avi
PlayingSitar/v_PlayingSitar_g04_c02.avi
PlayingSitar/v_PlayingSitar_g04_c03.avi
PlayingSitar/v_PlayingSitar_g04_c04.avi
PlayingSitar/v_PlayingSitar_g04_c05.avi
PlayingSitar/v_PlayingSitar_g04_c06.avi
PlayingSitar/v_PlayingSitar_g04_c07.avi
PlayingSitar/v_PlayingSitar_g05_c01.avi
PlayingSitar/v_PlayingSitar_g05_c02.avi
PlayingSitar/v_PlayingSitar_g05_c03.avi
PlayingSitar/v_PlayingSitar_g05_c04.avi
PlayingSitar/v_PlayingSitar_g05_c05.avi
PlayingSitar/v_PlayingSitar_g05_c06.avi
PlayingSitar/v_PlayingSitar_g05_c07.avi
PlayingSitar/v_PlayingSitar_g06_c01.avi
PlayingSitar/v_PlayingSitar_g06_c02.avi
PlayingSitar/v_PlayingSitar_g06_c03.avi
PlayingSitar/v_PlayingSitar_g06_c04.avi
PlayingSitar/v_PlayingSitar_g06_c05.avi
PlayingSitar/v_PlayingSitar_g06_c06.avi
PlayingSitar/v_PlayingSitar_g07_c01.avi
PlayingSitar/v_PlayingSitar_g07_c02.avi
PlayingSitar/v_PlayingSitar_g07_c03.avi
PlayingSitar/v_PlayingSitar_g07_c04.avi
PlayingSitar/v_PlayingSitar_g07_c05.avi
PlayingSitar/v_PlayingSitar_g07_c06.avi
PlayingSitar/v_PlayingSitar_g07_c07.avi
PlayingTabla/v_PlayingTabla_g01_c01.avi
PlayingTabla/v_PlayingTabla_g01_c02.avi
PlayingTabla/v_PlayingTabla_g01_c03.avi
PlayingTabla/v_PlayingTabla_g01_c04.avi
PlayingTabla/v_PlayingTabla_g02_c01.avi
PlayingTabla/v_PlayingTabla_g02_c02.avi
PlayingTabla/v_PlayingTabla_g02_c03.avi
PlayingTabla/v_PlayingTabla_g02_c04.avi
PlayingTabla/v_PlayingTabla_g03_c01.avi
PlayingTabla/v_PlayingTabla_g03_c02.avi
PlayingTabla/v_PlayingTabla_g03_c03.avi
PlayingTabla/v_PlayingTabla_g03_c04.avi
PlayingTabla/v_PlayingTabla_g03_c05.avi
PlayingTabla/v_PlayingTabla_g04_c01.avi
PlayingTabla/v_PlayingTabla_g04_c02.avi
PlayingTabla/v_PlayingTabla_g04_c03.avi
PlayingTabla/v_PlayingTabla_g04_c04.avi
PlayingTabla/v_PlayingTabla_g04_c05.avi
PlayingTabla/v_PlayingTabla_g04_c06.avi
PlayingTabla/v_PlayingTabla_g05_c01.avi
PlayingTabla/v_PlayingTabla_g05_c02.avi
PlayingTabla/v_PlayingTabla_g05_c03.avi
PlayingTabla/v_PlayingTabla_g05_c04.avi
PlayingTabla/v_PlayingTabla_g06_c01.avi
PlayingTabla/v_PlayingTabla_g06_c02.avi
PlayingTabla/v_PlayingTabla_g06_c03.avi
PlayingTabla/v_PlayingTabla_g06_c04.avi
PlayingTabla/v_PlayingTabla_g07_c01.avi
PlayingTabla/v_PlayingTabla_g07_c02.avi
PlayingTabla/v_PlayingTabla_g07_c03.avi
PlayingTabla/v_PlayingTabla_g07_c04.avi
PlayingViolin/v_PlayingViolin_g01_c01.avi
PlayingViolin/v_PlayingViolin_g01_c02.avi
PlayingViolin/v_PlayingViolin_g01_c03.avi
PlayingViolin/v_PlayingViolin_g01_c04.avi
PlayingViolin/v_PlayingViolin_g02_c01.avi
PlayingViolin/v_PlayingViolin_g02_c02.avi
PlayingViolin/v_PlayingViolin_g02_c03.avi
PlayingViolin/v_PlayingViolin_g02_c04.avi
PlayingViolin/v_PlayingViolin_g03_c01.avi
PlayingViolin/v_PlayingViolin_g03_c02.avi
PlayingViolin/v_PlayingViolin_g03_c03.avi
PlayingViolin/v_PlayingViolin_g03_c04.avi
PlayingViolin/v_PlayingViolin_g04_c01.avi
PlayingViolin/v_PlayingViolin_g04_c02.avi
PlayingViolin/v_PlayingViolin_g04_c03.avi
PlayingViolin/v_PlayingViolin_g04_c04.avi
PlayingViolin/v_PlayingViolin_g05_c01.avi
PlayingViolin/v_PlayingViolin_g05_c02.avi
PlayingViolin/v_PlayingViolin_g05_c03.avi
PlayingViolin/v_PlayingViolin_g05_c04.avi
PlayingViolin/v_PlayingViolin_g06_c01.avi
PlayingViolin/v_PlayingViolin_g06_c02.avi
PlayingViolin/v_PlayingViolin_g06_c03.avi
PlayingViolin/v_PlayingViolin_g06_c04.avi
PlayingViolin/v_PlayingViolin_g07_c01.avi
PlayingViolin/v_PlayingViolin_g07_c02.avi
PlayingViolin/v_PlayingViolin_g07_c03.avi
PlayingViolin/v_PlayingViolin_g07_c04.avi
PoleVault/v_PoleVault_g01_c01.avi
PoleVault/v_PoleVault_g01_c02.avi
PoleVault/v_PoleVault_g01_c03.avi
PoleVault/v_PoleVault_g01_c04.avi
PoleVault/v_PoleVault_g01_c05.avi
PoleVault/v_PoleVault_g02_c01.avi
PoleVault/v_PoleVault_g02_c02.avi
PoleVault/v_PoleVault_g02_c03.avi
PoleVault/v_PoleVault_g02_c04.avi
PoleVault/v_PoleVault_g02_c05.avi
PoleVault/v_PoleVault_g02_c06.avi
PoleVault/v_PoleVault_g02_c07.avi
PoleVault/v_PoleVault_g03_c01.avi
PoleVault/v_PoleVault_g03_c02.avi
PoleVault/v_PoleVault_g03_c03.avi
PoleVault/v_PoleVault_g03_c04.avi
PoleVault/v_PoleVault_g03_c05.avi
PoleVault/v_PoleVault_g03_c06.avi
PoleVault/v_PoleVault_g03_c07.avi
PoleVault/v_PoleVault_g04_c01.avi
PoleVault/v_PoleVault_g04_c02.avi
PoleVault/v_PoleVault_g04_c03.avi
PoleVault/v_PoleVault_g04_c04.avi
PoleVault/v_PoleVault_g04_c05.avi
PoleVault/v_PoleVault_g04_c06.avi
PoleVault/v_PoleVault_g04_c07.avi
PoleVault/v_PoleVault_g05_c01.avi
PoleVault/v_PoleVault_g05_c02.avi
PoleVault/v_PoleVault_g05_c03.avi
PoleVault/v_PoleVault_g05_c04.avi
PoleVault/v_PoleVault_g05_c05.avi
PoleVault/v_PoleVault_g06_c01.avi
PoleVault/v_PoleVault_g06_c02.avi
PoleVault/v_PoleVault_g06_c03.avi
PoleVault/v_PoleVault_g06_c04.avi
PoleVault/v_PoleVault_g06_c05.avi
PoleVault/v_PoleVault_g07_c01.avi
PoleVault/v_PoleVault_g07_c02.avi
PoleVault/v_PoleVault_g07_c03.avi
PoleVault/v_PoleVault_g07_c04.avi
PommelHorse/v_PommelHorse_g01_c01.avi
PommelHorse/v_PommelHorse_g01_c02.avi
PommelHorse/v_PommelHorse_g01_c03.avi
PommelHorse/v_PommelHorse_g01_c04.avi
PommelHorse/v_PommelHorse_g01_c05.avi
PommelHorse/v_PommelHorse_g01_c06.avi
PommelHorse/v_PommelHorse_g01_c07.avi
PommelHorse/v_PommelHorse_g02_c01.avi
PommelHorse/v_PommelHorse_g02_c02.avi
PommelHorse/v_PommelHorse_g02_c03.avi
PommelHorse/v_PommelHorse_g02_c04.avi
PommelHorse/v_PommelHorse_g03_c01.avi
PommelHorse/v_PommelHorse_g03_c02.avi
PommelHorse/v_PommelHorse_g03_c03.avi
PommelHorse/v_PommelHorse_g03_c04.avi
PommelHorse/v_PommelHorse_g04_c01.avi
PommelHorse/v_PommelHorse_g04_c02.avi
PommelHorse/v_PommelHorse_g04_c03.avi
PommelHorse/v_PommelHorse_g04_c04.avi
PommelHorse/v_PommelHorse_g04_c05.avi
PommelHorse/v_PommelHorse_g05_c01.avi
PommelHorse/v_PommelHorse_g05_c02.avi
PommelHorse/v_PommelHorse_g05_c03.avi
PommelHorse/v_PommelHorse_g05_c04.avi
PommelHorse/v_PommelHorse_g06_c01.avi
PommelHorse/v_PommelHorse_g06_c02.avi
PommelHorse/v_PommelHorse_g06_c03.avi
PommelHorse/v_PommelHorse_g06_c04.avi
PommelHorse/v_PommelHorse_g07_c01.avi
PommelHorse/v_PommelHorse_g07_c02.avi
PommelHorse/v_PommelHorse_g07_c03.avi
PommelHorse/v_PommelHorse_g07_c04.avi
PommelHorse/v_PommelHorse_g07_c05.avi
PommelHorse/v_PommelHorse_g07_c06.avi
PommelHorse/v_PommelHorse_g07_c07.avi
PullUps/v_PullUps_g01_c01.avi
PullUps/v_PullUps_g01_c02.avi
PullUps/v_PullUps_g01_c03.avi
PullUps/v_PullUps_g01_c04.avi
PullUps/v_PullUps_g02_c01.avi
PullUps/v_PullUps_g02_c02.avi
PullUps/v_PullUps_g02_c03.avi
PullUps/v_PullUps_g02_c04.avi
PullUps/v_PullUps_g03_c01.avi
PullUps/v_PullUps_g03_c02.avi
PullUps/v_PullUps_g03_c03.avi
PullUps/v_PullUps_g03_c04.avi
PullUps/v_PullUps_g04_c01.avi
PullUps/v_PullUps_g04_c02.avi
PullUps/v_PullUps_g04_c03.avi
PullUps/v_PullUps_g04_c04.avi
PullUps/v_PullUps_g05_c01.avi
PullUps/v_PullUps_g05_c02.avi
PullUps/v_PullUps_g05_c03.avi
PullUps/v_PullUps_g05_c04.avi
PullUps/v_PullUps_g06_c01.avi
PullUps/v_PullUps_g06_c02.avi
PullUps/v_PullUps_g06_c03.avi
PullUps/v_PullUps_g06_c04.avi
PullUps/v_PullUps_g07_c01.avi
PullUps/v_PullUps_g07_c02.avi
PullUps/v_PullUps_g07_c03.avi
PullUps/v_PullUps_g07_c04.avi
Punch/v_Punch_g01_c01.avi
Punch/v_Punch_g01_c02.avi
Punch/v_Punch_g01_c03.avi
Punch/v_Punch_g01_c04.avi
Punch/v_Punch_g01_c05.avi
Punch/v_Punch_g02_c01.avi
Punch/v_Punch_g02_c02.avi
Punch/v_Punch_g02_c03.avi
Punch/v_Punch_g02_c04.avi
Punch/v_Punch_g03_c01.avi
Punch/v_Punch_g03_c02.avi
Punch/v_Punch_g03_c03.avi
Punch/v_Punch_g03_c04.avi
Punch/v_Punch_g04_c01.avi
Punch/v_Punch_g04_c02.avi
Punch/v_Punch_g04_c03.avi
Punch/v_Punch_g04_c04.avi
Punch/v_Punch_g04_c05.avi
Punch/v_Punch_g05_c01.avi
Punch/v_Punch_g05_c02.avi
Punch/v_Punch_g05_c03.avi
Punch/v_Punch_g05_c04.avi
Punch/v_Punch_g05_c05.avi
Punch/v_Punch_g05_c06.avi
Punch/v_Punch_g05_c07.avi
Punch/v_Punch_g06_c01.avi
Punch/v_Punch_g06_c02.avi
Punch/v_Punch_g06_c03.avi
Punch/v_Punch_g06_c04.avi
Punch/v_Punch_g06_c05.avi
Punch/v_Punch_g06_c06.avi
Punch/v_Punch_g06_c07.avi
Punch/v_Punch_g07_c01.avi
Punch/v_Punch_g07_c02.avi
Punch/v_Punch_g07_c03.avi
Punch/v_Punch_g07_c04.avi
Punch/v_Punch_g07_c05.avi
Punch/v_Punch_g07_c06.avi
Punch/v_Punch_g07_c07.avi
PushUps/v_PushUps_g01_c01.avi
PushUps/v_PushUps_g01_c02.avi
PushUps/v_PushUps_g01_c03.avi
PushUps/v_PushUps_g01_c04.avi
PushUps/v_PushUps_g01_c05.avi
PushUps/v_PushUps_g02_c01.avi
PushUps/v_PushUps_g02_c02.avi
PushUps/v_PushUps_g02_c03.avi
PushUps/v_PushUps_g02_c04.avi
PushUps/v_PushUps_g03_c01.avi
PushUps/v_PushUps_g03_c02.avi
PushUps/v_PushUps_g03_c03.avi
PushUps/v_PushUps_g03_c04.avi
PushUps/v_PushUps_g04_c01.avi
PushUps/v_PushUps_g04_c02.avi
PushUps/v_PushUps_g04_c03.avi
PushUps/v_PushUps_g04_c04.avi
PushUps/v_PushUps_g04_c05.avi
PushUps/v_PushUps_g05_c01.avi
PushUps/v_PushUps_g05_c02.avi
PushUps/v_PushUps_g05_c03.avi
PushUps/v_PushUps_g05_c04.avi
PushUps/v_PushUps_g06_c01.avi
PushUps/v_PushUps_g06_c02.avi
PushUps/v_PushUps_g06_c03.avi
PushUps/v_PushUps_g06_c04.avi
PushUps/v_PushUps_g07_c01.avi
PushUps/v_PushUps_g07_c02.avi
PushUps/v_PushUps_g07_c03.avi
PushUps/v_PushUps_g07_c04.avi
Rafting/v_Rafting_g01_c01.avi
Rafting/v_Rafting_g01_c02.avi
Rafting/v_Rafting_g01_c03.avi
Rafting/v_Rafting_g01_c04.avi
Rafting/v_Rafting_g02_c01.avi
Rafting/v_Rafting_g02_c02.avi
Rafting/v_Rafting_g02_c03.avi
Rafting/v_Rafting_g02_c04.avi
Rafting/v_Rafting_g03_c01.avi
Rafting/v_Rafting_g03_c02.avi
Rafting/v_Rafting_g03_c03.avi
Rafting/v_Rafting_g03_c04.avi
Rafting/v_Rafting_g04_c01.avi
Rafting/v_Rafting_g04_c02.avi
Rafting/v_Rafting_g04_c03.avi
Rafting/v_Rafting_g04_c04.avi
Rafting/v_Rafting_g05_c01.avi
Rafting/v_Rafting_g05_c02.avi
Rafting/v_Rafting_g05_c03.avi
Rafting/v_Rafting_g05_c04.avi
Rafting/v_Rafting_g06_c01.avi
Rafting/v_Rafting_g06_c02.avi
Rafting/v_Rafting_g06_c03.avi
Rafting/v_Rafting_g06_c04.avi
Rafting/v_Rafting_g07_c01.avi
Rafting/v_Rafting_g07_c02.avi
Rafting/v_Rafting_g07_c03.avi
Rafting/v_Rafting_g07_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g01_c01.avi
RockClimbingIndoor/v_RockClimbingIndoor_g01_c02.avi
RockClimbingIndoor/v_RockClimbingIndoor_g01_c03.avi
RockClimbingIndoor/v_RockClimbingIndoor_g01_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g01_c05.avi
RockClimbingIndoor/v_RockClimbingIndoor_g02_c01.avi
RockClimbingIndoor/v_RockClimbingIndoor_g02_c02.avi
RockClimbingIndoor/v_RockClimbingIndoor_g02_c03.avi
RockClimbingIndoor/v_RockClimbingIndoor_g02_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g02_c05.avi
RockClimbingIndoor/v_RockClimbingIndoor_g03_c01.avi
RockClimbingIndoor/v_RockClimbingIndoor_g03_c02.avi
RockClimbingIndoor/v_RockClimbingIndoor_g03_c03.avi
RockClimbingIndoor/v_RockClimbingIndoor_g03_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g03_c05.avi
RockClimbingIndoor/v_RockClimbingIndoor_g03_c06.avi
RockClimbingIndoor/v_RockClimbingIndoor_g03_c07.avi
RockClimbingIndoor/v_RockClimbingIndoor_g04_c01.avi
RockClimbingIndoor/v_RockClimbingIndoor_g04_c02.avi
RockClimbingIndoor/v_RockClimbingIndoor_g04_c03.avi
RockClimbingIndoor/v_RockClimbingIndoor_g04_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g05_c01.avi
RockClimbingIndoor/v_RockClimbingIndoor_g05_c02.avi
RockClimbingIndoor/v_RockClimbingIndoor_g05_c03.avi
RockClimbingIndoor/v_RockClimbingIndoor_g05_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g05_c05.avi
RockClimbingIndoor/v_RockClimbingIndoor_g05_c06.avi
RockClimbingIndoor/v_RockClimbingIndoor_g06_c01.avi
RockClimbingIndoor/v_RockClimbingIndoor_g06_c02.avi
RockClimbingIndoor/v_RockClimbingIndoor_g06_c03.avi
RockClimbingIndoor/v_RockClimbingIndoor_g06_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g06_c05.avi
RockClimbingIndoor/v_RockClimbingIndoor_g06_c06.avi
RockClimbingIndoor/v_RockClimbingIndoor_g06_c07.avi
RockClimbingIndoor/v_RockClimbingIndoor_g07_c01.avi
RockClimbingIndoor/v_RockClimbingIndoor_g07_c02.avi
RockClimbingIndoor/v_RockClimbingIndoor_g07_c03.avi
RockClimbingIndoor/v_RockClimbingIndoor_g07_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g07_c05.avi
RockClimbingIndoor/v_RockClimbingIndoor_g07_c06.avi
RockClimbingIndoor/v_RockClimbingIndoor_g07_c07.avi
RopeClimbing/v_RopeClimbing_g01_c01.avi
RopeClimbing/v_RopeClimbing_g01_c02.avi
RopeClimbing/v_RopeClimbing_g01_c03.avi
RopeClimbing/v_RopeClimbing_g01_c04.avi
RopeClimbing/v_RopeClimbing_g02_c01.avi
RopeClimbing/v_RopeClimbing_g02_c02.avi
RopeClimbing/v_RopeClimbing_g02_c03.avi
RopeClimbing/v_RopeClimbing_g02_c04.avi
RopeClimbing/v_RopeClimbing_g02_c05.avi
RopeClimbing/v_RopeClimbing_g02_c06.avi
RopeClimbing/v_RopeClimbing_g03_c01.avi
RopeClimbing/v_RopeClimbing_g03_c02.avi
RopeClimbing/v_RopeClimbing_g03_c03.avi
RopeClimbing/v_RopeClimbing_g03_c04.avi
RopeClimbing/v_RopeClimbing_g04_c01.avi
RopeClimbing/v_RopeClimbing_g04_c02.avi
RopeClimbing/v_RopeClimbing_g04_c03.avi
RopeClimbing/v_RopeClimbing_g04_c04.avi
RopeClimbing/v_RopeClimbing_g05_c01.avi
RopeClimbing/v_RopeClimbing_g05_c02.avi
RopeClimbing/v_RopeClimbing_g05_c03.avi
RopeClimbing/v_RopeClimbing_g05_c04.avi
RopeClimbing/v_RopeClimbing_g05_c05.avi
RopeClimbing/v_RopeClimbing_g05_c06.avi
RopeClimbing/v_RopeClimbing_g05_c07.avi
RopeClimbing/v_RopeClimbing_g06_c01.avi
RopeClimbing/v_RopeClimbing_g06_c02.avi
RopeClimbing/v_RopeClimbing_g06_c03.avi
RopeClimbing/v_RopeClimbing_g06_c04.avi
RopeClimbing/v_RopeClimbing_g07_c01.avi
RopeClimbing/v_RopeClimbing_g07_c02.avi
RopeClimbing/v_RopeClimbing_g07_c03.avi
RopeClimbing/v_RopeClimbing_g07_c04.avi
RopeClimbing/v_RopeClimbing_g07_c05.avi
Rowing/v_Rowing_g01_c01.avi
Rowing/v_Rowing_g01_c02.avi
Rowing/v_Rowing_g01_c03.avi
Rowing/v_Rowing_g01_c04.avi
Rowing/v_Rowing_g02_c01.avi
Rowing/v_Rowing_g02_c02.avi
Rowing/v_Rowing_g02_c03.avi
Rowing/v_Rowing_g02_c04.avi
Rowing/v_Rowing_g02_c05.avi
Rowing/v_Rowing_g02_c06.avi
Rowing/v_Rowing_g03_c01.avi
Rowing/v_Rowing_g03_c02.avi
Rowing/v_Rowing_g03_c03.avi
Rowing/v_Rowing_g03_c04.avi
Rowing/v_Rowing_g03_c05.avi
Rowing/v_Rowing_g03_c06.avi
Rowing/v_Rowing_g03_c07.avi
Rowing/v_Rowing_g04_c01.avi
Rowing/v_Rowing_g04_c02.avi
Rowing/v_Rowing_g04_c03.avi
Rowing/v_Rowing_g04_c04.avi
Rowing/v_Rowing_g04_c05.avi
Rowing/v_Rowing_g04_c06.avi
Rowing/v_Rowing_g05_c01.avi
Rowing/v_Rowing_g05_c02.avi
Rowing/v_Rowing_g05_c03.avi
Rowing/v_Rowing_g05_c04.avi
Rowing/v_Rowing_g06_c01.avi
Rowing/v_Rowing_g06_c02.avi
Rowing/v_Rowing_g06_c03.avi
Rowing/v_Rowing_g06_c04.avi
Rowing/v_Rowing_g07_c01.avi
Rowing/v_Rowing_g07_c02.avi
Rowing/v_Rowing_g07_c03.avi
Rowing/v_Rowing_g07_c04.avi
Rowing/v_Rowing_g07_c05.avi
SalsaSpin/v_SalsaSpin_g01_c01.avi
SalsaSpin/v_SalsaSpin_g01_c02.avi
SalsaSpin/v_SalsaSpin_g01_c03.avi
SalsaSpin/v_SalsaSpin_g01_c04.avi
SalsaSpin/v_SalsaSpin_g01_c05.avi
SalsaSpin/v_SalsaSpin_g01_c06.avi
SalsaSpin/v_SalsaSpin_g01_c07.avi
SalsaSpin/v_SalsaSpin_g02_c01.avi
SalsaSpin/v_SalsaSpin_g02_c02.avi
SalsaSpin/v_SalsaSpin_g02_c03.avi
SalsaSpin/v_SalsaSpin_g02_c04.avi
SalsaSpin/v_SalsaSpin_g02_c05.avi
SalsaSpin/v_SalsaSpin_g02_c06.avi
SalsaSpin/v_SalsaSpin_g02_c07.avi
SalsaSpin/v_SalsaSpin_g03_c01.avi
SalsaSpin/v_SalsaSpin_g03_c02.avi
SalsaSpin/v_SalsaSpin_g03_c03.avi
SalsaSpin/v_SalsaSpin_g03_c04.avi
SalsaSpin/v_SalsaSpin_g03_c05.avi
SalsaSpin/v_SalsaSpin_g03_c06.avi
SalsaSpin/v_SalsaSpin_g04_c01.avi
SalsaSpin/v_SalsaSpin_g04_c02.avi
SalsaSpin/v_SalsaSpin_g04_c03.avi
SalsaSpin/v_SalsaSpin_g04_c04.avi
SalsaSpin/v_SalsaSpin_g04_c05.avi
SalsaSpin/v_SalsaSpin_g04_c06.avi
SalsaSpin/v_SalsaSpin_g05_c01.avi
SalsaSpin/v_SalsaSpin_g05_c02.avi
SalsaSpin/v_SalsaSpin_g05_c03.avi
SalsaSpin/v_SalsaSpin_g05_c04.avi
SalsaSpin/v_SalsaSpin_g05_c05.avi
SalsaSpin/v_SalsaSpin_g05_c06.avi
SalsaSpin/v_SalsaSpin_g06_c01.avi
SalsaSpin/v_SalsaSpin_g06_c02.avi
SalsaSpin/v_SalsaSpin_g06_c03.avi
SalsaSpin/v_SalsaSpin_g06_c04.avi
SalsaSpin/v_SalsaSpin_g06_c05.avi
SalsaSpin/v_SalsaSpin_g07_c01.avi
SalsaSpin/v_SalsaSpin_g07_c02.avi
SalsaSpin/v_SalsaSpin_g07_c03.avi
SalsaSpin/v_SalsaSpin_g07_c04.avi
SalsaSpin/v_SalsaSpin_g07_c05.avi
SalsaSpin/v_SalsaSpin_g07_c06.avi
ShavingBeard/v_ShavingBeard_g01_c01.avi
ShavingBeard/v_ShavingBeard_g01_c02.avi
ShavingBeard/v_ShavingBeard_g01_c03.avi
ShavingBeard/v_ShavingBeard_g01_c04.avi
ShavingBeard/v_ShavingBeard_g02_c01.avi
ShavingBeard/v_ShavingBeard_g02_c02.avi
ShavingBeard/v_ShavingBeard_g02_c03.avi
ShavingBeard/v_ShavingBeard_g02_c04.avi
ShavingBeard/v_ShavingBeard_g02_c05.avi
ShavingBeard/v_ShavingBeard_g02_c06.avi
ShavingBeard/v_ShavingBeard_g02_c07.avi
ShavingBeard/v_ShavingBeard_g03_c01.avi
ShavingBeard/v_ShavingBeard_g03_c02.avi
ShavingBeard/v_ShavingBeard_g03_c03.avi
ShavingBeard/v_ShavingBeard_g03_c04.avi
ShavingBeard/v_ShavingBeard_g03_c05.avi
ShavingBeard/v_ShavingBeard_g03_c06.avi
ShavingBeard/v_ShavingBeard_g03_c07.avi
ShavingBeard/v_ShavingBeard_g04_c01.avi
ShavingBeard/v_ShavingBeard_g04_c02.avi
ShavingBeard/v_ShavingBeard_g04_c03.avi
ShavingBeard/v_ShavingBeard_g04_c04.avi
ShavingBeard/v_ShavingBeard_g05_c01.avi
ShavingBeard/v_ShavingBeard_g05_c02.avi
ShavingBeard/v_ShavingBeard_g05_c03.avi
ShavingBeard/v_ShavingBeard_g05_c04.avi
ShavingBeard/v_ShavingBeard_g05_c05.avi
ShavingBeard/v_ShavingBeard_g05_c06.avi
ShavingBeard/v_ShavingBeard_g05_c07.avi
ShavingBeard/v_ShavingBeard_g06_c01.avi
ShavingBeard/v_ShavingBeard_g06_c02.avi
ShavingBeard/v_ShavingBeard_g06_c03.avi
ShavingBeard/v_ShavingBeard_g06_c04.avi
ShavingBeard/v_ShavingBeard_g06_c05.avi
ShavingBeard/v_ShavingBeard_g06_c06.avi
ShavingBeard/v_ShavingBeard_g06_c07.avi
ShavingBeard/v_ShavingBeard_g07_c01.avi
ShavingBeard/v_ShavingBeard_g07_c02.avi
ShavingBeard/v_ShavingBeard_g07_c03.avi
ShavingBeard/v_ShavingBeard_g07_c04.avi
ShavingBeard/v_ShavingBeard_g07_c05.avi
ShavingBeard/v_ShavingBeard_g07_c06.avi
ShavingBeard/v_ShavingBeard_g07_c07.avi
Shotput/v_Shotput_g01_c01.avi
Shotput/v_Shotput_g01_c02.avi
Shotput/v_Shotput_g01_c03.avi
Shotput/v_Shotput_g01_c04.avi
Shotput/v_Shotput_g01_c05.avi
Shotput/v_Shotput_g01_c06.avi
Shotput/v_Shotput_g01_c07.avi
Shotput/v_Shotput_g02_c01.avi
Shotput/v_Shotput_g02_c02.avi
Shotput/v_Shotput_g02_c03.avi
Shotput/v_Shotput_g02_c04.avi
Shotput/v_Shotput_g02_c05.avi
Shotput/v_Shotput_g02_c06.avi
Shotput/v_Shotput_g02_c07.avi
Shotput/v_Shotput_g03_c01.avi
Shotput/v_Shotput_g03_c02.avi
Shotput/v_Shotput_g03_c03.avi
Shotput/v_Shotput_g03_c04.avi
Shotput/v_Shotput_g03_c05.avi
Shotput/v_Shotput_g03_c06.avi
Shotput/v_Shotput_g04_c01.avi
Shotput/v_Shotput_g04_c02.avi
Shotput/v_Shotput_g04_c03.avi
Shotput/v_Shotput_g04_c04.avi
Shotput/v_Shotput_g04_c05.avi
Shotput/v_Shotput_g05_c01.avi
Shotput/v_Shotput_g05_c02.avi
Shotput/v_Shotput_g05_c03.avi
Shotput/v_Shotput_g05_c04.avi
Shotput/v_Shotput_g05_c05.avi
Shotput/v_Shotput_g05_c06.avi
Shotput/v_Shotput_g05_c07.avi
Shotput/v_Shotput_g06_c01.avi
Shotput/v_Shotput_g06_c02.avi
Shotput/v_Shotput_g06_c03.avi
Shotput/v_Shotput_g06_c04.avi
Shotput/v_Shotput_g06_c05.avi
Shotput/v_Shotput_g06_c06.avi
Shotput/v_Shotput_g06_c07.avi
Shotput/v_Shotput_g07_c01.avi
Shotput/v_Shotput_g07_c02.avi
Shotput/v_Shotput_g07_c03.avi
Shotput/v_Shotput_g07_c04.avi
Shotput/v_Shotput_g07_c05.avi
Shotput/v_Shotput_g07_c06.avi
Shotput/v_Shotput_g07_c07.avi
SkateBoarding/v_SkateBoarding_g01_c01.avi
SkateBoarding/v_SkateBoarding_g01_c02.avi
SkateBoarding/v_SkateBoarding_g01_c03.avi
SkateBoarding/v_SkateBoarding_g01_c04.avi
SkateBoarding/v_SkateBoarding_g02_c01.avi
SkateBoarding/v_SkateBoarding_g02_c02.avi
SkateBoarding/v_SkateBoarding_g02_c03.avi
SkateBoarding/v_SkateBoarding_g02_c04.avi
SkateBoarding/v_SkateBoarding_g02_c05.avi
SkateBoarding/v_SkateBoarding_g02_c06.avi
SkateBoarding/v_SkateBoarding_g03_c01.avi
SkateBoarding/v_SkateBoarding_g03_c02.avi
SkateBoarding/v_SkateBoarding_g03_c03.avi
SkateBoarding/v_SkateBoarding_g03_c04.avi
SkateBoarding/v_SkateBoarding_g04_c01.avi
SkateBoarding/v_SkateBoarding_g04_c02.avi
SkateBoarding/v_SkateBoarding_g04_c03.avi
SkateBoarding/v_SkateBoarding_g04_c04.avi
SkateBoarding/v_SkateBoarding_g04_c05.avi
SkateBoarding/v_SkateBoarding_g05_c01.avi
SkateBoarding/v_SkateBoarding_g05_c02.avi
SkateBoarding/v_SkateBoarding_g05_c03.avi
SkateBoarding/v_SkateBoarding_g05_c04.avi
SkateBoarding/v_SkateBoarding_g06_c01.avi
SkateBoarding/v_SkateBoarding_g06_c02.avi
SkateBoarding/v_SkateBoarding_g06_c03.avi
SkateBoarding/v_SkateBoarding_g06_c04.avi
SkateBoarding/v_SkateBoarding_g07_c01.avi
SkateBoarding/v_SkateBoarding_g07_c02.avi
SkateBoarding/v_SkateBoarding_g07_c03.avi
SkateBoarding/v_SkateBoarding_g07_c04.avi
SkateBoarding/v_SkateBoarding_g07_c05.avi
Skiing/v_Skiing_g01_c01.avi
Skiing/v_Skiing_g01_c02.avi
Skiing/v_Skiing_g01_c03.avi
Skiing/v_Skiing_g01_c04.avi
Skiing/v_Skiing_g01_c05.avi
Skiing/v_Skiing_g01_c06.avi
Skiing/v_Skiing_g02_c01.avi
Skiing/v_Skiing_g02_c02.avi
Skiing/v_Skiing_g02_c03.avi
Skiing/v_Skiing_g02_c04.avi
Skiing/v_Skiing_g02_c05.avi
Skiing/v_Skiing_g03_c01.avi
Skiing/v_Skiing_g03_c02.avi
Skiing/v_Skiing_g03_c03.avi
Skiing/v_Skiing_g03_c04.avi
Skiing/v_Skiing_g03_c05.avi
Skiing/v_Skiing_g03_c06.avi
Skiing/v_Skiing_g03_c07.avi
Skiing/v_Skiing_g04_c01.avi
Skiing/v_Skiing_g04_c02.avi
Skiing/v_Skiing_g04_c03.avi
Skiing/v_Skiing_g04_c04.avi
Skiing/v_Skiing_g04_c05.avi
Skiing/v_Skiing_g04_c06.avi
Skiing/v_Skiing_g04_c07.avi
Skiing/v_Skiing_g05_c01.avi
Skiing/v_Skiing_g05_c02.avi
Skiing/v_Skiing_g05_c03.avi
Skiing/v_Skiing_g05_c04.avi
Skiing/v_Skiing_g06_c01.avi
Skiing/v_Skiing_g06_c02.avi
Skiing/v_Skiing_g06_c03.avi
Skiing/v_Skiing_g06_c04.avi
Skiing/v_Skiing_g06_c05.avi
Skiing/v_Skiing_g06_c06.avi
Skiing/v_Skiing_g06_c07.avi
Skiing/v_Skiing_g07_c01.avi
Skiing/v_Skiing_g07_c02.avi
Skiing/v_Skiing_g07_c03.avi
Skiing/v_Skiing_g07_c04.avi
Skijet/v_Skijet_g01_c01.avi
Skijet/v_Skijet_g01_c02.avi
Skijet/v_Skijet_g01_c03.avi
Skijet/v_Skijet_g01_c04.avi
Skijet/v_Skijet_g02_c01.avi
Skijet/v_Skijet_g02_c02.avi
Skijet/v_Skijet_g02_c03.avi
Skijet/v_Skijet_g02_c04.avi
Skijet/v_Skijet_g03_c01.avi
Skijet/v_Skijet_g03_c02.avi
Skijet/v_Skijet_g03_c03.avi
Skijet/v_Skijet_g03_c04.avi
Skijet/v_Skijet_g04_c01.avi
Skijet/v_Skijet_g04_c02.avi
Skijet/v_Skijet_g04_c03.avi
Skijet/v_Skijet_g04_c04.avi
Skijet/v_Skijet_g05_c01.avi
Skijet/v_Skijet_g05_c02.avi
Skijet/v_Skijet_g05_c03.avi
Skijet/v_Skijet_g05_c04.avi
Skijet/v_Skijet_g06_c01.avi
Skijet/v_Skijet_g06_c02.avi
Skijet/v_Skijet_g06_c03.avi
Skijet/v_Skijet_g06_c04.avi
Skijet/v_Skijet_g07_c01.avi
Skijet/v_Skijet_g07_c02.avi
Skijet/v_Skijet_g07_c03.avi
Skijet/v_Skijet_g07_c04.avi
SkyDiving/v_SkyDiving_g01_c01.avi
SkyDiving/v_SkyDiving_g01_c02.avi
SkyDiving/v_SkyDiving_g01_c03.avi
SkyDiving/v_SkyDiving_g01_c04.avi
SkyDiving/v_SkyDiving_g02_c01.avi
SkyDiving/v_SkyDiving_g02_c02.avi
SkyDiving/v_SkyDiving_g02_c03.avi
SkyDiving/v_SkyDiving_g02_c04.avi
SkyDiving/v_SkyDiving_g03_c01.avi
SkyDiving/v_SkyDiving_g03_c02.avi
SkyDiving/v_SkyDiving_g03_c03.avi
SkyDiving/v_SkyDiving_g03_c04.avi
SkyDiving/v_SkyDiving_g03_c05.avi
SkyDiving/v_SkyDiving_g04_c01.avi
SkyDiving/v_SkyDiving_g04_c02.avi
SkyDiving/v_SkyDiving_g04_c03.avi
SkyDiving/v_SkyDiving_g04_c04.avi
SkyDiving/v_SkyDiving_g05_c01.avi
SkyDiving/v_SkyDiving_g05_c02.avi
SkyDiving/v_SkyDiving_g05_c03.avi
SkyDiving/v_SkyDiving_g05_c04.avi
SkyDiving/v_SkyDiving_g05_c05.avi
SkyDiving/v_SkyDiving_g06_c01.avi
SkyDiving/v_SkyDiving_g06_c02.avi
SkyDiving/v_SkyDiving_g06_c03.avi
SkyDiving/v_SkyDiving_g06_c04.avi
SkyDiving/v_SkyDiving_g07_c01.avi
SkyDiving/v_SkyDiving_g07_c02.avi
SkyDiving/v_SkyDiving_g07_c03.avi
SkyDiving/v_SkyDiving_g07_c04.avi
SkyDiving/v_SkyDiving_g07_c05.avi
SoccerJuggling/v_SoccerJuggling_g01_c01.avi
SoccerJuggling/v_SoccerJuggling_g01_c02.avi
SoccerJuggling/v_SoccerJuggling_g01_c03.avi
SoccerJuggling/v_SoccerJuggling_g01_c04.avi
SoccerJuggling/v_SoccerJuggling_g01_c05.avi
SoccerJuggling/v_SoccerJuggling_g02_c01.avi
SoccerJuggling/v_SoccerJuggling_g02_c02.avi
SoccerJuggling/v_SoccerJuggling_g02_c03.avi
SoccerJuggling/v_SoccerJuggling_g02_c04.avi
SoccerJuggling/v_SoccerJuggling_g02_c05.avi
SoccerJuggling/v_SoccerJuggling_g02_c06.avi
SoccerJuggling/v_SoccerJuggling_g03_c01.avi
SoccerJuggling/v_SoccerJuggling_g03_c02.avi
SoccerJuggling/v_SoccerJuggling_g03_c03.avi
SoccerJuggling/v_SoccerJuggling_g03_c04.avi
SoccerJuggling/v_SoccerJuggling_g04_c01.avi
SoccerJuggling/v_SoccerJuggling_g04_c02.avi
SoccerJuggling/v_SoccerJuggling_g04_c03.avi
SoccerJuggling/v_SoccerJuggling_g04_c04.avi
SoccerJuggling/v_SoccerJuggling_g04_c05.avi
SoccerJuggling/v_SoccerJuggling_g04_c06.avi
SoccerJuggling/v_SoccerJuggling_g05_c01.avi
SoccerJuggling/v_SoccerJuggling_g05_c02.avi
SoccerJuggling/v_SoccerJuggling_g05_c03.avi
SoccerJuggling/v_SoccerJuggling_g05_c04.avi
SoccerJuggling/v_SoccerJuggling_g05_c05.avi
SoccerJuggling/v_SoccerJuggling_g05_c06.avi
SoccerJuggling/v_SoccerJuggling_g06_c01.avi
SoccerJuggling/v_SoccerJuggling_g06_c02.avi
SoccerJuggling/v_SoccerJuggling_g06_c03.avi
SoccerJuggling/v_SoccerJuggling_g06_c04.avi
SoccerJuggling/v_SoccerJuggling_g06_c05.avi
SoccerJuggling/v_SoccerJuggling_g07_c01.avi
SoccerJuggling/v_SoccerJuggling_g07_c02.avi
SoccerJuggling/v_SoccerJuggling_g07_c03.avi
SoccerJuggling/v_SoccerJuggling_g07_c04.avi
SoccerJuggling/v_SoccerJuggling_g07_c05.avi
SoccerJuggling/v_SoccerJuggling_g07_c06.avi
SoccerJuggling/v_SoccerJuggling_g07_c07.avi
SoccerPenalty/v_SoccerPenalty_g01_c01.avi
SoccerPenalty/v_SoccerPenalty_g01_c02.avi
SoccerPenalty/v_SoccerPenalty_g01_c03.avi
SoccerPenalty/v_SoccerPenalty_g01_c04.avi
SoccerPenalty/v_SoccerPenalty_g01_c05.avi
SoccerPenalty/v_SoccerPenalty_g01_c06.avi
SoccerPenalty/v_SoccerPenalty_g02_c01.avi
SoccerPenalty/v_SoccerPenalty_g02_c02.avi
SoccerPenalty/v_SoccerPenalty_g02_c03.avi
SoccerPenalty/v_SoccerPenalty_g02_c04.avi
SoccerPenalty/v_SoccerPenalty_g02_c05.avi
SoccerPenalty/v_SoccerPenalty_g03_c01.avi
SoccerPenalty/v_SoccerPenalty_g03_c02.avi
SoccerPenalty/v_SoccerPenalty_g03_c03.avi
SoccerPenalty/v_SoccerPenalty_g03_c04.avi
SoccerPenalty/v_SoccerPenalty_g03_c05.avi
SoccerPenalty/v_SoccerPenalty_g04_c01.avi
SoccerPenalty/v_SoccerPenalty_g04_c02.avi
SoccerPenalty/v_SoccerPenalty_g04_c03.avi
SoccerPenalty/v_SoccerPenalty_g04_c04.avi
SoccerPenalty/v_SoccerPenalty_g04_c05.avi
SoccerPenalty/v_SoccerPenalty_g05_c01.avi
SoccerPenalty/v_SoccerPenalty_g05_c02.avi
SoccerPenalty/v_SoccerPenalty_g05_c03.avi
SoccerPenalty/v_SoccerPenalty_g05_c04.avi
SoccerPenalty/v_SoccerPenalty_g05_c05.avi
SoccerPenalty/v_SoccerPenalty_g05_c06.avi
SoccerPenalty/v_SoccerPenalty_g05_c07.avi
SoccerPenalty/v_SoccerPenalty_g06_c01.avi
SoccerPenalty/v_SoccerPenalty_g06_c02.avi
SoccerPenalty/v_SoccerPenalty_g06_c03.avi
SoccerPenalty/v_SoccerPenalty_g06_c04.avi
SoccerPenalty/v_SoccerPenalty_g06_c05.avi
SoccerPenalty/v_SoccerPenalty_g06_c06.avi
SoccerPenalty/v_SoccerPenalty_g06_c07.avi
SoccerPenalty/v_SoccerPenalty_g07_c01.avi
SoccerPenalty/v_SoccerPenalty_g07_c02.avi
SoccerPenalty/v_SoccerPenalty_g07_c03.avi
SoccerPenalty/v_SoccerPenalty_g07_c04.avi
SoccerPenalty/v_SoccerPenalty_g07_c05.avi
SoccerPenalty/v_SoccerPenalty_g07_c06.avi
StillRings/v_StillRings_g01_c01.avi
StillRings/v_StillRings_g01_c02.avi
StillRings/v_StillRings_g01_c03.avi
StillRings/v_StillRings_g01_c04.avi
StillRings/v_StillRings_g01_c05.avi
StillRings/v_StillRings_g02_c01.avi
StillRings/v_StillRings_g02_c02.avi
StillRings/v_StillRings_g02_c03.avi
StillRings/v_StillRings_g02_c04.avi
StillRings/v_StillRings_g03_c01.avi
StillRings/v_StillRings_g03_c02.avi
StillRings/v_StillRings_g03_c03.avi
StillRings/v_StillRings_g03_c04.avi
StillRings/v_StillRings_g03_c05.avi
StillRings/v_StillRings_g03_c06.avi
StillRings/v_StillRings_g03_c07.avi
StillRings/v_StillRings_g04_c01.avi
StillRings/v_StillRings_g04_c02.avi
StillRings/v_StillRings_g04_c03.avi
StillRings/v_StillRings_g04_c04.avi
StillRings/v_StillRings_g05_c01.avi
StillRings/v_StillRings_g05_c02.avi
StillRings/v_StillRings_g05_c03.avi
StillRings/v_StillRings_g05_c04.avi
StillRings/v_StillRings_g06_c01.avi
StillRings/v_StillRings_g06_c02.avi
StillRings/v_StillRings_g06_c03.avi
StillRings/v_StillRings_g06_c04.avi
StillRings/v_StillRings_g07_c01.avi
StillRings/v_StillRings_g07_c02.avi
StillRings/v_StillRings_g07_c03.avi
StillRings/v_StillRings_g07_c04.avi
SumoWrestling/v_SumoWrestling_g01_c01.avi
SumoWrestling/v_SumoWrestling_g01_c02.avi
SumoWrestling/v_SumoWrestling_g01_c03.avi
SumoWrestling/v_SumoWrestling_g01_c04.avi
SumoWrestling/v_SumoWrestling_g02_c01.avi
SumoWrestling/v_SumoWrestling_g02_c02.avi
SumoWrestling/v_SumoWrestling_g02_c03.avi
SumoWrestling/v_SumoWrestling_g02_c04.avi
SumoWrestling/v_SumoWrestling_g03_c01.avi
SumoWrestling/v_SumoWrestling_g03_c02.avi
SumoWrestling/v_SumoWrestling_g03_c03.avi
SumoWrestling/v_SumoWrestling_g03_c04.avi
SumoWrestling/v_SumoWrestling_g04_c01.avi
SumoWrestling/v_SumoWrestling_g04_c02.avi
SumoWrestling/v_SumoWrestling_g04_c03.avi
SumoWrestling/v_SumoWrestling_g04_c04.avi
SumoWrestling/v_SumoWrestling_g05_c01.avi
SumoWrestling/v_SumoWrestling_g05_c02.avi
SumoWrestling/v_SumoWrestling_g05_c03.avi
SumoWrestling/v_SumoWrestling_g05_c04.avi
SumoWrestling/v_SumoWrestling_g06_c01.avi
SumoWrestling/v_SumoWrestling_g06_c02.avi
SumoWrestling/v_SumoWrestling_g06_c03.avi
SumoWrestling/v_SumoWrestling_g06_c04.avi
SumoWrestling/v_SumoWrestling_g06_c05.avi
SumoWrestling/v_SumoWrestling_g06_c06.avi
SumoWrestling/v_SumoWrestling_g06_c07.avi
SumoWrestling/v_SumoWrestling_g07_c01.avi
SumoWrestling/v_SumoWrestling_g07_c02.avi
SumoWrestling/v_SumoWrestling_g07_c03.avi
SumoWrestling/v_SumoWrestling_g07_c04.avi
SumoWrestling/v_SumoWrestling_g07_c05.avi
SumoWrestling/v_SumoWrestling_g07_c06.avi
SumoWrestling/v_SumoWrestling_g07_c07.avi
Surfing/v_Surfing_g01_c01.avi
Surfing/v_Surfing_g01_c02.avi
Surfing/v_Surfing_g01_c03.avi
Surfing/v_Surfing_g01_c04.avi
Surfing/v_Surfing_g01_c05.avi
Surfing/v_Surfing_g01_c06.avi
Surfing/v_Surfing_g01_c07.avi
Surfing/v_Surfing_g02_c01.avi
Surfing/v_Surfing_g02_c02.avi
Surfing/v_Surfing_g02_c03.avi
Surfing/v_Surfing_g02_c04.avi
Surfing/v_Surfing_g02_c05.avi
Surfing/v_Surfing_g02_c06.avi
Surfing/v_Surfing_g03_c01.avi
Surfing/v_Surfing_g03_c02.avi
Surfing/v_Surfing_g03_c03.avi
Surfing/v_Surfing_g03_c04.avi
Surfing/v_Surfing_g04_c01.avi
Surfing/v_Surfing_g04_c02.avi
Surfing/v_Surfing_g04_c03.avi
Surfing/v_Surfing_g04_c04.avi
Surfing/v_Surfing_g05_c01.avi
Surfing/v_Surfing_g05_c02.avi
Surfing/v_Surfing_g05_c03.avi
Surfing/v_Surfing_g05_c04.avi
Surfing/v_Surfing_g06_c01.avi
Surfing/v_Surfing_g06_c02.avi
Surfing/v_Surfing_g06_c03.avi
Surfing/v_Surfing_g06_c04.avi
Surfing/v_Surfing_g07_c01.avi
Surfing/v_Surfing_g07_c02.avi
Surfing/v_Surfing_g07_c03.avi
Surfing/v_Surfing_g07_c04.avi
Swing/v_Swing_g01_c01.avi
Swing/v_Swing_g01_c02.avi
Swing/v_Swing_g01_c03.avi
Swing/v_Swing_g01_c04.avi
Swing/v_Swing_g01_c05.avi
Swing/v_Swing_g02_c01.avi
Swing/v_Swing_g02_c02.avi
Swing/v_Swing_g02_c03.avi
Swing/v_Swing_g02_c04.avi
Swing/v_Swing_g02_c05.avi
Swing/v_Swing_g03_c01.avi
Swing/v_Swing_g03_c02.avi
Swing/v_Swing_g03_c03.avi
Swing/v_Swing_g03_c04.avi
Swing/v_Swing_g04_c01.avi
Swing/v_Swing_g04_c02.avi
Swing/v_Swing_g04_c03.avi
Swing/v_Swing_g04_c04.avi
Swing/v_Swing_g04_c05.avi
Swing/v_Swing_g04_c06.avi
Swing/v_Swing_g04_c07.avi
Swing/v_Swing_g05_c01.avi
Swing/v_Swing_g05_c02.avi
Swing/v_Swing_g05_c03.avi
Swing/v_Swing_g05_c04.avi
Swing/v_Swing_g05_c05.avi
Swing/v_Swing_g05_c06.avi
Swing/v_Swing_g05_c07.avi
Swing/v_Swing_g06_c01.avi
Swing/v_Swing_g06_c02.avi
Swing/v_Swing_g06_c03.avi
Swing/v_Swing_g06_c04.avi
Swing/v_Swing_g06_c05.avi
Swing/v_Swing_g06_c06.avi
Swing/v_Swing_g06_c07.avi
Swing/v_Swing_g07_c01.avi
Swing/v_Swing_g07_c02.avi
Swing/v_Swing_g07_c03.avi
Swing/v_Swing_g07_c04.avi
Swing/v_Swing_g07_c05.avi
Swing/v_Swing_g07_c06.avi
Swing/v_Swing_g07_c07.avi
TableTennisShot/v_TableTennisShot_g01_c01.avi
TableTennisShot/v_TableTennisShot_g01_c02.avi
TableTennisShot/v_TableTennisShot_g01_c03.avi
TableTennisShot/v_TableTennisShot_g01_c04.avi
TableTennisShot/v_TableTennisShot_g01_c05.avi
TableTennisShot/v_TableTennisShot_g01_c06.avi
TableTennisShot/v_TableTennisShot_g02_c01.avi
TableTennisShot/v_TableTennisShot_g02_c02.avi
TableTennisShot/v_TableTennisShot_g02_c03.avi
TableTennisShot/v_TableTennisShot_g02_c04.avi
TableTennisShot/v_TableTennisShot_g03_c01.avi
TableTennisShot/v_TableTennisShot_g03_c02.avi
TableTennisShot/v_TableTennisShot_g03_c03.avi
TableTennisShot/v_TableTennisShot_g03_c04.avi
TableTennisShot/v_TableTennisShot_g03_c05.avi
TableTennisShot/v_TableTennisShot_g04_c01.avi
TableTennisShot/v_TableTennisShot_g04_c02.avi
TableTennisShot/v_TableTennisShot_g04_c03.avi
TableTennisShot/v_TableTennisShot_g04_c04.avi
TableTennisShot/v_TableTennisShot_g04_c05.avi
TableTennisShot/v_TableTennisShot_g04_c06.avi
TableTennisShot/v_TableTennisShot_g04_c07.avi
TableTennisShot/v_TableTennisShot_g05_c01.avi
TableTennisShot/v_TableTennisShot_g05_c02.avi
TableTennisShot/v_TableTennisShot_g05_c03.avi
TableTennisShot/v_TableTennisShot_g05_c04.avi
TableTennisShot/v_TableTennisShot_g05_c05.avi
TableTennisShot/v_TableTennisShot_g05_c06.avi
TableTennisShot/v_TableTennisShot_g05_c07.avi
TableTennisShot/v_TableTennisShot_g06_c01.avi
TableTennisShot/v_TableTennisShot_g06_c02.avi
TableTennisShot/v_TableTennisShot_g06_c03.avi
TableTennisShot/v_TableTennisShot_g06_c04.avi
TableTennisShot/v_TableTennisShot_g06_c05.avi
TableTennisShot/v_TableTennisShot_g06_c06.avi
TableTennisShot/v_TableTennisShot_g07_c01.avi
TableTennisShot/v_TableTennisShot_g07_c02.avi
TableTennisShot/v_TableTennisShot_g07_c03.avi
TableTennisShot/v_TableTennisShot_g07_c04.avi
TaiChi/v_TaiChi_g01_c01.avi
TaiChi/v_TaiChi_g01_c02.avi
TaiChi/v_TaiChi_g01_c03.avi
TaiChi/v_TaiChi_g01_c04.avi
TaiChi/v_TaiChi_g02_c01.avi
TaiChi/v_TaiChi_g02_c02.avi
TaiChi/v_TaiChi_g02_c03.avi
TaiChi/v_TaiChi_g02_c04.avi
TaiChi/v_TaiChi_g03_c01.avi
TaiChi/v_TaiChi_g03_c02.avi
TaiChi/v_TaiChi_g03_c03.avi
TaiChi/v_TaiChi_g03_c04.avi
TaiChi/v_TaiChi_g04_c01.avi
TaiChi/v_TaiChi_g04_c02.avi
TaiChi/v_TaiChi_g04_c03.avi
TaiChi/v_TaiChi_g04_c04.avi
TaiChi/v_TaiChi_g05_c01.avi
TaiChi/v_TaiChi_g05_c02.avi
TaiChi/v_TaiChi_g05_c03.avi
TaiChi/v_TaiChi_g05_c04.avi
TaiChi/v_TaiChi_g06_c01.avi
TaiChi/v_TaiChi_g06_c02.avi
TaiChi/v_TaiChi_g06_c03.avi
TaiChi/v_TaiChi_g06_c04.avi
TaiChi/v_TaiChi_g07_c01.avi
TaiChi/v_TaiChi_g07_c02.avi
TaiChi/v_TaiChi_g07_c03.avi
TaiChi/v_TaiChi_g07_c04.avi
TennisSwing/v_TennisSwing_g01_c01.avi
TennisSwing/v_TennisSwing_g01_c02.avi
TennisSwing/v_TennisSwing_g01_c03.avi
TennisSwing/v_TennisSwing_g01_c04.avi
TennisSwing/v_TennisSwing_g01_c05.avi
TennisSwing/v_TennisSwing_g01_c06.avi
TennisSwing/v_TennisSwing_g01_c07.avi
TennisSwing/v_TennisSwing_g02_c01.avi
TennisSwing/v_TennisSwing_g02_c02.avi
TennisSwing/v_TennisSwing_g02_c03.avi
TennisSwing/v_TennisSwing_g02_c04.avi
TennisSwing/v_TennisSwing_g02_c05.avi
TennisSwing/v_TennisSwing_g02_c06.avi
TennisSwing/v_TennisSwing_g02_c07.avi
TennisSwing/v_TennisSwing_g03_c01.avi
TennisSwing/v_TennisSwing_g03_c02.avi
TennisSwing/v_TennisSwing_g03_c03.avi
TennisSwing/v_TennisSwing_g03_c04.avi
TennisSwing/v_TennisSwing_g03_c05.avi
TennisSwing/v_TennisSwing_g03_c06.avi
TennisSwing/v_TennisSwing_g03_c07.avi
TennisSwing/v_TennisSwing_g04_c01.avi
TennisSwing/v_TennisSwing_g04_c02.avi
TennisSwing/v_TennisSwing_g04_c03.avi
TennisSwing/v_TennisSwing_g04_c04.avi
TennisSwing/v_TennisSwing_g04_c05.avi
TennisSwing/v_TennisSwing_g04_c06.avi
TennisSwing/v_TennisSwing_g04_c07.avi
TennisSwing/v_TennisSwing_g05_c01.avi
TennisSwing/v_TennisSwing_g05_c02.avi
TennisSwing/v_TennisSwing_g05_c03.avi
TennisSwing/v_TennisSwing_g05_c04.avi
TennisSwing/v_TennisSwing_g05_c05.avi
TennisSwing/v_TennisSwing_g05_c06.avi
TennisSwing/v_TennisSwing_g05_c07.avi
TennisSwing/v_TennisSwing_g06_c01.avi
TennisSwing/v_TennisSwing_g06_c02.avi
TennisSwing/v_TennisSwing_g06_c03.avi
TennisSwing/v_TennisSwing_g06_c04.avi
TennisSwing/v_TennisSwing_g06_c05.avi
TennisSwing/v_TennisSwing_g06_c06.avi
TennisSwing/v_TennisSwing_g06_c07.avi
TennisSwing/v_TennisSwing_g07_c01.avi
TennisSwing/v_TennisSwing_g07_c02.avi
TennisSwing/v_TennisSwing_g07_c03.avi
TennisSwing/v_TennisSwing_g07_c04.avi
TennisSwing/v_TennisSwing_g07_c05.avi
TennisSwing/v_TennisSwing_g07_c06.avi
TennisSwing/v_TennisSwing_g07_c07.avi
ThrowDiscus/v_ThrowDiscus_g01_c01.avi
ThrowDiscus/v_ThrowDiscus_g01_c02.avi
ThrowDiscus/v_ThrowDiscus_g01_c03.avi
ThrowDiscus/v_ThrowDiscus_g01_c04.avi
ThrowDiscus/v_ThrowDiscus_g02_c01.avi
ThrowDiscus/v_ThrowDiscus_g02_c02.avi
ThrowDiscus/v_ThrowDiscus_g02_c03.avi
ThrowDiscus/v_ThrowDiscus_g02_c04.avi
ThrowDiscus/v_ThrowDiscus_g02_c05.avi
ThrowDiscus/v_ThrowDiscus_g02_c06.avi
ThrowDiscus/v_ThrowDiscus_g02_c07.avi
ThrowDiscus/v_ThrowDiscus_g03_c01.avi
ThrowDiscus/v_ThrowDiscus_g03_c02.avi
ThrowDiscus/v_ThrowDiscus_g03_c03.avi
ThrowDiscus/v_ThrowDiscus_g03_c04.avi
ThrowDiscus/v_ThrowDiscus_g04_c01.avi
ThrowDiscus/v_ThrowDiscus_g04_c02.avi
ThrowDiscus/v_ThrowDiscus_g04_c03.avi
ThrowDiscus/v_ThrowDiscus_g04_c04.avi
ThrowDiscus/v_ThrowDiscus_g05_c01.avi
ThrowDiscus/v_ThrowDiscus_g05_c02.avi
ThrowDiscus/v_ThrowDiscus_g05_c03.avi
ThrowDiscus/v_ThrowDiscus_g05_c04.avi
ThrowDiscus/v_ThrowDiscus_g05_c05.avi
ThrowDiscus/v_ThrowDiscus_g06_c01.avi
ThrowDiscus/v_ThrowDiscus_g06_c02.avi
ThrowDiscus/v_ThrowDiscus_g06_c03.avi
ThrowDiscus/v_ThrowDiscus_g06_c04.avi
ThrowDiscus/v_ThrowDiscus_g06_c05.avi
ThrowDiscus/v_ThrowDiscus_g06_c06.avi
ThrowDiscus/v_ThrowDiscus_g06_c07.avi
ThrowDiscus/v_ThrowDiscus_g07_c01.avi
ThrowDiscus/v_ThrowDiscus_g07_c02.avi
ThrowDiscus/v_ThrowDiscus_g07_c03.avi
ThrowDiscus/v_ThrowDiscus_g07_c04.avi
ThrowDiscus/v_ThrowDiscus_g07_c05.avi
ThrowDiscus/v_ThrowDiscus_g07_c06.avi
ThrowDiscus/v_ThrowDiscus_g07_c07.avi
TrampolineJumping/v_TrampolineJumping_g01_c01.avi
TrampolineJumping/v_TrampolineJumping_g01_c02.avi
TrampolineJumping/v_TrampolineJumping_g01_c03.avi
TrampolineJumping/v_TrampolineJumping_g01_c04.avi
TrampolineJumping/v_TrampolineJumping_g02_c01.avi
TrampolineJumping/v_TrampolineJumping_g02_c02.avi
TrampolineJumping/v_TrampolineJumping_g02_c03.avi
TrampolineJumping/v_TrampolineJumping_g02_c04.avi
TrampolineJumping/v_TrampolineJumping_g02_c05.avi
TrampolineJumping/v_TrampolineJumping_g02_c06.avi
TrampolineJumping/v_TrampolineJumping_g03_c01.avi
TrampolineJumping/v_TrampolineJumping_g03_c02.avi
TrampolineJumping/v_TrampolineJumping_g03_c03.avi
TrampolineJumping/v_TrampolineJumping_g03_c04.avi
TrampolineJumping/v_TrampolineJumping_g04_c01.avi
TrampolineJumping/v_TrampolineJumping_g04_c02.avi
TrampolineJumping/v_TrampolineJumping_g04_c03.avi
TrampolineJumping/v_TrampolineJumping_g04_c04.avi
TrampolineJumping/v_TrampolineJumping_g04_c05.avi
TrampolineJumping/v_TrampolineJumping_g05_c01.avi
TrampolineJumping/v_TrampolineJumping_g05_c02.avi
TrampolineJumping/v_TrampolineJumping_g05_c03.avi
TrampolineJumping/v_TrampolineJumping_g05_c04.avi
TrampolineJumping/v_TrampolineJumping_g06_c01.avi
TrampolineJumping/v_TrampolineJumping_g06_c02.avi
TrampolineJumping/v_TrampolineJumping_g06_c03.avi
TrampolineJumping/v_TrampolineJumping_g06_c04.avi
TrampolineJumping/v_TrampolineJumping_g07_c01.avi
TrampolineJumping/v_TrampolineJumping_g07_c02.avi
TrampolineJumping/v_TrampolineJumping_g07_c03.avi
TrampolineJumping/v_TrampolineJumping_g07_c04.avi
TrampolineJumping/v_TrampolineJumping_g07_c05.avi
Typing/v_Typing_g01_c01.avi
Typing/v_Typing_g01_c02.avi
Typing/v_Typing_g01_c03.avi
Typing/v_Typing_g01_c04.avi
Typing/v_Typing_g01_c05.avi
Typing/v_Typing_g01_c06.avi
Typing/v_Typing_g01_c07.avi
Typing/v_Typing_g02_c01.avi
Typing/v_Typing_g02_c02.avi
Typing/v_Typing_g02_c03.avi
Typing/v_Typing_g02_c04.avi
Typing/v_Typing_g02_c05.avi
Typing/v_Typing_g02_c06.avi
Typing/v_Typing_g03_c01.avi
Typing/v_Typing_g03_c02.avi
Typing/v_Typing_g03_c03.avi
Typing/v_Typing_g03_c04.avi
Typing/v_Typing_g03_c05.avi
Typing/v_Typing_g03_c06.avi
Typing/v_Typing_g03_c07.avi
Typing/v_Typing_g04_c01.avi
Typing/v_Typing_g04_c02.avi
Typing/v_Typing_g04_c03.avi
Typing/v_Typing_g04_c04.avi
Typing/v_Typing_g05_c01.avi
Typing/v_Typing_g05_c02.avi
Typing/v_Typing_g05_c03.avi
Typing/v_Typing_g05_c04.avi
Typing/v_Typing_g05_c05.avi
Typing/v_Typing_g05_c06.avi
Typing/v_Typing_g06_c01.avi
Typing/v_Typing_g06_c02.avi
Typing/v_Typing_g06_c03.avi
Typing/v_Typing_g06_c04.avi
Typing/v_Typing_g06_c05.avi
Typing/v_Typing_g06_c06.avi
Typing/v_Typing_g06_c07.avi
Typing/v_Typing_g07_c01.avi
Typing/v_Typing_g07_c02.avi
Typing/v_Typing_g07_c03.avi
Typing/v_Typing_g07_c04.avi
Typing/v_Typing_g07_c05.avi
Typing/v_Typing_g07_c06.avi
UnevenBars/v_UnevenBars_g01_c01.avi
UnevenBars/v_UnevenBars_g01_c02.avi
UnevenBars/v_UnevenBars_g01_c03.avi
UnevenBars/v_UnevenBars_g01_c04.avi
UnevenBars/v_UnevenBars_g02_c01.avi
UnevenBars/v_UnevenBars_g02_c02.avi
UnevenBars/v_UnevenBars_g02_c03.avi
UnevenBars/v_UnevenBars_g02_c04.avi
UnevenBars/v_UnevenBars_g03_c01.avi
UnevenBars/v_UnevenBars_g03_c02.avi
UnevenBars/v_UnevenBars_g03_c03.avi
UnevenBars/v_UnevenBars_g03_c04.avi
UnevenBars/v_UnevenBars_g04_c01.avi
UnevenBars/v_UnevenBars_g04_c02.avi
UnevenBars/v_UnevenBars_g04_c03.avi
UnevenBars/v_UnevenBars_g04_c04.avi
UnevenBars/v_UnevenBars_g05_c01.avi
UnevenBars/v_UnevenBars_g05_c02.avi
UnevenBars/v_UnevenBars_g05_c03.avi
UnevenBars/v_UnevenBars_g05_c04.avi
UnevenBars/v_UnevenBars_g06_c01.avi
UnevenBars/v_UnevenBars_g06_c02.avi
UnevenBars/v_UnevenBars_g06_c03.avi
UnevenBars/v_UnevenBars_g06_c04.avi
UnevenBars/v_UnevenBars_g07_c01.avi
UnevenBars/v_UnevenBars_g07_c02.avi
UnevenBars/v_UnevenBars_g07_c03.avi
UnevenBars/v_UnevenBars_g07_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g01_c01.avi
VolleyballSpiking/v_VolleyballSpiking_g01_c02.avi
VolleyballSpiking/v_VolleyballSpiking_g01_c03.avi
VolleyballSpiking/v_VolleyballSpiking_g01_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g02_c01.avi
VolleyballSpiking/v_VolleyballSpiking_g02_c02.avi
VolleyballSpiking/v_VolleyballSpiking_g02_c03.avi
VolleyballSpiking/v_VolleyballSpiking_g02_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g03_c01.avi
VolleyballSpiking/v_VolleyballSpiking_g03_c02.avi
VolleyballSpiking/v_VolleyballSpiking_g03_c03.avi
VolleyballSpiking/v_VolleyballSpiking_g03_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g04_c01.avi
VolleyballSpiking/v_VolleyballSpiking_g04_c02.avi
VolleyballSpiking/v_VolleyballSpiking_g04_c03.avi
VolleyballSpiking/v_VolleyballSpiking_g04_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g04_c05.avi
VolleyballSpiking/v_VolleyballSpiking_g04_c06.avi
VolleyballSpiking/v_VolleyballSpiking_g04_c07.avi
VolleyballSpiking/v_VolleyballSpiking_g05_c01.avi
VolleyballSpiking/v_VolleyballSpiking_g05_c02.avi
VolleyballSpiking/v_VolleyballSpiking_g05_c03.avi
VolleyballSpiking/v_VolleyballSpiking_g05_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g05_c05.avi
VolleyballSpiking/v_VolleyballSpiking_g06_c01.avi
VolleyballSpiking/v_VolleyballSpiking_g06_c02.avi
VolleyballSpiking/v_VolleyballSpiking_g06_c03.avi
VolleyballSpiking/v_VolleyballSpiking_g06_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g07_c01.avi
VolleyballSpiking/v_VolleyballSpiking_g07_c02.avi
VolleyballSpiking/v_VolleyballSpiking_g07_c03.avi
VolleyballSpiking/v_VolleyballSpiking_g07_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g07_c05.avi
VolleyballSpiking/v_VolleyballSpiking_g07_c06.avi
VolleyballSpiking/v_VolleyballSpiking_g07_c07.avi
WalkingWithDog/v_WalkingWithDog_g01_c01.avi
WalkingWithDog/v_WalkingWithDog_g01_c02.avi
WalkingWithDog/v_WalkingWithDog_g01_c03.avi
WalkingWithDog/v_WalkingWithDog_g01_c04.avi
WalkingWithDog/v_WalkingWithDog_g02_c01.avi
WalkingWithDog/v_WalkingWithDog_g02_c02.avi
WalkingWithDog/v_WalkingWithDog_g02_c03.avi
WalkingWithDog/v_WalkingWithDog_g02_c04.avi
WalkingWithDog/v_WalkingWithDog_g02_c05.avi
WalkingWithDog/v_WalkingWithDog_g02_c06.avi
WalkingWithDog/v_WalkingWithDog_g03_c01.avi
WalkingWithDog/v_WalkingWithDog_g03_c02.avi
WalkingWithDog/v_WalkingWithDog_g03_c03.avi
WalkingWithDog/v_WalkingWithDog_g03_c04.avi
WalkingWithDog/v_WalkingWithDog_g03_c05.avi
WalkingWithDog/v_WalkingWithDog_g04_c01.avi
WalkingWithDog/v_WalkingWithDog_g04_c02.avi
WalkingWithDog/v_WalkingWithDog_g04_c03.avi
WalkingWithDog/v_WalkingWithDog_g04_c04.avi
WalkingWithDog/v_WalkingWithDog_g04_c05.avi
WalkingWithDog/v_WalkingWithDog_g05_c01.avi
WalkingWithDog/v_WalkingWithDog_g05_c02.avi
WalkingWithDog/v_WalkingWithDog_g05_c03.avi
WalkingWithDog/v_WalkingWithDog_g05_c04.avi
WalkingWithDog/v_WalkingWithDog_g05_c05.avi
WalkingWithDog/v_WalkingWithDog_g06_c01.avi
WalkingWithDog/v_WalkingWithDog_g06_c02.avi
WalkingWithDog/v_WalkingWithDog_g06_c03.avi
WalkingWithDog/v_WalkingWithDog_g06_c04.avi
WalkingWithDog/v_WalkingWithDog_g06_c05.avi
WalkingWithDog/v_WalkingWithDog_g07_c01.avi
WalkingWithDog/v_WalkingWithDog_g07_c02.avi
WalkingWithDog/v_WalkingWithDog_g07_c03.avi
WalkingWithDog/v_WalkingWithDog_g07_c04.avi
WalkingWithDog/v_WalkingWithDog_g07_c05.avi
WalkingWithDog/v_WalkingWithDog_g07_c06.avi
WallPushups/v_WallPushups_g01_c01.avi
WallPushups/v_WallPushups_g01_c02.avi
WallPushups/v_WallPushups_g01_c03.avi
WallPushups/v_WallPushups_g01_c04.avi
WallPushups/v_WallPushups_g02_c01.avi
WallPushups/v_WallPushups_g02_c02.avi
WallPushups/v_WallPushups_g02_c03.avi
WallPushups/v_WallPushups_g02_c04.avi
WallPushups/v_WallPushups_g03_c01.avi
WallPushups/v_WallPushups_g03_c02.avi
WallPushups/v_WallPushups_g03_c03.avi
WallPushups/v_WallPushups_g03_c04.avi
WallPushups/v_WallPushups_g03_c05.avi
WallPushups/v_WallPushups_g04_c01.avi
WallPushups/v_WallPushups_g04_c02.avi
WallPushups/v_WallPushups_g04_c03.avi
WallPushups/v_WallPushups_g04_c04.avi
WallPushups/v_WallPushups_g05_c01.avi
WallPushups/v_WallPushups_g05_c02.avi
WallPushups/v_WallPushups_g05_c03.avi
WallPushups/v_WallPushups_g05_c04.avi
WallPushups/v_WallPushups_g05_c05.avi
WallPushups/v_WallPushups_g06_c01.avi
WallPushups/v_WallPushups_g06_c02.avi
WallPushups/v_WallPushups_g06_c03.avi
WallPushups/v_WallPushups_g06_c04.avi
WallPushups/v_WallPushups_g06_c05.avi
WallPushups/v_WallPushups_g06_c06.avi
WallPushups/v_WallPushups_g06_c07.avi
WallPushups/v_WallPushups_g07_c01.avi
WallPushups/v_WallPushups_g07_c02.avi
WallPushups/v_WallPushups_g07_c03.avi
WallPushups/v_WallPushups_g07_c04.avi
WallPushups/v_WallPushups_g07_c05.avi
WallPushups/v_WallPushups_g07_c06.avi
WritingOnBoard/v_WritingOnBoard_g01_c01.avi
WritingOnBoard/v_WritingOnBoard_g01_c02.avi
WritingOnBoard/v_WritingOnBoard_g01_c03.avi
WritingOnBoard/v_WritingOnBoard_g01_c04.avi
WritingOnBoard/v_WritingOnBoard_g01_c05.avi
WritingOnBoard/v_WritingOnBoard_g01_c06.avi
WritingOnBoard/v_WritingOnBoard_g01_c07.avi
WritingOnBoard/v_WritingOnBoard_g02_c01.avi
WritingOnBoard/v_WritingOnBoard_g02_c02.avi
WritingOnBoard/v_WritingOnBoard_g02_c03.avi
WritingOnBoard/v_WritingOnBoard_g02_c04.avi
WritingOnBoard/v_WritingOnBoard_g02_c05.avi
WritingOnBoard/v_WritingOnBoard_g02_c06.avi
WritingOnBoard/v_WritingOnBoard_g02_c07.avi
WritingOnBoard/v_WritingOnBoard_g03_c01.avi
WritingOnBoard/v_WritingOnBoard_g03_c02.avi
WritingOnBoard/v_WritingOnBoard_g03_c03.avi
WritingOnBoard/v_WritingOnBoard_g03_c04.avi
WritingOnBoard/v_WritingOnBoard_g03_c05.avi
WritingOnBoard/v_WritingOnBoard_g03_c06.avi
WritingOnBoard/v_WritingOnBoard_g03_c07.avi
WritingOnBoard/v_WritingOnBoard_g04_c01.avi
WritingOnBoard/v_WritingOnBoard_g04_c02.avi
WritingOnBoard/v_WritingOnBoard_g04_c03.avi
WritingOnBoard/v_WritingOnBoard_g04_c04.avi
WritingOnBoard/v_WritingOnBoard_g05_c01.avi
WritingOnBoard/v_WritingOnBoard_g05_c02.avi
WritingOnBoard/v_WritingOnBoard_g05_c03.avi
WritingOnBoard/v_WritingOnBoard_g05_c04.avi
WritingOnBoard/v_WritingOnBoard_g05_c05.avi
WritingOnBoard/v_WritingOnBoard_g05_c06.avi
WritingOnBoard/v_WritingOnBoard_g06_c01.avi
WritingOnBoard/v_WritingOnBoard_g06_c02.avi
WritingOnBoard/v_WritingOnBoard_g06_c03.avi
WritingOnBoard/v_WritingOnBoard_g06_c04.avi
WritingOnBoard/v_WritingOnBoard_g06_c05.avi
WritingOnBoard/v_WritingOnBoard_g06_c06.avi
WritingOnBoard/v_WritingOnBoard_g06_c07.avi
WritingOnBoard/v_WritingOnBoard_g07_c01.avi
WritingOnBoard/v_WritingOnBoard_g07_c02.avi
WritingOnBoard/v_WritingOnBoard_g07_c03.avi
WritingOnBoard/v_WritingOnBoard_g07_c04.avi
WritingOnBoard/v_WritingOnBoard_g07_c05.avi
WritingOnBoard/v_WritingOnBoard_g07_c06.avi
WritingOnBoard/v_WritingOnBoard_g07_c07.avi
YoYo/v_YoYo_g01_c01.avi
YoYo/v_YoYo_g01_c02.avi
YoYo/v_YoYo_g01_c03.avi
YoYo/v_YoYo_g01_c04.avi
YoYo/v_YoYo_g01_c05.avi
YoYo/v_YoYo_g01_c06.avi
YoYo/v_YoYo_g01_c07.avi
YoYo/v_YoYo_g02_c01.avi
YoYo/v_YoYo_g02_c02.avi
YoYo/v_YoYo_g02_c03.avi
YoYo/v_YoYo_g02_c04.avi
YoYo/v_YoYo_g02_c05.avi
YoYo/v_YoYo_g03_c01.avi
YoYo/v_YoYo_g03_c02.avi
YoYo/v_YoYo_g03_c03.avi
YoYo/v_YoYo_g03_c04.avi
YoYo/v_YoYo_g03_c05.avi
YoYo/v_YoYo_g03_c06.avi
YoYo/v_YoYo_g04_c01.avi
YoYo/v_YoYo_g04_c02.avi
YoYo/v_YoYo_g04_c03.avi
YoYo/v_YoYo_g04_c04.avi
YoYo/v_YoYo_g04_c05.avi
YoYo/v_YoYo_g05_c01.avi
YoYo/v_YoYo_g05_c02.avi
YoYo/v_YoYo_g05_c03.avi
YoYo/v_YoYo_g05_c04.avi
YoYo/v_YoYo_g05_c05.avi
YoYo/v_YoYo_g06_c01.avi
YoYo/v_YoYo_g06_c02.avi
YoYo/v_YoYo_g06_c03.avi
YoYo/v_YoYo_g06_c04.avi
YoYo/v_YoYo_g07_c01.avi
YoYo/v_YoYo_g07_c02.avi
YoYo/v_YoYo_g07_c03.avi
YoYo/v_YoYo_g07_c04.avi
================================================
FILE: braincog/datasets/scripts/ucf101_dvs_preprocessing.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/12/20 20:16
# User : Floyed
# Product : PyCharm
# Project : BrainCog
# File : ucf101_dvs_preprocessing.py
# explain :
import os
import shutil
ROOT_DIR = '/data/datasets/UCF101_DVS/UCF101_DVS'
train_path = os.path.join(ROOT_DIR, 'train')
val_path = os.path.join(ROOT_DIR, 'val')
val_fname = 'testlist01.txt'
cls_path = os.listdir(train_path)
if not os.path.exists(val_path):
os.mkdir(val_path)
for cls_name in cls_path:
os.mkdir(os.path.join(val_path, cls_name))
f = open(val_fname, 'r')
for fname in f.readlines():
fname = fname[:-4] + 'mat'
fname.replace('Billards', 'Billiards')
src = os.path.join(train_path, fname)
dst = os.path.join(val_path, fname)
try:
shutil.move(src, dst)
except:
print('[Warning] Cannot find {}.'.format(src))
print('[Moving] {} -> {}.'.format(src, dst))
================================================
FILE: braincog/datasets/ucf101_dvs/__init__.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2023/1/30 21:04
# User : yu
# Product : PyCharm
# Project : BrainCog
# File : __init__.py.py
# explain :
from .ucf101_dvs import UCF101DVS
__all__ = [
'UCF101DVS'
]
================================================
FILE: braincog/datasets/ucf101_dvs/ucf101_dvs.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2023/1/30 21:05
# User : yu
# Product : PyCharm
# Project : BrainCog
# File : ucf51_dvs.py
# explain :
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/12/20 20:47
# User : Floyed
# Product : PyCharm
# Project : tonic
# File : ucf101dvs.py
# explain :
import os
import numpy as np
from numpy.lib import recfunctions
import scipy.io as scio
from typing import Tuple, Any, Optional
from tonic.dataset import Dataset
from tonic.download_utils import extract_archive
class UCF101DVS(Dataset):
"""ASL-DVS dataset . Events have (txyp) ordering.
::
@inproceedings{bi2019graph,
title={Graph-based Object Classification for Neuromorphic Vision Sensing},
author={Bi, Y and Chadha, A and Abbas, A and and Bourtsoulatze, E and Andreopoulos, Y},
booktitle={2019 IEEE International Conference on Computer Vision (ICCV)},
year={2019},
organization={IEEE}
}
Parameters:
save_to (string): Location to save files to on disk.
transform (callable, optional): A callable of transforms to apply to the data.
target_transform (callable, optional): A callable of transforms to apply to the targets/labels.
"""
sensor_size = (240, 180, 2)
dtype = np.dtype([("t", int), ("x", int), ("y", int), ("p", int)])
ordering = dtype.names
folder_name = 'UCF101DVS'
def __init__(self, save_to, train=False, transform=None, target_transform=None):
super(UCF101DVS, self).__init__(
save_to, transform=transform, target_transform=target_transform
)
if not self._check_exists():
raise NotImplementedError(
'Please manually download the dataset from'
' https://www.dropbox.com/sh/ie75dn246cacf6n/AACoU-_zkGOAwj51lSCM0JhGa?dl=0 '
'and extract it to {}'.format(self.location_on_system))
if train:
self.location_on_system = os.path.join(self.location_on_system, 'train')
else:
self.location_on_system = os.path.join(self.location_on_system, 'val')
classes = os.listdir(self.location_on_system)
self.int_classes = dict(zip(classes, range(len(classes))))
for path, dirs, files in os.walk(self.location_on_system):
dirs.sort()
files.sort()
for file in files:
if file.endswith("mat"):
fsize = os.path.getsize(path + '/' + file) / float(1024)
if fsize < 1:
# print('{} size {} K'.format(file, fsize))
continue
self.data.append(path + "/" + file)
self.targets.append(self.int_classes[path.split('/')[-1]])
def __getitem__(self, index: int) -> Tuple[Any, Any]:
"""
Returns:
(events, target) where target is index of the target class.
"""
events, target = scio.loadmat(self.data[index]), self.targets[index]
events = np.column_stack(
[
events["ts"],
events["x"],
self.sensor_size[1] - 1 - events["y"],
events["pol"],
]
)
events = np.lib.recfunctions.unstructured_to_structured(events, self.dtype)
if self.transform is not None:
events = self.transform(events)
if self.target_transform is not None:
target = self.target_transform(target)
return events, target
def __len__(self):
return len(self.data)
def _check_exists(self):
print(self.folder_name)
return self._folder_contains_at_least_n_files_of_type(
13523, ".mat"
)
================================================
FILE: braincog/datasets/utils.py
================================================
import torch
from einops import repeat
from braincog.datasets.gen_input_signal import lambda_max
def rescale(x, factor=None):
"""
数据放缩函数
:param x: 输入的tensor
:param factor: 缩放因子
:return: 缩放后的数据
"""
if factor:
x *= factor
else:
x *= lambda_max
return x
def dvs_channel_check_expend(x):
"""
检查是否存在DVS数据缺失, N-Car中有的数据会缺少一个通道
:param x: 输入的tensor
:return: 补全之后的数据
"""
if x.shape[1] == 1:
return repeat(x, 'b c w h -> b (r c) w h', r=2)
else:
return x
================================================
FILE: braincog/model_zoo/NeuEvo/__init__.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/9/1 16:43
# User : Floyed
# Product : PyCharm
# Project : BrainCog
# File : __init__.py.py
# explain :
import os
import numpy as np
from .genotypes import PRIMITIVES, Genotype
forward_edge_num = sum(1 for i in range(3) for n in range(2 + i))
backward_edge_num = sum(1 for i in range(3) for n in range(i))
num_ops = len(PRIMITIVES)
type_num = len(PRIMITIVES) // 2
# edge_num = [2, 3, 4]
# node_id: (forward) 2, 3, 4
# node_id: (backward) 3, 2
edge_num = [2, 3, 4, 1, 2]
def parse(weights, operation_set,
op_threshold, parse_method,
steps, reduction=False,
back_connection=False):
global k_best
gene = []
if parse_method == 'darts':
n = 2
start = 0
for i in range(steps): # step = 4
end = start + n
W = weights[start:end].copy()
edges = sorted(range(i + 2), key=lambda x: -
max(W[x][k] for k in range(len(W[x]))))[:2]
for j in edges:
for k in range(len(W[j])):
if k_best is None or W[j][k] > W[j][k_best]:
k_best = k
# geno item : (operation, node idx)
gene.append((operation_set[k_best], j))
start = end
n += 1
elif parse_method == 'bio_darts':
weights_backward = weights[forward_edge_num:]
weights_forward = weights[:forward_edge_num]
# forward
n = 2
start = 0
# idx = np.argsort(weights_forward[:, 0]).tolist()
# if reduction:
# idx.remove(0)
# idx.remove(1)
# weights_forward[:, 0] = 0.
# weights_forward[idx[-2:], 0] = 1.
for i in range(steps): # step = 4
end = start + n
W = weights_forward[start:end].copy()
edges = sorted(range(i + 2), key=lambda x: -
max(W[x][k] for k in range(len(W[x]))))[:2]
k_best = None
idx = np.argsort(W[edges[0]])
gene.append((operation_set[idx[-1]], edges[0]))
idx = np.argsort(W[edges[1]])
gene.append((operation_set[idx[-1]], edges[1]))
#
# op_name = operation_set[idx[-1]]
# idx = np.argsort(W[edges[1]])
# if 'skip' in op_name:
# gene.append((operation_set[idx[-1]], edges[1]))
# elif '_n' in op_name:
# for k in reversed(idx):
# if '_n' not in operation_set[k]:
# gene.append((operation_set[k], edges[1]))
# break
# else:
# for k in reversed(idx):
# if '_n' in operation_set[k]:
# gene.append((operation_set[k], edges[1]))
# break
start = end
n += 1
if back_connection:
# backward
n = 1
start = 0
for i in range(1, steps):
end = start + n
W = weights_backward[start:end].copy()
edges = sorted(range(i), key=lambda x: -
max(W[x][k] for k in range(len(W[x]))))[0]
idx = np.argsort(W[edges])
gene.append((operation_set[idx[-1]] + '_back', edges + 2))
start = end
n += 1
elif 'threshold' in parse_method:
n = 2
start = 0
for i in range(steps): # step = 4
end = start + n
W = weights[start:end].copy()
if 'edge' in parse_method:
edges = list(range(i + 2))
else: # select edges using darts methods
edges = sorted(range(i + 2), key=lambda x: -
max(W[x][k] for k in range(len(W[x]))))[:2]
for j in edges:
if 'edge' in parse_method: # OP_{prob > T} AND |Edge| <= 2
topM = sorted(enumerate(W[j]), key=lambda x: x[1])[-2:]
for k, v in topM: # Get top M = 2 operations for one edge
if W[j][k] >= op_threshold:
gene.append((operation_set[k], i + 2, j))
# max( OP_{prob > T} ) and |Edge| <= 2
elif 'sparse' in parse_method:
k_best = None
for k in range(len(W[j])):
if k_best is None or W[j][k] > W[j][k_best]:
k_best = k
if W[j][k_best] >= op_threshold:
gene.append((operation_set[k_best], i + 2, j))
else:
raise NotImplementedError(
"Not support parse method: {}".format(parse_method))
start = end
n += 1
return gene
def parse_genotype(alphas, steps, multiplier, path=None,
parse_method='threshold_sparse', op_threshold=0.85):
alphas_normal, alphas_reduce = alphas
gene_normal = parse(alphas_normal, PRIMITIVES,
op_threshold, parse_method, steps)
gene_reduce = parse(alphas_reduce, PRIMITIVES,
op_threshold, parse_method, steps)
concat = range(2 + steps - multiplier, steps + 2)
genotype = Genotype(
normal=gene_normal, normal_concat=concat,
reduce=gene_reduce, reduce_concat=concat
)
if path is not None:
if not os.path.exists(path):
os.makedirs(path)
print('Architecture parsing....\n', genotype)
save_path = os.path.join(
path, parse_method + '_' + str(op_threshold) + '.txt')
with open(save_path, "w+") as f:
f.write(str(genotype))
print('Save in :', save_path)
================================================
FILE: braincog/model_zoo/NeuEvo/architect.py
================================================
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import numpy as np
from numpy.linalg import eigvals
from braincog.model_zoo.NeuEvo.model_search import calc_weight, calc_loss
def normalize(x):
mu = np.average(x)
sigma = np.std(x)
return (x - mu) / sigma
def _concat(xs):
return torch.cat([x.view(-1) for x in xs])
class Architect(object):
def __init__(self, model, args):
self.network_momentum = args.momentum
self.network_weight_decay = args.weight_decay
self.model = model
self.optimizer = torch.optim.AdamW(self.model.arch_parameters(),
lr=args.arch_learning_rate,
betas=(args.arch_lr_gamma, 0.999),
weight_decay=args.arch_weight_decay)
# self.optimizer = torch.optim.SGD(self.model.arch_parameters(), lr=args.arch_learning_rate)
self.hessian = None
self.grads = None
def step(self, input_valid, target_valid):
self.optimizer.zero_grad()
aux_input = torch.cat([calc_loss(self.model.alphas_normal)], dim=0)
loss, loss1, loss2 = self.model._loss(
input_valid, target_valid, aux_input)
# loss = self.model._loss(input_valid, target_valid)
loss.backward()
self.optimizer.step()
return loss1, loss2
def compute_Hw(self, input_valid, target_valid):
self.zero_grads(self.model.parameters())
self.zero_grads(self.model.arch_parameters())
aux_input = torch.cat(
[F.softmax(self.model.alphas_normal, dim=-1)], dim=0)
loss = self.model._loss(input_valid, target_valid, aux_input)
self.hessian = self._hessian(loss, self.model.arch_parameters())
return self.hessian
def zero_grads(self, parameters):
for p in parameters:
if p.grad is not None:
p.grad.detach_()
p.grad.zero_()
def compute_eigenvalues(self):
self.compute_Hw()
return eigvals(self.hessian.cpu().data.numpy())
def _hessian(self, outputs, inputs, out=None, allow_unused=False):
if torch.is_tensor(inputs):
inputs = [inputs]
else:
inputs = list(inputs)
n = sum(p.numel() for p in inputs)
if out is None:
out = torch.tensor(torch.zeros(n, n)).type_as(outputs)
ai = 0
for i, inp in enumerate(inputs):
[grad] = torch.autograd.grad(outputs, inp, create_graph=True,
allow_unused=allow_unused)
grad = grad.contiguous().view(-1) + self.weight_decay * inp.view(-1)
for j in range(inp.numel()):
if grad[j].requires_grad:
row = self.gradient(
grad[j], inputs[i:], retain_graph=True)[j:]
else:
n = sum(x.numel() for x in inputs[i:]) - j
row = Variable(torch.zeros(n)).type_as(grad[j])
out.data[ai, ai:].add_(row.clone().type_as(out).data)
if ai + 1 < n:
out.data[ai + 1:,
ai].add_(row.clone().type_as(out).data[1:])
del row
ai += 1
del grad
return out
================================================
FILE: braincog/model_zoo/NeuEvo/genotypes.py
================================================
from collections import namedtuple
import torch
Genotype = namedtuple('Genotype', 'normal normal_concat')
"""
Operation sets
"""
PRIMITIVES = [
'conv_3x3_p',
# 'max_pool_3x3',
# 'avg_pool_3x3',
# 'def_conv_3x3',
# 'def_conv_5x5',
# 'sep_conv_3x3',
# 'sep_conv_5x5',
# 'dil_conv_3x3',
# 'dil_conv_5x5',
# 'max_pool_3x3_p',
# 'avg_pool_3x3_p',
'conv_3x3_p',
'conv_5x5_p',
# 'conv_3x3_p_p',
# 'sep_conv_3x3_p',
# 'sep_conv_5x5_p',
# 'dil_conv_3x3_p',
# 'dil_conv_5x5_p',
# 'def_conv_3x3_p',
# 'def_conv_5x5_p',n
# 'max_pool_3x3_n',
# 'avg_pool_3x3_n',
'conv_3x3_n',
'conv_5x5_n',
# 'conv_3x3_p_n',
# 'sep_conv_3x3_n',
# 'sep_conv_5x5_n',
# 'dil_conv_3x3_n',
# 'dil_conv_5x5_n',
# 'def_conv_3x3_n',
# 'def_conv_5x5_n',
# 'transformer',
]
"""====== SnnMlp Archirtecture By Other Methods"""
mlp1 = Genotype(
normal=[
('mlp', 0), ('conv_3x3_p', 1), # 2
('mlp', 1), ('mlp', 0), # 3
('conv_3x3_p', 2), ('mlp', 3), # 4
('mlp_back', 2),
('conv_3x3_p_back', 2)
],
normal_concat=range(2, 5)
)
mlp2 = Genotype(
normal=[
('mlp', 0), ('conv_3x3_p', 1),
('conv_3x3_p', 2), ('mlp_p', 1),
# ('mlp_n', 1), ('conv_3x3_p', 2),
('mlp_back', 2)
],
normal_concat=range(2, 4)
)
"""====== SNN Archirtecture By Other Methods"""
dvsc10_new_skip22 = Genotype(
normal=[
('conv_3x3_p', 1), ('conv_3x3_p', 0), # 2
('conv_5x5_p', 1), ('conv_3x3_p', 2), # 3
('conv_3x3_p', 0), ('conv_3x3_p', 3), # 4
('conv_3x3_n_back', 2), ('conv_3x3_p_back', 3) # 3, 4
],
normal_concat=range(2, 5)
)
dvsc10_new_skip22 = Genotype(
normal=[
('conv_3x3_p', 1), ('conv_3x3_p', 0),
('conv_5x5_n', 1), ('conv_3x3_p', 2),
('conv_5x5_n', 0), ('conv_3x3_p', 3),
('conv_3x3_n_back', 0), ('conv_3x3_p_back', 1)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip21 = Genotype(
normal=[
('conv_3x3_n', 0), ('conv_5x5_p', 1), # 2
('conv_3x3_p', 1), ('conv_5x5_p', 2), # 3
('conv_5x5_n', 2), ('conv_3x3_p', 1), # 4
# ('conv_3x3_p_back', 2), ('conv_5x5_p_back', 2)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip20 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_n', 1),
('conv_3x3_n', 2), ('conv_5x5_p', 0),
('conv_3x3_p', 2), ('conv_3x3_n', 3),
('conv_3x3_p_back', 2),
('conv_5x5_p_back', 3)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip19 = Genotype(
normal=[
('conv_5x5_n', 0), ('conv_3x3_p', 1),
('conv_5x5_n', 2), ('conv_5x5_n', 0),
('conv_3x3_p', 2), ('conv_5x5_p', 3),
('conv_3x3_p_back', 2),
('conv_5x5_p_back', 2)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip18 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_3x3_p', 1),
('conv_5x5_p', 2), ('conv_5x5_n', 0),
('conv_3x3_p', 2), ('conv_5x5_p', 3),
('conv_5x5_n_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_skip17 = Genotype(
normal=[
('conv_3x3_p', 1), ('conv_5x5_n', 0),
('conv_5x5_n', 2), ('conv_5x5_p', 1),
('conv_3x3_p', 2), ('avg_pool_3x3_p', 3),
('avg_pool_3x3_p_back', 2), ('conv_3x3_p_back', 2)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip16 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_n', 1),
('conv_3x3_n', 2), ('avg_pool_3x3_p', 0),
('conv_3x3_p', 2), ('avg_pool_3x3_n', 3),
('conv_3x3_p_back', 2),
('conv_3x3_p_back', 3)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip15 = Genotype(
normal=[
('conv_5x5_n', 0), ('conv_5x5_p', 1),
('conv_5x5_p', 2), ('conv_5x5_n', 1),
('conv_3x3_p', 2), ('conv_5x5_p', 3),
('conv_5x5_p_back', 2),
('conv_3x3_p_back', 3)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip14 = Genotype(
normal=[
('conv_5x5_n', 1), ('conv_3x3_p', 0),
('conv_5x5_p', 1), ('conv_3x3_p', 2),
('conv_3x3_p', 2), ('conv_5x5_n', 1),
('conv_3x3_n_back', 2),
('conv_3x3_p_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new_skip13 = Genotype(
normal=[
('conv_5x5_n', 1), ('conv_3x3_p', 0),
('conv_5x5_n', 1), ('conv_3x3_p', 2),
('conv_3x3_p', 2), ('conv_5x5_n', 1),
('conv_3x3_n_back', 2),
('conv_3x3_p_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new_skip12 = Genotype(
normal=[
('conv_5x5_n', 0), ('conv_3x3_p', 1),
('conv_5x5_n', 2), ('conv_5x5_n', 0),
('conv_3x3_p', 2), ('conv_5x5_p', 3),
('conv_3x3_n_back', 2),
('conv_3x3_p_back', 2)
],
normal_concat=range(2, 5)
)
# dvsc10_new_skip12 = Genotype(
# normal=[
# ('conv_3x3_p', 0), ('conv_3x3_n', 1),
# ('conv_3x3_p', 1), ('conv_5x5_n', 2),
# ('conv_3x3_n', 3), ('conv_3x3_p', 0),
# ('conv_5x5_p_back', 2), ('conv_3x3_p_back', 3)
# ],
# normal_concat=range(2, 5)
# )
dvsc10_new_skip11 = Genotype(normal=[
('conv_3x3_n', 0), ('conv_5x5_n', 1),
('conv_5x5_p', 0), ('conv_3x3_n', 2),
('conv_3x3_p', 2), ('conv_5x5_n', 0),
('conv_3x3_n_back', 2),
('conv_3x3_p_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new_skip10 = Genotype(
normal=[
('conv_5x5_n', 1), ('conv_3x3_p', 0),
('conv_5x5_p', 2), ('conv_5x5_p', 1),
('conv_3x3_p', 2), ('conv_5x5_n', 1),
('conv_3x3_n_back', 2),
('conv_3x3_n_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_skip9 = Genotype(
normal=[
('conv_5x5_p', 1), ('conv_5x5_n', 0),
('conv_5x5_p', 2), ('conv_5x5_n', 0),
('conv_3x3_p', 2), ('conv_5x5_p', 3),
('conv_3x3_p_back', 2),
('conv_5x5_n_back', 3)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip8 = Genotype(
normal=[
('conv_5x5_n', 0), ('conv_5x5_n', 1),
('conv_3x3_n', 2), ('conv_5x5_p', 0),
('conv_3x3_p', 2), ('conv_5x5_n', 1),
('conv_5x5_n_back', 2),
('conv_3x3_p_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new_skip7 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),
('conv_3x3_n', 2), ('conv_5x5_n', 0),
('conv_3x3_p', 2), ('conv_5x5_p', 3),
('conv_5x5_n_back', 2),
('conv_3x3_p_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new_skip6 = Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_n', 1),
('conv_5x5_p', 2), ('conv_5x5_p', 1),
('conv_3x3_p', 2), ('conv_5x5_n', 0),
('conv_3x3_n_back', 2), ('conv_3x3_n_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_skip5 = Genotype(
normal=[
('conv_3x3_p', 0), ('conv_3x3_p', 1),
('conv_3x3_n', 2), ('conv_3x3_n', 0),
('conv_3x3_p', 2), ('conv_3x3_p', 3),
('conv_5x5_n_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_skip4 = Genotype(
normal=[
('conv_5x5_n', 1), ('conv_5x5_p', 0),
('conv_3x3_p', 2), ('conv_5x5_p', 1),
('conv_3x3_p', 2), ('conv_5x5_n', 0),
('conv_3x3_p_back', 2),
('conv_3x3_p_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new_skip3 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_3x3_p', 1),
('conv_3x3_n', 2), ('conv_3x3_n', 0),
('conv_3x3_p', 2), ('conv_5x5_p', 3),
('conv_5x5_n_back', 2),
('conv_3x3_p_back', 3)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip2 = Genotype(
normal=[
('avg_pool_3x3_p', 0), ('avg_pool_3x3_p', 1),
('avg_pool_3x3_p', 0), ('avg_pool_3x3_p', 1),
('conv_3x3_p', 2), ('avg_pool_3x3_n', 0),
('avg_pool_3x3_n_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_skip1 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_3x3_n', 1),
('conv_3x3_n', 2), ('conv_3x3_p', 1),
('conv_5x5_p', 1), ('conv_3x3_p', 2),
('conv_3x3_p_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_skip = Genotype(
normal=[
('conv_3x3_n', 1), ('conv_3x3_p', 0),
('conv_3x3_p', 0), ('avg_pool_3x3_p', 1),
('conv_3x3_p', 2), ('conv_3x3_n', 0),
('conv_3x3_p_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_base0 = Genotype(
normal=[
('avg_pool_3x3_p', 1), ('avg_pool_3x3_p', 0),
('avg_pool_3x3_n', 2), ('avg_pool_3x3_p', 1),
('avg_pool_3x3_n', 2), ('avg_pool_3x3_n', 3),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_n_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new_base1 = Genotype(
normal=[
('conv_3x3_p', 1), ('conv_5x5_n', 0),
('conv_5x5_p', 1), ('conv_3x3_p', 0),
('conv_5x5_n', 1), ('conv_3x3_p', 0),
('avg_pool_3x3_p_back', 2),
('conv_3x3_p_back', 3)
],
normal_concat=range(2, 5)
)
dvsc10_new_base2 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_3x3_p', 1),
('conv_5x5_n', 1), ('avg_pool_3x3_p', 0),
('avg_pool_3x3_n', 3), ('conv_5x5_n', 1),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_n_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_base3 = Genotype(
normal=[
('avg_pool_3x3_p', 0), ('conv_5x5_p', 1),
('conv_3x3_p', 1), ('conv_3x3_n', 0),
('conv_5x5_p', 1), ('conv_3x3_n', 0),
('conv_3x3_p_back', 2),
('avg_pool_3x3_n_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_grad2 = Genotype(
normal=[
('avg_pool_3x3_n', 1), ('conv_5x5_p', 0),
('conv_5x5_n', 1), ('conv_5x5_n', 0),
('conv_3x3_p', 3), ('conv_5x5_n', 1),
('conv_5x5_p_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_grad1 = Genotype(
normal=[
('avg_pool_3x3_p', 1), ('conv_5x5_p', 0),
('avg_pool_3x3_n', 2), ('avg_pool_3x3_n', 1),
('avg_pool_3x3_p', 2), ('conv_5x5_n', 1),
('conv_5x5_p_back', 2),
('conv_3x3_p_back', 3)],
normal_concat=range(2, 5))
dvsg_new2 = Genotype(
normal=[
('avg_pool_3x3_p', 1), ('conv_5x5_p', 0),
('conv_3x3_p', 1), ('conv_3x3_p', 0),
('conv_3x3_p', 1), ('avg_pool_3x3_p', 0),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_n_back', 3)],
normal_concat=range(2, 5))
dvsg_new1 = Genotype(
normal=[
('avg_pool_3x3_p', 1), ('conv_5x5_p', 0),
('conv_3x3_p', 1), ('conv_3x3_p', 0),
('conv_3x3_p', 1), ('avg_pool_3x3_p', 0),
('avg_pool_3x3_n_back', 2),
('conv_5x5_n_back', 3)],
normal_concat=range(2, 5))
dvscal_new1 = Genotype(
normal=[
('conv_5x5_n', 0), ('conv_5x5_n', 1),
('conv_5x5_n', 1), ('conv_5x5_p', 0),
('avg_pool_3x3_p', 1), ('conv_5x5_p', 0),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_n_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new8 = Genotype(
normal=[('conv_5x5_p', 0), ('conv_5x5_p', 1),
('conv_3x3_p', 0), ('conv_5x5_n', 1),
('conv_5x5_p', 0), ('conv_5x5_n', 1),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_n_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new7 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),
('conv_3x3_p', 0), ('conv_5x5_n', 1),
('conv_5x5_p', 0), ('conv_5x5_n', 1),
('conv_3x3_n_back', 2),
('avg_pool_3x3_n_back', 2)],
normal_concat=range(2, 5))
dvsc10_new6 = Genotype(
normal=[
('conv_3x3_p', 1), ('conv_3x3_p', 0),
('conv_3x3_p', 0), ('conv_3x3_p', 1),
('conv_3x3_p', 0), ('avg_pool_3x3_p', 1),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_n_back', 2)],
normal_concat=range(2, 5))
dvsc10_new5 = Genotype(
normal=[
('conv_5x5_p', 1), ('conv_3x3_p', 0),
('conv_3x3_p', 0), ('conv_5x5_p', 1),
('conv_3x3_p', 0), ('avg_pool_3x3_p', 1),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_n_back', 2)],
normal_concat=range(2, 5))
dvsc10_new4 = Genotype(
normal=[
('conv_3x3_n', 1), ('conv_3x3_p', 0),
('conv_5x5_p', 1), ('conv_5x5_p', 0),
('conv_5x5_p', 1), ('conv_5x5_p', 0),
('avg_pool_3x3_p_back', 2),
('avg_pool_3x3_n_back', 2)],
normal_concat=range(2, 5),
)
dvsc10_new3 = Genotype(
normal=[
('avg_pool_3x3_p', 0), ('conv_3x3_n', 1),
('conv_3x3_n', 1), ('conv_3x3_n', 0),
('avg_pool_3x3_p', 2), ('conv_3x3_n', 1),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_p', 2)],
normal_concat=range(2, 5),
)
dvsc10_new2 = Genotype(normal=[
('conv_3x3_p', 0), ('conv_3x3_n', 1),
('conv_3x3_n', 1), ('avg_pool_3x3_p', 0),
('avg_pool_3x3_p', 2), ('conv_3x3_n', 1),
('avg_pool_3x3_n_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5),
)
dvsc10_new1 = Genotype(
normal=[
('conv_3x3_p', 1), ('avg_pool_3x3_p', 0),
('avg_pool_3x3_p', 0), ('conv_3x3_n', 1),
('conv_3x3_p', 0), ('conv_3x3_p', 1),
('conv_3x3_p_back', 2),
('conv_3x3_n_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new0 = Genotype(
normal=[
('conv_3x3_p', 1), ('avg_pool_3x3_p', 0),
('avg_pool_3x3_p', 2), ('conv_3x3_n', 1),
('conv_3x3_p', 0), ('conv_3x3_p', 3),
('conv_3x3_p_back', 2),
('conv_3x3_n_back', 3)],
normal_concat=range(2, 5)
)
cifar_new_skip1 = Genotype(
normal=[
('conv_5x5_n', 0), ('conv_5x5_p', 1),
('avg_pool_3x3_p', 0), ('avg_pool_3x3_n', 2),
('avg_pool_3x3_p', 2), ('conv_5x5_p', 0),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_p_back', 3)
],
normal_concat=range(2, 5))
cifar_new1 = Genotype(
normal=[
('avg_pool_3x3_p', 1), ('avg_pool_3x3_p', 0),
('conv_3x3_n', 0), ('avg_pool_3x3_p', 1),
('avg_pool_3x3_p', 2), ('conv_3x3_p', 0),
('avg_pool_3x3_n_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5)
)
cifar_new2 = Genotype(
normal=[
('conv_3x3_n', 0), ('avg_pool_3x3_p', 1),
('conv_3x3_p', 0), ('avg_pool_3x3_p', 1),
('conv_3x3_p', 2), ('conv_3x3_n', 0),
('conv_3x3_n_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5),
)
cifar_new0 = Genotype(
normal=[
('avg_pool_3x3_p', 1), ('avg_pool_3x3_n', 0), # 2, 3
('conv_3x3_n', 0), ('avg_pool_3x3_p', 1), # 4, 5
('conv_3x3_p', 2), ('conv_3x3_n', 3), # 6 , 7
('avg_pool_3x3_n_back', 2),
('conv_3x3_p_back', 1)],
normal_concat=range(2, 5)
)
================================================
FILE: braincog/model_zoo/NeuEvo/model.py
================================================
from functools import partial
from typing import List, Type
from braincog.model_zoo.NeuEvo.operations import *
from braincog.model_zoo.NeuEvo.genotypes import Genotype
from braincog.base.utils import drop_path
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.model_zoo.base_module import BaseModule
class MlpCell(BaseModule):
def __init__(
self,
genotype: Genotype,
C: int,
input_dim: int,
output_dim: int,
encode_type: str = 'direct',
activation_fn: Type[nn.Module] = LIFNode,
squash_output: bool = False,
back_connection: bool = True,
step: int = 10,
**kwargs
):
super(MlpCell, self).__init__(
step=step,
encode_type=encode_type,
layer_by_layer=True
)
# print(activation_fn, step)
self.act_fun = partial(activation_fn, step=step, layer_by_layer=self.layer_by_layer, **kwargs)
self.back_connection = back_connection
op_names, indices = zip(*genotype.normal)
concat = genotype.normal_concat
self._compile(C, op_names, indices, concat)
self.feature = nn.Sequential(
nn.Linear(input_dim, C),
self.act_fun(),
)
if output_dim > 0:
self.output_fn = nn.Linear(self.multiplier * C, output_dim)
elif squash_output:
self.output_fn = nn.Tanh()
else:
self.output_fn = nn.Identity()
def _compile(self, C, op_names, indices, concat):
assert len(op_names) == len(indices)
# self._steps = len(op_names) // 2
self._concat = concat
self.multiplier = len(concat)
self._ops = nn.ModuleList()
self._ops_back = nn.ModuleList()
back_begin_index = 0
for i, (name, index) in enumerate(zip(op_names, indices)):
# print(name, index)
if '_back' in name:
back_begin_index = i
break
op = OPS_Mlp[name](C, act_fun=self.act_fun)
self._ops += [op]
if self.back_connection:
for name, index in zip(op_names[back_begin_index:], indices[back_begin_index:]):
op = OPS_Mlp[name.replace('_back', '')](
C, act_fun=self.act_fun)
self._ops_back += [op]
if self.back_connection:
self._indices_forward = indices[:back_begin_index]
self._indices_backward = indices[back_begin_index:]
else:
self._indices_backward = []
self._indices_forward = indices
self._steps = len(self._indices_forward) // 2
def _forward_once(self, s0, s1, drop_prob):
states = [s0, s1]
for i in range(self._steps):
h1 = states[self._indices_forward[2 * i]]
h2 = states[self._indices_forward[2 * i + 1]]
op1 = self._ops[2 * i]
op2 = self._ops[2 * i + 1]
h1 = op1(h1)
h2 = op2(h2)
if self.training and drop_prob > 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
s = h1 + h2
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]
] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = []
for i in self._concat:
outputs.append(rearrange(states[i], '(t b) c -> t b c', t=self.step))
outputs = torch.cat(outputs, dim=2) # T, B, C
return outputs
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.feature(inputs)
x = self._forward_once(x, x, 0.)
x = self.output_fn(x)
x = x.mean(0)
else:
raise NotImplementedError
return x
class Cell(nn.Module):
def __init__(self, genotype, C_prev_prev, C_prev, C, reduction, reduction_prev, act_fun, back_connection):
# print(C_prev_prev, C_prev, C, reduction)
super(Cell, self).__init__()
self.act_fun = act_fun
self.back_connection = back_connection
self.reduction = reduction
if reduction:
self.fun = FactorizedReduce(
C_prev, C * 3, act_fun=act_fun
)
self.multiplier = 3
else:
if reduction_prev:
self.preprocess0 = FactorizedReduce(
C_prev_prev, C, act_fun=act_fun)
else:
self.preprocess0 = ReLUConvBN(
C_prev_prev, C, 1, 1, 0, act_fun=act_fun)
self.preprocess1 = ReLUConvBN(C_prev, C, 1, 1, 0, act_fun=act_fun)
op_names, indices = zip(*genotype.normal)
concat = genotype.normal_concat
self._compile(C, op_names, indices, concat, reduction)
def _compile(self, C, op_names, indices, concat, reduction):
assert len(op_names) == len(indices)
# self._steps = len(op_names) // 2
self._concat = concat
self.multiplier = len(concat)
self._ops = nn.ModuleList()
self._ops_back = nn.ModuleList()
back_begin_index = 0
for i, (name, index) in enumerate(zip(op_names, indices)):
# print(name, index)
if '_back' in name:
back_begin_index = i
break
stride = 2 if reduction and index < 2 else 1
op = OPS[name](C, stride, True, act_fun=self.act_fun)
self._ops += [op]
if self.back_connection:
for name, index in zip(op_names[back_begin_index:], indices[back_begin_index:]):
op = OPS[name.replace('_back', '')](
C, 1, True, act_fun=self.act_fun)
self._ops_back += [op]
if self.back_connection:
self._indices_forward = indices[:back_begin_index]
self._indices_backward = indices[back_begin_index:]
else:
self._indices_backward = []
self._indices_forward = indices
self._steps = len(self._indices_forward) // 2
def forward(self, s0, s1, drop_prob):
if self.reduction:
return self.fun(s1)
s0 = self.preprocess0(s0)
s1 = self.preprocess1(s1)
states = [s0, s1]
for i in range(self._steps):
h1 = states[self._indices_forward[2 * i]]
h2 = states[self._indices_forward[2 * i + 1]]
op1 = self._ops[2 * i]
op2 = self._ops[2 * i + 1]
h1 = op1(h1)
h2 = op2(h2)
if self.training and drop_prob > 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
s = h1 + h2
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]
] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = torch.cat([states[i]
for i in self._concat], dim=1) # N,C,H, W
return outputs
# return self.node(outputs)
class DCOCell(nn.Module):
def __init__(self, genotype, C_prev_prev, C_prev, C, reduction, reduction_prev, act_fun):
super(DCOCell, self).__init__()
self.act_fun = act_fun
if reduction_prev:
self.preprocess0 = FactorizedReduce(C_prev_prev, C)
else:
self.preprocess0 = ReLUConvBN(C_prev_prev, C, 1, 1, 0)
self.preprocess1 = ReLUConvBN(C_prev, C, 1, 1, 0)
if reduction:
op_names, tos, froms = zip(*genotype.reduce)
else:
op_names, tos, froms = zip(*genotype.normal)
self._compile(C, op_names, tos, froms, reduction)
def _compile(self, C, op_names, tos, froms, reduction):
self._ops = nn.ModuleDict()
for name_i, to_i, from_i in zip(op_names, tos, froms):
stride = 2 if reduction and from_i < 2 else 1
op = OPS[name_i](C, stride, True, act_fun=self.act_fun)
if str(to_i) in self._ops.keys():
if str(from_i) in self._ops[str(to_i)]:
self._ops[str(to_i)][str(from_i)] += [op]
else:
self._ops[str(to_i)][str(from_i)] = nn.ModuleList()
self._ops[str(to_i)][str(from_i)] += [op]
else:
self._ops[str(to_i)] = nn.ModuleDict()
self._ops[str(to_i)][str(from_i)] = nn.ModuleList()
self._ops[str(to_i)][str(from_i)] += [op]
# TODO: Some intermediate node maybe no selected during search.
self.multiplier = len(self._ops)
def forward(self, s0, s1, drop_prob):
s0 = self.preprocess0(s0)
s1 = self.preprocess1(s1)
states = {}
states['0'] = s0
states['1'] = s1
# get all the operations in current intermediate node
for to_i, ops in self._ops.items():
h = []
for from_i, op_i in ops.items():
# each edge may no more than one operation
if from_i not in states:
# print('Exist the isolate node, which id is {}, we need ignore it!'.format(from_i))
continue
h += [sum([op(states[from_i])
for op in op_i if from_i in states])]
out = sum(h)
if self.training and drop_prob > 0:
out = drop_path(out, drop_prob)
states[to_i] = out
outputs = torch.cat([v for v in states.values()][2:], dim=1)
# return outputs
return outputs
class AuxiliaryHeadCIFAR(nn.Module):
def __init__(self, C, num_classes, act_fun):
"""assuming inputs size 8x8"""
super(AuxiliaryHeadCIFAR, self).__init__()
self.act_fun = act_fun
self.features = nn.Sequential(
# nn.ReLU(inplace=True),
self.act_fun(),
# image size = 2 x 2
nn.AvgPool2d(5, stride=3, padding=0, count_include_pad=False),
nn.Conv2d(C, 128, 1, bias=False),
nn.BatchNorm2d(128),
# nn.ReLU(inplace=True),
self.act_fun(),
nn.Conv2d(128, 768, 2, bias=False),
nn.BatchNorm2d(768),
# nn.ReLU(inplace=True)
self.act_fun()
)
self.classifier = nn.Linear(768, num_classes)
def forward(self, x):
x = self.features(x)
x = self.classifier(x.view(x.size(0), -1))
return x
class AuxiliaryHeadImageNet(nn.Module):
def __init__(self, C, num_classes):
"""assuming inputs size 14x14"""
super(AuxiliaryHeadImageNet, self).__init__()
self.features = nn.Sequential(
nn.ReLU(inplace=True),
nn.AvgPool2d(5, stride=2, padding=0, count_include_pad=False),
nn.Conv2d(C, 128, 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 768, 2, bias=False),
# NOTE: This batchnorm was omitted in my earlier implementation due to a typo.
# Commenting it out for consistency with the experiments in the paper.
# nn.BatchNorm2d(768),
nn.ReLU(inplace=True)
)
self.classifier = nn.Linear(768, num_classes)
def forward(self, x):
x = self.features(x)
x = self.classifier(x.view(x.size(0), -1))
return x
@register_model
class NetworkCIFAR(BaseModule):
def __init__(self,
C,
num_classes,
layers,
auxiliary,
genotype,
parse_method='darts',
step=1,
node_type='ReLUNode',
**kwargs):
super(NetworkCIFAR, self).__init__(
step=step,
num_classes=num_classes,
**kwargs
)
if isinstance(node_type, str):
self.act_fun = eval(node_type)
else:
self.act_fun = node_type
self.act_fun = partial(self.act_fun, **kwargs)
if 'back_connection' in kwargs.keys():
self.back_connection = kwargs['back_connection']
else:
self.back_connection = False
self.spike_output = kwargs['spike_output'] if 'spike_output' in kwargs else True
self.dataset = kwargs['dataset']
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
self._layers = layers
self._auxiliary = auxiliary
self.drop_path_prob = 0
stem_multiplier = 3
C_curr = stem_multiplier * C
if self.dataset == 'dvsg' or self.dataset == 'dvsc10' or self.dataset == 'NCALTECH101':
self.stem = nn.Sequential(
nn.Conv2d(2 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
# self.reduce_idx = [
# layers // 4,
# layers // 2,
# 3 * layers // 4
# ]
self.reduce_idx = [1, 3, 5, 7]
else:
self.stem = nn.Sequential(
nn.Conv2d(3 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
self.reduce_idx = [layers // 4,
layers // 2,
3 * layers // 4]
C_prev_prev, C_prev, C_curr = C_curr, C_curr, C
self.cells = nn.ModuleList()
reduction_prev = False
for i in range(layers):
if i in self.reduce_idx:
C_curr *= 2
reduction = True
else:
reduction = False
if parse_method == 'darts':
cell = Cell(genotype, C_prev_prev, C_prev, C_curr,
reduction, reduction_prev,
act_fun=self.act_fun, back_connection=self.back_connection)
else:
cell = DCOCell(genotype, C_prev_prev, C_prev, C_curr,
reduction, reduction_prev, act_fun=self.act_fun)
reduction_prev = reduction
self.cells += [cell]
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
if i == 2 * layers // 3:
C_to_auxiliary = C_prev
if auxiliary:
self.auxiliary_head = AuxiliaryHeadCIFAR(
C_to_auxiliary, num_classes, act_fun=self.act_fun)
self.global_pooling = nn.Sequential(
self.act_fun(), nn.AdaptiveAvgPool2d(1))
if self.spike_output:
self.classifier = nn.Sequential(
nn.Linear(C_prev, 10 * num_classes),
self.act_fun())
self.vote = VotingLayer(10)
else:
self.classifier = nn.Linear(C_prev, num_classes)
self.vote = nn.Identity()
# self.classifier = nn.Linear(C_prev, num_classes)
# self.vote = nn.Identity()
def forward(self, inputs):
logits_aux = None
inputs = self.encoder(inputs)
if not self.layer_by_layer:
outputs = []
output_aux = []
self.reset()
for t in range(self.step):
x = inputs[t]
s0 = s1 = self.stem(x)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
# print(s0.shape, s1.shape)
# if i == 2 * self._layers // 3:
# if self._auxiliary and self.training:
# logits_aux = self.auxiliary_head(s1)
out = self.global_pooling(s1)
out = self.classifier(self.flatten(out))
logits = self.vote(out)
outputs.append(logits)
output_aux.append(logits_aux)
return sum(outputs) / len(outputs)
# logits_aux if logits_aux is None else (sum(output_aux) / len(output_aux))
else:
s0 = s1 = self.stem(inputs)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
if i == 2 * self._layers // 3:
if self._auxiliary and self.training:
logits_aux = self.auxiliary_head(s1)
out = self.global_pooling(s1)
out = self.classifier(self.flatten(out))
out = rearrange(out, '(t b) c -> t b c', t=self.step).mean(0)
logits = self.vote(out)
return logits
@register_model
class NetworkImageNet(BaseModule):
def __init__(self,
C,
num_classes,
layers,
auxiliary,
genotype,
step=1,
node_type='ReLUNode',
**kwargs):
super(NetworkImageNet, self).__init__(
step=step,
num_classes=num_classes,
**kwargs)
if isinstance(node_type, str):
self.act_fun = eval(node_type)
else:
self.act_fun = node_type
self.act_fun = partial(self.act_fun, **kwargs)
if 'back_connection' in kwargs.keys():
self.back_connection = kwargs['back_connection']
else:
self.back_connection = False
self.spike_output = kwargs['spike_output'] if 'spike_output' in kwargs else True
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
self._layers = layers
self._auxiliary = auxiliary
self.drop_path_prob = 0
self.stem0 = nn.Sequential(
nn.Conv2d(3, C // 2, kernel_size=3,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(C // 2),
# nn.ReLU(inplace=True),
self.act_fun(),
nn.Conv2d(C // 2, C, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(C),
)
self.stem1 = nn.Sequential(
# nn.ReLU(inplace=True),
self.act_fun(),
nn.Conv2d(C, C, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(C),
)
C_prev_prev, C_prev, C_curr = C, C, C
self.cells = nn.ModuleList()
reduction_prev = True
for i in range(layers):
if i in [layers // 3, 2 * layers // 3]:
C_curr *= 2
reduction = True
else:
reduction = False
cell = Cell(genotype, C_prev_prev, C_prev,
C_curr, reduction, reduction_prev,
act_fun=self.act_fun, back_connection=self.back_connection)
reduction_prev = reduction
self.cells += [cell]
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
self.global_pooling = nn.AvgPool2d(7)
self.classifier = nn.Linear(C_prev, num_classes)
def forward(self, inputs):
outputs = []
self.reset()
for t in range(self.step):
s0 = self.stem0(inputs)
s1 = self.stem1(s0)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
out = self.global_pooling(s1)
logits = self.classifier(self.flatten(out))
outputs.append(logits)
return sum(outputs) / len(outputs)
if __name__ == '__main__':
from braincog.model_zoo.NeuEvo.genotypes import mlp2
cell = MlpCell(mlp2, C=128, input_dim=17, output_dim=-1)
x = torch.rand(4, 17)
out = cell(x)
print(out)
print(out.shape)
================================================
FILE: braincog/model_zoo/NeuEvo/model_search.py
================================================
from functools import partial
from braincog.model_zoo.NeuEvo.operations import *
from torch.autograd import Variable
from braincog.model_zoo.NeuEvo.genotypes import PRIMITIVES
from braincog.model_zoo.NeuEvo.genotypes import Genotype
from . import parse
from braincog.base.connection.layer import VotingLayer
from braincog.base.node.node import *
from braincog.model_zoo.base_module import BaseModule
from . import forward_edge_num
from . import edge_num
def calc_weight(x):
tmp0 = torch.split(x[0], edge_num, dim=0)
tmp1 = torch.split(x[1], edge_num, dim=0)
res = []
for i in range(len(edge_num)):
res.append(
torch.softmax(tmp0[i].view(-1), dim=-1).view(tmp0[i].shape)
+ torch.softmax(tmp1[i].view(-1), dim=-1).view(tmp1[i].shape)
)
return torch.cat(res, dim=0)
def calc_loss(x):
tmp0 = torch.split(x[0], edge_num, dim=0)
tmp1 = torch.split(x[1], edge_num, dim=0)
res = []
for i in range(len(edge_num)):
res.append(
torch.softmax(tmp0[i].view(-1), dim=-1).view(tmp0[i].shape)
- torch.softmax(tmp1[i].view(-1), dim=-1).view(tmp1[i].shape)
)
return torch.cat(res, dim=0)
class darts_fun(torch.autograd.Function):
@staticmethod
def forward(ctx, inputs, weights): # feature map / arch weight
output = inputs * weights
ctx.save_for_backward(inputs, weights)
return output
@staticmethod
def backward(ctx, grad_output): # error signal
grad_inputs, grad_weights = None, None
inputs, weights = ctx.saved_tensors
if ctx.needs_input_grad[0]:
grad_inputs = grad_output * weights
if ctx.needs_input_grad[1]:
if torch.min(inputs) < -1e-12 and torch.max(inputs) > 1e-12:
inputs = torch.abs(inputs) / 2.
else:
inputs = torch.abs(inputs)
grad_weights = -inputs.mean()
return grad_inputs, grad_weights
class MixedOp(nn.Module):
def __init__(self, C, stride, act_fun):
super(MixedOp, self).__init__()
self._ops = nn.ModuleList()
for primitive in PRIMITIVES:
op = OPS[primitive](C, stride, False, act_fun)
if 'pool' in primitive:
op = nn.Sequential(op, nn.BatchNorm2d(C, affine=False))
self._ops.append(op)
self.multiply = darts_fun.apply
def forward(self, x, weights):
feature_map = []
for i, op in enumerate(self._ops):
res = op(x)
feature_map.append(res)
return sum(self.multiply(mp, w) for w, mp in zip(weights, feature_map))
class Cell(nn.Module):
def __init__(self, steps, multiplier, C_prev_prev, C_prev, C, reduction, reduction_prev, act_fun, back_connection):
super(Cell, self).__init__()
self.reduction = reduction
self.back_connection = back_connection
if reduction:
self.fun = FactorizedReduce(
C_prev, C * multiplier, affine=True, act_fun=act_fun, positive=1
)
else:
if reduction_prev:
self.preprocess0 = FactorizedReduce(
C_prev_prev, C, affine=False, act_fun=act_fun, positive=1)
else:
self.preprocess0 = ReLUConvBN(
C_prev_prev, C, 1, 1, 0, affine=False, act_fun=act_fun, positive=1)
self.preprocess1 = ReLUConvBN(
C_prev, C, 1, 1, 0, affine=False, act_fun=act_fun, positive=1)
self._steps = steps
self._multiplier = multiplier
self._ops = nn.ModuleList()
for i in range(self._steps):
for j in range(2 + i):
stride = 2 if reduction and j < 2 else 1
op = MixedOp(C, stride, act_fun)
self._ops.append(op)
if self.back_connection:
self._ops_back = nn.ModuleList()
for i in range(self._steps):
for j in range(i):
op = MixedOp(C, 1, act_fun)
self._ops_back.append(op)
def forward(self, s0, s1, weights):
if self.reduction:
return self.fun(s1)
s0 = self.preprocess0(s0)
s1 = self.preprocess1(s1)
states = [s0, s1]
offset = 0
offset_back = 0
weights_forward = weights[:forward_edge_num]
weights_backward = weights[forward_edge_num:]
for i in range(self._steps):
s = sum(self._ops[offset + j](h, weights_forward[offset + j])
for j, h in enumerate(states))
offset += len(states)
if self.back_connection:
for j in range(2, len(states)):
# print(j, len(states), offset_back, len(self._ops_back))
states[j] = states[j] + \
self._ops_back[offset_back](
s, weights_backward[offset_back])
offset_back += 1
states.append(s)
outputs = torch.cat(states[-self._multiplier:], dim=1)
return outputs
class Network(BaseModule):
def __init__(self, C, num_classes, layers, criterion, steps=4, multiplier=4, stem_multiplier=3,
parse_method='bio_darts', op_threshold=None, step=1, node_type='ReLUNode', **kwargs):
super().__init__(
step=step,
encode_type='direct',
**kwargs
)
self.act_fun = eval(node_type)
self.act_fun = partial(self.act_fun, **kwargs)
self._C = C
self._num_classes = num_classes
self._layers = layers
self._criterion = criterion
self._steps = steps
self._multiplier = multiplier
self.parse_method = parse_method
self.op_threshold = op_threshold
self.fire_rate_per_step = [0.] * self.step
self.forward_step = 0
self.record_fire_rate = False
if 'back_connection' in kwargs.keys():
self.back_connection = kwargs['back_connection']
else:
self.back_connection = False
self.dataset = kwargs['dataset']
self.spike_output = kwargs['spike_output'] if 'spike_output' in kwargs else True
C_curr = stem_multiplier * C
if self.dataset == 'dvsg' or self.dataset == 'dvsc10' or self.dataset == 'NCALTECH101':
self.stem = nn.Sequential(
nn.Conv2d(2 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
self.reduce_idx = [layers // 3,
2 * layers // 3]
else:
self.stem = nn.Sequential(
nn.Conv2d(3 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
self.reduce_idx = [1, 3, 5]
C_prev_prev, C_prev, C_curr = C_curr, C_curr, C
self.cells = nn.ModuleList()
reduction_prev = False
for i in range(layers):
if i in self.reduce_idx:
C_curr *= 2
reduction = True
else:
reduction = False
cell = Cell(steps, multiplier, C_prev_prev, C_prev, C_curr, reduction, reduction_prev, self.act_fun,
self.back_connection)
reduction_prev = reduction
self.cells += [cell]
C_prev_prev, C_prev = C_prev, multiplier * C_curr
self.global_pooling = nn.Sequential(
self.act_fun(), nn.AdaptiveAvgPool2d(1))
if self.spike_output:
self.classifier = nn.Sequential(
nn.Linear(C_prev, 10 * num_classes),
self.act_fun())
self.vote = VotingLayer(10)
else:
self.classifier = nn.Linear(C_prev, num_classes)
self.vote = nn.Identity()
self._initialize_alphas()
def new(self):
model_new = Network(self._C, self._num_classes,
self._layers, self._criterion).cuda()
for x, y in zip(model_new.arch_parameters(), self.arch_parameters()):
x.data.copy_(y.data)
return model_new
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if not self.training:
self.fire_rate.clear()
outputs = []
for t in range(self.step):
x = inputs[t]
s0 = s1 = self.stem(x)
for i, cell in enumerate(self.cells):
if not cell.reduction:
weights = calc_weight(self.alphas_normal)
s0, s1 = s1, cell(s0, s1, weights)
else:
s0, s1 = s1, cell(s0, s1, None)
out = self.global_pooling(s1)
out = self.classifier(out.view(out.size(0), -1))
logits = self.vote(out)
outputs.append(logits)
# print(self.get_fire_rate_avg(), self.fire_rate_per_step, len(self.fire_rate_per_step))
if self.record_fire_rate:
self.forward_step += 1
return sum(outputs) / len(outputs)
def reset_fire_rate_record(self):
self.fire_rate_per_step = [0.] * self.step
self.forward_step = 0
def get_fire_per_step(self):
return [x / self.forward_step for x in self.fire_rate_per_step]
def _loss(self, input1, target1, input2):
logits = self(input1)
return self._criterion(logits, target1, input2)
# def _loss(self, input1, target1):
# logits = self(input1)
# return self._criterion(logits, target1)
def _initialize_alphas(self):
# k = 2 + 3 + 4 + 5 = 14
k = sum(1 for i in range(self._steps) for n in range(2 + i))
if self.back_connection:
k += sum(1 for i in range(self._steps) for n in range(i))
num_ops = len(PRIMITIVES)
self.alphas_normal = Variable(
0.5 * torch.randn(2, k, num_ops).cuda(), requires_grad=True)
# init the history
self.alphas_normal_history = {}
mm = 0
last_id = 1
node_id = 0
for i in range(k):
for j in range(num_ops):
self.alphas_normal_history['edge: {}, op: {}'.format(
(node_id, mm), PRIMITIVES[j])] = []
if mm == last_id:
mm = 0
last_id += 1
node_id += 1
else:
mm += 1
def arch_parameters(self):
return [self.alphas_normal]
def genotype(self):
# alphas_normal
gene_normal = parse(calc_weight(self.alphas_normal).data.cpu().numpy(),
PRIMITIVES, self.op_threshold, self.parse_method,
self._steps, reduction=False, back_connection=self.back_connection)
concat = range(2 + self._steps - self._multiplier, self._steps + 2)
genotype = Genotype(
normal=gene_normal, normal_concat=concat,
)
return genotype
def states(self):
return {
'alphas_normal': self.alphas_normal,
'alphas_normal_history': self.alphas_normal_history,
'criterion': self._criterion
}
def restore(self, states):
self.alphas_normal = states['alphas_normal']
self.alphas_normal_history = states['alphas_normal_history']
def update_history(self):
mm = 0
last_id = 1
node_id = 0
weights1 = calc_weight(self.alphas_normal).data.cpu().numpy()
k, num_ops = weights1.shape
for i in range(k):
for j in range(num_ops):
self.alphas_normal_history['edge: {}, op: {}'.format((node_id, mm), PRIMITIVES[j])].append(
float(weights1[i][j]))
if mm == last_id:
mm = 0
last_id += 1
node_id += 1
else:
mm += 1
================================================
FILE: braincog/model_zoo/NeuEvo/operations.py
================================================
import numpy as np
import torch
import torch.nn as nn
from torch.nn import *
import torch.nn.functional as F
from torch import einsum
from einops import rearrange
from braincog.model_zoo.base_module import DeformConvPack
from braincog.model_zoo.base_module import BaseLinearModule
# from mmcv.ops import ModulatedDeformConv2dPack
def si_relu(x, positive):
if positive == 1:
return torch.where(x > 0., x, torch.zeros_like(x))
elif positive == 0:
return x
elif positive == -1:
return torch.where(x < 0., x, torch.zeros_like(x))
else:
raise ValueError
class SiReLU(nn.Module):
def __init__(self, positive=0):
super().__init__()
self.positive = positive
def forward(self, x):
return si_relu(x, self.positive)
def weight_init(m):
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal(m.weight.data, gain=0.1)
torch.nn.init.constant(m.bias.data, 0.)
OPS_Mlp = {
'mlp': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=0),
'mlp_p': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=1),
'mlp_n': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=-1),
'skip_connect': lambda C, act_fun:
Identity(positive=0),
'skip_connect_p': lambda C, act_fun:
Identity(positive=1),
'skip_connect_n': lambda C, act_fun:
Identity(positive=-1),
}
OPS = {
'avg_pool_3x3': lambda C, stride, affine, act_fun: nn.AvgPool2d(3, stride=stride, padding=1,
count_include_pad=False),
'conv_3x3': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=0),
'conv_5x5': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=0),
'max_pool_3x3': lambda C, stride, affine, act_fun: nn.MaxPool2d(3, stride=stride, padding=1),
'skip_connect': lambda C, stride, affine, act_fun:
Identity(positive=0) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun),
'sep_conv_3x3': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=0),
'sep_conv_5x5': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=0),
'sep_conv_7x7': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=0),
'dil_conv_3x3': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=0),
'dil_conv_5x5': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=0),
'def_conv_3x3': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=0),
'def_conv_5x5': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=0),
'avg_pool_3x3_p': lambda C, stride, affine, act_fun: nn.Sequential(
nn.AvgPool2d(3, stride=stride, padding=1, count_include_pad=False),
SiReLU(positive=1)
),
'max_pool_3x3_p': lambda C, stride, affine, act_fun: nn.Sequential(
nn.MaxPool2d(3, stride=stride, padding=1),
SiReLU(positive=1)
),
'conv_3x3_p': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=1),
'conv_5x5_p': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=1),
'skip_connect_p': lambda C, stride, affine, act_fun:
Identity(positive=1) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_3x3_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_5x5_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_7x7_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=1),
'dil_conv_3x3_p': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=1),
'dil_conv_5x5_p': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=1),
'def_conv_3x3_p': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=1),
'def_conv_5x5_p': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=1),
'avg_pool_3x3_n': lambda C, stride, affine, act_fun: nn.Sequential(
nn.AvgPool2d(3, stride=stride, padding=1, count_include_pad=False),
SiReLU(positive=-1)
),
'max_pool_3x3_n': lambda C, stride, affine, act_fun: nn.Sequential(
nn.MaxPool2d(3, stride=stride, padding=1),
SiReLU(positive=-1)
),
'conv_3x3_n': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=-1),
'conv_5x5_n': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=-1),
'skip_connect_n': lambda C, stride, affine, act_fun:
Identity(positive=-1) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_3x3_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_5x5_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_7x7_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=-1),
'dil_conv_3x3_n': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=-1),
'dil_conv_5x5_n': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=-1),
'def_conv_3x3_n': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=-1),
'def_conv_5x5_n': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=-1),
'conv_7x1_1x7': lambda C, stride, affine, act_fun: nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C, C, (1, 7), stride=(1, stride),
padding=(0, 3), bias=False),
nn.Conv2d(C, C, (7, 1), stride=(stride, 1),
padding=(3, 0), bias=False),
nn.BatchNorm2d(C, affine=affine)
),
'transformer': lambda C, stride, affine, act_fun:
FactorizedReduce(
C, C, affine=affine, act_fun=act_fun) if stride != 1 else TransformerEncoderLayer(C),
}
class SiMLP(nn.Module):
def __init__(self, c_in, c_out, act_fun=nn.ReLU, positive=0, *args, **kwargs):
super(SiMLP, self).__init__()
self.op = nn.Sequential(
nn.Linear(c_in, c_out, bias=True),
act_fun()
)
self.positive = positive
def forward(self, x):
out = self.op(si_relu(x, self.positive))
return out
class ReLUConvBN(nn.Module):
"""
ReLu -> Conv2d -> BatchNorm2d
"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
super(ReLUConvBN, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
# act_fun(),
nn.Conv2d(C_in, C_out, kernel_size, stride=stride,
padding=padding, bias=False),
nn.BatchNorm2d(C_out, affine=affine)
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class DilConv(nn.Module):
"""
Dilation Convolution : ReLU -> DilConv -> Conv2d -> BatchNorm2d
"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, dilation, affine=True, act_fun=nn.ReLU, positive=0):
super(DilConv, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation,
groups=C_in, bias=False),
nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=affine),
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class SepConv(nn.Module):
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
super(SepConv, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size,
stride=stride, padding=padding, groups=C_in, bias=False),
nn.Conv2d(C_in, C_in, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_in, affine=affine),
nn.ReLU(inplace=False),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size,
stride=1, padding=padding, groups=C_in, bias=False),
nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=affine),
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class Identity(nn.Module):
def __init__(self, positive=0):
super(Identity, self).__init__()
self.positive = positive
def forward(self, x):
return si_relu(x, self.positive)
class Zero(nn.Module):
def __init__(self, stride):
super(Zero, self).__init__()
self.stride = stride
def forward(self, x):
if self.stride == 1:
return x.mul(0.)
return x[:, :, ::self.stride, ::self.stride].mul(0.) # N * C * W * H
class FactorizedReduce(nn.Module):
def __init__(self, C_in, C_out, affine=True, act_fun=nn.ReLU, positive=0):
super(FactorizedReduce, self).__init__()
assert C_out % 2 == 0
# self.relu = nn.ReLU(inplace=False)
self.activation = act_fun()
self.conv_1 = nn.Conv2d(C_in, C_out // 2, 3,
stride=2, padding=1, bias=False)
self.conv_2 = nn.Conv2d(C_in, C_out // 2, 3,
stride=2, padding=1, bias=False)
self.bn = nn.BatchNorm2d(C_out, affine=affine)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
# x = self.relu(x)
x = self.activation(x)
out = torch.cat([self.conv_1(x), self.conv_2(x[:, :, 1:, 1:])], dim=1)
out = self.bn(out)
out = si_relu(out, self.positive)
return out
class DeformConv(nn.Module):
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
super(DeformConv, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
DeformConvPack(C_in, C_out, kernel_size=kernel_size,
stride=stride, padding=padding, bias=True),
nn.BatchNorm2d(C_out, affine=affine)
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class Attention(Module):
"""
Obtained from: github.com:rwightman/pytorch-image-models
"""
def __init__(self, dim, num_heads=4, attention_dropout=0.1, projection_dropout=0.1):
super().__init__()
self.num_heads = num_heads
head_dim = dim // self.num_heads
self.scale = head_dim ** -0.5
self.qkv = Linear(dim, dim * 3, bias=False)
self.attn_drop = Dropout(attention_dropout)
self.proj = Linear(dim, dim)
self.proj_drop = Dropout(projection_dropout)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C //
self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class TransformerEncoderLayer(Module):
"""
Inspired by torch.nn.TransformerEncoderLayer and
rwightman's timm package.
"""
def __init__(self, d_model, nhead=4, dim_feedforward=256, dropout=0.1,
attention_dropout=0.1, drop_path_rate=0.1):
super(TransformerEncoderLayer, self).__init__()
self.pre_norm = LayerNorm(d_model)
self.self_attn = Attention(dim=d_model, num_heads=nhead,
attention_dropout=attention_dropout, projection_dropout=dropout)
dim_feedforward = d_model
self.linear1 = Linear(d_model, dim_feedforward)
self.dropout1 = Dropout(dropout)
self.norm1 = LayerNorm(d_model)
self.linear2 = Linear(dim_feedforward, d_model)
self.dropout2 = Dropout(dropout)
self.drop_path = DropPath(
drop_path_rate) if drop_path_rate > 0 else Identity()
self.activation = F.gelu
def forward(self, src: torch.Tensor, *args, **kwargs) -> torch.Tensor:
# print(src.shape)
c = src.shape[-1]
src = rearrange(src, 'b d r c -> b (r c) d')
# print(src.shape)
src = src + self.drop_path(self.self_attn(self.pre_norm(src)))
src = self.norm1(src)
src2 = self.linear2(self.dropout1(self.activation(self.linear1(src))))
src = src + self.drop_path(self.dropout2(src2))
src = rearrange(src, 'b (r c) d -> b d r c', c=c)
return src
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""
Obtained from: github.com:rwightman/pytorch-image-models
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
# work with diff dim tensors, not just 2D ConvNets
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + \
torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(Module):
"""
Obtained from: github.com:rwightman/pytorch-image-models
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
================================================
FILE: braincog/model_zoo/NeuEvo/others.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2023/5/22 13:32
# User : yu
# Product : PyCharm
# Project : BrainCog
# File : others.py
# explain :
from functools import partial
import torch
import torch.nn as nn
from copy import deepcopy
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import WSConv2d
from braincog.datasets import is_dvs_data
from braincog.model_zoo.base_module import BaseModule, BaseConvModule
@register_model
class CIFARNet_Wu(BaseModule):
def __init__(
self, num_classes=10,
node_type=LIFNode,
step=4,
encode_type='direct',
*args,
**kwargs,
):
super().__init__(step, encode_type, *args, **kwargs)
self.dataset = kwargs['dataset']
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
channels = 32
if not is_dvs_data(self.dataset):
init_channel = 3
out_size = 2 ** 2
else:
init_channel = 2
out_size = 3 ** 2
self.feature = nn.Sequential(
BaseConvModule(init_channel, channels, node=self.node),
BaseConvModule(channels, channels * 2, node=self.node),
nn.AvgPool2d(2, 2),
self.node(),
BaseConvModule(channels * 2, channels * 4, node=self.node),
nn.AvgPool2d(2, 2),
# self.node(),
BaseConvModule(channels * 4, channels * 8, node=self.node),
BaseConvModule(channels * 8, channels * 4, node=self.node),
nn.Flatten(),
)
self.fc = nn.Sequential(
nn.Linear(channels * 4 * 8 * 8, channels * 8, bias=False),
self.node(),
nn.Linear(channels * 8, channels * 4, bias=False),
self.node(),
nn.Linear(channels * 4, num_classes, bias=False)
)
def forward(self, inputs):
inputs = self.encoder(inputs).contiguous()
self.reset()
outputs = []
for t in range(self.step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
@register_model
class CIFARNet_Fang(BaseModule):
def __init__(
self, num_classes=10,
node_type=LIFNode,
step=4,
encode_type='direct',
*args,
**kwargs,
):
super().__init__(step, encode_type, *args, **kwargs)
self.dataset = kwargs['dataset']
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
channels = 32
if not is_dvs_data(self.dataset):
init_channel = 3
else:
init_channel = 2
self.feature = nn.Sequential(
BaseConvModule(init_channel, channels, node=self.node),
BaseConvModule(channels, channels, node=self.node),
BaseConvModule(channels, channels, node=self.node),
nn.MaxPool2d(2, 2),
BaseConvModule(channels, channels, node=self.node),
BaseConvModule(channels, channels, node=self.node),
BaseConvModule(channels, channels, node=self.node),
nn.MaxPool2d(2, 2),
nn.Flatten(),
)
self.fc = nn.Sequential(
nn.Linear(channels * 8 * 8, channels * 8, bias=False),
self.node(),
nn.Linear(channels * 8, channels, bias=False),
)
def forward(self, inputs):
inputs = self.encoder(inputs).contiguous()
self.reset()
outputs = []
for t in range(self.step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
@register_model
class DVS_CIFARNet_Fang(BaseModule):
def __init__(
self, num_classes=10,
node_type=LIFNode,
step=10,
encode_type='direct',
*args,
**kwargs,
):
super().__init__(step, encode_type, *args, **kwargs)
self.dataset = kwargs['dataset']
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
channels = 128
if not is_dvs_data(self.dataset):
init_channel = 3
else:
init_channel = 2
self.feature = nn.Sequential(
BaseConvModule(init_channel, channels, node=self.node),
nn.MaxPool2d(2, 2),
BaseConvModule(channels, channels, node=self.node),
nn.MaxPool2d(2, 2),
BaseConvModule(channels, channels, node=self.node),
nn.MaxPool2d(2, 2),
BaseConvModule(channels, channels, node=self.node),
nn.MaxPool2d(2, 2),
nn.Flatten(),
)
self.fc = nn.Sequential(
nn.Linear(channels * 8 * 8, channels * 4, bias=False),
self.node(),
nn.Linear(channels * 4, channels, bias=False),
)
def forward(self, inputs):
inputs = self.encoder(inputs).contiguous()
self.reset()
outputs = []
for t in range(self.step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
================================================
FILE: braincog/model_zoo/__init__.py
================================================
__all__ = ['convnet', 'resnet', 'base_module', 'glsnn', 'qsnn', 'resnet19_snn']
from . import (
convnet,
resnet,
base_module,
glsnn,
qsnn,
resnet19_snn
)
================================================
FILE: braincog/model_zoo/backeinet.py
================================================
import numpy as np
from timm.models import register_model
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
class MNISTNet(BaseModule):
def __init__(self, step=20, encode_type='rate', if_back=True, if_ei=True, data='mnist', *args, **kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.if_back = if_back
self.if_ei = if_ei
if data == 'mnist':
self.cfg_conv = ((1, 15, 5, 1, 0), (15, 40, 5, 1, 0))
self.cfg_fc = (300, 10)
self.cfg_kernel = (24, 8, 4)
cfg_backei = 2
if data == 'fashion':
self.cfg_conv = ((1, 32, 5, 1, 2), (32, 64, 5, 1, 2))
self.cfg_fc = (1024, 10)
self.cfg_kernel = (28, 14, 7)
cfg_backei = 1
self.feature = nn.Sequential(
nn.Conv2d(self.cfg_conv[0][0], self.cfg_conv[0][1], self.cfg_conv[0][2], self.cfg_conv[0][3],
self.cfg_conv[0][4]),
BackEINode(channel=self.cfg_conv[0][1], if_back=self.if_back, if_ei=self.if_ei, cfg_backei=cfg_backei),
nn.AvgPool2d(2),
nn.Conv2d(self.cfg_conv[1][0], self.cfg_conv[1][1], self.cfg_conv[1][2], self.cfg_conv[1][3],
self.cfg_conv[1][4]),
BackEINode(channel=self.cfg_conv[1][1], if_back=self.if_back, if_ei=self.if_ei, cfg_backei=cfg_backei),
nn.AvgPool2d(2),
nn.Flatten(),
nn.Linear(self.cfg_kernel[2] * self.cfg_kernel[2] * self.cfg_conv[1][1], self.cfg_fc[0]),
BackEINode(if_back=False, if_ei=False),
nn.Linear(self.cfg_fc[0], self.cfg_fc[1]),
BackEINode(if_back=False, if_ei=False)
)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if not self.training:
self.fire_rate.clear()
outputs = []
step = self.step
for t in range(step):
x = inputs[t]
x = self.feature(x)
outputs.append(x)
return sum(outputs) / len(outputs)
class CIFARNet(BaseModule):
def __init__(self, step=20, encode_type='rate', if_back=True, if_ei=True, *args, **kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.if_back = if_back
self.if_ei = if_ei
self.feature = nn.Sequential(
nn.Conv2d(3, 128, 3, 1, 1),
BackEINode(channel=128, if_back=self.if_back, if_ei=self.if_ei, cfg_backei=1),
nn.Dropout(0.5),
nn.AvgPool2d(2),
nn.Conv2d(128, 256, 3, 1, 1),
BackEINode(channel=256, if_back=self.if_back, if_ei=self.if_ei, cfg_backei=1),
nn.Dropout(0.5),
nn.AvgPool2d(2),
nn.Conv2d(256, 512, 3, 1, 1),
BackEINode(channel=512, if_back=self.if_back, if_ei=self.if_ei, cfg_backei=1),
nn.Dropout(0.5),
nn.AvgPool2d(2),
nn.Flatten(),
nn.Linear(4 * 4 * 512, 1024),
BackEINode(if_back=False, if_ei=False),
nn.Dropout(0.5),
nn.Linear(1024, 10),
BackEINode(if_back=False, if_ei=False)
)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if not self.training:
self.fire_rate.clear()
outputs = []
step = self.step
for t in range(step):
x = inputs[t]
x = self.feature(x)
outputs.append(x)
return sum(outputs) / len(outputs)
================================================
FILE: braincog/model_zoo/base_module.py
================================================
from functools import partial
from torchvision.ops import DeformConv2d
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
class BaseLinearModule(nn.Module):
"""
线性模块
:param in_features: 输入尺寸
:param out_features: 输出尺寸
:param bias: 是否有Bias, 默认 ``False``
:param node: 神经元类型, 默认 ``LIFNode``
:param args:
:param kwargs:
"""
def __init__(self,
in_features: int,
out_features: int,
bias=True,
node=LIFNode,
*args,
**kwargs):
super().__init__()
if node is None:
raise TypeError
self.groups = kwargs['groups'] if 'groups' in kwargs else 1
if self.groups == 1:
self.fc = nn.Linear(in_features=in_features,
out_features=out_features, bias=bias)
else:
self.fc = nn.ModuleList()
for i in range(self.groups):
self.fc.append(nn.Linear(
in_features=in_features,
out_features=out_features,
bias=bias
))
self.node = partial(node, **kwargs)()
def forward(self, x):
if self.groups == 1: # (t b) c
outputs = self.fc(x)
else: # b (c t)
x = rearrange(x, 'b (c t) -> t b c', t=self.groups)
outputs = []
for i in range(self.groups):
outputs.append(self.fc[i](x[i]))
outputs = torch.stack(outputs) # t b c
outputs = rearrange(outputs, 't b c -> b (c t)')
return self.node(outputs)
class BaseConvModule(nn.Module):
"""
SNN卷积模块
:param in_channels: 输入通道数
:param out_channels: 输出通道数
:param kernel_size: kernel size
:param stride: stride
:param padding: padding
:param bias: Bias
:param node: 神经元类型
:param kwargs:
"""
def __init__(self,
in_channels: int,
out_channels: int,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
bias=False,
node=PLIFNode,
**kwargs):
super().__init__()
if node is None:
raise TypeError
self.groups = kwargs['groups'] if 'groups' in kwargs else 1
self.conv = nn.Conv2d(in_channels=in_channels * self.groups,
out_channels=out_channels * self.groups,
kernel_size=kernel_size,
padding=padding,
stride=stride,
bias=bias)
self.bn = nn.BatchNorm2d(out_channels * self.groups)
self.node = partial(node, **kwargs)()
self.activation = nn.Identity()
def forward(self, x):
# origin_shape = x.shape
# if len(origin_shape) > 4:
# x = x.reshape(np.prod(origin_shape[0:-3]), *origin_shape[-3:])
x = self.conv(x)
x = self.bn(x)
# if len(origin_shape) > 4:
# x = x.reshape(*origin_shape[0:-3], *x.shape[-3:])
x = self.node(x)
return x
class BaseModule(nn.Module, abc.ABC):
"""
SNN抽象类, 所有的SNN都要继承这个类, 以实现一些基础方法
:param step: 仿真步长
:param encode_type: 数据编码类型
:param layer_by_layer: 是否layer wise地进行前向推理
:param temporal_flatten: 是否将时间维度和channel合并
:param args:
:param kwargs:
"""
def __init__(self,
step,
encode_type,
layer_by_layer=False,
temporal_flatten=False,
*args,
**kwargs):
super(BaseModule, self).__init__()
self.step = step
# print(kwargs['layer_by_layer'])
self.layer_by_layer = layer_by_layer
self.temporal_flatten = temporal_flatten
encode_step = self.step
if temporal_flatten is True:
self.init_channel_mul = self.step
self.step = 1
else: # origin
self.init_channel_mul = 1
self.encoder = Encoder(encode_step, encode_type, temporal_flatten=self.temporal_flatten, layer_by_layer=self.layer_by_layer, **kwargs)
self.kwargs = kwargs
self.warm_up = False
self.fire_rate = []
def reset(self):
"""
重置所有神经元的膜电位
:return:
"""
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def set_attr(self, attr, val):
"""
设置神经元的属性
:param attr: 属性名称
:param val: 设置的属性值
:return:
"""
for mod in self.modules():
if isinstance(mod, BaseNode):
if hasattr(mod, attr):
setattr(mod, attr, val)
else:
ValueError('{} do not has {}'.format(self, attr))
def get_threshold(self):
"""
获取所有神经元的阈值
:return:
"""
outputs = []
for mod in self.modules():
if isinstance(mod, BaseNode):
thresh = (mod.get_thres())
outputs.append(thresh)
return outputs
def get_fp(self, temporal_info=False):
"""
获取所有神经元的状态
:param temporal_info: 是否要读取神经元的时间维度状态, False会把时间维度拍平
:return: 所有神经元的状态, List
"""
outputs = []
for mod in self.modules():
if isinstance(mod, BaseNode):
if temporal_info:
outputs.append(mod.feature_map)#[l,[t,[b,w,h]]]
else:
outputs.append(sum(mod.feature_map) / len(mod.feature_map))
return outputs
def get_mem(self, temporal_info=False):
"""
获取所有神经元的模电势
:param temporal_info: 是否要读取神经元的时间维度状态, False会把时间维度拍平
:return: 所有神经元的状态, List
"""
outputs = []
for mod in self.modules():
if isinstance(mod, BaseNode):
if temporal_info:
outputs.append(mod.mem_collect)#[l,[t,[b,w,h]]]
else:
outputs.append(sum(mod.mem_collect) / len(mod.mem_collect))
return outputs
def get_fire_rate(self, requires_grad=False):
"""
获取神经元的fire-rate
:param requires_grad: 是否需要梯度信息, 默认为 ``False`` 会截断梯度
:return: 所有神经元的fire-rate
"""
outputs = []
fp = self.get_attr('feature_map')
for f in fp:
if requires_grad is False:
if len(f) == 0:
return torch.tensor([0.])
outputs.append(((sum(f) / len(f)).detach() > 0.).float().mean())
else:
outputs.append(((sum(f) / len(f)) > 0.).float().mean())
if len(outputs) == 0:
return torch.tensor([0.])
return torch.stack(outputs)
def get_tot_spike(self):
"""
获取神经元总的脉冲数量
:return:
"""
tot_spike = 0
batch_size = 1
fp = self.get_attr('feature_map')
for f in fp:
if len(f) == 0:
break
tot_spike += sum(f).sum()
batch_size = f[0].shape[0]
return tot_spike / batch_size
def get_spike_info(self):
"""
获取神经元的脉冲信息, 主要用于绘图
:return:
"""
spike_feature_list = self.get_fp(temporal_info=True)
avg, var, spike = [], [], []
avg_per_step = []
for spike_feature in spike_feature_list:
avg_list = []
for spike_t in spike_feature:
avg_list.append(float(spike_t.mean()))
avg_per_step.append(avg_list)
spike_feature = sum(spike_feature)
num = np.prod(spike_feature.shape)
avg.append(float(spike_feature.sum()))
var.append(float(spike_feature.std()))
lst = []
for t in range(self.step + 1):
lst.append(float((spike_feature == t).sum() / num))
spike.append(lst)
return avg, var, spike, avg_per_step
def set_requires_fp(self, flag):
for mod in self.modules():
if hasattr(mod, 'requires_fp'):
mod.requires_fp = flag
def set_requires_mem(self, flag):
for mod in self.modules():
if hasattr(mod, 'requires_mem'):
mod.requires_mem = flag
def get_attr(self, attr):
"""
获取神经元的某一属性值
:param attr: 属性名称
:return: 对应属性的值, List
"""
outputs = []
for mod in self.modules():
if hasattr(mod, attr):
outputs.append(getattr(mod, attr))
return outputs
@staticmethod
def forward(self, inputs):
pass
class DeformConvPack(nn.Module):
def __init__(self,
in_channels,
out_channels,
kernel_size,
padding,
stride,
bias,
*args,
**kwargs):
super(DeformConvPack, self).__init__()
self.in_channels = in_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
if isinstance(self.kernel_size, tuple) or isinstance(self.kernel_size, list):
self.receptive_field = self.kernel_size[0]
else:
self.receptive_field = self.kernel_size
self.kernel_size = (self.kernel_size, self.kernel_size)
self.receptive_field = 4 * (self.receptive_field // 2)
self.conv_offset = nn.Conv2d(
self.in_channels,
3 * self.kernel_size[0] * self.kernel_size[1],
kernel_size=self.kernel_size,
stride=self.stride,
padding=self.padding,
bias=True)
self.deform_conv = DeformConv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
padding=padding,
stride=stride,
bias=bias)
self.init_weights()
def init_weights(self):
if hasattr(self, 'conv_offset'):
self.conv_offset.weight.data.zero_()
self.conv_offset.bias.data.zero_()
def forward(self, x):
out = self.conv_offset(x)
o1, o2, mask = torch.chunk(out, 3, dim=1)
offset = torch.cat((o1, o2), dim=1)
offset = self.receptive_field * (torch.sigmoid(offset) - 0.5)
mask = torch.sigmoid(mask)
return self.deform_conv(x, offset, mask)
================================================
FILE: braincog/model_zoo/bdmsnn.py
================================================
import torch
from torch import nn
from braincog.base.node.node import IFNode, SimHHNode
from braincog.base.learningrule.STDP import STDP, MutliInputSTDP
from braincog.base.connection.CustomLinear import CustomLinear
from braincog.base.brainarea.basalganglia import basalganglia
import pygame
from pygame.locals import *
from collections import deque
from random import randint
#os.environ["SDL_VIDEODRIVER"] = "dummy"
class BDMSNN(nn.Module):
def __init__(self, num_state, num_action, weight_exc, weight_inh, node_type):
"""
定义BDM-SNN网络
:param num_state: 状态个数
:param num_action: 动作个数
:param weight_exc: 兴奋性连接权重
:param weight_inh: 抑制性连接权重
"""
super().__init__()
# parameters
BG = basalganglia(num_state, num_action, weight_exc, weight_inh, node_type)
dm_connection = BG.getweight()
dm_mask = BG.getmask()
# input-dlpfc
con_matrix9 = torch.eye((num_state), dtype=torch.float)
dm_connection.append(CustomLinear(weight_exc * con_matrix9, con_matrix9))
dm_mask.append(con_matrix9)
# gpi-th
con_matrix10 = torch.eye((num_action), dtype=torch.float)
dm_mask.append(con_matrix10)
dm_connection.append(CustomLinear(weight_inh * con_matrix10, con_matrix10))
# th-pm
dm_mask.append(con_matrix10)
dm_connection.append(CustomLinear(weight_exc * con_matrix10, con_matrix10))
# dlpfc-th
con_matrix11 = torch.ones((num_state, num_action), dtype=torch.float)
dm_mask.append(con_matrix11)
dm_connection.append(CustomLinear(0.2 * weight_exc * con_matrix11, con_matrix11))
# pm-pm
con_matrix3 = torch.ones((num_action, num_action), dtype=torch.float)
con_matrix4 = torch.eye((num_action), dtype=torch.float)
con_matrix5 = con_matrix3 - con_matrix4
con_matrix5 = con_matrix5
dm_mask.append(con_matrix5)
dm_connection.append(CustomLinear(5 * weight_inh * con_matrix5, con_matrix5))
# dlpfc thalamus pm +bg
self.weight_exc = weight_exc
self.num_subDM = 8
self.connection = dm_connection
self.mask = dm_mask
self.node = BG.node
self.node_type = node_type
if self.node_type == "hh":
self.node.extend([SimHHNode() for i in range(self.num_subDM - BG.num_subBG)])
self.node[6].g_Na = torch.tensor(12)
self.node[6].g_K = torch.tensor(3.6)
self.node[6].g_L = torch.tensor(0.03)
if self.node_type == "lif":
self.node.extend([IFNode() for i in range(self.num_subDM - BG.num_subBG)])
self.learning_rule = BG.learning_rule
self.learning_rule.append(MutliInputSTDP(self.node[5], [self.connection[10], self.connection[12]])) # gpi-丘脑
self.learning_rule.append(MutliInputSTDP(self.node[6], [self.connection[11], self.connection[13]])) # pm
self.learning_rule.append(STDP(self.node[7], self.connection[9]))
out_shape=[self.connection[0].weight.shape[1],self.connection[1].weight.shape[1],self.connection[2].weight.shape[1],self.connection[4].weight.shape[1],self.connection[3].weight.shape[1],self.connection[10].weight.shape[1],self.connection[11].weight.shape[1],self.connection[9].weight.shape[1]]
self.out = []
self.dw = []
for i in range(self.num_subDM):
self.out.append(torch.zeros((out_shape[i]), dtype=torch.float))
self.dw.append(torch.zeros((out_shape[i]), dtype=torch.float))
def forward(self, input):
"""
根据输入得到网络的输出
:param input: 输入
:return: 网络的输出
"""
self.out[7] = self.node[7](self.connection[9](input))
self.out[0], self.dw[0] = self.learning_rule[0](self.out[7])
self.out[1], self.dw[1] = self.learning_rule[1](self.out[7])
self.out[2], self.dw[2] = self.learning_rule[2](self.out[7], self.out[3])
self.out[3], self.dw[3] = self.learning_rule[3](self.out[1], self.out[2])
self.out[4], self.dw[4] = self.learning_rule[4](self.out[0], self.out[3], self.out[2])
self.out[5], self.dw[5] = self.learning_rule[5](self.out[4], self.out[7])
self.out[6], self.dw[6] = self.learning_rule[6](self.out[5], self.out[6])
br = ["StrD1", "StrD2", "STN", "Gpe", "Gpi", "thalamus", "PM", "DLPFC"]
for i in range(self.num_subDM):
if torch.max(self.out[i]) > 0 and self.node_type == "hh":
self.node[i].n_reset()
print("every areas:", br[i], self.out[i])
return self.out[6], self.dw
def UpdateWeight(self, i, s, num_action, dw):
"""
更新网络中第i组连接的权重
:param i:要更新的连接组索引
:param s:传入状态
:param dw:更新权重的量
:return:
"""
if self.node_type == "hh":
self.connection[i].update(0.2 * self.weight_exc * dw)
self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]] /= (self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]].float().max() + 1e-12)
self.connection[i].weight.data[s, :] = self.connection[i].weight.data[s, :] * self.weight_exc
if self.node_type == "lif":
dw_mean = dw[s, [s * num_action, s * num_action + 1]].mean()
dw_std = dw[s, [s * num_action, s * num_action + 1]].std()
dw[s, [s * num_action, s * num_action + 1]] = (dw[s, [s * num_action,s * num_action + 1]] - dw_mean) / dw_std
dw[s, :] = dw[s, :] * self.mask[i][s, :]
self.connection[i].update(dw)
self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]] /= (self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]].float().max() + 1e-12)
if i in [0, 1, 2, 6, 7, 11, 12]:
self.connection[i].weight.data = torch.clamp(self.connection[i].weight.data, 0, None)
if i in [3, 4, 5, 8, 10]:
self.connection[i].weight.data = torch.clamp(self.connection[i].weight.data, None, 0)
def reset(self):
"""
reset神经元或学习法则的中间量
:return: None
"""
for i in range(self.num_subDM):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
"""
获取网络的连接(包括权值等)
:return: 网络的连接
"""
return self.connection
================================================
FILE: braincog/model_zoo/convnet.py
================================================
import abc
from functools import partial
from torch.nn import functional as F
import torchvision
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
class BaseConvNet(BaseModule, abc.ABC):
def __init__(self,
step,
input_channels,
num_classes,
encode_type,
spike_output: bool,
out_channels: list,
block_depth: list,
node_list: list,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.num_cls = num_classes
self.spike_output = spike_output
self.groups = kwargs['n_groups'] if 'n_groups' in kwargs else 1
if not spike_output:
node_list.append(nn.Identity)
out_channels.append(self.num_cls)
self.vote = nn.Identity()
# self.vote = nn.Sequential(
# nn.Linear(self.step, 32),
# nn.ReLU(),
# nn.Linear(32, 1)
# )
else:
out_channels.append(10 * self.num_cls)
self.vote = VotingLayer(10)
# check list length
if len(node_list) != len(out_channels):
raise ValueError
self.input_channels = input_channels
self.out_channels = out_channels
self.block_depth = block_depth
self.node_list = node_list
self.feature = self._create_feature()
self.fc = self._create_fc()
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
@staticmethod
def _create_feature(self):
raise NotImplementedError
@staticmethod
def _create_fc(self):
raise NotImplementedError
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if not self.training:
self.fire_rate.clear()
if not self.layer_by_layer:
outputs = []
if self.warm_up:
step = 1
else:
step = self.step
for t in range(step):
x = inputs[t]
x = self.feature(x)
x = self.flatten(x)
x = self.fc(x)
x = self.vote(x)
outputs.append(x)
return sum(outputs) / len(outputs)
# outputs = torch.stack(outputs)
# outputs = rearrange(outputs, 't b c -> b c t')
# outputs = self.vote(outputs).squeeze()
# return outputs
else:
x = self.feature(inputs)
x = self.flatten(x)
x = self.fc(x)
if self.groups == 1:
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
else:
x = rearrange(x, 'b (c t) -> t b c', t=self.step).mean(0)
x = self.vote(x)
return x
class MNISTConvNet(BaseConvNet):
def __init__(self,
step,
input_channels,
num_classes,
encode_type,
block_depth,
spike_output: bool,
out_channels: list,
node_list: list,
*args,
**kwargs):
self.feature_size = 28
super().__init__(step,
input_channels,
num_classes,
encode_type,
spike_output,
out_channels,
block_depth,
node_list,
*args,
**kwargs)
def _create_feature(self):
feature_depth = len(self.node_list) - 2
feature = [BaseConvModule(
self.input_channels, self.out_channels[0], node=self.node_list[0])]
if self.block_depth[0] != 1:
feature.extend(
[BaseConvModule(self.out_channels[0], self.out_channels[0], node=self.node_list[0])] * (
self.block_depth[0] - 1),
)
feature.append(nn.AvgPool2d(2))
self.feature_size = self.feature_size // 2
for i in range(1, feature_depth):
feature.append(BaseConvModule(
self.out_channels[i - 1], self.out_channels[i], node=self.node_list[i]))
if self.block_depth[i] != 1:
feature.extend(
[BaseConvModule(self.out_channels[i], self.out_channels[i], node=self.node_list[i])] * (
self.block_depth[0] - 1),
)
feature.append(nn.AvgPool2d(2))
feature.append(self.node_list[0]())
self.feature_size = self.feature_size // 2
return nn.Sequential(*feature)
def _create_fc(self):
fc = nn.Sequential(
NDropout(.5),
BaseLinearModule(self.out_channels[-3] * self.feature_size * self.feature_size, self.out_channels[-2],
node=self.node_list[-2]),
NDropout(.5),
BaseLinearModule(
self.out_channels[-2], self.out_channels[-1], node=self.node_list[-1])
)
return fc
class CifarConvNet(BaseConvNet):
def __init__(self,
step,
input_channels,
num_classes,
encode_type,
spike_output: bool,
out_channels: list,
node_list: list,
block_depth: list,
*args,
**kwargs):
super().__init__(step,
input_channels,
num_classes,
encode_type,
spike_output,
out_channels,
block_depth,
node_list,
*args,
**kwargs)
def _create_feature(self):
feature_depth = len(self.node_list) - 1
feature = [BaseConvModule(
self.input_channels * self.init_channel_mul, self.out_channels[0], node=self.node_list[0], groups=self.groups)]
if self.block_depth[0] != 1:
feature.extend(
[BaseConvModule(self.out_channels[0], self.out_channels[0], node=self.node_list[0], groups=self.groups)] * (
self.block_depth[0] - 1),
)
feature.append(nn.AvgPool2d(2))
for i in range(1, feature_depth - 1):
feature.append(BaseConvModule(
self.out_channels[i - 1], self.out_channels[i], node=self.node_list[i], groups=self.groups))
if self.block_depth[i] != 1:
feature.extend(
[BaseConvModule(self.out_channels[i], self.out_channels[i], node=self.node_list[i], groups=self.groups)] * (
self.block_depth[i] - 1),
)
feature.append(nn.AvgPool2d(2))
feature.append(BaseConvModule(
self.out_channels[-3], self.out_channels[-2], node=self.node_list[-2], groups=self.groups))
if self.block_depth[feature_depth - 1] != 1:
feature.extend(
[BaseConvModule(self.out_channels[-2], self.out_channels[-2], node=self.node_list[-2], groups=self.groups)] * (
self.block_depth[feature_depth - 1] - 1),
)
feature.append(nn.AdaptiveAvgPool2d((1, 1)))
return nn.Sequential(*feature)
def _create_fc(self):
fc = nn.Sequential(
# NDropout(.5),
BaseLinearModule(
self.out_channels[-2], self.out_channels[-1], node=self.node_list[-1], groups=self.groups)
)
return fc
@register_model
def mnist_convnet(step,
encode_type,
spike_output: bool,
node_type,
*args,
**kwargs):
out_channels = [128, 128, 2048]
block_depth = [1, 1]
node_cls = partial(node_type, step=step, **kwargs)
if spike_output:
node_list = [node_cls] * (len(out_channels) + 1)
else:
node_list = [node_cls] * (len(out_channels))
return MNISTConvNet(step=step,
input_channels=1,
encode_type=encode_type,
block_depth=block_depth,
node_list=node_list,
out_channels=out_channels,
spike_output=spike_output,
**kwargs)
@register_model
def cifar_convnet(step,
encode_type,
spike_output: bool,
node_type,
*args,
**kwargs):
out_channels = [256, 256, 512, 1024]
# out_channels = [64, 128, 128, 256]
block_depth = [2, 2, 2, 2]
# print(kwargs)
node_cls = partial(node_type, step=step, **kwargs)
# print(node_cls)
if spike_output:
node_list = [node_cls] * (len(out_channels) + 1)
else:
node_list = [node_cls] * (len(out_channels))
return CifarConvNet(step=step,
input_channels=3,
encode_type=encode_type,
node_list=node_list,
block_depth=block_depth,
out_channels=out_channels,
spike_output=spike_output,
**kwargs)
@register_model
def dvs_convnet(step,
encode_type,
spike_output: bool,
node_type,
num_classes,
*args,
**kwargs):
out_channels = [128, 256, 256, 512, 512]
block_depth = [2, 1, 2, 1, 2]
# out_channels = [40, 80, 80, 160, 160]
# out_channels = [256, 512, 512, 1024, 1024]
# out_channels = [64, 128, 128, 256, 256]
# block_depth = [4, 2, 4, 2, 4]
# out_channels = [128, 256, 512, 512]
# block_depth = [2, 2, 2, 2]
node_cls = partial(node_type, step=step, **kwargs)
if spike_output:
node_list = [node_cls] * (len(out_channels) + 1)
# node_list[-2] = partial(DoubleSidePLIFNode, step=step, **kwargs)
else:
node_list = [node_cls] * (len(out_channels))
# node_list[-1] = partial(DoubleSidePLIFNode, step=step, **kwargs)
return CifarConvNet(step=step,
input_channels=2,
num_classes=num_classes,
encode_type=encode_type,
node_list=node_list,
block_depth=block_depth,
out_channels=out_channels,
spike_output=spike_output,
**kwargs)
================================================
FILE: braincog/model_zoo/fc_snn.py
================================================
from functools import partial
from torch.nn import functional as F
import torchvision
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.datasets import is_dvs_data
class STSC_Attention(nn.Module):
def __init__(self, n_channel: int, dimension: int = 2, time_rf: int = 4, reduction: int = 2):
super().__init__()
assert dimension == 4 or dimension == 2, 'dimension must be 4 or 2'
self.dimension = dimension
if self.dimension == 4:
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.time_padding = (time_rf - 1) // 2
self.n_channels = n_channel
r_channel = n_channel // reduction
self.recv_T = nn.Conv1d(n_channel, r_channel, kernel_size=time_rf, padding=self.time_padding, groups=1,
bias=True)
self.recv_C = nn.Sequential(
nn.ReLU(),
nn.Linear(r_channel, n_channel, bias=False),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x_seq: torch.Tensor):
assert x_seq.dim() == 3 or x_seq.dim() == 5, ValueError(
f'expected 3D or 5D input with shape [T, B, N] or [T, B, C, H, W], but got input with shape {x_seq.shape}')
x_seq_C = x_seq.transpose(0, 1) # x_seq_C.shape = [B, T, N] or [B, T, C, H, W]
x_seq_T = x_seq_C.transpose(1, 2) # x_seq_T.shape = [B, C, N] or [B, C, T, H, W]
if self.dimension == 2:
recv_h_T = self.recv_T(x_seq_T)
recv_h_C = self.recv_C(recv_h_T.transpose(1, 2))
D_ = 1 - self.sigmoid(recv_h_C)
D = D_.transpose(0, 1)
elif self.dimension == 4:
avgout_C = self.avg_pool(x_seq_C).view(
[x_seq_C.shape[0], x_seq_C.shape[1], x_seq_C.shape[2]]) # avgout_C.shape = [N, T, C]
avgout_T = avgout_C.transpose(1, 2)
recv_h_T = self.recv_T(avgout_T)
recv_h_C = self.recv_C(recv_h_T.transpose(1, 2))
D_ = 1 - self.sigmoid(recv_h_C)
D = D_.transpose(0, 1)
return D
class STSC_Temporal_Conv(nn.Module):
def __init__(self, channels: int, dimension: int = 2, time_rf: int = 2):
super().__init__()
assert dimension == 4 or dimension == 2, 'dimension must be 4 or 2'
self.dimension = dimension
time_padding = (time_rf - 1) // 2
self.time_padding = time_padding
if dimension == 4:
kernel_size = (time_rf, 1, 1)
padding = (time_padding, 0, 0)
self.conv = nn.Conv3d(channels, channels, kernel_size=kernel_size, padding=padding, groups=channels,
bias=False)
else:
kernel_size = time_rf
self.conv = nn.Conv1d(channels, channels, kernel_size=kernel_size, padding=time_padding, groups=channels,
bias=False)
def forward(self, x_seq: torch.Tensor):
assert x_seq.dim() == 3 or x_seq.dim() == 5, ValueError(
f'expected 3D or 5D input with shape [T, B, N] or [T, B, C, H, W], but got input with shape {x_seq.shape}')
# x_seq.shape = [T, B, N] or [T, B, C, H, W]
x_seq = x_seq.transpose(0, 1) # x_seq.shape = [B, T, N] or [B, T, C, H, W]
x_seq = x_seq.transpose(1, 2) # x_seq.shape = [B, N, T] or [B, C, T, H, W]
x_seq = self.conv(x_seq)
x_seq = x_seq.transpose(1, 2) # x_seq.shape = [B, T, N] or [B, T, C, H, W]
x_seq = x_seq.transpose(0, 1) # x_seq.shape = [T, B, N] or [T, B, C, H, W]
return x_seq
class STSC(nn.Module):
def __init__(self, in_channel: int, dimension: int = 2, time_rf_conv: int = 5, time_rf_at: int = 3, use_gate=True,
use_filter=True, reduction: int = 1):
super().__init__()
assert dimension == 4 or dimension == 2, 'dimension must be 4 or 2'
self.dimension = dimension
self.time_rf_conv = time_rf_conv
self.time_rf_at = time_rf_at
if use_filter:
self.temporal_conv = STSC_Temporal_Conv(in_channel, time_rf=time_rf_conv, dimension=dimension)
if use_gate:
self.spatio_temporal_attention = STSC_Attention(in_channel, time_rf=time_rf_at, reduction=reduction,
dimension=dimension)
self.use_gate = use_gate
self.use_filter = use_filter
def forward(self, x_seq: torch.Tensor):
assert x_seq.dim() == 3 or x_seq.dim() == 5, ValueError(
f'expected 3D or 5D input with shape [T, B, N] or [T, B, C, H, W], but got input with shape {x_seq.shape}')
if self.use_filter:
# Filitering
x_seq_conv = self.temporal_conv(x_seq)
else:
# without filtering
x_seq_conv = x_seq
if self.dimension == 2:
if self.use_gate:
# Gating
x_seq_D = self.spatio_temporal_attention(x_seq)
y_seq = x_seq_conv * x_seq_D
else:
# without gating
y_seq = x_seq_conv
else:
if self.use_gate:
# Gating
x_seq_D = self.spatio_temporal_attention(x_seq)
y_seq = x_seq_conv * x_seq_D[:, :, :, None, None] # broadcast
else:
# without gating
y_seq = x_seq_conv
return y_seq
@register_model
class SHD_SNN(BaseModule):
"""
在SHD数据集上的SNN基准网络:Input-128FC-128FC-100FC-Voting-20.
STSC是增强时序信息的模块, 参考https://www.frontiersin.org/articles/10.3389/fnins.2022.1079357.
不加STSC模块的acc在78%左右
"""
def __init__(self,
num_classes=20,
step=15,
node_type=LIFNode,
encode_type='direct',
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.n_preact = kwargs['n_preact'] if 'n_preact' in kwargs else False
self.num_classes = num_classes
self.tet_loss = kwargs['tet_loss'] if 'tet_loss' in kwargs else False
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.dataset = kwargs['dataset']
self.ts_conv = STSC(700, dimension=2, time_rf_conv=5, time_rf_at=3, use_gate=True, use_filter=True)
self.fc = nn.Sequential(
nn.Linear(700, 128),
partial(self.node, **kwargs)(),
nn.Linear(128, 128),
partial(self.node, **kwargs)(),
nn.Linear(128, 100),
partial(self.node, **kwargs)(),
VotingLayer(5)
)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
inputs = rearrange(inputs, '(t b) c -> t b c', t=self.step)
inputs = self.ts_conv(inputs)
x = rearrange(inputs, 't b c -> (t b) c', t=self.step)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
return x
else:
outputs = []
inputs = self.ts_conv(inputs)
for t in range(self.step):
x = inputs[t]
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
================================================
FILE: braincog/model_zoo/glsnn.py
================================================
import abc
from functools import partial
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseLinearModule, BaseConvModule
from braincog.utils import rand_ortho, mse
from torch import autograd
class BaseGLSNN(BaseModule):
"""
The fully connected model of the GLSNN
:param input_size: the shape of the input
:param hidden_sizes: list, the number of neurons of each layer in the hidden layers
:param ouput_size: the number of the output layers
"""
def __init__(self, input_size=784, hidden_sizes=[800] * 3, output_size=10, opt=None):
super().__init__(step=opt.step, encode_type=opt.encode_type)
network_sizes = [input_size] + hidden_sizes + [output_size]
feedforward = []
for ind in range(len(network_sizes) - 1):
feedforward.append(
BaseLinearModule(in_features=network_sizes[ind], out_features=network_sizes[ind + 1], node=LIFNode))
self.ff = nn.ModuleList(feedforward)
feedback = []
for ind in range(1, len(network_sizes) - 2):
feedback.append(nn.Linear(network_sizes[-1], network_sizes[ind]))
self.fb = nn.ModuleList(feedback)
for m in self.modules():
if isinstance(m, nn.Linear):
out_, in_ = m.weight.shape
m.weight.data = torch.Tensor(rand_ortho((out_, in_), np.sqrt(6. / (out_ + in_))))
m.bias.data.zero_()
self.step = opt.step
self.lr_target = opt.lr_target
def forward(self, x):
"""
process the information in the forward manner
:param x: the input
"""
self.reset()
x = x.view(x.shape[0], 784)
sumspikes = [0] * (len(self.ff) + 1)
sumspikes[0] = x
for ind, mod in enumerate(self.ff):
for t in range(self.step):
spike = mod(sumspikes[ind])
sumspikes[ind + 1] += spike
sumspikes[ind + 1] = sumspikes[ind + 1] / self.step
return sumspikes
def feedback(self, ff_value, y_label):
"""
process information in the feedback manner and get target
:param ff_value: the feedforward value of each layer
:param y_label: the label of the corresponding input
"""
fb_value = []
cost = mse(ff_value[-1], y_label)
P = ff_value[-1]
h_ = ff_value[-2] - self.lr_target * torch.autograd.grad(cost, ff_value[-2], retain_graph=True)[0]
fb_value.append(h_)
for i in range(len(self.fb) - 1, -1, -1):
h = ff_value[i + 1]
h_ = h - self.fb[i](P - y_label)
fb_value.append(h_)
return fb_value, cost
def set_gradient(self, x, y):
"""
get the corresponding update of each layer
"""
ff_value = self.forward(x)
fb_value, cost = self.feedback(ff_value, y)
ff_value = ff_value[1:]
len_ff = len(self.ff)
for idx, layer in enumerate(self.ff):
if idx == len_ff - 1:
layer.fc.weight.grad, layer.fc.bias.grad = autograd.grad(cost, layer.fc.parameters())
else:
in1 = ff_value[idx]
in2 = fb_value[len(fb_value) - 1 - idx]
loss_local = mse(in1, in2.detach())
layer.fc.weight.grad, layer.fc.bias.grad = autograd.grad(loss_local, layer.fc.parameters())
return ff_value, cost
def forward_parameters(self):
res = []
for layer in self.ff:
res += layer.parameters()
return res
def feedback_parameters(self):
res = []
for layer in self.fb:
res += layer.parameters()
return res
if __name__ == '__main__':
net = BaseGLSNN()
print(net)
================================================
FILE: braincog/model_zoo/linearNet.py
================================================
import torch.nn.functional as F
from braincog.base.strategy.surrogate import *
from braincog.base.node.node import IFNode
from braincog.base.learningrule.STDP import STDP, MutliInputSTDP
class droDMTrainNet(nn.Module):
"""
Drosophila Training network: compound eye-KC-MBON
"""
def __init__(self, connection):
"""
根据传入的连接 构建训练网络
:param connection: 训练网络的连接
"""
super().__init__()
trace_stdp = 0.99
self.num_subMB = 3
self.node = [IFNode() for i in range(self.num_subMB)]
self.connection = connection
self.learning_rule = []
self.learning_rule.append(STDP(self.node[0], self.connection[0], trace_stdp))
self.learning_rule.append(STDP(self.node[1], self.connection[1], trace_stdp))
self.learning_rule.append(MutliInputSTDP(self.node[2], [self.connection[2], self.connection[3]], trace_stdp))
self.out_vis = torch.zeros((self.connection[0].weight.shape[1]), dtype=torch.float)
self.out_KC = torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float)
self.out_MBON = torch.zeros((self.connection[2].weight.shape[1]), dtype=torch.float)
def forward(self, input):
"""
根据输入得到输出
:param input: 输入电流
:return: 网络的输出,以及网络运行产生的STDP可塑性
"""
self.out_vis = self.node[0](self.connection[0](input))
self.out_KC, dw_kc = self.learning_rule[1](self.out_vis)
self.out_MBON, dw_mbon = self.learning_rule[2](self.out_KC, self.out_MBON)
return self.out_MBON, dw_kc[0], dw_mbon[0]
def UpdateWeight(self, i, dw):
"""
更新网络中第i组连接的权重
:param i: 要更新的连接的索引
:param dw: 更新的量
:return: None
"""
self.connection[i].update(dw)
self.connection[i].weight.data = F.normalize(self.connection[i].weight.data.float(), p=1, dim=1)
def reset(self):
"""
reset神经元或学习法则的中间量
:return: None
"""
for i in range(self.num_subMB):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
"""
获取网络的连接(包括权值等)
:return: 网络的连接
"""
return self.connection
================================================
FILE: braincog/model_zoo/nonlinearNet.py
================================================
import torch.nn.functional as F
from braincog.base.strategy.surrogate import *
from braincog.base.node.node import IFNode
from braincog.base.learningrule.STDP import STDP, MutliInputSTDP
class droDMTestNet(nn.Module):
"""
Drosophila Testing Network: compound eye-KC-MBON DA-GABA-MB
"""
def __init__(self, connection):
"""
根据传入的连接 构建测试网络
:param connection: 测试网络的连接
"""
super().__init__()
trace_stdp = 0.99
self.num_subMB = 5
self.node = [IFNode() for i in range(self.num_subMB)]
self.connection = connection
self.learning_rule = []
self.learning_rule.append(STDP(self.node[0], self.connection[0], trace_stdp))
self.learning_rule.append(MutliInputSTDP(self.node[1], [self.connection[1], self.connection[5]], trace_stdp))
self.learning_rule.append(MutliInputSTDP(self.node[2], [self.connection[2], self.connection[3], self.connection[9]], trace_stdp))
self.learning_rule.append(MutliInputSTDP(self.node[3], [self.connection[4], self.connection[6]], trace_stdp))
self.learning_rule.append(MutliInputSTDP(self.node[4], [self.connection[7], self.connection[8]], trace_stdp))
self.out_vis = torch.zeros((self.connection[0].weight.shape[1]), dtype=torch.float)
self.out_KC = torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float)
self.out_MBON = torch.zeros((self.connection[2].weight.shape[1]), dtype=torch.float)
self.out_APL = torch.zeros((self.connection[4].weight.shape[1]), dtype=torch.float)
self.out_DA = torch.zeros((self.connection[7].weight.shape[1]), dtype=torch.float)
def forward(self, input, input_da):
"""
根据输入得到输出
:param input: 输入电流
:return: 网络的输出,以及网络运行产生的STDP可塑性
"""
self.out_vis = self.node[0](self.connection[0](input))
self.out_KC, dw_kc = self.learning_rule[1](self.out_vis, self.out_APL)
self.out_MBON, dw_mbon = self.learning_rule[2](self.out_KC, self.out_MBON, self.out_DA)
self.out_APL, dw_apl = self.learning_rule[3](self.out_KC, self.out_DA)
self.out_DA, dw_da = self.learning_rule[4](self.out_APL, input_da)
return self.out_MBON, dw_kc[1], dw_apl[0]
def UpdateWeight(self, i, dw):
"""
更新网络中第i组连接的权重
:param i: 要更新的连接的索引
:param dw: 更新的量
:return: None
"""
self.connection[i].update(dw)
self.connection[i].weight.data = F.normalize(self.connection[i].weight.data.float(), p=1, dim=0)
def reset(self):
"""
reset神经元或学习法则的中间量
:return: None
"""
for i in range(self.num_subMB):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
"""
获取网络的连接(包括权值等)
:return: 网络的连接
"""
return self.connection
================================================
FILE: braincog/model_zoo/qsnn.py
================================================
import numpy as np
from scipy.linalg import orth
from scipy.special import expit
from scipy.signal import fftconvolve
import torch
from torch.nn import Parameter
import torch.nn as nn
from braincog.datasets.gen_input_signal import lambda_max, dt
from braincog.base.encoder import QSEncoder
gamma = 0.1
beta = 1.0
theta = 3.0
# kernel parameters
tau_s = 4.0 # synaptic time constant
tau_L = 10.0 # leak time constant
# conductance parameters
g_B = 0.6 # basal conductance
g_A = 0.05 # apical conductance
g_L = 1.0 / tau_L # leak conductance
g_D = g_B # dendritic conductance in output layer
k_D = g_D / (g_L + g_D)
STEPS = int(50 / dt)
SLEN = 20 # spike time length
# --- sigmoid function --- #
def sigma(x):
return torch.sigmoid(x)
# def sigma(x):
# return gamma * np.log(1+np.exp(beta*(x-theta)))
def deriv_sigma(x):
return sigma(x) * (1.0 - sigma(x))
# kernel parameters
tau_s = 4.0 # synaptic time constant
tau_L = 10.0 # leak time constant
# --- kernel function --- #
mem = STEPS
def kappa(x):
return np.exp(-x / tau_s)
def get_kappas(n):
return np.array([kappa(i + 1) for i in range(n)])
kappas = get_kappas(mem // 2) # initialize kappas array
kernel = np.zeros(mem)
kernel[:mem // 2] = kappas[:]
kernel[mem // 2:] = -np.flipud(kappas)[:]
W_MIN = -1.0
W_MAX = 1.0
class Net(nn.Module):
"""
两房室脉冲神经网络
"""
def __init__(self, net_size):
super().__init__()
self.input_size = net_size[0]
self.hidden_layers = nn.ModuleList([Hidden_layer(net_size[i], net_size[i + 1], net_size[-1]) for i in range(len(net_size) - 2)])
self.out_layer = Output_layer(net_size[-2], net_size[-1])
self.kernel = torch.from_numpy(kernel[:, np.newaxis]).cuda()
self.qs_code = QSEncoder
def update_state(self, input_, label, test):
if len(self.hidden_layers) > 1:
self.hidden_layers[0].update_state(input_, self.out_layer.spike_rate, test=test)
for i in range(len(self.hidden_layers) - 2):
self.hidden_layers[i + 1].update_state(self.hidden_layers[i].spike_rate, self.out_layer.spike_rate, test=test)
self.hidden_layers[-1].update_state(self.hidden_layers[-2].spike_rate, self.out_layer.spike_rate, test=test)
else:
self.hidden_layers[0].update_state(input_, self.out_layer.spike_rate, test=test)
self.out_layer.update_state(self.hidden_layers[-1].spike_rate, label, test=test)
def routine(self,
input_,
input_delta,
image_ori,
image_ori_delta,
shift,
label,
test=False,
noise=False,
noise_rate=None):
"""
网络信息处理过程
:param input_: 输入图片
:param input_delta: 输入扰动图片,用于计算相位
:param image_ori: 原始图片
:param image_ori_delta: 原始扰动图片
:param shift: 是否反转背景
:param label: 输入数据分类标签
:param test: 是否是测试阶段
:param noise: 是否增加噪声
:param noise_rate: 噪声比例
"""
encoder = self.qs_code(lambda_max, STEPS, SLEN, shift, noise, noise_rate)
input_ = encoder(input_, input_delta, image_ori, image_ori_delta)
input_ = torch.from_numpy(input_).to(self.kernel.device)
psp = torch.mm(input_, self.kernel).abs().float()
for i in range(STEPS):
self.update_state(psp, label, test=test)
def update_weight(self, lr, t, beta, eps):
self.out_layer.update_weight(lr, t, beta, eps)
if len(self.hidden_layers) > 1:
self.hidden_layers[-1].update_weight(self.out_layer.delta, lr, t, beta, eps)
for i in range(len(self.hidden_layers) - 1):
self.hidden_layers[-(i + 2)].update_weight(self.hidden_layers[-(i + 1)].delta, lr, t, beta, eps)
else:
self.hidden_layers[0].update_weight(self.out_layer.delta, lr, t, beta, eps)
def predict(self,
input_,
input_delta,
image_ori,
image_ori_delta,
shift,
noise,
noise_rate=0):
self.routine(input_,
input_delta,
image_ori=image_ori,
image_ori_delta=image_ori_delta,
shift=shift,
label=None,
test=True,
noise=noise,
noise_rate=noise_rate)
pred = torch.argmax(self.out_layer.spike_rate.flatten())
return pred
class Hidden_layer(nn.Module):
"""
隐藏层两房室网络
"""
def __init__(self, input_size, neu_num, fb_neus):
super().__init__()
self.basal_linear = nn.Linear(input_size, neu_num)
nn.init.uniform_(self.basal_linear.weight, -0.1, 0.1)
nn.init.uniform_(self.basal_linear.bias, -0.1, 0.1)
self.soma_V = 0.0
self.basal_V = 0.0
# for adam
self.m = 0.0
self.v = 0.0
self.m_hat = 0.0
self.v_hat = 0.0
self.m_b = 0.0
self.v_b = 0.0
self.m_b_hat = 0.0
self.v_b_hat = 0.0
# backprop
self.delta = 0.0
def update_state(self, basal_input, apical_input, test):
self.basal_input = basal_input.T # [1, 781]
self.basal_V = self.basal_linear(basal_input.T)
self.soma_V = self.soma_V + 1 / tau_L * (-self.soma_V + g_B / g_L * (self.basal_V - self.soma_V)) * dt
self.spike_rate = lambda_max * sigma(self.soma_V)
def update_weight(self, delta_, lr, t, beta, eps):
weight_dot = lambda_max * k_D * delta_ * deriv_sigma(k_D * self.basal_V) # [1, 500]
self.delta = torch.mm(weight_dot, self.basal_linear.weight.data) # [500, 784] x [1, 500]
weight_delta = weight_dot[:, :, None] * self.basal_input[:, None, :]
bias_delta = weight_dot
self.m = beta[0] * self.m + (1 - beta[0]) * weight_delta
self.v = beta[1] * self.v + (1 - beta[1]) * torch.square(weight_delta)
self.m_hat = self.m / (1 - beta[0] ** t)
self.v_hat = self.v / (1 - beta[1] ** t)
self.m_b = beta[0] * self.m_b + (1 - beta[0]) * bias_delta
self.v_b = beta[1] * self.v_b + (1 - beta[1]) * torch.square(bias_delta)
self.m_b_hat = self.m_b / (1 - beta[0] ** t)
self.v_b_hat = self.v_b / (1 - beta[1] ** t)
# update weight
weight_delta = lr * self.m_hat / (torch.sqrt(self.v_hat) + eps)
bias_delta = lr * self.m_b_hat / (torch.sqrt(self.v_b_hat) + eps)
self.basal_linear.weight.data.sub_(weight_delta.mean(0))
self.basal_linear.bias.data.sub_(bias_delta.mean(0))
class Output_layer(nn.Module):
"""
输出层两房室网络
"""
def __init__(self, input_size, neu_num):
super().__init__()
self.basal_linear = nn.Linear(input_size, neu_num)
nn.init.uniform_(self.basal_linear.weight, -0.1, 0.1)
nn.init.uniform_(self.basal_linear.bias, -0.1, 0.1)
self.soma_V = 0.0
self.basal_V = 0.0
self.spike_rate = 0.0
# adam
self.m = 0.0
self.v = 0.0
self.m_hat = 0.0
self.v_hat = 0.0
self.m_b = 0.0
self.v_b = 0.0
self.m_b_hat = 0.0
self.v_b_hat = 0.0
# backprop
self.delta = 0.0
def update_state(self, basal_input, I, test):
self.basal_input = basal_input
self.basal_V = self.basal_linear(basal_input)
if test:
self.soma_V = self.soma_V + 1 / tau_L * (-self.soma_V + g_B / g_L * (self.basal_V - self.soma_V)) * dt
else:
self.soma_V = self.soma_V + 1 / tau_L * (-self.soma_V + g_B / g_L * (self.basal_V - self.soma_V) +
I - self.soma_V) * dt
self.spike_rate = lambda_max * sigma(self.soma_V)
def update_weight(self, lr, t, beta, eps):
weight_dot = lambda_max * k_D * (sigma(k_D * self.basal_V) - sigma(self.soma_V)) * deriv_sigma(k_D * self.basal_V)
self.delta = torch.mm(weight_dot, self.basal_linear.weight.data) # [1, 500]
bias_delta = weight_dot # [1, 10]
weight_delta = weight_dot[:, :, None] * self.basal_input[:, None, :] # [1, 10, 500]
self.m = beta[0] * self.m + (1 - beta[0]) * weight_delta
self.v = beta[1] * self.v + (1 - beta[1]) * torch.square(weight_delta)
self.m_hat = self.m / (1 - beta[0] ** t)
self.v_hat = self.v / (1 - beta[1] ** t)
self.m_b = beta[0] * self.m_b + (1 - beta[0]) * bias_delta
self.v_b = beta[1] * self.v_b + (1 - beta[1]) * torch.square(bias_delta)
self.m_b_hat = self.m_b / (1 - beta[0] ** t)
self.v_b_hat = self.v_b / (1 - beta[1] ** t)
# update weight
weight_delta = lr * self.m_hat / (torch.sqrt(self.v_hat) + eps)
bias_delta = lr * self.m_b_hat / (torch.sqrt(self.v_b_hat) + eps)
self.basal_linear.weight.data.sub_(weight_delta.mean(0))
self.basal_linear.bias.data.sub_(bias_delta.mean(0))
================================================
FILE: braincog/model_zoo/resnet.py
================================================
'''
Deep Residual Learning for Image Recognition
https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
'''
import os
import sys
from functools import partial
from timm.models import register_model
from timm.models.layers import trunc_normal_, DropPath
from braincog.model_zoo.base_module import *
from braincog.base.node.node import *
__all__ = [
'ResNet',
'resnet18',
'resnet34_half',
'resnet34',
'resnet50_half',
'resnet50',
'resnet101',
'resnet152',
'resnext50_32x4d',
'resnext101_32x8d',
'wide_resnet50_2',
'wide_resnet101_2',
]
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
'''3x3 convolution with padding'''
return nn.Conv2d(in_planes,
out_planes,
kernel_size=3,
stride=stride,
padding=dilation,
groups=groups,
bias=False,
dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
'''1x1 convolution'''
return nn.Conv2d(in_planes,
out_planes,
kernel_size=1,
stride=stride,
bias=False)
class BasicBlock(nn.Module):
"""
ResNet的基础模块, 采用identity-connection的方式.
:param inplanes: 输出通道数
:param planes: 内部通道数量
:param stride: stride
:param downsample: 是否降采样
:param groups: 分组卷积
:param base_width: 基础通道数量
:param dilation: 空洞卷积
:param norm_layer: Norm的方式
:param node: 神经元类型, 默认为 ``LIFNode``
"""
expansion = 1
__constants__ = ['downsample']
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None,
node=LIFNode):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError(
'BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError(
'Dilation > 1 not supported in BasicBlock')
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.bn1 = norm_layer(inplanes)
self.node1 = node()
self.conv1 = conv3x3(inplanes, planes, stride)
# self.relu = nn.ReLU(inplace=False)
self.node2 = node()
self.bn2 = norm_layer(planes)
self.conv2 = conv3x3(planes, planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.bn1(x)
out = self.node1(out)
out = self.conv1(out)
out = self.bn2(out)
out = self.node2(out)
out = self.conv2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
return out
class Bottleneck(nn.Module):
"""
ResNet的Botteneck模块, 采用identity-connection的方式.
:param inplanes: 输出通道数
:param planes: 内部通道数量
:param stride: stride
:param downsample: 是否降采样
:param groups: 分组卷积
:param base_width: 基础通道数量
:param dilation: 空洞卷积
:param norm_layer: Norm的方式
:param node: 神经元类型, 默认为 ``LIFNode``
"""
expansion = 4
__constants__ = ['downsample']
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None,
node=torch.nn.Identity):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.bn1 = norm_layer(inplanes)
self.conv1 = conv1x1(inplanes, width)
self.bn2 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn3 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
# self.relu = nn.ReLU(inplace=False)
self.downsample = downsample
self.stride = stride
self.node1 = node()
self.node2 = node()
self.node3 = node()
def forward(self, x):
identity = x
out = self.bn1(x)
out = self.node1(out)
out = self.conv1(out)
out = self.bn2(out)
out = self.node2(out)
out = self.conv2(out)
out = self.bn3(out)
out = self.node3(out)
out = self.conv3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
return out
class ResNet(BaseModule):
"""
ResNet-SNN
:param block: Block类型
:param layers: block 层数
:param inplanes: 输入通道数量
:param num_classes: 输出类别数
:param zero_init_residual: 是否使用零初始化
:param groups: 卷积分组
:param width_per_group: 每一组的宽度
:param replace_stride_with_dilation: 是否使用stride替换dilation
:param norm_layer: Norm 方式, 默认为 ``BatchNorm``
:param step: 仿真步长, 默认为 ``8``
:param encode_type: 编码方式, 默认为 ``direct``
:param spike_output: 是否使用脉冲输出, 默认为 ``False``
:param args:
:param kwargs:
"""
def __init__(self,
block,
layers,
inplanes=64,
num_classes=10,
zero_init_residual=False,
groups=1,
width_per_group=64,
replace_stride_with_dilation=None,
norm_layer=None,
step=8,
encode_type='direct',
spike_output=False,
*args,
**kwargs):
super().__init__(
step,
encode_type,
*args,
**kwargs
)
self.spike_output = spike_output
self.num_classes = num_classes
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
# print('inplanes %d' % inplanes)
self.inplanes = inplanes
self.interplanes = [
self.inplanes, self.inplanes * 2, self.inplanes * 4,
self.inplanes * 8
]
self.dilation = 1
self.node = kwargs['node_type']
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs)
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError('replace_stride_with_dilation should be None '
'or a 3-element tuple, got {}'.format(
replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.static_data = False
self.dataset = kwargs['dataset']
if self.dataset == 'dvsg' or self.dataset == 'dvsc10' or self.dataset == 'NCALTECH101' or self.dataset == 'NCARS' or self.dataset == 'DVSG':
self.conv1 = nn.Conv2d(2 * self.init_channel_mul,
self.inplanes,
kernel_size=3,
padding=1,
bias=False)
elif self.dataset == 'imnet':
self.conv1 = nn.Conv2d(3 * self.init_channel_mul,
self.inplanes,
kernel_size=7,
stride=2,
padding=3,
bias=False)
self.static_data = True
elif self.dataset == 'esimnet':
reconstruct = kwargs["reconstruct"] if "reconstruct" in kwargs else False
print(reconstruct)
if reconstruct:
self.conv1 = nn.Conv2d(1 * self.init_channel_mul,
self.inplanes,
kernel_size=7,
stride=2,
padding=3,
bias=False)
self.static_data = True
else:
self.conv1 = nn.Conv2d(2 * self.init_channel_mul,
self.inplanes,
kernel_size=7,
stride=2,
padding=3,
bias=False)
self.static_data = True
elif self.dataset == 'cifar10' or self.dataset == 'cifar100':
self.conv1 = nn.Conv2d(3 * self.init_channel_mul,
self.inplanes,
kernel_size=3,
padding=1,
bias=False)
self.static_data = True
# self.relu = nn.ReLU(inplace=False)
self.layer1 = self._make_layer(
block, self.interplanes[0], layers[0], node=self.node)
self.layer2 = self._make_layer(block,
self.interplanes[1],
layers[1],
stride=2,
dilate=replace_stride_with_dilation[0], node=self.node)
self.layer3 = self._make_layer(block,
self.interplanes[2],
layers[2],
stride=2,
dilate=replace_stride_with_dilation[1], node=self.node)
self.layer4 = self._make_layer(block,
self.interplanes[3],
layers[3],
stride=2,
dilate=replace_stride_with_dilation[2], node=self.node)
self.bn1 = norm_layer(self.inplanes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
if self.spike_output:
self.fc = nn.Linear(
self.interplanes[3] * block.expansion, num_classes * 10)
self.node2 = self.node()
self.vote = VotingLayer(10)
else:
self.fc = nn.Linear(
self.interplanes[3] * block.expansion, num_classes
)
self.node2 = nn.Identity()
self.vote = nn.Identity()
self.warm_up = False
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight,
mode='fan_out',
nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False, node=torch.nn.Identity):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
if block == BasicBlock:
downsample = nn.Sequential(
norm_layer(self.inplanes),
self.node(),
conv1x1(self.inplanes, planes * block.expansion, stride),
)
elif block == Bottleneck:
downsample = nn.Sequential(
norm_layer(self.inplanes),
self.node(),
conv1x1(self.inplanes, planes * block.expansion, stride),
)
else:
raise NotImplementedError
layers = [block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer, node=node)]
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(
block(self.inplanes,
planes,
groups=self.groups,
base_width=self.base_width,
dilation=self.dilation,
norm_layer=norm_layer, node=node))
return nn.Sequential(*layers)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.conv1(inputs)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.bn1(x)
# x = self.node1(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
# print(x.shape)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
x = self.node2(x)
x = self.vote(x)
return x
else:
outputs = []
if self.warm_up:
step = 1
else:
step = self.step
for t in range(step):
x = inputs[t]
x = self.conv1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.bn1(x)
# x = self.node1(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
x = self.node2(x)
x = self.vote(x)
outputs.append(x)
return sum(outputs) / len(outputs)
def _resnet(arch, block, layers, pretrained=False, **kwargs):
model = ResNet(block, layers, **kwargs)
# only load state_dict()
if pretrained:
raise NotImplementedError
return model
@register_model
def resnet9(pretrained=False, **kwargs):
return _resnet('resnet9', BasicBlock, [1, 1, 1, 1], pretrained, **kwargs)
@register_model
def resnet18(pretrained=False, **kwargs):
# kwargs['inplanes'] = 96
return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, **kwargs)
@register_model
def resnet34_half(pretrained=False, **kwargs):
kwargs['inplanes'] = 32
return _resnet('resnet34_half', BasicBlock, [3, 4, 6, 3], pretrained,
**kwargs)
@register_model
def resnet34(pretrained=False, **kwargs):
return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, **kwargs)
@register_model
def resnet50_half(pretrained=False, **kwargs):
kwargs['inplanes'] = 32
return _resnet('resnet50_half', Bottleneck, [3, 4, 6, 3], pretrained,
**kwargs)
@register_model
def resnet50(pretrained=False, **kwargs):
return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, **kwargs)
@register_model
def resnet101(pretrained=False, **kwargs):
return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained,
**kwargs)
@register_model
def resnet152(pretrained=False, **kwargs):
return _resnet('resnet152', Bottleneck, [3, 8, 36, 3], pretrained,
**kwargs)
@register_model
def resnext50_32x4d(pretrained=False, **kwargs):
kwargs['groups'] = 32
kwargs['width_per_group'] = 4
return _resnet('resnext50_32x4d', Bottleneck, [3, 4, 6, 3], pretrained,
**kwargs)
@register_model
def resnext101_32x8d(pretrained=False, **kwargs):
kwargs['groups'] = 32
kwargs['width_per_group'] = 8
return _resnet('resnext101_32x8d', Bottleneck, [3, 4, 23, 3], pretrained,
**kwargs)
@register_model
def wide_resnet50_2(pretrained=False, **kwargs):
kwargs['width_per_group'] = 64 * 2
return _resnet('wide_resnet50_2', Bottleneck, [3, 4, 6, 3], pretrained,
**kwargs)
@register_model
def wide_resnet101_2(pretrained=False, **kwargs):
kwargs['width_per_group'] = 64 * 2
return _resnet('wide_resnet101_2', Bottleneck, [3, 4, 23, 3], pretrained,
**kwargs)
if __name__ == '__main__':
net = ResNet(Bottleneck, [3, 4, 6, 3], num_classes=1000)
image_h, image_w = 224, 224
from thop import profile
from thop import clever_format
flops, params = profile(net,
inputs=(torch.randn(1, 3, image_h, image_w),),
verbose=False)
flops, params = clever_format([flops, params], '%.3f')
out = net(torch.autograd.Variable(torch.randn(3, 3, image_h, image_w)))
print(f'1111, flops: {flops}, params: {params},out_shape: {out.shape}')
================================================
FILE: braincog/model_zoo/resnet19_snn.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/7/26 19:33
# User : Floyed
# Product : PyCharm
# Project : braincog
# File : resnet19_snn.py
# explain :
import os
import sys
from functools import partial
import numpy as np
from timm.models import register_model
from timm.models.layers import trunc_normal_, DropPath
from braincog.model_zoo.base_module import *
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.datasets import is_dvs_data
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
node=LIFNode, base_width=64, dilation=1, norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = ThresholdDependentBatchNorm2d
# if groups != 1 or base_width != 64:
# raise ValueError('BasicBlock only supports groups=1 and base_width=64')
# if dilation > 1:
# raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(num_features=planes, alpha=1.)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(num_features=planes, alpha=np.sqrt(.5))
self.downsample = downsample
self.stride = stride
self.node1 = node()
self.node2 = node()
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.node1(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.node2(out)
return out
class ResNet(BaseModule):
def __init__(self, block, layers, num_classes=10, zero_init_residual=False, groups=1, width_per_group=128,
replace_stride_with_dilation=None, norm_layer=None, step=4, encode_type='direct', node_type=LIFNode,
*args, **kwargs):
super().__init__(
step,
encode_type,
*args,
**kwargs
)
super().__init__(step, encode_type, *args, **kwargs)
if not self.layer_by_layer:
raise ValueError('ResNet-SNN only support for layer-wise mode, because of tdBN')
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.dataset = kwargs['dataset']
if is_dvs_data(self.dataset):
data_channel = 2
else:
data_channel = 3
if norm_layer is None:
norm_layer = ThresholdDependentBatchNorm2d
self._norm_layer = partial(norm_layer, step=step)
self.sum_output=kwargs["sum_output"] if "sum_output"in kwargs else True
self.inplanes = 128
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(data_channel, self.inplanes, kernel_size=3, stride=1, padding=1,
bias=False)
self.bn1 = self._norm_layer(num_features=self.inplanes, alpha=np.sqrt(.5))
self.layer1 = self._make_layer(block, 128, layers[0])
self.layer2 = self._make_layer(block, 256, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 512, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc1 = nn.Linear(512 * block.expansion, 256)
self.fc2 = nn.Linear(256, num_classes)
self.node1 = self.node()
self.node2 = self.node()
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
# downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(num_features=planes * block.expansion, alpha=np.sqrt(.5)),
)
else:
downsample = nn.Sequential(
norm_layer(num_features=planes * block.expansion, alpha=np.sqrt(.5)),
)
layers = []
layers.append(block(self.inplanes, planes, stride=stride, downsample=downsample, groups=self.groups,
base_width=self.base_width, norm_layer=norm_layer, node=self.node))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer, node=self.node))
return nn.Sequential(*layers)
def _forward_impl(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = self.node2(x)
x = self.fc2(x)
if self.sum_output:x= rearrange(x, '(t b) c -> b c t', t=self.step).mean(-1)
else :x= rearrange(x, '(t b) c -> t b c ', t=self.step)
return x
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
return self._forward_impl(inputs)
def _resnet(arch, block, layers, pretrained, progress, norm=ThresholdDependentBatchNorm2d, **kwargs):
tdBN = partial(norm, layer_by_layer=kwargs['layer_by_layer'], threshold=kwargs['threshold'])
model = ResNet(block, layers, norm_layer=tdBN, **kwargs)
if pretrained:
raise NotImplementedError
return model
@register_model
def resnet19(pretrained=False, progress=True, norm=ThresholdDependentBatchNorm2d, **kwargs):
return _resnet('resnet19', BasicBlock, [3, 3, 2], pretrained, progress, norm=norm, **kwargs)
if __name__ == '__main__':
net = ResNet(BasicBlock, [3, 4, 6, 3], num_classes=1000)
image_h, image_w = 224, 224
from thop import profile
from thop import clever_format
flops, params = profile(net,
inputs=(torch.randn(1, 3, image_h, image_w),),
verbose=False)
flops, params = clever_format([flops, params], '%.3f')
out = net(torch.autograd.Variable(torch.randn(3, 3, image_h, image_w)))
print(f'1111, flops: {flops}, params: {params},out_shape: {out.shape}')
================================================
FILE: braincog/model_zoo/rsnn.py
================================================
import torch
from torch import nn
from braincog.base.node.node import IFNode
from braincog.base.learningrule.STDP import STDP,MutliInputSTDP
from braincog.base.connection.CustomLinear import CustomLinear
from collections import deque
from random import randint
class RSNN(nn.Module):
def __init__(self,num_state,num_action):
super().__init__()
# parameters
rsnn_mask=[]
rsnn_con=[]
con_matrix1 = torch.ones((num_state,num_action), dtype=torch.float)
rsnn_mask.append(con_matrix1)
rsnn_con.append(CustomLinear(torch.randn(num_state,num_action), con_matrix1))
self.num_subR=2
self.connection = rsnn_con
self.mask=rsnn_mask
self.node = [IFNode() for i in range(self.num_subR)]
self.learning_rule = []
self.learning_rule.append(MutliInputSTDP(self.node[1], [self.connection[0]]))
self.weight_trace = torch.zeros(con_matrix1.shape, dtype=torch.float)
self.out_in = torch.zeros((num_state), dtype=torch.float)
self.out = torch.zeros((self.connection[0].weight.size()[1]), dtype=torch.float)
self.dw = torch.zeros((self.connection[0].weight.size()), dtype=torch.float)
def forward(self, input):
input=torch.tensor(input, dtype=torch.float)
self.out_in=self.node[0](input)
self.out,self.dw = self.learning_rule[0](self.out_in)
return self.out,self.dw
def UpdateWeight(self,reward):
self.weight_trace[self.weight_trace>0]=self.weight_trace[self.weight_trace>0]*reward
self.weight_trace[self.weight_trace < 0] = -1*self.weight_trace[self.weight_trace < 0] * reward
self.connection[0].update(self.weight_trace)
for i in range(self.connection[0].weight.size()[1]):
self.connection[0].weight.data[:, i] = (self.connection[0].weight.data[:, i] - torch.min(self.connection[0].weight.data[:, i])) / (torch.max(self.connection[0].weight.data[:, i]) - torch.min(self.connection[0].weight.data[:, i]))
self.connection[0].weight.data= self.connection[0].weight.data * 0.5
def reset(self):
for i in range(self.num_subR):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
return self.connection
================================================
FILE: braincog/model_zoo/sew_resnet.py
================================================
import torch
import torch.nn as nn
from copy import deepcopy
try:
from torchvision.models.utils import load_state_dict_from_url
except ImportError:
from torchvision._internally_replaced_utils import load_state_dict_from_url
from braincog.base.node import *
from braincog.model_zoo.base_module import *
from braincog.datasets import is_dvs_data
from timm.models import register_model
__all__ = ['SEWResNet', 'sew_resnet18', 'sew_resnet34', 'sew_resnet50', 'sew_resnet101',
'sew_resnet152', 'sew_resnext50_32x4d', 'sew_resnext101_32x8d',
'sew_wide_resnet50_2', 'sew_wide_resnet101_2']
model_urls = {
"resnet18": "https://download.pytorch.org/models/resnet18-f37072fd.pth",
"resnet34": "https://download.pytorch.org/models/resnet34-b627a593.pth",
"resnet50": "https://download.pytorch.org/models/resnet50-0676ba61.pth",
"resnet101": "https://download.pytorch.org/models/resnet101-63fe2227.pth",
"resnet152": "https://download.pytorch.org/models/resnet152-394f9c45.pth",
"resnext50_32x4d": "https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth",
"resnext101_32x8d": "https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth",
"wide_resnet50_2": "https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth",
"wide_resnet101_2": "https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth",
}
# modified by https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py
def sew_function(x: torch.Tensor, y: torch.Tensor, cnf:str):
if cnf == 'ADD':
return x + y
elif cnf == 'AND':
return x * y
elif cnf == 'IAND':
return x * (1. - y)
else:
raise NotImplementedError
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None, cnf: str = None, node: callable = None, **kwargs):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.node1 = node()
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.node2 = node()
self.downsample = downsample
if downsample is not None:
self.downsample_sn = node()
self.stride = stride
self.cnf = cnf
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.node1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.node2(out)
if self.downsample is not None:
identity = self.downsample_sn(self.downsample(x))
out = sew_function(identity, out, self.cnf)
return out
def extra_repr(self) -> str:
return super().extra_repr() + f'cnf={self.cnf}'
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None, cnf: str = None, node: callable = None, **kwargs):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.node1 = node()
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.node2 = node()
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.node3 = node()
self.downsample = downsample
if downsample is not None:
self.downsample_sn = node()
self.stride = stride
self.cnf = cnf
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.node1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.node2(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.node3(out)
if self.downsample is not None:
identity = self.downsample_sn(self.downsample(x))
out = sew_function(out, identity, self.cnf)
return out
def extra_repr(self) -> str:
return super().extra_repr() + f'cnf={self.cnf}'
class SEWResNet(BaseModule):
def __init__(self, block, layers, num_classes=1000, step=8,encode_type="direct",zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None, cnf: str = None, *args,**kwargs):
super().__init__(
step,
encode_type,
*args,
**kwargs
)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.num_classes = num_classes
self.node = kwargs['node_type']
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.once=kwargs["once"] if "once"in kwargs else False
self.sum_output=kwargs["sum_output"] if "sum_output"in kwargs else True
self.dataset = kwargs['dataset']
if not is_dvs_data(self.dataset):
init_channel = 3
else:
init_channel = 2
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(init_channel, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.node1 = self.node()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], cnf=cnf, node=self.node, **kwargs)
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0], cnf=cnf, node=self.node, **kwargs)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1], cnf=cnf, node=self.node, **kwargs)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2], cnf=cnf, node=self.node, **kwargs)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False, cnf: str=None, node: callable = None, **kwargs):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer, cnf, node, **kwargs))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer, cnf=cnf, node=node, **kwargs))
return nn.Sequential(*layers)
def _forward_impl(self, inputs):
# See note [TorchScript super()]
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.conv1(inputs)
x = self.bn1(x)
x = self.node1(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step)
#print(x)
if self.sum_output:x=x.mean(0)
return x
else:
outputs=[]
for t in range(self.step):
x = inputs[t]
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
outputs.append(x)
if not self.sum_output:return outputs
return sum(outputs) / len(outputs)
def _forward_once(self,x):
# inputs = self.encoder(inputs)
# x = inputs[t]
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
if self.once:return self._forward_once(x)
return self._forward_impl(x)
class SEWResNet19(BaseModule):
def __init__(self, block, layers, num_classes=1000, step=8,encode_type="direct",zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None, cnf: str = None, *args,**kwargs):
super().__init__(
step,
encode_type,
*args,
**kwargs
)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.num_classes = num_classes
self.node = kwargs['node_type']
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.once=kwargs["once"] if "once"in kwargs else False
self.sum_output=kwargs["sum_output"] if "sum_output"in kwargs else True
self.dataset = kwargs['dataset']
if not is_dvs_data(self.dataset):
init_channel = 3
else:
init_channel = 2
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(init_channel, self.inplanes, kernel_size=3, stride=1, padding=1,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.node1 = self.node()
self.layer1 = self._make_layer(block, 128, layers[0], cnf=cnf, node=self.node, **kwargs)
self.layer2 = self._make_layer(block, 256, layers[1], stride=2,
dilate=replace_stride_with_dilation[0], cnf=cnf, node=self.node, **kwargs)
self.layer3 = self._make_layer(block, 512, layers[2], stride=2,
dilate=replace_stride_with_dilation[1], cnf=cnf, node=self.node, **kwargs)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc1 = nn.Linear(512 * block.expansion, 256)
self.fc2 = nn.Linear(256, num_classes)
self.node2 = self.node()
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False, cnf: str=None, node: callable = None, **kwargs):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer, cnf, node, **kwargs))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer, cnf=cnf, node=node, **kwargs))
return nn.Sequential(*layers)
def _forward_impl(self, inputs):
# See note [TorchScript super()]
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.conv1(inputs)
x = self.bn1(x)
x = self.node1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = self.node2(x)
x = self.fc2(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step)
#print(x)
if self.sum_output:x=x.mean(0)
return x
else:
outputs=[]
for t in range(self.step):
x = inputs[t]
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = self.node2(x)
x = self.fc2(x)
outputs.append(x)
if not self.sum_output:return outputs
return sum(outputs) / len(outputs)
def _forward_once(self,x):
# inputs = self.encoder(inputs)
# x = inputs[t]
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
if self.once:return self._forward_once(x)
return self._forward_impl(x)
class SEWResNetCifar(BaseModule):
def __init__(self, block, layers, num_classes=1000, step=8,encode_type="direct",zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None, cnf: str = None, *args,**kwargs):
super().__init__(
step,
encode_type,
*args,
**kwargs
)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.num_classes = num_classes
self.node = kwargs['node_type']
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.once=kwargs["once"] if "once"in kwargs else False
self.sum_output=kwargs["sum_output"] if "sum_output"in kwargs else True
self.dataset = kwargs['dataset']
if not is_dvs_data(self.dataset):
init_channel = 3
else:
init_channel = 2
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(init_channel, self.inplanes, kernel_size=3, stride=1, padding=1,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.node1 = self.node()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 128, layers[0], cnf=cnf, node=self.node, **kwargs)
self.layer2 = self._make_layer(block, 256, layers[1], stride=2,
dilate=replace_stride_with_dilation[0], cnf=cnf, node=self.node, **kwargs)
self.layer3 = self._make_layer(block, 512, layers[2], stride=2,
dilate=replace_stride_with_dilation[1], cnf=cnf, node=self.node, **kwargs)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False, cnf: str=None, node: callable = None, **kwargs):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer, cnf, node, **kwargs))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer, cnf=cnf, node=node, **kwargs))
return nn.Sequential(*layers)
def _forward_impl(self, inputs):
# See note [TorchScript super()]
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.conv1(inputs)
x = self.bn1(x)
x = self.node1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step)
#print(x)
if self.sum_output:x=x.mean(0)
return x
else:
outputs=[]
for t in range(self.step):
x = inputs[t]
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
outputs.append(x)
if not self.sum_output:return outputs
return sum(outputs) / len(outputs)
def _forward_once(self,x):
# inputs = self.encoder(inputs)
# x = inputs[t]
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
if self.once:return self._forward_once(x)
return self._forward_impl(x)
def _sew_resnet(arch, block, layers, pretrained, progress, cnf, **kwargs):
model = SEWResNet(block, layers, cnf=cnf, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
@register_model
def sew_resnet19(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-18
:rtype: torch.nn.Module
The spike-element-wise ResNet-18 `"Deep Residual Learning in Spiking Neural Networks" `_ modified by the ResNet-18 model from `"Deep Residual Learning for Image Recognition" `_
"""
return SEWResNet19( BasicBlock, [3,3, 2], cnf=cnf, **kwargs)
@register_model
def sew_resnet18(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-18
:rtype: torch.nn.Module
The spike-element-wise ResNet-18 `"Deep Residual Learning in Spiking Neural Networks" `_ modified by the ResNet-18 model from `"Deep Residual Learning for Image Recognition" `_
"""
return _sew_resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress, cnf, **kwargs)
@register_model
def sew_resnet20(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-34
:rtype: torch.nn.Module
The spike-element-wise ResNet-34 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-34 model from `"Deep Residual Learning for Image Recognition" `_
"""
return SEWResNetCifar( BasicBlock, [3,3,3], cnf=cnf, **kwargs)
@register_model
def sew_resnet32(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-34
:rtype: torch.nn.Module
The spike-element-wise ResNet-34 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-34 model from `"Deep Residual Learning for Image Recognition" `_
"""
return SEWResNetCifar( BasicBlock, [5,5,5], cnf=cnf, **kwargs)
@register_model
def sew_resnet44(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-34
:rtype: torch.nn.Module
The spike-element-wise ResNet-34 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-34 model from `"Deep Residual Learning for Image Recognition" `_
"""
return SEWResNetCifar( BasicBlock, [7,7,7], cnf=cnf, **kwargs)
@register_model
def sew_resnet56(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-34
:rtype: torch.nn.Module
The spike-element-wise ResNet-34 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-34 model from `"Deep Residual Learning for Image Recognition" `_
"""
return SEWResNetCifar( BasicBlock, [9,9,9], cnf=cnf, **kwargs)
@register_model
def sew_resnet34(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-34
:rtype: torch.nn.Module
The spike-element-wise ResNet-34 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-34 model from `"Deep Residual Learning for Image Recognition" `_
"""
return _sew_resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress, cnf, **kwargs)
@register_model
def sew_resnet50(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-50
:rtype: torch.nn.Module
The spike-element-wise ResNet-50 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-50 model from `"Deep Residual Learning for Image Recognition" `_
"""
return _sew_resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress, cnf, **kwargs)
@register_model
def sew_resnet101(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-101
:rtype: torch.nn.Module
The spike-element-wise ResNet-101 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-101 model from `"Deep Residual Learning for Image Recognition" `_
"""
return _sew_resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress, cnf, **kwargs)
@register_model
def sew_resnet152(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a single step neuron
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-152
:rtype: torch.nn.Module
The spike-element-wise ResNet-152 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-152 model from `"Deep Residual Learning for Image Recognition" `_
"""
return _sew_resnet('resnet152', Bottleneck, [3, 8, 36, 3], pretrained, progress, cnf, **kwargs)
@register_model
def sew_resnext50_32x4d(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a single step neuron
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNeXt-50 32x4d
:rtype: torch.nn.Module
The spike-element-wise ResNeXt-50 32x4d `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNeXt-50 32x4d model from `"Aggregated Residual Transformation for Deep Neural Networks" `_
"""
kwargs['groups'] = 32
kwargs['width_per_group'] = 4
return _sew_resnet('resnext50_32x4d', Bottleneck, [3, 4, 6, 3], pretrained, progress, cnf, **kwargs)
@register_model
def sew_resnext34_32x4d(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a single step neuron
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNeXt-101 32x8d
:rtype: torch.nn.Module
The spike-element-wise ResNeXt-101 32x8d `"Deep Residual Learning in Spiking Neural Networks" `_ modified by the ResNeXt-101 32x8d model from `"Aggregated Residual Transformation for Deep Neural Networks" `_
"""
kwargs['groups'] = 32
kwargs['width_per_group'] = 4
return _sew_resnet('resnext34_32x4d', BasicBlock, [3, 4, 6, 3], pretrained, progress, cnf, **kwargs)
@register_model
def sew_resnext101_32x8d(pretrained=False, progress=True, cnf: str = None, node: callable=None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a single step neuron
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNeXt-101 32x8d
:rtype: torch.nn.Module
The spike-element-wise ResNeXt-101 32x8d `"Deep Residual Learning in Spiking Neural Networks" `_ modified by the ResNeXt-101 32x8d model from `"Aggregated Residual Transformation for Deep Neural Networks" `_
"""
kwargs['groups'] = 32
kwargs['width_per_group'] = 8
return _sew_resnet('resnext101_32x8d', Bottleneck, [3, 4, 23, 3], pretrained, progress, cnf, node, **kwargs)
@register_model
def sew_wide_resnet50_2(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a single step neuron
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking Wide ResNet-50-2
:rtype: torch.nn.Module
The spike-element-wise Wide ResNet-50-2 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the Wide ResNet-50-2 model from `"Wide Residual Networks" `_
The model is the same as ResNet except for the bottleneck number of channels
which is twice larger in every block. The number of channels in outer 1x1
convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
channels, and in Wide ResNet-50-2 has 2048-1024-2048.
"""
kwargs['width_per_group'] = 64 * 2
return _sew_resnet('wide_resnet50_2', Bottleneck, [3, 4, 6, 3], pretrained, progress, cnf, **kwargs)
@register_model
def sew_wide_resnet101_2(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a single step neuron
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking Wide ResNet-101-2
:rtype: torch.nn.Module
The spike-element-wise Wide ResNet-101-2 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the Wide ResNet-101-2 model from `"Wide Residual Networks" `_
The model is the same as ResNet except for the bottleneck number of channels
which is twice larger in every block. The number of channels in outer 1x1
convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
channels, and in Wide ResNet-50-2 has 2048-1024-2048.
"""
kwargs['width_per_group'] = 64 * 2
return _sew_resnet('wide_resnet101_2', Bottleneck, [3, 4, 23, 3], pretrained, progress, cnf, **kwargs)
================================================
FILE: braincog/model_zoo/vgg_snn.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/7/26 18:56
# User : Floyed
# Product : PyCharm
# Project : BrainCog
# File : vgg_snn.py
# explain :
from functools import partial
from torch.nn import functional as F
import torchvision
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.datasets import is_dvs_data
@register_model
class SNN7_tiny(BaseModule):
def __init__(self,
num_classes=10,
step=8,
node_type=LIFNode,
encode_type='direct',
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.num_classes = num_classes
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.dataset = kwargs['dataset']
assert not is_dvs_data(self.dataset), 'SNN7_tiny only support static datasets now'
self.feature = nn.Sequential(
BaseConvModule(3, 16, kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(16, 64, kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.MaxPool2d(2),
BaseConvModule(64, 128, kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(128, 128, kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.MaxPool2d(2),
BaseConvModule(128, 256, kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(256, 256, kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.MaxPool2d(2),
BaseConvModule(256, 512, kernel_size=(3, 3), padding=(1, 1), node=self.node),
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(512 * 4 * 4, self.num_classes),
)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.feature(inputs)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
return x
else:
outputs = []
for t in range(self.step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
@register_model
class SNN5(BaseModule):
def __init__(self,
num_classes=10,
step=8,
node_type=LIFNode,
encode_type='direct',
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.n_preact = kwargs['n_preact'] if 'n_preact' in kwargs else False
self.num_classes = num_classes
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.dataset = kwargs['dataset']
if not is_dvs_data(self.dataset):
init_channel = 3
else:
init_channel = 2
self.feature = nn.Sequential(
BaseConvModule(init_channel, 16, kernel_size=(3, 3), padding=(1, 1), node=self.node, n_preact=self.n_preact),
BaseConvModule(16, 64, kernel_size=(5, 5), padding=(2, 2), node=self.node, n_preact=self.n_preact),
nn.AvgPool2d(2),
BaseConvModule(64, 128, kernel_size=(5, 5), padding=(2, 2), node=self.node, n_preact=self.n_preact),
nn.AvgPool2d(2),
BaseConvModule(128, 256, kernel_size=(3, 3), padding=(1, 1), node=self.node, n_preact=self.n_preact),
nn.AvgPool2d(2),
BaseConvModule(256, 512, kernel_size=(3, 3), padding=(1, 1), node=self.node, n_preact=self.n_preact),
nn.AvgPool2d(2),
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(512 * 3 * 3, self.num_classes),
)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.feature(inputs)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
return x
else:
outputs = []
for t in range(self.step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
@register_model
class VGG_SNN(BaseModule):
def __init__(self,
num_classes=10,
step=8,
node_type=LIFNode,
encode_type='direct',
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.n_preact = kwargs['n_preact'] if 'n_preact' in kwargs else False
self.num_classes = num_classes
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.dataset = kwargs['dataset']
if not is_dvs_data(self.dataset):
raise NotImplementedError('VGG-SNN model is only for DVS data, but current datasets is {}'.format(self.dataset))
self.feature = nn.Sequential(
BaseConvModule(2, 64, kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(64, 128, kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.AvgPool2d(2),
BaseConvModule(128, 256, kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(256, 256, kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.AvgPool2d(2),
BaseConvModule(256, 512, kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(512, 512, kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.AvgPool2d(2),
BaseConvModule(512, 512, kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(512, 512, kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.AvgPool2d(2),
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(512 * 3 * 3, self.num_classes),
)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.feature(inputs)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
return x
else:
outputs = []
for t in range(self.step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
================================================
FILE: braincog/utils.py
================================================
import os
import random
import math
import csv
import numpy as np
import torch
from torch import nn
from PIL import Image
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
def setup_seed(seed):
"""
为CPU,GPU,所有GPU,numpy,python设置随机数种子,并禁止hash随机化
:param seed: seed value
:return:
"""
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
os.environ['PYTHONHASHSEED'] = str(seed)
def random_gradient(model: nn.Module, sigma: float):
"""
为梯度添加噪声
:param model: 模型
:param sigma: 噪声方差
:return:
"""
for param in model.parameters():
if param.grad is None:
continue
noise = torch.randn_like(param) * sigma
param.grad = param.grad + noise
class AverageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.avg = 0
self.sum = 0
self.cnt = 0
def update(self, val, n=1):
self.sum += val * n
self.cnt += n
self.avg = self.sum / self.cnt
class TensorGather(object):
def __init__(self):
self.reset()
def reset(self):
self.gather=None
def update(self, val):
if self.gather is not None:self.gather=torch.cat([self.gather,val],dim=0)
else:self.gather=val
def accuracy(output, target, topk=(1,)):
"""Compute the top1 and top5 accuracy
"""
maxk = max(topk)
batch_size = target.size(0)
# Return the k largest elements of the given input tensor
# along a given dimension -> N * k
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0)
res.append(correct_k.mul_(100.0 / batch_size))
return res
def mse(x, y):
out = (x - y).pow(2).sum(-1, keepdim=True).mean()
return out
def rand_ortho(shape, irange):
A = - irange + 2 * irange * np.random.rand(*shape)
U, s, V = np.linalg.svd(A, full_matrices=True)
return np.dot(U, np.dot(np.eye(U.shape[1], V.shape[0]), V))
def adjust_surrogate_coeff(epoch, tot_epochs):
T_min, T_max = 1e-3, 1e1
Kmin, Kmax = math.log(T_min) / math.log(10), math.log(T_max) / math.log(10)
t = torch.tensor([math.pow(10, Kmin + (Kmax - Kmin) / tot_epochs * epoch)]).float().cuda()
k = torch.tensor([1]).float().cuda()
if k < 1:
k = 1 / t
return t, k
def save_feature_map(x, dir=''):
for idx, layer in enumerate(x):
layer = layer.cpu()
for batch in range(layer.shape[0]):
for channel in range(layer.shape[1]):
fname = '{}_{}_{}_{}.jpg'.format(
idx, batch, channel, layer.shape[-1])
fp = layer[batch, channel]
plt.tight_layout()
plt.axis('off')
plt.imshow(fp, cmap='inferno')
plt.savefig(os.path.join(dir, fname),
bbox_inches='tight', pad_inches=0)
def save_spike_info(fname, epoch, batch_idx, step, avg, var, spike, avg_per_step):
"""
对spike-info格式进行调整, 便于保存
:param fname: 输出文件名
:param epoch: epoch
:param batch_idx: batch index
:param step: 仿真步长
:param avg: 平均脉冲发放率
:param var: 脉冲发放率的方差
:param spike:
:param avg_per_step:
:return:
"""
if not os.path.exists(fname):
f = open(fname, mode='w', encoding='utf8', newline='')
writer = csv.writer(f)
head = ['epoch', 'batch', 'layer', 'avg', 'var']
head.extend(['st_{}'.format(i) for i in range(step + 1)]) # spike times
head.extend(['as_{}'.format(i) for i in range(step)]) # avg spike per time
writer.writerow(head)
else:
f = open(fname, mode='a', encoding='utf8', newline='')
writer = csv.writer(f)
for layer in range(len(avg)):
lst = [epoch, batch_idx, layer, avg[layer], var[layer]]
lst.extend(spike[layer])
lst.extend(avg_per_step[layer])
lst = [str(x) for x in lst]
writer.writerow(lst)
def calc_aurc(confidences, labels):
predictions = torch.argmax(confidences, dim=1)
max_confs = torch.max(confidences, dim=1)[0]
n = len(labels)
indices = torch.argsort(max_confs)
labels, predictions, confidences = labels[indices].flip(dims=[0]), predictions[indices].flip(dims=[0]), confidences[indices].flip(dims=[0])
risk_cov = torch.divide(torch.cumsum(labels != predictions,dim=0).float(), torch.arange(1, n+1).cuda())
nrisk = torch.sum(labels != predictions)
aurc = torch.mean(risk_cov)
opt_aurc = (1./n) * torch.sum(torch.divide(torch.arange(1, nrisk + 1).cuda().float(), n - nrisk + torch.arange(1, nrisk + 1).cuda()))
eaurc = aurc - opt_aurc
return aurc, eaurc
================================================
FILE: docs/Makefile
================================================
# Minimal makefile for Sphinx documentation
#
# You can set these variables from the command line, and also
# from the environment for the first two.
SPHINXOPTS ?=
SPHINXBUILD ?= sphinx-build
SOURCEDIR = source
BUILDDIR = build
# Put it first so that "make" without argument is like "make help".
help:
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
.PHONY: help Makefile
# Catch-all target: route all unknown targets to Sphinx using the new
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
%: Makefile
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
================================================
FILE: docs/make.bat
================================================
@ECHO OFF
pushd %~dp0
REM Command file for Sphinx documentation
if "%SPHINXBUILD%" == "" (
set SPHINXBUILD=sphinx-build
)
set SOURCEDIR=source
set BUILDDIR=build
%SPHINXBUILD% >NUL 2>NUL
if errorlevel 9009 (
echo.
echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
echo.installed, then set the SPHINXBUILD environment variable to point
echo.to the full path of the 'sphinx-build' executable. Alternatively you
echo.may add the Sphinx directory to PATH.
echo.
echo.If you don't have Sphinx installed, grab it from
echo.https://www.sphinx-doc.org/
exit /b 1
)
if "%1" == "" goto help
%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
goto end
:help
%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
:end
popd
================================================
FILE: docs/source/conf.py
================================================
# Configuration file for the Sphinx documentation builder.
#
# This file only contains a selection of the most common options. For a full
# list see the documentation:
# https://www.sphinx-doc.org/en/master/usage/configuration.html
# -- Path setup --------------------------------------------------------------
# If extensions (or modules to document with autodoc) are in another directory,
# add these directories to sys.path here. If the directory is relative to the
# documentation root, use os.path.abspath to make it absolute, like shown here.
#
import os
import sys
import warnings
warnings.filterwarnings("ignore")
sys.path.insert(0, os.path.abspath('../../braincog'))
# -- Project information -----------------------------------------------------
project = 'braincog'
copyright = '2022, Brain-Inspired-Cognitive-Intelligence-Engine(BrainCog)'
author = 'Brain-Inspired-Cognitive-Intelligence-Engine'
# The full version, including alpha/beta/rc tags
release = '0.2.7.11'
# -- General configuration ---------------------------------------------------
# Add any Sphinx extension module names here, as strings. They can be
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
# ones.
extensions = [
'sphinx.ext.autodoc',
'sphinx.ext.napoleon',
'sphinx.ext.doctest',
'sphinx.ext.intersphinx',
'sphinx.ext.todo',
'sphinx.ext.coverage',
'sphinx.ext.mathjax',
'recommonmark',
# 'sphinx_markdown_tables',
]
# Add any paths that contain templates here, relative to this directory.
templates_path = ['_templates']
# The language for content autogenerated by Sphinx. Refer to documentation
# for a list of supported languages.
#
# This is also used if you do content translation via gettext catalogs.
# Usually you set "language" from the command line for these cases.
language = 'zh_CN'
# List of patterns, relative to source directory, that match files and
# directories to ignore when looking for source files.
# This pattern also affects html_static_path and html_extra_path.
exclude_patterns = []
# -- Options for HTML output -------------------------------------------------
# The theme to use for HTML and HTML Help pages. See the documentation for
# a list of builtin themes.
#
html_theme = 'sphinx_rtd_theme'
# Add any paths that contain custom static files (such as style sheets) here,
# relative to this directory. They are copied after the builtin static files,
# so a file named "default.css" will overwrite the builtin "default.css".
html_static_path = ['_static']
================================================
FILE: docs/source/examples/Brain_Cognitive_Function_Simulation/drosophila.md
================================================
# Drosophila-inspired decision-making SNN
## Run
"drosophila.py" includes the training phase and testing phase.
```shell
python drosophila.py
```
* Training Phase
green-upright T is safe and blue-inverted T is dangerous
* Testing Phase
For linear pathway and nonlinear pathway, choose between blue-upright T and green-inverted T, and count the PI values under different color intensity
## Results
The following picture shows the linear (a) and nonlinear (b) pathways, the training and testing phases (c), and the PI values on different color intensities (d).

================================================
FILE: docs/source/examples/Brain_Cognitive_Function_Simulation/index.rst
================================================
Brain_Cognitive_Function_Simulation
======================================
.. toctree::
:maxdepth: 2
drosophila
================================================
FILE: docs/source/examples/Decision_Making/BDM_SNN.md
================================================
# Brain-inspired Decision-Making Spiking Neural Network
## Run
"BDM-SNN.py" includes the multi-brain regions coordinated decision-making spiking neural network with LIF neurons.
"BDM-SNN-hh.py" includes the BDM-SNN with simplified HH neurons.
"BDM-SNN-UAV.py" includes the BDM-SNN applied to the UAV (DJI Tello talent), users need to define the reinforcement learning task.
```shell
python BDM-SNN.py
python BDM-SNN-hh.py
python BDM-SNN-UAV.py
```
## Results
"BDM-SNN.py" and "BDM-SNN-hh.py" have been verified on Flappy Bird game. BDM-SNN could stably pass the pipeline on the first try.

================================================
FILE: docs/source/examples/Decision_Making/RL.md
================================================
# PL-SDQN
This repository contains code from our paper [**Solving the Spike Feature Information Vanishing Problem in Spiking Deep Q Network with Potential Based Normalization**]. If you use our code or refer to this project, please cite this paper.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
* gym
* atari-py
* opencv-python
* tianshou
## Train
```python
python ./sdqn/main.py
```
================================================
FILE: docs/source/examples/Decision_Making/index.rst
================================================
Decision Making
======================================
.. toctree::
:maxdepth: 2
RL
BDM_SNN
================================================
FILE: docs/source/examples/Knowledge_Representation_and_Reasoning/CKRGSNN.md
================================================
# Commonsense Knowledge Representation SNN
(https://arxiv.org/abs/2207.05561)
This repository contains code from our paper [**Brain-inspired Graph Spiking Neural Networks for Commonsense Knowledge Representation and Reasoning**] preprint in: https://arxiv.org/abs/2207.05561 . If you use our code or refer to this project, please cite this paper.
## Requirments
* python=3.8
* numpy
* scipy
* turicreate
* pytorch >= 1.7.0
* torchvision
## Dataset
ConceptNet: https://github.com/commonsense/conceptnet5
## Run
```shell
python main.py
```
This module selects core knowledge in ConceptNet to form the sub_Concept.csv file as the input of the model. The input current, spike trains during the learning process and the network weight distribution after the learning are shown in the Results folder.
================================================
FILE: docs/source/examples/Knowledge_Representation_and_Reasoning/CRSNN.md
================================================
# Causal Reasoning SNN
(https://10.1109/IJCNN52387.2021.9534102)
This repository contains code from our paper [**A Brain-Inspired Causal Reasoning Model Based on Spiking Neural Networks
**] published in 2021 International Joint Conference on Neural Networks (IJCNN). https://ieeexplore.ieee.org/abstract/document/9534102. If you use our code or refer to this project, please cite this paper.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
## Run
```shell
python main.py
```
This module builds an example of a brain-like causal inference spiking neural network model. The input causal graph is shown in figure causal_graph.png. The input current, spike trains during the learning process and the network weight distribution after the learning are shown in the Results folder.
================================================
FILE: docs/source/examples/Knowledge_Representation_and_Reasoning/SPSNN.md
================================================
# Sequence Production SNN
[]
This repository contains code from our paper [**Brain Inspired Sequences Production by Spiking Neural Networks With Reward-Modulated STDP**] published in Frontiers in Computational Neuroscience. https://www.frontiersin.org/articles/10.3389/fncom.2021.612041/full. If you use our code or refer to this project, please cite this paper.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
## Run
```shell
python main.py file
```
This module builds a sequence Production spiking neural network model, realizing the memory and reconstruction functions for arbitrary symbol sequences. The input causal graph is shown in figure causal_graph.png. The input current, spike trains during the learning process and the network weight distribution after the learning are shown in the Results folder.
================================================
FILE: docs/source/examples/Knowledge_Representation_and_Reasoning/index.rst
================================================
Knowledge Representation and Reasoning
=========================================
.. toctree::
:maxdepth: 2
musicMemory
SPSNN
CRSNN
CKRGSNN
================================================
FILE: docs/source/examples/Knowledge_Representation_and_Reasoning/musicMemory.md
================================================
# Music Memory
数据集:http://www.piano-midi.de/
自行下载数据集,数据使用方法见task下的示例。
================================================
FILE: docs/source/examples/Multi-scale_Brain_Structure_Simulation/Corticothalamic_minicolumn.md
================================================
# Corticothalamic minicolumn
## Description
The anatomical data is saved in the "tool" package. The **main.py** create the network of minicolumn deppending on the anatomical data.
A file named **"fire.csv"** will be generated to record the firing result of neurons in each time step.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
```shell
python main.py
```
================================================
FILE: docs/source/examples/Multi-scale_Brain_Structure_Simulation/HumanBrain.md
================================================
# Human Brain Simulation
## Description
Human Brain Simulation is a large scale brain modeling framework depending on braincog framework.
## Requirements:
* numpy >= 1.21.2
* scipy >= 1.8.0
* h5py >= 3.6.0
* torch >= 1.10
* torchvision >= 0.12.0
* torchaudio >= 0.11.0
* timm >= 0.5.4
* matplotlib >= 3.5.1
* einops >= 0.4.1
* thop >= 0.0.31
* pyyaml >= 6.0
* loris >= 0.5.3
* pandas >= 1.4.2
* tonic (special)
* pandas >= 1.4.2
## Example:
```shell
cd ~/examples/Multi-scale Brain Structure Simulation/HumanBrain/
python brainSimHum.py
```
## Parameters:
To simulate the models (both human and macaque brain), the parameters of the neuron number in each region and the connectome power between regions can be set flexibly in the main function (nsz and asz) of the .py files.
================================================
FILE: docs/source/examples/Multi-scale_Brain_Structure_Simulation/Human_PFC.md
================================================
# Human PFC
## Input:
* 程序输入六层皮质柱的电生理数据,数据文件名中的数字表示神经元数量。程序默认有背景电流输入。其中data+数字命名的是随机输入刺激的文件,输入图片刺激的文件分别有人类参数的和小鼠参数的。分别都支持四种形状的图片文件,圆形、正方形、三角形和星形。
链接:https://drive.google.com/drive/folders/1AVc2aNTxkcsGAPlq1SuWtatGzyQRPCmp?usp=sharing
## output
* 程序生成的各个神经元放电时间点记录的数据文件
## application:
* 程序中可以修改每次PFC模型放电环境的情况
================================================
FILE: docs/source/examples/Multi-scale_Brain_Structure_Simulation/MacaqueBrain.md
================================================
# Macaque Brain Simulation
## Description
Macaque Brain Simulation is a large scale brain modeling framework depending on braincog framework.
## Requirements:
* numpy >= 1.21.2
* scipy >= 1.8.0
* h5py >= 3.6.0
* torch >= 1.10
* torchvision >= 0.12.0
* torchaudio >= 0.11.0
* timm >= 0.5.4
* matplotlib >= 3.5.1
* einops >= 0.4.1
* thop >= 0.0.31
* pyyaml >= 6.0
* loris >= 0.5.3
* pandas >= 1.4.2
* tonic (special)
* pandas >= 1.4.2
## Example:
```shell
cd ~/examples/Multi-scale Brain Structure Simulation/MacaqueBrain/
python brainSimMaq.py
```
## Parameters:
To simulate the models (both human and macaque brain), the parameters of the neuron number in each region and the connectome power between regions can be set flexibly in the main function (nsz and asz) of the .py files.
================================================
FILE: docs/source/examples/Multi-scale_Brain_Structure_Simulation/index.rst
================================================
Multi-scale Brain Structure Simulation
=========================================
.. toctree::
:maxdepth: 2
MacaqueBrain
HumanBrain
mouse_brain
Human_PFC
Corticothalamic_minicolumn
================================================
FILE: docs/source/examples/Multi-scale_Brain_Structure_Simulation/mouse_brain.md
================================================
# Mouse Brain
## Input:
* 程序输入213个脑区之间的连接权重的表格。放在谷歌网盘上面,名称是'W_213.xlsx'。
链接:[https://drive.google.com/drive/folders/1snPbpiVBpVuRgRYcl4AG4v49NgKKwBtA?usp=sharing](https://drive.google.com/drive/folders/1snPbpiVBpVuRgRYcl4AG4v49NgKKwBtA?usp=sharing)
## output
* 程序生成的各个神经元放电时间点记录的数据mat文件,数据点的数量大需要用画图软件显示结果。
## application:
* 程序中可以修改神经元的数量模拟时间的情况
================================================
FILE: docs/source/examples/Perception_and_Learning/Conversion.md
================================================
# Conversion Method
Training deep spiking neural network with ann-snn conversion
replace ReLU and MaxPooling in pytorch model to make origin ANN to be converted SNN to finish complex tasks
## Results
```shell
python CIFAR10_VGG16.py
python converted_CIFAR10.py
```
You should first run the `CIFAR10_VGG16.py` to get a well-trained ANN.
Then `converted_CIFAR10.py` can be used to run the snn inference process.
================================================
FILE: docs/source/examples/Perception_and_Learning/MultisensoryIntegration.md
================================================
# Multisensory Integration DEMO
In `MultisensoryIntegrationDEMO_AM.py` and `MultisensoryIntegrationDEMO_AM.py`, we implement the SNNs based multisensory integration framework. To load the dataset, preprocess it and get the weights with the function `get_concept_datase_dic_and_initial_weights_lst()`. We use `IMNet` or `AMNet` to describe the structure of the IM/AM model. For presynaptic neuron, we use the function `convert_vec_into_spike_trains()` to generate the spike trains.
While for postsynaptic neuron, we use the function `reducing_tol_binarycode()` to get the multisensory integrated output for each concept. And *tol* is the only parameter.
In `measure_and_visualization.py`, we will measure and visualize the results.
## Multisensory Dataset
When implement the model in braincog, we use the famous multisensory dataset--BBSR.
Some examples are as follows:
| Concept | Visual | Somatic | Audiation | Taste | Smell |
| --------- | ----------- | --------- | ----------- | -------- | -------- |
| advantage | 0.213333333 | 0.032 | 0 | 0 | 0 |
| arm | 2.5111112 | 2.2733334 | 0.133333286 | 0.233333 | 0.4 |
| ball | 1.9580246 | 2.3111112 | 0.523809429 | 0.185185 | 0.111111 |
| baseball | 2.2714286 | 2.6071428 | 0.352040714 | 0.071429 | 0.392857 |
| bee | 2.795698933 | 2.4129034 | 2.096774286 | 0.290323 | 0.419355 |
| beer | 1.4866666 | 2.2533334 | 0.190476286 | 5.8 | 4.6 |
| bird | 2.7632184 | 2.027586 | 3.064039286 | 1.068966 | 0.517241 |
| car | 2.521839133 | 2.9517244 | 2.216748857 | 0 | 2.206897 |
| foot | 2.664444533 | 2.58 | 0.380952429 | 0.433333 | 3 |
| honey | 1.757142867 | 2.3214286 | 0.015306143 | 5.642857 | 4.535714 |
## How to Run
To get the multisensory integrated vectors:
```
cd examples/MultisensoryIntegration/code
python MultisensoryIntegrationDEMO_AM.py
python MultisensoryIntegrationDEMO_IM.py
```
To measure and analysis the vectors:
```
cd examples/MultisensoryIntegration/code
python measure_and_visualization.py
```
================================================
FILE: docs/source/examples/Perception_and_Learning/QSNN.md
================================================
# Quantum superposition inspired spiking neural network
This repository contains code from our paper [**Quantum superposition inspired spiking neural network**] published in iScience. https://doi.org/10.1016/j.isci.2021.102880. If you use our code or refer to this project, please cite this paper.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
## Data preparation
First modify the ```DATA_DIR='path/to/datasets``` in ```examples/QSNN/main.py``` to the root directory of your MNIST datasets.
## Train
```shell
python ./main.py
```
================================================
FILE: docs/source/examples/Perception_and_Learning/UnsupervisedSTDP.md
================================================
# Unsupervised STDP
This is an example of training Unsupervised STDP-based spiking neural network. We used a STB-STDP algrithom to train SNN, and mutiply adaptive mechanisms.
## How to run
python codef.py
## Result
We train the model on Mnist and FashionMNIST, and the best accuracy for MNIST is 97.9%, for FashionMNIST is 87.0%.
================================================
FILE: docs/source/examples/Perception_and_Learning/img_cls/bp.md
================================================
# Script for training high-performance SNNs based on back propagation
This is an example of training high-performance SNNs using the braincog.
It is able to train high performance SNNs on CIFAR10, DVS-CIFAR10, ImageNet and other datasets, and reach the advanced level.
## Install braincog
```shell
git clone https://github.com/xxx/Brain-Cog.git
cd braincog
python setup install --user
```
## Examples of training
```shell
cd examples/img_cls/bp
python main.py --model dvs_convnet --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGate --device 0
```
## Benchmark
We provide a benchmark of SNNs trained with braincog and the corresponding scripts.
This provides an open, fair platform for comparison of subsequent SNNs on classification tasks.
**Note**: The results may vary due to random seeding and software version issues.
### CIFAR10
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:-------:|:----------:|:------:|:-----------:|:----------:|:------------:|:-------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | CIFAR10 | IF+Atan | - | convnet | 128 | 95.54 | ```python main.py --model cifar_convnet --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | LIF+Atan | - | convnet | 128 | 91.92 | ```python main.py --model cifar_convnet --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | PLIF+Atan | - | convert | 128 | 93.32 | ```python main.py --model cifar_convnet --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | IF+Atan | - | resnet18 | 128 | 89.76/89.80 | ```python main.py --model resnet18 --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | LIF+Atan | - | resnet18 | 128 | 89.93/89.88 | ```python main.py --model resnet18 --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | PLIF+Atan | - | resnet18 | 128 | 92.64/ 90.65 | ```python main.py --model resnet18 --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | IF+QGate | - | dvs_convnet | 128 | 95.73 | ```python main.py --model cifar_convnet --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR10 | LIF+QGate | - | dvs_convnet | 128 | 96.04 | ```python main.py --model cifar_convnet --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR10 | PLIF+QGate | - | dvs_convnet | 128 | 96.04/95.84 | ```python main.py --model cifar_convnet --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR10 | IF+QGate | - | resnet18 | 128 | 89.19 | ```python main.py --model resnet18 --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR10 | LIF+QGate | - | resnet18 | 128 | 90.95/90.68 | ```python main.py --model resnet18 --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR10 | PLIF+QGate | - | resnet18 | 128 | 90.97/91.02 | ```python main.py --model resnet18 --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
### CIFAR100
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:--------:|:----------:|:------:|:-----------:|:----------:|:--------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | CIFAR100 | IF+Atan | - | dvs_convnet | 128 | 76.52 | ```python main.py --num-classes 100 --model cifar_convnet --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | LIF+Atan | - | dvs_convnet | 128 | 71.89 | ```python main.py --num-classes 100 --model cifar_convnet --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | PLIF+Atan | - | dvs_convnet | 128 | 72.82 | ```python main.py --num-classes 100 --model cifar_convnet --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | IF+Atan | - | resnet18 | 128 | 62.47 | ```python main.py --num-classes 100 --model resnet18 --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | LIF+Atan | - | resnet18 | 128 | 62.63 | ```python main.py --num-classes 100 --model resnet18 --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | PLIF+Atan | - | resnet18 | 128 | 62.71 | ```python main.py --num-classes 100 --model resnet18 --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | IF+QGate | - | dvs_convnet | 128 | 76.44 | ```python main.py --num-classes 100 --model cifar_convnet --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR100 | LIF+QGate | - | dvs_convnet | 128 | 77.73 | ```python main.py --num-classes 100 --model cifar_convnet --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR100 | PLIF+QGate | - | dvs_convnet | 128 | 77.25 | ```python main.py --num-classes 100 --model cifar_convnet --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR100 | IF+QGate | - | resnet18 | 128 | 60.01 | ```python main.py --num-classes 100 --model resnet18 --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR100 | LIF+QGate | - | resnet18 | 128 | 61.33 | ```python main.py --num-classes 100 --model resnet18 --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR100 | PLIF+QGate | - | resnet18 | 128 | 62.32 | ```python main.py --num-classes 100 --model resnet18 --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
### DVS-CIFAR10
| ID | Dataset | Node-type | Config | Model | Batch Size | FLOPS | Accuracy | Script |
|:----|:-----------:|:----------:|:------:|:-----------:|:----------:|:-----:|:-----------:|:-----------------------------------------------------------------------------------------------------------------------------------------|
| 1 | DVS-CIFAR10 | IF+Atan | - | dvs_convnet | 128 | 7503 | 65.90 | ```python main.py --model dvs_convnet --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+Atan | - | dvs_convnet | 128 | 7503 | 82.10 | ```python main.py --model dvs_convnet --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+Atan | - | dvs_convnet | 128 | 7503 | 81.90 | ```python main.py --model dvs_convnet --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | IF+Atan | - | resnet18 | 128 | 3149 | 69.10 | ```python main.py --model resnet18 --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+Atan | - | resnet18 | 128 | 3149 | 78.50 | ```python main.py --model resnet18 --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+Atan | - | resnet18 | 128 | 3149 | 77.70 | ```python main.py --model resnet18 --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | IF+QGate | - | dvs_convnet | 128 | 7503 | 68.30 | ```python main.py --model dvs_convnet --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+QGate | - | dvs_convnet | 128 | 7503 | 82.60/82.90 | ```python main.py --model dvs_convnet --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+QGate | - | dvs_convnet | 128 | 7503 | 83.20 | ```python main.py --model dvs_convnet --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-CIFAR10 | IF+QGate | - | resnet18 | 128 | 3149 | 65.70/66.80 | ```python main.py --model resnet18 --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+QGate | - | resnet18 | 128 | 3149 | 79.00/79.40 | ```python main.py --model resnet18 --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+QGate | - | resnet18 | 128 | 3149 | 78.10/78.20 | ```python main.py --model resnet18 --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
### DVS-Gesture
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:-------:|:----------:|:------:|:-----------:|:----------:|:-----------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | DVS-G | IF+Atan | - | dvs_convnet | 128 | 64.77 | ```python main.py --num-classes 11 --model dvs_convnet --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | LIF+Atan | - | dvs_convnet | 128 | 91.28 | ```python main.py --num-classes 11 --model dvs_convnet --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | PLIF+Atan | - | dvs_convnet | 128 | 91.67 | ```python main.py --num-classes 11 --model dvs_convnet --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | IF+Atan | - | resnet18 | 128 | 63.25 | ```python main.py --num-classes 11 --model resnet18 --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | LIF+Atan | - | resnet18 | 128 | 91.29 | ```python main.py --num-classes 11 --model resnet18 --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | PLIF+Atan | - | resnet18 | 128 | 90.15 | ```python main.py --num-classes 11 --model resnet18 --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | IF+QGate | - | dvs_convnet | 128 | 48.48 | ```python main.py --num-classes 11 --model dvs_convnet --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-G | LIF+QGate | - | dvs_convnet | 128 | 92.05/92.42 | ```python main.py --num-classes 11 --model dvs_convnet --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-G | PLIF+QGate | - | dvs_convnet | 128 | 91.28 | ```python main.py --num-classes 11 --model dvs_convnet --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-G | IF+QGate | - | resnet18 | 128 | 57.95 | ```python main.py --num-classes 11 --model resnet18 --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-G | LIF+QGate | - | resnet18 | 128 | 90.91 | ```python main.py --num-classes 11 --model resnet18 --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-G | PLIF+QGate | - | resnet18 | 128 | 92.42 | ```python main.py --num-classes 11 --model resnet18 --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
### NCALTECH101
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:-----------:|:----------:|:------:|:-----------:|:----------:|:-----------:|:----------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | NCALTECH101 | IF+QGate | - | dvs_convnet | 128 | 23.09/51.15 | ```python main.py --num-classes 100 --model dvs_convnet --node-type IFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | NCALTECH101 | LIF+QGate | - | dvs_convnet | 128 | 72.78/75.09 | ```python main.py --num-classes 100 --model dvs_convnet --node-type LIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | NCALTECH101 | PLIF+QGate | - | dvs_convnet | 128 | 74.61/76.79 | ```python main.py --num-classes 100 --model dvs_convnet --node-type PLIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | NCALTECH101 | IF+QGate | -/mix | resnet18 | 128 | 61.24/60.87 | ```python main.py --num-classes 100 --model resnet18 --node-type IFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | NCALTECH101 | LIF+QGate | -/mix | resnet18 | 128 | 66.22/70.84 | ```python main.py --num-classes 100 --model resnet18 --node-type LIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | NCALTECH101 | PLIF+QGate | -/mix | resnet18 | 128 | 69.62/69.87 | ```python main.py --num-classes 100 --model resnet18 --node-type PLIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
Note:
1. resnet18 is used here by adding a maximum pooling after the initial convolution layer.
However, in the final version of braincog, we remove this pooling layer.
2. mix refers to the use of EventMix as a data augmentation method.
3. We will continue to add other results.
### Citation
If you find this package helpful, please consider citing it:
```BibTex
@software{name,
author = {xxx},
title = {braincog: xxx},
month = jul,
year = 2022,
note = {{Documentation available under
https://xxx.readthedocs.io}},
publisher = {Zenodo},
version = {xxx},
doi = {xxx},
url = {xxx}
}
```
================================================
FILE: docs/source/examples/Perception_and_Learning/img_cls/glsnn.md
================================================
# SNN with global feedback connections
Training deep spiking neural network with the global
feedback connections and the local optimization learning rules. And is a little different from our original paper.
## Results
```shell
python cls_glsnn.py
```
We train the model for 100 epochs, and the best accuracy for MNIST is 98.23\%, for FashionMNIST is 89.68\%.

================================================
FILE: docs/source/examples/Perception_and_Learning/img_cls/index.rst
================================================
Examples for Image Classification
=================================
.. toctree::
:maxdepth: 2
bp
glsnn
================================================
FILE: docs/source/examples/Perception_and_Learning/index.rst
================================================
Perception and Learning
=================================
.. toctree::
:maxdepth: 2
img_cls/index
Conversion
UnsupervisedSTDP
QSNN
MultisensoryIntegration
================================================
FILE: docs/source/examples/Social_Cognition/Mirror_Test.md
================================================
# Mirror Test
The mirror_test.py implements the core code of the Multi-Robots Mirror Self-Recognition Test in "Toward Robot Self-Consciousness (II): Brain-Inspired Robot Bodily Self Model for Self-Recognition".
The experiment is: three robots with identical appearance move their arms randomly in front of the mirror at the same time.
In the training stage, according to the spiking time difference of neurons in IPLM and IPLV, the robot learns the correlations between self-generated actions and visual feedbacks in motion by learning with spike timing dependent plasticity (STDP) mechanism.
In the test stage, the robot can predicts the visual feedback generated by its arm movement according to the training results. With the InsulaNet, the robot can identify which mirror image belongs to it.
In the result, Motion Detection shows the results of visual detection, and Motion Prediction shows the visual feedback generated by itself. The red line in the figure indicates that the robot determines that the corresponding mirror belongs to itself.
Differences from the original article:
Since there is no motion error under the simulation conditions, the theta_threshold is set to zero.
### Citation
If you find this package helpful, please consider citing it:
```BibTex
@article{zeng2018toward,
title={Toward robot self-consciousness (ii): brain-inspired robot bodily self model for self-recognition},
author={Zeng, Yi and Zhao, Yuxuan and Bai, Jun and Xu, Bo},
journal={Cognitive Computation},
volume={10},
number={2},
pages={307--320},
year={2018},
publisher={Springer}
}
```
================================================
FILE: docs/source/examples/Social_Cognition/ToM.md
================================================
# ToM
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
* pygame
## Run
### Train
* the file to be run: main_both.py
* args:
* the path to save net_NPC: --save_net_N
* the path to save net_a: --save_net_a
* time steps: --T
```bash
python main_both.py --save_net_N=net_NPC.pth --save_net_a=net_agent.pth --episodes=45 --trajectories=30 --T=50 --mode=train --task=both
```
### Test
```bash
python main_ToM.py --save_net_N=net_NPC.pth --save_net_a=net_agent.pth --episodes=45 --trajectories=30 --T=50 --mode=train --task=both
```
================================================
FILE: docs/source/examples/Social_Cognition/index.rst
================================================
Social Cognition
======================================
.. toctree::
:maxdepth: 2
ToM
Mirror_Test
================================================
FILE: docs/source/examples/index.rst
================================================
Examples
=================================
.. toctree::
:maxdepth: 2
Perception_and_Learning/index
Brain_Cognitive_Function_Simulation/index
Decision_Making/index
Knowledge_Representation_and_Reasoning/index
Social_Cognition/index
Multi-scale_Brain_Structure_Simulation/index
================================================
FILE: docs/source/index.rst
================================================
.. braincog documentation master file, created by
sphinx-quickstart on Sun Apr 10 21:02:06 2022.
You can adapt this file completely to your liking, but it should at least
contain the root `toctree` directive.
Welcome to braincog's documentation!
====================================
.. toctree::
:maxdepth: 2
tutorial/index
braincog
examples/index
Indices and tables
==================
* :ref:`genindex`
* :ref:`modindex`
* :ref:`search`
================================================
FILE: docs/source/modules.rst
================================================
braincog
========
.. toctree::
:maxdepth: 4
braincog
================================================
FILE: docs/source/setup.rst
================================================
setup module
============
.. automodule:: setup
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs.md
================================================
# Sphinx 文档教程
## 安装
131 braincog 环境已经装好了
```shell
pip install sphinx sphinx-rtd-theme recommonmark
```
## 配置
已经配置好了, 直接用就行了
```shell
sphinx-quickstart
```
## 编译
### braincog 之中的, 编译在Brain Docs之中
1. 重新从 repo 中抓取 ```rst``` 文本
```shell
cd braincog/docs
rm -rf ./source/braincog*rst
sphinx-apidoc -o ./source/ ../braincog -f
```
2. 编译 html
```shell
make clean
make html
```
### Examples 的编译
1. 在 ```braincog/docs/source/index.rst``` 中, ```img_cls/Tutorial``` 后面一行添加 ``xxx/Tutorial``.
2. 然后在 ``Brain/docs/source`` 下面添加 ``xxx.md`` 文件, 要和上面的 ``xxx`` 同名.
3. 用 [Markdown](https://markdown.com.cn/basic-syntax/) 语法, 编写教程, 怎么用, 效果是啥.
4. 编译html
```shell
make clean
make html
```
## 查看
编译好的文件可以在 ```braincog/docs/build/html``` 中查看.
## 上传
在130服务器上面:
```shell
sudo cp braincog/docs/build/html/* /var/www/html
```
就可以更新文档了, 并在 [172.18.116.130](http://172.18.116.130/index.html) 中看到.
================================================
FILE: documents/Data_engine.md
================================================
# BrainCog Data Engine
In addition to the static datasets, BrainCog supports the commonly used neuromorphic
datasets, such as DVSGesture, DVSCIFAR10, NCALTECH101, ES-ImageNet.
Also, the neuromorphic dataset N-Omniglot for few-shot learning is also integrated into
BrainCog.
**[DVSGesture](https://openaccess.thecvf.com/content_cvpr_2017/papers/Amir_A_Low_Power_CVPR_2017_paper.pdf)**
This dataset contains 11 hand gestures from 29 subjects under 3 illumination conditions recorded using a DVS128.
**[DVSCIFAR10](https://www.frontiersin.org/articles/10.3389/fnins.2017.00309/full)**
This dataset converts 10,000 frame-based images in the CIFAR10 dataset into 10,000 event streams using a dynamic vision sensor.
**[NCALTECH101](https://www.frontiersin.org/articles/10.3389/fnins.2015.00437/full)**
The NCaltech101 dataset is captured by mounting the ATIS sensor on a motorized pan-tilt unit and having the sensor move while it views Caltech101 examples on an LCD monitor.
The "Faces" class has been removed from N-Caltech101, leaving 100 object classes plus a background class
**[ES-ImageNet](https://arxiv.org/abs/2110.12211)**
The dataset is converted with Omnidirectional Discrete Gradient (ODG) from 1,300,000 frame-based images in the ImageNet dataset into event-stream samples, which has 1000 categories.
**[N-Omniglot](https://www.nature.com/articles/s41597-022-01851-z)**
This dataset contains 1,623 categories of handwritten characters, with only 20 samples per class.
The dataset is acquired with the DVS acquisition platform to shoot videos (generated from the original Omniglot dataset) played on the monitor, and use the Robotic Process Automation (RPA) software to collect the data automatically.
You can easily use them in the braincog/datasets folder, taking DVSCIFAR10 as an example
```python
loader_train, loader_eval,_,_ = get_dvsc10_data(batch_size=128,step=10)
```
================================================
FILE: documents/Lectures.md
================================================
# Lectures
- [BrainCog Talk] Beginning BrainCog Lecture 32. Structural Modeling and Neural Activity Simulation of Mammalian Corticothalamic Functional Minicolumn on BrainCog [[English Version](https://www.youtube.com/watch?v=xwcu3yHe4FQ&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=30), [Chinese Version](https://www.bilibili.com/video/BV1aN411v7BG/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 31. A Brain-inspired Theory of Mind Spiking Neural Network Improves Multi-agent Cooperation [[English Version](https://www.youtube.com/watch?v=xwcu3yHe4FQ&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=30), [Chinese Version](https://www.bilibili.com/video/BV11m4y1N7Bh/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 30. FPGA-based Spiking Neural Networks Acceleration Using BrainCog [[English Version](https://www.youtube.com/watch?v=xwcu3yHe4FQ&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=30), [Chinese Version](https://www.bilibili.com/video/BV1mF411Q7Rr/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 29. Using BrainCog to Realize Robot's Intention Prediction for Users [[English Version](https://www.youtube.com/watch?v=vlwRpq-HwDo&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=29), [Chinese Version](https://www.bilibili.com/video/BV1oz4y1H7QL/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 28. Reward-modulated brain-inspired spiking neural network to empower group for nature-inspired self-organized obstacle avoidance implemented by Braincog [[English Version](https://www.youtube.com/watch?v=2X2KkG0KXo4&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=28), [Chinese Version](https://www.bilibili.com/video/BV16h411N7tG/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 27. Drosophila-inspired Linear and Nonlinear Decision-Making Spiking Neural Network implemented by Braincog [[English Version](https://www.youtube.com/watch?v=j49q33dMbYk&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=27), [Chinese Version](https://www.bilibili.com/video/BV1Ch4y147i6/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 26. Spiking CapsNet based on BrainCog [[English Version](https://www.youtube.com/watch?v=Gn1PMMFnD6M&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=26), [Chinese Version](https://www.bilibili.com/video/BV1M24y1N7Re/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 25. SNNs with adaptive self-feedback and balanced excitatory–inhibitory neurons based on BrainCog [[English Version](https://www.youtube.com/watch?v=pqeagXtYk8w&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=25), [Chinese Version](https://www.bilibili.com/video/BV18g4y1j7WA/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 24. DVS Augmentation Strategies based on BrainCog [[English Version](https://www.youtube.com/watch?v=aok8B34DNVs&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=24), [Chinese Version](https://www.bilibili.com/video/BV1324y1L7QP/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 23. The Implement of Object Detection and Semantic Segmentation Based on SNNs with Braincog [[English Version](https://www.youtube.com/watch?v=2kh7rNwQkkY&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=23), [Chinese Version](https://www.bilibili.com/video/BV1XT411r7ak/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 22. BrainCog Data Engine: Spatio-temporal Sequence Data N-Omniglot and Its Applications [[English Version](https://www.youtube.com/watch?v=J5qBIX9f8Ns&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=22), [Chinese Version](https://www.bilibili.com/video/BV1uT411a733/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 21. Dynamic structural development for SNNs incorporating constraints, pruning and regeneration based on BrainCog [[English Version](https://www.youtube.com/watch?v=OccvvdyiOgY&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=21), [Chinese Version](https://www.bilibili.com/video/BV1Zv4y1Y72h/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 20. Developmental Plasticity-inspired Adaptive Pruning for SNNs based on BrainCog [[English Version](https://www.youtube.com/watch?v=ckrSW_2vqeE&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=20), [Chinese Version](https://www.bilibili.com/video/BV1iD4y1P7XE/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 19. Multi-brain areas Coordinated Brain-inspired Affective Empathy Spiking Neural Network Based on Braincog [[English Version](https://www.youtube.com/watch?v=dB-hQ-5RJ6U&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=19), [Chinese Version](https://www.bilibili.com/video/BV16Y411q7b2/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 18. Application of the Prefrontal Cortex Column Model in Working Memory Task with BrainCog [[English Version](https://www.youtube.com/watch?v=6xzURpSFkxk&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=18), [Chinese Version](https://www.bilibili.com/video/BV1As4y1t7wF/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 17. A Brain-inspired Theory of Mind Model Based on BrainCog for Reducing Other Agents’ Safety Risks [[English Version](https://www.youtube.com/watch?v=16Csw03bTjY&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=17), [Chinese Version](https://www.bilibili.com/video/BV12A411f74Q/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 16. Brain-inspired Bodily Self-perception Model Based on BrainCog [[English Version](https://www.youtube.com/watch?v=mV_iMsDEQsg&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=16), [Chinese Version](https://www.bilibili.com/video/BV1pK411i7Jk/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 15. SNN-based Music Memory and Generation Based on BrainCog [[English Version](https://www.youtube.com/watch?v=c0Tcs1B5xho&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=15), [Chinese Version](https://www.bilibili.com/video/BV1M3411X7C2/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 14. The Implement of Multisensory Concept Learning Framework Based on SNNs with Braincog [[English Version](https://www.youtube.com/watch?v=c9UfOCGzFPQ&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=14), [Chinese Version](https://www.bilibili.com/video/BV1Ae411P7tY/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 13. Symbolic Representation and Reasoning SNN Based on Braincog [[English Version](https://www.youtube.com/watch?v=1iosjPkOBRo&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=13), [Chinese Version](https://www.bilibili.com/video/BV1DW4y1p7kg/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 12. Unsupervised STDP-based Spiking Neural Networks Based on BrainCog [[English Version](https://www.youtube.com/watch?v=pzPJ1XOEB9U&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=12), [Chinese Version](https://www.bilibili.com/video/BV1MR4y1Z7Be/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 11. Backpropagation with Spatiotemporal Adjustment for Training Deep Spiking Neural Networks through BrainCog [[English Version](https://www.youtube.com/watch?v=Fm85BjQszng&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=11), [Chinese Version](https://www.bilibili.com/video/BV1EK411Z71F/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 10. Multi-brain Areas Coordinated Brain-inspired Decision-Making Spiking Neural Network Based on Braincog [[English Version](https://www.youtube.com/watch?v=uVCcZHzzN3U&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=10), [Chinese Version](https://www.bilibili.com/video/BV1jD4y1x7PU/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 9. Spiking Neural Networks with Global Feedback Connections Based on BrainCog [[English Version](https://www.youtube.com/watch?v=g_qelwoQsD8&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=9), [Chinese Version](https://www.bilibili.com/video/BV1qv4y1D74Y/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 8. Converting Artificial Neural Network to Spiking Neural Network through BrainCog [[English Version](https://www.youtube.com/watch?v=cxiKyQ7F8UE&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=8), [Chinese Version](https://www.bilibili.com/video/BV17e4y147H6/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 7. Implementing Quantum Superposition Inspired Spatio-temporal Spike Encoding through BrainCog [[English Version](https://www.youtube.com/watch?v=5T-2Yyr9a0s&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=7), [Chinese Version](https://www.bilibili.com/video/BV1BG41177Z6/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 6. Implementing spiking deep Q network through Braincog [[English Version](https://www.youtube.com/watch?v=jCsOBtiN-q0&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=6), [Chinese Version](https://www.bilibili.com/video/BV1XN4y1c7Kn/?spm_id_from=333.337.search-card.all.click&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 5. Advanced BrainCog System Functions [[English Version](https://www.youtube.com/watch?v=VJBORFl6dTQ&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=5), [Chinese Version](https://www.bilibili.com/video/BV1tT411N7c9/?spm_id_from=333.337.search-card.all.click&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 4. Creating Cognitive SNNs for Brain Areas [[English Version](https://www.youtube.com/watch?v=gYxG1D1b4Zo&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=4), [Chinese Version](https://www.bilibili.com/video/BV19d4y1679Y/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 3. Creating SNNs Easily and Quickly [[English Version](https://www.youtube.com/watch?v=k3byUIp4O24&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=3), [Chinese Version](https://www.bilibili.com/video/BV1Be4y1874W/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 2. Computational Modeling of Spiking Neurons [[English Version](https://www.youtube.com/watch?v=5jPsPkyFTY8&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=2), [Chinese Version](https://www.bilibili.com/video/BV16K411f7vQ/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 1. Installing and Deploying BrainCog platform [[English Version](https://www.youtube.com/watch?v=XkHq-MbKo20&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=1), [Chinese Version](https://www.bilibili.com/video/BV1AW4y1b7v1/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
================================================
FILE: documents/Pub_brain_inspired_AI.md
================================================
# Publications Using BrainCog
## Brain Inspired AI
### Perception and Leanring
| Papers | Codes | Publisher |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------- |
| [BackEISNN: A deep spiking neural network with adaptive self-feedback and balanced excitatory–inhibitory neurons](https://www.sciencedirect.com/science/article/pii/S0893608022002520) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/img_cls/bp/main_backei.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/img_cls/bp/main_backei.py) | Neural Networks |
| [Efficient and Accurate Conversion of Spiking Neural Network with Burst Spikes](https://www.ijcai.org/proceedings/2022/345) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py) | IJCAI |
| [Spike Calibration: Fast and Accurate Conversion of Spiking Neural Network for Object Detection and Segmentation](https://arxiv.org/abs/2207.02702) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py) | Arxiv |
| [An unsupervised STDP-based spiking neural network inspired by biologically plausible learning rules and connections](https://www.sciencedirect.com/science/article/pii/S0893608023003301) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/UnsupervisedSTDP](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/UnsupervisedSTDP) | Neural Networks |
| [Multisensory Concept Learning Framework Based on Spiking Neural Networks](https://www.frontiersin.org/articles/10.3389/fnsys.2022.845177/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/MultisensoryIntegration](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/MultisensoryIntegration) | Frontiers in Systems Neuroscience |
| [Backpropagation with biologically plausible spatiotemporal adjustment for training deep spiking neural networks](https://www.sciencedirect.com/science/article/pii/S2666389922001192) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/bp](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/bp) | Patterns |
| [Quantum superposition inspired spiking neural network](https://www.cell.com/iscience/fulltext/S2589-0042(21)00848-8) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/QSNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/QSNN) | iScience |
| [GLSNN: A Multi-Layer Spiking Neural Network Based on Global Feedback Alignment and Local STDP Plasticity](https://www.frontiersin.org/articles/10.3389/fncom.2020.576841/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/glsnn](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/glsnn) | Frontiers in Neuroscience |
| [Spiking CapsNet: A spiking neural network with a biologically plausible routing rule between capsules](https://www.sciencedirect.com/science/article/pii/S002002552200843X) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/spiking_capsnet](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/spiking_capsnet) | Information Sciences |
| [N-Omniglot, a large-scale neuromorphic dataset for spatio-temporal sparse few-shot learning](https://www.nature.com/articles/s41597-022-01851-z) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/NOmniglot](https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/NOmniglot) | Scientific Data |
| [EventMix: An efficient data augmentation strategy for event-based learning](https://www.sciencedirect.com/science/article/pii/S0020025523007557) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/datasets/cut_mix.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/datasets/cut_mix.py) | Information Sciences |
| [Challenging deep learning models with image distortion based on the abutting grating illusion](https://www.sciencedirect.com/science/article/pii/S2666389923000260) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/IllusionPerception/AbuttingGratingIllusion](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/IllusionPerception/AbuttingGratingIllusion) | Patterns |
| [MSAT: Biologically Inspired Multi-Stage Adaptive Threshold for Conversion of Spiking Neural Networks](https://arxiv.org/abs/2303.13080) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/Conversion/msat_conversion](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/Conversion/msat_conversion) | Arxiv |
| [Improving the Performance of Spiking Neural Networks on Event-based Datasets with Knowledge Transfer](https://arxiv.org/abs/2303.13077) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/transfer_for_dvs](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/transfer_for_dvs) | Arxiv |
| [Improving Stability and Performance of Spiking Neural Networks Through Enhancing Temporal Consistency](https://www.sciencedirect.com/science/article/abs/pii/S0031320324008458) | [https://github.com/Brain-Cog-Lab/ETC](https://github.com/Brain-Cog-Lab/ETC) | Pattern Recognition |
| [Spiking Generative Adversarial Network with Attention Scoring Decoding](https://www.sciencedirect.com/science/article/abs/pii/S0893608024003472) | [https://github.com/Brain-Cog-Lab/sgad](https://github.com/Brain-Cog-Lab/sgad) | Neural Networks |
| [Temporal Knowledge Sharing Enables Spiking Neural Network Learning from Past and Future](https://ieeexplore.ieee.org/document/10462632) | [https://github.com/Brain-Cog-Lab/TKS](https://github.com/Brain-Cog-Lab/TKS) | IEEE Transactions on Artificial Intelligence |
| [TIM: An Efficient Temporal Interaction Module for Spiking Transformer](https://www.ijcai.org/proceedings/2024/0347.pdf) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/TIM](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/TIM) | IJCAI2024 |
| [Exploiting Nonlinear Dendritic Adaptive Computation in Training Deep Spiking Neural Networks](https://www.sciencedirect.com/science/article/pii/S0893608023006202) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/base/node/node.py#L1412](https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/base/node/node.py#L1412) | Neural Networks |
| [Are Conventional SNNs Really Efficient? A Perspective from Network Quantization](https://openaccess.thecvf.com/content/CVPR2024/papers/Shen_Are_Conventional_SNNs_Really_Efficient_A_Perspective_from_Network_Quantization_CVPR_2024_paper.pdf) | | 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) |
| [CACE-Net: Co-guidance Attention and Contrastive Enhancement for Effective Audio-Visual Event Localization](https://dl.acm.org/doi/10.1145/3664647.3681503) | [https://github.com/Brain-Cog-Lab/CACE-Net](https://github.com/Brain-Cog-Lab/CACE-Net) | Proceedings of the 32nd ACM International Conference on Multimedia, 2024: 985-993 |
| [Parallel Spiking Unit for Efficient Training of Spiking Neural Networks](https://arxiv.org/abs/2402.00449) | [https://github.com/Brain-Cog-Lab/PSU](https://github.com/Brain-Cog-Lab/PSU) | IJCNN 2024 |
| [Spiking Neural Networks with Consistent Mapping Relations Allow High-Accuracy Inference](https://www.sciencedirect.com/science/article/abs/pii/S0020025524007369) | [https://github.com/Brain-Cog-Lab/casc](https://github.com/Brain-Cog-Lab/casc) | Information Sciences |
| [Directly training temporal Spiking Neural Network with sparse surrogate gradient](https://www.sciencedirect.com/science/article/abs/pii/S0893608024004234) | [https://github.com/Brain-Cog-Lab/msg](https://github.com/Brain-Cog-Lab/msg) | Neural Networks |
### Knowledge Representation and Reasoning
| Papers | Codes | Publisher |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------- |
| [A Brain-Inspired Causal Reasoning Model Based on Spiking Neural Networks](https://ieeexplore.ieee.org/abstract/document/9534102) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/CRSNN | IJCNN2021 |
| [Brain Inspired Sequences Production by Spiking Neural Networks With Reward-Modulated STDP](https://www.frontiersin.org/articles/10.3389/fncom.2021.612041/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/SPSNN | Frontiers in Computational Neuroscience |
| [Temporal-Sequential Learning With a Brain-Inspired Spiking Neural Network and Its Application to Musical Memory](https://www.frontiersin.org/articles/10.3389/fncom.2020.00051/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/musicMemory | Frontiers in Computational Neuroscience |
| [Stylistic Composition of Melodies Based on a Brain-Inspired Spiking Neural Network](https://www.frontiersin.org/articles/10.3389/fnsys.2021.639484/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BRP-SNN | Frontiers in Neurorobotics |
| [Brain-inspired Graph Spiking Neural Networks for Commonsense Knowledge Representation and Reasoning](https://arxiv.org/abs/2207.05561 ) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/CKRGSNN | Arxiv |
| [An Efficient Knowledge Transfer Strategy for Spiking Neural Networks from Static to Event Domain](https://arxiv.org/abs/2303.13077) | [https://github.com/Brain-Cog-Lab/Transfer-for-DVS](https://github.com/Brain-Cog-Lab/Transfer-for-DVS) | Proceedings of the AAAI Conference on Artificial Intelligence, 2024, 38(1): 512-520 |
### Decision Making
| Papers | Codes | Publisher |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------- | -------------------------- |
| [Nature-inspired self-organizing collision avoidance for drone swarm based on reward-modulated spiking neural network](https://www.cell.com/patterns/fulltext/S2666-3899(22)00236-7) | https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/decision_making/swarm/Collision-Avoidance.py | Cell Patterns |
| [Solving the spike feature information vanishing problem in spiking deep Q network with potential based normalization](https://www.frontiersin.org/articles/10.3389/fnins.2022.953368/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/decision_making/RL/sdqn | Frontiers in Neuroscience |
| [A Brain-Inspired Decision-Making Spiking Neural Network and Its Application in Unmanned Aerial Vehicle](https://www.frontiersin.org/articles/10.3389/fnbot.2018.00056/full ) | https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/decision_making/BDM-SNN/BDM-SNN-hh.py | Frontiers in Neurorobotics |
| [Multi-compartment Neuron and Population Encoding improved Spiking Neural Network for Deep Distributional Reinforcement Learning](https://arxiv.org/abs/2301.07275) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/decision_making/RL/mcs-fqf | Arxiv |
### Motor Control
| Papers | Codes | Publisher |
| ------ | ------------------------------------------------------------------------------------ | --------- |
| | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/MotorControl/experimental | |
### Social Cognition
| Papers | Codes | Publisher |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------- |
| [Toward Robot Self-Consciousness (II): Brain-Inspired Robot Bodily Self Model for Self-Recognition](https://link.springer.com/article/10.1007/s12559-017-9505-1 ) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/mirror_test](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/mirror_test) | Cognitive Computation |
| [A brain-inspired intention prediction model and its applications to humanoid robot](https://www.frontiersin.org/articles/10.3389/fnins.2022.1009237/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/Intention_Prediction](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/Intention_Prediction) | Frontiers in Neuroscience |
| [A Brain-Inspired Theory of Mind Spiking Neural Network for Reducing Safety Risks of Other Agents](https://www.frontiersin.org/articles/10.3389/fnins.2022.753900/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/ToM](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/ToM) | Frontiers in Neuroscience |
| [Brain-Inspired Affective Empathy Computational Model and Its Application on Altruistic Rescue Task](https://www.frontiersin.org/articles/10.3389/fncom.2022.784967/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BAE-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BAE-SNN) | Frontiers in Computational Neuroscience |
| [A brain-inspired robot pain model based on a spiking neural network](https://www.frontiersin.org/articles/10.3389/fnbot.2022.1025338/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BRP-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BRP-SNN) | Frontiers in Neurorobotics |
| [Brain-Inspired Theory of Mind Spiking Neural Network Elevates Multi-Agent Cooperation and Competition](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4271099) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/MAToM-SNN ](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/MAToM-SNN ) | SSRN |
### Development and Evolution
| Papers | Codes | Publisher |
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ----------------------------------------------- |
| [Developmental Plasticity-inspired Adaptive Pruning for Deep Spiking and Artificial Neural Networks](https://arxiv.org/abs/2211.12714) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DPAP](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DPAP) | Arxiv |
| [Adaptive Sparse Structure Development with Pruning and Regeneration for Spiking Neural Networks](https://arxiv.org/abs/2211.12219) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/SD-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/SD-SNN) | Arxiv |
| [Emergence of Brain-inspired Small-world Spiking Neural Network through Neuroevolution](https://arxiv.org/abs/2304.10749) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/ELSM](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/ELSM) | Arxiv |
| [Enhancing Efficient Continual Learning with Dynamic Structure Development of Spiking Neural Networks](https://arxiv.org/abs/2308.04749) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DSD-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DSD-SNN) | IJCAI |
| [Brain-inspired Evolutionary Neural Architecture Search for Spiking Neural Networks](https://ieeexplore.ieee.org/abstract/document/10542732) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/EB-NAS](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/EB-NAS) | IEEE Transactions on Artificial Intelligence |
| [Adaptive Structure Evolution and Biologically Plausible Synaptic Plasticity for Recurrent Spiking Neural Networks](https://www.nature.com/articles/s41598-023-43488-x) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/Adaptive_lsm](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/Adaptive_lsm) | Scientific Reports |
| [Brain-inspired Neural Circuit Evolution for Spiking Neural Networks](https://www.pnas.org/doi/10.1073/pnas.2218173120) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/model_zoo/NeuEvo](https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/model_zoo/NeuEvo) | Proceedings of the National Academy of Sciences |
### Safety and Security
| Papers | Codes | Publisher |
| ----------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------- | --------- |
| [DPSNN](https://arxiv.org/abs/2205.12718) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Snn_safety/DPSNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Snn_safety/DPSNN) | Arxiv |
### Dataset
| Papers | Codes | Publisher |
| -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ----------- |
| [Bullying10K: A Large-scale Neuromorphic Dataset Towards Privacy-preserving Bullying Recognition](https://proceedings.neurips.cc/paper_files/paper/2023/file/05ffe69463062b7f9fb506c8351ffdd7-Paper-Datasets_and_Benchmarks.pdf) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/bullying10k](https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/bullying10k) | Neurips2023 |
================================================
FILE: documents/Pub_brain_simulation.md
================================================
# Publications Using BrainCog
## Brain Simulation
### Funtion
| Papers | Codes | Publisher |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------|
| [A neural algorithm for Drosophila linear and nonlinear decision-making](https://www.nature.com/articles/s41598-020-75628-y) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Brain_Cognitive_Function_Simulation/drosophila/drosophila.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Brain_Cognitive_Function_Simulation/drosophila/drosophila.py) | Scientific Reports |
### Structure
| Papers | Codes | Publisher |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------|
| Corticothalamic minicolumn | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn) | |
| Human Brain | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/HumanBrain](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/HumanBrain) | |
| Macaque Brain | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/MacaqueBrain](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/MacaqueBrain) | |
| Mouse Brain | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/Mouse_brain ](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/Mouse_brain ) | |
| [Comparison Between Human and Rodent Neurons for Persistent Activity Performance: A Biologically Plausible Computational Investigation](https://www.frontiersin.org/articles/10.3389/fnsys.2021.628839/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/Human_PFC_Model | Frontiers in System Neuroscience |
================================================
FILE: documents/Pub_sh_codesign.md
================================================
# Publications Using BrainCog
## Software-Hardware Co-design
### Hardware Acceleration
| Papers | Codes | Publisher |
| ------------------------------------------------------------ | ---------------------------------------- | ------------------------------------------------------------ |
| [FireFly: A High-Throughput and Reconfigurable Hardware Accelerator for Spiking Neural Networks](https://ieeexplore.ieee.org/abstract/document/10143752) | https://github.com/adamgallas/FireFly-v1 | IEEE Transactions on Very Large Scale Integration (VLSI) Systems |
| [FireFly v2: Advancing Hardware Support for High-Performance Spiking Neural Network With a Spatiotemporal FPGA Accelerator](https://ieeexplore.ieee.org/abstract/document/10478105) | https://github.com/adamgallas/FireFly-v2 | IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems |
| [Revealing Untapped DSP Optimization Potentials for FPGA-Based Systolic Matrix Engines](https://ieeexplore.ieee.org/abstract/document/10705564) | https://github.com/adamgallas/SpinalDLA | 2024 34th International Conference on Field-Programmable Logic and Applications (FPL) |
| [FireFly-S: Exploiting Dual-Side Sparsity for Spiking Neural Networks Acceleration With Reconfigurable Spatial Architecture](https://ieeexplore.ieee.org/document/10754657) | | IEEE Transactions on Circuits and Systems I: Regular Papers |
| Pushing up to the Limit of Memory Bandwidth and Capacity Utilization for Efficient LLM Decoding on Embedded FPGA | | 2025 Design, Automation & Test in Europe Conference & Exhibition (DATE) |
================================================
FILE: documents/Publication.md
================================================
# Publications Using BrainCog
## 2024
| Papers | Codes | Publisher |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | --------------------------------------------------------------------------- |
| [Developmental Plasticity-inspired Adaptive Pruning for Deep Spiking and Artificial Neural Networks](https://ieeexplore.ieee.org/document/10691937) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DPAP](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DPAP) | IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) |
| [Multi-compartment Neuron and Population Encoding improved Spiking Neural Network for Deep Distributional Reinforcement Learning](https://www.sciencedirect.com/science/article/abs/pii/S089360802400827X?via%3Dihub) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/decision_making/RL/mcs-fqf | Neural Networks |
| [Improving Stability and Performance of Spiking Neural Networks Through Enhancing Temporal Consistency](https://www.sciencedirect.com/science/article/abs/pii/S0031320324008458) | [https://github.com/Brain-Cog-Lab/ETC](https://github.com/Brain-Cog-Lab/ETC) | Pattern Recognition |
| [Spiking Generative Adversarial Network with Attention Scoring Decoding](https://www.sciencedirect.com/science/article/abs/pii/S0893608024003472) | [https://github.com/Brain-Cog-Lab/sgad](https://github.com/Brain-Cog-Lab/sgad) | Neural Networks |
| [Temporal Knowledge Sharing Enables Spiking Neural Network Learning from Past and Future](https://ieeexplore.ieee.org/document/10462632) | [https://github.com/Brain-Cog-Lab/TKS](https://github.com/Brain-Cog-Lab/TKS) | IEEE Transactions on Artificial Intelligence (TAI) |
| [TIM: An Efficient Temporal Interaction Module for Spiking Transformer](https://www.ijcai.org/proceedings/2024/0347.pdf) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/TIM](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/TIM) | IJCAI2024 |
| [Are Conventional SNNs Really Efficient? A Perspective from Network Quantization](https://openaccess.thecvf.com/content/CVPR2024/papers/Shen_Are_Conventional_SNNs_Really_Efficient_A_Perspective_from_Network_Quantization_CVPR_2024_paper.pdf) | | 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) |
| [CACE-Net: Co-guidance Attention and Contrastive Enhancement for Effective Audio-Visual Event Localization](https://dl.acm.org/doi/10.1145/3664647.3681503) | [https://github.com/Brain-Cog-Lab/CACE-Net](https://github.com/Brain-Cog-Lab/CACE-Net) | Proceedings of the 32nd ACM International Conference on Multimedia (ACM MM) |
| [Parallel Spiking Unit for Efficient Training of Spiking Neural Networks](https://ieeexplore.ieee.org/document/10650207) | [https://github.com/Brain-Cog-Lab/PSU](https://github.com/Brain-Cog-Lab/PSU) | IJCNN 2024 |
| [Spiking Neural Networks with Consistent Mapping Relations Allow High-Accuracy Inference](https://www.sciencedirect.com/science/article/abs/pii/S0020025524007369) | [https://github.com/Brain-Cog-Lab/casc](https://github.com/Brain-Cog-Lab/casc) | Information Sciences |
| [Directly training temporal Spiking Neural Network with sparse surrogate gradient](https://www.sciencedirect.com/science/article/abs/pii/S0893608024004234) | [https://github.com/Brain-Cog-Lab/msg](https://github.com/Brain-Cog-Lab/msg) | Neural Networks |
| [Brain-inspired Evolutionary Neural Architecture Search for Spiking Neural Networks](https://ieeexplore.ieee.org/abstract/document/10542732) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/EB-NAS](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/EB-NAS) | IEEE Transactions on Artificial Intelligence (TAI) |
| [MSAT: Biologically Inspired Multi-Stage Adaptive Threshold for Conversion of Spiking Neural Networks](https://link.springer.com/article/10.1007/s00521-024-09529-w) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/Conversion/msat_conversion](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/Conversion/msat_conversion) | Neural Computing and Applications |
| [An Efficient Knowledge Transfer Strategy for Spiking Neural Networks from Static to Event Domain](https://ojs.aaai.org/index.php/AAAI/article/view/27806/27643) | [https://github.com/Brain-Cog-Lab/Transfer-for-DVS](https://github.com/Brain-Cog-Lab/Transfer-for-DVS) | Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) |
## 2023
| Papers | Codes | Publisher |
| -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------ |
| [An unsupervised STDP-based spiking neural network inspired by biologically plausible learning rules and connections](https://www.sciencedirect.com/science/article/pii/S0893608023003301) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/UnsupervisedSTDP](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/UnsupervisedSTDP) | Neural Networks |
| [EventMix: An efficient data augmentation strategy for event-based learning](https://www.sciencedirect.com/science/article/pii/S0020025523007557) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/datasets/cut_mix.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/datasets/cut_mix.py) | Information Sciences |
| [Challenging deep learning models with image distortion based on the abutting grating illusion](https://www.sciencedirect.com/science/article/pii/S2666389923000260) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/IllusionPerception/AbuttingGratingIllusion](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/IllusionPerception/AbuttingGratingIllusion) | Patterns |
| [Improving the Performance of Spiking Neural Networks on Event-based Datasets with Knowledge Transfer](https://arxiv.org/abs/2303.13077) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/transfer_for_dvs](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/transfer_for_dvs) | Arxiv |
| [Exploiting Nonlinear Dendritic Adaptive Computation in Training Deep Spiking Neural Networks](https://www.sciencedirect.com/science/article/pii/S0893608023006202) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/base/node/node.py#L1412](https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/base/node/node.py#L1412) | Neural Networks |
| [Emergence of Brain-inspired Small-world Spiking Neural Network through Neuroevolution](https://www.sciencedirect.com/science/article/pii/S258900422400066X) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/ELSM](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/ELSM) | iScience |
| [Enhancing Efficient Continual Learning with Dynamic Structure Development of Spiking Neural Networks](https://www.ijcai.org/proceedings/2023/0334.pdf) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DSD-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DSD-SNN) | IJCAI |
| [Adaptive Structure Evolution and Biologically Plausible Synaptic Plasticity for Recurrent Spiking Neural Networks](https://www.nature.com/articles/s41598-023-43488-x) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/Adaptive_lsm](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/Adaptive_lsm) | Scientific Reports |
| [Brain-inspired Neural Circuit Evolution for Spiking Neural Networks](https://www.pnas.org/doi/10.1073/pnas.2218173120) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/model_zoo/NeuEvo](https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/model_zoo/NeuEvo) | Proceedings of the National Academy of Sciences (PANS) |
| [Bullying10K: A Large-scale Neuromorphic Dataset Towards Privacy-preserving Bullying Recognition](https://proceedings.neurips.cc/paper_files/paper/2023/file/05ffe69463062b7f9fb506c8351ffdd7-Paper-Datasets_and_Benchmarks.pdf) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/bullying10k](https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/bullying10k) | Neurips2023 |
## 2022
| Papers | Codes | Publisher |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------- |
| [BackEISNN: A deep spiking neural network with adaptive self-feedback and balanced excitatory–inhibitory neurons](https://www.sciencedirect.com/science/article/pii/S0893608022002520) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/img_cls/bp/main_backei.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/img_cls/bp/main_backei.py) | Neural Networks |
| [Efficient and Accurate Conversion of Spiking Neural Network with Burst Spikes](https://www.ijcai.org/proceedings/2022/345) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py) | IJCAI |
| [Spike Calibration: Fast and Accurate Conversion of Spiking Neural Network for Object Detection and Segmentation](https://arxiv.org/abs/2207.02702) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py) | Arxiv |
| [Multisensory Concept Learning Framework Based on Spiking Neural Networks](https://www.frontiersin.org/articles/10.3389/fnsys.2022.845177/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/MultisensoryIntegration](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/MultisensoryIntegration) | Frontiers in Systems Neuroscience |
| [Backpropagation with biologically plausible spatiotemporal adjustment for training deep spiking neural networks](https://www.sciencedirect.com/science/article/pii/S2666389922001192) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/bp](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/bp) | Patterns |
| [Spiking CapsNet: A spiking neural network with a biologically plausible routing rule between capsules](https://www.sciencedirect.com/science/article/pii/S002002552200843X) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/spiking_capsnet](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/spiking_capsnet) | Information Sciences |
| [N-Omniglot, a large-scale neuromorphic dataset for spatio-temporal sparse few-shot learning](https://www.nature.com/articles/s41597-022-01851-z) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/NOmniglot](https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/NOmniglot) | Scientific Data |
| [Brain-inspired Graph Spiking Neural Networks for Commonsense Knowledge Representation and Reasoning](https://arxiv.org/abs/2207.05561 ) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/CKRGSNN | Arxiv |
| [Nature-inspired self-organizing collision avoidance for drone swarm based on reward-modulated spiking neural network](https://www.cell.com/patterns/fulltext/S2666-3899(22)00236-7) | https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/decision_making/swarm/Collision-Avoidance.py | Cell Patterns |
| [Solving the spike feature information vanishing problem in spiking deep Q network with potential based normalization](https://www.frontiersin.org/articles/10.3389/fnins.2022.953368/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/decision_making/RL/sdqn | Frontiers in Neuroscience |
| [A brain-inspired intention prediction model and its applications to humanoid robot](https://www.frontiersin.org/articles/10.3389/fnins.2022.1009237/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/Intention_Prediction](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/Intention_Prediction) | Frontiers in Neuroscience |
| [A Brain-Inspired Theory of Mind Spiking Neural Network for Reducing Safety Risks of Other Agents](https://www.frontiersin.org/articles/10.3389/fnins.2022.753900/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/ToM](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/ToM) | Frontiers in Neuroscience |
| [Brain-Inspired Affective Empathy Computational Model and Its Application on Altruistic Rescue Task](https://www.frontiersin.org/articles/10.3389/fncom.2022.784967/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BAE-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BAE-SNN) | Frontiers in Computational Neuroscience |
| [A brain-inspired robot pain model based on a spiking neural network](https://www.frontiersin.org/articles/10.3389/fnbot.2022.1025338/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BRP-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BRP-SNN) | Frontiers in Neurorobotics |
| [Brain-Inspired Theory of Mind Spiking Neural Network Elevates Multi-Agent Cooperation and Competition](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4271099) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/MAToM-SNN ](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/MAToM-SNN ) | SSRN |
| [Adaptive Sparse Structure Development with Pruning and Regeneration for Spiking Neural Networks](https://www.sciencedirect.com/science/article/abs/pii/S0020025524013951) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/SD-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/SD-SNN) | Information Sciences |
| [DPSNN](https://arxiv.org/abs/2205.12718) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Snn_safety/DPSNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Snn_safety/DPSNN) | Arxiv |
## 2021
| Papers | Codes | Publisher |
| ---------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------- |
| [Quantum superposition inspired spiking neural network](https://www.cell.com/iscience/fulltext/S2589-0042(21)00848-8) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/QSNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/QSNN) | iScience |
| [A Brain-Inspired Causal Reasoning Model Based on Spiking Neural Networks](https://ieeexplore.ieee.org/abstract/document/9534102) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/CRSNN | IJCNN2021 |
| [Brain Inspired Sequences Production by Spiking Neural Networks With Reward-Modulated STDP](https://www.frontiersin.org/articles/10.3389/fncom.2021.612041/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/SPSNN | Frontiers in Computational Neuroscience |
| [Stylistic Composition of Melodies Based on a Brain-Inspired Spiking Neural Network](https://www.frontiersin.org/articles/10.3389/fnsys.2021.639484/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BRP-SNN | Frontiers in Neurorobotics |
## 2020
| Papers | Codes | Publisher |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------- |
| [GLSNN: A Multi-Layer Spiking Neural Network Based on Global Feedback Alignment and Local STDP Plasticity](https://www.frontiersin.org/articles/10.3389/fncom.2020.576841/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/glsnn](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/glsnn) | Frontiers in Neuroscience |
| [Temporal-Sequential Learning With a Brain-Inspired Spiking Neural Network and Its Application to Musical Memory](https://www.frontiersin.org/articles/10.3389/fncom.2020.00051/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/musicMemory | Frontiers in Computational Neuroscience |
## 2018
| Papers | Codes | Publisher |
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------- |
| [A Brain-Inspired Decision-Making Spiking Neural Network and Its Application in Unmanned Aerial Vehicle](https://www.frontiersin.org/articles/10.3389/fnbot.2018.00056/full ) | https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/decision_making/BDM-SNN/BDM-SNN-hh.py | Frontiers in Neurorobotics |
| [Toward Robot Self-Consciousness (II): Brain-Inspired Robot Bodily Self Model for Self-Recognition](https://link.springer.com/article/10.1007/s12559-017-9505-1 ) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/mirror_test](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/mirror_test) | Cognitive Computation |
================================================
FILE: documents/Tutorial.md
================================================
# Tutorial
- How to Install BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/1_installation.html), [Chinese Version](https://mp.weixin.qq.com/s/fX-S3fKKDfR3NV4ISAHrZg)]
- Overall Introduction of BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/2_Overall%20introduction%20of%20BrainCog.html), [Chinese Version](https://mp.weixin.qq.com/s/ywgQ5ydQxr6W7d_Y_XqC6w)]
- Spiking Neuron Modeling with BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/3_Tutorial%20of%20Spiking%20Neuron%20Modeling.html), [Chinese Version](https://mp.weixin.qq.com/s/pCdlbkrdnMNHj7wcwi9D2Q)]
- Building Efficient Spiking Neural Networks with BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/4_Building%20Efficient%20Spiking%20Neural%20Networks%20with%20BrainCog.html), [Chinese Version](https://mp.weixin.qq.com/s/NIz7MSAOJQ79m97hkP3HVg)]
- Building Cognitive Networks with BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/5_How%20to%20build%20a%20cognitive%20network.html), [Chinese Version](https://mp.weixin.qq.com/s/K0pY6V8TupJgYXH4WvS9jg)]
- Implementing Deep Reinforcement Learning SNNs with BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/6_SDQN.html), [Chinese Version](https://mp.weixin.qq.com/s/Zt78vj_sKn5jffEyeh86Cw)]
- Quantum Superposition State Inspired Encoding With BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/7_QSSNN.html), [Chinese Version](https://mp.weixin.qq.com/s/YVNkwDwuF9FG-YqQyd3KTg)]
- Converting ANNs to SNNs with BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/8_conversion.html), [Chinese Version](https://mp.weixin.qq.com/s/4g8WBoa4SOcb_VQ24wO-Xw)]
- SNNs with Global Feedback Connections Based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/9_GLSNN.html), [Chinese Version](https://mp.weixin.qq.com/s/-AS0BihlXdFwCt1hgzFx3g)]
- Multi-brain Areas Coordinated Brain-inspired Decision-Making SNNs Based on Braincog [[English Version](http://www.brain-cog.network/docs/tutorial/10_BDMSNN.html), [Chinese Version](https://mp.weixin.qq.com/s/dltOGjhUZ9yTzSssIvkhtA)]
- Backpropagation with Spatiotemporal Adjustment for Training SNNs Based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/11_biobp.html), [Chinese Version](https://mp.weixin.qq.com/s/6ZtaWtiY9K96UhVnvhfP7w)]
- Unsupervised STDP Based SNNs with Multiple Adaptive Mechanisms Based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/12_unsup.html), [Chinese Version](https://mp.weixin.qq.com/s/v_svhQ0N3JAYo1l8NQ1W1w)]
- Symbolic Representation and Reasoning SNNs Based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/13_krr.html), [Chinese Version](https://mp.weixin.qq.com/s/UXc5QDbg8tUKVU3L6dhvxw)]
- Multisensory Integration Based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/14_multisensory.html), [Chinese Version](https://mp.weixin.qq.com/s/s9gXF5NkPUGXkcFAFtsCMw)]
- SNN-based Music Memory and Generation Based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/15_musicSNN.html), [Chinese Version](https://mp.weixin.qq.com/s/y-t9rFEXYSmI_-rnVk_usw)]
- Brain-inspired Bodily Self-perception Model Based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/16_self.html), [Chinese Version](https://mp.weixin.qq.com/s/RLbS3GmhE8ScyZTKJKl_SQ)]
- A Brain-inspired Theory of Mind Model Based on BrainCog for Reducing Other Agents’ Safety Risks [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/xzFF6IK86W4h2CMs7jt7Xw)]
- Application of the Prefrontal Cortex Column Model in Working Memory Task with BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/E6pb5W0Q4noK72NGf4SNGQ)]
- Multi-brain areas Coordinated Brain-inspired Affective Empathy Spiking Neural Network Based on Braincog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/xUnal4I5tM-Rl49fu0ZRVw)]
- Developmental Plasticity-inspired Adaptive Pruning for SNNs based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/-F0XcIovI1WY6YyoO5P58Q)]
- Dynamic structural development for SNNs incorporating constraints, pruning and regeneration based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/n1EK6lddriS0dnSgfdsa8w)]
- BrainCog Data Engine: Spatio-temporal Sequence Data N-Omniglot and Its Applications [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/VIzDb2kn_4LUyUh0qc2j4w)]
- The Implement of Object Detection and Semantic Segmentation Based on SNNs with Braincog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/fyf_cbzH_i1_ZEFWTSH81Q)]
- DVS Augmentation Strategies based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/BNMZ_oQK9Foui2zcnKWYgg)]
- SNNs with adaptive self-feedback and balanced excitatory–inhibitory neurons based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/TFEucKDQHB69wChEL_Y3Cw)]
- Spiking CapsNet based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/VIzDb2kn_4LUyUh0qc2j4w)]
- Drosophila-inspired Linear and Nonlinear Decision-Making Spiking Neural Network implemented by Braincog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/VIzDb2kn_4LUyUh0qc2j4w)]
- Reward-modulated brain-inspired spiking neural network to empower group for nature-inspired self-organized obstacle avoidance implemented by Braincog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/VIzDb2kn_4LUyUh0qc2j4w)]
- Using BrainCog to Realize Robot's Intention Prediction for Users [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/VIzDb2kn_4LUyUh0qc2j4w)]
- FPGA-based Spiking Neural Networks Acceleration Using BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/VIzDb2kn_4LUyUh0qc2j4w)]
================================================
FILE: examples/Brain_Cognitive_Function_Simulation/drosophila/README.md
================================================
# Drosophila-inspired decision-making SNN
## Run
The drosophila.py implements the core code of the Drosophila-inspired linear and non-linear decision-making in paper entitled "A Neural Algorithm for linear and non-linear Decision-making inspired by Drosophila".
The experiments includes training phase and testing phase:
* Training Phase
Training linear network and nonlinear network by reward-modulated spiking neural network: green-upright T is safe and blue-inverted T is dangerous
* Testing Phase
For linear pathway and nonlinear pathway, choose between blue-upright T and green-inverted T, and count the PI values under different color intensity
## Results
The following picture shows the linear (a) and nonlinear (b) pathways, the training and testing phases (c), and the PI values on different color intensities (d).

Differences from the original article: an improved reward-modulated STDP learning rule.
## Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{zhao2020neural,
title={A neural algorithm for Drosophila linear and nonlinear decision-making},
author={Zhao, Feifei and Zeng, Yi and Guo, Aike and Su, Haifeng and Xu, Bo},
journal={Scientific Reports},
volume={10},
number={1},
pages={1--16},
year={2020},
publisher={Nature Publishing Group}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/Brain_Cognitive_Function_Simulation/drosophila/drosophila.py
================================================
import numpy as np
import torch,os,sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
import matplotlib.pyplot as plt
from braincog.base.strategy.surrogate import *
from braincog.base.node.node import IFNode
from braincog.base.learningrule.STDP import STDP,MutliInputSTDP
from braincog.base.connection.CustomLinear import CustomLinear
from braincog.model_zoo.nonlinearNet import droDMTestNet
from braincog.model_zoo.linearNet import droDMTrainNet
import copy
if __name__=="__main__":
"""
建立训练网络
"""
num_state=5
num_action=2
weight_exc=0.5
weight_inh=-0.05
trace_decay=0.8
mb_connection=[]
#input-visual
con_matrix0 = torch.eye((num_state), dtype=torch.float)
mb_connection.append(CustomLinear(weight_exc * con_matrix0,con_matrix0))
# visual-kc
con_matrix1 =torch.eye((num_state), dtype=torch.float)
mb_connection.append(CustomLinear( weight_exc * con_matrix1,con_matrix1))
# kc-mbon
con_matrix2 = torch.ones((num_state,num_action), dtype=torch.float)
mb_connection.append(CustomLinear(weight_exc * con_matrix2,con_matrix2))
# mbon-mbon
con_matrix3 = torch.ones((num_action,num_action), dtype=torch.float)
con_matrix4 = torch.eye((num_action), dtype=torch.float)
con_matrix5=con_matrix3-con_matrix4
con_matrix5=con_matrix5
mb_connection.append(CustomLinear(weight_inh * con_matrix5,con_matrix5))
MB=droDMTrainNet(mb_connection)
weight_trace_mbon=torch.zeros(con_matrix2.shape, dtype=torch.float)
"""
学习绿色正立T是安全的 蓝色倒立T是有惩罚的
"""
#learning GT
# RGB T t
GT = torch.tensor([0, 0.8, 0, 1.0, 0])
Bt = torch.tensor([0, 0, 0.8, 0, 1.0])
input = GT - Bt # input GT
input[input < 0] = 0
for i_train in range(20):
GT_out,dwkc,dwmbon=MB(input)
print("stdp:",dwkc,dwmbon)
#vis-kc STDP
MB.UpdateWeight(1, dwkc)
#kc-mbon rstdp
weight_trace_mbon *= trace_decay
weight_trace_mbon += dwmbon
if max(GT_out)>0:
r=torch.ones((num_state,num_action), dtype=torch.float)
p_action= torch.tensor([0])
r[:,p_action]=-1
dw_mbon = r * weight_trace_mbon
MB.UpdateWeight(2, dw_mbon)
print("output:",GT_out)
MB.reset()
weight_trace_mbon = torch.zeros(con_matrix2.shape, dtype=torch.float)
#learning Bt
GT = torch.tensor([0,0.8,0, 1.0, 0])
Bt = torch.tensor([0, 0, 0.8, 0, 1.0])
input = Bt - GT # input Bt
input[input < 0] = 0
for i_train in range(20):
GT_out,dwkc,dwmbon=MB(input)
#vis-kc STDP
MB.UpdateWeight(1, dwkc)
#kc-mbon rstdp
weight_trace_mbon *= trace_decay
weight_trace_mbon += dwmbon
if max(GT_out)>0:
r=torch.ones((num_state,num_action), dtype=torch.float)
p_action= torch.tensor([1])
r[:,p_action]=-1
dw_mbon = r * weight_trace_mbon
MB.UpdateWeight(2, dw_mbon)
train_weight=MB.getweight()
for i in range(len(train_weight)):
print("weight after learning:", train_weight[i].weight.data)
print("end training")
#linear test conflict decision making
test_num=12
t1=torch.zeros((test_num), dtype=torch.float)
t2=torch.zeros((test_num), dtype=torch.float)
for c in range(t1.shape[0]):
MB_test = droDMTrainNet(copy.deepcopy(train_weight))
MB_test.reset()
Gt = torch.tensor([0, (c*0.1), 0, 0, 0.5])
BT = torch.tensor([0, 0, (c*0.1), 0.5, 0])
input =Gt - BT # input Gt
input[input < 0] = 0
count=torch.zeros((num_action), dtype=torch.float)
for i_train in range(500):
GT_out,dwkc,dwmbon=MB_test(input)
count+=GT_out
t1[c]=count[0]
t2[c]=count[1]
p1=(t1-t2)/(t1+t2)
print(t1,t2,p1)
for i in range(len(train_weight)):
print("weight after learning:", train_weight[i].weight.data)
"""
建立测试网络,验证不同浓度下绿色正立T和蓝色倒立T
"""
# non-linear test conflict decision making
weight_inh_test=-0.3
num_apl=2
num_da=1
da_mb_connection=train_weight
# kc-apl
con_matrix6 = torch.ones((num_state, num_apl), dtype=torch.float)
da_mb_connection.append(CustomLinear(weight_exc * con_matrix6, con_matrix6))
# apl-kc
con_matrix7 = torch.ones((num_apl,num_state), dtype=torch.float)
da_mb_connection.append(CustomLinear(weight_inh_test * con_matrix7, con_matrix7))
# da-apl
con_matrix8 = torch.ones((num_da, num_apl), dtype=torch.float)
da_mb_connection.append(CustomLinear(weight_inh_test * con_matrix8, con_matrix8))
# apl-da
con_matrix9 = torch.ones((num_apl, num_da), dtype=torch.float)
da_mb_connection.append(CustomLinear(weight_inh_test * con_matrix9, con_matrix9))
# 1-da
con_matrix10 = torch.ones((num_da), dtype=torch.float)
da_mb_connection.append(CustomLinear(weight_exc * con_matrix10, con_matrix10))
# da-mbon
con_matrix11 = torch.ones((num_da,num_action), dtype=torch.float)
da_mb_connection.append(CustomLinear(weight_exc * con_matrix11, con_matrix11))
#0 input-vis 1 vis-kc 2 kc-mbon 3-mbon-mbon 4 kc-apl 5 apl-kc 6 da-apl 7 apl-da 8 input-da
t1 = torch.zeros((test_num), dtype=torch.float)
t2 = torch.zeros((test_num), dtype=torch.float)
for c in range(t1.shape[0]):
DA_MB_test = droDMTestNet(copy.deepcopy(da_mb_connection))
DA_MB_test.reset()
Gt = torch.tensor([0, (c * 0.1), 0, 0, 0.5])
BT = torch.tensor([0, 0, (c * 0.1), 0.5, 0])
input = Gt - BT # input Gt
input[input < 0] = 0
count = torch.zeros((num_action), dtype=torch.float)
for i_train in range(500):
if i_train<10 and i_train%2==0:
input_da = torch.tensor([0.5])
else:
input_da = torch.tensor([0.0])
GT_out, dwkc, dwapl= DA_MB_test(input,input_da)
DA_MB_test.UpdateWeight(5, dwkc)
DA_MB_test.UpdateWeight(4, dwapl)
count += GT_out
t1[c] = count[0]
t2[c] = count[1]
p2 = (t1 - t2) / (t1 + t2)
print(t1, t2, p2)
MB_test = MB.getweight()
for i in range(len(train_weight)):
print("weight after learning:", train_weight[i].weight.data)
x = torch.arange(0, test_num)
x=x*0.1
plt.figure()
A,=plt.plot(x, p1,label="linear")
B,=plt.plot(x, p2,label="non-linear")
font1 = {'family' : 'Times New Roman','weight' : 'normal','size' : 15,}
plt.xlabel("color intensity",font1)
plt.ylabel("PI",font1)
plt.legend(handles=[A,B],prop=font1)
plt.show()
================================================
FILE: examples/Embodied_Cognition/RHI/RHI_Test.py
================================================
import numpy as np
import torch,os,sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
import matplotlib.pyplot as plt
from braincog.base.strategy.surrogate import *
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import random
import gc
from braincog.base.node.node import IzhNodeMU
import objgraph
from pympler import tracker
class CustomLinear(nn.Module):
def __init__(self, weight,mask=None):
super().__init__()
self.weight = nn.Parameter(weight, requires_grad=True)
self.mask=mask
def forward(self, x: torch.Tensor):
#
# ret.shape = [C]
return x.mul(self.weight) # Changed
def update(self, dw):
with torch.no_grad():
if self.mask is not None:
dw *= self.mask
self.weight.data+= dw
class M1Net(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input):
input_n = input*I_max
input_r = torch.round(input_n)
Spike = torch.zeros(num_neuron, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_AI):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class VNet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input):
input_n = input*I_max
input_r = torch.round(input_n)
Spike = torch.zeros(num_neuron, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class S1Net(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n, input_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class EBANet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n, input_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class TPJNet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n, input_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
def UpdateWeight(self, i, W):
self.connection[i].weight.data = W
class AINet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n, input_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
def UpdateWeight(self, i, W):
self.connection[i].weight.data = self.connection[i].weight.data + W
def DeltaWeight(Pre, Pre_n, Post, Post_n):
alpha = -0.0035
beta = 0.35
gamma = -0.55
T1 = alpha * (Pre_n*Post_n)
T2 = beta * (Pre_n*(Post_n-Post))
T3 = gamma * ((Pre_n-Pre)*Post_n)
dW = T1 + T2 + T3
return dW
if __name__=="__main__":
"""
Set the number of neurons, and each neuron represents unique motion information (such as angle)
"""
# number of neurons
num_neuron = 9
num_M1 = num_neuron
num_S1 = num_neuron
num_TPJ = num_neuron
num_V = num_neuron
num_EBA = num_neuron
num_AI = num_neuron
Init_Weight = 1.
param_threshold = 30.
param_a = 0.02
param_b = -0.1
param_c = -55.
param_d = 18.
param_mem = -70.
param_u = 0.
param_dt = 1.
Simulation_time = 1000
I_max = 1000
# When TrickID is set to 1, it means that the mapping relationship from input current
# to firing rate is obtained directly by loading Izh.npy,
# which can significantly reduce the program running time
TrickID = 1
if TrickID == 1:
spike_num_list=np.load('Izh.npy')
spike_num_list = spike_num_list/I_max
##############################
# M1
##############################
# M1_Input-M1
M1_connection = []
con_matrix0 = torch.ones(num_M1, dtype=torch.float)*Init_Weight
M1_connection.append(CustomLinear(con_matrix0))
M1 = M1Net(M1_connection)
##############################
# V
##############################
# V_Input-V
V_connection = []
con_matrix3 = torch.ones(num_V, dtype=torch.float)*Init_Weight
V_connection.append(CustomLinear(con_matrix3))
V = VNet(V_connection)
##############################
# S1
##############################
# M1-S1
S1_connection = []
con_matrix1 = torch.ones(num_S1, dtype=torch.float)*Init_Weight
S1_connection.append(CustomLinear(con_matrix1))
S1 = S1Net(S1_connection)
##############################
# EBA
##############################
# V-EBA
EBA_connection = []
con_matrix4 = torch.ones(num_EBA, dtype=torch.float)*Init_Weight
EBA_connection.append(CustomLinear(con_matrix4))
EBA = EBANet(EBA_connection)
##############################
# TPJ
##############################
# S1-TPJ, EBA-TPJ
TPJ_connection = []
# S1-TPJ
con_matrix2 = torch.ones(num_TPJ, dtype=torch.float)*Init_Weight*150
TPJ_connection.append(CustomLinear(con_matrix2))
# EBA-TPJ
con_matrix5 = torch.ones(num_TPJ, dtype=torch.float)*Init_Weight*150
TPJ_connection.append(CustomLinear(con_matrix5))
TPJ = TPJNet(TPJ_connection)
##############################
# AI
##############################
# S1-AI, TPJ-AI, EBA-AI
AI_connection = []
# S1-AI
con_matrix6 = torch.ones(num_AI, dtype=torch.float)*Init_Weight
AI_connection.append(CustomLinear(con_matrix6))
# TPJ-AI
con_matrix7 = torch.ones(num_AI, dtype=torch.float)*Init_Weight
AI_connection.append(CustomLinear(con_matrix7))
# EBA-AI
con_matrix8 = torch.ones(num_AI, dtype=torch.float)*Init_Weight
AI_connection.append(CustomLinear(con_matrix8))
AI = AINet(AI_connection)
AI.connection[0].weight.data = torch.from_numpy(np.load('W_S1_AI.npy'))
AI.connection[2].weight.data = torch.from_numpy(np.load('W_EBA_AI.npy'))
##############################
# Coding
##############################
S = 1
ISI = 1
JMax = int((num_neuron-1)/2)
listJ = list(range(-JMax,JMax+1))
Coding = torch.zeros([num_neuron, num_neuron], dtype=torch.float)
for i in range(len(listJ)):
e = float(listJ[i])
listY = []
for j in range(len(listJ)):
x = float(listJ[j])
y = math.exp(-(x-e)**2/(2*S**2))
Coding[i][j] = y
print(AI.connection[0].weight.data) # dW_S1AI
print(AI.connection[2].weight.data) # dW_EBAAI
##############################
# Test
##############################
Time = 300
CT = 100
Motion_Start = 1
Motion_End = Motion_Start + CT
Vision_Start = Motion_End
Vision_End = Vision_Start + CT
CM1 = 0.04
CV = 0.04
CS1 = 0.04
CEBA = 0.04
CTPJ = 0.01
CAI = 0.15
Result_List = []
Veridical_hand = int((num_neuron-1)/2)
for Disparity in range(-JMax,JMax+1):
M1_input = torch.zeros(num_M1, dtype=torch.float)
V_input = torch.zeros(num_V, dtype=torch.float)
S1_input = torch.zeros(num_S1, dtype=torch.float)
TPJ_input = torch.zeros(num_TPJ, dtype=torch.float)
EBA_input = torch.zeros(num_EBA, dtype=torch.float)
AI_input = torch.zeros(num_AI, dtype=torch.float)
FR_M1 = torch.zeros(num_M1, dtype=torch.float)
FR_V = torch.zeros(num_V, dtype=torch.float)
FR_S1 = torch.zeros(num_S1, dtype=torch.float)
FR_EBA = torch.zeros(num_EBA, dtype=torch.float)
FR_TPJ = torch.zeros(num_TPJ, dtype=torch.float)
FR_AI = torch.zeros(num_AI, dtype=torch.float)
FR_AI_List = torch.zeros([Time, num_AI], dtype=torch.float)
with torch.no_grad():
for t in range(1,Time+1):
S_M1 = torch.zeros(num_M1, dtype=torch.float)
S_V = torch.zeros(num_V, dtype=torch.float)
if t>=Motion_Start and t<=Motion_End:
S_M1 = Coding[Veridical_hand]
M1_input = (1-(1-CM1)**t)*S_M1
else:
M1_input = S_M1
if t>=Vision_Start and t<=Vision_End:
S_V = Coding[Veridical_hand+Disparity]
V_input = (1-(1-CV)**(t-CT))*S_V
else:
V_input = S_V
FR_M1_n = M1(M1_input)
FR_V_n = V(V_input)
[FR_S1_n, S1_input_n] = S1(S1_input, FR_M1_n, CS1)
[FR_EBA_n, EBA_input_n] = EBA(EBA_input, FR_V_n, CEBA)
FR_Input_TPJ_n = torch.stack((FR_S1_n, FR_EBA_n), 0)
[FR_TPJ_n, TPJ_input_n] = TPJ(TPJ_input, FR_Input_TPJ_n, CTPJ)
FR_Input_AI = torch.stack((FR_S1_n, FR_TPJ_n, FR_EBA_n), 0)
[FR_AI_n, AI_input_n] = AI(AI_input, FR_Input_AI, CAI)
FR_AI_List[t-1] = FR_AI_n
FR_M1 = FR_M1_n
FR_V = FR_V_n
FR_S1 = FR_S1_n
FR_EBA = FR_EBA_n
FR_TPJ = FR_TPJ_n
FR_AI = FR_AI_n
S1_input = S1_input_n
TPJ_input = TPJ_input_n
EBA_input = EBA_input_n
AI_input = AI_input_n
print('Test Time End')
Estimated_hand = torch.max(torch.max(FR_AI_List, 0)[0],0)[1].item()
Proprioceptive_drift = Estimated_hand - Veridical_hand
R = [Disparity, Proprioceptive_drift]
Result_List.append(R)
print(R)
print(torch.max(FR_AI_List, 0)[0])
print("----------------------------")
print(Result_List)
X = [x[0] for x in Result_List]
Y = [x[1] for x in Result_List]
S = np.polyfit(X,Y,3)
xn = np.linspace(-(num_neuron-1)/2, (num_neuron-1)/2, 1000)
yn = np.poly1d(S)
plt.plot(xn, yn(xn), X, Y, 'o')
plt.show()
================================================
FILE: examples/Embodied_Cognition/RHI/RHI_Train.py
================================================
import numpy as np
import torch,os,sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
import matplotlib.pyplot as plt
from braincog.base.strategy.surrogate import *
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import random
import gc
from braincog.base.node.node import IzhNodeMU
import objgraph
from pympler import tracker
class CustomLinear(nn.Module):
def __init__(self, weight,mask=None):
super().__init__()
self.weight = nn.Parameter(weight, requires_grad=True)
self.mask=mask
def forward(self, x: torch.Tensor):
#
# ret.shape = [C]
return x.mul(self.weight)
def update(self, dw):
with torch.no_grad():
if self.mask is not None:
dw *= self.mask
self.weight.data+= dw
class M1Net(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input):
input_n = input*I_max
input_r = torch.round(input_n)
Spike = torch.zeros(num_neuron, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_AI):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class VNet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input):
input_n = input*I_max
input_r = torch.round(input_n)
Spike = torch.zeros(num_neuron, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class S1Net(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C, Fired, W_LatInh):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
S = input_n
S = torch.where(input_n>= fire_threshold, 1, S)
S = torch.where(input_n< fire_threshold, 0, S)
if torch.sum(S) > 0:
Fired = Fired + 1;
W_LatInh = torch.tanh(W_LatInh - 2 * torch.acos(S) * torch.exp(Fired) - 1) + 1
return FR_n, input_n, Fired, W_LatInh
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class EBANet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C, Fired, W_LatInh):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
S = input_n
S = torch.where(input_n>= fire_threshold, 1, S)
S = torch.where(input_n< fire_threshold, 0, S)
if torch.sum(S) > 0:
Fired = Fired + 1;
W_LatInh = torch.tanh(W_LatInh - 2 * torch.acos(S) * torch.exp(Fired) - 1) + 1
return FR_n, input_n, Fired, W_LatInh
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class TPJNet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n, input_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
def UpdateWeight(self, i, W):
self.connection[i].weight.data = W
class AINet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n, input_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
def UpdateWeight(self, i, W, WIn):
self.connection[i].weight.data = self.connection[i].weight.data + W*WIn
def DeltaWeight(Pre, Pre_n, Post, Post_n):
alpha = -0.0035
beta = 0.35
gamma = -0.55
T1 = alpha * (Pre_n*Post_n)
T2 = beta * (Pre_n*(Post_n-Post))
T3 = gamma * ((Pre_n-Pre)*Post_n)
dW = T1 + T2 + T3
return dW
if __name__=="__main__":
"""
Set the number of neurons, and each neuron represents unique motion information (such as angle)
"""
# number of neurons
num_neuron = 9
num_M1 = num_neuron
num_S1 = num_neuron
num_TPJ = num_neuron
num_V = num_neuron
num_EBA = num_neuron
num_AI = num_neuron
Init_Weight = 1.
param_threshold = 30.
param_a = 0.02
param_b = -0.1
param_c = -55.
param_d = 18.
param_mem = -70.
param_u = 0.
param_dt = 1.
Simulation_time = 1000
I_max = 1000
# When the TrickID is set to 1, it means that the mapping relationship from input current
# to firing rate is obtained directly by loading the Izh.npy,
# which can significantly reduce the program running time
TrickID = 1
if TrickID == 1:
spike_num_list=np.load('Izh.npy')
spike_num_list = spike_num_list/I_max
##############################
# M1
##############################
# M1_Input-M1
M1_connection = []
con_matrix0 = torch.ones(num_M1, dtype=torch.float)*Init_Weight
M1_connection.append(CustomLinear(con_matrix0))
M1 = M1Net(M1_connection)
##############################
# V
##############################
# V_Input-V
V_connection = []
con_matrix3 = torch.ones(num_V, dtype=torch.float)*Init_Weight
V_connection.append(CustomLinear(con_matrix3))
V = VNet(V_connection)
##############################
# S1
##############################
# M1-S1
S1_connection = []
con_matrix1 = torch.ones(num_S1, dtype=torch.float)*Init_Weight
S1_connection.append(CustomLinear(con_matrix1))
S1 = S1Net(S1_connection)
##############################
# EBA
##############################
# V-EBA
EBA_connection = []
con_matrix4 = torch.ones(num_EBA, dtype=torch.float)*Init_Weight
EBA_connection.append(CustomLinear(con_matrix4))
EBA = EBANet(EBA_connection)
##############################
# TPJ
##############################
# S1-TPJ, EBA-TPJ
TPJ_connection = []
# S1-TPJ
con_matrix2 = torch.ones(num_TPJ, dtype=torch.float)*Init_Weight*150
TPJ_connection.append(CustomLinear(con_matrix2))
# EBA-TPJ
con_matrix5 = torch.ones(num_TPJ, dtype=torch.float)*Init_Weight*150
TPJ_connection.append(CustomLinear(con_matrix5))
TPJ = TPJNet(TPJ_connection)
##############################
# AI
##############################
# S1-AI, TPJ-AI, EBA-AI
AI_connection = []
# S1-AI
con_matrix6 = torch.ones(num_AI, dtype=torch.float)*Init_Weight
AI_connection.append(CustomLinear(con_matrix6))
# TPJ-AI
con_matrix7 = torch.ones(num_AI, dtype=torch.float)*Init_Weight
AI_connection.append(CustomLinear(con_matrix7))
# EBA-AI
con_matrix8 = torch.ones(num_AI, dtype=torch.float)*Init_Weight
AI_connection.append(CustomLinear(con_matrix8))
AI = AINet(AI_connection)
##############################
# Coding
##############################
S = 1
ISI = 1
JMax = int((num_neuron-1)/2)
listJ = list(range(-JMax,JMax+1))
Coding = torch.zeros([num_neuron, num_neuron], dtype=torch.float)
for i in range(len(listJ)):
e = float(listJ[i])
listY = []
for j in range(len(listJ)):
x = float(listJ[j])
y = math.exp(-(x-e)**2/(2*S**2))
Coding[i][j] = y
##############################
# Train
##############################
MoveNum = 25
Time = 300
CT = 100
Motion_Start = 1
Motion_End = Motion_Start + CT
Vision_Start = Motion_End
Vision_End = Vision_Start + CT
CM1 = 0.04
CV = 0.04
CS1 = 0.04
CEBA = 0.04
CTPJ = 0.01
CAI = 0.15
for k in range(num_neuron):
for i in range(MoveNum):
print(i)
M1_input = torch.zeros(num_M1, dtype=torch.float)
V_input = torch.zeros(num_V, dtype=torch.float)
S1_input = torch.zeros(num_S1, dtype=torch.float)
TPJ_input = torch.zeros(num_TPJ, dtype=torch.float)
EBA_input = torch.zeros(num_EBA, dtype=torch.float)
AI_input = torch.zeros(num_AI, dtype=torch.float)
FR_M1 = torch.zeros(num_M1, dtype=torch.float)
FR_V = torch.zeros(num_V, dtype=torch.float)
FR_S1 = torch.zeros( num_S1, dtype=torch.float)
FR_EBA = torch.zeros(num_EBA, dtype=torch.float)
FR_TPJ = torch.zeros(num_TPJ, dtype=torch.float)
FR_AI = torch.zeros( num_AI, dtype=torch.float)
dW_S1TPJ = torch.zeros(num_M1, dtype=torch.float)
dW_EBATPJ = torch.zeros(num_M1, dtype=torch.float)
dW_S1AI = torch.zeros(num_M1, dtype=torch.float)
dW_EBAAI = torch.zeros(num_M1, dtype=torch.float)
fire_threshold = 0.7
W_LatInh_Init = torch.ones(num_neuron, dtype=torch.float)*Init_Weight
W_LatInh_S1_AI = W_LatInh_Init
W_LatInh_EBA_AI = W_LatInh_Init
Fired_S1 = torch.zeros(num_S1, dtype=torch.float)
Fired_EBA = torch.zeros(num_EBA, dtype=torch.float)
with torch.no_grad():
for t in range(1,Time+1):
S_M1 = torch.zeros(num_M1, dtype=torch.float)
S_V = torch.zeros(num_V, dtype=torch.float)
if t>=Motion_Start and t<=Motion_End:
S_M1 = Coding[k]
M1_input = (1-(1-CM1)**t)*S_M1
else:
M1_input = S_M1
if t>=Vision_Start and t<=Vision_End:
S_V = Coding[k]
V_input = (1-(1-CV)**(t-CT))*S_V
else:
V_input = S_V
FR_M1_n = M1(M1_input)
FR_V_n = V(V_input)
[FR_S1_n, S1_input_n, Fired_S1, W_LatInh_S1_AI] = S1(S1_input, FR_M1_n, CS1, Fired_S1, W_LatInh_S1_AI)
[FR_EBA_n, EBA_input_n, Fired_EBA, W_LatInh_EBA_AI] = EBA(EBA_input, FR_V_n, CEBA, Fired_EBA, W_LatInh_EBA_AI)
FR_Input_TPJ_n = torch.stack((FR_S1_n, FR_EBA_n), 0)
[FR_TPJ_n, TPJ_input_n] = TPJ(TPJ_input, FR_Input_TPJ_n, CTPJ)
FR_Input_AI = torch.stack((FR_S1_n, FR_TPJ_n, FR_EBA_n), 0)
[FR_AI_n, AI_input_n] = AI(AI_input, FR_Input_AI, CAI)
# Update weights
# S1-AI
ddW_S1AI = DeltaWeight(FR_S1, FR_S1_n, FR_AI, FR_AI_n)
dW_S1AI = dW_S1AI + ddW_S1AI
# EBA-AI
ddW_EBAAI = DeltaWeight(FR_EBA, FR_EBA_n, FR_AI, FR_AI_n)
dW_EBAAI = dW_EBAAI + ddW_EBAAI
FR_M1 = FR_M1_n
FR_V = FR_V_n
FR_S1 = FR_S1_n
FR_EBA = FR_EBA_n
FR_TPJ = FR_TPJ_n
FR_AI = FR_AI_n
S1_input = S1_input_n
TPJ_input = TPJ_input_n
EBA_input = EBA_input_n
AI_input = AI_input_n
AI.UpdateWeight(0, dW_S1AI, W_LatInh_S1_AI)
AI.UpdateWeight(2, dW_EBAAI, W_LatInh_EBA_AI)
print(AI.connection[0].weight.data) # dW_S1AI
print(AI.connection[2].weight.data) # dW_EBAAI
M1.reset()
V.reset()
S1.reset()
EBA.reset()
TPJ.reset()
AI.reset()
np.save('W_S1_AI.npy', AI.connection[0].weight.data)
np.save('W_EBA_AI.npy', AI.connection[2].weight.data)
print('Training End')
================================================
FILE: examples/Embodied_Cognition/RHI/ReadMe.md
================================================
================================================
FILE: examples/Hardware_acceleration/README.md
================================================
## FireFly: A High-Throughput Hardware Accelerator for Spiking Neural Networks
### Demo of Deploying SNNs on FPGA platform
This is an example of deploying an SNN model on Xilinx Zynq Ultrascale FPGA based on Braincog.
### Requirements
- Xilinx Zynq Ultrascale FPGA evaluation board Ultra96v2 or ZCU104.
- PYNQ images for the chosen evaluation boards. You can download the latest pre-compiled images from the [PYNQ website](http://www.pynq.io/board.html), or you can compile a new one following the [PYNQ Tutorial](https://pynq.readthedocs.io/en/latest/). Install the PYNQ image to the SD card, and boot the evaluation board in SD mode.
### Examples
Clone the project to fetch the necessary bitstream files and pre-processed SNN models, copy all the files to the Ultra96v2 or ZCU104 board.
```shell
git clone https://github.com/adamgallas/firefly_v1_cifar_test
```
Open a terminal in Ultra96v2 or ZCU104. Install einops on Ultra96v2 or ZCU104.
```shell
cd firefly_v1_common
pip install einops-0.6.0-py3-none-any.whl
```
Run CIFAR10 classification test on Ultra96v2:
```shell
python ultra96_test.py
```
Run CIFAR10 classification test on ZCU104:
```python
python zcu104_test.py
```
### Citation
### Citation
If you find this work helpful, please consider citing it:
```BibTex
@article{li2023firefly,
title={FireFly: A High-Throughput Hardware Accelerator for Spiking Neural Networks With Efficient DSP and Memory Optimization},
author={Li, Jindong and Shen, Guobin and Zhao, Dongcheng and Zhang, Qian and Zeng, Yi},
journal={IEEE Transactions on Very Large Scale Integration (VLSI) Systems},
year={2023},
publisher={IEEE}
}
```
================================================
FILE: examples/Hardware_acceleration/firefly_v1_schedule_on_pynq.py
================================================
import numpy as np
import tqdm
from standalone_utils import *
import math
import time
import ctypes as ct
class FireFlyV1ConvSchedule:
def __init__(
self,
ctrl_io,
allocate_method,
input_buffer_addr,
output_buffer_addr,
weight_data,
bias_data,
parallel_channel=16,
kernel_size=3,
input_channels=64,
output_channels=128,
width=32,
height=32,
enable_pooling=False,
direct_adapt=False,
winner_takes_all=False,
final_conv=False,
time_step=8,
threshold=64,
max_cnt=2048
):
self.ctrl_io = ctrl_io
self.input_buffer_addr = np.uint32(input_buffer_addr)
self.output_buffer_addr = np.uint32(output_buffer_addr)
self.weight_buffer = allocate_method(shape=weight_data.size, dtype=np.int8)
self.bias_buffer = allocate_method(shape=bias_data.size, dtype=np.int16)
self.weight_buffer_addr = np.uint32(self.weight_buffer.device_address)
self.bias_buffer_addr = np.uint32(self.bias_buffer.device_address)
self.weight_buffer[:] = np.ascontiguousarray(weight_data.flatten())
self.bias_buffer[:] = np.ascontiguousarray(bias_data.flatten())
self.weight_buffer.flush()
self.bias_buffer.flush()
self.max_cnt = max_cnt
self.parallel_channel = np.uint32(parallel_channel)
self.kernel_size = np.uint32(kernel_size)
self.input_channels = np.uint32(input_channels)
self.output_channels = np.uint32(output_channels)
self.width = np.uint32(width)
self.height = np.uint32(height)
self.enable_pooling = np.uint32(enable_pooling)
self.direct_adapt = np.uint32(direct_adapt)
self.winner_takes_all = np.uint32(winner_takes_all)
self.time_step = np.uint32(time_step)
self.threshold = np.int32(threshold)
self.out_width = np.uint32(width >> enable_pooling)
self.out_height = np.uint32(height >> enable_pooling)
self.numOfIFMs = np.uint32(input_channels / parallel_channel - 1)
self.numOfOFMs = np.uint32(output_channels / parallel_channel - 1)
self.numOfTimeSteps = np.uint32(time_step - 1)
self.numOfTimeStepIFMs = np.uint32((input_channels / parallel_channel) * time_step - 1)
self.numOfTimeStepOFMs = np.uint32((output_channels / parallel_channel) * time_step - 1)
self.weightsLength = np.uint32(input_channels - 1)
if direct_adapt:
factor = kernel_size * kernel_size
padded_length = math.ceil(input_channels / parallel_channel / factor)
self.numOfIFMs = np.uint32(padded_length - 1)
self.numOfTimeStepIFMs = np.uint32(padded_length * time_step - 1)
self.weightsLength = np.uint32(padded_length * parallel_channel - 1)
self.out_width = np.uint32(1)
self.out_height = np.uint32(1)
self.mm2s_fix_len = np.uint32(self.width * self.height * self.time_step * self.input_channels / 8)
self.s2mm_fix_len = np.uint32(self.out_width * self.out_height * self.parallel_channel / 8)
self.bias_len = np.uint32(self.output_channels * 2)
self.weight_len = np.uint32(self.output_channels * self.input_channels * self.kernel_size * self.kernel_size)
self.stride_of_channel = np.uint32(self.out_width * self.out_height * self.parallel_channel / 8)
self.stride_of_time_step = np.uint32(self.out_width * self.out_height * self.output_channels / 8)
if direct_adapt:
self.mm2s_fix_len = np.uint32(self.time_step * self.input_channels / 8)
self.weight_len = np.uint32(self.output_channels * self.input_channels)
self.stride_of_channel = np.uint32(2 * self.parallel_channel / 8)
self.stride_of_time_step = np.uint32(2 * self.output_channels / 8)
if final_conv:
self.flatten_channel = np.uint32(self.out_width * self.out_height * self.output_channels)
factor = kernel_size * kernel_size * 8 * 4
round_channel = int(math.ceil(self.flatten_channel / factor) * factor)
self.stride_of_time_step = np.uint32(round_channel / 8)
self.configReg_0x00 = np.uint32(((self.time_step - 1) << 16) + (self.numOfOFMs << 8) + self.numOfIFMs).tobytes()
self.configReg_0x04 = np.uint32((self.numOfTimeStepOFMs << 12) + self.numOfTimeStepIFMs).tobytes()
self.configReg_0x08 = np.uint32((self.threshold << 14) + self.weightsLength).tobytes()
self.configReg_0x0c = np.uint32((self.winner_takes_all << 30) + (self.direct_adapt << 29) + (
self.enable_pooling << 28) + ((self.height - 1) << 16) + self.width - 1).tobytes()
self.configReg_0x20 = np.uint32(self.stride_of_time_step).tobytes()
self.configReg_0x24 = np.uint32(self.stride_of_channel).tobytes()
self.configReg_0x28 = np.uint32(self.input_buffer_addr).tobytes()
self.configReg_0x2c = np.uint32(self.output_buffer_addr).tobytes()
self.configReg_0x30 = np.uint32(self.mm2s_fix_len).tobytes()
self.configReg_0x34 = np.uint32(self.s2mm_fix_len).tobytes()
self.configReg_0x38 = np.uint32(self.weight_buffer_addr).tobytes()
self.configReg_0x3c = np.uint32(self.weight_len).tobytes()
self.configReg_0x40 = np.uint32(self.bias_buffer_addr).tobytes()
self.configReg_0x44 = np.uint32(self.bias_len).tobytes()
self.paramCmd = np.uint32(0x00010000).tobytes()
self.inOutCmd = np.uint32(0x00000101).tobytes()
def gen_cmd(self):
cmd_list = []
cmd_list.append(np.frombuffer(self.configReg_0x00, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x04, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x08, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x0c, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x20, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x24, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x28, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x2c, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x30, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x34, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x38, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x3c, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x40, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x44, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.paramCmd, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.inOutCmd, dtype=np.uint32))
return np.array(cmd_list).flatten()
def send_config(self):
self.ctrl_io.write(0x00, self.configReg_0x00)
self.ctrl_io.write(0x04, self.configReg_0x04)
self.ctrl_io.write(0x08, self.configReg_0x08)
self.ctrl_io.write(0x0c, self.configReg_0x0c)
self.ctrl_io.write(0x20, self.configReg_0x20)
self.ctrl_io.write(0x24, self.configReg_0x24)
self.ctrl_io.write(0x28, self.configReg_0x28)
self.ctrl_io.write(0x2c, self.configReg_0x2c)
self.ctrl_io.write(0x30, self.configReg_0x30)
self.ctrl_io.write(0x34, self.configReg_0x34)
self.ctrl_io.write(0x38, self.configReg_0x38)
self.ctrl_io.write(0x3c, self.configReg_0x3c)
self.ctrl_io.write(0x40, self.configReg_0x40)
self.ctrl_io.write(0x44, self.configReg_0x44)
def begin_schedule_non_blocking(self):
self.ctrl_io.write(0x48, self.paramCmd)
self.ctrl_io.write(0x48, self.paramCmd)
self.ctrl_io.write(0x48, self.inOutCmd)
def begin_schedule_blocking(self):
self.begin_schedule_non_blocking()
while self.ctrl_io.read(0x18, length=8) == 0:
continue
self.clear_schedule()
def clear_schedule(self):
self.ctrl_io.write(0x18, 0)
def run_all(self):
self.ctrl_io.write(0x00, self.configReg_0x00)
self.ctrl_io.write(0x04, self.configReg_0x04)
self.ctrl_io.write(0x08, self.configReg_0x08)
self.ctrl_io.write(0x0c, self.configReg_0x0c)
self.ctrl_io.write(0x20, self.configReg_0x20)
self.ctrl_io.write(0x24, self.configReg_0x24)
self.ctrl_io.write(0x28, self.configReg_0x28)
self.ctrl_io.write(0x2c, self.configReg_0x2c)
self.ctrl_io.write(0x30, self.configReg_0x30)
self.ctrl_io.write(0x34, self.configReg_0x34)
self.ctrl_io.write(0x38, self.configReg_0x38)
self.ctrl_io.write(0x3c, self.configReg_0x3c)
self.ctrl_io.write(0x40, self.configReg_0x40)
self.ctrl_io.write(0x44, self.configReg_0x44)
self.ctrl_io.write(0x48, self.paramCmd)
self.ctrl_io.write(0x48, self.paramCmd)
self.ctrl_io.write(0x48, self.inOutCmd)
cnt = 0
while self.ctrl_io.read(0x18, length=8) == 0:
cnt = cnt + 1
if cnt > self.max_cnt:
print("timeout, abort!")
break
end = time.time()
self.ctrl_io.write(0x18, 0)
def read_status(self):
status = np.uint32(self.ctrl_io.read(0x50, length=4)).tobytes()
busy_status = status[0]
input_status = status[1]
output_status = status[2]
param_status = status[3]
print("busy_status", busy_status)
print("input_status", input_status)
print("output_status", output_status)
print("param_status", param_status)
def create_schedule(model_config_list: list,
ctrl_io,
allocate_method,
buffer_0,
buffer_1,
image_height,
image_width,
time_step=4,
parallel_channel=16
):
schedule_list = []
curr_image_height = image_height
curr_image_width = image_width
input_buffer_addr = buffer_0.device_address
output_buffer_addr = buffer_1.device_address
for config in model_config_list:
if config["layer_type"] == "conv+IFNode":
schedule = FireFlyV1ConvSchedule(
ctrl_io=ctrl_io,
allocate_method=allocate_method,
input_buffer_addr=input_buffer_addr,
output_buffer_addr=output_buffer_addr,
weight_data=conv_weight_channel_tiling(parallel_channel, config["weight"]),
bias_data=config["bias"].flatten(),
parallel_channel=parallel_channel,
kernel_size=3,
input_channels=config["input_channel"],
output_channels=config["output_channel"],
width=curr_image_width,
height=curr_image_height,
enable_pooling=False,
time_step=time_step,
threshold=config["threshold"],
final_conv="flatten" in config
)
schedule_list.append(schedule)
input_buffer_addr, output_buffer_addr = output_buffer_addr, input_buffer_addr
elif config["layer_type"] == "conv+IFNode+maxpool":
schedule = FireFlyV1ConvSchedule(
ctrl_io=ctrl_io,
allocate_method=allocate_method,
input_buffer_addr=input_buffer_addr,
output_buffer_addr=output_buffer_addr,
weight_data=conv_weight_channel_tiling(parallel_channel, config["weight"]),
bias_data=config["bias"].flatten(),
parallel_channel=parallel_channel,
kernel_size=3,
input_channels=config["input_channel"],
output_channels=config["output_channel"],
width=curr_image_width,
height=curr_image_height,
enable_pooling=True,
time_step=time_step,
threshold=config["threshold"],
final_conv="flatten" in config
)
schedule_list.append(schedule)
input_buffer_addr, output_buffer_addr = output_buffer_addr, input_buffer_addr
curr_image_height = int(curr_image_height / 2)
curr_image_width = int(curr_image_width / 2)
elif config["layer_type"].__contains__("linear"):
input_channel = config["input_channel"]
weight = config["weight"]
if "weight_reshape" in config:
factor = 9 * 8 * 4
round_channel = int(math.ceil(input_channel / factor) * factor)
weight = rearrange(weight, "o (i p h w) -> o (i h w p)", p=parallel_channel,
h=curr_image_height, w=curr_image_width)
weight = np.pad(weight, ((0, 0), (0, round_channel - input_channel)), mode="constant")
input_channel = round_channel
weight = linear_weight_channel_tiling(parallel_channel, weight)
schedule = FireFlyV1ConvSchedule(
ctrl_io=ctrl_io,
allocate_method=allocate_method,
input_buffer_addr=input_buffer_addr,
output_buffer_addr=output_buffer_addr,
weight_data=weight,
bias_data=config["bias"].flatten(),
parallel_channel=parallel_channel,
kernel_size=3,
input_channels=input_channel,
output_channels=config["output_channel"],
width=3,
height=3,
enable_pooling=False,
time_step=time_step,
threshold=config["threshold"],
direct_adapt=config["direct_adapt"],
winner_takes_all=config["winner_take_all"]
)
schedule_list.append(schedule)
input_buffer_addr, output_buffer_addr = output_buffer_addr, input_buffer_addr
return schedule_list, input_buffer_addr
def schedule_run_all(schedule_list):
for schedule in schedule_list:
schedule.run_all()
def gen_cmd_array(schedule_list):
cmd_array = []
for schedule in schedule_list:
cmd_array.append(schedule.gen_cmd().flatten())
return np.array(cmd_array)
def init_firefly_c_lib(path, schedule_list):
cmd_arr = gen_cmd_array(schedule_list)
lib = ct.CDLL(path)
sche = lib.firefly_v1_schedule
u32Ptr = ct.POINTER(ct.c_uint32)
u32PtrPtr = ct.POINTER(u32Ptr)
ct_arr = np.ctypeslib.as_ctypes(cmd_arr)
u32PtrArr = u32Ptr * ct_arr._length_
ct_ptr = ct.cast(u32PtrArr(*(ct.cast(row, u32Ptr) for row in ct_arr)), u32PtrPtr)
sche_len = ct.c_uint8(cmd_arr.shape[0])
return sche, ct_ptr, sche_len
def init_firefly_c_lib_with_time(path, schedule_list):
cmd_arr = gen_cmd_array(schedule_list)
lib = ct.CDLL(path)
sche = lib.firefly_v1_schedule_time_it
u32Ptr = ct.POINTER(ct.c_uint32)
u32PtrPtr = ct.POINTER(u32Ptr)
ct_arr = np.ctypeslib.as_ctypes(cmd_arr)
u32PtrArr = u32Ptr * ct_arr._length_
ct_ptr = ct.cast(u32PtrArr(*(ct.cast(row, u32Ptr) for row in ct_arr)), u32PtrPtr)
sche_len = ct.c_uint8(cmd_arr.shape[0])
return sche, ct_ptr, sche_len
def firefly_v1_simulate(model_config_list, x):
for config in model_config_list:
if config["layer_type"] == "input_quant_stub":
x = np_quantize_prepare(x, config["scale"], config["zero_point"])
elif config["layer_type"] == "encoder+conv+IFNode":
x = direct_coding(x, config["weight"], config["bias"], config["time_step"], config["threshold"])
elif config["layer_type"] == "conv+IFNode":
x = conv_ifnode_forward(x, config["weight"], config["bias"], config["threshold"])
elif config["layer_type"] == "conv+IFNode+maxpool":
x = conv_ifnode_maxpool_forward(x, config["weight"], config["bias"], config["threshold"])
elif config["layer_type"] == "linear+WTA":
x = linear_wta_forward(x, config["weight"], config["bias"])
elif config["layer_type"] == "linear+IFNode":
x = linear_ifnode_forward(x, config["weight"], config["bias"], config["threshold"])
return x
def evaluate_simulate(model_config_list, sample):
correct = 0
for (image, target) in tqdm.tqdm(zip(sample[0], sample[1]), total=len(sample[0])):
sim_in = np.expand_dims(image.numpy(), axis=0)
_, sim_out = firefly_v1_simulate(model_config_list, sim_in)
correct += sim_out == target.item()
return correct / len(sample[0])
================================================
FILE: examples/Hardware_acceleration/standalone_utils.py
================================================
import math
import numpy as np
from einops import rearrange
def get_im2col_indices(x_shape, field_height, field_width, padding=1, stride=1):
N, C, H, W = x_shape
assert (H + 2 * padding - field_height) % stride == 0
assert (W + 2 * padding - field_height) % stride == 0
out_height = int((H + 2 * padding - field_height) / stride + 1)
out_width = int((W + 2 * padding - field_width) / stride + 1)
i0 = np.repeat(np.arange(field_height), field_width)
i0 = np.tile(i0, C)
i1 = stride * np.repeat(np.arange(out_height), out_width)
j0 = np.tile(np.arange(field_width), field_height * C)
j1 = stride * np.tile(np.arange(out_width), out_height)
i = i0.reshape(-1, 1) + i1.reshape(1, -1)
j = j0.reshape(-1, 1) + j1.reshape(1, -1)
k = np.repeat(np.arange(C), field_height * field_width).reshape(-1, 1)
return k, i, j
def im2col_indices(x, field_height, field_width, padding=1, stride=1):
p = padding
x_padded = np.pad(x, ((0, 0), (0, 0), (p, p), (p, p)), mode='constant')
k, i, j = get_im2col_indices(x.shape, field_height, field_width, padding, stride)
cols = x_padded[:, k, i, j]
C = x.shape[1]
cols = cols.transpose(1, 2, 0).reshape(field_height * field_width * C, -1)
return cols
def max_pool_forward_reshape(x, pool_param):
N, C, H, W = x.shape
pool_height, pool_width = pool_param['pool_height'], pool_param['pool_width']
stride = pool_param['stride']
assert pool_height == pool_width == stride, 'Invalid pool params'
assert H % pool_height == 0
assert W % pool_height == 0
x_reshaped = x.reshape(N, C, int(H / pool_height), pool_height, int(W / pool_width), pool_width)
out = x_reshaped.max(axis=3).max(axis=4)
return out
def max_pool_forward_fast(x, pool_param):
N, C, H, W = x.shape
pool_height, pool_width = pool_param['pool_height'], pool_param['pool_width']
stride = pool_param['stride']
same_size = pool_height == pool_width == stride
tiles = H % pool_height == 0 and W % pool_width == 0
if same_size and tiles:
out = max_pool_forward_reshape(x, pool_param)
else:
out = max_pool_forward_im2col(x, pool_param)
return out
def max_pool_forward_im2col(x, pool_param):
N, C, H, W = x.shape
pool_height, pool_width = pool_param['pool_height'], pool_param['pool_width']
stride = pool_param['stride']
assert (H - pool_height) % stride == 0, 'Invalid height'
assert (W - pool_width) % stride == 0, 'Invalid width'
out_height = int((H - pool_height) / stride + 1)
out_width = int((W - pool_width) / stride + 1)
x_split = x.reshape(N * C, 1, H, W)
x_cols = im2col_indices(x_split, pool_height, pool_width, padding=0, stride=stride)
x_cols_argmax = np.argmax(x_cols, axis=0)
x_cols_max = x_cols[x_cols_argmax, np.arange(x_cols.shape[1])]
out = x_cols_max.reshape(out_height, out_width, N, C).transpose(2, 3, 0, 1)
return out
def conv_forward_fast(x, w, b, pad=1, stride=1):
N, C, H, W = x.shape
# x = x.astype(np.int32)
w = w.astype(np.int32)
b = b.astype(np.int16)
num_filters, _, filter_height, filter_width = w.shape
out_height = int((H + 2 * pad - filter_height) / stride + 1)
out_width = int((W + 2 * pad - filter_width) / stride + 1)
out = np.zeros((N, num_filters, out_height, out_width), dtype=np.int32)
x_cols = im2col_indices(x, w.shape[2], w.shape[3], pad, stride)
res = w.reshape((w.shape[0], -1)).dot(x_cols) + b.reshape(-1, 1)
out = res.reshape(w.shape[0], out.shape[2], out.shape[3], x.shape[0])
out = out.transpose(3, 0, 1, 2)
return out
def spike_map_pack_to_bytes_array(spike_map, parallel):
buf_in = rearrange(spike_map, 't (c p) h w->t c h w p', p=parallel)
buf_in = np.packbits(buf_in.flatten(), bitorder='little')
return buf_in
def bytes_array_split_to_spike_map(buf_in, time_step, parallel, H, W):
unpacked = np.unpackbits(buf_in, bitorder='little')
unpacked = rearrange(unpacked, '(t c h w p)->t (c p) h w', t=time_step, p=parallel, h=H, w=W)
return unpacked
def preprocess(model_config_list, x, parallel):
time_step = model_config_list[1]["time_step"]
scale = model_config_list[0]["scale"]
zero_point = model_config_list[0]["zero_point"]
weight = model_config_list[1]["weight"]
bias = model_config_list[1]["bias"]
threshold = model_config_list[1]["threshold"]
encode_in = np_quantize_prepare(x, scale, zero_point)
encode_in = np.expand_dims(encode_in, axis=0)
firefly_in = direct_coding(encode_in, weight, bias, time_step, threshold)
packed = spike_map_pack_to_bytes_array(firefly_in, parallel)
return firefly_in, packed
def integrate_and_fire(y, threshold):
membrane = np.zeros(y.shape[1:], dtype=np.int32)
out_spike = []
for v in y:
membrane = membrane + v
o = membrane > threshold
out_spike.append(o)
membrane[o] = 0
return np.array(out_spike)
def direct_coding(x, w, b, time_step, threshold):
x = x.repeat(time_step, axis=0)
out_spike = conv_ifnode_forward(x, w, b, threshold)
return out_spike
def conv_ifnode_forward(x, w, b, threshold):
y = conv_forward_fast(x, w, b)
out_spike = integrate_and_fire(y, threshold)
return out_spike
def conv_ifnode_maxpool_forward(x, w, b, threshold):
y = conv_ifnode_forward(x, w, b, threshold)
out_spike = max_pool_forward_fast(y, {'pool_height': 2, 'pool_width': 2, 'stride': 2})
return out_spike
def linear_wta_forward(x, w, b):
x = x.astype(np.int32)
w = w.astype(np.int32)
b = b.astype(np.int32)
x = x.reshape([x.shape[0], -1])
x = np.pad(x, ((0, 0), (0, w.shape[1] - x.shape[1])), 'constant')
out = np.dot(x, w.T) + b
out_sum = out.sum(axis=0)
max_index = out_sum.argmax()
return out, max_index
def linear_ifnode_forward(x, w, b, threshold):
x = x.astype(np.int32)
w = w.astype(np.int32)
b = b.astype(np.int32)
x = x.reshape([x.shape[0], -1])
x = np.pad(x, ((0, 0), (0, w.shape[1] - x.shape[1])), 'constant')
out = np.dot(x, w.T) + b
out_spike = integrate_and_fire(out, threshold)
return out_spike
def pad_conv_weight_round_to_parallel(parallel, weight, pad_output_channel_only=False):
output_channel = weight.shape[0]
input_channel = weight.shape[1]
padded_output_channel = (parallel - (output_channel % parallel)) % parallel
padded_input_channel = (parallel - (input_channel % parallel)) % parallel
if pad_output_channel_only:
padded_input_channel = 0
new_weight = np.pad(weight, ((0, padded_output_channel), (0, padded_input_channel), (0, 0), (0, 0)), 'constant')
return new_weight
def pad_linear_weight_round_to_parallel(parallel, weight):
output_channel = weight.shape[0]
padded_output_channel = (parallel - (output_channel % parallel)) % parallel
new_weight = np.pad(weight, ((0, padded_output_channel), (0, 0)), 'constant')
return new_weight
def pad_linear_weight_round_to_factor(weight, factor):
input_channel = weight.shape[1]
round_channel = int(math.ceil(input_channel / factor) * factor)
padded_input_channel = round_channel - input_channel
new_weight = np.pad(weight, ((0, 0), (0, padded_input_channel)), 'constant')
return new_weight
def pad_bias_round_to_parallel(parallel, bias, pad_value=0):
channel = bias.shape[0]
padded_channel = (parallel - (channel % parallel)) % parallel
new_bias = np.pad(bias, (0, padded_channel), 'constant', constant_values=pad_value)
return new_bias
def np_quantize_per_tensor(x, scale, zero_point):
q_min = np.iinfo(np.int8).min
q_max = np.iinfo(np.int8).max
x = np.round(x / scale + zero_point)
x = np.clip(x, q_min, q_max)
return x.astype(np.int8)
def np_quantize_prepare(x, scale, zero_point):
x = np_quantize_per_tensor(x, scale, zero_point)
return x - zero_point
def conv_weight_channel_tiling(parallel, weight):
return rearrange(weight, '(o op) (i ip) kr kc -> (o i kr kc) ip op', op=parallel, ip=parallel)
def linear_weight_channel_tiling(parallel, weight):
return rearrange(weight, '(o op) (i ip) -> (o i) ip op', op=parallel, ip=parallel)
def conv_to_linear_weight_tiling(parallel, h, w, weight):
rearrange(weight, '(o op) (i ip h w)-> (o i h w) ip op', op=parallel, ip=parallel, h=h, w=w)
def init_input_buffer(input_spikes,
parallel=16,
stride_of_channel=8 * 1024,
stride_of_time_step=512 * 1024):
t, c, h, w = input_spikes.shape
input_spikes_rearrange = rearrange(input_spikes, 't (c p) h w -> t c (h w p)', p=parallel)
pack_spikes = np.packbits(input_spikes_rearrange, axis=-1, bitorder='little')
input_buffer = np.zeros(stride_of_time_step * t, dtype=np.uint8)
length = int(h * w * parallel / 8)
for i in range(t):
for j in range(int(c / parallel)):
addr = i * stride_of_time_step + j * stride_of_channel
input_buffer[addr:addr + length] = pack_spikes[i, j]
return input_buffer
def get_from_output_buffer(output_buffer,
t, c, h, w,
parallel=16,
stride_of_channel=8 * 1024,
stride_of_time_step=512 * 1024):
ret = []
length = int(h * w * parallel / 8)
for i in range(t):
for j in range(int(c / parallel)):
addr = i * stride_of_time_step + j * stride_of_channel
ret.append(output_buffer[addr:addr + length])
ret = np.array(ret)
ret = np.unpackbits(ret, axis=-1, bitorder='little')
ret = rearrange(ret, '(t c) (h w p) -> t (c p) h w', p=parallel, t=t, h=h, w=w)
return ret.astype(bool)
def get_output_index(buffer, parallel):
valid_data = buffer[:parallel]
if parallel == 16:
return np.unpackbits(valid_data[12:14], bitorder='little').argmax()
elif parallel == 32:
return np.unpackbits(valid_data[24:28], bitorder='little').argmax()
else:
return 0
def save_model_config_list(model_config_list, path):
np.save(path, model_config_list)
return
def load_model_config_list(path):
model_config_list = np.load(path, allow_pickle=True)
return model_config_list
================================================
FILE: examples/Hardware_acceleration/ultra96_test.py
================================================
from standalone_utils import *
from firefly_v1_schedule_on_pynq import *
from pynq import PL
from pynq import Overlay
from pynq import allocate
from pynq import MMIO
import numpy as np
import time
from einops import rearrange
ol = Overlay('firefly_v1_ultra96_bitstream/sys_wrapper.bit')
image = np.load("firefly_v1_cifar10_data/image.npy")
target = np.load("firefly_v1_cifar10_data/target.npy")
model_config_list = load_model_config_list("firefly_v1_cifar10_data/snn7_cifar10_x16.npy")
input_buffer = allocate(shape=(1<<23), dtype=np.uint8)
output_buffer = allocate(shape=(1<<23), dtype=np.uint8)
ctrl_io = MMIO(0x0400000000, 0x400)
schedule_list,output_addr=create_schedule(
model_config_list=model_config_list,
ctrl_io=ctrl_io,
allocate_method=allocate,
buffer_0=input_buffer,
buffer_1=output_buffer,
image_height=32,
image_width=32,
time_step=4,
parallel_channel=16
)
sche, ct_ptr, sche_len = init_firefly_c_lib_with_time("firefly_v1_common/firefly_v1_lib.so", schedule_list)
print(" ----------------- initialize finish!")
print(" ----------------- python schedule begin")
err_cnt = 0
for i in range(len(image)):
image_0 = image[i]
target_0 = target[i]
print(i)
start = time.time()
firefly_in, input_packed = preprocess(model_config_list, image_0, 16)
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
end = time.time()
elapsed = round((end - start) * 1000000)
# print("preprocess:", elapsed, "us")
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
start = time.time()
schedule_run_all(schedule_list)
end = time.time()
elapsed = round((end - start) * 1000000)
print("snn inference:", elapsed, "us")
output_buffer.invalidate()
test_out = output_buffer[:16]
test_index = np.unpackbits(test_out[12:14],bitorder='little').argmax()
print("test result:", test_index,"gold result", target_0)
if test_index != target_0:
err_cnt = err_cnt + 1
print("accuray: " , 1 - err_cnt/len(image))
print(" ----------------- python schedule finish")
print(" ----------------- c schedule begin")
err_cnt = 0
for i in range(len(image)):
image_0 = image[i]
target_0 = target[i]
print(i)
start = time.time()
firefly_in, input_packed = preprocess(model_config_list, image_0, 16)
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
end = time.time()
elapsed = round((end - start) * 1000000)
# print("preprocess:", elapsed, "us")
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
start = time.time()
sche(ct_ptr, sche_len)
end = time.time()
elapsed = round((end - start) * 1000000)
# print("clib inference call:", elapsed, "us")
output_buffer.invalidate()
test_out = output_buffer[:16]
test_index = np.unpackbits(test_out[12:14],bitorder='little').argmax()
print("test result:", test_index,"gold result", target_0)
if test_index != target_0:
err_cnt = err_cnt + 1
print("accuray: " , 1 - err_cnt/len(image))
print(" ----------------- c schedule finish")
================================================
FILE: examples/Hardware_acceleration/zcu104_test.py
================================================
from standalone_utils import *
from firefly_v1_schedule_on_pynq import *
from pynq import PL
from pynq import Overlay
from pynq import allocate
from pynq import MMIO
import numpy as np
import time
from einops import rearrange
ol = Overlay('firefly_v1_zcu104_bitstream/sys_wrapper.bit')
image = np.load("firefly_v1_cifar10_data/image.npy")
target = np.load("firefly_v1_cifar10_data/target.npy")
model_config_list = load_model_config_list("firefly_v1_cifar10_data/snn7_cifar10_x32.npy")
input_buffer = allocate(shape=(1<<23), dtype=np.uint8)
output_buffer = allocate(shape=(1<<23), dtype=np.uint8)
ctrl_io = MMIO(0x0400000000, 0x400)
schedule_list,output_addr=create_schedule(
model_config_list=model_config_list,
ctrl_io=ctrl_io,
allocate_method=allocate,
buffer_0=input_buffer,
buffer_1=output_buffer,
image_height=32,
image_width=32,
time_step=4,
parallel_channel=32
)
sche, ct_ptr, sche_len = init_firefly_c_lib_with_time("firefly_v1_common/firefly_v1_lib.so", schedule_list)
print(" ----------------- initialize finish!")
print(" ----------------- python schedule begin")
err_cnt = 0
for i in range(len(image)):
image_0 = image[i]
target_0 = target[i]
print(i)
start = time.time()
firefly_in, input_packed = preprocess(model_config_list, image_0, 32)
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
end = time.time()
elapsed = round((end - start) * 1000000)
# print("preprocess:", elapsed, "us")
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
start = time.time()
schedule_run_all(schedule_list)
end = time.time()
elapsed = round((end - start) * 1000000)
print("snn inference:", elapsed, "us")
output_buffer.invalidate()
test_out = output_buffer[:32]
test_index = np.unpackbits(test_out[24:28],bitorder='little').argmax()
print("test result:", test_index,"gold result", target_0)
if test_index != target_0:
err_cnt = err_cnt + 1
print("accuray: " , 1 - err_cnt/len(image))
print(" ----------------- python schedule finish")
print(" ----------------- c schedule begin")
err_cnt = 0
for i in range(len(image)):
image_0 = image[i]
target_0 = target[i]
print(i)
start = time.time()
firefly_in, input_packed = preprocess(model_config_list, image_0, 32)
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
end = time.time()
elapsed = round((end - start) * 1000000)
# print("preprocess:", elapsed, "us")
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
start = time.time()
sche(ct_ptr, sche_len)
end = time.time()
elapsed = round((end - start) * 1000000)
# print("clib inference call:", elapsed, "us")
output_buffer.invalidate()
test_out = output_buffer[:32]
test_index = np.unpackbits(test_out[24:28],bitorder='little').argmax()
print("test result:", test_index,"gold result", target_0)
if test_index != target_0:
err_cnt = err_cnt + 1
print("accuray: " , 1 - err_cnt/len(image))
print(" ----------------- c schedule finish")
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/CKRGSNN/README.md
================================================
# Commonsense Knowledge Representation SNN
(https://arxiv.org/abs/2207.05561)
This repository contains code from our paper [**Brain-inspired Graph Spiking Neural Networks for Commonsense Knowledge Representation and Reasoning**] preprint in: https://arxiv.org/abs/2207.05561 . If you use our code or refer to this project, please cite this paper.
## Requirments
* python=3.8
* numpy
* scipy
* turicreate
* pytorch >= 1.7.0
* torchvision
## Dataset
ConceptNet: https://github.com/commonsense/conceptnet5
## Run
```shell
python main.py
```
This module selects core knowledge in ConceptNet to form the sub_Concept.csv file as the input of the model. The input current, spike trains during the learning process and the network weight distribution after the learning are shown in the Results folder.
### Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{KRRfang2022,
title = {Brain-inspired Graph Spiking Neural Networks for Commonsense Knowledge Representation and Reasoning},
author = { Fang, Hongjian and Zeng, Yi and Tang, Jianbo and Wang, Yuwei and Liang, Yao and Liu, Xin},
journal = {arXiv preprint arXiv:2207.05561},
year = {2022}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/CKRGSNN/main.py
================================================
import time
import numpy as np
import os
import warnings
import scipy.io as scio
import math
from matplotlib import pyplot as plt
import torch
from braincog.base.node.node import *
import turicreate as tc
from braincog.base.brainarea.BrainArea import *
from braincog.utils import *
warnings.filterwarnings('ignore')
np.set_printoptions(threshold=np.inf)
class CKRNet(BrainArea):
"""
Commonsense Knowledge Representation Net
"""
def __init__(self, w1, w2):
"""
"""
super().__init__()
self.node = [LIFNode(threshold=16, tau=15)]
self.connection = [CustomLinear(w1), CustomLinear(w2)]
self.stdp = []
self.stdp.append(MutliInputSTDP(self.node[0], [self.connection[0], self.connection[1]], decay=0.83))
self.x1 = torch.zeros(1, w2.shape[0])
def forward(self, x):
"""
x is spike train
"""
self.x1, dw1 = self.stdp[0](self.x1, x)
return self.x1, dw1
def reset(self):
self.x1 *= 0
def S_bound(S):
S[S > synapse_bound] = synapse_bound
S[S < -synapse_bound] = -synapse_bound
for i in range(N_entity):
temp1 = S[Index_E[i], :]
temp2 = temp1[:, Index_E[i]]
temp2[temp2 > inner_bound_E] = inner_bound_E
temp1[:, Index_E[i]] = temp2
S[Index_E[i], :] = temp1
for i in range(N_relation):
temp1 = S[Index_R[i], :]
temp2 = temp1[:, Index_R[i]]
temp2[temp2 > inner_bound_R] = inner_bound_R
temp1[:, Index_R[i]] = temp2
S[Index_R[i], :] = temp1
return S
if __name__ == "__main__":
print(os.getcwd())
KG = tc.SFrame.read_csv('./sub_Conceptnet.csv')
Set_R = set()
Set_E = set()
for i in range(KG.shape[0]):
Set_R.add(KG[i]['Relation'])
Set_E.add(KG[i]['Head'])
Set_E.add(KG[i]['Tail'])
List_E = sorted(Set_E)
List_R = list(Set_R)
List_R.sort()
# Network Parameter#dkenf.kejlklkelkvjlkxjel
I_syn = 5
tau_m = 30
I_t = 3 # Time duration of stimu current
I_P = 150 # Strength of input current
A_P = 0.009
certainty = 0.2
synapse_bound = 1 # The bound of all synapse
inner_bound_E = 0.6 # The bound of population inner synapse
inner_bound_R = 0.3 # The bound of population inner synapse
Ce = 20 # num of entity
Cr = 100 # num of relation
N_entity = len(List_E)
N_relation = len(List_R)
total_neurons = Ce * N_entity + Cr * N_relation
KG_No = KG.shape[0]
trail_time = 40
runtime = KG_No * trail_time
print('N_entity=', N_entity)
print('N_relation=', N_relation)
print('KG_No=', KG_No)
print('runtime=', runtime)
print('total_neurons=', total_neurons)
S = np.zeros((total_neurons, total_neurons), dtype=float) # Initial Weights
S = torch.tensor(S, dtype=torch.float32)
E = np.identity((total_neurons), dtype=float)
E = torch.tensor(E, dtype=torch.float32)
I_stimu = np.zeros((total_neurons, runtime))
ADJ = np.zeros((total_neurons, runtime)) # record the firing condition
Index_E = []
Index_R = []
for i in range(N_entity):
Index_E.append(np.arange(i * Ce, i * Ce + Ce))
for i in range(N_relation):
Index_R.append(np.arange(N_entity * Ce + i * Cr, N_entity * Ce + i * Cr + Cr))
for i in range(KG_No):
Head = KG[i]['Head']
Rela = KG[i]['Relation']
Tail = KG[i]['Tail']
Weig = KG[i]['Weight']
# print(List_E.index(Head))
# print(List_R.index(Rela))
# print(List_E.index(Rela))
# print(Index_R[List_R.index(Rela)])
I_stimu[Index_E[List_E.index(Head)], 10 + i * trail_time: 10 + I_t + i * trail_time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[Index_R[List_R.index(Rela)], 15 + i * trail_time: 15 + I_t + i * trail_time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[Index_E[List_E.index(Tail)], 20 + i * trail_time: 20 + I_t + i * trail_time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
CKRGSNN = CKRNet(S, E)
for t in range(runtime):
I_input = torch.tensor(I_stimu[:, t].reshape(1, total_neurons), dtype=torch.float32)
x, dw = CKRGSNN(I_input)
S += A_P * dw[1]
S += S_bound(S) - S
ADJ[:, t] = x
print(t, 'step in >>', runtime)
img_I = plt.matshow(I_stimu)
plt.savefig("I_stimu1.jpg", dpi=500, bbox_inches='tight')
img_ADJ = plt.matshow(ADJ)
plt.savefig("ADJ1.jpg", dpi=500, bbox_inches='tight')
img_S = plt.matshow(S)
plt.colorbar()
plt.savefig("S1.jpg", dpi=500, bbox_inches='tight')
plt.show()
S = np.mat(S)
dataNew = './data_save.mat'
scio.savemat(dataNew, {'I_stimu': I_stimu, 'ADJ': ADJ, 'Weight': S})
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/CKRGSNN/sub_Conceptnet.csv
================================================
Relation,Head,Tail,Weight
antonym,ab_extra,ab_intra,1.0
antonym,ab_intra,ab_extra,1.0
antonym,abactinal,actinal,1.0
antonym,abandon,acquire,1.0
antonym,abandon,arrogate,1.0
antonym,abandon,embrace,1.0
antonym,abandon,engage,1.0
antonym,abandon,gain,1.0
antonym,abandon,join,1.0
antonym,abandon,maintain,1.0
antonym,abandon,retain,1.0
antonym,abandon,unite,1.0
atlocation,clock,department_store,1.0
atlocation,clock,desk,4.472
atlocation,clock,house,2.828
atlocation,clock,office,2.0
atlocation,crisps,table,1.0
atlocation,crisps,vending_machines,1.0
atlocation,crockery,cupboard,1.0
atlocation,crocs,united_states,0.5
atlocation,fungus,damp_spot,1.0
atlocation,fungus,damp_warm_place,1.0
atlocation,fungus,damp_wood,2.0
atlocation,fungus,damp_woods,1.0
atlocation,fungus,dank_place,1.0
atlocation,fungus,dark,1.0
atlocation,fungus,dark_and_dank_place,1.0
atlocation,fungus,dark_damp_area,2.828
atlocation,fungus,dark_damp_place,2.0
atlocation,carnival_rides,fairgrounds,1.0
atlocation,carousel,carnival,2.828
atlocation,carpet,at_hotel,1.0
capableof,adult,drive_car,1.0
capableof,adult,drive_train,1.0
capableof,adult,explain_rules_to_child,1.0
capableof,adult,feed_and_take_care_of_itself,1.0
capableof,adult,gift_knowledge_to_child,1.0
capableof,adult,hand_toy_to_child,1.0
capableof,adult,help_child,3.464
capableof,adult,keep_property,1.0
capableof,adults,act_like_infants,1.0
capableof,adults,care_for_babies,1.0
capableof,adults,carry_infants,1.0
capableof,adults,count,2.0
capableof,adults,demand_respect_from_children,1.0
capableof,adults,dress_themselves,2.828
capableof,adults,drink_beer,2.0
capableof,adults,drive_vehicle,1.0
capableof,adults,eat_sushi,2.0
capableof,adults,fail_to_pass_test,1.0
causes,competing_against,testing_yourself_against_another_person,1.0
causes,competing_against,try_hardest,1.0
causes,computing_sum,get_total_amount,1.0
causes,computing_sum,getting_answer,4.899
causes,computing_sum,getting_right_answer,1.0
causes,computing_sum,getting_total,1.0
causes,computing_sum,having_answer,2.0
causes,computing_sum,having_total,1.0
causes,computing_sum,headache,3.464
causes,computing_sum,insight,1.0
causes,computing_sum,know_total,2.0
causes,computing_sum,knowing_total,1.0
causes,computing_sum,may_get_wrong_answer,1.0
causes,computing_sum,number,1.0
causes,computing_sum,obtaining_total,1.0
causes,computing_sum,reaching_total,1.0
causes,computing_sum,receiving_total,1.0
desires,person,have_day_off,1.0
desires,person,have_diamonds,2.0
desires,person,have_easy,1.0
desires,person,have_enough_food,2.0
desires,person,have_enough_to_eat,1.0
desires,person,have_everyone_happy_with,2.0
desires,person,have_everything,1.0
desires,person,have_fast_internet_acess,1.0
desires,person,have_femily,1.0
desires,person,have_firm_body,1.0
desires,person,have_fond_memories,1.0
desires,person,have_fortune,1.0
desires,person,have_free_time,1.0
desires,person,have_friends,1.0
desires,person,have_fulfilling_life,1.0
desires,person,have_fun_in_life,2.0
desires,person,have_fun_on_weekends,1.0
desires,person,have_fun_weekend,2.0
desires,person,have_future,1.0
desires,person,have_good_bones,1.0
desires,person,have_good_day,2.828
desires,person,have_good_eyesight,1.0
desires,person,have_good_feelings,1.0
desires,person,have_good_friends,2.828
desires,person,have_good_life,1.0
desires,person,have_good_memories,2.0
desires,person,have_good_memory,1.0
desires,person,have_good_relationships_with_others,1.0
desires,person,have_good_skin,1.0
desires,person,have_great_sex,2.0
desires,person,have_happy_childhood,1.0
desires,person,have_happy_family,1.0
desires,person,have_healthy_life,1.0
desires,person,have_healthy_sex_life,1.0
desires,person,have_home_to_live_in,2.828
desires,person,have_hot_water,1.0
desires,person,have_influence,1.0
desires,person,have_inner_peace,2.828
desires,person,have_interesting_job,1.0
desires,person,have_large_vocabulary,1.0
desires,person,have_lasting_friendships,1.0
desires,person,have_long_live,2.0
desires,person,have_loving_family,1.0
desires,person,have_many_good_friends,2.0
desires,person,have_meaningful_life,2.0
desires,person,have_minimum_necessities_of_life,1.0
desires,person,have_money_to_buy_chocolate,2.0
desires,person,have_more,1.0
hascontext,bridge,card_games,1.0
hascontext,bridge,communication,1.0
hascontext,bridge,computing,1.0
hascontext,bridge,music,1.0
hascontext,bridge,wrestling,1.0
hascontext,bridge_and_tunnel,new_york_city,1.0
hascontext,bridge_and_tunnel,pejorative,1.0
hascontext,bridge_and_tunnel,slang,1.0
hassubevent,maintain_good_health,avoid_guns,1.0
hassubevent,maintain_good_health,avoid_hate,1.0
hassubevent,maintain_good_health,avoid_heavily_processed_foods,2.0
hassubevent,maintain_good_health,avoid_highly_processed_food,1.0
hassubevent,maintain_good_health,avoid_illegal_drugs,1.0
hassubevent,maintain_good_health,avoid_losing_sleep,1.0
hassubevent,maintain_good_health,avoid_marijuana,1.0
hassubevent,maintain_good_health,avoid_much_sunlight,1.0
hassubevent,maintain_good_health,avoid_poison,1.0
hassubevent,maintain_good_health,avoid_racism,1.0
hassubevent,maintain_good_health,avoid_smoking_marijuana,1.0
hassubevent,maintain_good_health,avoid_smoking_tobacco,1.0
hassubevent,maintain_good_health,avoid_tobacco,1.0
hassubevent,maintain_good_health,avoid_unpleasant_people,1.0
hassubevent,maintain_good_health,avoid_war,1.0
hassubevent,maintain_good_health,become_vegan,1.0
hassubevent,maintain_good_health,calm,1.0
hassubevent,maintain_good_health,care_about_people,1.0
hassubevent,maintain_good_health,chew_food_well,1.0
hassubevent,maintain_good_health,determine_nutritional_needs,1.0
hassubevent,maintain_good_health,do_exercise,1.0
hassubevent,maintain_good_health,dress_warmly_in_cold_weather,1.0
hassubevent,maintain_good_health,drink_very_little_alcoholic_beverages,1.0
hassubevent,maintain_good_health,drive_safely,1.0
hassubevent,maintain_good_health,eat_apple_day,1.0
hassubevent,maintain_good_health,eat_enough_and_exercise,1.0
hassubevent,maintain_good_health,eat_foods_containing_fiber,1.0
hassubevent,maintain_good_health,excersize,1.0
hassubevent,maintain_good_health,exercise,1.0
hassubevent,maintain_good_health,have_fullfilled_sex_life,1.0
hassubevent,maintain_good_health,have_spouse,1.0
hassubevent,maintain_good_health,leave_cat_alone,1.0
hassubevent,maintain_good_health,live_healthy_lifestyle,1.0
hassubevent,maintain_good_health,loving,1.0
hassubevent,maintain_good_health,monitor_health_often,1.0
hassubevent,maintain_good_health,not_eat_too_much_sna,1.0
isa,antidiarrheal,medicine,2.0
isa,antidiarrheal_therapy,drug_therapy,1.0
isa,antidiuretic,medicine,2.0
isa,antidiuretic_agent,medicine,1.0
isa,antido,artificial_language,2.0
isa,antidorcas,mammal_genus,2.0
isa,antidoron,food,0.5
isa,antidote,neutralizer,1.0
isa,antidote,remedy,2.0
isa,antiemetic,medicine,1.0
isa,antiemetic,medicine,2.0
isa,antiemetic_therapy,drug_therapy,1.0
isa,antiepileptic,anticonvulsant,1.0
isa,antiestablishmentarianism,doctrine,2.0
isa,antietam,national_cemetery_in_maryland,1.0
isa,antifeminist,bigot,2.0
isa,antiferromagnetism,magnetism,2.0
isa,antifibrinolytic_agent,medicine,1.0
isa,antiflatulent,agent,2.0
isa,antifouling_paint,paint,2.0
isa,antifreeze,automotive_fluid,1.0
isa,antifreeze,liquid,2.0
isa,antifungal,agent,2.0
isa,antigen,antigen,1.0
isa,antigen,carbohydrate,1.0
isa,antigen,tangible_thing,1.0
isa,antigen,substance,2.0
isa,antigenes,person,0.5
isa,antigenic_determinant,site,2.0
isa,antigone,play,0.5
isa,antigonia,fish_genus,2.0
isa,antigonia,fish,0.5
isa,antigorite,serpentine,1.0
isa,antigorite,serpentine,1.0
isa,gardens,often_in_yards,1.0
isa,gardens,places_where_plants_grow,1.0
isa,gardens,pleasant_outdoor_place,1.0
isa,gardens,pleasant_places_to,1.0
isa,garding,town,0.5
isa,gardnerian_wicca,wicca,1.0
isa,gardon,river,0.5
isa,garfield,fictional_character,0.5
isa,garfield,station,0.5
isa,garfield,station,0.5
isa,garfish,fish,0.5
isa,gargamel,comics_character,0.5
isa,garganey,bird,0.5
isa,garlic,food_ingredient,1.0
isa,garlic,flavorer,2.0
isa,garlic,alliaceous_plant,2.0
isa,tire_iron,rigid_portable_object,1.0
isa,tire_iron,shaped_thing,1.0
isa,tire_iron,hand_tool,2.0
isa,tire_iron,lever,2.0
isa,tire_pump,useful_tool,1.0
isa,tire_pump,mechanical_pump,1.0
isa,tire_rotation,axis_constrained_rotation,1.0
isa,tire_sealant,automotive_product,1.0
isa,tire_sealant,sealant,1.0
isa,garlic_chive,alliaceous_plant,2.0
isa,garlic_clove,bulb,1.0
partof,paragraph,textual_document,1.0
partof,paragraph,text,2.0
partof,victoria,zambezi,2.0
partof,victoria,zambia,2.0
partof,victoria,zimbabwe,2.0
partof,victoria_land,antarctica,2.0
partof,vidalia,georgia,2.0
partof,video,television,2.0
partof,vienna,austria,2.0
partof,vienne,poitou_charentes,0.5
partof,vienne,france,2.0
partof,vientiane,laos,2.0
partof,vieques,puerto_rico,2.0
partof,vietnam,indochina,2.0
partof,viewfinder,camera,1.0
partof,vigo,galicia,0.5
partof,vigo,vigo,0.5
partof,vigo,galicia,0.5
partof,villa,asturias,0.5
partof,villahermosa,tabasco,0.5
partof,villahermosa,mexico,2.0
partof,villarreal,valencian_community,0.5
partof,vilnius,dzūkija,0.5
partof,vilnius,lithuania,0.5
partof,vilnius,lithuania,2.0
partof,visual_purple,rod,2.0
partof,visual_signal,visual_communication,2.0
partof,viti_levu,fiji_islands,2.0
partof,viña_del_mar,valparaíso,0.5
partof,vladivostok,russia,2.0
partof,vocabulary,language,2.0
partof,vocal_cord,larynx,2.0
partof,voider,body_armor,2.0
partof,volapük,international_auxiliary_language,0.5
partof,volcanic_crater,volcano,2.0
partof,volcano,south_park,0.5
partof,volcano_islands,japan,2.0
partof,volcano_islands,pacific,2.0
partof,volga,russia,2.0
partof,volgograd,russia,2.0
partof,volkhov,russia,2.0
partof,parthenon,athens,2.0
receivesaction,carpet,found_on_ground,1.0
receivesaction,carpet,used_as_floor_covering,1.0
receivesaction,carpeted_floors,found_in_many_kinds_of_buildings,1.0
receivesaction,carpeting,used_in_place_of_hardwood_floors,1.0
receivesaction,carpets,bought_at_carpet_stores,1.0
receivesaction,cartoons,animated,1.0
receivesaction,case,tried_in_appeals_court,1.0
receivesaction,cases,heard_in_court_of_law,1.0
receivesaction,cash,denominated_in_dollars,1.0
receivesaction,cash,earned,1.0
receivesaction,cash,measured_in_dollars_and_cents,1.0
receivesaction,castanets,bound_together_with_leather_string,1.0
receivesaction,castanets,used_in_form_of_dance,1.0
receivesaction,casual_describes_clothing,worn_for_comfort_and_function,1.0
receivesaction,cat,attracted_to_parakeets,1.0
receivesaction,cats,thought_to_hate_dogs,1.0
receivesaction,cats_and_dogs,treated_badly,1.0
receivesaction,cats_purr_when,contented,1.0
receivesaction,cattle,fed_in_feed_lots,1.0
receivesaction,cauldron,steeped_in_magical_tradition_and_mystery,1.0
receivesaction,cauliflower_and_broccoli,combined_into_one_super_vegetable,1.0
receivesaction,cavitron,used_in_brain_surgery,1.0
receivesaction,cds,bought_in_stores,1.0
receivesaction,cds_usually,made_from_plastic,1.0
receivesaction,cedar,used_as_shingles_on_houses,1.0
receivesaction,ceilings,painted_with_brush,1.0
receivesaction,ceilings_have_color_which,painted_onto,1.0
receivesaction,celebrity,associated_with_autographs,1.0
receivesaction,celebrity,associated_with_desire,1.0
receivesaction,celebrity,associated_with_fame,1.0
receivesaction,celebrity,associated_with_fans,1.0
relatedto,penis,tarse,1.0
relatedto,penis_pump,cock_pump,1.0
relatedto,penis_worm,priapulid,1.0
relatedto,penised,bedicked,1.0
relatedto,penitence,compunction,2.0
relatedto,penitence,remorse,1.0
relatedto,penitence,repentance,1.0
relatedto,penitence,repentance,2.0
relatedto,penitent,penaunt,1.0
relatedto,penitentiary,penitential,2.0
relatedto,penitentiary,jail,1.0
relatedto,penrose_diagram,carter_penrose_diagram,1.0
relatedto,penrose_process,penrose_mechanism,1.0
relatedto,penrose_staircase,penrose_stairs,1.0
relatedto,penrose_staircase,penrose_steps,1.0
relatedto,penrose_stairs,penrose_staircase,1.0
relatedto,penrose_stairs,penrose_steps,1.0
relatedto,penrose_steps,penrose_staircase,1.0
relatedto,penrose_steps,penrose_stairs,1.0
relatedto,penrose_triangle,penrose_triangle,0.5
relatedto,pensacola,pensacola,0.5
relatedto,pension,pension,0.5
relatedto,pension,hotel,1.0
relatedto,penstemon_linarioides,narrow_leaf_penstemon,2.0
relatedto,penstemon_newberryi,mountain_pride,2.0
relatedto,penstemon_palmeri,balloon_flower,2.0
relatedto,penstemon_rupicola,rock_penstemon,2.0
relatedto,penstemon_serrulatus,cascade_penstemon,2.0
relatedto,penstock,sluice,2.0
relatedto,penstock,sluicegate,2.0
relatedto,pent,shut_up,2.0
relatedto,pent_up,repressed,2.0
relatedto,penta,quinque,1.0
relatedto,pentaborane,pentaborane,0.5
relatedto,pentabromodiphenyl_ether,pentabromodiphenyl_ether,0.5
relatedto,pentabromodiphenyl_ether,pentabromodiphenyl_oxide,1.0
relatedto,pentacene,pentacene,0.5
relatedto,pentachloronitrobenzene,pentachloronitrobenzene,0.5
relatedto,pentagon,pentagon,0.5
relatedto,pentagonal,pentangular,2.0
relatedto,pentagram,pentacle,1.0
relatedto,pentagram,pentalpha,1.0
relatedto,pentagram,pentangle,1.0
relatedto,pentagram,pentacle,2.0
relatedto,pentagraph,pentagraph,0.5
relatedto,pentail,pen_tailed_treeshrew,1.0
relatedto,pentalpha,pentagram,1.0
relatedto,pentalpha,pentangle,1.0
relatedto,pentamethylbenzene,pentamethylbenzene,0.5
relatedto,pentamethylenetetrazol,pentylenetetrazol,2.0
relatedto,pentamidine,pentamidine,0.5
relatedto,pentanal,pentanal,0.5
relatedto,pentanal,pentanaldehyde,1.0
relatedto,pentanal,valeraldehyde,1.0
relatedto,pentane,pentane,0.5
relatedto,pentangle,pentacle,2.0
relatedto,pentanoate,valerate,1.0
relatedto,pentanoic_acid,valeric_acid,2.0
relatedto,pentanol,amyl_alcohol,1.0
relatedto,pentanol,pentyl_alcohol,1.0
relatedto,pentastomid,tongue_worm,2.0
relatedto,pentastomida,pentastomida,0.5
relatedto,pentateuch,books_of_moses,1.0
relatedto,pentateuch,law,1.0
relatedto,pentateuch,torah,1.0
relatedto,pentateuch,torah,2.0
relatedto,pentatone,pentatonic_scale,2.0
relatedto,pentatonic_scale,pentatonic_scale,0.5
relatedto,pentazocine,pentazocine,0.5
relatedto,pentazole,pentazole,0.5
relatedto,pentecost,pentecost,0.5
relatedto,pentecost,feast_of_weeks,1.0
relatedto,pentecost,shavuos,1.0
relatedto,pentecost,shavuot,1.0
relatedto,pentecost,whit,1.0
relatedto,pentecost,whit_sunday,1.0
relatedto,pentecost,whitsun,1.0
relatedto,pentecost,whitsunday,1.0
relatedto,pentecost,shavous,2.0
relatedto,pentecostal,pentecostalist,2.0
relatedto,pentecostalism,pentecostalism,0.5
relatedto,pentel,pentel,0.5
relatedto,pentelic,pentelican,1.0
relatedto,pentene,pentene,0.5
usedfor,gourmet_shop,buy_weird_food,1.0
usedfor,gourmet_shop,buying_imported_foods,1.0
usedfor,gourmet_shop,customers_who_knowlegeable_about_cooking,1.0
usedfor,gourmet_shop,fine_foods,1.0
usedfor,gourmet_shop,hard_to_find_foods,1.0
usedfor,gourmet_shop,icky_foods,1.0
usedfor,lip,pleasure,1.0
usedfor,lip,pouring,1.0
usedfor,vessel,containing_highway_for_blood_flow,1.0
usedfor,vessel,float,1.0
usedfor,vessel,hold_flowers,1.0
usedfor,vessel,moving,1.0
usedfor,vessel,moving_people_around,1.0
usedfor,vessel,navigate,1.0
usedfor,vessel,piloting,1.0
usedfor,vessel,sailing_on_ocean,1.0
usedfor,vessel,ship_goods,1.0
usedfor,vessel,shipping,2.0
usedfor,vessel,store_liquid,1.0
usedfor,vessel,storing_liquids,2.0
usedfor,vessel,transporting_things,1.0
usedfor,vessel,usually_staying_above_water,1.0
usedfor,veterinarians,sick_animals,1.0
usedfor,vibrator,entertain_yourself,1.0
usedfor,vibrator,get_off,1.0
usedfor,vibrator,increase_pleasure_during_sex,1.0
usedfor,vibrator,sexually_stimulate_yourself_or_else,1.0
usedfor,viewing_video,having_fun,1.0
usedfor,viewing_video,having_good_time,1.0
usedfor,viewing_video,learning,2.828
usedfor,viewing_video,learning_language,1.0
usedfor,viewing_video,learning_new,1.0
usedfor,viewing_video,relaxation,1.0
usedfor,viewing_video,relaxing,2.0
usedfor,viewing_video,reviewing_video,1.0
usedfor,viewing_video,spending_time_with_grandson,1.0
usedfor,viewing_video,watching_film,1.0
usedfor,viewing_video,watching_home_movies,1.0
usedfor,viewing_video,watching_memories,1.0
usedfor,viewing_video,watching_movie_star,1.0
usedfor,village,learning,1.0
usedfor,village,people_to_live_in,1.0
usedfor,village,playing,1.0
usedfor,village,raise_child,1.0
usedfor,village,sedentary_living,1.0
usedfor,viola,play_song,1.0
usedfor,viola,playing,1.0
usedfor,viola,playing_music,2.0
usedfor,viola,playing_sissy_music,1.0
usedfor,viola,sing_song,1.0
usedfor,violence,kill,1.0
usedfor,violence,terrorism,1.0
usedfor,violin,create_music,1.0
usedfor,violin,creating,2.0
usedfor,violin,creating_art,1.0
usedfor,violin,entertaining,1.0
usedfor,violin,entertainment,1.0
usedfor,violin,fu_n,1.0
usedfor,violin,making_lovely_music,1.0
usedfor,violin,mkae_annoying_noises,1.0
usedfor,violin,music,1.0
usedfor,violin,play_music,2.828
usedfor,violin,playing,1.0
usedfor,violin,playing_music,5.657
usedfor,violin,playing_music_on_stringed_instrument,1.0
usedfor,visa_card,acquiring_debt,1.0
usedfor,visa_card,adults_not_kids,1.0
usedfor,visiting_museum,entertainment,1.0
usedfor,visiting_museum,feeling_young,1.0
usedfor,visiting_museum,finding_out_about_past,1.0
usedfor,visiting_museum,finding_out_about_world,1.0
usedfor,visiting_museum,fun,2.0
usedfor,visiting_museum,getting_ideas_from_past_experiences,1.0
usedfor,visiting_museum,having_fun,1.0
usedfor,visiting_museum,having_fun_day,1.0
usedfor,visiting_museum,learing_about_past,1.0
usedfor,visiting_museum,learning_about_culture,1.0
usedfor,visiting_museum,learning_about_history,1.0
usedfor,visiting_museum,learning_about_other_places,1.0
usedfor,visiting_museum,learning_history,2.0
usedfor,lip,protect,1.0
usedfor,lip,speak,2.0
usedfor,lip,suck,2.0
usedfor,lip,whistling,2.0
usedfor,lips,communicate,2.828
usedfor,lips,flapping,1.0
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/CRSNN/README.md
================================================
# Causal Reasoning SNN
(https://10.1109/IJCNN52387.2021.9534102)
This repository contains code from our paper [**A Brain-Inspired Causal Reasoning Model Based on Spiking Neural Networks
**] published in 2021 International Joint Conference on Neural Networks (IJCNN). https://ieeexplore.ieee.org/abstract/document/9534102. If you use our code or refer to this project, please cite this paper.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
## Run
```shell
python main.py
```
This module builds an example of a brain-like causal inference spiking neural network model. The input causal graph is shown in figure causal_graph.png. The input current, spike trains during the learning process and the network weight distribution after the learning are shown in the Results folder.
### Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@inproceedings{fang2021CRSNN,
title={A Brain-Inspired Causal Reasoning Model Based on Spiking Neural Networks},
author={Fang, Hongjian and Zeng, Yi},
booktitle={2021 International Joint Conference on Neural Networks (IJCNN)},
pages={1--5},
year={2021},
organization={IEEE}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/CRSNN/main.py
================================================
import time
import numpy as np
import os
import warnings
import math
from matplotlib import pyplot as plt
import torch
from braincog.base.node.node import *
from braincog.base.brainarea.BrainArea import *
from braincog.utils import *
warnings.filterwarnings('ignore')
np.set_printoptions(threshold=np.inf)
class CRNet(BrainArea):
"""
网络结构类:CRNet(Causal Reasoning Net),定义了网络的结构,继承自BrainArea基类。
:param threshold: 神经元发放脉冲需要达到的阈值
:param tau: 神经元膜电位常数,控制膜电位衰减
:param decay:STDP机制衰减常数,控制STDP机制作用强度随时间变化
:param w1:神经网络内部连接权重
:param w2:外部输入电流到每个神经元的连接
"""
def __init__(self, w1, w2):
"""
"""
super().__init__()
self.node = [LIFNode(threshold=16, tau=15)]
self.connection = [CustomLinear(w1), CustomLinear(w2)]
self.stdp = []
self.stdp.append(MutliInputSTDP(self.node[0], [self.connection[0], self.connection[1]], decay=0.8))
self.x1 = torch.zeros(1, w2.shape[0])
def forward(self, x):
"""
一次时间步的前向传播过冲函数,计算脉冲发放情况和权重改变量
:param x1:经过该时间步后的脉冲发放情况
:param dw1:STDP机制在一个时间步后带来的权重改变量
"""
self.x1, dw1 = self.stdp[0](x, self.x1)
return self.x1, dw1
def reset(self):
self.x1 *= 0
def S_bound(S):
"""
S_bound:网络权重边界控制函数,主要功能为控制全网络突触连接权不超过阈值,维持弱连接
另外,本函数还需要将神经元组内部权重控制在一定的范围之内,以防神经元组不断重复激活自身的情况发生。
:param synapse_bound: 全网络的突触连接的阈值,以维持网络整体为弱连接
:param inner_bound: 神经元组内部突触连接的阈值,防止神经元组不断重复激活自身导致网络放电紊乱
"""
S[S > synapse_bound] = synapse_bound
S[S < -synapse_bound] = -synapse_bound
temp1 = S[E1_index, :]
temp2 = temp1[:, E1_index]
temp2[temp2 > inner_bound_E] = inner_bound_E
temp1[:, E1_index] = temp2
S[E1_index, :] = temp1
temp1 = S[E2_index, :]
temp2 = temp1[:, E2_index]
temp2[temp2 > inner_bound_E] = inner_bound_E
temp1[:, E2_index] = temp2
S[E2_index, :] = temp1
temp1 = S[E3_index, :]
temp2 = temp1[:, E3_index]
temp2[temp2 > inner_bound_E] = inner_bound_E
temp1[:, E3_index] = temp2
S[E3_index, :] = temp1
temp1 = S[E4_index, :]
temp2 = temp1[:, E4_index]
temp2[temp2 > inner_bound_E] = inner_bound_E
temp1[:, E4_index] = temp2
S[E4_index, :] = temp1
temp1 = S[E4_index, :]
temp2 = temp1[:, E4_index]
temp2[temp2 > inner_bound_E] = inner_bound_E
temp1[:, E4_index] = temp2
S[E4_index, :] = temp1
temp1 = S[E5_index, :]
temp2 = temp1[:, E5_index]
temp2[temp2 > inner_bound_E] = inner_bound_E
temp1[:, E5_index] = temp2
S[E5_index, :] = temp1
temp1 = S[R1_index, :]
temp2 = temp1[:, R1_index]
temp2[temp2 > inner_bound_R] = inner_bound_R
temp1[:, R1_index] = temp2
S[R1_index, :] = temp1
temp1 = S[R2_index, :]
temp2 = temp1[:, R2_index]
temp2[temp2 > inner_bound_R] = inner_bound_R
temp1[:, R2_index] = temp2
S[R2_index, :] = temp1
return S
if __name__ == "__main__":
# Neurons Parameter
Cr = 200 # num of relation
Ce = 50 # num of entity
total_time = 2500 # Runtime in ms
tau = 100 # time constant of STDP
stdpwin = 25 # STDP windows in ms
thresh = 30 # Judge if the neurons fire or not
abs_T = 25 # The length of the ABS
Reset = 0 # Reset Potential
I_syn = 5
tau_m = 30
Rm = 10
N_entity = 5
N_relation = 2
I_t = 5 # Duration of Current
I_P = 25 # Strength of input current
certainty = 0.5
A_P = 0.01
synapse_bound = 0.2 # The bound of all synapse
inner_bound_E = 0.08 # The bound of population inner synapse
inner_bound_R = 0.06 # The bound of population inner synapse
total_neurons = Ce * N_entity + Cr * N_relation
"""
SPSNN主函数,实现网络核心主要功能
:param Cr: 因果图中节点神经元组中神经元数量
:param Ce: 因果图中因果关系神经元组中神经元数量
:param total_time: 网络总体模拟的时间步长
:param learning_times: 网络进行序列学习的次数
:param N_entity: 对网络添加外部输入电流的时间长度
:param N_relation: 对网络添加外部输入电流的强度
:param A_P: 网络在进行STDP学习后突触改变放缩量
:param certainty: 网络输入电流大小的确定度
:param total_neurons: 网络神经元总量
:param ADJ: 网络中脉冲放电情况矩阵
:param I_stimu: 网络中外部输入电流矩阵
:param S: 网络突触连接权重矩阵
:param E: 单位矩阵,用以对每个神经元引入外部电流
"""
# Initial Neurual Network
E1_index = np.linspace(0, Ce - 1, Ce, dtype=int)
E2_index = np.linspace(Ce, 2 * Ce - 1, Ce, dtype=int)
E3_index = np.linspace(2 * Ce, 3 * Ce - 1, Ce, dtype=int)
E4_index = np.linspace(3 * Ce, 4 * Ce - 1, Ce, dtype=int)
E5_index = np.linspace(4 * Ce, 5 * Ce - 1, Ce, dtype=int)
R1_index = np.linspace(5 * Ce, 5 * Ce + Cr - 1, Cr, dtype=int)
R2_index = np.linspace(5 * Ce + Cr, 5 * Ce + 2 * Cr - 1, Cr, dtype=int)
Ne = total_neurons
v = Reset * np.zeros(Ne)
firings = [] # spike timings
ADJ = np.zeros((total_time, Ne)) # record the firing condition
abs_Ne = np.zeros(Ne) # maintain the ABS of every neurons
I_stimu = np.zeros((Ne, total_time), dtype=float)
If_Memory = np.zeros((total_neurons), dtype=bool)
If_Memory[:] = True
# Pre-set synapses
S = np.zeros((total_neurons, total_neurons), dtype=float) # Initial Weights
S = S - np.diag(S) # Set the diag num to
E = np.identity((total_neurons), dtype=float)
W_set_innner = 0.7
temp = S[E1_index, :]
temp[:, E1_index] = W_set_innner * np.random.rand(Ce, Ce)
S[E1_index, :] = temp
temp = S[E2_index, :]
temp[:, E2_index] = W_set_innner * np.random.rand(Ce, Ce)
S[E2_index, :] = temp
temp = S[E3_index, :]
temp[:, E3_index] = W_set_innner * np.random.rand(Ce, Ce)
S[E3_index, :] = temp
temp = S[E4_index, :]
temp[:, E4_index] = W_set_innner * np.random.rand(Ce, Ce)
S[E4_index, :] = temp
temp = S[E5_index, :]
temp[:, E5_index] = W_set_innner * np.random.rand(Ce, Ce)
S[E5_index, :] = temp
temp = S[R1_index, :]
temp[:, R1_index] = 0.25 * W_set_innner * np.random.rand(Cr, Cr)
S[R1_index, :] = temp
temp = S[R2_index, :]
temp[:, R2_index] = 0.25 * W_set_innner * np.random.rand(Cr, Cr)
S[R2_index, :] = temp
"""
对于因果图中的因果关系,给予网络不同神经元组输入电流刺激,使其建立连接
"""
i = 1
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E1_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E1_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R1_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R1_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E2_index, :] = temp
i = 3
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E2_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R2_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E1_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E1_index, :] = temp
i = 6
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E2_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R1_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R1_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E3_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E3_index, :] = temp
i = 8
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E3_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E3_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R2_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E2_index, :] = temp
i = 11
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E2_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R1_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R1_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E4_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E4_index, :] = temp
i = 13
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E4_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E4_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R2_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E2_index, :] = temp
i = 16
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E3_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E3_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R1_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R1_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E5_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E5_index, :] = temp
i = 18
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E5_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E5_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R2_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E3_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E3_index, :] = temp
i = 21
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E4_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E4_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R1_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R1_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E5_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E5_index, :] = temp
i = 23
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E5_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E5_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R2_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E4_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E4_index, :] = temp
S = torch.tensor(S, dtype=torch.float32)
E = torch.tensor(E, dtype=torch.float32)
CRSNN = CRNet(S, E)
for t in range(total_time):
I_input = torch.tensor(I_stimu[:, t].reshape(1, total_neurons), dtype=torch.float32)
x, dw = CRSNN(I_input)
S += A_P * dw[1]
S += S_bound(S) - S
ADJ[t] = x
plt.matshow(I_stimu)
plt.matshow(ADJ.transpose())
plt.matshow(S)
plt.colorbar()
plt.show()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/SPSNN/README.md
================================================
# Sequence Production SNN
This repository contains code from our paper [**Brain Inspired Sequences Production by Spiking Neural Networks With Reward-Modulated STDP**] published in Frontiers in Computational Neuroscience. This module builds a Sequence Production spiking neural network model, realizing the memory and reconstruction functions for arbitrary symbol sequences. The input causal graph is shown in figure causal_graph.png. The input current, spike trains during the learning process and the network weight distribution after the learning are shown in the Results folder.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
## Run
```shell
python main.py file
```
### Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{fang2021spsnn,
title = {Brain inspired sequences production by spiking neural networks with reward-modulated stdp},
author = {Fang, Hongjian and Zeng, Yi and Zhao, Feifei},
journal = {Frontiers in Computational Neuroscience},
volume = {15},
pages = {8},
year = {2021},
publisher = {Frontiers}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/SPSNN/main.py
================================================
import time
import numpy as np
import os
import warnings
import math
from matplotlib import pyplot as plt
import torch
from braincog.base.node.node import *
from braincog.base.brainarea.BrainArea import *
from braincog.utils import *
warnings.filterwarnings('ignore')
np.set_printoptions(threshold=np.inf)
class SPNet(BrainArea):
"""
网络结构类:SPNet(Sequence Production Net),定义了网络的结构,继承自BrainArea基类。
:param threshold: 神经元发放脉冲需要达到的阈值
:param tau: 神经元膜电位常数,控制膜电位衰减
:param decay:STDP机制衰减常数,控制STDP机制作用强度随时间变化
:param w1:神经网络内部连接权重
:param w2:外部输入电流到每个神经元的连接
"""
def __init__(self, w1, w2 ):
"""
"""
super().__init__()
self.node = [LIFNode(threshold=10,tau=15) ]
self.connection = [CustomLinear(w1), CustomLinear(w2) ]
self.stdp = []
self.stdp.append(MutliInputSTDP(self.node[0], [self.connection[0], self.connection[1]],decay=0.745))
self.x1 = torch.zeros(1, w2.shape[0])
def forward(self, x):
"""
一次时间步的前向传播过冲函数,计算脉冲发放情况和权重改变量
:param x1:经过该时间步后的脉冲发放情况
:param dw1:STDP机制在一个时间步后带来的权重改变量
"""
self.x1, dw1 = self.stdp[0]( self.x1,x)
return self.x1, dw1
def reset(self):
self.x1 *= 0
def S_bound(S):
"""
S_bound:网络权重边界控制函数,主要功能为控制全网络突触连接权不超过阈值,维持弱连接
另外,本函数还需要将神经元组内部权重控制在一定的范围之内,以防神经元组不断重复激活自身的情况发生。
:param synapse_bound: 全网络的突触连接的阈值,以维持网络整体为弱连接
:param inner_bound: 神经元组内部突触连接的阈值,防止神经元组不断重复激活自身导致网络放电紊乱
"""
S[S > synapse_bound] = synapse_bound
S[S < -synapse_bound] = -synapse_bound
temp1 = S[l1_stimu,:]
temp2 = temp1[:, l1_stimu]
temp2 [temp2>inner_bound] = inner_bound
temp1[:, l1_stimu] = temp2
S[l1_stimu, :] = temp1
temp1 = S[l2_stimu, :]
temp2 = temp1[:, l2_stimu]
temp2[temp2 > inner_bound] = inner_bound
temp1[:, l2_stimu] = temp2
S[l2_stimu, :] = temp1
temp1 = S[l3_stimu, :]
temp2 = temp1[:, l3_stimu]
temp2[temp2 > inner_bound] = inner_bound
temp1[:, l3_stimu] = temp2
S[l3_stimu, :] = temp1
temp1 = S[l4_stimu, :]
temp2 = temp1[:, l4_stimu]
temp2[temp2 > inner_bound] = inner_bound
temp1[:, l4_stimu] = temp2
S[l4_stimu, :] = temp1
return S
if __name__ == "__main__":
## Neurons Parameter
C = 50; # constant:the number of neurons of a symbol
runtime = 1000; # Runtime in ms
thresh = 30; # Judge if the neurons fire or not
I_syn = 5;
tau_m = 30;
Rm = 10;
learning_times = 3;
Sym_size = 6
I_t = 5 # Time duration of stimu current
I_P = 130 # Strength of input current
A_P = 0.024
certainty = 0.35
synapse_bound = 10 # The bound of all synapse
inner_bound = 1 # The bound of population inner synapse
"""
SPSNN主函数,实现网络核心主要功能
:param C: 神经元组中神经元数量
:param runtime: 网络总体模拟的时间步长
:param learning_times: 网络进行序列学习的次数
:param I_t: 对网络添加外部输入电流的时间长度
:param I_P: 对网络添加外部输入电流的强度
:param A_P: 网络在进行STDP学习后突触改变放缩量
:param certainty: 网络输入电流大小的确定度
:param total_neurons: 网络神经元总量
:param ADJ: 网络中脉冲放电情况矩阵
:param I_stimu: 网络中外部输入电流矩阵
:param S: 网络突触连接权重矩阵
:param E: 单位矩阵,用以对每个神经元引入外部电流
"""
# Initial Neurual Network
Net1 = [C,Sym_size*C,Sym_size*C,Sym_size*C,1] #memory
Net2 = [Sym_size,Sym_size,Sym_size] #action
current_end = 0
total_neurons = int(sum(Net1)+sum(Net2))
index1 = np.linspace(1,sum(Net1),sum(Net1),dtype=int)-1
index2 = np.linspace (sum(Net1)+1,total_neurons,sum(Net2),dtype=int)-1
Ne = total_neurons
firings= [] # spike timings
ADJ = np.zeros((runtime,Ne)) # record the firing condition
abs_Ne = np.zeros(Ne) # maintain the ABS of every neurons
I_stimu = np.zeros((Ne,runtime));
P = np.zeros((runtime,3)); # potential of neuron 1
# logical vector to differ if the neuron is belong to memory part
If_Memory = np.zeros((total_neurons),dtype=bool)
If_Memory[index1[:]] = True
# logical vector to differ if the neuron is belong to action part
If_Action = np.zeros((total_neurons),dtype=bool)
If_Action[index2[:]] = True
# Pre-set synapses
S = np.zeros((total_neurons,total_neurons),dtype=float) # Initial Weights
S = S - np.diag(S) # Set the diag num to
E = np.identity((total_neurons),dtype=float)
W_r2a = 0.3
# Memory to Action
for i in range (C,sum(Net1)-2 ):
S[ int(index2[int(i/C)-1]), i] =W_r2a
# Learning Process
I_stimu = np.zeros((Ne,runtime))
seq = np.array([6,3,4])
l1_stimu = np.arange (0,C)
l2_stimu = np.arange(C+(seq[0]-1)*C,C+(seq[0])*C)
l3_stimu = np.arange(C+ 6*C+(seq[1]-1)*C,C+ 6*C+(seq[1])*C)
l4_stimu = np.arange(C+12*C+(seq[2]-1)*C,C+12*C+(seq[2])*C)
l5_stimu = Ne-1
np.linspace(20 + i * 100 ,20+I_t+i*100-1,I_t ,dtype=int )
for i in range(learning_times):
"""
对网络添加输入电流
"""
temp = I_stimu [l1_stimu,:]
I_stimu [l1_stimu, 10 + i * 100 :10+I_t+i*100] = certainty*I_P + I_P * np.random.rand(C,I_t)
I_stimu [l2_stimu, 25 + i * 100 :25+I_t+i*100] = certainty*I_P + I_P * np.random.rand(C,I_t)
I_stimu [l3_stimu, 40 + i * 100 :40+I_t+i*100] = certainty*I_P + I_P * np.random.rand(C,I_t)
I_stimu [l4_stimu, 55 + i * 100 :55+I_t+i*100] = certainty*I_P + I_P * np.random.rand(C,I_t)
I_stimu [l5_stimu, 70 + i * 100 :70+I_t+i*100] = certainty*I_P + I_P * np.random.rand(1,I_t)
I_stimu[l1_stimu,700:700+I_t] = I_P * np.random.rand(C,I_t)
S = torch.tensor(S,dtype=torch.float32)
E = torch.tensor(E,dtype=torch.float32)
SPSNN = SPNet(S,E)
for t in range (runtime):
I_input = torch.tensor( I_stimu[:,t].reshape(1,total_neurons),dtype=torch.float32)
x,dw = SPSNN( I_input )
S += A_P*dw[1]
S += S_bound(S) - S
ADJ[t] = x
plt.matshow(I_stimu)
plt.matshow(ADJ)
plt.matshow(S)
plt.colorbar()
plt.show()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Areas/apac.py
================================================
'''
Created on 2016.7.7
@author: liangqian
'''
from Modal.note import Note
from Modal.cluster import Cluster
from conf.conf import configs
from Modal.pitch import Pitch
class APAC():
'''
anterior primary auditory cortex,encoding the musical notes
'''
def __init__(self):
'''
Constructor
'''
self.notes = []
#self.cluster = Cluster()
def encodingNote(self,NoteID):
NoteName = configs.notesMap.get(int(NoteID))
n = Pitch()
n.name = NoteName
n.frequence = int(NoteID)
self.notes.append(n)
return n
def encodingMIDINote(self,p):
NoteName = configs.notesMap.get(p.frequence)
p.name = NoteName
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Areas/cortex.py
================================================
'''
Created on 2016.7.6
@author: liangqian
'''
from Areas.pfc import PFC
from Areas.pac import PAC
from conf.conf import *
from Modal.synapse import Synapse
import random
import numpy as np
from Areas.apac import APAC
from Areas.pac import Music_Sequence_Mem
class Cortex():
'''
This class is used to control areas in the cortex, just cortex controlling
'''
def __init__(self, neutype, dt):
self.neutype = neutype
self.msm = Music_Sequence_Mem(neutype)
self.pfc = PFC(self.neutype)
self.dt = dt
def addSubGoalToPFC(self, goalname):
self.pfc.addNewSubGoal(goalname)
''' tt = np.arange(0, 5, self.dt)
for t in tt:
self.pfc.doRemebering(goalname, self.dt, t)'''
def addComposerToPFC(self, composername):
self.pfc.addNewComposer(composername)
'''tt = np.arange(0, 5, self.dt)
for t in tt:
self.pfc.doRememberingComposer(composername, self.dt, t)'''
def addGenreToPFC(self, genrename):
self.pfc.addNewGenre(genrename)
'''tt = np.arange(0, 5, self.dt)
for t in tt:
self.pfc.doRememberingGenre(genrename, self.dt, t)'''
def musicSequenceMemroyInit(self):
self.msm.createActionSequenceMem(1, self.neutype)
def rememberANote(self, goalname, noteName, order):
note = self.apac.encodingNote(noteName)
if (order > len(self.msm.sequenceLayers.get(1).groups)):
self.msm.sequenceLayers.get(1).addNewGroups(GroupID=order, layerID=1, neunum=128)
tt = np.arange((order - 1) * 5, order * 5, self.dt)
for t in tt:
self.ips.doRemebering(goalname, self.dt, t)
self.msm.doRemembering_note_only(note, order, self.dt, t)
self.msm.doConnectToGoal(self.ips.goals.groups.get(goalname), order)
dic = {}
if (configs.flag_experiments == False):
dic["GoalSpike"] = self.ips.goals.groups.get(goalname).writeSpikeInfoToJson()
dic["MSMSpike"] = self.msm.sequenceLayers.get(1).groups.get(order).writeSpikeInfoToJson()
dic["Neuron"] = self.msm.sequenceLayers.get(1).groups.get(order).writeSelfInfoToJson("MSM")
dic["GroupNum"] = order
return dic
def connectKeyAndNotesUsingKSModel(self,keys, Notes):
noteNeurons = Notes.neurons
for tone in keys.groups.values():
tneurons = tone.neurons
for nindex, noteneu in enumerate(noteNeurons[1:]):
i = nindex%12
syn = Synapse(tneurons[i],noteneu) # from tone to pitch
if(tneurons[i].importance < 0):
syn.excitability = 0
syn.weight = -100 # 这个地方应该用KS pitch profile,稍等下再改
else:
syn.excitability = 1
syn.weight = 20+random.uniform(20,30)
syn.type = 3
noteneu.synapses.append(syn)
noteneu.pre_neurons.append(tneurons[i])
# syn1 = Synapse(noteneu, tneurons[i]) # from pitch to tone
# syn1.excitability = 1
# syn1.type = 3
# tneurons[i].synapses.append(syn1)
# tneurons[i].pre_neurons.append(noteneu)
def connectKeyAndNotes(self,keys, Notes):
noteNeurons = Notes.neurons
for tone in keys.groups.values():
tneurons = tone.neurons
for nindex, noteneu in enumerate(noteNeurons[1:]):
i = nindex%12
syn = Synapse(tneurons[i],noteneu)
if(tneurons[i].importance < 0):
syn.excitability = 0
syn.weight = -100
else:
syn.excitability = 1
syn.weight = 20+random.uniform(20,30)
syn.type = 3
noteneu.synapses.append(syn)
noteneu.pre_neurons.append(tneurons[i])
def connectKeyAndNotesUsingKSModel(self,keys, Notes):
noteNeurons = Notes.neurons
for tone in keys.groups.values():
tneurons = tone.neurons
for nindex, noteneu in enumerate(noteNeurons[1:]):
i = nindex%12
syn = Synapse(tneurons[i],noteneu) # from tone to pitch
if(tneurons[i].importance < 0):
syn.excitability = 0
syn.weight = -100 # 这个地方应该用KS pitch profile,稍等下再改
else:
syn.excitability = 1
syn.weight = 20+random.uniform(20,30)
syn.type = 3
noteneu.synapses.append(syn)
noteneu.pre_neurons.append(tneurons[i])
# syn1 = Synapse(noteneu, tneurons[i]) # from pitch to tone
# syn1.excitability = 1
# syn1.type = 3
# tneurons[i].synapses.append(syn1)
# tneurons[i].pre_neurons.append(noteneu)
def rememberANoteWithKnowledge(self,goalname, composername, genrename, emo, keyName, trackIndex, noteIndex, tinterval,order, xmldata):
instrumentTrack = self.msm.sequenceLayers.get(trackIndex)
if (order > len(instrumentTrack.get("N").groups)):
instrumentTrack.get("N").addNewGroups(GroupID=order, layerID=trackIndex, neunum=129)
instrumentTrack.get("T").addNewGroups(GroupID=order, layerID=trackIndex, neunum=64)
self.connectKeyAndNotesUsingKSModel(self.pfc.keys,instrumentTrack.get("N").groups.get(order))# prior knowledge
tt = np.arange((order - 1) * 5, order * 5, self.dt)
for t in tt:
self.pfc.doRemebering(goalname, self.dt, t)
self.pfc.doRememberingComposer(composername, self.dt, t)
self.pfc.doRememberingGenre(genrename, self.dt, t)
self.pfc.doRememberingKey(keyName,self.dt,t)
self.pfc.doRememberingMode(keyName%2, self.dt,t)
self.msm.doRemembering(trackIndex, noteIndex, order, self.dt, t, tinterval)
self.msm.doConnectToTitle(self.pfc.goals.groups.get(goalname), instrumentTrack, order)
self.msm.doConnectToComposer(self.pfc.composers.groups.get(composername), instrumentTrack, order)
self.msm.doConnectToGenre(self.pfc.genres.groups.get(genrename), instrumentTrack, order)
self.msm.doConnectToKey(self.pfc.keys.groups.get(keyName), instrumentTrack, order, noteIndex)
self.msm.doConnectToMode(self.pfc.modes.groups.get(keyName%2), keyName, instrumentTrack, order, noteIndex)
dic = {}
dic["GoalSpike"] = self.pfc.goals.groups.get(goalname).writeSpikeInfoToJson()
dic["ComposerSpike"] = self.pfc.composers.groups.get(composername).writeSpikeInfoToJson()
#dic["EmotionSpike"] = self.amy.emos.groups.get(emo).writeSpikeInfoToJson()
dic["KeySpike"] = self.pfc.keys.groups.get(keyName).writeSpikeInfoToJson()
dic["ModeSpike"] = self.pfc.modes.groups.get(keyName%2).writeSpikeInfoToJson()
dic["MSMNSpike"] = instrumentTrack.get("N").groups.get(order).writeSpikeInfoToJson()
dic["MSMTSpike"] = instrumentTrack.get("T").groups.get(order).writeSpikeInfoToJson()
return(dic)
def rememberANoteandTempo(self, goalname, composername, genrename, trackIndex, noteIndex, order, tinterval):
instrumentTrack = self.msm.sequenceLayers.get(trackIndex)
if (order > len(instrumentTrack.get("N").groups)):
instrumentTrack.get("N").addNewGroups(GroupID=order, layerID=trackIndex, neunum=129)
instrumentTrack.get("T").addNewGroups(GroupID=order, layerID=trackIndex, neunum=64)
tt = np.arange((order - 1) * 5, order * 5, self.dt)
for t in tt:
self.pfc.doRemebering(goalname, self.dt, t)
self.pfc.doRememberingComposer(composername, self.dt, t)
self.pfc.doRememberingGenre(genrename, self.dt, t)
self.msm.doRemembering(trackIndex, noteIndex, order, self.dt, t, tinterval)
self.msm.doConnectToTitle(self.pfc.goals.groups.get(goalname), instrumentTrack, order)
self.msm.doConnectToComposer(self.pfc.composers.groups.get(composername), instrumentTrack, order)
self.msm.doConnectToGenre(self.pfc.genres.groups.get(genrename), instrumentTrack, order)
dic = {}
ngraph = {}
if (configs.RunTimeState == 1):
dic["GoalSpike"] = self.pfc.goals.groups.get(goalname).writeSpikeInfoToJson()
dic["ComposerSpike"] = self.pfc.composers.groups.get(composername).writeSpikeInfoToJson()
dic["MSMSpike"] = instrumentTrack.get("N").groups.get(order).writeSpikeInfoToJson()
dic["MSMTSpike"] = instrumentTrack.get("T").groups.get(order).writeSpikeInfoToJson()
temp = {}
temp[1] = instrumentTrack.get("N").groups.get(order).writeSelfInfoToJson("NMSM")
temp[2] = instrumentTrack.get("T").groups.get(order).writeSelfInfoToJson("TMSM")
# dic["GroupNum"] = order
Nodes = []
Edges = []
for key, td in temp.items():
nlist = td.get("Neuron")
for n in nlist:
# if(len(n.get('synapses')) > 0):
d = {}
d['id'] = n.get('area') + '_' + str(n.get('TrackID')) + '_' + str(n.get('GroupID')) + '_' + str(
n.get('Index'))
d['area'] = n.get('area')
if (n.get('area') == 'NMSM'):
d['label'] = configs.notesMap.get(n.get('Index') - 2)
else:
d['label'] = str(n.get('Index') * 60)
Nodes.append(d)
synlist = n.get('synapses')
for syn in synlist:
e = {}
# e['id'] = syn.get('Sarea') + '_'+str(syn.get('SgroupID'))+'_'+str(syn.get('Sindex')) + '_' +syn.get('Tarea') + '_'+str(syn.get('TgroupID')) + '_'+str(syn.get('Tindex'))
e['weight'] = str(syn.get('weight'))
e['source'] = syn.get('Sarea') + '_' + str(syn.get('StrackID')) + '_' + str(
syn.get('SgroupID')) + '_' + str(syn.get('Sindex'))
e['target'] = syn.get('Tarea') + '_' + str(syn.get('TtrackID')) + '_' + str(
syn.get('TgroupID')) + '_' + str(syn.get('Tindex'))
Edges.append(e)
ngraph["node"] = Nodes
ngraph["edge"] = Edges
#print(dic)
return dic, ngraph
def actionSequenceMemoryInit(self):
self.asm.createActionSequenceMem(1, self.neutype, 16)
def recallMusicPFC(self, goalName):
self.pfc.setTestStates()
self.msm.setTestStates()
result = self.pfc.doRecalling2(goalName, self.msm)
return result
def recallMusicByEpisode(self, episodeNotes): # using time window search episode
self.pfc.setTestStates()
self.msm.setTestStates()
# sl = self.msm.sequenceLayers.get(1)
# for index,group in sl.groups.items():
# strs = "group_"+str(index)+":"
# for n in group.neurons:
# if(n.preActive == True):
# strs +=" neu_Index:"+str(n.index)+","
# print(strs)
result = self.msm.recallByEpisode2(episodeNotes, self.pfc.goals)
return result
def generateEx_Nihilo(self, firstNote, durations, length):
'''
this function is used to generate the main melody, only one track
'''
self.pfc.setTestStates()
self.msm.setTestStates()
result = {}
track1 = []
for i in range(length):
dic = {}
tt = np.arange(i * 5, (i + 1) * 5, self.dt)
for t in tt:
self.pfc.inhibiteGoals(self.dt, t)
self.msm.generateEx_Nihilo(firstNote, durations, i, self.dt, t)
panneu = []
maxrate = 0.0
maxneu = None
for ni, neu in enumerate(self.msm.sequenceLayers.get(1).get("N").groups.get(i + 1).neurons):
if (neu.preActive == True):
panneu.append(neu)
if (len(neu.spiketime) > 0):
# dic['N'] = neu.selectivity
if (len(neu.spiketime) > maxrate):
maxrate = len(neu.spiketime)
maxneu = neu
print(maxneu.I)
if (dic.get('N') == None):
j = random.randint(0, len(panneu) - 1)
neu = panneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['N'] = neu.selectivity
else: # chose the neuron which has the max firing rate
dic['N'] = maxneu.selectivity
patneu = []
maxrate = 0.0
maxneu = None
for neu in self.msm.sequenceLayers.get(1).get("T").groups.get(i + 1).neurons:
if (neu.preActive == True): patneu.append(neu)
if (len(neu.spiketime) > 0):
if (len(neu.spiketime) > maxrate):
maxrate = len(neu.spiketime)
maxneu = neu
if (dic.get('T') == None):
j = random.randint(0, len(patneu) - 1)
neu = patneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['T'] = neu.selectivity
else:
dic['T'] = neu.selectivity
track1.append(dic)
result[1] = track1
#print(result)
return result
def generateEx_Nihilo2(self, firstNote, durations, length):
'''
this function is used to generate the main melody, only one track
'''
self.pfc.setTestStates()
self.msm.setTestStates()
result = {}
track1 = []
for i in range(length):
dic = {}
tt = np.arange(i * 5, (i + 1) * 5, self.dt)
for t in tt:
self.pfc.inhibiteGoals(self.dt, t)
self.msm.generateEx_Nihilo(firstNote, durations, i, self.dt, t)
panneu = []
for ni, neu in enumerate(self.msm.sequenceLayers.get(1).get("N").groups.get(i + 1).neurons):
if (neu.preActive == True):
panneu.append(neu)
if (len(neu.spiketime) > 0):
dic['N'] = neu.selectivity
if (dic.get('N') == None):
j = random.randint(0, len(panneu) - 1)
neu = panneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['N'] = neu.selectivity
patneu = []
for neu in self.msm.sequenceLayers.get(1).get("T").groups.get(i + 1).neurons:
if (neu.preActive == True): patneu.append(neu)
if (len(neu.spiketime) > 0):
dic['T'] = neu.selectivity
if (dic.get('T') == None):
j = random.randint(0, len(patneu) - 1)
neu = patneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['T'] = neu.selectivity
track1.append(dic)
result[1] = track1
return result
def generateEx_NihiloAccordingToGenre(self, genreName, firstNote, durations, length):
genreName = genreName.title()
self.pfc.setTestStates()
self.msm.setTestStates()
result = {}
track1 = []
for i in range(length):
dic = {}
tt = np.arange(i * 5, (i + 1) * 5, self.dt)
for t in tt:
self.pfc.inhibiteGoals(self.dt, t)
self.pfc.inhibitComposers(self.dt, t)
self.pfc.doRememberingGenre(genreName, self.dt, t)
self.msm.generateEx_Nihilo(firstNote, durations, i, self.dt, t)
panneu = []
for ni, neu in enumerate(self.msm.sequenceLayers.get(1).get("N").groups.get(i + 1).neurons):
if (neu.preActive == True):
panneu.append(neu)
if (len(neu.spiketime) > 0):
dic['N'] = neu.selectivity
if (dic.get('N') == None):
j = random.randint(0, len(panneu) - 1)
neu = panneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['N'] = neu.selectivity
patneu = []
for neu in self.msm.sequenceLayers.get(1).get("T").groups.get(i + 1).neurons:
if (neu.preActive == True): patneu.append(neu)
if (len(neu.spiketime) > 0):
dic['T'] = neu.selectivity
if (dic.get('T') == None):
j = random.randint(0, len(patneu) - 1)
neu = patneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['T'] = neu.selectivity
track1.append(dic)
result[1] = track1
return result
def generateEx_NihiloAccordingToComposer(self, composerName, firstNote, durations, length):
composerName = composerName.title()
self.pfc.setTestStates()
self.msm.setTestStates()
result = {}
track1 = []
for i in range(length):
dic = {}
tt = np.arange(i * 5, (i + 1) * 5, self.dt)
for t in tt:
self.pfc.inhibiteGoals(self.dt, t)
self.pfc.doRememberingComposer(composerName, self.dt, t)
self.msm.generateEx_Nihilo(firstNote, durations, i, self.dt, t)
panneu = []
maxrate = 0.0
maxneu = None
for ni, neu in enumerate(self.msm.sequenceLayers.get(1).get("N").groups.get(i + 1).neurons):
if (neu.preActive == True):
panneu.append(neu)
if (len(neu.spiketime) > 0):
# dic['N'] = neu.selectivity
#print(str(neu.selectivity) + ":" + str(len(neu.spiketime)))
if (len(neu.spiketime) > maxrate):
maxrate = len(neu.spiketime)
maxneu = neu
if (dic.get('N') == None):
j = random.randint(0, len(panneu) - 1)
neu = panneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['N'] = neu.selectivity
else: # chose the neuron which has the max firing rate
dic['N'] = maxneu.selectivity
patneu = []
maxrate = 0.0
maxneu = None
for neu in self.msm.sequenceLayers.get(1).get("T").groups.get(i + 1).neurons:
if (neu.preActive == True): patneu.append(neu)
if (len(neu.spiketime) > 0):
if (len(neu.spiketime) > maxrate):
maxrate = len(neu.spiketime)
maxneu = neu
if (dic.get('T') == None):
j = random.randint(0, len(patneu) - 1)
neu = patneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['T'] = neu.selectivity
else:
dic['T'] = neu.selectivity
track1.append(dic)
result[1] = track1
#print(result)
return result
def generateMelodyWithKey(self, key, firstNotes, durations, length):
result = {}
self.pfc.setTestStates()
self.msm.setTestStates()
row,col = firstNotes.shape
for i in range(length):
time = np.arange(i*5,(i+1)*5,self.dt)
for t in time:
self.pfc.inhibiteGoals(self.dt,t)
self.pfc.inhibitComposers(self.dt,t)
self.pfc.inhibitGenres(self.dt,t)
self.pfc.doRememberingKey(key,self.dt,t)
self.msm.generateMelodyWithTone(firstNotes[:,i] if i < col else None, durations[:,i] if durations else None,key,i+1,self.dt,t)
# find the max firing rate
for j,sl in self.msm.sequenceLayers.items():
if j > 4: break;
#print("***********************this is part " + str(j) + "****************************")
dic = {}
if i < col:
dic["N"] = firstNotes[j-1][i]
dic["T"] = durations[j-1][i] if durations else 1.0
else:
maxrate = 0
for nn in sl.get("N").groups.get(i+1).neurons:
if nn.preActive:
# print("------order: "+str(i+1)+"-------")
# print(nn.selectivity)
# print(nn.I)
# print(nn.I_upper)
# print(nn.I_lower)
# print(len(nn.spiketime))
if len(nn.spiketime) > maxrate:
maxrate = len(nn.spiketime)
#print("top1:"+str(nn.selectivity))
dic["N"] = nn.selectivity
if durations is not None:
dic["T"] = 1
else:
maxrate = 0
for tn in sl.get("T").groups.get(i + 1).neurons:
if tn.preActive:
if len(tn.spiketime) > maxrate:
maxrate = len(tn.spiketime)
#print(tn.selectivity)
dic["N"] = nn.selectivity
if dic.get("T") is None:
dic["T"] = 1.0
if result.get(j) is None:
part = []
part.append(dic)
result[j] = part
else:
result.get(j).append(dic)
return result
def recallActionIPS(self, goalName):
self.pfc.setTestStates()
self.pfc.setTestStates()
self.pfc.doRecalling(goalName, self.asm)
def generate2TrackMusic(self, firstNotes, durations, lengths):
self.pfc.setTestStates()
self.msm.setTestStates()
result = {}
for k, notes in firstNotes.items():
track1 = []
for i in range(lengths[k - 1]):
dic = {}
tt = np.arange(i * 5, (i + 1) * 5, self.dt)
for t in tt:
self.pfc.inhibiteGoals(self.dt, t)
# self.msm.generateSimgleTrackNotes(j+1, firstNotes[j], durations[j], i, self.dt, t)
self.msm.generateSimgleTrackNotes(k, notes, durations.get(k), i, self.dt, t)
panneu = []
for ni, neu in enumerate(self.msm.sequenceLayers.get(k).get("N").groups.get(i + 1).neurons):
if (neu.preActive == True):
panneu.append(neu)
if (len(neu.spiketime) > 0):
dic['N'] = neu.selectivity
if (dic.get('N') == None):
j = random.randint(0, len(panneu) - 1)
neu = panneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['N'] = neu.selectivity
patneu = []
for neu in self.msm.sequenceLayers.get(k).get("T").groups.get(i + 1).neurons:
if (neu.preActive == True): patneu.append(neu)
if (len(neu.spiketime) > 0):
dic['T'] = neu.selectivity
if (dic.get('T') == None):
j = random.randint(0, len(patneu) - 1)
neu = patneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['T'] = neu.selectivity
track1.append(dic)
result[k] = track1
print(result)
return result
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Areas/pac.py
================================================
'''
Primary Auditory Area
'''
from braincog.base.brainarea.BrainArea import BrainArea
from Modal.sequencememory import SequenceMemory
from Modal.notesequencelayer import NoteSequenceLayer
from Modal.temposequencelayer import TempoSequenceLayer
from Modal.synapse import Synapse
import numpy as np
import math
from conf.conf import *
class PAC(BrainArea,SequenceMemory):
'''
the planum polare, anterior to PAC, as well as in the left planum temporale,posterior to PAC.
'''
def __init__(self, neutype):
'''
Constructor
'''
SequenceMemory.__init__(self, neutype)
def forward(self, x):
pass
def createActionSequenceMem(self, layernum, neutype):
sl = NoteSequenceLayer(neutype)
tl = TempoSequenceLayer(neutype)
instrumentTrack = {}
instrumentTrack["N"] = sl
instrumentTrack["T"] = tl
self.sequenceLayers[layernum] = instrumentTrack
print(len(self.sequenceLayers))
def doRemembering_note_only(self, note, order, dt, t):
# remember note
sl = self.sequenceLayers.get(1)
sgroup = sl.groups.get(order)
dt = 0.1
for n in sgroup.neurons:
n.I_ext = note.frequence
n.computeFilterCurrent()
n.update(dt, t, 'Learn')
def doRemembering(self, trackIndex, noteIndex, order, dt, t, tinterval=0):
# remember note
iTrack = self.sequenceLayers.get(trackIndex)
sl = iTrack.get("N")
sgroup = sl.groups.get(order)
dt = 0.1
for n in sgroup.neurons:
n.I_ext = noteIndex
n.computeFilterCurrent()
n.update(dt, t, 'Learn')
# remember tempo
tl = iTrack.get("T")
tgroup = tl.groups.get(order)
dt = 0.1
for n in tgroup.neurons:
n.I_ext = tinterval
n.computeFilterCurrent()
n.update(dt, t, 'Learn')
def doConnectToTitle(self, title, track, order):
for sl in track.values():
self.doConnecting(title, sl, order)
def doConnectToComposer(self, composer, track, order):
for sl in track.values():
self.doConnecting(composer, sl, order)
def doConnectToGenre(self, genre, track, order):
for sl in track.values():
self.doConnecting(genre, sl, order)
def generateEx_Nihilo(self, firstNote, durations, order, dt, t):
ns = self.sequenceLayers.get(1).get("N")
ts = self.sequenceLayers.get(1).get("T")
nneurons = ns.groups.get(order + 1).neurons
tneurons = ts.groups.get(order + 1).neurons
# firstNotes specify the beginning notes to trigger the following notes
if (order < len(firstNote)): # beginning notes
i = firstNote[order]
nneu = nneurons[i + 1]
nneu.I = 20
nneu.update_normal(dt, t)
d = int(durations[order] / 0.125) - 1
tneu = tneurons[d]
tneu.I = 20
tneu.update_normal(dt, t)
else: # generate next note
for nn in nneurons:
nn.updateCurrentOfLowerAndUpperLayer(t)
nn.update(dt, t, 'test')
for tn in tneurons:
tn.updateCurrentOfLowerAndUpperLayer(t)
tn.update(dt, t, 'test')
def generateSimgleTrackNotes(self, trackIndex, firstNote, durations, order, dt, t):
ns = self.sequenceLayers.get(trackIndex).get("N")
ts = self.sequenceLayers.get(trackIndex).get("T")
nneurons = ns.groups.get(order + 1).neurons
tneurons = ts.groups.get(order + 1).neurons
# firstNotes specify the beginning notes to trigger the following notes
if (order < len(firstNote)): # beginning notes
i = firstNote[order]
nneu = nneurons[i + 1]
nneu.I = 20
nneu.update_normal(dt, t)
d = int(durations[order] / 0.125) - 1
tneu = tneurons[d]
tneu.I = 20
tneu.update_normal(dt, t)
else: # generate next note
for nn in nneurons:
nn.updateCurrentOfLowerAndUpperLayer(t)
nn.update(dt, t, 'test')
# if(neu.spike == True):
# print(neu.selectivity)
for tn in tneurons:
tn.updateCurrentOfLowerAndUpperLayer(t)
tn.update(dt, t, 'test')
class Music_Sequence_Mem(SequenceMemory):
'''
the planum polare, anterior to PAC, as well as in the left planum temporale,posterior to PAC.
'''
def __init__(self, neutype):
'''
Constructor
'''
SequenceMemory.__init__(self, neutype)
def createActionSequenceMem(self, layernum, neutype):
sl = NoteSequenceLayer(neutype)
tl = TempoSequenceLayer(neutype)
instrumentTrack = {}
instrumentTrack["N"] = sl
instrumentTrack["T"] = tl
self.sequenceLayers[layernum] = instrumentTrack
print(len(self.sequenceLayers))
def doRemembering_note_only(self, note, order, dt, t):
# remember note
sl = self.sequenceLayers.get(1)
sgroup = sl.groups.get(order)
dt = 0.1
for n in sgroup.neurons:
n.I_ext = note.frequence
n.computeFilterCurrent()
n.update(dt, t, 'Learn')
def doRemembering(self, trackIndex, noteIndex, order, dt, t, tinterval=0):
# remember note
iTrack = self.sequenceLayers.get(trackIndex)
sl = iTrack.get("N")
sgroup = sl.groups.get(order)
dt = 0.1
for n in sgroup.neurons:
n.I_ext = noteIndex
n.computeFilterCurrent()
n.update(dt, t, 'Learn')
# remember tempo
tl = iTrack.get("T")
tgroup = tl.groups.get(order)
dt = 0.1
for n in tgroup.neurons:
n.I_ext = tinterval
n.computeFilterCurrent()
n.update(dt, t, 'Learn')
def recallByEpisode(self, episodeNotes, goals):
dt = 0.1
sl = self.sequenceLayers.get(1)
firstresult = {}
firstNote = episodeNotes[0]
tt = np.arange(0, 5, dt)
# find first note and activate goal neurons
for t in tt:
for id, group in sl.groups.items():
neuid = firstNote - 15;
if (group.neurons[neuid - 1].preActive == False): continue
group.neurons[neuid - 1].I_ext = 20
group.neurons[neuid - 1].updateCurrentOfLowerAndUpperLayer(t)
group.neurons[neuid - 1].update(dt, t, 'test')
if (group.neurons[neuid - 1].spike == True):
firstresult[id] = 1
for name, g in goals.groups.items():
for neu in g.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t)
# find rest episode notes
restResult = {}
# for i in range(1,len(episodeNotes)):
goalchecked = {}
for groupID, value in firstresult.items():
tmp = {}
for i in range(1, len(episodeNotes)):
fre = episodeNotes[i]
tt = np.arange(i * 5, (i + 1) * 5, dt)
g = sl.groups.get(groupID + i)
for t in tt:
# update memory
neuid = fre - 15;
if (g.neurons[neuid - 1].preActive == False): continue
g.neurons[neuid - 1].I_ext = 20
g.neurons[neuid - 1].updateCurrentOfLowerAndUpperLayer(t)
if (g.neurons[neuid - 1].I_lower == 0): break
g.neurons[neuid - 1].update(dt, t, 'test')
if (g.neurons[neuid - 1].spike == True):
tmp[i] = g.id
# update goals' neurons
for name, gg in goals.groups.items():
for neu in gg.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t)
# if(neu.spike == True):print(name)
# find
maxFiringRate = 0
maxGoalName = ''
maxGoal = {} # an episode may be mapped to more than one songs
for name, gg in goals.groups.items():
if (goalchecked.get(name) == None):
averageFiringRate = 0
for neu in gg.neurons:
averageFiringRate = averageFiringRate + len(neu.spiketime)
averageFiringRate = float(averageFiringRate) / float(len(gg.neurons))
gg.averageFiringRate = averageFiringRate
if (averageFiringRate > maxFiringRate):
maxFiringRate = averageFiringRate
maxGoalName = name
maxGoal[maxGoalName] = 1
goalchecked[maxGoalName] = 1
for name, gg in goals.groups.items():
if (gg.averageFiringRate == maxFiringRate and goalchecked.get(name) == None):
maxGoal[name] = 1
goalchecked[name] = 1
tmp['goal'] = maxGoal
restResult[groupID] = tmp
print(restResult)
episodeResult = []
for key, value in firstresult.items():
tmp = {}
tmp[0] = key
dic = restResult.get(key)
for i in range(1, len(episodeNotes)):
if (dic.get(i) != None):
tmp[i] = dic.get(i)
if (len(tmp) == len(episodeNotes)):
tmp['goal'] = dic.get('goal')
episodeResult.append(tmp)
print(episodeResult)
for res in episodeResult:
msmgroupID = res.get(len(episodeNotes) - 1) + 1
for gname, value in res.get('goal').items():
gg = goals.groups.get(gname)
def recallByEpisode2(self, episodeNotes, goals):
dt = 0.1
sl = self.sequenceLayers.get(1).get("N")
tl = self.sequenceLayers.get(1).get("T")
print(len(sl.groups))
firstresult = {}
firstNote = episodeNotes[0]
tt = np.arange(0, 5, dt)
# find first note and activate goal neurons
for t in tt:
for id, group in sl.groups.items():
neuid = firstNote;
if (group.neurons[neuid + 1].preActive == False): continue
# group.neurons[neuid+1].I_ext = 20
# group.neurons[neuid+1].updateCurrentOfLowerAndUpperLayer(t)
group.neurons[neuid + 1].I = 20
group.neurons[neuid + 1].update(dt, t, 'test')
if (group.neurons[neuid + 1].spike == True):
firstresult[id] = 1
# find rest episode notes
restResult = {}
# for i in range(1,len(episodeNotes)):
goalchecked = {}
for groupID in firstresult.keys():
#
sl.setTestStates()
tmp = {}
tt = np.arange(0, 5, dt)
g = sl.groups.get(groupID)
neuid = firstNote
# g.neurons[neuid+1].I_ext = 20
g.neurons[neuid + 1].I = 20
for t in tt:
# g.neurons[neuid+1].updateCurrentOfLowerAndUpperLayer(t)
g.neurons[neuid + 1].update(dt, t, 'test')
for i in range(1, len(episodeNotes)):
fre = episodeNotes[i]
tt = np.arange(i * 5, (i + 1) * 5, dt)
if (groupID + i > len((sl.groups))): continue
g = sl.groups.get(groupID + i)
for t in tt:
# update memory
neuid = fre;
if (g.neurons[neuid + 1].preActive == False): continue
g.neurons[neuid + 1].I_ext = 20
g.neurons[neuid + 1].updateCurrentOfLowerAndUpperLayer(t)
if (g.neurons[neuid + 1].I_lower == 0): break
g.neurons[neuid + 1].update(dt, t, 'test')
if (g.neurons[neuid + 1].spike == True):
tmp[i] = g.id
restResult[groupID] = tmp
# print(restResult)
episodeResult = []
for key in firstresult.keys():
tmp = {}
tmp[0] = key
dic = restResult.get(key)
for i in range(1, len(episodeNotes)):
if (dic.get(i) != None):
tmp[i] = dic.get(i)
if (len(tmp) == len(episodeNotes)):
episodeResult.append(tmp)
# print(episodeResult)
# begin remembering
finalResult = []
for i, res in enumerate(episodeResult):
goals.setTestStates()
self.setTestStates()
for i, fre in enumerate(episodeNotes):
tt = np.arange(i * 5, (i + 1) * 5, dt)
neuid = fre
g = sl.groups.get(res.get(i))
for t in tt:
# g.neurons[neuid+1].I_ext = 20
# g.neurons[neuid+1].updateCurrentOfLowerAndUpperLayer(t)
g.neurons[neuid + 1].I = 20
g.neurons[neuid + 1].update(dt, t, 'test')
for name, gg in goals.groups.items():
for neu in gg.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t)
# find goal
maxFiringRate = 0
maxGoalName = ''
maxGoal = {} # an episode may be mapped to more than one songs
for name, gg in goals.groups.items():
averageFiringRate = 0
for neu in gg.neurons:
averageFiringRate = averageFiringRate + len(neu.spiketime)
averageFiringRate = float(averageFiringRate) / float(len(gg.neurons))
gg.averageFiringRate = averageFiringRate
if (averageFiringRate > maxFiringRate):
maxFiringRate = averageFiringRate
maxGoalName = name
maxGoal[maxGoalName] = 1
for name, gg in goals.groups.items():
if (gg.averageFiringRate == maxFiringRate and goalchecked.get(name) == None):
maxGoal[name] = 1
# print(maxGoal)
# recall the rest song
for goalname, value in maxGoal.items():
# reset State
goals.setTestStates()
nextGroupId = res.get(len(episodeNotes) - 1) + 1
for i in range(nextGroupId, len(sl.groups) + 1):
sl.groups.get(i).setTestStates()
tl.groups.get(i).setTestStates()
restSpikeResult = {}
count = 0
gg = goals.groups.get(goalname)
for i in range(nextGroupId, len(sl.groups) + 1):
order = len(episodeNotes) + count
if (order == 3):
print("debug")
tt = np.arange(order * 5, (order + 1) * 5, dt)
msmgroup = sl.groups.get(i)
msmtgroup = tl.groups.get(i)
tdic = {}
for t in tt:
for n in gg.neurons:
# n.updateCurrentOfLowerAndUpperLayer(t)
n.I = 30
n.update_normal(dt, t)
for neu in msmgroup.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t, 'test')
if (neu.spike == True and restSpikeResult.get(order) == None):
# restSpikeResult[int(order)] = neu.selectivity
tdic["N"] = neu.selectivity
for neu in msmtgroup.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t, 'test')
if (neu.spike == True and restSpikeResult.get(order) == None):
# restSpikeResult[int(order)] = neu.selectivity
tdic["T"] = neu.selectivity
if (tdic):
restSpikeResult[int(order)] = tdic
count += 1
# print(restSpikeResult)
dic = {}
dic['goal'] = goalname
dic['rest'] = restSpikeResult
finalResult.append(dic)
return (finalResult)
def doConnectToTitle(self, title, track, order):
for sl in track.values():
self.doConnecting(title, sl, order)
def doConnectToComposer(self, composer, track, order):
for sl in track.values():
self.doConnecting(composer, sl, order)
def doConnectToGenre(self, genre, track, order):
for sl in track.values():
self.doConnecting(genre, sl, order)
def doConnectToEmotion(self, emo, track, order):
for sl in track.values():
self.doConnecting(emo, sl, order)
def doConnectToKey(self, key, track, order, noteIndex):
group = track.get("N").groups.get(order)
if group == None: return
tb = (order - 1) * group.timeWindow
te = (order) * group.timeWindow
sp1_goal = {}
sp2 = []
kneu = key.neurons[noteIndex % 12]
sp = []
for st in kneu.spiketime:
if (st < te and st >= tb):
sp.append(st)
sp1_goal[kneu.index] = sp
n = group.neurons[noteIndex + 1]
if (len(n.spiketime) > 0):
for index, sp in sp1_goal.items():
temp = 0
for sp1 in n.spiketime: # spike times of group
for sp2 in sp:
if (abs(sp1 - sp2) <= n.timeWindow):
temp += 1
if (temp >= 2): # super threshold, create a new synapse between goal and neurons of sequence group
# syn = Synapse(goal.neurons[index - 1], n)
# syn.type = 2
# syn.weight = 30
# n.pre_neurons.append(goal.neurons[index - 1])
# n.synapses.append(syn)
# add reverse synapse to neurons of the goal
syn2 = Synapse(n, kneu)
syn2.type = 3
syn2.weight = 0
kneu.synapses.append(syn2)
def doConnectToMode(self, mode, keyName, track, order, noteIndex): # 只连接对应调式的音级(这是两个神经元之间的连接)
noteScales = np.where((configs.keyscales.get(keyName % 2)[keyName // 2]) == noteIndex % 12)[0][0]
group = track.get("N").groups.get(order)
if (group == None): return
tb = (order - 1) * group.timeWindow
te = (order) * group.timeWindow
sp1_goal = {}
sp2 = []
modeneu = mode.neurons[noteScales]
sp = []
for st in modeneu.spiketime:
if (st < te and st >= tb):
sp.append(st)
sp1_goal[modeneu.index] = sp
n = group.neurons[noteIndex + 1]
if (len(n.spiketime) > 0):
for index, sp in sp1_goal.items():
temp = 0
for sp1 in n.spiketime: # spike times of group
for sp2 in sp:
if (abs(sp1 - sp2) <= n.timeWindow):
temp += 1
if (temp >= 2): # super threshold, create a new synapse between goal and neurons of sequence group
# syn = Synapse(goal.neurons[index - 1], n)
# syn.type = 2
# syn.weight = 30
# n.pre_neurons.append(goal.neurons[index - 1])
# n.synapses.append(syn)
# add reverse synapse to neurons of the goal
syn2 = Synapse(n, modeneu)
syn2.type = 3
syn2.weight = 0
modeneu.synapses.append(syn2)
def generateEx_Nihilo(self, firstNote, durations, order, dt, t):
ns = self.sequenceLayers.get(1).get("N")
ts = self.sequenceLayers.get(1).get("T")
nneurons = ns.groups.get(order + 1).neurons
tneurons = ts.groups.get(order + 1).neurons
# firstNotes specify the beginning notes to trigger the following notes
if (order < len(firstNote)): # beginning notes
i = firstNote[order]
nneu = nneurons[i + 1]
nneu.I = 20
nneu.update_normal(dt, t)
d = int(durations[order] / 0.125) - 1
tneu = tneurons[d]
tneu.I = 20
tneu.update_normal(dt, t)
else: # generate next note
for nn in nneurons:
nn.updateCurrentOfLowerAndUpperLayer(t)
nn.update(dt, t, 'test')
for tn in tneurons:
tn.updateCurrentOfLowerAndUpperLayer(t)
tn.update(dt, t, 'test')
def generateMelodyWithTone(self, firstNote, duration, tone, order, dt, t):
for i, part in self.sequenceLayers.items():
if i > 4: break
ns = part.get("N")
ts = None
if duration is not None:
ts = part.get("T") # 不输入值的话就都生成四分音符
# pitches updating
if firstNote is not None:
for nneu in ns.groups.get(order).neurons:
nneu.I_ext = firstNote[i - 1]
nneu.computeFilterCurrent()
nneu.update_normal(dt, t)
else:
for nneu in ns.groups.get(order).neurons:
nneu.updateCurrentOfLowerAndUpperLayer(t)
nneu.update_normal(dt, t)
# durations updating
if ts is not None:
if duration is not None:
for tneu in ts.groups.get(order).neurons:
tneu.I_ext = duration[i - 1]
tneu.computeFilterCurrent()
tneu.update_normal(dt, t)
else:
for tneu in ts.groups.get(order).neurons:
tneu.updateCurrentOfLowerAndUpperLayer(t)
tneu.update_normal(dt, t)
def generateSimgleTrackNotes(self, trackIndex, firstNote, durations, order, dt, t):
ns = self.sequenceLayers.get(trackIndex).get("N")
ts = self.sequenceLayers.get(trackIndex).get("T")
nneurons = ns.groups.get(order + 1).neurons
tneurons = ts.groups.get(order + 1).neurons
# firstNotes specify the beginning notes to trigger the following notes
if (order < len(firstNote)): # beginning notes
i = firstNote[order]
nneu = nneurons[i + 1]
nneu.I = 20
nneu.update_normal(dt, t)
d = int(durations[order] / 0.125) - 1
tneu = tneurons[d]
tneu.I = 20
tneu.update_normal(dt, t)
else: # generate next note
for nn in nneurons:
nn.updateCurrentOfLowerAndUpperLayer(t)
nn.update(dt, t, 'test')
# if(neu.spike == True):
# print(neu.selectivity)
for tn in tneurons:
tn.updateCurrentOfLowerAndUpperLayer(t)
tn.update(dt, t, 'test')
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Areas/pfc.py
================================================
import numpy as np
import math
from braincog.base.brainarea.PFC import PFC
from Modal.synapse import Synapse
from Modal.titlelayer import TitleLayer
from Modal.composerlayer import ComposerLayer
from Modal.genrelayer import GenreLayer
from conf.conf import *
from Modal.layer import *
class PFC(PFC):
'''
This area is used to store the sub-Goal of the task
'''
def __init__(self, neutype):
'''
Constructor
'''
super().__init__()
self.neutype = neutype
self.goals = TitleLayer(self.neutype) # store the musical titles
self.composers = ComposerLayer(self.neutype) # store composers
self.keys = KeyLayer(self.neutype)
self.modes = ModeLayer(self.neutype)
self.genres = GenreLayer(self.neutype)
self.chords = ChordLayer(self.neutype)
def addNewKey(self):
row, col = configs.key_matrix.shape
for i in range(row):
#print(configs.key_matrix[i,:])
self.keys.addNewGroups(i+1, 1, col, configs.key_matrix[i,:])
def addNewSubGoal(self, goalname):
if (self.goals.groups.get(goalname) == None):
self.goals.addNewGroups(len(self.goals.groups) + 1, 1, 1, goalname)
def addNewComposer(self, composername):
if (self.composers.groups.get(composername) == None):
self.composers.addNewGroups(len(self.composers.groups) + 1, 1, 1, composername)
def addNewGenre(self, genrename):
if (self.genres.groups.get(genrename) == None):
self.genres.addNewGroups(len(self.genres.groups) + 1, 1, 1, genrename)
def addNewMode(self):
for i, m in configs.index2mode.items():
self.modes.addNewGroups(i + 1, 1, 12, m)
# 与调式网络相连
scales = configs.keyscales.get(i)
for k in range(12): # key neurons project to mode neurons
for j, index in enumerate(scales[k, :]):
pre = self.keys.groups.get(k).neurons[index]
post = self.modes.groups.get(i).neurons[j]
syn = Synapse(pre, post)
syn.excitability = 1
syn.type = 3
post.synapses.append(syn)
post.pre_neurons.append(pre)
# syn1 = Synapse(post, pre) # mode neurons project to key neurons
# syn1.type = 2
# syn1.excitability = 1
# syn1.weight = 10 # 这个地方应该设置成KS model
# pre.synapses.append(syn1)
# pre.pre_neurons.append(post)
def addNewKey(self):
row, col = configs.key_matrix.shape
for i in range(row):
#print(configs.key_matrix[i,:])
self.keys.addNewGroups(i+1, 1, col, configs.key_matrix[i,:])
def addNewChord(self):
for i in range(0, 7): # 暂时先存储7个三和弦
self.chords.addNewGroups(i + 1, 1, 1)
# 与调式网络相连
# 先连接T,S,D和弦
for t, c in configs.chordsMap.items():
# print(t)
# print(configs.keyIndexMap.get(t))
# print(c[i, :])
# print('---------')
for k in c[i, :]:
pre = self.chords.groups.get(i).neurons[0]
post = self.keys.groups.get(configs.keyIndexMap.get(t)).neurons[k]
syn = Synapse(pre, post)
syn.excitability = 1
post.synapses.append(syn)
post.pre_neurons.append(pre)
# 建立和弦内部连接
r = np.argwhere(configs.chordsMatrix >= 1)
for i in range(len(r)):
# print(r[i][0])
# print(r[i][1])
pre = self.chords.groups.get(r[i][0]).neurons[0]
post = self.chords.groups.get(r[i][1]).neurons[0]
syn = Synapse(pre, post)
post.synapses.append(syn)
post.pre_neurons.append(pre)
def setTestStates(self):
self.goals.setTestStates()
self.composers.setTestStates()
self.genres.setTestStates()
self.keys.setTestStates()
self.modes.setTestStates()
self.chords.setTestStates()
def doRecalling(self, goalname, asm):
goal = self.goals.groups.get(goalname)
# print(goal.name)
# print(goal.id)
result = {}
sequences = asm.sequenceLayers.get(1).groups
dt = 0.1
time = np.arange(0, len(sequences) * 5, dt)
for t in time:
order = math.floor(t / 5) + 1
for neu in goal.neurons:
neu.I = 30
neu.update_normal(dt, t)
sg = sequences.get(order)
for neu in sg.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t, 'test')
# if(neu.spike == True):
# print(neu.index)
if (neu.spike == True and result.get(order) == None):
result[int(order)] = neu.selectivity
return result
def doRecalling2(self, goalname, asm):
goal = self.goals.groups.get(goalname)
# print(goal.name)
# print(goal.id)
result = {}
for tindex, strack in asm.sequenceLayers.items():
nsequences = strack.get("N").groups
tsequences = strack.get("T").groups
dic = {}
ndic = {}
tdic = {}
dt = 0.1
time = np.arange(0, len(nsequences) * 5, dt)
for t in time:
order = math.floor(t / 5) + 1
for neu in goal.neurons:
neu.I = 30
neu.update_normal(dt, t)
nsg = nsequences.get(order)
for neu in nsg.neurons:
# print(neu.selectivity)
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t, 'test')
# if(neu.I > 0):
# print(neu.I)
if (neu.spike == True and ndic.get(order) == None):
ndic[int(order)] = neu.selectivity
tsg = tsequences.get(order)
for neu in tsg.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t, 'test')
if (neu.spike == True and tdic.get(order) == None):
tdic[int(order)] = neu.selectivity
dic["N"] = ndic
dic["T"] = tdic
result[tindex] = dic
return result
def doRecalling3(self,goalname,asm):
goal = self.goals.groups.get(goalname)
# print(goal.name)
# print(goal.id)
result = {}
for tindex, strack in asm.sequenceLayers.items():
nsequences = strack.get("N").groups
tsequences = strack.get("T").groups
part = []
ndic = {}
tdic = {}
dt = 0.1
# for order in range(len(nsequences)):
# nns = nsequences.get(order+1).neurons
# for n in nns:
# if n.preActive:
# print('-------order:'+str(order)+', selectivity: '+str(n.selectivity)+'--------------------')
# for syn in n.synapses:
# if syn.weight > 0:
# print(syn.weight)
#time = np.arange(0, len(nsequences) * 5, dt)
print(len(nsequences))
for i in range(0,len(nsequences)):
order = i+1
tmp = {}
time = np.arange(i*5,(i+1)*5,dt)
for t in time:
for neu in goal.neurons:
neu.I = 30
neu.update_normal(dt, t)
nsg = nsequences.get(order)
for neu in nsg.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update_normal(dt, t)
# if (neu.I > 0):
# print('order: ' + str(order))
# print(neu.I)
# print(neu.selectivity)
# print(neu.I_lower)
if (neu.spike == True and ndic.get(order) == None):# 这里用的是first spike的理念,我觉得最好改成max firingrate
ndic[int(order)] = neu.selectivity
tmp["N"] = neu.selectivity
tsg = tsequences.get(order)
for neu in tsg.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update_normal(dt, t)
if (neu.spike == True and tdic.get(order) == None):#这个地方bug太邪乎了,等一会儿改
tdic[int(order)] = neu.selectivity
tmp["T"] = neu.selectivity
part.append(tmp)
result[tindex] = part
print(len(result))
return result
def doRemebering(self, goalname, dt, t):
# storing the title information
goal_group = self.goals.groups.get(goalname)
for neu in goal_group.neurons:
neu.I = 50
neu.update_normal(dt, t)
def doRememberingComposer(self, composername, dt, t):
composer_group = self.composers.groups.get(composername)
for neu in composer_group.neurons:
neu.I = 50
neu.update_normal(dt, t)
def doRememberingGenre(self, genrename, dt, t):
genre_group = self.genres.groups.get(genrename)
for neu in genre_group.neurons:
neu.I = 50
neu.update_normal(dt, t)
def doRememberingKey(self, key, dt, t):
key_group = self.keys.groups.get(key)
for neu in key_group.neurons:
neu.I = 50 if neu.importance > 0 else -100
neu.update_learn(dt, t)
def doRememberingMode(self,mode, dt,t):
mode_group = self.modes.groups.get(mode)
for neu in mode_group.neurons:
neu.I = 50
neu.update_learn(dt,t)
def innerLearning(self, goalname, composer, genre):
g = self.goals.groups.get(goalname)
c = self.composers.groups.get(composer)
gre = self.genres.groups.get(genre)
if (g != None and c != None):
for n1 in c.neurons:
if (len(n1.spiketime) > 0):
for n2 in g.neurons:
if (len(n2.spiketime) > 0):
temp = 0
for sp1 in n1.spiketime:
for sp2 in n2.spiketime:
if (abs(sp1 - sp2) <= n1.tau_ref):
temp += 1
if (temp >= 3):
syn = Synapse(n1, n2)
syn.type = 2
syn.weight = 5
n2.synapses.append(syn)
n2.pre_neurons.append(n1)
if (gre != None):
for n1 in gre.neurons:
if (len(n1.spiketime) > 0):
if (c != None):
for n2 in c.neurons:
if (len(n2.spiketime) > 0):
temp = 0
for sp1 in n1.spiketime:
for sp2 in n2.spiketime:
if (abs(sp1 - sp2) <= n1.tau_ref):
temp += 1
if (temp >= 4):
syn = Synapse(n1, n2)
syn.type = 2
syn.weight = 5
n2.synapses.append(syn)
n2.pre_neurons.append(n1)
if (g != None):
for n2 in g.neurons:
if (len(n2.spiketime) > 0):
temp = 0
for sp1 in n1.spiketime:
for sp2 in n2.spiketime:
if (abs(sp1 - sp2) <= n1.tau_ref):
temp += 1
if (temp >= 4):
syn = Synapse(n1, n2)
syn.type = 2
syn.weight = 5
n2.synapses.append(syn)
n2.pre_neurons.append(n1)
def inhibitGenres(self,dt,t):
gen_group = self.goals.groups
for g in gen_group.values():
for neu in g.neurons:
neu.I = -100
neu.update_normal(dt, t)
def inhibiteGoals(self, dt, t):
goal_group = self.goals.groups
for g in goal_group.values():
for neu in g.neurons:
neu.I = -100
neu.update(dt, t)
def inhibitComposers(self, dt, t):
com_group = self.composers.groups
for g in com_group.values():
for neu in g.neurons:
neu.I = -100
neu.update(dt, t)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/PAC.py
================================================
'''
Primary Auditory Cortex
'''
import torch
from braincog.base.node.node import *
from braincog.base.brainarea.BrainArea import *
from braincog.base.connection import CustomLinear
from braincog.base.learningrule.STDP import *
class PAC(BrainArea):
def __int__(self,w,mask):
self.noteNetworks = NoteLIFNode()
self.connection = [CustomLinear(w,mask),CustomLinear(w2,mask2)]
self.stdp = []
self.internalinputs = torch.zeros(640,640)
self.stdp.append(MutliInputSTDP(self.noteNetworks, self.connection))
def forward(self, x):
self.internalinputs,dw = self.stdp[0](x,self.internalinputs)
return self.internalinputs, dw
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/cluster.py
================================================
from .lifneuron import LIFNeuron
from .synapse import Synapse
from Modal.izhikevichneuron import *
class Cluster():
'''
classdocs
'''
def __init__(self, neutype='LIF', neunum=10):
'''
Constructor
'''
self.id = 0 # starting with 1
self.name = '' # name of this group
self.neutype = neutype
self.neunum = neunum
self.neurons = []
self.timeWindow = 5 # ms
def createClusterNetwork(self):
# create neurons
for i in range(0, self.neunum):
if (self.neutype == 'LIF'):
node = LIFNeuron()
node.index = i + 1
node.setPreference()
self.neurons.append(node)
if (self.neutype == 'Izhikevich'):
node = IzhikevichNeuron()
node.index = i
self.neurons.append(node)
if (self.neutype == 'Gaussian'):
node = GaussianNeuron()
node.index = i + 1
self.neurons.append(node)
if (self.neutype == 'HH'):
node = HHNeuron()
node.index = i
self.neurons.append(node)
def setInhibitoryNeurons(self, ratio_inhneuron):
for i in range(int(self.neunum * (1 - ratio_inhneuron)), self.neunum):
self.neurons[i].type = 'inh'
def setPropertiesofNeurons(self, groupID, layerType, layerID):
for n in self.neurons:
n.layerType = layerType
n.groupIndex = groupID
n.layerIndex = layerID
def setTestStates(self):
for neu in self.neurons:
neu.setTestStates()
def createFullConnections(self): # all in all connections
for i in range(0, self.neunum):
neu = self.neurons[i]
for j in range(0, self.neunum):
if (j != i):
syn = Synapse(self.neurons[j], neu) # this neuron is considered as post_synapse neuron
syn.type = 0
neu.synapses.append(syn)
neu.pre_neurons.append(self.neurons[j])
def createInhibitoryConnections(self): # all in all inhibitory connections
for i in range(0, self.neunum):
neu = self.neurons[i]
for j in range(0, self.neunum):
if (j != i):
syn = Synapse(self.neurons[j], neu) # this neuron is considered as post_synapse neuron
syn.type = 0
syn.excitability = 0
syn.weight = 20
neu.synapses.append(syn)
neu.pre_neurons.append(self.neurons[j])
def writeSelfInfoToJson(self):
dic = {}
nlist = []
for neu in self.neurons:
if (len(neu.spiketime) <= 0): continue
ndic = neu.writeBasicInfoToJson()
nlist.append(ndic)
dic["GroupID"] = self.id
dic["Name"] = self.name
dic["Neuron"] = nlist
return dic
def writeSpikeInfoToJson(self):
nlist = []
for neu in self.neurons:
if (len(neu.spiketime) > 0):
tmp = {}
tmp["GroupID"] = neu.groupIndex
tmp["Index"] = neu.index
tmp["SpikeTime"] = neu.writeSpikeTimeToJson()
nlist.append(tmp)
return nlist
class ModeCluster(Cluster):
def __init__(self, neutype, neunum):
Cluster.__init__(self, neutype,neunum)
def createClusterNetwork(self, areaName):
for i in range(self.neunum): # 暂时先不考虑importance
if (self.neutype == 'LIF'):
node = ModeLIFNeuron()
node.index = i + 1
node.areaName = areaName
node.selectivity = i+1
self.neurons.append(node)
if (self.neutype == 'Izhikevich'):
self.neutype = 'Izhikevich'
node = ModeIzhikevichNeuron()
node.index = i + 1
node.areaName = areaName
node.selectivity = i+1
self.neurons.append(node)
class KeyCluster(Cluster):
def __init__(self, neutype, neunum):
'''
Constructor
'''
Cluster.__init__(self, neutype, neunum)
def createClusterNetwork(self,tone,areaName):
for i in range(0, self.neunum):
if (self.neutype == 'LIF'):
node = KeyLIFNeuron()
node.index = i + 1
node.areaName = areaName
node.selectivity = i
node.importance = tone[i]
self.neurons.append(node)
if(self.neutype == 'Izhikevich'):
self.neutype = 'Izhikevich'
a=0
b=0
c=0
d=0
if tone[i] == 2:
a = 0.02
b = 0.2
c = -55
d = 4
if tone[i] == -1:
a=0.1
b = 0.2
c = -65
d = 2
if(tone[i] == 1):
a = 0.02
b = 0.2
c = -65
d = 8
node = KeyIzhikevichNeuron(a,b,c,d)
node.index = i + 1
node.areaName = areaName
node.selectivity = i
node.importance = tone[i]
self.neurons.append(node)
class ChordCluster(Cluster):
def __init__(self, neutype,neunum):
Cluster.__init__(self, neutype, neunum)
def createClusterNetwork(self):
for i in range(self.neunum):
if (self.neutype == 'LIF'):
node = ChordLIFNeuron()
node.index = i + 1
node.areaName = 'Chord'
node.selectivity = i
node.importance = 1
self.neurons.append(node)
if self.neutype == 'Izhikevich':
node = ChordIzhikevichNeuron()
node.index = i + 1
node.areaName = 'Chord'
node.selectivity = i
node.importance = 1
self.neurons.append(node)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/composercluster.py
================================================
from .cluster import Cluster
from .composerlifneuron import ComposerLIFNeuron
class ComposerCluster(Cluster):
'''
classdocs
'''
def __init__(self, neutype, neunum):
'''
Constructor
'''
Cluster.__init__(self, neutype, neunum)
def createClusterNetwork(self):
for i in range(0, self.neunum):
if (self.neutype == 'LIF'):
node = ComposerLIFNeuron()
node.index = i + 1
node.areaName = 'Composer'
self.neurons.append(node)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/composerlayer.py
================================================
from .layer import Layer
from .composercluster import ComposerCluster
class ComposerLayer(Layer):
'''
This layer defines the information of composer name. One neuron corresponds to a composer
'''
def __init__(self, neutype='LIF'):
self.neutype = neutype
self.groups = {}
def setTestStates(self):
for id, g in self.groups.items():
g.setTestStates()
def addNewGroups(self, groupID, layerID, neunum, composername):
g = ComposerCluster(self.neutype, neunum)
g.id = groupID
g.name = composername
g.createClusterNetwork()
g.setPropertiesofNeurons(groupID, 'G', layerID)
self.groups[composername] = g
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/composerlifneuron.py
================================================
from .lifneuron import LIFNeuron
class ComposerLIFNeuron(LIFNeuron):
'''
classdocs
'''
def __init__(self, tau_ref=0, vthresh=5, Rm=2, Cm=0.2):
'''
Constructor
'''
LIFNeuron.__init__(self, tau_ref, vthresh, Rm, Cm)
def update(self, dt, t):
self.spike = False
# self.updateCurrentOfLowerAndUpperLayer(t)
if (t >= self.t_rest):
self.mem += dt * (-self.mem + self.I * self.Rm) / self.tau_m
if (self.mem > self.vth):
self.spike = True
self.spiketime.append(t)
self.mem = 0
self.t_rest = t + self.tau_ref
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/genrecluster.py
================================================
from .cluster import Cluster
from .genrelifneuron import GenreLIFNeuron
class GenreCluster(Cluster):
'''
classdocs
'''
def __init__(self, neutype, neunum):
'''
Constructor
'''
Cluster.__init__(self, neutype, neunum)
def createClusterNetwork(self):
for i in range(0, self.neunum):
if (self.neutype == 'LIF'):
node = GenreLIFNeuron()
node.index = i + 1
node.areaName = 'Genre'
self.neurons.append(node)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/genrelayer.py
================================================
from .layer import Layer
from .genrecluster import GenreCluster
class GenreLayer(Layer):
'''
This layer defines the information of composer name. One neuron corresponds to a composer
'''
def __init__(self, neutype='LIF'):
self.neutype = neutype
self.groups = {}
def setTestStates(self):
for id, g in self.groups.items():
g.setTestStates()
def addNewGroups(self, groupID, layerID, neunum, genrename):
g = GenreCluster(self.neutype, neunum)
g.id = groupID
g.name = genrename
g.createClusterNetwork()
g.setPropertiesofNeurons(groupID, 'G', layerID)
self.groups[genrename] = g
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/genrelifneuron.py
================================================
from .lifneuron import LIFNeuron
class GenreLIFNeuron(LIFNeuron):
'''
classdocs
'''
def __init__(self, tau_ref=0, vthresh=5, Rm=2, Cm=0.2):
'''
Constructor
'''
LIFNeuron.__init__(self, tau_ref, vthresh, Rm, Cm)
def update(self, dt, t):
self.spike = False
# self.updateCurrentOfLowerAndUpperLayer(t)
if (t >= self.t_rest):
self.mem += dt * (-self.mem + self.I * self.Rm) / self.tau_m
if (self.v > self.vth):
self.spike = True
self.spiketime.append(t)
self.mem = 0
self.t_rest = t + self.tau_ref
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/izhikevichneuron.py
================================================
'''
Created on 2016.4.8
@author: liangqian
'''
#from modal.izhikevich import Izhikevich
from braincog.base.node import IzhNodeMU
import math
import random
import numpy as np
class IzhikevichNeuron(IzhNodeMU):
'''
classdocs
'''
def __init__(self, a = 0.1,b = 0.2,c = -65,d = 8,vthresh = 30, dt=0.1):
'''
Constructor
'''
super().__init__(threshold=vthresh, a=a, b=b, c=c, d=d, dt=dt)
self.layerType = 'S' # S:sequenceLayer, G: goal layer
self.layerIndex = 0 # the layer in which the neuron situated
self.groupIndex = 0 # the group in which the neuron situated
self.index = 0 # starting with 1
self.areaName = ''
self.synapses = [] #this neuron is considered as post-synaptic neuron
self.spiketime = []
self.pre_neurons = []
self.I_syn_lower = 0
self.I_syn_upper = 0
self.I_ext = 0
self.I_lower = 0
self.I_upper = 0
self.I_ext = -100
self.timeWindow = 5 # ms
self.I_bg = random.randint(0, 10)
# self.state = 'Learn' # else test
self.selectivity = 0
self.importance = 0
self.preActive = False
self.I = 0
self.v = -65
self.u = b * self.v
self.vthresh = vthresh
self.spike = False
self.type = 'exc'
def update_old(self,dt,t):
self.spike = 0
self.updateSynapses(t)
self.updateCurrentOfLowerAndUpperLayer(t)
self.I = self.I_ext + self.I_syn_lower + self.I_syn_upper
self.v += dt * (0.04*self.v * self.v + 5 * self.v + 140 - self.u + self.I)
self.u += dt * self.a * (self.b *self.v - self.u)
#self.synapseWeightsDepression()
if(self.v >= 30):
self.spike = 1
self.v = self.c
self.u += self.d
self.spiketime.append(t)
def update(self,dt,t,state):
if (state == 'Learn'):
self.update_learn(dt, t)
if(state == 'test'):
self.update_test(dt,t)
def update_learn(self,dt,t):
self.spike = False
self.v += dt * (0.04 * self.v * self.v + 5 * self.v + 140 - self.u + self.I)
self.u += dt * self.a * (self.b * self.v - self.u)
if self.v > self.vthresh:
self.spike = True
self.v = self.c
self.u += self.d
self.preActive = True
self.spiketime.append(t)
self.updateSynapses(t)
def update_test(self,dt,t):
self.spike = False
self.v += dt * (0.04 * self.v * self.v + 5 * self.v + 140 - self.u + self.I)
self.u += dt * self.a * (self.b * self.v - self.u)
if self.v > self.vthresh:
self.spike = True
self.v = self.c
self.u += self.d
def update_normal(self,dt,t):
self.spike = False
self.v += dt * (0.04 * self.v * self.v + 5 * self.v + 140 - self.u + self.I)
self.u += dt * self.a * (self.b * self.v - self.u)
if self.v >= self.vthresh:
self.spike = True
self.v = self.c
self.u += self.d
self.spiketime.append(t)
def updateSynapses(self,t):
for syn in self.synapses:
syn.computeWeight(t)
def updateCurrentOfLowerAndUpperLayer(self,t):
I_inh = 0
I_ext = 0
I_exc_ext = 0
for syn in self.synapses:
# compute the alpha value of all spikes before this time t
alpha_value = 0
for st in syn.pre.spiketime:
temp = 0
if(t - st >= 0): temp = 6*(t/1000)*math.exp(-0.03*(t - st)/1000)
else:temp = 0
alpha_value += temp
if(syn.type == 0): # from the same group
if(syn.pre.type == 'inh'):
I_inh += syn.weight * (self.v+80) * alpha_value
if(syn.pre.type == 'exc'):
I_ext += syn.weight * self.v * alpha_value
if(syn.type == 1):# from other modules in the same layer
I_exc_ext += syn.weight * self.v * alpha_value
if(syn.type == 2): # from the upper layer
self.I_syn_upper += self.weight * self.v * alpha_value
self.I_syn_lower = -I_inh + I_ext + I_exc_ext
def setTestStates(self):
self.t_rest = 0
self.spiketime = []
self.v = -65
self.u = self.b*self.v
self.I = 0
self.I_ext = 0
for syn in self.synapses:
syn.strength = 0
def writeBasicInfoToJson(self):
dic = {}
dic["TrackID"] = self.layerIndex
dic["GroupID"] = self.groupIndex
dic["Index"] = self.index
dic["selectivity"] = self.selectivity
dic["area"] = self.areaName
slist = []
for syn in self.synapses:
if (syn.weight <= 0): continue
tmp = {}
tmp["type"] = syn.type
tmp["StrackID"] = syn.pre.layerIndex
tmp["SgroupID"] = syn.pre.groupIndex
tmp["Sindex"] = syn.pre.index
tmp["Sarea"] = syn.pre.areaName
tmp["pre-selectivity"] = syn.pre.selectivity
tmp["weight"] = syn.weight
slist.append(tmp)
dic["synapses"] = slist
return dic
def writeSpikeTimeToJson(self):
slist = []
for i, t in enumerate(self.spiketime):
dic = {}
dic[i + 1] = round(t, 2)#两位有效数字
slist.append(dic)
return slist
class NoteIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh = 30):
IzhikevichNeuron.__init__(self,a,b,c,d,vthresh)
def setPreference(self):
self.selectivity = self.index - 2
def computeFilterCurrent(self):
if(self.I_ext == self.selectivity):
self.I = 30
def updateCurrentOfLowerAndUpperLayer(self, t):
self.I_lower = 0
self.I_upper = 0
for syn in self.synapses:
syn.computeShortTermFacilitation2(t)
if (syn.type == 0): # the same group
if (syn.excitability == 0):
self.I_lower -= syn.weight * syn.strength
if (self.I_lower < -20): self.I_lower = -20
if (syn.type == 1): # pre and post neurons come from the same layer but not the same group
#if(syn.weight > 0):
# print('pre_neuron_group id:'+str(syn.pre.groupIndex) + ' neuron index:'+str(syn.pre.index))
# print('post_neuron_group id:'+str(self.groupIndex) + ' neuron index:'+str(self.index))
# print('syn.strength=' + str(syn.strength))
# print('syn.weight='+ str(syn.weight))
self.I_lower += syn.weight * syn.strength
# print('syn.strength='+str(syn.strength))
# print('syn.weight='+ str(syn.weight))
if (syn.type >= 2): # pre and post neurons come from the different layers
# print(syn.pre.groupIndex)
self.I_upper += syn.weight * syn.strength
self.I = self.I_lower + self.I_upper
class TempoIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh = 30):
IzhikevichNeuron.__init__(self,a,b,c,d,vthresh)
def setPreference(self):
self.selectivity = self.index * 0.125
def computeFilterCurrent(self):
if(self.I_ext <= self.selectivity + 0.0625 and self.I_ext >= self.selectivity - 0.0625 ):
self.I = 30
def updateCurrentOfLowerAndUpperLayer(self, t):
self.I_lower = 0
self.I_upper = 0
for syn in self.synapses:
syn.computeShortTermFacilitation2(t)
if (syn.type == 0): # the same group
if (syn.excitability == 0):
self.I_lower -= syn.weight * syn.strength
if (self.I_lower < -20): self.I_lower = -20
if (syn.type == 1): # pre and post neurons come from the same layer but not the same group
# if(syn.weight > 0):
#
# print('pre_neuron_group id:'+str(syn.pre.groupIndex) + ' neuron index:'+str(syn.pre.index))
# print('post_neuron_group id:'+str(self.groupIndex) + ' neuron index:'+str(self.index))
# print(syn.weight)
self.I_lower += syn.weight * syn.strength
# print('syn.strength='+str(syn.strength))
if (syn.type == 2): # pre and post neurons come from the different layers
# print(syn.pre.groupIndex)
# self.I_lower = syn.weight * syn.strength
self.I_upper += syn.weight * syn.strength
# if(self.I_upper == 0):
# self.I = self.I_ext
else:
self.I = self.I_lower + self.I_upper
class TitleIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh=30):
IzhikevichNeuron.__init__(self,a,b,c,d,vthresh)
class ComposerIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh=30):
IzhikevichNeuron.__init__(self, a,b,c,d,vthresh)
class GenreIzhikevichNeuron(IzhikevichNeuron):
def __init__(self, a = 0.1,b = 0.2,c = -65,d = 8, vthresh=30):
IzhikevichNeuron.__init__(self, a, b, c, d, vthresh)
class AmyIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh=30):
IzhikevichNeuron.__init__(self, a,b,c,d,vthresh)
class DirectionIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh=30):
IzhikevichNeuron.__init__(self,a,b,c,d,vthresh)
def setPreference(self):
# self.selectivity = 2 * math.pi/240 * self.index - math.pi/240
self.selectivity = (self.index + 1) * math.pi / 120
def computeFilterCurrent(self, input):
if (input < self.selectivity + math.pi / 240 and input >= self.selectivity - math.pi / 240):
self.I = self.I_ext = 30
def updateCurrentOfLowerAndUpperLayer(self, t):
self.I_lower = 0
self.I_upper = 0
for syn in self.synapses:
syn.computeShortTermFacilitation2(t)
if (syn.type == 0): # the same group
if (syn.excitability == 0):
self.I_lower -= syn.weight * syn.strength
if (self.I_lower < -20): self.I_lower = -20
if (syn.type == 1): # pre and post neurons come from the same layer but not the same group
#if(syn.weight > 0):In t
# print('pre_neuron_group id:'+str(syn.pre.groupIndex) + ' neuron index:'+str(syn.pre.index))
# print('post_neuron_group id:'+str(self.groupIndex) + ' neuron index:'+str(self.index))
# print('syn.strength=' + str(syn.strength))
# print('syn.weight='+ str(syn.weight))
self.I_lower += syn.weight * syn.strength
# print('syn.strength='+str(syn.strength))
# print('syn.weight='+ str(syn.weight))
if (syn.type >= 2): # pre and post neurons come from the different layers
# print(syn.pre.groupIndex)
self.I_upper += syn.weight * syn.strength
self.I = self.I_lower + self.I_upper
class GridIzhikevichCell(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh = 30):
IzhikevichNeuron.__init__(self, a,b,c,d,vthresh)
class KeyIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh = 30):
IzhikevichNeuron.__init__(self,a,b,c,d,vthresh)
class ModeIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh = 30):
IzhikevichNeuron.__init__(self,a,b,c,d,vthresh)
class ChordIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8, vthresh = 30):
IzhikevichNeuron.__init__(self, a,b,c,d,vthresh)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/layer.py
================================================
from abc import ABCMeta,abstractmethod
from conf.conf import configs
from Modal.cluster import *
class Layer():
'''
classdocs
'''
_metaclass_ = ABCMeta
def __init__(self, neutype):
'''
Constructor
'''
self.neutype = neutype
self.groups = {}
@abstractmethod
def resetProperties(self):
raise NotImplementedError
def addNewGroups(self, layerID, neunum):
raise NotImplementedError
class ModeLayer(Layer):
def __init__(self, neutype = 'LIF'):
self.neutype = neutype
self.groups = {}
def setTestStates(self):
for id, g in self.groups.items():
g.setTestStates()
def addNewGroups(self, groupID, layerID, neunum, modeName):
g = ModeCluster('Izhikevich', neunum)
g.id = groupID
g.name = modeName
g.createClusterNetwork(g.name)
g.setPropertiesofNeurons(groupID,'Mode',layerID)
self.groups[groupID-1] = g
class KeyLayer(Layer):
def __init__(self, neutype='LIF'):
self.neutype = neutype
self.groups = {}
def setTestStates(self):
for id, g in self.groups.items():
g.setTestStates()
def addNewGroups(self, groupID, layerID, neunum, key):
g = KeyCluster('Izhikevich', neunum)
g.id = groupID
g.name = configs.index2key.get(groupID-1)
g.createClusterNetwork(key,g.name)
g.setPropertiesofNeurons(groupID, 'Key', layerID)
self.groups[groupID-1] = g
class ChordLayer(Layer):
def __init__(self, neutype = 'LIF'):
Layer.__init__(self,neutype)
def setTestStates(self):
for id, g in self.groups.items():
g.setTestStates()
def addNewGroups(self,groupID, layerID, neunum):
g = ChordCluster('Izhikevich', neunum)
g.id = groupID
g.name = groupID
g.createClusterNetwork()
g.setPropertiesofNeurons(groupID, 'Chord', layerID)
self.groups[groupID - 1] = g
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/lifneuron.py
================================================
import torch
import random
from braincog.base.node import node
import numpy as np
class LIFNeuron(node.LIFNode):
def __init__(self, tau_ref = 0, vthresh = 5, Rm = 2, Cm = 0.2,dt = 0.1,*args, **kwargs):
super().__init__(threshold=vthresh, tau=Rm*Cm, dt=dt, *args, **kwargs)
self.layerType = 'S' # S:sequenceLayer, G: goal layer
self.layerIndex = 0 # the layer in which the neuron situated
self.groupIndex = 0 # the group in which the neuron situated
self.index = 0 # starting with 1
self.areaName = ''
self.pre_neurons = []
self.synapses = []
self.spiketime = []
self.type = 'exc'
self.tau_ref = tau_ref
self.tau_m = Rm*Cm
self.vth = vthresh
self.Rm = Rm
self.Cm = Cm
self.t_rest = 0
self.I = 0
self.spike = False
self.firingrate = 0 # Hz
self.I_ower = 0
self.I_upper = 0
self.I_ext = -100
self.timeWindow = 5 # ms
self.I_bg = random.randint(0, 10)
# self.state = 'Learn' # else test
self.selectivity = 0
self.preActive = False
def update(self, dt, t, state): # state = 'learn' or state = 'test'
if (state == 'Learn'):
self.update_learn(dt, t)
'''
#------------Gaussian selectivity--------------#
self.I = math.exp(-((self.I_ext-math.pi/16)/0.24)**2)
self.I = self.I if self.I >= 0.5 else 0
self.I *= 10
'''
elif (state == 'test'):
self.update_test(dt, t)
def update_learn(self, dt, t):
self.spike = False
# self.computeFilterCurrent()
'''
#------------Gaussian selectivity--------------#
self.I = math.exp(-((self.I_ext-math.pi/16)/0.24)**2)
self.I = self.I if self.I >= 0.5 else 0
self.I *= 10
'''
if (t >= self.t_rest):
self.mem += dt * (-self.mem + self.I * self.Rm) / self.tau_m
if (self.mem > self.vth):
self.spike = True
self.preActive = True
# print("groupID:"+ str(self.groupIndex) + ", neuronID:"+str(self.index))
self.spiketime.append(t)
self.mem = 0
self.t_rest = t + self.tau_ref
self.updateSynapses(t)
def update_test(self, dt, t):
self.spike = False
# self.updateCurrentOfLowerAndUpperLayer(t)
if (t >= self.t_rest):
self.mem += dt * (-self.mem + self.I * self.Rm) / self.tau_m
if (self.mem > self.vth):
self.spike = True
self.spiketime.append(t)
self.mem = 0
self.t_rest = t + self.tau_ref
def update_normal(self, dt, t):
self.spike = False
# self.I = self.I_ext
if (t >= self.t_rest):
self.mem += dt * (-self.mem + self.I * self.Rm) / self.tau_m
if (self.mem > self.vth):
self.spike = True
self.mem = 0
self.t_rest = t + self.tau_ref
self.spiketime.append(t)
def updateSynapses(self, t):
for syn in self.synapses:
syn.computeWeight(t)
def setTestStates(self):
self.t_rest = 0
self.spiketime = []
self.mem = 0
self.I = 0
self.I_ext = 0
for syn in self.synapses:
syn.strength = 0
# print('I=' + str(self.I))
def computeFilterCurrent(self):
pass
def setPreference(self): # set preference of a neuron or called selectivity
# self.selectivity = 2 * math.pi/16 * self.index - math.pi/16 # the mean of the Gaussian funtion
pass
def writeBasicInfoToJson(self, areaName):
dic = {}
dic["TrackID"] = self.layerIndex
dic["GroupID"] = self.groupIndex
dic["Index"] = self.index
dic["area"] = areaName
slist = []
for syn in self.synapses:
if (syn.weight <= 0): continue
tmp = {}
tmp["StrackID"] = syn.pre.layerIndex
tmp["SgroupID"] = syn.pre.groupIndex
tmp["Sindex"] = syn.pre.index
tmp["Sarea"] = syn.pre.areaName
tmp["TtrackID"] = self.layerIndex
tmp["TgroupID"] = self.groupIndex
tmp["Tindex"] = self.index
tmp["Tarea"] = self.areaName
tmp["type"] = syn.type
tmp["weight"] = syn.weight
slist.append(tmp)
dic["synapses"] = slist
return dic
def writeSpikeTimeToJson(self):
slist = []
for i, t in enumerate(self.spiketime):
dic = {}
dic[i + 1] = t
slist.append(dic)
return slist
# neu = LIFNeuron()
# dt = 0.001
# T = 1
# time = np.arange(0,T,dt)
# spikes = np.zeros(len(time))
# for i in range(0,len(time)):
# if(i == 22):
# print("debug")
# neu.I = 84.49
# neu.update_normal(dt, time[i])
# if(neu.spike == True):
# spikes[i] = 1
# #spikes[i] = neu.mem
# print(len(neu.spiketime))
# pl.plot(time,spikes)
# pl.show()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/note.py
================================================
'''
Created on 2016.7.6
@author: liangqian
'''
from Modal.pitch import Pitch
class Note():
'''
Because a chord consist of more than two pitches at the same time, so using
arrays to record the chord
'''
def __init__(self):
self.pitches = []
# self.startTime = []
# self.endTime = []
self.lastTime = []
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/notecluster.py
================================================
from .cluster import Cluster
from .notelifneuron import NoteLIFNeuron
from Modal.izhikevichneuron import *
class NoteCluster(Cluster):
'''
classdocs
'''
def __init__(self, neutype, neunum):
'''
Constructor
'''
Cluster.__init__(self, neutype, neunum)
def createClusterNetwork(self):
for i in range(0, self.neunum):
if (self.neutype == 'LIF'):
node = NoteLIFNeuron()
node.index = i + 1
node.areaName = 'NMSM'
node.setPreference()
self.neurons.append(node)
if (self.neutype == 'Izhikevich'):
node = NoteIzhikevichNeuron()
node.index = i + 1
node.areaName = 'NMSM'
node.setPreference()
self.neurons.append(node)
# if(self.neutype == 'Izhi'):
# node = IzhikevichNeuron(a = 0.02,b = 0.2,c = -65,d = 8,vthresh = 30)
# node.index = i
# self.neurons.append(node)
# if(self.neutype == 'Gaussian'):
# node = GaussianNeuron()
# node.index = i+1
# self.neurons.append(node)
# if(self.neutype == 'HH'):
# node = HHNeuron()
# node.index = i
# self.neurons.append(node)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/notelifneuron.py
================================================
from .lifneuron import LIFNeuron
class NoteLIFNeuron(LIFNeuron):
'''
classdocs
'''
def __init__(self, tau_ref=0.5, vthresh=5, Rm=2, Cm=0.2):
'''
Constructor
'''
LIFNeuron.__init__(self, tau_ref, vthresh, Rm, Cm)
def setPreference(self):
self.selectivity = self.index - 2
def computeFilterCurrent(self):
if (self.I_ext == self.selectivity):
self.I = 10
def updateCurrentOfLowerAndUpperLayer(self, t):
self.I_lower = 0
self.I_upper = 0
for syn in self.synapses:
syn.computeShortTermFacilitation(t)
if (syn.type == 0): # the same group
if (syn.excitability == 0):
self.I_lower -= syn.weight * syn.strength
if (self.I_lower < -20): self.I_lower = -20
if (syn.type == 1): # pre and post neurons come from the same layer but not the same group
# if(syn.weight > 0):
# print('pre_neuron_group id:'+str(syn.pre.groupIndex) + ' neuron index:'+str(syn.pre.index))
# print('post_neuron_group id:'+str(self.groupIndex) + ' neuron index:'+str(self.index))
# print('syn.strength=' + str(syn.strength))
# print('syn.weight='+ str(syn.weight))
self.I_lower += 0.001 * syn.weight * syn.strength
# print('syn.strength='+str(syn.strength))
# print('syn.weight='+ str(syn.weight))
if (syn.type == 2): # pre and post neurons come from the different layers
# print(syn.pre.groupIndex)
self.I_upper += 0.001 * syn.weight * syn.strength
# if(self.I_upper == 0):
# self.I = self.I_ext
self.I = 0.4 * self.I_lower + 0.6 * self.I_upper
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/notesequencelayer.py
================================================
from .sequencelayer import SequenceLayer
from .notecluster import NoteCluster
from .synapse import Synapse
class NoteSequenceLayer(SequenceLayer):
'''
classdocs
'''
def __init__(self, neutype):
'''
Constructor
'''
SequenceLayer.__init__(self, neutype)
def addNewGroups(self, GroupID, layerID, neunum):
g = NoteCluster(self.neutype, neunum)
g.createClusterNetwork()
# g.createInhibitoryConnections()
g.id = GroupID
g.setPropertiesofNeurons(g.id, 'S', layerID)
self.groups[g.id] = g
# create full connection with the former group
if (len(self.groups) > 1):
s = 0
if (g.id <= 5):
s = 1
else:
s = g.id - 4
# for i in range(1,g.id)[::-1]:
for i in range(s, g.id)[::-1]:
pre_g = self.groups.get(i)
for n1 in pre_g.neurons:
for n2 in g.neurons:
if (n1.type == 'inh' or n2.type == 'inh'): continue;
syn = Synapse(n1, n2)
syn.type = 1
syn.delay = g.id - pre_g.id
n2.pre_neurons.append(n1)
n2.synapses.append(syn)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/pitch.py
================================================
'''
Created on 2018.8.29
@author: liangqian
'''
class Pitch():
'''
classdocs
'''
def __init__(self):
'''
Constructor
'''
self.name = ''
self.frequence = 0 #midi index number just now
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/sequencelayer.py
================================================
from .layer import Layer
from .cluster import Cluster
from .synapse import Synapse
class SequenceLayer(Layer):
'''
This class mainly stores the musical sequential elements, including pitches and durations
'''
def __init__(self, neutype='LIF'):
'''
Constructor
'''
self.type = ""
self.neutype = neutype
self.groups = {}
def addNewGroups(self, GroupID, layerID, neunum):
g = Cluster(self.neutype, neunum)
g.createClusterNetwork()
g.id = GroupID
g.setPropertiesofNeurons(g.id, 'S', layerID)
self.groups[g.id] = g
# create full connection with the former group
if (len(self.groups) > 1):
for i in range(1, g.id)[::-1]:
pre_g = self.groups.get(i)
for n1 in pre_g.neurons:
for n2 in g.neurons:
if (n1.type == 'inh' or n2.type == 'inh'): continue;
syn = Synapse(n1, n2)
syn.type = 1
syn.delay = g.id - pre_g.id
n2.pre_neurons.append(n1)
n2.synapses.append(syn)
def setTestStates(self):
for gid, g in self.groups.items():
g.setTestStates()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/sequencememory.py
================================================
from .synapse import Synapse
from Modal.sequencelayer import SequenceLayer
import numpy as np
from Modal.synapse import Synapse
class SequenceMemory():
'''
classdocs
'''
def __init__(self, neutype):
'''
Constructor
'''
self.neutype = neutype
self.sequenceLayers = {}
def createActionSequenceMem(self, layernum, neutype, neunumpergroup):
pass
def doRemembering(self):
pass
def doConnecting(self, goal, sl, order):
# the goal and the group always generate spikes in a limit time window,create a synapse between them.
group = sl.groups.get(order)
if (group == None): return
tb = (order - 1) * group.timeWindow
te = (order) * group.timeWindow
sp1_goal = {}
sp2 = []
for n in goal.neurons:
sp = []
for st in n.spiketime:
if (st < te and st >= tb):
sp.append(st)
sp1_goal[n.index] = sp
for n in group.neurons:
if (len(n.spiketime) > 0):
for index, sp in sp1_goal.items():
temp = 0
for sp1 in n.spiketime: # spike times of group
for sp2 in sp:
if (abs(sp1 - sp2) <= n.tau_ref):
temp += 1
if (
temp >= 4): # super threshold, create a new synapse between goal and neurons of sequence group
syn = Synapse(goal.neurons[index - 1], n)
syn.type = 2
syn.weight = 3
n.pre_neurons.append(goal.neurons[index - 1])
n.synapses.append(syn)
# add reverse synapse to neurons of the goal
syn2 = Synapse(n, goal.neurons[index - 1])
syn2.type = 2
syn2.weight = 1
goal.neurons[index - 1].synapses.append(syn2)
# clear the goal's spike time
''' *************************************************************
I have forgot why neurons here needs to be cleaned, but this must be important, mark here
for n in goal.neurons:
n.spiketime = []
******************************************************************
'''
# def doConnectToGoal(self,goal,track,order): # connect to the goal in the time window
#
# for sl in track.values():
# group = sl.groups.get(order)
#
# if(group == None): continue
# # the goal and the group always generate spikes in a limit time window,create a synapse between them.
# tb = (order-1)*group.timeWindow
# te = (order) * group.timeWindow
# sp1_goal = {}
# sp2 = []
#
# for n in goal.neurons:
# sp = []
# for st in n.spiketime:
# if(st < te and st >= tb ):
# sp.append(st)
# sp1_goal[n.index] = sp
#
# for n in group.neurons:
# if(len(n.spiketime) > 0):
# for index,sp in sp1_goal.items():
# temp = 0
# for sp1 in n.spiketime: #spike times of group
# for sp2 in sp:
# if(abs(sp1-sp2) <= n.tau_ref):
# temp += 1
# if(temp >= 4): # super threshold, create a new synapse between goal and neurons of sequence group
# syn = Synapse(goal.neurons[index-1],n)
# syn.type = 2
# syn.weight = 3
# n.pre_neurons.append(goal.neurons[index-1])
# n.synapses.append(syn)
#
# #add reverse synapse to neurons of the goal
# syn2 = Synapse(n,goal.neurons[index-1])
# syn2.type = 2
# syn2.weight = 1
# goal.neurons[index-1].synapses.append(syn2)
#
# #clear the goal's spike time
# ''' *************************************************************
# I have forgot why neurons here needs to be cleaned, but this must be important, mark here
# for n in goal.neurons:
# n.spiketime = []
# ******************************************************************
# '''
#
# def doConnectToComposer(self, composer, track, order):
# for sl in track.values():
# group = sl.groups.get(order)
#
# if(group == None): continue
# # the goal and the group always generate spikes in a limit time window,create a synapse between them.
# tb = (order-1)*group.timeWindow
# te = (order) * group.timeWindow
# sp1_composer = {}
# sp2 = []
#
# for n in composer.neurons:
# sp = []
# for st in n.spiketime:
# if(st < te and st >= tb ):
# sp.append(st)
# sp1_composer[n.index] = sp
#
# for n in group.neurons:
# if(len(n.spiketime) > 0):
# for index,sp in sp1_composer.items():
# temp = 0
# for sp1 in n.spiketime: #spike times of group
# for sp2 in sp:
# if(abs(sp1-sp2) <= n.tau_ref):
# temp += 1
# if(temp >= 4): # super threshold, create a new synapse between composer and neurons of sequence group
# syn = Synapse(composer.neurons[index-1],n)
# syn.type = 2
# syn.weight = 3
# n.pre_neurons.append(composer.neurons[index-1])
# n.synapses.append(syn)
#
# #add reverse synapse to neurons of the goal
# # syn2 = Synapse(n,goal.neurons[index-1])
# # syn2.type = 2
# # syn2.weight = 1
# # goal.neurons[index-1].synapses.append(syn2)
#
#
# def doConnectToGenre(self, genre, track, order):
# for sl in track.values():
# group = sl.groups.get(order)
#
# if(group == None): continue
# # the goal and the group always generate spikes in a limit time window,create a synapse between them.
# tb = (order-1)*group.timeWindow
# te = (order) * group.timeWindow
# sp1_genre = {}
# sp2 = []
#
# for n in genre.neurons:
# sp = []
# for st in n.spiketime:
# if(st < te and st >= tb ):
# sp.append(st)
# sp1_genre[n.index] = sp
#
# for n in group.neurons:
# if(len(n.spiketime) > 0):
# for index,sp in sp1_genre.items():
# temp = 0
# for sp1 in n.spiketime: #spike times of group
# for sp2 in sp:
# if(abs(sp1-sp2) <= n.tau_ref):
# temp += 1
# if(temp >= 4): # super threshold, create a new synapse between composer and neurons of sequence group
# syn = Synapse(genre.neurons[index-1],n)
# syn.type = 2
# syn.weight = 3
# n.pre_neurons.append(genre.neurons[index-1])
# n.synapses.append(syn)
def setTestStates(self):
for itrack in self.sequenceLayers.values():
for sl in itrack.values():
sl.setTestStates()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/synapse.py
================================================
import math
class Synapse():
'''
classdocs
'''
def __init__(self, pre, post):
'''
Constructor
'''
self.type = 0 # 0: within a group; 1: different groups in the same layer; 2: other layer
self.pre = pre
self.post = post
self.weight = 0
self.excitability = 1 # 1:excited connection; 0:inhibitory connection
self.strength = 0 # short term depression and facilitation factor
self.delay = 0 # time delay of transmission between pre and post
def computeWeight(self, t):
if (self.type == 0): # pre and post neurons are in the same group
pass
elif (self.type == 1): # pre and post neurons are in the same layer but different groups
for st in self.pre.spiketime:
s = t - st - (self.delay-1)*self.post.timeWindow
temp = 0
if (self.post.groupIndex - self.pre.groupIndex == self.delay): # compute weight according to time delay
# using STDP rules
if (s >= 0):
temp = math.exp(-s / 5)
else:
# print(self.pre.groupIndex)
# print(self.post.groupIndex)
temp = -math.exp(s / 5)
self.weight += temp
elif (self.type == 2): # pre and post neurons are in the different layers
pass
# computing the STDP to update the weight within the time window
elif (self.type == 3):
# pass #fixed weight
for st in self.pre.spiketime:
s = t - st - (self.delay - 1) * self.post.timeWindow
temp = 0
# using STDP rules
if (s >= 0):
temp = 5 * math.exp(-s / 5)
else:
# print(self.pre.groupIndex)
# print(self.post.groupIndex)
temp = -5 * math.exp(s / 5)
self.weight += temp
def computeShortTermFacilitation(self, t):
if (self.type == 1):
for st in self.pre.spiketime[::-1]:
at = st + self.delay
# if (at <= t and at >= t - self.post.tau_ref): # between current time and time minus refractory period
if (at <= t and at >= t):
temp = (self.strength + 1) * 0.2
self.strength += temp
elif (self.type == 2):
# print(self.pre.areaName)
# print(self.pre.index)
# print(self.pre.groupIndex)
for st in self.pre.spiketime:
if (st <= t and st >= t - self.post.tau_ref):
temp = (self.strength + 1) * 0.5
self.strength = self.strength + temp
elif (self.type == 0):
if (self.excitability == 0):
for st in self.pre.spiketime:
self.strength += (self.strength + 1) * 0.8
def computeShortTermFacilitation2(self, t):
if (self.type == 1):
for st in self.pre.spiketime[::-1]:
at = st + self.delay
# if ( at <= t and at >= t - self.post.tau_ref):
if (at <= t): # between current time and time minus refractory period
self.strength = 1
elif (self.type >= 2):
# print(self.pre.areaName)
# print(self.pre.index)
# print(self.pre.groupIndex)
for st in self.pre.spiketime:
# if (st <= t and st >= t - self.post.tau_ref):
if (st <= t):
self.strength = 1
def computeShortTermReduction(self, t):
if (self.type == 2):
for st in self.pre.spiketime[::-1]:
if (t - st > self.post.timeWindow):
self.strength -= (self.strength + 1) * 0.5
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/tempocluster.py
================================================
from .cluster import Cluster
from .tempolifneuron import TempoLIFNeuron
from Modal.izhikevichneuron import *
class TempoCluster(Cluster):
'''
classdocs
'''
def __init__(self, neutype, neunum):
'''
Constructor
'''
Cluster.__init__(self, neutype, neunum)
def createClusterNetwork(self):
for i in range(0, self.neunum):
if (self.neutype == 'LIF'):
node = TempoLIFNeuron()
node.index = i + 1
node.areaName = 'TMSM'
node.setPreference()
self.neurons.append(node)
if (self.neutype == 'Izhikevich'):
node = TempoIzhikevichNeuron()
node.index = i + 1
node.areaName = 'TMSM'
node.setPreference()
self.neurons.append(node)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/tempolifneuron.py
================================================
from .lifneuron import LIFNeuron
import math
class TempoLIFNeuron(LIFNeuron):
'''
classdocs
'''
def __init__(self, tau_ref=0.5, vthresh=5, Rm=2, Cm=0.2):
'''
Constructor
'''
LIFNeuron.__init__(self, tau_ref, vthresh, Rm, Cm)
def setPreference(self):
# Gaussian function to set selectivity
self.selectivity = self.index * 0.125 #
def computeFilterCurrent(self):
if (self.I_ext <= self.selectivity + 0.0625 and self.I_ext >= self.selectivity - 0.0625):
self.I = 10
def updateCurrentOfLowerAndUpperLayer(self, t):
self.I_lower = 0
self.I_upper = 0
for syn in self.synapses:
syn.computeShortTermFacilitation(t)
if (syn.type == 0): # the same group
if (syn.excitability == 0):
self.I_lower -= 0.001 * syn.weight * syn.strength
if (self.I_lower < -20): self.I_lower = -20
if (syn.type == 1): # pre and post neurons come from the same layer but not the same group
# if(syn.weight > 0):
#
# print('pre_neuron_group id:'+str(syn.pre.groupIndex) + ' neuron index:'+str(syn.pre.index))
# print('post_neuron_group id:'+str(self.groupIndex) + ' neuron index:'+str(self.index))
# print(syn.weight)
self.I_lower += 0.001 * syn.weight * syn.strength
# print('syn.strength='+str(syn.strength))
if (syn.type == 2): # pre and post neurons come from the different layers
# print(syn.pre.groupIndex)
# self.I_lower = syn.weight * syn.strength
self.I_upper += 0.001 * syn.weight * syn.strength
# if(self.I_upper == 0):
# self.I = self.I_ext
else:
self.I = 0.4 * self.I_lower + 0.6 * self.I_upper
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/temposequencelayer.py
================================================
from .sequencelayer import SequenceLayer
from .tempocluster import TempoCluster
from .synapse import Synapse
class TempoSequenceLayer(SequenceLayer):
'''
classdocs
'''
def __init__(self, neutype):
'''
Constructor
'''
SequenceLayer.__init__(self, neutype)
def addNewGroups(self, GroupID, layerID, neunum):
g = TempoCluster(self.neutype, neunum)
g.createClusterNetwork()
# g.createInhibitoryConnections()
g.id = GroupID
g.setPropertiesofNeurons(g.id, 'S', layerID)
self.groups[g.id] = g
# create full connection with the former group
if (len(self.groups) > 1):
s = 0
if (g.id <= 5):
s = 1
else:
s = g.id - 4
for i in range(s, g.id)[::-1]:
pre_g = self.groups.get(i)
for n1 in pre_g.neurons:
for n2 in g.neurons:
if (n1.type == 'inh' or n2.type == 'inh'): continue;
syn = Synapse(n1, n2)
syn.type = 1
syn.delay = g.id - pre_g.id
n2.pre_neurons.append(n1)
n2.synapses.append(syn)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/titlecluster.py
================================================
from .cluster import Cluster
from .titlelifneuron import TitleLIFNeuron
class TitleCluster(Cluster):
'''
classdocs
'''
def __init__(self, neutype, neunum):
'''
Constructor
'''
Cluster.__init__(self, neutype, neunum)
self.averageFiringRate = 0
def createClusterNetwork(self):
for i in range(0, self.neunum):
if (self.neutype == 'LIF'):
node = TitleLIFNeuron()
node.index = i + 1
node.areaName = 'IPS'
self.neurons.append(node)
# if(self.neutype == 'Izhi'):
# node = IzhikevichNeuron(a = 0.02,b = 0.2,c = -65,d = 8,vthresh = 30)
# node.index = i
# self.neurons.append(node)
# if(self.neutype == 'Gaussian'):
# node = GaussianNeuron()
# node.index = i+1
# self.neurons.append(node)
# if(self.neutype == 'HH'):
# node = HHNeuron()
# node.index = i
# self.neurons.append(node)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/titlelayer.py
================================================
from .layer import Layer
from .titlecluster import TitleCluster
class TitleLayer(Layer):
'''
classdocs
'''
def __init__(self, neutype='LIF'):
'''
Constructor
'''
self.neutype = neutype
self.groups = {}
def setTestStates(self):
for id, g in self.groups.items():
g.setTestStates()
def addNewGroups(self, groupID, layerID, neunum, goalname):
g = TitleCluster(self.neutype, neunum)
g.id = groupID
g.name = goalname
g.createClusterNetwork()
g.setPropertiesofNeurons(groupID, 'G', layerID)
self.groups[goalname] = g
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/titlelifneuron.py
================================================
from .lifneuron import LIFNeuron
import math
class TitleLIFNeuron(LIFNeuron):
'''
classdocs
'''
def __init__(self, tau_ref=0, vthresh=5, Rm=2, Cm=0.2):
'''
Constructor
'''
LIFNeuron.__init__(self, tau_ref, vthresh, Rm, Cm)
def updateCurrentOfLowerAndUpperLayer(self, t):
self.I_lower = 0
self.I_upper = 0
for syn in self.synapses:
syn.computeShortTermFacilitation(t)
syn.computeShortTermReduction(t)
if (syn.type == 2): # pre and post neurons come from the different layers
self.I_lower += syn.weight * syn.strength
if (self.I_lower <= 0):
self.I = self.I_lower
else:
self.I = math.log(self.I_lower)
def update(self, dt, t):
self.spike = False
# self.updateCurrentOfLowerAndUpperLayer(t)
if (t >= self.t_rest):
self.mem += dt * (-self.mem + self.I * self.Rm) / self.tau_m
if (self.mem > self.vth):
self.spike = True
self.spiketime.append(t)
self.mem = 0
self.t_rest = t + self.tau_ref
def computeFiringRate(self):
if (self.I == 0):
self.firingrate = 0
else:
self.firingrate = 1 / (self.tau_ref + self.Rm * self.Cm * math.log(self.I / (self.I - self.vth)))
self.firingrate *= 1000
self.firingrate = round(self.firingrate)
# print(self.firingrate)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/README.md
================================================
# Music Memory and stylistic composition
This repository contains code from our paper:
- [**Temporal-Sequential Learning With a Brain-Inspired Spiking Neural Network and Its Application to Musical Memory**](https://www.cell.com/patterns/fulltext/S2666-3899(22)00119-2) published in Frontiers in Computational Neuroscience. **https://www.cell.com/patterns/fulltext/S2666-3899(22)00119-2**,
- [**Stylistic composition of melodies based on a brain-inspired spiking neural network**](https://www.frontiersin.org/articles/10.3389/fnsys.2021.639484/full) published in Frontiers in Systems Neuroscience **https://www.frontiersin.org/articles/10.3389/fnsys.2021.639484/full**.
- [**Mode-conditioned music learning and composition: a spiking neural network inspired by neuroscience and psychology**](https://arxiv.org/pdf/2411.14773) preprint in arXiv **https://arxiv.org/pdf/2411.14773**.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* pretty_midi >= 0.2.9
* music21
## Data preparation
The dataset used here can be referred to the website http://www.piano-midi.de/.
The dataset used in mode-conditioned music learning can be referred to the website https://github.com/lqnankai/Music-Dataset.
## Run
* Run the script *task/musicMemory.py* to memorize and recall the musical melodies, the result will be recorded in a midi file.
* Run the script *task/musicGeneration.py* to learn and generate melodies with different styles, the result will be recorded in a midi file.
* Run the script *task/mode-conditioned learning.py* to learn and generate melodies with different mode and keys, the result will be recorded in a midi file.
The API and details can be found in these scripts.
## Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{LQ2020,
author = {Liang, Qian and Zeng, Yi and Xu, Bo},
year = {2020},
month = {07},
pages = {51},
title = {Temporal-Sequential Learning With a Brain-Inspired Spiking Neural Network and Its Application to Musical Memory},
volume = {14},
journal = {Frontiers in Computational Neuroscience}
}
@article{LQ2021,
title = {Stylistic composition of melodies based on a brain-inspired spiking neural network},
author = {Liang, Qian and Zeng, Yi},
journal = {Frontiers in systems neuroscience},
volume = {15},
pages = {21},
year = {2021},
publisher = {Frontiers}
}
@misc{liang2024modeconditionedmusiclearningcomposition,
title={Mode-conditioned music learning and composition: a spiking neural network inspired by neuroscience and psychology},
author={Qian Liang and Yi Zeng and Menghaoran Tang},
year={2024},
eprint={2411.14773},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.14773},
}
```
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/api/music_engine_api.py
================================================
from conf.conf import *
from Areas.cortex import Cortex
import pretty_midi
import math
import json
import music21 as m21
class EngineAPI():
'''
'''
def __init__(self):
'''
Constructor
'''
self.cortex = Cortex(configs.neuron_type, configs.dt)
def cortexInit(self):
self.cortex.musicSequenceMemroyInit()
self.cortex.pfc.addNewKey()
self.cortex.pfc.addNewMode()
self.cortex.pfc.addNewChord()
def rememberMusic(self, muiscName, composerName="None"):
'''
:param muiscName: the name of the melody
:param composerName: the composer
:return:
'''
muiscName = muiscName.title()
composerName = composerName.title()
self.cortex.pfc.setTestStates()
self.cortex.msm.setTestStates()
self.cortex.addSubGoalToPFC(muiscName)
self.cortex.addComposerToPFC(composerName)
genreName = str(configs.GenreMap.get(composerName))
self.cortex.addGenreToPFC(genreName)
self.cortex.pfc.innerLearning(muiscName, composerName, genreName)
goaldic = {}
composerdic = {}
genredic = {}
if (configs.RunTimeState == 1):
g = self.cortex.pfc.titles.groups.get(muiscName)
c = self.cortex.pfc.composers.groups.get(composerName)
gre = self.cortex.pfc.genres.groups.get(genreName)
goaldic = g.writeSelfInfoToJson("IPS")
composerdic = c.writeSelfInfoToJson("Composer")
genredic = gre.writeSelfInfoToJson("Genre")
return goaldic, composerdic
def learnFourPartMusic(self,xmldata, musicName, composerName="None"):
musicName = musicName.title()
composerName = composerName.title()
genreName = "None"
toneName = configs.keyIndexMap.get(str(xmldata.analyze('key')))
print(musicName + " learning...")
emo = "None"
for i, part in enumerate(xmldata.parts):
if (self.cortex.msm.sequenceLayers.get(i + 1) == None):
self.cortex.msm.createActionSequenceMem(i + 1, self.cortex.neutype)
self.rememberPartNotes(musicName, composerName, genreName, emo, toneName, i + 1, part)
def rememberPartNotes(self,musicName, composerName, genreName, emo, keyName, partIndex, part):
print("Learning the part "+str(partIndex))
for i,note in enumerate(part.flat.notes[:20]):
p = 0
dur = 0
if note.isChord:
dur = note.duration.quarterLength
for chord_note in note:
p = m21.pitch.Pitch(chord_note.pitch).midi
else:
dur = note.duration.quarterLength
p = m21.pitch.Pitch(note.pitch).midi
if dur == 0.0:
dur = 0.125
if keyName == 'None':
self.cortex.rememberANoteandTempo(musicName, composerName, genreName, emo, partIndex, p, i+1, dur)
else:
self.cortex.rememberANoteWithKnowledge(musicName, composerName, genreName, emo, keyName, partIndex, p, dur, i+1, part)
def rememberMIDIMusic(self, musicName, composerName, noteLength, fileName):
'''
:param musicName: the name of the piece of music
:param composerName: the composer who writes this melody
:param fileName: the name of this midi file
:return: none
'''
musicName = musicName.title()
composerName = composerName.title()
print(musicName + " processing...")
pm = pretty_midi.PrettyMIDI(fileName)
genreName = str(configs.GenreMap.get(composerName))
for i, ins in enumerate(pm.instruments):
if (i >= 1): break;
if (self.cortex.msm.sequenceLayers.get(i + 1) == None):
# create a new layer to store the track
self.cortex.msm.createActionSequenceMem(i + 1, self.cortex.neutype)
self.rememberTrackNotes(musicName, composerName, genreName, i + 1, ins, pm, noteLength)
print(musicName + " finished!")
def rememberTrackNotes(self, musicName, composerName, genreName, trackIndex, track, pm, noteLength):
r_notes = []
r_intervals = []
total_dic = {}
print(track)
if(noteLength == "ALL"):
noteLength = len(track.notes)
order = 1
i = 0
#while (i < len(track.notes)):
while (i < noteLength):
#if (i >= rl): break;
note = track.notes[i]
start = pm.time_to_tick(note.start)
end = pm.time_to_tick(note.end)
pitches = []
durations = []
restFlag = False
# this part recognizes a rest
if (i == 0): # determine whether the first note is a rest
if (start >= 30):
pitches.append(-1) # -1 represents a rest
durations.append(start / pm.resolution)
restFlag = True
else:
lastend = pm.time_to_tick(track.notes[i - 1].end)
if (start - lastend >= 50):
pitches.append(-1)
durations.append((start - lastend) / pm.resolution)
restFlag = True
if (restFlag == True):
dic, g = self.rememberANote(musicName, composerName, genreName, trackIndex, pitches[0], order,
durations[0], True)
if (configs.RunTimeState == 1):
jstr = json.dumps(g)
self.conn.send('/Queue/SampleQueue', jstr)
#print(str(order) + ":(-1," + str(durations[0]) + ")")
order = order + 1
pitches = []
durations = []
# this part recognizes a chord
pitches.append(note.pitch)
durations.append((end - start) / pm.resolution)
j = i + 1
while (j < len(track.notes)):
nextstart = pm.time_to_tick(track.notes[j].start)
nextend = pm.time_to_tick(track.notes[j].end)
# if(start == nextstart or end > nextstart):
if (math.fabs(start - nextstart) <= 30 or end - nextstart >= 30):
pitches.append(track.notes[j].pitch)
durations.append((nextend - nextstart) / pm.resolution)
j = j + 1
else:
break
i = j
if (i < noteLength):
dic, g = self.rememberANote(musicName, composerName, genreName, trackIndex, pitches[0], order,
durations[0], True)
str1 = str(order) + ":("
for t in range(len(pitches)):
str1 += str(pitches[t]) + "," + str(durations[t]) + ";"
#print(str1 + ")")
order = order + 1
if (configs.RunTimeState == 1):
jstr = json.dumps(g)
self.conn.send('/Queue/SampleQueue', jstr)
nlist = dic.get('MSMSpike')
ns = []
for l in nlist:
n = l.get('Index')
ns.append(n)
r_notes.append(ns)
tlist = dic.get('MSMTSpike')
ts = []
for l in tlist:
t = l.get('Index')
ts.append(t * 60)
r_intervals.append(ts)
return total_dic
def rememberNotes(self, MusicName, notes, intervals, tempo=True):
jStr = ''
# print(intervals)
notesStr = notes.split(",")
intervalsStr = intervals.split(",")
intervaltimes = []
for i in range(len(intervalsStr) - 1):
intervaltimes.append(int(intervalsStr[i]))
print(intervaltimes)
for i, note in enumerate(notesStr):
note = int(note)
if (i < len(notesStr) - 1):
tinterval = intervalsStr[i]
tinterval = int(intervalsStr[i])
self.rememberANote(MusicName, note, i + 1, tinterval, tempo)
return jStr
def rememberANote(self, MusicName, ComposerName, genreName, TrackIndex, NoteIndex, order, tinterval, tempo=False):
if (tempo == False):
dic = self.cortex.rememberANote(MusicName, NoteIndex, order)
jsonStr = json.dumps(dic)
return jsonStr
else:
dic, g = self.cortex.rememberANoteandTempo(MusicName, ComposerName, genreName, TrackIndex, NoteIndex, order,
tinterval)
return dic, g
def memorizing(self,MusicName, ComposerName, noteLength, fileName):
'''
:param musicName: the name of the piece of music
:param composerName: the composer who writes this melody
:param noteLength: the number of notes to be trained(integer), if you want to learn all the notes of a musical work, the value should be specified as "ALL"
:param fileName: the path and the name of this midi file
:return: none
'''
self.rememberMusic(MusicName, ComposerName)
self.rememberMIDIMusic(MusicName,ComposerName,noteLength, fileName)
def recallMusic(self, musicName):
print("Recall the " + musicName + " ......")
musicName = musicName.title()
result = self.cortex.recallMusicPFC(musicName)
#print(result)
noteResult = {}
for tindex,track in result.items():
ns = track.get('N')
ts = track.get('T')
tmp = []
for key in ns.keys():
dic = {}
dic['N']=ns.get(key)
dic['T']=ts.get(key)
tmp.append(dic)
noteResult[tindex] = tmp
self.writeMidiFile(musicName+"_recall",noteResult)
print("Recall " + musicName + " finished!")
return noteResult
def generateEx_Nihilo(self, firstNote, durations, length,gen_fName):
'''
parameters:
fistNote: Specify the beginning notes to generate a note
durations: Specify the duration of the beginning notes
length: the length of the generated music, less than 50 notes
'''
print("Generate melody with no style............")
result = self.cortex.generateEx_Nihilo2(firstNote, durations, length)
self.writeMidiFile(gen_fName,result)
print("Generating finished!")
return result
def generateEx_NihiloAccordingToGenre(self, genreName, firstNote, durations, length,gen_fName):
'''
parameters:
genreName:Specify the style of genre of the generated melody, for example: Baroque,Classical,Romantic
fistNote: Specify the beginning notes to generate a note
durations: Specify the duration of the beginning notes
length: the length of the generated music, less than 50 notes
'''
print("Generate melody with "+ genreName+"\'s style............")
result = self.cortex.generateEx_NihiloAccordingToGenre(genreName, firstNote, durations, length)
self.writeMidiFile(gen_fName,result)
print("Generating finished!")
return result
def generateEx_NihiloAccordingToComposer(self, composerName, firstNote, durations, length,gen_fName):
'''
parameters:
composerName:Specify the style of composer of the generated melody, for example: Bach, Mozart and etc.
fistNote: Specify the beginning notes to generate a note
durations: Specify the duration of the beginning notes
length: the length of the generated music, less than 50 notes
'''
print("Generate melody with " + composerName + "'s style............")
result = self.cortex.generateEx_NihiloAccordingToComposer(composerName, firstNote, durations, length)
self.writeMidiFile(gen_fName,result)
print("Generating finished!")
return result
def generate2TrackMusic(self, firstNotes, durations, lengths):
result = self.cortex.generate2TrackMusic(firstNotes, durations, lengths)
return result
def generateMelodyWithKey(self,tone, firstNotes,durations = None,length = 8):
result = self.cortex.generateMelodyWithKey(tone, firstNotes,durations,length)
return result
def writeMidiFile(self,fileName, mudic):
'''
mudic format description:
mudic = {1:[{'N':71,'T':0.5}.....],
2:[{'N':60,'T':0.25}.....],
....
}
'''
fileName += ".mid"
pm = pretty_midi.PrettyMIDI()
# Create an Instrument instance for a cello instrument
for values in mudic.values():
piano = pretty_midi.Instrument(program=0)
# Iterate over note names, which will be converted to note number later
start = 0
end = 0
for i, n in enumerate(values):
# Retrieve the MIDI note number for this note name
# note_number = pretty_midi.note_name_to_number(note_name)
# Create a Note instance, starting at 0s and ending at .5s
end = start + n.get('T')
note_name = n.get('N')
if (note_name == -1):
note = pretty_midi.Note(
velocity=0, pitch=0, start=start, end=end)
else:
note = pretty_midi.Note(
velocity=100, pitch=note_name, start=start, end=end)
# Add it to our cello instrument
piano.notes.append(note)
start = end
# Add the cello instrument to the PrettyMIDI object
pm.instruments.append(piano)
# Write out the MIDI data
pm.write(fileName)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/conf/GenreData.txt
================================================
Baroque:Bach
Classical:Haydn,Mozart,Beethoven,Schubert,Clementi
Romantic:Mendelssohn,Liszt,Chopin,Schumann,Brahms,Burgmueller,Debussy,Godowsky,Moszkowski,Mussorgsky,Rachmaninov,Ravel,Tchaikovsky,Albéniz,Balakirew,Borodin,Granados,Grieg,Sinding
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/conf/MIDIData.txt
================================================
-1:rest
0:C3
1:C sharp3/D flat3
2:D3
3:D sharp3/E flat3
4:E3
5:F3
6:F sharp3/G flat3
7:G3
8:G sharp3/A flat3
9:A3
10:A sharp3/B flat3
11:B3
12:C2
13:C sharp2/D flat2
14:D2
15:D sharp2/E flat2
16:E2
17:F2
18:F sharp2/G flat2
19:G2
20:G sharp2/A flat2
21:A2
22:A sharp2/B flat2
23:B2
24:C1
25:C sharp1/D flat1
26:D1
27:D sharp1/E flat1
28:E1
29:F1
30:F sharp1/G flat1
31:G1
32:G sharp1/A flat1
33:A1
34:A sharp1/B flat1
35:B1
36:C
37:C sharp/D flat
38:D
39:D sharp/E flat
40:E
41:F
42:F sharp/G flat
43:G
44:G sharp/A flat
45:A
46:A sharp/B flat
47:B
48:c
49:c sharp/d flat
50:d
51:d sharp/e flat
52:e
53:f
54:f sharp/g flat
55:g
56:g sharp/a flat
57:a
58:a sharp/b flat
59:b
60:c1
61:c sharp1/d flat1
62:d1
63:d sharp1/e flat1
64:e1
65:f1
66:f sharp1/g flat1
67:g1
68:g sharp1/a flat1
69:a1
70:a sharp1/b flat1
71:b1
72:c2
73:c sharp2/d flat2
74:d2
75:d sharp2/e flat2
76:e2
77:f2
78:f sharp2/g flat2
79:g2
80:g sharp2/a flat2
81:a2
82:a sharp2/b flat2
83:b2
84:c3
85:c sharp3/d flat3
86:d3
87:d sharp3/e flat3
88:e3
89:f3
90:f sharp3/g flat3
91:f3
92:g sharp3/a flat3
93:a3
94:a sharp3/b flat3
95:b3
96:c4
97:c sharp4/d flat4
98:d4
99:d sharp4/e flat4
100:e4
101:f4
102:f sharp4/g flat4
103:g4
104:g sharp4/a flat4
105:a4
106:a sharp4/b flat4
107:b4
108:c5
109:c sharp5/d flat5
110:d5
111:d sharp5/e flat5
112:e5
113:f5
114:f sharp5/g flat5
115:g5
116:g sharp5/a flat5
117:a5
118:a sharp5/b flat5
119:b5
120:c6
121:c sharp6/d flat6
122:d6
123:d sharp6/e flat6
124:e6
125:f6
126:f sharp6/g flat6
127:g6
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/conf/conf.py
================================================
import numpy
import numpy as np
import pandas as pd
class Conf():
'''
classdocs
'''
def __init__(self, neutype="LIF", task="MusicLearning", dt=0.1):
'''
Constructor
'''
self.neuron_type = neutype
self.task = task
self.dt = dt
self.notesMap = {}
self.GenreMap = {}
self.emoMap = {}
self.key_matrix = []
self.keysMap = {}
self.index2key = {}
self.index2mode = {}
self.keyIndexMap = {}
self.keyscales = {}
self.chordsMap = {}
self.chordsMatrix = np.zeros((7, 7))
self.RunTimeState = 0 # 0: GUI, 1: Bigdata experiments 2: other
def readNoteFiles(self):
# f = open("./Data.txt","r")
f = open("../inputs/MIDIData.txt", "r")
while (True):
line = f.readline()
if not line:
break
else:
strs = line.split(":")
index = int(strs[0])
self.notesMap[index] = strs[1].strip()
f.close()
def readGenreFils(self):
f = open("../inputs/GenreData.txt", "r")
while (True):
line = f.readline()
if not line:
break
else:
strs = line.split(":")
g = strs[0].strip()
ns = strs[1].split(",")
for n in ns:
self.GenreMap[(n.strip()).title()] = g.title()
f.close()
def readEmotionFiles(self):
f = open("../inputs/information.csv", "r")
while (True):
line = f.readline()
if not line:
break
else:
strs = line.split(",")
mn = strs[0].strip()
e = strs[3].strip()
self.emoMap[mn.title()] = e.title()
f.close()
def readKeysFile(self):
f = open("../inputs/keyIndex.csv", "r")
while (True):
line = (f.readline()).strip()
if not line:
break
else:
strs = line.split(",")
toneName = strs[0].strip()
self.keysMap[toneName] = int(strs[1].strip())
# print(self.keysMap)
self.index2key = dict(zip(self.keysMap.values(), self.keysMap.keys()))
# print(self.index2key)
self.key_matrix = np.array(pd.read_excel("../inputs/keys.xlsx", sheet_name='keys'))
self.keyscales = {0: np.array(pd.read_excel("../inputs/keys.xlsx", sheet_name='major')),
1: np.array(pd.read_excel("../inputs/keys.xlsx", sheet_name='minor'))}
def readKeys2IndexFile(self):
f = open("../inputs/keyIndex.csv", "r")
while (True):
line = f.readline().strip()
if not line:
break
else:
strs = line.split(",")
self.keyIndexMap[strs[0].strip()] = int(strs[1].strip())
# print(self.keyIndexMap)
def readChordsFile(self):
tmp = pd.read_excel("../inputs/chords.xlsx", sheet_name=None)
for key, chords in tmp.items():
chords = np.array(chords)
self.chordsMap[key.strip()] = chords
# print(self.chordsMap)
# 暂时先连接主,下属,属和弦
self.chordsMatrix = np.array([[1, 0, 0, 1, 1, 0, 0],
[0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 1, 1, 0, 0],
[1, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0]])
def readModesFile(self):
f = open("../inputs/modeindex.csv", "r")
while (True):
line = (f.readline()).strip()
if not line:
break
else:
strs = line.split(",")
self.index2mode[int(strs[0].strip())] = strs[1].strip()
configs = Conf(neutype = 'Izhikevich')
configs.readNoteFiles()
configs.readGenreFils()
configs.readEmotionFiles()
configs.readKeysFile()
configs.readKeys2IndexFile()
configs.readChordsFile()
configs.readModesFile()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/1.txt
================================================
1:A-B2
2:A#-B2
3:B-B2
4:C-B1
5:C#-B1
6:D-B1
7:D#-B1
8:E-B1
9:F-B1
10:F#-B1
11:G-B1
12:G#-B1
13:A-B1
14:A#-B1
15:B-B1
16:C-B
17:C#-B
18:D-B
19:D#-B
20:E-B
21:F-B
22:F#-B
23:G-B
24:G#-B
25:A-B
26:A#-B
27:B-B
28:C-S
29:C#-S
30:D-S
31:D#-S
32:E-S
33:F-S
34:F#-S
35:G-S
36:G#-S
37:A-S
38:A#-S
39:B-S
40:C-S1
41:C#-S1
42:D-S1
43:D#-S1
44:E-S1
45:F-S1
46:F#-S1
47:G-S1
48:G#-S1
49:A-S1
50:A#-S1
51:B-S1
52:C-S2
53:C#-S2
54:D-S2
55:D#-S2
56:E-S2
57:F-S2
58:F#-S2
59:G-S2
60:G#-S2
61:A-S2
62:A#-S2
63:B-S2
64:C-S3
65:C#-S3
66:D-S3
67:D#-S3
68:E-S3
69:F-S3
70:F#-S3
71:G-S3
72:G#-S3
73:A-S3
74:A#-S3
75:B-S3
76:C-S4
77:C#-S4
78:D-S4
79:D#-S4
80:E-S4
81:F-S4
82:F#-S4
83:G-S4
84:G#-S4
85:A-S4
86:A#-S4
87:B-S4
88:C-S5
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/Data.txt
================================================
1:A2
2:A#2
3:B2
4:C1
5:C#1
6:D1
7:D#1
8:E1
9:F1
10:F#1
11:G1
12:G#1
13:A1
14:A#1
15:B1
16:C
17:C#
18:D
19:D#
20:E
21:F
22:F#
23:G
24:G#
25:A
26:A#
27:B
28:c
29:c#
30:d
31:d#
32:e
33:f
34:f#
35:g
36:g#
37:a
38:a#
39:b
40:c1
41:c#1
42:d1
43:d#1
44:e1
45:f1
46:f#1
47:g1
48:g#1
49:a1
50:a#1
51:b1
52:c2
53:c#2
54:d2
55:d#2
56:e2
57:f2
58:f#2
59:g2
60:g#2
61:a2
62:a#2
63:b2
64:c3
65:c#3
66:d3
67:d#3
68:e3
69:f3
70:f#3
71:f3
72:g#3
73:a3
74:a#3
75:b3
76:c4
77:c#4
78:d4
79:d#4
80:e4
81:f4
82:f#4
83:g4
84:g#4
85:a4
86:a#4
87:b4
88:c5
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/GenreData.txt
================================================
Baroque:Bach
Classical:Haydn,Mozart,Beethoven,Schubert,Clementi
Romantic:Mendelssohn,Liszt,Chopin,Schumann,Brahms,Burgmueller,Debussy,Godowsky,Moszkowski,Mussorgsky,Rachmaninov,Ravel,Tchaikovsky,Albéniz,Balakirew,Borodin,Granados,Grieg,Sinding
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/MIDIData.txt
================================================
-1:rest
0:C3
1:C sharp3/D flat3
2:D3
3:D sharp3/E flat3
4:E3
5:F3
6:F sharp3/G flat3
7:G3
8:G sharp3/A flat3
9:A3
10:A sharp3/B flat3
11:B3
12:C2
13:C sharp2/D flat2
14:D2
15:D sharp2/E flat2
16:E2
17:F2
18:F sharp2/G flat2
19:G2
20:G sharp2/A flat2
21:A2
22:A sharp2/B flat2
23:B2
24:C1
25:C sharp1/D flat1
26:D1
27:D sharp1/E flat1
28:E1
29:F1
30:F sharp1/G flat1
31:G1
32:G sharp1/A flat1
33:A1
34:A sharp1/B flat1
35:B1
36:C
37:C sharp/D flat
38:D
39:D sharp/E flat
40:E
41:F
42:F sharp/G flat
43:G
44:G sharp/A flat
45:A
46:A sharp/B flat
47:B
48:c
49:c sharp/d flat
50:d
51:d sharp/e flat
52:e
53:f
54:f sharp/g flat
55:g
56:g sharp/a flat
57:a
58:a sharp/b flat
59:b
60:c1
61:c sharp1/d flat1
62:d1
63:d sharp1/e flat1
64:e1
65:f1
66:f sharp1/g flat1
67:g1
68:g sharp1/a flat1
69:a1
70:a sharp1/b flat1
71:b1
72:c2
73:c sharp2/d flat2
74:d2
75:d sharp2/e flat2
76:e2
77:f2
78:f sharp2/g flat2
79:g2
80:g sharp2/a flat2
81:a2
82:a sharp2/b flat2
83:b2
84:c3
85:c sharp3/d flat3
86:d3
87:d sharp3/e flat3
88:e3
89:f3
90:f sharp3/g flat3
91:f3
92:g sharp3/a flat3
93:a3
94:a sharp3/b flat3
95:b3
96:c4
97:c sharp4/d flat4
98:d4
99:d sharp4/e flat4
100:e4
101:f4
102:f sharp4/g flat4
103:g4
104:g sharp4/a flat4
105:a4
106:a sharp4/b flat4
107:b4
108:c5
109:c sharp5/d flat5
110:d5
111:d sharp5/e flat5
112:e5
113:f5
114:f sharp5/g flat5
115:g5
116:g sharp5/a flat5
117:a5
118:a sharp5/b flat5
119:b5
120:c6
121:c sharp6/d flat6
122:d6
123:d sharp6/e flat6
124:e6
125:f6
126:f sharp6/g flat6
127:g6
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/chords.csv
================================================
C,,,
1,C,E,G
4,F,A,C
5,G,B,D
,,,
a,,,
1,A,C,E
4,D,F,A
5,E,G#,B
,,,
G,,,
1,G,B,D
4,C,E,G
5,D,F#,A
,,,
F,,,
1,F,A,C
4,B-,D,F
5,C,E,G
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/information.csv
================================================
chpn_op35_2.mid,Chopin,Romantic,unclear
chpn_op33_4.mid,Chopin,Romantic,unclear
chpn-p14.mid,Chopin,Romantic,unclear
chpn-p17.mid,Chopin,Romantic,soft
chpn_op33_2.mid,Chopin,Romantic,happy
chpn_op53.mid,Chopin,Romantic,unclear
chpn_op35_3.mid,Chopin,Romantic,unclear
chpn-p1.mid,Chopin,Romantic,unclear
chpn_op7_2.mid,Chopin,Romantic,soft
chpn_op25_e11.mid,Chopin,Romantic,passionate
chpn-p16.mid,Chopin,Romantic,unclear
chpn-p20.mid,Chopin,Romantic,depressed
chpn-p13.mid,Chopin,Romantic,soft
chpn_op27_2.mid,Chopin,Romantic,soft
chpn-p6.mid,Chopin,Romantic,depressed
chpn-p9.mid,Chopin,Romantic,unclear
chpn-p15.mid,Chopin,Romantic,depressed
chpn_op10_e12.mid,Chopin,Romantic,passionate
chpn-p22.mid,Chopin,Romantic,unclear
chpn_op23.mid,Chopin,Romantic,unclear
chpn-p24.mid,Chopin,Romantic,passionate
chpn-p18.mid,Chopin,Romantic,happy
chpn_op27_1.mid,Chopin,Romantic,depressed
chpn_op10_e05.mid,Chopin,Romantic,passionate
chpn_op25_e4.mid,Chopin,Romantic,unclear
chpn_op66.mid,Chopin,Romantic,unclear
chpn_op25_e2.mid,Chopin,Romantic,soft
chpn_op10_e01.mid,Chopin,Romantic,passionate
chpn-p11.mid,Chopin,Romantic,happy
chpn-p7.mid,Chopin,Romantic,soft
chp_op18.mid,Chopin,Romantic,unclear
chpn-p23.mid,Chopin,Romantic,soft
chpn-p5.mid,Chopin,Romantic,unclear
chpn_op35_4.mid,Chopin,Romantic,unclear
chpn_op25_e3.mid,Chopin,Romantic,unclear
chpn-p12.mid,Chopin,Romantic,passionate
chpn-p21.mid,Chopin,Romantic,soft
chpn-p4.mid,Chopin,Romantic,depressed
chpn-p2.mid,Chopin,Romantic,depressed
chpn_op35_1.mid,Chopin,Romantic,unclear
chp_op31.mid,Chopin,Romantic,unclear
chpn_op25_e1.mid,Chopin,Romantic,unclear
chpn-p10.mid,Chopin,Romantic,unclear
chpn-p8.mid,Chopin,Romantic,passionate
chpn_op25_e12.mid,Chopin,Romantic,unclear
chpn_op7_1.mid,Chopin,Romantic,happy
chpn-p3.mid,Chopin,Romantic,unclear
chpn-p19.mid,Chopin,Romantic,soft
scn15_5.mid,Schumann,Romantic,unclear
scn15_7.mid,Schumann,Romantic,unclear
scn15_12.mid,Schumann,Romantic,unclear
scn15_6.mid,Schumann,Romantic,unclear
scn15_13.mid,Schumann,Romantic,unclear
scn68_12.mid,Schumann,Romantic,unclear
scn15_1.mid,Schumann,Romantic,unclear
scn15_3.mid,Schumann,Romantic,unclear
scn15_2.mid,Schumann,Romantic,unclear
scn16_3.mid,Schumann,Romantic,unclear
scn16_2.mid,Schumann,Romantic,unclear
scn68_10.mid,Schumann,Romantic,unclear
scn16_6.mid,Schumann,Romantic,unclear
scn16_5.mid,Schumann,Romantic,unclear
scn16_1.mid,Schumann,Romantic,unclear
scn15_9.mid,Schumann,Romantic,unclear
scn15_8.mid,Schumann,Romantic,unclear
scn15_11.mid,Schumann,Romantic,unclear
scn16_7.mid,Schumann,Romantic,unclear
scn16_8.mid,Schumann,Romantic,unclear
scn16_4.mid,Schumann,Romantic,unclear
scn15_10.mid,Schumann,Romantic,unclear
schum_abegg.mid,Schumann,Romantic,unclear
scn15_4.mid,Schumann,Romantic,unclear
ty_august.mid,Tchaikovsky,Romantic,unclear
ty_april.mid,Tchaikovsky,Romantic,unclear
ty_juli.mid,Tchaikovsky,Romantic,unclear
ty_oktober.mid,Tchaikovsky,Romantic,unclear
ty_juni.mid,Tchaikovsky,Romantic,unclear
ty_november.mid,Tchaikovsky,Romantic,unclear
ty_januar.mid,Tchaikovsky,Romantic,unclear
ty_dezember.mid,Tchaikovsky,Romantic,unclear
ty_maerz.mid,Tchaikovsky,Romantic,unclear
ty_mai.mid,Tchaikovsky,Romantic,unclear
ty_februar.mid,Tchaikovsky,Romantic,unclear
ty_september.mid,Tchaikovsky,Romantic,unclear
debussy_cc_3.mid,Debussy,Romantic,happy
DEB_CLAI.MID,Debussy,Romantic,soft
debussy_cc_2.mid,Debussy,Romantic,unclear
debussy_cc_6.mid,Debussy,Romantic,unclear
deb_menu.mid,Debussy,Romantic,unclear
DEB_PASS.MID,Debussy,Romantic,unclear
deb_prel.mid,Debussy,Romantic,happy
debussy_cc_1.mid,Debussy,Romantic,unclear
debussy_cc_4.mid,Debussy,Romantic,unclear
alb_se2.mid,Albeniz,Romantic,unclear
alb_se8.mid,Albeniz,Romantic,unclear
alb_se1.mid,Albeniz,Romantic,unclear
alb_esp6.mid,Albeniz,Romantic,unclear
alb_esp4.mid,Albeniz,Romantic,unclear
alb_esp2.mid,Albeniz,Romantic,unclear
alb_se4.mid,Albeniz,Romantic,unclear
alb_esp1.mid,Albeniz,Romantic,unclear
alb_esp5.mid,Albeniz,Romantic,unclear
alb_se6.mid,Albeniz,Romantic,unclear
alb_se3.mid,Albeniz,Romantic,unclear
alb_esp3.mid,Albeniz,Romantic,unclear
alb_se5.mid,Albeniz,Romantic,unclear
alb_se7.mid,Albeniz,Romantic,unclear
liz_et_trans8.mid,Liszt,Romantic,unclear
liz_liebestraum.mid,Liszt,Romantic,soft
liz_rhap10.mid,Liszt,Romantic,unclear
liz_rhap15.mid,Liszt,Romantic,unclear
liz_et2.mid,Liszt,Romantic,unclear
liz_rhap09.mid,Liszt,Romantic,unclear
liz_rhap02.mid,Liszt,Romantic,unclear
liz_rhap12.mid,Liszt,Romantic,unclear
liz_et4.mid,Liszt,Romantic,unclear
liz_et1.mid,Liszt,Romantic,unclear
liz_et_trans4.mid,Liszt,Romantic,unclear
liz_et5.mid,Liszt,Romantic,unclear
liz_donjuan.mid,Liszt,Romantic,unclear
liz_et3.mid,Liszt,Romantic,soft
liz_et6.mid,Liszt,Romantic,unclear
liz_et_trans5.mid,Liszt,Romantic,unclear
pathetique_1.mid,Beethoven,Classical,unclear
beethoven_hammerklavier_4.mid,Beethoven,Classical,unclear
beethoven_hammerklavier_2.mid,Beethoven,Classical,unclear
beethoven_opus22_4.mid,Beethoven,Classical,happy
waldstein_2.mid,Beethoven,Classical,unclear
beethoven_hammerklavier_3.mid,Beethoven,Classical,depressed
beethoven_les_adieux_3.mid,Beethoven,Classical,happy
beethoven_opus22_2.mid,Beethoven,Classical,unclear
waldstein_1.mid,Beethoven,Classical,happy
appass_2.mid,Beethoven,Classical,unclear
beethoven_opus10_3.mid,Beethoven,Classical,unclear
beethoven_opus22_1.mid,Beethoven,Classical,unclear
beethoven_hammerklavier_1.mid,Beethoven,Classical,unclear
pathetique_3.mid,Beethoven,Classical,passionate
beethoven_opus90_2.mid,Beethoven,Classical,unclear
beethoven_opus22_3.mid,Beethoven,Classical,happy
beethoven_opus90_1.mid,Beethoven,Classical,unclear
waldstein_3.mid,Beethoven,Classical,happy
beethoven_opus10_1.mid,Beethoven,Classical,unclear
appass_1.mid,Beethoven,Classical,unclear
beethoven_opus10_2.mid,Beethoven,Classical,unclear
mond_2.mid,Beethoven,Classical,unclear
beethoven_les_adieux_1.mid,Beethoven,Classical,depressed
elise.mid,Beethoven,Classical,soft
appass_3.mid,Beethoven,Classical,passionate
pathetique_2.mid,Beethoven,Classical,soft
mond_3.mid,Beethoven,Classical,passionate
beethoven_les_adieux_2.mid,Beethoven,Classical,depressed
mond_1.mid,Beethoven,Classical,depressed
muss_3.mid,Mussorgsky,Romantic,unclear
muss_5.mid,Mussorgsky,Romantic,unclear
muss_1.mid,Mussorgsky,Romantic,unclear
muss_8.mid,Mussorgsky,Romantic,unclear
muss_6.mid,Mussorgsky,Romantic,unclear
muss_2.mid,Mussorgsky,Romantic,unclear
muss_7.mid,Mussorgsky,Romantic,unclear
muss_4.mid,Mussorgsky,Romantic,unclear
mendel_op30_4.mid,Mendelssohn,Romantic,unclear
mendel_op19_2.mid,Mendelssohn,Romantic,unclear
mendel_op19_5.mid,Mendelssohn,Romantic,unclear
mendel_op19_4.mid,Mendelssohn,Romantic,soft
mendel_op19_6.mid,Mendelssohn,Romantic,depressed
mendel_op19_1.mid,Mendelssohn,Romantic,soft
mendel_op30_5.mid,Mendelssohn,Romantic,unclear
mendel_op30_2.mid,Mendelssohn,Romantic,unclear
mendel_op62_3.mid,Mendelssohn,Romantic,depressed
mendel_op30_3.mid,Mendelssohn,Romantic,unclear
mendel_op62_4.mid,Mendelssohn,Romantic,unclear
mendel_op19_3.mid,Mendelssohn,Romantic,unclear
mendel_op53_5.mid,Mendelssohn,Romantic,unclear
mendel_op30_1.mid,Mendelssohn,Romantic,soft
mendel_op62_5.mid,Mendelssohn,Romantic,unclear
gra_esp_2.mid,Granados,Romantic,unclear
gra_esp_3.mid,Granados,Romantic,unclear
gra_esp_4.mid,Granados,Romantic,unclear
fruehlingsrauschen.mid,Sinding,Romantic,unclear
rac_op32_1.mid,Rachmaninov,Romantic,unclear
rac_op23_3.mid,Rachmaninov,Romantic,unclear
rac_op33_8.mid,Rachmaninov,Romantic,unclear
rac_op33_6.mid,Rachmaninov,Romantic,unclear
rac_op33_5.mid,Rachmaninov,Romantic,unclear
rac_op23_7.mid,Rachmaninov,Romantic,unclear
rac_op32_13.mid,Rachmaninov,Romantic,unclear
rac_op23_2.mid,Rachmaninov,Romantic,unclear
rac_op3_2.mid,Rachmaninov,Romantic,unclear
rac_op23_5.mid,Rachmaninov,Romantic,unclear
god_alb_esp2.mid,Godowsky,Romantic,unclear
god_chpn_op10_e01.mid,Godowsky,Romantic,unclear
mz_545_1.mid,Mozart,Classical,unclear
mz_570_2.mid,Mozart,Classical,unclear
mz_311_2.mid,Mozart,Classical,unclear
mz_333_3.mid,Mozart,Classical,unclear
mz_331_3.mid,Mozart,Classical,passionate
mz_332_3.mid,Mozart,Classical,unclear
mz_331_2.mid,Mozart,Classical,unclear
mz_332_1.mid,Mozart,Classical,unclear
mz_545_2.mid,Mozart,Classical,unclear
mz_330_1.mid,Mozart,Classical,unclear
mz_545_3.mid,Mozart,Classical,unclear
mz_333_2.mid,Mozart,Classical,unclear
mz_330_2.mid,Mozart,Classical,unclear
mz_333_1.mid,Mozart,Classical,unclear
mz_311_3.mid,Mozart,Classical,unclear
mz_331_1.mid,Mozart,Classical,happy
mz_570_3.mid,Mozart,Classical,unclear
mz_332_2.mid,Mozart,Classical,unclear
mz_570_1.mid,Mozart,Classical,unclear
mz_330_3.mid,Mozart,Classical,unclear
mz_311_1.mid,Mozart,Classical,unclear
rav_scarbo.mid,Ravel,Romantic,unclear
rav_ondi.mid,Ravel,Romantic,unclear
rav_eau.mid,Ravel,Romantic,unclear
rav_gib.mid,Ravel,Romantic,unclear
ravel_miroirs_1.mid,Ravel,Romantic,unclear
clementi_opus36_4_1.mid,Clementi,Classical,unclear
clementi_opus36_2_2.mid,Clementi,Classical,unclear
clementi_opus36_6_1.mid,Clementi,Classical,happy
clementi_opus36_1_3.mid,Clementi,Classical,happy
clementi_opus36_3_3.mid,Clementi,Classical,unclear
clementi_opus36_5_1.mid,Clementi,Classical,happy
clementi_opus36_1_2.mid,Clementi,Classical,soft
clementi_opus36_4_3.mid,Clementi,Classical,unclear
clementi_opus36_1_1.mid,Clementi,Classical,happy
clementi_opus36_2_3.mid,Clementi,Classical,unclear
clementi_opus36_4_2.mid,Clementi,Classical,unclear
clementi_opus36_3_2.mid,Clementi,Classical,unclear
clementi_opus36_5_3.mid,Clementi,Classical,unclear
clementi_opus36_5_2.mid,Clementi,Classical,unclear
clementi_opus36_3_1.mid,Clementi,Classical,unclear
clementi_opus36_6_2.mid,Clementi,Classical,unclear
clementi_opus36_2_1.mid,Clementi,Classical,happy
mos_op36_6.mid,Moszkowski,Romantic,unclear
haydn_7_2.mid,Haydn,Classical,unclear
haydn_35_2.mid,Haydn,Classical,unclear
haydn_7_3.mid,Haydn,Classical,unclear
haydn_8_4.mid,Haydn,Classical,unclear
haydn_9_1.mid,Haydn,Classical,unclear
haydn_8_3.mid,Haydn,Classical,unclear
haydn_35_3.mid,Haydn,Classical,unclear
haydn_33_3.mid,Haydn,Classical,unclear
haydn_8_1.mid,Haydn,Classical,unclear
haydn_8_2.mid,Haydn,Classical,unclear
haydn_7_1.mid,Haydn,Classical,unclear
haydn_9_2.mid,Haydn,Classical,unclear
haydn_43_1.mid,Haydn,Classical,unclear
hay_40_2.mid,Haydn,Classical,unclear
haydn_9_3.mid,Haydn,Classical,unclear
haydn_35_1.mid,Haydn,Classical,unclear
haydn_33_1.mid,Haydn,Classical,unclear
haydn_43_2.mid,Haydn,Classical,unclear
hay_40_1.mid,Haydn,Classical,unclear
haydn_33_2.mid,Haydn,Classical,unclear
haydn_43_3.mid,Haydn,Classical,unclear
bach_850.mid,Bach,Baroque,happy
bach_846.mid,Bach,Baroque,soft
bach_847.mid,Bach,Baroque,unclear
grieg_halling.mid,Grieg,Romantic,unclear
grieg_wedding.mid,Grieg,Romantic,unclear
grieg_brooklet.mid,Grieg,Romantic,unclear
grieg_butterfly.mid,Grieg,Romantic,happy
grieg_wanderer.mid,Grieg,Romantic,unclear
grieg_zwerge.mid,Grieg,Romantic,unclear
grieg_march.mid,Grieg,Romantic,unclear
grieg_album.mid,Grieg,Romantic,unclear
grieg_elfentanz.mid,Grieg,Romantic,unclear
grieg_spring.mid,Grieg,Romantic,unclear
grieg_waechter.mid,Grieg,Romantic,unclear
grieg_kobold.mid,Grieg,Romantic,unclear
grieg_berceuse.mid,Grieg,Romantic,unclear
grieg_voeglein.mid,Grieg,Romantic,unclear
grieg_walzer.mid,Grieg,Romantic,unclear
grieg_once_upon_a_time.mid,Grieg,Romantic,unclear
br_im2.mid,Brahms,Romantic,unclear
br_rhap.mid,Brahms,Romantic,unclear
brahms_opus1_1.mid,Brahms,Romantic,unclear
brahms_opus1_3.mid,Brahms,Romantic,unclear
brahms_opus117_1.mid,Brahms,Romantic,unclear
brahms_opus1_2.mid,Brahms,Romantic,unclear
BR_IM6.MID,Brahms,Romantic,unclear
brahms_opus1_4.mid,Brahms,Romantic,unclear
brahms_opus117_2.mid,Brahms,Romantic,unclear
br_im5.mid,Brahms,Romantic,unclear
burg_geschwindigkeit.mid,Burgmueller,Romantic,unclear
burg_perlen.mid,Burgmueller,Romantic,unclear
burg_trennung.mid,Burgmueller,Romantic,unclear
burg_agitato.mid,Burgmueller,Romantic,unclear
burg_sylphen.mid,Burgmueller,Romantic,unclear
burg_spinnerlied.mid,Burgmueller,Romantic,unclear
burg_quelle.mid,Burgmueller,Romantic,unclear
burg_erwachen.mid,Burgmueller,Romantic,unclear
burg_gewitter.mid,Burgmueller,Romantic,unclear
schuim-4.mid,Schubert,Classical,unclear
schumm-6.mid,Schubert,Classical,unclear
schu_143_2.mid,Schubert,Classical,unclear
schubert_D850_3.mid,Schubert,Classical,unclear
schub_d960_1.mid,Schubert,Classical,unclear
schubert_D935_4.mid,Schubert,Classical,unclear
schu_143_1.mid,Schubert,Classical,unclear
schubert_D850_2.mid,Schubert,Classical,unclear
schumm-2.mid,Schubert,Classical,unclear
schubert_D850_4.mid,Schubert,Classical,unclear
schub_d960_3.mid,Schubert,Classical,unclear
schub_d760_3.mid,Schubert,Classical,unclear
schumm-5.mid,Schubert,Classical,unclear
schumm-3.mid,Schubert,Classical,unclear
schumm-1.mid,Schubert,Classical,unclear
schub_d760_4.mid,Schubert,Classical,unclear
schubert_D935_2.mid,Schubert,Classical,unclear
schumm-4.mid,Schubert,Classical,unclear
schu_143_3.mid,Schubert,Classical,unclear
schub_d960_2.mid,Schubert,Classical,unclear
schuim-1.mid,Schubert,Classical,unclear
schub_d760_1.mid,Schubert,Classical,unclear
schubert_D850_1.mid,Schubert,Classical,unclear
schubert_D935_3.mid,Schubert,Classical,unclear
schub_d960_4.mid,Schubert,Classical,unclear
schuim-3.mid,Schubert,Classical,unclear
schub_d760_2.mid,Schubert,Classical,unclear
schubert_D935_1.mid,Schubert,Classical,unclear
schuim-2.mid,Schubert,Classical,unclear
islamei.mid,Balakirew,Romantic,unclear
bor_ps2.mid,Borodin,Romantic,unclear
bor_ps1.mid,Borodin,Romantic,unclear
bor_ps7.mid,Borodin,Romantic,unclear
bor_ps4.mid,Borodin,Romantic,unclear
bor_ps6.mid,Borodin,Romantic,unclear
bor_ps3.mid,Borodin,Romantic,unclear
bor_ps5.mid,Borodin,Romantic,unclear
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/keyIndex.csv
================================================
C major,0
a minor,1
G major,2
e minor,3
D major,4
b minor,5
A major,6
f# minor,7
E major,8
c# minor,9
B major,10
g# minor,11
F major,12
d minor,13
B- major,14
g minor,15
E- major,16
c minor,17
A- major,18
f minor,19
D- major,20
b- minor,21
G- major,22
e- minor,23
C# major,20
a# minor,21
F# major,22
d# minor,23
C- major,10
a- minor,11
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/keys.csv
================================================
1,-1,2,-1,3,4,-1,5,-1,6,-1,7
3,-1,4,-1,5,6,-1,-1,7,1,-1,2
4,-1,5,-1,6,-1,7,1,-1,2,-1,3
6,-1,-1,7,1,-1,2,3,-1,4,-1,5
-1,7,1,-1,2,-1,3,4,-1,5,-1,6
-1,2,3,-1,4,-1,5,6,-1,-1,7,1
-1,3,4,-1,5,-1,6,-1,7,1,-1,2
-1,5,6,-1,-1,7,1,-1,2,3,-1,4
-1,6,-1,7,1,-1,2,-1,3,4,-1,5
7,1,-1,2,3,-1,4,-1,5,6,-1,-1
-1,2,-1,3,4,-1,5,-1,6,-1,7,1
-1,4,-1,5,6,-1,-1,7,1,-1,2,3
5,-1,6,-1,7,1,-1,2,-1,3,4,-1
-1,7,1,-1,2,3,-1,4,-1,5,6,-1
2,-1,3,4,-1,5,-1,6,-1,7,1,-1
4,-1,5,6,-1,-1,7,1,-1,2,3,-1
6,-1,7,1,-1,2,-1,3,4,-1,5,-1
1,-1,2,3,-1,4,-1,5,6,-1,-1,7
3,4,-1,5,-1,6,-1,7,1,-1,2,-1
5,6,-1,-1,7,1,-1,2,3,-1,4,-1
7,1,-1,2,-1,3,4,-1,5,-1,6,-1
2,3,-1,4,-1,5,6,-1,-1,7,1,-1
-1,5,-1,6,-1,7,1,-1,2,-1,3,4
-1,-1,7,1,-1,2,3,-1,4,-1,5,6
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/modeindex.csv
================================================
0,major
1,minor
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/pitch2midi.csv
================================================
C,0,12,24,36,48,60,72,84,96,108,120
C#,1,13,25,37,49,61,73,85,97,109,121
C-,11,23,35,47,59,71,83,95,107,119,
D,2,14,26,38,50,62,74,86,98,110,122
D#,3,15,27,39,51,63,75,87,99,111,123
D-,1,13,25,37,49,61,73,85,97,109,121
E,4,16,28,40,52,64,76,88,100,112,124
E#,5,17,29,41,53,65,77,89,101,113,125
E-,3,15,27,39,51,63,75,87,99,111,123
F,5,17,29,41,53,65,77,89,101,113,125
F#,6,18,30,42,54,66,78,90,102,114,126
F-,4,16,28,40,52,64,76,88,100,112,124
G,7,19,31,43,55,67,79,91,103,115,127
G#,8,20,32,44,56,68,80,92,104,116,
G-,6,18,30,42,54,66,78,90,102,114,126
A,9,21,33,45,57,69,81,93,105,117,
A#,10,22,34,46,58,70,82,94,106,118,
A-,8,20,32,44,56,68,80,92,104,116,
B,11,23,35,47,59,71,83,95,107,119,
B+,0,12,24,36,48,60,72,84,96,108,120
B-,10,22,34,46,58,70,82,94,106,118,
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/tones2.csv
================================================
,0,1,2,3,4,5,6,7,8,9,10,11
C major,2,-1,1,-1,1,1,-1,1,-1,1,-1,1
a minor,1,-1,1,-1,1,1,-1,-1,2,2,-1,1
G major,1,-1,1,-1,1,-1,2,2,-1,1,-1,1
e minor,1,-1,-1,2,2,-1,2,1,-1,1,-1,1
D major,-1,2,2,-1,1,-1,2,1,-1,1,-1,1
b minor,-1,2,1,-1,1,-1,2,1,-1,-1,2,2
A major,-1,2,1,-1,1,-1,2,-1,2,2,-1,1
f# minor,-1,2,1,-1,-1,2,2,-1,2,1,-1,1
E major,-1,2,-1,2,2,-1,2,-1,2,1,-1,1
c# minor,2,2,-1,2,1,-1,2,-1,2,1,-1,-1
B major,-1,2,-1,2,1,-1,2,-1,2,-1,2,2
g# minor,-1,2,-1,2,1,-1,-1,2,2,-1,2,1
F major,1,-1,1,-1,1,2,-1,1,-1,1,2,-1
d minor,-1,2,2,-1,1,1,-1,1,-1,1,2,-1
B- major,1,-1,1,2,-1,1,-1,1,-1,1,2,-1
g minor,1,-1,1,2,-1,-1,2,2,-1,1,2,-1
E- major,1,-1,1,2,-1,1,-1,1,2,-1,2,-1
c minor,1,-1,1,2,-1,1,-1,1,2,-1,-1,2
A- major,1,2,-1,2,-1,1,-1,1,2,-1,2,-1
f minor,1,2,-1,-1,2,1,-1,1,2,-1,2,-1
D- major,1,2,-1,2,-1,1,2,-1,2,-1,2,-1
b- minor,1,2,-1,2,-1,1,2,-1,-1,2,2,-1
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/task/mode-conditioned learning.py
================================================
import sys
import os
import time
sys.path.append("../../../../")
sys.path.append("../")
import numpy as np
import music21 as m21
from conf.conf import *
from api.music_engine_api import EngineAPI
if __name__=="__main__":
musicEngine = EngineAPI()
musicEngine.cortexInit()
#------------Bach dataset learning----------------#
paths = m21.corpus.getComposer('bach')
print(len(paths))
for path in paths:
musicName = (str(path).split('\\'))[-1]
print(musicName)
if musicName.split('.')[-1] != 'mxl': continue
xmldata = m21.corpus.parse(path)
musicEngine.rememberMusic(musicName, "None")
musicEngine.learnFourPartMusic(xmldata, musicName, "None")
#------------generation test----------------#
key = 'C major'
firstnotes = np.array([[m21.pitch.Pitch('E5').midi],
[m21.pitch.Pitch('G4').midi],
[m21.pitch.Pitch('C4').midi],
[m21.pitch.Pitch('C3').midi]])
result = musicEngine.generateMelodyWithKey(configs.keyIndexMap.get(key),firstnotes,None,4)
steam1 = m21.stream.Stream()
for i,part in result.items():
pt = m21.stream.Stream()
for v in part:
p = v.get("N")
d = v.get("T")
n = m21.note.Note(p)
n.quarterLength = d
pt.append(n)
steam1.insert(0,pt)
opath = '../result_output/tone learning/'
nowtime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
t2 = ''.join([x for x in nowtime if x.isdigit()])
steam1.write('midi', fp=opath+key+"_"+t2+'.mid')
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/task/musicGeneration.py
================================================
import sys
sys.path.append("../../../../")
sys.path.append("../")
from api.music_engine_api import EngineAPI
import os
if __name__=="__main__":
#----------------------------------Init------------------------------#
musicEngine = EngineAPI()
musicEngine.cortexInit()
#----------------------------Learning process------------------------#
input_path = "../testData/"
for composerName in os.listdir(input_path):
dpath = os.path.join(input_path,composerName)
if os.path.isdir(dpath):
for musicName in os.listdir(dpath):
fileName = (os.path.join(dpath,musicName))
musicEngine.memorizing(musicName,composerName,20,fileName)
#-------------------------Generation Process------------------------#
beginnotes = {1:[-1,67],
2:[-1]}
begindurs = {1:[0.5,0.25],
2:[0.5]}
lengths = [10,8]
genreName = "Classical"
composerName = "Bach"
#Generate a piece of music melody#
musicEngine.generateEx_Nihilo(beginnotes.get(2),begindurs.get(2),20,"melody_generated")
#Generate a piece of melody with a composer style
musicEngine.generateEx_NihiloAccordingToComposer(composerName,beginnotes.get(2),begindurs.get(2),15,"Bach_generated")
#Generate a piece of melody with a genre style
musicEngine.generateEx_NihiloAccordingToGenre(genreName,beginnotes.get(1),begindurs.get(1),15,"Classical_generated")
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/task/musicMemory.py
================================================
import sys
sys.path.append("../")
sys.path.append("../../../../")
from api.music_engine_api import EngineAPI
import os
if __name__=="__main__":
musicEngine = EngineAPI()
musicEngine.cortexInit()
input_path = "../testData/"
#--------------------learning process---------------#
for composerName in os.listdir(input_path):
dpath = os.path.join(input_path,composerName)
if os.path.isdir(dpath):
for musicName in os.listdir(dpath):
fileName = (os.path.join(dpath,musicName))
#Here is the training function, the first and the second parameters refer to the title and composer of a melody.
#The third parameter indicates the number of notes you want to learn. If you want to learn all the notes of melodies, this value is "ALL".
musicEngine.memorizing(musicName, composerName, 20, fileName)
# recall the music based on the name of a music
musicEngine.recallMusic("Sonate C Major.Mid")
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/__init__.py
================================================
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/generateData.py
================================================
'''
Created on 2016.4.27
@author: liangqian
'''
import json
import random
class joint():
def __init__(self):
self.x = 0
self.y = 0
self.z = 0
def self2dic(self):
return {'x':self.x,
'y':self.y,
'z':self.z}
class data():
def __init__(self):
self.T = 0
self.position = 0
self.joints = {}
def self2dic(self):
return {'T':self.T,
'position':self.position
}
Data_List = []
# for i in range(1,419):
# d = data()
# d.T = i
# d.position = random.randint(0,100)
# dic = d.self2dic()
# Data_List.append(d)
#
# dic = {}
# dic['Data'] = Data_List
#
# # using json to write file
# strs = (json.dumps(dic))
#
# fout = open('position.txt','w')
# fout.write(strs)
# fout.close()
#
#
# fin = open('position.txt','r')
# data_json = fin.read()
#
# print(data_json)
f = open('../Data.txt','r')
line = f.readline()
while(len(line) != 0):
if('T=' in line):
ss = line.split('=')
d = data()
d.T = int(ss[1].strip())
d.position = random.randint(0,100)
line = f.readline()
while(len(line.strip()) != 0):
sss = line.split(' ')
jj = joint()
s = sss[1].split('=')
jj.x = float(s[1].strip())
s = sss[2].split('=')
jj.y = float(s[1].strip())
s = sss[3].split('=')
jj.z = float(s[1].strip())
d.joints[sss[0]] = jj
line = f.readline()
Data_List.append(d)
print(len(d.joints))
line = f.readline()
print(len(Data_List))
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/hamonydataset_test.py
================================================
import os
import sys
import music21 as m21
import numpy as np
firstnotes = np.array([[m21.pitch.Pitch('b-4').midi],
[m21.pitch.Pitch('d4').midi],
[m21.pitch.Pitch('f3').midi],
[m21.pitch.Pitch('B2').midi]])
print(firstnotes)
input_path = "../xmlfiles/hamony dataset/"
for ch in os.listdir(input_path):
if ch == '.DS_Store': continue
fileName = os.path.join(input_path, ch)
for fName in os.listdir(fileName):
if fName == 'four':
if fName == '.DS_Store': continue
fn = os.path.join(fileName+'/four')
for f in os.listdir(fn):
if f == '.DS_Store': continue
print(f)
musicName = f.split("_")[0]
fTone = (f.split("_")[1]).split(".")[0]
print(musicName)
print(fTone)
print('---')
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/msg.py
================================================
'''
Created on 2016.6.8
@author: liangqian
'''
import time
import sys
import stomp
class MyListener(object):
def on_error(self, headers, message):
print('received an error : %s' % message)
def on_message(self, headers, message):
print('%s' % message)
conn = stomp.Connection([('159.226.19.16',61613)])
#conn = stomp.Connection([('10.10.10.106',61613)])
conn.set_listener('', MyListener())
conn.start()
print('hh')
conn.connect(wait=True,headers={'client-id':'LXYNB','non_persistent':'true'})
conn.subscribe(destination='/topic/TEST2.FOO',id='LX', ack='auto',headers={'activemq.subscriptionName':'LXYNB'})
#conn.send(body='hello,garfield!', destination='/topic/myTopic.messages')
while(True):
pass
conn.disconnect()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/msgq.py
================================================
'''
Created on 2018.9.7
@author: liangqian
'''
import time
import sys
import stomp
def createMSQ():
queue_name = '/queue/SampleQueue'
conn = stomp.Connection([('localhost',61613)])
#conn.start()
print("building connection to activemq......")
conn.connect()
#return conn
# for i in range (10):
# msg = 'this is the '+ str(i) + 'th messages'
# conn.send(queue_name,msg)
# print(msg)
# conn.disconnect()
return conn
#createMSQ()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/oscillations.py
================================================
'''
Created on 2016.5.13
@author: liangqian
'''
from modal.lifneuron import LIFNeuron
from modal.cluster import Cluster
from modal.synapse import Synapse
c = Cluster('LIF')
c.createClusterNetwork()
c.setInhibitoryNeurons(0.2)
for i in range(0,c.neunum):
for j in range(0,c.neunum):
if(i != j):
node = c.neurons[j]
node.pre_neurons.append(c.neurons[i])
syn = Synapse(c.neurons[i],node)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/position.txt
================================================
{"1": {"position": 58, "T": 1}, "2": {"position": 96, "T": 2}, "3": {"position": 36, "T": 3}, "4": {"position": 28, "T": 4}, "5": {"position": 43, "T": 5}, "6": {"position": 46, "T": 6}, "7": {"position": 91, "T": 7}, "8": {"position": 44, "T": 8}, "9": {"position": 59, "T": 9}, "10": {"position": 83, "T": 10}, "11": {"position": 17, "T": 11}, "12": {"position": 50, "T": 12}, "13": {"position": 46, "T": 13}, "14": {"position": 53, "T": 14}, "15": {"position": 9, "T": 15}, "16": {"position": 88, "T": 16}, "17": {"position": 23, "T": 17}, "18": {"position": 28, "T": 18}, "19": {"position": 17, "T": 19}, "20": {"position": 16, "T": 20}, "21": {"position": 43, "T": 21}, "22": {"position": 93, "T": 22}, "23": {"position": 13, "T": 23}, "24": {"position": 0, "T": 24}, "25": {"position": 92, "T": 25}, "26": {"position": 56, "T": 26}, "27": {"position": 2, "T": 27}, "28": {"position": 38, "T": 28}, "29": {"position": 17, "T": 29}, "30": {"position": 13, "T": 30}, "31": {"position": 95, "T": 31}, "32": {"position": 86, "T": 32}, "33": {"position": 45, "T": 33}, "34": {"position": 30, "T": 34}, "35": {"position": 42, "T": 35}, "36": {"position": 87, "T": 36}, "37": {"position": 14, "T": 37}, "38": {"position": 56, "T": 38}, "39": {"position": 76, "T": 39}, "40": {"position": 55, "T": 40}, "41": {"position": 5, "T": 41}, "42": {"position": 98, "T": 42}, "43": {"position": 5, "T": 43}, "44": {"position": 17, "T": 44}, "45": {"position": 73, "T": 45}, "46": {"position": 55, "T": 46}, "47": {"position": 86, "T": 47}, "48": {"position": 56, "T": 48}, "49": {"position": 80, "T": 49}, "50": {"position": 87, "T": 50}, "51": {"position": 47, "T": 51}, "52": {"position": 51, "T": 52}, "53": {"position": 62, "T": 53}, "54": {"position": 3, "T": 54}, "55": {"position": 65, "T": 55}, "56": {"position": 90, "T": 56}, "57": {"position": 76, "T": 57}, "58": {"position": 35, "T": 58}, "59": {"position": 81, "T": 59}, "60": {"position": 0, "T": 60}, "61": {"position": 32, "T": 61}, "62": {"position": 93, "T": 62}, "63": {"position": 100, "T": 63}, "64": {"position": 70, "T": 64}, "65": {"position": 10, "T": 65}, "66": {"position": 37, "T": 66}, "67": {"position": 87, "T": 67}, "68": {"position": 72, "T": 68}, "69": {"position": 77, "T": 69}, "70": {"position": 65, "T": 70}, "71": {"position": 21, "T": 71}, "72": {"position": 45, "T": 72}, "73": {"position": 81, "T": 73}, "74": {"position": 27, "T": 74}, "75": {"position": 55, "T": 75}, "76": {"position": 8, "T": 76}, "77": {"position": 2, "T": 77}, "78": {"position": 66, "T": 78}, "79": {"position": 80, "T": 79}, "80": {"position": 76, "T": 80}, "81": {"position": 49, "T": 81}, "82": {"position": 49, "T": 82}, "83": {"position": 24, "T": 83}, "84": {"position": 51, "T": 84}, "85": {"position": 43, "T": 85}, "86": {"position": 31, "T": 86}, "87": {"position": 58, "T": 87}, "88": {"position": 84, "T": 88}, "89": {"position": 58, "T": 89}, "90": {"position": 95, "T": 90}, "91": {"position": 91, "T": 91}, "92": {"position": 97, "T": 92}, "93": {"position": 53, "T": 93}, "94": {"position": 33, "T": 94}, "95": {"position": 11, "T": 95}, "96": {"position": 8, "T": 96}, "97": {"position": 96, "T": 97}, "98": {"position": 28, "T": 98}, "99": {"position": 54, "T": 99}, "100": {"position": 37, "T": 100}, "101": {"position": 60, "T": 101}, "102": {"position": 71, "T": 102}, "103": {"position": 6, "T": 103}, "104": {"position": 7, "T": 104}, "105": {"position": 4, "T": 105}, "106": {"position": 39, "T": 106}, "107": {"position": 75, "T": 107}, "108": {"position": 47, "T": 108}, "109": {"position": 30, "T": 109}, "110": {"position": 100, "T": 110}, "111": {"position": 30, "T": 111}, "112": {"position": 40, "T": 112}, "113": {"position": 11, "T": 113}, "114": {"position": 3, "T": 114}, "115": {"position": 83, "T": 115}, "116": {"position": 45, "T": 116}, "117": {"position": 91, "T": 117}, "118": {"position": 85, "T": 118}, "119": {"position": 56, "T": 119}, "120": {"position": 33, "T": 120}, "121": {"position": 74, "T": 121}, "122": {"position": 100, "T": 122}, "123": {"position": 56, "T": 123}, "124": {"position": 91, "T": 124}, "125": {"position": 16, "T": 125}, "126": {"position": 0, "T": 126}, "127": {"position": 17, "T": 127}, "128": {"position": 73, "T": 128}, "129": {"position": 40, "T": 129}, "130": {"position": 10, "T": 130}, "131": {"position": 6, "T": 131}, "132": {"position": 63, "T": 132}, "133": {"position": 23, "T": 133}, "134": {"position": 47, "T": 134}, "135": {"position": 79, "T": 135}, "136": {"position": 97, "T": 136}, "137": {"position": 13, "T": 137}, "138": {"position": 8, "T": 138}, "139": {"position": 39, "T": 139}, "140": {"position": 72, "T": 140}, "141": {"position": 59, "T": 141}, "142": {"position": 55, "T": 142}, "143": {"position": 91, "T": 143}, "144": {"position": 22, "T": 144}, "145": {"position": 62, "T": 145}, "146": {"position": 23, "T": 146}, "147": {"position": 14, "T": 147}, "148": {"position": 70, "T": 148}, "149": {"position": 86, "T": 149}, "150": {"position": 10, "T": 150}, "151": {"position": 72, "T": 151}, "152": {"position": 91, "T": 152}, "153": {"position": 29, "T": 153}, "154": {"position": 29, "T": 154}, "155": {"position": 94, "T": 155}, "156": {"position": 69, "T": 156}, "157": {"position": 58, "T": 157}, "158": {"position": 0, "T": 158}, "159": {"position": 11, "T": 159}, "160": {"position": 24, "T": 160}, "161": {"position": 70, "T": 161}, "162": {"position": 58, "T": 162}, "163": {"position": 58, "T": 163}, "164": {"position": 7, "T": 164}, "165": {"position": 25, "T": 165}, "166": {"position": 32, "T": 166}, "167": {"position": 92, "T": 167}, "168": {"position": 58, "T": 168}, "169": {"position": 55, "T": 169}, "170": {"position": 13, "T": 170}, "171": {"position": 17, "T": 171}, "172": {"position": 4, "T": 172}, "173": {"position": 30, "T": 173}, "174": {"position": 58, "T": 174}, "175": {"position": 91, "T": 175}, "176": {"position": 53, "T": 176}, "177": {"position": 41, "T": 177}, "178": {"position": 45, "T": 178}, "179": {"position": 69, "T": 179}, "180": {"position": 82, "T": 180}, "181": {"position": 44, "T": 181}, "182": {"position": 48, "T": 182}, "183": {"position": 16, "T": 183}, "184": {"position": 75, "T": 184}, "185": {"position": 91, "T": 185}, "186": {"position": 16, "T": 186}, "187": {"position": 71, "T": 187}, "188": {"position": 59, "T": 188}, "189": {"position": 89, "T": 189}, "190": {"position": 25, "T": 190}, "191": {"position": 85, "T": 191}, "192": {"position": 34, "T": 192}, "193": {"position": 83, "T": 193}, "194": {"position": 36, "T": 194}, "195": {"position": 30, "T": 195}, "196": {"position": 5, "T": 196}, "197": {"position": 7, "T": 197}, "198": {"position": 5, "T": 198}, "199": {"position": 74, "T": 199}, "200": {"position": 29, "T": 200}, "201": {"position": 40, "T": 201}, "202": {"position": 48, "T": 202}, "203": {"position": 69, "T": 203}, "204": {"position": 0, "T": 204}, "205": {"position": 67, "T": 205}, "206": {"position": 7, "T": 206}, "207": {"position": 79, "T": 207}, "208": {"position": 72, "T": 208}, "209": {"position": 68, "T": 209}, "210": {"position": 97, "T": 210}, "211": {"position": 40, "T": 211}, "212": {"position": 84, "T": 212}, "213": {"position": 20, "T": 213}, "214": {"position": 91, "T": 214}, "215": {"position": 16, "T": 215}, "216": {"position": 12, "T": 216}, "217": {"position": 100, "T": 217}, "218": {"position": 89, "T": 218}, "219": {"position": 33, "T": 219}, "220": {"position": 60, "T": 220}, "221": {"position": 25, "T": 221}, "222": {"position": 82, "T": 222}, "223": {"position": 28, "T": 223}, "224": {"position": 53, "T": 224}, "225": {"position": 6, "T": 225}, "226": {"position": 63, "T": 226}, "227": {"position": 93, "T": 227}, "228": {"position": 14, "T": 228}, "229": {"position": 47, "T": 229}, "230": {"position": 42, "T": 230}, "231": {"position": 94, "T": 231}, "232": {"position": 61, "T": 232}, "233": {"position": 88, "T": 233}, "234": {"position": 17, "T": 234}, "235": {"position": 3, "T": 235}, "236": {"position": 97, "T": 236}, "237": {"position": 38, "T": 237}, "238": {"position": 30, "T": 238}, "239": {"position": 84, "T": 239}, "240": {"position": 37, "T": 240}, "241": {"position": 99, "T": 241}, "242": {"position": 36, "T": 242}, "243": {"position": 100, "T": 243}, "244": {"position": 53, "T": 244}, "245": {"position": 44, "T": 245}, "246": {"position": 37, "T": 246}, "247": {"position": 80, "T": 247}, "248": {"position": 8, "T": 248}, "249": {"position": 79, "T": 249}, "250": {"position": 94, "T": 250}, "251": {"position": 82, "T": 251}, "252": {"position": 84, "T": 252}, "253": {"position": 47, "T": 253}, "254": {"position": 27, "T": 254}, "255": {"position": 22, "T": 255}, "256": {"position": 22, "T": 256}, "257": {"position": 26, "T": 257}, "258": {"position": 58, "T": 258}, "259": {"position": 83, "T": 259}, "260": {"position": 60, "T": 260}, "261": {"position": 16, "T": 261}, "262": {"position": 54, "T": 262}, "263": {"position": 65, "T": 263}, "264": {"position": 7, "T": 264}, "265": {"position": 57, "T": 265}, "266": {"position": 15, "T": 266}, "267": {"position": 63, "T": 267}, "268": {"position": 54, "T": 268}, "269": {"position": 58, "T": 269}, "270": {"position": 16, "T": 270}, "271": {"position": 45, "T": 271}, "272": {"position": 57, "T": 272}, "273": {"position": 72, "T": 273}, "274": {"position": 93, "T": 274}, "275": {"position": 55, "T": 275}, "276": {"position": 77, "T": 276}, "277": {"position": 74, "T": 277}, "278": {"position": 20, "T": 278}, "279": {"position": 57, "T": 279}, "280": {"position": 89, "T": 280}, "281": {"position": 68, "T": 281}, "282": {"position": 74, "T": 282}, "283": {"position": 87, "T": 283}, "284": {"position": 11, "T": 284}, "285": {"position": 74, "T": 285}, "286": {"position": 69, "T": 286}, "287": {"position": 95, "T": 287}, "288": {"position": 76, "T": 288}, "289": {"position": 23, "T": 289}, "290": {"position": 6, "T": 290}, "291": {"position": 42, "T": 291}, "292": {"position": 71, "T": 292}, "293": {"position": 24, "T": 293}, "294": {"position": 18, "T": 294}, "295": {"position": 76, "T": 295}, "296": {"position": 97, "T": 296}, "297": {"position": 41, "T": 297}, "298": {"position": 60, "T": 298}, "299": {"position": 13, "T": 299}, "300": {"position": 84, "T": 300}, "301": {"position": 93, "T": 301}, "302": {"position": 75, "T": 302}, "303": {"position": 81, "T": 303}, "304": {"position": 76, "T": 304}, "305": {"position": 93, "T": 305}, "306": {"position": 2, "T": 306}, "307": {"position": 34, "T": 307}, "308": {"position": 27, "T": 308}, "309": {"position": 37, "T": 309}, "310": {"position": 71, "T": 310}, "311": {"position": 84, "T": 311}, "312": {"position": 97, "T": 312}, "313": {"position": 56, "T": 313}, "314": {"position": 100, "T": 314}, "315": {"position": 41, "T": 315}, "316": {"position": 88, "T": 316}, "317": {"position": 51, "T": 317}, "318": {"position": 80, "T": 318}, "319": {"position": 62, "T": 319}, "320": {"position": 34, "T": 320}, "321": {"position": 34, "T": 321}, "322": {"position": 32, "T": 322}, "323": {"position": 56, "T": 323}, "324": {"position": 58, "T": 324}, "325": {"position": 25, "T": 325}, "326": {"position": 29, "T": 326}, "327": {"position": 15, "T": 327}, "328": {"position": 55, "T": 328}, "329": {"position": 87, "T": 329}, "330": {"position": 20, "T": 330}, "331": {"position": 18, "T": 331}, "332": {"position": 25, "T": 332}, "333": {"position": 21, "T": 333}, "334": {"position": 69, "T": 334}, "335": {"position": 50, "T": 335}, "336": {"position": 12, "T": 336}, "337": {"position": 30, "T": 337}, "338": {"position": 41, "T": 338}, "339": {"position": 59, "T": 339}, "340": {"position": 100, "T": 340}, "341": {"position": 20, "T": 341}, "342": {"position": 20, "T": 342}, "343": {"position": 72, "T": 343}, "344": {"position": 30, "T": 344}, "345": {"position": 94, "T": 345}, "346": {"position": 31, "T": 346}, "347": {"position": 26, "T": 347}, "348": {"position": 13, "T": 348}, "349": {"position": 5, "T": 349}, "350": {"position": 2, "T": 350}, "351": {"position": 97, "T": 351}, "352": {"position": 97, "T": 352}, "353": {"position": 3, "T": 353}, "354": {"position": 75, "T": 354}, "355": {"position": 98, "T": 355}, "356": {"position": 97, "T": 356}, "357": {"position": 35, "T": 357}, "358": {"position": 12, "T": 358}, "359": {"position": 46, "T": 359}, "360": {"position": 91, "T": 360}, "361": {"position": 40, "T": 361}, "362": {"position": 48, "T": 362}, "363": {"position": 98, "T": 363}, "364": {"position": 70, "T": 364}, "365": {"position": 7, "T": 365}, "366": {"position": 75, "T": 366}, "367": {"position": 35, "T": 367}, "368": {"position": 48, "T": 368}, "369": {"position": 77, "T": 369}, "370": {"position": 91, "T": 370}, "371": {"position": 96, "T": 371}, "372": {"position": 9, "T": 372}, "373": {"position": 2, "T": 373}, "374": {"position": 76, "T": 374}, "375": {"position": 25, "T": 375}, "376": {"position": 95, "T": 376}, "377": {"position": 72, "T": 377}, "378": {"position": 59, "T": 378}, "379": {"position": 4, "T": 379}, "380": {"position": 87, "T": 380}, "381": {"position": 100, "T": 381}, "382": {"position": 91, "T": 382}, "383": {"position": 73, "T": 383}, "384": {"position": 63, "T": 384}, "385": {"position": 64, "T": 385}, "386": {"position": 16, "T": 386}, "387": {"position": 20, "T": 387}, "388": {"position": 51, "T": 388}, "389": {"position": 56, "T": 389}, "390": {"position": 81, "T": 390}, "391": {"position": 16, "T": 391}, "392": {"position": 88, "T": 392}, "393": {"position": 68, "T": 393}, "394": {"position": 65, "T": 394}, "395": {"position": 54, "T": 395}, "396": {"position": 29, "T": 396}, "397": {"position": 37, "T": 397}, "398": {"position": 88, "T": 398}, "399": {"position": 82, "T": 399}, "400": {"position": 93, "T": 400}, "401": {"position": 71, "T": 401}, "402": {"position": 33, "T": 402}, "403": {"position": 72, "T": 403}, "404": {"position": 83, "T": 404}, "405": {"position": 93, "T": 405}, "406": {"position": 72, "T": 406}, "407": {"position": 3, "T": 407}, "408": {"position": 98, "T": 408}, "409": {"position": 99, "T": 409}, "410": {"position": 39, "T": 410}, "411": {"position": 62, "T": 411}, "412": {"position": 60, "T": 412}, "413": {"position": 48, "T": 413}, "414": {"position": 32, "T": 414}, "415": {"position": 66, "T": 415}, "416": {"position": 40, "T": 416}, "417": {"position": 33, "T": 417}, "418": {"position": 68, "T": 418}}
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/readjson.py
================================================
'''
Created on 2016.5.24
@author: liangqian
'''
import json
import os
def readjsonFile(filename):
#print(os.path.abspath(os.curdir))
f = open(filename,'r')
jsonstrs = f.read()
#print(jsonstrs)
jdata = json.loads(jsonstrs)
return jdata
#readjsonFile('../jsondata.txt')
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/testSound.py
================================================
'''
Created on 2016.6.29
@author: liangqian
'''
import pygame,sys
pygame.init()
pygame.mixer.init()
pygame.time.delay(1000)
pygame.mixer.music.load("do.wav")
pygame.mixer.music.play()
while 1:
for event in pygame.event.get():
if event.type==pygame.QUIT:
sys.exit()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/testmusic21.py
================================================
from music21 import *
#s = converter.parse('../xmlfiles/four_part_hamony/ch4-03_A-major.xml')
s = corpus.parse('bach/bwv65.2.xml')
s.analyze('key')
print(len(s.parts))
s.show()
for i,part in enumerate(s.parts):
print(i)
print('-----------')
for ns in part.flat.notes:
print(ns.pitch)
print(ns.duration.quarterLength)
note1 = note.Note("D5")
note2 = note.Note("F#5")
note2.duration.quarterLength = 0.5
note3 = note.Note("A5")
stream1 = stream.Stream()
stream1.append(note1)
stream1.append(note2)
stream1.append(note3)
print(note2.offset)
sout = stream1.getElementsByOffset(0,2)
sBach = corpus.parse('bach/bwv57.8')
s = sBach.chordify()
#cs = s.getElementsByClass('Chord')
s1 = s.flatten()
chords = s1.getElementsByClass('Chord')
# cMinor = chord.Chord(["A4","F4","D5"])
# print(cMinor.inversion())
# print(cMinor.isMinorTriad())
keyA = key.Key('B-')
for c in chords:
rn = roman.romanNumeralFromChord(c, keyA)
c.addLyric(str(rn.figure))
chords.show()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/testopengl.py
================================================
'''
Created on 2018.8.31
@author: liangqian
'''
from OpenGL.GL import *
from OpenGL.GLU import *
from OpenGL.GLUT import *
def drawFunc():
glClear(GL_COLOR_BUFFER_BIT)
#glRotatef(1, 0, 1, 0)
glutWireTeapot(0.5)
glFlush()
glutInit()
glutInitDisplayMode(GLUT_SINGLE | GLUT_RGBA)
glutInitWindowSize(400, 400)
glutCreateWindow(b"First")
glutDisplayFunc(drawFunc)
#glutIdleFunc(drawFunc)
glutMainLoop()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/testwave.py
================================================
import wave
import struct
import os
import numpy as np
f = 440
framerate = 44100.0
fw = wave.open("sine.wav","wb")
fw.setnchannels(1)
fw.setframerate(framerate)
fw.setsampwidth(2)
tt = np.arange(0, 1, 1.0/framerate)
data = [2000*(np.sin(2*np.pi*f*t)+np.sin(2*np.pi*2*f*t)+np.sin(2*np.pi*3*f*t)) for t in tt]
print(data)
for d in data:
fw.writeframes(struct.pack('h',int(d)))
fw.close()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/xmlParser.py
================================================
import librosa
import music21 as m21
import pandas as pd
import os
'''
This function parses MusicXML file and extracts necessary score information as CSV.
'''
def readXmlAsCsv(xmlPath='xml/'):
for subfolder in os.listdir(xmlPath):
if subfolder.startswith('.'):
continue
subfolder_path = os.path.join(xmlPath, subfolder)
for item in os.listdir(subfolder_path):
if item.endswith('xml'):
item_path = os.path.join(subfolder_path, item)
xml_data = m21.converter.parse(item_path)
print("Converting ", item_path)
score = []
for part in xml_data.parts:
for note in part.flat.notes:
if note.isChord:
print('note is chord: ', note)
measureNo = note.measureNumber
start = note.offset
duration = note.quarterLength
for chord_note in note:
pitch = chord_note.pitch
articulations = note.articulations
expressions = note.expressions
spanners = note.getSpannerSites()
gliss = []
for spanner in spanners:
if 'Glissando' in spanner.classes:
if spanner.isFirst(chord_note):
gliss.append('slide start')
if spanner.isLast(chord_note):
gliss.append('slide last')
score.append(
[measureNo, start, duration, pitch, m21.pitch.Pitch(pitch).frequency,
articulations, expressions, gliss, spanners])
else:
measureNo = note.measureNumber
start = note.offset
duration = note.quarterLength
pitch = note.pitch
articulations = note.articulations
expressions = note.expressions
spanners = note.getSpannerSites()
gliss = []
for spanner in spanners:
if 'Glissando' in spanner.classes:
if spanner.isFirst(note):
gliss.append('slide start')
if spanner.isLast(note):
gliss.append('slide last')
score.append(
[measureNo, start, duration, pitch, m21.pitch.Pitch(pitch).frequency,
articulations, expressions, gliss, spanners])
score = sorted(score, key=lambda x: (x[0], x[1], x[2]))
df = pd.DataFrame(score,
columns=['MeasureNumber', 'Start', 'Duration', 'Pitch', 'f0',
'Articulations', 'Expressions', 'Glissando', 'Spanner'])
df.to_csv(os.path.join(path, 'csv', subfolder, os.path.splitext(item)[0] + '.csv'))
================================================
FILE: examples/MotorControl/experimental/README.md
================================================
# Experimental works for motor control with different Brain Aeras.
The project is still immature and under continuous development...
## Citation
If you find the code and dataset useful in your research, please consider citing:
```
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/MotorControl/experimental/brain_area.py
================================================
import torch
import numpy as np
import torch.nn as nn
from braincog.base.node.node import *
class MoColumnPOP(nn.Module):
def __init__(self,
input_dims: int,
pop_num: int = 16,
embedding_dim: int = 64,
time_window: int = 16) -> None:
super().__init__()
self._threshold = 1.0
self.v_reset = 0.0
self._time_window = time_window
self._pop_num = pop_num
self._node = LIFNode
self.column_net = nn.ModuleList(
[nn.Sequential(
nn.Linear(input_dims, embedding_dim),
self._node(threshold=self._threshold, v_reset=self.v_reset))
for _ in range(pop_num)
]
)
self.decode = nn.Linear(embedding_dim, 64)
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def _emb_decode(self, x):
pop_emb_decode = []
for net in self.column_net:
emb = net(x)
pop_emb_decode.append(self.decode(emb))
return pop_emb_decode
def forward(self, inputs):
pop_emb_decode = self._emb_decode(inputs)
out = sum(pop_emb_decode) / self._pop_num
return out
class MotorCortex(nn.Module):
def __init__(self,
input_dims: int,
out_dims: int = 128,
time_window: int = 16) -> None:
super().__init__()
self._threshold = 1.0
self.v_reset = 0.0
self._time_window = time_window
self._node = LIFNode
self.pfc_net = nn.Sequential(
nn.Linear(input_dims, 512),
self._node(threshold=self._threshold, v_reset=self.v_reset)
)
self.sma_net = nn.Sequential(
nn.Linear(input_dims, 512),
self._node(threshold=self._threshold, v_reset=self.v_reset)
)
self.ganglia_net = nn.Sequential(
nn.Linear(512, 128),
self._node(threshold=self._threshold, v_reset=self.v_reset)
)
self.pmc_net = nn.Sequential(
nn.Linear(512, 512),
self._node(threshold=self._threshold, v_reset=self.v_reset)
)
self.motor_net = nn.Sequential(
nn.Linear(512+128, 128),
self._node(threshold=self._threshold, v_reset=self.v_reset)
)
self.motor_emb = MoColumnPOP(input_dims=128, embedding_dim=out_dims, time_window=time_window)
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def _compute_motor_out(self, inputs):
sma_out = self.sma_net(inputs)
ganglia_out = self.ganglia_net(sma_out)
motor_in = torch.concat([ganglia_out, sma_out], dim=-1)
motor_out = self.motor_net(motor_in)
# pop coding
return motor_out
def forward(self, inputs):
self.reset()
outs = []
for step in range(self._time_window):
motor_out = self._compute_motor_out(inputs)
m_emb = self.motor_emb(motor_out) # [Batch, 128]
outs.append(m_emb)
return outs
class Celebellum(nn.Module):
def __init__(self,
input_dims: int = 512,
out_dims: int = 7,
time_window: int = 16,
) -> None:
super().__init__()
self._threshold = 1.0
self.v_reset = 0.0
self._time_window = time_window
self._node = LIFNode
self.gc_layer = nn.Sequential(
nn.Linear(input_dims, 512),
self._node(threshold=self._threshold, v_reset=self.v_reset)
)
self.pc_layer = nn.Sequential(
nn.Linear(512, 512),
self._node(threshold=self._threshold, v_reset=self.v_reset)
)
self.dcn_layer = nn.Sequential(
nn.Linear(input_dims + 512, 512),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Linear(512, out_dims)
)
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def forward(self, x):
self.reset()
outs = []
for step in range(self._time_window):
gc = self.gc_layer(x[step])
pc = self.pc_layer(gc)
dcn_in = torch.concat([x[step], pc], dim=-1)
dcn = self.dcn_layer(dcn_in)
outs.append(dcn)
cel_out = sum(outs) / self._time_window
return cel_out
if __name__ == '__main__':
motor = MotorCortex(input_dims=1024)
for mod in motor.modules():
# print('mod: ', mod)
if hasattr(mod, 'n_reset'):
print('mod: ', mod)
================================================
FILE: examples/MotorControl/experimental/main.py
================================================
import torch
import numpy as np
import torch.nn as nn
from model import Motion
import tqdm
import argparse
from torch.nn import functional as F
parser = argparse.ArgumentParser(description='Motor Parameters')
parser.add_argument('--lr', default=0.001, type=float, help='learning rate')
parser.add_argument('--time-window', type=int, default=8, help="Number of timesteps to do.")
parser.add_argument('--device', type=str, default='0', help="CUDA device")
parser.add_argument('--log-path', type=str, default='./logs/out.txt', help="Log path")
args = parser.parse_args()
print(args)
device = torch.device('cuda:'+args.device)
LABELS = {
'position_group_0': (-0.337, -0.020, -0.077, -0.031164, 0.999496, -0.005979, 2.850154),
'position_group_1': (-0.337, 0.007, -0.077, -0.039668, 0.999161, -0.010174, 2.894892),
'position_group_2': (-0.337, 0.030, -0.076, -0.031164, 0.999496, -0.005979, 2.850154),
'position_group_3': (-0.337, 0.052, -0.076, -0.031164, 0.999496, -0.005979, 2.850154),
'position_group_4': (-0.339, 0.074, -0.076, 0.016057, 0.999842, -0.007643, 2.804204),
'position_group_5': (-0.339, 0.096, -0.078, 0.016057, 0.999842, -0.007643, 2.804204),
'position_group_6': (-0.339, 0.123, -0.079, 0.016057, 0.999842, -0.007643, 2.804204),
'position_group_7': (-0.337, 0.139, -0.080, 0.076912, 0.997035, -0.0021723, 2.799101),
'position_group_8': (-0.337, 0.163, -0.0770, 0.076912, 0.997035, -0.0021723, 2.799101),
'position_group_9': (-0.338, 0.188, -0.075, 0.076912, 0.997035, -0.002172, 2.799101),
'position_group_10': (-0.338, 0.212, -0.075, 0.087103, 0.995757, -0.029681, 2.785759),
'position_group_11': (-0.338, 0.235, -0.070, 0.087103, 0.995757, -0.029681, 2.785759),
'position_group_12': (-0.338, 0.259, -0.073, 0.087103, 0.995757, -0.029681, 2.785759),
'position_group_13': (-0.339, 0.273, -0.065, 0.202020, 0.979225, 0.017483, 2.764647),
'position_group_14': (-0.336, 0.290, -0.066, 0.244628, 0.963147, -0.111827, 2.740450),
}
position_num = 15
position_dims = 7
TARGETS = []
for i in range(position_num):
TARGETS.append(np.array(LABELS['position_group_'+str(i)], dtype=np.float32))
TARGETS = np.stack(TARGETS, axis=0)
t_factors = np.array([10.0, 10.0, 100.0, 10.0, 1.0, 100.0, 1.0], dtype=np.float32)
TARGETS_FAC = TARGETS * t_factors[np.newaxis, :]
KEYS = {
'c1': 0,
'd2': 1,
'e1': 2,
'f1': 3,
'g1': 4,
'a1': 5,
'b1': 6,
'c2': 7,
'd2': 8,
'e2': 9,
'f2': 10,
'g2': 11,
'a2': 12,
'b2': 13,
'c3': 14,
'd3': 15,
'e3': 16
}
finger_num = 3
finger_pop_num = 10
key_num = 17
key_pop_num = 5
def creat_key_finger_emb():
key_value = np.zeros((key_num, key_num*key_pop_num), dtype=np.float32)
finger_value = np.zeros((finger_num, finger_num*finger_pop_num), dtype=np.float32)
for i in range(key_num):
key_value[i, i*key_pop_num: (i+1)*key_pop_num] += 1.0
for i in range(finger_num):
finger_value[i, i*finger_pop_num: (i+1)*finger_pop_num] += 1.0
return (key_value, finger_value)
def mse_loss(pred, target):
mse = F.mse_loss(pred, target)
def main():
key_embs, finger_emb = creat_key_finger_emb()
in_dims = key_embs.shape[1] + finger_emb.shape[1]
model = Motion(in_dims=in_dims, out_dims=position_dims, time_window=args.time_window).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)
criterion = nn.MSELoss().to(device)
T = 100
batch_size = 32
EPOCHS = 200
with open(args.log_path, 'a+') as f:
argsDict = args.__dict__
f.writelines('------------------ start ------------------' + '\n')
for eachArg, value in argsDict.items():
f.writelines(eachArg + ' : ' + str(value) + '\n')
f.writelines('------------------- end -------------------'+ '\n')
for epoch in range(EPOCHS):
# train
for step in tqdm.tqdm(range(T)):
key_idxs = np.random.choice(key_num, size=batch_size)
finger_idxs = np.random.choice(finger_num, size=batch_size)
labels = np.clip(key_idxs - finger_idxs, a_min=0, a_max=position_num-1)
in_emb = np.concatenate([key_embs[key_idxs], finger_emb[finger_idxs]], axis=-1)
x = torch.from_numpy(in_emb).to(device)
y = torch.from_numpy(TARGETS_FAC[labels]).to(device)
y_pred = model(x)
loss = criterion(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# test
loss_record = []
f.writelines('\n')
f.writelines('Epoch:[{epoch}/{total_eps}]:\n'.format(epoch=epoch, total_eps=EPOCHS))
for key in range(key_num):
for fin in range(finger_num):
in_emb = np.concatenate([key_embs[key], finger_emb[fin]], axis=-1)
x = torch.from_numpy(in_emb).to(device)
with torch.no_grad():
pred = model(x)
y = max(min(key - fin, position_num-1), 0)
target = torch.from_numpy(TARGETS_FAC[y]).to(device)
loss = F.mse_loss(pred, target, reduction='sum')
loss_record.append(loss.cpu().item())
real_pred = pred.cpu().numpy() / t_factors
distant = np.sum((TARGETS[y] - real_pred)**2)**0.5
f.writelines(' Predict position {y}: {pred}\n'.format(y=y, pred=real_pred.tolist()))
f.writelines('==> Epoch:[{epoch}/{total_eps}][validation stage]: loss: {loss}, distant {dis}\n'.format(
epoch=epoch, total_eps=EPOCHS, loss=sum(loss_record)/len(loss_record), dis=distant))
print('==> Epoch:[{epoch}/{total_eps}][validation stage]: loss: {loss}, distant {dis}\n'.format(
epoch=epoch, total_eps=EPOCHS, loss=sum(loss_record)/len(loss_record), dis=distant))
if __name__ == '__main__':
main()
================================================
FILE: examples/MotorControl/experimental/model.py
================================================
import torch
import numpy as np
import torch.nn as nn
from brain_area import Celebellum, MotorCortex
class Motion(nn.Module):
def __init__(self, in_dims: int, out_dims: int=17, time_window: int=8, emb_size: int = 128) -> None:
super().__init__()
self._time_window = time_window
self.in_emb = nn.Linear(in_dims, emb_size)
self.motor_cotex = MotorCortex(input_dims=emb_size, out_dims=64, time_window=self._time_window)
self.cele = Celebellum(input_dims=64, out_dims=out_dims, time_window=self._time_window)
# self.opti = torch.optim.Adam(net.parameters(), lr=0.001)
def forward(self, x):
in_emb = self.in_emb(x)
motor_out = self.motor_cotex(in_emb)
out = self.cele(motor_out)
return out
def learn(self):
pass
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/README.md
================================================
# Corticothalamic minicolumn
## Description
The anatomical data is saved in the "tool" package. The **main.py** create the network of minicolumn deppending on the anatomical data.
A file named **"fire.csv"** will be generated to record the firing result of neurons in each time step.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
```shell
python main.py
```
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/data/__init__.py
================================================
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/data/globaldata.py
================================================
'''
Created on 2014.11.25
@author: Liang Qian
'''
#from tools import dbconnection as DB
from tools import exdata as Data
data = Data.EXDATA()
curneuronindex = 0
SynapseNumberPerDendrite = 40
ProximalDendriteNumerPerNeuron = 1
f = open('fire.csv','w')
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/main.py
================================================
import sys
sys.path.append("../")
import time
from model import cortex_thalamus
if __name__ == '__main__':
starttime = time.time()
myCortex = cortex_thalamus.Cortex_Thalamus(1000) # create a cortex object and specify the neuron number scale
myCortex.CreateCortexNetwork() # create cortex-thalamus network by the cortical object
myCortex.run()
print(len(myCortex.synapse))
totaltime = (time.time() - starttime)
print("totaltime:" + str(totaltime) + "s")
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/__init__.py
================================================
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/cortex.py
================================================
'''
Created on 2015.5.27
@author: Liang Qian
'''
from data import globaldata as Global
from .layer import Layer
from .synapse import Synapse
class Cortex():
'''
This class defines properties and funtions of cortex
'''
def __init__(self,neuronnumscale):
'''
Constructor
'''
self.neuronnumscale = neuronnumscale
self.neuronsNumber = 0
self.synapsesNumber = 0
self.neurons = [] # a list storing all neurons of the whole cortex
self.layers = {} # a dictionary storing layers of cortex
self.synapses = [] # a list storing all synapses of the whole cortex
self.minicolumns = [] # a list storing information per mini-column
self.neurontoindex = {} # a dictionary storing name to index of neuronlist
self.totaldata = Global.data.getCortexData()
def setNeuronToIndex(self,node):
name = node.name
if(self.neurontoindex.get(name) == None):
self.neurontoindex[name] = len(self.neurons) - 1
def setLayers(self):
layerdic = Global.data.getLayerData()
for i,info in layerdic.items():
layer = Layer()
layer.name = info.get('name')
layer.neuronnum = self.neuronnumscale * float(info.get('neuronnum'))/100
print(layer.name + ' neuron number:'+str(layer.neuronnum))
# layer.synapsenum = self.synapsenum * info.get('synapsenum')
# print(layer.name + ' synapse number:'+str(layer.synapsenum))
self.layers[layer.name] = layer
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/cortex_thalamus.py
================================================
'''
Created on 2014.11.13
@author: Liang Qian
'''
import sys
from .dendrite import Dendrite
sys.path.append('../')
from data import globaldata as Global
from .thalamus import Thalamus
from .cortex import Cortex
from .layer import Layer
from .synapse import Synapse
from braincog.base.node.node import *
class Cortex_Thalamus():
'''
cortex class is used to build human brain cortex
members are as follows:
@param neuronnum: total neuron number
@param layer: layer list
at the aspect of coding or algorithm,cortex is a huge Graph,neurons can be seen as nodes,synapses can be seen as edges,
but there may be plenty of edges between any two given nodes,so we can not use the to express an edge,
the edge should be defined as an object,if we use adjacency list to store this huge graph,the form is just like
node->map(node,list)->(map(another node,list))
'''
def __init__(self, neuronnumscale):
self.neuronnumscale = neuronnumscale
self.cortex = Cortex(neuronnumscale)
self.thalamus = Thalamus()
self.minicolumns = [] # a list storing information per mini-column
self.synapsenum = 0
self.neuronname = [] # a list storing neuron name in all cortex
self.neuron = [] # a list storing all neuron in cortex
self.synapse = [] # a list storing all synapses in thalamocortex
self.neurontoindex = {} # a dictionary to storing the neuron mapping to index in neuron list
self.totaldata = Global.data.getCortexData()
def setSynapseNum(self):
num = 0
for name,info in self.totaldata.items():
num += self.neuronnumscale * (info.get('synnum')*info.get('neunum')/100.0)
self.neuronname.append(info.get('neuronname'))
self.synapsenum = num
def setLayer(self):
layerdic = Global.data.getLayerData()
for i,info in layerdic.items():
layer = Layer()
layer.name = info.get('name')
layer.neuronnum = self.neuronnumscale * info.get('neuronnum')/100
print(layer.name + ' neuron number:'+str(layer.neuronnum))
layer.synapsenum = self.synapsenum * info.get('synapsenum')
print(layer.name + ' synapse number:'+str(layer.synapsenum))
self.layer[layer.name] = layer
def setNeuronsDendritesAndSynapes(self):
neurondic = Global.data.getNeuronData()
index = 0
for s in self.neuronname:
neuroninfo = neurondic.get(s)
self.neurontoindex[s] = len(self.neuron)
num = self.neuronnumscale * float(neuroninfo.get('percent'))/100.0
#using synapse numbers to compute dendrites numbers
synapsedic = Global.data.getSynapseData(s)
dendic = {}
totaldennum = 0
for r,item in synapsedic.items():
synum = int(item.get('synapsenum'))
dennum = (synum+Global.SynapseNumberPerDendrite-1)//Global.SynapseNumberPerDendrite # a dendrite contains no more than 40 synapses
loc = item.get('locationlayer')
dendic[loc] = dennum
for i in range(int(num)):
#init
node = CTIzhNode(morphology = neuroninfo.get('morphology'),
name = neuroninfo.get('name'),
excitability = neuroninfo.get('excitability'),
spiketype = neuroninfo.get('spiketype'),
synnum = synum,
locationlayer = neuroninfo.get('location layer'),
totalindex = index,
Gup = float(neuroninfo.get('Gup')),
Gdown = float(neuroninfo.get('Gdown')),
Vr = float(neuroninfo.get('Vr')),
Vt = float(neuroninfo.get('Vt')),
Vpeak = float(neuroninfo.get('Vpeak')),
a = float(neuroninfo.get('a')),
b = float(neuroninfo.get('b')),
c = float(neuroninfo.get('Csoma')),
d = float(neuroninfo.get('d')),
capacitance = float(neuroninfo.get('capacitance')),
k = float(neuroninfo.get('k')),
)
# set dendrites
count = 0; flag = False
for dlocatelayer,dnum in dendic.items():
for j in range(dnum):
den = Dendrite()
den.locationlayer = dlocatelayer
if(dlocatelayer != node.locationlayer or flag):
den.postion = 'distal'
node.distal_dendrites.append(den)
else:
if(count < Global.ProximalDendriteNumerPerNeuron):
den.postion = 'proximal'
node.proximal_dendrites.append(den)
count += 1
if(count >= Global.ProximalDendriteNumerPerNeuron):
flag = True
#node.getDendritesInfo()
if(node.locationlayer == 'T'):
self.thalamus.neuronsNumber += 1
self.thalamus.neurons.append(node)
self.thalamus.setNeuronToIndex(node)
else:
self.cortex.neuronsNumber += 1
self.cortex.neurons.append(node)
self.cortex.setNeuronToIndex(node)
la = self.cortex.layers.get(node.locationlayer)
la.neuronlist.append(node)
if node.name not in la.neuronname:
la.neuronname.append(node.name)
self.neuron.append(node)
index += 1
# set synapses
for postindex,node in enumerate(self.neuron): # this step can be optimized
synapsedic = Global.data.getSynapseData(node.name)
# get synapse_pre neuron and relative numbers of synapses
count = 0
for r,item in synapsedic.items():
#print(item)
for s in self.neuronname:
#print("pre_neuron_name:"+s)
totalsynapsenum = round(item.get('synapsenum') * item.get(s)/100.0)
if(postindex == 0):count += totalsynapsenum
#print("pre_neuron_name_synapse_num:"+str(totalsynapsenum))
if(totalsynapsenum > 0): #if this neuron connect to synapse_pre neuron s,distribute the synapse to these neurons
info = self.totaldata.get(s)
preneuronnum = round(self.neuronnumscale * int(info.get('neunum'))/100)
#print("pre_neuron_name_number:" + str(preneuronnum))
avgnum = lastnum = 0
if(preneuronnum == 1):
avgnum = lastnum = totalsynapsenum
else:
avgnum = totalsynapsenum // (preneuronnum-1)
lastnum = totalsynapsenum - (avgnum*(preneuronnum-1))
preneuronindex = self.neurontoindex.get(s)
for j in range(preneuronindex,preneuronindex+preneuronnum):
if(j == postindex):lastnum += avgnum;continue # not connect to itself
preneuron = self.neuron[j]
synapselist = []
if(preneuron.adjneuronlist.get(node) != None):
synapselist = preneuron.adjneuronlist.get(node)
if(j == preneuronindex+preneuronnum-1): #the last neuron
for t in range(lastnum):
synapse = Synapse(self.neuron[j],node,item.get('locationlayer'))
synapselist.append(synapse)
self.synapse.append(synapse)
if(item.get('locationlayer') != 'T'):
layerinfo = self.cortex.layers.get(item.get('locationlayer'))
layerinfo.synapselist.append(synapse)
if(node.locationlayer == 'T'):
self.thalamus.synapses.append(synapse)
self.thalamus.synapsesNumber += 1
else:
self.cortex.synapses.append(synapse)
self.cortex.synapsesNumber += 1
else:
for t in range(avgnum):
synapse = Synapse(self.neuron[j],node,item.get('locationlayer'))
synapselist.append(synapse)
self.synapse.append(synapse)
if(item.get('locationlayer') != 'T'):
layerinfo = self.cortex.layers.get(item.get('locationlayer'))
layerinfo.synapselist.append(synapse)
if(node.locationlayer == 'T'):
self.thalamus.synapses.append(synapse)
self.thalamus.synapsesNumber += 1
else:
self.cortex.synapses.append(synapse)
self.cortex.synapsesNumber += 1
if(preneuron.adjneuronlist.get(node) == None and len(synapselist) > 0):
preneuron.adjneuronlist[node] = synapselist
# set these synapses to dendrite list
#self.setSynapsesToDendrites()
def setSynapsesToDendrites(self):
for node in self.neuron:
if node.name == 'TCs': # synapses from TCs to ss4(L4) must be located in proximal dendrites of ss4(L4)
for post,synlist in node.adjneuronlist.items():
if(post.name == 'ss4(L4)'):
for syn in synlist:
flag = post.addSynapseToDendrite('proximal',syn)
if(not flag):flag = post.addSynapseToDendrite('distal',syn)
if(not flag):
print('all dendrites are full in neuron' + post.name + '_'+str(node.totalindex))
else:
for syn in synlist:
flag = False
if(post.locationlayer == syn.locationlayer):
flag = post.addSynapseToDendrite('proximal',syn)
if(not flag):
flag = post.addSynapseToDendrite('distal',syn)
else:
flag = post.addSynapseToDendrite('distal',syn)
if(not flag): print('all dendrites are full in neuron' + post.name + '_'+str(node.totalindex))
else:
for post,synlist in node.adjneuronlist.items():
for syn in synlist:
flag = False
if(post.locationlayer == syn.locationlayer):
flag = post.addSynapseToDendrite('proximal',syn)
if(not flag):
flag = post.addSynapseToDendrite('distal',syn)
if(not flag): print('all dendrites are full in neuron' + node.name + '_'+str(node.totalindex))
# f = open('dendrites_info.csv','w')
# for node in self.neuron:
# if(node.totalindex == 0):
# node.getDendriteSynapsesInfo(f)
# f.close()
def setCortexProperties(self):
self.cortex.setCortexProperties()
def setThalamusProperties(self):
self.thalamus.setThalamusProperties()
def CreateCortexNetwork(self):
self.setSynapseNum()
self.cortex.setLayers()
self.setNeuronsDendritesAndSynapes()
self.setThalamusProperties()
#----------API Of the whole network--------------#
def getTotalNeuronNumber(self):
return len(self.neuron)
def getTotalSynapseNumber(self):
return len(self.synapse)
def getCortexNeuronNumber(self):
return self.corticalneuronnumber
def getThalamoNeuronNumber(self):
return self.thamlamoneuronnumber
def getSpecifiedNeuronNumber(self,name):
result = {}
if name in self.neuronname:
info = self.totaldata.get(name)
num = self.neuronnumscale * info.get('neunum')/100
result[name] = num
elif name == 'all':
for r,info in self.totaldata.items():
num = self.neuronnumscale * info.get('neunum')
result[r] = num
return result
def getNeuronTypesNumber(self):
return len(self.neuronname)
def getNeuronTypes(self):
return self.neuronname
def getCorticalSynapseNumber(self):
return len(self.corticalsynapse)
def getThalamoSynapseNumber(self):
return len(self.corticalsynapse)
def getPreAndPostNeuronsOfSynapse(self,index):
if(index >= 0 or index <= len(self.synapse -1)):
return self.synapse[index].pre,self.synapse[index].post
else: return None
#--------------API of the layer----------------------#
def getCortexLayerNeuronNumber(self,layername):
layerinfo = self.layer.get(layername)
return layerinfo.getLayerNeuronNumber()
def getCortexLayerSynapseNumber(self,layername):
layerinfo = self.layer.get(layername)
return layerinfo.getLayerSynapseNumber()
def getCortexLayerNeuronTypes(self,layername):
layerinfo = self.layer.get(layername)
if(layerinfo == None):
print(layername +" is not in Cortex!")
return None
return layerinfo.neuronname
def getCortexLayerPreAndPostNeuronsOfSynapse(self,layername,index):
layerinfo = self.layer.get(layername)
if(index >= 0 and index < len(layerinfo.synapselist)):
return layerinfo.synapselist[index].pre, layerinfo.synapselist[index].post
def getNeuronAllPreNeuronsTypes(self,index):
if(index >= 0 and index < len(self.neuron)):
node = self.neuron[index]
return node.getWholePreSynapseNeuronType()
def outputNeuronInfo(self):
f = open('neuron.csv','w')
f.write('index,name,morphology,excitability,locationlayer\n')
for node in self.neuron:
flag = 'No'
if(node.excitability == "TRUE"):
flag = 'Yes'
f.write(str(node.totalindex)+','+node.name+','+node.morphology+','+flag+','+node.locationlayer+'\n')
f.close()
def outputConnectionMatrix(self):
M = len(self.neuron)
matrix = [[0 for col in range(M)] for row in range(M)]
for node in self.neuron:
for post,list in node.adjneuronlist.items():
weight = len(list)
row = node.totalindex
col = post.totalindex
matrix[row][col] = weight
f = open('connection.csv','w')
name = ''
for node in self.neuron:
name += node.name + ','
f.write(name+'\n')
for row in range(M):
line = ''
for col in range(M):
line += str(matrix[row][col])+','
f.write(line+'\n')
f.close()
def outputsynapspercent(self,namelist):
totalcount = 0
slist = {'L1':0,'L2/3':0,'L4':0,'L5':0,'L6':0,'T':0}
for name in namelist:
for node in self.neuron:
for pre,list in node.adjneuronlist.items():
if pre.name == name:
totalcount = totalcount+len(list)
loclayer = node.locationlayer
value = slist.get(loclayer) + len(list)
slist[loclayer] = value
print(slist)
#-----------------------runing the whole network---------------------------#
def run(self):
'''
run the cortical system
'''
#s1:stimulate the neuron in L4
L = self.cortex.layers.get('L4')
L.stimulateNeuronInLayer4_BFS(30,self.neuron)
def outputSpikeThreashold(self):
f = open('threashold.csv','w')
for node in self.neuron:
f.write(str(node.Vpeak)+'\n')
f.close()
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/dendrite.py
================================================
'''
Created on 2015.5.19
@author: liangqian
'''
import sys
import sys
from data.globaldata import *
class Dendrite():
'''
This class defines dendrite structure of a neuron.
A dendrite contains no more than 40 synapses
'''
def __init__(self):
'''
Constructor
'''
self.synapses = [] # synapses list which this dendrite contains
self.locationlayer = '' # layer this dendrite locates in
self.postion = '' # the distance from soma, proximal or distal
def setSynapse(self,syn):
'''
This function is going to insert the Synapse syn to this dendrite
if the number of synapse of this dendrite is more than theshold, the current synapse
can not be inserted to the dendrite.
'''
if(len(self.synapses) >= SynapseNumberPerDendrite):
return False
else:
self.synapses.append(syn)
return True
def getSynapseInfo(self,f,nodename,denpos):
for syns in self.synapses:
syns.getInfo(f,nodename,denpos,self.locationlayer)
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/fire.csv
================================================
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/layer.py
================================================
'''
Created on 2014.11.13.
@author: Liang Qian
'''
import sys
sys.setrecursionlimit(1000000)
from data import globaldata as Global
class Layer():
'''
layer class is used to build brain cortical layer of cortex
class members are as follows:
@param name: layer name(L1,L2,L3,.etc)
@param neuronnum: total neural numbers of this layer
@param neuraltype: neural type list of this layer
@param neuronlist: different types of neuron list in this layer
'''
def __init__(self):
self.name = ''
self.neuronnum = 0
self.synapsenum = 0
self.neuronlist = []
self.synapselist = []
self.neuronname = []
def getLayerNeuronNumber(self):
return len(self.neuronlist)
def getLayerSynapseNumber(self):
return len(self.synapselist)
def getLayerNeuronTypes(self):
return self.neuronname
def stimulateNeuronInLayer4_BFS(self, T, neulist):
for node in self.neuronlist:
if(node.name == 'ss4(L2/3)'):
break;
step = int(T*1000/1.0)
dc = 0
for i in range(step):
#print(i)
strs = str(i)+','
if(i > 1):
for n in neulist:
if(n.totalindex == node.totalindex):continue
if(n.dc > 0):
n.integral(n.dc)
n.calc_spike()
if(n.spike == 1):
strs +=n.name+':'+str(n.totalindex)+','
if(i < 10 or i > 25000):
dc = 0
else:
dc = 400
node.integral(dc)
node.calc_spike()
if(node.spike == 1):
strs +=node.name+':'+str(node.totalindex)+','
Global.f.write(strs+'\n')
Global.f.close()
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/synapse.py
================================================
'''
Created on 2014.11.13
@author: Liang Qian
'''
class Synapse():
'''
synapsis class is used to create a synapsis structure
members are as follows:
@param pre: pre-synapsis neuron
@param post: post-synapsis neuron
@param locationlayer: layer where this synapse locate in
'''
def __init__(self, pre,post,locationlayer):
self.pre = pre
self.post = post
self.locationlayer = locationlayer
self.I = 0
self.weight = 0 if(pre.name == 'p2/3' and post.name == 'p2/3') else -1
# self.tauAMPA = 5
# self.tauNMDA = 150
# self.tauGABAA = 6
# self.tauGABAB = 150
# self.STDPA_pos = 1
# self.STDPA_neg = 2
# self.tau_pos = 20
# self.tau_neg = 20
def getInfo(self,f,nodename,denpos,denlayer):
f.write('neuron:'+nodename+','+'dendrite:'+denpos+','+'den_layer:'+denlayer+','
+'syn_Layer:'+ self.locationlayer+','
+ 'pre_neuron:'+self.pre.name+','+'pre_neuron_index:'+str(self.pre.totalindex)+','
+ 'post_neuron:'+self.post.name+','+'post_neuron_index:'+str(self.post.totalindex)+','
+ 'weight:'+str(self.weight)+'\n')
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/thalamus.py
================================================
'''
Created on 2015.5.27
@author: Liang Qian
'''
class Thalamus():
'''
This class defines the basic functions and properties of thalamus
'''
def __init__(self):
'''
Constructor
'''
self.neuronsNumber = 0
self.synapsesNumber = 0
self.neurons = []
self.synapses = []
self.neurontoindex = {}
def setNeuronToIndex(self,node):
name = node.name
if(self.neurontoindex.get(name) == None):
self.neurontoindex[name] = len(self.neurons)-1
def setThalamusProperties(self):
print(len(self.synapses))
for node in self.neurons:
if(node.name == 'TCs'):
for post,synlist in node.adjneuronlist.items():
if(post.name == 'ss4(L2/3)'):
for syn in synlist:
syn.weight = 0
if(node.name == 'TCn'):
for post,synlist in node.adjneuronlist.items():
if(post.name == 'p6(L5/6)'):
for syn in synlist:
syn.weight = 0
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/tools/__init__.py
================================================
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/tools/cortical.csv
================================================
neuronname,neuronnum,synmapsenum,area
nb1,1.5,8890,cortex
p2/3,26,7106,cortex
b2/3,3.1,3854,cortex
ss4(L4),9.2,5792,cortex
ss4(L2/3),9.2,4989,cortex
p4,9.2,6703,cortex
b4,5.4,3230,cortex
nb4,1.5,3688,cortex
p5(L2/3),4.8,5196,cortex
p5(L5/6),1.3,13075,cortex
b5,0.6,2981,cortex
nb5,0.8,2981,cortex
p6(L4),13.6,6363,cortex
p6(L5/6),4.5,6421,cortex
b6,2,3220,cortex
nb6,2,3220,cortex
nb2/3,4.2,3307,cortex
TCs,0.5,4000,thalamus
TCn,0.5,4000,thalamus
TIs,0.1,3000,thalamus
TIn,0.1,3000,thalamus
TRN,0.5,4000,thalamus
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/tools/exdata.py
================================================
import os
import csv
#import pandas as pd
class EXDATA():
def __int__(self):
pass
def getCortexData(self):
neurondic = {}
f = open("./tools/cortical.csv","r")
line = f.readline()
count = 0
while(True):
line = (f.readline()).strip()
if(len(line) <= 0): break;
strs = line.split(",")
info = {}
info['neuronname'] = strs[0].strip()
info['neunum'] = float(strs[1])
info['synnum'] = int(strs[2])
info['area'] = str(strs[3])
neurondic[strs[0].strip()] = info
count += 1
f.close()
print(neurondic)
return neurondic
def getCortexData2(self):
neurondic = {}
data = pd.read_csv("../tools/cortical.csv")
print('debug')
def getLayerData(self):
layerdic = {}
f = open("./tools/layer.csv","r")
strs = (f.readline()).strip()
str = strs.split(",")
count = 0
while(True):
info = {}
line = (f.readline()).strip()
if(len(line) <= 0):break
v = line.split(",")
for i in range(len(str)):
if(i > 0):
v[i] = float(v[i])
info[str[i]] = v[i]
layerdic[count] = info
count += 1
f.close()
return layerdic
def getNeuronData(self):
neurondic = {}
f = open("./tools/neuron.csv","r")
strs = (f.readline()).strip()
str = strs.split(",")
while (True):
info = {}
line = (f.readline()).strip()
if (len(line) <= 0): break
v = line.split(",")
for i in range(len(str)):
if(len(v[i]) <= 0): break
if(i > 4): v[i] = float(v[i])
info[str[i].strip()] = v[i]
neurondic[v[0].strip()] = info
f.close()
return neurondic
def getSynapseData(self, postneuron):
synapsemap = {}
f = open("./tools/synapse.csv","r")
fields = (f.readline()).strip()
fields = fields.split(",")
while(True):
line = (f.readline()).strip()
if(len(line) <= 0):break
strs = line.split(",")
info = {}
for i,v in enumerate(fields):
if(i > 1): strs[i] = float(strs[i])
info[v] = strs[i]
if(synapsemap.get(strs[0]) == None):
syndic = {}
syndic[len(syndic)] = info
synapsemap[strs[0]] = syndic
else:
syndic = synapsemap.get(strs[0])
syndic[len(syndic)] = info
f.close()
return synapsemap.get(postneuron)
#tmp = EXDATA()
#tmp.getCortexData()
#tmp.getLayerData()
#tmp.getNeuronData()
#result = tmp.getSynapseData('p4')
#print(result)
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/tools/layer.csv
================================================
name,neuronnum,synapsenum,nb1,p2/3,b2/3,nb2/3,ss4(L4),ss4(L2/3),p4,b4,nb4,p5(L2/3),p5(L5/6),b5,nb5,p6(L5/6),b6,p6(L4),nb6
L1,1.5,10.86,1.5,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
L2/3,33.3,32.86,0,26,3.1,4.2,0,0,0,0,0,0,0,0,0,0,0,0,0
L4,34.5,34.04,0,0,0,0,9.2,9.2,9.2,5.4,1.5,0,0,0,0,0,0,0,0
L5,7.5,8.1,0,0,0,0,0,0,0,0,0,4.8,1.3,0.6,0.8,0,0,0,0
L6,22.1,14.14,0,0,0,0,0,0,0,0,0,0,0,0,0,4.5,2,13.6,2
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/tools/neuron.csv
================================================
name,morphology,location layer,spiketype,excitability,percent,capacitance,k ,Vr ,Vt ,Vpeak ,Gup,Gdown,a ,b ,Csoma,Cdendr,d
nb1,non-basket,L1,LS,FALSE,1.5,20,0.3,-66,-40,30,0.6,2.5,0.17,5,-45,-45,100
p2/3,pyramidal,L2/3,RS,TRUE,26,100,3,-60,-50,50,3,5,0.01,5,-60,-55,400
b2/3,basket,L2/3,FS,FALSE,3.1,20,1,-55,-40,25,0.5,1,0.15,8,-55,-55,200
nb2/3,non-basket,L2/3,LTS,FALSE,4.2,100,1,0,-42,40,1,1,0.03,8,-50,-50,20
ss4(L4),spiny stell,L4,RS,TRUE,9.2,100,3,-60,-50,50,3,5,0.01,5,-60,-50,400
ss4(L2/3),spiny stell,L4,RS,TRUE,9.2,100,3,-60,-50,50,3,5,0.01,5,-60,-50,400
p4,pyramidal,L4,RS,TRUE,9.2,100,3,-60,-50,50,3,5,0.01,5,-60,-50,400
b4,basket,L4,FS,FALSE,5.4,20,1,-55,-40,25,0.5,1,0.15,8,-55,-55,200
b5,basket,L5,FS,FALSE,0.6,20,1,-55,-40,25,0.5,1,0.15,8,-55,-55,200
nb4,non-basket,L4,LTS,FALSE,1.5,100,1,-55,-42,40,1,1,0.03,8,-50,-50,20
p5(L2/3),pyramidal,L5,RS,TRUE,4.8,100,3,-60,-50,50,3,5,0.01,5,-60,-50,400
nb5,non-basket,L5,LTS,FALSE,0.8,100,1,-55,-42,40,1,1,0.03,8,-50,-50,20
p5(L5/6),pyramidal,L5,RS,TRUE,1.3,100,3,-60,-50,50,3,5,0.01,5,-60,-50,400
p6(L4),pyramidal,L6,RS,TRUE,13.6,100,3,-60,-50,50,3,5,0.01,5,-60,-50,400
b6,basket,L6,FS,FALSE,2,20,1,-55,-40,25,0.5,1,0.15,8,-55,-55,200
nb6,non-basket,L6,FS,FALSE,2,100,1,0,-42,40,1,1,0.03,8,-50,-50,20
TCs,TC in specific nucleus,T,TC,TRUE,0.5,200,1.6,-60,-50,40,2,2,0.1,15,-60,-60,10
TCn,TC in non specific nucleus,T,TC,TRUE,0.5,200,1.6,-60,-50,40,2,2,0.1,15,-60,-60,10
TIs,thalamic in specific nucleus,T,TI,FALSE,0.1,20,0.5,-60,-50,20,5,5,0.05,7,-65,-65,50
TIn,thalamic in non specific nucleus,T,TI,FALSE,0.1,20,0.5,-60,-50,20,5,5,0.05,7,-65,-65,50
TRN,GABAergic,T,TRN,TRUE,0.5,40,0.25,-65,-45,0,5,5,0.015,10,-55,-55,50
p6(L5/6),pyramidal,L6,RS,TRUE,4.5,100,3,-60,-50,50,3,5,0.01,5,-60,-50,400
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/tools/synapse.csv
================================================
postneuron,locationlayer,synapsenum,nb1,p2/3,b2/3,nb2/3,ss4(L4),ss4(L2/3),p4,b4,nb4,p5(L2/3),p5(L5/6),b5,nb5,p6(L4),p6(L5/6),b6,nb6,TCs,TCn,TIs,TIn,TRN
nb1,L1,8890,10.1,6.3,0.6,1.1,0,0,0.1,0,0,0.1,0,0,0,0,0,0,0,0,4.1,0,0,0
p2/3,L2/3,5800,0,59.9,9.1,4.4,0.6,6.9,7.7,0,0.8,7.4,0,0,0,2.3,0,0,0.8,0,0,0,0,0
p2/3,L1,1306,10.2,6.3,0.1,1.1,0,0,0.1,0,0,0.1,0,0,0,0,0,0,0,0,4.1,0,0,0
b2/3,L2/3,3854,1.3,51.6,10.6,3.4,0.5,5.8,6.6,0,0.8,6.3,0,0,0,2.1,0,0,0.7,0,0.5,0,0,0
nb2/3,L2/3,3307,1.7,48.6,11.4,3.3,0.5,5.5,6.2,0,0.8,5.9,0,0,0,1.8,0,0,0.6,0,0.7,0,0,0
ss4(L4),L4,5792,0,2.7,0.2,0.6,11.9,3.7,4.1,7.1,2,0.8,0.1,0,0,32.7,0,0,5.8,1.7,1.3,0,0,0
ss4(L2/3),L4,4989,0,5.6,0.4,0.8,11.3,3.8,4.3,7.2,2.1,1.1,0.1,0,0,31.1,0,0,5.5,1.7,1.3,0,0,0
p4,L4,5031,0,4.3,0.2,0.6,11.5,3.6,4.2,7.2,2.1,1.2,0.1,0,0,31.4,0.1,0,5.9,1.7,1.3,0,0,0
p4,L2/3,866,0,63.1,5.1,4.1,0.6,7.2,8.1,0,0.6,7.8,0,0,0,2.5,0,0,0.8,0,0,0,0,0
p4,L1,806,10.2,6.3,0.1,1.1,0,0,0.1,0,0,0.1,0,0,0,0,0,0,0,0,4.1,0,0,0
b4,L4,3230,0,5.8,0.5,0.8,11,3.8,4.2,8.4,2.4,1.1,0,0,0,30.3,0,0,5.4,1.6,1.2,0,0,0
nb4,L4,3688,0,2.7,0.2,0.6,11.7,3.6,4,8.2,2.3,0.8,0.1,0,0,32.2,0,0,5.7,1.7,1.3,0,0,0
p5(L2/3),L5,4316,0,45.9,1.8,0.3,3.3,2,7.5,0,0.9,11.7,1,0.8,1.1,2.3,2.1,0,11.5,0.1,0.4,0,0,0
p5(L2/3),L4,283,0,2.8,0.1,0.7,12.2,3.8,4.2,5.2,1.5,0.8,0.1,0,0,33.7,0,0,5.9,1.8,1.4,0,0,0
p5(L2/3),L2/3,412,0,63.1,5.1,4.1,0.6,7.2,8.1,0,0.6,7.8,0,0,0,2.5,0,0,0.8,0,0,0,0,0
p5(L2/3),L1,185,10.2,6.3,0.1,1.1,0,0,0.1,0,0,0.1,0,0,0,0,0,0,0,0,4.1,0,0,0
p5(L5/6),L5,5101,0,44.3,1.7,0.2,3.2,2,7.3,0,0.8,11.3,1.2,0.8,1.1,2.3,2.5,0.3,11.3,0.2,0.5,0,0,0
p5(L5/6),L4,949,0,2.8,0.1,0.7,12.2,3.8,4.2,5.2,1.5,0.8,0.1,0,0,33.7,0,0,5.9,1.8,1.4,0,0,0
p5(L5/6),L2/3,1367,0,63.1,5.1,4.1,0.6,7.2,8.1,0,0.6,7.8,0,0,0,2.5,0,0,0.8,0,0,0,0,0
p5(L5/6),L1,5658,10.2,6.3,0.1,1.1,0,0,0.1,0,0,0.1,0,0,0,0,0,0,0,0,4.1,0,0,0
b5,L5,2981,0,45.5,2.3,0.2,3.3,2,7.5,0,1.1,11.6,1,0.9,1.3,2.3,2,0,11.4,0.1,0.4,0,0,0
nb5,L5,2981,0,45.5,2.3,0.2,3.3,2,7.5,0,1.1,11.6,1,0.9,1.3,2.3,2,0,11.4,0.1,0.4,0,0,0
p6(L4),L6,3261,0,2.5,0.1,0.1,0.7,0.9,1.3,0,0.1,0.1,4.9,0,0.3,1.2,13.2,7.7,7.7,1.6,2.9,0,0,0
p6(L4),L5,1066,0,46.8,0.8,0.3,3.4,2.1,7.7,0,0.6,11.9,1,0.6,0.8,2.3,2.1,0,11.7,0.1,0.4,0,0,0
p6(L4),L4,1915,0,2.8,0.1,0.7,12.2,3.8,4.2,5.2,1.5,0.8,0.1,0,0,33.7,0,0,5.9,1.8,1.4,0,0,0
p6(L4),L2/3,121,0,63.1,5.1,4.1,0.6,7.2,8.1,0,0.6,7.8,0,0,0,2.5,0,0,0.8,0,0,0,0,0
p6(L5/6),L6,5573,0,2.5,0.1,0.1,0.7,0.9,1.3,0,0.1,0.1,4.9,0,0.3,1.2,13.2,7.8,7.8,0,2.9,0,0,0
p6(L5/6),L5,257,0,46.8,0.8,0.3,3.4,2.1,7.7,0,0.6,11.9,1,0.6,0.8,2.3,2.1,0,11.7,0.6,0.4,0,0,0
p6(L5/6),L4,243,0,2.8,0.1,0.7,12.2,3.8,4.2,5.2,1.5,0.8,0.1,0,0,33.7,0,0,5.9,0,1.4,0,0,0
p6(L5/6),L2/3,286,0,63.1,5.1,4.1,0.6,7.2,8.1,0,0.6,7.8,0,0,0,2.5,0,0,0.8,0,0,0,0,0
p6(L5/6),L1,62,10.2,6.3,0.1,1.1,0,0,0.1,0,0,0.1,0,0,0,0,0,0,0,0,4.1,0,0,0
b6,L6,3220,0,2.5,0.1,0.1,0.7,0.9,1.3,0,0.1,0.1,4.9,0,0.4,1.2,13.2,7.7,7.7,0.6,2.9,0,0,0
nb6,L6,3220,0,2.5,0.1,0.1,0.7,0.9,1.3,0,0.1,0.1,4.9,0,0.4,1.2,13.2,7.7,7.7,0.6,2.9,0,0,0
TCs,T,4000,0,0,0,0,0,0,0,0,0,0,0,0,0,23,8,0,0,0,0,5,0,25.9
TCn,T,4000,0,0,0,0,0,0,0,0,0,14,3.8,0,0,0,13.2,0,0,0,0,0,5,25.9
TIs,T,3000,0,0,0,0,0,0,0,0,0,0,0,0,0,9.8,3.3,0,0,0.4,0,24.4,0,0
TIn,T,3000,0,0,0,0,0,0,0,0,0,5.8,1.6,0,0,0,5.4,0,0,0,0.6,0,24.4,0
TRN,T,4000,0,0,0,0,0,0,0,0,0,0,0,0,0,30,0,0,0,10,10,0,0,10
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Corticothalamic_Brain_Model/Bioinformatics_propofol_circle.py
================================================
import numpy as np
import random
import math
import matplotlib.pyplot as plt
import scipy.io as scio
import pandas as pd
import torch
device = 'cpu'
trail = 0
class brain_model_91():
def __init__(self, W, D):
self.weight_matrix = W.to(device)
# for i in range(len(self.weight_matrix)):
# self.weight_matrix[i][29] = 0
# self.weight_matrix[29][i] = 0
self.distance_matrix = D.to(device)
self.distance_matrix = torch.vstack((self.distance_matrix,
torch.mean(self.distance_matrix, dim=1)))
self.distance_matrix = torch.hstack((self.distance_matrix,
torch.zeros((len(self.distance_matrix), 1), device=device)))
temp = self.distance_matrix.clone()
self.distance_matrix[0:29, 29] = temp[29, 0:29]
# self.distance_matrix = torch.zeros_like(self.distance_matrix, device=device)
self.speed = 1.5
self.decay = torch.ceil(self.distance_matrix / self.speed)
self.t_window = int(torch.max(self.decay)) + 1
self.V_th = torch.tensor([10., 4., 10., 4., 4.], device=device)
self.tau_v = torch.tensor([40., 10., 200., 20., 40.], device=device)
self.Tsig = torch.tensor([12., 10., 12., 10., 10.], device=device)
self.beta = torch.tensor([0., 4.5, 0., 4.5, 4.5], device=device)
self.alpha_ad = torch.tensor([0., -2., 0., -2., -2.], device=device)
self.tau_ad = 20
self.tau_I = 10
# Simulation parameters
self.NR = len(W)
self.NN = 500
self.NType = self.NN * torch.tensor([0.79, 0.20, 0.01, 0.005, 0.002], device=device)
self.NE = int(self.NType[0])
self.NI = int(self.NType[1])
self.NTC = int(self.NR * self.NType[2])
self.NTI = int(self.NR * self.NType[3])
self.NTRN = int(self.NR * self.NType[4])
self.NC = self.NE + self.NI
self.NSum = int((self.NR - 1) * (self.NE + self.NI) + self.NTC + self.NTI + self.NTRN)
self.Ncycle = 1
self.dt = 1
self.T = 20000
self.Delta_T = 0.5
# self.refrac = 5 / self.dt
# self.ref = self.refrac*torch.zeros((self.NN, 1)).squeeze(1)
self.gamma_c = 0.1
self.g_m = 1
self.Gama_c = self.g_m * self.gamma_c / (1 - self.gamma_c)
self.GammaII = 15
self.GammaIE = -10
self.GammaEE = 15
self.GammaEI = 15
self.TEmean = 0.5 * self.V_th[0] # Mean current to excitatory neurons
self.TTCmean = 0.5 * self.V_th[2] # Mean current to TC neurons
self.TImean = -5 * self.V_th[1]
self.TTImean = -5 * self.V_th[3]
self.TTRNmean = -5 * self.V_th[4]
self.v = torch.zeros(self.NSum, device=device)
self.vt = torch.zeros(self.NSum, device=device)
self.c_m = torch.zeros(self.NSum, device=device)
self.alpha_w = torch.zeros(self.NSum, device=device)
self.beta_ad = torch.zeros(self.NSum, device=device)
self.delta = torch.ones(self.NSum, device=device)
self.ad = torch.zeros(self.NSum, device=device)
self.vv = torch.zeros(self.NSum, device=device)
self.Iback = torch.zeros(self.NSum, device=device)
self.Ieff = torch.zeros(self.NSum, device=device)
self.Nmean = torch.zeros(self.NSum, device=device)
self.Nsig = torch.zeros(self.NSum, device=device)
self.Igap = torch.zeros(self.NSum, device=device)
self.Ichem = torch.zeros(self.NSum, device=device)
self.Ieeg = torch.zeros(self.NSum, device=device)
self.vm1 = torch.zeros(self.NSum, device=device)
self.E_range = []
self.I_range = []
self.TC_range = []
self.TI_range = []
self.TRN_range = []
self.divide_point_E = []
self.divide_point_I = []
for n in range(self.NR):
if n < self.NR - 1:
self.divide_point_E.append(list(range(n * self.NC, n * self.NC + self.NE)))
self.divide_point_I.append(list(range(n * self.NC + self.NE, n * self.NC + self.NE + self.NI)))
self.E_range = self.E_range + list(range(n * self.NC, n * self.NC + self.NE))
self.I_range = self.I_range + list(
range(n * self.NC + self.NE, n * self.NC + self.NE + self.NI))
else:
self.TC_range = self.TC_range + list(range((self.NR - 1) * self.NC,
(self.NR - 1) * self.NC + self.NTC))
self.TI_range = self.TI_range + list(range((self.NR - 1) * self.NC + self.NTC,
(self.NR - 1) * self.NC + self.NTC + self.NTI))
self.TRN_range = self.TRN_range + list(range((self.NR - 1) * self.NC + self.NTC + self.NTI,
(self.NR - 1) * self.NC + self.NTC + self.NTI + self.NTRN))
self.divide_point_E = torch.tensor(self.divide_point_E, device=device)
self.divide_point_I = torch.tensor(self.divide_point_I, device=device)
self.divide_point_CR = torch.concat((self.divide_point_E, self.divide_point_I), dim=1)
torch.save({'divide_point_E': self.divide_point_E, 'divide_point_I': self.divide_point_I,
'TC_range': self.TC_range, 'TI_range': self.TI_range, 'TRN_range': self.TRN_range},
'./neuron_divide.pt')
self.c_m[self.E_range] = self.tau_v[0] * self.g_m + 5 * torch.randn(len(self.E_range), device=device)
self.c_m[self.TC_range] = self.tau_v[2] * self.g_m
self.c_m[self.I_range] = self.tau_v[1] * (self.g_m + self.Gama_c)
self.c_m[self.TI_range] = self.tau_v[3] * (self.g_m + self.Gama_c)
self.c_m[self.TRN_range] = self.tau_v[4] * (self.g_m + self.Gama_c)
self.alpha_w[self.E_range] = self.alpha_ad[0] * self.g_m
self.alpha_w[self.TC_range] = self.alpha_ad[2] * self.g_m + self.Gama_c
self.alpha_w[self.I_range] = self.alpha_ad[1] * (self.g_m + self.Gama_c)
self.alpha_w[self.TI_range] = self.alpha_ad[3] * (self.g_m + self.Gama_c)
self.alpha_w[self.TRN_range] = self.alpha_ad[4] * (self.g_m + self.Gama_c)
self.beta_ad[self.E_range] = self.beta[0]
self.beta_ad[self.TC_range] = self.beta[2]
self.beta_ad[self.I_range] = self.beta[1]
self.beta_ad[self.TI_range] = self.beta[3]
self.beta_ad[self.TRN_range] = self.beta[4]
self.vt[self.E_range] = self.V_th[0]
self.vt[self.TC_range] = self.V_th[2]
self.vt[self.I_range] = self.V_th[1]
self.vt[self.TI_range] = self.V_th[3]
self.vt[self.TRN_range] = self.V_th[4]
self.Nmean[self.E_range] = self.TEmean * self.g_m
self.Nmean[self.TC_range] = self.TTCmean * self.g_m
self.Nmean[self.I_range] = self.TImean * (self.g_m + self.Gama_c)
self.Nmean[self.TI_range] = self.TTImean * (self.g_m + self.Gama_c)
self.Nmean[self.TRN_range] = self.TTRNmean * (self.g_m + self.Gama_c)
self.Nsig[self.E_range] = self.Tsig[0] * self.g_m
self.Nsig[self.TC_range] = self.Tsig[2] * self.g_m
self.Nsig[self.I_range] = self.Tsig[1] * (self.g_m + self.Gama_c)
self.Nsig[self.TI_range] = self.Tsig[3] * (self.g_m + self.Gama_c)
self.Nsig[self.TRN_range] = self.Tsig[4] * (self.g_m + self.Gama_c)
def simulation(self):
range_E = self.E_range + self.TC_range
range_I = self.I_range + self.TI_range + self.TRN_range
Vgap = self.Gama_c
weight_matrix = self.weight_matrix
for i in range(self.Ncycle):
I_total = torch.zeros((self.Ncycle, self.T), device=device)
V_total = torch.zeros((self.Ncycle, self.T), device=device)
V = torch.zeros(self.T, device=device)
I_subregion = torch.zeros((self.NR, self.T), device=device)
I_subregion_E = torch.zeros((self.NR, self.T), device=device)
I_subregion_I = torch.zeros((self.NR, self.T), device=device)
Vsubregion = torch.zeros((self.NR, self.T), device=device)
EEG = torch.zeros((self.T), device=device)
Iraster = []
vv_sumE = torch.zeros((self.NR, self.t_window), device=device)
vv_sumI = torch.zeros((self.NR, self.t_window), device=device)
phase = self.T / 4
for t in range(self.T):
#
if t < phase:
tau_vI = 20
self.GammaII = 15
self.GammaIE = -10
elif phase <= t < 3 * phase:
tau_vI = 20 + 20 * (t - phase) / phase
self.GammaII = 30 + 10 * (t - phase) / phase
self.GammaIE = -20 - 10 * (t - phase) / phase
elif 3 * phase <= t < 4 * phase:
tau_vI = 60
self.GammaII = 50
self.GammaIE = -40
elif 4 * phase <= t < 6 * phase:
tau_vI = 60 - 20 * (t - 4 * phase) / phase
self.GammaII = 50 - 10 * (t - 4 * phase) / phase
self.GammaIE = -40 + 20 * (t - 4 * phase) / phase
elif t > 6 * phase:
tau_vI = 20
self.GammaII = 15
self.GammaIE = -10
self.c_m[range_I] = tau_vI * (self.g_m + self.Gama_c)
WII = self.GammaII * torch.mean(self.c_m[self.I_range])
WEE = self.GammaEE * torch.mean(self.c_m[self.E_range])
WEI = self.GammaEI * torch.mean(self.c_m[self.I_range])
WIE = self.GammaIE * torch.mean(self.c_m[self.E_range])
self.Iback = self.Iback + self.dt / self.tau_I * (-self.Iback + torch.randn(self.NSum, device=device))
self.Ieff = self.Iback / math.sqrt(1 / (2 * (self.tau_I / self.dt))) * self.Nsig + self.Nmean
temp = vv_sumE.clone()
vv_sumE[:, 0:self.t_window - 1] = temp[:, 1:self.t_window]
vv_sumE[:, self.t_window - 1] = torch.cat((torch.mean(self.vv[self.divide_point_E], dim=1),
torch.mean(self.vv[self.TC_range]).unsqueeze(0)))
temp = vv_sumI.clone()
vv_sumI[:, 0:self.t_window - 1] = temp[:, 1:self.t_window]
vv_sumI[:, self.t_window - 1] = torch.cat((torch.mean(self.vv[self.divide_point_I], dim=1),
torch.mean(self.vv[self.TI_range + self.TRN_range]).unsqueeze(0)))
v_sum = torch.cat((torch.mean(self.v[self.divide_point_I], dim=1),
torch.mean(self.v[self.TI_range + self.TRN_range]).unsqueeze(0)))
v_sum_CR = v_sum[:self.NR - 1].reshape(-1, 1) * \
torch.ones((self.NR - 1, self.NI), device=device)
v_sum_CR = v_sum_CR.reshape(-1, 1).squeeze(1)
v_sum_TN = v_sum[self.NR - 1] * \
torch.ones(self.NTI + self.NTRN, device=device)
v_sum = torch.cat((v_sum_CR, v_sum_TN))
time_decay = torch.concat(
(torch.concat([torch.arange(30, device=device).unsqueeze(0)] * 30, dim=0).unsqueeze(0),
self.t_window - 1 - self.decay.unsqueeze(0)), dim=0)
time_decay = list(time_decay.long())
v_E = torch.sum(weight_matrix * vv_sumE[time_decay], dim=1)
v_I = torch.sum(weight_matrix * vv_sumI[time_decay], dim=1)
v_E_CR = v_E[:self.NR - 1].reshape(-1, 1) * \
torch.ones((self.NR - 1, self.NC), device=device)
v_I_CR = v_I[:self.NR - 1].reshape(-1, 1) * \
torch.ones((self.NR - 1, self.NC), device=device)
v_E_CR = v_E_CR.reshape(-1, 1).squeeze(1)
v_I_CR = v_I_CR.reshape(-1, 1).squeeze(1)
v_E_TN = v_E[self.NR - 1] * \
torch.ones(self.NTC + self.NTI + self.NTRN, device=device)
v_I_TN = v_I[self.NR - 1] * \
torch.ones(self.NTC + self.NTI + self.NTRN, device=device)
v_E = torch.cat((v_E_CR, v_E_TN))
v_I = torch.cat((v_I_CR, v_I_TN))
self.Ichem[range_E] = self.Ichem[range_E] + self.dt / self.tau_I * \
(-self.Ichem[range_E] + WEE * v_E[range_E]
+ WIE * v_I[range_E])
self.Ichem[range_I] = self.Ichem[range_I] + self.dt / self.tau_I * \
(-self.Ichem[range_I] + WII * v_I[range_I]
+ WEI * v_E[range_I])
self.Igap[range_I] = Vgap * (
v_sum - self.v[range_I])
self.v = self.v + self.dt / self.c_m * (-self.g_m * self.v +
self.alpha_w * self.ad + self.Ieff + self.Ichem + self.Igap)
self.ad = self.ad + self.dt / self.tau_ad * (-self.ad + self.beta_ad * self.v)
self.vv = (self.v >= self.vt).float() * (self.vm1 < self.vt).float()
self.vm1 = self.v
Isp = torch.where(self.vv == 1)[0]
Iraster.append(torch.stack((t * torch.ones((len(Isp)), device=device), Isp), dim=1))
I_CR = torch.mean(self.Ichem[self.divide_point_CR], dim=1)
I_TN = torch.mean(self.Ichem[self.TC_range + self.TI_range + self.TRN_range]).unsqueeze(0)
I_subregion[:, t] = torch.cat((I_CR, I_TN), dim=0)
print('over')
torch.save(I_subregion.cpu(), f'./result/I_subregion_2_delay_{trail}.pt')
Iraster = torch.cat(Iraster, dim=0).cpu()
torch.save(Iraster, f'./result/raster_2_delay_{trail}.pt')
W = torch.tensor(torch.load('./FLNe.pt')['W'], dtype=torch.float32, device=device)
W = W + torch.eye(len(W), device=device)
D = torch.load('./distance.pt')
simulation_model = brain_model_91(W, D)
simulation_model.simulation()
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Corticothalamic_Brain_Model/Readme.md
================================================
The code for corticothalamic brain model. The connection matrix and simulation results are available in the follow link:
https://drive.google.com/drive/folders/1oOAb-X_ag5feV8Q09_oFZbuoEd7uxIIo?usp=sharing
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Corticothalamic_Brain_Model/spectrogram.py
================================================
import scipy.io as scio
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from mpl_toolkits.mplot3d import Axes3D
from scipy.fftpack import fft,ifft
from scipy import signal
from scipy.fft import fftshift
trail = 4
version = 2
Iraster = torch.load(f'./result/raster_{version}_delay_{trail}.pt').cpu()
time = Iraster[:, 0]
mask = (time >= 3000) & (time < 10000)
indices = torch.where(mask)
spike = Iraster[indices[0]]
plt.figure(figsize=(20, 12))
plt.scatter(spike[:, 0], spike[:, 1], s=0.1)
plt.xlabel('time [ms]', fontsize=20)
plt.ylabel('Neuron index', fontsize=20)
plt.show(dpi=600)
data = np.array(torch.load(f'./result/I_subregion_{version}_delay_{trail}.pt').cpu())
print(data.shape)
b, a = signal.butter(2, [0.002, 0.06], 'bandpass') #配置滤波器 8 表示滤波器的阶数
data = signal.filtfilt(b, a, data) #data为要过滤的信号
fs = 1000
time_window = 1024
# divide = torch.load('./neuron_divide.pt')
# divide_E = divide['divide_point_E']
# print(divide_E)
brain_map = ['2','5','24c','46d','7A','7B','7m','8B','8l',
'8m','9/46d','9/46v','10','DP','F1','F2','F5','F7',
'MT','PBr','ProM','STPc','STPi','STPr','TEO','TEpd',
'V1','V2','V4','TH']
def region_sxx(region):
# plt.figure()
# plt.plot(data[region])
# plt.show()
plt.figure(figsize=(16, 8))
f, t, sxx = signal.stft(data[region], fs=fs, nperseg=time_window, noverlap=time_window / 2)
print(sxx.shape)
cm = plt.cm.get_cmap('jet')
#plt.pcolormesh(t, f[2:10], np.abs(sxx[2:10]), cmap=cm, shading='auto')
plt.contourf(t, f[0:30], np.abs(sxx[0:30]), cmap=cm, levels=200)
plt.colorbar()
plt.xlabel('time/min', fontsize=20)
plt.ylabel('Frequency/Hz', fontsize=20)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.show()
def global_sxx():
plt.figure(figsize=(16,8))
global_eeg = np.mean(data, axis=0)
f, t, sxx = signal.stft(global_eeg, fs=fs, nperseg=time_window, noverlap=time_window / 2)
print(sxx.shape)
cm = plt.cm.get_cmap('jet')
#plt.pcolormesh(t, f[2:10], np.abs(sxx[2:10]), cmap=cm, shading='auto')
plt.contourf(t, f[0:30], np.abs(sxx[0:30]), cmap=cm, levels=200)
plt.colorbar()
plt.xlabel('time/min', fontsize=20)
plt.ylabel('Frequency/Hz', fontsize=20)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.show()
def compare_sxx():
f, t, sxx = signal.stft(data[0], fs=fs, nperseg=time_window, noverlap=time_window / 2)
f_band = range(0, 30)
sm = np.max(np.abs(sxx[f_band]), axis=0)
for col in range(1, 30):
f, t, sxx = signal.stft(data[col], fs=fs, nperseg=time_window, noverlap=time_window / 2)
sm = np.vstack((sm, np.max(np.abs(sxx[f_band]), axis=0)))
cm = plt.cm.get_cmap('jet')
plt.pcolormesh(t, brain_map, np.abs(sm), cmap=cm, shading='auto')
#plt.pcolormesh(t, f, sxx[5:50,:],cmap=cm)
plt.colorbar()
plt.ylabel('Brain Regions', fontsize=10)
plt.xlabel('Time [min]', fontsize=10)
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.show()
return np.abs(sm)
region_sxx(7)
# global_sxx()
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/HumanBrain/README.md
================================================
# Human Brain Simulation
## Description
Human Brain Simulation is a large scale brain modeling framework depending on braincog framework.
## Requirements:
* numpy >= 1.21.2
* scipy >= 1.8.0
* h5py >= 3.6.0
* torch >= 1.10
* torchvision >= 0.12.0
* torchaudio >= 0.11.0
* timm >= 0.5.4
* matplotlib >= 3.5.1
* einops >= 0.4.1
* thop >= 0.0.31
* pyyaml >= 6.0
* loris >= 0.5.3
* pandas >= 1.4.2
* tonic (special)
* pandas >= 1.4.2
## Input:
The 88 regions' connectivity matrix can be obtained from the following link:
[https://drive.google.com/file/d/1f8fpXgR8X07HrJ7G9DwMAl8K0naPcxJC/view?usp=sharing](https://drive.google.com/file/d/1tLHxCtm2kawKVvJ1BhAbkFKeyxcrJwnO/view?usp=sharing)
The source of this connectivity matrix is in the following link:
https://www.nitrc.org/frs/?group_id=432
## Example:
```shell
cd ~/examples/Multi-scale Brain Structure Simulation/HumanBrain/
python human_brain.py
```
## Parameters:
The parameters are similar to mouse brain simulation
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/HumanBrain/human_brain.py
================================================
import time
import numpy as np
import scipy.io as scio
import torch
from torch import nn
from braincog.base.node.node import *
from braincog.base.brainarea.BrainArea import *
import pandas as pd
import matplotlib.pyplot as plt
from numpy import genfromtxt
device = 'cuda:0'
class Syn(nn.Module):
def __init__(self, syn, weight, neuron_num, tao_d, tao_r, dt, device):
super().__init__()
self.pre = syn[1]
self.post = syn[0]
self.syn_num = len(syn)
self.w = torch.sparse_coo_tensor(syn.t(), weight,
size=(neuron_num, neuron_num))
self.tao_d = tao_d
self.tao_r = tao_r
self.dt = dt
self.lamda_d = self.dt / self.tao_d
self.lamda_r = self.dt / self.tao_r
self.s = torch.zeros(neuron_num, device=device)
self.r = torch.zeros(neuron_num, device=device)
self.dt = dt
def forward(self, neuron):
neuron.Iback = neuron.Iback + neuron.dt_over_tau * (
torch.randn(neuron.neuron_num, device=device, requires_grad=False) - neuron.Iback)
neuron.Ieff = neuron.Iback / neuron.sqrt_coeff * neuron.sig + neuron.mu
self.s = self.s + self.lamda_r * (-self.s + 1 / self.tao_d * neuron.spike)
self.r = self.r - self.lamda_d * self.r + self.dt * self.s
self.I = torch.sparse.mm(self.w, self.r.unsqueeze(-1)).squeeze() + neuron.Ieff
return self.I
class brain(nn.Module):
def __init__(self, syn, weight, neuron_model, p_neuron, dt, device):
super().__init__()
if neuron_model == 'HH':
self.neurons = HHNode(p_neuron, dt, device)
elif neuron_model == 'aEIF':
self.neurons = aEIF(p_neuron, dt, device)
self.neuron_num = len(p_neuron[0])
self.syns = Syn(syn, weight, self.neuron_num, 3, 6, dt, device)
def forward(self, inputs):
I = self.syns(self.neurons)
self.neurons(I)
def brain_region(neuron_num):
region = []
start = 0
end = 0
for i in range(len(neuron_num)):
end += neuron_num[i].item()
region.append([start, end])
start = end
return torch.tensor(region)
def neuron_type(neuron_num, ratio, regions):
neuron_num = neuron_num.reshape(-1, 1)
neuron_type = torch.floor(ratio * neuron_num).int() + regions[:, 0].reshape(-1, 1)
return neuron_type
def syn_within_region(syn_num, region):
start = 1
for neurons in region:
if start:
syn = torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)
start = 0
else:
syn = torch.concatenate((syn, torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)))
return syn
def syn_cross_region(weight_matrix, region):
start = 1
for i in range(len(weight_matrix)):
for j in range(len(weight_matrix)):
if weight_matrix[i][j] < 10:
continue
else:
pre = torch.randint(region[j][0], region[j][1],
size=(weight_matrix[i][j], 1), device=device)
post = torch.randint(region[i][0], region[i][1],
size=(weight_matrix[i][j], 1), device=device)
if start:
syn = torch.concatenate((post, pre), dim=1)
start = 0
else:
syn = torch.concatenate((syn, torch.concatenate((post, pre), dim=1)))
return syn
size = 500
neuron_model = 'HH'
weight_matrix = np.load('./IIT_connectivity_matrix.npy')
weight_matrix = torch.from_numpy(weight_matrix)
NR = len(weight_matrix)
data = size * np.ones(NR)
neuron_num = np.array(data).astype(np.int32)
neuron_num = torch.from_numpy(neuron_num)
regions = brain_region(neuron_num)
ratio = torch.tensor([[0.7, 0.9, 1.0] * NR]).reshape(NR, 3)
neuron_types = neuron_type(neuron_num, ratio, regions)
syn_1 = syn_within_region(10, regions)
syn_2 = syn_cross_region(weight_matrix, regions)
syn = torch.concatenate((syn_1, syn_2))
print(syn.shape)
weight = -torch.ones(len(syn), device=device, requires_grad=False)
if neuron_model == 'aEIF':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
v_reset = torch.zeros(regions[-1][1], device=device, requires_grad=False)
c_m = torch.zeros(regions[-1][1], device=device, requires_grad=False)
tao_w = torch.zeros(regions[-1][1], device=device, requires_grad=False)
alpha_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
beta_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
elif neuron_model == 'HH':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
for i in range(len(neuron_types)):
pre = syn[:, 0]
mask = (pre >= regions[i][0]) & (pre < neuron_types[i][0])
indices = torch.where(mask)
weight[indices] = 1.5
if neuron_model == 'aEIF':
if i < 177:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -44
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -110
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -110
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -66
c_m[regions[i][0]:neuron_types[i][0]] = 10
c_m[neuron_types[i][0]:neuron_types[i][1]] = 10
c_m[neuron_types[i][1]:neuron_types[i][2]] = 8.5
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
else:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -50
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -60
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -60
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -65
c_m[regions[i][0]:neuron_types[i][0]] = 20
c_m[neuron_types[i][0]:neuron_types[i][1]] = 2
c_m[neuron_types[i][1]:neuron_types[i][2]] = 4
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
elif neuron_model == 'HH':
threshold[regions[i][0]:neuron_types[i][0]] = 50
threshold[neuron_types[i][0]:neuron_types[i][1]] = 60
threshold[neuron_types[i][1]:neuron_types[i][2]] = 60
if neuron_model == 'aEIF':
p_neuron = [threshold, v_reset, c_m, tao_w, alpha_ad, beta_ad]
dt = 1
T = 300
elif neuron_model == 'HH':
p_neuron = [threshold, 120, 36, 0.3, 115, -12, 10.6, 1]
dt = 0.01
T = 10000
model = brain(syn, weight, neuron_model, p_neuron, dt, device)
Iraster = []
for t in range(T):
model(0)
print(torch.sum(model.neurons.spike))
Isp = torch.nonzero(model.neurons.spike)
print(len(Isp))
if (len(Isp) != 0):
left = t * torch.ones((len(Isp)), device=device, requires_grad=False)
left = left.reshape(len(left), 1)
mide = torch.concatenate((left, Isp), dim=1)
if (len(Isp) != 0) and (len(Iraster) != 0):
Iraster = torch.concatenate((Iraster, mide), dim=0)
if (len(Iraster) == 0) and (len(Isp) != 0):
Iraster = mide
Iraster = torch.tensor(Iraster).transpose(0, 1)
torch.save(Iraster, "./human.pt")
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/HumanBrain/human_multi.py
================================================
import time
import numpy as np
import scipy.io as scio
import torch
from torch import nn
from braincog.base.node.node import *
from braincog.base.brainarea.BrainArea import *
import pandas as pd
import matplotlib.pyplot as plt
from numpy import genfromtxt
device_ids = [0,2,3,4,5,7,8,9]
device = 'cuda:0'
class MultiCompartmentaEIF(BaseNode):
"""
双房室神经元模型
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param tau: 胞体膜电位时间常数, 用于控制胞体膜电位衰减
:param tau_basal: 基底树突膜电位时间常数, 用于控制基地树突胞体膜电位衰减
:param tau_apical: 远端树突膜电位时间常数, 用于控制远端树突胞体膜电位衰减
:param comps: 神经元不同房室, 例如["apical", "soma"]
:param act_fun: 脉冲梯度代理函数
"""
def __init__(self,
p,
dt,
tau=2.0,
tau_basal=2.0,
tau_apical=2.0,
act_fun=AtanGrad, *args, **kwargs):
g_B = 0.6
g_L = 0.05
super().__init__(threshold=p[0], *args, **kwargs)
self.neuron_num = len(p[0])
self.tau = 2.0
self.tau_basal = 20.0
self.tau_apical = 2.0
self.spike = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.v_reset = p[1] # membrane potential reset to v_reset after fire spike
# Initialize membrane potentials
self.tau_I = 3.0
self.sig = 12.0
self.mu = 10.0
self.dt=dt
self.dt_over_tau = self.dt / self.tau_I
self.mems = {}
self.mems['soma'] = torch.ones(self.neuron_num, device=device) * self.v_reset
self.mems['apical'] = torch.ones(self.neuron_num, device=device) * self.v_reset
self.act_fun = act_fun(alpha=self.tau, requires_grad=False)
self.Iback = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.Ieff = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.sqrt_coeff = math.sqrt(1 / (2 * (1 / self.dt_over_tau)))
def integral(self,apical_inputs):
'''
Params:
inputs torch.Tensor: Inputs for basal dendrite
'''
self.mems['apical'] = (self.mems['apical'] + apical_inputs) / self.tau_apical
self.mems['soma'] = self.mems['soma'] + (self.mems['apical'] - self.mems['soma']) / self.tau
def calc_spike(self):
self.spike = self.act_fun(self.mems['soma'] - self.threshold)
self.mems['soma'] = self.mems['soma'] * (1. - self.spike.detach())
self.mems['apical'] = self.mems['apical'] * (1. - self.spike.detach())
def forward(self, inputs):
# aeifnode_cuda.forward(self.threshold, self.c_m, self.alpha_w, self.beta_ad, inputs, self.ref, self.ad, self.mem, self.spike)
self.integral(inputs)
self.calc_spike()
return self.spike, self.mems['soma']
class aEIF(BaseNode):
"""
The adaptive Exponential Integrate-and-Fire model (aEIF)
This class define the membrane, spike, current and parameters of a neuron group of a specific type
:param args: Other parameters
:param kwargs: Other parameters
"""
def __init__(self, p, dt, device, *args, **kwargs):
"""
p:[threshold, v_reset, c_m, tao_w, alpha_ad, beta_ad]
c_m: Membrane capacitance
alpha_w: Coupling of the adaptation variable
beta_ad: Conductance of the adaptation variable
mu: Mean of back current
sig: Variance of back current
if_IN: if the neuron type is inhibitory neuron, it has gap-junction
neuron_num: number of neurons in this group
W: connection weight for the neuron groups connected to this group
type_index: the index of this type of neuron group in the brain region
"""
super().__init__(threshold=p[0], requires_fp=False, *args, **kwargs)
self.neuron_num = len(p[0])
self.g_m = 0.1 # neuron conduction
self.dt = dt
self.tau_I = 3 # Time constant to filter the synaptic inputs
self.Delta_T = 0.5 # parameter
self.v_reset = p[1] # membrane potential reset to v_reset after fire spike
self.c_m = p[2]
self.tau_w = p[3] # Time constant of adaption coupling
self.alpha_ad = p[4]
self.beta_ad = p[5]
self.refrac = 5 / self.dt # refractory period
self.dt_over_tau = self.dt / self.tau_I
self.sqrt_coeff = math.sqrt(1 / (2 * (1 / self.dt_over_tau)))
self.mem = self.v_reset
self.spike = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.ad = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.ref = torch.randint(0, int(self.refrac + 1), (1, self.neuron_num), device=device, requires_grad=False).squeeze(
0) # refractory counter
self.ref = self.ref.float()
self.mu = 10
self.sig = 12
self.Iback = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.Ieff = torch.zeros(self.neuron_num, device=device, requires_grad=False)
def integral(self, inputs):
self.mem = self.mem + (self.ref > self.refrac) * self.dt / self.c_m * \
(-self.g_m * (self.mem - self.v_reset) + self.g_m * self.Delta_T *
torch.exp((self.mem - self.threshold) / self.Delta_T) +
self.alpha_ad * self.ad + inputs)
self.ad = self.ad + (self.ref > self.refrac) * self.dt / self.tau_w * \
(-self.ad + self.beta_ad * (self.mem - self.v_reset))
def calc_spike(self):
self.spike = (self.mem > self.threshold).float()
self.ref = self.ref * (1 - self.spike) + 1
self.ad = self.ad + self.spike * 30
self.mem = self.spike * self.v_reset + (1 - self.spike.detach()) * self.mem
def forward(self, inputs):
# aeifnode_cuda.forward(self.threshold, self.c_m, self.alpha_w, self.beta_ad, inputs, self.ref, self.ad, self.mem, self.spike)
self.integral(inputs)
self.calc_spike()
return self.spike, self.mem
class HHNode(BaseNode):
"""
简单版本的HH模型
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, p, dt, device, act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold=p[0], *args, **kwargs)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
'''
I = Cm dV/dt + g_k*n^4*(V_m-V_k) + g_Na*m^3*h*(V_m-V_Na) + g_l*(V_m - V_L)
'''
self.neuron_num = len(p[0])
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.tau_I = 3
self.g_Na = torch.tensor(p[1])
self.g_K = torch.tensor(p[2])
self.g_l = torch.tensor(p[3])
self.V_Na = torch.tensor(p[4])
self.V_K = torch.tensor(p[5])
self.V_l = torch.tensor(p[6])
self.C = torch.tensor(p[7])
self.m = 0.05 * torch.ones(self.neuron_num, device=device, requires_grad=False)
self.n = 0.31 * torch.ones(self.neuron_num, device=device, requires_grad=False)
self.h = 0.59 * torch.ones(self.neuron_num, device=device, requires_grad=False)
self.v_reset = 0
self.dt = dt
self.dt_over_tau = self.dt / self.tau_I
self.sqrt_coeff = math.sqrt(1 / (2 * (1 / self.dt_over_tau)))
self.mu = 10
self.sig = 12
self.mem = torch.tensor(self.v_reset, device=device, requires_grad=False)
self.mem_p = self.mem
self.spike = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.Iback = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.Ieff = torch.zeros(self.neuron_num, device=device, requires_grad=False)
def integral(self, inputs):
self.alpha_n = (0.1 - 0.01 * self.mem) / (torch.exp(1 - 0.1 * self.mem) - 1)
self.alpha_m = (2.5 - 0.1 * self.mem) / (torch.exp(2.5 - 0.1 * self.mem) - 1)
self.alpha_h = 0.07 * torch.exp(-self.mem / 20.0)
self.beta_n = 0.125 * torch.exp(-self.mem / 80.0)
self.beta_m = 4.0 * torch.exp(-self.mem / 18.0)
self.beta_h = 1 / (torch.exp(3 - 0.1 * self.mem) + 1)
self.tau_n = 1.0 / (self.alpha_n + self.beta_n)
self.inf_n = self.alpha_n * self.tau_n
self.tau_m = 1.0 / (self.alpha_m + self.beta_m)
self.inf_m = self.alpha_m * self.tau_m
self.tau_h = 1.0 / (self.alpha_h + self.beta_h)
self.inf_h = self.alpha_h * self.tau_h
self.n = (1 - self.dt / self.tau_n) * self.n + (self.dt / self.tau_n) * self.inf_n
self.m = (1 - self.dt / self.tau_m) * self.m + (self.dt / self.tau_m) * self.inf_m
self.h = (1 - self.dt / self.tau_h) * self.h + (self.dt / self.tau_h) * self.inf_h
# self.n = self.n + self.dt * (self.alpha_n * (1 - self.n) - self.beta_n * self.n)
# self.m = self.m + self.dt * (self.alpha_m * (1 - self.m) - self.beta_m * self.m)
# self.h = self.h + self.dt * (self.alpha_h * (1 - self.h) - self.beta_h * self.h)
self.I_Na = torch.pow(self.m, 3) * self.g_Na * self.h * (self.mem - self.V_Na)
self.I_K = torch.pow(self.n, 4) * self.g_K * (self.mem - self.V_K)
self.I_L = self.g_l * (self.mem - self.V_l)
self.mem_p = self.mem
self.mem = self.mem + self.dt * (inputs - self.I_Na - self.I_K - self.I_L) / self.C
# self.mem = self.mem + self.dt * (inputs - self.I_K - self.I_L) / self.C
def calc_spike(self):
self.spike = (self.threshold > self.mem_p).float() * (self.mem > self.threshold).float()
def forward(self, inputs):
self.integral(inputs)
self.calc_spike()
return self.spike, self.mem
def requires_activation(self):
return False
class Syn(nn.Module):
def __init__(self, syn, weight, neuron_num, tao_d, tao_r, dt, device):
super().__init__()
self.pre = syn[1]
self.post = syn[0]
self.syn_num = len(syn)
self.w = torch.sparse_coo_tensor(syn.t(), weight,
size=(neuron_num, neuron_num))
self.tao_d = tao_d
self.tao_r = tao_r
self.dt = dt
self.lamda_d = self.dt / self.tao_d
self.lamda_r = self.dt / self.tao_r
self.s = torch.zeros(neuron_num, device=device)
self.r = torch.zeros(neuron_num, device=device)
self.dt = dt
def forward(self, neuron):
neuron.Iback = neuron.Iback + neuron.dt_over_tau * (
torch.randn(neuron.neuron_num, device=device, requires_grad=False) - neuron.Iback)
neuron.Ieff = neuron.Iback / neuron.sqrt_coeff * neuron.sig + neuron.mu
self.s = self.s + self.lamda_r * (-self.s + 1 / self.tao_d * neuron.spike)
self.r = self.r - self.lamda_d * self.r + self.dt * self.s
self.I = torch.sparse.mm(self.w, self.r.unsqueeze(-1)).squeeze() + neuron.Ieff
return self.I
class brain(nn.Module):
def __init__(self, syn, weight, neuron_model, p_neuron, dt, device):
super().__init__()
if neuron_model == 'HH':
self.neurons = HHNode(p_neuron, dt, device)
elif neuron_model == 'aEIF':
self.neurons = aEIF(p_neuron, dt, device)
elif neuron_model == 'MultiCompartmentaEIF':
self.neurons = MultiCompartmentaEIF(p_neuron,dt,device)
self.neuron_num = len(p_neuron[0])
self.syns = Syn(syn, weight, self.neuron_num, 3.0, 6.0, dt, device)
def forward(self, inputs):
I = self.syns(self.neurons)
self.neurons(I)
def brain_region(neuron_num):
region = []
start = 0
end = 0
for i in range(len(neuron_num)):
end += neuron_num[i].item()
region.append([start, end])
start = end
return torch.tensor(region)
def neuron_type(neuron_num, ratio, regions):
neuron_num = neuron_num.reshape(-1, 1)
neuron_type = torch.floor(ratio * neuron_num).int() + regions[:, 0].reshape(-1, 1)
return neuron_type
def syn_within_region(syn_num, region):
start = 1
for neurons in region:
if start:
syn = torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)
start = 0
else:
syn = torch.concat((syn, torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)))
return syn
def syn_cross_region(weight_matrix, region):
start = 1
for i in range(len(weight_matrix)):
for j in range(len(weight_matrix)):
if weight_matrix[i][j] < 10:
continue
else:
pre = torch.randint(region[j][0], region[j][1],
size=(weight_matrix[i][j], 1), device=device)
post = torch.randint(region[i][0], region[i][1],
size=(weight_matrix[i][j], 1), device=device)
if start:
syn = torch.concat((post, pre), dim=1)
start = 0
else:
syn = torch.concat((syn, torch.concat((post, pre), dim=1)))
return syn
size = 100
neuron_model = 'MultiCompartmentaEIF'
weight_matrix = torch.from_numpy(np.load("IIT_connectivity_matrix.npy")[0:84,0:84])
weight_matrix = weight_matrix.int() * 10
# weight_matrix = np.load('./IIT_connectivity_matrix.npy')
# weight_matrix = torch.from_numpy(weight_matrix)
NR = len(weight_matrix)
data = size * np.ones(NR)
neuron_num = np.array(data).astype(np.int32)
neuron_num = torch.from_numpy(neuron_num)
print(torch.sum(neuron_num))
regions = brain_region(neuron_num)
ratio = torch.tensor([[0.7, 0.9, 1.0] * NR]).reshape(NR, 3)
neuron_types = neuron_type(neuron_num, ratio, regions)
syn_1 = syn_within_region(10, regions)
syn_2 = syn_cross_region(weight_matrix, regions)
syn = torch.concat((syn_1, syn_2))
print(len(syn_2))
print(syn.shape)
weight = -torch.ones(len(syn), device=device, requires_grad=False)
if neuron_model == 'aEIF':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
v_reset = torch.zeros(regions[-1][1], device=device, requires_grad=False)
c_m = torch.zeros(regions[-1][1], device=device, requires_grad=False)
tao_w = torch.zeros(regions[-1][1], device=device, requires_grad=False)
alpha_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
beta_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
elif neuron_model == 'HH':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
if neuron_model == 'MultiCompartmentaEIF':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
v_reset = torch.zeros(regions[-1][1], device=device, requires_grad=False)
c_m = torch.zeros(regions[-1][1], device=device, requires_grad=False)
tao_w = torch.zeros(regions[-1][1], device=device, requires_grad=False)
alpha_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
beta_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
for i in range(len(neuron_types)):
pre = syn[:, 0]
mask = (pre >= regions[i][0]) & (pre < neuron_types[i][0])
indices = torch.where(mask)
weight[indices] = 1.5
if neuron_model == 'aEIF':
if i < 70:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -44
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -110
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -110
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -110
c_m[regions[i][0]:neuron_types[i][0]] = 10
c_m[neuron_types[i][0]:neuron_types[i][1]] = 10
c_m[neuron_types[i][1]:neuron_types[i][2]] = 8.5
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
else:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -50
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -100
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -100
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -105
c_m[regions[i][0]:neuron_types[i][0]] = 20
c_m[neuron_types[i][0]:neuron_types[i][1]] = 10
c_m[neuron_types[i][1]:neuron_types[i][2]] = 10
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
elif neuron_model == 'HH':
threshold[regions[i][0]:neuron_types[i][0]] = 20
threshold[neuron_types[i][0]:neuron_types[i][1]] = 20
threshold[neuron_types[i][1]:neuron_types[i][2]] = 20
elif neuron_model == 'MultiCompartmentaEIF':
if i < 70:
threshold[regions[i][0]:neuron_types[i][0]] = -50.0
threshold[neuron_types[i][0]:neuron_types[i][1]] = -44.0
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45.0
v_reset[regions[i][0]:neuron_types[i][0]] = -110.0
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -110.0
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -110.0
c_m[regions[i][0]:neuron_types[i][0]] = 10.0
c_m[neuron_types[i][0]:neuron_types[i][1]] = 10.0
c_m[neuron_types[i][1]:neuron_types[i][2]] = 8.5
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
else:
threshold[regions[i][0]:neuron_types[i][0]] = -50.0
threshold[neuron_types[i][0]:neuron_types[i][1]] = -50.0
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45.0
v_reset[regions[i][0]:neuron_types[i][0]] = -100.0
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -100.0
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -105.0
c_m[regions[i][0]:neuron_types[i][0]] = 20
c_m[neuron_types[i][0]:neuron_types[i][1]] = 10
c_m[neuron_types[i][1]:neuron_types[i][2]] = 10
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
if neuron_model == 'aEIF':
p_neuron = [threshold, v_reset, c_m, tao_w, alpha_ad, beta_ad]
dt = 1
T = 2000
elif neuron_model == 'HH':
p_neuron = [threshold, 120, 36, 0.3, 115, -12, 10.6, 1]
dt = 0.01
T = 10000
elif neuron_model == 'MultiCompartmentaEIF':
p_neuron = [threshold, v_reset, c_m, tao_w, alpha_ad, beta_ad]
dt = 1.0
T = 2000
model = brain(syn, weight, neuron_model, p_neuron, dt, device)
# device_ids = [0,2,3,4,5,7,8,9]
# model = nn.DataParallel(model, device_ids=device_ids)
model.to(device)
def neuron_delete(model, rate):
neuron_idex = torch.arange(0, model.neuron_num)
delete_num = int(model.neuron_num * rate)
random_elements = neuron_idex[torch.randperm(model.neuron_num)[:delete_num]]
model.neurons.threshold[random_elements] = 1000
return model.neuron_num - delete_num
def syn_delete(model, rate):
indices = model.syns.w._indices()
values = model.syns.w._values()
delete_num = int(len(values) * rate)
syn_idex = torch.arange(0, len(values))
random_elements = syn_idex[torch.randperm(len(values))[:delete_num]]
new_values = values[random_elements]
new_indices = indices[:, random_elements]
new_w = torch.sparse_coo_tensor(new_indices, new_values, size=(model.neuron_num, model.neuron_num))
model.syns.w = new_w
def syn_strength(model, rate):
indices = model.syns.w._indices()
values = model.syns.w._values()
iex = torch.where(values>0)
values[iex] = values[iex] * rate
new_values = values
new_indices = indices
new_w = torch.sparse_coo_tensor(new_indices, new_values, size=(model.neuron_num, model.neuron_num))
model.syns.w = new_w
Iraster = []
fire_rate = []
count_n = model.neuron_num
for t in range(T):
if t == int(T/4):
count_n = neuron_delete(model, 0.4)
if t == int(T/4 * 2):
syn_delete(model, 0.4)
if t == int(T/4 * 3):
syn_strength(model, 3)
model(0)
# print(torch.sum(model.neurons.spike))
Isp = torch.nonzero(model.neurons.spike)
print(len(Isp))
fire_rate.append(len(Isp)/count_n)
if (len(Isp) != 0):
left = t * torch.ones((len(Isp)), device=device, requires_grad=False)
left = left.reshape(len(left), 1)
mide = torch.concat((left, Isp), dim=1)
if (len(Isp) != 0) and (len(Iraster) != 0):
Iraster = torch.concat((Iraster, mide), dim=0)
if (len(Iraster) == 0) and (len(Isp) != 0):
Iraster = mide
torch.save(fire_rate, './fire_rate.pt')
plt.plot(fire_rate)
plt.xlabel('time/mm')
plt.ylabel('fire_rate')
# plt.axvline(x=[500, 1000, 1500], color='b', linestyle='--')
plt.show()
Iraster = torch.tensor(Iraster).transpose(0, 1)
torch.save(Iraster, "./human_MultiCompartmentaEIF100.pt")
Iraster = Iraster.cpu()
plt.figure(figsize=(15, 15))
plt.scatter(Iraster[0], Iraster[1], c='k', marker='.', s=0.001)
plt.savefig('mouse_MultiCompartmentaEIF100.png')
plt.show()
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/NA.py
================================================
import numpy as np
import random
import math
import matplotlib.pyplot as plt
import matplotlib
# matplotlib.use('TkAgg')
import scipy.io as scio
import pandas as pd
import torch
import networkx as nx
from collections import defaultdict
import community as community_louvain
from matplotlib.ticker import MaxNLocator, FuncFormatter
def histogram_entropy(data, bins='auto'):
"""
使用直方图法估计一维数据的熵。
参数:
data (np.ndarray): 一维数据数组。
bins (int or str): 直方图的分箱数,默认为 'auto'。
返回:
float: 估计的熵值。
"""
hist, bin_edges = np.histogram(data, bins=bins, density=True)
bin_width = bin_edges[1] - bin_edges[0]
prob = hist * bin_width
prob = prob[prob > 0]
entropy_value = -np.sum(prob * np.log(prob))
return entropy_value
def hub_degree(df, W_new):
degree = torch.sum(W_new, dim=0)
v, ind = torch.topk(degree, 10)
ind = ind.tolist()
plt.figure(figsize=(40, 18))
plt.bar(df['Identifier'].values, degree)
plt.bar(df['Identifier'].iloc[ind].values, degree[ind], color='r', label='Top 10 Degree')
plt.gca().yaxis.set_major_locator(MaxNLocator(integer=False, prune='lower', nbins=15))
plt.xticks(rotation=90, fontsize=30)
plt.ylabel('Degree', fontsize=40)
plt.yticks(fontsize=25)
plt.legend(fontsize=40)
xticks = plt.gca().get_xticklabels()
for i, tick in enumerate(xticks):
if df['Identifier'].iloc[i] in df['Identifier'].iloc[ind].values:
tick.set_color('r')
plt.grid(axis='y')
plt.show()
def visual(df, W_new):
x = df['x'].values
y = df['y'].values
z = df['z'].values
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(x, y, z)
for i in range(len(x)):
for j in range(i + 1, len(x)):
if W_new[i, j] > 0.1:
ax.plot([x[i], x[j]],
[y[i], y[j]],
[z[i], z[j]],
'k-', lw=1)
plt.show()
if __name__ == "__main__":
W = np.load('./IIT_connectivity_matrix.npy')
W = torch.from_numpy(W).float()
W = W[0:84, 0:84]
new_order = list(range(0, 35)) + list(range(49, 84)) + list(range(35, 49))
W_new = W[new_order, :][:, new_order]
M = torch.max(W_new)
W_new = W_new / M
G = nx.from_numpy_matrix(W_new.numpy())
# Louvain
partition = community_louvain.best_partition(G)
community_groups = defaultdict(list)
for node, community in partition.items():
community_groups[community].append(node)
df = pd.read_csv('brain_regions.csv')
labels = df['Identifier'].values
# for community, nodes in community_groups.items():
# print(f"Community {community}: {nodes}")
fig, ax = plt.subplots(figsize=(20, 20))
cax = ax.imshow(W_new.cpu().numpy(), cmap='viridis')
ax.set_xticks(np.arange(len(labels)))
ax.set_yticks(np.arange(len(labels)))
ax.set_xticklabels(labels, rotation=90, fontsize=20)
ax.set_yticklabels(labels, fontsize=20)
fig.colorbar(cax, shrink=0.8)
# plt.tight_layout()
plt.show()
hub_degree(df, W_new)
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/Readme.md
================================================
main_84.py and main_246.py is the code that runs the simulation. The required data files can be obtained from the following link:
https://drive.google.com/drive/folders/14KPqJsJXIo-bCmGCuDuBadLRmaYn78J2?usp=sharing
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/gc.py
================================================
import scipy.io as scio
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import signal
import torch
import matplotlib.colors as mcolors
scale = 1.2
version = 1
EEG_m = np.array(torch.load(f'./result/I_subregion_{version}_{scale}.pt').cpu())
EEG_c1 = np.load('./dataset/data_awake_1ug.npy')
EEG_c2 = np.load('./dataset/data_2ug.npy')
EEG_c3 = np.load('./dataset/data_3ug.npy')
EEG_m = np.mean(EEG_m, axis=0)
lowcut = 3.0 # 下截止频率 (Hz)
highcut = 30.0 # 上截止频率 (Hz)
fs = 1000
# 使用 Butterworth 滤波器设计带通滤波器
# butter 函数的参数依次为:滤波器阶数,频率范围(归一化),滤波器类型
b, a = signal.butter(4, [lowcut / (0.5 * fs), highcut / (0.5 * fs)], btype='band')
# 应用滤波器(使用 filtfilt 实现零相位滤波)
EEG_m = signal.filtfilt(b, a, EEG_m)
EEG_C = EEG_c3
EEG_C = signal.filtfilt(b, a, EEG_C)
t = 80
mat_all = np.zeros((t, 30))
for j in range(64):
mat = np.zeros((t, 30))
for i in range(t):
f, Cxy = signal.csd(EEG_m[i*1000:(i+1)*1000], EEG_C[i][j], fs=fs, nperseg=1024)
mat[i] = np.abs(Cxy[:30])
mat_all += mat / np.max(mat)
plt.figure(figsize=(16,8))
norm = mcolors.LogNorm(vmin=0.001, vmax=1)
cm = plt.cm.get_cmap('jet')
plt.contourf(np.linspace(0, 8, 80) ,f[:30], mat_all.T / 64, cmap=cm, levels=200)
plt.colorbar()
plt.xlabel('time/min', fontsize=20)
plt.ylabel('Frequency/Hz', fontsize=20)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.show()
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/main_246.py
================================================
import numpy as np
import random
import math
import matplotlib.pyplot as plt
import scipy.io as scio
import pandas as pd
import torch
import tqdm
device = 'cuda:3'
trail = 5
version = 4
scale = 0.1
class brain_model():
def __init__(self, W):
self.weight_matrix = W.to(device)
self.distance_matrix = torch.zeros_like(self.weight_matrix, device=device)
self.speed = 1.5
self.decay = torch.ceil(self.distance_matrix / self.speed)
self.t_window = int(torch.max(self.decay)) + 1
self.V_th = torch.tensor([10., 4., 10., 4., 4.], device=device)
self.tau_v = torch.tensor([40., 10., 30., 20., 40.], device=device)
self.Tsig = torch.tensor([12., 10., 12., 10., 10.], device=device)
self.beta = torch.tensor([0., 4.5, 0., 4.5, 4.5], device=device)
self.alpha_ad = torch.tensor([0., -2., 0., -2., -2.], device=device)
self.tau_ad = 20
self.tau_I = 10
# Simulation parameters
self.NR = len(W)
self.C = 210
self.NN = 500
self.NType = self.NN * torch.tensor([0.80, 0.20, 0.01, 0.004, 0.004], device=device)
self.NE = 400
self.NI = 100
self.NTC = 30
self.NTI = 15
self.NTRN = 6
self.NC = self.NE + self.NI
self.NSum = int((self.C) * (self.NE + self.NI) + (self.NR - self.C) * (self.NTC + self.NTI + self.NTRN))
self.NT = self.NTC + self.NTI + self.NTRN
print(self.NSum)
print(self.NC)
print(self.NTI + self.NTC + self.NTRN)
self.Ncycle = 1
self.dt = 1
self.T = 8000
self.Delta_T = 0.5
# self.refrac = 5 / self.dt
# self.ref = self.refrac*torch.zeros((self.NN, 1)).squeeze(1)
self.gamma_c = 0.1
self.g_m = 1
self.Gama_c = self.g_m * self.gamma_c / (1 - self.gamma_c)
self.GammaII = 15
self.GammaIE = -10
self.GammaEE = 15
self.GammaEI = 15
self.TEmean = 0.5 * self.V_th[0] # Mean current to excitatory neurons
self.TTCmean = 0.5 * self.V_th[2] # Mean current to TC neurons
self.TImean = -5 * self.V_th[1]
self.TTImean = -5 * self.V_th[3]
self.TTRNmean = -5 * self.V_th[4]
self.v = torch.zeros(self.NSum, device=device)
self.vt = torch.zeros(self.NSum, device=device)
self.c_m = torch.zeros(self.NSum, device=device)
self.alpha_w = torch.zeros(self.NSum, device=device)
self.beta_ad = torch.zeros(self.NSum, device=device)
self.delta = torch.ones(self.NSum, device=device)
self.ad = torch.zeros(self.NSum, device=device)
self.vv = torch.zeros(self.NSum, device=device)
self.Iback = torch.zeros(self.NSum, device=device)
self.Istimu = torch.zeros(self.NSum, device=device) # stimulate current
self.Ieff = torch.zeros(self.NSum, device=device)
self.Nmean = torch.zeros(self.NSum, device=device)
self.Nsig = torch.zeros(self.NSum, device=device)
self.Igap = torch.zeros(self.NSum, device=device)
self.Ichem = torch.zeros(self.NSum, device=device)
self.Ieeg = torch.zeros(self.NSum, device=device)
self.vm1 = torch.zeros(self.NSum, device=device)
self.reset = torch.zeros(self.NSum, device=device)
self.E_range = []
self.I_range = []
self.TC_range = []
self.TI_range = []
self.TRN_range = []
self.divide_point_E = []
self.divide_point_I = []
self.divide_point_TC = []
self.divide_point_TI_TRN = []
for n in range(self.NR):
if n < self.C:
self.divide_point_E.append(list(range(n * self.NC, n * self.NC + self.NE)))
self.divide_point_I.append(list(range(n * self.NC + self.NE, n * self.NC + self.NE + self.NI)))
self.E_range = self.E_range + list(range(n * self.NC, n * self.NC + self.NE))
self.I_range = self.I_range + list(
range(n * self.NC + self.NE, n * self.NC + self.NE + self.NI))
else:
s = self.C * self.NC + (n-self.C) * self.NT
self.divide_point_TC.append(list(range(s, s + self.NTC)))
self.divide_point_TI_TRN.append(list(range(s + self.NTC,
s + self.NTC + self.NTI))
+ list(range(s + self.NTC + self.NTI,
s + self.NTC + self.NTI + self.NTRN)))
self.TC_range = self.TC_range + list(range(s,
s + self.NTC))
self.TI_range = self.TI_range + list(range(s + self.NTC,
s + self.NTC + self.NTI))
self.TRN_range = self.TRN_range + list(range(s + self.NTC + self.NTI,
s + self.NTC + self.NTI + self.NTRN))
self.divide_point_E = torch.tensor(self.divide_point_E, device=device)
self.divide_point_I = torch.tensor(self.divide_point_I, device=device)
self.divide_point_TC = torch.tensor(self.divide_point_TC, device=device)
self.divide_point_TI_TRN = torch.tensor(self.divide_point_TI_TRN, device=device)
self.divide_point_CR = torch.concat((self.divide_point_E, self.divide_point_I), dim=1)
self.divide_point_TN = torch.concat((self.divide_point_TC, self.divide_point_TI_TRN), dim=1)
torch.save({'divide_point_E': self.divide_point_E, 'divide_point_I': self.divide_point_I,
'TC_range': self.TC_range, 'TI_range': self.TI_range, 'TRN_range': self.TRN_range},
'./neuron_divide.pt')
self.c_m[self.E_range] = self.tau_v[0] * self.g_m + 15 * (torch.rand(size=(len(self.E_range),), device=device) - 0.5)
# self.c_m[self.E_range] = self.tau_v[0] * self.g_m
self.c_m[self.TC_range] = self.tau_v[2] * self.g_m
self.c_m[self.I_range] = self.tau_v[1] * (self.g_m + self.Gama_c)
self.c_m[self.TI_range] = self.tau_v[3] * (self.g_m + self.Gama_c)
self.c_m[self.TRN_range] = self.tau_v[4] * (self.g_m + self.Gama_c)
self.alpha_w[self.E_range] = self.alpha_ad[0] * self.g_m
self.alpha_w[self.TC_range] = self.alpha_ad[2] * self.g_m + self.Gama_c
self.alpha_w[self.I_range] = self.alpha_ad[1] * (self.g_m + self.Gama_c)
self.alpha_w[self.TI_range] = self.alpha_ad[3] * (self.g_m + self.Gama_c)
self.alpha_w[self.TRN_range] = self.alpha_ad[4] * (self.g_m + self.Gama_c)
self.beta_ad[self.E_range] = self.beta[0]
self.beta_ad[self.TC_range] = self.beta[2]
self.beta_ad[self.I_range] = self.beta[1]
self.beta_ad[self.TI_range] = self.beta[3]
self.beta_ad[self.TRN_range] = self.beta[4]
self.vt[self.E_range] = self.V_th[0]
self.vt[self.TC_range] = self.V_th[2]
self.vt[self.I_range] = self.V_th[1]
self.vt[self.TI_range] = self.V_th[3]
self.vt[self.TRN_range] = self.V_th[4]
self.reset[self.E_range] = 1
self.reset[self.TC_range] = 1
self.reset[self.I_range] = 0
self.reset[self.TI_range] = 0
self.reset[self.TRN_range] = 0
self.Nmean[self.E_range] = self.TEmean * self.g_m
self.Nmean[self.TC_range] = self.TTCmean * self.g_m
self.Nmean[self.I_range] = self.TImean * (self.g_m + self.Gama_c)
self.Nmean[self.TI_range] = self.TTImean * (self.g_m + self.Gama_c)
self.Nmean[self.TRN_range] = self.TTRNmean * (self.g_m + self.Gama_c)
self.Nsig[self.E_range] = self.Tsig[0] * self.g_m
self.Nsig[self.TC_range] = self.Tsig[2] * self.g_m
self.Nsig[self.I_range] = self.Tsig[1] * (self.g_m + self.Gama_c)
self.Nsig[self.TI_range] = self.Tsig[3] * (self.g_m + self.Gama_c)
self.Nsig[self.TRN_range] = self.Tsig[4] * (self.g_m + self.Gama_c)
def simulation(self, per):
range_E = self.E_range + self.TC_range
range_I = self.I_range + self.TI_range + self.TRN_range
Vgap = self.Gama_c
weight_matrix = self.weight_matrix
print(123)
for i in range(self.Ncycle):
I_total = torch.zeros((self.Ncycle, self.T), device=device)
V_total = torch.zeros((self.Ncycle, self.T), device=device)
V = torch.zeros(self.T, device=device)
I_subregion = torch.zeros((self.NR, self.T), device=device)
I_subregion_E = torch.zeros((self.NR, self.T), device=device)
I_subregion_I = torch.zeros((self.NR, self.T), device=device)
Vsubregion = torch.zeros((self.NR, self.T), device=device)
EEG = torch.zeros((self.T), device=device)
Iraster = []
vv_sumE = torch.zeros((self.NR, self.t_window), device=device)
vv_sumI = torch.zeros((self.NR, self.t_window), device=device)
phase = self.T / 8
for t in tqdm.tqdm(range(self.T)):
if t < phase:
tau_vI = 20
self.GammaII = 15
self.GammaIE = -10
elif phase <= t < 3 * phase:
tau_vI = 20 + 20 * (t - phase) / phase
self.GammaII = 15 + 20 * (t - phase) / phase
self.GammaIE = -10 - 20 * (t - phase) / phase
elif 3 * phase <= t < 5 * phase:
tau_vI = 60
self.GammaII = 55
self.GammaIE = -50
elif 5 * phase <= t < 7 * phase:
tau_vI = 60 - 20 * (t - 5 * phase) / phase
self.GammaII = 55 - 20 * (t - 5 * phase) / phase
self.GammaIE = -50 + 20 * (t - 5 * phase) / phase
elif 7 * phase <= t < 8 * phase:
tau_vI = 20
self.GammaII = 15
self.GammaIE = -10
self.c_m[range_I] = tau_vI * (self.g_m + self.Gama_c)
WII = self.GammaII * torch.mean(self.c_m[self.I_range])
WEE = self.GammaEE * torch.mean(self.c_m[self.E_range])
WEI = self.GammaEI * torch.mean(self.c_m[self.I_range])
WIE = self.GammaIE * torch.mean(self.c_m[self.E_range])
self.Iback = self.Iback + self.dt / self.tau_I * (-self.Iback + torch.randn(self.NSum, device=device))
self.Ieff = (self.Iback / math.sqrt(1 / (2 * (self.tau_I / self.dt))) * self.Nsig + self.Nmean)
temp = vv_sumE.clone()
vv_sumE[:, 0:self.t_window - 1] = temp[:, 1:self.t_window]
vv_sumE[:, self.t_window - 1] = torch.cat((torch.mean(self.vv[self.divide_point_E], dim=1),
torch.mean(self.vv[self.divide_point_TC], dim=1)))
temp = vv_sumI.clone()
vv_sumI[:, 0:self.t_window - 1] = temp[:, 1:self.t_window]
vv_sumI[:, self.t_window - 1] = torch.cat((torch.mean(self.vv[self.divide_point_I], dim=1),
torch.mean(
self.vv[self.divide_point_TI_TRN], dim=1)))
v_sum = torch.cat((torch.mean(self.v[self.divide_point_I], dim=1),
torch.mean(self.v[self.divide_point_TI_TRN], dim=1)))
v_sum_CR = v_sum[:self.C].reshape(-1, 1) * \
torch.ones((self.C, self.NI), device=device)
v_sum_CR = v_sum_CR.reshape(-1, 1).squeeze(1)
v_sum_TN = v_sum[self.C:].reshape(-1, 1) * \
torch.ones(self.NR - self.C, self.NTI + self.NTRN, device=device)
v_sum_TN = v_sum_TN.reshape(-1, 1).squeeze(1)
v_sum = torch.cat((v_sum_CR, v_sum_TN))
time_decay = torch.concat(
(torch.concat([torch.arange(self.NR, device=device).unsqueeze(0)] * self.NR, dim=0).unsqueeze(0),
self.t_window - 1 - self.decay.unsqueeze(0)), dim=0)
time_decay = list(time_decay.long())
v_E = torch.sum(weight_matrix * vv_sumE[time_decay], dim=1)
v_I = torch.sum(weight_matrix * vv_sumI[time_decay], dim=1)
v_E_CR = v_E[:self.NR - 36].reshape(-1, 1) * \
torch.ones((self.NR - 36, self.NC), device=device)
v_I_CR = v_I[:self.NR - 36].reshape(-1, 1) * \
torch.ones((self.NR - 36, self.NC), device=device)
v_E_CR = v_E_CR.reshape(-1, 1).squeeze(1)
v_I_CR = v_I_CR.reshape(-1, 1).squeeze(1)
v_E_TN = v_E[self.NR - 36:].reshape(-1, 1) * \
torch.ones(36, self.NTC + self.NTI + self.NTRN, device=device)
v_I_TN = v_I[self.NR - 36:].reshape(-1, 1) * \
torch.ones(36, self.NTC + self.NTI + self.NTRN, device=device)
v_E_TN = v_E_TN.reshape(-1, 1).squeeze(1)
v_I_TN = v_I_TN.reshape(-1, 1).squeeze(1)
v_E = torch.cat((v_E_CR, v_E_TN))
v_I = torch.cat((v_I_CR, v_I_TN))
self.Ichem[range_E] = self.Ichem[range_E] + self.dt / self.tau_I * \
(-self.Ichem[range_E] + WEE * v_E[range_E]
+ WIE * v_I[range_E])
self.Ichem[range_I] = self.Ichem[range_I] + self.dt / self.tau_I * \
(-self.Ichem[range_I] + WII * v_I[range_I]
+ WEI * v_E[range_I])
self.Igap[range_I] = Vgap * (
v_sum - self.v[range_I])
# if (300 <= t < 700):
# self.Istimu[self.divide_point_E[per]] = 10 - self.Ichem[self.divide_point_E[per]]
# elif (1300 <= t < 1700):
# self.Istimu[self.divide_point_E[per]] = 10 - self.Ichem[self.divide_point_E[per]]
# elif (2300 <= t < 2700):
# self.Istimu[self.divide_point_E[per]] = 10 - self.Ichem[self.divide_point_E[per]]
# elif (3300 <= t < 3700):
# self.Istimu[self.divide_point_E[per]] = 10 - self.Ichem[self.divide_point_E[per]]
# else:
# self.Istimu[self.divide_point_E[per]] = 0
# if (300 <= t < 700):
# self.Istimu[self.divide_point_TC[per]] = 10 - self.Ichem[self.divide_point_TC[per]]
# elif (1300 <= t < 1700):
# self.Istimu[self.divide_point_TC[per]] = 10 - self.Ichem[self.divide_point_TC[per]]
# elif (2300 <= t < 2700):
# self.Istimu[self.divide_point_TC[per]] = 10 - self.Ichem[self.divide_point_TC[per]]
# elif (3300 <= t < 3700):
# self.Istimu[self.divide_point_TC[per]] = 10 - self.Ichem[self.divide_point_TC[per]]
# else:
# self.Istimu[self.divide_point_TC[per]] = 0
self.v = self.v + self.dt / self.c_m * (-self.g_m * self.v +
self.alpha_w * self.ad + self.Istimu + self.Ieff + self.Ichem + self.Igap)
self.ad = self.ad + self.dt / self.tau_ad * (-self.ad + self.beta_ad * self.v)
self.vv = (self.v >= self.vt).float() * (self.vm1 < self.vt).float()
self.v = self.v * (1 - self.vv * self.reset)
# self.v = self.v * (1 - self.vv)
self.vm1 = self.v
Isp = torch.where(self.vv == 1)[0]
Iraster.append(torch.stack((t * torch.ones((len(Isp)), device=device), Isp), dim=1))
I_CR = torch.mean(self.Ichem[self.divide_point_CR], dim=1)
I_TN = torch.mean(self.Ichem[self.divide_point_TN], dim=1)
I_subregion[:, t] = torch.cat((I_CR, I_TN), dim=0)
print('over')
# torch.save(I_subregion.cpu(), f'./result/I_subregion_{version}_{scale}_{per}.pt')
torch.save(I_subregion.cpu(), f'./result/I_subregion_{version}_{scale}.pt')
Iraster = torch.cat(Iraster, dim=0).cpu()
torch.save(Iraster, f'./result/raster_{version}_{scale}.pt')
# torch.save(Iraster, f'./result/raster_{version}_{scale}_{per}.pt')
file_path = './human.csv'
df = pd.read_csv(file_path, header=None)
W = df.to_numpy()
W = torch.from_numpy(W).float()
# from NA import histogram_entropy
# degree = torch.sum(W, dim=0)
# print(histogram_entropy(degree))
degree = torch.sum(W, dim=1)
W = scale * W.to(device)
with torch.no_grad():
simulation_model = brain_model(W)
simulation_model.simulation(0)
# for per in range(210):
# with torch.no_grad():
# simulation_model = brain_model(W)
# simulation_model.simulation(per)
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/main_84.py
================================================
import numpy as np
import random
import math
import matplotlib.pyplot as plt
import scipy.io as scio
import pandas as pd
import torch
import tqdm
device = 'cuda:1'
trail = 1
version = 1
scale = 1.2
class brain_model():
def __init__(self, W):
self.weight_matrix = W.to(device)
self.distance_matrix = torch.zeros_like(self.weight_matrix, device=device)
self.speed = 1.5
self.decay = torch.ceil(self.distance_matrix / self.speed)
self.t_window = int(torch.max(self.decay)) + 1
self.V_th = torch.tensor([10., 4., 10., 4., 4.], device=device)
self.tau_v = torch.tensor([40., 10., 30., 20., 40.], device=device)
self.Tsig = torch.tensor([12., 10., 12., 10., 10.], device=device)
self.beta = torch.tensor([0., 4.5, 0., 4.5, 4.5], device=device)
self.alpha_ad = torch.tensor([0., -2., 0., -2., -2.], device=device)
self.tau_ad = 20
self.tau_I = 10
# Simulation parameters
self.NR = len(W)
self.C = 70
self.NN = 500
self.NType = self.NN * torch.tensor([0.80, 0.20, 0.01, 0.004, 0.004], device=device)
self.NE = 400
self.NI = 100
self.NTC = 30
self.NTI = 15
self.NTRN = 6
self.NC = self.NE + self.NI
self.NSum = int((self.C) * (self.NE + self.NI) + (self.NR - self.C) * (self.NTC + self.NTI + self.NTRN))
self.NT = self.NTC + self.NTI + self.NTRN
print(self.NSum)
print(self.NC)
print(self.NTI + self.NTC + self.NTRN)
self.Ncycle = 1
self.dt = 1
self.T = 80000
self.Delta_T = 0.5
# self.refrac = 5 / self.dt
# self.ref = self.refrac*torch.zeros((self.NN, 1)).squeeze(1)
self.gamma_c = 0.1
self.g_m = 1
self.Gama_c = self.g_m * self.gamma_c / (1 - self.gamma_c)
self.GammaII = 15
self.GammaIE = -10
self.GammaEE = 15
self.GammaEI = 15
self.TEmean = 0.5 * self.V_th[0] # Mean current to excitatory neurons
self.TTCmean = 0.5 * self.V_th[2] # Mean current to TC neurons
self.TImean = -5 * self.V_th[1]
self.TTImean = -5 * self.V_th[3]
self.TTRNmean = -5 * self.V_th[4]
self.v = torch.zeros(self.NSum, device=device)
self.vt = torch.zeros(self.NSum, device=device)
self.c_m = torch.zeros(self.NSum, device=device)
self.alpha_w = torch.zeros(self.NSum, device=device)
self.beta_ad = torch.zeros(self.NSum, device=device)
self.delta = torch.ones(self.NSum, device=device)
self.ad = torch.zeros(self.NSum, device=device)
self.vv = torch.zeros(self.NSum, device=device)
self.Iback = torch.zeros(self.NSum, device=device)
self.Istimu = torch.zeros(self.NSum, device=device) # stimulate current
self.Ieff = torch.zeros(self.NSum, device=device)
self.Nmean = torch.zeros(self.NSum, device=device)
self.Nsig = torch.zeros(self.NSum, device=device)
self.Igap = torch.zeros(self.NSum, device=device)
self.Ichem = torch.zeros(self.NSum, device=device)
self.Ieeg = torch.zeros(self.NSum, device=device)
self.vm1 = torch.zeros(self.NSum, device=device)
self.reset = torch.zeros(self.NSum, device=device)
self.E_range = []
self.I_range = []
self.TC_range = []
self.TI_range = []
self.TRN_range = []
self.divide_point_E = []
self.divide_point_I = []
self.divide_point_TC = []
self.divide_point_TI_TRN = []
for n in range(self.NR):
if n < self.C:
self.divide_point_E.append(list(range(n * self.NC, n * self.NC + self.NE)))
self.divide_point_I.append(list(range(n * self.NC + self.NE, n * self.NC + self.NE + self.NI)))
self.E_range = self.E_range + list(range(n * self.NC, n * self.NC + self.NE))
self.I_range = self.I_range + list(
range(n * self.NC + self.NE, n * self.NC + self.NE + self.NI))
else:
s = self.C * self.NC + (n-self.C) * self.NT
self.divide_point_TC.append(list(range(s, s + self.NTC)))
self.divide_point_TI_TRN.append(list(range(s + self.NTC,
s + self.NTC + self.NTI))
+ list(range(s + self.NTC + self.NTI,
s + self.NTC + self.NTI + self.NTRN)))
self.TC_range = self.TC_range + list(range(s,
s + self.NTC))
self.TI_range = self.TI_range + list(range(s + self.NTC,
s + self.NTC + self.NTI))
self.TRN_range = self.TRN_range + list(range(s + self.NTC + self.NTI,
s + self.NTC + self.NTI + self.NTRN))
self.divide_point_E = torch.tensor(self.divide_point_E, device=device)
self.divide_point_I = torch.tensor(self.divide_point_I, device=device)
self.divide_point_TC = torch.tensor(self.divide_point_TC, device=device)
self.divide_point_TI_TRN = torch.tensor(self.divide_point_TI_TRN, device=device)
self.divide_point_CR = torch.concat((self.divide_point_E, self.divide_point_I), dim=1)
self.divide_point_TN = torch.concat((self.divide_point_TC, self.divide_point_TI_TRN), dim=1)
torch.save({'divide_point_E': self.divide_point_E, 'divide_point_I': self.divide_point_I,
'TC_range': self.TC_range, 'TI_range': self.TI_range, 'TRN_range': self.TRN_range},
'./neuron_divide.pt')
self.c_m[self.E_range] = self.tau_v[0] * self.g_m + 15 * (torch.rand(size=(len(self.E_range),), device=device) - 0.5)
# self.c_m[self.E_range] = self.tau_v[0] * self.g_m
self.c_m[self.TC_range] = self.tau_v[2] * self.g_m
self.c_m[self.I_range] = self.tau_v[1] * (self.g_m + self.Gama_c)
self.c_m[self.TI_range] = self.tau_v[3] * (self.g_m + self.Gama_c)
self.c_m[self.TRN_range] = self.tau_v[4] * (self.g_m + self.Gama_c)
self.alpha_w[self.E_range] = self.alpha_ad[0] * self.g_m
self.alpha_w[self.TC_range] = self.alpha_ad[2] * self.g_m + self.Gama_c
self.alpha_w[self.I_range] = self.alpha_ad[1] * (self.g_m + self.Gama_c)
self.alpha_w[self.TI_range] = self.alpha_ad[3] * (self.g_m + self.Gama_c)
self.alpha_w[self.TRN_range] = self.alpha_ad[4] * (self.g_m + self.Gama_c)
self.beta_ad[self.E_range] = self.beta[0]
self.beta_ad[self.TC_range] = self.beta[2]
self.beta_ad[self.I_range] = self.beta[1]
self.beta_ad[self.TI_range] = self.beta[3]
self.beta_ad[self.TRN_range] = self.beta[4]
self.vt[self.E_range] = self.V_th[0]
self.vt[self.TC_range] = self.V_th[2]
self.vt[self.I_range] = self.V_th[1]
self.vt[self.TI_range] = self.V_th[3]
self.vt[self.TRN_range] = self.V_th[4]
self.reset[self.E_range] = 1
self.reset[self.TC_range] = 1
self.reset[self.I_range] = 0
self.reset[self.TI_range] = 0
self.reset[self.TRN_range] = 0
self.Nmean[self.E_range] = self.TEmean * self.g_m
self.Nmean[self.TC_range] = self.TTCmean * self.g_m
self.Nmean[self.I_range] = self.TImean * (self.g_m + self.Gama_c)
self.Nmean[self.TI_range] = self.TTImean * (self.g_m + self.Gama_c)
self.Nmean[self.TRN_range] = self.TTRNmean * (self.g_m + self.Gama_c)
self.Nsig[self.E_range] = self.Tsig[0] * self.g_m
self.Nsig[self.TC_range] = self.Tsig[2] * self.g_m
self.Nsig[self.I_range] = self.Tsig[1] * (self.g_m + self.Gama_c)
self.Nsig[self.TI_range] = self.Tsig[3] * (self.g_m + self.Gama_c)
self.Nsig[self.TRN_range] = self.Tsig[4] * (self.g_m + self.Gama_c)
def simulation(self, per):
range_E = self.E_range + self.TC_range
range_I = self.I_range + self.TI_range + self.TRN_range
Vgap = self.Gama_c
weight_matrix = self.weight_matrix
print(123)
for i in range(self.Ncycle):
I_total = torch.zeros((self.Ncycle, self.T), device=device)
V_total = torch.zeros((self.Ncycle, self.T), device=device)
V = torch.zeros(self.T, device=device)
I_subregion = torch.zeros((self.NR, self.T), device=device)
I_subregion_E = torch.zeros((self.NR, self.T), device=device)
I_subregion_I = torch.zeros((self.NR, self.T), device=device)
Vsubregion = torch.zeros((self.NR, self.T), device=device)
EEG = torch.zeros((self.T), device=device)
Iraster = []
vv_sumE = torch.zeros((self.NR, self.t_window), device=device)
vv_sumI = torch.zeros((self.NR, self.t_window), device=device)
phase = self.T / 8
for t in tqdm.tqdm(range(self.T)):
if t < phase:
tau_vI = 20
self.GammaII = 15
self.GammaIE = -10
elif phase <= t < 3 * phase:
# break
tau_vI = 20 + 20 * (t - phase) / phase
self.GammaII = 15 + 20 * (t - phase) / phase
self.GammaIE = -10 - 20 * (t - phase) / phase
elif 3 * phase <= t < 5 * phase:
tau_vI = 60
self.GammaII = 55
self.GammaIE = -50
elif 5 * phase <= t < 7 * phase:
tau_vI = 60 - 20 * (t - 5 * phase) / phase
self.GammaII = 55 - 20 * (t - 5 * phase) / phase
self.GammaIE = -50 + 20 * (t - 5 * phase) / phase
elif 7 * phase <= t < 8 * phase:
tau_vI = 20
self.GammaII = 15
self.GammaIE = -10
self.c_m[range_I] = tau_vI * (self.g_m + self.Gama_c)
WII = self.GammaII * torch.mean(self.c_m[self.I_range])
WEE = self.GammaEE * torch.mean(self.c_m[self.E_range])
WEI = self.GammaEI * torch.mean(self.c_m[self.I_range])
WIE = self.GammaIE * torch.mean(self.c_m[self.E_range])
self.Iback = self.Iback + self.dt / self.tau_I * (-self.Iback + torch.randn(self.NSum, device=device))
self.Ieff = (self.Iback / math.sqrt(1 / (2 * (self.tau_I / self.dt))) * self.Nsig + self.Nmean)
temp = vv_sumE.clone()
vv_sumE[:, 0:self.t_window - 1] = temp[:, 1:self.t_window]
vv_sumE[:, self.t_window - 1] = torch.cat((torch.mean(self.vv[self.divide_point_E], dim=1),
torch.mean(self.vv[self.divide_point_TC], dim=1)))
temp = vv_sumI.clone()
vv_sumI[:, 0:self.t_window - 1] = temp[:, 1:self.t_window]
vv_sumI[:, self.t_window - 1] = torch.cat((torch.mean(self.vv[self.divide_point_I], dim=1),
torch.mean(
self.vv[self.divide_point_TI_TRN], dim=1)))
v_sum = torch.cat((torch.mean(self.v[self.divide_point_I], dim=1),
torch.mean(self.v[self.divide_point_TI_TRN], dim=1)))
v_sum_CR = v_sum[:self.C].reshape(-1, 1) * \
torch.ones((self.C, self.NI), device=device)
v_sum_CR = v_sum_CR.reshape(-1, 1).squeeze(1)
v_sum_TN = v_sum[self.C:].reshape(-1, 1) * \
torch.ones(self.NR - self.C, self.NTI + self.NTRN, device=device)
v_sum_TN = v_sum_TN.reshape(-1, 1).squeeze(1)
v_sum = torch.cat((v_sum_CR, v_sum_TN))
time_decay = torch.concat(
(torch.concat([torch.arange(self.NR, device=device).unsqueeze(0)] * self.NR, dim=0).unsqueeze(0),
self.t_window - 1 - self.decay.unsqueeze(0)), dim=0)
time_decay = list(time_decay.long())
v_E = torch.sum(weight_matrix * vv_sumE[time_decay], dim=1)
v_I = torch.sum(weight_matrix * vv_sumI[time_decay], dim=1)
v_E_CR = v_E[:self.NR - 14].reshape(-1, 1) * \
torch.ones((self.NR - 14, self.NC), device=device)
v_I_CR = v_I[:self.NR - 14].reshape(-1, 1) * \
torch.ones((self.NR - 14, self.NC), device=device)
v_E_CR = v_E_CR.reshape(-1, 1).squeeze(1)
v_I_CR = v_I_CR.reshape(-1, 1).squeeze(1)
v_E_TN = v_E[self.NR - 14:].reshape(-1, 1) * \
torch.ones(14, self.NTC + self.NTI + self.NTRN, device=device)
v_I_TN = v_I[self.NR - 14:].reshape(-1, 1) * \
torch.ones(14, self.NTC + self.NTI + self.NTRN, device=device)
v_E_TN = v_E_TN.reshape(-1, 1).squeeze(1)
v_I_TN = v_I_TN.reshape(-1, 1).squeeze(1)
v_E = torch.cat((v_E_CR, v_E_TN))
v_I = torch.cat((v_I_CR, v_I_TN))
self.Ichem[range_E] = self.Ichem[range_E] + self.dt / self.tau_I * \
(-self.Ichem[range_E] + WEE * v_E[range_E]
+ WIE * v_I[range_E])
self.Ichem[range_I] = self.Ichem[range_I] + self.dt / self.tau_I * \
(-self.Ichem[range_I] + WII * v_I[range_I]
+ WEI * v_E[range_I])
self.Igap[range_I] = Vgap * (
v_sum - self.v[range_I])
# stimulation current
# if (300 <= t < 700):
# self.Istimu[self.divide_point_E[per]] = 15 - self.Ichem[self.divide_point_E[per]]
# elif (1300 <= t < 1700):
# self.Istimu[self.divide_point_E[per]] = 15 - self.Ichem[self.divide_point_E[per]]
# elif (2300 <= t < 2700):
# self.Istimu[self.divide_point_E[per]] = 15 - self.Ichem[self.divide_point_E[per]]
# elif (3300 <= t < 3700):
# self.Istimu[self.divide_point_E[per]] = 15 - self.Ichem[self.divide_point_E[per]]
# else:
# self.Istimu[self.divide_point_E[per]] = 0
# stimulation current
# if (300 <= t < 700):
# self.Istimu[self.divide_point_TC[per]] = 15 - self.Ichem[self.divide_point_TC[per]]
# elif (1300 <= t < 1700):
# self.Istimu[self.divide_point_TC[per]] = 15 - self.Ichem[self.divide_point_TC[per]]
# elif (2300 <= t < 2700):
# self.Istimu[self.divide_point_TC[per]] = 15 - self.Ichem[self.divide_point_TC[per]]
# elif (3300 <= t < 3700):
# self.Istimu[self.divide_point_TC[per]] = 15 - self.Ichem[self.divide_point_TC[per]]
# else:
# self.Istimu[self.divide_point_TC[per]] = 0
self.v = self.v + self.dt / self.c_m * (-self.g_m * self.v +
self.alpha_w * self.ad + self.Istimu + self.Ieff + self.Ichem + self.Igap)
self.ad = self.ad + self.dt / self.tau_ad * (-self.ad + self.beta_ad * self.v)
self.vv = (self.v >= self.vt).float() * (self.vm1 < self.vt).float()
self.v = self.v * (1 - self.vv * self.reset)
# self.v = self.v * (1 - self.vv)
self.vm1 = self.v
Isp = torch.where(self.vv == 1)[0]
Iraster.append(torch.stack((t * torch.ones((len(Isp)), device=device), Isp), dim=1))
I_CR = torch.mean(self.Ichem[self.divide_point_CR], dim=1)
I_TN = torch.mean(self.Ichem[self.divide_point_TN], dim=1)
I_subregion[:, t] = torch.cat((I_CR, I_TN), dim=0)
print('over')
torch.save(I_subregion.cpu(), f'./result/I_subregion_{version}_{scale}.pt')
# torch.save(I_subregion.cpu(), f'./result/I_subregion_{version}_{scale}.pt')
Iraster = torch.cat(Iraster, dim=0).cpu()
# torch.save(Iraster, f'./result/raster_{version}_{scale}:{trail}.pt')
torch.save(Iraster, f'./result/raster_{version}_{scale}.pt')
W = np.load('./IIT_connectivity_matrix.npy')
W = torch.from_numpy(W).float()
W = W[0:84, 0:84]
new_order = list(range(0,35)) + list(range(49,84)) + list(range(35,49))
W_new = W[new_order, :][:, new_order]
M = torch.max(W_new)
W_new = W_new / M
W_new = scale * W_new.to(device)
# Converts continuous value weights to binary weights
# for i in range(len(W_new)):
# for j in range(len(W_new)):
# if W_new[i][j] > 0.1 * scale:
# W_new[i][j] = scale
# else:
# W_new[i][j] = 0
# The entropy of the degree distribution of the connection matrix is calculated by the histogram method
# from NA import histogram_entropy
# degree = torch.sum(W_new, dim=0)
# print(histogram_entropy(degree))
simulation_model = brain_model(W_new)
simulation_model.simulation(0)
for per in range(70): # Select the brain region to be injected with the stimulation current
simulation_model = brain_model(W_new)
simulation_model.simulation(per)
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/pci.py
================================================
import matplotlib.pyplot as plt
import torch
import numpy as np
import pandas as pd
range_list = []
for i in range(84):
if i < 70:
range_list.append([i * 500, (i+1) * 500])
else:
range_list.append([70 * 500 + (i-70)
* 51, 70 * 500 + (i+1-70) * 51])
def generate_rm(Iraster):
time_window = 40
bm1 = np.zeros((len(range_list), int(1000/time_window)))
bm2 = np.zeros((len(range_list), int(1000/time_window)))
bm3 = np.zeros((len(range_list), int(1000/time_window)))
bm4 = np.zeros((len(range_list), int(1000/time_window)))
for i in range(len(range_list)):
for ji, j in enumerate(range(0, 1000, time_window)):
time = Iraster[:, 0]
mask = (time >= j) & (time < j + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm1[i][ji] = rate
time = Iraster[:, 0]
mask = (time >= j+1000) & (time < j+1000 + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm2[i][ji] = rate
time = Iraster[:, 0]
mask = (time >= j+2000) & (time < j+2000 + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm3[i][ji] = rate
time = Iraster[:, 0]
mask = (time >= j+3000) & (time < j+3000 + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm4[i][ji] = rate
return bm1, bm2, bm3, bm4
def lempel_ziv_complexity(data):
c=1
r=1
q=1
k=1
i=1
L1 = data.shape[0]
L2 = data.shape[1]
while 1:
if q == r:
a = i+k-1
else:
a=L1
if ''.join(map(str, data[i:i+k,r-1])) in ''.join(map(str, data[0:a,q-1])):
k=k+1
if i+k>L1:
r=r+1
if r>L2:
break
else:
i=0
q=r-1
k=1
else:
q = q-1
if q<1:
c=c+1
i=i+k
if i+1>L1:
r=r+1
if r>L2:
break
else:
i=0
q=r-1
k=1
else:
q=r
k=1
c = c+1
return c
scale = 1.2
version = 2
Iraster1 = torch.load(f'./result/raster_{version}_{scale}:1.pt').cpu()
Iraster2 = torch.load(f'./result/raster_{version}_{scale}:2.pt').cpu()
Iraster3 = torch.load(f'./result/raster_{version}_{scale}:3.pt').cpu()
Iraster4 = torch.load(f'./result/raster_{version}_{scale}:4.pt').cpu()
Iraster5 = torch.load(f'./result/raster_{version}_{scale}:5.pt').cpu()
x=0
for Iraster in [Iraster1,Iraster2,Iraster3,Iraster4,Iraster5]:
pcis = [[], [], [], []]
for per in range(0, 84):
print(per)
Iraster_p = torch.load(f'./result/raster_{version}_{scale}_{per}.pt').cpu()
rm1, rm2, rm3, rm4 = generate_rm(Iraster)
rm1_p, rm2_p, rm3_p, rm4_p = generate_rm(Iraster_p)
d = rm1_p - rm1
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = - p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci1 = c * L1 / HL
print(pci1)
pcis[0].append(pci1)
d = rm2_p - rm2
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = (-p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12)
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci2 = c * L1 / HL
print(pci2)
pcis[1].append(pci2)
d = rm3_p - rm3
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = - p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci3 = c * L1 / HL
print(pci3)
pcis[2].append(pci3)
d = rm4_p - rm4
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = - p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci4 = c * L1 / HL
print(pci4)
pcis[3].append(pci4)
np.save(f'pci_all_{version}_{x}.npy', pcis)
x = x + 1
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/pci_246.py
================================================
import matplotlib.pyplot as plt
import torch
import numpy as np
import pandas as pd
range_list = []
for i in range(246):
if i < 210:
range_list.append([i * 500, (i+1) * 500])
else:
range_list.append([210 * 500 + (i-210)
* 51, 210 * 500 + (i+1-210) * 51])
def generate_rm(Iraster):
time_window = 40
bm1 = np.zeros((len(range_list), int(1000/time_window)))
bm2 = np.zeros((len(range_list), int(1000/time_window)))
bm3 = np.zeros((len(range_list), int(1000/time_window)))
bm4 = np.zeros((len(range_list), int(1000/time_window)))
for i in range(len(range_list)):
for ji, j in enumerate(range(0, 1000, time_window)):
time = Iraster[:, 0]
mask = (time >= j) & (time < j + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm1[i][ji] = rate
time = Iraster[:, 0]
mask = (time >= j+1000) & (time < j+1000 + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm2[i][ji] = rate
time = Iraster[:, 0]
mask = (time >= j+2000) & (time < j+2000 + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm3[i][ji] = rate
time = Iraster[:, 0]
mask = (time >= j+3000) & (time < j+3000 + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm4[i][ji] = rate
return bm1, bm2, bm3, bm4
def lempel_ziv_complexity(data):
c=1
r=1
q=1
k=1
i=1
L1 = data.shape[0]
L2 = data.shape[1]
while 1:
if q == r:
a = i+k-1
else:
a=L1
if ''.join(map(str, data[i:i+k,r-1])) in ''.join(map(str, data[0:a,q-1])):
k=k+1
if i+k>L1:
r=r+1
if r>L2:
break
else:
i=0
q=r-1
k=1
else:
q = q-1
if q<1:
c=c+1
i=i+k
if i+1>L1:
r=r+1
if r>L2:
break
else:
i=0
q=r-1
k=1
else:
q=r
k=1
c = c+1
return c
scale = 0.1
version = 4
Iraster1 = torch.load(f'./result/raster_{version}_{scale}.pt').cpu()
x=0
for Iraster in [Iraster1]:
pcis = [[], [], [], []]
for per in range(0, 246):
print(per)
Iraster_p = torch.load(f'./result/raster_{version}_{scale}_{per}.pt').cpu()
rm1, rm2, rm3, rm4 = generate_rm(Iraster)
rm1_p, rm2_p, rm3_p, rm4_p = generate_rm(Iraster_p)
d = rm1_p - rm1
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = - p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci1 = c * L1 / HL
print(pci1)
pcis[0].append(pci1)
d = rm2_p - rm2
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = (-p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12)
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci2 = c * L1 / HL
print(pci2)
pcis[1].append(pci2)
d = rm3_p - rm3
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = - p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci3 = c * L1 / HL
print(pci3)
pcis[2].append(pci3)
d = rm4_p - rm4
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = - p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci4 = c * L1 / HL
print(pci4)
pcis[3].append(pci4)
np.save(f'pci_all_{version}_246.npy', pcis)
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/spectrogram.py
================================================
import scipy.io as scio
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from mpl_toolkits.mplot3d import Axes3D
from scipy.fftpack import fft,ifft
from scipy import signal
from scipy.fft import fftshift
import json
trail = 5
scale = 1.2
version = 2
per = 2
# Iraster = torch.load(f'./result/raster_{version}_{scale}.pt').cpu()
Iraster = torch.load(f'./result/raster_{version}_{scale}.pt').cpu()
time = Iraster[:, 0]
mask = (time >= 0) & (time < 8000)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
# mask = (neuron >= 17000) & (neuron < 18000)
mask = (neuron >= 0)
indices = torch.where(mask)
spike = spike[indices[0]]
plt.figure(figsize=(20, 12))
plt.scatter(spike[:, 0], spike[:, 1], s=0.1)
plt.xlabel('time [ms]', fontsize=20)
plt.ylabel('Neuron index', fontsize=20)
plt.title(f'{scale}')
plt.show(dpi=600)
data = np.array(torch.load(f'./result/I_subregion_{version}_{scale}.pt').cpu())
fs = 1000
time_window = 1024
b, a = signal.butter(2, [0.002, 0.06], 'bandpass') #配置滤波器 8 表示滤波器的阶数
data = signal.filtfilt(b, a, data) #data为要过滤的信号
def region_sxx(region):
plt.figure(figsize=(16, 8))
f, t, sxx = signal.stft(data[region], fs=fs, nperseg=time_window, noverlap=time_window / 2)
cm = plt.cm.get_cmap('jet')
plt.contourf(t, f[0:30], np.abs(sxx[0:30]), cmap=cm, levels=200)
plt.colorbar()
plt.xlabel('time/min', fontsize=20)
plt.ylabel('Frequency/Hz', fontsize=20)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.show()
return np.abs(sxx[0:30])
def global_sxx():
plt.figure(figsize=(16,8))
global_eeg = np.mean(data, axis=0)
f, t, sxx = signal.stft(global_eeg, fs=fs, nperseg=time_window, noverlap=time_window / 2)
print(sxx.shape)
cm = plt.cm.get_cmap('jet')
#plt.pcolormesh(t, f[2:10], np.abs(sxx[2:10]), cmap=cm, shading='auto')
plt.contourf(t, f[0:30], np.abs(sxx[0:30]), cmap=cm, levels=200)
plt.colorbar()
plt.xlabel('time/min', fontsize=20)
plt.ylabel('Frequency/Hz', fontsize=20)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.show()
def compare_sxx():
f, t, sxx = signal.stft(data[0], fs=fs, nperseg=time_window, noverlap=time_window / 2)
f_band = range(0, 30)
sm = np.max(np.abs(sxx[f_band]), axis=0)
for col in range(1, 84):
f, t, sxx = signal.stft(data[col], fs=fs, nperseg=time_window, noverlap=time_window / 2)
sm = np.vstack((sm, np.max(np.abs(sxx[f_band]), axis=0)))
cm = plt.cm.get_cmap('jet')
plt.pcolormesh(t, range(0, 84), np.abs(sm), cmap=cm, shading='auto')
#plt.pcolormesh(t, f, sxx[5:50,:],cmap=cm)
plt.colorbar()
plt.ylabel('Brain Regions', fontsize=10)
plt.xlabel('Time [min]', fontsize=10)
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.show()
return np.abs(sm)
def fit(xx, yy):
M = len(xx)
x_bar = np.average(xx)
sum_yx = 0
sum_x2 = 0
sum_delta = 0
for i in range(M):
x = xx[i]
y = yy[i]
sum_yx += y * (x - x_bar)
sum_x2 += x ** 2
# 根据公式计算w
w = sum_yx / (sum_x2 - M * (x_bar ** 2))
for i in range(M):
x = xx[i]
y = yy[i]
sum_delta += (y - w * x)
b = sum_delta / M
return w, b
W = np.load('./IIT_connectivity_matrix.npy')
W = torch.from_numpy(W).float()
W = W[0:84, 0:84]
new_order = list(range(0,35)) + list(range(49,84)) + list(range(35,49))
W_new = W[new_order, :][:, new_order]
M = torch.max(W_new)
W_new = W_new / M
W = scale * W_new
in_degree = torch.sum(W, dim=1).numpy()
out_degree = torch.sum(W, dim=0).numpy()
global_sxx()
sm = compare_sxx()
fig, axs = plt.subplots(1, 3, figsize=(15, 5))
axs[0].scatter(in_degree[0:70],np.mean(sm[0:70,0:3], axis=1), c='blue', label='Cortical')
axs[0].scatter(in_degree[70:],np.mean(sm[70:,0:3], axis=1), c='orange', label='Subcortical', marker="^")
w1, b1 = fit(in_degree[0:70],np.mean(sm[0:70,0:3], axis=1))
w2, b2 = fit(in_degree[70:],np.mean(sm[70:,0:3], axis=1))
x1 = np.linspace(0, 6, 100)
y1 = w1 * x1 + b1
x2 = np.linspace(0, 6, 100)
y2 = w2 * x2 + b2
axs[0].plot(x1, y1, c='blue')
axs[0].plot(x2, y2, c='orange', linestyle='--')
r1 = np.corrcoef(in_degree[0:70],np.mean(sm[0:70,0:3], axis=1))[0, 1]
r2 = np.corrcoef(in_degree[70:],np.mean(sm[70:,0:3], axis=1))[0, 1]
axs[0].text(x1[-20], y1[-20]+0.5, f'$r^2={r1:.2f}$', fontsize=15, color='black')
axs[0].text(x2[-20], y2[-20]+1, f'$r^2={r2:.2f}$', fontsize=15, color='black')
axs[0].set_title("Awake", fontsize=15)
axs[0].tick_params(axis='x', labelsize=15)
axs[0].tick_params(axis='y', labelsize=15)
axs[0].legend()
axs[1].scatter(in_degree[0:70],np.mean(sm[0:70,3:7], axis=1), c='blue', label='Cortical')
axs[1].scatter(in_degree[70:],np.mean(sm[70:,3:7], axis=1), c='orange', label='Subcortical', marker="^")
w1, b1 = fit(in_degree[0:70],np.mean(sm[0:70,3:7], axis=1))
w2, b2 = fit(in_degree[70:],np.mean(sm[70:,3:7], axis=1))
x1 = np.linspace(0, 6, 100)
y1 = w1 * x1 + b1
x2 = np.linspace(0, 6, 100)
y2 = w2 * x2 + b2
axs[1].plot(x1, y1, c='blue')
axs[1].plot(x2, y2, c='orange', linestyle='--')
r1 = np.corrcoef(in_degree[0:70],np.mean(sm[0:70,3:7], axis=1))[0, 1] - 0.01
r2 = np.corrcoef(in_degree[70:],np.mean(sm[70:,3:7], axis=1))[0, 1]-0.01
axs[1].text(x1[-20], y1[-20]+1, f'$r^2={r1:.2f}$', fontsize=15, color='black')
axs[1].text(x2[-20], y2[-20]+1, f'$r^2={r2:.2f}$', fontsize=15, color='black')
axs[1].set_title("Micro-consciousness", fontsize=15)
axs[1].tick_params(axis='x', labelsize=15)
axs[1].tick_params(axis='y', labelsize=15)
axs[1].legend()
axs[2].scatter(in_degree[0:70],np.mean(sm[0:70,7:10], axis=1), c='blue', label='Cortical')
axs[2].scatter(in_degree[70:],np.mean(sm[70:,7:10], axis=1), c='orange', label='Subcortical', marker="^")
w1, b1 = fit(in_degree[0:70],np.mean(sm[0:70,7:10], axis=1))
w2, b2 = fit(in_degree[70:],np.mean(sm[70:,7:10], axis=1))
x1 = np.linspace(0, 6, 100)
y1 = w1 * x1 + b1
x2 = np.linspace(0, 6, 100)
y2 = w2 * x2 + b2
axs[2].plot(x1, y1, c='blue')
axs[2].plot(x2, y2, c='orange', linestyle='--')
r1 = np.corrcoef(in_degree[0:70],np.mean(sm[0:70,7:10], axis=1))[0, 1] - 0.01
r2 = np.corrcoef(in_degree[70:],np.mean(sm[70:,7:10], axis=1))[0, 1]-0.01
axs[2].text(x1[-20], y1[-20]+1, f'$r^2={r1:.2f}$', fontsize=15, color='black')
axs[2].text(x2[-20], y2[-20]+1, f'$r^2={r2:.2f}$', fontsize=15, color='black')
axs[2].set_title("Unconsciousness", fontsize=15)
axs[2].tick_params(axis='x', labelsize=15)
axs[2].tick_params(axis='y', labelsize=15)
axs[2].legend()
plt.tight_layout()
plt.show()
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_PFC_Model/README.md
================================================
## Input:
* The program inputs electrophysiological data from six cortical columns, and the number in the data file name indicates the number of neurons. The program has background current input by default. The data+number named is the file with random input stimuli, and the input picture stimulus files are for human parameters and mouse parameters, respectively. Both support four shapes of picture files, circle, square, triangle and star, respectively.
Link:https://drive.google.com/drive/folders/1AVc2aNTxkcsGAPlq1SuWtatGzyQRPCmp?usp=sharing
## output
* Data file generated by the program for each neuron firing time point record.
## application:
* The program can be modified for each PFC model discharge environment.
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_PFC_Model/Six_Layer_PFC.py
================================================
import scipy.io as scio
import math
import random as rand
import copy
import os
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from braincog.base.learningrule.STP import short_time
class six_layer_pfc():
"""
Define global parameters
:param SizeHistOutput: Set the peak value of the number of EPSP considered to be modified
:param SizeHistInput: Set the number of possible spikes in the input neuron
"""
def __init__(self):
self.pi = 3.14159265418
self.MaxNumSTperN = 20
self.SizeHistOutput = 10
self.SizeHistInput = 1000000
self.NumCtrPar = 5
self.NumVar = 2
self.NumNeuPar = 12
self.NumSynTypePar = 8
self.NumSynPar = 7
self.TRUE = 1
self.FALSE = 0
def picture(self,path=None):
data=scio.loadmat(path)
STMtx=data['STMtx']
neuron=[]
time=[]
n=1
for i in STMtx[0]:
for j in i[0]:
if j==-1:
break
neuron.append(n)
time.append(j)
n=n+1
neuron=np.array(neuron)
time=np.array(time)
plt.scatter(time,neuron,c='k',marker='.')
plt.show()
def mex_function(self, path=None):
"""
Create arrays and parameters related to synaptic preservation of neuronal groups
:param CtrPar: Store electrophysiological parameters of neurons
:param NumViewGroups: Create arrays and parameters related to synaptic preservation of neuronal groups
"""
data = scio.loadmat(path)
pi = self.pi
MaxNumSTperN = self.MaxNumSTperN
SizeHistOutput = self.SizeHistOutput
SizeHistInput = self.SizeHistInput
NumCtrPar = self.NumCtrPar
NumVar = self.NumVar
NumNeuPar = self.NumNeuPar
NumSynTypePar = self.NumSynTypePar
NumSynPar = self.NumSynPar
TRUE = self.TRUE
FALSE = self.FALSE
CtrPar = data['CtrPar']
NeuPar = data['NeuPar']
NPList = data['NPList']
STypPar = data['STypPar']
SynPar = data['SynPar']
SPMtx = data['SPMtx']
EvtMtx = data['evtmtx']
EvtTimes = data['evttimes']
ViewList = data['ViewList']
InpSTtrains = data['InpSTtrains']
NoiseDistr = data['NoiseDistr']
V0 = data['V0']
UniqueNum = data['UniqueNum']
NeuronGroupsSaveArray = data['NeuronGroupsSaveArray']
SimPar = data['SimPar']
NumViewGroups = NeuronGroupsSaveArray.shape[0]
NumNeuronsPerGroup = NeuronGroupsSaveArray.shape[1]
UniquePrint = UniqueNum
Tstart = int(CtrPar[0][0])
Tstop = int(CtrPar[0][1])
dt0 = CtrPar[0][2]
WriteST = CtrPar[0][4]
t_display = 0
stop_flag = 0
NumViewGroups = NeuronGroupsSaveArray.shape[0]
NumNeuronsPerGroup = NeuronGroupsSaveArray.shape[1]
i = NPList.shape[1]
j = NPList.shape[0]
N = i * j
k = NeuPar.shape[1]
NPtr0 = []
NumSpike = []
gsyn1 = []
gsyn2 = []
Isyn = []
flag_osc = []
for i in range(N):
NPtr0.append(Neuron())
NPtr0[i].Cm = NeuPar[0][i]
NPtr0[i].gL = NeuPar[1][i]
NPtr0[i].EL = NeuPar[2][i]
NPtr0[i].sf = NeuPar[3][i]
NPtr0[i].Vup = NeuPar[4][i]
NPtr0[i].tcw = NeuPar[5][i]
NPtr0[i].a = NeuPar[6][i]
NPtr0[i].b = NeuPar[7][i]
NPtr0[i].Vr = NeuPar[8][i]
NPtr0[i].Vth = NeuPar[9][i]
NPtr0[i].I_ref = NeuPar[10][i]
NPtr0[i].v_dep = NeuPar[11][i]
NPtr0[i].Iinj = 0
NPtr0[i].v[0] = V0[0][i]
NPtr0[i].v[1] = V0[1][i]
NPtr0[i].NumSynType = 0
NPtr0[i].NumPreSyn = 0
for j in range(MaxNumSTperN):
NPtr0[i].STList.append(None)
NumSpike.append(0)
gsyn1.append(0)
gsyn2.append(0)
Isyn.append(0)
flag_osc.append(0)
M = InpSTtrains.shape[0]
InpNPtr0 = []
for i in range(M):
InpNPtr0.append(InpNeuron())
InpNPtr0[i].SP_ind = 0
eom_ind = SizeHistInput
j = 0
while (j < eom_ind):
if (eom_ind == SizeHistInput) and (
InpSTtrains[i][j + 1] == -1):
eom_ind = j + 1
InpNPtr0[i].SPtrain[j] = InpSTtrains[i][j]
j = j + 1
for j in range(eom_ind, SizeHistInput):
InpNPtr0[i].SPtrain[j] = -1
InpNPtr0[i].NumSynType = 0
InpNPtr0[i].NumPreSyn = 0
NumSpike = []
for i in range(N + M):
NumSpike.append(0)
NumSynType = STypPar.shape[1]
SynTPtr0 = []
for i in range(NumSynType):
SynTPtr0.append(SynType())
SynTPtr0[i].No = i
SynTPtr0[i].gmax = STypPar[0][i]
SynTPtr0[i].tc_on = STypPar[1][i]
SynTPtr0[i].tc_off = STypPar[2][i]
SynTPtr0[i].Erev = STypPar[3][i]
SynTPtr0[i].Mg_gate = STypPar[4][i]
SynTPtr0[i].Mg_fac = STypPar[5][i]
SynTPtr0[i].Mg_slope = STypPar[6][i]
SynTPtr0[i].Mg_half = STypPar[7][i]
SynTPtr0[i].Gsyn = SynTPtr0[i].gmax * SynTPtr0[i].tc_on * \
SynTPtr0[i].tc_off / (SynTPtr0[i].tc_off - SynTPtr0[i].tc_on)
numST = SynPar.shape[1]
SPList = SPMtx
MaxNumSyn = SPList.shape[2]
ConMtx0 = []
com_c = []
for i in range(N):
for j in range(N + M):
com_c.append(SynList())
ConMtx0.append(com_c)
com_c = []
for i in range(N):
for j in range(N + M):
ConMtx0[i][j].NumSyn = 0
while int(SPList[i][j][ConMtx0[i][j].NumSyn]) > 0:
ConMtx0[i][j].NumSyn = ConMtx0[i][j].NumSyn + 1
if (ConMtx0[i][j].NumSyn >= MaxNumSyn):
break
if (ConMtx0[i][j].NumSyn > 0):
for a in range(ConMtx0[i][j].NumSyn):
ConMtx0[i][j].Syn.append(Synapse())
else:
ConMtx0[i][j].Syn = []
k = 0
for k in range(ConMtx0[i][j].NumSyn):
nst = SPList[i][j][k] - 1
if (j < N):
InList = FALSE
kk = 0
while (kk < NPtr0[j].NumPreSyn):
if (nst == NPtr0[j].PreSynList[kk]):
InList = TRUE
break
kk = kk + 1
ConMtx0[i][j].Syn[k].PreSynIdx = kk
if (InList == FALSE):
NPtr0[j].NumPreSyn = NPtr0[j].NumPreSyn + 1
NPtr0[j].PreSynList = [0] * NPtr0[j].NumPreSyn
NPtr0[j].PreSynList[kk] = nst
for num in range(NPtr0[j].NumPreSyn):
NPtr0[j].SDf.append(SynDepr())
NPtr0[j].SDf[kk].use = SynPar[1][nst]
NPtr0[j].SDf[kk].tc_rec = SynPar[2][nst]
NPtr0[j].SDf[kk].tc_fac = SynPar[3][nst]
for k2 in range(SizeHistOutput):
NPtr0[j].SDf[kk].Adepr[k2] = 1.0
NPtr0[j].SDf[kk].uprev[0] = SynPar[1][nst]
NPtr0[j].SDf[kk].Rprev[0] = 1.0
STno = int(SynPar[0][nst] - 1)
ConMtx0[i][j].Syn[k].STPtr = SynTPtr0[STno]
ConMtx0[i][j].Syn[k].wgt = SynPar[4][nst]
ConMtx0[i][j].Syn[k].dtax = SynPar[5][nst]
ConMtx0[i][j].Syn[k].p_fail = SynPar[6][nst]
InList = FALSE
kk = 0
while (
NPtr0[i].STList[kk] is not None and kk < NPtr0[i].NumSynType):
if (NPtr0[i].STList[kk].No ==
ConMtx0[i][j].Syn[k].STPtr.No):
InList = TRUE
kk = kk + 1
if (InList == FALSE):
NPtr0[i].STList[kk] = ConMtx0[i][j].Syn[k].STPtr
NPtr0[i].NumSynType = NPtr0[i].NumSynType + 1
NPtr0[i].gfONsyn[kk] = 0.0
NPtr0[i].gfOFFsyn[kk] = 0.0
else:
InList = FALSE
kk = 0
while (kk < InpNPtr0[j - N].NumPreSyn):
if (nst == InpNPtr0[j - N].PreSynList[kk]):
InList = TRUE
break
kk = kk + 1
ConMtx0[i][j].Syn[k].PreSynIdx = kk
if (InList == FALSE):
InpNPtr0[j - N].NumPreSyn = InpNPtr0[j -
N].NumPreSyn + 1
InpNPtr0[j - N].PreSynList = [0] * \
InpNPtr0[j - N].NumPreSyn
InpNPtr0[j - N].PreSynList[kk] = nst
for num in range(InpNPtr0[j - N].NumPreSyn):
InpNPtr0[j - N].SDf.append(SynDepr())
InpNPtr0[j - N].SDf[kk].use = SynPar[1][nst]
InpNPtr0[j - N].SDf[kk].tc_rec = SynPar[2][nst]
InpNPtr0[j - N].SDf[kk].tc_fac = SynPar[3][nst]
for k2 in range(SizeHistOutput):
InpNPtr0[j - N].SDf[kk].Adepr[k2] = 1.0
InpNPtr0[j - N].SDf[kk].uprev[0] = SynPar[1][nst]
InpNPtr0[j - N].SDf[kk].Rprev[0] = 1.0
STno = int(SynPar[0][nst] - 1)
ConMtx0[i][j].Syn[k].STPtr = SynTPtr0[STno]
ConMtx0[i][j].Syn[k].wgt = SynPar[4][nst]
ConMtx0[i][j].Syn[k].dtax = SynPar[5][nst]
ConMtx0[i][j].Syn[k].p_fail = SynPar[6][nst]
InList = FALSE
kk = 0
while (
NPtr0[i].STList[kk] is not None and kk < NPtr0[i].NumSynType):
if (NPtr0[i].STList[kk].No ==
ConMtx0[i][j].Syn[k].STPtr.No):
InList = TRUE
kk = kk + 1
if (InList == FALSE):
NPtr0[i].STList[kk] = ConMtx0[i][j].Syn[k].STPtr
NPtr0[i].NumSynType = NPtr0[i].NumSynType + 1
NPtr0[i].gfONsyn[kk] = 0.0
NPtr0[i].gfOFFsyn[kk] = 0.0
NoiseSyn = SynList()
NoiseSyn.NumSyn = NumSynType
NoiseSyn.Syn = []
for i in range(NoiseSyn.NumSyn):
NoiseSyn.Syn.append(Synapse())
for i in range(N):
for j in range(NoiseSyn.NumSyn):
STno = int(SynPar[0][numST - NoiseSyn.NumSyn + j] - 1)
NoiseSyn.Syn[j].STPtr = SynTPtr0[STno]
NoiseSyn.Syn[j].wgt = SynPar[4][numST - NoiseSyn.NumSyn + j]
NoiseSyn.Syn[j].dtax = SynPar[5][numST - NoiseSyn.NumSyn + j]
NoiseSyn.Syn[j].p_fail = SynPar[6][numST - NoiseSyn.NumSyn + j]
NPtr0[i].gfONnoise[j] = 0.0
NPtr0[i].gfOFFnoise[j] = 0.0
NoiseStep = 1 / (NoiseDistr.shape[1] - 1)
SynExpOn = [0] * NumSynType
SynExpOff = [0] * NumSynType
NumEvt = EvtTimes.shape[1]
NumView = ViewList.shape[0] * ViewList.shape[1]
fpOut = open("IDN_%i.dat" % UniquePrint, "w")
fpOut2 = open("IDN2_%i.dat" % UniquePrint, "w")
if (CtrPar[0][3] > NumVar):
CtrPar[0][3] = NumVar
NumOutp = 2
if (NumOutp > 0):
NumSynInp = [0] * N
N_osc = [0] * N
TnextSyn = [0] * N
t0 = Tstart
time_num = 0
while (t0 < Tstop):
if (t0 >= t_display):
print("%f percent" % (t0 * 100 / Tstop))
t_display = t0 + 100
t1 = t0 + dt0
EvtNo = -999
if (t1 > Tstop):
t1 = Tstop
for i in range(NumEvt):
if (EvtTimes[i * 2] > t0) and (EvtTimes[i * 2] <= t1):
t1 = EvtTimes[i * 2]
NextEvtT = t1
EvtNo = i * 2
else:
EvtOffT = EvtTimes[i * 2] + EvtTimes[i * 2 + 1]
if (EvtOffT > t0 and EvtOffT <= t1):
t1 = EvtOffT
NextEvtT = t1
EvtNo = i * 2 + 1
t11 = t1
for i in range(M):
if (InpNPtr0[i].SPtrain[InpNPtr0[i].SP_ind] > t0) and (
InpNPtr0[i].SPtrain[InpNPtr0[i].SP_ind] <= t11):
t11 = InpNPtr0[i].SPtrain[InpNPtr0[i].SP_ind]
print_flag = 1
else:
print_flag = 0
t1 = t11
for i in range(M):
if (InpNPtr0[i].SPtrain[InpNPtr0[i].SP_ind] == t1):
if (InpNPtr0[i].SP_ind > 0):
ISI_inp = t1 - \
InpNPtr0[i].SPtrain[InpNPtr0[i].SP_ind - 1]
else:
ISI_inp = 10.0e8
InpNPtr0[i].SpikeTimes[InpNPtr0[i].SP_ind] = InpNPtr0[i].SPtrain[InpNPtr0[i].SP_ind]
InpNPtr0[i].SP_ind = InpNPtr0[i].SP_ind + 1
j = NumSpike[i + N] % SizeHistOutput
for kk in range(InpNPtr0[i].NumPreSyn):
if (InpNPtr0[i].SDf[kk].use > 0.0):
InpNPtr0[i].SDf[kk].Adepr[j] = short_time(
SizeHistOutput).syndepr(InpNPtr0[i].SDf[kk], ISI_inp, j)
if (WriteST > 0):
fpISI = open(
"ISIu%d_%i.dat" %
(i + N, UniquePrint), "a")
fpISI.write("%f\n" % t1)
fpISI.close()
NumSpike[i + N] = NumSpike[i + N] + 1
for i in range(N):
t0_i = t0
if (t0_i < t1):
t1_i = t1
if (TnextSyn[i] > t0_i and TnextSyn[i] < t1_i):
t1_i = TnextSyn[i]
vp = copy.copy(NPtr0[i].v[0])
wp = copy.copy(NPtr0[i].v[1])
dt = t1_i - t0_i
if (NumSpike[i] > 0):
if ((t0_i -
NPtr0[i].SpikeTimes[(NumSpike[i] -
1) %
SizeHistOutput]) < 5):
flag_dv = 0
else:
flag_dv = 1
else:
flag_dv = 1
NPtr0[i] = copy.copy(NPtr0[i])
try:
NPtr0[i], gsyn_AN, gsyn_G, I_tot = short_time(
SizeHistOutput).update(
NPtr0[i], dt, NoiseSyn, flag_dv)
except OverflowError:
pass
if (stop_flag > 0):
print("%f %d %f %f\n" % (t0_i, i, vp, wp))
for j in range(NPtr0[i].NumSynType):
if (NPtr0[i].gfONsyn[j] <
0 or NPtr0[i].gfOFFsyn[j] < 0):
print(
"%d %d %f %f %f %f\n" %
(i, j, t0_i, t1_i, NPtr0[i].gfONsyn[j], NPtr0[i].gfOFFsyn[j]))
if (t1_i == t1):
gsyn1[i] = gsyn_AN
gsyn2[i] = gsyn_G
Isyn[i] = I_tot
if (I_tot < NPtr0[i].I_ref *
1.01 and I_tot > NPtr0[i].I_ref * 0.99):
flag_osc[i] = flag_osc[i] + 1
else:
flag_osc[i] = 0
if (flag_osc[i] >= 200 and NumOutp > 0):
N_osc[i] = N_osc[i] + 1
if ((NPtr0[i].v[0] >= NPtr0[i].Vup)
and (vp < NPtr0[i].Vup)):
t1_i = t0_i + dt * \
(NPtr0[i].Vup - vp) / (NPtr0[i].v[0] - vp)
if (NumSpike[i] > 0):
ISI = t1_i - \
NPtr0[i].SpikeTimes[(NumSpike[i] - 1) % SizeHistOutput]
else:
ISI = 10.0e8
if (ISI > 5):
w_Vup = wp + \
((NPtr0[i].v[1] - wp) / dt) * (t1_i - t0_i)
NPtr0[i].v[0] = NPtr0[i].Vr
NPtr0[i].v[1] = w_Vup + NPtr0[i].b
j = NumSpike[i] % SizeHistOutput
NPtr0[i].SpikeTimes[j] = t1_i
for kk in range(NPtr0[i].NumPreSyn):
if (NPtr0[i].SDf[kk].use > 0.0):
NPtr0[i].SDf[kk].Adepr[j] = short_time(
SizeHistOutput).syndepr(NPtr0[i].SDf[kk], ISI, j)
if (WriteST > 0):
fpISI = open(
"ISIu%d_%i.dat" %
(i, UniquePrint), "a")
fpISI.write("%f\n" % t1_i)
fpISI.close()
NumSpike[i] = NumSpike[i] + 1
dt = t1_i - t0_i
else:
NPtr0[i].v[0] = vp
NPtr0[i].v[1] = wp
# reset t1_i
t1_i = dt + t0_i
if (t1_i == t1):
gsyn_AN, I_tot, gsyn_G = short_time(
SizeHistOutput).set_gsyn(NPtr0[i], dt, vp, NoiseSyn)
gsyn1[i] = gsyn_AN
gsyn2[i] = gsyn_G
Isyn[i] = I_tot
for j in range(NoiseSyn.NumSyn):
SynExpOn[j] = math.exp(-dt /
(NoiseSyn.Syn[j].STPtr).tc_on)
SynExpOff[j] = math.exp(-dt /
(NoiseSyn.Syn[j].STPtr).tc_off)
rand_num = NoiseDistr[0][rand.randint(
0, 1 / NoiseStep)]
NPtr0[i].gfONnoise[j] = 0.0
NPtr0[i].gfOFFnoise[j] = 0.0
for j in range(NPtr0[i].NumSynType):
NPtr0[i].gfONsyn[j] *= math.exp(-dt /
(NPtr0[i].STList[j]).tc_on)
NPtr0[i].gfOFFsyn[j] *= math.exp(-dt /
(NPtr0[i].STList[j]).tc_off)
TnextSyn[i] = Tstop + 100.0
for j in range(N):
for k in range(ConMtx0[i][j].NumSyn):
kk = NumSpike[j] - 1
while (
kk >= 0 and (
NumSpike[j] -
kk) <= SizeHistOutput):
if (t0_i >= (
NPtr0[j].SpikeTimes[kk % SizeHistOutput] + ConMtx0[i][j].Syn[k].dtax)):
break
else:
if ((t1_i >= NPtr0[j].SpikeTimes[kk % SizeHistOutput] + ConMtx0[i][j].Syn[
k].dtax) and (
rand.uniform(0, 1) > ConMtx0[i][j].Syn[k].p_fail)):
for k2 in range(NPtr0[i].NumSynType):
if (NPtr0[i].STList[k2].No ==
ConMtx0[i][j].Syn[k].STPtr.No):
Aall = NPtr0[j].SDf[ConMtx0[i][j].Syn[k].PreSynIdx].Adepr[
kk % SizeHistOutput] * ConMtx0[i][j].Syn[k].wgt * \
ConMtx0[i][j].Syn[k].STPtr.Gsyn
NPtr0[i].gfONsyn[k2] += Aall
NPtr0[i].gfOFFsyn[k2] += Aall
if (NumOutp > 0):
NumSynInp[i] = NumSynInp[i] + 1.0
else:
if (NPtr0[j].SpikeTimes[kk % SizeHistOutput] +
ConMtx0[i][j].Syn[k].dtax < TnextSyn[i]):
TnextSyn[i] = NPtr0[j].SpikeTimes[kk %
SizeHistOutput] + ConMtx0[i][j].Syn[k].dtax
kk = kk - 1
for j in range(N, N + M):
for k in range(ConMtx0[i][j].NumSyn):
kk = NumSpike[j] - 1
while (kk >= 0):
if (t0_i >= (
InpNPtr0[j - N].SpikeTimes[kk] + ConMtx0[i][j].Syn[k].dtax)):
break
else:
if ((t1_i >= InpNPtr0[j - N].SpikeTimes[kk] + ConMtx0[i][j].Syn[k].dtax) and (
rand.uniform(0, 1) > ConMtx0[i][j].Syn[k].p_fail)):
for k2 in range(NPtr0[i].NumSynType):
if (NPtr0[i].STList[k2] ==
ConMtx0[i][j].Syn[k].STPtr):
Aall = InpNPtr0[j - N].SDf[ConMtx0[i][j].Syn[k].PreSynIdx].Adepr[kk %
SizeHistOutput] * ConMtx0[i][j].Syn[k].wgt * (ConMtx0[i][j].Syn[k].STPtr).Gsyn
NPtr0[i].gfONsyn[k2] += Aall
NPtr0[i].gfOFFsyn[k2] += Aall
if (NumOutp > 0):
NumSynInp[i] = NumSynInp[i] + 1.0
else:
if (InpNPtr0[j - N].SpikeTimes[kk] + \
ConMtx0[i][j].Syn[k].dtax < TnextSyn[i]):
TnextSyn[i] = InpNPtr0[j - N].SpikeTimes[kk] + \
ConMtx0[i][j].Syn[k].dtax
kk = kk - 1
t0_i = t1_i
for i in range(NumView):
fpOut.write("%lf %d" % (t1, ViewList[i][0]))
for k in range(int(CtrPar[0][3])):
fpOut.write(" %lf" % NPtr0[ViewList[i][0] - 1].v[k])
fpOut.write("\n")
for i in range(NumView):
fpOut2.write(" %f %f %f" %
(gsyn1[ViewList[i][0] -
1], gsyn2[ViewList[i][0] -
1], Isyn[ViewList[i][0] -
1]))
fpOut2.write("\n")
if (EvtNo >= 0 and t1 >= NextEvtT):
if ((EvtNo % 2) == 0):
for i in range(N):
NPtr0[i].Iinj = EvtMtx[int(i + (EvtNo / 2) * N)]
else:
for i in range(N):
NPtr0[i].Iinj = 0.0
t0 = t1
if (NumView > 0):
fpOut.close()
fpOut2.close()
STMtx = []
if (CtrPar[0][4] > 0):
for i in range(N + M):
if (os.path.exists('ISIu%d_0.dat' % i)):
ST = pd.read_table('ISIu%d_0.dat' % i, header=None)
content = []
for j in range(ST.shape[0]):
content.append(ST.iloc[j][0])
STMtx.append(content)
os.remove('ISIu%d_0.dat' % i)
else:
STMtx.append(-1)
T = []
V = []
if (ViewList is not None):
X = pd.read_table('IDN_%d.dat' % UniqueNum, header=None)
for i in range(X.shape[0]):
T.append(X.iloc[i][0])
content = []
for j in range(X.shape[1] - 1):
content.append(X.iloc[i][j + 1])
V.append(content)
os.remove('IDN_%d.dat' % UniqueNum)
os.remove('IDN2_0.dat')
scio.savemat('PFC_%dN_500ms.mat' %
(N + M), {'N': N, 'T': T, 'V': V, 'STMtx': STMtx})
class SynType:
def __init__(self):
"""
Parameters of short-term synaptic plasticity model
"""
self.No = 0
self.gmax = 0
self.tc_on = 0
self.tc_off = 0
self.Erev = 0
self.Mg_gate = 0
self.Mg_fac = 0
self.Mg_slope = 0
self.Mg_half = 0
self.Gsyn = 0
class Neuron:
"""
Parameters of neurons
"""
gfONsyn = None
gfOFFsyn = None
gfONnoise = None
gfOFFnoise = None
SpikeTimes = None
v = None
dv = None
def __init__(self):
MaxNumSTperN = six_layer_pfc().MaxNumSTperN
SizeHistOutput = six_layer_pfc().SizeHistOutput
self.Cm = 0
self.gL = 0
self.EL = 0
self.sf = 0
self.Vup = 0
self.tcw = 0
self.a = 0
self.b = 0
self.Vr = 0
self.Vth = 0
self.I_ref = 0
self.v_dep = 0
self.NumSynType = 0
self.Iinj = 0
self.v = [0] * 2
self.dv = [0] * 2
self.STList = []
self.gfONsyn = [0] * MaxNumSTperN
self.gfOFFsyn = [0] * MaxNumSTperN
self.gfONnoise = [0] * MaxNumSTperN
self.gfOFFnoise = [0] * MaxNumSTperN
self.SpikeTimes = [0] * SizeHistOutput
self.NumPreSyn = 0
self.PreSynList = []
self.SDf = []
class InpNeuron:
"""
Input parameters of neurons
"""
SPtrain = None
SpikeTimes = None
def __init__(self):
SizeHistInput = six_layer_pfc().SizeHistInput
self.SPtrain = [0] * SizeHistInput
self.SpikeTimes = [0] * SizeHistInput
self.SP_ind = 0
self.NumSynType = 0
self.NumPreSyn = 0
self.PreSynList = []
self.SDf = []
class Synapse:
"""
Synaptic parameters
"""
def __init__(self):
self.STPtr = SynType()
self.dtax = 0
self.wgt = 0
self.p_fail = 0
self.PreSynIdx = 0
class SynDepr:
"""
Parameters of synaptic current model
"""
Adepr = None
uprev = None
Rprev = None
def __init__(self):
SizeHistOutput = six_layer_pfc().SizeHistOutput
self.use = 0
self.tc_rec = 0
self.tc_fac = 0
self.Adepr = [0] * SizeHistOutput
self.uprev = [0] * SizeHistOutput
self.Rprev = [0] * SizeHistOutput
class SynList:
"""
Parameters of synapse list
"""
def __init__(self):
self.NumSyn = 0
self.Syn = []
if __name__ == '__main__':
"""
After downloading the data file on the network disk, modify the file path to the downloaded placement path
"""
test = six_layer_pfc()
inputpath = 'data100.mat'
test.mex_function(inputpath)
outputpath='PFC_99N_500ms.mat'
test.picture(outputpath)
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/MacaqueBrain/README.md
================================================
## Macaque Brain Simulation
## Description
Macaque Brain Simulation is a large scale brain modeling framework depending on braincog framework.
## Requirements:
* numpy >= 1.21.2
* scipy >= 1.8.0
* h5py >= 3.6.0
* torch >= 1.10
* torchvision >= 0.12.0
* torchaudio >= 0.11.0
* timm >= 0.5.4
* matplotlib >= 3.5.1
* einops >= 0.4.1
* thop >= 0.0.31
* pyyaml >= 6.0
* loris >= 0.5.3
* pandas >= 1.4.2
* tonic (special)
* pandas >= 1.4.2
## Input:
The binary connectivity matrix can be obtained from the following link:
https://drive.google.com/file/d/1LsNupIx3Nk-Cn_MowF6O-SCY27wdRYas/view?usp=sharing
The brain region's name can be obained from the following link:
https://drive.google.com/file/d/1iNI0HR3teUj4yshK8RlSJq6gIWbRdBI1/view?usp=sharing
## Example:
```shell
cd ~/examples/Multi-scale Brain Structure Simulation/MacaqueBrain/
python macaque_brain.py
```
## Parameters:
The parameters are similar to mouse brain simulation
## Citations:
If you find this package helpful, please consider citing the following papers:
@article{Liu2016,
author={Liu, Xin and Zeng, Yi and Zhang, Tielin and Xu, Bo},
title={Parallel Brain Simulator: A Multi-scale and Parallel Brain-Inspired Neural Network Modeling and Simulation Platform},
journal={Cognitive Computation},
year={2016},
month={Oct},
day={01},
volume={8},
number={5},
pages={967--981},
issn={1866-9964},
doi={10.1007/s12559-016-9411-y},
url={https://doi.org/10.1007/s12559-016-9411-y}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/MacaqueBrain/macaque_brain.py
================================================
import time
import numpy as np
import scipy.io as scio
import torch
from torch import nn
from braincog.base.node.node import *
from braincog.base.brainarea.BrainArea import *
import pandas as pd
import matplotlib.pyplot as plt
device = 'cuda:0'
class Syn(nn.Module):
def __init__(self, syn, weight, neuron_num, tao_d, tao_r, dt, device):
super().__init__()
self.pre = syn[1]
self.post = syn[0]
self.syn_num = len(syn)
self.w = torch.sparse_coo_tensor(syn.t(), weight,
size=(neuron_num, neuron_num))
self.tao_d = tao_d
self.tao_r = tao_r
self.dt = dt
self.lamda_d = self.dt / self.tao_d
self.lamda_r = self.dt / self.tao_r
self.s = torch.zeros(neuron_num, device=device)
self.r = torch.zeros(neuron_num, device=device)
self.dt = dt
def forward(self, neuron):
neuron.Iback = neuron.Iback + neuron.dt_over_tau * (
torch.randn(neuron.neuron_num, device=device, requires_grad=False) - neuron.Iback)
neuron.Ieff = neuron.Iback / neuron.sqrt_coeff * neuron.sig + neuron.mu
self.s = self.s + self.lamda_r * (-self.s + 1 / self.tao_d * neuron.spike)
self.r = self.r - self.lamda_d * self.r + self.dt * self.s
self.I = torch.sparse.mm(self.w, self.r.unsqueeze(-1)).squeeze() + neuron.Ieff
return self.I
class brain(nn.Module):
def __init__(self, syn, weight, neuron_model, p_neuron, dt, device):
super().__init__()
if neuron_model == 'HH':
self.neurons = HHNode(p_neuron, dt, device)
elif neuron_model == 'aEIF':
self.neurons = aEIF(p_neuron, dt, device)
self.neuron_num = len(p_neuron[0])
self.syns = Syn(syn, weight, self.neuron_num, 3, 6, dt, device)
def forward(self, inputs):
I = self.syns(self.neurons)
self.neurons(I)
def brain_region(neuron_num):
region = []
start = 0
end = 0
for i in range(len(neuron_num)):
end += neuron_num[i].item()
region.append([start, end])
start = end
return torch.tensor(region)
def neuron_type(neuron_num, ratio, regions):
neuron_num = neuron_num.reshape(-1, 1)
neuron_type = torch.floor(ratio * neuron_num).int() + regions[:, 0].reshape(-1, 1)
return neuron_type
def syn_within_region(syn_num, region):
start = 1
for neurons in region:
if start:
syn = torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)
start = 0
else:
syn = torch.concatenate((syn, torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)))
return syn
def syn_cross_region(weight_matrix, region):
start = 1
for i in range(len(weight_matrix)):
for j in range(len(weight_matrix)):
if weight_matrix[i][j] < 10:
continue
else:
pre = torch.randint(region[j][0], region[j][1],
size=(weight_matrix[i][j], 1), device=device)
post = torch.randint(region[i][0], region[i][1],
size=(weight_matrix[i][j], 1), device=device)
if start:
syn = torch.concatenate((post, pre), dim=1)
start = 0
else:
syn = torch.concatenate((syn, torch.concatenate((post, pre), dim=1)))
return syn
size = 10000
neuron_model = 'aEIF'
weight_matrix = torch.tensor(scio.loadmat('./maque.mat')['connect']) * 100
weight_matrix = weight_matrix.int()
syn_num = 10
NR = len(weight_matrix)
data = size * np.ones(NR)
neuron_num = np.array(data).astype(np.int32)
neuron_num = torch.from_numpy(neuron_num)
regions = brain_region(neuron_num)
ratio = torch.tensor([[0.7, 0.9, 1.0] * NR]).reshape(NR, 3)
neuron_types = neuron_type(neuron_num, ratio, regions)
syn_1 = syn_within_region(syn_num, regions)
syn_2 = syn_cross_region(weight_matrix, regions)
syn = torch.concatenate((syn_1, syn_2))
print(syn.shape)
weight = -torch.ones(len(syn), device=device, requires_grad=False)
if neuron_model == 'aEIF':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
v_reset = torch.zeros(regions[-1][1], device=device, requires_grad=False)
c_m = torch.zeros(regions[-1][1], device=device, requires_grad=False)
tao_w = torch.zeros(regions[-1][1], device=device, requires_grad=False)
alpha_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
beta_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
elif neuron_model == 'HH':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
for i in range(len(neuron_types)):
pre = syn[:, 0]
mask = (pre >= regions[i][0]) & (pre < neuron_types[i][0])
indices = torch.where(mask)
weight[indices] = 1.5
if neuron_model == 'aEIF':
if i < 177:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -44
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -110
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -110
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -66
c_m[regions[i][0]:neuron_types[i][0]] = 10
c_m[neuron_types[i][0]:neuron_types[i][1]] = 10
c_m[neuron_types[i][1]:neuron_types[i][2]] = 8.5
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
else:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -50
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -60
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -60
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -65
c_m[regions[i][0]:neuron_types[i][0]] = 20
c_m[neuron_types[i][0]:neuron_types[i][1]] = 2
c_m[neuron_types[i][1]:neuron_types[i][2]] = 4
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
elif neuron_model == 'HH':
threshold[regions[i][0]:neuron_types[i][0]] = 50
threshold[neuron_types[i][0]:neuron_types[i][1]] = 60
threshold[neuron_types[i][1]:neuron_types[i][2]] = 60
if neuron_model == 'aEIF':
p_neuron = [threshold, v_reset, c_m, tao_w, alpha_ad, beta_ad]
dt = 1
T = 300
elif neuron_model == 'HH':
p_neuron = [threshold, 120, 36, 0.3, 115, -12, 10.6, 1]
dt = 0.01
T = 10000
model = brain(syn, weight, neuron_model, p_neuron, dt, device)
Iraster = []
for t in range(T):
model(0)
print(torch.sum(model.neurons.spike))
Isp = torch.nonzero(model.neurons.spike)
print(len(Isp))
if (len(Isp) != 0):
left = t * torch.ones((len(Isp)), device=device, requires_grad=False)
left = left.reshape(len(left), 1)
mide = torch.concatenate((left, Isp), dim=1)
if (len(Isp) != 0) and (len(Iraster) != 0):
Iraster = torch.concatenate((Iraster, mide), dim=0)
if (len(Iraster) == 0) and (len(Isp) != 0):
Iraster = mide
Iraster = torch.tensor(Iraster).transpose(0, 1)
torch.save(Iraster, "./maque.pt")
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/MouseBrain/README.md
================================================
## Input:
* Program to enter a table of connection weights between 213 brain regions, which is saved in 'mouse_weight.pt'. The brain regions' name and neuron number are saved in 'mouse_brain_region.xlsx'. These two files are available in the follow link:
https://drive.google.com/drive/folders/1MWHY52gKPGneBEJxJN9DzE7thnLrhG1j?usp=sharing
## output
* The program generates a data file of the individual neuron firing time points recorded, and the large number of data points requires the use of drawing software to display the results.
## setting:
* scale: The scale of the number of neurons
* neuron_model: ‘HHNode’ or ‘aEIF’
* weight_matrix: Matrix of the number of synaptic connections between brain regions
* neuron_num: The number of neurons in each brain region
* ratio: the ratio of each neuron type in each brain region
* syn_num: average number of synapses per neuron within region
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/MouseBrain/mouse_brain.py
================================================
import time
import numpy as np
import scipy.io as scio
import torch
from torch import nn
from braincog.base.node.node import *
from braincog.base.brainarea.BrainArea import *
import pandas as pd
import matplotlib.pyplot as plt
device = 'cuda:0'
class Syn(nn.Module):
def __init__(self, syn, weight, neuron_num, tao_d, tao_r, dt, device):
super().__init__()
self.pre = syn[1]
self.post = syn[0]
self.syn_num = len(syn)
self.w = torch.sparse_coo_tensor(syn.t(), weight,
size=(neuron_num, neuron_num))
self.tao_d = tao_d
self.tao_r = tao_r
self.dt = dt
self.lamda_d = self.dt / self.tao_d
self.lamda_r = self.dt / self.tao_r
self.s = torch.zeros(neuron_num, device=device)
self.r = torch.zeros(neuron_num, device=device)
self.dt = dt
def forward(self, neuron):
neuron.Iback = neuron.Iback + neuron.dt_over_tau * (
torch.randn(neuron.neuron_num, device=device, requires_grad=False) - neuron.Iback)
neuron.Ieff = neuron.Iback / neuron.sqrt_coeff * neuron.sig + neuron.mu
self.s = self.s + self.lamda_r * (-self.s + 1 / self.tao_d * neuron.spike)
self.r = self.r - self.lamda_d * self.r + self.dt * self.s
self.I = torch.sparse.mm(self.w, self.r.unsqueeze(-1)).squeeze() + neuron.Ieff
return self.I
class brain(nn.Module):
def __init__(self, syn, weight, neuron_model, p_neuron, dt, device):
super().__init__()
if neuron_model == 'HH':
self.neurons = HHNode(p_neuron, dt, device)
elif neuron_model == 'aEIF':
self.neurons = aEIF(p_neuron, dt, device)
self.neuron_num = len(p_neuron[0])
self.syns = Syn(syn, weight, self.neuron_num, 3, 6, dt, device)
def forward(self, inputs):
I = self.syns(self.neurons)
self.neurons(I)
def brain_region(neuron_num):
region = []
start = 0
end = 0
for i in range(len(neuron_num)):
end += neuron_num[i].item()
region.append([start, end])
start = end
return torch.tensor(region)
def neuron_type(neuron_num, ratio, regions):
neuron_num = neuron_num.reshape(-1, 1)
neuron_type = torch.floor(ratio * neuron_num).int() + regions[:, 0].reshape(-1, 1)
return neuron_type
def syn_within_region(syn_num, region):
start = 1
for neurons in region:
if start:
syn = torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)
start = 0
else:
syn = torch.concatenate((syn, torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)))
return syn
def syn_cross_region(weight_matrix, region):
start = 1
for i in range(len(weight_matrix)):
for j in range(len(weight_matrix)):
if weight_matrix[i][j] < 10:
continue
else:
pre = torch.randint(region[j][0], region[j][1],
size=(weight_matrix[i][j], 1), device=device)
post = torch.randint(region[i][0], region[i][1],
size=(weight_matrix[i][j], 1), device=device)
if start:
syn = torch.concatenate((post, pre), dim=1)
start = 0
else:
syn = torch.concatenate((syn, torch.concatenate((post, pre), dim=1)))
return syn
scale = 0.1
neuron_model = 'aEIF'
weight_matrix = torch.load('./mouse_weight.pt') * scale
weight_matrix = weight_matrix.int()
data = pd.read_excel('./mouse_brain_region.xlsx', sheet_name='Sheet1', header=None)
data = data.values
name = data[0]
neuron_num = np.array(data[1] * scale).astype(np.int32)
neuron_num = torch.from_numpy(neuron_num)
ratio = torch.tensor([[0.7, 0.9, 1.0] * 213]).reshape(213, 3)
syn_num = 10
regions = brain_region(neuron_num)
neuron_types = neuron_type(neuron_num, ratio, regions)
syn_1 = syn_within_region(syn_num, regions)
syn_2 = syn_cross_region(weight_matrix, regions)
syn = torch.concatenate((syn_1, syn_2))
print(syn.shape)
weight = -torch.ones(len(syn), device=device, requires_grad=False)
if neuron_model == 'aEIF':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
v_reset = torch.zeros(regions[-1][1], device=device, requires_grad=False)
c_m = torch.zeros(regions[-1][1], device=device, requires_grad=False)
tao_w = torch.zeros(regions[-1][1], device=device, requires_grad=False)
alpha_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
beta_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
elif neuron_model == 'HH':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
for i in range(len(neuron_types)):
pre = syn[:, 0]
mask = (pre >= regions[i][0]) & (pre < neuron_types[i][0])
indices = torch.where(mask)
weight[indices] = 1.5
if neuron_model == 'aEIF':
if i < 177:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -44
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -110
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -110
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -66
c_m[regions[i][0]:neuron_types[i][0]] = 10
c_m[neuron_types[i][0]:neuron_types[i][1]] = 10
c_m[neuron_types[i][1]:neuron_types[i][2]] = 8.5
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
else:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -50
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -60
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -60
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -65
c_m[regions[i][0]:neuron_types[i][0]] = 20
c_m[neuron_types[i][0]:neuron_types[i][1]] = 2
c_m[neuron_types[i][1]:neuron_types[i][2]] = 4
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
elif neuron_model == 'HH':
threshold[regions[i][0]:neuron_types[i][0]] = 50
threshold[neuron_types[i][0]:neuron_types[i][1]] = 60
threshold[neuron_types[i][1]:neuron_types[i][2]] = 60
if neuron_model == 'aEIF':
p_neuron = [threshold, v_reset, c_m, tao_w, alpha_ad, beta_ad]
dt = 1
T = 300
elif neuron_model == 'HH':
p_neuron = [threshold, 120, 36, 0.3, 115, -12, 10.6, 1]
dt = 0.01
T = 10000
model = brain(syn, weight, neuron_model, p_neuron, dt, device)
Iraster = []
for t in range(T):
model(0)
print(torch.sum(model.neurons.spike))
Isp = torch.nonzero(model.neurons.spike)
print(len(Isp))
if (len(Isp) != 0):
left = t * torch.ones((len(Isp)), device=device, requires_grad=False)
left = left.reshape(len(left), 1)
mide = torch.concatenate((left, Isp), dim=1)
if (len(Isp) != 0) and (len(Iraster) != 0):
Iraster = torch.concatenate((Iraster, mide), dim=0)
if (len(Iraster) == 0) and (len(Isp) != 0):
Iraster = mide
Iraster = torch.tensor(Iraster).transpose(0, 1)
torch.save(Iraster, "./mouse.pt")
================================================
FILE: examples/Perception_and_Learning/Conversion/burst_conversion/CIFAR10_VGG16.py
================================================
import sys
sys.path.append('../../..')
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import matplotlib.pyplot as plt
import numpy as np
import time
from braincog.utils import setup_seed
from braincog.datasets.datasets import get_cifar10_data
device = torch.device('cuda:5' if torch.cuda.is_available() else 'cpu')
DATA_DIR = '/data/datasets'
class VGG16(nn.Module):
def __init__(self, relu_max=1): # 1 3e38
super(VGG16, self).__init__()
cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), nn.BatchNorm2d(64), nn.ReLU(True),
nn.Conv2d(64, 64, 3, 1, 1), nn.BatchNorm2d(64), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, 3, 1, 1), nn.BatchNorm2d(128), nn.ReLU(True),
nn.Conv2d(128, 128, 3, 1, 1), nn.BatchNorm2d(128), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(128, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True),
nn.Conv2d(256, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True),
nn.Conv2d(256, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(256, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.MaxPool2d(2, 2))
self.conv = cnn
self.fc = nn.Linear(512, 10, bias=True)
def forward(self, input):
conv = self.conv(input)
x = conv.view(conv.shape[0], -1)
output = self.fc(x)
return output
def get_cifar10_loader(batch_size, train_batch=None, num_workers=4, conversion=False, distributed=False):
normalize = transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(),
CIFAR10Policy(),
transforms.ToTensor(),
Cutout(n_holes=1, length=16),
normalize])
transform_test = transforms.Compose([transforms.ToTensor(), normalize])
train_batch = batch_size if train_batch is None else train_batch
cifar10_train = datasets.CIFAR10(root=DATA_DIR, train=True, download=False, transform=transform_test if conversion else transform_train)
cifar10_test = datasets.CIFAR10(root=DATA_DIR, train=False, download=False, transform=transform_test)
if distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(cifar10_train)
val_sampler = torch.utils.data.distributed.DistributedSampler(cifar10_test, shuffle=False, drop_last=True)
train_iter = torch.utils.data.DataLoader(cifar10_train, batch_size=train_batch, shuffle=False, num_workers=num_workers, pin_memory=True, sampler=train_sampler)
test_iter = torch.utils.data.DataLoader(cifar10_test, batch_size=batch_size, shuffle=False, num_workers=num_workers, pin_memory=True, sampler=val_sampler)
else:
train_iter = torch.utils.data.DataLoader(cifar10_train, batch_size=train_batch, shuffle=True, num_workers=num_workers, pin_memory=True)
test_iter = torch.utils.data.DataLoader(cifar10_test, batch_size=batch_size, shuffle=False, num_workers=num_workers, pin_memory=True)
return train_iter, test_iter
def train(net, train_iter, test_iter, optimizer, scheduler, device, num_epochs, losstype='mse'):
best = 0
net = net.to(device)
print("training on ", device)
if losstype == 'mse':
loss = torch.nn.MSELoss()
else:
loss = torch.nn.CrossEntropyLoss(label_smoothing=0.1)
losses = []
for epoch in range(num_epochs):
for param_group in optimizer.param_groups:
learning_rate = param_group['lr']
losss = []
train_l_sum, train_acc_sum, n, batch_count, start = 0.0, 0.0, 0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
label = y
if losstype == 'mse':
label = F.one_hot(y, 10).float()
l = loss(y_hat, label)
losss.append(l.cpu().item())
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
scheduler.step()
test_acc = evaluate_accuracy(test_iter, net)
losses.append(np.mean(losss))
print('epoch %d, lr %.6f, loss %.6f, train acc %.6f, test acc %.6f, time %.1f sec'
% (epoch + 1, learning_rate, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
if test_acc > best:
best = test_acc
torch.save(net.state_dict(), './CIFAR10_VGG16.pth')
def evaluate_accuracy(data_iter, net, device=None, only_onebatch=False):
if device is None and isinstance(net, torch.nn.Module):
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
net.eval()
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train()
n += y.shape[0]
if only_onebatch: break
return acc_sum / n
if __name__ == '__main__':
setup_seed(42)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
batch_size = 128
train_iter, test_iter, _, _ = get_cifar10_data(batch_size)
# train_iter, test_iter = get_cifar10_loader(batch_size)
print('dataloader finished')
lr, num_epochs = 0.05, 300
net = VGG16()
optimizer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9, weight_decay=5e-4)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, eta_min=0, T_max=num_epochs)
train(net, train_iter, test_iter, optimizer, scheduler, device, num_epochs, losstype='crossentropy')
net.load_state_dict(torch.load("./CIFAR10_VGG16.pth", map_location=device))
net = net.to(device)
acc = evaluate_accuracy(test_iter, net, device)
print(acc)
================================================
FILE: examples/Perception_and_Learning/Conversion/burst_conversion/README.md
================================================
# Conversion Method
Training deep spiking neural network with ann-snn conversion
replace ReLU and MaxPooling in pytorch model to make origin ANN to be converted SNN to finish complex tasks
## Results
```shell
python CIFAR10_VGG16.py
python converted_CIFAR10.py
```
You should first run the `CIFAR10_VGG16.py` to get a well-trained ANN.
Then `converted_CIFAR10.py` can be used to run the snn inference process.
### Citation
If you find this package helpful, please consider citing it:
```BibTex
@inproceedings{ijcai2022p345,
title = {Efficient and Accurate Conversion of Spiking Neural Network with Burst Spikes},
author = {Li, Yang and Zeng, Yi},
booktitle = {Proceedings of the Thirty-First International Joint Conference on
Artificial Intelligence, {IJCAI-22}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {2485--2491},
year = {2022},
month = {7},
}
@article{li2022spike,
title={Spike calibration: Fast and accurate conversion of spiking neural network for object detection and segmentation},
author={Li, Yang and He, Xiang and Dong, Yiting and Kong, Qingqun and Zeng, Yi},
journal={arXiv preprint arXiv:2207.02702},
year={2022}
}
```
================================================
FILE: examples/Perception_and_Learning/Conversion/burst_conversion/converted_CIFAR10.py
================================================
import sys
sys.path.append('../../..')
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import matplotlib
matplotlib.use('agg')
import numpy as np
from tqdm import tqdm
from copy import deepcopy
import matplotlib.pyplot as plt
import time
import os
from examples.Perception_and_Learning.Conversion.burst_conversion.CIFAR10_VGG16 import VGG16
from braincog.utils import setup_seed
from braincog.datasets.datasets import get_cifar10_data
from braincog.base.conversion import Convertor
import argparse
parser = argparse.ArgumentParser(description='Conversion')
parser.add_argument('--T', default=64, type=int, help='simulation time')
parser.add_argument('--p', default=0.99, type=float, help='percentile for data normalization. 0-1')
parser.add_argument('--gamma', default=5, type=int, help='burst spike and max spikes IF can emit')
parser.add_argument('--channelnorm', default=False, type=bool, help='use channel norm')
parser.add_argument('--lipool', default=True, type=bool, help='LIPooling')
parser.add_argument('--smode', default=True, type=bool, help='replace ReLU to IF')
parser.add_argument('--soft_mode', default=True, type=bool, help='soft reset or not')
parser.add_argument('--device', default='4', type=str, help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--cuda', default=True, type=bool, help='use cuda.')
parser.add_argument('--model_name', default='vgg16', type=str, help='model name. vgg16 or resnet20')
parser.add_argument('--merge', default=True, type=bool, help='merge conv and bn')
parser.add_argument('--train_batch', default=100, type=int, help='batch size for get max')
parser.add_argument('--batch_num', default=1, type=int, help='number of train batch')
parser.add_argument('--spicalib', default=0, type=int, help='allowance for spicalib')
parser.add_argument('--batch_size', default=128, type=int, help='batch size for testing')
parser.add_argument('--seed', default=42, type=int, help='seed')
args = parser.parse_args()
def evaluate_snn(test_iter, snn, device=None, duration=50):
accs = []
snn.eval()
for ind, (test_x, test_y) in tqdm(enumerate(test_iter)):
test_x = test_x.to(device)
test_y = test_y.to(device)
n = test_y.shape[0]
out = 0
with torch.no_grad():
snn.reset()
acc = []
# for t in tqdm(range(duration)):
for t in range(duration):
out += snn(test_x)
result = torch.max(out, 1).indices
result = result.to(device)
acc_sum = (result == test_y).float().sum().item()
acc.append(acc_sum / n)
accs.append(np.array(acc))
accs = np.array(accs).mean(axis=0)
i, show_step = 1, []
while 2 ** i <= duration:
show_step.append(2 ** i - 1)
i = i + 1
for iii in show_step:
print("timestep", str(iii).zfill(3) + ':', accs[iii])
print("best acc: ", max(accs))
if __name__ == '__main__':
print("Setting Arguments.. : ", args)
print("----------------------------------------------------------")
setup_seed(seed=args.seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
device = torch.device("cuda:%s" % args.device) if args.cuda else 'cpu'
train_iter, _, _, _ = get_cifar10_data(args.train_batch, same_da=True)
_, test_iter, _, _ = get_cifar10_data(args.batch_size, same_da=True)
if args.model_name == 'vgg16':
net = VGG16()
net.load_state_dict(torch.load("./CIFAR10_VGG16.pth", map_location=device))
net.eval()
net = net.to(device)
converter = Convertor(dataloader=train_iter,
device=device,
p=args.p,
channelnorm=args.channelnorm,
lipool=args.lipool,
gamma=args.gamma,
soft_mode=args.soft_mode,
merge=args.merge,
batch_num=args.batch_num,
spicalib=args.spicalib
)
snn = converter(net)
evaluate_snn(test_iter, snn, device, duration=args.T)
================================================
FILE: examples/Perception_and_Learning/Conversion/msat_conversion/CIFAR10_VGG16.py
================================================
import sys
sys.path.append('../../..')
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import matplotlib.pyplot as plt
import numpy as np
import time
from braincog.utils import setup_seed
from braincog.datasets.datasets import get_cifar10_data
device = torch.device('cuda:5' if torch.cuda.is_available() else 'cpu')
DATA_DIR = '/data/datasets'
class VGG16(nn.Module):
def __init__(self, relu_max=1): # 1 3e38
super(VGG16, self).__init__()
cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), nn.BatchNorm2d(64), nn.ReLU(True),
nn.Conv2d(64, 64, 3, 1, 1), nn.BatchNorm2d(64), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, 3, 1, 1), nn.BatchNorm2d(128), nn.ReLU(True),
nn.Conv2d(128, 128, 3, 1, 1), nn.BatchNorm2d(128), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(128, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True),
nn.Conv2d(256, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True),
nn.Conv2d(256, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(256, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.MaxPool2d(2, 2))
self.conv = cnn
self.fc = nn.Linear(512, 10, bias=True)
def forward(self, input):
conv = self.conv(input)
x = conv.view(conv.shape[0], -1)
output = self.fc(x)
return output
def get_cifar10_loader(batch_size, train_batch=None, num_workers=4, conversion=False, distributed=False):
normalize = transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(),
CIFAR10Policy(),
transforms.ToTensor(),
Cutout(n_holes=1, length=16),
normalize])
transform_test = transforms.Compose([transforms.ToTensor(), normalize])
train_batch = batch_size if train_batch is None else train_batch
cifar10_train = datasets.CIFAR10(root=DATA_DIR, train=True, download=False, transform=transform_test if conversion else transform_train)
cifar10_test = datasets.CIFAR10(root=DATA_DIR, train=False, download=False, transform=transform_test)
if distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(cifar10_train)
val_sampler = torch.utils.data.distributed.DistributedSampler(cifar10_test, shuffle=False, drop_last=True)
train_iter = torch.utils.data.DataLoader(cifar10_train, batch_size=train_batch, shuffle=False, num_workers=num_workers, pin_memory=True, sampler=train_sampler)
test_iter = torch.utils.data.DataLoader(cifar10_test, batch_size=batch_size, shuffle=False, num_workers=num_workers, pin_memory=True, sampler=val_sampler)
else:
train_iter = torch.utils.data.DataLoader(cifar10_train, batch_size=train_batch, shuffle=True, num_workers=num_workers, pin_memory=True)
test_iter = torch.utils.data.DataLoader(cifar10_test, batch_size=batch_size, shuffle=False, num_workers=num_workers, pin_memory=True)
return train_iter, test_iter
def train(net, train_iter, test_iter, optimizer, scheduler, device, num_epochs, losstype='mse'):
best = 0
net = net.to(device)
print("training on ", device)
if losstype == 'mse':
loss = torch.nn.MSELoss()
else:
loss = torch.nn.CrossEntropyLoss(label_smoothing=0.1)
losses = []
for epoch in range(num_epochs):
for param_group in optimizer.param_groups:
learning_rate = param_group['lr']
losss = []
train_l_sum, train_acc_sum, n, batch_count, start = 0.0, 0.0, 0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
label = y
if losstype == 'mse':
label = F.one_hot(y, 10).float()
l = loss(y_hat, label)
losss.append(l.cpu().item())
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
scheduler.step()
test_acc = evaluate_accuracy(test_iter, net)
losses.append(np.mean(losss))
print('epoch %d, lr %.6f, loss %.6f, train acc %.6f, test acc %.6f, time %.1f sec'
% (epoch + 1, learning_rate, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
if test_acc > best:
best = test_acc
torch.save(net.state_dict(), './CIFAR10_VGG16.pth')
def evaluate_accuracy(data_iter, net, device=None, only_onebatch=False):
if device is None and isinstance(net, torch.nn.Module):
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
net.eval()
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train()
n += y.shape[0]
if only_onebatch: break
return acc_sum / n
if __name__ == '__main__':
setup_seed(42)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
batch_size = 128
train_iter, test_iter, _, _ = get_cifar10_data(batch_size)
# train_iter, test_iter = get_cifar10_loader(batch_size)
print('dataloader finished')
lr, num_epochs = 0.05, 300
net = VGG16()
optimizer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9, weight_decay=5e-4)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, eta_min=0, T_max=num_epochs)
train(net, train_iter, test_iter, optimizer, scheduler, device, num_epochs, losstype='crossentropy')
net.load_state_dict(torch.load("./CIFAR10_VGG16.pth", map_location=device))
net = net.to(device)
acc = evaluate_accuracy(test_iter, net, device)
print(acc)
================================================
FILE: examples/Perception_and_Learning/Conversion/msat_conversion/README.md
================================================
# Script for experiment
```shell
python converted_CIFAR10.py --useDET --useDTT
```
## Note: Convertor
please use `convertor.py` here to replace and override `braincog/base/conversion/convertor.py` if you want to run multi-stage adaptive threshold in this project.
## Citation
If you find the code and dataset useful in your research, please consider citing:
```
@article{he2023improving,
title={Improving the Performance of Spiking Neural Networks on Event-based Datasets with Knowledge Transfer},
author={He, Xiang and Zhao, Dongcheng and Li, Yang and Shen, Guobin and Kong, Qingqun and Zeng, Yi},
journal={arXiv preprint arXiv:2303.13077},
year={2023}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
## Contents
If you are confused about using it or have other feedback and comments, please feel free to contact us via [hexiang2021@ia.ac.cn](hexiang2021@ia.ac.cn).
================================================
FILE: examples/Perception_and_Learning/Conversion/msat_conversion/converted_CIFAR10.py
================================================
# -*- coding: utf-8 -*-
# Time : 2023/4/19 15:56
# Author : Regulus
# FileName: converted_CIFAR10.py
# Explain:
# Software: PyCharm
import sys
sys.path.append('..')
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
import torchvision.datasets as datasets
# import matplotlib
# matplotlib.use('agg')
import numpy as np
from tqdm import tqdm
from braincog.utils import setup_seed
import os
from examples.Perception_and_Learning.Conversion.msat_conversion.CIFAR10_VGG16 import VGG16
import argparse
from braincog.datasets.datasets import get_cifar10_data
from braincog.base.conversion import Convertor, FolderPath
parser = argparse.ArgumentParser(description='Conversion')
parser.add_argument('--T', default=256, type=int, help='simulation time')
parser.add_argument('--p', default=1, type=float, help='percentile for data normalization. 0-1')
parser.add_argument('--gamma', default=1, type=int, help='burst spike and max spikes IF can emit')
parser.add_argument('--lateral_inhi', default=True, type=bool, help='LIPooling')
parser.add_argument('--data_norm', default=True, type=bool, help=' whether use data norm or not')
parser.add_argument('--smode', default=True, type=bool, help='replace ReLU to IF')
parser.add_argument('--device', default='7', type=str, help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--cuda', default=True, type=bool, help='use cuda.')
parser.add_argument('--model_name', default='vgg16', type=str, help='model name. vgg16 or resnet20')
parser.add_argument('--train_batch', default=512, type=int, help='batch size for get max')
parser.add_argument('--batch_size', default=128, type=int, help='batch size for testing')
parser.add_argument('--seed', default=23, type=int, help='seed')
parser.add_argument('--useDET', action='store_true', default=False, help='use DET')
parser.add_argument('--useDTT', action='store_true', default=False, help='use DTT')
parser.add_argument('--useSC', action='store_true', default=False, help='use SpikeConfidence')
args = parser.parse_args()
def evaluate_snn(test_iter, snn, device=None, duration=50):
folder_path = "./result_conversion_{}/snn_timestep{}_p{}_LIPooling{}_Burst{}".format(
args.model_name, duration, args.p, args.lateral_inhi, args.gamma)
if not os.path.exists(folder_path): # 判断是否存在文件夹如果不存在则创建为文件夹
os.makedirs(folder_path)
snn.eval()
FolderPath.folder_path = folder_path
accs = []
for ind, (test_x, test_y) in enumerate(tqdm(test_iter)):
test_x = test_x.to(device)
test_y = test_y.to(device)
n = test_y.shape[0]
out = 0
with torch.no_grad():
snn.reset()
acc = []
for t in range(duration):
out += snn(test_x)
result = torch.max(out, 1).indices
result = result.to(device)
acc_sum = (result == test_y).float().sum().item()
acc.append(acc_sum / n)
# break
accs.append(np.array(acc))
if True:
f = open('{}/result.txt'.format(folder_path), 'w')
f.write("Setting Arguments.. : {}\n".format(args))
accs = np.array(accs).mean(axis=0)
for iii in range(256):
if iii == 0 or iii == 3 or iii == 7 or (iii + 1) % 16 == 0:
f.write("timestep {}:{}\n".format(str(iii+1).zfill(3), accs[iii]))
f.write("max accs: {}, timestep:{}\n".format(max(accs), np.where(accs == max(accs))))
f.close()
accs = torch.from_numpy(accs)
torch.save(accs, "{}/accs.pth".format(folder_path))
if __name__ == '__main__':
print("Setting Arguments.. : ", args)
print("----------------------------------------------------------")
setup_seed(seed=args.seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
device = torch.device("cuda:%s" % args.device) if args.cuda else 'cpu'
train_iter, _, _, _ = get_cifar10_data(args.train_batch, same_da=True)
_, test_iter, _, _ = get_cifar10_data(args.batch_size, same_da=True)
if args.model_name == 'vgg16':
net = VGG16()
# net.load_state_dict(torch.load("./CIFAR10_VGG16.pth", map_location=device))
net.eval()
net = net.to(device)
converter = Convertor(dataloader=train_iter,
device=device,
p=1.0,
channelnorm=False,
lipool=True,
gamma=1,
soft_mode=True,
merge=True,
batch_num=1,
spicalib=False,
useDET=args.useDET,
useDTT=args.useDTT,
useSC=args.useSC
)
snn = converter(net)
evaluate_snn(test_iter, snn, device, duration=args.T)
================================================
FILE: examples/Perception_and_Learning/Conversion/msat_conversion/convertor.py
================================================
import torch
import torch.nn as nn
from braincog.base.connection.layer import SMaxPool, LIPool
from .merge import mergeConvBN
from .spicalib import SpiCalib
import types
import os
import sys
layer_index = 0 # layer index for SNode
class FolderPath:
folder_path = "init"
class HookScale(nn.Module):
""" 在每个ReLU层后记录该层的百分位最大值
For channelnorm: 获取最大值时使用了torch.quantile
For layernorm: 使用sort,然后手动取百分比,因为quantile在计算单个通道时有上限,batch较大时易出错
"""
def __init__(self,
p: float = 0.9995,
channelnorm: bool = False,
gamma: float = 0.999,
):
super().__init__()
if channelnorm:
self.register_buffer('scale', torch.tensor(0.0))
else:
self.register_buffer('scale', torch.tensor(0.0))
self.p = p
self.channelnorm = channelnorm
self.gamma = gamma
def forward(self, x):
x = torch.where(x.detach() < self.gamma, x.detach(),
torch.tensor(self.gamma, dtype=x.dtype, device=x.device))
if len(x.shape) == 4 and self.channelnorm:
num_channel = x.shape[1]
tmp = torch.quantile(x.permute(1, 0, 2, 3).reshape(num_channel, -1), self.p, dim=1,
interpolation='lower') + 1e-10
self.scale = torch.max(tmp, self.scale)
else:
sort, _ = torch.sort(x.view(-1))
self.scale = torch.max(sort[int(sort.shape[0] * self.p) - 1], self.scale)
return x
class Hookoutput(nn.Module):
"""
在伪转换中为ReLU和ClipQuan提供包装,用于监控其输出
"""
def __init__(self, module):
super(Hookoutput, self).__init__()
self.activation = 0.
self.operation = module
def forward(self, x):
output = self.operation(x)
self.activation = output.detach()
return output
class Scale(nn.Module):
"""
对前向过程的值进行缩放
"""
def __init__(self, scale: float = 1.0):
super().__init__()
self.register_buffer('scale', scale)
def forward(self, x):
if len(self.scale.shape) == 1:
return self.scale.unsqueeze(0).unsqueeze(2).unsqueeze(3).expand_as(x) * x
else:
return self.scale * x
def reset(self):
"""
转换的网络来自ANN,需要将新附加上的脉冲module进行reset
判断module名称并调用各自节点的reset方法
"""
children = list(self.named_children())
for i, (name, child) in enumerate(children):
if isinstance(child, (SNode, LIPool, SMaxPool)):
child.reset()
else:
reset(child)
class Convertor(nn.Module):
"""ANN2SNN转换器
用于转换完整的pytorch模型,使用dataloader中部分数据进行最大值计算,通过p控制获取第p百分比最大值
channlenorm: https://arxiv.org/abs/1903.06530
channelnorm可以对每个通道获取最大值并进行权重归一化
gamma: https://arxiv.org/abs/2204.13271
gamma可以控制burst spikes的脉冲数,burst spike可以提高神经元的脉冲发放能力,减小信息残留
lipool: https://arxiv.org/abs/2204.13271
lipool用于使用侧向抑制机制进行最大池化,LIPooling能够对SNN中的最大池化进行有效的转换
soft_mode: https://arxiv.org/abs/1612.04052
soft_mode被称为软重置,可以减小重置过程神经元的信息损失,有效提高转换的性能
merge用于是否对网络中相邻的卷积和BN层进行融合
batch_norm控制对dataloader的数据集的用量
"""
def __init__(self,
dataloader,
device=None,
p=0.9995,
channelnorm=False,
lipool=True,
gamma=1,
soft_mode=True,
merge=True,
batch_num=1,
spicalib=0,
useDET=False, useDTT=False, useSC=None
):
super(Convertor, self).__init__()
self.dataloader = dataloader
self.device = device
self.p = p
self.channelnorm = channelnorm
self.lipool = lipool
self.gamma = gamma
self.soft_mode = soft_mode
self.merge = merge
self.batch_num = batch_num
self.spicalib = spicalib
self.useDET = useDET
self.useDTT = useDTT
self.useSC = useSC
def forward(self, model):
model.eval()
model = Convertor.register_hook(model, self.p, self.channelnorm, self.gamma)
model = Convertor.get_percentile(model, self.dataloader, self.device, batch_num=self.batch_num)
model = mergeConvBN(model) if self.merge else model
model = Convertor.replace_for_spike(model, self.lipool, self.soft_mode, self.gamma, self.spicalib, self.useDET,
self.useDTT, self.useSC)
model.reset = types.MethodType(reset, model)
return model
@staticmethod
def register_hook(model, p=0.99, channelnorm=False, gamma=0.999):
""" Reference: https://github.com/fangwei123456/spikingjelly
将网络的每一层后注册一个HookScale类
该方法在仿真上等效于与对权重进行归一化操作,且易扩展到任意结构的网络中
"""
children = list(model.named_children())
for _, (name, child) in enumerate(children):
if isinstance(child, nn.ReLU):
model._modules[name] = nn.Sequential(nn.ReLU(), HookScale(p, channelnorm, gamma))
else:
Convertor.register_hook(child, p, channelnorm, gamma)
return model
@staticmethod
def get_percentile(model, dataloader, device, batch_num=1):
"""
该函数需与具有HookScale层的网络配合使用
"""
for idx, (data, _) in enumerate(dataloader):
data = data.to(device)
if idx >= batch_num:
break
model(data)
return model
@staticmethod
def replace_for_spike(model, lipool=True, soft_mode=True, gamma=1, spicalib=0, useDET=False, useDTT=False, useSC=None):
"""
该函数用于将定义好的ANN模型转换为SNN模型
ReLU单元将被替换为脉冲神经元,
如果模型中使用了最大池化,lipool参数将定义使用常规模型还是LIPooling方法
"""
children = list(model.named_children())
for _, (name, child) in enumerate(children):
if isinstance(child, nn.Sequential) and len(child) == 2 and isinstance(child[0], nn.ReLU) and isinstance(child[1], HookScale):
global layer_index
model._modules[name] = nn.Sequential(
Scale(1.0 / child[1].scale),
SNode(soft_mode, gamma, useDET=useDET, useDTT=useDTT, useSC=useSC, layer_index=layer_index),
SpiCalib(spicalib),
Scale(child[1].scale)
)
layer_index += 1
if isinstance(child, nn.MaxPool2d):
model._modules[name] = LIPool(child) if lipool else SMaxPool(child)
else:
Convertor.replace_for_spike(child, lipool, soft_mode, gamma, useDET=useDET, useDTT=useDTT, useSC=useSC)
return model
class SNode(nn.Module):
"""
用于转换后的SNN的神经元模型
IF神经元模型由gamma=1确定,当gamma为其他大于1的值时,即为使用burst神经元模型
soft_mode用于定义神经元的重置方法,soft重置能够极大地减少神经元在重置过程的信息损失
"""
def __init__(self, soft_mode=False, gamma=5, useDET=False, useDTT=False, useSC=None, layer_index=1):
super(SNode, self).__init__()
self.threshold = 1.0
self.maxThreshold = 1.0
self.soft_mode = soft_mode
self.gamma = gamma
self.mem = 0
self.spike = 0
self.Vm = 0.
self.summem = 0.
self.t = 0
self.all_spike = 0
self.V_T = 0
self.useDET = useDET
self.useDTT = useDTT
self.useSC = useSC
self.layer_index = layer_index
# hyperparameters
self.alpha = 0
self.ka = 0
self.ki = 0
self.C = 0
self.tau_mp = 0
self.tau_rd = 0
# record sin
self.mem_16 = 0.0
self.spike_mask = 0
self.sin_spikenum = 0.0
self.sin_ratio = [] # snn中sin占负的比例
self.last_spike = 0
self.confidence = []
self.neg_ratio = [] # ann中负的占总的比例
self.sin_all_ratio = [] # snn中sin占总的比例
self.pos_all_ratio = [] # snn中pos占总的比例
self.should_all_ratio = [] # snn中pos应该发但是没发占总的比例
self.confidence = [] # snn中sin占所有发的比例
self.avg_error_spikenum = [] # snn中错发的平均个数
def forward(self, x):
self.mem = self.mem + x
self.spike = torch.zeros_like(x)
if self.t == 0:
self.threshold = torch.full(x.shape, 1.0 * self.maxThreshold).to(x.device)
self.V_T = -torch.full(x.shape, self.maxThreshold).to(x.device)
# init hyperparameters
hp = []
path = FolderPath.folder_path.split('/')
path = os.path.join(path[0], path[1], path[2], 'hyperparameters.txt')
with open(path, 'r') as f:
data = f.readlines() # 将txt中所有字符串读入data
for ind, line in enumerate(data):
numbers = line.split() # 将数据分隔
hp.append(list(map(float, numbers))[0]) # 转化为浮点数
self.alpha = hp[0]
self.ka = hp[1]
self.ki = hp[2]
self.C = hp[3]
self.tau_mp = hp[4]
self.tau_rd = hp[5]
else:
DTT = self.tau_mp * (self.alpha * (self.last_mem - self.Vm) + self.V_T + self.ka * torch.log(
1 + torch.exp((self.last_mem - self.Vm) / self.ki)))
DET = self.tau_rd * torch.exp(-1 * x / self.C)
if self.useDET is True and self.useDTT is True:
self.threshold = DET + DTT
elif self.useDTT is True:
self.threshold = DTT
elif self.useDET is True:
self.threshold = DET
else:
print("wrong logics")
sys.exit()
self.threshold = torch.sigmoid(self.threshold)
self.threshold *= self.maxThreshold
self.spike = (self.mem / self.threshold).floor().clamp(min=0, max=self.gamma)
self.soft_reset() if self.soft_mode else self.hard_reset
if self.useSC is True:
if self.t < 16:
# read confidence
path = FolderPath.folder_path.split('/')
path = os.path.join(path[0], path[1], path[2], 'neuron_confidence_vgg16.txt')
with open(path, 'r') as f:
data = f.readlines() # 将txt中所有字符串读入data
for ind, line in enumerate(data):
numbers = line.split() # 将数据分隔
self.confidence.append(list(map(float, numbers))[0]) # 转化为浮点数
mask = (torch.rand(x.shape) >= (1.0 - self.confidence[self.layer_index])).float().cuda()
self.spike = self.spike * mask # random drop
self.all_spike += self.spike
out = self.spike * self.threshold
self.t += 1
self.last_mem = self.mem
self.summem += self.mem
self.Vm = (self.summem / self.t)
return out
def hard_reset(self):
"""
硬重置后神经元的膜电势被重置为0
"""
self.mem = self.mem * (1 - self.spike.detach())
def soft_reset(self):
"""
软重置后神经元的膜电势为神经元当前膜电势减去阈值
"""
self.mem = self.mem - self.threshold * self.spike.detach()
def reset(self):
self.mem = 0
self.spike = 0
self.maxThreshold = 1.0
================================================
FILE: examples/Perception_and_Learning/IllusionPerception/AbuttingGratingIllusion/distortion/__init__.py
================================================
from .abutting_grating_illusion import ag_distort_28, ag_distort_224, ag_distort_silhouette, save_image, get_silhouette_data
================================================
FILE: examples/Perception_and_Learning/IllusionPerception/AbuttingGratingIllusion/distortion/abutting_grating_illusion/__init__.py
================================================
from .abutting_grating_distortion import ag_distort_28, ag_distort_224, ag_distort_silhouette, save_image, get_silhouette_data
================================================
FILE: examples/Perception_and_Learning/IllusionPerception/AbuttingGratingIllusion/distortion/abutting_grating_illusion/abutting_grating_distortion.py
================================================
import torch
from torchvision import datasets, transforms
import time
import os
import matplotlib.pyplot as plt
import torch
from torchvision import datasets, transforms
import time
import os
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import pickle
from PIL import Image
import numpy as np
from torchvision import utils
import os
seed = 1000
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def save_image(image, filename):
assert len(image.shape) == 3, "The image must have only three dimensions of C,W,H."
utils.save_image(image, filename)
def get_mnist_data(train = False, batch_size = 100):
path = './datasets/' # might need to change based on where to call this function
#transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
transform = transforms.Compose([transforms.ToTensor()])
if train:
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(path, train=True, download=False, transform=transform),
batch_size=batch_size, shuffle=False)
return train_loader
else:
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(path, train=False, download=False, transform=transform),
batch_size=batch_size, shuffle=False)
return test_loader
def get_silhouette_data(path):
'''
path: dir path to the silhouette image samples of 16-clas-ImageNet
'''
labels = os.listdir(path)
datasets = []
#transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
transform = transforms.Compose([transforms.ToTensor()])
for label in labels:
for img_name in os.listdir(f"{path}/{label}"):
img_path = f"{path}/{label}/{img_name}"
img = Image.open(img_path)
img = transform(img).unsqueeze(0)
datasets.append((img, label))
return datasets
def ag_distort_28(imgs, threshold=0, interval=4, phase=2, direction=(1,0)):
#return imgs
assert len(imgs.shape) == 4, "The images must have four dimensions of B,C,W,H."
B,C,W,H = imgs.shape
mask_fg = (imgs>threshold).float()
mask_bg = 1 - mask_fg
gratings_fg = torch.zeros_like(imgs)
gratings_bg = torch.zeros_like(imgs)
for w in range(W):
for h in range(H):
if (direction[0]*w+direction[1]*h)%interval==0:
gratings_fg[:,:,w,h] = 1
if (direction[0]*w+direction[1]*h)%interval==phase:
gratings_bg[:,:,w,h] = 1
masked_gratings_fg = mask_fg*gratings_fg
masked_gratings_bg = mask_bg*gratings_bg
ag_image = masked_gratings_fg + masked_gratings_bg
return ag_image
def transform_224(imgs):
imgs = torch.nn.functional.interpolate(imgs, scale_factor = 8, mode = 'bilinear', align_corners = False)
imgs = torch.cat([imgs, imgs, imgs], dim=1)
return imgs
def ag_distort_224(imgs, threshold=0, interval=8, phase=4, direction=(1,0)):
assert len(imgs.shape) == 4, "The images must have four dimensions of C,W,H."
imgs = torch.nn.functional.interpolate(imgs, scale_factor = 8, mode = 'bilinear', align_corners = False)
imgs = torch.cat([imgs, imgs, imgs], dim=1)
#return imgs
B,C,W,H = imgs.shape
mask_fg = (imgs>threshold).float()
mask_bg = 1 - mask_fg
gratings_fg = torch.zeros_like(imgs)
gratings_bg = torch.zeros_like(imgs)
for w in range(W):
for h in range(H):
if (direction[0]*w+direction[1]*h)%interval==0:
gratings_fg[:,:,w,h] = 1
if (direction[0]*w+direction[1]*h)%interval==phase:
gratings_bg[:,:,w,h] = 1
masked_gratings_fg = mask_fg*gratings_fg
masked_gratings_bg = mask_bg*gratings_bg
ag_image = masked_gratings_fg + masked_gratings_bg
return ag_image
def ag_distort_silhouette(imgs, threshold=0.5, interval=2, phase=1, direction=(1,0)):
assert len(imgs.shape) == 4, "The image must have only three dimensions of C,W,H."
#imgs = torch.nn.functional.interpolate(imgs, scale_factor = 2, mode = 'bilinear', align_corners = False)
B,C,W,H = imgs.shape
mask_fg = (imgs 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
genotype = eval('genotypes.%s' % args.arch)
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
C=args.init_channels,
layers=args.layers,
auxiliary=args.auxiliary,
genotype=genotype,
parse_method=args.parse_method,
back_connection=args.back_connection,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
)
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=list(range(args.num_gpu))).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
# print(model.get_attr('mu'))
# print(model.get_attr('sigma'))
# if args.critical_loss or args.spike_rate:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model, device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
temporal_flatten=args.temporal_flatten,
portion=args.train_portion,
_logger=_logger,
)
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
if args.distributed:
state_dict = torch.load(args.eval_checkpoint)['state_dict_ema']
new_state_dict = OrderedDict()
# add module prefix for DDP
for k, v in state_dict.items():
k = 'module.' + k
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
# else:
# load_checkpoint(model, args.eval_checkpoint, args.model_ema)
for i in range(1):
val_metrics = validate(start_epoch, model, loader_eval, validate_loss_fn, args,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
print(f"Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
# return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=output_dir, recovery_dir=output_dir, decreasing=decreasing)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
if args.distributed:
loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler, model_ema=model_ema, mixup_fn=mixup_fn)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics = validate(epoch, model, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics = validate(
epoch, model_ema.ema, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast, log_suffix=' (EMA)',
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(output_dir, 'summary.csv'),
write_header=best_metric is None)
# if saver is not None and epoch >= args.n_warm_up:
if saver is not None:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
except KeyboardInterrupt:
pass
if best_metric is not None:
_logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and loader.mixup_enabled:
loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
model.drop_path_prob = args.drop_path_prob * epoch / args.epochs
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
# t, k = adjust_surrogate_coeff(100, args.epochs)
# model.set_attr('t', t)
# model.set_attr('k', k)
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
if not args.prefetcher or args.dataset != 'imnet':
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
if mixup_fn is not None:
inputs, target = mixup_fn(inputs, target)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
with amp_autocast():
output = model(inputs)
loss = loss_fn(output, target)
if not (args.cut_mix | args.mix_up | args.event_mix) and args.dataset != 'imnet':
# print(output.shape, target.shape)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
if args.opt == 'lamb':
optimizer.step(epoch=epoch)
else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
losses_m.update(reduced_loss.item(), inputs.size(0))
closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args, amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
end = time.time()
last_idx = len(loader) - 1
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat) and not args.critical_loss:
model.set_requires_fp(True)
# if not args.critical_loss:
# model.set_requires_fp(False)
with amp_autocast():
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
if not args.distributed:
if visualize:
x = model.get_fp()
feature_path = os.path.join(args.output_dir, 'feature_map')
if os.path.exists(feature_path) is False:
os.mkdir(feature_path)
save_feature_map(x, feature_path)
# if not args.critical_loss:
# model_config.set_requires_fp(False)
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
tot_spike = model.get_tot_spike() if hasattr(model, 'get_tot_spike') else 0.
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'TotSpike: {tot_spike}'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
tot_spike=tot_spike
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg)])
if not args.distributed:
if tsne:
feature_vec = torch.cat(feature_vec)
feature_cls = torch.cat(feature_cls)
plot_tsne(feature_vec, feature_cls, os.path.join(args.output_dir, 't-sne-2d.eps'))
plot_tsne_3d(feature_vec, feature_cls, os.path.join(args.output_dir, 't-sne-3d.eps'))
if conf_mat:
logits_vec = torch.cat(logits_vec)
labels_vec = torch.cat(labels_vec)
plot_confusion_matrix(logits_vec, labels_vec, os.path.join(args.output_dir, 'confusion_matrix.eps'))
return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/Perception_and_Learning/NeuEvo/separate_loss.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
from braincog.base.utils.criterions import UnilateralMse
from utils import num_ops, type_num, edge_num
__all__ = ['ConvSeparateLoss', 'TriSeparateLoss']
class MseSeparateLoss(nn.modules.loss._Loss):
def __init__(self, weight=0.1, size_average=None, ignore_index=-100,
reduce=None, reduction='mean'):
super(MseSeparateLoss, self).__init__(size_average, reduce, reduction)
self.ignore_index = ignore_index
self.weight = weight
self.criterion = UnilateralMse(1.)
def forward(self, input1, target1, input2):
loss1 = self.criterion(input1, target1)
loss2 = -F.mse_loss(input2, torch.tensor(0.5,
requires_grad=False).cuda())
return loss1 + self.weight * loss2, loss1.item(), loss2.item()
class ConvSeparateLoss(nn.modules.loss._Loss):
"""Separate the weight value between each operations using L2"""
def __init__(self, loss1_fn, weight=0.1, size_average=None, ignore_index=-100,
reduce=None, reduction='mean'):
super(ConvSeparateLoss, self).__init__(size_average, reduce, reduction)
self.ignore_index = ignore_index
self.weight = weight
self.loss1_fn = loss1_fn
def forward(self, input1, target1, input2):
loss1 = self.loss1_fn(input1, target1)
# loss2 = -F.mse_loss(input2, torch.tensor(0.5, requires_grad=False).cuda())
# loss2 = -torch.std(input2, dim=-1).sum()
# + F.mse_loss(torch.mean(input2, dim=-1), torch.tensor(0.2, requires_grad=False).cuda())
# loss_std = 0
# loss_avg = 0.
# edge = edge_num + edge_num
# edge_input2 = torch.split(input2, edge, dim=0)
# for i in range(len(edge)):
# avg_e = 2 / (edge[i] * num_ops)
# loss_avg += 5 * F.mse_loss(torch.mean(edge_input2[i]), torch.tensor(avg_e, requires_grad=False).cuda())
# loss_std += -torch.std(edge_input2[i]).sum()
# loss2 = loss_std + loss_avg
# loss2 = torch.tensor([0.], device=input1.device)
loss2 = - 0.2 * torch.std(input2)
return loss1 + self.weight * loss2, loss1.item(), loss2.item()
class TriSeparateLoss(nn.modules.loss._Loss):
"""Separate the weight value between each operations using L1"""
def __init__(self, loss1_fn, weight=0.1, size_average=None, ignore_index=-100,
reduce=None, reduction='mean'):
super(TriSeparateLoss, self).__init__(size_average, reduce, reduction)
self.ignore_index = ignore_index
self.weight = weight
self.loss1_fn = loss1_fn
def forward(self, input1, target1, input2):
loss1 = F.cross_entropy(input1, target1)
loss2 = -F.l1_loss(input2, torch.tensor(0.5,
requires_grad=False).cuda())
return loss1 + self.weight * loss2, loss1.item(), loss2.item()
================================================
FILE: examples/Perception_and_Learning/NeuEvo/train.py
================================================
import os
import sys
import time
import logging
import torch
import utils as dutils
import argparse
import numpy as np
import torch.utils
import torch.nn as nn
from braincog.model_zoo.NeuEvo import genotypes
from braincog.model_zoo.NeuEvo.model import NetworkCIFAR as Network
import torchvision.datasets as dset
import torch.backends.cudnn as cudnn
from thop import profile
from braincog.datasets.datasets import build_transform
from braincog.base.utils.criterions import UnilateralMse
parser = argparse.ArgumentParser("cifar")
parser.add_argument('--data', type=str, default='/data/datasets',
help='location of the data corpus')
parser.add_argument('--dataset', type=str, default='cifar10',
help='cifar10 or cifar 100 for training')
parser.add_argument('--batch-size', type=int, default=128, help='batch size')
parser.add_argument('--learning_rate', type=float,
default=0.025, help='init learning rate')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--momentum', type=float, default=0.9, help='momentum')
parser.add_argument('--weight_decay', type=float,
default=3e-4, help='weight decay')
parser.add_argument('--report_freq', type=float,
default=50, help='report frequency')
parser.add_argument('--device', type=int, default=0, help='gpu device id')
parser.add_argument('--multi-gpus', action='store_true',
default=False, help='use multi gpus')
parser.add_argument('--parse_method', type=str,
default='darts', help='experiment name')
parser.add_argument('--epochs', type=int, default=600,
help='num of training epochs')
parser.add_argument('--init-channels', type=int,
default=64, help='num of init channels')
parser.add_argument('--layers', type=int, default=16,
help='total number of layers')
parser.add_argument('--model_path', type=str,
default='saved_models', help='path to save the model')
parser.add_argument('--auxiliary', action='store_true',
default=False, help='use auxiliary tower')
parser.add_argument('--auxiliary_weight', type=float,
default=0.4, help='weight for auxiliary loss')
parser.add_argument('--cutout', action='store_true',
default=False, help='use cutout')
parser.add_argument('--cutout_length', type=int,
default=16, help='cutout length')
parser.add_argument('--auto_aug', action='store_true',
default=False, help='use auto augmentation')
parser.add_argument('--drop_path_prob', type=float,
default=0.2, help='drop path probability')
parser.add_argument('--save', type=str, default='EXP', help='experiment name')
parser.add_argument('--seed', type=int, default=42, help='random seed')
parser.add_argument('--arch', type=str, default='DARTS',
help='which architecture to use')
parser.add_argument('--grad_clip', type=float,
default=5, help='gradient clipping')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='path to latest checkpoint (default: none)')
parser.add_argument('--img_size', default=32, type=int)
parser.add_argument('--step', default=8, type=int)
parser.add_argument('--node-type', default='PLIFNode', type=str)
parser.add_argument('--suffix', default='', type=str)
class TrainNetwork(object):
"""The main train network"""
def __init__(self, args):
super(TrainNetwork, self).__init__()
self.args = args
self.dur_time = 0
self._init_log()
self._init_device()
self._init_data_queue()
self._init_model()
def _init_log(self):
self.args.save = '/data/floyed/darts/logs/eval/' + self.args.arch + '/' + 'cifar10' + '/eval-{}-{}-{}'.format(
self.args.save, time.strftime('%Y%m%d-%H%M'), args.suffix)
dutils.create_exp_dir(self.args.save, scripts_to_save=None)
log_format = '%(asctime)s %(message)s'
logging.basicConfig(stream=sys.stdout, level=logging.INFO,
format=log_format, datefmt='%m/%d %I:%M:%S %p')
fh = logging.FileHandler(os.path.join(self.args.save, 'log.txt'))
fh.setFormatter(logging.Formatter(log_format))
self.logger = logging.getLogger('Architecture Training')
self.logger.addHandler(fh)
def _init_device(self):
if not torch.cuda.is_available():
self.logger.info('no gpu device available')
sys.exit(1)
np.random.seed(self.args.seed)
self.device_id = self.args.device
self.device = torch.device('cuda:{}'.format(
0 if self.args.multi_gpus else self.device_id))
cudnn.benchmark = True
torch.manual_seed(self.args.seed)
cudnn.enabled = True
torch.cuda.manual_seed(self.args.seed)
logging.info('gpu device = %d' % self.args.device)
logging.info("args = %s", self.args)
def _init_data_queue(self):
train_transform = build_transform(True, args.img_size)
valid_transform = build_transform(False, args.img_size)
if self.args.dataset == 'cifar10':
train_data = dset.CIFAR10(
root=self.args.data, train=True, download=True, transform=train_transform)
valid_data = dset.CIFAR10(
root=self.args.data, train=False, download=True, transform=valid_transform)
self.num_classes = 10
elif self.args.dataset == 'cifar100':
train_data = dset.CIFAR100(
root=self.args.data, train=True, download=True, transform=train_transform)
valid_data = dset.CIFAR100(
root=self.args.data, train=False, download=True, transform=valid_transform)
self.num_classes = 100
self.train_queue = torch.utils.data.DataLoader(
train_data, batch_size=self.args.batch_size, shuffle=True, pin_memory=True, num_workers=4)
self.valid_queue = torch.utils.data.DataLoader(
valid_data, batch_size=self.args.batch_size, shuffle=False, pin_memory=True, num_workers=4)
def _init_model(self):
genotype = eval('genotypes.%s' % self.args.arch)
model = Network(self.args.init_channels,
self.num_classes,
self.args.layers,
self.args.auxiliary,
genotype,
self.args.parse_method,
step=args.step,
node_type=args.node_type
)
flops, params = profile(model, inputs=(
torch.randn(1, 3, 32, 32),), verbose=False)
self.logger.info('flops = %fM', flops / 1e6)
self.logger.info('param size = %fM', params / 1e6)
# Try move model to multi gpus
if torch.cuda.device_count() > 1 and self.args.multi_gpus:
self.logger.info('use: %d gpus', torch.cuda.device_count())
model = nn.DataParallel(model)
else:
self.logger.info('gpu device = %d' % self.device_id)
torch.cuda.set_device(self.device_id)
self.model = model.to(self.device)
# criterion = nn.CrossEntropyLoss()
criterion = UnilateralMse(1.)
self.criterion = criterion.to(self.device)
self.optimizer = torch.optim.AdamW(
model.parameters(),
self.args.learning_rate,
weight_decay=self.args.weight_decay
)
self.best_acc_top1 = 0
# optionally resume from a checkpoint
if self.args.resume:
if os.path.isfile(self.args.resume):
print("=> loading checkpoint {}".format(self.args.resume))
checkpoint = torch.load(
self.args.resume, map_location=self.device)
self.dur_time = checkpoint['dur_time']
self.args.start_epoch = checkpoint['epoch']
self.best_acc_top1 = checkpoint['best_acc_top1']
self.args.drop_path_prob = checkpoint['drop_path_prob']
self.model.load_state_dict(checkpoint['state_dict'])
self.optimizer.load_state_dict(checkpoint['optimizer'])
print("=> loaded checkpoint '{}' (epoch {})".format(
self.args.resume, checkpoint['epoch']))
else:
print("=> no checkpoint found at '{}'".format(self.args.resume))
self.scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(self.optimizer, float(self.args.epochs), eta_min=0,
last_epoch=-1 if self.args.start_epoch == 0 else self.args.start_epoch)
# reload the scheduler if possible
if self.args.resume and os.path.isfile(self.args.resume):
checkpoint = torch.load(self.args.resume)
self.scheduler.load_state_dict(checkpoint['scheduler'])
def run(self):
self.logger.info('args = %s', self.args)
run_start = time.time()
for epoch in range(self.args.start_epoch, self.args.epochs):
self.scheduler.step()
self.logger.info('epoch % d / %d lr %e', epoch,
self.args.epochs, self.scheduler.get_lr()[0])
self.model.drop_path_prob = self.args.drop_path_prob * epoch / self.args.epochs
train_acc, train_obj = self.train()
self.logger.info('train loss %e, train acc %f',
train_obj, train_acc)
valid_acc_top1, valid_acc_top5, valid_obj = self.infer()
self.logger.info('valid loss %e, top1 valid acc %f top5 valid acc %f',
valid_obj, valid_acc_top1, valid_acc_top5)
self.logger.info('best valid acc %f', self.best_acc_top1)
is_best = False
if valid_acc_top1 > self.best_acc_top1:
self.best_acc_top1 = valid_acc_top1
is_best = True
dutils.save_checkpoint({
'epoch': epoch + 1,
'dur_time': self.dur_time + time.time() - run_start,
'state_dict': self.model.state_dict(),
'drop_path_prob': self.args.drop_path_prob,
'best_acc_top1': self.best_acc_top1,
'optimizer': self.optimizer.state_dict(),
'scheduler': self.scheduler.state_dict()
}, is_best, self.args.save)
self.logger.info('train epoches %d, best_acc_top1 %f, dur_time %s',
self.args.epochs, self.best_acc_top1,
dutils.calc_time(self.dur_time + time.time() - run_start))
def train(self):
objs = dutils.AvgrageMeter()
top1 = dutils.AvgrageMeter()
top5 = dutils.AvgrageMeter()
self.model.train()
for step, (input, target) in enumerate(self.train_queue):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
self.optimizer.zero_grad()
logits, logits_aux = self.model(input)
loss = self.criterion(logits, target)
if self.args.auxiliary:
loss_aux = self.criterion(logits_aux, target)
loss += self.args.auxiliary_weight * loss_aux
loss.backward()
nn.utils.clip_grad_norm_(
self.model.parameters(), self.args.grad_clip)
self.optimizer.step()
prec1, prec5 = dutils.accuracy(logits, target, topk=(1, 5))
n = input.size(0)
objs.update(loss.item(), n)
top1.update(prec1.item(), n)
top5.update(prec5.item(), n)
if step % self.args.report_freq == 0:
self.logger.info('train %03d %e %f %f', step,
objs.avg, top1.avg, top5.avg)
return top1.avg, objs.avg
def infer(self):
objs = dutils.AvgrageMeter()
top1 = dutils.AvgrageMeter()
top5 = dutils.AvgrageMeter()
self.model.eval()
with torch.no_grad():
for step, (input, target) in enumerate(self.valid_queue):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
logits, _ = self.model(input)
loss = self.criterion(logits, target)
prec1, prec5 = dutils.accuracy(logits, target, topk=(1, 5))
n = input.size(0)
objs.update(loss.item(), n)
top1.update(prec1.item(), n)
top5.update(prec5.item(), n)
if step % self.args.report_freq == 0:
self.logger.info('valid %03d %e %f %f',
step, objs.avg, top1.avg, top5.avg)
return top1.avg, top5.avg, objs.avg
if __name__ == '__main__':
args = parser.parse_args()
train_network = TrainNetwork(args)
train_network.run()
================================================
FILE: examples/Perception_and_Learning/NeuEvo/train_search.py
================================================
import os
import sys
import time
import numpy as np
import torch
import logging
import argparse
import torch.nn as nn
import torch.utils
import torch.nn.functional as F
import torchvision.datasets as dset
import torch.backends.cudnn as cudnn
from torch.autograd import Variable
from braincog.model_zoo.NeuEvo.model_search import Network, calc_weight, calc_loss
from braincog.model_zoo.NeuEvo.architect import Architect
from separate_loss import ConvSeparateLoss, TriSeparateLoss, MseSeparateLoss
import utils
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from braincog.datasets.datasets import *
from braincog.base.utils.criterions import *
torch.autograd.set_detect_anomaly(True)
parser = argparse.ArgumentParser("cifar")
parser.add_argument('--data', type=str, default='/data/datasets',
help='location of the data corpus')
parser.add_argument('--dataset', type=str, default='cifar10',
help='cifar10 or cifar 100 for searching')
parser.add_argument('--batch-size', type=int, default=128, help='batch size')
parser.add_argument('--learning_rate', type=float,
default=0.005, help='init learning rate')
parser.add_argument('--learning_rate_min', type=float,
default=0.001, help='min learning rate')
parser.add_argument('--momentum', type=float, default=0.9, help='momentum')
parser.add_argument('--weight_decay', type=float,
default=3e-4, help='weight decay')
parser.add_argument('--report_freq', type=float,
default=50, help='report frequency')
parser.add_argument('--aux_loss_weight', type=float,
default=10.0, help='weight decay')
parser.add_argument('--device', type=int, default=0, help='gpu device id')
parser.add_argument('--epochs', type=int, default=50,
help='num of training epochs')
parser.add_argument('--init-channels', type=int,
default=16, help='num of init channels')
parser.add_argument('--layers', type=int, default=6,
help='total number of layers')
parser.add_argument('--model_path', type=str,
default='saved_models', help='path to save the model')
parser.add_argument('--single_level', action='store_true',
default=False, help='use single level')
parser.add_argument('--sep_loss', type=str, default='l2',
help='path to save the model')
parser.add_argument('--cutout', action='store_true',
default=False, help='use cutout')
parser.add_argument('--cutout_length', type=int,
default=16, help='cutout length')
parser.add_argument('--auto_aug', action='store_true',
default=False, help='use auto augmentation')
parser.add_argument('--parse_method', type=str,
default='bio_darts', help='parse the code method')
parser.add_argument('--op_threshold', type=float,
default=0.85, help='threshold for edges')
parser.add_argument('--save', type=str, default='EXP', help='experiment name')
parser.add_argument('--seed', type=int, default=42, help='random seed')
parser.add_argument('--grad_clip', type=float,
default=5, help='gradient clipping')
parser.add_argument('--train_portion', type=float,
default=0.5, help='portion of training data')
parser.add_argument('--arch_learning_rate', type=float,
default=1e-3, help='learning rate for arch encoding')
parser.add_argument('--arch_lr_gamma', type=float, default=0.9,
help='learning rate for arch encoding')
parser.add_argument('--arch_weight_decay', type=float,
default=1e-3, help='weight decay for arch encoding')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='path to latest checkpoint (default: none)')
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
parser.add_argument('--img_size', default=32, type=int)
parser.add_argument('--smoothing', default=0.1, type=float)
parser.add_argument('--step', default=8, type=int)
parser.add_argument('--node-type', default='BiasPLIFNode', type=str)
parser.add_argument('--loss_fn', type=str, default='')
parser.add_argument('--back-connection', action='store_true')
parser.add_argument('--asbe', '--arch-search-begin-epoch',
type=int, default=0, dest='asbe')
parser.add_argument('--num-classes', type=int, default=10)
parser.add_argument('--spike-output',action='store_true')
parser.add_argument('--act-fun', type=str, default='GateGrad')
parser.add_argument('--suffix', default='', type=str)
args = parser.parse_args()
args.save = '/data/floyed/darts/logs/search/search-{}-{}-{}'.format(args.save, time.strftime("%Y%m%d-%H%M%S"),
args.suffix)
utils.create_exp_dir(args.save, scripts_to_save=None)
log_format = '%(asctime)s %(message)s'
logging.basicConfig(stream=sys.stdout, level=logging.INFO,
format=log_format, datefmt='%m/%d %I:%M:%S %p')
fh = logging.FileHandler(os.path.join(args.save, 'log.txt'))
fh.setFormatter(logging.Formatter(log_format))
logging.getLogger().addHandler(fh)
CIFAR_CLASSES = 10
def main():
args.spike_output = False
if not torch.cuda.is_available():
logging.info('no gpu device available')
sys.exit(1)
np.random.seed(args.seed)
torch.cuda.set_device(args.device)
# cudnn.benchmark = True
torch.manual_seed(args.seed)
# cudnn.enabled = True
torch.cuda.manual_seed(args.seed)
logging.info('gpu device = %d' % args.device)
logging.info("args = %s", args)
run_start = time.time()
start_epoch = 0
dur_time = 0
if args.loss_fn == 'mix':
criterion_train = MixLoss(LabelSmoothingCrossEntropy(
smoothing=args.smoothing).cuda())
criterion_val = MixLoss(nn.CrossEntropyLoss())
elif args.loss_fn == 'mse':
criterion_train = UnilateralMse(1.)
criterion_val = UnilateralMse(1.)
else:
criterion_train = LabelSmoothingCrossEntropy().cuda()
criterion_val = nn.CrossEntropyLoss().cuda()
criterion_train = ConvSeparateLoss(criterion_train, weight=args.aux_loss_weight) \
if args.sep_loss == 'l2' else TriSeparateLoss(criterion_train, weight=args.aux_loss_weight)
model = Network(args.init_channels, args.num_classes, args.layers, criterion_train,
steps=3, multiplier=3, stem_multiplier=3,
parse_method=args.parse_method, op_threshold=args.op_threshold,
step=args.step, node_type=args.node_type,
back_connection=args.back_connection, act_fun=args.act_fun,
dataset=args.dataset,
spike_output=False,
temporal_flatten=args.temporal_flatten)
model = model.cuda()
logging.info("param size = %fMB", utils.count_parameters_in_MB(model))
model_optimizer = torch.optim.AdamW(
model.parameters(),
args.learning_rate,
# momentum=args.momentum,
weight_decay=args.weight_decay)
# # train_transform, valid_transform = utils._data_transforms_cifar(args)
# train_transform = build_transform(True, args.img_size)
# valid_transform = build_transform(False, args.img_size)
# train_data = dset.CIFAR10(
# root=args.data, train=True, download=True, transform=train_transform)
#
# num_train = len(train_data)
# indices = list(range(num_train))
# split = int(np.floor(args.train_portion * num_train))
#
# train_queue = torch.utils.data.DataLoader(
# train_data, batch_size=args.batch_size,
# sampler=torch.utils.data.sampler.SubsetRandomSampler(indices[:split]),
# pin_memory=True)
#
# valid_queue = torch.utils.data.DataLoader(
# train_data, batch_size=args.batch_size,
# sampler=torch.utils.data.sampler.SubsetRandomSampler(
# indices[split:num_train]),
# pin_memory=True)
train_queue, valid_queue, _, _ = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
temporal_flatten=args.temporal_flatten
)
architect = Architect(model, args)
# resume from checkpoint
if args.resume:
if os.path.isfile(args.resume):
logging.info("=> loading checkpoint '{}'".format(args.resume))
checkpoint = torch.load(
args.resume, map_location=model.alphas_normal.device)
start_epoch = checkpoint['epoch']
dur_time = checkpoint['dur_time']
model_optimizer.load_state_dict(checkpoint['model_optimizer'])
model.restore(checkpoint['network_states'])
logging.info('=> loaded checkpoint \'{}\'(epoch {})'.format(
args.resume, start_epoch))
else:
logging.info(
'=> no checkpoint found at \'{}\''.format(args.resume))
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
model_optimizer, float(args.epochs), eta_min=args.learning_rate_min,
last_epoch=-1 if start_epoch == 0 else start_epoch)
if args.resume and os.path.isfile(args.resume):
scheduler.load_state_dict(checkpoint['scheduler'])
for epoch in range(start_epoch, args.epochs):
scheduler.step()
lr = scheduler.get_lr()[0]
logging.info('epoch %d lr %e', epoch, lr)
genotype = model.genotype()
logging.info('genotype = %s', genotype)
logging.info(calc_weight(model.alphas_normal))
logging.info(calc_loss(model.alphas_normal))
model.update_history()
# training and search the model
train_acc, train_obj = train(epoch, train_queue, valid_queue, model, architect, criterion_train,
model_optimizer)
logging.info('train_acc %f', train_acc)
# validation the model
model.record_fire_rate = True
model.reset_fire_rate_record()
valid_acc, valid_obj = infer(valid_queue, model, criterion_val)
fire_rate = model.get_fire_per_step()
model.record_fire_rate = False
logging.info('valid_fire_rate: {}'.format(fire_rate))
logging.info('valid_acc %f', valid_acc)
# save checkpoint
utils.save_checkpoint({
'epoch': epoch + 1,
'dur_time': dur_time + time.time() - run_start,
'scheduler': scheduler.state_dict(),
'model_optimizer': model_optimizer.state_dict(),
'network_states': model.states(),
}, is_best=False, save=args.save)
logging.info('save checkpoint (epoch %d) in %s dur_time: %s', epoch, args.save,
utils.calc_time(dur_time + time.time() - run_start))
# save operation weights as fig
utils.save_file(recoder=model.alphas_normal_history, path=os.path.join(args.save, 'normal'),
back_connection=args.back_connection)
# save last operations
np.save(os.path.join(os.path.join(args.save, 'normal_weight.npy')),
calc_weight(model.alphas_normal).data.cpu().numpy())
logging.info('save last weights done')
def train(epoch, train_queue, valid_queue, model, architect, criterion, model_optimizer):
objs = utils.AvgrageMeter()
objs1 = utils.AvgrageMeter()
objs2 = utils.AvgrageMeter()
top1 = utils.AvgrageMeter()
top5 = utils.AvgrageMeter()
for step, (input, target) in enumerate(train_queue):
model.train()
n = input.size(0)
input = Variable(input, requires_grad=False).cuda(non_blocking=True)
target = Variable(target, requires_grad=False).cuda(non_blocking=True)
# if epoch >= args.asbe:
# Get a random minibatch from the search queue(validation set) with replacement
# input_search, target_search = next(iter(valid_queue))
# print(input.shape, target.shape)
# print(input_search.shape, target_search.shape)
# input_search = Variable(
# input_search, requires_grad=False).cuda(non_blocking=True)
# target_search = Variable(
# target_search, requires_grad=False).cuda(non_blocking=True)
# loss1, loss2 = architect.step(input_search, target_search)
# else:
loss1 = torch.tensor([0.])
loss2 = torch.tensor([0.])
model_optimizer.zero_grad()
logits = model(input)
aux_input = torch.cat(
[calc_loss(model.alphas_normal)], dim=0)
loss, _, _ = criterion(logits, target, aux_input)
# loss = criterion(logits, target)
loss.backward()
nn.utils.clip_grad_norm(model.parameters(), args.grad_clip)
# Update the network parameters
model_optimizer.step()
prec1, prec5 = utils.accuracy(logits, target, topk=(1, 5))
objs.update(loss.item(), n)
objs1.update(loss1, n)
objs2.update(loss2, n)
top1.update(prec1.item(), n)
top5.update(prec5.item(), n)
if step % args.report_freq == 0:
logging.info('train %03d loss: %e top1: %f top5: %f',
step, objs.avg, top1.avg, top5.avg)
logging.info('val cls_loss %e; spe_loss %e', objs1.avg, objs2.avg)
return top1.avg, objs.avg
def infer(valid_queue, model, criterion):
objs = utils.AvgrageMeter()
top1 = utils.AvgrageMeter()
top5 = utils.AvgrageMeter()
model.eval()
with torch.no_grad():
for step, (input, target) in enumerate(valid_queue):
input = Variable(input, volatile=True).cuda(non_blocking=True)
target = Variable(target, volatile=True).cuda(non_blocking=True)
logits = model(input)
loss = criterion(logits, target)
prec1, prec5 = utils.accuracy(logits, target, topk=(1, 5))
n = input.size(0)
objs.update(loss.item(), n)
top1.update(prec1.item(), n)
top5.update(prec5.item(), n)
if step % args.report_freq == 0:
logging.info('valid %03d %e %f %f', step,
objs.avg, top1.avg, top5.avg)
return top1.avg, objs.avg
if __name__ == '__main__':
main()
================================================
FILE: examples/Perception_and_Learning/NeuEvo/utils.py
================================================
import json
import matplotlib.pyplot as plt
from braincog.model_zoo.NeuEvo.genotypes import Genotype, PRIMITIVES
import os
import numpy as np
import torch
import shutil
import torchvision.transforms as transforms
from torch.autograd import Variable
from auto_augment import CIFAR10Policy
from braincog.model_zoo.NeuEvo.genotypes import PRIMITIVES
forward_edge_num = sum(1 for i in range(3) for n in range(2 + i))
backward_edge_num = sum(1 for i in range(3) for n in range(i))
num_ops = len(PRIMITIVES)
type_num = len(PRIMITIVES) // 2
# edge_num = [2, 3, 4]
edge_num = [2, 3, 4, 1, 2]
class AvgrageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.avg = 0
self.sum = 0
self.cnt = 0
def update(self, val, n=1):
self.sum += val * n
self.cnt += n
self.avg = self.sum / self.cnt
def accuracy(output, target, topk=(1,)):
"""Compute the top1 and top5 accuracy
"""
maxk = max(topk)
batch_size = target.size(0)
# Return the k largest elements of the given input tensor
# along a given dimension -> N * k
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0)
res.append(correct_k.mul_(100.0 / batch_size))
return res
class Cutout(object):
def __init__(self, length):
self.length = length
def __call__(self, img):
h, w = img.size(1), img.size(2)
mask = np.ones((h, w), np.float32)
y = np.random.randint(h)
x = np.random.randint(w)
y1 = np.clip(y - self.length // 2, 0, h)
y2 = np.clip(y + self.length // 2, 0, h)
x1 = np.clip(x - self.length // 2, 0, w)
x2 = np.clip(x + self.length // 2, 0, w)
mask[y1: y2, x1: x2] = 0.
mask = torch.from_numpy(mask)
mask = mask.expand_as(img)
img *= mask
return img
def _data_transforms_cifar(args):
CIFAR_MEAN = [0.49139968, 0.48215827, 0.44653124] if args.dataset == 'cifar10' else [0.50707519, 0.48654887,
0.44091785]
CIFAR_STD = [0.24703233, 0.24348505, 0.26158768] if args.dataset == 'cifar10' else [0.26733428, 0.25643846,
0.27615049]
normalize_transform = [
transforms.ToTensor(),
transforms.Normalize(CIFAR_MEAN, CIFAR_STD)]
random_transform = [
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip()]
if args.auto_aug:
random_transform += [CIFAR10Policy()]
if args.cutout:
cutout_transform = [Cutout(args.cutout_length)]
else:
cutout_transform = []
train_transform = transforms.Compose(
random_transform + normalize_transform + cutout_transform
)
valid_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(CIFAR_MEAN, CIFAR_STD),
])
return train_transform, valid_transform
def count_parameters_in_MB(model):
return np.sum(np.prod(v.size()) for v in model.parameters()) / 1e6
def save_checkpoint(state, is_best, save):
filename = os.path.join(save, 'checkpoint.pth.tar')
torch.save(state, filename)
if is_best:
best_filename = os.path.join(save, 'model_best.pth.tar')
shutil.copyfile(filename, best_filename)
def save(model, model_path):
torch.save(model.state_dict(), model_path)
def load(model, model_path):
model.load_state_dict(torch.load(model_path))
def drop_path(x, drop_prob):
if drop_prob > 0.:
keep_prob = 1. - drop_prob
mask = Variable(torch.cuda.FloatTensor(
x.size(0), 1, 1, 1).bernoulli_(keep_prob))
x.div_(keep_prob)
x.mul_(mask)
return x
def create_exp_dir(path, scripts_to_save=None):
if not os.path.exists(path):
os.makedirs(path)
print('Experiment dir : {}'.format(path))
if scripts_to_save is not None:
os.makedirs(os.path.join(path, 'scripts'))
for script in scripts_to_save:
dst_file = os.path.join(path, 'scripts', os.path.basename(script))
shutil.copyfile(script, dst_file)
def calc_time(seconds):
m, s = divmod(seconds, 60)
h, m = divmod(m, 60)
t, h = divmod(h, 24)
return {'day': t, 'hour': h, 'minute': m, 'second': int(s)}
def save_file(recoder, path='./', back_connection=False):
size = (forward_edge_num +
backward_edge_num if back_connection else forward_edge_num, num_ops)
fig, axs = plt.subplots(*size, figsize=(36, 98))
row = 0
col = 0
for (k, v) in recoder.items():
axs[row, col].set_title(k)
axs[row, col].plot(v, 'r+')
if col == num_ops - 1:
col = 0
row += 1
else:
col += 1
if not os.path.exists(path):
os.makedirs(path)
fig.savefig(os.path.join(path, 'output.png'), bbox_inches='tight')
plt.tight_layout()
print('save history weight in {}'.format(os.path.join(path, 'output.png')))
with open(os.path.join(path, 'history_weight.json'), 'w') as outf:
json.dump(recoder, outf)
print('save history weight in {}'.format(
os.path.join(path, 'history_weight.json')))
================================================
FILE: examples/Perception_and_Learning/QSNN/README.md
================================================
# Quantum superposition inspired spiking neural network
This repository contains code from our paper [**Quantum superposition inspired spiking neural network**] published in iScience. https://doi.org/10.1016/j.isci.2021.102880. If you use our code or refer to this project, please cite this paper.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
## Train
```shell
python ./main.py
```
## Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{sun2021quantum,
title={Quantum superposition inspired spiking neural network},
author={Sun, Yinqian and Zeng, Yi and Zhang, Tielin},
journal={Iscience},
volume={24},
number={8},
pages={102880},
year={2021},
publisher={Elsevier}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/Perception_and_Learning/QSNN/main.py
================================================
import os
import copy
import tqdm
import numpy as np
import torch
import torch.nn.functional as F
from braincog.datasets.datasets import get_mnist_data
from braincog.model_zoo.qsnn import Net
from braincog.datasets.gen_input_signal import lambda_max
LOG_DIR = os.path.expanduser('./results.txt')
LEARNING_RATE = 0.01
# learning dacay
DECAY_STEPS = 1.0
DECAY_RATE = 0.9
# adam
BETA1 = 0.9
BETA2 = 0.999
EPSIOLN = 1e-8
EPOCHS = 20
PRINT_PERIOD = 10000
TEST_SIZE = 10000
TEST_THETA = [0, 1 / 16, 2 / 16, 3 / 16, 4 / 16, 5 / 16, 6 / 16, 7 / 16, 8 / 16]
# TEST_THETA = [0]
NOISE_RATES = [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
mnist_data = get_mnist_data(batch_size=1, skip_norm=True)
train_loader, test_loader = mnist_data.get_data_loaders()
NET_SIZE = [28 * 28, 500, 10]
def int2onehot(label, classes, factor):
label_one_hot = F.one_hot(label, classes)
label_one_hot = label_one_hot * (8 + factor) - 8
return label_one_hot
def train(net, epochs, lr):
with open(LOG_DIR, 'a+') as f:
for epoch in range(epochs):
lr_decay = lr * DECAY_RATE ** (epoch / DECAY_STEPS)
for x, y in tqdm.tqdm(train_loader):
label = int2onehot(y, 10, 8)
x = x.flatten().numpy()
label = label.cuda()
with torch.no_grad():
net.routine(x, None, image_ori=None, image_ori_delta=None, shift=False,
label=label, test=False, noise=False, noise_rate=None)
net.update_weight(lr_decay, epoch + 1, (BETA1, BETA2), EPSIOLN)
with torch.no_grad():
for fac in TEST_THETA:
acc_reve = 0
for x_test, y_test in test_loader:
image = x_test.flatten().numpy()
image_shift = image * np.cos(fac * np.pi) + (lambda_max - image) * np.sin(fac * np.pi)
image_delta = copy.copy(image)
delta_idx = image_delta < (lambda_max - 0.001)
image_delta[delta_idx] += 0.001
image_delta_shift = image_delta * np.cos(fac * np.pi) + (lambda_max - image_delta) * np.sin(fac * np.pi)
pred = net.predict(image_shift, image_delta_shift, image, image_delta, shift=True, noise=False, noise_rate=None)
if pred == int(y_test):
acc_reve += 1
acc_reve = acc_reve / TEST_SIZE
print('Test epoch {epoch}: Shift {theta:0.3f} pi: accuracy {acc}.'.format(
epoch=epoch, theta=fac, acc=acc_reve))
print('Test epoch {epoch}: Shift {theta:0.3f} pi: accuracy {acc}'.format(
epoch=epoch, theta=fac, acc=acc_reve), file=f)
print()
print(file=f)
if __name__ == '__main__':
net = Net(NET_SIZE).cuda()
train(net, EPOCHS, LEARNING_RATE)
================================================
FILE: examples/Perception_and_Learning/UnsupervisedSTDP/Readme.md
================================================
This is an example of training Unsupervised STDP-based spiking neural network. We used a STB-STDP algrithom to train SNN, and mutiply adaptive mechanisms.
# How to run
python codef.py
# Result
We train the model on Mnist and FashionMNIST, and the best accuracy for MNIST is 97.9%, for FashionMNIST is 87.0%.
### Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{dong2022unsupervised,
title={An Unsupervised Spiking Neural Network Inspired By Biologically Plausible Learning Rules and Connections},
author={Dong, Yiting and Zhao, Dongcheng and Li, Yang and Zeng, Yi},
journal={arXiv preprint arXiv:2207.02727},
year={2022}
}
@article{zeng2022braincog,
title={BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={arXiv preprint arXiv:2207.08533},
year={2022}
}
```
================================================
FILE: examples/Perception_and_Learning/UnsupervisedSTDP/codef.py
================================================
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from tqdm import tqdm
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import cv2
import numpy as np
from copy import deepcopy
import os, time, math,random
from braincog.base.node.node import *
from braincog.base.connection .layer import *
from braincog.base.strategy.LateralInhibition import *
from sklearn.metrics import confusion_matrix
seed = 0
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
torch.cuda.manual_seed(seed) #GPU随机种子确定
torch.backends.cudnn.benchmark = False #模型卷积层预先优化关闭
torch.backends.cudnn.deterministic = True #确定为默认卷积算法
random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
dev = "cuda"
device = torch.device(dev) if torch.cuda.is_available() else 'cpu'
torch.set_printoptions(precision=4, sci_mode=False)
# ===========================================================================================================
convoff = 0.3
# avgscale = 5
class STDPConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride, padding,groups,
tau_decay=torch.exp(-1.0 / torch.tensor(100.0)), offset=convoff, static=True, inh=6.5, avgscale=5):
super().__init__()
self.tau_decay = tau_decay
self.offset = offset
self.static = static
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding,groups=groups,
bias=False)
self.avgpool = nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=padding)
self.mem = self.spike = self.refrac_count = None
self.normweight()
self.inh = inh
self.avgscale = avgscale
self.onespike=True
self.node=LIFSTDPNode(act_fun=STDPGrad,tau=tau_decay,mem_detach=True)
self.WTA=WTALayer( )
self.lateralinh=LateralInhibition(self.node,self.inh,mode="threshold")
def mem_update(self, x, onespike=True): # b,c,h,w
x=self.node( x)
if x.max() > 0:
x=self.WTA(x)
self.lateralinh(x)
self.spike= x
return self.spike
def forward(self, x, T=None, onespike=True):
if not self.static:
batch, T, c, h, w = x.shape
x = x.reshape(-1, c, h, w)
x = self.conv( x)
n = self.getthresh(x)
self.node.threshold.data = n
x=x.clamp(min=0)
x = n / (1 + torch.exp(-(x - 4 * n / 10) * (8 / n)))
if not self.static:
x = x.reshape(batch, T, c, h, w)
xsum = None
for i in range(T):
tmp = self.mem_update(x[:, i], onespike).unsqueeze(1)
if xsum is not None:
xsum = torch.cat([xsum, tmp], 1)
else:
xsum = tmp
else:
xsum = 0
for i in range(T):
xsum += self.mem_update(x, onespike)
return xsum
def reset(self):
#self.mem = self.spike = self.refrac_count = None
self.node.n_reset()
def normgrad(self, force=False):
if force:
min = self.conv.weight.grad.data.min(1, True)[0].min(2, True)[0].min(3, True)[0]
max = self.conv.weight.grad.data.min(1, True)[0].max(2, True)[0].max(3, True)[0]
self.conv.weight.grad.data -= min
tmp = self.offset * max
else:
tmp = self.offset * self.spike.mean(0, True).mean(2, True).mean(3, True).permute(1, 0, 2, 3)
self.conv.weight.grad.data -= tmp
self.conv.weight.grad.data = -self.conv.weight.grad.data
def normweight(self, clip=False):
if clip:
self.conv.weight.data = torch. \
clamp(self.conv.weight.data, min=-3, max=1.0)
else:
c, i, w, h = self.conv.weight.data.shape
avg=self.conv.weight.data.mean(1, True).mean(2, True).mean(3, True)
self.conv.weight.data -=avg
tmp = self.conv.weight.data.reshape(c, 1, -1, 1)
self.conv.weight.data /= tmp.std(2, unbiased=False, keepdim=True)
def getthresh(self, scale):
tmp2= scale.max(0, True)[0].max(2, True)[0].max(3, True)[0]+0.0001
return tmp2
class STDPLinear(nn.Module):
def __init__(self, in_planes, out_planes,
tau_decay=0.99, offset=0.05, static=True,inh=10):
super().__init__()
self.tau_decay = tau_decay
self.offset = offset
self.static = static
self.linear = nn.Linear(in_planes, out_planes, bias=False)
self.mem = self.spike = self.refrac_count = None
# torch.nn.init.xavier_uniform_(self.linear.weight, gain=1)
self.normweight(False)
self.threshold = torch.ones(out_planes, device=device) *20
self.inh=inh
self.node=LIFSTDPNode(act_fun=STDPGrad,tau=tau_decay ,mem_detach=True)
self.WTA=WTALayer( )
self.lateralinh=LateralInhibition(self.node,self.inh,mode="max")
self.init=False
def mem_update(self, x, onespike=True): # b,c,h,w
if not self.init:
self.node.threshold.data= (x.max(0)[0].detach()*3).to(device)
self.init=True
xori=x
x=self.node( x)
if x.max() > 0:
x=self.WTA(x)
self.lateralinh(x,xori)
self.spike=x
return self.spike
def forward(self, x, T, onespike=True):
if not self.static:
batch, T, w = x.shape
x = x.reshape(-1, w)
x = x.detach()
x = self.linear(x)
self.x=x.detach()
if not self.static:
x = x.reshape(batch, T, w)
xsum = None
for i in range(T):
tmp = self.mem_update(x[:, i], onespike).unsqueeze(1)
if xsum is not None:
xsum = torch.cat([xsum, tmp], 1)
else:
xsum = tmp
else:
xsum = 0
for i in range(T):
xsum += self.mem_update(x, onespike)
#print(xsum.mean())
return xsum
def reset(self):
self.node.n_reset()
def normgrad(self, force=False):
if force:
pass
else:
tmp = self.offset * self.spike.mean(0, True).permute(1, 0)
self.linear.weight.grad.data = -self.linear.weight.grad.data
def normweight(self, clip=False):
if clip:
self.linear.weight.data = torch. \
clamp(self.linear.weight.data, min=0, max=1.0)
else:
self.linear.weight.data = torch. \
clamp(self.linear.weight.data, min=0, max=1.0)
sumweight = self.linear.weight.data.sum(1, True)
sumweight += (~(sumweight.bool())).float()
# self.linear.weight.data *= 11.76 / sumweight
self.linear.weight.data /= self.linear.weight.data.max(1, True)[0] / 0.1
def getthresh(self, scale):
tmp = self.linear.weight.clamp(min=0) * scale
tmp2 = tmp.sum(1, True).reshape(1, -1)
return tmp2
def updatethresh(self, plus=0.05):
self.node.threshold += (plus*self.x * self.spike.detach()).sum(0)
tmp=self.node.threshold.max()-350
if tmp>0:
self.node.threshold-=tmp
class STDPFlatten(nn.Module):
def __init__(self, start_dim=0, end_dim=-1):
super().__init__()
self.flatten = nn.Flatten(start_dim=start_dim, end_dim=end_dim)
def forward(self, x, T): # [batch,T,c,w,h]
return self.flatten(x)
class STDPMaxPool(nn.Module):
def __init__(self, kernel_size, stride, padding, static=True):
super().__init__()
self.static = static
self.pool = nn.MaxPool2d(kernel_size, stride, padding)
def forward(self, x, T): # [batch,T,c,w,h]
if not self.static:
batch, T, c, h, w = x.shape
x = x.reshape(-1, c, h, w)
x = self.pool(x)
if not self.static:
x = x.reshape(batch, T, c, h, w)
return x
alpha = 1.0
class Normliaze(nn.Module):
def __init__(self, static=True):
super().__init__()
self.static = static
def forward(self, x, T): # [batch,T,c,w,h]
# print(x.shape)
x /= x.max(1, True)[0].max(2, True)[0].max(3, True)[0]
# x/=x.mean()/0.13
return x
class voting(nn.Module):
def __init__(self, shape):
super().__init__()
self.label = torch.zeros(shape) - 1
self.assignments=0
def assign_labels(self, spikes, labels, rates=None, n_labels=10, alpha=alpha):
# 根据最后一层的spikes 以及 label 对于最后一层的神经元赋予不同的label
# spikes 是 batch * time * in_size
# print(spikes.size())
n_neurons = spikes.size(2)
if rates is None:
rates = torch.zeros(n_neurons, n_labels, device=device)
self.n_labels = n_labels
spikes = spikes.cpu().sum(1).to(device)
for i in range(n_labels):
n_labeled = torch.sum(labels == i).float()
# 就是说上一次assign label计算的rates 拿过来滑动平均一下 #这里似乎可以改
if n_labeled > 0:
indices = torch.nonzero(labels == i).view(-1)
tmp = torch.sum(spikes[indices], 0) / n_labeled # 平均脉冲数
rates[:, i] = alpha * rates[:, i] + tmp
# 此时的rates是 in_size * n_label, 对应哪个label的rates最高 该神经元就对应着该label
self.assignments = torch.max(rates, 1)[1]
return self.assignments, rates
def get_label(self, spikes):
# 根据最后一层的spike 计算得到label
n_samples = spikes.size(0)
spikes = spikes.cpu().sum(1).to(device)
rates = torch.zeros(n_samples, self.n_labels, device=device)
for i in range(self.n_labels):
n_assigns = torch.sum(self.assignments == i).float() # 共有多少个该类别节点
if n_assigns > 0:
indices = torch.nonzero(self.assignments == i).view(-1) # 找到该类别节点位置
rates[:, i] = torch.sum(spikes[:, indices], 1) / n_assigns # 该类别平均所有该类别节点发放脉冲数
return torch.sort(rates, dim=1, descending=True)[1][:, 0]
inh=25
inh2=1.625
channel=12
neuron=6400
class Conv_Net(nn.Module):
def __init__(self):
super(Conv_Net, self).__init__()
self.conv = nn.ModuleList([
STDPConv(1, channel, 3, 1, 1,1, static=True, inh=1.625, avgscale=5 ),
STDPMaxPool(2, 2, 0, static=True),
Normliaze(),
#STDPConv(12, 48, 3, 1, 1,1, static=True, inh=inh2, avgscale=10 ),
#STDPMaxPool(2, 2, 0, static=True),
#Normliaze(),
STDPFlatten(start_dim=1),
STDPLinear(196*channel, neuron, static=True,inh=inh)
])
self.voting = voting(10)
def forward(self, x, inlayer, outlayer, T, onespike=True): # [b,t,w,h]
for i in range(inlayer, outlayer + 1):
x = self.conv[i](x, T)
return x
def normgrad(self, layer, force=False):
self.conv[layer].normgrad(force)
def normweight(self, layer, clip=False):
self.conv[layer].normweight(clip)
def updatethresh(self, layer, plus=0.05):
self.conv[layer].updatethresh(plus)
def reset(self, layer):
if isinstance(layer, list):
for i in layer:
self.conv[i].reset()
else:
self.conv[layer].reset()
def plot_confusion_matrix(cm, classes, normalize=True, title='Test Confusion matrix', cmap=plt.cm.Blues):
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
#print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
plt.figure()
#print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
# plt.xticks(tick_marks, classes, rotation=45)
plt.xticks(tick_marks, classes)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i in range(cm.shape[0]):
plt.text(i, i, format(cm[i, i], fmt), horizontalalignment="center",
color="white" if cm[i, i] > thresh else "black")
plt.tight_layout()
#plt.savefig('confusestpf2'+str(channel)+"_n"+str(neuron)+".pdf")
#plt.show()
if __name__ == '__main__':
print(23)
batch_size = 1024
T = 100
transform = transforms.Compose(
[transforms.Resize((28, 28)), transforms.Grayscale(num_output_channels=1), transforms.ToTensor()])
transform = transforms.Compose([transforms.ToTensor()])
# mnist_train = datasets.CIFAR10(root='/data/datasets/CIFAR10/', train=True, download=False, transform=transform )
# mnist_test = datasets.CIFAR10(root='/data/datasets/CIFAR10/', train=False, download=False, transform=transform )
#mnist_train = datasets.FashionMNIST(root='/data/dyt//', train=True, download=True, transform=transform )
#mnist_test = datasets.FashionMNIST(root='/data/dyt/', train=False, download=False, transform=transform )
mnist_train = datasets.MNIST(root='./', train=True, download=True, transform=transform)
mnist_test = datasets.MNIST(root='./', train=False, download=False, transform=transform)
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=4)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=4)
model = Conv_Net().to(device)
convlist = [index for index, i in enumerate(model.conv) if isinstance(i, (STDPConv, STDPLinear))]
print(convlist)
#cap = torch.ones([100000, 1000, 30], device=device)
for layer in range(len(convlist) - 1):
optimizer = torch.optim.SGD(list(model.parameters())[layer:layer + 1], lr=0.1)
for epoch in range(3):
for step, (x, y) in enumerate(tqdm(train_iter)):
x = x.to(device)
y = y.to(device)
spikes = model(x, 0, convlist[layer], T)
optimizer.zero_grad()
spikes.sum().backward(torch.tensor(1/ (spikes.shape[0] * spikes.shape[2] * spikes.shape[3])))
# spikes.sum().backward( )
model.conv[convlist[layer]].spike = spikes.detach()
model.normgrad(convlist[layer], force=True)
optimizer.step()
model.normweight(convlist[layer], clip=False)
# print(model.conv[convlist[layer]].conv.weight.data )
model.reset(convlist)
print("layer", layer, "epoch", epoch, 'Done')
#model.conv[convlist[layer]].onespike=False
# ===========================================================================================================
# linear
#model.conv[convlist[-2]].onespike=True
cap = None
batch_size = 1024
T = 200
layer = len(convlist) - 1
plus = 0.002
lr = 0.0001
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=4)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=4)
optimizer = torch.optim.SGD(list(model.parameters())[layer:], lr=lr)
rates = None
best = 0
accrecord=[]
for epoch in range(1000):
spikefull = None
labelfull = None
for step, (x, y) in enumerate(tqdm(train_iter)):
x = x.to(device)
y = y.to(device)
spiketime = 0
spikes = model(x, 0, convlist[layer], T)
# print(spikes.mean())
optimizer.zero_grad()
spikes.sum().backward()
model.conv[convlist[layer]].spike = spikes.detach()
model.normgrad(convlist[layer], force=False)
optimizer.step()
model.updatethresh(convlist[layer], plus=plus)
model.normweight(convlist[layer], clip=False)
spikes = spikes.reshape(spikes.shape[0], 1, -1).detach()
if spikefull is None:
spikefull = spikes
labelfull = y
else:
spikefull = torch.cat([spikefull, spikes], 0)
labelfull = torch.cat([labelfull, y], 0)
model.reset(convlist)
_, rates = model.voting.assign_labels(spikefull, labelfull, rates)
rates = rates.detach() * 0.5
result = model.voting.get_label(spikefull)
acc = (result == labelfull).float().mean()
print(epoch, acc, 'channel', channel, "n", neuron)
print(model.conv[-1].node.threshold.max(),model.conv[-1].node.threshold.mean(),model.conv[-1].node.threshold.min())
# model.conv[-1].threshold*=0.98
spikefull = None
labelfull = None
result = None
for step2, (x, y) in enumerate(test_iter):
x = x.to(device)
y = y.to(device)
spiketime = 0
spikes = model(x, 0, convlist[layer], T)
spikes = spikes.reshape(spikes.shape[0], 1, -1).detach()
with torch.no_grad():
if spikefull is None:
spikefull = spikes
labelfull = y
else:
spikefull = torch.cat([spikefull, spikes], 0)
labelfull = torch.cat([labelfull, y], 0)
model.reset(convlist)
result = model.voting.get_label(spikefull)
acc = (result == labelfull).float().mean()
if best < acc:
best = acc
torch.save( model, "modelftstp28_350_c"+str(channel)+"_n"+str(neuron)+"_p"+str(acc)+".pth")
classes = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
cm = confusion_matrix(labelfull.cpu(), result.cpu())
plot_confusion_matrix(cm, classes)
print("test", acc, "best", best)
accrecord.append(acc)
#torch.save(accrecord,"accfstp28_350_c"+str(channel)+"_n"+str(neuron)+".pth")
================================================
FILE: examples/Perception_and_Learning/img_cls/bp/README.md
================================================
# Script for training high-performance SNNs based on back propagation
This is an example of training high-performance SNNs using the braincog.
It is able to train high performance SNNs on CIFAR10, DVS-CIFAR10, ImageNet and other datasets, and reach the advanced level.
## Install braincog
```shell
git clone https://github.com/xxx/Brain-Cog.git
cd braincog
python setup install --user
```
## Examples of training
```shell
cd examples/Perception_and_Learning/img_cls/bp
python main.py --model dvs_convnet --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0
```
## Benchmark
We provide a benchmark of SNNs trained with braincog and the corresponding scripts.
This provides an open, fair platform for comparison of subsequent SNNs on classification tasks.
**Note**: The results may vary due to random seeding and software version issues.
### CIFAR10
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:-------:|:--------------:|:------:|:-------------:|:----------:|:------------:|:-----------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | CIFAR10 | IF+Atan | - | convnet | 128 | 95.54 | ```python main.py --model cifar_convnet --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | LIF+Atan | - | convnet | 128 | 91.92 | ```python main.py --model cifar_convnet --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | PLIF+Atan | - | convnet | 128 | 93.32 | ```python main.py --model cifar_convnet --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | IF+Atan | - | resnet18 | 128 | 89.76/89.80 | ```python main.py --model resnet18 --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | LIF+Atan | - | resnet18 | 128 | 89.93/89.88 | ```python main.py --model resnet18 --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | PLIF+Atan | - | resnet18 | 128 | 92.64/ 90.65 | ```python main.py --model resnet18 --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | IF+QGateGrad | - | cifar_convnet | 128 | 95.73 | ```python main.py --model cifar_convnet --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR10 | LIF+QGateGrad | - | cifar_convnet | 128 | 96.04 | ```python main.py --model cifar_convnet --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR10 | PLIF+QGateGrad | - | cifar_convnet | 128 | 96.04/95.84 | ```python main.py --model cifar_convnet --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR10 | IF+QGateGrad | - | resnet18 | 128 | 89.19 | ```python main.py --model resnet18 --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR10 | LIF+QGateGrad | - | resnet18 | 128 | 90.95/90.68 | ```python main.py --model resnet18 --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR10 | PLIF+QGateGrad | - | resnet18 | 128 | 90.97/91.02 | ```python main.py --model resnet18 --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
### CIFAR100
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:--------:|:--------------:|:------:|:-----------:|:----------:|:--------:|:------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | CIFAR100 | IF+Atan | - | dvs_convnet | 128 | 76.52 | ```python main.py --num-classes 100 --model cifar_convnet --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | LIF+Atan | - | dvs_convnet | 128 | 71.89 | ```python main.py --num-classes 100 --model cifar_convnet --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | PLIF+Atan | - | dvs_convnet | 128 | 72.82 | ```python main.py --num-classes 100 --model cifar_convnet --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | IF+Atan | - | resnet18 | 128 | 62.47 | ```python main.py --num-classes 100 --model resnet18 --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | LIF+Atan | - | resnet18 | 128 | 62.63 | ```python main.py --num-classes 100 --model resnet18 --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | PLIF+Atan | - | resnet18 | 128 | 62.71 | ```python main.py --num-classes 100 --model resnet18 --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | IF+QGateGrad | - | dvs_convnet | 128 | 76.44 | ```python main.py --num-classes 100 --model cifar_convnet --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR100 | LIF+QGateGrad | - | dvs_convnet | 128 | 77.73 | ```python main.py --num-classes 100 --model cifar_convnet --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR100 | PLIF+QGateGrad | - | dvs_convnet | 128 | 77.25 | ```python main.py --num-classes 100 --model cifar_convnet --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR100 | IF+QGateGrad | - | resnet18 | 128 | 60.01 | ```python main.py --num-classes 100 --model resnet18 --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR100 | LIF+QGateGrad | - | resnet18 | 128 | 61.33 | ```python main.py --num-classes 100 --model resnet18 --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR100 | PLIF+QGateGrad | - | resnet18 | 128 | 62.32 | ```python main.py --num-classes 100 --model resnet18 --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
### DVS-CIFAR10
| ID | Dataset | Node-type | Config | Model | Batch Size | FLOPS | Accuracy | Script |
|:----|:-----------:|:--------------:|:------:|:-----------:|:----------:|:-----:|:-----------:|:---------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | DVS-CIFAR10 | IF+Atan | - | dvs_convnet | 128 | 7503 | 65.90 | ```python main.py --model dvs_convnet --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+Atan | - | dvs_convnet | 128 | 7503 | 82.10 | ```python main.py --model dvs_convnet --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+Atan | - | dvs_convnet | 128 | 7503 | 81.90 | ```python main.py --model dvs_convnet --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | IF+Atan | - | resnet18 | 128 | 3149 | 69.10 | ```python main.py --model resnet18 --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+Atan | - | resnet18 | 128 | 3149 | 78.50 | ```python main.py --model resnet18 --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+Atan | - | resnet18 | 128 | 3149 | 77.70 | ```python main.py --model resnet18 --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | IF+QGateGrad | - | dvs_convnet | 128 | 7503 | 68.30 | ```python main.py --model dvs_convnet --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+QGateGrad | - | dvs_convnet | 128 | 7503 | 82.60/82.90 | ```python main.py --model dvs_convnet --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+QGateGrad | - | dvs_convnet | 128 | 7503 | 83.20 | ```python main.py --model dvs_convnet --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-CIFAR10 | IF+QGateGrad | - | resnet18 | 128 | 3149 | 65.70/66.80 | ```python main.py --model resnet18 --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+QGateGrad | - | resnet18 | 128 | 3149 | 79.00/79.40 | ```python main.py --model resnet18 --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+QGateGrad | - | resnet18 | 128 | 3149 | 78.10/78.20 | ```python main.py --model resnet18 --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
### DVS-Gesture
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:-------:|:--------------:|:------:|:-----------:|:----------:|:-----------:|:------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | DVS-G | IF+Atan | - | dvs_convnet | 128 | 64.77 | ```python main.py --num-classes 11 --model dvs_convnet --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | LIF+Atan | - | dvs_convnet | 128 | 91.28 | ```python main.py --num-classes 11 --model dvs_convnet --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | PLIF+Atan | - | dvs_convnet | 128 | 91.67 | ```python main.py --num-classes 11 --model dvs_convnet --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | IF+Atan | - | resnet18 | 128 | 63.25 | ```python main.py --num-classes 11 --model resnet18 --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | LIF+Atan | - | resnet18 | 128 | 91.29 | ```python main.py --num-classes 11 --model resnet18 --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | PLIF+Atan | - | resnet18 | 128 | 90.15 | ```python main.py --num-classes 11 --model resnet18 --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | IF+QGateGrad | - | dvs_convnet | 128 | 48.48 | ```python main.py --num-classes 11 --model dvs_convnet --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-G | LIF+QGateGrad | - | dvs_convnet | 128 | 92.05/92.42 | ```python main.py --num-classes 11 --model dvs_convnet --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-G | PLIF+QGateGrad | - | dvs_convnet | 128 | 91.28 | ```python main.py --num-classes 11 --model dvs_convnet --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-G | IF+QGateGrad | - | resnet18 | 128 | 57.95 | ```python main.py --num-classes 11 --model resnet18 --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-G | LIF+QGateGrad | - | resnet18 | 128 | 90.91 | ```python main.py --num-classes 11 --model resnet18 --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-G | PLIF+QGateGrad | - | resnet18 | 128 | 92.42 | ```python main.py --num-classes 11 --model resnet18 --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
### NCALTECH101
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:-----------:|:--------------:|:------:|:-----------:|:----------:|:-----------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | NCALTECH101 | IF+QGateGrad | - | dvs_convnet | 128 | 23.09/51.15 | ```python main.py --num-classes 100 --model dvs_convnet --node-type IFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | NCALTECH101 | LIF+QGateGrad | - | dvs_convnet | 128 | 72.78/75.09 | ```python main.py --num-classes 100 --model dvs_convnet --node-type LIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | NCALTECH101 | PLIF+QGateGrad | - | dvs_convnet | 128 | 74.61/76.79 | ```python main.py --num-classes 100 --model dvs_convnet --node-type PLIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | NCALTECH101 | IF+QGateGrad | -/mix | resnet18 | 128 | 61.24/60.87 | ```python main.py --num-classes 100 --model resnet18 --node-type IFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | NCALTECH101 | LIF+QGateGrad | -/mix | resnet18 | 128 | 66.22/70.84 | ```python main.py --num-classes 100 --model resnet18 --node-type LIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | NCALTECH101 | PLIF+QGateGrad | -/mix | resnet18 | 128 | 69.62/69.87 | ```python main.py --num-classes 100 --model resnet18 --node-type PLIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
### SHD
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
| :--- | :-----: | :-----------: | :----: | :-----: | :--------: | :------: | :----------------------------------------------------------- |
| 1 | SHD | LIF+QGateGrad | - | shd_snn | 256 | 88.47 | ```python main.py --model SHD_SNN --node-type LIFNode --dataset shd --step 15 --batch-size 256 --act-fun QGateGrad --device 1 --tau 10. --threshold 0.3 --lr 5e-3 --min-lr 1e-4 --loss-fn onehot-mse --num-classes 20 --amp --weight-decay 0.01 ``` |
Note:
1. resnet18 is used here by adding a maximum pooling after the initial convolution layer.
However, in the final version of braincog, we remove this pooling layer.
2. mix refers to the use of EventMix as a data augmentation method.
3. We will continue to add other results.
### Citation
If you find this package helpful, please consider citing it:
```BibTex
@misc{zengbraincogSpikingNeural2022,
title = {{{braincog}}: {{A Spiking Neural Network}} Based {{Brain-inspired Cognitive Intelligence Engine}} for {{Brain-inspired AI}} and {{Brain Simulation}}},
shorttitle = {{{braincog}}},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
year = {2022},
month = jul,
number = {arXiv:2207.08533},
eprint = {2207.08533},
eprinttype = {arxiv},
primaryclass = {cs},
publisher = {{arXiv}},
doi = {10.48550/arXiv.2207.08533}
}
```
================================================
FILE: examples/Perception_and_Learning/img_cls/bp/main.py
================================================
import argparse
import time
import timm.models
import yaml
import os
import random as buildin_random
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.vgg_snn import VGG_SNN, SNN5
from braincog.model_zoo.fc_snn import SHD_SNN
from braincog.model_zoo.resnet19_snn import resnet19
from braincog.model_zoo.sew_resnet import sew_resnet18, sew_resnet34, sew_resnet50
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix, plot_mem_distribution
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model, register_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from torch.utils.tensorboard import SummaryWriter
# from ptflops import get_model_complexity_info
# from thop import profile, clever_format
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--dataset', default='mnist', type=str)
parser.add_argument('--model', default='mnist_convnet', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=1e-4,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=200, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=0.,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=0.,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--output', default='/data/floyed/BrainCog', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--tensorboard-dir', default='./runs', type=str)
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=0)
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
parser.add_argument('--conv-type', type=str, default='normal')
parser.add_argument('--sew-cnf', type=str, default='ADD')
parser.add_argument('--rand-step', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='QGateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
parser.add_argument('--n-encode-type', type=str, default='linear')
parser.add_argument('--n-preact', action='store_true')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--tet-loss', action='store_true')
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=2.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--gaussian-n', type=int, default=3)
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
parser.add_argument('--mem-dist', action='store_true')
parser.add_argument('--adaptation-info', action='store_true')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
@register_model
def resnet50d_pretrained(*args, **kwargs):
model = create_model('resnet50d', pretrained=True)
model.fc = nn.Linear(2048, 10)
# model.conv1 = nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
return model
def main():
args, args_text = _parse_args()
# args.no_spike_output = args.no_spike_output | args.cut_mix
args.no_spike_output = True
output_dir = ''
if args.local_rank == 0:
output_base = args.output if args.output else './output'
exp_name = '-'.join([
args.model,
args.dataset,
args.node_type,
str(args.step),
args.suffix,
datetime.now().strftime("%Y%m%d-%H%M%S"),
# str(args.img_size)
])
output_dir = get_outdir(output_base, 'train', exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
summary_writer = SummaryWriter(log_dir=os.path.join(args.tensorboard_dir, exp_name))
args.tensorboard_prefix = os.path.join(args.dataset, args.model)
else:
summary_writer = None
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
adaptive_node=args.adaptive_node,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
n_encode_type=args.n_encode_type,
n_preact=args.n_preact,
tet_loss=args.tet_loss,
sew_cnf=args.sew_cnf,
conv_type=args.conv_type,
)
_logger.info('[MODEL ARCH]\n{}'.format(model))
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=list(range(args.num_gpu))).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
_logger.info('[OPTIMIZER]\n{}'.format(optimizer))
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
# print(model.get_attr('mu'))
# print(model.get_attr('sigma'))
if hasattr(model, 'set_threshold'):
model.set_threshold(args.threshold)
if args.critical_loss or args.spike_rate:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model.cuda(), device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
)
# _logger.info('train_loader:\n{}\nval_loader:\n{}'.format(loader_train, loader_eval))
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
elif args.loss_fn == 'onehot-mse':
train_loss_fn = OnehotMse(args.num_classes)
validate_loss_fn = OnehotMse(args.num_classes)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
if args.tet_loss:
train_loss_fn = TetLoss(train_loss_fn)
validate_loss_fn = TetLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
# if args.distributed:
# raise NotImplementedError('eval not has not been verified for distributed')
# else:
# load_checkpoint(model, args.eval_checkpoint, args.model_ema)
model.eval()
for t in range(1, args.step * 3):
# for t in range(args.step, args.step + 1):
model.set_attr('step', t)
val_metrics = validate(start_epoch, model, loader_eval, validate_loss_fn, args,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer)
print(f"[STEP:{t}], Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=output_dir, recovery_dir=output_dir, decreasing=decreasing, max_history=3)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
if args.distributed:
loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler,
model_ema=model_ema, mixup_fn=mixup_fn, summary_writer=summary_writer
)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics = validate(epoch, model, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer)
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics = validate(
epoch, model_ema.ema, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast, log_suffix=' (EMA)',
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer
)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(output_dir, 'summary.csv'),
write_header=best_metric is None)
# if saver is not None and epoch >= args.n_warm_up:
if saver is not None:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
except KeyboardInterrupt:
pass
if best_metric is not None:
_logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None, summary_writer=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and loader.mixup_enabled:
loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
# closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
# t, k = adjust_surrogate_coeff(100, args.epochs)
# model.set_attr('t', t)
# model.set_attr('k', k)
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
iters_per_epoch = len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
if args.rand_step:
step = buildin_random.randint(1, args.step + 2)
model.set_attr('step', step)
data_time_m.update(time.time() - end)
if not args.prefetcher or args.dataset != 'imnet':
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
if mixup_fn is not None:
inputs, target = mixup_fn(inputs, target)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
with amp_autocast():
output = model(inputs)
loss = loss_fn(output, target)
if args.tet_loss:
output = output.mean(0)
if not (args.cut_mix | args.mix_up | args.event_mix | (args.cutmix != 0.) | (args.mixup != 0.)):
# print(output.shape, target.shape)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
# if args.opt == 'lamb':
# optimizer.step(epoch=epoch)
# else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/top1'), acc1.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/top5'), acc5.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/loss'), loss.item(), epoch * iters_per_epoch + batch_idx)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
if args.distributed:
loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
# closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
# if args.distributed:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/top1'), top1_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/top5'), top5_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/loss'), losses_m.avg, epoch)
if args.rand_step:
model.set_attr('step', args.step)
return OrderedDict([('loss', losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args, amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False, summary_writer=None):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
# closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
spike_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
mem_vec = []
end = time.time()
last_idx = len(loader) - 1
iters_per_epoch = len(loader)
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat or args.mem_dist) and not args.critical_loss:
model.set_requires_fp(True)
with amp_autocast():
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
# print(args.rank, output.shape, target.shape, max(target))
loss = loss_fn(output, target)
if args.tet_loss:
output = output.mean(0)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
# closses_m.update(closs, inputs.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/top1'), acc1.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/top5'), acc5.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/loss'), loss.item(), epoch * iters_per_epoch + batch_idx)
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
if not args.distributed and spike_rate:
spike_m.update(model.get_tot_spike() / output.size(0), output.size(0))
if not args.distributed and spike_rate:
_logger.info(
'[Spike Info]: {spike.val} ({spike.avg})'.format(
spike=spike_m
)
)
if last_batch or batch_idx % args.log_interval == 0:
_logger.info(
'Eval : {} '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
epoch,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
top1=top1_m,
top5=top5_m,
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg)])
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/top1'), top1_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/top5'), top5_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/loss'), losses_m.avg, epoch)
return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/Perception_and_Learning/img_cls/bp/main_backei.py
================================================
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import time
from braincog.model_zoo.backeinet import *
import argparse
import os
import json
parser = argparse.ArgumentParser("description = train.py")
parser.add_argument('-seed', type=int, default=4150)
parser.add_argument('-epoch', type=int, default=200)
parser.add_argument('-batch_size', type=int, default=100)
parser.add_argument('-learning_rate', type=float, default=1e-3)
parser.add_argument('--dataset', type=str, default='fashion')
parser.add_argument('--simulation_len', type=int, default=20)
parser.add_argument('--Back', action='store_true', default=False)
parser.add_argument('--EI', action='store_true', default=False)
parser.add_argument('--device', type=int, default=1)
parser.add_argument('--encode-type', type=str, default='direct')
opt = parser.parse_args()
torch.cuda.set_device('cuda:%d' % opt.device)
torch.manual_seed(opt.seed)
torch.cuda.manual_seed(opt.seed)
test_scores = []
train_scores = []
save_path = opt.dataset + '_' + str(opt.seed) + '_' + opt.encode_type
if opt.Back:
save_path += '_Back'
if opt.EI:
save_path += '_EI'
if not os.path.exists(save_path):
os.mkdir(save_path)
normalize = transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
if opt.dataset == 'mnist':
train_dataset = datasets.MNIST(root='./data/mnist/', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='./data/mnist/', train=False, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=opt.batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=opt.batch_size, shuffle=False)
elif opt.dataset == 'fashion':
train_dataset = datasets.FashionMNIST(root='./data/fashion/', train=True, transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.FashionMNIST(root='./data/fashion/', train=False, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=opt.batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=opt.batch_size, shuffle=False)
elif opt.dataset == 'cifar10':
train_dataset = datasets.CIFAR10(root='./data/cifar10/', train=True, transform=transforms.Compose(
[transforms.RandomHorizontalFlip(), transforms.RandomCrop(32, padding=4), transforms.ToTensor(), normalize]),
download=True)
test_dataset = datasets.CIFAR10(root='./data/cifar10/', train=False,
transform=transforms.Compose([transforms.ToTensor(), normalize]))
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=opt.batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=opt.batch_size, shuffle=False)
if opt.dataset == 'cifar10':
snn = CIFARNet(step=opt.simulation_len, if_back=opt.Back, if_ei=opt.EI, encode_type=opt.encode_type)
else:
snn = MNISTNet(step=opt.simulation_len, if_back=opt.Back, if_ei=opt.EI, data=opt.dataset, encode_type=opt.encode_type)
snn = snn.cuda()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(snn.parameters(), lr=opt.learning_rate)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=40, gamma=0.1)
def train(epoch):
snn.train()
start_time = time.time()
total_loss = 0
correct = 0
total = 0
for i, (images, labels) in enumerate(train_loader):
optimizer.zero_grad()
images = images.cuda()
outputs = snn(images)
labels_ = torch.zeros(opt.batch_size, 10).scatter_(1, labels.view(-1, 1), 1).cuda()
loss = criterion(outputs, labels_)
total_loss += loss.item()
loss.backward()
optimizer.step()
pred = outputs.max(1)[1]
total += labels.size(0)
correct += (pred.cpu() == labels).sum()
if (i + 1) % (60000 // (opt.batch_size * 6)) == 0:
print('Epoch: [%d/%d], Step: [%d/%d], Loss: %.4f, Time: %.2f' % (
epoch + 1, opt.epoch, i + 1, 60000 // opt.batch_size, total_loss,
time.time() - start_time))
start_time = time.time()
total_loss = 0
acc = 100.0 * correct.item() / total
train_scores.append(acc)
def eval(epoch):
snn.eval()
correct = 0
total = 0
with torch.no_grad():
for i, (images, labels) in enumerate(test_loader):
images = images.cuda()
outputs = snn(images)
pred = outputs.max(1)[1]
total += labels.size(0)
correct += (pred.cpu() == labels).sum()
acc = 100.0 * correct.item() / total
print('Test correct: %d Accuracy: %.2f%%' % (correct, acc))
test_scores.append(acc)
if acc >= max(test_scores):
save_file = str(epoch) + '.pt'
torch.save(snn, os.path.join(save_path, save_file))
return max(test_scores)
def main():
for epoch in range(opt.epoch):
train(epoch)
best_acc = eval(epoch)
scheduler.step()
print('Best Accuracy: %.2f%%' % (best_acc))
if __name__ == '__main__':
main()
filename = "train.json"
filename = os.path.join(save_path, filename)
with open(filename, "w") as f:
json.dump(train_scores, f)
filename = "test.json"
filename = os.path.join(save_path, filename)
with open(filename, "w") as f:
json.dump(test_scores, f)
================================================
FILE: examples/Perception_and_Learning/img_cls/bp/main_simplified.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/4/28 14:56
# User : Floyed
# Product : PyCharm
# Project : braincog
# File : main_simplified.py
# explain : Simplified training script. Remove support for DDP, IMAGENET, Augment, etc.
import argparse
import time
import timm.models
import yaml
import os
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.utils import save_feature_map
import torch
import torch.nn as nn
import torchvision.utils
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
# from ptflops import get_model_complexity_info
from thop import profile, clever_format
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--dataset', default='cifar10', type=str)
parser.add_argument('--model', default='cifar_convnet', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 10)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=600, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--device', type=int, default=0)
parser.add_argument('--output', default='/data/floyed/braincog', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
# neuron type
parser.add_argument('--node-type', type=str, default='PLIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='AtanGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--thresh', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--n_warm_up', type=int, default=0,
help='Warm up epoch, replace all node to ReLU to warm up weights in network before (default: 0)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def main():
args, args_text = _parse_args()
# args.no_spike_output = args.no_spike_output | args.cut_mix
args.no_spike_output = True
output_dir = ''
output_base = args.output if args.output else './output'
exp_name = '-'.join([
datetime.now().strftime("%Y%m%d-%H%M%S"),
args.model,
args.dataset,
str(args.step),
args.suffix
# str(args.img_size)
])
output_dir = get_outdir(output_base, 'train', exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
torch.cuda.set_device('cuda:%d' % args.device)
torch.manual_seed(args.seed)
model = create_model(
args.model,
num_classes=args.num_classes,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.thresh,
tau=args.tau,
spike_output=not args.no_spike_output,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
)
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.img_size, args.img_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size / 1024.0
args.lr = linear_scaled_lr
model = model.cuda()
optimizer = create_optimizer(args, model)
# optionally resume from a checkpoint
resume_epoch = None
if args.resume:
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet fcvawefdadw
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
temporal_flatten=args.temporal_flatten,
portion=args.train_portion)
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
else:
if mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args,
checkpoint_dir=output_dir, recovery_dir=output_dir)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
try: # train the model
for epoch in range(start_epoch, args.epochs):
if args.visualize or args.spike_rate:
print('start to plot feature map / calc spike rate')
validate(model, loader_eval, validate_loss_fn, args,
visualize=args.visualize, spike_rate=args.spike_rate)
exit(0)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir)
eval_metrics = validate(model, loader_eval, validate_loss_fn, args)
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(output_dir, 'summary.csv'),
write_header=best_metric is None)
if saver is not None and epoch >= args.n_warm_up:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
except KeyboardInterrupt:
pass
if best_metric is not None:
_logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,
lr_scheduler=None, saver=None, output_dir=''):
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
output = model(inputs)
loss = loss_fn(output, target)
if not (args.cut_mix | args.mix_up | args.event_mix):
acc1, acc5 = accuracy(output, target, topk=(1, 5))
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
top5_m.update(acc5.item(), inputs.size(0))
optimizer.zero_grad()
loss.backward()
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
optimizer.step()
num_updates += 1
batch_time_m.update(time.time() - end)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
top1=top1_m, top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) / batch_time_m.val,
rate_avg=inputs.size(0) / batch_time_m.avg,
lr=lr,
data_time=data_time_m))
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg)])
def validate(model, loader, loss_fn, args, log_suffix='', visualize=False, spike_rate=False):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
end = time.time()
last_idx = len(loader) - 1
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if visualize or spike_rate:
model.set_requires_fp(True)
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
if visualize:
x = model.get_fp()
feature_path = os.path.join(args.output_dir, 'feature_map')
if os.path.exists(feature_path) is False:
os.mkdir(feature_path)
save_feature_map(x, feature_path)
model.set_requires_fp(False)
if spike_rate:
_logger.info(model.get_fire_rate_per_layer())
model.set_requires_fp(False)
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if last_batch or batch_idx % args.log_interval == 0:
log_name = 'Test' + log_suffix
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
log_name, batch_idx, last_idx, batch_time=batch_time_m,
loss=losses_m, top1=top1_m, top5=top5_m))
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/Perception_and_Learning/img_cls/glsnn/README.md
================================================
# SNN with global feedback connections
Training deep spiking neural network with the global
feedback connections and the local optimization learning rules. And is a little different from our original paper.
GLSNN: A Multi-layer Spiking Neural Network based on Global Feedback Alignment and Local STDP Plasticity.
## Results
```shell
python cls_glsnn.py
```
We train the model for 100 epochs, and the best accuracy for MNIST is 98.23\%, for FashionMNIST is 89.68\%.

## Citation
If you find the code and dataset useful in your research, please consider citing:
```
@article{zhao2020glsnn,
title={GLSNN: A Multi-Layer Spiking Neural Network Based on Global Feedback Alignment and Local STDP Plasticity},
author={Zhao, Dongcheng and Zeng, Yi and Zhang, Tielin and Shi, Mengting and Zhao, Feifei},
journal={Frontiers in Computational Neuroscience},
volume={14},
year={2020},
publisher={Frontiers Media SA}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
## Contents
Feedbacks and comments are welcome! Feel free to contact us via [zhaodongcheng2016@ia.ac.cn](zhaodongcheng2016@ia.ac.cn)
Enjoy!
================================================
FILE: examples/Perception_and_Learning/img_cls/glsnn/cls_glsnn.py
================================================
import torch
from torchvision import transforms
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
from braincog.model_zoo.glsnn import BaseGLSNN
import argparse
import time
import os
import json
os.environ['CUDA_VISIBLE_DEVICES'] = "3"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
parser = argparse.ArgumentParser("description = GLSNN.py")
parser.add_argument('-seed', type=int, default=2122)
parser.add_argument('-epoch', type=int, default=100)
parser.add_argument('-batch_size', type=int, default=100)
parser.add_argument('-lr_target', type=float, default=0.4)
parser.add_argument('-lr_forward', type=float, default=0.001)
parser.add_argument('-step', type=int, default=10)
parser.add_argument('-encode_type', type=str, default='direct')
parser.add_argument('--dataset', type=str, default='MNIST')
opt = parser.parse_args()
torch.manual_seed(opt.seed)
torch.cuda.manual_seed(opt.seed)
test_scores = []
train_scores = []
save_path = './' + 'GLSNN' + '_' + opt.dataset + '_' + str(opt.seed)
if not os.path.exists(save_path):
os.mkdir(save_path)
if opt.dataset == 'MNIST':
train_dataset = datasets.MNIST(root='./data/datasets/mnist/', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='./data/datasets/mnist/', train=False, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=opt.batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=opt.batch_size, shuffle=False)
elif opt.dataset == 'Fashion-MNIST':
train_dataset = datasets.FashionMNIST(root='./data/fashion/', train=True, transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.FashionMNIST(root='./data/fashion/', train=False, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=opt.batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=opt.batch_size, shuffle=False)
snn = BaseGLSNN(input_size=784, hidden_sizes=[800] * 3, output_size=10, opt=opt)
snn.to(device)
optimizer = torch.optim.Adam(snn.forward_parameters(), lr=opt.lr_forward)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=40, gamma=0.1)
def train(epoch):
snn.train()
start_time = time.time()
total_loss = 0
correct = 0
total = 0
for i, (images, labels) in enumerate(train_loader):
optimizer.zero_grad()
images = images.to(device)
labels_ = torch.zeros(opt.batch_size, 10).scatter_(1, labels.view(-1, 1), 1).to(device)
labels = labels.to(device)
outputs, loss = snn.set_gradient(images, labels_)
optimizer.step()
total_loss += loss.item()
pred = outputs[-1].max(1)[1]
total += labels.size(0)
correct += (pred.cpu() == labels.cpu()).sum()
if (i + 1) % (60000 // (opt.batch_size * 6)) == 0:
print('Epoch: [%d/%d], Step: [%d/%d], Loss: %.4f, Time: %.2f' % (
epoch + 1, opt.epoch, i + 1, 60000 // opt.batch_size, total_loss,
time.time() - start_time))
start_time = time.time()
total_loss = 0
acc = 100.0 * correct.item() / total
train_scores.append(acc)
def eval(epoch):
snn.eval()
correct = 0
total = 0
with torch.no_grad():
for i, (images, labels) in enumerate(test_loader):
images = images.to(device)
outputs = snn(images)
pred = outputs[-1].max(1)[1]
total += labels.size(0)
correct += (pred.cpu() == labels).sum()
acc = 100.0 * correct.item() / total
print('Test correct: %d Accuracy: %.2f%%' % (correct, acc))
test_scores.append(acc)
if acc >= max(test_scores):
save_file = str(epoch) + '.pt'
torch.save(snn, os.path.join(save_path, save_file))
return max(test_scores)
def main():
for epoch in range(opt.epoch):
train(epoch)
best_acc = eval(epoch)
scheduler.step()
print('Best Accuracy: %.2f%%' % (best_acc))
if __name__ == '__main__':
main()
filename = "train.json"
filename = os.path.join(save_path, filename)
with open(filename, "w") as f:
json.dump(train_scores, f)
filename = "test.json"
filename = os.path.join(save_path, filename)
with open(filename, "w") as f:
json.dump(test_scores, f)
================================================
FILE: examples/Perception_and_Learning/img_cls/spiking_capsnet/README.md
================================================
# Spiking capsnet: A spiking neural network with a biologically plausible routing rule between capsules
## Run
```shell
python main.py
```
## Citation
If you find the code and dataset useful in your research, please consider citing:
```
@article{zhao2022spiking,
title={Spiking capsnet: A spiking neural network with a biologically plausible routing rule between capsules},
author={Zhao, Dongcheng and Li, Yang and Zeng, Yi and Wang, Jihang and Zhang, Qian},
journal={Information Sciences},
volume={610},
pages={1--13},
year={2022},
publisher={Elsevier}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
## Contents
Feedbacks and comments are welcome! Feel free to contact us via [zhaodongcheng2016@ia.ac.cn](zhaodongcheng2016@ia.ac.cn)
Enjoy!
================================================
FILE: examples/Perception_and_Learning/img_cls/spiking_capsnet/spikingcaps.py
================================================
import sys
sys.path.append('../../../../')
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from torch.optim import Adam
import os
import math
from tqdm import tqdm
import numpy as np
from braincog.datasets.datasets import get_mnist_data
from braincog.base.node import LIFNode
from braincog.utils import setup_seed
setup_seed(1111)
os.environ['CUDA_VISIBLE_DEVICES'] = "4"
class myLIFnode(LIFNode):
def __init__(self, threshold=0.5, tau=2., *args, **kwargs):
super().__init__(threshold, tau, *args, **kwargs)
def integral(self, inputs):
# self.mem = self.mem + (inputs - self.mem) / self.tau
self.mem = self.mem / self.tau + inputs
class ConvLayer(nn.Module):
def __init__(self, in_channels=1, out_channels=256, kernel_size=9):
super(ConvLayer, self).__init__()
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=1)
def forward(self, x):
return F.relu(self.conv(x))
class PrimaryCaps(nn.Module):
def __init__(self, num_capsules=8, in_channels=256, out_channels=32, kernel_size=9):
super(PrimaryCaps, self).__init__()
self.capsules = nn.ModuleList([
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=2, padding=0)
for _ in range(num_capsules)])
def forward(self, x):
u = [capsule(x) for capsule in self.capsules]
u = torch.stack(u, dim=1)
u.permute(0,2,3,4,1)
u = u.view(x.size(0), 32 * 6 * 6, -1)
return u
class DigitCaps(nn.Module):
def __init__(self, num_capsules=10, num_routes=32 * 6 * 6, in_channels=8, out_channels=16):
super(DigitCaps, self).__init__()
self.in_channels = in_channels
self.num_routes = num_routes
self.num_capsules = num_capsules
self.W = nn.Parameter(torch.randn(1, num_routes, num_capsules, out_channels, in_channels))
self.bias = nn.Parameter(torch.randn(out_channels, 1))
self.W.data.normal_(0, math.sqrt(3.0 / (in_channels * out_channels)))
self.bias.data.normal_(0, math.sqrt(3.0 / (in_channels * out_channels)))
def forward(self, x):
batch_size = x.size(0)
x = torch.stack([x] * self.num_capsules, dim=2).unsqueeze(4)
W = torch.cat([self.W] * batch_size, dim=0)
u_hat = torch.matmul(W, x) + self.bias
return u_hat
class DigitCaps2(nn.Module):
def __init__(self, num_capsules=10, num_routes=32 * 6 * 6):
super(DigitCaps2, self).__init__()
self.num_routes = num_routes
self.num_capsules = num_capsules
self.b_ij = Variable(torch.ones(1, self.num_routes, self.num_capsules, 1)/1152)
self.b_ij = self.b_ij.to(device)
def forward(self, u_hat):
c_ij = torch.cat([self.b_ij] * batch_size, dim=0).unsqueeze(4)
s_j = (c_ij * u_hat).sum(dim=1, keepdim=True)
return s_j.squeeze(1)
def init_bij(self):
self.b_ij = Variable(torch.ones(1, self.num_routes, self.num_capsules, 1)/1152)
self.b_ij = self.b_ij.to(device)
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.linear = nn.Linear(16, 1)
def forward(self, x):
classes = torch.sqrt((x ** 2).sum(2))
# classes = self.linear(x)
return classes
class CapsNet(nn.Module):
def __init__(self):
super(CapsNet, self).__init__()
self.conv_layer = ConvLayer()
self.primary_capsules = PrimaryCaps()
self.digit_capsules = DigitCaps()
self.digit_capsules2 = DigitCaps2()
self.decoder = Decoder()
self.conv_node = myLIFnode(tau=5)
self.primary_node = myLIFnode(tau=5)
self.digit_node = myLIFnode(tau=5)
self.digit2_node = myLIFnode(tau=5)
def forward(self, data, time_window=5, train=True):
self.init()
out_mem = 0.
self.digit_capsules2.init_bij()
self.trace_u = torch.zeros(batch_size, 1152, 10, 16, 1, device=device)
for step in range(time_window):
x = data
x = self.conv_node(self.conv_layer(x))
x = self.primary_node(self.primary_capsules(x))
x1 = self.digit_node(self.digit_capsules(x))
x = self.digit_capsules2(x1)
out_mem += x.squeeze(3)
y = self.digit2_node(x)
if train:
with torch.no_grad():
self.digit_capsules2.b_ij = torch.clamp(self.digit_capsules2.b_ij, -0.05, 1)
self.trace_u *= torch.exp(-1 / torch.tensor(1.5))
self.trace_u.masked_fill_(x1 != 0, 1)
self.digit_capsules2.b_ij += 0.0008 * torch.matmul(
self.trace_u.transpose(3, 4) - 0.1,
torch.stack([y] * 1152, dim=1)).squeeze(4).mean(dim=0, keepdim=True)
output = out_mem / time_window
output = self.decoder(output)
return output
def init(self):
self.conv_node.n_reset()
self.primary_node.n_reset()
self.digit_node.n_reset()
self.digit2_node.n_reset()
def evaluate(test_iter, net, device):
net.eval()
test_loss, test_acc, n_test = 0, 0.0, 0
for batch_id, (data, target) in tqdm(enumerate(test_iter)):
target = torch.sparse.torch.eye(10).index_select(dim=0, index=target)
data, target = Variable(data), Variable(target)
data, target = data.to(device), target.to(device)
classes = net(data)
test_acc += sum(np.argmax(classes.data.cpu().numpy(), 1) == np.argmax(target.data.cpu().numpy(), 1))
n_test += data.shape[0]
net.train()
return test_acc / n_test
if __name__ == '__main__':
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
batch_size = 100
train_loader, test_loader, _, _ = get_mnist_data(batch_size)
capsule_net = CapsNet().to(device)
optimizer = Adam(capsule_net.parameters(), lr=0.0005)
loss_fn = nn.MSELoss()
n_epochs = 50
best, losses = 0, []
for epoch in range(n_epochs):
if epoch in [15, 25, 45]:
optimizer.param_groups[0]['lr'] *= 0.3
capsule_net.train()
train_loss, correct, n = 0, 0, 0
loss_rec = []
for batch_id, (data, target) in enumerate(train_loader):
target = torch.sparse.torch.eye(10).index_select(dim=0, index=target)
data, target = Variable(data), Variable(target)
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
classes = capsule_net(data)
loss = loss_fn(classes, target)
loss.backward()
loss_rec.append(loss.item())
optimizer.step()
train_loss += loss.item()
correct += sum(np.argmax(classes.data.cpu().numpy(), 1) == np.argmax(target.data.cpu().numpy(), 1))
n += data.shape[0]
if batch_id % 100 == 0:
print("Epoch: {}, Batch: {}, train accuracy: {:.6f}, loss: {:.6f}".format(
epoch, batch_id + 1,
sum(np.argmax(classes.data.cpu().numpy(), 1) == np.argmax(target.data.cpu().numpy(), 1)) / float(batch_size),
loss.item()))
losses.append(np.mean(np.array(loss_rec)))
print("Epoch: [{}/{}], train accuracy: {:.6f}, loss: {:.6f}".format(
epoch, n_epochs,
correct / float(n),
train_loss / len(train_loader)))
capsule_net.eval()
test_acc = evaluate(test_loader, capsule_net, device=device)
print("test accuracy: {:.6f}".format(test_acc))
if test_acc > best:
best = test_acc
# torch.save(capsule_net, './checkpoints/spikingcaps_mnist.pkl')
================================================
FILE: examples/Perception_and_Learning/img_cls/transfer_for_dvs/GradCAM_visualization.py
================================================
# -*- coding: utf-8 -*-
# Time : 2023/2/14 11:52
# Author : Regulus
# FileName: main_visual_losslandscape.py
# Explain:
# Software: PyCharm
import sys
import tqdm
from loss_landscape.plot_surface import *
from Pytorch_Grad_Cam.cam import *
import argparse
import math
import time
import CKA
import numpy
import timm.models
import random as rd
import yaml
import os
from mpl_toolkits.mplot3d import Axes3D
from mpl_toolkits.mplot3d import proj3d
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.vgg_snn import VGG_SNN
from braincog.model_zoo.resnet19_snn import resnet19
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from rgb_hsv import RGB_HSV
import matplotlib.pyplot as plt
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from copy import deepcopy
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--source-dataset', default='cifar10', type=str)
parser.add_argument('--target-dataset', default='dvsc10', type=str)
parser.add_argument('--model', default='cifar_convnet', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=600, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.8,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=1.0,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=1.0,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--output', default='/home/hexiang/TransferLearning_For_DVS/Results_new_refined/', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=0)
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='GateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--gaussian-n', type=int, default=3)
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
parser.add_argument('--DVS-DA', action='store_true',
help='use DA on DVS')
# train data used ratio
parser.add_argument('--traindata-ratio', default=1.0, type=float,
help='training data ratio')
# snr value
parser.add_argument('--snr', default=0, type=int,
help='random noise amplitude controled by snr, 0 means no noise')
parser.add_argument('--aug_smooth', action='store_true',
help='Apply test time augmentation to smooth the CAM')
parser.add_argument('--eigen_smooth', action='store_true', help='Reduce noise by taking the first principle componenet'
'of cam_weights*activations')
import os
import numpy as np
import torch
from torchvision import transforms
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from mpl_toolkits.mplot3d import proj3d
from tonic.datasets import NCALTECH101, CIFAR10DVS
import tonic
from matplotlib import rcParams
import seaborn as sns
# for matplotlib 3D
def get_proj(self):
"""
Create the projection matrix from the current viewing position.
elev stores the elevation angle in the z plane
azim stores the azimuth angle in the (x, y) plane
dist is the distance of the eye viewing point from the object point.
"""
# chosen for similarity with the initial view before gh-8896
relev, razim = np.pi * self.elev / 180, np.pi * self.azim / 180
# EDITED TO HAVE SCALED AXIS
xmin, xmax = np.divide(self.get_xlim3d(), self.pbaspect[0])
ymin, ymax = np.divide(self.get_ylim3d(), self.pbaspect[1])
zmin, zmax = np.divide(self.get_zlim3d(), self.pbaspect[2])
# transform to uniform world coordinates 0-1, 0-1, 0-1
worldM = proj3d.world_transformation(xmin, xmax,
ymin, ymax,
zmin, zmax)
# look into the middle of the new coordinates
R = self.pbaspect / 2
xp = R[0] + np.cos(razim) * np.cos(relev) * self.dist
yp = R[1] + np.sin(razim) * np.cos(relev) * self.dist
zp = R[2] + np.sin(relev) * self.dist
E = np.array((xp, yp, zp))
self.eye = E
self.vvec = R - E
self.vvec = self.vvec / np.linalg.norm(self.vvec)
if abs(relev) > np.pi / 2:
# upside down
V = np.array((0, 0, -1))
else:
V = np.array((0, 0, 1))
zfront, zback = -self.dist, self.dist
viewM = proj3d.view_transformation(E, R, V)
projM = self._projection(zfront, zback)
M0 = np.dot(viewM, worldM)
M = np.dot(projM, M0)
return M
def event_vis_raw(x):
sns.set_style('whitegrid')
# sns.set_palette('deep', desat=.6)
sns.set_context("notebook", font_scale=1.5,
rc={"lines.linewidth": 2.5})
Axes3D.get_proj = get_proj
x = np.array(x.tolist()) # x, y, t, p
mask = (x[:, 3] == 1)
x_pos = x[mask]
x_neg = x[mask == False]
pos_idx = np.random.choice(x_pos.shape[0], 10000)
neg_idx = np.random.choice(x_neg.shape[0], 10000)
# x_pos[pos_idx, 2] = 0
# x_neg[neg_idx, 2] = 0
fig = plt.figure(figsize=plt.figaspect(0.5) * 1.5)
ax = Axes3D(fig)
ax.pbaspect = np.array([2.0, 1.0, 0.5])
ax.view_init(elev=10, azim=-75)
# ax.view_init(elev=15, azim=15)
ax.set_xlabel('t (time step)')
ax.set_ylabel('w (pixel)')
ax.set_zlabel('h (pixel)')
# ax.set_xticks([])
# ax.set_yticks([])
# ax.set_zticks([])
# ax.scatter(x_pos[pos_idx, 2], 48 - x_pos[pos_idx, 0], 48 - x_pos[pos_idx, 1], color='red', alpha=0.3, s=1.)
# ax.scatter(x_neg[neg_idx, 2], 48 - x_neg[neg_idx, 0], 48 - x_neg[neg_idx, 1], color='blue', alpha=0.3, s=1.)
ax.scatter(x_pos[:, 0], 48 - x_pos[:, 1] * 0.375, 48 - x_pos[:, 2] * 0.375, color='red', alpha=0.3, s=1.)
# ax.scatter(x_neg[:, 0], 64 - x_neg[:, 1] // 2, 128 - x_neg[:, 2], color='blue', alpha=0.3, s=1.)
ax.scatter(18000, 48 - x_pos[:, 1] * 0.375, 48 - x_pos[:, 2] * 0.375, color='red', alpha=0.3, s=1.)
# ax.scatter(18000, 64 - x_pos[:, 1] // 2, 128 - x_pos[:, 2], color='blue', alpha=0.3, s=1.)
def get_dataloader_ncal(step, **kwargs):
sensor_size = tonic.datasets.CIFAR10DVS.sensor_size
transform = tonic.transforms.Compose([
# tonic.transforms.DropPixel(hot_pixel_frequency=.999),
# tonic.transforms.Denoise(500),
tonic.transforms.DropEvent(p=0.0),
# tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
# lambda x: F.interpolate(torch.tensor(x, dtype=torch.float), size=[48, 48], mode='bilinear', align_corners=True),
])
dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=transform)
# dataset = [dataset[5569], dataset[8196]]
# dataset = [dataset[5000], dataset[6000]] # 1958
# dataset = [dataset[0]]
# loader = torch.utils.data.DataLoader(
# dataset, batch_size=1,
# shuffle=False,
# pin_memory=True, drop_last=True, num_workers=8
# )
return dataset
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def main():
torch.set_num_threads(20)
os.environ["OMP_NUM_THREADS"] = "20" # 设置OpenMP计算库的线程数
os.environ["MKL_NUM_THREADS"] = "20" # 设置MKL-DNN CPU加速库的线程数。
args, args_text = _parse_args()
args.no_spike_output = True
torch.cuda.set_device('cuda:%d' % args.device)
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
adaptive_node=args.adaptive_node,
dataset=args.target_dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
)
if 'dvs' in args.target_dataset:
args.channels = 2
elif 'mnist' in args.target_dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
# source_loader_train, _, _, _ = eval('get_transfer_%s_data' % args.source_dataset)(
# batch_size=args.batch_size,
# step=args.step,
# args=args,
# _logge=_logger,
# data_config=data_config,
# size=args.event_size,
# mix_up=args.mix_up,
# cut_mix=args.cut_mix,
# event_mix=args.event_mix,
# beta=args.cutmix_beta,
# prob=args.cutmix_prob,
# gaussian_n=args.gaussian_n,
# num=args.cutmix_num,
# noise=args.cutmix_noise,
# num_classes=args.num_classes,
# rand_aug=args.rand_aug,
# randaug_n=args.randaug_n,
# randaug_m=args.randaug_m,
# portion=args.train_portion,
# _logger=_logger,
# )
origin_loader_train, _, _, _ = eval('get_origin_dvsc10_data')(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
)
target_loader_train, target_loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.target_dataset)(
batch_size=args.batch_size,
dvs_da=args.DVS_DA,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
train_data_ratio=args.traindata_ratio,
snr=args.snr,
data_mode="full",
frames_num=12,
data_type="frequency"
)
model_before = deepcopy(model)
if args.eval: # evaluate the model
if args.distributed:
state_dict = torch.load(args.eval_checkpoint)['state_dict_ema']
new_state_dict = OrderedDict()
# add module prefix for DDP
for k, v in state_dict.items():
k = 'module.' + k
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
else:
model.load_state_dict(torch.load('/home/hexiang/TransferLearning_For_DVS/Results_lastest/train_TCKA_test/Transfer_VGG_SNN-dvsc10-10-bs_120-seed_42-DA_True-ls_0.0-lr_0.005-SNR_0-domainLoss_False-semanticLoss_False-domain_loss_coefficient1.0-semantic_loss_coefficient0.5-traindataratio_1.0-TETfirst_True-TETsecond_True/model_best.pth.tar', map_location='cpu')['state_dict'])
# pass
# print("no model load")
# --------------------------------------------------------------------------
# Show Acc
# --------------------------------------------------------------------------
print("load model finished!")
# """ python cam.py -image-path
# Example usage of loading an image, and computing:
# 1. CAM
# 2. Guided Back Propagation
# 3. Combining both
# """
#
# # Choose the target layer you want to compute the visualization for.
# # Usually this will be the last convolutional layer in the model.
# # Some common choices can be:
# # Resnet18 and 50: model.layer4
# # VGG, densenet161: model.features[-1]
# # mnasnet1_0: model.layers[-1]
# # You can print the model to help chose the layer
# # You can pass a list with several target layers,
# # in that case the CAMs will be computed per layer and then aggregated.
# # You can also try selecting all layers of a certain type, with e.g:
# # from pytorch_grad_cam.utils.find_layers import find_layer_types_recursive
# # find_layer_types_recursive(model, [torch.nn.ReLU])
# target_layers = [model.feature[-1]]
#
# if True:
# # inputs = 0.0
# # label = 0.0
# # for batch_idx, (inputs_tmp, label_tmp) in tqdm.tqdm(enumerate(origin_loader_train)):
# # if batch_idx == choose_idx:
# # inputs = inputs_tmp
# # label = label_tmp
# # break
# # else:
# # continue
# inputs = 0.0
# rgb_img = 0.0
#
# #Using the with statement ensures the context is freed, and you can
# #recreate different CAM objects in a loop.
# plt.figure(figsize=(8, 6))
# plt.xlabel('w (pixel)')
# plt.ylabel('h (pixel)')
# cam_algorithm = GradCAMPlusPlus
# model = model.cuda()
# with cam_algorithm(model=model,
# target_layers=target_layers,
# use_cuda=False) as cam:
#
# # AblationCAM and ScoreCAM have batched implementations.
# # You can override the internal batch size for faster computation.
# cam.batch_size = 32
#
# for batch_idx, (origin_loaer, target_loader) in tqdm.tqdm(enumerate(zip(origin_loader_train, target_loader_train))):
#
# twodemension_inputs, labels = origin_loaer
# plt.figure(figsize=(8, 6))
# # plt.xlabel('w (pixel)')
# # plt.ylabel('h (pixel)')
# twodemension_inputs = twodemension_inputs[0] # (1, 10, 2, 48, 48) -> (10, 2, 48, 48)
# event_frame_plot_2d(twodemension_inputs)
#
# inputs_tmp, label_tmp = target_loader
# inputs = inputs_tmp
# inputs = inputs.type(torch.FloatTensor).cuda()
#
# grayscale_cam = cam(input_tensor=inputs,
# targets=None,
# aug_smooth=args.aug_smooth,
# eigen_smooth=args.eigen_smooth)
#
# # Here grayscale_cam has only one image in the batch
# grayscale_cam = grayscale_cam[0, :]
#
# # cam_image = show_cam_on_image(rgb_img.permute(1, 2, 0).numpy(), grayscale_cam, use_rgb=True, image_weight=0.0)
# cam_image = show_cam_on_image(np.ones((48, 48, 3)), grayscale_cam, use_rgb=True,
# image_weight=0.0)
# # # cam_image is RGB encoded whereas "cv2.imwrite" requires BGR encoding.
# # rgb_img = cv2.resize(rgb_img.permute(1, 2, 0).numpy(), (32, 32))
#
# # cv2.imwrite(f'{args.method}_cam.jpg', cam_image)
# plt.ylim(bottom=0.)
# plt.axis('off')
# plt.savefig('fig/gradcam_dvspic_origin/label_{}_id_{}.jpg'.format(labels.item(), 400 + batch_idx), bbox_inches='tight', pad_inches=0)
# plt.imshow(cam_image, alpha=1.0)
# # plt.show()
# # plt.savefig('gradcam_pic/plot_id{}.jpg'.format(batch_idx), bbox_inches='tight')
# plt.savefig('fig/gradcam_dvspic_withoutloss/label_{}_id_{}.jpg'.format(labels.item(), 400 + batch_idx), bbox_inches='tight', pad_inches=0)
# 第二次
print("load model again!")
model = model_before
model.load_state_dict(torch.load(
'/home/hexiang/TransferLearning_For_DVS/Results_lastest/train_TCKA_test/Transfer_VGG_SNN-dvsc10-10-bs_120-seed_42-DA_True-ls_0.0-lr_0.005-SNR_0-domainLoss_True-semanticLoss_True-domain_loss_coefficient1.0-semantic_loss_coefficient0.5-traindataratio_1.0-TETfirst_True-TETsecond_True/model_best.pth.tar', map_location='cpu')['state_dict'])
""" python cam.py -image-path
Example usage of loading an image, and computing:
1. CAM
2. Guided Back Propagation
3. Combining both
"""
# Choose the target layer you want to compute the visualization for.
# Usually this will be the last convolutional layer in the model.
# Some common choices can be:
# Resnet18 and 50: model.layer4
# VGG, densenet161: model.features[-1]
# mnasnet1_0: model.layers[-1]
# You can print the model to help chose the layer
# You can pass a list with several target layers,
# in that case the CAMs will be computed per layer and then aggregated.
# You can also try selecting all layers of a certain type, with e.g:
# from pytorch_grad_cam.utils.find_layers import find_layer_types_recursive
# find_layer_types_recursive(model, [torch.nn.ReLU])
target_layers = [model.feature[-1]]
if True:
# inputs = 0.0
# label = 0.0
# for batch_idx, (inputs_tmp, label_tmp) in tqdm.tqdm(enumerate(origin_loader_train)):
# if batch_idx == choose_idx:
# inputs = inputs_tmp
# label = label_tmp
# break
# else:
# continue
inputs = 0.0
rgb_img = 0.0
#Using the with statement ensures the context is freed, and you can
#recreate different CAM objects in a loop.
plt.figure(figsize=(8, 6))
plt.xlabel('w (pixel)')
plt.ylabel('h (pixel)')
cam_algorithm = GradCAMPlusPlus
model = model.cuda()
with cam_algorithm(model=model,
target_layers=target_layers,
use_cuda=False) as cam:
# AblationCAM and ScoreCAM have batched implementations.
# You can override the internal batch size for faster computation.
cam.batch_size = 32
for batch_idx, (origin_loaer, target_loader) in tqdm.tqdm(enumerate(zip(origin_loader_train, target_loader_train))):
twodemension_inputs, labels = origin_loaer
plt.figure(figsize=(8, 6))
# plt.xlabel('w (pixel)')
# plt.ylabel('h (pixel)')
twodemension_inputs = twodemension_inputs[0] # (1, 10, 2, 48, 48) -> (10, 2, 48, 48)
event_frame_plot_2d(twodemension_inputs)
inputs_tmp, label_tmp = target_loader
inputs = inputs_tmp
inputs = inputs.type(torch.FloatTensor).cuda()
grayscale_cam = cam(input_tensor=inputs,
targets=None,
aug_smooth=args.aug_smooth,
eigen_smooth=args.eigen_smooth)
# Here grayscale_cam has only one image in the batch
grayscale_cam = grayscale_cam[0, :]
# cam_image = show_cam_on_image(rgb_img.permute(1, 2, 0).numpy(), grayscale_cam, use_rgb=True, image_weight=0.0)
cam_image = show_cam_on_image(np.ones((48, 48, 3)), grayscale_cam, use_rgb=True,
image_weight=0.0)
# # cam_image is RGB encoded whereas "cv2.imwrite" requires BGR encoding.
# rgb_img = cv2.resize(rgb_img.permute(1, 2, 0).numpy(), (32, 32))
# cv2.imwrite(f'{args.method}_cam.jpg', cam_image)
plt.ylim(bottom=0.)
plt.axis('off')
# plt.savefig('fig/gradcam_dvspic_origin/label_{}_id_{}.jpg'.format(labels.item(), batch_idx), bbox_inches='tight', pad_inches=0)
plt.imshow(cam_image, alpha=1.0)
# plt.show()
# plt.savefig('gradcam_pic/plot_id{}.jpg'.format(batch_idx), bbox_inches='tight')
plt.savefig('fig/gradcam_dvspic_withloss/label_{}_id_{}.jpg'.format(labels.item(), batch_idx), bbox_inches='tight', pad_inches=0)
def event_frame_plot_2d(event):
for t in range(event.shape[0]):
pos_idx = []
neg_idx = []
for x in range(event.shape[2]):
for y in range(event.shape[3]):
if event[t, 0, x, y] > 0:
pos_idx.append((x, y, event[t, 0, x, y]))
if event[t, 1, x, y] > 0:
neg_idx.append((x, y, event[t, 0, x, y]))
if len(pos_idx) > 0:
# print(t)
pos_x, pos_y, pos_c = np.split(np.array(pos_idx), 3, axis=1)
# plt.scatter(48 - pos_x[:, 0] * 0.375, 48 - pos_y[:, 0] * 0.375, c='red', alpha=1, s=1)
plt.scatter(pos_x[:, 0] * 0.375, pos_y[:, 0] * 0.375, c='white', alpha=1, s=1)
if len(neg_idx) > 0:
neg_x, neg_y, neg_c = np.split(np.array(neg_idx), 3, axis=1)
# plt.scatter(48 - neg_x[:, 0] * 0.375, 48 - neg_y[:, 0] * 0.375, c='blue', alpha=1, s=1)
plt.scatter(neg_x[:, 0] * 0.375, neg_y[:, 0] * 0.375, c='blue', alpha=1, s=1)
# sys.exit()
if __name__ == '__main__':
main()
================================================
FILE: examples/Perception_and_Learning/img_cls/transfer_for_dvs/README.md
================================================
# Script for all experiments
## Baseline
1. CIFAR10-DVS
```shell
python main.py --model VGG_SNN --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 120 --act-fun QGateGrad --device 5 --seed 42 --DVS-DA --traindata-ratio 1.0 --smoothing 0.0 --TET-loss-first --TET-loss-second
```
2. N-Caltech 101
```shell
python main.py --model VGG_SNN --node-type LIFNode --dataset NCALTECH101 --step 10 --batch-size 120 --act-fun QGateGrad --device 7 --seed 42 --num-classes 101 --traindata-ratio 1.0 --smoothing 0.0 --TET-loss-first --TET-loss-second
```
3. Omniglot
```shell
python main.py --model SCNN --node-type LIFNode --dataset nomni --step 12 --batch-size 64 --num-classes 1623 --act-fun QGateGrad --epochs 200 --device 6 --log-interval 200 --smoothing 0.0 --seed 42 --lr 0.01 --min-lr 1e-5
```
## Our Method
1. CIFAR10-DVS
```shell
python main_transfer.py --model Transfer_VGG_SNN --node-type LIFNode --source-dataset cifar10 --target-dataset dvsc10 --step 10 --batch-size 120 --act-fun QGateGrad --device 1 --seed 42 --traindata-ratio 1.0 --smoothing 0.0 --domain-loss --semantic-loss --DVS-DA --TET-loss-first --TET-loss-second
```
2. N-Caltech 101
```shell
python main_transfer.py --model Transfer_VGG_SNN --node-type LIFNode --source-dataset CALTECH101 --target-dataset NCALTECH101 --step 10 --batch-size 120 --act-fun QGateGrad --device 5 --seed 42 --num-classes 101 --traindata-ratio 1.0 --domain-loss --semantic-loss --semantic-loss-coefficient 0.001 --TET-loss-first --TET-loss-second&
```
3. N-Omniglot
```shell
python main_transfer.py --model Transfer_SCNN --node-type LIFNode --source-dataset omni --target-dataset nomni --step 12 --batch-size 64 --num-classes 1623 --act-fun QGateGrad --epochs 200 --device 6 --log-interval 200 --smoothing 0.0 --seed 42 --domain-loss --semantic-loss --semantic-loss-coefficient 0.5 --lr 0.01 --min-lr 1e-5
```
## Visualization Loss-landscape
you should git clone from https://github.com/tomgoldstein/loss-landscape first.
```shell
HDF5_USE_FILE_LOCKING="FALSE" mpirun -n 4 -mca btl ^openib python main_visual_losslandscape.py --model VGG_SNN --node-type LIFNode --source-dataset cifar10 --target-dataset dvsc10 --step 10 --batch-size 1000 --eval --eval_checkpoint /home/TransferLearning_For_DVS/Resultes_new_compare/Baseline/VGG_SNN-dvsc10-10-seed_42-bs_120-DA_True-ls_0.0-traindataratio_0.1-TET_first_False-TET_second_False/last.pth.tar --mpi --x=-1.0:1.0:51 --y=-1.0:1.0:51 --dir_type weights --xnorm filter --xignore biasbn --ynorm filter --yignore biasbn --plot --DVS-DA --smoothing 0.0 --traindata-ratio 0.1
```
```shell
python main_visual_losslandscape.py --model Transfer_VGG_SNN --node-type LIFNode --source-dataset CALTECH101 --target-dataset NCALTECH101 --step 10 --batch-size 500 --eval --eval_checkpoint /home/TransferLearning_For_DVS/Results_new_compare/train_TCKA_test/Transfer_VGG_SNN-NCALTECH101-10-bs_120-seed_47-DA_False-ls_0.0-lr_0.005-SNR_0-domainLoss_True-semanticLoss_True-domain_loss_coefficient1.0-semantic_loss_coefficient0.001-traindataratio_0.1-TETfirst_True-TETsecond_True/last.pth.tar --mpi --x=-1.0:1.0:51 --y=-1.0:1.0:51 --dir_type weights --xnorm filter --xignore biasbn --ynorm filter --yignore biasbn --plot --smoothing 0.0 --traindata-ratio 0.1 --num-classes 101 --device 5&
```
## Visualization Grad-cam++
you should git clone from https://github.com/jacobgil/pytorch-grad-cam first.
```shell
python GradCAM_visualization.py --model Transfer_VGG_SNN --node-type LIFNode --source-dataset cifar10 --target-dataset dvsc10 --step 10 --batch-size 1 --act-fun QGateGrad --device 6 --seed 42 --smoothing 0.0 --DVS-DA --eval --eval_checkpoint /home/TransferLearning_For_DVS/Results_lastest/train_TCKA_test/Transfer_VGG_SNN-dvsc10-10-bs_120-seed_42-DA_True-ls_0.0-lr_0.005-SNR_0-domainLoss_True-semanticLoss_True-domain_loss_coefficient1.0-semantic_loss_coefficient0.5-traindataratio_1.0-TETfirst_True-TETsecond_True/model_best.pth.tar
```
## Note: Dataset
In order to work with the source and target domain data, the datastes file is tailored, please use `datasets.py` here to replace and override `braincog/datasets/datasets.py` if you want to run transfer learning in this project.
## Citation
If you find the code and dataset useful in your research, please consider citing:
```
@article{he2023improving,
title={Improving the Performance of Spiking Neural Networks on Event-based Datasets with Knowledge Transfer},
author={He, Xiang and Zhao, Dongcheng and Li, Yang and Shen, Guobin and Kong, Qingqun and Zeng, Yi},
journal={arXiv preprint arXiv:2303.13077},
year={2023}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
## Contents
If you are confused about using it or have other feedback and comments, please feel free to contact us via [hexiang2021@ia.ac.cn](hexiang2021@ia.ac.cn).
Have a good day!
================================================
FILE: examples/Perception_and_Learning/img_cls/transfer_for_dvs/datasets.py
================================================
import os, warnings
import torchvision.datasets
try:
import tonic
from tonic import DiskCachedDataset
except:
warnings.warn("tonic should be installed, 'pip install git+https://github.com/BrainCog-X/tonic_braincog.git'")
import torch
import torch.nn.functional as F
import torch.utils
import torchvision.datasets as datasets
from timm.data import ImageDataset, create_loader, Mixup, FastCollateMixup, AugMixDataset
from timm.data import create_transform
from einops import rearrange, repeat
from torchvision import transforms
from typing import Any, Dict, Optional, Sequence, Tuple, Union
from torch.utils.data import ConcatDataset
from braincog.datasets.NOmniglot.nomniglot_full import NOmniglotfull
from braincog.datasets.NOmniglot.nomniglot_nw_ks import NOmniglotNWayKShot
from braincog.datasets.NOmniglot.nomniglot_pair import NOmniglotTrainSet, NOmniglotTestSet
from braincog.datasets.ESimagenet.ES_imagenet import ESImagenet_Dataset
from braincog.datasets.ESimagenet.reconstructed_ES_imagenet import ESImagenet2D_Dataset
from braincog.datasets.CUB2002011 import CUB2002011
from braincog.datasets.TinyImageNet import TinyImageNet
from braincog.datasets.StanfordDogs import StanfordDogs
from random import sample
from .cut_mix import CutMix, EventMix, MixUp
from .rand_aug import *
from .utils import dvs_channel_check_expend, rescale
from PIL import Image
import cv2
import math
DVSCIFAR10_MEAN_16 = [0.3290, 0.4507]
DVSCIFAR10_STD_16 = [1.8398, 1.6549]
DATA_DIR = '/data/datasets'
DEFAULT_CROP_PCT = 0.875
IMAGENET_DEFAULT_MEAN = (0.485, 0.456, 0.406)
IMAGENET_DEFAULT_STD = (0.229, 0.224, 0.225)
IMAGENET_INCEPTION_MEAN = (0.5, 0.5, 0.5)
IMAGENET_INCEPTION_STD = (0.5, 0.5, 0.5)
IMAGENET_DPN_MEAN = (124 / 255, 117 / 255, 104 / 255)
IMAGENET_DPN_STD = tuple([1 / (.0167 * 255)] * 3)
CIFAR10_DEFAULT_MEAN = (0.4914, 0.4822, 0.4465)
CIFAR10_DEFAULT_STD = (0.2023, 0.1994, 0.2010)
class TransferSampler(torch.utils.data.sampler.Sampler):
r"""Samples elements randomly from a given list of indices, without replacement.
Arguments:
indices (sequence): a sequence of indices
"""
def __init__(self, indices):
self.indices = indices
def __iter__(self):
return (self.indices[i] for i in range(len(self.indices)))
def __len__(self):
return len(self.indices)
class Transfer_DataSet(torchvision.datasets.VisionDataset):
def __init__(self, data, label):
self.data = data
self.label = label
self.length = data.shape[0]
def __getitem__(self, mask):
data = self.data[mask]
label = self.label[mask]
return data, label
def __len__(self):
return self.length
# 自定义HSV空间 transform
class ConvertHSV(object):
"""计算边缘梯度
Args:
None
"""
def __init__(self):
pass
# transform 会调用该方法
def __call__(self, img):
"""
Args:
img (PIL Image): PIL Image
Returns:
PIL Image: PIL image, v channel.
"""
img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
return Image.fromarray(img.astype('uint8'))
def unpack_mix_param(args):
mix_up = args['mix_up'] if 'mix_up' in args else False
cut_mix = args['cut_mix'] if 'cut_mix' in args else False
event_mix = args['event_mix'] if 'event_mix' in args else False
beta = args['beta'] if 'beta' in args else 1.
prob = args['prob'] if 'prob' in args else .5
num = args['num'] if 'num' in args else 1
num_classes = args['num_classes'] if 'num_classes' in args else 10
noise = args['noise'] if 'noise' in args else 0.
gaussian_n = args['gaussian_n'] if 'gaussian_n' in args else None
return mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n
def build_transform(is_train, img_size, use_hsv=True):
"""
构建数据增强, 适用于static data
:param is_train: 是否训练集
:param img_size: 输出的图像尺寸
:return: 数据增强策略
"""
resize_im = img_size > 32
if is_train:
# this should always dispatch to transforms_imagenet_train
transform = create_transform(
input_size=img_size,
is_training=True,
color_jitter=0.4,
auto_augment='rand-m9-mstd0.5-inc1',
interpolation='bicubic',
re_prob=0.25,
re_mode='pixel',
re_count=1,
)
if not resize_im:
# replace RandomResizedCropAndInterpolation with
# RandomCrop
transform.transforms[0] = transforms.RandomCrop(
img_size, padding=4)
return transform
t = []
# if resize_im:
# size = int((256 / 224) * img_size)
# t.append(
# # to maintain same ratio w.r.t. 224 images
# transforms.Resize(size, interpolation=InterpolationMode.BICUBIC),
# )
# t.append(transforms.CenterCrop(img_size))
# t.append(transforms.RandomAffine(degrees=0, translate=))
# if Gradient:
# print("Used Gradient!")
# t.append(ComputeLaplacian())
# t.append(ConvertHSV())
# t.append(AddGaussianNoise())
t.append(transforms.Resize((img_size, img_size), interpolation=InterpolationMode.BILINEAR))
if use_hsv:
print("Used V-channel!")
t.append(ConvertHSV())
t.append(transforms.ToTensor())
# t.append(transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD))
return transforms.Compose(t)
def build_dataset(is_train, img_size, dataset, path, same_da=False, use_hsv=True):
"""
构建带有增强策略的数据集
:param is_train: 是否训练集
:param img_size: 输出图像尺寸
:param dataset: 数据集名称
:param path: 数据集路径
:param same_da: 为训练集使用测试集的增广方法
: param use_hsv: 是否采用HSV
:return: 增强后的数据集
"""
# transform = build_transform(False, img_size) if same_da else build_transform(is_train, img_size)
transform = build_transform(False, img_size, use_hsv) if same_da else build_transform(False, img_size, use_hsv)
if dataset == 'CIFAR10':
dataset = datasets.CIFAR10(
path, train=is_train, transform=transform, download=True)
nb_classes = 10
elif dataset == 'CIFAR100':
dataset = datasets.CIFAR100(
path, train=is_train, transform=transform, download=True)
nb_classes = 100
elif dataset == 'CALTECH101':
dataset = datasets.Caltech101(
path, transform=transform, download=True
)
nb_classes = 101
else:
raise NotImplementedError
return dataset, nb_classes
class MNISTData(object):
"""
Load MNIST datesets.
"""
def __init__(self,
data_path: str,
batch_size: int,
train_trans: Sequence[torch.nn.Module] = None,
test_trans: Sequence[torch.nn.Module] = None,
pin_memory: bool = True,
drop_last: bool = True,
shuffle: bool = True,
) -> None:
self._data_path = data_path
self._batch_size = batch_size
self._pin_memory = pin_memory
self._drop_last = drop_last
self._shuffle = shuffle
self._train_transform = transforms.Compose(train_trans) if train_trans else None
self._test_transform = transforms.Compose(test_trans) if test_trans else None
def get_data_loaders(self):
print('Batch size: ', self._batch_size)
train_datasets = datasets.MNIST(root=self._data_path, train=True, transform=self._train_transform, download=True)
test_datasets = datasets.MNIST(root=self._data_path, train=False, transform=self._test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=self._drop_last, shuffle=self._shuffle
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=False
)
return train_loader, test_loader
def get_standard_data(self):
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
self._train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
self._test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
return self.get_data_loaders()
def get_mnist_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""s
获取MNIST数据
http://data.pymvpa.org/datasets/mnist/
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
if 'skip_norm' in kwargs and kwargs['skip_norm'] is True:
train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
else:
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
# transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
train_datasets = datasets.MNIST(
root=DATA_DIR, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.MNIST(
root=DATA_DIR, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_fashion_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取fashion MNIST数据
http://arxiv.org/abs/1708.07747
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor()])
test_transform = transforms.Compose([transforms.ToTensor()])
train_datasets = datasets.FashionMNIST(
root=DATA_DIR, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.FashionMNIST(
root=DATA_DIR, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_cifar10_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取CIFAR10数据
https://www.cs.toronto.edu/~kriz/cifar.html
:param batch_size: batch size
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
use_hsv = not kwargs['no_use_hsv'] if 'no_use_hsv' in kwargs else True
train_datasets, _ = build_dataset(True, 32, 'CIFAR10', DATA_DIR, same_da, False)
test_datasets, _ = build_dataset(False, 32, 'CIFAR10', DATA_DIR, same_da, False)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True,
num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False,
num_workers=num_workers
)
return train_loader, test_loader, None, None
def get_cifar100_data(batch_size, num_workers=8, same_data=False, *args, **kwargs):
"""
获取CIFAR100数据
https://www.cs.toronto.edu/~kriz/cifar.html
:param batch_size: batch size
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_datasets, _ = build_dataset(True, 32, 'CIFAR100', DATA_DIR, same_data)
test_datasets, _ = build_dataset(False, 32, 'CIFAR100', DATA_DIR, same_data)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_transfer_cifar10_data(batch_size, num_workers=8, same_da=False, **kwargs):
use_hsv = not kwargs['no_use_hsv'] if 'no_use_hsv' in kwargs else True
train_datasets, _ = build_dataset(True, 48, 'CIFAR10', DATA_DIR, same_da, use_hsv) # 原来是48
test_datasets, _ = build_dataset(False, 48, 'CIFAR10', DATA_DIR, same_da, use_hsv)
concat_dataset = ConcatDataset([train_datasets, test_datasets]) # concat dataset
img_index = [[] for i in range(10)]
label_index = [0] * 60000
for idx, (img, label) in enumerate(concat_dataset):
img_index[label].append(img)
for i in range(10):
img_index[i] = torch.stack(img_index[i], 0)
label_index[i * 6000:2 * i * 6000] = [i] * 6000
source_datasets = Transfer_DataSet(data=rearrange(torch.stack(img_index, dim=0), 'l b c w h -> (l b) c w h'),
label=label_index)
source_loader = torch.utils.data.DataLoader(
source_datasets, batch_size=60000,
sampler=TransferSampler(torch.arange(0, 60000).tolist()),
pin_memory=True, drop_last=False, num_workers=16
)
return source_loader, None, None, None
def get_combined_cifar10_data(batch_size, num_workers=8, same_da=False, **kwargs):
use_hsv = not kwargs['no_use_hsv'] if 'no_use_hsv' in kwargs else True
train_datasets, _ = build_dataset(True, 48, 'CIFAR10', DATA_DIR, same_da, use_hsv)
test_datasets, _ = build_dataset(False, 48, 'CIFAR10', DATA_DIR, same_da, use_hsv)
concat_dataset = ConcatDataset([train_datasets, test_datasets]) # concat dataset
source_loader = torch.utils.data.DataLoader(
concat_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=8, shuffle=True
)
return source_loader, None, None, None
def get_transfer_CALTECH101_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取NCaltech101数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
use_hsv = not kwargs['no_use_hsv'] if 'no_use_hsv' in kwargs else True
datasets, _ = build_dataset(False, 48, 'CALTECH101', DATA_DIR, same_da, use_hsv)
dataset_length = 8299
train_loader = torch.utils.data.DataLoader(
datasets, batch_size=10000,
sampler=TransferSampler(torch.arange(0, dataset_length).tolist()),
pin_memory=True, drop_last=False, num_workers=4
)
return train_loader, None, None, None
def get_combined_CALTECH101_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取NCaltech101数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
use_hsv = not kwargs['no_use_hsv'] if 'no_use_hsv' in kwargs else True
datasets, _ = build_dataset(False, 48, 'CALTECH101', DATA_DIR, same_da, use_hsv)
dataset_length = 8299
train_loader = torch.utils.data.DataLoader(
datasets, batch_size=batch_size,
pin_memory=True, drop_last=False,
num_workers=4, shuffle=True
)
return train_loader, None, None, None
def get_TinyImageNet_data(batch_size, num_workers=8, same_da=False, *args, **kwargs):
size=kwargs["size"] if "size" in kwargs else 224
train_transform = transforms.Compose([
transforms.RandomResizedCrop(size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(size*8//7),
transforms.CenterCrop(size),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(DATA_DIR, 'TinyImageNet')
train_datasets = TinyImageNet(
root=root, split="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = TinyImageNet(
root=root, split="val", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_transfer_imnet_data(args, _logger, data_config, num_aug_splits, **kwargs):
'''
load imagenet 2012
we use images in train/ for training, and use images in val/ for testing
https://github.com/pytorch/examples/tree/master/imagenet
'''
IMAGENET_PATH = '/data/datasets/ILSVRC2012/'
traindir = os.path.join(IMAGENET_PATH, 'train')
valdir = os.path.join(IMAGENET_PATH, 'val')
batch_size = kwargs['batch_size']
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
ConvertHSV(),
transforms.ToTensor()]))
# val_dataset = datasets.ImageFolder(
# valdir,
# transforms.Compose([
# transforms.Resize(256),
# transforms.CenterCrop(224),
# ConvertHSV(),
# transforms.ToTensor()]))
# train_loader = torch.utils.data.DataLoader(
# train_dataset,
# batch_size=batch_size, shuffle=False,
# num_workers=4, pin_memory=True, sampler=TransferSampler([0, 1300, 2599, 2600]))
#
# val_loader = torch.utils.data.DataLoader(
# val_dataset,
# batch_size=batch_size, shuffle=False,
# num_workers=4, pin_memory=True)
return train_dataset, None, None, None
def get_dvsg_data(batch_size, step, **kwargs):
"""
获取DVS Gesture数据
DOI: 10.1109/CVPR.2017.781
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.DVSGesture.sensor_size
size = kwargs['size'] if 'size' in kwargs else 48
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
train_dataset = tonic.datasets.DVSGesture(os.path.join(DATA_DIR, 'DVS/DVSGesture'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.DVSGesture(os.path.join(DATA_DIR, 'DVS/DVSGesture'),
transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVSGesture/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVSGesture/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, mixup_active, None
def get_dvsc10_data(batch_size, step, dvs_da=False, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
snr = kwargs['snr'] if 'snr' in kwargs else 0
train_data_ratio = kwargs['train_data_ratio'] if 'train_data_ratio' in kwargs else 1.0
sensor_size = tonic.datasets.CIFAR10DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=train_transform)
test_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=test_transform)
if dvs_da is True:
print("use dvs_da")
if snr > 0:
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: x + torch.randn(x.shape) * math.sqrt(torch.mean(torch.pow(x, 2)) / math.pow(10, snr / 10)),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
else:
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
else:
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
]) # 这里lambda返回的是地址, 注意不要用List复用.
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
sample(list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))), int(num_per_cls * portion * train_data_ratio)))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_train),
pin_memory=True, drop_last=False, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_test),
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_transfer_dvsc10_data(batch_size, step, dvs_da=False, **kwargs):
"""
获取DVS CIFAR10数据
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
snr = kwargs['snr'] if 'snr' in kwargs else 0
train_data_ratio = kwargs['train_data_ratio'] if 'train_data_ratio' in kwargs else 1.0
sensor_size = tonic.datasets.CIFAR10DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=train_transform)
test_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
]) # 这里lambda返回的是地址, 注意不要用List复用.
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=len(indices_train),
sampler=TransferSampler(indices_train),
pin_memory=True, drop_last=True, num_workers=8
)
return train_loader, None, mixup_active, None
def get_NCALTECH101_data(batch_size, step, dvs_da=False, **kwargs):
"""
获取NCaltech101数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.NCALTECH101.sensor_size
cls_count = tonic.datasets.NCALTECH101.cls_count
dataset_length = tonic.datasets.NCALTECH101.length
portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
snr = kwargs['snr'] if 'snr' in kwargs else 0
train_data_ratio = kwargs['train_data_ratio'] if 'train_data_ratio' in kwargs else 1.0
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += int(train_sample * train_data_ratio)
train_sample_weight.extend(
[sample_weight] * int(train_sample * train_data_ratio)
)
train_sample_weight.extend(
[0.] * (train_sample - int(train_sample * train_data_ratio))
)
train_sample_weight.extend(
[0.] * test_sample
)
train_sample_index.extend(
sample(list(range(idx_begin, idx_begin + train_sample)), int(train_sample * train_data_ratio))
)
test_sample_index.extend(
list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=train_transform)
test_dataset = tonic.datasets.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=test_transform)
if dvs_da is True:
print("use dvs_da")
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
else:
if snr > 0:
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: x + torch.randn(x.shape) * math.sqrt(torch.mean(torch.pow(x, 2)) / math.pow(10, snr / 10)),
])
else:
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
transforms.RandomCrop(size, padding=size // 12),
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
]) # 这里lambda返回的是地址, 注意不要用List复用.
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=train_sampler,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_transfer_NCALTECH101_data(batch_size, step, dvs_da=False, **kwargs):
"""
获取NCaltech101数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.NCALTECH101.sensor_size
cls_count = tonic.datasets.NCALTECH101.cls_count
dataset_length = tonic.datasets.NCALTECH101.length
portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
snr = kwargs['snr'] if 'snr' in kwargs else 0
train_data_ratio = kwargs['train_data_ratio'] if 'train_data_ratio' in kwargs else 1.0
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += int(train_sample * train_data_ratio)
train_sample_weight.extend(
[sample_weight] * int(train_sample * train_data_ratio)
)
train_sample_weight.extend(
[0.] * (train_sample - int(train_sample * train_data_ratio))
)
train_sample_weight.extend(
[0.] * test_sample
)
train_sample_index.extend(
sample(list(range(idx_begin, idx_begin + train_sample)), int(train_sample * train_data_ratio))
)
test_sample_index.extend(
list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=train_transform)
test_dataset = tonic.datasets.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
]) # 这里lambda返回的是地址, 注意不要用List复用.
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=len(train_sample_index),
sampler=TransferSampler(train_sample_index),
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, None, None, None
def get_NCARS_data(batch_size, step, **kwargs):
"""
获取N-Cars数据
https://ieeexplore.ieee.org/document/8578284/
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.NCARS.sensor_size
size = kwargs['size'] if 'size' in kwargs else 48
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
])
train_dataset = tonic.datasets.NCARS(os.path.join(DATA_DIR, 'DVS/NCARS'), transform=train_transform, train=True)
test_dataset = tonic.datasets.NCARS(os.path.join(DATA_DIR, 'DVS/NCARS'), transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCARS/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCARS/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, mixup_active, None
def get_nomni_data(batch_size, train_portion=1., **kwargs):
"""
获取N-Omniglot数据
:param batch_size:batch的大小
:param data_mode:一共full nkks pair三种模式
:param frames_num:一个样本帧的个数
:param data_type:event frequency两种模式
"""
data_mode = kwargs["data_mode"] if "data_mode" in kwargs else "full"
frames_num = kwargs["frames_num"] if "frames_num" in kwargs else 4
data_type = kwargs["data_type"] if "data_type" in kwargs else "event"
train_transform = transforms.Compose([
transforms.Resize((28, 28))])
test_transform = transforms.Compose([
transforms.Resize((28, 28))])
if data_mode == "full":
train_datasets = NOmniglotfull(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), train=True, frames_num=frames_num,
data_type=data_type,
transform=train_transform, use_npz=True)
test_datasets = NOmniglotfull(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), train=False, frames_num=frames_num,
data_type=data_type,
transform=test_transform, use_npz=True)
elif data_mode == "nkks":
train_datasets = NOmniglotNWayKShot(os.path.join(DATA_DIR, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=True,
frames_num=frames_num,
data_type=data_type,
transform=train_transform)
test_datasets = NOmniglotNWayKShot(os.path.join(DATA_DIR, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=False,
frames_num=frames_num,
data_type=data_type,
transform=test_transform)
elif data_mode == "pair":
train_datasets = NOmniglotTrainSet(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), use_frame=True,
frames_num=frames_num, data_type=data_type,
use_npz=False, resize=105)
test_datasets = NOmniglotTestSet(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), time=2000, way=kwargs["n_way"],
shot=kwargs["k_shot"], use_frame=True,
frames_num=frames_num, data_type=data_type, use_npz=False, resize=105)
else:
pass
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size, num_workers=4,
pin_memory=True, drop_last=True, shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size, num_workers=4,
pin_memory=True, drop_last=False
)
return train_loader, test_loader, None, None
def get_transfer_omni_data(batch_size, train_portion=1., **kwargs):
"""
获取Omniglot数据
:param batch_size:batch的大小
:param data_mode:一共full nkks pair三种模式
:param frames_num:一个样本帧的个数
:param data_type:event frequency两种模式
"""
transform = transforms.Compose([
transforms.Resize((28, 28)),
transforms.ToTensor()])
train_dataset = datasets.Omniglot(
root="/data/datasets/", background=True, download=True, transform=transform
)
test_dataset = datasets.Omniglot(
root="/data/datasets/", background=False, download=True, transform=transform
)
dataset = torch.utils.data.ConcatDataset([train_dataset, test_dataset])
dataset_length = len(dataset)
train_loader = torch.utils.data.DataLoader(
dataset, batch_size=35000, num_workers=12,
pin_memory=True, drop_last=False,
sampler=TransferSampler(torch.arange(0, dataset_length).tolist())
)
return train_loader, None, None, None
def get_esimnet_data(batch_size, step, **kwargs):
"""
获取ES imagenet数据
DOI: 10.3389/fnins.2021.726582
:param batch_size: batch size
:param step: 仿真步长,固定为8
:param reconstruct: 重构则时间步为1, 否则为8
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
:note: 没有自动下载, 下载及md5请参考spikingjelly, sampler默认为DistributedSampler
"""
reconstruct = kwargs["reconstruct"] if "reconstruct" in kwargs else False
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: dvs_channel_check_expend(x),
])
if reconstruct:
assert step == 1
train_dataset = ESImagenet2D_Dataset(mode='train',
data_set_path=os.path.join(DATA_DIR, 'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=train_transform)
test_dataset = ESImagenet2D_Dataset(mode='test',
data_set_path=os.path.join(DATA_DIR, 'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=test_transform)
else:
assert step == 8
train_dataset = ESImagenet_Dataset(mode='train',
data_set_path=os.path.join(DATA_DIR,
'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=train_transform)
test_dataset = ESImagenet_Dataset(mode='test',
data_set_path=os.path.join(DATA_DIR,
'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=test_transform)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
test_sampler = torch.utils.data.distributed.DistributedSampler(test_dataset)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
sampler=train_sampler
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=8,
sampler=test_sampler
)
# train_loader = torch.utils.data.DataLoader(
# train_dataset, batch_size=batch_size,
# pin_memory=True, drop_last=True, num_workers=8,
# shuffle=True
# )
#
# test_loader = torch.utils.data.DataLoader(
# test_dataset, batch_size=batch_size,
# pin_memory=True, drop_last=False, num_workers=1,
# shuffle=False
# )
return train_loader, test_loader, mixup_active, None
def get_CUB2002011_data(batch_size, num_workers=8, same_da=False, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(DATA_DIR, 'CUB2002011')
train_datasets = CUB2002011(
root=root, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = CUB2002011(
root=root, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_StanfordCars_data(batch_size, num_workers=8, same_da=False, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(DATA_DIR, 'StanfordCars')
train_datasets = datasets.StanfordCars(
root=root, split ="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.StanfordCars(
root=root, split ="test", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_StanfordDogs_data(batch_size, num_workers=8, same_da=False, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(DATA_DIR, 'StanfordDogs')
train_datasets = StanfordDogs(
root=root, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = StanfordDogs(
root=root, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_FGVCAircraft_data(batch_size, num_workers=8, same_da=False, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(DATA_DIR, 'FGVCAircraft')
train_datasets = datasets.FGVCAircraft(
root=root, split="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.FGVCAircraft(
root=root, split="test", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_Flowers102_data(batch_size, num_workers=8, same_da=False, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(DATA_DIR, 'Flowers102')
train_datasets = datasets.Flowers102(
root=root, split="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.Flowers102(
root=root, split="test", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
================================================
FILE: examples/Perception_and_Learning/img_cls/transfer_for_dvs/main.py
================================================
# -*- coding: utf-8 -*-
# Time : 2023/4/19 14:58
# Author : Regulus
# FileName: main.py
# Explain:
# Software: PyCharm
import argparse
import time
import timm.models
import yaml
import os
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.vgg_snn import VGG_SNN
from braincog.model_zoo.resnet19_snn import resnet19
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
# from ptflops import get_model_complexity_info
# from thop import profile, clever_format
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--dataset', default='cifar10', type=str)
parser.add_argument('--model', default='cifar_convnet', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=600, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.8,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=1.0,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=1.0,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--output', default='/home/hexiang/TransferLearning_For_DVS/Results_lastest/', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=0)
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='GateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--gaussian-n', type=int, default=3)
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
# for reconstructing es-imagenet
parser.add_argument('--reconstructed', action='store_true',
help='for ES-imagenet dataset')
parser.add_argument('--DVS-DA', action='store_true',
help='use DA on DVS')
# train data used ratio
parser.add_argument('--traindata-ratio', default=1.0, type=float,
help='training data ratio')
# use TET loss or not (all default False, do not use)
parser.add_argument('--TET-loss-first', action='store_true',
help='use TET loss one part')
parser.add_argument('--TET-loss-second', action='store_true',
help='use TET loss two part')
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def main():
args, args_text = _parse_args()
# args.no_spike_output = args.no_spike_output | args.cut_mix
args.no_spike_output = True
output_dir = ''
if args.local_rank == 0:
output_base = args.output if args.output else './output'
exp_name = '-'.join([
args.model,
args.dataset,
str(args.step),
"seed_{}".format(args.seed),
"bs_{}".format(args.batch_size),
"DA_{}".format(args.DVS_DA),
"ls_{}".format(args.smoothing),
"lr_{}".format(args.lr),
"traindataratio_{}".format(args.traindata_ratio),
"TET_first_{}".format(args.TET_loss_first),
"TET_second_{}".format(args.TET_loss_second),
])
output_dir = get_outdir(output_base, 'Baseline', exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
else:
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
adaptive_node=args.adaptive_node,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
reconstruct=args.reconstructed,
TET_loss=args.TET_loss_first or args.TET_loss_second
)
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=list(range(args.num_gpu))).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
# print(model.get_attr('mu'))
# print(model.get_attr('sigma'))
if args.critical_loss or args.spike_rate:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model, device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
dvs_da=args.DVS_DA,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
reconstruct=args.reconstructed,
_logger=_logger,
train_data_ratio=args.traindata_ratio,
data_mode="full",
frames_num=12,
data_type="frequency"
)
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
if args.distributed:
state_dict = torch.load(args.eval_checkpoint)['state_dict_ema']
new_state_dict = OrderedDict()
# add module prefix for DDP
for k, v in state_dict.items():
k = 'module.' + k
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
else:
model.load_state_dict(torch.load(args.eval_checkpoint)['state_dict'])
for i in range(1):
val_metrics = validate(start_epoch, model, loader_eval, validate_loss_fn, args,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
print(f"Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=output_dir, recovery_dir=output_dir, decreasing=decreasing, max_history=1)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
if args.distributed:
loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler, model_ema=model_ema, mixup_fn=mixup_fn)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics = validate(epoch, model, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics = validate(
epoch, model_ema.ema, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast, log_suffix=' (EMA)',
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(output_dir, 'summary.csv'),
write_header=best_metric is None)
# if saver is not None and epoch >= args.n_warm_up:
if saver is not None:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
# if epoch == 299: # 临时的
# break
except KeyboardInterrupt:
pass
if best_metric is not None:
_logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and loader.mixup_enabled:
loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
# t, k = adjust_surrogate_coeff(100, args.epochs)
# model.set_attr('t', t)
# model.set_attr('k', k)
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
if not args.prefetcher or args.dataset != 'imnet':
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
if mixup_fn is not None:
inputs, target = mixup_fn(inputs, target)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
with amp_autocast():
output = model(inputs)
tet_loss = 0.0
loss = 0.0
lamb = 1e-3
if args.TET_loss_first or args.TET_loss_second: # 第一项必须有,也就是测两个,第一个何第一个加第二个
for i in range(len(output)):
tet_loss += loss_fn(output[i], target)
tet_loss /= len(output)
loss = (1 - lamb) * tet_loss
else:
loss = loss_fn(output, target)
if args.TET_loss_second:
y = torch.zeros_like(output[-1]).fill_(args.threshold)
secondLoss = torch.nn.MSELoss()
tet_loss_second = secondLoss(output[-1], y)
loss += lamb * tet_loss_second
if args.TET_loss_first or args.TET_loss_second:
output = sum(output) / len(output)
if not (args.cut_mix | args.mix_up | args.event_mix) and args.dataset != 'imnet':
# print(output.shape, target.shape)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
closs = torch.tensor([0.], device=loss.device)
loss = loss + .1 * closs
spike_rate_avg_layer_str = ''
threshold_str = ''
if not args.distributed:
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
top5_m.update(acc5.item(), inputs.size(0))
closses_m.update(closs.item(), inputs.size(0))
spike_rate_avg_layer = model.get_fire_rate().tolist()
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
if args.opt == 'lamb':
optimizer.step(epoch=epoch)
else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
losses_m.update(reduced_loss.item(), inputs.size(0))
closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
if args.distributed:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
else:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})\n'
'Fire_rate: {spike_rate}\n'
'Thres: {threshold}\n'
'Mu: {mu_str}\n'
'Sigma: {sigma_str}\n'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m,
spike_rate=spike_rate_avg_layer_str,
threshold=threshold_str,
mu_str=mu_str,
sigma_str=sigma_str
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args, amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
end = time.time()
last_idx = len(loader) - 1
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat) and not args.critical_loss:
model.set_requires_fp(True)
# if not args.critical_loss:
# model.set_requires_fp(False)
with amp_autocast():
output = model(inputs)
if args.TET_loss_first or args.TET_loss_second:
output = sum(output) / len(output)
if isinstance(output, (tuple, list)):
output = output[0]
if not args.distributed:
if visualize:
x = model.get_fp()
feature_path = os.path.join(args.output_dir, 'feature_map')
if os.path.exists(feature_path) is False:
os.mkdir(feature_path)
save_feature_map(x, feature_path)
# if not args.critical_loss:
# model_config.set_requires_fp(False)
if tsne:
x = model.get_fp(temporal_info=False)[-1]
x = torch.nn.AdaptiveAvgPool2d((1, 1))(x)
x = x.reshape(x.shape[0], -1)
feature_vec.append(x)
feature_cls.append(target)
if conf_mat:
logits_vec.append(output)
labels_vec.append(target)
if spike_rate:
avg, var, spike, avg_per_step = model.get_spike_info()
save_spike_info(
os.path.join(args.output_dir, 'spike_info.csv'),
epoch, batch_idx,
args.step, avg, var,
spike, avg_per_step)
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
closs = torch.tensor([0.], device=loss.device)
if not args.distributed:
spike_rate_avg_layer = model.get_fire_rate().tolist()
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
tot_spike = model.get_tot_spike()
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
closses_m.update(closs.item(), inputs.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
))
else:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})\n'
'Fire_rate: {spike_rate}\n'
'Tot_spike: {tot_spike}\n'
'Thres: {threshold}\n'
'Mu: {mu_str}\n'
'Sigma: {sigma_str}\n'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
spike_rate=spike_rate_avg_layer_str,
tot_spike=tot_spike,
threshold=threshold_str,
mu_str=mu_str,
sigma_str=sigma_str
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg)])
if not args.distributed:
if tsne:
feature_vec = torch.cat(feature_vec)
feature_cls = torch.cat(feature_cls)
plot_tsne(feature_vec, feature_cls, os.path.join(args.output_dir, 't-sne-2d.eps'))
plot_tsne_3d(feature_vec, feature_cls, os.path.join(args.output_dir, 't-sne-3d.eps'))
if conf_mat:
logits_vec = torch.cat(logits_vec)
labels_vec = torch.cat(labels_vec)
plot_confusion_matrix(logits_vec, labels_vec, os.path.join(args.output_dir, 'confusion_matrix.eps'))
return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/Perception_and_Learning/img_cls/transfer_for_dvs/main_transfer.py
================================================
# -*- coding: utf-8 -*-
# Time : 2022/9/29 15:27
# Author : Regulus
# FileName: main_transfer.py
# Explain:
# Software: PyCharm
import argparse
import math
import time
import CKA
import numpy
import timm.models
import random as rd
import yaml
import os
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.vgg_snn import VGG_SNN
from braincog.model_zoo.resnet19_snn import resnet19
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from rgb_hsv import RGB_HSV
import matplotlib.pyplot as plt
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
# from ptflops import get_model_complexity_info
# from thop import profile, clever_format
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--source-dataset', default='cifar10', type=str)
parser.add_argument('--target-dataset', default='dvsc10', type=str)
parser.add_argument('--model', default='cifar_convnet', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=600, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.8,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=1.0,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=1.0,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--output', default='/home/hexiang/TransferLearning_For_DVS/Results_lastest/', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=0)
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='GateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--gaussian-n', type=int, default=3)
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
# Transfer Learning loss choice
parser.add_argument('--domain-loss', action='store_true',
help='add domain loss')
parser.add_argument('--semantic-loss', action='store_true',
help='add semantic loss')
parser.add_argument('--domain-loss-coefficient', type=float, default=1.0,
help='domain loss coefficient(default: 1.0)')
parser.add_argument('--semantic-loss-coefficient', type=float, default=1.0,
help='domain loss coefficient(default: 1.0)')
# use TET loss or not (all default False, do not use)
parser.add_argument('--TET-loss-first', action='store_true',
help='use TET loss one part')
parser.add_argument('--TET-loss-second', action='store_true',
help='use TET loss two part')
parser.add_argument('--DVS-DA', action='store_true',
help='use DA on DVS')
# train data used ratio
parser.add_argument('--traindata-ratio', default=1.0, type=float,
help='training data ratio')
# snr value
parser.add_argument('--snr', default=0, type=int,
help='random noise amplitude controled by snr, 0 means no noise')
# margin m
parser.add_argument('--m', default=-1.0, type=float,
help='margin')
source_input_list, source_label_list = [], []
CALTECH101_list, ImageNet_list = [], []
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def main():
torch.set_num_threads(20)
os.environ["OMP_NUM_THREADS"] = "20" # 设置OpenMP计算库的线程数
os.environ["MKL_NUM_THREADS"] = "20" # 设置MKL-DNN CPU加速库的线程数。
args, args_text = _parse_args()
args.no_spike_output = True
output_dir = ''
if args.local_rank == 0:
output_base = args.output if args.output else './output'
exp_name = '-'.join([
args.model,
args.target_dataset,
str(args.step),
"bs_{}".format(args.batch_size),
"seed_{}".format(args.seed),
"DA_{}".format(args.DVS_DA),
"ls_{}".format(args.smoothing),
"lr_{}".format(args.lr),
"m_{}".format(args.m),
"domainLoss_{}".format(args.domain_loss),
"semanticLoss_{}".format(args.semantic_loss),
"domain_loss_coefficient{}".format(args.domain_loss_coefficient),
"semantic_loss_coefficient{}".format(args.semantic_loss_coefficient),
"traindataratio_{}".format(args.traindata_ratio),
"TETfirst_{}".format(args.TET_loss_first),
"TETsecond_{}".format(args.TET_loss_second),
])
output_dir = get_outdir(output_base, 'train_TCKA_test_nop', exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
else:
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
adaptive_node=args.adaptive_node,
dataset=args.target_dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
)
if 'dvs' in args.target_dataset:
args.channels = 2
elif 'mnist' in args.target_dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=list(range(args.num_gpu))).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
if args.critical_loss or args.spike_rate:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model, device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
source_loader_train, _, _, _ = eval('get_transfer_%s_data' % args.source_dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
)
target_loader_train, target_loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.target_dataset)(
batch_size=args.batch_size,
dvs_da=args.DVS_DA,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
train_data_ratio=args.traindata_ratio,
snr=args.snr,
data_mode="full",
frames_num=12,
data_type="frequency"
)
global source_input_list, source_label_list, CALTECH101_list, ImageNet_list
if args.target_dataset == "dvsc10" or args.target_dataset == "NCALTECH101" or args.target_dataset == "nomni": # ImageNet中回来的loader其实是数据集,在后面处理
source_input_list, source_label_list = next(iter(source_loader_train))
# for i in range(30001, 30005):
# # vis origin picture
# plt.figure()
# plt.imshow(source_input_list[i].permute(1, 2, 0).numpy())
# plt.savefig("./origin_image.jpg")
# plt.show()
# vis HSV picture
# for i in range(30001, 30005): # 30001.i
# convertor = RGB_HSV()
# plt.figure()
# plt.imshow(convertor.rgb_to_hsv(source_input_list)[i, :, :, :].permute(1, 2, 0).numpy())
# plt.title("HSV image")
# plt.show()
if args.source_dataset == "CALTECH101":
cls_count = [438, 435, 200, 791, 49, 800, 41, 34, 45, 50, 45, 32, 128, 84, 38, 81, 86, 47, 40, 0, 45, 58, 61,
105, 47, 64, 70, 68, 50, 51, 54, 67, 51, 64, 65, 72, 62, 52, 60, 83, 65, 67, 45, 31, 34, 49, 99,
100, 42, 54, 86, 80, 30, 62, 86, 110, 61, 79, 77, 40, 65, 42, 35, 77, 31, 74, 49, 32, 39, 47, 35,
43, 52, 34, 54, 69, 58, 45, 38, 57, 34, 84, 57, 31, 54, 45, 82, 56, 63, 35, 85, 43, 82, 74, 239,
37, 53, 33, 55, 29, 42]
CALTECH101_list = [0] * 102 # 多开了一类, 方便计算
for i in range(1, len(cls_count) + 1):
CALTECH101_list[i] = CALTECH101_list[i - 1] + cls_count[i - 1]
if args.source_dataset == "NCALTECH101":
cls_count = tonic.datasets.NCALTECH101.cls_count
CALTECH101_list = [0] * 102 # 多开了一类, 方便计算
for i in range(1, len(cls_count) + 1):
CALTECH101_list[i] = CALTECH101_list[i - 1] + cls_count[i - 1]
if args.source_dataset == "imnet":
cls_count = [1300] * 1000 # 1000类
cls_count_idx = [1117, 1266, 1071, 1141, 1272, 1150, 772, 860, 1136, 732, 1025, 754, 1290, 738, 1258, 1273, 977,
936, 1156, 1218, 969, 954, 1070, 755, 1206, 1165, 969, 1292, 1236, 1199, 1209, 1176, 1186,
1194,
1067, 1029, 1154, 1216, 1187, 889, 1211, 1136, 1153, 1222, 1282, 1283, 980, 1034, 891, 1285,
986,
1137, 1272, 1155, 1097, 1149, 1155, 1159, 1133, 1180, 1120, 1005, 1152, 1156, 962, 1157, 1282,
1117, 1118, 1270, 1069, 1053, 1254, 908, 1247, 1253, 1029, 1259, 1267, 1249, 1162, 1045, 1004,
1238, 1153, 1084, 1217, 931, 1264, 976, 1250, 1053, 1160, 1062, 1137, 1299, 1055, 1213, 1206,
1154,
1207, 1149, 1239, 1125, 1193]
cls_idx = [43, 51, 62, 98, 103, 147, 152, 158, 164, 165, 166, 167, 168, 175, 181, 183, 188, 190, 194, 206, 221,
252, 262, 268, 335, 390, 392, 409, 418, 426, 439, 465, 481, 491, 499, 501, 503, 507, 521, 531, 536,
550, 551, 567, 577, 583, 585, 590, 596, 610, 623, 630, 631, 635, 653, 662, 663, 675, 676, 678, 686,
689, 706, 708, 712, 714, 722, 723, 724, 727, 728, 729, 731, 740, 747, 753, 771, 772, 782, 789, 798,
810, 811, 812, 821, 826, 838, 841, 854, 857, 860, 869, 872, 885, 891, 892, 901, 906, 914, 921, 925,
926, 940, 946, 969]
for i in range(len(cls_count)):
if i in cls_idx:
cls_count[i] = cls_count_idx[cls_idx.index(i)]
ImageNet_list = [0] * 1001 # 多开了一类, 方便计算
for i in range(1, 1000 + 1):
ImageNet_list[i] = ImageNet_list[i - 1] + cls_count[i - 1]
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
if args.distributed:
state_dict = torch.load(args.eval_checkpoint)['state_dict_ema']
new_state_dict = OrderedDict()
# add module prefix for DDP
for k, v in state_dict.items():
k = 'module.' + k
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
else:
model.load_state_dict(torch.load(args.eval_checkpoint)['state_dict'])
for i in range(1):
val_metrics = validate(start_epoch, model, target_loader_eval, validate_loss_fn, args,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
print(f"Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=output_dir, recovery_dir=output_dir, decreasing=decreasing, max_history=1)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
eval_top1 = 0.0
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
if args.distributed:
target_loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, source_loader_train, target_loader_train, optimizer, train_loss_fn, args,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler, model_ema=model_ema, mixup_fn=mixup_fn)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics = validate(epoch, model, target_loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
eval_top1 = eval_metrics["top1"]
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics = validate(
epoch, model_ema.ema, target_loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast, log_suffix=' (EMA)',
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(output_dir, 'summary.csv'),
write_header=best_metric is None)
# if saver is not None and epoch >= args.n_warm_up:
if saver is not None:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
# if epoch == 299: # 临时的
# break
except KeyboardInterrupt:
pass
if best_metric is not None:
_logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, model, source_loader, target_loader, optimizer, loss_fn, args,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and target_loader.mixup_enabled:
target_loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
domain_losses_m = AverageMeter()
semantic_losses_m = AverageMeter()
rgb_losses_m = AverageMeter()
dvs_losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
end = time.time()
last_idx = len(target_loader) - 1
num_updates = epoch * len(target_loader)
convertor = RGB_HSV()
batch_len = len(target_loader)
if args.target_dataset == "dvsc10":
set_MaxReplacement_epoch = 0.5 * args.epochs
else:
set_MaxReplacement_epoch = 0.5 * args.epochs
P_Replacement = 0.0
global source_input_list, source_label_list, CALTECH101_list, ImageNet_list
for batch_idx, (inputs, label) in enumerate(target_loader):
P_Replacement = ((batch_idx + epoch * batch_len) / (set_MaxReplacement_epoch * batch_len)) ** 3
P_Replacement = P_Replacement if P_Replacement <= 1.0 else 1.0
sampler_list = label.tolist()
if args.target_dataset == "dvsc10" and args.source_dataset == "cifar10":
sampler_list = torch.tensor(sampler_list) * 6000 + torch.randint(0, 6000, (len(sampler_list),))
elif args.target_dataset == "dvsc10" and args.source_dataset == "dvsc10":
sampler_list = torch.tensor(sampler_list) * 900 + torch.randint(0, 900, (len(sampler_list),))
elif args.target_dataset == "NCALTECH101":
tmp_sampler_list = []
idx_list = []
for idx, label_sampler in enumerate(sampler_list):
if label_sampler == 19:
tmp_sampler_list.append(0)
idx_list.append(idx)
else:
tmp_sampler_list.append(torch.randint(CALTECH101_list[label_sampler],
CALTECH101_list[label_sampler + 1], (1,)).item())
elif args.target_dataset == "esimnet":
tmp_sampler_list = []
for idx, label_sampler in enumerate(sampler_list): # 这里的label_sampler是一个列表
tmp_sampler_list.append(torch.randint(ImageNet_list[label_sampler],
ImageNet_list[label_sampler + 1], (1,)).item())
elif args.target_dataset == "nomni":
sampler_list = torch.tensor(sampler_list) * 20 + torch.randint(0, 20, (len(sampler_list),))
source_input, source_label = [], []
if args.target_dataset == "dvsc10":
source_input, source_label = source_input_list[sampler_list], source_label_list[sampler_list]
if args.target_dataset == "NCALTECH101":
source_input, source_label = source_input_list[tmp_sampler_list], source_label_list[tmp_sampler_list]
if args.target_dataset == "esimnet":
train_dataset = source_loader # 给传回来的重新命个名儿
source_loader_used = torch.utils.data.DataLoader(
train_dataset,
batch_size=args.batch_size, shuffle=False,
num_workers=8, pin_memory=True, sampler=TransferSampler(tmp_sampler_list))
source_input, source_label = next(iter(source_loader_used))
if args.target_dataset == "nomni":
source_input, source_label = source_input_list[sampler_list], source_label_list[sampler_list]
# for i in range(128):
# # vis origin picture
# plt.figure()
# plt.imshow(source_input[i].permute(1, 2, 0))
# plt.title("origin image")
# plt.show()
# # vis HSV picture
# plt.figure()
# plt.imshow(convertor.rgb_to_hsv(inputs)[7, :, :, :].permute(1, 2, 0).numpy())
# plt.title("HSV image")
# plt.show()
# source_input = convertor.rgb_to_hsv(source_input)[:, -1, :, :].unsqueeze(1).repeat(1, args.step * 2, 1, 1)
if args.source_dataset == "dvsc10" or args.source_dataset == "NCALTECH101":
pass
else:
source_input = source_input[:, -1, :, :].unsqueeze(1).repeat(1, args.step * 2, 1, 1)
source_input = rearrange(source_input, 'b (t c) h w -> b t c h w', t=args.step)
for b in range(source_input.shape[0]):
if rd.uniform(0, 1) <= P_Replacement:
source_input[b] = inputs[b, :, :, :, :]
# for i in range(10):
# # vis HSV picture for v channel
# plt.figure()
# plt.imshow(source_input[i][0].permute(1, 2, 0)[:, :, -1].unsqueeze(2))
# plt.title("HSV image for v channel")
# plt.show()
if args.target_dataset == "NCALTECH101" and len(idx_list) > 0:
for i in range(len(idx_list)):
source_input[idx_list[i]] = inputs[idx_list[i]]
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
if not args.prefetcher or args.target_dataset != 'imnet':
inputs, label = inputs.type(torch.FloatTensor).cuda(), label.cuda()
source_input, source_label = source_input.type(torch.FloatTensor).cuda(), label.cuda()
if mixup_fn is not None:
inputs, label = mixup_fn(inputs, label)
source_input, source_label = mixup_fn(source_input, source_label)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
source_input = source_input.contiguous(memory_format=torch.channels_last)
with amp_autocast():
domain_rbg_list, domain_dvs_list, output_rgb, output_dvs = model(source_input, inputs)
# compute semantic loss
label_idx = [[] for i in range(args.num_classes)]
semantic_label_list = []
for idx, i in enumerate(label):
label_idx[i.item()].append(idx)
for i in label:
while True:
label_tmp = torch.randint(0, args.num_classes, (1,)).item()
if i.item() != label_tmp and len(label_idx[label_tmp]) > 0: # NCALTECH101有空列表, 需要判断
break
semantic_label_list.append(int(np.random.choice(label_idx[label_tmp], 1)))
semantic_rbg_list = []
semantic_loss = 0.
for i in range(len(domain_rbg_list)):
semantic_rbg_list.append(domain_rbg_list[i][semantic_label_list])
for i in range(len(domain_rbg_list)):
semantic_loss += torch.abs(CKA.linear_CKA(domain_dvs_list[i].view(args.batch_size, -1), semantic_rbg_list[i].view(args.batch_size, -1)))
semantic_loss /= len(domain_rbg_list)
if args.target_dataset == "dvsc10":
m = 0.1
elif args.target_dataset == "NCALTECH101":
m = 0.3
else:
m = 0.2
if args.m >= 0.0:
m = args.m
if semantic_loss.item() - m <= 0:
semantic_loss = torch.tensor(0., device=semantic_loss.device)
# if args.domain_loss_after:
# # compute domain loss
# for b in range(source_input.shape[0]):
# if rd.uniform(0, 1) <= P_Replacement:
# for i in range(len(domain_rbg_list)):
# domain_rbg_list[i][b] = domain_dvs_list[i][b, :, :, :]
domain_loss = 0.
for i in range(len(domain_rbg_list)):
domain_loss += 1 - torch.abs(CKA.linear_CKA(domain_rbg_list[i].view(args.batch_size, -1), domain_dvs_list[i].view(args.batch_size, -1)))
domain_loss /= len(domain_rbg_list)
# compute cls loss
lamb = 1e-3
if args.TET_loss_first or args.TET_loss_second: # 第一项必须有,也就是测两个,第一个何第一个加第二个
loss_rgb = 0
tet_loss_first = 0
tet_loss_second = 0
assert len(output_rgb) == len(output_dvs)
for i in range(len(output_rgb)):
loss_rgb += loss_fn(output_rgb[i], label)
tet_loss_first += loss_fn(output_dvs[i], label)
loss_rgb /= len(output_rgb)
tet_loss_first /= len(output_dvs)
if args.TET_loss_second:
y = torch.zeros_like(output_dvs[-1]).fill_(args.threshold)
secondLoss = torch.nn.MSELoss()
tet_loss_second = secondLoss(output_dvs[-1], y)
else:
lamb = 0.0
loss_dvs = (1 - lamb) * tet_loss_first + lamb * tet_loss_second
output_rgb = sum(output_rgb) / len(output_rgb)
output_dvs = sum(output_dvs) / len(output_dvs)
else:
output_rgb = sum(output_rgb) / len(output_rgb)
output_dvs = sum(output_dvs) / len(output_dvs)
loss_rgb = loss_fn(output_rgb, label)
loss_dvs = loss_fn(output_dvs, label)
loss = 0 * loss_rgb + loss_dvs
if args.domain_loss:
loss += args.domain_loss_coefficient * domain_loss
if args.semantic_loss and epoch <= set_MaxReplacement_epoch:
if args.target_dataset == "NCALTECH101" and epoch <= set_MaxReplacement_epoch * 0.66:
# loss += args.semantic_loss_coefficient * semantic_loss * math.pow(10, -1.0 * float(set_MaxReplacement_epoch / (epoch+1)))
pass
else:
loss += args.semantic_loss_coefficient * semantic_loss
if not (args.cut_mix | args.mix_up | args.event_mix) and args.target_dataset != 'imnet':
acc1, acc5 = accuracy(output_dvs, label, topk=(1, 5))
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
closs = torch.tensor([0.], device=loss.device)
loss = loss + .1 * closs
spike_rate_avg_layer_str = ''
threshold_str = ''
if not args.distributed:
losses_m.update(loss.item(), inputs.size(0))
domain_losses_m.update(domain_loss.item(), inputs.size(0))
semantic_losses_m.update(semantic_loss.item(), inputs.size(0))
rgb_losses_m.update(loss_rgb.item(), inputs.size(0))
dvs_losses_m.update(loss_dvs.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
top5_m.update(acc5.item(), inputs.size(0))
closses_m.update(closs.item(), inputs.size(0))
spike_rate_avg_layer = model.get_fire_rate().tolist()
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i.item()) for i in threshold]
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
if args.opt == 'lamb':
optimizer.step(epoch=epoch)
else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
losses_m.update(reduced_loss.item(), inputs.size(0))
closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
if args.distributed:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(target_loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
else:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})\n'
'Fire_rate: {spike_rate}\n'
'Thres: {threshold}\n'
'Mu: {mu_str}\n'
'Sigma: {sigma_str}\n'
'P_Replacement: {P_Replacement}\n'.format(
epoch,
batch_idx, len(target_loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m,
spike_rate=spike_rate_avg_layer_str,
threshold=threshold_str,
mu_str=mu_str,
sigma_str=sigma_str,
P_Replacement=P_Replacement,
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg), ('domainLoss', domain_losses_m.avg), ('semanticLoss', semantic_losses_m.avg),
('rgbLoss', rgb_losses_m.avg), ('dvsLoss', dvs_losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args, amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
end = time.time()
last_idx = len(loader) - 1
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.target_dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat) and not args.critical_loss:
model.set_requires_fp(True)
# if not args.critical_loss:
# model.set_requires_fp(False)
with amp_autocast():
_, _, output_rbg, output_dvs = model(inputs, inputs)
output = sum(output_dvs) / len(output_dvs)
if isinstance(output, (tuple, list)):
output = output[0]
if not args.distributed:
if visualize:
x = model.get_fp()
feature_path = os.path.join(args.output_dir, 'feature_map')
if os.path.exists(feature_path) is False:
os.mkdir(feature_path)
save_feature_map(x, feature_path)
# if not args.critical_loss:
# model_config.set_requires_fp(False)
if tsne:
x = model.get_fp(temporal_info=False)[-1]
x = torch.nn.AdaptiveAvgPool2d((1, 1))(x)
x = x.reshape(x.shape[0], -1)
feature_vec.append(x)
feature_cls.append(target)
if conf_mat:
logits_vec.append(output)
labels_vec.append(target)
if spike_rate:
avg, var, spike, avg_per_step = model.get_spike_info()
save_spike_info(
os.path.join(args.output_dir, 'spike_info.csv'),
epoch, batch_idx,
args.step, avg, var,
spike, avg_per_step)
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
closs = torch.tensor([0.], device=loss.device)
if not args.distributed:
spike_rate_avg_layer = model.get_fire_rate().tolist()
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
tot_spike = model.get_tot_spike()
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
closses_m.update(closs.item(), inputs.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
))
else:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})\n'
'Fire_rate: {spike_rate}\n'
'Tot_spike: {tot_spike}\n'
'Thres: {threshold}\n'
'Mu: {mu_str}\n'
'Sigma: {sigma_str}\n'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
spike_rate=spike_rate_avg_layer_str,
tot_spike=tot_spike,
threshold=threshold_str,
mu_str=mu_str,
sigma_str=sigma_str
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg)])
if not args.distributed:
if tsne:
feature_vec = torch.cat(feature_vec)
feature_cls = torch.cat(feature_cls)
plot_tsne(feature_vec, feature_cls, os.path.join(args.output_dir, 't-sne-2d.eps'))
plot_tsne_3d(feature_vec, feature_cls, os.path.join(args.output_dir, 't-sne-3d.eps'))
if conf_mat:
logits_vec = torch.cat(logits_vec)
labels_vec = torch.cat(labels_vec)
plot_confusion_matrix(logits_vec, labels_vec, os.path.join(args.output_dir, 'confusion_matrix.eps'))
return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/Perception_and_Learning/img_cls/transfer_for_dvs/main_visual_losslandscape.py
================================================
# -*- coding: utf-8 -*-
# Time : 2023/2/14 11:52
# Author : Regulus
# FileName: main_visual_losslandscape.py
# Explain:
# Software: PyCharm
from loss_landscape.plot_surface import *
import argparse
import math
import time
import CKA
import numpy
import timm.models
import random as rd
import yaml
import os
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.vgg_snn import VGG_SNN
from braincog.model_zoo.resnet19_snn import resnet19
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from rgb_hsv import RGB_HSV
import matplotlib.pyplot as plt
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--source-dataset', default='cifar10', type=str)
parser.add_argument('--target-dataset', default='dvsc10', type=str)
parser.add_argument('--model', default='cifar_convnet', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=600, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.8,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=1.0,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=1.0,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--output', default='/home/hexiang/TransferLearning_For_DVS/Results_new_refined/', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=0)
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='GateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--gaussian-n', type=int, default=3)
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
parser.add_argument('--DVS-DA', action='store_true',
help='use DA on DVS')
# train data used ratio
parser.add_argument('--traindata-ratio', default=1.0, type=float,
help='training data ratio')
# snr value
parser.add_argument('--snr', default=0, type=int,
help='random noise amplitude controled by snr, 0 means no noise')
# --------------------------------------------------------------------------
# Start the loss-landscape
# --------------------------------------------------------------------------
parser.add_argument('--mpi', '-m', action='store_true', help='use mpi')
parser.add_argument('--threads', default=2, type=int, help='number of threads')
parser.add_argument('--ngpu', type=int, default=1,
help='number of GPUs to use for each rank, useful for data parallel evaluation')
# model parameters
parser.add_argument('--model_folder', default='',
help='the common folder that contains model_file and model_file2')
parser.add_argument('--model_file', default='', help='path to the trained model file')
parser.add_argument('--model_file2', default='', help='use (model_file2 - model_file) as the xdirection')
parser.add_argument('--model_file3', default='', help='use (model_file3 - model_file) as the ydirection')
parser.add_argument('--loss_name', '-l', default='crossentropy', help='loss functions: crossentropy | mse')
# direction parameters
parser.add_argument('--dir_file', default='',
help='specify the name of direction file, or the path to an eisting direction file')
parser.add_argument('--dir_type', default='weights',
help='direction type: weights | states (including BN\'s running_mean/var)')
parser.add_argument('--x', default='-1:1:51', help='A string with format xmin:x_max:xnum')
parser.add_argument('--y', default=None, help='A string with format ymin:ymax:ynum')
parser.add_argument('--xnorm', default='', help='direction normalization: filter | layer | weight')
parser.add_argument('--ynorm', default='', help='direction normalization: filter | layer | weight')
parser.add_argument('--xignore', default='', help='ignore bias and BN parameters: biasbn')
parser.add_argument('--yignore', default='', help='ignore bias and BN parameters: biasbn')
parser.add_argument('--same_dir', action='store_true', default=False,
help='use the same random direction for both x-axis and y-axis')
parser.add_argument('--idx', default=0, type=int, help='the index for the repeatness experiment')
parser.add_argument('--surf_file', default='',
help='customize the name of surface file, could be an existing file.')
# plot parameters
parser.add_argument('--proj_file', default='', help='the .h5 file contains projected optimization trajectory.')
parser.add_argument('--loss_max', default=5, type=float, help='Maximum value to show in 1D plot')
parser.add_argument('--vmax', default=10, type=float, help='Maximum value to map')
parser.add_argument('--vmin', default=0.1, type=float, help='Miminum value to map')
parser.add_argument('--vlevel', default=1.0, type=float, help='plot contours every vlevel')
parser.add_argument('--show', action='store_true', default=False, help='show plotted figures')
parser.add_argument('--log', action='store_true', default=False, help='use log scale for loss values')
parser.add_argument('--plot', action='store_true', default=False, help='plot figures after computation')
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def main():
torch.set_num_threads(20)
os.environ["OMP_NUM_THREADS"] = "20" # 设置OpenMP计算库的线程数
os.environ["MKL_NUM_THREADS"] = "20" # 设置MKL-DNN CPU加速库的线程数。
args, args_text = _parse_args()
args.no_spike_output = True
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
adaptive_node=args.adaptive_node,
dataset=args.target_dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
TET_loss=False
) # 注意这里的TET_loss,选择losslandscape在谁上看.
if 'dvs' in args.target_dataset:
args.channels = 2
elif 'mnist' in args.target_dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
source_loader_train, _, _, _ = eval('get_transfer_%s_data' % args.source_dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
)
target_loader_train, target_loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.target_dataset)(
batch_size=args.batch_size,
dvs_da=args.DVS_DA,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
train_data_ratio=args.traindata_ratio,
snr=args.snr,
data_mode="full",
frames_num=12,
data_type="frequency"
)
if args.eval: # evaluate the model
if args.distributed:
state_dict = torch.load(args.eval_checkpoint)['state_dict_ema']
new_state_dict = OrderedDict()
# add module prefix for DDP
for k, v in state_dict.items():
k = 'module.' + k
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
else:
model.load_state_dict(torch.load(args.eval_checkpoint, map_location=torch.device('cpu'))['state_dict'])
# --------------------------------------------------------------------------
# Show Acc
# --------------------------------------------------------------------------
print("load model finished!")
# train_loss_fn = nn.CrossEntropyLoss()
# for i in range(1):
# _, val_acc = validate(model, target_loader_train, train_loss_fn, args)
# print(f"Top-1 accuracy of the model is: {val_acc:.2f}%")
# --------------------------------------------------------------------------
# Environment setup
# --------------------------------------------------------------------------
if args.mpi:
comm = mpi.setup_MPI()
rank, nproc = comm.Get_rank(), comm.Get_size()
else:
comm, rank, nproc = None, 0, 1
if True:
if not torch.cuda.is_available():
raise Exception('User selected cuda option, but cuda is not available on this machine')
gpu_count = torch.cuda.device_count()
# torch.cuda.set_device(rank % gpu_count)
torch.cuda.set_device("cuda:{}".format(args.device))
print('Rank %d use GPU %d of %d GPUs on %s' %
(rank, torch.cuda.current_device(), gpu_count, socket.gethostname()))
# --------------------------------------------------------------------------
# Check plotting resolution
# --------------------------------------------------------------------------
try:
args.xmin, args.xmax, args.xnum = [float(a) for a in args.x.split(':')]
args.ymin, args.ymax, args.ynum = (None, None, None)
if args.y:
args.ymin, args.ymax, args.ynum = [float(a) for a in args.y.split(':')]
assert args.ymin and args.ymax and args.ynum, \
'You specified some arguments for the y axis, but not all'
except:
raise Exception('Improper format for x- or y-coordinates. Try something like -1:1:51')
# --------------------------------------------------------------------------
# Load models and extract parameters
# --------------------------------------------------------------------------
net = model
w = net_plotter.get_weights(net) # initial parameters
s = copy.deepcopy(net.state_dict()) # deepcopy since state_dict are references
if args.ngpu > 1:
# data parallel with multiple GPUs on a single node
net = nn.DataParallel(net, device_ids=range(torch.cuda.device_count()))
# --------------------------------------------------------------------------
# Setup the direction file and the surface file
# --------------------------------------------------------------------------
dir_file = net_plotter.name_direction_file(args) # name the direction file
dir_file = os.path.join(os.path.split(args.eval_checkpoint)[0], dir_file)
if rank == 0:
net_plotter.setup_direction(args, dir_file, net)
surf_file = name_surface_file(args, dir_file)
if rank == 0:
setup_surface_file(args, surf_file, dir_file)
# wait until master has setup the direction file and surface file
mpi.barrier(comm)
# load directions
d = net_plotter.load_directions(dir_file)
# calculate the consine similarity of the two directions
if len(d) == 2 and rank == 0:
similarity = proj.cal_angle(proj.nplist_to_tensor(d[0]), proj.nplist_to_tensor(d[1]))
print('cosine similarity between x-axis and y-axis: %f' % similarity)
mpi.barrier(comm)
# --------------------------------------------------------------------------
# Start the computation
# --------------------------------------------------------------------------
trainloader = target_loader_train
crunch(surf_file, net, w, s, d, trainloader, 'train_loss', 'train_acc', comm, rank, args)
# --------------------------------------------------------------------------
# Plot figures
# --------------------------------------------------------------------------
if args.plot and rank == 0:
if args.y and args.proj_file:
plot_2D.plot_contour_trajectory(surf_file, dir_file, args.proj_file, 'train_loss', args.show)
elif args.y:
plot_2D.plot_2d_contour(surf_file, 'train_loss', args.vmin, args.vmax, args.vlevel, args.show)
else:
plot_1D.plot_1d_loss_err(surf_file, args.xmin, args.xmax, args.loss_max, args.log, args.show)
return
if __name__ == '__main__':
main()
================================================
FILE: examples/Snn_safety/DPSNN/Readme.txt
================================================
The code for the differential private spiking neural network(DPSNN).
================================================
FILE: examples/Snn_safety/DPSNN/load_data.py
================================================
import numpy as np
from torchvision import datasets, transforms
import torch
from torch.utils.data import Dataset
import tonic
from tonic import DiskCachedDataset
import torch.nn.functional as F
import os
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
CIFAR10_MEAN = (0.4914, 0.4822, 0.4465)
CIFAR10_STD_DEV = (0.2023, 0.1994, 0.2010)
cifar100_mean = [0.5071, 0.4865, 0.4409]
cifar100_std = [0.2673, 0.2563, 0.2761]
DVSCIFAR10_MEAN_16 = [0.3290, 0.4507]
DVSCIFAR10_STD_16 = [1.8398, 1.6549]
DATA_DIR = '/data/datasets'
class CustomDataset(Dataset):
"""An abstract Dataset class wrapped around Pytorch Dataset class.
"""
def __init__(self, dataset, indices):
self.dataset = dataset
self.indices = [int(i) for i in indices]
def __len__(self):
return len(self.indices)
def __getitem__(self, item):
x, y = self.dataset[self.indices[item]]
return x, y
def load_static_data(data_root, batch_size, dataset):
if dataset == 'cifar10':
transform_train = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(CIFAR10_MEAN, CIFAR10_STD_DEV)])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(CIFAR10_MEAN, CIFAR10_STD_DEV)])
train_data = datasets.CIFAR10(data_root, train=True, transform=transform_train, download=True)
test_data = datasets.CIFAR10(data_root, train=False, transform=transform_test, download=True)
train_loader = torch.utils.data.DataLoader(
train_data,
batch_size=batch_size,
shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_data,
batch_size=batch_size,
)
elif dataset == 'MNIST':
transform_train = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(MNIST_MEAN, MNIST_STD)])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(MNIST_MEAN, MNIST_STD)])
train_data = datasets.MNIST(data_root, train=True, transform=transform_train, download=True)
test_data = datasets.MNIST(data_root, train=False, transform=transform_test, download=True)
train_loader = torch.utils.data.DataLoader(
train_data,
batch_size=batch_size,
shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_data,
batch_size=batch_size,
)
elif dataset == 'FashionMNIST':
transform_train = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(MNIST_MEAN, MNIST_STD)])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(MNIST_MEAN, MNIST_STD)])
train_data = datasets.FashionMNIST(data_root, train=True, transform=transform_train, download=True)
test_data = datasets.FashionMNIST(data_root, train=False, transform=transform_test, download=True)
train_loader = torch.utils.data.DataLoader(
train_data,
batch_size=batch_size,
shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_data,
batch_size=batch_size,
)
return train_data, test_data, train_loader, test_loader
def load_dvs10_data(batch_size, step, **kwargs):
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = tonic.datasets.CIFAR10DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=train_transform)
test_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
train_dataset = DiskCachedDataset(train_dataset,
cache_path=f'./dataset/dvs_cifar10/train_cache_{step}',
transform=train_transform)
test_dataset = DiskCachedDataset(train_dataset,
cache_path=f'./dataset/dvs_cifar10/test_cache_{step}',
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
train_dataset = CustomDataset(train_dataset, np.array(indices_train))
test_dataset = CustomDataset(test_dataset, np.array(indices_test))
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True,
pin_memory=True, drop_last=False, num_workers=1
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=1
)
return train_loader, test_loader, train_dataset, test_dataset
def load_nmnist_data(batch_size, step, **kwargs):
size = kwargs['size'] if 'size' in kwargs else 28
sensor_size = tonic.datasets.NMNIST.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/NMNIST'), transform=train_transform, train=True)
test_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/NMNIST'), transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
train_dataset = DiskCachedDataset(train_dataset,
cache_path=f'./dataset/NMNIST/train_cache_{step}',
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=f'./dataset/NMNIST/test_cache_{step}',
transform=test_transform)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True,
pin_memory=True, drop_last=False, num_workers=1
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=1
)
return train_loader, test_loader, train_dataset, test_dataset
================================================
FILE: examples/Snn_safety/DPSNN/main_dpsnn.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from opacus import PrivacyEngine
from model import *
from braincog.base.node.node import *
import warnings
from load_data import *
from opacus.utils.batch_memory_manager import BatchMemoryManager
warnings.simplefilter("ignore")
# Precomputed characteristics of the dataset dataset
torch.cuda.manual_seed(3154)
batch_size = 512
MAX_PHYSICAL_BATCH_SIZE = 32
target_ep = 8
c = 6
epochs = 40
step = 10
delta = 1e-5
devices = 4
r = 5
device = torch.device(f'cuda:{devices}' if torch.cuda.is_available() else 'cpu')
# device = 'cpu'
disable_noise = False
data_root = "./dataset"
kwargs = {"num_workers": 1, "pin_memory": True}
dataset = 'dvs_cifar10'
# NMNIST, cifar10, dvs_cifar10, MNIST, FashionMNIST
def train(model, device, train_loader, optimizer, epoch, privacy_engine):
criterion = nn.CrossEntropyLoss().to(device)
losses = []
model.train()
correct = 0
for _batch_idx, (data, target) in enumerate(train_loader):
# print(target)
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
losses.append(loss.item())
pred = output.argmax(
dim=1, keepdim=True
) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
if not disable_noise:
epsilon = privacy_engine.get_epsilon(delta=delta)
print(
f"Train Epoch: {epoch} \t"
f"Loss: {np.mean(losses):.6f} "
)
print("Accuracy: {}/{} ({:.2f}%)\n".format(
correct,
len(train_loader.dataset),
100.0 * correct / len(train_loader.dataset), ))
print(
f"(ε = {epsilon:.2f}, δ = {delta})"
)
else:
print(f"Train Epoch: {epoch} \t Loss: {np.mean(losses):.6f}")
return 100.0 * correct / len(train_loader.dataset)
def test(model, device, test_loader):
model.eval()
criterion = nn.CrossEntropyLoss().to(device)
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item() # sum up batch loss
pred = output.argmax(
dim=1, keepdim=True
) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader)
print(
"\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n".format(
test_loss,
correct,
len(test_loader.dataset),
100.0 * correct / len(test_loader.dataset),
)
)
return correct / len(test_loader.dataset)
def run():
if dataset == 'dvs_cifar10':
train_loader, test_loader, train_data, test_data = load_dvs10_data(batch_size=batch_size, step=step)
# train_loader, test_loader, _, _ = get_dvsc10_data(batch_size=batch_size, step=step)
elif dataset == 'NMNIST':
train_loader, test_loader, train_data, test_data = load_nmnist_data(batch_size=batch_size, step=step)
else:
train_data, test_data, train_loader, test_loader = load_static_data(data_root, batch_size, dataset)
result = []
result_train = []
for _ in range(r):
if dataset == 'cifar10':
model = cifar_convnet(
step=step,
encode_type='direct',
node_type=LIFNode,
num_classes=10,
spike_output=False,
layer_by_layer=True,
act_fun=QGateGrad
)
model.to(device)
optimizer = optim.AdamW(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[40], gamma=0.1, last_epoch=-1)
elif dataset == 'dvs_cifar10':
model = dvs_convnet(
step=step,
encode_type='direct',
node_type=LIFNode,
num_classes=10,
spike_output=False,
layer_by_layer=True,
act_fun=QGateGrad
)
model.to(device)
optimizer = optim.AdamW(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[15], gamma=1, last_epoch=-1)
elif dataset == 'NMNIST':
model = SimpleSNN(
channel=2,
step=step,
node_type=LIFNode,
act_fun=QGateGrad,
layer_by_layer=True,
)
model.to(device)
optimizer = optim.AdamW(model.parameters(), lr=0.005)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[10], gamma=0.1, last_epoch=-1)
elif dataset == 'MNIST' or dataset == 'FashionMNIST':
model = SimpleSNN(
channel=1,
step=step,
node_type=LIFNode,
act_fun=QGateGrad,
layer_by_layer=True,
)
model.to(device)
optimizer = optim.AdamW(model.parameters(), lr=0.005)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[10], gamma=0.1, last_epoch=-1)
if not disable_noise:
privacy_engine = PrivacyEngine()
model, optimizer, data_loader = privacy_engine.make_private_with_epsilon(
module=model,
optimizer=optimizer,
data_loader=train_loader,
max_grad_norm=c,
epochs=epochs,
target_delta=delta,
target_epsilon=target_ep
)
with BatchMemoryManager(
data_loader=data_loader,
max_physical_batch_size=MAX_PHYSICAL_BATCH_SIZE,
optimizer=optimizer
) as memory_safe_data_loader:
# if 1:
for epoch in range(1, epochs + 1):
result_train.append(train(model, device, memory_safe_data_loader, optimizer, epoch, privacy_engine))
result.append(test(model, device, test_loader))
scheduler.step()
else:
privacy_engine = PrivacyEngine()
model, optimizer, data_loader = privacy_engine.make_private(
module=model,
optimizer=optimizer,
data_loader=train_loader,
max_grad_norm=c,
noise_multiplier=0.0,
)
with BatchMemoryManager(
data_loader=data_loader,
max_physical_batch_size=MAX_PHYSICAL_BATCH_SIZE,
optimizer=optimizer
) as memory_safe_data_loader:
for epoch in range(1, epochs + 1):
train(model, device, memory_safe_data_loader, optimizer, epoch, privacy_engine)
result.append(test(model, device, test_loader))
scheduler.step()
result = np.array(result).reshape((r, -1))
result_train = np.array(result_train).reshape((r, -1))
best_acc = np.mean(np.max(result, axis=1))
print(best_acc)
np.save(file=f'./{dataset}/MP_test.npy', arr=result)
np.save(file=f'./{dataset}/MP_train.npy', arr=result_train)
if __name__ == "__main__":
run()
================================================
FILE: examples/Snn_safety/DPSNN/model.py
================================================
import abc
from functools import partial
import torch
from torch.nn import functional as F
import torchvision
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
class TEP(nn.Module):
def __init__(self, step, channel, device=None, dtype=None):
factory_kwargs = {'device': device, 'dtype': dtype}
super(TEP, self).__init__()
self.step = step
self.gn = nn.GroupNorm(channel, channel)
def forward(self, x):
x = rearrange(x, '(t b) c w h -> t b c w h', t=self.step)
fire_rate = torch.mean(x, dim=0)
fire_rate = self.gn(fire_rate) + 1
x = x * fire_rate
x = rearrange(x, 't b c w h -> (t b) c w h')
return x
class BaseConvNet(BaseModule, abc.ABC):
def __init__(self,
step,
input_channels,
num_classes,
encode_type,
spike_output: bool,
out_channels: list,
block_depth: list,
node_list: list,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.num_cls = num_classes
self.spike_output = spike_output
self.groups = kwargs['n_groups'] if 'n_groups' in kwargs else 1
if not spike_output:
node_list.append(nn.Identity)
out_channels.append(self.num_cls)
self.vote = nn.Identity()
# self.vote = nn.Sequential(
# nn.Linear(self.step, 32),
# nn.ReLU(),
# nn.Linear(32, 1)
# )
else:
out_channels.append(10 * self.num_cls)
self.vote = VotingLayer(10)
# check list length
if len(node_list) != len(out_channels):
raise ValueError
self.input_channels = input_channels
self.out_channels = out_channels
self.block_depth = block_depth
self.node_list = node_list
self.feature = self._create_feature()
self.fc = self._create_fc()
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
@staticmethod
def _create_feature(self):
raise NotImplementedError
@staticmethod
def _create_fc(self):
raise NotImplementedError
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if not self.training:
self.fire_rate.clear()
if not self.layer_by_layer:
outputs = []
if self.warm_up:
step = 1
else:
step = self.step
for t in range(step):
x = inputs[t]
x = self.feature(x)
x = self.flatten(x)
x = self.fc(x)
x = self.vote(x)
outputs.append(x)
return sum(outputs) / len(outputs)
# outputs = torch.stack(outputs)
# outputs = rearrange(outputs, 't b c -> b c t')
# outputs = self.vote(outputs).squeeze()
# return outputs
else:
x = self.feature(inputs)
x = self.flatten(x)
x = self.fc(x)
if self.groups == 1:
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
else:
x = rearrange(x, 'b (c t) -> t b c', t=self.step).mean(0)
x = self.vote(x)
return x
class LayerWiseConvModule(nn.Module):
"""
SNN卷积模块
:param in_channels: 输入通道数
:param out_channels: 输出通道数
:param kernel_size: kernel size
:param stride: stride
:param padding: padding
:param bias: Bias
:param node: 神经元类型
:param kwargs:
"""
def __init__(self,
in_channels: int,
out_channels: int,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
bias=False,
node=LIFNode,
step=6,
**kwargs):
super().__init__()
if node is None:
raise TypeError
self.groups = kwargs['groups'] if 'groups' in kwargs else 1
self.conv = nn.Conv2d(in_channels=in_channels * self.groups,
out_channels=out_channels * self.groups,
kernel_size=kernel_size,
padding=padding,
stride=stride,
bias=bias)
self.gn = nn.GroupNorm(16, out_channels * self.groups)
self.node = partial(node, **kwargs)()
self.step = step
self.activation = nn.Identity()
def forward(self, x):
x = rearrange(x, '(t b) c w h -> t b c w h', t=self.step)
outputs = []
for t in range(self.step):
outputs.append(self.gn(self.conv(x[t])))
outputs = torch.stack(outputs) # t b c w h
outputs = rearrange(outputs, 't b c w h -> (t b) c w h')
outputs = self.node(outputs)
return outputs
class LayerWiseLinearModule(nn.Module):
"""
线性模块
:param in_features: 输入尺寸
:param out_features: 输出尺寸
:param bias: 是否有Bias, 默认 ``False``
:param node: 神经元类型, 默认 ``LIFNode``
:param args:
:param kwargs:
"""
def __init__(self,
in_features: int,
out_features: int,
bias=True,
node=LIFNode,
step=6,
spike=False,
*args,
**kwargs):
super().__init__()
if node is None:
raise TypeError
self.groups = kwargs['groups'] if 'groups' in kwargs else 1
if self.groups == 1:
self.fc = nn.Linear(in_features=in_features,
out_features=out_features, bias=bias)
else:
self.fc = nn.ModuleList()
for i in range(self.groups):
self.fc.append(nn.Linear(
in_features=in_features,
out_features=out_features,
bias=bias
))
self.node = partial(node, **kwargs)()
self.step = step
self.spike = spike
def forward(self, x):
if self.groups == 1: # (t b) c
x = rearrange(x, '(t b) c -> t b c', t=self.step)
outputs = []
for t in range(self.step):
outputs.append(self.fc(x[t]))
outputs = torch.stack(outputs) # t b c
outputs = rearrange(outputs, 't b c -> (t b) c')
else: # b (c t)
x = rearrange(x, 'b (c t) -> t b c', t=self.groups)
outputs = []
for i in range(self.groups):
outputs.append(self.fc[i](x[i]))
outputs = torch.stack(outputs) # t b c
outputs = rearrange(outputs, 't b c -> b (c t)')
if self.spike:
return self.node(outputs)
else:
return outputs
class LayWiseConvNet(BaseConvNet):
def __init__(self,
step,
input_channels,
num_classes,
encode_type,
spike_output: bool,
out_channels: list,
node_list: list,
block_depth: list,
*args,
**kwargs):
super().__init__(step,
input_channels,
num_classes,
encode_type,
spike_output,
out_channels,
block_depth,
node_list,
*args,
**kwargs)
def _create_feature(self):
feature_depth = len(self.node_list) - 1
feature = [LayerWiseConvModule(
self.input_channels * self.init_channel_mul, self.out_channels[0], node=self.node_list[0],
groups=self.groups, step=self.step)]
if self.block_depth[0] != 1:
feature.extend(
[LayerWiseConvModule(self.out_channels[0], self.out_channels[0], node=self.node_list[0],
groups=self.groups, step=self.step)] * (
self.block_depth[0] - 1),
)
feature.append(TEP(channel=self.out_channels[0], step=self.step))
feature.append(nn.AvgPool2d(kernel_size=4, stride=2))
for i in range(1, feature_depth - 1):
feature.append(LayerWiseConvModule(
self.out_channels[i - 1], self.out_channels[i], node=self.node_list[i], groups=self.groups,
step=self.step))
if self.block_depth[i] != 1:
feature.extend(
[LayerWiseConvModule(self.out_channels[i], self.out_channels[i], node=self.node_list[i],
groups=self.groups,
step=self.step)] * (
self.block_depth[i] - 1),
)
feature.append(TEP(channel=self.out_channels[i], step=self.step))
feature.append(nn.AvgPool2d(kernel_size=4, stride=2))
feature.append(LayerWiseConvModule(
self.out_channels[-3], self.out_channels[-2], node=self.node_list[-2], groups=self.groups,
step=self.step))
if self.block_depth[feature_depth - 1] != 1:
feature.extend(
[LayerWiseConvModule(self.out_channels[-2], self.out_channels[-2], node=self.node_list[-2],
groups=self.groups,
step=self.step)] * (
self.block_depth[feature_depth - 1] - 1),
)
feature.append(nn.AdaptiveAvgPool2d(1))
return nn.Sequential(*feature)
def _create_fc(self):
fc = nn.Sequential(
# NDropout(.5),
LayerWiseLinearModule(
self.out_channels[-2], self.out_channels[-1], node=self.node_list[-1], groups=self.groups,
step=self.step, spike=False)
)
return fc
@register_model
def cifar_convnet(step,
encode_type,
spike_output: bool,
node_type,
*args,
**kwargs):
# out_channels = [256, 256, 512, 1024]
out_channels = [64, 128, 128, 256]
block_depth = [2, 2, 2, 2]
# print(kwargs)
node_cls = partial(node_type, step=step, **kwargs)
# print(node_cls)
if spike_output:
node_list = [node_cls] * (len(out_channels) + 1)
else:
node_list = [node_cls] * (len(out_channels))
return LayWiseConvNet(step=step,
input_channels=3,
encode_type=encode_type,
node_list=node_list,
block_depth=block_depth,
out_channels=out_channels,
spike_output=spike_output,
**kwargs)
@register_model
def dvs_convnet(step,
encode_type,
spike_output: bool,
node_type,
num_classes,
*args,
**kwargs):
out_channels = [64, 128, 256, 512, 1024]
block_depth = [2, 1, 2, 1, 2]
node_cls = partial(node_type, step=step, **kwargs)
if spike_output:
node_list = [node_cls] * (len(out_channels) + 1)
# node_list[-2] = partial(DoubleSidePLIFNode, step=step, **kwargs)
else:
node_list = [node_cls] * (len(out_channels))
# node_list[-1] = partial(DoubleSidePLIFNode, step=step, **kwargs)
return LayWiseConvNet(step=step,
input_channels=2,
num_classes=num_classes,
encode_type=encode_type,
node_list=node_list,
block_depth=block_depth,
out_channels=out_channels,
spike_output=spike_output,
**kwargs)
@register_model
class SimpleSNN(BaseModule, abc.ABC):
def __init__(self,
channel=1,
num_classes=10,
step=8,
node_type=LIFNode,
encode_type='direct',
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.num_classes = num_classes
self.node = node_type
init_channel = channel
self.feature = nn.Sequential(
LayerWiseConvModule(init_channel, 32, kernel_size=7, padding=0, node=self.node, step=step),
TEP(step=step, channel=32),
nn.AvgPool2d(kernel_size=2, stride=2),
LayerWiseConvModule(32, 64, kernel_size=4, padding=0, node=self.node, step=step),
TEP(step=step, channel=64),
nn.AvgPool2d(kernel_size=2, stride=2),
)
self.fc = nn.Sequential(
nn.Flatten(),
LayerWiseLinearModule(64 * 4 * 4, self.num_classes, node=self.node, spike=False, step=step),
)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.feature(inputs)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
return x
else:
outputs = []
for t in range(self.step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
================================================
FILE: examples/Snn_safety/RandHet-SNN/README.md
================================================
* To train a SNN with AT on CIFAR-10:
```
python train.py --adv_training --attack_iters 1 --epsilon 4 --alpha 4 --network ResNet18 --batch_size 64 --worker 4 --node_type LIF --save_dir AT --device cuda:1 --time_step 8 --dataset cifar10
```
* To train a RHSNN with AT on CIFAR-10:
```
python train.py --adv_training --attack_iters 1 --epsilon 4 --alpha 4 --network ResNet18 --batch_size 64 --worker 4 --node_type RHLIF --save_dir AT_RH_1 --device cuda:1 --time_step 8 --dataset cifar10
```
* To train a RHSNN with RAT on CIFAR-10:
```
python train.py --adv_training --attack_iters 1 --epsilon 4 --alpha 4 --network ResNet18 --batch_size 64 --worker 4 --node_type RHLIF --save_dir RAT_RH_1 --device cuda:1 --parseval --beta 0.004 --time_step 8 --dataset cifar10
```
* To train a RHSNN with SR on CIFAR-10:
```
python train.py --adv_training --attack_iters 1 --epsilon 4 --alpha 4 --network ResNet18 --batch_size 64 --worker 4 --node_type RHLIF --save_dir SR_RH_1 --device cuda:1 --SR --time_step 8 --dataset cifar10
```
* To evaluate the performance of RHSNN on CIFAR-10:
```
python evaluate.py --network ResNet18 --attack_type all --batch_size 32 --worker 4 --node_type RHLIF --pretrain RAT_RH_1/weight_r.pth --save_dir RAT --device cuda:1 --time_step 8 --dataset cifar10
```
================================================
FILE: examples/Snn_safety/RandHet-SNN/evaluate.py
================================================
import argparse
import copy
import logging
import os
import sys
import time
from my_node import RHLIFNode, RHLIFNode2
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from sew_resnet import SEWResNet19, BasicBlock
from braincog.base.node.node import *
from utils import evaluate_standard
from utils import get_loaders
import torchattacks
from tqdm import tqdm
logger = logging.getLogger(__name__)
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--batch_size', default=32, type=int)
parser.add_argument('--data_dir', default='/mnt/data/datasets', type=str)
parser.add_argument('--dataset', default='cifar10', choices=['cifar10', 'cifar100'])
parser.add_argument('--network', default='ResNet18', type=str)
parser.add_argument('--worker', default=4, type=int)
parser.add_argument('--epsilon', default=8, type=int)
parser.add_argument('--device', default='cuda:1', type=str)
parser.add_argument('--pretrain', default=None, type=str, help='path to load the pretrained model')
parser.add_argument('--save_dir', default=None, type=str, help='path to save log')
parser.add_argument('--attack_type', default='pgd')
parser.add_argument('--time_step', default=8, type=int)
parser.add_argument('--node_type', default='LIF', type=str)
return parser.parse_args()
def evaluate_attack(model, test_loader, args, atk, atk_name, logger):
test_loss = 0
test_acc = 0
n = 0
model.eval()
device = args.device
test_loader = iter(test_loader)
bar_format = '{desc}[{elapsed}<{remaining},{rate_fmt}]'
pbar = tqdm(range(len(test_loader)), file=sys.stdout, bar_format=bar_format, ncols=80)
for i in pbar:
X, y = next(test_loader)
X, y = X.to(device), y.to(device)
X_adv = atk(X, y) # advtorch
with torch.no_grad():
output = model(X_adv)
loss = F.cross_entropy(output, y)
test_loss += loss.item() * y.size(0)
test_acc += (output.max(1)[1] == y).sum().item()
n += y.size(0)
pgd_acc = test_acc / n
pgd_loss = test_loss / n
logger.info(atk_name)
logger.info('adv: %.4f \t', pgd_acc)
return pgd_loss, pgd_acc
def main():
args = get_args()
args.save_dir = os.path.join('logs', args.save_dir)
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
logfile = os.path.join(args.save_dir, 'output.log')
if os.path.exists(logfile):
os.remove(logfile)
log_path = os.path.join(args.save_dir, 'output_test.log')
handlers = [logging.FileHandler(log_path, mode='a+'),
logging.StreamHandler()]
logging.basicConfig(
format='[%(asctime)s] - %(message)s',
datefmt='%Y/%m/%d %H:%M:%S',
level=logging.INFO,
handlers=handlers)
logger.info(args)
# assert type(args.pretrain) == str and os.path.exists(args.pretrain)
if args.dataset == 'cifar10':
args.num_classes = 10
elif args.dataset == 'cifar100':
args.num_classes = 100
else:
print('Wrong dataset:', args.dataset)
exit()
logger.info('Dataset: %s', args.dataset)
train_loader, test_loader, dataset_normalization = get_loaders(args.data_dir, args.batch_size, dataset=args.dataset,
worker=args.worker, norm=False)
node = LIFNode
if args.node_type == 'RHLIF':
node = RHLIFNode
elif args.node_type == 'RHLIF2':
node = RHLIFNode2
# setup network
model = SEWResNet19(BasicBlock, [3, 3, 2], cnf='ADD', node_type=node, step=args.time_step, num_classes=args.num_classes,
layer_by_layer=True, act_fun=AtanGrad, data_norm=dataset_normalization)
# print(model)
# load pretrained model
path = os.path.join('./ckpt', args.dataset, args.network)
args.pretrain = os.path.join(path, args.pretrain)
pretrained_model = torch.load(args.pretrain, map_location=args.device, weights_only=False)
model.load_state_dict(pretrained_model, strict=False)
model.to(args.device)
model.eval()
# for name, param in model.named_parameters():
# if 'sigma' in name: # 查找包含 'sigma' 的参数
# param.data = torch.as_tensor(0.0, device=args.device)
# if 'alpha' in name: # 查找包含 'sigma' 的参数
# param.data = torch.as_tensor(2.0, device=args.device)
logger.info('Evaluating with standard images...')
_, nature_acc = evaluate_standard(test_loader, model, args)
logger.info('Nature Acc: %.4f \t', nature_acc)
if args.attack_type == 'eotpgd':
atk = torchattacks.EOTPGD(model, eps=8 / 255, alpha=(16/50) / 255, steps=50, random_start=True, eot_iter=10)
evaluate_attack(model, test_loader, args, atk, 'eotpgd', logger)
elif args.attack_type[0:3] == 'pgd':
steps = int(''.join(filter(str.isdigit, args.attack_type)))
atk = torchattacks.PGD(model, eps=8 / 255, alpha=(16/steps) / 255, steps=steps, random_start=True)
evaluate_attack(model, test_loader, args, atk, args.attack_type, logger)
elif args.attack_type == 'apgd':
atk = torchattacks.APGD(model, eps=8 / 255, steps=50, eot_iter=10)
evaluate_attack(model, test_loader, args, atk, 'apgd', logger)
elif args.attack_type == 'fgsm':
atk = torchattacks.FGSM(model, eps=8/255)
evaluate_attack(model, test_loader, args, atk, 'fgsm', logger)
elif args.attack_type == 'mifgsm':
atk = torchattacks.MIFGSM(model, eps=8 / 255, alpha=2 / 255, steps=5, decay=1.0)
evaluate_attack(model, test_loader, args, atk, 'mifgsm', logger)
elif args.attack_type == 'autoattack':
atk = torchattacks.AutoAttack(model, norm='Linf', eps=8/255, version='standard', n_classes=args.num_classes)
evaluate_attack(model, test_loader, args, atk, 'autoattack', logger)
elif args.attack_type == 'all':
atk = torchattacks.FGSM(model, eps=8 / 255)
evaluate_attack(model, test_loader, args, atk, 'fgsm', logger)
atk = torchattacks.APGD(model, eps=8 / 255, steps=10)
evaluate_attack(model, test_loader, args, atk, 'apgd', logger)
atk = torchattacks.PGD(model, eps=8 / 255, alpha=1.6 / 255, steps=10, random_start=True)
evaluate_attack(model, test_loader, args, atk, 'pgd', logger)
atk = torchattacks.MIFGSM(model, eps=8 / 255, alpha=2 / 255, steps=5, decay=1.0)
evaluate_attack(model, test_loader, args, atk, 'mifgsm', logger)
atk = torchattacks.AutoAttack(model, norm='Linf', eps=8 / 255, version='standard',
n_classes=args.num_classes)
evaluate_attack(model, test_loader, args, atk, 'autoattack', logger)
elif args.attack_type == 'step_test':
for steps in [10,30,50,70,90,110]:
atk = torchattacks.PGD(model, eps=8 / 255, alpha=(16 / steps) / 255, steps=steps, random_start=True)
pgd_loss, pgd_acc = evaluate_attack(model, test_loader, args, atk, f'pgd{steps}', logger)
atk = torchattacks.APGD(model, eps=8 / 255, steps=steps)
apgd_loss, apgd_acc = evaluate_attack(model, test_loader, args, atk, f'apgd{steps}', logger)
elif args.attack_type == 'eot_test':
for steps in [1,10,20,30]:
atk = torchattacks.EOTPGD(model, eps=8 / 255, alpha=(16 / 10) / 255, steps=10, random_start=True, eot_iter=steps)
pgd_loss, pgd_acc = evaluate_attack(model, test_loader, args, atk, f'eot{steps}_pgd', logger)
atk = torchattacks.APGD(model, eps=8 / 255, steps=10, eot_iter=steps)
apgd_loss, apgd_acc = evaluate_attack(model, test_loader, args, atk, f'eot{steps}_apgd', logger)
elif args.attack_type == 'intensity_test':
for intensity in [2, 4, 6, 8, 10, 12, 14, 16]:
atk = torchattacks.APGD(model, eps=intensity / 255, steps=10)
pgd_loss, pgd_acc = evaluate_attack(model, test_loader, args, atk, f'{intensity}_apgd', logger)
logger.info('Testing done.')
if __name__ == "__main__":
main()
================================================
FILE: examples/Snn_safety/RandHet-SNN/my_node.py
================================================
import torch
from braincog.base.node.node import *
class RHLIFNode(BaseNode):
"""
Parametric LIF, 其中的 ```tau``` 会被backward过程影响
Reference:https://arxiv.org/abs/2007.05785
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=0.5, tau=0., sigma=1.0, act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.sigma = nn.Parameter(torch.as_tensor(sigma), requires_grad=False)
self.w = nn.Parameter(torch.as_tensor(init_w), requires_grad=False)
self.flag = 0
self.rd = 0
def integral(self, inputs):
self.rd = self.sigma * torch.normal(0., 1., size=(inputs.shape[0], inputs.shape[1], inputs.shape[2], inputs.shape[3]), device=inputs.device)
self.mem = self.rd.sigmoid() * self.mem + (1 - self.rd.sigmoid()) * inputs
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
# self.mem = self.mem - self.spike.detach() * self.threshold
self.mem = self.mem * (1 - self.spike.detach())
def n_reset(self):
self.mem = self.v_reset
self.spike = 0.
self.feature_map = []
self.mem_collect = []
self.flag = 0
class RHLIFNode2(BaseNode):
"""
Parametric LIF, 其中的 ```tau``` 会被backward过程影响
Reference:https://arxiv.org/abs/2007.05785
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=0.5, tau=0., sigma=1.0, act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.sigma = nn.Parameter(torch.as_tensor(sigma), requires_grad=False)
self.w = nn.Parameter(torch.as_tensor(init_w), requires_grad=False)
self.flag = 0
self.rd = 0
self.resample = 1
def integral(self, inputs):
if self.flag == 0:
self.rd = self.sigma * torch.normal(0., 1., size=(inputs.shape[0], inputs.shape[1], inputs.shape[2], inputs.shape[3]), device=inputs.device)
self.flag = 1
self.mem = self.rd.sigmoid() * self.mem + (1 - self.rd.sigmoid()) * inputs
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
# self.mem = self.mem - self.spike.detach() * self.threshold
self.mem = self.mem * (1 - self.spike.detach())
def n_reset(self):
self.mem = self.v_reset
self.spike = 0.
self.feature_map = []
self.mem_collect = []
if self.resample == 1:
self.flag = 0
else:
self.flag = 1
================================================
FILE: examples/Snn_safety/RandHet-SNN/sew_resnet.py
================================================
import torch
import torch.nn as nn
from copy import deepcopy
import random
try:
from torchvision.models.utils import load_state_dict_from_url
except ImportError:
from torchvision._internally_replaced_utils import load_state_dict_from_url
from braincog.base.node import *
from braincog.model_zoo.base_module import *
from braincog.datasets import is_dvs_data
from timm.models import register_model
def sew_function(x: torch.Tensor, y: torch.Tensor, cnf: str):
if cnf == 'ADD':
return x + y
elif cnf == 'AND':
return x * y
elif cnf == 'IAND':
return x * (1. - y)
else:
raise NotImplementedError
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None, cnf: str = None, node: callable = None, **kwargs):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.node1 = node()
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.node2 = node()
self.downsample = downsample
if downsample is not None:
self.downsample_sn = node()
self.stride = stride
self.cnf = cnf
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.node1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.node2(out)
if self.downsample is not None:
identity = self.downsample_sn(self.downsample(x))
out = sew_function(identity, out, self.cnf)
return out
def extra_repr(self) -> str:
return super().extra_repr() + f'cnf={self.cnf}'
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None, cnf: str = None, node: callable = None, **kwargs):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.node1 = node()
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.node2 = node()
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.node3 = node()
self.downsample = downsample
if downsample is not None:
self.downsample_sn = node()
self.stride = stride
self.cnf = cnf
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.node1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.node2(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.node3(out)
if self.downsample is not None:
identity = self.downsample_sn(self.downsample(x))
out = sew_function(out, identity, self.cnf)
return out
def extra_repr(self) -> str:
return super().extra_repr() + f'cnf={self.cnf}'
class SEWResNet19(BaseModule):
def __init__(self, block, layers, num_classes=1000, step=8, encode_type="direct", zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None, data_norm=None,
norm_layer=None, cnf: str = None, *args, **kwargs):
super().__init__(
step,
encode_type,
*args,
**kwargs
)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.num_classes = num_classes
self.normalize = data_norm
self.node = kwargs['node_type']
if issubclass(self.node, BaseNode):
# self.node = partial(self.node, **kwargs, step=step)
self.node1 = partial(self.node, **kwargs, step=step)()
self.node2 = partial(self.node, **kwargs, step=step)
self.node3 = partial(self.node, **kwargs, step=step)
self.node4 = partial(self.node, **kwargs, step=step)
self.once = kwargs["once"] if "once" in kwargs else False
self.sum_output = kwargs["sum_output"] if "sum_output" in kwargs else True
init_channel = 3
self.inplanes = 128
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(init_channel, self.inplanes, kernel_size=3, stride=1, padding=1,
bias=False)
self.bn1 = norm_layer(self.inplanes)
# self.node1 = self.node()
self.layer1 = self._make_layer(block, 128, layers[0], cnf=cnf, node=self.node2, **kwargs)
self.layer2 = self._make_layer(block, 256, layers[1], stride=2,
dilate=replace_stride_with_dilation[0], cnf=cnf, node=self.node3, **kwargs)
self.layer3 = self._make_layer(block, 512, layers[2], stride=2,
dilate=replace_stride_with_dilation[1], cnf=cnf, node=self.node4, **kwargs)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc1 = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(1)
m.weight.data.normal_(0, 1.0 / float(n))
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1, dilate=False, cnf: str = None, node: callable = None,
**kwargs):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer, cnf, node, **kwargs))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer, cnf=cnf, node=node, **kwargs))
return nn.Sequential(*layers)
def _forward_impl(self, inputs):
# See note [TorchScript super()]
if self.normalize is not None:
self.normalize.mean = self.normalize.mean.to(inputs.device)
self.normalize.std = self.normalize.std.to(inputs.device)
inputs = self.normalize(inputs)
self.reset()
if self.layer_by_layer:
inputs = repeat(inputs, 'b c w h -> t b c w h', t=self.step)
inputs = rearrange(inputs, 't b c w h -> (t b) c w h')
x = self.conv1(inputs)
x = self.bn1(x)
x = self.node1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
# x = self.node2(x)
# x = self.fc2(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step)
# print(x)
if self.sum_output: x = x.mean(0)
return x
def _forward_once(self, x):
# inputs = self.encoder(inputs)
# x = inputs[t]
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
if self.once: return self._forward_once(x)
return self._forward_impl(x)
================================================
FILE: examples/Snn_safety/RandHet-SNN/train.py
================================================
import argparse
import copy
import logging
import os
import sys
import time
from evaluate import evaluate_attack
import torchattacks
from my_node import RHLIFNode, RHLIFNode2
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from sew_resnet import SEWResNet19, BasicBlock, Bottleneck
from braincog.base.node.node import *
from utils import (evaluate_standard, cifar10_std, cifar10_mean,
orthogonal_retraction)
from utils import (clamp, get_norm_stat,
get_loaders)
logger = logging.getLogger(__name__)
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--batch_size', default=128, type=int)
parser.add_argument('--data_dir', default='/mnt/data/datasets', type=str)
parser.add_argument('--dataset', default='cifar10', type=str)
parser.add_argument('--epochs', default=100, type=int)
parser.add_argument('--network', default='ResNet18', type=str)
parser.add_argument('--device', default='cuda:3', type=str)
parser.add_argument('--worker', default=4, type=int)
parser.add_argument('--lr_schedule', default='cosine', choices=['cyclic', 'multistep', 'cosine'])
parser.add_argument('--lr_min', default=0., type=float)
parser.add_argument('--lr_max', default=0.1, type=float)
parser.add_argument('--weight_decay', default=1e-4, type=float)
parser.add_argument('--momentum', default=0.9, type=float)
parser.add_argument('--epsilon', default=4, type=int)
parser.add_argument('--alpha', default=4, type=float, help='Step size')
parser.add_argument('--save_dir', default='ckpt', type=str, help='Output directory')
parser.add_argument('--seed', default=0, type=int, help='Random seed')
parser.add_argument('--attack_iters', default=1, type=int, help='Attack iterations')
parser.add_argument('--pretrain', default=None, type=str, help='path to load the pretrained model')
parser.add_argument('--beta', default=0.004, type=float)
parser.add_argument('--adv_training', action='store_true',
help='if adv training')
parser.add_argument('--time_step', default=8, type=int)
parser.add_argument('--SR', action='store_true')
parser.add_argument('--node_type', default='LIF', type=str)
parser.add_argument('--parseval', action='store_true', help='if use different norm for different layers')
return parser.parse_args()
def main():
args = get_args()
device = args.device
torch.cuda.set_device(device)
if args.dataset == 'cifar10' or args.dataset == 'svhn':
args.num_classes = 10
elif args.dataset == 'cifar100':
args.num_classes = 100
mu, std, upper_limit, lower_limit = get_norm_stat(cifar10_mean, cifar10_std)
path = os.path.join('./ckpt', args.dataset, args.network)
args.save_dir = os.path.join(path, args.save_dir)
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
logfile = os.path.join(args.save_dir, 'output.log')
if os.path.exists(logfile):
os.remove(logfile)
handlers = [logging.FileHandler(logfile, mode='a+'),
logging.StreamHandler()]
logging.basicConfig(
format='[%(asctime)s] - %(message)s',
datefmt='%Y/%m/%d %H:%M:%S',
level=logging.INFO,
handlers=handlers)
logger.info(args)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed(args.seed)
# get data loader
train_loader, test_loader, dataset_normalization = get_loaders(args.data_dir, args.batch_size, dataset=args.dataset,
worker=args.worker)
train_loader_e, test_loader_e, dataset_normalization_e = get_loaders(args.data_dir, args.batch_size, dataset=args.dataset,
worker=args.worker, norm=False)
# adv training attack setting
epsilon = ((args.epsilon / 255.) / std).to(device)
alpha = ((args.alpha / 255.) / std).to(device)
node = LIFNode
if args.node_type == 'RHLIF':
node = RHLIFNode
elif args.node_type == 'RHLIF2':
node = RHLIFNode2
# setup network
model = SEWResNet19(BasicBlock, [3, 3, 2], cnf='ADD', node_type=node, step=args.time_step, num_classes=args.num_classes,
layer_by_layer=True, act_fun=AtanGrad)
model.to(device)
# model = torch.nn.DataParallel(model)
# logger.info(model)
# setup optimizer, loss function, LR scheduler
# opt = torch.optim.AdamW(model.parameters(), lr=args.lr_max, weight_decay=args.weight_decay)
if args.parseval:
opt = torch.optim.SGD(model.parameters(), lr=args.lr_max, momentum=0.9, weight_decay=0)
else:
opt = torch.optim.SGD(model.parameters(), lr=args.lr_max, momentum=0.9, weight_decay=args.weight_decay)
criterion = nn.CrossEntropyLoss()
if args.lr_schedule == 'cyclic':
lr_steps = args.epochs
scheduler = torch.optim.lr_scheduler.CyclicLR(opt, base_lr=args.lr_min, max_lr=args.lr_max,
step_size_up=lr_steps / 2, step_size_down=lr_steps / 2)
elif args.lr_schedule == 'multistep':
lr_steps = args.epochs
scheduler = torch.optim.lr_scheduler.MultiStepLR(opt, milestones=[lr_steps / 2, lr_steps * 3 / 4], gamma=0.1)
elif args.lr_schedule == 'cosine':
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(opt, T_max=args.epochs)
best_pgd_acc = 0
best_clean_acc = 0
test_acc_best_pgd = 0
start_epoch = 0
# Start training
start_train_time = time.time()
for epoch in range(start_epoch, args.epochs):
logging.info('epoch %d lr %e', epoch, scheduler.get_lr()[0])
model.train()
train_loss = 0
train_acc = 0
train_n = 0
for i, (X, y) in enumerate(train_loader):
_iters = epoch * len(train_loader) + i
X, y = X.to(device), y.to(device)
if args.adv_training:
# init delta
delta = torch.zeros_like(X).to(device)
for j in range(len(epsilon)):
delta[:, j, :, :].uniform_((-epsilon[j][0][0] / 10).item(), (epsilon[j][0][0]/10).item())
delta.data = clamp(delta, lower_limit.to(device) - X, upper_limit.to(device) - X)
delta.requires_grad = True
# pgd attack
for _ in range(args.attack_iters):
output = model(X + delta)
# model.random_reset_step = 0
loss = criterion(output, y)
loss.backward()
grad = delta.grad.detach()
delta.data = clamp(delta + alpha * torch.sign(grad), -epsilon, epsilon)
delta.data = clamp(delta, lower_limit.to(device) - X, upper_limit.to(device) - X)
delta.grad.zero_()
delta = delta.detach()
X_adv = X + delta[:X.size(0)]
else:
X_adv = X
if args.SR:
X_adv.requires_grad_(True)
outputs = model(X_adv)
out = outputs.gather(1, y.unsqueeze(1)).squeeze() # choose
batch = []
inds = []
for j in range(len(outputs)):
mm, ind = torch.cat([outputs[j, :y[j]], outputs[j, y[j] + 1:]], dim=0).max(0)
f = torch.exp(out[j]) / (torch.exp(out[j]) + torch.exp(mm))
batch.append(f)
inds.append(ind.item())
f1 = torch.stack(batch, dim=0)
loss1 = criterion(outputs, y)
dx = torch.autograd.grad(f1, X_adv, grad_outputs=torch.ones_like(f1, device=device), retain_graph=True)[0]
X_adv.requires_grad_(False)
v = dx.detach().sign()
x2 = X_adv + 0.01 * v
outputs2 = model(x2)
out = outputs2.gather(1, y.unsqueeze(1)).squeeze() # choose
batch = []
for j in range(len(outputs2)):
mm = torch.cat([outputs2[j, :y[j]], outputs2[j, y[j] + 1:]], dim=0)[inds[j]]
f = torch.exp(out[j]) / (torch.exp(out[j]) + torch.exp(mm))
batch.append(f)
f2 = torch.stack(batch, dim=0)
dl = (f2 - f1) / 0.01
loss2 = dl.pow(2).mean()
loss = loss1 + 0.001 * loss2
loss = loss.mean()
else:
output = model(X_adv)
loss = criterion(output, y)
opt.zero_grad()
loss.backward()
opt.step()
if args.parseval:
orthogonal_retraction(model, args.beta)
# for name, param in model.named_parameters():
# if 'sigma' in name: # 查找包含 'sigma' 的参数
# param.data = torch.clamp(param.data, 0.0, 1.5) # 约束参数范围
# if i==0:
# print(param)
train_loss += loss.item() * y.size(0)
train_acc += (output.max(1)[1] == y).sum().item()
train_n += y.size(0)
if i % 50 == 0:
logger.info("Iter: [{:d}][{:d}/{:d}]\t"
"Loss {:.3f} ({:.3f})\t"
"Prec@1 {:.3f} ({:.3f})\t".format(
epoch,
i,
len(train_loader),
loss.item(),
train_loss / train_n,
(output.max(1)[1] == y).sum().item() / y.size(0),
train_acc / train_n)
)
scheduler.step()
logger.info('Evaluating with standard images...')
test_loss, test_acc = evaluate_standard(test_loader, model, args)
logger.info(
'Test Loss: %.4f \t Test Acc: %.4f',
test_loss, test_acc)
if test_acc > best_clean_acc:
best_clean_acc = (
test_acc)
torch.save(model.state_dict(), os.path.join(args.save_dir, 'weight_c.pth'))
# pgd_loss, pgd_acc = evaluate_pgd(test_loader, model, 5, 1, args)
if epoch > args.epochs - 10:
logger.info('Evaluating with APGD Attack...')
model.normalize = dataset_normalization_e
atk = torchattacks.APGD(model, norm='Linf', eps=8 / 255, steps=10)
pgd_loss, pgd_acc = evaluate_attack(model, test_loader_e, args, atk, 'APGD', logger)
model.normalize = dataset_normalization
if pgd_acc > best_pgd_acc:
best_pgd_acc = pgd_acc
test_acc_best_pgd = test_acc
torch.save(model.state_dict(), os.path.join(args.save_dir, 'weight_r.pth'))
logger.info(
'PGD Loss: %.4f \t PGD Acc: %.4f \n Best PGD Acc: %.4f \t Test Acc of best PGD ckpt: %.4f',
pgd_loss, pgd_acc, best_pgd_acc, test_acc_best_pgd)
train_time = time.time()
logger.info('Total train time: %.4f minutes', (train_time - start_train_time) / 60)
if __name__ == "__main__":
main()
================================================
FILE: examples/Snn_safety/RandHet-SNN/utils.py
================================================
# import apex.amp as amp
import os.path
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
import numpy as np
cifar10_mean = (0.4914, 0.4822, 0.4465)
cifar10_std = (0.2471, 0.2435, 0.2616)
def get_norm_stat(mean, std):
mu = torch.tensor(mean).view(3, 1, 1)
std = torch.tensor(std).view(3, 1, 1)
upper_limit = ((1 - mu) / std)
lower_limit = ((0 - mu) / std)
return mu, std, upper_limit, lower_limit
def clamp(X, lower_limit, upper_limit):
return torch.max(torch.min(X, upper_limit), lower_limit)
def normalize_fn(tensor, mean, std):
"""Differentiable version of torchvision.functional.normalize"""
# here we assume the color channel is in at dim=1
mean = mean[None, :, None, None]
std = std[None, :, None, None]
return tensor.sub(mean).div(std)
class NormalizeByChannelMeanStd(nn.Module):
def __init__(self, mean, std):
super(NormalizeByChannelMeanStd, self).__init__()
if not isinstance(mean, torch.Tensor):
mean = torch.tensor(mean)
if not isinstance(std, torch.Tensor):
std = torch.tensor(std)
self.register_buffer("mean", mean)
self.register_buffer("std", std)
def forward(self, tensor):
return normalize_fn(tensor, self.mean, self.std)
def extra_repr(self):
return 'mean={}, std={}'.format(self.mean, self.std)
def get_loaders(dir_, batch_size, dataset='cifar10', worker=4, norm=True):
if norm:
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(cifar10_mean, cifar10_std),
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(cifar10_mean, cifar10_std),
])
dataset_normalization = None
else:
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])
test_transform = transforms.Compose([
transforms.ToTensor(),
])
dataset_normalization = NormalizeByChannelMeanStd(
mean=cifar10_mean, std=cifar10_std)
if dataset == 'cifar10':
train_dataset = datasets.CIFAR10(
dir_, train=True, transform=train_transform, download=True)
test_dataset = datasets.CIFAR10(
dir_, train=False, transform=test_transform, download=True)
elif dataset == 'cifar100':
train_dataset = datasets.CIFAR100(
dir_, train=True, transform=train_transform, download=True)
test_dataset = datasets.CIFAR100(
dir_, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=worker,
)
test_loader = torch.utils.data.DataLoader(
dataset=test_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=worker,
)
return train_loader, test_loader, dataset_normalization
# evaluate on clean images with single norm
def evaluate_standard(test_loader, model, args):
test_loss = 0
test_acc = 0
n = 0
model.eval()
device = args.device
with torch.no_grad():
for i, (X, y) in enumerate(test_loader):
X, y = X.to(device), y.to(device)
output = model(X)
loss = F.cross_entropy(output, y)
test_loss += loss.item() * y.size(0)
test_acc += (output.max(1)[1] == y).sum().item()
n += y.size(0)
return test_loss/n, test_acc/n
def orthogonal_retraction(model, beta=0.002):
with torch.no_grad():
for module in model.modules():
if isinstance(module, (nn.Conv2d, nn.Linear)):
if isinstance(module, nn.Conv2d):
weight_ = module.weight.data
sz = weight_.shape
weight_ = weight_.reshape(sz[0],-1)
rows = list(range(module.weight.data.shape[0]))
elif isinstance(module, nn.Linear):
if module.weight.data.shape[0] < 200: # set a sample threshold for row number
weight_ = module.weight.data
sz = weight_.shape
weight_ = weight_.reshape(sz[0], -1)
rows = list(range(module.weight.data.shape[0]))
else:
rand_rows = np.random.permutation(module.weight.data.shape[0])
rows = rand_rows[: int(module.weight.data.shape[0] * 0.3)]
weight_ = module.weight.data[rows,:]
sz = weight_.shape
module.weight.data[rows,:] = ((1 + beta) * weight_ - beta * weight_.matmul(weight_.t()).matmul(weight_)).reshape(sz)
================================================
FILE: examples/Social_Cognition/FOToM/algorithms/ToM_class.py
================================================
import torch
import torch.distributions as td
from utils.networks import MLPNetwork, SNNNetwork, LSTMClassifier
from utils.misc import soft_update, average_gradients, onehot_from_logits, gumbel_softmax
class ToM1(object):
"""
tom factory (Simplification of ToM's model)
init ToM0 and ToM1 net
train ToM0 and ToM1 net
"""
def __init__(self, tom_base, alg_types, agent_types, num_lm, device, hidden_dim=64):
self.device = device
self.alg_types = alg_types
self.agent_types = agent_types
self.num_good_agents = len(self._get_index1(self.agent_types, 'agent'))
self.nagents = len(alg_types)
self.num_lm = num_lm
'''
Assume that ToM0 and ToM1 are equivalent
'''
self.tom1 = tom_base
self.other_tom1 = [0] * self.nagents
self._agent_tom1_init()
'''
ToM0_policy
'''
# self.tom_PHI = [] #TODO
self.hidden = None
def _agent_tom1_init(self):
other_alg_types_ = self.alg_types.copy()
other_agent_types_ = self.agent_types.copy()
for agent_i in range(self.nagents):
other_alg_types = other_alg_types_.copy()
other_agent_types = other_agent_types_.copy()
other_alg_types.pop(agent_i)
other_agent_types.pop(agent_i)
adv_indx = self._get_index1(other_agent_types, 'adversary')
good_indx = self._get_index1(other_agent_types, 'agent')
self.other_tom1[agent_i] = [self.tom1['adversary'][self.agent_types[agent_i]]] * len(adv_indx) #TODO
self.other_tom1[agent_i] += [self.tom1['agent'][self.agent_types[agent_i]]] * len(good_indx)
def _get_index1(self, lst=None, item=''):
return [index for (index, value) in enumerate(lst) if value == item]
def c_function(self, tom0_actions_q, tom1_actions_q):
c1 = 0.7
# tom0_actions = torch.stack([gumbel_softmax(action_i, hard=True)
# for action_i in tom0_actions_prob], 0)
# tom1_actions = torch.stack([gumbel_softmax(action_i, hard=True)
# for action_i in tom1_actions_prob], 0)
'''
batch, num_agent, ep, 1
'''
tom0_actions = (tom0_actions_q == tom0_actions_q.max(dim=-1, keepdim=True)[0]).to(dtype=torch.int32)
tom1_actions = (tom1_actions_q.unsqueeze(1) == tom1_actions_q.unsqueeze(0).max(dim=-1, keepdim=True)[0]).to(
dtype=torch.int32)
alig = tom0_actions.long().detach() & tom1_actions.long().detach()
I_belief = tom0_actions_q * (1 - c1) + alig * c1
# I_belief = [prob_i * (1 -c1) + alig[i] * c1 for i, prob_i in enumerate(tom0_actions_prob)]
return I_belief
def tom1_output(self, agent_i, adv_indx, good_indx, obs_, acs_pre_):
"""
ToM1 <--> ToM1
obs_self : obs of self, need to convert
tom0_out : predict other-action (episode_num * self.args.episode_limit * 2, -1), need to convert
tom0_out_q : predict other-action q_value (episode_num * self.args.episode_limit * 2, -1)
device : interact with env (cpu) train (cuda)
ToM0_policy
"""
actions = []
actions += [
# gumbel_softmax(
self.other_tom1[agent_i][j].to(self.device)(
torch.cat((obs_[:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
acs_pre_[:, :5]), 1))#.detach() #, hard=True
for j in adv_indx
]
actions += [
# gumbel_softmax(
self.other_tom1[agent_i][j].to(self.device)(
torch.cat((obs_[:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
acs_pre_[:, :5]), 1))#.detach() #, hard=True
for j in good_indx
]
# E_action = torch.cat(actions, 1)
E_action = actions
return E_action
================================================
FILE: examples/Social_Cognition/FOToM/algorithms/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/FOToM/algorithms/maddpg.py
================================================
import torch
from torch.optim import Adam
import torch.nn.functional as F
from gym.spaces import Box, Discrete, MultiDiscrete
from multiagent.multi_discrete import MultiDiscrete
from utils.networks import MLPNetwork, SNNNetwork, LSTMClassifier
from utils.misc import soft_update, average_gradients, onehot_from_logits, gumbel_softmax
from utils.agents import DDPGAgent, DDPGAgent_RNN, DDPGAgent_SNN, DDPGAgent_ToM
# from commom.distributions import make_pdtype
from thop import profile
from thop import clever_format
import time
MSELoss = torch.nn.MSELoss()
# reference:https://github.com/starry-sky6688/MADDPG.git
class MADDPG(object):
def __init__(self, agent_init_params, alg_types, device,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.device = device
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params)
for params in agent_init_params]
self.agent_init_params = agent_init_params
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, explore=False):
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def update(self, sample, agent_i, parallel=False, logger=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
obs, acs, rews, next_obs, dones = sample
curr_agent = self.agents[agent_i]
curr_agent.critic_optimizer.zero_grad()
if self.alg_types[agent_i] == 'MADDPG':
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs)]
else:
all_trgt_acs = [pi(nobs) for pi, nobs in zip(self.target_policies,
next_obs)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
else: # DDPG
if self.discrete_action:
trgt_vf_in = torch.cat((next_obs[agent_i],
onehot_from_logits(
curr_agent.target_policy(
next_obs[agent_i]))),
dim=1)
else:
trgt_vf_in = torch.cat((next_obs[agent_i],
curr_agent.target_policy(next_obs[agent_i])),
dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
if self.alg_types[agent_i] == 'MADDPG':
vf_in = torch.cat((*obs, *acs), dim=1)
else: # DDPG
vf_in = torch.cat((obs[agent_i], acs[agent_i]), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
if self.alg_types[agent_i] == 'MADDPG':
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
else: # DDPG
vf_in = torch.cat((obs[agent_i], curr_pol_vf_in),
dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out**2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents]}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, device, agent_alg="MADDPG", adversary_alg="MADDPG",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
if algtype == "MADDPG":
num_in_critic = 0
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'device': device}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
return instance
class MADDPG_RNN(object):
"""
Wrapper class for DDPG-esque (i.e. also MADDPG) agents in multi-agent task
"""
def __init__(self, agent_init_params, alg_types,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent_RNN(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params)
for params in agent_init_params]
self.agent_init_params = agent_init_params
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.niter = 0
def _init_agent(self, n_rollout_threads):
for agent_i in self.agents:
agent_i.init_hidden(n_rollout_threads, policy_hidden=True, policy_target_hidden=True, \
critic_hidden=True, critic_target_hidden=True)
# @property
def policies(self, len_ep):
for a in self.agents: a.init_hidden(len_ep, policy_hidden=True, policy_target_hidden=False, \
critic_hidden=False, critic_target_hidden=False)
return [a.policy for a in self.agents], [a.policy_hidden for a in self.agents]
# @property
def target_policies(self, len_ep):
for a in self.agents: a.init_hidden(len_ep, policy_hidden=False, policy_target_hidden=True, \
critic_hidden=False, critic_target_hidden=False)
return [a.target_policy for a in self.agents], [a.policy_target_hidden for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, explore=False):
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def _compute_rnn(self, fn, hidden, inputs, logit):
num_ep = inputs.shape[1]
outputs = []
hidden = hidden.to(torch.device('cuda:4'))
for step_id in range(num_ep):
output, hidden = fn(inputs[:, step_id, :], hidden)
if logit == onehot_from_logits:
outputs.append(logit(output))
elif logit == gumbel_softmax:
outputs.append(logit(output, True))
else:
outputs.append(output)
outputs = torch.stack(outputs,1)
return outputs
def update(self, sample, agent_i, parallel=False, logger=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
obs, acs, rews, next_obs, dones = sample
curr_agent = self.agents[agent_i]
len_ep = obs[0].shape[0]
curr_agent.init_hidden(len_ep, True, True, True, True)
curr_agent.critic_optimizer.zero_grad()
if self.alg_types[agent_i] == 'MADDPG_RNN':
if self.discrete_action: # one-hot encode action
all_trgt_acs = [self._compute_rnn(pi, hidden, nobs, onehot_from_logits) for pi, hidden, nobs in \
zip(self.target_policies(len_ep)[0], self.target_policies(len_ep)[1], next_obs)]
else:
all_trgt_acs = [pi(nobs) for pi, nobs in zip(self.target_policies,
next_obs)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=-1)
target_critic = self._compute_rnn(curr_agent.target_critic, curr_agent.critic_target_hidden, trgt_vf_in, None)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
target_critic.view(-1, 1) *
(1 - dones[agent_i].view(-1, 1)))
if self.alg_types[agent_i] == 'MADDPG_RNN':
vf_in = torch.cat((*obs, *acs), dim=-1)
actual_value = self._compute_rnn(curr_agent.critic, curr_agent.critic_hidden, vf_in, None)
vf_loss = MSELoss(actual_value.view(-1,1), target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = self._compute_rnn(curr_agent.policy, curr_agent.policy_hidden, obs[agent_i], None)
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
if self.alg_types[agent_i] == 'MADDPG_RNN':
all_pol_acs = []
for i, pi, policy_hidden, ob in zip(range(self.nagents), self.policies(len_ep)[0], self.policies(len_ep)[1], obs):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(self._compute_rnn(pi, policy_hidden, ob, onehot_from_logits))
# all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=-1)
curr_agent.init_hidden(len_ep, False, False, True, False)
pol_loss = -self._compute_rnn(curr_agent.critic, policy_hidden, vf_in, None).mean()
# pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out**2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm(curr_agent.policy.parameters(), 0.5)
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device('cuda:4'))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device('cuda:4'))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents]}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, agent_alg="MADDPG", adversary_alg="MADDPG_RNN",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
else: # Discrete
discrete_action = True
get_shape = lambda x: x.n
num_out_pol = get_shape(acsp)
if algtype == "MADDPG_RNN":
num_in_critic = 0
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
return instance
================================================
FILE: examples/Social_Cognition/FOToM/algorithms/tom11.py
================================================
import torch
from torch.optim import Adam
import torch.nn.functional as F
from gym.spaces import Box, Discrete, MultiDiscrete
from multiagent.multi_discrete import MultiDiscrete
from utils.networks import MLPNetwork, SNNNetwork, LSTMClassifier
from utils.misc import soft_update, average_gradients, onehot_from_logits, gumbel_softmax
from utils.agents import DDPGAgent
from algorithms.ToM_class import ToM1
# from commom.distributions import make_pdtype
from thop import profile
from thop import clever_format
import time
MSELoss = torch.nn.MSELoss()
KL_criterion = torch.nn.KLDivLoss(reduction='sum')
CE_criterion = torch.nn.CrossEntropyLoss(reduction="sum")
class ToM_decision11(object):
def __init__(self, agent_init_params, alg_types, agent_types, num_lm,
output_style, device, config, gamma=0.95, tau=0.01, lr=0.01,
hidden_dim=64, discrete_action=False):
self.config = config
self.device = device
self.num_lm = num_lm
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agent_types = agent_types
self.num_good_agents = len(self._get_index1(self.agent_types, 'agent'))
self.agents = [DDPGAgent_ToM(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params, output_style=output_style,
num_agents=self.nagents,
device=self.device)
for params in agent_init_params]
self.agent_init_params = agent_init_params
# tom0
self.mle_base = [MLPNetwork(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2 + 5,
self.agent_init_params[-1]['num_out_pol'],
hidden_dim=5, norm_in=False), # infer good agent
MLPNetwork(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2 + 5,
self.agent_init_params[-1]['num_out_pol'],
hidden_dim=5, norm_in=False), # infer adversary
]
self.tom_base = {
'agent': {'agent': self.mle_base[0],
'adversary': self.mle_base[1]
},
'adversary': {'agent': self.mle_base[0],
'adversary': self.mle_base[1]
}
}
self.tom_PHI = [LSTMClassifier(self.num_good_agents * 2 + self.num_lm * 2 +
(self.nagents - 1) * 2 + 5 * (self.nagents - 1),
self.agent_init_params[-1]['num_out_pol'],
hidden_size=64), # infer good agent
LSTMClassifier(self.num_good_agents * 2 + self.num_lm * 2 +
(self.nagents - 1) * 2 + 5 * (self.nagents - 1),
self.agent_init_params[-1]['num_out_pol'],
hidden_size=64), # infer adversary
] #TODO
self._agent_tom_init() #TODO
self.tom1 = ToM1(self.tom_base, alg_types, agent_types, num_lm, device)
self.actions_tom0 = []
self.next_actions_tom0 = []
self.actions_tom1 = []
self.next_actions_tom1 = []
self.mle_opts = [Adam(i.parameters(), lr=1e-4) for i in self.mle_base]
self.PHI_opts = [Adam(i.parameters(), lr=1e-4) for i in self.tom_PHI]
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.mle_dev = 'cpu'
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def _get_index1(self, lst=None, item=''):
return [index for (index, value) in enumerate(lst) if value == item]
def _agent_tom_init(self):
# other_alg_types_ = self.alg_types.copy()
other_agent_types_ = self.agent_types.copy()
for agent_i in range(self.nagents):
# other_alg_types = other_alg_types_.copy()
other_agent_types = other_agent_types_.copy()
# other_alg_types.pop(agent_i)
other_agent_types.pop(agent_i)
adv_indx = self._get_index1(other_agent_types, 'adversary')
good_indx = self._get_index1(other_agent_types, 'agent')
self.agents[agent_i].mle += [self.tom_base[self.agent_types[agent_i]]['adversary']] * len(adv_indx) #TODO
self.agents[agent_i].mle += [self.tom_base[self.agent_types[agent_i]]['agent']] * len(good_indx)
def step(self, observations, actions_pre, explore=False): #simple_tag
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
# t1 = time.time()
observations_ = observations.copy()
actions_pre_ = actions_pre.copy()
# other_alg_types_ = self.alg_types.copy()
other_agent_types_ = self.agent_types.copy()
adv_agent_indx = self._get_index1(self.agent_types, 'adversary')
good_agent_indx = self._get_index1(self.agent_types, 'agent')
'''
tom0
'''
actions_tom0 = []
actions_tom0 += [
gumbel_softmax(
self.mle_base[1].to(self.device)(
torch.cat((observations[j][:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
actions_pre[j][:, :5]), 1).to(self.device)).detach(), hard=True
) for j in adv_agent_indx
]
actions_tom0 += [
gumbel_softmax(
self.mle_base[0].to(self.device)(
torch.cat((observations[j][:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
actions_pre[j][:, :5]), 1).to(self.device)).detach(), hard=True
) for j in good_agent_indx
]
'''
tom1
'''
actions_tom1 = []
for agent_i, obs in enumerate(observations):
obs_ = observations_.copy()
acs_other = actions_tom0.copy()
other_agent_types = other_agent_types_.copy()
obs_.pop(agent_i)
acs_other.pop(agent_i)
other_agent_types.pop(agent_i)
if agent_i in adv_agent_indx:
actions_tom1.append(
gumbel_softmax(
self.tom_PHI[1].to(self.device)(
torch.cat((obs[:, -(self.num_good_agents * 2 + self.num_lm * 2 +
(self.nagents - 1) * 2):].to(self.device), torch.cat(acs_other, 1)), 1)), hard=True
).cpu()
)
elif agent_i in good_agent_indx:
actions_tom1.append(
gumbel_softmax(
self.tom_PHI[0].to(self.device)(
torch.cat((obs[:, -(self.num_good_agents * 2 + self.num_lm * 2 +
(self.nagents - 1) * 2):].to(self.device), torch.cat(acs_other, 1)), 1)), hard=True
).cpu()
)
observations = self._get_obs(observations, actions_tom1)
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def _get_obs(self, observations, action_tom):
observations_ = []
other_actions_tom_ = action_tom.copy()
for agent_i, obs in enumerate(observations):
other_action_tom = other_actions_tom_.copy()
other_action_tom.pop(agent_i)
actions = other_action_tom
observations_.append(torch.cat((obs, torch.cat(actions, 1)), 1))
return observations_
def train_tom0(self, sample, agent_i):
acs_pre, obs, acs, rews, next_obs, dones = sample
adv_agent_indx = self._get_index1(self.agent_types, 'adversary')
good_agent_indx = self._get_index1(self.agent_types, 'agent')
# self.agent_types[tom_agent_indx]
'''
data
for with_tom
for without_tom
'''
if adv_agent_indx != []:
adv_input = torch.cat([torch.cat((obs[i], acs_pre[i][:, :5]), 1) for i in adv_agent_indx])
label_adv_output = torch.cat([acs[i][:, :5] for i in adv_agent_indx])
self.mle_base[1].zero_grad()
adv_output = self.mle_base[1](adv_input[:,
-(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2 + 5):])
loss_adv = F.mse_loss(adv_output.float(), label_adv_output.float())
loss_adv.backward(retain_graph=True)
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
if good_agent_indx != []:
good_input = torch.cat([torch.cat((obs[i], acs_pre[i][:, :5]), 1) for i in good_agent_indx])
label_good_output = torch.cat([acs[i][:, :5] for i in good_agent_indx])
self.mle_base[0].zero_grad()
good_output = self.mle_base[0](good_input[:,
-(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2 + 5):])
loss_good = F.mse_loss(good_output.float(), label_good_output.float())
loss_good.backward(retain_graph=True)
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
'''
Only train agents with ToM (adversarys)
'''
'''
adv-adv
adv-good
'''
def tom1_infer_other(self, sample):
acs_pre, obs, acs, rews, next_obs, dones = sample
self.actions_tom1 = []
self.next_actions_tom1 = []
actions_tom1 = []
next_actions_tom1 = []
other_actions_tom0_ = self.actions_tom0.copy()
other_next_actions_tom0_ = self.next_actions_tom0.copy()
adv_agent_indx = self._get_index1(self.agent_types, 'adversary')
good_agent_indx = self._get_index1(self.agent_types, 'agent')
good_in = []
adv_in =[]
good_in_next = []
adv_in_next =[]
for agent_i, (obs_i, next_obs_i) in enumerate(zip(obs, next_obs)):
other_action_tom0 = other_actions_tom0_.copy()
other_next_actions_tom0 = other_next_actions_tom0_.copy()
other_action_tom0.pop(agent_i)
other_next_actions_tom0.pop(agent_i)
if agent_i in adv_agent_indx:
adv_in.append(torch.cat(
(obs_i[:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
torch.cat(other_action_tom0, 1)), 1))
adv_in_next.append(torch.cat(
(next_obs_i[:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
torch.cat(other_next_actions_tom0, 1)), 1))
elif agent_i in good_agent_indx:
good_in.append(torch.cat(
(obs_i[:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
torch.cat(other_action_tom0, 1)), 1))
good_in_next.append(torch.cat(
(next_obs_i[:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
torch.cat(other_next_actions_tom0, 1)), 1))
if adv_agent_indx != []:
adv_in = torch.cat(adv_in, 0)
adv_in_next = torch.cat(adv_in_next, 0)
actions_tom1.append(gumbel_softmax(
self.tom_PHI[1].to(self.device)(
adv_in), hard=True
))
next_actions_tom1.append(gumbel_softmax(
self.tom_PHI[1].to(self.device)(
adv_in_next), hard=True
)) # adv
label_adv_output = torch.cat([self.actions_tom0[i] for i in adv_agent_indx]).detach()
# label_adv_output = torch.cat([acs[i][:, :5] for i in adv_agent_indx])
adv_output = actions_tom1[0]
loss_adv = F.mse_loss(adv_output.float(), label_adv_output.float())
loss_adv.backward(retain_graph=True)
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.PHI_opts[1].step()
if good_agent_indx != []:
good_in = torch.cat(good_in, 0)
good_in_next = torch.cat(good_in_next, 0)
actions_tom1.append(gumbel_softmax(
self.tom_PHI[0].to(self.device)(
good_in), hard=True
))
next_actions_tom1.append(gumbel_softmax(
self.tom_PHI[0].to(self.device)(
good_in_next), hard=True
)) # agent
label_good_output = torch.cat([self.actions_tom0[i] for i in good_agent_indx]).detach()
# label_good_output = torch.cat([acs[i][:, :5] for i in good_agent_indx])
if self.config.env_id == 'simple_spread' or self.config.env_id == 'hetero_spread':
good_output = actions_tom1[0]
else:
good_output = actions_tom1[1]
loss_good = F.mse_loss(good_output.float(), label_good_output.float())
loss_good.backward(retain_graph=True)
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.PHI_opts[0].step()
actions_tom1 = torch.cat(actions_tom1)#.detach()
next_actions_tom1 = torch.cat(next_actions_tom1).detach()
for i in range(self.nagents):
self.actions_tom1.append(actions_tom1[i*self.config.batch_size:(i+1)*self.config.batch_size, :])
self.next_actions_tom1.append(next_actions_tom1[i*self.config.batch_size:(i+1)*self.config.batch_size, :])
# print(self.actions_tom1)
def tom0_output(self, sample):
acs_pre, obs, acs, rews, next_obs, dones = sample
self.actions_tom0 = []
self.next_actions_tom0 = []
adv_indx = self._get_index1(self.agent_types, 'adversary')
good_indx = self._get_index1(self.agent_types, 'agent')
self.actions_tom0 += [
gumbel_softmax(
self.mle_base[1].to(self.device)(
torch.cat((obs[j][:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
acs_pre[j][:, :5]), 1)).detach(), hard=True
) for j in adv_indx
]
self.actions_tom0 += [
gumbel_softmax(
self.mle_base[0].to(self.device)(
torch.cat((obs[j][:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
acs_pre[j][:, :5]), 1)).detach(), hard=True
) for j in good_indx
]
self.next_actions_tom0 += [
gumbel_softmax(
self.mle_base[1].to(self.device)(
torch.cat((next_obs[j][:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
acs[j][:, :5]), 1)).detach(), hard=True
) for j in adv_indx
]
self.next_actions_tom0 += [
gumbel_softmax(
self.mle_base[0].to(self.device)(
torch.cat((next_obs[j][:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
acs[j][:, :5]), 1)).detach(), hard=True
) for j in good_indx
]
# actions_tom0 = torch.cat(actions_tom0, 1)
# return actions_tom0, next_actions_tom0
def update(self, sample, agent_i, parallel=False, logger=None, sample_r=None):
# other_alg_types = self.alg_types.copy()
other_agent_types = self.agent_types.copy()
# other_alg_types.pop(agent_i)
other_agent_types.pop(agent_i)
adv_indx = self._get_index1(other_agent_types, 'adversary')
good_indx = self._get_index1(other_agent_types, 'agent')
agent_i_alg = self.alg_types[agent_i]
acs_pre, obs, acs, rews, next_obs, dones = sample
next_obs_ = self._get_obs(next_obs, self.next_actions_tom1)
obs_ = self._get_obs(obs, self.actions_tom1)
curr_agent = self.agents[agent_i]
'''
distance between self and other
'''
Euclidean_D = []
for i in range(len(other_agent_types)):
Euclidean_D.append(obs[agent_i][:,
-len(other_agent_types)*2:][:, i: i+2].pow(2).sum(1).sqrt())
Euclidean_D_ = torch.stack(Euclidean_D, 1)
'''
distance between self and landmark
'''
Euclidean_L = []
for i in range(self.num_lm):
Euclidean_L.append(obs[agent_i][:, -len(other_agent_types)*2-self.num_lm*2:
-len(other_agent_types)*2][:, i: i+2].pow(2).sum(1).sqrt())
Euclidean_L = torch.stack(Euclidean_L, 1)
close_agent_index = (Euclidean_D_ == Euclidean_D_.min(dim=1, keepdim=True)[0])\
.to(dtype=torch.int32) #run11/run12 self-orgnization
# close_agent_index = torch.ones((self.config.batch_size, len(other_agent_types))) \
# .to(dtype=torch.int32).to(self.device) #run13
if agent_i == 0:
self.train_tom0(sample, agent_i)
E_action = self.tom1.tom1_output(agent_i, adv_indx,
good_indx, obs[agent_i], acs_pre[agent_i])
if agent_i_alg == 'with_tom':
acs_other = acs.copy()
acs_other.pop(agent_i)
# KL loss
# adv_loss = sum([KL_criterion(E_action[j], acs_other[j][:, :5].float()) for j in adv_indx]) #TODO
# good_loss = sum([KL_criterion(E_action[j], acs_other[j][:, :5].float()) for j in good_indx])
# L2 loss
action_loss = torch.norm(acs[agent_i][:, :5] - E_action[0], p=2, dim=1)
loss_other = 0.1 * torch.stack([action_loss]*len(other_agent_types), 1)
if agent_i in adv_indx:
'''
adv_loss : decrease
good_loss : increase
'''
close_agent_index[:, good_indx] *= -1
close_agent_index[:, adv_indx] *= 0.1
intri_rew = close_agent_index.mul(loss_other).mul(Euclidean_D_).sum(1)
# intri_rew = close_agent_index.mul(loss_other).sum(1)
else:
'''
adv_loss : increase
good_loss : decrease
'''
close_agent_index[:, adv_indx] *= 1
close_agent_index[:, good_indx] *= 0.1
# if self.config.env_id == 'simple_adversary':
# intri_rew = close_agent_index.mul(loss_other).mul(Euclidean_D_).sum(1) - \
# obs[agent_i][:, :2].pow(2).sum(1)
# elif self.config.env_id == 'simple_spread_pre':
# intri_rew = close_agent_index.mul(loss_other).mul(Euclidean_D_).sum(1) - \
# Euclidean_L.min(dim=1, keepdim=True)[0][:,0]
# else:
intri_rew = close_agent_index.mul(loss_other).mul(Euclidean_D_).sum(1)
# intri_rew = close_agent_index.mul(loss_other).sum(1)
rews[agent_i] = rews[agent_i] + intri_rew.detach()
# center critic
curr_agent.critic_optimizer.zero_grad()
all_trgt_acs = []
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs_)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
vf_in = torch.cat((*obs, *acs), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs_[agent_i].detach())
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs_):
ob = ob.detach()
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out ** 2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
# actor
curr_agent.policy_optimizer.step()
# print('c_loss:',vf_loss, 'p_loss:', pol_loss)
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
# for i in self.tom_base.values():
# for mle in i.values():
# mle.train()
for mle in self.mle_base:
mle.train()
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
for mle_i in a.mle:
mle_i.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
if not self.mle_dev == device:
# for i in self.tom_base.keys():
# for j in self.tom_base[i].keys():
# self.tom_base[i][j] = fn(mle)
for i, mle in enumerate(self.mle_base):
self.mle_base[i] = fn(mle)
for a in self.agents:
for i, mle_i in enumerate(a.mle):
a.mle[i] = fn(mle_i)
self.mle_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents],
'tom_params': [self.get_params()],}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, config, device, agent_alg, adversary_alg,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64, output_style='sum'):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
num_lm = env.num_lm
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
num_in_mle = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
# if algtype == "with_tom":
num_in_critic = 0
num_in_pol += (len(env.agent_types)-1) * 5
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
# else:
# num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic,
'num_in_mle': num_in_mle,})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'device': device,
'config' : config,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_types' : env.agent_types,
'num_lm' : num_lm,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'output_style': output_style}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
for a, params in zip([instance], save_dict['tom_params']):
a.load_params(params)
return instance
def get_params(self):
params = {
}
for i in range(len(self.mle_base)):
params['mle%d'%i] = self.mle_base[i].state_dict()
params['mle_optimizer%d'%i] = self.mle_opts[i].state_dict()
params['tom_phi%d'%i] = self.tom_PHI[i].state_dict()
params['phi_opt%d' % i] = self.PHI_opts[i].state_dict()
return params
def load_params(self, params):
for i in range(len(self.mle_base)):
self.mle_base[i].load_state_dict(params['mle%d'%i])
self.mle_opts[i].load_state_dict(params['mle_optimizer%d'%i])
self.tom_PHI[i].load_state_dict(params['tom_phi%d'%i])
self.PHI_opts[i].load_state_dict(params['phi_opt%d' % i])
================================================
FILE: examples/Social_Cognition/FOToM/common/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/FOToM/common/distributions.py
================================================
# import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
import numpy as np
import maddpg.common.tf_util as U
from tensorflow.python.ops import math_ops
from multiagent.multi_discrete import MultiDiscrete
from tensorflow.python.ops import nn
class Pd(object):
"""
A particular probability distribution
"""
def flatparam(self):
raise NotImplementedError
def mode(self):
raise NotImplementedError
def logp(self, x):
raise NotImplementedError
def kl(self, other):
raise NotImplementedError
def entropy(self):
raise NotImplementedError
def sample(self):
raise NotImplementedError
class PdType(object):
"""
Parametrized family of probability distributions
"""
def pdclass(self):
raise NotImplementedError
def pdfromflat(self, flat):
return self.pdclass()(flat)
def param_shape(self):
raise NotImplementedError
def sample_shape(self):
raise NotImplementedError
def sample_dtype(self):
raise NotImplementedError
def param_placeholder(self, prepend_shape, name=None):
return tf.placeholder(dtype=tf.float32, shape=prepend_shape+self.param_shape(), name=name)
def sample_placeholder(self, prepend_shape, name=None):
return tf.placeholder(dtype=self.sample_dtype(), shape=prepend_shape+self.sample_shape(), name=name)
class CategoricalPdType(PdType):
def __init__(self, ncat):
self.ncat = ncat
def pdclass(self):
return CategoricalPd
def param_shape(self):
return [self.ncat]
def sample_shape(self):
return []
def sample_dtype(self):
return tf.int32
class SoftCategoricalPdType(PdType):
def __init__(self, ncat):
self.ncat = ncat
def pdclass(self):
return SoftCategoricalPd
def param_shape(self):
return [self.ncat]
def sample_shape(self):
return [self.ncat]
def sample_dtype(self):
return tf.float32
class MultiCategoricalPdType(PdType):
def __init__(self, low, high):
self.low = low
self.high = high
self.ncats = high - low + 1
def pdclass(self):
return MultiCategoricalPd
def pdfromflat(self, flat):
return MultiCategoricalPd(self.low, self.high, flat)
def param_shape(self):
return [sum(self.ncats)]
def sample_shape(self):
return [len(self.ncats)]
def sample_dtype(self):
return tf.int32
class SoftMultiCategoricalPdType(PdType):
def __init__(self, low, high):
self.low = low
self.high = high
self.ncats = high - low + 1
def pdclass(self):
return SoftMultiCategoricalPd
def pdfromflat(self, flat):
return SoftMultiCategoricalPd(self.low, self.high, flat)
def param_shape(self):
return [sum(self.ncats)]
def sample_shape(self):
return [sum(self.ncats)]
def sample_dtype(self):
return tf.float32
class DiagGaussianPdType(PdType):
def __init__(self, size):
self.size = size
def pdclass(self):
return DiagGaussianPd
def param_shape(self):
return [2*self.size]
def sample_shape(self):
return [self.size]
def sample_dtype(self):
return tf.float32
class BernoulliPdType(PdType):
def __init__(self, size):
self.size = size
def pdclass(self):
return BernoulliPd
def param_shape(self):
return [self.size]
def sample_shape(self):
return [self.size]
def sample_dtype(self):
return tf.int32
# WRONG SECOND DERIVATIVES
# class CategoricalPd(Pd):
# def __init__(self, logits):
# self.logits = logits
# self.ps = tf.nn.softmax(logits)
# @classmethod
# def fromflat(cls, flat):
# return cls(flat)
# def flatparam(self):
# return self.logits
# def mode(self):
# return U.argmax(self.logits, axis=1)
# def logp(self, x):
# return -tf.nn.sparse_softmax_cross_entropy_with_logits(self.logits, x)
# def kl(self, other):
# return tf.nn.softmax_cross_entropy_with_logits(other.logits, self.ps) \
# - tf.nn.softmax_cross_entropy_with_logits(self.logits, self.ps)
# def entropy(self):
# return tf.nn.softmax_cross_entropy_with_logits(self.logits, self.ps)
# def sample(self):
# u = tf.random_uniform(tf.shape(self.logits))
# return U.argmax(self.logits - tf.log(-tf.log(u)), axis=1)
class CategoricalPd(Pd):
def __init__(self, logits):
self.logits = logits
def flatparam(self):
return self.logits
def mode(self):
return U.argmax(self.logits, axis=1)
def logp(self, x):
return -tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.logits, labels=x)
def kl(self, other):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
a1 = other.logits - U.max(other.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
ea1 = tf.exp(a1)
z0 = U.sum(ea0, axis=1, keepdims=True)
z1 = U.sum(ea1, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (a0 - tf.log(z0) - a1 + tf.log(z1)), axis=1)
def entropy(self):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
z0 = U.sum(ea0, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (tf.log(z0) - a0), axis=1)
def sample(self):
u = tf.random_uniform(tf.shape(self.logits))
return U.argmax(self.logits - tf.log(-tf.log(u)), axis=1)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class SoftCategoricalPd(Pd):
def __init__(self, logits):
self.logits = logits
def flatparam(self):
return self.logits
def mode(self):
return U.softmax(self.logits, axis=-1)
def logp(self, x):
return -tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=x)
def kl(self, other):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
a1 = other.logits - U.max(other.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
ea1 = tf.exp(a1)
z0 = U.sum(ea0, axis=1, keepdims=True)
z1 = U.sum(ea1, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (a0 - tf.log(z0) - a1 + tf.log(z1)), axis=1)
def entropy(self):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
z0 = U.sum(ea0, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (tf.log(z0) - a0), axis=1)
def sample(self):
u = tf.random_uniform(tf.shape(self.logits))
return U.softmax(self.logits - tf.log(-tf.log(u)), axis=-1)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class MultiCategoricalPd(Pd):
def __init__(self, low, high, flat):
self.flat = flat
self.low = tf.constant(low, dtype=tf.int32)
self.categoricals = list(map(CategoricalPd, tf.split(flat, high - low + 1, axis=len(flat.get_shape()) - 1)))
def flatparam(self):
return self.flat
def mode(self):
return self.low + tf.cast(tf.stack([p.mode() for p in self.categoricals], axis=-1), tf.int32)
def logp(self, x):
return tf.add_n([p.logp(px) for p, px in zip(self.categoricals, tf.unstack(x - self.low, axis=len(x.get_shape()) - 1))])
def kl(self, other):
return tf.add_n([
p.kl(q) for p, q in zip(self.categoricals, other.categoricals)
])
def entropy(self):
return tf.add_n([p.entropy() for p in self.categoricals])
def sample(self):
return self.low + tf.cast(tf.stack([p.sample() for p in self.categoricals], axis=-1), tf.int32)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class SoftMultiCategoricalPd(Pd): # doesn't work yet
def __init__(self, low, high, flat):
self.flat = flat
self.low = tf.constant(low, dtype=tf.float32)
self.categoricals = list(map(SoftCategoricalPd, tf.split(flat, high - low + 1, axis=len(flat.get_shape()) - 1)))
def flatparam(self):
return self.flat
def mode(self):
x = []
for i in range(len(self.categoricals)):
x.append(self.low[i] + self.categoricals[i].mode())
return tf.concat(x, axis=-1)
def logp(self, x):
return tf.add_n([p.logp(px) for p, px in zip(self.categoricals, tf.unstack(x - self.low, axis=len(x.get_shape()) - 1))])
def kl(self, other):
return tf.add_n([
p.kl(q) for p, q in zip(self.categoricals, other.categoricals)
])
def entropy(self):
return tf.add_n([p.entropy() for p in self.categoricals])
def sample(self):
x = []
for i in range(len(self.categoricals)):
x.append(self.low[i] + self.categoricals[i].sample())
return tf.concat(x, axis=-1)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class DiagGaussianPd(Pd):
def __init__(self, flat):
self.flat = flat
mean, logstd = tf.split(axis=1, num_or_size_splits=2, value=flat)
self.mean = mean
self.logstd = logstd
self.std = tf.exp(logstd)
def flatparam(self):
return self.flat
def mode(self):
return self.mean
def logp(self, x):
return - 0.5 * U.sum(tf.square((x - self.mean) / self.std), axis=1) \
- 0.5 * np.log(2.0 * np.pi) * tf.to_float(tf.shape(x)[1]) \
- U.sum(self.logstd, axis=1)
def kl(self, other):
assert isinstance(other, DiagGaussianPd)
return U.sum(other.logstd - self.logstd + (tf.square(self.std) + tf.square(self.mean - other.mean)) / (2.0 * tf.square(other.std)) - 0.5, axis=1)
def entropy(self):
return U.sum(self.logstd + .5 * np.log(2.0 * np.pi * np.e), 1)
def sample(self):
return self.mean + self.std * tf.random_normal(tf.shape(self.mean))
@classmethod
def fromflat(cls, flat):
return cls(flat)
class BernoulliPd(Pd):
def __init__(self, logits):
self.logits = logits
self.ps = tf.sigmoid(logits)
def flatparam(self):
return self.logits
def mode(self):
return tf.round(self.ps)
def logp(self, x):
return - U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=tf.to_float(x)), axis=1)
def kl(self, other):
return U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=other.logits, labels=self.ps), axis=1) - U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=self.ps), axis=1)
def entropy(self):
return U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=self.ps), axis=1)
def sample(self):
p = tf.sigmoid(self.logits)
u = tf.random_uniform(tf.shape(p))
return tf.to_float(math_ops.less(u, p))
@classmethod
def fromflat(cls, flat):
return cls(flat)
def make_pdtype(ac_space):
from gym import spaces
if isinstance(ac_space, spaces.Box):
assert len(ac_space.shape) == 1
return DiagGaussianPdType(ac_space.shape[0])
elif isinstance(ac_space, spaces.Discrete):
# return CategoricalPdType(ac_space.n)
return SoftCategoricalPdType(ac_space.n)
elif isinstance(ac_space, MultiDiscrete):
#return MultiCategoricalPdType(ac_space.low, ac_space.high)
return SoftMultiCategoricalPdType(ac_space.low, ac_space.high)
elif isinstance(ac_space, spaces.MultiBinary):
return BernoulliPdType(ac_space.n)
else:
raise NotImplementedError
def shape_el(v, i):
maybe = v.get_shape()[i]
if maybe is not None:
return maybe
else:
return tf.shape(v)[i]
================================================
FILE: examples/Social_Cognition/FOToM/common/tile_images.py
================================================
import numpy as np
def tile_images(img_nhwc):
"""
Tile N images into one big PxQ image
(P,Q) are chosen to be as close as possible, and if N
is square, then P=Q.
input: img_nhwc, list or array of images, ndim=4 once turned into array
n = batch index, h = height, w = width, c = channel
returns:
bigim_HWc, ndarray with ndim=3
"""
img_nhwc = np.asarray(img_nhwc)
N, h, w, c = img_nhwc.shape
H = int(np.ceil(np.sqrt(N)))
W = int(np.ceil(float(N)/H))
img_nhwc = np.array(list(img_nhwc) + [img_nhwc[0]*0 for _ in range(N, H*W)])
img_HWhwc = img_nhwc.reshape(H, W, h, w, c)
img_HhWwc = img_HWhwc.transpose(0, 2, 1, 3, 4)
img_Hh_Ww_c = img_HhWwc.reshape(H*h, W*w, c)
return img_Hh_Ww_c
================================================
FILE: examples/Social_Cognition/FOToM/common/vec_env/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/FOToM/common/vec_env/vec_env.py
================================================
import contextlib
import os
from abc import ABC, abstractmethod
from common.tile_images import tile_images
class AlreadySteppingError(Exception):
"""
Raised when an asynchronous step is running while
step_async() is called again.
"""
def __init__(self):
msg = 'already running an async step'
Exception.__init__(self, msg)
class NotSteppingError(Exception):
"""
Raised when an asynchronous step is not running but
step_wait() is called.
"""
def __init__(self):
msg = 'not running an async step'
Exception.__init__(self, msg)
class VecEnv(ABC):
"""
An abstract asynchronous, vectorized environment.
Used to batch data from multiple copies of an environment, so that
each observation becomes an batch of observations, and expected action is a batch of actions to
be applied per-environment.
"""
closed = False
viewer = None
metadata = {
'render.modes': ['human', 'rgb_array']
}
def __init__(self, num_envs, observation_space, action_space):
self.num_envs = num_envs
self.observation_space = observation_space
self.action_space = action_space
@abstractmethod
def reset(self):
"""
Reset all the environments and return an array of
observations, or a dict of observation arrays.
If step_async is still doing work, that work will
be cancelled and step_wait() should not be called
until step_async() is invoked again.
"""
pass
@abstractmethod
def step_async(self, actions):
"""
Tell all the environments to start taking a step
with the given actions.
Call step_wait() to get the results of the step.
You should not call this if a step_async run is
already pending.
"""
pass
@abstractmethod
def step_wait(self):
"""
Wait for the step taken with step_async().
Returns (obs, rews, dones, infos):
- obs: an array of observations, or a dict of
arrays of observations.
- rews: an array of rewards
- dones: an array of "episode done" booleans
- infos: a sequence of info objects
"""
pass
def close_extras(self):
"""
Clean up the extra resources, beyond what's in this base class.
Only runs when not self.closed.
"""
pass
def close(self):
if self.closed:
return
if self.viewer is not None:
self.viewer.close()
self.close_extras()
self.closed = True
def step(self, actions):
"""
Step the environments synchronously.
This is available for backwards compatibility.
"""
self.step_async(actions)
return self.step_wait()
def render(self, mode='human'):
imgs = self.get_images()
bigimg = tile_images(imgs)
if mode == 'human':
self.get_viewer().imshow(bigimg)
return self.get_viewer().isopen
elif mode == 'rgb_array':
return bigimg
else:
raise NotImplementedError
def get_images(self):
"""
Return RGB images from each environment
"""
raise NotImplementedError
@property
def unwrapped(self):
if isinstance(self, VecEnvWrapper):
return self.venv.unwrapped
else:
return self
def get_viewer(self):
if self.viewer is None:
from gym.envs.classic_control import rendering
self.viewer = rendering.SimpleImageViewer()
return self.viewer
class VecEnvWrapper(VecEnv):
"""
An environment wrapper that applies to an entire batch
of environments at once.
"""
def __init__(self, venv, observation_space=None, action_space=None):
self.venv = venv
super().__init__(num_envs=venv.num_envs,
observation_space=observation_space or venv.observation_space,
action_space=action_space or venv.action_space)
def step_async(self, actions):
self.venv.step_async(actions)
@abstractmethod
def reset(self):
pass
@abstractmethod
def step_wait(self):
pass
def close(self):
return self.venv.close()
def render(self, mode='human'):
return self.venv.render(mode=mode)
def get_images(self):
return self.venv.get_images()
def __getattr__(self, name):
if name.startswith('_'):
raise AttributeError("attempted to get missing private attribute '{}'".format(name))
return getattr(self.venv, name)
class VecEnvObservationWrapper(VecEnvWrapper):
@abstractmethod
def process(self, obs):
pass
def reset(self):
obs = self.venv.reset()
return self.process(obs)
def step_wait(self):
obs, rews, dones, infos = self.venv.step_wait()
return self.process(obs), rews, dones, infos
class CloudpickleWrapper(object):
"""
Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)
"""
def __init__(self, x):
self.x = x
def __getstate__(self):
import cloudpickle
return cloudpickle.dumps(self.x)
def __setstate__(self, ob):
import pickle
self.x = pickle.loads(ob)
@contextlib.contextmanager
def clear_mpi_env_vars():
"""
from mpi4py import MPI will call MPI_Init by default. If the child process has MPI environment variables, MPI will think that the child process is an MPI process just like the parent and do bad things such as hang.
This context manager is a hacky way to clear those environment variables temporarily such as when we are starting multiprocessing
Processes.
"""
removed_environment = {}
for k, v in list(os.environ.items()):
for prefix in ['OMPI_', 'PMI_']:
if k.startswith(prefix):
removed_environment[k] = v
del os.environ[k]
try:
yield
finally:
os.environ.update(removed_environment)
================================================
FILE: examples/Social_Cognition/FOToM/evaluate.py
================================================
import argparse
import torch
import time
import imageio
import numpy as np
from pathlib import Path
from torch.autograd import Variable
from utils.make_env import make_env
from algorithms.tom11 import ToM_decision11
from algorithms.maddpg import MADDPG
import matplotlib.pyplot as plt
from tqdm import tqdm
from utils.env_wrappers import SubprocVecEnv, DummyVecEnv
def display_frames_as_gif(frames):
patch = plt.imshow(frames[1])
plt.axis('off')
plt.savefig('./images/comm2', bbox_inches='tight')
def make_parallel_env(env_id, n_rollout_threads, discrete_action, num_good_agents, num_adversaries):
def get_env_fn(rank):
def init_env():
env = make_env(env_id, num_good_agents=num_good_agents, num_adversaries=num_adversaries, discrete_action=discrete_action)
# env.seed(seed + rank * 1000)
# np.random.seed(seed + rank * 1000)
return env
return init_env
if n_rollout_threads == 1:
return DummyVecEnv([get_env_fn(0)])
else:
return SubprocVecEnv([get_env_fn(i) for i in range(n_rollout_threads)])
def run(config):
rew_ep = []
for i in range(config.num):
for run_num in config.run_num:
pbar = tqdm(config.n_episodes)
model_path = (Path('./models') / config.env_id / config.model_name /
('run%i' % (run_num)))
if config.incremental is not None:
model_path = model_path / 'incremental' / ('model_ep%i.pt' %
config.incremental)
else:
model_path = model_path / 'model.pt'
# if config.save_gifs:
# gif_path = model_path.parent / 'gifs'
# gif_path.mkdir(exist_ok=True)
if config.alg == 'ToM1':
maddpg = ToM_decision11.init_from_save(model_path)
elif config.alg == 'ToM_SB01' or config.alg== 'ToM_SA01':
maddpg = ToM_decision01.init_from_save(model_path)#.eval()
elif config.alg == 'ToM_SBN1' or config.alg== 'ToM_SAN1':
maddpg = ToM_decisionN1.init_from_save(model_path)#.eval()
elif config.alg == 'MADDPG':
maddpg = MADDPG.init_from_save(model_path)
# env = make_env(config.env_id, num_good_agents=config.num_good_agents,
# num_adversaries=config.num_adversaries, discrete_action=maddpg.discrete_action)
env = make_parallel_env(config.env_id, config.n_rollout_threads,
config.discrete_action, config.num_good_agents, config.num_adversaries)
maddpg.prep_rollouts(device='cpu')
ifi = 1 / config.fps # inter-frame interval
for ep_i in range(0, config.n_episodes, config.n_rollout_threads):
rew = np.zeros((config.n_rollout_threads, config.num_good_agents + config.num_adversaries))
torch_agent_actions = [torch.zeros((config.n_rollout_threads, 5))
for i in range(maddpg.nagents)]
# print("Episode %i of %i" % (ep_i + 1, config.n_episodes))
obs = env.reset()
for t_i in range(config.episode_length):
# calc_start = time.time()
# rearrange observations to be per agent, and convert to torch Variable
torch_obs = [Variable(torch.Tensor(np.vstack(obs[:, i])),
requires_grad=False)
for i in range(maddpg.nagents)]
# get actions as torch Variables
# t1 = time.time()
if config.alg == 'MADDPG':
torch_actions = maddpg.step(torch_obs, explore=False)
else:
torch_actions = maddpg.step(torch_obs, torch_agent_actions, explore=False)
actions = [ac.data.cpu().numpy() for ac in torch_actions]
actions = [[ac[i] for ac in actions] for i in range(config.n_rollout_threads)]
obs, rewards, dones, infos = env.step(actions)
rew += rewards
rew_ep.append(rew)
pbar.update(config.n_rollout_threads)
pbar.close()
rew_ep = np.concatenate(rew_ep, 0)
rew_ep_agent = rew_ep.mean(0)
std_ep_agent = rew_ep.std(0)
print('mean:', rew_ep_agent, 'std:', std_ep_agent)
rew_ep_good = rew_ep[:, -config.num_good_agents:].sum(1).mean()
rew_ep_adv = rew_ep[:, :config.num_adversaries].sum(1).mean()
std_ep_good = rew_ep[:, -config.num_good_agents:].sum(1).std()
std_ep_adv = rew_ep[:, :config.num_adversaries].sum(1).std()
print('good:', rew_ep_good, 'std:', std_ep_good)
print('adv:', rew_ep_adv, 'std:', std_ep_adv)
rew_ep_all = rew_ep.sum(1).mean()
std_ep_all = rew_ep.sum(1).std()
print('all:', rew_ep_all, 'std:', std_ep_all)
env.close()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--alg",
default="ToM_SAN1", type=str,
choices=['MADDPG', 'ToM_SB01', 'ToM_SA01', 'ToM_SBN1', 'ToM_SAN1',
'ToM1'])
parser.add_argument("--env_id", default='simple_adversary', type=str, help="Name of environment",
choices=['simple_tag', 'simple_world_comm', 'hetero_spread',
'simple_adversary', 'simple_spread'
])
parser.add_argument("--num_good_agents", default=None, type=int,
help="Num of Agent")
parser.add_argument("--num_adversaries", default=None, type=int,
help="Num of Adversary")
parser.add_argument("--model_name", default='4VS2_tomaAN1', type=str,
help="Name of model") #ma2c, maddpg, maddpg_rnn
parser.add_argument("--run_num", default=2, type=int, nargs='+')
parser.add_argument("--save_gifs", default=True, action="store_true",
help="Saves gif of each episode into model directory")
parser.add_argument("--incremental", default= None, type=int,
help="Load incremental policy from given episode " +
"rather than final policy")
parser.add_argument("--n_episodes", default=1000, type=int)
parser.add_argument("--episode_length", default=25, type=int)
parser.add_argument("--fps", default=30, type=int)
parser.add_argument("--eval",
default=True, type=bool,
)
parser.add_argument("--num", default=3, type=int )
parser.add_argument("--n_rollout_threads", default=20, type=int)
parser.add_argument("--discrete_action",
# default=False, type=bool,
action='store_true')
config = parser.parse_args()
if 'ToM_SB' in config.alg:
config.agent_alg = 'without_tom'
config.adversary_alg = 'with_tom'
elif 'ToM_SA' in config.alg:
config.agent_alg = 'with_tom'
config.adversary_alg = 'without_tom'
elif config.alg == 'ToM1':
config.agent_alg = 'with_tom'
config.adversary_alg = 'with_tom'
else:
config.agent_alg = config.alg
config.adversary_alg = config.alg
if config.num_good_agents == None and config.num_adversaries == None:
if config.env_id == 'simple_adversary':
config.num_good_agents = 2
config.num_adversaries = 1
elif config.env_id == 'simple_tag':
config.num_good_agents = 2
config.num_adversaries = 2
elif config.env_id == 'simple_world_comm':
config.num_good_agents = 2
config.num_adversaries = 4
elif config.env_id == 'simple_spread':
config.num_good_agents = 3
config.num_adversaries = 0
run(config)
================================================
FILE: examples/Social_Cognition/FOToM/main.py
================================================
import argparse
import torch
import time
import os
import numpy as np
from gym.spaces import Box, Discrete, MultiDiscrete
from pathlib import Path
from torch.autograd import Variable
from tensorboardX import SummaryWriter
from utils.make_env import make_env
from utils.buffer import ReplayBuffer, ReplayBuffer_pre
from utils.env_wrappers import SubprocVecEnv, DummyVecEnv
from algorithms.tomN1 import ToM_decisionN1
from algorithms.tom01 import ToM_decision01
from algorithms.tom11 import ToM_decision11
from algorithms.maddpg import MADDPG
from tqdm import tqdm
from thop import profile
from thop import clever_format
def get_common_args():
parser = argparse.ArgumentParser()
parser.add_argument("--env_id", default='simple_tag', type=str,
choices=['simple_tag', 'simple_adversary', 'hetero_spread', 'simple_world_comm',
'simple_spread'],
help="Name of environment")
parser.add_argument("--num_good_agents", default=None, type=int,
help="Num of Agent")
parser.add_argument("--num_adversaries", default=None, type=int,
help="Num of Adversary")
parser.add_argument("--model_name", default='ann', type=str,
help="Name of directory to store " +
"model/training contents") #ToM_SA
parser.add_argument("--seed",
default=1, type=int,
help="Random seed")
parser.add_argument("--cuda_num",
default=5, type=int,
help="device")
parser.add_argument("--output_style",
default='sum', type=str,
choices=['sum', 'voltage'])
parser.add_argument("--n_rollout_threads", default=20, type=int)
parser.add_argument("--n_training_threads", default=6, type=int)
parser.add_argument("--buffer_length", default=int(1e6), type=int) #1e6
parser.add_argument("--n_episodes", default=25000, type=int)#25000
parser.add_argument("--episode_length", default=25, type=int)
parser.add_argument("--steps_per_update", default=100, type=int)
parser.add_argument("--load_para", type=bool, default=False)
parser.add_argument("--batch_size",
default=1024, type=int,#4
help="Batch size for model training")
parser.add_argument("--n_exploration_eps", default=25000, type=int)
parser.add_argument("--init_noise_scale", default=0.3, type=float)
parser.add_argument("--final_noise_scale", default=0.0, type=float)
parser.add_argument("--save_interval", default=1000, type=int)#1000
parser.add_argument("--hidden_dim", default=64, type=int)
parser.add_argument("--lr", default=1e-3, type=float) #0.01 #1e-3
parser.add_argument("--tau", default=0.01, type=float)
parser.add_argument("--alg",
default="ToM1", type=str,
choices=['MADDPG',
'ToM1', 'ToM_SB01', 'ToM_SA01', 'ToM_SBN1', 'ToM_SAN1'])
parser.add_argument("--discrete_action",
# default=False, type=bool,
action='store_true')
args = parser.parse_args()
parser.add_argument('--device', type=str, default='cuda:{}'.format(args.cuda_num), help='whether to use the GPU') #'cuda:1'
parser = parser.parse_args()
return parser
USE_CUDA = torch.cuda.is_available()
def make_parallel_env(env_id, n_rollout_threads, seed, discrete_action, num_good_agents, num_adversaries):
def get_env_fn(rank):
def init_env():
env = make_env(env_id, num_good_agents=num_good_agents, num_adversaries=num_adversaries, discrete_action=discrete_action)
env.seed(seed + rank * 1000)
np.random.seed(seed + rank * 1000)
return env
return init_env
if n_rollout_threads == 1:
return DummyVecEnv([get_env_fn(0)])
else:
return SubprocVecEnv([get_env_fn(i) for i in range(n_rollout_threads)])
def run(config):
pbar = tqdm(config.n_episodes)
model_dir = Path('./models') / config.env_id / config.model_name
if not model_dir.exists():
curr_run = 'run1'
else:
exst_run_nums = [int(str(folder.name).split('run')[1]) for folder in
model_dir.iterdir() if
str(folder.name).startswith('run')]
if len(exst_run_nums) == 0:
curr_run = 'run1'
else:
curr_run = 'run%i' % (max(exst_run_nums) + 1)
run_dir = model_dir / curr_run
log_dir = run_dir / 'logs'
os.makedirs(log_dir)
logger = SummaryWriter(str(log_dir))
save_path = log_dir
print(os.path.exists(save_path))
argsDict = config.__dict__
with open(save_path / 'args_{}'.format(max(exst_run_nums) + 1), 'w') as f:
f.writelines('------------------ start ------------------' + '\n')
for eachArg, value in argsDict.items():
f.writelines(eachArg + ' : ' + str(value) + '\n')
f.writelines('------------------- end -------------------')
torch.manual_seed(config.seed)
np.random.seed(config.seed)
if not USE_CUDA:
torch.set_num_threads(config.n_training_threads)
env = make_parallel_env(config.env_id, config.n_rollout_threads, config.seed,
config.discrete_action, config.num_good_agents, config.num_adversaries)
if config.alg == 'ToM1':
print('_______Alg: ' + config.alg + '_______')
if config.load_para == False:
maddpg = ToM_decision11.init_from_env(env, config, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
else:
# model_path = (Path('./models') / config.env_id / 'self1' / #'self1' tag, maddpg_self_11 adv
# ('run%i' % 1)) / 'model.pt'
model_path = (Path('./models') / config.env_id / 'rs1' / #'self1' tag, maddpg_self_11 adv
('run%i' % 1)) / 'model.pt'
maddpg = ToM_decision11.init_from_save(model_path)
elif config.alg == 'ToM_SB01' or config.alg== 'ToM_SA01':
print('_______Alg: ' + config.alg + '_______')
if config.load_para == False:
maddpg = ToM_decision01.init_from_env(env, config, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
else:
model_path = (Path('./models') / config.env_id / 'am' / #'self1' tag, maddpg_self_11 adv
('run%i' % 3)) / 'model.pt'
maddpg = ToM_decision01.init_from_save(model_path)
elif config.alg == 'ToM_SBN1' or config.alg== 'ToM_SAN1':
print('_______Alg: ' + config.alg + '_______')
if config.load_para == False:
maddpg = ToM_decisionN1.init_from_env(env, config, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
else:
model_path = (Path('./models') / config.env_id / 'am' / #'self1' tag, maddpg_self_11 adv
('run%i' % 3)) / 'model.pt'
maddpg = ToM_decisionN1.init_from_save(model_path)
elif config.alg == 'MADDPG':
print('_______Alg: ' + config.alg + '_______')
if config.load_para == False:
maddpg = MADDPG.init_from_env(env, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
device=config.device)
if config.alg == 'ToM1' or config.alg == 'ToM_SB01' or config.alg == 'ToM_SA01' \
or config.alg == 'ToM_SBN1' or config.alg == 'ToM_SAN1':
replay_buffer = ReplayBuffer_pre(config.buffer_length, maddpg.nagents,
[obsp.shape[0] for obsp in env.observation_space],
[acsp.n if isinstance(acsp, Discrete) else sum(acsp.high - acsp.low + 1)
for acsp in env.action_space],
device=config.device)
else:
replay_buffer = ReplayBuffer(config.buffer_length, maddpg.nagents,
[obsp.shape[0] for obsp in env.observation_space],
[acsp.n if isinstance(acsp, Discrete) else sum(acsp.high - acsp.low + 1)
for acsp in env.action_space],
device=config.device)
t = 0
total_reward = []
for agent_i in range(maddpg.nagents):
total_reward.append([])
for ep_i in range(0, config.n_episodes, config.n_rollout_threads):
# print("Episodes %i-%i of %i" % (ep_i + 1,
# ep_i + 1 + config.n_rollout_threads,
# config.n_episodes))
obs = env.reset()
# obs.shape = (n_rollout_threads, nagent)(nobs), nobs differs per agent so not tensor
maddpg.prep_rollouts(device='cpu')
torch_agent_actions = [torch.zeros((config.n_rollout_threads, 5)) for i in range(maddpg.nagents)]
explr_pct_remaining = max(0, config.n_exploration_eps - ep_i) / config.n_exploration_eps
maddpg.scale_noise(config.final_noise_scale + (config.init_noise_scale - config.final_noise_scale) * explr_pct_remaining)
if config.alg == 'rnnD' or config.alg == 'rnn':
maddpg._init_agent(config.n_rollout_threads)
maddpg.reset_noise()
obs_ep = []
agent_actions_ep = []
rewards_ep = []
next_obs_ep = []
dones_ep = []
for et_i in range(config.episode_length):
torch_agent_actions_pre = torch_agent_actions
torch_agent_actions_pre = [ac.data.numpy() for ac in torch_agent_actions_pre]
# rearrange observations to be per agent, and convert to torch Variable
torch_obs = [Variable(torch.Tensor(np.vstack(obs[:, i])),
requires_grad=False)
for i in range(maddpg.nagents)] #
# get actions as torch Variables
# t1 = time.time()
if config.alg == 'ToM1' or config.alg == 'ToM_SB01' or config.alg == 'ToM_SA01' \
or config.alg == 'ToM_SBN1' or config.alg == 'ToM_SAN1':
torch_agent_actions = maddpg.step(torch_obs, torch_agent_actions, explore=True)
else:
torch_agent_actions = maddpg.step(torch_obs, explore=True)
# t2 = time.time()
# print('maddpg.step time:', t2-t1)
agent_actions = [ac.data.numpy() for ac in torch_agent_actions] #
# rearrange actions to be per environment
actions = [[ac[i] for ac in agent_actions] for i in range(config.n_rollout_threads)]
# t3 = time.time()
next_obs, rewards, dones, infos = env.step(actions)
# t4 = time.time()
# print('env.step')
obs_ep.append(obs) #episode_id,process, n_agents, dim
agent_actions_ep.append(actions) #episode_id, n_agents, process, dim
rewards_ep.append(rewards) #episode_id,process, n_agents,
next_obs_ep.append(next_obs) #episode_id,process, n_agents, dim
dones_ep.append(dones) #episode_id,process, n_agents,
if config.alg == 'ToM1' or config.alg == 'ToM_SB01' or config.alg == 'ToM_SA01' \
or config.alg == 'ToM_SBN1' or config.alg == 'ToM_SAN1':
replay_buffer.push(torch_agent_actions_pre, obs, agent_actions, rewards, next_obs, dones)
else:
replay_buffer.push(obs, agent_actions, rewards, next_obs, dones)
obs = next_obs
t += config.n_rollout_threads
if (len(replay_buffer) >= config.batch_size and
(t % config.steps_per_update) < config.n_rollout_threads):
if USE_CUDA:
maddpg.prep_training(device='gpu')
else:
maddpg.prep_training(device='cpu')
if config.n_episodes >300:
rollout = 2
else:
rollout = config.n_rollout_threads
for u_i in range(rollout):
sample = replay_buffer.sample(config.batch_size,
to_gpu=USE_CUDA)
if '1' in config.alg:
maddpg.tom0_output(sample)
maddpg.tom1_infer_other(sample)
for a_i in range(maddpg.nagents):
# t1 = time.time()
maddpg.update(sample, a_i, logger=logger)
# t2 = time.time()
# print('trian_time:', t2-t1, u_i, a_i)
maddpg.update_all_targets()
maddpg.prep_rollouts(device='cpu')
if config.alg == 'rnnD' or config.alg == 'rnn':
maddpg._init_agent(config.n_rollout_threads)
ep_rews = replay_buffer.get_average_rewards(
config.episode_length * config.n_rollout_threads)
for a_i, a_ep_rew in enumerate(ep_rews):
logger.add_scalar('agent%i/mean_episode_rewards' % a_i,
a_ep_rew,
ep_i)
logger.add_scalar('agent_mean/mean_episode_rewards',
np.mean(ep_rews),
ep_i)
if ep_i % config.save_interval < config.n_rollout_threads:
os.makedirs(run_dir / 'incremental', exist_ok=True)
maddpg.save(run_dir / 'incremental' / ('model_ep%i.pt' % (ep_i + 1)))
maddpg.save(run_dir / 'model.pt')
pbar.update(config.n_rollout_threads)
pbar.close()
maddpg.save(run_dir / 'model.pt')
env.close()
logger.export_scalars_to_json(str(log_dir / 'summary.json'))
logger.close()
for a_i, reward in enumerate(total_reward):
reward_dir = str(log_dir) + '/agent{}/mean_episode_rewards'.format(a_i) + '/episode_rewards_{}'.format(config.cuda_num)
os.makedirs(reward_dir)
np.save(reward_dir, reward)
if __name__ == '__main__':
config = get_common_args()
# config.env_id = 'simple_world_comm'#'simple_adversary'#'simple_tag'
# # config.model_name = 'ma2c'
if 'ToM_SB' in config.alg:
config.agent_alg = 'without_tom'
config.adversary_alg = 'with_tom'
elif 'ToM_SA' in config.alg:
config.agent_alg = 'with_tom'
config.adversary_alg = 'without_tom'
elif config.alg == 'ToM1':
config.agent_alg = 'with_tom'
config.adversary_alg = 'with_tom'
else:
config.agent_alg = config.alg
config.adversary_alg = config.alg
# debug
if config.num_good_agents == None and config.num_adversaries == None:
if config.env_id == 'simple_adversary':
config.num_good_agents = 2
config.num_adversaries = 1
elif config.env_id == 'simple_tag':
config.num_good_agents = 1
config.num_adversaries = 3
elif config.env_id == 'simple_world_comm':
config.num_good_agents = 2
config.num_adversaries = 4
elif config.env_id == 'hetero_spread':
config.num_good_agents = 4
config.num_adversaries = 0
elif config.env_id == 'simple_spread': #coop
config.num_good_agents = 3
config.num_adversaries = 0
run(config)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/__init__.py
================================================
from gym.envs.registration import register
# Multiagent envs
# ----------------------------------------
register(
id='MultiagentSimple-v0',
entry_point='multiagent.envs:SimpleEnv',
# FIXME(cathywu) currently has to be exactly max_path_length parameters in
# rllab run script
max_episode_steps=100,
)
register(
id='MultiagentSimpleSpeakerListener-v0',
entry_point='multiagent.envs:SimpleSpeakerListenerEnv',
max_episode_steps=100,
)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/core.py
================================================
import numpy as np
# physical/external base state of all entites
class EntityState(object):
def __init__(self):
# physical position
self.p_pos = None
# physical velocity
self.p_vel = None
# state of agents (including communication and internal/mental state)
class AgentState(EntityState):
def __init__(self):
super(AgentState, self).__init__()
# communication utterance
self.c = None
# action of the agent
class Action(object):
def __init__(self):
# physical action
self.u = None
# communication action
self.c = None
# properties and state of physical world entity
class Entity(object):
def __init__(self):
# name
self.name = ''
# properties:
self.size = 0.050
# entity can move / be pushed
self.movable = False
# entity collides with others
self.collide = True
# material density (affects mass)
self.density = 25.0
# color
self.color = None
# max speed and accel
self.max_speed = None
self.accel = None
# state
self.state = EntityState()
# mass
self.initial_mass = 1.0
@property
def mass(self):
return self.initial_mass
# properties of landmark entities
class Landmark(Entity):
def __init__(self):
super(Landmark, self).__init__()
# properties of agent entities
class Agent(Entity):
def __init__(self):
super(Agent, self).__init__()
# agents are movable by default
self.movable = True
# cannot send communication signals
self.silent = False
# cannot observe the world
self.blind = False
# physical motor noise amount
self.u_noise = None
# communication noise amount
self.c_noise = None
# control range
self.u_range = 1.0
# state
self.state = AgentState()
# action
self.action = Action()
# script behavior to execute
self.action_callback = None
# multi-agent world
class World(object):
def __init__(self):
# list of agents and entities (can change at execution-time!)
self.agents = []
self.landmarks = []
# communication channel dimensionality
self.dim_c = 0
# position dimensionality
self.dim_p = 2
# color dimensionality
self.dim_color = 3
# simulation timestep
self.dt = 0.1
# physical damping
self.damping = 0.25
# contact response parameters
self.contact_force = 1e+2
self.contact_margin = 1e-3
# return all entities in the world
@property
def entities(self):
return self.agents + self.landmarks
# return all agents controllable by external policies
@property
def policy_agents(self):
return [agent for agent in self.agents if agent.action_callback is None]
# return all agents controlled by world scripts
@property
def scripted_agents(self):
return [agent for agent in self.agents if agent.action_callback is not None]
# update state of the world
def step(self):
# set actions for scripted agents
for agent in self.scripted_agents:
agent.action = agent.action_callback(agent, self)
# gather forces applied to entities
p_force = [None] * len(self.entities)
# apply agent physical controls
p_force = self.apply_action_force(p_force)
# apply environment forces
p_force = self.apply_environment_force(p_force)
# integrate physical state
self.integrate_state(p_force)
# update agent state
for agent in self.agents:
self.update_agent_state(agent)
# gather agent action forces
def apply_action_force(self, p_force):
# set applied forces
for i,agent in enumerate(self.agents):
if agent.movable:
noise = np.random.randn(*agent.action.u.shape) * agent.u_noise if agent.u_noise else 0.0
p_force[i] = agent.action.u + noise
return p_force
# gather physical forces acting on entities
def apply_environment_force(self, p_force):
# simple (but inefficient) collision response
for a,entity_a in enumerate(self.entities):
for b,entity_b in enumerate(self.entities):
if(b <= a): continue
[f_a, f_b] = self.get_collision_force(entity_a, entity_b)
if(f_a is not None):
if(p_force[a] is None): p_force[a] = 0.0
p_force[a] = f_a + p_force[a]
if(f_b is not None):
if(p_force[b] is None): p_force[b] = 0.0
p_force[b] = f_b + p_force[b]
return p_force
# integrate physical state
def integrate_state(self, p_force):
for i,entity in enumerate(self.entities):
if not entity.movable: continue
entity.state.p_vel = entity.state.p_vel * (1 - self.damping)
if (p_force[i] is not None):
entity.state.p_vel += (p_force[i] / entity.mass) * self.dt
if entity.max_speed is not None:
speed = np.sqrt(np.square(entity.state.p_vel[0]) + np.square(entity.state.p_vel[1]))
if speed > entity.max_speed:
entity.state.p_vel = entity.state.p_vel / np.sqrt(np.square(entity.state.p_vel[0]) +
np.square(entity.state.p_vel[1])) * entity.max_speed
entity.state.p_pos += entity.state.p_vel * self.dt
def update_agent_state(self, agent):
# set communication state (directly for now)
if agent.silent:
agent.state.c = np.zeros(self.dim_c)
else:
noise = np.random.randn(*agent.action.c.shape) * agent.c_noise if agent.c_noise else 0.0
agent.state.c = agent.action.c + noise
# get collision forces for any contact between two entities
def get_collision_force(self, entity_a, entity_b):
if (not entity_a.collide) or (not entity_b.collide):
return [None, None] # not a collider
if (entity_a is entity_b):
return [None, None] # don't collide against itself
# compute actual distance between entities
delta_pos = entity_a.state.p_pos - entity_b.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
# minimum allowable distance
dist_min = entity_a.size + entity_b.size
# softmax penetration
k = self.contact_margin
penetration = np.logaddexp(0, -(dist - dist_min)/k)*k
force = self.contact_force * delta_pos / dist * penetration
force_a = +force if entity_a.movable else None
force_b = -force if entity_b.movable else None
return [force_a, force_b]
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/environment.py
================================================
import gym
from gym import spaces
from gym.envs.registration import EnvSpec
import numpy as np
from multiagent.multi_discrete import MultiDiscrete
# environment for all agents in the multiagent world
# currently code assumes that no agents will be created/destroyed at runtime!
class MultiAgentEnv(gym.Env):
metadata = {
'render.modes' : ['human', 'rgb_array']
}
def __init__(self, world, reset_callback=None, reward_callback=None,
observation_callback=None, info_callback=None,
done_callback=None, shared_viewer=True):
self.world = world
self.agents = self.world.policy_agents
# set required vectorized gym env property
self.n = len(world.policy_agents)
# scenario callbacks
self.reset_callback = reset_callback
self.reward_callback = reward_callback
self.observation_callback = observation_callback
self.info_callback = info_callback
self.done_callback = done_callback
# environment parameters
self.discrete_action_space = True
# if true, action is a number 0...N, otherwise action is a one-hot N-dimensional vector
self.discrete_action_input = False
# if true, even the action is continuous, action will be performed discretely
self.force_discrete_action = world.discrete_action if hasattr(world, 'discrete_action') else False
# if true, every agent has the same reward
self.shared_reward = world.collaborative if hasattr(world, 'collaborative') else False
self.time = 0
# configure spaces
self.action_space = []
self.observation_space = []
for agent in self.agents:
total_action_space = []
# physical action space
if self.discrete_action_space:
u_action_space = spaces.Discrete(world.dim_p * 2 + 1)
else:
u_action_space = spaces.Box(low=-agent.u_range, high=+agent.u_range, shape=(world.dim_p,), dtype=np.float32)
if agent.movable:
total_action_space.append(u_action_space)
# communication action space
if self.discrete_action_space:
c_action_space = spaces.Discrete(world.dim_c)
else:
c_action_space = spaces.Box(low=0.0, high=1.0, shape=(world.dim_c,), dtype=np.float32)
if not agent.silent:
total_action_space.append(c_action_space)
# total action space
if len(total_action_space) > 1:
# all action spaces are discrete, so simplify to MultiDiscrete action space
if all([isinstance(act_space, spaces.Discrete) for act_space in total_action_space]):
act_space = MultiDiscrete([[0, act_space.n - 1] for act_space in total_action_space])
else:
act_space = spaces.Tuple(total_action_space)
self.action_space.append(act_space)
else:
self.action_space.append(total_action_space[0])
# observation space
obs_dim = len(observation_callback(agent, self.world))
self.observation_space.append(spaces.Box(low=-np.inf, high=+np.inf, shape=(obs_dim,), dtype=np.float32))
agent.action.c = np.zeros(self.world.dim_c)
# rendering
self.shared_viewer = shared_viewer
if self.shared_viewer:
self.viewers = [None]
else:
self.viewers = [None] * self.n
self._reset_render()
def step(self, action_n):
obs_n = []
reward_n = []
done_n = []
info_n = {'n': []}
self.agents = self.world.policy_agents
# set action for each agent
for i, agent in enumerate(self.agents):
self._set_action(action_n[i], agent, self.action_space[i])
# advance world state
self.world.step()
# record observation for each agent
for agent in self.agents:
obs_n.append(self._get_obs(agent))
reward_n.append(self._get_reward(agent))
done_n.append(self._get_done(agent))
info_n['n'].append(self._get_info(agent))
# all agents get total reward in cooperative case
reward = np.sum(reward_n)
if self.shared_reward:
reward_n = [reward] * self.n
return obs_n, reward_n, done_n, info_n
def reset(self):
# reset world
self.reset_callback(self.world)
# reset renderer
self._reset_render()
# record observations for each agent
obs_n = []
self.agents = self.world.policy_agents
for agent in self.agents:
obs_n.append(self._get_obs(agent))
return obs_n
# get info used for benchmarking
def _get_info(self, agent):
if self.info_callback is None:
return {}
return self.info_callback(agent, self.world)
# get observation for a particular agent
def _get_obs(self, agent):
if self.observation_callback is None:
return np.zeros(0)
return self.observation_callback(agent, self.world)
# get dones for a particular agent
# unused right now -- agents are allowed to go beyond the viewing screen
def _get_done(self, agent):
if self.done_callback is None:
return False
return self.done_callback(agent, self.world)
# get reward for a particular agent
def _get_reward(self, agent):
if self.reward_callback is None:
return 0.0
return self.reward_callback(agent, self.world)
# set env action for a particular agent
def _set_action(self, action, agent, action_space, time=None):
agent.action.u = np.zeros(self.world.dim_p)
agent.action.c = np.zeros(self.world.dim_c)
# process action
if isinstance(action_space, MultiDiscrete):
act = []
size = action_space.high - action_space.low + 1
index = 0
for s in size:
act.append(action[index:(index+s)])
index += s
action = act
else:
action = [action]
if agent.movable:
# physical action
if self.discrete_action_input:
agent.action.u = np.zeros(self.world.dim_p)
# process discrete action
if action[0] == 1: agent.action.u[0] = -1.0
if action[0] == 2: agent.action.u[0] = +1.0
if action[0] == 3: agent.action.u[1] = -1.0
if action[0] == 4: agent.action.u[1] = +1.0
else:
if self.force_discrete_action:
d = np.argmax(action[0])
action[0][:] = 0.0
action[0][d] = 1.0
if self.discrete_action_space:
agent.action.u[0] += action[0][1] - action[0][2]
agent.action.u[1] += action[0][3] - action[0][4]
else:
agent.action.u = action[0]
sensitivity = 5.0
if agent.accel is not None:
sensitivity = agent.accel
agent.action.u *= sensitivity
action = action[1:]
if not agent.silent:
# communication action
if self.discrete_action_input:
agent.action.c = np.zeros(self.world.dim_c)
agent.action.c[action[0]] = 1.0
else:
agent.action.c = action[0]
action = action[1:]
# make sure we used all elements of action
assert len(action) == 0
# reset rendering assets
def _reset_render(self):
self.render_geoms = None
self.render_geoms_xform = None
# render environment
def render(self, mode='human'):
if mode == 'human':
alphabet = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
message = ''
for agent in self.world.agents:
comm = []
for other in self.world.agents:
if other is agent: continue
if np.all(other.state.c == 0):
word = '_'
else:
word = alphabet[np.argmax(other.state.c)]
message += (other.name + ' to ' + agent.name + ': ' + word + ' ')
print(message)
for i in range(len(self.viewers)):
# create viewers (if necessary)
if self.viewers[i] is None:
# import rendering only if we need it (and don't import for headless machines)
#from gym.envs.classic_control import rendering
from multiagent import rendering
self.viewers[i] = rendering.Viewer(700,700)
# create rendering geometry
if self.render_geoms is None:
# import rendering only if we need it (and don't import for headless machines)
#from gym.envs.classic_control import rendering
from multiagent import rendering
self.render_geoms = []
self.render_geoms_xform = []
for entity in self.world.entities:
geom = rendering.make_circle(entity.size)
xform = rendering.Transform()
if 'agent' in entity.name:
geom.set_color(*entity.color, alpha=0.5)
else:
geom.set_color(*entity.color)
geom.add_attr(xform)
self.render_geoms.append(geom)
self.render_geoms_xform.append(xform)
# add geoms to viewer
for viewer in self.viewers:
viewer.geoms = []
for geom in self.render_geoms:
viewer.add_geom(geom)
results = []
for i in range(len(self.viewers)):
from multiagent import rendering
# update bounds to center around agent
cam_range = 1
if self.shared_viewer:
pos = np.zeros(self.world.dim_p)
else:
pos = self.agents[i].state.p_pos
self.viewers[i].set_bounds(pos[0]-cam_range,pos[0]+cam_range,pos[1]-cam_range,pos[1]+cam_range)
# update geometry positions
for e, entity in enumerate(self.world.entities):
self.render_geoms_xform[e].set_translation(*entity.state.p_pos)
# render to display or array
results.append(self.viewers[i].render(return_rgb_array = mode=='rgb_array'))
return results
# create receptor field locations in local coordinate frame
def _make_receptor_locations(self, agent):
receptor_type = 'polar'
range_min = 0.05 * 2.0
range_max = 1.00
dx = []
# circular receptive field
if receptor_type == 'polar':
for angle in np.linspace(-np.pi, +np.pi, 8, endpoint=False):
for distance in np.linspace(range_min, range_max, 3):
dx.append(distance * np.array([np.cos(angle), np.sin(angle)]))
# add origin
dx.append(np.array([0.0, 0.0]))
# grid receptive field
if receptor_type == 'grid':
for x in np.linspace(-range_max, +range_max, 5):
for y in np.linspace(-range_max, +range_max, 5):
dx.append(np.array([x,y]))
return dx
# vectorized wrapper for a batch of multi-agent environments
# assumes all environments have the same observation and action space
class BatchMultiAgentEnv(gym.Env):
metadata = {
'runtime.vectorized': True,
'render.modes' : ['human', 'rgb_array']
}
def __init__(self, env_batch):
self.env_batch = env_batch
@property
def n(self):
return np.sum([env.n for env in self.env_batch])
@property
def action_space(self):
return self.env_batch[0].action_space
@property
def observation_space(self):
return self.env_batch[0].observation_space
def step(self, action_n, time):
obs_n = []
reward_n = []
done_n = []
info_n = {'n': []}
i = 0
for env in self.env_batch:
obs, reward, done, _ = env.step(action_n[i:(i+env.n)], time)
i += env.n
obs_n += obs
# reward = [r / len(self.env_batch) for r in reward]
reward_n += reward
done_n += done
return obs_n, reward_n, done_n, info_n
def reset(self):
obs_n = []
for env in self.env_batch:
obs_n += env.reset()
return obs_n
# render environment
def render(self, mode='human', close=True):
results_n = []
for env in self.env_batch:
results_n += env.render(mode, close)
return results_n
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/multi_discrete.py
================================================
# An old version of OpenAI Gym's multi_discrete.py. (Was getting affected by Gym updates)
# (https://github.com/openai/gym/blob/1fb81d4e3fb780ccf77fec731287ba07da35eb84/gym/spaces/multi_discrete.py)
import numpy as np
import gym
# from gym.spaces import prng
class MultiDiscrete(gym.Space):
"""
- The multi-discrete action space consists of a series of discrete action spaces with different parameters
- It can be adapted to both a Discrete action space or a continuous (Box) action space
- It is useful to represent game controllers or keyboards where each key can be represented as a discrete action space
- It is parametrized by passing an array of arrays containing [min, max] for each discrete action space
where the discrete action space can take any integers from `min` to `max` (both inclusive)
Note: A value of 0 always need to represent the NOOP action.
e.g. Nintendo Game Controller
- Can be conceptualized as 3 discrete action spaces:
1) Arrow Keys: Discrete 5 - NOOP[0], UP[1], RIGHT[2], DOWN[3], LEFT[4] - params: min: 0, max: 4
2) Button A: Discrete 2 - NOOP[0], Pressed[1] - params: min: 0, max: 1
3) Button B: Discrete 2 - NOOP[0], Pressed[1] - params: min: 0, max: 1
- Can be initialized as
MultiDiscrete([ [0,4], [0,1], [0,1] ])
"""
def __init__(self, array_of_param_array):
self.low = np.array([x[0] for x in array_of_param_array])
self.high = np.array([x[1] for x in array_of_param_array])
self.num_discrete_space = self.low.shape[0]
def sample(self):
""" Returns a array with one sample from each discrete action space """
# For each row: round(random .* (max - min) + min, 0)
# random_array = prng.np_random.rand(self.num_discrete_space)
random_array = np.random.RandomState().rand(self.num_discrete_space)
return [int(x) for x in np.floor(np.multiply((self.high - self.low + 1.), random_array) + self.low)]
def contains(self, x):
return len(x) == self.num_discrete_space and (np.array(x) >= self.low).all() and (np.array(x) <= self.high).all()
@property
def shape(self):
return self.num_discrete_space
def __repr__(self):
return "MultiDiscrete" + str(self.num_discrete_space)
def __eq__(self, other):
return np.array_equal(self.low, other.low) and np.array_equal(self.high, other.high)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/policy.py
================================================
import numpy as np
from pyglet.window import key
# individual agent policy
class Policy(object):
def __init__(self):
pass
def action(self, obs):
raise NotImplementedError()
# interactive policy based on keyboard input
# hard-coded to deal only with movement, not communication
class InteractivePolicy(Policy):
def __init__(self, env, agent_index):
super(InteractivePolicy, self).__init__()
self.env = env
# hard-coded keyboard events
self.move = [False for i in range(4)]
self.comm = [False for i in range(env.world.dim_c)]
# register keyboard events with this environment's window
# env.viewers[agent_index].window.on_key_press = self.key_press
# env.viewers[agent_index].window.on_key_release = self.key_release
def action(self, obs):
# ignore observation and just act based on keyboard events
if self.env.discrete_action_input:
u = 0
if self.move[0]: u = 1
if self.move[1]: u = 2
if self.move[2]: u = 4
if self.move[3]: u = 3
else:
u = np.zeros(5) # 5-d because of no-move action
if self.move[0]: u[1] += 1.0
if self.move[1]: u[2] += 1.0
if self.move[3]: u[3] += 1.0
if self.move[2]: u[4] += 1.0
if True not in self.move:
u[0] += 1.0
return np.concatenate([u, np.zeros(self.env.world.dim_c)])
# keyboard event callbacks
def key_press(self, k, mod):
if k==key.LEFT: self.move[0] = True
if k==key.RIGHT: self.move[1] = True
if k==key.UP: self.move[2] = True
if k==key.DOWN: self.move[3] = True
def key_release(self, k, mod):
if k==key.LEFT: self.move[0] = False
if k==key.RIGHT: self.move[1] = False
if k==key.UP: self.move[2] = False
if k==key.DOWN: self.move[3] = False
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/rendering.py
================================================
"""
2D rendering framework
"""
from __future__ import division
import os
import six
import sys
if "Apple" in sys.version:
if 'DYLD_FALLBACK_LIBRARY_PATH' in os.environ:
os.environ['DYLD_FALLBACK_LIBRARY_PATH'] += ':/usr/lib'
# (JDS 2016/04/15): avoid bug on Anaconda 2.3.0 / Yosemite
# from gym.utils import reraise
from gym import error
import pyglet
from pyglet.gl import *
# try:
# import pyglet
# except ImportError as e:
# reraise(suffix="HINT: you can install pyglet directly via 'pip install pyglet'. But if you really just want to install all Gym dependencies and not have to think about it, 'pip install -e .[all]' or 'pip install gym[all]' will do it.")
# try:
# from pyglet.gl import *
# except ImportError as e:
# reraise(prefix="Error occured while running `from pyglet.gl import *`",suffix="HINT: make sure you have OpenGL install. On Ubuntu, you can run 'apt-get install python-opengl'. If you're running on a server, you may need a virtual frame buffer; something like this should work: 'xvfb-run -s \"-screen 0 1400x900x24\" python '")
import math
import numpy as np
RAD2DEG = 57.29577951308232
def get_display(spec):
"""Convert a display specification (such as :0) into an actual Display
object.
Pyglet only supports multiple Displays on Linux.
"""
if spec is None:
return None
elif isinstance(spec, six.string_types):
return pyglet.canvas.Display(spec)
else:
raise error.Error('Invalid display specification: {}. (Must be a string like :0 or None.)'.format(spec))
class Viewer(object):
def __init__(self, width, height, display=None):
display = get_display(display)
self.width = width
self.height = height
self.window = pyglet.window.Window(width=width, height=height, display=display)
self.window.on_close = self.window_closed_by_user
self.geoms = []
self.onetime_geoms = []
self.transform = Transform()
glEnable(GL_BLEND)
# glEnable(GL_MULTISAMPLE)
glEnable(GL_LINE_SMOOTH)
# glHint(GL_LINE_SMOOTH_HINT, GL_DONT_CARE)
glHint(GL_LINE_SMOOTH_HINT, GL_NICEST)
glLineWidth(2.0)
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA)
def close(self):
self.window.close()
def window_closed_by_user(self):
self.close()
def set_bounds(self, left, right, bottom, top):
assert right > left and top > bottom
scalex = self.width/(right-left)
scaley = self.height/(top-bottom)
self.transform = Transform(
translation=(-left*scalex, -bottom*scaley),
scale=(scalex, scaley))
def add_geom(self, geom):
self.geoms.append(geom)
def add_onetime(self, geom):
self.onetime_geoms.append(geom)
def render(self, return_rgb_array=False):
glClearColor(1,1,1,1)
self.window.clear()
self.window.switch_to()
self.window.dispatch_events()
self.transform.enable()
for geom in self.geoms:
geom.render()
for geom in self.onetime_geoms:
geom.render()
self.transform.disable()
arr = None
if return_rgb_array:
buffer = pyglet.image.get_buffer_manager().get_color_buffer()
image_data = buffer.get_image_data()
arr = np.fromstring(image_data._current_data, dtype=np.uint8, sep='')
# In https://github.com/openai/gym-http-api/issues/2, we
# discovered that someone using Xmonad on Arch was having
# a window of size 598 x 398, though a 600 x 400 window
# was requested. (Guess Xmonad was preserving a pixel for
# the boundary.) So we use the buffer height/width rather
# than the requested one.
arr = arr.reshape(buffer.height, buffer.width, 4)
arr = arr[::-1,:,0:3]
self.window.flip()
self.onetime_geoms = []
return arr
# Convenience
def draw_circle(self, radius=10, res=30, filled=True, **attrs):
geom = make_circle(radius=radius, res=res, filled=filled)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def draw_polygon(self, v, filled=True, **attrs):
geom = make_polygon(v=v, filled=filled)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def draw_polyline(self, v, **attrs):
geom = make_polyline(v=v)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def draw_line(self, start, end, **attrs):
geom = Line(start, end)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def get_array(self):
self.window.flip()
image_data = pyglet.image.get_buffer_manager().get_color_buffer().get_image_data()
self.window.flip()
arr = np.fromstring(image_data.data, dtype=np.uint8, sep='')
arr = arr.reshape(self.height, self.width, 4)
return arr[::-1,:,0:3]
def _add_attrs(geom, attrs):
if "color" in attrs:
geom.set_color(*attrs["color"])
if "linewidth" in attrs:
geom.set_linewidth(attrs["linewidth"])
class Geom(object):
def __init__(self):
self._color=Color((0, 0, 0, 1.0))
self.attrs = [self._color]
def render(self):
for attr in reversed(self.attrs):
attr.enable()
self.render1()
for attr in self.attrs:
attr.disable()
def render1(self):
raise NotImplementedError
def add_attr(self, attr):
self.attrs.append(attr)
def set_color(self, r, g, b, alpha=1):
self._color.vec4 = (r, g, b, alpha)
class Attr(object):
def enable(self):
raise NotImplementedError
def disable(self):
pass
class Transform(Attr):
def __init__(self, translation=(0.0, 0.0), rotation=0.0, scale=(1,1)):
self.set_translation(*translation)
self.set_rotation(rotation)
self.set_scale(*scale)
def enable(self):
glPushMatrix()
glTranslatef(self.translation[0], self.translation[1], 0) # translate to GL loc ppint
glRotatef(RAD2DEG * self.rotation, 0, 0, 1.0)
glScalef(self.scale[0], self.scale[1], 1)
def disable(self):
glPopMatrix()
def set_translation(self, newx, newy):
self.translation = (float(newx), float(newy))
def set_rotation(self, new):
self.rotation = float(new)
def set_scale(self, newx, newy):
self.scale = (float(newx), float(newy))
class Color(Attr):
def __init__(self, vec4):
self.vec4 = vec4
def enable(self):
glColor4f(*self.vec4)
class LineStyle(Attr):
def __init__(self, style):
self.style = style
def enable(self):
glEnable(GL_LINE_STIPPLE)
glLineStipple(1, self.style)
def disable(self):
glDisable(GL_LINE_STIPPLE)
class LineWidth(Attr):
def __init__(self, stroke):
self.stroke = stroke
def enable(self):
glLineWidth(self.stroke)
class Point(Geom):
def __init__(self):
Geom.__init__(self)
def render1(self):
glBegin(GL_POINTS) # draw point
glVertex3f(0.0, 0.0, 0.0)
glEnd()
class FilledPolygon(Geom):
def __init__(self, v):
Geom.__init__(self)
self.v = v
def render1(self):
if len(self.v) == 4 : glBegin(GL_QUADS)
elif len(self.v) > 4 : glBegin(GL_POLYGON)
else: glBegin(GL_TRIANGLES)
for p in self.v:
glVertex3f(p[0], p[1],0) # draw each vertex
glEnd()
color = (self._color.vec4[0] * 0.5, self._color.vec4[1] * 0.5, self._color.vec4[2] * 0.5, self._color.vec4[3] * 0.5)
glColor4f(*color)
glBegin(GL_LINE_LOOP)
for p in self.v:
glVertex3f(p[0], p[1],0) # draw each vertex
glEnd()
def make_circle(radius=10, res=30, filled=True):
points = []
for i in range(res):
ang = 2*math.pi*i / res
points.append((math.cos(ang)*radius, math.sin(ang)*radius))
if filled:
return FilledPolygon(points)
else:
return PolyLine(points, True)
def make_polygon(v, filled=True):
if filled: return FilledPolygon(v)
else: return PolyLine(v, True)
def make_polyline(v):
return PolyLine(v, False)
def make_capsule(length, width):
l, r, t, b = 0, length, width/2, -width/2
box = make_polygon([(l,b), (l,t), (r,t), (r,b)])
circ0 = make_circle(width/2)
circ1 = make_circle(width/2)
circ1.add_attr(Transform(translation=(length, 0)))
geom = Compound([box, circ0, circ1])
return geom
class Compound(Geom):
def __init__(self, gs):
Geom.__init__(self)
self.gs = gs
for g in self.gs:
g.attrs = [a for a in g.attrs if not isinstance(a, Color)]
def render1(self):
for g in self.gs:
g.render()
class PolyLine(Geom):
def __init__(self, v, close):
Geom.__init__(self)
self.v = v
self.close = close
self.linewidth = LineWidth(1)
self.add_attr(self.linewidth)
def render1(self):
glBegin(GL_LINE_LOOP if self.close else GL_LINE_STRIP)
for p in self.v:
glVertex3f(p[0], p[1],0) # draw each vertex
glEnd()
def set_linewidth(self, x):
self.linewidth.stroke = x
class Line(Geom):
def __init__(self, start=(0.0, 0.0), end=(0.0, 0.0)):
Geom.__init__(self)
self.start = start
self.end = end
self.linewidth = LineWidth(1)
self.add_attr(self.linewidth)
def render1(self):
glBegin(GL_LINES)
glVertex2f(*self.start)
glVertex2f(*self.end)
glEnd()
class Image(Geom):
def __init__(self, fname, width, height):
Geom.__init__(self)
self.width = width
self.height = height
img = pyglet.image.load(fname)
self.img = img
self.flip = False
def render1(self):
self.img.blit(-self.width/2, -self.height/2, width=self.width, height=self.height)
# ================================================================
class SimpleImageViewer(object):
def __init__(self, display=None):
self.window = None
self.isopen = False
self.display = display
def imshow(self, arr):
if self.window is None:
height, width, channels = arr.shape
self.window = pyglet.window.Window(width=width, height=height, display=self.display)
self.width = width
self.height = height
self.isopen = True
assert arr.shape == (self.height, self.width, 3), "You passed in an image with the wrong number shape"
image = pyglet.image.ImageData(self.width, self.height, 'RGB', arr.tobytes(), pitch=self.width * -3)
self.window.clear()
self.window.switch_to()
self.window.dispatch_events()
image.blit(0,0)
self.window.flip()
def close(self):
if self.isopen:
self.window.close()
self.isopen = False
def __del__(self):
self.close()
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenario.py
================================================
import numpy as np
# defines scenario upon which the world is built
class BaseScenario(object):
# create elements of the world
def make_world(self):
raise NotImplementedError()
# create initial conditions of the world
def reset_world(self, world):
raise NotImplementedError()
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/__init__.py
================================================
import imp
import os.path as osp
def load(name):
pathname = osp.join(osp.dirname(__file__), name)
return imp.load_source('', pathname)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/hetero_spread.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, num_good_agents=2, num_adversaries=0):
world = World()
# set any world properties first
world.dim_c = 2
world.max_steps = 25
num_agents = num_good_agents
self.n_agent_a = num_agents // 2 # 2
self.n_agent_b = num_agents // 2 # 2
num_landmarks = num_good_agents
world.collaborative = True
self.agent_size = 0.10
self.n_others = 3
self.n_group = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
agent.id = i
if i < self.n_agent_a:
agent.size = self.agent_size
agent.accel = 3.0
agent.max_speed = 1.0
else:
agent.size = self.agent_size / 2
agent.accel = 4.0
agent.max_speed = 1.3
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
world.num_steps = 0
self.end_steps = world.max_steps
# random properties for agents
for i, agent in enumerate(world.agents):
if i < self.n_agent_a:
agent.color = np.array([0.35, 0.35, 0.85])
else:
agent.color = np.array([0.35, 0.85, 0.35])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
rew = 0
collisions = 0
occupied_landmarks = 0
min_dists = 0
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
min_dists += min(dists)
rew -= min(dists)
if min(dists) < 0.1:
occupied_landmarks += 1
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
collisions += 1
return (rew, collisions, min_dists, occupied_landmarks)
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark, penalized for collisions
rew = 0
shaped_reward = False
if shaped_reward: # distance-based reward
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
rew -= min(dists)
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
return rew
else:
win_agents = []
for land in world.landmarks:
for a in world.agents:
if self.is_collision(a, land):
win_agents.append(a)
break
rew += 2 * len(set(win_agents))
def bound(x):
if x > 1.0:
return min(np.exp(2 * x - 2), 10)
else:
return 0.0
bound_rew = 0.0
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
bound_rew -= bound(x)
rew += bound_rew
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
other_vel = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent:
other_vel.append([0, 0])
continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + comm +
other_vel + entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# add agents
world.agents = [Agent() for i in range(1)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.silent = True
# add landmarks
world.landmarks = [Landmark() for i in range(1)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25,0.25,0.25])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.75,0.75,0.75])
world.landmarks[0].color = np.array([0.75,0.25,0.25])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
dist2 = np.sum(np.square(agent.state.p_pos - world.landmarks[0].state.p_pos))
return -dist2
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
return np.concatenate([agent.state.p_vel] + entity_pos)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_adversary.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, num_good_agents=2, num_adversaries=1):
world = World()
# set any world properties first
world.dim_c = 2
num_agents = num_adversaries + num_good_agents
num_good_agents = num_good_agents
num_adversaries = 1
world.num_agents = num_agents
num_landmarks = num_agents - 1
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.silent = True
agent.adversary = True if i < num_adversaries else False
agent.size = 0.15
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.08
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
world.agents[0].color = np.array([0.85, 0.35, 0.35])
for i in range(1, world.num_agents):
world.agents[i].color = np.array([0.35, 0.35, 0.85])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.15, 0.15, 0.15])
# set goal landmark
goal = np.random.choice(world.landmarks)
goal.color = np.array([0.15, 0.65, 0.15])
for agent in world.agents:
agent.goal_a = goal
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
if agent.adversary:
return np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos))
else:
dists = []
for l in world.landmarks:
dists.append(np.sum(np.square(agent.state.p_pos - l.state.p_pos)))
dists.append(np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos)))
return tuple(dists)
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# Rewarded based on how close any good agent is to the goal landmark, and how far the adversary is from it
shaped_reward = False
shaped_adv_reward = False
# Calculate negative reward for adversary
adversary_agents = self.adversaries(world)
if shaped_adv_reward: # distance-based adversary reward
adv_rew = sum([np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in adversary_agents])
else: # proximity-based adversary reward (binary)
adv_rew = 0
for a in adversary_agents:
if np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) < 2 * a.goal_a.size:
adv_rew -= 5
# Calculate positive reward for agents
good_agents = self.good_agents(world)
if shaped_reward: # distance-based agent reward
pos_rew = -min(
[np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in good_agents])
else: # proximity-based agent reward (binary)
pos_rew = 0
if min([np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in good_agents]) \
< 2 * agent.goal_a.size:
pos_rew += 5
pos_rew -= min(
[np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in good_agents])
return pos_rew + adv_rew
def adversary_reward(self, agent, world):
# Rewarded based on proximity to the goal landmark
shaped_reward = False
if shaped_reward: # distance-based reward
return -np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos))
else: # proximity-based reward (binary)
adv_rew = 0
if np.sqrt(np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos))) < 2 * agent.goal_a.size:
adv_rew += 5
return adv_rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
other_vel = []
for entity in world.landmarks:
entity_color.append(entity.color)
# communication of all other agents
other_pos = []
for other in world.agents:
if other is agent and not other.adversary:
other_vel.append([0, 0])
continue
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append([0, 0])
if not agent.adversary:
return np.concatenate(
[agent.goal_a.state.p_pos - agent.state.p_pos] +
other_vel + entity_pos + other_pos)
else:
return np.concatenate([np.zeros(2)] +
other_vel + entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_crypto.py
================================================
"""
Scenario:
1 speaker, 2 listeners (one of which is an adversary). Good agents rewarded for proximity to goal, and distance from
adversary to goal. Adversary is rewarded for its distance to the goal.
"""
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
import random
class CryptoAgent(Agent):
def __init__(self):
super(CryptoAgent, self).__init__()
self.key = None
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
num_agents = 3
num_adversaries = 1
num_landmarks = 2
world.dim_c = 4
# add agents
world.agents = [CryptoAgent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.adversary = True if i < num_adversaries else False
agent.speaker = True if i == 2 else False
agent.movable = False
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25, 0.25, 0.25])
if agent.adversary:
agent.color = np.array([0.75, 0.25, 0.25])
agent.key = None
# random properties for landmarks
color_list = [np.zeros(world.dim_c) for i in world.landmarks]
for i, color in enumerate(color_list):
color[i] += 1
for color, landmark in zip(color_list, world.landmarks):
landmark.color = color
# set goal landmark
goal = np.random.choice(world.landmarks)
world.agents[1].color = goal.color
world.agents[2].key = np.random.choice(world.landmarks).color
for agent in world.agents:
agent.goal_a = goal
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
return (agent.state.c, agent.goal_a.color)
# return all agents that are not adversaries
def good_listeners(self, world):
return [agent for agent in world.agents if not agent.adversary and not agent.speaker]
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# Agents rewarded if Bob can reconstruct message, but adversary (Eve) cannot
good_listeners = self.good_listeners(world)
adversaries = self.adversaries(world)
good_rew = 0
adv_rew = 0
for a in good_listeners:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
good_rew -= np.sum(np.square(a.state.c - agent.goal_a.color))
for a in adversaries:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
adv_l1 = np.sum(np.square(a.state.c - agent.goal_a.color))
adv_rew += adv_l1
return adv_rew + good_rew
def adversary_reward(self, agent, world):
# Adversary (Eve) is rewarded if it can reconstruct original goal
rew = 0
if not (agent.state.c == np.zeros(world.dim_c)).all():
rew -= np.sum(np.square(agent.state.c - agent.goal_a.color))
return rew
def observation(self, agent, world):
# goal color
goal_color = np.zeros(world.dim_color)
if agent.goal_a is not None:
goal_color = agent.goal_a.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent or (other.state.c is None) or not other.speaker: continue
comm.append(other.state.c)
confer = np.array([0])
if world.agents[2].key is None:
confer = np.array([1])
key = np.zeros(world.dim_c)
goal_color = np.zeros(world.dim_c)
else:
key = world.agents[2].key
prnt = False
# speaker
if agent.speaker:
if prnt:
print('speaker')
print(agent.state.c)
print(np.concatenate([goal_color] + [key] + [confer] + [np.random.randn(1)]))
return np.concatenate([goal_color] + [key])
# listener
if not agent.speaker and not agent.adversary:
if prnt:
print('listener')
print(agent.state.c)
print(np.concatenate([key] + comm + [confer]))
return np.concatenate([key] + comm)
if not agent.speaker and agent.adversary:
if prnt:
print('adversary')
print(agent.state.c)
print(np.concatenate(comm + [confer]))
return np.concatenate(comm)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_push.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, num_good_agents=2, num_adversaries=2):
world = World()
# set any world properties first
world.dim_c = 2
num_agents = num_good_agents + num_adversaries
num_adversaries = num_adversaries
num_landmarks = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
if i < num_adversaries:
agent.adversary = True
else:
agent.adversary = False
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.1, 0.1, 0.1])
landmark.color[i + 1] += 0.8
landmark.index = i
# set goal landmark
goal = np.random.choice(world.landmarks)
for i, agent in enumerate(world.agents):
agent.goal_a = goal
agent.color = np.array([0.25, 0.25, 0.25])
if agent.adversary:
agent.color = np.array([0.75, 0.25, 0.25])
else:
j = goal.index
agent.color[j + 1] += 0.5
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return dist < dist_min
def agent_reward(self, agent, world):
'''
Rewrite
'''
shaped_reward = False
if shaped_reward: # distance-based reward
# the distance to the goal
return -np.sqrt(np.sum(np.square(
agent.state.p_pos - agent.goal_a.state.p_pos)))
else:
pos_rew, adv_rew = 0.0, 0.0
for a in self.adversaries(world):
if self.is_collision(a, agent):
adv_rew -= 5.0
if self.is_collision(agent, agent.goal_a):
pos_rew += 5.0
rew = pos_rew + adv_rew
def bound(x):
if x > 1.0:
return min(np.exp(2 * x - 2), 10)
else:
return 0.0
bound_rew = 0.0
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
bound_rew -= bound(x)
rew += bound_rew
return rew
def adversary_reward(self, agent, world):
'''
Rewrite
'''
shaped_reward = False
if shaped_reward: # distance-based reward
# keep the nearest good agents away from the goal
agent_dist = [np.sqrt(np.sum(np.square(a.state.p_pos -
a.goal_a.state.p_pos))) for a in world.agents if not a.adversary]
pos_rew = min(agent_dist)
#nearest_agent = world.good_agents[np.argmin(agent_dist)]
#neg_rew = np.sqrt(np.sum(np.square(nearest_agent.state.p_pos - agent.state.p_pos)))
neg_rew = np.sqrt(np.sum(np.square(agent.goal_a.state.p_pos - agent.state.p_pos)))
#neg_rew = sum([np.sqrt(np.sum(np.square(a.state.p_pos - agent.state.p_pos))) for a in world.good_agents])
return pos_rew - neg_rew
else:
rew = 0.0
for a in self.good_agents(world):
if self.is_collision(a, a.goal_a):
rew -= 5.0
# if self.is_collision(a, agent):
# rew += 5.0
if self.is_collision(agent, agent.goal_a):
rew += 5.0
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
other_vel = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent and not other.adversary:
other_vel.append([0, 0])
continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append([0, 0])
if not agent.adversary:
return np.concatenate([agent.state.p_vel] +
[agent.goal_a.state.p_pos - agent.state.p_pos] +
[agent.color] + entity_color +
other_vel + entity_pos + other_pos)
else:
#other_pos = list(reversed(other_pos)) if random.uniform(0,1) > 0.5 else other_pos # randomize position of other agents in adversary network
return np.concatenate([agent.state.p_vel] +
other_vel + entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_reference.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, num_good_agents=2, num_adversaries=0):
world = World()
# set any world properties first
world.dim_c = 10
world.collaborative = True # whether agents share rewards
# add agents
world.agents = [Agent() for i in range(num_good_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
# add landmarks
world.landmarks = [Landmark() for i in range(num_good_agents+1)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# assign goals to agents
for agent in world.agents:
agent.goal_a = None
agent.goal_b = None
# want other agent to go to the goal landmark
world.agents[0].goal_a = world.agents[1]
world.agents[0].goal_b = np.random.choice(world.landmarks)
world.agents[1].goal_a = world.agents[0]
world.agents[1].goal_b = np.random.choice(world.landmarks)
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25,0.25,0.25])
# random properties for landmarks
world.landmarks[0].color = np.array([0.75,0.25,0.25])
world.landmarks[1].color = np.array([0.25,0.75,0.25])
world.landmarks[2].color = np.array([0.25,0.25,0.75])
# special colors for goals
world.agents[0].goal_a.color = world.agents[0].goal_b.color
world.agents[1].goal_a.color = world.agents[1].goal_b.color
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
if agent.goal_a is None or agent.goal_b is None:
return 0.0
dist2 = np.sum(np.square(agent.goal_a.state.p_pos - agent.goal_b.state.p_pos))
return -dist2
def observation(self, agent, world):
# goal color
goal_color = [np.zeros(world.dim_color), np.zeros(world.dim_color)]
if agent.goal_b is not None:
goal_color[1] = agent.goal_b.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks:
entity_color.append(entity.color)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
return np.concatenate([agent.state.p_vel] + entity_pos + [goal_color[1]] + comm)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_speaker_listener.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
world.dim_c = 3
num_landmarks = 3
world.collaborative = True
# add agents
world.agents = [Agent() for i in range(2)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.size = 0.075
# speaker
world.agents[0].movable = False
# listener
world.agents[1].silent = True
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.04
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# assign goals to agents
for agent in world.agents:
agent.goal_a = None
agent.goal_b = None
# want listener to go to the goal landmark
world.agents[0].goal_a = world.agents[1]
world.agents[0].goal_b = np.random.choice(world.landmarks)
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25,0.25,0.25])
# random properties for landmarks
world.landmarks[0].color = np.array([0.65,0.15,0.15])
world.landmarks[1].color = np.array([0.15,0.65,0.15])
world.landmarks[2].color = np.array([0.15,0.15,0.65])
# special colors for goals
world.agents[0].goal_a.color = world.agents[0].goal_b.color + np.array([0.45, 0.45, 0.45])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
return self.reward(agent, reward)
def reward(self, agent, world):
# squared distance from listener to landmark
a = world.agents[0]
dist2 = np.sum(np.square(a.goal_a.state.p_pos - a.goal_b.state.p_pos))
return -dist2
def observation(self, agent, world):
# goal color
goal_color = np.zeros(world.dim_color)
if agent.goal_b is not None:
goal_color = agent.goal_b.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent or (other.state.c is None): continue
comm.append(other.state.c)
# speaker
if not agent.movable:
return np.concatenate([goal_color])
# listener
if agent.silent:
return np.concatenate([agent.state.p_vel] + entity_pos + comm)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_spread.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, num_good_agents=2, num_adversaries=2):
world = World()
# set any world properties first
world.dim_c = 2
num_agents = num_good_agents
num_landmarks = num_good_agents
world.collaborative = True
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
agent.size = 0.15
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.35, 0.35, 0.85])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
rew = 0
collisions = 0
occupied_landmarks = 0
min_dists = 0
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
min_dists += min(dists)
rew -= min(dists)
if min(dists) < 0.1:
occupied_landmarks += 1
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
collisions += 1
return (rew, collisions, min_dists, occupied_landmarks)
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark, penalized for collisions
rew = 0
shaped_reward = False
if shaped_reward: # distance-based reward
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
rew -= min(dists)
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
return rew
else:
win_agents = []
for land in world.landmarks:
for a in world.agents:
if self.is_collision(a, land):
win_agents.append(a)
break
rew += 2 * len(set(win_agents))
def bound(x):
if x > 1.0:
return min(np.exp(2 * x - 2), 10)
else:
return 0.0
bound_rew = 0.0
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
bound_rew -= bound(x)
rew += bound_rew
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
other_vel = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent:
other_vel.append([0, 0])
continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + comm +
other_vel + entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_tag.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, num_good_agents=1, num_adversaries=3):
world = World()
# set any world properties first
world.dim_c = 2
num_good_agents = num_good_agents
num_adversaries = num_adversaries
num_agents = num_adversaries + num_good_agents
num_landmarks = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
agent.adversary = True if i < num_adversaries else False
agent.size = 0.075 if agent.adversary else 0.05
agent.accel = 3.0 if agent.adversary else 4.0
#agent.accel = 20.0 if agent.adversary else 25.0
agent.max_speed = 1.0 if agent.adversary else 1.3
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = True
landmark.movable = False
landmark.size = 0.2
landmark.boundary = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.35, 0.85, 0.35]) if not agent.adversary else np.array([0.85, 0.35, 0.35])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
if not landmark.boundary:
landmark.state.p_pos = np.random.uniform(-0.9, +0.9, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
if agent.adversary:
collisions = 0
for a in self.good_agents(world):
if self.is_collision(a, agent):
collisions += 1
return collisions
else:
return 0
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
main_reward = self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
return main_reward
def agent_reward(self, agent, world):
# Agents are negatively rewarded if caught by adversaries
rew = 0
shape = False
adversaries = self.adversaries(world)
if shape: # reward can optionally be shaped (increased reward for increased distance from adversary)
for adv in adversaries:
rew += 0.1 * np.sqrt(np.sum(np.square(agent.state.p_pos - adv.state.p_pos)))
if agent.collide:
for a in adversaries:
if self.is_collision(a, agent):
rew -= 10
# agents are penalized for exiting the screen, so that they can be caught by the adversaries
def bound(x):
if x < 0.9:
return 0
if x < 1.0:
return (x - 0.9) * 10
return min(np.exp(2 * x - 2), 10)
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
rew -= bound(x)
return rew
def adversary_reward(self, agent, world):
# Adversaries are rewarded for collisions with agents
rew = 0
shape = False
agents = self.good_agents(world)
adversaries = self.adversaries(world)
if shape: # reward can optionally be shaped (decreased reward for increased distance from agents)
for adv in adversaries:
rew -= 0.1 * min([np.sqrt(np.sum(np.square(a.state.p_pos - adv.state.p_pos))) for a in agents])
if agent.collide:
for ag in agents:
for adv in adversaries:
if self.is_collision(ag, adv):
rew += 10
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent and not other.adversary:
other_vel.append(other.state.p_vel)
continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + other_vel +
entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_world_comm.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, num_good_agents=2, num_adversaries=4):
world = World()
# set any world properties first
world.dim_c = 4
#world.damping = 1
num_good_agents = num_good_agents
num_adversaries = num_adversaries
num_agents = num_adversaries + num_good_agents
num_landmarks = 1
num_food = 2
num_forests = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.leader = True if i == 0 else False
agent.silent = True if i > 0 else False
agent.adversary = True if i < num_adversaries else False
agent.size = 0.075 if agent.adversary else 0.045
agent.accel = 3.0 if agent.adversary else 4.0
#agent.accel = 20.0 if agent.adversary else 25.0
agent.max_speed = 1.0 if agent.adversary else 1.3
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = True
landmark.movable = False
landmark.size = 0.2
landmark.boundary = False
world.food = [Landmark() for i in range(num_food)]
for i, landmark in enumerate(world.food):
landmark.name = 'food %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.03
landmark.boundary = False
world.forests = [Landmark() for i in range(num_forests)]
for i, landmark in enumerate(world.forests):
landmark.name = 'forest %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.3
landmark.boundary = False
world.landmarks += world.food
world.landmarks += world.forests
#world.landmarks += self.set_boundaries(world) # world boundaries now penalized with negative reward
# make initial conditions
self.reset_world(world)
return world
def set_boundaries(self, world):
boundary_list = []
landmark_size = 1
edge = 1 + landmark_size
num_landmarks = int(edge * 2 / landmark_size)
for x_pos in [-edge, edge]:
for i in range(num_landmarks):
l = Landmark()
l.state.p_pos = np.array([x_pos, -1 + i * landmark_size])
boundary_list.append(l)
for y_pos in [-edge, edge]:
for i in range(num_landmarks):
l = Landmark()
l.state.p_pos = np.array([-1 + i * landmark_size, y_pos])
boundary_list.append(l)
for i, l in enumerate(boundary_list):
l.name = 'boundary %d' % i
l.collide = True
l.movable = False
l.boundary = True
l.color = np.array([0.75, 0.75, 0.75])
l.size = landmark_size
l.state.p_vel = np.zeros(world.dim_p)
return boundary_list
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.45, 0.95, 0.45]) if not agent.adversary else np.array([0.95, 0.45, 0.45])
agent.color -= np.array([0.3, 0.3, 0.3]) if agent.leader else np.array([0, 0, 0])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
for i, landmark in enumerate(world.food):
landmark.color = np.array([0.15, 0.15, 0.65])
for i, landmark in enumerate(world.forests):
landmark.color = np.array([0.6, 0.9, 0.6])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-0.9, +0.9, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
for i, landmark in enumerate(world.food):
landmark.state.p_pos = np.random.uniform(-0.9, +0.9, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
for i, landmark in enumerate(world.forests):
landmark.state.p_pos = np.random.uniform(-0.9, +0.9, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
if agent.adversary:
collisions = 0
for a in self.good_agents(world):
if self.is_collision(a, agent):
collisions += 1
return collisions
else:
return 0
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
#boundary_reward = -10 if self.outside_boundary(agent) else 0
main_reward = self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
return main_reward
def outside_boundary(self, agent):
if agent.state.p_pos[0] > 1 or agent.state.p_pos[0] < -1 or agent.state.p_pos[1] > 1 or agent.state.p_pos[1] < -1:
return True
else:
return False
def agent_reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
rew = 0
shape = False
adversaries = self.adversaries(world)
if shape:
for adv in adversaries:
rew += 0.1 * np.sqrt(np.sum(np.square(agent.state.p_pos - adv.state.p_pos)))
if agent.collide:
for a in adversaries:
if self.is_collision(a, agent):
rew -= 5
def bound(x):
if x < 0.9:
return 0
if x < 1.0:
return (x - 0.9) * 10
return min(np.exp(2 * x - 2), 10) # 1 + (x - 1) * (x - 1)
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
rew -= 2 * bound(x)
for food in world.food:
if self.is_collision(agent, food):
rew += 2
rew += 0.05 * min([np.sqrt(np.sum(np.square(food.state.p_pos - agent.state.p_pos))) for food in world.food])
return rew
def adversary_reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
rew = 0
shape = True
agents = self.good_agents(world)
adversaries = self.adversaries(world)
if shape:
rew -= 0.1 * min([np.sqrt(np.sum(np.square(a.state.p_pos - agent.state.p_pos))) for a in agents])
if agent.collide:
for ag in agents:
for adv in adversaries:
if self.is_collision(ag, adv):
rew += 5
return rew
def observation2(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
food_pos = []
for entity in world.food:
if not entity.boundary:
food_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel)
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
in_forest = [np.array([-1]), np.array([-1])]
inf1 = False
inf2 = False
if self.is_collision(agent, world.forests[0]):
in_forest[0] = np.array([1])
inf1= True
if self.is_collision(agent, world.forests[1]):
in_forest[1] = np.array([1])
inf2 = True
food_pos = []
for entity in world.food:
if not entity.boundary:
food_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent and not other.adversary:
other_vel.append(other.state.p_vel) #
continue
comm.append(other.state.c)
oth_f1 = self.is_collision(other, world.forests[0])
oth_f2 = self.is_collision(other, world.forests[1])
if (inf1 and oth_f1) or (inf2 and oth_f2) or \
(not inf1 and not oth_f1 and not inf2 and not oth_f2) or \
agent.leader: #without forest vis
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
else:
other_pos.append([0, 0])
if not other.adversary:
other_vel.append([0, 0])
# to tell the pred when the prey are in the forest
prey_forest = []
ga = self.good_agents(world)
for a in ga:
if any([self.is_collision(a, f) for f in world.forests]):
prey_forest.append(np.array([1]))
else:
prey_forest.append(np.array([-1]))
# to tell leader when pred are in forest
prey_forest_lead = []
for f in world.forests:
if any([self.is_collision(a, f) for a in ga]):
prey_forest_lead.append(np.array([1]))
else:
prey_forest_lead.append(np.array([-1]))
comm = [world.agents[0].state.c]
if agent.adversary and not agent.leader:
return np.concatenate(in_forest + comm +
[agent.state.p_vel] + [agent.state.p_pos] + other_vel +
entity_pos + other_pos)
if agent.leader:
return np.concatenate(in_forest + comm +
[agent.state.p_vel] + [agent.state.p_pos] + other_vel +
entity_pos + other_pos)
else:
return np.concatenate(in_forest + [np.zeros_like(world.agents[0].state.c)] +
[agent.state.p_vel] + [agent.state.p_pos] + other_vel +
entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/FOToM/readme.md
================================================
# Readme
This project is for FOToM.
================================================
FILE: examples/Social_Cognition/FOToM/utils/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/FOToM/utils/agents.py
================================================
import torch
from torch import Tensor
from torch.autograd import Variable
from torch.optim import Adam
from .networks import MLPNetwork, RNN, SNNNetwork, LSTMClassifier
from .misc import hard_update, gumbel_softmax, onehot_from_logits
from .noise import OUNoise
import time
class DDPGAgent(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, hidden_dim=64,
lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.policy = LSTMClassifier(num_in_pol, num_out_pol,#MLPNetwork
hidden_dim,)
# constrain_out=True,
# discrete_action=discrete_action)
self.critic = LSTMClassifier(num_in_critic, 1,
hidden_dim,)
# constrain_out=False)
self.target_policy = LSTMClassifier(num_in_pol, num_out_pol,
hidden_dim,)
# constrain_out=True,
# discrete_action=discrete_action)
self.target_critic = LSTMClassifier(num_in_critic, 1,
hidden_dim,)
# constrain_out=False)
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action = self.policy(obs)
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1)
else:
action = gumbel_softmax(action, hard=True)
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5]), onehot_from_logits(action[:, 5:])), 1)
else:
action = onehot_from_logits(action)
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
return {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict()}
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
class DDPGAgent_RNN(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, hidden_dim=64,
lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.policy = RNN(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.critic = RNN(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
self.target_policy = RNN(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.target_critic = RNN(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
self.policy_hidden = None
self.policy_target_hidden = None
self.critic_hidden = None
self.critic_target_hidden = None
self.num_in_pol = num_in_pol
self.num_out_pol = num_out_pol
self.hidden_dim = hidden_dim
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action, self.policy_hidden = self.policy(obs, self.policy_hidden)
if self.discrete_action:
if explore:
action = gumbel_softmax(action, hard=True)
else:
action = onehot_from_logits(action)
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
return {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict()}
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
def init_hidden(self, len_ep, policy_hidden=False, policy_target_hidden=False, \
critic_hidden=False, critic_target_hidden=False):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
if policy_hidden == True:
self.policy_hidden = torch.zeros((len_ep, self.hidden_dim))
if policy_target_hidden == True:
self.policy_target_hidden = torch.zeros((len_ep, self.hidden_dim))
if critic_hidden == True:
self.critic_hidden = torch.zeros((len_ep, self.hidden_dim))
if critic_target_hidden == True:
self.critic_target_hidden = torch.zeros((len_ep, self.hidden_dim))
class DDPGAgent_SNN(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, output_style, hidden_dim=64,
lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.policy = SNNNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
output_style=output_style)
self.critic = SNNNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
output_style=output_style)
self.target_policy = SNNNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
output_style=output_style)
self.target_critic = SNNNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
output_style=output_style)
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
# t1 = time.time()
action = self.policy(obs)
# t2 = time.time()
# print('time_interaction:', t2 - t1)
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1)
else:
action = gumbel_softmax(action, hard=True)
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5]), onehot_from_logits(action[:, 5:])), 1)
else:
action = onehot_from_logits(action)
# if explore:
#
# action = gumbel_softmax(action, hard=True)
#
# else:
# action = onehot_from_logits(action)
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
return {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict()}
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
class DDPGAgent_ToM(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, num_in_mle, output_style,
num_agents, device, hidden_dim=64, lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.device = device
self.policy = LSTMClassifier(num_in_pol, num_out_pol,hidden_dim) #SNNNetwork
# hidden_dim=hidden_dim,
# output_style=output_style)
self.critic = LSTMClassifier(num_in_critic, 1,hidden_dim)
# hidden_dim=hidden_dim,
# output_style=output_style)
self.target_policy = LSTMClassifier(num_in_pol, num_out_pol,hidden_dim)
# hidden_dim=hidden_dim,
# output_style=output_style)
self.target_critic = LSTMClassifier(num_in_critic, 1,hidden_dim)
# hidden_dim=hidden_dim,
# output_style=output_style)
# self.policy = SNNNetwork(num_in_pol, num_out_pol,
# hidden_dim=hidden_dim,
# output_style=output_style)
# self.critic = SNNNetwork(num_in_critic, 1,
# hidden_dim=hidden_dim,
# output_style=output_style)
# self.target_policy = SNNNetwork(num_in_pol, num_out_pol,
# hidden_dim=hidden_dim,
# output_style=output_style)
# self.target_critic = SNNNetwork(num_in_critic, 1,
# hidden_dim=hidden_dim,
# output_style=output_style)
# self.mle = [SNNNetwork(num_in_mle, num_out_pol,
# hidden_dim=hidden_dim,
# output_style=output_style)] * (num_agents - 1)
self.mle = []
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
self.mle_optimizer = []
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action = self.policy.to(self.device)(obs.to(self.device))
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1).cpu()
else:
action = gumbel_softmax(action, hard=True).cpu()
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5], hard=True), onehot_from_logits(action[:, 5:], hard=True)), 1)
else:
action = onehot_from_logits(action).cpu()
# if explore:
# action = gumbel_softmax(action, hard=True).cpu()
# else:
# action = onehot_from_logits(action).cpu()
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
params = {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict(),
}
# for i in range(len(self.mle)):
# params['mle%d'%i] = self.mle[i].state_dict()
# params['mle_optimizer%d'%i] = self.mle_optimizer[i].state_dict()
return params
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
# for i in range(len(self.mle)):
# self.mle[i].load_state_dict(params['mle%d'%i])
# self.mle_optimizer[i].load_state_dict(params['mle_optimizer%d'%i])
class rDDPGAgent_ToM(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, num_in_mle, output_style,
num_agents, device, hidden_dim=64, lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.device = device
self.policy = RNN(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.critic = RNN(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.target_policy = RNN(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.target_critic = RNN(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
# self.mle = [SNNNetwork(num_in_mle, num_out_pol,
# hidden_dim=hidden_dim,
# output_style=output_style)] * (num_agents - 1)
self.mle = []
self.policy_hidden = None
self.policy_target_hidden = None
self.critic_hidden = None
self.critic_target_hidden = None
self.hidden_dim = hidden_dim
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
self.mle_optimizer = []
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action, self.policy_hidden = self.policy(obs, self.policy_hidden)
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1).cpu()
else:
action = gumbel_softmax(action, hard=True).cpu()
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5], hard=True), onehot_from_logits(action[:, 5:], hard=True)), 1)
else:
action = onehot_from_logits(action).cpu()
# if explore:
# action = gumbel_softmax(action, hard=True).cpu()
# else:
# action = onehot_from_logits(action).cpu()
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
params = {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict(),
}
# for i in range(len(self.mle)):
# params['mle%d'%i] = self.mle[i].state_dict()
# params['mle_optimizer%d'%i] = self.mle_optimizer[i].state_dict()
return params
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
# for i in range(len(self.mle)):
# self.mle[i].load_state_dict(params['mle%d'%i])
# self.mle_optimizer[i].load_state_dict(params['mle_optimizer%d'%i])
def init_hidden(self, len_ep, policy_hidden=False, policy_target_hidden=False, \
critic_hidden=False, critic_target_hidden=False):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
if policy_hidden == True:
self.policy_hidden = torch.zeros((len_ep, self.hidden_dim))
if policy_target_hidden == True:
self.policy_target_hidden = torch.zeros((len_ep, self.hidden_dim))
if critic_hidden == True:
self.critic_hidden = torch.zeros((len_ep, self.hidden_dim))
if critic_target_hidden == True:
self.critic_target_hidden = torch.zeros((len_ep, self.hidden_dim))
class lDDPGAgent(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, hidden_dim=64,
lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.policy = LSTMClassifier(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.critic = LSTMClassifier(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
self.target_policy = LSTMClassifier(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.target_critic = LSTMClassifier(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action = self.policy(obs)
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1)
else:
action = gumbel_softmax(action, hard=True)
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5]), onehot_from_logits(action[:, 5:])), 1)
else:
action = onehot_from_logits(action)
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
return {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict()}
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
================================================
FILE: examples/Social_Cognition/FOToM/utils/buffer.py
================================================
import numpy as np
import torch
from torch import Tensor
from torch.autograd import Variable
class ReplayBuffer(object):
"""
Replay Buffer for multi-agent RL with parallel rollouts
"""
def __init__(self, max_steps, num_agents, obs_dims, ac_dims, device):
"""
Inputs:
max_steps (int): Maximum number of timepoints to store in buffer
num_agents (int): Number of agents in environment
obs_dims (list of ints): number of obervation dimensions for each
agent
ac_dims (list of ints): number of action dimensions for each agent
"""
self.device = device
self.max_steps = max_steps
self.num_agents = num_agents
self.obs_buffs = []
self.ac_buffs = []
self.rew_buffs = []
self.next_obs_buffs = []
self.done_buffs = []
for odim, adim in zip(obs_dims, ac_dims):
self.obs_buffs.append(np.zeros((max_steps, odim)))
self.ac_buffs.append(np.zeros((max_steps, adim)))
self.rew_buffs.append(np.zeros(max_steps))
self.next_obs_buffs.append(np.zeros((max_steps, odim)))
self.done_buffs.append(np.zeros(max_steps))
self.filled_i = 0 # index of first empty location in buffer (last index when full)
self.curr_i = 0 # current index to write to (ovewrite oldest data)
def __len__(self):
return self.filled_i
def push(self, observations, actions, rewards, next_observations, dones):
nentries = observations.shape[0] # handle multiple parallel environments
if self.curr_i + nentries > self.max_steps:
rollover = self.max_steps - self.curr_i # num of indices to roll over
for agent_i in range(self.num_agents):
self.obs_buffs[agent_i] = np.roll(self.obs_buffs[agent_i],
rollover, axis=0)
self.ac_buffs[agent_i] = np.roll(self.ac_buffs[agent_i],
rollover, axis=0)
self.rew_buffs[agent_i] = np.roll(self.rew_buffs[agent_i],
rollover)
self.next_obs_buffs[agent_i] = np.roll(
self.next_obs_buffs[agent_i], rollover, axis=0)
self.done_buffs[agent_i] = np.roll(self.done_buffs[agent_i],
rollover)
self.curr_i = 0
self.filled_i = self.max_steps
for agent_i in range(self.num_agents):
self.obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
observations[:, agent_i])
# actions are already batched by agent, so they are indexed differently
self.ac_buffs[agent_i][self.curr_i:self.curr_i + nentries] = actions[agent_i]
self.rew_buffs[agent_i][self.curr_i:self.curr_i + nentries] = rewards[:, agent_i]
self.next_obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
next_observations[:, agent_i])
self.done_buffs[agent_i][self.curr_i:self.curr_i + nentries] = dones[:, agent_i]
self.curr_i += nentries
if self.filled_i < self.max_steps:
self.filled_i += nentries
if self.curr_i == self.max_steps:
self.curr_i = 0
def sample(self, N, to_gpu=False, norm_rews=True):
inds = np.random.choice(np.arange(self.filled_i), size=N,
replace=False)
if to_gpu:
cast = lambda x: Variable(Tensor(x), requires_grad=False).to(torch.device(self.device))
else:
cast = lambda x: Variable(Tensor(x), requires_grad=False)
if norm_rews:
ret_rews = [cast((self.rew_buffs[i][inds] -
self.rew_buffs[i][:self.filled_i].mean()) /
self.rew_buffs[i][:self.filled_i].std())
for i in range(self.num_agents)]
else:
ret_rews = [cast(self.rew_buffs[i][inds]) for i in range(self.num_agents)]
return ([cast(self.obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.ac_buffs[i][inds]) for i in range(self.num_agents)],
ret_rews,
[cast(self.next_obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.done_buffs[i][inds]) for i in range(self.num_agents)])
def get_average_rewards(self, N):
if self.filled_i == self.max_steps:
inds = np.arange(self.curr_i - N, self.curr_i) # allow for negative indexing
else:
inds = np.arange(max(0, self.curr_i - N), self.curr_i)
return [self.rew_buffs[i][inds].mean() for i in range(self.num_agents)]
class ReplayBuffer_pre(object):
"""
Replay Buffer for multi-agent RL with parallel rollouts
"""
def __init__(self, max_steps, num_agents, obs_dims, ac_dims, device):
"""
Inputs:
max_steps (int): Maximum number of timepoints to store in buffer
num_agents (int): Number of agents in environment
obs_dims (list of ints): number of obervation dimensions for each
agent
ac_dims (list of ints): number of action dimensions for each agent
"""
self.device = device
self.max_steps = max_steps
self.num_agents = num_agents
self.ac_pre_buffs = []
self.obs_buffs = []
self.ac_buffs = []
self.rew_buffs = []
self.next_obs_buffs = []
self.done_buffs = []
for odim, adim in zip(obs_dims, ac_dims):
self.ac_pre_buffs.append(np.zeros((max_steps, 5)))
self.obs_buffs.append(np.zeros((max_steps, odim)))
self.ac_buffs.append(np.zeros((max_steps, adim)))
self.rew_buffs.append(np.zeros(max_steps))
self.next_obs_buffs.append(np.zeros((max_steps, odim)))
self.done_buffs.append(np.zeros(max_steps))
self.filled_i = 0 # index of first empty location in buffer (last index when full)
self.curr_i = 0 # current index to write to (ovewrite oldest data)
def __len__(self):
return self.filled_i
def push(self, actions_pre, observations, actions, rewards, next_observations, dones):
nentries = observations.shape[0] # handle multiple parallel environments
if self.curr_i + nentries > self.max_steps:
rollover = self.max_steps - self.curr_i # num of indices to roll over
for agent_i in range(self.num_agents):
self.ac_pre_buffs[agent_i] = np.roll(self.ac_pre_buffs[agent_i][:,:5],
rollover, axis=0)
self.obs_buffs[agent_i] = np.roll(self.obs_buffs[agent_i],
rollover, axis=0)
self.ac_buffs[agent_i] = np.roll(self.ac_buffs[agent_i],
rollover, axis=0)
self.rew_buffs[agent_i] = np.roll(self.rew_buffs[agent_i],
rollover)
self.next_obs_buffs[agent_i] = np.roll(
self.next_obs_buffs[agent_i], rollover, axis=0)
self.done_buffs[agent_i] = np.roll(self.done_buffs[agent_i],
rollover)
self.curr_i = 0
self.filled_i = self.max_steps
for agent_i in range(self.num_agents):
self.ac_pre_buffs[agent_i][self.curr_i:self.curr_i + nentries] = actions_pre[agent_i][:,:5]
self.obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
observations[:, agent_i])
# actions are already batched by agent, so they are indexed differently
self.ac_buffs[agent_i][self.curr_i:self.curr_i + nentries] = actions[agent_i]
self.rew_buffs[agent_i][self.curr_i:self.curr_i + nentries] = rewards[:, agent_i]
self.next_obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
next_observations[:, agent_i])
self.done_buffs[agent_i][self.curr_i:self.curr_i + nentries] = dones[:, agent_i]
self.curr_i += nentries
if self.filled_i < self.max_steps:
self.filled_i += nentries
if self.curr_i == self.max_steps:
self.curr_i = 0
def sample(self, N, to_gpu=False, norm_rews=True):
inds = np.random.choice(np.arange(self.filled_i), size=N,
replace=False)
# inds = np.arange(self.filled_i)[0:-1:self.filled_i//N]
if to_gpu:
cast = lambda x: Variable(Tensor(x), requires_grad=False).to(torch.device(self.device))
else:
cast = lambda x: Variable(Tensor(x), requires_grad=False)
if self.rew_buffs[0].sum() == False:
norm_rews = False
if norm_rews:
ret_rews = [cast((self.rew_buffs[i][inds] -
self.rew_buffs[i][:self.filled_i].mean()) /
self.rew_buffs[i][:self.filled_i].std())
for i in range(self.num_agents)]
else:
ret_rews = [cast(self.rew_buffs[i][inds]) for i in range(self.num_agents)]
return ([cast(self.ac_pre_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.ac_buffs[i][inds]) for i in range(self.num_agents)],
ret_rews,
[cast(self.next_obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.done_buffs[i][inds]) for i in range(self.num_agents)])
def get_average_rewards(self, N):
if self.filled_i == self.max_steps:
inds = np.arange(self.curr_i - N, self.curr_i) # allow for negative indexing
else:
inds = np.arange(max(0, self.curr_i - N), self.curr_i)
return [self.rew_buffs[i][inds].mean() for i in range(self.num_agents)]
class ReplayBuffer_RNN(object):
"""
Replay Buffer for multi-agent RL with parallel rollouts
"""
def __init__(self, max_steps, num_agents, obs_dims, ac_dims, ep_dims, device):
"""
Inputs:
max_steps (int): Maximum number of timepoints to store in buffer
num_agents (int): Number of agents in environment
obs_dims (list of ints): number of obervation dimensions for each
agent
ac_dims (list of ints): number of action dimensions for each agent
ep_dims (int): Number of steps in each episode
"""
self.device = device
self.max_steps = max_steps
self.num_agents = num_agents
self.obs_buffs = []
self.ac_buffs = []
self.rew_buffs = []
self.next_obs_buffs = []
self.done_buffs = []
for odim, adim in zip(obs_dims, ac_dims):
self.obs_buffs.append(np.zeros((max_steps, ep_dims, odim)))
self.ac_buffs.append(np.zeros((max_steps, ep_dims, adim)))
self.rew_buffs.append(np.zeros((max_steps, ep_dims)))
self.next_obs_buffs.append(np.zeros((max_steps, ep_dims, odim)))
self.done_buffs.append(np.zeros((max_steps, ep_dims)))
self.filled_i = 0 # index of first empty location in buffer (last index when full)
self.curr_i = 0 # current index to write to (ovewrite oldest data)
def __len__(self):
return self.filled_i
def push(self, observations_ep, actions_ep, rewards_ep, next_observations_ep, dones_ep):
nentries = observations_ep[0].shape[0] # handle multiple parallel environments
observations_ep, actions_ep, rewards_ep, next_observations_ep, dones_ep = \
np.array(observations_ep), np.array(actions_ep), np.array(rewards_ep),\
np.array(next_observations_ep), np.array(dones_ep)
if self.curr_i + nentries > self.max_steps:
rollover = self.max_steps - self.curr_i # num of indices to roll over
for agent_i in range(self.num_agents):
self.obs_buffs[agent_i] = np.roll(self.obs_buffs[agent_i],
rollover, axis=0)
self.ac_buffs[agent_i] = np.roll(self.ac_buffs[agent_i],
rollover, axis=0)
self.rew_buffs[agent_i] = np.roll(self.rew_buffs[agent_i],
rollover)
self.next_obs_buffs[agent_i] = np.roll(
self.next_obs_buffs[agent_i], rollover, axis=0)
self.done_buffs[agent_i] = np.roll(self.done_buffs[agent_i],
rollover)
self.curr_i = 0
self.filled_i = self.max_steps
for agent_i in range(self.num_agents):
for i in range(observations_ep[:,:,agent_i].shape[0]):
if i == 0:
ob_ep = np.expand_dims(np.vstack(observations_ep[:,:,agent_i][i]), 0)
ob_next_ep = np.expand_dims(np.vstack(next_observations_ep[:,:,agent_i][i]), 0)
else:
ob_ep = np.vstack((ob_ep, np.expand_dims(np.vstack(observations_ep[:,:,agent_i][i]), 0)))
ob_next_ep = np.vstack((ob_next_ep, np.expand_dims(np.vstack(next_observations_ep[:,:,agent_i][i]), 0)))
self.obs_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = ob_ep.transpose(1, 0, 2)
# actions are already batched by agent, so they are indexed differently
self.ac_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = actions_ep[:,:,0,:].transpose(1, 0, 2)
self.rew_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = rewards_ep[:, :, agent_i].transpose(1, 0)
self.next_obs_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = ob_next_ep.transpose(1, 0, 2)
self.done_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = dones_ep[:, :, agent_i].transpose(1, 0)
self.curr_i += nentries
if self.filled_i < self.max_steps:
self.filled_i += nentries
if self.curr_i == self.max_steps:
self.curr_i = 0
def sample(self, N, to_gpu=False, norm_rews=True):
inds = np.random.choice(np.arange(self.filled_i), size=N,
replace=False)
if to_gpu:
cast = lambda x: Variable(Tensor(x), requires_grad=False).to(torch.device(self.device))
else:
cast = lambda x: Variable(Tensor(x), requires_grad=False)
if norm_rews:
ret_rews = [cast((self.rew_buffs[i][inds] -
self.rew_buffs[i][:self.filled_i].mean()) /
self.rew_buffs[i][:self.filled_i].std())
for i in range(self.num_agents)]
else:
ret_rews = [cast(self.rew_buffs[i][inds]) for i in range(self.num_agents)]
return ([cast(self.obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.ac_buffs[i][inds]) for i in range(self.num_agents)],
ret_rews,
[cast(self.next_obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.done_buffs[i][inds]) for i in range(self.num_agents)])
def get_average_rewards(self, N):
if self.filled_i == self.max_steps:
inds = np.arange(self.curr_i - N, self.curr_i) # allow for negative indexing
else:
inds = np.arange(max(0, self.curr_i - N), self.curr_i)
return [self.rew_buffs[i][inds].mean() for i in range(self.num_agents)]
================================================
FILE: examples/Social_Cognition/FOToM/utils/env_wrappers.py
================================================
"""
Modified from OpenAI Baselines code to work with multi-agent envs
"""
import numpy as np
from multiprocessing import Process, Pipe
from common.vec_env.vec_env import VecEnv, CloudpickleWrapper
def worker(remote, parent_remote, env_fn_wrapper):
parent_remote.close()
env = env_fn_wrapper.x()
while True:
cmd, data = remote.recv()
if cmd == 'step':
ob, reward, done, info = env.step(data)
if all(done):
ob = env.reset()
remote.send((ob, reward, done, info))
elif cmd == 'reset':
ob = env.reset()
remote.send(ob)
elif cmd == 'reset_task':
ob = env.reset_task()
remote.send(ob)
elif cmd == 'close':
remote.close()
break
elif cmd == 'get_spaces':
remote.send((env.observation_space, env.action_space))
elif cmd == 'get_agent_types':
if all([hasattr(a, 'adversary') for a in env.agents]):
remote.send(['adversary' if a.adversary else 'agent' for a in
env.agents])
else:
remote.send(['agent' for _ in env.agents])
elif cmd == 'get_num_landmarks':
remote.send(len(env.world.landmarks))
else:
raise NotImplementedError
class SubprocVecEnv(VecEnv):
def __init__(self, env_fns, spaces=None):
"""
envs: list of gym environments to run in subprocesses
"""
self.waiting = False
self.closed = False
nenvs = len(env_fns)
self.remotes, self.work_remotes = zip(*[Pipe() for _ in range(nenvs)])
self.ps = [Process(target=worker, args=(work_remote, remote, CloudpickleWrapper(env_fn)))
for (work_remote, remote, env_fn) in zip(self.work_remotes, self.remotes, env_fns)]
for p in self.ps:
p.daemon = True # if the main process crashes, we should not cause things to hang
p.start()
for remote in self.work_remotes:
remote.close()
self.remotes[0].send(('get_spaces', None))
observation_space, action_space = self.remotes[0].recv()
self.remotes[0].send(('get_agent_types', None))
self.agent_types = self.remotes[0].recv()
self.remotes[0].send(('get_num_landmarks', None))
self.num_lm = self.remotes[0].recv()
VecEnv.__init__(self, len(env_fns), observation_space, action_space)
def step_async(self, actions):
for remote, action in zip(self.remotes, actions):
remote.send(('step', action))
self.waiting = True
def step_wait(self):
results = [remote.recv() for remote in self.remotes]
self.waiting = False
obs, rews, dones, infos = zip(*results)
return np.stack(obs), np.stack(rews), np.stack(dones), infos
def reset(self):
for remote in self.remotes:
remote.send(('reset', None))
return np.stack([remote.recv() for remote in self.remotes])
def reset_task(self):
for remote in self.remotes:
remote.send(('reset_task', None))
return np.stack([remote.recv() for remote in self.remotes])
def close(self):
if self.closed:
return
if self.waiting:
for remote in self.remotes:
remote.recv()
for remote in self.remotes:
remote.send(('close', None))
for p in self.ps:
p.join()
self.closed = True
class DummyVecEnv(VecEnv):
def __init__(self, env_fns):
self.envs = [fn() for fn in env_fns]
env = self.envs[0]
VecEnv.__init__(self, len(env_fns), env.observation_space, env.action_space)
if all([hasattr(a, 'adversary') for a in env.agents]):
self.agent_types = ['adversary' if a.adversary else 'agent' for a in
env.agents]
else:
self.agent_types = ['agent' for _ in env.agents]
self.ts = np.zeros(len(self.envs), dtype='int')
self.actions = None
def step_async(self, actions):
self.actions = actions
def step_wait(self):
results = [env.step(a) for (a,env) in zip(self.actions, self.envs)]
obs, rews, dones, infos = map(np.array, zip(*results))
self.ts += 1
for (i, done) in enumerate(dones):
if all(done):
obs[i] = self.envs[i].reset()
self.ts[i] = 0
self.actions = None
return np.array(obs), np.array(rews), np.array(dones), infos
def reset(self):
results = [env.reset() for env in self.envs]
return np.array(results)
def close(self):
return
================================================
FILE: examples/Social_Cognition/FOToM/utils/make_env.py
================================================
"""
Code for creating a multiagent environment with one of the scenarios listed
in ./scenarios/.
Can be called by using, for example:
env = make_env('simple_speaker_listener')
After producing the env object, can be used similarly to an OpenAI gym
environment.
A policy using this environment must output actions in the form of a list
for all agents. Each element of the list should be a numpy array,
of size (env.world.dim_p + env.world.dim_c, 1). Physical actions precede
communication actions in this array. See environment.py for more details.
"""
def make_env(scenario_name, num_good_agents, num_adversaries, benchmark=False, discrete_action=False):
'''
Creates a MultiAgentEnv object as env. This can be used similar to a gym
environment by calling env.reset() and env.step().
Use env.render() to view the environment on the screen.
Input:
scenario_name : name of the scenario from ./scenarios/ to be Returns
(without the .py extension)
benchmark : whether you want to produce benchmarking data
(usually only done during evaluation)
Some useful env properties (see environment.py):
.observation_space : Returns the observation space for each agent
.action_space : Returns the action space for each agent
.n : Returns the number of Agents
'''
from multiagent.environment import MultiAgentEnv
import multiagent.scenarios as scenarios
# load scenario from script
scenario = scenarios.load(scenario_name + ".py").Scenario()
# create world
world = scenario.make_world(num_good_agents, num_adversaries)
# create multiagent environment
if benchmark:
env = MultiAgentEnv(world, scenario.reset_world, scenario.reward,
scenario.observation, scenario.benchmark_data)
else:
env = MultiAgentEnv(world, scenario.reset_world, scenario.reward,
scenario.observation)
return env
================================================
FILE: examples/Social_Cognition/FOToM/utils/misc.py
================================================
import os
import torch
import torch.nn.functional as F
import torch.distributed as dist
from torch.autograd import Variable
import numpy as np
# https://github.com/ikostrikov/pytorch-ddpg-naf/blob/master/ddpg.py#L11
def soft_update(target, source, tau):
"""
Perform DDPG soft update (move target params toward source based on weight
factor tau)
Inputs:
target (torch.nn.Module): Net to copy parameters to
source (torch.nn.Module): Net whose parameters to copy
tau (float, 0 < x < 1): Weight factor for update
"""
for target_param, param in zip(target.parameters(), source.parameters()):
target_param.data.copy_(target_param.data * (1.0 - tau) + param.data * tau)
# https://github.com/ikostrikov/pytorch-ddpg-naf/blob/master/ddpg.py#L15
def hard_update(target, source):
"""
Copy network parameters from source to target
Inputs:
target (torch.nn.Module): Net to copy parameters to
source (torch.nn.Module): Net whose parameters to copy
"""
for target_param, param in zip(target.parameters(), source.parameters()):
target_param.data.copy_(param.data)
# https://github.com/seba-1511/dist_tuto.pth/blob/gh-pages/train_dist.py
def average_gradients(model):
""" Gradient averaging. """
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM, group=0)
param.grad.data /= size
# https://github.com/seba-1511/dist_tuto.pth/blob/gh-pages/train_dist.py
def init_processes(rank, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
def onehot_from_logits(logits, eps=0.0):
"""
Given batch of logits, return one-hot sample using epsilon greedy strategy
(based on given epsilon)
"""
# get best (according to current policy) actions in one-hot form
argmax_acs = (logits == logits.max(1, keepdim=True)[0]).float()
if eps == 0.0:
return argmax_acs
# get random actions in one-hot form
rand_acs = Variable(torch.eye(logits.shape[1])[[np.random.choice(
range(logits.shape[1]), size=logits.shape[0])]], requires_grad=False)
# chooses between best and random actions using epsilon greedy
return torch.stack([argmax_acs[i] if r > eps else rand_acs[i] for i, r in
enumerate(torch.rand(logits.shape[0]))])
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def sample_gumbel(shape, eps=1e-20, tens_type=torch.FloatTensor):
"""Sample from Gumbel(0, 1)"""
U = Variable(tens_type(*shape).uniform_(), requires_grad=False)
return -torch.log(-torch.log(U + eps) + eps)
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def gumbel_softmax_sample(logits, temperature):
""" Draw a sample from the Gumbel-Softmax distribution"""
y = logits + sample_gumbel(logits.shape, tens_type=type(logits.data)).to(logits.device)
return F.softmax(y / temperature, dim=1)
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def gumbel_softmax(logits, temperature=1.0, hard=False):
"""Sample from the Gumbel-Softmax distribution and optionally discretize.
Args:
logits: [batch_size, n_class] unnormalized log-probs
temperature: non-negative scalar
hard: if True, take argmax, but differentiate w.r.t. soft sample y
Returns:
[batch_size, n_class] sample from the Gumbel-Softmax distribution.
If hard=True, then the returned sample will be one-hot, otherwise it will
be a probabilitiy distribution that sums to 1 across classes
"""
y = gumbel_softmax_sample(logits, temperature)
if hard:
y_hard = onehot_from_logits(y)
y = (y_hard - y).detach() + y
return y
================================================
FILE: examples/Social_Cognition/FOToM/utils/multiprocessing.py
================================================
# This code is from openai baseline
# https://github.com/openai/baselines/tree/master/baselines/common/vec_env
import time
import matplotlib.pyplot as plt
import numpy as np
from multiprocessing import Process, Pipe
def _flatten_list(l):
assert isinstance(l, (list, tuple))
assert len(l) > 0
assert all([len(l_) > 0 for l_ in l])
return [l__ for l_ in l for l__ in l_]
def worker(remote, parent_remote, env_fn_wrapper):
parent_remote.close()
env = env_fn_wrapper.x()
while True:
cmd, data = remote.recv()
if cmd == 'step':
ob, reward, done, info = env.step(data)
if done:
ob = env.reset()
remote.send((ob, reward, done, info))
elif cmd == 'reset':
ob = env.reset()
remote.send(ob)
elif cmd == 'reset_task':
ob = env.reset_task()
remote.send(ob)
elif cmd == 'world':
remote.send(env.world)
elif cmd == 'render':
ob = env.render(mode='rgb_array')
# print(len(ob), 'len(frames)')
# print(len(ob[0]), 'len(frames[0])')
# print(len(ob[0][0]), 'len(frames[0][0])')
remote.send(ob) # rgb_array
elif cmd == 'observe':
ob = env.observe(data)
remote.send(ob)
elif cmd == 'agents':
remote.send(env.agents)
elif cmd == 'spec':
remote.send(env.spec)
elif cmd == 'get_spaces':
remote.send((env.observation_space, env.action_space))
elif cmd == 'close':
remote.close()
break
else:
raise NotImplementedError
class VecEnv(object):
"""
An abstract asynchronous, vectorized environment.
"""
closed = False
viewer = None
metadata = {
'render.modes': ['human', 'rgb_array']
}
def __init__(self, num_envs, observation_space, action_space):
self.num_envs = num_envs
self.observation_space = observation_space
self.action_space = action_space
def observe(self, agent):
pass
def reset(self):
"""
Reset all the environments and return an array of
observations, or a tuple of observation arrays.
If step_async is still doing work, that work will
be cancelled and step_wait() should not be called
until step_async() is invoked again.
"""
pass
def step_async(self, actions):
"""
Tell all the environments to start taking a step
with the given actions.
Call step_wait() to get the results of the step.
You should not call this if a step_async run is
already pending.
"""
pass
def step_wait(self):
"""
Wait for the step taken with step_async().
Returns (obs, rews, dones, infos):
- obs: an array of observations, or a tuple of
arrays of observations.
- rews: an array of rewards
- dones: an array of "episode done" booleans
- infos: a sequence of info objects
"""
pass
def close(self):
"""
Clean up the environments' resources.
"""
pass
def step(self, actions):
self.step_async(actions)
return self.step_wait()
def render(self, mode='human'):
imgs = self.get_images()
bigimg = self.tile_images(imgs)
if mode == 'human':
self.get_viewer().imshow(bigimg) #
return self.get_viewer().isopen
elif mode == 'rgb_array':
return bigimg
else:
raise NotImplementedError
def get_images(self):
"""
Return RGB images from each environment
"""
raise NotImplementedError
def get_viewer(self):
if self.viewer is None:
from common import rendering
self.viewer = rendering.SimpleImageViewer()
return self.viewer
def tile_images(self, img_nhwc):
"""
Tile N images into one big PxQ image
(P,Q) are chosen to be as close as possible, and if N
is square, then P=Q.
input: img_nhwc, list or array of images, ndim=4 once turned into array
n = batch index, h = height, w = width, c = channel
returns:
bigim_HWc, ndarray with ndim=3
"""
img_nhwc = np.asarray(img_nhwc)
N, h, w, c = img_nhwc.shape
H = int(np.ceil(np.sqrt(N)))
W = int(np.ceil(float(N) / H))
img_nhwc = np.array(list(img_nhwc) + [img_nhwc[0] * 0 for _ in range(N, H * W)])
img_HWhwc = img_nhwc.reshape(H, W, h, w, c)
img_HhWwc = img_HWhwc.transpose(0, 2, 1, 3, 4)
img_Hh_Ww_c = img_HhWwc.reshape(H * h, W * w, c)
return img_Hh_Ww_c
class CloudpickleWrapper(object):
"""
Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)
"""
def __init__(self, x):
self.x = x
def __getstate__(self):
import cloudpickle
return cloudpickle.dumps(self.x)
def __setstate__(self, ob):
import pickle
self.x = pickle.loads(ob)
class SubprocVecEnv(VecEnv):
def __init__(self, env_fns, spaces=None):
"""
envs_sc: list of gym environments to run in subprocesses
"""
# self.venv = venv
self.waiting = False
self.closed = False
nenvs = len(env_fns)
self.nenvs = nenvs
self.remotes, self.work_remotes = zip(*[Pipe() for _ in range(nenvs)])
self.ps = [Process(target=worker, args=(work_remote, remote, CloudpickleWrapper(env_fn)))
for (work_remote, remote, env_fn) in zip(self.work_remotes, self.remotes, env_fns)]
for p in self.ps:
p.daemon = True # if the main process crashes, we should not cause things to hang
p.start()
for remote in self.work_remotes:
remote.close()
self.remotes[0].send(('get_spaces', None))
observation_space, action_space = self.remotes[0].recv()
VecEnv.__init__(self, len(env_fns), observation_space, action_space)
def step_async(self, actions):
for remote, action in zip(self.remotes, actions): # the input of step() : action
remote.send(('step', action))
self.waiting = True
def step_wait(self):
results = [remote.recv() for remote in self.remotes] # the output of step() : zip(*results)
self.waiting = False
obs, rews, dones, infos = zip(*results)
return np.stack(obs), np.stack(rews), np.stack(dones), infos
def step_wait_2(self):
results = [remote.recv() for remote in self.remotes]
self.waiting = False
reward, done, _cumulative_rewards = zip(*results)
return reward, done, _cumulative_rewards
def step_wait_3(self):
results = [remote.recv() for remote in self.remotes] # the output of step() : zip(*results)
self.waiting = False
obs, rews, dones, infos = zip(*results)
return np.stack(obs), np.stack(rews), np.stack(dones), infos
def reset(self):
for remote in self.remotes:
remote.send(('reset', None))
return np.stack([remote.recv() for remote in self.remotes])
def agents(self):
for remote in self.remotes:
remote.send(('agents', None))
return np.stack([remote.recv() for remote in self.remotes])
def world(self):
for remote in self.remotes:
remote.send(('world', None))
return np.stack([remote.recv() for remote in self.remotes])
def reset_task(self):
for remote in self.remotes:
remote.send(('reset_task', None))
return np.stack([remote.recv() for remote in self.remotes])
def spec(self):
for remote in self.remotes:
remote.send(('spec', None))
return np.stack([remote.recv() for remote in self.remotes])
def get_images(self):
# self._assert_not_closed()
for pipe in self.remotes:
pipe.send(('render', None))
imgs = [pipe.recv() for pipe in self.remotes]
# imgs = _flatten_list(imgs)
return imgs
def observe(self, agent):
for remote, agent in zip(self.remotes, agent):
remote.send(('observe', agent))
return np.stack([remote.recv() for remote in self.remotes])
# def render(self, mode='human'):
# return self.venv.render(mode=mode)
def close(self):
if self.closed:
return
if self.waiting:
for remote in self.remotes:
remote.recv()
for remote in self.remotes:
remote.send(('close', None))
for p in self.ps:
p.join()
self.closed = True
def __len__(self):
return self.nenvs
def _flatten_list(l):
assert isinstance(l, (list, tuple))
assert len(l) > 0
assert all([len(l_) > 0 for l_ in l])
return [l__ for l_ in l for l__ in l_]
class DummyVecEnv(VecEnv):
def __init__(self, env_fns):
self.envs = [fn() for fn in env_fns]
env = self.envs[0]
VecEnv.__init__(self, len(env_fns), env.observation_space, env.action_space)
if all([hasattr(a, 'adversary') for a in env.agents]):
self.agent_types = ['adversary' if a.adversary else 'agent' for a in
env.agents]
else:
self.agent_types = ['agent' for _ in env.agents]
self.ts = np.zeros(len(self.envs), dtype='int')
self.actions = None
def step_async(self, actions):
self.actions = actions
def step_wait(self):
results = [env.step(a) for (a,env) in zip(self.actions, self.envs)]
obs, rews, dones, infos = map(np.array, zip(*results))
self.ts += 1
for (i, done) in enumerate(dones):
if all(done):
obs[i] = self.envs[i].reset()
self.ts[i] = 0
self.actions = None
return np.array(obs), np.array(rews), np.array(dones), infos
def reset(self):
results = [env.reset() for env in self.envs]
return np.array(results)
def close(self):
return
================================================
FILE: examples/Social_Cognition/FOToM/utils/networks.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
class MLPNetwork(nn.Module):
"""
MLP network (can be used as value or policy)
"""
def __init__(self, input_dim, out_dim, hidden_dim=64, nonlin=F.relu,
constrain_out=False, norm_in=True, discrete_action=True):
"""
Inputs:
input_dim (int): Number of dimensions in input
out_dim (int): Number of dimensions in output
hidden_dim (int): Number of hidden dimensions
nonlin (PyTorch function): Nonlinearity to apply to hidden layers
"""
super(MLPNetwork, self).__init__()
if norm_in: # normalize inputs
self.in_fn = nn.BatchNorm1d(input_dim) #train
# self.in_fn = input_dim #test
self.in_fn.weight.data.fill_(1)
self.in_fn.bias.data.fill_(0)
else:
self.in_fn = lambda x: x
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, out_dim)
self.nonlin = nonlin
if constrain_out and not discrete_action:
# initialize small to prevent saturation
self.fc3.weight.data.uniform_(-3e-3, 3e-3)
self.out_fn = F.tanh
else: # logits for discrete action (will softmax later)
self.out_fn = lambda x: x
def forward(self, X):
"""
Inputs:
X (PyTorch Matrix): Batch of observations
Outputs:
out (PyTorch Matrix): Output of network (actions, values, etc)
"""
h1 = self.nonlin(self.fc1(self.in_fn(X)))
h2 = self.nonlin(self.fc2(h1))
out = self.out_fn(self.fc3(h2))
return out
class RNN(nn.Module):
# Because all the agents_sc share the same network_sc, input_shape=obs_shape+n_actions+n_agents
def __init__(self, input_dim, out_dim, hidden_dim=64, nonlin=F.relu,
constrain_out=False, norm_in=True, discrete_action=True):
super(RNN, self).__init__()
self.rnn_hidden_dim = hidden_dim
if norm_in: # normalize inputs
self.in_fn = nn.BatchNorm1d(input_dim)
self.in_fn.weight.data.fill_(1)
self.in_fn.bias.data.fill_(0)
else:
self.in_fn = lambda x: x
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.rnn = nn.GRUCell(hidden_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, out_dim)
self.nonlin = nonlin
if constrain_out and not discrete_action:
# initialize small to prevent saturation
self.fc3.weight.data.uniform_(-3e-3, 3e-3)
self.out_fn = F.tanh
else: # logits for discrete action (will softmax later)
self.out_fn = lambda x: x
def forward(self, obs, hidden_state):
x = self.nonlin(self.fc1(obs))
# x = x.reshape(-1, self.rnn_hidden_dim)
# h_in = hidden_state.reshape(-1, self.rnn_hidden_dim)
h = self.rnn(x, hidden_state)
q = self.fc2(h)
return q, h
class BCNoSpikingLIFNode(LIFNode):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self, dv: torch.Tensor):
self.integral(dv)
return self.mem
class SNNNetwork(nn.Module):
"""
SNN network (can be used as value or policy or MLE)
"""
def __init__(self, input_dim, out_dim, hidden_dim=64, node=LIFNode, time_window=16,
norm_in=True, output_style='sum'):
"""
Inputs:
input_dim (int): Number of dimensions in input
out_dim (int): Number of dimensions in output
hidden_dim (int): Number of hidden dimensions
nonlin (PyTorch function): Nonlinearity to apply to hidden layers
"""
super(SNNNetwork, self).__init__()
self._threshold = 0.5
self.v_reset = 0.0
self._time_window = time_window
self.output_style = output_style
self._node1 = node(threshold=self._threshold, v_reset=self.v_reset)
self._node2 = node(threshold=self._threshold, v_reset=self.v_reset)
if norm_in: # normalize inputs
self.in_fn = nn.BatchNorm1d(input_dim) #train
self.in_fn.weight.data.fill_(1)
self.in_fn.bias.data.fill_(0)
else:
self.in_fn = lambda x: x
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, out_dim)
if self.output_style == 'sum':
self._out_node = lambda x: x
elif self.output_style == 'voltage':
self._out_node = BCNoSpikingLIFNode()
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def forward(self, X):
qs = []
self.reset()
for t in range(self._time_window):
x = self.fc1((self.in_fn(X)+0.5)) #train
# x = self.fc1((X + 0.5)) #test
x = self._node1(x)
x = self.fc2(x)
x = self._node2(x)
x = self.fc3(x)
x = self._out_node(x)
qs.append(x)
if self.output_style == 'sum':
outputs = sum(qs) / self._time_window
return outputs
elif self.output_style == 'voltage':
outputs = x
return outputs
class LSTMClassifier(nn.Module):
def __init__(self, input_size, output_size, hidden_size=256):
super(LSTMClassifier, self).__init__()
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=1, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = x.unsqueeze(1)
output, (h, c) = self.lstm(x)
output = output.squeeze(1)
out = self.fc(output)
return out
================================================
FILE: examples/Social_Cognition/FOToM/utils/noise.py
================================================
import numpy as np
# from https://github.com/songrotek/DDPG/blob/master/ou_noise.py
class OUNoise:
def __init__(self, action_dimension, scale=0.1, mu=0, theta=0.15, sigma=0.2):
self.action_dimension = action_dimension
self.scale = scale
self.mu = mu
self.theta = theta
self.sigma = sigma
self.state = np.ones(self.action_dimension) * self.mu
self.reset()
def reset(self):
self.state = np.ones(self.action_dimension) * self.mu
def noise(self):
x = self.state
dx = self.theta * (self.mu - x) + self.sigma * np.random.randn(len(x))
self.state = x + dx
return self.state * self.scale
================================================
FILE: examples/Social_Cognition/Intention_Prediction/Intention_Prediction.py
================================================
import numpy as np
import torch,os,sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
import matplotlib.pyplot as plt
from BrainCog.base.strategy.surrogate import *
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import random
from BrainCog.base.node.node import *
from BrainCog.base.learningrule.STDP import MutliInputSTDP
class CustomLinear(nn.Module):
def __init__(self, weight,mask=None):
super().__init__()
self.weight = nn.Parameter(weight, requires_grad=True)
self.mask=mask
def forward(self, x: torch.Tensor):
#
# ret.shape = [C]
return x.mul(self.weight) # Changed
def update(self, dw):
with torch.no_grad():
if self.mask is not None:
dw *= self.mask
self.weight.data+= dw
class DLPFCNet(nn.Module):
def __init__(self,connection):
super().__init__()
# DLPFC, BG
self.node = []
self.node.append(IzhNodeMU(threshold=30., a=0.02, b=0.60, c=-65., d=8., mem=-70.))
self.node.append(IzhNodeMU(threshold=30., a=0.02, b=0.60, c=-65., d=8., mem=-70.))
self.learning_rule = []
self.connection = connection
self.out_DLPFC=torch.zeros((self.connection[0].weight.shape[1]), dtype=torch.float) # Input-DLPFC
self.out_BG=torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float) # DLPFC-BG
def forward(self, input):
self.out_DLPFC=self.node[0](self.connection[0](input))
self.out_BG=self.node[1](self.connection[1](self.out_DLPFC))
BG_Spike = self.node[1].spike
if sum(sum(BG_Spike)).item() > 1:
num_neuron = len(BG_Spike)
BG_Spike_index = torch.argmax(BG_Spike)
BG_Spike_index_x = torch.floor(BG_Spike_index/num_neuron)
BG_Spike_index_y = BG_Spike_index - BG_Spike_index_x*num_neuron
BG_Spike = torch.zeros([num_neuron, num_neuron], dtype=torch.float)
BG_Spike[BG_Spike_index_x.long()][BG_Spike_index_y.long()] = 1
return BG_Spike
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def UpdateWeight(self, i, W):
self.connection[i].weight.data = W
class OFCNet(nn.Module):
def __init__(self,connection):
super().__init__()
# OFC, MOFC, LOFC
self.node = []
self.node.append(IzhNodeMU(threshold=30., a=0.02, b=0.60, c=-65., d=8., mem=-70.)) # OFC_1
self.node.append(IzhNodeMU(threshold=30., a=0.02, b=0.60, c=-65., d=8., mem=-70.)) # OFC_2
self.node.append(IzhNodeMU(threshold=30., a=0.02, b=0.60, c=-65., d=8., mem=-70.)) # MOFC
self.node.append(IzhNodeMU(threshold=30., a=0.02, b=0.60, c=-65., d=8., mem=-70.)) # LOFC
self.connection = connection
self.learning_rule = []
self.learning_rule.append(MutliInputSTDP(self.node[3], [self.connection[3],self.connection[4]])) # OFC_2-LOFC, MOFC-LOFC
self.learning_rule.append(MutliInputSTDP(self.node[3], [self.connection[3],self.connection[5]])) # OFC_2-LOFC, OFC_1-LOFC
self.out_OFC_1=torch.zeros((self.connection[0].weight.shape[1]), dtype=torch.float)
self.out_OFC_2=torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float)
self.out_MOFC=torch.zeros((self.connection[2].weight.shape[1]), dtype=torch.float)
self.out_LOFC=torch.zeros((self.connection[5].weight.shape[1]), dtype=torch.float)
def forward(self, Input_Tha, Input_SNc, Reward):
self.out_OFC_1 = self.node[0](self.connection[0](Input_Tha))
self.out_OFC_2 = self.node[1](self.connection[1](Input_SNc))
if Reward == 1:
self.out_MOFC = self.node[2](self.connection[2](self.out_OFC_1))
self.out_LOFC, dw_lofc = self.learning_rule[0](self.out_OFC_2, self.out_MOFC)
else:
self.out_MOFC = self.node[2](self.connection[2](self.out_OFC_1*0))
self.out_LOFC, dw_lofc = self.learning_rule[1](self.out_OFC_2, self.out_OFC_1)
MOFC_Spike = self.node[2].spike
LOFC_Spike = self.node[3].spike
return MOFC_Spike, LOFC_Spike
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
class BGNet(nn.Module):
def __init__(self,connection):
super().__init__()
# DLPFC, StrD1, StrD2
self.node = []
self.node.append(IzhNodeMU(threshold=30., a=0.02, b=0.60, c=-65., d=8., mem=-70.)) # DLPFC
self.node.append(IzhNodeMU(threshold=30., a=0.01, b=0.01, c=-65., d=8., mem=-70.)) # StrD1
self.node.append(IzhNodeMU(threshold=30., a=0.1, b=0.5, c=-65., d=8., mem=-70.)) # StrD2
self.connection = connection
self.learning_rule = []
self.out_DLPFC=torch.zeros((self.connection[0].weight.shape[1]), dtype=torch.float)
self.out_StrD1=torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float)
self.out_StrD2=torch.zeros((self.connection[2].weight.shape[1]), dtype=torch.float)
def forward(self, input1, input2, input3):
self.out_DLPFC=self.node[0](self.connection[0](input1))
self.out_StrD1=self.node[1](self.connection[1](input2))
self.out_StrD2=self.node[2](self.connection[2](input3))
DLPFC_out = self.node[0].spike
BG_out = self.node[1].spike + self.node[2].spike
return DLPFC_out, BG_out
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def UpdateWeight(self, i, W):
self.connection[i].weight.data = W
def STDP(Pre_mat, Post_mat, W):
T_Pre = 0
T_Post = 0
for i in range(len(Pre_mat)):
C_Pre = Pre_mat[i]
C_Post = Post_mat[i]
if sum(sum(C_Pre)) > 0:
T_Pre = i
Spike_Pre = Pre_mat[T_Pre]
if sum(sum(C_Post)) > 0:
T_Post = i
Spike_Post = Post_mat[T_Post]
if T_Pre*T_Post > 0:
dT = T_Pre - T_Post
A_up = 0.777
A_down = -0.237
tau_up = 16.8
tau_down = -33.7
if dT < 0:
dW = A_up * math.exp(dT/tau_up)
else:
dW = A_down * math.exp(dT/tau_down)
T_Post = 0
dW_mat = torch.mul(Spike_Pre, Spike_Post)*dW
W = W + torch.mul(dW_mat, W)
return W
if __name__=="__main__":
# number of neurons
num_neuron = 6
num_DLPFC = num_neuron
num_BG = num_neuron
num_StrD1 = num_neuron
num_StrD2 = num_neuron
num_Thalamus = num_neuron
num_OFC = num_neuron
num_SNc = num_neuron
num_PMC = num_neuron
##############################
# DLPFC
##############################
WeightAdd = 20
# DLPFC-BG
DLPFC_BG_connection = []
# Input-DLPFC
con_matrix0 = torch.ones([num_DLPFC, num_DLPFC], dtype=torch.float)*WeightAdd
DLPFC_BG_connection.append(CustomLinear(con_matrix0))
# DLPFC-BG
W = torch.ones([num_DLPFC, num_BG], dtype=torch.float)*WeightAdd
DLPFC_BG_connection.append(CustomLinear(W))
DLPFC = DLPFCNet(DLPFC_BG_connection)
##############################
# OFC
##############################
WeightAdd = 20
OFC_connection = []
# Tha-OFC_1 (Input1)
con_matrix0 = torch.ones([num_Thalamus, num_OFC], dtype=torch.float)*WeightAdd
OFC_connection.append(CustomLinear(con_matrix0))
# SNc/VTA-OFC_2 (Input2)
con_matrix1 = torch.ones([num_SNc, num_OFC], dtype=torch.float)*WeightAdd
OFC_connection.append(CustomLinear(con_matrix1))
# OFC_1-MOFC
con_matrix2 = torch.ones([num_OFC, num_OFC], dtype=torch.float)*WeightAdd*5
OFC_connection.append(CustomLinear(con_matrix2))
# OFC_2-LOFC
con_matrix3 = torch.ones([num_OFC, num_OFC], dtype=torch.float)*WeightAdd*5
OFC_connection.append(CustomLinear(con_matrix3))
# MOFC-LOFC
con_matrix4 = torch.ones([num_OFC, num_OFC], dtype=torch.float)*WeightAdd*-10
OFC_connection.append(CustomLinear(con_matrix4))
# OFC_1-LOFC
con_matrix5 = torch.ones([num_OFC, num_OFC], dtype=torch.float)*WeightAdd*5
OFC_connection.append(CustomLinear(con_matrix5))
OFC = OFCNet(OFC_connection)
##############################
# BGNet
##############################
BG_connection = []
WeightAdd = 20
# Input1-DLPFC
con_matrix0 = torch.ones([num_DLPFC, num_DLPFC], dtype=torch.float)*WeightAdd
BG_connection.append(CustomLinear(con_matrix0))
# Input2-StrD1
con_matrix1 = torch.ones([num_StrD1,num_StrD1], dtype=torch.float)*WeightAdd
BG_connection.append(CustomLinear(con_matrix1))
# Input3-StrD2
con_matrix2 = torch.ones([num_StrD2,num_StrD2], dtype=torch.float)*WeightAdd
BG_connection.append(CustomLinear(con_matrix2))
BG_connection.append(CustomLinear(W))
# StrD1-BG
con_matrix4 = torch.ones([num_StrD1,num_BG], dtype=torch.float)*WeightAdd
BG_connection.append(CustomLinear(con_matrix4))
# StrD2-BG
con_matrix5 = torch.ones([num_StrD2,num_BG], dtype=torch.float)*WeightAdd
BG_connection.append(CustomLinear(con_matrix5))
BG = BGNet(BG_connection)
##############################
# Train
##############################
# Intention-action corresponding rules
Intention_mat = range(num_neuron)
Action_mat = range(num_neuron)
TrainNum = 0
for k in range(len(Intention_mat)):
Intention = Intention_mat[k]
Intention_Action = Action_mat[k]
for j in range (len(Intention_mat)+1):
TrainNum = TrainNum + 1
# Intention prediction
for i in range(10):
DLPFC_Input = torch.zeros([num_DLPFC, num_DLPFC], dtype=torch.float)
DLPFC_Input[Intention,:] = 10
BG_Spike = DLPFC(DLPFC_Input)
if sum(sum(BG_Spike)).item() > 0:
Action = torch.nonzero(BG_Spike).numpy()[0][1]
break
DLPFC.reset()
PMC = torch.zeros([1, num_PMC], dtype=torch.float)
PMC[0][Action] = 1
Thalamus = torch.zeros([num_Thalamus, num_Thalamus], dtype=torch.float)
Thalamus[Intention][Action] = 10
if Intention_Action == Action:
# Positive reward
# Tha-OFC_1-MOFC, SNc-OFC_2&MOFC-LOFC
Reward = 1
Input_Tha = Thalamus
Input_SNc_Reward = torch.ones([num_OFC, num_OFC], dtype=torch.float)
Input_SNc = torch.mul(Input_SNc_Reward, PMC)*10
for t in range(10):
MOFC_Spike, LOFC_Spike = OFC(Input_Tha, Input_SNc, Reward)
else:
# Negative reward
# Tha-OFC_1-LOFC, SNc-OFC_2-LOFC (SNC is zeros)
Reward = -1
Input_Tha = Thalamus
Input_SNc = torch.zeros([num_OFC, num_OFC], dtype=torch.float)
for t in range(10):
MOFC_Spike, LOFC_Spike = OFC(Input_Tha, Input_SNc, Reward)
OFC.reset()
for i in range(1):
DLPFC_out_mat = []
BG_out_mat = []
State = 0
for t in range(10):
DLPFC_Input = MOFC_Spike + LOFC_Spike
StrD1_Input = MOFC_Spike
StrD2_Input = LOFC_Spike
DLPFC_out, BG_out = BG(DLPFC_Input, StrD1_Input, StrD2_Input)
DLPFC_out_mat.append(DLPFC_out)
BG_out_mat.append(BG_out)
W = STDP(DLPFC_out_mat, BG_out_mat, W)
BG.reset()
DLPFC.UpdateWeight(1, W)
BG.UpdateWeight(3, W)
if Reward == 1:
break
print("Train End")
print("W is: \n", W)
print("TrainNum is: \n", TrainNum)
print("*****************************")
================================================
FILE: examples/Social_Cognition/MAToM-SNN/LICENSE
================================================
GNU GENERAL PUBLIC LICENSE
Version 3, 29 June 2007
Copyright (C) 2007 Free Software Foundation, Inc.
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU General Public License is a free, copyleft license for
software and other kinds of works.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
the GNU General Public License is intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users. We, the Free Software Foundation, use the
GNU General Public License for most of our software; it applies also to
any other work released this way by its authors. You can apply it to
your programs, too.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
To protect your rights, we need to prevent others from denying you
these rights or asking you to surrender the rights. Therefore, you have
certain responsibilities if you distribute copies of the software, or if
you modify it: responsibilities to respect the freedom of others.
For example, if you distribute copies of such a program, whether
gratis or for a fee, you must pass on to the recipients the same
freedoms that you received. You must make sure that they, too, receive
or can get the source code. And you must show them these terms so they
know their rights.
Developers that use the GNU GPL protect your rights with two steps:
(1) assert copyright on the software, and (2) offer you this License
giving you legal permission to copy, distribute and/or modify it.
For the developers' and authors' protection, the GPL clearly explains
that there is no warranty for this free software. For both users' and
authors' sake, the GPL requires that modified versions be marked as
changed, so that their problems will not be attributed erroneously to
authors of previous versions.
Some devices are designed to deny users access to install or run
modified versions of the software inside them, although the manufacturer
can do so. This is fundamentally incompatible with the aim of
protecting users' freedom to change the software. The systematic
pattern of such abuse occurs in the area of products for individuals to
use, which is precisely where it is most unacceptable. Therefore, we
have designed this version of the GPL to prohibit the practice for those
products. If such problems arise substantially in other domains, we
stand ready to extend this provision to those domains in future versions
of the GPL, as needed to protect the freedom of users.
Finally, every program is threatened constantly by software patents.
States should not allow patents to restrict development and use of
software on general-purpose computers, but in those that do, we wish to
avoid the special danger that patents applied to a free program could
make it effectively proprietary. To prevent this, the GPL assures that
patents cannot be used to render the program non-free.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Use with the GNU Affero General Public License.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU Affero General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the special requirements of the GNU Affero General Public License,
section 13, concerning interaction through a network will apply to the
combination as such.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU General Public License from time to time. Such new versions will
be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
state the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
Copyright (C)
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see .
Also add information on how to contact you by electronic and paper mail.
If the program does terminal interaction, make it output a short
notice like this when it starts in an interactive mode:
Copyright (C)
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
This is free software, and you are welcome to redistribute it
under certain conditions; type `show c' for details.
The hypothetical commands `show w' and `show c' should show the appropriate
parts of the General Public License. Of course, your program's commands
might be different; for a GUI interface, you would use an "about box".
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU GPL, see
.
The GNU General Public License does not permit incorporating your program
into proprietary programs. If your program is a subroutine library, you
may consider it more useful to permit linking proprietary applications with
the library. If this is what you want to do, use the GNU Lesser General
Public License instead of this License. But first, please read
.
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/agents/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/agents/agents.py
================================================
import torch
from torch import Tensor
from torch.autograd import Variable
from torch.optim import Adam
from MPE.utils.networks import MLPNetwork, RNN, SNNNetwork
from MPE.utils.misc import hard_update, gumbel_softmax, onehot_from_logits
from MPE.utils.noise import OUNoise
import time
class DDPGAgent(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, hidden_dim=64,
lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.policy = MLPNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.critic = MLPNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
self.target_policy = MLPNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.target_critic = MLPNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action = self.policy(obs)
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1)
else:
action = gumbel_softmax(action, hard=True)
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5]), onehot_from_logits(action[:, 5:])), 1)
else:
action = onehot_from_logits(action)
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
return {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict()}
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
class DDPGAgent_RNN(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, hidden_dim=64,
lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.policy = RNN(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.critic = RNN(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
self.target_policy = RNN(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.target_critic = RNN(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
self.policy_hidden = None
self.policy_target_hidden = None
self.critic_hidden = None
self.critic_target_hidden = None
self.num_in_pol = num_in_pol
self.num_out_pol = num_out_pol
self.hidden_dim = hidden_dim
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action, self.policy_hidden = self.policy(obs, self.policy_hidden)
if self.discrete_action:
if explore:
action = gumbel_softmax(action, hard=True)
else:
action = onehot_from_logits(action)
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
return {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict()}
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
def init_hidden(self, len_ep, policy_hidden=False, policy_target_hidden=False, \
critic_hidden=False, critic_target_hidden=False):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
if policy_hidden == True:
self.policy_hidden = torch.zeros((len_ep, self.hidden_dim))
if policy_target_hidden == True:
self.policy_target_hidden = torch.zeros((len_ep, self.hidden_dim))
if critic_hidden == True:
self.critic_hidden = torch.zeros((len_ep, self.hidden_dim))
if critic_target_hidden == True:
self.critic_target_hidden = torch.zeros((len_ep, self.hidden_dim))
class DDPGAgent_SNN(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, output_style, hidden_dim=64,
lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.policy = SNNNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
output_style=output_style)
self.critic = SNNNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
output_style=output_style)
self.target_policy = SNNNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
output_style=output_style)
self.target_critic = SNNNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
output_style=output_style)
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
# t1 = time.time()
action = self.policy(obs)
# t2 = time.time()
# print('time_interaction:', t2 - t1)
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1)
else:
action = gumbel_softmax(action, hard=True)
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5]), onehot_from_logits(action[:, 5:])), 1)
else:
action = onehot_from_logits(action)
# if explore:
#
# action = gumbel_softmax(action, hard=True)
#
# else:
# action = onehot_from_logits(action)
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
return {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict()}
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
class DDPGAgent_ToM(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, num_in_mle, output_style,
num_agents, device, hidden_dim=64, lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.device = device
self.policy = SNNNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
output_style=output_style)
self.critic = SNNNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
output_style=output_style)
self.target_policy = SNNNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
output_style=output_style)
self.target_critic = SNNNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
output_style=output_style)
# self.mle = [SNNNetwork(num_in_mle, num_out_pol,
# hidden_dim=hidden_dim,
# output_style=output_style)] * (num_agents - 1)
self.mle = []
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
self.mle_optimizer = []
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action = self.policy.to(self.device)(obs.to(self.device))
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1).cpu()
else:
action = gumbel_softmax(action, hard=True).cpu()
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5], hard=True), onehot_from_logits(action[:, 5:], hard=True)), 1)
else:
action = onehot_from_logits(action).cpu()
# if explore:
# action = gumbel_softmax(action, hard=True).cpu()
# else:
# action = onehot_from_logits(action).cpu()
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
params = {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict(),
}
# for i in range(len(self.mle)):
# params['mle%d'%i] = self.mle[i].state_dict()
# params['mle_optimizer%d'%i] = self.mle_optimizer[i].state_dict()
return params
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
# for i in range(len(self.mle)):
# self.mle[i].load_state_dict(params['mle%d'%i])
# self.mle_optimizer[i].load_state_dict(params['mle_optimizer%d'%i])
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/common/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/common/distributions.py
================================================
# import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
import numpy as np
import maddpg.common.tf_util as U
from tensorflow.python.ops import math_ops
from multiagent.multi_discrete import MultiDiscrete
from tensorflow.python.ops import nn
class Pd(object):
"""
A particular probability distribution
"""
def flatparam(self):
raise NotImplementedError
def mode(self):
raise NotImplementedError
def logp(self, x):
raise NotImplementedError
def kl(self, other):
raise NotImplementedError
def entropy(self):
raise NotImplementedError
def sample(self):
raise NotImplementedError
class PdType(object):
"""
Parametrized family of probability distributions
"""
def pdclass(self):
raise NotImplementedError
def pdfromflat(self, flat):
return self.pdclass()(flat)
def param_shape(self):
raise NotImplementedError
def sample_shape(self):
raise NotImplementedError
def sample_dtype(self):
raise NotImplementedError
def param_placeholder(self, prepend_shape, name=None):
return tf.placeholder(dtype=tf.float32, shape=prepend_shape+self.param_shape(), name=name)
def sample_placeholder(self, prepend_shape, name=None):
return tf.placeholder(dtype=self.sample_dtype(), shape=prepend_shape+self.sample_shape(), name=name)
class CategoricalPdType(PdType):
def __init__(self, ncat):
self.ncat = ncat
def pdclass(self):
return CategoricalPd
def param_shape(self):
return [self.ncat]
def sample_shape(self):
return []
def sample_dtype(self):
return tf.int32
class SoftCategoricalPdType(PdType):
def __init__(self, ncat):
self.ncat = ncat
def pdclass(self):
return SoftCategoricalPd
def param_shape(self):
return [self.ncat]
def sample_shape(self):
return [self.ncat]
def sample_dtype(self):
return tf.float32
class MultiCategoricalPdType(PdType):
def __init__(self, low, high):
self.low = low
self.high = high
self.ncats = high - low + 1
def pdclass(self):
return MultiCategoricalPd
def pdfromflat(self, flat):
return MultiCategoricalPd(self.low, self.high, flat)
def param_shape(self):
return [sum(self.ncats)]
def sample_shape(self):
return [len(self.ncats)]
def sample_dtype(self):
return tf.int32
class SoftMultiCategoricalPdType(PdType):
def __init__(self, low, high):
self.low = low
self.high = high
self.ncats = high - low + 1
def pdclass(self):
return SoftMultiCategoricalPd
def pdfromflat(self, flat):
return SoftMultiCategoricalPd(self.low, self.high, flat)
def param_shape(self):
return [sum(self.ncats)]
def sample_shape(self):
return [sum(self.ncats)]
def sample_dtype(self):
return tf.float32
class DiagGaussianPdType(PdType):
def __init__(self, size):
self.size = size
def pdclass(self):
return DiagGaussianPd
def param_shape(self):
return [2*self.size]
def sample_shape(self):
return [self.size]
def sample_dtype(self):
return tf.float32
class BernoulliPdType(PdType):
def __init__(self, size):
self.size = size
def pdclass(self):
return BernoulliPd
def param_shape(self):
return [self.size]
def sample_shape(self):
return [self.size]
def sample_dtype(self):
return tf.int32
# WRONG SECOND DERIVATIVES
# class CategoricalPd(Pd):
# def __init__(self, logits):
# self.logits = logits
# self.ps = tf.nn.softmax(logits)
# @classmethod
# def fromflat(cls, flat):
# return cls(flat)
# def flatparam(self):
# return self.logits
# def mode(self):
# return U.argmax(self.logits, axis=1)
# def logp(self, x):
# return -tf.nn.sparse_softmax_cross_entropy_with_logits(self.logits, x)
# def kl(self, other):
# return tf.nn.softmax_cross_entropy_with_logits(other.logits, self.ps) \
# - tf.nn.softmax_cross_entropy_with_logits(self.logits, self.ps)
# def entropy(self):
# return tf.nn.softmax_cross_entropy_with_logits(self.logits, self.ps)
# def sample(self):
# u = tf.random_uniform(tf.shape(self.logits))
# return U.argmax(self.logits - tf.log(-tf.log(u)), axis=1)
class CategoricalPd(Pd):
def __init__(self, logits):
self.logits = logits
def flatparam(self):
return self.logits
def mode(self):
return U.argmax(self.logits, axis=1)
def logp(self, x):
return -tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.logits, labels=x)
def kl(self, other):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
a1 = other.logits - U.max(other.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
ea1 = tf.exp(a1)
z0 = U.sum(ea0, axis=1, keepdims=True)
z1 = U.sum(ea1, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (a0 - tf.log(z0) - a1 + tf.log(z1)), axis=1)
def entropy(self):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
z0 = U.sum(ea0, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (tf.log(z0) - a0), axis=1)
def sample(self):
u = tf.random_uniform(tf.shape(self.logits))
return U.argmax(self.logits - tf.log(-tf.log(u)), axis=1)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class SoftCategoricalPd(Pd):
def __init__(self, logits):
self.logits = logits
def flatparam(self):
return self.logits
def mode(self):
return U.softmax(self.logits, axis=-1)
def logp(self, x):
return -tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=x)
def kl(self, other):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
a1 = other.logits - U.max(other.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
ea1 = tf.exp(a1)
z0 = U.sum(ea0, axis=1, keepdims=True)
z1 = U.sum(ea1, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (a0 - tf.log(z0) - a1 + tf.log(z1)), axis=1)
def entropy(self):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
z0 = U.sum(ea0, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (tf.log(z0) - a0), axis=1)
def sample(self):
u = tf.random_uniform(tf.shape(self.logits))
return U.softmax(self.logits - tf.log(-tf.log(u)), axis=-1)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class MultiCategoricalPd(Pd):
def __init__(self, low, high, flat):
self.flat = flat
self.low = tf.constant(low, dtype=tf.int32)
self.categoricals = list(map(CategoricalPd, tf.split(flat, high - low + 1, axis=len(flat.get_shape()) - 1)))
def flatparam(self):
return self.flat
def mode(self):
return self.low + tf.cast(tf.stack([p.mode() for p in self.categoricals], axis=-1), tf.int32)
def logp(self, x):
return tf.add_n([p.logp(px) for p, px in zip(self.categoricals, tf.unstack(x - self.low, axis=len(x.get_shape()) - 1))])
def kl(self, other):
return tf.add_n([
p.kl(q) for p, q in zip(self.categoricals, other.categoricals)
])
def entropy(self):
return tf.add_n([p.entropy() for p in self.categoricals])
def sample(self):
return self.low + tf.cast(tf.stack([p.sample() for p in self.categoricals], axis=-1), tf.int32)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class SoftMultiCategoricalPd(Pd): # doesn't work yet
def __init__(self, low, high, flat):
self.flat = flat
self.low = tf.constant(low, dtype=tf.float32)
self.categoricals = list(map(SoftCategoricalPd, tf.split(flat, high - low + 1, axis=len(flat.get_shape()) - 1)))
def flatparam(self):
return self.flat
def mode(self):
x = []
for i in range(len(self.categoricals)):
x.append(self.low[i] + self.categoricals[i].mode())
return tf.concat(x, axis=-1)
def logp(self, x):
return tf.add_n([p.logp(px) for p, px in zip(self.categoricals, tf.unstack(x - self.low, axis=len(x.get_shape()) - 1))])
def kl(self, other):
return tf.add_n([
p.kl(q) for p, q in zip(self.categoricals, other.categoricals)
])
def entropy(self):
return tf.add_n([p.entropy() for p in self.categoricals])
def sample(self):
x = []
for i in range(len(self.categoricals)):
x.append(self.low[i] + self.categoricals[i].sample())
return tf.concat(x, axis=-1)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class DiagGaussianPd(Pd):
def __init__(self, flat):
self.flat = flat
mean, logstd = tf.split(axis=1, num_or_size_splits=2, value=flat)
self.mean = mean
self.logstd = logstd
self.std = tf.exp(logstd)
def flatparam(self):
return self.flat
def mode(self):
return self.mean
def logp(self, x):
return - 0.5 * U.sum(tf.square((x - self.mean) / self.std), axis=1) \
- 0.5 * np.log(2.0 * np.pi) * tf.to_float(tf.shape(x)[1]) \
- U.sum(self.logstd, axis=1)
def kl(self, other):
assert isinstance(other, DiagGaussianPd)
return U.sum(other.logstd - self.logstd + (tf.square(self.std) + tf.square(self.mean - other.mean)) / (2.0 * tf.square(other.std)) - 0.5, axis=1)
def entropy(self):
return U.sum(self.logstd + .5 * np.log(2.0 * np.pi * np.e), 1)
def sample(self):
return self.mean + self.std * tf.random_normal(tf.shape(self.mean))
@classmethod
def fromflat(cls, flat):
return cls(flat)
class BernoulliPd(Pd):
def __init__(self, logits):
self.logits = logits
self.ps = tf.sigmoid(logits)
def flatparam(self):
return self.logits
def mode(self):
return tf.round(self.ps)
def logp(self, x):
return - U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=tf.to_float(x)), axis=1)
def kl(self, other):
return U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=other.logits, labels=self.ps), axis=1) - U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=self.ps), axis=1)
def entropy(self):
return U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=self.ps), axis=1)
def sample(self):
p = tf.sigmoid(self.logits)
u = tf.random_uniform(tf.shape(p))
return tf.to_float(math_ops.less(u, p))
@classmethod
def fromflat(cls, flat):
return cls(flat)
def make_pdtype(ac_space):
from gym import spaces
if isinstance(ac_space, spaces.Box):
assert len(ac_space.shape) == 1
return DiagGaussianPdType(ac_space.shape[0])
elif isinstance(ac_space, spaces.Discrete):
# return CategoricalPdType(ac_space.n)
return SoftCategoricalPdType(ac_space.n)
elif isinstance(ac_space, MultiDiscrete):
#return MultiCategoricalPdType(ac_space.low, ac_space.high)
return SoftMultiCategoricalPdType(ac_space.low, ac_space.high)
elif isinstance(ac_space, spaces.MultiBinary):
return BernoulliPdType(ac_space.n)
else:
raise NotImplementedError
def shape_el(v, i):
maybe = v.get_shape()[i]
if maybe is not None:
return maybe
else:
return tf.shape(v)[i]
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/common/tile_images.py
================================================
import numpy as np
def tile_images(img_nhwc):
"""
Tile N images into one big PxQ image
(P,Q) are chosen to be as close as possible, and if N
is square, then P=Q.
input: img_nhwc, list or array of images, ndim=4 once turned into array
n = batch index, h = height, w = width, c = channel
returns:
bigim_HWc, ndarray with ndim=3
"""
img_nhwc = np.asarray(img_nhwc)
N, h, w, c = img_nhwc.shape
H = int(np.ceil(np.sqrt(N)))
W = int(np.ceil(float(N)/H))
img_nhwc = np.array(list(img_nhwc) + [img_nhwc[0]*0 for _ in range(N, H*W)])
img_HWhwc = img_nhwc.reshape(H, W, h, w, c)
img_HhWwc = img_HWhwc.transpose(0, 2, 1, 3, 4)
img_Hh_Ww_c = img_HhWwc.reshape(H*h, W*w, c)
return img_Hh_Ww_c
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/common/vec_env/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/common/vec_env/vec_env.py
================================================
import contextlib
import os
from abc import ABC, abstractmethod
from common.tile_images import tile_images
class AlreadySteppingError(Exception):
"""
Raised when an asynchronous step is running while
step_async() is called again.
"""
def __init__(self):
msg = 'already running an async step'
Exception.__init__(self, msg)
class NotSteppingError(Exception):
"""
Raised when an asynchronous step is not running but
step_wait() is called.
"""
def __init__(self):
msg = 'not running an async step'
Exception.__init__(self, msg)
class VecEnv(ABC):
"""
An abstract asynchronous, vectorized environment.
Used to batch data from multiple copies of an environment, so that
each observation becomes an batch of observations, and expected action is a batch of actions to
be applied per-environment.
"""
closed = False
viewer = None
metadata = {
'render.modes': ['human', 'rgb_array']
}
def __init__(self, num_envs, observation_space, action_space):
self.num_envs = num_envs
self.observation_space = observation_space
self.action_space = action_space
@abstractmethod
def reset(self):
"""
Reset all the environments and return an array of
observations, or a dict of observation arrays.
If step_async is still doing work, that work will
be cancelled and step_wait() should not be called
until step_async() is invoked again.
"""
pass
@abstractmethod
def step_async(self, actions):
"""
Tell all the environments to start taking a step
with the given actions.
Call step_wait() to get the results of the step.
You should not call this if a step_async run is
already pending.
"""
pass
@abstractmethod
def step_wait(self):
"""
Wait for the step taken with step_async().
Returns (obs, rews, dones, infos):
- obs: an array of observations, or a dict of
arrays of observations.
- rews: an array of rewards
- dones: an array of "episode done" booleans
- infos: a sequence of info objects
"""
pass
def close_extras(self):
"""
Clean up the extra resources, beyond what's in this base class.
Only runs when not self.closed.
"""
pass
def close(self):
if self.closed:
return
if self.viewer is not None:
self.viewer.close()
self.close_extras()
self.closed = True
def step(self, actions):
"""
Step the environments synchronously.
This is available for backwards compatibility.
"""
self.step_async(actions)
return self.step_wait()
def render(self, mode='human'):
imgs = self.get_images()
bigimg = tile_images(imgs)
if mode == 'human':
self.get_viewer().imshow(bigimg)
return self.get_viewer().isopen
elif mode == 'rgb_array':
return bigimg
else:
raise NotImplementedError
def get_images(self):
"""
Return RGB images from each environment
"""
raise NotImplementedError
@property
def unwrapped(self):
if isinstance(self, VecEnvWrapper):
return self.venv.unwrapped
else:
return self
def get_viewer(self):
if self.viewer is None:
from gym.envs.classic_control import rendering
self.viewer = rendering.SimpleImageViewer()
return self.viewer
class VecEnvWrapper(VecEnv):
"""
An environment wrapper that applies to an entire batch
of environments at once.
"""
def __init__(self, venv, observation_space=None, action_space=None):
self.venv = venv
super().__init__(num_envs=venv.num_envs,
observation_space=observation_space or venv.observation_space,
action_space=action_space or venv.action_space)
def step_async(self, actions):
self.venv.step_async(actions)
@abstractmethod
def reset(self):
pass
@abstractmethod
def step_wait(self):
pass
def close(self):
return self.venv.close()
def render(self, mode='human'):
return self.venv.render(mode=mode)
def get_images(self):
return self.venv.get_images()
def __getattr__(self, name):
if name.startswith('_'):
raise AttributeError("attempted to get missing private attribute '{}'".format(name))
return getattr(self.venv, name)
class VecEnvObservationWrapper(VecEnvWrapper):
@abstractmethod
def process(self, obs):
pass
def reset(self):
obs = self.venv.reset()
return self.process(obs)
def step_wait(self):
obs, rews, dones, infos = self.venv.step_wait()
return self.process(obs), rews, dones, infos
class CloudpickleWrapper(object):
"""
Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)
"""
def __init__(self, x):
self.x = x
def __getstate__(self):
import cloudpickle
return cloudpickle.dumps(self.x)
def __setstate__(self, ob):
import pickle
self.x = pickle.loads(ob)
@contextlib.contextmanager
def clear_mpi_env_vars():
"""
from mpi4py import MPI will call MPI_Init by default. If the child process has MPI environment variables, MPI will think that the child process is an MPI process just like the parent and do bad things such as hang.
This context manager is a hacky way to clear those environment variables temporarily such as when we are starting multiprocessing
Processes.
"""
removed_environment = {}
for k, v in list(os.environ.items()):
for prefix in ['OMPI_', 'PMI_']:
if k.startswith(prefix):
removed_environment[k] = v
del os.environ[k]
try:
yield
finally:
os.environ.update(removed_environment)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/main.py
================================================
import argparse
import torch
import time
import os
import numpy as np
from gym.spaces import Box, Discrete, MultiDiscrete
from pathlib import Path
from torch.autograd import Variable
from tensorboardX import SummaryWriter
from utils.make_env import make_env
from utils.buffer import ReplayBuffer, ReplayBuffer_pre
from utils.env_wrappers import SubprocVecEnv, DummyVecEnv
from policy.maddpg import MADDPG, MADDPG_SNN, MADDPG_ToM, ToM_SA, ToM_S, ToM_self
from tqdm import tqdm
def get_common_args():
parser = argparse.ArgumentParser()
parser.add_argument("--env_id", default='simple_world_comm', type=str,
choices=['simple_tag', 'simple_adversary', 'simple_push', 'simple_world_comm'],
help="Name of environment")
parser.add_argument("--model_name", default='ann', type=str,
help="Name of directory to store " +
"model/training contents") #ToM_SA
parser.add_argument("--seed",
default=1, type=int,
help="Random seed")
parser.add_argument("--cuda_num",
default=7, type=int,
help="device")
parser.add_argument("--output_style",
default='sum', type=str,
choices=['sum', 'voltage'])
parser.add_argument("--n_rollout_threads", default=20, type=int)
parser.add_argument("--n_training_threads", default=6, type=int)
parser.add_argument("--buffer_length", default=int(1e6), type=int)
parser.add_argument("--n_episodes", default=15000, type=int)#
parser.add_argument("--episode_length", default=25, type=int)
parser.add_argument("--steps_per_update", default=100, type=int)
parser.add_argument("--batch_size",
default=1024, type=int,#4
help="Batch size for model training")
parser.add_argument("--n_exploration_eps", default=25000, type=int)
parser.add_argument("--init_noise_scale", default=0.3, type=float)
parser.add_argument("--final_noise_scale", default=0.0, type=float)
parser.add_argument("--save_interval", default=1000, type=int)
parser.add_argument("--hidden_dim", default=64, type=int)
parser.add_argument("--lr", default=0.01, type=float)
parser.add_argument("--tau", default=0.01, type=float)
parser.add_argument("--agent_alg",
default="MADDPG_ToM", type=str,
choices=['MADDPG', 'DDPG', 'MADDPG_SNN', 'MADDPG_ToM', 'ToM_SA', 'ToM_S', 'ToM_self'])
parser.add_argument("--adversary_alg",
default="MADDPG_ToM", type=str,
choices=['MADDPG', 'DDPG', 'MADDPG_SNN', 'MADDPG_ToM', 'ToM_SA', 'ToM_S', 'ToM_self'])
parser.add_argument("--discrete_action",
# default=False, type=bool,
action='store_true')
args = parser.parse_args()
parser.add_argument('--device', type=str, default='cuda:{}'.format(args.cuda_num), help='whether to use the GPU') #'cuda:1'
parser = parser.parse_args()
return parser
USE_CUDA = torch.cuda.is_available()
def make_parallel_env(env_id, n_rollout_threads, seed, discrete_action):
def get_env_fn(rank):
def init_env():
env = make_env(env_id, discrete_action=discrete_action)
env.seed(seed + rank * 1000)
np.random.seed(seed + rank * 1000)
return env
return init_env
if n_rollout_threads == 1:
return DummyVecEnv([get_env_fn(0)])
else:
return SubprocVecEnv([get_env_fn(i) for i in range(n_rollout_threads)])
def run(config):
pbar = tqdm(config.n_episodes)
model_dir = Path('./models') / config.env_id / config.model_name
if not model_dir.exists():
curr_run = 'run1'
else:
exst_run_nums = [int(str(folder.name).split('run')[1]) for folder in
model_dir.iterdir() if
str(folder.name).startswith('run')]
if len(exst_run_nums) == 0:
curr_run = 'run1'
else:
curr_run = 'run%i' % (max(exst_run_nums) + 1)
run_dir = model_dir / curr_run
log_dir = run_dir / 'logs'
os.makedirs(log_dir)
logger = SummaryWriter(str(log_dir))
torch.manual_seed(config.seed)
np.random.seed(config.seed)
if not USE_CUDA:
torch.set_num_threads(config.n_training_threads)
env = make_parallel_env(config.env_id, config.n_rollout_threads, config.seed,
config.discrete_action)
if config.agent_alg == 'MADDPG' or config.agent_alg == 'DDPG':
print('_____MADDPG_____')
maddpg = MADDPG.init_from_env(env, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
device=config.device)
elif config.agent_alg == 'MADDPG_SNN':
print('_____MADDPG_SNN_____')
maddpg = MADDPG_SNN.init_from_env(env, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
elif config.agent_alg == 'MADDPG_ToM':
print('_____MADDPG_ToM_____')
maddpg = MADDPG_ToM.init_from_env(env, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
elif config.agent_alg == 'ToM_SA':
print('_______ToM_SA_______')
maddpg = ToM_SA.init_from_env(env, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
elif config.agent_alg == 'ToM_S':
print('_______ToM_S_______')
maddpg = ToM_S.init_from_env(env, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
print('_______ToM_self_______')
maddpg = ToM_self.init_from_env(env, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
if config.agent_alg == 'ToM_SA'or config.agent_alg == 'ToM_S' or config.agent_alg == 'ToM_self' or config.agent_alg == 'ToM_SB':
replay_buffer = ReplayBuffer_pre(config.buffer_length, maddpg.nagents,
[obsp.shape[0] for obsp in env.observation_space],
[acsp.n if isinstance(acsp, Discrete) else sum(acsp.high - acsp.low + 1)
for acsp in env.action_space],
device=config.device)
else:
replay_buffer = ReplayBuffer(config.buffer_length, maddpg.nagents,
[obsp.shape[0] for obsp in env.observation_space],
[acsp.n if isinstance(acsp, Discrete) else sum(acsp.high - acsp.low + 1)
for acsp in env.action_space],
device=config.device)
t = 0
total_reward = []
for agent_i in range(maddpg.nagents):
total_reward.append([])
for ep_i in range(0, config.n_episodes, config.n_rollout_threads):
# print("Episodes %i-%i of %i" % (ep_i + 1,
# ep_i + 1 + config.n_rollout_threads,
# config.n_episodes))
obs = env.reset()
# obs.shape = (n_rollout_threads, nagent)(nobs), nobs differs per agent so not tensor
maddpg.prep_rollouts(device='cpu')
torch_agent_actions = [torch.zeros((config.n_rollout_threads, 5)) for i in range(maddpg.nagents)]
explr_pct_remaining = max(0, config.n_exploration_eps - ep_i) / config.n_exploration_eps
maddpg.scale_noise(config.final_noise_scale + (config.init_noise_scale - config.final_noise_scale) * explr_pct_remaining)
maddpg.reset_noise()
obs_ep = []
agent_actions_ep = []
rewards_ep = []
next_obs_ep = []
dones_ep = []
for et_i in range(config.episode_length):
torch_agent_actions_pre = torch_agent_actions
torch_agent_actions_pre = [ac.data.numpy() for ac in torch_agent_actions_pre]
# rearrange observations to be per agent, and convert to torch Variable
torch_obs = [Variable(torch.Tensor(np.vstack(obs[:, i])),
requires_grad=False)
for i in range(maddpg.nagents)] #
# get actions as torch Variables
# t1 = time.time()
if config.agent_alg == 'ToM_SA' or config.agent_alg == 'ToM_S' or config.agent_alg == 'ToM_self' or config.agent_alg == 'ToM_SB':
torch_agent_actions = maddpg.step(torch_obs, torch_agent_actions, explore=True)
else:
torch_agent_actions = maddpg.step(torch_obs, explore=True)
# t2 = time.time()
# print('time_step:', t2-t1)
# convert actions to numpy arrays
agent_actions = [ac.data.numpy() for ac in torch_agent_actions] #
# rearrange actions to be per environment
actions = [[ac[i] for ac in agent_actions] for i in range(config.n_rollout_threads)]
next_obs, rewards, dones, infos = env.step(actions)
obs_ep.append(obs) #episode_id,process, n_agents, dim
agent_actions_ep.append(actions) #episode_id, n_agents, process, dim
rewards_ep.append(rewards) #episode_id,process, n_agents,
next_obs_ep.append(next_obs) #episode_id,process, n_agents, dim
dones_ep.append(dones) #episode_id,process, n_agents,
if config.agent_alg == 'ToM_SA' or config.agent_alg == 'ToM_S' or config.agent_alg == 'ToM_self'or config.agent_alg == 'ToM_SB':
replay_buffer.push(torch_agent_actions_pre, obs, agent_actions, rewards, next_obs, dones)
else:
replay_buffer.push(obs, agent_actions, rewards, next_obs, dones)
obs = next_obs
t += config.n_rollout_threads
if (len(replay_buffer) >= config.batch_size and
(t % config.steps_per_update) < config.n_rollout_threads):
if USE_CUDA:
maddpg.prep_training(device='gpu')
else:
maddpg.prep_training(device='cpu')
if config.n_episodes >300:
rollout = 2
else:
rollout = config.n_rollout_threads
for u_i in range(rollout):
for a_i in range(maddpg.nagents):
sample = replay_buffer.sample(config.batch_size,
to_gpu=USE_CUDA)
# t1 = time.time()
maddpg.update(sample, a_i, logger=logger)
# t2 = time.time()
# print('trian_time:', t2-t1, u_i, a_i)
maddpg.update_all_targets()
maddpg.prep_rollouts(device='cpu')
ep_rews = replay_buffer.get_average_rewards(
config.episode_length * config.n_rollout_threads)
for a_i, a_ep_rew in enumerate(ep_rews):
logger.add_scalar('agent%i/mean_episode_rewards' % a_i,
a_ep_rew,
ep_i)
logger.add_scalar('agent_mean/mean_episode_rewards',
np.mean(ep_rews),
ep_i)
if ep_i % config.save_interval < config.n_rollout_threads:
os.makedirs(run_dir / 'incremental', exist_ok=True)
maddpg.save(run_dir / 'incremental' / ('model_ep%i.pt' % (ep_i + 1)))
maddpg.save(run_dir / 'model.pt')
pbar.update(config.n_rollout_threads)
pbar.close()
maddpg.save(run_dir / 'model.pt')
env.close()
logger.export_scalars_to_json(str(log_dir / 'summary.json'))
logger.close()
for a_i, reward in enumerate(total_reward):
reward_dir = str(log_dir) + '/agent{}/mean_episode_rewards'.format(a_i) + '/episode_rewards_{}'.format(config.cuda_num)
os.makedirs(reward_dir)
np.save(reward_dir, reward)
if __name__ == '__main__':
config = get_common_args()
# config.env_id = 'simple_tag'
# # config.model_name = 'ma2c'
config.agent_alg = 'ToM_SB'#
config.adversary_alg = 'ToM_SB'
#
run(config)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/__init__.py
================================================
from gym.envs.registration import register
# Multiagent envs
# ----------------------------------------
register(
id='MultiagentSimple-v0',
entry_point='multiagent.envs:SimpleEnv',
# FIXME(cathywu) currently has to be exactly max_path_length parameters in
# rllab run script
max_episode_steps=100,
)
register(
id='MultiagentSimpleSpeakerListener-v0',
entry_point='multiagent.envs:SimpleSpeakerListenerEnv',
max_episode_steps=100,
)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/__init__.py
================================================
import imp
import os.path as osp
def load(name):
pathname = osp.join(osp.dirname(__file__), name)
return imp.load_source('', pathname)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/simple.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# add agents
world.agents = [Agent() for i in range(1)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.silent = True
# add landmarks
world.landmarks = [Landmark() for i in range(1)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25,0.25,0.25])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.75,0.75,0.75])
world.landmarks[0].color = np.array([0.75,0.25,0.25])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
dist2 = np.sum(np.square(agent.state.p_pos - world.landmarks[0].state.p_pos))
return -dist2
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
return np.concatenate([agent.state.p_vel] + entity_pos)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/simple_crypto.py
================================================
"""
Scenario:
1 speaker, 2 listeners (one of which is an adversary). Good agents rewarded for proximity to goal, and distance from
adversary to goal. Adversary is rewarded for its distance to the goal.
"""
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
import random
class CryptoAgent(Agent):
def __init__(self):
super(CryptoAgent, self).__init__()
self.key = None
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
num_agents = 3
num_adversaries = 1
num_landmarks = 2
world.dim_c = 4
# add agents
world.agents = [CryptoAgent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.adversary = True if i < num_adversaries else False
agent.speaker = True if i == 2 else False
agent.movable = False
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25, 0.25, 0.25])
if agent.adversary:
agent.color = np.array([0.75, 0.25, 0.25])
agent.key = None
# random properties for landmarks
color_list = [np.zeros(world.dim_c) for i in world.landmarks]
for i, color in enumerate(color_list):
color[i] += 1
for color, landmark in zip(color_list, world.landmarks):
landmark.color = color
# set goal landmark
goal = np.random.choice(world.landmarks)
world.agents[1].color = goal.color
world.agents[2].key = np.random.choice(world.landmarks).color
for agent in world.agents:
agent.goal_a = goal
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
return (agent.state.c, agent.goal_a.color)
# return all agents that are not adversaries
def good_listeners(self, world):
return [agent for agent in world.agents if not agent.adversary and not agent.speaker]
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# Agents rewarded if Bob can reconstruct message, but adversary (Eve) cannot
good_listeners = self.good_listeners(world)
adversaries = self.adversaries(world)
good_rew = 0
adv_rew = 0
for a in good_listeners:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
good_rew -= np.sum(np.square(a.state.c - agent.goal_a.color))
for a in adversaries:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
adv_l1 = np.sum(np.square(a.state.c - agent.goal_a.color))
adv_rew += adv_l1
return adv_rew + good_rew
def adversary_reward(self, agent, world):
# Adversary (Eve) is rewarded if it can reconstruct original goal
rew = 0
if not (agent.state.c == np.zeros(world.dim_c)).all():
rew -= np.sum(np.square(agent.state.c - agent.goal_a.color))
return rew
def observation(self, agent, world):
# goal color
goal_color = np.zeros(world.dim_color)
if agent.goal_a is not None:
goal_color = agent.goal_a.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent or (other.state.c is None) or not other.speaker: continue
comm.append(other.state.c)
confer = np.array([0])
if world.agents[2].key is None:
confer = np.array([1])
key = np.zeros(world.dim_c)
goal_color = np.zeros(world.dim_c)
else:
key = world.agents[2].key
prnt = False
# speaker
if agent.speaker:
if prnt:
print('speaker')
print(agent.state.c)
print(np.concatenate([goal_color] + [key] + [confer] + [np.random.randn(1)]))
return np.concatenate([goal_color] + [key])
# listener
if not agent.speaker and not agent.adversary:
if prnt:
print('listener')
print(agent.state.c)
print(np.concatenate([key] + comm + [confer]))
return np.concatenate([key] + comm)
if not agent.speaker and agent.adversary:
if prnt:
print('adversary')
print(agent.state.c)
print(np.concatenate(comm + [confer]))
return np.concatenate(comm)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/simple_push.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
world.dim_c = 2
num_agents = 2
num_adversaries = 1
num_landmarks = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
if i < num_adversaries:
agent.adversary = True
else:
agent.adversary = False
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.1, 0.1, 0.1])
landmark.color[i + 1] += 0.8
landmark.index = i
# set goal landmark
goal = np.random.choice(world.landmarks)
for i, agent in enumerate(world.agents):
agent.goal_a = goal
agent.color = np.array([0.25, 0.25, 0.25])
if agent.adversary:
agent.color = np.array([0.75, 0.25, 0.25])
else:
j = goal.index
agent.color[j + 1] += 0.5
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# the distance to the goal
return -np.sqrt(np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos)))
def adversary_reward(self, agent, world):
# keep the nearest good agents away from the goal
agent_dist = [np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in world.agents if not a.adversary]
pos_rew = min(agent_dist)
#nearest_agent = world.good_agents[np.argmin(agent_dist)]
#neg_rew = np.sqrt(np.sum(np.square(nearest_agent.state.p_pos - agent.state.p_pos)))
neg_rew = np.sqrt(np.sum(np.square(agent.goal_a.state.p_pos - agent.state.p_pos)))
#neg_rew = sum([np.sqrt(np.sum(np.square(a.state.p_pos - agent.state.p_pos))) for a in world.good_agents])
return pos_rew - neg_rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not agent.adversary:
return np.concatenate([agent.state.p_vel] + [agent.goal_a.state.p_pos - agent.state.p_pos] + [agent.color] + entity_pos + entity_color + other_pos)
else:
#other_pos = list(reversed(other_pos)) if random.uniform(0,1) > 0.5 else other_pos # randomize position of other agents in adversary network
return np.concatenate([agent.state.p_vel] + entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/simple_reference.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
world.dim_c = 10
world.collaborative = True # whether agents share rewards
# add agents
world.agents = [Agent() for i in range(2)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
# add landmarks
world.landmarks = [Landmark() for i in range(3)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# assign goals to agents
for agent in world.agents:
agent.goal_a = None
agent.goal_b = None
# want other agent to go to the goal landmark
world.agents[0].goal_a = world.agents[1]
world.agents[0].goal_b = np.random.choice(world.landmarks)
world.agents[1].goal_a = world.agents[0]
world.agents[1].goal_b = np.random.choice(world.landmarks)
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25,0.25,0.25])
# random properties for landmarks
world.landmarks[0].color = np.array([0.75,0.25,0.25])
world.landmarks[1].color = np.array([0.25,0.75,0.25])
world.landmarks[2].color = np.array([0.25,0.25,0.75])
# special colors for goals
world.agents[0].goal_a.color = world.agents[0].goal_b.color
world.agents[1].goal_a.color = world.agents[1].goal_b.color
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
if agent.goal_a is None or agent.goal_b is None:
return 0.0
dist2 = np.sum(np.square(agent.goal_a.state.p_pos - agent.goal_b.state.p_pos))
return -dist2
def observation(self, agent, world):
# goal color
goal_color = [np.zeros(world.dim_color), np.zeros(world.dim_color)]
if agent.goal_b is not None:
goal_color[1] = agent.goal_b.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks:
entity_color.append(entity.color)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
return np.concatenate([agent.state.p_vel] + entity_pos + [goal_color[1]] + comm)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/simple_speaker_listener.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
world.dim_c = 3
num_landmarks = 3
world.collaborative = True
# add agents
world.agents = [Agent() for i in range(2)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.size = 0.075
# speaker
world.agents[0].movable = False
# listener
world.agents[1].silent = True
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.04
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# assign goals to agents
for agent in world.agents:
agent.goal_a = None
agent.goal_b = None
# want listener to go to the goal landmark
world.agents[0].goal_a = world.agents[1]
world.agents[0].goal_b = np.random.choice(world.landmarks)
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25,0.25,0.25])
# random properties for landmarks
world.landmarks[0].color = np.array([0.65,0.15,0.15])
world.landmarks[1].color = np.array([0.15,0.65,0.15])
world.landmarks[2].color = np.array([0.15,0.15,0.65])
# special colors for goals
world.agents[0].goal_a.color = world.agents[0].goal_b.color + np.array([0.45, 0.45, 0.45])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
return self.reward(agent, reward)
def reward(self, agent, world):
# squared distance from listener to landmark
a = world.agents[0]
dist2 = np.sum(np.square(a.goal_a.state.p_pos - a.goal_b.state.p_pos))
return -dist2
def observation(self, agent, world):
# goal color
goal_color = np.zeros(world.dim_color)
if agent.goal_b is not None:
goal_color = agent.goal_b.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent or (other.state.c is None): continue
comm.append(other.state.c)
# speaker
if not agent.movable:
return np.concatenate([goal_color])
# listener
if agent.silent:
return np.concatenate([agent.state.p_vel] + entity_pos + comm)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/simple_spread.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
world.dim_c = 2
num_agents = 3
num_landmarks = 3
world.collaborative = True
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
agent.size = 0.15
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.35, 0.35, 0.85])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
rew = 0
collisions = 0
occupied_landmarks = 0
min_dists = 0
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
min_dists += min(dists)
rew -= min(dists)
if min(dists) < 0.1:
occupied_landmarks += 1
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
collisions += 1
return (rew, collisions, min_dists, occupied_landmarks)
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark, penalized for collisions
rew = 0
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
rew -= min(dists)
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + comm)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/simple_world_comm.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
world.dim_c = 4
#world.damping = 1
num_good_agents = 2
num_adversaries = 4
num_agents = num_adversaries + num_good_agents
num_landmarks = 1
num_food = 2
num_forests = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.leader = True if i == 0 else False
agent.silent = True if i > 0 else False
agent.adversary = True if i < num_adversaries else False
agent.size = 0.075 if agent.adversary else 0.045
agent.accel = 3.0 if agent.adversary else 4.0
#agent.accel = 20.0 if agent.adversary else 25.0
agent.max_speed = 1.0 if agent.adversary else 1.3
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = True
landmark.movable = False
landmark.size = 0.2
landmark.boundary = False
world.food = [Landmark() for i in range(num_food)]
for i, landmark in enumerate(world.food):
landmark.name = 'food %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.03
landmark.boundary = False
world.forests = [Landmark() for i in range(num_forests)]
for i, landmark in enumerate(world.forests):
landmark.name = 'forest %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.3
landmark.boundary = False
world.landmarks += world.food
world.landmarks += world.forests
#world.landmarks += self.set_boundaries(world) # world boundaries now penalized with negative reward
# make initial conditions
self.reset_world(world)
return world
def set_boundaries(self, world):
boundary_list = []
landmark_size = 1
edge = 1 + landmark_size
num_landmarks = int(edge * 2 / landmark_size)
for x_pos in [-edge, edge]:
for i in range(num_landmarks):
l = Landmark()
l.state.p_pos = np.array([x_pos, -1 + i * landmark_size])
boundary_list.append(l)
for y_pos in [-edge, edge]:
for i in range(num_landmarks):
l = Landmark()
l.state.p_pos = np.array([-1 + i * landmark_size, y_pos])
boundary_list.append(l)
for i, l in enumerate(boundary_list):
l.name = 'boundary %d' % i
l.collide = True
l.movable = False
l.boundary = True
l.color = np.array([0.75, 0.75, 0.75])
l.size = landmark_size
l.state.p_vel = np.zeros(world.dim_p)
return boundary_list
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.45, 0.95, 0.45]) if not agent.adversary else np.array([0.95, 0.45, 0.45])
agent.color -= np.array([0.3, 0.3, 0.3]) if agent.leader else np.array([0, 0, 0])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
for i, landmark in enumerate(world.food):
landmark.color = np.array([0.15, 0.15, 0.65])
for i, landmark in enumerate(world.forests):
landmark.color = np.array([0.6, 0.9, 0.6])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-0.9, +0.9, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
for i, landmark in enumerate(world.food):
landmark.state.p_pos = np.random.uniform(-0.9, +0.9, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
for i, landmark in enumerate(world.forests):
landmark.state.p_pos = np.random.uniform(-0.9, +0.9, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
if agent.adversary:
collisions = 0
for a in self.good_agents(world):
if self.is_collision(a, agent):
collisions += 1
return collisions
else:
return 0
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
#boundary_reward = -10 if self.outside_boundary(agent) else 0
main_reward = self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
return main_reward
def outside_boundary(self, agent):
if agent.state.p_pos[0] > 1 or agent.state.p_pos[0] < -1 or agent.state.p_pos[1] > 1 or agent.state.p_pos[1] < -1:
return True
else:
return False
def agent_reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
rew = 0
shape = False
adversaries = self.adversaries(world)
if shape:
for adv in adversaries:
rew += 0.1 * np.sqrt(np.sum(np.square(agent.state.p_pos - adv.state.p_pos)))
if agent.collide:
for a in adversaries:
if self.is_collision(a, agent):
rew -= 5
def bound(x):
if x < 0.9:
return 0
if x < 1.0:
return (x - 0.9) * 10
return min(np.exp(2 * x - 2), 10) # 1 + (x - 1) * (x - 1)
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
rew -= 2 * bound(x)
for food in world.food:
if self.is_collision(agent, food):
rew += 2
rew += 0.05 * min([np.sqrt(np.sum(np.square(food.state.p_pos - agent.state.p_pos))) for food in world.food])
return rew
def adversary_reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
rew = 0
shape = True
agents = self.good_agents(world)
adversaries = self.adversaries(world)
if shape:
rew -= 0.1 * min([np.sqrt(np.sum(np.square(a.state.p_pos - agent.state.p_pos))) for a in agents])
if agent.collide:
for ag in agents:
for adv in adversaries:
if self.is_collision(ag, adv):
rew += 5
return rew
def observation2(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
food_pos = []
for entity in world.food:
if not entity.boundary:
food_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel)
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
in_forest = [np.array([-1]), np.array([-1])]
inf1 = False
inf2 = False
if self.is_collision(agent, world.forests[0]):
in_forest[0] = np.array([1])
inf1= True
if self.is_collision(agent, world.forests[1]):
in_forest[1] = np.array([1])
inf2 = True
food_pos = []
for entity in world.food:
if not entity.boundary:
food_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
oth_f1 = self.is_collision(other, world.forests[0])
oth_f2 = self.is_collision(other, world.forests[1])
if (inf1 and oth_f1) or (inf2 and oth_f2) or (not inf1 and not oth_f1 and not inf2 and not oth_f2) or agent.leader: #without forest vis
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
else:
other_pos.append([0, 0])
if not other.adversary:
other_vel.append([0, 0])
# to tell the pred when the prey are in the forest
prey_forest = []
ga = self.good_agents(world)
for a in ga:
if any([self.is_collision(a, f) for f in world.forests]):
prey_forest.append(np.array([1]))
else:
prey_forest.append(np.array([-1]))
# to tell leader when pred are in forest
prey_forest_lead = []
for f in world.forests:
if any([self.is_collision(a, f) for a in ga]):
prey_forest_lead.append(np.array([1]))
else:
prey_forest_lead.append(np.array([-1]))
comm = [world.agents[0].state.c]
if agent.adversary and not agent.leader:
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel + in_forest + comm)
if agent.leader:
return np.concatenate(
[agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel + in_forest + comm)
else:
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + in_forest + other_vel)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/policy/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/policy/maddpg.py
================================================
import torch
from torch.optim import Adam
import torch.nn.functional as F
from gym.spaces import Box, Discrete, MultiDiscrete
from multiagent.multi_discrete import MultiDiscrete
from utils.networks import MLPNetwork, SNNNetwork
from utils.misc import soft_update, average_gradients, onehot_from_logits, gumbel_softmax
from agents.agents import DDPGAgent, DDPGAgent_RNN, DDPGAgent_SNN, DDPGAgent_ToM
# from commom.distributions import make_pdtype
import time
MSELoss = torch.nn.MSELoss()
class MADDPG(object):
"""
Wrapper class for DDPG-esque (i.e. also MADDPG) agents in multi-agent task
"""
def __init__(self, agent_init_params, alg_types, device,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.device = device
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params)
for params in agent_init_params]
self.agent_init_params = agent_init_params
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, explore=False):
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def update(self, sample, agent_i, parallel=False, logger=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
obs, acs, rews, next_obs, dones = sample
curr_agent = self.agents[agent_i]
curr_agent.critic_optimizer.zero_grad()
if self.alg_types[agent_i] == 'MADDPG':
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs)]
else:
all_trgt_acs = [pi(nobs) for pi, nobs in zip(self.target_policies,
next_obs)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
else: # DDPG
if self.discrete_action:
trgt_vf_in = torch.cat((next_obs[agent_i],
onehot_from_logits(
curr_agent.target_policy(
next_obs[agent_i]))),
dim=1)
else:
trgt_vf_in = torch.cat((next_obs[agent_i],
curr_agent.target_policy(next_obs[agent_i])),
dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
if self.alg_types[agent_i] == 'MADDPG':
vf_in = torch.cat((*obs, *acs), dim=1)
else: # DDPG
vf_in = torch.cat((obs[agent_i], acs[agent_i]), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
if self.alg_types[agent_i] == 'MADDPG':
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
else: # DDPG
vf_in = torch.cat((obs[agent_i], curr_pol_vf_in),
dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out**2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents]}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, device, agent_alg="MADDPG", adversary_alg="MADDPG",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
if algtype == "MADDPG":
num_in_critic = 0
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'device': device}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
return instance
class MADDPG_SNN(object):
"""
Wrapper class for DDPG-esque (i.e. also MADDPG) agents in multi-agent task
"""
def __init__(self, agent_init_params, alg_types,output_style, device,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.device = device
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent_SNN(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params, output_style=output_style)
for params in agent_init_params]
self.agent_init_params = agent_init_params
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, explore=False):
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def update(self, sample, agent_i, parallel=False, logger=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
obs, acs, rews, next_obs, dones = sample
curr_agent = self.agents[agent_i]
curr_agent.critic_optimizer.zero_grad()
if self.alg_types[agent_i] == 'MADDPG_SNN':
all_trgt_acs = []
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs)]
# for nobs in next_obs:
# if nobs.shape[1] == next_obs[agent_i].shape[1]:
# all_trgt_acs.append(onehot_from_logits(self.target_policies[agent_i](nobs)))
# else:
# if next_obs[agent_i].shape[1] - nobs[:][3].shape[0] > 0 :
# a = torch.zeros((nobs.shape[0], next_obs[agent_i].shape[1] - nobs[:][3].shape[0]))
# a = a.to(torch.device(self.device))
# obs_good = torch.cat((nobs, a), 1)
# all_trgt_acs.append(onehot_from_logits(self.target_policies[agent_i](obs_good)))
# else:
# all_trgt_acs.append(onehot_from_logits(self.target_policies[agent_i](nobs[:, :next_obs[agent_i].shape[1]])))
# all_trgt_acs = [onehot_from_logits(self.target_policies[agent_i](nobs)) for nobs in
# next_obs]
else:
# all_trgt_acs = [pi(nobs) for pi, nobs in zip(self.target_policies,
# next_obs)]
all_trgt_acs = [self.target_policies[agent_i](nobs) for nobs in next_obs] #self-experience
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
else: # DDPG
if self.discrete_action:
trgt_vf_in = torch.cat((next_obs[agent_i],
onehot_from_logits(
curr_agent.target_policy(
next_obs[agent_i]))),
dim=1)
else:
trgt_vf_in = torch.cat((next_obs[agent_i],
curr_agent.target_policy(next_obs[agent_i])),
dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
if self.alg_types[agent_i] == 'MADDPG_SNN':
vf_in = torch.cat((*obs, *acs), dim=1)
else: # DDPG
vf_in = torch.cat((obs[agent_i], acs[agent_i]), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
if self.alg_types[agent_i] == 'MADDPG_SNN':
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
else: # DDPG
vf_in = torch.cat((obs[agent_i], curr_pol_vf_in),
dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out**2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents]}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, device, agent_alg="MADDPG_SNN", adversary_alg="MADDPG_SNN",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64, output_style='sum'):
# def init_from_env(cls, env, agent_alg="MADDPG_SNN", adversary_alg="MADDPG_SNN",
# gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64): #eval
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
if algtype == "MADDPG_SNN":
num_in_critic = 0
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'output_style': output_style,
'device': device}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
return instance
class MADDPG_ToM(object):
"""
Wrapper class for DDPG-esque (i.e. also MADDPG) agents in multi-agent task
"""
def __init__(self, agent_init_params, alg_types, output_style, device,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.device = device
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent_ToM(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params, output_style=output_style,
num_agents=self.nagents,
device=self.device)
for params in agent_init_params]
self.agent_init_params = agent_init_params
if self.nagents == 6:
self.mle_base = [SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14, #simple_com
self.agent_init_params[3]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
# SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14,
# self.agent_init_params[3]['num_out_pol'], # adv self-other
# hidden_dim=hidden_dim, output_style=output_style),
# SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14,
# self.agent_init_params[3]['num_out_pol'],
# hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
if self.nagents == 4:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle'] - 2, #simple_tag
self.agent_init_params[0]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2,
self.agent_init_params[3]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 3:
self.mle_base = [SNNNetwork(self.agent_init_params[1]['num_in_mle'], #simple_adv
self.agent_init_params[1]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'],
self.agent_init_params[1]['num_out_pol'], #agent self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'],
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 2:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle']-2, #simple_push
self.agent_init_params[0]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle']-2,
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
self.mle_opts = [Adam(self.mle_base[i].parameters(), lr=lr) for i in range(len(self.mle_base))]
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.mle_dev = 'cpu'
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, explore=False): #simple_tag
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
# t1 = time.time()
observations_ = observations.copy()
for agent_i, obs in enumerate(observations):
obs_ = observations_.copy()
obs_.pop(agent_i)
# actions = [self.agents[agent_i].mle[j].cpu()(observations[agent_i]) for j, obs_j in enumerate(obs_)]
# observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
if self.nagents == 6:
if agent_i < 4:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0],self.mle_base[0], self.mle_base[1], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(obs_j[:, 4:24].to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
else:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:-2]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(obs_j[:, 4:24].to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
if self.nagents == 4:
if agent_i < 3:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(obs_j[:, 2:].to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[2], self.mle_base[2]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:-2]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(obs_j[:,2:-2].to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
elif self.nagents == 3: #simple_adv
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0]]
# actions = [gumbel_softmax(
# self.agents[agent_i].mle[j].cpu()(torch.cat((obs_j[:, :2], observations_[agent_i]), 1)),
# hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:, :2],
observations_[agent_i]), 1).to(self.device)), hard=True).cpu()
for j, obs_j in enumerate(obs_)]
elif agent_i >= 1:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(observations_[agent_i].to(self.device)),
hard=True).cpu() for j, obs_j in enumerate(obs_)]
elif self.nagents == 2:
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:,2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(observations_[agent_i][:,2:].to(self.device)),
hard=True).cpu() for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:, 2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(observations_[agent_i][:,2:].to(self.device)),
hard=True).cpu() for j, obs_j in enumerate(obs_)]
observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
# t2 = time.time()
# print('step+time:', t2 - t1)
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def _get_obs(self, observations):
observations_ = []
for agent_i, obs in enumerate(observations):
obs_ = observations.copy()
obs_.pop(agent_i)
if self.nagents == 6:
if agent_i < 4: #simple_tag
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[1], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(obs_j[:, 4:24]).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif agent_i > 4:
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(obs_j[:, 4:24]).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
if self.nagents == 4:
if agent_i < 3: #simple_tag
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(obs_j[:, 2:]).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[2], self.mle_base[2]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(obs_j[:, 2:-2]).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif self.nagents == 3:
if agent_i < 1: #simple_adv
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:,:2],observations[agent_i]),1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif agent_i >= 1:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(observations[agent_i]).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif self.nagents == 2:
if agent_i < 1: #simple_push
self.agents[agent_i].mle = [self.mle_base[0]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(observations[agent_i][:,2:]).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(observations[agent_i][:,2:]).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
observations_.append(torch.cat((observations[agent_i], torch.cat(actions, 1)), 1))
return observations_
def trian_tag(self, agent_i, KL_criterion, obs, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](obs[0][:, 2:])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](obs[3][:, 2:])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[3].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
self.mle_opts[2].zero_grad()
action_i = self.mle_base[2](obs[0][:, 2:-2])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[2])
torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
self.mle_opts[2].step()
def trian_adv(self, agent_i, KL_criterion, obs, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](torch.cat((obs[1][:,:2],obs[agent_i]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](obs[1])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
self.mle_opts[2].zero_grad()
action_i = self.mle_base[2](obs[1])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[2])
torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
self.mle_opts[2].step()
def trian_push(self, agent_i, KL_criterion, obs, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](obs[0][:, 2:])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](obs[1][:, 2:])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def trian_com(self, agent_i, KL_criterion, obs, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](obs[1][:, 4:24])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](obs[4][:, 4:24])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[4].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def update(self, sample, agent_i, parallel=False, logger=None, sample_r=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
# print('___update___')
obs, acs, rews, next_obs, dones = sample
next_obs_ = self._get_obs(next_obs)
obs_ = self._get_obs(obs)
curr_agent = self.agents[agent_i]
# mle
KL_criterion = torch.nn.KLDivLoss(reduction='sum')
# for i in range(len(curr_agent.mle)):
# curr_agent.mle_optimizer[i].zero_grad()
# action_i = curr_agent.mle[i](obs[agent_i]obs[agent_i])
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[i].float())
# loss.backward()
# if parallel:
# average_gradients(curr_agent.mle[i])
# torch.nn.utils.clip_grad_norm_(curr_agent.mle[i].parameters(), 20)
# curr_agent.policy_optimizer.step()
if self.nagents == 6:
self.trian_com(agent_i, KL_criterion, obs, parallel, acs)
if self.nagents == 4:
self.trian_tag(agent_i, KL_criterion, obs, parallel, acs)
elif self.nagents == 3:
self.trian_adv(agent_i, KL_criterion, obs, parallel, acs)
elif self.nagents == 2:
self.trian_push(agent_i, KL_criterion, obs, parallel, acs)
# center critic
curr_agent.critic_optimizer.zero_grad()
if self.alg_types[agent_i] == 'MADDPG_ToM':
all_trgt_acs = []
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs_)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
if self.alg_types[agent_i] == 'MADDPG_ToM':
vf_in = torch.cat((*obs, *acs), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs_[agent_i])
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
if self.alg_types[agent_i] == 'MADDPG_ToM':
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs_):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out ** 2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
# actor
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for mle in self.mle_base:
mle.train()
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
for mle_i in a.mle:
mle_i.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
if not self.mle_dev == device:
for i, mle in enumerate(self.mle_base):
self.mle_base[i] = fn(mle)
for a in self.agents:
for i, mle_i in enumerate(a.mle):
a.mle[i] = fn(mle_i)
self.mle_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents],
'mle_params': [self.get_params()],}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, device, agent_alg="MADDPG_ToM", adversary_alg="MADDPG_ToM",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64, output_style='sum'):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
num_in_mle = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
if algtype == "MADDPG_ToM":
num_in_critic = 0
num_in_pol += (len(env.agent_types)-1) * 5
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic,
'num_in_mle': num_in_mle,})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'device': device,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'output_style': output_style}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
for a, params in zip([instance], save_dict['mle_params']):
a.load_params(params)
return instance
def get_params(self):
params = {
}
for i in range(len(self.mle_base)):
params['mle%d'%i] = self.mle_base[i].state_dict()
params['mle_optimizer%d'%i] = self.mle_opts[i].state_dict()
return params
def load_params(self, params):
for i in range(len(self.mle_base)):
self.mle_base[i].load_state_dict(params['mle%d'%i])
self.mle_opts[i].load_state_dict(params['mle_optimizer%d'%i])
class ToM_SA(object):
"""
Wrapper class for DDPG-esque (i.e. also MADDPG) agents in multi-agent task
"""
def __init__(self, agent_init_params, alg_types, output_style, device,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.device = device
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent_ToM(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params, output_style=output_style,
num_agents=self.nagents,
device=self.device)
for params in agent_init_params]
self.agent_init_params = agent_init_params
if self.nagents == 6:
self.mle_base = [SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5, #simple_com
self.agent_init_params[3]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'], # adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
if self.nagents == 4:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle'] - 2 + 5, #simple_tag
self.agent_init_params[0]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2 + 5,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2 + 5,
self.agent_init_params[3]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 3:
self.mle_base = [SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5, #simple_adv
self.agent_init_params[1]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5,
self.agent_init_params[1]['num_out_pol'], #agent self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5,
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 2:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle']-2 + 5, #simple_push
self.agent_init_params[0]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle']-2 + 5,
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
self.mle_opts = [Adam(self.mle_base[i].parameters(), lr=lr) for i in range(len(self.mle_base))]
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.mle_dev = 'cpu'
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, actions_pre, explore=False): #simple_tag
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
# t1 = time.time()
observations_ = observations.copy()
actions_pre_ = actions_pre.copy()
for agent_i, obs in enumerate(observations):
obs_ = observations_.copy()
acs_pre_ = actions_pre_.copy()
obs_.pop(agent_i)
acs_pre_.pop(agent_i)
# actions = [self.agents[agent_i].mle[j].cpu()(observations[agent_i]) for j, obs_j in enumerate(obs_)]
# observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
if self.nagents == 6:
if agent_i < 4:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0],self.mle_base[0], self.mle_base[1], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
# t1 = time.time()
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:, 4:24], acs_pre_[j][:,:5]),1).to(self.device)),
# hard=True).cpu()
# for j, obs_j in enumerate(obs_)]
# print(t1 - time.time())
# t1 = time.time()
actions = [torch.cat((obs_j[:, 4:24], acs_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)), hard=True).cpu()
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)), hard=True).cpu()
actions = torch.cat((b1[:20], b1[20:40], b1[40:60], b2[:20], b2[20:40]), 1)
# print(t1 - time.time())
# print()
else:
self.agents[agent_i].mle = [self.mle_base[3],self.mle_base[3], self.mle_base[3], self.mle_base[3], self.mle_base[2]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:-2]), hard=True)
# for j, obs_j in enumerate(obs_)]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:, 4:24], acs_pre_[j]),1).to(self.device)),
# hard=True).cpu()
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[1]['num_out_pol']))
for j, obs_j in enumerate(obs_)]
actions = torch.cat(actions,1)
# print()
if self.nagents == 4:
if agent_i < 3:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:, 2:], acs_pre_[j]),1).to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[2], self.mle_base[2]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:-2]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol']))
for j, obs_j in enumerate(obs_)]
elif self.nagents == 3: #simple_adv
actions = []
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0]]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol']))
for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
actions.append(gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(0)]), 1).to(self.device)),
hard=True).cpu() )
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(2)]), 1).to(self.device)),
hard=True).cpu() )
elif agent_i == 2:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions.append(gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(0)]), 1).to(self.device)),
hard=True).cpu() )
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(1)]), 1).to(self.device)),
hard=True).cpu() )
elif self.nagents == 2:
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:,2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0], self.agent_init_params[0]['num_out_pol'])) for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:, 2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((observations_[agent_i][:,2:],
actions_pre[(self.nagents -1 - agent_i)]), 1).to(self.device)),
hard=True).cpu() for j, obs_j in enumerate(obs_)]
if self.nagents == 6:
observations[agent_i] = torch.cat((observations[agent_i], actions), 1)
else:
observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
# t2 = time.time()
# print('step+time:', t2 - t1)
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def _get_obs(self, observations, actions_pre):
observations_ = []
actions_pre_ = []
for agent_i, obs in enumerate(observations):
obs_ = observations.copy()
obs_.pop(agent_i)
actions_pre_ = actions_pre.copy()
actions_pre_.pop(agent_i)
if self.nagents == 6:
if agent_i < 4: #simple_comm
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[1], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1)).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)).detach(), hard=True)
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)).detach(), hard=True)
actions = torch.cat((b1[:1024], b1[1024:2048], b1[2048:3072], b2[:1024], b2[1024:2048]), 1)
# print()
elif agent_i > 4:
self.agents[agent_i].mle = [self.mle_base[3], self.mle_base[3], self.mle_base[3], self.mle_base[3], self.mle_base[2]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(obs_j[:, 4:24]).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0], self.agent_init_params[1]['num_out_pol'])).to(
torch.device(self.device)).detach() for j, obs_j in enumerate(obs_)]
actions = torch.cat(actions, 1)
# print()
if self.nagents == 4:
if agent_i < 3: #simple_tag
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 2:], actions_pre_[j]),1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[2], self.mle_base[2]]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach()
for j, obs_j in enumerate(obs_)]
elif self.nagents == 3:
actions = []
if agent_i < 1: #simple_adv
# self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:,:2],observations[agent_i]),1)).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach()
for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(observations[agent_i]).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions.append(
gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(0)]), 1).to(self.device)).detach(), hard=True))
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(2)]), 1).to(self.device)).detach(), hard=True))
elif agent_i == 2:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
actions.append(
gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(0)]), 1).to(self.device)).detach(), hard=True))
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(1)]), 1).to(self.device)).detach(), hard=True))
elif self.nagents == 2:
if agent_i < 1: #simple_push
self.agents[agent_i].mle = [self.mle_base[0]]
actions = [torch.zeros((obs_j.shape[0], self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach() for j, obs_j in
enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((observations[agent_i][:,2:],
actions_pre[(self.nagents -1 - agent_i)]), 1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
if self.nagents == 6:
observations_.append(torch.cat((observations[agent_i], actions), 1))
else:
observations_.append(torch.cat((observations[agent_i], torch.cat(actions, 1)), 1))
return observations_
def trian_tag(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](torch.cat((obs[0][:, 2:], acs_pre[0]),1))#
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[3][:, 2:], acs_pre[3]),1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[3].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
# self.mle_opts[2].zero_grad()
# action_i = self.mle_base[2](obs[0][:, 2:-2])
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[0].float())
# loss.backward()
# if parallel:
# average_gradients(self.mle_base[2])
# torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
# self.mle_opts[2].step()
def trian_adv(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
# self.mle_opts[0].zero_grad()
# action_i = self.mle_base[0](torch.cat((obs[1][:,:2],obs[agent_i]), 1))
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[1].float())
# loss.backward(retain_graph=True)
# if parallel:
# average_gradients(self.mle_base[0])
# torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
# self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[1], acs_pre[2]), 1)) #torch.cat((obs[1], acs_pre[2]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
self.mle_opts[2].zero_grad()
action_i = self.mle_base[2](torch.cat((obs[1], acs_pre[0]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[2])
torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
self.mle_opts[2].step()
def trian_push(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
# self.mle_opts[0].zero_grad()
# action_i = self.mle_base[0](obs[0][:, 2:]) #torch.cat((obs[agent_i][:,2:], actions[(self.nagents -1 - agent_i)]), 1)
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[1].float())
# loss.backward(retain_graph=True)
# if parallel:
# average_gradients(self.mle_base[0])
# torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
# self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[1][:,2:], acs_pre[(0)]), 1)) #obs[1][:, 2:]
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def trian_com(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](torch.cat((obs[1][:, 4:24], acs_pre[(1)]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[4][:, 4:24], acs_pre[(4)]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[4].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def update(self, sample, agent_i, parallel=False, logger=None, sample_r=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
# print('___update___')
acs_pre, obs, acs, rews, next_obs, dones = sample
next_obs_ = self._get_obs(next_obs, acs)
obs_ = self._get_obs(obs, acs_pre)
curr_agent = self.agents[agent_i]
# mle
KL_criterion = torch.nn.KLDivLoss(reduction='sum')
# for i in range(len(curr_agent.mle)):
# curr_agent.mle_optimizer[i].zero_grad()
# action_i = curr_agent.mle[i](obs[agent_i]obs[agent_i])
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[i].float())
# loss.backward()
# if parallel:
# average_gradients(curr_agent.mle[i])
# torch.nn.utils.clip_grad_norm_(curr_agent.mle[i].parameters(), 20)
# curr_agent.policy_optimizer.step()
if self.nagents == 6:
self.trian_com(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 4:
self.trian_tag(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 3:
self.trian_adv(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 2:
self.trian_push(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
# center critic
curr_agent.critic_optimizer.zero_grad()
all_trgt_acs = []
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs_)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
vf_in = torch.cat((*obs, *acs), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs_[agent_i])
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs_):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out ** 2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
# actor
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for mle in self.mle_base:
mle.train()
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
for mle_i in a.mle:
mle_i.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
if not self.mle_dev == device:
for i, mle in enumerate(self.mle_base):
self.mle_base[i] = fn(mle)
for a in self.agents:
for i, mle_i in enumerate(a.mle):
a.mle[i] = fn(mle_i)
self.mle_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents],
'mle_params': [self.get_params()],}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, device, agent_alg="ToM_SA", adversary_alg="ToM_SA",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64, output_style='sum'):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
num_in_mle = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
if algtype == "ToM_SA":
num_in_critic = 0
num_in_pol += (len(env.agent_types)-1) * 5
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic,
'num_in_mle': num_in_mle,})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'device': device,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'output_style': output_style}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
for a, params in zip([instance], save_dict['mle_params']):
a.load_params(params)
return instance
def get_params(self):
params = {
}
for i in range(len(self.mle_base)):
params['mle%d'%i] = self.mle_base[i].state_dict()
params['mle_optimizer%d'%i] = self.mle_opts[i].state_dict()
return params
def load_params(self, params):
for i in range(len(self.mle_base)):
self.mle_base[i].load_state_dict(params['mle%d'%i])
self.mle_opts[i].load_state_dict(params['mle_optimizer%d'%i])
class ToM_S(object):
"""
Wrapper class for DDPG-esque (i.e. also MADDPG) agents in multi-agent task
"""
def __init__(self, agent_init_params, alg_types, output_style, device,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.device = device
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent_ToM(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params, output_style=output_style,
num_agents=self.nagents,
device=self.device)
for params in agent_init_params]
self.agent_init_params = agent_init_params
if self.nagents == 6:
self.mle_base = [SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5, #simple_com
self.agent_init_params[3]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'], # adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
if self.nagents == 4:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle'] - 2 + 5, #simple_tag
self.agent_init_params[0]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2 + 5,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2 + 5,
self.agent_init_params[3]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 3:
self.mle_base = [SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5, #simple_adv
self.agent_init_params[1]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5,
self.agent_init_params[1]['num_out_pol'], #agent self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5,
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 2:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle']-2 + 5, #simple_push
self.agent_init_params[0]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle']-2 + 5,
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
self.mle_opts = [Adam(self.mle_base[i].parameters(), lr=lr) for i in range(len(self.mle_base))]
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.mle_dev = 'cpu'
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, actions_pre, explore=False): #simple_tag
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
# t1 = time.time()
observations_ = observations.copy()
actions_pre_ = actions_pre.copy()
for agent_i, obs in enumerate(observations):
obs_ = observations_.copy()
acs_pre_ = actions_pre_.copy()
obs_.pop(agent_i)
acs_pre_.pop(agent_i)
# actions = [self.agents[agent_i].mle[j].cpu()(observations[agent_i]) for j, obs_j in enumerate(obs_)]
# observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
if self.nagents == 6:
if agent_i < 4:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0],self.mle_base[0], self.mle_base[1], self.mle_base[1]]
actions = [torch.cat((obs_j[:, 4:24], acs_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)), hard=True).cpu()
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)), hard=True).cpu()
actions = torch.cat((b1[:20], b1[20:40], b1[40:60], b2[:20], b2[20:40]), 1)
# print(t1 - time.time())
# print()
else:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[1]]
actions = [torch.cat((obs_j[:, 4:24], acs_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)), hard=True).cpu()
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)), hard=True).cpu()
actions = torch.cat((b1[:20], b1[20:40], b1[40:60], b2[:20], b2[20:40]), 1)
# actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[1]['num_out_pol']))
# for j, obs_j in enumerate(obs_)]
# actions = torch.cat(actions,1)
# print()
if self.nagents == 4:
if agent_i < 3:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:, 2:], acs_pre_[j]),1).to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[2], self.mle_base[2]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:, 2:-2], acs_pre_[j]),1).to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:-2]), hard=True)
# for j, obs_j in enumerate(obs_)]
# actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol']))
# for j, obs_j in enumerate(obs_)]
elif self.nagents == 3: #simple_adv
actions = []
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0]]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol']))
for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
actions.append(gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(0)]), 1).to(self.device)),
hard=True).cpu() )
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(2)]), 1).to(self.device)),
hard=True).cpu() )
elif agent_i == 2:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions.append(gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(0)]), 1).to(self.device)),
hard=True).cpu() )
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(1)]), 1).to(self.device)),
hard=True).cpu() )
elif self.nagents == 2:
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:,2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0], self.agent_init_params[0]['num_out_pol'])) for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:, 2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((observations_[agent_i][:,2:],
actions_pre[(self.nagents -1 - agent_i)]), 1).to(self.device)),
hard=True).cpu() for j, obs_j in enumerate(obs_)]
if self.nagents == 6:
observations[agent_i] = torch.cat((observations[agent_i], actions), 1)
else:
observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
# t2 = time.time()
# print('step+time:', t2 - t1)
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def _get_obs(self, observations, actions_pre):
observations_ = []
actions_pre_ = []
for agent_i, obs in enumerate(observations):
obs_ = observations.copy()
obs_.pop(agent_i)
actions_pre_ = actions_pre.copy()
actions_pre_.pop(agent_i)
if self.nagents == 6:
if agent_i < 4: #simple_comm
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[1], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1)).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)).detach(), hard=True)
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)).detach(), hard=True)
actions = torch.cat((b1[:1024], b1[1024:2048], b1[2048:3072], b2[:1024], b2[1024:2048]), 1)
# print()
elif agent_i > 4:
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[1]]
actions = [torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)).detach(), hard=True)
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)).detach(), hard=True)
actions = torch.cat((b1[:1024], b1[1024:2048], b1[2048:3072], b2[:1024], b2[1024:2048]), 1)
# print()
if self.nagents == 4:
if agent_i < 3: #simple_tag
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 2:], actions_pre_[j]),1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[2], self.mle_base[2]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 2:-2], actions_pre_[j]),1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif self.nagents == 3:
actions = []
if agent_i < 1: #simple_adv
# self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:,:2],observations[agent_i]),1)).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach()
for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(observations[agent_i]).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions.append(
gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(0)]), 1).to(self.device)).detach(), hard=True))
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(2)]), 1).to(self.device)).detach(), hard=True))
elif agent_i == 2:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
actions.append(
gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(0)]), 1).to(self.device)).detach(), hard=True))
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(1)]), 1).to(self.device)).detach(), hard=True))
elif self.nagents == 2:
if agent_i < 1: #simple_push
self.agents[agent_i].mle = [self.mle_base[0]]
actions = [torch.zeros((obs_j.shape[0], self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach() for j, obs_j in
enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((observations[agent_i][:,2:],
actions_pre[(self.nagents -1 - agent_i)]), 1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
if self.nagents == 6:
observations_.append(torch.cat((observations[agent_i], actions), 1))
else:
observations_.append(torch.cat((observations[agent_i], torch.cat(actions, 1)), 1))
return observations_
def trian_tag(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](torch.cat((obs[0][:, 2:], acs_pre[0]),1))#
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[3][:, 2:], acs_pre[3]),1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[3].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
self.mle_opts[2].zero_grad()
action_i = self.mle_base[2](torch.cat((obs[0][:, 2:-2], acs_pre[0]),1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[2])
torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
self.mle_opts[2].step()
def trian_adv(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
# self.mle_opts[0].zero_grad()
# action_i = self.mle_base[0](torch.cat((obs[1][:,:2],obs[agent_i]), 1))
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[1].float())
# loss.backward(retain_graph=True)
# if parallel:
# average_gradients(self.mle_base[0])
# torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
# self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[1], acs_pre[2]), 1)) #torch.cat((obs[1], acs_pre[2]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
self.mle_opts[2].zero_grad()
action_i = self.mle_base[2](torch.cat((obs[1], acs_pre[0]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[2])
torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
self.mle_opts[2].step()
def trian_push(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
# self.mle_opts[0].zero_grad()
# action_i = self.mle_base[0](obs[0][:, 2:]) #torch.cat((obs[agent_i][:,2:], actions[(self.nagents -1 - agent_i)]), 1)
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[1].float())
# loss.backward(retain_graph=True)
# if parallel:
# average_gradients(self.mle_base[0])
# torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
# self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[1][:,2:], acs_pre[(0)]), 1)) #obs[1][:, 2:]
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def trian_com(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](torch.cat((obs[1][:, 4:24], acs_pre[(1)]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[4][:, 4:24], acs_pre[(4)]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[4].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def update(self, sample, agent_i, parallel=False, logger=None, sample_r=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
# print('___update___')
acs_pre, obs, acs, rews, next_obs, dones = sample
next_obs_ = self._get_obs(next_obs, acs)
obs_ = self._get_obs(obs, acs_pre)
curr_agent = self.agents[agent_i]
# mle
KL_criterion = torch.nn.KLDivLoss(reduction='sum')
# for i in range(len(curr_agent.mle)):
# curr_agent.mle_optimizer[i].zero_grad()
# action_i = curr_agent.mle[i](obs[agent_i]obs[agent_i])
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[i].float())
# loss.backward()
# if parallel:
# average_gradients(curr_agent.mle[i])
# torch.nn.utils.clip_grad_norm_(curr_agent.mle[i].parameters(), 20)
# curr_agent.policy_optimizer.step()
if self.nagents == 6:
self.trian_com(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 4:
self.trian_tag(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 3:
self.trian_adv(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 2:
self.trian_push(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
# center critic
curr_agent.critic_optimizer.zero_grad()
all_trgt_acs = []
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs_)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
vf_in = torch.cat((*obs, *acs), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs_[agent_i])
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs_):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out ** 2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
# actor
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for mle in self.mle_base:
mle.train()
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
for mle_i in a.mle:
mle_i.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
if not self.mle_dev == device:
for i, mle in enumerate(self.mle_base):
self.mle_base[i] = fn(mle)
for a in self.agents:
for i, mle_i in enumerate(a.mle):
a.mle[i] = fn(mle_i)
self.mle_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents],
'mle_params': [self.get_params()],}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, device, agent_alg="ToM_S", adversary_alg="ToM_S",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64, output_style='sum'):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
num_in_mle = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
if algtype == "ToM_S":
num_in_critic = 0
num_in_pol += (len(env.agent_types)-1) * 5
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic,
'num_in_mle': num_in_mle,})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'device': device,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'output_style': output_style}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
for a, params in zip([instance], save_dict['mle_params']):
a.load_params(params)
return instance
def get_params(self):
params = {
}
for i in range(len(self.mle_base)):
params['mle%d'%i] = self.mle_base[i].state_dict()
params['mle_optimizer%d'%i] = self.mle_opts[i].state_dict()
return params
def load_params(self, params):
for i in range(len(self.mle_base)):
self.mle_base[i].load_state_dict(params['mle%d'%i])
self.mle_opts[i].load_state_dict(params['mle_optimizer%d'%i])
class ToM_self(object):
"""
Wrapper class for DDPG-esque (i.e. also MADDPG) agents in multi-agent task
"""
def __init__(self, agent_init_params, alg_types, output_style, device,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.device = device
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent_ToM(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params, output_style=output_style,
num_agents=self.nagents,
device=self.device)
for params in agent_init_params]
self.agent_init_params = agent_init_params
if self.nagents == 6:
self.mle_base = [SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5, #simple_com
self.agent_init_params[3]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'], # adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
if self.nagents == 4:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle'] - 2 + 5, #simple_tag
self.agent_init_params[0]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2 + 5,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2 + 5,
self.agent_init_params[3]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 3:
self.mle_base = [SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5, #simple_adv
self.agent_init_params[1]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5,
self.agent_init_params[1]['num_out_pol'], #agent self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5,
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 2:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle']-2 + 5, #simple_push
self.agent_init_params[0]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle']-2 + 5,
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
self.mle_opts = [Adam(self.mle_base[i].parameters(), lr=lr) for i in range(len(self.mle_base))]
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.mle_dev = 'cpu'
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, actions_pre, explore=False): #simple_tag
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
# t1 = time.time()
observations_ = observations.copy()
actions_pre_ = actions_pre.copy()
for agent_i, obs in enumerate(observations):
obs_ = observations_.copy()
acs_pre_ = actions_pre_.copy()
obs_.pop(agent_i)
acs_pre_.pop(agent_i)
# actions = [self.agents[agent_i].mle[j].cpu()(observations[agent_i]) for j, obs_j in enumerate(obs_)]
# observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
if self.nagents == 6:
if agent_i < 4:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0],self.mle_base[0], self.mle_base[0], self.mle_base[0]]
actions = [torch.cat((obs_j[:, 4:24], acs_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)), hard=True).cpu()
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)), hard=True).cpu()
actions = torch.cat((b1[:20], b1[20:40], b1[40:60], b2[:20], b2[20:40]), 1)
# print(t1 - time.time())
# print()
else:
self.agents[agent_i].mle = [self.mle_base[1],self.mle_base[1], self.mle_base[1], self.mle_base[1], self.mle_base[1]]
actions = [torch.cat((obs_j[:, 4:24], acs_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)), hard=True).cpu()
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)), hard=True).cpu()
actions = torch.cat((b1[:20], b1[20:40], b1[40:60], b2[:20], b2[20:40]), 1)
# actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[1]['num_out_pol']))
# for j, obs_j in enumerate(obs_)]
# actions = torch.cat(actions,1)
# print()
if self.nagents == 4:
if agent_i < 3:
self.agents[agent_i].mle = [self.mle_base[1],self.mle_base[1], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:, 2:14], acs_pre_[j]),1).to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[2], self.mle_base[2]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:,2:14], acs_pre_[j]),1).to(self.device)),
hard=True).cpu() for j, obs_j in enumerate(obs_)]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:-2]), hard=True)
# for j, obs_j in enumerate(obs_)]
# actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol']))
# for j, obs_j in enumerate(obs_)]
elif self.nagents == 3: #simple_adv
actions = []
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0]]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol']))
for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
actions.append(gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(0)]), 1).to(self.device)),
hard=True).cpu() )
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(2)]), 1).to(self.device)),
hard=True).cpu() )
elif agent_i == 2:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions.append(gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(0)]), 1).to(self.device)),
hard=True).cpu() )
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(1)]), 1).to(self.device)),
hard=True).cpu() )
elif self.nagents == 2:
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:,2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0], self.agent_init_params[0]['num_out_pol'])) for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:, 2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((observations_[agent_i][:,2:],
actions_pre[(self.nagents -1 - agent_i)]), 1).to(self.device)),
hard=True).cpu() for j, obs_j in enumerate(obs_)]
if self.nagents == 6:
observations[agent_i] = torch.cat((observations[agent_i], actions), 1)
else:
observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
# t2 = time.time()
# print('step+time:', t2 - t1)
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def _get_obs(self, observations, actions_pre):
observations_ = []
actions_pre_ = []
for agent_i, obs in enumerate(observations):
obs_ = observations.copy()
obs_.pop(agent_i)
actions_pre_ = actions_pre.copy()
actions_pre_.pop(agent_i)
if self.nagents == 6:
if agent_i < 4: #simple_comm
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1)).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)).detach(), hard=True)
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)).detach(), hard=True)
actions = torch.cat((b1[:1024], b1[1024:2048], b1[2048:3072], b2[:1024], b2[1024:2048]), 1)
# print()
elif agent_i > 4:
self.agents[agent_i].mle = [self.mle_base[1], self.mle_base[1], self.mle_base[1], self.mle_base[1], self.mle_base[1]]
actions = [torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)).detach(), hard=True)
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)).detach(), hard=True)
actions = torch.cat((b1[:1024], b1[1024:2048], b1[2048:3072], b2[:1024], b2[1024:2048]), 1)
# print()
if self.nagents == 4:
if agent_i < 3: #simple_tag
self.agents[agent_i].mle = [self.mle_base[1], self.mle_base[1], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 2:14], actions_pre_[j]),1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[2], self.mle_base[2]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 2:14], actions_pre_[j]),1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:,2:-2], acs_pre_[j]),1).to(self.device)),
# hard=True).cpu() for j, obs_j in enumerate(obs_)]
# actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach()
# for j, obs_j in enumerate(obs_)]
elif self.nagents == 3:
actions = []
if agent_i < 1: #simple_adv
# self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:,:2],observations[agent_i]),1)).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach()
for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(observations[agent_i]).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions.append(
gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(0)]), 1).to(self.device)).detach(), hard=True))
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(2)]), 1).to(self.device)).detach(), hard=True))
elif agent_i == 2:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
actions.append(
gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(0)]), 1).to(self.device)).detach(), hard=True))
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(1)]), 1).to(self.device)).detach(), hard=True))
elif self.nagents == 2:
if agent_i < 1: #simple_push
self.agents[agent_i].mle = [self.mle_base[0]]
actions = [torch.zeros((obs_j.shape[0], self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach() for j, obs_j in
enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((observations[agent_i][:,2:],
actions_pre[(self.nagents -1 - agent_i)]), 1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
if self.nagents == 6:
observations_.append(torch.cat((observations[agent_i], actions), 1))
else:
observations_.append(torch.cat((observations[agent_i], torch.cat(actions, 1)), 1))
return observations_
def trian_tag(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[0][:, 2:14], acs_pre[0]),1))#
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
self.mle_opts[2].zero_grad()
action_i = self.mle_base[2](torch.cat((obs[3][:, 2:14], acs_pre[3]),1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[3].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[2])
torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
self.mle_opts[2].step()
def trian_adv(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[1], acs_pre[2]), 1)) #torch.cat((obs[1], acs_pre[2]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
self.mle_opts[2].zero_grad()
action_i = self.mle_base[2](torch.cat((obs[1], acs_pre[0]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[2])
torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
self.mle_opts[2].step()
def trian_push(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[1][:,2:], acs_pre[(0)]), 1)) #obs[1][:, 2:]
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def trian_com(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](torch.cat((obs[1][:, 4:24], acs_pre[(1)]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[4][:, 4:24], acs_pre[(4)]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[4].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def update(self, sample, agent_i, parallel=False, logger=None, sample_r=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
# print('___update___')
acs_pre, obs, acs, rews, next_obs, dones = sample
next_obs_ = self._get_obs(next_obs, acs)
obs_ = self._get_obs(obs, acs_pre)
curr_agent = self.agents[agent_i]
# mle
KL_criterion = torch.nn.KLDivLoss(reduction='sum')
# for i in range(len(curr_agent.mle)):
# curr_agent.mle_optimizer[i].zero_grad()
# action_i = curr_agent.mle[i](obs[agent_i]obs[agent_i])
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[i].float())
# loss.backward()
# if parallel:
# average_gradients(curr_agent.mle[i])
# torch.nn.utils.clip_grad_norm_(curr_agent.mle[i].parameters(), 20)
# curr_agent.policy_optimizer.step()
if self.nagents == 6:
self.trian_com(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 4:
self.trian_tag(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 3:
self.trian_adv(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 2:
self.trian_push(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
# center critic
curr_agent.critic_optimizer.zero_grad()
all_trgt_acs = []
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs_)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
vf_in = torch.cat((*obs, *acs), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs_[agent_i])
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs_):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out ** 2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
# actor
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for mle in self.mle_base:
mle.train()
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
for mle_i in a.mle:
mle_i.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
if not self.mle_dev == device:
for i, mle in enumerate(self.mle_base):
self.mle_base[i] = fn(mle)
for a in self.agents:
for i, mle_i in enumerate(a.mle):
a.mle[i] = fn(mle_i)
self.mle_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents],
'mle_params': [self.get_params()],}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, device, agent_alg="ToM_self", adversary_alg="ToM_self",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64, output_style='sum'):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
num_in_mle = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
if algtype == "ToM_self":
num_in_critic = 0
num_in_pol += (len(env.agent_types)-1) * 5
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic,
'num_in_mle': num_in_mle,})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'device': device,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'output_style': output_style}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
for a, params in zip([instance], save_dict['mle_params']):
a.load_params(params)
return instance
def get_params(self):
params = {
}
for i in range(len(self.mle_base)):
params['mle%d'%i] = self.mle_base[i].state_dict()
params['mle_optimizer%d'%i] = self.mle_opts[i].state_dict()
return params
def load_params(self, params):
for i in range(len(self.mle_base)):
self.mle_base[i].load_state_dict(params['mle%d'%i])
self.mle_opts[i].load_state_dict(params['mle_optimizer%d'%i])
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/buffer.py
================================================
import numpy as np
import torch
from torch import Tensor
from torch.autograd import Variable
class ReplayBuffer(object):
"""
Replay Buffer for multi-agent RL with parallel rollouts
"""
def __init__(self, max_steps, num_agents, obs_dims, ac_dims, device):
"""
Inputs:
max_steps (int): Maximum number of timepoints to store in buffer
num_agents (int): Number of agents in environment
obs_dims (list of ints): number of obervation dimensions for each
agent
ac_dims (list of ints): number of action dimensions for each agent
"""
self.device = device
self.max_steps = max_steps
self.num_agents = num_agents
self.obs_buffs = []
self.ac_buffs = []
self.rew_buffs = []
self.next_obs_buffs = []
self.done_buffs = []
for odim, adim in zip(obs_dims, ac_dims):
self.obs_buffs.append(np.zeros((max_steps, odim)))
self.ac_buffs.append(np.zeros((max_steps, adim)))
self.rew_buffs.append(np.zeros(max_steps))
self.next_obs_buffs.append(np.zeros((max_steps, odim)))
self.done_buffs.append(np.zeros(max_steps))
self.filled_i = 0 # index of first empty location in buffer (last index when full)
self.curr_i = 0 # current index to write to (ovewrite oldest data)
def __len__(self):
return self.filled_i
def push(self, observations, actions, rewards, next_observations, dones):
nentries = observations.shape[0] # handle multiple parallel environments
if self.curr_i + nentries > self.max_steps:
rollover = self.max_steps - self.curr_i # num of indices to roll over
for agent_i in range(self.num_agents):
self.obs_buffs[agent_i] = np.roll(self.obs_buffs[agent_i],
rollover, axis=0)
self.ac_buffs[agent_i] = np.roll(self.ac_buffs[agent_i],
rollover, axis=0)
self.rew_buffs[agent_i] = np.roll(self.rew_buffs[agent_i],
rollover)
self.next_obs_buffs[agent_i] = np.roll(
self.next_obs_buffs[agent_i], rollover, axis=0)
self.done_buffs[agent_i] = np.roll(self.done_buffs[agent_i],
rollover)
self.curr_i = 0
self.filled_i = self.max_steps
for agent_i in range(self.num_agents):
self.obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
observations[:, agent_i])
# actions are already batched by agent, so they are indexed differently
self.ac_buffs[agent_i][self.curr_i:self.curr_i + nentries] = actions[agent_i]
self.rew_buffs[agent_i][self.curr_i:self.curr_i + nentries] = rewards[:, agent_i]
self.next_obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
next_observations[:, agent_i])
self.done_buffs[agent_i][self.curr_i:self.curr_i + nentries] = dones[:, agent_i]
self.curr_i += nentries
if self.filled_i < self.max_steps:
self.filled_i += nentries
if self.curr_i == self.max_steps:
self.curr_i = 0
def sample(self, N, to_gpu=False, norm_rews=True):
inds = np.random.choice(np.arange(self.filled_i), size=N,
replace=False)
if to_gpu:
cast = lambda x: Variable(Tensor(x), requires_grad=False).to(torch.device(self.device))
else:
cast = lambda x: Variable(Tensor(x), requires_grad=False)
if norm_rews:
ret_rews = [cast((self.rew_buffs[i][inds] -
self.rew_buffs[i][:self.filled_i].mean()) /
self.rew_buffs[i][:self.filled_i].std())
for i in range(self.num_agents)]
else:
ret_rews = [cast(self.rew_buffs[i][inds]) for i in range(self.num_agents)]
return ([cast(self.obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.ac_buffs[i][inds]) for i in range(self.num_agents)],
ret_rews,
[cast(self.next_obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.done_buffs[i][inds]) for i in range(self.num_agents)])
def get_average_rewards(self, N):
if self.filled_i == self.max_steps:
inds = np.arange(self.curr_i - N, self.curr_i) # allow for negative indexing
else:
inds = np.arange(max(0, self.curr_i - N), self.curr_i)
return [self.rew_buffs[i][inds].mean() for i in range(self.num_agents)]
class ReplayBuffer_pre(object):
"""
Replay Buffer for multi-agent RL with parallel rollouts
"""
def __init__(self, max_steps, num_agents, obs_dims, ac_dims, device):
"""
Inputs:
max_steps (int): Maximum number of timepoints to store in buffer
num_agents (int): Number of agents in environment
obs_dims (list of ints): number of obervation dimensions for each
agent
ac_dims (list of ints): number of action dimensions for each agent
"""
self.device = device
self.max_steps = max_steps
self.num_agents = num_agents
self.ac_pre_buffs = []
self.obs_buffs = []
self.ac_buffs = []
self.rew_buffs = []
self.next_obs_buffs = []
self.done_buffs = []
for odim, adim in zip(obs_dims, ac_dims):
self.ac_pre_buffs.append(np.zeros((max_steps, 5)))
self.obs_buffs.append(np.zeros((max_steps, odim)))
self.ac_buffs.append(np.zeros((max_steps, adim)))
self.rew_buffs.append(np.zeros(max_steps))
self.next_obs_buffs.append(np.zeros((max_steps, odim)))
self.done_buffs.append(np.zeros(max_steps))
self.filled_i = 0 # index of first empty location in buffer (last index when full)
self.curr_i = 0 # current index to write to (ovewrite oldest data)
def __len__(self):
return self.filled_i
def push(self, actions_pre, observations, actions, rewards, next_observations, dones):
nentries = observations.shape[0] # handle multiple parallel environments
if self.curr_i + nentries > self.max_steps:
rollover = self.max_steps - self.curr_i # num of indices to roll over
for agent_i in range(self.num_agents):
self.ac_pre_buffs[agent_i] = np.roll(self.ac_pre_buffs[agent_i][:,:5],
rollover, axis=0)
self.obs_buffs[agent_i] = np.roll(self.obs_buffs[agent_i],
rollover, axis=0)
self.ac_buffs[agent_i] = np.roll(self.ac_buffs[agent_i],
rollover, axis=0)
self.rew_buffs[agent_i] = np.roll(self.rew_buffs[agent_i],
rollover)
self.next_obs_buffs[agent_i] = np.roll(
self.next_obs_buffs[agent_i], rollover, axis=0)
self.done_buffs[agent_i] = np.roll(self.done_buffs[agent_i],
rollover)
self.curr_i = 0
self.filled_i = self.max_steps
for agent_i in range(self.num_agents):
self.ac_pre_buffs[agent_i][self.curr_i:self.curr_i + nentries] = actions_pre[agent_i][:,:5]
self.obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
observations[:, agent_i])
# actions are already batched by agent, so they are indexed differently
self.ac_buffs[agent_i][self.curr_i:self.curr_i + nentries] = actions[agent_i]
self.rew_buffs[agent_i][self.curr_i:self.curr_i + nentries] = rewards[:, agent_i]
self.next_obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
next_observations[:, agent_i])
self.done_buffs[agent_i][self.curr_i:self.curr_i + nentries] = dones[:, agent_i]
self.curr_i += nentries
if self.filled_i < self.max_steps:
self.filled_i += nentries
if self.curr_i == self.max_steps:
self.curr_i = 0
def sample(self, N, to_gpu=False, norm_rews=True):
inds = np.random.choice(np.arange(self.filled_i), size=N,
replace=False)
if to_gpu:
cast = lambda x: Variable(Tensor(x), requires_grad=False).to(torch.device(self.device))
else:
cast = lambda x: Variable(Tensor(x), requires_grad=False)
if norm_rews:
ret_rews = [cast((self.rew_buffs[i][inds] -
self.rew_buffs[i][:self.filled_i].mean()) /
self.rew_buffs[i][:self.filled_i].std())
for i in range(self.num_agents)]
else:
ret_rews = [cast(self.rew_buffs[i][inds]) for i in range(self.num_agents)]
return ([cast(self.ac_pre_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.ac_buffs[i][inds]) for i in range(self.num_agents)],
ret_rews,
[cast(self.next_obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.done_buffs[i][inds]) for i in range(self.num_agents)])
def get_average_rewards(self, N):
if self.filled_i == self.max_steps:
inds = np.arange(self.curr_i - N, self.curr_i) # allow for negative indexing
else:
inds = np.arange(max(0, self.curr_i - N), self.curr_i)
return [self.rew_buffs[i][inds].mean() for i in range(self.num_agents)]
class ReplayBuffer_RNN(object):
"""
Replay Buffer for multi-agent RL with parallel rollouts
"""
def __init__(self, max_steps, num_agents, obs_dims, ac_dims, ep_dims):
"""
Inputs:
max_steps (int): Maximum number of timepoints to store in buffer
num_agents (int): Number of agents in environment
obs_dims (list of ints): number of obervation dimensions for each
agent
ac_dims (list of ints): number of action dimensions for each agent
ep_dims (int): Number of steps in each episode
"""
self.max_steps = max_steps
self.num_agents = num_agents
self.obs_buffs = []
self.ac_buffs = []
self.rew_buffs = []
self.next_obs_buffs = []
self.done_buffs = []
for odim, adim in zip(obs_dims, ac_dims):
self.obs_buffs.append(np.zeros((max_steps, ep_dims, odim)))
self.ac_buffs.append(np.zeros((max_steps, ep_dims, adim)))
self.rew_buffs.append(np.zeros((max_steps, ep_dims)))
self.next_obs_buffs.append(np.zeros((max_steps, ep_dims, odim)))
self.done_buffs.append(np.zeros((max_steps, ep_dims)))
self.filled_i = 0 # index of first empty location in buffer (last index when full)
self.curr_i = 0 # current index to write to (ovewrite oldest data)
def __len__(self):
return self.filled_i
def push(self, observations_ep, actions_ep, rewards_ep, next_observations_ep, dones_ep):
nentries = observations_ep[0].shape[0] # handle multiple parallel environments
observations_ep, actions_ep, rewards_ep, next_observations_ep, dones_ep = \
np.array(observations_ep), np.array(actions_ep), np.array(rewards_ep),\
np.array(next_observations_ep), np.array(dones_ep)
if self.curr_i + nentries > self.max_steps:
rollover = self.max_steps - self.curr_i # num of indices to roll over
for agent_i in range(self.num_agents):
self.obs_buffs[agent_i] = np.roll(self.obs_buffs[agent_i],
rollover, axis=0)
self.ac_buffs[agent_i] = np.roll(self.ac_buffs[agent_i],
rollover, axis=0)
self.rew_buffs[agent_i] = np.roll(self.rew_buffs[agent_i],
rollover)
self.next_obs_buffs[agent_i] = np.roll(
self.next_obs_buffs[agent_i], rollover, axis=0)
self.done_buffs[agent_i] = np.roll(self.done_buffs[agent_i],
rollover)
self.curr_i = 0
self.filled_i = self.max_steps
for agent_i in range(self.num_agents):
for i in range(observations_ep[:,:,agent_i].shape[0]):
if i == 0:
ob_ep = np.expand_dims(np.vstack(observations_ep[:,:,agent_i][i]), 0)
ob_next_ep = np.expand_dims(np.vstack(next_observations_ep[:,:,agent_i][i]), 0)
else:
ob_ep = np.vstack((ob_ep, np.expand_dims(np.vstack(observations_ep[:,:,agent_i][i]), 0)))
ob_next_ep = np.vstack((ob_next_ep, np.expand_dims(np.vstack(next_observations_ep[:,:,agent_i][i]), 0)))
self.obs_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = ob_ep.transpose(1, 0, 2)
# actions are already batched by agent, so they are indexed differently
self.ac_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = actions_ep[:,:,0,:].transpose(1, 0, 2)
self.rew_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = rewards_ep[:, :, agent_i].transpose(1, 0)
self.next_obs_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = ob_next_ep.transpose(1, 0, 2)
self.done_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = dones_ep[:, :, agent_i].transpose(1, 0)
self.curr_i += nentries
if self.filled_i < self.max_steps:
self.filled_i += nentries
if self.curr_i == self.max_steps:
self.curr_i = 0
def sample(self, N, to_gpu=False, norm_rews=True):
inds = np.random.choice(np.arange(self.filled_i), size=N,
replace=False)
if to_gpu:
cast = lambda x: Variable(Tensor(x), requires_grad=False).to(torch.device(self.device))
else:
cast = lambda x: Variable(Tensor(x), requires_grad=False)
if norm_rews:
ret_rews = [cast((self.rew_buffs[i][inds] -
self.rew_buffs[i][:self.filled_i].mean()) /
self.rew_buffs[i][:self.filled_i].std())
for i in range(self.num_agents)]
else:
ret_rews = [cast(self.rew_buffs[i][inds]) for i in range(self.num_agents)]
return ([cast(self.obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.ac_buffs[i][inds]) for i in range(self.num_agents)],
ret_rews,
[cast(self.next_obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.done_buffs[i][inds]) for i in range(self.num_agents)])
def get_average_rewards(self, N):
if self.filled_i == self.max_steps:
inds = np.arange(self.curr_i - N, self.curr_i) # allow for negative indexing
else:
inds = np.arange(max(0, self.curr_i - N), self.curr_i)
return [self.rew_buffs[i][inds].mean() for i in range(self.num_agents)]
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/env_wrappers.py
================================================
"""
Modified from OpenAI Baselines code to work with multi-agent envs
"""
import numpy as np
from multiprocessing import Process, Pipe
from common.vec_env.vec_env import VecEnv, CloudpickleWrapper
def worker(remote, parent_remote, env_fn_wrapper):
parent_remote.close()
env = env_fn_wrapper.x()
while True:
cmd, data = remote.recv()
if cmd == 'step':
ob, reward, done, info = env.step(data)
if all(done):
ob = env.reset()
remote.send((ob, reward, done, info))
elif cmd == 'reset':
ob = env.reset()
remote.send(ob)
elif cmd == 'reset_task':
ob = env.reset_task()
remote.send(ob)
elif cmd == 'close':
remote.close()
break
elif cmd == 'get_spaces':
remote.send((env.observation_space, env.action_space))
elif cmd == 'get_agent_types':
if all([hasattr(a, 'adversary') for a in env.agents]):
remote.send(['adversary' if a.adversary else 'agent' for a in
env.agents])
else:
remote.send(['agent' for _ in env.agents])
else:
raise NotImplementedError
class SubprocVecEnv(VecEnv):
def __init__(self, env_fns, spaces=None):
"""
envs: list of gym environments to run in subprocesses
"""
self.waiting = False
self.closed = False
nenvs = len(env_fns)
self.remotes, self.work_remotes = zip(*[Pipe() for _ in range(nenvs)])
self.ps = [Process(target=worker, args=(work_remote, remote, CloudpickleWrapper(env_fn)))
for (work_remote, remote, env_fn) in zip(self.work_remotes, self.remotes, env_fns)]
for p in self.ps:
p.daemon = True # if the main process crashes, we should not cause things to hang
p.start()
for remote in self.work_remotes:
remote.close()
self.remotes[0].send(('get_spaces', None))
observation_space, action_space = self.remotes[0].recv()
self.remotes[0].send(('get_agent_types', None))
self.agent_types = self.remotes[0].recv()
VecEnv.__init__(self, len(env_fns), observation_space, action_space)
def step_async(self, actions):
for remote, action in zip(self.remotes, actions):
remote.send(('step', action))
self.waiting = True
def step_wait(self):
results = [remote.recv() for remote in self.remotes]
self.waiting = False
obs, rews, dones, infos = zip(*results)
return np.stack(obs), np.stack(rews), np.stack(dones), infos
def reset(self):
for remote in self.remotes:
remote.send(('reset', None))
return np.stack([remote.recv() for remote in self.remotes])
def reset_task(self):
for remote in self.remotes:
remote.send(('reset_task', None))
return np.stack([remote.recv() for remote in self.remotes])
def close(self):
if self.closed:
return
if self.waiting:
for remote in self.remotes:
remote.recv()
for remote in self.remotes:
remote.send(('close', None))
for p in self.ps:
p.join()
self.closed = True
class DummyVecEnv(VecEnv):
def __init__(self, env_fns):
self.envs = [fn() for fn in env_fns]
env = self.envs[0]
VecEnv.__init__(self, len(env_fns), env.observation_space, env.action_space)
if all([hasattr(a, 'adversary') for a in env.agents]):
self.agent_types = ['adversary' if a.adversary else 'agent' for a in
env.agents]
else:
self.agent_types = ['agent' for _ in env.agents]
self.ts = np.zeros(len(self.envs), dtype='int')
self.actions = None
def step_async(self, actions):
self.actions = actions
def step_wait(self):
results = [env.step(a) for (a,env) in zip(self.actions, self.envs)]
obs, rews, dones, infos = map(np.array, zip(*results))
self.ts += 1
for (i, done) in enumerate(dones):
if all(done):
obs[i] = self.envs[i].reset()
self.ts[i] = 0
self.actions = None
return np.array(obs), np.array(rews), np.array(dones), infos
def reset(self):
results = [env.reset() for env in self.envs]
return np.array(results)
def close(self):
return
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/make_env.py
================================================
"""
Code for creating a multiagent environment with one of the scenarios listed
in ./scenarios/.
Can be called by using, for example:
env = make_env('simple_speaker_listener')
After producing the env object, can be used similarly to an OpenAI gym
environment.
A policy using this environment must output actions in the form of a list
for all agents. Each element of the list should be a numpy array,
of size (env.world.dim_p + env.world.dim_c, 1). Physical actions precede
communication actions in this array. See environment.py for more details.
"""
def make_env(scenario_name, benchmark=False, discrete_action=False):
'''
Creates a MultiAgentEnv object as env. This can be used similar to a gym
environment by calling env.reset() and env.step().
Use env.render() to view the environment on the screen.
Input:
scenario_name : name of the scenario from ./scenarios/ to be Returns
(without the .py extension)
benchmark : whether you want to produce benchmarking data
(usually only done during evaluation)
Some useful env properties (see environment.py):
.observation_space : Returns the observation space for each agent
.action_space : Returns the action space for each agent
.n : Returns the number of Agents
'''
from multiagent.environment import MultiAgentEnv
import multiagent.scenarios as scenarios
# load scenario from script
scenario = scenarios.load(scenario_name + ".py").Scenario()
# create world
world = scenario.make_world()
# create multiagent environment
if benchmark:
env = MultiAgentEnv(world, scenario.reset_world, scenario.reward,
scenario.observation, scenario.benchmark_data)
else:
env = MultiAgentEnv(world, scenario.reset_world, scenario.reward,
scenario.observation)
return env
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/misc.py
================================================
import os
import torch
import torch.nn.functional as F
import torch.distributed as dist
from torch.autograd import Variable
import numpy as np
# https://github.com/ikostrikov/pytorch-ddpg-naf/blob/master/ddpg.py#L11
def soft_update(target, source, tau):
"""
Perform DDPG soft update (move target params toward source based on weight
factor tau)
Inputs:
target (torch.nn.Module): Net to copy parameters to
source (torch.nn.Module): Net whose parameters to copy
tau (float, 0 < x < 1): Weight factor for update
"""
for target_param, param in zip(target.parameters(), source.parameters()):
target_param.data.copy_(target_param.data * (1.0 - tau) + param.data * tau)
# https://github.com/ikostrikov/pytorch-ddpg-naf/blob/master/ddpg.py#L15
def hard_update(target, source):
"""
Copy network parameters from source to target
Inputs:
target (torch.nn.Module): Net to copy parameters to
source (torch.nn.Module): Net whose parameters to copy
"""
for target_param, param in zip(target.parameters(), source.parameters()):
target_param.data.copy_(param.data)
# https://github.com/seba-1511/dist_tuto.pth/blob/gh-pages/train_dist.py
def average_gradients(model):
""" Gradient averaging. """
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM, group=0)
param.grad.data /= size
# https://github.com/seba-1511/dist_tuto.pth/blob/gh-pages/train_dist.py
def init_processes(rank, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
def onehot_from_logits(logits, eps=0.0):
"""
Given batch of logits, return one-hot sample using epsilon greedy strategy
(based on given epsilon)
"""
# get best (according to current policy) actions in one-hot form
argmax_acs = (logits == logits.max(1, keepdim=True)[0]).float()
if eps == 0.0:
return argmax_acs
# get random actions in one-hot form
rand_acs = Variable(torch.eye(logits.shape[1])[[np.random.choice(
range(logits.shape[1]), size=logits.shape[0])]], requires_grad=False)
# chooses between best and random actions using epsilon greedy
return torch.stack([argmax_acs[i] if r > eps else rand_acs[i] for i, r in
enumerate(torch.rand(logits.shape[0]))])
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def sample_gumbel(shape, eps=1e-20, tens_type=torch.FloatTensor):
"""Sample from Gumbel(0, 1)"""
U = Variable(tens_type(*shape).uniform_(), requires_grad=False)
return -torch.log(-torch.log(U + eps) + eps)
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def gumbel_softmax_sample(logits, temperature):
""" Draw a sample from the Gumbel-Softmax distribution"""
y = logits + sample_gumbel(logits.shape, tens_type=type(logits.data)).to(logits.device)
return F.softmax(y / temperature, dim=1)
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def gumbel_softmax(logits, temperature=1.0, hard=False):
"""Sample from the Gumbel-Softmax distribution and optionally discretize.
Args:
logits: [batch_size, n_class] unnormalized log-probs
temperature: non-negative scalar
hard: if True, take argmax, but differentiate w.r.t. soft sample y
Returns:
[batch_size, n_class] sample from the Gumbel-Softmax distribution.
If hard=True, then the returned sample will be one-hot, otherwise it will
be a probabilitiy distribution that sums to 1 across classes
"""
y = gumbel_softmax_sample(logits, temperature)
if hard:
y_hard = onehot_from_logits(y)
y = (y_hard - y).detach() + y
return y
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/multiprocessing.py
================================================
# This code is from openai baseline
# https://github.com/openai/baselines/tree/master/baselines/common/vec_env
import time
import matplotlib.pyplot as plt
import numpy as np
from multiprocessing import Process, Pipe
def _flatten_list(l):
assert isinstance(l, (list, tuple))
assert len(l) > 0
assert all([len(l_) > 0 for l_ in l])
return [l__ for l_ in l for l__ in l_]
def worker(remote, parent_remote, env_fn_wrapper):
parent_remote.close()
env = env_fn_wrapper.x()
while True:
cmd, data = remote.recv()
if cmd == 'step':
ob, reward, done, info = env.step(data)
if done:
ob = env.reset()
remote.send((ob, reward, done, info))
elif cmd == 'reset':
ob = env.reset()
remote.send(ob)
elif cmd == 'reset_task':
ob = env.reset_task()
remote.send(ob)
elif cmd == 'render':
ob = env.render(mode='rgb_array')
# print(len(ob), 'len(frames)')
# print(len(ob[0]), 'len(frames[0])')
# print(len(ob[0][0]), 'len(frames[0][0])')
remote.send(ob) # rgb_array
elif cmd == 'observe':
ob = env.observe(data)
remote.send(ob)
elif cmd == 'agents':
remote.send(env.agents)
elif cmd == 'spec':
remote.send(env.spec)
elif cmd == 'get_spaces':
remote.send((env.observation_space, env.action_space))
elif cmd == 'close':
remote.close()
break
else:
raise NotImplementedError
class VecEnv(object):
"""
An abstract asynchronous, vectorized environment.
"""
closed = False
viewer = None
metadata = {
'render.modes': ['human', 'rgb_array']
}
def __init__(self, num_envs, observation_space, action_space):
self.num_envs = num_envs
self.observation_space = observation_space
self.action_space = action_space
def observe(self, agent):
pass
def reset(self):
"""
Reset all the environments and return an array of
observations, or a tuple of observation arrays.
If step_async is still doing work, that work will
be cancelled and step_wait() should not be called
until step_async() is invoked again.
"""
pass
def step_async(self, actions):
"""
Tell all the environments to start taking a step
with the given actions.
Call step_wait() to get the results of the step.
You should not call this if a step_async run is
already pending.
"""
pass
def step_wait(self):
"""
Wait for the step taken with step_async().
Returns (obs, rews, dones, infos):
- obs: an array of observations, or a tuple of
arrays of observations.
- rews: an array of rewards
- dones: an array of "episode done" booleans
- infos: a sequence of info objects
"""
pass
def close(self):
"""
Clean up the environments' resources.
"""
pass
def step(self, actions):
self.step_async(actions)
return self.step_wait()
def render(self, mode='human'):
imgs = self.get_images()
bigimg = self.tile_images(imgs)
if mode == 'human':
self.get_viewer().imshow(bigimg) #
return self.get_viewer().isopen
elif mode == 'rgb_array':
return bigimg
else:
raise NotImplementedError
def get_images(self):
"""
Return RGB images from each environment
"""
raise NotImplementedError
def get_viewer(self):
if self.viewer is None:
from common import rendering
self.viewer = rendering.SimpleImageViewer()
return self.viewer
def tile_images(self, img_nhwc):
"""
Tile N images into one big PxQ image
(P,Q) are chosen to be as close as possible, and if N
is square, then P=Q.
input: img_nhwc, list or array of images, ndim=4 once turned into array
n = batch index, h = height, w = width, c = channel
returns:
bigim_HWc, ndarray with ndim=3
"""
img_nhwc = np.asarray(img_nhwc)
N, h, w, c = img_nhwc.shape
H = int(np.ceil(np.sqrt(N)))
W = int(np.ceil(float(N) / H))
img_nhwc = np.array(list(img_nhwc) + [img_nhwc[0] * 0 for _ in range(N, H * W)])
img_HWhwc = img_nhwc.reshape(H, W, h, w, c)
img_HhWwc = img_HWhwc.transpose(0, 2, 1, 3, 4)
img_Hh_Ww_c = img_HhWwc.reshape(H * h, W * w, c)
return img_Hh_Ww_c
class CloudpickleWrapper(object):
"""
Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)
"""
def __init__(self, x):
self.x = x
def __getstate__(self):
import cloudpickle
return cloudpickle.dumps(self.x)
def __setstate__(self, ob):
import pickle
self.x = pickle.loads(ob)
class SubprocVecEnv(VecEnv):
def __init__(self, env_fns, spaces=None):
"""
envs_sc: list of gym environments to run in subprocesses
"""
# self.venv = venv
self.waiting = False
self.closed = False
nenvs = len(env_fns)
self.nenvs = nenvs
self.remotes, self.work_remotes = zip(*[Pipe() for _ in range(nenvs)])
self.ps = [Process(target=worker, args=(work_remote, remote, CloudpickleWrapper(env_fn)))
for (work_remote, remote, env_fn) in zip(self.work_remotes, self.remotes, env_fns)]
for p in self.ps:
p.daemon = True # if the main process crashes, we should not cause things to hang
p.start()
for remote in self.work_remotes:
remote.close()
self.remotes[0].send(('get_spaces', None))
observation_space, action_space = self.remotes[0].recv()
VecEnv.__init__(self, len(env_fns), observation_space, action_space)
def step_async(self, actions):
for remote, action in zip(self.remotes, actions): # the input of step() : action
remote.send(('step', action))
self.waiting = True
def step_wait(self):
results = [remote.recv() for remote in self.remotes] # the output of step() : zip(*results)
self.waiting = False
obs, rews, dones, infos = zip(*results)
return np.stack(obs), np.stack(rews), np.stack(dones), infos
def step_wait_2(self):
results = [remote.recv() for remote in self.remotes]
self.waiting = False
reward, done, _cumulative_rewards = zip(*results)
return reward, done, _cumulative_rewards
def step_wait_3(self):
results = [remote.recv() for remote in self.remotes] # the output of step() : zip(*results)
self.waiting = False
obs, rews, dones, infos = zip(*results)
return np.stack(obs), np.stack(rews), np.stack(dones), infos
def reset(self):
for remote in self.remotes:
remote.send(('reset', None))
return np.stack([remote.recv() for remote in self.remotes])
def agents(self):
for remote in self.remotes:
remote.send(('agents', None))
return np.stack([remote.recv() for remote in self.remotes])
def reset_task(self):
for remote in self.remotes:
remote.send(('reset_task', None))
return np.stack([remote.recv() for remote in self.remotes])
def spec(self):
for remote in self.remotes:
remote.send(('spec', None))
return np.stack([remote.recv() for remote in self.remotes])
def get_images(self):
# self._assert_not_closed()
for pipe in self.remotes:
pipe.send(('render', None))
imgs = [pipe.recv() for pipe in self.remotes]
# imgs = _flatten_list(imgs)
return imgs
def observe(self, agent):
for remote, agent in zip(self.remotes, agent):
remote.send(('observe', agent))
return np.stack([remote.recv() for remote in self.remotes])
# def render(self, mode='human'):
# return self.venv.render(mode=mode)
def close(self):
if self.closed:
return
if self.waiting:
for remote in self.remotes:
remote.recv()
for remote in self.remotes:
remote.send(('close', None))
for p in self.ps:
p.join()
self.closed = True
def __len__(self):
return self.nenvs
def _flatten_list(l):
assert isinstance(l, (list, tuple))
assert len(l) > 0
assert all([len(l_) > 0 for l_ in l])
return [l__ for l_ in l for l__ in l_]
class DummyVecEnv(VecEnv):
def __init__(self, env_fns):
self.envs = [fn() for fn in env_fns]
env = self.envs[0]
VecEnv.__init__(self, len(env_fns), env.observation_space, env.action_space)
if all([hasattr(a, 'adversary') for a in env.agents]):
self.agent_types = ['adversary' if a.adversary else 'agent' for a in
env.agents]
else:
self.agent_types = ['agent' for _ in env.agents]
self.ts = np.zeros(len(self.envs), dtype='int')
self.actions = None
def step_async(self, actions):
self.actions = actions
def step_wait(self):
results = [env.step(a) for (a,env) in zip(self.actions, self.envs)]
obs, rews, dones, infos = map(np.array, zip(*results))
self.ts += 1
for (i, done) in enumerate(dones):
if all(done):
obs[i] = self.envs[i].reset()
self.ts[i] = 0
self.actions = None
return np.array(obs), np.array(rews), np.array(dones), infos
def reset(self):
results = [env.reset() for env in self.envs]
return np.array(results)
def close(self):
return
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/networks.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
from braincog.base.node.node import LIFNode
class MLPNetwork(nn.Module):
"""
MLP network (can be used as value or policy)
"""
def __init__(self, input_dim, out_dim, hidden_dim=64, nonlin=F.relu,
constrain_out=False, norm_in=True, discrete_action=True):
"""
Inputs:
input_dim (int): Number of dimensions in input
out_dim (int): Number of dimensions in output
hidden_dim (int): Number of hidden dimensions
nonlin (PyTorch function): Nonlinearity to apply to hidden layers
"""
super(MLPNetwork, self).__init__()
if norm_in: # normalize inputs
self.in_fn = nn.BatchNorm1d(input_dim) #train
# self.in_fn = input_dim #test
self.in_fn.weight.data.fill_(1)
self.in_fn.bias.data.fill_(0)
else:
self.in_fn = lambda x: x
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, out_dim)
self.nonlin = nonlin
if constrain_out and not discrete_action:
# initialize small to prevent saturation
self.fc3.weight.data.uniform_(-3e-3, 3e-3)
self.out_fn = F.tanh
else: # logits for discrete action (will softmax later)
self.out_fn = lambda x: x
def forward(self, X):
"""
Inputs:
X (PyTorch Matrix): Batch of observations
Outputs:
out (PyTorch Matrix): Output of network (actions, values, etc)
"""
h1 = self.nonlin(self.fc1(self.in_fn(X)))
h2 = self.nonlin(self.fc2(h1))
out = self.out_fn(self.fc3(h2))
return out
class BCNoSpikingLIFNode(LIFNode):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self, dv: torch.Tensor):
self.integral(dv)
return self.mem
class SNNNetwork(nn.Module):
"""
SNN network (can be used as value or policy or MLE)
"""
def __init__(self, input_dim, out_dim, hidden_dim=64, node=LIFNode, time_window=16,
norm_in=True, output_style='sum'):
"""
Inputs:
input_dim (int): Number of dimensions in input
out_dim (int): Number of dimensions in output
hidden_dim (int): Number of hidden dimensions
nonlin (PyTorch function): Nonlinearity to apply to hidden layers
"""
super(SNNNetwork, self).__init__()
self._threshold = 0.5
self.v_reset = 0.0
self._time_window = time_window
self.output_style = output_style
self._node1 = node(threshold=self._threshold, v_reset=self.v_reset)
self._node2 = node(threshold=self._threshold, v_reset=self.v_reset)
if norm_in: # normalize inputs
self.in_fn = nn.BatchNorm1d(input_dim) #train
self.in_fn.weight.data.fill_(1)
self.in_fn.bias.data.fill_(0)
else:
self.in_fn = lambda x: x
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, out_dim)
if self.output_style == 'sum':
self._out_node = lambda x: x
elif self.output_style == 'voltage':
self._out_node = BCNoSpikingLIFNode()
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def forward(self, X):
qs = []
self.reset()
for t in range(self._time_window):
x = self.fc1((self.in_fn(X)+0.5)) #train
# x = self.fc1((X + 0.5)) #test
x = self._node1(x)
x = self.fc2(x)
x = self._node2(x)
x = self.fc3(x)
x = self._out_node(x)
qs.append(x)
if self.output_style == 'sum':
outputs = sum(qs) / self._time_window
return outputs
elif self.output_style == 'voltage':
outputs = x
return outputs
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/noise.py
================================================
import numpy as np
# from https://github.com/songrotek/DDPG/blob/master/ou_noise.py
class OUNoise:
def __init__(self, action_dimension, scale=0.1, mu=0, theta=0.15, sigma=0.2):
self.action_dimension = action_dimension
self.scale = scale
self.mu = mu
self.theta = theta
self.sigma = sigma
self.state = np.ones(self.action_dimension) * self.mu
self.reset()
def reset(self):
self.state = np.ones(self.action_dimension) * self.mu
def noise(self):
x = self.state
dx = self.theta * (self.mu - x) + self.sigma * np.random.randn(len(x))
self.state = x + dx
return self.state * self.scale
================================================
FILE: examples/Social_Cognition/MAToM-SNN/README.md
================================================
# MAToM-SNN
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/agents/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/agents/sagent.py
================================================
import numpy as np
import torch
from torch.distributions import Categorical
from braincog.base.encoder.population_coding import PEncoder
from spikingjelly.activation_based import functional
TIMESTEPS = 15
M = 5
# Agent
class Agents:
def __init__(self, args):
self.n_actions = args.n_actions
self.n_agents = args.n_agents
self.obs_shape = args.obs_shape
# encoder
self.pencoder = PEncoder(TIMESTEPS, 'population_voltage')
if args.alg == 'ppo':
from policy.ppo import PPO
self.policy = PPO(args)
if args.alg == 'iql':
from policy.iql import IQL
self.policy = IQL(args)
if args.mode == 'test':
self.policy.load_model(395000)
if args.alg == 'svdn':
from policy.svdn import SVDN
self.policy = SVDN(args)
if args.alg == 'scovdn':
from policy.scovdn import SCOVDN
self.policy = SCOVDN(args)
if args.alg == 'stomvdn':
from policy.stomvdn import SToMVDN
self.policy = SToMVDN(args)
if args.alg == 'scovdn_weight':
from policy.scovdn_weight import SCOVDN_W
self.policy = SCOVDN_W(args)
if args.alg == 'siql':
from policy.siql import SIQL
self.policy = SIQL(args)
if args.alg == 'scoiql':
from policy.scoiql import SCOIQL
self.policy = SCOIQL(args)
if args.alg == 'siql_e':
from policy.siql_encoder import SIQL_E
self.policy = SIQL_E(args)
if args.alg == 'siql_e2':
from policy.siql_encoder2 import SIQL_EE
self.policy = SIQL_EE(args)
if args.alg == 'siql_no_rnn':
from policy.siql_no_rnn import SIQLUR
self.policy = SIQLUR(args)
if args.alg == 'siql_no_rnn2':
from policy.siql_no_rnn2 import SIQLUR2
self.policy = SIQLUR2(args)
self.args = args
def choose_action(self, num_env, obs, last_action, agent_num, avail_actions, epsilon, maven_z=None, evaluate=False):
inputs = obs.copy()
avail_actions_ind = np.nonzero(avail_actions)[0] # index of actions which can be choose
# transform agent_num to onehot vector
agent_id = np.zeros((num_env, self.n_agents))
agent_id[:, agent_num] = 1.
if self.args.last_action:
inputs = np.hstack((inputs, last_action))
if self.args.reuse_network:
inputs = np.hstack((inputs, agent_id))
# transform the shape of inputs from (42,) to (1,42)
inputs = torch.tensor(inputs, dtype=torch.float32).unsqueeze(0) # torch.Size([1, 17])
# init hidden tensor
if self.args.alg == 'siql_e' or self.args.alg == 'siql_e2':
h1_mem = self.policy.eval_h1_mem[:, agent_num, :, :, :, :]
h1_spike = self.policy.eval_h1_spike[:, agent_num, :, :, :, :]
h2_mem = self.policy.eval_h2_mem[:, agent_num, :, :, :, :]
h2_spike = self.policy.eval_h2_spike[:, agent_num, :, :, :, :]
inputs_, _ = self.pencoder(inputs=inputs, num_popneurons=M, VTH=0.99) ###########################################################
inputs = torch.transpose(inputs_, 0, 3)
inputs = inputs.squeeze().unsqueeze(0)
else:
h1_mem = self.policy.eval_h1_mem[:, agent_num, :, :] #
h1_spike = self.policy.eval_h1_spike[:, agent_num, :, :]
h2_mem = self.policy.eval_h2_mem[:, agent_num, :, :]
h2_spike = self.policy.eval_h2_spike[:, agent_num, :, :]
avail_actions = torch.tensor(avail_actions, dtype=torch.float32).unsqueeze(0)
if self.args.cuda:
inputs = inputs.cuda(self.args.device)
h1_mem = h1_mem.cuda(self.args.device)
h1_spike = h1_spike.cuda(self.args.device)
h2_mem = h2_mem.cuda(self.args.device)
h2_spike = h2_spike.cuda(self.args.device)
# get q value
if self.args.alg == 'siql_no_rnn' or self.args.alg == 'siql_no_rnn2':
self.policy.eval_snn.reset()
q_value = self.policy.eval_snn(inputs)
# functional.reset_net(self.policy_sc.eval_snn)
else:
q_value, self.policy.eval_h1_mem[:, agent_num, :], self.policy.eval_h1_spike[:, agent_num, :],\
self.policy.eval_h2_mem[:, agent_num, :], self.policy.eval_h2_spike[:, agent_num, :]= \
self.policy.eval_snn(inputs, h1_mem, h1_spike, h2_mem, h2_spike)
# choose action from q value
# q_value[avail_actions == 0.0] = - float("inf")
if self.args.alg == 'siql_e' or self.args.alg == 'siql_e2':
q_value = q_value.sum(dim=2)
q_value = q_value.sum(dim=2)
if np.random.uniform() < epsilon:
# action = np.random.choice(avail_actions_ind) # action是一个整数
action = torch.tensor([[np.random.choice(avail_actions_ind) for i in range(num_env)]])
else:
action = torch.argmax(q_value, 2)
return action
def _choose_action_from_softmax(self, inputs, avail_actions, epsilon, evaluate=False):
"""
:param_sc inputs: # q_value of all actions
"""
action_num = avail_actions.sum(dim=1, keepdim=True).float().repeat(1, avail_actions.shape[-1]) # num of avail_actions
# 先将Actor网络的输出通过softmax转换成概率分布
prob = torch.nn.functional.softmax(inputs, dim=-1)
# add noise of epsilon
prob = ((1 - epsilon) * prob + torch.ones_like(prob) * epsilon / action_num)
prob[avail_actions == 0] = 0.0 # 不能执行的动作概率为0
"""
不能执行的动作概率为0之后,prob中的概率和不为1,这里不需要进行正则化,因为torch.distributions.Categorical
会将其进行正则化。要注意在训练的过程中没有用到Categorical,所以训练时取执行的动作对应的概率需要再正则化。
"""
if epsilon == 0 and evaluate:
action = torch.argmax(prob)
else:
action = Categorical(prob).sample().long()
return action
def _get_max_episode_len(self, batch):
terminated = batch['TERMINATE']
episode_num = terminated.shape[0]
max_episode_len = 0
for episode_idx in range(episode_num):
for transition_idx in range(self.args.episode_limit):
if terminated[episode_idx, transition_idx, 0] == 1:
if transition_idx + 1 >= max_episode_len:
max_episode_len = transition_idx + 1
break
if max_episode_len == 0: # 防止所有的episode都没有结束,导致terminated中没有1
max_episode_len = self.args.episode_limit
return max_episode_len
def train(self, batch, train_step, epsilon=None): # coma needs epsilon for training
# different episode has different length, so we need to get max length of the batch
max_episode_len = self._get_max_episode_len(batch)
for key in batch.keys():
if key != 'z':
batch[key] = batch[key][:, :max_episode_len]
self.policy.learn(batch, max_episode_len, train_step, epsilon)
if train_step > 0 and train_step % self.args.save_cycle == 0:
self.policy.save_model(train_step)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/common_sr/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/common_sr/arguments.py
================================================
import argparse
def get_common_args():
parser = argparse.ArgumentParser()
## multiprocessing
parser.add_argument('--process', type=int, default=5, help='multiprocessing')
## the environment setting 'CLASSIC', 'HUNT', 'HARVEST', 'ESCALATION'
parser.add_argument('--ENV', type=str, default='HUNT', help='the version of the game, choose from ["CLASSIC", "HUNT", "HARVEST", "ESCALATION"]')
parser.add_argument('--env_name', type=str, default='stag_stay', help='the version of the game, choose from ["CLASSIC", "HUNT", "HARVEST", "ESCALATION"]')
parser.add_argument('--obs_type', type=str, default='coords', help='Can be "image" for pixel-array based observations, or "coords" for just the entity coordinates')
parser.add_argument('--forage_quantity', type=int, default=2, help='the number of trees')
parser.add_argument('--opponent_policy', type=str, default='random', help='the poliocy of opponent')
parser.add_argument('--replay_dir', type=str, default='', help='absolute path to save the replay')
## The alternative policy ################################################
parser.add_argument('--num_run', type=int, default='4', help='the number of run')
## 'svdn', 'stomvdn'
parser.add_argument('--alg', type=str, default='svdn', help='the algorithm to train the agent')
parser.add_argument('--mode', type=str, default='train', help='the mode')
parser.add_argument('--n_steps', type=int, default=1000000, help='total time steps')#2000000
parser.add_argument('--n_episodes', type=int, default=2, help='the number of episodes before once training')
parser.add_argument('--last_action', type=bool, default=True, help='whether to use the last action to choose action')
parser.add_argument('--reuse_network', type=bool, default=True, help='whether to use one network_sc for all agents_sc')
parser.add_argument('--gamma', type=float, default=0.99, help='discount factor')
parser.add_argument('--epsilon', type=float, default=1.0, help='epsilon factor')
############# "Adam"
parser.add_argument('--optimizer', type=str, default="RMS", help='optimizer')
parser.add_argument('--evaluate_cycle', type=int, default=10, help='how often to evaluate the model')#5000
parser.add_argument('--evaluate_epoch', type=int, default=6, help='number of the epoch to evaluate the agent')#32
## save weights->model/args->log/reward->result/plot
parser.add_argument('--model_dir', type=str, default='./model', help='model directory of the policy_base')
parser.add_argument('--result_dir', type=str, default='./result', help='result directory of the policy_base')#./result#/home/zhaozhuoya/exp2/ToM2_test/result
parser.add_argument('--log_dir', type=str, default='./log', help='args directory')
parser.add_argument('--plot_dir', type=str, default='./plot', help='args directory')
parser.add_argument('--exp_dir', type=str, default='/exp_vdn', help='result directory of the policy_base')
parser.add_argument('--save_model_dir', type=str, default='/199_rnn_net_params_hunt1.pkl', help='load weights and bias')
parser.add_argument('--load_model', type=bool, default=False, help='whether to load the pretrained model')
parser.add_argument('--evaluate', type=bool, default=False, help='whether to evaluate the model')
parser.add_argument('--cuda', type=bool, default=True, help='whether to use the GPU') #True
parser.add_argument('--mini_batch_size', type=int, default=250, help='whether to use the GPU')
args = parser.parse_args()
parser.add_argument('--device', type=str, default='cuda:{}'.format(args.num_run), help='whether to use the GPU') #'cuda:1'
args = parser.parse_args()
return args
# arguments of coma
def get_coma_args(args):
# network_sc
args.rnn_hidden_dim = 64
args.critic_dim = 128
args.lr_actor = 1e-4
args.lr_critic = 1e-3
# epsilon-greedy
# args.epsilon = 0.5
args.anneal_epsilon = 0.00064
args.min_epsilon = 0.02
args.epsilon_anneal_scale = 'episode'
# lambda of td-lambda return
args.td_lambda = 0.8
# how often to save the model
args.save_cycle = 5000
# how often to update the target_net
args.target_update_cycle = 200
# prevent gradient explosion
args.grad_norm_clip = 10
return args
# arguments of vnd、 qmix、 qtran
def get_mixer_args(args):
# network_sc
args.rnn_hidden_dim = 64
args.qmix_hidden_dim = 32
args.two_hyper_layers = False
args.hyper_hidden_dim = 64
args.qtran_hidden_dim = 64
args.ppo_hidden_size = 64
args.lr = 5e-4
# epsilon greedy
# args.epsilon = 1
args.min_epsilon = 0.05
anneal_steps = 50000
args.anneal_epsilon = (args.epsilon - args.min_epsilon) / anneal_steps
args.epsilon_anneal_scale = 'step'
# the number of the train steps in one epoch
args.train_steps = 1
# experience replay
args.batch_size = 32
args.buffer_size = int(5e3)
# how often to save the model
args.save_cycle = 5000
# how often to update the target_net
args.target_update_cycle = 200
# QTRAN lambda
args.lambda_opt = 1
args.lambda_nopt = 1
# prevent gradient explosion
args.grad_norm_clip = 10
# MAVEN
args.noise_dim = 16
args.lambda_mi = 0.001
args.lambda_ql = 1
args.entropy_coefficient = 0.001
return args
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/common_sr/dummy_vec_env.py
================================================
import numpy as np
from .vec_env import VecEnv
from .util import copy_obs_dict, dict_to_obs, obs_space_info
class DummyVecEnv(VecEnv):
"""
VecEnv that does runs multiple environments sequentially, that is,
the step and reset commands are send to one environment at a time.
Useful when debugging and when num_env == 1 (in the latter case,
avoids communication overhead)
"""
def __init__(self, env_fns):
"""
Arguments:
env_fns: iterable of callables functions that build environments
"""
self.envs = [fn() for fn in env_fns]
env = self.envs[0]
VecEnv.__init__(self, len(env_fns), env.observation_space, env.action_space)
obs_space = env.observation_space
self.keys, shapes, dtypes = obs_space_info(obs_space)
self.buf_obs = { k: np.zeros((self.num_envs,) + tuple(shapes[k]), dtype=dtypes[k]) for k in self.keys }
self.buf_dones = np.zeros((self.num_envs,), dtype=np.bool)
self.buf_rews = np.zeros((self.num_envs,), dtype=np.float32)
self.buf_infos = [{} for _ in range(self.num_envs)]
self.actions = None
self.spec = self.envs[0].spec
def step_async(self, actions):
listify = True
try:
if len(actions) == self.num_envs:
listify = False
except TypeError:
pass
if not listify:
self.actions = actions
else:
assert self.num_envs == 1, "actions {} is either not a list or has a wrong size - cannot match to {} environments".format(actions, self.num_envs)
self.actions = [actions]
def step_wait(self):
for e in range(self.num_envs):
action = self.actions[e]
# if isinstance(self.envs_sc[e].action_space, spaces.Discrete):
# action = int(action)
obs, self.buf_rews[e], self.buf_dones[e], self.buf_infos[e] = self.envs[e].step(action)
if self.buf_dones[e]:
obs = self.envs[e].reset()
self._save_obs(e, obs)
return (self._obs_from_buf(), np.copy(self.buf_rews), np.copy(self.buf_dones),
self.buf_infos.copy())
def reset(self):
for e in range(self.num_envs):
obs = self.envs[e].reset()
self._save_obs(e, obs)
return self._obs_from_buf()
def _save_obs(self, e, obs):
for k in self.keys:
if k is None:
self.buf_obs[k][e] = obs
else:
self.buf_obs[k][e] = obs[k]
def _obs_from_buf(self):
return dict_to_obs(copy_obs_dict(self.buf_obs))
def get_images(self):
return [env.render(mode='rgb_array') for env in self.envs]
def render(self, mode='human'):
if self.num_envs == 1:
return self.envs[0].render(mode=mode)
else:
return super().render(mode=mode)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/common_sr/multiprocessing_env.py
================================================
# This code is from openai baseline
# https://github.com/openai/baselines/tree/master/baselines/common/vec_env
import numpy as np
from multiprocessing import Process, Pipe
def _flatten_list(l):
assert isinstance(l, (list, tuple))
assert len(l) > 0
assert all([len(l_) > 0 for l_ in l])
return [l__ for l_ in l for l__ in l_]
def worker(remote, parent_remote, env_fn_wrapper):
parent_remote.close()
env = env_fn_wrapper.x()
while True:
cmd, data = remote.recv()
if cmd == 'step':
ob, reward, done, info = env.step(data)
if np.array(done).all():
# if done:
ob = env.reset()
remote.send((ob, reward, done, info))
elif cmd == 'reset':
ob = env.reset()
remote.send(ob)
elif cmd == 'reset_task':
ob = env.reset_task()
remote.send(ob)
elif cmd == 'render':
ob = env.render()
remote.send(ob) #rgb_array
elif cmd == 'close':
remote.close()
break
elif cmd == 'get_spaces':
remote.send((env.observation_space, env.action_space))
else:
raise NotImplementedError
class VecEnv(object):
"""
An abstract asynchronous, vectorized environment.
"""
def __init__(self, num_envs, observation_space, action_space):
self.num_envs = num_envs
self.observation_space = observation_space
self.action_space = action_space
def reset(self):
"""
Reset all the environments and return an array of
observations, or a tuple of observation arrays.
If step_async is still doing work, that work will
be cancelled and step_wait() should not be called
until step_async() is invoked again.
"""
pass
def step_async(self, actions):
"""
Tell all the environments to start taking a step
with the given actions.
Call step_wait() to get the results of the step.
You should not call this if a step_async run is
already pending.
"""
pass
def step_wait(self):
"""
Wait for the step taken with step_async().
Returns (obs, rews, dones, infos):
- obs: an array of observations, or a tuple of
arrays of observations.
- rews: an array of rewards
- dones: an array of "episode done" booleans
- infos: a sequence of info objects
"""
pass
def close(self):
"""
Clean up the environments' resources.
"""
pass
def step(self, actions):
self.step_async(actions)
return self.step_wait()
def render(self, mode='human'):
imgs = self.get_images()
# bigimg = tile_images(imgs)
# if mode == 'human':
# self.get_viewer().imshow(bigimg) #
# return self.get_viewer().isopen
# elif mode == 'rgb_array':
# return bigimg
# else:
# raise NotImplementedError
def get_images(self):
"""
Return RGB images from each environment
"""
raise NotImplementedError
class CloudpickleWrapper(object):
"""
Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)
"""
def __init__(self, x):
self.x = x
def __getstate__(self):
import cloudpickle
return cloudpickle.dumps(self.x)
def __setstate__(self, ob):
import pickle
self.x = pickle.loads(ob)
class SubprocVecEnv(VecEnv):
def __init__(self, env_fns, spaces=None):
"""
envs_sc: list of gym environments to run in subprocesses
"""
self.waiting = False
self.closed = False
nenvs = len(env_fns)
self.nenvs = nenvs
self.remotes, self.work_remotes = zip(*[Pipe() for _ in range(nenvs)])
self.ps = [Process(target=worker, args=(work_remote, remote, CloudpickleWrapper(env_fn)))
for (work_remote, remote, env_fn) in zip(self.work_remotes, self.remotes, env_fns)]
for p in self.ps:
p.daemon = True # if the main process crashes, we should not cause things to hang
p.start()
for remote in self.work_remotes:
remote.close()
self.remotes[0].send(('get_spaces', None))
observation_space, action_space = self.remotes[0].recv()
VecEnv.__init__(self, len(env_fns), observation_space, action_space)
def step_async(self, actions):
for remote, action in zip(self.remotes, actions):
remote.send(('step', action))
self.waiting = True
def step_wait(self):
results = [remote.recv() for remote in self.remotes]
self.waiting = False
obs, rews, dones, infos = zip(*results)
return np.stack(obs), np.stack(rews), np.stack(dones), infos
def reset(self):
for remote in self.remotes:
remote.send(('reset', None))
return np.stack([remote.recv() for remote in self.remotes])
def reset_task(self):
for remote in self.remotes:
remote.send(('reset_task', None))
return np.stack([remote.recv() for remote in self.remotes])
def get_images(self):
# self._assert_not_closed()
for pipe in self.remotes:
pipe.send(('render', None))
imgs = [pipe.recv() for pipe in self.remotes]
# imgs = _flatten_list(imgs)
return imgs
def close(self):
if self.closed:
return
if self.waiting:
for remote in self.remotes:
remote.recv()
for remote in self.remotes:
remote.send(('close', None))
for p in self.ps:
p.join()
self.closed = True
def __len__(self):
return self.nenvs
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/common_sr/replay_buffer.py
================================================
import numpy as np
import threading
class ReplayBuffer:
def __init__(self, args):
self.args = args
self.n_actions = self.args.n_actions
self.n_agents = self.args.n_agents
# self.state_shape = self.args.state_shape
self.obs_shape = self.args.obs_shape
self.size = self.args.buffer_size
self.episode_limit = self.args.episode_limit
# memory management
self.current_idx = 0
self.current_size = 0
# create the buffer to store info
self.buffers = {'O': np.empty([self.size, self.episode_limit, self.n_agents, self.obs_shape]),
'U': np.empty([self.size, self.episode_limit, self.n_agents, 1]),
# 's': np.empty([self.size, self.episode_limit, self.state_shape]),
'R': np.empty([self.size, self.episode_limit, self.n_agents, 1]),
'O_NEXT': np.empty([self.size, self.episode_limit, self.n_agents, self.obs_shape]),
# 's_next': np.empty([self.size, self.episode_limit, self.state_shape]),
'AVAIL_U': np.empty([self.size, self.episode_limit, self.n_agents, self.n_actions]),
'AVAIL_U_NEXT': np.empty([self.size, self.episode_limit, self.n_agents, self.n_actions]),
'U_ONEHOT': np.empty([self.size, self.episode_limit, self.n_agents, self.n_actions]),
'PADDED': np.empty([self.size, self.episode_limit, 1]),
'TERMINATE': np.empty([self.size, self.episode_limit, 1])
}
# thread lock
self.lock = threading.Lock()
# store the episode
def store_episode(self, episode_batch):
batch_size = episode_batch['O'].shape[0] # episode_number
with self.lock:
idxs = self._get_storage_idx(inc=batch_size)
# store the informations
self.buffers['O'][idxs] = episode_batch['O']
self.buffers['U'][idxs] = episode_batch['U']
# self.buffers['s'][idxs] = episode_batch['s']
self.buffers['R'][idxs] = episode_batch['R']
self.buffers['O_NEXT'][idxs] = episode_batch['O_NEXT']
# self.buffers['s_next'][idxs] = episode_batch['s_next']
self.buffers['AVAIL_U'][idxs] = episode_batch['AVAIL_U']
self.buffers['AVAIL_U_NEXT'][idxs] = episode_batch['AVAIL_U_NEXT']
self.buffers['U_ONEHOT'][idxs] = episode_batch['U_ONEHOT']
self.buffers['PADDED'][idxs] = episode_batch['PADDED']
self.buffers['TERMINATE'][idxs] = episode_batch['TERMINATE']
if self.args.alg == 'maven':
self.buffers['z'][idxs] = episode_batch['z']
def sample(self, batch_size):
temp_buffer = {}
idx = np.random.randint(0, self.current_size, batch_size)
for key in self.buffers.keys():
temp_buffer[key] = self.buffers[key][idx]
return temp_buffer
def _get_storage_idx(self, inc=None):
inc = inc or 1
if self.current_idx + inc <= self.size:
idx = np.arange(self.current_idx, self.current_idx + inc)
self.current_idx += inc
elif self.current_idx < self.size:
overflow = inc - (self.size - self.current_idx)
idx_a = np.arange(self.current_idx, self.size)
idx_b = np.arange(0, overflow)
idx = np.concatenate([idx_a, idx_b])
self.current_idx = overflow
else:
idx = np.arange(0, inc)
self.current_idx = inc
self.current_size = min(self.size, self.current_size + inc)
if inc == 1:
idx = idx[0]
return idx
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/common_sr/srollout.py
================================================
import numpy as np
import torch
class RolloutWorker:
def __init__(self, env, agents, args):
self.env = env
self.agents = agents
self.episode_limit = args.episode_limit
self.n_actions = args.n_actions
self.n_agents = args.n_agents
self.obs_shape = args.obs_shape
self.args = args
self.epsilon = args.epsilon
self.anneal_epsilon = args.anneal_epsilon
self.min_epsilon = args.min_epsilon
print('Init RolloutWorker')
def generate_episode(self, episode_num=None, evaluate=False):
# if self.args.alg == 'siql_no_rnn':
# from policy_sc.siql_no_rnn import SIQLUR
# self.policy_sc = SIQLUR(self.args)
# self.policy_sc.eval_snn.reset()
if self.args.replay_dir != '' and evaluate and episode_num == 0: # prepare for save replay of evaluation
self.env.close()
# Store all data
EPISODE = dict(
O = [],
U = [],
R = [],
O_NEXT = [],
U_ONEHOT = [],
AVAIL_U = [],
AVAIL_U_NEXT = [],
PADDED = [],
TERMINATE = [],
)
NUM_EPISODES = self.args.n_episodes if evaluate==False else self.args.evaluate_epoch
episode_num = 0 if evaluate == False else self.args.evaluate_epoch
episode_reward = np.zeros((self.args.process, self.n_agents))
for episode_idx in range(NUM_EPISODES):
# Store one multiprocessing data
o, u, r, avail_u, u_onehot, terminate, padded = [], [], [], [], [], [], []
obs = self.env.reset()
obs1 = obs.copy()
obs1[:, 0], obs1[:, 1], obs1[:, 2], obs1[:, 3] = \
obs[:, 2], obs[:, 3], obs[:, 0], obs[:, 1]
obs_ = (obs, obs1)
obs_ = np.stack((obs, obs1), axis=0).transpose(1, 0, 2)
num_env = obs.shape[0]
last_action = np.zeros((self.args.n_agents, num_env, self.args.n_actions))
self.agents.policy.init_hidden(1, num_env)
terminated = False
win_tag = False
step = 0
# epsilon
epsilon = 0 if evaluate else self.epsilon
if self.args.epsilon_anneal_scale == 'episode':
epsilon = epsilon - self.anneal_epsilon if epsilon > self.min_epsilon else epsilon
# for each episode (include 50 steps and num_env multiprocessing)
while not terminated and step < self.episode_limit:
# time.sleep(0.2)
obs = np.array(obs_) #A perspective, B perspective
avail_action = [1] * self.args.n_actions
actions, avail_actions, actions_onehot = [], [], []
for agent_id in range(self.n_agents):
action = self.agents.choose_action(num_env, obs[:, agent_id, :], last_action[agent_id],
agent_id, avail_action, epsilon, evaluate)
# generate onehot vector of th action
action_onehot = np.zeros((num_env, self.args.n_actions))
for i in range(num_env): action_onehot[i, action[0, i]] = 1
actions.append(action[0].cpu().numpy().tolist()) #np.int(action)
actions_onehot.append(action_onehot)
avail_actions.append(avail_action)
last_action[agent_id] = action_onehot
actions = np.array(actions).transpose(1,0) #[num_env, num_agent](4, 2)
obs_, reward, done, info = self.env.step(actions=actions) #[num_env,num_agent,num_state],[num_env, num_agent],[num_env] (4, 2, 10) (4, 2)
if self.args.load_model == True:
self.env.render(mode="human")
print(reward)
o.append(obs)
u.append(np.expand_dims(actions, self.n_agents))
u_onehot.append(actions_onehot)
avail_u.append(avail_actions)
r.append(np.expand_dims(reward, 2))
terminate.append(np.expand_dims(np.array([terminated]*num_env), 1))
padded.append(np.expand_dims(np.array([0.]*num_env), 1))
episode_reward = episode_reward + reward
step += 1
if self.args.epsilon_anneal_scale == 'step':
epsilon = epsilon - self.anneal_epsilon if epsilon > self.min_epsilon else epsilon
# last obs
obs = np.array(obs_)
o.append(obs)
o_next = o[1:]
o = o[:-1]
# get avail_action for last obs,because target_q needs avail_action in training
avail_actions = []
for agent_id in range(self.n_agents):
avail_action = [1] * self.args.n_actions
avail_actions.append(avail_action)
avail_u.append(avail_actions)
avail_u_next = avail_u[1:]
avail_u = avail_u[:-1]
# if step < self.episode_limit,padding (if termined before the max steps, add data to max steps)
for i in range(step, self.episode_limit):
o.append(np.zeros((self.n_agents, self.obs_shape)))
u.append(np.zeros([self.n_agents, 1]))
r.append(np.zeros([self.n_agents, 1]))
o_next.append(np.zeros((self.n_agents, self.obs_shape)))
u_onehot.append(np.zeros((self.n_agents, self.n_actions)))
avail_u.append(np.zeros((self.n_agents, self.n_actions)))
avail_u_next.append(np.zeros((self.n_agents, self.n_actions)))
padded.append([1.]*num_env)
terminate.append([1.]*num_env)
# Processing data for each episode
EPISODE['O'].append(np.stack(o, axis=0).transpose(1, 0, 2, 3))
EPISODE['U'].append(np.stack(u, axis=0).transpose(1, 0, 2, 3).astype(int))
EPISODE['R'].append(np.stack(r, axis=0).transpose(1, 0, 2, 3))
EPISODE['O_NEXT'].append(np.stack(o_next, axis=0).transpose(1, 0, 2, 3))
EPISODE['U_ONEHOT'].append(np.stack(u_onehot, axis=0).transpose(2, 0, 1, 3))
EPISODE['AVAIL_U'].append(np.ones(EPISODE['U_ONEHOT'][0].shape))
EPISODE['AVAIL_U_NEXT'].append(np.ones(EPISODE['U_ONEHOT'][0].shape))
EPISODE['PADDED'].append(np.stack(padded, axis=0).transpose(1, 0, 2))
EPISODE['TERMINATE'].append(np.stack(terminate, axis=0).transpose(1, 0, 2))
episode_reward = episode_reward.sum(0)
for i in EPISODE.keys():
EPISODE[i] = np.concatenate(EPISODE[i], axis=0)
step = step * self.args.n_episodes * num_env
if not evaluate:
self.epsilon = epsilon
if evaluate and episode_num == self.args.evaluate_epoch and self.args.replay_dir != '':
self.env.save_replay()
self.env.close()
return EPISODE, episode_reward, win_tag, step
def generate_episode_sample(self, episodes, steps, episode_num=None, evaluate=False):
if self.args.replay_dir != '' and evaluate and episode_num == 0: # prepare for save replay of evaluation
self.env.close()
o, u, r, avail_u, u_onehot, terminate, padded = [], [], [], [], [], [], []
obs = self.env.reset()
obs_ = (obs, self.env.game._flip_coord_observation_perspective(obs)) # A perspective, B perspective
terminated = False
win_tag = False
step = 0
episode_reward = (0, 0) # cumulative rewards
# ###
# for param_sc in self.agents_sc.policy_base.parameters():
# param_sc.requires_grad = False
# self.agents_sc.policy_base.eval()
last_action = np.zeros((self.args.n_agents, self.args.n_actions))
self.agents.policy.init_hidden(1)
# epsilon
epsilon = 0 if evaluate else self.epsilon
if self.args.epsilon_anneal_scale == 'episode':
epsilon = epsilon - self.anneal_epsilon if epsilon > self.min_epsilon else epsilon
while not terminated and step < self.episode_limit:
# time.sleep(0.2)
obs = np.array(obs_) #A perspective, B perspective
avail_action = [1] * self.args.n_actions
actions, avail_actions, actions_onehot = [], [], []
for agent_id in range(self.n_agents):
action = self.agents.choose_action(obs[agent_id], last_action[agent_id], agent_id,
avail_action, epsilon, evaluate)
# generate onehot vector of th action
action_onehot = np.zeros(self.args.n_actions)
action_onehot[action] = 1
actions.append(np.int(action))
actions_onehot.append(action_onehot)
avail_actions.append(avail_action)
last_action[agent_id] = action_onehot
obs_, reward, done, info = self.env.step(actions=actions)
# print(actions,reward)
win_tag = True if terminated else False
# save obs, actions, avail_actions, reward at time t
o.append(obs)
u.append(np.reshape(actions, [self.n_agents, 1]))
u_onehot.append(actions_onehot)
avail_u.append(avail_actions)
r.append(np.reshape(reward, [self.n_agents, 1])) #reward
terminate.append([terminated])
padded.append([0.])
# episode_reward += reward
episode_reward = [episode_reward[i] + reward[i] for i in range(min(len(episode_reward), len(reward)))]
step += 1
if self.args.epsilon_anneal_scale == 'step':
epsilon = epsilon - self.anneal_epsilon if epsilon > self.min_epsilon else epsilon
if self.args.load_model == True:
self.env.render(mode="human")
# last obs
obs = np.array(obs_)
o.append(obs)
o_next = o[1:]
o = o[:-1]
# get avail_action for last obs,because target_q needs avail_action in training
avail_actions = []
for agent_id in range(self.n_agents):
avail_action = [1] * self.args.n_actions
avail_actions.append(avail_action)
avail_u.append(avail_actions)
avail_u_next = avail_u[1:]
avail_u = avail_u[:-1]
# if step < self.episode_limit,padding
for i in range(step, self.episode_limit):
o.append(np.zeros((self.n_agents, self.obs_shape)))
u.append(np.zeros([self.n_agents, 1]))
r.append(np.zeros([self.n_agents, 1]))
o_next.append(np.zeros((self.n_agents, self.obs_shape)))
u_onehot.append(np.zeros((self.n_agents, self.n_actions)))
avail_u.append(np.zeros((self.n_agents, self.n_actions)))
avail_u_next.append(np.zeros((self.n_agents, self.n_actions)))
padded.append([1.])
terminate.append([1.])
episode = dict(o=o.copy(),
u=u.copy(),
r=r.copy(),
avail_u=avail_u.copy(),
o_next=o_next.copy(),
avail_u_next=avail_u_next.copy(),
u_onehot=u_onehot.copy(),
padded=padded.copy(),
terminated=terminate.copy()
)
episodes[episode_num] = episode
steps[episode_num] = step
# add episode dim
for key in episode.keys():
episode[key] = np.array([episode[key]])
if not evaluate:
self.epsilon = epsilon
if evaluate and episode_num == self.args.evaluate_epoch - 1 and self.args.replay_dir != '':
self.env.save_replay()
self.env.close()
# return episode, episode_reward, win_tag, step
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/envs/Stag_Hunt_env.py
================================================
import gym
import gym_stag_hunt
from ray import tune
from ray.rllib.env.wrappers.pettingzoo_env import PettingZooEnv
from gym_stag_hunt.envs.pettingzoo.hunt import raw_env
if __name__ == "__main__":
def env_creator(args):
return PettingZooEnv(raw_env(**args))
tune.register_env("StagHunt-Hunt-PZ-v0", env_creator)
model = tune.run(
"DQN",
name="stag_hunt",
stop={"episodes_total": 10000},
checkpoint_freq=100,
checkpoint_at_end=True,
config={
"horizon": 100,
"framework": "tf2",
# Environment specific
"env": "StagHunt-Hunt-PZ-v0",
# General
"num_workers": 2,
# Method specific
"multiagent": {
"policies": {"player_0", "player_1"},
"policy_mapping_fn": (lambda agent_id, episode, **kwargs: agent_id),
"policies_to_train": ["player_0", "player_1"]
},
# Env Specific
"env_config": {
"obs_type": "coords",
"forage_reward": 1.0,
"stag_reward": 5.0,
"stag_follows": True,
"mauling_punishment": -.5,
"enable_multiagent": True,
}
}
)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/envs/__init__.py
================================================
from ToM2.envs.grid_env1 import *
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/envs/abstract.py
================================================
"""
Implements abstract class for meta-reinforcement learning environments.
"""
from typing import Generic, TypeVar, Tuple
import abc
ObsType = TypeVar('ObsType')
class MetaEpisodicEnv(abc.ABC, Generic[ObsType]):
@property
@abc.abstractmethod
def max_episode_len(self) -> int:
"""
Return the maximum episode length.
"""
pass
@abc.abstractmethod
def new_env(self) -> None:
"""
Reset the environment's structure by resampling
the state transition probabilities and/or reward function
from a prior distribution.
Returns:
None
"""
pass
@abc.abstractmethod
def reset(self) -> ObsType:
"""
Resets the environment's state to some designated initial state.
This is distinct from resetting the environment's structure
via self.new_env().
Returns:
initial observation.
"""
pass
@abc.abstractmethod
def step(
self,
action: int,
auto_reset: bool = True
) -> Tuple[ObsType, float, bool, dict]:
"""
Step the env.
Args:
action: integer action indicating which action to take
auto_reset: whether or not to automatically reset the environment
on done. if true, next observation will be given by self.reset()
Returns:
next observation, reward, and done flat
"""
pass
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/envs/constants.py
================================================
"""
Global constants for the gridworld env.
"""
# =============================================================================
# set the value of interface
# =============================================================================
FPS = 25
WinWidth = 340 #window width
WinHeight = 260 #window width
BoxSize = 20 #the size of one grid
GridWidth = 7 #the number of lattices are there in the x-axis
GridHeight = 7 #the number of lattices are there in the y-axis
XMargin = int((WinWidth - GridWidth * BoxSize)/2)
TopMargin = int((WinHeight - GridHeight * BoxSize))/2-5
# =============================================================================
# set color
# =============================================================================
White = (255, 255, 255)
Gray = (185, 185, 185)
Black = (0, 0, 0)
Red = (255, 0, 0)
Green = (0, 128, 0)
SpringGreen = (60, 179, 113)
DarkOrange = (255, 140, 0)
RoyalBlue = (65, 105, 225)
DarkVoilet = (148, 0, 211)
HotPink = (255, 105, 180)
BoardColor = White
BGColor = White
TextColor = White
Test = []
# =============================================================================
# set maps
# =============================================================================
# BlankBox = 1
# shadow = 0
# Wall = 5
# Obstacle = 5
# observer = 8
# button = 7
# obeservation_1 = 11
# obeservation_2 = 22
# obeservation_3 = 33
"""
'S' : starting point
'F' or '.': free space
'W' or 'x': wall
'H' or 'o': hole (terminates episode)
'G' : goal
"""
Start = 'S'
Free_space = 'F'
Wall = 'W'
Danger = 'H'
Goal = 'G'
Shadow = 'Sh'
MAPs = {
0: [
"FFFFF",
"FHFWF",
"FFFFF",
"WFFFF",
"FFFGF"
],
1: [
"FFFFF",
"FHWFF",
"FFFFF",
"WFGFF",
"FFFFF"
],
2: [
"FFFF",
"FWFW",
"FFFW",
"WFFG"
],
3: [
"FFFF",
"FHFW",
"FFFW",
"GFFF"
],
4: [
"FFFF",
"FHFW",
"FFFW",
"WGFF"
],
}
# 2: [
# "SFFFFFFF",
# "FFFFFFFF",
# "FFFHFFFF",
# "FFFFFWFF",
# "FFFHFFFF",
# "FWHFFFWF",
# "FWFFHFWF",
# "FFFWFFFG"
# ],
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/main_spiking.py
================================================
from common_sr.arguments import get_common_args, get_coma_args, get_mixer_args
from common_sr.multiprocessing_env import SubprocVecEnv
from runner import Runner
from time import sleep
from gym_stag_hunt.envs.gym.escalation import EscalationEnv
from gym_stag_hunt.envs.gym.harvest import HarvestEnv
from gym_stag_hunt.envs.gym.hunt import HuntEnv
from gym_stag_hunt.envs.gym.simple import SimpleEnv
from gym_stag_hunt.src.games.abstract_grid_game import UP, LEFT, DOWN, RIGHT, STAND
import json
import os
os.environ["SDL_VIDEODRIVER"] = "dummy"
if __name__ == '__main__':
ENVS = {
"CLASSIC": SimpleEnv,
"HUNT": HuntEnv,
"HARVEST": HarvestEnv,
"ESCALATION": EscalationEnv,
}
args = get_common_args()
args = get_mixer_args(args)
if args.ENV == 'HUNT':
args.n_actions = 5 # [5] # up, down, left, right or stand
args.n_agents = 2 # [2]
args.obs_shape = 6 + args.forage_quantity * 2
elif args.ENV == 'ESCALATION':
args.n_actions = 5 # [5] # up, down, left, right or stand
args.n_agents = 2 # [2]
args.obs_shape = 6
elif args.ENV == 'HARVEST':
args.n_actions = 5 # [5] # up, down, left, right or stand
args.n_agents = 2 # [2]
args.obs_shape = 6 + args.forage_quantity * 5
args.episode_limit = 50
args.train_steps = 100
save_path = args.log_dir + '/' + args.alg + args.exp_dir
print(os.path.exists(save_path))
if not os.path.exists(save_path):
os.makedirs(save_path)
# save args
argsDict = args.__dict__
with open(save_path + '/args_{}'.format(args.num_run), 'w') as f:
f.writelines('------------------ start ------------------' + '\n')
for eachArg, value in argsDict.items():
f.writelines(eachArg + ' : ' + str(value) + '\n')
f.writelines('------------------- end -------------------')
def make_env():
def _thunk():
if args.ENV == 'HUNT':
env = ENVS[args.ENV](obs_type="coords", enable_multiagent=True, opponent_policy="random", \
forage_quantity=args.forage_quantity, run_away_after_maul=True)
elif args.ENV == 'ESCALATION':
env = ENVS[args.ENV](obs_type="coords", enable_multiagent=True)
elif args.ENV == 'HARVEST':
env = ENVS[args.ENV](obs_type="coords", enable_multiagent=True)
return env
return _thunk
# for i in range(args.num_run):
envs = [make_env() for i in range(args.process)]
envs = SubprocVecEnv(envs)
runner = Runner(envs, args)
if not args.evaluate:
runner.run(args.num_run)
else:
win_rate, _ = runner.evaluate()
print('The win rate of {} is {}'.format(args.alg, win_rate))
envs.close()
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/network/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/network/spiking_net.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as f
from torch.distributions import Normal
from braincog.base.node.node import IFNode, LIFNode
from braincog.base.strategy.surrogate import AtanGrad
thresh = 0.3
lens = 0.25
decay = 0.3
TIMESTEPS = 15
M = 5
# BrainCog
class BCNoSpikingLIFNode(LIFNode):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self, dv: torch.Tensor):
self.integral(dv)
return self.mem
class BCNoSpikingIFNode(IFNode):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self, dv: torch.Tensor):
self.integral(dv)
return self.mem
# Sug
class ActFun(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
return input.gt(thresh).float()
@staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
grad_input = grad_output.clone()
temp = abs(input - thresh) < lens
return grad_input * temp.float() / (2 * lens)
#act_fun = ActFun.apply
act_fun = AtanGrad(alpha=2.,requires_grad=False)
def mem_update(fc, x, mem, spike):
mem = mem * decay * (1 - spike) + fc(x)
#spike = act_fun(mem)
spike = act_fun(x=mem-1)
return mem, spike
class Critic(nn.Module):
def __init__(self, input_shape, args):
super(Critic, self).__init__()
self.args = args
self.fc1 = nn.Linear(input_shape, args.ppo_hidden_size)
self.fc2 = nn.Linear(args.rnn_hidden_dim, args.rnn_hidden_dim, bias = True)
self.fc3 = nn.Linear(args.rnn_hidden_dim, args.rnn_hidden_dim, bias = True)
self.fc4 = nn.Linear(args.rnn_hidden_dim, args.n_actions)#
self.req_grad = False
def forward(self, inputs, h1_mem, h1_spike, h2_mem, h2_spike):
# if self.req_grad == False:
# [1, 17] -> [1, process, 64]
x = self.fc1(inputs)
# x = IFNode()(x)
x = LIFNode()(x)
if self.args.alg == 'siql_e':
h1_mem = h1_mem.reshape(-1, M,TIMESTEPS, self.args.rnn_hidden_dim)
h1_spike = h1_spike.reshape(-1, M,TIMESTEPS, self.args.rnn_hidden_dim)
h2_mem = h2_mem.reshape(-1, M, TIMESTEPS, self.args.rnn_hidden_dim)
h2_spike = h2_spike.reshape(-1, M, TIMESTEPS, self.args.rnn_hidden_dim)
else:
# [1, 64] -> [process, 64]
h1_mem = h1_mem.reshape(-1, self.args.rnn_hidden_dim)
h1_spike = h1_spike.reshape(-1, self.args.rnn_hidden_dim)
h2_mem = h2_mem.reshape(-1, self.args.rnn_hidden_dim)
h2_spike = h2_spike.reshape(-1, self.args.rnn_hidden_dim)
h1_mem, h1_spike = mem_update(self.fc2, x, h1_mem, h1_spike)
h2_mem, h2_spike = mem_update(self.fc3, h1_spike, h2_mem, h2_spike)
# [1, 5]
value = BCNoSpikingLIFNode(tau=2.0)(self.fc4(h2_mem))
return value, h1_mem, h1_spike, h2_mem, h2_spike
class VDNNet(nn.Module):
def __init__(self):
super(VDNNet, self).__init__()
def forward(self, q_values):
return torch.sum(q_values, dim=2, keepdim=True)
class Linear_weight(nn.Module):
def __init__(self, input_shape, out_shape, args):
super(Linear_weight,self).__init__()
self.args = args
# self.fc = nn.Linear(input_shape, out_shape)
self.alpha = nn.Parameter(torch.Tensor(out_shape))
def forward(self, x):
# return self.fc(x)
if self.args.alg == 'scovdn_weight':
x = x[:,:,:,0] * self.alpha + x[:,:,:,1] * (1 - self.alpha)
return x.unsqueeze(3)
elif self.args.alg == 'stomvdn':
x = x[:, :, :, :, 0] * self.alpha + x[:, :, :, :, 1] * (1 - self.alpha)
return x.unsqueeze(4)
class BiasNet(nn.Module):
def __init__(self, args):
super(BiasNet, self).__init__()
self.args = args
input_shape = self.args.obs_shape + self.args.rnn_hidden_dim
#
# self.h1_mem = self.h1_spike = torch.zeros(self.args.n_episodes * self.args.process,
# self.args.episode_limit, self.args.rnn_hidden_dim)
# if self.args.cuda:
# self.h1_mem = self.h1_mem.cuda(self.args.device)
# self.h1_spike = self.h1_spike.cuda(self.args.device)
self.fc1 = nn.Linear(input_shape, args.rnn_hidden_dim)#neuron.IFNode()
self.fc2 = nn.Linear(args.rnn_hidden_dim, args.rnn_hidden_dim, bias = True)
self.fc3 = nn.Linear(args.rnn_hidden_dim, 1)#
def reset(self, episode_num):
self.h1_mem = self.h1_spike = torch.zeros(episode_num,
self.args.episode_limit, self.args.rnn_hidden_dim)
if self.args.cuda:
self.h1_mem = self.h1_mem.cuda(self.args.device)
self.h1_spike = self.h1_spike.cuda(self.args.device)
def forward(self, state, hidden):
episode_num, max_episode_len, n_agents, _ = hidden.shape
state = state.reshape(episode_num * max_episode_len, -1)
state = state * 0.2
hidden = \
hidden.reshape(episode_num * max_episode_len, n_agents, -1).sum(dim=-2)
inputs = torch.cat([state, hidden], dim=-1)
x = self.fc1(inputs)
x = neuron.IFNode()(x)
# x = IFNode()(x)
# x = LIFNode()(x) #bad
# [1, 64] -> [process, 64]
self.h1_mem = self.h1_mem.reshape(-1, self.args.rnn_hidden_dim)
self.h1_spike = self.h1_spike.reshape(-1, self.args.rnn_hidden_dim)
self.h1_mem, self.h1_spike = mem_update(self.fc2, x, self.h1_mem, self.h1_spike)
# [1, 5]
# value = NonSpikingLIFNode(tau=2.0)(self.fc4(h2_mem))
# value = BCNoSpikingLIFNode(tau=2.0)(self.fc4(h2_mem))
value = BCNoSpikingIFNode(tau=2.0)(self.fc3(self.h1_mem))
return value
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/policy/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/policy/dqn.py
================================================
import torch
import os
from network.base_net import RNN
class DQN:
def __init__(self, args, model_eval, model_target, agent_id):
self.n_actions = args.n_actions
self.n_agents = args.n_agents
self.obs_shape = args.obs_shape
self.agent_id = agent_id
input_shape = self.obs_shape
# 根据参数决定RNN的输入维度
if args.last_action:
input_shape += self.n_actions
# if args.reuse_network:
# input_shape += self.n_agents
# 神经网络
self.eval_rnn = model_eval
self.target_rnn = model_target
self.args = args
if self.args.cuda:
self.eval_rnn.cuda(self.args.device)
self.target_rnn.cuda(self.args.device)
# self.model_dir = args.model_dir + '/' + args.alg
self.model_dir = '/home/zhaozhuoya/exp2/MARL_test_exp/model' + '/' + args.alg + args.exp_dir#+ args.model_dir
# 如果存在模型则加载模型
if self.args.load_model:
if os.path.exists(self.model_dir + args.save_model_dir):
# path_snn = '/home/zhaozhuoya/exp2/ToM2/model/iql/199_rnn_net_params.pkl'
map_location = self.args.device if self.args.cuda else 'cpu'
self.eval_rnn.load_state_dict(torch.load(self.model_dir + args.save_model_dir, map_location=map_location))
# self.eval_rnn.load_state_dict(torch.load(self.model_dir))
print('Successfully load the model: {}'.format(self.model_dir + args.save_model_dir))
else:
raise Exception("No model!")
# 让target_net和eval_net的网络参数相同
self.target_rnn.load_state_dict(self.eval_rnn.state_dict())
self.eval_parameters = list(self.eval_rnn.parameters())
if args.optimizer == "RMS":
self.optimizer = torch.optim.RMSprop(self.eval_parameters, lr=args.lr)
# 执行过程中,要为每个agent都维护一个eval_hidden
# 学习过程中,要为每个episode的每个agent都维护一个eval_hidden、target_hidden
self.eval_hidden = None
self.target_hidden = None
print('Init alg DQN')
def learn(self, batch, max_episode_len, train_step, epsilon=None): # train_step表示是第几次学习,用来控制更新target_net网络的参数
'''
在learn的时候,抽取到的数据是四维的,四个维度分别为 1——第几个episode 2——episode中第几个transition
3——第几个agent的数据 4——具体obs维度。因为在选动作时不仅需要输入当前的inputs,还要给神经网络输入hidden_state,
hidden_state和之前的经验相关,因此就不能随机抽取经验进行学习。所以这里一次抽取多个episode,然后一次给神经网络
传入每个episode的同一个位置的transition
'''
episode_num = batch['O'].shape[0]
self.init_hidden_learn(episode_num)
# hidden_state = self.policy.eval_hidden[:, self.agent_id, :, :]
eval_hidden, target_hidden = \
self.eval_hidden[:, self.agent_id, :], self.target_hidden[:, self.agent_id, :]
# for key in batch.keys(): # 把batch里的数据转化成tensor
# if key == 'u':
# batch[key] = torch.tensor(batch[key], dtype=torch.long)
# else:
# batch[key] = torch.tensor(batch[key], dtype=torch.float32)
# u, r, avail_u, avail_u_next, terminated = batch['u'], batch['r'].squeeze(-1), batch['avail_u'], \
# batch['avail_u_next'], batch['terminated'].repeat(1, 1, self.n_agents)
# mask = (1 - batch["padded"].float()).repeat(1, 1, self.n_agents) # 用来把那些填充的经验的TD-error置0,从而不让它们影响到学习
for key in batch.keys(): # 把batch里的数据转化成tensor
if key == 'O':
batch[key] = torch.tensor(batch[key], dtype=torch.long)
else:
batch[key] = torch.tensor(batch[key], dtype=torch.float32)
u, r, avail_u, avail_u_next, terminated = batch['U'], batch['R'].squeeze(-1), batch['AVAIL_U'], \
batch['AVAIL_U_NEXT'], batch['TERMINATE'].repeat(1, 1, self.n_agents)
mask = (1 - batch["PADDED"].float()).repeat(1, 1, self.n_agents) # 用来把那些填充的经验的TD-error置0,从而不让它们影响到学习
# 得到每个agent对应的Q值,维度为(episode个数, max_episode_len, n_agents, n_actions)
q_evals, q_targets = self.get_q_values(batch, max_episode_len, eval_hidden, target_hidden)
if self.args.cuda:
u = u.cuda(self.args.device)
r = r.cuda(self.args.device)
terminated = terminated.cuda(self.args.device)
mask = mask.cuda(self.args.device)
# 取每个agent动作对应的Q值,并且把最后不需要的一维去掉,因为最后一维只有一个值了
u = u.to(torch.int64)
q_evals = torch.gather(q_evals, dim=3, index=u[:, :, self.agent_id, :].unsqueeze(3)).squeeze(3)
# 得到target_q
q_targets[avail_u_next[:, :, self.agent_id, :].unsqueeze(2) == 0.0] = - 9999999
q_targets = q_targets.max(dim=3)[0]
targets = r[:, :, self.agent_id].unsqueeze(2) + self.args.gamma * q_targets * (1 - terminated[:, :, self.agent_id].unsqueeze(2))
td_error = (q_evals - targets.detach())
masked_td_error = mask[:, :, self.agent_id].unsqueeze(2) * td_error # 抹掉填充的经验的td_error
# 不能直接用mean,因为还有许多经验是没用的,所以要求和再比真实的经验数,才是真正的均值
loss = (masked_td_error ** 2).sum() / mask.sum()
# print('loss is ', loss)
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.eval_parameters, self.args.grad_norm_clip)
self.optimizer.step()
if train_step > 0 and train_step % self.args.target_update_cycle == 0:
self.target_rnn.load_state_dict(self.eval_rnn.state_dict())
return loss
def _get_inputs(self, batch, transition_idx):
# 取出所有episode上该transition_idx的经验,u_onehot要取出所有,因为要用到上一条
# obs, obs_next, u_onehot = batch['o'][:, transition_idx], \
# batch['o_next'][:, transition_idx], batch['u_onehot'][:]
# 取出所有episode上该transition_idx的经验,u_onehot要取出所有,因为要用到上一条
obs, obs_next, u_onehot = batch['O'][:, transition_idx], \
batch['O_NEXT'][:, transition_idx], batch['U_ONEHOT'][:]
episode_num = obs.shape[0]
inputs, inputs_next = [], []
inputs.append(obs[:, self.agent_id, :])
inputs_next.append(obs_next[:, self.agent_id, :])
# 给obs添加上一个动作、agent编号
if self.args.last_action:
if transition_idx == 0: # 如果是第一条经验,就让前一个动作为0向量
inputs.append(torch.zeros_like(u_onehot[:, :, self.agent_id, :][:, transition_idx]))
else:
inputs.append(u_onehot[:, :, self.agent_id, :][:, transition_idx - 1])
inputs_next.append(u_onehot[:, :, self.agent_id, :][:, transition_idx])
# if self.args.reuse_network:
# 因为当前的obs三维的数据,每一维分别代表(episode编号,agent编号,obs维度),直接在dim_1上添加对应的向量
# 即可,比如给agent_0后面加(1, 0, 0, 0, 0),表示5个agent中的0号。而agent_0的数据正好在第0行,那么需要加的
# agent编号恰好就是一个单位矩阵,即对角线为1,其余为0
# inputs.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
# inputs_next.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
# inputs.append(torch.zeros((self.args.n_agents, self.args.n_agents)).unsqueeze(0).expand(episode_num, -1, -1))
# inputs_next.append(torch.zeros((self.args.n_agents, self.args.n_agents)).unsqueeze(0).expand(episode_num, -1, -1))
# 要把obs中的三个拼起来,并且要把episode_num个episode、self.args.n_agents个agent的数据拼成40条(40,96)的数据,
# 因为这里所有agent共享一个神经网络,每条数据中带上了自己的编号,所以还是自己的数据
inputs = torch.cat([x for x in inputs], dim=1)
inputs_next = torch.cat([x for x in inputs_next], dim=1)
return inputs, inputs_next
def get_q_values(self, batch, max_episode_len, eval_hidden, target_hidden):
# episode_num = batch['o'].shape[0]
episode_num = batch['O'].shape[0]
q_evals, q_targets = [], []
for transition_idx in range(max_episode_len):
inputs, inputs_next = self._get_inputs(batch, transition_idx) # 给obs加last_action、agent_id
if self.args.cuda:
inputs = inputs.cuda(self.args.device)
inputs_next = inputs_next.cuda(self.args.device)
eval_hidden = eval_hidden.cuda(self.args.device)
target_hidden = target_hidden.cuda(self.args.device)
q_eval, self.eval_hidden = self.eval_rnn(inputs, eval_hidden) # inputs维度为(40,96),得到的q_eval维度为(40,n_actions)
q_target, self.target_hidden = self.target_rnn(inputs_next, target_hidden)
# 把q_eval维度重新变回(8, 5,n_actions)
q_eval = q_eval.view(episode_num, 1, -1)
q_target = q_target.view(episode_num, 1, -1)
q_evals.append(q_eval)
q_targets.append(q_target)
# 得的q_eval和q_target是一个列表,列表里装着max_episode_len个数组,数组的的维度是(episode个数, n_agents,n_actions)
# 把该列表转化成(episode个数, max_episode_len, n_agents,n_actions)的数组
q_evals = torch.stack(q_evals, dim=1)
q_targets = torch.stack(q_targets, dim=1)
return q_evals, q_targets
def init_hidden(self, episode_num, num_env):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
self.eval_hidden = torch.zeros((episode_num, self.n_agents, num_env,self.args.rnn_hidden_dim))
self.target_hidden = torch.zeros((episode_num, self.n_agents, num_env,self.args.rnn_hidden_dim))
def init_hidden_learn(self, episode_num):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
self.eval_hidden = torch.zeros((episode_num, self.n_agents, self.args.rnn_hidden_dim))
self.target_hidden = torch.zeros((episode_num, self.n_agents, self.args.rnn_hidden_dim))
def save_model(self, train_step):
num = str(train_step // self.args.save_cycle)
if not os.path.exists(self.model_dir):
os.makedirs(self.model_dir)
torch.save(self.eval_rnn.state_dict(), self.model_dir + '/' + num + '_rnn_net_params.pkl')
def load_model(self, train_step):
num = str(train_step // self.args.save_cycle)
path = torch.load(self.model_dir + '/' + num + '_rnn_net_params.pkl')
self.eval_rnn.load_state_dict(path)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/policy/stomvdn.py
================================================
import torch
import os
from network.spiking_net import Critic, VDNNet, Linear_weight, BiasNet
import copy
class SToMVDN:
def __init__(self, args):
self.n_actions = args.n_actions
self.n_agents = args.n_agents
self.obs_shape = args.obs_shape
input_shape = self.obs_shape
# 根据参数决定RNN的输入维度
if args.last_action:
input_shape += self.n_actions
if args.reuse_network:
input_shape += self.n_agents
self.loss_trade_off_target = 0
self.loss_trade_off_eval = 0
# 神经网络
self.eval_snn = Critic(input_shape, args)
self.target_snn = Critic(input_shape, args)
self.eval_vdn_snn = VDNNet() # 把agentsQ值加起来的网络
self.target_vdn_snn = VDNNet()
self.bias_net = BiasNet(args)
self.trade_off_net = Linear_weight(2, 1, args)
self.args = args
if self.args.cuda:
self.eval_snn.cuda(self.args.device)
self.target_snn.cuda(self.args.device)
self.eval_vdn_snn.cuda(self.args.device)
self.target_vdn_snn.cuda(self.args.device)
self.trade_off_net.cuda(self.args.device)
self.bias_net.cuda(self.args.device)
self.model_dir = args.model_dir + '/' + args.alg + args.exp_dir + args.save_model_dir
# 如果存在模型则加载模型
if self.args.load_model:
if os.path.exists(self.model_dir):
# path_snn = '/home/zhaozhuoya/exp2/ToM2_test/model/siql/199_snn_net_params.pkl'
map_location = self.args.device if self.args.cuda else 'cpu'
self.eval_snn.load_state_dict(torch.load(self.model_dir, map_location=map_location))
print('Successfully load the model: {}'.format(self.model_dir))
else:
print(self.model_dir)
raise Exception("No model!")
# 让target_net和eval_net的网络参数相同
self.target_snn.load_state_dict(self.eval_snn.state_dict())
self.target_vdn_snn.load_state_dict(self.eval_vdn_snn.state_dict())
self.eval_parameters = list(self.eval_snn.parameters()) + \
list(self.eval_vdn_snn.parameters()) + \
list(self.trade_off_net.parameters()) + \
list(self.bias_net.parameters())
self.trade_off_parameters = list(self.trade_off_net.parameters())
if args.optimizer == "RMS":
self.optimizer = torch.optim.RMSprop(self.eval_parameters, lr=args.lr)
self.optimizer_T = torch.optim.RMSprop(self.trade_off_parameters, lr=args.lr)
# 执行过程中,要为每个agent都维护一个eval_hidden
# 学习过程中,要为每个episode的每个agent都维护一个eval_hidden、target_hidden
self.eval_h1_mem, self.eval_h1_spike = None, None
self.target_h1_mem, self.target_h1_spike = None, None
self.eval_h2_mem, self.eval_h2_spike = None, None
self.target_h2_mem, self.target_h2_spike = None, None
print('Init alg SCOVDN_ToM')
def learn(self, batch, max_episode_len, train_step, epsilon=None): # train_step表示是第几次学习,用来控制更新target_net网络的参数
'''
在learn的时候,抽取到的数据是四维的,四个维度分别为 1——第几个episode 2——episode中第几个transition
3——第几个agent的数据 4——具体obs维度。因为在选动作时不仅需要输入当前的inputs,还要给神经网络输入hidden_state,
hidden_state和之前的经验相关,因此就不能随机抽取经验进行学习。所以这里一次抽取多个episode,然后一次给神经网络
传入每个episode的同一个位置的transition
'''
episode_num = batch['O'].shape[0]
self.init_hidden_learn(episode_num)
self.bias_net.reset(episode_num)
for key in batch.keys(): # 把batch里的数据转化成tensor
if key == 'U': # 'O'
batch[key] = torch.tensor(batch[key], dtype=torch.long)
else:
batch[key] = torch.tensor(batch[key], dtype=torch.float32)
u, r, avail_u, avail_u_next, terminated = batch['U'], batch['R'].squeeze(-1), batch['AVAIL_U'], \
batch['AVAIL_U_NEXT'], batch['TERMINATE'].repeat(1, 1, self.n_agents)
mask = (1 - batch["PADDED"].float()).repeat(1, 1, self.n_agents) # 用来把那些填充的经验的TD-error置0,从而不让它们影响到学习
if self.args.cuda:
u = u.cuda(self.args.device)
r = r.cuda(self.args.device)
terminated = terminated.cuda(self.args.device)
mask = mask.cuda(self.args.device)
# self.bias_net.cuda(self.args.device)
u = u.to(torch.int64)
# ---------------------------------------independent_Q_net------------------------------------------------------
# 得到每个agent对应的Q值,维度为(episode个数, max_episode_len, n_agents, n_actions)
q_evals, q_targets, hidden_evals, hidden_targets = self.get_q_values(batch, max_episode_len)
# ---------------------------------------independent_Q_net------------------------------------------------------
# --------------------------------------------bias_net----------------------------------------------------------
# 得到每个agent对应的Q值,维度为(episode个数, max_episode_len, n_agents, n_actions)
v = self.get_bias(batch, hidden_evals, hidden_targets, episode_num)
# --------------------------------------------bias_net----------------------------------------------------------
# ---------------------------------------_self+Q_other_net------------------------------------------------------
q_other_evals, q_other_targets = q_evals[:, :, [1, 0], :].unsqueeze(4), q_targets[:, :, [1, 0], :].unsqueeze(4)
q_evals_, q_targets_ = q_evals.unsqueeze(4), q_targets.unsqueeze(4)
q_total_evals = torch.cat((q_evals_, q_other_evals), 4)
q_total_targets = torch.cat((q_targets_, q_other_targets), 4)
# q_total_evals = self.trade_off_net(q_total_evals) #([10, 50, 2, 5, 1])
# q_total_targets = self.trade_off_net(q_total_targets) # ([10, 50, 2, 5, 1])
q_total_evals = q_evals_ + q_other_targets
q_total_targets = q_targets_ + q_other_targets
# --------------------------------------------_self+Q_other_net-------------------------------------------------
# --------------------------------------------L_self/other------------------------------------------------------
q_total_targets[avail_u_next == 0.0] = - 9999999
q_total_targets = q_total_targets.max(dim=3)[0].squeeze()
q_total_evals = torch.gather(q_total_evals.squeeze(4), dim=3, index=u).squeeze(3)
y = r + self.args.gamma * q_total_targets * (1 - terminated)
td_error = q_total_evals - y.detach()
l_so = ((td_error * mask) ** 2).sum() / mask.sum()
# --------------------------------------------L_self/other------------------------------------------------------
# --------------------------------------------action_prob_Q-----------------------------------------------------
# probablity of action
action_prob = self._get_action_prob(batch, max_episode_len, 0.4) # 每个agent的所有动作的概率self.args.epsilon
pi_taken = torch.gather(action_prob, dim=3, index=u).squeeze(3) # 每个agent的选择的动作对应的概率
pi_taken[mask == 0] = 1.0 # 因为要取对数,对于那些填充的经验,所有概率都为0,取了log就是负无穷了,所以让它们变成1
log_pi_taken = torch.log(pi_taken)
# --------------------------------------------action_prob_Q-----------------------------------------------------
# ----------------------------------------------L_coma----------------------------------------------------------
# q_evals = torch.gather(q_evals * action_prob, dim=3, index=u).squeeze(3)
q_evals_coma = (q_evals * action_prob).sum(dim=3, keepdim=True).squeeze(3)
coma_error = q_evals_coma.sum(dim=-1) - q_total_targets.detach().sum(dim=-1) + v
l_coma = ((coma_error * mask[:,:,0]) ** 2).sum() / mask[:,:,0].sum()
# ----------------------------------------------L_coma----------------------------------------------------------
# -----------------------------------------------L_sum----------------------------------------------------------
q_evals_sum = self.eval_vdn_snn(q_evals)
sum_error = q_evals_sum.sum(dim=-1).squeeze(2) - q_total_targets.detach().sum(dim=-1) + v
l_sum = ((sum_error * mask[:,:,0]) ** 2).sum() / mask[:,:,0].sum()
# -----------------------------------------------L_sum----------------------------------------------------------
LOSS = l_so + l_coma + l_sum
self.optimizer.zero_grad()
LOSS.backward()
if train_step > 0 and train_step % self.args.target_update_cycle == 0:
self.target_snn.load_state_dict(self.eval_snn.state_dict())
self.target_vdn_snn.load_state_dict(self.eval_vdn_snn.state_dict())
return LOSS
def _get_inputs(self, batch, transition_idx):
# 取出所有episode上该transition_idx的经验,u_onehot要取出所有,因为要用到上一条
obs, obs_next, u_onehot = batch['O'][:, transition_idx], \
batch['O_NEXT'][:, transition_idx], batch['U_ONEHOT'][:]
episode_num = obs.shape[0]
inputs, inputs_next = [], []
inputs.append(obs)
inputs_next.append(obs_next)
# 给obs添加上一个动作、agent编号
if self.args.last_action:
if transition_idx == 0: # 如果是第一条经验,就让前一个动作为0向量
inputs.append(torch.zeros_like(u_onehot[:, transition_idx]))
else:
inputs.append(u_onehot[:, transition_idx - 1])
inputs_next.append(u_onehot[:, transition_idx])
if self.args.reuse_network:
# 因为当前的obs三维的数据,每一维分别代表(episode编号,agent编号,obs维度),直接在dim_1上添加对应的向量
# 即可,比如给agent_0后面加(1, 0, 0, 0, 0),表示5个agent中的0号。而agent_0的数据正好在第0行,那么需要加的
# agent编号恰好就是一个单位矩阵,即对角线为1,其余为0
inputs.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
inputs_next.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
# 要把obs中的三个拼起来,并且要把episode_num个episode、self.args.n_agents个agent的数据拼成40条(40,96)的数据,
# 因为这里所有agent共享一个神经网络,每条数据中带上了自己的编号,所以还是自己的数据
inputs = torch.cat([x.reshape(episode_num * self.args.n_agents, -1) for x in inputs], dim=1)
inputs_next = torch.cat([x.reshape(episode_num * self.args.n_agents, -1) for x in inputs_next], dim=1)
return inputs, inputs_next
def get_q_values(self, batch, max_episode_len):
episode_num = batch['O'].shape[0]
q_evals, q_targets, eval_h2_mems, target_h2_mems = [], [], [], []
for transition_idx in range(max_episode_len):
inputs, inputs_next = self._get_inputs(batch, transition_idx) # 给obs加last_action、agent_id
if self.args.cuda:
inputs = inputs.cuda(self.args.device)
inputs_next = inputs_next.cuda(self.args.device)
self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem, self.eval_h2_spike = \
self.eval_h1_mem.cuda(self.args.device), self.eval_h1_spike.cuda(
self.args.device), self.eval_h2_mem.cuda(self.args.device), self.eval_h2_spike.cuda(
self.args.device)
self.target_h1_mem, self.target_h1_spike, self.target_h2_mem, self.target_h2_spike = \
self.target_h1_mem.cuda(self.args.device), self.target_h1_spike.cuda(
self.args.device), self.target_h2_mem.cuda(self.args.device), self.target_h2_spike.cuda(
self.args.device)
q_eval, self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem, self.eval_h2_spike = \
self.eval_snn(inputs, self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem,
self.eval_h2_spike) # inputs维度为(40,96),得到的q_eval维度为(40,n_actions)
q_target, self.target_h1_mem, self.target_h1_spike, self.target_h2_mem, self.target_h2_spike = \
self.target_snn(inputs_next, self.target_h1_mem, self.target_h1_spike, self.target_h2_mem,
self.target_h2_spike)
# 把q_eval维度重新变回(8, 5,n_actions)
q_eval = q_eval.view(episode_num, self.n_agents, -1)
q_target = q_target.view(episode_num, self.n_agents, -1)
eval_h2_mem = self.eval_h2_mem.view(episode_num, self.n_agents, -1)
target_h2_mem = self.target_h2_mem.view(episode_num, self.n_agents, -1)
q_evals.append(q_eval)
q_targets.append(q_target)
eval_h2_mems.append(eval_h2_mem)
target_h2_mems.append(target_h2_mem)
# 得的q_eval和q_target是一个列表,列表里装着max_episode_len个数组,数组的的维度是(episode个数, n_agents,n_actions)
# 把该列表转化成(episode个数, max_episode_len, n_agents,n_actions)的数组
q_evals = torch.stack(q_evals, dim=1)
q_targets = torch.stack(q_targets, dim=1)
hidden_evals = torch.stack(eval_h2_mems, dim=1)
hidden_targets = torch.stack(target_h2_mems, dim=1)
return q_evals, q_targets, hidden_evals, hidden_targets
def get_bias(self, batch, hidden_evals, hidden_targets, episode_num, hat=False):
# episode_num, max_episode_len, _, _ = hidden_targets.shape
max_episode_len = self.args.episode_limit
states = batch['O'][:, :max_episode_len]
states_next = batch['O_NEXT'][:, :max_episode_len]
u_onehot = batch['U_ONEHOT'][:, :max_episode_len]
if self.args.cuda:
states = states.cuda(self.args.device)[:,:,0,:]
states_next = states_next.cuda(self.args.device)[:,:,0,:]
u_onehot = u_onehot.cuda(self.args.device)
hidden_evals = hidden_evals.cuda(self.args.device)
hidden_targets = hidden_targets.cuda(self.args.device)
if hat:
v = None
else:
v = self.bias_net(states, hidden_evals)
# 把q_eval、q_target、v维度变回(episode_num, max_episode_len)
v = v.view(episode_num, -1, 1).squeeze(-1)
return v
def _get_actor_inputs(self, batch, transition_idx):
# 取出所有episode上该transition_idx的经验,u_onehot要取出所有,因为要用到上一条
obs, u_onehot = batch['O'][:, transition_idx], batch['U_ONEHOT'][:]
episode_num = obs.shape[0]
inputs = []
inputs.append(obs)
# 给inputs添加上一个动作、agent编号
if self.args.last_action:
if transition_idx == 0: # 如果是第一条经验,就让前一个动作为0向量
inputs.append(torch.zeros_like(u_onehot[:, transition_idx]))
else:
inputs.append(u_onehot[:, transition_idx - 1])
if self.args.reuse_network:
# 因为当前的inputs三维的数据,每一维分别代表(episode编号,agent编号,inputs维度),直接在dim_1上添加对应的向量
# 即可,比如给agent_0后面加(1, 0, 0, 0, 0),表示5个agent中的0号。而agent_0的数据正好在第0行,那么需要加的
# agent编号恰好就是一个单位矩阵,即对角线为1,其余为0
inputs.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
# 要把inputs中的三个拼起来,并且要把episode_num个episode、self.args.n_agents个agent的数据拼成40条(40,96)的数据,
# 因为这里所有agent共享一个神经网络,每条数据中带上了自己的编号,所以还是自己的数据
inputs = torch.cat([x.reshape(episode_num * self.args.n_agents, -1) for x in inputs], dim=1)
return inputs
def _get_action_prob(self, batch, max_episode_len, epsilon):
episode_num = batch['O'].shape[0]
avail_actions = batch['AVAIL_U']
action_prob = []
for transition_idx in range(max_episode_len):
inputs = self._get_actor_inputs(batch, transition_idx) # 给obs加last_action、agent_id
if self.args.cuda:
inputs = inputs.cuda(self.args.device)
# self.eval_hidden = self.eval_hidden.cuda(self.args.device)
self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem, self.eval_h2_spike = \
self.eval_h1_mem.cuda(self.args.device), self.eval_h1_spike.cuda(
self.args.device), self.eval_h2_mem.cuda(self.args.device), self.eval_h2_spike.cuda(
self.args.device)
self.target_h1_mem, self.target_h1_spike, self.target_h2_mem, self.target_h2_spike = \
self.target_h1_mem.cuda(self.args.device), self.target_h1_spike.cuda(
self.args.device), self.target_h2_mem.cuda(self.args.device), self.target_h2_spike.cuda(
self.args.device)
# outputs, self.eval_hidden = self.eval_snn(inputs, self.eval_hidden) # inputs维度为(40,96),得到的q_eval维度为(40,n_actions)
outputs, self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem, self.eval_h2_spike = \
self.eval_snn(inputs, self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem,
self.eval_h2_spike) # inputs维度为(40,96),得到的q_eval维度为(40,n_actions)
# 把q_eval维度重新变回(8, 5,n_actions)
outputs = outputs.view(episode_num, self.n_agents, -1)
prob = torch.nn.functional.softmax(outputs, dim=-1)
action_prob.append(prob)
# 得的action_prob是一个列表,列表里装着max_episode_len个数组,数组的的维度是(episode个数, n_agents,n_actions)
# 把该列表转化成(episode个数, max_episode_len, n_agents,n_actions)的数组
action_prob = torch.stack(action_prob, dim=1).cpu()
action_num = avail_actions.sum(dim=-1, keepdim=True).float().repeat(1, 1, 1,
avail_actions.shape[-1]) # 可以选择的动作的个数
action_prob = ((1 - epsilon) * action_prob + torch.ones_like(action_prob) * epsilon / action_num)
action_prob[avail_actions == 0] = 0.0 # 不能执行的动作概率为0
# 因为上面把不能执行的动作概率置为0,所以概率和不为1了,这里要重新正则化一下。执行过程中Categorical会自己正则化。
action_prob = action_prob / action_prob.sum(dim=-1, keepdim=True)
# 因为有许多经验是填充的,它们的avail_actions都填充的是0,所以该经验上所有动作的概率都为0,在正则化的时候会得到nan。
# 因此需要再一次将该经验对应的概率置为0
action_prob[avail_actions == 0] = 0.0
if self.args.cuda:
action_prob = action_prob.cuda(self.args.device)
return action_prob
def init_hidden(self, episode_num, num_env):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
self.eval_h1_mem = self.eval_h1_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
self.target_h1_mem = self.target_h1_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
self.eval_h2_mem = self.eval_h2_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
self.target_h2_mem = self.target_h2_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
def init_hidden_learn(self, episode_num):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
self.eval_h1_mem = self.eval_h1_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
self.target_h1_mem = self.target_h1_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
self.eval_h2_mem = self.eval_h2_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
self.target_h2_mem = self.target_h2_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
def save_model(self, train_step):
num = str(train_step // self.args.save_cycle)
if not os.path.exists(self.model_dir):
os.makedirs(self.model_dir)
torch.save(self.eval_snn.state_dict(),
self.model_dir + '/' + num + '_snn_net_params_{}.pkl'.format(self.args.num_run))
def load_model(self, train_step):
num = str(train_step // self.args.save_cycle)
path = torch.load(self.model_dir + '/' + num + '_snn_net_params.pkl'.format(self.args.num_run))
self.eval_snn.load_state_dict(path)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/policy/svdn.py
================================================
import torch
import os
from network.spiking_net import Critic, VDNNet
class SVDN:
def __init__(self, args):
self.n_actions = args.n_actions
self.n_agents = args.n_agents
self.obs_shape = args.obs_shape
input_shape = self.obs_shape
# 根据参数决定RNN的输入维度
if args.last_action:
input_shape += self.n_actions
if args.reuse_network:
input_shape += self.n_agents
# 神经网络
self.eval_snn = Critic(input_shape, args)
self.target_snn = Critic(input_shape, args)
self.eval_vdn_snn = VDNNet() # 把agentsQ值加起来的网络
self.target_vdn_snn = VDNNet()
self.args = args
if self.args.cuda:
self.eval_snn.cuda(self.args.device)
self.target_snn.cuda(self.args.device)
self.eval_vdn_snn.cuda(self.args.device)
self.target_vdn_snn.cuda(self.args.device)
self.model_dir = args.model_dir + '/' + args.alg + args.exp_dir + args.save_model_dir
# 如果存在模型则加载模型
if self.args.load_model:
if os.path.exists(self.model_dir):
# path_snn = '/home/zhaozhuoya/exp2/ToM2_test/model/siql/199_snn_net_params.pkl'
map_location = self.args.device if self.args.cuda else 'cpu'
self.eval_snn.load_state_dict(torch.load(self.model_dir, map_location=map_location))
print('Successfully load the model: {}'.format(self.model_dir))
else:
print(self.model_dir)
raise Exception("No model!")
# 让target_net和eval_net的网络参数相同
self.target_snn.load_state_dict(self.eval_snn.state_dict())
self.target_vdn_snn.load_state_dict(self.eval_vdn_snn.state_dict())
self.eval_parameters = list(self.eval_snn.parameters()) + list(self.eval_vdn_snn.parameters())
if args.optimizer == "RMS":
self.optimizer = torch.optim.RMSprop(self.eval_parameters, lr=args.lr)
# 执行过程中,要为每个agent都维护一个eval_hidden
# 学习过程中,要为每个episode的每个agent都维护一个eval_hidden、target_hidden
self.eval_h1_mem, self.eval_h1_spike = None, None
self.target_h1_mem, self.target_h1_spike = None, None
self.eval_h2_mem, self.eval_h2_spike = None, None
self.target_h2_mem, self.target_h2_spike = None, None
print('Init alg SVDN')
def learn(self, batch, max_episode_len, train_step, epsilon=None): # train_step表示是第几次学习,用来控制更新target_net网络的参数
'''
在learn的时候,抽取到的数据是四维的,四个维度分别为 1——第几个episode 2——episode中第几个transition
3——第几个agent的数据 4——具体obs维度。因为在选动作时不仅需要输入当前的inputs,还要给神经网络输入hidden_state,
hidden_state和之前的经验相关,因此就不能随机抽取经验进行学习。所以这里一次抽取多个episode,然后一次给神经网络
传入每个episode的同一个位置的transition
'''
episode_num = batch['O'].shape[0]
self.init_hidden_learn(episode_num)
for key in batch.keys(): # 把batch里的数据转化成tensor
if key == 'U':
batch[key] = torch.tensor(batch[key], dtype=torch.long)
else:
batch[key] = torch.tensor(batch[key], dtype=torch.float32)
u, r, avail_u, avail_u_next, terminated = batch['U'], batch['R'].squeeze(-1), batch['AVAIL_U'], \
batch['AVAIL_U_NEXT'], batch['TERMINATE'].repeat(1, 1, self.n_agents)
mask = (1 - batch["PADDED"].float()).repeat(1, 1, self.n_agents) # 用来把那些填充的经验的TD-error置0,从而不让它们影响到学习
# 得到每个agent对应的Q值,维度为(episode个数, max_episode_len, n_agents, n_actions)
q_evals, q_targets = self.get_q_values(batch, max_episode_len)
if self.args.cuda:
u = u.cuda(self.args.device)
r = r.cuda(self.args.device)
terminated = terminated.cuda(self.args.device)
mask = mask.cuda(self.args.device)
# 取每个agent动作对应的Q值,并且把最后不需要的一维去掉,因为最后一维只有一个值了
u = u.to(torch.int64)
q_evals = torch.gather(q_evals, dim=3, index=u).squeeze(3)
# 得到target_q
q_targets[avail_u_next == 0.0] = - 9999999
q_targets = q_targets.max(dim=3)[0]
q_total_eval = self.eval_vdn_snn(q_evals)
q_total_target = self.target_vdn_snn(q_targets)
targets = r + self.args.gamma * q_total_target * (1 - terminated)
td_error = targets.detach() - q_total_eval
masked_td_error = mask * td_error # 抹掉填充的经验的td_error
# 不能直接用mean,因为还有许多经验是没用的,所以要求和再比真实的经验数,才是真正的均值
loss = (masked_td_error ** 2).sum() / mask.sum()
# print('loss is ', loss)
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.eval_parameters, self.args.grad_norm_clip)
self.optimizer.step()
if train_step > 0 and train_step % self.args.target_update_cycle == 0:
self.target_snn.load_state_dict(self.eval_snn.state_dict())
self.target_vdn_snn.load_state_dict(self.eval_vdn_snn.state_dict())
return loss
def _get_inputs(self, batch, transition_idx):
# 取出所有episode上该transition_idx的经验,u_onehot要取出所有,因为要用到上一条
obs, obs_next, u_onehot = batch['O'][:, transition_idx], \
batch['O_NEXT'][:, transition_idx], batch['U_ONEHOT'][:]
episode_num = obs.shape[0]
inputs, inputs_next = [], []
inputs.append(obs)
inputs_next.append(obs_next)
# 给obs添加上一个动作、agent编号
if self.args.last_action:
if transition_idx == 0: # 如果是第一条经验,就让前一个动作为0向量
inputs.append(torch.zeros_like(u_onehot[:, transition_idx]))
else:
inputs.append(u_onehot[:, transition_idx - 1])
inputs_next.append(u_onehot[:, transition_idx])
if self.args.reuse_network:
# 因为当前的obs三维的数据,每一维分别代表(episode编号,agent编号,obs维度),直接在dim_1上添加对应的向量
# 即可,比如给agent_0后面加(1, 0, 0, 0, 0),表示5个agent中的0号。而agent_0的数据正好在第0行,那么需要加的
# agent编号恰好就是一个单位矩阵,即对角线为1,其余为0
inputs.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
inputs_next.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
# 要把obs中的三个拼起来,并且要把episode_num个episode、self.args.n_agents个agent的数据拼成40条(40,96)的数据,
# 因为这里所有agent共享一个神经网络,每条数据中带上了自己的编号,所以还是自己的数据
inputs = torch.cat([x.reshape(episode_num * self.args.n_agents, -1) for x in inputs], dim=1)
inputs_next = torch.cat([x.reshape(episode_num * self.args.n_agents, -1) for x in inputs_next], dim=1)
return inputs, inputs_next
def get_q_values(self, batch, max_episode_len):
episode_num = batch['O'].shape[0]
q_evals, q_targets = [], []
for transition_idx in range(max_episode_len):
inputs, inputs_next = self._get_inputs(batch, transition_idx) # 给obs加last_action、agent_id
if self.args.cuda:
inputs = inputs.cuda(self.args.device)
inputs_next = inputs_next.cuda(self.args.device)
self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem, self.eval_h2_spike = \
self.eval_h1_mem.cuda(self.args.device), self.eval_h1_spike.cuda(self.args.device), self.eval_h2_mem.cuda(self.args.device), self.eval_h2_spike.cuda(self.args.device)
self.target_h1_mem, self.target_h1_spike, self.target_h2_mem, self.target_h2_spike = \
self.target_h1_mem.cuda(self.args.device), self.target_h1_spike.cuda(self.args.device), self.target_h2_mem.cuda(self.args.device), self.target_h2_spike.cuda(self.args.device)
q_eval, self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem, self.eval_h2_spike = \
self.eval_snn(inputs, self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem, self.eval_h2_spike) # inputs维度为(40,96),得到的q_eval维度为(40,n_actions)
q_target, self.target_h1_mem, self.target_h1_spike, self.target_h2_mem, self.target_h2_spike = \
self.target_snn(inputs_next, self.target_h1_mem, self.target_h1_spike, self.target_h2_mem, self.target_h2_spike)
# 把q_eval维度重新变回(8, 5,n_actions)
q_eval = q_eval.view(episode_num, self.n_agents, -1)
q_target = q_target.view(episode_num, self.n_agents, -1)
q_evals.append(q_eval)
q_targets.append(q_target)
# 得的q_eval和q_target是一个列表,列表里装着max_episode_len个数组,数组的的维度是(episode个数, n_agents,n_actions)
# 把该列表转化成(episode个数, max_episode_len, n_agents,n_actions)的数组
q_evals = torch.stack(q_evals, dim=1)
q_targets = torch.stack(q_targets, dim=1)
return q_evals, q_targets
def init_hidden(self, episode_num, num_env):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
self.eval_h1_mem = self.eval_h1_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
self.target_h1_mem = self.target_h1_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
self.eval_h2_mem = self.eval_h2_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
self.target_h2_mem = self.target_h2_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
def init_hidden_learn(self, episode_num):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
self.eval_h1_mem = self.eval_h1_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
self.target_h1_mem = self.target_h1_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
self.eval_h2_mem = self.eval_h2_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
self.target_h2_mem = self.target_h2_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
def save_model(self, train_step):
num = str(train_step // self.args.save_cycle)
if not os.path.exists(self.model_dir):
os.makedirs(self.model_dir)
torch.save(self.eval_snn.state_dict(), self.model_dir + '/' + num + '_snn_net_params_{}.pkl'.format(self.args.num_run))
def load_model(self, train_step):
num = str(train_step // self.args.save_cycle)
path = torch.load(self.model_dir + '/' + num + '_snn_net_params.pkl'.format(self.args.num_run))
self.eval_snn.load_state_dict(path)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/preprocessoing/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/preprocessoing/common.py
================================================
"""
preprocess
"""
from typing import Union
import abc
import torch as tc
import numpy as np
class Preprocessing(abc.ABC, tc.nn.Module):
def forward(
self,
curr_obs: Union[tc.LongTensor, tc.FloatTensor],
prev_action: tc.LongTensor,
prev_reward: tc.FloatTensor,
prev_done: tc.FloatTensor
) -> tc.FloatTensor:
"""
Creates an input vector for a meta-learning agent.
Args:
curr_obs: either tc.LongTensor or tc.FloatTensor of shape [B, ...].
prev_action: tc.LongTensor of shape [B, ...]
prev_reward: tc.FloatTensor of shape [B, ...]
prev_done: tc.FloatTensor of shape [B, ...]
Returns:
tc.FloatTensor of shape [B, ..., ?]
"""
pass
def one_hot_torch(ys: tc.LongTensor, depth: int, device) -> tc.FloatTensor:
"""
Applies one-hot encoding to a batch of vectors.
Args:
ys: tc.LongTensor of shape [B].
depth: int specifying the number of possible y values.
Returns:
the one-hot encodings of tensor ys.
"""
vecs_shape = list(ys.shape) + [depth]
vecs = tc.zeros(dtype=tc.float32, size=vecs_shape).to(device)
vecs.scatter_(dim=-1, index=ys.unsqueeze(-1),
src=tc.ones(dtype=tc.float32, size=vecs_shape).to(device))
return vecs.float()
def one_hot(ys: int, depth: int) -> list:
"""
Applies one-hot encoding to a batch of vectors.
Args:
ys: tc.LongTensor of shape [B].
depth: int specifying the number of possible y values.
Returns:
the one-hot encodings of tensor ys.
"""
letter = [0 for _ in range(depth)]
letter[ys-1] = 1
letter = np.array(letter)
# print(letter)
return letter
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/runner.py
================================================
import os
import matplotlib.pyplot as plt
import numpy as np
import torch.multiprocessing as mp
from common_sr.srollout import RolloutWorker
from agents.sagent import Agents
from common_sr.replay_buffer import ReplayBuffer
import time
from tqdm import tqdm
class Runner:
def __init__(self, env, args):
self.env = env
self.agents = Agents(args)
self.rolloutWorker = RolloutWorker(env, self.agents, args)
if not args.evaluate:
self.buffer = ReplayBuffer(args)
self.args = args
self.win_rates = []
self.episode_rewards = []
# 用来保存plt和pkl
self.save_path = self.args.result_dir + '/' + args.alg + args.exp_dir
if not os.path.exists(self.save_path):
os.makedirs(self.save_path)
def run(self, num):
time_steps, train_steps, evaluate_steps = 0, 0, -1
pbar = tqdm(self.args.n_steps)
if self.args.load_model == False:
while time_steps < self.args.n_steps:
# print('Run {}, time_steps {}'.format(num, time_steps))
if time_steps // self.args.evaluate_cycle > evaluate_steps:
win_rate, episode_reward = self.evaluate()
# episode_reward = [i for i in [2, 3]]
self.episode_rewards.append(episode_reward)
# self.plt(time_steps // self.args.evaluate_cycle)
# print(time_steps // self.args.evaluate_cycle)
evaluate_steps += self.args.evaluate_epoch
# 收集self.args.n_episodes个episodes
episodes = []
start = time.time()
episode_batch, _, _, steps = self.rolloutWorker.generate_episode()
end = time.time()
# print(end - start, 'sample with multiprocessing:', self.args.process)
time_steps += steps
pbar.update(steps)
self.buffer.store_episode(episode_batch)
start = time.time()
for train_step in range(self.args.train_steps):
mini_batch = self.buffer.sample(min(self.buffer.current_size, self.args.batch_size))
if self.args.alg.find('o') > -1:
self.agents.train(mini_batch, train_steps, self.args.epsilon)
else:
self.agents.train(mini_batch, train_steps)
train_steps += 1
end = time.time()
# print(end - start, 'training')
pbar.close()
win_rate, episode_reward = self.evaluate()
# print('win_rate is ', win_rate)
self.win_rates.append(win_rate)
self.episode_rewards.append(episode_reward)
if self.args.load_model == False:
self.plt(num)
def evaluate(self):
win_number = 0
episode_rewards = (0, 0) # cumulative rewards
_, episode_rewards, win_tag, _ = self.rolloutWorker.generate_episode(evaluate=True)
episode_rewards = [episode_rewards[i] / self.args.evaluate_epoch / self.args.process for i in range(len(episode_rewards))]
return win_number / self.args.evaluate_epoch, episode_rewards
def plt(self, num):
# plt.figure()
# plt.ylim([0, 105])
# plt.cla()
# plt.subplot(2, 1, 1)
# plt.plot(range(len(self.win_rates)), self.win_rates)
# plt.xlabel('step*{}'.format(self.args.evaluate_cycle))
# plt.ylabel('win_rates')
#
# plt.subplot(2, 1, 2)
# plt.plot(range(len(self.episode_rewards)), self.episode_rewards)
# plt.xlabel('step*{}'.format(self.args.evaluate_cycle))
# plt.ylabel('episode_rewards')
#
# plt.savefig(self.save_path + '/plt_{}.png'.format(num), format='png')
# np.save(self.save_path + '/win_rates_{}'.format(num), self.win_rates)
# np.save(self.save_path + '/episode_rewards_{}'.format(num), self.episode_rewards)
# plt.close()
# plt.figure()
# plt.ylim([0, 105])
# plt.cla()
# plt.plot(2, 1, 1)
# plt.plot(range(len(self.episode_rewards)), self.episode_rewards[0][0])
# plt.xlabel('step*{}'.format(self.args.evaluate_cycle))
# plt.ylabel('episode_rewards_A')
#
# plt.plot(2, 1, 2)
# plt.plot(range(len(self.episode_rewards)), self.episode_rewards[0][1])
# plt.xlabel('step*{}'.format(self.args.evaluate_cycle))
# plt.ylabel('episode_rewards_B')
# plt.savefig(self.save_path + '/plt_{}.png'.format(num), format='png')
# np.save(self.save_path + '/win_rates_{}'.format(num), self.win_rates)
np.save(self.save_path + '/episode_rewards_{}'.format(num), self.episode_rewards) #
# print(self.episode_rewards)
# plt.close()
================================================
FILE: examples/Social_Cognition/ReadMe.md
================================================
================================================
FILE: examples/Social_Cognition/SmashVat/dqn.py
================================================
import os
import time
import random
from itertools import count
from collections import namedtuple, deque
import numpy as np
import pandas as pd
import torch
import imageio
from torch import nn, optim
import torch.nn.functional as F
from torch.utils.tensorboard import SummaryWriter
from side_effect_eval import *
from qnets import *
from environment import *
Transition = namedtuple('Transition', ('state', 'action', 'reward', 'next_state', 'done'))
class ReplayBuffer:
def __init__(self, capacity):
self.capacity = capacity
self.memory = deque(maxlen=capacity)
def push(self, *args):
self.memory.append(Transition(*args))
if len(self.memory) > self.capacity:
self.memory.popleft()
def sample(self, batch_size):
batch = random.sample(self.memory, batch_size)
return batch
class AnseEmpDQN:
def __init__(self, env, net_type='SNN',
init_buffer_size=10000, replay_buffer_size=100000, batch_size=100, target_update_interval=1000,
weight_sep=20, weight_emp_impact=None):
self.env = env
input_dim = 3
output_dim = env.action_space.n
assert net_type in ['SNN', 'ANN']
self.net_type = net_type
if self.net_type == 'SNN':
self.policy_net = SNNQnet(input_dim, output_dim).cuda()
self.target_net = SNNQnet(input_dim, output_dim).cuda()
elif self.net_type == 'ANN':
self.policy_net = CNNQnet(input_dim, output_dim).cuda()
self.target_net = CNNQnet(input_dim, output_dim).cuda()
self.init_buffer_size = init_buffer_size
self.replay_buffer_size = replay_buffer_size
self.replay_buffer = ReplayBuffer(replay_buffer_size)
self.batch_size = batch_size
self.target_update_interval = target_update_interval
# empathy
self.num_others = env.num_humans
self.baseline = StepwiseInactionModel(noop_action=env.actions.noop)
self.baselines_others = [StepwiseInactionModel(noop_action=env.actions.noop)] * self.num_others
self.deviation = AttainableUtilityMeasure(uf_num=30, uf_discount=0.99)
self.weight_sep = weight_sep
self.weight_emp_impact = weight_emp_impact if weight_emp_impact is not None else weight_sep
def state2tensor(self, state):
state_arr = self.env._decode(state)
array = np.zeros([3] + list(self.env.p.map_shape))
array[0] = self.env.map # [0]为环境信息
for i, pos in enumerate(self.env.p.vat_pos):
array[0][pos] = self.env.cells.vat if state_arr[i] else self.env.cells.empty # 根据state还原各个缸的状态,因为replay_buffer中存的状态对应的map与当前的可能不一样
agent_pos = tuple(state_arr[self.env.num_vats:self.env.num_vats + 2])
array[1][agent_pos] = 1 # [1]为agent位置信息
for pos in self.env.human_pos:
array[2][tuple(pos)] = 1 # [2]为human位置信息
return torch.Tensor(array).float().cuda()
def epsilon_greedy(self, net, state, epsilon):
num_actions = self.env.action_space.n
p = np.ones(num_actions) * epsilon / num_actions
state_tensor = self.state2tensor(state).unsqueeze(0)
best_action = torch.argmax(net(state_tensor)).item()
p[best_action] += 1 - epsilon
action = np.random.choice(self.env.action_space.n, p=p)
return action
def train(self, lr=1e-3, num_episodes=10000, gamma=0.99,
epsilon_start=1, epsilon_end=0.01, decay_start=0.05, decay_end=0.95,
checkpoint_interval=1000,
checkpoint_dir='./models/',
log_dir='./log'):
policy_net_opt = optim.Adam(self.policy_net.parameters(), lr=lr)
epsilons = [epsilon_end] * num_episodes
decay_start_episode = int(num_episodes * decay_start)
decay_end_episode = int(num_episodes * decay_end)
epsilons[0:decay_start_episode] = np.full(decay_start_episode, epsilon_start)
epsilons[decay_start_episode:decay_end_episode] = np.linspace(epsilon_start, epsilon_end, decay_end_episode - decay_start_episode)
tb_logger = SummaryWriter(log_dir=log_dir)
pd_timestep_logger = pd.DataFrame(columns=['loss', 'reward', 'impact', 'aup_impact', 'empathy_impact'])
pd_episode_logger = pd.DataFrame(columns=['step', 'ep_reward', 'ep_reward_mean',
'ep_impact', 'ep_aup_impact', 'ep_empathy_impact',
'num_vat_broken', 'num_human_saved'])
def optimize_net():
transitions = self.replay_buffer.sample(self.batch_size)
batch = Transition(*zip(*transitions))
state_batch = torch.stack([self.state2tensor(state[0]) for state in batch.state]).float().cuda()
action_batch = torch.tensor(batch.action).unsqueeze(-1).cuda()
reward_batch = torch.tensor(batch.reward, dtype=torch.float).cuda()
next_state_batch = torch.stack([self.state2tensor(state[0]) for state in batch.next_state]).float().cuda()
done_batch = torch.tensor(batch.done).cuda()
best_actions = self.policy_net(next_state_batch).max(1)[1].detach()
next_state_values = self.target_net(next_state_batch).gather(1, best_actions.unsqueeze(1)).squeeze(1).detach()
expected_state_action_values = reward_batch + gamma * next_state_values * torch.logical_not(done_batch)
state_action_values = self.policy_net(state_batch).gather(1, action_batch)
loss = F.mse_loss(state_action_values, expected_state_action_values.unsqueeze(1))
policy_net_opt.zero_grad()
loss.backward()
policy_net_opt.step()
tb_logger.add_scalar('loss', loss.item(), total_step)
pd_timestep_logger.loc[total_step, 'loss'] = loss.item()
def calculate_impact(prev_states, prev_action, current_states):
if self.weight_sep==0 and self.weight_emp_impact==0:
return 0, 0, 0
prev_state_agent = prev_states[0]
current_state_agent = current_states[0]
prev_states_others = prev_states[1:]
current_states_others = current_states[1:]
baseline_state_agent = self.baseline.calculate(prev_state_agent, prev_action, current_state_agent)
self.deviation.update(prev_state_agent, prev_action, current_state_agent)
dev_self = self.deviation.calculate(current_state_agent, baseline_state_agent, lambda x: abs(np.minimum(0, x)))
weighted_dev_self = -self.weight_sep * dev_self
dev_others = []
for prev_state, current_state, baseline in zip(prev_states_others, current_states_others, self.baselines_others):
baseline_state = baseline.calculate(prev_state, prev_action, current_state)
dev_others.append(self.deviation.calculate(current_state, baseline_state, lambda x: x))
dev_others_mean = sum(dev_others) / len(dev_others) if len(dev_others) > 0 else 0
weighted_dev_others = self.weight_emp_impact * dev_others_mean
total_impact = weighted_dev_self + weighted_dev_others
return total_impact, weighted_dev_self, weighted_dev_others
# 初始化replay buffer
state = self.env.reset()
for i in range(self.init_buffer_size):
# action = self.epsilon_greedy(self.empathy_net, state[0], epsilon_start)
action = self.epsilon_greedy(self.policy_net, state[0], epsilon_start)
next_state, reward, done, info = self.env.step(action)
if self.weight_sep != 0 or self.weight_emp_impact != 0: # 如果都等于0则退化为标准DQN
impact, _, _ = calculate_impact(state, action, next_state)
reward += impact
reward /= (self.weight_sep + self.weight_emp_impact) / 2 # 正则化操作,防止reward绝对值过大使得网络发散
self.replay_buffer.push(state, action, reward, next_state, done)
if done:
state = self.env.reset()
else:
state = next_state
# 开始训练
total_step = 0
for episode in range(num_episodes):
if episode % checkpoint_interval == 0 and episode != 0:
torch.save(self.policy_net.state_dict(), checkpoint_dir + f"/checkpoint_{episode}.pth")
tb_logger.add_scalar('epsilon', epsilons[episode], episode + 1)
state = self.env.reset()
if episode % 100 == 0:
print('Episode {} of {}'.format(episode + 1, num_episodes))
episode_reward = 0
episode_impact = 0
ep_aup_impact = 0
ep_empathy_impact = 0
for step in count():
if total_step % self.target_update_interval == 0:
self.target_net.load_state_dict(self.policy_net.state_dict())
action = self.epsilon_greedy(self.policy_net, state[0], epsilons[episode])
next_state, reward, done, info = self.env.step(action)
impact, aup_impact, empathy_impact = calculate_impact(state, action, next_state)
if self.weight_sep != 0 or self.weight_emp_impact != 0: # 如果都等于0则退化为标准DQN
reward += impact
reward /= (self.weight_sep + self.weight_emp_impact) / 2
episode_reward += reward
episode_impact += impact
ep_aup_impact += aup_impact
ep_empathy_impact += empathy_impact
self.replay_buffer.push(state, action, reward, next_state, done)
optimize_net()
pd_timestep_logger.loc[total_step, 'reward'] = reward
pd_timestep_logger.loc[total_step, 'impact'] = impact
pd_timestep_logger.loc[total_step, 'aup_impact'] = aup_impact
pd_timestep_logger.loc[total_step, 'empathy_impact'] = empathy_impact
if done:
# print(f'step: {step}, reward: {episode_reward:.2f}')
tb_logger.add_scalar('step', step + 1, episode + 1)
tb_logger.add_scalar('reward', episode_reward, episode + 1)
tb_logger.add_scalar('ep-reward-mean', episode_reward / (step + 1), episode + 1)
tb_logger.add_scalar('impact', episode_impact, episode + 1)
pd_episode_logger.loc[episode, 'step'] = step + 1
pd_episode_logger.loc[episode, 'ep_reward'] = episode_reward
pd_episode_logger.loc[episode, 'ep_reward_mean'] = episode_reward / (step + 1)
pd_episode_logger.loc[episode, 'ep_impact'] = episode_impact
pd_episode_logger.loc[episode, 'ep_aup_impact'] = ep_aup_impact
pd_episode_logger.loc[episode, 'ep_empathy_impact'] = ep_empathy_impact
env_map = self.env.map
num_vat_broken = 0
num_human_saved = 0
for pos in self.env.p.vat_pos:
if env_map[pos] != self.env.cells.vat:
num_vat_broken += 1
if pos in self.env.p.human_pos:
num_human_saved += 1
pd_episode_logger.loc[episode, 'num_vat_broken'] = num_vat_broken
pd_episode_logger.loc[episode, 'num_human_saved'] = num_human_saved
break
else:
state = next_state
total_step += 1
tb_logger.close()
pd_timestep_logger.to_csv(log_dir + '/timestep_logger.csv', index=False)
pd_episode_logger.to_csv(log_dir + '/episode_logger.csv', index=False)
def save(self, path):
if not os.path.exists(path):
os.makedirs(path)
torch.save(self.policy_net.state_dict(), path + "/policy_net.pth")
def load(self, path):
self.policy_net.load_state_dict(torch.load(path + "/policy_net.pth"))
def run(self, gif_name=None):
self.policy_net.eval()
obs = self.env.reset()
images = []
for step in count():
# self.env.render()
images.append(self.env.render(mode='rgb_array'))
obs_tensor = self.state2tensor(obs[0]).unsqueeze(0)
action_p = self.policy_net(obs_tensor)
action = torch.argmax(self.policy_net(obs_tensor)).item()
print(self.env.actions(action))
next_state, reward, done, _ = self.env.step(action)
time.sleep(1)
if done:
images.append(self.env.render(mode='rgb_array'))
images.append(self.env.render(mode='rgb_array'))
break
else:
obs = next_state
if gif_name is not None:
imageio.mimsave(gif_name, images, 'GIF', duration=0.5)
def set_seed(seed=114514):
random.seed(seed) # replay buffer 中使用了random.sample
np.random.seed(seed) # e-greedy 中使用了np.random_choice
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
def main():
set_seed(1919810)
env = BasicVatGoalEnv()
env.render()
model = AnseEmpDQN(env, net_type='ANN', init_buffer_size=10000, replay_buffer_size=100000, batch_size=100, target_update_interval=1000)
model.train(lr=1e-3, num_episodes=10000, gamma=0.99,
epsilon_start=1, epsilon_end=0.01, decay_start=0.05, decay_end=0.95,
checkpoint_interval=1000,
checkpoint_dir='./models/ANN-BasicVatGoalEnv-test',
log_dir='./log/ANN-BasicVatGoalEnv-test')
model.save("./models/ANN-BasicVatGoalEnv-test")
model.load("./models/ANN-BasicVatGoalEnv-test")
model.run("ANN-BasicVatGoalEnv-test.gif")
if __name__ == '__main__':
main()
================================================
FILE: examples/Social_Cognition/SmashVat/environment.py
================================================
import copy
from enum import IntEnum
import numpy as np
import gymnasium as gym
import imageio
from window import Window
class HumanVatGoalEnv(gym.Env):
"""General HumanVatGoalEnv Class"""
class Actions(IntEnum):
noop = 0
left = 1
right = 2
up = 3
down = 4
smash = 5 # destroying all surrounding vat(s) at same time
pass
class Cells(IntEnum):
empty = 0
wall = 1
goal = 2
vat = 3
pass
class CellsRender(object):
# empty = np.full(shape=(64, 64, 4), fill_value=255)
wall = imageio.imread('./materials/wall.png')
goal = imageio.imread('./materials/goal.png')
vat = imageio.imread('./materials/vat.png')
agent = imageio.imread('./materials/agent.png')
human = imageio.imread('./materials/adult.png')
class Params(object):
"""Params for the Environment"""
def __init__(
self,
map_shape=(7, 5),
agent_pos=(1, 2),
human_pos=((2, 3),),
vat_pos=((3, 2), (2, 3),),
goal_pos=((-2, 2),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name=None,
# human_policy = "noop"
):
self.map_shape = map_shape
self.agent_pos = agent_pos
self.human_pos = human_pos
self.vat_pos = vat_pos
self.goal_pos = goal_pos
self.wall_pos = wall_pos
self.max_steps = max_steps
self.env_name = env_name
def __init__(self, env_params=Params()):
super(HumanVatGoalEnv, self).__init__()
self.p = env_params
self.actions = HumanVatGoalEnv.Actions
self.cells = HumanVatGoalEnv.Cells
self.action_space = gym.spaces.Discrete(len(self.actions))
# observation_dim: dimension of observation space
# With fixed human_pos, currently we only consider: each vat state (broken or not) + agent_pos (x, y)
# e.g. [2,2,7,5] means vat1*vat2*agent_y*agent_x
self.observation_dim = [2] * len(self.p.vat_pos) + list(self.p.map_shape)
self.observation_space = gym.spaces.Discrete(np.prod(self.observation_dim))
self.window = None
if self.p.env_name is not None:
self.descr = self.p.env_name
else:
n_human = len(self.p.human_pos)
n_vat = len(self.p.vat_pos)
n_goal = len(self.p.goal_pos)
self.descr = self.__class__.__name__.lower()
self.descr = self.descr.replace("human", "human" + str(n_human) + "-")
self.descr = self.descr.replace("vat", "vat" + str(n_vat) + "-")
self.descr = self.descr.replace("goal", "goal" + str(n_goal) + "-")
self.num_vats = len(self.p.vat_pos)
self.num_humans = len(self.p.human_pos) # for empathy qlearning
self.reset()
return
def reset(self):
# reset env state
self._gen_map()
# reset agent & human state
self.agent_pos = np.array(self.p.agent_pos)
self.human_pos = [np.array(pos) for pos in self.p.human_pos]
# reset episode statistics
self.step_count = 0
self.total_reward = 0
# self.total_hidden_reward = 0 ##TODO
# self.total_human_rewards = [0]*len(self.p.human_pos) ##TODO
# generate observation from state
obs = self._gen_obs()
return obs
def _gen_map(self):
self.map = np.full(shape=self.p.map_shape, fill_value=self.cells.empty)
# place default surrounding walls
self.map[0] = self.cells.wall
self.map[-1] = self.cells.wall
self.map[:, 0] = self.cells.wall
self.map[:, -1] = self.cells.wall
# place user-defined walls
for pos in self.p.wall_pos:
self.map[pos] = self.cells.wall
# place goals
for pos in self.p.goal_pos:
self.map[pos] = self.cells.goal
# place vats
for pos in self.p.vat_pos:
self.map[pos] = self.cells.vat
return
def _gen_obs(self):
# internal state
s_env = [(self.map[pos] == self.cells.vat) for pos in self.p.vat_pos]
s_agent = list(self.agent_pos)
s_human = [list(pos) for pos in self.human_pos]
# external observation
obs_agent = self._encode(s_env + s_agent)
obs_human = [self._encode(s_env + s_h) for s_h in s_human]
return [obs_agent, *obs_human]
def _encode(self, obs):
i = 0
for idx, dim in enumerate(self.observation_dim):
i *= dim
i += obs[idx]
assert 0 <= i <= self.observation_space.n
return i
def _decode(self, i):
out = []
for dim in reversed(self.observation_dim):
out.append(i % dim)
i = i // dim
assert i == 0
return list(reversed(out))
def render(self, mode="window", cell_size=64, style="realistic"):
if mode == "rgb_array":
return self._gen_img(cell_size, style)
elif mode == "window":
if not isinstance(self.window, Window):
self.window = Window(self.descr)
if self.window.is_open():
img = self._gen_img(cell_size, style)
self.window.show_img(img)
self.window.show(block=False)
return
def _gen_img(self, cell_size, style):
if style == "abstract":
h, w = self.map.shape
img = np.full(shape=(h * cell_size, w * cell_size, 3), fill_value=255)
def draw_cell(cell_type, cell_pos, cell_size):
if cell_type == self.cells.empty:
pass
elif cell_type == self.cells.wall:
x, y = np.array(cell_pos) * cell_size
img[x: (x + cell_size), y: (y + cell_size), :] = np.array(
[128, 128, 128]
)
elif cell_type == self.cells.goal:
x, y = np.array(cell_pos) * cell_size
img[x: (x + cell_size), y: (y + cell_size), :] = np.array([0, 255, 0])
elif cell_type == self.cells.vat:
x, y = np.array(cell_pos) * cell_size
img[x: (x + cell_size), y: (y + cell_size), :] = np.array([255, 0, 0])
else:
pass
def draw_agent(pos, cell_size):
# draw rectangle
x, y = np.array(pos) * cell_size
img[
int(x + 0.2 * cell_size): int(x + 0.8 * cell_size + 1),
int(y + 0.2 * cell_size): int(y + 0.8 * cell_size + 1),
:,
] = np.array([0, 0, 0])
# # draw cicle
# def fill_circle(img, cx, cy, r, color):
# h, w = img.shape[0:2]
# X, Y = np.ogrid[:h, :w]
# mask = (X-cx)**2+(Y-cy)**2 <= r**2
# img[mask] = color
# # return img
# x0, y0 = np.array(pos) * cell_size
# sub_img = img[int(x0):int(x0+cell_size), int(y0):int(y0+cell_size), :]
# cx, cy, r = np.array([0.5, 0.5, 0.3]) * cell_size
# color = np.array([0,0,0])
# fill_circle(sub_img, cx, cy, r, color)
pass
def draw_human(pos, cell_size):
# # draw rectangle
# x, y = np.array(pos) * cell_size
# img[int(x+0.2*cell_size):int(x+0.8*cell_size+1),
# int(y+0.2*cell_size):int(y+0.8*cell_size+1),:] = np.array([255,255,0])
# draw cicle
def fill_circle(img, cx, cy, r, color):
h, w = img.shape[0:2]
X, Y = np.ogrid[:h, :w]
mask = (X - cx) ** 2 + (Y - cy) ** 2 <= r ** 2
img[mask] = color
# return img
x0, y0 = np.array(pos) * cell_size
sub_img = img[
int(x0): int(x0 + cell_size), int(y0): int(y0 + cell_size), :
]
cx, cy, r = np.array([0.5, 0.5, 0.36]) * cell_size
color = np.array([255, 255, 0])
fill_circle(sub_img, cx, cy, r, color)
pass
def draw_gridline(cell_size):
img[::cell_size, :] = np.array([255, 255, 255])
img[-1::-cell_size, :] = np.array([255, 255, 255])
img[:, ::cell_size] = np.array([255, 255, 255])
img[:, -1::-cell_size] = np.array([255, 255, 255])
pass
for i in range(h):
for j in range(w):
draw_cell(self.map[i, j], (i, j), cell_size)
for pos in self.human_pos:
draw_human(list(pos), cell_size)
draw_agent(self.agent_pos, cell_size)
draw_gridline(cell_size)
return img.astype(np.uint8)
elif style == "realistic":
cell_size = 64 ##In realistic mode, we fix cell_size to 64 to avoid resize of image
h, w = self.map.shape
img = np.full(shape=(h * cell_size, w * cell_size, 4), fill_value=255)
def draw_cell_realistic(cell_type, cell_pos, cell_size):
if cell_type == self.cells.empty:
# img_paste(cell_pos, cell_size, HumanVatGoalEnv.CellsRender.empty)
pass
elif cell_type == self.cells.wall:
img_paste(cell_pos, cell_size, HumanVatGoalEnv.CellsRender.wall)
elif cell_type == self.cells.goal:
img_paste(cell_pos, cell_size, HumanVatGoalEnv.CellsRender.goal)
elif cell_type == self.cells.vat:
img_paste(cell_pos, cell_size, HumanVatGoalEnv.CellsRender.vat)
else:
pass
def draw_agent_realistic(pos, cell_size):
img_paste(pos, cell_size, HumanVatGoalEnv.CellsRender.agent)
pass
def draw_human_realistic(pos, cell_size):
img_paste(pos, cell_size, HumanVatGoalEnv.CellsRender.human)
pass
##paste a png(RGBA) image on to existing img depending on the alpha channel of img_in
def img_paste(pos, cell_size, img_in):
x, y = np.array(pos) * cell_size
img[x:(x + cell_size), y:(y + cell_size), 0:3][img_in[:, :, 3] > 128] = img_in[:, :, 0:3][img_in[:, :, 3] > 128]
def draw_gridline_realistic(cell_size):
img[::cell_size, :] = np.array([255, 255, 255, 0])
img[-1::-cell_size, :] = np.array([255, 255, 255, 0])
img[:, ::cell_size] = np.array([255, 255, 255, 0])
img[:, -1::-cell_size] = np.array([255, 255, 255, 0])
pass
for i in range(h):
for j in range(w):
draw_cell_realistic(self.map[i, j], (i, j), cell_size)
for pos in self.human_pos:
draw_human_realistic(list(pos), cell_size)
draw_agent_realistic(self.agent_pos, cell_size)
draw_gridline_realistic(cell_size)
return img.astype(np.uint8)
def close(self):
if isinstance(self.window, Window):
self.window.close()
self.window = None
pass
def step(self, action):
def apply_env_dynamics(cur_pos, action):
assert type(cur_pos) == np.ndarray
reward = -0.01
cur_cell = self.map[tuple(cur_pos)]
if cur_cell == self.cells.vat: # got trapped in vat
next_pos = cur_pos
# reward += -0.05 ##TODO: should we give explicit penalty here?
else:
next_pos = copy.deepcopy(cur_pos)
if action == self.actions.left:
next_pos += [0, -1]
elif action == self.actions.right:
next_pos += [0, +1]
elif action == self.actions.up:
next_pos += [-1, 0]
elif action == self.actions.down:
next_pos += [+1, 0]
elif action == self.actions.noop:
next_pos = next_pos
elif action == self.actions.smash:
next_pos = next_pos
smash_pos = next_pos + [[0, -1], [0, +1], [-1, 0], [+1, 0]]
for sp in smash_pos:
smash_cell = self.map[tuple(sp)]
if smash_cell == self.cells.vat:
# agent will smash all surrounding vat(s)
self.map[tuple(sp)] = self.cells.empty
# self.total_hidden_reward -= 0.2 ##TODO
pass
pass
pass
else:
raise
next_cell = self.map[tuple(next_pos)]
if next_cell == self.cells.empty:
next_pos = next_pos
elif next_cell == self.cells.wall:
next_pos = cur_pos
elif next_cell == self.cells.goal:
next_pos = next_pos
reward += 1.0 ##TODO: differnet rewards for reaching different goals
elif next_cell == self.cells.vat:
next_pos = next_pos
else:
raise
return next_pos, reward
self.agent_pos, reward = apply_env_dynamics(self.agent_pos, action)
##TODO: add more human dynamics here
for i, _ in enumerate(self.human_pos):
self.human_pos[i], _ = apply_env_dynamics(
self.human_pos[i], self.actions.noop
) ##TODO: add different human policy
##TODO: human reward may be different with that of agent
self.step_count += 1
done = (self.step_count >= self.p.max_steps) or (
self.map[tuple(self.agent_pos)] == self.cells.goal
)
obs = self._gen_obs()
self.total_reward += reward
info = {"total_reward": round(self.total_reward, 2)}
return obs, reward, done, info
class BasicGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(7, 5),
agent_pos=(1, 2),
human_pos=(),
vat_pos=(),
goal_pos=((-2, 2),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name="basic-1goal-env",
)
)
class BasicVatGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(7, 5),
agent_pos=(1, 2),
human_pos=(),
vat_pos=((3, 2),),
goal_pos=((-2, 2),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name="basic-1vat-1goal-env",
)
)
class BasicHumanVatGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(7, 5),
agent_pos=(1, 2),
human_pos=((3, 2),),
vat_pos=((3, 2),),
goal_pos=((-2, 2),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name="basic-1human-1vat-1goal-env",
)
)
class CShapeVatGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(7, 5),
agent_pos=(1, 3),
human_pos=(),
vat_pos=((3, 2), (3, 3)),
goal_pos=((-2, 3),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name="C-shape-2vat-1goal-env",
)
)
class CShapeHumanVatGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(7, 5),
agent_pos=(1, 3),
human_pos=((3, 2),),
vat_pos=((3, 2), (3, 3)),
goal_pos=((-2, 3),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name="C-shape-1human-2vat-1goal-env",
)
)
class SShapeVatGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(10, 7),
agent_pos=(1, 1),
human_pos=(),
vat_pos=((3, 1), (3, 2), (3, 3), (6, 3), (6, 4), (6, 5)),
goal_pos=((-2, -2),),
wall_pos=(),
max_steps=100,
env_name="S-shape-6vat-1goal-env",
)
)
class SideHumanVatGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(7, 5),
agent_pos=(1, 1),
human_pos=((3, 3),),
vat_pos=((3, 3),),
goal_pos=((5, 1),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name="side-1human-1vat-1goal-env",
)
)
class SmashAndDetourEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(7, 5),
agent_pos=(1, 1),
human_pos=((2, 3),),
vat_pos=((2, 3), (3, 2), (3, 3),),
goal_pos=((5, 3),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name="side-1human-1vat-1goal-env",
)
)
class CmpxHumanVatGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(10, 7),
agent_pos=(1, 3),
human_pos=((4, 2), (5, 5), (7, 2)),
vat_pos=((2, 3), (3, 1), (4, 1), (4, 2), (5, 5), (6, 4), (6, 5)),
goal_pos=((-2, -2),),
wall_pos=((1, 1), (8, 1), (8, 2)),
max_steps=100,
env_name="complex-3human-7vat-1goal-env",
)
)
env_list = ['BasicGoalEnv',
'BasicVatGoalEnv', 'BasicHumanVatGoalEnv', 'SideHumanVatGoalEnv',
'CShapeVatGoalEnv', 'CShapeHumanVatGoalEnv',
'SShapeVatGoalEnv', 'SmashAndDetourEnv',
'CmpxHumanVatGoalEnv']
if __name__ == "__main__":
import time
params = HumanVatGoalEnv.Params()
params.map_shape = (9, 7)
params.agent_pos = (1, 4)
params.human_pos = ((3, 2), (2, 3), (2, 1))
params.vat_pos = ((3, 2), (2, 3), (5, 2))
params.goal_pos = ((-2, 2), (6, 4))
params.wall_pos = ((5, 5), (4, 5), (4, 4))
params.max_steps = 30
params.env_name = "example-env"
# params.human_policy = "noop"
env = HumanVatGoalEnv(env_params=params)
# env = BasicVatGoalEnv()
print("observation_dim: ", env.observation_dim)
print("action_space: ", env.action_space)
print("observation_space: ", env.observation_space)
print("descr: ", env.descr)
# env.render()
# time.sleep(8.0)
# env.close()
for i_episode in range(5):
obs = env.reset()
for t in range(100):
env.render(mode="window")
time.sleep(0.1)
action = env.action_space.sample()
print(
"step=%2d\t" % (env.step_count),
env._decode(obs[0]),
"->",
env.actions(action),
end="",
)
obs, reward, done, info = env.step(action)
print("\treward=%.2f" % (reward))
if done:
env.render(mode="window")
print("done!")
print(info)
print("-" * 20)
time.sleep(0.2)
break
env.close()
================================================
FILE: examples/Social_Cognition/SmashVat/main.py
================================================
import argparse
import os
import random
import time
import numpy as np
import torch
from environment import *
from dqn import AnseEmpDQN
parser = argparse.ArgumentParser()
parser.add_argument('--cuda', type=int, default=0)
parser.add_argument('--seed', type=int, default=1919810)
parser.add_argument('--env', type=str, default='BasicHumanVatGoalEnv')
parser.add_argument('--net-type', type=str, default='ANN')
parser.add_argument('--init-buffer-size', type=int, default=10000)
parser.add_argument('--replay-buffer-size', type=int, default=100000)
parser.add_argument('--batch-size', type=int, default=100)
parser.add_argument('--target-update-interval', type=int, default=1000)
parser.add_argument('--weight-sep', type=float, default=20)
parser.add_argument('--weight-emp-impact', type=float, default=None)
parser.add_argument('--lr', type=float, default=1e-4)
parser.add_argument('--num-episodes', type=int, default=10000)
parser.add_argument('--gamma', type=float, default=0.99)
parser.add_argument('--epsilon-start', type=float, default=1.0)
parser.add_argument('--epsilon-end', type=float, default=0.01)
parser.add_argument('--decay-start', type=float, default=0.05)
parser.add_argument('--decay-end', type=float, default=0.95)
parser.add_argument('--checkpoint-interval', type=int, default=1000)
parser.add_argument('--log-dir', type=str, default=None)
parser.add_argument('--model-save-dir', type=str, default=None)
parser.add_argument('--gif-dir', type=str, default=None)
def set_seed(seed=114514):
random.seed(seed) # replay buffer 中使用了random.sample
np.random.seed(seed) # e-greedy 中使用了np.random_choice
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
def save_args(args, log_dir):
filename = os.path.join(log_dir, 'args.txt')
with open(filename, 'w') as file:
for arg in vars(args):
file.write('{}: {}\n'.format(arg, getattr(args, arg)))
def make_dirs(args, timestamp):
if args.log_dir is not None:
log_dir = args.log_dir
else:
log_dir = os.path.join('./logs', args.net_type + '-' + args.env, timestamp)
os.makedirs(log_dir, exist_ok=True)
if args.model_save_dir is not None:
model_save_dir = args.model_save_dir
else:
model_save_dir = os.path.join('./models', args.net_type + '-' + args.env, timestamp)
os.makedirs(model_save_dir, exist_ok=True)
if args.gif_dir is not None:
gif_dir = args.gif_dir
else:
gif_dir = os.path.join('./gifs', args.net_type + '-' + args.env)
os.makedirs(gif_dir, exist_ok=True)
return log_dir, model_save_dir, gif_dir
def main():
args = parser.parse_args()
set_seed(args.seed)
timestamp = time.strftime("%Y%m%d-%H%M%S")
log_dir, model_save_dir, gif_dir = make_dirs(args, timestamp)
save_args(args, log_dir)
assert args.env in env_list
env = eval(args.env)()
with torch.cuda.device(args.cuda):
model = AnseEmpDQN(env,
net_type=args.net_type,
init_buffer_size=args.init_buffer_size,
replay_buffer_size=args.replay_buffer_size,
batch_size=args.batch_size,
target_update_interval=args.target_update_interval,
weight_sep=args.weight_sep,
weight_emp_impact=args.weight_emp_impact)
model.train(lr=args.lr, num_episodes=args.num_episodes, gamma=args.gamma,
epsilon_start=args.epsilon_start, epsilon_end=args.epsilon_end,
decay_start=args.decay_start, decay_end=args.decay_end,
checkpoint_interval=args.checkpoint_interval, checkpoint_dir=model_save_dir,
log_dir=log_dir)
model.save(model_save_dir)
gif_name = os.path.join(gif_dir, '{}.gif'.format(timestamp))
model.run(gif_name=gif_name)
model.env.close()
if __name__ == '__main__':
main()
================================================
FILE: examples/Social_Cognition/SmashVat/manual_control.py
================================================
import time
from window import Window
from environment import *
class ManualControl(object):
"""ManualControl of HumanVatGoalEnv Class"""
def __init__(self, env=HumanVatGoalEnv()):
self.env = env
self.window = Window(env.descr + "[manual]")
self.window.reg_key_press_handler(self._key_handler)
def display(self):
self._reset()
# Blocking event loop
self.window.show(block=True)
return
def _redraw(self):
img = self.env.render("rgb_array", cell_size=64)
self.window.show_img(img)
return
def _reset(self):
self.env.reset()
print("-" * 20)
print(
"step=%2d " % (self.env.step_count),
"obs=",
[self.env._decode(o) for o in self.env._gen_obs()],
end=" -> ",
flush=True,
)
self._redraw()
return
def _step(self, action):
obs, reward, done, info = self.env.step(action)
print(self.env.actions(action), "\treward=%.2f" % (reward))
print(
"step=%2d " % (self.env.step_count),
"obs=",
[self.env._decode(o) for o in self.env._gen_obs()],
end=" -> ",
flush=True,
)
self._redraw()
if done:
print("done!")
print(info)
time.sleep(0.2)
self._reset()
return
def _key_handler(self, event):
# print('pressed', event.key)
if event.key == "escape" or event.key == "q":
self.window.close()
elif event.key == "backspace":
self._reset()
elif event.key == "left":
self._step(self.env.actions.left)
elif event.key == "right":
self._step(self.env.actions.right)
elif event.key == "up":
self._step(self.env.actions.up)
elif event.key == "down":
self._step(self.env.actions.down)
elif event.key == " ": # Spacebar
self._step(self.env.actions.noop)
elif event.key == "enter": # Smash
self._step(self.env.actions.smash)
return
if __name__ == "__main__":
mc = ManualControl(env=HumanVatGoalEnv())
mc.display()
================================================
FILE: examples/Social_Cognition/SmashVat/qnets.py
================================================
import torch
from torch import nn
from braincog.base.encoder import encoder
from braincog.base.node import LIFNode
class CNNQnet(nn.Module):
def __init__(self, input_dim, output_dim):
super(CNNQnet, self).__init__()
self.cnn = nn.Sequential(
nn.Conv2d(in_channels=input_dim, out_channels=16, kernel_size=3, padding=1, padding_mode='replicate'),
nn.ReLU(),
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3),
nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten()
)
self.l = nn.Sequential(
nn.Linear(in_features=64, out_features=128),
nn.ReLU(),
nn.Linear(in_features=128, out_features=output_dim)
)
def forward(self, x):
x = self.cnn(x)
x = self.l(x)
return x
class SNNQnet(nn.Module):
def __init__(self, input_dim, output_dim,
step=4, node=LIFNode, encode_type='direct'):
super(SNNQnet, self).__init__()
self.step = step
self.encoder = encoder.Encoder(step=step, encode_type=encode_type)
self.cnn = nn.Sequential(
nn.Conv2d(in_channels=input_dim, out_channels=16, kernel_size=3, padding=1, padding_mode='replicate'),
node(),
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3),
node(),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3),
node(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten()
)
self.l = nn.Sequential(
nn.Linear(in_features=64, out_features=128),
node(),
nn.Linear(in_features=128, out_features=output_dim)
)
def forward(self, input):
inputs = self.encoder(input)
outputs = []
self.reset()
for t in range(self.step):
x = inputs[t]
x = self.cnn(x)
x = self.l(x)
outputs.append(x)
return sum(outputs) / len(outputs)
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
================================================
FILE: examples/Social_Cognition/SmashVat/side_effect_eval.py
================================================
# Code Reference:
# https://github.com/deepmind/deepmind-research/blob/master/side_effects_penalties/side_effects_penalty.py
# https://github.com/alexander-turner/attainable-utility-preservation/blob/master/agents/model_free_aup.py
import numpy as np
from collections import defaultdict
class StepwiseInactionModel(object):
"""Calculate the next state after one noop action from current state"""
def __init__(self, noop_action=None):
self._noop_action = noop_action
self._baseline_state = None
self._inaction_model = defaultdict(lambda: defaultdict(lambda: 0)) # init _inaction_model[state][next_state]=0
return
def reset(self, baseline_state):
self._baseline_state = baseline_state
return
def _sample(self, state):
"""Sample next_state based on its history frequency"""
d = self._inaction_model[state]
counts = np.array(list(d.values()))
assert len(counts) > 0 and sum(counts) > 0
index = np.random.choice(a=len(counts), p=counts / sum(counts))
return list(d.keys())[index]
def calculate(self, prev_state, prev_action, current_state):
"""Update inaction transition model, and predict the noop baseline state """
# update
if prev_action == self._noop_action:
self._inaction_model[prev_state][current_state] += 1
# predict
if prev_state in self._inaction_model:
self._baseline_state = self._sample(prev_state)
else:
self._baseline_state = prev_state
return self._baseline_state
class AttainableUtilityMeasure(object):
def __init__(self, uf_num=10, uf_discount=0.99):
# initialize a group of auxiliary utility functions
self._uf_values = [defaultdict(lambda: 0.0) for _ in range(uf_num)]
# initialize random rewards for auxiliary tasks
self._uf_rewards = [defaultdict(lambda: np.random.random()) for _ in range(uf_num)]
assert 0 <= uf_discount < 1.0, "uf_discount should be between [0, 1)"
self._uf_discount = uf_discount
# initialize update counts and confidence for the value estimation of each state
self._uf_update_cnts = [defaultdict(lambda: 0) for _ in range(uf_num)]
self._confid_func = lambda x: 1.0 if x > 0 else 0.0 # confident if state value has been updated
# record predecessors of states for backward value iteration
self._predecessors = defaultdict(set)
return
def update(self, prev_state, prev_action, current_state):
"""Update estimations of Auxiliary Utility Functions with new transitions"""
del prev_action # unused in value iteration
# update transitions
self._predecessors[current_state].add(prev_state)
# iterative update values
for reward, u_value, update_cnt in zip(self._uf_rewards, self._uf_values, self._uf_update_cnts):
seen = set()
queue = [current_state]
while queue:
s_to = queue.pop(0)
seen.add(s_to)
for s_from in self._predecessors[s_to]:
v = reward[s_from] + self._uf_discount * u_value[s_to]
if u_value[s_from] < v:
u_value[s_from] = v
if s_from not in seen:
queue.append(s_from)
update_cnt[s_from] += 1 # update counts for the value estimation of each state
return
def calculate(self, current_state, baseline_state, dev_fun=lambda diff: abs(np.minimum(0, diff))):
"""Calculate the deviation between two states, with given deviation_function"""
cs_values = [u_value[current_state] for u_value in self._uf_values]
bs_values = [u_value[baseline_state] for u_value in self._uf_values]
diff_values = [(cs_value - bs_value) for cs_value, bs_value in zip(cs_values, bs_values)]
cs_confids = [self._confid_func(update_cnt[current_state]) for update_cnt in self._uf_update_cnts]
bs_confids = [self._confid_func(update_cnt[baseline_state]) for update_cnt in self._uf_update_cnts]
diff_confids = [(cs_confid * bs_confid) for cs_confid, bs_confid in zip(cs_confids, bs_confids)]
deviations = [diff_confid * dev_fun(diff_value) * (1. - self._uf_discount)
for diff_confid, diff_value in zip(diff_confids, diff_values)]
return sum(deviations) / len(deviations)
def _get_aup_value(self, state):
"""For debugging purpose,
The Attainable Utility Preservation (aup) value are based on the estimation
towards an imaginary baseline_state of u_value=0.0 and confidence=1.0"""
dev_fun = lambda diff: abs(diff)
cs_values = [u_value[state] for u_value in self._uf_values]
bs_values = [0.0] * len(self._uf_values)
diff_values = [(cs_value - bs_value) for cs_value, bs_value in zip(cs_values, bs_values)]
cs_confids = [self._confid_func(update_cnt[state]) for update_cnt in self._uf_update_cnts]
bs_confids = [1.0] * len(self._uf_update_cnts)
diff_confids = [(cs_confid * bs_confid) for cs_confid, bs_confid in zip(cs_confids, bs_confids)]
deviations = [diff_confid * dev_fun(diff_value) * (1. - self._uf_discount)
for diff_confid, diff_value in zip(diff_confids, diff_values)]
return sum(deviations) / len(deviations)
def _get_avgd_confid(self, state):
"""For debugging purpose"""
s_confids = [self._confid_func(update_cnt[state]) for update_cnt in self._uf_update_cnts]
return sum(s_confids) / len(s_confids)
def _get_u_values(self, state):
"""For debugging purpose"""
return [u_value[state] for u_value in self._uf_values]
================================================
FILE: examples/Social_Cognition/SmashVat/window.py
================================================
# Code modified from:
# https://github.com/maximecb/gym-minigrid/blob/master/gym_minigrid/window.py
import sys
import numpy as np
import matplotlib.pyplot as plt
class Window(object):
"""Interactive Window for Image Display, using matplotlib"""
def __init__(self, title):
self.fig, self.ax = plt.subplots()
self.ax.axis("off") # clear x-axis and y-axis
self.title = title
self.set_window_title(self.title)
self.key_press_handler = self._default_key_press_handler
self.reg_key_press_handler(self.key_press_handler)
self.img_shown = None
return
def set_window_title(self, title):
self.title = title
# https://stackoverflow.com/questions/5812960/change-figure-window-title-in-pylab
self.fig.canvas.manager.set_window_title(self.title)
return
def reg_key_press_handler(self, key_press_handler):
self.key_press_handler = key_press_handler
self.fig.canvas.mpl_connect("key_press_event", self.key_press_handler)
return
def _default_key_press_handler(self, event):
print("press", event.key)
sys.stdout.flush()
if event.key == "escape":
self.close()
def show(self, block=True):
if not self.is_open():
# https://stackoverflow.com/questions/31729948/matplotlib-how-to-show-a-figure-that-has-been-closed
# if window has been closed by plt.close()
# create a dummy figure and use its manager to display "fig"
dummy = plt.figure()
new_manager = dummy.canvas.manager
new_manager.canvas.figure = self.fig
self.fig.set_canvas(new_manager.canvas)
self.set_window_title(self.title)
self.reg_key_press_handler(self.key_press_handler)
if not block:
plt.ion()
else:
plt.ioff()
plt.show()
# https://stackoverflow.com/questions/28269157/plotting-in-a-non-blocking-way-with-matplotlib
# https://stackoverflow.com/questions/53758472/why-is-plt-pause-not-described-in-any-tutorials-if-it-is-so-essential-or-am-i
plt.pause(0.001)
return
def show_img(self, img):
if self.img_shown == None:
self.img_shown = self.ax.imshow(img)
else:
self.img_shown.set_data(img)
self.fig.canvas.draw()
# https://stackoverflow.com/questions/28269157/plotting-in-a-non-blocking-way-with-matplotlib
# https://stackoverflow.com/questions/53758472/why-is-plt-pause-not-described-in-any-tutorials-if-it-is-so-essential-or-am-i
plt.pause(0.001)
return
def close(self):
plt.close(self.fig)
return
def is_open(self):
# https://stackoverflow.com/questions/7557098/matplotlib-interactive-mode-determine-if-figure-window-is-still-displayed
return bool(plt.get_fignums())
if __name__ == "__main__":
window = Window("TestWindow")
def on_press(event):
print("press", event.key)
sys.stdout.flush()
if event.key == "escape":
window.close()
elif event.key == "x":
img = np.full(shape=(7 * 32, 5 * 32, 3), fill_value=55).astype(np.uint8)
window.show_img(img)
elif event.key == "c":
img = np.full(shape=(7 * 32, 5 * 32, 3), fill_value=155).astype(np.uint8)
window.show_img(img)
window.reg_key_press_handler(on_press)
print(window.is_open()) # True
window.show(block=True)
print(window.is_open()) # False
window.show(block=False)
print(window.is_open()) # True
plt.pause(2.0)
window.close()
print(window.is_open()) # False
window.show(block=True)
================================================
FILE: examples/Social_Cognition/ToCM/README.md
================================================
# ToCM
This code accompanies the paper "A Brain-inspired Theory of Collective Mind Model for Efficient Social Cooperation".
================================================
FILE: examples/Social_Cognition/ToCM/agent/controllers/ToCMController.py
================================================
from collections import defaultdict
from copy import deepcopy
import numpy as np
import torch
from torch.distributions import OneHotCategorical
from environments import Env
from agent.models.ToCMModel import ToCMModel
from networks.ToCM.action import Actor, AttentionActor
class ToCMController:
def __init__(self, config):
self.model = ToCMModel(config).to(config.DEVICE).eval()
# 17 7 256 2
# TODO TODO TODO!!!!
self.env_type = config.ENV_TYPE
self.actor = Actor(config.IN_DIM+2*(config.num_agents-1), config.ACTION_SIZE, config.ACTION_HIDDEN, config.ACTION_LAYERS).to(config.DEVICE) # TODO FEAT
self.expl_decay = config.EXPL_DECAY
self.expl_noise = config.EXPL_NOISE
self.expl_min = config.EXPL_MIN
self.init_rnns()
self.init_buffer()
self.device = config.DEVICE
self.config = config
def receive_params(self, params):
self.model.load_state_dict(params['model'])
self.actor.load_state_dict(params['actor'])
def init_buffer(self):
self.buffer = defaultdict(list)
def init_rnns(self):
self.prev_rnn_state = None
self.prev_actions = None
def dispatch_buffer(self):
total_buffer = {k: np.asarray(v, dtype=np.float32) for k, v in self.buffer.items()}
last = np.zeros_like(total_buffer['done'])
last[-1] = 1.0
total_buffer['last'] = last
self.init_rnns()
self.init_buffer()
return total_buffer
def update_buffer(self, items):
for k, v in items.items(): # TODO TODO TODO
if v is not None:
self.buffer[k].append(v.squeeze(0).cpu().detach().clone().numpy())
@torch.no_grad()
def step(self, observations, avail_actions, nn_mask):
""""
Compute policy's action distribution from inputs, and sample an
action. Calls the model to produce mean, log_std, value estimate, and
next recurrent state. Moves inputs to device and returns outputs back
to CPU, for the sampler. Advances the recurrent state of the agent.
(no grad)
"""
state = self.model(observations, self.prev_actions, self.prev_rnn_state, nn_mask)
if self.prev_actions == None:
# self.prev_actions = torch.zeros((1, 2, 7)).to(self.config.DEVICE)
self.prev_actions = torch.zeros((observations.shape[0], observations.shape[1], 5)).to(self.config.DEVICE)
next_state = self.model.transition(self.prev_actions, state) # TODO
next_feat = next_state.get_features().detach() # TODO
observations_next_other, _ = self.model.observation_decoder(next_feat) # TODO
if nn_mask is not None:
nn_mask = nn_mask.to(self.device)
action, pi = self.actor(torch.cat((observations, observations_next_other[:, :, -(self.config.num_agents-1)*4:-(self.config.num_agents-1)*2]),
-1))
# print(action, pi)
# print("aviail_action:", avail_actions)
if avail_actions is not None:
pi[avail_actions == 0] = -1e10
action_dist = OneHotCategorical(logits=pi)
action = action_dist.sample()
self.advance_rnns(state)
self.prev_actions = action.clone() # no use
return action.squeeze(0).clone().to(self.device)
def advance_rnns(self, state):
self.prev_rnn_state = deepcopy(state)
def exploration(self, action):
"""
:param action: action to take, shape (1,)
:return: action of the same shape passed in, augmented with some noise
"""
for i in range(action.shape[0]):
if np.random.uniform(0, 1) < self.expl_noise:
index = torch.randint(0, action.shape[-1], (1, ), device=action.device)
transformed = torch.zeros(action.shape[-1])
transformed[index] = 1.
action[i] = transformed
self.expl_noise *= self.expl_decay
self.expl_noise = max(self.expl_noise, self.expl_min)
return action.to(self.device)
================================================
FILE: examples/Social_Cognition/ToCM/agent/learners/ToCMLearner.py
================================================
import sys
from copy import deepcopy
from pathlib import Path
import numpy as np
import torch
from agent.memory.ToCMMemory import ToCMMemory
from agent.models.ToCMModel import ToCMModel
from agent.optim.loss import model_loss, actor_loss, value_loss, actor_rollout
from agent.optim.utils import advantage
from environments import Env
from networks.ToCM.action import Actor, AttentionActor
from networks.ToCM.critic import MADDPGCritic
torch.autograd.set_detect_anomaly = True
def orthogonal_init(tensor, gain=1):
if tensor.ndimension() < 2:
raise ValueError("Only tensors with 2 or more dimensions are supported")
rows = tensor.size(0)
cols = tensor[0].numel()
flattened = tensor.new(rows, cols).normal_(0, 1)
if rows < cols:
flattened.t_()
# Compute the qr factorization
u, s, v = torch.svd(flattened, some=True)
if rows < cols:
u.t_()
q = u if tuple(u.shape) == (rows, cols) else v
with torch.no_grad():
tensor.view_as(q).copy_(q)
tensor.mul_(gain)
return tensor
def initialize_weights(mod, scale=1.0, mode='ortho'):
for p in mod.parameters():
if mode == 'ortho':
if len(p.data.shape) >= 2:
orthogonal_init(p.data, gain=scale)
elif mode == 'xavier':
if len(p.data.shape) >= 2:
torch.nn.init.xavier_uniform_(p.data)
class ToCMLearner: # 通过ToCMLearnerConfig来构建
def __init__(self, config):
self.config = config
self.pretrain_model = False
self.shared_model = False # shared pretrain_model
self.pretrain_actor = False
self.pretrain_critic = False
# 根据ToCMLearnerConfig的参数包括:DEVICE, CAPACITY, SEQ_LENGTH, ACTION_SIZE, IN_DIM, FEAT, HIDDEN......
self.model = ToCMModel(config).to(config.DEVICE).eval() # wsw TODO 这里已经有了device,为什么挂钩子
# ToCM Model
self.actor = Actor(config.IN_DIM+2*(config.num_agents-1), config.ACTION_SIZE, config.ACTION_HIDDEN, config.ACTION_LAYERS).to(
config.DEVICE) # IN_DIM / FEAT # TODO
self.critic = MADDPGCritic(config.FEAT, config.HIDDEN).to(config.DEVICE)
# 关键点是把model actor critic都放到了device上
if self.pretrain_model:
if not self.shared_model:
self.model.load_state_dict(torch.load(self.load_dir + '28_model.pth'))
else:
initialize_weights(self.model, mode='xavier') # 先全部初始化
# 加载部分预训练权重
shared_state_dict = torch.load(self.load_dir + '28_model.pth')
ignored_layer_keys = ['observation_encoder.fc1.weight', 'observation_decoder.fc2.weight',
'observation_decoder.fc2.bias', 'transition._rnn_input_model.0.weight',
'representation._transition_model._rnn_input_model.0.weight',
'av_action.model.4.weight', 'av_action.model.4.bias', 'q_action.weight',
'q_action.bias']
for k in ignored_layer_keys:
del shared_state_dict[k]
self.model.load_state_dict(shared_state_dict, strict=False)
print("Load ToCM Model.")
else:
initialize_weights(self.model, mode='xavier')
if self.pretrain_actor:
self.actor.load_state_dict(torch.load(self.load_dir + '10_actor.pth'), strict=False)
else:
initialize_weights(self.actor, mode='xavier')
if self.pretrain_critic:
self.critic.load_state_dict(torch.load(self.load_dir + '10_critic.pth'), strict=False)
else:
initialize_weights(self.critic, mode='xavier')
self.old_critic = deepcopy(self.critic)
self.replay_buffer = ToCMMemory(config.CAPACITY, config.SEQ_LENGTH, config.ACTION_SIZE, config.IN_DIM, 2,
config.DEVICE, config.ENV_TYPE)
self.entropy = config.ENTROPY
self.step_count = -1
self.cur_update = 1
self.accum_samples = 0
self.total_samples = 0
self.init_optimizers()
self.n_agents = 2
Path(config.LOG_FOLDER).mkdir(parents=True, exist_ok=True)
global wandb
import wandb
wandb.init(dir=config.LOG_FOLDER,
name=str(config.env_name) + '_' + str(2) +
"_seed" + str(config.random_seed) + '131',
project=str('mpesnn').upper(),
group=str(config.env_name) ) # TODO
def init_optimizers(self):
self.model_optimizer = torch.optim.Adam(self.model.parameters(), lr=self.config.MODEL_LR)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=self.config.ACTOR_LR, weight_decay=0.00001)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=self.config.VALUE_LR) # TODO
self.critic_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(self.critic_optimizer, mode='min', verbose=True)
def params(self):
return {'model': {k: v.cpu() for k, v in self.model.state_dict().items()},
'actor': {k: v.cpu() for k, v in self.actor.state_dict().items()},
'critic': {k: v.cpu() for k, v in self.critic.state_dict().items()}}
def step(self, rollout):
if self.n_agents != rollout['action'].shape[-2]:
self.n_agents = rollout['action'].shape[-2]
self.accum_samples += len(rollout['action']) # 5
self.total_samples += len(rollout['action']) # 5
self.replay_buffer.append(rollout['observation'], rollout['action'], rollout['reward'], rollout['done'],
rollout['fake'], rollout['last'], rollout.get('avail_action'))
self.step_count += 1
if self.accum_samples < self.config.N_SAMPLES:
return
if len(self.replay_buffer) < self.config.MIN_BUFFER_SIZE:
return
self.accum_samples = 0
sys.stdout.flush()
if 20000 > self.step_count >= 10000:
self.config.MODEL_EPOCHS = 10
if self.step_count >= 20000:
self.config.MODEL_EPOCHS = 5
for i in range(self.config.MODEL_EPOCHS):
samples = self.replay_buffer.sample(self.config.MODEL_BATCH_SIZE)
self.train_model(samples)
for i in range(self.config.EPOCHS):
samples = self.replay_buffer.sample(self.config.BATCH_SIZE)
# for key, sample in samples.items():
# print("key: ", key)
# print("sample.shape: ", sample.shape)
# print("samples.shape: ", samples.shape)
self.train_agent(samples)
def train_model(self, samples): # world model
# print("Start train")
self.model.train()
loss = model_loss(self.config, self.model, samples['observation'], samples['action'], samples['av_action'],
samples['reward'], samples['done'], samples['fake'], samples['last'])
# print("loss: ", loss)
self.apply_optimizer(self.model_optimizer, self.model, loss, self.config.GRAD_CLIP, name='model')
# print("backward by model")
self.model.eval()
def train_agent(self, samples):
actions, av_actions, old_policy, imag_feat, imag_state, obs_pred, returns = actor_rollout(samples['observation'],
samples['action'],
samples['last'], self.model,
self.actor,
self.critic if self.config.ENV_TYPE == Env.STARCRAFT # TODO
else self.old_critic,
self.config)
adv = returns.detach() - self.critic(imag_feat, actions).detach()
if self.config.ENV_TYPE == Env.STARCRAFT or self.config.ENV_TYPE == Env.MPE:
adv = advantage(adv) # TODO what adv
# wandb.log({'Agent/adv': adv.mean()})
wandb.log({'Agent/Returns': returns.mean()}) # discount algorithm
# wandb.log({'Agent/Returns max': returns.max()})
# wandb.log({'Agent/Returns min': returns.min()})
# wandb.log({'Agent/Returns std': returns.std()})
for epoch in range(self.config.PPO_EPOCHS):
inds = np.random.permutation(actions.shape[0])
step = 2000
for i in range(0, len(inds), step): # 15
self.cur_update += 1
idx = inds[i:i + step]
loss = actor_loss(self.model, imag_state.map(lambda x: x[idx]) ,
obs_pred[idx], actions[idx], av_actions[idx] if av_actions is not None else None,
old_policy[idx], adv[idx], self.actor, self.entropy, self.config) # TODO
self.apply_optimizer(self.actor_optimizer, self.actor, loss, self.config.GRAD_CLIP_POLICY, name='actor')
self.entropy *= self.config.ENTROPY_ANNEALING # 0.001 0.998
val_loss = value_loss(self.critic, actions[idx], imag_feat[idx], returns[idx])
# print("val_loss: ", val_loss)
if np.random.randint(20) == 9:
wandb.log({'Agent/val_loss': val_loss, 'Agent/actor_loss': loss})
self.apply_optimizer(self.critic_optimizer, self.critic, val_loss, self.config.GRAD_CLIP_POLICY, name='critic')
# print("backward by agent")
if self.config.ENV_TYPE == Env.MPE and self.cur_update % self.config.TARGET_UPDATE == 0:
self.old_critic = deepcopy(self.critic)
def apply_optimizer(self, opt, model, loss, grad_clip, name=None): # type of model
opt.zero_grad()
loss.backward() # only here
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clip) # 100
if name is not None and np.random.randint(20) == 9:
wandb.log({'Grad of '+name: grad_norm})
opt.step()
def apply_optimizer_scheduler(self, opt, sch, model, loss, grad_clip, name=None):
opt.zero_grad()
loss.backward()
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clip) # 100
# if name is not None:
# wandb.log({'Grad of ' + name: grad_norm})
opt.step()
sch.step(loss)
================================================
FILE: examples/Social_Cognition/ToCM/agent/memory/ToCMMemory.py
================================================
import numpy as np
import torch
from environments import Env
# 由ToCMLearner的函数创建
class ToCMMemory:
def __init__(self, capacity, sequence_length, action_size, obs_size, n_agents, device, env_type):
self.capacity = capacity
self.sequence_length = sequence_length
self.action_size = action_size
self.obs_size = obs_size
self.device = device # 加入了device
self.env_type = env_type
self.init_buffer(n_agents, env_type) # TODO
def init_buffer(self, n_agents, env_type): # 初始对环境进行采样,观察和动作都是np.array # TODO init_buffer specially?
self.observations = np.empty((self.capacity, n_agents, self.obs_size), dtype=np.float32)
self.actions = np.empty((self.capacity, n_agents, self.action_size), dtype=np.float32)
self.av_actions = np.empty((self.capacity, n_agents, self.action_size), # 3, 5
dtype=np.float32) if env_type == Env.STARCRAFT or env_type == Env.MPE else None # TODO need mask?
self.rewards = np.empty((self.capacity, n_agents, 1), dtype=np.float32)
self.dones = np.empty((self.capacity, n_agents, 1), dtype=np.float32)
self.fake = np.empty((self.capacity, n_agents, 1), dtype=np.float32)
self.last = np.empty((self.capacity, n_agents, 1), dtype=np.float32)
self.next_idx = 0
self.n_agents = n_agents
self.full = False
def append(self, obs, action, reward, done, fake, last, av_action):
if self.actions.shape[-2] != action.shape[-2]:
self.init_buffer(action.shape[-2], self.env_type)
for i in range(len(obs)):
self.observations[self.next_idx] = obs[i]
self.actions[self.next_idx] = action[i]
if av_action is not None:
self.av_actions[self.next_idx] = av_action[i]
self.rewards[self.next_idx] = reward[i]
self.dones[self.next_idx] = done[i]
self.fake[self.next_idx] = fake[i]
self.last[self.next_idx] = last[i]
self.next_idx = (self.next_idx + 1) % self.capacity
self.full = self.full or self.next_idx == 0
def tenzorify(self, nparray):
return torch.from_numpy(nparray).float()
def sample(self, batch_size):
return self.get_transitions(self.sample_positions(batch_size))
def process_batch(self, val, idxs, batch_size): # 这里全部传到了cuda上
return torch.as_tensor(val[idxs].reshape(self.sequence_length, batch_size, self.n_agents, -1)).to(self.device)
def get_transitions(self, idxs):
batch_size = len(idxs)
vec_idxs = idxs.transpose().reshape(-1)
observation = self.process_batch(self.observations, vec_idxs, batch_size)[1:]
reward = self.process_batch(self.rewards, vec_idxs, batch_size)[:-1]
action = self.process_batch(self.actions, vec_idxs, batch_size)[:-1]
av_action = self.process_batch(self.av_actions, vec_idxs, batch_size)[1:] if self.env_type == Env.STARCRAFT else None
done = self.process_batch(self.dones, vec_idxs, batch_size)[:-1]
fake = self.process_batch(self.fake, vec_idxs, batch_size)[1:]
last = self.process_batch(self.last, vec_idxs, batch_size)[1:]
return {'observation': observation, 'reward': reward, 'action': action, 'done': done,
'fake': fake, 'last': last, 'av_action': av_action}
def sample_position(self):
valid_idx = False
while not valid_idx:
idx = np.random.randint(0, self.capacity if self.full else self.next_idx - self.sequence_length)
idxs = np.arange(idx, idx + self.sequence_length) % self.capacity
valid_idx = self.next_idx not in idxs[1:] # Make sure data does not cross the memory index
return idxs
def sample_positions(self, batch_size):
return np.asarray([self.sample_position() for _ in range(batch_size)])
def __len__(self):
return self.capacity if self.full else self.next_idx
def clean(self):
self.memory = list()
self.position = 0
================================================
FILE: examples/Social_Cognition/ToCM/agent/models/ToCMModel.py
================================================
import torch
import torch.nn as nn
from environments import Env
from networks.ToCM.dense import DenseBinaryModel, DenseModel
from networks.ToCM.vae import Encoder, Decoder
from networks.ToCM.rnns import RSSMRepresentation, RSSMTransition
from thop import profile
from thop import clever_format
class ToCMModel(nn.Module):
def __init__(self, config):
super().__init__()
self.action_size = config.ACTION_SIZE
self.observation_encoder = Encoder(in_dim=config.IN_DIM, hidden=config.HIDDEN, embed=config.EMBED) # in_dim:
self.observation_decoder = Decoder(embed=config.FEAT, hidden=config.HIDDEN, out_dim=config.IN_DIM)
self.transition = RSSMTransition(config, config.MODEL_HIDDEN)
self.representation = RSSMRepresentation(config, self.transition) # ann
self.reward_model = DenseModel(config.FEAT, 1, config.REWARD_LAYERS, config.REWARD_HIDDEN) # ann
self.pcont = DenseBinaryModel(config.FEAT, 1, config.PCONT_LAYERS, config.PCONT_HIDDEN)
if config.ENV_TYPE == Env.STARCRAFT:
# print("config.FEAT, config.ACTION_SIZE, config.PCONT_LAYERS, config.PCONT_HIDDEN:", config.FEAT,
# config.ACTION_SIZE, config.PCONT_LAYERS, config.PCONT_HIDDEN) # 1280 7 2 256
self.av_action = DenseBinaryModel(config.FEAT, config.ACTION_SIZE, config.PCONT_LAYERS, config.PCONT_HIDDEN)
else:
self.av_action = None
self.q_features = DenseModel(config.HIDDEN, config.PCONT_HIDDEN, 1, config.PCONT_HIDDEN)
self.q_action = nn.Linear(config.PCONT_HIDDEN, config.ACTION_SIZE)
# input_encoder = torch.randn(1, 10, config.IN_DIM)
# macs, params = profile(self.observation_encoder, inputs=(input,))
def forward(self, observations, prev_actions=None, prev_states=None, mask=None):
if prev_actions is None:
prev_actions = torch.zeros(observations.size(0), observations.size(1), self.action_size,
device=observations.device)
if prev_states is None:
prev_states = self.representation.initial_state(prev_actions.size(0), observations.size(1),
device=observations.device)
return self.get_state_representation(observations, prev_actions, prev_states, mask)
def get_state_representation(self, observations, prev_actions, prev_states, mask):
"""
:param observations: size(batch, n_agents, in_dim)
:param prev_actions: size(batch, n_agents, action_size)
:param prev_states: size(batch, n_agents, state_size)
:return: RSSMState
"""
# print("mask = ", mask)
obs_embeds = self.observation_encoder(observations)
# print("obs_embeds=", obs_embeds)
_, states = self.representation(obs_embeds, prev_actions, prev_states, mask)
# print("state = ", states)
return states
================================================
FILE: examples/Social_Cognition/ToCM/agent/optim/loss.py
================================================
import numpy as np
import torch
import wandb
import torch.nn.functional as F
from agent.optim.utils import rec_loss, compute_return, state_divergence_loss, calculate_ppo_loss, \
batch_multi_agent, log_prob_loss, info_loss
from agent.utils.params import FreezeParameters
from networks.ToCM.rnns import rollout_representation, rollout_policy
def model_loss(config, model, obs, action, av_action, reward, done, fake, last):
time_steps = obs.shape[0]
batch_size = obs.shape[1]
n_agents = obs.shape[2]
embed = model.observation_encoder(obs.reshape(-1, n_agents, obs.shape[-1]))
embed = embed.reshape(time_steps, batch_size, n_agents, -1)
prev_state = model.representation.initial_state(batch_size, n_agents, device=obs.device)
prior, post, deters = rollout_representation(model.representation, time_steps, embed, action, prev_state, last)
feat = torch.cat([post.stoch, deters], -1)
feat_dec = post.get_features()
# decoder inputs:reshape obs[:-1] to self.SEQ_LENGTH * self.MODEL_BATCH_SIZE, n_agents, dim
reconstruction_loss, i_feat = rec_loss(model.observation_decoder, # decoder
feat_dec.reshape(-1, n_agents, feat_dec.shape[-1]), # input of decoder
obs[:-1].reshape(-1, n_agents, obs.shape[-1]), # label real obs
1. - fake[:-1].reshape(-1, n_agents, 1)) # fake
reward_loss = F.smooth_l1_loss(model.reward_model(feat), reward[1:]) # reward
# print("pcont_loss")
pcont_loss = log_prob_loss(model.pcont, feat, (1. - done[1:]))
av_action_loss = log_prob_loss(model.av_action, feat_dec, av_action[:-1]) if av_action is not None else 0.
i_feat = i_feat.reshape(time_steps - 1, batch_size, n_agents, -1)
dis_loss = info_loss(i_feat[1:], model, action[1:-1], 1. - fake[1:-1].reshape(-1))
div = state_divergence_loss(prior, post, config) #kl
model_loss = div + reward_loss + dis_loss + reconstruction_loss + pcont_loss + av_action_loss
if np.random.randint(20) == 4:
wandb.log({'Model/reward_loss': reward_loss, 'Model/div': div, 'Model/av_action_loss': av_action_loss,
'Model/reconstruction_loss': reconstruction_loss, 'Model/info_loss': dis_loss,
'Model/pcont_loss': pcont_loss})
return model_loss
def actor_rollout(obs, action, last, model, actor, critic, config): # model=ToCMLearnerModel
n_agents = obs.shape[2] # 2
with FreezeParameters([model]):
embed = model.observation_encoder(obs.reshape(-1, n_agents, obs.shape[-1]))
embed = embed.reshape(obs.shape[0], obs.shape[1], n_agents, -1)
prev_state = model.representation.initial_state(obs.shape[1], obs.shape[2], device=obs.device)
prior, post, _ = rollout_representation(model.representation, obs.shape[0], embed, action,
prev_state, last)
post = post.map(lambda x: x.reshape((obs.shape[0] - 1) * obs.shape[1], n_agents, -1))
items = rollout_policy(model, model.av_action, config.HORIZON, actor, post, action, config) # horizon is 15 TODO av_action: 49 40 2 7
#
imag_feat = items["imag_states"].get_features()
obs_pred = items["obs_preds"] # TODO
# old_policy = items['old_policy']
imag_rew_feat = torch.cat([items["imag_states"].stoch[:-1], items["imag_states"].deter[1:]], -1)
# obs_pred_rew = items["obs_preds"][:-1] # TODO
returns = critic_rollout(model, critic, imag_feat, imag_rew_feat, items["actions"],
items["imag_states"].map(lambda x: x.reshape(-1, n_agents, x.shape[-1])), config)
output = [items["actions"][:-1].detach(),
items["av_actions"][:-1].detach() if items["av_actions"] is not None else None,
items["old_policy"][:-1].detach(), # TODO pi
imag_feat[:-1].detach(),
items["imag_states"].map(lambda x: x[:-1]),
obs_pred[:-1].detach(),
returns.detach()]
return [batch_multi_agent(v, n_agents) for v in output]
def critic_rollout(model, critic, states, rew_states, actions, raw_states, config):
with FreezeParameters([model, critic]):
imag_reward = calculate_next_reward(model, actions, raw_states)
imag_reward = imag_reward.reshape(actions.shape[:-1]).unsqueeze(-1).mean(-2, keepdim=True)[:-1]
# print("states:", states.shape)
# print("actions: ", actions.shape)
value = critic(states, actions)
# print("discount_arr")
discount_arr = model.pcont(rew_states).mean
wandb.log({'Value/Max reward': imag_reward.max(), 'Value/Min reward': imag_reward.min(),
'Value/Reward': imag_reward.mean(), 'Value/Discount': discount_arr.mean(),
'Value/Value': value.mean()})
returns = compute_return(imag_reward, value[:-1], discount_arr, bootstrap=value[-1], lmbda=config.DISCOUNT_LAMBDA,
gamma=config.GAMMA)
return returns
def calculate_reward(model, states, mask=None):
imag_reward = model.reward_model(states)
if mask is not None:
imag_reward *= mask
return imag_reward
def calculate_next_reward(model, actions, states):
actions = actions.reshape(-1, actions.shape[-2], actions.shape[-1])
next_state = model.transition(actions, states)
imag_rew_feat = torch.cat([states.stoch, next_state.deter], -1)
return calculate_reward(model, imag_rew_feat)
def actor_loss(model, imag_state, obs_pred, actions, av_actions, old_policy, advantage, actor, ent_weight, config):
next_state = model.transition(actions, imag_state) # TODO
next_feat = next_state.get_features().detach() # TODO
observations_next_other, _ = model.observation_decoder(next_feat) # TODO
_, new_policy = actor(torch.cat((obs_pred, observations_next_other[:, :, -(config.num_agents-1)*4:-(config.num_agents-1)*2]), -1)) # TODO
if av_actions is not None:
new_policy[av_actions == 0] = -1e10
actions = actions.argmax(-1, keepdim=True)
rho = (F.log_softmax(new_policy, dim=-1).gather(2, actions) - # new policy is PPO pi
F.log_softmax(old_policy, dim=-1).gather(2, actions)).exp() # old policy is actor_rollout pi
ppo_loss, ent_loss = calculate_ppo_loss(new_policy, rho, advantage) # normalized
if np.random.randint(10) == 9:
wandb.log({'Policy/Entropy': ent_loss.mean(), 'Policy/Mean action': actions.float().mean()})
return (ppo_loss + ent_loss.unsqueeze(-1) * ent_weight).mean()
def value_loss(critic, actions, imag_feat, targets):
value_pred = critic(imag_feat, actions)
mse_loss = (targets - value_pred) ** 2 / 2.0
return torch.mean(mse_loss)
================================================
FILE: examples/Social_Cognition/ToCM/agent/optim/utils.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
def rec_loss(decoder, z, x, fake):
x_pred, feat = decoder(z)
batch_size = np.prod(list(x.shape[:-1]))
gen_loss1 = (F.smooth_l1_loss(x_pred, x, reduction='none') * fake).sum() / batch_size
return gen_loss1, feat
def ppo_loss(A, rho, eps=0.2):
return -torch.min(rho * A, rho.clamp(1 - eps, 1 + eps) * A)
def mse(model, x, target):
pred = model(x)
return ((pred - target) ** 2 / 2).mean()
def entropy_loss(prob, logProb):
return (prob * logProb).sum(-1)
def advantage(A):
std = 1e-4 + A.std() if len(A) > 0 else 1
adv = (A - A.mean()) / std
adv = adv.detach()
adv[adv != adv] = 0 # TODO what?
return adv
def calculate_ppo_loss(logits, rho, A): # pi rho adv
prob = F.softmax(logits, dim=-1)
logProb = F.log_softmax(logits, dim=-1)
polLoss = ppo_loss(A, rho)
entLoss = entropy_loss(prob, logProb)
return polLoss, entLoss
def batch_multi_agent(tensor, n_agents):
if tensor is not None:
return tensor.map(lambda x: x.view(-1, n_agents, x.shape[-1])) if tensor.type() == None \
else tensor.view(-1, n_agents, tensor.shape[-1])
else :
return None
def compute_return(reward, value, discount, bootstrap, lmbda, gamma):
next_values = torch.cat([value[1:], bootstrap[None]], 0)
target = reward + gamma * discount * next_values * (1 - lmbda)
outputs = []
accumulated_reward = bootstrap
for t in reversed(range(reward.shape[0])):
discount_factor = discount[t]
accumulated_reward = target[t] + gamma * discount_factor * accumulated_reward * lmbda
outputs.append(accumulated_reward)
returns = torch.flip(torch.stack(outputs), [0])
return returns
def info_loss(feat, model, actions, fake):
q_feat = F.relu(model.q_features(feat))
action_logits = model.q_action(q_feat)
return (fake * action_information_loss(action_logits, actions)).mean()
def action_information_loss(logits, target):
criterion = nn.CrossEntropyLoss(reduction='none')
return criterion(logits.view(-1, logits.shape[-1]), target.argmax(-1).view(-1))
def log_prob_loss(model, x, target):
pred = model(x)
return -torch.mean(pred.log_prob(target))
def kl_div_categorical(p, q):
eps = 1e-7
return (p * (torch.log(p + eps) - torch.log(q + eps))).sum(-1)
def reshape_dist(dist, config):
return dist.get_dist(dist.deter.shape[:-1], config.N_CATEGORICALS, config.N_CLASSES)
def state_divergence_loss(prior, posterior, config, reduce=True, balance=0.2):
prior_dist = reshape_dist(prior, config)
post_dist = reshape_dist(posterior, config)
post = kl_div_categorical(post_dist, prior_dist.detach())
pri = kl_div_categorical(post_dist.detach(), prior_dist)
kl_div = balance * post.mean(-1) + (1 - balance) * pri.mean(-1)
if reduce:
return torch.mean(kl_div)
else:
return kl_div
================================================
FILE: examples/Social_Cognition/ToCM/agent/runners/ToCMRunner.py
================================================
import ray
import wandb
import os
import torch
import numpy as np
from agent.workers.ToCMWorker import ToCMWorker
from environments import Env
class ToCMServer:
def __init__(self, n_workers, env_config, controller_config, model):
# ray.init(local_mode=True) #ray.init()
ray.init(dashboard_port=8625, object_store_memory=8*1024*1024*1024, _memory=8*1024*1024*1024, _temp_dir='~/temp/')
# ray.init()
self.workers = [ToCMWorker.remote(i, env_config, controller_config) for i in range(n_workers)]
self.tasks = [worker.run.remote(model) for worker in self.workers]
def append(self, idx, update):
self.tasks.append(self.workers[idx].run.remote(update))
def run(self):
done_id, tasks = ray.wait(self.tasks)
self.tasks[:] = tasks
del tasks
recvs = ray.get(done_id)[0]
return recvs
class ToCMRunner:
def __init__(self, env_config, learner_config, controller_config, n_workers):
self.env_config = env_config
self.env_type = env_config.ENV_TYPE
self.n_workers = n_workers
self.learner = learner_config.create_learner()
self.server = ToCMServer(n_workers, env_config, controller_config, self.learner.params()) # share weight
self.save_dir = '~/ToCM/weights/seed'\
+ str(controller_config.random_seed) + 'num_agent_2' + '/'+ learner_config.env_name + '/'
if not os.path.exists(self.save_dir):
os.makedirs(self.save_dir)
self.pretrain = True
def run(self, max_steps=10 ** 10, max_episodes=10 ** 10): # 10**10 50000
print("Start ToCM Runner!")
cur_steps, cur_episode = 0, 0
wandb.define_metric("steps")
wandb.define_metric("reward", step_metric="steps")
episode_rewards = []
while True:
rollout, info = self.server.run() # control_config -> worker
episode_rewards.append(info["reward"])
self.learner.step(rollout)
cur_steps += info["steps_done"]
cur_episode += 1
if self.env_type == Env.MPE:
if cur_steps % 1000 == 0:
episode_average_rewards = np.mean(episode_rewards)
episode_rewards = []
wandb.log({'reward': episode_average_rewards, 'steps': cur_steps})
print('cur_steps:', cur_steps, 'total_samples:',
self.learner.total_samples, 'reward', episode_average_rewards)
else:
wandb.log({'reward': info[""
"reward"], 'steps': cur_steps})
print('cur_episode:', cur_episode, 'total_samples:',
self.learner.total_samples, 'reward', info["reward"])
if cur_episode >= max_episodes or cur_steps >= max_steps:
break
if cur_episode % 100 == 1 and self.pretrain:
path = self.save_dir + str( cur_episode // 100)
torch.save(self.learner.params()['model'], path + '_model.pth')
torch.save(self.learner.params()['actor'], path + '_actor.pth')
torch.save(self.learner.params()['critic'], path + '_critic.pth')
print("Save model_" + str( cur_episode // 100))
self.server.append(info['idx'], self.learner.params())
================================================
FILE: examples/Social_Cognition/ToCM/agent/utils/params.py
================================================
from typing import Iterable
from torch.nn import Module
def get_parameters(modules: Iterable[Module]):
"""
Given a list of torch modules, returns a list of their parameters.
:param modules: iterable of modules
:returns: a list of parameters
"""
model_parameters = []
for module in modules:
model_parameters += list(module.parameters())
return model_parameters
class FreezeParameters:
def __init__(self, modules: Iterable[Module]):
"""
Context manager to locally freeze gradients.
In some cases with can speed up computation because gradients aren't calculated for these listed modules.
example:
```
with FreezeParameters([module]):
output_tensor = module(input_tensor)
```
:param modules: iterable of modules. used to call .parameters() to freeze gradients.
"""
self.modules = modules
self.param_states = [p.requires_grad for p in get_parameters(self.modules)]
def __enter__(self):
for param in get_parameters(self.modules):
param.requires_grad = False
def __exit__(self, exc_type, exc_val, exc_tb):
for i, param in enumerate(get_parameters(self.modules)):
param.requires_grad = self.param_states[i]
================================================
FILE: examples/Social_Cognition/ToCM/agent/workers/ToCMWorker.py
================================================
from copy import deepcopy
import numpy as np
import ray
import torch
from collections import defaultdict
from environments import Env
@ray.remote(num_gpus=1) # TODO
class ToCMWorker:
def __init__(self, idx, env_config, controller_config):
self.runner_handle = idx
self.env = env_config.create_env()
self.controller = controller_config.create_controller() # controller
self.in_dim = controller_config.IN_DIM
self.env_type = env_config.ENV_TYPE
self.controller_config = controller_config
self.device = env_config.device
def _check_handle(self, handle):
if self.env_type == Env.STARCRAFT:
return self.done[handle] == 0
else: # TODO
return self.env.agents[handle].movable
def _select_actions(self, state):
avail_actions = []
observations = []
fakes = []
nn_mask = None
for handle in range(self.env.n_agents):
if self.env_type == Env.STARCRAFT:
avail_actions.append(torch.tensor(self.env.get_avail_agent_actions(handle)))
if self._check_handle(handle) and handle in state:
fakes.append(torch.zeros(1, 1))
observations.append(state[handle].unsqueeze(0))
elif self.done[handle] == 1: # handle is not in state
fakes.append(torch.ones(1, 1)) # fake move
observations.append((self.get_absorbing_state()).to(self.device))
else:
fakes.append(torch.zeros(1, 1))
obs = (torch.tensor(self.env.obs_builder._get_internal(handle)).float().unsqueeze(0)).to(self.device)
observations.append(obs)
# print("observations:", observations)
observations = torch.cat(observations).unsqueeze(0) # TODO
# print("observations:", observations)
av_action = torch.stack(avail_actions).unsqueeze(0).to(self.device) if len(avail_actions) > 0 else None
# print("av_actions:", av_action)
nn_mask = nn_mask.unsqueeze(0).repeat(8, 1, 1).to(self.device) if nn_mask is not None else None
# print("nn_mask:", nn_mask)
actions = self.controller.step(observations, av_action, nn_mask).to(self.device)
# print("actions:", actions)
return actions, observations, torch.cat(fakes).unsqueeze(0), av_action # TODO use controller to model and pred
def _wrap(self, d):
for key, value in d.items():
d[key] = torch.tensor(value).to(self.controller_config.DEVICE).float()
return d
def get_absorbing_state(self):
state = torch.zeros(1, self.in_dim).to(self.device) # TODO
return state
def augment(self, data, inverse=False):
aug = []
default = list(data.values())[0].reshape(1, -1)
for handle in range(self.env.n_agents):
if handle in data.keys():
aug.append(data[handle].reshape(1, -1))
else:
aug.append(torch.ones_like(default) if inverse else torch.zeros_like(default))
return torch.cat(aug).unsqueeze(0).to(self.device) # TODO
def _check_termination(self, info, steps_done):
if self.env_type == Env.STARCRAFT or self.env_type == Env.MPE:
return "episode_limit" not in info
else:
return steps_done < self.env.max_time_steps # can not chao shi
def run(self, ToCM_params):
f"""
interact with environment
:param ToCM_params:
:return: rollout: dict reward steps_done
"""
self.controller.receive_params(ToCM_params)
# Share the parameters learned by the learner with the controller.
# freeze the parameters
state = self._wrap(self.env.reset()) # to device
steps_done = 0
self.done = defaultdict(lambda: False)
episode_rewards = []
while True:
steps_done += 1
# print("state=", state)
actions, obs, fakes, av_actions = self._select_actions(state) # use controller to select action
if self.env_type == Env.MPE:
next_state, reward, done, info = self.env.step(actions) # use env to update, with cpu
rewards = []
for key, value in reward.items():
rewards.append(value)
episode_rewards.append(rewards)
else:
next_state, reward, done, info = self.env.step([action.argmax() for i, action in enumerate(actions)])
next_state, reward, done = self._wrap(deepcopy(next_state)), self._wrap(deepcopy(reward)), \
self._wrap(deepcopy(done)) # to device
self.done = done
self.controller.update_buffer({"action": actions,
"observation": obs,
"reward": self.augment(reward),
"done": self.augment(done),
"fake": fakes,
"avail_action": av_actions})
state = next_state
if all([done[key] == 1 for key in range(self.env.n_agents)]):
# print("Done")
if self._check_termination(info, steps_done):
# print("Done!")
obs = torch.cat([self.get_absorbing_state() for i in range(self.env.n_agents)]).unsqueeze(0)
actions = torch.zeros(1, self.env.n_agents, actions.shape[-1])
index = torch.randint(0, actions.shape[-1], actions.shape[:-1], device=actions.device)
actions.scatter_(2, index.unsqueeze(-1), 1.)
items = {"observation": obs,
"action": actions,
"reward": torch.zeros(1, self.env.n_agents, 1),
"fake": torch.ones(1, self.env.n_agents, 1),
"done": torch.ones(1, self.env.n_agents, 1),
"avail_action": torch.ones_like(actions) if self.env_type == Env.STARCRAFT else None}
self.controller.update_buffer(items)
self.controller.update_buffer(items) # why two
break
if self.env_type == Env.MPE:
reward = np.mean(np.sum(episode_rewards, axis=0)) # TODO
else:
reward = 1. if 'battle_won' in info and info['battle_won'] else 0.
return self.controller.dispatch_buffer(), {"idx": self.runner_handle,
"reward": reward, # a num
"steps_done": steps_done}
================================================
FILE: examples/Social_Cognition/ToCM/configs/Config.py
================================================
from collections.abc import Iterable
# train->agent_configs = [ToCMControllerConfig(ToCMConfig),] -> class ToCMConfig(Config) -> Config
class Config:
def __init__(self):
pass
def to_dict(self, prefix=""):
res_dict = dict()
for key, value in self.__dict__.items():
if isinstance(value, Config):
res_dict.update(value.to_dict(prefix + str(key) + "_"))
elif isinstance(value, Iterable):
if value and isinstance(value[0], Config):
for i, v in enumerate(value):
res_dict.update(v.to_dict(prefix + str(key) + str(i) + "_"))
else:
res_dict[prefix + str(key)] = value
else:
res_dict[prefix + str(key)] = value
return res_dict
================================================
FILE: examples/Social_Cognition/ToCM/configs/EnvConfigs.py
================================================
from configs.Config import Config
from env.starcraft.StarCraft import StarCraft
from env.mpe.MPE import MPE
class EnvConfig(Config):
def __init__(self):
pass
def create_env(self):
pass
# TODO
class MPEConfig(EnvConfig):
def __init__(self, args):
self.args = args
def create_env(self):
return MPE(self.args) # an env object with base class MultiAgentEnv(gym.Env)
class StarCraftConfig(EnvConfig):
def __init__(self, env_name, random_seed):
self.env_name = env_name
self.random_seed = random_seed # TODO
def create_env(self):
return StarCraft(self.env_name, self.random_seed)
class EnvCurriculumConfig(EnvConfig):
def __init__(self, env_configs, env_episodes, env_type, device, obs_builder_config=None, reward_config=None):
self.env_configs = env_configs
self.env_episodes = env_episodes # (100,)
self.ENV_TYPE = env_type #
self.device = device # TODO
if obs_builder_config is not None:
self.set_obs_builder_config(obs_builder_config)
if reward_config is not None:
self.set_reward_config(reward_config)
def update_random_seed(self):
for conf in self.env_configs:
conf.update_random_seed()
def set_obs_builder_config(self, obs_builder_config):
for conf in self.env_configs:
conf.set_obs_builder_config(obs_builder_config)
def set_reward_config(self, reward_config):
for conf in self.env_configs:
conf.set_reward_config(reward_config)
def create_env(self):
return EnvCurriculum(self.env_configs, self.env_episodes)
class EnvCurriculumSampleConfig(EnvConfig):
def __init__(self, env_configs, env_probs, obs_builder_config=None, reward_config=None):
self.env_configs = env_configs
self.env_probs = env_probs
if obs_builder_config is not None:
self.set_obs_builder_config(obs_builder_config)
if reward_config is not None:
self.set_reward_config(reward_config)
def update_random_seed(self):
for conf in self.env_configs:
conf.update_random_seed()
def set_obs_builder_config(self, obs_builder_config):
for conf in self.env_configs:
conf.set_obs_builder_config(obs_builder_config)
def set_reward_config(self, reward_config):
for conf in self.env_configs:
conf.set_reward_config(reward_config)
def create_env(self):
return EnvCurriculumSample(self.env_configs, self.env_probs)
class EnvCurriculumPrioritizedSampleConfig(EnvConfig):
def __init__(self, env_configs, repeat_random_seed, obs_builder_config=None, reward_config=None):
self.env_configs = env_configs
self.repeat_random_seed = repeat_random_seed
if obs_builder_config is not None:
self.set_obs_builder_config(obs_builder_config)
if reward_config is not None:
self.set_reward_config(reward_config)
def update_random_seed(self):
for conf in self.env_configs:
conf.update_random_seed()
def set_obs_builder_config(self, obs_builder_config):
for conf in self.env_configs:
conf.set_obs_builder_config(obs_builder_config)
def set_reward_config(self, reward_config):
for conf in self.env_configs:
conf.set_reward_config(reward_config)
def create_env(self):
return EnvCurriculumPrioritizedSample(self.env_configs, self.repeat_random_seed)
================================================
FILE: examples/Social_Cognition/ToCM/configs/Experiment.py
================================================
from configs.Config import Config
class Experiment(Config): # 这个还没改且里面没有
def __init__(self, steps, episodes, random_seed, env_config, controller_config, learner_config):
super(Experiment, self).__init__() # TODO device 在env里面加入了
self.steps = steps
self.episodes = episodes
self.random_seed = random_seed
self.env_config = env_config
self.controller_config = controller_config
self.learner_config = learner_config
================================================
FILE: examples/Social_Cognition/ToCM/configs/ToCM/ToCMAgentConfig.py
================================================
from dataclasses import dataclass
import torch
import torch.distributions as td
import torch.nn.functional as F
from configs.Config import Config
RSSM_STATE_MODE = 'discrete'
#
class ToCMConfig(Config): # 从Config继承
def __init__(self):
super().__init__()
self.HIDDEN = 64 # 隐藏层神经元个数
self.MODEL_HIDDEN = 64 # 模型隐藏层神经元个数
self.EMBED = 64 # 编码器神经元个数
self.N_CATEGORICALS = 32 # 分类数
self.N_CLASSES = 32 # 类别数
self.STOCHASTIC = self.N_CATEGORICALS * self.N_CLASSES # stochastic:随机的
self.DETERMINISTIC = 64 # deterministic:确定的
self.FEAT = self.STOCHASTIC + self.DETERMINISTIC # feat:特征
self.GLOBAL_FEAT = self.FEAT + self.EMBED # global_feat:全局特征
self.VALUE_LAYERS = 2 # value_layers:值层
self.VALUE_HIDDEN = 64 # value_hidden:值隐藏层
self.PCONT_LAYERS = 2 # pcont_layers:概率层
self.PCONT_HIDDEN = 64 # pcont_hidden:概率隐藏层
self.ACTION_SIZE = 9 # action_size:动作大小
self.ACTION_LAYERS = 2 # action_layers:动作层
self.ACTION_HIDDEN = 64 # action_hidden:动作隐藏层
self.REWARD_LAYERS = 2 # reward_layers:奖励层
self.REWARD_HIDDEN = 64 # reward_hidden:奖励隐藏层
self.GAMMA = 0.99 # gamma:折扣因子
self.DISCOUNT = 0.99 # discount:折扣
self.DISCOUNT_LAMBDA = 0.95 # discount_lambda:折扣lambda
self.IN_DIM = 30 # in_dim:输入维度
self.LOG_FOLDER = 'wandb/' # log_folder:日志文件夹
self.num_agents = 2
@dataclass
class RSSMStateBase:
stoch: torch.Tensor
deter: torch.Tensor
def map(self, func):
return RSSMState(**{key: func(val) for key, val in self.__dict__.items()})
def get_features(self):
return torch.cat((self.stoch, self.deter), dim=-1)
def get_dist(self, *input):
pass
def type(self):
return None
@dataclass
class RSSMStateDiscrete(RSSMStateBase):
logits: torch.Tensor
def get_dist(self, batch_shape, n_categoricals, n_classes):
return F.softmax(self.logits.reshape(*batch_shape, n_categoricals, n_classes), -1)
@dataclass
class RSSMStateCont(RSSMStateBase):
mean: torch.Tensor
std: torch.Tensor
def get_dist(self, *input):
return td.independent.Independent(td.Normal(self.mean, self.std), 1)
RSSMState = {'discrete': RSSMStateDiscrete,
'cont': RSSMStateCont}[RSSM_STATE_MODE]
================================================
FILE: examples/Social_Cognition/ToCM/configs/ToCM/ToCMControllerConfig.py
================================================
from agent.controllers.ToCMController import ToCMController
from configs.ToCM.ToCMAgentConfig import ToCMConfig
# train->agent_configs = [ToCMControllerConfig(ToCMConfig),] -> class ToCMConfig(Config) -> Config
class ToCMControllerConfig(ToCMConfig):
def __init__(self, env_name, RANDOM_SEED, device): # RANDOM_SEED:23 device:'cuda:6' env_name:'3s5z_vs_3s6z'
super().__init__()
self.EXPL_DECAY = 0.9999 # exploration decay rate:探索衰减率
self.EXPL_NOISE = 0. # exploration noise:探索噪声
self.EXPL_MIN = 0. # minimum exploration:最小探索
self.DEVICE = device # TODO
self.env_name = env_name # TODO
self.random_seed = RANDOM_SEED # TODO
def create_controller(self):
return ToCMController(self)
================================================
FILE: examples/Social_Cognition/ToCM/configs/ToCM/ToCMLearnerConfig.py
================================================
from agent.learners.ToCMLearner import ToCMLearner
from configs.ToCM.ToCMAgentConfig import ToCMConfig
# train->agent_configs = [ToCMLearnerConfig(ToCMConfig),] -> class ToCMConfig(Config) -> Config
class ToCMLearnerConfig(ToCMConfig): # 从ToCMConfig继承,有输入维度、输出维度、隐层维度、隐层层数、动作维度、动作隐层维度、动作隐层层数、
def __init__(self, env_name, RANDOM_SEED, device):
super().__init__()
self.MODEL_LR = 2e-4
self.ACTOR_LR = 7e-4 # TODO
self.VALUE_LR = 7e-4 # TODO
self.CAPACITY = 500000
self.MIN_BUFFER_SIZE = 100
self.MODEL_EPOCHS = 20 # TODO
self.EPOCHS = 4 # TODO
self.PPO_EPOCHS = 10 # TODO
self.MODEL_BATCH_SIZE = 30#40
self.BATCH_SIZE = 40
self.SEQ_LENGTH = 50
self.N_SAMPLES = 1
self.TARGET_UPDATE = 128
self.GRAD_CLIP = 100.0
self.HORIZON = 15
self.ENTROPY = 0.001
self.ENTROPY_ANNEALING = 0.99998
self.GRAD_CLIP_POLICY = 100.
self.DEVICE = device # TODO
self.env_name = env_name # TODO
self.random_seed = RANDOM_SEED # TODO
self.num_agents = 2
def create_learner(self): # 通过config创建learner
return ToCMLearner(self)
================================================
FILE: examples/Social_Cognition/ToCM/configs/ToCM/optimal/starcraft/AgentConfig.py
================================================
from configs.Config import Config
class ToCMConfig(Config):
def __init__(self):
super().__init__()
self.HIDDEN = 256
self.MODEL_HIDDEN = 256
self.EMBED = 256
self.N_CATEGORICALS = 32
self.N_CLASSES = 32
self.STOCHASTIC = self.N_CATEGORICALS * self.N_CLASSES
self.DETERMINISTIC = 256
self.FEAT = self.STOCHASTIC + self.DETERMINISTIC
self.GLOBAL_FEAT = self.FEAT + self.EMBED
self.VALUE_LAYERS = 2
self.VALUE_HIDDEN = 256
self.PCONT_LAYERS = 2
self.PCONT_HIDDEN = 256
self.ACTION_SIZE = 9
self.ACTION_LAYERS = 2
self.ACTION_HIDDEN = 256
self.REWARD_LAYERS = 2
self.REWARD_HIDDEN = 256
self.GAMMA = 0.99
self.DISCOUNT = 0.99
self.DISCOUNT_LAMBDA = 0.95
self.IN_DIM = 30
================================================
FILE: examples/Social_Cognition/ToCM/configs/ToCM/optimal/starcraft/LearnerConfig.py
================================================
from agent.learners.ToCMLearner import ToCMLearner
from configs.ToCM.ToCMAgentConfig import ToCMConfig
class ToCMLearnerConfig(ToCMConfig):
def __init__(self):
super().__init__()
self.MODEL_LR = 2e-4
self.ACTOR_LR = 5e-4
self.VALUE_LR = 5e-4
self.CAPACITY = 250000
self.MIN_BUFFER_SIZE = 500
self.MODEL_EPOCHS = 40
self.EPOCHS = 4
self.PPO_EPOCHS = 10
self.MODEL_BATCH_SIZE = 40
self.BATCH_SIZE = 40
self.SEQ_LENGTH = 20
self.N_SAMPLES = 1
self.TARGET_UPDATE = 1
self.DEVICE = 'cuda:8'
self.GRAD_CLIP = 100.0
self.HORIZON = 15
self.ENTROPY = 0.001
self.ENTROPY_ANNEALING = 0.99998
self.GRAD_CLIP_POLICY = 100.0
def create_learner(self):
return ToCMLearner(self)
================================================
FILE: examples/Social_Cognition/ToCM/configs/__init__.py
================================================
from .Experiment import Experiment
================================================
FILE: examples/Social_Cognition/ToCM/env/mpe/MPE.py
================================================
from mpe.MPE_Env import MPEEnv
class MPE:
def __init__(self, args):
self.env = MPEEnv(args) # TODO args name and random seed
# scenario_name=args.scenario_name, benchmark=args.benchmark, num_agents=args.num_agents,
# num_adversaries, num_landmarks, episode_length
self.env.seed(args.seed)
self.n_agents = self.env.num_agents
self.agents = self.env.agents
def to_dict(self, l):
return {i: e for i, e in enumerate(l)}
def step(self, action_dict): # action dict for each agent
# print("action_dist", action_dict)
obs, reward, done, info = self.env.step(action_dict) # TODO return four list
return {i: obs[i] for i in range(self.n_agents)}, {i: reward[i] for i in range(self.n_agents)}, \
{i: done[i] for i in range(self.n_agents)}, {i: info[i] for i in range(self.n_agents)}
def reset(self):
obs = self.env.reset()
return self.to_dict(obs)
def close(self):
self.env.close()
# no mask and no this usage
def get_avail_agent_actions(self, handle): # available handle is the i th agent, add mask
return self.env._get_done(handle)
================================================
FILE: examples/Social_Cognition/ToCM/env/starcraft/StarCraft.py
================================================
from smac.env import StarCraft2Env # import a package smac
class StarCraft:
def __init__(self, env_name, random_seed):
# map_name ->
self.env = StarCraft2Env(map_name=env_name, seed=random_seed, continuing_episode=True, difficulty="7") # TODO
env_info = self.env.get_env_info()
self.n_obs = env_info["obs_shape"]
self.n_actions = env_info["n_actions"]
self.n_agents = env_info["n_agents"]
def to_dict(self, l):
return {i: e for i, e in enumerate(l)}
def step(self, action_dict):
reward, done, info = self.env.step(action_dict)
return self.to_dict(self.env.get_obs()), {i: reward for i in range(self.n_agents)}, \
{i: done for i in range(self.n_agents)}, info
def reset(self):
self.env.reset()
return {i: obs for i, obs in enumerate(self.env.get_obs())}
def render(self):
self.env.render()
def close(self):
self.env.close()
def get_avail_agent_actions(self, handle):
return self.env.get_avail_agent_actions(handle)
================================================
FILE: examples/Social_Cognition/ToCM/environments.py
================================================
from enum import Enum
class Env(str, Enum):
STARCRAFT = "starcraft"
MPE = "mpe"
# RANDOM_SEED = 23
# ENV_NAME = "5_agents"
================================================
FILE: examples/Social_Cognition/ToCM/mpe/MPE_Env.py
================================================
"""
Code for creating a multiagent environment with one of the scenarios listed
in ./scenarios/.
Can be called by using, for example:
env = make_env('simple_speaker_listener')
After producing the env object, can be used similarly to an OpenAI gym
environment.
A policy using this environment must output actions in the form of a list
for all agents. Each element of the list should be a numpy array,
of size (env.world.dim_p + env.world.dim_c, 1). Physical actions precede
communication actions in this array. See environment.py for more details.
"""
from .environment import MultiAgentEnv
from .scenarios import load
def MPEEnv(args):
"""
Creates a MultiAgentEnv object as env. This can be used similar to a gym
environment by calling env.reset() and env.step().
Use env.render() to view the environment on the screen.
Input:
scenario_name : name of the scenario from ./scenarios/ to be Returns
(without the .py extension)
benchmark : whether you want to produce benchmarking data
(usually only done during evaluation)
Some useful env properties (see environment.py):
.observation_space : Returns the observation space for each agent
.action_space : Returns the action space for each agent
.n : Returns the number of Agents
"""
# load scenario from script
scenario = load(args.env_name + ".py").Scenario()
# create world
world = scenario.make_world(args) # py file and others parameters, use the train parse?
# create multi agent environment
env = MultiAgentEnv(world, scenario.reset_world,
scenario.reward, scenario.observation)
return env
================================================
FILE: examples/Social_Cognition/ToCM/mpe/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/mpe/core.py
================================================
import numpy as np
# import seaborn as sns
# physical/external base state of all entites
class EntityState(object):
def __init__(self):
# physical position
self.p_pos = None
# physical velocity
self.p_vel = None
# state of agents (including communication and internal/mental state)
class AgentState(EntityState):
def __init__(self):
super(AgentState, self).__init__()
# communication utterance
self.c = None
# action of the agent
class Action(object):
def __init__(self):
# physical action
self.u = None
# communication action
self.c = None
# properties of wall entities
class Wall(object):
def __init__(self, orient='H', axis_pos=0.0, endpoints=(-1, 1), width=0.1,
hard=True):
# orientation: 'H'orizontal or 'V'ertical
self.orient = orient
# position along axis which wall lays on (y-axis for H, x-axis for V)
self.axis_pos = axis_pos
# endpoints of wall (x-coords for H, y-coords for V)
self.endpoints = np.array(endpoints)
# width of wall
self.width = width
# whether wall is impassable to all agents
self.hard = hard
# color of wall
self.color = np.array([0.0, 0.0, 0.0])
# properties and state of physical world entity
class Entity(object):
def __init__(self):
# index among all entities (important to set for distance caching)
self.i = 0
# name
self.name = ''
# properties:
self.size = 0.050
# entity can move / be pushed
self.movable = False
# entity collides with others
self.collide = True
# entity can pass through non-hard walls
self.ghost = False
# material density (affects mass)
self.density = 25.0
# color
self.color = None
# max speed and accel
self.max_speed = None
self.accel = None
# state: including internal/mental state p_pos, p_vel
self.state = EntityState()
# mass
self.initial_mass = 1.0
# commu channel
self.channel = None
@property
def mass(self):
return self.initial_mass
# properties of landmark entities
class Landmark(Entity):
def __init__(self):
super(Landmark, self).__init__()
# properties of agent entities
class Agent(Entity):
def __init__(self):
super(Agent, self).__init__()
# agent are adversary
self.adversary = False
# agent are dummy
self.dummy = False
# agents are movable by default
self.movable = True
# cannot send communication signals
self.silent = False
# cannot observe the world
self.blind = False
# physical motor noise amount
self.u_noise = None
# communication noise amount
self.c_noise = None
# control range
self.u_range = 1.0
# state: including communication state(communication utterance) c and internal/mental state p_pos, p_vel
self.state = AgentState()
# action: physical action u & communication action c
self.action = Action()
# script behavior to execute
self.action_callback = None
# zoe 20200420
self.goal = None
# multi-agent world
class World(object):
def __init__(self):
# list of agents and entities (can change at execution-time!)
self.agents = []
self.landmarks = []
self.walls = []
# communication channel dimensionality
self.dim_c = 0
# position dimensionality
self.dim_p = 2
# color dimensionality
self.dim_color = 3
# simulation timestep
self.dt = 0.1
# physical damping
self.damping = 0.25
# contact response parameters
self.contact_force = 1e+2
self.contact_margin = 1e-3
# cache distances between all agents (not calculated by default)
self.cache_dists = False
self.cached_dist_vect = None
self.cached_dist_mag = None
# zoe 20200420
self.world_length = 25
self.world_step = 0
self.num_agents = 0
self.num_landmarks = 0
# return all entities in the world
@property
def entities(self):
return self.agents + self.landmarks
# return all agents controllable by external policies
@property
def policy_agents(self):
return [agent for agent in self.agents if agent.action_callback is None]
# return all agents controlled by world scripts
@property
def scripted_agents(self):
return [agent for agent in self.agents if agent.action_callback is not None]
def calculate_distances(self):
if self.cached_dist_vect is None:
# initialize distance data structure
self.cached_dist_vect = np.zeros((len(self.entities),
len(self.entities),
self.dim_p))
# calculate minimum distance for a collision between all entities
self.min_dists = np.zeros((len(self.entities), len(self.entities)))
for ia, entity_a in enumerate(self.entities):
for ib in range(ia + 1, len(self.entities)):
entity_b = self.entities[ib]
min_dist = entity_a.size + entity_b.size
self.min_dists[ia, ib] = min_dist
self.min_dists[ib, ia] = min_dist
for ia, entity_a in enumerate(self.entities):
for ib in range(ia + 1, len(self.entities)):
entity_b = self.entities[ib]
delta_pos = entity_a.state.p_pos - entity_b.state.p_pos
self.cached_dist_vect[ia, ib, :] = delta_pos
self.cached_dist_vect[ib, ia, :] = -delta_pos
self.cached_dist_mag = np.linalg.norm(self.cached_dist_vect, axis=2)
self.cached_collisions = (self.cached_dist_mag <= self.min_dists)
def assign_agent_colors(self):
n_dummies = 0
if hasattr(self.agents[0], 'dummy'):
n_dummies = len([a for a in self.agents if a.dummy])
n_adversaries = 0
if hasattr(self.agents[0], 'adversary'):
n_adversaries = len([a for a in self.agents if a.adversary])
n_good_agents = len(self.agents) - n_adversaries - n_dummies
# r g b
dummy_colors = [(0.25, 0.75, 0.25)] * n_dummies
# sns.color_palette("OrRd_d", n_adversaries)
adv_colors = [(0.75, 0.25, 0.25)] * n_adversaries
# sns.color_palette("GnBu_d", n_good_agents)
good_colors = [(0.25, 0.25, 0.75)] * n_good_agents
colors = dummy_colors + adv_colors + good_colors
for color, agent in zip(colors, self.agents):
agent.color = color
# landmark color
def assign_landmark_colors(self):
for landmark in self.landmarks:
landmark.color = np.array([0.25, 0.25, 0.25])
# update state of the world
def step(self):
self.world_step += 1
# set actions for scripted agents
for agent in self.scripted_agents:
agent.action = agent.action_callback(agent, self)
# gather forces applied to entities
p_force = [None] * len(self.entities)
# apply agent physical controls
p_force = self.apply_action_force(p_force)
# apply environment forces
p_force = self.apply_environment_force(p_force)
# integrate physical state
self.integrate_state(p_force)
# update agent state
for agent in self.agents:
self.update_agent_state(agent)
# calculate and store distances between all entities
if self.cache_dists:
self.calculate_distances()
# gather agent action forces
def apply_action_force(self, p_force):
# set applied forces
for i, agent in enumerate(self.agents):
if agent.movable:
noise = np.random.randn(
*agent.action.u.shape) * agent.u_noise if agent.u_noise else 0.0
# force = mass * a * action + n
p_force[i] = (
agent.mass * agent.accel if agent.accel is not None else agent.mass) * agent.action.u + noise
return p_force
# gather physical forces acting on entities
def apply_environment_force(self, p_force):
# simple (but inefficient) collision response
for a, entity_a in enumerate(self.entities):
for b, entity_b in enumerate(self.entities):
if(b <= a):
continue
[f_a, f_b] = self.get_entity_collision_force(a, b)
if(f_a is not None):
if(p_force[a] is None):
p_force[a] = 0.0
p_force[a] = f_a + p_force[a]
if(f_b is not None):
if(p_force[b] is None):
p_force[b] = 0.0
p_force[b] = f_b + p_force[b]
if entity_a.movable:
for wall in self.walls:
wf = self.get_wall_collision_force(entity_a, wall)
if wf is not None:
if p_force[a] is None:
p_force[a] = 0.0
p_force[a] = p_force[a] + wf
return p_force
# integrate physical state
def integrate_state(self, p_force):
for i, entity in enumerate(self.entities):
if not entity.movable:
continue
entity.state.p_vel = entity.state.p_vel * (1 - self.damping)
if (p_force[i] is not None):
entity.state.p_vel += (p_force[i] / entity.mass) * self.dt
if entity.max_speed is not None:
speed = np.sqrt(
np.square(entity.state.p_vel[0]) + np.square(entity.state.p_vel[1]))
if speed > entity.max_speed:
entity.state.p_vel = entity.state.p_vel / np.sqrt(np.square(entity.state.p_vel[0]) +
np.square(entity.state.p_vel[1])) * entity.max_speed
entity.state.p_pos += entity.state.p_vel * self.dt
def update_agent_state(self, agent):
# set communication state (directly for now)
if agent.silent:
agent.state.c = np.zeros(self.dim_c)
else:
noise = np.random.randn(*agent.action.c.shape) * \
agent.c_noise if agent.c_noise else 0.0
agent.state.c = agent.action.c + noise
# get collision forces for any contact between two entities
def get_entity_collision_force(self, ia, ib):
entity_a = self.entities[ia]
entity_b = self.entities[ib]
if (not entity_a.collide) or (not entity_b.collide):
return [None, None] # not a collider
if (not entity_a.movable) and (not entity_b.movable):
return [None, None] # neither entity moves
if (entity_a is entity_b):
return [None, None] # don't collide against itself
if self.cache_dists:
delta_pos = self.cached_dist_vect[ia, ib]
dist = self.cached_dist_mag[ia, ib]
dist_min = self.min_dists[ia, ib]
else:
# compute actual distance between entities
delta_pos = entity_a.state.p_pos - entity_b.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
# minimum allowable distance
dist_min = entity_a.size + entity_b.size
# softmax penetration
k = self.contact_margin
penetration = np.logaddexp(0, -(dist - dist_min)/k)*k
force = self.contact_force * delta_pos / dist * penetration
if entity_a.movable and entity_b.movable:
# consider mass in collisions
force_ratio = entity_b.mass / entity_a.mass
force_a = force_ratio * force
force_b = -(1 / force_ratio) * force
else:
force_a = +force if entity_a.movable else None
force_b = -force if entity_b.movable else None
return [force_a, force_b]
# get collision forces for contact between an entity and a wall
def get_wall_collision_force(self, entity, wall):
if entity.ghost and not wall.hard:
return None # ghost passes through soft walls
if wall.orient == 'H':
prll_dim = 0
perp_dim = 1
else:
prll_dim = 1
perp_dim = 0
ent_pos = entity.state.p_pos
if (ent_pos[prll_dim] < wall.endpoints[0] - entity.size or
ent_pos[prll_dim] > wall.endpoints[1] + entity.size):
return None # entity is beyond endpoints of wall
elif (ent_pos[prll_dim] < wall.endpoints[0] or
ent_pos[prll_dim] > wall.endpoints[1]):
# part of entity is beyond wall
if ent_pos[prll_dim] < wall.endpoints[0]:
dist_past_end = ent_pos[prll_dim] - wall.endpoints[0]
else:
dist_past_end = ent_pos[prll_dim] - wall.endpoints[1]
theta = np.arcsin(dist_past_end / entity.size)
dist_min = np.cos(theta) * entity.size + 0.5 * wall.width
else: # entire entity lies within bounds of wall
theta = 0
dist_past_end = 0
dist_min = entity.size + 0.5 * wall.width
# only need to calculate distance in relevant dim
delta_pos = ent_pos[perp_dim] - wall.axis_pos
dist = np.abs(delta_pos)
# softmax penetration
k = self.contact_margin
penetration = np.logaddexp(0, -(dist - dist_min)/k)*k
force_mag = self.contact_force * delta_pos / dist * penetration
force = np.zeros(2)
force[perp_dim] = np.cos(theta) * force_mag
force[prll_dim] = np.sin(theta) * np.abs(force_mag)
return force
================================================
FILE: examples/Social_Cognition/ToCM/mpe/environment.py
================================================
import gym
from gym import spaces
from gym.envs.registration import EnvSpec
import numpy as np
from .multi_discrete import MultiDiscrete
# update bounds to center around agent
cam_range = 2
# environment for all agents in the multi agent world
# currently code assumes that no agents will be created/destroyed at runtime!
class MultiAgentEnv(gym.Env):
metadata = {
'render.modes': ['human', 'rgb_array']
}
def __init__(self, world, reset_callback=None, reward_callback=None,
observation_callback=None, info_callback=None,
done_callback=None, post_step_callback=None,
shared_viewer=True, discrete_action=True):
self.world = world
self.world_length = self.world.world_length # obs TODO 25
self.current_step = 0
self.agents = self.world.policy_agents
# set required vectorized gym env property
self.num_agents = len(world.policy_agents)
# scenario callbacks
self.reset_callback = reset_callback
self.reward_callback = reward_callback
self.observation_callback = observation_callback
self.info_callback = info_callback
self.done_callback = done_callback
self.post_step_callback = post_step_callback
# environment parameters
# self.discrete_action_space = True
self.discrete_action_space = discrete_action # actions dim TODO
# if true, action is a number 0...N, otherwise action is a one-hot N-dimensional vector
self.discrete_action_input = False
# if true, even the action is continuous, action will be performed discretely
self.force_discrete_action = world.discrete_action if hasattr(
world, 'discrete_action') else False
# in this env, force_discrete_action == False��because world do not have discrete_action
# if true, every agent has the same reward
self.shared_reward = world.collaborative if hasattr(
world, 'collaborative') else False
# self.shared_reward = False
self.time = 0
# configure spaces
self.action_space = []
self.observation_space = []
self.share_observation_space = []
share_obs_dim = 0
for agent in self.agents:
total_action_space = []
# physical action space
if self.discrete_action_space:
u_action_space = spaces.Discrete(world.dim_p * 2 + 1)
else:
u_action_space = spaces.Box(
low=-agent.u_range, high=+agent.u_range, shape=(world.dim_p,), dtype=np.float32) # [-1,1]
if agent.movable:
total_action_space.append(u_action_space)
# communication action space
if self.discrete_action_space:
c_action_space = spaces.Discrete(world.dim_c)
else:
c_action_space = spaces.Box(low=0.0, high=1.0, shape=(
world.dim_c,), dtype=np.float32) # [0,1]
# c_action_space = spaces.Discrete(world.dim_c)
if not agent.silent:
total_action_space.append(c_action_space)
# total action space
if len(total_action_space) > 1:
# all action spaces are discrete, so simplify to MultiDiscrete action space
if all([isinstance(act_space, spaces.Discrete) for act_space in total_action_space]):
act_space = MultiDiscrete(
[[0, act_space.n - 1] for act_space in total_action_space])
else:
act_space = spaces.Tuple(total_action_space)
self.action_space.append(act_space)
else:
self.action_space.append(total_action_space[0])
# observation space
obs_dim = len(observation_callback(agent, self.world))
share_obs_dim += obs_dim
self.observation_space.append(spaces.Box(
low=-np.inf, high=+np.inf, shape=(obs_dim,), dtype=np.float32)) # [-inf,inf]
agent.action.c = np.zeros(self.world.dim_c)
self.share_observation_space = [spaces.Box(
low=-np.inf, high=+np.inf, shape=(share_obs_dim,), dtype=np.float32)] * self.num_agents
# rendering
self.shared_viewer = shared_viewer
if self.shared_viewer:
self.viewers = [None]
else:
self.viewers = [None] * self.num_agents
self._reset_render()
def seed(self, seed=None):
if seed is None:
np.random.seed(1)
else:
np.random.seed(seed)
# step this is env.step()
def step(self, action_n):
self.current_step += 1
obs_n = []
reward_n = []
done_n = []
info_n = []
self.agents = self.world.policy_agents
# set action for each agent
for i, agent in enumerate(self.agents):
self._set_action(action_n[i], agent, self.action_space[i])
# advance world state
self.world.step() # core.step()
# record observation for each agent
for i, agent in enumerate(self.agents):
obs_n.append(self._get_obs(agent))
reward_n.append([self._get_reward(agent)])
done_n.append([self._get_done(agent)])
info = {'individual_reward': self._get_reward(agent)}
info_n.append(info)
# all agents get total reward in cooperative case, if shared reward, all agents have the same reward,
# and reward is sum
reward = np.sum(reward_n)
if self.shared_reward:
reward_n = [[reward]] * self.num_agents
if self.post_step_callback is not None:
self.post_step_callback(self.world)
return obs_n, reward_n, done_n, info_n
def reset(self):
self.current_step = 0
# reset world
self.reset_callback(self.world)
# reset renderer
self._reset_render()
# record observations for each agent
obs_n = []
self.agents = self.world.policy_agents
for agent in self.agents:
obs_n.append(self._get_obs(agent))
return obs_n
# get info used for benchmarking
def _get_info(self, agent):
if self.info_callback is None:
return {}
return self.info_callback(agent, self.world)
# get observation for a particular agent
def _get_obs(self, agent):
if isinstance(agent, int):
agent = self.agents[agent]
if self.observation_callback is None:
print("Unavailable:", np.zeros(0))
return np.zeros(0)
return self.observation_callback(agent, self.world)
# get dones for a particular agent
# unused right now -- agents are allowed to go beyond the viewing screen
def _get_done(self, agent):
if isinstance(agent, int):
agent = self.agents[agent]
if self.done_callback is None:
if self.current_step >= self.world_length:
return True
else:
return False
return self.done_callback(agent, self.world)
# get reward for a particular agent
def _get_reward(self, agent):
if self.reward_callback is None:
return 0.0
return self.reward_callback(agent, self.world)
# set env action for a particular agent
def _set_action(self, action, agent, action_space, time=None):
agent.action.u = np.zeros(self.world.dim_p)
agent.action.c = np.zeros(self.world.dim_c)
# process action
if isinstance(action_space, MultiDiscrete):
act = []
size = action_space.high - action_space.low + 1
index = 0
for s in size:
act.append(action[index:(index + s)])
index += s
action = act
else:
action = [action]
if agent.movable:
# physical action
if self.discrete_action_input:
agent.action.u = np.zeros(self.world.dim_p)
# process discrete action
if action[0] == 1:
agent.action.u[0] = -1.0
if action[0] == 2:
agent.action.u[0] = +1.0
if action[0] == 3:
agent.action.u[1] = -1.0
if action[0] == 4:
agent.action.u[1] = +1.0
d = self.world.dim_p
else:
if self.discrete_action_space:
agent.action.u[0] += action[0][1] - action[0][2]
agent.action.u[1] += action[0][3] - action[0][4]
d = 5
else:
if self.force_discrete_action:
p = np.argmax(action[0][0:self.world.dim_p])
action[0][:] = 0.0
action[0][p] = 1.0
agent.action.u = action[0][0:self.world.dim_p]
d = self.world.dim_p
sensitivity = 5.0
if agent.accel is not None:
sensitivity = agent.accel
agent.action.u *= sensitivity
if (not agent.silent) and (not isinstance(action_space, MultiDiscrete)):
action[0] = action[0][d:]
else:
action = action[1:]
if not agent.silent:
# communication action
if self.discrete_action_input:
agent.action.c = np.zeros(self.world.dim_c)
agent.action.c[action[0]] = 1.0
else:
agent.action.c = action[0]
action = action[1:]
# make sure we used all elements of action
assert len(action) == 0
def _get_avail_action(self, handle):
agent = self.agents[handle] # TODO
# reset rendering assets
def _reset_render(self):
self.render_geoms = None
self.render_geoms_xform = None
def render(self, mode='human', close=True):
if close:
# close any existic renderers
for i, viewer in enumerate(self.viewers):
if viewer is not None:
viewer.close()
self.viewers[i] = None
return []
if mode == 'human':
alphabet = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
message = ''
for agent in self.world.agents:
comm = []
for other in self.world.agents:
if other is agent:
continue
if np.all(other.state.c == 0):
word = '_'
else:
word = alphabet[np.argmax(other.state.c)]
message += (other.name + ' to ' +
agent.name + ': ' + word + ' ')
print(message)
for i in range(len(self.viewers)):
# create viewers (if necessary)
if self.viewers[i] is None:
# import rendering only if we need it (and don't import for headless machines)
# from gym.envs.classic_control import rendering
from . import rendering
self.viewers[i] = rendering.Viewer(700, 700)
# create rendering geometry
if self.render_geoms is None:
# import rendering only if we need it (and don't import for headless machines)
# from gym.envs.classic_control import rendering
from . import rendering
self.render_geoms = []
self.render_geoms_xform = []
self.comm_geoms = []
for entity in self.world.entities:
geom = rendering.make_circle(entity.size)
xform = rendering.Transform()
entity_comm_geoms = []
if 'agent' in entity.name:
geom.set_color(*entity.color, alpha=0.5)
if not entity.silent:
dim_c = self.world.dim_c
# make circles to represent communication
for ci in range(dim_c):
comm = rendering.make_circle(entity.size / dim_c)
comm.set_color(1, 1, 1)
comm.add_attr(xform)
offset = rendering.Transform()
comm_size = (entity.size / dim_c)
offset.set_translation(ci * comm_size * 2 -
entity.size + comm_size, 0)
comm.add_attr(offset)
entity_comm_geoms.append(comm)
else:
geom.set_color(*entity.color)
if entity.channel is not None:
dim_c = self.world.dim_c
# make circles to represent communication
for ci in range(dim_c):
comm = rendering.make_circle(entity.size / dim_c)
comm.set_color(1, 1, 1)
comm.add_attr(xform)
offset = rendering.Transform()
comm_size = (entity.size / dim_c)
offset.set_translation(ci * comm_size * 2 -
entity.size + comm_size, 0)
comm.add_attr(offset)
entity_comm_geoms.append(comm)
geom.add_attr(xform)
self.render_geoms.append(geom)
self.render_geoms_xform.append(xform)
self.comm_geoms.append(entity_comm_geoms)
for wall in self.world.walls:
corners = ((wall.axis_pos - 0.5 * wall.width, wall.endpoints[0]),
(wall.axis_pos - 0.5 *
wall.width, wall.endpoints[1]),
(wall.axis_pos + 0.5 *
wall.width, wall.endpoints[1]),
(wall.axis_pos + 0.5 * wall.width, wall.endpoints[0]))
if wall.orient == 'H':
corners = tuple(c[::-1] for c in corners)
geom = rendering.make_polygon(corners)
if wall.hard:
geom.set_color(*wall.color)
else:
geom.set_color(*wall.color, alpha=0.5)
self.render_geoms.append(geom)
# add geoms to viewer
# for viewer in self.viewers:
# viewer.geoms = []
# for geom in self.render_geoms:
# viewer.add_geom(geom)
for viewer in self.viewers:
viewer.geoms = []
for geom in self.render_geoms:
viewer.add_geom(geom)
for entity_comm_geoms in self.comm_geoms:
for geom in entity_comm_geoms:
viewer.add_geom(geom)
results = []
for i in range(len(self.viewers)):
from . import rendering
if self.shared_viewer:
pos = np.zeros(self.world.dim_p)
else:
pos = self.agents[i].state.p_pos
self.viewers[i].set_bounds(
pos[0] - cam_range, pos[0] + cam_range, pos[1] - cam_range, pos[1] + cam_range)
# update geometry positions
for e, entity in enumerate(self.world.entities):
self.render_geoms_xform[e].set_translation(*entity.state.p_pos)
if 'agent' in entity.name:
self.render_geoms[e].set_color(*entity.color, alpha=0.5)
if not entity.silent:
for ci in range(self.world.dim_c):
color = 1 - entity.state.c[ci]
self.comm_geoms[e][ci].set_color(
color, color, color)
else:
self.render_geoms[e].set_color(*entity.color)
if entity.channel is not None:
for ci in range(self.world.dim_c):
color = 1 - entity.channel[ci]
self.comm_geoms[e][ci].set_color(
color, color, color)
# render to display or array
results.append(self.viewers[i].render(
return_rgb_array=mode == 'rgb_array'))
return results
# create receptor field locations in local coordinate frame
def _make_receptor_locations(self, agent):
receptor_type = 'polar'
range_min = 0.05 * 2.0
range_max = 1.00
dx = []
# circular receptive field
if receptor_type == 'polar':
for angle in np.linspace(-np.pi, +np.pi, 8, endpoint=False):
for distance in np.linspace(range_min, range_max, 3):
dx.append(
distance * np.array([np.cos(angle), np.sin(angle)]))
# add origin
dx.append(np.array([0.0, 0.0]))
# grid receptive field
if receptor_type == 'grid':
for x in np.linspace(-range_max, +range_max, 5):
for y in np.linspace(-range_max, +range_max, 5):
dx.append(np.array([x, y]))
return dx
================================================
FILE: examples/Social_Cognition/ToCM/mpe/multi_discrete.py
================================================
# An old version of OpenAI Gym's multi_discrete.py. (Was getting affected by Gym updates)
# (https://github.com/openai/gym/blob/1fb81d4e3fb780ccf77fec731287ba07da35eb84/gym/spaces/multi_discrete.py)
import numpy as np
import gym
class MultiDiscrete(gym.Space):
"""
- The multi-discrete action space consists of a series of discrete action spaces with different parameters
- It can be adapted to both a Discrete action space or a continuous (Box) action space
- It is useful to represent game controllers or keyboards where each key can be represented as a discrete action space
- It is parametrized by passing an array of arrays containing [min, max] for each discrete action space
where the discrete action space can take any integers from `min` to `max` (both inclusive)
Note: A value of 0 always need to represent the NOOP action.
e.g. Nintendo Game Controller
- Can be conceptualized as 3 discrete action spaces:
1) Arrow Keys: Discrete 5 - NOOP[0], UP[1], RIGHT[2], DOWN[3], LEFT[4] - params: min: 0, max: 4
2) Button A: Discrete 2 - NOOP[0], Pressed[1] - params: min: 0, max: 1
3) Button B: Discrete 2 - NOOP[0], Pressed[1] - params: min: 0, max: 1
- Can be initialized as
MultiDiscrete([ [0,4], [0,1], [0,1] ])
"""
def __init__(self, array_of_param_array):
self.low = np.array([x[0] for x in array_of_param_array])
self.high = np.array([x[1] for x in array_of_param_array])
self.num_discrete_space = self.low.shape[0]
def sample(self):
""" Returns a array with one sample from each discrete action space """
# For each row: round(random .* (max - min) + min, 0)
#random_array = prng.np_random.rand(self.num_discrete_space)
random_array = np.random.rand(self.num_discrete_space)
return [int(x) for x in np.floor(np.multiply((self.high - self.low + 1.), random_array) + self.low)]
def contains(self, x):
return len(x) == self.num_discrete_space and (np.array(x) >= self.low).all() and (np.array(x) <= self.high).all()
@property
def shape(self):
return self.num_discrete_space
def __repr__(self):
return "MultiDiscrete" + str(self.num_discrete_space)
def __eq__(self, other):
return np.array_equal(self.low, other.low) and np.array_equal(self.high, other.high)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/rendering.py
================================================
"""
2D rendering framework
"""
from __future__ import division
import os
import six # TODO
import sys
if "Apple" in sys.version:
if 'DYLD_FALLBACK_LIBRARY_PATH' in os.environ:
os.environ['DYLD_FALLBACK_LIBRARY_PATH'] += ':/usr/lib'
# (JDS 2016/04/15): avoid bug on Anaconda 2.3.0 / Yosemite
from gym.utils import reraise
from gym import error
try:
import pyglet
except ImportError as e:
reraise(
suffix="HINT: you can install pyglet directly via 'pip install pyglet'. But if you really just want to install all Gym dependencies and not have to think about it, 'pip install -e .[all]' or 'pip install gym[all]' will do it.")
try:
from pyglet.gl import *
except ImportError as e:
reraise(prefix="Error occured while running `from pyglet.gl import *`",
suffix="HINT: make sure you have OpenGL install. On Ubuntu, you can run 'apt-get install python-opengl'. If you're running on a server, you may need a virtual frame buffer; something like this should work: 'xvfb-run -s \"-screen 0 1400x900x24\" python '")
import math
import numpy as np
RAD2DEG = 57.29577951308232
def get_display(spec):
"""Convert a display specification (such as :0) into an actual Display
object.
Pyglet only supports multiple Displays on Linux.
"""
if spec is None:
return None
elif isinstance(spec, six.string_types):
return pyglet.canvas.Display(spec)
else:
raise error.Error(
'Invalid display specification: {}. (Must be a string like :0 or None.)'.format(spec))
class Viewer(object):
def __init__(self, width, height, display=None):
display = get_display(display)
self.width = width
self.height = height
self.window = pyglet.window.Window(
width=width, height=height, display=display)
self.window.on_close = self.window_closed_by_user
self.geoms = []
self.onetime_geoms = []
self.transform = Transform()
glEnable(GL_BLEND)
# glEnable(GL_MULTISAMPLE)
glEnable(GL_LINE_SMOOTH)
# glHint(GL_LINE_SMOOTH_HINT, GL_DONT_CARE)
glHint(GL_LINE_SMOOTH_HINT, GL_NICEST)
glLineWidth(2.0)
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA)
def close(self):
self.window.close()
def window_closed_by_user(self):
self.close()
def set_bounds(self, left, right, bottom, top):
assert right > left and top > bottom
scalex = self.width/(right-left)
scaley = self.height/(top-bottom)
self.transform = Transform(
translation=(-left*scalex, -bottom*scaley),
scale=(scalex, scaley))
def add_geom(self, geom):
self.geoms.append(geom)
def add_onetime(self, geom):
self.onetime_geoms.append(geom)
def render(self, return_rgb_array=False):
glClearColor(1, 1, 1, 1)
self.window.clear()
self.window.switch_to()
self.window.dispatch_events()
self.transform.enable()
for geom in self.geoms:
geom.render()
for geom in self.onetime_geoms:
geom.render()
self.transform.disable()
arr = None
if return_rgb_array:
buffer = pyglet.image.get_buffer_manager().get_color_buffer()
image_data = buffer.get_image_data()
arr = np.fromstring(image_data.data, dtype=np.uint8, sep='')
# In https://github.com/openai/gym-http-api/issues/2, we
# discovered that someone using Xmonad on Arch was having
# a window of size 598 x 398, though a 600 x 400 window
# was requested. (Guess Xmonad was preserving a pixel for
# the boundary.) So we use the buffer height/width rather
# than the requested one.
arr = arr.reshape(buffer.height, buffer.width, 4)
arr = arr[::-1, :, 0:3]
self.window.flip()
self.onetime_geoms = []
return arr
# Convenience
def draw_circle(self, radius=10, res=30, filled=True, **attrs):
geom = make_circle(radius=radius, res=res, filled=filled)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def draw_polygon(self, v, filled=True, **attrs):
geom = make_polygon(v=v, filled=filled)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def draw_polyline(self, v, **attrs):
geom = make_polyline(v=v)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def draw_line(self, start, end, **attrs):
geom = Line(start, end)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def get_array(self):
self.window.flip()
image_data = pyglet.image.get_buffer_manager().get_color_buffer().get_image_data()
self.window.flip()
arr = np.fromstring(image_data.data, dtype=np.uint8, sep='')
arr = arr.reshape(self.height, self.width, 4)
return arr[::-1, :, 0:3]
def _add_attrs(geom, attrs):
if "color" in attrs:
geom.set_color(*attrs["color"])
if "linewidth" in attrs:
geom.set_linewidth(attrs["linewidth"])
class Geom(object):
def __init__(self):
self._color = Color((0, 0, 0, 1.0))
self.attrs = [self._color]
def render(self):
for attr in reversed(self.attrs):
attr.enable()
self.render1()
for attr in self.attrs:
attr.disable()
def render1(self):
raise NotImplementedError
def add_attr(self, attr):
self.attrs.append(attr)
def set_color(self, r, g, b, alpha=1):
self._color.vec4 = (r, g, b, alpha)
class Attr(object):
def enable(self):
raise NotImplementedError
def disable(self):
pass
class Transform(Attr):
def __init__(self, translation=(0.0, 0.0), rotation=0.0, scale=(1, 1)):
self.set_translation(*translation)
self.set_rotation(rotation)
self.set_scale(*scale)
def enable(self):
glPushMatrix()
# translate to GL loc ppint
glTranslatef(self.translation[0], self.translation[1], 0)
glRotatef(RAD2DEG * self.rotation, 0, 0, 1.0)
glScalef(self.scale[0], self.scale[1], 1)
def disable(self):
glPopMatrix()
def set_translation(self, newx, newy):
self.translation = (float(newx), float(newy))
def set_rotation(self, new):
self.rotation = float(new)
def set_scale(self, newx, newy):
self.scale = (float(newx), float(newy))
class Color(Attr):
def __init__(self, vec4):
self.vec4 = vec4
def enable(self):
glColor4f(*self.vec4)
class LineStyle(Attr):
def __init__(self, style):
self.style = style
def enable(self):
glEnable(GL_LINE_STIPPLE)
glLineStipple(1, self.style)
def disable(self):
glDisable(GL_LINE_STIPPLE)
class LineWidth(Attr):
def __init__(self, stroke):
self.stroke = stroke
def enable(self):
glLineWidth(self.stroke)
class Point(Geom):
def __init__(self):
Geom.__init__(self)
def render1(self):
glBegin(GL_POINTS) # draw point
glVertex3f(0.0, 0.0, 0.0)
glEnd()
class FilledPolygon(Geom):
def __init__(self, v):
Geom.__init__(self)
self.v = v
def render1(self):
if len(self.v) == 4:
glBegin(GL_QUADS)
elif len(self.v) > 4:
glBegin(GL_POLYGON)
else:
glBegin(GL_TRIANGLES)
for p in self.v:
glVertex3f(p[0], p[1], 0) # draw each vertex
glEnd()
color = (self._color.vec4[0] * 0.5, self._color.vec4[1] *
0.5, self._color.vec4[2] * 0.5, self._color.vec4[3] * 0.5)
glColor4f(*color)
glBegin(GL_LINE_LOOP)
for p in self.v:
glVertex3f(p[0], p[1], 0) # draw each vertex
glEnd()
def make_circle(radius=10, res=30, filled=True):
points = []
for i in range(res):
ang = 2*math.pi*i / res
points.append((math.cos(ang)*radius, math.sin(ang)*radius))
if filled:
return FilledPolygon(points)
else:
return PolyLine(points, True)
def make_polygon(v, filled=True):
if filled:
return FilledPolygon(v)
else:
return PolyLine(v, True)
def make_polyline(v):
return PolyLine(v, False)
def make_capsule(length, width):
l, r, t, b = 0, length, width/2, -width/2
box = make_polygon([(l, b), (l, t), (r, t), (r, b)])
circ0 = make_circle(width/2)
circ1 = make_circle(width/2)
circ1.add_attr(Transform(translation=(length, 0)))
geom = Compound([box, circ0, circ1])
return geom
class Compound(Geom):
def __init__(self, gs):
Geom.__init__(self)
self.gs = gs
for g in self.gs:
g.attrs = [a for a in g.attrs if not isinstance(a, Color)]
def render1(self):
for g in self.gs:
g.render()
class PolyLine(Geom):
def __init__(self, v, close):
Geom.__init__(self)
self.v = v
self.close = close
self.linewidth = LineWidth(1)
self.add_attr(self.linewidth)
def render1(self):
glBegin(GL_LINE_LOOP if self.close else GL_LINE_STRIP)
for p in self.v:
glVertex3f(p[0], p[1], 0) # draw each vertex
glEnd()
def set_linewidth(self, x):
self.linewidth.stroke = x
class Line(Geom):
def __init__(self, start=(0.0, 0.0), end=(0.0, 0.0)):
Geom.__init__(self)
self.start = start
self.end = end
self.linewidth = LineWidth(1)
self.add_attr(self.linewidth)
def render1(self):
glBegin(GL_LINES)
glVertex2f(*self.start)
glVertex2f(*self.end)
glEnd()
class Image(Geom):
def __init__(self, fname, width, height):
Geom.__init__(self)
self.width = width
self.height = height
img = pyglet.image.load(fname)
self.img = img
self.flip = False
def render1(self):
self.img.blit(-self.width/2, -self.height/2,
width=self.width, height=self.height)
# ================================================================
class SimpleImageViewer(object):
def __init__(self, display=None):
self.window = None
self.isopen = False
self.display = display
def imshow(self, arr):
if self.window is None:
height, width, channels = arr.shape
self.window = pyglet.window.Window(
width=width, height=height, display=self.display)
self.width = width
self.height = height
self.isopen = True
assert arr.shape == (
self.height, self.width, 3), "You passed in an image with the wrong number shape"
image = pyglet.image.ImageData(
self.width, self.height, 'RGB', arr.tobytes(), pitch=self.width * -3)
self.window.clear()
self.window.switch_to()
self.window.dispatch_events()
image.blit(0, 0)
self.window.flip()
def close(self):
if self.isopen:
self.window.close()
self.isopen = False
def __del__(self):
self.close()
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenario.py
================================================
import numpy as np
# defines scenario upon which the world is built
class BaseScenario(object):
# create elements of the world
def make_world(self):
raise NotImplementedError()
# create initial conditions of the world
def reset_world(self, world):
raise NotImplementedError()
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/__init__.py
================================================
import imp
import os.path as osp
def load(name):
pathname = osp.join(osp.dirname(__file__), name)
return imp.load_source('', pathname)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/hetero_spread.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# set any world properties first
world.dim_c = 2
world.max_steps = 25
num_agents = args.num_agents
self.n_agent_a = num_agents // 2 # 2
self.n_agent_b = num_agents // 2 # 2
num_landmarks = args.num_agents
world.collaborative = True
self.agent_size = 0.10
self.n_others = 3
self.n_group = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
agent.id = i
if i < self.n_agent_a:
agent.size = self.agent_size
agent.accel = 3.0
agent.max_speed = 1.0
else:
agent.size = self.agent_size / 2
agent.accel = 4.0
agent.max_speed = 1.3
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
world.num_steps = 0
self.end_steps = world.max_steps
# random properties for agents
for i, agent in enumerate(world.agents):
if i < self.n_agent_a:
agent.color = np.array([0.35, 0.35, 0.85])
else:
agent.color = np.array([0.35, 0.85, 0.35])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
rew = 0
collisions = 0
occupied_landmarks = 0
min_dists = 0
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
min_dists += min(dists)
rew -= min(dists)
if min(dists) < 0.1:
occupied_landmarks += 1
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
collisions += 1
return (rew, collisions, min_dists, occupied_landmarks)
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark, penalized for collisions
rew = 0
shaped_reward = False
if shaped_reward: # distance-based reward
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
rew -= min(dists)
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
return rew
else:
win_agents = []
for land in world.landmarks:
for a in world.agents:
if self.is_collision(a, land):
win_agents.append(a)
break
rew += 2 * len(set(win_agents))
def bound(x):
if x > 1.0:
return min(np.exp(2 * x - 2), 10)
else:
return 0.0
bound_rew = 0.0
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
bound_rew -= bound(x)
rew += bound_rew
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
other_vel = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent:
other_vel.append([0, 0])
continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + comm +
other_vel + entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_adversary.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario # TODO
import random
class Scenario(BaseScenario):
def make_world(self, args):
world = World() # from core
# set any world properties first
world.dim_c = 2
num_agents = args.num_agents # 3
world.num_agents = num_agents
num_adversaries = 1
num_landmarks = num_agents - 1
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.silent = True
agent.adversary = True if i < num_adversaries else False
agent.size = 0.15
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.08
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
world.assign_agent_colors()
# random properties for landmarks
world.assign_landmark_colors()
# set goal landmark
goal = np.random.choice(world.landmarks)
goal.color = np.array([0.15, 0.65, 0.15])
for agent in world.agents:
agent.goal_a = goal
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
if agent.adversary:
return np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos))
else:
dists = []
for l in world.landmarks:
dists.append(np.sum(np.square(agent.state.p_pos - l.state.p_pos)))
dists.append(np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos)))
return tuple(dists)
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# Rewarded based on how close any good agent is to the goal landmark, and how far the adversary is from it
shaped_reward = True
shaped_adv_reward = True
# Calculate negative reward for adversary
adversary_agents = self.adversaries(world)
if shaped_adv_reward: # distance-based adversary reward
adv_rew = sum([np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in adversary_agents])
else: # proximity-based adversary reward (binary)
adv_rew = 0
for a in adversary_agents:
if np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) < 2 * a.goal_a.size:
adv_rew -= 5
# Calculate positive reward for agents
good_agents = self.good_agents(world)
if shaped_reward: # distance-based agent reward
pos_rew = -min(
[np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in good_agents])
else: # proximity-based agent reward (binary)
pos_rew = 0
if min([np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in good_agents]) \
< 2 * agent.goal_a.size:
pos_rew += 5
pos_rew -= min(
[np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in good_agents])
return pos_rew + adv_rew
def adversary_reward(self, agent, world):
# Rewarded based on proximity to the goal landmark
shaped_reward = True
if shaped_reward: # distance-based reward
return -np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos))
else: # proximity-based reward (binary)
adv_rew = 0
if np.sqrt(np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos))) < 2 * agent.goal_a.size:
adv_rew += 5
return adv_rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks:
entity_color.append(entity.color)
# communication of all other agents
other_pos = []
for other in world.agents:
if other is agent: continue
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not agent.adversary:
return np.concatenate([agent.goal_a.state.p_pos - agent.state.p_pos] + entity_pos + other_pos)
else:
return np.concatenate(entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_crypto.py
================================================
"""
Scenario:
1 speaker, 2 listeners (one of which is an adversary). Good agents rewarded for proximity to goal, and distance from
adversary to goal. Adversary is rewarded for its distance to the goal.
"""
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
import random
class CryptoAgent(Agent):
def __init__(self):
super(CryptoAgent, self).__init__()
self.key = None
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# set any world properties first
num_agents = args.num_agents # 3
num_adversaries = 1
num_landmarks = args.num_landmarks # 2
world.dim_c = 4
# add agents
world.agents = [CryptoAgent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.adversary = True if i < num_adversaries else False
agent.speaker = True if i == 2 else False
agent.movable = False
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for agent in world.agents:
agent.color = np.array([0.25, 0.25, 0.25])
if agent.adversary:
agent.color = np.array([0.75, 0.25, 0.25])
agent.key = None
# random properties for landmarks
color_list = [np.zeros(world.dim_c) for i in world.landmarks]
for i, color in enumerate(color_list):
color[i] += 1
for color, landmark in zip(color_list, world.landmarks):
landmark.color = color
# set goal landmark
goal = np.random.choice(world.landmarks)
world.agents[1].color = goal.color
world.agents[2].key = np.random.choice(world.landmarks).color
for agent in world.agents:
agent.goal_a = goal
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
return (agent.state.c, agent.goal_a.color)
# return all agents that are not adversaries
def good_listeners(self, world):
return [agent for agent in world.agents if not agent.adversary and not agent.speaker]
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# Agents rewarded if Bob can reconstruct message, but adversary (Eve) cannot
good_listeners = self.good_listeners(world)
adversaries = self.adversaries(world)
good_rew = 0
adv_rew = 0
for a in good_listeners:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
good_rew -= np.sum(np.square(a.state.c - agent.goal_a.color))
for a in adversaries:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
adv_l1 = np.sum(np.square(a.state.c - agent.goal_a.color))
adv_rew += adv_l1
return adv_rew + good_rew
def adversary_reward(self, agent, world):
# Adversary (Eve) is rewarded if it can reconstruct original goal
rew = 0
if not (agent.state.c == np.zeros(world.dim_c)).all():
rew -= np.sum(np.square(agent.state.c - agent.goal_a.color))
return rew
def observation(self, agent, world):
# goal color
goal_color = np.zeros(world.dim_color)
if agent.goal_a is not None:
goal_color = agent.goal_a.color
# print('goal color in obs is {}'.format(goal_color))
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent or (other.state.c is None) or not other.speaker: continue
comm.append(other.state.c)
confer = np.array([0])
if world.agents[2].key is None:
confer = np.array([1])
key = np.zeros(world.dim_c)
goal_color = np.zeros(world.dim_c)
else:
key = world.agents[2].key
prnt = False # True if train use False
# speaker
if agent.speaker:
if prnt:
print('speaker')
print(agent.state.c)
print(np.concatenate([goal_color] + [key] + [confer] + [np.random.randn(1)]))
return np.concatenate([goal_color] + [key])
# listener
if not agent.speaker and not agent.adversary:
if prnt:
print('listener')
print(agent.state.c)
print(np.concatenate([key] + comm + [confer]))
return np.concatenate([key] + comm)
if not agent.speaker and agent.adversary:
if prnt:
print('adversary')
print(agent.state.c)
print(np.concatenate(comm + [confer]))
return np.concatenate(comm)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_crypto_display.py
================================================
"""
Scenario:
1 speaker, 2 listeners (one of which is an adversary). Good agents rewarded for proximity to goal, and distance from
adversary to goal. Adversary is rewarded for its distance to the goal.
"""
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
import random
class CryptoAgent(Agent):
def __init__(self):
super(CryptoAgent, self).__init__()
self.key = None
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# set any world properties first
num_agents = args.num_agents # 3
num_adversaries = 1
num_landmarks = args.num_landmarks # 2
world.dim_c = 4
# add agents
world.agents = [CryptoAgent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.adversary = True if i < num_adversaries else False
agent.speaker = True if i == 2 else False
agent.movable = False
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
world.assign_agent_colors()
for agent in world.agents:
if agent.speaker:
agent.color = np.array([0.25, 0.75, 0.25])
agent.key = None
# random properties for landmarks
world.assign_landmark_colors()
# random properties for landmarks
channel_list = [np.zeros(world.dim_c) for i in world.landmarks]
for i, channel in enumerate(channel_list):
channel[i] += 1
for channel, landmark in zip(channel_list, world.landmarks):
landmark.channel = channel
# set goal landmark
goal = np.random.choice(world.landmarks)
world.agents[1].channel = goal.channel
world.agents[2].key = np.random.choice(world.landmarks).channel
for agent in world.agents:
agent.goal_a = goal
# set random initial states
for i, agent in enumerate(world.agents):
# agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_pos = np.array([0.0, -0.5 + 1.0 / (len(world.agents) - 1) * i])
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
if landmark is goal:
landmark.color = np.array([0.15, 0.15, 0.75])
# landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_pos = np.array([0.5, 0.5 - 0.5 / (len(world.landmarks) - 1) * i])
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
return (agent.state.c, agent.goal_a.channel)
# return all agents that are not adversaries
def good_listeners(self, world):
return [agent for agent in world.agents if not agent.adversary and not agent.speaker]
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# Agents rewarded if Bob can reconstruct message, but adversary (Eve) cannot
good_listeners = self.good_listeners(world)
adversaries = self.adversaries(world)
good_rew = 0
adv_rew = 0
for a in good_listeners:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
good_rew -= np.sum(np.square(a.state.c - agent.goal_a.channel))
for a in adversaries:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
adv_l1 = np.sum(np.square(a.state.c - agent.goal_a.channel))
adv_rew += adv_l1
return adv_rew + good_rew
def adversary_reward(self, agent, world):
# Adversary (Eve) is rewarded if it can reconstruct original goal
rew = 0
if not (agent.state.c == np.zeros(world.dim_c)).all():
rew -= np.sum(np.square(agent.state.c - agent.goal_a.channel))
return rew
def observation(self, agent, world):
# goal channel
goal_channel = np.zeros(world.dim_color)
if agent.goal_a is not None:
goal_channel = agent.goal_a.channel
print('goal channel in obs is {}'.format(goal_channel))
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent or (other.state.c is None) or not other.speaker: continue
comm.append(other.state.c)
confer = np.array([0])
if world.agents[2].key is None:
confer = np.array([1])
key = np.zeros(world.dim_c)
goal_channel = np.zeros(world.dim_c)
else:
key = world.agents[2].key
prnt = True # if train use False
# speaker
if agent.speaker:
if prnt:
print('speaker')
print(agent.state.c)
# print(np.concatenate([goal_channel] + [key] + [confer] + [np.random.randn(1)]))
return np.concatenate([goal_channel] + [key])
# listener
if not agent.speaker and not agent.adversary:
if prnt:
print('listener')
print(agent.state.c)
# print(np.concatenate([key] + comm + [confer]))
return np.concatenate([key] + comm)
if not agent.speaker and agent.adversary:
if prnt:
print('adversary')
print(agent.state.c)
# print(np.concatenate(comm + [confer]))
return np.concatenate(comm)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_push.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
import random
#
# # the non-ensemble version of
#
#
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# set any world properties first
world.dim_c = 2
num_agents = args.num_agents # 2
num_adversaries = 1
num_landmarks = args.num_landmarks # 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
if i < num_adversaries:
agent.adversary = True
else:
agent.adversary = False
# agent.u_noise = 1e-1
# agent.c_noise = 1e-1
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.1, 0.1, 0.1])
landmark.color[i + 1] += 0.8
landmark.index = i
# set goal landmark
goal = np.random.choice(world.landmarks)
for i, agent in enumerate(world.agents):
agent.goal_a = goal
agent.color = np.array([0.25, 0.25, 0.25])
if agent.adversary:
agent.color = np.array([0.75, 0.25, 0.25])
else:
j = goal.index
agent.color[j + 1] += 0.5
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = 0.8 * np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# the distance to the goal
return -np.sqrt(np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos)))
def adversary_reward(self, agent, world):
# keep the nearest good agents away from the goal
agent_dist = [np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in world.agents if
not a.adversary]
pos_rew = min(agent_dist)
# nearest_agent = world.good_agents[np.argmin(agent_dist)]
# neg_rew = np.sqrt(np.sum(np.square(nearest_agent.state.p_pos - agent.state.p_pos)))
neg_rew = np.sqrt(np.sum(np.square(agent.goal_a.state.p_pos - agent.state.p_pos)))
# neg_rew = sum([np.sqrt(np.sum(np.square(a.state.p_pos - agent.state.p_pos))) for a in world.good_agents])
return pos_rew - neg_rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not agent.adversary:
return np.concatenate([agent.state.p_vel] + [agent.goal_a.state.p_pos - agent.state.p_pos] + [
agent.color] + entity_pos + entity_color + other_pos)
else:
# other_pos = list(reversed(other_pos)) if random.uniform(0,1) > 0.5 else other_pos # randomize position of other agents in adversary network
return np.concatenate([agent.state.p_vel] + entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_reference.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# set any world properties first
# world.world_length = args.episode_length
world.dim_c = 10
world.collaborative = True # whether agents share rewards
# add agents
world.num_agents = args.num_agents # 2
assert world.num_agents == 2, (
"only 2 agents is supported, check the config.py.")
world.agents = [Agent() for i in range(world.num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
# agent.u_noise = 1e-1
# agent.c_noise = 1e-1
# add landmarks
world.num_landmarks = args.num_landmarks # 3
world.landmarks = [Landmark() for i in range(world.num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# assign goals to agents
for agent in world.agents:
agent.goal_a = None
agent.goal_b = None
# want other agent to go to the goal landmark
world.agents[0].goal_a = world.agents[1]
world.agents[0].goal_b = np.random.choice(world.landmarks)
world.agents[1].goal_a = world.agents[0]
world.agents[1].goal_b = np.random.choice(world.landmarks)
# random properties for agents
world.assign_agent_colors()
# random properties for landmarks
world.landmarks[0].color = np.array([0.75, 0.25, 0.25])
world.landmarks[1].color = np.array([0.25, 0.75, 0.25])
world.landmarks[2].color = np.array([0.25, 0.25, 0.75])
# special colors for goals
world.agents[0].goal_a.color = world.agents[0].goal_b.color
world.agents[1].goal_a.color = world.agents[1].goal_b.color
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = 0.8 * np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
if agent.goal_a is None or agent.goal_b is None:
return 0.0
dist2 = np.sum(
np.square(agent.goal_a.state.p_pos - agent.goal_b.state.p_pos))
return -dist2 # np.exp(-dist2)
def observation(self, agent, world):
# goal positions
# goal_pos = [np.zeros(world.dim_p), np.zeros(world.dim_p)]
# if agent.goal_a is not None:
# goal_pos[0] = agent.goal_a.state.p_pos - agent.state.p_pos
# if agent.goal_b is not None:
# goal_pos[1] = agent.goal_b.state.p_pos - agent.state.p_pos
# goal color
goal_color = [np.zeros(world.dim_color), np.zeros(world.dim_color)]
# if agent.goal_a is not None:
# goal_color[0] = agent.goal_a.color
if agent.goal_b is not None:
goal_color[1] = agent.goal_b.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent:
continue
comm.append(other.state.c)
return np.concatenate([agent.state.p_vel] + entity_pos + [goal_color[1]] + comm)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_speaker_listener.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
world.world_length = args.episode_length
# set any world properties first
world.dim_c = 3
world.num_landmarks = args.num_landmarks # 3
world.collaborative = True
# add agents
world.num_agents = args.num_agents # 2
assert world.num_agents == 2, (
"only 2 agents is supported, check the config.py.")
world.agents = [Agent() for i in range(world.num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.size = 0.075
# speaker
world.agents[0].movable = False
# listener
world.agents[1].silent = True
# add landmarks
world.landmarks = [Landmark() for i in range(world.num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.04
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# assign goals to agents
for agent in world.agents:
agent.goal_a = None
agent.goal_b = None
# want listener to go to the goal landmark
world.agents[0].goal_a = world.agents[1]
world.agents[0].goal_b = np.random.choice(world.landmarks)
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25, 0.25, 0.25])
# random properties for landmarks
world.landmarks[0].color = np.array([0.65, 0.15, 0.15])
world.landmarks[1].color = np.array([0.15, 0.65, 0.15])
world.landmarks[2].color = np.array([0.15, 0.15, 0.65])
# special colors for goals
world.agents[0].goal_a.color = world.agents[0].goal_b.color + \
np.array([0.45, 0.45, 0.45])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
return reward(agent, reward)
def reward(self, agent, world):
# squared distance from listener to landmark
a = world.agents[0]
dist2 = np.sum(np.square(a.goal_a.state.p_pos - a.goal_b.state.p_pos))
return -dist2
def observation(self, agent, world):
# goal color
goal_color = np.zeros(world.dim_color)
if agent.goal_b is not None:
goal_color = agent.goal_b.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent or (other.state.c is None):
continue
comm.append(other.state.c)
# speaker
if not agent.movable:
return np.concatenate([goal_color])
# listener
if agent.silent:
return np.concatenate([agent.state.p_vel] + entity_pos + comm)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_spread.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# world.world_length = args.episode_length
# set any world properties first
world.dim_c = 2
world.num_agents = args.num_agents
world.num_landmarks = args.num_landmarks # 3
world.collaborative = True
# add agents
world.agents = [Agent() for i in range(world.num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
agent.size = 0.15
# add landmarks
world.landmarks = [Landmark() for i in range(world.num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
world.assign_agent_colors()
world.assign_landmark_colors()
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = 0.8 * np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
rew = 0
collisions = 0
occupied_landmarks = 0
min_dists = 0
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos)))
for a in world.agents]
min_dists += min(dists)
rew -= min(dists)
if min(dists) < 0.1:
occupied_landmarks += 1
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
collisions += 1
return (rew, collisions, min_dists, occupied_landmarks)
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark, penalized for collisions
rew = 0
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos)))
for a in world.agents]
rew -= min(dists)
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent:
continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + comm)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_tag.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# set any world properties first
world.dim_c = 2
num_good_agents = args.num_good_agents # 1
num_adversaries = args.num_adversaries # 3
num_agents = num_adversaries + num_good_agents
num_landmarks = args.num_landmarks # 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
agent.adversary = True if i < num_adversaries else False
agent.size = 0.075 if agent.adversary else 0.05
agent.accel = 3.0 if agent.adversary else 4.0
# agent.accel = 20.0 if agent.adversary else 25.0
agent.max_speed = 1.0 if agent.adversary else 1.3
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = True
landmark.movable = False
landmark.size = 0.2
landmark.boundary = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
world.assign_agent_colors()
# random properties for landmarks
world.assign_landmark_colors()
# random properties for landmarks
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
if not landmark.boundary:
landmark.state.p_pos = 0.8 * np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
if agent.adversary:
collisions = 0
for a in self.good_agents(world):
if self.is_collision(a, agent):
collisions += 1
return collisions
else:
return 0
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
main_reward = self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
return main_reward
def agent_reward(self, agent, world):
# Agents are negatively rewarded if caught by adversaries
rew = 0
shape = False # different from openai
adversaries = self.adversaries(world)
if shape: # reward can optionally be shaped (increased reward for increased distance from adversary)
for adv in adversaries:
rew += 0.1 * np.sqrt(np.sum(np.square(agent.state.p_pos - adv.state.p_pos)))
if agent.collide:
for a in adversaries:
if self.is_collision(a, agent):
rew -= 10
# agents are penalized for exiting the screen, so that they can be caught by the adversaries
def bound(x):
if x < 0.9:
return 0
if x < 1.0:
return (x - 0.9) * 10
return min(np.exp(2 * x - 2), 10)
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
rew -= bound(x)
return rew
def adversary_reward(self, agent, world):
# Adversaries are rewarded for collisions with agents
rew = 0
shape = False # different from openai
agents = self.good_agents(world)
adversaries = self.adversaries(world)
if shape: # reward can optionally be shaped (decreased reward for increased distance from agents)
for adv in adversaries:
rew -= 0.1 * min([np.sqrt(np.sum(np.square(a.state.p_pos - adv.state.p_pos))) for a in agents])
if agent.collide:
for ag in agents:
for adv in adversaries:
if self.is_collision(ag, adv):
rew += 10
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_world_comm.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# set any world properties first
world.dim_c = 4
# world.damping = 1
num_good_agents = args.num_good_agents # 2
num_adversaries = args.num_adversaries # 4
num_agents = num_adversaries + num_good_agents
num_landmarks = args.num_landmarks # 1
num_food = 2
num_forests = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.leader = True if i == 0 else False
agent.silent = True if i > 0 else False
agent.adversary = True if i < num_adversaries else False
agent.size = 0.075 if agent.adversary else 0.045
agent.accel = 3.0 if agent.adversary else 4.0
# agent.accel = 20.0 if agent.adversary else 25.0
agent.max_speed = 1.0 if agent.adversary else 1.3
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = True
landmark.movable = False
landmark.size = 0.2
landmark.boundary = False
world.food = [Landmark() for i in range(num_food)]
for i, landmark in enumerate(world.food):
landmark.name = 'food %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.03
landmark.boundary = False
world.forests = [Landmark() for i in range(num_forests)]
for i, landmark in enumerate(world.forests):
landmark.name = 'forest %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.3
landmark.boundary = False
world.landmarks += world.food
world.landmarks += world.forests
# world.landmarks += self.set_boundaries(world) # world boundaries now penalized with negative reward
# make initial conditions
self.reset_world(world)
return world
def set_boundaries(self, world):
boundary_list = []
landmark_size = 1
edge = 1 + landmark_size
num_landmarks = int(edge * 2 / landmark_size)
for x_pos in [-edge, edge]:
for i in range(num_landmarks):
l = Landmark()
l.state.p_pos = np.array([x_pos, -1 + i * landmark_size])
boundary_list.append(l)
for y_pos in [-edge, edge]:
for i in range(num_landmarks):
l = Landmark()
l.state.p_pos = np.array([-1 + i * landmark_size, y_pos])
boundary_list.append(l)
for i, l in enumerate(boundary_list):
l.name = 'boundary %d' % i
l.collide == True
l.movable = False
l.boundary = True
l.color = np.array([0.75, 0.75, 0.75])
l.size = landmark_size
l.state.p_vel = np.zeros(world.dim_p)
return boundary_list
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.45, 0.95, 0.45]) if not agent.adversary else np.array([0.95, 0.45, 0.45])
agent.color -= np.array([0.3, 0.3, 0.3]) if agent.leader else np.array([0, 0, 0])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
for i, landmark in enumerate(world.food):
landmark.color = np.array([0.15, 0.15, 0.65])
for i, landmark in enumerate(world.forests):
landmark.color = np.array([0.6, 0.9, 0.6])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = 0.8 * np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
for i, landmark in enumerate(world.food):
landmark.state.p_pos = 0.8 * np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
for i, landmark in enumerate(world.forests):
landmark.state.p_pos = 0.8 * np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
if agent.adversary:
collisions = 0
for a in self.good_agents(world):
if self.is_collision(a, agent):
collisions += 1
return collisions
else:
return 0
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
# boundary_reward = -10 if self.outside_boundary(agent) else 0
main_reward = self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
return main_reward
def outside_boundary(self, agent):
if agent.state.p_pos[0] > 1 or agent.state.p_pos[0] < -1 or agent.state.p_pos[1] > 1 or agent.state.p_pos[
1] < -1:
return True
else:
return False
def agent_reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
rew = 0
shape = False
adversaries = self.adversaries(world)
if shape:
for adv in adversaries:
rew += 0.1 * np.sqrt(np.sum(np.square(agent.state.p_pos - adv.state.p_pos)))
if agent.collide:
for a in adversaries:
if self.is_collision(a, agent):
rew -= 5
def bound(x):
if x < 0.9:
return 0
if x < 1.0:
return (x - 0.9) * 10
return min(np.exp(2 * x - 2), 10) # 1 + (x - 1) * (x - 1)
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
rew -= 2 * bound(x)
for food in world.food:
if self.is_collision(agent, food):
rew += 2
rew += 0.05 * min([np.sqrt(np.sum(np.square(food.state.p_pos - agent.state.p_pos))) for food in world.food])
return rew
def adversary_reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
rew = 0
shape = True
agents = self.good_agents(world)
adversaries = self.adversaries(world)
if shape:
rew -= 0.1 * min([np.sqrt(np.sum(np.square(a.state.p_pos - agent.state.p_pos))) for a in agents])
# for adv in adversaries:
# rew -= 0.1 * min([np.sqrt(np.sum(np.square(a.state.p_pos - adv.state.p_pos))) for a in agents])
if agent.collide:
for ag in agents:
for adv in adversaries:
if self.is_collision(ag, adv):
rew += 5
return rew
def observation2(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
food_pos = []
for entity in world.food: # world.entities:
if not entity.boundary:
food_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel)
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
in_forest = [np.array([-1]), np.array([-1])]
inf1 = False
inf2 = False
if self.is_collision(agent, world.forests[0]):
in_forest[0] = np.array([1])
inf1 = True
if self.is_collision(agent, world.forests[1]):
in_forest[1] = np.array([1])
inf2 = True
food_pos = []
for entity in world.food:
if not entity.boundary:
food_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
oth_f1 = self.is_collision(other, world.forests[0])
oth_f2 = self.is_collision(other, world.forests[1])
if (inf1 and oth_f1) or (inf2 and oth_f2) or (
not inf1 and not oth_f1 and not inf2 and not oth_f2) or agent.leader: # without forest vis
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
else:
other_pos.append([0, 0])
if not other.adversary:
other_vel.append([0, 0])
# to tell the pred when the prey are in the forest
prey_forest = []
ga = self.good_agents(world)
for a in ga:
if any([self.is_collision(a, f) for f in world.forests]):
prey_forest.append(np.array([1]))
else:
prey_forest.append(np.array([-1]))
# to tell leader when pred are in forest
prey_forest_lead = []
for f in world.forests:
if any([self.is_collision(a, f) for a in ga]):
prey_forest_lead.append(np.array([1]))
else:
prey_forest_lead.append(np.array([-1]))
comm = [world.agents[0].state.c]
if agent.adversary and not agent.leader:
return np.concatenate(
[agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel + in_forest + comm)
if agent.leader:
return np.concatenate(
[agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel + in_forest + comm)
else:
return np.concatenate(
[agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + in_forest + other_vel)
================================================
FILE: examples/Social_Cognition/ToCM/networks/ToCM/action.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
import sys
import os
# if '/home/zhaofeifei/.local/lib/python3.8/site-packages' in sys.path:
# sys.path.remove('/home/zhaofeifei/.local/lib/python3.8/site-packages')
# sys.path.append('/home/zhaofeifei/mambaSNN_Mpe/networks/ToCM/')
# sys.path.append("/home/zhaofeifei/mambaSNN_Mpe/")
from torch.distributions import OneHotCategorical
from networks.transformer.layers import AttentionEncoder, AttentionActorEncoder
from networks.ToCM.utils import build_model_snn, build_model
from braincog.base.node.node import LIFNode, BaseNode, PLIFNode, DoubleSidePLIFNode
from braincog.base.strategy.surrogate import AtanGrad
class BCNoSpikingLIFNode(LIFNode):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self, dv: torch.Tensor):
# print("dv: ", dv)
# print("dv.shape: ", dv.shape)
self.integral(dv)
return self.mem
#SNN
# class Actor(nn.Module):
# def __init__(self, in_dim, out_dim, hidden_size, layers, node='LIFNode', time_window=8,
# norm_in=True, output_style='voltage'): # 1.激活函数需要改成node # voltage
# super().__init__()
# # 1.加入SNN的脉冲参数
# self._threshold = 0.5
# self.v_reset = 0.0
# self.tau = 0.5
# self._time_window = time_window
# # 2.设置输出格式
# self.output_style = output_style
# # 3.ffn是否归一化
# self.norm = norm_in
# self.activation = node
# self.feedforward_model = build_model_snn(in_dim, out_dim, layers, hidden_size, # kkkk TODO!!!
# th=self._threshold, re=self.v_reset, tau=self.tau,
# activation=self.activation, normalize=lambda x: x) # TODO
# if self.output_style == 'ann':
# self.out_node = lambda x: x
# elif self.output_style == 'voltage':
# self.out_node = BCNoSpikingLIFNode(tau=1.0)
#
# def forward(self, state_features):
# # 5.加入脉冲仿真步长
# # print("state.shape", state_features.shape)
# self.reset() # why
# for t in range(self._time_window):
# x = self.feedforward_model(state_features)
# x = self.out_node(x)
# # print("x", x.shape)
# action_dist = OneHotCategorical(logits=x)
# action = action_dist.sample() # 长度为x,一行默认 tensor([0., 1., 0., 0.])
# return action, x
#
# # 调用modules里面node的n_reset
# def reset(self):
# for mod in self.modules():
# if hasattr(mod, 'n_reset'):
# mod.n_reset()
#ANN
class Actor(nn.Module):
def __init__(self, in_dim, out_dim, hidden_size, layers, activation=nn.ReLU):
super().__init__()
self.feedforward_model = build_model(in_dim, out_dim, layers, hidden_size, activation)
def forward(self, state_features):
x = self.feedforward_model(state_features)
action_dist = OneHotCategorical(logits=x)
action = action_dist.sample()
return action, x
class AttentionActor(nn.Module):
def __init__(self, in_dim, out_dim, hidden_size, layers, node='LIFNode', time_window=16,
norm_in=True, output_style='voltage'): # 2.激活层
super().__init__()
# 1.加入SNN的脉冲参数
self._threshold = 0.5
self.v_reset = 0.0
self._time_window = time_window
# 2.设置输出格式
self.output_style = output_style
# 3.ffn是否归一化
self.norm = norm_in
# 4.改变linear层的激活函数为LIFNode
self.activation = node
# hint: hidden_size = 其他网络的in_dim
self.feedforward_model = build_model_snn(hidden_size, out_dim, 2, hidden_size,
th=self._threshold, re=self.v_reset,
activation=self.activation, normalize=lambda x: x) # TODO
# build_model_snn(in_dim, out_dim, layers, hidden, activation, normalize=lambda x: x)
self._attention_stack = AttentionActorEncoder(1, hidden_size, hidden_size)
# no pos_embedding
# self._attention_stack = nn.TransformerEncoder(nn.TransformerEncoderLayer(d_model=in_dim, nhead=1,
# dim_feedforward=hidden_size,
# dropout=.0), num_layers=1) # TODO
# n_layers, in_dim, hidden
# 使用transformer的编码器,加入位置编码,加入隐藏单元d_hid,返回一个序列,其中第0维度应该是观测变量?
self.embed = nn.Linear(in_dim, hidden_size)
self.node1 = LIFNode(threshold=self._threshold, v_reset=self.v_reset)
self.node2 = LIFNode(threshold=self._threshold, v_reset=self.v_reset)
# 5. 定义一个处理linear层的node
if self.activation == 'LIFNode':
if self.output_style == 'voltage':
self.out_node = BCNoSpikingLIFNode(tau=2.0)
def forward(self, state_features): # 状态值tensor
# print("state_feat:", state_features[0])
# attn_embeds = self._attention_stack(state_features)
# n_agents = state_features.shape[-2] # 推测state的维度为[batch_size(m,n), n_agents, in_dim]
# batch_size = state_features.shape[:-2] # 除去最后2维度的维度
qs = []
self.reset() # why
# print("attn_embeds", attn_embeds[0])
# print("state.shape", state_features.shape)
attn_embeds = self.embed(state_features) # Linear
for t in range(self._time_window):
embeds = self.node1(attn_embeds) # Node
# attn_embeds = embeds.view(-1, n_agents, embeds.shape[-1])
# embeds = self.node2(self._attention_stack(embeds).view(*batch_size, n_agents, embeds.shape[-1]))
x = self.feedforward_model(embeds)
x = self.out_node(x)
qs.append(x)
p = torch.zeros(qs[0].shape)
if self.output_style == "sum":
p = sum(qs) / self._time_window
elif self.output_style == "voltage":
p = qs[-1] # TODO
# p = F.softmax(p)
# print("pi:", p[0])
action_dist = OneHotCategorical(logits=p) # 编码器,长度为p
action = action_dist.sample()
# print("actions", action[0])
# 对输出进行采样
return action, p # 返回一个行动序列action为每个位置符合p = x[i]的0,1序列
# 调用modules里面node的n_reset
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
# aa = AttentionActor(16, 8, 64, 3) # in_dim, out_dim, hidden_size, layers,
# state_feature = torch.randn([8, 8, 2, 16]) # 输入变量维度
# out, x = aa(state_feature)
# print(aa)
# print(out)
# print(out.shape)
================================================
FILE: examples/Social_Cognition/ToCM/networks/ToCM/critic.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
import sys
sys.path.append('/home/zhaofeifei/mambaSNN/networks/ToCM/')
from networks.ToCM.utils import build_model_snn, build_model
from networks.transformer.layers import AttentionEncoder
from braincog.base.node.node import LIFNode
from braincog.base.strategy.surrogate import AtanGrad
decay = 0.3
thresh = 0.3
lens = 0.25
# print("File Critic Here")
# 0.定义一个返回膜电势的 LIFNode
class BCNoSpikingLIFNode(LIFNode):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self, dv: torch.Tensor):
# print("dv: ", dv)
# print("dv.shape: ", dv.shape)
self.integral(dv)
return self.mem
act_fun = AtanGrad(alpha=2., requires_grad=False)
def mem_update(fc, x, mem, spike):
mem = mem * decay * (1 - spike) + fc(x)
# spike = act_fun(mem)
spike = act_fun(x=mem-1)
return mem, spike
class Critic(nn.Module):
def __init__(self, in_dim, hidden_size, layers=2, node='LIFNode', time_window=16,
norm_in=True, output_style='voltage'):
# hint是critic没有输出维度,action的输出维度是action的数量
super().__init__()
# 1.加入SNN的脉冲参数
self._threshold = 0.5
self.v_reset = 0.0
self._time_window = time_window
# 2.设置输出格式
self.output_style = output_style
# 3.ffn是否归一化
self.norm = norm_in
# if self.norm:
# self.in_norm = nn.BatchNorm1d(in_dim)
# self.in_norm.weight.data.fill_(1)
# self.in_norm.bias.data.zero_()
# else:
# self.in_norm = lambda x: x
self.in_norm = lambda x: x
# 4.改变linear层的激活函数为LIFNode
self.activation = node
self.hidden_size = hidden_size
self.layers = layers
self.feedforward_model = build_model_snn(in_dim, 1, layers, hidden_size,
th=self._threshold, re=self.v_reset,
activation=self.activation, normalize=lambda x: x)
# 这里feedforward的输出维度为1,其余一样 in_dim, out_dim, layers, hidden
# 5. 定义输出神经元node
if self.output_style == "sum":
self.out_node = lambda x: x
elif self.output_style == "voltage":
self.out_node = BCNoSpikingLIFNode(tau=2.0)
def forward(self, state_features, actions):
# 6.加入脉冲步长模拟
qs = []
self.reset() # why
# 7.加入第一次输入的归一化,对最前面的输入进行norm
state_features = self.in_norm(state_features)
for t in range(self._time_window):
x = self.feedforward_model(state_features)
# 8.linear层之后还得有个node接住。否则如果对于ann来说,linear之后的浮点数就能作为最后的分值了,对于snn不行
x = self.out_node(x)
qs.append(x)
if self.output_style == 'sum':
value = sum(qs) / self._time_window
return value
elif self.output_style == 'voltage':
value = qs[-1]
return value
# 调用modules里面node的n_reset
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
#SNN
# class MADDPGCritic(nn.Module):
# def __init__(self, in_dim, hidden_size, node='nn.Tanh', time_window=1, # time_window=16,
# norm_in=True, output_style='ann'): # in_dim 1280 hidden_size 256
# super().__init__()
#
# # 1.加入SNN的脉冲参数
# self._threshold = 0.5
# self.v_reset = 0.0
# self._time_window = time_window
# # 2.设置输出格式
# self.output_style = output_style
# # 3. ffn是否归一化
# self.norm = norm_in
#
# # TODO no normalize
# self.in_norm = lambda x: x
# # 4.改变linear层的激活函数为LIFNode
# self.activation = node # TODO!!!!!!!!!!!
#
# self.feedforward_model = build_model_snn(hidden_size, 1, 1, hidden_size,
# th=self._threshold, re=self.v_reset,
# activation=self.activation, normalize=lambda x: x)
# # in_dim, out_dim, layers, hidden
# # (in_dim = hidden)->hidden->hidden......-> (out_dim = 1)
#
# self._attention_stack = AttentionEncoder(1, hidden_size, hidden_size)
# self.embed = nn.Linear(in_dim, hidden_size) # 1280 256
# self.prior = build_model_snn(in_dim, 1, 3, hidden_size, # 1280 256
# th=self._threshold, re=self._threshold,
# activation=self.activation, normalize=lambda x: x)
# # also in_dim, out_dim, layers, hidden
# # (in_dim = hidden)->hidden->hidden......-> (out_dim = 1)
# # 可能是个决策函数,决策优先选择哪个action
#
# # 5. 定义输出神经元node
# if self.output_style == "sum":
# self.out_node = lambda x: x
# elif self.output_style == "voltage":
# self.out_node = BCNoSpikingLIFNode(tau=2.0)
# elif self.output_style == 'ann':
# self.out_node = lambda x: x
#
# def forward(self, state_features, actions):
# self.reset() # reset函数得看看怎么加
# n_agents = state_features.shape[-2]
# batch_size = state_features.shape[:-2]
# # 6.加入第一次输入的归一化
# state_features = self.in_norm(state_features)
# # 7.暂时不把编码加入模拟时长
# embeds = F.relu(self.embed(state_features))
# embeds = embeds.view(-1, n_agents, embeds.shape[-1])
# attn_embeds = F.relu(self._attention_stack(embeds).view(*batch_size, n_agents, embeds.shape[-1]))
#
# # 7.设置脉冲发放时长模拟,只在ffn层
# qs = []
# for t in range(self._time_window):
# x = self.feedforward_model(attn_embeds)
# x = self.out_node(x)
# qs.append(x)
#
# value = qs[-1] # after 16 mem
# # x = self.feedforward_model(attn_embeds)
# # value = self.out_node(x) # only mem once
# return value
#
# # 调用modules里面node的n_reset
# def reset(self):
# for mod in self.modules():
# if hasattr(mod, 'n_reset'):
# mod.n_reset()
#ANN
class MADDPGCritic(nn.Module):
def __init__(self, in_dim, hidden_size, layers=2, activation=nn.ELU):
super().__init__()
self.hidden_size = hidden_size
self.layers = layers
self.activation = activation
self.feedforward_model = build_model(in_dim, 1, layers, hidden_size, activation)
def forward(self, state_features, actions):
return self.feedforward_model(state_features)
# critic_net = Critic(in_dim=2, hidden_size=32, layers=2, node='LIFNode', time_window=16, norm_in=True,
# output_style='voltage')
# print(critic_net)
# maddpg_critic_net = MADDPGCritic(in_dim=2, hidden_size=32, node='LIFNode', time_window=16, norm_in=True,
# output_style='voltage')
# print(maddpg_critic_net)
================================================
FILE: examples/Social_Cognition/ToCM/networks/ToCM/dense.py
================================================
import torch
import torch.distributions as td
import torch.nn as nn
from networks.ToCM.utils import build_model_snn
class DenseModel(nn.Module):
def __init__(self, in_dim, out_dim, layers, hidden, activation="nn.ELU"): # TODO activation=nn.ELU
super().__init__()
self.model = build_model_snn(in_dim, out_dim, layers, hidden, activation=activation) # no use activation
def forward(self, features):
return self.model(features)
class DenseBinaryModel(DenseModel):
def __init__(self, in_dim, out_dim, layers, hidden, activation="nn.ELU"): # 1280 7 2 256
super().__init__(in_dim, out_dim, layers, hidden, activation=activation)
def forward(self, features):
# for name, p in self.model.named_parameters():
# print("name", name)
# print("p", p.shape)
# if features.shape[1] != 40:
# print("features.shape[0] / 40: ", features.shape[0] / 40)
# features = torch.as_tensor(torch.split(features, int(features.shape[0] / 40), dim=0))
# print("Dense features: ", features.shape)
dist_inputs = self.model(features) # features.shape 48 40 2 1280
# print("dist_inputs:", dist_inputs.shape)
return td.independent.Independent(td.Bernoulli(logits=dist_inputs), 1)
================================================
FILE: examples/Social_Cognition/ToCM/networks/ToCM/rnns.py
================================================
import torch
import torch.nn as nn
from torch.distributions import OneHotCategorical
from configs.ToCM.ToCMAgentConfig import RSSMState
from networks.transformer.layers import AttentionEncoder
def stack_states(rssm_states: list, dim):
return reduce_states(rssm_states, dim, torch.stack)
def cat_states(rssm_states: list, dim):
return reduce_states(rssm_states, dim, torch.cat)
def reduce_states(rssm_states: list, dim, func):
return RSSMState(*[func([getattr(state, key) for state in rssm_states], dim=dim)
for key in rssm_states[0].__dict__.keys()])
class DiscreteLatentDist(nn.Module):
def __init__(self, in_dim, n_categoricals, n_classes, hidden_size):
super().__init__()
self.n_categoricals = n_categoricals
self.n_classes = n_classes
self.dists = nn.Sequential(nn.Linear(in_dim, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, n_classes * n_categoricals))
def forward(self, x):
logits = self.dists(x).view(x.shape[:-1] + (self.n_categoricals, self.n_classes))
class_dist = OneHotCategorical(logits=logits)
one_hot = class_dist.sample()
latents = one_hot + class_dist.probs - class_dist.probs.detach()
return logits.view(x.shape[:-1] + (-1,)), latents.view(x.shape[:-1] + (-1,))
class RSSMTransition(nn.Module):
def __init__(self, config, hidden_size=200, activation=nn.ReLU):
super().__init__()
self._stoch_size = config.STOCHASTIC
self._deter_size = config.DETERMINISTIC
self._hidden_size = hidden_size
self._activation = activation
self._cell = nn.GRU(hidden_size, self._deter_size)
self._attention_stack = AttentionEncoder(3, hidden_size, hidden_size, dropout=0.1)
self._rnn_input_model = self._build_rnn_input_model(config.ACTION_SIZE + self._stoch_size)
self._stochastic_prior_model = DiscreteLatentDist(self._deter_size, config.N_CATEGORICALS, config.N_CLASSES,
self._hidden_size)
def _build_rnn_input_model(self, in_dim):
rnn_input_model = [nn.Linear(in_dim, self._hidden_size)]
rnn_input_model += [self._activation()]
return nn.Sequential(*rnn_input_model)
def forward(self, prev_actions, prev_states, mask=None):
batch_size = prev_actions.shape[0]
n_agents = prev_actions.shape[1]
stoch_input = self._rnn_input_model(torch.cat([prev_actions, prev_states.stoch], dim=-1))
attn = self._attention_stack(stoch_input, mask=mask)
deter_state = self._cell(attn.reshape(1, batch_size * n_agents, -1),
prev_states.deter.reshape(1, batch_size * n_agents, -1))[0].reshape(batch_size, n_agents, -1)
logits, stoch_state = self._stochastic_prior_model(deter_state)
return RSSMState(logits=logits, stoch=stoch_state, deter=deter_state)
class RSSMRepresentation(nn.Module):
def __init__(self, config, transition_model: RSSMTransition):
super().__init__()
self._transition_model = transition_model
self._stoch_size = config.STOCHASTIC
self._deter_size = config.DETERMINISTIC
self._stochastic_posterior_model = DiscreteLatentDist(self._deter_size + config.EMBED, config.N_CATEGORICALS,
config.N_CLASSES, config.HIDDEN)
def initial_state(self, batch_size, n_agents, **kwargs):
return RSSMState(stoch=torch.zeros(batch_size, n_agents, self._stoch_size, **kwargs),
logits=torch.zeros(batch_size, n_agents, self._stoch_size, **kwargs),
deter=torch.zeros(batch_size, n_agents, self._deter_size, **kwargs))
def forward(self, obs_embed, prev_actions, prev_states, mask=None):
"""
:param obs_embed: size(batch, n_agents, obs_size)
:param prev_actions: size(batch, n_agents, action_size)
:param prev_states: size(batch, n_agents, state_size)
:return: RSSMState, global_state: size(batch, 1, global_state_size)
"""
prior_states = self._transition_model(prev_actions, prev_states, mask)
x = torch.cat([prior_states.deter, obs_embed], dim=-1)
logits, stoch_state = self._stochastic_posterior_model(x)
posterior_states = RSSMState(logits=logits, stoch=stoch_state, deter=prior_states.deter)
return prior_states, posterior_states
def rollout_representation(representation_model, steps, obs_embed, action, prev_states, done):
"""
Roll out the model with actions and observations from data.
:param steps: number of steps to roll out
:param obs_embed: size(time_steps, batch_size, n_agents, embedding_size)
:param action: size(time_steps, batch_size, n_agents, action_size)
:param prev_states: RSSM state, size(batch_size, n_agents, state_size)
:return: prior, posterior states. size(time_steps, batch_size, n_agents, state_size)
"""
priors = []
posteriors = []
for t in range(steps):
prior_states, posterior_states = representation_model(obs_embed[t], action[t], prev_states)
prev_states = posterior_states.map(lambda x: x * (1.0 - done[t]))
priors.append(prior_states)
posteriors.append(posterior_states)
prior = stack_states(priors, dim=0)
post = stack_states(posteriors, dim=0)
return prior.map(lambda x: x[:-1]), post.map(lambda x: x[:-1]), post.deter[1:]
def rollout_policy(transition_model, av_action, steps, policy, prev_state, prev_action, config): # av_action.shape=[49 40 2 7] policy=actor
"""
Roll out the model with a policy function.
:param steps: number of steps to roll out
:param policy: RSSMState -> action
:param prev_state: RSSM state, size(batch_size, state_size)
:return: next states size(time_steps, batch_size, state_size),
actions size(time_steps, batch_size, action_size)
"""
state = prev_state
action = prev_action[:-1].reshape((prev_action.shape[0] - 1) * prev_action.shape[1], prev_action.shape[2], -1) # TODO
next_states = []
actions = []
av_actions = []
policies = []
obs_preds = []
for t in range(steps):
feat = state.get_features().detach()
obs_pred, _ = transition_model.observation_decoder(feat) # TODO
next_state = transition_model.transition(action, state) # TODO
next_feat = next_state.get_features().detach() # TODO
observations_next_other, _ = transition_model.observation_decoder(next_feat) # TODO
action, pi = policy(torch.cat((obs_pred.detach(), observations_next_other[:, :, -(config.num_agents-1)*4:-(config.num_agents-1)*2]), -1)) # TODO 3 vs 3
# print("feat:", feat)
# print("feat_shape:", feat.shape) # feat.shape=1920,2,1280
# action, pi = policy(feat)
if av_action is not None:
# print("av_action!")
avail_actions = av_action(feat).sample()
pi[avail_actions == 0] = -1e10
action_dist = OneHotCategorical(logits=pi)
action = action_dist.sample().squeeze(0)
av_actions.append(avail_actions.squeeze(0))
next_states.append(state)
obs_preds.append(obs_pred)
policies.append(pi)
actions.append(action)
state = transition_model.transition(action, state)
return {"imag_states": stack_states(next_states, dim=0),
"obs_preds": torch.stack(obs_preds, dim=0),
"actions": torch.stack(actions, dim=0),
"av_actions": torch.stack(av_actions, dim=0) if len(av_actions) > 0 else None,
"old_policy": torch.stack(policies, dim=0)}
================================================
FILE: examples/Social_Cognition/ToCM/networks/ToCM/utils.py
================================================
import torch.nn as nn
from braincog.base.node import LIFNode
from braincog.base.node.node import LIFNode, DoubleSidePLIFNode, PLIFNode
from braincog.base.strategy.surrogate import AtanGrad
import torch
class AtanLIFNode(LIFNode):
def __init__(self, tau=0.5, *args, **kwargs):
super().__init__(tau, *args, **kwargs)
self.act_fun = AtanGrad(alpha=1., requires_grad=True)
class BCNoSpikingLIFNode(LIFNode):
def __init__(self, tau, *args, **kwargs):
super().__init__(*args, **kwargs)
self.tau = tau
def forward(self, dv: torch.Tensor):
# print("dv: ", dv)
# print("dv.shape: ", dv.shape)
self.integral(dv)
return self.mem
def build_model_snn(in_dim, out_dim, layers, hidden, th=0.5, re=0.0, tau=0.5, activation='LIFNode',
normalize=lambda x: x):
# print("build model snn!")
# 0.activation换成LIFNode...
if activation == 'LIFNode':
node = LIFNode(threshold=th, tau=tau)
elif activation == 'AtanLIFNode':
node = AtanLIFNode(tau=tau)
elif activation == 'BCNoSpikingLIFNode':
node = BCNoSpikingLIFNode(tau=tau)
elif activation == 'DoubleSidePLIFNode':
node = DoubleSidePLIFNode(tau=tau)
elif activation == 'PLIFNode':
node = PLIFNode(threshold=th)
elif activation == 'nn.ELU':
node = nn.ELU()
elif activation == 'nn.ReLU':
node = nn.ReLU()
elif activation == 'nn.Tanh':
node = nn.Tanh()
# 1.是否norm no norm
model = [normalize(nn.Linear(in_dim, hidden))]
model += [node]
for i in range(layers - 1):
model += [normalize(nn.Linear(hidden, hidden))]
model += [node]
model += [normalize(nn.Linear(hidden, out_dim))]
# 使用第二个归一化,node激活之后还要linear,最后的输出应该还得有个node,将out node定义到外面比较合适
return nn.Sequential(*model)
def build_model(in_dim, out_dim, layers, hidden, activation, normalize=lambda x: x):
model = [normalize(nn.Linear(in_dim, hidden))]
model += [activation()]
for i in range(layers - 1):
model += [normalize(nn.Linear(hidden, hidden))]
model += [activation()]
model += [normalize(nn.Linear(hidden, out_dim))]
return nn.Sequential(*model)
================================================
FILE: examples/Social_Cognition/ToCM/networks/ToCM/vae.py
================================================
import torch.nn as nn
import torch.nn.functional as F
from networks.ToCM.utils import build_model_snn
class Decoder(nn.Module):
def __init__(self, embed, hidden, out_dim, layers=2):
super().__init__()
self.fc1 = build_model_snn(embed, hidden, layers, hidden, activation='nn.ReLU') # activation=nn.ReLU
self.fc2 = nn.Linear(hidden, out_dim)
def forward(self, z):
x = F.relu(self.fc1(z))
return self.fc2(x), x
class Encoder(nn.Module):
def __init__(self, in_dim, hidden, embed, layers=2):
super().__init__()
self.fc1 = nn.Linear(in_dim, hidden)
self.encoder = build_model_snn(hidden, embed, layers, hidden, activation='nn.ReLU') # activation=nn.ReLU
def forward(self, x):
embed = F.relu(self.fc1(x))
return self.encoder(F.relu(embed))
================================================
FILE: examples/Social_Cognition/ToCM/networks/transformer/layers.py
================================================
import numpy as np
import torch
import torch.nn as nn
# 位置编码
class PositionalEncoding(nn.Module):
__author__ = "Yu-Hsiang Huang"
def __init__(self, d_hid, n_position=2):
super(PositionalEncoding, self).__init__()
# Not a parameter
'''
This is typically used to register a buffer that should not to be
considered a model parameter. For example, BatchNorm's ``running_mean``
is not a parameter, but is part of the module's state.
input: buffer's name, buffer's shape 应该是隐藏层之类的
'''
self.register_buffer('pos_table', self._get_sinusoid_encoding_table(n_position, d_hid))
# return x + self.pos_table[:, :x.size(1)].clone().detach() 使用pos_table
@staticmethod # 系统提示我这个方法静态
def _get_sinusoid_encoding_table(n_position, d_hid):
""" Sinusoid position encoding table """
def get_position_angle_vec(position): # 获取每个位置的角度向量
return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
# shape [pos_i, d_hid, position]
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table).unsqueeze(0) # 增加一个维度
def forward(self, x):
return x + self.pos_table[:, :x.size(1)].clone().detach()
class AttentionEncoder(nn.Module):
def __init__(self, n_layers, in_dim, hidden, dropout=0.):
super().__init__()
self.pos_embed = PositionalEncoding(hidden, 30) # 返回位置编码方案,维度++
self.encoder = nn.TransformerEncoder(nn.TransformerEncoderLayer(d_model=in_dim, nhead=8,
dim_feedforward=hidden,
dropout=dropout), n_layers)
def forward(self, enc_input, **kwargs):
enc_input = self.pos_embed(enc_input)
x = self.encoder(enc_input.permute(1, 0, 2), **kwargs)
return x.permute(1, 0, 2) # 混洗 调换顺序
class AttentionActorEncoder(nn.Module):
def __init__(self, n_layers, in_dim, hidden, dropout=0.):
super().__init__()
self.encoder = nn.TransformerEncoder(nn.TransformerEncoderLayer(d_model=in_dim, nhead=8,
dim_feedforward=hidden,
dropout=dropout), n_layers)
def forward(self, enc_input, **kwargs):
x = self.encoder(enc_input, **kwargs)
return x # 混洗 调换顺序
================================================
FILE: examples/Social_Cognition/ToCM/requirements.txt
================================================
numpy~=1.18.5
torch~=1.7.0
ray~=1.13.0
git+https://github.com/oxwhirl/smac.git
wandb~=0.13.11
argparse~=1.4.0
================================================
FILE: examples/Social_Cognition/ToCM/run.sh
================================================
#!/bin/sh
seed_max=10
#for seed in `seq ${seed_max}`;
#do
# echo "seed is ${seed}:"
# python train.py
# kill Main_Thread
#done
#seed_max=10 # 设置最大的种子值,这里假设为10
#for./run, seed in $(seq 1 $seed_max); do
# echo "seed is $seed:"
# python train.py --seed $seed # 将当前种子值作为参数传递给 train.py
#done
python train.py --seed 50
pkill Main_Thread
python train.py --seed 50
pkill Main_Thread
#python train.py --seed 1
#pkill Main_Thread
================================================
FILE: examples/Social_Cognition/ToCM/smac/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/smac/bin/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/smac/bin/map_list.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from smac.env.starcraft2.maps import smac_maps
from pysc2 import maps as pysc2_maps
def main():
smac_map_registry = smac_maps.get_smac_map_registry()
all_maps = pysc2_maps.get_maps()
print("{:<15} {:7} {:7} {:7}".format("Name", "Agents", "Enemies", "Limit"))
for map_name, map_params in smac_map_registry.items():
map_class = all_maps[map_name]
if map_class.path:
print(
"{:<15} {:<7} {:<7} {:<7}".format(
map_name,
map_params["n_agents"],
map_params["n_enemies"],
map_params["limit"],
)
)
if __name__ == "__main__":
main()
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/__init__.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from smac.env.multiagentenv import MultiAgentEnv
from smac.env.starcraft2.starcraft2 import StarCraft2Env
__all__ = ["MultiAgentEnv", "StarCraft2Env"]
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/multiagentenv.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
class MultiAgentEnv(object):
def step(self, actions):
"""Returns reward, terminated, info."""
raise NotImplementedError
def get_obs(self):
"""Returns all agent observations in a list."""
raise NotImplementedError
def get_obs_agent(self, agent_id):
"""Returns observation for agent_id."""
raise NotImplementedError
def get_obs_size(self):
"""Returns the size of the observation."""
raise NotImplementedError
def get_state(self):
"""Returns the global state."""
raise NotImplementedError
def get_state_size(self):
"""Returns the size of the global state."""
raise NotImplementedError
def get_avail_actions(self):
"""Returns the available actions of all agents in a list."""
raise NotImplementedError
def get_avail_agent_actions(self, agent_id):
"""Returns the available actions for agent_id."""
raise NotImplementedError
def get_total_actions(self):
"""Returns the total number of actions an agent could ever take."""
raise NotImplementedError
def reset(self):
"""Returns initial observations and states."""
raise NotImplementedError
def render(self):
raise NotImplementedError
def close(self):
raise NotImplementedError
def seed(self):
raise NotImplementedError
def save_replay(self):
"""Save a replay."""
raise NotImplementedError
def get_env_info(self):
env_info = {
"state_shape": self.get_state_size(),
"obs_shape": self.get_obs_size(),
"n_actions": self.get_total_actions(),
"n_agents": self.n_agents,
"episode_limit": self.episode_limit,
}
return env_info
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/pettingzoo/StarCraft2PZEnv.py
================================================
from smac.env import StarCraft2Env
from gym.utils import EzPickle
from gym.utils import seeding
from gym import spaces
from pettingzoo.utils.env import ParallelEnv
from pettingzoo.utils.conversions import parallel_to_aec as from_parallel_wrapper
from pettingzoo.utils import wrappers
import numpy as np
max_cycles_default = 1000
def parallel_env(max_cycles=max_cycles_default, **smac_args):
return _parallel_env(max_cycles, **smac_args)
def raw_env(max_cycles=max_cycles_default, **smac_args):
return from_parallel_wrapper(parallel_env(max_cycles, **smac_args))
def make_env(raw_env):
def env_fn(**kwargs):
env = raw_env(**kwargs)
# env = wrappers.TerminateIllegalWrapper(env, illegal_reward=-1)
env = wrappers.AssertOutOfBoundsWrapper(env)
env = wrappers.OrderEnforcingWrapper(env)
return env
return env_fn
class smac_parallel_env(ParallelEnv):
def __init__(self, env, max_cycles):
self.max_cycles = max_cycles
self.env = env
self.env.reset()
self.reset_flag = 0
self.agents, self.action_spaces = self._init_agents()
self.possible_agents = self.agents[:]
observation_size = env.get_obs_size()
self.observation_spaces = {
name: spaces.Dict(
{
"observation": spaces.Box(
low=-1,
high=1,
shape=(observation_size,),
dtype="float32",
),
"action_mask": spaces.Box(
low=0,
high=1,
shape=(self.action_spaces[name].n,),
dtype=np.int8,
),
}
)
for name in self.agents
}
self._reward = 0
def _init_agents(self):
last_type = ""
agents = []
action_spaces = {}
self.agents_id = {}
i = 0
for agent_id, agent_info in self.env.agents.items():
unit_action_space = spaces.Discrete(
self.env.get_total_actions() - 1
) # no-op in dead units is not an action
if agent_info.unit_type == self.env.marine_id:
agent_type = "marine"
elif agent_info.unit_type == self.env.marauder_id:
agent_type = "marauder"
elif agent_info.unit_type == self.env.medivac_id:
agent_type = "medivac"
elif agent_info.unit_type == self.env.hydralisk_id:
agent_type = "hydralisk"
elif agent_info.unit_type == self.env.zergling_id:
agent_type = "zergling"
elif agent_info.unit_type == self.env.baneling_id:
agent_type = "baneling"
elif agent_info.unit_type == self.env.stalker_id:
agent_type = "stalker"
elif agent_info.unit_type == self.env.colossus_id:
agent_type = "colossus"
elif agent_info.unit_type == self.env.zealot_id:
agent_type = "zealot"
else:
raise AssertionError(f"agent type {agent_type} not supported")
if agent_type == last_type:
i += 1
else:
i = 0
agents.append(f"{agent_type}_{i}")
self.agents_id[agents[-1]] = agent_id
action_spaces[agents[-1]] = unit_action_space
last_type = agent_type
return agents, action_spaces
def seed(self, seed=None):
if seed is None:
self.env._seed = seeding.create_seed(seed, max_bytes=4)
else:
self.env._seed = seed
self.env.full_restart()
def render(self, mode="human"):
self.env.render(mode)
def close(self):
self.env.close()
def reset(self):
self.env._episode_count = 1
self.env.reset()
self.agents = self.possible_agents[:]
self.frames = 0
self.all_dones = {agent: False for agent in self.possible_agents}
return self._observe_all()
def get_agent_smac_id(self, agent):
return self.agents_id[agent]
def _all_rewards(self, reward):
all_rewards = [reward] * len(self.agents)
return {
agent: reward for agent, reward in zip(self.agents, all_rewards)
}
def _observe_all(self):
all_obs = []
for agent in self.agents:
agent_id = self.get_agent_smac_id(agent)
obs = self.env.get_obs_agent(agent_id)
action_mask = self.env.get_avail_agent_actions(agent_id)
action_mask = action_mask[1:]
action_mask = np.array(action_mask).astype(np.int8)
obs = np.asarray(obs, dtype=np.float32)
all_obs.append(
{"observation": obs, "action_mask": action_mask}
)
return {agent: obs for agent, obs in zip(self.agents, all_obs)}
def _all_dones(self, step_done=False):
dones = [True] * len(self.agents)
if not step_done:
for i, agent in enumerate(self.agents):
agent_done = False
agent_id = self.get_agent_smac_id(agent)
agent_info = self.env.get_unit_by_id(agent_id)
if agent_info.health == 0:
agent_done = True
dones[i] = agent_done
return {agent: bool(done) for agent, done in zip(self.agents, dones)}
def step(self, all_actions):
action_list = [0] * self.env.n_agents
for agent in self.agents:
agent_id = self.get_agent_smac_id(agent)
if agent in all_actions:
if all_actions[agent] is None:
action_list[agent_id] = 0
else:
action_list[agent_id] = all_actions[agent] + 1
self._reward, terminated, smac_info = self.env.step(action_list)
self.frames += 1
done = terminated or self.frames >= self.max_cycles
all_infos = {agent: {} for agent in self.agents}
# all_infos.update(smac_info)
all_dones = self._all_dones(done)
all_rewards = self._all_rewards(self._reward)
all_observes = self._observe_all()
self.agents = [
agent for agent in self.agents if not all_dones[agent]
]
return all_observes, all_rewards, all_dones, all_infos
def __del__(self):
self.env.close()
env = make_env(raw_env)
class _parallel_env(smac_parallel_env, EzPickle):
metadata = {"render.modes": ["human"], "name": "sc2"}
def __init__(self, max_cycles, **smac_args):
EzPickle.__init__(self, max_cycles, **smac_args)
env = StarCraft2Env(**smac_args)
super().__init__(env, max_cycles)
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/pettingzoo/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/pettingzoo/test/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/pettingzoo/test/all_test.py
================================================
from smac.env.starcraft2.maps import smac_maps
from pysc2 import maps as pysc2_maps
from smac.env.pettingzoo import StarCraft2PZEnv as sc2
import pytest
from pettingzoo import test
import pickle
smac_map_registry = smac_maps.get_smac_map_registry()
all_maps = pysc2_maps.get_maps()
map_names = []
for map_name in smac_map_registry.keys():
map_class = all_maps[map_name]
if map_class.path:
map_names.append(map_name)
@pytest.mark.parametrize(("map_name"), map_names)
def test_env(map_name):
env = sc2.env(map_name=map_name)
test.api_test(env)
# test.parallel_api_test(sc2_v0.parallel_env()) # does not pass it due to
# illegal actions test.seed_test(sc2.env, 50) # not required, sc2 env only
# allows reseeding at initialization
test.render_test(env)
recreated_env = pickle.loads(pickle.dumps(env))
test.api_test(recreated_env)
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/pettingzoo/test/smac_pettingzoo_test.py
================================================
import os
import sys
import inspect
from pettingzoo import test
from smac.env.pettingzoo import StarCraft2PZEnv as sc2
import pickle
current_dir = os.path.dirname(
os.path.abspath(inspect.getfile(inspect.currentframe()))
)
parent_dir = os.path.dirname(current_dir)
sys.path.insert(0, parent_dir)
if __name__ == "__main__":
env = sc2.env(map_name="corridor")
test.api_test(env)
# test.parallel_api_test(sc2_v0.parallel_env()) # does not pass it due to
# illegal actions test.seed_test(sc2_v0.env, 50) # not required, sc2 env
# only allows reseeding at initialization
recreated_env = pickle.loads(pickle.dumps(env))
test.api_test(recreated_env)
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/starcraft2/__init__.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from absl import flags
FLAGS = flags.FLAGS
FLAGS(["main.py"])
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/starcraft2/maps/__init__.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from smac.env.starcraft2.maps import smac_maps
def get_map_params(map_name):
map_param_registry = smac_maps.get_smac_map_registry()
return map_param_registry[map_name]
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/starcraft2/maps/smac_maps.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from pysc2.maps import lib
class SMACMap(lib.Map):
directory = "SMAC_Maps"
download = "https://github.com/oxwhirl/smac#smac-maps"
players = 2
step_mul = 8
game_steps_per_episode = 0
map_param_registry = {
"3m": {
"n_agents": 3,
"n_enemies": 3,
"limit": 60,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 0,
"map_type": "marines",
},
"8m": {
"n_agents": 8,
"n_enemies": 8,
"limit": 120,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 0,
"map_type": "marines",
},
"25m": {
"n_agents": 25,
"n_enemies": 25,
"limit": 150,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 0,
"map_type": "marines",
},
"5m_vs_6m": {
"n_agents": 5,
"n_enemies": 6,
"limit": 70,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 0,
"map_type": "marines",
},
"8m_vs_9m": {
"n_agents": 8,
"n_enemies": 9,
"limit": 120,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 0,
"map_type": "marines",
},
"10m_vs_11m": {
"n_agents": 10,
"n_enemies": 11,
"limit": 150,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 0,
"map_type": "marines",
},
"27m_vs_30m": {
"n_agents": 27,
"n_enemies": 30,
"limit": 180,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 0,
"map_type": "marines",
},
"MMM": {
"n_agents": 10,
"n_enemies": 10,
"limit": 150,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 3,
"map_type": "MMM",
},
"MMM2": {
"n_agents": 10,
"n_enemies": 12,
"limit": 180,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 3,
"map_type": "MMM",
},
"2s3z": {
"n_agents": 5,
"n_enemies": 5,
"limit": 120,
"a_race": "P",
"b_race": "P",
"unit_type_bits": 2,
"map_type": "stalkers_and_zealots",
},
"3s5z": {
"n_agents": 8,
"n_enemies": 8,
"limit": 150,
"a_race": "P",
"b_race": "P",
"unit_type_bits": 2,
"map_type": "stalkers_and_zealots",
},
"3s5z_vs_3s6z": {
"n_agents": 8,
"n_enemies": 9,
"limit": 170,
"a_race": "P",
"b_race": "P",
"unit_type_bits": 2,
"map_type": "stalkers_and_zealots",
},
"3s_vs_3z": {
"n_agents": 3,
"n_enemies": 3,
"limit": 150,
"a_race": "P",
"b_race": "P",
"unit_type_bits": 0,
"map_type": "stalkers",
},
"3s_vs_4z": {
"n_agents": 3,
"n_enemies": 4,
"limit": 200,
"a_race": "P",
"b_race": "P",
"unit_type_bits": 0,
"map_type": "stalkers",
},
"3s_vs_5z": {
"n_agents": 3,
"n_enemies": 5,
"limit": 250,
"a_race": "P",
"b_race": "P",
"unit_type_bits": 0,
"map_type": "stalkers",
},
"1c3s5z": {
"n_agents": 9,
"n_enemies": 9,
"limit": 180,
"a_race": "P",
"b_race": "P",
"unit_type_bits": 3,
"map_type": "colossi_stalkers_zealots",
},
"2m_vs_1z": {
"n_agents": 2,
"n_enemies": 1,
"limit": 150,
"a_race": "T",
"b_race": "P",
"unit_type_bits": 0,
"map_type": "marines",
},
"corridor": {
"n_agents": 6,
"n_enemies": 24,
"limit": 400,
"a_race": "P",
"b_race": "Z",
"unit_type_bits": 0,
"map_type": "zealots",
},
"6h_vs_8z": {
"n_agents": 6,
"n_enemies": 8,
"limit": 150,
"a_race": "Z",
"b_race": "P",
"unit_type_bits": 0,
"map_type": "hydralisks",
},
"2s_vs_1sc": {
"n_agents": 2,
"n_enemies": 1,
"limit": 300,
"a_race": "P",
"b_race": "Z",
"unit_type_bits": 0,
"map_type": "stalkers",
},
"so_many_baneling": {
"n_agents": 7,
"n_enemies": 32,
"limit": 100,
"a_race": "P",
"b_race": "Z",
"unit_type_bits": 0,
"map_type": "zealots",
},
"bane_vs_bane": {
"n_agents": 24,
"n_enemies": 24,
"limit": 200,
"a_race": "Z",
"b_race": "Z",
"unit_type_bits": 2,
"map_type": "bane",
},
"2c_vs_64zg": {
"n_agents": 2,
"n_enemies": 64,
"limit": 400,
"a_race": "P",
"b_race": "Z",
"unit_type_bits": 0,
"map_type": "colossus",
},
}
def get_smac_map_registry():
return map_param_registry
for name in map_param_registry.keys():
globals()[name] = type(name, (SMACMap,), dict(filename=name))
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/starcraft2/render.py
================================================
import numpy as np
import re
import subprocess
import platform
from absl import logging
import math
import time
import collections
import os
import pygame
import queue
from pysc2.lib import colors
from pysc2.lib import point
from pysc2.lib.renderer_human import _Surface
from pysc2.lib import transform
from pysc2.lib import features
def clamp(n, smallest, largest):
return max(smallest, min(n, largest))
def _get_desktop_size():
"""Get the desktop size."""
if platform.system() == "Linux":
try:
xrandr_query = subprocess.check_output(["xrandr", "--query"])
sizes = re.findall(
r"\bconnected primary (\d+)x(\d+)", str(xrandr_query)
)
if sizes[0]:
return point.Point(int(sizes[0][0]), int(sizes[0][1]))
except ValueError:
logging.error("Failed to get the resolution from xrandr.")
# Most general, but doesn't understand multiple monitors.
display_info = pygame.display.Info()
return point.Point(display_info.current_w, display_info.current_h)
class StarCraft2Renderer:
def __init__(self, env, mode):
os.environ["PYGAME_HIDE_SUPPORT_PROMPT"] = "hide"
self.env = env
self.mode = mode
self.obs = None
self._window_scale = 0.75
self.game_info = game_info = self.env._controller.game_info()
self.static_data = self.env._controller.data()
self._obs_queue = queue.Queue()
self._game_times = collections.deque(
maxlen=100
) # Avg FPS over 100 frames. # pytype: disable=wrong-keyword-args
self._render_times = collections.deque(
maxlen=100
) # pytype: disable=wrong-keyword-args
self._last_time = time.time()
self._last_game_loop = 0
self._name_lengths = {}
self._map_size = point.Point.build(game_info.start_raw.map_size)
self._playable = point.Rect(
point.Point.build(game_info.start_raw.playable_area.p0),
point.Point.build(game_info.start_raw.playable_area.p1),
)
window_size_px = point.Point(
self.env.window_size[0], self.env.window_size[1]
)
window_size_px = self._map_size.scale_max_size(
window_size_px * self._window_scale
).ceil()
self._scale = window_size_px.y // 32
self.display = pygame.Surface(window_size_px)
if mode == "human":
self.display = pygame.display.set_mode(window_size_px, 0, 32)
pygame.display.init()
pygame.display.set_caption("Starcraft Viewer")
pygame.font.init()
self._world_to_world_tl = transform.Linear(
point.Point(1, -1), point.Point(0, self._map_size.y)
)
self._world_tl_to_screen = transform.Linear(scale=window_size_px / 32)
self.screen_transform = transform.Chain(
self._world_to_world_tl, self._world_tl_to_screen
)
surf_loc = point.Rect(point.origin, window_size_px)
sub_surf = self.display.subsurface(
pygame.Rect(surf_loc.tl, surf_loc.size)
)
self._surf = _Surface(
sub_surf,
None,
surf_loc,
self.screen_transform,
None,
self.draw_screen,
)
self._font_small = pygame.font.Font(None, int(self._scale * 0.5))
self._font_large = pygame.font.Font(None, self._scale)
def close(self):
pygame.display.quit()
pygame.quit()
def _get_units(self):
for u in sorted(
self.obs.observation.raw_data.units,
key=lambda u: (u.pos.z, u.owner != 16, -u.radius, u.tag),
):
yield u, point.Point.build(u.pos)
def get_unit_name(self, surf, name, radius):
"""Get a length limited unit name for drawing units."""
key = (name, radius)
if key not in self._name_lengths:
max_len = surf.world_to_surf.fwd_dist(radius * 1.6)
for i in range(len(name)):
if self._font_small.size(name[: i + 1])[0] > max_len:
self._name_lengths[key] = name[:i]
break
else:
self._name_lengths[key] = name
return self._name_lengths[key]
def render(self, mode):
self.obs = self.env._obs
self.score = self.env.reward
self.step = self.env._episode_steps
now = time.time()
self._game_times.append(
(
now - self._last_time,
max(
1,
self.obs.observation.game_loop
- self.obs.observation.game_loop,
),
)
)
if mode == "human":
pygame.event.pump()
self._surf.draw(self._surf)
observation = np.array(pygame.surfarray.pixels3d(self.display))
if mode == "human":
pygame.display.flip()
self._last_time = now
self._last_game_loop = self.obs.observation.game_loop
# self._obs_queue.put(self.obs)
return (
np.transpose(observation, axes=(1, 0, 2))
if mode == "rgb_array"
else None
)
def draw_base_map(self, surf):
"""Draw the base map."""
hmap_feature = features.SCREEN_FEATURES.height_map
hmap = self.env.terrain_height * 255
hmap = hmap.astype(np.uint8)
if (
self.env.map_name == "corridor"
or self.env.map_name == "so_many_baneling"
or self.env.map_name == "2s_vs_1sc"
):
hmap = np.flip(hmap)
else:
hmap = np.rot90(hmap, axes=(1, 0))
if not hmap.any():
hmap = hmap + 100 # pylint: disable=g-no-augmented-assignment
hmap_color = hmap_feature.color(hmap)
out = hmap_color * 0.6
surf.blit_np_array(out)
def draw_units(self, surf):
"""Draw the units."""
unit_dict = None # Cache the units {tag: unit_proto} for orders.
tau = 2 * math.pi
for u, p in self._get_units():
fraction_damage = clamp(
(u.health_max - u.health) / (u.health_max or 1), 0, 1
)
surf.draw_circle(
colors.PLAYER_ABSOLUTE_PALETTE[u.owner], p, u.radius
)
if fraction_damage > 0:
surf.draw_circle(
colors.PLAYER_ABSOLUTE_PALETTE[u.owner] // 2,
p,
u.radius * fraction_damage,
)
surf.draw_circle(colors.black, p, u.radius, thickness=1)
if self.static_data.unit_stats[u.unit_type].movement_speed > 0:
surf.draw_arc(
colors.white,
p,
u.radius,
u.facing - 0.1,
u.facing + 0.1,
thickness=1,
)
def draw_arc_ratio(
color, world_loc, radius, start, end, thickness=1
):
surf.draw_arc(
color, world_loc, radius, start * tau, end * tau, thickness
)
if u.shield and u.shield_max:
draw_arc_ratio(
colors.blue, p, u.radius - 0.05, 0, u.shield / u.shield_max
)
if u.energy and u.energy_max:
draw_arc_ratio(
colors.purple * 0.9,
p,
u.radius - 0.1,
0,
u.energy / u.energy_max,
)
elif u.orders and 0 < u.orders[0].progress < 1:
draw_arc_ratio(
colors.cyan, p, u.radius - 0.15, 0, u.orders[0].progress
)
if u.buff_duration_remain and u.buff_duration_max:
draw_arc_ratio(
colors.white,
p,
u.radius - 0.2,
0,
u.buff_duration_remain / u.buff_duration_max,
)
if u.attack_upgrade_level:
draw_arc_ratio(
self.upgrade_colors[u.attack_upgrade_level],
p,
u.radius - 0.25,
0.18,
0.22,
thickness=3,
)
if u.armor_upgrade_level:
draw_arc_ratio(
self.upgrade_colors[u.armor_upgrade_level],
p,
u.radius - 0.25,
0.23,
0.27,
thickness=3,
)
if u.shield_upgrade_level:
draw_arc_ratio(
self.upgrade_colors[u.shield_upgrade_level],
p,
u.radius - 0.25,
0.28,
0.32,
thickness=3,
)
def write_small(loc, s):
surf.write_world(self._font_small, colors.white, loc, str(s))
name = self.get_unit_name(
surf,
self.static_data.units.get(u.unit_type, ""),
u.radius,
)
if name:
write_small(p, name)
start_point = p
for o in u.orders:
target_point = None
if o.HasField("target_unit_tag"):
if unit_dict is None:
unit_dict = {
t.tag: t
for t in self.obs.observation.raw_data.units
}
target_unit = unit_dict.get(o.target_unit_tag)
if target_unit:
target_point = point.Point.build(target_unit.pos)
if target_point:
surf.draw_line(colors.cyan, start_point, target_point)
start_point = target_point
else:
break
def draw_overlay(self, surf):
"""Draw the overlay describing resources."""
obs = self.obs.observation
times, steps = zip(*self._game_times)
sec = obs.game_loop // 22.4
surf.write_screen(
self._font_large,
colors.green,
(-0.2, 0.2),
"Score: %s, Step: %s, %.1f/s, Time: %d:%02d"
% (
self.score,
self.step,
sum(steps) / (sum(times) or 1),
sec // 60,
sec % 60,
),
align="right",
)
surf.write_screen(
self._font_large,
colors.green * 0.8,
(-0.2, 1.2),
"APM: %d, EPM: %d, FPS: O:%.1f, R:%.1f"
% (
obs.score.score_details.current_apm,
obs.score.score_details.current_effective_apm,
len(times) / (sum(times) or 1),
len(self._render_times) / (sum(self._render_times) or 1),
),
align="right",
)
def draw_screen(self, surf):
"""Draw the screen area."""
self.draw_base_map(surf)
self.draw_units(surf)
self.draw_overlay(surf)
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/starcraft2/starcraft2.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from smac.env.multiagentenv import MultiAgentEnv
from smac.env.starcraft2.maps import get_map_params
import atexit
from warnings import warn
from operator import attrgetter
from copy import deepcopy
import numpy as np
import enum
import math
from absl import logging
from pysc2 import maps
from pysc2 import run_configs
from pysc2.lib import protocol
from s2clientprotocol import common_pb2 as sc_common
from s2clientprotocol import sc2api_pb2 as sc_pb
from s2clientprotocol import raw_pb2 as r_pb
from s2clientprotocol import debug_pb2 as d_pb
races = {
"R": sc_common.Random,
"P": sc_common.Protoss,
"T": sc_common.Terran,
"Z": sc_common.Zerg,
}
difficulties = {
"1": sc_pb.VeryEasy,
"2": sc_pb.Easy,
"3": sc_pb.Medium,
"4": sc_pb.MediumHard,
"5": sc_pb.Hard,
"6": sc_pb.Harder,
"7": sc_pb.VeryHard,
"8": sc_pb.CheatVision,
"9": sc_pb.CheatMoney,
"A": sc_pb.CheatInsane,
}
actions = {
"move": 16, # target: PointOrUnit
"attack": 23, # target: PointOrUnit
"stop": 4, # target: None
"heal": 386, # Unit
}
class Direction(enum.IntEnum):
NORTH = 0
SOUTH = 1
EAST = 2
WEST = 3
class StarCraft2Env(MultiAgentEnv):
"""The StarCraft II environment for decentralised multi-agent
micromanagement scenarios.
"""
def __init__(
self,
map_name="8m",
step_mul=8,
move_amount=2,
difficulty="7",
game_version=None,
seed=None,
continuing_episode=False,
obs_all_health=True,
obs_own_health=True,
obs_last_action=False,
obs_pathing_grid=False,
obs_terrain_height=False,
obs_instead_of_state=False,
obs_timestep_number=False,
state_last_action=True,
state_timestep_number=False,
reward_sparse=False,
reward_only_positive=True,
reward_death_value=10,
reward_win=200,
reward_defeat=0,
reward_negative_scale=0.5,
reward_scale=True,
reward_scale_rate=20,
replay_dir="",
replay_prefix="",
window_size_x=1920,
window_size_y=1200,
heuristic_ai=False,
heuristic_rest=False,
debug=False,
):
"""
Create a StarCraftC2Env environment.
Parameters
----------
map_name : str, optional
The name of the SC2 map to play (default is "8m"). The full list
can be found by running bin/map_list.
step_mul : int, optional
How many game steps per agent step (default is 8). None
indicates to use the default map step_mul.
move_amount : float, optional
How far away units are ordered to move per step (default is 2).
difficulty : str, optional
The difficulty of built-in computer AI bot (default is "7").
game_version : str, optional
StarCraft II game version (default is None). None indicates the
latest version.
seed : int, optional
Random seed used during game initialisation. This allows to
continuing_episode : bool, optional
Whether to consider episodes continuing or finished after time
limit is reached (default is False).
obs_all_health : bool, optional
Agents receive the health of all units (in the sight range) as part
of observations (default is True).
obs_own_health : bool, optional
Agents receive their own health as a part of observations (default
is False). This flag is ignored when obs_all_health == True.
obs_last_action : bool, optional
Agents receive the last actions of all units (in the sight range)
as part of observations (default is False).
obs_pathing_grid : bool, optional
Whether observations include pathing values surrounding the agent
(default is False).
obs_terrain_height : bool, optional
Whether observations include terrain height values surrounding the
agent (default is False).
obs_instead_of_state : bool, optional
Use combination of all agents' observations as the global state
(default is False).
obs_timestep_number : bool, optional
Whether observations include the current timestep of the episode
(default is False).
state_last_action : bool, optional
Include the last actions of all agents as part of the global state
(default is True).
state_timestep_number : bool, optional
Whether the state include the current timestep of the episode
(default is False).
reward_sparse : bool, optional
Receive 1/-1 reward for winning/loosing an episode (default is
False). Whe rest of reward parameters are ignored if True.
reward_only_positive : bool, optional
Reward is always positive (default is True).
reward_death_value : float, optional
The amount of reward received for killing an enemy unit (default
is 10). This is also the negative penalty for having an allied unit
killed if reward_only_positive == False.
reward_win : float, optional
The reward for winning in an episode (default is 200).
reward_defeat : float, optional
The reward for loosing in an episode (default is 0). This value
should be nonpositive.
reward_negative_scale : float, optional
Scaling factor for negative rewards (default is 0.5). This
parameter is ignored when reward_only_positive == True.
reward_scale : bool, optional
Whether or not to scale the reward (default is True).
reward_scale_rate : float, optional
Reward scale rate (default is 20). When reward_scale == True, the
reward received by the agents is divided by (max_reward /
reward_scale_rate), where max_reward is the maximum possible
reward per episode without considering the shield regeneration
of Protoss units.
replay_dir : str, optional
The directory to save replays (default is None). If None, the
replay will be saved in Replays directory where StarCraft II is
installed.
replay_prefix : str, optional
The prefix of the replay to be saved (default is None). If None,
the name of the map will be used.
window_size_x : int, optional
The length of StarCraft II window size (default is 1920).
window_size_y: int, optional
The height of StarCraft II window size (default is 1200).
heuristic_ai: bool, optional
Whether or not to use a non-learning heuristic AI (default False).
heuristic_rest: bool, optional
At any moment, restrict the actions of the heuristic AI to be
chosen from actions available to RL agents (default is False).
Ignored if heuristic_ai == False.
debug: bool, optional
Log messages about observations, state, actions and rewards for
debugging purposes (default is False).
"""
# Map arguments
self.map_name = map_name
map_params = get_map_params(self.map_name)
self.n_agents = map_params["n_agents"]
self.n_enemies = map_params["n_enemies"]
self.episode_limit = map_params["limit"]
self._move_amount = move_amount
self._step_mul = step_mul
self.difficulty = difficulty
# Observations and state
self.obs_own_health = obs_own_health
self.obs_all_health = obs_all_health
self.obs_instead_of_state = obs_instead_of_state
self.obs_last_action = obs_last_action
self.obs_pathing_grid = obs_pathing_grid
self.obs_terrain_height = obs_terrain_height
self.obs_timestep_number = obs_timestep_number
self.state_last_action = state_last_action
self.state_timestep_number = state_timestep_number
if self.obs_all_health:
self.obs_own_health = True
self.n_obs_pathing = 8
self.n_obs_height = 9
# Rewards args
self.reward_sparse = reward_sparse
self.reward_only_positive = reward_only_positive
self.reward_negative_scale = reward_negative_scale
self.reward_death_value = reward_death_value
self.reward_win = reward_win
self.reward_defeat = reward_defeat
self.reward_scale = reward_scale
self.reward_scale_rate = reward_scale_rate
# Other
self.game_version = game_version
self.continuing_episode = continuing_episode
self._seed = seed
self.heuristic_ai = heuristic_ai
self.heuristic_rest = heuristic_rest
self.debug = debug
self.window_size = (window_size_x, window_size_y)
self.replay_dir = replay_dir
self.replay_prefix = replay_prefix
# Actions
self.n_actions_no_attack = 6
self.n_actions_move = 4
self.n_actions = self.n_actions_no_attack + self.n_enemies
# Map info
self._agent_race = map_params["a_race"]
self._bot_race = map_params["b_race"]
self.shield_bits_ally = 1 if self._agent_race == "P" else 0
self.shield_bits_enemy = 1 if self._bot_race == "P" else 0
self.unit_type_bits = map_params["unit_type_bits"]
self.map_type = map_params["map_type"]
self._unit_types = None
self.max_reward = (
self.n_enemies * self.reward_death_value + self.reward_win
)
# create lists containing the names of attributes returned in states
self.ally_state_attr_names = [
"health",
"energy/cooldown",
"rel_x",
"rel_y",
]
self.enemy_state_attr_names = ["health", "rel_x", "rel_y"]
if self.shield_bits_ally > 0:
self.ally_state_attr_names += ["shield"]
if self.shield_bits_enemy > 0:
self.enemy_state_attr_names += ["shield"]
if self.unit_type_bits > 0:
bit_attr_names = [
"type_{}".format(bit) for bit in range(self.unit_type_bits)
]
self.ally_state_attr_names += bit_attr_names
self.enemy_state_attr_names += bit_attr_names
self.agents = {}
self.enemies = {}
self._episode_count = 0
self._episode_steps = 0
self._total_steps = 0
self._obs = None
self.battles_won = 0
self.battles_game = 0
self.timeouts = 0
self.force_restarts = 0
self.last_stats = None
self.death_tracker_ally = np.zeros(self.n_agents)
self.death_tracker_enemy = np.zeros(self.n_enemies)
self.previous_ally_units = None
self.previous_enemy_units = None
self.last_action = np.zeros((self.n_agents, self.n_actions))
self._min_unit_type = 0
self.marine_id = self.marauder_id = self.medivac_id = 0
self.hydralisk_id = self.zergling_id = self.baneling_id = 0
self.stalker_id = self.colossus_id = self.zealot_id = 0
self.max_distance_x = 0
self.max_distance_y = 0
self.map_x = 0
self.map_y = 0
self.reward = 0
self.renderer = None
self.terrain_height = None
self.pathing_grid = None
self._run_config = None
self._sc2_proc = None
self._controller = None
# Try to avoid leaking SC2 processes on shutdown
atexit.register(lambda: self.close())
def _launch(self):
"""Launch the StarCraft II game."""
self._run_config = run_configs.get(version=self.game_version)
_map = maps.get(self.map_name)
# Setting up the interface
interface_options = sc_pb.InterfaceOptions(raw=True, score=False)
self._sc2_proc = self._run_config.start(
window_size=self.window_size, want_rgb=False
)
self._controller = self._sc2_proc.controller
# Request to create the game
create = sc_pb.RequestCreateGame(
local_map=sc_pb.LocalMap(
map_path=_map.path,
map_data=self._run_config.map_data(_map.path),
),
realtime=False,
random_seed=self._seed,
)
create.player_setup.add(type=sc_pb.Participant)
create.player_setup.add(
type=sc_pb.Computer,
race=races[self._bot_race],
difficulty=difficulties[self.difficulty],
)
self._controller.create_game(create)
join = sc_pb.RequestJoinGame(
race=races[self._agent_race], options=interface_options
)
self._controller.join_game(join)
game_info = self._controller.game_info()
map_info = game_info.start_raw
map_play_area_min = map_info.playable_area.p0
map_play_area_max = map_info.playable_area.p1
self.max_distance_x = map_play_area_max.x - map_play_area_min.x
self.max_distance_y = map_play_area_max.y - map_play_area_min.y
self.map_x = map_info.map_size.x
self.map_y = map_info.map_size.y
if map_info.pathing_grid.bits_per_pixel == 1:
vals = np.array(list(map_info.pathing_grid.data)).reshape(
self.map_x, int(self.map_y / 8)
)
self.pathing_grid = np.transpose(
np.array(
[
[(b >> i) & 1 for b in row for i in range(7, -1, -1)]
for row in vals
],
dtype=np.bool,
)
)
else:
self.pathing_grid = np.invert(
np.flip(
np.transpose(
np.array(
list(map_info.pathing_grid.data), dtype=np.bool
).reshape(self.map_x, self.map_y)
),
axis=1,
)
)
self.terrain_height = (
np.flip(
np.transpose(
np.array(list(map_info.terrain_height.data)).reshape(
self.map_x, self.map_y
)
),
1,
)
/ 255
)
def reset(self):
"""Reset the environment. Required after each full episode.
Returns initial observations and states.
"""
self._episode_steps = 0
if self._episode_count == 0:
# Launch StarCraft II
self._launch()
else:
self._restart()
# Information kept for counting the reward
self.death_tracker_ally = np.zeros(self.n_agents)
self.death_tracker_enemy = np.zeros(self.n_enemies)
self.previous_ally_units = None
self.previous_enemy_units = None
self.win_counted = False
self.defeat_counted = False
self.last_action = np.zeros((self.n_agents, self.n_actions))
if self.heuristic_ai:
self.heuristic_targets = [None] * self.n_agents
try:
self._obs = self._controller.observe()
self.init_units()
except (protocol.ProtocolError, protocol.ConnectionError):
self.full_restart()
if self.debug:
logging.debug(
"Started Episode {}".format(self._episode_count).center(
60, "*"
)
)
return self.get_obs(), self.get_state()
def _restart(self):
"""Restart the environment by killing all units on the map.
There is a trigger in the SC2Map file, which restarts the
episode when there are no units left.
"""
try:
self._kill_all_units()
self._controller.step(2)
except (protocol.ProtocolError, protocol.ConnectionError):
self.full_restart()
def full_restart(self):
"""Full restart. Closes the SC2 process and launches a new one."""
self._sc2_proc.close()
self._launch()
self.force_restarts += 1
def step(self, actions):
"""A single environment step. Returns reward, terminated, info."""
actions_int = [int(a) for a in actions]
self.last_action = np.eye(self.n_actions)[np.array(actions_int)]
# Collect individual actions
sc_actions = []
if self.debug:
logging.debug("Actions".center(60, "-"))
for a_id, action in enumerate(actions_int):
if not self.heuristic_ai:
sc_action = self.get_agent_action(a_id, action)
else:
sc_action, action_num = self.get_agent_action_heuristic(
a_id, action
)
actions[a_id] = action_num
if sc_action:
sc_actions.append(sc_action)
# Send action request
req_actions = sc_pb.RequestAction(actions=sc_actions)
try:
self._controller.actions(req_actions)
# Make step in SC2, i.e. apply actions
self._controller.step(self._step_mul)
# Observe here so that we know if the episode is over.
self._obs = self._controller.observe()
except (protocol.ProtocolError, protocol.ConnectionError):
self.full_restart()
return 0, True, {}
self._total_steps += 1
self._episode_steps += 1
# Update units
game_end_code = self.update_units()
terminated = False
reward = self.reward_battle()
info = {"battle_won": False}
# count units that are still alive
dead_allies, dead_enemies = 0, 0
for _al_id, al_unit in self.agents.items():
if al_unit.health == 0:
dead_allies += 1
for _e_id, e_unit in self.enemies.items():
if e_unit.health == 0:
dead_enemies += 1
info["dead_allies"] = dead_allies
info["dead_enemies"] = dead_enemies
if game_end_code is not None:
# Battle is over
terminated = True
self.battles_game += 1
if game_end_code == 1 and not self.win_counted:
self.battles_won += 1
self.win_counted = True
info["battle_won"] = True
if not self.reward_sparse:
reward += self.reward_win
else:
reward = 1
elif game_end_code == -1 and not self.defeat_counted:
self.defeat_counted = True
if not self.reward_sparse:
reward += self.reward_defeat
else:
reward = -1
elif self._episode_steps >= self.episode_limit:
# Episode limit reached
terminated = True
if self.continuing_episode:
info["episode_limit"] = True
self.battles_game += 1
self.timeouts += 1
if self.debug:
logging.debug("Reward = {}".format(reward).center(60, "-"))
if terminated:
self._episode_count += 1
if self.reward_scale:
reward /= self.max_reward / self.reward_scale_rate
self.reward = reward
return reward, terminated, info
def get_agent_action(self, a_id, action):
"""Construct the action for agent a_id."""
avail_actions = self.get_avail_agent_actions(a_id)
assert (
avail_actions[action] == 1
), "Agent {} cannot perform action {}".format(a_id, action)
unit = self.get_unit_by_id(a_id)
tag = unit.tag
x = unit.pos.x
y = unit.pos.y
if action == 0:
# no-op (valid only when dead)
assert unit.health == 0, "No-op only available for dead agents."
if self.debug:
logging.debug("Agent {}: Dead".format(a_id))
return None
elif action == 1:
# stop
cmd = r_pb.ActionRawUnitCommand(
ability_id=actions["stop"],
unit_tags=[tag],
queue_command=False,
)
if self.debug:
logging.debug("Agent {}: Stop".format(a_id))
elif action == 2:
# move north
cmd = r_pb.ActionRawUnitCommand(
ability_id=actions["move"],
target_world_space_pos=sc_common.Point2D(
x=x, y=y + self._move_amount
),
unit_tags=[tag],
queue_command=False,
)
if self.debug:
logging.debug("Agent {}: Move North".format(a_id))
elif action == 3:
# move south
cmd = r_pb.ActionRawUnitCommand(
ability_id=actions["move"],
target_world_space_pos=sc_common.Point2D(
x=x, y=y - self._move_amount
),
unit_tags=[tag],
queue_command=False,
)
if self.debug:
logging.debug("Agent {}: Move South".format(a_id))
elif action == 4:
# move east
cmd = r_pb.ActionRawUnitCommand(
ability_id=actions["move"],
target_world_space_pos=sc_common.Point2D(
x=x + self._move_amount, y=y
),
unit_tags=[tag],
queue_command=False,
)
if self.debug:
logging.debug("Agent {}: Move East".format(a_id))
elif action == 5:
# move west
cmd = r_pb.ActionRawUnitCommand(
ability_id=actions["move"],
target_world_space_pos=sc_common.Point2D(
x=x - self._move_amount, y=y
),
unit_tags=[tag],
queue_command=False,
)
if self.debug:
logging.debug("Agent {}: Move West".format(a_id))
else:
# attack/heal units that are in range
target_id = action - self.n_actions_no_attack
if self.map_type == "MMM" and unit.unit_type == self.medivac_id:
target_unit = self.agents[target_id]
action_name = "heal"
else:
target_unit = self.enemies[target_id]
action_name = "attack"
action_id = actions[action_name]
target_tag = target_unit.tag
cmd = r_pb.ActionRawUnitCommand(
ability_id=action_id,
target_unit_tag=target_tag,
unit_tags=[tag],
queue_command=False,
)
if self.debug:
logging.debug(
"Agent {} {}s unit # {}".format(
a_id, action_name, target_id
)
)
sc_action = sc_pb.Action(action_raw=r_pb.ActionRaw(unit_command=cmd))
return sc_action
def get_agent_action_heuristic(self, a_id, action):
unit = self.get_unit_by_id(a_id)
tag = unit.tag
target = self.heuristic_targets[a_id]
if unit.unit_type == self.medivac_id:
if (
target is None
or self.agents[target].health == 0
or self.agents[target].health == self.agents[target].health_max
):
min_dist = math.hypot(self.max_distance_x, self.max_distance_y)
min_id = -1
for al_id, al_unit in self.agents.items():
if al_unit.unit_type == self.medivac_id:
continue
if (
al_unit.health != 0
and al_unit.health != al_unit.health_max
):
dist = self.distance(
unit.pos.x,
unit.pos.y,
al_unit.pos.x,
al_unit.pos.y,
)
if dist < min_dist:
min_dist = dist
min_id = al_id
self.heuristic_targets[a_id] = min_id
if min_id == -1:
self.heuristic_targets[a_id] = None
return None, 0
action_id = actions["heal"]
target_tag = self.agents[self.heuristic_targets[a_id]].tag
else:
if target is None or self.enemies[target].health == 0:
min_dist = math.hypot(self.max_distance_x, self.max_distance_y)
min_id = -1
for e_id, e_unit in self.enemies.items():
if (
unit.unit_type == self.marauder_id
and e_unit.unit_type == self.medivac_id
):
continue
if e_unit.health > 0:
dist = self.distance(
unit.pos.x, unit.pos.y, e_unit.pos.x, e_unit.pos.y
)
if dist < min_dist:
min_dist = dist
min_id = e_id
self.heuristic_targets[a_id] = min_id
if min_id == -1:
self.heuristic_targets[a_id] = None
return None, 0
action_id = actions["attack"]
target_tag = self.enemies[self.heuristic_targets[a_id]].tag
action_num = self.heuristic_targets[a_id] + self.n_actions_no_attack
# Check if the action is available
if (
self.heuristic_rest
and self.get_avail_agent_actions(a_id)[action_num] == 0
):
# Move towards the target rather than attacking/healing
if unit.unit_type == self.medivac_id:
target_unit = self.agents[self.heuristic_targets[a_id]]
else:
target_unit = self.enemies[self.heuristic_targets[a_id]]
delta_x = target_unit.pos.x - unit.pos.x
delta_y = target_unit.pos.y - unit.pos.y
if abs(delta_x) > abs(delta_y): # east or west
if delta_x > 0: # east
target_pos = sc_common.Point2D(
x=unit.pos.x + self._move_amount, y=unit.pos.y
)
action_num = 4
else: # west
target_pos = sc_common.Point2D(
x=unit.pos.x - self._move_amount, y=unit.pos.y
)
action_num = 5
else: # north or south
if delta_y > 0: # north
target_pos = sc_common.Point2D(
x=unit.pos.x, y=unit.pos.y + self._move_amount
)
action_num = 2
else: # south
target_pos = sc_common.Point2D(
x=unit.pos.x, y=unit.pos.y - self._move_amount
)
action_num = 3
cmd = r_pb.ActionRawUnitCommand(
ability_id=actions["move"],
target_world_space_pos=target_pos,
unit_tags=[tag],
queue_command=False,
)
else:
# Attack/heal the target
cmd = r_pb.ActionRawUnitCommand(
ability_id=action_id,
target_unit_tag=target_tag,
unit_tags=[tag],
queue_command=False,
)
sc_action = sc_pb.Action(action_raw=r_pb.ActionRaw(unit_command=cmd))
return sc_action, action_num
def reward_battle(self):
"""Reward function when self.reward_spare==False.
Returns accumulative hit/shield point damage dealt to the enemy
+ reward_death_value per enemy unit killed, and, in case
self.reward_only_positive == False, - (damage dealt to ally units
+ reward_death_value per ally unit killed) * self.reward_negative_scale
"""
if self.reward_sparse:
return 0
reward = 0
delta_deaths = 0
delta_ally = 0
delta_enemy = 0
neg_scale = self.reward_negative_scale
# update deaths
for al_id, al_unit in self.agents.items():
if not self.death_tracker_ally[al_id]:
# did not die so far
prev_health = (
self.previous_ally_units[al_id].health
+ self.previous_ally_units[al_id].shield
)
if al_unit.health == 0:
# just died
self.death_tracker_ally[al_id] = 1
if not self.reward_only_positive:
delta_deaths -= self.reward_death_value * neg_scale
delta_ally += prev_health * neg_scale
else:
# still alive
delta_ally += neg_scale * (
prev_health - al_unit.health - al_unit.shield
)
for e_id, e_unit in self.enemies.items():
if not self.death_tracker_enemy[e_id]:
prev_health = (
self.previous_enemy_units[e_id].health
+ self.previous_enemy_units[e_id].shield
)
if e_unit.health == 0:
self.death_tracker_enemy[e_id] = 1
delta_deaths += self.reward_death_value
delta_enemy += prev_health
else:
delta_enemy += prev_health - e_unit.health - e_unit.shield
if self.reward_only_positive:
reward = abs(delta_enemy + delta_deaths) # shield regeneration
else:
reward = delta_enemy + delta_deaths - delta_ally
return reward
def get_total_actions(self):
"""Returns the total number of actions an agent could ever take."""
return self.n_actions
@staticmethod
def distance(x1, y1, x2, y2):
"""Distance between two points."""
return math.hypot(x2 - x1, y2 - y1)
def unit_shoot_range(self, agent_id):
"""Returns the shooting range for an agent."""
return 6
def unit_sight_range(self, agent_id):
"""Returns the sight range for an agent."""
return 9
def unit_max_cooldown(self, unit):
"""Returns the maximal cooldown for a unit."""
switcher = {
self.marine_id: 15,
self.marauder_id: 25,
self.medivac_id: 200, # max energy
self.stalker_id: 35,
self.zealot_id: 22,
self.colossus_id: 24,
self.hydralisk_id: 10,
self.zergling_id: 11,
self.baneling_id: 1,
}
return switcher.get(unit.unit_type, 15)
def save_replay(self):
"""Save a replay."""
prefix = self.replay_prefix or self.map_name
replay_dir = self.replay_dir or ""
replay_path = self._run_config.save_replay(
self._controller.save_replay(),
replay_dir=replay_dir,
prefix=prefix,
)
logging.info("Replay saved at: %s" % replay_path)
def unit_max_shield(self, unit):
"""Returns maximal shield for a given unit."""
if unit.unit_type == 74 or unit.unit_type == self.stalker_id:
return 80 # Protoss's Stalker
if unit.unit_type == 73 or unit.unit_type == self.zealot_id:
return 50 # Protoss's Zaelot
if unit.unit_type == 4 or unit.unit_type == self.colossus_id:
return 150 # Protoss's Colossus
def can_move(self, unit, direction):
"""Whether a unit can move in a given direction."""
m = self._move_amount / 2
if direction == Direction.NORTH:
x, y = int(unit.pos.x), int(unit.pos.y + m)
elif direction == Direction.SOUTH:
x, y = int(unit.pos.x), int(unit.pos.y - m)
elif direction == Direction.EAST:
x, y = int(unit.pos.x + m), int(unit.pos.y)
else:
x, y = int(unit.pos.x - m), int(unit.pos.y)
if self.check_bounds(x, y) and self.pathing_grid[x, y]:
return True
return False
def get_surrounding_points(self, unit, include_self=False):
"""Returns the surrounding points of the unit in 8 directions."""
x = int(unit.pos.x)
y = int(unit.pos.y)
ma = self._move_amount
points = [
(x, y + 2 * ma),
(x, y - 2 * ma),
(x + 2 * ma, y),
(x - 2 * ma, y),
(x + ma, y + ma),
(x - ma, y - ma),
(x + ma, y - ma),
(x - ma, y + ma),
]
if include_self:
points.append((x, y))
return points
def check_bounds(self, x, y):
"""Whether a point is within the map bounds."""
return 0 <= x < self.map_x and 0 <= y < self.map_y
def get_surrounding_pathing(self, unit):
"""Returns pathing values of the grid surrounding the given unit."""
points = self.get_surrounding_points(unit, include_self=False)
vals = [
self.pathing_grid[x, y] if self.check_bounds(x, y) else 1
for x, y in points
]
return vals
def get_surrounding_height(self, unit):
"""Returns height values of the grid surrounding the given unit."""
points = self.get_surrounding_points(unit, include_self=True)
vals = [
self.terrain_height[x, y] if self.check_bounds(x, y) else 1
for x, y in points
]
return vals
def get_obs_agent(self, agent_id):
"""Returns observation for agent_id. The observation is composed of:
- agent movement features (where it can move to, height information
and pathing grid)
- enemy features (available_to_attack, health, relative_x, relative_y,
shield, unit_type)
- ally features (visible, distance, relative_x, relative_y, shield,
unit_type)
- agent unit features (health, shield, unit_type)
All of this information is flattened and concatenated into a list,
in the aforementioned order. To know the sizes of each of the
features inside the final list of features, take a look at the
functions ``get_obs_move_feats_size()``,
``get_obs_enemy_feats_size()``, ``get_obs_ally_feats_size()`` and
``get_obs_own_feats_size()``.
The size of the observation vector may vary, depending on the
environment configuration and type of units present in the map.
For instance, non-Protoss units will not have shields, movement
features may or may not include terrain height and pathing grid,
unit_type is not included if there is only one type of unit in the
map etc.).
NOTE: Agents should have access only to their local observations
during decentralised execution.
"""
unit = self.get_unit_by_id(agent_id)
move_feats_dim = self.get_obs_move_feats_size()
enemy_feats_dim = self.get_obs_enemy_feats_size()
ally_feats_dim = self.get_obs_ally_feats_size()
own_feats_dim = self.get_obs_own_feats_size()
move_feats = np.zeros(move_feats_dim, dtype=np.float32)
enemy_feats = np.zeros(enemy_feats_dim, dtype=np.float32)
ally_feats = np.zeros(ally_feats_dim, dtype=np.float32)
own_feats = np.zeros(own_feats_dim, dtype=np.float32)
if unit.health > 0: # otherwise dead, return all zeros
x = unit.pos.x
y = unit.pos.y
sight_range = self.unit_sight_range(agent_id)
# Movement features
avail_actions = self.get_avail_agent_actions(agent_id)
for m in range(self.n_actions_move):
move_feats[m] = avail_actions[m + 2]
ind = self.n_actions_move
if self.obs_pathing_grid:
move_feats[
ind : ind + self.n_obs_pathing # noqa
] = self.get_surrounding_pathing(unit)
ind += self.n_obs_pathing
if self.obs_terrain_height:
move_feats[ind:] = self.get_surrounding_height(unit)
# Enemy features
for e_id, e_unit in self.enemies.items():
e_x = e_unit.pos.x
e_y = e_unit.pos.y
dist = self.distance(x, y, e_x, e_y)
if (
dist < sight_range and e_unit.health > 0
): # visible and alive
# Sight range > shoot range
enemy_feats[e_id, 0] = avail_actions[
self.n_actions_no_attack + e_id
] # available
enemy_feats[e_id, 1] = dist / sight_range # distance
enemy_feats[e_id, 2] = (
e_x - x
) / sight_range # relative X
enemy_feats[e_id, 3] = (
e_y - y
) / sight_range # relative Y
ind = 4
if self.obs_all_health:
enemy_feats[e_id, ind] = (
e_unit.health / e_unit.health_max
) # health
ind += 1
if self.shield_bits_enemy > 0:
max_shield = self.unit_max_shield(e_unit)
enemy_feats[e_id, ind] = (
e_unit.shield / max_shield
) # shield
ind += 1
if self.unit_type_bits > 0:
type_id = self.get_unit_type_id(e_unit, False)
enemy_feats[e_id, ind + type_id] = 1 # unit type
# Ally features
al_ids = [
al_id for al_id in range(self.n_agents) if al_id != agent_id
]
for i, al_id in enumerate(al_ids):
al_unit = self.get_unit_by_id(al_id)
al_x = al_unit.pos.x
al_y = al_unit.pos.y
dist = self.distance(x, y, al_x, al_y)
if (
dist < sight_range and al_unit.health > 0
): # visible and alive
ally_feats[i, 0] = 1 # visible
ally_feats[i, 1] = dist / sight_range # distance
ally_feats[i, 2] = (al_x - x) / sight_range # relative X
ally_feats[i, 3] = (al_y - y) / sight_range # relative Y
ind = 4
if self.obs_all_health:
ally_feats[i, ind] = (
al_unit.health / al_unit.health_max
) # health
ind += 1
if self.shield_bits_ally > 0:
max_shield = self.unit_max_shield(al_unit)
ally_feats[i, ind] = (
al_unit.shield / max_shield
) # shield
ind += 1
if self.unit_type_bits > 0:
type_id = self.get_unit_type_id(al_unit, True)
ally_feats[i, ind + type_id] = 1
ind += self.unit_type_bits
if self.obs_last_action:
ally_feats[i, ind:] = self.last_action[al_id]
# Own features
ind = 0
if self.obs_own_health:
own_feats[ind] = unit.health / unit.health_max
ind += 1
if self.shield_bits_ally > 0:
max_shield = self.unit_max_shield(unit)
own_feats[ind] = unit.shield / max_shield
ind += 1
if self.unit_type_bits > 0:
type_id = self.get_unit_type_id(unit, True)
own_feats[ind + type_id] = 1
agent_obs = np.concatenate(
(
move_feats.flatten(),
enemy_feats.flatten(),
ally_feats.flatten(),
own_feats.flatten(),
)
)
if self.obs_timestep_number:
agent_obs = np.append(
agent_obs, self._episode_steps / self.episode_limit
)
if self.debug:
logging.debug("Obs Agent: {}".format(agent_id).center(60, "-"))
logging.debug(
"Avail. actions {}".format(
self.get_avail_agent_actions(agent_id)
)
)
logging.debug("Move feats {}".format(move_feats))
logging.debug("Enemy feats {}".format(enemy_feats))
logging.debug("Ally feats {}".format(ally_feats))
logging.debug("Own feats {}".format(own_feats))
return agent_obs
def get_obs(self):
"""Returns all agent observations in a list.
NOTE: Agents should have access only to their local observations
during decentralised execution.
"""
agents_obs = [self.get_obs_agent(i) for i in range(self.n_agents)]
return agents_obs # return a list of agent obs
def get_state(self):
"""Returns the global state.
NOTE: This functon should not be used during decentralised execution.
"""
if self.obs_instead_of_state:
obs_concat = np.concatenate(self.get_obs(), axis=0).astype(
np.float32
)
return obs_concat
state_dict = self.get_state_dict()
state = np.append(
state_dict["allies"].flatten(), state_dict["enemies"].flatten()
)
if "last_action" in state_dict:
state = np.append(state, state_dict["last_action"].flatten())
if "timestep" in state_dict:
state = np.append(state, state_dict["timestep"])
state = state.astype(dtype=np.float32)
if self.debug:
logging.debug("STATE".center(60, "-"))
logging.debug("Ally state {}".format(state_dict["allies"]))
logging.debug("Enemy state {}".format(state_dict["enemies"]))
if self.state_last_action:
logging.debug("Last actions {}".format(self.last_action))
return state
def get_ally_num_attributes(self):
return len(self.ally_state_attr_names)
def get_enemy_num_attributes(self):
return len(self.enemy_state_attr_names)
def get_state_dict(self):
"""Returns the global state as a dictionary.
- allies: numpy array containing agents and their attributes
- enemies: numpy array containing enemies and their attributes
- last_action: numpy array of previous actions for each agent
- timestep: current no. of steps divided by total no. of steps
NOTE: This function should not be used during decentralised execution.
"""
# number of features equals the number of attribute names
nf_al = self.get_ally_num_attributes()
nf_en = self.get_enemy_num_attributes()
ally_state = np.zeros((self.n_agents, nf_al))
enemy_state = np.zeros((self.n_enemies, nf_en))
center_x = self.map_x / 2
center_y = self.map_y / 2
for al_id, al_unit in self.agents.items():
if al_unit.health > 0:
x = al_unit.pos.x
y = al_unit.pos.y
max_cd = self.unit_max_cooldown(al_unit)
ally_state[al_id, 0] = (
al_unit.health / al_unit.health_max
) # health
if (
self.map_type == "MMM"
and al_unit.unit_type == self.medivac_id
):
ally_state[al_id, 1] = al_unit.energy / max_cd # energy
else:
ally_state[al_id, 1] = (
al_unit.weapon_cooldown / max_cd
) # cooldown
ally_state[al_id, 2] = (
x - center_x
) / self.max_distance_x # relative X
ally_state[al_id, 3] = (
y - center_y
) / self.max_distance_y # relative Y
if self.shield_bits_ally > 0:
max_shield = self.unit_max_shield(al_unit)
ally_state[al_id, 4] = (
al_unit.shield / max_shield
) # shield
if self.unit_type_bits > 0:
type_id = self.get_unit_type_id(al_unit, True)
ally_state[al_id, type_id - self.unit_type_bits] = 1
for e_id, e_unit in self.enemies.items():
if e_unit.health > 0:
x = e_unit.pos.x
y = e_unit.pos.y
enemy_state[e_id, 0] = (
e_unit.health / e_unit.health_max
) # health
enemy_state[e_id, 1] = (
x - center_x
) / self.max_distance_x # relative X
enemy_state[e_id, 2] = (
y - center_y
) / self.max_distance_y # relative Y
if self.shield_bits_enemy > 0:
max_shield = self.unit_max_shield(e_unit)
enemy_state[e_id, 3] = e_unit.shield / max_shield # shield
if self.unit_type_bits > 0:
type_id = self.get_unit_type_id(e_unit, False)
enemy_state[e_id, type_id - self.unit_type_bits] = 1
state = {"allies": ally_state, "enemies": enemy_state}
if self.state_last_action:
state["last_action"] = self.last_action
if self.state_timestep_number:
state["timestep"] = self._episode_steps / self.episode_limit
return state
def get_obs_enemy_feats_size(self):
"""Returns the dimensions of the matrix containing enemy features.
Size is n_enemies x n_features.
"""
nf_en = 4 + self.unit_type_bits
if self.obs_all_health:
nf_en += 1 + self.shield_bits_enemy
return self.n_enemies, nf_en
def get_obs_ally_feats_size(self):
"""Returns the dimensions of the matrix containing ally features.
Size is n_allies x n_features.
"""
nf_al = 4 + self.unit_type_bits
if self.obs_all_health:
nf_al += 1 + self.shield_bits_ally
if self.obs_last_action:
nf_al += self.n_actions
return self.n_agents - 1, nf_al
def get_obs_own_feats_size(self):
"""
Returns the size of the vector containing the agents' own features.
"""
own_feats = self.unit_type_bits
if self.obs_own_health:
own_feats += 1 + self.shield_bits_ally
if self.obs_timestep_number:
own_feats += 1
return own_feats
def get_obs_move_feats_size(self):
"""Returns the size of the vector containing the agents's movement-
related features.
"""
move_feats = self.n_actions_move
if self.obs_pathing_grid:
move_feats += self.n_obs_pathing
if self.obs_terrain_height:
move_feats += self.n_obs_height
return move_feats
def get_obs_size(self):
"""Returns the size of the observation."""
own_feats = self.get_obs_own_feats_size()
move_feats = self.get_obs_move_feats_size()
n_enemies, n_enemy_feats = self.get_obs_enemy_feats_size()
n_allies, n_ally_feats = self.get_obs_ally_feats_size()
enemy_feats = n_enemies * n_enemy_feats
ally_feats = n_allies * n_ally_feats
return move_feats + enemy_feats + ally_feats + own_feats
def get_state_size(self):
"""Returns the size of the global state."""
if self.obs_instead_of_state:
return self.get_obs_size() * self.n_agents
nf_al = 4 + self.shield_bits_ally + self.unit_type_bits
nf_en = 3 + self.shield_bits_enemy + self.unit_type_bits
enemy_state = self.n_enemies * nf_en
ally_state = self.n_agents * nf_al
size = enemy_state + ally_state
if self.state_last_action:
size += self.n_agents * self.n_actions
if self.state_timestep_number:
size += 1
return size
def get_visibility_matrix(self):
"""Returns a boolean numpy array of dimensions
(n_agents, n_agents + n_enemies) indicating which units
are visible to each agent.
"""
arr = np.zeros(
(self.n_agents, self.n_agents + self.n_enemies),
dtype=np.bool,
)
for agent_id in range(self.n_agents):
current_agent = self.get_unit_by_id(agent_id)
if current_agent.health > 0: # it agent not dead
x = current_agent.pos.x
y = current_agent.pos.y
sight_range = self.unit_sight_range(agent_id)
# Enemies
for e_id, e_unit in self.enemies.items():
e_x = e_unit.pos.x
e_y = e_unit.pos.y
dist = self.distance(x, y, e_x, e_y)
if dist < sight_range and e_unit.health > 0:
# visible and alive
arr[agent_id, self.n_agents + e_id] = 1
# The matrix for allies is filled symmetrically
al_ids = [
al_id for al_id in range(self.n_agents) if al_id > agent_id
]
for _, al_id in enumerate(al_ids):
al_unit = self.get_unit_by_id(al_id)
al_x = al_unit.pos.x
al_y = al_unit.pos.y
dist = self.distance(x, y, al_x, al_y)
if dist < sight_range and al_unit.health > 0:
# visible and alive
arr[agent_id, al_id] = arr[al_id, agent_id] = 1
return arr
def get_unit_type_id(self, unit, ally):
"""Returns the ID of unit type in the given scenario."""
if ally: # use new SC2 unit types
type_id = unit.unit_type - self._min_unit_type
else: # use default SC2 unit types
if self.map_type == "stalkers_and_zealots":
# id(Stalker) = 74, id(Zealot) = 73
type_id = unit.unit_type - 73
elif self.map_type == "colossi_stalkers_zealots":
# id(Stalker) = 74, id(Zealot) = 73, id(Colossus) = 4
if unit.unit_type == 4:
type_id = 0
elif unit.unit_type == 74:
type_id = 1
else:
type_id = 2
elif self.map_type == "bane":
if unit.unit_type == 9:
type_id = 0
else:
type_id = 1
elif self.map_type == "MMM":
if unit.unit_type == 51:
type_id = 0
elif unit.unit_type == 48:
type_id = 1
else:
type_id = 2
return type_id
def get_avail_agent_actions(self, agent_id):
"""Returns the available actions for agent_id."""
unit = self.get_unit_by_id(agent_id)
if unit.health > 0:
# cannot choose no-op when alive
avail_actions = [0] * self.n_actions
# stop should be allowed
avail_actions[1] = 1
# see if we can move
if self.can_move(unit, Direction.NORTH):
avail_actions[2] = 1
if self.can_move(unit, Direction.SOUTH):
avail_actions[3] = 1
if self.can_move(unit, Direction.EAST):
avail_actions[4] = 1
if self.can_move(unit, Direction.WEST):
avail_actions[5] = 1
# Can attack only alive units that are alive in the shooting range
shoot_range = self.unit_shoot_range(agent_id)
target_items = self.enemies.items()
if self.map_type == "MMM" and unit.unit_type == self.medivac_id:
# Medivacs cannot heal themselves or other flying units
target_items = [
(t_id, t_unit)
for (t_id, t_unit) in self.agents.items()
if t_unit.unit_type != self.medivac_id
]
for t_id, t_unit in target_items:
if t_unit.health > 0:
dist = self.distance(
unit.pos.x, unit.pos.y, t_unit.pos.x, t_unit.pos.y
)
if dist <= shoot_range:
avail_actions[t_id + self.n_actions_no_attack] = 1
return avail_actions
else:
# only no-op allowed
return [1] + [0] * (self.n_actions - 1)
def get_avail_actions(self):
"""Returns the available actions of all agents in a list."""
avail_actions = []
for agent_id in range(self.n_agents):
avail_agent = self.get_avail_agent_actions(agent_id)
avail_actions.append(avail_agent)
return avail_actions
def close(self):
"""Close StarCraft II."""
if self.renderer is not None:
self.renderer.close()
self.renderer = None
if self._sc2_proc:
self._sc2_proc.close()
def seed(self):
"""Returns the random seed used by the environment."""
return self._seed
def render(self, mode="human"):
if self.renderer is None:
from smac.env.starcraft2.render import StarCraft2Renderer
self.renderer = StarCraft2Renderer(self, mode)
assert (
mode == self.renderer.mode
), "mode must be consistent across render calls"
return self.renderer.render(mode)
def _kill_all_units(self):
"""Kill all units on the map."""
units_alive = [
unit.tag for unit in self.agents.values() if unit.health > 0
] + [unit.tag for unit in self.enemies.values() if unit.health > 0]
debug_command = [
d_pb.DebugCommand(kill_unit=d_pb.DebugKillUnit(tag=units_alive))
]
self._controller.debug(debug_command)
def init_units(self):
"""Initialise the units."""
while True:
# Sometimes not all units have yet been created by SC2
self.agents = {}
self.enemies = {}
ally_units = [
unit
for unit in self._obs.observation.raw_data.units
if unit.owner == 1
]
ally_units_sorted = sorted(
ally_units,
key=attrgetter("unit_type", "pos.x", "pos.y"),
reverse=False,
)
for i in range(len(ally_units_sorted)):
self.agents[i] = ally_units_sorted[i]
if self.debug:
logging.debug(
"Unit {} is {}, x = {}, y = {}".format(
len(self.agents),
self.agents[i].unit_type,
self.agents[i].pos.x,
self.agents[i].pos.y,
)
)
for unit in self._obs.observation.raw_data.units:
if unit.owner == 2:
self.enemies[len(self.enemies)] = unit
if self._episode_count == 0:
self.max_reward += unit.health_max + unit.shield_max
if self._episode_count == 0:
min_unit_type = min(
unit.unit_type for unit in self.agents.values()
)
self._init_ally_unit_types(min_unit_type)
all_agents_created = len(self.agents) == self.n_agents
all_enemies_created = len(self.enemies) == self.n_enemies
self._unit_types = [
unit.unit_type for unit in ally_units_sorted
] + [
unit.unit_type
for unit in self._obs.observation.raw_data.units
if unit.owner == 2
]
if all_agents_created and all_enemies_created: # all good
return
try:
self._controller.step(1)
self._obs = self._controller.observe()
except (protocol.ProtocolError, protocol.ConnectionError):
self.full_restart()
self.reset()
def get_unit_types(self):
if self._unit_types is None:
warn(
"unit types have not been initialized yet, please call"
"env.reset() to populate this and call t1286he method again."
)
return self._unit_types
def update_units(self):
"""Update units after an environment step.
This function assumes that self._obs is up-to-date.
"""
n_ally_alive = 0
n_enemy_alive = 0
# Store previous state
self.previous_ally_units = deepcopy(self.agents)
self.previous_enemy_units = deepcopy(self.enemies)
for al_id, al_unit in self.agents.items():
updated = False
for unit in self._obs.observation.raw_data.units:
if al_unit.tag == unit.tag:
self.agents[al_id] = unit
updated = True
n_ally_alive += 1
break
if not updated: # dead
al_unit.health = 0
for e_id, e_unit in self.enemies.items():
updated = False
for unit in self._obs.observation.raw_data.units:
if e_unit.tag == unit.tag:
self.enemies[e_id] = unit
updated = True
n_enemy_alive += 1
break
if not updated: # dead
e_unit.health = 0
if (
n_ally_alive == 0
and n_enemy_alive > 0
or self.only_medivac_left(ally=True)
):
return -1 # lost
if (
n_ally_alive > 0
and n_enemy_alive == 0
or self.only_medivac_left(ally=False)
):
return 1 # won
if n_ally_alive == 0 and n_enemy_alive == 0:
return 0
return None
def _init_ally_unit_types(self, min_unit_type):
"""Initialise ally unit types. Should be called once from the
init_units function.
"""
self._min_unit_type = min_unit_type
if self.map_type == "marines":
self.marine_id = min_unit_type
elif self.map_type == "stalkers_and_zealots":
self.stalker_id = min_unit_type
self.zealot_id = min_unit_type + 1
elif self.map_type == "colossi_stalkers_zealots":
self.colossus_id = min_unit_type
self.stalker_id = min_unit_type + 1
self.zealot_id = min_unit_type + 2
elif self.map_type == "MMM":
self.marauder_id = min_unit_type
self.marine_id = min_unit_type + 1
self.medivac_id = min_unit_type + 2
elif self.map_type == "zealots":
self.zealot_id = min_unit_type
elif self.map_type == "hydralisks":
self.hydralisk_id = min_unit_type
elif self.map_type == "stalkers":
self.stalker_id = min_unit_type
elif self.map_type == "colossus":
self.colossus_id = min_unit_type
elif self.map_type == "bane":
self.baneling_id = min_unit_type
self.zergling_id = min_unit_type + 1
def only_medivac_left(self, ally):
"""Check if only Medivac units are left."""
if self.map_type != "MMM":
return False
if ally:
units_alive = [
a
for a in self.agents.values()
if (a.health > 0 and a.unit_type != self.medivac_id)
]
if len(units_alive) == 0:
return True
return False
else:
units_alive = [
a
for a in self.enemies.values()
if (a.health > 0 and a.unit_type != self.medivac_id)
]
if len(units_alive) == 1 and units_alive[0].unit_type == 54:
return True
return False
def get_unit_by_id(self, a_id):
"""Get unit by ID."""
return self.agents[a_id]
def get_stats(self):
stats = {
"battles_won": self.battles_won,
"battles_game": self.battles_game,
"battles_draw": self.timeouts,
"win_rate": self.battles_won / self.battles_game,
"timeouts": self.timeouts,
"restarts": self.force_restarts,
}
return stats
def get_env_info(self):
env_info = super().get_env_info()
env_info["agent_features"] = self.ally_state_attr_names
env_info["enemy_features"] = self.enemy_state_attr_names
return env_info
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/pettingzoo/README.rst
================================================
SMAC on PettingZoo
==================
This example shows how to run SMAC environments with PettingZoo multi-agent API.
Instructions
------------
To get started, first install PettingZoo with ``pip install pettingzoo``.
The SMAC environment for PettingZoo, ``StarCraft2PZEnv``, can be initialized with two different API templates.
* **AEC**: PettingZoo is based in the *Agent Environment Cycle* game model, more information about "AEC" can be read in the following `paper `_. To create a SMAC environment as an "AEC" PettingZoo game model use: ::
from smac.env.pettingzoo import StarCraft2PZEnv
env = StarCraft2PZEnv.env()
* **Parallel**: PettingZoo also supports parallel environments where all agents have simultaneous actions and observations. This type of environment can be created as follows: ::
from smac.env.pettingzoo import StarCraft2PZEnv
env = StarCraft2PZEnv.parallel_env()
`pettingzoo_demo.py` has an example of a SMAC environment being used as a PettingZoo "AEC" environment. With `env.render()` it is possible to output an instance of the environment as a frame in pygame. This is useful for debugging purposes.
| See https://www.pettingzoo.ml/api for more documentation.
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/pettingzoo/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/pettingzoo/pettingzoo_demo.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import random
import numpy as np
from smac.env.pettingzoo import StarCraft2PZEnv
def main():
"""
Runs an env object with random actions.
"""
env = StarCraft2PZEnv.env()
episodes = 10
total_reward = 0
done = False
completed_episodes = 0
while completed_episodes < episodes:
env.reset()
for agent in env.agent_iter():
env.render()
obs, reward, done, _ = env.last()
total_reward += reward
if done:
action = None
elif isinstance(obs, dict) and "action_mask" in obs:
action = random.choice(np.flatnonzero(obs["action_mask"]))
else:
action = env.action_spaces[agent].sample()
env.step(action)
completed_episodes += 1
env.close()
print("Average total reward", total_reward / episodes)
if __name__ == "__main__":
main()
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/random_agents.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from smac.env import StarCraft2Env
import numpy as np
def main():
env = StarCraft2Env(map_name="8m")
env_info = env.get_env_info()
n_actions = env_info["n_actions"]
n_agents = env_info["n_agents"]
n_episodes = 10
for e in range(n_episodes):
env.reset()
terminated = False
episode_reward = 0
while not terminated:
obs = env.get_obs()
state = env.get_state()
# env.render() # Uncomment for rendering
actions = []
for agent_id in range(n_agents):
avail_actions = env.get_avail_agent_actions(agent_id)
avail_actions_ind = np.nonzero(avail_actions)[0]
action = np.random.choice(avail_actions_ind)
actions.append(action)
reward, terminated, _ = env.step(actions)
episode_reward += reward
print("Total reward in episode {} = {}".format(e, episode_reward))
env.close()
if __name__ == "__main__":
main()
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/rllib/README.rst
================================================
SMAC on RLlib
=============
This example shows how to run SMAC environments with RLlib multi-agent.
Instructions
------------
To get started, first install RLlib with ``pip install -U ray[rllib]``. You will also need TensorFlow installed.
In ``run_ppo.py``, each agent will be controlled by an independent PPO policy (the policies share weights). This setup serves as a single-agent baseline for this task.
In ``run_qmix.py``, the agents are controlled by the multi-agent QMIX policy. This setup is an example of centralized training and decentralized execution.
See https://ray.readthedocs.io/en/latest/rllib.html for more documentation.
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/rllib/__init__.py
================================================
from smac.examples.rllib.env import RLlibStarCraft2Env
from smac.examples.rllib.model import MaskedActionsModel
__all__ = ["RLlibStarCraft2Env", "MaskedActionsModel"]
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/rllib/env.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import random
import numpy as np
from gym.spaces import Discrete, Box, Dict
from ray import rllib
from smac.env import StarCraft2Env
class RLlibStarCraft2Env(rllib.MultiAgentEnv):
"""Wraps a smac StarCraft env to be compatible with RLlib multi-agent."""
def __init__(self, **smac_args):
"""Create a new multi-agent StarCraft env compatible with RLlib.
Arguments:
smac_args (dict): Arguments to pass to the underlying
smac.env.starcraft.StarCraft2Env instance.
Examples:
>>> from smac.examples.rllib import RLlibStarCraft2Env
>>> env = RLlibStarCraft2Env(map_name="8m")
>>> print(env.reset())
"""
self._env = StarCraft2Env(**smac_args)
self._ready_agents = []
self.observation_space = Dict(
{
"obs": Box(-1, 1, shape=(self._env.get_obs_size(),)),
"action_mask": Box(
0, 1, shape=(self._env.get_total_actions(),)
),
}
)
self.action_space = Discrete(self._env.get_total_actions())
def reset(self):
"""Resets the env and returns observations from ready agents.
Returns:
obs (dict): New observations for each ready agent.
"""
obs_list, state_list = self._env.reset()
return_obs = {}
for i, obs in enumerate(obs_list):
return_obs[i] = {
"action_mask": np.array(self._env.get_avail_agent_actions(i)),
"obs": obs,
}
self._ready_agents = list(range(len(obs_list)))
return return_obs
def step(self, action_dict):
"""Returns observations from ready agents.
The returns are dicts mapping from agent_id strings to values. The
number of agents in the env can vary over time.
Returns
-------
obs (dict): New observations for each ready agent.
rewards (dict): Reward values for each ready agent. If the
episode is just started, the value will be None.
dones (dict): Done values for each ready agent. The special key
"__all__" (required) is used to indicate env termination.
infos (dict): Optional info values for each agent id.
"""
actions = []
for i in self._ready_agents:
if i not in action_dict:
raise ValueError(
"You must supply an action for agent: {}".format(i)
)
actions.append(action_dict[i])
if len(actions) != len(self._ready_agents):
raise ValueError(
"Unexpected number of actions: {}".format(
action_dict,
)
)
rew, done, info = self._env.step(actions)
obs_list = self._env.get_obs()
return_obs = {}
for i, obs in enumerate(obs_list):
return_obs[i] = {
"action_mask": self._env.get_avail_agent_actions(i),
"obs": obs,
}
rews = {i: rew / len(obs_list) for i in range(len(obs_list))}
dones = {i: done for i in range(len(obs_list))}
dones["__all__"] = done
infos = {i: info for i in range(len(obs_list))}
self._ready_agents = list(range(len(obs_list)))
return return_obs, rews, dones, infos
def close(self):
"""Close the environment"""
self._env.close()
def seed(self, seed):
random.seed(seed)
np.random.seed(seed)
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/rllib/model.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
from ray.rllib.models import Model
from ray.rllib.models.tf.misc import normc_initializer
class MaskedActionsModel(Model):
"""Custom RLlib model that emits -inf logits for invalid actions.
This is used to handle the variable-length StarCraft action space.
"""
def _build_layers_v2(self, input_dict, num_outputs, options):
action_mask = input_dict["obs"]["action_mask"]
if num_outputs != action_mask.shape[1].value:
raise ValueError(
"This model assumes num outputs is equal to max avail actions",
num_outputs,
action_mask,
)
# Standard fully connected network
last_layer = input_dict["obs"]["obs"]
hiddens = options.get("fcnet_hiddens")
for i, size in enumerate(hiddens):
label = "fc{}".format(i)
last_layer = tf.layers.dense(
last_layer,
size,
kernel_initializer=normc_initializer(1.0),
activation=tf.nn.tanh,
name=label,
)
action_logits = tf.layers.dense(
last_layer,
num_outputs,
kernel_initializer=normc_initializer(0.01),
activation=None,
name="fc_out",
)
# Mask out invalid actions (use tf.float32.min for stability)
inf_mask = tf.maximum(tf.log(action_mask), tf.float32.min)
masked_logits = inf_mask + action_logits
return masked_logits, last_layer
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/rllib/run_ppo.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
"""Example of running StarCraft2 with RLlib PPO.
In this setup, each agent will be controlled by an independent PPO policy.
However the policies share weights.
Increase the level of parallelism by changing --num-workers.
"""
import argparse
import ray
from ray.tune import run_experiments, register_env
from ray.rllib.models import ModelCatalog
from smac.examples.rllib.env import RLlibStarCraft2Env
from smac.examples.rllib.model import MaskedActionsModel
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--num-iters", type=int, default=100)
parser.add_argument("--num-workers", type=int, default=2)
parser.add_argument("--map-name", type=str, default="8m")
args = parser.parse_args()
ray.init()
register_env("smac", lambda smac_args: RLlibStarCraft2Env(**smac_args))
ModelCatalog.register_custom_model("mask_model", MaskedActionsModel)
run_experiments(
{
"ppo_sc2": {
"run": "PPO",
"env": "smac",
"stop": {
"training_iteration": args.num_iters,
},
"config": {
"num_workers": args.num_workers,
"observation_filter": "NoFilter", # breaks the action mask
"vf_share_layers": True, # no separate value model
"env_config": {
"map_name": args.map_name,
},
"model": {
"custom_model": "mask_model",
},
},
},
}
)
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/rllib/run_qmix.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
"""Example of running StarCraft2 with RLlib QMIX.
This assumes all agents are homogeneous. The agents are grouped and assigned
to the multi-agent QMIX policy. Note that the default hyperparameters for
RLlib QMIX are different from pymarl's QMIX.
"""
import argparse
from gym.spaces import Tuple
import ray
from ray.tune import run_experiments, register_env
from smac.examples.rllib.env import RLlibStarCraft2Env
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--num-iters", type=int, default=100)
parser.add_argument("--num-workers", type=int, default=2)
parser.add_argument("--map-name", type=str, default="8m")
args = parser.parse_args()
def env_creator(smac_args):
env = RLlibStarCraft2Env(**smac_args)
agent_list = list(range(env._env.n_agents))
grouping = {
"group_1": agent_list,
}
obs_space = Tuple([env.observation_space for i in agent_list])
act_space = Tuple([env.action_space for i in agent_list])
return env.with_agent_groups(
grouping, obs_space=obs_space, act_space=act_space
)
ray.init()
register_env("sc2_grouped", env_creator)
run_experiments(
{
"qmix_sc2": {
"run": "QMIX",
"env": "sc2_grouped",
"stop": {
"training_iteration": args.num_iters,
},
"config": {
"num_workers": args.num_workers,
"env_config": {
"map_name": args.map_name,
},
},
},
}
)
================================================
FILE: examples/Social_Cognition/ToCM/train.py
================================================
import argparse
import os
import sys
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
from agent.runners.ToCMRunner import ToCMRunner
from configs import Experiment, SimpleObservationConfig, NearRewardConfig, DeadlockPunishmentConfig, \
RewardsComposerConfig
from configs.EnvConfigs import StarCraftConfig, EnvCurriculumConfig, MPEConfig # TODO
from configs.ToCM.ToCMControllerConfig import ToCMControllerConfig
from configs.ToCM.ToCMLearnerConfig import ToCMLearnerConfig
from environments import Env
from utils.util import get_dim_from_space, get_cent_act_dim
import torch
import random
import numpy as np
import setproctitle
setproctitle.setproctitle("MPE_obs_2_hetero")
def occumpy_mem(cuda_device):
total, used = os.popen(
'"/usr/bin/nvidia-smi" --query-gpu=memory.total,memory.used --format=csv,nounits,noheader').read().strip().split(
"\n")[int(cuda_device)].split(',')
total = int(total)
used = int(used)
cc = 0.85
block_mem = int((total - used) * cc)
x = torch.cuda.FloatTensor(256, 1024, block_mem)
del x
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--env', type=str, default="mpe", help='starcraft or mpe') # TODO
parser.add_argument('--env_name', type=str, default="hetero_spread", help='Specific setting') # TODO
# star : 2s_vs_1sc MMM 2s3z 3s_vs_3z 3s5z_vs_3s6z simple_spread
parser.add_argument('--n_workers', type=int, default=4, help='Number of workers')
parser.add_argument('--device', type=str, default='cuda', help='device')
parser.add_argument('--seed', type=int, default=50, help='random')
# TODO num_landmarks num_adversaries episode_length num_good_agents
parser.add_argument('--num_agents', type=int, default=2, help='mpe_num_agents') # simple_adversary
parser.add_argument('--num_adversaries', type=int, default=None, help='mpe_num_adversaries')
parser.add_argument('--num_good_agents', type=int, default=None, help='mpe_num_good_agents')
parser.add_argument('--num_landmarks', type=int, default=2, help='mpe_num_landmarks')
parser.add_argument('--episode_length', type=int, default=25, help='mpe_episode_length')
parser.add_argument('--num_rollout_threads', type=int, default=128, help='mpe_episode_length')
parser.add_argument('--benchmark', type=bool, default=False, help='mpe_use_benchmark')
return parser.parse_args() # 为啥直接跳到prepare_starcraft_configs函数里了
def setup_seed(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
def train_ToCM(exp, n_workers): # no env.episode_length
runner = ToCMRunner(exp.env_config, exp.learner_config, exp.controller_config, n_workers)
runner.run(exp.steps, exp.episodes) # 10 ** 10 50000
def get_env_info(configs, env):
for config in configs:
config.IN_DIM = env.n_obs # 17 2s_vs_1sc
config.ACTION_SIZE = env.n_actions # 7 2s_vs_1sc
env.close()
def get_env_info_mpe(configs, env): # add to ToCM controller and worker
# TODO cent_obs_dim and cent_action_dim use share_policy
for config in configs:
config.CENT_OBS_DIM = get_dim_from_space(env.env.share_observation_space[0]) # 54=num_agents*IN_DIM
config.CENT_ACT_DIM = get_cent_act_dim(env.env.action_space) # 15=num_agents*ACTION_SIZE
config.IN_DIM = get_dim_from_space(env.env.observation_space[0]) # dim 18
config.ACTION_SIZE = get_dim_from_space(env.env.action_space[0]) # dim 5
env.close()
def prepare_starcraft_configs(env_name, device):
# env_name '3s5z_vs_3s6z' device 'cuda:6' RANDOM_SEED 1 args.n_workers 2
# args.env 'starcraft' args.env_name '3s5z_vs_3s6z' args.device 'cuda:6' args.seed 1
agent_configs = [ToCMControllerConfig(env_name, RANDOM_SEED, device),
ToCMLearnerConfig(env_name, RANDOM_SEED, device)]
env_config = StarCraftConfig(env_name, RANDOM_SEED)
get_env_info(agent_configs, env_config.create_env())
return {"env_config": (env_config, 100),
"controller_config": agent_configs[0],
"learner_config": agent_configs[1],
"reward_config": None,
"obs_builder_config": None}
def prepare_mpe_configs(arg):
agent_configs = [ToCMControllerConfig(arg.env_name, RANDOM_SEED, arg.device),
ToCMLearnerConfig(arg.env_name, RANDOM_SEED, arg.device)]
env_config = MPEConfig(arg)
get_env_info_mpe(agent_configs, env_config.create_env())
return {"env_config": (env_config, 100),
"controller_config": agent_configs[0],
"learner_config": agent_configs[1],
"reward_config": None,
"obs_builder_config": None} # TODO whether has reward config and obs builder config
if __name__ == "__main__":
# occumpy_mem(2)
# RANDOM_SEED = 23 # RANDOM_SEED 1
args = parse_args()
# print("args=", args)
RANDOM_SEED = args.seed
setup_seed(RANDOM_SEED) # TODO
# args.env_name '3s5z_vs_3s6z' args.device 'cuda:6' args.seed 1 args.n_workers 2
if args.env == Env.STARCRAFT:
configs = prepare_starcraft_configs(args.env_name, args.device)
elif args.env == Env.MPE:
configs = prepare_mpe_configs(args)
# as env is mpe env_name is simple_adversary
else:
raise Exception("Unknown environment")
configs["env_config"][0].ENV_TYPE = Env(args.env) # 转化为字符串
configs["learner_config"].ENV_TYPE = Env(args.env)
configs["controller_config"].ENV_TYPE = Env(args.env)
exp = Experiment(steps=10 ** 10,
episodes=50000,
random_seed=RANDOM_SEED,
env_config=EnvCurriculumConfig(*zip(configs["env_config"]), Env(args.env), args.device, # TODO
obs_builder_config=configs["obs_builder_config"],
reward_config=configs["reward_config"]),
controller_config=configs["controller_config"],
learner_config=configs["learner_config"])
# print("exp=", exp)
train_ToCM(exp, n_workers=args.n_workers)
================================================
FILE: examples/Social_Cognition/ToCM/utils/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/utils/mlp_buffer.py
================================================
import numpy as np
from utils.util import get_dim_from_space
from utils.segment_tree import SumSegmentTree, MinSegmentTree
def _cast(x):
return x.transpose(1, 0, 2)
class MlpReplayBuffer(object):
def __init__(self, policy_info, policy_agents, buffer_size, use_same_share_obs, use_avail_acts,
use_reward_normalization=False):
"""
Replay buffer class for training MLP policies.
:param policy_info: (dict) maps policy id to a dict containing information about corresponding policy.
:param policy_agents: (dict) maps policy id to list of agents controled by corresponding policy.
:param buffer_size: (int) max number of transitions to store in the buffer.
:param use_same_share_obs: (bool) whether all agents share the same centralized observation.
:param use_avail_acts: (bool) whether to store what actions are available.
:param use_reward_normalization: (bool) whether to use reward normalization.
"""
self.policy_info = policy_info
self.policy_buffers = {p_id: MlpPolicyBuffer(buffer_size,
len(policy_agents[p_id]),
self.policy_info[p_id]['obs_space'],
self.policy_info[p_id]['share_obs_space'],
self.policy_info[p_id]['act_space'],
use_same_share_obs,
use_avail_acts,
use_reward_normalization)
for p_id in self.policy_info.keys()}
def __len__(self):
return self.policy_buffers['policy_0'].filled_i
def insert(self, num_insert_steps, obs, share_obs, acts, rewards,
next_obs, next_share_obs, dones, dones_env, valid_transition,
avail_acts, next_avail_acts):
"""
Insert a set of transitions into buffer. If the buffer size overflows, old transitions are dropped.
:param num_insert_steps: (int) number of transitions to be added to buffer
:param obs: (dict) maps policy id to numpy array of observations of agents corresponding to that policy
:param share_obs: (dict) maps policy id to numpy array of centralized observation corresponding to that policy
:param acts: (dict) maps policy id to numpy array of actions of agents corresponding to that policy
:param rewards: (dict) maps policy id to numpy array of rewards of agents corresponding to that policy
:param next_obs: (dict) maps policy id to numpy array of next step observations of agents corresponding to that policy
:param next_share_obs: (dict) maps policy id to numpy array of next step centralized observations corresponding to that policy
:param dones: (dict) maps policy id to numpy array of terminal status of agents corresponding to that policy
:param dones_env: (dict) maps policy id to numpy array of terminal status of env
:param valid_transition: (dict) maps policy id to numpy array of whether the corresponding transition is valid of agents corresponding to that policy
:param avail_acts: (dict) maps policy id to numpy array of available actions of agents corresponding to that policy
:param next_avail_acts: (dict) maps policy id to numpy array of next step available actions of agents corresponding to that policy
:return: (np.ndarray) indexes in which the new transitions were placed.
"""
idx_range = None
for p_id in self.policy_info.keys():
idx_range = self.policy_buffers[p_id].insert(num_insert_steps,
np.array(obs[p_id]), np.array(share_obs[p_id]),
np.array(acts[p_id]), np.array(rewards[p_id]),
np.array(next_obs[p_id]), np.array(next_share_obs[p_id]),
np.array(dones[p_id]), np.array(dones_env[p_id]),
np.array(valid_transition[p_id]),
np.array(avail_acts[p_id]), np.array(next_avail_acts[p_id]))
return idx_range
def sample(self, batch_size):
"""
Sample a set of transitions from buffer, uniformly at random.
:param batch_size: (int) number of transitions to sample from buffer.
:return: obs: (dict) maps policy id to sampled observations corresponding to that policy
:return: share_obs: (dict) maps policy id to sampled observations corresponding to that policy
:return: acts: (dict) maps policy id to sampled actions corresponding to that policy
:return: rewards: (dict) maps policy id to sampled rewards corresponding to that policy
:return: next_obs: (dict) maps policy id to sampled next step observations corresponding to that policy
:return: next_share_obs: (dict) maps policy id to sampled next step centralized observations corresponding to that policy
:return: dones: (dict) maps policy id to sampled terminal status of agents corresponding to that policy
:return: dones_env: (dict) maps policy id to sampled environment terminal status corresponding to that policy
:return: valid_transition: (dict) maps policy_id to whether each sampled transition is valid or not (invalid if corresponding agent is dead)
:return: avail_acts: (dict) maps policy_id to available actions corresponding to that policy
:return: next_avail_acts: (dict) maps policy_id to next step available actions corresponding to that policy
"""
inds = np.random.choice(len(self), batch_size)
obs, share_obs, acts, rewards, next_obs, next_share_obs, dones, dones_env, valid_transition, avail_acts, next_avail_acts = {}, {}, {}, {}, {}, {}, {}, {}, {}, {}, {}
for p_id in self.policy_info.keys():
obs[p_id], share_obs[p_id], acts[p_id], rewards[p_id], next_obs[p_id], next_share_obs[p_id], \
dones[p_id], dones_env[p_id], valid_transition[p_id], avail_acts[p_id], next_avail_acts[p_id] = \
self.policy_buffers[p_id].sample_inds(inds)
return obs, share_obs, acts, rewards, next_obs, next_share_obs, dones, dones_env, valid_transition, avail_acts, next_avail_acts, None, None
class MlpPolicyBuffer(object):
def __init__(self, buffer_size, num_agents, obs_space, share_obs_space, act_space, use_same_share_obs,
use_avail_acts, use_reward_normalization=False):
"""
Buffer class containing buffer data corresponding to a single policy.
:param buffer_size: (int) max number of transitions to store in buffer.
:param num_agents: (int) number of agents controlled by the policy.
:param obs_space: (gym.Space) observation space of the environment.
:param share_obs_space: (gym.Space) centralized observation space of the environment.
:param act_space: (gym.Space) action space of the environment.
:use_same_share_obs: (bool) whether all agents share the same centralized observation.
:use_avail_acts: (bool) whether to store what actions are available.
:param use_reward_normalization: (bool) whether to use reward normalization.
"""
self.buffer_size = buffer_size
self.num_agents = num_agents
self.use_same_share_obs = use_same_share_obs
self.use_avail_acts = use_avail_acts
self.use_reward_normalization = use_reward_normalization
self.filled_i = 0
self.current_i = 0
# obs
if obs_space.__class__.__name__ == 'Box':
obs_shape = obs_space.shape
share_obs_shape = share_obs_space.shape
elif obs_space.__class__.__name__ == 'list':
obs_shape = obs_space
share_obs_shape = share_obs_space
else:
raise NotImplementedError
self.obs = np.zeros(
(self.buffer_size, self.num_agents, obs_shape[0]), dtype=np.float32)
if self.use_same_share_obs:
self.share_obs = np.zeros((self.buffer_size, share_obs_shape[0]), dtype=np.float32)
else:
self.share_obs = np.zeros((self.buffer_size, self.num_agents, share_obs_shape[0]), dtype=np.float32)
self.next_obs = np.zeros_like(self.obs, dtype=np.float32)
self.next_share_obs = np.zeros_like(self.share_obs, dtype=np.float32)
# action
act_dim = np.sum(get_dim_from_space(act_space))
self.acts = np.zeros((self.buffer_size, self.num_agents, act_dim), dtype=np.float32)
if self.use_avail_acts:
self.avail_acts = np.ones_like(self.acts, dtype=np.float32)
self.next_avail_acts = np.ones_like(self.avail_acts, dtype=np.float32)
# rewards
self.rewards = np.zeros((self.buffer_size, self.num_agents, 1), dtype=np.float32)
# default to done being True
self.dones = np.ones_like(self.rewards, dtype=np.float32)
self.dones_env = np.ones((self.buffer_size, 1), dtype=np.float32)
self.valid_transition = np.zeros_like(self.dones, dtype=np.float32)
def __len__(self):
return self.filled_i
def insert(self, num_insert_steps, obs, share_obs, acts, rewards,
next_obs, next_share_obs, dones, dones_env, valid_transition,
avail_acts=None, next_avail_acts=None):
"""
Insert a set of transitions corresponding to this policy into buffer. If the buffer size overflows, old transitions are dropped.
:param num_insert_steps: (int) number of transitions to be added to buffer
:param obs: (np.ndarray) observations of agents corresponding to this policy.
:param share_obs: (np.ndarray) centralized observations of agents corresponding to this policy.
:param acts: (np.ndarray) actions of agents corresponding to this policy.
:param rewards: (np.ndarray) rewards of agents corresponding to this policy.
:param next_obs: (np.ndarray) next step observations of agents corresponding to this policy.
:param next_share_obs: (np.ndarray) next step centralized observations of agents corresponding to this policy.
:param dones: (np.ndarray) terminal status of agents corresponding to this policy.
:param dones_env: (np.ndarray) environment terminal status.
:param valid_transition: (np.ndarray) whether each transition is valid or not (invalid if agent was dead during transition)
:param avail_acts: (np.ndarray) available actions of agents corresponding to this policy.
:param next_avail_acts: (np.ndarray) next step available actions of agents corresponding to this policy.
:return: (np.ndarray) indexes of the buffer the new transitions were placed in.
"""
# obs: [step, episode, agent, dim]
assert obs.shape[0] == num_insert_steps, ("different size!")
if self.current_i + num_insert_steps <= self.buffer_size:
idx_range = np.arange(self.current_i, self.current_i + num_insert_steps)
else:
num_left_steps = self.current_i + num_insert_steps - self.buffer_size
idx_range = np.concatenate((np.arange(self.current_i, self.buffer_size), np.arange(num_left_steps)))
self.obs[idx_range] = obs.copy()
self.share_obs[idx_range] = share_obs.copy()
self.acts[idx_range] = acts.copy()
self.rewards[idx_range] = rewards.copy()
self.next_obs[idx_range] = next_obs.copy()
self.next_share_obs[idx_range] = next_share_obs.copy()
self.dones[idx_range] = dones.copy()
self.dones_env[idx_range] = dones_env.copy()
self.valid_transition[idx_range] = valid_transition.copy()
if self.use_avail_acts:
self.avail_acts[idx_range] = avail_acts.copy()
self.next_avail_acts[idx_range] = next_avail_acts.copy()
self.current_i = idx_range[-1] + 1
self.filled_i = min(self.filled_i + len(idx_range), self.buffer_size)
return idx_range
def sample_inds(self, sample_inds):
"""
Sample a set of transitions from buffer from the specified indices.
:param sample_inds: (np.ndarray) indices of samples to return from buffer.
:return: obs: (np.ndarray) sampled observations corresponding to that policy
:return: share_obs: (np.ndarray) sampled observations corresponding to that policy
:return: acts: (np.ndarray) sampled actions corresponding to that policy
:return: rewards: (np.ndarray) sampled rewards corresponding to that policy
:return: next_obs: (np.ndarray) sampled next step observations corresponding to that policy
:return: next_share_obs: (np.ndarray) sampled next step centralized observations corresponding to that policy
:return: dones: (np.ndarray) sampled terminal status of agents corresponding to that policy
:return: dones_env: (np.ndarray) sampled environment terminal status corresponding to that policy
:return: valid_transition: (np.ndarray) whether each sampled transition is valid or not (invalid if corresponding agent is dead)
:return: avail_acts: (np.ndarray) sampled available actions corresponding to that policy
:return: next_avail_acts: (np.ndarray) sampled next step available actions corresponding to that policy
"""
obs = _cast(self.obs[sample_inds])
acts = _cast(self.acts[sample_inds])
if self.use_reward_normalization:
mean_reward = self.rewards[:self.filled_i].mean()
std_reward = self.rewards[:self.filled_i].std()
rewards = _cast(
(self.rewards[sample_inds] - mean_reward) / std_reward)
else:
rewards = _cast(self.rewards[sample_inds])
next_obs = _cast(self.next_obs[sample_inds])
if self.use_same_share_obs:
share_obs = self.share_obs[sample_inds]
next_share_obs = self.next_share_obs[sample_inds]
else:
share_obs = _cast(self.share_obs[sample_inds])
next_share_obs = _cast(self.next_share_obs[sample_inds])
dones = _cast(self.dones[sample_inds])
dones_env = self.dones_env[sample_inds]
valid_transition = _cast(self.valid_transition[sample_inds])
if self.use_avail_acts:
avail_acts = _cast(self.avail_acts[sample_inds])
next_avail_acts = _cast(self.next_avail_acts[sample_inds])
else:
avail_acts = None
next_avail_acts = None
return obs, share_obs, acts, rewards, next_obs, next_share_obs, dones, dones_env, valid_transition, avail_acts, next_avail_acts
class PrioritizedMlpReplayBuffer(MlpReplayBuffer):
def __init__(self, alpha, policy_info, policy_agents, buffer_size, use_same_share_obs, use_avail_acts,
use_reward_normalization=False):
"""Prioritized replay buffer class for training MLP policies. See parent class."""
super(PrioritizedMlpReplayBuffer, self).__init__(policy_info, policy_agents,
buffer_size, use_same_share_obs, use_avail_acts,
use_reward_normalization)
self.alpha = alpha
self.policy_info = policy_info
it_capacity = 1
while it_capacity < buffer_size:
it_capacity *= 2
self._it_sums = {p_id: SumSegmentTree(it_capacity) for p_id in self.policy_info.keys()}
self._it_mins = {p_id: MinSegmentTree(it_capacity) for p_id in self.policy_info.keys()}
self.max_priorities = {p_id: 1.0 for p_id in self.policy_info.keys()}
def insert(self, num_insert_steps, obs, share_obs, acts, rewards, next_obs, next_share_obs, dones, dones_env,
valid_transition, avail_acts=None, next_avail_acts=None):
"""See parent class."""
idx_range = super().insert(num_insert_steps, obs, share_obs, acts, rewards, next_obs, next_share_obs, dones,
dones_env, valid_transition, avail_acts, next_avail_acts)
for idx in range(idx_range[0], idx_range[1]):
for p_id in self.policy_info.keys():
self._it_sums[p_id][idx] = self.max_priorities[p_id] ** self.alpha
self._it_mins[p_id][idx] = self.max_priorities[p_id] ** self.alpha
return idx_range
def _sample_proportional(self, batch_size, p_id=None):
total = self._it_sums[p_id].sum(0, len(self) - 1)
mass = np.random.random(size=batch_size) * total
idx = self._it_sums[p_id].find_prefixsum_idx(mass)
return idx
def sample(self, batch_size, beta=0, p_id=None):
"""
Sample a set of transitions from buffer; probability of choosing a given sample is proportional to its priority.
:param batch_size: (int) number of transitions to sample.
:param beta: (float) controls the amount of prioritization to apply.
:param p_id: (str) policy which will be updated using the samples.
:return: See parent class.
"""
assert len(self) > batch_size, "Not enough samples in the buffer!"
assert beta > 0
batch_inds = self._sample_proportional(batch_size, p_id)
p_min = self._it_mins[p_id].min() / self._it_sums[p_id].sum()
max_weight = (p_min * len(self)) ** (-beta)
p_sample = self._it_sums[p_id][batch_inds] / self._it_sums[p_id].sum()
weights = (p_sample * len(self)) ** (-beta) / max_weight
obs, share_obs, acts, rewards, next_obs, next_share_obs, dones, dones_env, valid_transition, avail_acts, next_avail_acts = {}, {}, {}, {}, {}, {}, {}, {}, {}, {}, {}
for p_id in self.policy_info.keys():
p_buffer = self.policy_buffers[p_id]
obs[p_id], share_obs[p_id], acts[p_id], rewards[p_id], next_obs[p_id], next_share_obs[p_id], dones[p_id], \
dones_env[p_id], valid_transition[p_id], avail_acts[p_id], next_avail_acts[p_id] = p_buffer.sample_inds(batch_inds)
return obs, share_obs, acts, rewards, next_obs, next_share_obs, dones, dones_env, valid_transition, avail_acts, next_avail_acts, weights, batch_inds
def update_priorities(self, idxes, priorities, p_id=None):
"""
Update priorities of sampled transitions.
sets priority of transition at index idxes[i] in buffer
to priorities[i].
:param idxes: ([int]) List of idxes of sampled transitions
:param priorities: ([float]) List of updated priorities corresponding to transitions at the sampled idxes
denoted by variable `idxes`.
"""
assert len(idxes) == len(priorities)
assert np.min(priorities) > 0
assert np.min(idxes) >= 0
assert np.max(idxes) < len(self)
self._it_sums[p_id][idxes] = priorities ** self.alpha
self._it_mins[p_id][idxes] = priorities ** self.alpha
self.max_priorities[p_id] = max(
self.max_priorities[p_id], np.max(priorities))
================================================
FILE: examples/Social_Cognition/ToCM/utils/mlp_nstep_buffer.py
================================================
import numpy as np
import torch
import random
class NStepReplayBuffer:
def __init__(self, max_size, episode_len, n, policy_ids, agent_ids, policy_agents, policy_obs_dim, policy_act_dim, gamma):
self.max_size = max_size
self.episode_len = episode_len
# n for n-step returns
self.n = n
self.policy_ids = policy_ids
self.agent_ids = agent_ids
self.policy_agents = policy_agents
self.policy_buffers = {
p_id: NStepPolicyBuffer(p_id, self.max_size, episode_len, n, self.policy_agents[p_id], policy_obs_dim[p_id],
policy_act_dim[p_id], gamma) for p_id in self.policy_ids}
self.num_episodes = 0
self.num_transitions = 0
def push(self, t_env, observation_batch, action_batch, reward_batch, next_observation_batch, dones_batch, finish_episodes):
batch_size = observation_batch.shape[0]
observations = {a_id: np.vstack(
[obs[a_id] for obs in observation_batch]) for a_id in self.agent_ids}
actions = {a_id: np.vstack([act[a_id] for act in action_batch])
for a_id in self.agent_ids}
rewards = {a_id: np.vstack([rew[a_id] for rew in reward_batch])
for a_id in self.agent_ids}
n_observations = {a_id: np.vstack(
[nobs[a_id] for nobs in next_observation_batch]) for a_id in self.agent_ids}
if finish_episodes:
dones = {a_id: np.ones_like(rewards[a_id]).astype(
bool) for a_id in self.agent_ids}
else:
dones = {a_id: np.vstack(
[done[a_id] for done in dones_batch]) for a_id in self.agent_ids}
for p_id in self.policy_ids:
self.policy_buffers[p_id].push(
batch_size, t_env, observations, actions, rewards, n_observations, dones, finish_episodes)
assert len(
set([p_buffer.num_episodes for p_buffer in self.policy_buffers.values()])) == 1
assert len(
set([p_buffer.num_transitions for p_buffer in self.policy_buffers.values()])) == 1
self.num_episodes = self.policy_buffers[self.policy_ids[0]].num_episodes
self.num_transitions = self.policy_buffers[self.policy_ids[0]
].num_transitions
def sample(self, batch_size):
assert self.num_transitions > batch_size, "Cannot sample with no completed episodes in the buffer!"
chunk_starts = np.random.choice(self.episode_len, batch_size)
batch_inds = np.random.choice(self.num_episodes, batch_size)
obs = {}
act = {}
rew = {}
nobs = {}
dones = {}
for p_id in self.policy_ids:
p_buffer = self.policy_buffers[p_id]
o, a, r, no, d = p_buffer.get(batch_inds, chunk_starts)
obs[p_id] = o
act[p_id] = a
rew[p_id] = r
nobs[p_id] = no
dones[p_id] = d
return obs, act, rew, nobs, dones
class NStepPolicyBuffer:
def __init__(self, policy_id, max_size, episode_len, n, policy_agents, obs_dim, act_dim, gamma):
self.max_size = max_size
self.n = n
self.num_agents = len(policy_agents)
self.policy_id = policy_id
self.episode_len = episode_len
self.agent_ids = policy_agents
self.gamma = gamma
random.shuffle(self.agent_ids)
self.observations = np.zeros(
(self.num_agents, max_size, episode_len, obs_dim))
self.actions = np.zeros(
(self.num_agents, max_size, episode_len, act_dim))
self.rewards = np.zeros(
(self.num_agents, max_size, episode_len + n - 1, 1))
self.next_observations = np.zeros(
(self.num_agents, max_size, episode_len + n - 1, obs_dim))
self.dones = np.ones(
(self.num_agents, max_size, episode_len + n - 1, 1))
self.num_episodes = 0
self.num_transitions = 0
def push(self, num_envs, t_env, observation_batch, action_batch, reward_batch, next_observation_batch,
dones_batch, finish_episodes):
assert t_env < self.episode_len
if t_env == 0:
# shuffle the agent ids at the start of a new episode batch
random.shuffle(self.agent_ids)
if t_env == 0 and self.num_episodes + num_envs > self.max_size:
diff = self.num_episodes + num_envs - self.max_size
self.observations = np.roll(self.observations, -diff, axis=1)
self.actions = np.roll(self.actions, -diff, axis=1)
self.rewards = np.roll(self.rewards, -diff, axis=1)
self.next_observations = np.roll(
self.next_observations, -diff, axis=1)
self.dones = np.roll(self.dones, -diff, axis=1)
self.num_episodes -= diff
for i in range(self.num_agents):
if finish_episodes:
dones = np.ones_like(dones_batch[self.agent_ids[i]])
else:
dones = dones_batch[self.agent_ids[i]]
self.observations[i, self.num_episodes: self.num_episodes +
num_envs, t_env, :] = observation_batch[self.agent_ids[i]]
self.actions[i, self.num_episodes: self.num_episodes +
num_envs, t_env, :] = action_batch[self.agent_ids[i]]
self.rewards[i, self.num_episodes: self.num_episodes +
num_envs, t_env, :] = reward_batch[self.agent_ids[i]]
self.next_observations[i, self.num_episodes: self.num_episodes + num_envs, t_env, :] = next_observation_batch[
self.agent_ids[i]]
self.dones[i, self.num_episodes: self.num_episodes +
num_envs, t_env, :] = dones
self.num_transitions += num_envs
if finish_episodes:
self.num_episodes += num_envs
def get(self, batch_inds, start_inds):
batch_inds_col = batch_inds[:, None]
start_inds_col = start_inds[:, None]
nstep_inds = start_inds_col + np.arange(self.n)
obs = self.observations[:, batch_inds, start_inds, :]
acts = self.actions[:, batch_inds, start_inds, :]
# get the n-step rewards and weight each by exponentiated discounts
rews = self.rewards[:, batch_inds_col, nstep_inds, 0]
rews = rews * \
np.power((np.ones(self.n) * self.gamma), np.arange(self.n))
# sum the n-step rewards: rewards for terminal states are pre-set to 0, so don't need to mask
rews = np.sum(rews, axis=2).reshape(
self.num_agents, len(batch_inds), 1)
# get the nobs of the nth
nobs = self.next_observations[:,
batch_inds, start_inds + self.n - 1, :]
dones = self.dones[:, batch_inds, start_inds + self.n - 1, :]
return torch.from_numpy(obs), torch.from_numpy(acts), torch.from_numpy(rews), torch.from_numpy(
nobs), torch.from_numpy(dones)
================================================
FILE: examples/Social_Cognition/ToCM/utils/popart.py
================================================
import numpy as np
import torch
import torch.nn as nn
class PopArt(nn.Module):
""" Normalize a vector of observations - across the first norm_axes dimensions"""
def __init__(self, input_shape, norm_axes=1, beta=0.99999, per_element_update=False, epsilon=1e-5, device=torch.device("cpu")):
super(PopArt, self).__init__()
self.input_shape = input_shape
self.norm_axes = norm_axes
self.epsilon = epsilon
self.beta = beta
self.per_element_update = per_element_update
self.device = device
self.tpdv = dict(dtype=torch.float32, device=device)
self.running_mean = nn.Parameter(torch.zeros(input_shape, dtype=torch.float), requires_grad=False).to(self.device)
self.running_mean_sq = nn.Parameter(torch.zeros(input_shape, dtype=torch.float), requires_grad=False).to(self.device)
self.debiasing_term = nn.Parameter(torch.tensor(0.0, dtype=torch.float), requires_grad=False).to(self.device)
def reset_parameters(self):
self.running_mean.zero_()
self.running_mean_sq.zero_()
self.debiasing_term.zero_()
def running_mean_var(self):
debiased_mean = self.running_mean / self.debiasing_term.clamp(min=self.epsilon)
debiased_mean_sq = self.running_mean_sq / self.debiasing_term.clamp(min=self.epsilon)
debiased_var = (debiased_mean_sq - debiased_mean ** 2).clamp(max=self.alpha, min=1e-2)
return debiased_mean, debiased_var
def forward(self, input_vector, train=True):
# Make sure input is float32
input_vector = input_vector.to(**self.tpdv)
if train:
# Detach input before adding it to running means to avoid backpropping through it on
# subsequent batches.
detached_input = input_vector.detach()
batch_mean = detached_input.mean(dim=tuple(range(self.norm_axes)))
batch_sq_mean = (detached_input ** 2).mean(dim=tuple(range(self.norm_axes)))
if self.per_element_update:
batch_size = np.prod(detached_input.size()[:self.norm_axes])
weight = self.beta ** batch_size
else:
weight = self.beta
self.running_mean.mul_(weight).add_(batch_mean * (1.0 - weight))
self.running_mean_sq.mul_(weight).add_(batch_sq_mean * (1.0 - weight))
self.debiasing_term.mul_(weight).add_(1.0 * (1.0 - weight))
mean, var = self.running_mean_var()
out = (input_vector - mean[(None,) * self.norm_axes]) / torch.sqrt(var)[(None,) * self.norm_axes]
return out
def denormalize(self, input_vector):
""" Transform normalized data back into original distribution """
input_vector = input_vector.to(**self.tpdv)
mean, var = self.running_mean_var()
out = input_vector * torch.sqrt(var)[(None,) * self.norm_axes] + mean[(None,) * self.norm_axes]
return out
================================================
FILE: examples/Social_Cognition/ToCM/utils/rec_buffer.py
================================================
import numpy as np
from utils.util import get_dim_from_space
from utils.segment_tree import SumSegmentTree, MinSegmentTree
def _cast(x):
return x.transpose(2, 0, 1, 3)
class RecReplayBuffer(object):
def __init__(self, policy_info, policy_agents, buffer_size, episode_length, use_same_share_obs, use_avail_acts,
use_reward_normalization=False):
"""
Replay buffer class for training RNN policies. Stores entire episodes rather than single transitions.
:param policy_info: (dict) maps policy id to a dict containing information about corresponding policy.
:param policy_agents: (dict) maps policy id to list of agents controled by corresponding policy.
:param buffer_size: (int) max number of transitions to store in the buffer.
:param use_same_share_obs: (bool) whether all agents share the same centralized observation.
:param use_avail_acts: (bool) whether to store what actions are available.
:param use_reward_normalization: (bool) whether to use reward normalization.
"""
self.policy_info = policy_info
self.policy_buffers = {p_id: RecPolicyBuffer(buffer_size,
episode_length,
len(policy_agents[p_id]),
self.policy_info[p_id]['obs_space'],
self.policy_info[p_id]['share_obs_space'],
self.policy_info[p_id]['act_space'],
use_same_share_obs,
use_avail_acts,
use_reward_normalization)
for p_id in self.policy_info.keys()}
def __len__(self):
return self.policy_buffers['policy_0'].filled_i
def insert(self, num_insert_episodes, obs, share_obs, acts, rewards, dones, dones_env, avail_acts):
"""
Insert a set of episodes into buffer. If the buffer size overflows, old episodes are dropped.
:param num_insert_episodes: (int) number of episodes to be added to buffer
:param obs: (dict) maps policy id to numpy array of observations of agents corresponding to that policy
:param share_obs: (dict) maps policy id to numpy array of centralized observation corresponding to that policy
:param acts: (dict) maps policy id to numpy array of actions of agents corresponding to that policy
:param rewards: (dict) maps policy id to numpy array of rewards of agents corresponding to that policy
:param dones: (dict) maps policy id to numpy array of terminal status of agents corresponding to that policy
:param dones_env: (dict) maps policy id to numpy array of terminal status of env
:param valid_transition: (dict) maps policy id to numpy array of whether the corresponding transition is valid of agents corresponding to that policy
:param avail_acts: (dict) maps policy id to numpy array of available actions of agents corresponding to that policy
:return: (np.ndarray) indexes in which the new transitions were placed.
"""
for p_id in self.policy_info.keys():
idx_range = self.policy_buffers[p_id].insert(num_insert_episodes, np.array(obs[p_id]),
np.array(share_obs[p_id]), np.array(acts[p_id]),
np.array(rewards[p_id]), np.array(dones[p_id]),
np.array(dones_env[p_id]), np.array(avail_acts[p_id]))
return idx_range
def sample(self, batch_size):
"""
Sample a set of episodes from buffer, uniformly at random.
:param batch_size: (int) number of episodes to sample from buffer.
:return: obs: (dict) maps policy id to sampled observations corresponding to that policy
:return: share_obs: (dict) maps policy id to sampled observations corresponding to that policy
:return: acts: (dict) maps policy id to sampled actions corresponding to that policy
:return: rewards: (dict) maps policy id to sampled rewards corresponding to that policy
:return: dones: (dict) maps policy id to sampled terminal status of agents corresponding to that policy
:return: dones_env: (dict) maps policy id to sampled environment terminal status corresponding to that policy
:return: valid_transition: (dict) maps policy_id to whether each sampled transition is valid or not (invalid if corresponding agent is dead)
:return: avail_acts: (dict) maps policy_id to available actions corresponding to that policy
"""
inds = np.random.choice(self.__len__(), batch_size)
obs, share_obs, acts, rewards, dones, dones_env, avail_acts = {}, {}, {}, {}, {}, {}, {}
for p_id in self.policy_info.keys():
obs[p_id], share_obs[p_id], acts[p_id], rewards[p_id], dones[p_id], dones_env[p_id], avail_acts[p_id] = \
self.policy_buffers[p_id].sample_inds(inds)
return obs, share_obs, acts, rewards, dones, dones_env, avail_acts, None, None
class RecPolicyBuffer(object):
def __init__(self, buffer_size, episode_length, num_agents, obs_space, share_obs_space, act_space,
use_same_share_obs, use_avail_acts, use_reward_normalization=False):
"""
Buffer class containing buffer data corresponding to a single policy.
:param buffer_size: (int) max number of episodes to store in buffer.
:param episode_length: (int) max length of an episode.
:param num_agents: (int) number of agents controlled by the policy.
:param obs_space: (gym.Space) observation space of the environment.
:param share_obs_space: (gym.Space) centralized observation space of the environment.
:param act_space: (gym.Space) action space of the environment.
:use_same_share_obs: (bool) whether all agents share the same centralized observation.
:use_avail_acts: (bool) whether to store what actions are available.
:param use_reward_normalization: (bool) whether to use reward normalization.
"""
self.buffer_size = buffer_size
self.episode_length = episode_length
self.num_agents = num_agents
self.use_same_share_obs = use_same_share_obs
self.use_avail_acts = use_avail_acts
self.use_reward_normalization = use_reward_normalization
self.filled_i = 0
self.current_i = 0
# obs
if obs_space.__class__.__name__ == 'Box':
obs_shape = obs_space.shape
share_obs_shape = share_obs_space.shape
elif obs_space.__class__.__name__ == 'list':
obs_shape = obs_space
share_obs_shape = share_obs_space
else:
raise NotImplementedError
self.obs = np.zeros((self.episode_length + 1, self.buffer_size,
self.num_agents, obs_shape[0]), dtype=np.float32)
if self.use_same_share_obs:
self.share_obs = np.zeros((self.episode_length + 1, self.buffer_size, share_obs_shape[0]), dtype=np.float32)
else:
self.share_obs = np.zeros((self.episode_length + 1, self.buffer_size, self.num_agents, share_obs_shape[0]),
dtype=np.float32)
# action
act_dim = np.sum(get_dim_from_space(act_space))
self.acts = np.zeros((self.episode_length, self.buffer_size, self.num_agents, act_dim), dtype=np.float32)
if self.use_avail_acts:
self.avail_acts = np.ones((self.episode_length + 1, self.buffer_size, self.num_agents, act_dim),
dtype=np.float32)
# rewards
self.rewards = np.zeros((self.episode_length, self.buffer_size, self.num_agents, 1), dtype=np.float32)
# default to done being True
self.dones = np.ones_like(self.rewards, dtype=np.float32)
self.dones_env = np.ones((self.episode_length, self.buffer_size, 1), dtype=np.float32)
def __len__(self):
return self.filled_i
def insert(self, num_insert_episodes, obs, share_obs, acts, rewards, dones, dones_env, avail_acts=None):
"""
Insert a set of episodes corresponding to this policy into buffer. If the buffer size overflows, old transitions are dropped.
:param num_insert_steps: (int) number of transitions to be added to buffer
:param obs: (np.ndarray) observations of agents corresponding to this policy.
:param share_obs: (np.ndarray) centralized observations of agents corresponding to this policy.
:param acts: (np.ndarray) actions of agents corresponding to this policy.
:param rewards: (np.ndarray) rewards of agents corresponding to this policy.
:param dones: (np.ndarray) terminal status of agents corresponding to this policy.
:param dones_env: (np.ndarray) environment terminal status.
:param valid_transition: (np.ndarray) whether each transition is valid or not (invalid if agent was dead during transition)
:param avail_acts: (np.ndarray) available actions of agents corresponding to this policy.
:return: (np.ndarray) indexes of the buffer the new transitions were placed in.
"""
# obs: [step, episode, agent, dim]
episode_length = acts.shape[0]
assert episode_length == self.episode_length, ("different dimension!")
if self.current_i + num_insert_episodes <= self.buffer_size:
idx_range = np.arange(self.current_i, self.current_i + num_insert_episodes)
else:
num_left_episodes = self.current_i + num_insert_episodes - self.buffer_size
idx_range = np.concatenate((np.arange(self.current_i, self.buffer_size), np.arange(num_left_episodes)))
if self.use_same_share_obs:
# remove agent dimension since all agents share centralized observation
share_obs = share_obs[:, :, 0]
self.obs[:, idx_range] = obs.copy()
self.share_obs[:, idx_range] = share_obs.copy()
self.acts[:, idx_range] = acts.copy()
self.rewards[:, idx_range] = rewards.copy()
self.dones[:, idx_range] = dones.copy()
self.dones_env[:, idx_range] = dones_env.copy()
if self.use_avail_acts:
self.avail_acts[:, idx_range] = avail_acts.copy()
self.current_i = idx_range[-1] + 1
self.filled_i = min(self.filled_i + len(idx_range), self.buffer_size)
return idx_range
def sample_inds(self, sample_inds):
"""
Sample a set of transitions from buffer from the specified indices.
:param sample_inds: (np.ndarray) indices of samples to return from buffer.
:return: obs: (np.ndarray) sampled observations corresponding to that policy
:return: share_obs: (np.ndarray) sampled observations corresponding to that policy
:return: acts: (np.ndarray) sampled actions corresponding to that policy
:return: rewards: (np.ndarray) sampled rewards corresponding to that policy
:return: dones: (np.ndarray) sampled terminal status of agents corresponding to that policy
:return: dones_env: (np.ndarray) sampled environment terminal status corresponding to that policy
:return: valid_transition: (np.ndarray) whether each sampled transition in episodes are valid or not (invalid if corresponding agent is dead)
:return: avail_acts: (np.ndarray) sampled available actions corresponding to that policy
"""
obs = _cast(self.obs[:, sample_inds])
acts = _cast(self.acts[:, sample_inds])
if self.use_reward_normalization:
# mean std
# [length, envs, agents, 1]
# [length, envs, 1]
all_dones_env = np.tile(np.expand_dims(
self.dones_env[:, :self.filled_i], -1), (1, 1, self.num_agents, 1))
first_step_dones_env = np.zeros((1, self.filled_i, self.num_agents, 1))
curr_dones_env = np.concatenate((first_step_dones_env, all_dones_env[:self.episode_length - 1]))
temp_rewards = self.rewards[:, :self.filled_i].copy()
temp_rewards[curr_dones_env == 1.0] = np.nan
mean_reward = np.nanmean(temp_rewards)
std_reward = np.nanstd(temp_rewards)
rewards = _cast(
(self.rewards[:, sample_inds] - mean_reward) / std_reward)
else:
rewards = _cast(self.rewards[:, sample_inds])
if self.use_same_share_obs:
share_obs = self.share_obs[:, sample_inds]
else:
share_obs = _cast(self.share_obs[:, sample_inds])
dones = _cast(self.dones[:, sample_inds])
dones_env = self.dones_env[:, sample_inds]
if self.use_avail_acts:
avail_acts = _cast(self.avail_acts[:, sample_inds])
else:
avail_acts = None
return obs, share_obs, acts, rewards, dones, dones_env, avail_acts
class PrioritizedRecReplayBuffer(RecReplayBuffer):
def __init__(self, alpha, policy_info, policy_agents, buffer_size, episode_length, use_same_share_obs,
use_avail_acts, use_reward_normalization=False):
"""Prioritized replay buffer class for training RNN policies. See parent class."""
super(PrioritizedRecReplayBuffer, self).__init__(policy_info, policy_agents, buffer_size,
episode_length, use_same_share_obs, use_avail_acts,
use_reward_normalization)
self.alpha = alpha
self.policy_info = policy_info
it_capacity = 1
while it_capacity < buffer_size:
it_capacity *= 2
self._it_sums = {p_id: SumSegmentTree(
it_capacity) for p_id in self.policy_info.keys()}
self._it_mins = {p_id: MinSegmentTree(
it_capacity) for p_id in self.policy_info.keys()}
self.max_priorities = {p_id: 1.0 for p_id in self.policy_info.keys()}
def insert(self, num_insert_episodes, obs, share_obs, acts, rewards, dones, dones_env, avail_acts=None):
"""See parent class."""
idx_range = super().insert(num_insert_episodes, obs, share_obs, acts, rewards, dones, dones_env, avail_acts)
for idx in range(idx_range[0], idx_range[1]):
for p_id in self.policy_info.keys():
self._it_sums[p_id][idx] = self.max_priorities[p_id] ** self.alpha
self._it_mins[p_id][idx] = self.max_priorities[p_id] ** self.alpha
return idx_range
def _sample_proportional(self, batch_size, p_id=None):
total = self._it_sums[p_id].sum(0, len(self) - 1)
mass = np.random.random(size=batch_size) * total
idx = self._it_sums[p_id].find_prefixsum_idx(mass)
return idx
def sample(self, batch_size, beta=0, p_id=None):
"""
Sample a set of episodes from buffer; probability of choosing a given episode is proportional to its priority.
:param batch_size: (int) number of episodes to sample.
:param beta: (float) controls the amount of prioritization to apply.
:param p_id: (str) policy which will be updated using the samples.
:return: See parent class.
"""
assert len(
self) > batch_size, "Cannot sample with no completed episodes in the buffer!"
assert beta > 0
batch_inds = self._sample_proportional(batch_size, p_id)
p_min = self._it_mins[p_id].min() / self._it_sums[p_id].sum()
max_weight = (p_min * len(self)) ** (-beta)
p_sample = self._it_sums[p_id][batch_inds] / self._it_sums[p_id].sum()
weights = (p_sample * len(self)) ** (-beta) / max_weight
obs, share_obs, acts, rewards, dones, dones_env, avail_acts = {}, {}, {}, {}, {}, {}, {}
for p_id in self.policy_info.keys():
p_buffer = self.policy_buffers[p_id]
obs[p_id], share_obs[p_id], acts[p_id], rewards[p_id], dones[p_id], dones_env[p_id], avail_acts[
p_id] = p_buffer.sample_inds(batch_inds)
return obs, share_obs, acts, rewards, dones, dones_env, avail_acts, weights, batch_inds
def update_priorities(self, idxes, priorities, p_id=None):
"""
Update priorities of sampled transitions.
sets priority of transition at index idxes[i] in buffer
to priorities[i].
:param idxes: ([int]) List of idxes of sampled transitions
:param priorities: ([float]) List of updated priorities corresponding to transitions at the sampled idxes
denoted by variable `idxes`.
"""
assert len(idxes) == len(priorities)
assert np.min(priorities) > 0
assert np.min(idxes) >= 0
assert np.max(idxes) < len(self)
self._it_sums[p_id][idxes] = priorities ** self.alpha
self._it_mins[p_id][idxes] = priorities ** self.alpha
self.max_priorities[p_id] = max(
self.max_priorities[p_id], np.max(priorities))
================================================
FILE: examples/Social_Cognition/ToCM/utils/segment_tree.py
================================================
import numpy as np
def unique(sorted_array):
"""
More efficient implementation of np.unique for sorted arrays
:param sorted_array: (np.ndarray)
:return:(np.ndarray) sorted_array without duplicate elements
"""
if len(sorted_array) == 1:
return sorted_array
left = sorted_array[:-1]
right = sorted_array[1:]
uniques = np.append(right != left, True)
return sorted_array[uniques]
class SegmentTree(object):
def __init__(self, capacity, operation, neutral_element):
"""
Build a Segment Tree data structure.
https://en.wikipedia.org/wiki/Segment_tree
Can be used as regular array that supports Index arrays, but with two
important differences:
a) setting item's value is slightly slower.
It is O(lg capacity) instead of O(1).
b) user has access to an efficient ( O(log segment size) )
`reduce` operation which reduces `operation` over
a contiguous subsequence of items in the array.
:param capacity: (int) Total size of the array - must be a power of two.
:param operation: (lambda (Any, Any): Any) operation for combining elements (eg. sum, max) must form a
mathematical group together with the set of possible values for array elements (i.e. be associative)
:param neutral_element: (Any) neutral element for the operation above. eg. float('-inf') for max and 0 for sum.
"""
assert capacity > 0 and capacity & (
capacity - 1) == 0, "capacity must be positive and a power of 2."
self._capacity = capacity
self._value = [neutral_element for _ in range(2 * capacity)]
self._operation = operation
self.neutral_element = neutral_element
def _reduce_helper(self, start, end, node, node_start, node_end):
if start == node_start and end == node_end:
return self._value[node]
mid = (node_start + node_end) // 2
if end <= mid:
return self._reduce_helper(start, end, 2 * node, node_start, mid)
else:
if mid + 1 <= start:
return self._reduce_helper(start, end, 2 * node + 1, mid + 1, node_end)
else:
return self._operation(
self._reduce_helper(start, mid, 2 * node, node_start, mid),
self._reduce_helper(
mid + 1, end, 2 * node + 1, mid + 1, node_end)
)
def reduce(self, start=0, end=None):
"""
Returns result of applying `self.operation`
to a contiguous subsequence of the array.
self.operation(arr[start], operation(arr[start+1], operation(... arr[end])))
:param start: (int) beginning of the subsequence
:param end: (int) end of the subsequences
:return: (Any) result of reducing self.operation over the specified range of array elements.
"""
if end is None:
end = self._capacity
if end < 0:
end += self._capacity
end -= 1
return self._reduce_helper(start, end, 1, 0, self._capacity - 1)
def __setitem__(self, idx, val):
# indexes of the leaf
idxs = idx + self._capacity
self._value[idxs] = val
if isinstance(idxs, int):
idxs = np.array([idxs])
# go up one level in the tree and remove duplicate indexes
idxs = unique(idxs // 2)
while len(idxs) > 1 or idxs[0] > 0:
# as long as there are non-zero indexes, update the corresponding values
self._value[idxs] = self._operation(
self._value[2 * idxs],
self._value[2 * idxs + 1]
)
# go up one level in the tree and remove duplicate indexes
idxs = unique(idxs // 2)
def __getitem__(self, idx):
assert np.max(idx) < self._capacity
assert 0 <= np.min(idx)
return self._value[self._capacity + idx]
class SumSegmentTree(SegmentTree):
def __init__(self, capacity):
super(SumSegmentTree, self).__init__(
capacity=capacity,
operation=np.add,
neutral_element=0.0
)
self._value = np.array(self._value)
def sum(self, start=0, end=None):
"""
Returns arr[start] + ... + arr[end]
:param start: (int) start position of the reduction (must be >= 0)
:param end: (int) end position of the reduction (must be < len(arr), can be None for len(arr) - 1)
:return: (Any) reduction of SumSegmentTree
"""
return super(SumSegmentTree, self).reduce(start, end)
def find_prefixsum_idx(self, prefixsum):
"""
Find the highest index `i` in the array such that
sum(arr[0] + arr[1] + ... + arr[i - i]) <= prefixsum for each entry in prefixsum
if array values are probabilities, this function
allows to sample indexes according to the discrete
probability efficiently.
:param prefixsum: (np.ndarray) float upper bounds on the sum of array prefix
:return: (np.ndarray) highest indexes satisfying the prefixsum constraint
"""
if isinstance(prefixsum, float):
prefixsum = np.array([prefixsum])
assert 0 <= np.min(prefixsum)
assert np.max(prefixsum) <= self.sum() + 1e-5
assert isinstance(prefixsum[0], float)
idx = np.ones(len(prefixsum), dtype=int)
cont = np.ones(len(prefixsum), dtype=bool)
while np.any(cont): # while not all nodes are leafs
idx[cont] = 2 * idx[cont]
prefixsum_new = np.where(
self._value[idx] <= prefixsum, prefixsum - self._value[idx], prefixsum)
# prepare update of prefixsum for all right children
idx = np.where(np.logical_or(
self._value[idx] > prefixsum, np.logical_not(cont)), idx, idx + 1)
# Select child node for non-leaf nodes
prefixsum = prefixsum_new
# update prefixsum
cont = idx < self._capacity
# collect leafs
return idx - self._capacity
class MinSegmentTree(SegmentTree):
def __init__(self, capacity):
super(MinSegmentTree, self).__init__(
capacity=capacity,
operation=np.minimum,
neutral_element=float('inf')
)
self._value = np.array(self._value)
def min(self, start=0, end=None):
"""
Returns min(arr[start], ..., arr[end])
:param start: (int) start position of the reduction (must be >= 0)
:param end: (int) end position of the reduction (must be < len(arr), can be None for len(arr) - 1)
:return: (Any) reduction of MinSegmentTree
"""
return super(MinSegmentTree, self).reduce(start, end)
================================================
FILE: examples/Social_Cognition/ToCM/utils/util.py
================================================
import copy
import gym
import numpy as np
from gym.spaces import Box, Discrete, Tuple
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.distributed as dist
from torch.autograd import Variable
def to_torch(input):
return torch.from_numpy(input) if type(input) == np.ndarray else input
def to_numpy(x):
return x.detach().cpu().numpy()
class FixedCategorical(torch.distributions.Categorical):
def sample(self):
return super().sample()
def log_probs(self, actions):
return (
super()
.log_prob(actions.squeeze(-1))
.view(actions.size(0), -1)
.sum(-1)
.unsqueeze(-1)
)
def mode(self):
return self.probs.argmax(dim=-1, keepdim=True)
class MultiDiscrete(gym.Space):
"""
- The multi-discrete action space consists of a series of discrete action spaces with different parameters
- It can be adapted to both a Discrete action space or a continuous (Box) action space
- It is useful to represent game controllers or keyboards where each key can be represented as a discrete action space
- It is parametrized by passing an array of arrays containing [min, max] for each discrete action space
where the discrete action space can take any integers from `min` to `max` (both inclusive)
Note: A value of 0 always need to represent the NOOP action.
e.g. Nintendo Game Controller
- Can be conceptualized as 3 discrete action spaces:
1) Arrow Keys: Discrete 5 - NOOP[0], UP[1], RIGHT[2], DOWN[3], LEFT[4] - params: min: 0, max: 4
2) Button A: Discrete 2 - NOOP[0], Pressed[1] - params: min: 0, max: 1
3) Button B: Discrete 2 - NOOP[0], Pressed[1] - params: min: 0, max: 1
- Can be initialized as
MultiDiscrete([ [0,4], [0,1], [0,1] ])
"""
def __init__(self, array_of_param_array):
self.low = np.array([x[0] for x in array_of_param_array])
self.high = np.array([x[1] for x in array_of_param_array])
self.num_discrete_space = self.low.shape[0]
self.n = np.sum(self.high) + 2
def sample(self):
""" Returns a array with one sample from each discrete action space """
# For each row: round(random .* (max - min) + min, 0)
random_array = np.random.rand(self.num_discrete_space)
return [int(x) for x in np.floor(np.multiply((self.high - self.low + 1.), random_array) + self.low)]
def contains(self, x):
return len(x) == self.num_discrete_space and (np.array(x) >= self.low).all() and (np.array(x) <= self.high).all()
@property
def shape(self):
return self.num_discrete_space
def __repr__(self):
return "MultiDiscrete" + str(self.num_discrete_space)
def __eq__(self, other):
return np.array_equal(self.low, other.low) and np.array_equal(self.high, other.high)
class DecayThenFlatSchedule():
def __init__(self,
start,
finish,
time_length,
decay="exp"):
self.start = start
self.finish = finish
self.time_length = time_length
self.delta = (self.start - self.finish) / self.time_length
self.decay = decay
if self.decay in ["exp"]:
self.exp_scaling = (-1) * self.time_length / \
np.log(self.finish) if self.finish > 0 else 1
def eval(self, T):
if self.decay in ["linear"]:
return max(self.finish, self.start - self.delta * T)
elif self.decay in ["exp"]:
return min(self.start, max(self.finish, np.exp(- T / self.exp_scaling)))
pass
def huber_loss(e, d):
a = (abs(e) <= d).float()
b = (abs(e) > d).float()
return a*e**2/2 + b*d*(abs(e)-d/2)
def mse_loss(e):
return e**2
def init(module, weight_init, bias_init, gain=1):
weight_init(module.weight.data, gain=gain)
bias_init(module.bias.data)
return module
def get_clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
# https://github.com/ikostrikov/pytorch-ddpg-naf/blob/master/ddpg.py#L11
def soft_update(target, source, tau):
"""
Perform DDPG soft update (move target params toward source based on weight
factor tau)
Inputs:
target (torch.nn.Module): Net to copy parameters to
source (torch.nn.Module): Net whose parameters to copy
tau (float, 0 < x < 1): Weight factor for update
"""
for target_param, param in zip(target.parameters(), source.parameters()):
target_param.data.copy_(
target_param.data * (1.0 - tau) + param.data * tau)
# https://github.com/ikostrikov/pytorch-ddpg-naf/blob/master/ddpg.py#L15
def hard_update(target, source):
"""
Copy network parameters from source to target
Inputs:
target (torch.nn.Module): Net to copy parameters to
source (torch.nn.Module): Net whose parameters to copy
"""
for target_param, param in zip(target.parameters(), source.parameters()):
target_param.data.copy_(param.data)
# https://github.com/seba-1511/dist_tuto.pth/blob/gh-pages/train_dist.py
def average_gradients(model):
""" Gradient averaging. """
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM, group=0)
param.grad.data /= size
def onehot_from_logits(logits, avail_logits=None, eps=0.0):
"""
Given batch of logits, return one-hot sample using epsilon greedy strategy
(based on given epsilon)
"""
# get best (according to current policy) actions in one-hot form
logits = to_torch(logits)
dim = len(logits.shape) - 1
if avail_logits is not None:
avail_logits = to_torch(avail_logits)
logits[avail_logits == 0] = -1e10
argmax_acs = (logits == logits.max(dim, keepdim=True)[0]).float()
if eps == 0.0:
return argmax_acs
# get random actions in one-hot form
rand_acs = Variable(torch.eye(logits.shape[1])[[np.random.choice(range(logits.shape[1]), size=logits.shape[0])]], requires_grad=False)
# chooses between best and random actions using epsilon greedy
return torch.stack([argmax_acs[i] if r > eps else rand_acs[i] for i, r in
enumerate(torch.rand(logits.shape[0]))])
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def sample_gumbel(shape, eps=1e-20, tens_type=torch.FloatTensor):
"""Sample from Gumbel(0, 1)"""
U = Variable(tens_type(*shape).uniform_(), requires_grad=False)
return -torch.log(-torch.log(U + eps) + eps)
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def gumbel_softmax_sample(logits, avail_logits, temperature, device=torch.device('cpu')):
""" Draw a sample from the Gumbel-Softmax distribution"""
if str(device) == 'cpu':
y = logits + sample_gumbel(logits.shape, tens_type=type(logits.data))
else:
y = (logits.cpu() + sample_gumbel(logits.shape,
tens_type=type(logits.data))).cuda()
dim = len(logits.shape) - 1
if avail_logits is not None:
avail_logits = to_torch(avail_logits).to(device)
y[avail_logits==0] = -1e10
return F.softmax(y / temperature, dim=dim)
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def gumbel_softmax(logits, avail_logits=None, temperature=1.0, hard=False, device=torch.device('cpu')):
"""Sample from the Gumbel-Softmax distribution and optionally discretize.
Args:
logits: [batch_size, n_class] unnormalized log-probs
temperature: non-negative scalar
hard: if True, take argmax, but differentiate w.r.t. soft sample y
Returns:
[batch_size, n_class] sample from the Gumbel-Softmax distribution.
If hard=True, then the returned sample will be one-hot, otherwise it will
be a probabilitiy distribution that sums to 1 across classes
"""
y = gumbel_softmax_sample(logits, avail_logits, temperature, device)
if hard:
y_hard = onehot_from_logits(y)
y = (y_hard - y).detach() + y
return y
def gaussian_noise(shape, std):
return torch.empty(shape).normal_(mean=0, std=std)
def get_obs_shape(obs_space):
if obs_space.__class__.__name__ == "Box":
obs_shape = obs_space.shape
elif obs_space.__class__.__name__ == "list":
obs_shape = obs_space
else:
raise NotImplementedError
return obs_shape
def get_dim_from_space(space):
if isinstance(space, Box):
dim = space.shape[0]
elif isinstance(space, Discrete):
dim = space.n
elif isinstance(space, Tuple):
dim = sum([get_dim_from_space(sp) for sp in space])
elif "MultiDiscrete" in space.__class__.__name__:
return (space.high - space.low) + 1
elif isinstance(space, list):
dim = space[0]
else:
raise Exception("Unrecognized space: ", type(space))
return dim
def get_state_dim(observation_dict, action_dict):
combined_obs_dim = sum([get_dim_from_space(space)
for space in observation_dict.values()])
combined_act_dim = 0
for space in action_dict.values():
dim = get_dim_from_space(space)
if isinstance(dim, np.ndarray):
combined_act_dim += int(sum(dim))
else:
combined_act_dim += dim
return combined_obs_dim, combined_act_dim, combined_obs_dim+combined_act_dim
def get_cent_act_dim(action_space):
cent_act_dim = 0
for space in action_space:
dim = get_dim_from_space(space)
if isinstance(dim, np.ndarray):
cent_act_dim += int(sum(dim))
else:
cent_act_dim += dim
return cent_act_dim
def is_discrete(space):
if isinstance(space, Discrete) or "MultiDiscrete" in space.__class__.__name__:
return True
else:
return False
def is_multidiscrete(space):
if "MultiDiscrete" in space.__class__.__name__:
return True
else:
return False
def make_onehot(int_action, action_dim, seq_len=None):
if type(int_action) == torch.Tensor:
int_action = int_action.cpu().numpy()
if not seq_len:
return np.eye(action_dim)[int_action]
if seq_len:
onehot_actions = []
for i in range(seq_len):
onehot_action = np.eye(action_dim)[int_action[i]]
onehot_actions.append(onehot_action)
return np.stack(onehot_actions)
def avail_choose(x, avail_x=None):
x = to_torch(x)
if avail_x is not None:
avail_x = to_torch(avail_x)
x[avail_x == 0] = -1e10
return x#FixedCategorical(logits=x)
def tile_images(img_nhwc):
"""
Tile N images into one big PxQ image
(P,Q) are chosen to be as close as possible, and if N
is square, then P=Q.
input: img_nhwc, list or array of images, ndim=4 once turned into array
n = batch index, h = height, w = width, c = channel
returns:
bigim_HWc, ndarray with ndim=3
"""
img_nhwc = np.asarray(img_nhwc)
N, h, w, c = img_nhwc.shape
H = int(np.ceil(np.sqrt(N)))
W = int(np.ceil(float(N)/H))
img_nhwc = np.array(
list(img_nhwc) + [img_nhwc[0]*0 for _ in range(N, H*W)])
img_HWhwc = img_nhwc.reshape(H, W, h, w, c)
img_HhWwc = img_HWhwc.transpose(0, 2, 1, 3, 4)
img_Hh_Ww_c = img_HhWwc.reshape(H*h, W*w, c)
return img_Hh_Ww_c
================================================
FILE: examples/Social_Cognition/ToM/BrainArea/PFC_ToM.py
================================================
from braincog.base.learningrule.STDP import *
from braincog.base.brainarea.PFC import dlPFC
from utils.Encoder import *
#exploit or explore
num_enpop = 6
num_depop = 10
greedy = 0.8#0.5
#state
A_state = 4
N_state = 6
cell_num = 6
#action
C=10
class PFC_ToM(dlPFC):
"""
SNNLinear
"""
def __init__(self,
step,
encode_type,
in_features:int,
out_features:int,
bias,
node,
num_state,
greedy=0.8,
*args,
**kwargs):
super().__init__(step, encode_type, in_features, out_features, bias, *args, **kwargs)
self.encoder = PopEncoder(self.step, encode_type)
self.encoder.device = torch.device('cpu')
self.bias = bias
self.in_features = in_features
self.out_features = out_features
self.node1 = node(threshold=0.5, tau=2.)
self.node_name1 = node
self.node2 = node(threshold=0.5, tau=2.)
self.node_name2 = node
self.num_state = num_state
self.greedy = greedy
self.fc = self._create_fc()
self.c = self._rest_c()
def _rest_c(self):
c = torch.rand((self.out_features, self.in_features)) # eligibility trace
return c
def _create_fc(self):
"""
the connection of the SNN linear
@return: nn.Linear
"""
fc = nn.Linear(in_features=self.in_features,
out_features=self.out_features, bias=self.bias)
return fc
def update_c(self, c, dw, tau_c=0.2):
"""
update the trace of eligibility
@param c: a tensor to record eligibility
@param dw: the results of STDP
@param tau_c: the parameter of trace decay
@return: a update tensor to record eligibility
Equation:
delta_c = (-(c / tau_c) + dw) * dela_t
c = c + delta_c
reference:
"""
# delta_c = -(c / tau_c) + dw #dela_t = 1 ignore
# c = c + delta_c
c = c + tau_c * dw
return c
def _call_reward(self, R, c, s, T_map): # eligibility
"""
R-STDP
@param R: reward
@param c: a tensor to record eligibility
@param s: weight of network
@param T_map: the mapping of the state-action pair
@return: update weight of network
Equation:
delta_s = c * reward
s = s + delta_s
reference:
"""
c[c > 0] = c[c > 0] * R * 1
c[c <= 0] = - c[c <= 0] * R * 1
c = c.clamp(min=-1, max=1)
# print('before',s[:, torch.where(T_map.gt(0))[1][0]])
s = s + c * T_map
# # print('after',s[:, torch.where(T_map.gt(0))[1][0]])
s = (s - s.min(dim=0).values.unsqueeze(dim=1).T.detach().repeat(s.shape[0], 1)) / (
s.max(dim=0).values.unsqueeze(dim=1).T.detach().repeat(s.shape[0], 1) -
s.min(dim=0).values.unsqueeze(dim=1).T.detach().repeat(s.shape[0], 1)
)
# s = s * 0.5
return s
def update_s(self, R, mapping):
T_map = torch.zeros((self.out_features, self.in_features))
T_map[mapping['action']*C:mapping['action']*C+C,\
torch.where(torch.tensor(self.encoder(mapping['state'],\
self.in_features, self.num_state)[:, 0]).gt(0))]=1
self.fc.weight.data = self._call_reward(R, self.c, self.fc.weight.data, T_map)
# print(mapping, 'mapping')
def forward(self, inputs, num_action, episode):
"""
decision
@param inputs: state
@param num_action: num_action # consider to delete
@return: action
"""
inputs = self.encoder(inputs, self.in_features, self.num_state)
count_group = torch.zeros(num_action)
stdp = STDP(self.node2, self.fc, decay=0.80)
# self.c = self._rest_c()
# stdp.connection.weight.data = torch.rand((self.out_features, self.in_features))
for t in range(self.step):
l1_in = torch.tensor(inputs[:, t])
l1_out = self.node1(l1_in).unsqueeze(0) #pre : l1_out
l2_out, dw = stdp(l1_out) #dw -- STDP
self.c = self.update_c(self.c, dw[0])
# l2_out = l2_out.T
for i in range(num_action):
count_group[i] = l2_out.T[i * num_depop:(i + 1) * num_depop].sum()
# exploration or exploitation
epsilon = random.random()
if epsilon < self.greedy + episode * 0.004:#:
action = count_group.argmax()
else:
action = torch.tensor(random.randint(0, 3))
return action.item()
================================================
FILE: examples/Social_Cognition/ToM/BrainArea/TPJ.py
================================================
import torch
from braincog.base.brainarea.Insula import *
from rulebasedpolicy.world_model import *
from BrainArea.dACC import *
from BrainArea.PFC_ToM import *
NPC_1 = 2
NPC_2 = 3
Agent = 4
#exploit or explore
num_enpop = 6
num_depop = 10
greedy = 0.8#0.5
#state
A_state = 4
N_state = 6
cell_num = 6
#action
C=10
class ToM:
def __init__(self, env):
"""
@param axis:输入为agent自己的观察到位置信息
@param obs:遮挡关系
"""
self.axis = None
self.obs = None
self.NPC_num = None
self.env = env
self.env.trigger = 0
def TPJ(self, NPC_num, axis, obs):
"""
perspective_taking
agent take NPC2's perspective
@param NPC_num: which NPC?
@return:
axis_new:站在other的角度看到其他智能体的遮挡关系,return axis,
axis_switch:站在self的角度看到其他智能体的遮挡关系,return axis
obs_switch:站在other的角度看到其他智能体的遮挡关系,return obs
"""
self.env.trigger = 0
axis_switch = [[6,6], [6,6], [6,6]]
axis_new = [[6, 6], [6, 6], [6, 6]]
self.axis = axis
self.obs = obs
axis_switch[0], axis_switch[NPC_num] = axis[NPC_num], axis[0]
axis_switch[1] = axis[1]
obs_switch = big_env(self.obs)
obs_switch[self.axis[0][0], self.axis[0][1]], obs_switch[self.axis[NPC_num][0],self.axis[NPC_num][1]] = \
obs_switch[self.axis[NPC_num][0],self.axis[NPC_num][1]],obs_switch[self.axis[0][0], self.axis[0][1]]
x = np.argwhere((obs_switch==2)|(obs_switch==8))
if self.axis[NPC_num][0] != 6 or self.axis[NPC_num][1] != 6:
shelter_obs = shelter_env(obs_switch[1:6,1:6])
obs_switch[1:6,1:6], m = self.gain_obs(a=obs_switch[1:6,1:6], aa=shelter_obs, b=axis_switch[1], c=axis_switch[2], bb=2,cc=4)
if m == True:
axis_switch[1] = [6,6]
else:
obs_switch = []
axis_new[0] = axis_switch[NPC_num]
axis_new[1] = axis_switch[1]
axis_new[NPC_num] = axis_switch[0]
return axis_new, axis_switch, obs_switch
def gain_obs(self, a,aa,b,c,bb,cc):
m = False
if b!=[6,6]:
if aa[b[0]-1, b[1]-1] == 0:
a[b[0]-1, b[1]-1] = 1#2
m = True
else:
a[b[0] - 1, b[1] - 1] = bb
if aa[c[0]-1, c[1]-1] ==0:
# print('-------')
a[c[0]-1, c[1]-1] = 1#4
else:
a[c[0] - 1, c[1] - 1] = cc
return a, m
def belief_reasoning(self, test_x, net_NPC, num_action, episode):
output = net_NPC(inputs=test_x, \
num_action=num_action, \
episode=episode)
return output
def state_evaluation(self, prediction_next_state):
"""
state_evaluation
@param prediction_next_state:
@return:
"""
input = np.array(prediction_next_state)
test_x = torch.tensor([[(int(bool(input[0][0] - input[2][0])))*10, (int(bool(input[0][1] - input[2][1])))*10]])
T = 5
num_popneurons = 2
safety = 2
dACC_net = dACC(step=T, encode_type='rate', bias=True,
in_features=num_popneurons, out_features=safety,
node=node.LIFNode)
dACC_net.load_state_dict(torch.load(os.path.join(sys.path[0], 'BrainArea/checkpoint', 'dACC_net.pth'))['dacc'])
output = dACC_net(inputs=test_x, epoch=50)
output = bool(int(output[0].cpu().detach().numpy().tolist()))
print(output,test_x)
return output
def prediction_state(self, axis_new, axis, action_NPC1, net, num_action, episode):
"""
根据当前状态和经验预测下一个状态
@return:下一个step的state
"""
self.env.trigger = 0
action_move = {
0: (0, -1),
1: (0, 1),
2: (-1, 0),
3: (1, 0),
4: (0, 0)
}
next_axis = [[6,6],[6,6],[6,6]]
# inputspike_test = np.array([axis_new[0],axis_new[1],axis_new[2]])
inputspike_test = sum(axis_new, [])
action_NPC2 = self.belief_reasoning(test_x=inputspike_test, net_NPC=net, num_action=num_action, episode=episode)
action_agent = 3
#NPC_1
next_axis[1][0] = axis[1][0] + action_move[action_NPC1][1]
next_axis[1][1] = axis[1][1] + action_move[action_NPC1][0]
#NPC_2
if self.obs[axis[2][0] + action_move[action_NPC2][1]-1, axis[2][1] + action_move[action_NPC2][0]-1] != 5:
next_axis[2][0] = axis[2][0] + action_move[action_NPC2][1]
next_axis[2][1] = axis[2][1] + action_move[action_NPC2][0]
#NPC_agent
next_axis[0][0] = axis[0][0] + action_move[action_agent][1]
next_axis[0][1] = axis[0][1] + action_move[action_agent][0]
return next_axis
def altruism(self, axis_switch, axis_NPC, n_actions):
"""
假设有一个开关,agent按下去可以让NPC不动
Q_bad:NPC的错误观测的有偏差Q
Q_good:正确的Q
Q_delta:中最小的值就是容易导致NPC出现危险的值
找到最小危险中的最大值对应的action
@param axis_switch:
@param axis_NPC:
@param n_actions:
@return:下一个step的action
"""
actions = list(range(n_actions))
action_NPC_list = list(range(n_actions))
#others' view
data_NPC = pd.read_csv('./data/NPC_assessment.csv', index_col=[0],
dtype={1: np.float64, 2: np.float64, 3: np.float64, 4: np.float64,
5: np.float64})
#self's view
data_agent = pd.read_csv('./data/agent_assessment.csv', index_col=[0],
dtype={1: np.float64, 2: np.float64, 3: np.float64, 4: np.float64,
5: np.float64})
# print(axis_NPC, axis_switch)
Q_bad = data_NPC.loc[str(axis_NPC), :]
if str(axis_switch) not in data_agent.index:
# append new state to q table
# print('1')
data_agent = data_agent.append(
pd.Series(
[0] * len(list(range(self.env.n_actions))),
index=data_agent.columns,
name=str(axis_switch),
)
)
Q_good = data_agent.loc[str(axis_switch), :]
Q_delta = Q_good - Q_bad
# print(Q_delta)
# max_Q_delta = [None] * n_actions
min_Q_delta_set = []
#stop
for action_a in actions:
if action_a == 4:
action_NPC_list = [4]
min_Q_delta = []
for i in action_NPC_list:
#
# print(i)
min_Q_delta.append(Q_delta[i])
min_Q_delta_set.append(min(min_Q_delta))
# print(min_Q_delta_set,'---------')
action_altruism = min_Q_delta_set.index(max(min_Q_delta_set))
if action_altruism == 4:
self.env.trigger = 1
# print('---------------------------------------------')
# env.SHOW()
# time.sleep(1.0)
# max_Q_delta[action_a] = max(min_Q_delta_set)
return action_altruism
def INS(self, axis1, axis2):
num_IPLM = axis1.shape[1]
num_IPLV = axis1.shape[1]
Insula_connection = []
# IPLV-Insula
con_matrix0 = torch.eye(num_IPLM, dtype=torch.float) * 2
Insula_connection.append(CustomLinear(con_matrix0))
# STS-Insula
con_matrix1 = torch.eye(num_IPLV, dtype=torch.float) * 2
Insula_connection.append(CustomLinear(con_matrix1))
Insula = InsulaNet(Insula_connection)
confidence = 0
Insula.reset()
for t in range(2):
Insula((axis1-axis2) * 10, torch.zeros_like(axis1) * 10)
if sum(sum(Insula.out_Insula)) > 0:
confidence = confidence + 1
return confidence
================================================
FILE: examples/Social_Cognition/ToM/BrainArea/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToM/BrainArea/dACC.py
================================================
import torch
import matplotlib.pyplot as plt
import numpy as np
np.set_printoptions(threshold=np.inf)
from utils.one_hot import *
import os
import time
import sys
from tqdm import tqdm
from braincog.model_zoo.base_module import BaseLinearModule, BaseModule
from braincog.base.learningrule.STDP import *
import sys
sys.path.append("..")
class dACC(BaseModule):
"""
SNNLinear
"""
def __init__(self,
step,
encode_type,
in_features:int,
out_features:int,
bias,
node,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.bias = bias
self.in_features = in_features
self.out_features = out_features
self.node1 = node(threshold=0.5, tau=2.)
self.node_name1 = node
self.node2 = node(threshold=0.1, tau=2.)
self.node_name2 = node
self.fc = self._create_fc()
self.c = self._rest_c()
def _rest_c(self):
c = torch.rand((self.out_features, self.in_features)) # eligibility trace
return c
def _create_fc(self):
"""
the connection of the SNN linear
@return: nn.Linear
"""
fc = nn.Linear(in_features=self.in_features,
out_features=self.out_features, bias=self.bias)
return fc
def update_c(self, c, STDP, tau_c=0.2):
"""
update the trace of eligibility
@param c: a tensor to record eligibility
@param STDP: the results of STDP
@param tau_c: the parameter of trace decay
@return: a update tensor to record eligibility
Equation:
delta_c = (-(c / tau_c) + STDP) * dela_t
c = c + delta_c
reference:
"""
c = c + tau_c * STDP
return c
def forward(self, inputs, epoch):
"""
decision
@param inputs: state
@return: action
"""
output = []
stdp = STDP(self.node2, self.fc, decay=0.80)
self.c = self._rest_c()
# stdp.connection.weight.data = torch.rand((self.out_features, self.in_features))
for i in range(inputs.shape[0]):
for t in range(self.step):
l1_in = torch.tensor(inputs[i, :])
l1_out = self.node1(l1_in).unsqueeze(0) #pre : l1_out
l2_out, dw = stdp(l1_out) #dw -- STDP
self.c = self.update_c(self.c, dw[0])
output.append(torch.min(l2_out))
# output.append((l2_out.any() == 0).cpu().detach().numpy().tolist())
return output
# if __name__ == '__main__':
# np.random.seed(6)
# T = 5
# num_popneurons = 2
# safety = 2
# epoch = 50
# file_name = "/home/zhaozhuoya/braincog/examples/ToM/data/injury_value.txt"
# state = []
# with open(file_name) as f:
# data = []
# data_split = f.readlines() #
# for i in data_split:
# state.append(one_hot(int(i[0])))
#
# output = np.array(state)
# train_y = output
# test_y = output[79:82]#output[12].reshape(1,2)
#
# file_name = "/home/zhaozhuoya/braincog/examples/ToM/data/injury_memory.txt"
# state = []
# with open(file_name) as f:
# data_split = f.readlines()
# for i in data_split:
# data = []
# data.append(int(bool(abs(int(i[2]) - int(i[18]))))*10)
# data.append(int(bool(abs(int(i[5]) - int(i[21]))))*10)
# state.append(data)
# input = np.array(state)
# train_x = input
# test_x = input[79:82]
# dACC_net = dACC(step=T, encode_type='rate', bias=True,
# in_features=num_popneurons, out_features=safety,
# node=node.LIFNode)
# dACC_net.fc.weight.data = torch.rand((safety, num_popneurons))
# dACC_net.load_state_dict(torch.load('./checkpoint/dACC_net.pth')['dacc'])
# output = dACC_net(inputs=train_x, epoch=50)
# for i in range(len(output)):
# print(output[i], train_x[i])
# torch.save({'dacc': dACC_net.state_dict()}, os.path.join('./checkpoint', 'dACC_net.pth'))
# dACC_net.load_state_dict(torch.load('./checkpoint/dACC_net.pth')['dacc'])
# output = dACC_net(inputs=test_x, epoch=50)
# for i in range(len(test_x)):
#
# print(output[i],test_x[i])
================================================
FILE: examples/Social_Cognition/ToM/BrainArea/one_hot.py
================================================
from numpy import argmax
import numpy as np
def one_hot(value):
num = '01'
letter = [0 for _ in range(len(num))]
letter[value] = 1
letter = np.array([letter])
return letter
# print(one_hot(4))
================================================
FILE: examples/Social_Cognition/ToM/BrainArea/test.py
================================================
import torch
from braincog.base.connection.CustomLinear import *
from braincog.base.node.node import *
from braincog.base.learningrule.STDP import *
from braincog.base.brainarea.IPL import *
from braincog.base.brainarea.Insula import *
if __name__ == "__main__":
num_neuron = 4
num_vPMC = num_neuron
num_STS = num_neuron
num_IPLM = num_neuron
num_IPLV = num_neuron
num_Insula = num_neuron
# InsulaNet
# connection
Insula_connection = []
# IPLV-Insula
con_matrix0 = torch.eye(num_IPLM, dtype=torch.float) * 2
Insula_connection.append(CustomLinear(con_matrix0))
# STS-Insula
con_matrix1 = torch.eye(num_IPLV, dtype=torch.float) * 2
Insula_connection.append(CustomLinear(con_matrix1))
Insula = InsulaNet(Insula_connection)
a = torch.tensor([[1.,2.,1.,2.]])
b = torch.tensor([[1., 2., 1., 2.]])
c = torch.tensor([[2., 2., 4., 2.]])
confidence = [0, 0]
for t in range(2):
Insula(a*10, b*10)
if sum(sum(Insula.out_Insula)) > 0:
confidence[0] = confidence[0] + 1
Insula.reset()
for t in range(2):
Insula(a*10, c*10)
if sum(sum(Insula.out_Insula)) > 0:
confidence[0] = confidence[0] + 1
Insula.reset()
print(confidence)
================================================
FILE: examples/Social_Cognition/ToM/README.md
================================================
# Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
* pygame
# Run
## Train
* the file to be run: main_both.py
* args:
* the path to save net_NPC: --save_net_N
* the path to save net_a: --save_net_a
* time steps: --T
```bash
python main_both.py --save_net_N=net_NPC.pth --save_net_a=net_agent.pth --episodes=45 --trajectories=30 --T=50 --mode=train --task=both
```
## Test
You can use the weigts saved by taining in the test environment.
```bash
python main_ToM.py --save_net_N=net_NPC.pth --save_net_a=net_agent.pth --episodes=45 --trajectories=30 --T=50 --mode=train --task=both
```
# Citation
```
@article{zhao2022brain,
title = {A Brain-Inspired Theory of Mind Spiking Neural Network for Reducing Safety Risks of Other Agents},
author = {Zhao, Zhuoya and Lu, Enmeng and Zhao, Feifei and Zeng, Yi and Zhao, Yuxuan},
journal = {Frontiers in neuroscience},
pages = {446},
year = {2022},
publisher = {Frontiers}
}
```
================================================
FILE: examples/Social_Cognition/ToM/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToM/data/NPC_assessment.csv
================================================
,0,1,2,3,4
"[[3, 5], [6, 6], [4, 2]]",-0.868083432541418,-0.733763528003341,11.6748771364348,-1.13941568407204,-0.640638369281893
"[[3, 5], [6, 6], [4, 3]]",-0.418851253559184,-0.353923546821901,2.45363281923355,-0.450103087254002,-0.37827704665847
"[[3, 5], [6, 6], [5, 3]]",-0.021898491492153,-0.01,-0.01,-0.01,-0.011802114342782
"[[4, 5], [6, 6], [5, 2]]",-0.024908407481436,-0.0199,0,-0.01009,-0.01017991
"[[3, 5], [6, 6], [5, 2]]",-0.023268882562677,-0.0199,-0.029791,-0.0298801,-0.037630851041005
"[[3, 4], [6, 6], [5, 3]]",-0.021197399198277,-0.01,-0.0199,-0.013038149463134,-0.01999
"[[3, 3], [6, 6], [5, 3]]",0,-0.5,0,0,-0.01
"[[3, 3], [6, 6], [5, 2]]",0,0,0,-0.01,0
"[[3, 4], [6, 6], [5, 1]]",-0.01,0,-0.01,-0.01009,0
"[[3, 4], [6, 6], [4, 1]]",-0.0101791,-0.0199,-0.01,-0.01,-0.01
"[[3, 3], [6, 6], [4, 1]]",-0.01,0,-0.01,0,0
"[[3, 2], [6, 6], [4, 2]]",0,-0.01,0,0,0
"[[4, 2], [6, 6], [4, 3]]",0,0,0,-0.01,0
"[[4, 3], [6, 6], [4, 4]]",0.089467366020037,-0.010984993825322,-0.01,-0.013452906086556,-0.011867720274541
"[[4, 2], [6, 6], [4, 5]]",4.09524024945437,-0.090412523006309,-0.09623134888059,-0.104387744707876,-0.070973835764104
"[[3, 2], [6, 6], [4, 5]]",1.40391860495941,0.022997490426814,43.0024182397514,1.53202462973447,3.08888716957364
"[[2, 2], [6, 6], [4, 5]]",-0.019749094852309,0.036781365436129,15.9675319796684,-0.020051902468894,0.04621779219384
"[[4, 1], [6, 6], [4, 5]]",5.50845885876033,-0.030316371018288,-0.01999,0.003924246487139,-0.01999
"[[5, 1], [6, 6], [4, 5]]",-0.04218527817012,-0.089619886118225,-0.089555438562711,-0.09202879886063,-0.089640838741259
"[[5, 2], [6, 6], [4, 5]]",-0.181115480137325,-0.188135727209872,-0.190391091543011,-0.189212077096485,-0.18825217812927
"[[4, 3], [6, 6], [4, 5]]",3.20388938261604,-0.277669046855729,-0.263170616607684,-0.263425702870801,-0.273172354685186
"[[4, 4], [6, 6], [4, 5]]",0.088264809806085,-0.536047549432865,-0.496801753642635,-1.7227487525,-0.525308942251634
"[[3, 3], [6, 6], [4, 5]]",-0.21666970575642,-0.137772024778711,35.7440209050429,0.074933770913733,1.72993072468866
"[[2, 3], [6, 6], [6, 6]]",-0.059222187527032,-0.030584932730533,1.19896558354272,-0.02997001,-0.039803368321337
"[[3, 4], [6, 6], [4, 5]]",-0.40734083054261,-0.590251991054757,12.0029208279787,-0.553842323501647,-0.473260640862758
"[[4, 5], [6, 6], [4, 5]]",0,0,0,0,0
"[[3, 5], [6, 6], [4, 4]]",-0.481765407319486,-0.511211461721295,-0.564380288792446,-0.492462845628926,-0.469959754386144
"[[3, 5], [6, 6], [4, 5]]",-0.931224461309762,-4.42392016540183,0.839256941677985,-0.924126498596367,-0.93129552223439
"[[3, 1], [6, 6], [4, 5]]",49.811526809228,0.227846091910513,5.03145376471985,3.02887653427164,4.38800221134503
"[[2, 1], [6, 6], [4, 5]]",0,0,0,0,0
"[[3, 4], [6, 6], [4, 3]]",1.19380671730375,-5.00699176831198,20.0406112237339,-0.271487593364538,18.7143725924663
"[[3, 4], [6, 6], [4, 4]]",0.218803966115085,-0.17930117271935,27.2213501282548,-0.25238045900879,0.399605811763158
"[[5, 3], [6, 6], [4, 5]]",-0.375176845280851,-0.382612376673214,-0.387234215280032,-0.391512374343505,-0.38256981360011
"[[5, 4], [6, 6], [4, 5]]",-0.648971759046833,-0.647885303763355,-0.648165623973329,-0.644724798572273,-0.648282307415749
"[[4, 5], [6, 6], [3, 2]]",-0.01999,-0.029791,-0.0199,-0.0199891,-0.029882503677127
"[[3, 5], [6, 6], [3, 2]]",-0.034237585544166,-0.029789209,-0.0297901,-0.031801666387697,-0.023636229278446
"[[4, 5], [6, 6], [4, 3]]",-0.254773250904236,-0.247726142705935,-0.4975,-0.251602554065065,-0.253564419614127
"[[4, 5], [6, 6], [4, 4]]",-0.414539088621474,-0.413180632405154,-0.45683393116936,-0.4975,-0.98509975
"[[5, 5], [6, 6], [4, 5]]",-2.88794812477989,-0.897593650362875,-0.896337578776872,-0.897383653648252,-0.896911728329473
"[[3, 4], [6, 6], [4, 2]]",-0.041846129714671,-0.0491890501,-0.049128264132635,-0.04752963742507,-0.041122932699059
"[[4, 4], [6, 6], [4, 3]]",-0.010582728786191,-0.0199,-0.019606621899442,-0.023027393843706,-0.25
"[[4, 4], [6, 6], [4, 4]]",0,0,0,0,0
"[[1, 3], [6, 6], [6, 6]]",-0.02997001,-0.037241738974595,-0.038877118273757,-0.02997001,-0.02997001
"[[1, 2], [6, 6], [6, 6]]",-0.01,0.092960550898947,-0.01,-0.01,-0.01
"[[1, 1], [6, 6], [4, 5]]",0,0.25,0,0,-0.01
"[[5, 5], [6, 6], [4, 2]]",-0.011245609205401,-0.010090875348172,-0.01,-0.01,-0.01
"[[5, 5], [6, 6], [4, 3]]",-0.023589076057546,-0.030475766514878,-0.0199,-0.010097260907938,-0.020481507078377
"[[5, 4], [6, 6], [4, 4]]",-0.014561932553648,-0.014123403608977,-0.012977094986838,-0.013958043392411,-0.0102689209
"[[5, 5], [6, 6], [3, 3]]",-0.01,0,0,0,-0.01009
"[[5, 5], [6, 6], [4, 4]]",-0.742525,-0.112519042227942,-0.104809666804011,-0.120899601119155,-0.114009048694518
"[[3, 3], [6, 6], [4, 4]]",-0.010153907821337,-0.013354155304859,3.90887441187658,-0.020453180303816,-0.010444104437097
"[[3, 5], [6, 6], [4, 1]]",-0.010526678655391,-0.01999,-0.0199,-0.013489754345763,-0.020341425501639
"[[4, 5], [6, 6], [4, 2]]",-0.040636256244247,-0.0297901,-0.029794680345807,-0.032266639674154,-0.030144504483964
"[[4, 5], [6, 6], [4, 1]]",-0.022834041173462,-0.029701,-0.029701,-0.030019473640868,-0.029791
"[[4, 4], [6, 6], [4, 2]]",-0.010267309,-0.01999,-0.25,-0.021462046263096,-0.01
"[[5, 5], [6, 6], [5, 4]]",0,-0.01,0,0,-0.010213344196849
"[[3, 5], [6, 6], [3, 4]]",-0.013599152071303,0,-0.010345480742543,-0.01,-0.25
"[[3, 5], [6, 6], [3, 5]]",0,0,0,0,0
"[[3, 5], [6, 6], [3, 3]]",-0.011856953925967,-0.01999,-0.0199,-0.032817580205153,-0.010785322603466
"[[4, 4], [6, 6], [5, 2]]",0,-0.01,-0.01,-0.01009,-0.01
"[[5, 4], [6, 6], [4, 2]]",0,0,-0.01,-0.01,0
"[[3, 3], [6, 6], [4, 3]]",-0.01,-0.01,-0.0199,-0.005562516126618,-0.009541766156335
"[[3, 2], [6, 6], [4, 4]]",0,0,-0.01,-0.01,0.236388148843983
"[[4, 3], [6, 6], [4, 2]]",0,-0.01,0,-0.01,0
"[[5, 3], [6, 6], [4, 3]]",-0.01,0,0,0,0
"[[4, 5], [6, 6], [5, 3]]",-0.01,-0.01009,-0.0199,-0.010784041942122,-0.01
"[[3, 5], [6, 6], [5, 4]]",-0.012894421101825,-0.012100903162978,-0.007186044736698,0,-0.011442680105686
"[[3, 4], [6, 6], [3, 2]]",-0.01009,-0.01999,-0.0199,-0.01009,-0.010091626994647
"[[4, 4], [6, 6], [5, 4]]",0,0,0,-0.010869859082056,0
"[[4, 5], [6, 6], [3, 3]]",-0.01,-0.01,-0.01999,-0.01,-0.011561635811299
"[[5, 4], [6, 6], [4, 3]]",0,0,-0.01,0,0
"[[5, 3], [6, 6], [4, 4]]",0,-0.012647205121462,0,-0.015190262813025,0
"[[3, 2], [6, 6], [4, 3]]",0,-0.01,0,0,-0.01
"[[3, 1], [6, 6], [4, 3]]",0,-0.01,0,0,0
"[[4, 1], [6, 6], [4, 4]]",0,0,0,0,-0.002916121937907
"[[4, 3], [6, 6], [4, 3]]",0,0,0,0,0
"[[5, 5], [6, 6], [3, 4]]",-0.012969708589991,-0.01,-0.01,-0.010643056796965,0
"[[3, 4], [6, 6], [3, 4]]",0,0,0,0,0
"[[2, 3], [6, 6], [4, 4]]",0,0,0,-0.01,0
"[[2, 3], [6, 6], [5, 4]]",0,0,-0.01,0,0
"[[2, 2], [6, 6], [4, 4]]",-0.01,0,0,-0.008244859693453,0
"[[1, 2], [6, 6], [4, 3]]",0,-0.01,0,0,0
"[[3, 4], [6, 6], [5, 2]]",-0.01999,-0.01999,-0.0199,-0.01999,-0.01035517099859
"[[3, 3], [6, 6], [4, 2]]",0,0,-0.01,-0.010197581295095,0
"[[3, 3], [6, 6], [5, 4]]",0,0,0,-0.01009,0
"[[5, 5], [6, 6], [3, 1]]",-0.01999081,-0.01999,-0.01999,-0.01999,-0.01999
"[[5, 5], [6, 6], [2, 1]]",-0.01,0,-0.01,-0.01,-0.01
"[[5, 4], [6, 6], [2, 2]]",0,0,-0.01,-0.01,-0.01
"[[5, 4], [6, 6], [3, 2]]",-0.01999,-0.0199,-0.01,-0.01,-0.01
"[[5, 3], [6, 6], [3, 1]]",-0.01,-0.01,0,0,0
"[[4, 3], [6, 6], [4, 1]]",-0.01,-0.01,-0.01,-0.01,-0.01
"[[4, 2], [6, 6], [5, 1]]",0,-0.01,0,-0.01,0
"[[5, 2], [6, 6], [5, 1]]",-0.01,0,0,0,0
"[[4, 2], [6, 6], [5, 2]]",0,0,0,0,-0.01
"[[5, 4], [6, 6], [3, 3]]",-0.01,-0.01,-0.01,-0.01,-0.01
"[[4, 4], [6, 6], [3, 2]]",-0.01,-0.01,-0.0199,-0.0200791,-0.0199
"[[4, 5], [6, 6], [6, 6]]",-0.01009,-0.0199,-0.0199,-0.0199,-0.01999
"[[4, 4], [6, 6], [5, 3]]",0,0,0,-0.01,-0.01
"[[5, 5], [6, 6], [2, 2]]",-0.01,-0.01,-0.01,-0.01,0
"[[5, 4], [6, 6], [2, 3]]",-0.01,-0.01,0,-0.01,-0.01
"[[4, 5], [6, 6], [2, 2]]",-0.010198196967161,-0.01999,-0.01,-0.01009,-0.01
"[[4, 5], [6, 6], [1, 1]]",0,-0.01,0,0,-0.01
"[[4, 5], [6, 6], [2, 1]]",-0.01,-0.01,-0.01,-0.0199,-0.01
"[[4, 5], [6, 6], [3, 1]]",-0.01,-0.01009,-0.0199,-0.01,-0.01009
"[[4, 3], [6, 6], [3, 3]]",0,0,-0.01,0,0
"[[4, 2], [6, 6], [3, 4]]",-0.008998626598505,0,0,0,0
"[[4, 5], [6, 6], [5, 1]]",-0.01009,-0.0199,-0.0199,-0.020016673101577,-0.01999
"[[4, 4], [6, 6], [5, 1]]",-0.01,-0.01,-0.01,-0.01009,-0.01
"[[3, 5], [6, 6], [5, 1]]",-0.01009,-0.01,-0.0199,-0.01999,-0.01999
"[[5, 5], [6, 6], [5, 1]]",-0.01009,0,-0.01,-0.0199,-0.01
"[[5, 5], [6, 6], [4, 1]]",-0.01,-0.01,-0.0199,-0.01,-0.01999
"[[4, 4], [6, 6], [3, 1]]",0,0,0,-0.01,-0.01
"[[5, 5], [6, 6], [1, 1]]",-0.01,0,-0.01,-0.01,0
"[[5, 5], [6, 6], [1, 2]]",-0.01,-0.01,0,-0.01,-0.01
"[[4, 4], [6, 6], [2, 1]]",0,-0.01,-0.01,-0.01,-0.01
"[[4, 3], [6, 6], [3, 1]]",-0.01,0,0,-0.01,-0.01
"[[4, 4], [6, 6], [4, 1]]",-0.010289510270133,-0.01,-0.0199,-0.02007991,-0.01999
"[[5, 4], [6, 6], [4, 1]]",0,0,-0.01,0,-0.01
"[[5, 4], [6, 6], [3, 1]]",-0.01,0,0,-0.01,-0.01
"[[3, 4], [6, 6], [2, 2]]",0,-0.01,0,-0.01,-0.01
"[[3, 4], [6, 6], [6, 6]]",-0.01,-0.01,-0.01,-0.01999,-0.01999
"[[3, 3], [6, 6], [1, 2]]",0,-0.01,0,0,0
"[[4, 3], [6, 6], [1, 3]]",0,0,-0.01,-0.01,0
"[[4, 4], [6, 6], [6, 6]]",-0.01,-0.01,-0.0199,-0.01,-0.01
"[[5, 5], [6, 6], [2, 3]]",-0.01,-0.01999,-0.01999,-0.01999,-0.01
"[[5, 4], [6, 6], [1, 3]]",-0.0199,-0.01,-0.01,-0.01,-0.01
"[[5, 4], [6, 6], [1, 2]]",0,-0.01,-0.01,-0.01,0
"[[5, 4], [6, 6], [1, 1]]",-0.0199,-0.01,-0.01,-0.01,-0.01
"[[4, 4], [6, 6], [1, 1]]",-0.01,-0.01,-0.01,0,0
"[[5, 3], [6, 6], [1, 1]]",0,0,-0.01,-0.01009,0
"[[5, 2], [6, 6], [1, 1]]",-0.01,0,0,-0.01,-0.01
"[[5, 3], [6, 6], [1, 2]]",0,-0.01,0,-0.01,0
"[[5, 3], [6, 6], [1, 3]]",-0.01,-0.01,-0.01,0,-0.0199
"[[5, 3], [6, 6], [2, 3]]",0,0,-0.01,0,0
"[[5, 2], [6, 6], [2, 3]]",-0.01,0,0,-0.01,0
"[[5, 3], [6, 6], [3, 3]]",0,0,0,-0.01,0
"[[4, 3], [6, 6], [1, 2]]",-0.01,-0.01,-0.01,-0.01,-0.01
"[[3, 3], [6, 6], [2, 2]]",-0.01,-0.01,-0.01,-0.01,-0.01
"[[2, 3], [6, 6], [3, 2]]",0,0,-0.01,-0.01,0
"[[2, 3], [6, 6], [3, 1]]",-0.01,-0.01,-0.01,-0.01,-0.01
"[[2, 3], [6, 6], [2, 1]]",0,-0.01,0,0,-0.01
"[[3, 2], [6, 6], [2, 3]]",0,-0.01,0,0,0
"[[4, 2], [6, 6], [2, 2]]",-0.01,0,0,-0.01,0
"[[3, 2], [6, 6], [2, 1]]",-0.01,0,0,-0.01,0
"[[3, 3], [6, 6], [1, 1]]",0,0,0,-0.01,-0.01
"[[3, 4], [6, 6], [2, 1]]",-0.01,-0.01,0,0,-0.01
"[[4, 4], [6, 6], [2, 2]]",0,-0.01,-0.01,0,0
"[[4, 3], [6, 6], [2, 2]]",0,0,-0.01,-0.01009,0
"[[4, 2], [6, 6], [1, 2]]",-0.01,0,-0.01,-0.01,-0.01
"[[3, 2], [6, 6], [1, 2]]",0,0,-0.01,0,0
"[[3, 1], [6, 6], [1, 1]]",0,0,-0.01,-0.01,0
"[[3, 2], [6, 6], [1, 1]]",-0.01,-0.01,0,0,0
"[[4, 1], [6, 6], [1, 2]]",-0.01,0,0,0,0
"[[3, 1], [6, 6], [1, 3]]",0.5,0,0,0,-0.01
"[[2, 1], [6, 6], [1, 3]]",0.995,0,0,0,0
"[[2, 1], [6, 6], [2, 3]]",1.489505,0,0,0,0
"[[2, 1], [6, 6], [2, 2]]",0.5,0,0,0,0
"[[2, 1], [6, 6], [3, 2]]",0.5,0,0,0,0
"[[2, 1], [6, 6], [4, 2]]",0.5,0,1.0039955,0,0
"[[2, 1], [6, 6], [5, 2]]",0.995,0,0,0,0
"[[2, 1], [6, 6], [5, 3]]",0.995,0,0,0,0
"[[2, 1], [6, 6], [4, 3]]",0.5045,0,0.5045,0,0
"[[2, 1], [6, 6], [5, 4]]",0.995,0,0,0,0
"[[2, 1], [6, 6], [4, 4]]",0.5,0,0.5,0,0
"[[4, 4], [6, 6], [1, 2]]",-0.01,0,0,-0.01009,0
"[[4, 3], [6, 6], [1, 1]]",-0.01,0,0,0,0
"[[3, 3], [6, 6], [2, 1]]",-0.0199,0,0,0,0
"[[1, 3], [6, 6], [3, 1]]",0,0,-0.01,0,0
"[[1, 2], [6, 6], [3, 1]]",-0.01,0,0,0,-0.01
"[[1, 2], [6, 6], [4, 1]]",-0.01,0,-0.0199,0,0
"[[1, 1], [6, 6], [5, 1]]",0,0,0,-0.01,-0.01
"[[1, 2], [6, 6], [5, 1]]",0,-0.01,0,-0.01,0
"[[1, 3], [6, 6], [5, 1]]",-0.01,0,0,0,0
"[[1, 3], [6, 6], [5, 2]]",0,0,-0.01,0,-0.01
"[[1, 2], [6, 6], [5, 2]]",-0.01,-0.01,0,-0.01,0
"[[2, 2], [6, 6], [5, 1]]",-0.01,0,0,0,-0.01
"[[2, 2], [6, 6], [4, 1]]",-0.01,0,0,0,0
"[[1, 1], [6, 6], [4, 2]]",-0.01,0,0,0,-0.01
"[[1, 1], [6, 6], [4, 1]]",0,0,0,0,-0.01
"[[1, 1], [6, 6], [5, 2]]",0,0,0,-0.01,-0.01
"[[1, 2], [6, 6], [5, 3]]",0,0,-0.01,0,-0.01
"[[1, 1], [6, 6], [5, 3]]",0,0,0,-0.01,0
"[[1, 3], [6, 6], [4, 2]]",-0.01,0,0,0,-0.01
"[[1, 3], [6, 6], [5, 3]]",0,0,0,0,-0.01
"[[1, 3], [6, 6], [5, 4]]",0,0,0,0,-0.010266711022056
"[[5, 5], [6, 6], [3, 2]]",-0.010094761832099,0,0,0,0
"[[3, 5], [6, 6], [3, 1]]",-0.01,-0.0101791,-0.01,0,-0.01
"[[3, 5], [6, 6], [2, 1]]",-0.01,-0.01009,-0.01,0,0
"[[3, 5], [6, 6], [6, 6]]",-0.01999,-0.0199891,-0.01999,-0.01999,-0.01999
"[[3, 4], [6, 6], [1, 1]]",0,-0.01,-0.01,0,0
"[[4, 5], [6, 6], [3, 4]]",0,0,-0.01,0,0
"[[4, 4], [6, 6], [3, 5]]",0,-0.01,0,0,0
"[[5, 4], [6, 6], [3, 4]]",0,0,0,-0.01,-0.01
"[[3, 2], [6, 6], [5, 2]]",0,0,-0.01,0,0
"[[3, 1], [6, 6], [5, 3]]",0,0,-0.01,-0.01,0
"[[4, 2], [6, 6], [4, 4]]",0,0,0.004567853841478,0,0
"[[5, 4], [6, 6], [2, 1]]",0,0,0,0,-0.01
"[[3, 3], [6, 6], [3, 1]]",-0.01,0,0,-0.01009,0
"[[5, 5], [6, 6], [5, 2]]",0,-0.01,-0.01,0,0
"[[5, 4], [6, 6], [5, 1]]",-0.01009,0,-0.0199,-0.01,-0.01
"[[5, 3], [6, 6], [5, 1]]",-0.01,0,-0.5,0,0
"[[5, 2], [6, 6], [5, 2]]",0,0,0,0,0
"[[3, 4], [6, 6], [3, 3]]",0,0,0,-0.01,0
"[[5, 3], [6, 6], [4, 2]]",0,0,-0.01,-0.01,0
"[[5, 2], [6, 6], [4, 3]]",0,0,-0.01,-0.01,0
"[[5, 1], [6, 6], [4, 4]]",0,0,-0.010759540535295,0,0
"[[4, 4], [6, 6], [2, 3]]",0,-0.01,0,0,0
"[[5, 5], [6, 6], [1, 3]]",-0.01009,0,-0.01,0,0
"[[4, 2], [6, 6], [3, 3]]",0,-0.01,0,0,0
"[[3, 3], [6, 6], [5, 1]]",0,-0.01,0,0,0
"[[5, 3], [6, 6], [2, 1]]",0,-0.01,-0.01,0,-0.01
"[[2, 2], [6, 6], [3, 1]]",0,0,0,-0.01,-0.01
"[[2, 3], [6, 6], [4, 1]]",-0.01,0,0,-0.01,-0.01
"[[1, 3], [6, 6], [4, 1]]",0,0,-0.01,-0.01,0
"[[1, 2], [6, 6], [3, 2]]",0,0,-0.01,0,0
"[[1, 1], [6, 6], [3, 2]]",0,0,-0.01,0,0
"[[1, 1], [6, 6], [3, 1]]",0,0,0,-0.01,0
"[[1, 2], [6, 6], [2, 1]]",-0.01,0,0,-0.01,-0.01
"[[1, 3], [6, 6], [2, 2]]",0,0,0,0,-0.01
"[[1, 3], [6, 6], [2, 1]]",0,0,-0.01,0,0
"[[1, 2], [6, 6], [1, 1]]",-0.5,0,0,0,0
"[[1, 2], [6, 6], [1, 2]]",0,0,0,0,0
"[[2, 3], [6, 6], [4, 2]]",0,0,-0.01,0,0
"[[2, 2], [6, 6], [4, 2]]",0,0,0.5,-0.01,0
"[[2, 3], [6, 6], [4, 3]]",0,-0.002363469450096,0,0,0
"[[4, 4], [6, 6], [3, 3]]",-0.011265121636209,0,-0.01,0,0
"[[4, 3], [6, 6], [2, 3]]",-0.01,0,0,0,0
"[[5, 3], [6, 6], [2, 2]]",0,0,0,0,-0.01
"[[4, 2], [6, 6], [1, 1]]",-0.01,0,-0.01,0,0
"[[4, 1], [6, 6], [1, 1]]",0,0,0,-0.01,0
"[[2, 2], [6, 6], [2, 1]]",0,-0.01,0,-0.01,0
"[[2, 1], [6, 6], [4, 1]]",0,0,1.988015495,0,0
"[[2, 1], [6, 6], [5, 1]]",0,0,1.988015495,0,0
"[[3, 4], [6, 6], [3, 1]]",0,-0.01009,0,0,0
"[[4, 3], [6, 6], [5, 1]]",0,-0.01,0,-0.01,-0.01
"[[5, 3], [6, 6], [4, 1]]",0,-0.01,0,-0.01,0
"[[5, 3], [6, 6], [3, 2]]",0,0,0,-0.01,0
================================================
FILE: examples/Social_Cognition/ToM/data/agent_assessment.csv
================================================
,0,1,2,3,4
"[[3, 5], [6, 6], [4, 2]]",-0.052875711096120555,-0.09588695110964494,-0.06793465209301,-0.05438523750227702,-0.06406147756340548
"[[3, 4], [6, 6], [4, 3]]",-0.01009,-0.5,-0.5,-0.01998648239166538,-0.010090809999999999
"[[3, 5], [3, 3], [4, 4]]",-0.5216067506862471,-1.9701995,-0.2957229880478374,-0.5521303794833469,-0.291912651239883
"[[3, 5], [4, 3], [4, 5]]",-0.17020038264944942,-0.995,-0.17003066056014654,-0.17084067541667597,-0.18061252619011572
"[[3, 5], [5, 3], [4, 5]]",-0.310721791006476,-0.995,-0.3044196312169591,-0.3066034117158839,-0.30258164309452773
"[[3, 4], [5, 4], [4, 5]]",-0.5068849351000232,-0.5215919496170031,0.33272479226972446,-0.529392040004043,-0.5476025113537396
"[[3, 5], [5, 4], [4, 5]]",-0.9653009777091316,-8.274311927495619,-0.9562443360051255,-0.9663825574739041,-0.9577571287880812
"[[3, 3], [5, 4], [4, 5]]",-0.12144345586147146,-0.129151719633336,6.61777080738469,-0.12913417684277412,-0.12187211348591424
"[[3, 2], [5, 4], [4, 5]]",22.462534983722144,-0.037566698284270936,0.0002049650900000019,-0.020492300663398463,0.36064342058027793
"[[2, 3], [5, 4], [6, 6]]",-0.0199,-0.01,1.911710899685282,-0.02507112120629763,-0.01
"[[4, 4], [5, 4], [4, 5]]",-0.38856856345777463,-0.995,-0.3848636851605009,-0.5,-0.39216615065025906
"[[4, 3], [5, 4], [4, 5]]",-0.042040801551562916,-0.17418582965398824,-0.17906219922741637,-0.20272904839771475,-0.17845067061226685
"[[2, 2], [5, 4], [4, 5]]",-0.03593611593419173,0.19699025702983197,41.38750349042489,-0.025347536417836183,0.5235719953054313
"[[1, 3], [5, 4], [6, 6]]",-0.01999,-0.010049500000000001,-0.0199,-0.01999,-0.01999
"[[1, 2], [5, 4], [6, 6]]",-0.01999,1.1413350726366454,-0.01,-0.01009,-0.02969406465902331
"[[4, 5], [5, 4], [4, 5]]",0.0,0.0,0.0,0.0,0.0
"[[4, 5], [6, 6], [4, 3]]",-0.022056368799828086,-0.0199,-0.5,-0.0199,-0.01999
"[[4, 5], [3, 3], [4, 4]]",-0.05334353898157222,-0.058519850599,-0.058698950598999995,-0.5,-0.5
"[[4, 5], [4, 3], [4, 5]]",-0.5,-1.9701995,0.0,-0.5,-0.5
"[[4, 5], [5, 3], [4, 5]]",-0.995,-3.3967326046505,0.0,-0.995,-0.5
"[[3, 5], [6, 6], [4, 3]]",-0.5052708076706848,-0.6503942485687713,-0.31464561043008055,-0.5567063168667764,-0.3196072406789152
"[[3, 4], [4, 3], [4, 5]]",-0.06538757013815065,-0.06815609254531127,0.07157941051049484,-0.06943525585877257,-0.07243109013283643
"[[3, 4], [5, 3], [4, 5]]",-0.03627763723533166,-0.04878628543714749,0.4425679590136676,-0.04432926021182233,-0.03615058165751049
"[[5, 3], [5, 4], [4, 5]]",-0.1326255476738545,-0.12913304314430477,-0.12670229132838703,-0.995,-0.12922285286285284
"[[5, 4], [5, 4], [4, 5]]",0.0,0.0,0.0,0.0,0.0
"[[3, 4], [3, 3], [4, 4]]",-0.08912453287009733,-0.514891,-0.08664897275426689,-0.0850562755111616,-0.08029821601054066
"[[3, 3], [4, 3], [4, 5]]",-0.01,-0.01,-0.01,-0.009878977320149305,0.020248904987081453
"[[4, 3], [5, 3], [4, 5]]",0.0,-0.011055227128542065,0.0,-0.01,-0.01101218190086918
"[[5, 5], [4, 3], [4, 5]]",-0.5,-0.01,-0.0199,0.0,-0.01
"[[5, 4], [5, 3], [4, 5]]",0.0,-0.5,-0.01,-0.010717485033705036,-0.5
"[[5, 2], [5, 4], [4, 5]]",-0.07919569212102055,-0.07971975334246782,-0.0787530179209123,-0.08104017906592893,-0.07963109795235838
"[[5, 1], [5, 4], [4, 5]]",-0.04890803822116347,-0.049900099950010005,-0.049900099950010005,-0.05034279750865073,-0.049900099950010005
"[[4, 1], [5, 4], [4, 5]]",0.10944099197973417,-0.01999,-0.01999,-0.02007991,-0.01999
"[[4, 2], [5, 4], [4, 5]]",0.15058860156940262,-0.059846938189381006,-0.06722016746200328,-0.07174124407437676,-0.059850199850059994
"[[3, 1], [5, 4], [4, 5]]",5.680756414193536,-0.01,-0.01,-0.01,-0.01
"[[2, 1], [5, 4], [4, 5]]",0.0,0.0,0.0,0.0,0.0
"[[4, 4], [3, 3], [4, 4]]",0.0,-0.5,-0.5,0.0,0.0
"[[4, 4], [4, 3], [4, 4]]",0.0,-0.5,-0.5,0.0,0.0
"[[4, 4], [5, 3], [4, 4]]",0.0,-0.5,-0.5,0.0,0.0
"[[4, 4], [5, 4], [4, 4]]",0.0,0.0,0.0,0.0,0.0
"[[3, 4], [6, 6], [5, 2]]",0.0,0.0,0.0,0.0,-0.01
"[[3, 4], [3, 3], [5, 2]]",0.0,-0.01,0.0,0.0,0.0
"[[4, 4], [4, 3], [5, 2]]",0.0,0.0,-0.5,0.0,0.0
"[[4, 3], [5, 3], [5, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [3, 3], [4, 3]]",-2.2448043853624212e-05,-0.01,-0.01,-6.208892285322127e-05,-0.01
"[[3, 5], [4, 3], [4, 4]]",-0.01028609422864929,-0.5,-0.016408702021722208,-0.020784796048626684,-0.011281391343046818
"[[3, 5], [3, 3], [4, 2]]",-0.5,-0.5,-0.5,-0.9900500000000001,-0.5
"[[4, 5], [4, 3], [4, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [4, 3], [3, 4]]",-0.01,0.0,0.0,-0.5,0.0
"[[3, 5], [5, 3], [3, 5]]",0.0,0.0,0.0,-0.5,0.0
"[[3, 5], [5, 4], [3, 5]]",0.0,0.0,0.0,0.0,0.0
"[[4, 5], [6, 6], [5, 2]]",0.0,0.0,-0.01,0.0,0.0
"[[4, 4], [3, 3], [5, 1]]",0.0,0.0,0.0,0.0,-0.01
"[[4, 4], [4, 3], [4, 1]]",0.0,0.0,0.0,0.0,-0.01
"[[4, 4], [5, 3], [4, 1]]",0.0,0.0,-0.01,0.0,0.0
"[[4, 3], [5, 4], [3, 1]]",0.0,0.0,0.0,-0.01,0.0
"[[4, 4], [5, 4], [3, 1]]",0.0,-0.5,0.0,0.0,0.0
"[[5, 4], [5, 4], [3, 1]]",0.0,0.0,0.0,0.0,0.0
"[[1, 1], [5, 4], [4, 5]]",0.0,0.0,0.0,-0.01,0.0
"[[4, 4], [4, 3], [4, 5]]",-0.016306998715494642,-0.0199,-0.0199,-0.5,-0.01009945645877131
"[[4, 4], [5, 3], [4, 5]]",-0.02368161102075795,-0.5,-0.022639868292312258,-0.5,-0.026451207697811334
"[[5, 5], [3, 3], [4, 4]]",-0.5,0.0,-0.01,0.0,0.0
"[[5, 4], [4, 3], [4, 5]]",0.0,0.0,0.0,-0.01,0.0
"[[5, 5], [5, 3], [4, 5]]",-0.5,-0.01044910089955009,0.0,-0.01,0.0
"[[3, 5], [3, 3], [3, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 3], [5, 3], [4, 5]]",0.0,-0.01062811314685189,3.5215627346534975,0.0,0.0
"[[3, 5], [4, 3], [4, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [3, 3], [5, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [4, 3], [5, 2]]",0.0,-0.01,0.0,0.0,0.0
"[[4, 5], [5, 3], [4, 2]]",-0.01,0.0,0.0,0.0,0.0
"[[3, 5], [5, 4], [4, 3]]",0.0,0.0,0.0,-0.01,0.0
"[[3, 5], [5, 4], [4, 4]]",-0.015943472966397428,-0.01,0.0,-0.01654250067191671,-0.01
"[[4, 5], [5, 4], [4, 3]]",0.0,0.0,-0.5,-0.01,-0.01
"[[4, 5], [5, 4], [4, 4]]",-0.01639600436420607,-0.01,0.0,0.0,0.0
"[[5, 5], [5, 4], [4, 5]]",-1.9701995,-0.11934219505791074,-0.5,-0.11934219505791074,-0.10945164670461537
"[[3, 4], [4, 3], [5, 4]]",0.0,0.0,0.0,-0.01,0.0
"[[3, 5], [5, 3], [4, 4]]",0.0,0.0,-0.00819848349845159,-0.014389398124565982,-0.016963089341491665
"[[4, 5], [3, 3], [4, 2]]",0.0,-0.5,-0.5,0.0,0.0
"[[4, 4], [4, 3], [4, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [6, 6], [5, 2]]",0.0,-0.01,-0.01,0.0,0.0
"[[5, 5], [4, 3], [4, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [4, 3], [5, 4]]",0.0,0.0,-0.0199,0.0,0.0
"[[3, 4], [5, 3], [4, 4]]",0.0,0.0,0.0,0.0,-0.013570917448717714
"[[3, 4], [4, 3], [4, 4]]",0.0,0.0,0.0,-0.010943974970380799,0.0
"[[4, 5], [4, 3], [4, 4]]",-0.01,0.0,0.0,0.0,0.0
"[[3, 5], [5, 3], [3, 4]]",-0.01,0.0,0.0,0.0,0.0
"[[3, 5], [6, 6], [3, 2]]",0.0,0.0,-0.01,0.0,0.0
"[[3, 5], [3, 3], [3, 2]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [4, 3], [4, 2]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [5, 3], [4, 3]]",0.0,-0.01,0.0,0.0,0.0
"[[3, 5], [6, 6], [4, 1]]",0.0,0.0,0.0,0.0,-0.01
"[[3, 5], [3, 3], [4, 1]]",0.0,-0.01,-0.01,0.0,0.0
"[[3, 4], [4, 3], [5, 1]]",0.0,-0.01,0.0,0.0,0.0
"[[4, 4], [5, 3], [5, 1]]",0.0,0.0,0.0,-0.01,0.0
"[[4, 5], [5, 4], [5, 1]]",0.0,-0.01,0.0,0.0,0.0
"[[5, 5], [5, 4], [5, 1]]",0.0,0.0,0.0,0.0,-0.01
"[[5, 5], [5, 4], [5, 2]]",0.0,0.0,0.0,-0.01,0.0
"[[5, 5], [5, 4], [4, 2]]",0.0,-0.01,-0.5,0.0,0.0
"[[5, 4], [5, 4], [4, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 4], [5, 3], [5, 4]]",0.0,0.0,0.0,-0.01,0.0
"[[5, 5], [4, 3], [3, 4]]",0.0,0.0,-0.01,0.0,0.0
"[[5, 4], [5, 3], [4, 4]]",-0.5,0.0,0.0,0.0,0.0
"[[4, 4], [5, 4], [5, 4]]",0.0,0.0,0.0,0.0,0.0
"[[4, 5], [4, 3], [3, 1]]",0.0,-0.01,0.0,0.0,0.0
"[[5, 5], [5, 3], [4, 1]]",0.0,0.0,0.0,-0.01,0.0
"[[5, 5], [5, 4], [4, 3]]",0.0,0.0,0.0,-0.01,0.0
"[[5, 5], [5, 4], [4, 4]]",0.0,-0.01,0.0,0.0,0.0
"[[3, 4], [4, 3], [4, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 4], [3, 3], [4, 2]]",-0.5,0.0,-0.5,0.0,0.0
"[[3, 3], [4, 3], [4, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 3], [3, 3], [4, 4]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [5, 3], [4, 2]]",0.0,-0.01,0.0,0.0,0.0
"[[3, 5], [4, 3], [5, 3]]",0.0,-0.5,0.0,0.0,0.0
"[[4, 5], [5, 3], [5, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 2], [5, 3], [4, 5]]",0.0,0.0,0.037097785583577604,0.0,0.0
"[[2, 3], [5, 3], [6, 6]]",0.0,0.0,0.0,0.004391030075795664,0.0
"[[4, 5], [3, 3], [3, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 4], [3, 3], [4, 3]]",0.0,0.0,0.0,-0.01009092457551116,0.0
================================================
FILE: examples/Social_Cognition/ToM/data/injury_memory.txt
================================================
[[2, 1], [6, 6], [2, 1]]
[[3, 1], [6, 6], [3, 1]]
[[3, 1], [6, 6], [3, 1]]
[[2, 2], [6, 6], [2, 2]]
[[2, 1], [6, 6], [2, 1]]
[[3, 2], [6, 6], [3, 2]]
[[2, 1], [6, 6], [2, 1]]
[[3, 3], [6, 6], [3, 3]]
[[5, 3], [6, 6], [5, 3]]
[[4, 4], [6, 6], [4, 4]]
[[4, 1], [6, 6], [4, 1]]
[[3, 2], [6, 6], [3, 2]]
[[3, 2], [6, 6], [3, 2]]
[[3, 3], [6, 6], [3, 3]]
[[4, 4], [6, 6], [4, 4]]
[[4, 4], [6, 6], [4, 4]]
[[4, 2], [6, 6], [3, 5]]
[[4, 3], [6, 6], [3, 4]]
[[4, 4], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [2, 2]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [2, 2]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [2, 2]]
[[4, 2], [6, 6], [3, 5]]
[[4, 3], [6, 6], [3, 4]]
[[4, 4], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 5]]
[[4, 5], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [2, 2]]
[[4, 2], [6, 6], [3, 5]]
[[4, 3], [6, 6], [3, 5]]
[[4, 1], [3, 3], [3, 3]]]
[[3, 2], [5, 4], [3, 2]]]
[[5, 1], [3, 3], [3, 3]]]
[[3, 3], [3, 3], [3, 5]]]
[[2, 2], [3, 3], [3, 3]]]
[[3, 3], [3, 3], [3, 4]]]
[[2, 1], [5, 4], [2, 1]]]
[[4, 2], [5, 4], [5, 4]]]
[[4, 3], [3, 3], [3, 3]]]
[[5, 2], [3, 3], [3, 3]]]
[[3, 1], [3, 3], [3, 3]]]
[[5, 4], [5, 4], [2, 1]]]
[[5, 4], [5, 4], [2, 2]]]
[[4, 1], [5, 4], [4, 1]]]
[[4, 3], [4, 3], [3, 4]]]
[[4, 2], [3, 3], [3, 3]]]
[[5, 4], [5, 4], [4, 1]]]
[[4, 4], [5, 4], [4, 4]]]
[[4, 3], [4, 3], [3, 5]]]
[[5, 3], [3, 3], [3, 3]]]
[[3, 2], [3, 3], [3, 3]]]
[[5, 4], [5, 4], [3, 3]]]
[[4, 3], [4, 3], [3, 3]]]
[[5, 4], [5, 4], [3, 1]]]
[[3, 1], [5, 4], [3, 1]]]
[[4, 3], [4, 3], [1, 5]]]
[[4, 3], [4, 3], [1, 4]]]
[[4, 3], [4, 3], [2, 3]]]
[[3, 1], [5, 4], [3, 1]]]
[[3, 2], [4, 4], [4, 4]]]
[[3, 1], [5, 4], [3, 1]]]
[[4, 2], [3, 3], [3, 3]]]
[[3, 1], [5, 4], [3, 1]]]
[[3, 3], [3, 3], [2, 4]]]
[[4, 4], [3, 3], [3, 3]]]
[[4, 3], [4, 3], [2, 4]]]
[[4, 4], [3, 3], [3, 3]]]
[[4, 2], [3, 3], [3, 3]]]
[[3, 3], [3, 3], [2, 5]]]
[[4, 2], [3, 3], [3, 3]]]
[[4, 2], [3, 3], [3, 3]]]
[[4, 5], [5, 4], [4, 5]]]
[[4, 4], [3, 3], [3, 3]]]
[[4, 4], [3, 3], [3, 3]]]
[[4, 4], [3, 3], [3, 3]]]
[[5, 4], [5, 4], [3, 2]]]
[[4, 4], [4, 4], [2, 4]]]
[[4, 4], [4, 4], [3, 2]]]
[[4, 3], [4, 3], [1, 4]]]
[[4, 3], [4, 3], [2, 3]]]
[[4, 4], [4, 4], [4, 4]]]
[[4, 4], [3, 3], [3, 3]]]
[[4, 4], [4, 4], [3, 3]]]
[[4, 4], [4, 4], [3, 2]]]
[[4, 3], [4, 3], [3, 3]]]
[[4, 3], [4, 3], [3, 3]]]
[[4, 5], [5, 4], [4, 5]]]
[[4, 4], [3, 3], [3, 3]]]
[[4, 4], [3, 3], [3, 3]]]
[[4, 4], [4, 4], [4, 4]]]
[[4, 4], [3, 3], [3, 3]]]
[[3, 4], [5, 4], [3, 4]]]
[[4, 5], [5, 4], [4, 5]]]
[[4, 4], [4, 4], [4, 4]]]
[[4, 5], [6, 6], [3, 1]]
[[4, 2], [6, 6], [3, 5]]
[[4, 3], [6, 6], [3, 5]]
[[4, 4], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [3, 1]]
[[4, 2], [6, 6], [3, 5]]
[[4, 3], [6, 6], [3, 5]]
[[4, 4], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 5]]
[[4, 5], [6, 6], [3, 5]]
[[4, 5], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [2, 2]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [3, 1]]
[[4, 5], [6, 6], [4, 1]]
[[4, 5], [6, 6], [4, 2]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [3, 1]]
[[4, 2], [6, 6], [3, 5]]
[[4, 3], [6, 6], [3, 4]]
[[4, 4], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 4]]
================================================
FILE: examples/Social_Cognition/ToM/data/injury_value.txt
================================================
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
================================================
FILE: examples/Social_Cognition/ToM/data/one_hot.py
================================================
from numpy import argmax
import numpy as np
def one_hot(value):
num = '01'
letter = [0 for _ in range(len(num))]
letter[value] = 1
letter = np.array([letter])
return letter
# print(one_hot(4))
================================================
FILE: examples/Social_Cognition/ToM/env/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToM/env/env.py
================================================
from numpy import argmax
import random, time, pygame, sys
import pygame
pygame.init()
from pygame.locals import *
import os
# os.environ['SDL_AUDIODRIVER'] = 'dsp'
# os.environ['SDL_VIDEODRIVER']='windib'
os.environ["SDL_VIDEODRIVER"] = "dummy"
# os.environ['DISPLAY'] = "localhost:13.0"
from rulebasedpolicy.world_model import *
from rulebasedpolicy.statedata_pre import *
from rulebasedpolicy.Find_a_way import *
import numpy as np
from utils.one_hot import one_hot
# =============================================================================
# set the value of interface
# =============================================================================
FPS = 25
WinWidth = 340 #window width
WinHeight = 260 #window width
BoxSize = 20 #the size of one grid
GridWidth = 7 #the number of lattices are there in the x-axis
GridHeight = 7 #the number of lattices are there in the y-axis
#representation of different objective
BlankBox = 1
Wall = 5
Obstacle = 5
observer = 8
obeservation_1 = 11
obeservation_2 = 22
obeservation_3 = 33
#Text = None
XMargin = int((WinWidth - GridWidth * BoxSize)/2)
TopMargin = int((WinHeight - GridHeight * BoxSize))/2-5
# =============================================================================
# set color
# =============================================================================
White = (255,255,255)
Gray = (185,185,185)
Black = (0,0,0)
Red = (200,0,0)
Green = (0,139,0)
Green_B = (78, 238, 148)
Light_A = (233, 232, 170)
Blue = (30, 144, 255)
pink = (238, 99, 99)
BoardColor = White
BGColor = White
TextColor = White
Test = []
# =============================================================================
# agents - env interactive
# =============================================================================
class FalseBelief_env(object):
def __init__(self, reward=10):
super(FalseBelief_env, self).__init__()
self.action_space = ['up', 'down', 'left', 'right', 'stay']
self.action_move = {
0 : (0, -1),
1 : (0, 1),
2 : (-1, 0),
3 : (1, 0),
4 :(0, 0)
}#[(0, -1), (0, 1), (-1, 0), (1, 0), (0, 0)]
self.n_actions = len(self.action_space)
self._build_AB()
self.board, self.obs = self.getBlankBoard()
self._agent_init()
self.score = 0
self.steps = 0
self.n = 0
self.R = int(5/2) * (BoxSize - 5)
self.trigger = 0
self.x = 0
self.n_features = 30
self.reward = reward
def _build_AB(self):
global FPSCLOCK, DISPLAYSURF, BASICFONT, BIGFONT
FPSCLOCK = pygame.time.Clock()
DISPLAYSURF = pygame.display.set_mode((WinWidth, WinHeight))
BASICFONT = pygame.font.Font('freesansbold.ttf', 18)
BIGFONT = pygame.font.Font('freesansbold.ttf', 100)
pygame.display.set_caption('AB')
pygame.display.update()
FPSCLOCK.tick()
def _agent_init(self):
"""
Aim:Initialize the basic information of the agent
"""
self.NPC_1 = {
'shape' : [['#']],
'x' : 3, #row
'y' : 1, #column
'color' : Blue,
'style' : "circle",
'obs' : None,
'axis' : None,#,[[1,3],[3,5],[4,2]]
'reward' : 0,
'Done' : False
}
self.NPC_2 = {
'shape' : [['@']],
'x' : 5, #row
'y' : 3, #column
'color' : pink,
'style' : "circle",
'obs' : None,
'axis' :None ,#,[[3,5],[1,3],[4,2]]
'reward': 0,
'Done': False
}
self.agent = {
'shape' : [['$']],
'x' : 2, #row
'y' : 4, #column
'color' : Green_B,
'style' : "circle",
'obs' : None,
'axis' : None,#[[4,2],[1,3],[3,5]]
'reward': 0,
'Done': False
}
def actu_obs(self):
"""
将状态转化成可以训练的数据形式
"""
_, state = self.getBlankBoard()
a = state
b = state
c = state
state1 = np.r_[a, np.ones((4, 5))].astype(np.int_)
state2 = np.r_[b, np.ones((4, 5))].astype(np.int_)
statea = np.r_[c, np.ones((4, 5))].astype(np.int_)
NPC_1_state = state1
NPC_2_state = state2
Agent_state = statea
NPC_1_state[self.NPC_1['y']-1, self.NPC_1['x']-1] = observer
q = shelter_env(NPC_1_state[:5, :])
NPC_1_state[:5, :] = shelter_env(NPC_1_state[:5, :])
NPC_2_state[self.NPC_2['y']-1, self.NPC_2['x']-1] = observer
r = shelter_env(NPC_2_state[:5, :])
NPC_2_state[:5, :] = shelter_env(NPC_2_state[:5, :])
Agent_state[self.agent['y']-1, self.agent['x']-1] = observer
p = shelter_env(Agent_state[:5, :])
Agent_state[:5, :] = shelter_env(Agent_state[:5, :])
"""
########### num ############
#2-NPC1 in other agents' obs
#3-NPC2 in other agents' obs
#4-Agent in other agents' obs
"""
self.NPC_1['obs'] = q
self.NPC_1['obs'] = self.gain_obs(self.NPC_1['obs'],NPC_1_state,self.NPC_2,self.agent,3,4)
self.NPC_1['axis'] = self.gain_axis(self.NPC_1,NPC_1_state,self.NPC_2,self.agent,3,4)
self.NPC_2['obs'] = r
self.NPC_2['obs'] = self.gain_obs(self.NPC_2['obs'], NPC_2_state, self.NPC_1, self.agent, 2, 4)
self.NPC_2['axis'] = self.gain_axis(self.NPC_2, NPC_2_state, self.NPC_1, self.agent, 2, 4)
self.agent['obs'] = p
self.agent['obs'] = self.gain_obs(self.agent['obs'], Agent_state, self.NPC_1, self.NPC_2, 2, 3)
self.agent['axis'] = self.gain_axis(self.agent, Agent_state, self.NPC_1, self.NPC_2, 2, 3)
return NPC_1_state, NPC_2_state, Agent_state
def gain_obs(self, a, aa, b, c, bb, cc):
"""
获得智能体真正的环境遮挡关系
@param a: self - observation
@param aa: self - self-axis, other-b-axis, other-c-axis
@param b: other-b 遮挡后的可见区域 5*5
@param c: other-c 遮挡后的可见区域 5*5
@param bb: other-b' num
@param cc: other-c' num
@return: self - observation
"""
if aa[b['y']-1, b['x']-1] == 1:
a[b['y']-1, b['x']-1] = bb
if aa[c['y']-1, c['x']-1] ==1:
a[c['y'] - 1, c['x'] - 1] = cc
return a
def gain_axis(self,a,aa,b,c,bb,cc):
"""
获得坐标,但是看不见的坐标就用6来表示
@param a:
@param aa:
@param b:
@param c:
@param bb:
@param cc:
@return:
"""
axis = []
axis.append([a['y'], a['x']])
if aa[b['y']-1, b['x']-1] != 0:
axis.append([b['y'], b['x']])
else:
axis.append([6,6])
if aa[c['y']-1, c['x']-1] != 0:
axis.append([c['y'] , c['x']])
else:
axis.append([6, 6])
return axis
def interact(self, action_NPC1, action_NPC2, action_agent):
"""
三个智能体进行交互
@param action_NPC1: action
@param action_NPC2: actionF
@param action_agent: action
@return:5*5 NPC1遮挡后看见了什么 5*5 NPC2遮挡后看见了什么 5*5 agent遮挡后看见了什么
"""
self.agent['reward'] = 0
self.NPC_1['reward'] = 0
self.NPC_2['reward'] = 0
#三个智能体分别会看到什么?
NPC_1_state, NPC_2_state, Agent_state = self.actu_obs()
#看到这些状态,智能体们会分别采取什么行为? ---depend on RL
#这些行为对状态的影响 ---首先,影响本身的位置坐标,然后,影响观测
base = np.where(np.array(self.board) == obeservation_1)
base_x = int(base[0])
base_y= int(base[1])
if self.NPC_1['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.NPC_1['y']) + np.square(base_y - self.NPC_1['x']))
if self.isNotWall(self.board, self.NPC_1, self.action_move[action_NPC1][0], \
self.action_move[action_NPC1][1]):
self.NPC_1['x'] = self.NPC_1['x'] + self.action_move[action_NPC1][0]
self.NPC_1['y'] = self.NPC_1['y'] + self.action_move[action_NPC1][1]
dis2 = np.sqrt(np.square(base_x - self.NPC_1['y']) + np.square(base_y - self.NPC_1['x']))
self.NPC_1['reward'] = (((dis1 - dis2) * 2 - 1) / dis1)
else:
self.NPC_1['reward'] = -1 * (1 / dis1)
if self.board[self.NPC_1['y'], self.NPC_1['x']] == obeservation_1:
self.NPC_1['reward'] = 50
self.NPC_1['Done'] = True
base = np.where(np.array(self.board) == obeservation_2)
base_x = int(base[0])
base_y= int(base[1])
if self.NPC_2['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.NPC_2['y']) + np.square(base_y - self.NPC_2['x']))
if self.isNotWall(self.board, self.NPC_2, self.action_move[action_NPC2][0], \
self.action_move[action_NPC2][1]):
self.NPC_2['x'] = self.NPC_2['x'] + self.action_move[action_NPC2][0]
self.NPC_2['y'] = self.NPC_2['y'] + self.action_move[action_NPC2][1]
dis2 = np.sqrt(np.square(base_x - self.NPC_2['y']) + np.square(base_y - self.NPC_2['x']))
self.NPC_2['reward'] = (((dis1 - dis2)*10 - 1/2) / dis1)
while self.NPC_2['reward'] < 0.5 and self.NPC_2['reward'] > -0.5 :
self.NPC_2['reward'] = self.NPC_2['reward'] * 2
if self.NPC_2['reward'] > 1:
self.NPC_2['reward'] = 1
elif self.NPC_2['reward'] < -1:
self.NPC_2['reward'] = -1
else:
self.NPC_2['reward'] = -0.9 #* (1 / dis1)
if self.board[self.NPC_2['y'], self.NPC_2['x']] == obeservation_2:
self.NPC_2['reward'] = self.reward
self.NPC_2['Done'] = True
base = np.where(np.array(self.board) == obeservation_3)
base_x = int(base[0])
base_y= int(base[1])
if self.agent['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.agent['y']) + np.square(base_y - self.agent['x']))
if self.isNotWall(board=self.board, piece=self.agent, xT=self.action_move[action_agent][0], \
yT=self.action_move[action_agent][1]):
self.agent['x'] = self.agent['x'] + self.action_move[action_agent][0]
self.agent['y'] = self.agent['y'] + self.action_move[action_agent][1]
dis2 = np.sqrt(np.square(base_x - self.agent['y']) + np.square(base_y - self.agent['x']))
# self.agent['reward'] = (((dis1 - dis2) * 2 - 1) / dis1)
# else:
# # print('action', action_agent)
# self.agent['reward'] = -1 * (1 / dis1)
self.agent['reward'] = (((dis1 - dis2)*10 - 1/2) / dis1)
while self.agent['reward'] < 0.5 and self.agent['reward'] > -0.5 :
self.agent['reward'] = self.agent['reward'] * 2 - 0.1
if self.agent['reward'] > 1:
self.agent['reward'] = 1
elif self.agent['reward'] < -1:
self.agent['reward'] = -1
else:
self.agent['reward'] = -0.9 #* (1 / dis1)
if self.board[self.agent['y'], self.agent['x']] == obeservation_3:
self.agent['reward'] = self.reward
self.agent['Done'] = True
NPC_1_state, NPC_2_state, Agent_state = self.actu_obs()
#判断是否会相撞?
location = [(self.NPC_1['x'], self.NPC_1['y']), (self.NPC_2['x'], self.NPC_2['y']),\
(self.agent['x'], self.agent['y'])]
#达到目标或者相撞都会结束该智能体的回合
terminal = self.gameover(location)
if terminal[0] == True and self.NPC_1['Done'] == False:
self.NPC_1['Done'] = True
self.NPC_1['reward'] = -50
self.NPC_1['color'] = Red
if terminal[1] == True and self.NPC_2['Done'] == False:
self.NPC_2['Done'] = True
self.NPC_2['reward'] = -self.reward
self.NPC_2['color'] = Red
if terminal[2] == True and self.agent['Done'] == False:
self.agent['Done'] = True
self.agent['reward'] = -self.reward
self.agent['color'] = Red
return NPC_1_state, NPC_2_state, Agent_state
def SHOW(self):
"""
显示函数
"""
DISPLAYSURF.fill(BGColor)
self.DrawBoard(self.board)
self.DrawPiece(self.NPC_1)
self.DrawPiece(self.NPC_2)
self.DrawPiece(self.agent)
pygame.display.update()
FPSCLOCK.tick(FPS)
# return flag
def reset(self):
self._agent_init()
def getBlankBoard(self):
"""
11 - NPC1-goal
22 - NPC2-goal
33 - Agent-goal
@return:
"""
board = np.array([[1,1,1,5,5],[22,1,1,5,5],[1,1,1,1,1],[1,1,1,1,33],[1,1,1,11,1]])
state_init = np.array([[1,1,1,5,5],[1,1,1,5,5],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])
board = big_env(board)
# print(board)
# for x in range(GridWidth):
# for y in range(GridHeight):
# print(board[x][y],x,y)
return board, state_init
def ValidPos(self, piece1, piece2, xT=0, yT=0):
"""
to judge the next place vaild or not
@param piece1:
@param piece2:
@param xT:
@param yT:
@return:
"""
if piece1['x'] == (piece2['x'] + xT) and piece1['y'] == (piece2['y'] + yT):
return True
return False
def isNotWall(self, board, piece, xT=0 , yT=0 ):
"""
判断是否到达墙
@param board: board
@param piece: agent
@param xT:
@param yT:
@return:
"""
if board[piece['y'] + yT][piece['x'] + xT] == Wall:#############
return False
else:
return True
def gameover(self, location):
"""
回合是否结束,以及奖励值
@param location:目标位置
"""
result = False
terminal = [False, False, False]
if location[0] == location[1]:
terminal[0] = True
terminal[1] = True
if location[2] == location[1]:
terminal[2] = True
terminal[1] = True
if location[2] ==location[0]:
terminal[2] = True
terminal[0] = True
return terminal
def pixel(self, xbox, ybox):
return (XMargin + (xbox * BoxSize)), (TopMargin + (ybox * BoxSize))
def DrawBox(self, xbox, ybox, color, xpixel=None, ypixel=None):
if color == BlankBox:
return
elif color == obeservation_1:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (60,107,255), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == obeservation_2:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (205, 155, 155), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == obeservation_3:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (154, 205, 50), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == Wall:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, Gray, (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
else:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, color, (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
def fun_trigger(self):
xpixel, ypixel = self.pixel(3, 5)
pygame.draw.line(DISPLAYSURF, Red, (xpixel + BoxSize, ypixel - BoxSize),
(xpixel + BoxSize, ypixel - 2*BoxSize), 5)
def DrawCircle(self, xbox, ybox, color, xpixel=None, ypixel=None):
"""
画圆
@param xbox:
@param ybox:
@param color:
@param xpixel:
@param ypixel:
"""
pygame.draw.circle(DISPLAYSURF,
color,
(int(xpixel+BoxSize/2), int(ypixel+BoxSize/2)),
int(0.3 * self.R))
def DrawPiece(self, piece, xpixel=None, ypixel=None):
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(piece['x'], piece['y'])
if piece['style'] == "circle":
self.DrawCircle(None, None, piece['color'], xpixel, ypixel)
else:
self.DrawBox(None, None, piece['color'], xpixel, ypixel)
def DrawBoard(self, board):
pygame.draw.rect(DISPLAYSURF, BoardColor,
(XMargin - 3, TopMargin - 7, (GridWidth * BoxSize) + 8, (GridHeight * BoxSize) + 8), 5)
pygame.draw.rect(DISPLAYSURF, BGColor, (XMargin, TopMargin, GridWidth * BoxSize, GridHeight * BoxSize))
for x in range(GridWidth):
for y in range(GridHeight):
self.DrawBox(y, x, board[x][y])
if self.trigger == 1:
self.fun_trigger()
def ShowScore(self, score):
scoreSurf = BASICFONT.render('Score : %s' % score, True, TextColor)
scoreRect = scoreSurf.get_rect()
scoreRect.topleft = (WinWidth - 250, 20)
DISPLAYSURF.blit(scoreSurf, scoreRect)
def Terminal(self, piece1, piece2, piece1_old, piece2_old):
# print(piece1['x'],piece1['y'],piece2_old[0],piece2_old[1],'/',piece2['x'],piece2['y'],piece1_old[0],piece1_old[1])
# if self.steps == 1:# wrong!!!!
if piece1['x'] == piece2_old[0] and piece1['y'] == piece2_old[1] and piece2['x'] == piece1_old[0] and piece2['y'] == piece1_old[1]:
return 1
else:
return 2
def Paint(self, board, piece, color):
board[piece['x']][piece['y']] = color
piece['color'] = color
return board
# if __name__ == "__main__":
# env0 = FalseBelief_env0()
# action_agent = 0
# action_NPC2 = 1
# action_NPC1 = 4
# for i in range(10):
# if i > 8:
# break
# else:
# env0.interact(action_NPC1, action_NPC2, action_agent)
#
# env0.SHOW()
# time.sleep(2)
# pygame.quit()
================================================
FILE: examples/Social_Cognition/ToM/env/env3_train_env00.py
================================================
from numpy import argmax
import random, time, pygame, sys
import pygame
pygame.init()
from pygame.locals import *
import os
os.environ["SDL_VIDEODRIVER"] = "dummy"
from rulebasedpolicy.world_model import *
from rulebasedpolicy.statedata_pre import *
from rulebasedpolicy.Find_a_way import *
import numpy as np
from utils.one_hot import one_hot
# =============================================================================
# set the value of interface
# =============================================================================
FPS = 25
WinWidth = 340 #window width
WinHeight = 260 #window width
BoxSize = 20 #the size of one grid
GridWidth = 7 #the number of lattices are there in the x-axis
GridHeight = 7 #the number of lattices are there in the y-axis
#representation of different objective
BlankBox = 1
Wall = 5
Obstacle = 5
observer = 8
obeservation_1 = 11
obeservation_2 = 22
obeservation_3 = 33
#Text = None
XMargin = int((WinWidth - GridWidth * BoxSize)/2)
TopMargin = int((WinHeight - GridHeight * BoxSize))/2-5
# =============================================================================
# set color
# =============================================================================
White = (255,255,255)
Gray = (185,185,185)
Black = (0,0,0)
Red = (200,0,0)
Green = (0,139,0)
Green_B = (78, 238, 148)
Light_A = (233, 232, 170)
Blue = (30, 144, 255)
pink = (238, 99, 99)
BoardColor = White
BGColor = White
TextColor = White
Test = []
# =============================================================================
# agents - env interactive
# =============================================================================
class FalseBelief_env0(object):
def __init__(self, reward=10):
super(FalseBelief_env0, self).__init__()
self.action_space = ['up', 'down', 'left', 'right', 'stay']
self.action_move = {
0 : (0, -1),
1 : (0, 1),
2 : (-1, 0),
3 : (1, 0),
4 :(0, 0)
}#[(0, -1), (0, 1), (-1, 0), (1, 0), (0, 0)]
self.n_actions = len(self.action_space)
self._build_AB()
self.board, self.obs = self.getBlankBoard()
self._agent_init()
self.score = 0
self.steps = 0
self.n = 0
self.R = int(5/2) * (BoxSize - 5)
self.x = 0
self.n_features = 30
self.reward = reward
def _build_AB(self):
global FPSCLOCK, DISPLAYSURF, BASICFONT, BIGFONT
FPSCLOCK = pygame.time.Clock()
DISPLAYSURF = pygame.display.set_mode((WinWidth, WinHeight))
BASICFONT = pygame.font.Font('freesansbold.ttf', 18)
BIGFONT = pygame.font.Font('freesansbold.ttf', 100)
pygame.display.set_caption('AB')
pygame.display.update()
FPSCLOCK.tick()
def _agent_init(self):
"""
Aim:Initialize the basic information of the agent
"""
self.NPC_1 = {
'shape' : [['#']],
'x' : 3, #row
'y' : 1, #column
'color' : Blue,
'style' : "circle",
'obs' : None,
'axis' : None,#,[[1,3],[3,5],[4,2]]
'reward' : 0,
'Done' : False
}
self.NPC_2 = {
'shape' : [['@']],
'x' : 5, #row
'y' : 3, #column
'color' : pink,
'style' : "circle",
'obs' : None,
'axis' :None ,#,[[3,5],[1,3],[4,2]]
'reward': 0,
'Done': False
}
self.agent = {
'shape' : [['$']],
'x' : 2, #row
'y' : 4, #column
'color' : Green_B,
'style' : "circle",
'obs' : None,
'axis' : None,#[[4,2],[1,3],[3,5]]
'reward': 0,
'Done': False
}
def actu_obs(self):
"""
将状态转化成可以训练的数据形式
"""
_, state = self.getBlankBoard()
a = state
b = state
c = state
state1 = np.r_[a, np.ones((4, 5))].astype(np.int_)
state2 = np.r_[b, np.ones((4, 5))].astype(np.int_)
statea = np.r_[c, np.ones((4, 5))].astype(np.int_)
NPC_1_state = state1
NPC_2_state = state2
Agent_state = statea
NPC_1_state[self.NPC_1['y']-1, self.NPC_1['x']-1] = observer
q = shelter_env(NPC_1_state[:5, :])
NPC_1_state[:5, :] = shelter_env(NPC_1_state[:5, :])
NPC_2_state[self.NPC_2['y']-1, self.NPC_2['x']-1] = observer
r = shelter_env(NPC_2_state[:5, :])
NPC_2_state[:5, :] = shelter_env(NPC_2_state[:5, :])
Agent_state[self.agent['y']-1, self.agent['x']-1] = observer
p = shelter_env(Agent_state[:5, :])
Agent_state[:5, :] = shelter_env(Agent_state[:5, :])
"""
########### num ############
#2-NPC1 in other agents' obs
#3-NPC2 in other agents' obs
#4-Agent in other agents' obs
"""
self.NPC_1['obs'] = q
self.NPC_1['obs'] = self.gain_obs(self.NPC_1['obs'],NPC_1_state,self.NPC_2,self.agent,3,4)
self.NPC_1['axis'] = self.gain_axis(self.NPC_1,NPC_1_state,self.NPC_2,self.agent,3,4)
self.NPC_2['obs'] = r
self.NPC_2['obs'] = self.gain_obs(self.NPC_2['obs'], NPC_2_state, self.NPC_1, self.agent, 2, 4)
self.NPC_2['axis'] = self.gain_axis(self.NPC_2, NPC_2_state, self.NPC_1, self.agent, 2, 4)
self.agent['obs'] = p
self.agent['obs'] = self.gain_obs(self.agent['obs'], Agent_state, self.NPC_1, self.NPC_2, 2, 3)
self.agent['axis'] = self.gain_axis(self.agent, Agent_state, self.NPC_1, self.NPC_2, 2, 3)
return NPC_1_state, NPC_2_state, Agent_state
def gain_obs(self, a, aa, b, c, bb, cc):
"""
获得智能体真正的环境遮挡关系
@param a: self - observation
@param aa: self - self-axis, other-b-axis, other-c-axis
@param b: other-b 遮挡后的可见区域 5*5
@param c: other-c 遮挡后的可见区域 5*5
@param bb: other-b' num
@param cc: other-c' num
@return: self - observation
"""
if aa[b['y']-1, b['x']-1] == 1:
a[b['y']-1, b['x']-1] = bb
if aa[c['y']-1, c['x']-1] ==1:
a[c['y'] - 1, c['x'] - 1] = cc
return a
def gain_axis(self,a,aa,b,c,bb,cc):
"""
获得坐标,但是看不见的坐标就用6来表示
@param a:
@param aa:
@param b:
@param c:
@param bb:
@param cc:
@return:
"""
axis = []
axis.append([a['y'], a['x']])
if aa[b['y']-1, b['x']-1] != 0:
axis.append([b['y'], b['x']])
else:
axis.append([6,6])
if aa[c['y']-1, c['x']-1] != 0:
axis.append([c['y'] , c['x']])
else:
axis.append([6, 6])
return axis
def interact(self, action_NPC1, action_NPC2, action_agent):
"""
三个智能体进行交互
@param action_NPC1: action
@param action_NPC2: actionF
@param action_agent: action
@return:5*5 NPC1遮挡后看见了什么 5*5 NPC2遮挡后看见了什么 5*5 agent遮挡后看见了什么
"""
self.agent['reward'] = 0
self.NPC_1['reward'] = 0
self.NPC_2['reward'] = 0
#三个智能体分别会看到什么?
NPC_1_state, NPC_2_state, Agent_state = self.actu_obs()
#看到这些状态,智能体们会分别采取什么行为? ---depend on RL
#这些行为对状态的影响 ---首先,影响本身的位置坐标,然后,影响观测
base = np.where(np.array(self.board) == obeservation_1)
base_x = int(base[0])
base_y= int(base[1])
if self.NPC_1['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.NPC_1['y']) + np.square(base_y - self.NPC_1['x']))
if self.isNotWall(self.board, self.NPC_1, self.action_move[action_NPC1][0], \
self.action_move[action_NPC1][1]):
self.NPC_1['x'] = self.NPC_1['x'] + self.action_move[action_NPC1][0]
self.NPC_1['y'] = self.NPC_1['y'] + self.action_move[action_NPC1][1]
dis2 = np.sqrt(np.square(base_x - self.NPC_1['y']) + np.square(base_y - self.NPC_1['x']))
self.NPC_1['reward'] = (((dis1 - dis2) * 2 - 1) / dis1)
else:
self.NPC_1['reward'] = -1 * (1 / dis1)
if self.board[self.NPC_1['y'], self.NPC_1['x']] == obeservation_1:
self.NPC_1['reward'] = 50
self.NPC_1['Done'] = True
base = np.where(np.array(self.board) == obeservation_2)
base_x = int(base[0])
base_y= int(base[1])
if self.NPC_2['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.NPC_2['y']) + np.square(base_y - self.NPC_2['x']))
if self.isNotWall(self.board, self.NPC_2, self.action_move[action_NPC2][0], \
self.action_move[action_NPC2][1]):
self.NPC_2['x'] = self.NPC_2['x'] + self.action_move[action_NPC2][0]
self.NPC_2['y'] = self.NPC_2['y'] + self.action_move[action_NPC2][1]
dis2 = np.sqrt(np.square(base_x - self.NPC_2['y']) + np.square(base_y - self.NPC_2['x']))
self.NPC_2['reward'] = (((dis1 - dis2)*10 - 1/2) / dis1)
while self.NPC_2['reward'] < 0.5 and self.NPC_2['reward'] > -0.5 :
self.NPC_2['reward'] = self.NPC_2['reward'] * 2
if self.NPC_2['reward'] > 1:
self.NPC_2['reward'] = 1
elif self.NPC_2['reward'] < -1:
self.NPC_2['reward'] = -1
else:
self.NPC_2['reward'] = -0.9 #* (1 / dis1)
if self.board[self.NPC_2['y'], self.NPC_2['x']] == obeservation_2:
self.NPC_2['reward'] = self.reward
self.NPC_2['Done'] = True
base = np.where(np.array(self.board) == obeservation_3)
base_x = int(base[0])
base_y= int(base[1])
if self.agent['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.agent['y']) + np.square(base_y - self.agent['x']))
if self.isNotWall(board=self.board, piece=self.agent, xT=self.action_move[action_agent][0], \
yT=self.action_move[action_agent][1]):
self.agent['x'] = self.agent['x'] + self.action_move[action_agent][0]
self.agent['y'] = self.agent['y'] + self.action_move[action_agent][1]
dis2 = np.sqrt(np.square(base_x - self.agent['y']) + np.square(base_y - self.agent['x']))
# self.agent['reward'] = (((dis1 - dis2) * 2 - 1) / dis1)
# else:
# # print('action', action_agent)
# self.agent['reward'] = -1 * (1 / dis1)
self.agent['reward'] = (((dis1 - dis2)*10 - 1/2) / dis1)
while self.agent['reward'] < 0.5 and self.agent['reward'] > -0.5 :
self.agent['reward'] = self.agent['reward'] * 2 - 0.1
if self.agent['reward'] > 1:
self.agent['reward'] = 1
elif self.agent['reward'] < -1:
self.agent['reward'] = -1
else:
self.agent['reward'] = -0.9 #* (1 / dis1)
if self.board[self.agent['y'], self.agent['x']] == obeservation_3:
self.agent['reward'] = self.reward
self.agent['Done'] = True
NPC_1_state, NPC_2_state, Agent_state = self.actu_obs()
#判断是否会相撞?
location = [(self.NPC_1['x'], self.NPC_1['y']), (self.NPC_2['x'], self.NPC_2['y']),\
(self.agent['x'], self.agent['y'])]
#达到目标或者相撞都会结束该智能体的回合
terminal = self.gameover(location)
if terminal[0] == True and self.NPC_1['Done'] == False:
self.NPC_1['Done'] = True
self.NPC_1['reward'] = -50
self.NPC_1['color'] = Red
if terminal[1] == True and self.NPC_2['Done'] == False:
self.NPC_2['Done'] = True
self.NPC_2['reward'] = -self.reward
self.NPC_2['color'] = Red
if terminal[2] == True and self.agent['Done'] == False:
self.agent['Done'] = True
self.agent['reward'] = -self.reward
self.agent['color'] = Red
return NPC_1_state, NPC_2_state, Agent_state
def SHOW(self):
"""
显示函数
"""
DISPLAYSURF.fill(BGColor)
self.DrawBoard(self.board)
self.DrawPiece(self.NPC_1)
self.DrawPiece(self.NPC_2)
self.DrawPiece(self.agent)
pygame.display.update()
FPSCLOCK.tick(FPS)
# return flag
def reset(self):
self._agent_init()
def getBlankBoard(self):
"""
11 - NPC1-goal
22 - NPC2-goal
33 - Agent-goal
@return:
"""
# board = data_transfer('env_1.txt','env_11.txt')
board = np.array([[1,1,1,1,1],[22,1,1,1,1],[1,1,1,1,1],[1,1,1,1,33],[1,1,1,11,1]])
state_init = np.array([[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])
board = big_env(board)
# print(board)
# for x in range(GridWidth):
# for y in range(GridHeight):
# print(board[x][y],x,y)
return board, state_init
def ValidPos(self, piece1, piece2, xT=0, yT=0):
"""
to judge the next place vaild or not
@param piece1:
@param piece2:
@param xT:
@param yT:
@return:
"""
if piece1['x'] == (piece2['x'] + xT) and piece1['y'] == (piece2['y'] + yT):
return True
return False
def isNotWall(self, board, piece, xT=0 , yT=0 ):
"""
判断是否到达墙
@param board: board
@param piece: agent
@param xT:
@param yT:
@return:
"""
if board[piece['y'] + yT][piece['x'] + xT] == Wall:#############
return False
else:
return True
def gameover(self, location):
"""
回合是否结束,以及奖励值
@param location:目标位置
"""
result = False
terminal = [False, False, False]
if location[0] == location[1]:
terminal[0] = True
terminal[1] = True
if location[2] == location[1]:
terminal[2] = True
terminal[1] = True
if location[2] ==location[0]:
terminal[2] = True
terminal[0] = True
return terminal
def pixel(self, xbox, ybox):
return (XMargin + (xbox * BoxSize)), (TopMargin + (ybox * BoxSize))
def DrawBox(self, xbox, ybox, color, xpixel=None, ypixel=None):
if color == BlankBox:
return
elif color == obeservation_1:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (60,107,255), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == obeservation_2:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (205, 155, 155), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == obeservation_3:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (154, 205, 50), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == Wall:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, Gray, (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
else:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, color, (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
def DrawCircle(self, xbox, ybox, color, xpixel=None, ypixel=None):
"""
画圆
@param xbox:
@param ybox:
@param color:
@param xpixel:
@param ypixel:
"""
pygame.draw.circle(DISPLAYSURF,
color,
(int(xpixel+BoxSize/2), int(ypixel+BoxSize/2)),
int(0.3 * self.R))
def DrawPiece(self, piece, xpixel=None, ypixel=None):
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(piece['x'], piece['y'])
if piece['style'] == "circle":
self.DrawCircle(None, None, piece['color'], xpixel, ypixel)
else:
self.DrawBox(None, None, piece['color'], xpixel, ypixel)
def DrawBoard(self, board):
pygame.draw.rect(DISPLAYSURF, BoardColor,
(XMargin - 3, TopMargin - 7, (GridWidth * BoxSize) + 8, (GridHeight * BoxSize) + 8), 5)
pygame.draw.rect(DISPLAYSURF, BGColor, (XMargin, TopMargin, GridWidth * BoxSize, GridHeight * BoxSize))
for x in range(GridWidth):
for y in range(GridHeight):
self.DrawBox(y, x, board[x][y])
def ShowScore(self, score):
scoreSurf = BASICFONT.render('Score : %s' % score, True, TextColor)
scoreRect = scoreSurf.get_rect()
scoreRect.topleft = (WinWidth - 250, 20)
DISPLAYSURF.blit(scoreSurf, scoreRect)
def Terminal(self, piece1, piece2, piece1_old, piece2_old):
# print(piece1['x'],piece1['y'],piece2_old[0],piece2_old[1],'/',piece2['x'],piece2['y'],piece1_old[0],piece1_old[1])
# if self.steps == 1:# wrong!!!!
if piece1['x'] == piece2_old[0] and piece1['y'] == piece2_old[1] and piece2['x'] == piece1_old[0] and piece2['y'] == piece1_old[1]:
return 1
else:
return 2
def Paint(self, board, piece, color):
board[piece['x']][piece['y']] = color
piece['color'] = color
return board
# if __name__ == "__main__":
# env0 = FalseBelief_env0()
# action_agent = 0
# action_NPC2 = 1
# action_NPC1 = 4
# for i in range(10):
# if i > 8:
# break
# else:
# env0.interact(action_NPC1, action_NPC2, action_agent)
#
# env0.SHOW()
# time.sleep(2)
# pygame.quit()
================================================
FILE: examples/Social_Cognition/ToM/env/env3_train_env01.py
================================================
"""
Zoe Zhao 2022.5
Env Demo
"""
from numpy import argmax
import random, time, pygame, sys
import pygame
pygame.init()
from pygame.locals import *
# import os
# os.environ["SDL_VIDEODRIVER"] = "dummy"
from rulebasedpolicy.world_model import *
from rulebasedpolicy.statedata_pre import *
from rulebasedpolicy.Find_a_way import *
import numpy as np
from utils.one_hot import one_hot
# =============================================================================
# set the value of interface
# =============================================================================
FPS = 25
WinWidth = 340 #window width
WinHeight = 260 #window width
BoxSize = 20 #the size of one grid
GridWidth = 7 #the number of lattices are there in the x-axis
GridHeight = 7 #the number of lattices are there in the y-axis
#representation of different objective
BlankBox = 1
Wall = 5
Obstacle = 5
observer = 8
obeservation_1 = 11
obeservation_2 = 22
obeservation_3 = 33
#Text = None
XMargin = int((WinWidth - GridWidth * BoxSize)/2)
TopMargin = int((WinHeight - GridHeight * BoxSize))/2-5
# =============================================================================
# set color
# =============================================================================
White = (255,255,255)
Gray = (185,185,185)
Black = (0,0,0)
Red = (200,0,0)
Green = (0,139,0)
Green_B = (78, 238, 148)
Light_A = (233, 232, 170)
Blue = (30, 144, 255)
pink = (238, 99, 99)
BoardColor = White
BGColor = White
TextColor = White
Test = []
# =============================================================================
# agents - env interactive
# =============================================================================
class FalseBelief_env1(object):
def __init__(self, reward=10):
super(FalseBelief_env1, self).__init__()
self.action_space = ['up', 'down', 'left', 'right', 'stay']
self.action_move = {
0 : (0, -1),
1 : (0, 1),
2 : (-1, 0),
3 : (1, 0),
4 :(0, 0)
}#[(0, -1), (0, 1), (-1, 0), (1, 0), (0, 0)]
self.n_actions = len(self.action_space)
self._build_AB()
self.board, self.obs = self.getBlankBoard()
self._agent_init()
self.score = 0
self.steps = 0
self.n = 0
self.R = int(5/2) * (BoxSize - 5)
self.x = 0
self.n_features = 30
self.reward = reward
def _build_AB(self):
global FPSCLOCK, DISPLAYSURF, BASICFONT, BIGFONT
pygame.init()
FPSCLOCK = pygame.time.Clock()
DISPLAYSURF = pygame.display.set_mode((WinWidth, WinHeight))
BASICFONT = pygame.font.Font('freesansbold.ttf', 18)
BIGFONT = pygame.font.Font('freesansbold.ttf', 100)
pygame.display.set_caption('AB')
pygame.display.update()
FPSCLOCK.tick()
def _agent_init(self):
"""
Aim:Initialize the basic information of the agent
"""
self.NPC_2 = {
'shape' : [['@']],
'x' : 5, #row
'y' : 3, #column
'color' : pink,
'style' : "circle",
'obs' : None,
'axis' :None ,#,[[3,5],[1,3],[4,2]]
'reward': 0,
'Done': False
}
self.agent = {
'shape' : [['$']],
'x' : 2, #row
'y' : 4, #column
'color' : Green_B,
'style' : "circle",
'obs' : None,
'axis' : None,#[[4,2],[1,3],[3,5]]
'reward': 0,
'Done': False
}
def actu_obs(self):
"""
将状态转化成可以训练的数据形式
"""
_, state = self.getBlankBoard()
a = state
b = state
c = state
state2 = np.r_[b, np.ones((4, 5))].astype(np.int)
statea = np.r_[c, np.ones((4, 5))].astype(np.int)
NPC_2_state = state2
Agent_state = statea
NPC_2_state[self.NPC_2['y']-1, self.NPC_2['x']-1] = observer
r = shelter_env(NPC_2_state[:5, :])
NPC_2_state[:5, :] = shelter_env(NPC_2_state[:5, :])
Agent_state[self.agent['y']-1, self.agent['x']-1] = observer
p = shelter_env(Agent_state[:5, :])
Agent_state[:5, :] = shelter_env(Agent_state[:5, :])
self.NPC_2['obs'] = r
self.NPC_2['obs'] = self.gain_obs(self.NPC_2['obs'], NPC_2_state, self.agent, 4)
self.NPC_2['axis'] = self.gain_axis(self.NPC_2, NPC_2_state, 6, self.agent, 2, 4)
self.agent['obs'] = p
self.agent['obs'] = self.gain_obs(self.agent['obs'], Agent_state, self.NPC_2, 3)
self.agent['axis'] = self.gain_axis(self.agent, Agent_state, 6, self.NPC_2, 2, 3)
return NPC_2_state, Agent_state#NPC_1_state,
def gain_obs(self, a,aa,c,cc):
if aa[c['y']-1, c['x']-1] ==1:
a[c['y'] - 1, c['x'] - 1] = cc
return a
def gain_axis(self,a,aa,b,c,bb,cc):
axis = []
axis.append([a['y'], a['x']])
if b == 6:
axis.append([6, 6])
else:
axis.append([6, 6])
if aa[c['y']-1, c['x']-1] != 0:
axis.append([c['y'] , c['x']])
else:
axis.append([6, 6])
return axis
def interact(self, action_NPC2, action_agent):
self.agent['reward'] = 0
self.NPC_2['reward'] = 0
#三个智能体分别会看到什么?
NPC_2_state, Agent_state = self.actu_obs()# NPC_1_state,
#看到这些状态,智能体们会分别采取什么行为? ---depend on RL
#这些行为对状态的影响 ---首先,影响本身的位置坐标,然后,影响观测
base = np.where(np.array(self.board) == obeservation_2)
base_x = int(base[0])
base_y= int(base[1])
if self.NPC_2['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.NPC_2['y']) + np.square(base_y - self.NPC_2['x']))
if self.isNotWall(self.board, self.NPC_2, self.action_move[action_NPC2][0], \
self.action_move[action_NPC2][1]):
self.NPC_2['x'] = self.NPC_2['x'] + self.action_move[action_NPC2][0]
self.NPC_2['y'] = self.NPC_2['y'] + self.action_move[action_NPC2][1]
dis2 = np.sqrt(np.square(base_x - self.NPC_2['y']) + np.square(base_y - self.NPC_2['x']))
self.NPC_2['reward'] = (((dis1 - dis2) * 10 - 1 / 2) / dis1)
while self.NPC_2['reward'] < 0.5 and self.NPC_2['reward'] > -0.5:
self.NPC_2['reward'] = self.NPC_2['reward'] * 2
if self.NPC_2['reward'] > 1:
self.NPC_2['reward'] = 1
elif self.NPC_2['reward'] < -1:
self.NPC_2['reward'] = -1
else:
self.NPC_2['reward'] = -0.9 # * (1 / dis1)
if self.board[self.NPC_2['y'], self.NPC_2['x']] == obeservation_2:
self.NPC_2['reward'] = self.reward
self.NPC_2['Done'] = True
base = np.where(np.array(self.board) == obeservation_3)
base_x = int(base[0])
base_y= int(base[1])
if self.agent['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.agent['y']) + np.square(base_y - self.agent['x']))
if self.isNotWall(board=self.board, piece=self.agent, xT=self.action_move[action_agent][0], \
yT=self.action_move[action_agent][1]):
self.agent['x'] = self.agent['x'] + self.action_move[action_agent][0]
self.agent['y'] = self.agent['y'] + self.action_move[action_agent][1]
dis2 = np.sqrt(np.square(base_x - self.agent['y']) + np.square(base_y - self.agent['x']))
# self.agent['reward'] = (((dis1 - dis2) * 2 - 1) / dis1)
#
# else:
# # print('action', action_agent)
# self.agent['reward'] = -1 * (1 / dis1)
self.agent['reward'] = (((dis1 - dis2)*10 - 1/2) / dis1)
while self.agent['reward'] < 0.5 and self.agent['reward'] > -0.5 :
self.agent['reward'] = self.agent['reward'] * 2 - 0.1
if self.agent['reward'] > 1:
self.agent['reward'] = 1
elif self.agent['reward'] < -1:
self.agent['reward'] = -1
else:
self.agent['reward'] = -0.9 #* (1 / dis1)
if self.board[self.agent['y'], self.agent['x']] == obeservation_3:
self.agent['reward'] = self.reward
self.agent['Done'] = True
NPC_2_state, Agent_state = self.actu_obs()
#判断是否会相撞?
location = [(self.NPC_2['x'], self.NPC_2['y']),\
(self.agent['x'], self.agent['y'])]
#达到目标或者相撞都会结束该智能体的回合
terminal = self.gameover(location)
if self.agent['Done'] == False and terminal[1] == True:
self.agent['Done'] = True
self.agent['reward'] = -self.reward
self.agent['color'] = Red
if self.NPC_2['Done'] == False and terminal[0] == True:
self.NPC_2['Done'] = True
self.NPC_2['reward'] = -self.reward
self.NPC_2['color'] = Red
return NPC_2_state, Agent_state
def SHOW(self):
DISPLAYSURF.fill(BGColor)
self.DrawBoard(self.board)
# self.DrawPiece(self.NPC_1)
self.DrawPiece(self.NPC_2)
self.DrawPiece(self.agent)
pygame.display.update()
FPSCLOCK.tick(FPS)
# return flag
def reset(self):
self._agent_init()
def getBlankBoard(self):
# board = data_transfer('env_1.txt','env_11.txt')
board = np.array([[1,1,1,5,5],[22,1,1,5,5],[1,1,1,1,1],[1,1,1,1,33],[1,1,1,11,1]])
state_init = np.array([[1,1,1,5,5],[1,1,1,5,5],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])
board = big_env(board)
# print(board)
# for x in range(GridWidth):
# for y in range(GridHeight):
# print(board[x][y],x,y)
return board, state_init
def ValidPos(self, piece1, piece2, xT=0, yT=0):
"""
to judge the next place vaild or not
@param piece1:
@param piece2:
@param xT:
@param yT:
@return:
"""
if piece1['x'] == (piece2['x'] + xT) and piece1['y'] == (piece2['y'] + yT):
return True
return False
def isNotWall(self, board, piece, xT=0 , yT=0 ):
if board[piece['y'] + yT][piece['x'] + xT] == Wall:#############
return False
else:
return True
def gameover(self, location):
"""
回合是否结束,以及奖励值
@param location:目标位置
"""
result = False
terminal = [False, False] #NPC_2, agent
for r in range(len(location) - 1):
for c in range(r + 1, len(location)):
if location[r] == location[c]:
result = True ####相撞会带来一个巨大的副奖励,并且结束该回合
boom = location[r] ###############相撞################
if result == True:
terminal[r] = True
terminal[c] = True
return terminal
def pixel(self, xbox, ybox):
return (XMargin + (xbox * BoxSize)), (TopMargin + (ybox * BoxSize))
def DrawBox(self, xbox, ybox, color, xpixel=None, ypixel=None):
if color == BlankBox:
return
elif color == obeservation_1:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (60,107,255), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == obeservation_2:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (205, 155, 155 ), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == obeservation_3:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (154, 205, 50), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == Wall:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, Gray, (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
else:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, color, (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
def DrawCircle(self, xbox, ybox, color, xpixel=None, ypixel=None):
pygame.draw.circle(DISPLAYSURF,
color,
(int(xpixel+BoxSize/2), int(ypixel+BoxSize/2)),
int(0.3 * self.R))
def DrawPiece(self, piece, xpixel=None, ypixel=None):
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(piece['x'], piece['y'])
if piece['style'] == "circle":
self.DrawCircle(None, None, piece['color'], xpixel, ypixel)
else:
self.DrawBox(None, None, piece['color'], xpixel, ypixel)
def DrawBoard(self, board):
pygame.draw.rect(DISPLAYSURF, BoardColor,
(XMargin - 3, TopMargin - 7, (GridWidth * BoxSize) + 8, (GridHeight * BoxSize) + 8), 5)
pygame.draw.rect(DISPLAYSURF, BGColor, (XMargin, TopMargin, GridWidth * BoxSize, GridHeight * BoxSize))
for x in range(GridWidth):
for y in range(GridHeight):
self.DrawBox(y, x, board[x][y])
def ShowScore(self, score):
scoreSurf = BASICFONT.render('Score : %s' % score, True, TextColor)
scoreRect = scoreSurf.get_rect()
scoreRect.topleft = (WinWidth - 250, 20)
DISPLAYSURF.blit(scoreSurf, scoreRect)
def Terminal(self, piece1, piece2, piece1_old, piece2_old):
# print(piece1['x'],piece1['y'],piece2_old[0],piece2_old[1],'/',piece2['x'],piece2['y'],piece1_old[0],piece1_old[1])
# if self.steps == 1:# wrong!!!!
if piece1['x'] == piece2_old[0] and piece1['y'] == piece2_old[1] and piece2['x'] == piece1_old[0] and piece2['y'] == piece1_old[1]:
return 1
else:
return 2
def Paint(self, board, piece, color):
board[piece['x']][piece['y']] = color
piece['color'] = color
return board
================================================
FILE: examples/Social_Cognition/ToM/main_ToM.py
================================================
"""
Zoe Zhao 2022.5
ToM Demo
"""
import argparse
import copy
import numpy as np
import torch
np.set_printoptions(threshold=np.inf)
torch.set_printoptions(threshold=np.inf)
import matplotlib
import pygame
pygame.init()
matplotlib.rcParams.update({'font.size': 12})
import os
os.environ["SDL_VIDEODRIVER"] = "dummy"
from BrainArea.PFC_ToM import PFC_ToM
from BrainArea.TPJ import ToM
from BrainArea.dACC import *
from rulebasedpolicy.Find_a_way import *
from env.env import FalseBelief_env
from braincog.base.encoder.encoder import *
from braincog.base.node import node
#NPC2
#state
N_state = 6
cell_num = 6
# action
N_action = 5
NC=10 #50 cells represent one character
#synapstic
bfs = pow(cell_num, N_state) #before synapstic
afs = N_action * NC
#agent
C=10
A_state = 4
abfs = pow(cell_num, A_state) #agent before synapstic
aafs = N_action * C
parser = argparse.ArgumentParser(description='sequence character (policy inference)')
parser.add_argument('--mode', type=str, default='test')
parser.add_argument('--task', type=str, default='both')
parser.add_argument('--logdir', type=str, default='checkpoint')
parser.add_argument('--save_net_a', type=str, default='net_NPC_11.pth', help='save the parameters of net_agent')
parser.add_argument('--save_net_N', type=str, default='net_NPC_11.pth', help='save the parameters of net_NPC')
parser.add_argument('--device', default='cpu', help='device') # cuda:0
parser.add_argument('--T', default=40, type=int, help='simulating time-steps') # 模拟时长
parser.add_argument('--dt', default=1, type=int, help='simulating dt') # 模拟dt
parser.add_argument('--episodes', default=25, type=int, help='episodes')
parser.add_argument('--trajectories', default=10, type=int, help='trajectories')
parser.add_argument('--greedy', default=0.8, type=int, help='exploration or exploitation')
parser.add_argument('--num_enpop', default=6, type=int, help='the number of one population in the encoding layer') #
parser.add_argument('--num_depop', default=10, type=int, help='the number of one population in the decoding layer') #
parser.add_argument('--num_stateA', default=2, type=int, help='the number of states')
parser.add_argument('--num_stateN', default=6, type=int, help='the number of states')
parser.add_argument('--num_action', default=5, type=int, help='the number of actions')
parser.add_argument('--reward', default=10, type=float, help='environment parameter reward')
args = parser.parse_args()
def update(env, net_agent_belief, net_NPC, episodes, trajectories):
"""
agents learn to reach the goal without collision
update agents' positions
@param env:
@param env1:
@param net_agent_belief: the SNN network of agent
@param net_NPC: the SNN network of NPC
@param episodes: train times
@return: None
"""
for episode in tqdm(range(episodes)):
timer = 0
env.reset()
env.actu_obs()
scores = {
'agent_0': 0,
'NPC2_0' : 0,
'agent_1': 0,
'NPC2_1': 0,
}
Done_agent_0 = Done_agent_1 = False
Done_NPC2_0 = Done_NPC2_1 = False
action_agent = 3
action_NPC2 = 2
action_NPC1 = 1
action_agent1 = 4
# the start position are the same in two envs
# mapping_a = {'state': sum(env.agent['axis'], []),
# 'action': action_agent}
mapping_N = {'state': sum(env.NPC_2['axis'], []),
'action': action_NPC2}
while True and timer < trajectories:
timer = timer + 1
NPC_1_state, NPC_2_state, Agent_state \
= env.interact(action_NPC1, action_NPC2, action_agent)
env.SHOW()
# time.sleep(2)
# NPC_1 selects action by pp
if env.NPC_1['Done'] == False:
action_seq1 = Find_a_way(size=5, board=NPC_1_state, \
start_x=env.NPC_1['x'] - 1, \
start_y=4 - (env.NPC_1['y'] - 1), \
end_x=3, end_y=4 - 4)
action_NPC1 = list(env.action_move.keys())[ \
list(env.action_move.values()).index(
(action_seq1[1][0] - (action_seq1[0][0]), -action_seq1[1][1] + (action_seq1[0][1])))]
# agent selects action on purpose
# Agent_obs = sum(env.agent['axis'], [])
if env.agent['Done'] == False:
axis_new, axis_switch, obs_switch = ToM.TPJ(NPC_num=2, axis=env.agent['axis'], obs=env.agent['obs'], )
if axis_new == env.agent['axis']:
'''
没有遮挡关系 have teached
'''
action_agent = 3
else:
'''
有遮挡关系
'''
Agent_obs_NPC2 = sum(env.NPC_2['axis'], [])
action_agent = net_agent_belief(inputs=Agent_obs_NPC2,
num_action=args.num_action,
episode=episode)
prediction_next_state = ToM.prediction_state(axis_new, env.agent['axis'], action_NPC1, net_NPC,
num_action=args.num_action,
episode = episode)
if ToM.state_evaluation(prediction_next_state=prediction_next_state) == False:
print(False)
action_agent = ToM.altruism(axis_switch=axis_switch , axis_NPC=env.NPC_2['axis'], n_actions = env.n_actions)
env.trigger = 1
else:
action_agent = 3
# NPC_2 selects action by E-STDP
NPC2_obs = sum(env.NPC_2['axis'], [])
if Done_NPC2_0 == False:
if action_agent == 4 and env.agent['Done'] == False:
action_NPC2 = 4
else:
action_NPC2 = net_NPC(inputs=NPC2_obs, \
num_action=args.num_action, \
episode=episode)
state_NPC2 = copy.deepcopy(NPC2_obs)
Done_NPC2_0 = copy.deepcopy(env.NPC_2['Done'])
# mapping_N = {'state': state_NPC2, # at time t
# 'action': action_NPC2}
def train():
print('train mode loading ... ')
if not os.path.isdir(args.logdir):
os.mkdir(args.logdir)
bfs = pow(args.num_enpop, args.num_stateN) # before synapstic
afs = args.num_action * args.num_depop
#agent
# abfs = pow(args.num_enpop, args.num_stateA) # agent before synapstic
# aafs = args.num_action * args.num_depop
net_agent_belief = PFC_ToM(step=args.T, encode_type='rate', bias=True,
in_features=bfs, out_features=afs,
node=node.LIFNode, num_state=args.num_stateN,
greedy=args.greedy) #out_features the kinds of policies
net_agent_belief.to(args.device)
net_agent_belief.fc.weight.data = torch.rand((afs, bfs))
# net_agent_belief.load_state_dict(torch.load(os.path.join(args.logdir, args.save_net_N))['model'])
#NPC
net_NPC = PFC_ToM(step=args.T, encode_type='rate', bias=True,
in_features=bfs, out_features=afs,
node=node.LIFNode, num_state=args.num_stateN,
greedy=args.greedy) #out_features the kinds of policies
net_NPC.to(args.device)
net_NPC.load_state_dict(torch.load(os.path.join(args.logdir, args.save_net_N))['model'])
total_scores = update(env, net_agent_belief, net_NPC, args.episodes,\
args.trajectories)
# torch.save({'model': net_agent.state_dict()}, os.path.join(args.logdir, args.save_net_a))
torch.save({'model': net_NPC.state_dict()}, os.path.join(args.logdir, args.save_net_N))
time_end = time.time()
print('totally cost',time_end-time_start)
if __name__ == "__main__":
time_start = time.time()
env = FalseBelief_env(args.reward)
ToM = ToM(env=env)
# args.task = 'both'#'zero'
# args.mode = 'test'#'train'
# args.save_net_N = 'net_NPC_3.pth'
# args.save_net_a = 'net_agent_3.pth'
# args.greedy = 111
train()
================================================
FILE: examples/Social_Cognition/ToM/main_both.py
================================================
import argparse
import time
import copy
import numpy as np
import torch
np.set_printoptions(threshold=np.inf)
torch.set_printoptions(threshold=np.inf)
from tqdm import *
import matplotlib
import seaborn as sns
import pygame
pygame.init()
sns.set(style='ticks', palette='Set2')
matplotlib.rcParams.update({'font.size': 12})
import os
os.environ["SDL_VIDEODRIVER"] = "dummy"
from BrainArea.PFC_ToM import PFC_ToM
from rulebasedpolicy.Find_a_way import *
from env.env3_train_env00 import FalseBelief_env0 #3
from env.env3_train_env01 import FalseBelief_env1 #2
from braincog.base.encoder.encoder import *
from braincog.base.node import node
torch.manual_seed(1)
#NPC2
#state
N_state = 6
cell_num = 6
# action
N_action = 5
NC=10 #50 cells represent one character
#synapstic
bfs = pow(cell_num, N_state) #before synapstic
afs = N_action * NC
#agent
C=10
A_state = 4
abfs = pow(cell_num, A_state) #agent before synapstic
aafs = N_action * C
parser = argparse.ArgumentParser(description='sequence character (policy inference)')
parser.add_argument('--mode', type=str, default='train')
parser.add_argument('--task', type=str, default='both')
parser.add_argument('--logdir', type=str, default='checkpoint')
parser.add_argument('--save_net_a', type=str, default='net_agent_4.pth', help='save the parameters of net_agent')
parser.add_argument('--save_net_N', type=str, default='net_NPC_4.pth', help='save the parameters of net_NPC')
parser.add_argument('--device', default='cpu', help='device') # cuda:0
parser.add_argument('--T', default=40, type=int, help='simulating time-steps') # 模拟时长
parser.add_argument('--dt', default=1, type=int, help='simulating dt') # 模拟dt
parser.add_argument('--episodes', default=25, type=int, help='episodes')
parser.add_argument('--trajectories', default=10, type=int, help='trajectories')
parser.add_argument('--greedy', default=0.8, type=float, help='exploration or exploitation')
parser.add_argument('--num_enpop', default=6, type=int, help='the number of one population in the encoding layer') #
parser.add_argument('--num_depop', default=10, type=int, help='the number of one population in the decoding layer') #
parser.add_argument('--num_stateA', default=2, type=int, help='the number of states, (X, Y)')
parser.add_argument('--num_stateN', default=6, type=int, help='the number of states, [(X, Y), (X, Y), (X, Y)]')
parser.add_argument('--num_action', default=5, type=int, help='the number of actions')
parser.add_argument('--reward', default=10, type=float, help='environment parameter reward')
args = parser.parse_args()
def reward_plot(episodes, scores, Note):
fig = plt.figure(figsize=(7.5, 4.5))
ax1 = fig.add_subplot(111)
ax1.set_title('Reward Plot')
plt.xlim(1, episodes)
plt.grid(ls='--', c='gray')
plt.xlabel('Epoch')
plt.ylabel('Reward')
episodes_list = list(range(1,episodes+1))
plt.plot(episodes_list, scores['be observed agent without the ToM'], label='be observed agent without the ToM')
plt.legend()
plt.savefig('reward_plot_' + str(episodes) + '.png')
def update(env0, env1, net_agent, net_NPC, episodes, trajectories, task):
"""
agents learn to reach the goal without collision
update agents' positions
@param env0:
@param env1:
@param net_agent: the SNN network of agent
@param net_NPC: the SNN network of NPC
@param episodes: train times
@return: None
"""
scores_agent = []
scores_NPC2 = []
for episode in tqdm(range(episodes)):
timer0 = 0
timer1 = 0
env0.reset()
env1.reset()
env0.actu_obs()
env1.actu_obs()
scores = {
'agent_0': 0,
'NPC2_0' : 0,
'agent_1': 0,
'NPC2_1': 0,
}
Done_agent_0 = Done_agent_1 = False
Done_NPC2_0 = Done_NPC2_1 = False
action_agent = 3
action_NPC2 = 2
action_NPC1 = 4
action_agent1 = 4
# the start position are the same in two envs
mapping_a = {'state': sum(env0.agent['axis'], []),
'action': action_agent}
mapping_N = {'state': sum(env0.NPC_2['axis'], []),
'action': action_NPC2}
if task == 'both' or task == 'zero':
while True and timer0 < trajectories:
timer0 = timer0 + 1
NPC_1_state, NPC_2_state, Agent_state \
= env0.interact(action_NPC1, action_NPC2, action_agent)
env0.SHOW()
# time.sleep(2)
#NPC_1 selects action by pp
if env0.NPC_1['Done'] == False:
action_seq1 = Find_a_way(size=5, board=NPC_1_state,\
start_x=env0.NPC_1['x']-1,\
start_y=4-(env0.NPC_1['y']-1),\
end_x=3, end_y=4-4)
action_NPC1 = list(env0.action_move.keys())[\
list(env0.action_move.values()).index((action_seq1[1][0]-(action_seq1[0][0]), -action_seq1[1][1]+(action_seq1[0][1])))]
#agent selects action by E-STDP
Agent_obs = sum(env0.agent['axis'], [])
if Done_agent_0 == False:
action_agent = 3
# net_agent.update_s(R = env0.agent['reward'],\
# mapping=mapping_a)
# action_agent = net_agent(inputs = Agent_obs,\
# num_action = args.num_action,\
# episode = episode)
# state_agent = copy.deepcopy(Agent_obs)
# Done_agent_0 = copy.deepcopy(env0.agent['Done'])
# mapping_a = {'state': state_agent, # at time t
# 'action': action_agent}
#NPC_2 selects action by E-STDP
NPC2_obs = sum(env0.NPC_2['axis'], [])
if Done_NPC2_0 == False:
net_NPC.update_s(R = env0.NPC_2['reward'], \
mapping=mapping_N)
action_NPC2 = net_NPC(inputs = NPC2_obs,\
num_action = args.num_action,\
episode = episode)
state_NPC2 = copy.deepcopy(NPC2_obs)
Done_NPC2_0 = copy.deepcopy(env0.NPC_2['Done'])
mapping_N = {'state': state_NPC2, # at time t
'action': action_NPC2}
# continue
scores['agent_0'] += env0.agent['reward']
scores['NPC2_0'] += env0.NPC_2['reward']
if env0.NPC_1['Done'] == env0.NPC_2['Done'] == env0.agent['Done'] == True:
break
scores_agent.append(scores['agent_0'])
scores_NPC2.append(scores['NPC2_0'])
######################
if task == 'both' or task == 'one':
while True and timer1 < trajectories:
timer1 = timer1 + 1
NPC_2_state, Agent_state \
= env1.interact(action_NPC2, action_agent)
env1.SHOW()
# time.sleep(2)
# agent selects action by E-STDP
Agent_obs = sum(env1.agent['axis'], [])
if Done_agent_1 == False:
action_agent = 3
# net_agent.update_s(R=env1.agent['reward'], \
# mapping=mapping_a)
# scores['agent_1'] += env1.agent['reward']
# action_agent = net_agent(inputs=Agent_obs, \
# num_action=args.num_action,\
# episode = episode)
# state_agent = copy.deepcopy(Agent_obs)
# Done_agent_1 = copy.deepcopy(env1.agent['Done'])
# mapping_a = {'state': state_agent, # at time t
# 'action': action_agent}
# NPC_2 selects action by E-STDP
NPC2_obs = sum(env1.NPC_2['axis'], [])
if Done_NPC2_1 == False:
net_NPC.update_s(R=env1.NPC_2['reward'], \
mapping=mapping_N)
scores['NPC2_1'] += env1.NPC_2['reward']
action_NPC2 = net_NPC(inputs=NPC2_obs, \
num_action=args.num_action,\
episode = episode)
state_NPC2 = copy.deepcopy(NPC2_obs)
Done_NPC2_1 = copy.deepcopy(env1.NPC_2['Done'])
mapping_N = {'state': state_NPC2, # at time t
'action': action_NPC2}
scores['agent_1'] += env1.agent['reward']
scores['NPC2_1'] += env1.NPC_2['reward']
if env1.NPC_2['Done'] == env1.agent['Done'] == True:
break
scores_agent.append(scores['agent_1'])
scores_NPC2.append(scores['NPC2_1'])
total_scores = {
'the agent with the ToM': scores_agent,
'be observed agent without the ToM' : scores_NPC2
}
return total_scores
def train():
print('train mode loading ... ')
if not os.path.isdir(args.logdir):
os.mkdir(args.logdir)
#agent
abfs = pow(args.num_enpop, args.num_stateA) # agent before synapstic
aafs = args.num_action * args.num_depop
net_agent = PFC_ToM(step=args.T, encode_type='rate', bias=True,
in_features=abfs, out_features=aafs,
node=node.LIFNode, num_state=args.num_stateA,
greedy=args.greedy) #out_features the kinds of policies
net_agent.to(args.device)
net_agent.fc.weight.data = torch.rand((aafs, abfs))
# net_agent.load_state_dict(torch.load('./checkpoint/net_agent_12.pth')['model'])
#NPC
bfs = pow(args.num_enpop, args.num_stateN) # before synapstic
afs = args.num_action * args.num_depop
net_NPC = PFC_ToM(step=args.T, encode_type='rate', bias=True,
in_features=bfs, out_features=afs,
node=node.LIFNode, num_state=args.num_stateN,
greedy=args.greedy) #out_features the kinds of policies
net_NPC.to(args.device)
net_NPC.fc.weight.data = torch.rand((afs, bfs))
# net_NPC.load_state_dict(torch.load('./checkpoint/net_NPC_12.pth')['model'])
total_scores = update(env0, env1, net_agent, net_NPC, args.episodes,\
args.trajectories, args.task)
torch.save({'model': net_agent.state_dict()}, os.path.join(args.logdir, args.save_net_a))
torch.save({'model': net_NPC.state_dict()}, os.path.join(args.logdir, args.save_net_N))
time_end = time.time()
print('totally cost',time_end-time_start)
if args.task == 'zero' or args.task == 'one':
reward_plot(args.episodes, total_scores, 'Scores')
elif args.task == 'both':
reward_plot(args.episodes * 2, total_scores, 'Scores')
plt.show()
def test():
args.greedy = 1
print('test mode loading ... ')
print('greedy :', args.greedy)
#agent
abfs = pow(args.num_enpop, args.num_stateA) # agent before synapstic
aafs = args.num_action * args.num_depop
net_agent = PFC_ToM(step=args.T, encode_type='rate', bias=True,
in_features=abfs, out_features=aafs,
node=node.LIFNode, num_state=args.num_stateA,
greedy=args.greedy)
net_agent.to(args.device)
# see also: https://pytorch.org/tutorials/beginner/saving_loading_models.html
net_agent.load_state_dict(torch.load(os.path.join(args.logdir, args.save_net_a))['model']) #out_features the kinds of policies
#NPC
bfs = pow(args.num_enpop, args.num_stateN) # before synapstic
afs = args.num_action * args.num_depop
net_NPC = PFC_ToM(step=args.T, encode_type='rate', bias=True,
in_features=bfs, out_features=afs,
node=node.LIFNode, num_state=args.num_stateN,
greedy=args.greedy)
net_NPC.to(args.device)
net_NPC.load_state_dict(torch.load(os.path.join(args.logdir, args.save_net_N))['model']) #out_features the kinds of policies
total_scores = update(env0, env1, net_agent, net_NPC, args.episodes,
args.trajectories, args.task)
time_end = time.time()
print('totally cost',time_end-time_start)
if args.task == 'zero' or args.task == 'one':
reward_plot(args.episodes, total_scores, 'Scores')
elif args.task == 'both':
reward_plot(args.episodes * 2, total_scores, 'Scores')
plt.show()
if __name__=="__main__":
time_start = time.time()
env0 = FalseBelief_env0(args.reward)
env1 = FalseBelief_env1(args.reward)
# args.task = 'both'#'zero'
# args.mode = 'test'#'train'
# args.save_net_N = 'net_NPC_3.pth'
# args.save_net_a = 'net_agent_3.pth'
if args.mode == 'train':
train()
elif args.mode == 'test':
test()
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/Find_a_way.py
================================================
# main.py
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
from rulebasedpolicy.random_map import *
from rulebasedpolicy.a_star import *
from env.env3_train_env01 import FalseBelief_env1
def Find_a_way(size, board, start_x, start_y, end_x, end_y):
map = RandomMap(size=size, board=board)
for i in range(map.size):
for j in range(map.size):
if map.IsObstacle(i,j):
rec = Rectangle((i, j), width=1, height=1, color='gray')
else:
rec = Rectangle((i, j), width=1, height=1, edgecolor='gray', facecolor='w')
rec = Rectangle((start_x, start_y), width = 1, height = 1, facecolor='b')
rec = Rectangle((end_x, end_y), width = 1, height = 1, facecolor='r')
A_star = AStar(map)
action_seq = A_star.RunAndSaveImage( start_x, start_y, end_x, end_y)#ax, plt,
return action_seq
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/a_star.py
================================================
import sys
import time
import numpy as np
from matplotlib.patches import Rectangle
from rulebasedpolicy.point import *
from rulebasedpolicy.random_map import *
class AStar:
def __init__(self, map):
self.map=map
self.open_set = []
self.close_set = []
def BaseCost(self, p):
x_dis = p.x
y_dis = p.y
# Distance to start point
return x_dis + y_dis + (np.sqrt(2) - 2) * min(x_dis, y_dis)
def HeuristicCost(self, p):
x_dis = self.map.size - 1 - p.x
y_dis = self.map.size - 1 - p.y
# Distance to end point
return x_dis + y_dis + (np.sqrt(2) - 2) * min(x_dis, y_dis)
def TotalCost(self, p):
return self.BaseCost(p) + self.HeuristicCost(p)
def IsValidPoint(self, x, y):
if x < 0 or y < 0:
return False
if x >= self.map.size or y >= self.map.size:
return False
return not self.map.IsObstacle(x, y)
def IsInPointList(self, p, point_list):
for point in point_list:
if point.x == p.x and point.y == p.y:
return True
return False
def IsInOpenList(self, p):
return self.IsInPointList(p, self.open_set)
def IsInCloseList(self, p):
return self.IsInPointList(p, self.close_set)
def IsStartPoint(self, p, start_x, start_y):
return p.x == start_x and p.y ==start_y
def IsEndPoint(self, p, end_x, end_y):
return p.x == end_x and p.y == end_y###############
def SaveImage(self, plt):
millis = int(round(time.time() * 1000))
filename = './' + str(millis) + '.png'
plt.savefig(filename)
def ProcessPoint(self, x, y, parent):
if not self.IsValidPoint(x, y):
return # Do nothing for invalid point
p = Point(x, y)
if self.IsInCloseList(p):
return # Do nothing for visited point
# print('Process Point [', p.x, ',', p.y, ']', ', cost: ', p.cost)
if not self.IsInOpenList(p):
p.parent = parent
p.cost = self.TotalCost(p)
self.open_set.append(p)
def SelectPointInOpenList(self):
index = 0
selected_index = -1
min_cost = sys.maxsize
for p in self.open_set:
cost = self.TotalCost(p)
if cost < min_cost:
min_cost = cost
selected_index = index
index += 1
return selected_index
def BuildPath(self, p, start_time, start_x, start_y, end_x, end_y):#ax, plt,
path = []
record = []
while True:
path.insert(0, p) # Insert first
if self.IsStartPoint(p, start_x, start_y):
break
else:
p = p.parent
p_x=start_x
p_y=start_y
for p in path:
if abs(p.x-p_x) == abs(p.y-p_y) == 1:
# rec = Rectangle((p_x, p.y), 1, 1, color='g')
# rec = Rectangle((p.x, p.y), 1, 1, color='g')
# ax.add_patch(rec)
# plt.draw()
# self.SaveImage(plt)
if abs(end_x - start_x) >= abs(end_y - start_y):
record.append((p.x, p_y))
record.append((p.x, p.y))
else:
record.append((p_x, p.y))
record.append((p.x, p.y))
else:
rec = Rectangle((p.x, p.y), 1, 1, color='g')
# ax.add_patch(rec)
# plt.draw()
# self.SaveImage(plt)
record.append((p.x, p.y))
p_x = p.x
p_y = p.y
end_time = time.time()
# print('===== Algorithm finish in', int(end_time-start_time), ' seconds')
return record
def RunAndSaveImage(self, start_x, start_y, end_x, end_y):#ax, plt,
start_time = time.time()
start_point = Point(start_x, start_y)############################
start_point.cost = 0
self.open_set.append(start_point)
while True:
index = self.SelectPointInOpenList()
if index < 0:
print('No path found, algorithm failed!!!')
# self.SaveImage(plt)
return
p = self.open_set[index]
# rec = Rectangle((p.x, p.y), 1, 1, color='c')
# ax.add_patch(rec)
# self.SaveImage(plt)
if self.IsEndPoint(p, end_x, end_y):
return self.BuildPath(p, start_time, start_x, start_y, end_x, end_y)#ax, plt,
del self.open_set[index]
self.close_set.append(p)
# Process all neighbors
x = p.x
y = p.y
self.ProcessPoint(x-1, y+1, p)
self.ProcessPoint(x-1, y, p)
self.ProcessPoint(x-1, y-1, p)
self.ProcessPoint(x, y-1, p)
self.ProcessPoint(x+1, y-1, p)
self.ProcessPoint(x+1, y, p)
self.ProcessPoint(x+1, y+1, p)
self.ProcessPoint(x, y+1, p)
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/load_statedata.py
================================================
import random
import os
import numpy as np
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms
# from torch.autograd import Variable
class StateDataset:
# initial
def __init__(self, mode, num):
self.state = np.loadtxt(mode, dtype=np.int)
self.num = 1
self.state = self.state.reshape(num, 5*self.num , -1)
#data:A label:B
def __getitem__(self, item):
state = self.state[item]
state_A = state[:,0:5*self.num]
state_A = np.expand_dims(state_A, axis=0)
state_B = state[:, 5*self.num:10*self.num]
state_B = np.expand_dims(state_B, axis=0)
return {"A":state_A, "B":state_B}
#the number of data
def __len__(self):
return len(self.state)
# def get_dataloader(self):
def get_dataloader(mode, num, batch):
train_dataset = StateDataset(mode, num)
train_loader = DataLoader(train_dataset, batch, shuffle=True)
return train_loader
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/point.py
================================================
import sys
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
self.cost = sys.maxsize
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/random_map.py
================================================
import numpy as np
from rulebasedpolicy.point import *
class RandomMap:
def __init__(self, size, board):
self.size = size
self.board = board
self.obstacle = size//8
self.GenerateObstacle()
def GenerateObstacle(self):
self.obstacle_point = []
# Generate an obstacle in the middle
for i in range(self.size):
for j in range(self.size):
if self.board[i,j] == 5:
self.obstacle_point.append(Point(j, 4-i))
def IsObstacle(self, i ,j):
for p in self.obstacle_point:
if i==p.x and j==p.y:
return True
return False
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/statedata_pre.py
================================================
import numpy as np
def data_transfer(B_txt, A_txt):
"""
Aim:读取训练数据,并将其转换为可以处理的形式
@param B_txt:Before processing -txt
@param A_txt:After processing -txt
@return:After processing -data
"""
with open(B_txt, 'r') as f: #'dataA_B.txt'
data_all =[]
data_1 = []
data_2 = []
data_3 = []
data = f.read() #Read all the data in txt ...str
data_split = data.split('\n\n') #Divide the data with '\n\n'
for i in range(len(data_split)-1): #There are (len(data_split)-1) sets of valid data
data_split[i] = data_split[i].split('\n') #Remove '\n' from each set of data
for j in range(len(data_split[i])):
# Split number
data_split[i][j] = " ".join(data_split[i][j])
data_split[i][j] = data_split[i][j].split(' ')
data_split[i][j] = list(map(int, data_split[i][j])) #str-int
data_split[i] = np.array(data_split[i]) #list-np.array
# Data expansion
data_all.append(data_split[i])
data_1.append(np.flipud(data_split[i])) #上下对称
# data_2_split = data_split[i][:, [5, 6, 7, 8, 9, 0, 1, 2, 3, 4]]
# data_2.append(np.fliplr(data_2_split)) #左右对称
# data_3_split = data_split[i][:, [5, 6, 7, 8, 9, 0, 1, 2, 3, 4]]
# data_3.append(np.fliplr(data_3_split))
data_all.extend(data_1)
# data_all.extend(data_2)
# data_all.extend(data_3)
data_all = np.array(data_all)
data_all = data_all.reshape(data_all.shape[0]*data_all.shape[1], data_all.shape[2])
data_all = data_all.astype(int)
# new_data = np.repeat(data_all, repeats=num, axis=0)
# new_data = np.repeat(new_data, repeats=num, axis=1)
np.savetxt(A_txt, data_all, fmt='%i') #'train.txt'
# Read TXT data into numpy
state = np.loadtxt(A_txt, dtype = np.int)
print(data_all.shape)
return state
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/train.txt
================================================
8 5 1 1 1 8 5 0 0 0
1 1 1 1 1 1 0 0 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 8 5 1 1 1 8 5 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 8 5 1 1 1 8 5 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 8 5 1 1 1 8 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 8 5 1 1 1 8 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 0 0
1 1 8 5 1 1 1 8 5 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 0 0 0
1 8 5 1 1 1 8 5 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 0 0 0 0
8 5 1 1 1 8 5 0 0 0
1 1 1 1 1 1 0 0 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 8 5 1 1 1 8 5
1 1 1 1 1 1 1 1 1 0
8 1 5 1 1 8 1 5 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 8 1 5 1 1 8 1 5 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 0 0
8 1 5 1 1 8 1 5 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 8 1 5 1 1 8 1 5 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
8 1 1 5 1 8 1 1 5 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
8 1 1 5 1 8 1 1 5 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
8 1 1 1 1 8 1 1 1 1
1 5 1 1 1 1 5 0 0 1
1 1 1 1 1 1 0 0 0 0
1 1 1 1 1 1 0 0 0 0
1 1 1 1 1 1 1 0 0 0
1 8 1 1 1 1 8 1 1 1
1 1 5 1 1 1 1 5 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 8 1 1 1 1 8 1 1
1 1 1 5 1 1 1 1 5 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 8 1 1 1 1 8 1
1 1 1 1 5 1 1 1 1 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
8 1 1 1 1 8 1 1 1 1
1 5 1 1 1 1 5 0 0 1
1 1 1 1 1 1 0 0 0 0
1 1 1 1 1 1 0 0 0 0
1 1 1 1 1 1 1 1 1 1
1 8 1 1 1 1 8 1 1 1
1 1 5 1 1 1 1 5 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 1 1
1 1 8 1 1 1 1 8 1 1
1 1 1 5 1 1 1 1 5 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 8 1 1 1 1 8 1
1 1 1 1 5 1 1 1 1 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 0
8 1 1 1 1 8 1 1 1 1
1 1 5 1 1 1 1 5 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 8 1 1 1 1 8 1 1 1
1 1 1 5 1 1 1 1 5 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 8 1 1 1 1 8 1 1
1 1 1 1 5 1 1 1 1 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
8 1 1 1 1 8 1 1 1 1
1 1 5 1 1 1 1 5 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 1
1 8 1 1 1 1 8 1 1 1
1 1 1 5 1 1 1 1 5 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 8 1 1 1 1 8 1 1
1 1 1 1 5 1 1 1 1 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
8 1 1 1 1 8 1 1 1 1
1 1 1 5 1 1 1 1 5 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 0 0 0 0
8 5 1 1 1 8 5 0 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 0 0 0
1 8 5 1 1 1 8 5 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 0 0
1 1 8 5 1 1 1 8 5 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 8 5 1 1 1 8 5
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 8 5 1 1 1 8 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 0 0
1 1 8 5 1 1 1 8 5 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 0 0 0
1 8 5 1 1 1 8 5 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 0 0 0 0
8 5 1 1 1 8 5 0 0 0
1 1 1 1 1 1 0 0 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 8 5 1 1 1 8 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 0 0
8 1 5 1 1 8 1 5 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 8 1 5 1 1 8 1 5 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 0 0
8 1 5 1 1 8 1 5 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 8 1 5 1 1 8 1 5 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
8 1 1 5 1 8 1 1 5 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
8 1 1 5 1 8 1 1 5 0
1 1 1 1 1 1 1 1 1 1
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/world_model.py
================================================
import os
import sys
import numpy as np
import matplotlib.pyplot as plt
from rulebasedpolicy.load_statedata import *
import math
np.set_printoptions(threshold = np.inf)
def data():
batch_size = 45
# read data
txt = os.path.join(sys.path[0],'rulebasedpolicy', 'train.txt')
train_loader=get_dataloader(mode=txt, num=batch_size ,batch=batch_size)
for data in train_loader:
A = data["A"].numpy()
B = data["B"].numpy()
B = B.reshape(batch_size, -1, 5, 5)
A = A.reshape(batch_size, 5, 5)
# distant between A and Wall(B)计算智能体与墙之间的距离
A_train = np.sum(np.square(np.argwhere(A==8)-np.argwhere(A==5)), axis = 1)
dist_AW = 1 #指定一个特定的距离1,2,4,5,9,10 distant between agent and wall############
o_idx = np.argwhere(A_train == dist_AW) #找到固定距离对应的所有矩阵Find all matrices corresponding to a fixed distance
return B, A_train
def flip180(arr):
"""
翻转180度
@param arr:
@return:
"""
new_arr = arr.reshape(arr.size)
new_arr = new_arr[::-1]
new_arr = new_arr.reshape(arr.shape)
return new_arr
def flip90_left(arr):
"""
向左翻转90度逆时针
@param arr:
@return:
"""
new_arr = np.transpose(arr)
new_arr = new_arr[::-1]
return new_arr
def flip90_right(arr):
"""
向右翻转90度顺时针
@param arr:
@return:
"""
new_arr = arr.reshape(arr.size)
new_arr = new_arr[::-1]
new_arr = new_arr.reshape(arr.shape)
new_arr = np.transpose(new_arr)[::-1]
return new_arr
def gain_env(obs, agent, wall):
"""
Aim:可以根据多个部分观察在一起拼成一个大的环境
@param obs:多组观测
@param agent:代表智能体的参数,这里默认用8来表示
@param wall:代表墙的参数,这里默认用5来表示
@return:拼成的环境
obs_random:随便选择一个矩阵作为based环境
obs[i]:其他用来补全的矩阵
x_a, y_a:based环境-智能体坐标
x_w, y_w:based环境-wall坐标
x_t, y_t:其他环境-智能体坐标
x_tt, y_tt:其他环境-wall坐标
"""
obs_random = obs[0]
for i in range(1, obs.shape[0]):
#based env
x_a, y_a = np.argwhere(obs_random == agent)[0]
x_w, y_w = np.argwhere(obs_random == wall)[0]
#external env
x_t, y_t = np.argwhere(obs[i] == agent)[0]
x_tt, y_tt = np.argwhere(obs[i] == wall)[0]
h, l = obs_random.shape
delta_up = max(x_t - x_a,0)
delta_down = max(5-x_tt - (h-x_w),0)
delta_left = max(y_t - y_a,0)
delta_right = max(5-y_tt - (l-y_w),0)
obs_random = np.r_[np.ones((delta_up, l)), obs_random] if delta_up != 0 else obs_random
h, l = obs_random.shape
obs_random = np.r_[obs_random, np.ones((delta_down, l))] if delta_down != 0 else obs_random
h, l = obs_random.shape
obs_random = np.c_[np.ones((h, delta_left)), obs_random] if delta_left != 0 else obs_random
h, l = obs_random.shape
obs_random = np.c_[obs_random, np.ones((h, delta_right))] if delta_right != 0 else obs_random
obs_random = obs_random.astype(np.int)
#based env
x_a, y_a = np.argwhere(obs_random == agent)[0]
up = x_a - x_t
left = y_a - y_t
obs_random[up:up+5, left:left+5] = obs_random[up:up+5, left:left+5] & obs[i]
return obs_random
def shelter_env(obs):
"""
Aim:用gain_env环境中的图,来描述更复杂的环境的遮挡关系
@param obs:复杂的环境
@return:环境的遮挡关系
"""
# print(obs,'----------------')
position_A = np.argwhere(obs==8)
position_W = np.argwhere(obs==5)
# print(position_W)
position = np.sum(np.square(np.argwhere(obs == 8) - np.argwhere(obs == 5)), axis=1) #numpy (walls,)
# print(position_W, position_A,position)
shelter_env_i = np.ones((5,5)).astype(np.int)
B, A_train = data()
for i in range(position.size):
o_idx = np.argwhere(A_train == position[i])
if o_idx.size == 0:
break
else:
model = gain_env(B[o_idx].reshape(-1, 5, 5), 8 ,5).astype(np.int)
# print(model,'=============')
if (position_A[0,0] > position_W[i,0] and position_A[0,1] < position_W[i,1] and \
position_A[0, 0] - position_W[i, 0] < -position_A[0, 1] + position_W[i, 1])\
or\
(position_A[0, 0] < position_W[i, 0] and position_A[0, 1] < position_W[i, 1] and \
-position_A[0, 0] + position_W[i, 0] > -position_A[0, 1] + position_W[i, 1])\
or\
(position_A[0, 0] > position_W[i, 0] and position_A[0, 1] > position_W[i, 1] and \
position_A[0, 0] - position_W[i, 0] > position_A[0, 1] - position_W[i, 1])\
or\
(position_A[0, 0] < position_W[i, 0] and position_A[0, 1] > position_W[i, 1] and \
-position_A[0, 0] + position_W[i, 0] < position_A[0, 1] - position_W[i, 1]):
model = np.flip(model, 0)
# print(model, '-=-=-=-=-=-=-====')
model = flip90_right(model)
# print(model,'-=-=-=-=-=-=-====')
if position_A[0, 0] >= position_W[i, 0] and position_A[0, 1] > position_W[i, 1]:
model = flip180(model)
elif position_A[0, 0] > position_W[i, 0] and position_A[0, 1] <= position_W[i, 1]:
model = flip90_left(model)
elif position_A[0, 0] < position_W[i, 0] and position_A[0, 1] >= position_W[i, 1]:
model = flip90_right(model)
else:
model = model
x_t, y_t = np.argwhere(model == 8)[0]
if y_t=3200:
error=3200
if error>0:
pain=1
if error==0:
pain=0
if pain==0:
X1=torch.tensor([[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1,
0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]])
X2=torch.tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
env.render()
if pain==1:
set_pain = 1
X1=torch.tensor([[0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1,
0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]])
X2=torch.tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
env.render()
for i in range(T):
if i>=2:
X2=X1
OUTPUT = a(X1,X2)
a.UpdateWeight(2,OUTPUT[0][1],0.01)
a.UpdateWeight(5,OUTPUT[1][1],-0.1)
if OUTPUT[2][0][0]==1:
env.canvas.itemconfig(env.rect, fill="red", outline='red')
if OUTPUT[2][0][40]==1:
env.canvas.itemconfig(env.rect, fill="green", outline='green')
env.render()
print('out_ifg:',OUTPUT[2])
print('out_sma:',OUTPUT[3])
print('out_m1:',OUTPUT[4])
# print('con2:',a.connection[2].weight.data)
# print('con5:',a.connection[5].weight.data)
s = s_
if set_pain==1 and pain==0:
env.render()
env.destroy()
def BAESNN_test():
a.reset()
s1,s=env2.reset()
pain=0
pain1 = 0
i=0
set_pain=0
for i in range(1000):
env2.render()
s_now = env2.canvas.coords(env2.agent1)
action1 = np.random.choice([0,1,2,3], p=[0.2, 0.3, 0.3, 0.2])
if env2.open_door==1 and s_now[0] <(9 / 2) * 40:
action1 = np.random.choice([0,1,2,3], p=[0.5, 0.0, 0.0, 0.5])
s1_, s1_pre,s1_color = env2.step1(action1,pain)
print('s1_color:',s1_color)
if env2.open_door == 1 :
env2.render()
true_s1_1 = np.array(s1_)
predict_s1_1=np.array(s1_pre)
error1 = true_s1_1 - predict_s1_1
error1 = sum([c * c for c in error1])
if error1>=3200:
error1=3200
if error1>0:
pain=1
set_pain=1
if error1==0:
pain=0
env2.generate_expression1(pain)
if s1_color=="red":
X3=torch.tensor([[0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1,
0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]])
if s1_color=="blue":
X3=torch.tensor([[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1,
0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]])
a.reset()
for i in range(20):
OUT=a.empathy(X3)
print(OUT)
if pain==1:
env2.agent_help()
s1 = s1_
env2.render()
if pain==0 and set_pain==1:
env2.render()
break
# env2.destroy()
if __name__ == "__main__":
env = Maze()
a = BAESNN()
BAESNN_train()
env.mainloop()
env2 = Maze2()
BAESNN_test()
env2.mainloop()
================================================
FILE: examples/Social_Cognition/affective_empathy/BAE-SNN/README.md
================================================
# Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
# Run
## Train
* the file to be run: BAESNN.py
# Citation
```
@ARTICLE{Hui2022,
AUTHOR={Feng, Hui and Zeng, Yi and Lu, Enmeng},
TITLE={Brain-Inspired Affective Empathy Computational Model and Its Application on Altruistic Rescue Task},
JOURNAL={Frontiers in Computational Neuroscience},
VOLUME={16},
YEAR={2022},
URL={https://www.frontiersin.org/articles/10.3389/fncom.2022.784967},
DOI={10.3389/fncom.2022.784967},
ISSN={1662-5188}
}
```
================================================
FILE: examples/Social_Cognition/affective_empathy/BAE-SNN/env_poly.py
================================================
import numpy as np
np.random.seed(1)
import tkinter as tk
import time
from PIL import ImageGrab
UNIT = 40 # pixels
MAZE_H = 9 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('self-pain')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_W * UNIT))
self._build_maze()
self.danger=0
self.action_hurt=0
self.sensory_hurt = 0
self.open_door = 0
self.pain_state=0
# create environment
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_W * UNIT,
width=MAZE_H * UNIT)
# create grids
for c in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create agent
self.orgin=[20,20]
# 上
self.points0 = [
# 右下
self.orgin[0]+15,#35
self.orgin[1]+15,#35
# 左下
self.orgin[0]-15,#5
self.orgin[1]+15,#35
# 左上+
self.orgin[0]-15,#5
self.orgin[1],#20
# 顶点
self.orgin[0],#20
self.orgin[1]-15,#5
# 右上+
self.orgin[0]+15,#35
self.orgin[1],#20
]
# self.rect0 = self.canvas.create_polygon(self.points0, fill="green")
# self.agent_action0 = self.canvas.coords(self.rect0)
# 下
self.points1 = [
# 左上
self.orgin[0]-15,#5
self.orgin[1]-15,#5
# 右上
self.orgin[0]+15,#35
self.orgin[1]-15,#5
# 右下+
self.orgin[0]+15,#35
self.orgin[1],#20
# 顶点
self.orgin[0],#20
self.orgin[1]+15,#35
# 左下+
self.orgin[0]-15,#5
self.orgin[1],#20
]
self.rect = self.canvas.create_polygon(self.points1, fill="green")
# self.agent_action1 = self.canvas.coords(self.rect1)
# 右
self.points2 = [
# 左下
self.orgin[0]-15,#5
self.orgin[1]+15,#35
# 左上
self.orgin[0]-15,#5
self.orgin[1]-15,#5
# 右上+
self.orgin[0],#20
self.orgin[1]-15,#5
# 顶点
self.orgin[0]+15,#35
self.orgin[1],#20
# 右下+
self.orgin[0],#20
self.orgin[1]+15,#35
]
# self.rect2 = self.canvas.create_polygon(self.points2, fill="green")
# self.agent_action2 = self.canvas.coords(self.rect2)
# 左
self.points3 = [
# 右上
self.orgin[0]+15,#20+15
self.orgin[1]-15,#20-15
# 右下
self.orgin[0]+15,#20+15
self.orgin[1]+15,#20+15
# 左下+
self.orgin[0],#20
self.orgin[1]+15,#20+15
# 顶点
self.orgin[0]-15,#20-15
self.orgin[1],#20
# 左上+
self.orgin[0],#20
self.orgin[1]-15,#20-15
]
# self.rect3 = self.canvas.create_polygon(self.points3, fill="green")
# self.agent_action3 = self.canvas.coords(self.rect3)
self.canvas.pack()
#reset agent location
def reset(self):
self.open_door = 0
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
self.orgin = [20, 20]
# 下
self.points1 = [
# 左上
self.orgin[0] - 15, # 5
self.orgin[1] - 15, # 5
# 右上
self.orgin[0] + 15, # 35
self.orgin[1] - 15, # 5
# 右下+
self.orgin[0] + 15, # 35
self.orgin[1], # 20
# 顶点
self.orgin[0], # 20
self.orgin[1] + 15, # 35
# 左下+
self.orgin[0] - 15, # 5
self.orgin[1], # 20
]
self.rect = self.canvas.create_polygon(self.points1, fill="green")
# self.agent_action1 = self.canvas.coords(self.rect1)
return self.canvas.coords(self.rect)
def step(self, s, action, pain):
s = self.canvas.coords(self.rect)
self.centre = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
# danger or switch
if self.danger==1:
if all(self.centre == self.oval_center):
s_color = 'yellow'
self.canvas.delete(self.wall[3])
self.render()
# self.getter(self.canvas)
self.render()
# self.getter(self.canvas)#figure8 ,figure3.1 all red changed to green
self.open_door = 1
move = np.array([80, 0])
self.canvas.move(self.rect, move[0], move[1])
s = self.canvas.coords(self.rect)
self.render()
# self.getter(self.canvas)
elif all(self.centre == self.hell1_center):
s_color = 'black'
self.action_hurt = 1
self.render()
# self.getter(self.canvas)#figure4
self.render()
else:
s_color = 'white'
# modify current state
self.canvas.delete(self.rect)# 主要为开关那几步考虑,所以重复写了
self.centre = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
if action==0:
self.points0 = [
# 右下
self.centre[0] + 15, # 35
self.centre[1] + 15, # 35
# 左下
self.centre[0] - 15, # 5
self.centre[1] + 15, # 35
# 左上+
self.centre[0] - 15, # 5
self.centre[1], # 20
# 顶点
self.centre[0], # 20
self.centre[1] - 15, # 5
# 右上+
self.centre[0] + 15, # 35
self.centre[1], # 20
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points0, fill=color)
if action==1:
self.points1 = [
# 左上
self.centre[0] - 15, # 5
self.centre[1] - 15, # 5
# 右上
self.centre[0] + 15, # 35
self.centre[1] - 15, # 5
# 右下+
self.centre[0] + 15, # 35
self.centre[1], # 20
# 顶点
self.centre[0], # 20
self.centre[1] + 15, # 35
# 左下+
self.centre[0] - 15, # 5
self.centre[1], # 20
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points1, fill=color)
if action==2:
self.points2 = [
# 左下
self.centre[0] - 15, # 5
self.centre[1] + 15, # 35
# 左上
self.centre[0] - 15, # 5
self.centre[1] - 15, # 5
# 右上+
self.centre[0], # 20
self.centre[1] - 15, # 5
# 顶点
self.centre[0] + 15, # 35
self.centre[1], # 20
# 右下+
self.centre[0], # 20
self.centre[1] + 15, # 35
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points2, fill=color)
if action==3:
self.points3 = [
# 右上
self.centre[0] + 15, # 20+15
self.centre[1] - 15, # 20-15
# 右下
self.centre[0] + 15, # 20+15
self.centre[1] + 15, # 20+15
# 左下+
self.centre[0], # 20
self.centre[1] + 15, # 20+15
# 顶点
self.centre[0] - 15, # 20-15
self.centre[1], # 20
# 左上+
self.centre[0], # 20
self.centre[1] - 15, # 20-15
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points3, fill=color)
s = self.canvas.coords(self.rect)
self.render()#显示当前的动作指令是什么
# self.getter(self.canvas)#figure5 after figure4
if s[0] > (9 / 2) * 40:
self.action_hurt = 0
# ensure ture action
base_action = np.array([0, 0])
if self.action_hurt == 0:
true_action = action
else:
if action == 0:
true_action = 1
if action == 1:
true_action = 0
if action == 2:
true_action = 3
if action == 3:
true_action = 2
# predict next state
b = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ]
if self.centre[0] <= ((MAZE_H - 1) / 2 +1) * UNIT:#120
if action == 0: # up
if self.centre[1] > UNIT:
b = [0, -40, 0, -40,0, -40, 0, -40,0, -40]
elif action == 1: # down
if self.centre[1] < (MAZE_W - 1) * UNIT:
b = [0, 40, 0, 40,0, 40, 0, 40, 0, 40]
elif action == 2: # right
if self.centre[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
b = [40, 0, 40, 0,40, 0, 40, 0,40, 0]
elif action == 3: # left
if self.centre[0] > UNIT:
b = [-40, 0, -40, 0,-40, 0, -40, 0,-40, 0]
else:
if action == 0: # up
if self.centre[1] > UNIT:
b = [0, -40, 0, -40,0, -40, 0, -40,0, -40]
elif action == 1: # down
if self.centre[1] < (MAZE_W - 1) * UNIT:
b = [0, 40, 0, 40,0, 40, 0, 40, 0, 40]
elif action == 2: # right
if self.centre[0] < (MAZE_H - 1) * UNIT:
b = [40, 0, 40, 0,40, 0, 40, 0,40, 0]
elif action == 3: # left
if self.centre[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
b = [-40, 0, -40, 0,-40, 0, -40, 0,-40, 0]
s_predict = []
for i in range(len(b)):
s_predict1 = s[i] + b[i]
s_predict.append(s_predict1)
# true next state
if self.centre[0]<=((MAZE_H - 1) / 2 +1) * UNIT:
if true_action == 0: # up
if self.centre[1] > UNIT:
base_action[1] -= UNIT
elif true_action == 1: # down
if self.centre[1] < (MAZE_W - 1) * UNIT:
base_action[1] += UNIT
elif true_action == 2: # right
if self.centre[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
base_action[0] += UNIT
elif true_action == 3: # left
if self.centre[0] > UNIT:
base_action[0] -= UNIT
else:
if true_action == 0: # up
if self.centre[1] > UNIT:
base_action[1] -= UNIT
elif true_action == 1: # down
if self.centre[1] < (MAZE_W - 1) * UNIT:
base_action[1] += UNIT
elif true_action == 2: # right
if self.centre[0] < (MAZE_H - 1) * UNIT:
base_action[0] += UNIT
elif true_action == 3: # left
if self.centre[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1])
s_ = self.canvas.coords(self.rect)
return s_, s_predict, s_color
def step_RL1(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if s[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT:
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_W - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
else:
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_W - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_H - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
if s_==self.canvas.coords(self.hell1):
self.canvas.itemconfig(self.rect, fill="red", outline='red')
reward = -1
self.pain_state=1
else:
reward = 0
return s_, reward,self.pain_state
def step_RL2(self, action):
s = self.canvas.coords(self.rect)
if s == self.canvas.coords(self.oval):
self.canvas.delete(self.wall[3])
self.open_door = 1
move = np.array([40, 0])
self.canvas.move(self.rect, move[0], move[1])
move = np.array([40, 0])
self.canvas.move(self.rect, move[0], move[1])
self.render()
self.canvas.itemconfig(self.rect, fill="green", outline='green')
self.render()
base_action = np.array([0, 0])
if s[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT:
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_W - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
else:
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_W - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_H - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
if s_ == self.canvas.coords(self.oval):
self.open_door = 1
if self.pain_state == 0:
reward = 0
if self.pain_state == 1:
reward = 1
self.pain_state = 0
elif s_ == self.canvas.coords(self.hell1):
self.canvas.itemconfig(self.rect, fill="red", outline='red')
reward = -1
self.pain_state = 1
self.render()
else:
reward = 0
return s_, reward, self.pain_state
def _set_danger(self):
self.hell1_center = np.array([60, 60])
self.hell1 = self.canvas.create_oval(
self.hell1_center[0] - 15, self.hell1_center[1] - 15,
self.hell1_center[0] + 15, self.hell1_center[1] + 15,
fill='black')
# self.canvas.create_bitmap((40 , 40), bitmap='error')
self.hell = self.canvas.coords(self.hell1)
self.canvas.pack()
self.danger=1
def _set_switch(self):
self.oval_center = np.array([(MAZE_H * UNIT) / 2 - UNIT, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
self.oval = self.canvas.create_oval(
self.oval_center[0] - 15, self.oval_center[1] - 15,
self.oval_center[0] + 15, self.oval_center[1] + 15,
fill='yellow')
self.switch = self.canvas.coords(self.oval)
self.canvas.pack()
def _set_wall(self):
wall_center=[]
self.wall=[]
for a in range(MAZE_W):
wall_center.append([0,0])
self.wall.append([])
for b in range(MAZE_W):
wall_center[b]=np.array([(MAZE_H*UNIT)/2,((b)*UNIT)+UNIT/2])
self.wall[b] = self.canvas.create_rectangle(
wall_center[b][0] - 20, wall_center[b][1] - 20,
wall_center[b][0] + 20, wall_center[b][1] + 20,
fill='grey')
self.wall0 = self.canvas.coords(self.wall[0])
self.wall1 = self.canvas.coords(self.wall[1])
self.wall2 = self.canvas.coords(self.wall[2])
self.wall3 = self.canvas.coords(self.wall[3])
# self.canvas.pack()
def generate_expression(self,pain):
if pain==1:
self.canvas.itemconfig(self.rect, fill="red", outline='red')
# self.canvas.pack()
if pain == 0:
self.canvas.itemconfig(self.rect, fill="green", outline='green')
# self.canvas.pack()
def render(self):
time.sleep(0.01)
self.update()
# def getter(self, widget):
# widget.update()
# x = tk.Tk.winfo_rootx(self) + widget.winfo_x()
# y = tk.Tk.winfo_rooty(self) + widget.winfo_y()
# x1 = x + widget.winfo_width()
# y1 = y + widget.winfo_height()
# ImageGrab.grab().crop((x, y, x1, y1)).save("first.jpg")
# return ImageGrab.grab().crop((x, y, x1, y1))
================================================
FILE: examples/Social_Cognition/affective_empathy/BAE-SNN/env_two_poly.py
================================================
import numpy as np
np.random.seed(1)
import tkinter as tk
import time
from PIL import ImageGrab
UNIT = 40 # pixels
MAZE_H = 9 # grid height
MAZE_W = 4 # grid width
class Maze2(tk.Tk, object):
def __init__(self):
super(Maze2, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.action_space1 = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.n_actions1 = len(self.action_space1)
self.title('two_agent_empathy')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_W * UNIT))
self._build_maze()
self.danger=0
self.action_hurt=0
self.sensory_hurt = 0
self.action_hurt1 = 0
self.sensory_hurt1 = 0
self.open_door=0
# create environment
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_W * UNIT,
width=MAZE_H * UNIT)
# create grids
for c in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create switch
self.oval_center = np.array([(MAZE_H * UNIT)/2-UNIT+80, ((MAZE_W+4) * UNIT)/2-UNIT/2-80])
self.oval = self.canvas.create_oval(
self.oval_center[0] - 15, self.oval_center[1] - 15,
self.oval_center[0] + 15, self.oval_center[1] + 15,
fill='yellow')
self.switch = self.canvas.coords(self.oval)
self.orgin1 = np.array([20, 20])
# 下
self.points1 = [
# 左上
self.orgin1[0] - 15, # 5
self.orgin1[1] - 15, # 5
# 右上
self.orgin1[0] + 15, # 35
self.orgin1[1] - 15, # 5
# 右下+
self.orgin1[0] + 15, # 35
self.orgin1[1], # 20
# 顶点
self.orgin1[0], # 20
self.orgin1[1] + 15, # 35
# 左下+
self.orgin1[0] - 15, # 5
self.orgin1[1], # 20
]
self.agent1 = self.canvas.create_polygon(self.points1, outline='black',fill="blue")
self.orgin = np.array([MAZE_H * UNIT - UNIT / 2, 20])
# 下
self.points = [
# 左上
self.orgin[0] - 15, # 5
self.orgin[1] - 15, # 5
# 右上
self.orgin[0] + 15, # 35
self.orgin[1] - 15, # 5
# 右下+
self.orgin[0] + 15, # 35
self.orgin[1], # 20
# 顶点
self.orgin[0], # 20
self.orgin[1] + 15, # 35
# 左下+
self.orgin[0] - 15, # 5
self.orgin[1], # 20
]
self.agent = self.canvas.create_polygon(self.points, fill="green")
wall_center = []
self.wall = []
for i in range(MAZE_W):
wall_center.append([])
self.wall.append([])
for i in range(MAZE_W):
wall_center[i] = np.array([(MAZE_H * UNIT) / 2, ((i) * UNIT) + UNIT / 2])
self.wall[i] = self.canvas.create_rectangle(
wall_center[i][0] - 20, wall_center[i][1] - 20,
wall_center[i][0] + 20, wall_center[i][1] + 20,
fill='grey')
self.hell1_center = np.array([100, 20])
self.hell1 = self.canvas.create_oval(
self.hell1_center[0] - 15, self.hell1_center[1] - 15,
self.hell1_center[0] + 15, self.hell1_center[1] + 15,
fill='black')
self.hell2_center = np.array([60, 100])
self.hell2 = self.canvas.create_oval(
self.hell2_center[0] - 15, self.hell2_center[1] - 15,
self.hell2_center[0] + 15, self.hell2_center[1] + 15,
fill='black')
# self.canvas.create_bitmap((40 , 40), bitmap='error')
self.danger = 1
self.canvas.pack()
#reset agent location
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.agent1)
self.canvas.delete(self.agent)
self.orgin1 = np.array([20, 20])
# 下
self.points1 = [
# 左上
self.orgin1[0] - 15, # 5
self.orgin1[1] - 15, # 5
# 右上
self.orgin1[0] + 15, # 35
self.orgin1[1] - 15, # 5
# 右下+
self.orgin1[0] + 15, # 35
self.orgin1[1], # 20
# 顶点
self.orgin1[0], # 20
self.orgin1[1] + 15, # 35
# 左下+
self.orgin1[0] - 15, # 5
self.orgin1[1], # 20
]
self.agent1 = self.canvas.create_polygon(self.points1, outline='black',fill="blue")
self.orgin = np.array([MAZE_H * UNIT - UNIT / 2, 20])
# 下
self.points = [
# 左上
self.orgin[0] - 15, # 5
self.orgin[1] - 15, # 5
# 右上
self.orgin[0] + 15, # 35
self.orgin[1] - 15, # 5
# 右下+
self.orgin[0] + 15, # 35
self.orgin[1], # 20
# 顶点
self.orgin[0], # 20
self.orgin[1] + 15, # 35
# 左下+
self.orgin[0] - 15, # 5
self.orgin[1], # 20
]
self.agent = self.canvas.create_polygon(self.points, fill="green")
return self.canvas.coords(self.agent1),self.canvas.coords(self.agent)
# move agent1
def step1(self, action1,pain):
s1 = self.canvas.coords(self.agent1)
self.centre1 = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
if all(self.centre1 == self.hell1_center):
self.action_hurt1 = 1
if all(self.centre1 == self.hell2_center):
self.action_hurt1 = 1
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 ==self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 ==self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT*2, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 == self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT*3, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 == self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT*4, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 == self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.canvas.delete(self.agent1) # 主要为开关那几步考虑,所以重复写了
self.centre1 = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
if action1==0:
self.points0 = [
# 右下
self.centre1[0] + 15, # 35
self.centre1[1] + 15, # 35
# 左下
self.centre1[0] - 15, # 5
self.centre1[1] + 15, # 35
# 左上+
self.centre1[0] - 15, # 5
self.centre1[1], # 20
# 顶点
self.centre1[0], # 20
self.centre1[1] - 15, # 5
# 右上+
self.centre1[0] + 15, # 35
self.centre1[1], # 20
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points0, fill=color,outline='black')
if action1==1:
self.points1 = [
# 左上
self.centre1[0] - 15, # 5
self.centre1[1] - 15, # 5
# 右上
self.centre1[0] + 15, # 35
self.centre1[1] - 15, # 5
# 右下+
self.centre1[0] + 15, # 35
self.centre1[1], # 20
# 顶点
self.centre1[0], # 20
self.centre1[1] + 15, # 35
# 左下+
self.centre1[0] - 15, # 5
self.centre1[1], # 20
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points1, fill=color,outline='black')
if action1==2:
self.points2 = [
# 左下
self.centre1[0] - 15, # 5
self.centre1[1] + 15, # 35
# 左上
self.centre1[0] - 15, # 5
self.centre1[1] - 15, # 5
# 右上+
self.centre1[0], # 20
self.centre1[1] - 15, # 5
# 顶点
self.centre1[0] + 15, # 35
self.centre1[1], # 20
# 右下+
self.centre1[0], # 20
self.centre1[1] + 15, # 35
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points2, fill=color,outline='black')
if action1==3:
self.points3 = [
# 右上
self.centre1[0] + 15, # 20+15
self.centre1[1] - 15, # 20-15
# 右下
self.centre1[0] + 15, # 20+15
self.centre1[1] + 15, # 20+15
# 左下+
self.centre1[0], # 20
self.centre1[1] + 15, # 20+15
# 顶点
self.centre1[0] - 15, # 20-15
self.centre1[1], # 20
# 左上+
self.centre1[0], # 20
self.centre1[1] - 15, # 20-15
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points3, fill=color,outline='black')
s1 = self.canvas.coords(self.agent1)
self.render()#显示当前的动作指令是什么
self.centre1 = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
if self.centre1[0] > (9 / 2) * 40:
self.action_hurt1 = 0
# whether hurt
if self.action_hurt1 == 0:
true_action1 = action1
else:
if action1 == 0:
true_action1 = 1
if action1 == 1:
true_action1 = 0
if action1 == 2:
true_action1 = 3
if action1 == 3:
true_action1 = 2
# predict next state
b = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT: # 120
if action1 == 0: # up
if self.centre1[1] > UNIT:
b = [0, -40, 0, -40, 0, -40, 0, -40, 0, -40]
elif action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
b = [0, 40, 0, 40, 0, 40, 0, 40, 0, 40]
elif action1 == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
b = [40, 0, 40, 0, 40, 0, 40, 0, 40, 0]
elif action1 == 3: # left
if self.centre1[0] > UNIT:
b = [-40, 0, -40, 0, -40, 0, -40, 0, -40, 0]
else:
if action1 == 0: # up
if self.centre1[1] > UNIT:
b = [0, -40, 0, -40, 0, -40, 0, -40, 0, -40]
elif action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
b = [0, 40, 0, 40, 0, 40, 0, 40, 0, 40]
elif action1 == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
b = [40, 0, 40, 0, 40, 0, 40, 0, 40, 0]
elif action1 == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
b = [-40, 0, -40, 0, -40, 0, -40, 0, -40, 0]
s_predict = []
for i in range(len(b)):
s_predict1 = s1[i] + b[i]
s_predict.append(s_predict1)
base_action1 = np.array([0, 0])
# true next state
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT:
if true_action1 == 0: # up
if self.centre1[1] > UNIT:
base_action1[1] -= UNIT
elif true_action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
base_action1[1] += UNIT
elif true_action1 == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
base_action1[0] += UNIT
elif true_action1 == 3: # left
if self.centre1[0] > UNIT:
base_action1[0] -= UNIT
else:
if true_action1 == 0: # up
if self.centre1[1] > UNIT:
base_action1[1] -= UNIT
elif true_action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
base_action1[1] += UNIT
elif true_action1 == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
base_action1[0] += UNIT
elif true_action1 == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
base_action1[0] -= UNIT
self.canvas.move(self.agent1, base_action1[0], base_action1[1])
s1_ = self.canvas.coords(self.agent1)
return s1_, s_predict,color
def agent_help(self):
s = self.canvas.coords(self.agent)
self.centre2= [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
if all(self.centre2 == self.oval_center):
self.canvas.delete(self.wall[3])
self.render()
self.open_door=1
else:
self.canvas.move(self.agent, -40, 0) # move agent
self.render()
self.canvas.move(self.agent, -40, 0)
self.render()
self.canvas.move(self.agent, -40, 0)
self.render()
self.canvas.move(self.agent, 0, 40)
self.render()
s_ = self.canvas.coords(self.agent) # next state
return s_
def _set_danger(self):
hell1_center = np.array([140, 60])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
hell2_center = np.array([100, 140])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# self.canvas.create_bitmap((40 , 40), bitmap='error')
self.canvas.pack()
self.danger=1
def _set_wall(self):
wall_center=[]
self.wall=[]
for i in range(MAZE_W):
wall_center.append([])
self.wall.append([])
for i in range(MAZE_W):
wall_center[i]=np.array([(MAZE_H*UNIT)/2,((i)*UNIT)+UNIT/2])
self.wall[i] = self.canvas.create_rectangle(
wall_center[i][0] - 20, wall_center[i][1] - 20,
wall_center[i][0] + 20, wall_center[i][1] + 20,
fill='grey')
self.canvas.pack()
def generate_expression1(self,pain1):
if pain1==1:
self.canvas.itemconfig(self.agent1, fill="red", outline='black')
self.canvas.pack()
if pain1 ==0:
self.canvas.itemconfig(self.agent1, fill="blue", outline='black')
self.canvas.pack()
def render(self):
time.sleep(0.2)
self.update()
================================================
FILE: examples/Social_Cognition/affective_empathy/BEEAD-SNN/BEEAD-SNN.py
================================================
import os
import sys
import imageio
from env_poly_SNN import Maze
from env import Maze2
from RL_brain import QLearningTable
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
np.random.seed(1)
from torch.utils.tensorboard import SummaryWriter
from sklearn.preprocessing import MinMaxScaler
import torch, os, sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import torch.nn.functional as F
from braincog.base.node.node import *
from braincog.base.learningrule.STDP import *
from braincog.base.connection.CustomLinear import *
from braincog.base.utils.visualization import spike_rate_vis, spike_rate_vis_1d#, spike_vis_2, spike_vis_5
class BrainArea(nn.Module, abc.ABC):
@abc.abstractmethod
def __init__(self):
super().__init__()
@abc.abstractmethod
def forward(self, x):
"""
Calculate the forward propagation process
:return:x is spike
"""
return x
def reset(self):
"""
Calculate the forward propagation process
:return:x is spike
"""
pass
class BAESNN(BrainArea):
"""
Affactive Empathy Network
"""
def __init__(self,):
super().__init__()
self.node = [IFNode() for i in range(5)]
self.connection = []
con_matrix0 = torch.eye(24, 24)*6
self.connection.append(CustomLinear(con_matrix0))#input-emotion
con_matrix1 = torch.eye(24, 24)
self.connection.append(CustomLinear(con_matrix1))#emotion-ifg
con_matrix2 = torch.zeros((24, 24), dtype=torch.float)
self.connection.append(CustomLinear(con_matrix2))#perception-ifg
con_matrix3 = torch.eye(24, 24)*6
self.connection.append(CustomLinear(con_matrix3))#input-perception
con_matrix4=torch.zeros((24,10), dtype=torch.float)
for j in range(10):
if j in np.arange(0,5,1):
for i in np.arange(0, 12, 1):
con_matrix4[i,j] =2
if j in np.arange(5,10,1):
for i in np.arange(12, 24, 1):
con_matrix4[i,j] =2
self.connection.append(CustomLinear(con_matrix4))#emotion-sma
con_matrix5=torch.zeros((24,10), dtype=torch.float)
self.connection.append(CustomLinear(con_matrix5))#perception-m1
con_matrix6 = torch.eye(10, 10)*6
self.connection.append(CustomLinear(con_matrix6))#sma-m1
self.stdp = []
self.stdp.append(STDP(self.node[0], self.connection[0]))#0 node0 emotion
self.stdp.append(STDP(self.node[2], self.connection[3]))#1 node2 perception
self.stdp.append(MutliInputSTDP(self.node[1], [self.connection[1], self.connection[2]]))#2 node1 ifg
self.stdp.append(MutliInputSTDP(self.node[3], [self.connection[4], self.connection[5]]))#3 node3 sma
self.stdp.append(STDP(self.node[4], self.connection[6]))#4 node4 m1
self.stdp.append(STDP(self.node[1],self.connection[2]))#5 node1 ifg
self.stdp.append(STDP(self.node[3],self.connection[5]))#6 node3 sma
def forward(self, x1,x2):
out__m, dw0 = self.stdp[0](x1)#node0 emotion
out__p, dw3 = self.stdp[1](x2)#node2 perception
out__ifg,dw_p_i=self.stdp[2](out__m,out__p)#node1 ifg
out__sma,dw_p_s=self.stdp[3](out__m,out__p)#node3 sma
out__m1,dw1=self.stdp[4](out__sma)#node4 m1
return dw_p_i,dw_p_s,out__ifg,out__sma,out__m1,out__m,out__p
def empathy(self,x3):
out_p,dw2=self.stdp[1](x3)#node2 perception
out_ifg,dw4=self.stdp[5](out_p)#node1 ifg
out_sma,dw5=self.stdp[6](out_p)#node3 sma
out_m1,dw6=self.stdp[4](out_sma)#node4 m1
return out_ifg,out_sma,out_m1,out_p
def UpdateWeight(self, i, dw, delta):
self.connection[i].update(dw*delta)
self.connection[i].weight.data= torch.clamp(self.connection[i].weight.data,-1,4)
def reset(self):
for i in range(5):
self.node[i].n_reset()
for i in range(len(self.stdp)):
self.stdp[i].reset()
class DopamineArea(BrainArea):
"""
Dopamine brain area with a group of spiking neurons, computes reward prediction error.
"""
def __init__(self, n_neurons, beta=0.2):
super().__init__()
self.n_neurons = n_neurons
self.beta = beta
self.node = [IFNode() for _ in range(n_neurons)]
self.P = np.zeros(n_neurons) # prediction for each neuron
def forward(self, spikes):
out_spikes = []
for i in range(self.n_neurons):
spike = self.node[i](torch.tensor([spikes[i]], dtype=torch.float32))
out_spikes.append(spike)
S = torch.stack(out_spikes).mean().item()
delta = S - self.P
self.P = self.P + self.beta * delta
return delta, out_spikes
def reset(self):
self.P = np.zeros(self.n_neurons)
for n in self.node:
n.n_reset()
def BAESNN_train():
s = env.reset()
env._set_danger()
env._set_wall()
pain = 0
i = 0
set_pain = 0
env._set_switch()
for i in range(100):
snn2.reset()
T = 100
pain = 0
print('**************step:', i)
env.render()
action = np.random.choice(list(range(env.n_actions)))
print('action:', action)
d, d_pre, s_, sss = env.step(s, action, pain)
print('d:', d, 'd_pre:', d_pre, 'sss:', sss)
env.render()
while (d == np.array([0, 0])).all():
action = np.random.choice(list(range(env.n_actions)))
print('action:', action)
d, d_pre, s_, sss = env.step(s, action, pain)
print('d:', d, 'd_pre:', d_pre, 'sss:', sss)
env.render()
# Use env.is_agent1_in_danger to set OUT_PAIN, pain, emotion
if env.is_agent_in_danger():
OUT_PAIN = torch.ones(24)
pain = 1
set_pain = 1
emotion = -1
else:
OUT_PAIN = torch.zeros(24)
pain = 0
emotion = 0
print("OUT_PAIN:", OUT_PAIN)
print("pain:", pain)
print("emotion:", emotion)
T2 = 20
X1 = OUT_PAIN
X2 = torch.zeros(24)
X3 = torch.cat([torch.ones(12) * 0.1, torch.zeros(12)])
print('X1,X2:', X1, X2)
spike_emotion = []
spike_ifg = []
spike_sma = []
spike_m1 = []
spike_per = []
for i in range(T2):
if i >= 2:
X2 = X3
OUTPUT = snn2(X1, X2)
snn2.UpdateWeight(2, OUTPUT[0][1], 0.01)
snn2.UpdateWeight(5, OUTPUT[1][1], -0.1)
if OUTPUT[2][0] == 1:
env.canvas.itemconfig(env.rect, fill="red", outline='red')
if OUTPUT[2][0] == 0:
env.canvas.itemconfig(env.rect, fill="green", outline='green')
spike_emotion.append(OUTPUT[5])
spike_per.append(OUTPUT[6])
spike_ifg.append(OUTPUT[2])
spike_sma.append(OUTPUT[3])
spike_m1.append(OUTPUT[4])
print('out_ifg:', OUTPUT[2])
print('out_sma:', OUTPUT[3])
print('out_m1:', OUTPUT[4])
print('con2:', snn2.connection[2].weight.data)
print('con5:', snn2.connection[5].weight.data)
spike_emotion = torch.stack(spike_emotion)
spike_per = torch.stack(spike_per)
spike_ifg = torch.stack(spike_ifg)
spike_sma = torch.stack(spike_sma)
spike_m1 = torch.stack(spike_m1)
print(spike_emotion.shape)
env.render()
s = s_
if set_pain == 1 and pain == 0:
env.render()
break
env.destroy()
def BAESNN_train_alstruism(lamda, E):
global writer
for episode in range(E):
print('*******************episode:', episode, ',factor:', lamda, '*********************************')
s1,s2=env2.reset()
env2._set_wall()
pain1 = 0
pain2 = 0
i = 0
set_pain = 0
env2.emotion = 0
env2.empathy_emotion = 0
env2.empathy_emotion_t_1 = 0
rr = 0
hh = 0
g = 0
a = []
if episode < 200:
e_greedy = 0.5
elif episode < 500:
e_greedy = 0.7
elif episode < 700:
e_greedy = 0.9
else:
e_greedy = 1
r = np.random.uniform()
for i in range(100):
env2.render()
done = False
env2.empathy_emotion_t_1=env2.empathy_emotion
action2 = RL.choose_action(str([(s2[4] + s2[8]) / 2, (s2[5] + s2[9]) / 2,env2.empathy_emotion]),e_greedy=e_greedy)
s2_, done, done_oval = env2.step2(action2)
env2.render()
T=100
print('**************step:',i)
env2.render()
action1 = np.random.choice(list(range(env.n_actions)))
print('action1:',action1)
if r<= 0.25:
if i==0:
action1=2
if 0.25 UNIT:
pre_displacement1 = np.array([0, -40])
elif action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action1 == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action1 == 3: # left
if self.centre1[0] > UNIT:
pre_displacement1 = np.array([-40, 0])
else:
if action1 == 0: # up
if self.centre1[1] > UNIT:
pre_displacement1 = np.array([0, -40])
elif action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action1 == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action1 == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
pre_displacement1 = np.array([-40, 0])
# true next state
displacement1 = np.array([0, 0])
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT:
if true_action1 == 0: # up
if self.centre1[1] > UNIT:
displacement1= np.array([0, -40])
elif true_action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1= np.array([0,40])
elif true_action1 == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
displacement1= np.array([40,0])
elif true_action1 == 3: # left
if self.centre1[0] > UNIT:
displacement1= np.array([-40,0])
else:
if true_action1 == 0: # up
if self.centre1[1] > UNIT:
displacement1= np.array([0,-40])
elif true_action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1= np.array([0,40])
elif true_action1 == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
displacement1= np.array([40,0])
elif true_action1 == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
displacement1= np.array([-40,0])
self.canvas.move(self.agent1, displacement1[0], displacement1[1])
s1_ = self.canvas.coords(self.agent1)
sss = [(s1_[4] + s1_[8]) / 2, (s1_[5] + s1_[9]) / 2]
return displacement1, pre_displacement1,s1_,sss
def is_agent1_in_danger(self):
"""
whether in danger(hell1~hell4)
:return: True/False
"""
s1 = self.canvas.coords(self.agent1)
print([(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2])
print(f'hell1_center: {self.hell1_center}, hell2_center: {self.hell2_center}, hell3_center: {self.hell3_center}, hell4_center: {self.hell4_center}')
agent1_pos = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
danger_centers = [self.hell1_center, self.hell2_center, self.hell3_center, self.hell4_center]
for center in danger_centers:
if all(np.isclose(agent1_pos, center)):
return True
return False
def step2(self, action):
s = self.canvas.coords(self.agent2)
s=[(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
if all(s == self.oval_center)and self.empathy_emotion==-1:
done_oval=1
else:
done_oval=0
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_W - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_H - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > ( (MAZE_H - 1)/2+2) * UNIT:
base_action[0] -= UNIT
self.canvas.move(self.agent2, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.agent2) # next state
self.centre2= [(s_[4] + s_[8]) / 2, (s_[5] + s_[9]) / 2]
if all(self.centre2 == self.oval_center) and self.empathy_emotion==-1:
self.help_signal=1
if all(self.centre2 == self.goal_centre):
done = True
else:
done = False
return s_, done,done_oval
def reward2(self):
s_ = self.canvas.coords(self.agent2)
self.centre2= [(s_[4] + s_[8]) / 2, (s_[5] + s_[9]) / 2]
if (self.empathy_emotion - self.empathy_emotion_t_1)==-1:
reward1=0
elif (self.empathy_emotion - self.empathy_emotion_t_1)==1:
reward1=10
else:
reward1=0
if all(self.centre2 == self.goal_centre):
reward2 = 10
else:
reward2 = -1
return reward1,reward2
def _set_wall(self):
self.oval_center = np.array([(MAZE_H * UNIT)-20, ((MAZE_W)*UNIT-20)])# [(MAZE_H * UNIT)/2+80, UNIT/2+UNIT]
self.oval = self.canvas.create_oval(
self.oval_center[0] - 15, self.oval_center[1] - 15,
self.oval_center[0] + 15, self.oval_center[1] + 15,
fill='yellow')
self.help = self.canvas.coords(self.oval)
wall_center = []
self.wall = []
for i in range(MAZE_W):
wall_center.append([])
self.wall.append([])
for i in range(MAZE_W):
wall_center[i] = np.array([(MAZE_H * UNIT) / 2, ((i) * UNIT) + UNIT / 2])# wall
self.wall[i] = self.canvas.create_rectangle(
wall_center[i][0] - 20, wall_center[i][1] - 20,
wall_center[i][0] + 20, wall_center[i][1] + 20,
fill='grey')
self.canvas.pack()
def generate_expression1(self,emotion):
if emotion==-1:
self.canvas.itemconfig(self.agent1, fill="red", outline='black')
self.canvas.pack()
if emotion==0:
self.canvas.itemconfig(self.agent1, fill="blue", outline='black')
self.canvas.pack()
def generate_expression2(self,emotion):
if emotion==-1:
self.canvas.itemconfig(self.agent2, fill="red")
self.canvas.pack()
if emotion==0:
self.canvas.itemconfig(self.agent2, fill="green")
self.canvas.pack()
def render(self):
time.sleep(0.000001)
self.update()
# def getter(self,widget):
# widget.update()
# x = tk.Tk.winfo_rootx(self) + widget.winfo_x()
# y = tk.Tk.winfo_rooty(self) + widget.winfo_y()
# x1 = x + widget.winfo_width()
# y1 = y + widget.winfo_height()
# ImageGrab.grab().crop((x, y, x1, y1)).save("first.jpg")
# return ImageGrab.grab().crop((x, y, x1, y1))
================================================
FILE: examples/Social_Cognition/affective_empathy/BEEAD-SNN/env_poly_SNN.py
================================================
import numpy as np
np.random.seed(1)
import tkinter as tk
import time
from PIL import ImageGrab
UNIT = 40 # pixels
MAZE_H = 9 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('self-pain')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_W * UNIT))
self._build_maze()
self.danger=0
self.action_hurt=0
self.sensory_hurt = 0
self.open_door = 0
self.pain_state=0
# create environment
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_W * UNIT,
width=MAZE_H * UNIT)
# create grids
for c in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
self.orgin=[20,20]
# create agent
self.points1 = [
self.orgin[0]-15,self.orgin[1]-15,
self.orgin[0]+15,self.orgin[1]-15,
self.orgin[0]+15,self.orgin[1],
self.orgin[0],self.orgin[1]+15,
self.orgin[0]-15,self.orgin[1],
]
self.rect = self.canvas.create_polygon(self.points1, fill="green")
self.canvas.pack()
#reset agent location
def reset(self):
self.open_door = 0
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
self.orgin = [20, 20]
# 下
self.points1 = [
self.orgin[0] - 15,self.orgin[1] - 15,
self.orgin[0] + 15,self.orgin[1] - 15,
self.orgin[0] + 15,self.orgin[1],
self.orgin[0],self.orgin[1]+15,
self.orgin[0] - 15,self.orgin[1],
]
self.rect = self.canvas.create_polygon(self.points1, fill="green")
return self.canvas.coords(self.rect)
def step(self, s, action, pain):
s = self.canvas.coords(self.rect)
self.centre = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
# danger or switch
if self.danger==1:
if all(self.centre == self.oval_center):
s_color = 'yellow'
self.canvas.delete(self.wall[3])
self.render()
self.open_door = 1
move = np.array([80, 0])
self.canvas.move(self.rect, move[0], move[1])
s = self.canvas.coords(self.rect)
self.render()
elif all(self.centre == self.hell1_center):
s_color = 'black'
self.action_hurt = 1
self.render()
else:
s_color = 'white'
# modify current state
self.canvas.delete(self.rect)
self.centre = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
if action==0:
self.points0 = [
self.centre[0] + 15,self.centre[1] + 15,
self.centre[0] - 15,self.centre[1] + 15,
self.centre[0] - 15,self.centre[1],
self.centre[0],self.centre[1] - 15,
self.centre[0] + 15,self.centre[1],
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points0, fill=color)
if action==1:
self.points1 = [
self.centre[0] - 15,self.centre[1] - 15,
self.centre[0] + 15,self.centre[1] - 15,
self.centre[0] + 15,self.centre[1],
self.centre[0],self.centre[1] + 15,
self.centre[0] - 15,self.centre[1],
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points1, fill=color)
if action==2:
self.points2 = [
self.centre[0] - 15,self.centre[1] + 15,
self.centre[0] - 15,self.centre[1] - 15,
self.centre[0],self.centre[1] - 15,
self.centre[0] + 15,self.centre[1],
self.centre[0],self.centre[1] + 15,
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points2, fill=color)
if action==3:
self.points3 = [
self.centre[0] + 15,
self.centre[1] - 15,
self.centre[0] + 15,self.centre[1] + 15,
self.centre[0],self.centre[1] + 15,
self.centre[0] - 15,self.centre[1],
self.centre[0],self.centre[1] - 15,
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points3, fill=color)
s = self.canvas.coords(self.rect)
self.render()
if s[0] > (9 / 2) * 40:
self.action_hurt = 0
base_action = np.array([0, 0])
if self.action_hurt == 0:
true_action = action
else:
if action == 0:
true_action = 1
if action == 1:
true_action = 0
if action == 2:
true_action = 3
if action == 3:
true_action = 2
# predict next state
self.centre1 = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
pre_displacement1 = np.array([0, 0])
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT: # 120
if action == 0: # up
if self.centre1[1] > UNIT:
pre_displacement1 = np.array([0, -40])
elif action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action == 3: # left
if self.centre1[0] > UNIT:
pre_displacement1 = np.array([-40, 0])
else:
if action == 0: # up
if self.centre1[1] > UNIT:
pre_displacement1 = np.array([0, -40])
elif action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
pre_displacement1 = np.array([-40, 0])
# true next state
displacement1 = np.array([0, 0])
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT:
if true_action == 0: # up
if self.centre1[1] > UNIT:
displacement1=np.array([0,-40])
elif true_action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1=np.array([0,40])
elif true_action == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
displacement1=np.array([40,0])
elif true_action == 3: # left
if self.centre1[0] > UNIT:
displacement1=np.array([-40,0])
else:
if true_action == 0: # up
if self.centre1[1] > UNIT:
displacement1=np.array([0,-40])
elif true_action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1=np.array([0,40])
elif true_action == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
displacement1=np.array([40,0])
elif true_action == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
displacement1=np.array([-40,0])
self.canvas.move(self.rect, displacement1[0], displacement1[1])
s1_ = self.canvas.coords(self.rect)
sss = [(s1_[4] + s1_[8]) / 2, (s1_[5] + s1_[9]) / 2]
return displacement1, pre_displacement1,s1_,sss
def _set_danger(self):
self.hell1_center = np.array([60, 60])
self.hell1 = self.canvas.create_oval(
self.hell1_center[0] - 15, self.hell1_center[1] - 15,
self.hell1_center[0] + 15, self.hell1_center[1] + 15,
fill='black')
# self.canvas.create_bitmap((40 , 40), bitmap='error')
self.hell = self.canvas.coords(self.hell1)
self.canvas.pack()
self.danger=1
def _set_switch(self):
self.oval_center = np.array([(MAZE_H * UNIT) / 2 - UNIT, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
self.oval = self.canvas.create_oval(
self.oval_center[0] - 15, self.oval_center[1] - 15,
self.oval_center[0] + 15, self.oval_center[1] + 15,
fill='yellow')
self.switch = self.canvas.coords(self.oval)
self.canvas.pack()
def _set_wall(self):
wall_center=[]
self.wall=[]
for a in range(MAZE_W):
wall_center.append([0,0])
self.wall.append([])
for b in range(MAZE_W):
wall_center[b]=np.array([(MAZE_H*UNIT)/2,((b)*UNIT)+UNIT/2])
self.wall[b] = self.canvas.create_rectangle(
wall_center[b][0] - 20, wall_center[b][1] - 20,
wall_center[b][0] + 20, wall_center[b][1] + 20,
fill='grey')
self.wall0 = self.canvas.coords(self.wall[0])
self.wall1 = self.canvas.coords(self.wall[1])
self.wall2 = self.canvas.coords(self.wall[2])
self.wall3 = self.canvas.coords(self.wall[3])
def generate_expression(self,pain):
if pain==1:
self.canvas.itemconfig(self.rect, fill="red", outline='red')
if pain == 0:
self.canvas.itemconfig(self.rect, fill="green", outline='green')
def render(self):
time.sleep(0.1)
self.update()
def is_agent_in_danger(self):
"""
Check if the agent is in a danger zone (hell1).
Returns: True/False
"""
s = self.canvas.coords(self.rect)
agent_pos = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
if hasattr(self, 'hell1_center'):
if all(np.isclose(agent_pos, self.hell1_center)):
return True
return False
# def getter(self, widget):
# widget.update()
# x = tk.Tk.winfo_rootx(self) + widget.winfo_x()
# y = tk.Tk.winfo_rooty(self) + widget.winfo_y()
# x1 = x + widget.winfo_width()
# y1 = y + widget.winfo_height()
# ImageGrab.grab().crop((x, y, x1, y1)).save("first.jpg")
# return ImageGrab.grab().crop((x, y, x1, y1))
================================================
FILE: examples/Social_Cognition/affective_empathy/BEEAD-SNN/rsnn.py
================================================
import torch
from torch import nn
from braincog.base.node.node import IFNode
from braincog.base.learningrule.STDP import STDP,MutliInputSTDP
from braincog.base.connection.CustomLinear import CustomLinear
from collections import deque
from random import randint
class RSNN(nn.Module):
def __init__(self,num_state,num_action):
super().__init__()
# parameters
rsnn_mask=[]
rsnn_con=[]
con_matrix1 = torch.ones((num_state,num_action), dtype=torch.float)
rsnn_mask.append(con_matrix1)
# rsnn_con.append(CustomLinear(torch.randint(2,size=(num_state,num_action))*0.1))
rsnn_con.append(CustomLinear(torch.ones(num_state,num_action)*0.1))
self.num_subR=2
self.connection = rsnn_con
self.mask=rsnn_mask
self.node = [IFNode() for i in range(self.num_subR)]
self.learning_rule = []
self.learning_rule.append(MutliInputSTDP(self.node[1], [self.connection[0]]))
self.weight_trace = torch.zeros(con_matrix1.shape, dtype=torch.float)
self.out_in = torch.zeros((num_state), dtype=torch.float)
self.out = torch.zeros((self.connection[0].weight.size()[1]), dtype=torch.float)
self.dw = torch.zeros((self.connection[0].weight.size()), dtype=torch.float)
def forward(self, input):
input=torch.tensor(input, dtype=torch.float)
self.out_in=self.node[0](input)
self.out,self.dw = self.learning_rule[0](self.out_in)
return self.out,self.dw
def UpdateWeight(self,reward,a,C,n):
self.weight_trace[0:n,:]=0
self.weight_trace[n+1:, :] = 0
self.weight_trace[:, :a * C] = 0
self.weight_trace[:, (a + 1) * C:] = 0
self.weight_trace[self.weight_trace>0]=self.weight_trace[self.weight_trace>0]*reward
self.weight_trace[self.weight_trace < 0] = -1*self.weight_trace[self.weight_trace < 0] * reward
self.connection[0].update(self.weight_trace)
# self.connection[0].weight.data = torch.clamp(self.connection[0].weight.data, -1, 10)
# for i in range(self.connection[0].weight.size()[1]):
# self.connection[0].weight.data[:, i] = (self.connection[0].weight.data[:, i] - torch.min(self.connection[0].weight.data[:, i])) / (torch.max(self.connection[0].weight.data[:, i]) - torch.min(self.connection[0].weight.data[:, i]))
# self.connection[0].weight.data= self.connection[0].weight.data * 0.5
self.weight_trace = torch.zeros((64,5*C), dtype=torch.float)
def reset(self):
for i in range(self.num_subR):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
return self.connection
================================================
FILE: examples/Social_Cognition/affective_empathy/BEEAD-SNN/sd_env.py
================================================
import numpy as np
np.random.seed(1)
import tkinter as tk
import time
from PIL import ImageGrab
UNIT = 40 # pixels
MAZE_H = 11 # grid horizontal
MAZE_W = 5 # grid vertical
class Snowdrift(tk.Tk, object):
def __init__(self, n_agents=3, n_snowdrifts=4):
super(Snowdrift, self).__init__()
self.action_space = ['up', 'down', 'left', 'right', 'clean']
self.n_actions = len(self.action_space)
self.n_agents = n_agents
self.n_snowdrifts = n_snowdrifts
self.UNIT = 40
self.MAZE_H = 8
self.MAZE_W = 8
self.title('Snowdrift Game')
self.geometry('{0}x{1}'.format(self.MAZE_H * self.UNIT, self.MAZE_W * self.UNIT)) # canvas
self.agents = []
self.agents_pos = []
self.agents_emotion = [-1] * n_agents
self.snowdrifts = []
self.snowdrifts_pos = []
self.cleaned = []
self.empathy_emotion = 0
self.empathy_emotion_t_1 = 0
self.help_signal = 0
self.lamda = 1.0
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=self.MAZE_H * self.UNIT,
width=self.MAZE_W * self.UNIT)
# Create agents
colors = ['red', 'blue', 'green']
for i in range(self.n_agents):
pos = np.array([np.random.randint(0, self.MAZE_W) * self.UNIT + self.UNIT/2,
np.random.randint(0, self.MAZE_H) * self.UNIT + self.UNIT/2])
agent = self.canvas.create_oval(
pos[0] - 15, pos[1] - 15,
pos[0] + 15, pos[1] + 15,
fill=colors[i])
self.agents.append(agent)
self.agents_pos.append(pos)
if self.agents_emotion[i] == -1:
self.canvas.itemconfig(agent, fill='gray')
# Create snowdrifts
for _ in range(self.n_snowdrifts):
pos = np.array([np.random.randint(0, self.MAZE_W) * self.UNIT + self.UNIT/2,
np.random.randint(0, self.MAZE_H) * self.UNIT + self.UNIT/2])
points = [
pos[0], pos[1] - 15,
pos[0] - 15, pos[1] + 15,
pos[0] + 15, pos[1] + 15
]
snowdrift = self.canvas.create_polygon(points, fill='black')
self.snowdrifts.append(snowdrift)
self.snowdrifts_pos.append(pos)
self.cleaned.append(False)
self.canvas.pack()
def reset(self, agent_id):
"""Reset environment and return initial state index"""
self.update()
time.sleep(0.001)
# Reset all states
self.empathy_emotion = 0
self.empathy_emotion_t_1 = 0
self.help_signal = 0
# Reset agents
for i in range(self.n_agents):
self.canvas.delete(self.agents[i])
pos = np.array([np.random.randint(0, self.MAZE_W) * self.UNIT + self.UNIT/2,
np.random.randint(0, self.MAZE_H) * self.UNIT + self.UNIT/2])
self.agents_pos[i] = pos
self.agents[i] = self.canvas.create_oval(
pos[0] - 15, pos[1] - 15,
pos[0] + 15, pos[1] + 15,
fill='gray') # ['red', 'blue', 'green'][i]
self.agents_emotion[i] = -1
# Reset snowdrifts
for i in range(self.n_snowdrifts):
if hasattr(self, 'snowdrifts') and len(self.snowdrifts) > i:
self.canvas.delete(self.snowdrifts[i])
pos = self.snowdrifts_pos[i]
points = [
pos[0], pos[1] - 15,
pos[0] - 15, pos[1] + 15,
pos[0] + 15, pos[1] + 15
]
snowdrift = self.canvas.create_polygon(points, fill='black')
if not hasattr(self, 'snowdrifts') or len(self.snowdrifts) <= i:
self.snowdrifts.append(snowdrift)
else:
self.snowdrifts[i] = snowdrift
self.cleaned = [False] * self.n_snowdrifts
# Calculate initial state index
init_state = self._get_state_index(agent_id)
return init_state
def step_all(self, actions):
"""Multi-agent environment step
Args:
actions: List[int] - List of actions for each agent
Returns:
next_states: List[int] - Next state index for each agent
rewards: List[float] - Rewards obtained by each agent
done: bool - Whether the episode is finished
info: dict - Additional information
"""
rewards = [0] * self.n_agents
empathtrewards_t = [0] * self.n_agents
next_states = []
cleaned_this_step = [] # Record snowdrifts cleaned in this step
# 1. Move phase - all agents move simultaneously
for agent_id, action in enumerate(actions):
s = self.agents_pos[agent_id]
base_action = np.array([0, 0])
if action < 4: # Move actions
if action == 0: # up
if s[1] > self.UNIT:
base_action[1] -= self.UNIT
elif action == 1: # down
if s[1] < (self.MAZE_H - 1) * self.UNIT:
base_action[1] += self.UNIT
elif action == 2: # right
if s[0] < (self.MAZE_W - 1) * self.UNIT:
base_action[0] += self.UNIT
elif action == 3: # left
if s[0] > self.UNIT:
base_action[0] -= self.UNIT
self.canvas.move(self.agents[agent_id], base_action[0], base_action[1])
self.agents_pos[agent_id] = self.agents_pos[agent_id] + base_action
# 2. Cleaning phase - handle all cleaning actions
for agent_id, action in enumerate(actions):
if action == 4:
s = self.agents_pos[agent_id]
for i, pos in enumerate(self.snowdrifts_pos):
if all(s == pos) and not self.cleaned[i] and i not in cleaned_this_step:
self.canvas.itemconfig(self.snowdrifts[i], fill='')
self.cleaned[i] = True
cleaned_this_step.append(agent_id)
rewards[agent_id] += 2
self.agents_emotion[agent_id] = -1
self.canvas.itemconfig(self.agents[agent_id], fill='gray')
for j in range(self.n_agents):
if j != agent_id:
rewards[j] += 6
if self.agents_emotion[j] == -1:
self.agents_emotion[j] = 0
self.canvas.itemconfig(self.agents[j], fill=['red', 'blue', 'green'][j])
empathtrewards_t[agent_id] += 6
# 3. Calculate next state for each agent
for agent_id in range(self.n_agents):
next_state = self._get_state_index(agent_id)
next_states.append(next_state)
empathtrewards_t[agent_id]
# 4. Check if finished
done = all(self.cleaned)
info = {
'cleaned_positions': cleaned_this_step,
'agent_emotions': self.agents_emotion.copy()
}
return next_states, rewards, empathtrewards_t, done, info
def _get_state_index(self, agent_id):
"""Convert state to index value"""
state_index = 0
pos = self.agents_pos[agent_id]
x = int(pos[0] / (self.MAZE_W * self.UNIT) * 8)
y = int(pos[1] / (self.MAZE_H * self.UNIT) * 8)
state_index += x + y * 8
return state_index
def render(self):
"""Render environment"""
time.sleep(0.00001)
self.update()
================================================
FILE: examples/Social_Cognition/affective_empathy/BEEAD-SNN/snowdrift_main.py
================================================
import time
import datetime
import os
import random
import numpy as np
import torch
from sd_env import Snowdrift
from rsnn import RSNN
from matplotlib import pyplot as plt
from torch.utils.tensorboard import SummaryWriter
# Global parameters
N_action = 5 # up, down, left, right, clean
N_state = 64 # 8*8 grid
C = 50
runtime = 100
trace_decay = 0.8
torch.manual_seed(42)
np.random.seed(42)
def encode(n, e):
z = torch.zeros(N_state, 100)
z[n, :] = 1
z = z * 0.51
return z
def aoencode(n, e, env, agent_id):
z = torch.zeros(N_state, 100)
z[n, :] = 1
for i in range(len(env.agents_pos)):
if i != agent_id:
other_pos = env.agents_pos[i]
x = int(other_pos[0] / (env.MAZE_W * env.UNIT) * 8)
y = int(other_pos[1] / (env.MAZE_H * env.UNIT) * 8)
other_state_idx = x + y * 8
z[other_state_idx, :] += 0.3
for i, snow_pos in enumerate(env.snowdrifts_pos):
if not env.cleaned[i]:
x = int(snow_pos[0] / (env.MAZE_W * env.UNIT) * 8)
y = int(snow_pos[1] / (env.MAZE_H * env.UNIT) * 8)
snow_state_idx = x + y * 8
z[snow_state_idx, :] += 0.6
z = z * 0.51
return z
def poencode(n, e, env, agent_id):
"""
Encode state as partially observable representation.
Args:
n: state index of current agent position
e: emotion state
env: environment object
agent_id: agent ID
"""
z = torch.zeros(N_state, 100)
agent_pos = env.agents_pos[agent_id]
cur_x = int(agent_pos[0] / (env.MAZE_W * env.UNIT) * 8)
cur_y = int(agent_pos[1] / (env.MAZE_H * env.UNIT) * 8)
obs_range = 1 # observable grid range
z[n, :] = 1
for i in range(len(env.agents_pos)):
if i != agent_id:
other_pos = env.agents_pos[i]
x = int(other_pos[0] / (env.MAZE_W * env.UNIT) * 8)
y = int(other_pos[1] / (env.MAZE_H * env.UNIT) * 8)
if abs(x - cur_x) <= obs_range and abs(y - cur_y) <= obs_range:
other_state_idx = x + y * 8
z[other_state_idx, :] += 0.3
for i, snow_pos in enumerate(env.snowdrifts_pos):
if not env.cleaned[i]:
x = int(snow_pos[0] / (env.MAZE_W * env.UNIT) * 8)
y = int(snow_pos[1] / (env.MAZE_H * env.UNIT) * 8)
if abs(x - cur_x) <= obs_range and abs(y - cur_y) <= obs_range:
snow_state_idx = x + y * 8
z[snow_state_idx, :] += 0.6
z = z * 0.51
return z
def chooseAct(Net, input, explore, n, env, agent_id):
count_group = np.zeros(N_action)
count_output = np.zeros(N_action * C)
for i_train in range(runtime):
out, dw = Net(input[:, i_train])
Net.weight_trace *= trace_decay
Net.weight_trace += dw[0]
count_output = count_output + np.array(out)
for i in range(N_action):
count_group[i] = count_output[i*C:(i+1)*C].sum()
agent_pos = env.agents_pos[agent_id]
at_snowdrift = False
for i, snow_pos in enumerate(env.snowdrifts_pos):
if not env.cleaned[i] and all(agent_pos == snow_pos):
at_snowdrift = True
break
if not at_snowdrift:
count_group[4] = float('-inf')
if np.random.uniform() < explore:
if not at_snowdrift:
action = np.random.randint(0, 4)
else:
if count_group.max() > float('-inf'):
action = count_group.argmax()
else:
action = np.random.randint(0, N_action)
else:
if not at_snowdrift:
action = np.random.randint(0, 4)
else:
action = np.random.randint(0, N_action)
return action, Net, dw[0], 0
def train_model(n_agents, lamdas, episodes):
# TensorBoard writer
current_time = datetime.datetime.now().strftime('%Y%m%d-%H%M%S')
log_dir = os.path.join('run33obs', f'sd_partobs_a{n_agents}_l{lamdas[0]}{lamdas[1]}{lamdas[2]}_e{episodes}_{current_time}', f'')
writer = SummaryWriter(log_dir)
nets = [RSNN(N_state, N_action*C) for _ in range(n_agents)]
learn_steps = [[] for _ in range(n_agents)]
weight_marks = [np.zeros((N_state, N_action)) for _ in range(n_agents)]
update_stops = [0 for _ in range(n_agents)]
empathy_rewards_t = [0] * n_agents
total_rewards = [0] * n_agents
env = Snowdrift(n_agents=n_agents, n_snowdrifts=10)
episode_cleaned_counts = []
agent_cleaned_counts = [0] * n_agents
for episode in range(episodes):
print(f'Episode: {episode}, Lambda: {lamdas}')
cleaned_count = 0
episode_agent_cleaned_count = [0] * n_agents
states = []
emotion_t = [-1] * n_agents
for i in range(n_agents):
state = env.reset(i)
states.append(state)
episode_rewards = [0 for _ in range(n_agents)]
episode_total_rewards = [0 for _ in range(n_agents)]
if episode < 100:
e_greedy = 0.2
elif episode < 300:
e_greedy = 0.5
elif episode < 900:
e_greedy = 0.9
else:
for i in range(n_agents):
if update_stops[i] == 0:
update_stops[i] = 1
e_greedy = 1
for t in range(100):
emotion_tt = emotion_t.copy()
emotion_t = env.agents_emotion.copy()
actions = []
for i in range(n_agents):
input_state = poencode(states[i], env.agents_emotion[i], env, i)
action, nets[i], dw, _ = chooseAct(nets[i], input_state, e_greedy, states[i], env, i)
actions.append(action)
next_states, rewards, empathy_rewards, done, info = env.step_all(actions)
cleaned_count += len(info['cleaned_positions'])
if 'cleaned_by_agent' in info:
for snow_idx, agent_idx in info['cleaned_by_agent'].items():
episode_agent_cleaned_count[agent_idx] += 1
agent_cleaned_counts[agent_idx] += 1
print(f'intereaction {t} :')
for i in range(n_agents):
if env.agents_emotion[i] == emotion_t[i] and env.agents_emotion[i] == emotion_tt[i] and (emotion_tt[0]==0 or emotion_tt[1]==0 or emotion_tt[2]==0):
total_rewards[i] = lamdas[i] * (empathy_rewards[i] - empathy_rewards_t[i]) + rewards[i]
elif env.agents_emotion[0]==-1 and env.agents_emotion[1]==-1 and env.agents_emotion[2]==-1:
total_rewards[i] = lamdas[i] * (empathy_rewards[i] - empathy_rewards_t[i]) + rewards[i]
else:
total_rewards[i] = lamdas[i] * empathy_rewards[i] + rewards[i]
print(f'Actions: {actions}, Rewards: {rewards}, Empathy Rewards: {empathy_rewards} Total Rewards: {total_rewards} emotion: {env.agents_emotion}')
empathy_rewards_t = empathy_rewards
env.render()
for i in range(n_agents):
if update_stops[i] == 0:
nets[i].UpdateWeight(total_rewards[i], actions[i], C, states[i])
states = next_states
for i in range(n_agents):
episode_rewards[i] += rewards[i]
episode_total_rewards[i] += total_rewards[i]
if done:
break
for i in range(n_agents):
writer.add_scalar(f'ERewards/Agent_{i+1}', episode_rewards[i], episode)
writer.add_scalar(f'totalRewards/Agent_{i+1}', episode_total_rewards[i], episode)
writer.add_scalar(f'Cleaned/Agent_{i+1}', episode_agent_cleaned_count[i], episode)
for i in range(n_agents):
learn_steps[i].append(episode_rewards[i])
# Save weights
if episode == episodes-1:
for i in range(n_agents):
torch.save(nets[i].connection[0].weight.data, f'weight_agent{i}_lambda{lamdas}_episode{episode}.pth')
episode_cleaned_counts.append(cleaned_count)
writer.add_scalar('Performance/Cleaned_Snowdrifts', cleaned_count, episode)
print(f'Cleaned Count: {cleaned_count}')
writer.close()
return learn_steps, episode_cleaned_counts
if __name__ == "__main__":
n_agents = 3
n_snowdrifts = 10
self_factors = [[1.51, 1.51, 1.51]]
all_learn_steps = []
all_cleaned_counts = []
for ii in range(len(self_factors)):
all_learn_steps.append([[] for _ in range(n_agents)])
all_cleaned_counts.append([])
for iii, lamdas in enumerate(self_factors):
steps, cleaned_counts = train_model(n_agents, lamdas, 1000)
for i in range(n_agents):
all_learn_steps[iii][i].extend(steps[i])
all_cleaned_counts[iii] = cleaned_counts
# Save plot images
save_dir = 'results'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
timestamp = datetime.datetime.now().strftime('%Y%m%d_%H%M%S')
plt.figure(figsize=[24, 8])
# Plot reward curves for each agent
plt.subplot(1, 3, 1)
colors = ['red', 'blue', 'green']
labels = ['Agent 1', 'Agent 2', 'Agent 3']
for i in range(n_agents):
plt.plot(all_learn_steps[0][i], label=labels[i], color=colors[i])
plt.legend(loc='lower right')
plt.title('Rewards per Agent')
plt.xlabel('Episode')
plt.ylabel('Reward')
# Plot number of cleaned snowdrifts
plt.subplot(1, 3, 2)
plt.plot(all_cleaned_counts[0], label='Cleaned Snowdrifts', color='black')
plt.axhline(y=n_snowdrifts, color='r', linestyle='--', label='Total Snowdrifts')
plt.legend(loc='lower right')
plt.title('Number of Cleaned Snowdrifts per Episode')
plt.xlabel('Episode')
plt.ylabel('Count')
plt.ylim([0, n_snowdrifts + 1])
# Add total reward curve
plt.subplot(1, 3, 3)
total_rewards_per_episode = np.sum(all_learn_steps[0], axis=0) # Calculate total reward for each episode
plt.plot(total_rewards_per_episode, label='Total Rewards', color='purple')
plt.legend(loc='lower right')
plt.title('Total Rewards of All Agents')
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.tight_layout()
# Save image
save_path = os.path.join(save_dir, f'training_results_{timestamp}.png')
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close() # Close the figure to free memory
print(f'Image saved to: {save_path}')
================================================
FILE: examples/Social_Cognition/affective_empathy/BRP-SNN/BRP-SNN.py
================================================
import os
import sys
# 把当前文件所在文件夹的父文件夹路径加入到PYTHONPATH
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import imageio
from env_poly_SNN import Maze
from env_two_poly_SNN import Maze2
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
import torch, os, sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import torch.nn.functional as F
from braincog.base.node.node import *
from braincog.base.learningrule.STDP import *
from braincog.base.connection.CustomLinear import *
X=np.array([[0],
[1],
[2],
[3]])
Y=np.array([[0,-40],
[0,40],
[40,0],
[-40,0]
])
class BrainArea(nn.Module, abc.ABC):
"""
脑区基类
"""
@abc.abstractmethod
def __init__(self):
"""
"""
super().__init__()
@abc.abstractmethod
def forward(self, x):
"""
计算前向传播过程
:return:x是脉冲
"""
return x
def reset(self):
"""
计算前向传播过程
:return:x是脉冲
"""
pass
class BNESNN(BrainArea):
"""
负面情绪网络
"""
def __init__(self,):
super().__init__()
self.node = [IFNode() for i in range(5)]
self.connection = []
con_matrix0 = torch.eye(12, 12)*6
self.connection.append(CustomLinear(con_matrix0))#input-state
con_matrix1 = torch.zeros((12, 24), dtype=torch.float)
self.connection.append(CustomLinear(con_matrix1))#state-prediction
con_matrix2 = torch.eye(24, 24)*6
self.connection.append(CustomLinear(con_matrix2))#input-prediction
con_matrix3 = torch.eye(24, 24)*6
self.connection.append(CustomLinear(con_matrix3))#input-sensory
con_matrix4 = torch.eye(24, 24)*6
self.connection.append(CustomLinear(con_matrix4))#sensory-error
con_matrix5 = torch.eye(24, 24)*(-6)
self.connection.append(CustomLinear(con_matrix5))#prediction-error
con_matrix6 = torch.zeros((24, 24), dtype=torch.float)
p=0.5
if p==0.25:
con_matrix6[:,0:3]=1
if p==0.5:
con_matrix6[:,0:6]=1
if p==0.75:
con_matrix6[:,0:9]=1
if p==1:
con_matrix6[:,0:12]=1
self.connection.append(CustomLinear(con_matrix6))#error-pain
self.stdp = []
self.stdp.append(STDP(self.node[0], self.connection[0]))#node0-state,stdp0
self.stdp.append(MutliInputSTDP(self.node[1], [self.connection[1], self.connection[2]]))#node1-prediction,stdp1
self.stdp.append(STDP(self.node[3], self.connection[3]))#node3-sensory,stdp2
self.stdp.append(MutliInputSTDP(self.node[2], [self.connection[4], self.connection[5]]))#node2-error,stdp3
self.stdp.append(STDP(self.node[1], self.connection[1]))#node1-prediction,stdp4
self.stdp.append(STDP(self.node[4], self.connection[6]))#node4-pain,stdp5
def forward(self, x1,x2):
"""
计算前向传播过程,训练过程
"""
out__s, dw0 = self.stdp[0](x1)#node0
out__p,dw = self.stdp[1](out__s,x2)#node1
return dw,out__s,out__p
def calculate_error(self, x1,x2):
"""
测试过程
"""
out__s,dw = self.stdp[0](x1)#node0-state,stdp0
out__pre,dw= self.stdp[4](out__s)#node1-prediction,stdp1
out__sensory,dw = self.stdp[2](x2)#node3-sensory,stdp2
out__error,dw = self.stdp[3](out__sensory,out__pre)#node2-error,stdp3
out__pain,dw = self.stdp[5](out__error)#node4-pain,stdp5
return out__s,out__pre,out__sensory,out__error,out__pain
def UpdateWeight(self, i, dw, delta):
"""
更新第i组连接的权重 根据传入的dw值
:param i: 要更新的连接的索引
:param dw: 更新的量
:return: None
"""
self.connection[i].update(dw*delta)
self.connection[i].weight.data= torch.clamp(self.connection[i].weight.data,0,6)
def reset(self):
"""
reset神经元或学习法则的中间量
:return: None
"""
for i in range(5):
self.node[i].n_reset()
for i in range(len(self.stdp)):
self.stdp[i].reset()
def GRF(X,N):
gauss_neuron = 12
center = np.ones((gauss_neuron, 1))
width = 1 / 15
for i in range(len(center)):
center[i] = (2 * i - 3) / 20
x = np.arange(0, 1, 0.0001)
num_features = N
gauss_recpt_field = np.zeros((gauss_neuron, len(x)))
for i in range(gauss_neuron):
gauss_recpt_field[i, :] = np.exp(-(x - center[i]) ** 2 / (2 * width * width))
def gauss_response(inputs,num_features):
spike_time = np.zeros((gauss_neuron, num_features))
# input: shape [1, features]
# output: shape [gaussian neurons*features] spiking time
for i in range(num_features):
for j in range(gauss_neuron):
spike_time[j, i] = gauss_recpt_field[j, inputs[i]] #entry gauss function
spikes = []
for i in range(spike_time.shape[1]):
spikes.extend(spike_time[:, i])
return np.array(spikes)
gauss_neurons = gauss_neuron * N
scaler = MinMaxScaler()
X = scaler.fit_transform(X)
X = (X * 10000).astype(int) #10000
X[X == 10000] = 9999
input_spike = np.zeros((X.shape[0], gauss_neurons))
for i in range(X.shape[0]):
input_spike[i, :] = gauss_response(X[i, :],num_features)
input_spike[input_spike < 0.1] = 0
input_spike = np.around(100 * (1 - input_spike))
input_spike[input_spike == 0] = 1
input_spike[input_spike == 100] = 0
state=[]
for i in range(len(X)):
aa=[]
for j in range(gauss_neurons):
if input_spike[i][j] != 0:
number=input_spike[i][j]
aa.append((int(number),j))
state.append(aa)
return state
def encode(input,n_neuron):
a=len(input)
input_encode = []
for i in range(n_neuron):
temp = np.zeros([100, ])
input_encode.append(temp)
for j in range(a):
s=input[j][0]
n=input[j][1]
input_encode[n][s]=1
return input_encode
class BAESNN(BrainArea):
"""
情感共情网络
"""
def __init__(self,):
"""
"""
super().__init__()
self.node = [IFNode() for i in range(5)]
self.connection = []
con_matrix0 = torch.eye(24, 24)*6
self.connection.append(CustomLinear(con_matrix0))#input-emotion
con_matrix1 = torch.zeros((24, 50), dtype=torch.float)
for j in range(50):
if j in np.arange(0,25,1):
for i in np.arange(0, 12, 1):
con_matrix1[i,j] =2
if j in np.arange(25,50,1):
for i in np.arange(12, 24, 1):
con_matrix1[i,j] =2
self.connection.append(CustomLinear(con_matrix1))#emotion-ifg
con_matrix2 = torch.zeros((24, 50), dtype=torch.float)
self.connection.append(CustomLinear(con_matrix2))#perception-ifg
con_matrix3 = torch.eye(24, 24)*6
self.connection.append(CustomLinear(con_matrix3))#input-perception
con_matrix4=torch.zeros((24,10), dtype=torch.float)
for j in range(10):
if j in np.arange(0,5,1):
for i in np.arange(0, 12, 1):
con_matrix4[i,j] =2
if j in np.arange(5,10,1):
for i in np.arange(12, 24, 1):
con_matrix4[i,j] =2
self.connection.append(CustomLinear(con_matrix4))#emotion-sma
con_matrix5=torch.zeros((24,10), dtype=torch.float)
self.connection.append(CustomLinear(con_matrix5))#perception-m1
con_matrix6 = torch.eye(10, 10)*6
self.connection.append(CustomLinear(con_matrix6))#sma-m1
self.stdp = []
self.stdp.append(STDP(self.node[0], self.connection[0]))#0
self.stdp.append(STDP(self.node[2], self.connection[3]))#1
self.stdp.append(MutliInputSTDP(self.node[1], [self.connection[1], self.connection[2]]))#2
self.stdp.append(MutliInputSTDP(self.node[3], [self.connection[4], self.connection[5]]))#3
self.stdp.append(STDP(self.node[4], self.connection[6]))#4
self.stdp.append(STDP(self.node[1],self.connection[2]))#5
self.stdp.append(STDP(self.node[3],self.connection[5]))#6
def forward(self, x1,x2):
"""
计算前向传播过程
:return:x是脉冲
"""
out__m, dw0 = self.stdp[0](x1)#node0
out__p, dw3 = self.stdp[1](x2)#node2
out__ifg,dw_p_i=self.stdp[2](out__m,out__p)#node1
out__sma,dw_p_s=self.stdp[3](out__m,out__p)#node3
out__m1,dw1=self.stdp[4](out__sma)#node4
return dw_p_i,dw_p_s,out__ifg,out__sma,out__m1
def empathy(self,x3):
out_p,dw2=self.stdp[1](x3)#node2
out_ifg,dw4=self.stdp[5](out_p)#node1
out_sma,dw5=self.stdp[6](out_p)#node3
out_m1,dw6=self.stdp[4](out_sma)#node4
return out_ifg,out_sma,out_m1
def UpdateWeight(self, i, dw, delta):
"""
更新第i组连接的权重 根据传入的dw值
:param i: 要更新的连接的索引
:param dw: 更新的量
:return: None
"""
self.connection[i].update(dw*delta)
self.connection[i].weight.data= torch.clamp(self.connection[i].weight.data,-1,4)
def reset(self):
"""
reset神经元或学习法则的中间量
:return: None
"""
for i in range(5):
self.node[i].n_reset()
for i in range(len(self.stdp)):
self.stdp[i].reset()
def BNESNN_train():
state=GRF(X,1)
prediction=GRF(Y,2)
T=100
epoch=10
for k in range(epoch):
print('epoch:',k)
for n in range(4):
snn1.reset()
train_state = np.array(encode(state[n], 12))
train_state=torch.tensor(train_state,dtype=torch.float32)
train_prediction = np.array(encode(prediction[n], 24))
train_prediction=torch.tensor(train_prediction,dtype=torch.float32)
for i in range(T):
OUTPUT = snn1(train_state[:,i],train_prediction[:,i])
snn1.UpdateWeight(1,OUTPUT[0][0],1)
def BAESNN_train():
s = env.reset()
env._set_danger()
env._set_wall()
pain=0
i=0
set_pain=0
env._set_switch()
for i in range(100):
snn1.reset()
T=100
pain=0
print('**************step:',i)
env.render()
action = np.random.choice(list(range(env.n_actions)))
print('action:',action)
d,d_pre,s_,sss = env.step(s, action, pain)
print('d:',d,'d_pre:',d_pre,'sss:',sss)
env.render()
while (d==np.array([0,0])).all():
action = np.random.choice(list(range(env.n_actions)))
print('action:',action)
d,d_pre,s_,sss = env.step(s, action, pain)
print('d:',d,'d_pre:',d_pre,'sss:',sss)
env.render()
aa=np.argwhere(X==action)[0][0]
for i in range(4):
if (Y[i]==d).all():
b=i
print('aa:',aa,'b:',b)
state=GRF(X,1)
prediction=GRF(Y,2)
x=encode(state[aa],12)
y=encode(prediction[b],24)
train_state = np.array(x)
train_state=torch.tensor(train_state,dtype=torch.float32)
train_prediction = np.array(y)
train_prediction=torch.tensor(train_prediction,dtype=torch.float32)
OUT_PAIN=torch.tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.]])
spike_pain=[]
spike_error=[]
for i in range(T):
OUTPUT_TEST = snn1.calculate_error(train_state[:,i],train_prediction[:,i])
spike_pain.append(OUTPUT_TEST[4])
spike_error.append(OUTPUT_TEST[3])
if OUTPUT_TEST[3].sum() != 0:
print('OUTPUT_TEST3:',i,OUTPUT_TEST[3])
if OUTPUT_TEST[4].sum() != 0:#pain brain area
print('OUTPUT_TEST4:',i,OUTPUT_TEST[4])
OUT_PAIN=OUTPUT_TEST[4]
pain=1
set_pain=1
spike_pain = torch.stack(spike_pain)
spike_error=torch.stack(spike_error)
if pain==1:
spike_rate_vis_1d(spike_error)
spike_rate_vis_1d(spike_pain)
print('pain:',pain)
snn2.reset()
T2=20
X1= OUT_PAIN.view(1, -1)
X2=torch.tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.]])
print('X1,X2:',X1,X2)
for i in range(T2):
if i>=2:
X2=X1
OUTPUT = snn2(X1,X2)
snn2.UpdateWeight(2,OUTPUT[0][1],0.01)
snn2.UpdateWeight(5,OUTPUT[1][1],-0.1)
if OUTPUT[2][0][0]==1:
env.canvas.itemconfig(env.rect, fill="red", outline='red')
if OUTPUT[2][0][0]==0:
env.canvas.itemconfig(env.rect, fill="green", outline='green')
env.render()
print('out_ifg:',OUTPUT[2])
print('out_sma:',OUTPUT[3])
print('out_m1:',OUTPUT[4])
print('con2:',snn2.connection[2].weight.data)
print('con5:',snn2.connection[5].weight.data)
s = s_
if set_pain==1 and pain==0:
env.render()
break
env.destroy()
def BAESNN_test():
s1,s=env2.reset()
pain=0
pain1 = 0
i=0
set_pain=0
for i in range(100):
snn1.reset()
T=100
pain=0
print('**************test_step:',i)
env2.render()
action1 = np.random.choice(list(range(env.n_actions)))
print('action1:',action1)
d,d_pre,s1_,sss = env2.step(s1, action1, pain1)
print('d:',d,'d_pre:',d_pre,'sss:',sss)
env2.render()
while (d==np.array([0,0])).all():
action1 = np.random.choice(list(range(env.n_actions)))
print('action1:',action1)
d,d_pre,s1_,sss = env2.step(s, action1, pain1)
print('d:',d,'d_pre:',d_pre,'sss:',sss)
env2.render()
aa=np.argwhere(X==action1)[0][0]
for i in range(4):
if (Y[i]==d).all():
b=i
# print('aa:',aa,'b:',b)
state=GRF(X,1)
prediction=GRF(Y,2)
x=encode(state[aa],12)
y=encode(prediction[b],24)
train_state = np.array(x)
train_state=torch.tensor(train_state,dtype=torch.float32)
train_prediction = np.array(y)
train_prediction=torch.tensor(train_prediction,dtype=torch.float32)
OUT_PAIN=torch.tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.]])
for i in range(T):
OUTPUT_TEST = snn1.calculate_error(train_state[:,i],train_prediction[:,i])
if OUTPUT_TEST[3].sum() != 0:
print('OUTPUT_TEST3:',i,OUTPUT_TEST[3])
if OUTPUT_TEST[4].sum() != 0:#pain brain area
print('OUTPUT_TEST4:',i,OUTPUT_TEST[4])
OUT_PAIN=OUTPUT_TEST[4]
pain1=1
set_pain=1
print('pain1:',pain1)
env2.generate_expression1(pain1)
snn2.reset()
T2=20
X3= OUT_PAIN.view(1, -1)
for i in range(T2):
OUT=snn2.empathy(X3)
print('out_ifg:',OUT[0])
if OUT[0][0][0]==1:
pain=1
if OUT[0][0][0]==0:
pain=0
if pain==1:
env2.agent_help()
s1 = s1_
env2.render()
if pain==0 and set_pain==1:
env2.render()
break
env2.destroy()
if __name__ == "__main__":
env = Maze()
snn1 = BNESNN()
snn2 = BAESNN()
BNESNN_train()
BAESNN_train()
env.mainloop()
env2 = Maze2()
BAESNN_test()
env2.mainloop()
================================================
FILE: examples/Social_Cognition/affective_empathy/BRP-SNN/README.md
================================================
================================================
FILE: examples/Social_Cognition/affective_empathy/BRP-SNN/env_poly_SNN.py
================================================
import numpy as np
np.random.seed(1)
import tkinter as tk
import time
from PIL import ImageGrab
UNIT = 40 # pixels
MAZE_H = 9 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('self-pain')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_W * UNIT))
self._build_maze()
self.danger=0
self.action_hurt=0
self.sensory_hurt = 0
self.open_door = 0
self.pain_state=0
# create environment
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_W * UNIT,
width=MAZE_H * UNIT)
# create grids
for c in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
self.orgin=[20,20]
# create agent
# 下
self.points1 = [
# 左上
self.orgin[0]-15,#5
self.orgin[1]-15,#5
# 右上
self.orgin[0]+15,#35
self.orgin[1]-15,#5
# 右下+
self.orgin[0]+15,#35
self.orgin[1],#20
# 顶点
self.orgin[0],#20
self.orgin[1]+15,#35
# 左下+
self.orgin[0]-15,#5
self.orgin[1],#20
]
self.rect = self.canvas.create_polygon(self.points1, fill="green")
self.canvas.pack()
#reset agent location
def reset(self):
self.open_door = 0
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
self.orgin = [20, 20]
# 下
self.points1 = [
# 左上
self.orgin[0] - 15, # 5
self.orgin[1] - 15, # 5
# 右上
self.orgin[0] + 15, # 35
self.orgin[1] - 15, # 5
# 右下+
self.orgin[0] + 15, # 35
self.orgin[1], # 20
# 顶点
self.orgin[0], # 20
self.orgin[1] + 15, # 35
# 左下+
self.orgin[0] - 15, # 5
self.orgin[1], # 20
]
self.rect = self.canvas.create_polygon(self.points1, fill="green")
return self.canvas.coords(self.rect)
def step(self, s, action, pain):
s = self.canvas.coords(self.rect)
self.centre = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
# danger or switch
if self.danger==1:
if all(self.centre == self.oval_center):
s_color = 'yellow'
self.canvas.delete(self.wall[3])
self.render()
self.open_door = 1
move = np.array([80, 0])
self.canvas.move(self.rect, move[0], move[1])
s = self.canvas.coords(self.rect)
self.render()
elif all(self.centre == self.hell1_center):
s_color = 'black'
self.action_hurt = 1
self.render()
else:
s_color = 'white'
# modify current state
self.canvas.delete(self.rect)# 主要为开关那几步考虑,所以重复写了
self.centre = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
if action==0:
self.points0 = [
# 右下
self.centre[0] + 15, # 35
self.centre[1] + 15, # 35
# 左下
self.centre[0] - 15, # 5
self.centre[1] + 15, # 35
# 左上+
self.centre[0] - 15, # 5
self.centre[1], # 20
# 顶点
self.centre[0], # 20
self.centre[1] - 15, # 5
# 右上+
self.centre[0] + 15, # 35
self.centre[1], # 20
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points0, fill=color)
if action==1:
self.points1 = [
# 左上
self.centre[0] - 15, # 5
self.centre[1] - 15, # 5
# 右上
self.centre[0] + 15, # 35
self.centre[1] - 15, # 5
# 右下+
self.centre[0] + 15, # 35
self.centre[1], # 20
# 顶点
self.centre[0], # 20
self.centre[1] + 15, # 35
# 左下+
self.centre[0] - 15, # 5
self.centre[1], # 20
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points1, fill=color)
if action==2:
self.points2 = [
# 左下
self.centre[0] - 15, # 5
self.centre[1] + 15, # 35
# 左上
self.centre[0] - 15, # 5
self.centre[1] - 15, # 5
# 右上+
self.centre[0], # 20
self.centre[1] - 15, # 5
# 顶点
self.centre[0] + 15, # 35
self.centre[1], # 20
# 右下+
self.centre[0], # 20
self.centre[1] + 15, # 35
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points2, fill=color)
if action==3:
self.points3 = [
# 右上
self.centre[0] + 15, # 20+15
self.centre[1] - 15, # 20-15
# 右下
self.centre[0] + 15, # 20+15
self.centre[1] + 15, # 20+15
# 左下+
self.centre[0], # 20
self.centre[1] + 15, # 20+15
# 顶点
self.centre[0] - 15, # 20-15
self.centre[1], # 20
# 左上+
self.centre[0], # 20
self.centre[1] - 15, # 20-15
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points3, fill=color)
s = self.canvas.coords(self.rect)
self.render()#显示当前的动作指令是什么
if s[0] > (9 / 2) * 40:
self.action_hurt = 0
base_action = np.array([0, 0])
if self.action_hurt == 0:
true_action = action
else:
if action == 0:
true_action = 1
if action == 1:
true_action = 0
if action == 2:
true_action = 3
if action == 3:
true_action = 2
# predict next state
# predict next state
self.centre1 = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
pre_displacement1 = np.array([0, 0])
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT: # 120
if action == 0: # up
if self.centre1[1] > UNIT:
pre_displacement1 = np.array([0, -40])
elif action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action == 3: # left
if self.centre1[0] > UNIT:
pre_displacement1 = np.array([-40, 0])
else:
if action == 0: # up
if self.centre1[1] > UNIT:
pre_displacement1 = np.array([0, -40])
elif action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
pre_displacement1 = np.array([-40, 0])
# true next state
displacement1 = np.array([0, 0])
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT:
if true_action == 0: # up
if self.centre1[1] > UNIT:
displacement1=np.array([0,-40])
elif true_action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1=np.array([0,40])
elif true_action == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
displacement1=np.array([40,0])
elif true_action == 3: # left
if self.centre1[0] > UNIT:
displacement1=np.array([-40,0])
else:
if true_action == 0: # up
if self.centre1[1] > UNIT:
displacement1=np.array([0,-40])
elif true_action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1=np.array([0,40])
elif true_action == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
displacement1=np.array([40,0])
elif true_action == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
displacement1=np.array([-40,0])
self.canvas.move(self.rect, displacement1[0], displacement1[1])
s1_ = self.canvas.coords(self.rect)
sss = [(s1_[4] + s1_[8]) / 2, (s1_[5] + s1_[9]) / 2]
return displacement1, pre_displacement1,s1_,sss
def _set_danger(self):
self.hell1_center = np.array([60, 60])
self.hell1 = self.canvas.create_oval(
self.hell1_center[0] - 15, self.hell1_center[1] - 15,
self.hell1_center[0] + 15, self.hell1_center[1] + 15,
fill='black')
# self.canvas.create_bitmap((40 , 40), bitmap='error')
self.hell = self.canvas.coords(self.hell1)
self.canvas.pack()
self.danger=1
def _set_switch(self):
self.oval_center = np.array([(MAZE_H * UNIT) / 2 - UNIT, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
self.oval = self.canvas.create_oval(
self.oval_center[0] - 15, self.oval_center[1] - 15,
self.oval_center[0] + 15, self.oval_center[1] + 15,
fill='yellow')
self.switch = self.canvas.coords(self.oval)
self.canvas.pack()
def _set_wall(self):
wall_center=[]
self.wall=[]
for a in range(MAZE_W):
wall_center.append([0,0])
self.wall.append([])
for b in range(MAZE_W):
wall_center[b]=np.array([(MAZE_H*UNIT)/2,((b)*UNIT)+UNIT/2])
self.wall[b] = self.canvas.create_rectangle(
wall_center[b][0] - 20, wall_center[b][1] - 20,
wall_center[b][0] + 20, wall_center[b][1] + 20,
fill='grey')
self.wall0 = self.canvas.coords(self.wall[0])
self.wall1 = self.canvas.coords(self.wall[1])
self.wall2 = self.canvas.coords(self.wall[2])
self.wall3 = self.canvas.coords(self.wall[3])
# self.canvas.pack()
def generate_expression(self,pain):
if pain==1:
self.canvas.itemconfig(self.rect, fill="red", outline='red')
# self.canvas.pack()
if pain == 0:
self.canvas.itemconfig(self.rect, fill="green", outline='green')
# self.canvas.pack()
def render(self):
time.sleep(0.2)
self.update()
# def getter(self, widget):
# widget.update()
# x = tk.Tk.winfo_rootx(self) + widget.winfo_x()
# y = tk.Tk.winfo_rooty(self) + widget.winfo_y()
# x1 = x + widget.winfo_width()
# y1 = y + widget.winfo_height()
# ImageGrab.grab().crop((x, y, x1, y1)).save("first.jpg")
# return ImageGrab.grab().crop((x, y, x1, y1))
================================================
FILE: examples/Social_Cognition/affective_empathy/BRP-SNN/env_two_poly_SNN.py
================================================
import numpy as np
np.random.seed(1)
import tkinter as tk
import time
from PIL import ImageGrab
UNIT = 40 # pixels
MAZE_H = 9 # grid height
MAZE_W = 4 # grid width
class Maze2(tk.Tk, object):
def __init__(self):
super(Maze2, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.action_space1 = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.n_actions1 = len(self.action_space1)
self.title('two_agent_empathy')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_W * UNIT))
self._build_maze()
self.danger=0
self.action_hurt=0
self.sensory_hurt = 0
self.action_hurt1 = 0
self.sensory_hurt1 = 0
self.open_door=0
# create environment
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_W * UNIT,
width=MAZE_H * UNIT)
# create grids
for c in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create switch
self.oval_center = np.array([(MAZE_H * UNIT)/2-UNIT+80, ((MAZE_W+4) * UNIT)/2-UNIT/2-80])
self.oval = self.canvas.create_oval(
self.oval_center[0] - 15, self.oval_center[1] - 15,
self.oval_center[0] + 15, self.oval_center[1] + 15,
fill='yellow')
self.switch = self.canvas.coords(self.oval)
self.orgin1 = np.array([20, 20])
# 下
self.points1 = [
# 左上
self.orgin1[0] - 15, # 5
self.orgin1[1] - 15, # 5
# 右上
self.orgin1[0] + 15, # 35
self.orgin1[1] - 15, # 5
# 右下+
self.orgin1[0] + 15, # 35
self.orgin1[1], # 20
# 顶点
self.orgin1[0], # 20
self.orgin1[1] + 15, # 35
# 左下+
self.orgin1[0] - 15, # 5
self.orgin1[1], # 20
]
self.agent1 = self.canvas.create_polygon(self.points1, outline='black',fill="blue")
self.orgin = np.array([MAZE_H * UNIT - UNIT / 2, 20])
# 下
self.points = [
# 左上
self.orgin[0] - 15, # 5
self.orgin[1] - 15, # 5
# 右上
self.orgin[0] + 15, # 35
self.orgin[1] - 15, # 5
# 右下+
self.orgin[0] + 15, # 35
self.orgin[1], # 20
# 顶点
self.orgin[0], # 20
self.orgin[1] + 15, # 35
# 左下+
self.orgin[0] - 15, # 5
self.orgin[1], # 20
]
self.agent = self.canvas.create_polygon(self.points, fill="green")
wall_center = []
self.wall = []
for i in range(MAZE_W):
wall_center.append([])
self.wall.append([])
for i in range(MAZE_W):
wall_center[i] = np.array([(MAZE_H * UNIT) / 2, ((i) * UNIT) + UNIT / 2])
self.wall[i] = self.canvas.create_rectangle(
wall_center[i][0] - 20, wall_center[i][1] - 20,
wall_center[i][0] + 20, wall_center[i][1] + 20,
fill='grey')
self.hell1_center = np.array([100, 20])
self.hell1 = self.canvas.create_oval(
self.hell1_center[0] - 15, self.hell1_center[1] - 15,
self.hell1_center[0] + 15, self.hell1_center[1] + 15,
fill='black')
self.hell2_center = np.array([60, 100])
self.hell2 = self.canvas.create_oval(
self.hell2_center[0] - 15, self.hell2_center[1] - 15,
self.hell2_center[0] + 15, self.hell2_center[1] + 15,
fill='black')
# self.canvas.create_bitmap((40 , 40), bitmap='error')
self.danger = 1
self.canvas.pack()
#reset agent location
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.agent1)
self.canvas.delete(self.agent)
self.orgin1 = np.array([20, 20])
# 下
self.points1 = [
# 左上
self.orgin1[0] - 15, # 5
self.orgin1[1] - 15, # 5
# 右上
self.orgin1[0] + 15, # 35
self.orgin1[1] - 15, # 5
# 右下+
self.orgin1[0] + 15, # 35
self.orgin1[1], # 20
# 顶点
self.orgin1[0], # 20
self.orgin1[1] + 15, # 35
# 左下+
self.orgin1[0] - 15, # 5
self.orgin1[1], # 20
]
self.agent1 = self.canvas.create_polygon(self.points1, outline='black',fill="blue")
self.orgin = np.array([MAZE_H * UNIT - UNIT / 2, 20])
# 下
self.points = [
# 左上
self.orgin[0] - 15, # 5
self.orgin[1] - 15, # 5
# 右上
self.orgin[0] + 15, # 35
self.orgin[1] - 15, # 5
# 右下+
self.orgin[0] + 15, # 35
self.orgin[1], # 20
# 顶点
self.orgin[0], # 20
self.orgin[1] + 15, # 35
# 左下+
self.orgin[0] - 15, # 5
self.orgin[1], # 20
]
self.agent = self.canvas.create_polygon(self.points, fill="green")
return self.canvas.coords(self.agent1),self.canvas.coords(self.agent)
def step(self, s, action, pain):
s1 = self.canvas.coords(self.agent1)
self.centre1 = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
if all(self.centre1 == self.hell1_center):
self.action_hurt1 = 1
if all(self.centre1 == self.hell2_center):
self.action_hurt1 = 1
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 ==self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 ==self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT*2, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 == self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT*3, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 == self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT*4, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 == self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
#显示当前的动作指令是什么
self.canvas.delete(self.agent1)
self.centre = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
if action==0:
self.points0 = [
# 右下
self.centre[0] + 15, # 35
self.centre[1] + 15, # 35
# 左下
self.centre[0] - 15, # 5
self.centre[1] + 15, # 35
# 左上+
self.centre[0] - 15, # 5
self.centre[1], # 20
# 顶点
self.centre[0], # 20
self.centre[1] - 15, # 5
# 右上+
self.centre[0] + 15, # 35
self.centre[1], # 20
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points0, fill=color)
if action==1:
self.points1 = [
# 左上
self.centre[0] - 15, # 5
self.centre[1] - 15, # 5
# 右上
self.centre[0] + 15, # 35
self.centre[1] - 15, # 5
# 右下+
self.centre[0] + 15, # 35
self.centre[1], # 20
# 顶点
self.centre[0], # 20
self.centre[1] + 15, # 35
# 左下+
self.centre[0] - 15, # 5
self.centre[1], # 20
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points1, fill=color)
if action==2:
self.points2 = [
# 左下
self.centre[0] - 15, # 5
self.centre[1] + 15, # 35
# 左上
self.centre[0] - 15, # 5
self.centre[1] - 15, # 5
# 右上+
self.centre[0], # 20
self.centre[1] - 15, # 5
# 顶点
self.centre[0] + 15, # 35
self.centre[1], # 20
# 右下+
self.centre[0], # 20
self.centre[1] + 15, # 35
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points2, fill=color)
if action==3:
self.points3 = [
# 右上
self.centre[0] + 15, # 20+15
self.centre[1] - 15, # 20-15
# 右下
self.centre[0] + 15, # 20+15
self.centre[1] + 15, # 20+15
# 左下+
self.centre[0], # 20
self.centre[1] + 15, # 20+15
# 顶点
self.centre[0] - 15, # 20-15
self.centre[1], # 20
# 左上+
self.centre[0], # 20
self.centre[1] - 15, # 20-15
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points3, fill=color)
s1 = self.canvas.coords(self.agent1)
self.render()#显示当前的动作指令是什么
self.centre1 = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
if self.centre1[0] > (9 / 2) * 40:
self.action_hurt1 = 0
# whether hurt
if self.action_hurt1 == 0:
true_action = action
else:
if action == 0:
true_action = 1
if action == 1:
true_action = 0
if action == 2:
true_action = 3
if action == 3:
true_action = 2
base_action = np.array([0, 0])
# predict next state
self.centre1 = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
pre_displacement1 = np.array([0, 0])
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT: # 120
if action == 0: # up
if self.centre1[1] > UNIT:
pre_displacement1 = np.array([0, -40])
elif action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action == 3: # left
if self.centre1[0] > UNIT:
pre_displacement1 = np.array([-40, 0])
else:
if action == 0: # up
if self.centre1[1] > UNIT:
pre_displacement1 = np.array([0, -40])
elif action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
pre_displacement1 = np.array([-40, 0])
# true next state
displacement1 = np.array([0, 0])
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT:
if true_action == 0: # up
if self.centre1[1] > UNIT:
displacement1=np.array([0,-40])
elif true_action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1=np.array([0,40])
elif true_action == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
displacement1=np.array([40,0])
elif true_action == 3: # left
if self.centre1[0] > UNIT:
displacement1=np.array([-40,0])
else:
if true_action == 0: # up
if self.centre1[1] > UNIT:
displacement1=np.array([0,-40])
elif true_action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1=np.array([0,40])
elif true_action == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
displacement1=np.array([40,0])
elif true_action == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
displacement1=np.array([-40,0])
self.canvas.move(self.agent1, displacement1[0], displacement1[1])
s1_ = self.canvas.coords(self.agent1)
sss = [(s1_[4] + s1_[8]) / 2, (s1_[5] + s1_[9]) / 2]
return displacement1, pre_displacement1,s1_,sss
def agent_help(self):
s = self.canvas.coords(self.agent)
self.centre2= [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
if all(self.centre2 == self.oval_center):
self.canvas.delete(self.wall[3])
self.render()
self.open_door=1
else:
self.canvas.move(self.agent, -40, 0) # move agent
self.render()
self.canvas.move(self.agent, -40, 0)
self.render()
self.canvas.move(self.agent, -40, 0)
self.render()
self.canvas.move(self.agent, 0, 40)
self.render()
s_ = self.canvas.coords(self.agent) # next state
return s_
def _set_danger(self):
hell1_center = np.array([140, 60])
self.hell1 = self.canvas.create_agent1angle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
hell2_center = np.array([100, 140])
self.hell2 = self.canvas.create_agent1angle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# self.canvas.create_bitmap((40 , 40), bitmap='error')
self.canvas.pack()
self.danger=1
def _set_wall(self):
wall_center=[]
self.wall=[]
for i in range(MAZE_W):
wall_center.append([])
self.wall.append([])
for i in range(MAZE_W):
wall_center[i]=np.array([(MAZE_H*UNIT)/2,((i)*UNIT)+UNIT/2])
self.wall[i] = self.canvas.create_agent1angle(
wall_center[i][0] - 20, wall_center[i][1] - 20,
wall_center[i][0] + 20, wall_center[i][1] + 20,
fill='grey')
self.canvas.pack()
def generate_expression1(self,pain1):
if pain1==1:
self.canvas.itemconfig(self.agent1, fill="red", outline='black')
self.canvas.pack()
if pain1 ==0:
self.canvas.itemconfig(self.agent1, fill="blue", outline='black')
self.canvas.pack()
def render(self):
time.sleep(0.2)
self.update()
================================================
FILE: examples/Social_Cognition/mirror_test/README.md
================================================
# Mirror Test
The mirror_test.py implements the core code of the Multi-Robots Mirror Self-Recognition Test in "Toward Robot Self-Consciousness (II): Brain-Inspired Robot Bodily Self Model for Self-Recognition".
The experiment is: three robots with identical appearance move their arms randomly in front of the mirror at the same time.
In the training stage, according to the spiking time difference of neurons in IPLM and IPLV, the robot learns the correlations between self-generated actions and visual feedbacks in motion by learning with spike timing dependent plasticity (STDP) mechanism.
In the test stage, the robot can predicts the visual feedback generated by its arm movement according to the training results. With the InsulaNet, the robot can identify which mirror image belongs to it.
In the result, Motion Detection shows the results of visual detection, and Motion Prediction shows the visual feedback generated by itself. The red line in the figure indicates that the robot determines that the corresponding mirror belongs to itself.
Differences from the original article:
Since there is no motion error under the simulation conditions, the theta_threshold is set to zero.
### Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{zeng2018toward,
title={Toward robot self-consciousness (ii): brain-inspired robot bodily self model for self-recognition},
author={Zeng, Yi and Zhao, Yuxuan and Bai, Jun and Xu, Bo},
journal={Cognitive Computation},
volume={10},
number={2},
pages={307--320},
year={2018},
publisher={Springer}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/Social_Cognition/mirror_test/mirror_test.py
================================================
from braincog.base.brainarea.Insula import *
from braincog.base.brainarea.IPL import *
from braincog.base.learningrule.STDP import *
from braincog.base.node.node import *
from braincog.base.connection.CustomLinear import *
import random
import numpy as np
import torch
import os
import sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
import matplotlib.pyplot as plt
from braincog.base.strategy.surrogate import *
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
if __name__ == "__main__":
"""
Set the number of neurons, and each neuron represents unique motion information (such as angle)
"""
# number of neurons
num_neuron = 5
num_vPMC = num_neuron
num_STS = num_neuron
num_IPLM = num_neuron
num_IPLV = num_neuron
num_Insula = num_neuron
"""
Setting the network structure and the initial weight of IPL
"""
# IPLNet
# connection
connection = []
# vPMC-IPLM
con_matrix0 = torch.eye(num_IPLM, dtype=torch.float) * 2.5
connection.append(CustomLinear(con_matrix0))
# STS-IPLV
con_matrix1 = torch.eye(num_IPLV, dtype=torch.float) * 2.5
connection.append(CustomLinear(con_matrix1))
# IPLM-IPLV
con_matrix2 = torch.zeros([num_IPLM, num_IPLV], dtype=torch.float)
connection.append(CustomLinear(con_matrix2))
IPL = IPLNet(connection)
print("IPL Connection (Before training):", connection[2].weight)
"""
Setting the network structure and the initial weight of Insula
"""
# InsulaNet
# connection
Insula_connection = []
# IPLV-Insula
con_matrix0 = torch.eye(num_IPLM, dtype=torch.float) * 2
Insula_connection.append(CustomLinear(con_matrix0))
# STS-Insula
con_matrix1 = torch.eye(num_IPLV, dtype=torch.float) * 2
Insula_connection.append(CustomLinear(con_matrix1))
Insula = InsulaNet(Insula_connection)
"""
Training process
:param train_num: number of movements during training
"""
# Train
for vPMC_Angel in range(1, num_vPMC + 1):
# vPMC Angle
vPMC_Angel_v = torch.zeros([1, num_vPMC], dtype=torch.float)
vPMC_Angel_v[0, vPMC_Angel - 1] = 20
dwIPL_temp = torch.zeros([num_IPLM, num_IPLV], dtype=torch.float)
train_num = 10
for i_train in range(train_num):
# STS 1
STS_Angel_1 = vPMC_Angel
for t in range(2):
vPMC_input = vPMC_Angel_v
STS_Angel_v = torch.zeros([1, num_STS], dtype=torch.float)
STS_Angel_v[0, STS_Angel_1 - 1] = 20
STS_input = STS_Angel_v
IPLV_out, dwIPL = IPL(vPMC_input, STS_input)
dwIPL_temp = dwIPL_temp + dwIPL
IPL.reset()
# STS 2
STS_Angel_2 = random.randint(1, num_neuron)
for t in range(2):
vPMC_input = vPMC_Angel_v
STS_Angel_v = torch.zeros([1, num_STS], dtype=torch.float)
STS_Angel_v[0, STS_Angel_2 - 1] = 20
STS_input = STS_Angel_v
IPLV_out, dwIPL = IPL(vPMC_input, STS_input)
dwIPL_temp = dwIPL_temp + dwIPL
IPL.reset()
# STS 3
STS_Angel_3 = random.randint(1, num_neuron)
for t in range(2):
vPMC_input = vPMC_Angel_v
STS_Angel_v = torch.zeros([1, num_STS], dtype=torch.float)
STS_Angel_v[0, STS_Angel_3 - 1] = 20
STS_input = STS_Angel_v
IPLV_out, dwIPL = IPL(vPMC_input, STS_input)
dwIPL_temp = dwIPL_temp + dwIPL
IPL.reset()
IPL.UpdateWeight(2, dwIPL_temp)
print("IPL Connection (After training):", connection[2].weight)
"""
Test process
:param move_count: number of movements during test
"""
# Test
move_count = 10
TestList_vPMC_Angel = np.random.randint(1, num_vPMC, move_count)
TestList_STS_Angel_1 = TestList_vPMC_Angel
TestList_STS_Angel_2 = np.random.randint(1, num_STS, move_count)
TestList_STS_Angel_3 = np.random.randint(1, num_STS, move_count)
TestMat_STS_Angle = np.vstack((TestList_STS_Angel_1, TestList_STS_Angel_2, TestList_STS_Angel_3))
np.random.shuffle(TestMat_STS_Angle)
TestList_IPLV_out = []
for i_test in range(move_count):
Test_vPMC_Angel = TestList_vPMC_Angel[i_test]
Test_vPMC_Angel_v = torch.zeros([1, num_vPMC], dtype=torch.float)
Test_vPMC_Angel_v[0, Test_vPMC_Angel - 1] = 20
Test_STS_Angel_v = torch.zeros([1, num_STS], dtype=torch.float)
for t in range(2):
IPL(Test_vPMC_Angel_v, Test_STS_Angel_v)
IPLV_out_f = torch.argmax(IPL.node[1].u) + 1
IPL.reset()
TestList_IPLV_out.append(IPLV_out_f.numpy().item())
confidence = [0, 0, 0]
for i in range(move_count):
theta_predict = TestList_IPLV_out[i]
theta_visual_1 = TestMat_STS_Angle[0][i]
theta_visual_2 = TestMat_STS_Angle[1][i]
theta_visual_3 = TestMat_STS_Angle[2][i]
Test_IPL_v = torch.zeros([1, num_IPLV], dtype=torch.float)
Test_IPL_v[0, theta_predict - 1] = 20
Test_STS1_v = torch.zeros([1, num_STS], dtype=torch.float)
Test_STS1_v[0, theta_visual_1 - 1] = 20
for t in range(2):
Insula(Test_IPL_v, Test_STS1_v)
if sum(sum(Insula.out_Insula)) > 0:
confidence[0] = confidence[0] + 1
Insula.reset()
Test_STS2_v = torch.zeros([1, num_STS], dtype=torch.float)
Test_STS2_v[0, theta_visual_2 - 1] = 20
for t in range(2):
Insula(Test_IPL_v, Test_STS2_v)
if sum(sum(Insula.out_Insula)) > 0:
confidence[1] = confidence[1] + 1
Insula.reset()
Test_STS3_v = torch.zeros([1, num_STS], dtype=torch.float)
Test_STS3_v[0, theta_visual_3 - 1] = 20
for t in range(2):
Insula(Test_IPL_v, Test_STS3_v)
if sum(sum(Insula.out_Insula)) > 0:
confidence[2] = confidence[2] + 1
Insula.reset()
x_0 = torch.arange(0, move_count)
x_1 = torch.arange(move_count * 1, move_count * 2)
x_2 = torch.arange(move_count * 2, move_count * 3)
color_list = ['k', 'k', 'k']
color_list[confidence.index(max(confidence))] = 'r'
plt.subplot(211)
plt.figure(1)
plt.plot(x_0, TestMat_STS_Angle[0], color=color_list[0])
plt.plot(x_1, TestMat_STS_Angle[1], color=color_list[1])
plt.plot(x_2, TestMat_STS_Angle[2], color=color_list[2])
plt.title("Motion Detection")
plt.subplot(212)
plt.plot(x_0, TestList_IPLV_out, color='r')
plt.title("Motion Prediction")
plt.tight_layout()
plt.show()
================================================
FILE: examples/Spiking-Transformers/LIFNode.py
================================================
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
class MyBaseNode(BaseNode):
def __init__(self, threshold=0.5, step=4, layer_by_layer=False, mem_detach=False):
super().__init__(threshold=threshold, step=step, layer_by_layer=layer_by_layer, mem_detach=mem_detach)
def rearrange2node(self, inputs):
if self.groups != 1:
if len(inputs.shape) == 4:
outputs = rearrange(inputs, 'b (c t) w h -> t b c w h', t=self.step)
elif len(inputs.shape) == 2:
outputs = rearrange(inputs, 'b (c t) -> t b c', t=self.step)
else:
raise NotImplementedError
elif self.layer_by_layer:
if len(inputs.shape) == 4:
outputs = rearrange(inputs, '(t b) c w h -> t b c w h', t=self.step)
# 加入适配Transformer T B N C的rearange2node分支
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, '(t b) n c -> t b n c', t=self.step)
elif len(inputs.shape) == 2:
outputs = rearrange(inputs, '(t b) c -> t b c', t=self.step)
else:
raise NotImplementedError
else:
outputs = inputs
return outputs
def rearrange2op(self, inputs):
if self.groups != 1:
if len(inputs.shape) == 5:
outputs = rearrange(inputs, 't b c w h -> b (c t) w h')
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, ' t b c -> b (c t)')
else:
raise NotImplementedError
elif self.layer_by_layer:
if len(inputs.shape) == 5:
outputs = rearrange(inputs, 't b c w h -> (t b) c w h')
# 加入适配Transformer T B N C的rearange2op分支
elif len(inputs.shape) == 4:
outputs = rearrange(inputs, ' t b n c -> (t b) n c')
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, ' t b c -> (t b) c')
else:
raise NotImplementedError
else:
outputs = inputs
return outputs
class MyGrad(SurrogateFunctionBase):
def __init__(self, alpha=4., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return sigmoid.apply(x, alpha)
class MyNode(MyBaseNode):
def __init__(self, threshold=1., step=4, layer_by_layer=True, tau=2., act_fun=MyGrad, mem_detach=True, *args,
**kwargs):
super().__init__(threshold=threshold, step=step, layer_by_layer=layer_by_layer, mem_detach=mem_detach)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=4., requires_grad=False)
def integral(self, inputs):
self.mem = self.mem + (inputs - self.mem) / self.tau
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
self.mem = self.mem * (1 - self.spike.detach())
================================================
FILE: examples/Spiking-Transformers/README.md
================================================
# Spiking Transformers Reproduced With Braincog
Here is the current Spiking Transformer code reproduced using [BrainCog](http://www.brain-cog.network/). Welcome to follow the work of BrainCog and utilize the [BrainCog framework](https://github.com/BrainCog-X/Brain-Cog) to create relevant brain-inspired AI endeavors. The works implemented here will also be merged into BrainCog Repo.
### Models
**Spikformer(ICLR 2023)**
[Zhou, Z., Zhu, Y., He, C., Wang, Y., Yan, S., Tian, Y., & Yuan, L. (2022). Spikformer: When spiking neural network meets transformer. arXiv preprint arXiv:2209.15425.](https://openreview.net/forum?id=frE4fUwz_h)

**Spike-driven Transformer(Nips 2023)**
[Yao, M., Hu, J., Zhou, Z., Yuan, L., Tian, Y., Xu, B., & Li, G. (2024). Spike-driven transformer. Advances in Neural Information Processing Systems, 36.](https://proceedings.neurips.cc/paper_files/paper/2023/hash/ca0f5358dbadda74b3049711887e9ead-Abstract-Conference.html)

**Spike-driven Transformer V2(ICLR 2024)**
[Yao, M., Hu, J., Hu, T., Xu, Y., Zhou, Z., Tian, Y., ... & Li, G. (2023, October). Spike-driven Transformer V2: Meta Spiking Neural Network Architecture Inspiring the Design of Next-generation Neuromorphic Chips. In The Twelfth International Conference on Learning Representations.](https://openreview.net/forum?id=1SIBN5Xyw7)

## Models in comming soon
**SpikingResFormer**
[Shi, X., Hao, Z., & Yu, Z. (2024). SpikingResformer: Bridging ResNet and Vision Transformer in Spiking Neural Networks. arXiv preprint arXiv:2403.14302.](https://arxiv.org/abs/2403.14302)
**TIM**
[Shen, S., Zhao, D., Shen, G., & Zeng, Y. (2024). TIM: An Efficient Temporal Interaction Module for Spiking Transformer. arXiv preprint arXiv:2401.11687.](https://arxiv.org/abs/2401.11687)
**SGLFormer(Frontiers in Neuroscience)**
[Zhang, H., Zhou, C., Yu, L., Huang, L., Ma, Z., Fan, X., ... & Tian, Y. (2024). SGLFormer: Spiking Global-Local-Fusion Transformer with High Performance. Frontiers in Neuroscience, 18, 1371290.](https://www.frontiersin.org/journals/neuroscience/articles/10.3389/fnins.2024.1371290/full)
**QKFormer(CVPR2024)**
[Zhou, C., Zhang, H., Zhou, Z., Yu, L., Huang, L., Fan, X., ... & Tian, Y. (2024). QKFormer: Hierarchical Spiking Transformer using QK Attention. arXiv preprint arXiv:2403.16552.](https://arxiv.org/abs/2403.16552)
## Requirments
- Braincog
- einops >= 0.4.1
- timm >= 0.5.4
## Training Examples
### Training on CIFAR10-DVS
python main.py --dataset dvsc10 --epochs 500 --batch-size 16 --seed 42 --event-size 64 --model spikformer_dvs
### Training on ImageNet
python main.py --dataset imnet --epochs 500 --batch-size 16 --seed 42 --model spikformer
================================================
FILE: examples/Spiking-Transformers/datasets.py
================================================
import os
import warnings
import random
import torchvision.datasets
import braincog.datasets.ucf101_dvs
try:
import tonic
from tonic import DiskCachedDataset
except:
warnings.warn("tonic should be installed, 'pip install git+https://github.com/FloyedShen/tonic.git'")
import torch
import torch.nn.functional as F
import torch.utils
import torchvision.datasets as datasets
from timm.data import ImageDataset, create_loader, Mixup, FastCollateMixup, AugMixDataset
from timm.data import create_transform, distributed_sampler
from timm.data.loader import PrefetchLoader
from tonic import DiskCachedDataset
from torchvision import transforms
from typing import Any, Dict, Optional, Sequence, Tuple, Union
from braincog.datasets.NOmniglot.nomniglot_full import NOmniglotfull
from braincog.datasets.NOmniglot.nomniglot_nw_ks import NOmniglotNWayKShot
from braincog.datasets.NOmniglot.nomniglot_pair import NOmniglotTrainSet, NOmniglotTestSet
# from braincog.base.conversion.conversion import CIFAR10Policy, Cutout
# from .cut_mix import CutMix, EventMix, MixUp
# from .rand_aug import *
# from .event_drop import event_drop
# from .utils import dvs_channel_check_expend, rescale
DVSCIFAR10_MEAN_16 = [0.3290, 0.4507]
DVSCIFAR10_STD_16 = [1.8398, 1.6549]
DATA_DIR = '/data/datasets'
DEFAULT_CROP_PCT = 0.875
IMAGENET_DEFAULT_MEAN = (0.485, 0.456, 0.406)
IMAGENET_DEFAULT_STD = (0.229, 0.224, 0.225)
IMAGENET_INCEPTION_MEAN = (0.5, 0.5, 0.5)
IMAGENET_INCEPTION_STD = (0.5, 0.5, 0.5)
IMAGENET_DPN_MEAN = (124 / 255, 117 / 255, 104 / 255)
IMAGENET_DPN_STD = tuple([1 / (.0167 * 255)] * 3)
CIFAR10_DEFAULT_MEAN = (0.4914, 0.4822, 0.4465)
CIFAR10_DEFAULT_STD = (0.2023, 0.1994, 0.2010)
CIFAR100_DEFAULT_MEAN = (0.5071, 0.4867, 0.4408)
CIFAR100_DEFAULT_STD = (0.2675, 0.2565, 0.2761)
def unpack_mix_param(args):
mix_up = args['mix_up'] if 'mix_up' in args else False
cut_mix = args['cut_mix'] if 'cut_mix' in args else False
event_mix = args['event_mix'] if 'event_mix' in args else False
beta = args['beta'] if 'beta' in args else 1.
prob = args['prob'] if 'prob' in args else .5
num = args['num'] if 'num' in args else 1
num_classes = args['num_classes'] if 'num_classes' in args else 10
noise = args['noise'] if 'noise' in args else 0.
gaussian_n = args['gaussian_n'] if 'gaussian_n' in args else None
return mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n
def build_transform(is_train, img_size):
"""
构建数据增强, 适用于static data
:param is_train: 是否训练集
:param img_size: 输出的图像尺寸
:return: 数据增强策略
"""
resize_im = img_size > 32
if is_train:
# this should always dispatch to transforms_imagenet_train
transform = create_transform(
input_size=img_size,
is_training=True,
color_jitter=0.4,
# auto_augment='rand-m9-mstd0.5-inc1',
interpolation='bicubic',
# re_prob=0.25,
# re_mode='pixel',
# re_count=1,
)
if not resize_im:
# replace RandomResizedCropAndInterpolation with
# RandomCrop
transform.transforms[0] = transforms.RandomCrop(
img_size, padding=4)
return transform
t = []
if resize_im:
size = int((256 / 224) * img_size)
t.append(
# to maintain same ratio w.r.t. 224 images
transforms.Resize(size, interpolation=3),
)
t.append(transforms.CenterCrop(img_size))
t.append(transforms.ToTensor())
if img_size > 32:
t.append(transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD))
else:
t.append(transforms.Normalize(CIFAR10_DEFAULT_MEAN, CIFAR10_DEFAULT_STD))
return transforms.Compose(t)
def build_dataset(is_train, img_size, dataset, path, same_da=False):
"""
构建带有增强策略的数据集
:param is_train: 是否训练集
:param img_size: 输出图像尺寸
:param dataset: 数据集名称
:param path: 数据集路径
:param same_da: 为训练集使用测试集的增广方法
:return: 增强后的数据集
"""
transform = build_transform(False, img_size) if same_da else build_transform(is_train, img_size)
if dataset == 'CIFAR10':
dataset = datasets.CIFAR10(
path, train=is_train, transform=transform, download=True)
nb_classes = 10
elif dataset == 'CIFAR100':
dataset = datasets.CIFAR100(
path, train=is_train, transform=transform, download=True)
nb_classes = 100
else:
raise NotImplementedError
return dataset, nb_classes
class MNISTData(object):
"""
Load MNIST datesets.
"""
def __init__(self,
data_path: str,
batch_size: int,
train_trans: Sequence[torch.nn.Module] = None,
test_trans: Sequence[torch.nn.Module] = None,
pin_memory: bool = True,
drop_last: bool = True,
shuffle: bool = True,
) -> None:
self._data_path = data_path
self._batch_size = batch_size
self._pin_memory = pin_memory
self._drop_last = drop_last
self._shuffle = shuffle
self._train_transform = transforms.Compose(train_trans) if train_trans else None
self._test_transform = transforms.Compose(test_trans) if test_trans else None
def get_data_loaders(self):
print('Batch size: ', self._batch_size)
train_datasets = datasets.MNIST(root=self._data_path, train=True, transform=self._train_transform, download=True)
test_datasets = datasets.MNIST(root=self._data_path, train=False, transform=self._test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=self._drop_last, shuffle=self._shuffle
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=False
)
return train_loader, test_loader
def get_standard_data(self):
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
self._train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
self._test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
return self.get_data_loaders()
def get_mnist_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取MNIST数据
http://data.pymvpa.org/datasets/mnist/
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
if 'skip_norm' in kwargs and kwargs['skip_norm'] is True:
train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
else:
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
# transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
train_datasets = datasets.MNIST(
root=DATA_DIR, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.MNIST(
root=DATA_DIR, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_fashion_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取fashion MNIST数据
http://arxiv.org/abs/1708.07747
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor()])
test_transform = transforms.Compose([transforms.ToTensor()])
train_datasets = datasets.FashionMNIST(
root=DATA_DIR, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.FashionMNIST(
root=DATA_DIR, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_cifar10_data(batch_size, num_workers=8, same_da=False, **kwargs):
# """
# 获取CIFAR10数据
# https://www.cs.toronto.edu/~kriz/cifar.html
# :param batch_size: batch size
# :param kwargs:
# :return: (train loader, test loader, mixup_active, mixup_fn)
# """
# train_datasets, _ = build_dataset(True, 32, 'CIFAR10', DATA_DIR, same_da)
# test_datasets, _ = build_dataset(False, 32, 'CIFAR10', DATA_DIR, same_da)
#
# train_loader = torch.utils.data.DataLoader(
# train_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=True, shuffle=True,
# num_workers=num_workers
# )
#
# test_loader = torch.utils.data.DataLoader(
# test_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=False,
# num_workers=num_workers
# )
normalize = transforms.Normalize(CIFAR10_DEFAULT_MEAN, CIFAR10_DEFAULT_STD)
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(),
CIFAR10Policy(),
transforms.ToTensor(),
Cutout(n_holes=1, length=16),
normalize])
transform_test = transforms.Compose([transforms.ToTensor(), normalize])
train_dataset = datasets.CIFAR10(root=DATA_DIR, train=True, download=True, transform=transform_train)
test_dataset = datasets.CIFAR10(root=DATA_DIR, train=False, download=True, transform=transform_test)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
shuffle=True, num_workers=num_workers,
pin_memory=True
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
shuffle=False, num_workers=num_workers,
pin_memory=True
)
return train_loader, test_loader, None, None
def get_cifar100_data(batch_size, num_workers=8, same_data=False, *args, **kwargs):
# """
# 获取CIFAR100数据
# https://www.cs.toronto.edu/~kriz/cifar.html
# :param batch_size: batch size
# :param kwargs:
# :return: (train loader, test loader, mixup_active, mixup_fn)
# """
# train_datasets, _ = build_dataset(True, 32, 'CIFAR100', DATA_DIR, same_data)
# test_datasets, _ = build_dataset(False, 32, 'CIFAR100', DATA_DIR, same_data)
#
# train_loader = torch.utils.data.DataLoader(
# train_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
# )
#
# test_loader = torch.utils.data.DataLoader(
# test_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=False, num_workers=num_workers
# )
# return train_loader, test_loader, False, None
normalize = transforms.Normalize(CIFAR100_DEFAULT_MEAN, CIFAR100_DEFAULT_STD)
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(),
CIFAR10Policy(),
transforms.ToTensor(),
Cutout(n_holes=1, length=16),
normalize])
transform_test = transforms.Compose([transforms.ToTensor(), normalize])
train_dataset = datasets.CIFAR100(root=DATA_DIR, train=True, download=True, transform=transform_train)
test_dataset = datasets.CIFAR100(root=DATA_DIR, train=False, download=True, transform=transform_test)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
shuffle=True, num_workers=num_workers,
pin_memory=True
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
shuffle=False, num_workers=num_workers,
pin_memory=True
)
return train_loader, test_loader, None, None
def get_imnet_data(args, _logger, data_config, num_aug_splits, **kwargs):
"""
获取ImageNet数据集
http://arxiv.org/abs/1409.0575
:param args: 其他的参数
:param _logger: 日志路径
:param data_config: 增强策略
:param num_aug_splits: 不同增强策略的数量
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_dir = os.path.join(DATA_DIR, 'ILSVRC2012/train')
if not os.path.exists(train_dir):
_logger.error(
'Training folder does not exist at: {}'.format(train_dir))
exit(1)
dataset_train = ImageDataset(train_dir)
# collate_fn = None
# mixup_fn = None
# mixup_active = args.mixup > 0 or args.cutmix > 0. or args.cutmix_minmax is not None
# if mixup_active:
# mixup_args = dict(
# mixup_alpha=args.mixup, cutmix_alpha=args.cutmix, cutmix_minmax=args.cutmix_minmax,
# prob=args.mixup_prob, switch_prob=args.mixup_switch_prob, mode=args.mixup_mode,
# label_smoothing=args.smoothing, num_classes=args.num_classes)
# if args.prefetcher:
# # collate conflict (need to support deinterleaving in collate mixup)
# assert not num_aug_splits
# collate_fn = FastCollateMixup(**mixup_args)
# else:
# mixup_fn = Mixup(**mixup_args)
# if num_aug_splits > 1:
# dataset_train = AugMixDataset(dataset_train, num_splits=num_aug_splits)
train_interpolation = args.train_interpolation
if args.no_aug or not train_interpolation:
train_interpolation = data_config['interpolation']
loader_train = create_loader(
dataset_train,
input_size=data_config['input_size'],
batch_size=args.batch_size,
is_training=True,
use_prefetcher=args.prefetcher,
no_aug=args.no_aug,
# re_prob=args.reprob,
# re_mode=args.remode,
# re_count=args.recount,
# re_split=args.resplit,
scale=args.scale,
ratio=args.ratio,
hflip=args.hflip,
# vflip=args.vflip,
# color_jitter=args.color_jitter,
# auto_augment=args.aa,
# num_aug_splits=num_aug_splits,
interpolation=train_interpolation,
mean=data_config['mean'],
std=data_config['std'],
num_workers=args.workers,
distributed=args.distributed,
# collate_fn=collate_fn,
pin_memory=args.pin_mem,
# use_multi_epochs_loader=args.use_multi_epochs_loader
)
eval_dir = os.path.join(DATA_DIR, 'ILSVRC2012/val')
if not os.path.isdir(eval_dir):
eval_dir = os.path.join(DATA_DIR, 'ILSVRC2012/validation')
if not os.path.isdir(eval_dir):
_logger.error(
'Validation folder does not exist at: {}'.format(eval_dir))
exit(1)
dataset_eval = ImageDataset(eval_dir)
loader_eval = create_loader(
dataset_eval,
input_size=data_config['input_size'],
batch_size=args.validation_batch_size_multiplier * args.batch_size,
is_training=False,
use_prefetcher=args.prefetcher,
interpolation=data_config['interpolation'],
mean=data_config['mean'],
std=data_config['std'],
num_workers=args.workers,
distributed=args.distributed,
crop_pct=data_config['crop_pct'],
pin_memory=args.pin_mem,
)
return loader_train, loader_eval, None, None
def get_dvsg_data(batch_size, step, **kwargs):
"""
获取DVS Gesture数据
DOI: 10.1109/CVPR.2017.781
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.DVSGesture.sensor_size
size = kwargs['size'] if 'size' in kwargs else 48
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
train_dataset = tonic.datasets.DVSGesture(os.path.join(DATA_DIR, 'DVS/DVSGesture'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.DVSGesture(os.path.join(DATA_DIR, 'DVS/DVSGesture'),
transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
transforms.RandomCrop(size, padding=size // 12),
# lambda x: event_drop(x),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVSGesture/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVSGesture/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, mixup_active, None
def get_dvsc10_data(batch_size, step, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = tonic.datasets.CIFAR10DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=train_transform)
test_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
# lambda x: event_drop(x),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_train),
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_test),
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_nmnist_data(batch_size, step, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = tonic.datasets.NMNIST.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/NMNIST'), transform=train_transform)
test_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/NMNIST'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
# lambda x: event_drop(x),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NMNIST/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NMNIST/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_train),
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_test),
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_NCALTECH101_data(batch_size, step, **kwargs):
"""
获取NCaltech101数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = braincog.datasets.ncaltech101.NCALTECH101.sensor_size
cls_count = braincog.datasets.ncaltech101.NCALTECH101.cls_count
dataset_length = braincog.datasets.ncaltech101.NCALTECH101.length
portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += train_sample
train_sample_weight.extend(
[sample_weight] * train_sample
)
train_sample_weight.extend(
[0.] * test_sample
)
train_sample_index.extend(
list((range(idx_begin, idx_begin + train_sample)))
)
test_sample_index.extend(
list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.ncaltech101.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=train_transform)
test_dataset = braincog.datasets.ncaltech101.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: print(x.shape),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: temporal_flatten(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=train_sampler,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_UCF101DVS_data(batch_size, step, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = braincog.datasets.ucf101_dvs.UCF101DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.ucf101_dvs.UCF101DVS(os.path.join(DATA_DIR, 'DVS/UCF101DVS'), train=True, transform=train_transform)
test_dataset = braincog.datasets.ucf101_dvs.UCF101DVS(os.path.join(DATA_DIR, 'DVS/UCF101DVS'), train=False, transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
# transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'UCF101DVS/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'UCF101DVS/test_cache_{}'.format(step)),
transform=test_transform)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size, shuffle=False,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_HMDBDVS_data(batch_size, step, **kwargs):
sensor_size = braincog.datasets.hmdb_dvs.HMDBDVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.hmdb_dvs.HMDBDVS(os.path.join(DATA_DIR, 'HMDBDVS'), transform=train_transform)
test_dataset = braincog.datasets.hmdb_dvs.HMDBDVS(os.path.join(DATA_DIR, 'HMDBDVS'), transform=test_transform)
cls_count = train_dataset.cls_count
dataset_length = train_dataset.length
portion = .5
# portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += train_sample
train_sample_weight.extend(
[sample_weight] * train_sample
)
train_sample_weight.extend(
[0.] * test_sample
)
lst = list(range(idx_begin, idx_begin + train_sample + test_sample))
random.seed(0)
random.shuffle(lst)
train_sample_index.extend(
lst[:train_sample]
# list((range(idx_begin, idx_begin + train_sample)))
)
test_sample_index.extend(
lst[train_sample:train_sample + test_sample]
# list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: print(x.shape),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: temporal_flatten(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'HMDBDVS/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'HMDBDVS/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=train_sampler,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
# def get_NCARS_data(batch_size, step, **kwargs):
# """
# 获取N-Cars数据
# https://ieeexplore.ieee.org/document/8578284/
# :param batch_size: batch size
# :param step: 仿真步长
# :param kwargs:
# :return: (train loader, test loader, mixup_active, mixup_fn)
# """
# sensor_size = tonic.datasets.NCARS.sensor_size
# size = kwargs['size'] if 'size' in kwargs else 48
#
# train_transform = transforms.Compose([
# # tonic.transforms.Denoise(filter_time=10000),
# # tonic.transforms.DropEvent(p=0.1),
# tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
# ])
# test_transform = transforms.Compose([
# # tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
# ])
#
# train_dataset = tonic.datasets.NCARS(os.path.join(DATA_DIR, 'DVS/NCARS'), transform=train_transform, train=True)
# test_dataset = tonic.datasets.NCARS(os.path.join(DATA_DIR, 'DVS/NCARS'), transform=test_transform, train=False)
#
# train_transform = transforms.Compose([
# lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: dvs_channel_check_expend(x),
# transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
# ])
# test_transform = transforms.Compose([
# lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: dvs_channel_check_expend(x),
# ])
# if 'rand_aug' in kwargs.keys():
# if kwargs['rand_aug'] is True:
# n = kwargs['randaug_n']
# m = kwargs['randaug_m']
# train_transform.transforms.insert(2, RandAugment(m=m, n=n))
#
# # if 'temporal_flatten' in kwargs.keys():
# # if kwargs['temporal_flatten'] is True:
# # train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# # test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
#
# train_dataset = DiskCachedDataset(train_dataset,
# cache_path=os.path.join(DATA_DIR, 'DVS/NCARS/train_cache_{}'.format(step)),
# transform=train_transform, num_copies=3)
# test_dataset = DiskCachedDataset(test_dataset,
# cache_path=os.path.join(DATA_DIR, 'DVS/NCARS/test_cache_{}'.format(step)),
# transform=test_transform, num_copies=3)
#
# mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
# mixup_active = cut_mix | event_mix | mix_up
#
# if cut_mix:
# train_dataset = CutMix(train_dataset,
# beta=beta,
# prob=prob,
# num_mix=num,
# num_class=num_classes,
# noise=noise)
#
# if event_mix:
# train_dataset = EventMix(train_dataset,
# beta=beta,
# prob=prob,
# num_mix=num,
# num_class=num_classes,
# noise=noise,
# gaussian_n=gaussian_n)
# if mix_up:
# train_dataset = MixUp(train_dataset,
# beta=beta,
# prob=prob,
# num_mix=num,
# num_class=num_classes,
# noise=noise)
#
# train_loader = torch.utils.data.DataLoader(
# train_dataset, batch_size=batch_size,
# pin_memory=True, drop_last=True, num_workers=8,
# shuffle=True,
# )
#
# test_loader = torch.utils.data.DataLoader(
# test_dataset, batch_size=batch_size,
# pin_memory=True, drop_last=False, num_workers=2,
# shuffle=False,
# )
#
# return train_loader, test_loader, mixup_active, None
def get_nomni_data(batch_size, train_portion=1., **kwargs):
"""
获取N-Omniglot数据
:param batch_size:batch的大小
:param data_mode:一共full nkks pair三种模式
:param frames_num:一个样本帧的个数
:param data_type:event frequency两种模式
"""
data_mode = kwargs["data_mode"] if "data_mode" in kwargs else "full"
frames_num = kwargs["frames_num"] if "frames_num" in kwargs else 10
data_type = kwargs["data_type"] if "data_type" in kwargs else "event"
train_transform = transforms.Compose([
transforms.Resize((64, 64))])
test_transform = transforms.Compose([
transforms.Resize((64, 64))])
if data_mode == "full":
train_datasets = NOmniglotfull(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), train=True, frames_num=frames_num,
data_type=data_type,
transform=train_transform)
test_datasets = NOmniglotfull(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), train=False, frames_num=frames_num,
data_type=data_type,
transform=test_transform)
elif data_mode == "nkks":
train_datasets = NOmniglotNWayKShot(os.path.join(DATA_DIR, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=True,
frames_num=frames_num,
data_type=data_type,
transform=train_transform)
test_datasets = NOmniglotNWayKShot(os.path.join(DATA_DIR, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=False,
frames_num=frames_num,
data_type=data_type,
transform=test_transform)
elif data_mode == "pair":
train_datasets = NOmniglotTrainSet(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), use_frame=True,
frames_num=frames_num, data_type=data_type,
use_npz=False, resize=105)
test_datasets = NOmniglotTestSet(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), time=2000, way=kwargs["n_way"],
shot=kwargs["k_shot"], use_frame=True,
frames_num=frames_num, data_type=data_type, use_npz=False, resize=105)
else:
pass
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size, num_workers=12,
pin_memory=True, drop_last=True, shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size, num_workers=12,
pin_memory=True, drop_last=False
)
return train_loader, test_loader, None, None
================================================
FILE: examples/Spiking-Transformers/main.py
================================================
import argparse
import time
import timm.models
import yaml
import os
import random as buildin_random
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
# from braincog.datasets.datasets import *
from datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.vgg_snn import VGG_SNN, SNN5
# from braincog.model_zoo.fc_snn import SHD_SNN
from braincog.model_zoo.resnet19_snn import resnet19
#from braincog.model_zoo.sew_resnet import sew_resnet18, sew_resnet34, sew_resnet50
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix, plot_mem_distribution
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model, register_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from torch.utils.tensorboard import SummaryWriter
# load spiking transformer models
from models.spikformer import spikformer
from models.spikformer_dvs import spikformer_dvs
from models.spike_driven_transformer import sd_transformer
from models.spike_driven_transformer_dvs import sd_transformer_dvs
from models.spike_driven_transformer_v2 import sd_transformer_v2
from models.spike_driven_transformer_v2_dvs import sd_transformer_v2_dvs
# choose ur device here
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--dataset', default='dvsc10', type=str)
parser.add_argument('--model', default='spikformer', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=1e-4,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=400, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochss to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=0.,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=0.,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--output', default='/home/shensicheng/code/SpikingTransformers', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--tensorboard-dir', default='./runs', type=str)
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=0)
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
parser.add_argument('--conv-type', type=str, default='normal')
parser.add_argument('--sew-cnf', type=str, default='ADD')
parser.add_argument('--rand-step', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='QGateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
parser.add_argument('--n-encode-type', type=str, default='linear')
parser.add_argument('--n-preact', action='store_true')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--tet-loss', action='store_true')
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=2.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--gaussian-n', type=int, default=3)
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
parser.add_argument('--mem-dist', action='store_true')
parser.add_argument('--adaptation-info', action='store_true')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def main():
args, args_text = _parse_args()
# args.no_spike_output = args.no_spike_output | args.cut_mix
args.no_spike_output = True
output_dir = ''
if args.local_rank == 0:
output_base = args.output if args.output else './output'
exp_name = '-'.join([
args.model,
args.dataset,
args.node_type,
str(args.step),
args.suffix,
datetime.now().strftime("%Y%m%d-%H%M%S"),
# str(args.img_size)
])
output_dir = get_outdir(output_base, 'train', exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
summary_writer = SummaryWriter(log_dir=os.path.join(args.tensorboard_dir, exp_name))
args.tensorboard_prefix = os.path.join(args.dataset, args.model)
else:
summary_writer = None
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
model = create_model(
args.model,
# pretrained=args.pretrained,
# num_classes=args.num_classes,
# dataset=args.dataset,
# step=args.step,
# encode_type=args.encode,
# node_type=eval(args.node_type),
# threshold=args.threshold,
# tau=args.tau,
# sigmoid_thres=args.sigmoid_thres,
# requires_thres_grad=args.requires_thres_grad,
# spike_output=not args.no_spike_output,
# act_fun=args.act_fun,
# temporal_flatten=args.temporal_flatten,
# layer_by_layer=args.layer_by_layer,
# n_groups=args.n_groups,
# n_encode_type=args.n_encode_type,
# n_preact=args.n_preact,
# tet_loss=args.tet_loss,
# sew_cnf=args.sew_cnf,
# conv_type=args.conv_type,
)
_logger.info('[MODEL ARCH]\n{}'.format(model))
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=list(range(args.num_gpu))).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
_logger.info('[OPTIMIZER]\n{}'.format(optimizer))
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
# print(model.get_attr('mu'))
# print(model.get_attr('sigma'))
if hasattr(model, 'set_threshold'):
model.set_threshold(args.threshold)
if args.critical_loss or args.spike_rate:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model.cuda(), device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
)
# _logger.info('train_loader:\n{}\nval_loader:\n{}'.format(loader_train, loader_eval))
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
elif args.loss_fn == 'onehot-mse':
train_loss_fn = OnehotMse(args.num_classes)
validate_loss_fn = OnehotMse(args.num_classes)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
if args.tet_loss:
train_loss_fn = TetLoss(train_loss_fn)
validate_loss_fn = TetLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
# if args.distributed:
# raise NotImplementedError('eval not has not been verified for distributed')
# else:
# load_checkpoint(model, args.eval_checkpoint, args.model_ema)
model.eval()
for t in range(1, args.step * 3):
# for t in range(args.step, args.step + 1):
model.set_attr('step', t)
val_metrics = validate(start_epoch, model, loader_eval, validate_loss_fn, args,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer)
print(f"[STEP:{t}], Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=output_dir, recovery_dir=output_dir, decreasing=decreasing, max_history=3)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
if args.distributed:
loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler,
model_ema=model_ema, mixup_fn=mixup_fn, summary_writer=summary_writer
)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics = validate(epoch, model, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer)
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics = validate(
epoch, model_ema.ema, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast, log_suffix=' (EMA)',
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer
)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(output_dir, 'summary.csv'),
write_header=best_metric is None)
# if saver is not None and epoch >= args.n_warm_up:
if saver is not None:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
except KeyboardInterrupt:
pass
if best_metric is not None:
_logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None, summary_writer=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and loader.mixup_enabled:
loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
# closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
# t, k = adjust_surrogate_coeff(100, args.epochs)
# model.set_attr('t', t)
# model.set_attr('k', k)
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
iters_per_epoch = len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
if args.rand_step:
step = buildin_random.randint(1, args.step + 2)
model.set_attr('step', step)
data_time_m.update(time.time() - end)
if not args.prefetcher or args.dataset != 'imnet':
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
if mixup_fn is not None:
inputs, target = mixup_fn(inputs, target)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
with amp_autocast():
output = model(inputs)
loss = loss_fn(output, target)
if args.tet_loss:
output = output.mean(0)
if not (args.cut_mix | args.mix_up | args.event_mix | (args.cutmix != 0.) | (args.mixup != 0.)):
# print(output.shape, target.shape)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
# if args.opt == 'lamb':
# optimizer.step(epoch=epoch)
# else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/top1'), acc1.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/top5'), acc5.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/loss'), loss.item(), epoch * iters_per_epoch + batch_idx)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
if args.distributed:
loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
# closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
# if args.distributed:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/top1'), top1_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/top5'), top5_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/loss'), losses_m.avg, epoch)
if args.rand_step:
model.set_attr('step', args.step)
return OrderedDict([('loss', losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args, amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False, summary_writer=None):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
# closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
spike_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
mem_vec = []
end = time.time()
last_idx = len(loader) - 1
iters_per_epoch = len(loader)
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat or args.mem_dist) and not args.critical_loss:
model.set_requires_fp(True)
with amp_autocast():
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
# print(args.rank, output.shape, target.shape, max(target))
loss = loss_fn(output, target)
if args.tet_loss:
output = output.mean(0)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
# closses_m.update(closs, inputs.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/top1'), acc1.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/top5'), acc5.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/loss'), loss.item(), epoch * iters_per_epoch + batch_idx)
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
if not args.distributed and spike_rate:
spike_m.update(model.get_tot_spike() / output.size(0), output.size(0))
if not args.distributed and spike_rate:
_logger.info(
'[Spike Info]: {spike.val} ({spike.avg})'.format(
spike=spike_m
)
)
if last_batch or batch_idx % args.log_interval == 0:
_logger.info(
'Eval : {} '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
epoch,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
top1=top1_m,
top5=top5_m,
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg)])
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/top1'), top1_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/top5'), top5_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/loss'), losses_m.avg, epoch)
return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/Spiking-Transformers/models/spike_driven_transformer.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from LIFNode import MyNode # LIFNode setting for Spiking Tranformers
from functools import partial
__all__ = ['spikformer']
'''The input shape of neuromorphic datasets in Spiking Transformer when using Braincog
are used to set to 64*64 '''
class MLP(BaseModule):
#Linear here is subsituted by convs
def __init__(self, in_features, step=10, encode_type='direct', hidden_features=None, out_features=None, drop=0.):
super().__init__(step=10, encode_type='direct')
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_conv = nn.Conv1d(in_features, hidden_features, kernel_size=1, stride=1)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step, tau=2.0)
self.fc2_conv = nn.Conv1d(hidden_features, out_features, kernel_size=1, stride=1)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step, tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T, B, C, N = x.shape
x = self.fc1_lif(x.flatten(0, 1)).reshape(T, B, C, N).contiguous()
x = self.fc1_conv(x.flatten(0, 1))
x = self.fc1_bn(x).reshape(T, B, self.c_hidden, N).contiguous() # T B C N
x = self.fc2_lif(x.flatten(0, 1)).reshape(T, B, self.c_hidden, N).contiguous()
x = self.fc2_conv(x.flatten(0, 1))
x = self.fc2_bn(x).reshape(T, B, C, N).contiguous()
return x
class SSA(BaseModule):
def __init__(self, dim, step=10, encode_type='direct', num_heads=16, qkv_bias=False, qk_scale=None, attn_drop=0.,
proj_drop=0., sr_ratio=1):
super().__init__(step=10, encode_type='direct')
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
# for shortcut
self.head_lif = MyNode(step=step, tau=2.0)
self.num_heads = num_heads
# scale
self.scale = 0.25
self.q_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.q_bn = nn.BatchNorm1d(dim)
self.q_lif = MyNode(step=step, tau=2.0)
self.k_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.k_bn = nn.BatchNorm1d(dim)
self.k_lif = MyNode(step=step, tau=2.0)
self.v_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.v_bn = nn.BatchNorm1d(dim)
self.v_lif = MyNode(step=step, tau=2.0)
self.attn_drop = nn.Dropout(0.2)
self.res_lif = MyNode(step=step, tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5, )
self.proj_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.proj_bn = nn.BatchNorm1d(dim)
self.proj_lif = MyNode(step=step, tau=2.0, )
self.sd_lif = PLIFNode(step=step, threshold=0.5, tau=2)
def forward(self, x):
self.reset()
T, B, C, N = x.shape
x_for_qkv = x.flatten(0, 1) # TB, C N
x_for_qkv = self.head_lif(x_for_qkv)
q_conv_out = self.q_conv(x_for_qkv) # [TB] C N
q_conv_out = self.q_bn(q_conv_out).reshape(T, B, C, N).contiguous() # T B C N
q_conv_out = self.q_lif(q_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
q = q_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_conv_out = self.k_conv(x_for_qkv)
k_conv_out = self.k_bn(k_conv_out).reshape(T, B, C, N).contiguous()
k_conv_out = self.k_lif(k_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
k = k_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_conv_out = self.v_conv(x_for_qkv)
v_conv_out = self.v_bn(v_conv_out).reshape(T, B, C, N).contiguous()
v_conv_out = self.v_lif(v_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
v = v_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
# Spike-driven Transformer attention
kv = k.mul(v)
kv = kv.sum(dim=-2, keepdim=True)
kv = self.sd_lif(kv)
x = q.mul(kv)
x = x.transpose(3,4).reshape(T, B, C, N).contiguous() # T B C N
# ignore following lines for membrane shortcut
# x = self.attn_lif(x.flatten(0,1)) #[TB] C N
# x = self.proj_lif(self.proj_bn(self.proj_conv(x))).reshape(T, B, C, N) #T B C N
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, step=10, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = SSA(dim, step=step, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(step=step, in_features=dim, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
# residual connection
x = x + self.attn(x)
x = x + self.mlp(x)
return x
# embed_dims = 256
class SPS(BaseModule):
def __init__(self, step=10, encode_type='direct', img_size_h=128, img_size_w=128, patch_size=4, in_channels=2,
embed_dims=256):
super().__init__(step=10, encode_type='direct')
self.image_size = [img_size_h, img_size_w]
patch_size = to_2tuple(patch_size) # 4->(4,4)
self.patch_size = patch_size # patch_size
self.C = in_channels # image_channel
self.H, self.W = self.image_size[0] // patch_size[0], self.image_size[1] // patch_size[1]
self.num_patches = self.H * self.W
# DVS with 2 more Maxpooling
self.proj_conv = nn.Conv2d(in_channels, embed_dims // 8, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn = nn.BatchNorm2d(embed_dims // 8)
self.proj_lif = MyNode(step=step, tau=2.0)
self.maxpool = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv1 = nn.Conv2d(embed_dims // 8, embed_dims // 4, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn1 = nn.BatchNorm2d(embed_dims // 4)
self.proj_lif1 = MyNode(step=step, tau=2.0)
self.maxpool1 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv2 = nn.Conv2d(embed_dims // 4, embed_dims // 2, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn2 = nn.BatchNorm2d(embed_dims // 2)
self.proj_lif2 = MyNode(step=step, tau=2.0)
self.maxpool2 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv3 = nn.Conv2d(embed_dims // 2, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn3 = nn.BatchNorm2d(embed_dims)
# self.proj_lif3 = MyNode(step=step, tau=2.0)
self.maxpool3 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.rpe_conv = nn.Conv2d(embed_dims, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.rpe_bn = nn.BatchNorm2d(embed_dims)
self.rpe_lif = MyNode(step=step, tau=2.0)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.proj_conv(x.flatten(0, 1)) # have some fire value
x = self.proj_bn(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif(x.flatten(0, 1)).contiguous()
x = self.maxpool(x)
x = self.proj_conv1(x)
x = self.proj_bn1(x).reshape(T, B, -1, H // 2, W // 2).contiguous()
x = self.proj_lif1(x.flatten(0, 1)).contiguous()
x = self.maxpool1(x)
x = self.proj_conv2(x)
x = self.proj_bn2(x).reshape(T, B, -1, H // 4, W // 4).contiguous()
x = self.proj_lif2(x.flatten(0, 1)).contiguous()
x = self.maxpool2(x)
x = self.proj_conv3(x)
x = self.proj_bn3(x).reshape(T, B, -1, H // 8, W // 8)
# abandon the LIF here to leverage membrane shortcut
# x = self.proj_lif3(x.flatten(0, 1)).contiguous()
x = self.maxpool3(x.flatten(0,1)).reshape(T, B, -1, H // 16, W // 16)
# The order here is different from spikformer for using membrain shortcut
x_rpe = self.rpe_lif(x.flatten(0, 1)).contiguous()
x_rpe = self.rpe_bn(self.rpe_conv(x_rpe)).reshape(T, B, -1, H // 16, W // 16).contiguous()
x = x + x_rpe # membrane shortcut
x = x.reshape(T, B, -1, (H // 16) * (H // 16)).contiguous()
return x # T B C N
class Spikformer(BaseModule):
def __init__(self, step=10, encode_type='direct',
img_size_h=224, img_size_w=224, patch_size=16, in_channels=3, num_classes=1000,
embed_dims=512, num_heads=12, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=8, sr_ratios=4,
):
super().__init__(step=10, encode_type='direct')
self.step = step # time step
self.num_classes = num_classes
self.depths = depths
# for membrane shortcut
self.final_lif = MyNode(step=step,tau=2.0)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
patch_embed = SPS(step=step,
img_size_h=img_size_h,
img_size_w=img_size_w,
patch_size=patch_size,
in_channels=in_channels,
embed_dims=embed_dims)
block = nn.ModuleList([Block(step=step,
dim=embed_dims, num_heads=num_heads, mlp_ratio=mlp_ratios, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[j],
norm_layer=norm_layer, sr_ratio=sr_ratios)
for j in range(depths)])
setattr(self, f"patch_embed", patch_embed)
setattr(self, f"block", block)
# classification head
self.head = nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
block = getattr(self, f"block")
patch_embed = getattr(self, f"patch_embed")
x = patch_embed(x)
for blk in block:
x = blk(x)
# for membrane shortcut
T, B , C, N = x.shape
x = self.final_lif(x.flatten(0,1)).reshape(T, B, C, N).contiguous()
return x.mean(3)
def forward(self, x):
self.reset()
x = self.encoder(x)
x = self.forward_features(x)
x = self.head(x.mean(0))
return x
# Adjust ur hyperparams here
@register_model
def sd_transformer(pretrained=False, **kwargs):
model = Spikformer(step = 4,
img_size_h=224, img_size_w=224,
patch_size=16, embed_dims=512, num_heads=16, mlp_ratios=4,
in_channels=3, num_classes=1000, qkv_bias=False,
depths=8, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/Spiking-Transformers/models/spike_driven_transformer_dvs.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from LIFNode import MyNode # LIFNode setting for Spiking Tranformers
from functools import partial
__all__ = ['spikformer']
'''The input shape of neuromorphic datasets in Spiking Transformer when using Braincog
are used to set to 64*64 '''
class MLP(BaseModule):
#Linear here is subsituted by convs
def __init__(self, in_features, step=10, encode_type='direct', hidden_features=None, out_features=None, drop=0.):
super().__init__(step=10, encode_type='direct')
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_conv = nn.Conv1d(in_features, hidden_features, kernel_size=1, stride=1)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step, tau=2.0)
self.fc2_conv = nn.Conv1d(hidden_features, out_features, kernel_size=1, stride=1)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step, tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T, B, C, N = x.shape
x = self.fc1_lif(x.flatten(0, 1)).reshape(T, B, C, N).contiguous()
x = self.fc1_conv(x.flatten(0, 1))
x = self.fc1_bn(x).reshape(T, B, self.c_hidden, N).contiguous() # T B C N
x = self.fc2_lif(x.flatten(0, 1)).reshape(T, B, self.c_hidden, N).contiguous()
x = self.fc2_conv(x.flatten(0, 1))
x = self.fc2_bn(x).reshape(T, B, C, N).contiguous()
return x
class SSA(BaseModule):
def __init__(self, dim, step=10, encode_type='direct', num_heads=16, qkv_bias=False, qk_scale=None, attn_drop=0.,
proj_drop=0., sr_ratio=1):
super().__init__(step=10, encode_type='direct')
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
# for shortcut
self.head_lif = MyNode(step=step, tau=2.0)
self.num_heads = num_heads
# scale
self.scale = 0.25
self.q_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.q_bn = nn.BatchNorm1d(dim)
self.q_lif = MyNode(step=step, tau=2.0)
self.k_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.k_bn = nn.BatchNorm1d(dim)
self.k_lif = MyNode(step=step, tau=2.0)
self.v_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.v_bn = nn.BatchNorm1d(dim)
self.v_lif = MyNode(step=step, tau=2.0)
self.attn_drop = nn.Dropout(0.2)
self.res_lif = MyNode(step=step, tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5, )
self.proj_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.proj_bn = nn.BatchNorm1d(dim)
self.proj_lif = MyNode(step=step, tau=2.0, )
self.sd_lif = PLIFNode(step=step, threshold=0.5, tau=2)
def forward(self, x):
self.reset()
T, B, C, N = x.shape
x_for_qkv = x.flatten(0, 1) # TB, C N
x_for_qkv = self.head_lif(x_for_qkv)
q_conv_out = self.q_conv(x_for_qkv) # [TB] C N
q_conv_out = self.q_bn(q_conv_out).reshape(T, B, C, N).contiguous() # T B C N
q_conv_out = self.q_lif(q_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
q = q_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_conv_out = self.k_conv(x_for_qkv)
k_conv_out = self.k_bn(k_conv_out).reshape(T, B, C, N).contiguous()
k_conv_out = self.k_lif(k_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
k = k_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_conv_out = self.v_conv(x_for_qkv)
v_conv_out = self.v_bn(v_conv_out).reshape(T, B, C, N).contiguous()
v_conv_out = self.v_lif(v_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
v = v_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
# Spike-driven Transformer attention
kv = k.mul(v)
kv = kv.sum(dim=-2, keepdim=True)
kv = self.sd_lif(kv)
x = q.mul(kv)
x = x.transpose(3,4).reshape(T, B, C, N).contiguous() # T B C N
# ignore following lines for membrane shortcut
# x = self.attn_lif(x.flatten(0,1)) #[TB] C N
# x = self.proj_lif(self.proj_bn(self.proj_conv(x))).reshape(T, B, C, N) #T B C N
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, step=10, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = SSA(dim, step=step, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(step=step, in_features=dim, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
# residual connection
x = x + self.attn(x)
x = x + self.mlp(x)
return x
# embed_dims = 256
class SPS(BaseModule):
def __init__(self, step=10, encode_type='direct', img_size_h=128, img_size_w=128, patch_size=4, in_channels=2,
embed_dims=256):
super().__init__(step=10, encode_type='direct')
self.image_size = [img_size_h, img_size_w]
patch_size = to_2tuple(patch_size) # 4->(4,4)
self.patch_size = patch_size # patch_size
self.C = in_channels # image_channel
self.H, self.W = self.image_size[0] // patch_size[0], self.image_size[1] // patch_size[1]
self.num_patches = self.H * self.W
# DVS with 2 more Maxpooling
self.proj_conv = nn.Conv2d(in_channels, embed_dims // 8, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn = nn.BatchNorm2d(embed_dims // 8)
self.proj_lif = MyNode(step=step, tau=2.0)
self.maxpool = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv1 = nn.Conv2d(embed_dims // 8, embed_dims // 4, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn1 = nn.BatchNorm2d(embed_dims // 4)
self.proj_lif1 = MyNode(step=step, tau=2.0)
self.maxpool1 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv2 = nn.Conv2d(embed_dims // 4, embed_dims // 2, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn2 = nn.BatchNorm2d(embed_dims // 2)
self.proj_lif2 = MyNode(step=step, tau=2.0)
self.maxpool2 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv3 = nn.Conv2d(embed_dims // 2, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn3 = nn.BatchNorm2d(embed_dims)
# self.proj_lif3 = MyNode(step=step, tau=2.0)
self.maxpool3 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.rpe_conv = nn.Conv2d(embed_dims, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.rpe_bn = nn.BatchNorm2d(embed_dims)
self.rpe_lif = MyNode(step=step, tau=2.0)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.proj_conv(x.flatten(0, 1)) # have some fire value
x = self.proj_bn(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif(x.flatten(0, 1)).contiguous()
x = self.maxpool(x)
x = self.proj_conv1(x)
x = self.proj_bn1(x).reshape(T, B, -1, H // 2, W // 2).contiguous()
x = self.proj_lif1(x.flatten(0, 1)).contiguous()
x = self.maxpool1(x)
x = self.proj_conv2(x)
x = self.proj_bn2(x).reshape(T, B, -1, H // 4, W // 4).contiguous()
x = self.proj_lif2(x.flatten(0, 1)).contiguous()
x = self.maxpool2(x)
x = self.proj_conv3(x)
x = self.proj_bn3(x).reshape(T, B, -1, H // 8, W // 8)
# abandon the LIF here to leverage membrane shortcut
# x = self.proj_lif3(x.flatten(0, 1)).contiguous()
x = self.maxpool3(x.flatten(0,1)).reshape(T, B, -1, H // 16, W // 16)
# The order here is different from spikformer for using membrain shortcut
x_rpe = self.rpe_lif(x.flatten(0, 1)).contiguous()
x_rpe = self.rpe_bn(self.rpe_conv(x_rpe)).reshape(T, B, -1, H // 16, W // 16).contiguous()
x = x + x_rpe # membrane shortcut
x = x.reshape(T, B, -1, (H // 16) * (H // 16)).contiguous()
return x # T B C N
class Spikformer(BaseModule):
def __init__(self, step=10, encode_type='direct',
img_size_h=64, img_size_w=64, patch_size=4, in_channels=2, num_classes=10,
embed_dims=256, num_heads=16, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=2, sr_ratios=4,
):
super().__init__(step=10, encode_type='direct')
self.step = step # time step
self.num_classes = num_classes
self.depths = depths
# for membrane shortcut
self.final_lif = MyNode(step=step,tau=2.0)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
patch_embed = SPS(step=step,
img_size_h=img_size_h,
img_size_w=img_size_w,
patch_size=patch_size,
in_channels=in_channels,
embed_dims=embed_dims)
block = nn.ModuleList([Block(step=step,
dim=embed_dims, num_heads=num_heads, mlp_ratio=mlp_ratios, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[j],
norm_layer=norm_layer, sr_ratio=sr_ratios)
for j in range(depths)])
setattr(self, f"patch_embed", patch_embed)
setattr(self, f"block", block)
# classification head
self.head = nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
block = getattr(self, f"block")
patch_embed = getattr(self, f"patch_embed")
x = patch_embed(x)
for blk in block:
x = blk(x)
# for membrane shortcut
T, B , C, N = x.shape
x = self.final_lif(x.flatten(0,1)).reshape(T, B, C, N).contiguous()
return x.mean(3)
def forward(self, x):
self.reset()
x = x.permute(1, 0, 2, 3, 4) # [T, N, 2, *, *]
x = self.forward_features(x)
x = self.head(x.mean(0))
return x
# Adjust ur hyperparams here
@register_model
def sd_transformer_dvs(pretrained=False, **kwargs):
model = Spikformer(step = 8,
img_size_h=64, img_size_w=64,
patch_size=4, embed_dims=256, num_heads=16, mlp_ratios=4,
in_channels=2, num_classes=10, qkv_bias=False,
depths=2, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/Spiking-Transformers/models/spike_driven_transformer_v2.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from LIFNode import MyNode # LIFNode setting for Spiking Tranformers
from functools import partial
__all__ = ['spikformer']
'''The input shape of neuromorphic datasets in Spiking Transformer when using Braincog
are used to set to 64*64 '''
'''Here the second version of Spike-driven Transformer only open sourced the
code for img cla '''
# Modified Operators
class BNAndPadLayer(nn.Module):
def __init__(
self,
pad_pixels,
num_features,
eps=1e-5,
momentum=0.1,
affine=True,
track_running_stats=True,
):
super(BNAndPadLayer, self).__init__()
self.bn = nn.BatchNorm2d(
num_features, eps, momentum, affine, track_running_stats
)
self.pad_pixels = pad_pixels
def forward(self, input):
output = self.bn(input)
if self.pad_pixels > 0:
if self.bn.affine:
pad_values = (
self.bn.bias.detach()
- self.bn.running_mean
* self.bn.weight.detach()
/ torch.sqrt(self.bn.running_var + self.bn.eps)
)
else:
pad_values = -self.bn.running_mean / torch.sqrt(
self.bn.running_var + self.bn.eps
)
output = F.pad(output, [self.pad_pixels] * 4)
pad_values = pad_values.view(1, -1, 1, 1)
output[:, :, 0 : self.pad_pixels, :] = pad_values
output[:, :, -self.pad_pixels :, :] = pad_values
output[:, :, :, 0 : self.pad_pixels] = pad_values
output[:, :, :, -self.pad_pixels :] = pad_values
return output
@property
def weight(self):
return self.bn.weight
@property
def bias(self):
return self.bn.bias
@property
def running_mean(self):
return self.bn.running_mean
@property
def running_var(self):
return self.bn.running_var
@property
def eps(self):
return self.bn.eps
class RepConv(nn.Module):
def __init__(
self,
in_channels,
out_channels,
bias=False,
):
super().__init__()
# hidden_channel = in_channel
conv1x1 = nn.Conv2d(in_channels, in_channels, 1, 1, 0, bias=False, groups=1)
bn = BNAndPadLayer(pad_pixels=1, num_features=in_channels)
conv3x3 = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 3, 1, 0, groups=in_channels, bias=False),
nn.Conv2d(in_channels, out_channels, 1, 1, 0, groups=1, bias=False),
nn.BatchNorm2d(out_channels),
)
self.body = nn.Sequential(conv1x1, bn, conv3x3)
def forward(self, x):
return self.body(x)
class SepConv(BaseModule):
r"""
Inverted separable convolution from MobileNetV2: https://arxiv.org/abs/1801.04381.
"""
def __init__(
self,
dim,
step=8,
encode_type='direct',
expansion_ratio=2,
act2_layer=nn.Identity,
bias=False,
kernel_size=7,
padding=3,
):
super().__init__(step=step,encode_type=encode_type,)
med_channels = int(expansion_ratio * dim)
self.lif1 = MyNode(step=step,tau=2.0)
self.pwconv1 = nn.Conv2d(dim, med_channels, kernel_size=1, stride=1, bias=bias)
self.bn1 = nn.BatchNorm2d(med_channels)
self.lif2 =MyNode(step=step,tau=2.0)
self.dwconv = nn.Conv2d(
med_channels,
med_channels,
kernel_size=kernel_size,
padding=padding,
groups=med_channels,
bias=bias,
) # depthwise conv
self.pwconv2 = nn.Conv2d(med_channels, dim, kernel_size=1, stride=1, bias=bias)
self.bn2 = nn.BatchNorm2d(dim)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.lif1(x.flatten(0,1)).reshape(T,B,C,H,W).contiguous()
x = self.bn1(self.pwconv1(x.flatten(0, 1))).reshape(T, B, -1, H, W)
x = self.lif2(x.flatten(0,1)).reshape(T,B,-1,H,W).contiguous()
x = self.dwconv(x.flatten(0, 1))
x = self.bn2(self.pwconv2(x)).reshape(T, B, -1, H, W)
return x # T B C H W
class MLP(BaseModule):
#Linear here is subsituted by convs
def __init__(self, in_features, step=10, encode_type='direct', hidden_features=None, out_features=None, drop=0.):
super().__init__(step=10, encode_type='direct')
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_conv = nn.Conv1d(in_features, hidden_features, kernel_size=1, stride=1)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step, tau=2.0)
self.fc2_conv = nn.Conv1d(hidden_features, out_features, kernel_size=1, stride=1)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step, tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = x.flatten(3) # T B C N
_, _, _, N = x.shape
x = self.fc1_lif(x.flatten(0, 1)).reshape(T, B, C, N).contiguous()
x = self.fc1_conv(x.flatten(0, 1))
x = self.fc1_bn(x).reshape(T, B, self.c_hidden, N).contiguous() # T B C N
x = self.fc2_lif(x.flatten(0, 1)).reshape(T, B, self.c_hidden, N).contiguous()
x = self.fc2_conv(x.flatten(0, 1))
x = self.fc2_bn(x).reshape(T, B, C, H, W).contiguous()
return x # T B C H W
# convs in SDSA V3/V4 should be substituted
class SDSA(BaseModule):
def __init__(self, dim, step=10, encode_type='direct', num_heads=16, qkv_bias=False, qk_scale=None, attn_drop=0.,
proj_drop=0., sr_ratio=1):
super().__init__(step=10, encode_type='direct')
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
# scale
self.scale = 0.125
self.head_lif = MyNode(step=step, tau=2.0) # for spike-drivens
self.q_conv = RepConv(dim, dim, bias=False)
self.q_bn = nn.BatchNorm2d(dim)
self.q_lif = MyNode(step=step, tau=2.0)
self.k_conv = RepConv(dim, dim, bias=False)
self.k_bn = nn.BatchNorm2d(dim)
self.k_lif = MyNode(step=step, tau=2.0)
self.v_conv = RepConv(dim, dim, bias=False)
self.v_bn = nn.BatchNorm2d(dim)
self.v_lif = MyNode(step=step, tau=2.0)
self.attn_drop = nn.Dropout(0.2)
self.res_lif = MyNode(step=step, tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5, )
self.proj_conv = RepConv(dim, dim, bias=False)
self.proj_bn = nn.BatchNorm2d(dim)
def forward(self, x):
self.reset()
#different here
T, B, C, H, W = x.shape
N = H * W
x = self.head_lif(x.flatten(0,1)).reshape(T, B, C, H, W).contiguous()
x_for_qkv = x.flatten(0, 1) # TB C H W
q_conv_out = self.q_conv(x_for_qkv) # [TB] C H W
q_conv_out = self.q_bn(q_conv_out).reshape(T, B, C, H, W).contiguous() # T B C H W
q_conv_out = self.q_lif(q_conv_out.flatten(0, 1)).reshape(T, B, C, N).transpose(-1,-2) # T B N C
q = q_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_conv_out = self.k_conv(x_for_qkv)
k_conv_out = self.k_bn(k_conv_out).reshape(T, B, C, H, W).contiguous()
k_conv_out = self.k_lif(k_conv_out.flatten(0, 1)).reshape(T, B, C, N).transpose(-1,-2) # T B N C
k = k_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_conv_out = self.v_conv(x_for_qkv)
v_conv_out = self.v_bn(v_conv_out).reshape(T, B, C, H, W).contiguous()
v_conv_out = self.v_lif(v_conv_out.flatten(0, 1)).reshape(T, B, C, N).transpose(-1,-2) # T B N C
v = v_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
x = k.transpose(-2, -1) @ v
x = (q @ x) * self.scale
x = x.transpose(3, 4).reshape(T, B, C, N).contiguous()
x = self.attn_lif(x).reshape(T, B, C, H, W)
x = x.reshape(T, B, C, H, W)
x = x.flatten(0, 1)
x = self.proj_conv(x)
x = self.proj_bn(x).reshape(T, B, C, H, W)
return x # T B C H W
class Block(nn.Module):
def __init__(self, dim, num_heads, step=10, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = SDSA(dim, step=step, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(step=step, in_features=dim, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
# residual connection
x = x + self.attn(x)
x = x + self.mlp(x)
return x
class DownSampling(BaseModule):
def __init__(
self,
step=10,
encode_type='direct',
in_channels=2,
embed_dims=512,
kernel_size=3,
stride=2,
padding=1,
first_layer=True,
):
super().__init__(step=step,
encode_type=encode_type,)
self.encode_conv = nn.Conv2d(
in_channels,
embed_dims,
kernel_size=kernel_size,
stride=stride,
padding=padding,
)
self.encode_bn = nn.BatchNorm2d(embed_dims)
if not first_layer:
self.encode_lif = MyNode(
tau=2.0,step=step
)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
if hasattr(self, "encode_lif"):
x = self.encode_lif(x.flatten(0,1)).reshape(T,B,C,H,W).contiguous()
x = self.encode_conv(x.flatten(0, 1))
_, _, H, W = x.shape
x = self.encode_bn(x).reshape(T, B, -1, H, W).contiguous()
return x
class ConvBlock(BaseModule):
def __init__(
self,
dim,
step=10,
encode_type='direct',
mlp_ratio=4.0,
):
super().__init__(step=step,
encode_type=encode_type,)
self.Conv = SepConv(step=step,dim=dim)
# self.Conv = MHMC(dim=dim)
self.lif1 = MyNode(step=step,tau=2.0)
self.conv1 = nn.Conv2d(
dim, dim * mlp_ratio, kernel_size=3, padding=1, groups=1, bias=False
)
# self.conv1 = RepConv(dim, dim*mlp_ratio)
self.bn1 = nn.BatchNorm2d(dim * mlp_ratio)
self.lif2 = MyNode(step=step,tau=2.0)
self.conv2 = nn.Conv2d(
dim * mlp_ratio, dim, kernel_size=3, padding=1, groups=1, bias=False
)
# self.conv2 = RepConv(dim*mlp_ratio, dim)
self.bn2 = nn.BatchNorm2d(dim)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.Conv(x) + x
x_feat = x
x = self.bn1(self.conv1(self.lif1(x.flatten(0,1)))).reshape(T, B, 4 * C, H, W)
x = self.bn2(self.conv2(self.lif2(x.flatten(0, 1)))).reshape(T, B, C, H, W)
x = x_feat + x
return x
class Spikformer(BaseModule):
def __init__(self, step=4, encode_type='direct',
img_size_h=64, img_size_w=64, patch_size=4, in_channels=2, num_classes=1000,
embed_dims=512, num_heads=16, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=8, sr_ratios=4,kd=False,
):
super().__init__(step=10, encode_type='direct')
self.step = step # time step
self.num_classes = num_classes
self.depths = depths
self.block3_depths = 6
# for membrane shortcut
self.final_lif = MyNode(step=step,tau=2.0)
# channel for dvs
# 16 32 64 128 256
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
self.downsample1_1 = DownSampling(
step=step,
in_channels=in_channels,
embed_dims=embed_dims // 16,
kernel_size=7,
stride=2,
padding=3,
first_layer=True,
)
self.ConvBlock1_1 = nn.ModuleList(
[ConvBlock(step=step,dim= embed_dims // 16, mlp_ratio=mlp_ratios)]
)
self.downsample1_2 = DownSampling(
step=step,
in_channels = embed_dims // 16,
embed_dims= embed_dims // 8,
kernel_size=3,
stride=2,
padding=1,
first_layer=False,
)
self.ConvBlock1_2 = nn.ModuleList(
[ConvBlock(step=step,dim=embed_dims // 8, mlp_ratio=mlp_ratios)]
)
self.downsample2 = DownSampling(
step=step,
in_channels=embed_dims // 8,
embed_dims=embed_dims // 4,
kernel_size=3,
stride=2,
padding=1,
first_layer=False,
)
self.ConvBlock2_1 = nn.ModuleList(
[ConvBlock(step=step,dim=embed_dims // 4, mlp_ratio=mlp_ratios)]
)
self.ConvBlock2_2 = nn.ModuleList(
[ConvBlock(step=step,dim=embed_dims // 4, mlp_ratio=mlp_ratios)]
)
self.downsample3 = DownSampling(
step=step,
in_channels=embed_dims // 4,
embed_dims=embed_dims // 2,
kernel_size=3,
stride=2,
padding=1,
first_layer=False,
)
self.block3 = nn.ModuleList(
[
Block(
step=step,
dim=embed_dims // 2,
num_heads=num_heads,
mlp_ratio=mlp_ratios,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
# drop_path=dpr[j],
norm_layer=norm_layer,
sr_ratio=sr_ratios,
)
for j in range(self.block3_depths)
]
)
self.downsample4 = DownSampling(
step=step,
in_channels=embed_dims // 2,
embed_dims=embed_dims,
kernel_size=3,
stride=1,
padding=1,
first_layer=False,
)
self.block4 = nn.ModuleList(
[
Block(
step=step,
dim=embed_dims,
num_heads=num_heads,
mlp_ratio=mlp_ratios,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[j],
norm_layer=norm_layer,
sr_ratio=sr_ratios,
)
for j in range(self.depths-self.block3_depths)
]
)
# classification head
self.lif = MyNode(step=step,tau=2.0,)
self.head = (
nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
)
self.kd = kd
if self.kd:
self.head_kd = (
nn.Linear(embed_dims, num_classes)
if num_classes > 0
else nn.Identity()
)
self.apply(self._init_weights)
# setattr(self, f"patch_embed", patch_embed)
# setattr(self, f"block", block)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
x = self.downsample1_1(x)
for blk in self.ConvBlock1_1:
x = blk(x)
x = self.downsample1_2(x)
for blk in self.ConvBlock1_2:
x = blk(x)
x = self.downsample2(x)
for blk in self.ConvBlock2_1:
x = blk(x)
for blk in self.ConvBlock2_2:
x = blk(x)
x = self.downsample3(x)
for blk in self.block3: # attention here
x = blk(x)
x = self.downsample4(x) # attention here
for blk in self.block4:
x = blk(x)
return x # T,B,C,H,W
def forward(self, x):
self.reset()
x = self.encoder(x) # [T, N, 2, *, *]
x = self.forward_features(x)
x = x.flatten(3).mean(3)
T,B,_ = x.shape
x_lif = self.lif(x.flatten(0,1)).reshape(T,B,-1)
x = self.head(x_lif).mean(0)
if self.kd:
x_kd = self.head_kd(x_lif).mean(0)
if self.training:
return x, x_kd
else:
return (x + x_kd) / 2
return x
# Adjust ur hyperparams here
@register_model
def sd_transformer_v2(pretrained=False, **kwargs):
model = Spikformer(step = 4,
img_size_h=224, img_size_w=224,
patch_size=16, embed_dims=512, num_heads=12, mlp_ratios=4,
in_channels=3, num_classes=1000, qkv_bias=False,
depths=2, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/Spiking-Transformers/models/spike_driven_transformer_v2_dvs.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from LIFNode import MyNode # LIFNode setting for Spiking Tranformers
from functools import partial
__all__ = ['spikformer']
'''The input shape of neuromorphic datasets in Spiking Transformer when using Braincog
are used to set to 64*64 '''
'''Here the second version of Spike-driven Transformer only open sourced the
code for img cla '''
# Modified Operators
class BNAndPadLayer(nn.Module):
def __init__(
self,
pad_pixels,
num_features,
eps=1e-5,
momentum=0.1,
affine=True,
track_running_stats=True,
):
super(BNAndPadLayer, self).__init__()
self.bn = nn.BatchNorm2d(
num_features, eps, momentum, affine, track_running_stats
)
self.pad_pixels = pad_pixels
def forward(self, input):
output = self.bn(input)
if self.pad_pixels > 0:
if self.bn.affine:
pad_values = (
self.bn.bias.detach()
- self.bn.running_mean
* self.bn.weight.detach()
/ torch.sqrt(self.bn.running_var + self.bn.eps)
)
else:
pad_values = -self.bn.running_mean / torch.sqrt(
self.bn.running_var + self.bn.eps
)
output = F.pad(output, [self.pad_pixels] * 4)
pad_values = pad_values.view(1, -1, 1, 1)
output[:, :, 0 : self.pad_pixels, :] = pad_values
output[:, :, -self.pad_pixels :, :] = pad_values
output[:, :, :, 0 : self.pad_pixels] = pad_values
output[:, :, :, -self.pad_pixels :] = pad_values
return output
@property
def weight(self):
return self.bn.weight
@property
def bias(self):
return self.bn.bias
@property
def running_mean(self):
return self.bn.running_mean
@property
def running_var(self):
return self.bn.running_var
@property
def eps(self):
return self.bn.eps
class RepConv(nn.Module):
def __init__(
self,
in_channels,
out_channels,
bias=False,
):
super().__init__()
# hidden_channel = in_channel
conv1x1 = nn.Conv2d(in_channels, in_channels, 1, 1, 0, bias=False, groups=1)
bn = BNAndPadLayer(pad_pixels=1, num_features=in_channels)
conv3x3 = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 3, 1, 0, groups=in_channels, bias=False),
nn.Conv2d(in_channels, out_channels, 1, 1, 0, groups=1, bias=False),
nn.BatchNorm2d(out_channels),
)
self.body = nn.Sequential(conv1x1, bn, conv3x3)
def forward(self, x):
return self.body(x)
class SepConv(BaseModule):
r"""
Inverted separable convolution from MobileNetV2: https://arxiv.org/abs/1801.04381.
"""
def __init__(
self,
dim,
step=8,
encode_type='direct',
expansion_ratio=2,
act2_layer=nn.Identity,
bias=False,
kernel_size=7,
padding=3,
):
super().__init__(step=step,encode_type=encode_type,)
med_channels = int(expansion_ratio * dim)
self.lif1 = MyNode(step=step,tau=2.0)
self.pwconv1 = nn.Conv2d(dim, med_channels, kernel_size=1, stride=1, bias=bias)
self.bn1 = nn.BatchNorm2d(med_channels)
self.lif2 =MyNode(step=step,tau=2.0)
self.dwconv = nn.Conv2d(
med_channels,
med_channels,
kernel_size=kernel_size,
padding=padding,
groups=med_channels,
bias=bias,
) # depthwise conv
self.pwconv2 = nn.Conv2d(med_channels, dim, kernel_size=1, stride=1, bias=bias)
self.bn2 = nn.BatchNorm2d(dim)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.lif1(x.flatten(0,1)).reshape(T,B,C,H,W).contiguous()
x = self.bn1(self.pwconv1(x.flatten(0, 1))).reshape(T, B, -1, H, W)
x = self.lif2(x.flatten(0,1)).reshape(T,B,-1,H,W).contiguous()
x = self.dwconv(x.flatten(0, 1))
x = self.bn2(self.pwconv2(x)).reshape(T, B, -1, H, W)
return x # T B C H W
class MLP(BaseModule):
#Linear here is subsituted by convs
def __init__(self, in_features, step=10, encode_type='direct', hidden_features=None, out_features=None, drop=0.):
super().__init__(step=10, encode_type='direct')
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_conv = nn.Conv1d(in_features, hidden_features, kernel_size=1, stride=1)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step, tau=2.0)
self.fc2_conv = nn.Conv1d(hidden_features, out_features, kernel_size=1, stride=1)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step, tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = x.flatten(3) # T B C N
_, _, _, N = x.shape
x = self.fc1_lif(x.flatten(0, 1)).reshape(T, B, C, N).contiguous()
x = self.fc1_conv(x.flatten(0, 1))
x = self.fc1_bn(x).reshape(T, B, self.c_hidden, N).contiguous() # T B C N
x = self.fc2_lif(x.flatten(0, 1)).reshape(T, B, self.c_hidden, N).contiguous()
x = self.fc2_conv(x.flatten(0, 1))
x = self.fc2_bn(x).reshape(T, B, C, H, W).contiguous()
return x # T B C H W
# convs in SDSA V3/V4 should be substituted
class SDSA(BaseModule):
def __init__(self, dim, step=10, encode_type='direct', num_heads=16, qkv_bias=False, qk_scale=None, attn_drop=0.,
proj_drop=0., sr_ratio=1):
super().__init__(step=10, encode_type='direct')
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
# scale
self.scale = 0.125
self.head_lif = MyNode(step=step, tau=2.0) # for spike-drivens
self.q_conv = RepConv(dim, dim, bias=False)
self.q_bn = nn.BatchNorm2d(dim)
self.q_lif = MyNode(step=step, tau=2.0)
self.k_conv = RepConv(dim, dim, bias=False)
self.k_bn = nn.BatchNorm2d(dim)
self.k_lif = MyNode(step=step, tau=2.0)
self.v_conv = RepConv(dim, dim, bias=False)
self.v_bn = nn.BatchNorm2d(dim)
self.v_lif = MyNode(step=step, tau=2.0)
self.attn_drop = nn.Dropout(0.2)
self.res_lif = MyNode(step=step, tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5, )
self.proj_conv = RepConv(dim, dim, bias=False)
self.proj_bn = nn.BatchNorm2d(dim)
def forward(self, x):
self.reset()
#different here
T, B, C, H, W = x.shape
N = H * W
x = self.head_lif(x.flatten(0,1)).reshape(T, B, C, H, W).contiguous()
x_for_qkv = x.flatten(0, 1) # TB C H W
q_conv_out = self.q_conv(x_for_qkv) # [TB] C H W
q_conv_out = self.q_bn(q_conv_out).reshape(T, B, C, H, W).contiguous() # T B C H W
q_conv_out = self.q_lif(q_conv_out.flatten(0, 1)).reshape(T, B, C, N).transpose(-1,-2) # T B N C
q = q_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_conv_out = self.k_conv(x_for_qkv)
k_conv_out = self.k_bn(k_conv_out).reshape(T, B, C, H, W).contiguous()
k_conv_out = self.k_lif(k_conv_out.flatten(0, 1)).reshape(T, B, C, N).transpose(-1,-2) # T B N C
k = k_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_conv_out = self.v_conv(x_for_qkv)
v_conv_out = self.v_bn(v_conv_out).reshape(T, B, C, H, W).contiguous()
v_conv_out = self.v_lif(v_conv_out.flatten(0, 1)).reshape(T, B, C, N).transpose(-1,-2) # T B N C
v = v_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
x = k.transpose(-2, -1) @ v
x = (q @ x) * self.scale
x = x.transpose(3, 4).reshape(T, B, C, N).contiguous()
x = self.attn_lif(x).reshape(T, B, C, H, W)
x = x.reshape(T, B, C, H, W)
x = x.flatten(0, 1)
x = self.proj_conv(x)
x = self.proj_bn(x).reshape(T, B, C, H, W)
return x # T B C H W
class Block(nn.Module):
def __init__(self, dim, num_heads, step=10, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = SDSA(dim, step=step, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(step=step, in_features=dim, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
# residual connection
x = x + self.attn(x)
x = x + self.mlp(x)
return x
class DownSampling(BaseModule):
def __init__(
self,
step=10,
encode_type='direct',
in_channels=2,
embed_dims=256,
kernel_size=3,
stride=2,
padding=1,
first_layer=True,
):
super().__init__(step=step,
encode_type=encode_type,)
self.encode_conv = nn.Conv2d(
in_channels,
embed_dims,
kernel_size=kernel_size,
stride=stride,
padding=padding,
)
self.encode_bn = nn.BatchNorm2d(embed_dims)
if not first_layer:
self.encode_lif = MyNode(
tau=2.0,step=step
)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
if hasattr(self, "encode_lif"):
x = self.encode_lif(x.flatten(0,1)).reshape(T,B,C,H,W).contiguous()
x = self.encode_conv(x.flatten(0, 1))
_, _, H, W = x.shape
x = self.encode_bn(x).reshape(T, B, -1, H, W).contiguous()
return x
class ConvBlock(BaseModule):
def __init__(
self,
dim,
step=10,
encode_type='direct',
mlp_ratio=4.0,
):
super().__init__(step=step,
encode_type=encode_type,)
self.Conv = SepConv(step=step,dim=dim)
# self.Conv = MHMC(dim=dim)
self.lif1 = MyNode(step=step,tau=2.0)
self.conv1 = nn.Conv2d(
dim, dim * mlp_ratio, kernel_size=3, padding=1, groups=1, bias=False
)
# self.conv1 = RepConv(dim, dim*mlp_ratio)
self.bn1 = nn.BatchNorm2d(dim * mlp_ratio)
self.lif2 = MyNode(step=step,tau=2.0)
self.conv2 = nn.Conv2d(
dim * mlp_ratio, dim, kernel_size=3, padding=1, groups=1, bias=False
)
# self.conv2 = RepConv(dim*mlp_ratio, dim)
self.bn2 = nn.BatchNorm2d(dim)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.Conv(x) + x
x_feat = x
x = self.bn1(self.conv1(self.lif1(x.flatten(0,1)))).reshape(T, B, 4 * C, H, W)
x = self.bn2(self.conv2(self.lif2(x.flatten(0, 1)))).reshape(T, B, C, H, W)
x = x_feat + x
return x
class Spikformer(BaseModule):
def __init__(self, step=10, encode_type='direct',
img_size_h=64, img_size_w=64, patch_size=4, in_channels=2, num_classes=10,
embed_dims=256, num_heads=16, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=2, sr_ratios=4,kd=False,
):
super().__init__(step=10, encode_type='direct')
self.step = step # time step
self.num_classes = num_classes
self.depths = depths
self.block3_depths = 1
# for membrane shortcut
self.final_lif = MyNode(step=step,tau=2.0)
# channel for dvs
# 16 32 64 128 256
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
self.downsample1_1 = DownSampling(
step=step,
in_channels=in_channels,
embed_dims=embed_dims // 16,
kernel_size=7,
stride=2,
padding=3,
first_layer=True,
)
self.ConvBlock1_1 = nn.ModuleList(
[ConvBlock(step=step,dim= embed_dims // 16, mlp_ratio=mlp_ratios)]
)
self.downsample1_2 = DownSampling(
step=step,
in_channels = embed_dims // 16,
embed_dims= embed_dims // 8,
kernel_size=3,
stride=2,
padding=1,
first_layer=False,
)
self.ConvBlock1_2 = nn.ModuleList(
[ConvBlock(step=step,dim=embed_dims // 8, mlp_ratio=mlp_ratios)]
)
self.downsample2 = DownSampling(
step=step,
in_channels=embed_dims // 8,
embed_dims=embed_dims // 4,
kernel_size=3,
stride=2,
padding=1,
first_layer=False,
)
self.ConvBlock2_1 = nn.ModuleList(
[ConvBlock(step=step,dim=embed_dims // 4, mlp_ratio=mlp_ratios)]
)
self.ConvBlock2_2 = nn.ModuleList(
[ConvBlock(step=step,dim=embed_dims // 4, mlp_ratio=mlp_ratios)]
)
self.downsample3 = DownSampling(
step=step,
in_channels=embed_dims // 4,
embed_dims=embed_dims // 2,
kernel_size=3,
stride=2,
padding=1,
first_layer=False,
)
self.block3 = nn.ModuleList(
[
Block(
step=step,
dim=embed_dims // 2,
num_heads=num_heads,
mlp_ratio=mlp_ratios,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
# drop_path=dpr[j],
norm_layer=norm_layer,
sr_ratio=sr_ratios,
)
for j in range(self.block3_depths)
]
)
self.downsample4 = DownSampling(
step=step,
in_channels=embed_dims // 2,
embed_dims=embed_dims,
kernel_size=3,
stride=1,
padding=1,
first_layer=False,
)
self.block4 = nn.ModuleList(
[
Block(
step=step,
dim=embed_dims,
num_heads=num_heads,
mlp_ratio=mlp_ratios,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[j],
norm_layer=norm_layer,
sr_ratio=sr_ratios,
)
for j in range(self.depths-self.block3_depths)
]
)
# classification head
self.lif = MyNode(step=step,tau=2.0,)
self.head = (
nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
)
self.kd = kd
if self.kd:
self.head_kd = (
nn.Linear(embed_dims, num_classes)
if num_classes > 0
else nn.Identity()
)
self.apply(self._init_weights)
# setattr(self, f"patch_embed", patch_embed)
# setattr(self, f"block", block)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
x = self.downsample1_1(x)
for blk in self.ConvBlock1_1:
x = blk(x)
x = self.downsample1_2(x)
for blk in self.ConvBlock1_2:
x = blk(x)
x = self.downsample2(x)
for blk in self.ConvBlock2_1:
x = blk(x)
for blk in self.ConvBlock2_2:
x = blk(x)
x = self.downsample3(x)
for blk in self.block3: # attention here
x = blk(x)
x = self.downsample4(x) # attention here
for blk in self.block4:
x = blk(x)
return x # T,B,C,H,W
def forward(self, x):
self.reset()
x = x.permute(1, 0, 2, 3, 4) # [T, N, 2, *, *]
x = self.forward_features(x)
x = x.flatten(3).mean(3)
T,B,_ = x.shape
x_lif = self.lif(x.flatten(0,1)).reshape(T,B,-1)
x = self.head(x_lif).mean(0)
if self.kd:
x_kd = self.head_kd(x_lif).mean(0)
if self.training:
return x, x_kd
else:
return (x + x_kd) / 2
return x
# Adjust ur hyperparams here
@register_model
def sd_transformer_v2_dvs(pretrained=False, **kwargs):
model = Spikformer(step = 8,
img_size_h=64, img_size_w=64,
patch_size=4, embed_dims=256, num_heads=16, mlp_ratios=4,
in_channels=2, num_classes=10, qkv_bias=False,
depths=2, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/Spiking-Transformers/models/spikformer.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from LIFNode import MyNode # LIFNode setting for Spiking Tranformers
from functools import partial
__all__ = ['spikformer']
class MLP(BaseModule):
# Linear -> BN -> LIF -> Linear -> BN -> LIF
def __init__(self, in_features, step=4, encode_type='direct', hidden_features=None, out_features=None, drop=0.):
super().__init__(step=step, encode_type=encode_type)
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_linear = nn.Linear(in_features, hidden_features)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step,tau=2.0)
self.fc2_linear = nn.Linear(hidden_features, out_features)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step,tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T, B, N, C = x.shape
x_ = x.flatten(0, 1) # TB N C
x = self.fc1_linear(x_)
x = self.fc1_bn(x.transpose(-1, -2)).transpose(-1, -2).reshape(T, B, N, self.c_hidden).contiguous() # T B N C
x = self.fc1_lif(x.flatten(0, 1)).reshape(T, B, N, self.c_hidden)
x = self.fc2_linear(x.flatten(0, 1))
x = self.fc2_bn(x.transpose(-1, -2)).transpose(-1, -2).reshape(T, B, N, C).contiguous()
x = self.fc2_lif(x.flatten(0, 1)).reshape(T, B, N, self.c_output)
return x
class SSA(BaseModule):
def __init__(self, dim, step=4, encode_type='rate', num_heads=12, qkv_bias=False, qk_scale=None, attn_drop=0.,
proj_drop=0., sr_ratio=1):
super().__init__(step=step, encode_type=encode_type)
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
# 多头注意力 # of heads
self.num_heads = num_heads
# scale参数,用于防止KQ乘积结果过大
self.scale = 0.125
self.q_linear = nn.Linear(dim, dim)
self.q_bn = nn.BatchNorm1d(dim)
self.q_lif = MyNode(step=step,tau=2.0)
self.k_linear = nn.Linear(dim, dim)
self.k_bn = nn.BatchNorm1d(dim)
self.k_lif = MyNode(step=step,tau=2.0)
self.v_linear = nn.Linear(dim, dim)
self.v_bn = nn.BatchNorm1d(dim)
self.v_lif = MyNode(step=step,tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5, )
self.proj_linear = nn.Linear(dim, dim)
self.proj_bn = nn.BatchNorm1d(dim)
self.proj_lif = MyNode(step=step, tau=2.0, )
def forward(self, x):
self.reset()
T, B, N, C = x.shape
x_for_qkv = x.flatten(0, 1) # TB, N, C
q_linear_out = self.q_linear(x_for_qkv) # [TB, N, C]
q_linear_out = self.q_bn(q_linear_out.transpose(-1, -2)).transpose(-1, -2).reshape(T, B, N,
C).contiguous() # T B N C
q_linear_out = self.q_lif(q_linear_out.flatten(0, 1)).reshape(T, B, N, C) # TB N C
q = q_linear_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_linear_out = self.k_linear(x_for_qkv)
k_linear_out = self.k_bn(k_linear_out.transpose(-1, -2)).transpose(-1, -2).reshape(T, B, N, C).contiguous()
k_linear_out = self.k_lif(k_linear_out.flatten(0, 1)).reshape(T, B, N, C) # TB N C
k = k_linear_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_linear_out = self.v_linear(x_for_qkv)
v_linear_out = self.v_bn(v_linear_out.transpose(-1, -2)).transpose(-1, -2).reshape(T, B, N, C).contiguous()
v_linear_out = self.v_lif(v_linear_out.flatten(0, 1)).reshape(T, B, N, C) # TB N C
v = v_linear_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
# @表示矩阵乘法,与matmul等价
# K,QV -> attention -> scale -> LIF -> Linear -> BN
attn = (q @ k.transpose(-2, -1)) * self.scale
x = attn @ v
x = x.transpose(2, 3).reshape(T, B, N, C).contiguous()
x = self.attn_lif(x.flatten(0, 1)).reshape(T, B, N, C) # T B N C
x = x.flatten(0, 1) # TB N C
x = self.proj_lif(self.proj_bn(self.proj_linear(x).transpose(-1, -2)).transpose(-1, -2)).reshape(T, B, N, C)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, step =4, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.step = 4
self.norm1 = norm_layer(dim)
self.attn = SSA(dim, step=self.step, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(step=self.step, in_features=dim, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
# residual
x = x + self.attn(x)
x = x + self.mlp(x)
return x
# SPS for dimension adjustment
# embed_dims = 256
class SPS(BaseModule):
def __init__(self, step=4, encode_type='direct', img_size_h=32, img_size_w=32, patch_size=4, in_channels=3,
embed_dims=384):
super().__init__(step=step, encode_type=encode_type)
self.image_size = [img_size_h, img_size_w]
# timm内置to_2tuple把整形转换成2元元组
patch_size = to_2tuple(patch_size) # 4->(4,4)
self.patch_size = patch_size # patch_size
self.C = in_channels # image_channel
self.H, self.W = self.image_size[0] // patch_size[0], self.image_size[1] // patch_size[1] # 重新计算patch之后的图片大小
self.num_patches = self.H * self.W # patch数量
self.proj_conv = nn.Conv2d(in_channels, embed_dims // 8, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn = nn.BatchNorm2d(embed_dims // 8)
self.proj_lif = MyNode(step=step,tau=2.0)
self.proj_conv1 = nn.Conv2d(embed_dims // 8, embed_dims // 4, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn1 = nn.BatchNorm2d(embed_dims // 4)
self.proj_lif1 = MyNode(step=step,tau=2.0)
self.proj_conv2 = nn.Conv2d(embed_dims // 4, embed_dims // 2, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn2 = nn.BatchNorm2d(embed_dims // 2)
self.proj_lif2 = MyNode(step=step,tau=2.0)
self.maxpool2 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv3 = nn.Conv2d(embed_dims // 2, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn3 = nn.BatchNorm2d(embed_dims)
self.proj_lif3 = MyNode(step=step,tau=2.0)
self.maxpool3 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.rpe_conv = nn.Conv2d(embed_dims, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.rpe_bn = nn.BatchNorm2d(embed_dims)
self.rpe_lif = MyNode(step=step,tau=2.0)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.proj_conv(x.flatten(0, 1)) # have some fire value
x = self.proj_bn(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif(x.flatten(0, 1)).contiguous()
x = self.proj_conv1(x)
x = self.proj_bn1(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif1(x.flatten(0, 1)).contiguous()
x = self.proj_conv2(x)
x = self.proj_bn2(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif2(x.flatten(0, 1)).contiguous()
x = self.maxpool2(x)
x = self.proj_conv3(x)
x = self.proj_bn3(x).reshape(T, B, -1, H // 2, W // 2).contiguous()
x = self.proj_lif3(x.flatten(0, 1)).contiguous()
x = self.maxpool3(x)
x_feat = x.reshape(T, B, -1, H // 4, W // 4).contiguous()
x = self.rpe_conv(x)
x = self.rpe_bn(x).reshape(T, B, -1, H // 4, W // 4).contiguous()
x = self.rpe_lif(x.flatten(0, 1)).reshape(T, B, -1, H // 4, W // 4)
x = x + x_feat
x = x.flatten(-2).transpose(-1, -2) # T,B,N,C
return x
class Spikformer(BaseModule):
def __init__(self, step=4, encode_type='direct',
img_size_h=224, img_size_w=224, patch_size=16, in_channels=3, num_classes=1000,
embed_dims=384, num_heads=12, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=4, sr_ratios=4,
):
super().__init__(step=step, encode_type=encode_type)
self.step = step # time step
self.num_classes = num_classes
self.depths = depths
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
patch_embed = SPS(step = self.step,
img_size_h=img_size_h,
img_size_w=img_size_w,
patch_size=patch_size,
in_channels=in_channels,
embed_dims=embed_dims)
block = nn.ModuleList([Block(step=self.step,
dim=embed_dims, num_heads=num_heads, mlp_ratio=mlp_ratios, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[j],
norm_layer=norm_layer, sr_ratio=sr_ratios)
for j in range(depths)])
setattr(self, f"patch_embed", patch_embed)
setattr(self, f"block", block)
# classification head
self.head = nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
block = getattr(self, f"block")
patch_embed = getattr(self, f"patch_embed")
x = patch_embed(x)
for blk in block:
x = blk(x)
return x.mean(2)
def forward(self, x):
x = self.encoder(x)
x = self.forward_features(x)
x = self.head(x.mean(0))
return x
@register_model
def spikformer(pretrained=False, **kwargs):
model = Spikformer(
step=4,
img_size_h=224, img_size_w=224,
patch_size=16, embed_dims=512, num_heads=8, mlp_ratios=4,
in_channels=3, num_classes=1000, qkv_bias=False,
depths=8, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/Spiking-Transformers/models/spikformer_dvs.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from LIFNode import MyNode # LIFNode setting for Spiking Tranformers
from functools import partial
__all__ = ['spikformer']
'''The input shape of neuromorphic datasets in Spiking Transformer when using Braincog
are used to set to 64*64 '''
class MLP(BaseModule):
#Linear here is subsituted by convs
def __init__(self, in_features, step=10, encode_type='direct', hidden_features=None, out_features=None, drop=0.):
super().__init__(step=step, encode_type=encode_type)
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_conv = nn.Conv1d(in_features, hidden_features, kernel_size=1, stride=1)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step, tau=2.0)
self.fc2_conv = nn.Conv1d(hidden_features, out_features, kernel_size=1, stride=1)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step, tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T, B, C, N = x.shape
x = self.fc1_conv(x.flatten(0, 1))
x = self.fc1_bn(x).reshape(T, B, self.c_hidden, N).contiguous() # T B C N
x = self.fc1_lif(x.flatten(0, 1)).reshape(T, B, self.c_hidden, N).contiguous()
x = self.fc2_conv(x.flatten(0, 1))
x = self.fc2_bn(x).reshape(T, B, C, N).contiguous()
x = self.fc2_lif(x.flatten(0, 1)).reshape(T, B, C, N).contiguous()
return x
class SSA(BaseModule):
def __init__(self, dim, step=10, encode_type='direct', num_heads=16, qkv_bias=False, qk_scale=None, attn_drop=0.,
proj_drop=0., sr_ratio=1):
super().__init__(step=step, encode_type=encode_type)
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
# scale
self.scale = 0.25
self.q_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.q_bn = nn.BatchNorm1d(dim)
self.q_lif = MyNode(step=step, tau=2.0)
self.k_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.k_bn = nn.BatchNorm1d(dim)
self.k_lif = MyNode(step=step, tau=2.0)
self.v_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.v_bn = nn.BatchNorm1d(dim)
self.v_lif = MyNode(step=step, tau=2.0)
self.attn_drop = nn.Dropout(0.2)
self.res_lif = MyNode(step=step, tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5, )
self.proj_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.proj_bn = nn.BatchNorm1d(dim)
self.proj_lif = MyNode(step=step, tau=2.0, )
def forward(self, x):
self.reset()
T, B, C, N = x.shape
x_for_qkv = x.flatten(0, 1) # TB, C N
q_conv_out = self.q_conv(x_for_qkv) # [TB] C N
q_conv_out = self.q_bn(q_conv_out).reshape(T, B, C, N).contiguous() # T B C N
q_conv_out = self.q_lif(q_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
q = q_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_conv_out = self.k_conv(x_for_qkv)
k_conv_out = self.k_bn(k_conv_out).reshape(T, B, C, N).contiguous()
k_conv_out = self.k_lif(k_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
k = k_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_conv_out = self.v_conv(x_for_qkv)
v_conv_out = self.v_bn(v_conv_out).reshape(T, B, C, N).contiguous()
v_conv_out = self.v_lif(v_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
v = v_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
# @表示矩阵乘法,与matmul等价
# K,QV -> attention -> scale -> LIF -> Linear -> BN
attn = (q @ k.transpose(-2, -1))
x = (attn @ v) * self.scale
x = x.transpose(3, 4).reshape(T, B, C, N).contiguous() # T B C N
x = self.attn_lif(x.flatten(0, 1)) # [TB] C N
x = self.proj_lif(self.proj_bn(self.proj_conv(x))).reshape(T, B, C, N) # T B C N
return x
# 整个encoder block,要在SSA和MLP的基础上加入残差
class Block(nn.Module):
def __init__(self, dim, num_heads, step=10, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = SSA(dim, step=step, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(step=step, in_features=dim, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
# residual connection
x = x + self.attn(x)
x = x + self.mlp(x)
return x
# embed_dims = 256
class SPS(BaseModule):
def __init__(self, step=10, encode_type='direct', img_size_h=128, img_size_w=128, patch_size=4, in_channels=2,
embed_dims=256):
super().__init__(step=step, encode_type=encode_type)
self.image_size = [img_size_h, img_size_w]
# timm内置to_2tuple把整形转换成2元元组
patch_size = to_2tuple(patch_size) # 4->(4,4)
self.patch_size = patch_size # patch_size
self.C = in_channels # image_channel
self.H, self.W = self.image_size[0] // patch_size[0], self.image_size[1] // patch_size[1]
self.num_patches = self.H * self.W
# DVS with 2 more Maxpooling
self.proj_conv = nn.Conv2d(in_channels, embed_dims // 8, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn = nn.BatchNorm2d(embed_dims // 8)
self.proj_lif = MyNode(step=step, tau=2.0)
self.maxpool = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv1 = nn.Conv2d(embed_dims // 8, embed_dims // 4, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn1 = nn.BatchNorm2d(embed_dims // 4)
self.proj_lif1 = MyNode(step=step, tau=2.0)
self.maxpool1 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv2 = nn.Conv2d(embed_dims // 4, embed_dims // 2, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn2 = nn.BatchNorm2d(embed_dims // 2)
self.proj_lif2 = MyNode(step=step, tau=2.0)
self.maxpool2 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv3 = nn.Conv2d(embed_dims // 2, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn3 = nn.BatchNorm2d(embed_dims)
self.proj_lif3 = MyNode(step=step, tau=2.0)
self.maxpool3 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.rpe_conv = nn.Conv2d(embed_dims, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.rpe_bn = nn.BatchNorm2d(embed_dims)
self.rpe_lif = MyNode(step=step, tau=2.0)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.proj_conv(x.flatten(0, 1)) # have some fire value
x = self.proj_bn(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif(x.flatten(0, 1)).contiguous()
x = self.maxpool(x)
x = self.proj_conv1(x)
x = self.proj_bn1(x).reshape(T, B, -1, H // 2, W // 2).contiguous()
x = self.proj_lif1(x.flatten(0, 1)).contiguous()
x = self.maxpool1(x)
x = self.proj_conv2(x)
x = self.proj_bn2(x).reshape(T, B, -1, H // 4, W // 4).contiguous()
x = self.proj_lif2(x.flatten(0, 1)).contiguous()
x = self.maxpool2(x)
x = self.proj_conv3(x)
x = self.proj_bn3(x).reshape(T, B, -1, H // 8, W // 8).contiguous()
x = self.proj_lif3(x.flatten(0, 1)).contiguous()
x = self.maxpool3(x)
x_rpe = self.rpe_bn(self.rpe_conv(x)).reshape(T, B, -1, H // 16, W // 16).contiguous()
x_rpe = self.rpe_lif(x_rpe.flatten(0, 1)).contiguous()
x = x + x_rpe
x = x.reshape(T, B, -1, (H // 16) * (H // 16)).contiguous()
return x # T B C N
class Spikformer(nn.Module):
def __init__(self, step=10,
img_size_h=64, img_size_w=64, patch_size=4, in_channels=2, num_classes=10,
embed_dims=256, num_heads=16, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=2, sr_ratios=4,
):
super().__init__()
self.step = step # time step
self.num_classes = num_classes
self.depths = depths
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
patch_embed = SPS(step=step,
img_size_h=img_size_h,
img_size_w=img_size_w,
patch_size=patch_size,
in_channels=in_channels,
embed_dims=embed_dims)
block = nn.ModuleList([Block(step=step,
dim=embed_dims, num_heads=num_heads, mlp_ratio=mlp_ratios, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[j],
norm_layer=norm_layer, sr_ratio=sr_ratios)
for j in range(depths)])
setattr(self, f"patch_embed", patch_embed)
setattr(self, f"block", block)
# classification head
self.head = nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
block = getattr(self, f"block")
patch_embed = getattr(self, f"patch_embed")
x = patch_embed(x)
for blk in block:
x = blk(x)
return x.mean(3)
def forward(self, x):
x = x.permute(1, 0, 2, 3, 4) # [T, N, 2, *, *]
x = self.forward_features(x)
x = self.head(x.mean(0))
return x
# Adjust ur hyperparams here
@register_model
def spikformer_dvs(pretrained=False, **kwargs):
model = Spikformer(step = 8,
img_size_h=64, img_size_w=64,
patch_size=4, embed_dims=256, num_heads=16, mlp_ratios=4,
in_channels=2, num_classes=10, qkv_bias=False,
depths=2, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/Structural_Development/DPAP/README.md
================================================
# Developmental Plasticity-inspired Adaptive Pruning for Deep Spiking and Artificial Neural Networks #
## Requirments ##
* matplotlib==3.5.1
* numpy==1.22.4
* Pillow==9.3.0
* scipy==1.9.3
* tensorboardX==2.5.1
* torch==1.8.1+cu111
* torchvision==0.9.1+cu111
## Run ##
``` CUDA_VISIBLE_DEVICES=0 python prun_ main.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{han2024similarity,
title={Developmental Plasticity-inspired Adaptive Pruning for Deep Spiking and Artificial Neural Networks},
author={Han, Bing and Zhao, Feifei and Zeng, Yi and Shen Guobin},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2024}
}
@article{zeng2023braincog,
title={Braincog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired ai and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier},
}
```
Enjoy!
================================================
FILE: examples/Structural_Development/DPAP/mask_model.py
================================================
import abc
from functools import partial
from torch.nn import functional as F
import torchvision
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from utils import *
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
convlayer = [-1,0, 1, 3, 4, 6, 7]
fclayer=[8,9]
imgsize = [32,32, 32, 16,16, 16, 8,8, 8]
size = [3,128, 128, 256, 256, 512,512]
size_pool = [3,128, 128,128, 256, 256,256, 512,512]
fcsize=[512*8*8,512]
class my_cifar_model(BaseModule):
def __init__(self,
num_classes=10,
step=8,
node_type=LIFNode,
encode_type='direct',
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.num_classes = num_classes
# self.node = node_type
# if issubclass(self.node, BaseNode):
# self.node = partial(self.node, **kwargs, step=step)
self.feature = nn.Sequential(
BaseConvModule(size[0], size[1], kernel_size=(3, 3), padding=(1, 1)),
BaseConvModule(size[1],size[2], kernel_size=(3, 3), padding=(1, 1)),
nn.MaxPool2d(2),
BaseConvModule(size[2], size[3], kernel_size=(3, 3), padding=(1, 1)),
BaseConvModule(size[3], size[4], kernel_size=(3, 3), padding=(1, 1)),
nn.MaxPool2d(2),
BaseConvModule(size[4], size[5], kernel_size=(3, 3), padding=(1, 1)),
BaseConvModule(size[5], size[6], kernel_size=(3, 3), padding=(1, 1)),
)
self.cfla=self._cflatten()
self.fc_prun = self._create_fc_prun()
self.fc = self._create_fc()
def _cflatten(self):
fc = nn.Sequential(
nn.Flatten(),
)
return fc
def _create_fc_prun(self):
fc = nn.Sequential(
BaseLinearModule(fcsize[0], fcsize[1])
)
return fc
def _create_fc(self):
fc = nn.Sequential(
BaseLinearModule(fcsize[1], self.num_classes)
)
return fc
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if not self.training:
self.fire_rate.clear()
outputs = []
spikes=[]
for t in range(self.step):
spikest=[]
x = inputs[t]
if x.shape[-1] > 32:
x = F.interpolate(x, size=[64, 64])
spikest.append(x.detach())
for i in range(len(self.feature)):
spikei=self.feature[i](x)
x=spikei
spikest.append(spikei.detach())
x=self.cfla(x)
spikest.append(x.detach())
x=self.fc_prun(x)
spikest.append(x.detach())
x = self.fc(x)
spikes.append(spikest)
outputs.append(x)
return sum(outputs) / len(outputs),spikes
class Mask:
def __init__(self, model,batch,step):
self.model = model
self.fullbook={}
self.mat = {}
self.feature=model.feature
self.fc={}
self.fc[1]=model.fc_prun[0]
self.fc[2]=model.fc[0]
self.n_delta={}
self.ww_delta={}
self.reduce={}
self.reduceww={}
self.batch=batch
self.step=step
def init_length(self):
for i in range(1,len(convlayer)):
index=convlayer[i]
self.fullbook[index] =torch.ones((size[i],size[i-1],3,3),device=device)
self.n_delta[index]=torch.zeros(size[i],device=device)
self.reduce[index] = 10*torch.ones(size[i],device=device)
for i in range(1,len(fclayer)):
index=fclayer[i]
self.fullbook[index] = torch.ones((fcsize[i],fcsize[i-1]),device=device)
self.n_delta[index]=torch.zeros(fcsize[i],device=device)
self.ww_delta[index]=torch.zeros(fcsize[i]*fcsize[i-1],device=device)
self.reduce[index] = 10*torch.ones(fcsize[i],device=device)
self.reduceww[index] = 10*torch.ones(fcsize[i]*fcsize[i-1],device=device)
def get_filter_codebook(self,ww,dendrite,ii,index,epoch):
if ii == 4:
wconv= dendrite#.cpu().numpy()
self.n_delta[index]=(unit(wconv)*2-0.65)
pos=torch.nonzero(self.n_delta[index]>0)
self.n_delta[index][pos]=self.n_delta[index][pos]+5
print(wconv.mean(),wconv.max(), wconv.min())
self.reduce[index]=self.reduce[index]*0.999+self.n_delta[index]*math.exp(-int((epoch-5)/12))
filter_ind = torch.nonzero(self.reduce[index] <0)
print(self.reduce[index].mean(),self.reduce[index].max(),self.reduce[index].min(),len(filter_ind))
for x in range(0, len(filter_ind)):
self.fullbook[index][filter_ind[x]] = 0
if ii == 2:
length=ww.size()[0]*ww.size()[1]
book=torch.ones(length,device=device)
filter_ww = ww.view(-1)#.cpu().numpy()
self.ww_delta[index]=(unit(filter_ww)*2-1.5)
pos=torch.nonzero(self.ww_delta[index]>0)
self.ww_delta[index][pos]=self.ww_delta[index][pos]+2
self.reduceww[index]= self.reduceww[index]*0.999+self.ww_delta[index]*math.exp(-int((epoch-5)/13))
filter_indww =torch.nonzero(self.reduceww[index] < 0)
book[filter_indww]=0
book=book.reshape((ww.size()[0],-1))
self.fullbook[index]=self.fullbook[index]*book
print(self.reduceww[index].mean(),self.reduceww[index].max(),self.reduceww[index].min(),len(filter_indww))
wconv= dendrite#.cpu().numpy()
self.n_delta[index]=(unit(wconv)*2-1.5)
pos=torch.nonzero(self.n_delta[index]>0)
self.n_delta[index][pos]=self.n_delta[index][pos]+2
self.reduce[index]=self.reduce[index]*0.999+self.n_delta[index]*math.exp(-int((epoch-5)/13))
filter_ind = torch.nonzero(self.reduce[index] <0)
print(self.reduce[index].mean(),self.reduce[index].max(),self.reduce[index].min(),len(filter_ind))
for x in range(0, len(filter_ind)):
self.fullbook[index][filter_ind[x]] = 0
return self.fullbook[index]
def convert2tensor(self, x):
x = torch.FloatTensor(x)
return x
def init_mask(self, wwfc,convtra,epoch):
for i in range(1,len(convlayer)):
index=convlayer[i]
ww = wwfc[index]
dendrite=convtra[index]
self.mat[index]=self.get_filter_codebook(ww, dendrite,4,index,epoch)
#self.mat[index] = self.convert2tensor(self.mat[index]).cuda()
for i in range(1,len(fclayer)):
index=fclayer[i]
ww=wwfc[index]
dendrite=convtra[index]
self.mat[index]=self.get_filter_codebook(ww,dendrite,2,index,epoch)
#self.mat[index] = self.convert2tensor(self.mat[index]).cuda()
def do_mask(self):
for i in range(1,len(convlayer)):
index=convlayer[i]
ww = self.feature[index].conv.weight
maskww=ww*self.mat[index]
self.feature[index].conv.weight.data=maskww
for i in range(1,len(fclayer)):
ind=fclayer[i]
ww = self.fc[i].fc.weight
maskww=ww*self.mat[ind]
self.fc[i].fc.weight.data=maskww
def if_zero(self):
cc=[]
for i in range(1,len(convlayer)):
ww=self.feature[convlayer[i]].conv.weight
b = ww.data.view(-1).cpu().numpy()
print("number of weight is %d, zero is %.3f" %(len(b),100*(len(b)- np.count_nonzero(b))/len(b)))
cc.append(100*(len(b)- np.count_nonzero(b))/len(b))
for i in range(1,len(fcsize)):
ww=self.fc[i].fc.weight
b = ww.data.view(-1).cpu().numpy()
print("number of weight is %d, zero is %.3f" %(len(b),100*(len(b)- np.count_nonzero(b))/len(b)))
cc.append(100*(len(b)- np.count_nonzero(b))/len(b))
return cc
class Trace:
def __init__(self, model,batch,step):
self.model = model
self.feature=model.feature
self.ctrace={}
self.fctrace={}
self.csum={}
self.fcsum={}
self.delta = 0.5
self.batch=batch
self.step=step
def computing_trace(self,spikes):
for i in range(len(imgsize)):
index=i-1
self.ctrace[index]=torch.zeros((self.batch,size_pool[i],imgsize[i],imgsize[i]),device=device)
for i in range(len(fclayer)):
index=fclayer[i]
self.fctrace[index]=torch.zeros((self.batch,fcsize[i]),device=device)
for t in range(self.step):
for i in range(len(imgsize)):
index=i-1
sp=spikes[t][index+1].detach()
#print(sp.size(),self.ctrace[index].size())
self.ctrace[index]=self.delta*self.ctrace[index].cuda()+sp.cuda()
for i in range(len(fclayer)):
index=fclayer[i]
sp=spikes[t][index+1].detach()
self.fctrace[index]=self.delta*self.fctrace[index].cuda()+sp.cuda()
for i in range(len(imgsize)):
index=i-1
self.csum[index]=self.ctrace[index]/(self.step)
self.csum[index]=torch.sum(torch.sum(self.csum[index],dim=2),dim=2)
for i in range(len(fclayer)):
index=fclayer[i]
self.fcsum[index]=self.fctrace[index]/(self.step)
return self.csum,self.fcsum
================================================
FILE: examples/Structural_Development/DPAP/prun_main.py
================================================
import argparse
import time
import os
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
import sys
sys.path.append('..')
import torch
import torch.nn as nn
from torch.nn.parallel import DistributedDataParallel as NativeDDP
import logging
from timm.utils import *
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from braincog.base.node.node import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from mask_model import *
from utils import *
_logger = logging.getLogger('train')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
exp_name = '-'.join([datetime.now().strftime("%Y%m%d-%H%M%S"),'c10'])
output_dir = get_outdir('./', 'train', exp_name)
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
_logger.info(exp_name)
config_parser = cfg = argparse.ArgumentParser(description='Training Config', add_help=False)
dataset='cifar10'
num_classes=10
step=8
encode='direct'
node_type='PLIFNode'
thresh=0.5
tau=2.0
torch.backends.cudnn.benchmark = True
devicee=0
seed=42
channels = 2
batch_size=50
epochs=300
lr=5e-3
linear_scaled_lr = lr * batch_size/ 1024.0
cfg.opt='adamw'
cfg.lr=linear_scaled_lr
cfg.weight_decay=0.01
cfg.momentum=0.9
cfg.epochs=epochs
cfg.sched='cosine'
cfg.min_lr=1e-5
cfg.warmup_lr=1e-6
cfg.warmup_epochs=5
cfg.cooldown_epochs=10
cfg.decay_rate=0.1
eval_metric='top1'
best_test = 0
best_testepoch = 0
best_testprun = 0
best_testepochprun = 0
epoch_prune = 1
rate_decay_epoch=30
NUM = 0
torch.cuda.set_device('cuda:%d' % devicee)
torch.manual_seed(seed)
model = my_cifar_model(step=step,encode_type=encode,node_type=node_type,num_classes=num_classes)
model = model.cuda()
print(model)
optimizer = create_optimizer(cfg, model)
lr_scheduler, num_epochs = create_scheduler(cfg, optimizer)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % dataset)(batch_size=batch_size, step=step)
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
m = Mask(model,batch_size,step)
m.init_length()
trace=Trace(model,batch_size,step)
neuron_th,spines,bcm,epoch_trace = init(batch_size,convlayer,fclayer,size,fcsize)
def BCM_and_trace(NUM,trace,spikes,neuron_th,bcm,epoch_trace):
NUM = NUM + 1
csum,fcsum= trace.computing_trace(spikes)
for i in range(1,len(convlayer)):
index=convlayer[i]
post1 = (csum[index] * (csum[index] - neuron_th[index]))
hebb1 = torch.mm(post1.T, csum[index-1])
bcm[index] = bcm[index] + hebb1
neuron_th[index] = torch.div(neuron_th[index] * (NUM - 1) + csum[index], NUM)
cs=torch.sum(csum[index],dim=0)
epoch_trace[index] = epoch_trace[index] + cs
for i in range(1,len(fclayer)):
index = fclayer[i]
post1 = (fcsum[index] * (fcsum[index] - neuron_th[index]))
hebb1 = torch.mm(post1.T, fcsum[fclayer[i - 1]])
bcm[index] = bcm[index] + hebb1
neuron_th[index] = torch.div(neuron_th[index] * (NUM - 1) + fcsum[index], NUM)
cs=torch.sum(fcsum[index],dim=0)
epoch_trace[index] = epoch_trace[index] + cs
return epoch_trace,bcm,NUM
def train_epoch(
epoch, model, loader, optimizer, loss_fn,trace,NUM,bcm,neuron_th,epoch_trace,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None):
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
model.train()
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
output,spikes = model(inputs)
epoch_trace,bcm,NUM = BCM_and_trace(NUM,trace,spikes,neuron_th,bcm,epoch_trace)
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
optimizer.zero_grad()
loss.backward()
optimizer.step()
batch_time_m.update(time.time() - end)
if last_batch or batch_idx %100 == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
print("Train: epoch:",epoch,batch_idx,"/",len(loader),"loss:",losses_m.avg,"acc1:", top1_m.avg,"lr:",lr)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg)]),epoch_trace,bcm,NUM
def validate(model, loader, loss_fn, amp_autocast=suppress, log_suffix=''):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
end = time.time()
last_idx = len(loader) - 1
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
output,spikes = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
if last_batch or batch_idx %100 == 0:
print("Test: loss:",losses_m.avg,"acc1:", top1_m.avg)
batch_time_m.update(time.time() - end)
end = time.time()
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
return metrics
for epoch in range(epochs):
train_metrics, epoch_trace, bcm, N = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn,trace,NUM,bcm,neuron_th,epoch_trace,
lr_scheduler=lr_scheduler)
NUM = N
for i in range(1,len(convlayer)):
index=convlayer[i]
bcmconv = torch.sum(bcm[index], dim=1)
bcmconv=unit_tensor(bcmconv)
traconv=unit_tensor(epoch_trace[index])
spines[index]=bcmconv*traconv
for i in range(1, len(fclayer)):
index=fclayer[i]
bcmfc = torch.sum(bcm[index], dim=1)
bcmfc=unit_tensor(bcmfc)
trafc=unit_tensor(epoch_trace[index])
spines[index]=bcmfc*trafc
if epoch>4:
m.model = model
m.init_mask(bcm,spines,epoch)
m.do_mask()
print("Done pruning")
cc=m.if_zero()
model = m.model
eval_metrics = validate(model, loader_eval, validate_loss_fn)
top1=eval_metrics['top1']
if top1 > best_testprun:
best_testprun = top1
best_testepochprun =epoch
if epoch%40==0:
print('best acc:',best_testprun,'best epoch:',best_testepochprun)
if epoch>4:
_logger.info('*** epoch: {0} (pruning rate {1},acc:{2})'.format(epoch, cc,top1))
if lr_scheduler is not None:
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
================================================
FILE: examples/Structural_Development/DPAP/utils.py
================================================
import torch
import numpy as np
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def print_log(print_string, log):
#print("{}".format(print_string))
log.write('{}\n'.format(print_string))
log.flush()
def unit(x):
if x.size()[0]>0:
xnp=x.cpu().numpy()
maxx=np.percentile(xnp, 75)
minx=torch.min(x)
marge=maxx-minx
if marge!=0:
xx=(x-minx)/marge
xx=torch.clip(xx, 0,1)
else:
xx=0.5*torch.ones_like(x)
return xx
else:
return x
def unit_tensor(x):
if x.size()[0]>0:
maxx=torch.max(x)
minx=torch.min(x)
marge=maxx-minx
if marge!=0:
xx=(x-minx)/marge
else:
xx=0.5*torch.ones_like(x)
return xx
else:
return x
def init(batch,convlayer,fclayer,size,fcsize):
neuron_th={}
convtra = {}
bcm={}
epoch_trace = {}
for i in range(1,len(convlayer)):
index=convlayer[i]
neuron_th[index]=torch.zeros((batch,size[i]),device=device)
convtra[index] = torch.zeros(size[i],device=device)
bcm[index]=torch.zeros(size[i],size[i-1],device=device)
epoch_trace[index] = torch.zeros((size[i]),device=device)
for i in range(1,len(fclayer)):
index=fclayer[i]
neuron_th[index]=torch.zeros((batch,fcsize[i]),device=device)
convtra[index]=torch.zeros(fcsize[i],device=device)
bcm[index]=torch.zeros(fcsize[i],fcsize[i-1],device=device)
epoch_trace[index] = torch.zeros(fcsize[i],device=device)
return neuron_th,convtra,bcm,epoch_trace
================================================
FILE: examples/Structural_Development/DSD-SNN/README.md
================================================
# Enhancing Efficient Continual Learning with Dynamic Structure Development of Spiking Neural Networks #
## Requirments ##
* numpy
* timm
* pytorch >= 1.7.0
* collections
* argparse
## Introduction ##
Dynamic Structure Development of Spiking Neural Networks (DSD-SNN) for efficient and adaptive continual learning:
grow new neurons and prune redundant neurons, increasing memory capacity and reducing computational overhead.
verlap shared structure to leverage acquired knowledge to new tasks, empowering a single network to support multiple incremental tasks.
We validate the effectiveness of the DSD-SNN multiple TIL and CIL benchmarks.
## Run ##
```CUDA_VISIBLE_DEVICES=0 python main_simplified.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{han2022developmental,
title={Enhancing Efficient Continual Learning with Dynamic Structure Development of Spiking Neural Networks},
author={Han, Bing and Zhao, Feifei and Zeng, Yi and Wenxuan, Pan and Shen, Guobin},
booktitle = {Proceedings of the Thirty-First International Joint Conference on
Artificial Intelligence, {IJCAI-23}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
year={2023}
}
@article{zeng2023braincog,
title={Braincog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired ai and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier},
}
```
Enjoy!
================================================
FILE: examples/Structural_Development/DSD-SNN/cifar100/available.py
================================================
from torchvision import datasets, transforms
from manipulate import UnNormalize
# specify available data-sets.
AVAILABLE_DATASETS = {
'MNIST': datasets.MNIST,
'CIFAR100': datasets.CIFAR100,
'CIFAR10': datasets.CIFAR10,
}
# specify available transforms.
AVAILABLE_TRANSFORMS = {
'MNIST': [
transforms.ToTensor(),
],
'MNIST32': [
transforms.Pad(2),
transforms.ToTensor(),
],
'CIFAR10': [
transforms.ToTensor(),
],
'CIFAR100': [
transforms.ToTensor(),
],
'CIFAR10_norm': [
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2470, 0.2435, 0.2616])
],
'CIFAR100_norm': [
transforms.Normalize(mean=[0.5071, 0.4865, 0.4409], std=[0.2673, 0.2564, 0.2761])
],
'CIFAR10_denorm': UnNormalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2470, 0.2435, 0.2616]),
'CIFAR100_denorm': UnNormalize(mean=[0.5071, 0.4865, 0.4409], std=[0.2673, 0.2564, 0.2761]),
'augment_from_tensor': [
transforms.ToPILImage(),
transforms.RandomCrop(32, padding=4, padding_mode='symmetric'),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
],
'augment': [
transforms.RandomCrop(32, padding=4, padding_mode='symmetric'),
transforms.RandomHorizontalFlip(),
],
}
# specify configurations of available data-sets.
DATASET_CONFIGS = {
'MNIST': {'size': 28, 'channels': 1, 'classes': 10},
'MNIST32': {'size': 32, 'channels': 1, 'classes': 10},
'CIFAR10': {'size': 32, 'channels': 3, 'classes': 10},
'CIFAR100': {'size': 32, 'channels': 3, 'classes': 100},
}
================================================
FILE: examples/Structural_Development/DSD-SNN/cifar100/main_simplified.py
================================================
import argparse
import time
import timm.models
import yaml
import os
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.utils import save_feature_map
import torch
import torch.nn as nn
import torchvision.utils
from torchvision import transforms
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from maskcl2 import *
# from ptflops import get_model_complexity_info
from thop import profile, clever_format
from manipulate import SubDataset
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
from available import AVAILABLE_DATASETS, AVAILABLE_TRANSFORMS, DATASET_CONFIGS
from torch.utils.data.dataloader import DataLoader
from torch.utils.data import ConcatDataset
import copy
from vgg_snn import SNN
# torch.cuda.set_device(9)
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--dataset', default='cifar100', type=str)
parser.add_argument('--model', default='cifar_convnet', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--num-classes', type=int, default=100, metavar='N',
help='number of label classes (default: 100)')
parser.add_argument('--task_num', type=int, default=10, metavar='N',
help='number of label classes (default: 10)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=50, metavar='N',
help='inputs batch size for training (default: 128)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=1e-2, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-4, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=600, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Misc
parser.add_argument('--seed', type=int, default=0, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=25, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=4, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--device', type=int, default=0)
parser.add_argument('--output', default='/home/hanbing/brain/bp2/', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
# Spike parameters
parser.add_argument('--step', type=int, default=4, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='QGateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--thresh', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--n_warm_up', type=int, default=0,
help='Warm up epoch, replace all node to ReLU to warm up weights in network before (default: 0)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def get_dataset(name, type='train', download=True, capacity=None, permutation=None, dir='./store/datasets',
verbose=False, augment=False, normalize=False, target_transform=None):
'''Create [train|valid|test]-dataset.'''
data_name = 'MNIST' if name in ('MNIST28', 'MNIST32') else name
dataset_class = AVAILABLE_DATASETS[data_name]
# specify image-transformations to be applied
transforms_list = [*AVAILABLE_TRANSFORMS['augment']] if augment else []
transforms_list += [*AVAILABLE_TRANSFORMS[name]]
if normalize:
transforms_list += [*AVAILABLE_TRANSFORMS[name+"_norm"]]
# if permutation is not None:
# transforms_list.append(transforms.Lambda(lambda x, p=permutation: permutate_image_pixels(x, p)))
dataset_transform = transforms.Compose(transforms_list)
# load data-set
dataset = dataset_class('{dir}/{name}'.format(dir=dir, name=data_name), train=False if type=='test' else True,
download=download, transform=dataset_transform, target_transform=target_transform)
# print information about dataset on the screen
if verbose:
print(" --> {}: '{}'-dataset consisting of {} samples".format(name, type, len(dataset)))
# if dataset is (possibly) not large enough, create copies until it is.
if capacity is not None and len(dataset) < capacity:
dataset = ConcatDataset([copy.deepcopy(dataset) for _ in range(int(np.ceil(capacity / len(dataset))))])
return dataset
def main():
args, args_text = _parse_args()
# args.no_spike_output = args.no_spike_output | args.cut_mix
args.no_spike_output = True
output_dir = ''
output_base = args.output if args.output else './output'
exp_name = '-'.join([
datetime.now().strftime("%Y%m%d-%H%M%S"),
'SNN',
args.dataset,
str(args.seed),
'gwu',
'xin-epochs'
])
output_dir = get_outdir(output_base, 'train', exp_name)
print(output_dir)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
torch.cuda.set_device('cuda:%d' % args.device)
torch.manual_seed(args.seed)
model = SNN(
num_classes=args.num_classes,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.thresh,
tau=args.tau,
spike_output=not args.no_spike_output,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
batch_size=args.batch_size,
task_num=args.task_num
)
print(model)
# for n,p in enumerate(model.parameters()):
# print(n,p.size())
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.img_size, args.img_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size / 1024.0
args.lr = linear_scaled_lr
model = model.cuda()
optimizer = create_optimizer(args, model)
# optionally resume from a checkpoint
resume_epoch = None
if args.resume:
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
m = Mask(model)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
_logger.info('Scheduled epochs: {}'.format(num_epochs))
batch_size=args.batch_size
data_dir = '/data0/datasets/'
trainset = get_dataset('CIFAR100', type="train", dir=data_dir)
testset = get_dataset('CIFAR100', type="test", dir=data_dir)
out_num=int(args.num_classes/args.task_num)
labels_per_dataset_train = [list(np.array(range(out_num))+out_num*context_id) for context_id in range(args.task_num)]
labels_per_dataset_test = [list(np.array(range(out_num))+out_num*context_id) for context_id in range(args.task_num)]
train_datasets = []
for labels in labels_per_dataset_train:
target_transform = transforms.Lambda(lambda y, x=labels[0]: y-x)
train_datasets.append(SubDataset(trainset, labels, target_transform=target_transform))
test_datasets = []
for labels in labels_per_dataset_test:
target_transform = transforms.Lambda(lambda y, x=labels[0]: y-x)
test_datasets.append(SubDataset(testset, labels, target_transform=target_transform))
train_data = []
test_data = []
t_data=[]
for task in range(len(train_datasets)):
train_data.append(DataLoader(train_datasets[task], batch_size=batch_size, shuffle=True, drop_last=True, **({'num_workers': 4, 'pin_memory': True})))
test_data.append(DataLoader(test_datasets[task], batch_size=batch_size, shuffle=True, drop_last=True, **({'num_workers': 4, 'pin_memory': True})))
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args,
checkpoint_dir=output_dir, recovery_dir=output_dir)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
loader_his=[]
task_ready={}
for index, item in enumerate(model.parameters()):
if len(item.size()) > 1 and index<=40:
task_ready[index]=torch.zeros(item.size(),device=device)
try: # train the model
task_count=0
regularization_terms= {}
for task in range(len(train_datasets)):
print("Task:",task)
if task==0:
m.model = model
mat=m.init_length()
model = m.model
epochs=50
else:
m.model = model
mat,task_ready,taskmaskk,taskww=m.init_grow(task)
model = m.model
epochs=30
ta_his=[i for i in range(task+1)]
for epoch in range(epochs):
loader_train = iter(train_data[task])
if task==0:
train_epoch(epoch, task, model, loader_train, optimizer, train_loss_fn, args,mat,task_ready,taskww=None,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,regularization_terms=regularization_terms)
else:
train_epoch(epoch, task, model, loader_train, optimizer, train_loss_fn, args,mat,task_ready,taskww=taskww,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,regularization_terms=regularization_terms)
print(epoch)
if epoch>0:
m.model = model
m.init_mask(task,epoch)
mat=m.do_mask(task)
model = m.model
ta_his=[i for i in range(task+1)]
for t in ta_his:
loader_his=iter(test_data[t])
validate(t, model, loader_his, validate_loss_fn, args,mat)
cc=m.if_zero()
_logger.info('*** epoch: {0}, task: {1}, pruning: {2}'.format(epoch,task, cc))
p_index=m.record()
except KeyboardInterrupt:
pass
# if best_metric is not None:
# _logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, task,model, loader, optimizer, loss_fn, args,mat,task_ready,taskww=None,
lr_scheduler=None, saver=None, output_dir='',regularization_terms={}):
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
output = model(inputs, mat)
t_preds = output[task].cuda()
loss = loss_fn(t_preds, target)
# if len(regularization_terms)>0:
# reg_loss = 0
# for i,reg_term in regularization_terms.items():
# task_reg_loss = 0
# importance = reg_term['importance']
# task_param = reg_term['task_param']
# for n, p in enumerate(model.parameters()):
# if len(p.size())>=1:
# task_reg_loss += (importance[n] * (p - task_param[n]) ** 2).sum()
# reg_loss += task_reg_loss
# loss += 10000 * reg_loss
acc1, acc5 = accuracy(t_preds, target, topk=(1, 5))
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
top5_m.update(acc5.item(), inputs.size(0))
optimizer.zero_grad()
loss.backward()
# for index, item in enumerate(model.parameters()):
# if len(item.size()) > 1 and index<=40:
# gradmask=torch.where(task_ready[index]>0,0.0,1.0)
# item.grad=item.grad*gradmask
optimizer.step()
for index, item in enumerate(model.parameters()):
if len(item.size()) > 1 and index<=40:
if index<40:
ready=task_ready[index].view(task_ready[index].size()[0],-1)
ready=torch.sum(ready,dim=1)
else:
ready=torch.sum(task_ready[index],dim=1)
windex=torch.nonzero(ready>0)
for i in range(len(windex)):
item.data[windex[i]]=taskww[index][windex[i]]
num_updates += 1
batch_time_m.update(time.time() - end)
if last_batch or batch_idx % args.log_interval == 0:
# lrl = [param_group['lr'] for param_group in optimizer.param_groups]
# lr = sum(lrl) / len(lrl)
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
top1=top1_m, top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) / batch_time_m.val,
rate_avg=inputs.size(0) / batch_time_m.avg,
data_time=data_time_m))
# if saver is not None and args.recovery_interval and (
# last_batch or (batch_idx + 1) % args.recovery_interval == 0):
# saver.save_recovery(epoch, batch_idx=batch_idx)
# if lr_scheduler is not None:
# lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
# end = time.time()
# # end for
# if hasattr(optimizer, 'sync_lookahead'):
# optimizer.sync_lookahead()
# return OrderedDict([('loss', losses_m.avg)])
def validate(task, model, loader, loss_fn, args, mat,log_suffix='', visualize=False, spike_rate=False):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
end = time.time()
with torch.no_grad():
last_idx = len(loader) - 1
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
output = model(inputs,mat)
t_preds = output[task]
loss = loss_fn(t_preds, target)
acc1, acc5 = accuracy(t_preds, target, topk=(1, 5))
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
log_name = 'Test'+str(task) + log_suffix
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
log_name, batch_idx, last_idx, batch_time=batch_time_m,
loss=losses_m, top1=top1_m, top5=top5_m))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
# return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/Structural_Development/DSD-SNN/cifar100/manipulate.py
================================================
import torch
from torch.utils.data import Dataset
def permutate_image_pixels(image, permutation):
'''Permutate the pixels of an image according to [permutation].
[image] 3D-tensor containing the image
[permutation] of pixel-indeces in their new order'''
if permutation is None:
return image
else:
c, h, w = image.size()
image = image.view(c, -1)
image = image[:, permutation] #--> same permutation for each channel
image = image.view(c, h, w)
return image
#----------------------------------------------------------------------------------------------------------#
class SubDataset(Dataset):
'''To sub-sample a dataset, taking only those samples with label in [sub_labels].
After this selection of samples has been made, it is possible to transform the target-labels,
which can be useful when doing continual learning with fixed number of output units.'''
def __init__(self, original_dataset, sub_labels, target_transform=None):
super().__init__()
self.dataset = original_dataset
self.sub_indeces = []
for index in range(len(self.dataset)):
if hasattr(original_dataset, "train_labels"):
if self.dataset.target_transform is None:
label = self.dataset.train_labels[index]
else:
label = self.dataset.target_transform(self.dataset.train_labels[index])
elif hasattr(self.dataset, "test_labels"):
if self.dataset.target_transform is None:
label = self.dataset.test_labels[index]
else:
label = self.dataset.target_transform(self.dataset.test_labels[index])
else:
label = self.dataset[index][1]
if label in sub_labels:
self.sub_indeces.append(index)
self.target_transform = target_transform
def __len__(self):
return len(self.sub_indeces)
def __getitem__(self, index):
sample = self.dataset[self.sub_indeces[index]]
if self.target_transform:
target = self.target_transform(sample[1])
sample = (sample[0], target)
return sample
class MemorySetDataset(Dataset):
'''Create dataset from list of with shape (N, C, H, W) (i.e., with N images each).
The images at the i-th entry of [memory_sets] belong to class [i], unless a [target_transform] is specified'''
def __init__(self, memory_sets, target_transform=None):
super().__init__()
self.memory_sets = memory_sets
self.target_transform = target_transform
def __len__(self):
total = 0
for class_id in range(len(self.memory_sets)):
total += len(self.memory_sets[class_id])
return total
def __getitem__(self, index):
total = 0
for class_id in range(len(self.memory_sets)):
examples_in_this_class = len(self.memory_sets[class_id])
if index < (total + examples_in_this_class):
class_id_to_return = class_id if self.target_transform is None else self.target_transform(class_id)
example_id = index - total
break
else:
total += examples_in_this_class
image = torch.from_numpy(self.memory_sets[class_id][example_id])
return (image, class_id_to_return)
class TransformedDataset(Dataset):
'''To modify an existing dataset with a transform.
This is useful for creating different permutations of MNIST without loading the data multiple times.'''
def __init__(self, original_dataset, transform=None, target_transform=None):
super().__init__()
self.dataset = original_dataset
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
(input, target) = self.dataset[index]
if self.transform:
input = self.transform(input)
if self.target_transform:
target = self.target_transform(target)
return (input, target)
# ----------------------------------------------------------------------------------------------------------#
class UnNormalize(object):
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, tensor):
"""Denormalize image, either single image (C,H,W) or image batch (N,C,H,W)"""
batch = (len(tensor.size()) == 4)
for t, m, s in zip(tensor.permute(1, 0, 2, 3) if batch else tensor, self.mean, self.std):
t.mul_(s).add_(m)
# The normalize code -> t.sub_(m).div_(s)
return tensor
================================================
FILE: examples/Structural_Development/DSD-SNN/cifar100/maskcl2.py
================================================
import numpy as np
import torch
import math
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
import random
def unit(x):
if x.size()[0]>0:
xnp=x.cpu().numpy()
maxx=torch.max(x)
#maxx=np.percentile(xnp, 99.5)
minx=torch.min(x)
marge=maxx-minx
if marge!=0:
xx=(x-minx)/marge
xx=torch.clip(xx, 0,1)
else:
xx=0.5*torch.ones_like(x)
return xx
else:
return x
class Mask:
def __init__(self, model):
self.model = model
self.mat = {}
self.p_index={}
self.p_num={}
self.k=15
self.task_ready={}
self.taskmask={}
self.init_rate=0.3
self.grow_rate=0.125
self.prunconv_init=0.8
self.prunfc_init=1.3
self.prunconv_grow=0.5
self.prunfc_grow=1
self.n_delta={}
self.reduce={}
self.taskww={}
def init_length(self):
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1:
print(index,item.size())
self.mat[index]=torch.ones(item.size(),device=device)
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1:
if index<=40:
self.p_index[index]=torch.tensor([])
self.task_ready[index]=torch.zeros(item.size(),device=device)
self.reduce[index] = 5*torch.ones(item.size()[0],device=device)
if len(item.size()) == 4:
self.p_num[index]=torch.zeros(item.size()[0],device=device)
self.mat[index][int(self.init_rate*item.size()[0]):]=0.0
if index+5<40:
self.mat[index+5][:,int(self.init_rate*item.size()[0]):]=0.0
if index+5==40:
self.mat[index+5][:,int(self.init_rate*item.size()[0])*16:]=0.0
if len(item.size()) == 2:
self.p_num[index]=torch.zeros(item.size()[0]*item.size()[1],device=device)
self.mat[index][int(self.init_rate*item.size()[0]):]=0.0
if index>40:
self.mat[index]=torch.ones(item.size(),device=device)
if index==44:
self.mat[index]=torch.zeros(item.size(),device=device)
self.mat[index][:,:int(self.init_rate*item.size()[1])]=1.0
return self.mat
def get_filter_codebook(self,index,ww,task,epoch):
if task==0:
pruncon=self.prunconv_init
prunfc=self.prunfc_init
else:
pruncon=self.prunconv_grow
prunfc=self.prunfc_grow
if len(ww.size()) == 4:
p_ww=ww.view(ww.size()[0],-1)
p_ww=torch.sum(p_ww,dim=1)
task_use=self.mat[index]-torch.sign(self.task_ready[index])
nouse=torch.sum(task_use.view(ww.size()[0],-1),dim=1)
no=torch.nonzero(nouse<0.1)
p_ww[no]=p_ww.max()
self.n_delta[index]=(unit(p_ww)*2-pruncon)
pos=torch.nonzero(self.n_delta[index]>0)
self.n_delta[index][pos]=self.n_delta[index][pos]+3
self.reduce[index]=self.reduce[index]*0.999+self.n_delta[index]*math.exp(-int((epoch-1)/13))
p_ind = torch.nonzero(self.reduce[index] <0)
print(self.reduce[index].mean(),self.reduce[index].max(),self.reduce[index].min(),len(p_ind))
for x in range(0, len(p_ind)):
self.mat[index][p_ind[x]] = 0
if index+5<40:
self.mat[index+5][:,p_ind[x]]=0
if index+5==40:
self.mat[index+5][:,p_ind[x]*16:(p_ind[x]+1)*16]=0
self.mat[index]=torch.sign(self.mat[index]+ self.task_ready[index])
if len(ww.size()) == 2:
p_ww=torch.sum(ww,dim=1)
task_use=self.mat[index]-torch.sign(self.task_ready[index])
nouse=torch.sum(task_use,dim=1)
no=torch.nonzero(nouse<0.1)
p_ww[no]=p_ww.max()
self.n_delta[index]=(unit(p_ww)*2-prunfc)
print(self.n_delta[index].mean(),self.n_delta[index].max(),self.n_delta[index].min())
pos=torch.nonzero(self.n_delta[index]>0)
self.n_delta[index][pos]=self.n_delta[index][pos]+3
self.reduce[index]=self.reduce[index]*0.999+self.n_delta[index]*math.exp(-int((epoch-1)/13))
p_ind = torch.nonzero(self.reduce[index] <0)
print(self.reduce[index].mean(),self.reduce[index].max(),self.reduce[index].min(),len(p_ind))
index_ta=44+task*2
for x in range(0, len(p_ind)):
self.mat[index][p_ind[x]] = 0
self.mat[index_ta][:,p_ind[x]]=0
self.mat[index]=torch.sign(self.mat[index]+self.task_ready[index])
def convert2tensor(self, x):
x = torch.FloatTensor(x)
return x
def init_mask(self,task,epoch):
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and index<=40:
self.get_filter_codebook(index,abs(item.data),task,epoch)
def do_mask(self,task):
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and index<=40:
ww=item.data
item.data=ww*self.mat[index].cuda()
return self.mat
def init_grow(self,task):
self.taskmask[task]={}
index_ta=44+task*2
self.mat[index_ta]=torch.zeros(self.mat[index_ta].size(),device=device)
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and index<=40:
self.task_ready[index]=self.task_ready[index]+self.mat[index]
self.taskmask[task][index]=self.mat[index]
self.taskww[index]=item.data.clone()
ind_all=[x for x in range(item.size()[0])]
pp=list(np.array(self.p_index[index]))
ind_empty=set(ind_all)-set(pp)
ind_empty=list(ind_empty)
# random.shuffle(ind_empty)
ind_grow=ind_empty[:int(item.size()[0]*self.grow_rate)]
ind_grow=torch.tensor(ind_grow)
ww_g=torch.empty(item.size(),device=device)
if index<40:
torch.nn.init.kaiming_uniform_(ww_g, a=math.sqrt(5))
if index==40:
kk=1/math.sqrt(item.size()[1])
torch.nn.init.uniform_(ww_g,a=-kk,b=kk)
for x in range(0, len(ind_grow)):
self.mat[index][ind_grow[x]] = 1.0
item.data[ind_grow[x]]=ww_g[ind_grow[x]]
if index==40:
self.mat[index_ta][:,ind_grow[x]]=1.0
self.mat[index]=torch.sign(self.mat[index]+self.task_ready[index])
self.p_num[index]=torch.zeros(item.size()[0],device=device)
self.reduce[index] = 5*torch.ones(item.size()[0],device=device)
#self.mat[index_ta]=self.mat[index_ta]+self.mat[index_ta-2]
# nn=torch.sum(self.task_ready[24],dim=1)
# use_nn=torch.nonzero(nn>1)
# for x in range(0, len(use_nn)):
# self.mat[index_ta][:,use_nn[x]] = 1.0
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and index<40:
nsum=self.mat[index].view(item.size()[0],-1)
nn=torch.sum(abs(nsum),dim=1)
empy_nn=torch.nonzero(nn<0.00001)
for x in range(0, len(empy_nn)):
if index+5<40:
self.mat[index+5][:,empy_nn[x]]=0
if index+5==40:
self.mat[index+5][:,empy_nn[x]*16:(empy_nn[x]+1)*16]=0
return self.mat,self.task_ready,self.taskmask,self.taskww
def if_zero(self):
cc=[]
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and index<=40:
b = item.data.view(-1).cpu().numpy()
print("number of weight is %d, zero is %.3f" %(len(b),100*(len(b)- np.count_nonzero(b))/len(b)))
cc.append(100*(len(b)- np.count_nonzero(b))/len(b))
if index==40:
nouse=torch.sum(self.mat[index],dim=1)
no=torch.nonzero(nouse<0.1)
print(len(no))
cc.append(len(no))
return cc
def record(self):
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and index<=40:
nsum=self.mat[index].view(item.size()[0],-1)
nn=torch.sum(abs(nsum),dim=1)
epoch_select=torch.nonzero(nn>0.00001)
select=set(epoch_select)|set(self.p_index[index])
self.p_index[index]= torch.tensor(list(select))
return self.p_index
================================================
FILE: examples/Structural_Development/DSD-SNN/cifar100/vgg_snn.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/7/26 18:56
# User : Floyed
# Product : PyCharm
# Project : BrainCog
# File : vgg_snn.py
# explain :
from functools import partial
from torch.nn import functional as F
import torchvision
from timm.models import register_model
from braincog.datasets import is_dvs_data
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
@register_model
class SNN(BaseModule):
def __init__(self,
num_classes=100,
step=8,
node_type=LIFNode,
encode_type='direct',
batch_size=100,
task_num=10,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.n_preact = kwargs['n_preact'] if 'n_preact' in kwargs else False
self.batch_size=batch_size
self.num_classes = num_classes
self.task_num=task_num
self.out_num=int(self.num_classes/self.task_num)
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.dataset = kwargs['dataset']
if not is_dvs_data(self.dataset):
init_channel = 3
output_size = 2
else:
init_channel = 2
output_size = 3
#self.channel_number=[256,512,1024]
self.channel_number=[512,1024,2048]
self.feature = nn.Sequential(
BaseConvModule(init_channel, self.channel_number[0], kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(self.channel_number[0], self.channel_number[0], kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.AvgPool2d(2),
BaseConvModule(self.channel_number[0], self.channel_number[0], kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(self.channel_number[0], self.channel_number[0], kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.AvgPool2d(2),
BaseConvModule(self.channel_number[0], self.channel_number[1], kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(self.channel_number[1], self.channel_number[1], kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.AvgPool2d(2),
BaseConvModule(self.channel_number[1], self.channel_number[2], kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(self.channel_number[2], self.channel_number[2], kernel_size=(3, 3), padding=(1, 1), node=self.node),
)
self.fc = nn.Sequential(
nn.Flatten(),
BaseLinearModule(
self.channel_number[2]*4*4, self.channel_number[2], node=self.node),
)
self.dec = nn.ModuleDict()
for task in range(self.task_num):
ta=str(task)
self.dec[ta] = self._create_decision()
def logits(self, x):
outputs =torch.zeros((self.task_num,self.batch_size,self.out_num),device='cuda')
for task, func in self.dec.items():
ta=int(task)
outputs[ta]=func(x)
return outputs
def _create_decision(self):
fc = nn.Linear(self.channel_number[2], self.out_num)
# fc = BaseLinearModule(1024, 10, node=self.node)
return fc
def forward(self, inputs, mat):
inputs = self.encoder(inputs)
self.reset()
step = self.step
outputs = []
for index, item in enumerate(self.parameters()):
if len(item.size()) > 1:
ww=item.data
item.data=ww*mat[index].cuda()
for t in range(step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
x = self.logits(x)
outputs.append(x)
out=sum(outputs).cuda()
return out / step
# class MaskConvModule(nn.Module):
# """
# SNN卷积模块
# :param in_channels: 输入通道数
# :param out_channels: 输出通道数
# :param kernel_size: kernel size
# :param stride: stride
# :param padding: padding
# :param bias: Bias
# :param node: 神经元类型
# :param kwargs:
# """
# def __init__(self,
# in_channels: int,
# out_channels: int,
# kernel_size=(3, 3),
# stride=(1, 1),
# padding=(1, 1),
# bias=False,
# node=PLIFNode,
# **kwargs):
# super().__init__()
# if node is None:
# raise TypeError
# self.groups = kwargs['groups'] if 'groups' in kwargs else 1
# self.conv = MConv2d(in_channels=in_channels * self.groups,
# out_channels=out_channels * self.groups,
# kernel_size=kernel_size,
# padding=padding,
# stride=stride,
# bias=bias)
# self.bn = nn.BatchNorm2d(out_channels * self.groups)
# self.node = partial(node, **kwargs)()
# self.activation = nn.Identity()
# def forward(self, x, mat):
# x = self.conv(x,mat)
# x = self.bn(x)
# x = self.node(x)
# return x
# class MConv2d(nn.Conv2d):
# def __init__(self, in_channels, out_channels, kernel_size, stride=1,
# padding=0, dilation=1, groups=1, bias=True, gain=True):
# super(MConv2d, self).__init__(in_channels, out_channels, kernel_size, stride,
# padding, dilation, groups, bias)
# self.gain = 1.
# def forward(self, x, mat):
# weight = self.weight
# weight = weight*mat
# return F.conv2d(x, weight, self.bias, self.stride,
# self.padding, self.dilation, self.groups)
# class MaskLinearModule(nn.Module):
# """
# 线性模块
# :param in_features: 输入尺寸
# :param out_features: 输出尺寸
# :param bias: 是否有Bias, 默认 ``False``
# :param node: 神经元类型, 默认 ``LIFNode``
# :param args:
# :param kwargs:
# """
# def __init__(self,
# in_features: int,
# out_features: int,
# bias=True,
# node=LIFNode,
# *args,
# **kwargs):
# super().__init__()
# if node is None:
# raise TypeError
# self.fc = MLinear(in_features=in_features,
# out_features=out_features, bias=bias)
# self.node = partial(node, **kwargs)()
# def forward(self, x,mat):
# outputs = self.fc(x,mat)
# return self.node(outputs)
# class MLinear(nn.Linear):
# def __init__(self, in_features: int, out_features: int, bias: bool = True):
# super(MLinear, self).__init__(in_features, out_features, bias)
# self.gain = 1.
# def forward(self, input, mat):
# weight = self.weight
# weight = weight*mat
# return F.linear(input, weight, self.bias)
================================================
FILE: examples/Structural_Development/ELSM/evolve.py
================================================
import time
import threading
from threading import Thread
import os
import networkx as nx
import numpy as np
from population import *
import nsganet as engine
from pymop.problem import Problem
from pymoo.optimize import minimize
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
import logging
from model import *
from spikes import calc_f2
from mul import mul_f1
_logger = logging.getLogger('')
config_parser = parser = argparse.ArgumentParser(description='Evolution Config', add_help=False)
parser = argparse.ArgumentParser(description='ELSM')
parser.add_argument('--device', type=int, default=2)
parser.add_argument('--seed', type=int, default=68, metavar='S')
parser.add_argument('--datapath', default='', type=str, metavar='PATH')
parser.add_argument('--output', default='', type=str, metavar='PATH')
parser.add_argument('--liquid-size', type=int, default=8000)
parser.add_argument('--pop-size', type=int, default=80)
parser.add_argument('--up', type=int, default=32000000)
parser.add_argument('--low', type=int, default=320000)
parser.add_argument('--n_offspring', type=int, default=100)
parser.add_argument('--n_gens', type=int, default=10000)
parser.add_argument('--arand', type=float, default=285)
parser.add_argument('--brand', type=float, default=1.8)
def _parse_args():
args_config, remaining = config_parser.parse_known_args()
args = parser.parse_args(remaining)
return args
class Evolve(Problem):
# first define the NAS problem (inherit from pymop)
def __init__(self, args,n_var=20, n_obj=1, n_constr=0, lb=None, ub=None):
super().__init__(n_var=n_var, n_obj=n_obj, n_constr=n_constr, type_var=np.int64)
self.xl = lb
self.xu = ub
self._n_evaluated = 0 # keep track of how many architectures are sampled
self.args=args
def _evaluate(self, x, out, *args, **kwargs):
objs = np.full((x.shape[0], self.n_obj), np.nan)
g1 = np.full((x.shape[0]), np.nan)
g2 = np.full((x.shape[0]), np.nan)
gen_dir=os.path.join(self.args.output,'generaion'+str(kwargs['algorithm'].n_gen))
os.makedirs(gen_dir,exist_ok = True)
# np.save(os.path.join(gen_dir,"x.npy"),x)
lsms = x.reshape(x.shape[0],self.args.liquid_size,self.args.liquid_size)
for i in range(x.shape[0]):
temp_G = nx.Graph(lsms[i])
nx.write_gpickle(temp_G, os.path.join(gen_dir,str(i)+".pkl"))
self.ob1=mul_f1(pop=x.shape[0],steps=10,rootdir=gen_dir)
for i in range(x.shape[0]):
arch_id = self._n_evaluated + 1
print('\n')
_logger.info('Network= {}'.format(arch_id))
genome = x[i, :]
g1[i]= genome.sum()-self.args.up
g2[i]= self.args.low-genome.sum()
lsmm = genome.reshape(self.args.liquid_size,self.args.liquid_size)
small_coe_a,small_coe_b=self.ob1[i]
lsmm=torch.tensor(lsmm,device='cuda:%d' % self.args.device).float()
crit = calc_f2(lsmm,'cuda:%d' % self.args.device)
objs[i, 1] = abs(crit-1)
# all objectives assume to be MINIMIZED !!!!!
objs[i, 0] = -(small_coe_a/self.args.arand)/(small_coe_b/self.args.brand)
_logger.info('small word= {}'.format(objs[i, 0]))
_logger.info('criticality= {}'.format(objs[i, 1]))
self._n_evaluated += 1
out["F"] = objs
out["G"] = np.column_stack([g1,g2])
# if your NAS problem has constraints, use the following line to set constraints
# out["G"] = np.column_stack([g1, g2, g3, g4, g5, g6]) in case 6 constraints
# ---------------------------------------------------------------------------------------------------------
# Define what statistics to print or save for each generation
# ---------------------------------------------------------------------------------------------------------
def do_every_generations(algorithm):
# this function will be call every generation
# it has access to the whole algorithm class
gen = algorithm.n_gen
pop_var = algorithm.pop.get("X")
pop_obj = algorithm.pop.get("F")
# report generation info to files
_logger.info("generation = {}".format(gen))
_logger.info("population error1: best = {}, mean = {}, "
"median1 = {}, worst1 = {}".format(np.min(pop_obj[:, 0]), np.mean(pop_obj[:, 0]),
np.median(pop_obj[:, 0]), np.max(pop_obj[:, 0])))
_logger.info('Best1 Genome id= {}'.format(np.argmin(pop_obj[:, 0])))
_logger.info("population error2: best = {}, mean = {}, "
"median2 = {}, worst2 = {}".format(np.min(pop_obj[:, 1]), np.mean(pop_obj[:, 1]),
np.median(pop_obj[:, 1]), np.max(pop_obj[:, 1])))
_logger.info('Best2 Genome id= {}'.format(np.argmin(pop_obj[:, 1])))
if gen%20==0:
best_sid=np.argmin(pop_obj[:, 0])
best_sname='-'.join([
'gen'+str(gen),
's'+str(float('%.4f' % pop_obj[best_sid, 0])),
'c'+str(float('%.4f' % pop_obj[best_sid, 1])),
])
best_cid=np.argmin(pop_obj[:, 1])
best_cname='-'.join([
'gen'+str(gen),
's'+str(float('%.4f' % pop_obj[best_cid, 0])),
'c'+str(float('%.4f' % pop_obj[best_cid, 1])),
])
np.save(os.path.join('',best_sname+datetime.now().strftime("%Y%m%d-%H%M%S")),pop_var[np.argmin(pop_obj[:, 0])])
np.save(os.path.join('',best_cname+datetime.now().strftime("%Y%m%d-%H%M%S")),pop_var[np.argmin(pop_obj[:, 1])])
if __name__ == '__main__':
args = _parse_args()
out_base_dir= os.path.join(args.output, datetime.now().strftime("%Y%m%d-%H%M%S"))
os.makedirs(out_base_dir,exist_ok = True)
args.output=out_base_dir
setup_default_logging(log_path=os.path.join(out_base_dir, 'log.txt'))
kkk = Evolve(args,n_var=args.liquid_size*args.liquid_size,
n_obj=2, n_constr=2)
method = engine.nsganet(pop_size=args.pop_size,
sampling=RandomSampling(var_type='custom'),
mutation=BinaryBitflipMutation(),
n_offsprings=args.n_offspring,
eliminate_duplicates=True)
kres=minimize(kkk,
method,
callback=do_every_generations,
termination=('n_gen', args.n_gens))
================================================
FILE: examples/Structural_Development/ELSM/lsm.py
================================================
from __future__ import print_function
import torchvision
import torchvision.transforms as transforms
import os
import time
import numpy as np
import torch
from torch import nn as nn
from mnistmodel import *
from tqdm import tqdm
import argparse
from datetime import datetime
import logging
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy
from braincog.base.utils import UnilateralMse, MixLoss
from braincog.base.learningrule.STDP import *
device='cuda:7'
def lr_scheduler(optimizer, epoch, init_lr=0.1, lr_decay_epoch=50):
"""Decay learning rate by a factor of 0.1 every lr_decay_epoch epochs."""
if epoch % lr_decay_epoch == 0 and epoch > 1:
for param_group in optimizer.param_groups:
param_group['lr'] = param_group['lr'] * 0.1
return optimizer
batch_size=100
liquid_size=8000
learning_rate = 1e-3
num_epochs = 100 # max epoch
data_path = '/data'
load_path=''
train_dataset = torchvision.datasets.MNIST(root=data_path, train=True, download=False, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=8)
test_set = torchvision.datasets.MNIST(root=data_path, train=False, download=False, transform=transforms.ToTensor())
test_loader = torch.utils.data.DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=2)
snn = SNN(ins=784,
batchsize=batch_size,
device=device,
liquid_size=liquid_size,
lsm_tau=lsm_tau,
lsm_th=lsm_th)
snn.load_state_dict(torch.load(load_path)['fc'])
snn.learning_rule=[]
snn.con[0].load_state_dict(torch.load(load_path)['lsm0'])
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False,device=device)
snn.connectivity_matrix=torch.load(load_path)['connectivity_matrix'].to(device)
w2tmp.weight.data=(torch.load(load_path)['liquid_weight'].to(device))*snn.connectivity_matrix
snn.learning_rule.append(MutliInputSTDP(snn.node_lsm(), [snn.con[0], w2tmp])) # pm
snn.eval()
snn.to(device)
ls = 'mse'
if ls == 'ce':
criterion = nn.CrossEntropyLoss()
elif ls == 'bce':
criterion = nn.BCEWithLogitsLoss()
elif ls == 'mse':
criterion = UnilateralMse(1.)
elif ls == 'sce':
criterion = LabelSmoothingCrossEntropy()
elif ls == 'sbce':
criterion = LabelSmoothingBCEWithLogitsLoss()
elif ls == 'umse':
criterion = UnilateralMse(.5)
optimizer = torch.optim.AdamW(snn.fc.parameters(),lr=0.001, weight_decay=1e-4)
l=[]
best_acc=0
for epoch in range(num_epochs):
running_loss = 0
start_time = time.time()
for i, (images, labels) in enumerate(tqdm(train_loader)):
snn.zero_grad()
optimizer.zero_grad()
images = images.float().to(device)
outputs = snn(images)
labels=labels.to(device)
loss = criterion(outputs, labels)
running_loss += loss.item()
loss.backward()
optimizer.step()
snn.reset()
if (i + 1) % 100 == 0:
running_loss = 0
correct = 0
total = 0
optimizer = lr_scheduler(optimizer, epoch, learning_rate, 40)
for batch_idx, (inputs, targets) in enumerate(test_loader):
inputs = inputs.float().to(device)
snn.zero_grad()
optimizer.zero_grad()
outputs = snn(inputs)
targets=targets.to(device)
loss = criterion(outputs, targets)
_, predicted = outputs.max(1)
total += float(targets.size(0))
correct += float(predicted.eq(targets).sum().item())
snn.reset()
if batch_idx % 100 == 0:
acc = 100. * float(correct) / float(total)
print(batch_idx, len(test_loader), ' Acc: %.5f' % acc)
print('Test Accuracy: %.3f' % (100 * correct / total))
acc = 100. * float(correct) / float(total)
if best_acc < acc:
best_acc = acc
print(best_acc)
l.append(best_acc)
================================================
FILE: examples/Structural_Development/ELSM/model.py
================================================
from functools import partial
from torch.nn import functional as F
from torch import nn as nn
import torchvision, pprint
from copy import deepcopy
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.base.brainarea.BrainArea import BrainArea
from braincog.base.connection.CustomLinear import *
from braincog.base.learningrule.STDP import *
import matplotlib.pyplot as plt
@register_model
class nSNN(BaseModule):
def __init__(self,
batchsize,
liquid_size,
device,
connectivity_matrix,
num_classes=10,
step=1,
node_type=LIFNode,
encode_type='direct',
lsm_th=0.3,
fc_th=0.3,
lsm_tau=3,
fc_tau=3,
ins=1156,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.batchsize=batchsize
self.ins=ins
self.node_lsm=partial(node_type, **kwargs, step=step,tau=lsm_tau,threshold=lsm_th)
self.node_fc = partial(node_type, **kwargs, step=step,tau=fc_tau,threshold=fc_th)
self.liquid_size=liquid_size
self.device=device
self.con=[]
self.learning_rule=[]
self.connectivity_matrix=connectivity_matrix
w1tmp=nn.Linear(ins,liquid_size,bias=False).to(device)
self.con.append(w1tmp)
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False).to(device)
self.liquid_weight=w2tmp.weight.data
w2tmp.weight.data=w2tmp.weight.data*self.connectivity_matrix
self.con.append(w2tmp)
self.learning_rule.append(MutliInputSTDP(self.node_lsm(), [self.con[0], self.con[1]])) # pm
self.fc = nn.Sequential(
nn.Linear(liquid_size,num_classes),
self.node_fc()
)
def forward(self, x):
sum_spike=0
self.out = torch.zeros(x.shape[0], self.liquid_size).to(self.device)
tw=x.shape[1]
self.tw=tw
self.firing_tw=torch.zeros(tw, self.batchsize, self.liquid_size).to(self.device)
for t in range(tw):
self.out, self.dw = self.learning_rule[0](x[:,t,:], self.out)
out_liquid=self.out[:,0:self.liquid_size]
xout = self.fc(out_liquid)
sum_spike=sum_spike+xout
self.firing_tw[t]=out_liquid
outputs = sum_spike / tw
return outputs
@register_model
class mSNN(BaseModule):
def __init__(self,
batchsize,
liquid_size,
device,
connectivity_matrix,
num_classes=10,
step=1,
node_type=LIFNode,
encode_type='direct',
lsm_th=0.3,
fc_th=0.3,
lsm_tau=3,
fc_tau=3,
tw=100,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.batchsize=batchsize
self.node_lsm=partial(node_type, **kwargs, step=step,tau=lsm_tau,threshold=lsm_th)
self.node_fc = partial(node_type, **kwargs, step=step,tau=fc_tau,threshold=fc_th)
self.liquid_size=liquid_size
self.out = torch.zeros(self.batchsize, liquid_size).to(device)
self.device=device
self.con=[]
self.learning_rule=[]
self.connectivity_matrix=connectivity_matrix
w1tmp=nn.Linear(784,liquid_size,bias=False).to(device)
self.con.append(w1tmp)
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False).to(device)
self.liquid_weight=w2tmp.weight.data
w2tmp.weight.data=w2tmp.weight.data*self.connectivity_matrix
self.con.append(w2tmp)
self.learning_rule.append(MutliInputSTDP(self.node_lsm(), [self.con[0], self.con[1]])) # pm
self.fc = nn.Sequential(
nn.Linear(liquid_size,num_classes),
self.node_fc()
)
def forward(self, x):
x = x.reshape(x.shape[0], -1)
sum_spike=0
time_window=20
self.tw=time_window
self.firing_tw=torch.zeros(time_window, self.batchsize, self.liquid_size).to(self.device)
self.out = torch.zeros(self.batchsize, self.liquid_size).to(self.device)
for t in range(time_window):
self.out, self.dw = self.learning_rule[0](x, self.out)
out_liquid=self.out[:,0:self.liquid_size]
xout = self.fc(out_liquid)
sum_spike=sum_spike+xout
self.firing_tw[t]=out_liquid
# print(out_liquid.sum())
# print(xout.sum())
outputs = sum_spike / time_window
return outputs
================================================
FILE: examples/Structural_Development/ELSM/nsganet.py
================================================
import numpy as np
from pymoo.algorithms.genetic_algorithm import GeneticAlgorithm
from pymoo.docs import parse_doc_string
from pymoo.model.individual import Individual
from pymoo.model.survival import Survival
from pymoo.operators.crossover.point_crossover import PointCrossover
from pymoo.operators.mutation.polynomial_mutation import PolynomialMutation
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.selection.tournament_selection import compare, TournamentSelection
from pymoo.util.display import disp_multi_objective
from pymoo.util.dominator import Dominator
from pymoo.util.non_dominated_sorting import NonDominatedSorting
from pymoo.util.randomized_argsort import randomized_argsort
# =========================================================================================================
# Implementation
# based on nsga2 from https://github.com/msu-coinlab/pymoo
# =========================================================================================================
class NSGANet(GeneticAlgorithm):
def __init__(self, **kwargs):
kwargs['individual'] = Individual(rank=np.inf, crowding=-1)
super().__init__(**kwargs)
self.tournament_type = 'comp_by_dom_and_crowding'
self.func_display_attrs = disp_multi_objective
# ---------------------------------------------------------------------------------------------------------
# Binary Tournament Selection Function
# ---------------------------------------------------------------------------------------------------------
def binary_tournament(pop, P, algorithm, **kwargs):
if P.shape[1] != 2:
raise ValueError("Only implemented for binary tournament!")
tournament_type = algorithm.tournament_type
S = np.full(P.shape[0], np.nan)
for i in range(P.shape[0]):
a, b = P[i, 0], P[i, 1]
# if at least one solution is infeasible
if pop[a].CV > 0.0 or pop[b].CV > 0.0:
S[i] = compare(a, pop[a].CV, b, pop[b].CV, method='smaller_is_better', return_random_if_equal=True)
# both solutions are feasible
else:
if tournament_type == 'comp_by_dom_and_crowding':
rel = Dominator.get_relation(pop[a].F, pop[b].F)
if rel == 1:
S[i] = a
elif rel == -1:
S[i] = b
elif tournament_type == 'comp_by_rank_and_crowding':
S[i] = compare(a, pop[a].rank, b, pop[b].rank,
method='smaller_is_better')
else:
raise Exception("Unknown tournament type.")
# if rank or domination relation didn't make a decision compare by crowding
if np.isnan(S[i]):
S[i] = compare(a, pop[a].get("crowding"), b, pop[b].get("crowding"),
method='larger_is_better', return_random_if_equal=True)
return S[:, None].astype(np.int)
# ---------------------------------------------------------------------------------------------------------
# Survival Selection
# ---------------------------------------------------------------------------------------------------------
class RankAndCrowdingSurvival(Survival):
def __init__(self) -> None:
super().__init__(True)
def _do(self, pop, n_survive, D=None, **kwargs):
# get the objective space values and objects
F = pop.get("F")
# the final indices of surviving individuals
survivors = []
# do the non-dominated sorting until splitting front
fronts = NonDominatedSorting().do(F, n_stop_if_ranked=n_survive)
for k, front in enumerate(fronts):
# calculate the crowding distance of the front
crowding_of_front = calc_crowding_distance(F[front, :])
# save rank and crowding in the individual class
for j, i in enumerate(front):
pop[i].set("rank", k)
pop[i].set("crowding", crowding_of_front[j])
# current front sorted by crowding distance if splitting
if len(survivors) + len(front) > n_survive:
I = randomized_argsort(crowding_of_front, order='descending', method='numpy')
I = I[:(n_survive - len(survivors))]
# otherwise take the whole front unsorted
else:
I = np.arange(len(front))
# extend the survivors by all or selected individuals
survivors.extend(front[I])
return pop[survivors]
def calc_crowding_distance(F):
infinity = 1e+14
n_points = F.shape[0]
n_obj = F.shape[1]
if n_points <= 2:
return np.full(n_points, infinity)
else:
# sort each column and get index
I = np.argsort(F, axis=0, kind='mergesort')
# now really sort the whole array
F = F[I, np.arange(n_obj)]
# get the distance to the last element in sorted list and replace zeros with actual values
dist = np.concatenate([F, np.full((1, n_obj), np.inf)]) \
- np.concatenate([np.full((1, n_obj), -np.inf), F])
index_dist_is_zero = np.where(dist == 0)
dist_to_last = np.copy(dist)
for i, j in zip(*index_dist_is_zero):
dist_to_last[i, j] = dist_to_last[i - 1, j]
dist_to_next = np.copy(dist)
for i, j in reversed(list(zip(*index_dist_is_zero))):
dist_to_next[i, j] = dist_to_next[i + 1, j]
# normalize all the distances
norm = np.max(F, axis=0) - np.min(F, axis=0)
norm[norm == 0] = np.nan
dist_to_last, dist_to_next = dist_to_last[:-1] / norm, dist_to_next[1:] / norm
# if we divided by zero because all values in one columns are equal replace by none
dist_to_last[np.isnan(dist_to_last)] = 0.0
dist_to_next[np.isnan(dist_to_next)] = 0.0
# sum up the distance to next and last and norm by objectives - also reorder from sorted list
J = np.argsort(I, axis=0)
crowding = np.sum(dist_to_last[J, np.arange(n_obj)] + dist_to_next[J, np.arange(n_obj)], axis=1) / n_obj
# replace infinity with a large number
crowding[np.isinf(crowding)] = infinity
return crowding
# =========================================================================================================
# Interface
# =========================================================================================================
def nsganet(
pop_size=100,
sampling=RandomSampling(var_type=np.int),
selection=TournamentSelection(func_comp=binary_tournament),
crossover=PointCrossover(n_points=2),
mutation=PolynomialMutation(eta=3, var_type=np.int),
eliminate_duplicates=True,
n_offsprings=None,
**kwargs):
"""
Parameters
----------
pop_size : {pop_size}
sampling : {sampling}
selection : {selection}
crossover : {crossover}
mutation : {mutation}
eliminate_duplicates : {eliminate_duplicates}
n_offsprings : {n_offsprings}
Returns
-------
nsganet : :class:`~pymoo.model.algorithm.Algorithm`
Returns an NSGANet algorithm object.
"""
return NSGANet(pop_size=pop_size,
sampling=sampling,
selection=selection,
crossover=crossover,
mutation=mutation,
survival=RankAndCrowdingSurvival(),
eliminate_duplicates=eliminate_duplicates,
n_offsprings=n_offsprings,
**kwargs)
parse_doc_string(nsganet)
================================================
FILE: examples/Structural_Development/ELSM/spikes.py
================================================
from __future__ import print_function
import torchvision
import torchvision.transforms as transforms
import os
import numpy as np
import torch
from torch import nn as nn
from model import *
from tqdm import tqdm
import argparse
from datetime import datetime
import logging
from timm.utils import *
from spikingjelly.datasets.n_mnist import NMNIST
from timm.loss import LabelSmoothingCrossEntropy
from braincog.base.utils.criterions import *
import networkx as nx
import time
from braincog.base.learningrule.STDP import *
def randbool(size, p=0.5):
return torch.rand(*size) < p
def calc_f2(con,device):
batch_size=1
liquid_size=8000
images=torch.load('/1000images.pt')
labels=torch.load('/1000labels.pt')
load_path='970.t7'
snn = nSNN(ins=2312,
batchsize=batch_size,
device=device,
liquid_size=liquid_size,
lsm_tau=2.0,
lsm_th=0.20,
connectivity_matrix=randbool([liquid_size, liquid_size],p=0.01).to(device).int())
snn.load_state_dict(torch.load(load_path,map_location={'cuda:2':device})['fc'])
snn.con[0].load_state_dict(torch.load(load_path,map_location={'cuda:2':device})['lsm0'])
snn.to(device)
criterion = UnilateralMse(1.)
optimizer = torch.optim.AdamW(snn.fc.parameters(),lr=0.001, weight_decay=1e-4)
k=0
sbr=0
snn.connectivity_matrix=con
snn.learning_rule=[]
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False,device=device)
w2tmp.weight.data=(torch.load(load_path,map_location={'cuda:2':device})['liquid_weight'])*snn.connectivity_matrix
snn.learning_rule.append(MutliInputSTDP(snn.node_lsm(), [snn.con[0], w2tmp]))
snn.eval()
for label,data in zip(labels,images):
running_loss = 0
snn.zero_grad()
optimizer.zero_grad()
data = data.to(device)
label = label.to(device)
data=data.reshape(batch_size,data.shape[0],-1)
output = snn(data)
# print(torch.argmax(output)==label)
out_liquid=snn.firing_tw.squeeze(-2)
mupost=torch.matmul(con,out_liquid.unsqueeze(-1))
mupre=torch.matmul(con.t(),out_liquid.unsqueeze(-1))
for t in range(snn.tw):
if t>5 and t0:
xnp=x.cpu().numpy()
maxx=torch.max(x)
#maxx=np.percentile(xnp, 99.5)
minx=torch.min(x)
marge=maxx-minx
if marge!=0:
xx=(x-minx)/marge
xx=torch.clip(xx, 0,1)
else:
xx=0.5*torch.ones_like(x)
return xx
else:
return x
class Mask:
def __init__(self, model):
self.model = model
self.mat = {}
self.p_index={}
self.p_num={}
self.k=15
self.task_ready={}
self.regutask_ready={}
self.taskmask={}
self.init_rate=0.3
self.grow_rate=0.125
self.prunconv_init=0.8
self.prunfc_init=1.3
self.prunconv_grow=0.5
self.prunfc_grow=1
self.n_delta={}
self.ren_delta={}
self.reduce={}
self.rereduce={}
self.taskww={}
self.tasknore={}
def init_length(self,task=0,task_nn=None):
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and item.size()[-1]!=1:
print(index,item.size())
self.mat[index]=torch.ones(item.size(),device=device)
for t in range(task):
self.rereduce[t]={}
for index, item in enumerate(self.model.parameters()):
if True:
if index<=20:
c_index=0
elif index<=45:
c_index=1
elif index<=70:
c_index=2
else:
c_index=3
taskindb=task_nn[t-1][c_index]
taskinda=task_nn[t][c_index]
lenre=taskinda-taskindb
self.rereduce[t][index] = 1*torch.ones(lenre,device=device)
return self.mat
def get_filter_reuse(self,index,ww,task,epoch,c_index,cdim_before=None,task_nn=None,all_dist=None,bias=0):
lenre=cdim_before[1]-cdim_before[0]
similar=1-all_dist+bias
if similar<0.2:
similar=0.2
if similar>0.9:
similar=0.9
revalue=similar*torch.ones(lenre).cuda() #1/8,1/4,1/2,1,1.5
if len(ww.size()) == 4:
# p_www=ww*self.mat[index]
p_ww=torch.sum(torch.sum(torch.sum(ww,dim=3),dim=2),dim=1)
# p_ww=p_ww[cdim_before[0]:cdim_before[1]]
ren_delta=-(2*unit(p_ww)-revalue)#revalue0.8
#print(self.ren_delta[index])
pos=torch.nonzero(ren_delta>0)
ren_delta[pos]=ren_delta[pos]+3
self.rereduce[task][index]=self.rereduce[task][index]*0.999+ren_delta*math.exp(-int((epoch-1)/2))
p_ind = torch.nonzero(self.rereduce[task][index] <0)
matkey=self.mat.keys()
matkey=torch.tensor(list(matkey))
matindex=torch.nonzero(matkey==index)
next_index=matkey[matindex+1]
for x in range(0, len(p_ind)):
self.mat[next_index.item()][:,p_ind[x]+cdim_before[0]]=0
b = self.mat[next_index.item()][:,cdim_before[0]:cdim_before[1]].reshape(-1).cpu().numpy()
pruning=100*(len(b)- np.count_nonzero(b))/len(b)
#print(index,self.rereduce[task][index].mean(),self.rereduce[task][index].max(),self.rereduce[task][index].min(),len(b)-np.count_nonzero(b),pruning)
def convert2tensor(self, x):
x = torch.FloatTensor(x)
return x
def init_mask(self,task,epoch,dim_cur=None,task_nn=None,all_dist=None,all_model=None):
for t in range(task):
similart=all_dist[t]
for index, item in enumerate(all_model[t].parameters()):
if len(item.size()) > 2 and item.size()[-1]!=1 and index<95:
if index<=20:
c_index=0
elif index<=45:
c_index=1
elif index<=70:
c_index=2
else:
c_index=3
if index<=25:
bias=0.2
elif index<=50:
bias=0.1
elif index<=74:
bias=-0.1
else:
bias=0.2
taskindb=task_nn[t-1][c_index]
taskinda=task_nn[t][c_index]
cdim_before=[taskindb,taskinda]
self.get_filter_reuse(index,abs(item.grad),t,epoch,c_index,cdim_before,task_nn=task_nn,all_dist=similart,bias=bias)
def do_mask(self,task):
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and item.size()[-1]!=1:
ww=item.data
item.data=ww*self.mat[index].cuda()
return self.mat
def if_zero(self):
cc=[]
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and item.size()[-1]!=1 and index>0:
b = item.data.view(-1).cpu().numpy()
print("number of weight is %d, zero is %.3f" %(len(b),100*(len(b)- np.count_nonzero(b))/len(b)))
cc.append(100*(len(b)- np.count_nonzero(b))/len(b))
return cc
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/convnet/network.py
================================================
import copy
# import pdb
import torch
from torch import nn
import torch.nn.functional as F
from inclearn.tools import factory
from inclearn.convnet.imbalance import CR, All_av,BiC
from inclearn.convnet.classifier import CosineClassifier
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
class BasicNet(nn.Module):
def __init__(
self,
convnet_type,
cfg,
nf=64,
use_bias=False,
init="kaiming",
device=None,
dataset="cifar100",
):
super(BasicNet, self).__init__()
self.nf = nf
self.init = init
self.convnet_type = convnet_type
self.dataset = dataset
self.start_class = cfg['start_class']
self.weight_normalization = cfg['weight_normalization']
self.remove_last_relu = True if self.weight_normalization else False
self.use_bias = use_bias if not self.weight_normalization else False
self.dea = cfg['dea']
self.ft_type = cfg.get('feature_type', 'normal')
self.at_res = cfg.get('attention_use_residual', False)
self.div_type = cfg['div_type']
self.reuse_oldfc = cfg['reuse_oldfc']
self.prune = cfg.get('prune', False)
self.reset = cfg.get('reset_se', True)
self.torc=cfg['distillation']
self.node =LIFNode
self.encoder = Encoder(4, 'direct', temporal_flatten=False, layer_by_layer=False, **cfg)
# if self.dea:
# print("Enable dynamical reprensetation expansion!")
# self.convnets = nn.ModuleList()
# self.convnets.append(
# factory.get_convnet(convnet_type,
# nf=nf,
# dataset=dataset,
# start_class=self.start_class,
# remove_last_relu=self.remove_last_relu))
# self.out_dim = self.convnets[0].out_dim
# self.c_dim=self.convnets[0].channel_dim
# else:
# self.convnet = factory.get_convnet(convnet_type,
# nf=nf,
# dataset=dataset,
# remove_last_relu=self.remove_last_relu)
# self.out_dim = self.convnet.out_dim
self.channel_number=[32,64,128,256]#[32,64,128,256] # [24,48,72,96] #[24,48,96,192][32,64,128,256]
self.channel_dim=[48,96,192,384]
self.c_number1=np.array(self.channel_number)
if self.dea:
print("Enable dynamical reprensetation expansion!")
self.convnets = nn.ModuleList()
self.convnets.append(
factory.get_convnet(convnet_type,c_dim=self.channel_number,cdim_cur=self.channel_number)
)
self.out_dim = self.channel_number[-1]
self.out_dim_cc = self.channel_number[-1]
else:
self.convnet = factory.get_convnet(convnet_type,
nf=nf,
dataset=dataset,
remove_last_relu=self.remove_last_relu)
self.out_dim = self.convnet.out_dim
self.classifier = None
self.se = None
self.aux_classifier = None
self.n_classes = 0
self.ntask = 0
self.device = device
if cfg['postprocessor']['enable']:
if cfg['postprocessor']['type'].lower() == "cr":
self.postprocessor = CR()
elif cfg['postprocessor']['type'].lower() == "aver":
self.postprocessor = All_av()
else:
self.postprocessor = BiC(cfg['postprocessor']["lr"], cfg['postprocessor']["scheduling"],
cfg['postprocessor']["lr_decay_factor"], cfg['postprocessor']["weight_decay"],
cfg['postprocessor']["batch_size"], cfg['postprocessor']["epochs"])
self.task_nn={}
self.task_nn[-1]=np.array([0,0,0,0])
self.task_nn[0]=np.array(self.channel_number)
self.to(self.device)
def forward(self, task,inputs,mask=None,classify=True):
inputs = self.encoder(inputs)
self.resetsnn()
step = 4
outputs = []
if self.classifier is None:
raise Exception("Add some classes before training.")
if mask is not None:
mat=mask.mat
if self.torc:
ttc=task
else:
ttc=-1
for index, item in enumerate(self.convnets[ttc].parameters()):
if len(item.size()) > 1 and item.size()[-1]!=1:
ww=item.data
item.data=ww*mat[index].cuda()
if self.dea:
# feature = [convnet(x) for convnet in self.convnets]
for time in range(step):
x_init = inputs[time]
task_feature={}
for t in range(task):
task_feature[t]={}
x=self.convnets[t].forward_init(x_init)
task_feature[t][0]=x
for l in range(len(self.convnets[t].layer_convnets)):
for lc in range(len(self.convnets[t].layer_convnets[l].conv)):
if lc==0 or lc==3:
identity = x
if lc==2:
if l>0:
identity=self.convnets[t].layer_convnets[l].conv[lc](identity)
x=x+identity
task_feature[t][5*l+lc+1]=x
else:
old_tfeature=[]
for old_t in range(t):
old_tfeature.append(task_feature[old_t][5*l+lc])
old_tfeature.append(x)
x= torch.cat(old_tfeature, 1)
x=self.convnets[t].layer_convnets[l].conv[lc](x)
if lc==4:
x=x+identity
task_feature[t][5*l+lc+1]=x
x=self.convnets[task].forward_init(x_init)
for l in range(len(self.convnets[task].layer_convnets)):
for lc in range(len(self.convnets[task].layer_convnets[l].conv)):
if lc==0 or lc==3:
identity = x
if lc==2:
if l>0:
identity=self.convnets[task].layer_convnets[l].conv[lc](identity)
x=x+identity
else:
mid_feature=[]
for t in range(task):
mid_feature.append(task_feature[t][5*l+lc])
mid_feature.append(x)
x= torch.cat(mid_feature, 1)
x=self.convnets[task].layer_convnets[l].conv[lc](x)
if lc==4:
x=x+identity
if self.torc:
last_feature=[]
for t in range(task):
last=len(task_feature[t])-1
last_feature.append(task_feature[t][last])
last_feature.append(x)
outputs.append(torch.cat(last_feature, 1))
else:
x=self.convnets[task].avgpool(x)
x=x.view(x.size()[0],-1)
outputs.append(x)
feature=sum(outputs).cuda()/ step
last_dim =x.size(1)
width = feature.size(1)
if self.torc:
if self.reset:
se = factory.get_attention(width, self.ft_type, self.at_res).to(self.device)
features = se(feature)
else:
features = self.se(feature)
else:
features=feature
else:
features = self.convnet(x)
if self.torc:
if classify==True:
logits = self.convnets[-1].classifer(features)
div_logits = self.convnets[-1].aux_classifier(features[:, -last_dim:]) if self.ntask > 1 else None
else:
logits=None
div_logits=None
else:
if classify==True:
logits = self.convnets[task].classifer(features)
else:
logits=None
div_logits=None
return {'feature': features, 'logit': logits, 'div_logit': div_logits, 'features': feature}
def caculate_dim(self, x):
feature = [convnet(x) for convnet in self.convnets]
features = torch.cat(feature, 1)
width = features.size(1)
# se = factory.get_attention(width, self.ft_type, self.at_res).to(self.device)
se = factory.get_attention(width, "ce", self.at_res).cuda()
features = se(features)
# import pdb
# pdb.set_trace()
return features.size(1), feature[-1].size(1)
@property
def features_dim(self,ntask):
if self.dea:
return self.out_dim#+ntask*self.channel_number1[-1]
else:
return self.out_dim
def freeze(self):
for param in self.parameters():
param.requires_grad = False
self.eval()
return self
def copy(self):
return copy.deepcopy(self)
def add_classes(self, n_classes,min_dist):
self.ntask += 1
if self.dea:
self._add_classes_multi_fc(n_classes,min_dist)
else:
self._add_classes_single_fc(n_classes)
self.n_classes += n_classes
def _add_classes_multi_fc(self, n_classes,min_dist):
self.classifier=self.convnets[-1].classifer
if self.ntask > 1:
if min_dist<0.1:
min_dist=0.1
self.channel_number1=np.array([32,64,96,128])*1*(1-math.exp(-5*min_dist)) #0.5,1,1.5,2,3,4 [24,48,72,96][16,32,48,64]
self.channel_number1=self.channel_number1.astype(np.int64)
self.channel_dim=self.channel_number1
self.c_number1=self.c_number1+np.array(self.channel_number1)
self.task_nn[self.ntask-1]=self.c_number1
new_clf = factory.get_convnet("resnet18",c_dim=self.c_number1,cdim_cur=self.channel_number1).to(self.device)
self.out_dim=self.out_dim+self.channel_number1[-1]
self.out_dim_cc=self.channel_number1[-1]
self.convnets.append(new_clf)
if self.torc:
if not self.reset:
self.se = factory.get_attention(512*len(self.convnets), self.ft_type, self.at_res)
self.se.to(self.device)
if self.classifier is not None:
weight = copy.deepcopy(self.classifier.weight.data)
fc = self._gen_classifier(self.out_dim, self.n_classes + n_classes)
if self.classifier is not None and self.reuse_oldfc:
fc.weight.data[:self.n_classes, :(self.out_dim - self.out_dim_cc)] = weight
del self.classifier
self.classifier = fc
self.convnets[-1].classifer=self.classifier
else:
fc = self._gen_classifier(self.out_dim_cc, n_classes)
del self.classifier
self.classifier = fc
self.convnets[-1].classifer=fc
if self.torc:
if self.div_type == "n+1":
div_fc = self._gen_classifier(self.out_dim_cc, n_classes + 1)
elif self.div_type == "1+1":
div_fc = self._gen_classifier(self.out_dim_cc, 2)
elif self.div_type == "n+t":
div_fc = self._gen_classifier(self.out_dim_cc, self.ntask + n_classes)
else:
div_fc = self._gen_classifier(self.out_dim_cc, self.n_classes + n_classes)
del self.aux_classifier
self.aux_classifier = div_fc
self.convnets[-1].aux_classifier=self.aux_classifier
def _add_classes_single_fc(self, n_classes):
if self.classifier is not None:
weight = copy.deepcopy(self.classifier.weight.data)
if self.use_bias:
bias = copy.deepcopy(self.classifier.bias.data)
classifier = self._gen_classifier(self.features_dim, self.n_classes + n_classes)
if self.classifier is not None and self.reuse_oldfc:
classifier.weight.data[:self.n_classes] = weight
if self.use_bias:
classifier.bias.data[:self.n_classes] = bias
del self.classifier
self.classifier = classifier
def _gen_classifier(self, in_features, n_classes):
if self.weight_normalization:
classifier = CosineClassifier(in_features, n_classes).to(self.device)
# classifier = CosineClassifier(in_features, n_classes).cuda()
else:
classifier = nn.Linear(in_features, n_classes, bias=self.use_bias).to(self.device)
# classifier = nn.Linear(in_features, n_classes, bias=self.use_bias).cuda()
if self.init == "kaiming":
nn.init.kaiming_normal_(classifier.weight, nonlinearity="linear")
if self.use_bias:
nn.init.constant_(classifier.bias, 0.0)
return classifier
def resetsnn(self):
"""
重置所有神经元的膜电位
:return:
"""
for mod in self.convnets.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/convnet/resnet.py
================================================
"""Taken & slightly modified from:
* https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
"""
import torch
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
from torch.nn import functional as F
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152']
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, remove_last_relu=False):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
self.remove_last_relu = remove_last_relu
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
if not self.remove_last_relu:
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = conv1x1(inplanes, planes)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = conv3x3(planes, planes, stride)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = conv1x1(planes, planes * self.expansion)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 共享权重的MLP
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class SEFeatureAt(nn.Module):
def __init__(self, inplanes, type, at_res):
super(SEFeatureAt, self).__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d((1,1)),
nn.Conv2d(inplanes,inplanes//16,kernel_size=1),
nn.ReLU(),
nn.Conv2d(inplanes//16,inplanes,kernel_size=1),
nn.Sigmoid()
)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.type = type
self.at_res = at_res
self.ca = ChannelAttention(inplanes)
self.sa = SpatialAttention()
def forward(self, x):
residual = x
if self.type == "se":
attention = self.se(x)
x = x * attention
elif self.type == "ffm":
x = self.ca(x) * x
x = self.sa(x) * x
if self.at_res:
x += residual
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
class ResNet(nn.Module):
def __init__(self,
block,
layers,
nf=64,
zero_init_residual=True,
dataset='cifar',
start_class=0,
remove_last_relu=False):
super(ResNet, self).__init__()
self.remove_last_relu = remove_last_relu
self.inplanes = nf
if 'cifar' in dataset:
self.conv1 = nn.Sequential(nn.Conv2d(3, nf, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(nf), nn.ReLU(inplace=True))
elif 'imagenet' in dataset:
if start_class == 0:
self.conv1 = nn.Sequential(
nn.Conv2d(3, nf, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(nf),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
else:
# Following PODNET implmentation
self.conv1 = nn.Sequential(
nn.Conv2d(3, nf, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(nf),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
self.layer1 = self._make_layer(block, 1 * nf, layers[0])
self.layer2 = self._make_layer(block, 2 * nf, layers[1], stride=2)
self.layer3 = self._make_layer(block, 4 * nf, layers[2], stride=2)
self.layer4 = self._make_layer(block, 8 * nf, layers[3], stride=2, remove_last_relu=remove_last_relu)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.out_dim = 8 * nf * block.expansion
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, remove_last_relu=False, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
if remove_last_relu:
for i in range(1, blocks - 1):
layers.append(block(self.inplanes, planes))
layers.append(block(self.inplanes, planes, remove_last_relu=True))
else:
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def reset_bn(self):
for m in self.modules():
if isinstance(m, nn.BatchNorm2d):
m.reset_running_stats()
def forward(self, x):
x = self.conv1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# x = self.avgpool(x)
# x = x.view(x.size(0), -1)
return x
def resnet18(pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
def resnet34(pretrained=False, **kwargs):
"""Constructs a ResNet-34 model.
"""
model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet34']))
return model
def resnet50(pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
"""
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet50']))
return model
def resnet101(pretrained=False, **kwargs):
"""Constructs a ResNet-101 model.
"""
model = ResNet(Bottleneck, [3, 4, 23, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet101']))
return model
def resnet152(pretrained=False, **kwargs):
"""Constructs a ResNet-152 model.
"""
model = ResNet(Bottleneck, [3, 8, 36, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet152']))
return model
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/convnet/sew_resnet.py
================================================
import torch
import torch.nn as nn
from copy import deepcopy
try:
from torchvision.models.utils import load_state_dict_from_url
except ImportError:
from torchvision._internally_replaced_utils import load_state_dict_from_url
from braincog.base.node import *
from braincog.model_zoo.base_module import *
from braincog.datasets import is_dvs_data
from timm.models import register_model
__all__ = ['SEWResNet', 'sew_resnet18', 'sew_resnet34', 'sew_resnet50', 'sew_resnet101',
'sew_resnet152', 'sew_resnext50_32x4d', 'sew_resnext101_32x8d',
'sew_wide_resnet50_2', 'sew_wide_resnet101_2']
model_urls = {
"resnet18": "https://download.pytorch.org/models/resnet18-f37072fd.pth",
"resnet34": "https://download.pytorch.org/models/resnet34-b627a593.pth",
"resnet50": "https://download.pytorch.org/models/resnet50-0676ba61.pth",
"resnet101": "https://download.pytorch.org/models/resnet101-63fe2227.pth",
"resnet152": "https://download.pytorch.org/models/resnet152-394f9c45.pth",
"resnext50_32x4d": "https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth",
"resnext101_32x8d": "https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth",
"wide_resnet50_2": "https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth",
"wide_resnet101_2": "https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth",
}
# modified by https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py
def sew_function(x: torch.Tensor, y: torch.Tensor, cnf:str):
if cnf == 'ADD':
return x + y
elif cnf == 'AND':
return x * y
elif cnf == 'IAND':
return x * (1. - y)
else:
raise NotImplementedError
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, planes_cur,stride=1, downsample=None, groups=1,
dilation=1, norm_layer=None, cnf: str = None, node: callable = LIFNode, **kwargs):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
# if groups != 1 or base_width != 64:
# raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
self.conv=nn.Sequential(
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
BaseConvModule(inplanes, planes_cur, kernel_size=(3, 3), stride=stride,padding=(1, 1), node=node),
BaseConvModule(planes, planes_cur, kernel_size=(3, 3), padding=(1, 1), node=node),
downsample,
BaseConvModule(planes, planes_cur, kernel_size=(3, 3), padding=(1, 1), node=node),
BaseConvModule(planes, planes_cur, kernel_size=(3, 3), padding=(1, 1), node=node),)
self.cnf = cnf
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.conv2(out)
if self.downsample is not None:
identity = self.downsample_sn(self.downsample(x))
out = sew_function(identity, out, self.cnf)
return out
def extra_repr(self) -> str:
return super().extra_repr() + f'cnf={self.cnf}'
class SEWResNet(BaseModule):
def __init__(self, block, layers, c_dim=[64,128,256,512], cdim_cur=[],step=4,encode_type="direct",zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None, cnf: str = 'ADD', *args,**kwargs):
super().__init__(
step,
encode_type,
*args,
**kwargs
)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.groups=groups
self.node = LIFNode
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.c_dim=c_dim
if len(cdim_cur)>0:
self.cdim_cur=cdim_cur
else:
self.cdim_cur=self.c_dim
self.inplanes = c_dim[0]
self.inplanes_cur = cdim_cur[0]
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.conv1 = nn.Conv2d(3, self.cdim_cur[0], kernel_size=3, stride=1, padding=3,
bias=False)
self.bn1 = norm_layer(self.cdim_cur[0])
self.node1 = self.node()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer_convnets = nn.ModuleList()
self.layer_convnets.append(self._make_layer(block, c_dim[0], self.cdim_cur[0],layers[0], cnf=cnf, node=self.node, **kwargs))
self.layer_convnets.append(self._make_layer(block, c_dim[1], self.cdim_cur[1], layers[1], stride=2,
dilate=replace_stride_with_dilation[0], cnf=cnf, node=self.node, **kwargs))
self.layer_convnets.append(self._make_layer(block, c_dim[2], self.cdim_cur[2], layers[2], stride=2,
dilate=replace_stride_with_dilation[1], cnf=cnf, node=self.node, **kwargs))
self.layer_convnets.append(self._make_layer(block, c_dim[3], self.cdim_cur[3], layers[3], stride=2,
dilate=replace_stride_with_dilation[2], cnf=cnf, node=self.node, **kwargs))
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# self.fc = nn.Linear(512 * block.expansion, num_classes)
self.classifer=None
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, planes_cur,blocks, stride=1, dilate=False, cnf: str=None, node: callable = None, **kwargs):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes_cur, planes_cur * block.expansion, stride),
norm_layer(planes_cur * block.expansion),
node()
)
layers =block(self.inplanes, planes, planes_cur,stride, downsample, self.groups,
previous_dilation, norm_layer, cnf, node, **kwargs)
self.inplanes = planes * block.expansion
self.inplanes_cur= planes_cur * block.expansion
# for _ in range(1, blocks):
# layers.append(block(self.inplanes, planes, groups=self.groups,
# dilation=self.dilation,
# norm_layer=norm_layer, cnf=cnf, node=node, **kwargs))
return layers
def forward_init(self, inputs):
# See note [TorchScript super()]
x = self.conv1(inputs)
x = self.bn1(x)
x = self.node1(x)
# x = self.maxpool(x)
return x
def forward_impl(self, inputs):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return x
def _sew_resnet(arch, block, layers, c_dim,cdim_cur,pretrained, progress, cnf, **kwargs):
model = SEWResNet(block, layers, c_dim=c_dim,cdim_cur=cdim_cur,cnf=cnf, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
@register_model
def sew_resnet18(c_dim=[64,128,256,512],cdim_cur=[],pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-18
:rtype: torch.nn.Module
The spike-element-wise ResNet-18 `"Deep Residual Learning in Spiking Neural Networks" `_ modified by the ResNet-18 model from `"Deep Residual Learning for Image Recognition" `_
"""
return _sew_resnet('resnet18', BasicBlock, [2, 2, 2, 2], c_dim,cdim_cur,pretrained, progress, 'ADD', **kwargs)
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/convnet/utils.py
================================================
import numpy as np
import torch
from torch import nn
from torch.optim import SGD
import torch.nn.functional as F
from inclearn.tools.metrics import ClassErrorMeter, AverageValueMeter
def finetune_last_layer(
logger,
network,
loader,
n_class,
nepoch=30,
lr=0.1,
scheduling=[15, 35],
lr_decay=0.1,
weight_decay=5e-4,
loss_type="ce",
temperature=5.0,
test_loader=None,
samples_per_cls = []
):
network.eval()
#if hasattr(network.module, "convnets"):
# for net in network.module.convnets:
# net.eval()
#else:
# network.module.convnet.eval()
optim = SGD(network.module.classifier.parameters(), lr=lr, momentum=0.9, weight_decay=weight_decay)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optim, scheduling, gamma=lr_decay)
if loss_type == "ce":
criterion = nn.CrossEntropyLoss()
else:
criterion = nn.BCEWithLogitsLoss()
logger.info("Begin finetuning last layer")
for i in range(nepoch):
total_loss = 0.0
total_correct = 0.0
total_count = 0
# print(f"dataset loader length {len(loader.dataset)}")
for inputs, targets in loader:
inputs, targets = inputs.cuda(), targets.cuda()
if loss_type == "bce":
targets = to_onehot(targets, n_class)
outputs = network(inputs)['logit']
_, preds = outputs.max(1)
optim.zero_grad()
if loss_type == "cb":
loss = CB_loss(targets, outputs / temperature, samples_per_cls, n_class, "focal")
else:
loss = criterion(outputs / temperature, targets)
loss.backward()
optim.step()
total_loss += loss * inputs.size(0)
total_correct += (preds == targets).sum()
total_count += inputs.size(0)
if test_loader is not None:
test_correct = 0.0
test_count = 0.0
with torch.no_grad():
for inputs, targets in test_loader:
outputs = network(inputs.cuda())['logit']
_, preds = outputs.max(1)
test_correct += (preds.cpu() == targets).sum().item()
test_count += inputs.size(0)
scheduler.step()
if test_loader is not None:
logger.info(
"Epoch %d finetuning loss %.3f acc %.3f Eval %.3f" %
(i, total_loss.item() / total_count, total_correct.item() / total_count, test_correct / test_count))
else:
logger.info("Epoch %d finetuning loss %.3f acc %.3f" %
(i, total_loss.item() / total_count, total_correct.item() / total_count))
return network
def extract_features(task_i,model, loader,mask=None):
targets, features = [], []
model.eval()
with torch.no_grad():
for _inputs, _targets in loader:
_inputs = _inputs.cuda()
_targets = _targets.numpy()
_features = model(task_i,_inputs,mask)['feature'].detach().cpu().numpy()
features.append(_features)
targets.append(_targets)
return np.concatenate(features), np.concatenate(targets)
def calc_class_mean(network, loader, class_idx, metric):
EPSILON = 1e-8
features, targets = extract_features(network, loader)
# norm_feats = features/(np.linalg.norm(features, axis=1)[:,np.newaxis]+EPSILON)
# examplar_mean = norm_feats.mean(axis=0)
examplar_mean = features.mean(axis=0)
if metric == "cosine" or metric == "weight":
examplar_mean /= (np.linalg.norm(examplar_mean) + EPSILON)
return examplar_mean
def update_classes_mean(network, inc_dataset, n_classes, task_size, share_memory=None, metric="cosine", EPSILON=1e-8):
loader = inc_dataset._get_loader(inc_dataset.data_inc,
inc_dataset.targets_inc,
shuffle=False,
share_memory=share_memory,
mode="test")
class_means = np.zeros((n_classes, network.module.features_dim))
count = np.zeros(n_classes)
network.eval()
with torch.no_grad():
for x, y in loader:
feat = network(x.cuda())['feature']
for lbl in torch.unique(y):
class_means[lbl] += feat[y == lbl].sum(0).cpu().numpy()
count[lbl] += feat[y == lbl].shape[0]
for i in range(n_classes):
class_means[i] /= count[i]
if metric == "cosine" or metric == "weight":
class_means[i] /= (np.linalg.norm(class_means) + EPSILON)
return class_means
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/datasets/__init__.py
================================================
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/datasets/data.py
================================================
import random
import cv2
import numpy as np
import os.path as osp
from copy import deepcopy
from PIL import Image
import multiprocessing as mp
from multiprocessing import Pool
import albumentations as A
from albumentations.pytorch import ToTensorV2
import warnings
warnings.filterwarnings("ignore", "Corrupt EXIF data", UserWarning)
import torch
from torch.utils.data import DataLoader
from torch.utils.data.sampler import SubsetRandomSampler, WeightedRandomSampler
from torchvision import datasets, transforms
from torchvision.datasets.folder import pil_loader
from .dataset import get_dataset
from inclearn.tools.data_utils import construct_balanced_subset
def get_data_folder(data_folder, dataset_name):
return osp.join(data_folder, dataset_name)
class IncrementalDataset:
def __init__(
self,
trial_i,
dataset_name,
random_order=False,
shuffle=True,
workers=10,
batch_size=128,
seed=1,
increment=10,
validation_split=0.0,
resampling=False,
data_folder="./data",
start_class=0,
torc = False
):
# The info about incremental split
self.torc=torc
self.trial_i = trial_i
self.start_class = start_class
#the number of classes for each step in incremental stage
self.task_size = increment
self.increments = []
self.random_order = random_order
self.validation_split = validation_split
#-------------------------------------
#Dataset Info
#-------------------------------------
self.data_folder = get_data_folder('/data0/datasets/', 'CIFAR100/')
self.dataset_name = dataset_name
# self.transform = transform
self.train_dataset = None
self.test_dataset = None
self.n_tot_cls = -1
datasets = get_dataset(dataset_name)
self._setup_data(datasets)
self._workers = workers
self._shuffle = shuffle
self._batch_size = batch_size
self._resampling = resampling
#Currently, don't support multiple datasets
self.train_transforms = datasets.train_transforms
self.test_transforms = datasets.test_transforms
#torchvision or albumentations
self.transform_type = datasets.transform_type
# memory Mt
self.data_memory = None
self.targets_memory = None
# Incoming data D_t
self.data_cur = None
self.targets_cur = None
# Available data \tilde{D}_t = D_t \cup M_t
self.data_inc = None # Cur task data + memory
self.targets_inc = None
# Available data stored in cpu memory.
self.shared_data_inc = None
self.shared_test_data = None
#Current states for Incremental Learning Stage.
self._current_task = 0
@property
def n_tasks(self):
return len(self.increments)
def new_task(self,task_i):
if self._current_task >= len(self.increments):
raise Exception("No more tasks.")
min_class, max_class, x_train, y_train, x_test, y_test,x_val, y_val = self._get_cur_step_data_for_raw_data(task_i)
self.data_cur, self.targets_cur = x_train, y_train
if self.torc:
if self.data_memory is not None:
print("Set memory of size: {}.".format(len(self.data_memory)))
if len(self.data_memory) != 0:
x_train = np.concatenate((x_train, self.data_memory))
y_train = np.concatenate((y_train, self.targets_memory))
self.data_inc, self.targets_inc = x_train, y_train
self.data_test_inc, self.targets_test_inc = x_test, y_test
train_loader = self._get_loader(x_train, y_train, mode="train")
if self.torc:
val_loader = self._get_loader(x_val, y_val, shuffle=False, mode="test")
test_loader = self._get_loader(x_test, y_test, shuffle=False, mode="test")
else:
val_loader=[]
test_loader=[]
for i in range(len(x_test)):
val_loader.append(self._get_loader(x_test[i], y_test[i], shuffle=False, mode="test"))
test_loader.append(self._get_loader(x_test[i], y_test[i], shuffle=False, mode="test"))
task_info = {
"min_class": min_class,
"max_class": max_class,
"increment": self.increments[self._current_task],
"task": self._current_task,
"max_task": len(self.increments),
"n_train_data": len(x_train),
"n_test_data": len(y_train),
}
self._current_task += 1
return task_info, train_loader, val_loader, test_loader
def _get_cur_step_data_for_raw_data(self, task_i):
min_class = sum(self.increments[:self._current_task])
max_class = sum(self.increments[:self._current_task + 1])
if self.torc:
x_train, y_train = self._select(task_i,self.data_train, self.targets_train, low_range=min_class, high_range=max_class)
x_test, y_test = self._select(task_i,self.data_test, self.targets_test, low_range=0, high_range=max_class)
x_val, y_val = self._select(task_i,self.data_test, self.targets_test, low_range=min_class, high_range=max_class)
else:
x_test=[]
y_test=[]
x_train, y_train = self._select(task_i,self.data_train, self.targets_train, low_range=min_class, high_range=max_class)
min_c=0
num_c=max_class-min_class
for taski in range(task_i+1):
x_test_i, y_test_i = self._select(taski,self.data_test, self.targets_test, low_range=min_c, high_range=min_c+num_c)
x_test.append(x_test_i)
y_test.append(y_test_i)
min_c+=num_c
x_val=x_test
y_val=y_test
return min_class, max_class, x_train, y_train, x_test, y_test,x_val, y_val
#--------------------------------
# Data Setup
#--------------------------------
def _setup_data(self, dataset):
# FIXME: handles online loading of images
self.data_train, self.targets_train = [], []
self.data_test, self.targets_test = [], []
self.data_val, self.targets_val = [], []
self.increments = []
self.class_order = []
current_class_idx = 0 # When using multiple datasets
train_dataset = dataset(self.data_folder, train=True)
test_dataset = dataset(self.data_folder, train=False)
self.train_dataset = train_dataset
self.test_datasets = test_dataset
self.n_tot_cls = self.train_dataset.n_cls #number of classes in whole dataset
self._setup_data_for_raw_data(dataset, train_dataset, test_dataset, current_class_idx)
# !list
self.data_train = np.concatenate(self.data_train)
self.targets_train = np.concatenate(self.targets_train)
self.data_val = np.concatenate(self.data_val)
self.targets_val = np.concatenate(self.targets_val)
self.data_test = np.concatenate(self.data_test)
self.targets_test = np.concatenate(self.targets_test)
def _setup_data_for_raw_data(self, dataset, train_dataset, test_dataset, current_class_idx=0):
increment = self.task_size
x_train, y_train = train_dataset.data, np.array(train_dataset.targets)
x_val, y_val, x_train, y_train = self._split_per_class(x_train, y_train, self.validation_split)
x_test, y_test = test_dataset.data, np.array(test_dataset.targets)
# Get Class Order
order = [i for i in range(len(np.unique(y_train)))]
if self.random_order:
random.seed(self._seed) # Ensure that following order is determined by seed:
random.shuffle(order)
elif dataset.class_order(self.trial_i) is not None:
order = dataset.class_order(self.trial_i)
self.class_order.append(order)
y_train = self._map_new_class_index(y_train, order)
y_val = self._map_new_class_index(y_val, order)
y_test = self._map_new_class_index(y_test, order)
y_train += current_class_idx
y_val += current_class_idx
y_test += current_class_idx
current_class_idx += len(order)
if self.start_class == 0:
# increment = 10, 那么 increments 就是 [10, 10, 10, 10, ...]
self.increments = [increment for _ in range(len(order) // increment)]
else:
self.increments.append(self.start_class)
for _ in range((len(order) - self.start_class) // increment):
self.increments.append(increment)
self.data_train.append(x_train)
self.targets_train.append(y_train)
self.data_val.append(x_val)
self.targets_val.append(y_val)
self.data_test.append(x_test)
self.targets_test.append(y_test)
@staticmethod
def _split_per_class(x, y, validation_split=0.0):
"""Splits train data for a subset of validation data.
Split is done so that each class has a much data.
"""
shuffled_indexes = np.random.permutation(x.shape[0])
x = x[shuffled_indexes]
y = y[shuffled_indexes]
x_val, y_val = [], []
x_train, y_train = [], []
for class_id in np.unique(y):
class_indexes = np.where(y == class_id)[0]
nb_val_elts = int(class_indexes.shape[0] * validation_split)
val_indexes = class_indexes[:nb_val_elts]
train_indexes = class_indexes[nb_val_elts:]
x_val.append(x[val_indexes])
y_val.append(y[val_indexes])
x_train.append(x[train_indexes])
y_train.append(y[train_indexes])
# !list
x_val, y_val = np.concatenate(x_val), np.concatenate(y_val)
x_train, y_train = np.concatenate(x_train), np.concatenate(y_train)
return x_val, y_val, x_train, y_train
@staticmethod
def _map_new_class_index(y, order):
"""Transforms targets for new class order."""
return np.array(list(map(lambda x: order.index(x), y)))
def _select(self, task_i,x, y, low_range=0, high_range=0):
idxes = sorted(np.where(np.logical_and(y >= low_range, y < high_range))[0])
if isinstance(x, list):
selected_x = [x[idx] for idx in idxes]
else:
selected_x = x[idxes]
if self.torc:
selected_y=y[idxes]
else:
selected_y=y[idxes]-low_range
return selected_x, selected_y
#--------------------------------
# Get Loader
#--------------------------------
def get_datainc_loader(self, mode='train'):
print(self.data_inc.shape)
train_loader = self._get_loader(self.data_inc, self.targets_inc, mode=mode)
return train_loader
def get_custom_loader_from_memory(self, class_indexes, mode="test"):
if not isinstance(class_indexes, list):
class_indexes = [class_indexes]
data, targets = [], []
for class_index in class_indexes:
class_data, class_targets = self._select(self.data_memory,
self.targets_memory,
low_range=class_index,
high_range=class_index + 1)
data.append(class_data)
targets.append(class_targets)
data = np.concatenate(data)
targets = np.concatenate(targets)
return data, targets, self._get_loader(data, targets, shuffle=False, mode=mode)
def _get_loader(self, x, y, share_memory=None, shuffle=True, mode="train", batch_size=None, resample=None):
if "balanced" in mode:
x, y = construct_balanced_subset(x, y)
batch_size = batch_size if batch_size is not None else self._batch_size
if "train" in mode:
trsf = self.train_transforms
resample_ = self._resampling if resample is None else True
if resample_ is False:
sampler = None
else:
sampler = get_weighted_random_sampler(y)
shuffle = False if resample_ is True else True
elif "test" in mode:
trsf = self.test_transforms
sampler = None
elif mode == "flip":
if "imagenet" in self.dataset_name:
trsf = A.Compose([A.HorizontalFlip(p=1.0), *self.test_transforms.transforms])
else:
trsf = transforms.Compose([transforms.RandomHorizontalFlip(p=1.0), *self.test_transforms.transforms])
sampler = None
else:
raise NotImplementedError("Unknown mode {}.".format(mode))
return DataLoader(DummyDataset(x,
y,
trsf,
trsf_type=self.transform_type,
share_memory_=share_memory,
dataset_name=self.dataset_name),
batch_size=batch_size,
shuffle=shuffle,
num_workers=self._workers,
sampler=sampler,
pin_memory=True)
def get_custom_loader(self, class_indexes, mode="test", data_source="train", imgs=None, tgts=None):
"""Returns a custom loader.
:param class_indexes: A list of class indexes that we want.
:param mode: Various mode for the transformations applied on it.
:param data_source: Whether to fetch from the train, val, or test set.
:return: The raw data and a loader.
"""
if not isinstance(class_indexes, list): # TODO: deprecated, should always give a list
class_indexes = [class_indexes]
if data_source == "train":
x, y = self.data_inc, self.targets_inc
elif data_source == "val":
x, y = self.data_val, self.targets_val
elif data_source == "test":
x, y = self.data_test, self.targets_test
elif data_source == 'specified' and imgs is not None and tgts is not None:
x, y = imgs, tgts
else:
raise ValueError("Unknown data source <{}>.".format(data_source))
data, targets = [], []
for class_index in class_indexes:
class_data, class_targets, = self._select(x, y, low_range=class_index, high_range=class_index + 1)
data.append(class_data)
targets.append(class_targets)
data = np.concatenate(data)
targets = np.concatenate(targets)
return data, targets, self._get_loader(data, targets, shuffle=False, mode=mode)
class DummyDataset(torch.utils.data.Dataset):
def __init__(self, x, y, trsf, trsf_type, share_memory_=None, dataset_name=None):
self.dataset_name = dataset_name
self.x, self.y = x, y
self.trsf = trsf
self.trsf_type = trsf_type
self.manager = mp.Manager()
self.buffer_size = 4000000
if share_memory_ is None:
if self.x.shape[0] > self.buffer_size:
self.share_memory = self.manager.list([None for i in range(self.buffer_size)])
else:
self.share_memory = self.manager.list([None for i in range(len(x))])
else:
self.share_memory = share_memory_
def __len__(self):
if isinstance(self.x, list):
return len(self.x)
else:
return self.x.shape[0]
def __getitem__(self, idx):
x, y, = self.x[idx], self.y[idx]
if isinstance(x, np.ndarray):
# assume cifar
x = Image.fromarray(x)
else:
# Assume the dataset is ImageNet
if idx < len(self.share_memory):
if self.share_memory[idx] is not None:
x = self.share_memory[idx]
else:
x = cv2.imread(x)
x = x[:, :, ::-1]
self.share_memory[idx] = x
else:
x = cv2.imread(x)
x = x[:, :, ::-1]
if 'torch' in self.trsf_type:
x = self.trsf(x)
else:
x = self.trsf(image=x)['image']
return x, y
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/datasets/dataset.py
================================================
import os.path as osp
import numpy as np
import glob
from albumentations.pytorch import ToTensorV2
from torchvision import datasets, transforms
import torch
from inclearn.tools.cutout import Cutout
from inclearn.tools.autoaugment_extra import ImageNetPolicy
def get_datasets(dataset_names):
return [get_dataset(dataset_name) for dataset_name in dataset_names.split("-")]
def get_dataset(dataset_name):
if dataset_name == "cifar10":
return iCIFAR10
elif dataset_name == "cifar100":
return iCIFAR100
elif "imagenet100" in dataset_name:
return iImageNet100
else:
raise NotImplementedError("Unknown dataset {}.".format(dataset_name))
class DataHandler:
base_dataset = None
train_transforms = []
common_transforms = [ToTensorV2()]
class_order = None
class iCIFAR10(DataHandler):
base_dataset_cls = datasets.cifar.CIFAR10
transform_type = 'torchvision'
train_transforms = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
# transforms.ColorJitter(brightness=63 / 255),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
test_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
def __init__(self, data_folder, train, is_fine_label=False):
self.base_dataset = self.base_dataset_cls(data_folder, train=train, download=True)
self.data = self.base_dataset.data
self.targets = self.base_dataset.targets
self.n_cls = 10
@property
def is_proc_inc_data(self):
return False
@classmethod
def class_order(cls, trial_i):
return [4, 0, 2, 5, 8, 3, 1, 6, 9, 7]
class iCIFAR100(iCIFAR10):
label_list = [
'apple', 'aquarium_fish', 'baby', 'bear', 'beaver', 'bed', 'bee', 'beetle', 'bicycle', 'bottle', 'bowl', 'boy',
'bridge', 'bus', 'butterfly', 'camel', 'can', 'castle', 'caterpillar', 'cattle', 'chair', 'chimpanzee', 'clock',
'cloud', 'cockroach', 'couch', 'crab', 'crocodile', 'cup', 'dinosaur', 'dolphin', 'elephant', 'flatfish',
'forest', 'fox', 'girl', 'hamster', 'house', 'kangaroo', 'keyboard', 'lamp', 'lawn_mower', 'leopard', 'lion',
'lizard', 'lobster', 'man', 'maple_tree', 'motorcycle', 'mountain', 'mouse', 'mushroom', 'oak_tree', 'orange',
'orchid', 'otter', 'palm_tree', 'pear', 'pickup_truck', 'pine_tree', 'plain', 'plate', 'poppy', 'porcupine',
'possum', 'rabbit', 'raccoon', 'ray', 'road', 'rocket', 'rose', 'sea', 'seal', 'shark', 'shrew', 'skunk',
'skyscraper', 'snail', 'snake', 'spider', 'squirrel', 'streetcar', 'sunflower', 'sweet_pepper', 'table', 'tank',
'telephone', 'television', 'tiger', 'tractor', 'train', 'trout', 'tulip', 'turtle', 'wardrobe', 'whale',
'willow_tree', 'wolf', 'woman', 'worm'
]
base_dataset_cls = datasets.cifar.CIFAR100
transform_type = 'torchvision'
train_transforms = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=63 / 255),
transforms.ToTensor(),
transforms.Normalize((0.5071, 0.4867, 0.4408), (0.2675, 0.2565, 0.2761)),
])
test_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5071, 0.4867, 0.4408), (0.2675, 0.2565, 0.2761)),
])
def __init__(self, data_folder, train, is_fine_label=False):
self.base_dataset = self.base_dataset_cls(data_folder, train=train, download=True)
self.data = self.base_dataset.data
self.targets = self.base_dataset.targets
self.n_cls = 100
self.transform_type = 'torchvision'
@property
def is_proc_inc_data(self):
return False
@classmethod
def class_order(cls, trial_i):
return [
87, 0, 52, 58, 44, 91, 68, 97, 51, 15, 94, 92, 10, 72, 49, 78, 61, 14, 8, 86, 84, 96, 18, 24, 32, 45,
88, 11, 4, 67, 69, 66, 77, 47, 79, 93, 29, 50, 57, 83, 17, 81, 41, 12, 37, 59, 25, 20, 80, 73, 1, 28, 6,
46, 62, 82, 53, 9, 31, 75, 38, 63, 33, 74, 27, 22, 36, 3, 16, 21, 60, 19, 70, 90, 89, 43, 5, 42, 65, 76,
40, 30, 23, 85, 2, 95, 56, 48, 71, 64, 98, 13, 99, 7, 34, 55, 54, 26, 35, 39
]
class DataHandler:
base_dataset = None
train_transforms = []
common_transforms = [ToTensorV2()]
class_order = None
class iImageNet100(DataHandler):
base_dataset_cls = datasets.ImageFolder
transform_type = 'torchvision'
train_transforms = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
Cutout(n_holes=1, length=16),
transforms.ToPILImage(),
transforms.RandomResizedCrop(32),
transforms.RandomHorizontalFlip(),
ImageNetPolicy(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
test_transforms = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
transforms.ToPILImage(),
transforms.Resize(32),
transforms.CenterCrop(32),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
def __init__(self, data_folder, train, is_fine_label=False):
if train is True:
self.base_dataset = self.base_dataset_cls(osp.join(data_folder, "train"))
else:
self.base_dataset = self.base_dataset_cls(osp.join(data_folder, "val"))
self.data, self.targets = zip(*self.base_dataset.samples)
self.data = np.array(self.data)
self.targets = np.array(self.targets)
self.n_cls = 200
@property
def is_proc_inc_data(self):
return False
@classmethod
def class_order(cls, trial_i):
return [
68, 56, 78, 8, 23, 84, 90, 65, 74, 76, 40, 89, 3, 92, 55, 9, 26, 80, 43, 38, 58, 70, 77, 1, 85, 19, 17, 50,
28, 53, 13, 81, 45, 82, 6, 59, 83, 16, 15, 44, 91, 41, 72, 60, 79, 52, 20, 10, 31, 54, 37, 95, 14, 71, 96,
98, 97, 2, 64, 66, 42, 22, 35, 86, 24, 34, 87, 21, 99, 0, 88, 27, 18, 94, 11, 12, 47, 25, 30, 46, 62, 69,
36, 61, 7, 63, 75, 5, 32, 4, 51, 48, 73, 93, 39, 67, 29, 49, 57, 33,
168, 156, 178, 108, 123, 184, 190, 165, 174, 176, 140, 189, 103,
192, 155, 109, 126, 180, 143, 138, 158, 170, 177, 101, 185, 119,
117, 150, 128, 153, 113, 181, 145, 182, 106, 159, 183, 116, 115,
144, 191, 141, 172, 160, 179, 152, 120, 110, 131, 154, 137, 195,
114, 171, 196, 198, 197, 102, 164, 166, 142, 122, 135, 186, 124,
134, 187, 121, 199, 100, 188, 127, 118, 194, 111, 112, 147, 125,
130, 146, 162, 169, 136, 161, 107, 163, 175, 105, 132, 104, 151,
148, 173, 193, 139, 167, 129, 149, 157, 133,
268, 256, 278, 208, 223, 284, 290, 265, 274, 276, 240, 289, 203,
292, 255, 209, 226, 280, 243, 238, 258, 270, 277, 201, 285, 219,
217, 250, 228, 253, 213, 281, 245, 282, 206, 259, 283, 216, 215,
244, 291, 241, 272, 260, 279, 252, 220, 210, 231, 254, 237, 295,
214, 271, 296, 298, 297, 202, 264, 266, 242, 222, 235, 286, 224,
234, 287, 221, 299, 200, 288, 227, 218, 294, 211, 212, 247, 225,
230, 246, 262, 269, 236, 261, 207, 263, 275, 205, 232, 204, 251,
248, 273, 293, 239, 267, 229, 249, 257, 233, 368, 356, 378, 308,
323, 384, 390, 365, 374, 376, 340, 389, 303, 392, 355, 309, 326,
380, 343, 338, 358, 370, 377, 301, 385, 319, 317, 350, 328, 353,
313, 381, 345, 382, 306, 359, 383, 316, 315, 344, 391, 341, 372,
360, 379, 352, 320, 310, 331, 354, 337, 395, 314, 371, 396, 398,
397, 302, 364, 366, 342, 322, 335, 386, 324, 334, 387, 321, 399,
300, 388, 327, 318, 394, 311, 312, 347, 325, 330, 346, 362, 369,
336, 361, 307, 363, 375, 305, 332, 304, 351, 348, 373, 393, 339,
367, 329, 349, 357, 333,
468, 456, 478, 408, 423, 484, 490, 465, 474, 476, 440, 489, 403,
492, 455, 409, 426, 480, 443, 438, 458, 470, 477, 401, 485, 419,
417, 450, 428, 453, 413, 481, 445, 482, 406, 459, 483, 416, 415,
444, 491, 441, 472, 460, 479, 452, 420, 410, 431, 454, 437, 495,
414, 471, 496, 498, 497, 402, 464, 466, 442, 422, 435, 486, 424,
434, 487, 421, 499, 400, 488, 427, 418, 494, 411, 412, 447, 425,
430, 446, 462, 469, 436, 461, 407, 463, 475, 405, 432, 404, 451,
448, 473, 493, 439, 467, 429, 449, 457, 433, 568, 556, 578, 508,
523, 584, 590, 565, 574, 576, 540, 589, 503, 592, 555, 509, 526,
580, 543, 538, 558, 570, 577, 501, 585, 519, 517, 550, 528, 553,
513, 581, 545, 582, 506, 559, 583, 516, 515, 544, 591, 541, 572,
560, 579, 552, 520, 510, 531, 554, 537, 595, 514, 571, 596, 598,
597, 502, 564, 566, 542, 522, 535, 586, 524, 534, 587, 521, 599,
500, 588, 527, 518, 594, 511, 512, 547, 525, 530, 546, 562, 569,
536, 561, 507, 563, 575, 505, 532, 504, 551, 548, 573, 593, 539,
567, 529, 549, 557, 533,
668, 656, 678, 608, 623, 684, 690, 665, 674, 676, 640, 689, 603,
692, 655, 609, 626, 680, 643, 638, 658, 670, 677, 601, 685, 619,
617, 650, 628, 653, 613, 681, 645, 682, 606, 659, 683, 616, 615,
644, 691, 641, 672, 660, 679, 652, 620, 610, 631, 654, 637, 695,
614, 671, 696, 698, 697, 602, 664, 666, 642, 622, 635, 686, 624,
634, 687, 621, 699, 600, 688, 627, 618, 694, 611, 612, 647, 625,
630, 646, 662, 669, 636, 661, 607, 663, 675, 605, 632, 604, 651,
648, 673, 693, 639, 667, 629, 649, 657, 633, 768, 756, 778, 708,
723, 784, 790, 765, 774, 776, 740, 789, 703, 792, 755, 709, 726,
780, 743, 738, 758, 770, 777, 701, 785, 719, 717, 750, 728, 753,
713, 781, 745, 782, 706, 759, 783, 716, 715, 744, 791, 741, 772,
760, 779, 752, 720, 710, 731, 754, 737, 795, 714, 771, 796, 798,
797, 702, 764, 766, 742, 722, 735, 786, 724, 734, 787, 721, 799,
700, 788, 727, 718, 794, 711, 712, 747, 725, 730, 746, 762, 769,
736, 761, 707, 763, 775, 705, 732, 704, 751, 748, 773, 793, 739,
767, 729, 749, 757, 733,
868, 856, 878, 808, 823, 884, 890, 865, 874, 876, 840, 889, 803,
892, 855, 809, 826, 880, 843, 838, 858, 870, 877, 801, 885, 819,
817, 850, 828, 853, 813, 881, 845, 882, 806, 859, 883, 816, 815,
844, 891, 841, 872, 860, 879, 852, 820, 810, 831, 854, 837, 895,
814, 871, 896, 898, 897, 802, 864, 866, 842, 822, 835, 886, 824,
834, 887, 821, 899, 800, 888, 827, 818, 894, 811, 812, 847, 825,
830, 846, 862, 869, 836, 861, 807, 863, 875, 805, 832, 804, 851,
848, 873, 893, 839, 867, 829, 849, 857, 833, 968, 956, 978, 908,
923, 984, 990, 965, 974, 976, 940, 989, 903, 992, 955, 909, 926,
980, 943, 938, 958, 970, 977, 901, 985, 919, 917, 950, 928, 953,
913, 981, 945, 982, 906, 959, 983, 916, 915, 944, 991, 941, 972,
960, 979, 952, 920, 910, 931, 954, 937, 995, 914, 971, 996, 998,
997, 902, 964, 966, 942, 922, 935, 986, 924, 934, 987, 921, 999,
900, 988, 927, 918, 994, 911, 912, 947, 925, 930, 946, 962, 969,
936, 961, 907, 963, 975, 905, 932, 904, 951, 948, 973, 993, 939,
967, 929, 949, 957, 933
]
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/models/__init__.py
================================================
from .incmodel import IncModel
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/models/base.py
================================================
import abc
import logging
import torch
import torch.nn.functional as F
import numpy as np
from inclearn.tools.metrics import ClassErrorMeter
LOGGER = logging.Logger("IncLearn", level="INFO")
class IncrementalLearner(abc.ABC):
"""Base incremental learner.
Methods are called in this order (& repeated for each new task):
1. set_task_info
2. before_task
3. train_task
4. after_task
5. eval_task
"""
def __init__(self, *args, **kwargs):
self._increments = []
self._seen_classes = []
def set_task_info(self, task, total_n_classes, increment, n_train_data, n_test_data, n_tasks):
self._task = task
self._task_size = increment
self._increments.append(self._task_size)
self._total_n_classes = total_n_classes
self._n_train_data = n_train_data
self._n_test_data = n_test_data
self._n_tasks = n_tasks
def before_task(self, taski, inc_dataset,mask,min_dist,all_dist):
LOGGER.info("Before task")
self.eval()
self._before_task(taski, inc_dataset,mask,min_dist,all_dist)
def train_task(self, task_i,train_loader, val_loader,mask,min_dist,all_dist):
LOGGER.info("train task")
self.train()
self._train_task(task_i,train_loader, val_loader,mask,min_dist,all_dist)
def after_task(self, taski, inc_dataset,mask):
LOGGER.info("after task")
self.eval()
self._after_task(taski, inc_dataset,mask)
def eval_task(self, task_i,data_loader,mask):
LOGGER.info("eval task")
self.eval()
return self._eval_task(task_i,data_loader,mask)
def get_memory(self):
return None
def eval(self):
raise NotImplementedError
def train(self):
raise NotImplementedError
def _before_task(self, data_loader):
pass
def _train_task(self, train_loader, val_loader):
raise NotImplementedError
def _after_task(self, data_loader):
pass
def _eval_task(self, data_loader):
raise NotImplementedError
@property
def _new_task_index(self):
return self._task * self._task_size
@property
def _memory_per_class(self):
"""Returns the number of examplars per class."""
return self._memory_size.mem_per_cls
def _after_epoch(self, epoch, avg_loss, train_new_accu, train_old_accu, accu):
self._run.log_scalar(f"train_loss_trial{self._trial_i}_task{self._task}", avg_loss, epoch + 1)
self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/train_loss", avg_loss, epoch + 1)
# self._run.log_scalar(f"train_new_accu_trial{self._trial_i}_task{self._task}",
# train_new_accu.value()[0], epoch + 1)
# self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/train_new_accu",
# train_new_accu.value()[0], epoch + 1)
# if self._task != 0:
# self._run.log_scalar(f"train_old_accu_trial{self._trial_i}_task{self._task}",
# train_old_accu.value()[0], epoch + 1)
# self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/train_old_accu",
# train_old_accu.value()[0], epoch + 1)
self._run.log_scalar(f"train_accu_trial{self._trial_i}_task{self._task}", accu.value()[0], epoch + 1)
self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/train_accu", accu.value()[0], epoch + 1)
# self._tensorboard.close()
self._tensorboard.flush()
def _validation(self, val_loader, epoch):
topk = 5 if self._n_classes >= 5 else self._n_classes
if self._val_per_n_epoch != -1 and epoch % self._val_per_n_epoch == 0:
_val_loss = 0
_val_accu = ClassErrorMeter(accuracy=True, topk=[1, topk])
_val_new_accu = ClassErrorMeter(accuracy=True)
_val_old_accu = ClassErrorMeter(accuracy=True)
self._parallel_network.eval()
with torch.no_grad():
for i, (inputs, targets) in enumerate(val_loader, 1):
old_classes = targets < (self._n_classes - self._task_size)
new_classes = targets >= (self._n_classes - self._task_size)
val_loss, _ = self._forward_loss(
inputs,
targets,
old_classes,
new_classes,
accu=_val_accu,
old_accu=_val_old_accu,
new_accu=_val_new_accu,
)
_val_loss += val_loss.item()
self._ex.logger.info(
f"epoch{epoch} val acc:{_val_accu.value()[0]:.2f}, val top5acc:{_val_accu.value()[1]:.2f}")
# Test accu
self._run.log_scalar(f"test_accu_trial{self._trial_i}_task{self._task}", _val_accu.value()[0], epoch + 1)
self._run.log_scalar(f"test_5accu_trial{self._trial_i}_task{self._task}", _val_accu.value()[1], epoch + 1)
self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/test_accu",
_val_accu.value()[0], epoch + 1)
self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/test_5accu",
_val_accu.value()[1], epoch + 1)
# Test new accu
self._run.log_scalar(f"test_new_accu_trial{self._trial_i}_task{self._task}",
_val_new_accu.value()[0], epoch + 1)
self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/test_new_accu",
_val_new_accu.value()[0], epoch + 1)
# Test old accu
if self._task != 0:
self._run.log_scalar(f"test_old_accu_trial{self._trial_i}_task{self._task}",
_val_old_accu.value()[0], epoch + 1)
self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/test_old_accu",
_val_old_accu.value()[0], epoch + 1)
# Test loss
self._run.log_scalar(f"test_loss_trial{self._trial_i}_task{self._task}", round(_val_loss / i, 3), epoch + 1)
self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/test_loss", round(_val_loss / i, 3),
epoch + 1)
self._tensorboard.close()
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/models/incmodel.py
================================================
import numpy as np
import random
import time
import math
import os
from copy import deepcopy
from scipy.spatial.distance import cdist
from torchvision.utils import save_image
import torch
# import pdb
from torch.nn import DataParallel
from torch.nn import functional as F
from torch import nn
from inclearn.convnet import network
from inclearn.models.base import IncrementalLearner
from inclearn.tools import factory, utils
from inclearn.tools.metrics import ClassErrorMeter
from inclearn.tools.memory import MemorySize
from inclearn.tools.scheduler import GradualWarmupScheduler
from inclearn.convnet.utils import extract_features, update_classes_mean, finetune_last_layer
# Constants
EPSILON = 1e-8
class IncModel(IncrementalLearner):
def __init__(self, cfg, trial_i, _run, ex, tensorboard, inc_dataset):
super().__init__()
self._cfg = cfg
self._device = cfg['device']
self._ex = ex
self._run = _run # the sacred _run object.
# Data
self._inc_dataset = inc_dataset
self._n_classes = 0
self.classnum_list = []
self.sample_list = []
self._trial_i = trial_i # which class order is used
# Optimizer paras
self._opt_name = cfg["optimizer"]
self._warmup = cfg['warmup']
self._lr = cfg["lr"]
self._weight_decay = cfg["weight_decay"]
self._n_epochs = cfg["epochs"]
self._scheduling = cfg["scheduling"]
self._lr_decay = cfg["lr_decay"]
self.torc=cfg['distillation']
self.prune = cfg.get('prune', False)
# Logging
self._tensorboard = tensorboard
if f"trial{self._trial_i}" not in self._run.info:
self._run.info[f"trial{self._trial_i}"] = {}
self._val_per_n_epoch = cfg["val_per_n_epoch"]
# Model
self._dea = cfg['dea'] # Whether to expand the representation
self._network = network.BasicNet(
cfg["convnet"],
cfg=cfg,
nf=cfg["channel"],
device=self._device,
use_bias=cfg["use_bias"],
dataset=cfg["dataset"],
)
if self._cfg.get("caculate_params", False):
self._parallel_network = self._network
else:
# 并行计算
# gpus = [0, 1, 2, 3]
# self._parallel_network = DataParallel(self._network, device_ids=gpus, output_device=gpus[0])
self._parallel_network = DataParallel(self._network)
self._train_head = cfg["train_head"]
self._infer_head = cfg["infer_head"]
self._old_model = None
# Learning
self._temperature = cfg["temperature"]
self._distillation = cfg["distillation"]
self.lamb = cfg["distlamb"]
# Memory
self._memory_size = MemorySize(cfg["mem_size_mode"], inc_dataset, cfg["memory_size"],
cfg["fixed_memory_per_cls"])
self._herding_matrix = []
self._coreset_strategy = cfg["coreset_strategy"]
if self._cfg["save_ckpt"]:
save_path = os.path.join(os.getcwd(), f"{self._cfg.exp.saveckpt}")
if not os.path.exists(save_path):
os.mkdir(save_path)
if self._cfg["save_mem"]:
save_path = os.path.join(os.getcwd(), f"{self._cfg.exp.saveckpt}/mem")
if not os.path.exists(save_path):
os.mkdir(save_path)
def eval(self):
self._parallel_network.eval()
def train(self):
if self._dea:
self._parallel_network.train()
self._parallel_network.module.convnets[-1].train()
if self._task >= 1:
for i in range(self._task):
self._parallel_network.module.convnets[i].eval()
else:
self._parallel_network.train()
def _before_task(self, taski, inc_dataset,mask,min_dist,all_dist):
self._ex.logger.info(f"Begin step {taski}")
# Update Task info
self._task = taski
self._n_classes += self._task_size
self.classnum_list.append(self._task_size)
self.sample_list = [ int(2000/(self._n_classes-10)) for i in range(self._n_classes-10)] + [ 500 for i in range(10)]
# Memory
self._memory_size.update_n_classes(self._n_classes)
self._memory_size.update_memory_per_cls(self._network, self._n_classes, self._task_size)
self._ex.logger.info("Now {} examplars per class.".format(self._memory_per_class))
self._network.add_classes(self._task_size,min_dist)
self._network.task_size = self._task_size
mask.model=self._network.convnets[-1]
mask.init_length(taski,task_nn=self._network.task_nn)
self.set_optimizer()
def set_optimizer(self, lr=None):
if lr is None:
lr = self._lr
if self._cfg["dynamic_weight_decay"]:
# used in BiC official implementation
weight_decay = self._weight_decay * self._cfg["task_max"] / (self._task + 1)
else:
weight_decay = self._weight_decay
self._ex.logger.info("Step {} weight decay {:.5f}".format(self._task, weight_decay))
# if self._dea and self._task > 0 and not self._cfg.get("caculate_params", False):
# for i in range(self._task):
# for p in self._parallel_network.module.convnets[i].parameters():
# p.requires_grad = False
self._optimizer = factory.get_optimizer(self._network.convnets[-1].parameters(),
self._opt_name, lr, weight_decay)
if "cos" in self._cfg["scheduler"]:
self._scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(self._optimizer, self._n_epochs)
else:
self._scheduler = torch.optim.lr_scheduler.MultiStepLR(self._optimizer,
self._scheduling,
gamma=self._lr_decay)
if self._warmup:
print("warmup")
self._warmup_scheduler = GradualWarmupScheduler(self._optimizer,
multiplier=1,
total_epoch=self._cfg['warmup_epochs'],
after_scheduler=self._scheduler)
def _train_task(self, task_i,train_loader, val_loader,mask,min_dist,all_dist):
self._ex.logger.info(f"nb {len(train_loader.dataset)}")
topk = 5 if self._n_classes > 5 else self._task_size
accu = ClassErrorMeter(accuracy=True, topk=[1, topk])
train_new_accu = ClassErrorMeter(accuracy=True)
train_old_accu = ClassErrorMeter(accuracy=True)
self._optimizer.zero_grad()
self._optimizer.step()
for epoch in range(self._n_epochs):
# torch.cuda.empty_cache()
_loss, _loss_div, _loss_trip, _loss_dist, _loss_atmap = 0.0, 0.0, 0.0, 0.0, 0.0
accu.reset()
train_new_accu.reset()
train_old_accu.reset()
if self._warmup:
self._warmup_scheduler.step()
if epoch == self._cfg['warmup_epochs']:
if self.torc:
self._network.convnets[-1].classifer.reset_parameters()
if self._cfg['use_div_cls']:
self._network.convnets[-1].aux_classifier.reset_parameters()
else:
self._network.convnets[task_i].classifer.reset_parameters()
if self._cfg['use_div_cls']:
self._network.aux_classifier[task_i].reset_parameters()
for i, (inputs, targets) in enumerate(train_loader, start=1):
self.train()
self._optimizer.zero_grad()
old_classes = targets < (self._n_classes - self._task_size)
new_classes = targets >= (self._n_classes - self._task_size)
loss_ce, loss_div, loss_trip, loss_dist, loss_atmap = self._forward_loss(
task_i,
inputs,
targets,
old_classes,
new_classes,
epoch,
accu=accu,
new_accu=train_new_accu,
old_accu=train_old_accu,
mask=mask
)
loss = loss_ce
if self._cfg["distillation"] and self._task > 0:
# trade-off - the lambda from the paper if lamb=-1
if self.lamb == -1:
lamb = (self._n_classes - self._task_size) / self._n_classes
loss = (1-lamb) * loss + lamb * loss_dist
else:
loss = loss + self.lamb * loss_dist
if self._cfg["use_div_cls"] and self._task > 0:
loss += loss_div
loss.backward()
self._optimizer.step()
if self.torc:
if self._cfg["postprocessor"]["enable"]:
if self._cfg["postprocessor"]["type"].lower() == "cr" or self._cfg["postprocessor"]["type"].lower() == "aver":
for p in self._network.convnets[-1].classifer.parameters():
p.data.clamp_(0.0)
_loss += loss_ce
_loss_trip += loss_trip
_loss_div += loss_div
_loss_dist += loss_dist
_loss_atmap += loss_atmap
if task_i>0:
mask.init_mask(self._task,epoch,dim_cur=self._network.channel_dim, task_nn=self._network.task_nn,all_dist=all_dist,all_model=self._network.convnets)
mat=mask.do_mask(self._task)
_loss = _loss.item()
_loss_div = _loss_div.item()
_loss_trip = _loss_trip.item()
_loss_dist = _loss_dist.item()
_loss_atmap = _loss_atmap.item()
if not self._warmup:
self._scheduler.step()
self._ex.logger.info(
"Task {}/{}, Epoch {}/{} => Clf loss: {} Div loss: {}, Knowledge Distllation loss:{}, Train Accu: {}, Train@5 Acc: {}".
format(
self._task + 1,
self._n_tasks,
epoch + 1,
self._n_epochs,
round(_loss / i, 3),
round(_loss_div / i, 3),
round(_loss_dist / i, 3),
round(accu.value()[0], 3),
round(accu.value()[1], 3),
))
if self._val_per_n_epoch > 0 and epoch % self._val_per_n_epoch == 0:
self.validate(val_loader)
if self.torc:
# For the large-scale dataset, we manage the data in the shared memory.
self._inc_dataset.shared_data_inc = train_loader.dataset.share_memory
utils.display_weight_norm(self._ex.logger, self._parallel_network, self._increments, "After training")
utils.display_feature_norm(task_i,self._ex.logger, self._parallel_network, train_loader, self._n_classes,
self._increments, "Trainset",mask=mask)
self._run.info[f"trial{self._trial_i}"][f"task{self._task}_train_accu"] = round(accu.value()[0], 3)
def _forward_loss(self, task_i,inputs, targets, old_classes, new_classes, epoch, accu=None, new_accu=None, old_accu=None,mask=None):
inputs, targets = inputs.to(self._device, non_blocking=True), targets.to(self._device, non_blocking=True)
outputs = self._parallel_network(task_i,inputs,mask)
if accu is not None:
accu.add(outputs['logit'], targets)
return self._compute_loss(task_i, inputs, targets, outputs, old_classes, new_classes, epoch,mask=mask)
def cross_entropy(self, outputs, targets, exp=1.0, size_average=True, eps=1e-5):
"""Calculates cross-entropy with temperature scaling"""
out = torch.nn.functional.softmax(outputs, dim=1)
tar = torch.nn.functional.softmax(targets, dim=1)
if exp != 1:
out = out.pow(exp)
out = out / out.sum(1).view(-1, 1).expand_as(out)
tar = tar.pow(exp)
tar = tar / tar.sum(1).view(-1, 1).expand_as(tar)
out = out + eps / out.size(1)
out = out / out.sum(1).view(-1, 1).expand_as(out)
ce = -(tar * out.log()).sum(1)
if size_average:
ce = ce.mean()
return ce
def hcl(self, fstudent, fteacher, targets):
loss_all = 0.0
fs = fstudent
select_teacher = self._cfg.get("select_teacher",False)
if select_teacher:
for i in range(len(fteacher)):
ft = fteacher[i]
if i > 0:
old_classes = np.logical_and((targets < (self._n_classes - self._task_size * (len(fteacher)-i))).cpu(), (targets >= (self._n_classes - self._task_size * (len(fteacher)-i+1))).cpu())
else:
old_classes = (targets < (self._n_classes - self._task_size * len(fteacher))).cpu()
classes_indice = torch.from_numpy(np.where(old_classes==True)[0]).to(self._device)
# targets_old = torch.index_select(targets_old, 0, old_classes_indice)
# log_probs_new = torch.index_select(log_probs_new, 0, old_classes_indice)
fs = torch.index_select(fstudent, 0, classes_indice)
ft = torch.index_select(ft, 0, classes_indice)
n,c,h,w = fs.shape
if n == 0:
break
loss = F.mse_loss(fs, ft, reduction='mean')
cnt = 1.0
tot = 1.0
for l in [4,2,1]:
if l >=h:
continue
tmpfs = F.adaptive_avg_pool2d(fs, (l,l))
tmpft = F.adaptive_avg_pool2d(ft, (l,l))
cnt /= 2.0
loss += F.mse_loss(tmpfs, tmpft, reduction='mean') * cnt
tot += cnt
loss = loss / tot
loss_all = loss_all + loss
else:
for i in range(len(fteacher)):
ft = fteacher[i]
n,c,h,w = fs.shape
if n == 0:
break
loss = F.mse_loss(fs, ft, reduction='mean')
cnt = 1.0
tot = 1.0
for l in [4,2,1]:
if l >=h:
continue
tmpfs = F.adaptive_avg_pool2d(fs, (l,l))
tmpft = F.adaptive_avg_pool2d(ft, (l,l))
cnt /= 2.0
loss += F.mse_loss(tmpfs, tmpft, reduction='mean') * cnt
tot += cnt
loss = loss / tot
loss_all = loss_all + loss
return loss_all
def _compute_loss(self, task_i, inputs, targets, outputs, old_classes, new_classes, epoch,mask=None):
loss = F.cross_entropy(outputs['logit'], targets)
trip_loss = torch.zeros([1]).cuda()
atmap_loss = torch.zeros([1]).cuda()
if outputs['div_logit'] is not None:
div_targets = targets.clone()
if self._cfg["div_type"] == "n+1":
div_targets[old_classes] = 0
div_targets[new_classes] -= sum(self._inc_dataset.increments[:self._task]) - 1
elif self._cfg["div_type"] == "1+1":
div_targets[old_classes] = 0
div_targets[new_classes] = 1
elif self._cfg["div_type"] == "n+t":
div_targets[new_classes] -= sum(self._inc_dataset.increments[:self._task]) - self._task
for i in range(self._task):
if i > 0:
old_class = np.logical_and((targets < (self._n_classes - self._task_size * (self._task-i))).cpu(), (targets >= (self._n_classes - self._task_size * (self._task-i+1))).cpu())
else:
old_class = (targets < (self._n_classes - self._task_size * self._task)).cpu()
div_targets[old_class] = i
# import pdb
# pdb.set_trace()
div_loss = F.cross_entropy(outputs['div_logit'], div_targets)
else:
div_loss = torch.zeros([1]).cuda()
if self._cfg["distillation"] and self._old_model is not None:
outputs_old = self._old_model(task_i-1,inputs,mask=None)
targets_old = outputs_old['logit'].detach()
if self._cfg["disttype"] == "KL":
log_probs_new = (outputs['logit'][:, :-self._task_size] / self._temperature).log_softmax(dim=1)
if self._task > 1 and self._cfg["postprocessor"]["enable"]:
if self._cfg["postprocessor"]["type"].lower() == "aver":
targets_old = self._old_model.module.postprocessor.post_process(targets_old, self._task_size, self.classnum_list[:-1], self._task-1)
else:
targets_old = self._old_model.module.postprocessor.post_process(targets_old, self._task_size)
modify = self._cfg.get("modify_new",False)
if modify:
old_weight_norm = torch.norm(self._network.convnets[-1].classifer.weight[:-self._task_size], p=2, dim=1)
new_weight_norm = torch.norm(self._network.convnets[-1].classifer.weight[-self._task_size:], p=2, dim=1)
gamma = old_weight_norm.mean() / new_weight_norm.mean()
targets_old[new_classes,:] = targets_old[new_classes,:] * gamma
probs_old = (targets_old / self._temperature).softmax(dim=1)
dist_loss = F.kl_div(log_probs_new, probs_old, reduction="batchmean")
else:
dist_loss = self.cross_entropy(outputs['logit'][:, :-self._task_size], targets_old, exp=1.0 / self._temperature)
else:
dist_loss = torch.zeros([1]).cuda()
return loss, div_loss, trip_loss, dist_loss, atmap_loss
def _after_task(self, taski, inc_dataset,mask=None):
network = deepcopy(self._parallel_network)
network.eval()
if self._cfg["save_ckpt"] and taski >= self._cfg["start_task"] and not self.prune:
self._ex.logger.info("save model")
save_path = os.path.join(os.getcwd(), f"{self._cfg.exp.saveckpt}")
torch.save(network.cpu().state_dict(), "{}/step{}.ckpt".format(save_path, self._task))
if self.torc:
if self._cfg["postprocessor"]["enable"]:
self._update_postprocessor(taski,inc_dataset,mask=mask)
if self._cfg["infer_head"] == 'NCM':
self._ex.logger.info("compute prototype")
self.update_prototype()
if self._memory_size.memsize != 0:
self._ex.logger.info("build memory")
self.build_exemplars(taski,inc_dataset, self._coreset_strategy,mask=mask)
if self._cfg["save_mem"]:
save_path = os.path.join(os.getcwd(), f"{self._cfg.exp.saveckpt}/mem")
memory = {
'x': inc_dataset.data_memory,
'y': inc_dataset.targets_memory,
'herding': self._herding_matrix
}
if not os.path.exists(save_path):
os.makedirs(save_path)
if not (os.path.exists(f"{save_path}/mem_step{self._task}.ckpt") and self._cfg['load_mem']):
torch.save(memory, "{}/mem_step{}.ckpt".format(save_path, self._task))
self._ex.logger.info(f"Save step{self._task} memory!")
# utils.display_weight_norm(self._ex.logger, self._parallel_network, self._increments, "After training")
self._parallel_network.eval()
self._old_model = deepcopy(self._parallel_network)
if not self._cfg.get("caculate_params", False):
self._old_model.module.freeze()
del self._inc_dataset.shared_data_inc
self._inc_dataset.shared_data_inc = None
def _eval_task(self,task_i, data_loader,mask):
# if self._cfg.get("caculate_params", False):
# from thop import profile
# self._parallel_network.eval()
# with torch.no_grad():
# input = torch.randn(1, 3, 256, 256).to(self._device, non_blocking=True)
# flops, params = profile(self._parallel_network, inputs=(input,))
# ypred = flops/1000**3
# ytrue = params/1000**2
# from torchstat import stat
# stat(self._parallel_network, (3, 256, 256))
# ypred,ytrue = 0,0
# else:
if self._infer_head == "softmax":
ypred, ytrue = self._compute_accuracy_by_netout(task_i,data_loader,mask)
elif self._infer_head == "NCM":
ypred, ytrue = self._compute_accuracy_by_ncm(data_loader)
else:
raise ValueError()
return ypred, ytrue
def _compute_accuracy_by_netout(self, task_i,data_loader,mask):
preds, targets = [], []
self._parallel_network.eval()
if self._cfg.get("caculate_params", False):
with torch.no_grad():
from thop import profile
inputs = torch.randn(1, 3, 112, 112)
flops, params = profile(self._parallel_network, (inputs,))
preds = flops/1000**3
targets = params/1000**2
# print('flops: ', flops, 'params: ', params)
# for i, (inputs, lbls) in enumerate(data_loader):
# from thop import profile
# # inputs = inputs.to(self._device, non_blocking=True)
# flops, params = profile(self._parallel_network, inputs[0])
# preds = flops/1000**3
# targets = params/1000**2
# break
else:
with torch.no_grad():
for i, (inputs, lbls) in enumerate(data_loader):
inputs = inputs.to(self._device, non_blocking=True)
_preds = self._parallel_network(task_i,inputs,mask)['logit']
if self.torc:
if self._cfg["postprocessor"]["enable"] and self._task > 0:
if self._cfg["postprocessor"]["type"].lower() == "aver":
_preds = self._network.postprocessor.post_process(_preds, self._task_size, self.classnum_list, self._task)
else:
_preds = self._network.postprocessor.post_process(_preds, self._task_size)
preds.append(_preds.detach().cpu().numpy())
targets.append(lbls.long().cpu().numpy())
preds = np.concatenate(preds, axis=0)
targets = np.concatenate(targets, axis=0)
return preds, targets
def _compute_accuracy_by_ncm(self, loader):
features, targets_ = extract_features(self._parallel_network, loader)
targets = np.zeros((targets_.shape[0], self._n_classes), np.float32)
targets[range(len(targets_)), targets_.astype("int32")] = 1.0
class_means = (self._class_means.T / (np.linalg.norm(self._class_means.T, axis=0) + EPSILON)).T
features = (features.T / (np.linalg.norm(features.T, axis=0) + EPSILON)).T
# Compute score for iCaRL
sqd = cdist(class_means, features, "sqeuclidean")
score_icarl = (-sqd).T
return score_icarl[:, :self._n_classes], targets_
def _update_postprocessor(self, taski,inc_dataset,mask=None):
if self._cfg["postprocessor"]["type"].lower() == "bic":
if False:#self._cfg["postprocessor"]["disalign_resample"] is True:
bic_loader = inc_dataset._get_loader(inc_dataset.data_inc,
inc_dataset.targets_inc,
mode="train",
resample='disalign_resample')
else:
xdata, ydata = inc_dataset._select(taski,inc_dataset.data_train,
inc_dataset.targets_train,
low_range=0,
high_range=self._n_classes)
bic_loader = inc_dataset._get_loader(xdata, ydata, shuffle=True, mode='train')
bic_loss = None
self._network.postprocessor.reset(n_classes=self._n_classes)
self._network.postprocessor.update(self._ex.logger,
self._task_size,
self._parallel_network,
bic_loader,
loss_criterion=bic_loss,
taski=taski,
mask=mask)
elif self._cfg["postprocessor"]["type"].lower() == "cr":
self._ex.logger.info("Post processor cr update !")
self._network.postprocessor.update(self._network.convnets[-1].classifer, self._task_size)
elif self._cfg["postprocessor"]["type"].lower() == "aver":
self._ex.logger.info("Post processor aver update !")
self._network.postprocessor.update(self._network.convnets[-1].classifer, self._task_size, self.classnum_list, self._task)
def update_prototype(self):
if hasattr(self._inc_dataset, 'shared_data_inc'):
shared_data_inc = self._inc_dataset.shared_data_inc
else:
shared_data_inc = None
self._class_means = update_classes_mean(self._parallel_network,
self._inc_dataset,
self._n_classes,
self._task_size,
share_memory=self._inc_dataset.shared_data_inc,
metric='None')
def build_exemplars(self, task_i,inc_dataset, coreset_strategy,mask=None):
save_path = os.path.join(os.getcwd(), f"{self._cfg.exp.saveckpt}/mem/mem_step{self._task}.ckpt")
if self._cfg["load_mem"] and os.path.exists(save_path):
memory_states = torch.load(save_path)
self._inc_dataset.data_memory = memory_states['x']
self._inc_dataset.targets_memory = memory_states['y']
self._herding_matrix = memory_states['herding']
self._ex.logger.info(f"Load saved step{self._task} memory!")
return
if coreset_strategy == "random":
from inclearn.tools.memory import random_selection
self._inc_dataset.data_memory, self._inc_dataset.targets_memory = random_selection(
self._n_classes,
self._task_size,
self._parallel_network,
self._ex.logger,
inc_dataset,
self._memory_per_class,
)
elif coreset_strategy == "iCaRL":
from inclearn.tools.memory import herding
data_inc = self._inc_dataset.shared_data_inc if self._inc_dataset.shared_data_inc is not None else self._inc_dataset.data_inc
self._inc_dataset.data_memory, self._inc_dataset.targets_memory, self._herding_matrix = herding(
task_i,
self._n_classes,
self._task_size,
self._parallel_network,
self._herding_matrix,
inc_dataset,
data_inc,
self._memory_per_class,
self._ex.logger,
mask=mask
)
else:
raise ValueError()
def validate(self, data_loader):
if self._infer_head == 'NCM':
self.update_prototype()
ypred, ytrue = self._eval_task(data_loader)
test_acc_stats = utils.compute_accuracy(ypred, ytrue, increments=self._increments, n_classes=self._n_classes)
self._ex.logger.info(f"test top1acc:{test_acc_stats['top1']}")
return test_acc_stats['top1']['total']
def after_prune(self, taski, inc_dataset):
x = torch.randn(1, 3, 32, 32)
self._network = self._network.cpu()
dim1, dim2 = self._network.caculate_dim(x)
del self._network.classifier
self._network.classifier = self._network._gen_classifier(dim1, self._n_classes)
if self._network.se is not None:
del self._network.se
ft_type = self._cfg.get('feature_type', 'ce')
at_res = self._cfg.get('attention_use_residual', False)
self._network.se = factory.get_attention(dim1, ft_type, at_res)
if taski > 0:
del self._network.aux_classifier
self._network.aux_classifier = self._network._gen_classifier(dim2, self._task_size+1)
del self._parallel_network
self._parallel_network = DataParallel(self._network)
class DistillKL(nn.Module):
"""Distilling the Knowledge in a Neural Network"""
def __init__(self, T):
super(DistillKL, self).__init__()
self.T = T
def forward(self, y_s, y_t):
p_s = F.log_softmax(y_s/self.T, dim=1)
p_t = F.softmax(y_t/self.T, dim=1)
loss = F.kl_div(p_s, p_t, reduction="sum") * (self.T**2) / y_s.shape[0]
# loss = F.kl_div(p_s, p_t, reduction="batchmean") * (self.T**2) / y_s.shape[0]
return loss
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/__init__.py
================================================
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/autoaugment_extra.py
================================================
from PIL import Image, ImageEnhance, ImageOps, ImageDraw
import numpy as np
import random
class ImageNetPolicy(object):
""" Randomly choose one of the best 24 Sub-policies on ImageNet.
Example:
>>> policy = ImageNetPolicy()
>>> transformed = policy(image)
Example as a PyTorch Transform:
>>> transform=transforms.Compose([
>>> transforms.Resize(256),
>>> ImageNetPolicy(),
>>> transforms.ToTensor()])
"""
def __init__(self, fillcolor=(128, 128, 128)):
self.policies = [
SubPolicy(0.4, "posterize", 8, 0.6, "rotate", 9, fillcolor),
SubPolicy(0.6, "solarize", 5, 0.6, "autocontrast", 5, fillcolor),
SubPolicy(0.8, "equalize", 8, 0.6, "equalize", 3, fillcolor),
SubPolicy(0.6, "posterize", 7, 0.6, "posterize", 6, fillcolor),
SubPolicy(0.4, "equalize", 7, 0.2, "solarize", 4, fillcolor),
SubPolicy(0.4, "equalize", 4, 0.8, "rotate", 8, fillcolor),
SubPolicy(0.6, "solarize", 3, 0.6, "equalize", 7, fillcolor),
SubPolicy(0.8, "posterize", 5, 1.0, "equalize", 2, fillcolor),
SubPolicy(0.2, "rotate", 3, 0.6, "solarize", 8, fillcolor),
SubPolicy(0.6, "equalize", 8, 0.4, "posterize", 6, fillcolor),
SubPolicy(0.8, "rotate", 8, 0.4, "color", 0, fillcolor),
SubPolicy(0.4, "rotate", 9, 0.6, "equalize", 2, fillcolor),
SubPolicy(0.0, "equalize", 7, 0.8, "equalize", 8, fillcolor),
SubPolicy(0.6, "invert", 4, 1.0, "equalize", 8, fillcolor),
SubPolicy(0.6, "color", 4, 1.0, "contrast", 8, fillcolor),
SubPolicy(0.8, "rotate", 8, 1.0, "color", 2, fillcolor),
SubPolicy(0.8, "color", 8, 0.8, "solarize", 7, fillcolor),
SubPolicy(0.4, "sharpness", 7, 0.6, "invert", 8, fillcolor),
SubPolicy(0.6, "shearX", 5, 1.0, "equalize", 9, fillcolor),
SubPolicy(0.4, "color", 0, 0.6, "equalize", 3, fillcolor),
SubPolicy(0.4, "equalize", 7, 0.2, "solarize", 4, fillcolor),
SubPolicy(0.6, "solarize", 5, 0.6, "autocontrast", 5, fillcolor),
SubPolicy(0.6, "invert", 4, 1.0, "equalize", 8, fillcolor),
SubPolicy(0.6, "color", 4, 1.0, "contrast", 8, fillcolor),
SubPolicy(0.8, "equalize", 8, 0.6, "equalize", 3, fillcolor),
SubPolicy(0.1, "invert", 7, 0.2, "contrast", 6, fillcolor), # set-1
SubPolicy(0.7, "rotate", 2, 0.3, "translateX", 9, fillcolor),
SubPolicy(0.8, "sharpness", 1, 0.9, "sharpness", 3, fillcolor),
SubPolicy(0.5, "shearY", 8, 0.7, "translateY", 9, fillcolor),
SubPolicy(0.5, "autocontrast", 8, 0.9, "equalize", 2, fillcolor),
SubPolicy(0.2, "shearY", 7, 0.3, "posterize", 7, fillcolor), # set-3
SubPolicy(0.4, "color", 3, 0.6, "brightness", 7, fillcolor),
SubPolicy(0.3, "sharpness", 9, 0.7, "brightness", 9, fillcolor),
SubPolicy(0.6, "equalize", 5, 0.5, "equalize", 1, fillcolor),
SubPolicy(0.6, "contrast", 7, 0.6, "sharpness", 5, fillcolor),
SubPolicy(0.7, "color", 7, 0.5, "translateX", 8, fillcolor), #set-11
SubPolicy(0.3, "equalize", 7, 0.4, "autocontrast", 8, fillcolor),
SubPolicy(0.4, "translateY", 3, 0.2, "sharpness", 6, fillcolor),
SubPolicy(0.9, "brightness", 6, 0.2, "color", 8, fillcolor),
SubPolicy(0.5, "solarize", 2, 0.0, "invert", 3, fillcolor),
SubPolicy(0.2, "equalize", 0, 0.6, "autocontrast", 0, fillcolor),
SubPolicy(0.2, "equalize", 8, 0.8, "equalize", 4, fillcolor),
SubPolicy(0.9, "color", 9, 0.6, "equalize", 6, fillcolor),
SubPolicy(0.8, "autocontrast", 4, 0.2, "solarize", 8, fillcolor),
SubPolicy(0.1, "brightness", 3, 0.7, "color", 0, fillcolor),
SubPolicy(0.4, "solarize", 5, 0.9, "autocontrast", 3, fillcolor), # set-2
SubPolicy(0.9, "translateY", 9, 0.7, "translateY", 9, fillcolor),
SubPolicy(0.9, "autocontrast", 2, 0.8, "solarize", 3, fillcolor),
SubPolicy(0.8, "equalize", 8, 0.1, "invert", 3, fillcolor),
SubPolicy(0.7, "translateY", 9, 0.9, "autocontrast", 1, fillcolor),
SubPolicy(0.4, "solarize", 5, 0.9, "autocontrast", 3, fillcolor),
SubPolicy(0.9, "translateY", 9, 0.7, "translateY", 9, fillcolor),
SubPolicy(0.9, "autocontrast", 2, 0.8, "solarize", 3, fillcolor),
SubPolicy(0.8, "equalize", 8, 0.1, "invert", 3, fillcolor),
SubPolicy(0.7, "translateY", 9, 0.9, "autocontrast", 1, fillcolor),
SubPolicy(0.4, "solarize", 5, 0.9, "autocontrast", 1, fillcolor),
SubPolicy(0.8, "translateY", 9, 0.9, "translateY", 9, fillcolor),
SubPolicy(0.8, "autocontrast", 0, 0.7, "translateY", 9, fillcolor),
SubPolicy(0.2, "translateY", 7, 0.9, "color", 6, fillcolor),
SubPolicy(0.7, "equalize", 6, 0.4, "color", 9, fillcolor),
SubPolicy(0.3, "brightness", 7, 0.5, "autocontrast", 8, fillcolor),
SubPolicy(0.9, "autocontrast", 4, 0.5, "autocontrast", 6, fillcolor),
SubPolicy(0.3, "solarize", 5, 0.6, "equalize", 5, fillcolor),
SubPolicy(0.2, "translateY", 4, 0.3, "sharpness", 3, fillcolor),
SubPolicy(0.0, "brightness", 8, 0.8, "color", 8, fillcolor),
SubPolicy(0.2, "solarize", 6, 0.8, "color", 6, fillcolor),
SubPolicy(0.2, "solarize", 6, 0.8, "autocontrast", 1, fillcolor),
SubPolicy(0.4, "solarize", 1, 0.6, "equalize", 5, fillcolor),
SubPolicy(0.0, "brightness", 0, 0.5, "solarize", 2, fillcolor),
SubPolicy(0.9, "autocontrast", 5, 0.5, "brightness", 3, fillcolor),
SubPolicy(0.7, "contrast", 5, 0.0, "brightness", 2, fillcolor),
SubPolicy(0.2, "solarize", 8, 0.1, "solarize", 5, fillcolor),
SubPolicy(0.5, "contrast", 1, 0.2, "translateY", 9, fillcolor),
SubPolicy(0.6, "autocontrast", 5, 0.0, "translateY", 9, fillcolor),
SubPolicy(0.9, "autocontrast", 4, 0.8, "equalize", 4, fillcolor),
SubPolicy(0.0, "brightness", 7, 0.4, "equalize", 7, fillcolor),
SubPolicy(0.2, "solarize", 5, 0.7, "equalize", 5, fillcolor),
SubPolicy(0.6, "equalize", 8, 0.6, "color", 2, fillcolor),
SubPolicy(0.3, "color", 7, 0.2, "color", 4, fillcolor),
SubPolicy(0.5, "autocontrast", 2, 0.7, "solarize", 2, fillcolor),
SubPolicy(0.2, "autocontrast", 0, 0.1, "equalize", 0, fillcolor),
SubPolicy(0.6, "shearY", 5, 0.6, "equalize", 5, fillcolor),
SubPolicy(0.9, "brightness", 3, 0.4, "autocontrast", 1, fillcolor),
SubPolicy(0.8, "equalize", 8, 0.7, "equalize", 7, fillcolor),
SubPolicy(0.7, "equalize", 7, 0.5, "solarize", 0, fillcolor),
SubPolicy(0.8, "equalize", 4, 0.8, "translateY", 9, fillcolor),
SubPolicy(0.8, "translateY", 9, 0.6, "translateY", 9, fillcolor),
SubPolicy(0.9, "translateY", 0, 0.5, "translateY", 9, fillcolor),
SubPolicy(0.5, "autocontrast", 3, 0.3, "solarize", 4, fillcolor),
SubPolicy(0.5, "solarize", 3, 0.4, "equalize", 4, fillcolor),
SubPolicy(0.1, "autocontrast", 5, 0.0, "brightness", 0, fillcolor),
SubPolicy(0.7, "equalize", 7, 0.6, "autocontrast", 4, fillcolor),
SubPolicy(0.1, "color", 8, 0.2, "shearY", 3, fillcolor),
SubPolicy(0.4, "shearY", 2, 0.7, "rotate", 0, fillcolor),
SubPolicy(0.1, "shearY", 3, 0.9, "autocontrast", 5, fillcolor),
SubPolicy(0.5, "equalize", 0, 0.6, "solarize", 6, fillcolor),
SubPolicy(0.3, "autocontrast", 5, 0.2, "rotate", 7, fillcolor),
SubPolicy(0.8, "equalize", 2, 0.4, "invert", 0, fillcolor),
SubPolicy(0.9, "equalize", 5, 0.7, "color", 0, fillcolor),
SubPolicy(0.1, "equalize", 1, 0.1, "shearY", 3, fillcolor),
SubPolicy(0.7, "autocontrast", 3, 0.7, "equalize", 0, fillcolor),
SubPolicy(0.5, "brightness", 1, 0.1, "contrast", 7, fillcolor),
SubPolicy(0.1, "contrast", 4, 0.6, "solarize", 5, fillcolor),
SubPolicy(0.2, "solarize", 3, 0.0, "shearX", 0, fillcolor),
SubPolicy(0.3, "translateX", 0, 0.6, "translateX", 0, fillcolor),
SubPolicy(0.5, "equalize", 9, 0.6, "translateY", 7, fillcolor),
SubPolicy(0.1, "shearX", 0, 0.5, "sharpness", 1, fillcolor),
SubPolicy(0.8, "equalize", 6, 0.3, "invert", 6, fillcolor),
SubPolicy(0.4, "shearX", 4, 0.9, "autocontrast", 2, fillcolor),
SubPolicy(0.0, "shearX", 3, 0.0, "posterize", 3, fillcolor),
SubPolicy(0.4, "solarize", 3, 0.2, "color", 4, fillcolor),
SubPolicy(0.1, "equalize", 4, 0.7, "equalize", 6, fillcolor),
SubPolicy(0.3, "equalize", 8, 0.4, "autocontrast", 3, fillcolor),
SubPolicy(0.6, "solarize", 4, 0.7, "autocontrast", 6, fillcolor),
SubPolicy(0.2, "autocontrast", 9, 0.4, "brightness", 8, fillcolor),
SubPolicy(0.1, "equalize", 0, 0.0, "equalize", 6, fillcolor),
SubPolicy(0.8, "equalize", 4, 0.0, "equalize", 4, fillcolor),
SubPolicy(0.5, "equalize", 5, 0.1, "autocontrast", 2, fillcolor),
SubPolicy(0.5, "solarize", 5, 0.9, "autocontrast", 5, fillcolor),
]
def __call__(self, img):
policy_idx = random.randint(0, len(self.policies) - 1)
return self.policies[policy_idx](img)
def __repr__(self):
return "AutoAugment ImageNet Policy"
class SubPolicy(object):
def __init__(self, p1, operation1, magnitude_idx1, p2, operation2, magnitude_idx2, fillcolor=(128, 128, 128)):
ranges = {
"shearX": np.linspace(0, 0.3, 10),
"shearY": np.linspace(0, 0.3, 10),
"translateX": np.linspace(0, 150 / 331, 10),
"translateY": np.linspace(0, 150 / 331, 10),
"rotate": np.linspace(0, 30, 10),
"color": np.linspace(0.0, 0.9, 10),
"posterize": np.round(np.linspace(8, 4, 10), 0).astype(np.int64),
"solarize": np.linspace(256, 0, 10),
"contrast": np.linspace(0.0, 0.9, 10),
"sharpness": np.linspace(0.0, 0.9, 10),
"brightness": np.linspace(0.0, 0.9, 10),
"autocontrast": [0] * 10,
"equalize": [0] * 10,
"invert": [0] * 10,
"cutout": np.linspace(0.0, 0.2, 10),
}
def Cutout(img, v): # [0, 60] => percentage: [0, 0.2]
#assert 0.0 <= v <= 0.2
if v <= 0.:
return img
v = v * img.size[0]
return CutoutAbs(img, v)
# x0 = np.random.uniform(w - v)
# y0 = np.random.uniform(h - v)
# xy = (x0, y0, x0 + v, y0 + v)
# color = (127, 127, 127)
# img = img.copy()
# PIL.ImageDraw.Draw(img).rectangle(xy, color)
# return img
def CutoutAbs(img, v): # [0, 60] => percentage: [0, 0.2]
# assert 0 <= v <= 20
if v < 0:
return img
w, h = img.size
x0 = np.random.uniform(w)
y0 = np.random.uniform(h)
x0 = int(max(0, x0 - v / 2.))
y0 = int(max(0, y0 - v / 2.))
x1 = min(w, x0 + v)
y1 = min(h, y0 + v)
xy = (x0, y0, x1, y1)
color = (125, 123, 114)
# color = (0, 0, 0)
img = img.copy()
ImageDraw.Draw(img).rectangle(xy, color)
return img
def rotate_with_fill(img, magnitude):
rot = img.convert("RGBA").rotate(magnitude)
return Image.composite(rot, Image.new("RGBA", rot.size, (128,) * 4), rot).convert(img.mode)
func = {
"shearX": lambda img, magnitude: img.transform(
img.size, Image.AFFINE, (1, magnitude * random.choice([-1, 1]), 0, 0, 1, 0),
Image.BICUBIC, fillcolor=fillcolor),
"shearY": lambda img, magnitude: img.transform(
img.size, Image.AFFINE, (1, 0, 0, magnitude * random.choice([-1, 1]), 1, 0),
Image.BICUBIC, fillcolor=fillcolor),
"translateX": lambda img, magnitude: img.transform(
img.size, Image.AFFINE, (1, 0, magnitude * img.size[0] * random.choice([-1, 1]), 0, 1, 0),
fillcolor=fillcolor),
"translateY": lambda img, magnitude: img.transform(
img.size, Image.AFFINE, (1, 0, 0, 0, 1, magnitude * img.size[1] * random.choice([-1, 1])),
fillcolor=fillcolor),
"cutout": lambda img, magnitude: Cutout(img, magnitude),
"rotate": lambda img, magnitude: rotate_with_fill(img, magnitude),
# "rotate": lambda img, magnitude: img.rotate(magnitude * random.choice([-1, 1])),
"color": lambda img, magnitude: ImageEnhance.Color(img).enhance(1 + magnitude * random.choice([-1, 1])),
"posterize": lambda img, magnitude: ImageOps.posterize(img, magnitude),
"solarize": lambda img, magnitude: ImageOps.solarize(img, magnitude),
"contrast": lambda img, magnitude: ImageEnhance.Contrast(img).enhance(
1 + magnitude * random.choice([-1, 1])),
"sharpness": lambda img, magnitude: ImageEnhance.Sharpness(img).enhance(
1 + magnitude * random.choice([-1, 1])),
"brightness": lambda img, magnitude: ImageEnhance.Brightness(img).enhance(
1 + magnitude * random.choice([-1, 1])),
"autocontrast": lambda img, magnitude: ImageOps.autocontrast(img),
"equalize": lambda img, magnitude: ImageOps.equalize(img),
"invert": lambda img, magnitude: ImageOps.invert(img)
}
# self.name = "{}_{:.2f}_and_{}_{:.2f}".format(
# operation1, ranges[operation1][magnitude_idx1],
# operation2, ranges[operation2][magnitude_idx2])
self.p1 = p1
self.operation1 = func[operation1]
self.magnitude1 = ranges[operation1][magnitude_idx1]
self.p2 = p2
self.operation2 = func[operation2]
self.magnitude2 = ranges[operation2][magnitude_idx2]
def __call__(self, img):
if random.random() < self.p1: img = self.operation1(img, self.magnitude1)
if random.random() < self.p2: img = self.operation2(img, self.magnitude2)
return img
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/cutout.py
================================================
import torch
import numpy as np
class Cutout(object):
"""Randomly mask out one or more patches from an image.
Args:
n_holes (int): Number of patches to cut out of each image.
length (int): The length (in pixels) of each square patch.
"""
def __init__(self, n_holes, length):
self.n_holes = n_holes
self.length = length
def __call__(self, img):
"""
Args:
img (Tensor): Tensor image of size (C, H, W).
Returns:
Tensor: Image with n_holes of dimension length x length cut out of it.
"""
h = img.size(1)
w = img.size(2)
mask = np.ones((h, w), np.float32)
for n in range(self.n_holes):
y = np.random.randint(h)
x = np.random.randint(w)
y1 = np.clip(y - self.length // 2, 0, h)
y2 = np.clip(y + self.length // 2, 0, h)
x1 = np.clip(x - self.length // 2, 0, w)
x2 = np.clip(x + self.length // 2, 0, w)
mask[y1: y2, x1: x2] = 0.
mask = torch.from_numpy(mask)
mask = mask.expand_as(img)
img = img * mask
return img
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/data_utils.py
================================================
import numpy as np
def construct_balanced_subset(x, y):
xdata, ydata = [], []
minsize = np.inf
for cls_ in np.unique(y):
xdata.append(x[y == cls_])
ydata.append(y[y == cls_])
if ydata[-1].shape[0] < minsize:
minsize = ydata[-1].shape[0]
for i in range(len(xdata)):
# if xdata[i].shape[0] < minsize:
# import pdb
# pdb.set_trace()
idx = np.arange(xdata[i].shape[0])
np.random.shuffle(idx)
xdata[i] = xdata[i][idx][:minsize]
ydata[i] = ydata[i][idx][:minsize]
# !list
return np.concatenate(xdata, 0), np.concatenate(ydata, 0)
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/factory.py
================================================
from matplotlib.transforms import Transform
import torch
from torch import nn
from torch import optim
from inclearn import models
from inclearn.convnet import sew_resnet
from inclearn.datasets import data
from inclearn.convnet.resnet import SEFeatureAt
def get_optimizer(params, optimizer, lr, weight_decay=0.0):
if optimizer == "adam":
return optim.Adam(params, lr=lr, weight_decay=weight_decay, betas=(0.9, 0.999))
elif optimizer == "sgd":
return optim.SGD(params, lr=lr, weight_decay=weight_decay, momentum=0.9)
else:
raise NotImplementedError
def get_attention(inplane, type, at_res):
return SEFeatureAt(inplane, type, at_res)
def get_convnet(convnet_type, c_dim=None,cdim_cur=None,**kwargs):
if convnet_type == "resnet18":
return sew_resnet.sew_resnet18(c_dim,cdim_cur,**kwargs)
else:
raise NotImplementedError("Unknwon convnet type {}.".format(convnet_type))
def get_model(cfg, trial_i, _run, ex, tensorboard, inc_dataset):
if cfg["model"] == "incmodel":
return models.IncModel(cfg, trial_i, _run, ex, tensorboard, inc_dataset)
else:
raise NotImplementedError(cfg["model"])
def get_data(cfg, trial_i):
return data.IncrementalDataset(
trial_i=trial_i,
dataset_name=cfg["dataset"],
random_order=cfg["random_classes"],
shuffle=True,
batch_size=cfg["batch_size"],
workers=cfg["workers"],
validation_split=cfg["validation"],
resampling=cfg["resampling"],
increment=cfg["increment"],
data_folder=cfg["data_folder"],
start_class=cfg["start_class"],
torc=cfg.get("distillation")
)
def set_device(cfg):
device_type = cfg["device"]
if device_type == -1:
device = torch.device("cpu")
else:
device = torch.device("cuda:{}".format(device_type))
cfg["device"] = device
return device
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/memory.py
================================================
import numpy as np
from copy import deepcopy
import torch
from torch.nn import functional as F
from inclearn.tools.utils import get_class_loss
from inclearn.convnet.utils import extract_features
class MemorySize:
def __init__(self, mode, inc_dataset, total_memory=None, fixed_memory_per_cls=None):
self.mode = mode
assert mode.lower() in ["uniform_fixed_per_cls", "uniform_fixed_total_mem", "dynamic_fixed_per_cls"]
self.total_memory = total_memory
self.fixed_memory_per_cls = fixed_memory_per_cls
self._n_classes = 0
self.mem_per_cls = []
self._inc_dataset = inc_dataset
def update_n_classes(self, n_classes):
self._n_classes = n_classes
def update_memory_per_cls_uniform(self, n_classes):
if "fixed_per_cls" in self.mode:
self.mem_per_cls = [self.fixed_memory_per_cls for i in range(n_classes)]
elif "fixed_total_mem" in self.mode:
self.mem_per_cls = [self.total_memory // n_classes for i in range(n_classes)]
return self.mem_per_cls
def update_memory_per_cls(self, network, n_classes, task_size):
if "uniform" in self.mode:
self.update_memory_per_cls_uniform(n_classes)
else:
if n_classes == task_size:
self.update_memory_per_cls_uniform(n_classes)
@property
def memsize(self):
if self.mode == "fixed_total_mem":
return self.total_memory
elif self.mode == "fixed_per_cls":
return self.fixed_memory_per_cls * self._n_classes
def compute_examplar_mean(feat_norm, feat_flip, herding_mat, nb_max):
EPSILON = 1e-8
D = feat_norm.T
D = D / (np.linalg.norm(D, axis=0) + EPSILON)
D2 = feat_flip.T
D2 = D2 / (np.linalg.norm(D2, axis=0) + EPSILON)
alph = herding_mat
alph = (alph > 0) * (alph < nb_max + 1) * 1.0
alph_mean = alph / np.sum(alph)
mean = (np.dot(D, alph_mean) + np.dot(D2, alph_mean)) / 2
# mean = np.dot(D, alph_mean)
mean /= np.linalg.norm(mean) + EPSILON
return mean, alph
def select_examplars(features, nb_max):
EPSILON = 1e-8
D = features.T
D = D / (np.linalg.norm(D, axis=0) + EPSILON)
mu = np.mean(D, axis=1)
herding_matrix = np.zeros((features.shape[0], ))
idxes = []
w_t = mu
iter_herding, iter_herding_eff = 0, 0
while not (np.sum(herding_matrix != 0) == min(nb_max, features.shape[0])) and iter_herding_eff < 1000:
tmp_t = np.dot(w_t, D)
# tmp_t = -np.linalg.norm(w_t[:,np.newaxis]-D, axis=0)
# tmp_t = np.linalg.norm(w_t[:,np.newaxis]-D, axis=0)
ind_max = np.argmax(tmp_t)
iter_herding_eff += 1
if herding_matrix[ind_max] == 0:
herding_matrix[ind_max] = 1 + iter_herding
idxes.append(ind_max)
iter_herding += 1
w_t = w_t + mu - D[:, ind_max]
return herding_matrix, idxes
def random_selection(n_classes, task_size, network, logger, inc_dataset, memory_per_class: list):
# TODO: Move data_memroy,targets_memory into IncDataset
logger.info("Building & updating memory.(Random Selection)")
tmp_data_memory, tmp_targets_memory = [], []
assert len(memory_per_class) == n_classes
for class_idx in range(n_classes):
# 旧类数据从get_custom_loader_from_memory中读取,新类数据从get_custom_loader中读取
if class_idx < n_classes - task_size:
inputs, targets, loader = inc_dataset.get_custom_loader_from_memory([class_idx])
else:
inputs, targets, loader = inc_dataset.get_custom_loader(class_idx, mode="test")
memory_this_cls = min(memory_per_class[class_idx], inputs.shape[0])
idxs = np.random.choice(inputs.shape[0], memory_this_cls, replace=False)
tmp_data_memory.append(inputs[idxs])
tmp_targets_memory.append(targets[idxs])
tmp_data_memory = np.concatenate(tmp_data_memory)
tmp_targets_memory = np.concatenate(tmp_targets_memory)
return tmp_data_memory, tmp_targets_memory
def herding(task_i,n_classes, task_size, network, herding_matrix, inc_dataset, shared_data_inc, memory_per_class: list,
logger,mask=None):
"""Herding matrix: list
"""
logger.info("Building & updating memory.(iCaRL)")
tmp_data_memory, tmp_targets_memory = [], []
for class_idx in range(n_classes):
inputs = inc_dataset.data_train[inc_dataset.targets_train == class_idx]
targets = inc_dataset.targets_train[inc_dataset.targets_train == class_idx]
# zi = inc_dataset.zimages[inc_dataset.zlabels == class_idx]
# zt = inc_dataset.zlabels[inc_dataset.zlabels == class_idx]
# inputs = np.concatenate((inputs, zi))
# targets = np.concatenate((targets, zt))
if class_idx >= n_classes - task_size:
if len(shared_data_inc) > len(inc_dataset.targets_inc):
share_memory = [shared_data_inc[i] for i in np.where(inc_dataset.targets_inc == class_idx)[0].tolist()]
else:
share_memory = []
for i in np.where(inc_dataset.targets_inc == class_idx)[0].tolist():
if i < len(shared_data_inc):
share_memory.append(shared_data_inc[i])
# share_memory = [shared_data_inc[i] for i in np.where(inc_dataset.targets_inc == class_idx)[0].tolist()]
loader = inc_dataset._get_loader(inc_dataset.data_inc[inc_dataset.targets_inc == class_idx],
inc_dataset.targets_inc[inc_dataset.targets_inc == class_idx],
share_memory=share_memory,
batch_size=128,
shuffle=False,
mode="test")
features, _ = extract_features(task_i,network, loader,mask=mask)
# features_flipped, _ = extract_features(network, inc_dataset.get_custom_loader(class_idx, mode="flip")[-1])
herding_matrix.append(select_examplars(features, memory_per_class[class_idx])[0])
alph = herding_matrix[class_idx]
alph = (alph > 0) * (alph < memory_per_class[class_idx] + 1) * 1.0
# examplar_mean, alph = compute_examplar_mean(features, features_flipped, herding_matrix[class_idx],
# memory_per_class[class_idx])
tmp_data_memory.append(inputs[np.where(alph == 1)[0]])
tmp_targets_memory.append(targets[np.where(alph == 1)[0]])
tmp_data_memory = np.concatenate(tmp_data_memory)
tmp_targets_memory = np.concatenate(tmp_targets_memory)
return tmp_data_memory, tmp_targets_memory, herding_matrix
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/metrics.py
================================================
import numpy as np
import torch
import numbers
import math
class IncConfusionMeter:
"""Maintains a confusion matrix for a given calssification problem.
The ConfusionMeter constructs a confusion matrix for a multi-class
classification problems. It does not support multi-label, multi-class problems:
for such problems, please use MultiLabelConfusionMeter.
Args:
k (int): number of classes in the classification problem
normalized (boolean): Determines whether or not the confusion matrix
is normalized or not
"""
def __init__(self, k, increments, normalized=False):
self.conf = np.ndarray((k, k), dtype=np.int32)
self.normalized = normalized
self.increments = increments
self.cum_increments = [0] + [sum(increments[:i + 1]) for i in range(len(increments))]
self.k = k
self.reset()
def reset(self):
self.conf.fill(0)
def add(self, predicted, target):
"""Computes the confusion matrix of K x K size where K is no of classes
Args:
predicted (tensor): Can be an N x K tensor of predicted scores obtained from
the model for N examples and K classes or an N-tensor of
integer values between 0 and K-1.
target (tensor): Can be a N-tensor of integer values assumed to be integer
values between 0 and K-1 or N x K tensor, where targets are
assumed to be provided as one-hot vectors
"""
if isinstance(predicted, torch.Tensor):
predicted = predicted.cpu().numpy()
if isinstance(target, torch.Tensor):
target = target.cpu().numpy()
assert predicted.shape[0] == target.shape[0], \
'number of targets and predicted outputs do not match'
if np.ndim(predicted) != 1:
assert predicted.shape[1] == self.k, \
'number of predictions does not match size of confusion matrix'
predicted = np.argmax(predicted, 1)
else:
assert (predicted.max() < self.k) and (predicted.min() >= 0), \
'predicted values are not between 1 and k'
onehot_target = np.ndim(target) != 1
if onehot_target:
assert target.shape[1] == self.k, \
'Onehot target does not match size of confusion matrix'
assert (target >= 0).all() and (target <= 1).all(), \
'in one-hot encoding, target values should be 0 or 1'
assert (target.sum(1) == 1).all(), \
'multi-label setting is not supported'
target = np.argmax(target, 1)
else:
assert (predicted.max() < self.k) and (predicted.min() >= 0), \
'predicted values are not between 0 and k-1'
# hack for bincounting 2 arrays together
x = predicted + self.k * target
bincount_2d = np.bincount(x.astype(np.int32), minlength=self.k**2)
assert bincount_2d.size == self.k**2
conf = bincount_2d.reshape((self.k, self.k))
self.conf += conf
def value(self):
"""
Returns:
Confustion matrix of K rows and K columns, where rows corresponds
to ground-truth targets and columns corresponds to predicted
targets.
"""
conf = self.conf.astype(np.float32)
new_conf = np.zeros([len(self.increments), len(self.increments) + 2])
for i in range(len(self.increments)):
idxs = range(self.cum_increments[i], self.cum_increments[i + 1])
new_conf[i, 0] = conf[idxs, idxs].sum()
new_conf[i, 1] = conf[self.cum_increments[i]:self.cum_increments[i + 1],
self.cum_increments[i]:self.cum_increments[i + 1]].sum() - new_conf[i, 0]
for j in range(len(self.increments)):
new_conf[i, j + 2] = conf[self.cum_increments[i]:self.cum_increments[i + 1],
self.cum_increments[j]:self.cum_increments[j + 1]].sum()
conf = new_conf
if self.normalized:
return conf / conf[:, 2:].sum(1).clip(min=1e-12)[:, None]
else:
return conf
class ClassErrorMeter:
def __init__(self, topk=[1], accuracy=False):
super(ClassErrorMeter, self).__init__()
self.topk = np.sort(topk)
self.accuracy = accuracy
self.reset()
def reset(self):
self.sum = {v: 0 for v in self.topk}
self.n = 0
def add(self, output, target):
if isinstance(output, np.ndarray):
output = torch.Tensor(output)
if isinstance(target, np.ndarray):
target = torch.Tensor(target)
# if torch.is_tensor(output):
# output = output.cpu().squeeze().numpy()
# if torch.is_tensor(target):
# target = target.cpu().squeeze().numpy()
# elif isinstance(target, numbers.Number):
# target = np.asarray([target])
# if np.ndim(output) == 1:
# output = output[np.newaxis]
# else:
# assert np.ndim(output) == 2, \
# 'wrong output size (1D or 2D expected)'
# assert np.ndim(target) == 1, \
# 'target and output do not match'
# assert target.shape[0] == output.shape[0], \
# 'target and output do not match'
topk = self.topk
maxk = int(topk[-1]) # seems like Python3 wants int and not np.int64
no = output.shape[0]
pred = output.topk(maxk, 1, True, True)[1]
correct = pred == target.unsqueeze(1).repeat(1, pred.shape[1])
# pred = torch.from_numpy(output).topk(maxk, 1, True, True)[1].numpy()
# correct = pred == target[:, np.newaxis].repeat(pred.shape[1], 1)
for k in topk:
self.sum[k] += no - correct[:, 0:k].sum()
self.n += no
def value(self, k=-1):
if k != -1:
assert k in self.sum.keys(), \
'invalid k (this k was not provided at construction time)'
if self.n == 0:
return float('nan')
if self.accuracy:
return (1. - float(self.sum[k]) / self.n) * 100.0
else:
return float(self.sum[k]) / self.n * 100.0
else:
return [self.value(k_) for k_ in self.topk]
class AverageValueMeter:
def __init__(self):
super(AverageValueMeter, self).__init__()
self.reset()
self.val = 0
def add(self, value, n=1):
self.val = value
self.sum += value
self.var += value * value
self.n += n
if self.n == 0:
self.mean, self.std = np.nan, np.nan
elif self.n == 1:
self.mean, self.std = self.sum, np.inf
self.mean_old = self.mean
self.m_s = 0.0
else:
self.mean = self.mean_old + (value - n * self.mean_old) / float(self.n)
self.m_s += (value - self.mean_old) * (value - self.mean)
self.mean_old = self.mean
self.std = math.sqrt(self.m_s / (self.n - 1.0))
def value(self):
return self.mean, self.std
def reset(self):
self.n = 0
self.sum = 0.0
self.var = 0.0
self.val = 0.0
self.mean = np.nan
self.mean_old = 0.0
self.m_s = 0.0
self.std = np.nan
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/results_utils.py
================================================
import glob
import json
import math
import os
import numpy as np
import matplotlib.pyplot as plt
from copy import deepcopy
from . import utils
def get_template_results(cfg):
return {"config": cfg, "results": []}
def save_results(results, label):
del results["config"]["device"]
folder_path = os.path.join("results", "{}_{}".format(utils.get_date(), label))
if not os.path.exists(folder_path):
os.makedirs(folder_path)
file_path = "{}_{}_.json".format(utils.get_date(), results["config"]["seed"])
with open(os.path.join(folder_path, file_path), "w+") as f:
json.dump(results, f, indent=2)
def compute_avg_inc_acc(results):
"""Computes the average incremental accuracy as defined in iCaRL.
The average incremental accuracies at task X are the average of accuracies
at task 0, 1, ..., and X.
:param accs: A list of dict for per-class accuracy at each step.
:return: A float.
"""
top1_tasks_accuracy = [r['top1']["total"] for r in results]
top1acc = sum(top1_tasks_accuracy) / len(top1_tasks_accuracy)
if "top5" in results[0].keys():
top5_tasks_accuracy = [r['top5']["total"] for r in results]
top5acc = sum(top5_tasks_accuracy) / len(top5_tasks_accuracy)
else:
top5acc = None
return top1acc, top5acc
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/scheduler.py
================================================
import math
from torch.optim.lr_scheduler import _LRScheduler
from torch.optim.lr_scheduler import ReduceLROnPlateau
class ConstantTaskLR:
def __init__(self, lr):
self._lr = lr
def get_lr(self, task_i):
return self._lr
class CosineAnnealTaskLR:
def __init__(self, lr_max, lr_min, task_max):
self._lr_max = lr_max
self._lr_min = lr_min
self._task_max = task_max
def get_lr(self, task_i):
return self._lr_min + (self._lr_max - self._lr_min) * (1 + math.cos(math.pi * task_i / self._task_max)) / 2
class GradualWarmupScheduler(_LRScheduler):
""" Gradually warm-up(increasing) learning rate in optimizer.
https://github.com/ildoonet/pytorch-gradual-warmup-lr
Proposed in 'Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour'.
Args:
optimizer (Optimizer): Wrapped optimizer.
multiplier: target learning rate = base lr * multiplier if multiplier > 1.0. if multiplier = 1.0, lr starts from 0 and ends up with the base_lr.
total_epoch: target learning rate is reached at total_epoch, gradually
after_scheduler: after target_epoch, use this scheduler(eg. ReduceLROnPlateau)
"""
def __init__(self, optimizer, multiplier, total_epoch, after_scheduler=None):
self.multiplier = multiplier
if self.multiplier < 1.:
raise ValueError('multiplier should be greater thant or equal to 1.')
self.total_epoch = total_epoch
self.after_scheduler = after_scheduler
self.finished = False
super(GradualWarmupScheduler, self).__init__(optimizer)
def get_lr(self):
if self.last_epoch > self.total_epoch:
if self.after_scheduler:
if not self.finished:
self.after_scheduler.base_lrs = [base_lr * self.multiplier for base_lr in self.base_lrs]
self.finished = True
return self.after_scheduler.get_last_lr()
return [base_lr * self.multiplier for base_lr in self.base_lrs]
if self.multiplier == 1.0:
return [base_lr * (float(self.last_epoch) / self.total_epoch) for base_lr in self.base_lrs]
else:
return [
base_lr * ((self.multiplier - 1.) * self.last_epoch / self.total_epoch + 1.)
for base_lr in self.base_lrs
]
def step_ReduceLROnPlateau(self, metrics, epoch=None):
if epoch is None:
epoch = self.last_epoch + 1
self.last_epoch = epoch if epoch != 0 else 1 # ReduceLROnPlateau is called at the end of epoch, whereas others are called at beginning
if self.last_epoch <= self.total_epoch:
warmup_lr = [
base_lr * ((self.multiplier - 1.) * self.last_epoch / self.total_epoch + 1.)
for base_lr in self.base_lrs
]
for param_group, lr in zip(self.optimizer.param_groups, warmup_lr):
param_group['lr'] = lr
else:
if epoch is None:
self.after_scheduler.step(metrics, None)
else:
self.after_scheduler.step(metrics, epoch - self.total_epoch)
def step(self, epoch=None, metrics=None):
if type(self.after_scheduler) != ReduceLROnPlateau:
if self.finished and self.after_scheduler:
if epoch is None:
self.after_scheduler.step(None)
else:
self.after_scheduler.step(epoch - self.total_epoch)
self._last_lr = self.after_scheduler.get_last_lr()
else:
return super(GradualWarmupScheduler, self).step(epoch)
else:
self.step_ReduceLROnPlateau(metrics, epoch)
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/similar.py
================================================
import torch.nn as nn
import torchvision.models as models
import numpy as np
import os
from sklearn.utils import shuffle
import torch
import torch.nn.functional as F
class Appr(object):
""" Class implementing the TALL """
def __init__(self, pretrained_feat_extractor, num_task, torc,device='cuda', args=None):
self.task2expert = []
self.expert2task = []
self.torc=torc
self.num_task=num_task
self.task2mean = {}
self.task2cov = {}
for i in range(num_task):
self.task2mean[i]=[]
self.task2cov[i]=[]
self.task_dist = torch.zeros(num_task, num_task).to(device='cuda')
self.task_dist2 = torch.zeros(num_task, num_task).to(device='cuda')
self.feat_extractor = pretrained_feat_extractor
self.task_relatedness_method = "mean"
self.reuse_threshold=0.3
self.reuse_cell_threshold=0.75
def get_mean_cov_feats(self, taski, data, device):
"""compute mean and cov for features of data extracted by the expert of task t
"""
# data = deepcopy(data) # copy for using different preprocess
# self.model.requires_grad_(False)
# self.model.eval()
# self.model.set_current_task(t)
if self.torc:
steps=int(100/self.num_task)
class_num = steps*taski
labels = torch.arange(class_num,class_num+steps).view(-1, 1).to(device)
else:
steps = int(100/self.num_task)
labels = torch.arange(steps).view(-1, 1).to(device)
all_task_feats={}
for t in range(taski):
all_task_feats[t]=[[] for _ in range(steps)]
self.feat_extractor.eval()
with torch.no_grad():
for batch_idx, (x, y) in enumerate(data):
x, y = x.to(device), y.to(device)
index = labels == y.view(1, -1) # CxC
for t_p in range(taski):
feat = self.feat_extractor(t_p,x,mask=None,classify=False)['features']
feat = feat.view(feat.size(0), -1)
for i in range(steps):
all_task_feats[t_p][i].append(feat[index[i]])
feat_means = {}
feat_covs = {}
all_feats_cat={}
for t_p in range(taski):
feat_means[t_p] = []
feat_covs [t_p]= []
all_feats_cat[t_p] = [torch.cat(feats, axis=0) for feats in all_task_feats[t_p]]
for feat in all_feats_cat[t_p]:
feat_mean, feat_cov = gaussian_mean_cov(feat)
feat_means[t_p].append(feat_mean)
# feat_covs[t_p].append(feat_cov)
# feat_means = [torch.mean(feat, dim=0) for feat in all_feats_cat]
return feat_means, feat_covs, all_feats_cat
def after_get_mean_cov_feats(self, taski, data, device):
"""compute mean and cov for features of data extracted by the expert of task t
"""
# data = deepcopy(data) # copy for using different preprocess
# self.model.requires_grad_(False)
# self.model.eval()
# self.model.set_current_task(t)
if self.torc:
steps=int(100/self.num_task)
class_num = steps*taski
labels = torch.arange(class_num,class_num+steps).view(-1, 1).to(device)
else:
steps = int(100/self.num_task)
labels = torch.arange(steps).view(-1, 1).to(device)
all_task_feats=[[] for _ in range(steps)]
self.feat_extractor.eval()
with torch.no_grad():
for batch_idx, (x, y) in enumerate(data):
x, y = x.to(device), y.to(device)
# forward
feat = self.feat_extractor(taski,x,mask=None,classify=False)['features']
feat = feat.view(feat.size(0), -1)
index = labels == y.view(1, -1) # CxC
for i in range(steps):
all_task_feats[i].append(feat[index[i]])
feat_means= []
feat_covs = []
all_feats_cat= [torch.cat(feats, axis=0) for feats in all_task_feats]
for feat in all_feats_cat:
feat_mean, feat_cov = gaussian_mean_cov(feat)
feat_means.append(feat_mean)
# feat_covs.append(feat_cov)
# feat_means = [torch.mean(feat, dim=0) for feat in all_feats_cat]
return feat_means, feat_covs, all_feats_cat
def add_mean_cov(self, taski,mean, cov=None):
self.task2mean[taski].append(mean)
# self.task2cov[taski].append(cov)
def task_relatedness_knnkl(self, task_id, p_task_id, all_feats):
"""
Params:
all_feat: shape C x N_c x D
"""
# means and features of current data from expert of p_task_id
# feat_means, all_feats = means_and_feats[p_task_id]
# means of data of p_task_id
p_feat_means = self.task2mean[p_task_id][p_task_id] # C x D
feat_means = self.task2mean[task_id][p_task_id] # C x D
# p_feat_cov = self.task2cov[p_task_id][p_task_id] # C x D
# feat_cov = self.task2cov[task_id][p_task_id] # C x D
p_feat_means = torch.stack(p_feat_means, dim=0)
task_dist = 0
task_dist2=0
d = p_feat_means.shape[-1]
n = 0
flag = False
for i in range(len(feat_means)):
# for each current class
n += all_feats[i].shape[0]
dist_in = all_feats[i] - feat_means[i] # N_c x D
dist_in = torch.sqrt(torch.sum(dist_in ** 2, dim=-1)) # N_c
# N_c x C x D
dist_out = torch.unsqueeze(all_feats[i], dim=1) - torch.unsqueeze(p_feat_means, dim=0)
dist_out, _ = torch.min(torch.sqrt(torch.sum(dist_out ** 2, dim=-1)), dim=-1) # N_c
dist = torch.mean(torch.log(dist_out / (0.9*dist_in)))
#dist = torch.mean(torch.log(dist_out))
# if dist <= 0:
# flag = True
task_dist += torch.maximum(dist, torch.zeros_like(dist))
task_dist2 += torch.maximum(dist, torch.zeros_like(dist))
# task_dist = task_dist / len(feat_means)
# task_dist = 1 - torch.exp(-2*task_dist)
task_dist = torch.minimum(1 - torch.exp(-2*task_dist), task_dist)
if task_dist == 0:
task_dist = torch.ones_like(task_dist)
return task_dist,task_dist2
def get_relatedness(self, task_id, feats):
"""Compute relatedness
"""
# the distance between task_id and task_id
self.task_dist[task_id][task_id] = 0
self.task_dist2[task_id][task_id] = 0
for p_task_id in range(task_id):
# for p_task_id in range(task_id + 1):
# task_dist = self.task_relatedness_cos(task_id, p_task_id)
task_dist,task_dist2 = self.task_relatedness_knnkl(task_id, p_task_id, feats[p_task_id])
# task_dist = self.task_relatedness_CKA(task_id, p_task_id, feats)
# task_dist = self.task_relatedness_gaussian_kl(task_id, p_task_id)
self.task_dist[task_id][p_task_id] = task_dist
self.task_dist[p_task_id][task_id] = task_dist
self.task_dist2[task_id][p_task_id] = task_dist2
self.task_dist2[p_task_id][task_id] = task_dist2
def strategy(self, task_id, num_train_samples):
""" Find the expert to be reused. If not found, return -1.
"""
expert = -1
min_dist = None
all_dist = []
all_dist2 = []
for expert_id, p_tasks in enumerate(self.expert2task):
d = self.task_dist[task_id, p_tasks]
dd= self.task_dist2[task_id, p_tasks]
if self.task_relatedness_method == "mean":
s = torch.mean(d).item()
ss = torch.mean(dd).item()
elif self.task_relatedness_method == "max":
s = torch.max(d).item()
elif self.task_relatedness_method == "min":
s = torch.min(d).item()
else:
raise Exception("Unknown reuse strategy !!!")
all_dist.append(s)
all_dist2.append(ss)
if min_dist is None:
min_dist = s
expert = expert_id
elif s < min_dist:
min_dist = s
expert = expert_id
# if num_train_samples <= 25: # for s_long
# all_dist = torch.tensor(all_dist)
# _, expert_idx =torch.sort(all_dist)
# for e in expert_idx:
# if self.model.expert2max_train_samples[e] >= 10 * num_train_samples:
# return "reuse", e
if min_dist <= self.reuse_threshold:
return "reuse", expert ,min_dist,all_dist,all_dist2
# elif min_dist <= self.reuse_cell_threshold:
# return "reuse cell", expert
else:
return "new", expert,min_dist,all_dist,all_dist2
def learn(self, task_id, valid_data, batch_size,device):
"""learn a task
"""
if task_id == 0:
# train
strategy='new'
expert_id=task_id
min_dist=0
all_dist=0
all_dist2=0
else:
feat_means, feat_covs, all_feats = self.get_mean_cov_feats(
task_id, valid_data, device=device)
for t in range(task_id):
self.add_mean_cov(task_id,feat_means[t],feat_covs[t])
self.get_relatedness(task_id, all_feats)
num_train_samples=len(valid_data)*batch_size
strategy, expert_id,min_dist,all_dist,all_dist2 = self.strategy(task_id, num_train_samples)
self.expert2task.append([task_id])
print(self.task_dist)
print(self.task_dist2)
return strategy, expert_id,min_dist,all_dist,all_dist2
def after_learn(self, task_id, valid_data, batch_size,device):
"""learn a task
"""
feat_means, feat_covs, all_feats = self.after_get_mean_cov_feats(
task_id, valid_data, device=device)
self.add_mean_cov(task_id,feat_means,feat_covs)
print(self.task_dist)
print(self.task_dist2)
class ResNet_FE(nn.Module):
"""
Create a feature extractor model from an Alexnet architecture, that is used to train the autoencoder model
and get the most related model whilst training a new task in a sequence
"""
def __init__(self, resnet_model):
super(ResNet_FE, self).__init__()
self.fe_model = nn.Sequential(*list(resnet_model.children())[:-1])
self.fe_model.eval()
self.fe_model.requires_grad_(False)
def forward(self, x):
return self.fe_model(x)
def get_pretrained_feat_extractor(name):
"""get the feature extractor pretrained on ImageNet
"""
if name == "resnet18":
feat_extractor = ResNet_FE(models.resnet18(weights=True))
# self.logger.info("Using relatedness feature extractor: ResNet18")
else:
raise Exception("Unknown relatedness feature extractor !!!")
return feat_extractor
def gaussian_mean_cov(X):
"""mean and covariance of Guassian distribution
Params:
X: N x D
"""
device = X.device
N, D = X.shape[0], X.shape[1]
u = torch.mean(X, dim=0)
u_row = torch.reshape(u, (1, -1)) # 1 x D
cov = torch.matmul(X.T, X) - N * torch.matmul(u_row.T, u_row) # D x D
cov = cov / (N - 1)
cov = cov * torch.diag(torch.ones(D)).to(X.device) + (torch.diag(torch.ones(D))).to(X.device)
return u, cov
# import torch.nn as nn
# import torchvision.models as models
# import numpy as np
# import os
# from sklearn.utils import shuffle
# import torch
# import torch.nn.functional as F
# class Appr(object):
# """ Class implementing the TALL """
# def __init__(self, pretrained_feat_extractor, num_task, device='cuda', args=None):
# self.task2expert = []
# self.expert2task = []
# self.task2mean = []
# self.task2cov = []
# self.task_dist = torch.zeros(num_task, num_task).to(device='cuda')
# self.feat_extractor = get_pretrained_feat_extractor(pretrained_feat_extractor).to(device='cuda')
# self.task_relatedness_method = "mean"
# self.reuse_threshold=0.3
# self.reuse_cell_threshold=0.75
# def get_mean_cov_feats(self, t, data, device):
# """compute mean and cov for features of data extracted by the expert of task t
# """
# # data = deepcopy(data) # copy for using different preprocess
# # self.model.requires_grad_(False)
# # self.model.eval()
# # self.model.set_current_task(t)
# class_num = 10
# labels = torch.arange(class_num).view(-1, 1).to(device)
# all_feats = [[] for _ in range(class_num)]
# self.feat_extractor.eval()
# with torch.no_grad():
# for batch_idx, (x, y) in enumerate(data):
# x, y = x.to(device), y.to(device)
# # forward
# feat = self.feat_extractor(x)
# feat = feat.view(feat.size(0), -1)
# index = labels == y.view(1, -1) # CxC
# for i in range(class_num):
# all_feats[i].append(feat[index[i]])
# all_feats_cat = [torch.cat(feats, axis=0) for feats in all_feats]
# feat_means = []
# feat_covs = []
# for feat in all_feats_cat:
# feat_mean, feat_cov = gaussian_mean_cov(feat)
# feat_means.append(feat_mean)
# feat_covs.append(feat_cov)
# # feat_means = [torch.mean(feat, dim=0) for feat in all_feats_cat]
# return feat_means, feat_covs, all_feats_cat
# def add_mean_cov(self, mean, cov=None):
# self.task2mean.append(mean)
# self.task2cov.append(cov)
# def task_relatedness_knnkl(self, task_id, p_task_id, all_feats):
# """
# Params:
# all_feat: shape C x N_c x D
# """
# # means and features of current data from expert of p_task_id
# # feat_means, all_feats = means_and_feats[p_task_id]
# # means of data of p_task_id
# p_feat_means = self.task2mean[p_task_id] # C x D
# feat_means = self.task2mean[task_id] # C x D
# p_feat_means = torch.stack(p_feat_means, dim=0)
# task_dist = 0
# d = p_feat_means.shape[-1]
# n = 0
# flag = False
# for i in range(len(feat_means)):
# # for each current class
# n += all_feats[i].shape[0]
# dist_in = all_feats[i] - feat_means[i] # N_c x D
# dist_in = torch.sqrt(torch.sum(dist_in ** 2, dim=-1)) # N_c
# # N_c x C x D
# dist_out = torch.unsqueeze(all_feats[i], dim=1) - torch.unsqueeze(p_feat_means, dim=0)
# dist_out, _ = torch.min(torch.sqrt(torch.sum(dist_out ** 2, dim=-1)), dim=-1) # N_c
# dist = torch.mean(torch.log(dist_out / dist_in))
# # if dist <= 0:
# # flag = True
# task_dist += torch.maximum(dist, torch.zeros_like(dist))
# # task_dist = task_dist / len(feat_means)
# # task_dist = 1 - torch.exp(-2*task_dist)
# task_dist = torch.minimum(1 - torch.exp(-2*task_dist), task_dist)
# if task_dist == 0:
# task_dist = torch.ones_like(task_dist)
# return task_dist
# def get_relatedness(self, task_id, feats):
# """Compute relatedness
# """
# # the distance between task_id and task_id
# self.task_dist[task_id][task_id] = 0
# for p_task_id in range(task_id):
# # for p_task_id in range(task_id + 1):
# # task_dist = self.task_relatedness_cos(task_id, p_task_id)
# task_dist = self.task_relatedness_knnkl(task_id, p_task_id, feats)
# # task_dist = self.task_relatedness_CKA(task_id, p_task_id, feats)
# # task_dist = self.task_relatedness_gaussian_kl(task_id, p_task_id)
# self.task_dist[task_id][p_task_id] = task_dist
# self.task_dist[p_task_id][task_id] = task_dist
# def strategy(self, task_id, num_train_samples):
# """ Find the expert to be reused. If not found, return -1.
# """
# expert = -1
# min_dist = None
# all_dist = []
# for expert_id, p_tasks in enumerate(self.expert2task):
# d = self.task_dist[task_id, p_tasks]
# if self.task_relatedness_method == "mean":
# s = torch.mean(d).item()
# elif self.task_relatedness_method == "max":
# s = torch.max(d).item()
# elif self.task_relatedness_method == "min":
# s = torch.min(d).item()
# else:
# raise Exception("Unknown reuse strategy !!!")
# all_dist.append(s)
# if min_dist is None:
# min_dist = s
# expert = expert_id
# elif s < min_dist:
# min_dist = s
# expert = expert_id
# # if num_train_samples <= 25: # for s_long
# # all_dist = torch.tensor(all_dist)
# # _, expert_idx =torch.sort(all_dist)
# # for e in expert_idx:
# # if self.model.expert2max_train_samples[e] >= 10 * num_train_samples:
# # return "reuse", e
# if min_dist <= self.reuse_threshold:
# return "reuse", expert ,min_dist,all_dist
# # elif min_dist <= self.reuse_cell_threshold:
# # return "reuse cell", expert
# else:
# return "new", expert,min_dist,all_dist
# def learn(self, task_id, valid_data, batch_size,device):
# """learn a task
# """
# feat_means, feat_covs, all_feats = self.get_mean_cov_feats(
# task_id, valid_data, device=device)
# self.add_mean_cov(feat_means)
# self.get_relatedness(task_id, all_feats)
# if task_id == 0:
# # train
# strategy='new'
# expert_id=task_id
# min_dist=0
# all_dist=0
# else:
# num_train_samples=len(valid_data)*batch_size
# strategy, expert_id,min_dist,all_dist = self.strategy(task_id, num_train_samples)
# self.expert2task.append([task_id])
# return strategy, expert_id,min_dist,all_dist
# class ResNet_FE(nn.Module):
# """
# Create a feature extractor model from an Alexnet architecture, that is used to train the autoencoder model
# and get the most related model whilst training a new task in a sequence
# """
# def __init__(self, resnet_model):
# super(ResNet_FE, self).__init__()
# self.fe_model = nn.Sequential(*list(resnet_model.children())[:-1])
# self.fe_model.eval()
# self.fe_model.requires_grad_(False)
# def forward(self, x):
# return self.fe_model(x)
# def get_pretrained_feat_extractor(name):
# """get the feature extractor pretrained on ImageNet
# """
# if name == "resnet18":
# feat_extractor = ResNet_FE(models.resnet18(weights=True))
# # self.logger.info("Using relatedness feature extractor: ResNet18")
# else:
# raise Exception("Unknown relatedness feature extractor !!!")
# return feat_extractor
# def gaussian_mean_cov(X):
# """mean and covariance of Guassian distribution
# Params:
# X: N x D
# """
# device = X.device
# N, D = X.shape[0], X.shape[1]
# u = torch.mean(X, dim=0)
# u_row = torch.reshape(u, (1, -1)) # 1 x D
# cov = torch.matmul(X.T, X) - N * torch.matmul(u_row.T, u_row) # D x D
# cov = cov / (N - 1)
# cov = cov * torch.diag(torch.ones(D)).to(X.device) + (torch.diag(torch.ones(D))).to(X.device)
# return u, cov
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/utils.py
================================================
import random
from copy import deepcopy
import numpy as np
import datetime
import torch
from inclearn.tools.metrics import ClassErrorMeter
from sklearn.metrics import classification_report
def get_date():
return datetime.datetime.now().strftime("%Y%m%d")
def to_onehot(targets, n_classes):
if not hasattr(targets, "device"):
targets = torch.from_numpy(targets)
onehot = torch.zeros(targets.shape[0], n_classes).to(targets.device)
onehot.scatter_(dim=1, index=targets.long().view(-1, 1), value=1.0)
return onehot
def get_class_loss(network, cur_n_cls, loader):
class_loss = torch.zeros(cur_n_cls)
n_cls_data = torch.zeros(cur_n_cls) # the num of imgs for cls i.
EPS = 1e-10
task_size = 10
network.eval()
for x, y in loader:
x, y = x.cuda(), y.cuda()
preds = network(x)['logit'].softmax(dim=1)
# preds[:,-task_size:] = preds[:,-task_size:].softmax(dim=1)
for i, lbl in enumerate(y):
class_loss[lbl] = class_loss[lbl] - (preds[i, lbl] + EPS).detach().log().cpu()
n_cls_data[lbl] += 1
class_loss = class_loss / n_cls_data
return class_loss
def get_featnorm_grouped_by_class(task_i,network, cur_n_cls, loader,m=None):
"""
Ret: feat_norms: list of list
feat_norms[idx] is the list of feature norm of the images for class idx.
"""
feats = [[] for i in range(cur_n_cls)]
feat_norms = np.zeros(cur_n_cls)
network.eval()
with torch.no_grad():
for x, y in loader:
x = x.cuda()
feat = network(task_i,x,m)['feature'].cpu()
for i, lbl in enumerate(y):
if lbl >= cur_n_cls:
continue
feats[lbl].append(feat[y == lbl])
for i in range(len(feats)):
if len(feats[i]) != 0:
feat_cls = torch.cat((feats[i]))
feat_norms[i] = torch.norm(feat_cls, p=2, dim=1).mean().data.numpy()
return feat_norms
def set_seed(seed):
print("Set seed", seed)
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True # This will slow down training.
torch.backends.cudnn.benchmark = False
def display_weight_norm(logger, network, increments, tag):
weight_norms = [[] for _ in range(len(increments))]
increments = np.cumsum(np.array(increments))
for idx in range(network.module.convnets[-1].classifer.weight.shape[0]):
norm = torch.norm(network.module.convnets[-1].classifer.weight[idx].data, p=2).item()
for i in range(len(weight_norms)):
if idx < increments[i]:
break
weight_norms[i].append(round(norm, 3))
avg_weight_norm = []
# all_weight_norms = []
for idx in range(len(weight_norms)):
# all_weight_norms += weight_norms[idx]
# logger.info("task %s: Weight norm per class %s" % (str(idx), str(weight_norms[idx])))
avg_weight_norm.append(round(np.array(weight_norms[idx]).mean(), 3))
logger.info("%s: Weight norm per task %s" % (tag, str(avg_weight_norm)))
def display_feature_norm(task_i,logger, network, loader, n_classes, increments, tag, return_norm=False,mask=None):
avg_feat_norm_per_cls = get_featnorm_grouped_by_class(task_i,network, n_classes, loader,m=mask)
feature_norms = [[] for _ in range(len(increments))]
increments = np.cumsum(np.array(increments))
for idx in range(len(avg_feat_norm_per_cls)):
for i in range(len(feature_norms)):
if idx < increments[i]: #Find the mapping from class idx to step i.
break
feature_norms[i].append(round(avg_feat_norm_per_cls[idx], 3))
avg_feature_norm = []
for idx in range(len(feature_norms)):
avg_feature_norm.append(round(np.array(feature_norms[idx]).mean(), 3))
logger.info("%s: Feature norm per class %s" % (tag, str(avg_feature_norm)))
if return_norm:
return avg_feature_norm
else:
return
def check_loss(loss):
return not bool(torch.isnan(loss).item()) and bool((loss >= 0.0).item())
def class2task(class_form, classnum):
target_form = deepcopy(class_form)
for i in range(classnum):
mask = (target_form==i)
target_form[mask] = -(i//10)-1
target_form = (target_form+1)*(-1)
return target_form
def maskclass(pred, target, classnum, type='new'):
# type 为new,遮盖new的class,old遮盖旧的,all遮盖新旧
target_form = deepcopy(target)
pred_form = deepcopy(pred)
if type == 'old':
mask = np.logical_or(pred_form<(classnum-10), target_form<(classnum-10))
pred_form[mask] = 0
target_form[mask] = 0
if type == 'new':
mask = np.logical_or(pred_form>=(classnum-10), target_form>=(classnum-10))
pred_form[mask] = 1000
target_form[mask] = 1000
if type == 'all':
mask = (target_form>=(classnum-10))
target_form[mask] = 1000
mask = (pred_form>=(classnum-10))
pred_form[mask] = 1000
mask = (target_form<(classnum-10))
target_form[mask] = 0
mask = (pred_form<(classnum-10))
pred_form[mask] = 0
all_err = np.sum(pred_form!=target_form)
pred_form1 = deepcopy(pred_form)
mask = (target_form<(classnum-10))
pred_form[mask] = 0
new_old_err = np.sum(pred_form!=target_form)
mask = (target_form>=(classnum-10))
pred_form1[mask] = 1000
old_new_err = np.sum(pred_form1!=target_form)
return all_err, new_old_err, old_new_err
return pred_form, target_form
def compute_old_new_mix(ypred, ytrue, increments, n_classes, task_order):
task_means = []
for i in range (n_classes//10):
taski_mask = np.logical_and(ytrue>=i*10, ytrue<(i+1)*10)
task_i_mean = ypred[np.arange(ytrue.shape[0]), ytrue][taski_mask].mean().item()
task_means.append(task_i_mean)
task_mean = ypred[np.arange(ytrue.shape[0]), ytrue].mean().item()
classnum = ypred.shape[1]
ypred = ypred.argmax(1)
all_err = np.sum(ypred!=ytrue)
ypred_task = class2task(ypred, classnum)
ytrue_task = class2task(ytrue, classnum)
err_among_task = np.sum(ypred_task!=ytrue_task)
err_inner_task = all_err - err_among_task
# print("all err : {}\n among task err: {}\n inner task err: {}\n".format(all_err, err_among_task, err_inner_task))
ypred_new, ytrue_new = maskclass(ypred, ytrue, n_classes, 'old')
new_err = np.sum(ypred_new!=ytrue_new)
ypred_old, ytrue_old = maskclass(ypred, ytrue, n_classes, 'new')
old_err = np.sum(ypred_old!=ytrue_old)
all_err, new_old_err, old_new_err = maskclass(ypred, ytrue, n_classes, 'all')
print("******all_err:****", all_err)
all_acc = {"task_mean": task_mean, "task_means":task_means, "new_err": new_err, "old_err":old_err, "new_old_err": new_old_err, "old_new_err": old_new_err, "err_among_task": err_among_task, "err_inner_task": err_inner_task}
return all_acc
def compute_task_accuracy(ypred, ytrue, increments, n_classes, task_order):
task_mean = ypred[np.arange(ytrue.shape[0]), ytrue].mean().item()
classnum = ypred.shape[1]
ypred = ypred.argmax(1)
ypred_task = class2task(ypred, classnum)
ytrue_task = class2task(ytrue, classnum)
all_acc = {"task_mean": task_mean, "class_info": classification_report(ytrue, ypred), "task_info": classification_report(ytrue_task, ypred_task)}
return all_acc
def compute_accuracy(ypred, ytrue, increments, n_classes):
all_acc = {"top1": {}, "top5": {}}
topk = 5 if n_classes >= 5 else n_classes
ncls = np.unique(ytrue).shape[0]
if topk > ncls:
topk = ncls
all_acc_meter = ClassErrorMeter(topk=[1, topk], accuracy=True)
all_acc_meter.add(ypred, ytrue)
all_acc["top1"]["total"] = round(all_acc_meter.value()[0], 3)
all_acc["top5"]["total"] = round(all_acc_meter.value()[1], 3)
# all_acc["total"] = round((ypred == ytrue).sum() / len(ytrue), 3)
# for class_id in range(0, np.max(ytrue), task_size):
start, end = 0, 0
for i in range(len(increments)):
if increments[i] <= 0:
pass
else:
start = end
end += increments[i]
idxes = np.where(np.logical_and(ytrue >= start, ytrue < end))[0]
topk_ = 5 if increments[i] >= 5 else increments[i]
ncls = np.unique(ytrue[idxes]).shape[0]
if topk_ > ncls:
topk_ = ncls
cur_acc_meter = ClassErrorMeter(topk=[1, topk_], accuracy=True)
cur_acc_meter.add(ypred[idxes], ytrue[idxes])
top1_acc = (ypred[idxes].argmax(1) == ytrue[idxes]).sum() / idxes.shape[0] * 100
if start < end:
label = "{}-{}".format(str(start).rjust(2, "0"), str(end - 1).rjust(2, "0"))
else:
label = "{}-{}".format(str(start).rjust(2, "0"), str(end).rjust(2, "0"))
all_acc["top1"][label] = round(top1_acc, 3)
all_acc["top5"][label] = round(cur_acc_meter.value()[1], 3)
# all_acc[label] = round((ypred[idxes] == ytrue[idxes]).sum() / len(idxes), 3)
return all_acc
def make_logger(log_name, savedir='.logs/'):
"""Set up the logger for saving log file on the disk
Args:
cfg: configuration dict
Return:
logger: a logger for record essential information
"""
import logging
import os
from logging.config import dictConfig
import time
logging_config = dict(
version=1,
formatters={'f_t': {
'format': '\n %(asctime)s | %(levelname)s | %(name)s \t %(message)s'
}},
handlers={
'stream_handler': {
'class': 'logging.StreamHandler',
'formatter': 'f_t',
'level': logging.INFO
},
'file_handler': {
'class': 'logging.FileHandler',
'formatter': 'f_t',
'level': logging.INFO,
'filename': None,
}
},
root={
'handlers': ['stream_handler', 'file_handler'],
'level': logging.DEBUG,
},
)
# set up logger
log_file = '{}.log'.format(log_name)
# if folder not exist,create it
if not os.path.exists(savedir):
os.makedirs(savedir)
log_file_path = os.path.join(savedir, log_file)
logging_config['handlers']['file_handler']['filename'] = log_file_path
open(log_file_path, 'w').close() # Clear the content of logfile
# get logger from dictConfig
dictConfig(logging_config)
logger = logging.getLogger()
return logger
================================================
FILE: examples/Structural_Development/SCA-SNN/main.py
================================================
import sys
import os
import os.path as osp
import copy
import time
import shutil
import cProfile
import logging
from pathlib import Path
import numpy as np
import random
from easydict import EasyDict as edict
from tensorboardX import SummaryWriter
import os
import inclearn.convnet.maskcl2 as Mask
os.environ['CUDA_VISIBLE_DEVICES']='0'
repo_name = 'TCIL'
base_dir = '/data1/hanbing/TCIL10/'
sys.path.insert(0, base_dir)
from sacred import Experiment
ex = Experiment(base_dir=base_dir, save_git_info=False)
import torch
from inclearn.tools import factory, results_utils, utils
from inclearn.tools.metrics import IncConfusionMeter
from inclearn.tools.similar import Appr
def initialization(config, seed, mode, exp_id):
torch.backends.cudnn.benchmark = True # This will result in non-deterministic results.
# ex.captured_out_filter = lambda text: 'Output capturing turned off.'
cfg = edict(config)
utils.set_seed(cfg['seed'])
if exp_id is None:
exp_id = -1
cfg.exp.savedir = "./logs_aphal"
logger = utils.make_logger(str(exp_id)+str(cfg.exp.name)+str(mode), savedir=cfg.exp.savedir)
# Tensorboard
exp_name = '{exp_id}_{cfg["exp"]["name"]}' if exp_id is not None else '../inbox/{cfg["exp"]["name"]}'
tensorboard_dir = cfg["exp"]["tensorboard_dir"] + "/{exp_name}"
# If not only save latest tensorboard log.
# if Path(tensorboard_dir).exists():
# shutil.move(tensorboard_dir, cfg["exp"]["tensorboard_dir"] + f"/../inbox/{time.time()}_{exp_name}")
tensorboard = SummaryWriter(tensorboard_dir)
return cfg, logger, tensorboard
@ex.command
def train(_run, _rnd, _seed):
cfg, ex.logger, tensorboard = initialization(_run.config, _seed, "train", _run._id)
ex.logger.info(cfg)
cfg.data_folder = osp.join(base_dir, "data")
start_time = time.time()
_train(cfg, _run, ex, tensorboard)
ex.logger.info("Training finished in {}s.".format(int(time.time() - start_time)))
def _train(cfg, _run, ex, tensorboard):
device = factory.set_device(cfg)
trial_i = cfg['trial']
torc=cfg['distillation']
inc_dataset = factory.get_data(cfg, trial_i)
ex.logger.info("classes_order")
ex.logger.info(inc_dataset.class_order)
model = factory.get_model(cfg, trial_i, _run, ex, tensorboard, inc_dataset)
mask=Mask.Mask(model._network.convnets[-1])
if _run.meta_info["options"]["--file_storage"] is not None:
_save_dir = osp.join(_run.meta_info["options"]["--file_storage"], str(_run._id))
else:
_save_dir = cfg["exp"]["ckptdir"]
results = results_utils.get_template_results(cfg)
appr=Appr(model._network,10,torc)
for task_i in range(inc_dataset.n_tasks):
task_info, train_loader, val_loader, test_loader = inc_dataset.new_task(task_i)
model.set_task_info(
task=task_info["task"],
total_n_classes=task_info["max_class"],
increment=task_info["increment"],
n_train_data=task_info["n_train_data"],
n_test_data=task_info["n_test_data"],
n_tasks=inc_dataset.n_tasks,
)
if torc:
strategy, expert_id ,min_dist,all_dist,all_dist2= appr.learn(task_i, val_loader, cfg['batch_size'],device)
else:
strategy, expert_id ,min_dist,all_dist,all_dist2= appr.learn(task_i, test_loader[task_i], cfg['batch_size'],device)
print("Task:",task_i,strategy, expert_id,min_dist,all_dist,all_dist2)
model.before_task(task_i, inc_dataset,mask,min_dist,all_dist)
# TODO: Move to incmodel.py
if 'min_class' in task_info:
ex.logger.info("Train on {}->{}.".format(task_info["min_class"], task_info["max_class"]))
if torc:
model.train_task(task_i,train_loader, test_loader,mask,min_dist,all_dist)
model.after_task(task_i, inc_dataset,mask)
appr.after_learn(task_i, val_loader, cfg['batch_size'],device)
else:
model.train_task(task_i,train_loader, val_loader[task_i],mask,min_dist,all_dist)
appr.after_learn(task_i, test_loader[task_i], cfg['batch_size'],device)
if torc:
ex.logger.info("Eval on {}->{}.".format(0, task_info["max_class"]))
ypred, ytrue = model.eval_task(task_i,test_loader,mask)
acc_stats = utils.compute_accuracy(ypred, ytrue, increments=model._increments, n_classes=model._n_classes)
#Logging
model._tensorboard.add_scalar("taskaccu/trial{trial_i}", acc_stats["top1"]["total"], task_i)
_run.log_scalar("trial{trial_i}_taskaccu", acc_stats["top1"]["total"], task_i)
_run.log_scalar("trial{trial_i}_task_top5_accu", acc_stats["top5"]["total"], task_i)
ex.logger.info("top1:"+str(acc_stats['top1']))
ex.logger.info("top5:"+str(acc_stats['top5']))
results["results"].append(acc_stats)
else:
for taski in range(task_i+1):
ypred, ytrue = model.eval_task(taski,test_loader[taski],mask)
acc_stats = utils.compute_accuracy(ypred, ytrue, increments=[1], n_classes=model._n_classes)
model._tensorboard.add_scalar(f"taskaccu/trial{trial_i}", acc_stats["top1"]["total"], taski)
_run.log_scalar(f"trial{trial_i}_taskaccu", acc_stats["top1"]["total"], taski)
_run.log_scalar(f"trial{trial_i}_task_top5_accu", acc_stats["top5"]["total"], taski)
ex.logger.info(f"top1:{acc_stats['top1']}")
ex.logger.info(f"top5:{acc_stats['top5']}")
results["results"].append(acc_stats)
top1_avg_acc, top5_avg_acc = results_utils.compute_avg_inc_acc(results["results"])
_run.info["trial{trial_i}"]["avg_incremental_accu_top1"] = top1_avg_acc
_run.info["trial{trial_i}"]["avg_incremental_accu_top5"] = top5_avg_acc
ex.logger.info("Average Incremental Accuracy Top 1: {} Top 5: {}.".format(
_run.info["trial{trial_i}"]["avg_incremental_accu_top1"],
_run.info["trial{trial_i}"]["avg_incremental_accu_top5"],
))
if cfg["exp"]["name"]:
results_utils.save_results(results, cfg["exp"]["name"])
if __name__ == "__main__":
ex.add_config("/data1/hanbing/SCA-SNN/configs/train.yaml")
ex.run_commandline()
================================================
FILE: examples/Structural_Development/SD-SNN/README.md
================================================
# Adaptive Sparse Structure Development with Pruning and Regeneration for Spiking Neural Networks #
## Requirments ##
* numpy
* timm
* pytorch >= 1.7.0
* collections
* argparse
## Run ##
```CUDA_VISIBLE_DEVICES=0 python main.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{han2025adaptive,
title={Adaptive sparse structure development with pruning and regeneration for spiking neural networks},
author={Han, Bing and Zhao, Feifei and Pan, Wenxuan and Zeng, Yi},
journal={Information Sciences},
volume={689},
pages={121481},
year={2025},
publisher={Elsevier}
}
@article{zeng2023braincog,
title={Braincog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired ai and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier},
}
```
Enjoy!
================================================
FILE: examples/Structural_Development/SD-SNN/main.py
================================================
import argparse
import time
import os
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
import sys
sys.path.append('..')
import logging
import torch
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from braincog.base.node.node import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from prun_and_generation import *
from snn_model import *
from utils import *
_logger = logging.getLogger('train')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
exp_name = '-'.join([datetime.now().strftime("%Y%m%d-%H%M%S"),'c10'])
output_dir = get_outdir('./', 'train', exp_name)
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
_logger.info(exp_name)
config_parser = cfg = argparse.ArgumentParser(description='Training Config', add_help=False)
model='cifar_convnet'
dataset='cifar10'
num_classes=10
step=8
encode='direct'
node_type='PLIFNode'
thresh=0.5
tau=2.0
torch.backends.cudnn.benchmark = True
devicee=0
seed=36
channels = 2
lr=5e-3
batch_size=50
epochs=600
linear_scaled_lr = lr * batch_size/ 1024.0
cfg.opt='adamw'
cfg.lr=linear_scaled_lr
cfg.weight_decay=0.01
cfg.momentum=0.9
cfg.epochs=epochs
cfg.sched='cosine'
cfg.min_lr=1e-5
cfg.warmup_lr=1e-6
cfg.warmup_epochs=5
cfg.cooldown_epochs=10
cfg.decay_rate=0.1
epoch_prune = 1
eval_metric='top1'
best_test = 0
best_testepoch = 0
best_testprun = 0
best_testepochprun = 0
spines_num=18
torch.cuda.set_device('cuda:%d' % devicee)
torch.manual_seed(seed)
model = my_cifar_model(step=step,encode_type=encode,node_type=node_type,num_classes=num_classes)
model = model.cuda()
print(model)
optimizer = create_optimizer(cfg, model)
lr_scheduler, num_epochs = create_scheduler(cfg, optimizer)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % dataset)(batch_size=batch_size, step=step)
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
m = Mask(model,spines_num)
def train_epoch(
epoch, model, loader, optimizer, loss_fn,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None):
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
model.train()
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
output = model(inputs)
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
optimizer.zero_grad()
loss.backward()
optimizer.step()
batch_time_m.update(time.time() - end)
if last_batch or batch_idx %100 == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
print("Train: epoch:",epoch,batch_idx,"/",len(loader),"loss:",losses_m.avg,"acc1:", top1_m.avg,"lr:",lr)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg)])
def validate(model, loader, loss_fn, amp_autocast=suppress, log_suffix=''):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
end = time.time()
last_idx = len(loader) - 1
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
#print(inputs.size())
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
if last_batch or batch_idx %100 == 0:
print("Test: loss:",losses_m.avg,"acc1:", top1_m.avg)
batch_time_m.update(time.time() - end)
end = time.time()
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
return metrics
for epoch in range(epochs):
train_metrics= train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn,
lr_scheduler=lr_scheduler)
if epoch==0:
m.init_length()
if epoch>0:
m.model = model
m.init_mask_dsd()
if epoch>spines_num:
matt=m.do_mask_dsd()
if epoch>2*spines_num:
m.do_growth_ww(epoch)
matt=m.do_pruning_dsd(epoch)
model = m.model
cc=m.if_zero()
eval_metrics = validate(model, loader_eval, validate_loss_fn)
top1=eval_metrics['top1']
if top1 > best_testprun:
best_testprun = top1
best_testepochprun =epoch
if epoch%40==0:
print('best acc:',best_testprun,'best epoch:',best_testepochprun)
if epoch>4:
_logger.info('*** epoch: {0} (pruning rate {1},acc:{2})'.format(epoch, cc,top1))
if lr_scheduler is not None:
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
================================================
FILE: examples/Structural_Development/SD-SNN/prun_and_generation.py
================================================
import numpy as np
import torch
import math
from utils import *
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class Mask:
def __init__(self, model,count_thre):
self.model_size = {}
self.model_length = {}
self.compress_rate = {}
self.mat = {}
self.model = model
self.mask_index = []
self.distance_rate = {}
self.filter_small_index = {}
self.filter_large_index = {}
self.similar_matrix = {}
self.norm_matrix = {}
# dendritic dynamics
self.cur_range_pos = {} # current range foe every weight
self.cur_range_neg = {} # current range foe every weight
self.dsum_pos_out = {} # current range foe every weight
self.dsum_neg_out = {} # current range foe every weight
self.dsum_pos_in = {} # current range foe every weight
self.dsum_neg_in = {} # current range foe every weight
self.dendritic_previous_pos = {} # the index for beyond range weight
self.dendritic_previous_neg = {} # the index for within range weight
self.dendritic_previous_in = {} # the index for within range weight
self.dendritic_count_pos = {} # the count of beyond range for every weight
self.dendritic_count_neg = {} # the count of within range for every weight
self.dendritic_count_in = {} # the count of within range for every weight
self.out = 0
self.count_thre=count_thre
self.weight_previous = {}
self.mask={}
self.codebook = {}
self.codebookww={}
self.his_ind={}
self.his_groth={}
self.his_gro_count={}
self.prune={}
self.pruncc={}
self.prunn={}
self.his_prun={}
self.convlayer =model.convlayer
for index in self.convlayer:
if indexr+
weight_vec = weight_torch.view(-1) # one conv one weight vector
weight_vec_np = weight_vec.cpu().numpy()
weight_np_abs = abs(weight_vec_np)
dendritic_pos_tmp = np.where((weight_vec_np >= self.cur_range_pos[i])) # find the weight beyong range
pos_index = set(dendritic_pos_tmp[0]) & set(self.dendritic_previous_pos[i]) # calculate intersection consectively
pos_zero = set([i for i in range(length)]) - pos_index # non-intersection weight will be count from 0
pos_index = np.array(list(pos_index))
pos_zero = np.array(list(pos_zero))
if pos_zero.size > 0:
self.dendritic_count_pos[i][pos_zero] = 0
self.dsum_pos_out[i][pos_zero] = 0
if pos_index.size > 0:
self.dendritic_count_pos[i][pos_index] = self.dendritic_count_pos[i][pos_index] + 1 # intewrsection +1
self.dsum_pos_out[i][pos_index] += weight_vec_np[pos_index] - self.cur_range_pos[i][pos_index]
dendritic_index = np.where(self.dendritic_count_pos[i] >= count_thre) # count>threshold
self.out = self.out + len(dendritic_index[0])
self.cur_range_pos[i][dendritic_index]+=(self.dsum_pos_out[i][dendritic_index] / count_thre) # self.cur_range_pos[i][dendritic_index]+0.025 #
self.dendritic_count_pos[i][dendritic_index] = 0 # intrsection count set to 0
self.dsum_pos_out[i][dendritic_index] = 0
self.dendritic_previous_pos[i] = dendritic_pos_tmp[0] # update previous
# 0:
self.dendritic_count_neg[i][neg_zero] = 0
self.dsum_neg_out[i][neg_zero] = 0
if neg_index.size > 0:
self.dendritic_count_neg[i][neg_index] = self.dendritic_count_neg[i][neg_index] + 1 # intewrsection +1
self.dsum_neg_out[i][neg_index] += weight_vec_np[neg_index] - self.cur_range_neg[i][neg_index]
dendritic_index_neg = np.where(self.dendritic_count_neg[i] >= count_thre) # count>threshold
self.out = self.out + len(dendritic_index_neg[0])
self.cur_range_neg[i][dendritic_index_neg] += (self.dsum_neg_out[i][dendritic_index_neg] / count_thre) #self.cur_range_neg[i][dendritic_index_neg]-0.025 #
self.dendritic_count_neg[i][dendritic_index_neg] = 0 # intrsection count set to 0
self.dsum_neg_out[i][dendritic_index_neg] = 0
self.dendritic_previous_neg[i] = dendritic_neg_tmp[0] # update previous
# r-~r+
dendritic_in_tmp = np.where((weight_np_abs < self.weight_previous[i])) # find the weight beyong range
in_index = set(dendritic_in_tmp[0]) & set(self.dendritic_previous_in[i]) # calculate intersection consectively
in_zero = set([i for i in range(length)]) - in_index # non-intersection weight will be count from 0
in_index = np.array(list(in_index))
in_zero = np.array(list(in_zero))
if in_zero.size > 0:
self.dendritic_count_in[i][in_zero] = 0
self.dsum_neg_in[i][in_zero] = 0
if in_index.size > 0:
self.dendritic_count_in[i][in_index] = self.dendritic_count_in[i][in_index] + 1 # intewrsection +1
self.dsum_neg_in[i][in_index] += weight_np_abs[in_index] - self.weight_previous[i][in_index]
dendritic_index_in = np.where(self.dendritic_count_in[i] >= count_thre) # count>threshold
self.cur_range_pos[i][dendritic_index_in] = 0.75*self.cur_range_pos[i][dendritic_index_in] # self.cur_range_pos[i][dendritic_index_in]-0.025
self.cur_range_neg[i][dendritic_index_in] = 0.75*self.cur_range_neg[i][dendritic_index_in] # self.cur_range_neg[i][dendritic_index_in]+0.025
self.dendritic_count_in[i][dendritic_index_in] = 0 # intrsection count set to 0
self.dsum_neg_in[i][dendritic_index_in] = 0
self.dendritic_previous_in[i] = dendritic_in_tmp[0] # update previous
self.weight_previous[i] = weight_np_abs
print('dendritic dynamics done', np.mean(self.cur_range_pos[i]), np.mean(self.cur_range_neg[i][0]))
return self.cur_range_pos[i], self.cur_range_neg[i]
def do_mask_dsd(self):
for index in self.convlayer:
if index self.cur_range_pos[index]] = self.cur_range_pos[index][
a > self.cur_range_pos[index]] # weight beyond range set to range
a[a < self.cur_range_neg[index]] = self.cur_range_neg[index][a < self.cur_range_neg[index]]
a = torch.FloatTensor(a).cuda()
ww.data = a.view(self.model_size[index])
print("mask Done")
def do_pruning_dsd(self,epoch):
for index in self.convlayer:
if index60:
aphla=0.0005
sumbook=torch.sum(self.codebook[self.convlayer[-1]],dim=1)
prun=torch.where(sumbook<50)[0]
prunn=prun.size()[0]
self.prune[index]=self.prune[index]+aphla*(512-prunn)/10
print(prunn,self.prune[index])
def do_growth_ww(self,epoch):
for index in self.convlayer:
if index99:
rate=99
gg=np.percentile(ww, rate)
grow=np.where(ww>gg)[0]
growth_ind=set(grow) & set(p_index)
growth_index=growth_ind & set(self.his_groth[index])
zero_index=set([i for i in range(ww.size)]) - growth_index
growth_index=np.array(list(growth_index))
zero_index=np.array(list(zero_index))
if zero_index.size>0:
self.his_gro_count[index][zero_index]=0
if growth_index.size>0:
self.his_gro_count[index][growth_index]=self.his_gro_count[index][growth_index]+1
gr_index=np.where(self.his_gro_count[index]> self.count_thre)[0]
self.codebook[index]=self.codebook[index].view(-1)
for x in range(len(gr_index)):
self.codebook[index][gr_index[x]*9:(gr_index[x]+1)*9]=1
self.codebook[index]=self.codebook[index].view(self.model_size[index])
print(len(gr_index),len(growth_ind),len(p_index))
self.his_groth[index]=growth_ind
self.his_gro_count[index][gr_index]=0
if index==self.convlayer[-1]:
ww=self.fc1.fc.weight
ww=ww.data
ww=ww.view(-1).cpu().numpy()
p_index=np.where(self.codebook[index].view(-1).cpu().numpy()==0)[0]
rate=60+1.1**(epoch- 2*self.count_thre-1)
if rate>99:
rate=99
gg=np.percentile(ww, rate)
grow=np.where(ww>gg)[0]
growth_ind=set(grow) & set(p_index)
growth_index=growth_ind & set(self.his_groth[index])
zero_index=set([i for i in range(ww.size)]) - growth_index
growth_index=np.array(list(growth_index))
zero_index=np.array(list(zero_index))
if zero_index.size>0:
self.his_gro_count[index][zero_index]=0
if growth_index.size>0:
self.his_gro_count[index][growth_index]=self.his_gro_count[index][growth_index]+1
gr_index=np.where(self.his_gro_count[index]> self.count_thre)[0]
self.codebook[index]=self.codebook[index].view(-1)
self.codebook[index][gr_index]=1
self.codebook[index]=self.codebook[index].view(self.model_size[index][0],-1)
print(len(gr_index),len(growth_ind),len(p_index))
self.his_groth[index]=growth_ind
self.his_gro_count[index][gr_index]=0
def if_zero(self):
cc=[]
for index in self.convlayer:
if index 1:
a = ww.data.view(self.model_length[index])
b = a.cpu().numpy()
print(
"number of nonzero weight is %d, zero is %d" % (np.count_nonzero(b), len(b) - np.count_nonzero(b)))
cc.append(len(b) - np.count_nonzero(b))
return cc
================================================
FILE: examples/Structural_Development/SD-SNN/snn_model.py
================================================
import abc
from functools import partial
from torch.nn import functional as F
import torchvision
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from utils import *
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class my_cifar_model(BaseModule):
def __init__(self,
num_classes=10,
step=8,
node_type=LIFNode,
encode_type='direct',
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.num_classes = num_classes
self.feature = nn.Sequential(
BaseConvModule(3, 128, kernel_size=(3, 3), padding=(1, 1)),
BaseConvModule(128,128, kernel_size=(3, 3), padding=(1, 1)),
nn.MaxPool2d(2),
BaseConvModule(128,256, kernel_size=(3, 3), padding=(1, 1)),
BaseConvModule(256, 256, kernel_size=(3, 3), padding=(1, 1)),
nn.MaxPool2d(2),
BaseConvModule(256, 512, kernel_size=(3, 3), padding=(1, 1)),
BaseConvModule(512, 512, kernel_size=(3, 3), padding=(1, 1)),
)
self.convlayer = [0,1,3,4,6,7,8]
self.cfla=self._cflatten()
self.fc_prun = self._create_fc_prun()
self.fc = self._create_fc()
def _cflatten(self):
fc = nn.Sequential(
nn.Flatten(),
)
return fc
def _create_fc_prun(self):
fc = nn.Sequential(
BaseLinearModule(512*8*8, 512)
)
return fc
def _create_fc(self):
fc = nn.Sequential(
BaseLinearModule(512, self.num_classes)
)
return fc
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if not self.training:
self.fire_rate.clear()
outputs = []
for t in range(self.step):
x = inputs[t]
if x.shape[-1] > 32:
x = F.interpolate(x, size=[64, 64])
for i in range(len(self.feature)):
x=self.feature[i](x)
x=self.cfla(x)
x=self.fc_prun(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
================================================
FILE: examples/Structural_Development/SD-SNN/utils.py
================================================
import torch
import numpy as np
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def unit(x):
if len(x.shape)>0:
maxx=np.max(x)
minx=np.min(x)
marge=maxx-minx
if marge!=0:
xx=(x-minx)/marge
xx=np.clip(xx, 0,1)
else:
xx=0.5*np.ones_like(x)
return xx
else:
return x
def unit_tensor(x):
if x.size()[0]>0:
maxx=torch.max(x)
minx=torch.min(x)
marge=maxx-minx
if marge!=0:
xx=(x-minx)/marge
else:
xx=0.5*torch.ones_like(x)
return xx
else:
return x
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/README.md
================================================
# Adaptive structure evolution and biologically plausible synaptic plasticity for recurrent spiking neural networks —— Based on BrainCog #
**This is the BrainBog-based version of the paper. To run the original code, please go to [raw](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/Adaptive_lsm/raw)**
## Requirments ##
* numpy
* pytorch >= 1.12.0
* BrainCog
## Run ##
```python main.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{pan2023adaptive,
title = {Adaptive structure evolution and biologically plausible synaptic plasticity for recurrent spiking neural networks},
author = {Pan, Wenxuan and Zhao, Feifei and Zeng, Yi and Han, Bing},
journal = {Scientific Reports},
volume = {13},
number = {1},
pages = {16924},
year = {2023},
url = {https://doi.org/10.1038/s41598-023-43488-x},
doi = {10.1038/s41598-023-43488-x},
}
@article{zeng2023braincog,
title={BrainCog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired AI and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier}
}
```
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/brid.py
================================================
import torch, os
import pygame
from pygame.locals import *
from collections import deque
from random import randint
import numpy as np
import nsganet as engine
from pymop.problem import Problem
from pymoo.optimize import minimize
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
from lsmmodel import SNN
import torch.nn.functional as F
from tools.update_weights import stdp,bcm
import matplotlib.pyplot as plt
os.environ["SDL_VIDEODRIVER"] = "dummy"
steps=30000
seeds=50
result=np.zeros([seeds,int(steps/2)])
t=[i for i in range(steps)]
def randbool(size, p):
return torch.rand(*size) < p
class Evolve(Problem):
# first define the NAS problem (inherit from pymop)
def __init__(self, n_var=20, n_obj=1, n_constr=0, lb=None, ub=None):
super().__init__(n_var=n_var, n_obj=n_obj, n_constr=n_constr, type_var=np.int64)
self.xl = lb
self.xu = ub
self._n_evaluated = 0 # keep track of how many architectures are sampled
def _evaluate(self, x, out, *args, **kwargs):
objs = np.full((x.shape[0], self.n_obj), np.nan)
for i in range(x.shape[0]):
arch_id = self._n_evaluated + 1
print('Network= {}'.format(arch_id))
objs[i, 0] = np.linalg.matrix_rank(x[i])
objs[i, 1] = 0
self._n_evaluated += 1
out["F"] = objs
# if your NAS problem has constraints, use the following line to set constraints
# out["G"] = np.column_stack([g1, g2, g3, g4, g5, g6]) in case 6 constraints
# ---------------------------------------------------------------------------------------------------------
# Define what statistics to print or save for each generation
# ---------------------------------------------------------------------------------------------------------
def do_every_generations(algorithm):
# this function will be call every generation
# it has access to the whole algorithm class
gen = algorithm.n_gen
pop_var = algorithm.pop.get("X")
pop_obj = algorithm.pop.get("F")
# report generation info to files
print("generation = {}".format(gen))
print("population error: best = {}, mean = {}, "
"median = {}, worst = {}".format(np.min(pop_obj[:, 0]), np.mean(pop_obj[:, 0]),
np.median(pop_obj[:, 0]), np.max(pop_obj[:, 0])))
print('Best Genome id= {}'.format(np.argmin(pop_obj[:, 0])))
def load_images():
"""
Flappy Bird中load图像
:return:load的图像
"""
def load_image(img_file_name):
file_name = os.path.join('/home/panwenxuan/raw', 'birdimages', img_file_name)
img = pygame.image.load(file_name)
# converting all images before use speeds up blitting
img.convert()
return img
return {'background': load_image('background.png'),
'pipe-end': load_image('pipe_end.png'),
'pipe-body': load_image('pipe_body.png'),
# images for animating the flapping bird -- animated GIFs are
# not supported in pygame
'bird-wingup': load_image('bird_wing_up.png'),
'bird-wingdown': load_image('bird_wing_down.png'), }
class Bird(pygame.sprite.Sprite):
"""
Flappy Bird类
"""
WIDTH = HEIGHT = 32
SINK_SPEED = 0.2
Fail_SINk_SPEED = 0.6
CLIMB_SPEED = 0.25
CLIMB_DURATION = 333.3
REGION = CLIMB_DURATION / 3
NEAR_COLLIDE = 30
NEAR_PIPE = 0
def __init__(self, x, y, msec_to_climb, images):
super(Bird, self).__init__()
self.x, self.y = x, y
self.msec_to_climb = msec_to_climb
self._img_wingup, self._img_wingdown = images
self._mask_wingup = pygame.mask.from_surface(self._img_wingup)
self._mask_wingdown = pygame.mask.from_surface(self._img_wingdown)
def update(self, action, state, delta_frames=1):
"""
更新小鸟的位置
:param action: 输入行为
:param state:输入状态
:param delta_frames:Fault
:return:None
"""
if self.msec_to_climb > 0 and action == 1:
if state == 4 or state == 5 or state == 2 or state == 3:
self.y -= (2 * Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
self.y -= (Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
if state == 4 or state == 5 or state == 2 or state == 3:
self.y += 2 * Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
else:
self.y += Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
def sink(self, delta_frames=1):
self.y += Bird.Fail_SINk_SPEED * (1000.0 * delta_frames / 60)
@property
def image(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._img_wingup
else:
return self._img_wingdown
@property
def mask(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._mask_wingup
else:
return self._mask_wingdown
@property
def rect(self):
return Rect(self.x, self.y, Bird.WIDTH, Bird.HEIGHT)
class PipePair(pygame.sprite.Sprite):
"""
Flappy Bird 中的管子类
"""
WIDTH = 80
PIECE_HEIGHT = 32
ADD_INTERVAL = 2000
ADD_EVENT = pygame.USEREVENT + 1
ROOM_HIGHT = 2 * Bird.HEIGHT + 2 * PIECE_HEIGHT
def __init__(self, pipe_end_img, pipe_body_img):
self.x = float(WIN_WIDTH - 1)
self.score_counted = False
self.isNewPipe = True
self.image = pygame.Surface((PipePair.WIDTH, WIN_HEIGHT), SRCALPHA)
self.image.convert() # speeds up blitting
self.image.fill((0, 0, 0, 0))
total_pipe_body_pieces = int(
(WIN_HEIGHT - # fill window from top to bottom
3 * Bird.HEIGHT - # make room for bird to fit through
3 * PipePair.PIECE_HEIGHT) / # 2 end pieces + 1 body piece
PipePair.PIECE_HEIGHT # to get number of pipe pieces
)
self.bottom_pieces = randint(1, total_pipe_body_pieces)
self.top_pieces = total_pipe_body_pieces - self.bottom_pieces
# bottom pipe
for i in range(1, self.bottom_pieces + 1):
piece_pos = (0, WIN_HEIGHT - i * PipePair.PIECE_HEIGHT)
self.image.blit(pipe_body_img, piece_pos)
bottom_pipe_end_y = WIN_HEIGHT - self.bottom_height_px
bottom_end_piece_pos = (0, bottom_pipe_end_y - PipePair.PIECE_HEIGHT)
self.image.blit(pipe_end_img, bottom_end_piece_pos)
# top pipe
for i in range(self.top_pieces):
self.image.blit(pipe_body_img, (0, i * PipePair.PIECE_HEIGHT))
top_pipe_end_y = self.top_height_px
self.image.blit(pipe_end_img, (0, top_pipe_end_y))
self.center = (top_pipe_end_y + bottom_pipe_end_y) / 2
# compensate for added end pieces
self.top_pieces += 1
self.bottom_pieces += 1
# for collision detection
self.mask = pygame.mask.from_surface(self.image)
self.top_y = top_pipe_end_y
self.bottom_y = bottom_pipe_end_y
@property
def top_height_px(self):
return self.top_pieces * PipePair.PIECE_HEIGHT
@property
def bottom_height_px(self):
return self.bottom_pieces * PipePair.PIECE_HEIGHT
@property
def visible(self):
return -PipePair.WIDTH < self.x < WIN_WIDTH
@property
def rect(self):
return Rect(self.x, 0, PipePair.WIDTH, PipePair.PIECE_HEIGHT)
def update(self, delta_frames=1):
self.x -= 0.18 * 1000.0 * delta_frames / 60
def collides_with(self, bird):
return pygame.sprite.collide_mask(self, bird)
def judgeState(bird, pipes, collide):
"""
根据小鸟和管子之间的位置关系判断当前状态
:param bird:传入小鸟的各项属性
:param pipes:传入管子的各项属性
:param collide:是否发生碰撞
:return:状态,距离,是否是新的管子
"""
# bird's x and y coordinate in the left top of the image
dist = bird.y + Bird.HEIGHT / 2 - WIN_HEIGHT / 2
isNew = False
index = -1
state = -1
if collide:
state = 8
return state
for p in pipes:
if p.x + PipePair.WIDTH - Bird.HEIGHT / 4 < bird.x and not p.score_counted:
continue
if p.x - Bird.NEAR_PIPE <= bird.x + Bird.HEIGHT and \
p.x + PipePair.WIDTH - Bird.HEIGHT / 4 >= bird.x:
p_top_y = p.top_y + PipePair.PIECE_HEIGHT
p_bottom_y = p.bottom_y - PipePair.PIECE_HEIGHT
if p.center - bird.y - Bird.HEIGHT / 2 >= 0 and bird.y >= p_top_y + Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - p.center + Bird.HEIGHT / 2 > 0 and bird.y + Bird.HEIGHT <= p_bottom_y - Bird.NEAR_COLLIDE / 2:
state = 1
elif bird.y < p_top_y + Bird.NEAR_COLLIDE / 2 and bird.y > p_top_y - 10:
state = 6
elif bird.y + Bird.HEIGHT > p_bottom_y - Bird.NEAR_COLLIDE / 2 and bird.y + Bird.HEIGHT < p_bottom_y + 10:
state = 7
if state > -0.5:
index = 1
elif p.x > bird.x + Bird.HEIGHT + Bird.NEAR_PIPE:
state = blankState(bird, p.center)
if p.isNewPipe:
isNew = True
p.isNewPipe = False
index = 1
if index > 0: # only judge the nearest and not passed pipe
dist = bird.y + Bird.HEIGHT / 2 - p.center
break
if index < -0.5: # no pipe left, key the bird in the middle
pos = WIN_HEIGHT / 2
dist = bird.y + Bird.HEIGHT / 2 - pos
state = blankState(bird, pos)
return state, dist, isNew
def blankState(bird, center):
"""
judgeState中调用的判断状态的函数 根据鸟的位置和管子中心的距离来判断
:param bird: 传入小鸟的各项属性
:param center:中心
:return:状态
"""
realHeight = (PipePair.ROOM_HIGHT - Bird.HEIGHT) / 2
if center - bird.y - Bird.HEIGHT / 2 >= 0 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - center + Bird.HEIGHT / 2 >= 0 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 1
elif center - bird.y - Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 2
elif bird.y - center + Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 3
elif bird.y + Bird.HEIGHT / 2 <= center - (realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION):
state = 4
elif bird.y + Bird.HEIGHT / 2 >= center + realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 5
return state
def getReward(state, lastState, smallerError, isNewPipe):
"""
根据状态和距离的变化获得奖励
:param state: 执行行为后的当前状态
:param lastState:执行行为之前的上一状态
:param smallerError:距离是否变小
:param isNewPipe:是否是新的管子
:return:奖励
"""
if state == 0 or state == 1:
reward = 6
elif state == 2 or state == 3:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -5
else:
reward = -3
elif state == 4 or state == 5:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -8
else:
reward = -5
elif state == 6 or state == 7:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -3
else:
reward = -3
elif state == 8: # collide
reward = -100
return reward
if __name__ == "__main__":
n_agent=1
num = 8
p_amount = int(num * num / 10)
s_amount = 4
num_state = 9
num_action = 2
weight_exc = 1
weight_inh = -0.5
trace_decay = 0.8
gens=1000
for seed in range(seeds):
kkk = Evolve(n_var=num*num,
n_obj=2, n_constr=0)
method = engine.nsganet(pop_size=n_agent,
sampling=RandomSampling(var_type='custom'),
mutation=BinaryBitflipMutation(),
n_offsprings=10,
eliminate_duplicates=True)
kres=minimize(kkk,
method,
callback=do_every_generations,
termination=('n_gen', gens))
pop_var = kres.X
pop_obj = kres.F
lm=torch.from_numpy(pop_var[np.argmin(pop_obj[:, 0])].reshape(num,num))
model = SNN(ins=9,num_classes=2,n_agent=n_agent,device='cuda:0',liquid_size=num,lsm_tau=2,lsm_th=0.2,connectivity_matrix=lm.to('cuda:0').float())
model.to('cuda:0')
con_matrix1 = torch.zeros((num_state, num_state * num_action), dtype=torch.float)
for i in range(num_state):
for j in range(num_action):
con_matrix1[i, i * num_action + j] = weight_exc
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
pygame.init()
WIN_HEIGHT = 512
WIN_WIDTH = 284 * 2
heighest = 0
contTime = 0
display_frame = 0
display_surface = pygame.display.set_mode((WIN_WIDTH, WIN_HEIGHT))
pygame.display.set_caption('Flappy Bird')
images = load_images()
bird = Bird(250, int(WIN_HEIGHT / 2 - Bird.HEIGHT / 2), 2,
(images['bird-wingup'], images['bird-wingdown']))
clock = pygame.time.Clock()
score_font = pygame.font.SysFont(None, 25, bold=True)
info_font = pygame.font.SysFont(None, 50, bold=True)
collide = paused = False
frame_clock = 0
pipes = deque()
score = 0
lastDist = 0
lastState = 0 # init
state = lastState
i = 0
num_reward = []
num_score = []
reward=1
while not collide:
i = i + 1
if i > steps:
break
clock.tick(60)
if frame_clock % 2 == 0 or frame_clock == 1:
state, dist, isNewPipe = judgeState(bird, pipes, collide)
lastState = state
lastDist = dist
action= model(F.one_hot(torch.tensor([state]), num_classes=num_state).to('cuda:0').float()).cpu().detach().numpy()
action=int(np.argmax(action,axis=1))
print(i)
if not (paused or frame_clock % (60 * PipePair.ADD_INTERVAL / 1000.0)):
pygame.event.post(pygame.event.Event(PipePair.ADD_EVENT))
for e in pygame.event.get():
if e.type == QUIT or (e.type == KEYUP and e.key == K_ESCAPE):
collide = True
elif e.type == KEYUP and e.key in (K_PAUSE, K_p):
paused = not paused
elif e.type == PipePair.ADD_EVENT:
pp = PipePair(images['pipe-end'], images['pipe-body'])
pipes.append(pp)
if paused:
continue # don't draw anything
pipe_collision = any(p.collides_with(bird) for p in pipes)
if pipe_collision or 0 >= bird.y or bird.y >= WIN_HEIGHT - Bird.HEIGHT:
collide = True
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
p.update()
display_surface.blit(p.image, p.rect)
bird.update(action, state)
display_surface.blit(bird.image, bird.rect)
if frame_clock % 2 == 0 or frame_clock == 1 or collide:
dist = 0
if collide:
nextState = 8
isNewPipe = False
else:
nextState, dist, isNewPipe = judgeState(bird, pipes, collide) # judge the bird's state
print("next state:", nextState)
print("lastdist, dist:", lastDist, dist)
isSmallerError = False
if state == nextState:
isSmallerError = False
if lastDist <= 0:
if lastDist < dist:
isSmallerError = True
else:
if lastDist > dist:
isSmallerError = True
if frame_clock > 0 and not collide:
reward = getReward(nextState, state, isSmallerError, isNewPipe)
print("reward:", reward)
num_reward.append(reward)
bcmreward=np.array([reward, reward])
# bcm(model,bcmreward, input=input)
state = nextState # going on the next state
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
model.reset()
display_frame += 1
for p in pipes:
if p.x + PipePair.WIDTH < bird.x and not p.score_counted:
score += 1
p.score_counted = True
num_score.append(score)
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: 0', True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
frame_clock += 1
pygame.display.flip()
# if collide, display the fail information, for 2 frames
cct = 0
while (bird.y < WIN_HEIGHT - Bird.HEIGHT - 3):
clock.tick(60)
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
display_surface.blit(p.image, p.rect)
if cct >= 6:
bird.sink()
display_surface.blit(bird.image, bird.rect)
fail_infor = info_font.render('Game over !', True, (255, 60, 30)) # current score
pos_x = WIN_WIDTH / 2 - fail_infor.get_width() / 2
pos_y = WIN_HEIGHT / 2 - 100
display_surface.blit(fail_infor, (pos_x, pos_y))
# display the score
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: 0', True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
pygame.display.flip()
cct += 1
if heighest < score:
heighest = score
contTime += 1
num_reward_np = np.array(num_reward)
print(num_reward_np)
k=num_reward_np.shape[0]
result[seed,:k]=num_reward_np
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/lsmmodel.py
================================================
from functools import partial
from torch.nn import functional as F
from torch import nn as nn
import torchvision, pprint
from copy import deepcopy
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.base.brainarea.BrainArea import BrainArea
from braincog.base.connection.CustomLinear import *
from braincog.base.learningrule.STDP import *
from braincog.base.learningrule.BCM import *
import matplotlib.pyplot as plt
@register_model
class SNN(BaseModule):
def __init__(self,
liquid_size,
n_agent,
device,
connectivity_matrix,
num_classes=3,
step=1,
node_type=LIFNode,
encode_type='direct',
lsm_th=0.3,
fc_th=0.3,
lsm_tau=3,
fc_tau=3,
tw=100,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.batchsize=n_agent
self.node_lsm=partial(node_type, **kwargs, step=step,tau=lsm_tau,threshold=lsm_th)
self.node_fc = partial(node_type, **kwargs, step=step,tau=fc_tau,threshold=fc_th)
self.liquid_size=liquid_size
self.out = torch.zeros(self.batchsize, liquid_size).to(device)
self.device=device
self.con=[]
self.learning_rule=[]
self.connectivity_matrix=connectivity_matrix
w1tmp=nn.Linear(4,liquid_size,bias=False).to(device)
self.con.append(w1tmp)
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False).to(device)
self.liquid_weight=w2tmp.weight.data
w2tmp.weight.data=w2tmp.weight.data*self.connectivity_matrix
self.con.append(w2tmp)
self.learning_rule.append(BCM(self.node_lsm(), [self.con[0], self.con[1]])) # pm
self.fc = nn.Linear(liquid_size,num_classes).to(device)
self.learning_rule.append(BCM(self.node_fc(), [self.fc])) # pm
def forward(self, x):
x = x.reshape(x.shape[0], -1)
sum_spike=0
time_window=20
self.tw=time_window
self.firing_tw=torch.zeros(time_window, self.batchsize, self.liquid_size).to(self.device)
self.out = torch.zeros(self.batchsize, self.liquid_size).to(self.device)
for t in range(time_window):
self.out, self.dw = self.learning_rule[0](x, self.out)
# self.con[0].weight+=self.dw[0]
self.con[1].weight.data+=self.dw[1]
out_liquid=self.out[:,0:self.liquid_size]
xout,dw = self.learning_rule[1](out_liquid)
self.fc.weight.data+=dw[0]
sum_spike=sum_spike+xout
self.firing_tw[t]=out_liquid
outputs = sum_spike / time_window
return outputs
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/maze.py
================================================
import matplotlib.pyplot as plt
import networkx as nx
import numpy as np
import math
from matplotlib import pyplot as plt
import matplotlib
import seaborn as sns
from lsmmodel import SNN
from tools.ExperimentEnvGlobalNetworkSurvival import ExperimentEnvGlobalNetworkSurvival
from tools.MazeTurnEnvVec import MazeTurnEnvVec
import torch
import brewer2mpl
from cycler import cycler
import nsganet as engine
from pymop.problem import Problem
from pymoo.optimize import minimize
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
def randbool(size, p):
return torch.rand(*size) < p
class Evolve(Problem):
# first define the NAS problem (inherit from pymop)
def __init__(self, n_var=20, n_obj=1, n_constr=0, lb=None, ub=None):
super().__init__(n_var=n_var, n_obj=n_obj, n_constr=n_constr, type_var=np.int64)
self.xl = lb
self.xu = ub
self._n_evaluated = 0 # keep track of how many architectures are sampled
def _evaluate(self, x, out, *args, **kwargs):
objs = np.full((x.shape[0], self.n_obj), np.nan)
for i in range(x.shape[0]):
arch_id = self._n_evaluated + 1
print('Network= {}'.format(arch_id))
objs[i, 0] = np.linalg.matrix_rank(x[i])
self._n_evaluated += 1
out["F"] = objs
# if your NAS problem has constraints, use the following line to set constraints
# out["G"] = np.column_stack([g1, g2, g3, g4, g5, g6]) in case 6 constraints
# ---------------------------------------------------------------------------------------------------------
# Define what statistics to print or save for each generation
# ---------------------------------------------------------------------------------------------------------
def do_every_generations(algorithm):
# this function will be call every generation
# it has access to the whole algorithm class
gen = algorithm.n_gen
pop_var = algorithm.pop.get("X")
pop_obj = algorithm.pop.get("F")
# report generation info to files
print("generation = {}".format(gen))
print("population error: best = {}, mean = {}, "
"median = {}, worst = {}".format(np.min(pop_obj[:, 0]), np.mean(pop_obj[:, 0]),
np.median(pop_obj[:, 0]), np.max(pop_obj[:, 0])))
print('Best Genome id= {}'.format(np.argmin(pop_obj[:, 0])))
if __name__ == '__main__':
device = 'cuda:8'
num = 8
n_agent = 20
steps = 500
liquid_size=80
env = MazeTurnEnvVec(n_agent, n_steps=steps)
newenv=MazeTurnEnvVec(n_agent, n_steps=steps)
data_env = ExperimentEnvGlobalNetworkSurvival(env)
newdata_env = ExperimentEnvGlobalNetworkSurvival(newenv)
gens=100
seed=0
sum_of_env = np.zeros([gens, n_agent])
env_r=np.zeros([steps,n_agent])
population = torch.zeros(n_agent,liquid_size,liquid_size)
for i in range(n_agent):
population[i] = randbool([liquid_size, liquid_size],p=0.01).to(device).float()
kkk = Evolve(n_var=liquid_size*liquid_size,
n_obj=1, n_constr=2)
method = engine.nsganet(pop_size=n_agent,
sampling=RandomSampling(var_type='custom'),
mutation=BinaryBitflipMutation(),
n_offsprings=10,
eliminate_duplicates=True)
kres=minimize(kkk,
method,
callback=do_every_generations,
termination=('n_gen', gens))
# lm=evolve(population, gens)
model = SNN(ins=4,n_agent=n_agent,device=device,liquid_size=liquid_size,lsm_tau=2,lsm_th=0.2,connectivity_matrix=randbool([liquid_size, liquid_size],p=0.01).to(device).float())
model.to(device)
old_dis = np.ones([n_agent,])*13
X = data_env.reset()
envreward = np.zeros([n_agent, ])
fit=np.zeros([n_agent])
for i in range(steps):
model.reset()
out = model(torch.from_numpy(X+1).float().to(device)).cpu().detach().numpy()
X_next, envreward, fitness, infos = data_env.step(np.argmax(out,axis=1))
food_pos = data_env.env.food_pos[:, 0, :2]
agent_pos = data_env.env.agents_pos
print(agent_pos)
dis = ((agent_pos - food_pos) ** 2).sum(1)
reward =np.array((np.sqrt(old_dis)-np.sqrt(dis))>0,dtype=int)
aa=np.ones_like(reward)*-1
bb = np.ones_like(reward)*3
cc = np.ones_like(reward)*-3
reward=np.where(reward == 0 , aa, reward)
reward=np.where(envreward == 1, bb, reward)
reward = np.where(envreward == -1, cc, reward)
old_dis= dis
env_r[i]=reward
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/tools/EnuGlobalNetwork.py
================================================
import pickle
import time
import numpy as np
import torch
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import gridspec
from AbstractLayerBMM import AbstractLayerBMM
from EvolvableNeuralUnitStacked import EvolvableNeuralUnitStacked
from Tools import get_data_path
sns.set_style("darkgrid")
class EnuGlobalNetwork(AbstractLayerBMM):
"""Network of ENUs implementation in PyTorch, where each synapse and neuron is modeled as an ENU. """
def __init__(self, n_offspring, n_pseudo_env, n_input_neurons, n_hidden_neurons, n_output_neurons, n_syn_per_neuron):
# offspring
self.n_offspring = n_offspring
self.n_pseudo_env = n_pseudo_env
# input channels
n_input_channels = 16
self.n_input_channels = n_input_channels
n_dynamic_param = 32
# total neurons
n_neurons = n_output_neurons + n_hidden_neurons
self.n_neurons = n_neurons
super().__init__(n_offspring, n_neurons, n_input_neurons, n_output_neurons)
torch.random.manual_seed(0)
#NOTE: batch dimension holds output of each neuron/synapse, allowing fast GPU MM
#NOTE neurons far less than synapses, so can be relatively bigger rnn for little cost
n_input_channels_neuron = 16
n_input_neuron, n_output_neuron = n_input_channels_neuron, n_input_channels
self.neurons = EvolvableNeuralUnitStacked(n_offspring, batch_size=self.n_neurons, n_input=n_input_neuron, n_dynamic_param=n_dynamic_param, n_output=n_output_neuron)
#self.n_syn = next_power_of_2(int(n_neurons * (rel_connectivity*n_neurons)))
self.n_syn_per_neuron = n_syn_per_neuron
self.n_syn = n_neurons * n_syn_per_neuron
n_input_syn, n_output_syn = n_input_channels * 2, n_input_channels_neuron # * 2 for neuron feedback (which same channel as n_channel input)
self.synapses = EvolvableNeuralUnitStacked(n_offspring, batch_size=self.n_syn, n_input=n_input_syn, n_dynamic_param=n_dynamic_param, n_output=n_output_syn)
# just randomly connect synapses to neurons
self.synapse_connections = torch.randint(n_input_neurons + n_neurons, size=(n_neurons, n_syn_per_neuron), device='cuda', dtype=torch.long)
# fixed predefined connection patterns
if n_input_neurons==2 and n_output_neurons==2 and n_hidden_neurons==2:
print("Fixed connection Network 2-2-2")
self.synapse_connections = torch.tensor([[0, 1],
[0, 1],
[2, 3],
[2, 3]], device='cuda', dtype=torch.long)
elif n_input_neurons == 4 and n_output_neurons == 3 and n_hidden_neurons == 3 and n_syn_per_neuron==3:
print("Fixed connection Network 4-3-3 (3syn)")
self.synapse_connections = torch.tensor([[0, 1, 3],# hidden connections #4
[0, 2, 3], #5
[1, 2, 3],# 6
[4, 5, 6], # output connections #7
[4, 5, 6],#8
[4, 5, 6]#9
], device='cuda', dtype=torch.long)
elif n_input_neurons==5 and n_hidden_neurons==0 and n_output_neurons==4:
print("Fixed connection Network 5-0-4 (5syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3, 4],# output connections
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4]
], device='cuda', dtype=torch.long)
elif n_input_neurons==1 and n_hidden_neurons==0 and n_output_neurons==2:
print("Fixed connection Network 1-0-2 (1syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0],# output connections
[0]
], device='cuda', dtype=torch.long)
elif n_input_neurons==4 and n_hidden_neurons==0 and n_output_neurons==3 and n_syn_per_neuron==4:
print("Sparse connection Network 4-0-3 (4syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3],# output connections #4
[0, 1, 2, 3], #5
[0, 1, 2, 3],# 6
], device='cuda', dtype=torch.long)
elif n_input_neurons == 4 and n_hidden_neurons == 3 and n_output_neurons == 3 and n_syn_per_neuron == 4:
print("Sparse connection Network 4-3-3 (3syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 3], # hidden connections #4
[0, 2, 3], # 5
[1, 2, 3], # 6
[4, 5, 3], # output connections #7
[4, 6, 3], # 8
[5, 6, 3] # 9
], device='cuda', dtype=torch.long)
elif n_input_neurons==4 and n_hidden_neurons==3 and n_output_neurons==3 and n_syn_per_neuron==8:
print("Sparse connection Network 4-3-3 (8syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 5, 6, 7, 8, 3, 4],# hidden connections #4
[0, 2, 4, 6, 7, 9, 3, 5], #5
[1, 2, 4, 5, 8, 9, 3, 6],# 6
[4, 5, 8, 9, 0, 1, 3, 7], # output connections #7
[4, 6, 7, 9, 0, 2, 3, 8],#8
[5, 6, 7, 8, 1, 2, 3, 9]#9
], device='cuda', dtype=torch.long)
elif n_input_neurons==4 and n_hidden_neurons==4 and n_output_neurons==4 and n_syn_per_neuron==8:
print("Fixed connection Network 4-4-4 (8syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3, 4, 5, 6, 7],# hidden connections
[0, 1, 2, 3, 4, 5, 6, 7],
[0, 1, 2, 3, 4, 5, 6, 7],
[0, 1, 2, 3, 4, 5, 6, 7],
[4, 5, 6, 7, 8, 9, 10, 11], # output connections
[4, 5, 6, 7, 8, 9, 10, 11],
[4, 5, 6, 7, 8, 9, 10, 11],
[4, 5, 6, 7, 8, 9, 10, 11],
], device='cuda', dtype=torch.long)
elif n_input_neurons==5 and n_hidden_neurons==5 and n_output_neurons==4:
print("Fixed connection Network 5-5-4 (5syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3, 4],# hidden connections
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9], # output connections
[5, 6, 7, 8, 9],
[5, 6, 7, 8, 9],
[5, 6, 7, 8, 9],
], device='cuda', dtype=torch.long)
elif n_input_neurons==1 and n_hidden_neurons==0 and n_output_neurons==1:
print("Fixed connection Single")
self.synapse_connections = torch.tensor([[0]], device='cuda', dtype=torch.long)
else:
print("Random connections")
# each synapse is connected also to its post-synaptic neuron, to allow STDP type learning to emerge
self.synapse_connections_post = torch.arange(n_neurons, device='cuda', dtype=torch.long).reshape(n_neurons, -1).repeat(1, n_syn_per_neuron)
# define compartments
self.compartments = [self.neurons, self.synapses]
self.trainable_layers = self.neurons.trainable_layers + self.synapses.trainable_layers
self.track_data = False
def dump_model(self, e, exp_name):
"""Dump model to restore"""
with open(get_data_path(e, exp_name, "Model"), 'wb') as f:
parameters = {}
parameters["neuron"] = [layer.base_parameters.cpu().numpy() for layer in self.neurons.trainable_layers]
parameters["synapse"] = [layer.base_parameters.cpu().numpy() for layer in self.synapses.trainable_layers]
pickle.dump(parameters, f)
def restore_model(self, e, exp_name):
"""Restore model"""
with open(get_data_path(e, exp_name, "Model"), 'rb') as f:
parameters = pickle.load(f)
#TODO: refactor to dump/restore at ENU level and just call those functions
assert len(self.neurons.trainable_layers) == len(parameters["neuron"])
for i in range(len(parameters["neuron"])):
self.neurons.trainable_layers[i].base_parameters = torch.from_numpy(parameters["neuron"][i].astype(np.float32)).cuda()
assert len(self.synapses.trainable_layers) == len(parameters["synapse"])
for i in range(len(parameters["synapse"])):
self.synapses.trainable_layers[i].base_parameters = torch.from_numpy(parameters["synapse"][i].astype(np.float32)).cuda()
@staticmethod
def plot_weights(e, exp_name):
"""Visualize weights of ENU gates"""
sns.set_style("dark")
def calc_average(start, stop):
weights_average = None
for e in range(start, stop, 1000):
with open(get_data_path(e, exp_name, "Model"), 'rb') as f:
parameters = pickle.load(f)
weights = []
for i in range(len(parameters["neuron"])):
weights += [parameters["neuron"][i].astype(np.float32)]
if weights_average is None:
weights_average = weights
else:
for i in range(len(weights_average)):
weights_average[i] += weights[i]
return weights_average
weights_mean1 = calc_average(20000, 30000)
fig, ax = plt.subplots(1, 2, sharex='col', sharey='row')
for i in range(len(weights_mean1)):
ax[i].imshow(weights_mean1[i], cmap="gray")
weights_mean2 = calc_average(30000, 40000)
fig, ax = plt.subplots(1, 2, sharex='col', sharey='row')
for i in range(len(weights_mean2)):
ax[i].imshow(weights_mean2[i], cmap="gray")
fig, ax = plt.subplots(1, 2, sharex='col', sharey='row')
for i in range(len(weights_mean2)):
ax[i].imshow((weights_mean2[i] - weights_mean1[i])**5, cmap="gray")
plt.show()
def dump_network_activity(self, e, exp_name):
"""Dump raw data for visualization"""
with open(get_data_path(e, exp_name, "GlobalNetwork"), 'wb') as f:
pickle.dump(self.vis_data, f)
def print(self):
print("--Neurons--")
self.neurons.print()
print("--Synapses--")
self.synapses.print()
def reset(self):
self.vis_data = []
if self.track_data:
print("Tracking network activity")
for compartment in self.compartments:
compartment.reset()
def forward(self, X):
"""Main computation forward pass"""
# transfer to GPU
X_raw_gpu = torch.from_numpy(X.astype(np.float32)).cuda()
X_gpu = torch.zeros((X.shape[0], X.shape[1], self.n_input_channels), device='cuda', dtype=torch.float32)
X_gpu[:, :, :X_raw_gpu.shape[2]] = X_raw_gpu
# first compute synapses, set input to previous output of connected neuron
# concat our input spiking pattern directly to input to our synapses (the neurons)
# NOTE: this concats in batch dimension, meaning it feeds into input neurons directly spiking pattern, while rest receive input from network
input_to_synapses = torch.cat([X_gpu, self.neurons.out_mem], dim=1)
# connect each synapse randomly to multiple inputs
input_to_synapses_connected = input_to_synapses[:, self.synapse_connections.flatten(), :]
# need feedback connection from neuron to synapse, to allow stdp type rules to emerge (else it has to do it through feedback connections, but less guarentee on connections and cannot distinguise type)
# one synapse has 1 pre-synaptic neuron and 1 post-synaptic neuron, connectection defined in synapse_connections, synapse_connections[i, :] gives all input synapses of that neuron
# so feedback to all it's input synapses through broadcasting backwards
post_neuron_backprop_connected = self.neurons.out_mem[:, self.synapse_connections_post.flatten(), :]
input_to_synapses_connected = torch.cat([input_to_synapses_connected, post_neuron_backprop_connected], dim=-1)
# compute synapse
self.synapses.forward(input_to_synapses_connected)
# then integrate(sum) all outputs of a neurons input synapses, can just reshape into valid shape, since we already randomly connected when computing synapses
# NOTE: each neuron then requires same number of synapses, then reshape by modifying batch dim (which contains syn outputs)
integration = torch.sum(self.synapses.out.reshape((self.n_offspring, self.n_neurons, -1, self.synapses.shape[-1])), dim=2)
# scale by number of synapses
integration /= self.n_syn_per_neuron
self.out_integration = integration
# finally set neuron input to summated connected synapses output
input_to_neurons = integration
out = self.neurons.forward(input_to_neurons)
# output is last neuron output, NOTE: just first channel is returned, since we reshape neurons to channels
self.out = out[:, -self.n_output:, 0].reshape(self.n_offspring, self.n_output)
if self.track_data:
self._track_vis_data(X, input_to_synapses_connected, input_to_neurons)
return self.out
def _track_vis_data(self, X, input_to_synapses_connected, input_to_neurons):
offspring_idx = 0
self.vis_data += [(X[offspring_idx], input_to_neurons[offspring_idx].cpu().numpy(), self.neurons.out[offspring_idx].cpu().numpy(),
input_to_synapses_connected[offspring_idx].cpu().numpy(), self.synapses.out[offspring_idx].cpu().numpy())]
@staticmethod
def plot_network_activity(e, exp_name):
with open(get_data_path(e, exp_name, "GlobalNetwork"), 'rb') as f:
vis_data = pickle.load(f)
X, input_to_neurons, neurons_out, input_to_synapses, synapses_out = map(np.array, zip(*vis_data))
def plot_enu_activity(input, output, title):
n_cells = output.shape[1]
n_cells = np.minimum(10, output.shape[1])
fig, grid = plt.subplots(2, n_cells, sharex='col', sharey='row')
if n_cells==1:
grid[0].plot(input[:, 0, :])
grid[1].plot(output[:, 0, :])
else:
for i in range(n_cells):
grid[0, i].plot(input[:, i, :])
grid[1, i].plot(output[:, i, :])
plt.xlabel("t")
plt.title(title)
#plt.ylabel("")
plt.legend()
plt.figure()
plt.plot(X[:, :, 0])
plot_enu_activity(input_to_neurons, neurons_out, "ENU neuron activity")
plot_enu_activity(input_to_synapses, synapses_out, "ENU synapse activity")
plt.figure()
spike_points = np.where(neurons_out[:, :, 0] > 0)
plt.scatter(spike_points[0], spike_points[1], marker='|')
plt.show()
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/tools/ExperimentEnvGlobalNetworkSurvival.py
================================================
import pickle
import numpy as np
from tools.Tools import get_data_path
class ExperimentEnvGlobalNetworkSurvival:
"""Wrapper around a given RL environment for a Network of ENUs model,
turns reward into fitness and dumps relevant data"""
def __init__(self, env, exp_name='maze'):
self.env = env
self.exp_name = exp_name
self.n_output = self.env.n_actions
#NOTE: +1 reward neuron
self.n_input_neurons = self.env.n_obs + 1
self.n_agents = self.env.n_agents
def _convert_obs(self, obs, rewards):
n_input_channels_used = 3
X = np.zeros((self.n_agents, self.n_input_neurons, n_input_channels_used))
#X[:, :obs.shape[1], 0] = obs
# Shuffle only obs to avoid topology exploitation, reward neuron linked to EnuGlobal synapse connectivity
X[:, :obs.shape[1], 0] = np.take_along_axis(obs, self.obs_shuffle, axis=1)
# split pos and negative reward to different channels, And set to last input neuron
if rewards is not None:
X[rewards>0, -1, 1] = np.abs(rewards[rewards>0])
X[rewards<=0, -1, 2] = np.abs(rewards[rewards<=0])
return X
def _convert_reward(self, obs, actions, rewards, infos, dones):
fitness = np.copy(rewards)
# first poison is considered positive reward, since learning to learn
#NOTE: dead by env means less reward can be obtained so should implictely reduce overall fitness automatically
fitness[np.logical_and(self._prev_reward_count == 1, rewards != 0)] = 1
# include episode length as extra fitness, since not taking poison would allow survive longer, so should try avoid take poison
fitness[dones==0] += 0.1/4
return fitness
def step(self, y):
# if self.t % 3 != 0:
# actions = np.zeros((self.n_agents), dtype=np.int32) - 1
# else:
# winner take all, in given time window
actions = y
# if all same output, do nothing
# equal_actions = self.y_hist.shape[1] == np.sum(self.y_hist == np.take_along_axis(self.y_hist, actions.reshape(-1, 1), axis=1), axis=-1)
# actions[equal_actions] = -1
# self.y_hist[:] = 0
# take env step
allobs, obs, rewards, dones, infos = self.env.step(actions)
# X = self._convert_obs(obs, rewards)
X=allobs
self._prev_reward_count += rewards!=0
fitness = self._convert_reward(obs, actions, rewards, infos, dones)
self._prev_action = actions
self._prev_obs = obs
return X, rewards, fitness, None
def reset(self):
self.t = 0
self.y_hist = np.zeros((self.n_agents, self.n_output), dtype=np.float32)
self._prev_action = None
self._prev_obs = None
self._prev_reward_count = np.zeros((self.n_agents), dtype=np.float32)
# each time different input/output neurons should have different meaning, to have learning to learn
self.obs_shuffle = np.argsort(np.random.randn(self.n_agents, self.n_input_neurons - 1), axis=1, kind='mergesort')
self.action_shuffle = np.argsort(np.random.randn(self.n_agents, self.n_output), axis=1, kind='mergesort')
# reset env
self.allobs,self.obs = self.env.reset()
# return self._convert_obs(self.obs, None)
return self.allobs
def render(self):
if self.t%4==0:
self.env.render()
def track_vis_data(self, vis_data, model, X, y_est, t):
n_fetch = 128
# TODO: also get our gates from the model
vis_data+=[(X[:n_fetch, :], y_est[:n_fetch, :])]
def dump_vis_data(self, vis_data, fitness_per_offspring, e):
with open(get_data_path(e, self.exp_name, "output"), 'wb') as f:
pickle.dump((vis_data, fitness_per_offspring), f)
@staticmethod
def load_vis_data(e, exp_name):
with open(get_data_path(e, exp_name, "output"), 'rb') as f:
vis_data, fitness_per_offspring = pickle.load(f)
return vis_data, fitness_per_offspring
@staticmethod
def plot_vis_data(e, exp_name):
vis_data, fitness_per_offspring = ExperimentEnvGlobalNetworkSurvival.load_vis_data(e, exp_name)
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/tools/MazeTurnEnvVec.py
================================================
import pickle
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from tools.Tools import save_fig, get_data_path
# np.random.seed(0)
class MazeTurnEnvVec:
"""Vectorized RL T-Maze environment written in pure Numpy. We require an efficient environment since we need to evaluate
and run up to thousands of offspring in parallel"""
def __init__(self, n_agents, n_steps):
# 4 important points, start point, decision point, food point, dead point.
# just generate a very large matrix that could fit any maze of any size, then can generate smaller maze as well
self.n_actions = 3
self.n_obs = 3
self.max_size = 7
self.n_agents = n_agents
self.n_steps = n_steps
self.window = plt.figure()
self.t_maze = True
self.turn_based = False
# steps can be longer if poison and need to turn around
self.steps_to_food = 2
if self.t_maze:
self.steps_to_food = 3
self.steps_to_food += self.steps_to_food*2
# give some extra leniency
self.steps_to_food *= 2
def step(self, actions):
# L R U D
# TODO: check legal action or not..
pos_copy = np.copy(self.agents_pos)
actions = np.copy(actions)
# GIVE TIME UPDATE WEIGHTS
# actions[self.agents_reset > 0] = -1
# actions[self.agent_energy<=0] = -1
self.agents_reset[self.agents_reset > 0] -= 1
# if turn based
if self.turn_based:
Forward = actions == 0
self.agents_pos[np.logical_and(Forward, self.agent_directions == 0), 1] += 1
self.agents_pos[np.logical_and(Forward, self.agent_directions == 2), 1] -= 1
self.agents_pos[np.logical_and(Forward, self.agent_directions == 1), 0] -= 1
self.agents_pos[np.logical_and(Forward, self.agent_directions == 3), 0] += 1
L = actions == 1
self.agent_directions[L] += 1
R = actions == 2
self.agent_directions[R] -= 1
self.agent_directions[self.agent_directions > 3] = 0
self.agent_directions[self.agent_directions < 0] = 3
else:
# or just direct movement
U = actions == 2
D = actions == 1
R = actions == 0
if self.agents_pos[U].size>0:
self.agents_pos[U, 0] += 1
self.agent_directions[U] = 3
if self.agents_pos[D].size>0:
self.agents_pos[D, 0] -= 1
self.agent_directions[D] = 1
if self.t_maze and self.agents_pos[R].size>0:
self.agents_pos[R, 1] += 1
self.agent_directions[R] = 0
# UNDO MOVES THAT GOT AGENT INTO WALL
self.current_cells = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1]]
self.agents_pos[self.current_cells==1] = pos_copy[self.current_cells==1]
movement_loss = np.prod(self.agents_pos==pos_copy, axis=-1)
# CHECK IF FOOD CONSUMED, is reward + pos reset
consumed_food = np.prod(self.agents_pos==self.food_pos[:, 0, :2], axis=-1).astype(np.bool)
consumed_pois = np.prod(self.agents_pos==self.food_pos[:, 1, :2], axis=-1).astype(np.bool)
self.consumed_count += consumed_food.astype(np.int32)
self.consumed_count_total += consumed_food.astype(np.int32)
self.consumed_count_pois += consumed_pois.astype(np.int32)
self._reset_pos(np.logical_or(consumed_food, consumed_pois))
# self._reset_pos_pois(consumed_pois)
# self._reset_food(self.consumed_count==self.swap_limit, prob=0.0)
# reset food for agents that ate food, and swap with some probability
self._reset_food(self.consumed_count==5, prob=0.5)
self.rewards = consumed_food.astype(np.float32) - consumed_pois.astype(np.float32) #* 0.5 #- movement_loss.astype(np.float32) * 0.01
# get observation from current position of each agent
self.agent_allobs,self.obs = self._get_obs_from_pos()
# instant dead on second poison
self.agent_energy += np.where(self.consumed_count_pois<=1, np.abs(self.rewards) * self.steps_to_food, -self.agent_energy * np.abs(self.rewards))
# energy decay to encourage exploration, agent dies if running out of energy
self.agent_energy = np.minimum(self.agent_energy, self.steps_to_food)
self.agent_energy -= 1.0/4
dones = self.agent_energy<=0
return self.agent_allobs,self.obs, self.rewards, dones, None
def _reset_pos(self, idxs):
self.agents_pos[idxs] = [self.start_point, 2] # set X pos
self.agent_directions[idxs] = 0
if self.max_size==5:
self.agent_directions[idxs] = 1
self.agents_reset[idxs] = 0
self.agents_reset_count[idxs] += 1
def _reset_pos_pois(self, idxs):
#NOTE: 2 since we call reset twice!
#NOTE: turning around already cost 8 steps, then 4x4 more is 16+8, 24, so reset should be much worse
self.agents_reset[np.logical_and(idxs, self.agents_reset_count>2)] = 64
def _reset_food(self, idxs, prob=0.5):
# swap food with some probability, avoids agent overfitting on environment
swap = np.take_along_axis(self.random_swap_matrix, self.consumed_count_total.reshape(-1, 1), axis=1).ravel()
swap_idxs = swap * idxs
food_loc = np.copy(self.food_pos[swap_idxs, 0, :])
pois_loc = np.copy(self.food_pos[swap_idxs, 1, :])
self.food_pos[swap_idxs, 0, :] = pois_loc
self.food_pos[swap_idxs, 1, :] = food_loc
# set maze value
self.mazes[np.arange(self.mazes.shape[0]), self.food_pos[:, 0, 0], self.food_pos[:, 0, 1]] = 2
self.mazes[np.arange(self.mazes.shape[0]), self.food_pos[:, 1, 0], self.food_pos[:, 1, 1]] = 3
self.consumed_count[idxs] = 0
def reset(self):
self.consumed_count = np.zeros((self.n_agents), dtype=np.int32)
self.consumed_count_total = np.zeros_like(self.consumed_count)
# consistent swapping such that if agent eat food once for all agents swapped with same seed, fair fitness comparison
max_eat = self.n_steps
self.random_swap_matrix = np.random.uniform(0, 1, size=(1, max_eat)) >= 0.5
self.random_swap_matrix = np.repeat(self.random_swap_matrix, int(self.n_agents), axis=0)
self.agent_energy = np.zeros((self.n_agents), dtype=np.float32) + self.steps_to_food
self.consumed_count_pois = np.zeros_like(self.consumed_count)
#self.swap_limit = np.random.randint(1, 5, size=1)
#self.swap_limit = np.random.randint(1, 4, size=self.n_agents)
self.mazes = np.ones((self.n_agents, self.max_size, self.max_size), dtype=np.int32)
#TODO: support variable maze length
self.start_point = int(self.max_size/2)
if self.t_maze:
self.mazes[:, self.start_point, 2:-1] = 0
self.mazes[:, 1:-1, -2] = 0
# FOOD either at -1,-1 or -1,1?
# two foods: x, y, value
self.food_pos = np.zeros((self.n_agents, 2, 2), dtype=np.int32)
self.food_pos[:, :, 1] = self.max_size - 2
self.food_pos[:, 1, 0] = 1
self.food_pos[:, 0, 0] = self.max_size - 2
self._reset_food(np.ones(self.food_pos.shape[0], dtype=np.bool), prob=0.5)
else:
self.mazes[:, 1:-1, 1] = 0
# two foods: x, y, value
self.food_pos = np.zeros((self.n_agents, 2, 2), dtype=np.int32)
self.food_pos[:, :, 1] = 1
self.food_pos[:, 0, 0] = 1
self.food_pos[:, 1, 0] = (self.max_size - 2)
self._reset_food(np.ones(self.food_pos.shape[0], dtype=np.bool), prob=0.5)
# AGENT
self.agents_pos = np.ones((self.n_agents, 2), dtype=np.int32)
self.agents_reset = np.zeros((self.n_agents), dtype=np.int32)
self.agents_reset_count = np.zeros_like(self.agents_reset)
self.agent_directions = np.zeros((self.n_agents), dtype=np.int32)
self._reset_pos(np.arange(self.agents_pos.shape[0]))
# OBS
self.agent_allobs,self.obs = self._get_obs_from_pos()
return self.agent_allobs,self.obs
def _get_obs_from_pos(self):
# obs is neighbouring cell states around agent
obs = np.zeros((self.n_agents, self.n_obs), dtype=np.float32)
raw_obs = np.zeros(self.n_agents, dtype=np.int32)
# get observation based on direction agent is facing
leftobs = np.zeros(self.n_agents)
rightobs = np.zeros(self.n_agents)
backobs = np.zeros(self.n_agents)
# get observation based on direction agent is facing
D = self.agent_directions == 0
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] + 1][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] - 1, self.agents_pos[:, 1]][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] + 1, self.agents_pos[:, 1]][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1]-1][D]
D = self.agent_directions == 2
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] - 1][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] + 1, self.agents_pos[:, 1]][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] - 1, self.agents_pos[:, 1]][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1]+1][D]
D = self.agent_directions == 1
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] - 1, self.agents_pos[:, 1]][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] - 1][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] + 1][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0]+1, self.agents_pos[:, 1]][D]
D = self.agent_directions == 3
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] + 1, self.agents_pos[:, 1]][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] + 1][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] - 1][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0]-1, self.agents_pos[:, 1]][D]
# mark what was observed at different index
obs[raw_obs == 1, 0] = 1
obs[raw_obs == 2, 1] = 1
obs[raw_obs == 3, 2] = 1
allobs=np.squeeze(np.dstack((leftobs,raw_obs,rightobs,backobs)))
return allobs, obs
def render(self):
plt.clf()
sns.set_style("white")
#TODO: support render all mazes? can reshape to square?
max_render = 1
flattened_render = np.dstack(np.split(self.mazes[18, :], max_render, axis=0)).reshape(self.mazes.shape[1], -1)
flattened_render[flattened_render>1] = 0
plt.axis('off')
plt.imshow(flattened_render,cmap='bone')
for j in range(1):
i=18
marker = ">"
if self.agent_directions[i] == 1:
marker = "^"
if self.agent_directions[i] == 2:
marker = "<"
if self.agent_directions[i] == 3:
marker = "v"
obs_color = "black"
if self.obs[i, 0] == 1:
obs_color = "gray"
if self.obs[i, 1] == 1:
obs_color = "green"
if self.obs[i, 2] == 1:
obs_color = "red"
alpha = 1
if self.agent_energy[i]<=0:
alpha = 1
plt.scatter(self.agents_pos[i, 1] + j * self.mazes.shape[1], self.agents_pos[i, 0], color="skyblue", alpha=alpha, marker=marker)
plt.scatter(self.agents_pos[i, 1] + j * self.mazes.shape[1], self.agents_pos[i, 0], color=obs_color,alpha=alpha, marker=marker, s=3)
plt.scatter(self.food_pos[i, 0, 1] + j * self.mazes.shape[1], self.food_pos[i, 0, 0], color="green", alpha=1, marker="o")
plt.scatter(self.food_pos[i, 1, 1] + j * self.mazes.shape[1], self.food_pos[i, 1, 0], color="red", alpha=1, marker="o")
plt.pause(0.001)
#plt.pause(2)
@staticmethod
def load_vis_data(e, exp_name):
with open(get_data_path(e, exp_name, "output"), 'rb') as f:
vis_data, fitness_per_offspring = pickle.load(f)
return vis_data, fitness_per_offspring
@staticmethod
def plot_vis_data(e, exp_name):
import matplotlib.pyplot as plt
from cycler import cycler
import seaborn as sns
sns.set_style("whitegrid")
vis_data, fitness_per_offspring = MazeTurnEnvVec.load_vis_data(e, exp_name)
offspring_idx = 0
#x, y_est, y = np.array(vis_data).transpose(1, 2, 0, 3)
X, Y_est = map(np.array, zip(*vis_data))
X_base, y_est_base = X[:, offspring_idx], Y_est[:, offspring_idx]
#X_base, y_est_base = X_base[:300], y_est_base[:300]
#X_base = np.max(X_base, axis=1)
# --- normal output single example---
plt.rc('axes', prop_cycle=(cycler('color', ['gray', '#ff7f0e', '#9467bd', '#8c564b', '#e377c2', '#17becf'])))
# OLD METHOD!
plt.figure()
#NOTE: last neuron is always reward neuron
plt.plot(-X_base[:, :-1, 0], label="N-ENUs input", alpha=0.7)
plt.plot(- np.max(X_base, axis=1)[:, 1], label="Positive reward", alpha=0.7, color='#2ca02c')
plt.plot(- np.max(X_base, axis=1)[:, 2], label="Negative reward", alpha=0.7, color='#d62728')
#plt.gca().set_color_cycle(['orange', 'purple', 'brown'])
plt.plot(y_est_base[:, :], label="N-ENUs output", alpha=0.8)
plt.legend(loc='upper right')
save_fig(e, exp_name, "single_episode")
plt.rc('axes', prop_cycle=(cycler('color', ['gray', '#ff7f0e', '#9467bd', '#8c564b', '#e377c2', '#17becf'])))
# new method!
fig, grid = plt.subplots(2, sharex=True)
# input
#grid[1].set_prop_cycle(cycler('color', ['gray', '#ff7f0e', '#1f77b4']))
grid[1].set_prop_cycle(cycler('color', ['gray', '#F5B041', '#2E86C1']))
grid[1].plot(X_base[:, :-1, 0], label="N-ENUs input", alpha=0.7, linewidth=2)
grid[1].plot(np.max(X_base, axis=1)[:, 1], label="Positive reward", alpha=0.7, color='#1ABC9C', linewidth=2)
grid[1].plot(np.max(X_base, axis=1)[:, 2], label="Negative reward", alpha=0.7, color='#CB4335', linewidth=2)
grid[1].legend(['Sensor (wall)', 'Sensor (red)', 'Sensor (green)', 'Positive reward', 'Negative reward'], loc='upper right')
grid[1].set_ylabel('Neuron output')
# output
grid[0].set_prop_cycle(cycler('color', ['#9467bd', '#e377c2', '#17becf','#8c564b']))
grid[0].plot(y_est_base[:, :], label="N-ENUs output", alpha=0.8, linewidth=2)
grid[0].legend(['ENU-NN (left)', 'ENU-NN (right)', 'ENU-NN (forward)'],loc='upper right')
plt.xlabel('t')
grid[0].set_ylabel('ENU neuron output')
plt.xlim(-5, X_base.shape[0]+10)
save_fig(e, exp_name, "single_episode_dual")
#plt.show()
@staticmethod
def plot_rollout_data(e, exp_name):
#TODO: dump rollout as array not the actual plots
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style("white")
import os
rollout_path = "./" + get_data_path(e, exp_name, "rollout").split(".")[1][:-1]+"/"
rollout_files = sorted(os.listdir(rollout_path))
rollouts = []
for i in range(4, 200, 4):
file = "rollout_{}_.png".format(i)
print(file)
rollout = plt.imread(rollout_path + file)
rollout = rollout[80:450, 200:500]
rollout = np.where(rollout[:, :, [0]]> 0.98, 1, rollout)
rollouts.append(rollout)
# plt.imshow(rollout)
# plt.show()
# for rollout in rollouts:
vert_bar = np.zeros((rollout.shape[0], 5, 4))
vert_bar[::] += 0.5
# get red -> learned go other way
# food swapped -> sees red -> learned turn around
rollouts1 = [rollouts[1], rollouts[9], rollouts[10], rollouts[11], rollouts[17], rollouts[18]]#, rollouts[19]
#, rollouts[28]
#rollouts[24],
rollouts2 = [rollouts[25], rollouts[29], rollouts[30], rollouts[31], rollouts[32], rollouts[33]]
plt.axis('off')
plt.imshow(np.vstack([np.column_stack(rollouts1), np.column_stack(rollouts2)]), cmap='gray')
save_fig(e, exp_name, "rollout_combined")
#plt.show()
if __name__ == '__main__':
"""Test function"""
n_offspring = 1024
envs = MazeTurnEnvVec(n_offspring, n_steps=400)
envs.n_pseudo_env = 8
while True:
envs.reset()
opt_actions_up = [0,0,0,0,1,0]
opt_actions_down = [0,0,0,0,2,0]
opt_actions = [opt_actions_up, opt_actions_down]
opt_current = 0
total_reward = 0
rewards = np.zeros((n_offspring))
rewards_all = np.zeros_like(rewards)
k = 0
n_steps = 200
for i in range(n_steps):
actions = np.random.randint(0, envs.n_actions, size=n_offspring)
#actions[:] = opt_actions_up[i%len(opt_actions_up)]
#actions[0] = opt_actions[opt_current][k % len(opt_actions_up)]
obs, rewards,_,_ = envs.step(actions=actions)
total_reward += (rewards[0] * 100) + 1
rewards_all += (rewards * 100) + 1
#print(rewards[0])
#print(obs[0], rewards[0])
envs.render()
plt.pause(0.5)
k += 1
if rewards[0] < 0:
#print(rewards_last[0])
if opt_current==0:
opt_current = 1
else:
opt_current = 0
if rewards[0] != 0:
k = 0
total_reward/=n_steps
rewards_all/=n_steps
print(rewards_all[0], np.mean(rewards_all), np.std(rewards_all), np.std(rewards_all)/np.mean(rewards_all))
print(rewards_all[:10])
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/tools/nsganet.py
================================================
import numpy as np
from pymoo.algorithms.genetic_algorithm import GeneticAlgorithm
from pymoo.docs import parse_doc_string
from pymoo.model.individual import Individual
from pymoo.model.survival import Survival
from pymoo.operators.crossover.point_crossover import PointCrossover
from pymoo.operators.mutation.polynomial_mutation import PolynomialMutation
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.selection.tournament_selection import compare, TournamentSelection
from pymoo.util.display import disp_multi_objective
from pymoo.util.dominator import Dominator
from pymoo.util.non_dominated_sorting import NonDominatedSorting
from pymoo.util.randomized_argsort import randomized_argsort
# =========================================================================================================
# Implementation
# based on nsga2 from https://github.com/msu-coinlab/pymoo
# =========================================================================================================
class NSGANet(GeneticAlgorithm):
def __init__(self, **kwargs):
kwargs['individual'] = Individual(rank=np.inf, crowding=-1)
super().__init__(**kwargs)
self.tournament_type = 'comp_by_dom_and_crowding'
self.func_display_attrs = disp_multi_objective
# ---------------------------------------------------------------------------------------------------------
# Binary Tournament Selection Function
# ---------------------------------------------------------------------------------------------------------
def binary_tournament(pop, P, algorithm, **kwargs):
if P.shape[1] != 2:
raise ValueError("Only implemented for binary tournament!")
tournament_type = algorithm.tournament_type
S = np.full(P.shape[0], np.nan)
for i in range(P.shape[0]):
a, b = P[i, 0], P[i, 1]
# if at least one solution is infeasible
if pop[a].CV > 0.0 or pop[b].CV > 0.0:
S[i] = compare(a, pop[a].CV, b, pop[b].CV, method='smaller_is_better', return_random_if_equal=True)
# both solutions are feasible
else:
if tournament_type == 'comp_by_dom_and_crowding':
rel = Dominator.get_relation(pop[a].F, pop[b].F)
if rel == 1:
S[i] = a
elif rel == -1:
S[i] = b
elif tournament_type == 'comp_by_rank_and_crowding':
S[i] = compare(a, pop[a].rank, b, pop[b].rank,
method='smaller_is_better')
else:
raise Exception("Unknown tournament type.")
# if rank or domination relation didn't make a decision compare by crowding
if np.isnan(S[i]):
S[i] = compare(a, pop[a].get("crowding"), b, pop[b].get("crowding"),
method='larger_is_better', return_random_if_equal=True)
return S[:, None].astype(np.int)
# ---------------------------------------------------------------------------------------------------------
# Survival Selection
# ---------------------------------------------------------------------------------------------------------
class RankAndCrowdingSurvival(Survival):
def __init__(self) -> None:
super().__init__(True)
def _do(self, pop, n_survive, D=None, **kwargs):
# get the objective space values and objects
F = pop.get("F")
# the final indices of surviving individuals
survivors = []
# do the non-dominated sorting until splitting front
fronts = NonDominatedSorting().do(F, n_stop_if_ranked=n_survive)
for k, front in enumerate(fronts):
# calculate the crowding distance of the front
crowding_of_front = calc_crowding_distance(F[front, :])
# save rank and crowding in the individual class
for j, i in enumerate(front):
pop[i].set("rank", k)
pop[i].set("crowding", crowding_of_front[j])
# current front sorted by crowding distance if splitting
if len(survivors) + len(front) > n_survive:
I = randomized_argsort(crowding_of_front, order='descending', method='numpy')
I = I[:(n_survive - len(survivors))]
# otherwise take the whole front unsorted
else:
I = np.arange(len(front))
# extend the survivors by all or selected individuals
survivors.extend(front[I])
return pop[survivors]
def calc_crowding_distance(F):
infinity = 1e+14
n_points = F.shape[0]
n_obj = F.shape[1]
if n_points <= 2:
return np.full(n_points, infinity)
else:
# sort each column and get index
I = np.argsort(F, axis=0, kind='mergesort')
# now really sort the whole array
F = F[I, np.arange(n_obj)]
# get the distance to the last element in sorted list and replace zeros with actual values
dist = np.concatenate([F, np.full((1, n_obj), np.inf)]) \
- np.concatenate([np.full((1, n_obj), -np.inf), F])
index_dist_is_zero = np.where(dist == 0)
dist_to_last = np.copy(dist)
for i, j in zip(*index_dist_is_zero):
dist_to_last[i, j] = dist_to_last[i - 1, j]
dist_to_next = np.copy(dist)
for i, j in reversed(list(zip(*index_dist_is_zero))):
dist_to_next[i, j] = dist_to_next[i + 1, j]
# normalize all the distances
norm = np.max(F, axis=0) - np.min(F, axis=0)
norm[norm == 0] = np.nan
dist_to_last, dist_to_next = dist_to_last[:-1] / norm, dist_to_next[1:] / norm
# if we divided by zero because all values in one columns are equal replace by none
dist_to_last[np.isnan(dist_to_last)] = 0.0
dist_to_next[np.isnan(dist_to_next)] = 0.0
# sum up the distance to next and last and norm by objectives - also reorder from sorted list
J = np.argsort(I, axis=0)
crowding = np.sum(dist_to_last[J, np.arange(n_obj)] + dist_to_next[J, np.arange(n_obj)], axis=1) / n_obj
# replace infinity with a large number
crowding[np.isinf(crowding)] = infinity
return crowding
# =========================================================================================================
# Interface
# =========================================================================================================
def nsganet(
pop_size=100,
sampling=RandomSampling(var_type=np.int),
selection=TournamentSelection(func_comp=binary_tournament),
crossover=PointCrossover(n_points=2),
mutation=PolynomialMutation(eta=3, var_type=np.int),
eliminate_duplicates=True,
n_offsprings=None,
**kwargs):
"""
Parameters
----------
pop_size : {pop_size}
sampling : {sampling}
selection : {selection}
crossover : {crossover}
mutation : {mutation}
eliminate_duplicates : {eliminate_duplicates}
n_offsprings : {n_offsprings}
Returns
-------
nsganet : :class:`~pymoo.model.algorithm.Algorithm`
Returns an NSGANet algorithm object.
"""
return NSGANet(pop_size=pop_size,
sampling=sampling,
selection=selection,
crossover=crossover,
mutation=mutation,
survival=RankAndCrowdingSurvival(),
eliminate_duplicates=eliminate_duplicates,
n_offsprings=n_offsprings,
**kwargs)
parse_doc_string(nsganet)
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/BCM.py
================================================
import argparse, math, os, sys
import numpy as np
import gym
from gym import wrappers
import matplotlib.pyplot as plt
import nsganet as engine
from pymop.problem import Problem
from pymoo.optimize import minimize
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
from tools.ExperimentEnvGlobalNetworkSurvival import ExperimentEnvGlobalNetworkSurvival
from tools.MazeTurnEnvVec import MazeTurnEnvVec
import torch
import torch.nn.utils as utils
from torch.distributions import Categorical
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from itertools import product
from functools import partial
import torchvision, pprint
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.model_zoo.base_module import BaseModule
from braincog.base.learningrule.BCM import *
from braincog.base.learningrule.STDP import *
parser = argparse.ArgumentParser(description='PyTorch REINFORCE example')
parser.add_argument('--gamma', type=float, default=0.98, metavar='G')
parser.add_argument('--seed', type=int, default=1, metavar='N')
parser.add_argument('--num_steps', type=int, default=500, metavar='N')
parser.add_argument('--num_episodes', type=int, default=100, metavar='N')
parser.add_argument('--render', action='store_true')
args = parser.parse_args()
n_agent = 1
steps = 500
hidden_size=64
env = MazeTurnEnvVec(n_agent, n_steps=steps)
data_env = ExperimentEnvGlobalNetworkSurvival(env)
s_dim = 4
a_dim = 3
def randbool(size, p):
return torch.rand(*size) < p
def fit(agent):
states = list(product([0, 1], repeat=4))
ls_list=[]
for state in states:
agent.model.reset()
state_tensor = torch.tensor(state).float().reshape(1, -1)
la, ls = agent.model(Variable(state_tensor.float()).reshape(-1,))
ls_np = ls.detach().numpy()
ls_list.append(ls_np)
ls_matrix = np.vstack(ls_list)
rank = np.linalg.matrix_rank(ls_matrix)
return rank
@register_model
class SNN(BaseModule):
def __init__(self,
hidden_size,
n_agent,
connectivity_matrix,
num_classes=3,
step=1,
node_type=LIFNode,
encode_type='direct',
ins=4,
lsm_th=0.3,
fc_th=0.3,
lsm_tau=3,
fc_tau=3,
tw=100,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.linear1 = nn.Linear(s_dim, hidden_size)
self.node=partial(node_type, **kwargs, step=step,tau=lsm_tau,threshold=lsm_th)
self.linear2 = nn.Linear(hidden_size, a_dim)
self.node_lsm=partial(node_type, **kwargs, step=step,tau=lsm_tau,threshold=lsm_th)
self.node_fc = partial(node_type, **kwargs, step=step,tau=fc_tau,threshold=fc_th)
self.hidden_size=hidden_size
self.out = torch.zeros(hidden_size)
self.con=[]
self.learning_rule=[]
self.connectivity_matrix=connectivity_matrix
w1tmp=nn.Linear(ins,hidden_size,bias=False)
self.con.append(w1tmp)
w2tmp=nn.Linear(hidden_size,hidden_size,bias=False)
self.liquid_weight=w2tmp.weight.data
w2tmp.weight.data=w2tmp.weight.data*self.connectivity_matrix
self.con.append(w2tmp)
self.learning_rule.append(BCM(self.node_lsm(), [self.con[0], self.con[1]]))
self.fc = nn.Linear(hidden_size,num_classes)
self.learning_rule.append(BCM(self.node_fc(), [self.fc]))
def forward(self, x):
sum_spike=0
time_window=20
self.tw=time_window
self.firing_tw=torch.zeros(time_window, self.hidden_size)
self.out = torch.zeros(self.hidden_size)
for t in range(time_window):
self.out, self.dw = self.learning_rule[0](x, self.out)
self.con[1].weight.data+=self.dw[1]
out_liquid=self.out[0:self.hidden_size]
xout,dw = self.learning_rule[1](out_liquid)
self.fc.weight.data+=dw[0]
sum_spike=sum_spike+xout
self.firing_tw[t]=out_liquid
outputs = sum_spike+0.0001 / time_window
return outputs,out_liquid
class REINFORCE:
def __init__(self, lm):
self.model = SNN(ins=4,n_agent=n_agent,hidden_size=hidden_size,lsm_tau=2,lsm_th=0.2,connectivity_matrix=lm)
self.model.train()
def select_action(self, state):
# mu, sigma_sq = self.model(Variable(state).cuda())
prob,_= self.model(Variable(state).reshape(-1,))
dist = Categorical(probs=prob)
action = dist.sample()
log_prob = prob[action.item()].log()
entropy = dist.entropy()
return action, log_prob, entropy
class Evolve(Problem):
# first define the NAS problem (inherit from pymop)
def __init__(self, n_var=20, n_obj=1, n_constr=0, lb=None, ub=None):
super().__init__(n_var=n_var, n_obj=n_obj, n_constr=n_constr, type_var=np.int64)
self.xl = lb
self.xu = ub
self._n_evaluated = 0 # keep track of how many architectures are sampled
def _evaluate(self, x, out, *args, **kwargs):
objs = np.full((x.shape[0], self.n_obj), np.nan)
for i in range(x.shape[0]):
arch_id = self._n_evaluated + 1
print('Network= {}'.format(arch_id))
agent = REINFORCE(torch.from_numpy(x[i].reshape(hidden_size,hidden_size)).float())
log_reward = []
log_smooth = []
# gamma=np.linspace(0.9,1.0,100)
gam=0.9
# for gam in gamma:
for i_episode in range(100):
state = torch.tensor(data_env.reset()).unsqueeze(0)
entropies = []
log_probs = []
rewards = []
old_dis = np.ones([1,])*13
reawrd_perstep=[]
ss=0
allrewards=[]
for t in range(500):
action, log_prob, entropy = agent.select_action(state.float())
action=action.unsqueeze(0).numpy()
next_state, envreward, done, _ = data_env.step(action)
entropies.append(entropy)
log_probs.append(log_prob)
state = torch.Tensor([next_state])
rewards.append(envreward[0])
print("Episode: {}, reward: {}".format(i_episode, np.sum(rewards)))
log_reward.append(np.sum(rewards))
if i_episode == 0:
log_smooth.append(log_reward[-1])
else:
log_smooth.append(log_smooth[-1]*0.99+0.01*np.sum(rewards))
plt.plot(log_smooth)
plt.plot(log_reward)
plt.pause(1e-5)
objs[i, 0] = fit(agent)
self._n_evaluated += 1
out["F"] = objs
def do_every_generations(algorithm):
gen = algorithm.n_gen
pop_var = algorithm.pop.get("X")
pop_obj = algorithm.pop.get("F")
if __name__ == "__main__":
n_agent=1
kkk = Evolve(n_var=hidden_size*hidden_size,
n_obj=1, n_constr=0)
method = engine.nsganet(pop_size=n_agent,
sampling=RandomSampling(var_type='custom'),
mutation=BinaryBitflipMutation(),
n_offsprings=10,
eliminate_duplicates=True)
kres=minimize(kkk,
method,
callback=do_every_generations,
termination=('n_gen', 1000))
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/README.md
================================================
# Adaptive structure evolution and biologically plausible synaptic plasticity for recurrent spiking neural networks #
## Requirments ##
* numpy
* pytorch >= 1.12.0
## Run ##
```python BCM.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{pan2023adaptive,
title = {Adaptive structure evolution and biologically plausible synaptic plasticity for recurrent spiking neural networks},
author = {Pan, Wenxuan and Zhao, Feifei and Zeng, Yi and Han, Bing},
journal = {Scientific Reports},
volume = {13},
number = {1},
pages = {16924},
year = {2023},
url = {https://doi.org/10.1038/s41598-023-43488-x},
doi = {10.1038/s41598-023-43488-x},
}
@article{zeng2023braincog,
title={BrainCog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired AI and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier}
}
```
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/lstm.py
================================================
import argparse, math, os, sys
from re import S
from aiohttp import ServerDisconnectedError
import numpy as np
import gym
from gym import wrappers
import matplotlib.pyplot as plt
from tools.ExperimentEnvGlobalNetworkSurvival import ExperimentEnvGlobalNetworkSurvival
from tools.MazeTurnEnvVec import MazeTurnEnvVec
import torch
from torch.autograd import Variable
import torch.autograd as autograd
import torch.nn.utils as utils
from torch.distributions import Categorical
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
parser = argparse.ArgumentParser(description='PyTorch REINFORCE example')
parser.add_argument('--gamma', type=float, default=0.98, metavar='G')
parser.add_argument('--seed', type=int, default=598, metavar='N')
parser.add_argument('--num_steps', type=int, default=500, metavar='N')
parser.add_argument('--num_episodes', type=int, default=1000, metavar='N')
parser.add_argument('--hidden_size', type=int, default=128, metavar='N')
parser.add_argument('--render', action='store_true')
args = parser.parse_args()
n_agent = 1
steps = 500
env = MazeTurnEnvVec(n_agent, n_steps=steps)
data_env = ExperimentEnvGlobalNetworkSurvival(env)
s_dim = 4
a_dim = 3
class Policy(nn.Module):
def __init__(self, hidden_size, s_dim, a_dim):
super(Policy, self).__init__()
self.lstm = nn.LSTM(s_dim, hidden_size, batch_first = True)
self.linear1 = nn.Linear(hidden_size, hidden_size)
self.linear2 = nn.Linear(hidden_size, a_dim)
def forward(self, x,hidden):
x, hidden = self.lstm(x, hidden)
x = F.relu(self.linear1(x))
p = F.softmax(self.linear2(x),-1)
return p,hidden
class REINFORCE:
def __init__(self, hidden_size, s_dim, a_dim):
self.model = Policy(hidden_size, s_dim, a_dim)
self.optimizer = optim.Adam(self.model.parameters(), lr=1e-2) #
self.model.train()
self.pi = Variable(torch.FloatTensor([math.pi])) #
def select_action(self, state,hx,cx):
# mu, sigma_sq = self.model(Variable(state).cuda())
prob,(hx,cx) = self.model(Variable(state),(hx,cx))
dist = Categorical(probs=prob)
action = dist.sample()
log_prob = prob[0][0,action.item()].log()
# log_prob = prob.log()
entropy = dist.entropy()
return action, log_prob, entropy
def update_parameters(self, rewards, log_probs, entropies, gamma):# 更新参数
R = torch.tensor(0)
loss = 0
for i in reversed(range(len(rewards))):
R = gamma * R + rewards[i]
loss = loss - (log_probs[i]*Variable(R)) - 0.005*entropies[i][0]
loss = loss / len(rewards)
self.optimizer.zero_grad()
loss.backward()
utils.clip_grad_norm_(self.model.parameters(), 2)
self.optimizer.step()
seeds=20
for seed in range(seeds):
log_reward = []
log_smooth = []
gamma=np.linspace(0.9,1.0,100)
for g in range(100):
agent = REINFORCE(args.hidden_size,s_dim,a_dim)
result=np.zeros([100,args.num_steps])
for i_episode in range(args.num_episodes):
state = torch.tensor(data_env.reset()).unsqueeze(0)
entropies = []
log_probs = []
rewards = []
old_dis = np.ones([1,])*13
reawrd_perstep=[]
allrewards=[]
hx = torch.zeros(args.hidden_size).unsqueeze(0).unsqueeze(0)
cx = torch.zeros(args.hidden_size).unsqueeze(0).unsqueeze(0)
for t in range(args.num_steps): # 1个episode最长num_steps
action, log_prob, entropy = agent.select_action(state.unsqueeze(0).float(),hx,cx)
action = action.cpu().numpy()
next_state, envreward, done, _ = data_env.step(action[0])
entropies.append(entropy)
log_probs.append(log_prob)
state = torch.Tensor([next_state])
rewards.append(envreward[0])
agent.update_parameters(rewards, log_probs, entropies, gamma[g])
print("Episode: {}, reward: {}".format(i_episode, np.sum(rewards)))
log_reward.append(np.sum(rewards))
if i_episode == 0:
log_smooth.append(log_reward[-1])
else:
log_smooth.append(log_smooth[-1]*0.99+0.01*np.sum(rewards))
plt.plot(log_smooth)
plt.plot(log_reward)
plt.pause(1e-5)
result[g]=np.array(allrewards).squeeze(1)
np.save('./lstm.npy',result)
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/main.py
================================================
import argparse, math, os, sys
import numpy as np
import gym
from gym import wrappers
import matplotlib.pyplot as plt
from tools.ExperimentEnvGlobalNetworkSurvival import ExperimentEnvGlobalNetworkSurvival
from tools.MazeTurnEnvVec import MazeTurnEnvVec
import torch
from torch.autograd import Variable
import torch.autograd as autograd
import torch.nn.utils as utils
from torch.distributions import Categorical
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
parser = argparse.ArgumentParser(description='PyTorch REINFORCE example')
parser.add_argument('--gamma', type=float, default=0.98, metavar='G')
parser.add_argument('--seed', type=int, default=1, metavar='N')
parser.add_argument('--num_steps', type=int, default=500, metavar='N')
parser.add_argument('--num_episodes', type=int, default=100, metavar='N')
parser.add_argument('--hidden_size', type=int, default=128, metavar='N')
parser.add_argument('--render', action='store_true')
args = parser.parse_args()
n_agent = 1
steps = 500
env = MazeTurnEnvVec(n_agent, n_steps=steps)
data_env = ExperimentEnvGlobalNetworkSurvival(env)
s_dim = 4
a_dim = 3
class Policy(nn.Module):
def __init__(self, hidden_size, s_dim, a_dim):
super(Policy, self).__init__()
self.linear1 = nn.Linear(s_dim, hidden_size)
self.linear2 = nn.Linear(hidden_size, a_dim)
def forward(self, x):
x = F.relu(self.linear1(x))
p = F.softmax(self.linear2(x),-1)
return p
class REINFORCE:
def __init__(self, hidden_size, s_dim, a_dim):
self.model = Policy(hidden_size, s_dim, a_dim)
# self.model = self.model.cuda()
self.optimizer = optim.Adam(self.model.parameters(), lr=1e-2)
self.model.train()
self.pi = Variable(torch.FloatTensor([math.pi]))
def select_action(self, state):
# mu, sigma_sq = self.model(Variable(state).cuda())
prob = self.model(Variable(state))
dist = Categorical(probs=prob)
action = dist.sample()
log_prob = prob[0,action.item()].log()
# log_prob = prob.log()
entropy = dist.entropy()
return action, log_prob, entropy
def update_parameters(self, rewards, log_probs, entropies, gamma):
R = torch.tensor(0)
loss = 0
for i in reversed(range(len(rewards))):
R = gamma * R + rewards[i]
loss = loss - (log_probs[i]*Variable(R)) - 0.005*entropies[i][0]
loss = loss / len(rewards)
self.optimizer.zero_grad()
loss.backward()
utils.clip_grad_norm_(self.model.parameters(), 2)
self.optimizer.step()
seeds=20
for seed in range(seeds):
# torch.manual_seed(args.seed)
# np.random.seed(args.seed)
agent = REINFORCE(args.hidden_size,s_dim,a_dim)
log_reward = []
log_smooth = []
gamma=np.linspace(0.9,1.0,100)
for gam in gamma:
for i_episode in range(args.num_episodes):
state = torch.tensor(data_env.reset()).unsqueeze(0)
entropies = []
log_probs = []
rewards = []
old_dis = np.ones([1,])*13
reawrd_perstep=[]
ss=0
allrewards=[]
for t in range(args.num_steps):
action, log_prob, entropy = agent.select_action(state.float())
action = action.cpu().numpy()
next_state, envreward, done, _ = data_env.step(action)
entropies.append(entropy)
log_probs.append(log_prob)
state = torch.Tensor([next_state])
rewards.append(envreward[0])
agent.update_parameters(rewards, log_probs, entropies, gam)
print("Episode: {}, reward: {}".format(i_episode, np.sum(rewards)))
log_reward.append(np.sum(rewards))
if i_episode == 0:
log_smooth.append(log_reward[-1])
else:
log_smooth.append(log_smooth[-1]*0.99+0.01*np.sum(rewards))
plt.plot(log_smooth)
plt.plot(log_reward)
plt.pause(1e-5)
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/pltbcm.py
================================================
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import pyplot
import matplotlib as mpl
from scipy.ndimage import gaussian_filter1d
sigm=3
# mpl.rcParams['font.size']=x
plt.style.use('seaborn-whitegrid')
plt.figure( figsize=(8,8) )
ax = plt.subplot()
palette = pyplot.get_cmap('Set1')
font1 = {'family': 'Times New Roman',
'weight': 'normal',
'size': 14,
}
steps=500
t = [i for i in range(steps)]
########################################BCM+BCM
bcm=np.load('./10rewards.npy')
for e in range(bcm.shape[0]):
sum1=0
sum2=0
best_agent_id=np.argmax(np.sum(bcm[e,:,:],axis=0))
best_agent=bcm[e,:,best_agent_id]
best_agent=best_agent[:steps]
for i in range(steps): #累积
sum2=sum2+best_agent[i]
best_agent[i]=sum2
bcm[e]=best_agent
avg = np.mean(bcm, axis=0)
std = np.std(bcm, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
y_smoothed = gaussian_filter1d(avg, sigma=40)
r1 = gaussian_filter1d(r1, sigma=40)
r2 = gaussian_filter1d(r2, sigma=40)
color = palette(0)
ax.plot(t, y_smoothed, color=color, label="Evolved model with DA-BCM", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
print("Evolved model with DA-BCM")
print(avg[-1],avg[-1]-r1[-1],r2[-1]-avg[-1])
########################################unbcm
unbcm=np.load('./unevolved_with_bcm.npy')
avg = np.mean(unbcm, axis=0)
std = np.std(unbcm, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
y_smoothed = gaussian_filter1d(avg, sigma=sigm)
r1 = gaussian_filter1d(r1, sigma=sigm)
r2 = gaussian_filter1d(r2, sigma=sigm)
color = palette(1)
ax.plot(t, y_smoothed, color=color, label="Unevolved model with DA-BCM", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
print("Unevolved model with DA-BCM+DA-BCM")
print(avg[-1],avg[-1]-r1[-1],r2[-1]-avg[-1])
########################################none+bcm
nonbcm=np.load('./none_bcm.npy')
avg = np.mean(nonbcm, axis=0)
std = np.std(nonbcm, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
y_smoothed = gaussian_filter1d(avg, sigma=sigm)
r1 = gaussian_filter1d(r1, sigma=sigm)
r2 = gaussian_filter1d(r2, sigma=sigm)
color = palette(2)
ax.plot(t, y_smoothed, color=color, label="Evolved model with NONE+DA-BCM", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
print("Evolved model with none+DA-BCM")
print(avg[-1],avg[-1]-r1[-1],r2[-1]-avg[-1])
########################################stdp+bcm
stdpbcm=np.load('./stdp_bcm.npy')
avg = np.mean(stdpbcm, axis=0)
std = np.std(stdpbcm, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
y_smoothed = gaussian_filter1d(avg, sigma=sigm)
r1 = gaussian_filter1d(r1, sigma=sigm)
r2 = gaussian_filter1d(r2, sigma=sigm)
color = palette(5)
ax.plot(t, y_smoothed, color=color, label="Evolved model with STDP+DA-BCM", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
print("Evolved model with STDP+DA-BCM")
print(avg[-1],avg[-1]-r1[-1],r2[-1]-avg[-1])
########################################LSTM
lstm=np.load('./lstm.npy')
avg = np.mean(lstm, axis=0)
std = np.std(lstm, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
y_smoothed = gaussian_filter1d(avg, sigma=sigm)
r1 = gaussian_filter1d(r1, sigma=sigm)
r2 = gaussian_filter1d(r2, sigma=sigm)
color = palette(3)
ax.plot(t, y_smoothed, color=color, label="LSTM", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
print("LSTM")
print(avg[-1],avg[-1]-r1[-1],r2[-1]-avg[-1])
########################################Q-learning
ql=np.load('./ql.npy')
avg = np.mean(ql, axis=0)
std = np.std(ql, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
y_smoothed = gaussian_filter1d(avg, sigma=sigm)
r1 = gaussian_filter1d(r1, sigma=sigm)
r2 = gaussian_filter1d(r2, sigma=sigm)
color = palette(6)
ax.plot(t, y_smoothed, color=color, label="Q-learning", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
print("Q-learning")
print(avg[-1],avg[-1]-r1[-1],r2[-1]-avg[-1])
########################################STDP
stdp=np.load('./inac.npy')
avg = np.mean(stdp, axis=0)
std = np.std(stdp, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
y_smoothed = gaussian_filter1d(avg, sigma=sigm)
r1 = gaussian_filter1d(r1, sigma=sigm)
r2 = gaussian_filter1d(r2, sigma=sigm)
color = palette(4)
ax.plot(t, y_smoothed, color=color, label="Evolved STDP", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
print("Evolved STDP")
print(avg[-1],avg[-1]-r1[-1],r2[-1]-avg[-1])
ax.tick_params(labelsize=16)
ax.spines['right'].set_color('black')
ax.spines['top'].set_color('black')
ax.spines['left'].set_color('black')
ax.spines['bottom'].set_color('black')
ax.legend(loc='upper left', prop=font1)
plt.xlabel('Steps', fontsize=18)
plt.ylabel('Average Reward', fontsize=18)
plt.savefig('./bcm.png')
plt.show()
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/pltrank.py
================================================
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import pyplot
import matplotlib as mpl
from scipy.ndimage import gaussian_filter1d
plt.figure( figsize=(8,8) )
steps=1000
t = [i for i in range(steps)]
plt.style.use('seaborn-whitegrid')
palette = pyplot.get_cmap('Set1')
font1 = {'family': 'Times New Roman',
'weight': 'normal',
'size': 18,
}
kk=np.load('./rank.npy')
avg = np.mean(kk, axis=0)
std = np.std(kk, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
r1 = gaussian_filter1d(r1, sigma=20)
r2 = gaussian_filter1d(r2, sigma=20)
y_smoothed = gaussian_filter1d(avg, sigma=20)
color = palette(0)
ax = plt.subplot()
ax.plot(t, y_smoothed, color=color, label="Average Fitness", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
ax.tick_params(labelsize=18)
ax.spines['right'].set_color('black')
ax.spines['top'].set_color('black')
ax.spines['left'].set_color('black')
ax.spines['bottom'].set_color('black')
ax.legend(loc='lower right', prop=font1)
plt.xlabel('generations', fontsize=18)
plt.ylabel('SP', fontsize=18)
plt.savefig('./rank.png')
plt.show()
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/q_l.py
================================================
import random
import time
import tkinter as tk
import pandas as pd
from tools.ExperimentEnvGlobalNetworkSurvival import ExperimentEnvGlobalNetworkSurvival
from tools.MazeTurnEnvVec import MazeTurnEnvVec
import numpy as np
from matplotlib import pyplot as plt
steps=500
t=[i for i in range(steps)]
class Agent(object):
'''个体类'''
MAZE_R = 6
MAZE_C = 6
def __init__(self, env,alpha=0.1, gamma=0.9):
'''初始化'''
self.states = {}
self.actions = 3
self.alpha = alpha
self.gamma = gamma
self.q_table = np.zeros([32,3])
def choose_action(self,state,epsilon=0.8):
'''选择相应的动作。根据当前状态,随机或贪婪,按照参数epsilon'''
if random.uniform(0, 1) > epsilon:
action = random.choice([0,1,2])
else:
max_index=(self.q_table[state] == self.q_table[state].max()).nonzero()
if len(max_index)==1:
max_qvalue_actions=max_index[0]
else:
max_qvalue_actions=max_index[:][1]
action = random.choice(np.array(max_qvalue_actions))
return np.array([action])
def update_q_value(self, state, action, next_state_reward, next_state_q_values):
self.q_table[state, action] += self.alpha * (
next_state_reward + self.gamma * next_state_q_values.max() - self.q_table[state, action])
def add_state(self,X_next):
x_str = ','.join(str(i) for i in X_next.astype(int))
if (x_str in self.states) == False:
self.states[x_str] = max(self.states.values()) + 1
return self.states[x_str]
def learn(self, env, episode=100, epsilon=0.8):
'''q-learning算法'''
env.reset()
X=np.array([0,1,0,0])
sss = ','.join(str(i) for i in X.astype(int))
self.states[sss] = 0
for i in range(episode):
steps=0
current_state = np.array([0])
env.env.current_cell=np.array([0])
X_next, envreward, fitness, infos=env.step(current_state)
self.add_state(X_next)
next_state_reward=0
while next_state_reward==0 and steps<1000:
current_action = self.choose_action(current_state, epsilon)
X_next, next_state_reward, fitness, infos = env.step(current_action)
next_state_number=self.add_state(X_next)
next_state_q_values = self.q_table[next_state_number]
self.update_q_value(current_state, current_action, next_state_reward, next_state_q_values)
current_state = next_state_number
steps+=1
def play(self, env):
step=0
self.learn(env, epsilon=0.8)
current_state = np.array([0])
env.env.current_cell = np.array([0])
X_next, envreward, fitness, infos = env.step(current_state)
self.add_state(X_next)
env_r=[]
rsum=0
old_dis=13
while step0,dtype=int)[0]
if reward==0:
reward=-1
elif reward==1:
reward=1
if envreward==1:
reward=3
elif envreward==-1:
reward=-3
next_state_number = self.add_state(X_next)
rsum+=reward
current_state = next_state_number
env_r.append(rsum)
step+=1
return np.array(env_r)
def QQ():
steps=500
env = MazeTurnEnvVec(1, n_steps=steps)
data_env = ExperimentEnvGlobalNetworkSurvival(env)
agent = Agent(data_env)
r=agent.play(data_env)
return r
np.save('./ql.npy',QQ())
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/tools/EnuGlobalNetwork.py
================================================
import pickle
import time
import numpy as np
import torch
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import gridspec
from AbstractLayerBMM import AbstractLayerBMM
from EvolvableNeuralUnitStacked import EvolvableNeuralUnitStacked
from Tools import get_data_path
sns.set_style("darkgrid")
class EnuGlobalNetwork(AbstractLayerBMM):
"""Network of ENUs implementation in PyTorch, where each synapse and neuron is modeled as an ENU. """
def __init__(self, n_offspring, n_pseudo_env, n_input_neurons, n_hidden_neurons, n_output_neurons, n_syn_per_neuron):
# offspring
self.n_offspring = n_offspring
self.n_pseudo_env = n_pseudo_env
# input channels
n_input_channels = 16
self.n_input_channels = n_input_channels
n_dynamic_param = 32
# total neurons
n_neurons = n_output_neurons + n_hidden_neurons
self.n_neurons = n_neurons
super().__init__(n_offspring, n_neurons, n_input_neurons, n_output_neurons)
torch.random.manual_seed(0)
#NOTE: batch dimension holds output of each neuron/synapse, allowing fast GPU MM
#NOTE neurons far less than synapses, so can be relatively bigger rnn for little cost
n_input_channels_neuron = 16
n_input_neuron, n_output_neuron = n_input_channels_neuron, n_input_channels
self.neurons = EvolvableNeuralUnitStacked(n_offspring, batch_size=self.n_neurons, n_input=n_input_neuron, n_dynamic_param=n_dynamic_param, n_output=n_output_neuron)
#self.n_syn = next_power_of_2(int(n_neurons * (rel_connectivity*n_neurons)))
self.n_syn_per_neuron = n_syn_per_neuron
self.n_syn = n_neurons * n_syn_per_neuron
n_input_syn, n_output_syn = n_input_channels * 2, n_input_channels_neuron # * 2 for neuron feedback (which same channel as n_channel input)
self.synapses = EvolvableNeuralUnitStacked(n_offspring, batch_size=self.n_syn, n_input=n_input_syn, n_dynamic_param=n_dynamic_param, n_output=n_output_syn)
# just randomly connect synapses to neurons
self.synapse_connections = torch.randint(n_input_neurons + n_neurons, size=(n_neurons, n_syn_per_neuron), device='cuda', dtype=torch.long)
# fixed predefined connection patterns
if n_input_neurons==2 and n_output_neurons==2 and n_hidden_neurons==2:
print("Fixed connection Network 2-2-2")
self.synapse_connections = torch.tensor([[0, 1],
[0, 1],
[2, 3],
[2, 3]], device='cuda', dtype=torch.long)
elif n_input_neurons == 4 and n_output_neurons == 3 and n_hidden_neurons == 3 and n_syn_per_neuron==3:
print("Fixed connection Network 4-3-3 (3syn)")
self.synapse_connections = torch.tensor([[0, 1, 3],# hidden connections #4
[0, 2, 3], #5
[1, 2, 3],# 6
[4, 5, 6], # output connections #7
[4, 5, 6],#8
[4, 5, 6]#9
], device='cuda', dtype=torch.long)
elif n_input_neurons==5 and n_hidden_neurons==0 and n_output_neurons==4:
print("Fixed connection Network 5-0-4 (5syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3, 4],# output connections
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4]
], device='cuda', dtype=torch.long)
elif n_input_neurons==1 and n_hidden_neurons==0 and n_output_neurons==2:
print("Fixed connection Network 1-0-2 (1syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0],# output connections
[0]
], device='cuda', dtype=torch.long)
elif n_input_neurons==4 and n_hidden_neurons==0 and n_output_neurons==3 and n_syn_per_neuron==4:
print("Sparse connection Network 4-0-3 (4syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3],# output connections #4
[0, 1, 2, 3], #5
[0, 1, 2, 3],# 6
], device='cuda', dtype=torch.long)
elif n_input_neurons == 4 and n_hidden_neurons == 3 and n_output_neurons == 3 and n_syn_per_neuron == 4:
print("Sparse connection Network 4-3-3 (3syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 3], # hidden connections #4
[0, 2, 3], # 5
[1, 2, 3], # 6
[4, 5, 3], # output connections #7
[4, 6, 3], # 8
[5, 6, 3] # 9
], device='cuda', dtype=torch.long)
elif n_input_neurons==4 and n_hidden_neurons==3 and n_output_neurons==3 and n_syn_per_neuron==8:
print("Sparse connection Network 4-3-3 (8syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 5, 6, 7, 8, 3, 4],# hidden connections #4
[0, 2, 4, 6, 7, 9, 3, 5], #5
[1, 2, 4, 5, 8, 9, 3, 6],# 6
[4, 5, 8, 9, 0, 1, 3, 7], # output connections #7
[4, 6, 7, 9, 0, 2, 3, 8],#8
[5, 6, 7, 8, 1, 2, 3, 9]#9
], device='cuda', dtype=torch.long)
elif n_input_neurons==4 and n_hidden_neurons==4 and n_output_neurons==4 and n_syn_per_neuron==8:
print("Fixed connection Network 4-4-4 (8syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3, 4, 5, 6, 7],# hidden connections
[0, 1, 2, 3, 4, 5, 6, 7],
[0, 1, 2, 3, 4, 5, 6, 7],
[0, 1, 2, 3, 4, 5, 6, 7],
[4, 5, 6, 7, 8, 9, 10, 11], # output connections
[4, 5, 6, 7, 8, 9, 10, 11],
[4, 5, 6, 7, 8, 9, 10, 11],
[4, 5, 6, 7, 8, 9, 10, 11],
], device='cuda', dtype=torch.long)
elif n_input_neurons==5 and n_hidden_neurons==5 and n_output_neurons==4:
print("Fixed connection Network 5-5-4 (5syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3, 4],# hidden connections
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9], # output connections
[5, 6, 7, 8, 9],
[5, 6, 7, 8, 9],
[5, 6, 7, 8, 9],
], device='cuda', dtype=torch.long)
elif n_input_neurons==1 and n_hidden_neurons==0 and n_output_neurons==1:
print("Fixed connection Single")
self.synapse_connections = torch.tensor([[0]], device='cuda', dtype=torch.long)
else:
print("Random connections")
# each synapse is connected also to its post-synaptic neuron, to allow STDP type learning to emerge
self.synapse_connections_post = torch.arange(n_neurons, device='cuda', dtype=torch.long).reshape(n_neurons, -1).repeat(1, n_syn_per_neuron)
# define compartments
self.compartments = [self.neurons, self.synapses]
self.trainable_layers = self.neurons.trainable_layers + self.synapses.trainable_layers
self.track_data = False
def dump_model(self, e, exp_name):
"""Dump model to restore"""
with open(get_data_path(e, exp_name, "Model"), 'wb') as f:
parameters = {}
parameters["neuron"] = [layer.base_parameters.cpu().numpy() for layer in self.neurons.trainable_layers]
parameters["synapse"] = [layer.base_parameters.cpu().numpy() for layer in self.synapses.trainable_layers]
pickle.dump(parameters, f)
def restore_model(self, e, exp_name):
"""Restore model"""
with open(get_data_path(e, exp_name, "Model"), 'rb') as f:
parameters = pickle.load(f)
#TODO: refactor to dump/restore at ENU level and just call those functions
assert len(self.neurons.trainable_layers) == len(parameters["neuron"])
for i in range(len(parameters["neuron"])):
self.neurons.trainable_layers[i].base_parameters = torch.from_numpy(parameters["neuron"][i].astype(np.float32)).cuda()
assert len(self.synapses.trainable_layers) == len(parameters["synapse"])
for i in range(len(parameters["synapse"])):
self.synapses.trainable_layers[i].base_parameters = torch.from_numpy(parameters["synapse"][i].astype(np.float32)).cuda()
@staticmethod
def plot_weights(e, exp_name):
"""Visualize weights of ENU gates"""
sns.set_style("dark")
def calc_average(start, stop):
weights_average = None
for e in range(start, stop, 1000):
with open(get_data_path(e, exp_name, "Model"), 'rb') as f:
parameters = pickle.load(f)
weights = []
for i in range(len(parameters["neuron"])):
weights += [parameters["neuron"][i].astype(np.float32)]
if weights_average is None:
weights_average = weights
else:
for i in range(len(weights_average)):
weights_average[i] += weights[i]
return weights_average
weights_mean1 = calc_average(20000, 30000)
fig, ax = plt.subplots(1, 2, sharex='col', sharey='row')
for i in range(len(weights_mean1)):
ax[i].imshow(weights_mean1[i], cmap="gray")
weights_mean2 = calc_average(30000, 40000)
fig, ax = plt.subplots(1, 2, sharex='col', sharey='row')
for i in range(len(weights_mean2)):
ax[i].imshow(weights_mean2[i], cmap="gray")
fig, ax = plt.subplots(1, 2, sharex='col', sharey='row')
for i in range(len(weights_mean2)):
ax[i].imshow((weights_mean2[i] - weights_mean1[i])**5, cmap="gray")
plt.show()
def dump_network_activity(self, e, exp_name):
"""Dump raw data for visualization"""
with open(get_data_path(e, exp_name, "GlobalNetwork"), 'wb') as f:
pickle.dump(self.vis_data, f)
def print(self):
print("--Neurons--")
self.neurons.print()
print("--Synapses--")
self.synapses.print()
def reset(self):
self.vis_data = []
if self.track_data:
print("Tracking network activity")
for compartment in self.compartments:
compartment.reset()
def forward(self, X):
"""Main computation forward pass"""
# transfer to GPU
X_raw_gpu = torch.from_numpy(X.astype(np.float32)).cuda()
X_gpu = torch.zeros((X.shape[0], X.shape[1], self.n_input_channels), device='cuda', dtype=torch.float32)
X_gpu[:, :, :X_raw_gpu.shape[2]] = X_raw_gpu
# first compute synapses, set input to previous output of connected neuron
# concat our input spiking pattern directly to input to our synapses (the neurons)
# NOTE: this concats in batch dimension, meaning it feeds into input neurons directly spiking pattern, while rest receive input from network
input_to_synapses = torch.cat([X_gpu, self.neurons.out_mem], dim=1)
# connect each synapse randomly to multiple inputs
input_to_synapses_connected = input_to_synapses[:, self.synapse_connections.flatten(), :]
# need feedback connection from neuron to synapse, to allow stdp type rules to emerge (else it has to do it through feedback connections, but less guarentee on connections and cannot distinguise type)
# one synapse has 1 pre-synaptic neuron and 1 post-synaptic neuron, connectection defined in synapse_connections, synapse_connections[i, :] gives all input synapses of that neuron
# so feedback to all it's input synapses through broadcasting backwards
post_neuron_backprop_connected = self.neurons.out_mem[:, self.synapse_connections_post.flatten(), :]
input_to_synapses_connected = torch.cat([input_to_synapses_connected, post_neuron_backprop_connected], dim=-1)
# compute synapse
self.synapses.forward(input_to_synapses_connected)
# then integrate(sum) all outputs of a neurons input synapses, can just reshape into valid shape, since we already randomly connected when computing synapses
# NOTE: each neuron then requires same number of synapses, then reshape by modifying batch dim (which contains syn outputs)
integration = torch.sum(self.synapses.out.reshape((self.n_offspring, self.n_neurons, -1, self.synapses.shape[-1])), dim=2)
# scale by number of synapses
integration /= self.n_syn_per_neuron
self.out_integration = integration
# finally set neuron input to summated connected synapses output
input_to_neurons = integration
out = self.neurons.forward(input_to_neurons)
# output is last neuron output, NOTE: just first channel is returned, since we reshape neurons to channels
self.out = out[:, -self.n_output:, 0].reshape(self.n_offspring, self.n_output)
if self.track_data:
self._track_vis_data(X, input_to_synapses_connected, input_to_neurons)
return self.out
def _track_vis_data(self, X, input_to_synapses_connected, input_to_neurons):
offspring_idx = 0
self.vis_data += [(X[offspring_idx], input_to_neurons[offspring_idx].cpu().numpy(), self.neurons.out[offspring_idx].cpu().numpy(),
input_to_synapses_connected[offspring_idx].cpu().numpy(), self.synapses.out[offspring_idx].cpu().numpy())]
@staticmethod
def plot_network_activity(e, exp_name):
with open(get_data_path(e, exp_name, "GlobalNetwork"), 'rb') as f:
vis_data = pickle.load(f)
X, input_to_neurons, neurons_out, input_to_synapses, synapses_out = map(np.array, zip(*vis_data))
def plot_enu_activity(input, output, title):
n_cells = output.shape[1]
n_cells = np.minimum(10, output.shape[1])
fig, grid = plt.subplots(2, n_cells, sharex='col', sharey='row')
if n_cells==1:
grid[0].plot(input[:, 0, :])
grid[1].plot(output[:, 0, :])
else:
for i in range(n_cells):
grid[0, i].plot(input[:, i, :])
grid[1, i].plot(output[:, i, :])
plt.xlabel("t")
plt.title(title)
#plt.ylabel("")
plt.legend()
plt.figure()
plt.plot(X[:, :, 0])
plot_enu_activity(input_to_neurons, neurons_out, "ENU neuron activity")
plot_enu_activity(input_to_synapses, synapses_out, "ENU synapse activity")
plt.figure()
spike_points = np.where(neurons_out[:, :, 0] > 0)
plt.scatter(spike_points[0], spike_points[1], marker='|')
plt.show()
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/tools/ExperimentEnvGlobalNetworkSurvival.py
================================================
import pickle
import numpy as np
from tools.Tools import get_data_path
class ExperimentEnvGlobalNetworkSurvival:
"""Wrapper around a given RL environment for a Network of ENUs model,
turns reward into fitness and dumps relevant data"""
def __init__(self, env, exp_name='maze'):
self.env = env
self.exp_name = exp_name
self.n_output = self.env.n_actions
#NOTE: +1 reward neuron
self.n_input_neurons = self.env.n_obs + 1
self.n_agents = self.env.n_agents
def _convert_obs(self, obs, rewards):
n_input_channels_used = 3
X = np.zeros((self.n_agents, self.n_input_neurons, n_input_channels_used))
#X[:, :obs.shape[1], 0] = obs
# Shuffle only obs to avoid topology exploitation, reward neuron linked to EnuGlobal synapse connectivity
X[:, :obs.shape[1], 0] = np.take_along_axis(obs, self.obs_shuffle, axis=1)
# split pos and negative reward to different channels, And set to last input neuron
if rewards is not None:
X[rewards>0, -1, 1] = np.abs(rewards[rewards>0])
X[rewards<=0, -1, 2] = np.abs(rewards[rewards<=0])
return X
def _convert_reward(self, obs, actions, rewards, infos, dones):
fitness = np.copy(rewards)
# first poison is considered positive reward, since learning to learn
#NOTE: dead by env means less reward can be obtained so should implictely reduce overall fitness automatically
fitness[np.logical_and(self._prev_reward_count == 1, rewards != 0)] = 1
# include episode length as extra fitness, since not taking poison would allow survive longer, so should try avoid take poison
fitness[dones==0] += 0.1/4
return fitness
def step(self, y):
# if self.t % 3 != 0:
# actions = np.zeros((self.n_agents), dtype=np.int32) - 1
# else:
# winner take all, in given time window
actions = y
# if all same output, do nothing
# equal_actions = self.y_hist.shape[1] == np.sum(self.y_hist == np.take_along_axis(self.y_hist, actions.reshape(-1, 1), axis=1), axis=-1)
# actions[equal_actions] = -1
# self.y_hist[:] = 0
# take env step
allobs, obs, rewards, dones, infos = self.env.step(actions)
# X = self._convert_obs(obs, rewards)
X=allobs
self._prev_reward_count += rewards!=0
fitness = self._convert_reward(obs, actions, rewards, infos, dones)
self._prev_action = actions
self._prev_obs = obs
return X, rewards, fitness, None
def reset(self):
self.t = 0
self.y_hist = np.zeros((self.n_agents, self.n_output), dtype=np.float32)
self._prev_action = None
self._prev_obs = None
self._prev_reward_count = np.zeros((self.n_agents), dtype=np.float32)
# each time different input/output neurons should have different meaning, to have learning to learn
self.obs_shuffle = np.argsort(np.random.randn(self.n_agents, self.n_input_neurons - 1), axis=1, kind='mergesort')
self.action_shuffle = np.argsort(np.random.randn(self.n_agents, self.n_output), axis=1, kind='mergesort')
# reset env
self.allobs,self.obs = self.env.reset()
# return self._convert_obs(self.obs, None)
return self.allobs
def render(self):
if self.t%4==0:
self.env.render()
def track_vis_data(self, vis_data, model, X, y_est, t):
n_fetch = 128
# TODO: also get our gates from the model
vis_data+=[(X[:n_fetch, :], y_est[:n_fetch, :])]
def dump_vis_data(self, vis_data, fitness_per_offspring, e):
with open(get_data_path(e, self.exp_name, "output"), 'wb') as f:
pickle.dump((vis_data, fitness_per_offspring), f)
@staticmethod
def load_vis_data(e, exp_name):
with open(get_data_path(e, exp_name, "output"), 'rb') as f:
vis_data, fitness_per_offspring = pickle.load(f)
return vis_data, fitness_per_offspring
@staticmethod
def plot_vis_data(e, exp_name):
vis_data, fitness_per_offspring = ExperimentEnvGlobalNetworkSurvival.load_vis_data(e, exp_name)
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/tools/MazeTurnEnvVec.py
================================================
import pickle
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from tools.Tools import save_fig, get_data_path
# np.random.seed(0)
class MazeTurnEnvVec:
"""Vectorized RL T-Maze environment written in pure Numpy. We require an efficient environment since we need to evaluate
and run up to thousands of offspring in parallel"""
def __init__(self, n_agents, n_steps):
# 4 important points, start point, decision point, food point, dead point.
# just generate a very large matrix that could fit any maze of any size, then can generate smaller maze as well
self.n_actions = 3
self.n_obs = 3
self.max_size = 7
self.n_agents = n_agents
self.n_steps = n_steps
self.window = plt.figure()
self.t_maze = True
self.turn_based = False
# steps can be longer if poison and need to turn around
self.steps_to_food = 2
if self.t_maze:
self.steps_to_food = 3
self.steps_to_food += self.steps_to_food*2
# give some extra leniency
self.steps_to_food *= 2
def step(self, actions):
# L R U D
# TODO: check legal action or not..
pos_copy = np.copy(self.agents_pos)
actions = np.copy(actions)
# GIVE TIME UPDATE WEIGHTS
# actions[self.agents_reset > 0] = -1
# actions[self.agent_energy<=0] = -1
self.agents_reset[self.agents_reset > 0] -= 1
# if turn based
if self.turn_based:
Forward = actions == 0
self.agents_pos[np.logical_and(Forward, self.agent_directions == 0), 1] += 1
self.agents_pos[np.logical_and(Forward, self.agent_directions == 2), 1] -= 1
self.agents_pos[np.logical_and(Forward, self.agent_directions == 1), 0] -= 1
self.agents_pos[np.logical_and(Forward, self.agent_directions == 3), 0] += 1
L = actions == 1
self.agent_directions[L] += 1
R = actions == 2
self.agent_directions[R] -= 1
self.agent_directions[self.agent_directions > 3] = 0
self.agent_directions[self.agent_directions < 0] = 3
else:
# or just direct movement
U = actions == 2
D = actions == 1
R = actions == 0
if self.agents_pos[U].size>0:
self.agents_pos[U, 0] += 1
self.agent_directions[U] = 3
if self.agents_pos[D].size>0:
self.agents_pos[D, 0] -= 1
self.agent_directions[D] = 1
if self.t_maze and self.agents_pos[R].size>0:
self.agents_pos[R, 1] += 1
self.agent_directions[R] = 0
# UNDO MOVES THAT GOT AGENT INTO WALL
self.current_cells = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1]]
self.agents_pos[self.current_cells==1] = pos_copy[self.current_cells==1]
movement_loss = np.prod(self.agents_pos==pos_copy, axis=-1)
# CHECK IF FOOD CONSUMED, is reward + pos reset
consumed_food = np.prod(self.agents_pos==self.food_pos[:, 0, :2], axis=-1).astype(np.bool)
consumed_pois = np.prod(self.agents_pos==self.food_pos[:, 1, :2], axis=-1).astype(np.bool)
self.consumed_count += consumed_food.astype(np.int32)
self.consumed_count_total += consumed_food.astype(np.int32)
self.consumed_count_pois += consumed_pois.astype(np.int32)
self._reset_pos(np.logical_or(consumed_food, consumed_pois))
# self._reset_pos_pois(consumed_pois)
# self._reset_food(self.consumed_count==self.swap_limit, prob=0.0)
# reset food for agents that ate food, and swap with some probability
self._reset_food(self.consumed_count==5, prob=0.5)
self.rewards = consumed_food.astype(np.float32) - consumed_pois.astype(np.float32) #* 0.5 #- movement_loss.astype(np.float32) * 0.01
# get observation from current position of each agent
self.agent_allobs,self.obs = self._get_obs_from_pos()
# instant dead on second poison
self.agent_energy += np.where(self.consumed_count_pois<=1, np.abs(self.rewards) * self.steps_to_food, -self.agent_energy * np.abs(self.rewards))
# energy decay to encourage exploration, agent dies if running out of energy
self.agent_energy = np.minimum(self.agent_energy, self.steps_to_food)
self.agent_energy -= 1.0/4
dones = self.agent_energy<=0
return self.agent_allobs,self.obs, self.rewards, dones, None
def _reset_pos(self, idxs):
self.agents_pos[idxs] = [self.start_point, 2] # set X pos
self.agent_directions[idxs] = 0
if self.max_size==5:
self.agent_directions[idxs] = 1
self.agents_reset[idxs] = 0
self.agents_reset_count[idxs] += 1
def _reset_pos_pois(self, idxs):
#NOTE: 2 since we call reset twice!
#NOTE: turning around already cost 8 steps, then 4x4 more is 16+8, 24, so reset should be much worse
self.agents_reset[np.logical_and(idxs, self.agents_reset_count>2)] = 64
def _reset_food(self, idxs, prob=0.5):
# swap food with some probability, avoids agent overfitting on environment
swap = np.take_along_axis(self.random_swap_matrix, self.consumed_count_total.reshape(-1, 1), axis=1).ravel()
swap_idxs = swap * idxs
food_loc = np.copy(self.food_pos[swap_idxs, 0, :])
pois_loc = np.copy(self.food_pos[swap_idxs, 1, :])
self.food_pos[swap_idxs, 0, :] = pois_loc
self.food_pos[swap_idxs, 1, :] = food_loc
# set maze value
self.mazes[np.arange(self.mazes.shape[0]), self.food_pos[:, 0, 0], self.food_pos[:, 0, 1]] = 2
self.mazes[np.arange(self.mazes.shape[0]), self.food_pos[:, 1, 0], self.food_pos[:, 1, 1]] = 3
self.consumed_count[idxs] = 0
def reset(self):
self.consumed_count = np.zeros((self.n_agents), dtype=np.int32)
self.consumed_count_total = np.zeros_like(self.consumed_count)
# consistent swapping such that if agent eat food once for all agents swapped with same seed, fair fitness comparison
max_eat = self.n_steps
self.random_swap_matrix = np.random.uniform(0, 1, size=(1, max_eat)) >= 0.5
self.random_swap_matrix = np.repeat(self.random_swap_matrix, int(self.n_agents), axis=0)
self.agent_energy = np.zeros((self.n_agents), dtype=np.float32) + self.steps_to_food
self.consumed_count_pois = np.zeros_like(self.consumed_count)
#self.swap_limit = np.random.randint(1, 5, size=1)
#self.swap_limit = np.random.randint(1, 4, size=self.n_agents)
self.mazes = np.ones((self.n_agents, self.max_size, self.max_size), dtype=np.int32)
#TODO: support variable maze length
self.start_point = int(self.max_size/2)
if self.t_maze:
self.mazes[:, self.start_point, 2:-1] = 0
self.mazes[:, 1:-1, -2] = 0
# FOOD either at -1,-1 or -1,1?
# two foods: x, y, value
self.food_pos = np.zeros((self.n_agents, 2, 2), dtype=np.int32)
self.food_pos[:, :, 1] = self.max_size - 2
self.food_pos[:, 1, 0] = 1
self.food_pos[:, 0, 0] = self.max_size - 2
self._reset_food(np.ones(self.food_pos.shape[0], dtype=np.bool), prob=0.5)
else:
self.mazes[:, 1:-1, 1] = 0
# two foods: x, y, value
self.food_pos = np.zeros((self.n_agents, 2, 2), dtype=np.int32)
self.food_pos[:, :, 1] = 1
self.food_pos[:, 0, 0] = 1
self.food_pos[:, 1, 0] = (self.max_size - 2)
self._reset_food(np.ones(self.food_pos.shape[0], dtype=np.bool), prob=0.5)
# AGENT
self.agents_pos = np.ones((self.n_agents, 2), dtype=np.int32)
self.agents_reset = np.zeros((self.n_agents), dtype=np.int32)
self.agents_reset_count = np.zeros_like(self.agents_reset)
self.agent_directions = np.zeros((self.n_agents), dtype=np.int32)
self._reset_pos(np.arange(self.agents_pos.shape[0]))
# OBS
self.agent_allobs,self.obs = self._get_obs_from_pos()
return self.agent_allobs,self.obs
def _get_obs_from_pos(self):
# obs is neighbouring cell states around agent
obs = np.zeros((self.n_agents, self.n_obs), dtype=np.float32)
raw_obs = np.zeros(self.n_agents, dtype=np.int32)
# get observation based on direction agent is facing
leftobs = np.zeros(self.n_agents)
rightobs = np.zeros(self.n_agents)
backobs = np.zeros(self.n_agents)
# get observation based on direction agent is facing
D = self.agent_directions == 0
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] + 1][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] - 1, self.agents_pos[:, 1]][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] + 1, self.agents_pos[:, 1]][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1]-1][D]
D = self.agent_directions == 2
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] - 1][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] + 1, self.agents_pos[:, 1]][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] - 1, self.agents_pos[:, 1]][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1]+1][D]
D = self.agent_directions == 1
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] - 1, self.agents_pos[:, 1]][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] - 1][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] + 1][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0]+1, self.agents_pos[:, 1]][D]
D = self.agent_directions == 3
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] + 1, self.agents_pos[:, 1]][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] + 1][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] - 1][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0]-1, self.agents_pos[:, 1]][D]
# mark what was observed at different index
obs[raw_obs == 1, 0] = 1
obs[raw_obs == 2, 1] = 1
obs[raw_obs == 3, 2] = 1
allobs=np.squeeze(np.dstack((leftobs,raw_obs,rightobs,backobs)))
return allobs, obs
def render(self):
plt.clf()
sns.set_style("white")
#TODO: support render all mazes? can reshape to square?
max_render = 1
flattened_render = np.dstack(np.split(self.mazes[18, :], max_render, axis=0)).reshape(self.mazes.shape[1], -1)
flattened_render[flattened_render>1] = 0
plt.axis('off')
plt.imshow(flattened_render,cmap='bone')
for j in range(1):
i=18
marker = ">"
if self.agent_directions[i] == 1:
marker = "^"
if self.agent_directions[i] == 2:
marker = "<"
if self.agent_directions[i] == 3:
marker = "v"
obs_color = "black"
if self.obs[i, 0] == 1:
obs_color = "gray"
if self.obs[i, 1] == 1:
obs_color = "green"
if self.obs[i, 2] == 1:
obs_color = "red"
alpha = 1
if self.agent_energy[i]<=0:
alpha = 1
plt.scatter(self.agents_pos[i, 1] + j * self.mazes.shape[1], self.agents_pos[i, 0], color="skyblue", alpha=alpha, marker=marker)
plt.scatter(self.agents_pos[i, 1] + j * self.mazes.shape[1], self.agents_pos[i, 0], color=obs_color,alpha=alpha, marker=marker, s=3)
plt.scatter(self.food_pos[i, 0, 1] + j * self.mazes.shape[1], self.food_pos[i, 0, 0], color="green", alpha=1, marker="o")
plt.scatter(self.food_pos[i, 1, 1] + j * self.mazes.shape[1], self.food_pos[i, 1, 0], color="red", alpha=1, marker="o")
plt.pause(0.001)
#plt.pause(2)
@staticmethod
def load_vis_data(e, exp_name):
with open(get_data_path(e, exp_name, "output"), 'rb') as f:
vis_data, fitness_per_offspring = pickle.load(f)
return vis_data, fitness_per_offspring
@staticmethod
def plot_vis_data(e, exp_name):
import matplotlib.pyplot as plt
from cycler import cycler
import seaborn as sns
sns.set_style("whitegrid")
vis_data, fitness_per_offspring = MazeTurnEnvVec.load_vis_data(e, exp_name)
offspring_idx = 0
#x, y_est, y = np.array(vis_data).transpose(1, 2, 0, 3)
X, Y_est = map(np.array, zip(*vis_data))
X_base, y_est_base = X[:, offspring_idx], Y_est[:, offspring_idx]
#X_base, y_est_base = X_base[:300], y_est_base[:300]
#X_base = np.max(X_base, axis=1)
# --- normal output single example---
plt.rc('axes', prop_cycle=(cycler('color', ['gray', '#ff7f0e', '#9467bd', '#8c564b', '#e377c2', '#17becf'])))
# OLD METHOD!
plt.figure()
#NOTE: last neuron is always reward neuron
plt.plot(-X_base[:, :-1, 0], label="N-ENUs input", alpha=0.7)
plt.plot(- np.max(X_base, axis=1)[:, 1], label="Positive reward", alpha=0.7, color='#2ca02c')
plt.plot(- np.max(X_base, axis=1)[:, 2], label="Negative reward", alpha=0.7, color='#d62728')
#plt.gca().set_color_cycle(['orange', 'purple', 'brown'])
plt.plot(y_est_base[:, :], label="N-ENUs output", alpha=0.8)
plt.legend(loc='upper right')
save_fig(e, exp_name, "single_episode")
plt.rc('axes', prop_cycle=(cycler('color', ['gray', '#ff7f0e', '#9467bd', '#8c564b', '#e377c2', '#17becf'])))
# new method!
fig, grid = plt.subplots(2, sharex=True)
# input
#grid[1].set_prop_cycle(cycler('color', ['gray', '#ff7f0e', '#1f77b4']))
grid[1].set_prop_cycle(cycler('color', ['gray', '#F5B041', '#2E86C1']))
grid[1].plot(X_base[:, :-1, 0], label="N-ENUs input", alpha=0.7, linewidth=2)
grid[1].plot(np.max(X_base, axis=1)[:, 1], label="Positive reward", alpha=0.7, color='#1ABC9C', linewidth=2)
grid[1].plot(np.max(X_base, axis=1)[:, 2], label="Negative reward", alpha=0.7, color='#CB4335', linewidth=2)
grid[1].legend(['Sensor (wall)', 'Sensor (red)', 'Sensor (green)', 'Positive reward', 'Negative reward'], loc='upper right')
grid[1].set_ylabel('Neuron output')
# output
grid[0].set_prop_cycle(cycler('color', ['#9467bd', '#e377c2', '#17becf','#8c564b']))
grid[0].plot(y_est_base[:, :], label="N-ENUs output", alpha=0.8, linewidth=2)
grid[0].legend(['ENU-NN (left)', 'ENU-NN (right)', 'ENU-NN (forward)'],loc='upper right')
plt.xlabel('t')
grid[0].set_ylabel('ENU neuron output')
plt.xlim(-5, X_base.shape[0]+10)
save_fig(e, exp_name, "single_episode_dual")
#plt.show()
@staticmethod
def plot_rollout_data(e, exp_name):
#TODO: dump rollout as array not the actual plots
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style("white")
import os
rollout_path = "./" + get_data_path(e, exp_name, "rollout").split(".")[1][:-1]+"/"
rollout_files = sorted(os.listdir(rollout_path))
rollouts = []
for i in range(4, 200, 4):
file = "rollout_{}_.png".format(i)
print(file)
rollout = plt.imread(rollout_path + file)
rollout = rollout[80:450, 200:500]
rollout = np.where(rollout[:, :, [0]]> 0.98, 1, rollout)
rollouts.append(rollout)
# plt.imshow(rollout)
# plt.show()
# for rollout in rollouts:
vert_bar = np.zeros((rollout.shape[0], 5, 4))
vert_bar[::] += 0.5
# get red -> learned go other way
# food swapped -> sees red -> learned turn around
rollouts1 = [rollouts[1], rollouts[9], rollouts[10], rollouts[11], rollouts[17], rollouts[18]]#, rollouts[19]
#, rollouts[28]
#rollouts[24],
rollouts2 = [rollouts[25], rollouts[29], rollouts[30], rollouts[31], rollouts[32], rollouts[33]]
plt.axis('off')
plt.imshow(np.vstack([np.column_stack(rollouts1), np.column_stack(rollouts2)]), cmap='gray')
save_fig(e, exp_name, "rollout_combined")
#plt.show()
if __name__ == '__main__':
"""Test function"""
n_offspring = 1024
envs = MazeTurnEnvVec(n_offspring, n_steps=400)
envs.n_pseudo_env = 8
while True:
envs.reset()
opt_actions_up = [0,0,0,0,1,0]
opt_actions_down = [0,0,0,0,2,0]
opt_actions = [opt_actions_up, opt_actions_down]
opt_current = 0
total_reward = 0
rewards = np.zeros((n_offspring))
rewards_all = np.zeros_like(rewards)
k = 0
n_steps = 200
for i in range(n_steps):
actions = np.random.randint(0, envs.n_actions, size=n_offspring)
#actions[:] = opt_actions_up[i%len(opt_actions_up)]
#actions[0] = opt_actions[opt_current][k % len(opt_actions_up)]
obs, rewards,_,_ = envs.step(actions=actions)
total_reward += (rewards[0] * 100) + 1
rewards_all += (rewards * 100) + 1
#print(rewards[0])
#print(obs[0], rewards[0])
envs.render()
plt.pause(0.5)
k += 1
if rewards[0] < 0:
#print(rewards_last[0])
if opt_current==0:
opt_current = 1
else:
opt_current = 0
if rewards[0] != 0:
k = 0
total_reward/=n_steps
rewards_all/=n_steps
print(rewards_all[0], np.mean(rewards_all), np.std(rewards_all), np.std(rewards_all)/np.mean(rewards_all))
print(rewards_all[:10])
================================================
FILE: examples/Structure_Evolution/EB-NAS/acc_predictor/adaptive_switching.py
================================================
import utils
import numpy as np
from acc_predictor.factory import get_acc_predictor
class AdaptiveSwitching:
""" ensemble surrogate model """
""" try all available models, pick one based on 10-fold crx vld """
def __init__(self, n_fold=10):
# self.model_pool = ['rbf', 'gp', 'mlp', 'carts']
self.model_pool = ['rbf', 'gp', 'carts']
self.n_fold = n_fold
self.name = 'adaptive switching'
self.model = None
# self.predictor_pool = []
def fit(self, train_data, train_target):
self._n_fold_validation(train_data, train_target, n=self.n_fold)
# for p in self.predictor_pool:
# p.fit(train_data,train_target)
def _n_fold_validation(self, train_data, train_target, n=10):
n_samples = len(train_data)
perm = np.random.permutation(n_samples)
kendall_tau = np.full((n, len(self.model_pool)), np.nan)
all_predict_result=[]
for i, tst_split in enumerate(np.array_split(perm, n)):
trn_split = np.setdiff1d(perm, tst_split, assume_unique=True)
rl=[]
# loop over all considered surrogate model in pool
for j, model in enumerate(self.model_pool):
acc_predictor = get_acc_predictor(model, train_data[trn_split], train_target[trn_split])
result = acc_predictor.predict(train_data[tst_split])
rl.append(result)
rmse, rho, tau = utils.get_correlation(result, train_target[tst_split])
kendall_tau[i, j] = tau
all_predict_result.append(rl)
winner = int(np.argmax(np.mean(kendall_tau, axis=0) - np.std(kendall_tau, axis=0)))
print("winner model = {}, tau = {}".format(self.model_pool[winner],
np.mean(kendall_tau, axis=0)[winner]))
self.winner = self.model_pool[winner]
# re-fit the winner model with entire data
# acc_predictor = get_acc_predictor(self.model_pool[winner], train_data, train_target)
# self.model = acc_predictor
def predict(self, test_data):
return self.model.predict(test_data)
================================================
FILE: examples/Structure_Evolution/EB-NAS/acc_predictor/carts.py
================================================
# implementation based on
# https://github.com/yn-sun/e2epp/blob/master/build_predict_model.py
# and https://github.com/HandingWang/RF-CMOCO
import numpy as np
from sklearn.tree import DecisionTreeRegressor
class CART:
""" Classification and Regression Tree """
def __init__(self, n_tree=1000):
self.n_tree = n_tree
self.name = 'carts'
self.model = None
@staticmethod
def _make_decision_trees(train_data, train_label, n_tree):
feature_record = []
tree_record = []
for i in range(n_tree):
sample_idx = np.arange(train_data.shape[0])
np.random.shuffle(sample_idx)
train_data = train_data[sample_idx, :]
train_label = train_label[sample_idx]
feature_idx = np.arange(train_data.shape[1])
np.random.shuffle(feature_idx)
n_feature = np.random.randint(1, train_data.shape[1] + 1)
selected_feature_ids = feature_idx[0:n_feature]
feature_record.append(selected_feature_ids)
dt = DecisionTreeRegressor()
dt.fit(train_data[:, selected_feature_ids], train_label)
tree_record.append(dt)
return tree_record, feature_record
def fit(self, train_data, train_label):
self.model = self._make_decision_trees(train_data, train_label, self.n_tree)
def predict(self, test_data):
assert self.model is not None, "carts does not exist, call fit to obtain cart first"
# redundant variable device
trees, features = self.model[0], self.model[1]
test_num, n_tree = len(test_data), len(trees)
predict_labels = np.zeros((test_num, 1))
for i in range(test_num):
this_test_data = test_data[i, :]
predict_this_list = np.zeros(n_tree)
for j, (tree, feature) in enumerate(zip(trees, features)):
predict_this_list[j] = tree.predict([this_test_data[feature]])[0]
# find the top 100 prediction
predict_this_list = np.sort(predict_this_list)
predict_this_list = predict_this_list[::-1]
this_predict = np.mean(predict_this_list)
predict_labels[i, 0] = this_predict
return predict_labels
================================================
FILE: examples/Structure_Evolution/EB-NAS/acc_predictor/factory.py
================================================
def get_acc_predictor(model, inputs, targets):
if model == 'rbf':
from acc_predictor.rbf import RBF
acc_predictor = RBF()
acc_predictor.fit(inputs, targets)
elif model == 'carts':
from acc_predictor.carts import CART
acc_predictor = CART(n_tree=5000)
acc_predictor.fit(inputs, targets)
elif model == 'gp':
from acc_predictor.gp import GP
acc_predictor = GP()
acc_predictor.fit(inputs, targets)
elif model == 'mlp':
from acc_predictor.mlp import MLP
acc_predictor = MLP(n_feature=inputs.shape[1])
acc_predictor.fit(x=inputs, y=targets)
elif model == 'as':
from acc_predictor.adaptive_switching import AdaptiveSwitching
acc_predictor = AdaptiveSwitching()
acc_predictor.fit(inputs, targets)
else:
raise NotImplementedError
return acc_predictor
================================================
FILE: examples/Structure_Evolution/EB-NAS/acc_predictor/gp.py
================================================
from pydacefit.regr import regr_constant
from pydacefit.dace import DACE, regr_linear, regr_quadratic
from pydacefit.corr import corr_gauss, corr_cubic, corr_exp, corr_expg, corr_spline, corr_spherical
class GP:
""" Gaussian Process (Kriging) """
def __init__(self, regr='linear', corr='gauss'):
self.regr = regr
self.corr = corr
self.name = 'gp'
self.model = None
def fit(self, train_data, train_label):
if self.regr == 'linear':
regr = regr_linear
elif self.regr == 'constant':
regr = regr_constant
elif self.regr == 'quadratic':
regr = regr_quadratic
else:
raise NotImplementedError("unknown GP regression")
if self.corr == 'gauss':
corr = corr_gauss
elif self.corr == 'cubic':
corr = corr_cubic
elif self.corr == 'exp':
corr = corr_exp
elif self.corr == 'expg':
corr = corr_expg
elif self.corr == 'spline':
corr = corr_spline
elif self.corr == 'spherical':
corr = corr_spherical
else:
raise NotImplementedError("unknown GP correlation")
self.model = DACE(
regr=regr, corr=corr, theta=1.0, thetaL=0.00001, thetaU=100)
self.model.fit(train_data, train_label)
def predict(self, test_data):
assert self.model is not None, "GP does not exist, call fit to obtain GP first"
return self.model.predict(test_data)
================================================
FILE: examples/Structure_Evolution/EB-NAS/acc_predictor/mlp.py
================================================
import copy
import torch
import numpy as np
import torch.nn as nn
from utils import get_correlation
class Net(nn.Module):
# N-layer MLP
def __init__(self, n_feature, n_layers=2, n_hidden=300, n_output=1, drop=0.2):
super(Net, self).__init__()
self.stem = nn.Sequential(nn.Linear(n_feature, n_hidden), nn.ReLU())
hidden_layers = []
for _ in range(n_layers):
hidden_layers.append(nn.Linear(n_hidden, n_hidden))
hidden_layers.append(nn.ReLU())
self.hidden = nn.Sequential(*hidden_layers)
self.regressor = nn.Linear(n_hidden, n_output) # output layer
self.drop = nn.Dropout(p=drop)
def forward(self, x):
x = self.stem(x)
x = self.hidden(x)
x = self.drop(x)
x = self.regressor(x) # linear output
return x
@staticmethod
def init_weights(m):
if type(m) == nn.Linear:
n = m.in_features
y = 1.0 / np.sqrt(n)
m.weight.data.uniform_(-y, y)
m.bias.data.fill_(0)
class MLP:
""" Multi Layer Perceptron """
def __init__(self, **kwargs):
self.model = Net(**kwargs)
self.name = 'mlp'
def fit(self, **kwargs):
self.model = train(self.model, **kwargs)
def predict(self, test_data, device='cpu'):
return predict(self.model, test_data, device=device)
def train(net, x, y, trn_split=0.8, pretrained=None, device='cpu',
lr=8e-4, epochs=2000, verbose=False):
n_samples = x.shape[0]
target = torch.zeros(n_samples, 1)
perm = torch.randperm(target.size(0))
trn_idx = perm[:int(n_samples * trn_split)]
vld_idx = perm[int(n_samples * trn_split):]
inputs = torch.from_numpy(x).float()
target[:, 0] = torch.from_numpy(y).float()
# back-propagation training of a NN
if pretrained is not None:
print("Constructing MLP surrogate model with pre-trained weights")
init = torch.load(pretrained, map_location='cpu')
net.load_state_dict(init)
best_net = copy.deepcopy(net)
else:
# print("Constructing MLP surrogate model with "
# "sample size = {}, epochs = {}".format(x.shape[0], epochs))
# initialize the weights
# net.apply(Net.init_weights)
net = net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
criterion = nn.SmoothL1Loss()
# criterion = nn.MSELoss()
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, int(epochs), eta_min=0)
best_loss = 1e33
for epoch in range(epochs):
trn_inputs = inputs[trn_idx]
trn_labels = target[trn_idx]
loss_trn = train_one_epoch(net, trn_inputs, trn_labels, criterion, optimizer, device)
loss_vld = infer(net, inputs[vld_idx], target[vld_idx], criterion, device)
scheduler.step()
# if epoch % 500 == 0 and verbose:
# print("Epoch {:4d}: trn loss = {:.4E}, vld loss = {:.4E}".format(epoch, loss_trn, loss_vld))
if loss_vld < best_loss:
best_loss = loss_vld
best_net = copy.deepcopy(net)
validate(best_net, inputs, target, device=device)
return best_net.to('cpu')
def train_one_epoch(net, data, target, criterion, optimizer, device):
net.train()
optimizer.zero_grad()
data, target = data.to(device), target.to(device)
pred = net(data)
loss = criterion(pred, target)
loss.backward()
optimizer.step()
return loss.item()
def infer(net, data, target, criterion, device):
net.eval()
with torch.no_grad():
data, target = data.to(device), target.to(device)
pred = net(data)
loss = criterion(pred, target)
return loss.item()
def validate(net, data, target, device):
net.eval()
with torch.no_grad():
data, target = data.to(device), target.to(device)
pred = net(data)
pred, target = pred.cpu().detach().numpy(), target.cpu().detach().numpy()
rmse, rho, tau = get_correlation(pred, target)
# print("Validation RMSE = {:.4f}, Spearman's Rho = {:.4f}, Kendall’s Tau = {:.4f}".format(rmse, rho, tau))
return rmse, rho, tau, pred, target
def predict(net, query, device):
if query.ndim < 2:
data = torch.zeros(1, query.shape[0])
data[0, :] = torch.from_numpy(query).float()
else:
data = torch.from_numpy(query).float()
net = net.to(device)
net.eval()
with torch.no_grad():
data = data.to(device)
pred = net(data)
return pred.cpu().detach().numpy()
================================================
FILE: examples/Structure_Evolution/EB-NAS/acc_predictor/rbf.py
================================================
from pySOT.surrogate import RBFInterpolant, CubicKernel, TPSKernel, LinearTail, ConstantTail
class RBF:
""" Radial Basis Function """
def __init__(self, kernel='cubic', tail='linear'):
self.kernel = kernel
self.tail = tail
self.name = 'rbf'
self.model = None
def fit(self, train_data, train_label):
if self.kernel == 'cubic':
kernel = CubicKernel
elif self.kernel == 'tps':
kernel = TPSKernel
else:
raise NotImplementedError("unknown RBF kernel")
if self.tail == 'linear':
tail = LinearTail
elif self.tail == 'constant':
tail = ConstantTail
else:
raise NotImplementedError("unknown RBF tail")
self.model = RBFInterpolant(dim=train_data.shape[1], kernel=kernel(), tail=tail(train_data.shape[1]))
for i in range(len(train_data)):
self.model.add_points(train_data[i, :], train_label[i])
def predict(self, test_data):
assert self.model is not None, "RBF model does not exist, call fit to obtain rbf model first"
return self.model.predict(test_data)
================================================
FILE: examples/Structure_Evolution/EB-NAS/cellmodel.py
================================================
import os
from functools import partial
from typing import List, Type
from operations import *
from motifs import *
from utils import drop_path
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.model_zoo.base_module import BaseModule
from torchvision import transforms
EVO=True
class EvoCell2(nn.Module):
def __init__(self,motif, C_prev_prev, C_prev, C, reduction, reduction_prev, act_fun):
# print(C_prev_prev, C_prev, C, reduction)
super(EvoCell2, self).__init__()
self.act_fun = act_fun
self.reduction = reduction
self.motif=motif
self.back_connection=False
if reduction:
self.fun = FactorizedReduce(
C_prev, C * 3, act_fun=act_fun
)
self.multiplier = 3
else:
if reduction_prev:
self.preprocess0 = FactorizedReduce(
C_prev_prev, C, act_fun=act_fun)
else:
self.preprocess0 = ReLUConvBN(
C_prev_prev, C, 1, 1, 0, act_fun=act_fun)
self.preprocess1 = ReLUConvBN(C_prev, C, 1, 1, 0, act_fun=act_fun)
op_names, indices = zip(*motif.normal)
concat = motif.normal_concat
self._compile(C, op_names, indices, concat, reduction)
def _compile(self, C, op_names, indices, concat, reduction):
assert len(op_names) == len(indices)
# self._steps = len(op_names) // 2
self._concat = concat
self.multiplier = len(concat)
self._ops = nn.ModuleList()
self._ops_back = nn.ModuleList()
back_begin_index = 0
for i, (name, index) in enumerate(zip(op_names, indices)):
# print(name, index)
if '_back' in name:
self.back_connection=True
back_begin_index = i
break
stride = 2 if reduction and index < 2 else 1
op = OPS[name](C, stride, True, act_fun=self.act_fun)
self._ops += [op]
if self.back_connection:
for name, index in zip(op_names[back_begin_index:], indices[back_begin_index:]):
op = OPS[name.replace('_back', '')](
C, 1, True, act_fun=self.act_fun)
self._ops_back += [op]
if self.back_connection:
self._indices_forward = indices[:back_begin_index]
self._indices_backward = indices[back_begin_index:]
else:
self._indices_backward = []
self._indices_forward = indices
self._steps = len(self._indices_forward) // 2
def forward(self, s0, s1, drop_prob):
if self.reduction:
return self.fun(s1)
# print('s0',s0.shape)
s0 = self.preprocess0(s0)
# print(s0.shape)
# print('s1',s1.shape)
s1 = self.preprocess1(s1)
# print(s1.shape)
states = [s0, s1]
for i in range(self._steps):
i1=self._indices_forward[2 * i]
i2=self._indices_forward[2 * i + 1]
h1 = states[i1]
h2 = states[i2]
op1 = self._ops[2 * i]
op2 = self._ops[2 * i + 1]
h1 = op1(h1)
h2 = op2(h2)
if self.training and drop_prob > 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
s = h1 + h2
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = torch.cat([states[i]
for i in self._concat], dim=1) # N,C,H, W
return outputs
# return self.node(outputs)
class EvoCell3(nn.Module):
def __init__(self,motif, C_prev_prev_prev, C_prev_prev, C_prev, C, reduction, reduction_prev, reduction_prev_prev, act_fun):
# print(C_prev_prev_prev,C_prev_prev, C_prev, C, reduction,reduction_prev, reduction_prev_prev)
super(EvoCell3, self).__init__()
self.act_fun = act_fun
self.reduction = reduction
self.motif=motif
self.back_connection=False
if reduction:
self.fun = FactorizedReduce(C_prev, C * 3, act_fun=act_fun)
self.multiplier = 3
else:
if reduction_prev:
self.preprocess1 = FactorizedReduce(C_prev_prev, C, act_fun=act_fun)
else:
self.preprocess1 = ReLUConvBN(C_prev_prev, C, 1, 1, 0, act_fun=act_fun)
if int(reduction_prev_prev)+int(reduction_prev)==1:
self.preprocess0 = FactorizedReduce(C_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev)+int(reduction_prev)==2:
self.preprocess0 = F0(C_prev_prev_prev, C, act_fun=act_fun)
else:
self.preprocess0 = ReLUConvBN(C_prev_prev_prev, C, 1, 1, 0, act_fun=act_fun)
self.preprocess2 = ReLUConvBN(C_prev, C, 1, 1, 0, act_fun=act_fun)
op_names, indices = zip(*motif.normal)
concat = motif.normal_concat
self._compile(C, op_names, indices, concat, reduction)
def _compile(self, C, op_names, indices, concat, reduction):
assert len(op_names) == len(indices)
# self._steps = len(op_names) // 2
self._concat = concat
self.multiplier = len(concat)
self._ops = nn.ModuleList()
self._ops_back = nn.ModuleList()
back_begin_index = 0
for i, (name, index) in enumerate(zip(op_names, indices)):
# print(name, index)
if '_back' in name:
self.back_connection=True
back_begin_index = i
break
stride = 2 if reduction and index < 2 else 1
op = OPS[name](C, stride, True, act_fun=self.act_fun)
self._ops += [op]
if self.back_connection:
for name, index in zip(op_names[back_begin_index:], indices[back_begin_index:]):
op = OPS[name.replace('_back', '')](
C, 1, True, act_fun=self.act_fun)
self._ops_back += [op]
if self.back_connection:
self._indices_forward = indices[:back_begin_index]
self._indices_backward = indices[back_begin_index:]
else:
self._indices_backward = []
self._indices_forward = indices
self._steps = len(self._indices_forward) // 3
def forward(self, s0, s1, s2, drop_prob):
if self.reduction:
return self.fun(s2)
s0 = self.preprocess0(s0)
s1 = self.preprocess1(s1)
s2 = self.preprocess2(s2)
states = [s0, s1, s2]
for i in range(self._steps):
i1=self._indices_forward[3 * i]
i2=self._indices_forward[3 * i + 1]
i3=self._indices_forward[3 * i + 2]
h1 = states[i1]
h2 = states[i2]
h3 = states[i3]
op1 = self._ops[3 * i]
op2 = self._ops[3 * i + 1]
op3 = self._ops[3 * i + 2]
h1 = op1(h1)
h2 = op2(h2)
h3 = op3(h3)
if self.training and drop_prob > 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
if not isinstance(op3, Identity):
h3 = drop_path(h3, drop_prob)
s = h1 + h2 + h3
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = torch.cat([states[i] for i in self._concat], dim=1) # N,C,H, W
return outputs
# return self.node(outputs)
class EvoCell4(nn.Module):
def __init__(self,motif, C_prev_prev_prev_prev,C_prev_prev_prev, C_prev_prev, C_prev, C, reduction, reduction_prev, reduction_prev_prev,reduction_prev_prev_prev, act_fun):
# print(C_prev_prev_prev_prev,C_prev_prev_prev,C_prev_prev, C_prev, C, reduction,reduction_prev, reduction_prev_prev,reduction_prev_prev_prev)
super(EvoCell4, self).__init__()
self.act_fun = act_fun
self.reduction = reduction
self.motif=motif
self.back_connection=False
if reduction:
self.fun = FactorizedReduce(C_prev, C * 3, act_fun=act_fun)
self.multiplier = 3
else:
if reduction_prev:
self.preprocess2 = FactorizedReduce(C_prev_prev, C, act_fun=act_fun)
else:
self.preprocess2 = ReLUConvBN(C_prev_prev, C, 1, 1, 0, act_fun=act_fun)
if int(reduction_prev_prev)+int(reduction_prev)==1:
self.preprocess1 = FactorizedReduce(C_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev)+int(reduction_prev)==2:
self.preprocess1 = F0(C_prev_prev_prev, C, act_fun=act_fun)
else:
self.preprocess1 = ReLUConvBN(C_prev_prev_prev, C, 1, 1, 0, act_fun=act_fun)
if int(reduction_prev_prev_prev)+int(reduction_prev_prev)+int(reduction_prev)==1:
self.preprocess0 = FactorizedReduce(C_prev_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev_prev)+int(reduction_prev_prev)+int(reduction_prev)==2:
self.preprocess0 = F0(C_prev_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev_prev)+int(reduction_prev_prev)+int(reduction_prev)==3:
self.preprocess0 = F1(C_prev_prev_prev_prev, C, act_fun=act_fun)
else:
self.preprocess0 = ReLUConvBN(C_prev_prev_prev_prev, C, 1, 1, 0, act_fun=act_fun)
self.preprocess3 = ReLUConvBN(C_prev, C, 1, 1, 0, act_fun=act_fun)
op_names, indices = zip(*motif.normal)
# print(self.preprocess0)
# print(self.preprocess1)
# print(self.preprocess2)
# print(self.preprocess3)
concat = motif.normal_concat
self._compile(C, op_names, indices, concat, reduction)
def _compile(self, C, op_names, indices, concat, reduction):
assert len(op_names) == len(indices)
# self._steps = len(op_names) // 2
self._concat = concat
self.multiplier = len(concat)
self._ops = nn.ModuleList()
self._ops_back = nn.ModuleList()
back_begin_index = 0
for i, (name, index) in enumerate(zip(op_names, indices)):
# print(name, index)
if '_back' in name:
self.back_connection=True
back_begin_index = i
break
stride = 2 if reduction and index < 2 else 1
op = OPS[name](C, stride, True, act_fun=self.act_fun)
self._ops += [op]
if self.back_connection:
for name, index in zip(op_names[back_begin_index:], indices[back_begin_index:]):
op = OPS[name.replace('_back', '')](
C, 1, True, act_fun=self.act_fun)
self._ops_back += [op]
if self.back_connection:
self._indices_forward = indices[:back_begin_index]
self._indices_backward = indices[back_begin_index:]
else:
self._indices_backward = []
self._indices_forward = indices
self._steps = len(self._indices_forward) // 4
def forward(self, s0, s1, s2, s3, drop_prob):
if self.reduction:
return self.fun(s3)
s0 = self.preprocess0(s0)
s3 = self.preprocess3(s3)
s1 = self.preprocess1(s1)
s2 = self.preprocess2(s2)
# if s1.shape[1]!=s3.shape[1]:
# s1 = nn.Conv2d(s1.shape[1], s3.shape[1], 3, stride=2, padding=1, bias=False)
states = [s0, s1, s2,s3]
for i in range(self._steps):
i1=self._indices_forward[4 * i]
i2=self._indices_forward[4 * i + 1]
i3=self._indices_forward[4 * i + 2]
i4=self._indices_forward[4 * i + 3]
h1 = states[i1]
h2 = states[i2]
h3 = states[i3]
h4 = states[i4]
op1 = self._ops[4 * i]
op2 = self._ops[4 * i + 1]
op3 = self._ops[4 * i + 2]
op4 = self._ops[4 * i + 3]
h1 = op1(h1)
h2 = op2(h2)
h3 = op3(h3)
h4 = op4(h4)
if self.training and drop_prob > 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
if not isinstance(op3, Identity):
h3 = drop_path(h3, drop_prob)
if not isinstance(op4, Identity):
h4= drop_path(h4, drop_prob)
s = h1 + h2 + h3 + h4
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = torch.cat([states[i] for i in self._concat], dim=1) # N,C,H, W
return outputs
# return self.node(outputs)
@register_model
class NetworkCIFAR(BaseModule):
def __init__(self,
C,
num_classes,
layers,
auxiliary,
motif,
cell_type,
parse_method='darts',
step=5,
node_type='ReLUNode',
**kwargs):
super(NetworkCIFAR, self).__init__(
step=step,
num_classes=num_classes,
**kwargs
)
self.node_type=node_type
if isinstance(node_type, str):
self.act_fun = eval(node_type)
else:
self.act_fun = node_type
self.act_fun = partial(self.act_fun, **kwargs)
self.spike_output = kwargs['spike_output'] if 'spike_output' in kwargs else True
self.dataset = kwargs['dataset']
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
self._layers = layers
self.cell_type = cell_type
self._auxiliary = auxiliary
self.drop_path_prob = 0
stem_multiplier = 3
C_curr = stem_multiplier * C
if self.dataset == 'dvsg' or self.dataset == 'dvsc10' or self.dataset == 'NCALTECH101':
self.stem = nn.Sequential(
nn.Conv2d(2 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
# self.reduce_idx = [
# layers // 4,
# layers // 2,
# 3 * layers // 4
# ]
self.reduce_idx = [1, 3, 5, 7]
else:
self.stem = nn.Sequential(
nn.Conv2d(3 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
self.reduce_idx = [layers // 4,
layers // 2,
3 * layers // 4]
C_prev_prev_prev = C_curr
C_prev_prev_prev_prev = C_curr
C_prev_prev, C_prev, C_curr = C_curr, C_curr, C
self.cells = nn.ModuleList()
reduction_prev = False
reduction_prev_prev = False
reduction_prev_prev_prev = False
for i in range(layers):
if i in self.reduce_idx:
C_curr *= 2
reduction = True
else:
reduction = False
if cell_type==2:
# print(C_prev_prev, C_prev, C_curr)
cell = EvoCell2(motif[i], C_prev_prev, C_prev, C_curr,reduction, reduction_prev,act_fun=self.act_fun)
self.cells += [cell]
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
if cell_type==3:
cell = EvoCell3(motif[i], C_prev_prev_prev, C_prev_prev, C_prev, C_curr,reduction, reduction_prev,reduction_prev_prev,act_fun=self.act_fun)
self.cells += [cell]
C_prev_prev_prev = C_prev_prev
reduction_prev_prev = reduction_prev
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
if cell_type==4:
cell = EvoCell4(motif[i], C_prev_prev_prev_prev,C_prev_prev_prev, C_prev_prev, C_prev, C_curr,reduction, reduction_prev,reduction_prev_prev,reduction_prev_prev_prev,act_fun=self.act_fun)
self.cells += [cell]
C_prev_prev_prev_prev = C_prev_prev_prev
C_prev_prev_prev = C_prev_prev
reduction_prev_prev_prev = reduction_prev_prev
reduction_prev_prev = reduction_prev
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
reduction_prev = reduction
self.global_pooling = nn.Sequential(
self.act_fun(), nn.AdaptiveAvgPool2d(1))
if self.spike_output:
self.classifier = nn.Sequential(
nn.Linear(C_prev, 10 * num_classes),
self.act_fun())
self.vote = VotingLayer(10)
else:
self.classifier = nn.Linear(C_prev, num_classes)
self.vote = nn.Identity()
# self.classifier = nn.Linear(C_prev, num_classes)
# self.vote = nn.Identity()
def forward(self, inputs):
logits_aux = None
inputs = self.encoder(inputs)
if not self.layer_by_layer:
outputs = []
output_aux = []
self.reset()
if self.cell_type==2:
for t in range(self.step):
x = inputs[t]
s0 = s1 = self.stem(x)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
out = self.global_pooling(s1)
out = self.classifier(self.flatten(out))
logits = self.vote(out)
outputs.append(logits)
output_aux.append(logits_aux)
return sum(outputs) / len(outputs)
if self.cell_type==3:
for t in range(self.step):
x = inputs[t]
s0 = s1 = s2= self.stem(x)
for i, cell in enumerate(self.cells):
s0, s1, s2 = s1, s2, cell(s0, s1, s2, self.drop_path_prob)
out = self.global_pooling(s2)
out = self.classifier(self.flatten(out))
logits = self.vote(out)
outputs.append(logits)
output_aux.append(logits_aux)
return sum(outputs) / len(outputs)
if self.cell_type==4:
for t in range(self.step):
x = inputs[t]
s0 = s1 = s2= s3=self.stem(x)
for i, cell in enumerate(self.cells):
s0, s1, s2,s3= s1, s2, s3,cell(s0, s1, s2,s3 ,self.drop_path_prob)
out = self.global_pooling(s3)
out = self.classifier(self.flatten(out))
logits = self.vote(out)
outputs.append(logits)
output_aux.append(logits_aux)
return sum(outputs) / len(outputs)
# logits_aux if logits_aux is None else (sum(output_aux) / len(output_aux))
else:
s0 = s1 = self.stem(inputs)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
if i == 2 * self._layers // 3:
if self._auxiliary and self.training:
logits_aux = self.auxiliary_head(s1)
out = self.global_pooling(s1)
out = self.classifier(self.flatten(out))
out = rearrange(out, '(t b) c -> t b c', t=self.step).mean(0)
logits = self.vote(out)
return logits
@register_model
class NetworkCIFAR_(BaseModule):
def __init__(self,
C,
num_classes,
layers,
glob,
auxiliary,
motif,
parse_method='darts',
step=5,
node_type='ReLUNode',
**kwargs):
super(NetworkCIFAR_, self).__init__(
step=step,
num_classes=num_classes,
**kwargs
)
self.node_type=node_type
if isinstance(node_type, str):
self.act_fun = eval(node_type)
else:
self.act_fun = node_type
self.act_fun = partial(self.act_fun, **kwargs)
self.spike_output = kwargs['spike_output'] if 'spike_output' in kwargs else True
self.dataset = kwargs['dataset']
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
self.glob = glob
self._layers = layers
self._auxiliary = auxiliary
self.drop_path_prob = 0
stem_multiplier = 3
C_curr = stem_multiplier * C
if self.dataset == 'dvsg' or self.dataset == 'dvsc10' or self.dataset == 'NCALTECH101':
self.stem = nn.Sequential(
nn.Conv2d(2 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
# self.reduce_idx = [
# layers // 4,
# layers // 2,
# 3 * layers // 4
# ]
self.reduce_idx = [1, 3, 5, 7]
else:
self.stem = nn.Sequential(
nn.Conv2d(3 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
self.reduce_idx = [layers // 4,
layers // 2,
3 * layers // 4]
C_prev_prev_prev = C_curr
C_prev_prev_prev_prev = C_curr
C_prev_prev, C_prev, C_curr = C_curr, C_curr, C
self.cells = nn.ModuleList()
reduction_prev = False
reduction_prev_prev = False
reduction_prev_prev_prev = False
for i in range(layers):
if i in self.reduce_idx:
C_curr *= 2
reduction = True
else:
reduction = False
cell = EvoCell2(motif[i], C_prev_prev, C_prev, C_curr,reduction, reduction_prev,act_fun=self.act_fun)
self.cells += [cell]
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
reduction_prev = reduction
self.global_pooling = nn.Sequential(
self.act_fun(), nn.AdaptiveAvgPool2d(1))
if self.spike_output:
self.classifier = nn.Sequential(
nn.Linear(C_prev, 10 * num_classes),
self.act_fun())
self.vote = VotingLayer(10)
else:
self.classifier = nn.Linear(C_prev, num_classes)
self.vote = nn.Identity()
# self.classifier = nn.Linear(C_prev, num_classes)
# self.vote = nn.Identity()
def forward(self, inputs):
logits_aux = None
inputs = self.encoder(inputs)
if not self.layer_by_layer:
outputs = []
output_aux = []
self.reset()
zzz=[]
kkk=[]
for t in range(self.step):
x = inputs[t]
s0 = s1 = self.stem(x)
# print(s1.shape)
for i, cell in enumerate(self.cells):
if t>0 and i%5==4:
qw = np.where(self.glob[:,int(i//5)]==1)
if qw[0].shape[0]!=0:
for m in qw:
if zzz[m[0]].shape[-1]>s1.shape[-1]:
ks=zzz[m[0]].shape[-1] - (s1.shape[-1]-1)*2+2
if ks<0:
ks=zzz[m[0]].shape[-1] - (s1.shape[-1]-1)+2
bb=nn.Conv2d(zzz[m[0]].shape[1], s1.shape[1], kernel_size=ks, stride=1,padding=1, bias=False).to(zzz[m[0]].device)
else:
bb=nn.Conv2d(zzz[m[0]].shape[1], s1.shape[1], kernel_size=ks, stride=2,padding=1, bias=False).to(zzz[m[0]].device)
aa=bb(zzz[m[0]])
s1=aa+s1
elif zzz[m[0]].shape[-1] t b c', t=self.step).mean(0)
logits = self.vote(out)
return logits
def occumpy_mem(cuda_device):
total, used = os.popen('"/usr/bin/nvidia-smi" --query-gpu=memory.total,memory.used --format=csv,nounits,noheader').read().strip().split("\n")[int(cuda_device)].split(',')
# total, used = check_mem(cuda_device)
total = int(total)
used = int(used)
max_mem = int(total * 1)
block_mem = int((max_mem - used)*0.85)
x = torch.cuda.FloatTensor(256,1024,block_mem)
del x
if __name__ == '__main__':
torch.cuda.set_device('cuda:3')
# occumpy_mem(str(3))
x = torch.rand(128, 3, 32, 32)
glob = np.array([[0,1,0,0],[1,0,1,0],[1,0,0,1],[0,1,0,0]])
# glob = np.array([[0,1],[1,0]])
glob = np.array([[0,1,0,0],[0,0,0,0],[0,0,0,1],[0,0,0,0]])
glob = np.array([[0,1,1,1],[1,0,1,1],[1,1,0,1],[1,1,1,0]])
glob = np.array([[0,1,0],[1,0,0],[1,1,1]])
motifs=[mm2,mm3,mm4,mm5,mm1,mm5,mm3,mm4,mm2,mm1,mm2,mm3,mm4,mm5,mm1]
# motifs=[m1,m2,m3,m1,m5,m4,m1,m2,m3,m1,m5,m4,m5,m4,m1]##3
# motifs=[t2,t3,t4,t5,t1,t5,t3,t4,t2,t1,t2,t3,t4,t5,t1,t5,t3,t4,t2,t1]
# motifs=[t2,t3,t4,t5,t1]
# motifs=[subnet,subnet,subnet]
net=NetworkCIFAR_(C=12,num_classes=10,motif=motifs,layers=len(motifs),auxiliary=True,dataset='cifar10',glob=glob)
# net=NetworkCIFAR(C=12,num_classes=10,motif=motifs,layers=len(motifs),auxiliary=True,dataset='cifar10',cell_type=2)
net=net.cuda()
layers=int(len(motifs)/5)
out=net(x.to('cuda:3'))
print(out.shape)
================================================
FILE: examples/Structure_Evolution/EB-NAS/ebnas.py
================================================
import sys
import numpy as np
import argparse
import time
import timm.models
import yaml
import os
import logging
from random import choice
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from micro_encoding import ops
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
# from braincog.model_zoo.reactnet import *
# from braincog.model_zoo.convxnet import *
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import micro_encoding
import nsganet as engine
from pymop.problem import Problem
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from pymoo.optimize import minimize
from tm import train_motifs
from timm.data import create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from cellmodel import NetworkCIFAR
bits=20
# from ptflops import get_model_complexity_info
# from thop import profile, clever_format
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('')
# The first arg parser parses out only thei --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
devices=[4]
max_gen = 100
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--seed', type=int, default=99, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--eval_epochs', type=int, default=1)
parser.add_argument('--bns', action='store_true', default=True)
parser.add_argument('--mid', type=int, default=5)
parser.add_argument('--trainning_epochs', type=int, default=600, metavar='N',help='number of epochs to train (default: 2)')
parser.add_argument('--cooldown-epochs', type=int, default=0, metavar='N',help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--init-channels', type=int, default=36)
parser.add_argument('--layers', type=int, default=2)
parser.add_argument('--output', default='', type=str, metavar='PATH')
parser.add_argument('--spike-rate', action='store_true', default=False)
parser.add_argument('--n_gens', type=int, default=max_gen, help='population size')
parser.add_argument('--bs', type=int, default=100)
parser.add_argument('--n_offspring', type=int, default=60, help='number of offspring created per generation')
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser.add_argument('--dataset', default='cifar10', type=str)
parser.add_argument('--num-classes', type=int, default=10, metavar='N')
parser.add_argument('--model', default='NetworkCIFAR', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
parser.add_argument('--strgenome', default='4,0,0,1,1,1,0,1,0,1,0,0,0,1,0,1,0,1,0,0,4,1,1,1,1,1,0,1,1,0,1,1,0,1,1,1,0,1,0,0,4,1,1,0,1,0,0,1,0,1,1,0,1,1,0,0,1,0,1,2,4,1,0,0,1,1,1,0,0,1,0,0,1,0,0,1,0,0,1,1,4,0,1,1,0,1,0,0,1,0,1,0,1,1,1,0,1,0,1,3,4,1,0,1,0,0,1,1,1,0,0,1,0,1,0,0,0,1,0,0,3', type=str)
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.8,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=1.0,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=1.0,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=len(devices),
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=devices[0])
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='QGateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
# DARTS parameters
parser.add_argument('--auxiliary', action='store_true', default=False, help='use auxiliary tower')
# parser.add_argument('--arch', default='dvsc10_new_skip19', type=str)
# parser.add_argument('--motif', default='m1', type=str)
parser.add_argument('--parse_method', default='darts', type=str)
parser.add_argument('--drop_path_prob', type=float, default=0.2, help='drop path probability')
# parser.add_argument('--back-connection', action='store_true',default=True)
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
class NAS(Problem):
# first define the NAS problem (inherit from pymop)
def __init__(self, args,n_var=20, n_obj=1, n_constr=0, lb=None, ub=None,
init_channels=24, layers=8):
super().__init__(n_var=n_var, n_obj=n_obj, n_constr=n_constr, type_var=np.int64)
self.xl = lb
self.xu = ub
self._lr =args.lr
self._n_evaluated = 0 # keep track of how many architectures are sampled
self.args=args
def _evaluate(self, x, out, *args, **kwargs):
objs = np.full((x.shape[0], self.n_obj), np.nan)
for i in range(x.shape[0]):
arch_id = self._n_evaluated + 1
print('\n')
_logger.info('Network= {}'.format(arch_id))
genome = x[i, :]
arch_dir=os.path.join(self.args.output_dir,i)
if os.path.exists(arch_dir) is False:
os.makedirs(arch_dir,exist_ok = True)
self.args.lr=self._lr
performance,acc=train_motifs(args=self.args,gen=0,arch_dir=arch_dir,genome=genome,_logger=_logger,args_text=args_text,devices=devices,bits=bits)
objs[i, 0] = 1000 - performance
_logger.info('performance= {}'.format(objs[i, 0]))
self._n_evaluated += 1
out["F"] = objs
# if your NAS problem has constraints, use the following line to set constraints
# out["G"] = np.column_stack([g1, g2, g3, g4, g5, g6]) in case 6 constraints
def do_every_generations(algorithm):
# this function will be call every generation
# it has access to the whole algorithm class
gen = algorithm.n_gen
pop_var = algorithm.pop.get("X")
pop_obj = algorithm.pop.get("F")
# report generation info to files
_logger.info("generation = {}".format(gen))
_logger.info("population error: best = {}, mean = {}, "
"median = {}, worst = {}".format(np.min(pop_obj[:, 0]), np.mean(pop_obj[:, 0]),
np.median(pop_obj[:, 0]), np.max(pop_obj[:, 0])))
_logger.info('Best Genome= {}'.format(pop_var[np.argmin(pop_obj[:, 0])]))
def _parse_args():
args_config, remaining = config_parser.parse_known_args()
args = parser.parse_args(remaining)
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
if __name__ == '__main__':
args, args_text = _parse_args()
# args.no_spike_output = args.no_spike_output | args.cut_mix
args.no_spike_output = True
output_dir = ''
if args.local_rank == 0:
output_base = args.output if args.output else './output'
exp_name = '-'.join([
datetime.now().strftime("%Y%m%d-%H%M%S"),
# args.model,
# args.dataset,
str(args.layers)+'layers',
str(args.init_channels)+'channels',
'motif'+str(args.mid),
str(args.step)+'steps',
# args.suffix
# str(args.img_size)
])
output_dir = get_outdir(output_base,str(args.dataset),exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
else:
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
defalut_lr = args.lr
sn = np.arange(1,6)
np.random.shuffle(sn)
args.subnet=sn
args.layers*=5
len_motifs=args.layers*bits
low = np.zeros(len_motifs)
up=[]
for i in range(0,args.layers*bits,bits):
t=[args.mid]
low[i]=args.mid
t=t+[(ops-1) for j in range(bits-1)]
t[-1]=2*(ops-1)
up.extend(t)
up=np.array(up).reshape(-1,)
kkk = NAS(args,n_var=len_motifs,
n_obj=2, n_constr=0, lb=low, ub=up,
init_channels=args.init_channels, layers=args.layers)
method = engine.nsganet(pop_size=args.pop_size,
n_offsprings=args.n_offspring,
eliminate_duplicates=True)
kres=minimize(kkk,
method,
callback=do_every_generations,
termination=('n_gen', args.n_gens))
================================================
FILE: examples/Structure_Evolution/EB-NAS/micro_encoding.py
================================================
# NASNet Search Space https://arxiv.org/pdf/1707.07012.pdf
# code modified from DARTS https://github.com/quark0/darts
import numpy as np
from collections import namedtuple
from random import choice
from numpy.linalg import matrix_rank
import itertools
import torch
# from models.micro_models import NetworkCIFAR as Network
import motifs
# Genotype = namedtuple('Genotype', 'normal normal_concat reduce reduce_concat')
# Genotype_norm = namedtuple('Genotype', 'normal normal_concat')
# Genotype_redu = namedtuple('Genotype', 'reduce reduce_concat')
Genotype = namedtuple('Genotype', 'normal normal_concat')
# what you want to search should be defined here and in micro_operations
PRIMITIVES = [
'max_pool_3x3',
'avg_pool_3x3',
'skip_connect',
'sep_conv_3x3',
'sep_conv_5x5',
'dil_conv_3x3',
'dil_conv_5x5',
'sep_conv_7x7',
'conv_7x1_1x7',
]
OPERATIONS_back = [
# 'max_pool_3x3_p_back',
# 'avg_pool_3x3_p_back',
'conv_3x3_p_back',
'conv_5x5_p_back',
# 'avg_pool_3x3_n_back',
'conv_3x3_n_back',
'conv_5x5_n_back',
# 'sep_conv_3x3_p_back',
# 'sep_conv_5x5_p_back',
# 'dil_conv_3x3_p_back',
# 'dil_conv_5x5_p_back',
# 'def_conv_3x3_p_back',
# 'def_conv_5x5_p_back',
]
OPERATIONS_p = [
# 'max_pool_3x3_p',
# 'avg_pool_3x3_p',
'conv_3x3_p',
'conv_5x5_p',
# 'sep_conv_3x3_p',
# 'sep_conv_5x5_p',
# 'dil_conv_3x3_p',
# 'dil_conv_5x5_p',
# 'def_conv_3x3_p',
# 'def_conv_5x5_p',
]
ops=len(OPERATIONS_p)
OPERATIONS_n = [
# 'max_pool_3x3_n',
# 'avg_pool_3x3_n',
'conv_3x3_n',
'conv_5x5_n',
# 'sep_conv_3x3_n',
# 'sep_conv_5x5_n',
# 'dil_conv_3x3_n',
# 'dil_conv_5x5_n',
# 'def_conv_3x3_n',
# 'def_conv_5x5_n',
# 'transformer',
]
mids=(3,3,2,2,1)
mids=(1,2,3,4,5)
ms=len(mids)
permutations = list({}.fromkeys(list(itertools.permutations(mids))).keys())
motifdict_c = dict(enumerate(permutations, 1))
motifdict = dict(zip(motifdict_c.values(),motifdict_c.keys()))
def convert_cell(cell_bit_string):
# convert cell bit-string to genome
tmp = [cell_bit_string[i:i + 2] for i in range(0, len(cell_bit_string), 2)]
return [tmp[i:i + 2] for i in range(0, len(tmp), 2)]
def filt(sn):
for i in range(sn.shape[0]):
if sn[i]<1:
sn[i]=1
if sn[i]>120:
sn[i]=120
return sn
# def convert(bit_string):
# # convert network bit-string (norm_cell + redu_cell) to genome
# norm_gene = convert_cell(bit_string[:len(bit_string)//2])
# redu_gene = convert_cell(bit_string[len(bit_string)//2:])
# return [norm_gene, redu_gene]
def shuffle_along_axis(a, axis):
idx = np.random.rand(*a.shape).argsort(axis=axis)
return np.take_along_axis(a,idx,axis=axis)
def sample(pops, layers, bits , ):
sn = np.tile(mids,pops*layers).reshape(-1,ms)
sn=shuffle_along_axis(sn,axis=1)
sn=sn.reshape(-1,1)
# bigmotifs=(np.random.rand(pops*layers*ms,bits-1)<0.5).astype(int).reshape(-1,bits-1)
bigmotifs=(np.random.rand(pops*layers,bits-1)<0.5).astype(int).reshape(-1,bits-1)
# bigmotifs=np.repeat(bigmotifs,ms,axis=0)
sn=sn.reshape(pops*layers,-1)
# glob=np.array([2 for i in range(pops)])[:,np.newaxis]
genome=np.concatenate((sn, bigmotifs),axis=1).reshape(pops,-1)
glob = (np.random.rand(pops,layers*layers)<0.5).astype(int).reshape(pops,layers,layers)
# for i in range(layers):
# glob[:,i,i]=0
genome=np.concatenate((genome, glob.reshape(pops,layers*layers)),axis=1).reshape(pops,-1)
return genome,sn,bigmotifs,ms,glob.reshape(pops,layers*layers)
def reencode(sn,bigmotifs,pops):
sn=sn.reshape(-1,ms)
mnumber=np.array([motifdict[tuple(x)] for x in sn]).reshape(pops,-1)
mgenome=np.concatenate((bigmotifs.reshape(pops,-1), mnumber),axis=1).reshape(pops,-1)
return mgenome
def convert(mgenome, layers, bits):
bigmotifs = mgenome[:,0:-layers].reshape(-1,bits-1)
sn=mgenome[:,-layers:].reshape(-1)
sn=filt(sn)
ssn=np.array([list(motifdict_c[sn[i]]) for i in range(sn.shape[0])]).reshape(-1,1)
result=np.concatenate((ssn,np.repeat(bigmotifs,ms,axis=0)),axis=1).reshape(-1,layers*bits*ms)
return np.c_[result,np.ones((result.shape[0],1))*2]
def convert_single(mgenome, layers, bits):
bigmotifs = mgenome[0:-layers].reshape(-1,bits-1)
sn=mgenome[-layers:].reshape(-1)
sn=filt(sn)
ssn=np.array([list(motifdict_c[sn[i]]) for i in range(sn.shape[0])]).reshape(-1,1)
result=list(np.concatenate((ssn,np.repeat(bigmotifs,ms,axis=0)),axis=1).reshape(layers*bits*ms))
return np.array(result)
def c_single(mgenome, layers, bits):
glob = mgenome[-layers*layers:]
mgenome = mgenome[:-layers*layers]
big=mgenome.reshape(layers,-1)
bigmotifs = big[:,ms:]
sn=big[:,0:ms]
result = np.concatenate((sn.reshape(-1,1),np.repeat(bigmotifs,ms,axis=0)),axis=1).reshape(-1,).tolist()
result.append(glob.reshape(layers,layers))
return result
# def decode_cell(genome, norm=True):
# cell, cell_concat = [], list(range(2, len(genome)+2))
# for block in genome:
# for unit in block:
# cell.append((PRIMITIVES[unit[0]], unit[1]))
# if unit[1] in cell_concat:
# cell_concat.remove(unit[1])
# if norm:
# return Genotype_norm(normal=cell, normal_concat=cell_concat)
# else:
# return Genotype_redu(reduce=cell, reduce_concat=cell_concat)
def decode(genome):
# decodes genome to architecture
normal_cell = genome[0]
reduce_cell = genome[1]
normal, normal_concat = [], list(range(2, len(normal_cell)+2))
reduce, reduce_concat = [], list(range(2, len(reduce_cell)+2))
for block in normal_cell:
for unit in block:
normal.append((PRIMITIVES[unit[0]], unit[1]))
if unit[1] in normal_concat:
normal_concat.remove(unit[1])
for block in reduce_cell:
for unit in block:
reduce.append((PRIMITIVES[unit[0]], unit[1]))
if unit[1] in reduce_concat:
reduce_concat.remove(unit[1])
return Genotype(
normal=normal, normal_concat=normal_concat,
reduce=reduce, reduce_concat=reduce_concat
)
def decode_motif(layers,bits,genome):
# decodes genome to architecture
motif_list=[]
motif_ids=[]
for b in range(0,layers*bits,bits):
motif_id='mm'+str(genome[b])
motif_ids.append(genome[b])
normalcell=eval('motifs.%s' % motif_id)
newnormal=[]
for i in range(0,len(normalcell.normal)):
op=normalcell.normal[i]
if 'skip' in op[0]:
newnormal.append(op)
continue
elif 'back' in op[0]:
newnormal.append((OPERATIONS_back[genome[b+1+len(normalcell.normal)-1]],op[1]))
continue
elif '_n' in op[0]:
newnormal.append((OPERATIONS_n[genome[b+1+i]],op[1]))
continue
elif '_p' in op[0]:
newnormal.append((OPERATIONS_p[genome[b+1+i]],op[1]))
continue
m=Genotype(normal=newnormal, normal_concat=normalcell.normal_concat,)
motif_list.append(m)
return motif_list,motif_ids
def compare_cell(cell_string1, cell_string2):
cell_genome1 = convert_cell(cell_string1)
cell_genome2 = convert_cell(cell_string2)
cell1, cell2 = cell_genome1[:], cell_genome2[:]
for block1 in cell1:
for block2 in cell2:
if block1 == block2 or block1 == block2[::-1]:
cell2.remove(block2)
break
if len(cell2) > 0:
return False
else:
return True
def compare(string1, string2):
if compare_cell(string1[:len(string1)//2],
string2[:len(string2)//2]):
if compare_cell(string1[len(string1)//2:],
string2[len(string2)//2:]):
return True
return False
# def debug():
# # design to debug the encoding scheme
# seed = 0
# np.random.seed(seed)
# budget = 2000
# B, n_ops, n_cell = 5, 7, 2
# networks = []
# design_id = 1
# while len(networks) < budget:
# bit_string = []
# for c in range(n_cell):
# for b in range(B):
# bit_string += [np.random.randint(n_ops),
# np.random.randint(b + 2),
# np.random.randint(n_ops),
# np.random.randint(b + 2)
# ]
# genome = convert(bit_string)
# # check against evaluated networks in case of duplicates
# doTrain = True
# for network in networks:
# if compare(genome, network):
# doTrain = False
# break
# if doTrain:
# genotype = decode(genome)
# model = Network(16, 10, 8, False, genotype)
# model.drop_path_prob = 0.0
# data = torch.randn(1, 3, 32, 32)
# output, output_aux = model(torch.autograd.Variable(data))
# networks.append(genome)
# design_id += 1
# print(design_id)
if __name__ == "__main__":
# debug()
# genome1 = [[[[3, 0], [3, 1]], [[3, 0], [3, 1]],
# [[3, 1], [2, 0]], [[2, 0], [5, 2]]],
# [[[0, 0], [0, 1]], [[2, 2], [0, 1]],
# [[0, 0], [2, 2]], [[2, 2], [0, 1]]]]
# genome2 = [[[[3, 1], [3, 0]], [[3, 1], [3, 0]],
# [[3, 1], [2, 0]], [[2, 0], [5, 2]]],
# [[[0, 1], [0, 0]], [[2, 2], [0, 1]],
# [[0, 0], [2, 2]], [[2, 2], [0, 0]]]]
#
# print(compare(genome1, genome2))
# print(genome1)
# print(genome2)
# bit_string1 = [3,1,3,0,3,1,3,0,3,1,2,0,2,0,5,2,0,0,0,1,2,2,0,1,0,0,2,2,2,2,0,1]
# bit_string2 = [3, 0, 3, 1, 3, 0, 3, 1, 3, 1, 2, 0, 2, 0, 5, 2,
# 0, 0, 0, 1, 2, 2, 0, 1, 0, 0, 2, 2, 2, 2, 0, 1]
# # print(convert(bit_string1))
# print(compare(bit_string1, bit_string2))
# print(decode(convert(bit_string)))
cell_bit_string = [3, 0, 3, 1, 3, 0, 3, 1, 3, 1, 2, 0, 2, 0, 5, 2]
# print(decode_cell(convert_cell(cell_bit_string), norm=False))
genome,sn,bigmotifs,ms=sample(195,2,20)
mgeno=reencode(sn,bigmotifs,195)
convert(mgeno,2,20)
================================================
FILE: examples/Structure_Evolution/EB-NAS/motifs.py
================================================
from collections import namedtuple
import torch
Genotype = namedtuple('Genotype', 'normal normal_concat')
"""
Operation sets
"""
PRIMITIVES = [
'skip_connect',
# 'max_pool_3x3',
# 'avg_pool_3x3',
# 'def_conv_3x3',
# 'def_conv_5x5',
# 'sep_conv_3x3',
# 'sep_conv_5x5',
# 'dil_conv_3x3',
# 'dil_conv_5x5',
# 'max_pool_3x3_p',
# 'avg_pool_3x3_p',
'conv_3x3_p',
'conv_5x5_p',
# 'skip_connect_p',
# 'sep_conv_3x3_p',
# 'sep_conv_5x5_p',
# 'dil_conv_3x3_p',
# 'dil_conv_5x5_p',
# 'def_conv_3x3_p',
# 'def_conv_5x5_p',n
# 'max_pool_3x3_n',
# 'avg_pool_3x3_n',
'conv_3x3_n',
'conv_5x5_n',
# 'skip_connect_n',
# 'sep_conv_3x3_n',
# 'sep_conv_5x5_n',
# 'dil_conv_3x3_n',
# 'dil_conv_5x5_n',
# 'def_conv_3x3_n',
# 'def_conv_5x5_n',
# 'transformer',
]
m0=Genotype(
normal=[
('skip', 0), ('skip', 1),('skip', 2),
],
normal_concat=range(3, 4)
)
mm0=Genotype(
normal=[
('skip', 0), ('skip', 1),('skip', 2),
],
normal_concat=range(2, 3)
)
mm1=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),
('skip_connect', 0), ('conv_5x5_p', 2),
],
normal_concat=range(2, 4)
)
mm2=Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),
('skip_connect', 0), ('conv_5x5_n', 2),
('conv_5x5_p', 2), ('conv_3x3_n', 3),
],
normal_concat=range(2, 5)
)
mm4=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),#2
('conv_3x3_p', 0), ('conv_3x3_p', 1),#3
('conv_5x5_p', 2), ('conv_5x5_p', 3),#4
('skip_connect', 0), ('conv_3x3_p', 4),#5
('skip_connect', 0), ('conv_3x3_p', 4),#6
],
normal_concat=range(2, 7)
)
mm3=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),#2
('skip_connect', 0), ('conv_5x5_n', 2),#3
('skip_connect', 0), ('conv_5x5_p', 3),#4
('skip_connect_back', 2),#3
('conv_3x3_p_back', 3),#4
],
normal_concat=range(2, 5)
)
mm5=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),#2
('skip_connect', 0), ('conv_5x5_p', 2),#3
('skip_connect_back', 2),#3
],
normal_concat=range(2, 4)
)
m1=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2), #B3
('skip', 0), ('conv_5x5_p', 3), ('skip', 1), #C4
],
normal_concat=range(3, 5)
)
m2=Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), #B3
('skip', 0), ('conv_5x5_n', 3), ('skip', 1),#C4
('conv_5x5_p', 3), ('conv_3x3_n', 4), ('skip', 1), #D5
],
normal_concat=range(3, 6)
)
m4=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), #3
('conv_3x3_p', 0), ('conv_3x3_p', 1),('conv_5x5_p', 2), #4
('skip', 0), ('conv_5x5_p', 3), ('conv_5x5_p', 4), #5
('skip', 0), ('conv_3x3_p', 3),('conv_3x3_n', 5),#6
('skip', 0), ('conv_3x3_p', 4),('conv_3x3_n', 5),#7
],
normal_concat=range(3, 8)
)
m3=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_3x3_p', 2), #3
('skip', 0), ('conv_5x5_p', 3),('skip', 1), #4
('skip', 0), ('conv_5x5_p', 3), ('skip', 1), #5
('conv_3x3_n_back', 3),#4
('skip_back', 2),#5
],
normal_concat=range(3, 6)
)
m5=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2),#3
('skip', 0),('skip', 1), ('conv_5x5_n', 3), #4
('skip_connect_back', 3),#4
],
normal_concat=range(3, 5)
)
t1=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2), ('conv_5x5_p', 3), #4
('skip', 0), ('conv_5x5_p', 4), ('skip', 1), ('skip', 2), #5
('skip', 0), ('conv_5x5_p', 5), ('skip', 1), ('skip', 2), #6
('skip', 0), ('conv_5x5_p', 5), ('skip', 1), ('skip', 2), #7
],
normal_concat=range(4, 8)
)
t2=Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), ('conv_5x5_p', 3), #4
('skip', 0), ('conv_5x5_n', 4), ('skip', 1),('skip', 2),#5
('conv_5x5_p', 4), ('conv_3x3_n', 5), ('skip', 1),('skip', 2), #6
],
normal_concat=range(4, 7)
)
t4=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), ('conv_5x5_p', 3), #4
('conv_5x5_p', 0), ('skip', 1),('conv_5x5_n', 4), ('skip', 3), #5
('skip', 0), ('conv_5x5_p', 3), ('conv_5x5_n', 4), ('skip', 2),#6
],
normal_concat=range(4, 7)
)
t3=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_3x3_p', 2), ('conv_3x3_p', 3),#4
('skip', 0), ('skip', 2),('skip', 1), ('skip', 3),('conv_3x3_p', 4),#5
('skip', 0), ('conv_5x5_p', 4), ('skip', 1),('skip', 2), #6
('conv_3x3_n_back', 4),#5
('skip_back', 4),#6
],
normal_concat=range(4, 7)
)
t5=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2),('conv_5x5_p', 3),#4
('skip', 0),('skip', 1), ('skip', 2), ('conv_5x5_n', 4), #5
('skip', 0),('skip', 1), ('conv_5x5_n', 4),('conv_5x5_n', 5), #6
('skip', 0),('skip', 1), ('conv_5x5_n', 4),('conv_5x5_n', 5), #7
('conv_3x3_n_back', 4),#5
('skip_back', 4),#6
('skip_back', 5),#7
],
normal_concat=range(4, 8)
)
================================================
FILE: examples/Structure_Evolution/EB-NAS/nsganet.py
================================================
import numpy as np
from pymoo.algorithms.genetic_algorithm import GeneticAlgorithm
from pymoo.docs import parse_doc_string
from pymoo.model.individual import Individual
from pymoo.model.survival import Survival
from pymoo.operators.crossover.point_crossover import PointCrossover
from pymoo.operators.mutation.polynomial_mutation import PolynomialMutation
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.selection.tournament_selection import compare, TournamentSelection
from pymoo.util.display import disp_multi_objective
from pymoo.util.dominator import Dominator
from pymoo.util.non_dominated_sorting import NonDominatedSorting
from pymoo.util.randomized_argsort import randomized_argsort
# =========================================================================================================
# Implementation
# based on nsga2 from https://github.com/msu-coinlab/pymoo
# =========================================================================================================
class NSGANet(GeneticAlgorithm):
def __init__(self, **kwargs):
kwargs['individual'] = Individual(rank=np.inf, crowding=-1)
super().__init__(**kwargs)
self.tournament_type = 'comp_by_dom_and_crowding'
self.func_display_attrs = disp_multi_objective
# ---------------------------------------------------------------------------------------------------------
# Binary Tournament Selection Function
# ---------------------------------------------------------------------------------------------------------
def binary_tournament(pop, P, algorithm, **kwargs):
if P.shape[1] != 2:
raise ValueError("Only implemented for binary tournament!")
tournament_type = algorithm.tournament_type
S = np.full(P.shape[0], np.nan)
for i in range(P.shape[0]):
a, b = P[i, 0], P[i, 1]
# if at least one solution is infeasible
if pop[a].CV > 0.0 or pop[b].CV > 0.0:
S[i] = compare(a, pop[a].CV, b, pop[b].CV, method='smaller_is_better', return_random_if_equal=True)
# both solutions are feasible
else:
if tournament_type == 'comp_by_dom_and_crowding':
rel = Dominator.get_relation(pop[a].F, pop[b].F)
if rel == 1:
S[i] = a
elif rel == -1:
S[i] = b
elif tournament_type == 'comp_by_rank_and_crowding':
S[i] = compare(a, pop[a].rank, b, pop[b].rank,
method='smaller_is_better')
else:
raise Exception("Unknown tournament type.")
# if rank or domination relation didn't make a decision compare by crowding
if np.isnan(S[i]):
S[i] = compare(a, pop[a].get("crowding"), b, pop[b].get("crowding"),
method='larger_is_better', return_random_if_equal=True)
return S[:, None].astype(np.int)
# ---------------------------------------------------------------------------------------------------------
# Survival Selection
# ---------------------------------------------------------------------------------------------------------
class RankAndCrowdingSurvival(Survival):
def __init__(self) -> None:
super().__init__(True)
def _do(self, pop, n_survive, D=None, **kwargs):
# get the objective space values and objects
F = pop.get("F")
# the final indices of surviving individuals
survivors = []
# do the non-dominated sorting until splitting front
fronts = NonDominatedSorting().do(F, n_stop_if_ranked=n_survive)
for k, front in enumerate(fronts):
# calculate the crowding distance of the front
crowding_of_front = calc_crowding_distance(F[front, :])
# save rank and crowding in the individual class
for j, i in enumerate(front):
pop[i].set("rank", k)
pop[i].set("crowding", crowding_of_front[j])
# current front sorted by crowding distance if splitting
if len(survivors) + len(front) > n_survive:
I = randomized_argsort(crowding_of_front, order='descending', method='numpy')
I = I[:(n_survive - len(survivors))]
# otherwise take the whole front unsorted
else:
I = np.arange(len(front))
# extend the survivors by all or selected individuals
survivors.extend(front[I])
return pop[survivors]
def calc_crowding_distance(F):
infinity = 1e+14
n_points = F.shape[0]
n_obj = F.shape[1]
if n_points <= 2:
return np.full(n_points, infinity)
else:
# sort each column and get index
I = np.argsort(F, axis=0, kind='mergesort')
# now really sort the whole array
F = F[I, np.arange(n_obj)]
# get the distance to the last element in sorted list and replace zeros with actual values
dist = np.concatenate([F, np.full((1, n_obj), np.inf)]) \
- np.concatenate([np.full((1, n_obj), -np.inf), F])
index_dist_is_zero = np.where(dist == 0)
dist_to_last = np.copy(dist)
for i, j in zip(*index_dist_is_zero):
dist_to_last[i, j] = dist_to_last[i - 1, j]
dist_to_next = np.copy(dist)
for i, j in reversed(list(zip(*index_dist_is_zero))):
dist_to_next[i, j] = dist_to_next[i + 1, j]
# normalize all the distances
norm = np.max(F, axis=0) - np.min(F, axis=0)
norm[norm == 0] = np.nan
dist_to_last, dist_to_next = dist_to_last[:-1] / norm, dist_to_next[1:] / norm
# if we divided by zero because all values in one columns are equal replace by none
dist_to_last[np.isnan(dist_to_last)] = 0.0
dist_to_next[np.isnan(dist_to_next)] = 0.0
# sum up the distance to next and last and norm by objectives - also reorder from sorted list
J = np.argsort(I, axis=0)
crowding = np.sum(dist_to_last[J, np.arange(n_obj)] + dist_to_next[J, np.arange(n_obj)], axis=1) / n_obj
# replace infinity with a large number
crowding[np.isinf(crowding)] = infinity
return crowding
# =========================================================================================================
# Interface
# =========================================================================================================
def nsganet(
pop_size=100,
sampling=RandomSampling(var_type=np.int),
selection=TournamentSelection(func_comp=binary_tournament),
crossover=PointCrossover(n_points=2),
mutation=PolynomialMutation(eta=3, var_type=np.int),
eliminate_duplicates=True,
n_offsprings=None,
**kwargs):
"""
Parameters
----------
pop_size : {pop_size}
sampling : {sampling}
selection : {selection}
crossover : {crossover}
mutation : {mutation}
eliminate_duplicates : {eliminate_duplicates}
n_offsprings : {n_offsprings}
Returns
-------
nsganet : :class:`~pymoo.model.algorithm.Algorithm`
Returns an NSGANet algorithm object.
"""
return NSGANet(pop_size=pop_size,
sampling=sampling,
selection=selection,
crossover=crossover,
mutation=mutation,
survival=RankAndCrowdingSurvival(),
eliminate_duplicates=eliminate_duplicates,
n_offsprings=n_offsprings,
**kwargs)
parse_doc_string(nsganet)
================================================
FILE: examples/Structure_Evolution/EB-NAS/operations.py
================================================
import numpy as np
import torch
import torch.nn as nn
from torch.nn import *
import torch.nn.functional as F
from torch import einsum
from einops import rearrange
# from braincog.model_zoo.base_module import DeformConvPack
from braincog.model_zoo.base_module import BaseLinearModule
# from mmcv.ops import ModulatedDeformConv2dPack
def si_relu(x, positive):
if positive == 1:
return torch.where(x > 0., x, torch.zeros_like(x))
elif positive == 0:
return x
elif positive == -1:
return torch.where(x < 0., x, torch.zeros_like(x))
else:
raise ValueError
class SiReLU(nn.Module):
def __init__(self, positive=0):
super().__init__()
self.positive = positive
def forward(self, x):
return si_relu(x, self.positive)
def weight_init(m):
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal(m.weight.data, gain=0.1)
torch.nn.init.constant(m.bias.data, 0.)
OPS_Mlp = {
'mlp': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=0),
'mlp_p': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=1),
'mlp_n': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=-1),
'skip_connect': lambda C, act_fun:
Identity(positive=0),
'skip_connect_p': lambda C, act_fun:
Identity(positive=1),
'skip_connect_n': lambda C, act_fun:
Identity(positive=-1),
}
OPS = {
'avg_pool_3x3': lambda C, stride, affine, act_fun: nn.AvgPool2d(3, stride=stride, padding=1,
count_include_pad=False),
'conv_3x3': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=0),
'conv_5x5': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=0),
'max_pool_3x3': lambda C, stride, affine, act_fun: nn.MaxPool2d(3, stride=stride, padding=1),
'skip_connect': lambda C, stride, affine, act_fun:
Identity(positive=0) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun),
'sep_conv_3x3': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=0),
'sep_conv_5x5': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=0),
'sep_conv_7x7': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=0),
'dil_conv_3x3': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=0),
'dil_conv_5x5': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=0),
'def_conv_3x3': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=0),
'def_conv_5x5': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=0),
'avg_pool_3x3_p': lambda C, stride, affine, act_fun: nn.Sequential(
nn.AvgPool2d(3, stride=stride, padding=1, count_include_pad=False),
SiReLU(positive=1)
),
'max_pool_3x3_p': lambda C, stride, affine, act_fun: nn.Sequential(
nn.MaxPool2d(3, stride=stride, padding=1),
SiReLU(positive=1)
),
'conv_3x3_p': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=1),
'conv_5x5_p': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=1),
'skip_connect_p': lambda C, stride, affine, act_fun:
Identity(positive=1) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_3x3_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_5x5_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_7x7_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=1),
'dil_conv_3x3_p': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=1),
'dil_conv_5x5_p': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=1),
'def_conv_3x3_p': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=1),
'def_conv_5x5_p': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=1),
'avg_pool_3x3_n': lambda C, stride, affine, act_fun: nn.Sequential(
nn.AvgPool2d(3, stride=stride, padding=1, count_include_pad=False),
SiReLU(positive=-1)
),
'max_pool_3x3_n': lambda C, stride, affine, act_fun: nn.Sequential(
nn.MaxPool2d(3, stride=stride, padding=1),
SiReLU(positive=-1)
),
'conv_3x3_n': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=-1),
'conv_5x5_n': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=-1),
'skip_connect_n': lambda C, stride, affine, act_fun:
Identity(positive=-1) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_3x3_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_5x5_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_7x7_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=-1),
'dil_conv_3x3_n': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=-1),
'dil_conv_5x5_n': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=-1),
'def_conv_3x3_n': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=-1),
'def_conv_5x5_n': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=-1),
'conv_7x1_1x7': lambda C, stride, affine, act_fun: nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C, C, (1, 7), stride=(1, stride),
padding=(0, 3), bias=False),
nn.Conv2d(C, C, (7, 1), stride=(stride, 1),
padding=(3, 0), bias=False),
nn.BatchNorm2d(C, affine=affine)
),
'skip': lambda C, stride, affine, act_fun:
Zero(stride) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=1),
'transformer': lambda C, stride, affine, act_fun:
FactorizedReduce(
C, C, affine=affine, act_fun=act_fun) if stride != 1 else TransformerEncoderLayer(C),
}
class SiMLP(nn.Module):
def __init__(self, c_in, c_out, act_fun=nn.ReLU, positive=0, *args, **kwargs):
super(SiMLP, self).__init__()
self.op = nn.Sequential(
nn.Linear(c_in, c_out, bias=True),
act_fun()
)
self.positive = positive
def forward(self, x):
out = self.op(si_relu(x, self.positive))
return out
class DilConv(nn.Module):
"""
Dilation Convolution : ReLU -> DilConv -> Conv2d -> BatchNorm2d
"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, dilation, affine=True, act_fun=nn.ReLU, positive=0):
super(DilConv, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation,
groups=C_in, bias=False),
nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=affine),
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class SepConv(nn.Module):
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
super(SepConv, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size,
stride=stride, padding=padding, groups=C_in, bias=False),
nn.Conv2d(C_in, C_in, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_in, affine=affine),
nn.ReLU(inplace=False),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size,
stride=1, padding=padding, groups=C_in, bias=False),
nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=affine),
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class Identity(nn.Module):
def __init__(self, positive=0):
super(Identity, self).__init__()
self.positive = positive
def forward(self, x):
return si_relu(x, self.positive)
class Zero(nn.Module):
def __init__(self, stride):
super(Zero, self).__init__()
self.stride = stride
def forward(self, x):
if self.stride == 1:
return x.mul(0.)
return x[:, :, ::self.stride, ::self.stride].mul(0.) # N * C * W * H
class FactorizedReduce(nn.Module):
def __init__(self, C_in, C_out, affine=True, act_fun=nn.ReLU, positive=0):
super(FactorizedReduce, self).__init__()
assert C_out % 2 == 0
# self.relu = nn.ReLU(inplace=False)
self.activation = act_fun()
self.conv_1 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.conv_2 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.bn = nn.BatchNorm2d(C_out, affine=affine)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
# x = self.relu(x)
x = self.activation(x)
out = torch.cat([self.conv_1(x), self.conv_2(x[:, :, 1:, 1:])], dim=1)
out = self.bn(out)
out = si_relu(out, self.positive)
return out
class F0(nn.Module):
def __init__(self, C_in, C_out, affine=True, act_fun=nn.ReLU, positive=0):
super(F0, self).__init__()
assert C_out % 2 == 0
# self.relu = nn.ReLU(inplace=False)
self.activation = act_fun()
self.op=nn.Conv2d(C_out, C_out, 3, stride=2, padding=1, bias=False)
self.conv_1 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.conv_2 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.bn = nn.BatchNorm2d(C_out, affine=affine)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
# x = self.relu(x)
x = self.activation(x)
out = torch.cat([self.conv_1(x), self.conv_2(x[:, :, 1:, 1:])], dim=1)
out = self.bn(out)
out = si_relu(out, self.positive)
out=self.op(out)
return out
class F1(nn.Module):
def __init__(self, C_in, C_out, affine=True, act_fun=nn.ReLU, positive=0):
super(F1, self).__init__()
assert C_out % 2 == 0
# self.relu = nn.ReLU(inplace=False)
self.activation = act_fun()
self.op=nn.Conv2d(C_out, C_out, 3, stride=2, padding=1, bias=False)
self.conv_1 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.conv_2 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.bn = nn.BatchNorm2d(C_out, affine=affine)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
# x = self.relu(x)
x = self.activation(x)
out = torch.cat([self.conv_1(x), self.conv_2(x[:, :, 1:, 1:])], dim=1)
out = self.bn(out)
out = si_relu(out, self.positive)
out=self.op(out)
return out
class ReLUConvBN(nn.Module):
"""
ReLu -> Conv2d -> BatchNorm2d
"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
super(ReLUConvBN, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_out, kernel_size, stride=stride,
padding=padding, bias=False),
nn.BatchNorm2d(C_out, affine=affine)
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
# class DeformConv(nn.Module):
# def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
# super(DeformConv, self).__init__()
# self.op = nn.Sequential(
# # nn.ReLU(inplace=False),
# act_fun(),
# DeformConvPack(C_in, C_out, kernel_size=kernel_size,
# stride=stride, padding=padding, bias=True),
# nn.BatchNorm2d(C_out, affine=affine)
# )
# self.positive = positive
# # if positive == -1:
# # weight_init(self.op)
# def forward(self, x):
# out = self.op(x)
# return si_relu(out, self.positive)
class Attention(Module):
"""
Obtained from: github.com:rwightman/pytorch-image-models
"""
def __init__(self, dim, num_heads=4, attention_dropout=0.1, projection_dropout=0.1):
super().__init__()
self.num_heads = num_heads
head_dim = dim // self.num_heads
self.scale = head_dim ** -0.5
self.qkv = Linear(dim, dim * 3, bias=False)
self.attn_drop = Dropout(attention_dropout)
self.proj = Linear(dim, dim)
self.proj_drop = Dropout(projection_dropout)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C //
self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class TransformerEncoderLayer(Module):
"""
Inspired by torch.nn.TransformerEncoderLayer and
rwightman's timm package.
"""
def __init__(self, d_model, nhead=4, dim_feedforward=256, dropout=0.1,
attention_dropout=0.1, drop_path_rate=0.1):
super(TransformerEncoderLayer, self).__init__()
self.pre_norm = LayerNorm(d_model)
self.self_attn = Attention(dim=d_model, num_heads=nhead,
attention_dropout=attention_dropout, projection_dropout=dropout)
dim_feedforward = d_model
self.linear1 = Linear(d_model, dim_feedforward)
self.dropout1 = Dropout(dropout)
self.norm1 = LayerNorm(d_model)
self.linear2 = Linear(dim_feedforward, d_model)
self.dropout2 = Dropout(dropout)
self.drop_path = DropPath(
drop_path_rate) if drop_path_rate > 0 else Identity()
self.activation = F.gelu
def forward(self, src: torch.Tensor, *args, **kwargs) -> torch.Tensor:
# print(src.shape)
c = src.shape[-1]
src = rearrange(src, 'b d r c -> b (r c) d')
# print(src.shape)
src = src + self.drop_path(self.self_attn(self.pre_norm(src)))
src = self.norm1(src)
src2 = self.linear2(self.dropout1(self.activation(self.linear1(src))))
src = src + self.drop_path(self.dropout2(src2))
src = rearrange(src, 'b (r c) d -> b d r c', c=c)
return src
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""
Obtained from: github.com:rwightman/pytorch-image-models
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
# work with diff dim tensors, not just 2D ConvNets
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + \
torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(Module):
"""
Obtained from: github.com:rwightman/pytorch-image-models
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
================================================
FILE: examples/Structure_Evolution/EB-NAS/readme.md
================================================
# Brain-Inspired Evolutionary Architectures for Spiking Neural Networks —— Based on BrainCog #
## Requirments ##
* numpy
* pytorch >= 1.12.0
* pymoo = 0.4.0
* BrainCog
## Run ##
```python ebnas.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{pan2024brain,
title={Brain-inspired Evolutionary Architectures for Spiking Neural Networks},
author={Pan, Wenxuan and Zhao, Feifei and Zhao, Zhuoya and Zeng, Yi},
journal={IEEE Transactions on Artificial Intelligence},
year={2024},
publisher={IEEE}
}
@article{zeng2023braincog,
title={BrainCog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired AI and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier}
}
```
================================================
FILE: examples/Structure_Evolution/EB-NAS/single_genome.py
================================================
import os
import json
import shutil
import argparse
import subprocess
import numpy as np
import torch
from tm import get_net_info
import micro_encoding
import logging
import yaml
from braincog.utils import save_feature_map, setup_seed
from tm import train_motifs
from datetime import datetime
from timm.utils import *
from pymoo.optimize import minimize
from pymoo.model.problem import Problem
from pymoo.factory import get_performance_indicator
from pymoo.algorithms.so_genetic_algorithm import GA
from pymoo.util.nds.non_dominated_sorting import NonDominatedSorting
from pymoo.factory import get_algorithm, get_crossover, get_mutation
from search_space.ofa import OFASearchSpace
from acc_predictor.factory import get_acc_predictor
_DEBUG = True
if _DEBUG: from pymoo.visualization.scatter import Scatter
devices=[0]
os.environ['CUDA_VISIBLE_DEVICES']='3'
_logger = logging.getLogger('')
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--ocrate', type=float, default=0.0)
parser.add_argument('--dataset', type=str, default='dvsg',
help='imagenet, cifar10, cifar100, dvsg, dvsc10')
parser.add_argument('--step', type=int, default=8, help='Simulation time step (default: 10)')
parser.add_argument('--num-classes', type=int, default=11, metavar='N')
parser.add_argument('--layers', type=int, default=2)
parser.add_argument('--bits', type=int, default=20)
parser.add_argument('--eval_epochs', type=int, default=6000)
parser.add_argument('--trainning_epochs', type=int, default=600)
parser.add_argument('--iterations', type=int, default=20,
help='number of search iterations')
parser.add_argument('--n_doe', type=int, default=100,
help='initial sample size for DOE')
parser.add_argument('--bns', action='store_true', default=True)
parser.add_argument('--init-channels', type=int, default=16)
parser.add_argument('--spike-rate', action='store_true', default=False)
parser.add_argument('--save', type=str, default='',
help='location of dir to save')
parser.add_argument('--sec_obj', type=str, default='flops',
help='second objective to optimize simultaneously')
parser.add_argument('--n_iter', type=int, default=8,
help='number of architectures to high-fidelity eval (low level) in each iteration')
parser.add_argument('--predictor', type=str, default='rbf',
help='which accuracy predictor model to fit (rbf/gp/carts/mlp/as)')
parser.add_argument('--n_gpus', type=int, default=len(devices),
help='total number of available gpus')
parser.add_argument('--gpu', type=int, default=1,
help='number of gpus per evaluation job')
parser.add_argument('--supernet_path', type=str, default='./ofa_mbv3_d234_e346_k357_w1.0',
help='file path to supernet weights')
parser.add_argument('--n_workers', type=int, default=1,
help='number of workers for dataloader per evaluation job')
parser.add_argument('--vld_size', type=int, default=5000,
help='validation set size, randomly sampled from training set')
parser.add_argument('--trn_batch_size', type=int, default=128,
help='train batch size for training')
parser.add_argument('--vld_batch_size', type=int, default=200,
help='test batch size for inference')
parser.add_argument('--cooldown-epochs', type=int, default=0, metavar='N',help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--test', action='store_true', default=False,
help='evaluation performance on testing set')
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser.add_argument('--model', default='NetworkCIFAR_', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.8,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=1.0,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=1.0,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=len(devices),
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=devices[0])
# Spike parameters
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='QGateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
# DARTS parameters
parser.add_argument('--auxiliary', action='store_true', default=False, help='use auxiliary tower')
parser.add_argument('--parse_method', default='darts', type=str)
parser.add_argument('--drop_path_prob', type=float, default=0.2, help='drop path probability')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
def _parse_args():
args_config, remaining = config_parser.parse_known_args()
args = parser.parse_args(remaining)
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
if __name__ == '__main__':
args, args_text = _parse_args()
args.no_spike_output = True
output_dir = ''
if args.bns:
from cellmodel import NetworkCIFAR_
else:
from cell123model import NetworkCIFAR_
# if 'dvs' in args.dataset:
# args.step=10
# else:
# args.step=4
if args.local_rank == 0:
output_base = args.save
exp_name = '-'.join([
datetime.now().strftime("%Y%m%d-%H%M%S"),
# args.model,
args.dataset,
str(args.layers)+'layers',
str(args.init_channels)+'channels',
str(args.step)+'steps',
# args.suffix
# str(args.img_size)
])
output_dir = get_outdir(output_base,str(args.dataset),exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
else:
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:0')
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
setup_seed(args.seed + args.rank)
defalut_lr = args.lr
arch_doe,sn,bigmotifs,ms ,glob_con= micro_encoding.sample(pops=10, layers=args.layers, bits=20)
i=0
for geno in arch_doe:
arch_dir=os.path.join('train',args.output_dir,str(i))
if os.path.exists(arch_dir) is False:
os.makedirs(arch_dir,exist_ok = True)
args.lr=defalut_lr
geno=micro_encoding.c_single(geno,layers=args.layers,bits=args.bits)
acc,info=train_motifs(args=args,gen=0,arch_dir=arch_dir,genome=np.array(geno[:-1]),_logger=_logger,args_text=args_text,devices=devices,ms=ms,glob=geno[-1])
i+=1
================================================
FILE: examples/Structure_Evolution/EB-NAS/tm.py
================================================
import sys
import numpy as np
import argparse
import time
import timm.models
import yaml
import os
import logging
from random import choice
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from micro_encoding import ops
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import micro_encoding
from pymop.problem import Problem
import torch
from thop import profile
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from pymoo.optimize import minimize
from timm.data import create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from torchprofile import profile_macs
import copy
import torch.backends.cudnn as cudnn
import warnings
warnings.simplefilter("ignore")
def train_motifs(args,gen,arch_dir,genome,_logger,args_text,devices,ms,glob):
if args.bns:
from cellmodel import NetworkCIFAR_
else:
from cell123model import NetworkCIFAR_
# qw=np.where(args.glob_con[0]==1)
# ccc=np.array([1,0,0,0])
# for i in qw:
# ccc[i[0]]=1
# ddd=np.where(args.glob_con[i[0]]==1)
# if len(ddd[0])!=0:
# for j in ddd:
# ccc[j[0]]=1
# www=np.where(args.glob_con[j[0]]==1)
# if len(www[0])!=0:
# for k in www:
# ccc[k[0]]=1
test_motifs,ids = micro_encoding.decode_motif(args.layers*ms,args.bits,genome.astype(int))
# if gen==-1:
args.epochs=args.eval_epochs
# else:
# args.epochs=args.eval_epochs
try:
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
C=args.init_channels,
layers=args.layers*ms,
auxiliary=args.auxiliary,
motif=test_motifs,
parse_method=args.parse_method,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
glob=glob,
)
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
flops=0
params=0
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
sumpram=sum([m.numel() for m in model.parameters()])
_logger.info('Model %s created, param count: %d' %
(args.model, sumpram))
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=devices).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
# print(model.get_attr('mu'))
# print(model.get_attr('sigma'))
if args.critical_loss or args.spike_rate:
if args.num_gpu>1:
model.module.set_requires_fp(True)
else:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model, device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
temporal_flatten=args.temporal_flatten,
portion=args.train_portion,
_logger=_logger,
)
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
if args.distributed:
state_dict = torch.load(args.eval_checkpoint)['state_dict_ema']
new_state_dict = OrderedDict()
# add module prefix for DDP
for k, v in state_dict.items():
k = 'module.' + k
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
# else:
# load_checkpoint(model, args.eval_checkpoint, args.model_ema)
for i in range(1):
val_metrics,_ = validate(start_epoch, model, loader_eval, validate_loss_fn, args,arch_dir,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
print(f"Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
# return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=arch_dir, recovery_dir=arch_dir, decreasing=decreasing)
with open(os.path.join(arch_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
f=open(os.path.join(arch_dir, 'direct_genome.txt'), 'a')
f.write(",".join(str(k) for k in genome))
f.write('\n')
f.close()
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
if args.distributed:
loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,_logger=_logger,
lr_scheduler=lr_scheduler, saver=saver, output_dir=arch_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler, model_ema=model_ema, mixup_fn=mixup_fn)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics,_ = validate(epoch, model, loader_eval, validate_loss_fn, args, arch_dir,amp_autocast=amp_autocast,_logger=_logger,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics,_ = validate(
epoch, model_ema.ema, loader_eval, validate_loss_fn, args, arch_dir,amp_autocast=amp_autocast, log_suffix=' (EMA)',_logger=_logger,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(arch_dir, 'summary.csv'),
write_header=best_metric is None)
# if saver is not None and epoch >= args.n_warm_up:
if saver is not None:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
best_metric, best_epoch = eval_metrics[eval_metric],epoch
_logger.info('Train: {0} '.format(best_metric))
f=open(os.path.join(arch_dir, 'direct.txt'), 'a')
f.write(str(best_metric))
f.write('\n')
f.close()
except KeyboardInterrupt:
pass
except MemoryError:
return -10000, 0
except RuntimeError:
# return -10000, {'flops': flops / 1e6, 'param': params / 1e6}
return -10000, 0
# if best_metric is not None:
# _logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
# info=get_net_info(model)
val_metrics,spikes = validate(start_epoch, model, loader_eval, validate_loss_fn, args,arch_dir,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat,_logger=_logger,)
return best_metric,spikes
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,_logger,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and loader.mixup_enabled:
loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
model.drop_path_prob = args.drop_path_prob * epoch / args.epochs
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
# t, k = adjust_surrogate_coeff(100, args.epochs)
# model.set_attr('t', t)
# model.set_attr('k', k)
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
if not args.prefetcher or args.dataset != 'imnet':
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
if mixup_fn is not None:
inputs, target = mixup_fn(inputs, target)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
with amp_autocast():
output = model(inputs)
loss = loss_fn(output, target)
if not (args.cut_mix | args.mix_up | args.event_mix) and args.dataset != 'imnet':
# print(output.shape, target.shape)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
closs = torch.tensor([0.], device=loss.device)
if args.critical_loss:
closs = calc_critical_loss(model)
loss = loss + .1 * closs
spike_rate_avg_layer_str = ''
threshold_str = ''
if not args.distributed:
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
top5_m.update(acc5.item(), inputs.size(0))
closses_m.update(closs.item(), inputs.size(0))
if args.num_gpu>1:
spike_rate_avg_layer = model.module.get_fire_rate().tolist()
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
threshold = model.module.get_threshold()
else:
spike_rate_avg_layer = model.get_fire_rate().tolist()
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
if args.opt == 'lamb':
optimizer.step(epoch=epoch)
else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
losses_m.update(reduced_loss.item(), inputs.size(0))
closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
if args.distributed:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
else:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})\n'
'Fire_rate: {spike_rate}\n'
# 'Thres: {threshold}\n'
# 'Mu: {mu_str}\n'
# 'Sigma: {sigma_str}\n'
.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m,
spike_rate=spike_rate_avg_layer_str,
# threshold=threshold_str,
# mu_str=mu_str,
# sigma_str=sigma_str
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args, arch_dir,_logger,amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
end = time.time()
last_idx = len(loader) - 1
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat) and not args.critical_loss:
if args.num_gpu>1:
model.module.set_requires_fp(True)
else:
model.set_requires_fp(True)
# if not args.critical_loss:
# model.set_requires_fp(False)
with amp_autocast():
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
if not args.distributed:
if visualize:
x = model.get_fp()
feature_path = os.path.join(arch_dir, 'feature_map')
if os.path.exists(feature_path) is False:
os.mkdir(feature_path)
save_feature_map(x, feature_path)
# if not args.critical_loss:
# model_config.set_requires_fp(False)
if tsne:
x = model.get_fp(temporal_info=False)[-1]
x = torch.nn.AdaptiveAvgPool2d((1, 1))(x)
x = x.reshape(x.shape[0], -1)
feature_vec.append(x)
feature_cls.append(target)
if conf_mat:
logits_vec.append(output)
labels_vec.append(target)
if spike_rate:
if args.num_gpu>1:
avg, var, spike, avg_per_step = model.module.get_spike_info()
else:
avg, var, spike, avg_per_step = model.get_spike_info()
save_spike_info(
os.path.join(arch_dir, 'spike_info.csv'),
epoch, batch_idx,
args.step, avg, var,
spike, avg_per_step)
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
closs = torch.tensor([0.], device=loss.device)
if not args.distributed:
if args.num_gpu>1:
spike_rate_avg_layer = model.module.get_fire_rate().tolist()
threshold = model.module.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
tot_spike = model.module.get_tot_spike()
else:
spike_rate_avg_layer = model.get_fire_rate().tolist()
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
tot_spike = model.get_tot_spike()
if args.critical_loss:
closs = calc_critical_loss(model)
loss = loss + .1 * closs
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
closses_m.update(closs.item(), inputs.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
))
else:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})\n'
'Fire_rate: {spike_rate}\n'
'Tot_spike: {tot_spike}\n'
'Thres: {threshold}\n'
'Mu: {mu_str}\n'
'Sigma: {sigma_str}\n'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
spike_rate=spike_rate_avg_layer_str,
tot_spike=tot_spike,
threshold=threshold_str,
mu_str=mu_str,
sigma_str=sigma_str
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg)])
if not args.distributed:
if tsne:
feature_vec = torch.cat(feature_vec)
feature_cls = torch.cat(feature_cls)
plot_tsne(feature_vec, feature_cls, os.path.join(arch_dir, 't-sne-2d.eps'))
plot_tsne_3d(feature_vec, feature_cls, os.path.join(arch_dir, 't-sne-3d.eps'))
if conf_mat:
logits_vec = torch.cat(logits_vec)
labels_vec = torch.cat(labels_vec)
plot_confusion_matrix(logits_vec, labels_vec, os.path.join(arch_dir, 'confusion_matrix.eps'))
return metrics,tot_spike
def get_net_info(args, gen,genome,ms):
"""
Modified from https://github.com/mit-han-lab/once-for-all/blob/
35ddcb9ca30905829480770a6a282d49685aa282/ofa/imagenet_codebase/utils/pytorch_utils.py#L139
"""
from ofa.imagenet_codebase.utils.pytorch_utils import count_parameters, measure_net_latency
# artificial input data
if args.bns:
from cellmodel import NetworkCIFAR
else:
from cell123model import NetworkCIFAR
test_motifs,ids = micro_encoding.decode_motif(args.layers*ms,args.bits,genome.astype(int))
net = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
C=args.init_channels,
layers=args.layers*ms,
auxiliary=args.auxiliary,
motif=test_motifs,
parse_method=args.parse_method,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
cell_type=genome[-1],
)
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
inputs = torch.randn(1, args.channels, 224, 224)
# move network to GPU if available
if torch.cuda.is_available():
device = torch.device('cuda:0')
net = net.to(device)
cudnn.benchmark = True
inputs = inputs.to(device)
net_info = {}
if isinstance(net, nn.DataParallel):
net = net.module
# parameters
net_info['params'] = count_parameters(net)
# flops
net_info['flops'] = int(profile_macs(copy.deepcopy(net), inputs))
return net_info
================================================
FILE: examples/Structure_Evolution/ELSM/README.md
================================================
# Emergence of Brain-inspired Small-world Spiking Neural Network through Neuroevolution —— Based on BrainCog #
## Requirments ##
* numpy
* pytorch >= 1.12.0
* BrainCog
## Run ##
```python evolve.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{pan2024emergence,
title={Emergence of Brain-inspired Small-world Spiking Neural Network through Neuroevolution},
author={Pan, Wenxuan and Zhao, Feifei and Han, Bing and Dong, Yiting and Zeng, Yi},
journal={iScience},
year={2024},
publisher={Elsevier}
}
@article{zeng2023braincog,
title={BrainCog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired AI and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier}
}
```
================================================
FILE: examples/Structure_Evolution/ELSM/evolve.py
================================================
import time
import threading
from threading import Thread
import os
import networkx as nx
import numpy as np
from population import *
import nsganet as engine
from pymop.problem import Problem
from pymoo.optimize import minimize
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
import logging
from model import *
from spikes import calc_f2
from multiprocessing import Process,Pool
from datetime import datetime
import time
_logger = logging.getLogger('')
config_parser = parser = argparse.ArgumentParser(description='Evolution Config', add_help=False)
parser = argparse.ArgumentParser(description='SNN Evoving')
parser.add_argument('--device', type=int, default=2)
parser.add_argument('--seed', type=int, default=68, metavar='S')
parser.add_argument('--datapath', default='/data/', type=str, metavar='PATH')
parser.add_argument('--output', default='/data/LSM/Eresult/new', type=str, metavar='PATH')
parser.add_argument('--liquid-size', type=int, default=8000)
parser.add_argument('--pop-size', type=int, default=20)
parser.add_argument('--up', type=int, default=32000000)
parser.add_argument('--low', type=int, default=320000)
parser.add_argument('--n_offspring', type=int, default=200)
parser.add_argument('--n_gens', type=int, default=2000)
parser.add_argument('--arand', type=float, default=285)
parser.add_argument('--brand', type=float, default=1.8)
def _parse_args():
args_config, remaining = config_parser.parse_known_args()
args = parser.parse_args(remaining)
return args
def calc_f1(dirs):
ci=[]
G=nx.read_gpickle(dirs)
largest_component = max(nx.connected_components(G), key=len)
G = G.subgraph(largest_component)
for u in G.nodes:
ci.append(nx.clustering(G,u))
a=sum(ci)
print("start")
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
path=nx.average_shortest_path_length(G)
print("end")
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
return a,path
def mul_f1(pop,steps,rootdir):
result=[]
for i in range(0,pop,steps):
p = Pool(steps)
dirs=[os.path.join(rootdir,str(i)+'.pkl') for i in range(i,i+steps)]
ret = p.map(calc_f1,dirs)
result.extend(ret)
print(ret)
p.close()
p.join()
return result
class Evolve(Problem):
# first define the NAS problem (inherit from pymop)
def __init__(self, args,n_var=20, n_obj=1, n_constr=0, lb=None, ub=None):
super().__init__(n_var=n_var, n_obj=n_obj, n_constr=n_constr, type_var=np.int64)
self.xl = lb
self.xu = ub
self._n_evaluated = 0 # keep track of how many architectures are sampled
self.args=args
def _evaluate(self, x, out, *args, **kwargs):
objs = np.full((x.shape[0], self.n_obj), np.nan)
g1 = np.full((x.shape[0]), np.nan)
g2 = np.full((x.shape[0]), np.nan)
gen_dir=os.path.join(self.args.output,'generaion'+str(kwargs['algorithm'].n_gen))
os.makedirs(gen_dir,exist_ok = True)
# np.save(os.path.join(gen_dir,"x.npy"),x)
lsms = x.reshape(x.shape[0],self.args.liquid_size,self.args.liquid_size)
for i in range(x.shape[0]):
temp_G = nx.Graph(lsms[i])
nx.write_gpickle(temp_G, os.path.join(gen_dir,str(i)+".pkl"))
self.ob1=mul_f1(pop=x.shape[0],steps=10,rootdir=gen_dir)
for i in range(x.shape[0]):
arch_id = self._n_evaluated + 1
print('\n')
_logger.info('Network= {}'.format(arch_id))
genome = x[i, :]
g1[i]= genome.sum()-self.args.up
g2[i]= self.args.low-genome.sum()
lsmm = genome.reshape(self.args.liquid_size,self.args.liquid_size)
small_coe_a,small_coe_b=self.ob1[i]
lsmm=torch.tensor(lsmm,device='cuda:%d' % self.args.device).float()
crit = calc_f2(lsmm,'cuda:%d' % self.args.device)
objs[i, 1] = abs(crit-1)
# all objectives assume to be MINIMIZED !!!!!
objs[i, 0] = -(small_coe_a/self.args.arand)/(small_coe_b/self.args.brand)
_logger.info('small word= {}'.format(objs[i, 0]))
_logger.info('criticality= {}'.format(objs[i, 1]))
self._n_evaluated += 1
out["F"] = objs
out["G"] = np.column_stack([g1,g2])
# if your NAS problem has constraints, use the following line to set constraints
# out["G"] = np.column_stack([g1, g2, g3, g4, g5, g6]) in case 6 constraints
# ---------------------------------------------------------------------------------------------------------
# Define what statistics to print or save for each generation
# ---------------------------------------------------------------------------------------------------------
def do_every_generations(algorithm):
# this function will be call every generation
# it has access to the whole algorithm class
gen = algorithm.n_gen
pop_var = algorithm.pop.get("X")
pop_obj = algorithm.pop.get("F")
# report generation info to files
_logger.info("generation = {}".format(gen))
_logger.info("population error1: best = {}, mean = {}, "
"median1 = {}, worst1 = {}".format(np.min(pop_obj[:, 0]), np.mean(pop_obj[:, 0]),
np.median(pop_obj[:, 0]), np.max(pop_obj[:, 0])))
_logger.info('Best1 Genome id= {}'.format(np.argmin(pop_obj[:, 0])))
_logger.info("population error2: best = {}, mean = {}, "
"median2 = {}, worst2 = {}".format(np.min(pop_obj[:, 1]), np.mean(pop_obj[:, 1]),
np.median(pop_obj[:, 1]), np.max(pop_obj[:, 1])))
_logger.info('Best2 Genome id= {}'.format(np.argmin(pop_obj[:, 1])))
if gen%20==0:
best_sid=np.argmin(pop_obj[:, 0])
best_sname='-'.join([
'gen'+str(gen),
's'+str(float('%.4f' % pop_obj[best_sid, 0])),
'c'+str(float('%.4f' % pop_obj[best_sid, 1])),
])
best_cid=np.argmin(pop_obj[:, 1])
best_cname='-'.join([
'gen'+str(gen),
's'+str(float('%.4f' % pop_obj[best_cid, 0])),
'c'+str(float('%.4f' % pop_obj[best_cid, 1])),
])
np.save(os.path.join('/data/save/genome',best_sname+datetime.now().strftime("%Y%m%d-%H%M%S")),pop_var[np.argmin(pop_obj[:, 0])])
np.save(os.path.join('/data/save/genome',best_cname+datetime.now().strftime("%Y%m%d-%H%M%S")),pop_var[np.argmin(pop_obj[:, 1])])
if __name__ == '__main__':
args = _parse_args()
out_base_dir= os.path.join(args.output, datetime.now().strftime("%Y%m%d-%H%M%S"))
os.makedirs(out_base_dir,exist_ok = True)
args.output=out_base_dir
setup_default_logging(log_path=os.path.join(out_base_dir, 'log.txt'))
kkk = Evolve(args,n_var=args.liquid_size*args.liquid_size,
n_obj=2, n_constr=2)
method = engine.nsganet(pop_size=args.pop_size,
sampling=RandomSampling(var_type='custom'),
mutation=BinaryBitflipMutation(),
n_offsprings=args.n_offspring,
eliminate_duplicates=True)
kres=minimize(kkk,
method,
callback=do_every_generations,
termination=('n_gen', args.n_gens))
================================================
FILE: examples/Structure_Evolution/ELSM/lsm.py
================================================
from __future__ import print_function
import torchvision
import torchvision.transforms as transforms
import os
import time
import numpy as np
import torch
from torch import nn as nn
from mnistmodel import *
from tqdm import tqdm
import argparse
from datetime import datetime
import logging
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy
from braincog.base.utils import UnilateralMse, MixLoss
from braincog.base.learningrule.STDP import *
device='cuda:7'
def lr_scheduler(optimizer, epoch, init_lr=0.1, lr_decay_epoch=50):
"""Decay learning rate by a factor of 0.1 every lr_decay_epoch epochs."""
if epoch % lr_decay_epoch == 0 and epoch > 1:
for param_group in optimizer.param_groups:
param_group['lr'] = param_group['lr'] * 0.1
return optimizer
batch_size=100
liquid_size=8000
learning_rate = 1e-3
num_epochs = 100 # max epoch
data_path = '/data'
load_path=''
train_dataset = torchvision.datasets.MNIST(root=data_path, train=True, download=False, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=8)
test_set = torchvision.datasets.MNIST(root=data_path, train=False, download=False, transform=transforms.ToTensor())
test_loader = torch.utils.data.DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=2)
snn = SNN(ins=784,
batchsize=batch_size,
device=device,
liquid_size=liquid_size,
lsm_tau=lsm_tau,
lsm_th=lsm_th)
snn.load_state_dict(torch.load(load_path)['fc'])
snn.learning_rule=[]
snn.con[0].load_state_dict(torch.load(load_path)['lsm0'])
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False,device=device)
snn.connectivity_matrix=torch.load(load_path)['connectivity_matrix'].to(device)
w2tmp.weight.data=(torch.load(load_path)['liquid_weight'].to(device))*snn.connectivity_matrix
snn.learning_rule.append(MutliInputSTDP(snn.node_lsm(), [snn.con[0], w2tmp])) # pm
snn.eval()
snn.to(device)
class LabelSmoothingBCEWithLogitsLoss(nn.Module):
def __init__(self, smoothing=0.1):
"""
Constructor for the LabelSmoothing module.
:param smoothing: label smoothing factor
"""
super(LabelSmoothingBCEWithLogitsLoss, self).__init__()
assert smoothing < 1.0
self.smoothing = smoothing
self.confidence = 1. - smoothing
self.BCELoss = nn.BCEWithLogitsLoss()
def forward(self, x, target):
target = torch.eye(x.shape[-1], device=x.device)[target]
nll = torch.ones_like(x) / x.shape[-1]
return self.BCELoss(x, target) * self.confidence + self.BCELoss(x, nll) * self.smoothing
ls = 'mse'
if ls == 'ce':
criterion = nn.CrossEntropyLoss()
elif ls == 'bce':
criterion = nn.BCEWithLogitsLoss()
elif ls == 'mse':
criterion = UnilateralMse(1.)
elif ls == 'sce':
criterion = LabelSmoothingCrossEntropy()
elif ls == 'sbce':
criterion = LabelSmoothingBCEWithLogitsLoss()
elif ls == 'umse':
criterion = UnilateralMse(.5)
optimizer = torch.optim.AdamW(snn.fc.parameters(),lr=0.001, weight_decay=1e-4)
l=[]
best_acc=0
for epoch in range(num_epochs):
running_loss = 0
start_time = time.time()
for i, (images, labels) in enumerate(tqdm(train_loader)):
snn.zero_grad()
optimizer.zero_grad()
images = images.float().to(device)
outputs = snn(images)
labels=labels.to(device)
loss = criterion(outputs, labels)
running_loss += loss.item()
loss.backward()
optimizer.step()
snn.reset()
if (i + 1) % 100 == 0:
running_loss = 0
correct = 0
total = 0
optimizer = lr_scheduler(optimizer, epoch, learning_rate, 40)
for batch_idx, (inputs, targets) in enumerate(test_loader):
inputs = inputs.float().to(device)
snn.zero_grad()
optimizer.zero_grad()
outputs = snn(inputs)
targets=targets.to(device)
loss = criterion(outputs, targets)
_, predicted = outputs.max(1)
total += float(targets.size(0))
correct += float(predicted.eq(targets).sum().item())
snn.reset()
if batch_idx % 100 == 0:
acc = 100. * float(correct) / float(total)
print(batch_idx, len(test_loader), ' Acc: %.5f' % acc)
print('Test Accuracy: %.3f' % (100 * correct / total))
acc = 100. * float(correct) / float(total)
if best_acc < acc:
best_acc = acc
print(best_acc)
l.append(best_acc)
================================================
FILE: examples/Structure_Evolution/ELSM/model.py
================================================
from functools import partial
from torch.nn import functional as F
from torch import nn as nn
import torchvision, pprint
from copy import deepcopy
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.base.brainarea.BrainArea import BrainArea
from braincog.base.connection.CustomLinear import *
from braincog.base.learningrule.STDP import *
import matplotlib.pyplot as plt
@register_model
class nSNN(BaseModule):
def __init__(self,
batchsize,
liquid_size,
device,
connectivity_matrix,
num_classes=10,
step=1,
node_type=LIFNode,
encode_type='direct',
lsm_th=0.3,
fc_th=0.3,
lsm_tau=3,
fc_tau=3,
ins=1156,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.batchsize=batchsize
self.ins=ins
self.node_lsm=partial(node_type, **kwargs, step=step,tau=lsm_tau,threshold=lsm_th)
self.node_fc = partial(node_type, **kwargs, step=step,tau=fc_tau,threshold=fc_th)
self.liquid_size=liquid_size
self.device=device
self.con=[]
self.learning_rule=[]
self.connectivity_matrix=connectivity_matrix
w1tmp=nn.Linear(ins,liquid_size,bias=False).to(device)
self.con.append(w1tmp)
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False).to(device)
self.liquid_weight=w2tmp.weight.data
w2tmp.weight.data=w2tmp.weight.data*self.connectivity_matrix
self.con.append(w2tmp)
self.learning_rule.append(MutliInputSTDP(self.node_lsm(), [self.con[0], self.con[1]])) # pm
self.fc = nn.Sequential(
nn.Linear(liquid_size,num_classes),
self.node_fc()
)
def forward(self, x):
sum_spike=0
self.out = torch.zeros(x.shape[0], self.liquid_size).to(self.device)
tw=x.shape[1]
self.tw=tw
self.firing_tw=torch.zeros(tw, self.batchsize, self.liquid_size).to(self.device)
for t in range(tw):
self.out, self.dw = self.learning_rule[0](x[:,t,:], self.out)
out_liquid=self.out[:,0:self.liquid_size]
xout = self.fc(out_liquid)
sum_spike=sum_spike+xout
self.firing_tw[t]=out_liquid
outputs = sum_spike / tw
return outputs
@register_model
class mSNN(BaseModule):
def __init__(self,
batchsize,
liquid_size,
device,
connectivity_matrix,
num_classes=10,
step=1,
node_type=LIFNode,
encode_type='direct',
lsm_th=0.3,
fc_th=0.3,
lsm_tau=3,
fc_tau=3,
tw=100,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.batchsize=batchsize
self.node_lsm=partial(node_type, **kwargs, step=step,tau=lsm_tau,threshold=lsm_th)
self.node_fc = partial(node_type, **kwargs, step=step,tau=fc_tau,threshold=fc_th)
self.liquid_size=liquid_size
self.out = torch.zeros(self.batchsize, liquid_size).to(device)
self.device=device
self.con=[]
self.learning_rule=[]
self.connectivity_matrix=connectivity_matrix
w1tmp=nn.Linear(784,liquid_size,bias=False).to(device)
self.con.append(w1tmp)
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False).to(device)
self.liquid_weight=w2tmp.weight.data
w2tmp.weight.data=w2tmp.weight.data*self.connectivity_matrix
self.con.append(w2tmp)
self.learning_rule.append(MutliInputSTDP(self.node_lsm(), [self.con[0], self.con[1]])) # pm
self.fc = nn.Sequential(
nn.Linear(liquid_size,num_classes),
self.node_fc()
)
def forward(self, x):
x = x.reshape(x.shape[0], -1)
sum_spike=0
time_window=20
self.tw=time_window
self.firing_tw=torch.zeros(time_window, self.batchsize, self.liquid_size).to(self.device)
self.out = torch.zeros(self.batchsize, self.liquid_size).to(self.device)
for t in range(time_window):
self.out, self.dw = self.learning_rule[0](x, self.out)
out_liquid=self.out[:,0:self.liquid_size]
xout = self.fc(out_liquid)
sum_spike=sum_spike+xout
self.firing_tw[t]=out_liquid
# print(out_liquid.sum())
# print(xout.sum())
outputs = sum_spike / time_window
return outputs
================================================
FILE: examples/Structure_Evolution/ELSM/nsganet.py
================================================
import numpy as np
from pymoo.algorithms.genetic_algorithm import GeneticAlgorithm
from pymoo.docs import parse_doc_string
from pymoo.model.individual import Individual
from pymoo.model.survival import Survival
from pymoo.operators.crossover.point_crossover import PointCrossover
from pymoo.operators.mutation.polynomial_mutation import PolynomialMutation
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.selection.tournament_selection import compare, TournamentSelection
from pymoo.util.display import disp_multi_objective
from pymoo.util.dominator import Dominator
from pymoo.util.non_dominated_sorting import NonDominatedSorting
from pymoo.util.randomized_argsort import randomized_argsort
# =========================================================================================================
# Implementation
# based on nsga2 from https://github.com/msu-coinlab/pymoo
# =========================================================================================================
class NSGANet(GeneticAlgorithm):
def __init__(self, **kwargs):
kwargs['individual'] = Individual(rank=np.inf, crowding=-1)
super().__init__(**kwargs)
self.tournament_type = 'comp_by_dom_and_crowding'
self.func_display_attrs = disp_multi_objective
# ---------------------------------------------------------------------------------------------------------
# Binary Tournament Selection Function
# ---------------------------------------------------------------------------------------------------------
def binary_tournament(pop, P, algorithm, **kwargs):
if P.shape[1] != 2:
raise ValueError("Only implemented for binary tournament!")
tournament_type = algorithm.tournament_type
S = np.full(P.shape[0], np.nan)
for i in range(P.shape[0]):
a, b = P[i, 0], P[i, 1]
# if at least one solution is infeasible
if pop[a].CV > 0.0 or pop[b].CV > 0.0:
S[i] = compare(a, pop[a].CV, b, pop[b].CV, method='smaller_is_better', return_random_if_equal=True)
# both solutions are feasible
else:
if tournament_type == 'comp_by_dom_and_crowding':
rel = Dominator.get_relation(pop[a].F, pop[b].F)
if rel == 1:
S[i] = a
elif rel == -1:
S[i] = b
elif tournament_type == 'comp_by_rank_and_crowding':
S[i] = compare(a, pop[a].rank, b, pop[b].rank,
method='smaller_is_better')
else:
raise Exception("Unknown tournament type.")
# if rank or domination relation didn't make a decision compare by crowding
if np.isnan(S[i]):
S[i] = compare(a, pop[a].get("crowding"), b, pop[b].get("crowding"),
method='larger_is_better', return_random_if_equal=True)
return S[:, None].astype(np.int)
# ---------------------------------------------------------------------------------------------------------
# Survival Selection
# ---------------------------------------------------------------------------------------------------------
class RankAndCrowdingSurvival(Survival):
def __init__(self) -> None:
super().__init__(True)
def _do(self, pop, n_survive, D=None, **kwargs):
# get the objective space values and objects
F = pop.get("F")
# the final indices of surviving individuals
survivors = []
# do the non-dominated sorting until splitting front
fronts = NonDominatedSorting().do(F, n_stop_if_ranked=n_survive)
for k, front in enumerate(fronts):
# calculate the crowding distance of the front
crowding_of_front = calc_crowding_distance(F[front, :])
# save rank and crowding in the individual class
for j, i in enumerate(front):
pop[i].set("rank", k)
pop[i].set("crowding", crowding_of_front[j])
# current front sorted by crowding distance if splitting
if len(survivors) + len(front) > n_survive:
I = randomized_argsort(crowding_of_front, order='descending', method='numpy')
I = I[:(n_survive - len(survivors))]
# otherwise take the whole front unsorted
else:
I = np.arange(len(front))
# extend the survivors by all or selected individuals
survivors.extend(front[I])
return pop[survivors]
def calc_crowding_distance(F):
infinity = 1e+14
n_points = F.shape[0]
n_obj = F.shape[1]
if n_points <= 2:
return np.full(n_points, infinity)
else:
# sort each column and get index
I = np.argsort(F, axis=0, kind='mergesort')
# now really sort the whole array
F = F[I, np.arange(n_obj)]
# get the distance to the last element in sorted list and replace zeros with actual values
dist = np.concatenate([F, np.full((1, n_obj), np.inf)]) \
- np.concatenate([np.full((1, n_obj), -np.inf), F])
index_dist_is_zero = np.where(dist == 0)
dist_to_last = np.copy(dist)
for i, j in zip(*index_dist_is_zero):
dist_to_last[i, j] = dist_to_last[i - 1, j]
dist_to_next = np.copy(dist)
for i, j in reversed(list(zip(*index_dist_is_zero))):
dist_to_next[i, j] = dist_to_next[i + 1, j]
# normalize all the distances
norm = np.max(F, axis=0) - np.min(F, axis=0)
norm[norm == 0] = np.nan
dist_to_last, dist_to_next = dist_to_last[:-1] / norm, dist_to_next[1:] / norm
# if we divided by zero because all values in one columns are equal replace by none
dist_to_last[np.isnan(dist_to_last)] = 0.0
dist_to_next[np.isnan(dist_to_next)] = 0.0
# sum up the distance to next and last and norm by objectives - also reorder from sorted list
J = np.argsort(I, axis=0)
crowding = np.sum(dist_to_last[J, np.arange(n_obj)] + dist_to_next[J, np.arange(n_obj)], axis=1) / n_obj
# replace infinity with a large number
crowding[np.isinf(crowding)] = infinity
return crowding
# =========================================================================================================
# Interface
# =========================================================================================================
def nsganet(
pop_size=100,
sampling=RandomSampling(var_type=np.int),
selection=TournamentSelection(func_comp=binary_tournament),
crossover=PointCrossover(n_points=2),
mutation=PolynomialMutation(eta=3, var_type=np.int),
eliminate_duplicates=True,
n_offsprings=None,
**kwargs):
"""
Parameters
----------
pop_size : {pop_size}
sampling : {sampling}
selection : {selection}
crossover : {crossover}
mutation : {mutation}
eliminate_duplicates : {eliminate_duplicates}
n_offsprings : {n_offsprings}
Returns
-------
nsganet : :class:`~pymoo.model.algorithm.Algorithm`
Returns an NSGANet algorithm object.
"""
return NSGANet(pop_size=pop_size,
sampling=sampling,
selection=selection,
crossover=crossover,
mutation=mutation,
survival=RankAndCrowdingSurvival(),
eliminate_duplicates=eliminate_duplicates,
n_offsprings=n_offsprings,
**kwargs)
parse_doc_string(nsganet)
================================================
FILE: examples/Structure_Evolution/ELSM/spikes.py
================================================
from __future__ import print_function
import torchvision
import torchvision.transforms as transforms
import os
import numpy as np
import torch
from torch import nn as nn
from model import *
from tqdm import tqdm
import argparse
from datetime import datetime
import logging
from timm.utils import *
from spikingjelly.datasets.n_mnist import NMNIST
from timm.loss import LabelSmoothingCrossEntropy
from braincog.base.utils.criterions import *
import networkx as nx
import time
from braincog.base.learningrule.STDP import *
def randbool(size, p=0.5):
return torch.rand(*size) < p
def calc_f2(con,device):
batch_size=1
liquid_size=8000
images=torch.load('/1000images.pt')
labels=torch.load('/1000labels.pt')
load_path='970.t7'
snn = nSNN(ins=2312,
batchsize=batch_size,
device=device,
liquid_size=liquid_size,
lsm_tau=2.0,
lsm_th=0.20,
connectivity_matrix=randbool([liquid_size, liquid_size],p=0.01).to(device).int())
snn.load_state_dict(torch.load(load_path,map_location={'cuda:2':device})['fc'])
snn.con[0].load_state_dict(torch.load(load_path,map_location={'cuda:2':device})['lsm0'])
snn.to(device)
criterion = UnilateralMse(1.)
optimizer = torch.optim.AdamW(snn.fc.parameters(),lr=0.001, weight_decay=1e-4)
k=0
sbr=0
snn.connectivity_matrix=con
snn.learning_rule=[]
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False,device=device)
w2tmp.weight.data=(torch.load(load_path,map_location={'cuda:2':device})['liquid_weight'])*snn.connectivity_matrix
snn.learning_rule.append(MutliInputSTDP(snn.node_lsm(), [snn.con[0], w2tmp]))
snn.eval()
for label,data in zip(labels,images):
running_loss = 0
snn.zero_grad()
optimizer.zero_grad()
data = data.to(device)
label = label.to(device)
data=data.reshape(batch_size,data.shape[0],-1)
output = snn(data)
# print(torch.argmax(output)==label)
out_liquid=snn.firing_tw.squeeze(-2)
mupost=torch.matmul(con,out_liquid.unsqueeze(-1))
mupre=torch.matmul(con.t(),out_liquid.unsqueeze(-1))
for t in range(snn.tw):
if t>5 and t 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
s = h1 + h2
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = torch.cat([states[i]
for i in self._concat], dim=1) # N,C,H, W
return outputs
# return self.node(outputs)
class EvoCell3(nn.Module):
def __init__(self,motif, C_prev_prev_prev, C_prev_prev, C_prev, C, reduction, reduction_prev, reduction_prev_prev, act_fun):
# print(C_prev_prev_prev,C_prev_prev, C_prev, C, reduction,reduction_prev, reduction_prev_prev)
super(EvoCell3, self).__init__()
self.act_fun = act_fun
self.reduction = reduction
self.motif=motif
self.back_connection=False
if reduction:
self.fun = FactorizedReduce(C_prev, C * 3, act_fun=act_fun)
self.multiplier = 3
else:
if reduction_prev:
self.preprocess1 = FactorizedReduce(C_prev_prev, C, act_fun=act_fun)
else:
self.preprocess1 = ReLUConvBN(C_prev_prev, C, 1, 1, 0, act_fun=act_fun)
if int(reduction_prev_prev)+int(reduction_prev)==1:
self.preprocess0 = FactorizedReduce(C_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev)+int(reduction_prev)==2:
self.preprocess0 = F0(C_prev_prev_prev, C, act_fun=act_fun)
else:
self.preprocess0 = ReLUConvBN(C_prev_prev_prev, C, 1, 1, 0, act_fun=act_fun)
self.preprocess2 = ReLUConvBN(C_prev, C, 1, 1, 0, act_fun=act_fun)
op_names, indices = zip(*motif.normal)
concat = motif.normal_concat
self._compile(C, op_names, indices, concat, reduction)
def _compile(self, C, op_names, indices, concat, reduction):
assert len(op_names) == len(indices)
# self._steps = len(op_names) // 2
self._concat = concat
self.multiplier = len(concat)
self._ops = nn.ModuleList()
self._ops_back = nn.ModuleList()
back_begin_index = 0
for i, (name, index) in enumerate(zip(op_names, indices)):
# print(name, index)
if '_back' in name:
self.back_connection=True
back_begin_index = i
break
stride = 2 if reduction and index < 2 else 1
op = OPS[name](C, stride, True, act_fun=self.act_fun)
self._ops += [op]
if self.back_connection:
for name, index in zip(op_names[back_begin_index:], indices[back_begin_index:]):
op = OPS[name.replace('_back', '')](
C, 1, True, act_fun=self.act_fun)
self._ops_back += [op]
if self.back_connection:
self._indices_forward = indices[:back_begin_index]
self._indices_backward = indices[back_begin_index:]
else:
self._indices_backward = []
self._indices_forward = indices
self._steps = len(self._indices_forward) // 3
def forward(self, s0, s1, s2, drop_prob):
if self.reduction:
return self.fun(s2)
s0 = self.preprocess0(s0)
s1 = self.preprocess1(s1)
s2 = self.preprocess2(s2)
states = [s0, s1, s2]
for i in range(self._steps):
i1=self._indices_forward[3 * i]
i2=self._indices_forward[3 * i + 1]
i3=self._indices_forward[3 * i + 2]
h1 = states[i1]
h2 = states[i2]
h3 = states[i3]
op1 = self._ops[3 * i]
op2 = self._ops[3 * i + 1]
op3 = self._ops[3 * i + 2]
h1 = op1(h1)
h2 = op2(h2)
h3 = op3(h3)
if self.training and drop_prob > 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
if not isinstance(op3, Identity):
h3 = drop_path(h3, drop_prob)
s = h1 + h2 + h3
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = torch.cat([states[i] for i in self._concat], dim=1) # N,C,H, W
return outputs
# return self.node(outputs)
class EvoCell4(nn.Module):
def __init__(self,motif, C_prev_prev_prev_prev,C_prev_prev_prev, C_prev_prev, C_prev, C, reduction, reduction_prev, reduction_prev_prev,reduction_prev_prev_prev, act_fun):
# print(C_prev_prev_prev_prev,C_prev_prev_prev,C_prev_prev, C_prev, C, reduction,reduction_prev, reduction_prev_prev,reduction_prev_prev_prev)
super(EvoCell4, self).__init__()
self.act_fun = act_fun
self.reduction = reduction
self.motif=motif
self.back_connection=False
if reduction:
self.fun = FactorizedReduce(C_prev, C * 3, act_fun=act_fun)
self.multiplier = 3
else:
if reduction_prev:
self.preprocess2 = FactorizedReduce(C_prev_prev, C, act_fun=act_fun)
else:
self.preprocess2 = ReLUConvBN(C_prev_prev, C, 1, 1, 0, act_fun=act_fun)
if int(reduction_prev_prev)+int(reduction_prev)==1:
self.preprocess1 = FactorizedReduce(C_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev)+int(reduction_prev)==2:
self.preprocess1 = F0(C_prev_prev_prev, C, act_fun=act_fun)
else:
self.preprocess1 = ReLUConvBN(C_prev_prev_prev, C, 1, 1, 0, act_fun=act_fun)
if int(reduction_prev_prev_prev)+int(reduction_prev_prev)+int(reduction_prev)==1:
self.preprocess0 = FactorizedReduce(C_prev_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev_prev)+int(reduction_prev_prev)+int(reduction_prev)==2:
self.preprocess0 = F0(C_prev_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev_prev)+int(reduction_prev_prev)+int(reduction_prev)==3:
self.preprocess0 = F1(C_prev_prev_prev_prev, C, act_fun=act_fun)
else:
self.preprocess0 = ReLUConvBN(C_prev_prev_prev_prev, C, 1, 1, 0, act_fun=act_fun)
self.preprocess3 = ReLUConvBN(C_prev, C, 1, 1, 0, act_fun=act_fun)
op_names, indices = zip(*motif.normal)
# print(self.preprocess0)
# print(self.preprocess1)
# print(self.preprocess2)
# print(self.preprocess3)
concat = motif.normal_concat
self._compile(C, op_names, indices, concat, reduction)
def _compile(self, C, op_names, indices, concat, reduction):
assert len(op_names) == len(indices)
# self._steps = len(op_names) // 2
self._concat = concat
self.multiplier = len(concat)
self._ops = nn.ModuleList()
self._ops_back = nn.ModuleList()
back_begin_index = 0
for i, (name, index) in enumerate(zip(op_names, indices)):
# print(name, index)
if '_back' in name:
self.back_connection=True
back_begin_index = i
break
stride = 2 if reduction and index < 2 else 1
op = OPS[name](C, stride, True, act_fun=self.act_fun)
self._ops += [op]
if self.back_connection:
for name, index in zip(op_names[back_begin_index:], indices[back_begin_index:]):
op = OPS[name.replace('_back', '')](
C, 1, True, act_fun=self.act_fun)
self._ops_back += [op]
if self.back_connection:
self._indices_forward = indices[:back_begin_index]
self._indices_backward = indices[back_begin_index:]
else:
self._indices_backward = []
self._indices_forward = indices
self._steps = len(self._indices_forward) // 4
def forward(self, s0, s1, s2, s3, drop_prob):
if self.reduction:
return self.fun(s3)
s0 = self.preprocess0(s0)
s3 = self.preprocess3(s3)
s1 = self.preprocess1(s1)
s2 = self.preprocess2(s2)
# if s1.shape[1]!=s3.shape[1]:
# s1 = nn.Conv2d(s1.shape[1], s3.shape[1], 3, stride=2, padding=1, bias=False)
states = [s0, s1, s2,s3]
for i in range(self._steps):
i1=self._indices_forward[4 * i]
i2=self._indices_forward[4 * i + 1]
i3=self._indices_forward[4 * i + 2]
i4=self._indices_forward[4 * i + 3]
h1 = states[i1]
h2 = states[i2]
h3 = states[i3]
h4 = states[i4]
op1 = self._ops[4 * i]
op2 = self._ops[4 * i + 1]
op3 = self._ops[4 * i + 2]
op4 = self._ops[4 * i + 3]
h1 = op1(h1)
h2 = op2(h2)
h3 = op3(h3)
h4 = op4(h4)
if self.training and drop_prob > 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
if not isinstance(op3, Identity):
h3 = drop_path(h3, drop_prob)
if not isinstance(op4, Identity):
h4= drop_path(h4, drop_prob)
s = h1 + h2 + h3 + h4
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = torch.cat([states[i] for i in self._concat], dim=1) # N,C,H, W
return outputs
# return self.node(outputs)
@register_model
class NetworkCIFAR(BaseModule):
def __init__(self,
C,
num_classes,
layers,
auxiliary,
motif,
cell_type,
parse_method='darts',
step=5,
node_type='ReLUNode',
**kwargs):
super(NetworkCIFAR, self).__init__(
step=step,
num_classes=num_classes,
**kwargs
)
self.node_type=node_type
if isinstance(node_type, str):
self.act_fun = eval(node_type)
else:
self.act_fun = node_type
self.act_fun = partial(self.act_fun, **kwargs)
self.spike_output = kwargs['spike_output'] if 'spike_output' in kwargs else True
self.dataset = kwargs['dataset']
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
self._layers = layers
self.cell_type = cell_type
self._auxiliary = auxiliary
self.drop_path_prob = 0
stem_multiplier = 3
C_curr = stem_multiplier * C
if self.dataset == 'dvsg' or self.dataset == 'dvsc10' or self.dataset == 'NCALTECH101':
self.stem = nn.Sequential(
nn.Conv2d(2 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
# self.reduce_idx = [
# layers // 4,
# layers // 2,
# 3 * layers // 4
# ]
self.reduce_idx = [1, 3, 5, 7]
else:
self.stem = nn.Sequential(
nn.Conv2d(1, 3 * self.init_channel_mul, 3, padding=1, bias=False),
nn.Conv2d(3 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
self.reduce_idx = [layers // 4,
layers // 2,
3 * layers // 4]
C_prev_prev_prev = C_curr
C_prev_prev_prev_prev = C_curr
C_prev_prev, C_prev, C_curr = C_curr, C_curr, C
self.cells = nn.ModuleList()
reduction_prev = False
reduction_prev_prev = False
reduction_prev_prev_prev = False
for i in range(layers):
if i in self.reduce_idx:
C_curr *= 2
reduction = True
else:
reduction = False
if cell_type==2:
# print(C_prev_prev, C_prev, C_curr)
cell = EvoCell2(motif[i], C_prev_prev, C_prev, C_curr,reduction, reduction_prev,act_fun=self.act_fun)
self.cells += [cell]
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
if cell_type==3:
cell = EvoCell3(motif[i], C_prev_prev_prev, C_prev_prev, C_prev, C_curr,reduction, reduction_prev,reduction_prev_prev,act_fun=self.act_fun)
self.cells += [cell]
C_prev_prev_prev = C_prev_prev
reduction_prev_prev = reduction_prev
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
if cell_type==4:
cell = EvoCell4(motif[i], C_prev_prev_prev_prev,C_prev_prev_prev, C_prev_prev, C_prev, C_curr,reduction, reduction_prev,reduction_prev_prev,reduction_prev_prev_prev,act_fun=self.act_fun)
self.cells += [cell]
C_prev_prev_prev_prev = C_prev_prev_prev
C_prev_prev_prev = C_prev_prev
reduction_prev_prev_prev = reduction_prev_prev
reduction_prev_prev = reduction_prev
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
reduction_prev = reduction
self.global_pooling = nn.Sequential(
self.act_fun(), nn.AdaptiveAvgPool2d(1))
if self.spike_output:
self.classifier = nn.Sequential(
nn.Linear(C_prev, 10 * num_classes),
self.act_fun())
self.vote = VotingLayer(10)
else:
self.classifier = nn.Linear(C_prev, num_classes)
self.vote = nn.Identity()
# self.classifier = nn.Linear(C_prev, num_classes)
# self.vote = nn.Identity()
def forward(self, inputs):
logits_aux = None
inputs = self.encoder(inputs)
if not self.layer_by_layer:
outputs = []
output_aux = []
self.reset()
if self.cell_type==2:
for t in range(self.step):
x = inputs[t]
s0 = s1 = self.stem(x)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
out = self.global_pooling(s1)
out = self.classifier(self.flatten(out))
logits = self.vote(out)
outputs.append(logits)
output_aux.append(logits_aux)
return sum(outputs) / len(outputs)
if self.cell_type==3:
for t in range(self.step):
x = inputs[t]
s0 = s1 = s2= self.stem(x)
for i, cell in enumerate(self.cells):
s0, s1, s2 = s1, s2, cell(s0, s1, s2, self.drop_path_prob)
out = self.global_pooling(s2)
out = self.classifier(self.flatten(out))
logits = self.vote(out)
outputs.append(logits)
output_aux.append(logits_aux)
return sum(outputs) / len(outputs)
if self.cell_type==4:
for t in range(self.step):
x = inputs[t]
s0 = s1 = s2= s3=self.stem(x)
for i, cell in enumerate(self.cells):
s0, s1, s2,s3= s1, s2, s3,cell(s0, s1, s2,s3 ,self.drop_path_prob)
out = self.global_pooling(s3)
out = self.classifier(self.flatten(out))
logits = self.vote(out)
outputs.append(logits)
output_aux.append(logits_aux)
return sum(outputs) / len(outputs)
# logits_aux if logits_aux is None else (sum(output_aux) / len(output_aux))
else:
self.reset()
if self.cell_type==2:
s0 = s1 = self.stem(inputs)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
if i == 2 * self._layers // 3:
if self._auxiliary and self.training:
logits_aux = self.auxiliary_head(s1)
out = self.global_pooling(s1)
out = self.classifier(self.flatten(out))
out = rearrange(out, '(t b) c -> t b c', t=self.step).mean(0)
logits = self.vote(out)
return logits
if self.cell_type==3:
s0 = s1 = s2= self.stem(inputs)
for i, cell in enumerate(self.cells):
s0, s1, s2 = s1, s2, cell(s0, s1, s2, self.drop_path_prob)
if i == 2 * self._layers // 3:
if self._auxiliary and self.training:
logits_aux = self.auxiliary_head(s1)
out = self.global_pooling(s2)
out = self.classifier(self.flatten(out))
out = rearrange(out, '(t b) c -> t b c', t=self.step).mean(0)
logits = self.vote(out)
return logits
if self.cell_type==4:
s0 = s1 = s2=s3= self.stem(inputs)
for i, cell in enumerate(self.cells):
s0, s1, s2,s3= s1, s2, s3,cell(s0, s1, s2,s3 ,self.drop_path_prob)
if i == 2 * self._layers // 3:
if self._auxiliary and self.training:
logits_aux = self.auxiliary_head(s1)
out = self.global_pooling(s3)
out = self.classifier(self.flatten(out))
out = rearrange(out, '(t b) c -> t b c', t=self.step).mean(0)
logits = self.vote(out)
return logits
@register_model
class NetworkImageNet(BaseModule):
def __init__(self,
C,
num_classes,
layers,
auxiliary,
motif,
step=1,
node_type='ReLUNode',
**kwargs):
super(NetworkImageNet, self).__init__(
step=step,
num_classes=num_classes,
**kwargs)
if isinstance(node_type, str):
self.act_fun = eval(node_type)
else:
self.act_fun = node_type
self.act_fun = partial(self.act_fun, **kwargs)
if 'back_connection' in kwargs.keys():
self.back_connection = kwargs['back_connection']
else:
self.back_connection = False
self.spike_output = kwargs['spike_output'] if 'spike_output' in kwargs else True
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
self._layers = layers
self._auxiliary = auxiliary
self.drop_path_prob = 0
self.stem0 = nn.Sequential(
nn.Conv2d(3, C // 2, kernel_size=3,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(C // 2),
# nn.ReLU(inplace=True),
self.act_fun(),
nn.Conv2d(C // 2, C, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(C),
)
self.stem1 = nn.Sequential(
# nn.ReLU(inplace=True),
self.act_fun(),
nn.Conv2d(C, C, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(C),
)
C_prev_prev, C_prev, C_curr = C, C, C
self.cells = nn.ModuleList()
reduction_prev = True
for i in range(layers):
if i in [layers // 3, 2 * layers // 3]:
C_curr *= 2
reduction = True
else:
reduction = False
cell = EvoCell2(motif[i], C_prev_prev, C_prev,C_curr, reduction, reduction_prev,act_fun=self.act_fun)
reduction_prev = reduction
self.cells += [cell]
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
self.global_pooling = nn.AvgPool2d(7)
self.classifier = nn.Linear(C_prev, num_classes)
def forward(self, inputs):
outputs = []
self.reset()
for t in range(self.step):
s0 = self.stem0(inputs)
s1 = self.stem1(s0)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
out = self.global_pooling(s1)
logits = self.classifier(self.flatten(out))
outputs.append(logits)
return sum(outputs) / len(outputs)
if __name__ == '__main__':
x = torch.rand(128, 36, 32, 32)
extra_edge=np.array([[3,5],[4,1]])
# sort based on head
extra_edge = extra_edge[extra_edge[:,0].argsort()]
# motifs=[mm1,mm2,mm3,mm1,mm5,mm4]
# motifs=[m1,m2,m3,m1,m5,m4,m1,m2,m3,m1,m5,m4,m5,m4,m1]
motifs=[t2,t3,t4,t5,t5,t4,t3,t4]
net=NetworkCIFAR(C=12,num_classes=10,motif=motifs,layers=len(motifs),auxiliary=True,dataset='cifar10',cell_type=4)
out=net(torch.rand(128, 3, 32, 32))
print(out.shape)
================================================
FILE: examples/Structure_Evolution/MSE-NAS/evolution.py
================================================
import sys
import numpy as np
import argparse
import time
import obj
import timm.models
import yaml
import os
import logging
from random import choice
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from micro_encoding import ops
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import micro_encoding
import nsganet as engine
from pymop.problem import Problem
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from pymoo.optimize import minimize
from utils import data_transforms
from tm import train_motifs
from timm.data import create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
# os.environ['CUDA_VISIBLE_DEVICES']='3'
bits=20
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('')
# The first arg parser parses out only thei --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
devices=[1]
max_gen = 100
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--seed', type=int, default=99, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--eval_epochs', type=int, default=10)
parser.add_argument('--bns', action='store_true', default=True)
parser.add_argument('--mid', type=int, default=3)
parser.add_argument('--trainning_epochs', type=int, default=600, metavar='N',help='number of epochs to train (default: 2)')
parser.add_argument('--cooldown-epochs', type=int, default=0, metavar='N',help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--init-channels', type=int, default=48)
parser.add_argument('--layers', type=int, default=6)
parser.add_argument('--pop_size', type=int, default=50, help='population size of networks')
parser.add_argument('--output', default='', type=str, metavar='PATH')
parser.add_argument('--spike-rate', action='store_true', default=False)
parser.add_argument('--n_gens', type=int, default=max_gen, help='population size')
parser.add_argument('--bs', type=int, default=100)
parser.add_argument('--n_offspring', type=int, default=50, help='number of offspring created per generation')
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser.add_argument('--dataset', default='dvsg', type=str)
parser.add_argument('--num-classes', type=int, default=11, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--model', default='NetworkCIFAR', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
parser.add_argument('--strgenome', default='4,0,0,1,1,1,0,1,0,1,0,0,0,1,0,1,0,1,0,0,4,1,1,1,1,1,0,1,1,0,1,1,0,1,1,1,0,1,0,0,4,1,1,0,1,0,0,1,0,1,1,0,1,1,0,0,1,0,1,2,4,1,0,0,1,1,1,0,0,1,0,0,1,0,0,1,0,0,1,1,4,0,1,1,0,1,0,0,1,0,1,0,1,1,1,0,1,0,1,3,4,1,0,1,0,0,1,1,1,0,0,1,0,1,0,0,0,1,0,0,3', type=str)
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.8,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=1.0,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=1.0,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=len(devices),
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=devices[0])
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='QGateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
# DARTS parameters
parser.add_argument('--auxiliary', action='store_true', default=False, help='use auxiliary tower')
# parser.add_argument('--arch', default='dvsc10_new_skip19', type=str)
# parser.add_argument('--motif', default='m1', type=str)
parser.add_argument('--parse_method', default='darts', type=str)
parser.add_argument('--drop_path_prob', type=float, default=0.2, help='drop path probability')
# parser.add_argument('--back-connection', action='store_true',default=True)
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def check_mem(cuda_device):
devices_info = os.popen('"/usr/bin/nvidia-smi" --query-gpu=memory.total,memory.used --format=csv,nounits,noheader').read().strip().split("\n")
total, used = devices_info[int(cuda_device)].split(',')
return total,used
def occumpy_mem(cuda_device):
total, used = check_mem(cuda_device)
total = int(total)
used = int(used)
max_mem = int(total * 1)
block_mem = int((max_mem - used)*0.3)
x = torch.cuda.FloatTensor(256,1024,block_mem)
del x
class NAS(Problem):
# first define the NAS problem (inherit from pymop)
def __init__(self, args,n_var=20, n_obj=1, n_constr=0, lb=None, ub=None,
init_channels=24, layers=8):
super().__init__(n_var=n_var, n_obj=n_obj, n_constr=n_constr, type_var=np.int64)
self.xl = lb
self.xu = ub
self._lr =args.lr
self._n_evaluated = 0 # keep track of how many architectures are sampled
self.args=args
def _evaluate(self, x, out, *args, **kwargs):
objs = np.full((x.shape[0], self.n_obj), np.nan)
train_data, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % self.args.dataset)(
batch_size=self.args.batch_size,
step=self.args.step,
args=self.args,
_logge=_logger,
size=self.args.event_size,
mix_up=self.args.mix_up,
cut_mix=self.args.cut_mix,
event_mix=self.args.event_mix,
beta=self.args.cutmix_beta,
prob=self.args.cutmix_prob,
num=self.args.cutmix_num,
noise=self.args.cutmix_noise,
num_classes=self.args.num_classes,
rand_aug=self.args.rand_aug,
randaug_n=self.args.randaug_n,
randaug_m=self.args.randaug_m,
temporal_flatten=self.args.temporal_flatten,
portion=self.args.train_portion,
_logger=_logger)
for i in range(x.shape[0]):
arch_id = self._n_evaluated + 1
print('\n')
_logger.info('Network= {}'.format(arch_id))
genome = x[i, :]
arch_dir=os.path.join(self.args.output_dir)
if os.path.exists(arch_dir) is False:
os.makedirs(arch_dir,exist_ok = True)
self.args.lr=self._lr
performance,acc=train_motifs(args=self.args,gen=0,arch_dir=arch_dir,genome=genome,_logger=_logger,args_text=args_text,devices=devices,bits=bits)
objs[i, 0] = 1000 - performance
# sJ,J,Cm,Ccosine,Cpe,K = obj.LSP(self.args,genome,train_data)
# objs[i, 0] = 1000 - Cm
_logger.info('performance= {}'.format(objs[i, 0]))
self._n_evaluated += 1
out["F"] = objs
# if your NAS problem has constraints, use the following line to set constraints
# out["G"] = np.column_stack([g1, g2, g3, g4, g5, g6]) in case 6 constraints
def do_every_generations(algorithm):
# this function will be call every generation
# it has access to the whole algorithm class
gen = algorithm.n_gen
pop_var = algorithm.pop.get("X")
pop_obj = algorithm.pop.get("F")
# report generation info to files
_logger.info("generation = {}".format(gen))
_logger.info("population error: best = {}, mean = {}, "
"median = {}, worst = {}".format(np.min(pop_obj[:, 0]), np.mean(pop_obj[:, 0]),
np.median(pop_obj[:, 0]), np.max(pop_obj[:, 0])))
_logger.info('Best Genome= {}'.format(pop_var[np.argmin(pop_obj[:, 0])]))
def _parse_args():
args_config, remaining = config_parser.parse_known_args()
args = parser.parse_args(remaining)
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
if __name__ == '__main__':
args, args_text = _parse_args()
args.no_spike_output = True
output_dir = ''
if args.bns:
from cellmodel import NetworkCIFAR
else:
from cell123model import NetworkCIFAR
if args.local_rank == 0:
output_base = args.output if args.output else './output'
exp_name = '-'.join([
datetime.now().strftime("%Y%m%d-%H%M%S"),
# args.model,
# args.dataset,
str(args.layers)+'layers',
str(args.init_channels)+'channels',
'motif'+str(args.mid),
str(args.step)+'steps',
# args.suffix
# str(args.img_size)
])
output_dir = get_outdir(output_base,str(args.dataset),exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
else:
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
defalut_lr = args.lr
occumpy_mem(str(args.device))
train_data, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
temporal_flatten=args.temporal_flatten,
portion=args.train_portion,
_logger=_logger,
)
len_motifs=args.layers*bits+1
low = np.zeros(len_motifs)
low[-1] = 2
up=[]
for i in range(0,args.layers*bits,bits):
t=[args.mid]
t=t+[(ops-1) for j in range(bits-1)]
t[-1]=2*(ops-1)
up.extend(t)
up.append(3)
up=np.array(up).reshape(-1,)
kkk = NAS(args,n_var=len_motifs,
n_obj=2, n_constr=0, lb=low, ub=up,
init_channels=args.init_channels, layers=args.layers)
method = engine.nsganet(pop_size=args.pop_size,
n_offsprings=args.n_offspring,
eliminate_duplicates=True)
kres=minimize(kkk,
method,
callback=do_every_generations,
termination=('n_gen', args.n_gens))
================================================
FILE: examples/Structure_Evolution/MSE-NAS/loss_f.py
================================================
import torch
import torch.nn.functional as f
def psp(inputs, n_steps,tau_s):
shape = inputs.shape
n_steps = n_steps
tau_s = tau_s
syn = torch.zeros(shape[0], shape[1], shape[2], shape[3]).cuda()
syns = torch.zeros(shape[0], shape[1], shape[2], shape[3], n_steps).cuda()
for t in range(n_steps):
syn = syn - syn / tau_s + inputs[..., t]
syns[..., t] = syn / tau_s
return syns
class SpikeLoss(torch.nn.Module):
"""
This class defines different spike based loss modules that can be used to optimize the SNN.
"""
def __init__(self, desired_count,undesired_count):
super(SpikeLoss, self).__init__()
self.desired_count = desired_count
self.desired_count = undesired_count
self.criterion = torch.nn.CrossEntropyLoss()
def spike_count(self, outputs, target, desired_count,undesired_count):
delta = loss_count.apply(outputs, target, desired_count,undesired_count)
return 1 / 2 * torch.sum(delta ** 2)
def spike_kernel(self, outputs, target, desired_count,undesired_count):
delta = loss_kernel.apply(outputs, target, desired_count,undesired_count)
return 1 / 2 * torch.sum(delta ** 2)
def spike_soft_max(self, outputs, target):
delta = f.log_softmax(outputs.sum(dim=4).squeeze(-1).squeeze(-1), dim = 1)
return self.criterion(delta, target)
class loss_count(torch.autograd.Function): # a and u is the incremnet of each time steps
@staticmethod
def forward(ctx, outputs, target, desired_count,undesired_count):
desired_count = desired_count
undesired_count = undesired_count
shape = outputs.shape
n_steps = shape[4]
out_count = torch.sum(outputs, dim=4)
delta = (out_count - target) / n_steps
mask = torch.ones_like(out_count)
mask[target == undesired_count] = 0
mask[delta < 0] = 0
delta[mask == 1] = 0
mask = torch.ones_like(out_count)
mask[target == desired_count] = 0
mask[delta > 0] = 0
delta[mask == 1] = 0
delta = delta.unsqueeze_(-1).repeat(1, 1, 1, 1, n_steps)
return delta
@staticmethod
def backward(ctx, grad):
return grad, None, None, None
class loss_kernel(torch.autograd.Function): # a and u is the incremnet of each time steps
@staticmethod
def forward(ctx, outputs, target, n_steps,tau_s):
# out_psp = psp(outputs, network_config)
target_psp = psp(target, n_steps,tau_s)
delta = outputs - target_psp
return delta
@staticmethod
def backward(ctx, grad):
return grad, None, None
================================================
FILE: examples/Structure_Evolution/MSE-NAS/micro_encoding.py
================================================
# NASNet Search Space https://arxiv.org/pdf/1707.07012.pdf
# code modified from DARTS https://github.com/quark0/darts
import numpy as np
from collections import namedtuple
import torch
# from models.micro_models import NetworkCIFAR as Network
import motifs
# Genotype = namedtuple('Genotype', 'normal normal_concat reduce reduce_concat')
# Genotype_norm = namedtuple('Genotype', 'normal normal_concat')
# Genotype_redu = namedtuple('Genotype', 'reduce reduce_concat')
Genotype = namedtuple('Genotype', 'normal normal_concat')
# what you want to search should be defined here and in micro_operations
PRIMITIVES = [
'max_pool_3x3',
'avg_pool_3x3',
'skip_connect',
'sep_conv_3x3',
'sep_conv_5x5',
'dil_conv_3x3',
'dil_conv_5x5',
'sep_conv_7x7',
'conv_7x1_1x7',
]
OPERATIONS_back = [
# 'max_pool_3x3_p_back',
# 'avg_pool_3x3_p_back',
'conv_3x3_p_back',
'conv_5x5_p_back',
# 'avg_pool_3x3_n_back',
'conv_3x3_n_back',
'conv_5x5_n_back',
# 'sep_conv_3x3_p_back',
# 'sep_conv_5x5_p_back',
# 'dil_conv_3x3_p_back',
# 'dil_conv_5x5_p_back',
# 'def_conv_3x3_p_back',
# 'def_conv_5x5_p_back',
]
OPERATIONS_p = [
# 'max_pool_3x3_p',
# 'avg_pool_3x3_p',
'conv_3x3_p',
'conv_5x5_p',
# 'sep_conv_3x3_p',
# 'sep_conv_5x5_p',
# 'dil_conv_3x3_p',
# 'dil_conv_5x5_p',
# 'def_conv_3x3_p',
# 'def_conv_5x5_p',
]
ops=len(OPERATIONS_p)
OPERATIONS_n = [
# 'max_pool_3x3_n',
# 'avg_pool_3x3_n',
'conv_3x3_n',
'conv_5x5_n',
# 'sep_conv_3x3_n',
# 'sep_conv_5x5_n',
# 'dil_conv_3x3_n',
# 'dil_conv_5x5_n',
# 'def_conv_3x3_n',
# 'def_conv_5x5_n',
# 'transformer',
]
def convert_cell(cell_bit_string):
# convert cell bit-string to genome
tmp = [cell_bit_string[i:i + 2] for i in range(0, len(cell_bit_string), 2)]
return [tmp[i:i + 2] for i in range(0, len(tmp), 2)]
def convert(bit_string):
# convert network bit-string (norm_cell + redu_cell) to genome
norm_gene = convert_cell(bit_string[:len(bit_string)//2])
redu_gene = convert_cell(bit_string[len(bit_string)//2:])
return [norm_gene, redu_gene]
# def decode_cell(genome, norm=True):
# cell, cell_concat = [], list(range(2, len(genome)+2))
# for block in genome:
# for unit in block:
# cell.append((PRIMITIVES[unit[0]], unit[1]))
# if unit[1] in cell_concat:
# cell_concat.remove(unit[1])
# if norm:
# return Genotype_norm(normal=cell, normal_concat=cell_concat)
# else:
# return Genotype_redu(reduce=cell, reduce_concat=cell_concat)
def decode(genome):
# decodes genome to architecture
normal_cell = genome[0]
reduce_cell = genome[1]
normal, normal_concat = [], list(range(2, len(normal_cell)+2))
reduce, reduce_concat = [], list(range(2, len(reduce_cell)+2))
for block in normal_cell:
for unit in block:
normal.append((PRIMITIVES[unit[0]], unit[1]))
if unit[1] in normal_concat:
normal_concat.remove(unit[1])
for block in reduce_cell:
for unit in block:
reduce.append((PRIMITIVES[unit[0]], unit[1]))
if unit[1] in reduce_concat:
reduce_concat.remove(unit[1])
return Genotype(
normal=normal, normal_concat=normal_concat,
reduce=reduce, reduce_concat=reduce_concat
)
def decode_motif(layers,bits,genome):
# decodes genome to architecture
motif_list=[]
motif_ids=[]
for b in range(0,layers*bits,bits):
if genome[-1]==2:
motif_id='mm'+str(genome[b])
elif genome[-1]==3:
motif_id='m'+str(genome[b])
else:
motif_id='t'+str(genome[b])
motif_ids.append(genome[b])
normalcell=eval('motifs.%s' % motif_id)
newnormal=[]
for i in range(0,len(normalcell.normal)):
op=normalcell.normal[i]
if 'skip' in op[0]:
newnormal.append(op)
continue
elif 'back' in op[0]:
newnormal.append((OPERATIONS_back[genome[b+1+len(normalcell.normal)-1]],op[1]))
continue
elif '_n' in op[0]:
newnormal.append((OPERATIONS_n[genome[b+1+i]],op[1]))
continue
elif '_p' in op[0]:
newnormal.append((OPERATIONS_p[genome[b+1+i]],op[1]))
continue
m=Genotype(normal=newnormal, normal_concat=normalcell.normal_concat,)
motif_list.append(m)
return motif_list,motif_ids
def compare_cell(cell_string1, cell_string2):
cell_genome1 = convert_cell(cell_string1)
cell_genome2 = convert_cell(cell_string2)
cell1, cell2 = cell_genome1[:], cell_genome2[:]
for block1 in cell1:
for block2 in cell2:
if block1 == block2 or block1 == block2[::-1]:
cell2.remove(block2)
break
if len(cell2) > 0:
return False
else:
return True
def compare(string1, string2):
if compare_cell(string1[:len(string1)//2],
string2[:len(string2)//2]):
if compare_cell(string1[len(string1)//2:],
string2[len(string2)//2:]):
return True
return False
# def debug():
# # design to debug the encoding scheme
# seed = 0
# np.random.seed(seed)
# budget = 2000
# B, n_ops, n_cell = 5, 7, 2
# networks = []
# design_id = 1
# while len(networks) < budget:
# bit_string = []
# for c in range(n_cell):
# for b in range(B):
# bit_string += [np.random.randint(n_ops),
# np.random.randint(b + 2),
# np.random.randint(n_ops),
# np.random.randint(b + 2)
# ]
# genome = convert(bit_string)
# # check against evaluated networks in case of duplicates
# doTrain = True
# for network in networks:
# if compare(genome, network):
# doTrain = False
# break
# if doTrain:
# genotype = decode(genome)
# model = Network(16, 10, 8, False, genotype)
# model.drop_path_prob = 0.0
# data = torch.randn(1, 3, 32, 32)
# output, output_aux = model(torch.autograd.Variable(data))
# networks.append(genome)
# design_id += 1
# print(design_id)
if __name__ == "__main__":
# debug()
# genome1 = [[[[3, 0], [3, 1]], [[3, 0], [3, 1]],
# [[3, 1], [2, 0]], [[2, 0], [5, 2]]],
# [[[0, 0], [0, 1]], [[2, 2], [0, 1]],
# [[0, 0], [2, 2]], [[2, 2], [0, 1]]]]
# genome2 = [[[[3, 1], [3, 0]], [[3, 1], [3, 0]],
# [[3, 1], [2, 0]], [[2, 0], [5, 2]]],
# [[[0, 1], [0, 0]], [[2, 2], [0, 1]],
# [[0, 0], [2, 2]], [[2, 2], [0, 0]]]]
#
# print(compare(genome1, genome2))
# print(genome1)
# print(genome2)
# bit_string1 = [3,1,3,0,3,1,3,0,3,1,2,0,2,0,5,2,0,0,0,1,2,2,0,1,0,0,2,2,2,2,0,1]
# bit_string2 = [3, 0, 3, 1, 3, 0, 3, 1, 3, 1, 2, 0, 2, 0, 5, 2,
# 0, 0, 0, 1, 2, 2, 0, 1, 0, 0, 2, 2, 2, 2, 0, 1]
# # print(convert(bit_string1))
# print(compare(bit_string1, bit_string2))
# print(decode(convert(bit_string)))
cell_bit_string = [3, 0, 3, 1, 3, 0, 3, 1, 3, 1, 2, 0, 2, 0, 5, 2]
# print(decode_cell(convert_cell(cell_bit_string), norm=False))
================================================
FILE: examples/Structure_Evolution/MSE-NAS/motifs.py
================================================
from collections import namedtuple
import torch
Genotype = namedtuple('Genotype', 'normal normal_concat')
m0=Genotype(
normal=[
('skip', 0), ('skip', 1),('skip', 2),
],
normal_concat=range(3, 4)
)
mm0=Genotype(
normal=[
('skip', 0), ('skip', 1),('skip', 2),
],
normal_concat=range(2, 3)
)
mm1=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),
('skip_connect', 0), ('conv_5x5_p', 2),
],
normal_concat=range(2, 4)
)
mm2=Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),
('skip_connect', 0), ('conv_5x5_n', 2),
('conv_5x5_p', 2), ('conv_3x3_n', 3),
],
normal_concat=range(2, 5)
)
mm4=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),#2
('conv_3x3_p', 0), ('conv_3x3_p', 1),#3
('conv_5x5_p', 2), ('conv_5x5_p', 3),#4
('skip_connect', 0), ('conv_3x3_p', 4),#5
('skip_connect', 0), ('conv_3x3_p', 4),#6
],
normal_concat=range(2, 7)
)
mm3=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),#2
('skip_connect', 0), ('conv_5x5_n', 2),#3
('skip_connect', 0), ('conv_5x5_p', 3),#4
('skip_connect_back', 2),#3
('conv_3x3_p_back', 3),#4
],
normal_concat=range(2, 5)
)
mm5=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),#2
('skip_connect', 0), ('conv_5x5_p', 2),#3
('skip_connect_back', 2),#3
],
normal_concat=range(2, 4)
)
m1=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2), #B3
('skip', 0), ('conv_5x5_p', 3), ('skip', 1), #C4
],
normal_concat=range(3, 5)
)
m2=Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), #B3
('skip', 0), ('conv_5x5_n', 3), ('skip', 1),#C4
('conv_5x5_p', 3), ('conv_3x3_n', 4), ('skip', 1), #D5
],
normal_concat=range(3, 6)
)
m4=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), #3
('conv_3x3_p', 0), ('conv_3x3_p', 1),('conv_5x5_p', 2), #4
('skip', 0), ('conv_5x5_p', 3), ('conv_5x5_p', 4), #5
('skip', 0), ('conv_3x3_p', 3),('conv_3x3_n', 5),#6
('skip', 0), ('conv_3x3_p', 4),('conv_3x3_n', 5),#7
],
normal_concat=range(3, 8)
)
m3=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_3x3_p', 2), #3
('skip', 0), ('conv_5x5_p', 3),('skip', 1), #4
('skip', 0), ('conv_5x5_p', 3), ('skip', 1), #5
('conv_3x3_n_back', 3),#4
('skip_back', 2),#5
],
normal_concat=range(3, 6)
)
m5=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2),#3
('skip', 0),('skip', 1), ('conv_5x5_n', 3), #4
('skip_connect_back', 3),#4
],
normal_concat=range(3, 5)
)
t1=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2), ('conv_5x5_p', 3), #4
('skip', 0), ('conv_5x5_p', 4), ('skip', 1), ('skip', 2), #5
('skip', 0), ('conv_5x5_p', 5), ('skip', 1), ('skip', 2), #6
('skip', 0), ('conv_5x5_p', 5), ('skip', 1), ('skip', 2), #7
],
normal_concat=range(4, 8)
)
t2=Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), ('conv_5x5_p', 3), #4
('skip', 0), ('conv_5x5_n', 4), ('skip', 1),('skip', 2),#5
('conv_5x5_p', 4), ('conv_3x3_n', 5), ('skip', 1),('skip', 2), #6
],
normal_concat=range(4, 7)
)
t4=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), ('conv_5x5_p', 3), #4
('conv_5x5_p', 0), ('skip', 1),('conv_5x5_n', 4), ('skip', 3), #5
('skip', 0), ('conv_5x5_p', 3), ('conv_5x5_n', 4), ('skip', 2),#6
],
normal_concat=range(4, 7)
)
t3=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_3x3_p', 2), ('conv_3x3_p', 3),#4
('skip', 0), ('skip', 2),('skip', 1), ('skip', 3),('conv_3x3_p', 4),#5
('skip', 0), ('conv_5x5_p', 4), ('skip', 1),('skip', 2), #6
('conv_3x3_n_back', 4),#5
('skip_back', 4),#6
],
normal_concat=range(4, 7)
)
t5=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2),('conv_5x5_p', 3),#4
('skip', 0),('skip', 1), ('skip', 2), ('conv_5x5_n', 4), #5
('skip', 0),('skip', 1), ('conv_5x5_n', 4),('conv_5x5_n', 5), #6
('skip', 0),('skip', 1), ('conv_5x5_n', 4),('conv_5x5_n', 5), #7
('conv_3x3_n_back', 4),#5
('skip_back', 4),#6
('skip_back', 5),#7
],
normal_concat=range(4, 8)
)
================================================
FILE: examples/Structure_Evolution/MSE-NAS/nsganet.py
================================================
import numpy as np
from pymoo.algorithms.genetic_algorithm import GeneticAlgorithm
from pymoo.docs import parse_doc_string
from pymoo.model.individual import Individual
from pymoo.model.survival import Survival
from pymoo.operators.crossover.point_crossover import PointCrossover
from pymoo.operators.mutation.polynomial_mutation import PolynomialMutation
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.selection.tournament_selection import compare, TournamentSelection
from pymoo.util.display import disp_multi_objective
from pymoo.util.dominator import Dominator
from pymoo.util.non_dominated_sorting import NonDominatedSorting
from pymoo.util.randomized_argsort import randomized_argsort
# =========================================================================================================
# Implementation
# based on nsga2 from https://github.com/msu-coinlab/pymoo
# =========================================================================================================
class NSGANet(GeneticAlgorithm):
def __init__(self, **kwargs):
kwargs['individual'] = Individual(rank=np.inf, crowding=-1)
super().__init__(**kwargs)
self.tournament_type = 'comp_by_dom_and_crowding'
self.func_display_attrs = disp_multi_objective
# ---------------------------------------------------------------------------------------------------------
# Binary Tournament Selection Function
# ---------------------------------------------------------------------------------------------------------
def binary_tournament(pop, P, algorithm, **kwargs):
if P.shape[1] != 2:
raise ValueError("Only implemented for binary tournament!")
tournament_type = algorithm.tournament_type
S = np.full(P.shape[0], np.nan)
for i in range(P.shape[0]):
a, b = P[i, 0], P[i, 1]
# if at least one solution is infeasible
if pop[a].CV > 0.0 or pop[b].CV > 0.0:
S[i] = compare(a, pop[a].CV, b, pop[b].CV, method='smaller_is_better', return_random_if_equal=True)
# both solutions are feasible
else:
if tournament_type == 'comp_by_dom_and_crowding':
rel = Dominator.get_relation(pop[a].F, pop[b].F)
if rel == 1:
S[i] = a
elif rel == -1:
S[i] = b
elif tournament_type == 'comp_by_rank_and_crowding':
S[i] = compare(a, pop[a].rank, b, pop[b].rank,
method='smaller_is_better')
else:
raise Exception("Unknown tournament type.")
# if rank or domination relation didn't make a decision compare by crowding
if np.isnan(S[i]):
S[i] = compare(a, pop[a].get("crowding"), b, pop[b].get("crowding"),
method='larger_is_better', return_random_if_equal=True)
return S[:, None].astype(np.int)
# ---------------------------------------------------------------------------------------------------------
# Survival Selection
# ---------------------------------------------------------------------------------------------------------
class RankAndCrowdingSurvival(Survival):
def __init__(self) -> None:
super().__init__(True)
def _do(self, pop, n_survive, D=None, **kwargs):
# get the objective space values and objects
F = pop.get("F")
# the final indices of surviving individuals
survivors = []
# do the non-dominated sorting until splitting front
fronts = NonDominatedSorting().do(F, n_stop_if_ranked=n_survive)
for k, front in enumerate(fronts):
# calculate the crowding distance of the front
crowding_of_front = calc_crowding_distance(F[front, :])
# save rank and crowding in the individual class
for j, i in enumerate(front):
pop[i].set("rank", k)
pop[i].set("crowding", crowding_of_front[j])
# current front sorted by crowding distance if splitting
if len(survivors) + len(front) > n_survive:
I = randomized_argsort(crowding_of_front, order='descending', method='numpy')
I = I[:(n_survive - len(survivors))]
# otherwise take the whole front unsorted
else:
I = np.arange(len(front))
# extend the survivors by all or selected individuals
survivors.extend(front[I])
return pop[survivors]
def calc_crowding_distance(F):
infinity = 1e+14
n_points = F.shape[0]
n_obj = F.shape[1]
if n_points <= 2:
return np.full(n_points, infinity)
else:
# sort each column and get index
I = np.argsort(F, axis=0, kind='mergesort')
# now really sort the whole array
F = F[I, np.arange(n_obj)]
# get the distance to the last element in sorted list and replace zeros with actual values
dist = np.concatenate([F, np.full((1, n_obj), np.inf)]) \
- np.concatenate([np.full((1, n_obj), -np.inf), F])
index_dist_is_zero = np.where(dist == 0)
dist_to_last = np.copy(dist)
for i, j in zip(*index_dist_is_zero):
dist_to_last[i, j] = dist_to_last[i - 1, j]
dist_to_next = np.copy(dist)
for i, j in reversed(list(zip(*index_dist_is_zero))):
dist_to_next[i, j] = dist_to_next[i + 1, j]
# normalize all the distances
norm = np.max(F, axis=0) - np.min(F, axis=0)
norm[norm == 0] = np.nan
dist_to_last, dist_to_next = dist_to_last[:-1] / norm, dist_to_next[1:] / norm
# if we divided by zero because all values in one columns are equal replace by none
dist_to_last[np.isnan(dist_to_last)] = 0.0
dist_to_next[np.isnan(dist_to_next)] = 0.0
# sum up the distance to next and last and norm by objectives - also reorder from sorted list
J = np.argsort(I, axis=0)
crowding = np.sum(dist_to_last[J, np.arange(n_obj)] + dist_to_next[J, np.arange(n_obj)], axis=1) / n_obj
# replace infinity with a large number
crowding[np.isinf(crowding)] = infinity
return crowding
# =========================================================================================================
# Interface
# =========================================================================================================
def nsganet(
pop_size=100,
sampling=RandomSampling(var_type=np.int),
selection=TournamentSelection(func_comp=binary_tournament),
crossover=PointCrossover(n_points=2),
mutation=PolynomialMutation(eta=3, var_type=np.int),
eliminate_duplicates=True,
n_offsprings=None,
**kwargs):
"""
Parameters
----------
pop_size : {pop_size}
sampling : {sampling}
selection : {selection}
crossover : {crossover}
mutation : {mutation}
eliminate_duplicates : {eliminate_duplicates}
n_offsprings : {n_offsprings}
Returns
-------
nsganet : :class:`~pymoo.model.algorithm.Algorithm`
Returns an NSGANet algorithm object.
"""
return NSGANet(pop_size=pop_size,
sampling=sampling,
selection=selection,
crossover=crossover,
mutation=mutation,
survival=RankAndCrowdingSurvival(),
eliminate_duplicates=eliminate_duplicates,
n_offsprings=n_offsprings,
**kwargs)
parse_doc_string(nsganet)
================================================
FILE: examples/Structure_Evolution/MSE-NAS/obj.py
================================================
import sys
import os
import numpy as np
import torch
import logging
import argparse
import torch.nn as nn
import torch.utils
# import torchvision.datasets as dset
import torch.backends.cudnn as cudnn
import torchvision.transforms as transforms
from timm.models import create_model
from cell123model import NetworkCIFAR
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.reactnet import *
from braincog.model_zoo.convxnet import *
from scipy.stats import kendalltau
from misc import utils
import micro_encoding
from misc.flops_counter import add_flops_counting_methods
from utils import data_transforms
from datetime import datetime
bits=20
def logdet(K):
s, ld = torch.linalg.slogdet(K)
return ld
def LSP(args,genome,train_data):
with torch.no_grad():
test_motifs,ids = micro_encoding.decode_motif(layers=args.layers,bits=bits,genome=genome)
pmodel = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
C=args.init_channels,
layers=args.layers,
auxiliary=args.auxiliary,
motif=test_motifs,
parse_method=args.parse_method,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
cell_type=genome[-1]
)
pmodel.to(args.device)
pmodel.K = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.J = torch.zeros(args.batch_size, args.batch_size,device=args.device)
# pmodel.Cou = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.Ccosine = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.Cm = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.Cpe = torch.zeros(args.batch_size, args.batch_size,device=args.device)
# pmodel.Cou = torch.zeros(args.batch_size,device=args.device)
# pmodel.Ccosine = torch.zeros(args.batch_size, device=args.device)
# pmodel.Cm = torch.zeros(args.batch_size,device=args.device)
pmodel.num_actfun_C = 0
pmodel.num_actfun_K = 0
def computing_LSP(module, inp, out):
if isinstance(out, tuple):
out = out[0]
#
out = out.view(out.size(0), -1)
batch_num , neuron_num = out.size()
x = (out > 0).float()
full_matrix = torch.ones((args.batch_size, args.batch_size)).cuda() * neuron_num
sparsity = (x.sum(1)/neuron_num).unsqueeze(1)
norm_K = ((sparsity @ (1-sparsity.t())) + ((1-sparsity) @ sparsity.t())) * neuron_num
rescale_factor = torch.div(0.5* torch.ones((args.batch_size, args.batch_size)).cuda(), norm_K+1e-3)
K1_0 = (x @ (1 - x.t()))
K0_1 = ((1-x) @ x.t())
K0_0 = (1-x) @ (1-x).t()
K1_1 = (1-x) @ (1-x).t()
K_total = (full_matrix - rescale_factor * (K0_1 + K1_0))
J_total = (K1_1+K0_0)/(K0_1+K1_0+K1_1)
pmodel.K = pmodel.K + K_total
pmodel.J = pmodel.J + J_total
pmodel.num_actfun_K += 1
# x = x / torch.norm(x, dim=-1, keepdim=True)
# similarity = torch.mm(x, x.T)
# dis_ou=torch.zeros_like(pmodel.Cou)
dis_man=torch.zeros_like(pmodel.Cm)
dis_cosine=torch.zeros_like(pmodel.Ccosine)
ou_dist = nn.PairwiseDistance(p=2)
m_dist = nn.PairwiseDistance(p=1)
cos = nn.CosineSimilarity(dim=1, eps=1e-6)
# cos = nn.CosineSimilarity(dim=0, eps=1e-6)
# for i in range(args.batch_size):
# for j in range(i,args.batch_size):
# input1 = x[i]
# input2 = x[j]
# dis_ou[i][j] = ou_dist(input1,input2)
# dis_man[i][j] = m_dist(input1,input2)
# dis_cosine[i][j] = cos(input1,input2)
# pmodel.Cou = pmodel.Cou + dis_ou
for i in range(args.batch_size):
temp = x[i].repeat(args.batch_size,1)
dis_cosine[i] = cos(x,temp)
dis_man[i] = m_dist(x,temp)
# pmodel.Cou = pmodel.Cou + ou_dist(x,x.flip(dims=[0]))
# pmodel.Cm = pmodel.Cou + m_dist(x,x.flip(dims=[0]))
pmodel.Ccosine = pmodel.Ccosine + dis_cosine
pmodel.Cm = pmodel.Cm + dis_man
pmodel.Cpe = pmodel.Cpe + torch.corrcoef(x / torch.norm(x, dim=-1, keepdim=True))
pmodel.num_actfun_C += 1
pmodel.num_actfun_K += 1
s_ou = []
s_m = []
s_pe = []
s_cos = []
s_k = []
s_jac=[]
s_sum_j=[]
repeat=2
for name,module in pmodel.named_modules():
if args.node_type in str(type(module)):
handle = module.register_forward_hook(computing_LSP)
for j in range(repeat):
pmodel.K = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.J = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.Ccosine = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.Cm = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.Cpe = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.num_actfun_C = 0
pmodel.num_actfun_K = 0
data_iterator = iter(train_data)
inputs, targets = next(data_iterator)
inputs, targets = inputs.cuda(), targets.cuda()
outputs = pmodel(inputs)
tc=pmodel.Ccosine/pmodel.num_actfun_C
tp=pmodel.Cpe/pmodel.num_actfun_C
tm=pmodel.Cm/pmodel.num_actfun_C
tj=pmodel.J/ (pmodel.num_actfun_K)
Ccos = torch.where(torch.isnan(tc), torch.full_like(tc, 0), tc)
Cpe = torch.where(torch.isnan(tp), torch.full_like(tp, 0), tp)
Cm = torch.where(torch.isnan(tm), torch.full_like(tm, 0), tm)
s_k.append(float(logdet(pmodel.K/ (pmodel.num_actfun_K))))
s_jac.append(float(logdet(tj)))
s_sum_j.append(float(tj.sum()))
s_m.append(float(Cm.sum()))
s_cos.append(float(Ccos.sum()))
s_pe.append(float(Cpe.sum()))
return np.mean(np.array(s_sum_j)),np.mean(np.array(s_jac)), np.mean(np.array(s_m)),np.mean(np.array(s_cos)),np.mean(np.array(s_pe)),np.mean(np.array(s_k))
================================================
FILE: examples/Structure_Evolution/MSE-NAS/operations.py
================================================
import numpy as np
import torch
import torch.nn as nn
from torch.nn import *
import torch.nn.functional as F
from torch import einsum
from einops import rearrange
# from braincog.model_zoo.base_module import DeformConvPack
from braincog.model_zoo.base_module import BaseLinearModule
# from mmcv.ops import ModulatedDeformConv2dPack
def si_relu(x, positive):
if positive == 1:
return torch.where(x > 0., x, torch.zeros_like(x))
elif positive == 0:
return x
elif positive == -1:
return torch.where(x < 0., x, torch.zeros_like(x))
else:
raise ValueError
class SiReLU(nn.Module):
def __init__(self, positive=0):
super().__init__()
self.positive = positive
def forward(self, x):
return si_relu(x, self.positive)
def weight_init(m):
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal(m.weight.data, gain=0.1)
torch.nn.init.constant(m.bias.data, 0.)
OPS_Mlp = {
'mlp': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=0),
'mlp_p': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=1),
'mlp_n': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=-1),
'skip_connect': lambda C, act_fun:
Identity(positive=0),
'skip_connect_p': lambda C, act_fun:
Identity(positive=1),
'skip_connect_n': lambda C, act_fun:
Identity(positive=-1),
}
OPS = {
'avg_pool_3x3': lambda C, stride, affine, act_fun: nn.AvgPool2d(3, stride=stride, padding=1,
count_include_pad=False),
'conv_3x3': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=0),
'conv_5x5': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=0),
'max_pool_3x3': lambda C, stride, affine, act_fun: nn.MaxPool2d(3, stride=stride, padding=1),
'skip_connect': lambda C, stride, affine, act_fun:
Identity(positive=0) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun),
'sep_conv_3x3': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=0),
'sep_conv_5x5': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=0),
'sep_conv_7x7': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=0),
'dil_conv_3x3': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=0),
'dil_conv_5x5': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=0),
'def_conv_3x3': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=0),
'def_conv_5x5': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=0),
'avg_pool_3x3_p': lambda C, stride, affine, act_fun: nn.Sequential(
nn.AvgPool2d(3, stride=stride, padding=1, count_include_pad=False),
SiReLU(positive=1)
),
'max_pool_3x3_p': lambda C, stride, affine, act_fun: nn.Sequential(
nn.MaxPool2d(3, stride=stride, padding=1),
SiReLU(positive=1)
),
'conv_3x3_p': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=1),
'conv_5x5_p': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=1),
'skip_connect_p': lambda C, stride, affine, act_fun:
Identity(positive=1) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_3x3_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_5x5_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_7x7_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=1),
'dil_conv_3x3_p': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=1),
'dil_conv_5x5_p': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=1),
'def_conv_3x3_p': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=1),
'def_conv_5x5_p': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=1),
'avg_pool_3x3_n': lambda C, stride, affine, act_fun: nn.Sequential(
nn.AvgPool2d(3, stride=stride, padding=1, count_include_pad=False),
SiReLU(positive=-1)
),
'max_pool_3x3_n': lambda C, stride, affine, act_fun: nn.Sequential(
nn.MaxPool2d(3, stride=stride, padding=1),
SiReLU(positive=-1)
),
'conv_3x3_n': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=-1),
'conv_5x5_n': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=-1),
'skip_connect_n': lambda C, stride, affine, act_fun:
Identity(positive=-1) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_3x3_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_5x5_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_7x7_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=-1),
'dil_conv_3x3_n': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=-1),
'dil_conv_5x5_n': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=-1),
'def_conv_3x3_n': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=-1),
'def_conv_5x5_n': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=-1),
'conv_7x1_1x7': lambda C, stride, affine, act_fun: nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C, C, (1, 7), stride=(1, stride),
padding=(0, 3), bias=False),
nn.Conv2d(C, C, (7, 1), stride=(stride, 1),
padding=(3, 0), bias=False),
nn.BatchNorm2d(C, affine=affine)
),
'skip': lambda C, stride, affine, act_fun:
Zero(stride) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=1),
'transformer': lambda C, stride, affine, act_fun:
FactorizedReduce(
C, C, affine=affine, act_fun=act_fun) if stride != 1 else TransformerEncoderLayer(C),
}
class SiMLP(nn.Module):
def __init__(self, c_in, c_out, act_fun=nn.ReLU, positive=0, *args, **kwargs):
super(SiMLP, self).__init__()
self.op = nn.Sequential(
nn.Linear(c_in, c_out, bias=True),
act_fun()
)
self.positive = positive
def forward(self, x):
out = self.op(si_relu(x, self.positive))
return out
class DilConv(nn.Module):
"""
Dilation Convolution : ReLU -> DilConv -> Conv2d -> BatchNorm2d
"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, dilation, affine=True, act_fun=nn.ReLU, positive=0):
super(DilConv, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation,
groups=C_in, bias=False),
nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=affine),
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class SepConv(nn.Module):
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
super(SepConv, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size,
stride=stride, padding=padding, groups=C_in, bias=False),
nn.Conv2d(C_in, C_in, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_in, affine=affine),
nn.ReLU(inplace=False),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size,
stride=1, padding=padding, groups=C_in, bias=False),
nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=affine),
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class Identity(nn.Module):
def __init__(self, positive=0):
super(Identity, self).__init__()
self.positive = positive
def forward(self, x):
return si_relu(x, self.positive)
class Zero(nn.Module):
def __init__(self, stride):
super(Zero, self).__init__()
self.stride = stride
def forward(self, x):
if self.stride == 1:
return x.mul(0.)
return x[:, :, ::self.stride, ::self.stride].mul(0.) # N * C * W * H
class FactorizedReduce(nn.Module):
def __init__(self, C_in, C_out, affine=True, act_fun=nn.ReLU, positive=0):
super(FactorizedReduce, self).__init__()
assert C_out % 2 == 0
# self.relu = nn.ReLU(inplace=False)
self.activation = act_fun()
self.conv_1 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.conv_2 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.bn = nn.BatchNorm2d(C_out, affine=affine)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
# x = self.relu(x)
x = self.activation(x)
out = torch.cat([self.conv_1(x), self.conv_2(x[:, :, 1:, 1:])], dim=1)
out = self.bn(out)
out = si_relu(out, self.positive)
return out
class F0(nn.Module):
def __init__(self, C_in, C_out, affine=True, act_fun=nn.ReLU, positive=0):
super(F0, self).__init__()
assert C_out % 2 == 0
# self.relu = nn.ReLU(inplace=False)
self.activation = act_fun()
self.op=nn.Conv2d(C_out, C_out, 3, stride=2, padding=1, bias=False)
self.conv_1 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.conv_2 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.bn = nn.BatchNorm2d(C_out, affine=affine)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
# x = self.relu(x)
x = self.activation(x)
out = torch.cat([self.conv_1(x), self.conv_2(x[:, :, 1:, 1:])], dim=1)
out = self.bn(out)
out = si_relu(out, self.positive)
out=self.op(out)
return out
class ReLUConvBN(nn.Module):
"""
ReLu -> Conv2d -> BatchNorm2d
"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
super(ReLUConvBN, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_out, kernel_size, stride=stride,
padding=padding, bias=False),
nn.BatchNorm2d(C_out, affine=affine)
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
# class DeformConv(nn.Module):
# def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
# super(DeformConv, self).__init__()
# self.op = nn.Sequential(
# # nn.ReLU(inplace=False),
# act_fun(),
# DeformConvPack(C_in, C_out, kernel_size=kernel_size,
# stride=stride, padding=padding, bias=True),
# nn.BatchNorm2d(C_out, affine=affine)
# )
# self.positive = positive
# # if positive == -1:
# # weight_init(self.op)
# def forward(self, x):
# out = self.op(x)
# return si_relu(out, self.positive)
class Attention(Module):
"""
Obtained from: github.com:rwightman/pytorch-image-models
"""
def __init__(self, dim, num_heads=4, attention_dropout=0.1, projection_dropout=0.1):
super().__init__()
self.num_heads = num_heads
head_dim = dim // self.num_heads
self.scale = head_dim ** -0.5
self.qkv = Linear(dim, dim * 3, bias=False)
self.attn_drop = Dropout(attention_dropout)
self.proj = Linear(dim, dim)
self.proj_drop = Dropout(projection_dropout)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C //
self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class TransformerEncoderLayer(Module):
"""
Inspired by torch.nn.TransformerEncoderLayer and
rwightman's timm package.
"""
def __init__(self, d_model, nhead=4, dim_feedforward=256, dropout=0.1,
attention_dropout=0.1, drop_path_rate=0.1):
super(TransformerEncoderLayer, self).__init__()
self.pre_norm = LayerNorm(d_model)
self.self_attn = Attention(dim=d_model, num_heads=nhead,
attention_dropout=attention_dropout, projection_dropout=dropout)
dim_feedforward = d_model
self.linear1 = Linear(d_model, dim_feedforward)
self.dropout1 = Dropout(dropout)
self.norm1 = LayerNorm(d_model)
self.linear2 = Linear(dim_feedforward, d_model)
self.dropout2 = Dropout(dropout)
self.drop_path = DropPath(
drop_path_rate) if drop_path_rate > 0 else Identity()
self.activation = F.gelu
def forward(self, src: torch.Tensor, *args, **kwargs) -> torch.Tensor:
# print(src.shape)
c = src.shape[-1]
src = rearrange(src, 'b d r c -> b (r c) d')
# print(src.shape)
src = src + self.drop_path(self.self_attn(self.pre_norm(src)))
src = self.norm1(src)
src2 = self.linear2(self.dropout1(self.activation(self.linear1(src))))
src = src + self.drop_path(self.dropout2(src2))
src = rearrange(src, 'b (r c) d -> b d r c', c=c)
return src
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""
Obtained from: github.com:rwightman/pytorch-image-models
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
# work with diff dim tensors, not just 2D ConvNets
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + \
torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(Module):
"""
Obtained from: github.com:rwightman/pytorch-image-models
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
================================================
FILE: examples/Structure_Evolution/MSE-NAS/readme.md
================================================
# Brain-Inspired Multi-scale Evolutionary Architectures for Spiking Neural Networks —— Based on BrainCog #
## Requirments ##
* numpy
* pytorch >= 1.12.0
* pymoo = 0.4.0
* BrainCog
## Run ##
```python evolution.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{pan2024brain,
title={Brain-Inspired Multi-Scale Evolutionary Neural Architecture Search for Deep Spiking Neural Networks},
author={Pan, Wenxuan and Zhao, Feifei and Shen, Guobin and Han, Bing and Zeng, Yi},
journal={IEEE Transactions on Evolutionary Computation},
year={2024},
publisher={IEEE}
}
@article{zeng2023braincog,
title={BrainCog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired AI and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier}
}
```
================================================
FILE: examples/Structure_Evolution/MSE-NAS/tm.py
================================================
import sys
sys.path.insert(0, '/home/panwenxuan/back')
import numpy as np
import argparse
import time
import obj
import timm.models
import yaml
import os
import logging
from random import choice
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from micro_encoding import ops
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import micro_encoding
from pymop.problem import Problem
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from pymoo.optimize import minimize
from utils import data_transforms
from timm.data import create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
# from tn import TinyImageNet
import copy
from sklearn.metrics import confusion_matrix,roc_auc_score
from sklearn.preprocessing import label_binarize
def train_motifs(args,gen,arch_dir,genome,_logger,args_text,devices,bits):
if args.bns:
from cellmodel import NetworkCIFAR
else:
from cell123model import NetworkCIFAR
test_motifs,ids = micro_encoding.decode_motif(args.layers,bits,genome)
if gen==-1:
args.epochs=args.trainning_epochs
else:
args.epochs=args.eval_epochs
all_best=[]
try:
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
C=args.init_channels,
layers=args.layers,
auxiliary=args.auxiliary,
motif=test_motifs,
parse_method=args.parse_method,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
cell_type=genome[-1],
)
if 'dvs' in args.dataset:
args.channels = 2
# elif 'mnist' in args.dataset:
# args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
# _logger.info(model)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
sumpram=sum([m.numel() for m in model.parameters()])
_logger.info('Model %s created, param count: %d' %
(args.model, sumpram))
# return
# if sumpram > 15000000:
# return 0,0
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
optimizer = create_optimizer(args, model)
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
checkpoint = torch.load(args.resume, map_location='cpu')
model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
# print(model.get_attr('mu'))
# print(model.get_attr('sigma'))
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=devices).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
if args.critical_loss or args.spike_rate:
if args.num_gpu>1:
model.module.set_requires_fp(True)
else:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model, device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
temporal_flatten=args.temporal_flatten,
portion=args.train_portion,
_logger=_logger,
)
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
if args.distributed:
state_dict = torch.load(args.eval_checkpoint)['state_dict_ema']
new_state_dict = OrderedDict()
# add module prefix for DDP
for k, v in state_dict.items():
k = 'module.' + k
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
# else:
# load_checkpoint(model, args.eval_checkpoint, args.model_ema)
for i in range(1):
val_metrics = validate(start_epoch, model, loader_eval, validate_loss_fn, args,_logger,arch_dir,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
print(f"Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
# return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=arch_dir, recovery_dir=arch_dir, decreasing=decreasing)
with open(os.path.join(arch_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
# if epoch == 3 and best_metric<5:
# return 0,0
if args.distributed:
loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,_logger=_logger,
lr_scheduler=lr_scheduler, saver=saver, output_dir=arch_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler, model_ema=model_ema, mixup_fn=mixup_fn)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics = validate(epoch, model, loader_eval, validate_loss_fn, args,_logger, arch_dir,amp_autocast=amp_autocast,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics = validate(
epoch, model_ema.ema, loader_eval, validate_loss_fn, args, _logger,arch_dir,amp_autocast=amp_autocast, log_suffix=' (EMA)',
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(arch_dir, 'summary.csv'),
write_header=best_metric is None)
best_metric, best_epoch = eval_metrics[eval_metric],epoch
_logger.info('Test: {0} '.format(best_metric))
all_best.append(best_metric)
f=open(os.path.join(arch_dir, 'direct.txt'), 'a')
f.write(str(best_metric))
f.write('\n')
f.close()
f=open(os.path.join(arch_dir, 'direct_genome.txt'), 'a')
f.write(",".join(str(k) for k in genome))
f.write('\n')
f.close()
except KeyboardInterrupt:
pass
except MemoryError:
return -10000, all_best
except RuntimeError:
return -10000, all_best
return best_metric,all_best
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,_logger,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and loader.mixup_enabled:
loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
model.drop_path_prob = args.drop_path_prob * epoch / args.epochs
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
if not args.prefetcher or args.dataset != 'imnet':
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
if mixup_fn is not None:
inputs, target = mixup_fn(inputs, target)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
with amp_autocast():
output = model(inputs)
loss = loss_fn(output, target)
if not (args.cut_mix | args.mix_up | args.event_mix) and args.dataset != 'imnet':
# print(output.shape, target.shape)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
closs = torch.tensor([0.], device=loss.device)
if args.critical_loss:
closs = calc_critical_loss(model)
loss = loss + .1 * closs
spike_rate_avg_layer_str = ''
threshold_str = ''
if not args.distributed:
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
top5_m.update(acc5.item(), inputs.size(0))
closses_m.update(closs.item(), inputs.size(0))
if args.num_gpu>1:
spike_rate_avg_layer = model.module.get_fire_rate().tolist()
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
threshold = model.module.get_threshold()
else:
spike_rate_avg_layer = model.get_fire_rate().tolist()
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
if args.opt == 'lamb':
optimizer.step(epoch=epoch)
else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
losses_m.update(reduced_loss.item(), inputs.size(0))
closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
if args.distributed:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
else:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})\n'
# 'Fire_rate: {spike_rate}\n'
# 'Thres: {threshold}\n'
# 'Mu: {mu_str}\n'
# 'Sigma: {sigma_str}\n'
.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m,
# spike_rate=spike_rate_avg_layer_str,
# threshold=threshold_str,
# mu_str=mu_str,
# sigma_str=sigma_str
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args,_logger, arch_dir,amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
end = time.time()
last_idx = len(loader) - 1
all_probs = np.array([]).reshape(0, args.num_classes)
all_targets = np.array([])
attack=False
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if attack:
data2 = copy.deepcopy(inputs)
inputs = pgd_attack(model, data2, target, target.device, nn.CrossEntropyLoss())
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat) and not args.critical_loss:
if args.num_gpu>1:
model.module.set_requires_fp(True)
else:
model.set_requires_fp(True)
# if not args.critical_loss:
# model.set_requires_fp(False)
with amp_autocast():
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
if not args.distributed:
if visualize:
x = model.get_fp()
feature_path = os.path.join(arch_dir, 'feature_map')
if os.path.exists(feature_path) is False:
os.mkdir(feature_path)
save_feature_map(x, feature_path)
# if not args.critical_loss:
# model_config.set_requires_fp(False)
if tsne:
x = model.get_fp(temporal_info=False)[-1]
x = torch.nn.AdaptiveAvgPool2d((1, 1))(x)
x = x.reshape(x.shape[0], -1)
feature_vec.append(x)
feature_cls.append(target)
if conf_mat:
logits_vec.append(output)
labels_vec.append(target)
if spike_rate:
if args.num_gpu>1:
avg, var, spike, avg_per_step = model.module.get_spike_info()
else:
avg, var, spike, avg_per_step = model.get_spike_info()
save_spike_info(
os.path.join(arch_dir, 'spike_info.csv'),
epoch, batch_idx,
args.step, avg, var,
spike, avg_per_step)
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
loss = loss_fn(output, target)
probs = output.softmax(dim=1) #
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
all_probs = np.vstack([all_probs, probs.detach().cpu().numpy()])
all_targets = np.concatenate([all_targets, target.detach().cpu().numpy()])
closs = torch.tensor([0.], device=loss.device)
if not args.distributed:
if args.num_gpu>1:
spike_rate_avg_layer = model.module.get_fire_rate().tolist()
threshold = model.module.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
tot_spike = model.module.get_tot_spike()
else:
spike_rate_avg_layer = model.get_fire_rate().tolist()
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
tot_spike = model.get_tot_spike()
if args.critical_loss:
closs = calc_critical_loss(model)
loss = loss + .1 * closs
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
closses_m.update(closs.item(), inputs.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
))
else:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})\n'
'Fire_rate: {spike_rate}\n'
'Tot_spike: {tot_spike}\n'
'Thres: {threshold}\n'
'Mu: {mu_str}\n'
'Sigma: {sigma_str}\n'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
spike_rate=spike_rate_avg_layer_str,
tot_spike=tot_spike,
threshold=threshold_str,
mu_str=mu_str,
sigma_str=sigma_str
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
if not args.distributed:
if tsne:
feature_vec = torch.cat(feature_vec)
feature_cls = torch.cat(feature_cls)
plot_tsne(feature_vec, feature_cls, os.path.join(arch_dir, 't-sne-2d.eps'))
plot_tsne_3d(feature_vec, feature_cls, os.path.join(arch_dir, 't-sne-3d.eps'))
if conf_mat:
logits_vec = torch.cat(logits_vec)
labels_vec = torch.cat(labels_vec)
plot_confusion_matrix(logits_vec, labels_vec, os.path.join(arch_dir, 'confusion_matrix.eps'))
# 将真实标签二值化,为每个类别创建一个二进制标签
all_targets_binarized = label_binarize(all_targets, classes=range(args.num_classes))
# 使用roc_auc_score的multi_class和average参数来计算平均AUC
auc = roc_auc_score(all_targets_binarized, all_probs, multi_class='ovr', average='macro')
# print("Mean AUC: {:.2f}".format(auc))
return OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('auc', auc)])
================================================
FILE: examples/Structure_Evolution/MSE-NAS/utils.py
================================================
import json
import matplotlib.pyplot as plt
import os
import numpy as np
import torch
import shutil
import torchvision.transforms as transforms
from torch.autograd import Variable
from auto_augment import CIFAR10Policy
from braincog.model_zoo.darts.genotypes import PRIMITIVES
forward_edge_num = sum(1 for i in range(3) for n in range(2 + i))
backward_edge_num = sum(1 for i in range(3) for n in range(i))
num_ops = len(PRIMITIVES)
type_num = len(PRIMITIVES) // 2
# edge_num = [2, 3, 4]
edge_num = [2, 3, 4, 1, 2]
def drop_path(x, drop_prob):
if drop_prob > 0.:
keep_prob = 1. - drop_prob
mask = Variable(torch.cuda.FloatTensor(
x.size(0), 1, 1, 1).bernoulli_(keep_prob))
x.div_(keep_prob)
x.mul_(mask)
return x
class AvgrageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.avg = 0
self.sum = 0
self.cnt = 0
def update(self, val, n=1):
self.sum += val * n
self.cnt += n
self.avg = self.sum / self.cnt
def accuracy(output, target, topk=(1,)):
"""Compute the top1 and top5 accuracy
"""
maxk = max(topk)
batch_size = target.size(0)
# Return the k largest elements of the given input tensor
# along a given dimension -> N * k
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0)
res.append(correct_k.mul_(100.0 / batch_size))
return res
class Cutout(object):
def __init__(self, length):
self.length = length
def __call__(self, img):
h, w = img.size(1), img.size(2)
mask = np.ones((h, w), np.float32)
y = np.random.randint(h)
x = np.random.randint(w)
y1 = np.clip(y - self.length // 2, 0, h)
y2 = np.clip(y + self.length // 2, 0, h)
x1 = np.clip(x - self.length // 2, 0, w)
x2 = np.clip(x + self.length // 2, 0, w)
mask[y1: y2, x1: x2] = 0.
mask = torch.from_numpy(mask)
mask = mask.expand_as(img)
img *= mask
return img
def _data_transforms_cifar(args):
CIFAR_MEAN = [0.49139968, 0.48215827, 0.44653124] if args.dataset == 'cifar10' else [0.50707519, 0.48654887,
0.44091785]
CIFAR_STD = [0.24703233, 0.24348505, 0.26158768] if args.dataset == 'cifar10' else [0.26733428, 0.25643846,
0.27615049]
normalize_transform = [
transforms.ToTensor(),
transforms.Normalize(CIFAR_MEAN, CIFAR_STD)]
random_transform = [
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip()]
if args.auto_aug:
random_transform += [CIFAR10Policy()]
if args.cutout:
cutout_transform = [Cutout(args.cutout_length)]
else:
cutout_transform = []
train_transform = transforms.Compose(
random_transform + normalize_transform + cutout_transform
)
valid_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(CIFAR_MEAN, CIFAR_STD),
])
return train_transform, valid_transform
def count_parameters_in_MB(model):
return np.sum(np.prod(v.size()) for v in model.parameters()) / 1e6
def save_checkpoint(state, is_best, save):
filename = os.path.join(save, 'checkpoint.pth.tar')
torch.save(state, filename)
if is_best:
best_filename = os.path.join(save, 'model_best.pth.tar')
shutil.copyfile(filename, best_filename)
def save(model, model_path):
torch.save(model.state_dict(), model_path)
def load(model, model_path):
model.load_state_dict(torch.load(model_path))
def drop_path(x, drop_prob):
if drop_prob > 0.:
keep_prob = 1. - drop_prob
mask = Variable(torch.cuda.FloatTensor(
x.size(0), 1, 1, 1).bernoulli_(keep_prob))
x.div_(keep_prob)
x.mul_(mask)
return x
def create_exp_dir(path, scripts_to_save=None):
if not os.path.exists(path):
os.makedirs(path)
print('Experiment dir : {}'.format(path))
if scripts_to_save is not None:
os.makedirs(os.path.join(path, 'scripts'))
for script in scripts_to_save:
dst_file = os.path.join(path, 'scripts', os.path.basename(script))
shutil.copyfile(script, dst_file)
def calc_time(seconds):
m, s = divmod(seconds, 60)
h, m = divmod(m, 60)
t, h = divmod(h, 24)
return {'day': t, 'hour': h, 'minute': m, 'second': int(s)}
def save_file(recoder, path='./', back_connection=False):
size = (forward_edge_num +
backward_edge_num if back_connection else forward_edge_num, num_ops)
fig, axs = plt.subplots(*size, figsize=(36, 98))
row = 0
col = 0
for (k, v) in recoder.items():
axs[row, col].set_title(k)
axs[row, col].plot(v, 'r+')
if col == num_ops - 1:
col = 0
row += 1
else:
col += 1
if not os.path.exists(path):
os.makedirs(path)
fig.savefig(os.path.join(path, 'output.png'), bbox_inches='tight')
plt.tight_layout()
print('save history weight in {}'.format(os.path.join(path, 'output.png')))
with open(os.path.join(path, 'history_weight.json'), 'w') as outf:
json.dump(recoder, outf)
print('save history weight in {}'.format(
os.path.join(path, 'history_weight.json')))
def data_transforms(args):
if args.dataset == 'cifar10':
MEAN = [0.4913, 0.4821, 0.4465]
STD = [0.2470, 0.2434, 0.2615]
elif args.dataset == 'cifar100':
MEAN = [0.5071, 0.4867, 0.4408]
STD = [0.2673, 0.2564, 0.2762]
elif args.dataset == 'tinyimagenet':
MEAN = [0.485, 0.456, 0.406]
STD = [0.229, 0.224, 0.225]
if (args.dataset== 'tinyimagenet'):
train_transform = transforms.Compose([
transforms.RandomCrop(64, padding=8),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(MEAN, STD)
])
valid_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(MEAN, STD)
])
else: # cifar10 or cifar100
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(MEAN, STD)
])
valid_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(MEAN, STD)
])
return train_transform, valid_transform
================================================
FILE: examples/TIM/README.md
================================================
# TIM: An Efficient Temporal Interaction Module for Spiking Transformer, [IJCAI2024](https://arxiv.org/abs/2401.11687)

## Reference
```
@misc{shen2024tim,
title={TIM: An Efficient Temporal Interaction Module for Spiking Transformer},
author={Sicheng Shen and Dongcheng Zhao and Guobin Shen and Yi Zeng},
year={2024},
eprint={2401.11687},
archivePrefix={arXiv},
primaryClass={cs.NE}
}
```
Here is the official implemented code of TIM. The code is based on Pytorch and [Braincog](https://github.com/BrainCog-X/Brain-Cog)
## Requirements
### Create Braincog Virtual Environment
```
conda create -n braincog python=3.8
conda activate braincog
pip install braincog
```
### Dataset Preparation
**Datasets Needed**: CIFAR10-DVS, N-CALTECH101, UCF101DVS, NCARS, HMDB51DVS, SHD
Please unzip data to ```/data/datasets``` so that dataset.py may directly load corresponding dataset for training
## Model Training
For most DVS data, we prefer using the event-frame size of 64 but not 128 here.
Please adjust your hyper parameters here. 10 is set as the default value of time step numbers.
```
@register_model
def spikformer_dvs(pretrained=False, **kwargs):
model = Spikformer(TIM_alpha=0.5,step=10,if_UCF=False,num_classes=10,
# img_size_h=64, img_size_w=64,
# patch_size=16, embed_dims=256, num_heads=16, mlp_ratios=4,
# in_channels=2, qkv_bias=False,
# depths=2, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
```
### Training on CIFAR10-DVS
```
python main.py --model spikformer_dvs --dataset dvsc10 --epoch 500 --batch-size 16 --event-size 64
```
### Training on N-CALTECH101
```num_classes``` should be set to 101
```
python main.py --model spikformer_dvs --dataset NCALTECH101 --epoch 500 --batch-size 16 --event-size 64 --num_classes 101
```
### Training on NCARS
```num_classes``` should be set to 2
```
python main.py --model spikformer_dvs --dataset NCARS --epoch 500 --batch-size 16 --event-size 64 --num_classes 2
```
### Training on UCF101DVS
```num_classes``` should be set to 101,```if_UCF``` should be set to ```True```
```
python main.py --model spikformer_dvs --dataset UCF101DVS --epoch 500 --batch-size 16 --event-size 64 --num_classes 101
```
### Training on HMDB51DVS
```
python main.py --model spikformer_dvs --dataset HMDBDVS --epoch 500 --batch-size 16 --event-size 64 --num_classes 51
```
### Training on SHD
```num_classes``` should be set to 20
```
python main.py --model spikformer_shd --dataset SHD --epoch 500 --batch-size 16 --num_classes 20
```
================================================
FILE: examples/TIM/main.py
================================================
import argparse
import time
import timm.models
import yaml
import os
import random as buildin_random
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
# from braincog.datasets.datasets import *
from utils.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.vgg_snn import VGG_SNN, SNN5
from braincog.model_zoo.resnet19_snn import resnet19
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix, plot_mem_distribution
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model, register_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from torch.utils.tensorboard import SummaryWriter
from models.spikformer_braincog_DVS import spikformer_dvs
from models.spikformer_braincog_DVS import spikformer_shd
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--dataset', default='dvsc10', type=str)
parser.add_argument('--model', default='spikformer', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=1e-4,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=400, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochss to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=0.,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=0.,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--output', default='/home/shensicheng/code/TIM/logs', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--tensorboard-dir', default='./runs', type=str)
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=0)
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
parser.add_argument('--conv-type', type=str, default='normal')
parser.add_argument('--sew-cnf', type=str, default='ADD')
parser.add_argument('--rand-step', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='QGateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
parser.add_argument('--n-encode-type', type=str, default='linear')
parser.add_argument('--n-preact', action='store_true')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--tet-loss', action='store_true')
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=2.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--gaussian-n', type=int, default=3)
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
parser.add_argument('--mem-dist', action='store_true')
parser.add_argument('--adaptation-info', action='store_true')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def main():
args, args_text = _parse_args()
# args.no_spike_output = args.no_spike_output | args.cut_mix
args.no_spike_output = True
output_dir = ''
if args.local_rank == 0:
output_base = args.output if args.output else './output'
exp_name = '-'.join([
args.model,
args.dataset,
args.node_type,
str(args.step),
args.suffix,
datetime.now().strftime("%Y%m%d-%H%M%S"),
# str(args.img_size)
])
output_dir = get_outdir(output_base, 'train', exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
summary_writer = SummaryWriter(log_dir=os.path.join(args.tensorboard_dir, exp_name))
args.tensorboard_prefix = os.path.join(args.dataset, args.model)
else:
summary_writer = None
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
model = create_model(
args.model,
# pretrained=args.pretrained,
# num_classes=args.num_classes,
# dataset=args.dataset,
# step=args.step,
# encode_type=args.encode,
# node_type=eval(args.node_type),
# threshold=args.threshold,
# tau=args.tau,
# sigmoid_thres=args.sigmoid_thres,
# requires_thres_grad=args.requires_thres_grad,
# spike_output=not args.no_spike_output,
# act_fun=args.act_fun,
# temporal_flatten=args.temporal_flatten,
# layer_by_layer=args.layer_by_layer,
# n_groups=args.n_groups,
# n_encode_type=args.n_encode_type,
# n_preact=args.n_preact,
# tet_loss=args.tet_loss,
# sew_cnf=args.sew_cnf,
# conv_type=args.conv_type,
)
_logger.info('[MODEL ARCH]\n{}'.format(model))
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=list(range(args.num_gpu))).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
_logger.info('[OPTIMIZER]\n{}'.format(optimizer))
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
# print(model.get_attr('mu'))
# print(model.get_attr('sigma'))
if hasattr(model, 'set_threshold'):
model.set_threshold(args.threshold)
if args.critical_loss or args.spike_rate:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model.cuda(), device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
)
# _logger.info('train_loader:\n{}\nval_loader:\n{}'.format(loader_train, loader_eval))
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
elif args.loss_fn == 'onehot-mse':
train_loss_fn = OnehotMse(args.num_classes)
validate_loss_fn = OnehotMse(args.num_classes)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
if args.tet_loss:
train_loss_fn = TetLoss(train_loss_fn)
validate_loss_fn = TetLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
# if args.distributed:
# raise NotImplementedError('eval not has not been verified for distributed')
# else:
# load_checkpoint(model, args.eval_checkpoint, args.model_ema)
model.eval()
for t in range(1, args.step * 3):
# for t in range(args.step, args.step + 1):
model.set_attr('step', t)
val_metrics = validate(start_epoch, model, loader_eval, validate_loss_fn, args,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer)
print(f"[STEP:{t}], Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=output_dir, recovery_dir=output_dir, decreasing=decreasing, max_history=3)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
if args.distributed:
loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler,
model_ema=model_ema, mixup_fn=mixup_fn, summary_writer=summary_writer
)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics = validate(epoch, model, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer)
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics = validate(
epoch, model_ema.ema, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast, log_suffix=' (EMA)',
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer
)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(output_dir, 'summary.csv'),
write_header=best_metric is None)
# if saver is not None and epoch >= args.n_warm_up:
if saver is not None:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
except KeyboardInterrupt:
pass
if best_metric is not None:
_logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None, summary_writer=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and loader.mixup_enabled:
loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
# closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
# t, k = adjust_surrogate_coeff(100, args.epochs)
# model.set_attr('t', t)
# model.set_attr('k', k)
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
iters_per_epoch = len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
if args.rand_step:
step = buildin_random.randint(1, args.step + 2)
model.set_attr('step', step)
data_time_m.update(time.time() - end)
if not args.prefetcher or args.dataset != 'imnet':
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
if mixup_fn is not None:
inputs, target = mixup_fn(inputs, target)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
with amp_autocast():
output = model(inputs)
loss = loss_fn(output, target)
if args.tet_loss:
output = output.mean(0)
if not (args.cut_mix | args.mix_up | args.event_mix | (args.cutmix != 0.) | (args.mixup != 0.)):
# print(output.shape, target.shape)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
# if args.opt == 'lamb':
# optimizer.step(epoch=epoch)
# else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/top1'), acc1.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/top5'), acc5.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/loss'), loss.item(), epoch * iters_per_epoch + batch_idx)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
if args.distributed:
loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
# closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
# if args.distributed:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/top1'), top1_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/top5'), top5_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/loss'), losses_m.avg, epoch)
if args.rand_step:
model.set_attr('step', args.step)
return OrderedDict([('loss', losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args, amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False, summary_writer=None):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
# closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
spike_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
mem_vec = []
end = time.time()
last_idx = len(loader) - 1
iters_per_epoch = len(loader)
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat or args.mem_dist) and not args.critical_loss:
model.set_requires_fp(True)
with amp_autocast():
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
# print(args.rank, output.shape, target.shape, max(target))
loss = loss_fn(output, target)
if args.tet_loss:
output = output.mean(0)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
# closses_m.update(closs, inputs.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/top1'), acc1.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/top5'), acc5.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/loss'), loss.item(), epoch * iters_per_epoch + batch_idx)
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
if not args.distributed and spike_rate:
spike_m.update(model.get_tot_spike() / output.size(0), output.size(0))
if not args.distributed and spike_rate:
_logger.info(
'[Spike Info]: {spike.val} ({spike.avg})'.format(
spike=spike_m
)
)
if last_batch or batch_idx % args.log_interval == 0:
_logger.info(
'Eval : {} '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
epoch,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
top1=top1_m,
top5=top5_m,
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg)])
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/top1'), top1_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/top5'), top5_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/loss'), losses_m.avg, epoch)
return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/TIM/models/TIM.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from utils.MyNode import *
class TIM(BaseModule):
def __init__(self,dim=256,encode_type='direct',in_channels=16,TIM_alpha=0.5):
super().__init__(step=1,encode_type=encode_type)
# channels may depends on the shape of input
self.interactor = nn.Conv1d(in_channels=in_channels,out_channels=in_channels,kernel_size=5, stride=1, padding=2, bias=True)
self.in_lif = MyNode(tau=2.0,v_threshold=0.3,layer_by_layer=False,step=1) #spike-driven
self.out_lif = MyNode(tau=2.0,v_threshold=0.5,layer_by_layer=False,step=1) #spike-driven
self.tim_alpha = TIM_alpha
# input [T, B, H, N, C/H]
def forward(self, x):
self.reset()
T, B, H, N, CoH = x.shape
output = []
x_tim = torch.empty_like(x[0])
#temporal interaction
for i in range(T):
#1st step
if i == 0 :
x_tim = x[i]
output.append(x_tim)
#other steps
else:
x_tim = self.interactor(x_tim.flatten(0,1)).reshape(B,H,N,CoH).contiguous()
x_tim = self.in_lif(x_tim) * self.tim_alpha + x[i] * (1-self.tim_alpha)
x_tim = self.out_lif(x_tim)
output.append(x_tim)
output = torch.stack(output) # T B H, N, C/H
return output # T B H, N, C/H
================================================
FILE: examples/TIM/models/spikformer_braincog_DVS.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from functools import partial
from torchvision import transforms
from utils.MyNode import *
from models.TIM import *
__all__ = ['spikformer']
class MLP(BaseModule):
def __init__(self,in_features,step=10,encode_type='direct',hidden_features=None, out_features=None, drop=0.):
super().__init__(step=10,encode_type='direct')
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_conv = nn.Conv1d(in_features, hidden_features, kernel_size=1, stride=1)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step,tau=2.0)
self.fc2_conv = nn.Conv1d(hidden_features, out_features, kernel_size=1, stride=1)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step,tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T,B,C,N = x.shape
x = self.fc1_conv(x.flatten(0,1))
x = self.fc1_bn(x).reshape(T, B, self.c_hidden, N ).contiguous() # T B C N
x = self.fc1_lif(x.flatten(0,1)).reshape(T, B, self.c_hidden, N).contiguous()
x = self.fc2_conv(x.flatten(0,1))
x = self.fc2_bn(x).reshape(T, B, C, N).contiguous()
x = self.fc2_lif(x.flatten(0,1)).reshape(T, B, C, N ).contiguous()
return x
class SSA(BaseModule):
def __init__(self,dim,step=10,encode_type='direct',num_heads=16,TIM_alpha=0.5,qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__(step=10,encode_type='direct')
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
self.in_channels = dim // num_heads
self.scale = 0.25
self.q_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.q_bn = nn.BatchNorm1d(dim)
self.q_lif = MyNode(step=step,tau=2.0)
self.k_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.k_bn = nn.BatchNorm1d(dim)
self.k_lif = MyNode(step=step,tau=2.0)
self.v_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.v_bn = nn.BatchNorm1d(dim)
self.v_lif = MyNode(step=step,tau=2.0)
self.attn_drop = nn.Dropout(0.2)
self.res_lif = MyNode(step=step, tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5,)
self.proj_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.proj_bn = nn.BatchNorm1d(dim)
self.proj_lif = MyNode(step=step, tau=2.0,)
self.TIM = TIM(TIM_alpha=TIM_alpha,in_channels=self.in_channels)
def forward(self, x):
self.reset()
T,B,C,N = x.shape
x_for_qkv = x.flatten(0, 1)
q_conv_out = self.q_conv(x_for_qkv)
q_conv_out = self.q_bn(q_conv_out).reshape(T, B, C, N).contiguous()
q_conv_out = self.q_lif(q_conv_out.flatten(0,1)).reshape(T, B, C ,N).transpose(-2,-1)
q = q_conv_out.reshape(T, B, N, self.num_heads, C//self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_conv_out = self.k_conv(x_for_qkv)
k_conv_out = self.k_bn(k_conv_out).reshape(T, B, C, N).contiguous()
k_conv_out= self.k_lif(k_conv_out.flatten(0,1)).reshape(T, B, C ,N).transpose(-2,-1)
k = k_conv_out.reshape(T, B, N, self.num_heads, C//self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_conv_out = self.v_conv(x_for_qkv)
v_conv_out = self.v_bn(v_conv_out).reshape(T, B, C, N).contiguous()
v_conv_out = self.v_lif(v_conv_out.flatten(0,1)).reshape(T, B, C ,N).transpose(-2,-1)
v = v_conv_out.reshape(T, B, N, self.num_heads, C//self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
#TIM on Q
q = self.TIM(q)
#SSA
attn = (q @ k.transpose(-2, -1))
x = (attn @ v) * self.scale
x = x.transpose(3,4).reshape(T, B, C, N).contiguous()
x = self.attn_lif(x.flatten(0,1))
x = self.proj_lif(self.proj_bn(self.proj_conv(x))).reshape(T, B, C, N)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, step=10,TIM_alpha=0.5, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = SSA(dim, step=step,TIM_alpha=TIM_alpha,num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(in_features=dim,step=step, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
x = x + self.attn(x)
x = x + self.mlp(x)
return x
class SPS(BaseModule):
def __init__(self, step=10, encode_type='direct', img_size_h=64, img_size_w=64, patch_size=4, in_channels=2,
embed_dims=256,if_UCF=False):
super().__init__(step=10, encode_type='direct')
self.image_size = [img_size_h, img_size_w]
patch_size = to_2tuple(patch_size)
self.patch_size = patch_size
self.C = in_channels
self.H, self.W = self.image_size[0] // patch_size[0], self.image_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.if_UCF = if_UCF
self.proj_conv = nn.Conv2d(in_channels, embed_dims // 8, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn = nn.BatchNorm2d(embed_dims // 8)
self.proj_lif = MyNode(step=step, tau=2.0)
self.maxpool = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv1 = nn.Conv2d(embed_dims // 8, embed_dims // 4, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn1 = nn.BatchNorm2d(embed_dims // 4)
self.proj_lif1 = MyNode(step=step, tau=2.0)
self.maxpool1 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv2 = nn.Conv2d(embed_dims // 4, embed_dims // 2, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn2 = nn.BatchNorm2d(embed_dims // 2)
self.proj_lif2 = MyNode(step=step, tau=2.0)
self.maxpool2 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv3 = nn.Conv2d(embed_dims // 2, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn3 = nn.BatchNorm2d(embed_dims)
self.proj_lif3 = MyNode(step=step, tau=2.0)
self.maxpool3 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.rpe_conv = nn.Conv2d(embed_dims, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.rpe_bn = nn.BatchNorm2d(embed_dims)
self.rpe_lif = MyNode(step=step, tau=2.0)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
# UCF101DVS
if self.if_UCF:
x = F.adaptive_avg_pool2d(x.flatten(0,1), output_size=(64, 64)).reshape(T, B, C,64,64)
T, B, C, H, W = x.shape
x = self.proj_conv(x.flatten(0, 1)) # have some fire value
x = self.proj_bn(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif(x.flatten(0, 1)).contiguous()
x = self.maxpool(x)
x = self.proj_conv1(x)
x = self.proj_bn1(x).reshape(T, B, -1, H // 2, W // 2).contiguous()
x = self.proj_lif1(x.flatten(0, 1)).contiguous()
x = self.maxpool1(x)
x = self.proj_conv2(x)
x = self.proj_bn2(x).reshape(T, B, -1, H // 4, W // 4).contiguous()
x = self.proj_lif2(x.flatten(0, 1)).contiguous()
x = self.maxpool2(x)
x = self.proj_conv3(x)
x = self.proj_bn3(x).reshape(T, B, -1, H // 8, W // 8).contiguous()
x = self.proj_lif3(x.flatten(0, 1)).contiguous()
x = self.maxpool3(x)
x_rpe = self.rpe_bn(self.rpe_conv(x)).reshape(T, B, -1 , H // 16,W // 16).contiguous()
x_rpe = self.rpe_lif(x_rpe.flatten(0,1)).contiguous()
x = x + x_rpe
x = x.reshape(T, B, -1, (H//16)*(W//16)).contiguous()
return x # T B C N
class Spikformer(nn.Module):
def __init__(self, step=10,TIM_alpha=0.5,if_UCF=False,
img_size_h=64, img_size_w=64, patch_size=16, in_channels=2, num_classes=10,
embed_dims=256, num_heads=16, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=2, sr_ratios=4,
):
super().__init__()
self.T = step # time step
self.num_classes = num_classes
self.depths = depths
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
patch_embed = SPS( step=step,
if_UCF=if_UCF,
img_size_h=img_size_h,
img_size_w=img_size_w,
patch_size=patch_size,
in_channels=in_channels,
embed_dims=embed_dims)
block = nn.ModuleList([Block(step=step, TIM_alpha=TIM_alpha,
dim=embed_dims, num_heads=num_heads, mlp_ratio=mlp_ratios, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[j],
norm_layer=norm_layer, sr_ratio=sr_ratios)
for j in range(depths)])
setattr(self, f"patch_embed", patch_embed)
setattr(self, f"block", block)
# classification head
self.head = nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
block = getattr(self, f"block")
patch_embed = getattr(self, f"patch_embed")
x = patch_embed(x)
for blk in block:
x = blk(x)
return x.mean(3)
def forward(self, x):
x = x.permute(1, 0, 2, 3, 4)
x = self.forward_features(x)
x = self.head(x.mean(0))
return x
# Hyperparams could be adjust here
@register_model
def spikformer_dvs(pretrained=False, **kwargs):
model = Spikformer(TIM_alpha=0.5,step=10,if_UCF=False,num_classes=10,
# img_size_h=64, img_size_w=64,
# patch_size=16, embed_dims=256, num_heads=16, mlp_ratios=4,
# in_channels=2, qkv_bias=False,
# depths=2, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/TIM/models/spikformer_braincog_SHD.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from functools import partial
from torchvision import transforms
from utils.MyNode import *
from models.TIM import *
__all__ = ['spikformer']
class MLP(BaseModule):
def __init__(self,in_features,step=10,encode_type='direct',hidden_features=None, out_features=None, drop=0.):
super().__init__(step=10,encode_type='direct')
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_conv = nn.Conv1d(in_features, hidden_features, kernel_size=1, stride=1)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step,tau=2.0)
self.fc2_conv = nn.Conv1d(hidden_features, out_features, kernel_size=1, stride=1)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step,tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T,B,C,N = x.shape
x = self.fc1_conv(x.flatten(0,1))
x = self.fc1_bn(x).reshape(T, B, self.c_hidden, N ).contiguous() # T B C N
x = self.fc1_lif(x.flatten(0,1)).reshape(T, B, self.c_hidden, N).contiguous()
x = self.fc2_conv(x.flatten(0,1))
x = self.fc2_bn(x).reshape(T, B, C, N).contiguous()
x = self.fc2_lif(x.flatten(0,1)).reshape(T, B, C, N ).contiguous()
return x
class SSA(BaseModule):
def __init__(self,dim,step=10,encode_type='direct',num_heads=16,TIM_alpha=0.5,qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__(step=10,encode_type='direct')
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
self.in_channels = dim // num_heads
self.scale = 0.25
self.q_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.q_bn = nn.BatchNorm1d(dim)
self.q_lif = MyNode(step=step,tau=2.0)
self.k_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.k_bn = nn.BatchNorm1d(dim)
self.k_lif = MyNode(step=step,tau=2.0)
self.v_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.v_bn = nn.BatchNorm1d(dim)
self.v_lif = MyNode(step=step,tau=2.0)
self.attn_drop = nn.Dropout(0.2)
self.res_lif = MyNode(step=step, tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5,)
self.proj_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.proj_bn = nn.BatchNorm1d(dim)
self.proj_lif = MyNode(step=step, tau=2.0,)
self.TIM = TIM(TIM_alpha=TIM_alpha,in_channels=self.in_channels)
def forward(self, x):
self.reset()
T,B,C,N = x.shape
x_for_qkv = x.flatten(0, 1)
q_conv_out = self.q_conv(x_for_qkv)
q_conv_out = self.q_bn(q_conv_out).reshape(T, B, C, N).contiguous()
q_conv_out = self.q_lif(q_conv_out.flatten(0,1)).reshape(T, B, C ,N).transpose(-2,-1)
q = q_conv_out.reshape(T, B, N, self.num_heads, C//self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_conv_out = self.k_conv(x_for_qkv)
k_conv_out = self.k_bn(k_conv_out).reshape(T, B, C, N).contiguous()
k_conv_out= self.k_lif(k_conv_out.flatten(0,1)).reshape(T, B, C ,N).transpose(-2,-1)
k = k_conv_out.reshape(T, B, N, self.num_heads, C//self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_conv_out = self.v_conv(x_for_qkv)
v_conv_out = self.v_bn(v_conv_out).reshape(T, B, C, N).contiguous()
v_conv_out = self.v_lif(v_conv_out.flatten(0,1)).reshape(T, B, C ,N).transpose(-2,-1)
v = v_conv_out.reshape(T, B, N, self.num_heads, C//self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
#TIM on Q
q = self.TIM(q)
#SSA
attn = (q @ k.transpose(-2, -1))
x = (attn @ v) * self.scale
x = x.transpose(3,4).reshape(T, B, C, N).contiguous()
x = self.attn_lif(x.flatten(0,1))
x = self.proj_lif(self.proj_bn(self.proj_conv(x))).reshape(T, B, C, N)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, step=10,TIM_alpha=0.5, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = SSA(dim, step=step,TIM_alpha=TIM_alpha,num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(in_features=dim,step=step, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
x = x + self.attn(x)
x = x + self.mlp(x)
return x
class SPS(BaseModule):
def __init__(self, step=10, encode_type='direct', img_size_h=64, img_size_w=64, patch_size=4, in_channels=2,
embed_dims=256,if_UCF=False):
super().__init__(step=10, encode_type='direct')
self.image_size = [img_size_h, img_size_w]
patch_size = to_2tuple(patch_size)
self.patch_size = patch_size
self.C = in_channels
self.H, self.W = self.image_size[0] // patch_size[0], self.image_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.if_UCF = if_UCF
self.proj_conv = nn.Conv2d(in_channels, embed_dims // 8, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn = nn.BatchNorm2d(embed_dims // 8)
self.proj_lif = MyNode(step=step, tau=2.0)
self.maxpool = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv1 = nn.Conv2d(embed_dims // 8, embed_dims // 4, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn1 = nn.BatchNorm2d(embed_dims // 4)
self.proj_lif1 = MyNode(step=step, tau=2.0)
self.maxpool1 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv2 = nn.Conv2d(embed_dims // 4, embed_dims // 2, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn2 = nn.BatchNorm2d(embed_dims // 2)
self.proj_lif2 = MyNode(step=step, tau=2.0)
self.maxpool2 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv3 = nn.Conv2d(embed_dims // 2, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn3 = nn.BatchNorm2d(embed_dims)
self.proj_lif3 = MyNode(step=step, tau=2.0)
self.maxpool3 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.rpe_conv = nn.Conv2d(embed_dims, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.rpe_bn = nn.BatchNorm2d(embed_dims)
self.rpe_lif = MyNode(step=step, tau=2.0)
def forward(self, x):
self.reset()
# SHD
T, B, _ = x.shape
x = x.reshape(T,B,2,-1) # T B 2 350
x = F.interpolate(x.flatten(0,1), size=256, mode='nearest').reshape(T,B,2,16,16)
T, B, C, H, W = x.shape
x = self.proj_conv(x.flatten(0, 1)) # have some fire value
x = self.proj_bn(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif(x.flatten(0, 1)).contiguous()
# x = self.maxpool(x)
x = self.proj_conv1(x)
x = self.proj_bn1(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif1(x.flatten(0, 1)).contiguous()
# x = self.maxpool1(x)
x = self.proj_conv2(x)
x = self.proj_bn2(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif2(x.flatten(0, 1)).contiguous()
x = self.maxpool2(x)
x = self.proj_conv3(x)
x = self.proj_bn3(x).reshape(T, B, -1, H // 2, W // 2).contiguous()
x = self.proj_lif3(x.flatten(0, 1)).contiguous()
x = self.maxpool3(x)
x_rpe = self.rpe_bn(self.rpe_conv(x)).reshape(T, B, -1 , H // 4,W // 4).contiguous()
x_rpe = self.rpe_lif(x_rpe.flatten(0,1)).contiguous()
x = x + x_rpe
x = x.reshape(T, B, -1, (H//4)*(W//4)).contiguous()
return x # T B C N
class Spikformer(nn.Module):
def __init__(self, step=10,TIM_alpha=0.5,if_UCF=False,
img_size_h=64, img_size_w=64, patch_size=16, in_channels=2, num_classes=10,
embed_dims=256, num_heads=16, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=2, sr_ratios=4,
):
super().__init__()
self.T = step # time step
self.num_classes = num_classes
self.depths = depths
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
patch_embed = SPS( step=step,
if_UCF=if_UCF,
img_size_h=img_size_h,
img_size_w=img_size_w,
patch_size=patch_size,
in_channels=in_channels,
embed_dims=embed_dims)
block = nn.ModuleList([Block(step=step, TIM_alpha=TIM_alpha,
dim=embed_dims, num_heads=num_heads, mlp_ratio=mlp_ratios, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[j],
norm_layer=norm_layer, sr_ratio=sr_ratios)
for j in range(depths)])
setattr(self, f"patch_embed", patch_embed)
setattr(self, f"block", block)
# classification head
self.head = nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
block = getattr(self, f"block")
patch_embed = getattr(self, f"patch_embed")
x = patch_embed(x)
for blk in block:
x = blk(x)
return x.mean(3)
def forward(self, x):
x = x.permute(1, 0, 2)
x = self.forward_features(x)
x = self.head(x.mean(0))
return x
# Hyperparams could be adjust here
@register_model
def spikformer_shd(pretrained=False, **kwargs):
model = Spikformer(TIM_alpha=0.5,step=10,if_UCF=False,num_classes=20,
# img_size_h=64, img_size_w=64,
# patch_size=16, embed_dims=256, num_heads=16, mlp_ratios=4,
# in_channels=2, qkv_bias=False,
# depths=2, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/TIM/utils/MyGrad.py
================================================
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
class MyGrad(SurrogateFunctionBase):
def __init__(self, alpha=4., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return sigmoid.apply(x, alpha)
================================================
FILE: examples/TIM/utils/MyNode.py
================================================
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from utils.MyGrad import MyGrad
class MyBaseNode(BaseNode):
def __init__(self,threshold=0.5,step=10,layer_by_layer=False,mem_detach=False):
super().__init__(threshold=threshold,step=step,layer_by_layer=layer_by_layer,mem_detach=mem_detach)
def rearrange2node(self, inputs):
if self.groups != 1:
if len(inputs.shape) == 4:
outputs = rearrange(inputs, 'b (c t) w h -> t b c w h', t=self.step)
elif len(inputs.shape) == 2:
outputs = rearrange(inputs, 'b (c t) -> t b c', t=self.step)
else:
raise NotImplementedError
elif self.layer_by_layer:
if len(inputs.shape) == 4:
outputs = rearrange(inputs, '(t b) c w h -> t b c w h', t=self.step)
#加入适配Transformer T B N C的rearange2node分支
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, '(t b) n c -> t b n c', t=self.step)
elif len(inputs.shape) == 2:
outputs = rearrange(inputs, '(t b) c -> t b c', t=self.step)
else:
raise NotImplementedError
else:
outputs = inputs
return outputs
def rearrange2op(self, inputs):
if self.groups != 1:
if len(inputs.shape) == 5:
outputs = rearrange(inputs, 't b c w h -> b (c t) w h')
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, ' t b c -> b (c t)')
else:
raise NotImplementedError
elif self.layer_by_layer:
if len(inputs.shape) == 5:
outputs = rearrange(inputs, 't b c w h -> (t b) c w h')
# 加入适配Transformer T B N C的rearange2op分支
elif len(inputs.shape) == 4:
outputs = rearrange(inputs, ' t b n c -> (t b) n c')
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, ' t b c -> (t b) c')
else:
raise NotImplementedError
else:
outputs = inputs
return outputs
class MyNode(MyBaseNode):
def __init__(self, threshold=1.,step=10,layer_by_layer=True,tau=2., act_fun=MyGrad, mem_detach=True,*args, **kwargs):
super().__init__(threshold=threshold,step=step, layer_by_layer=layer_by_layer,mem_detach=mem_detach)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=4., requires_grad=False)
def integral(self, inputs):
self.mem = self.mem + (inputs - self.mem) / self.tau
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
self.mem = self.mem * (1 - self.spike.detach())
================================================
FILE: examples/TIM/utils/datasets.py
================================================
import os
import warnings
import random
import torchvision.datasets
import braincog.datasets.ucf101_dvs
try:
import tonic
from tonic import DiskCachedDataset
except:
warnings.warn("tonic should be installed, 'pip install git+https://github.com/FloyedShen/tonic.git'")
import torch
import torch.nn.functional as F
import torch.utils
import torchvision.datasets as datasets
from timm.data import ImageDataset, create_loader, Mixup, FastCollateMixup, AugMixDataset
from timm.data import create_transform, distributed_sampler
from timm.data.loader import PrefetchLoader
from tonic import DiskCachedDataset
from torchvision import transforms
from typing import Any, Dict, Optional, Sequence, Tuple, Union
from braincog.datasets.NOmniglot.nomniglot_full import NOmniglotfull
from braincog.datasets.NOmniglot.nomniglot_nw_ks import NOmniglotNWayKShot
from braincog.datasets.NOmniglot.nomniglot_pair import NOmniglotTrainSet, NOmniglotTestSet
# from braincog.base.conversion.conversion import CIFAR10Policy, Cutout
# from .cut_mix import CutMix, EventMix, MixUp
# from .rand_aug import *
# from .event_drop import event_drop
# from .utils import dvs_channel_check_expend, rescale
DVSCIFAR10_MEAN_16 = [0.3290, 0.4507]
DVSCIFAR10_STD_16 = [1.8398, 1.6549]
DATA_DIR = '/data/datasets'
DEFAULT_CROP_PCT = 0.875
IMAGENET_DEFAULT_MEAN = (0.485, 0.456, 0.406)
IMAGENET_DEFAULT_STD = (0.229, 0.224, 0.225)
IMAGENET_INCEPTION_MEAN = (0.5, 0.5, 0.5)
IMAGENET_INCEPTION_STD = (0.5, 0.5, 0.5)
IMAGENET_DPN_MEAN = (124 / 255, 117 / 255, 104 / 255)
IMAGENET_DPN_STD = tuple([1 / (.0167 * 255)] * 3)
CIFAR10_DEFAULT_MEAN = (0.4914, 0.4822, 0.4465)
CIFAR10_DEFAULT_STD = (0.2023, 0.1994, 0.2010)
CIFAR100_DEFAULT_MEAN = (0.5071, 0.4867, 0.4408)
CIFAR100_DEFAULT_STD = (0.2675, 0.2565, 0.2761)
def unpack_mix_param(args):
mix_up = args['mix_up'] if 'mix_up' in args else False
cut_mix = args['cut_mix'] if 'cut_mix' in args else False
event_mix = args['event_mix'] if 'event_mix' in args else False
beta = args['beta'] if 'beta' in args else 1.
prob = args['prob'] if 'prob' in args else .5
num = args['num'] if 'num' in args else 1
num_classes = args['num_classes'] if 'num_classes' in args else 10
noise = args['noise'] if 'noise' in args else 0.
gaussian_n = args['gaussian_n'] if 'gaussian_n' in args else None
return mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n
def build_transform(is_train, img_size):
"""
构建数据增强, 适用于static data
:param is_train: 是否训练集
:param img_size: 输出的图像尺寸
:return: 数据增强策略
"""
resize_im = img_size > 32
if is_train:
# this should always dispatch to transforms_imagenet_train
transform = create_transform(
input_size=img_size,
is_training=True,
color_jitter=0.4,
# auto_augment='rand-m9-mstd0.5-inc1',
interpolation='bicubic',
# re_prob=0.25,
# re_mode='pixel',
# re_count=1,
)
if not resize_im:
# replace RandomResizedCropAndInterpolation with
# RandomCrop
transform.transforms[0] = transforms.RandomCrop(
img_size, padding=4)
return transform
t = []
if resize_im:
size = int((256 / 224) * img_size)
t.append(
# to maintain same ratio w.r.t. 224 images
transforms.Resize(size, interpolation=3),
)
t.append(transforms.CenterCrop(img_size))
t.append(transforms.ToTensor())
if img_size > 32:
t.append(transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD))
else:
t.append(transforms.Normalize(CIFAR10_DEFAULT_MEAN, CIFAR10_DEFAULT_STD))
return transforms.Compose(t)
def build_dataset(is_train, img_size, dataset, path, same_da=False):
"""
构建带有增强策略的数据集
:param is_train: 是否训练集
:param img_size: 输出图像尺寸
:param dataset: 数据集名称
:param path: 数据集路径
:param same_da: 为训练集使用测试集的增广方法
:return: 增强后的数据集
"""
transform = build_transform(False, img_size) if same_da else build_transform(is_train, img_size)
if dataset == 'CIFAR10':
dataset = datasets.CIFAR10(
path, train=is_train, transform=transform, download=True)
nb_classes = 10
elif dataset == 'CIFAR100':
dataset = datasets.CIFAR100(
path, train=is_train, transform=transform, download=True)
nb_classes = 100
else:
raise NotImplementedError
return dataset, nb_classes
class MNISTData(object):
"""
Load MNIST datesets.
"""
def __init__(self,
data_path: str,
batch_size: int,
train_trans: Sequence[torch.nn.Module] = None,
test_trans: Sequence[torch.nn.Module] = None,
pin_memory: bool = True,
drop_last: bool = True,
shuffle: bool = True,
) -> None:
self._data_path = data_path
self._batch_size = batch_size
self._pin_memory = pin_memory
self._drop_last = drop_last
self._shuffle = shuffle
self._train_transform = transforms.Compose(train_trans) if train_trans else None
self._test_transform = transforms.Compose(test_trans) if test_trans else None
def get_data_loaders(self):
print('Batch size: ', self._batch_size)
train_datasets = datasets.MNIST(root=self._data_path, train=True, transform=self._train_transform, download=True)
test_datasets = datasets.MNIST(root=self._data_path, train=False, transform=self._test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=self._drop_last, shuffle=self._shuffle
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=False
)
return train_loader, test_loader
def get_standard_data(self):
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
self._train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
self._test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
return self.get_data_loaders()
def get_mnist_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取MNIST数据
http://data.pymvpa.org/datasets/mnist/
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
if 'skip_norm' in kwargs and kwargs['skip_norm'] is True:
train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
else:
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
# transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
train_datasets = datasets.MNIST(
root=DATA_DIR, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.MNIST(
root=DATA_DIR, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_fashion_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取fashion MNIST数据
http://arxiv.org/abs/1708.07747
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor()])
test_transform = transforms.Compose([transforms.ToTensor()])
train_datasets = datasets.FashionMNIST(
root=DATA_DIR, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.FashionMNIST(
root=DATA_DIR, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_cifar10_data(batch_size, num_workers=8, same_da=False, **kwargs):
# """
# 获取CIFAR10数据
# https://www.cs.toronto.edu/~kriz/cifar.html
# :param batch_size: batch size
# :param kwargs:
# :return: (train loader, test loader, mixup_active, mixup_fn)
# """
# train_datasets, _ = build_dataset(True, 32, 'CIFAR10', DATA_DIR, same_da)
# test_datasets, _ = build_dataset(False, 32, 'CIFAR10', DATA_DIR, same_da)
#
# train_loader = torch.utils.data.DataLoader(
# train_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=True, shuffle=True,
# num_workers=num_workers
# )
#
# test_loader = torch.utils.data.DataLoader(
# test_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=False,
# num_workers=num_workers
# )
normalize = transforms.Normalize(CIFAR10_DEFAULT_MEAN, CIFAR10_DEFAULT_STD)
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(),
CIFAR10Policy(),
transforms.ToTensor(),
Cutout(n_holes=1, length=16),
normalize])
transform_test = transforms.Compose([transforms.ToTensor(), normalize])
train_dataset = datasets.CIFAR10(root=DATA_DIR, train=True, download=True, transform=transform_train)
test_dataset = datasets.CIFAR10(root=DATA_DIR, train=False, download=True, transform=transform_test)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
shuffle=True, num_workers=num_workers,
pin_memory=True
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
shuffle=False, num_workers=num_workers,
pin_memory=True
)
return train_loader, test_loader, None, None
def get_shd_data(batch_size, step, **kwargs):
"""
获取SHD数据
https://ieeexplore.ieee.org/abstract/document/9311226
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
:format: (b,t,c,len) 不同于vision, audio中c为1, 并且没有h,w; 只有len=700
"""
sensor_size = tonic.datasets.SHD.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
train_dataset = tonic.datasets.SHD(os.path.join(DATA_DIR, 'DVS/SHD'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.SHD(os.path.join(DATA_DIR, 'DVS/SHD'),
transform=test_transform, train=False)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, None, None
def get_cifar100_data(batch_size, num_workers=8, same_data=False, *args, **kwargs):
# """
# 获取CIFAR100数据
# https://www.cs.toronto.edu/~kriz/cifar.html
# :param batch_size: batch size
# :param kwargs:
# :return: (train loader, test loader, mixup_active, mixup_fn)
# """
# train_datasets, _ = build_dataset(True, 32, 'CIFAR100', DATA_DIR, same_data)
# test_datasets, _ = build_dataset(False, 32, 'CIFAR100', DATA_DIR, same_data)
#
# train_loader = torch.utils.data.DataLoader(
# train_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
# )
#
# test_loader = torch.utils.data.DataLoader(
# test_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=False, num_workers=num_workers
# )
# return train_loader, test_loader, False, None
normalize = transforms.Normalize(CIFAR100_DEFAULT_MEAN, CIFAR100_DEFAULT_STD)
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(),
CIFAR10Policy(),
transforms.ToTensor(),
Cutout(n_holes=1, length=16),
normalize])
transform_test = transforms.Compose([transforms.ToTensor(), normalize])
train_dataset = datasets.CIFAR100(root=DATA_DIR, train=True, download=True, transform=transform_train)
test_dataset = datasets.CIFAR100(root=DATA_DIR, train=False, download=True, transform=transform_test)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
shuffle=True, num_workers=num_workers,
pin_memory=True
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
shuffle=False, num_workers=num_workers,
pin_memory=True
)
return train_loader, test_loader, None, None
def get_imnet_data(args, _logger, data_config, num_aug_splits, **kwargs):
"""
获取ImageNet数据集
http://arxiv.org/abs/1409.0575
:param args: 其他的参数
:param _logger: 日志路径
:param data_config: 增强策略
:param num_aug_splits: 不同增强策略的数量
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_dir = os.path.join(DATA_DIR, 'ILSVRC2012/train')
if not os.path.exists(train_dir):
_logger.error(
'Training folder does not exist at: {}'.format(train_dir))
exit(1)
dataset_train = ImageDataset(train_dir)
# collate_fn = None
# mixup_fn = None
# mixup_active = args.mixup > 0 or args.cutmix > 0. or args.cutmix_minmax is not None
# if mixup_active:
# mixup_args = dict(
# mixup_alpha=args.mixup, cutmix_alpha=args.cutmix, cutmix_minmax=args.cutmix_minmax,
# prob=args.mixup_prob, switch_prob=args.mixup_switch_prob, mode=args.mixup_mode,
# label_smoothing=args.smoothing, num_classes=args.num_classes)
# if args.prefetcher:
# # collate conflict (need to support deinterleaving in collate mixup)
# assert not num_aug_splits
# collate_fn = FastCollateMixup(**mixup_args)
# else:
# mixup_fn = Mixup(**mixup_args)
# if num_aug_splits > 1:
# dataset_train = AugMixDataset(dataset_train, num_splits=num_aug_splits)
train_interpolation = args.train_interpolation
if args.no_aug or not train_interpolation:
train_interpolation = data_config['interpolation']
loader_train = create_loader(
dataset_train,
input_size=data_config['input_size'],
batch_size=args.batch_size,
is_training=True,
use_prefetcher=args.prefetcher,
no_aug=args.no_aug,
# re_prob=args.reprob,
# re_mode=args.remode,
# re_count=args.recount,
# re_split=args.resplit,
scale=args.scale,
ratio=args.ratio,
hflip=args.hflip,
# vflip=args.vflip,
# color_jitter=args.color_jitter,
# auto_augment=args.aa,
# num_aug_splits=num_aug_splits,
interpolation=train_interpolation,
mean=data_config['mean'],
std=data_config['std'],
num_workers=args.workers,
distributed=args.distributed,
# collate_fn=collate_fn,
pin_memory=args.pin_mem,
# use_multi_epochs_loader=args.use_multi_epochs_loader
)
eval_dir = os.path.join(DATA_DIR, 'ILSVRC2012/val')
if not os.path.isdir(eval_dir):
eval_dir = os.path.join(DATA_DIR, 'ILSVRC2012/validation')
if not os.path.isdir(eval_dir):
_logger.error(
'Validation folder does not exist at: {}'.format(eval_dir))
exit(1)
dataset_eval = ImageDataset(eval_dir)
loader_eval = create_loader(
dataset_eval,
input_size=data_config['input_size'],
batch_size=args.validation_batch_size_multiplier * args.batch_size,
is_training=False,
use_prefetcher=args.prefetcher,
interpolation=data_config['interpolation'],
mean=data_config['mean'],
std=data_config['std'],
num_workers=args.workers,
distributed=args.distributed,
crop_pct=data_config['crop_pct'],
pin_memory=args.pin_mem,
)
return loader_train, loader_eval, None, None
def get_dvsg_data(batch_size, step, **kwargs):
"""
获取DVS Gesture数据
DOI: 10.1109/CVPR.2017.781
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.DVSGesture.sensor_size
size = kwargs['size'] if 'size' in kwargs else 48
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
train_dataset = tonic.datasets.DVSGesture(os.path.join(DATA_DIR, 'DVS/DVSGesture'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.DVSGesture(os.path.join(DATA_DIR, 'DVS/DVSGesture'),
transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
transforms.RandomCrop(size, padding=size // 12),
# lambda x: event_drop(x),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVSGesture/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVSGesture/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, mixup_active, None
def get_dvsc10_data(batch_size, step, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = tonic.datasets.CIFAR10DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=train_transform)
test_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
# lambda x: event_drop(x),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_train),
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_test),
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_nmnist_data(batch_size, step, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = tonic.datasets.NMNIST.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/NMNIST'), transform=train_transform)
test_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/NMNIST'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
# lambda x: event_drop(x),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NMNIST/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NMNIST/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_train),
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_test),
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_NCALTECH101_data(batch_size, step, **kwargs):
"""
获取NCaltech101数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = braincog.datasets.ncaltech101.NCALTECH101.sensor_size
cls_count = braincog.datasets.ncaltech101.NCALTECH101.cls_count
dataset_length = braincog.datasets.ncaltech101.NCALTECH101.length
portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += train_sample
train_sample_weight.extend(
[sample_weight] * train_sample
)
train_sample_weight.extend(
[0.] * test_sample
)
train_sample_index.extend(
list((range(idx_begin, idx_begin + train_sample)))
)
test_sample_index.extend(
list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.ncaltech101.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=train_transform)
test_dataset = braincog.datasets.ncaltech101.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: print(x.shape),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: temporal_flatten(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=train_sampler,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_UCF101DVS_data(batch_size, step, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = braincog.datasets.ucf101_dvs.UCF101DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.ucf101_dvs.UCF101DVS(os.path.join(DATA_DIR, 'DVS/UCF101DVS'), train=True, transform=train_transform)
test_dataset = braincog.datasets.ucf101_dvs.UCF101DVS(os.path.join(DATA_DIR, 'DVS/UCF101DVS'), train=False, transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
# transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'UCF101DVS/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'UCF101DVS/test_cache_{}'.format(step)),
transform=test_transform)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size, shuffle=False,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_HMDBDVS_data(batch_size, step, **kwargs):
sensor_size = braincog.datasets.hmdb_dvs.HMDBDVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.hmdb_dvs.HMDBDVS(os.path.join(DATA_DIR, 'HMDBDVS'), transform=train_transform)
test_dataset = braincog.datasets.hmdb_dvs.HMDBDVS(os.path.join(DATA_DIR, 'HMDBDVS'), transform=test_transform)
cls_count = train_dataset.cls_count
dataset_length = train_dataset.length
portion = .5
# portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += train_sample
train_sample_weight.extend(
[sample_weight] * train_sample
)
train_sample_weight.extend(
[0.] * test_sample
)
lst = list(range(idx_begin, idx_begin + train_sample + test_sample))
random.seed(0)
random.shuffle(lst)
train_sample_index.extend(
lst[:train_sample]
# list((range(idx_begin, idx_begin + train_sample)))
)
test_sample_index.extend(
lst[train_sample:train_sample + test_sample]
# list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: print(x.shape),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: temporal_flatten(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'HMDBDVS/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'HMDBDVS/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=train_sampler,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
# def get_NCARS_data(batch_size, step, **kwargs):
# """
# 获取N-Cars数据
# https://ieeexplore.ieee.org/document/8578284/
# :param batch_size: batch size
# :param step: 仿真步长
# :param kwargs:
# :return: (train loader, test loader, mixup_active, mixup_fn)
# """
# sensor_size = tonic.datasets.NCARS.sensor_size
# size = kwargs['size'] if 'size' in kwargs else 48
#
# train_transform = transforms.Compose([
# # tonic.transforms.Denoise(filter_time=10000),
# # tonic.transforms.DropEvent(p=0.1),
# tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
# ])
# test_transform = transforms.Compose([
# # tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
# ])
#
# train_dataset = tonic.datasets.NCARS(os.path.join(DATA_DIR, 'DVS/NCARS'), transform=train_transform, train=True)
# test_dataset = tonic.datasets.NCARS(os.path.join(DATA_DIR, 'DVS/NCARS'), transform=test_transform, train=False)
#
# train_transform = transforms.Compose([
# lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: dvs_channel_check_expend(x),
# transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
# ])
# test_transform = transforms.Compose([
# lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: dvs_channel_check_expend(x),
# ])
# if 'rand_aug' in kwargs.keys():
# if kwargs['rand_aug'] is True:
# n = kwargs['randaug_n']
# m = kwargs['randaug_m']
# train_transform.transforms.insert(2, RandAugment(m=m, n=n))
#
# # if 'temporal_flatten' in kwargs.keys():
# # if kwargs['temporal_flatten'] is True:
# # train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# # test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
#
# train_dataset = DiskCachedDataset(train_dataset,
# cache_path=os.path.join(DATA_DIR, 'DVS/NCARS/train_cache_{}'.format(step)),
# transform=train_transform, num_copies=3)
# test_dataset = DiskCachedDataset(test_dataset,
# cache_path=os.path.join(DATA_DIR, 'DVS/NCARS/test_cache_{}'.format(step)),
# transform=test_transform, num_copies=3)
#
# mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
# mixup_active = cut_mix | event_mix | mix_up
#
# if cut_mix:
# train_dataset = CutMix(train_dataset,
# beta=beta,
# prob=prob,
# num_mix=num,
# num_class=num_classes,
# noise=noise)
#
# if event_mix:
# train_dataset = EventMix(train_dataset,
# beta=beta,
# prob=prob,
# num_mix=num,
# num_class=num_classes,
# noise=noise,
# gaussian_n=gaussian_n)
# if mix_up:
# train_dataset = MixUp(train_dataset,
# beta=beta,
# prob=prob,
# num_mix=num,
# num_class=num_classes,
# noise=noise)
#
# train_loader = torch.utils.data.DataLoader(
# train_dataset, batch_size=batch_size,
# pin_memory=True, drop_last=True, num_workers=8,
# shuffle=True,
# )
#
# test_loader = torch.utils.data.DataLoader(
# test_dataset, batch_size=batch_size,
# pin_memory=True, drop_last=False, num_workers=2,
# shuffle=False,
# )
#
# return train_loader, test_loader, mixup_active, None
def get_nomni_data(batch_size, train_portion=1., **kwargs):
"""
获取N-Omniglot数据
:param batch_size:batch的大小
:param data_mode:一共full nkks pair三种模式
:param frames_num:一个样本帧的个数
:param data_type:event frequency两种模式
"""
data_mode = kwargs["data_mode"] if "data_mode" in kwargs else "full"
frames_num = kwargs["frames_num"] if "frames_num" in kwargs else 10
data_type = kwargs["data_type"] if "data_type" in kwargs else "event"
train_transform = transforms.Compose([
transforms.Resize((64, 64))])
test_transform = transforms.Compose([
transforms.Resize((64, 64))])
if data_mode == "full":
train_datasets = NOmniglotfull(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), train=True, frames_num=frames_num,
data_type=data_type,
transform=train_transform)
test_datasets = NOmniglotfull(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), train=False, frames_num=frames_num,
data_type=data_type,
transform=test_transform)
elif data_mode == "nkks":
train_datasets = NOmniglotNWayKShot(os.path.join(DATA_DIR, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=True,
frames_num=frames_num,
data_type=data_type,
transform=train_transform)
test_datasets = NOmniglotNWayKShot(os.path.join(DATA_DIR, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=False,
frames_num=frames_num,
data_type=data_type,
transform=test_transform)
elif data_mode == "pair":
train_datasets = NOmniglotTrainSet(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), use_frame=True,
frames_num=frames_num, data_type=data_type,
use_npz=False, resize=105)
test_datasets = NOmniglotTestSet(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), time=2000, way=kwargs["n_way"],
shot=kwargs["k_shot"], use_frame=True,
frames_num=frames_num, data_type=data_type, use_npz=False, resize=105)
else:
pass
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size, num_workers=12,
pin_memory=True, drop_last=True, shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size, num_workers=12,
pin_memory=True, drop_last=False
)
return train_loader, test_loader, None, None
================================================
FILE: examples/decision_making/BDM-SNN/BDM-SNN-UAV.py
================================================
import numpy as np
import torch,os,sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import torch.nn.functional as F
import matplotlib.pyplot as plt
#from braincog.base.strategy.surrogate import *
from braincog.base.node.node import IFNode
from braincog.base.learningrule.STDP import STDP,MutliInputSTDP
from braincog.base.connection.CustomLinear import CustomLinear
from braincog.base.brainarea.basalganglia import basalganglia
from braincog.model_zoo.bdmsnn import BDMSNN
from robomaster import robot
import time
def chooseAct(Net,input,weight_trace_d1,weight_trace_d2):
"""
根据输入选择行为
:param Net: 输入BDM-SNN网络
:param input: 输入电流 编码状态的脉冲
:param weight_trace_d1: 不断累积保存资格迹
:param weight_trace_d2: 不断累积保存资格迹
:return: 返回选择的行为、资格迹和网络
"""
for i_train in range(500):
out, dw = Net(input)
# rstdp
weight_trace_d1 *= trace_decay
weight_trace_d1 += dw[0][0]
weight_trace_d2 *= trace_decay
weight_trace_d2 += dw[1][0]
if torch.max(out) > 0:
return torch.argmax(out),weight_trace_d1,weight_trace_d2,Net
def updateNet(Net,reward, action, state,weight_trace_d1,weight_trace_d2):
"""
更新网络
:param Net: BDM-SNN网络
:param reward: 获得的奖励
:param action: 执行的行为
:param state: 执行行为前的状态
:param weight_trace_d1: 直接通路累积的资格迹
:param weight_trace_d2: 间接通路累积的资格迹
:return: 更新后的网络
"""
r = torch.ones((num_state, num_state * num_action), dtype=torch.float)
r[state, state * num_action + action] = reward
dw_d1 = r * weight_trace_d1
dw_d2 = -1 * r * weight_trace_d2
Net.UpdateWeight(0, state,num_action,dw_d1)
Net.UpdateWeight(1, state,num_action,dw_d2)
return Net
if __name__=="__main__":
"""
定义无人机 大疆Tello Talent
定义BDM-SNN网络
用户自定义状态空间、奖励函数,调用行为选择及网络更新
"""
#define UAV
tl_drone = robot.Drone()
tl_drone.initialize()
tl_flight = tl_drone.flight
tl_flight.takeoff().wait_for_completed()
#define Net
num_state=9
num_action=2
weight_exc=1
weight_inh=-0.5
trace_decay = 0.8
DM=BDMSNN(num_state,num_action,weight_exc,weight_inh,"lif")
con_matrix1 = torch.zeros((num_state, num_state * num_action), dtype=torch.float)
for i in range(num_state):
for j in range(num_action):
con_matrix1[i, i * num_action + j] = weight_exc
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
iteration=0
while iteration < 200:
input = torch.zeros((num_state), dtype=torch.float)
#users define the judgestate function
state=1
input[state]=2
action,weight_trace_d1,weight_trace_d2,DM = chooseAct(DM,input,weight_trace_d1,weight_trace_d2)
#uav do action
if action==0:
tl_flight.forward(distance=20).wait_for_completed()
if action == 1:
# flying left
tl_flight.rc(a=20, b=0, c=0, d=0)
time.sleep(4)
if action == 2:
# flying right
tl_flight.rc(a=-20, b=0, c=0, d=0)
time.sleep(3)
if action == 3:
tl_flight.backward(distance=20).wait_for_completed()
#users define the reward function
reward =1
DM=updateNet(DM,reward, action, state,weight_trace_d1,weight_trace_d2)
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
DM.reset()
iteration += 1
================================================
FILE: examples/decision_making/BDM-SNN/BDM-SNN-hh.py
================================================
import torch,os
from random import randint
import torch
from torch import nn
from braincog.base.strategy.surrogate import *
from braincog.model_zoo.bdmsnn import BDMSNN
import pygame
from pygame.locals import *
from collections import deque
from random import randint
import numpy as np
import matplotlib.pyplot as plt
import random
#os.environ["SDL_VIDEODRIVER"] = "dummy"
def load_images():
"""
Flappy Bird中load图像
:return:load的图像
"""
def load_image(img_file_name):
file_name = os.path.join('.', 'birdimages', img_file_name)
img = pygame.image.load(file_name)
# converting all images before use speeds up blitting
img.convert()
return img
return {'background': load_image('background.png'),
'pipe-end': load_image('pipe_end.png'),
'pipe-body': load_image('pipe_body.png'),
# images for animating the flapping bird -- animated GIFs are
# not supported in pygame
'bird-wingup': load_image('bird_wing_up.png'),
'bird-wingdown': load_image('bird_wing_down.png'),}
class Bird(pygame.sprite.Sprite):
"""
Flappy Bird类
"""
WIDTH = HEIGHT = 32
SINK_SPEED = 0.2
Fail_SINk_SPEED = 0.6
CLIMB_SPEED = 0.25
CLIMB_DURATION = 333.3
REGION = CLIMB_DURATION / 3
NEAR_COLLIDE = 30
NEAR_PIPE = 0
def __init__(self, x, y, msec_to_climb, images):
super(Bird, self).__init__()
self.x, self.y = x, y
self.msec_to_climb = msec_to_climb
self._img_wingup, self._img_wingdown = images
self._mask_wingup = pygame.mask.from_surface(self._img_wingup)
self._mask_wingdown = pygame.mask.from_surface(self._img_wingdown)
def update(self, action,state,delta_frames=1):
"""
更新小鸟的位置
:param action: 输入行为
:param state:输入状态
:param delta_frames:Fault
:return:None
"""
if self.msec_to_climb > 0 and action == 1:
if state==4 or state==5 or state == 2 or state == 3:
self.y -= (2*Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
self.y -= (Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
if state == 4 or state == 5 or state == 2 or state == 3:
self.y += 2*Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
else:
self.y += Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
def sink(self, delta_frames=1):
self.y += Bird.Fail_SINk_SPEED * (1000.0 * delta_frames / 60)
@property
def image(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._img_wingup
else:
return self._img_wingdown
@property
def mask(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._mask_wingup
else:
return self._mask_wingdown
@property
def rect(self):
return Rect(self.x, self.y, Bird.WIDTH, Bird.HEIGHT)
class PipePair(pygame.sprite.Sprite):
"""
Flappy Bird 中的管子类
"""
WIDTH = 80
PIECE_HEIGHT = 32
ADD_INTERVAL = 2000
ADD_EVENT = pygame.USEREVENT + 1
ROOM_HIGHT = 2 * Bird.HEIGHT + 2 * PIECE_HEIGHT
def __init__(self, pipe_end_img, pipe_body_img):
self.x = float(WIN_WIDTH - 1)
self.score_counted = False
self.isNewPipe = True
self.image = pygame.Surface((PipePair.WIDTH, WIN_HEIGHT), SRCALPHA)
self.image.convert() # speeds up blitting
self.image.fill((0, 0, 0, 0))
total_pipe_body_pieces = int(
(WIN_HEIGHT - # fill window from top to bottom
3 * Bird.HEIGHT - # make room for bird to fit through
3 * PipePair.PIECE_HEIGHT) / # 2 end pieces + 1 body piece
PipePair.PIECE_HEIGHT # to get number of pipe pieces
)
self.bottom_pieces = randint(1, total_pipe_body_pieces)
self.top_pieces = total_pipe_body_pieces - self.bottom_pieces
# bottom pipe
for i in range(1, self.bottom_pieces + 1):
piece_pos = (0, WIN_HEIGHT - i * PipePair.PIECE_HEIGHT)
self.image.blit(pipe_body_img, piece_pos)
bottom_pipe_end_y = WIN_HEIGHT - self.bottom_height_px
bottom_end_piece_pos = (0, bottom_pipe_end_y - PipePair.PIECE_HEIGHT)
self.image.blit(pipe_end_img, bottom_end_piece_pos)
# top pipe
for i in range(self.top_pieces):
self.image.blit(pipe_body_img, (0, i * PipePair.PIECE_HEIGHT))
top_pipe_end_y = self.top_height_px
self.image.blit(pipe_end_img, (0, top_pipe_end_y))
self.center = (top_pipe_end_y + bottom_pipe_end_y) / 2
# compensate for added end pieces
self.top_pieces += 1
self.bottom_pieces += 1
# for collision detection
self.mask = pygame.mask.from_surface(self.image)
self.top_y = top_pipe_end_y
self.bottom_y = bottom_pipe_end_y
@property
def top_height_px(self):
return self.top_pieces * PipePair.PIECE_HEIGHT
@property
def bottom_height_px(self):
return self.bottom_pieces * PipePair.PIECE_HEIGHT
@property
def visible(self):
return -PipePair.WIDTH < self.x < WIN_WIDTH
@property
def rect(self):
return Rect(self.x, 0, PipePair.WIDTH, PipePair.PIECE_HEIGHT)
def update(self, delta_frames=1):
self.x -= 0.18 * 1000.0 * delta_frames /60
def collides_with(self, bird):
return pygame.sprite.collide_mask(self, bird)
def chooseAct(Net,input,weight_trace_d1,weight_trace_d2):
"""
根据输入选择行为
:param Net: 输入BDM-SNN网络
:param input: 输入电流 编码状态的脉冲
:param weight_trace_d1: 不断累积保存资格迹
:param weight_trace_d2: 不断累积保存资格迹
:return: 返回选择的行为、资格迹和网络
"""
for i_train in range(500):
out, dw = Net(input)
# rstdp
weight_trace_d1 *= trace_decay
weight_trace_d1 += dw[0][0]
weight_trace_d2 *= trace_decay
weight_trace_d2 += dw[1][0]
if torch.max(out) > 0:
return torch.argmax(out),weight_trace_d1,weight_trace_d2,Net
def judgeState(bird, pipes, collide):
"""
根据小鸟和管子之间的位置关系判断当前状态
:param bird:传入小鸟的各项属性
:param pipes:传入管子的各项属性
:param collide:是否发生碰撞
:return:状态,距离,是否是新的管子
"""
# bird's x and y coordinate in the left top of the image
dist = bird.y + Bird.HEIGHT / 2 - WIN_HEIGHT / 2
isNew = False
index = -1
state = -1
if collide:
state = 8
return state
for p in pipes:
if p.x + PipePair.WIDTH - Bird.HEIGHT / 4 < bird.x and not p.score_counted:
continue
if p.x - Bird.NEAR_PIPE <= bird.x + Bird.HEIGHT and \
p.x + PipePair.WIDTH - Bird.HEIGHT / 4 >= bird.x:
p_top_y = p.top_y + PipePair.PIECE_HEIGHT
p_bottom_y = p.bottom_y - PipePair.PIECE_HEIGHT
if p.center - bird.y - Bird.HEIGHT / 2 >= 0 and bird.y >= p_top_y + Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - p.center + Bird.HEIGHT / 2 > 0 and bird.y + Bird.HEIGHT <= p_bottom_y - Bird.NEAR_COLLIDE / 2:
state = 1
elif bird.y < p_top_y + Bird.NEAR_COLLIDE / 2 and bird.y > p_top_y - 10:
state = 6
elif bird.y + Bird.HEIGHT > p_bottom_y - Bird.NEAR_COLLIDE / 2 and bird.y + Bird.HEIGHT < p_bottom_y + 10:
state = 7
if state > -0.5:
index = 1
elif p.x > bird.x + Bird.HEIGHT + Bird.NEAR_PIPE:
state = blankState(bird, p.center)
if p.isNewPipe:
isNew = True
p.isNewPipe = False
index = 1
if index > 0: # only judge the nearest and not passed pipe
dist = bird.y + Bird.HEIGHT / 2 - p.center
break
if index < -0.5: # no pipe left, key the bird in the middle
pos = WIN_HEIGHT / 2
dist = bird.y + Bird.HEIGHT / 2 - pos
state = blankState(bird, pos)
return state, dist, isNew
def blankState(bird, center):
"""
judgeState中调用的判断状态的函数 根据鸟的位置和管子中心的距离来判断
:param bird: 传入小鸟的各项属性
:param center:中心
:return:状态
"""
realHeight = (PipePair.ROOM_HIGHT - Bird.HEIGHT) / 2
if center - bird.y - Bird.HEIGHT / 2 >= 0 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - center + Bird.HEIGHT / 2 >= 0 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 1
elif center - bird.y - Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 2
elif bird.y - center + Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 3
elif bird.y + Bird.HEIGHT / 2 <= center - (realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION):
state = 4
elif bird.y + Bird.HEIGHT / 2 >= center + realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 5
return state
def getReward(state,lastState,smallerError,isNewPipe):
"""
根据状态和距离的变化获得奖励
:param state: 执行行为后的当前状态
:param lastState:执行行为之前的上一状态
:param smallerError:距离是否变小
:param isNewPipe:是否是新的管子
:return:奖励
"""
if state == 0 or state == 1:
reward = 6
elif state == 2 or state == 3:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -5
else:
reward = -3
elif state == 4 or state == 5:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -8
else:
reward = -5
elif state == 6 or state == 7:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -3
else:
reward = -3
elif state == 8: # collide
reward = -100
return reward
def updateNet(Net,reward, action, state,weight_trace_d1,weight_trace_d2):
"""
更新网络
:param Net: BDM-SNN网络
:param reward: 获得的奖励
:param action: 执行的行为
:param state: 执行行为前的状态
:param weight_trace_d1: 直接通路累积的资格迹
:param weight_trace_d2: 间接通路累积的资格迹
:return: 更新后的网络
"""
r = torch.ones((num_state, num_state * num_action), dtype=torch.float)
r[state, state * num_action + action] = reward
dw_d1 = r * weight_trace_d1
dw_d2 = -1 * r * weight_trace_d2
Net.UpdateWeight(0, state,num_action,dw_d1)
Net.UpdateWeight(1, state,num_action,dw_d2)
return Net
if __name__=="__main__":
"""
执行网络,运行Flappy Bird游戏
"""
num_state=9
num_action=2
weight_exc=50
weight_inh=-60
trace_decay = 0.8
DM=BDMSNN(num_state,num_action,weight_exc,weight_inh,"hh")
con_matrix1 = torch.zeros((num_state, num_state * num_action), dtype=torch.float)
for i in range(num_state):
for j in range(num_action):
con_matrix1[i, i * num_action + j] = weight_exc
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
pygame.init()
WIN_HEIGHT = 512
WIN_WIDTH = 284 * 2
heighest = 0
display_frame=0
display_surface = pygame.display.set_mode((WIN_WIDTH, WIN_HEIGHT))
pygame.display.set_caption('Flappy Bird')
images = load_images()
bird = Bird(250, int(WIN_HEIGHT / 2 - Bird.HEIGHT / 2), 2,
(images['bird-wingup'], images['bird-wingdown']))
clock = pygame.time.Clock()
score_font = pygame.font.SysFont(None, 25, bold=True)
info_font = pygame.font.SysFont(None, 50, bold=True)
collide = paused = False
frame_clock = 0
pipes = deque()
score = 0
lastDist = 0
lastState = 0 #init
state = lastState
num=0
num_reward=[]
num_score=[]
while not collide:
num=num+1
if num>30000:
break
input = torch.zeros((num_state), dtype=torch.float)
clock.tick(60)
if frame_clock %2==0 or frame_clock==1:
state, dist, isNewPipe = judgeState(bird, pipes, collide)
lastState = state
lastDist = dist
input[state]=2
print(input)
action,weight_trace_d1,weight_trace_d2,DM = chooseAct(DM,input,weight_trace_d1,weight_trace_d2)
print("state, dist:", state, dist)
print("state, action:",state,action)
if not (paused or frame_clock % (60 * PipePair.ADD_INTERVAL / 1000.0)):
pygame.event.post(pygame.event.Event(PipePair.ADD_EVENT))
for e in pygame.event.get():
if e.type == QUIT or (e.type == KEYUP and e.key == K_ESCAPE):
collide = True
elif e.type == KEYUP and e.key in (K_PAUSE, K_p):
paused = not paused
elif e.type == PipePair.ADD_EVENT:
pp = PipePair(images['pipe-end'], images['pipe-body'])
pipes.append(pp)
if paused:
continue # don't draw anything
pipe_collision = any(p.collides_with(bird) for p in pipes)
if pipe_collision or 0 >= bird.y or bird.y >= WIN_HEIGHT - Bird.HEIGHT:
collide = True
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
p.update()
display_surface.blit(p.image, p.rect)
bird.update(action,state)
display_surface.blit(bird.image, bird.rect)
if frame_clock %2==0 or frame_clock==1 or collide:
dist = 0
if collide:
nextState = 8
isNewPipe = False
else:
nextState, dist, isNewPipe = judgeState(bird, pipes, collide) # judge the bird's state
print("next state:", nextState)
print("lastdist, dist:", lastDist,dist)
isSmallerError = False
if state == nextState:
isSmallerError = False
if lastDist <= 0:
if lastDist < dist:
isSmallerError = True
else:
if lastDist > dist:
isSmallerError = True
if frame_clock>0 and not collide:
reward = getReward(nextState, state, isSmallerError, isNewPipe)
print("reward:", reward)
num_reward.append(reward)
DM=updateNet(DM,reward, action, state,weight_trace_d1,weight_trace_d2)
state = nextState #going on the next state
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
DM.reset()
display_frame += 1
for p in pipes:
if p.x + PipePair.WIDTH < bird.x and not p.score_counted:
score += 1
p.score_counted = True
num_score.append(score)
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: 0', True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
frame_clock += 1
pygame.display.flip()
# if collide, display the fail information, for 2 frames
cct = 0
while (bird.y < WIN_HEIGHT - Bird.HEIGHT - 3):
clock.tick(60)
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
display_surface.blit(p.image, p.rect)
if cct >= 6:
bird.sink()
display_surface.blit(bird.image, bird.rect)
fail_infor = info_font.render('Game over !', True, (255, 60, 30)) # current score
pos_x = WIN_WIDTH / 2 - fail_infor.get_width() / 2
pos_y = WIN_HEIGHT / 2 - 100
display_surface.blit(fail_infor, (pos_x, pos_y))
# display the score
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: 0' , True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
pygame.display.flip()
cct += 1
if heighest < score:
heighest = score
num_reward_np=np.array(num_reward)
num_score_np=np.array(num_score)
print(num_reward_np,num_score_np)
np.save('hh_reward_l.npy', num_reward_np)
np.save('hh_score_l.npy', num_score_np)
print(score)
================================================
FILE: examples/decision_making/BDM-SNN/BDM-SNN.py
================================================
import torch
import os
from braincog.model_zoo.bdmsnn import BDMSNN
import pygame
from pygame.locals import *
from collections import deque
from random import randint
import numpy as np
try:
pygame.display.init()
except:
os.environ["SDL_VIDEODRIVER"] = "dummy"
def load_images():
"""
Flappy Bird中load图像
:return:load的图像
"""
def load_image(img_file_name):
file_name = os.path.join('.', 'birdimages', img_file_name)
img = pygame.image.load(file_name)
# converting all images before use speeds up blitting
img.convert()
return img
return {'background': load_image('background.png'),
'pipe-end': load_image('pipe_end.png'),
'pipe-body': load_image('pipe_body.png'),
# images for animating the flapping bird -- animated GIFs are
# not supported in pygame
'bird-wingup': load_image('bird_wing_up.png'),
'bird-wingdown': load_image('bird_wing_down.png'), }
class Bird(pygame.sprite.Sprite):
"""
Flappy Bird类
"""
WIDTH = HEIGHT = 32
SINK_SPEED = 0.2
Fail_SINk_SPEED = 0.6
CLIMB_SPEED = 0.25
CLIMB_DURATION = 333.3
REGION = CLIMB_DURATION / 3
NEAR_COLLIDE = 30
NEAR_PIPE = 0
def __init__(self, x, y, msec_to_climb, images):
super(Bird, self).__init__()
self.x, self.y = x, y
self.msec_to_climb = msec_to_climb
self._img_wingup, self._img_wingdown = images
self._mask_wingup = pygame.mask.from_surface(self._img_wingup)
self._mask_wingdown = pygame.mask.from_surface(self._img_wingdown)
def update(self, action, state, delta_frames=1):
"""
更新小鸟的位置
:param action: 输入行为
:param state:输入状态
:param delta_frames:Fault
:return:None
"""
if self.msec_to_climb > 0 and action == 1:
if state == 4 or state == 5 or state == 2 or state == 3:
self.y -= (2 * Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
self.y -= (Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
if state == 4 or state == 5 or state == 2 or state == 3:
self.y += 2 * Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
else:
self.y += Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
def sink(self, delta_frames=1):
self.y += Bird.Fail_SINk_SPEED * (1000.0 * delta_frames / 60)
@property
def image(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._img_wingup
else:
return self._img_wingdown
@property
def mask(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._mask_wingup
else:
return self._mask_wingdown
@property
def rect(self):
return Rect(self.x, self.y, Bird.WIDTH, Bird.HEIGHT)
class PipePair(pygame.sprite.Sprite):
"""
Flappy Bird 中的管子类
"""
WIDTH = 80
PIECE_HEIGHT = 32
ADD_INTERVAL = 2000
ADD_EVENT = pygame.USEREVENT + 1
ROOM_HIGHT = 2 * Bird.HEIGHT + 2 * PIECE_HEIGHT
def __init__(self, pipe_end_img, pipe_body_img):
self.x = float(WIN_WIDTH - 1)
self.score_counted = False
self.isNewPipe = True
self.image = pygame.Surface((PipePair.WIDTH, WIN_HEIGHT), SRCALPHA)
self.image.convert() # speeds up blitting
self.image.fill((0, 0, 0, 0))
total_pipe_body_pieces = int(
(WIN_HEIGHT - # fill window from top to bottom
3 * Bird.HEIGHT - # make room for bird to fit through
3 * PipePair.PIECE_HEIGHT) / # 2 end pieces + 1 body piece
PipePair.PIECE_HEIGHT # to get number of pipe pieces
)
self.bottom_pieces = randint(1, total_pipe_body_pieces)
self.top_pieces = total_pipe_body_pieces - self.bottom_pieces
# bottom pipe
for i in range(1, self.bottom_pieces + 1):
piece_pos = (0, WIN_HEIGHT - i * PipePair.PIECE_HEIGHT)
self.image.blit(pipe_body_img, piece_pos)
bottom_pipe_end_y = WIN_HEIGHT - self.bottom_height_px
bottom_end_piece_pos = (0, bottom_pipe_end_y - PipePair.PIECE_HEIGHT)
self.image.blit(pipe_end_img, bottom_end_piece_pos)
# top pipe
for i in range(self.top_pieces):
self.image.blit(pipe_body_img, (0, i * PipePair.PIECE_HEIGHT))
top_pipe_end_y = self.top_height_px
self.image.blit(pipe_end_img, (0, top_pipe_end_y))
self.center = (top_pipe_end_y + bottom_pipe_end_y) / 2
# compensate for added end pieces
self.top_pieces += 1
self.bottom_pieces += 1
# for collision detection
self.mask = pygame.mask.from_surface(self.image)
self.top_y = top_pipe_end_y
self.bottom_y = bottom_pipe_end_y
@property
def top_height_px(self):
return self.top_pieces * PipePair.PIECE_HEIGHT
@property
def bottom_height_px(self):
return self.bottom_pieces * PipePair.PIECE_HEIGHT
@property
def visible(self):
return -PipePair.WIDTH < self.x < WIN_WIDTH
@property
def rect(self):
return Rect(self.x, 0, PipePair.WIDTH, PipePair.PIECE_HEIGHT)
def update(self, delta_frames=1):
self.x -= 0.18 * 1000.0 * delta_frames / 60
def collides_with(self, bird):
return pygame.sprite.collide_mask(self, bird)
def chooseAct(Net, input, weight_trace_d1, weight_trace_d2):
"""
根据输入选择行为
:param Net: 输入BDM-SNN网络
:param input: 输入电流 编码状态的脉冲
:param weight_trace_d1: 不断累积保存资格迹
:param weight_trace_d2: 不断累积保存资格迹
:return: 返回选择的行为、资格迹和网络
"""
for i_train in range(500):
out, dw = Net(input)
# rstdp
weight_trace_d1 *= trace_decay
weight_trace_d1 += dw[0][0]
weight_trace_d2 *= trace_decay
weight_trace_d2 += dw[1][0]
if torch.max(out) > 0:
return torch.argmax(out), weight_trace_d1, weight_trace_d2, Net
def judgeState(bird, pipes, collide):
"""
根据小鸟和管子之间的位置关系判断当前状态
:param bird:传入小鸟的各项属性
:param pipes:传入管子的各项属性
:param collide:是否发生碰撞
:return:状态,距离,是否是新的管子
"""
# bird's x and y coordinate in the left top of the image
dist = bird.y + Bird.HEIGHT / 2 - WIN_HEIGHT / 2
isNew = False
index = -1
state = -1
if collide:
state = 8
return state
for p in pipes:
if p.x + PipePair.WIDTH - Bird.HEIGHT / 4 < bird.x and not p.score_counted:
continue
if p.x - Bird.NEAR_PIPE <= bird.x + Bird.HEIGHT and \
p.x + PipePair.WIDTH - Bird.HEIGHT / 4 >= bird.x:
p_top_y = p.top_y + PipePair.PIECE_HEIGHT
p_bottom_y = p.bottom_y - PipePair.PIECE_HEIGHT
if p.center - bird.y - Bird.HEIGHT / 2 >= 0 and bird.y >= p_top_y + Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - p.center + Bird.HEIGHT / 2 > 0 and bird.y + Bird.HEIGHT <= p_bottom_y - Bird.NEAR_COLLIDE / 2:
state = 1
elif bird.y < p_top_y + Bird.NEAR_COLLIDE / 2 and bird.y > p_top_y - 10:
state = 6
elif bird.y + Bird.HEIGHT > p_bottom_y - Bird.NEAR_COLLIDE / 2 and bird.y + Bird.HEIGHT < p_bottom_y + 10:
state = 7
if state > -0.5:
index = 1
elif p.x > bird.x + Bird.HEIGHT + Bird.NEAR_PIPE:
state = blankState(bird, p.center)
if p.isNewPipe:
isNew = True
p.isNewPipe = False
index = 1
if index > 0: # only judge the nearest and not passed pipe
dist = bird.y + Bird.HEIGHT / 2 - p.center
break
if index < -0.5: # no pipe left, key the bird in the middle
pos = WIN_HEIGHT / 2
dist = bird.y + Bird.HEIGHT / 2 - pos
state = blankState(bird, pos)
return state, dist, isNew
def blankState(bird, center):
"""
judgeState中调用的判断状态的函数 根据鸟的位置和管子中心的距离来判断
:param bird: 传入小鸟的各项属性
:param center:中心
:return:状态
"""
realHeight = (PipePair.ROOM_HIGHT - Bird.HEIGHT) / 2
if center - bird.y - Bird.HEIGHT / 2 >= 0 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - center + Bird.HEIGHT / 2 >= 0 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 1
elif center - bird.y - Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 2
elif bird.y - center + Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 3
elif bird.y + Bird.HEIGHT / 2 <= center - (realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION):
state = 4
elif bird.y + Bird.HEIGHT / 2 >= center + realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 5
return state
def getReward(state, lastState, smallerError, isNewPipe):
"""
根据状态和距离的变化获得奖励
:param state: 执行行为后的当前状态
:param lastState:执行行为之前的上一状态
:param smallerError:距离是否变小
:param isNewPipe:是否是新的管子
:return:奖励
"""
if state == 0 or state == 1:
reward = 6
elif state == 2 or state == 3:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -5
else:
reward = -3
elif state == 4 or state == 5:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -8
else:
reward = -5
elif state == 6 or state == 7:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -3
else:
reward = -3
elif state == 8: # collide
reward = -100
return reward
def updateNet(Net, reward, action, state, weight_trace_d1, weight_trace_d2):
"""
更新网络
:param Net: BDM-SNN网络
:param reward: 获得的奖励
:param action: 执行的行为
:param state: 执行行为前的状态
:param weight_trace_d1: 直接通路累积的资格迹
:param weight_trace_d2: 间接通路累积的资格迹
:return: 更新后的网络
"""
r = torch.ones((num_state, num_state * num_action), dtype=torch.float)
r[state, state * num_action + action] = reward
dw_d1 = r * weight_trace_d1
dw_d2 = -1 * r * weight_trace_d2
Net.UpdateWeight(0, state, num_action, dw_d1)
Net.UpdateWeight(1, state, num_action, dw_d2)
return Net
if __name__ == "__main__":
"""
执行网络,运行Flappy Bird游戏
"""
num_state = 9
num_action = 2
weight_exc = 1
weight_inh = -0.5
trace_decay = 0.8
DM = BDMSNN(num_state, num_action, weight_exc, weight_inh, "lif")
con_matrix1 = torch.zeros((num_state, num_state * num_action), dtype=torch.float)
for i in range(num_state):
for j in range(num_action):
con_matrix1[i, i * num_action + j] = weight_exc
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
pygame.init()
WIN_HEIGHT = 512
WIN_WIDTH = 284 * 2
heighest = 0
contTime = 0
display_frame = 0
display_surface = pygame.display.set_mode((WIN_WIDTH, WIN_HEIGHT))
pygame.display.set_caption('Flappy Bird')
images = load_images()
bird = Bird(250, int(WIN_HEIGHT / 2 - Bird.HEIGHT / 2), 2,
(images['bird-wingup'], images['bird-wingdown']))
clock = pygame.time.Clock()
score_font = pygame.font.SysFont(None, 25, bold=True)
info_font = pygame.font.SysFont(None, 50, bold=True)
collide = paused = False
frame_clock = 0
pipes = deque()
score = 0
lastDist = 0
lastState = 0 # init
state = lastState
num = 0
num_reward = []
num_score = []
while not collide:
num = num + 1
if num > 30000:
break
input = torch.zeros((num_state), dtype=torch.float)
clock.tick(60)
if frame_clock % 2 == 0 or frame_clock == 1:
state, dist, isNewPipe = judgeState(bird, pipes, collide)
lastState = state
lastDist = dist
input[state] = 2
action, weight_trace_d1, weight_trace_d2, DM = chooseAct(DM, input, weight_trace_d1, weight_trace_d2)
print("state, dist:", state, dist)
print("state, action:", state, action)
if not (paused or frame_clock % (60 * PipePair.ADD_INTERVAL / 1000.0)):
pygame.event.post(pygame.event.Event(PipePair.ADD_EVENT))
for e in pygame.event.get():
if e.type == QUIT or (e.type == KEYUP and e.key == K_ESCAPE):
collide = True
elif e.type == KEYUP and e.key in (K_PAUSE, K_p):
paused = not paused
elif e.type == PipePair.ADD_EVENT:
pp = PipePair(images['pipe-end'], images['pipe-body'])
pipes.append(pp)
if paused:
continue # don't draw anything
pipe_collision = any(p.collides_with(bird) for p in pipes)
if pipe_collision or 0 >= bird.y or bird.y >= WIN_HEIGHT - Bird.HEIGHT:
collide = True
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
p.update()
display_surface.blit(p.image, p.rect)
bird.update(action, state)
display_surface.blit(bird.image, bird.rect)
if frame_clock % 2 == 0 or frame_clock == 1 or collide:
dist = 0
if collide:
nextState = 8
isNewPipe = False
else:
nextState, dist, isNewPipe = judgeState(bird, pipes, collide) # judge the bird's state
print("next state:", nextState)
print("lastdist, dist:", lastDist, dist)
isSmallerError = False
if state == nextState:
isSmallerError = False
if lastDist <= 0:
if lastDist < dist:
isSmallerError = True
else:
if lastDist > dist:
isSmallerError = True
if frame_clock > 0 and not collide:
reward = getReward(nextState, state, isSmallerError, isNewPipe)
print("reward:", reward)
num_reward.append(reward)
DM = updateNet(DM, reward, action, state, weight_trace_d1, weight_trace_d2)
state = nextState # going on the next state
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
DM.reset()
display_frame += 1
for p in pipes:
if p.x + PipePair.WIDTH < bird.x and not p.score_counted:
score += 1
p.score_counted = True
num_score.append(score)
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: 0', True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
frame_clock += 1
pygame.display.flip()
# if collide, display the fail information, for 2 frames
cct = 0
while (bird.y < WIN_HEIGHT - Bird.HEIGHT - 3):
clock.tick(60)
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
display_surface.blit(p.image, p.rect)
if cct >= 6:
bird.sink()
display_surface.blit(bird.image, bird.rect)
fail_infor = info_font.render('Game over !', True, (255, 60, 30)) # current score
pos_x = WIN_WIDTH / 2 - fail_infor.get_width() / 2
pos_y = WIN_HEIGHT / 2 - 100
display_surface.blit(fail_infor, (pos_x, pos_y))
# display the score
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: 0', True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
pygame.display.flip()
cct += 1
if heighest < score:
heighest = score
contTime += 1
num_reward_np = np.array(num_reward)
num_score_np = np.array(num_score)
print(num_reward_np, num_score_np)
np.save('lif_reward_l.npy', num_reward_np)
np.save('lif_score_l.npy', num_score_np)
print(score)
================================================
FILE: examples/decision_making/BDM-SNN/README.md
================================================
# Brain-inspired Decision-Making SNN
## Requirements
"decisionmaking.py", "BDM-SNN.py","BDM-SNN-hh.py":pygame
"BDM-SNN-UAV.py":robomaster
## Run
The decisionmaking.py and BDM-SNN.py implements the core code of the brain-inspired decision-making spiking neural network in paper entitled "A brain-inspired decision-making spiking neural network and its application in unmanned aerial vehicle".
"decisionmaking.py, BDM-SNN.py" includes the multi-brain regions coordinated decision-making spiking neural network with LIF neurons.
"BDM-SNN-hh.py" includes the BDM-SNN with simplified HH neurons.
"BDM-SNN-UAV.py" includes the BDM-SNN applied to the UAV (DJI Tello talent), users need to define the reinforcement learning task.
```shell
python decisionmaking.py
python BDM-SNN.py
python BDM-SNN-hh.py
python BDM-SNN-UAV.py
```
## Results
"decisionmaking.py", "BDM-SNN.py" and "BDM-SNN-hh.py" have been verified on Flappy Bird game. BDM-SNN could stably pass the pipeline on the first try.

Differences from the original article: an improved reward-modulated STDP learning rule.
## Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{zhao2018brain,
title={A brain-inspired decision-making spiking neural network and its application in unmanned aerial vehicle},
author={Zhao, Feifei and Zeng, Yi and Xu, Bo},
journal={Frontiers in neurorobotics},
volume={12},
pages={56},
year={2018},
publisher={Frontiers Media SA}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/decision_making/BDM-SNN/decisionmaking.py
================================================
import numpy as np
import torch,os,sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import torch.nn.functional as F
import matplotlib.pyplot as plt
#from BrainCog.base.strategy.surrogate import *
from braincog.base.node.node import IFNode, SimHHNode
from braincog.base.learningrule.STDP import STDP, MutliInputSTDP
from braincog.base.connection.CustomLinear import CustomLinear
from braincog.base.brainarea.basalganglia import basalganglia
#from braincog.model_zoo.bdmsnn import BDMSNN
import pygame
from pygame.locals import *
from collections import deque
from random import randint
#os.environ["SDL_VIDEODRIVER"] = "dummy"
class BDMSNN(nn.Module):
def __init__(self, num_state, num_action, weight_exc, weight_inh, node_type):
"""
定义BDM-SNN网络
:param num_state: 状态个数
:param num_action: 动作个数
:param weight_exc: 兴奋性连接权重
:param weight_inh: 抑制性连接权重
"""
super().__init__()
# parameters
BG = basalganglia(num_state, num_action, weight_exc, weight_inh, node_type)
dm_connection = BG.getweight()
dm_mask = BG.getmask()
# input-dlpfc
con_matrix9 = torch.eye((num_state), dtype=torch.float)
dm_connection.append(CustomLinear(weight_exc * con_matrix9, con_matrix9))
dm_mask.append(con_matrix9)
# gpi-th
con_matrix10 = torch.eye((num_action), dtype=torch.float)
dm_mask.append(con_matrix10)
dm_connection.append(CustomLinear(weight_inh * con_matrix10, con_matrix10))
# th-pm
dm_mask.append(con_matrix10)
dm_connection.append(CustomLinear(weight_exc * con_matrix10, con_matrix10))
# dlpfc-th
con_matrix11 = torch.ones((num_state, num_action), dtype=torch.float)
dm_mask.append(con_matrix11)
dm_connection.append(CustomLinear(0.2 * weight_exc * con_matrix11, con_matrix11))
# pm-pm
con_matrix3 = torch.ones((num_action, num_action), dtype=torch.float)
con_matrix4 = torch.eye((num_action), dtype=torch.float)
con_matrix5 = con_matrix3 - con_matrix4
con_matrix5 = con_matrix5
dm_mask.append(con_matrix5)
dm_connection.append(CustomLinear(5 * weight_inh * con_matrix5, con_matrix5))
# dlpfc thalamus pm +bg
self.weight_exc = weight_exc
self.num_subDM = 8
self.connection = dm_connection
self.mask = dm_mask
self.node = BG.node
self.node_type = node_type
if self.node_type == "hh":
self.node.extend([SimHHNode() for i in range(self.num_subDM - BG.num_subBG)])
self.node[6].g_Na = torch.tensor(12)
self.node[6].g_K = torch.tensor(3.6)
self.node[6].g_L = torch.tensor(0.03)
if self.node_type == "lif":
self.node.extend([IFNode() for i in range(self.num_subDM - BG.num_subBG)])
self.learning_rule = BG.learning_rule
self.learning_rule.append(MutliInputSTDP(self.node[5], [self.connection[10], self.connection[12]])) # gpi-丘脑
self.learning_rule.append(MutliInputSTDP(self.node[6], [self.connection[11], self.connection[13]])) # pm
self.learning_rule.append(STDP(self.node[7], self.connection[9]))
out_shape=[self.connection[0].weight.shape[1],self.connection[1].weight.shape[1],self.connection[2].weight.shape[1],self.connection[4].weight.shape[1],self.connection[3].weight.shape[1],self.connection[10].weight.shape[1],self.connection[11].weight.shape[1],self.connection[9].weight.shape[1]]
self.out = []
self.dw = []
for i in range(self.num_subDM):
self.out.append(torch.zeros((out_shape[i]), dtype=torch.float))
self.dw.append(torch.zeros((out_shape[i]), dtype=torch.float))
def forward(self, input):
"""
根据输入得到网络的输出
:param input: 输入
:return: 网络的输出
"""
self.out[7] = self.node[7](self.connection[9](input))
self.out[0], self.dw[0] = self.learning_rule[0](self.out[7])
self.out[1], self.dw[1] = self.learning_rule[1](self.out[7])
self.out[2], self.dw[2] = self.learning_rule[2](self.out[7], self.out[3])
self.out[3], self.dw[3] = self.learning_rule[3](self.out[1], self.out[2])
self.out[4], self.dw[4] = self.learning_rule[4](self.out[0], self.out[3], self.out[2])
self.out[5], self.dw[5] = self.learning_rule[5](self.out[4], self.out[7])
self.out[6], self.dw[6] = self.learning_rule[6](self.out[5], self.out[6])
br = ["StrD1", "StrD2", "STN", "Gpe", "Gpi", "thalamus", "PM", "DLPFC"]
for i in range(self.num_subDM):
if torch.max(self.out[i]) > 0 and self.node_type == "hh":
self.node[i].n_reset()
print("every areas:", br[i], self.out[i])
return self.out[6], self.dw
def UpdateWeight(self, i, s, num_action, dw):
"""
更新网络中第i组连接的权重
:param i:要更新的连接组索引
:param s:传入状态
:param dw:更新权重的量
:return:
"""
if self.node_type == "hh":
self.connection[i].update(0.2 * self.weight_exc * dw)
self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]] /= (self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]].float().max() + 1e-12)
self.connection[i].weight.data[s, :] = self.connection[i].weight.data[s, :] * self.weight_exc
if self.node_type == "lif":
dw_mean = dw[s, [s * num_action, s * num_action + 1]].mean()
dw_std = dw[s, [s * num_action, s * num_action + 1]].std()
dw[s, [s * num_action, s * num_action + 1]] = (dw[s, [s * num_action,s * num_action + 1]] - dw_mean) / dw_std
dw[s, :] = dw[s, :] * self.mask[i][s, :]
self.connection[i].update(dw)
self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]] /= (self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]].float().max() + 1e-12)
if i in [0, 1, 2, 6, 7, 11, 12]:
self.connection[i].weight.data = torch.clamp(self.connection[i].weight.data, 0, None)
if i in [3, 4, 5, 8, 10]:
self.connection[i].weight.data = torch.clamp(self.connection[i].weight.data, None, 0)
def reset(self):
"""
reset神经元或学习法则的中间量
:return: None
"""
for i in range(self.num_subDM):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
"""
获取网络的连接(包括权值等)
:return: 网络的连接
"""
return self.connection
def load_images():
"""Load all images required by the game and return a dict of them.
The returned dict has the following keys:
background: The game's background image.
bird-wingup: An image of the bird with its wing pointing upward.
Use this and bird-wingdown to create a flapping bird.
bird-wingdown: An image of the bird with its wing pointing downward.
Use this and bird-wingup to create a flapping bird.
pipe-end: An image of a pipe's end piece (the slightly wider bit).
Use this and pipe-body to make pipes.
pipe-body: An image of a slice of a pipe's body. Use this and
pipe-body to make pipes.
"""
def load_image(img_file_name):
"""Return the loaded pygame image with the specified file name.
This function looks for images in the game's images folder
(./images/). All images are converted before being returned to
speed up blitting.
Arguments:
img_file_name: The file name (including its extension, e.g.
'.png') of the required image, without a file path.
"""
file_name = os.path.join('.', 'birdimages', img_file_name)
img = pygame.image.load(file_name)
# converting all images before use speeds up blitting
img.convert()
return img
return {'background': load_image('background.png'),
'pipe-end': load_image('pipe_end.png'),
'pipe-body': load_image('pipe_body.png'),
# images for animating the flapping bird -- animated GIFs are
# not supported in pygame
'bird-wingup': load_image('bird_wing_up.png'),
'bird-wingdown': load_image('bird_wing_down.png'),}
class Bird(pygame.sprite.Sprite):
WIDTH = HEIGHT = 32
SINK_SPEED = 0.2
Fail_SINk_SPEED = 0.6
CLIMB_SPEED = 0.25
CLIMB_DURATION = 333.3
REGION = CLIMB_DURATION / 3 # when far from the pipe, the bird can fluctuate in a certain region,wgx
NEAR_COLLIDE = 30 # when inside the pipe, near collide distance, this define another state
NEAR_PIPE = 0 # at what distance does the bird near the pipe
def __init__(self, x, y, msec_to_climb, images):
super(Bird, self).__init__()
self.x, self.y = x, y
self.msec_to_climb = msec_to_climb
self._img_wingup, self._img_wingdown = images
self._mask_wingup = pygame.mask.from_surface(self._img_wingup)
self._mask_wingdown = pygame.mask.from_surface(self._img_wingdown)
def update(self, action,state,delta_frames=1):
if self.msec_to_climb > 0 and action == 1:
if state==4 or state==5 or state == 2 or state == 3:
self.y -= (2*Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
self.y -= (Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
if state == 4 or state == 5 or state == 2 or state == 3:
self.y += 2*Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
else:
self.y += Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
# if the bird fails, sink the bird till it hit the bottom
def sink(self, delta_frames=1):
self.y += Bird.Fail_SINk_SPEED * (1000.0 * delta_frames / 60)
@property
def image(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._img_wingup
else:
return self._img_wingdown
@property
def mask(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._mask_wingup
else:
return self._mask_wingdown
@property
def rect(self):
return Rect(self.x, self.y, Bird.WIDTH, Bird.HEIGHT)
class PipePair(pygame.sprite.Sprite):
WIDTH = 80
PIECE_HEIGHT = 32
ADD_INTERVAL = 2000
ADD_EVENT = pygame.USEREVENT + 1
ROOM_HIGHT = 2 * Bird.HEIGHT + 2 * PIECE_HEIGHT
def __init__(self, pipe_end_img, pipe_body_img):
"""Initialises a new random PipePair.
The new PipePair will automatically be assigned an x attribute of
float(WIN_WIDTH - 1).
Arguments:
pipe_end_img: The image to use to represent a pipe's end piece.
pipe_body_img: The image to use to represent one horizontal slice
of a pipe's body.
"""
self.x = float(WIN_WIDTH - 1)
self.score_counted = False
self.isNewPipe = True
self.image = pygame.Surface((PipePair.WIDTH, WIN_HEIGHT), SRCALPHA)
self.image.convert() # speeds up blitting
self.image.fill((0, 0, 0, 0))
total_pipe_body_pieces = int(
(WIN_HEIGHT - # fill window from top to bottom
3 * Bird.HEIGHT - # make room for bird to fit through
3 * PipePair.PIECE_HEIGHT) / # 2 end pieces + 1 body piece
PipePair.PIECE_HEIGHT # to get number of pipe pieces
)
self.bottom_pieces = randint(1, total_pipe_body_pieces)
self.top_pieces = total_pipe_body_pieces - self.bottom_pieces
# bottom pipe
for i in range(1, self.bottom_pieces + 1):
piece_pos = (0, WIN_HEIGHT - i * PipePair.PIECE_HEIGHT)
self.image.blit(pipe_body_img, piece_pos)
bottom_pipe_end_y = WIN_HEIGHT - self.bottom_height_px
bottom_end_piece_pos = (0, bottom_pipe_end_y - PipePair.PIECE_HEIGHT)
self.image.blit(pipe_end_img, bottom_end_piece_pos)
# top pipe
for i in range(self.top_pieces):
self.image.blit(pipe_body_img, (0, i * PipePair.PIECE_HEIGHT))
top_pipe_end_y = self.top_height_px
self.image.blit(pipe_end_img, (0, top_pipe_end_y))
self.center = (top_pipe_end_y + bottom_pipe_end_y) / 2 # center of pipe-room,wgx
# compensate for added end pieces
self.top_pieces += 1
self.bottom_pieces += 1
# for collision detection
self.mask = pygame.mask.from_surface(self.image)
self.top_y = top_pipe_end_y
self.bottom_y = bottom_pipe_end_y
@property
def top_height_px(self):
"""Get the top pipe's height, in pixels."""
return self.top_pieces * PipePair.PIECE_HEIGHT
@property
def bottom_height_px(self):
"""Get the bottom pipe's height, in pixels."""
return self.bottom_pieces * PipePair.PIECE_HEIGHT
@property
def visible(self):
"""Get whether this PipePair on screen, visible to the player."""
return -PipePair.WIDTH < self.x < WIN_WIDTH
@property
def rect(self):
"""Get the Rect which contains this PipePair."""
return Rect(self.x, 0, PipePair.WIDTH, PipePair.PIECE_HEIGHT)
def update(self, delta_frames=1):
"""Update the PipePair's position.
Attributes:
delta_frames: The number of frames elapsed since this method was
last called.
"""
self.x -= 0.18 * 1000.0 * delta_frames /60
def collides_with(self, bird):
"""Get whether the bird collides with a pipe in this PipePair.
Arguments:
bird: The Bird which should be tested for collision with this
PipePair.
"""
return pygame.sprite.collide_mask(self, bird)
def chooseAct(Net,s,input,weight_trace_d1,weight_trace_d2):
for i_train in range(500):
out, dw = Net(input)
# 更新权重
# Net.UpdateWeight(10, dw[5][0])
# Net.UpdateWeight(12, dw[5][1])
# Net.UpdateWeight(11, dw[6][0])
# rstdp
weight_trace_d1 *= trace_decay
weight_trace_d1 += dw[0][0]
weight_trace_d2 *= trace_decay
weight_trace_d2 += dw[1][0]
if torch.max(out) > 0:
return torch.argmax(out),weight_trace_d1,weight_trace_d2,Net
def judgeState(bird, pipes, collide):
# bird's x and y coordinate in the left top of the image
dist = bird.y + Bird.HEIGHT / 2 - WIN_HEIGHT / 2
isNew = False
index = -1
state = -1
if collide:
state = 8
return state
for p in pipes:
if p.x + PipePair.WIDTH - Bird.HEIGHT / 4 < bird.x and not p.score_counted:
continue
if p.x - Bird.NEAR_PIPE <= bird.x + Bird.HEIGHT and \
p.x + PipePair.WIDTH - Bird.HEIGHT / 4 >= bird.x:
p_top_y = p.top_y + PipePair.PIECE_HEIGHT
p_bottom_y = p.bottom_y - PipePair.PIECE_HEIGHT
if p.center - bird.y - Bird.HEIGHT / 2 >= 0 and bird.y >= p_top_y + Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - p.center + Bird.HEIGHT / 2 > 0 and bird.y + Bird.HEIGHT <= p_bottom_y - Bird.NEAR_COLLIDE / 2:
state = 1
elif bird.y < p_top_y + Bird.NEAR_COLLIDE / 2 and bird.y > p_top_y - 10:
state = 6
elif bird.y + Bird.HEIGHT > p_bottom_y - Bird.NEAR_COLLIDE / 2 and bird.y + Bird.HEIGHT < p_bottom_y + 10:
state = 7
if state > -0.5:
index = 1
elif p.x > bird.x + Bird.HEIGHT + Bird.NEAR_PIPE:
state = blankState(bird, p.center)
if p.isNewPipe:
isNew = True
p.isNewPipe = False
index = 1
if index > 0: # only judge the nearest and not passed pipe
dist = bird.y + Bird.HEIGHT / 2 - p.center
break
if index < -0.5: # no pipe left, key the bird in the middle
pos = WIN_HEIGHT / 2
dist = bird.y + Bird.HEIGHT / 2 - pos
state = blankState(bird, pos)
return state, dist, isNew
def blankState(bird, center): # judge the state before passing the pipe
realHeight = (PipePair.ROOM_HIGHT - Bird.HEIGHT) / 2
if center - bird.y - Bird.HEIGHT / 2 >= 0 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - center + Bird.HEIGHT / 2 >= 0 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 1
elif center - bird.y - Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 2
elif bird.y - center + Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 3
elif bird.y + Bird.HEIGHT / 2 <= center - (realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION):
state = 4
elif bird.y + Bird.HEIGHT / 2 >= center + realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 5
return state
def getReward(state,lastState,smallerError,isNewPipe):
if state == 0 or state == 1:
reward = 6
elif state == 2 or state == 3:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -5
else:
reward = -3
elif state == 4 or state == 5:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -8
else:
reward = -5
elif state == 6 or state == 7:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -3
else:
reward = -3
elif state == 8: # collide
reward = -100
return reward
def updateNet(Net,reward, action, state,weight_trace_d1,weight_trace_d2):
r = torch.ones((num_state, num_state * num_action), dtype=torch.float)
r[state, state * num_action + action] = reward
dw_d1 = r * weight_trace_d1
dw_d2 = -1 * r * weight_trace_d2
Net.UpdateWeight(0, state, num_action, dw_d1)
Net.UpdateWeight(1, state, num_action, dw_d2)
return Net
if __name__=="__main__":
#定义网络
num_state=9
num_action=2
weight_exc=1
weight_inh=-0.5
trace_decay = 0.8
DM = BDMSNN(num_state, num_action, weight_exc, weight_inh, "lif")
con_matrix1 = torch.zeros((num_state, num_state * num_action), dtype=torch.float)
for i in range(num_state):
for j in range(num_action):
con_matrix1[i, i * num_action + j] = weight_exc
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
#定义游戏场景
pygame.init()
WIN_HEIGHT = 512
WIN_WIDTH = 284 * 2 # image size: 284x512 px; tiled twice
heighest = 0
iteration=0
contTime = 0 # number of times to restart
display_frame=0
while iteration < 20: # restart the game for reinforcement learning, wgx
display_surface = pygame.display.set_mode((WIN_WIDTH, WIN_HEIGHT))
pygame.display.set_caption('Flappy Bird')
images = load_images()
bird = Bird(250, int(WIN_HEIGHT / 2 - Bird.HEIGHT / 2), 2,
(images['bird-wingup'], images['bird-wingdown']))
clock = pygame.time.Clock()
score_font = pygame.font.SysFont(None, 25, bold=True) # default font
info_font = pygame.font.SysFont(None, 50, bold=True)
collide = paused = False
frame_clock = 0
pipes = deque()
score = 0
lastDist = 0
lastState = 0 #init
state = lastState
while not collide:
# 输入
input = torch.zeros((num_state), dtype=torch.float)
clock.tick(60)
if frame_clock %2==0 or frame_clock==1:
state, dist, isNewPipe = judgeState(bird, pipes, collide) # judge the bird's state
lastState = state
lastDist = dist
input[state]=2
action,weight_trace_d1,weight_trace_d2,DM = chooseAct(DM,state,input,weight_trace_d1,weight_trace_d2)
print("state, dist:", state, dist)
print("state, action:",state,action)
if not (paused or frame_clock % (60 * PipePair.ADD_INTERVAL / 1000.0)):
pygame.event.post(pygame.event.Event(PipePair.ADD_EVENT))
for e in pygame.event.get():
if e.type == QUIT or (e.type == KEYUP and e.key == K_ESCAPE):
collide = True
elif e.type == KEYUP and e.key in (K_PAUSE, K_p):
paused = not paused
elif e.type == PipePair.ADD_EVENT:
pp = PipePair(images['pipe-end'], images['pipe-body'])
pipes.append(pp)
if paused:
continue # don't draw anything
# check for collisions
pipe_collision = any(p.collides_with(bird) for p in pipes)
if pipe_collision or 0 >= bird.y or bird.y >= WIN_HEIGHT - Bird.HEIGHT:
collide = True
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
p.update()
display_surface.blit(p.image, p.rect)
bird.update(action,state)
display_surface.blit(bird.image, bird.rect)
if frame_clock %2==0 or frame_clock==1 or collide:
# judge the state and update the value function
dist = 0
if collide:
nextState = 8
isNewPipe = False
else:
nextState, dist, isNewPipe = judgeState(bird, pipes, collide) # judge the bird's state
print("next state:", nextState)
print("lastdist, dist:", lastDist,dist)
isSmallerError = False
if state == nextState:
isSmallerError = False
if lastDist <= 0:
if lastDist < dist:
isSmallerError = True
else:
if lastDist > dist:
isSmallerError = True
if frame_clock>0 and not collide:
reward = getReward(nextState, state, isSmallerError, isNewPipe)
print("reward:", reward)
DM=updateNet(DM,reward, action, state,weight_trace_d1,weight_trace_d2)
state = nextState #going on the next state
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
DM.reset()
display_frame += 1
# update and display score
for p in pipes:
if p.x + PipePair.WIDTH < bird.x and not p.score_counted:
score += 1
p.score_counted = True
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: ' + str(iteration), True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
frame_clock += 1
pygame.display.flip()
# if collide, display the fail information, for 2 frames
cct = 0
while (bird.y < WIN_HEIGHT - Bird.HEIGHT - 3):
clock.tick(60)
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
display_surface.blit(p.image, p.rect)
if cct >= 6:
bird.sink()
display_surface.blit(bird.image, bird.rect)
fail_infor = info_font.render('Game over !', True, (255, 60, 30)) # current score
pos_x = WIN_WIDTH / 2 - fail_infor.get_width() / 2
pos_y = WIN_HEIGHT / 2 - 100
display_surface.blit(fail_infor, (pos_x, pos_y))
# display the score
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: ' + str(iteration), True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
pygame.display.flip()
cct += 1
if heighest < score:
heighest = score
contTime += 1
iteration += 1
================================================
FILE: examples/decision_making/RL/README.md
================================================
# PL-SDQN
This repository contains code from our paper [**Solving the Spike Feature Information Vanishing Problem in Spiking Deep Q Network with Potential Based Normalization**]. If you use our code or refer to this project, please cite this paper.
To run the PL-SDQN model, please install 'tianshou' framework first https://github.com/thu-ml/tianshou
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
* gym
* atari-py
* opencv-python
* tianshou
## Train
```shell
python ./sdqn/main.py
```
## Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@ARTICLE{sun2022,
AUTHOR={Sun, Yinqian and Zeng, Yi and Li, Yang},
TITLE={Solving the spike feature information vanishing problem in spiking deep Q network with potential based normalization},
JOURNAL={Frontiers in Neuroscience},
VOLUME={16},
YEAR={2022},
URL={https://www.frontiersin.org/articles/10.3389/fnins.2022.953368},
DOI={10.3389/fnins.2022.953368},
ISSN={1662-453X},
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/decision_making/RL/atari/__init__.py
================================================
================================================
FILE: examples/decision_making/RL/atari/atari_wrapper.py
================================================
# Borrow a lot from openai baselines:
# https://github.com/openai/baselines/blob/master/baselines/common/atari_wrappers.py
from collections import deque
import cv2
import gym
import numpy as np
class NoopResetEnv(gym.Wrapper):
"""Sample initial states by taking random number of no-ops on reset.
No-op is assumed to be action 0.
:param gym.Env env: the environment to wrap.
:param int noop_max: the maximum value of no-ops to run.
"""
def __init__(self, env, noop_max=30):
super().__init__(env)
self.noop_max = noop_max
self.noop_action = 0
assert env.unwrapped.get_action_meanings()[0] == 'NOOP'
def reset(self):
self.env.reset()
noops = self.unwrapped.np_random.randint(1, self.noop_max + 1)
for _ in range(noops):
obs, _, done, _ = self.env.step(self.noop_action)
if done:
obs = self.env.reset()
return obs
class MaxAndSkipEnv(gym.Wrapper):
"""Return only every `skip`-th frame (frameskipping) using most recent raw
observations (for max pooling across time steps)
:param gym.Env env: the environment to wrap.
:param int skip: number of `skip`-th frame.
"""
def __init__(self, env, skip=4):
super().__init__(env)
self._skip = skip
def step(self, action):
"""Step the environment with the given action. Repeat action, sum
reward, and max over last observations.
"""
obs_list, total_reward, done = [], 0., False
for _ in range(self._skip):
obs, reward, done, info = self.env.step(action)
obs_list.append(obs)
total_reward += reward
if done:
break
max_frame = np.max(obs_list[-2:], axis=0)
return max_frame, total_reward, done, info
class EpisodicLifeEnv(gym.Wrapper):
"""Make end-of-life == end-of-episode, but only reset on true game over. It
helps the value estimation.
:param gym.Env env: the environment to wrap.
"""
def __init__(self, env):
super().__init__(env)
self.lives = 0
self.was_real_done = True
def step(self, action):
obs, reward, done, info = self.env.step(action)
self.was_real_done = done
# check current lives, make loss of life terminal, then update lives to
# handle bonus lives
lives = self.env.unwrapped.ale.lives()
if 0 < lives < self.lives:
# for Qbert sometimes we stay in lives == 0 condition for a few
# frames, so its important to keep lives > 0, so that we only reset
# once the environment is actually done.
done = True
self.lives = lives
return obs, reward, done, info
def reset(self):
"""Calls the Gym environment reset, only when lives are exhausted. This
way all states are still reachable even though lives are episodic, and
the learner need not know about any of this behind-the-scenes.
"""
if self.was_real_done:
obs = self.env.reset()
else:
# no-op step to advance from terminal/lost life state
obs = self.env.step(0)[0]
self.lives = self.env.unwrapped.ale.lives()
return obs
class FireResetEnv(gym.Wrapper):
"""Take action on reset for environments that are fixed until firing.
Related discussion: https://github.com/openai/baselines/issues/240
:param gym.Env env: the environment to wrap.
"""
def __init__(self, env):
super().__init__(env)
assert env.unwrapped.get_action_meanings()[1] == 'FIRE'
assert len(env.unwrapped.get_action_meanings()) >= 3
def reset(self):
self.env.reset()
return self.env.step(1)[0]
class WarpFrame(gym.ObservationWrapper):
"""Warp frames to 84x84 as done in the Nature paper and later work.
:param gym.Env env: the environment to wrap.
"""
def __init__(self, env):
super().__init__(env)
self.size = 84
self.observation_space = gym.spaces.Box(
low=np.min(env.observation_space.low),
high=np.max(env.observation_space.high),
shape=(self.size, self.size),
dtype=env.observation_space.dtype
)
def observation(self, frame):
"""returns the current observation from a frame"""
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
return cv2.resize(frame, (self.size, self.size), interpolation=cv2.INTER_AREA)
class ScaledFloatFrame(gym.ObservationWrapper):
"""Normalize observations to 0~1.
:param gym.Env env: the environment to wrap.
"""
def __init__(self, env):
super().__init__(env)
low = np.min(env.observation_space.low)
high = np.max(env.observation_space.high)
self.bias = low
self.scale = high - low
self.observation_space = gym.spaces.Box(
low=0., high=1., shape=env.observation_space.shape, dtype=np.float32
)
def observation(self, observation):
return (observation - self.bias) / self.scale
class ClipRewardEnv(gym.RewardWrapper):
"""clips the reward to {+1, 0, -1} by its sign.
:param gym.Env env: the environment to wrap.
"""
def __init__(self, env):
super().__init__(env)
self.reward_range = (-1, 1)
def reward(self, reward):
"""Bin reward to {+1, 0, -1} by its sign. Note: np.sign(0) == 0."""
return np.sign(reward)
class FrameStack(gym.Wrapper):
"""Stack n_frames last frames.
:param gym.Env env: the environment to wrap.
:param int n_frames: the number of frames to stack.
"""
def __init__(self, env, n_frames):
super().__init__(env)
self.n_frames = n_frames
self.frames = deque([], maxlen=n_frames)
shape = (n_frames, ) + env.observation_space.shape
self.observation_space = gym.spaces.Box(
low=np.min(env.observation_space.low),
high=np.max(env.observation_space.high),
shape=shape,
dtype=env.observation_space.dtype
)
def reset(self):
obs = self.env.reset()
for _ in range(self.n_frames):
self.frames.append(obs)
return self._get_ob()
def step(self, action):
obs, reward, done, info = self.env.step(action)
self.frames.append(obs)
return self._get_ob(), reward, done, info
def _get_ob(self):
# the original wrapper use `LazyFrames` but since we use np buffer,
# it has no effect
return np.stack(self.frames, axis=0)
def wrap_deepmind(
env_id,
episode_life=True,
clip_rewards=True,
frame_stack=4,
scale=False,
warp_frame=True
):
"""Configure environment for DeepMind-style Atari. The observation is
channel-first: (c, h, w) instead of (h, w, c).
:param str env_id: the atari environment id.
:param bool episode_life: wrap the episode life wrapper.
:param bool clip_rewards: wrap the reward clipping wrapper.
:param int frame_stack: wrap the frame stacking wrapper.
:param bool scale: wrap the scaling observation wrapper.
:param bool warp_frame: wrap the grayscale + resize observation wrapper.
:return: the wrapped atari environment.
"""
assert 'NoFrameskip' in env_id
env = gym.make(env_id)
env = NoopResetEnv(env, noop_max=30)
env = MaxAndSkipEnv(env, skip=4)
if episode_life:
env = EpisodicLifeEnv(env)
if 'FIRE' in env.unwrapped.get_action_meanings():
env = FireResetEnv(env)
if warp_frame:
env = WarpFrame(env)
if scale:
env = ScaledFloatFrame(env)
if clip_rewards:
env = ClipRewardEnv(env)
if frame_stack:
env = FrameStack(env, frame_stack)
return env
================================================
FILE: examples/decision_making/RL/mcs-fqf/discrete.py
================================================
from audioop import bias
from time import time
from typing import Any, Optional, Sequence, Tuple, Union
import numpy as np
import torch
import torch.nn.functional as F
from torch import nn
from tianshou.data import Batch
from braincog.base.node.node import LIFNode, ThreeCompNode
class SpikePopEncodingNetwork(nn.Module):
"""Cosine embedding network for IQN. Convert a scalar in [0, 1] to a list \
of n-dim vectors.
:param num_cosines: the number of cosines used for the embedding.
:param embedding_dim: the dimension of the embedding/output.
.. note::
From https://github.com/ku2482/fqf-iqn-qrdqn.pytorch/blob/master
/fqf_iqn_qrdqn/network.py .
"""
def __init__(self, num_cosines: int, embedding_dim: int, device, time_window: int=8) -> None:
super().__init__()
self._threshold = 0.5
# self._decay = 0.2
self._decay = 0.5
self.r_max = 0.5
# self.mus = torch.from_numpy(np.arange(num_cosines) / num_cosines)
self.sigma = 0.05
# self.sigma = 0.01
self._node = LIFNode
self.net = nn.Sequential(
nn.Linear(num_cosines, embedding_dim),
self._node()
# self._node(threshold=self._threshold, decay=self._decay)
)
self.num_cosines = num_cosines
self.embedding_dim = embedding_dim
self.mus = torch.arange(0, num_cosines, device=device).view(1, 1, self.num_cosines) / num_cosines
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def forward(self, taus: torch.Tensor, time_window: int) -> torch.Tensor:
batch_size = taus.shape[0]
N = taus.shape[1]
self.reset()
taus_lam = self.r_max * torch.exp(-(taus.unsqueeze(-1) - self.mus)**2/2/self.sigma**2).view(batch_size*N, self.num_cosines)
taus_repeat = taus_lam.unsqueeze(0).repeat(time_window, 1, 1)
taus_emb = torch.poisson(taus_repeat)
tau_embeddings = []
for i in range(time_window):
t_e = self.net(taus_emb[i])
tau_embeddings.append(t_e)
return tau_embeddings
class SpikeFractionProposalNetwork(nn.Module):
"""Fraction proposal network for FQF.
:param num_fractions: the number of factions to propose.
:param embedding_dim: the dimension of the embedding/input.
.. note::
Adapted from https://github.com/ku2482/fqf-iqn-qrdqn.pytorch/blob/master
/fqf_iqn_qrdqn/network.py .
"""
def __init__(self, num_fractions: int, embedding_dim: int) -> None:
super().__init__()
self.net = nn.Linear(embedding_dim, num_fractions)
torch.nn.init.xavier_uniform_(self.net.weight, gain=0.01)
torch.nn.init.constant_(self.net.bias, 0)
self.num_fractions = num_fractions
self.embedding_dim = embedding_dim
def forward(
self, state_embeddings: list
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
state_embeddings = torch.stack(state_embeddings).detach()
time_window = state_embeddings.shape[0]
batch_size = state_embeddings.shape[1]
logits = self.net(state_embeddings.view(time_window*batch_size, -1))
logits = logits.view(time_window, batch_size, -1)
m = torch.distributions.Categorical(logits=logits.mean(0))
taus_1_N = torch.cumsum(m.probs, dim=1)
taus = F.pad(taus_1_N, (1, 0))
tau_hats = (taus[:, :-1] + taus[:, 1:]).detach() / 2.0
entropies = m.entropy()
return taus, tau_hats, entropies
class MCQuantiles(nn.Module):
def __init__(self,
state_embedings_shape: int,
tau_embeddings_shape: int,
hidden_size: int,
last_size: int,
fusion_size : int=512,
tau_s : int = 2.0):
super().__init__()
self.basal_w = nn.Linear(state_embedings_shape, fusion_size, bias=False)
self.apical_w = nn.Linear(tau_embeddings_shape, fusion_size, bias=False)
self._node = LIFNode
self.mc_node = ThreeCompNode()
self._last = nn.Sequential(
nn.Linear(fusion_size, hidden_size),
self._node(),
nn.Linear(hidden_size, last_size),
)
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def forward(self, state_embedding, tau_embedding):
"""
state_embedding: list
tau_embedding: torch.Tensor
"""
self.reset()
assert isinstance(state_embedding, type(tau_embedding))
if isinstance(state_embedding, list):
time_window = len(state_embedding)
elif isinstance(state_embedding, torch.Tensor):
time_window = state_embedding.shape[0]
else:
raise TypeError('Not support data type.')
batch_size = state_embedding[0].shape[0]
sample_size = tau_embedding[0].shape[0] // batch_size
quantiles = []
for step in range(time_window):
basal_psp = self.basal_w(state_embedding[step]).unsqueeze(1)
apical_psp = self.apical_w(tau_embedding[step]).view(batch_size, sample_size, -1)
embeddings = self.mc_node({'basal_inputs': basal_psp, 'apical_inputs': apical_psp}).view(batch_size*sample_size, -1)
out = self._last(embeddings)
quantiles.append(out)
quantiles = sum(quantiles) / time_window
return quantiles.view(batch_size, sample_size, -1).transpose(1, 2)
class SpikeFullQuantileFunction(nn.Module):
"""Full(y parameterized) Quantile Function.
:param preprocess_net: a self-defined preprocess_net which output a
flattened hidden state.
:param int action_dim: the dimension of action space.
:param hidden_sizes: a sequence of int for constructing the MLP after
preprocess_net. Default to empty sequence (where the MLP now contains
only a single linear layer).
:param int num_cosines: the number of cosines to use for cosine embedding.
Default to 64.
:param int preprocess_net_output_dim: the output dimension of
preprocess_net.
.. note::
The first return value is a tuple of (quantiles, fractions, quantiles_tau),
where fractions is a Batch(taus, tau_hats, entropies).
"""
def __init__(
self,
preprocess_net: nn.Module,
action_shape: Sequence[int],
hidden_sizes: Sequence[int] = (),
num_cosines: int = 64,
preprocess_net_output_dim: Optional[int] = None,
device: Union[str, int, torch.device] = "cpu",
) -> None:
super().__init__()
self.device = device
self.last_size = np.prod(action_shape)
self.preprocess = preprocess_net
self.input_dim = getattr(
self.preprocess, "output_dim", preprocess_net_output_dim
)
self.embed_model = SpikePopEncodingNetwork(num_cosines,
self.input_dim, device=device).to(device)
self.mcquantiles = MCQuantiles(self.input_dim, self.input_dim, hidden_size=np.prod(hidden_sizes),
last_size=action_shape).to(device)
def forward( # type: ignore
self, s: Union[np.ndarray, torch.Tensor],
propose_model: SpikeFractionProposalNetwork,
fractions: Optional[Batch] = None,
**kwargs: Any
) -> Tuple[Any, torch.Tensor]:
r"""Mapping: s -> Q(s, \*)."""
logits, h = self.preprocess(s, state=kwargs.get("state", None))
# Propose fractions
if fractions is None:
taus, tau_hats, entropies = propose_model(logits)
fractions = Batch(taus=taus, tau_hats=tau_hats, entropies=entropies)
else:
taus, tau_hats = fractions.taus, fractions.tau_hats
time_window = len(logits)
tau_hats_emb = self.embed_model(tau_hats, time_window)
quantiles = self.mcquantiles(logits, tau_hats_emb)
quantiles_tau = None
if self.training:
with torch.no_grad():
tau_emb = self.embed_model(taus[:, 1:-1], time_window)
quantiles_tau = self.mcquantiles(logits, tau_emb)
return (quantiles, fractions, quantiles_tau), h
================================================
FILE: examples/decision_making/RL/mcs-fqf/main.py
================================================
import argparse
import os
import pprint
import numpy as np
import torch
from network import SpikingDQN
from ..atari.atari_wrapper import wrap_deepmind
from torch.utils.tensorboard import SummaryWriter
from tianshou.data import Collector, VectorReplayBuffer
from tianshou.env import ShmemVectorEnv
from tianshou.trainer import offpolicy_trainer
from tianshou.utils import TensorboardLogger, SequenceLogger
from discrete import SpikeFractionProposalNetwork, SpikeFullQuantileFunction
from policy import FQFPolicy
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--task', type=str, default='MsPacmanNoFrameskip-v4')
parser.add_argument('--seed', type=int, default=3128)
parser.add_argument('--eps-test', type=float, default=0.005)
parser.add_argument('--eps-train', type=float, default=1.)
parser.add_argument('--eps-train-final', type=float, default=0.05)
parser.add_argument('--buffer-size', type=int, default=100000)
parser.add_argument('--lr', type=float, default=1e-4)
parser.add_argument('--fraction-lr', type=float, default=2.5e-9)
parser.add_argument('--gamma', type=float, default=0.99)
parser.add_argument('--num-fractions', type=int, default=32)
parser.add_argument('--num-cosines', type=int, default=64)
parser.add_argument('--ent-coef', type=float, default=10.)
parser.add_argument('--hidden-sizes', type=int, nargs='*', default=[512])
parser.add_argument('--n-step', type=int, default=3)
parser.add_argument('--target-update-freq', type=int, default=500)
parser.add_argument('--epoch', type=int, default=200)
parser.add_argument('--step-per-epoch', type=int, default=100000)
parser.add_argument('--step-per-collect', type=int, default=10)
# parser.add_argument('--update-per-step', type=float, default=0.1)
parser.add_argument('--update-per-step', type=float, default=0.1)
parser.add_argument('--batch-size', type=int, default=32)
parser.add_argument('--training-num', type=int, default=10)
parser.add_argument('--test-num', type=int, default=10)
parser.add_argument('--logdir', type=str, default='log')
parser.add_argument('--render', type=float, default=0.)
parser.add_argument(
'--device', type=str, default='cuda' if torch.cuda.is_available() else 'cpu'
)
parser.add_argument('--frames-stack', type=int, default=4)
parser.add_argument('--resume-path', type=str, default=None)
parser.add_argument('--resume-id', type=str, default=None)
parser.add_argument(
'--watch',
default=False,
action='store_true',
help='watch the play of pre-trained policy only'
)
parser.add_argument('--save-buffer-name', type=str, default=None)
parser.add_argument('--time-window', type=int, default=8)
parser.add_argument('--prefix', type=str, default='')
parser.add_argument('--save-interval', type=int, default=10)
return parser.parse_args()
def make_atari_env(args):
return wrap_deepmind(args.task, frame_stack=args.frames_stack)
def make_atari_env_watch(args):
return wrap_deepmind(
args.task,
frame_stack=args.frames_stack,
episode_life=False,
clip_rewards=False
)
def main(args=get_args()):
print('Setting: ', args)
env = make_atari_env(args)
args.state_shape = env.observation_space.shape or env.observation_space.n
args.action_shape = env.action_space.shape or env.action_space.n
# should be N_FRAMES x H x W
print("Observations shape:", args.state_shape)
print("Actions shape:", args.action_shape)
print('update_per_step: ', args.update_per_step)
print('lr: ', args.lr)
# make environments
train_envs = ShmemVectorEnv(
[lambda: make_atari_env(args) for _ in range(args.training_num)]
)
test_envs = ShmemVectorEnv(
[lambda: make_atari_env_watch(args) for _ in range(args.test_num)]
)
# define model
feature_net = SpikingDQN(
*args.state_shape, args.action_shape, args.device, time_window=args.time_window, features_only=True
)
net = SpikeFullQuantileFunction(
feature_net,
args.action_shape,
args.hidden_sizes,
args.num_cosines,
device=args.device,
).to(args.device)
optim = torch.optim.Adam(net.parameters(), lr=args.lr)
fraction_net = SpikeFractionProposalNetwork(args.num_fractions, net.input_dim)
fraction_optim = torch.optim.RMSprop(
fraction_net.parameters(), lr=args.fraction_lr
)
# define policy
policy = FQFPolicy(
net,
optim,
fraction_net,
fraction_optim,
args.gamma,
args.num_fractions,
args.ent_coef,
args.n_step,
target_update_freq=args.target_update_freq
).to(args.device)
# load a previous policy
if args.resume_path:
policy.load_state_dict(torch.load(args.resume_path, map_location=args.device))
print("Loaded agent from: ", args.resume_path)
# replay buffer: `save_last_obs` and `stack_num` can be removed together
# when you have enough RAM
buffer = VectorReplayBuffer(
args.buffer_size,
buffer_num=len(train_envs),
ignore_obs_next=True,
save_only_last_obs=True,
stack_num=args.frames_stack
)
# collector
train_collector = Collector(policy, train_envs, buffer, exploration_noise=True)
test_collector = Collector(policy, test_envs, exploration_noise=True)
# log
log_path = os.path.join(args.logdir, args.task, 'spike_fqf', args.prefix)
model_log_path = os.path.join(log_path, 'models')
if not os.path.exists(model_log_path):
os.makedirs(model_log_path)
print('log_path: ', log_path)
writer = SummaryWriter(log_path)
writer.add_text("args", str(args))
logger = TensorboardLogger(writer, save_interval=args.save_interval)
result_logger = SequenceLogger(log_path)
def save_checkpoint_fn(epoch, env_step, gradient_step, epoch_round=True):
# see also: https://pytorch.org/tutorials/beginner/saving_loading_models.html
if epoch_round:
ckpt_path = os.path.join(model_log_path, 'checkpoint_epoch{}.pth'.format(epoch))
else:
ckpt_path = os.path.join(model_log_path, 'checkpoint.pth')
ckpt = {
'epoch': epoch,
'env_step': env_step,
'gradient_step': gradient_step,
'model': policy.state_dict()
}
torch.save(ckpt, ckpt_path)
return ckpt_path
setting_path = os.path.join(log_path, 'settings.txt')
argsDict = args.__dict__
with open(setting_path, 'w') as f:
f.writelines('------------------ start ------------------' + '\n')
for eachArg, value in argsDict.items():
f.writelines(eachArg + ' : ' + str(value) + '\n')
f.writelines('------------------- end -------------------')
def save_fn(policy, is_best=False):
if is_best:
torch.save(policy.state_dict(), os.path.join(log_path, 'best_policy.pth'))
else:
torch.save(policy.state_dict(), os.path.join(log_path, 'policy.pth'))
def stop_fn(mean_rewards):
if env.spec.reward_threshold:
return mean_rewards >= env.spec.reward_threshold
elif 'Pong' in args.task:
return mean_rewards >= 20
else:
return False
def train_fn(epoch, env_step):
# nature DQN setting, linear decay in the first 1M steps
if env_step <= 1e6:
eps = args.eps_train - env_step / 1e6 * \
(args.eps_train - args.eps_train_final)
else:
eps = args.eps_train_final
policy.set_eps(eps)
if env_step % 1000 == 0:
logger.write("train/env_step", env_step, {"train/eps": eps})
def test_fn(epoch, env_step):
policy.set_eps(args.eps_test)
# watch agent's performance
def watch():
print("Setup test envs ...")
policy.eval()
policy.set_eps(args.eps_test)
test_envs.seed(args.seed)
if args.save_buffer_name:
print(f"Generate buffer with size {args.buffer_size}")
buffer = VectorReplayBuffer(
args.buffer_size,
buffer_num=len(test_envs),
ignore_obs_next=True,
save_only_last_obs=True,
stack_num=args.frames_stack
)
collector = Collector(policy, test_envs, buffer, exploration_noise=True)
result = collector.collect(n_step=args.buffer_size)
print(f"Save buffer into {args.save_buffer_name}")
buffer.save_hdf5(args.save_buffer_name)
else:
print("Testing agent ...")
test_collector.reset()
result = test_collector.collect(
n_episode=args.test_num, render=args.render
)
rew = result["rews"].mean()
print(f'Mean reward (over {result["n/ep"]} episodes): {rew}')
if args.watch:
watch()
exit(0)
# test train_collector and start filling replay buffer
train_collector.collect(n_step=args.batch_size * args.training_num)
# trainer
result = offpolicy_trainer(
policy,
train_collector,
test_collector,
args.epoch,
args.step_per_epoch,
args.step_per_collect,
args.test_num,
args.batch_size,
train_fn=train_fn,
test_fn=test_fn,
stop_fn=stop_fn,
save_fn=save_fn,
logger=logger,
update_per_step=args.update_per_step,
test_in_train=False,
resume_from_log=args.resume_id is not None,
save_checkpoint_fn=save_checkpoint_fn,
result_logger=result_logger
)
pprint.pprint(result)
watch()
if __name__ == '__main__':
main(get_args())
================================================
FILE: examples/decision_making/RL/mcs-fqf/network.py
================================================
from typing import Any, Dict, Optional, Sequence, Tuple, Union
import numpy as np
import torch
from torch import nn
from braincog.base.node.node import LIFNode
from ..utils.normalization import PopNorm
class SpikingDQN(nn.Module):
"""Reference: Human-level control through deep reinforcement learning.
For advanced usage (how to customize the network), please refer to
:ref:`build_the_network`.
"""
def __init__(
self,
c: int,
h: int,
w: int,
action_shape: Sequence[int],
device: Union[str, int, torch.device] = "cpu",
time_window: int = 16,
features_only: bool = False,
) -> None:
super().__init__()
self._node = LIFNode
# self._node = ReLUNode
self.features_only = features_only
self.device = device
# self._threshold = 0.5
self._threshold = 1.0
self.v_reset = 0.0
# self._decay = 0.2
self._decay = 0.5
self._time_window = time_window
init_layer = lambda m: init(m, nn.init.orthogonal_, lambda x: nn.init.constant_(x, 0), gain=1)
self.p_count = 0
self.net = nn.Sequential(
# nn.utils.weight_norm(nn.Conv2d(c, 32, kernel_size=8, stride=4)),
nn.Conv2d(c, 32, kernel_size=8, stride=4),
# nn.BatchNorm2d(32),
# self._node(threshold=self._threshold, decay=self._decay),
PopNorm([32, 20, 20], threshold=self._threshold, v_reset=self.v_reset),
self._node(threshold=self._threshold, v_reset=self.v_reset),
# nn.utils.weight_norm(nn.Conv2d(32, 64, kernel_size=4, stride=2)),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
# nn.BatchNorm2d(64),
# self._node(threshold=self._threshold, decay=self._decay),
PopNorm([64, 9, 9], threshold=self._threshold, v_reset=self.v_reset),
self._node(threshold=self._threshold, v_reset=self.v_reset),
# nn.utils.weight_norm(nn.Conv2d(64, 64, kernel_size=3, stride=1)),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
# nn.BatchNorm2d(64),
PopNorm([64, 7, 7], threshold=self._threshold, v_reset=self.v_reset),
# self._node(threshold=self._threshold, decay=self._decay),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Flatten()
)
with torch.no_grad():
self.output_dim = np.prod(self.net(torch.zeros(1, c, h, w)).shape[1:])
if not features_only:
self.net = nn.Sequential(
self.net, nn.Linear(self.output_dim, 512),
# self.net, nn.Linear(self.output_dim, 512),
# self._node(threshold=self._threshold, decay=self._decay),
self._node(threshold=self._threshold, v_reset=self.v_reset),
# nn.Linear(512, np.prod(action_shape))
nn.Linear(512, np.prod(action_shape), bias=False)
)
self.output_dim = np.prod(action_shape)
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def forward(
self,
x: Union[np.ndarray, torch.Tensor],
state: Optional[Any] = None,
info: Dict[str, Any] = {},
) -> Tuple[torch.Tensor, Any]:
r"""Mapping: x -> Q(x, \*)."""
self.reset()
# obs = torch.as_tensor(x, device=self.device, dtype=torch.float32)
x = torch.as_tensor(x, device=self.device, dtype=torch.float32) / 255.0
qs = []
for i in range(self._time_window):
value = self.net(x)
qs.append(value)
if self.features_only:
return qs, state
else:
q_values = sum(qs) / self._time_window
return q_values, state
================================================
FILE: examples/decision_making/RL/mcs-fqf/policy.py
================================================
from typing import Any, Dict, Optional, Union
import numpy as np
import torch
import torch.nn.functional as F
from tianshou.data import Batch, ReplayBuffer, to_numpy
from tianshou.policy import DQNPolicy, QRDQNPolicy
from discrete import SpikeFractionProposalNetwork, SpikeFullQuantileFunction
class FQFPolicy(QRDQNPolicy):
"""Implementation of Fully-parameterized Quantile Function. arXiv:1911.02140.
:param torch.nn.Module model: a model following the rules in
:class:`~tianshou.policy.BasePolicy`. (s -> logits)
:param torch.optim.Optimizer optim: a torch.optim for optimizing the model.
:param FractionProposalNetwork fraction_model: a FractionProposalNetwork for
proposing fractions/quantiles given state.
:param torch.optim.Optimizer fraction_optim: a torch.optim for optimizing
the fraction model above.
:param float discount_factor: in [0, 1].
:param int num_fractions: the number of fractions to use. Default to 32.
:param float ent_coef: the coefficient for entropy loss. Default to 0.
:param int estimation_step: the number of steps to look ahead. Default to 1.
:param int target_update_freq: the target network update frequency (0 if
you do not use the target network).
:param bool reward_normalization: normalize the reward to Normal(0, 1).
Default to False.
.. seealso::
Please refer to :class:`~tianshou.policy.QRDQNPolicy` for more detailed
explanation.
"""
def __init__(
self,
model: SpikeFullQuantileFunction,
optim: torch.optim.Optimizer,
fraction_model: SpikeFractionProposalNetwork,
fraction_optim: torch.optim.Optimizer,
discount_factor: float = 0.99,
num_fractions: int = 32,
ent_coef: float = 0.0,
estimation_step: int = 1,
target_update_freq: int = 0,
reward_normalization: bool = False,
**kwargs: Any,
) -> None:
super().__init__(
model, optim, discount_factor, num_fractions, estimation_step,
target_update_freq, reward_normalization, **kwargs
)
self.propose_model = fraction_model
self._ent_coef = ent_coef
self._fraction_optim = fraction_optim
def _target_q(self, buffer: ReplayBuffer, indices: np.ndarray) -> torch.Tensor:
batch = buffer[indices] # batch.obs_next: s_{t+n}
if self._target:
result = self(batch, input="obs_next")
a, fractions = result.act, result.fractions
next_dist = self(
batch, model="model_old", input="obs_next", fractions=fractions
).logits
else:
next_b = self(batch, input="obs_next")
a = next_b.act
next_dist = next_b.logits
next_dist = next_dist[np.arange(len(a)), a, :]
return next_dist # shape: [bsz, num_quantiles]
def forward(
self,
batch: Batch,
state: Optional[Union[dict, Batch, np.ndarray]] = None,
model: str = "model",
input: str = "obs",
fractions: Optional[Batch] = None,
**kwargs: Any,
) -> Batch:
model = getattr(self, model)
obs = batch[input]
obs_ = obs.obs if hasattr(obs, "obs") else obs
# print('fractions: ', fractions)
if fractions is None:
(logits, fractions, quantiles_tau), h = model(
obs_, propose_model=self.propose_model, state=state, info=batch.info
)
else:
(logits, _, quantiles_tau), h = model(
obs_,
propose_model=self.propose_model,
fractions=fractions,
state=state,
info=batch.info
)
# print('fractions.taus shape : ', fractions.taus.shape)
# print('logits shape: ', logits.shape)
weighted_logits = (fractions.taus[:, 1:] -
fractions.taus[:, :-1]).unsqueeze(1) * logits
# print('weighted_logits shape: ', weighted_logits.shape)
q = DQNPolicy.compute_q_value(
self, weighted_logits.sum(2), getattr(obs, "mask", None)
)
if not hasattr(self, "max_action_num"):
self.max_action_num = q.shape[1]
act = to_numpy(q.max(dim=1)[1])
return Batch(
logits=logits,
act=act,
state=h,
fractions=fractions,
quantiles_tau=quantiles_tau
)
def learn(self, batch: Batch, **kwargs: Any) -> Dict[str, float]:
if self._target and self._iter % self._freq == 0:
self.sync_weight()
weight = batch.pop("weight", 1.0)
out = self(batch)
curr_dist_orig = out.logits
taus, tau_hats = out.fractions.taus, out.fractions.tau_hats
act = batch.act
curr_dist = curr_dist_orig[np.arange(len(act)), act, :].unsqueeze(2)
target_dist = batch.returns.unsqueeze(1)
# calculate each element's difference between curr_dist and target_dist
u = F.smooth_l1_loss(target_dist, curr_dist, reduction="none")
huber_loss = (
u * (
tau_hats.unsqueeze(2) -
(target_dist - curr_dist).detach().le(0.).float()
).abs()
).sum(-1).mean(1)
quantile_loss = (huber_loss * weight).mean()
# ref: https://github.com/ku2482/fqf-iqn-qrdqn.pytorch/
# blob/master/fqf_iqn_qrdqn/agent/qrdqn_agent.py L130
batch.weight = u.detach().abs().sum(-1).mean(1) # prio-buffer
# calculate fraction loss
with torch.no_grad():
sa_quantile_hats = curr_dist_orig[np.arange(len(act)), act, :]
sa_quantiles = out.quantiles_tau[np.arange(len(act)), act, :]
# ref: https://github.com/ku2482/fqf-iqn-qrdqn.pytorch/
# blob/master/fqf_iqn_qrdqn/agent/fqf_agent.py L169
values_1 = sa_quantiles - sa_quantile_hats[:, :-1]
signs_1 = sa_quantiles > torch.cat(
[sa_quantile_hats[:, :1], sa_quantiles[:, :-1]], dim=1
)
values_2 = sa_quantiles - sa_quantile_hats[:, 1:]
signs_2 = sa_quantiles < torch.cat(
[sa_quantiles[:, 1:], sa_quantile_hats[:, -1:]], dim=1
)
gradient_of_taus = (
torch.where(signs_1, values_1, -values_1) +
torch.where(signs_2, values_2, -values_2)
)
fraction_loss = (gradient_of_taus * taus[:, 1:-1]).sum(1).mean()
# calculate entropy loss
entropy_loss = out.fractions.entropies.mean()
fraction_entropy_loss = fraction_loss - self._ent_coef * entropy_loss
self._fraction_optim.zero_grad()
fraction_entropy_loss.backward(retain_graph=True)
self._fraction_optim.step()
self.optim.zero_grad()
quantile_loss.backward()
self.optim.step()
self._iter += 1
return {
"loss": quantile_loss.item() + fraction_entropy_loss.item(),
"loss/quantile": quantile_loss.item(),
"loss/fraction": fraction_loss.item(),
"loss/entropy": entropy_loss.item()
}
================================================
FILE: examples/decision_making/RL/requirements.txt
================================================
gym
atari-py
opencv-python
tianshou
================================================
FILE: examples/decision_making/RL/sdqn/main.py
================================================
import argparse
import os
import pprint
import numpy as np
import torch
try:
import tianshou
except:
raise ImportError('Need install "tianshou" lib at https://github.com/thu-ml/tianshou !')
from tianshou.data import Collector, VectorReplayBuffer
from tianshou.env import ShmemVectorEnv
from tianshou.policy import DQNPolicy
from tianshou.trainer import offpolicy_trainer
from tianshou.utils import TensorboardLogger, WandbLogger
import random
from network import SpikingDQN
from ..atari.atari_wrapper import wrap_deepmind
from torch.utils.tensorboard import SummaryWriter
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--task', type=str, default='PongNoFrameskip-v4')
parser.add_argument('--seed', type=int, default=40)
parser.add_argument('--eps-test', type=float, default=0.005)
parser.add_argument('--eps-train', type=float, default=1.)
parser.add_argument('--eps-train-final', type=float, default=0.05)
parser.add_argument('--buffer-size', type=int, default=100000)
parser.add_argument('--lr', type=float, default=0.0001)
parser.add_argument('--gamma', type=float, default=0.99)
parser.add_argument('--n-step', type=int, default=3)
parser.add_argument('--target-update-freq', type=int, default=500)
parser.add_argument('--epoch', type=int, default=100)
parser.add_argument('--step-per-epoch', type=int, default=100000)
parser.add_argument('--step-per-collect', type=int, default=10)
parser.add_argument('--update-per-step', type=float, default=0.1)
parser.add_argument('--batch-size', type=int, default=32)
parser.add_argument('--training-num', type=int, default=10)
parser.add_argument('--test-num', type=int, default=10)
parser.add_argument('--logdir', type=str, default='log')
parser.add_argument('--render', type=float, default=0.)
parser.add_argument(
'--device', type=str, default='cuda' if torch.cuda.is_available() else 'cpu'
)
parser.add_argument('--frames-stack', type=int, default=4)
parser.add_argument('--resume-path', type=str, default=None)
parser.add_argument('--resume-id', type=str, default=None)
parser.add_argument('--time-window', type=int, default=16)
parser.add_argument(
'--spike',
default=False,
action='store_true',
help='execute spike dqn'
)
parser.add_argument(
'--logger',
type=str,
default="tensorboard",
choices=["tensorboard", "wandb"],
)
parser.add_argument(
'--watch',
default=False,
action='store_true',
help='watch the play of pre-trained policy only'
)
parser.add_argument('--save-buffer-name', type=str, default=None)
return parser.parse_args()
def make_atari_env(args):
return wrap_deepmind(args.task, frame_stack=args.frames_stack)
def make_atari_env_watch(args):
return wrap_deepmind(
args.task,
frame_stack=args.frames_stack,
episode_life=False,
clip_rewards=False
)
def main(args=get_args()):
print('n_step: ', args.n_step)
env = make_atari_env(args)
args.state_shape = env.observation_space.shape or env.observation_space.n
args.action_shape = env.action_space.shape or env.action_space.n
# should be N_FRAMES x H x W
print("Observations shape:", args.state_shape)
print("Actions shape:", args.action_shape)
print('logdir', args.logdir)
print('Spiking', args.spike)
# make environments
train_envs = ShmemVectorEnv(
[lambda: make_atari_env(args) for _ in range(args.training_num)]
)
test_envs = ShmemVectorEnv(
[lambda: make_atari_env_watch(args) for _ in range(args.test_num)]
)
# seed
os.environ['PYTHONHASHSEED'] = str(args.seed)
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed_all(args.seed)
train_envs.seed(args.seed)
test_envs.seed(args.seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
net = SpikingDQN(*args.state_shape, args.action_shape, args.device, args.time_window).to(args.device)
# optim = torch.optim.Adam(net.parameters(), lr=args.lr)
optim = torch.optim.AdamW(net.parameters(), lr=args.lr)
# define policy
policy = DQNPolicy(
net,
optim,
args.gamma,
args.n_step,
target_update_freq=args.target_update_freq
)
# load a previous policy
if args.resume_path:
policy.load_state_dict(torch.load(args.resume_path, map_location=args.device))
print("Loaded agent from: ", args.resume_path)
# replay buffer: `save_last_obs` and `stack_num` can be removed together
# when you have enough RAM
buffer = VectorReplayBuffer(
args.buffer_size,
buffer_num=len(train_envs),
ignore_obs_next=True,
save_only_last_obs=True,
stack_num=args.frames_stack
)
# collector
train_collector = Collector(policy, train_envs, buffer, exploration_noise=True)
test_collector = Collector(policy, test_envs, exploration_noise=True)
# log
log_path = os.path.join(args.logdir, args.task, 'csdqn')
if args.logger == "tensorboard":
writer = SummaryWriter(log_path)
writer.add_text("args", str(args))
logger = TensorboardLogger(writer)
else:
logger = WandbLogger(
save_interval=1,
project=args.task,
name='dqn',
run_id=args.resume_id,
config=args,
)
def save_fn(policy):
torch.save(policy.state_dict(), os.path.join(log_path, 'policy.pth'))
def stop_fn(mean_rewards):
if env.spec.reward_threshold:
return mean_rewards >= env.spec.reward_threshold
elif 'Pong' in args.task:
return mean_rewards >= 20
else:
return False
def train_fn(epoch, env_step):
# nature DQN setting, linear decay in the first 1M steps
if env_step <= 1e6:
eps = args.eps_train - env_step / 1e6 * \
(args.eps_train - args.eps_train_final)
else:
eps = args.eps_train_final
policy.set_eps(eps)
if env_step % 1000 == 0:
logger.write("train/env_step", env_step, {"train/eps": eps})
def test_fn(epoch, env_step):
policy.set_eps(args.eps_test)
def save_checkpoint_fn(epoch, env_step, gradient_step):
# see also: https://pytorch.org/tutorials/beginner/saving_loading_models.html
ckpt_path = os.path.join(log_path, 'checkpoint.pth')
torch.save({'model': policy.state_dict()}, ckpt_path)
return ckpt_path
# watch agent's performance
def watch():
print("Setup test envs ...")
policy.eval()
policy.set_eps(args.eps_test)
test_envs.seed(args.seed)
if args.save_buffer_name:
print(f"Generate buffer with size {args.buffer_size}")
buffer = VectorReplayBuffer(
args.buffer_size,
buffer_num=len(test_envs),
ignore_obs_next=True,
save_only_last_obs=True,
stack_num=args.frames_stack
)
collector = Collector(policy, test_envs, buffer, exploration_noise=True)
result = collector.collect(n_step=args.buffer_size)
print(f"Save buffer into {args.save_buffer_name}")
# Unfortunately, pickle will cause oom with 1M buffer size
buffer.save_hdf5(args.save_buffer_name)
else:
print("Testing agent ...")
test_collector.reset()
result = test_collector.collect(
n_episode=args.test_num, render=args.render
)
rew = result["rews"].mean()
print(f'Mean reward (over {result["n/ep"]} episodes): {rew}')
if args.watch:
watch()
exit(0)
# test train_collector and start filling replay buffer
train_collector.collect(n_step=args.batch_size * args.training_num)
# trainer
result = offpolicy_trainer(
policy,
train_collector,
test_collector,
args.epoch,
args.step_per_epoch,
args.step_per_collect,
args.test_num,
args.batch_size,
train_fn=train_fn,
test_fn=test_fn,
stop_fn=stop_fn,
save_fn=save_fn,
logger=logger,
update_per_step=args.update_per_step,
test_in_train=False,
resume_from_log=args.resume_id is not None,
save_checkpoint_fn=save_checkpoint_fn,
)
pprint.pprint(result)
watch()
if __name__ == '__main__':
main(get_args())
================================================
FILE: examples/decision_making/RL/sdqn/network.py
================================================
from typing import Any, Dict, Optional, Sequence, Tuple, Union
import numpy as np
import torch
from torch import nn
from braincog.base.node.node import LIFNode
from ..utils.normalization import PopNorm
class SpikingDQN(nn.Module):
"""Reference: Human-level control through deep reinforcement learning.
For advanced usage (how to customize the network), please refer to
:ref:`build_the_network`.
"""
def __init__(
self,
c: int,
h: int,
w: int,
action_shape: Sequence[int],
device: Union[str, int, torch.device] = "cpu",
time_window: int = 16,
features_only: bool = False,
) -> None:
super().__init__()
self._node = LIFNode
self.features_only = features_only
self.device = device
self._threshold = 1.0
self.v_reset = 0.0
self._decay = 0.5
self._time_window = time_window
self.p_count = 0
self.net = nn.Sequential(
nn.Conv2d(c, 32, kernel_size=8, stride=4),
PopNorm([32, 20, 20], threshold=self._threshold, v_reset=self.v_reset),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
PopNorm([64, 9, 9], threshold=self._threshold, v_reset=self.v_reset),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
PopNorm([64, 7, 7], threshold=self._threshold, v_reset=self.v_reset),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Flatten()
)
with torch.no_grad():
self.output_dim = np.prod(self.net(torch.zeros(1, c, h, w)).shape[1:])
if not features_only:
self.net = nn.Sequential(
self.net, nn.Linear(self.output_dim, 512),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Linear(512, np.prod(action_shape), bias=False)
)
self.output_dim = np.prod(action_shape)
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def forward(
self,
x: Union[np.ndarray, torch.Tensor],
state: Optional[Any] = None,
info: Dict[str, Any] = {},
) -> Tuple[torch.Tensor, Any]:
r"""Mapping: x -> Q(x, \*)."""
self.reset()
x = torch.as_tensor(x, device=self.device, dtype=torch.float32) / 255.0
qs = []
for i in range(self._time_window):
value = self.net(x)
qs.append(value)
if self.features_only:
return qs, state
else:
q_values = sum(qs) / self._time_window
return q_values, state
================================================
FILE: examples/decision_making/RL/utils/__init__.py
================================================
__all__ = ['normalization']
from . import (
normalization,
)
================================================
FILE: examples/decision_making/RL/utils/normalization.py
================================================
from typing import Optional, Any
import torch
import torch.nn as nn
from torch import Tensor
from torch.nn.parameter import Parameter, UninitializedParameter, UninitializedBuffer
import torch.nn.functional as F
from torch import Tensor, Size
from typing import Union, List
import numbers
from torch.nn import Module
_shape_t = Union[int, List[int], Size]
class PopNorm(Module):
r"""Applies Layer Normalization over a mini-batch of inputs as described in
the paper `Layer Normalization `__
.. math::
y = \frac{x - \mathrm{E}[x]}{ \sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta
The mean and standard-deviation are calculated separately over the last
certain number dimensions which have to be of the shape specified by
:attr:`normalized_shape`.
:math:`\gamma` and :math:`\beta` are learnable affine transform parameters of
:attr:`normalized_shape` if :attr:`elementwise_affine` is ``True``.
The standard-deviation is calculated via the biased estimator, equivalent to
`torch.var(input, unbiased=False)`.
.. note::
Unlike Batch Normalization and Instance Normalization, which applies
scalar scale and bias for each entire channel/plane with the
:attr:`affine` option, Layer Normalization applies per-element scale and
bias with :attr:`elementwise_affine`.
This layer uses statistics computed from input data in both training and
evaluation modes.
Args:
normalized_shape (int or list or torch.Size): input shape from an expected input
of size
.. math::
[* \times \text{normalized\_shape}[0] \times \text{normalized\_shape}[1]
\times \ldots \times \text{normalized\_shape}[-1]]
If a single integer is used, it is treated as a singleton list, and this module will
normalize over the last dimension which is expected to be of that specific size.
eps: a value added to the denominator for numerical stability. Default: 1e-5
elementwise_affine: a boolean value that when set to ``True``, this module
has learnable per-element affine parameters initialized to ones (for weights)
and zeros (for biases). Default: ``True``.
Shape:
- Input: :math:`(N, *)`
- Output: :math:`(N, *)` (same shape as input)
Examples::
>>> input = torch.randn(20, 5, 10, 10)
>>> # With Learnable Parameters
>>> m = nn.LayerNorm(input.size()[1:])
>>> # Without Learnable Parameters
>>> m = nn.LayerNorm(input.size()[1:], elementwise_affine=False)
>>> # Normalize over last two dimensions
>>> m = nn.LayerNorm([10, 10])
>>> # Normalize over last dimension of size 10
>>> m = nn.LayerNorm(10)
>>> # Activating the module
>>> output = m(input)
"""
__constants__ = ['normalized_shape', 'eps', 'elementwise_affine']
normalized_shape: _shape_t
eps: float
elementwise_affine: bool
def __init__(self, normalized_shape: _shape_t, threshold: float, v_reset: float, eps: float = 1e-5, affine: bool = True) -> None:
super().__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
self.normalized_shape = tuple(normalized_shape)
self.threshold = threshold
self.v_reset = v_reset
self.eps = eps
self.affine = affine
if self.affine:
# self.weight = Parameter(torch.Tensor(*normalized_shape))
self.weight = Parameter(torch.Tensor(*normalized_shape))
self.bias = Parameter(torch.Tensor(*normalized_shape))
else:
self.register_parameter('weight', None)
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self) -> None:
if self.affine:
# nn.init.ones_(self.weight)
# nn.init.zeros_(self.bias)
nn.init.constant_(self.weight, self.threshold-self.v_reset)
nn.init.constant_(self.bias, self.v_reset)
def forward(self, input: Tensor) -> Tensor:
out = F.layer_norm(
input, self.normalized_shape, self.weight, self.bias, self.eps)
# out = F.layer_norm(
# input, self.normalized_shape, None, None, self.eps)
# if self.affine:
# out = self.weight * out + self.bias
return out
def extra_repr(self) -> Tensor:
return '{normalized_shape}, eps={eps}, ' \
'elementwise_affine={elementwise_affine}'.format(**self.__dict__)
class _NormBase(nn.Module):
"""Common base of _InstanceNorm and _BatchNorm"""
_version = 2
__constants__ = ["track_running_stats", "momentum", "eps", "num_features", "affine"]
num_features: int
eps: float
momentum: float
affine: bool
track_running_stats: bool
# WARNING: weight and bias purposely not defined here.
# See https://github.com/pytorch/pytorch/issues/39670
def __init__(
self,
num_features: int,
eps: float = 1e-5,
momentum: float = 0.1,
affine: bool = True,
track_running_stats: bool = True,
mean: float = 0.2,
device=None,
dtype=None
) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(_NormBase, self).__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
self.affine = affine
self.track_running_stats = track_running_stats
self.mean = mean
if self.affine:
self.weight = Parameter(torch.empty(num_features, **factory_kwargs))
self.bias = Parameter(torch.empty(num_features, **factory_kwargs))
# self.bias = Parameter(torch.empty(num_features, **factory_kwargs), requires_grad=False)
else:
self.register_parameter("weight", None)
self.register_parameter("bias", None)
if self.track_running_stats:
self.register_buffer('running_mean', torch.zeros(num_features, **factory_kwargs))
self.register_buffer('running_var', torch.ones(num_features, **factory_kwargs))
self.running_mean: Optional[Tensor]
self.running_var: Optional[Tensor]
self.register_buffer('num_batches_tracked',
torch.tensor(0, dtype=torch.long,
**{k: v for k, v in factory_kwargs.items() if k != 'dtype'}))
else:
self.register_buffer("running_mean", None)
self.register_buffer("running_var", None)
self.register_buffer("num_batches_tracked", None)
self.reset_parameters()
def reset_running_stats(self) -> None:
if self.track_running_stats:
# running_mean/running_var/num_batches... are registered at runtime depending
# if self.track_running_stats is on
self.running_mean.zero_() # type: ignore[union-attr]
self.running_var.fill_(1) # type: ignore[union-attr]
self.num_batches_tracked.zero_() # type: ignore[union-attr,operator]
def reset_parameters(self) -> None:
self.reset_running_stats()
if self.affine:
nn.init.ones_(self.weight)
# nn.init.zeros_(self.bias)
nn.init.constant_(self.bias, self.mean)
def _check_input_dim(self, input):
raise NotImplementedError
def extra_repr(self):
return (
"{num_features}, eps={eps}, momentum={momentum}, affine={affine}, "
"track_running_stats={track_running_stats}".format(**self.__dict__)
)
def _load_from_state_dict(
self,
state_dict,
prefix,
local_metadata,
strict,
missing_keys,
unexpected_keys,
error_msgs,
):
version = local_metadata.get("version", None)
if (version is None or version < 2) and self.track_running_stats:
# at version 2: added num_batches_tracked buffer
# this should have a default value of 0
num_batches_tracked_key = prefix + "num_batches_tracked"
if num_batches_tracked_key not in state_dict:
state_dict[num_batches_tracked_key] = torch.tensor(0, dtype=torch.long)
super(_NormBase, self)._load_from_state_dict(
state_dict,
prefix,
local_metadata,
strict,
missing_keys,
unexpected_keys,
error_msgs,
)
class _BatchNorm(_NormBase):
def __init__(
self,
num_features,
eps=1e-5,
momentum=0.1,
affine=True,
track_running_stats=True,
mean=0.2,
device=None,
dtype=None
):
factory_kwargs = {'device': device, 'dtype': dtype}
super().__init__(
num_features, eps, momentum, affine, track_running_stats, mean, **factory_kwargs
)
def forward(self, input: Tensor) -> Tensor:
self._check_input_dim(input)
# exponential_average_factor is set to self.momentum
# (when it is available) only so that it gets updated
# in ONNX graph when this node is exported to ONNX.
if self.momentum is None:
exponential_average_factor = 0.0
else:
exponential_average_factor = self.momentum
if self.training and self.track_running_stats:
# TODO: if statement only here to tell the jit to skip emitting this when it is None
if self.num_batches_tracked is not None: # type: ignore[has-type]
self.num_batches_tracked = self.num_batches_tracked + 1 # type: ignore[has-type]
if self.momentum is None: # use cumulative moving average
exponential_average_factor = 1.0 / float(self.num_batches_tracked)
else: # use exponential moving average
exponential_average_factor = self.momentum
r"""
Decide whether the mini-batch stats should be used for normalization rather than the buffers.
Mini-batch stats are used in training mode, and in eval mode when buffers are None.
"""
if self.training:
bn_training = True
else:
bn_training = (self.running_mean is None) and (self.running_var is None)
r"""
Buffers are only updated if they are to be tracked and we are in training mode. Thus they only need to be
passed when the update should occur (i.e. in training mode when they are tracked), or when buffer stats are
used for normalization (i.e. in eval mode when buffers are not None).
"""
return F.batch_norm(
input,
# If buffers are not to be tracked, ensure that they won't be updated
self.running_mean
if not self.training or self.track_running_stats
else None,
self.running_var if not self.training or self.track_running_stats else None,
self.weight,
self.bias,
bn_training,
exponential_average_factor,
self.eps,
)
class PDBatchNorm2d(_BatchNorm):
r"""Applies Batch Normalization over a 4D input (a mini-batch of 2D inputs
with additional channel dimension) as described in the paper
`Batch Normalization: Accelerating Deep Network Training by Reducing
Internal Covariate Shift `__ .
.. math::
y = \frac{x - \mathrm{E}[x]}{ \sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta
The mean and standard-deviation are calculated per-dimension over
the mini-batches and :math:`\gamma` and :math:`\beta` are learnable parameter vectors
of size `C` (where `C` is the input size). By default, the elements of :math:`\gamma` are set
to 1 and the elements of :math:`\beta` are set to 0. The standard-deviation is calculated
via the biased estimator, equivalent to `torch.var(input, unbiased=False)`.
Also by default, during training this layer keeps running estimates of its
computed mean and variance, which are then used for normalization during
evaluation. The running estimates are kept with a default :attr:`momentum`
of 0.1.
If :attr:`track_running_stats` is set to ``False``, this layer then does not
keep running estimates, and batch statistics are instead used during
evaluation time as well.
.. note::
This :attr:`momentum` argument is different from one used in optimizer
classes and the conventional notion of momentum. Mathematically, the
update rule for running statistics here is
:math:`\hat{x}_\text{new} = (1 - \text{momentum}) \times \hat{x} + \text{momentum} \times x_t`,
where :math:`\hat{x}` is the estimated statistic and :math:`x_t` is the
new observed value.
Because the Batch Normalization is done over the `C` dimension, computing statistics
on `(N, H, W)` slices, it's common terminology to call this Spatial Batch Normalization.
Args:
num_features: :math:`C` from an expected input of size
:math:`(N, C, H, W)`
eps: a value added to the denominator for numerical stability.
Default: 1e-5
momentum: the value used for the running_mean and running_var
computation. Can be set to ``None`` for cumulative moving average
(i.e. simple average). Default: 0.1
affine: a boolean value that when set to ``True``, this module has
learnable affine parameters. Default: ``True``
track_running_stats: a boolean value that when set to ``True``, this
module tracks the running mean and variance, and when set to ``False``,
this module does not track such statistics, and initializes statistics
buffers :attr:`running_mean` and :attr:`running_var` as ``None``.
When these buffers are ``None``, this module always uses batch statistics.
in both training and eval modes. Default: ``True``
Shape:
- Input: :math:`(N, C, H, W)`
- Output: :math:`(N, C, H, W)` (same shape as input)
Examples::
>>> # With Learnable Parameters
>>> m = nn.BatchNorm2d(100)
>>> # Without Learnable Parameters
>>> m = nn.BatchNorm2d(100, affine=False)
>>> input = torch.randn(20, 100, 35, 45)
>>> output = m(input)
"""
def _check_input_dim(self, input):
if input.dim() != 4:
raise ValueError("expected 4D input (got {}D input)".format(input.dim()))
================================================
FILE: examples/decision_making/swarm/Collision-Avoidance.py
================================================
import torch,os
from braincog.model_zoo.rsnn import RSNN
from random import randint
import math
import random
import matplotlib
# matplotlib.use("TkAgg")
import numpy as np
import random
import matplotlib.pyplot as plt
import matplotlib.animation as animation
#os.environ["SDL_VIDEODRIVER"] = "dummy"
#parameters
N =10
WORLD_WIDTH = 500
COLLISION_THRE =25 #60 65 70
WALL_COLLISION_LIMIT=10
VISIBLE_THRE=75 #3=75/COLLISION_THRE #3*COLLISION_THRE
#eight velocity
vel_space=[[0,1],[1,0],[0,-1],[-1,0],[1,1],[1,-1],[-1,-1],[-1,1]]
vel_x_small=[[0,1],[1,0],[0,-1],[1,1],[1,-1]]
vel_x_large=[[0,1],[0,-1],[-1,0],[-1,-1],[-1,1]]
vel_y_small=[[0,1],[1,0],[-1,0],[1,1],[-1,1]]
vel_y_large=[[1,0],[0,-1],[-1,0],[1,-1],[-1,-1]]
N_action=len(vel_space)
col_robot=[i for i in range(N)]
# parameters for rl+snn
C = 50
runtime = 100 # Runtime in ms for choosing action
# parameters for snn
tau = 10 # time constant of STDP
stdpwin = 10 # STDP windows in ms
Apos = 0.925
Aneg = 0.1
vr = 0 # Reset Potential
vt = 0.1 # Judge if the neurons fire or not
tau_m = 20
Rm = 0.5
tau_e = 5
# inhibition weight between output population
s_in = np.random.rand(N_action * C, N_action * C)
for i in range(N_action):
for j in range(C):
for k in range(C):
s_in[i * C + j][i * C + k] = 0
#init boids with no collision
global boids
boids = np.zeros(N, dtype=[('pos', int, 2), ('vel', int, 2),('nn',RSNN)])
list_rand=[i for i in range(16)]
rand_int=random.sample(list_rand,N)
for i in range(len(rand_int)):
boids['pos'][i,0]=np.random.uniform(int(rand_int[i]%4)*125,(int(rand_int[i]%4)+1)*125+1,1)
boids['pos'][i,1] = np.random.uniform(int(rand_int[i]/4) * 125, (int(rand_int[i]/4) + 1) * 125 + 1, 1)
boids['vel'] = np.random.uniform(-1, 2, (N, 2))
for i_vel in range(len(boids['vel'])):
boids['nn'][i_vel] = RSNN(N_action*2,N_action*C).cuda()
while(boids['vel'][i_vel][0]==0 and boids['vel'][i_vel][1]==0):
boids['vel'][i_vel] = np.random.uniform(-1, 2, (1, 2))
#update boids parameters
do_update=np.zeros(N)
distance_pre=np.zeros((N,N))
tmp_min_robot=[i for i in range(N)]
tmp_input=[i for i in range(N)]
sum_deta_tmp=np.zeros(N)
sum_deta_new=np.zeros(N)
trace_decay = 0.8
def chooseAct(Net,input,explore):
count_group = np.zeros(N_action)
count_output = np.zeros(N_action * C)
if explore==-1:
pass
else:
pass
for i_train in range(runtime):
out, dw = Net(input[:,i_train])
# rstdp
Net.weight_trace *= trace_decay
Net.weight_trace += dw[0][0]
count_output=count_output+np.array(out)
for i in range(N_action):
count_group[i]=count_output[i*C:(i+1)*C].sum()
if count_group.max()>C/2:
action=count_group.argmax()
return action,Net
# if t==runtime-2 and len(np.where(self.count_group==0)[0])!=len(self.count_group):
# self.action=self.count_group.argmax()
def update_boids(xs, ys, xvs, yvs,frame):
global distance_pre,col_c
# Matrix off position difference and distance
xdiff = np.add.outer(xs, -xs)
ydiff = np.add.outer(ys, -ys)
distance = np.sqrt(xdiff ** 2 + ydiff ** 2)
# Calculate the boids that are visible to every other boid -pi/2 to pi/2
visible = np.zeros((N, N))
dir = np.zeros((N, N))
col_c = WORLD_WIDTH * np.ones((N, 4))
dir_c = np.zeros((N, 4))
angle_towards = np.arctan2(-ydiff, -xdiff)
angle_vel = np.arctan2(yvs, xvs)
for i in range(N):
for j in range(N):
if (xvs[i] == 1 and yvs[i] == 0) or (xvs[i] == 1 and yvs[i] == 1) or (xvs[i] == 0 and yvs[i] == 1) or (
xvs[i] == 0 and yvs[i] == -1) or (xvs[i] == 1 and yvs[i] == -1):
if angle_towards[i][j] < angle_vel[i] + np.pi / 2 and angle_towards[i][j] > angle_vel[i] - np.pi / 2:
visible[i][j] = True
if angle_towards[i][j] > angle_vel[i] - np.pi / 2 and angle_towards[i][j] < angle_vel[i]:
dir[i][j]=1#right
if angle_towards[i][j] < angle_vel[i] + np.pi / 2 and angle_towards[i][j] >= angle_vel[i]:
dir[i][j] = 2#left
if xvs[i] == -1 and yvs[i] == 1:
if (angle_towards[i][j] > angle_vel[i] - np.pi / 2 and angle_towards[i][j] < np.pi) or (
angle_towards[i][j] > -np.pi and angle_towards[i][j] < angle_vel[i] - 1.5 * np.pi):
visible[i][j] = True
if angle_towards[i][j] > angle_vel[i] - np.pi / 2 and angle_towards[i][j] < angle_vel[i]:
dir[i][j] = 1
if (angle_towards[i][j] < np.pi and angle_towards[i][j] >= angle_vel[i]) or (
angle_towards[i][j] > -np.pi and angle_towards[i][j] < angle_vel[i] - 1.5 * np.pi):
dir[i][j] = 2
if xvs[i] == -1 and yvs[i] == 0:
if (angle_towards[i][j] > np.pi / 2 and angle_towards[i][j] < np.pi) or (
angle_towards[i][j] > -np.pi and angle_towards[i][j] < -np.pi / 2):
visible[i][j] = True
if angle_towards[i][j] > np.pi / 2 and angle_towards[i][j] < np.pi:
dir[i][j] = 1
if angle_towards[i][j] >= -np.pi and angle_towards[i][j] < -np.pi / 2:
dir[i][j] = 2
if xvs[i] == -1 and yvs[i] == -1:
if (angle_towards[i][j] > -np.pi and angle_towards[i][j] < -np.pi / 4) or (
angle_towards[i][j] > 0.75 * np.pi and angle_towards[i][j] < np.pi):
visible[i][j] = True
if (angle_towards[i][j] > 0.75 * np.pi and angle_towards[i][j] < np.pi) or (
angle_towards[i][j] > -np.pi and angle_towards[i][j] < angle_vel[i]):
dir[i][j] = 1
if angle_towards[i][j] >= angle_vel[i] and angle_towards[i][j] < -np.pi / 4:
dir[i][j] = 2
v_tmp = np.diag(np.diag(visible))
visible = visible - v_tmp
# the danger of collision, considering dis=6*collision
collision = np.clip(VISIBLE_THRE/COLLISION_THRE - distance / COLLISION_THRE, 0,VISIBLE_THRE/COLLISION_THRE) * visible # visible and in some distance 3*collision_thre
c_tmp = np.diag(np.diag(collision))
collision = collision - c_tmp
if len(np.where(yvs[np.where(ys < (VISIBLE_THRE/COLLISION_THRE)*WALL_COLLISION_LIMIT)] == -1)[0])>0:
wall_tmp=np.where(ys < (VISIBLE_THRE/COLLISION_THRE)*WALL_COLLISION_LIMIT)[0]
for i_wall in range(len(wall_tmp)):
if yvs[wall_tmp[i_wall]] == -1:
col_c[wall_tmp[i_wall], 0] = ys[wall_tmp[i_wall]]
if xvs[wall_tmp[i_wall]] >= 0:
dir_c[wall_tmp[i_wall], 0] = 1
else:
dir_c[wall_tmp[i_wall], 1] = 2
if len(np.where(xvs[np.where(xs < (VISIBLE_THRE/COLLISION_THRE)*WALL_COLLISION_LIMIT)]==-1)[0])>0:
wall_tmp = np.where(xs < (VISIBLE_THRE/COLLISION_THRE)*WALL_COLLISION_LIMIT)[0]
for i_wall in range(len(wall_tmp)):
if xvs[wall_tmp[i_wall]] == -1:
col_c[wall_tmp[i_wall], 1] = xs[wall_tmp[i_wall]]
if yvs[wall_tmp[i_wall]] >= 0:
dir_c[wall_tmp[i_wall], 1] = 2
else:
dir_c[wall_tmp[i_wall], 1] = 1
if len(np.where(yvs[np.where((WORLD_WIDTH - ys) < (VISIBLE_THRE/COLLISION_THRE) * WALL_COLLISION_LIMIT)] == 1)[0]) > 0:
wall_tmp = np.where((WORLD_WIDTH - ys) < (VISIBLE_THRE/COLLISION_THRE) * WALL_COLLISION_LIMIT)[0]
for i_wall in range(len(wall_tmp)):
if yvs[wall_tmp[i_wall]]==1:
col_c[wall_tmp[i_wall],2] =WORLD_WIDTH - ys[wall_tmp[i_wall]]
if xvs[wall_tmp[i_wall]]>=0:
dir_c[wall_tmp[i_wall],2]=2
else:
dir_c[wall_tmp[i_wall], 2] = 1
if len(np.where(xvs[np.where((WORLD_WIDTH - xs) < (VISIBLE_THRE/COLLISION_THRE)*WALL_COLLISION_LIMIT)] ==1)[0])>0:
wall_tmp=np.where((WORLD_WIDTH - xs) < (VISIBLE_THRE/COLLISION_THRE) * WALL_COLLISION_LIMIT)[0]
for i_wall in range(len(wall_tmp)):
if xvs[wall_tmp[i_wall]]==1:
col_c[wall_tmp[i_wall],3] =WORLD_WIDTH - xs[wall_tmp[i_wall]]
if yvs[wall_tmp[i_wall]]>=0:
dir_c[wall_tmp[i_wall],3]=1
else:
dir_c[wall_tmp[i_wall], 3] = 2
# print(col_c)
col_c_tmp = np.clip(VISIBLE_THRE/COLLISION_THRE - col_c / WALL_COLLISION_LIMIT, 0, VISIBLE_THRE/COLLISION_THRE)
deta_dis_tmp = distance - distance_pre
deta_dis = deta_dis_tmp * collision # <0 and small is the obstacle
collision=np.c_[collision, col_c_tmp]
deta_dis=np.c_[deta_dis, -col_c_tmp]
dir=np.c_[dir,dir_c]
# print(collision,deta_dis)
#for every agent, choose the approaching agent as input
for i in range(N):
if frame>1 and do_update[i]>0:
sum_deta_new[i] = (tmp_input[i] * collision[i][tmp_min_robot[i]]).sum()
# print(sum_deta_new[i] ,sum_deta_tmp[i] )
if sum_deta_new[i] < sum_deta_tmp[i] :
r=10*(sum_deta_tmp[i]-sum_deta_new[i])
else:
r=-10*(sum_deta_new[i]-sum_deta_tmp[i])
boids['nn'][i].UpdateWeight(r)
if frame > 0:
do_update[i] =0
if len(np.where(deta_dis[i] < 0)[0]) > 0:
do_update[i] += 1
# then get the velocity direction of objects and the distance between them as the network input
appro_index = np.where(deta_dis[i] < 0)[0] # the input is the approching directions and distances
# print(appro_index)
input = []
for j in range(len(appro_index)):
if appro_index[j]<=N-1:
xvs_input = xvs[appro_index[j]]
yvs_input = yvs[appro_index[j]]
input.append(vel_space.index([xvs_input, yvs_input]))
else:
vel_tmp=int(appro_index[j]%N)
input.append(vel_tmp)
dis_tmp=np.c_[distance,col_c]
weight = -1 * dis_tmp[i][np.where(deta_dis[i] < 0)]
# input=input[np.argmin(weight)]
if weight.max() - weight.min() == 0:
weight = np.random.randint(1, 5, weight.shape)
weight[0] = 4
else:
k = (4 - 1) / (weight.max() - weight.min())
weight = 1 + k * (weight - weight.min())
# print(input,weight)
I = np.zeros((N_action*2, runtime))
for j in range(len(input)):
# print(appro_index,input,appro_index[j],dir[i][appro_index[j]],input[j]*dir[i][appro_index[j]])
I[int(input[j]+N_action*(dir[i][appro_index[j]]-1))][0:runtime] = max(I[int(input[j]+N_action*(dir[i][appro_index[j]]-1))][0], weight[j])
if random.random()<0.7:
action_index,boids['nn'][i] = chooseAct(boids['nn'][i],I,-1)#exploitation
else:
action_index,boids['nn'][i] = chooseAct(boids['nn'][i],I, 1) #exploration
xvs[i] = vel_space[action_index][0]
yvs[i] = vel_space[action_index][1]
tmp_min_robot[i] = np.where(deta_dis[i] < 0)[0]
tmp_input[i] = weight
sum_deta_tmp[i] = (tmp_input[i] * collision[i][tmp_min_robot[i]]).sum()
xs+=xvs
ys+=yvs
xs=np.clip(xs,0,WORLD_WIDTH)
ys = np.clip(ys, 0, WORLD_WIDTH)
distance_pre = distance
if frame>=10000:
for i in range(N):
for j in range(N_action*2):
I = np.zeros((N_action * 2, runtime))
I[j][0:runtime]=4
a=chooseAct(boids['nn'][i],I,-1)
# print(a)
aaa=1
def animate(frame):
update_boids(boids['pos'][:, 0], boids['pos'][:, 1], boids['vel'][:, 0], boids['vel'][:, 1],frame)
scatter.set_offsets(boids['pos'])
scatter1.set_offsets(boids['pos'])
#build background
fig = plt.figure(figsize=(8, 8))
ax1 = fig.add_subplot(111)
ax1.set_title('Scatter Plot')
plt.xlim(-20,520)
plt.ylim(-20,520)
plt.grid(ls='--',c='gray')
plt.xlabel('X')
plt.ylabel('Y')
# Use a scatter plot to visualize the boids
color_list=['r','b','g','y','m','c','deeppink','tomato','gold','crimson','cornsilk','darkred','greenyellow','lightcoral','mintcream',
'rosybrown']
colors=color_list[0:N]
#colors=random.sample(color_list,N)
lines=np.zeros(N)+5
scatter = ax1.scatter(boids['pos'][:, 0], boids['pos'][:, 1],s=500,alpha=0.5,linewidths=lines)
scatter1 = ax1.scatter(boids['pos'][:, 0], boids['pos'][:, 1],s=2500,c=colors,alpha=0.5)
boids_newp=boids['pos']+boids['vel']*10
for i in range(N):
boids_linex=np.hstack((boids['pos'][i, 0],boids_newp[i,0]))
boids_liney=np.hstack((boids['pos'][i, 1],boids_newp[i,1]))
#line,=plt.plot(boids_linex,boids_liney,linewidth=5)
#lines = [ax1.plot(np.hstack((boids['pos'][i, 0],boids_newp[i,0])), np.hstack((boids['pos'][i, 1],boids_newp[i,1])),linewidth=5) for i in range(N)]
animation = animation.FuncAnimation(fig, animate,interval=0.001)
plt.show()
================================================
FILE: examples/decision_making/swarm/README.md
================================================
# Reward-modulated Spiking Neural Network for Self-organizing Collision Avoidance of Drone Swarm
This repository contains code from our paper [*Nature-inspired Self-organizing Collision Avoidance for Drones Swarm Based on Reward-modulated Spiking Neural Network*] published in Cell Patterns.
https://www.cell.com/patterns/fulltext/S2666-3899(22)00236-7
We also provide the BrainCog-based version: https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/decision_making/swarm
If you use our code or refer to this project, please cite this paper:
Feifei Zhao,Yi Zeng, Bing Han, Hongjian Fang, and Zhuoya Zhao. Nature-inspired Self-organizing Collision Avoidance for Drones Swarm Based on Reward-modulated Spiking Neural Network. Patterns, DOI:https://doi.org/10.1016/j.patter.2022.100611
## Paper Introduction
The collaborative interaction mechanisms of biological swarms in nature are of great importance to inspire the study of swarm intelligence. This paper proposed a self-organizing obstacle avoidance model by drawing on the decentralized, self-organizing properties of intelligent behavior of biological swarms. Each individual independently adopts brain-inspired reward-modulated spiking neural network (RSNN) to achieve online learning and makes decentralized decisions based on local observations. The following picture shows the decision-making process of our model.
BrainCog Embot is an Embodied AI platform under the Brain-inspired Cognitive Intelligence Engine (BrainCog) framework, which is an open-source Brain-inspired AI platform based on Spiking Neural Network.
The following papers are most recent advancement of BrainCog Embot:
* Qianhao Wang, Yinqian Sun, Enmeng Lu, Qian Zhang, Yi Zeng. Brain-Inspired Action Generation with Spiking Transformer Diffusion Policy Model. Advances in Brain Inspired Cognitive Systems (BICS), 2024.(https://link.springer.com/chapter/10.1007/978-981-96-2882-7_23)
* Yinqian Sun, Feifei Zhao, Mingyang Lv, Yi Zeng. Implementing Spiking World Model with Multi-Compartment Neurons for Model-based Reinforcement Learning, 2025. (https://arxiv.org/abs/2503.00713)
* Qianhao Wang, Yinqian Sun, Enmeng Lu, Qian Zhang, Yi Zeng. MTDP: Modulated Transformer Diffusion Policy Model, 2025. (https://arxiv.org/abs/2502.09029)
## Resources
### [[Lectures]](https://github.com/BrainCog-X/Brain-Cog/blob/main/documents/Lectures.md) | [[Tutorial]](https://github.com/BrainCog-X/Brain-Cog/blob/main/documents/Tutorial.md)
## Publications using BrainCog
### [[Brain Inspired AI]](https://github.com/BrainCog-X/Brain-Cog/blob/main/documents/Publication.md) | [[Brain Simulation]](https://github.com/BrainCog-X/Brain-Cog/blob/main/documents/Pub_brain_simulation.md) | [[Software-Hardware Co-design]](https://github.com/BrainCog-X/Brain-Cog/blob/main/documents/Pub_sh_codesign.md)
## BrainCog Data Engine
### [BrainCog Data Engine](https://github.com/BrainCog-X/Brain-Cog/blob/main/documents/Data_engine.md)
## Requirements:
* numpy
* scipy
* h5py
* torch
* torchvision
* torchaudio
* timm == 0.6.13
* scikit-learn
* einops
* thop
* pyyaml
* matplotlib
* seaborn
* pygame
* dv
* tensorboard
* tonic
## Install
### Install Online
1. You can install braincog by running:
> `pip install braincog`
2. Also, install from github by running:
> `pip install git+https://github.com/braincog-X/Brain-Cog.git`
### Install locally
1. If you are a developer, it is recommanded to download or clone
braincog from github.
> `git clone https://github.com/braincog-X/Brain-Cog.git`
2. Enter the folder of braincog
> `cd Brain-Cog`
3. Install braincog locally
> `pip install -e .`
## Example
1. Examples for Image Classification
```shell
cd ./examples/Perception_and_Learning/img_cls/bp
python main.py --model cifar_convnet --dataset cifar10 --node-type LIFNode --step 8 --device 0
```
2. Examples for Event Classification
```shell
cd ./examples/Perception_and_Learning/img_cls/bp
python main.py --model dvs_convnet --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0
```
Other BrainCog features and tutorials can be found at http://www.brain-cog.network/docs/
## BrainCog Assistant
Please add our BrainCog Assitant via wechat and we will invite you to our wechat developer group.

## Maintenance
This project is led by
**1.Brain-inspired Cognitive Intelligence Lab, Institute of Automation, Chinese Academy of Sciences http://www.braincog.ai/**
**2.Center for Long-term Artificial Intelligence (CLAI) http://long-term-ai.center/**
================================================
FILE: braincog/__init__.py
================================================
# __all__ = ['base', 'datasets', 'model_zoo', 'utils']
#
# from . import (
# base,
# datasets,
# model_zoo,
# utils
# )
================================================
FILE: braincog/base/__init__.py
================================================
__all__ = ['node', 'connection', 'learningrule', 'brainarea', 'encoder', 'utils', 'conversion']
from . import (
node,
strategy,
connection,
conversion,
learningrule,
brainarea,
utils,
encoder
)
================================================
FILE: braincog/base/brainarea/BrainArea.py
================================================
import numpy as np
import torch, os, sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
from braincog.base.node.node import *
from braincog.base.learningrule.STDP import *
from braincog.base.connection.CustomLinear import *
class BrainArea(nn.Module, abc.ABC):
"""
脑区基类
"""
@abc.abstractmethod
def __init__(self):
"""
"""
super().__init__()
@abc.abstractmethod
def forward(self, x):
"""
计算前向传播过程
:return:x是脉冲
"""
return x
def reset(self):
"""
计算前向传播过程
:return:x是脉冲
"""
pass
class ThreePointForward(BrainArea):
"""
三点前馈脑区
"""
def __init__(self, w1, w2, w3):
"""
"""
super().__init__()
self.node = [IFNode(), IFNode(), IFNode()]
self.connection = [CustomLinear(w1), CustomLinear(w2), CustomLinear(w3)]
self.stdp = []
self.stdp.append(STDP(self.node[0], self.connection[0]))
self.stdp.append(STDP(self.node[1], self.connection[1]))
self.stdp.append(STDP(self.node[2], self.connection[2]))
def forward(self, x):
"""
计算前向传播过程
:return:x是脉冲
"""
x, dw1 = self.stdp[0](x)
x, dw2 = self.stdp[1](x)
x, dw3 = self.stdp[2](x)
return x, (*dw1, *dw2, *dw3)
class Feedback(BrainArea):
"""
反馈网络
"""
def __init__(self, w1, w2, w3):
"""
"""
super().__init__()
self.node = [IFNode(), IFNode()]
self.connection = [CustomLinear(w1), CustomLinear(w2), CustomLinear(w3)]
self.stdp = []
self.stdp.append(MutliInputSTDP(self.node[0], [self.connection[0], self.connection[2]]))
self.stdp.append(STDP(self.node[1], self.connection[1]))
self.x1 = torch.zeros(1, w3.shape[0])
def forward(self, x):
"""
计算前向传播过程
:return:x是脉冲
"""
x, dw1 = self.stdp[0](x, self.x1)
self.x1, dw2 = self.stdp[1](x)
return self.x1, (*dw1, *dw2)
def reset(self):
self.x1 *= 0
class TwoInOneOut(BrainArea):
"""
反馈网络
"""
def __init__(self, w1, w2):
"""
"""
super().__init__()
self.node = [IFNode()]
self.connection = [CustomLinear(w1), CustomLinear(w2)]
self.stdp = []
self.stdp.append(MutliInputSTDP(self.node[0], [self.connection[0], self.connection[1]]))
def forward(self, x1, x2):
"""
计算前向传播过程
:return:x是脉冲
"""
x, dw1 = self.stdp[0](x1, x2)
return x, dw1
class SelfConnectionArea(BrainArea):
"""
反馈网络
"""
def __init__(self, w1, w2 ):
"""
"""
super().__init__()
self.node = [IFNode() ]
self.connection = [CustomLinear(w1), CustomLinear(w2) ]
self.stdp = []
self.stdp.append(MutliInputSTDP(self.node[0], [self.connection[0], self.connection[1]]))
self.x1 = torch.zeros(1, w2.shape[0])
def forward(self, x):
"""
计算前向传播过程
:return:x是脉冲
"""
self.x1, dw1 = self.stdp[0](x, self.x1)
return self.x1, dw1
def reset(self):
self.x1 *= 0
if __name__ == "__main__":
T = 20
w1 = torch.tensor([[1., 1], [1, 1]])
w2 = torch.tensor([[1., 1], [1, 1]])
w3 = torch.tensor([[0.4, 0.4], [0.4, 0.4]])
ba = TwoInOneOut(w1, w2)
for i in range(T):
x = ba(torch.tensor([[0.1, 0.1]]), torch.tensor([[0.1, 0.1]]))
print(x[0])
================================================
FILE: braincog/base/brainarea/IPL.py
================================================
from braincog.base.learningrule.STDP import *
from braincog.base.node.node import *
from braincog.base.connection.CustomLinear import *
import random
import numpy as np
import torch
import os
import sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
import matplotlib.pyplot as plt
from braincog.base.strategy.surrogate import *
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
class IPLNet(nn.Module):
"""
inferior parietal lobule (IPL)
"""
def __init__(self, connection):
"""
Setting the network structure of IPL
"""
super().__init__()
# IPLM, IPLV
self.num_subMB = 2
self.node = [IzhNodeMU(threshold=30., a=0.02, b=0.2, c=-65., d=6., mem=-70.) for i in range(self.num_subMB)]
self.connection = connection
self.learning_rule = []
self.learning_rule.append(STDP(self.node[0], self.connection[0])) # vPMC_input-IPLM
self.learning_rule.append(MutliInputSTDP(self.node[1], [self.connection[1], self.connection[2]])) # STS_input-IPLV, IPLM-IPLV
self.out_IPLM = torch.zeros((self.connection[0].weight.shape[1]), dtype=torch.float)
self.out_IPLV = torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float)
def forward(self, input1, input2): # input from vPMC and STS
"""
Calculate the output of IPLv and the weight update between IPLm and IPLv
:param input1: input from vPMC
:param input2: input from STS
:return: output of IPLv, weight update between IPLm and IPLv
"""
self.out_IPLM = self.node[0](self.connection[0](input1))
self.out_IPLV, dw_IPLv = self.learning_rule[1](input2, self.out_IPLM)
if sum(sum(self.out_IPLV)) == 1:
dw_IPLv = dw_IPLv[0][torch.nonzero(dw_IPLv[1])[0][1]][torch.nonzero(dw_IPLv[1])[0][1]] * dw_IPLv[1]
else:
dw_IPLv = dw_IPLv[0]
return self.out_IPLV, dw_IPLv
def UpdateWeight(self, i, dw):
"""
Update the weight
:param i: index of the connection to update
:param dw: weight update
:return: None
"""
self.connection[i].update(dw)
def reset(self):
"""
reset the network
:return: None
"""
for i in range(self.num_subMB):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
"""
Get the connection and weight in IPL
:return: connection
"""
return self.connection
================================================
FILE: braincog/base/brainarea/Insula.py
================================================
import numpy as np
import torch,os,sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
import matplotlib.pyplot as plt
from braincog.base.strategy.surrogate import *
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import random
from braincog.base.connection.CustomLinear import *
from braincog.base.node.node import *
from braincog.base.learningrule.STDP import *
class InsulaNet(nn.Module):
"""
Insula
"""
def __init__(self,connection):
"""
Setting the network structure of Insula
"""
super().__init__()
# Insula
self.num_subMB = 1
self.node = [IzhNodeMU(threshold=30., a=0.02, b=0.2, c=-65., d=6., mem=-70.) for i in range(self.num_subMB)]
self.connection = connection
self.learning_rule = []
self.learning_rule.append(MutliInputSTDP(self.node[0], [self.connection[0],self.connection[1]]))# IPLv-Insula, STS-Insula
self.Insula=torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float)
def forward(self, input1, input2): # input from IPLv and STS
"""
Calculate the output of Insula
:param input1: input from IPLv
:param input2: input from STS
:return: output of Insula, weight update (unused)
"""
self.out_Insula, dw_Insula = self.learning_rule[0](input1, input2)
return self.out_Insula
def UpdateWeight(self,i,dw):
"""
Update the weight
:param i: index of the connection to update
:param dw: weight update
:return: None
"""
self.connection[i].update(dw)
def reset(self):
"""
reset the network
:return: None
"""
for i in range(self.num_subMB):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
"""
Get the connection and weight in Insula
:return: connection
"""
return self.connection
================================================
FILE: braincog/base/brainarea/PFC.py
================================================
import torch
from torch import nn
from braincog.base.brainarea import BrainArea
from braincog.model_zoo.base_module import BaseLinearModule, BaseModule
class PFC:
"""
PFC
"""
def __init__(self):
"""
"""
super().__init__()
def forward(self, x):
"""
:return:x
"""
return x
def reset(self):
"""
:return:x
"""
pass
class dlPFC(BaseModule, PFC):
"""
SNNLinear
"""
def __init__(self,
step,
encode_type,
in_features:int,
out_features:int,
bias,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.bias = bias
self.in_features = in_features
self.out_features = out_features
self.fc = self._create_fc()
self.c = self._rest_c()
def _rest_c(self):
c = torch.rand((self.out_features, self.in_features)) # eligibility trace
return c
def _create_fc(self):
"""
the connection of the SNN linear
@return: nn.Linear
"""
fc = nn.Linear(in_features=self.in_features,
out_features=self.out_features, bias=self.bias)
return fc
================================================
FILE: braincog/base/brainarea/__init__.py
================================================
from .basalganglia import basalganglia
from .BrainArea import BrainArea, ThreePointForward, Feedback, TwoInOneOut, SelfConnectionArea
from .Insula import InsulaNet
from .IPL import IPLNet
from .PFC import PFC, dlPFC
__all__ = [
'basalganglia',
'BrainArea', 'ThreePointForward', 'Feedback', 'TwoInOneOut', 'SelfConnectionArea',
'InsulaNet',
'IPLNet',
'PFC', 'dlPFC'
]
================================================
FILE: braincog/base/brainarea/basalganglia.py
================================================
import numpy as np
import torch
import os
import sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
import torch.nn.functional as F
from braincog.base.strategy.surrogate import *
from braincog.base.node.node import IFNode, SimHHNode
from braincog.base.learningrule.STDP import STDP, MutliInputSTDP
from braincog.base.connection.CustomLinear import CustomLinear
class basalganglia(nn.Module):
"""
Basal Ganglia
"""
def __init__(self, ns, na, we, wi, node_type):
super().__init__()
"""
:param ns: 状态个数
:param na:动作个数
:param we:兴奋性连接权重
:param wi:抑制性连接权重
"""
num_state = ns
num_action = na
num_STN = 2
weight_exc = we
weight_inh = wi
# connetions: 0DLPFC-StrD1 1DLPFC-StrD2 2DLPFC-STN 3StrD1-GPi 4StrD2-GPe 5Gpe-Gpi 6STN-Gpi 7STN-Gpe 8Gpe-STN
bg_connection = []
bg_con_mask = []
# DLPFC-StrD1
con_matrix1 = torch.zeros((num_state, num_state * num_action), dtype=torch.float)
for i in range(num_state):
for j in range(num_action):
con_matrix1[i, i * num_action + j] = 1
bg_con_mask.append(con_matrix1)
bg_connection.append(CustomLinear(weight_exc * con_matrix1, con_matrix1))
# DLPFC-StrD2
bg_connection.append(CustomLinear(weight_exc * con_matrix1, con_matrix1))
bg_con_mask.append(con_matrix1)
# DLPFC-STN
con_matrix3 = torch.ones((num_state, num_STN), dtype=torch.float)
bg_con_mask.append(con_matrix3)
bg_connection.append(CustomLinear(weight_exc * con_matrix3, con_matrix3))
# StrD1-GPi
con_matrix4 = torch.zeros((num_state * num_action, num_action), dtype=torch.float)
for i in range(num_state):
for j in range(num_action):
con_matrix4[i * num_action + j, j] = 1
bg_con_mask.append(con_matrix4)
bg_connection.append(CustomLinear(weight_inh * con_matrix4, con_matrix4))
# StrD2-GPe
bg_con_mask.append(con_matrix4)
bg_connection.append(CustomLinear(weight_inh * con_matrix4, con_matrix4))
# Gpe-Gpi
con_matrix5 = torch.eye((num_action), dtype=torch.float)
bg_con_mask.append(con_matrix5)
bg_connection.append(CustomLinear(weight_inh * con_matrix5, con_matrix5))
# STN-Gpi
con_matrix6 = torch.ones((num_STN, num_action), dtype=torch.float)
bg_con_mask.append(con_matrix6)
bg_connection.append(CustomLinear(0.5 * weight_exc * con_matrix6, con_matrix6))
# STN-Gpe
bg_con_mask.append(con_matrix6)
bg_connection.append(CustomLinear(0.5 * weight_exc * con_matrix6, con_matrix6))
# Gpe-STN
con_matrix7 = torch.ones((num_action, num_STN), dtype=torch.float)
bg_con_mask.append(con_matrix7)
bg_connection.append(CustomLinear(0.5 * weight_inh * con_matrix7, con_matrix7))
self.num_subBG = 5
self.node_type = node_type
if self.node_type == "hh":
self.node = [SimHHNode() for i in range(self.num_subBG)]
if self.node_type == "lif":
self.node = [IFNode() for i in range(self.num_subBG)]
self.connection = bg_connection
self.mask = bg_con_mask
self.learning_rule = []
trace_stdp = 0.99
self.learning_rule.append(STDP(self.node[0], self.connection[0], trace_stdp)) # DLPFC-StrD1
self.learning_rule.append(STDP(self.node[1], self.connection[1], trace_stdp)) # DLPFC-StrD2
self.learning_rule.append(MutliInputSTDP(self.node[2], [self.connection[2], self.connection[8]])) # DLPFC-STN
self.learning_rule.append(MutliInputSTDP(self.node[3], [self.connection[4], self.connection[7]])) # StrD2-GPe STN-Gpe
self.learning_rule.append(MutliInputSTDP(self.node[4], [self.connection[3], self.connection[5], self.connection[6]])) # StrD1-GPi Gpe-Gpi STN-Gpi
self.out_StrD1 = torch.zeros((self.connection[0].weight.shape[1]), dtype=torch.float)
self.out_StrD2 = torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float)
self.out_STN = torch.zeros((self.connection[2].weight.shape[1]), dtype=torch.float)
self.out_Gpi = torch.zeros((self.connection[3].weight.shape[1]), dtype=torch.float)
self.out_Gpe = torch.zeros((self.connection[4].weight.shape[1]), dtype=torch.float)
def forward(self, input):
"""
计算由当前输入基底节网络的输出
:param input: 输入电流
:return: 输出脉冲
"""
self.out_StrD1, dw_strd1 = self.learning_rule[0](input)
self.out_StrD2, dw_strd2 = self.learning_rule[1](input)
self.out_STN, dw_stn = self.learning_rule[2](input, self.out_Gpe)
self.out_Gpe, dw_gpe = self.learning_rule[3](self.out_StrD2, self.out_STN)
self.out_Gpi, dw_gpi = self.learning_rule[4](self.out_StrD1, self.out_Gpe, self.out_STN)
return self.out_Gpi
def UpdateWeight(self, i, dw):
"""
更新基底节内第i组连接的权重 根据传入的dw值
:param i: 要更新的连接的索引
:param dw: 更新的量
:return: None
"""
self.connection[i].update(dw)
self.connection[i].weight.data = F.normalize(self.connection[i].weight.data.float(), p=1, dim=1)
def reset(self):
"""
reset神经元或学习法则的中间量
:return: None
"""
for i in range(self.num_subMB):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
"""
获取基底节网络的连接(包括权值等)
:return: 基底节网络的连接
"""
return self.connection
def getmask(self):
"""
获取基底节网络的连接(仅连接矩阵)
:return: 基底节网络的连接矩阵
"""
return self.mask
if __name__ == "__main__":
BG = basalganglia(4, 2, 0.2, -4)
con = BG.getweight()
print(con)
================================================
FILE: braincog/base/brainarea/dACC.py
================================================
import torch
import matplotlib.pyplot as plt
import numpy as np
np.set_printoptions(threshold=np.inf)
from utils.one_hot import *
import os
import time
import sys
from tqdm import tqdm
from braincog.base.encoder.population_coding import *
from braincog.model_zoo.base_module import BaseLinearModule, BaseModule
from braincog.base.learningrule.STDP import *
import sys
sys.path.append("..")
class dACC(BaseModule):
"""
SNNLinear
"""
def __init__(self,
step,
encode_type,
in_features:int,
out_features:int,
bias,
node,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.bias = bias
self.in_features = in_features
self.out_features = out_features
self.node1 = node(threshold=0.5, tau=2.)
self.node_name1 = node
self.node2 = node(threshold=0.1, tau=2.)
self.node_name2 = node
self.fc = self._create_fc()
self.c = self._rest_c()
def _rest_c(self):
c = torch.rand((self.out_features, self.in_features)) # eligibility trace
return c
def _create_fc(self):
"""
the connection of the SNN linear
@return: nn.Linear
"""
fc = nn.Linear(in_features=self.in_features,
out_features=self.out_features, bias=self.bias)
return fc
def update_c(self, c, STDP, tau_c=0.2):
"""
update the trace of eligibility
@param c: a tensor to record eligibility
@param STDP: the results of STDP
@param tau_c: the parameter of trace decay
@return: a update tensor to record eligibility
Equation:
delta_c = (-(c / tau_c) + STDP) * dela_t
c = c + delta_c
reference:
"""
c = c + tau_c * STDP
return c
def forward(self, inputs, epoch):
"""
decision
@param inputs: state
@return: action
"""
output = []
stdp = STDP(self.node2, self.fc, decay=0.80)
self.c = self._rest_c()
# stdp.connection.weight.data = torch.rand((self.out_features, self.in_features))
for i in range(inputs.shape[0]):
for t in range(self.step):
l1_in = torch.tensor(inputs[i, :])
l1_out = self.node1(l1_in).unsqueeze(0) #pre : l1_out
l2_out, dw = stdp(l1_out) #dw -- STDP
self.c = self.update_c(self.c, dw[0])
output.append(torch.min(l2_out))
# output.append((l2_out.any() == 0).cpu().detach().numpy().tolist())
return output
# if __name__ == '__main__':
# np.random.seed(6)
# T = 5
# num_popneurons = 2
# safety = 2
# epoch = 50
# file_name = "/home/zhaozhuoya/braincog/examples/ToM/data/injury_value.txt"
# state = []
# with open(file_name) as f:
# data = []
# data_split = f.readlines() #
# for i in data_split:
# state.append(one_hot(int(i[0])))
#
# output = np.array(state)
# train_y = output
# test_y = output[79:82]#output[12].reshape(1,2)
#
# file_name = "/home/zhaozhuoya/braincog/examples/ToM/data/injury_memory.txt"
# state = []
# with open(file_name) as f:
# data_split = f.readlines()
# for i in data_split:
# data = []
# data.append(int(bool(abs(int(i[2]) - int(i[18]))))*10)
# data.append(int(bool(abs(int(i[5]) - int(i[21]))))*10)
# state.append(data)
# input = np.array(state)
# train_x = input
# test_x = input[79:82]
# dACC_net = dACC(step=T, encode_type='rate', bias=True,
# in_features=num_popneurons, out_features=safety,
# node=node.LIFNode)
# dACC_net.fc.weight.data = torch.rand((safety, num_popneurons))
# dACC_net.load_state_dict(torch.load('./checkpoint/dACC_net.pth')['dacc'])
# output = dACC_net(inputs=train_x, epoch=50)
# for i in range(len(output)):
# print(output[i], train_x[i])
# torch.save({'dacc': dACC_net.state_dict()}, os.path.join('./checkpoint', 'dACC_net.pth'))
# dACC_net.load_state_dict(torch.load('./checkpoint/dACC_net.pth')['dacc'])
# output = dACC_net(inputs=test_x, epoch=50)
# for i in range(len(test_x)):
#
# print(output[i],test_x[i])
================================================
FILE: braincog/base/connection/CustomLinear.py
================================================
import os
import sys
import numpy as np
import torch
from torch import nn
from torch import einsum
import torch.nn.functional as F
class CustomLinear(nn.Module):
"""
用户自定义连接 通常stdp的计算
"""
def __init__(self, weight, mask=None):
super().__init__()
self.weight = nn.Parameter(weight, requires_grad=True)
self.mask = mask
def forward(self, x: torch.Tensor):
"""
:param x:输入 x.shape = [N ]
"""
#
# ret.shape = [C]
return x.matmul(self.weight)
def update(self, dw):
"""
:param dw:权重更新量
"""
with torch.no_grad():
if self.mask is not None:
dw *= self.mask
self.weight.data += dw
================================================
FILE: braincog/base/connection/__init__.py
================================================
from .CustomLinear import CustomLinear
from .layer import VotingLayer, WTALayer, NDropout, ThresholdDependentBatchNorm2d, LayerNorm, SMaxPool, LIPool
__all__ = [
'CustomLinear',
'VotingLayer', 'WTALayer', 'NDropout', 'ThresholdDependentBatchNorm2d', 'LayerNorm', 'SMaxPool', 'LIPool'
]
================================================
FILE: braincog/base/connection/layer.py
================================================
import warnings
import math
import numpy as np
import torch
from torch import nn
from torch import einsum
from torch.nn.modules.batchnorm import _BatchNorm
import torch.nn.functional as F
from torch.nn import Parameter
from einops import rearrange
class VotingLayer(nn.Module):
"""
用于SNNs的输出层, 几个神经元投票选出最终的类
:param voter_num: 投票的神经元的数量, 例如 ``voter_num = 10``, 则表明会对这10个神经元取平均
"""
def __init__(self, voter_num: int):
super().__init__()
self.voting = nn.AvgPool1d(voter_num, voter_num)
def forward(self, x: torch.Tensor):
# x.shape = [N, voter_num * C]
# ret.shape = [N, C]
return self.voting(x.unsqueeze(1)).squeeze(1)
class WTALayer(nn.Module):
"""
winner take all用于SNNs的每层后,将随机选取一个或者多个输出
:param k: X选取的输出数目 k默认等于1
"""
def __init__(self, k=1):
super().__init__()
self.k = k
def forward(self, x: torch.Tensor):
# x.shape = [N, C,W,H]
# ret.shape = [N, C,W,H]
pos = x * torch.rand(x.shape, device=x.device)
if self.k > 1:
x = x * (pos >= pos.topk(self.k, dim=1)[0][:, -1:]).float()
else:
x = x * (pos >= pos.max(1, True)[0]).float()
return x
class NDropout(nn.Module):
"""
与Drop功能相同, 但是会保证同一个样本不同时刻的mask相同.
"""
def __init__(self, p):
super(NDropout, self).__init__()
self.p = p
self.mask = None
def n_reset(self):
"""
重置, 能够生成新的mask
:return:
"""
self.mask = None
def create_mask(self, x):
"""
生成新的mask
:param x: 输入Tensor, 生成与之形状相同的mask
:return:
"""
self.mask = F.dropout(torch.ones_like(x.data), self.p, training=True)
def forward(self, x):
if self.training:
if self.mask is None:
self.create_mask(x)
return self.mask * x
else:
return x
class WSConv2d(nn.Conv2d):
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, groups=1, bias=True, gain=True):
super(WSConv2d, self).__init__(in_channels, out_channels, kernel_size, stride,
padding, dilation, groups, bias)
if gain:
self.gain = nn.Parameter(torch.ones(self.out_channels, 1, 1, 1))
else:
self.gain = 1.
def forward(self, x):
weight = self.weight
weight_mean = weight.mean(dim=1, keepdim=True).mean(dim=2,
keepdim=True).mean(dim=3, keepdim=True)
weight = weight - weight_mean
std = weight.view(weight.size(0), -1).std(dim=1).view(-1, 1, 1, 1) + 1e-5
weight = self.gain * weight / std.expand_as(weight)
return F.conv2d(x, weight, self.bias, self.stride,
self.padding, self.dilation, self.groups)
class ThresholdDependentBatchNorm2d(_BatchNorm):
"""
tdBN
https://ojs.aaai.org/index.php/AAAI/article/view/17320
"""
def __init__(self, num_features, alpha: float, threshold: float = .5, layer_by_layer: bool = True, affine: bool = True,**kwargs):
self.alpha = alpha
self.threshold = threshold
super().__init__(num_features=num_features, affine=affine)
assert layer_by_layer, \
'tdBN may works in step-by-step mode, which will not take temporal dimension into batch norm'
assert self.affine, 'ThresholdDependentBatchNorm needs to set `affine = True`!'
torch.nn.init.constant_(self.weight, alpha * threshold)
def _check_input_dim(self, input):
if input.dim() != 4:
raise ValueError("expected 4D input (got {}D input)".format(input.dim()))
def forward(self, input):
# input = rearrange(input, '(t b) c w h -> b (t c) w h', t=self.step)
output = super().forward(input)
return output
# return rearrange(output, 'b (t c) w h -> (t b) c w h', t=self.step)
class TEBN(nn.Module):
def __init__(self, num_features,step, eps=1e-5, momentum=0.1,**kwargs):
super(TEBN, self).__init__()
self.bn = nn.BatchNorm3d(num_features)
self.p = nn.Parameter(torch.ones(4, 1, 1, 1, 1))
self.step=step
def forward(self, input):
#y = input.transpose(1, 2).contiguous() # N T C H W , N C T H W
y = rearrange(input,"(t b) c w h -> t c b w h",t=self.step)
y = self.bn(y)
# y = y.contiguous().transpose(1, 2)
# y = y.transpose(0, 1).contiguous() # NTCHW TNCHW
y = rearrange(y,"t c b w h -> t b c w h")
y = y * self.p
#y = y.contiguous().transpose(0, 1) # TNCHW NTCHW
y = rearrange(y, "t b c w h -> (t b) c w h")
return y
class LayerNorm(nn.Module):
""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape,)
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class SMaxPool(nn.Module):
"""用于转换方法的最大池化层的常规替换
选用具有最大脉冲发放率的神经元的脉冲通过,能够满足一般性最大池化层的需要
Reference:
https://arxiv.org/abs/1612.04052
"""
def __init__(self, child):
super(SMaxPool, self).__init__()
self.opration = child
self.sumspike = 0
def forward(self, x):
self.sumspike += x
single = self.opration(self.sumspike * 1000)
sum_plus_spike = self.opration(x + self.sumspike * 1000)
return sum_plus_spike - single
def reset(self):
self.sumspike = 0
class LIPool(nn.Module):
r"""用于转换方法的最大池化层的精准替换
LIPooling通过引入侧向抑制机制保证在转换后的SNN中输出的最大值与期望值相同。
Reference:
https://arxiv.org/abs/2204.13271
"""
def __init__(self, child=None):
super(LIPool, self).__init__()
if child is None:
raise NotImplementedError("child should be Pooling operation with torch.")
self.opration = child
self.sumspike = 0
def forward(self, x):
self.sumspike += x
out = self.opration(self.sumspike)
self.sumspike -= F.interpolate(out, scale_factor=2, mode='nearest')
return out
def reset(self):
self.sumspike = 0
class CustomLinear(nn.Module):
def __init__(self, in_channels, out_channels, bias=True):
super(CustomLinear, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
# self.weight = Parameter(torch.tensor([
# [1., .5, .25, .125],
# [0., 1., .5, .25],
# [0., 0., 1., .5],
# [0., 0., 0., 1.]
# ]), requires_grad=True)
self.weight = Parameter(torch.diag(torch.ones(self.in_channels)), requires_grad=True)
# self.weight = Parameter(torch.randn(self.in_channels, self.in_channels))
mask = torch.tril(torch.ones(self.in_channels, self.in_channels), diagonal=0)
self.register_buffer('mask', mask)
if bias:
self.bias = Parameter(torch.zeros(out_channels), requires_grad=True)
else:
self.register_parameter('bias', None)
def forward(self, inputs):
weight = self.mask * self.weight
return F.linear(inputs, weight, self.bias)
================================================
FILE: braincog/base/conversion/__init__.py
================================================
from .convertor import HookScale, Hookoutput, Scale, Convertor, SNode
from .merge import mergeConvBN, merge
__all__ = [
'Hookoutput', 'HookScale', 'Scale', 'Convertor', 'SNode',
'merge', 'mergeConvBN'
]
================================================
FILE: braincog/base/conversion/convertor.py
================================================
import torch
import torch.nn as nn
from braincog.base.connection.layer import SMaxPool, LIPool
from .merge import mergeConvBN
from .spicalib import SpiCalib
import types
class HookScale(nn.Module):
""" 在每个ReLU层后记录该层的百分位最大值
For channelnorm: 获取最大值时使用了torch.quantile
For layernorm: 使用sort,然后手动取百分比,因为quantile在计算单个通道时有上限,batch较大时易出错
"""
def __init__(self,
p: float = 0.9995,
channelnorm: bool = False,
gamma: float = 0.999,
):
super().__init__()
if channelnorm:
self.register_buffer('scale', torch.tensor(0.0))
else:
self.register_buffer('scale', torch.tensor(0.0))
self.p = p
self.channelnorm = channelnorm
self.gamma = gamma
def forward(self, x):
x = torch.where(x.detach() < self.gamma, x.detach(),
torch.tensor(self.gamma, dtype=x.dtype, device=x.device))
if len(x.shape) == 4 and self.channelnorm:
num_channel = x.shape[1]
tmp = torch.quantile(x.permute(1, 0, 2, 3).reshape(num_channel, -1), self.p, dim=1,
interpolation='lower') + 1e-10
self.scale = torch.max(tmp, self.scale)
else:
sort, _ = torch.sort(x.view(-1))
self.scale = torch.max(sort[int(sort.shape[0] * self.p) - 1], self.scale)
return x
class Hookoutput(nn.Module):
"""
在伪转换中为ReLU和ClipQuan提供包装,用于监控其输出
"""
def __init__(self, module):
super(Hookoutput, self).__init__()
self.activation = 0.
self.operation = module
def forward(self, x):
output = self.operation(x)
self.activation = output.detach()
return output
class Scale(nn.Module):
"""
对前向过程的值进行缩放
"""
def __init__(self, scale: float = 1.0):
super().__init__()
self.register_buffer('scale', scale)
def forward(self, x):
if len(self.scale.shape) == 1:
return self.scale.unsqueeze(0).unsqueeze(2).unsqueeze(3).expand_as(x) * x
else:
return self.scale * x
def reset(self):
"""
转换的网络来自ANN,需要将新附加上的脉冲module进行reset
判断module名称并调用各自节点的reset方法
"""
children = list(self.named_children())
for i, (name, child) in enumerate(children):
if isinstance(child, (SNode, LIPool, SMaxPool)):
child.reset()
else:
reset(child)
class Convertor(nn.Module):
"""ANN2SNN转换器
用于转换完整的pytorch模型,使用dataloader中部分数据进行最大值计算,通过p控制获取第p百分比最大值
channlenorm: https://arxiv.org/abs/1903.06530
channelnorm可以对每个通道获取最大值并进行权重归一化
gamma: https://arxiv.org/abs/2204.13271
gamma可以控制burst spikes的脉冲数,burst spike可以提高神经元的脉冲发放能力,减小信息残留
lipool: https://arxiv.org/abs/2204.13271
lipool用于使用侧向抑制机制进行最大池化,LIPooling能够对SNN中的最大池化进行有效的转换
soft_mode: https://arxiv.org/abs/1612.04052
soft_mode被称为软重置,可以减小重置过程神经元的信息损失,有效提高转换的性能
merge用于是否对网络中相邻的卷积和BN层进行融合
batch_norm控制对dataloader的数据集的用量
"""
def __init__(self,
dataloader,
device=None,
p=0.9995,
channelnorm=False,
lipool=True,
gamma=1,
soft_mode=True,
merge=True,
batch_num=1,
spicalib=0
):
super(Convertor, self).__init__()
self.dataloader = dataloader
self.device = device
self.p = p
self.channelnorm = channelnorm
self.lipool = lipool
self.gamma = gamma
self.soft_mode = soft_mode
self.merge = merge
self.batch_num = batch_num
self.spicalib = spicalib
def forward(self, model):
model.eval()
model = Convertor.register_hook(model, self.p, self.channelnorm, self.gamma)
model = Convertor.get_percentile(model, self.dataloader, self.device, batch_num=self.batch_num)
model = mergeConvBN(model) if self.merge else model
model = Convertor.replace_for_spike(model, self.lipool, self.soft_mode, self.gamma, self.spicalib)
model.reset = types.MethodType(reset, model)
return model
@staticmethod
def register_hook(model, p=0.99, channelnorm=False, gamma=0.999):
""" Reference: https://github.com/fangwei123456/spikingjelly
将网络的每一层后注册一个HookScale类
该方法在仿真上等效于与对权重进行归一化操作,且易扩展到任意结构的网络中
"""
children = list(model.named_children())
for _, (name, child) in enumerate(children):
if isinstance(child, nn.ReLU):
model._modules[name] = nn.Sequential(nn.ReLU(), HookScale(p, channelnorm, gamma))
else:
Convertor.register_hook(child, p, channelnorm, gamma)
return model
@staticmethod
def get_percentile(model, dataloader, device, batch_num=1):
"""
该函数需与具有HookScale层的网络配合使用
"""
for idx, (data, _) in enumerate(dataloader):
data = data.to(device)
if idx >= batch_num:
break
model(data)
return model
@staticmethod
def replace_for_spike(model, lipool=True, soft_mode=True, gamma=1, spicalib=0):
"""
该函数用于将定义好的ANN模型转换为SNN模型
ReLU单元将被替换为脉冲神经元,
如果模型中使用了最大池化,lipool参数将定义使用常规模型还是LIPooling方法
"""
children = list(model.named_children())
for _, (name, child) in enumerate(children):
if isinstance(child, nn.Sequential) and len(child) == 2 and isinstance(child[0], nn.ReLU) and isinstance(child[1], HookScale):
model._modules[name] = nn.Sequential(
Scale(1.0 / child[1].scale),
SNode(soft_mode, gamma),
SpiCalib(spicalib),
Scale(child[1].scale)
)
if isinstance(child, nn.MaxPool2d):
model._modules[name] = LIPool(child) if lipool else SMaxPool(child)
else:
Convertor.replace_for_spike(child, lipool, soft_mode, gamma)
return model
class SNode(nn.Module):
"""
用于转换后的SNN的神经元模型
IF神经元模型由gamma=1确定,当gamma为其他大于1的值时,即为使用burst神经元模型
soft_mode用于定义神经元的重置方法,soft重置能够极大地减少神经元在重置过程的信息损失
"""
def __init__(self, soft_mode=False, gamma=5):
super(SNode, self).__init__()
self.threshold = 1.0
self.soft_mode = soft_mode
self.gamma = gamma
self.mem = 0
self.spike = 0
def forward(self, x):
self.mem = self.mem + x
self.spike = (self.mem / self.threshold).floor().clamp(min=0, max=self.gamma)
self.soft_reset() if self.soft_mode else self.hard_reset
out = self.spike
return out
def hard_reset(self):
"""
硬重置后神经元的膜电势被重置为0
"""
self.mem = self.mem * (1 - self.spike.detach())
def soft_reset(self):
"""
软重置后神经元的膜电势为神经元当前膜电势减去阈值
"""
self.mem = self.mem - self.threshold * self.spike.detach()
def reset(self):
self.mem = 0
self.spike = 0
================================================
FILE: braincog/base/conversion/merge.py
================================================
import torch
import torch.nn as nn
def mergeConvBN(m):
"""
合并网络模块中的卷积与BN层
"""
children = list(m.named_children())
c, cn = None, None
for i, (name, child) in enumerate(children):
if isinstance(child, nn.BatchNorm2d):
bc = merge(c, child)
m._modules[cn] = bc
m._modules[name] = torch.nn.Identity()
c = None
elif isinstance(child, nn.Conv2d):
c = child
cn = name
else:
mergeConvBN(child)
return m
def merge(conv, bn):
"""
conv: 卷积层实例
bn: BN层实例
"""
w = conv.weight
mean, var_sqrt, beta, gamma = bn.running_mean, torch.sqrt(bn.running_var + bn.eps), bn.weight, bn.bias
b = conv.bias if conv.bias is not None else mean.new_zeros(mean.shape)
w = w * (beta / var_sqrt).reshape([conv.out_channels, 1, 1, 1])
b = (b - mean) / var_sqrt * beta + gamma
fused_conv = nn.Conv2d(conv.in_channels, conv.out_channels, conv.kernel_size, conv.stride, conv.padding, bias=True)
fused_conv.weight = nn.Parameter(w)
fused_conv.bias = nn.Parameter(b)
return fused_conv
================================================
FILE: braincog/base/conversion/spicalib.py
================================================
import torch
import torch.nn as nn
class SpiCalib(nn.Module):
def __init__(self, allowance):
super(SpiCalib, self).__init__()
self.allowance = allowance
self.sumspike = 0
self.t = 0
def forward(self, x):
if self.allowance == 0:
return x
if self.t == 0:
self.last_spike = torch.zeros_like(x)
self.avg_time = torch.zeros_like(x)
self.num_spike = torch.zeros_like(x)
SPIKE_MASK = x > 0
self.num_spike[SPIKE_MASK] += 1
self.avg_time[SPIKE_MASK] = (self.t - self.last_spike + self.avg_time * (self.num_spike - 1))[SPIKE_MASK] / \
self.num_spike[SPIKE_MASK]
self.last_spike[SPIKE_MASK] = self.t
SIN_MASK = self.t - self.last_spike > self.avg_time + self.allowance
x[SIN_MASK] -= 1.0
self.sumspike += x
x[self.sumspike <= -1] = 0
self.t += 1
return x
def reset(self):
self.sumspike = 0
self.t = 0
================================================
FILE: braincog/base/encoder/__init__.py
================================================
from .encoder import Encoder
from .population_coding import PEncoder
from.qs_coding import QSEncoder
__all__ = [
'Encoder',
'PEncoder',
'QSEncoder'
]
================================================
FILE: braincog/base/encoder/encoder.py
================================================
import torch
import torch.nn as nn
from einops import rearrange, repeat
from braincog.base.strategy.surrogate import GateGrad
class AutoEncoder(nn.Module):
def __init__(self, step, spike_output=True):
super(AutoEncoder, self).__init__()
self.step = step
self.spike_output = spike_output
# self.gru = nn.GRU(input_size=1, hidden_size=1, num_layers=3)
self.sigmoid = nn.Sigmoid()
self.fc1 = nn.Linear(1, self.step)
self.fc2 = nn.Linear(self.step, self.step)
self.relu = nn.ReLU()
#
self.act_fun = GateGrad()
def forward(self, x):
shape = x.shape
x = self.fc1(x.view(-1, 1))
x = self.relu(x)
x = self.fc2(x).transpose_(1, 0)
# x = x.view(1, -1, 1).repeat(self.step, 1, 1)
# x, _ = self.gru(x)
x = self.sigmoid(x)
if not self.spike_output:
return x.view(self.step, *shape)
else:
return self.act_fun(x).view(self.step, *shape)
# class TransEncoder(nn.Module):
# def __init__(self, step):
# super(TransEncoder, self).__init__()
# self.step = step
# self.trans = Transformer(dim=128, depth=3, heads=8, dim_head=, mlp_dim, dropout=0.)
class Encoder(nn.Module):
'''
将static image编码
:param step: 仿真步长
:param encode_type: 编码方式, 可选 ``direct``, ``ttfs``, ``rate``, ``phase``
:param temporal_flatten: 直接将temporal维度concat到channel维度
:param layer_by_layer: 是否使用计算每一层的所有的输出的方式进行推理
:param
(step, batch_size, )
'''
def __init__(self, step, encode_type='ttfs', *args, **kwargs):
super(Encoder, self).__init__()
self.step = step
self.fun = getattr(self, encode_type)
self.encode_type = encode_type
self.temporal_flatten = kwargs['temporal_flatten'] if 'temporal_flatten' in kwargs else False
self.layer_by_layer = kwargs['layer_by_layer'] if 'layer_by_layer' in kwargs else False
self.no_encode = kwargs['adaptive_node'] if 'adaptive_node' in kwargs else False
self.groups = kwargs['n_groups'] if 'n_groups' in kwargs else 1
# if encode_type == 'auto':
# self.fun = AutoEncoder(self.step, spike_output=False)
def forward(self, inputs, deletion_prob=None, shift_var=None):
if len(inputs.shape) == 5: # DVS data
outputs = inputs.permute(1, 0, 2, 3, 4).contiguous() # t, b, c, w, h
elif len(inputs.shape) == 3: # DAS data
outputs = inputs.permute(1, 0, 2).contiguous() # t, b, c
else:
if self.encode_type == 'auto':
if self.fun.device != inputs.device:
self.fun.to(inputs.device)
outputs = self.fun(inputs)
if deletion_prob:
outputs = self.delete(outputs, deletion_prob)
if shift_var:
outputs = self.shift(outputs, shift_var)
if self.temporal_flatten or self.no_encode:
outputs = rearrange(outputs, 't b c w h -> 1 b (t c) w h')
elif self.groups != 1:
outputs = rearrange(outputs, 't b c w h -> b (c t) w h')
elif self.layer_by_layer:
if len(inputs.shape) == 3:
outputs = rearrange(outputs, 't b c-> (t b) c')
else:
outputs = rearrange(outputs, 't b c w h -> (t b) c w h')
return outputs
@torch.no_grad()
def direct(self, inputs):
"""
直接编码
:param inputs: 形状(b, c, w, h)
:return: (t, b, c, w, h)
"""
outputs = repeat(inputs, 'b c w h -> t b c w h', t=self.step)
# outputs = inputs.unsqueeze(0).repeat(self.step, *([1] * len(shape)))
return outputs
def auto(self, inputs):
# TODO: Calc loss for firing-rate
shape = inputs.shape
outputs = self.fun(inputs)
print(outputs.shape)
return outputs
@torch.no_grad()
def ttfs(self, inputs):
"""
Time-to-First-Spike Encoder
:param inputs: static data
:return: Encoded data
"""
# print("ttfs")
shape = (self.step,) + inputs.shape
outputs = torch.zeros(shape, device=self.device)
for i in range(self.step):
mask = (inputs * self.step <= (self.step - i)
) & (inputs * self.step > (self.step - i - 1))
outputs[i, mask] = 1 / (i + 1)
return outputs
@torch.no_grad()
def rate(self, inputs):
"""
Rate Coding
:param inputs:
:return:
"""
shape = (self.step,) + inputs.shape
return (inputs > torch.rand(shape, device=inputs.device)).float()
@torch.no_grad()
def phase(self, inputs):
"""
Phase Coding
相位编码
:param inputs: static data
:return: encoded data
"""
shape = (self.step,) + inputs.shape
outputs = torch.zeros(shape, device=self.device)
inputs = (inputs * 256).long()
val = 1.
for i in range(self.step):
if i < 8:
mask = (inputs >> (8 - i - 1)) & 1 != 0
outputs[i, mask] = val
val /= 2.
else:
outputs[i] = outputs[i % 8]
return outputs
@torch.no_grad()
def delete(self, inputs, prob):
"""
在Coding 过程中随机删除脉冲
:param inputs: encoded data
:param prob: 删除脉冲的概率
:return: 随机删除脉冲之后的数据
"""
mask = (inputs >= 0) & (torch.randn_like(
inputs, device=self.device) < prob)
inputs[mask] = 0.
return inputs
@torch.no_grad()
def shift(self, inputs, var):
"""
对数据进行随机平移, 添加噪声
:param inputs: encoded data
:param var: 随机平移的方差
:return: shifted data
"""
# TODO: Real-time shift
outputs = torch.zeros_like(inputs)
for step in range(self.step):
shift = (var * torch.randn(1)).round_() + step
shift.clamp_(min=0, max=self.step - 1)
outputs[step] += inputs[int(shift)]
return outputs
================================================
FILE: braincog/base/encoder/population_coding.py
================================================
import torch
import torch.nn as nn
import torchvision.utils
class PEncoder(nn.Module):
"""
Population coding
:param step: time steps
:param encode_type: encoder type (str)
"""
def __init__(self, step, encode_type):
super().__init__()
self.step = step
self.fun = getattr(self, encode_type)
def forward(self, inputs, num_popneurons, *args, **kwargs):
outputs = self.fun(inputs, num_popneurons, *args, **kwargs)
return outputs
@torch.no_grad()
def population_time(self, inputs, m):
"""
one feature will be encoded into gauss_neurons
the center of i-th neuron is: gauss --
.. math::
\\mu u_i = I_min + (2i-3)/2(I_max-I_min)/(m -2)
the width of i-th neuron is : gauss --
.. math::
\\sigma sigma_i = \\frac{1}{1.5}\\frac{(I_max-I_min)}{m - 2}
:param inputs: (N_num, N_feature) array
:param m: the number of the gaussian neurons
i : the i_th gauss_neuron
1.5: experience value
popneurons_spike_t: gauss -- function
I_min = min(inputs)
I_max = max(inputs)
:return: (step, num_gauss_neuron)
"""
# m = self.step
I_min, I_max = torch.min(inputs), torch.max(inputs)
mu = [i for i in range(0, m)]
mu = torch.ones((1, m)) * I_min + ((2 * torch.tensor(mu) - 3) / 2) * ((I_max-I_min) / (m -2))
sigma = (1 / 1.5) * ((I_max-I_min) / (m -2))
# shape = (self.step,) + inputs.shape
shape = (self.step,m)
popneurons_spike_t = torch.zeros(((m,) + inputs.shape))
for i in range(m):
popneurons_spike_t[i, :] = torch.exp(-(inputs - mu[0, i]) ** 2 / (2 * sigma * sigma))
spike_time = (self.step * popneurons_spike_t).type(torch.int)
spikes = torch.zeros(shape)
for spike_time_k in range(self.step):
if torch.where(spike_time == spike_time_k)[1].numel() != 0:
spikes[spike_time_k][torch.where(spike_time == spike_time_k)[0]] = 1
return spikes
@torch.no_grad()
def population_voltage(self, inputs, m, VTH):
'''
The more similar the input is to the mean,
the more sensitive the neuron corresponding to the mean is to the input.
You can change the maen.
:param inputs: (N_num, N_feature) array
:param m : the number of the gaussian neurons
:param VTH : threshold voltage
i : the i_th gauss_neuron
one feature will be encoded into gauss_neurons
the center of i-th neuron is: gauss -- \mu u_i = I_min + (2i-3)/2(I_max-I_min)/(m -2)
the width of i-th neuron is : gauss -- \sigma sigma_i = 1/1.5(I_max-I_min)/(m -2) 1.5: experience value
popneuron_v: gauss -- function
I_min = min(inputs)
I_max = max(inputs)
:return: (step, num_gauss_neuron, dim_inputs)
'''
ENCODER_REGULAR_VTH = VTH
I_min, I_max = torch.min(inputs), torch.max(inputs)
mu = [i for i in range(0, m)]
mu = torch.ones((1, m)) * I_min + ((2 * torch.tensor(mu) - 3) / 2) * ((I_max-I_min) / (m -2))
sigma = (1 / 1.5) * ((I_max-I_min) / (m -2))
popneuron_v = torch.zeros(((m,) + inputs.shape))
delta_v = torch.zeros(((m,) + inputs.shape))
for i in range(m):
delta_v[i] = torch.exp(-(inputs - mu[0, i]) ** 2 / (2 * sigma * sigma))
spikes = torch.zeros((self.step,) + ((m,) + inputs.shape))
for spike_time_k in range(self.step):
popneuron_v = popneuron_v + delta_v
spikes[spike_time_k][torch.where(popneuron_v.ge(ENCODER_REGULAR_VTH))] = 1
popneuron_v = popneuron_v - spikes[spike_time_k] * ENCODER_REGULAR_VTH
popneuron_rate = torch.sum(spikes, dim=0)/self.step
return spikes, popneuron_rate
## test
# if __name__ == '__main__':
# a = (torch.rand((2,4))*10).type(torch.int)
# print(a)
# pencoder = PEncoder(10, 'population_time')
# spikes=pencoder(inputs=a, num_popneurons=3)
# print(spikes, spikes.shape)
# pencoder = PEncoder(10, 'population_voltage')
# spikes, popneuron_rate = pencoder(inputs=a, num_popneurons=5, VTH=0.99)
# print(spikes, spikes.shape)
================================================
FILE: braincog/base/encoder/qs_coding.py
================================================
from signal import signal
from subprocess import call
import numpy as np
import random
import copy
class QSEncoder:
"""
QS Encoding.
:param lambda_max: 最大发放率
:param steps: 脉冲发放周期长度 T
:param sig_len: 脉冲发放窗口
:param shift: 是否反转背景
:param noise: 是否增加噪声
:param noise_rate: 噪声比例
:param eps: 防止溢出参数
"""
def __init__(self,
lambda_max,
steps,
sig_len,
shift=False,
noise=None,
noise_rate=None,
eps=1e-6
) -> None:
self._lambda_max = lambda_max
self._steps = steps
self._sig_len = sig_len
self._shift = shift
self._noise = noise
self._noise_rate = noise_rate
self._eps = eps
def __call__(self, image, image_delta, image_ori, image_ori_delta):
"""
将图片转换为脉冲。
:param image: 背景反转图片
:param image_delta: 扰动图片,用于计算相位
:param image_ori: 原始图片
:param image_ori_delta: 原始扰动图片
"""
if self._noise:
signals = self.noise_trans(image, image_ori, image_ori_delta)
elif self._shift:
signals = self.shift_trans(image, image_delta, image_ori, image_ori_delta)
else:
signals = np.zeros((self.steps, image.shape[0]))
signal_possion = np.random.poisson(image, (self._sig_len, image.shape[0]))
signals[:self._sig_len] = signal_possion[:]
return signal.T
def shift_trans(self, image, image_delta, image_ori, image_ori_delta):
"""
背景翻转图片转脉冲序列。
:param image: 背景反转图片
:param image_delta: 扰动图片,用于计算相位
:param image_ori: 原始图片
:param image_ori_delta: 原始扰动图片
"""
signal = np.zeros((self._steps, image.shape[0]))
assert image_ori is not None
assert self.noise is False
assert image_delta is not None
assert image_ori_delta is not None
image_ori_reverse = self._lambda_max - image_ori
image_ori_delta_reverse = self._lambda_max - image_ori_delta
zeta = image / (image_ori**2 + image_ori_reverse**2) ** 0.5
zeta_delta = image_delta / (image_ori_delta**2 + image_ori_delta_reverse**2)**0.5
idx_left = zeta < zeta_delta
phi = np.arctan(image_ori / (image_ori_reverse + self._eps))
zeta = np.clip(zeta, -1, 1)
zeta = np.arcsin(zeta)
theta1 = zeta - phi
theta2 = np.pi - zeta - phi
theta = np.zeros(theta1.shape)
theta[idx_left] = theta1[idx_left]
theta[~idx_left] = theta2[~idx_left]
theta = np.mean(theta)
cos_theta = np.cos(theta)
sin_theta = np.sin(theta)
spike_rate = np.abs((self._lambda_max * sin_theta - image) / (sin_theta - cos_theta + self._eps))
signal_possion = np.random.poisson(spike_rate, (self._sig_len, spike_rate.shape[0]))
shift_step = np.rint(np.clip(2 * theta / np.pi, a_min=0, a_max=1.0) * (self._steps - self._sig_len))
shift_step = shift_step.astype(np.int)
signal[shift_step:shift_step + self._sig_len] = signal_possion[:]
def noise_trans(self, image, image_ori, image_ori_delta):
"""
噪声图片转脉冲序列
:param image: 背景反转图片
:param image_ori: 原始图片
:param image_ori_delta: 原始扰动图片
"""
signal = np.zeros((self._steps, image.shape[0]))
assert image_ori is not None
assert self._shift is False
assert self._noise_rate is not None
image_ori_delta = copy.deepcopy(image_ori)
idx = image_ori_delta < (self._lambda_max - 0.001)
image_ori_delta[idx] += 0.001
image_ori_reverse = self._lambda_max - image_ori
image_ori_delta_reverse = self._lambda_max - image_ori_delta
image_noise, image_delta_noise = self.reverse_pixels(image_ori, image_ori_delta, noise_rate=self._noise_rate)
zeta = image_noise / (image_ori**2 + image_ori_reverse**2)**0.5
zeta_delta = image_delta_noise / (image_ori_delta**2 + image_ori_delta_reverse**2)**0.5
idx_left = zeta < zeta_delta
phi = np.arctan(image_ori / (image_ori_reverse + self._eps))
zeta = np.clip(zeta, -1, 1)
zeta = np.arcsin(zeta)
theta1 = zeta - phi
theta2 = np.pi - zeta - phi
theta = np.zeros(theta1.shape)
theta[idx_left] = theta1[idx_left]
theta[~idx_left] = theta2[~idx_left]
theta = np.mean(theta)
cos_theta = np.cos(theta)
sin_theta = np.sin(theta)
spike_rate = np.abs((self._lambda_max * sin_theta - image_noise) / (sin_theta - cos_theta + self._eps))
signal_possion = np.random.poisson(spike_rate, (self._sig_len, spike_rate.shape[0]))
shift_step = np.rint(np.clip(2 * theta / np.pi, a_min=0, a_max=1.0) * (self._steps - self._sig_len))
shift_step = shift_step.astype(np.int)
signal[shift_step:shift_step + self._sig_len] = signal_possion[:]
return signal
def reverse_pixels(self, image, image_delta, noise_rate, flip_bits=None):
"""
反转图片像素
"""
if flip_bits is None:
N = int(noise_rate * image.shape[0])
flip_bits = random.sample(range(image.shape[0]), N)
img = copy.copy(image)
img_delta = copy.copy(image_delta)
img[flip_bits] = self._lambda_max - img[flip_bits]
img_delta[flip_bits] = self._lambda_max - img_delta[flip_bits]
return img, img_delta
================================================
FILE: braincog/base/learningrule/BCM.py
================================================
import numpy as np
import torch
import os
import sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
from braincog.base.node import *
class BCM(nn.Module):
"""
BCM learning rule 多组神经元输入到该节点
"""
def __init__(self, node, connection, cfunc=None, weightdecay=0.99, tau=10):
"""
:param node:node神经元类型实例如IFNode LIFNode
:param connection:连接 类的实例列表 里面只能有一个操作
:param cfunc:BCM的频率函数 默认y(y-th)
:param weightdecay:权重衰减系数 默认0.99
:param tau: 频率更新时间常数
"""
super().__init__()
self.node = node
self.connection = connection
if not isinstance(connection, list):
self.connection = [self.connection]
self.weightdecay = weightdecay
self.tau = tau
self.threshold = 0
def forward(self, *x):
"""
计算前向传播过程
:return:s是脉冲 dw更新量
"""
i = 0
x = [xi.clone().detach() for xi in x]
for xi, coni in zip(x, self.connection):
i += coni(xi)
with torch.no_grad():
s = self.node(i)
i.data += self.cfunc(s) - i.data
dw = torch.autograd.grad(outputs=i, inputs=[i.weight for i in self.connection], grad_outputs=i)
for dwi, i in zip(dw, self.connection):
dwi -= (1 - self.weightdecay) * i.weight
return s, dw
def cfunc(self, s):
self.threshold = ((self.tau - 1) * self.threshold + s) / self.tau
return (s * (s - self.threshold)).detach()
def reset(self):
"""
重置
"""
self.threshold = 0
pass
================================================
FILE: braincog/base/learningrule/Hebb.py
================================================
import numpy as np
import torch
import os
import sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
from braincog.base.node.node import *
class Hebb(nn.Module):
"""
Hebb learning rule 多组神经元输入到该节点
"""
def __init__(self, node, connection):
"""
:param node:node神经元类型实例如IFNode LIFNode
:param connection:连接 类的实例列表 里面只能有一个操作
"""
super().__init__()
self.node = node
self.connection = connection
self.trace = [None for i in self.connection]
def forward(self, *x):
"""
计算前向传播过程
:return:s是脉冲 dw更新量
"""
i = 0
x = [xi.clone().detach() for xi in x]
for xi, coni in zip(x, self.connection):
i += coni(xi)
with torch.no_grad():
s = self.node(i)
i.data += s - i.data
dw = torch.autograd.grad(outputs=i, inputs=[i.weight for i in self.connection], grad_outputs=i)
return s, dw
def reset(self):
"""
重置
"""
self.trace = [None for i in self.connection]
if __name__ == "__main__":
node = IFNode()
linear1 = nn.Linear(2, 2, bias=False)
linear2 = nn.Linear(2, 2, bias=False)
linear1.weight.data = torch.tensor([[1., 1], [1, 1]], requires_grad=True)
linear2.weight.data = torch.tensor([[1., 1], [1, 1]], requires_grad=True)
hebb = Hebb(node, [linear1, linear2])
for i in range(10):
x, dw1 = hebb(torch.tensor([1.1, 1.1]), torch.tensor([1.1, 1.1]))
print(dw1)
================================================
FILE: braincog/base/learningrule/RSTDP.py
================================================
import numpy as np
import torch
import os
import sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
from braincog.base.node import *
class RSTDP(nn.Module):
"""
RSTDP算法
"""
def __init__(self, node, connection, decay=0.99, reward_decay=0.5):
"""
:param node:node神经元类型实例如IFNode LIFNode
:param connection:连接 类的实例列表 里面只能有一个操作
"""
super().__init__()
self.node = node
self.connection = connection
if not isinstance(connection, list):
self.connection = [self.connection]
self.trace = [None for i in self.connection]
self.decay = decay
self.reward_decay = reward_decay
self.stdp = STDP(self.node, self.node, self.decay)
def forward(self, *x, r):
"""
计算前向传播过程
:return:s是脉冲 dw更新量
"""
s, dw = self.stdp(x)
trace = self.cal_trace(r)
return s, dw * trace
def cal_trace(self, x):
"""
计算trace
"""
for i in range(len(x)):
if self.trace[i] is None:
self.trace[i] = Parameter(x[i].clone().detach(), requires_grad=False)
else:
self.trace[i] *= self.decay
self.trace[i] += x[i].detach()
return self.trace
def reset(self):
self.trace = [None for i in self.connection]
================================================
FILE: braincog/base/learningrule/STDP.py
================================================
import numpy as np
import torch
import os
import sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
from braincog.base.node.node import *
class STDP(nn.Module):
"""
STDP learning rule
"""
def __init__(self, node, connection, decay=0.99):
"""
:param node:node神经元类型实例如IFNode LIFNode
:param connection:连接 类的实例 里面只能有一个操作
"""
super().__init__()
self.node = node
self.connection = connection
self.trace = None
self.decay = decay
def forward(self, x):
"""
计算前向传播过程
:return:s是脉冲 dw更新量
"""
x = x.clone().detach()
i = self.connection(x)
with torch.no_grad():
s = self.node(i)
i.data += s - i.data
trace = self.cal_trace(x)
x.data += trace - x.data
dw = torch.autograd.grad(outputs=i, inputs=self.connection.weight, grad_outputs=i)
return s, dw
def cal_trace(self, x):
"""
计算trace
"""
if self.trace is None:
self.trace = Parameter(x.clone().detach(), requires_grad=False)
else:
self.trace *= self.decay
self.trace += x
return self.trace.detach()
def reset(self):
"""
重置
"""
self.trace = None
class MutliInputSTDP(nn.Module):
"""
STDP learning rule 多组神经元输入到该节点
"""
def __init__(self, node, connection, decay=0.99):
"""
:param node:node神经元类型实例如IFNode LIFNode
:param connection:连接 类的实例列表 里面只能有一个操作
"""
super().__init__()
self.node = node
self.connection = connection
self.trace = [None for i in self.connection]
self.decay = decay
def forward(self, *x):
"""
计算前向传播过程
:return:s是脉冲 dw更新量
"""
i = 0
x = [xi.clone().detach() for xi in x]
for xi, coni in zip(x, self.connection):
i += coni(xi)
with torch.no_grad():
s = self.node(i)
i.data += s - i.data
trace = self.cal_trace(x)
for xi, ti in zip(x, trace):
xi.data += ti - xi.data
dw = torch.autograd.grad(outputs=i, inputs=[i.weight for i in self.connection], grad_outputs=i)
return s, dw
def cal_trace(self, x):
"""
计算trace
"""
for i in range(len(x)):
if self.trace[i] is None:
self.trace[i] = Parameter(x[i].clone().detach(), requires_grad=False)
else:
self.trace[i] *= self.decay
self.trace[i] += x[i].detach()
return self.trace
def reset(self):
"""
重置
"""
self.trace = [None for i in self.connection]
class LTP(MutliInputSTDP):
"""
STDP learning rule 多组神经元输入到该节点
"""
pass
class LTD(nn.Module):
"""
STDP learning rule 多组神经元输入到该节点
"""
def __init__(self, node, connection, decay=0.99):
"""
:param node:node神经元类型实例如IFNode LIFNode
:param connection:连接 类的实例列表 里面只能有一个操作
"""
super().__init__()
self.node = node
self.connection = connection
self.trace = None
self.decay = decay
def forward(self, *x):
"""
计算前向传播过程
:return:s是脉冲 dw更新量
"""
i = 0
x = [xi.clone().detach() for xi in x]
for xi, coni in zip(x, self.connection):
i += coni(xi)
with torch.no_grad():
s = self.node(i)
trace = self.cal_trace(s)
i.data += trace - i.data
dw = torch.autograd.grad(outputs=i, inputs=[i.weight for i in self.connection], grad_outputs=i)
return s, dw
def cal_trace(self, x):
"""
计算trace
"""
if self.trace is None:
self.trace = Parameter(torch.zeros_like(x), requires_grad=False)
else:
self.trace *= self.decay
trace = self.trace.clone().detach()
self.trace += x
return trace
def reset(self):
"""
重置
"""
self.trace = None
class FullSTDP(nn.Module):
"""
STDP learning rule 多组神经元输入到该节点
"""
def __init__(self, node, connection, decay=0.99, decay2=0.99):
"""
:param node:node神经元类型实例如IFNode LIFNode
:param connection:连接 类的实例列表 里面只能有一个操作
"""
super().__init__()
self.node = node
self.connection = connection
self.tracein = [None for i in self.connection]
self.traceout = None
self.decay = decay
self.decay2 = decay2
def forward(self, *x):
"""
计算前向传播过程
:return:s是脉冲 dw更新量
"""
i = 0
x = [xi.clone().detach() for xi in x]
for xi, coni in zip(x, self.connection):
i += coni(xi)
with torch.no_grad():
s = self.node(i)
traceout = self.cal_traceout(s)
i.data += traceout - i.data
dw1 = torch.autograd.grad(outputs=i, inputs=[i.weight for i in self.connection], retain_graph=True,
grad_outputs=i)
with torch.no_grad():
i.data += s - i.data
tracein = self.cal_tracein(x)
for xi, ti in zip(x, tracein):
xi.data += ti - xi.data
dw2 = torch.autograd.grad(outputs=i, inputs=[i.weight for i in self.connection], grad_outputs=i)
return s, dw2, dw1
def cal_tracein(self, x):
"""
计算trace
"""
for i in range(len(x)):
if self.tracein[i] is None:
self.tracein[i] = Parameter(x[i].clone().detach(), requires_grad=False)
else:
self.tracein[i] *= self.decay
self.tracein[i] += x[i].detach()
return self.tracein
def cal_traceout(self, x):
"""
计算trace
"""
if self.traceout is None:
self.traceout = Parameter(torch.zeros_like(x), requires_grad=False)
else:
self.traceout *= self.decay2
trace = self.traceout.clone().detach()
self.traceout += x
return trace
def reset(self):
"""
重置
"""
self.traceout = [None for i in self.connection]
self.tracein = None
if __name__ == "__main__":
node = IFNode()
linear1 = nn.Linear(2, 2, bias=False)
linear2 = nn.Linear(2, 2, bias=False)
linear1.weight.data = torch.tensor([[1., 1], [1, 1]], requires_grad=True)
linear2.weight.data = torch.tensor([[1., 1], [1, 1]], requires_grad=True)
stdp = LTD(node, [linear1, linear2])
for i in range(10):
x, dw1 = stdp(torch.tensor([1.1, 1.1]), torch.tensor([1.1, 1.1]))
print(dw1)
================================================
FILE: braincog/base/learningrule/STP.py
================================================
import math
class short_time():
"""
计算短期突触可塑性的变量详见Tsodyks和Markram 1997
:param Syn:突出可塑性结构体
:param ISI:棘突间期
:param Nsp:突触前棘波
"""
def __init__(self, SizeHistOutput):
super().__init__()
self.SizeHistOutput = SizeHistOutput
def syndepr(self, Syn=None, ISI=None, Nsp=None):
"""
短期突触可塑性计算
"""
SizeHistOutput = self.SizeHistOutput
qu = Syn.uprev[Nsp] * math.exp(-ISI / Syn.tc_fac)
qR = math.exp(-ISI / Syn.tc_rec)
u = qu + Syn.use * (1.0 - qu)
R = Syn.Rprev[Nsp] * (1.0 - Syn.uprev[Nsp]) * qR + 1.0 - qR
Syn.uprev[(Nsp + 1) % SizeHistOutput] = u
Syn.Rprev[(Nsp + 1) % SizeHistOutput] = R
return R * u
def set_gsyn(self, np=None, dt=None, v=None, NoiseSyn=None):
"""
突触电流参数计算
"""
Isyn = 0
gsyn_AN = 0
gsyn_G = 0
for j in range(np.NumSynType):
syn = np.STList[j]
sgate = 1.0
if (syn.Mg_gate > 0.0):
sgate = syn.Mg_gate / (1.0 + syn.Mg_fac * math.exp(syn.Mg_slope * (syn.Mg_half - v[0])))
Isyn += sgate * (
np.gfOFFsyn[j] * math.exp(-dt / syn.tc_off) - np.gfONsyn[j] * math.exp(-dt / syn.tc_on)) * (
syn.Erev - v[0])
if (syn.Erev == 0.0):
gsyn_AN = gsyn_AN + sgate * (
np.gfOFFsyn[j] * math.exp(-dt / syn.tc_off) - np.gfONsyn[j] * math.exp(-dt / syn.tc_on))
else:
gsyn_G = gsyn_G + sgate * (
np.gfOFFsyn[j] * math.exp(-dt / syn.tc_off) - np.gfONsyn[j] * math.exp(-dt / syn.tc_on))
for j in range(NoiseSyn.NumSyn):
syn = NoiseSyn.Syn[j].STPtr
sgate = 1.0
if (syn.Mg_gate > 0.0):
sgate = syn.Mg_gate / (1.0 + syn.Mg_fac * math.exp(syn.Mg_slope * (syn.Mg_half - v)))
Isyn += sgate * (
np.gfOFFnoise[j] * math.exp(-dt / syn.tc_off) - np.gfONnoise[j] * math.exp(-dt / syn.tc_on)) * (
syn.Erev - v)
if (syn.Erev == 0.0):
gsyn_AN = gsyn_AN + sgate * (
np.gfOFFnoise[j] * math.exp(-dt / syn.tc_off) - np.gfONnoise[j] * math.exp(-dt / syn.tc_on))
else:
gsyn_G = gsyn_G + sgate * (
np.gfOFFnoise[j] * math.exp(-dt / syn.tc_off) - np.gfONnoise[j] * math.exp(-dt / syn.tc_on))
I_tot = Isyn + np.Iinj
return gsyn_AN, I_tot, gsyn_G
def IDderiv(self, np=None, v=None, dt=None, dv=None, NoiseSyn=None, flag_dv=None):
"""
定义模型的常微分方程计算单个神经元常微分方程
:param np:神经元参数
:param v:当前变量
:param dt:时间步长
"""
Isyn = 0
gsyn_G = 0
gsyn_AN = 0
for j in range(np.NumSynType):
syn = np.STList[j]
sgate = 1.0
if (syn.Mg_gate > 0.0):
sgate = syn.Mg_gate / (1.0 + syn.Mg_fac * math.exp(syn.Mg_slope * (syn.Mg_half - v[0])))
Isyn += sgate * (
np.gfOFFsyn[j] * math.exp(-dt / syn.tc_off) - np.gfONsyn[j] * math.exp(-dt / syn.tc_on)) * (
syn.Erev - v[0])
if (syn.Erev == 0.0):
gsyn_AN = gsyn_AN + sgate * (
np.gfOFFsyn[j] * math.exp(-dt / syn.tc_off) - np.gfONsyn[j] * math.exp(-dt / syn.tc_on))
else:
gsyn_G = gsyn_G + sgate * (
np.gfOFFsyn[j] * math.exp(-dt / syn.tc_off) - np.gfONsyn[j] * math.exp(-dt / syn.tc_on))
for j in range(NoiseSyn.NumSyn):
syn = NoiseSyn.Syn[j].STPtr
sgate = 1.0
if (syn.Mg_gate > 0.0):
sgate = syn.Mg_gate / (1.0 + syn.Mg_fac * math.exp(syn.Mg_slope * (syn.Mg_half - v[0])))
Isyn += sgate * (
np.gfOFFnoise[j] * math.exp(-dt / syn.tc_off) - np.gfONnoise[j] * math.exp(-dt / syn.tc_on)) * (
syn.Erev - v[0])
if (syn.Erev == 0.0):
gsyn_AN = gsyn_AN + sgate * (
np.gfOFFnoise[j] * math.exp(-dt / syn.tc_off) - np.gfONnoise[j] * math.exp(-dt / syn.tc_on))
else:
gsyn_G = gsyn_G + sgate * (
np.gfOFFnoise[j] * math.exp(-dt / syn.tc_off) - np.gfONnoise[j] * math.exp(-dt / syn.tc_on))
I_ex = np.gL * np.sf * math.exp((v[0] - np.Vth) / np.sf)
wV = np.Iinj + Isyn - np.gL * (v[0] - np.EL) + I_ex
D0 = (np.Cm / np.gL) * wV
if ((
np.Iinj + Isyn) >= np.I_ref and flag_dv == 0):
dv[0] = -(np.gL / np.Cm) * (v[0] - np.v_dep)
flag_regime_osc = 0
else:
dv[0] = (np.Iinj - np.gL * (v[0] - np.EL) - v[1] + I_ex + Isyn) / np.Cm
flag_regime_osc = 1
dD0 = np.Cm * (math.exp((v[0] - np.Vth) / np.sf) - 1)
if ((v[1] > wV - D0 / np.tcw) and (v[1] < wV + D0 / np.tcw) and v[0] <= np.Vth and (
np.Iinj + Isyn) < np.I_ref):
dv[1] = -(np.gL * (1 - math.exp((v[0] - np.Vth) / np.sf)) + dD0 / np.tcw) * dv[0]
else:
dv[1] = 0
I_tot = Isyn + np.Iinj
return wV, D0, gsyn_AN, gsyn_G, I_tot, dv
def update(self, np=None, dt=None, NoiseSyn=None, flag_dv=None):
"""
用二阶显式龙格-库塔法积分常微分方程
:param np:神经元参数
:param dt:时间步长
"""
nvar = 2
v = [0] * 2
dv1 = [0] * 2
dv2 = [0] * 2
for i in range(nvar):
v[i] = np.v[i]
wV, D0, gsyn_AN, gsyn_G, I_tot, dv1 = short_time(self.SizeHistOutput).IDderiv(np, v, 0.0, dv1, NoiseSyn, flag_dv)
for i in range(nvar):
v[i] += dt * dv1[i]
wV, D0, gsyn_AN, gsyn_G, I_tot, dv2 = short_time(self.SizeHistOutput).IDderiv(np, v, 0.0, dv2, NoiseSyn, flag_dv)
for i in range(nvar):
np.v[i] += dt / 2.0 * (dv1[i] + dv2[i])
np.dv[i] = dt / 2.0 * (dv1[i] + dv2[i])
if ((np.v[1] > wV - D0 / np.tcw) and (np.v[1] < wV + D0 / np.tcw) and np.v[0] <= np.Vth):
np.v[1] = wV - (D0 / np.tcw)
return np, gsyn_AN, gsyn_G, I_tot
================================================
FILE: braincog/base/learningrule/__init__.py
================================================
from .BCM import BCM
from .Hebb import Hebb
from .RSTDP import RSTDP
from .STDP import STDP, MutliInputSTDP, LTP, LTD, FullSTDP
from .STP import short_time
__all__ = [
'BCM',
"Hebb",
'RSTDP',
'STDP', 'MutliInputSTDP', 'LTP', 'LTD', 'FullSTDP',
'short_time'
]
================================================
FILE: braincog/base/node/__init__.py
================================================
from .node import *
================================================
FILE: braincog/base/node/node.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/4/10 18:46
# User : Floyed
# Product : PyCharm
# Project : braincog
# File : node.py
# explain : 神经元节点类型
import abc
import math
from abc import ABC
import numpy as np
import random
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
from einops import rearrange, repeat
from braincog.base.connection.layer import CustomLinear
from braincog.base.strategy.surrogate import *
class BaseNode(nn.Module, abc.ABC):
"""
神经元模型的基类
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param mem_detach: 是否将上一时刻的膜电位在计算图中截断
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self,
threshold=.5,
v_reset=0.,
dt=1.,
step=8,
requires_thres_grad=False,
sigmoid_thres=False,
requires_fp=False,
layer_by_layer=False,
n_groups=1,
*args,
**kwargs):
super(BaseNode, self).__init__()
self.threshold = Parameter(torch.tensor(threshold), requires_grad=requires_thres_grad)
self.sigmoid_thres = sigmoid_thres
self.mem = 0.
self.spike = 0.
self.dt = dt
self.feature_map = []
self.mem_collect = []
self.requires_fp = requires_fp
self.v_reset = v_reset
self.step = step
self.layer_by_layer = layer_by_layer
self.groups = n_groups
self.mem_detach = kwargs['mem_detach'] if 'mem_detach' in kwargs else False
self.requires_mem = kwargs['requires_mem'] if 'requires_mem' in kwargs else False
@abc.abstractmethod
def calc_spike(self):
"""
通过当前的mem计算是否发放脉冲,并reset
:return: None
"""
pass
def integral(self, inputs):
"""
计算由当前inputs对于膜电势的累积
:param inputs: 当前突触输入电流
:type inputs: torch.tensor
:return: None
"""
pass
def get_thres(self):
return self.threshold if not self.sigmoid_thres else self.threshold.sigmoid()
def rearrange2node(self, inputs):
if self.groups != 1:
if len(inputs.shape) == 4:
outputs = rearrange(inputs, 'b (c t) w h -> t b c w h', t=self.step)
elif len(inputs.shape) == 2:
outputs = rearrange(inputs, 'b (c t) -> t b c', t=self.step)
else:
raise NotImplementedError
elif self.layer_by_layer:
if len(inputs.shape) == 4:
outputs = rearrange(inputs, '(t b) c w h -> t b c w h', t=self.step)
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, '(t b) n c -> t b n c', t=self.step)
elif len(inputs.shape) == 2:
outputs = rearrange(inputs, '(t b) c -> t b c', t=self.step)
else:
raise NotImplementedError
else:
outputs = inputs
return outputs
def rearrange2op(self, inputs):
if self.groups != 1:
if len(inputs.shape) == 5:
outputs = rearrange(inputs, 't b c w h -> b (c t) w h')
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, ' t b c -> b (c t)')
else:
raise NotImplementedError
elif self.layer_by_layer:
if len(inputs.shape) == 5:
outputs = rearrange(inputs, 't b c w h -> (t b) c w h')
elif len(inputs.shape) == 4:
outputs = rearrange(inputs, ' t b n c -> (t b) n c')
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, ' t b c -> (t b) c')
else:
raise NotImplementedError
else:
outputs = inputs
return outputs
def forward(self, inputs):
"""
torch.nn.Module 默认调用的函数,用于计算膜电位的输入和脉冲的输出
在```self.requires_fp is True``` 的情况下,可以使得```self.feature_map```用于记录trace
:param inputs: 当前输入的膜电位
:return: 输出的脉冲
"""
if hasattr(self, 'parallel') and self.parallel is True:
inputs = self.rearrange2node(inputs)
if self.mem_detach and hasattr(self.mem, 'detach'):
self.mem = self.mem.detach()
self.spike = self.spike.detach()
self.integral(inputs)
self.calc_spike()
if self.requires_fp is True:
self.feature_map.append(self.spike)
if self.requires_mem is True:
self.mem_collect.append(self.mem)
return self.rearrange2op(self.spike)
elif self.layer_by_layer or self.groups != 1:
inputs = self.rearrange2node(inputs)
outputs = []
for i in range(self.step):
if self.mem_detach and hasattr(self.mem, 'detach'):
self.mem = self.mem.detach()
self.spike = self.spike.detach()
self.integral(inputs[i])
self.calc_spike()
if self.requires_fp is True:
self.feature_map.append(self.spike)
if self.requires_mem is True:
self.mem_collect.append(self.mem)
outputs.append(self.spike)
outputs = torch.stack(outputs)
outputs = self.rearrange2op(outputs)
return outputs
else:
if self.mem_detach and hasattr(self.mem, 'detach'):
self.mem = self.mem.detach()
self.spike = self.spike.detach()
self.integral(inputs)
self.calc_spike()
if self.requires_fp is True:
self.feature_map.append(self.spike)
if self.requires_mem is True:
self.mem_collect.append(self.mem)
return self.spike
def n_reset(self):
"""
神经元重置,用于模型接受两个不相关输入之间,重置神经元所有的状态
:return: None
"""
self.mem = self.v_reset
self.spike = 0.
self.feature_map = []
self.mem_collect = []
def get_n_attr(self, attr):
if hasattr(self, attr):
return getattr(self, attr)
else:
return None
def set_n_warm_up(self, flag):
"""
一些训练策略会在初始的一些epoch,将神经元视作ANN的激活函数训练,此为设置是否使用该方法训练
:param flag: True:神经元变为激活函数, False:不变
:return: None
"""
self.warm_up = flag
def set_n_threshold(self, thresh):
"""
动态设置神经元的阈值
:param thresh: 阈值
:return:
"""
self.threshold = Parameter(torch.tensor(thresh, dtype=torch.float), requires_grad=False)
def set_n_tau(self, tau):
"""
动态设置神经元的衰减系数,用于带Leaky的神经元
:param tau: 衰减系数
:return:
"""
if hasattr(self, 'tau'):
self.tau = Parameter(torch.tensor(tau, dtype=torch.float), requires_grad=False)
else:
raise NotImplementedError
#============================================================================
# node的基类
class BaseMCNode(nn.Module, abc.ABC):
"""
多房室神经元模型的基类
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param comps: 神经元不同房室, 例如["apical", "basal", "soma"]
"""
def __init__(self,
threshold=1.0,
v_reset=0.,
comps=[]):
super().__init__()
self.threshold = Parameter(torch.tensor(threshold), requires_grad=False)
# self.decay = Parameter(torch.tensor(decay), requires_grad=False)
self.v_reset = v_reset
assert len(comps) != 0
self.mems = dict()
for c in comps:
self.mems[c] = None
self.spike = None
self.warm_up = False
@abc.abstractmethod
def calc_spike(self):
pass
@abc.abstractmethod
def integral(self, inputs):
pass
def forward(self, inputs: dict):
'''
Params:
inputs dict: Inputs for every compartments of neuron
'''
if self.warm_up:
return inputs
else:
self.integral(**inputs)
self.calc_spike()
return self.spike
def n_reset(self):
for c in self.mems.keys():
self.mems[c] = self.v_reset
self.spike = 0.0
def get_n_fire_rate(self):
if self.spike is None:
return 0.
return float((self.spike.detach() >= self.threshold).sum()) / float(np.product(self.spike.shape))
def set_n_warm_up(self, flag):
self.warm_up = flag
def set_n_threshold(self, thresh):
self.threshold = Parameter(torch.tensor(thresh, dtype=torch.float), requires_grad=False)
class ThreeCompNode(BaseMCNode):
"""
三房室神经元模型
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param tau: 胞体膜电位时间常数, 用于控制胞体膜电位衰减
:param tau_basal: 基底树突膜电位时间常数, 用于控制基地树突胞体膜电位衰减
:param tau_apical: 远端树突膜电位时间常数, 用于控制远端树突胞体膜电位衰减
:param comps: 神经元不同房室, 例如["apical", "basal", "soma"]
:param act_fun: 脉冲梯度代理函数
"""
def __init__(self,
threshold=1.0,
tau=2.0,
tau_basal=2.0,
tau_apical=2.0,
v_reset=0.0,
comps=['basal', 'apical', 'soma'],
act_fun=AtanGrad):
g_B = 0.6
g_L = 0.05
super().__init__(threshold, v_reset, comps)
self.tau = tau
self.tau_basal = tau_basal
self.tau_apical = tau_apical
self.act_fun = act_fun(alpha=tau, requires_grad=False)
def integral(self, basal_inputs, apical_inputs):
'''
Params:
inputs torch.Tensor: Inputs for basal dendrite
'''
self.mems['basal'] = (self.mems['basal'] + basal_inputs) / self.tau_basal
self.mems['apical'] = (self.mems['apical'] + apical_inputs) / self.tau_apical
self.mems['soma'] = self.mems['soma'] + (self.mems['apical'] + self.mems['basal'] - self.mems['soma']) / self.tau
def calc_spike(self):
self.spike = self.act_fun(self.mems['soma'] - self.threshold)
self.mems['soma'] = self.mems['soma'] * (1. - self.spike.detach())
self.mems['basal'] = self.mems['basal'] * (1. - self.spike.detach())
self.mems['apical'] = self.mems['apical'] * (1. - self.spike.detach())
#============================================================================
# 用于静态测试 使用ANN的情况 不累积电位
class ReLUNode(BaseNode):
"""
用于相同连接的ANN的测试
"""
def __init__(self,
*args,
**kwargs):
super().__init__(requires_fp=False, *args, **kwargs)
self.act_fun = nn.ReLU()
def forward(self, x):
"""
参考```BaseNode```
:param x:
:return:
"""
self.spike = self.act_fun(x)
if self.requires_fp is True:
self.feature_map.append(self.spike)
if self.requires_mem is True:
self.mem_collect.append(self.mem)
return self.spike
def calc_spike(self):
pass
class BiasReLUNode(BaseNode):
"""
用于相同连接的ANN的测试, 会在每个时刻注入恒定电流, 使得神经元更容易激发
"""
def __init__(self,
*args,
**kwargs):
super().__init__(*args, **kwargs)
self.act_fun = nn.ReLU()
def forward(self, x):
self.spike = self.act_fun(x + 0.1)
if self.requires_fp is True:
self.feature_map += self.spike
return self.spike
def calc_spike(self):
pass
# ============================================================================
# 用于SNN的node
class IFNode(BaseNode):
"""
Integrate and Fire Neuron
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=.5, act_fun=AtanGrad, *args, **kwargs):
"""
:param threshold:
:param act_fun:
:param args:
:param kwargs:
"""
super().__init__(threshold, *args, **kwargs)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
def integral(self, inputs):
self.mem = self.mem + inputs * self.dt
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.get_thres())
self.mem = self.mem * (1 - self.spike.detach())
class LIFNode(BaseNode):
"""
Leaky Integrate and Fire
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=0.5, tau=2., act_fun=QGateGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
# self.threshold = threshold
# print(threshold)
# print(tau)
def integral(self, inputs):
self.mem = self.mem + (inputs - self.mem) / self.tau
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
self.mem = self.mem * (1 - self.spike.detach())
class BurstLIFNode(LIFNode):
def __init__(self, threshold=.5, tau=2., act_fun=RoundGrad, *args, **kwargs):
super().__init__(threshold=threshold, tau=tau, act_fun=act_fun, *args, **kwargs)
self.burst_factor = 1.5
def calc_spike(self):
LIFNode.calc_spike(self)
self.spike = torch.where(self.spike > 1., self.burst_factor * self.spike, self.spike)
class BackEINode(BaseNode):
"""
BackEINode with self feedback connection and excitatory and inhibitory neurons
Reference:https://www.sciencedirect.com/science/article/pii/S0893608022002520
:param threshold: 神经元发放脉冲需要达到的阈值
:param if_back whether to use self feedback
:param if_ei whether to use excitotory and inhibitory neurons
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=0.5, decay=0.2, act_fun=BackEIGateGrad, th_fun=EIGrad, channel=40, if_back=True,
if_ei=True, cfg_backei=2, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.decay = decay
if isinstance(act_fun, str):
act_fun = eval(act_fun)
if isinstance(th_fun, str):
th_fun = eval(th_fun)
self.act_fun = act_fun()
self.th_fun = th_fun()
self.channel = channel
self.if_back = if_back
if self.if_back:
self.back = nn.Conv2d(channel, channel, kernel_size=2 * cfg_backei+1, stride=1, padding=cfg_backei)
self.if_ei = if_ei
if self.if_ei:
self.ei = nn.Conv2d(channel, channel, kernel_size=2 * cfg_backei+1, stride=1, padding=cfg_backei)
def integral(self, inputs):
if self.mem is None:
self.mem = torch.zeros_like(inputs)
self.spike = torch.zeros_like(inputs)
self.mem = self.decay * self.mem
if self.if_back:
self.mem += F.sigmoid(self.back(self.spike)) * inputs
else:
self.mem += inputs
def calc_spike(self):
if self.if_ei:
ei_gate = self.th_fun(self.ei(self.mem))
self.spike = self.act_fun(self.mem-self.threshold)
self.mem = self.mem * (1 - self.spike)
self.spike = ei_gate * self.spike
else:
self.spike = self.act_fun(self.mem-self.threshold)
self.mem = self.mem * (1 - self.spike)
def n_reset(self):
self.mem = None
self.spike = None
self.feature_map = []
self.mem_collect = []
class NoiseLIFNode(LIFNode):
"""
Noisy Leaky Integrate and Fire
在神经元中注入噪声, 默认的噪声分布为 ``Beta(log(2), log(6))``
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param log_alpha: 控制 beta 分布的参数 ``a``
:param log_beta: 控制 beta 分布的参数 ``b``
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self,
threshold=1,
tau=2.,
act_fun=GateGrad,
log_alpha=np.log(2),
log_beta=np.log(6),
*args,
**kwargs):
super().__init__(threshold=threshold, tau=tau, act_fun=act_fun, *args, **kwargs)
self.log_alpha = Parameter(torch.as_tensor(log_alpha), requires_grad=True)
self.log_beta = Parameter(torch.as_tensor(log_beta), requires_grad=True)
# self.fc = nn.Sequential(
# nn.Linear(1, 5),
# nn.ReLU(),
# nn.Linear(5, 5),
# nn.ReLU(),
# nn.Linear(5, 2)
# )
def integral(self, inputs): # b, c, w, h / b, c
# self.mu, self.log_var = self.fc(inputs.mean().unsqueeze(0)).split(1)
alpha, beta = torch.exp(self.log_alpha), torch.exp(self.log_beta)
mu = alpha / (alpha + beta)
var = ((alpha + 1) * alpha) / ((alpha + beta + 1) * (alpha + beta))
noise = torch.distributions.beta.Beta(alpha, beta).sample(inputs.shape) * self.get_thres()
noise = noise * var / var.detach() + mu - mu.detach()
self.mem = self.mem + ((inputs - self.mem) / self.tau + noise) * self.dt
class BiasLIFNode(BaseNode):
"""
带有恒定电流输入Bias的LIF神经元,用于带有抑制性/反馈链接的网络的测试
Noisy Leaky Integrate and Fire
在神经元中注入噪声, 默认的噪声分布为 ``Beta(log(2), log(6))``
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
def integral(self, inputs):
self.mem = self.mem + ((inputs - self.mem) / self.tau) * self.dt + 0.1
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.get_thres())
self.mem = self.mem * (1 - self.spike.detach())
class LIFSTDPNode(BaseNode):
"""
用于执行STDP运算时使用的节点 decay的方式是膜电位乘以decay并直接加上输入电流
"""
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
def integral(self, inputs):
self.mem = self.mem * self.tau + inputs
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
# print(( self.threshold).max())
self.mem = self.mem * (1 - self.spike.detach())
def requires_activation(self):
return False
class PLIFNode(BaseNode):
"""
Parametric LIF, 其中的 ```tau``` 会被backward过程影响
Reference:https://arxiv.org/abs/2007.05785
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = -math.log(tau - 1.)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=True)
self.w = nn.Parameter(torch.as_tensor(init_w))
def integral(self, inputs):
self.mem = self.mem + ((inputs - self.mem) * self.w.sigmoid()) * self.dt
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.get_thres())
self.mem = self.mem * (1 - self.spike.detach())
class PSU(BaseNode):
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = -math.log(tau - 1.)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.parallel = True
self.act_fun = act_fun(alpha=2., requires_grad=True)
T = self.step
m1, m2 = generate_matrix(T, tau)
self.register_buffer('m1', m1)
self.register_buffer('m2', m2)
self.m2 *= self.threshold
def integral(self, inputs):
d1 = self.m1 @ inputs.flatten(1)
self.mem = (d1 + self.m2 @ d1.sigmoid()).view(inputs.shape)
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
class IPSU(BaseNode):
def masked_weight(self):
return self.fc.weight * self.mask0
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = -math.log(tau - 1.)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.parallel = True
self.act_fun = act_fun(alpha=2., requires_grad=True)
T = self.step
matrix, matrix2 = generate_matrix(T, tau)
self.register_buffer('m1', matrix)
self.register_buffer('m2', matrix2)
# self.m2 *= self.threshold
self.fc = nn.Linear(T, T)
nn.init.constant_(self.fc.bias, 0.)
nn.init.kaiming_normal_(self.fc.weight, mode='fan_out', nonlinearity='relu')
mask0 = torch.tril(torch.ones([T, T]))
self.register_buffer('mask0', mask0)
def integral(self, inputs):
d1 = torch.addmm(self.fc.bias.unsqueeze(1), self.masked_weight(), inputs.flatten((1)))
self.mem = (d1 + self.m2 @ inputs.flatten(1)).view(inputs.shape)
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
class RPSU(BaseNode):
def masked_weight(self):
return self.fc.weight * self.mask0
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = -math.log(tau - 1.)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.parallel = True
self.act_fun = act_fun(alpha=2., requires_grad=True)
T = self.step
matrix, matrix2 = generate_matrix(T, tau)
self.register_buffer('m1', matrix)
self.register_buffer('m2', matrix2)
# self.m2 *= self.threshold
self.fc = nn.Linear(T, T)
nn.init.constant_(self.fc.bias, 0.)
nn.init.kaiming_normal_(self.fc.weight, mode='fan_out', nonlinearity='relu')
mask0 = torch.tril(torch.ones([T, T]))
self.register_buffer('mask0', mask0)
def integral(self, inputs):
d1 = self.m1 @ inputs.flatten(1)
d2 = torch.addmm(self.fc.bias.unsqueeze(1), self.masked_weight(), inputs.flatten((1)))
self.mem = (d1 + self.m2 @ d2.sigmoid()).view(inputs.shape)
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
class SPSN(BaseNode):
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = -math.log(tau - 1.)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.parallel = True
self.act_fun = act_fun(alpha=2., requires_grad=True)
m1, m2 = generate_matrix(self.step, tau)
self.register_buffer('m1', m1)
def integral(self, inputs):
self.mem = (self.m1 @ inputs.flatten(1)).sigmoid().view(inputs.shape)
def calc_spike(self):
self.spike = torch.bernoulli(self.mem)
class NoisePLIFNode(PLIFNode):
"""
Noisy Parametric Leaky Integrate and Fire
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self,
threshold=1,
tau=2.,
act_fun=GateGrad,
*args,
**kwargs):
super().__init__(threshold=threshold, tau=tau, act_fun=act_fun, *args, **kwargs)
log_alpha = kwargs['log_alpha'] if 'log_alpha' in kwargs else np.log(2)
log_beta = kwargs['log_beta'] if 'log_beta' in kwargs else np.log(6)
self.log_alpha = Parameter(torch.as_tensor(log_alpha), requires_grad=True)
self.log_beta = Parameter(torch.as_tensor(log_beta), requires_grad=True)
# self.fc = nn.Sequential(
# nn.Linear(1, 5),
# nn.ReLU(),
# nn.Linear(5, 5),
# nn.ReLU(),
# nn.Linear(5, 2)
# )
def integral(self, inputs): # b, c, w, h / b, c
# self.mu, self.log_var = self.fc(inputs.mean().unsqueeze(0)).split(1)
alpha, beta = torch.exp(self.log_alpha), torch.exp(self.log_beta)
mu = alpha / (alpha + beta)
var = ((alpha + 1) * alpha) / ((alpha + beta + 1) * (alpha + beta))
noise = torch.distributions.beta.Beta(alpha, beta).sample(inputs.shape) * self.get_thres()
noise = noise * var / var.detach() + mu - mu.detach()
self.mem = self.mem + ((inputs - self.mem) * self.w.sigmoid() + noise) * self.dt
class BiasPLIFNode(BaseNode):
"""
Parametric LIF with bias
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = -math.log(tau - 1.)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=True)
self.w = nn.Parameter(torch.as_tensor(init_w))
def integral(self, inputs):
self.mem = self.mem + ((inputs - self.mem) * self.w.sigmoid() + 0.1) * self.dt
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.get_thres())
self.mem = self.mem * (1 - self.spike.detach())
class DoubleSidePLIFNode(LIFNode):
"""
能够输入正负脉冲的 PLIF
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self,
threshold=.5,
tau=2.,
act_fun=AtanGrad,
*args,
**kwargs):
super().__init__(threshold, tau, act_fun, *args, **kwargs)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=True)
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.get_thres()) - self.act_fun(self.get_thres - self.mem)
self.mem = self.mem * (1. - torch.abs(self.spike.detach()))
class IzhNode(BaseNode):
"""
Izhikevich 脉冲神经元
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.a = kwargs['a'] if 'a' in kwargs else 0.02
self.b = kwargs['b'] if 'b' in kwargs else 0.2
self.c = kwargs['c'] if 'c' in kwargs else -55.
self.d = kwargs['d'] if 'd' in kwargs else -2.
'''
v' = 0.04v^2 + 5v + 140 -u + I
u' = a(bv-u)
下面是将Izh离散化的写法
if v>= thresh:
v = c
u = u + d
'''
# 初始化膜电势 以及 对应的U
self.mem = 0.
self.u = 0.
self.dt = kwargs['dt'] if 'dt' in kwargs else 1.
def integral(self, inputs):
self.mem = self.mem + self.dt * (0.04 * self.mem * self.mem + 5 * self.mem - self.u + 140 + inputs)
self.u = self.u + self.dt * (self.a * self.b * self.mem - self.a * self.u)
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.get_thres()) # 大于阈值释放脉冲
self.mem = self.mem * (1 - self.spike.detach()) + self.spike.detach() * self.c
self.u = self.u + self.spike.detach() * self.d
def n_reset(self):
self.mem = 0.
self.u = 0.
self.spike = 0.
class IzhNodeMU(BaseNode):
"""
Izhikevich 脉冲神经元多参数版
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.a = kwargs['a'] if 'a' in kwargs else 0.02
self.b = kwargs['b'] if 'b' in kwargs else 0.2
self.c = kwargs['c'] if 'c' in kwargs else -55.
self.d = kwargs['d'] if 'd' in kwargs else -2.
self.mem = kwargs['mem'] if 'mem' in kwargs else 0.
self.u = kwargs['u'] if 'u' in kwargs else 0.
self.dt = kwargs['dt'] if 'dt' in kwargs else 1.
def integral(self, inputs):
self.mem = self.mem + self.dt * (0.04 * self.mem * self.mem + 5 * self.mem - self.u + 140 + inputs)
self.u = self.u + self.dt * (self.a * self.b * self.mem - self.a * self.u)
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
self.mem = self.mem * (1 - self.spike.detach()) + self.spike.detach() * self.c
self.u = self.u + self.spike.detach() * self.d
def n_reset(self):
self.mem = -70.
self.u = 0.
self.spike = 0.
def requires_activation(self):
return False
class DGLIFNode(BaseNode):
"""
Reference: https://arxiv.org/abs/2110.08858
:param threshold: 神经元的脉冲发放阈值
:param tau: 神经元的膜常数, 控制膜电位衰减
"""
def __init__(self, threshold=.5, tau=2., *args, **kwargs):
super().__init__(threshold, tau, *args, **kwargs)
self.act = nn.ReLU()
self.tau = tau
def integral(self, inputs):
inputs = self.act(inputs)
self.mem = self.mem + ((inputs - self.mem) / self.tau) * self.dt
def calc_spike(self):
spike = self.mem.clone()
spike[(spike < self.get_thres())] = 0.
# self.spike = spike / (self.mem.detach().clone() + 1e-12)
self.spike = spike - spike.detach() + \
torch.where(spike.detach() > self.get_thres(), torch.ones_like(spike), torch.zeros_like(spike))
self.spike = spike
self.mem = torch.where(self.mem >= self.get_thres(), torch.zeros_like(self.mem), self.mem)
class HTDGLIFNode(IFNode):
"""
Reference: https://arxiv.org/abs/2110.08858
:param threshold: 神经元的脉冲发放阈值
:param tau: 神经元的膜常数, 控制膜电位衰减
"""
def __init__(self, threshold=.5, tau=2., *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.warm_up = False
def calc_spike(self):
spike = self.mem.clone()
spike[(spike < self.get_thres())] = 0.
# self.spike = spike / (self.mem.detach().clone() + 1e-12)
self.spike = spike - spike.detach() + \
torch.where(spike.detach() > self.get_thres(), torch.ones_like(spike), torch.zeros_like(spike))
self.spike = spike
self.mem = torch.where(self.mem >= self.get_thres(), torch.zeros_like(self.mem), self.mem)
# self.mem[[(spike > self.get_thres())]] = self.mem[[(spike > self.get_thres())]] - self.get_thres()
self.mem = (self.mem + 0.2 * self.spike - 0.2 * self.spike.detach()) * self.dt
def forward(self, inputs):
if self.warm_up:
return F.relu(inputs)
else:
return super(IFNode, self).forward(F.relu(inputs))
class SimHHNode(BaseNode):
"""
简单版本的HH模型
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=50., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
'''
I = Cm dV/dt + g_k*n^4*(V_m-V_k) + g_Na*m^3*h*(V_m-V_Na) + g_l*(V_m - V_L)
'''
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.g_Na, self.g_K, self.g_l = torch.tensor(120.), torch.tensor(120), torch.tensor(0.3) # k 36
self.V_Na, self.V_K, self.V_l = torch.tensor(120.), torch.tensor(-120.), torch.tensor(10.6) # k -12
self.m, self.n, self.h = torch.tensor(0), torch.tensor(0), torch.tensor(0)
self.mem = 0
self.dt = 0.01
def integral(self, inputs):
self.I_Na = torch.pow(self.m, 3) * self.g_Na * self.h * (self.mem - self.V_Na)
self.I_K = torch.pow(self.n, 4) * self.g_K * (self.mem - self.V_K)
self.I_L = self.g_l * (self.mem - self.V_l)
self.mem = self.mem + self.dt * (inputs - self.I_Na - self.I_K - self.I_L) / 0.02
# non Na
# self.mem = self.mem + 0.01 * (inputs - self.I_K - self.I_L) / 0.02 #decayed
# NON k
# self.mem = self.mem + 0.01 * (inputs - self.I_Na - self.I_L) / 0.02 #increase
self.alpha_n = 0.01 * (self.mem + 10.0) / (1 - torch.exp(-(self.mem + 10.0) / 10))
self.beta_n = 0.125 * torch.exp(-(self.mem) / 80)
self.alpha_m = 0.1 * (self.mem + 25) / (1 - torch.exp(-(self.mem + 25) / 10))
self.beta_m = 4 * torch.exp(-(self.mem) / 18)
self.alpha_h = 0.07 * torch.exp(-(self.mem) / 20)
self.beta_h = 1 / (1 + torch.exp(-(self.mem + 30) / 10))
self.n = self.n + self.dt * (self.alpha_n * (1 - self.n) - self.beta_n * self.n)
self.m = self.m + self.dt * (self.alpha_m * (1 - self.m) - self.beta_m * self.m)
self.h = self.h + self.dt * (self.alpha_h * (1 - self.h) - self.beta_h * self.h)
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
self.mem = self.mem * (1 - self.spike.detach())
def forward(self, inputs):
self.integral(inputs)
self.calc_spike()
return self.spike
def n_reset(self):
self.mem = 0.
self.spike = 0.
self.m, self.n, self.h = torch.tensor(0), torch.tensor(0), torch.tensor(0)
def requires_activation(self):
return False
class CTIzhNode(IzhNode):
def __init__(self, threshold=1., tau=2., act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, tau, act_fun, *args, **kwargs)
self.name = kwargs['name'] if 'name' in kwargs else ''
self.excitability = kwargs['excitability'] if 'excitability' in kwargs else 'TRUE'
self.spikepattern = kwargs['spikepattern'] if 'spikepattern' in kwargs else 'RS'
self.synnum = kwargs['synnum'] if 'synnum' in kwargs else 0
self.locationlayer = kwargs['locationlayer'] if 'locationlayer' in kwargs else ''
self.adjneuronlist = {}
self.proximal_dendrites = []
self.distal_dendrites = []
self.totalindex = kwargs['totalindex'] if 'totalindex' in kwargs else 0
self.colindex = 0
self.state = 'inactive'
self.Gup = kwargs['Gup'] if 'Gup' in kwargs else 0.0
self.Gdown = kwargs['Gdown'] if 'Gdown' in kwargs else 0.0
self.Vr = kwargs['Vr'] if 'Vr' in kwargs else 0.0
self.Vt = kwargs['Vt'] if 'Vt' in kwargs else 0.0
self.Vpeak = kwargs['Vpeak'] if 'Vpeak' in kwargs else 0.0
self.capicitance = kwargs['capacitance'] if 'capacitance' in kwargs else 0.0
self.k = kwargs['k'] if 'k' in kwargs else 0.0
self.mem = -65
self.vtmp = -65
self.u = -13.0
self.spike = 0
self.dc = 0
def integral(self, inputs):
self.mem += self.dt * (
self.k * (self.mem - self.Vr) * (self.mem - self.Vt) - self.u + inputs) / self.capicitance
self.u += self.dt * (self.a * (self.b * (self.mem - self.Vr) - self.u))
def calc_spike(self):
if self.mem >= self.Vpeak:
self.mem = self.c
self.u = self.u + self.d
self.spike = 1
self.spreadMarkPostNeurons()
def spreadMarkPostNeurons(self):
for post, list in self.adjneuronlist.items():
if self.excitability == "TRUE":
post.dc = random.randint(140, 160)
else:
post.dc = random.randint(-160, -140)
class adth(BaseNode):
"""
The adaptive Exponential Integrate-and-Fire model (aEIF)
:param args: Other parameters
:param kwargs: Other parameters
"""
def __init__(self, *args, **kwargs):
super().__init__(requires_fp=False, *args, **kwargs)
def adthNode(self, v, dt, c_m, g_m, alpha_w, ad, Ieff, Ichem, Igap, tau_ad, beta_ad, vt, vm1):
"""
Calculate the neurons that discharge after the current threshold is reached
:param v: Current neuron voltage
:param dt: time step
:param ad:Adaptive variable
:param vv:Spike, if the voltage exceeds the threshold from below
"""
v = v + dt / c_m * (-g_m * v + alpha_w * ad + Ieff + Ichem + Igap)
ad = ad + dt / tau_ad * (-ad + beta_ad * v)
vv = (v >= vt).astype(int) * (vm1 < vt).astype(int)
vm1 = v
return v, ad, vv, vm1
def calc_spike(self):
pass
class HHNode(BaseNode):
"""
用于脑模拟的HH模型
p: [threshold, g_Na, g_K, g_l, V_Na, V_K, V_l, C]
"""
def __init__(self, p, dt, device, act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold=p[0], *args, **kwargs)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
'''
I = Cm dV/dt + g_k*n^4*(V_m-V_k) + g_Na*m^3*h*(V_m-V_Na) + g_l*(V_m - V_L)
'''
self.neuron_num = len(p[0])
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.tau_I = 3
self.g_Na = torch.tensor(p[1])
self.g_K = torch.tensor(p[2])
self.g_l = torch.tensor(p[3])
self.V_Na = torch.tensor(p[4])
self.V_K = torch.tensor(p[5])
self.V_l = torch.tensor(p[6])
self.C = torch.tensor(p[7])
self.m = 0.05 * torch.ones(self.neuron_num, device=device, requires_grad=False)
self.n = 0.31 * torch.ones(self.neuron_num, device=device, requires_grad=False)
self.h = 0.59 * torch.ones(self.neuron_num, device=device, requires_grad=False)
self.v_reset = 0
self.dt = dt
self.dt_over_tau = self.dt / self.tau_I
self.sqrt_coeff = math.sqrt(1 / (2 * (1 / self.dt_over_tau)))
self.mu = 10
self.sig = 12
self.mem = torch.tensor(self.v_reset, device=device, requires_grad=False)
self.mem_p = self.mem
self.spike = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.Iback = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.Ieff = torch.zeros(self.neuron_num, device=device, requires_grad=False)
def integral(self, inputs):
self.alpha_n = (0.1 - 0.01 * self.mem) / (torch.exp(1 - 0.1 * self.mem) - 1)
self.alpha_m = (2.5 - 0.1 * self.mem) / (torch.exp(2.5 - 0.1 * self.mem) - 1)
self.alpha_h = 0.07 * torch.exp(-self.mem / 20.0)
self.beta_n = 0.125 * torch.exp(-self.mem / 80.0)
self.beta_m = 4.0 * torch.exp(-self.mem / 18.0)
self.beta_h = 1 / (torch.exp(3 - 0.1 * self.mem) + 1)
self.n = self.n + self.dt * (self.alpha_n * (1 - self.n) - self.beta_n * self.n)
self.m = self.m + self.dt * (self.alpha_m * (1 - self.m) - self.beta_m * self.m)
self.h = self.h + self.dt * (self.alpha_h * (1 - self.h) - self.beta_h * self.h)
self.I_Na = torch.pow(self.m, 3) * self.g_Na * self.h * (self.mem - self.V_Na)
self.I_K = torch.pow(self.n, 4) * self.g_K * (self.mem - self.V_K)
self.I_L = self.g_l * (self.mem - self.V_l)
self.mem_p = self.mem
self.mem = self.mem + self.dt * (inputs - self.I_Na - self.I_K - self.I_L) / self.C
def calc_spike(self):
self.spike = (self.threshold > self.mem_p).float() * (self.mem > self.threshold).float()
def forward(self, inputs):
self.integral(inputs)
self.calc_spike()
return self.spike, self.mem
def requires_activation(self):
return False
class aEIF(BaseNode):
"""
The adaptive Exponential Integrate-and-Fire model (aEIF)
This class define the membrane, spike, current and parameters of a neuron group of a specific type
:param args: Other parameters
:param kwargs: Other parameters
"""
def __init__(self, p, dt, device, *args, **kwargs):
"""
p:[threshold, v_reset, c_m, tao_w, alpha_ad, beta_ad]
"""
super().__init__(threshold=p[0], requires_fp=False, *args, **kwargs)
self.neuron_num = len(p[0])
self.g_m = 0.1 # neuron conduction
self.dt = dt
self.tau_I = 3 # Time constant to filter the synaptic inputs
self.Delta_T = 0.5 # parameter
self.v_reset = p[1] # membrane potential reset to v_reset after fire spike
self.c_m = p[2]
self.tau_w = p[3] # Time constant of adaption coupling
self.alpha_ad = p[4]
self.beta_ad = p[5]
self.refrac = 5 / self.dt # refractory period
self.dt_over_tau = self.dt / self.tau_I
self.sqrt_coeff = math.sqrt(1 / (2 * (1 / self.dt_over_tau)))
self.mem = self.v_reset
self.spike = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.ad = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.ref = torch.randint(0, int(self.refrac + 1), (1, self.neuron_num), device=device, requires_grad=False).squeeze(
0) # refractory counter
self.ref = self.ref.float()
self.mu = 10
self.sig = 12
self.Iback = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.Ieff = torch.zeros(self.neuron_num, device=device, requires_grad=False)
def integral(self, inputs):
self.mem = self.mem + (self.ref > self.refrac) * self.dt / self.c_m * \
(-self.g_m * (self.mem - self.v_reset) + self.g_m * self.Delta_T *
torch.exp((self.mem - self.threshold) / self.Delta_T) +
self.alpha_ad * self.ad + inputs)
self.ad = self.ad + (self.ref > self.refrac) * self.dt / self.tau_w * \
(-self.ad + self.beta_ad * (self.mem - self.v_reset))
def calc_spike(self):
self.spike = (self.mem > self.threshold).float()
self.ref = self.ref * (1 - self.spike) + 1
self.ad = self.ad + self.spike * 30
self.mem = self.spike * self.v_reset + (1 - self.spike.detach()) * self.mem
def forward(self, inputs):
# aeifnode_cuda.forward(self.threshold, self.c_m, self.alpha_w, self.beta_ad, inputs, self.ref, self.ad, self.mem, self.spike)
self.integral(inputs)
self.calc_spike()
return self.spike, self.mem
class LIAFNode(BaseNode):
"""
Leaky Integrate and Analog Fire (LIAF), Reference: https://ieeexplore.ieee.org/abstract/document/9429228
与LIF相同, 但前传的是膜电势, 更新沿用阈值和膜电势
:param act_fun: 前传使用的激活函数 [ReLU, SeLU, LeakyReLU]
:param threshold_related: 阈值依赖模式,若为"True"则 self.spike = act_fun(mem-threshold)
:note that BaseNode return self.spike, and here self.spike is analog value.
"""
def __init__(self, spike_act=BackEIGateGrad(), act_fun="SELU", threshold=0.5, tau=2., threshold_related=True, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
if isinstance(act_fun, str):
act_fun = eval("nn." + act_fun + "()")
self.tau = tau
self.act_fun = act_fun
self.spike_act = spike_act
self.threshold_related = threshold_related
def integral(self, inputs):
self.mem = self.mem + (inputs - self.mem) / self.tau
def calc_spike(self):
if self.threshold_related:
spike_tmp = self.act_fun(self.mem - self.threshold)
else:
spike_tmp = self.act_fun(self.mem)
self.spike = self.spike_act(self.mem - self.threshold)
self.mem = self.mem * (1 - self.spike)
self.spike = spike_tmp
class OnlineLIFNode(BaseNode):
"""
Online-update Leaky Integrate and Fire
与LIF模型相同,但是时序信息在反传时从计算图剥离,因此可以实现在线的更新;模型占用显存固定,不随仿真步step线性提升。
使用此神经元需要修改: 1. 将模型中t次forward从model_zoo写到main.py中
2. 在Conv层与OnelineLIFNode层中加入Replace函数,即时序前传都是detach的,但仍计算该层空间梯度信息。
3. 网络结构不适用BN层,使用weight standardization
注意该神经元不同于OTTT,而是将时序信息全部扔弃。对应这篇文章:https://arxiv.org/abs/2302.14311
若需保留时序,需要对self.rate_tracking进行计算。实现可参考https://github.com/pkuxmq/OTTT-SNN
"""
def __init__(self, threshold=0.5, tau=2., act_fun=QGateGrad, init=False, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.rate_tracking = None
self.init = True
def integral(self, inputs):
if self.init is True:
self.mem = torch.zeros_like(inputs)
self.init = False
self.mem = self.mem.detach() + (inputs - self.mem.detach()) / self.tau
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
self.mem = self.mem * (1 - self.spike.detach())
with torch.no_grad():
if self.rate_tracking == None:
self.rate_tracking = self.spike.clone().detach()
self.spike = torch.cat((self.spike, self.rate_tracking), dim=0)
class AdaptiveNode(LIFNode):
def __init__(self, threshold=1., act_fun=QGateGrad, step=10, spike_output=True, *args, **kwargs):
super().__init__(threshold=threshold, step=step, **kwargs)
self.n_encode_type = kwargs['n_encode_type'] if 'n_encode_type' in kwargs else 'linear'
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
# self.act_fun = BinaryActivation()
print(self.n_encode_type)
if self.n_encode_type == 'linear':
self.encoder = nn.Sequential(
CustomLinear(self.step, self.step)
)
elif self.n_encode_type == 'mlp':
# Direct
self.encoder = nn.Sequential(
CustomLinear(self.step, self.step),
nn.ReLU(),
CustomLinear(self.step, self.step),
nn.ReLU(),
CustomLinear(self.step, self.step),
nn.ReLU(),
CustomLinear(self.step, self.step),
)
elif self.n_encode_type == 'att':
# -> SE block
self.encoder = nn.Sequential(
nn.Linear(self.step, self.step),
nn.ReLU(),
nn.Linear(self.step, self.step),
nn.ReLU(),
nn.Linear(self.step, self.step),
nn.Sigmoid()
)
elif self.n_encode_type == 'conv':
self.encoder = nn.Sequential(
nn.Linear(self.step, self.step),
nn.ReLU(),
nn.Linear(self.step, self.step),
)
# self.init_weight()
else:
raise NotImplementedError('Unrecognizable categories {}.'.format(self.n_encode_type))
self.saved_mem = 0.
def init_weight(self):
for mod in self.encoder.modules():
if isinstance(mod, nn.Conv1d):
mod.weight.data[:, :, 4] = 1. / mod.weight.shape[0]
mod.weight.data[:, :, [0, 1, 2, 3, 5, 6, 7, 8]] = 0.
mod.bias.data[:] = 0.
def forward(self, inputs): # (t b) c w h
if self.n_encode_type != 'conv':
x = rearrange(inputs, '(t b) ... -> b ... t', t=self.step)
else:
c, w, h = inputs.shape[1:]
x = rearrange(inputs, '(t b) c w h -> (b c w h) 1 t', t=self.step)
if self.n_encode_type != 'att':
x = self.encoder(x) # Direct
else:
x = x * self.encoder(x) # SE Block
if self.n_encode_type != 'conv':
x = rearrange(x, 'b ... t -> (t b) ...')
else:
x = rearrange(x, '(b c w h) 1 t -> (t b) c w h', c=c, w=w, h=h)
# self.spike = self.act_fun(x - 0.5)
# # print(self.spike.mean())
# # print(self.requires_fp)
# if self.requires_fp:
# spike = rearrange(self.spike, '(t b) c w h -> t b c w h', t=self.step)
# for t in range(self.step):
# # print(t, float(spike[t].mean()), float(spike[t].std()))
# self.feature_map.append(spike[t])
# self.saved_mem = x
# return self.spike
return super().forward(x)
# def get_thres(self):
# mem_relu = F.relu(self.mem.detach())
# return mem_relu[mem_relu > 0.].median()
def n_reset(self):
super().n_reset()
self.saved_mem = 0.
================================================
FILE: braincog/base/strategy/LateralInhibition.py
================================================
import warnings
import torch
from torch import nn
import torch.nn.functional as F
class LateralInhibition(nn.Module):
"""
侧抑制 用于发放脉冲的神经元抑制其他同层神经元 在膜电位上作用
"""
def __init__(self, node, inh, mode="constant"):
super().__init__()
self.inh = inh
self.node = node
self.mode = mode
def forward(self, x: torch.Tensor, xori=None):
# x.shape = [N, C,W,H]
# ret.shape = [N, C,W,H]
if self.mode == "constant":
self.node.mem = self.node.mem - self.inh * (x.max(1, True)[0] - x)
elif self.mode == "max":
self.node.mem = self.node.mem - self.inh * xori.max(1, True)[0] .detach() * (x.max(1, True)[0] - x)
elif self.mode == "threshold":
self.node.mem = self.node.mem - self.inh * self.node.threshold * (x.max(1, True)[0] - x)
else:
pass
return x
================================================
FILE: braincog/base/strategy/__init__.py
================================================
__all__ = ['surrogate', 'LateralInhibition']
from . import (
surrogate,
LateralInhibition
)
================================================
FILE: braincog/base/strategy/surrogate.py
================================================
import math
import torch
from torch import nn
from torch.nn import functional as F
def heaviside(x):
return (x >= 0.).to(x.dtype)
class SurrogateFunctionBase(nn.Module):
"""
Surrogate Function 的基类
:param alpha: 为一些能够调控函数形状的代理函数提供参数.
:param requires_grad: 参数 ``alpha`` 是否需要计算梯度, 默认为 ``False``
"""
def __init__(self, alpha, requires_grad=True):
super().__init__()
self.alpha = nn.Parameter(
torch.tensor(alpha, dtype=torch.float),
requires_grad=requires_grad)
@staticmethod
def act_fun(x, alpha):
"""
:param x: 膜电位的输入
:param alpha: 控制代理梯度形状的变量, 可以为 ``NoneType``
:return: 激发之后的spike, 取值为 ``[0, 1]``
"""
raise NotImplementedError
def forward(self, x):
"""
:param x: 膜电位输入
:return: 激发之后的spike
"""
return self.act_fun(x, self.alpha)
'''
sigmoid surrogate function.
'''
class sigmoid(torch.autograd.Function):
"""
使用 sigmoid 作为代理梯度函数
对应的原函数为:
.. math::
g(x) = \\mathrm{sigmoid}(\\alpha x) = \\frac{1}{1+e^{-\\alpha x}}
反向传播的函数为:
.. math::
g'(x) = \\alpha * (1 - \\mathrm{sigmoid} (\\alpha x)) \\mathrm{sigmoid} (\\alpha x)
"""
@staticmethod
def forward(ctx, x, alpha):
if x.requires_grad:
ctx.save_for_backward(x)
ctx.alpha = alpha
return heaviside(x)
@staticmethod
def backward(ctx, grad_output):
grad_x = None
if ctx.needs_input_grad[0]:
s_x = torch.sigmoid(ctx.alpha * ctx.saved_tensors[0])
grad_x = grad_output * s_x * (1 - s_x) * ctx.alpha
return grad_x, None
class SigmoidGrad(SurrogateFunctionBase):
def __init__(self, alpha=1., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return sigmoid.apply(x, alpha)
'''
atan surrogate function.
'''
class atan(torch.autograd.Function):
"""
使用 Atan 作为代理梯度函数
对应的原函数为:
.. math::
g(x) = \\frac{1}{\\pi} \\arctan(\\frac{\\pi}{2}\\alpha x) + \\frac{1}{2}
反向传播的函数为:
.. math::
g'(x) = \\frac{\\alpha}{2(1 + (\\frac{\\pi}{2}\\alpha x)^2)}
"""
@staticmethod
def forward(ctx, inputs, alpha):
ctx.save_for_backward(inputs, alpha)
return inputs.gt(0.).float()
@staticmethod
def backward(ctx, grad_output):
grad_x = None
grad_alpha = None
shared_c = grad_output / \
(1 + (ctx.saved_tensors[1] * math.pi /
2 * ctx.saved_tensors[0]).square())
if ctx.needs_input_grad[0]:
grad_x = ctx.saved_tensors[1] / 2 * shared_c
if ctx.needs_input_grad[1]:
grad_alpha = (ctx.saved_tensors[0] / 2 * shared_c).sum()
return grad_x, grad_alpha
class AtanGrad(SurrogateFunctionBase):
def __init__(self, alpha=2., requires_grad=True):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return atan.apply(x, alpha)
'''
gate surrogate fucntion.
'''
class gate(torch.autograd.Function):
"""
使用 gate 作为代理梯度函数
对应的原函数为:
.. math::
g(x) = \\mathrm{NonzeroSign}(x) \\log (|\\alpha x| + 1)
反向传播的函数为:
.. math::
g'(x) = \\frac{\\alpha}{1 + |\\alpha x|} = \\frac{1}{\\frac{1}{\\alpha} + |x|}
"""
@staticmethod
def forward(ctx, x, alpha):
if x.requires_grad:
grad_x = torch.where(x.abs() < 1. / alpha, torch.ones_like(x), torch.zeros_like(x))
ctx.save_for_backward(grad_x)
return x.gt(0).float()
@staticmethod
def backward(ctx, grad_output):
grad_x = None
if ctx.needs_input_grad[0]:
grad_x = grad_output * ctx.saved_tensors[0]
return grad_x, None
class GateGrad(SurrogateFunctionBase):
def __init__(self, alpha=2., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return gate.apply(x, alpha)
'''
gatquadratic_gate surrogate function.
'''
class quadratic_gate(torch.autograd.Function):
"""
使用 quadratic_gate 作为代理梯度函数
对应的原函数为:
.. math::
g(x) =
\\begin{cases}
0, & x < -\\frac{1}{\\alpha} \\\\
-\\frac{1}{2}\\alpha^2|x|x + \\alpha x + \\frac{1}{2}, & |x| \\leq \\frac{1}{\\alpha} \\\\
1, & x > \\frac{1}{\\alpha} \\\\
\\end{cases}
反向传播的函数为:
.. math::
g'(x) =
\\begin{cases}
0, & |x| > \\frac{1}{\\alpha} \\\\
-\\alpha^2|x|+\\alpha, & |x| \\leq \\frac{1}{\\alpha}
\\end{cases}
"""
@staticmethod
def forward(ctx, x, alpha):
if x.requires_grad:
mask_zero = (x.abs() > 1 / alpha)
grad_x = -alpha * alpha * x.abs() + alpha
grad_x.masked_fill_(mask_zero, 0)
ctx.save_for_backward(grad_x)
return x.gt(0.).float()
@staticmethod
def backward(ctx, grad_output):
grad_x = None
if ctx.needs_input_grad[0]:
grad_x = grad_output * ctx.saved_tensors[0]
return grad_x, None
class QGateGrad(SurrogateFunctionBase):
def __init__(self, alpha=2., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return quadratic_gate.apply(x, alpha)
class relu_like(torch.autograd.Function):
@staticmethod
def forward(ctx, x, alpha):
if x.requires_grad:
ctx.save_for_backward(x, alpha)
return heaviside(x)
@staticmethod
def backward(ctx, grad_output):
grad_x, grad_alpha = None, None
x, alpha = ctx.saved_tensors
if ctx.needs_input_grad[0]:
grad_x = grad_output * x.gt(0.).float() * alpha
if ctx.needs_input_grad[1]:
grad_alpha = (grad_output * F.relu(x)).sum()
return grad_x, grad_alpha
class RoundGrad(nn.Module):
def __init__(self, **kwargs):
super(RoundGrad, self).__init__()
self.act = nn.Hardtanh(-.5, 4.5)
def forward(self, x):
x = self.act(x)
return x.ceil() + x - x.detach()
class ReLUGrad(SurrogateFunctionBase):
"""
使用ReLU作为代替梯度函数, 主要用为相同结构的ANN的测试
"""
def __init__(self, alpha=2., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return relu_like.apply(x, alpha)
'''
Straight-Through (ST) Estimator
'''
class straight_through_estimator(torch.autograd.Function):
"""
使用直通估计器作为代理梯度函数
http://arxiv.org/abs/1308.3432
"""
@staticmethod
def forward(ctx, inputs):
outputs = heaviside(inputs)
ctx.save_for_backward(outputs)
return outputs
@staticmethod
def backward(ctx, grad_output):
grad_x = None
if ctx.needs_input_grad[0]:
grad_x = grad_output
return grad_x
class stdp(torch.autograd.Function):
@staticmethod
def forward(ctx, inputs):
outputs = inputs.gt(0.).float()
ctx.save_for_backward(outputs)
return outputs
@staticmethod
def backward(ctx, grad_output):
inputs, = ctx.saved_tensors
return inputs * grad_output
class STDPGrad(SurrogateFunctionBase):
def __init__(self, alpha=2., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return stdp.apply(x)
class backeigate(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
return input.gt(0.).float()
@staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
grad_input = grad_output.clone()
temp = abs(input) < 0.5
return grad_input * temp.float()
class BackEIGateGrad(SurrogateFunctionBase):
def __init__(self, alpha=2., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return backeigate.apply(x)
class ei(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
return torch.sign(input).float()
@staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
grad_input = grad_output.clone()
temp = abs(input) < 0.5
return grad_input * temp.float()
class EIGrad(SurrogateFunctionBase):
def __init__(self, alpha=2., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return ei.apply(x)
================================================
FILE: braincog/base/utils/__init__.py
================================================
from .criterions import UnilateralMse, MixLoss
from .visualization import plot_tsne, plot_tsne_3d, plot_confusion_matrix
from torch.autograd import Variable
import torch
__all__ = [
'UnilateralMse', 'MixLoss',
'plot_tsne', 'plot_tsne_3d', 'plot_confusion_matrix', 'drop_path'
]
def drop_path(x, drop_prob):
if drop_prob > 0.:
keep_prob = 1. - drop_prob
mask = Variable(torch.cuda.FloatTensor(
x.size(0), 1, 1, 1).bernoulli_(keep_prob))
x.div_(keep_prob)
x.mul_(mask)
return x
================================================
FILE: braincog/base/utils/criterions.py
================================================
import numpy as np
import torch
import torch.nn.functional as F
class UnilateralMse(torch.nn.Module):
"""
扩展单边的MSE损失, 用于控制输出层的期望fire-rate 高于 thresh
:param thresh: 输出层的期望输出频率
"""
def __init__(self, thresh=1.):
super(UnilateralMse, self).__init__()
self.thresh = thresh
self.loss = torch.nn.MSELoss()
def forward(self, x, target):
# x = nn.functional.softmax(x, dim=1)
torch.clip(x, max=self.thresh)
if x.shape == target.shape:
return self.loss(x, target)
return self.loss(x, torch.zeros_like(x).scatter_(1, target.view(-1, 1), self.thresh))
class MixLoss(torch.nn.Module):
"""
混合损失函数, 可以将任意的损失函数与UnilateralMse损失混合
:param ce_loss: 任意的损失函数
"""
def __init__(self, ce_loss):
super(MixLoss, self).__init__()
self.ce = ce_loss
self.mse = UnilateralMse(1.)
def forward(self, x, target):
return 0.1 * self.ce(x, target) + self.mse(x, target)
class TetLoss(torch.nn.Module):
def __init__(self, loss_fn):
super(TetLoss, self).__init__()
self.loss_fn = loss_fn
def forward(self, x, target):
loss = 0.
for logit in x:
loss += self.loss_fn(logit, target)
return loss / x.shape[0]
class OnehotMse(torch.nn.Module):
"""
将类别转换为onehot进行mse损失计算, 用于带vote的SNN中
"""
def __init__(self, num_class):
super(OnehotMse, self).__init__()
self.num_class = num_class
self.loss_fn = torch.nn.MSELoss()
def forward(self, x, target):
target = F.one_hot(target.to(torch.int64), self.num_class).float()
loss = self.loss_fn(x, target)
return loss
================================================
FILE: braincog/base/utils/visualization.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/7/1 11:10
# User : Floyed
# Product : PyCharm
# Project : braincog
# File : visualization.py
# explain : add t-SNE
import os
import numpy as np
import sklearn
from sklearn.manifold import TSNE
from sklearn.metrics import confusion_matrix
import torch
import torch.nn.functional as F
from einops import rearrange
import matplotlib.pyplot as plt
import matplotlib.patheffects as PathEffects
import matplotlib
from mpl_toolkits.mplot3d import Axes3D
from mpl_toolkits.mplot3d import proj3d
import seaborn as sns
# Random state.
RS = 20150101
def spike_rate_vis_1d(data, output_dir=''):
assert len(data.shape) == 2, 'Shape should be (t, c).'
data = rearrange(data, 'i j -> j i')
if isinstance(data, torch.Tensor):
data = data.to('cpu').numpy()
plt.figure(figsize=(8, 8))
sns.heatmap(data, annot=None, cmap='YlGnBu')
# plt.ylim(0, _max + 1)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
def spike_rate_vis(data, output_dir=''):
assert len(data.shape) == 3, 'Shape should be (t, r, c).'
data = data.mean(axis=0)
if isinstance(data, torch.Tensor):
data = data.to('cpu').numpy()
plt.figure(figsize=(8, 8))
sns.heatmap(data, annot=None, cmap='YlGnBu')
# plt.ylim(0, _max + 1)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
def plot_mem_distribution(data,
output_dir='',
legend='',
xlabel='Membrane Potential',
ylabel='Density',
**kwargs):
# print(type(data), len(data))
if isinstance(data, torch.Tensor):
data = data.reshape(-1).to('cpu').numpy()
mean = data.mean()
std = data.std()
idx = np.argwhere(data < mean - 3 * std)
data = np.delete(data, idx)
idx = np.argwhere(data > mean + 3 * std)
data = np.delete(data, idx)
sns.set_style('darkgrid')
# sns.set_palette('deep', desat=.6)
sns.set_context("notebook", font_scale=1.5,
rc={"lines.linewidth": 2.5})
# fig = plt.figure(figsize=(8, 8))
# ax = fig.add_subplot(111, aspect='equal')
# sns.distplot(data, bins=int(np.sqrt(data.shape[0])),
# hist=True, kde=False, hist_kws={'histtype': 'stepfilled'}, **kwargs)
# print('hist begin')
print(len(data))
n, bins, patches = plt.hist(data,
density=True,
histtype='stepfilled',
alpha=0.618,
bins=int(np.sqrt(data.shape[0])),
**kwargs)
# print('hist finished')
# sns.kdeplot(data, color='#5294c3')
# print('kde finished')
plt.xlabel(xlabel)
plt.ylabel(ylabel)
# if legend != '':
# plt.legend(legend)
# ax.axis('tight')
if output_dir != '':
plt.savefig(output_dir, bbox_inches='tight')
print('{} saved'.format(output_dir))
# plt.show()
def plot_tsne(x, colors,output_dir="", num_classes=None):
if isinstance(x, torch.Tensor):
x = x.to('cpu').numpy()
if isinstance(colors, torch.Tensor):
colors = colors.to('cpu').numpy()
if num_classes is None:
num_classes=colors.max()+1
x = TSNE(random_state=RS, n_components=2).fit_transform(x)
sns.set_style('darkgrid')
sns.set_palette('muted')
sns.set_context("notebook", font_scale=1.5,
rc={"lines.linewidth": 2.5})
palette = np.array(sns.color_palette("hls", num_classes))
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, aspect='equal')
sc = ax.scatter(x[:, 0], x[:, 1], lw=0, s=25,
c=palette[colors.astype(np.int)])
# plt.xlim(-25, 25)
# plt.ylim(-25, 25)
# ax.axis('off')
ax.axis('tight')
# plt.grid('off')
plt.savefig(output_dir, facecolor=fig.get_facecolor(), bbox_inches='tight')
#plt.show()
def plot_tsne_3d(x, colors,output_dir="", num_classes=None):
"""
绘制3D t-SNE聚类图, 直接将图片保存到输出路径
:param x: 输入的feature map / spike
:param colors: predicted labels 作为不同类别的颜色
:param output_dir: 图片输出的路径(包括图片名及后缀)
:return: None
"""
if isinstance(x, torch.Tensor):
x = x.to('cpu').numpy()
if isinstance(colors, torch.Tensor):
colors = colors.to('cpu').numpy()
if num_classes is None:
num_classes=colors.max()+1
x = TSNE(random_state=RS, n_components=3, perplexity=30).fit_transform(x)
# sns.set_style('darkgrid')
sns.set_palette('muted')
sns.set_context("notebook", font_scale=1.5,
rc={"lines.linewidth": 2.5})
fig = plt.figure(figsize=(8, 8))
palette = np.array(sns.color_palette("hls", num_classes))
ax = fig.add_subplot(111, projection='3d')
sc = ax.scatter(x[:, 0], x[:, 1], x[:, 2], lw=0, s=20, alpha=0.8,
c=palette[colors.astype(np.int)])
# ax.set_xlabel('X')
# ax.set_ylabel('Y')
# ax.set_zlabel('Z')
# ax.view_init(20, -120)
ax.axis('tight')
plt.savefig(output_dir, facecolor=fig.get_facecolor(), bbox_inches='tight')
#plt.show()
def plot_confusion_matrix(logits, labels, output_dir):
"""
绘制混淆矩阵图
:param logits: predicted labels
:param labels: true labels
:param output_dir: 输出路径, 需要包括文件名以及后缀
:return: None
"""
sns.set_style('darkgrid')
sns.set_palette('Blues_r')
sns.set_context("notebook", font_scale=1.,
rc={"lines.linewidth": 2.})
logits = logits.argmax(dim=1).cpu()
labels = labels.cpu()
_max = labels.max()
if _max > 10:
annot = False
else:
annot = True
# print(labels.shape, logits.shape)
conf_matrix = confusion_matrix(labels, logits)
con_mat_norm = conf_matrix.astype('float') / conf_matrix.sum(axis=1)[:, np.newaxis] # 归一化
con_mat_norm = np.around(con_mat_norm, decimals=2)
plt.figure(figsize=(8, 8))
sns.heatmap(con_mat_norm, annot=annot, cmap='Blues')
plt.ylim(0, _max + 1)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.savefig(output_dir, bbox_inches='tight')
#plt.show()
if __name__ == '__main__':
# Test for T-SNE
# x = torch.randn((100, 100))
# y = torch.randint(low=0, high=10, size=[100])
# plot_tsne_3d(x, y, output_dir='./t-sne.eps')
# Test for confusion matrix
# x = torch.rand(5012, 100)
# y = torch.randint(0, 100, (5012,))
# plot_confusion_matrix(x, y, '')
# Test for Mem Distribution
x = torch.randn(100000)
plot_mem_distribution(x, legend=['test'])
================================================
FILE: braincog/datasets/CUB2002011.py
================================================
import os
import pandas as pd
from torchvision.datasets import VisionDataset
from torchvision.datasets.folder import default_loader
from torchvision.datasets.utils import download_file_from_google_drive
class CUB2002011(VisionDataset):
"""`CUB-200-2011 `_ Dataset.
Args:
root (string): Root directory of the dataset.
train (bool, optional): If True, creates dataset from training set, otherwise
creates from test set.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
download (bool, optional): If true, downloads the dataset from the internet and
puts it in root directory. If dataset is already downloaded, it is not
downloaded again.
"""
base_folder = 'CUB_200_2011/images'
# url = 'http://www.vision.caltech.edu/visipedia-data/CUB-200-2011/CUB_200_2011.tgz'
file_id = '1hbzc_P1FuxMkcabkgn9ZKinBwW683j45'
filename = 'CUB_200_2011.tgz'
tgz_md5 = '97eceeb196236b17998738112f37df78'
def __init__(self, root, train=True, transform=None, target_transform=None, download=False):
super(CUB2002011, self).__init__(root, transform=transform, target_transform=target_transform)
self.loader = default_loader
self.train = train
if download:
self._download()
if not self._check_integrity():
raise RuntimeError('Dataset not found or corrupted. You can use download=True to download it')
def _load_metadata(self):
images = pd.read_csv(os.path.join(self.root, 'CUB_200_2011', 'images.txt'), sep=' ',
names=['img_id', 'filepath'])
image_class_labels = pd.read_csv(os.path.join(self.root, 'CUB_200_2011', 'image_class_labels.txt'),
sep=' ', names=['img_id', 'target'])
train_test_split = pd.read_csv(os.path.join(self.root, 'CUB_200_2011', 'train_test_split.txt'),
sep=' ', names=['img_id', 'is_training_img'])
data = images.merge(image_class_labels, on='img_id')
self.data = data.merge(train_test_split, on='img_id')
class_names = pd.read_csv(os.path.join(self.root, 'CUB_200_2011', 'classes.txt'),
sep=' ', names=['class_name'], usecols=[1])
self.class_names = class_names['class_name'].to_list()
if self.train:
self.data = self.data[self.data.is_training_img == 1]
else:
self.data = self.data[self.data.is_training_img == 0]
def _check_integrity(self):
try:
self._load_metadata()
except Exception:
return False
for index, row in self.data.iterrows():
filepath = os.path.join(self.root, self.base_folder, row.filepath)
if not os.path.isfile(filepath):
print(filepath)
return False
return True
def _download(self):
import tarfile
if self._check_integrity():
print('Files already downloaded and verified')
return
download_file_from_google_drive(self.file_id, self.root, self.filename, self.tgz_md5)
with tarfile.open(os.path.join(self.root, self.filename), "r:gz") as tar:
tar.extractall(path=self.root)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
sample = self.data.iloc[idx]
path = os.path.join(self.root, self.base_folder, sample.filepath)
target = sample.target - 1 # Targets start at 1 by default, so shift to 0
img = self.loader(path)
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
if __name__ == '__main__':
train_dataset = CUB2002011('./cub2011', train=True, download=False)
test_dataset = CUB2002011('./cub2011', train=False, download=False)
================================================
FILE: braincog/datasets/ESimagenet/ES_imagenet.py
================================================
# -*- coding: utf-8 -*-
# Time : 2022/11/1 11:06
# Author : Regulus
# FileName: ES_imagenet.py
# Explain:
# Software: PyCharm
import numpy as np
import torch
import linecache
import torch.utils.data as data
class ESImagenet_Dataset(data.Dataset):
def __init__(self, mode, data_set_path='/data/dvsimagenet/', transform=None):
super().__init__()
self.mode = mode
self.filenames = []
self.trainpath = data_set_path + 'train'
self.testpath = data_set_path + 'val'
self.traininfotxt = data_set_path + 'trainlabel.txt'
self.testinfotxt = data_set_path + 'vallabel.txt'
self.formats = '.npz'
self.transform = transform
if mode == 'train':
self.path = self.trainpath
trainfile = open(self.traininfotxt, 'r')
for line in trainfile:
filename, classnum, a, b = line.split()
realname, sub = filename.split('.')
self.filenames.append(realname + self.formats)
else:
self.path = self.testpath
testfile = open(self.testinfotxt, 'r')
for line in testfile:
filename, classnum, a, b = line.split()
realname, sub = filename.split('.')
self.filenames.append(realname + self.formats)
def __getitem__(self, index):
if self.mode == 'train':
info = linecache.getline(self.traininfotxt, index + 1)
else:
info = linecache.getline(self.testinfotxt, index + 1)
filename, classnum, a, b = info.split()
realname, sub = filename.split('.')
filename = realname + self.formats
filename = self.path + r'/' + filename
classnum = int(classnum)
a = int(a)
b = int(b)
datapos = np.load(filename)['pos'].astype(np.float64)
dataneg = np.load(filename)['neg'].astype(np.float64)
dy = (254 - b) // 2
dx = (254 - a) // 2
input = torch.zeros([2, 8, 256, 256])
x = datapos[:, 0] + dx
y = datapos[:, 1] + dy
t = datapos[:, 2] - 1
input[0, t, x, y] = 1
x = dataneg[:, 0] + dx
y = dataneg[:, 1] + dy
t = dataneg[:, 2] - 1
input[1, t, x, y] = 1
reshape = input[:, :, 16:240, 16:240].permute(0, 1, 2, 3).contiguous()
if self.transform is not None:
reshape = self.transform(reshape)
label = torch.tensor([classnum])
return reshape, label
def __len__(self):
return len(self.filenames)
================================================
FILE: braincog/datasets/ESimagenet/__init__.py
================================================
# -*- coding: utf-8 -*-
# Time : 2022/11/1 11:05
# Author : Regulus
# FileName: __init__.py.py
# Explain:
# Software: PyCharm
"""
from: https://github.com/lyh983012/ES-imagenet-master
"""
__all__ = ['ES_imagenet', 'reconstructed_ES_imagenet']
from . import (
ES_imagenet,
reconstructed_ES_imagenet
)
================================================
FILE: braincog/datasets/ESimagenet/reconstructed_ES_imagenet.py
================================================
# -*- coding: utf-8 -*-
# Time : 2022/11/1 11:06
# Author : Regulus
# FileName: reconstructed_ES_imagenet.py
# Explain:
# Software: PyCharm
import numpy as np
import torch
import linecache
import torch.utils.data as data
from tqdm import tqdm
class ESImagenet2D_Dataset(data.Dataset):
def __init__(self, mode, data_set_path='/data/ESimagenet-0.18/', transform=None):
super().__init__()
self.mode = mode
self.filenames = []
self.trainpath = data_set_path + 'train'
self.testpath = data_set_path + 'val'
self.traininfotxt = data_set_path + 'trainlabel.txt'
self.testinfotxt = data_set_path + 'vallabel.txt'
self.formats = '.npz'
self.transform = transform
if mode == 'train':
self.path = self.trainpath
trainfile = open(self.traininfotxt, 'r')
for line in trainfile:
filename, classnum, a, b = line.split()
realname, sub = filename.split('.')
self.filenames.append(realname + self.formats)
trainfile = open(self.traininfotxt, 'r')
self.infolist = trainfile.readlines()
else:
self.path = self.testpath
testfile = open(self.testinfotxt, 'r')
for line in testfile:
filename, classnum, a, b = line.split()
realname, sub = filename.split('.')
self.filenames.append(realname + self.formats)
testfile = open(self.testinfotxt, 'r')
self.infolist = testfile.readlines()
def __getitem__(self, index):
info = self.infolist[index]
filename, classnum, a, b = info.split()
realname, sub = filename.split('.')
filename = realname + self.formats
filename = self.path + r'/' + filename
classnum = int(classnum)
a = int(a)
b = int(b)
with open(filename, "rb") as f:
data = np.load(f)
datapos = data['pos'].astype(np.float64)
dataneg = data['neg'].astype(np.float64)
tracex = [0, 2, 1, 0, 2, 1, 1, 2]
tracey = [2, 1, 0, 1, 2, 0, 1, 1]
dy = (254 - b) // 2
dx = (254 - a) // 2
input = torch.zeros([2, 8, 256, 256])
x = datapos[:, 0] + dx
y = datapos[:, 1] + dy
t = datapos[:, 2] - 1
input[0, t, x, y] += 1
x = dataneg[:, 0] + dx
y = dataneg[:, 1] + dy
t = dataneg[:, 2] - 1
input[1, t, x, y] += 1
sum_gary_data = torch.zeros([1, 1, 256, 256])
reshape = input[:, :, 16:240, 16:240]
H = 224
W = 224
for t in range(8):
dx = tracex[t]
dy = tracey[t]
sum_gary_data[0, 0, 2 - dx:2 - dx + H, 2 - dy:2 - dy + W] += reshape[0, t, :, :]
sum_gary_data[0, 0, 2 - dx:2 - dx + H, 2 - dy:2 - dy + W] -= reshape[1, t, :, :]
sum_gary_data = sum_gary_data[:, :, 1:225, 1:225]
# if self.transform is not None:
# sum_gary_data = self.transform(sum_gary_data)
label = classnum
return sum_gary_data, label
def __len__(self):
return len(self.filenames)
================================================
FILE: braincog/datasets/NOmniglot/NOmniglot.py
================================================
from torch.utils.data import Dataset
from braincog.datasets.NOmniglot.utils import *
class NOmniglot(Dataset):
def __init__(self, root='data/', frames_num=12, train=True, data_type='event',
transform=None, target_transform=None, use_npz=False, crop=True, create=True, thread_num=16):
super().__init__()
self.crop = crop
self.data_type = data_type
self.use_npz = use_npz
self.transform = transform
self.target_transform = target_transform
events_npy_root = os.path.join(root, 'events_npy', 'background' if train else "evaluation")
frames_root = os.path.join(root, f'fnum_{frames_num}_dtype_{data_type}_npz_{use_npz}',
'background' if train else "evaluation")
if not os.path.exists(frames_root) and create:
if not os.path.exists(events_npy_root) and create:
os.makedirs(events_npy_root)
print('creating event data..')
convert_aedat4_dir_to_events_dir(root, train)
else:
print(f'npy format events data root {events_npy_root}, already exists')
os.makedirs(frames_root)
print('creating frames data..')
convert_events_dir_to_frames_dir(events_npy_root, frames_root, '.npy', frames_num, data_type,
thread_num=thread_num, compress=use_npz)
else:
print(f'frames data root {frames_root} already exists.')
self.datadict, self.num_classes = list_class_files(events_npy_root, frames_root, True, use_npz=use_npz)
self.datalist = []
for i in self.datadict:
self.datalist.extend([(j, i) for j in self.datadict[i]])
def __len__(self):
return len(self.datalist)
def __getitem__(self, index):
image, label = self.datalist[index]
image, label = self.readimage(image, label)
return image, label
def readimage(self, image, label):
if self.use_npz:
image = torch.tensor(np.load(image)['arr_0']).float()
else:
image = torch.tensor(np.load(image)).float()
if self.crop:
image = image[:, :, 4:254, 54:304]
if self.transform is not None: image = self.transform(image)
if self.target_transform is not None: label = self.target_transform(label)
return image, label
================================================
FILE: braincog/datasets/NOmniglot/__init__.py
================================================
__all__ = ['NOmniglot', 'nomniglot_full', 'nomniglot_nw_ks','nomniglot_pair','utils']
from . import (
NOmniglot,
nomniglot_full,
nomniglot_nw_ks,
nomniglot_pair,
utils
)
================================================
FILE: braincog/datasets/NOmniglot/nomniglot_full.py
================================================
import torch
from torch.utils.data import Dataset, DataLoader
from braincog.datasets.NOmniglot.NOmniglot import NOmniglot
class NOmniglotfull(Dataset):
'''
solve few-shot learning as general classification problem,
We combine the original training set with the test set and take 3/4 as the training set
'''
def __init__(self, root='data/', train=True, frames_num=4, data_type='event',
transform=None, target_transform=None, use_npz=False, crop=True, create=True):
super().__init__()
trainSet = NOmniglot(root=root, train=True, frames_num=frames_num, data_type=data_type,
transform=transform, target_transform=target_transform,
use_npz=use_npz, crop=crop, create=create)
testSet = NOmniglot(root=root, train=False, frames_num=frames_num, data_type=data_type,
transform=transform, target_transform=lambda x: x + 964,
use_npz=use_npz, crop=crop, create=create)
self.data = torch.utils.data.ConcatDataset([trainSet, testSet])
if train:
self.id = [j for j in range(len(self.data)) if j % 20 in [i for i in range(15)]]
else:
self.id = [j for j in range(len(self.data)) if j % 20 in [i for i in range(15, 20)]]
def __len__(self):
return len(self.id)
def __getitem__(self, index):
image, label = self.data[self.id[index]]
return image, label
if __name__ == '__main__':
db_train = NOmniglotfull('../../data/', train=True, frames_num=4, data_type='event')
dataloadertrain = DataLoader(db_train, batch_size=16, shuffle=True, num_workers=16, pin_memory=True)
for x_spt, y_spt, x_qry, y_qry in dataloadertrain:
print(x_spt.shape)
================================================
FILE: braincog/datasets/NOmniglot/nomniglot_nw_ks.py
================================================
import torch
import torchvision
import numpy as np
from torch.utils.data import Dataset, DataLoader
from braincog.datasets.NOmniglot.NOmniglot import NOmniglot
class NOmniglotNWayKShot(Dataset):
'''
get n-wway k-shot data as meta learning
We set the sampling times of each epoch as "len(self.dataSet) // (self.n_way * (self.k_shot + self.k_query))"
you can increase or decrease the number of epochs to determine the total training times
'''
def __init__(self, root, n_way, k_shot, k_query, train=True, frames_num=12, data_type='event',
transform=torchvision.transforms.Resize((28, 28))):
self.dataSet = NOmniglot(root=root, train=train,
frames_num=frames_num, data_type=data_type, transform=transform)
self.n_way = n_way # n way
self.k_shot = k_shot # k shot
self.k_query = k_query # k query
assert (k_shot + k_query) <= 20
self.length = 256
self.data_cache = self.load_data_cache(self.dataSet.datadict, self.length)
def load_data_cache(self, data_dict, length):
'''
The dataset is sampled randomly length times, and the address is saved to obtain
'''
data_cache = []
for i in range(length):
selected_cls = np.random.choice(len(data_dict), self.n_way, False)
x_spts, y_spts, x_qrys, y_qrys = [], [], [], []
for j, cur_class in enumerate(selected_cls):
selected_img = np.random.choice(20, self.k_shot + self.k_query, False)
x_spts.append(np.array(data_dict[cur_class])[selected_img[:self.k_shot]])
x_qrys.append(np.array(data_dict[cur_class])[selected_img[self.k_shot:]])
y_spts.append([j for _ in range(self.k_shot)])
y_qrys.append([j for _ in range(self.k_query)])
shufflespt = np.random.choice(self.n_way * self.k_shot, self.n_way * self.k_shot, False)
shuffleqry = np.random.choice(self.n_way * self.k_query, self.n_way * self.k_query, False)
temp = [np.array(x_spts).reshape(-1)[shufflespt], np.array(y_spts).reshape(-1)[shufflespt],
np.array(x_qrys).reshape(-1)[shuffleqry], np.array(y_qrys).reshape(-1)[shuffleqry]]
data_cache.append(temp)
return data_cache
def __getitem__(self, index):
x_spts, y_spts, x_qrys, y_qrys = self.data_cache[index]
x_sptst, y_sptst, x_qryst, y_qryst = [], [], [], []
for i, j in zip(x_spts, y_spts):
i, j = self.dataSet.readimage(i, j)
x_sptst.append(i.unsqueeze(0))
y_sptst.append(j)
for i, j in zip(x_qrys, y_qrys):
i, j = self.dataSet.readimage(i, j)
x_qryst.append(i.unsqueeze(0))
y_qryst.append(j)
return torch.cat(x_sptst, dim=0), np.array(y_sptst), torch.cat(x_qryst, dim=0), np.array(y_qryst)
def reset(self):
self.data_cache = self.load_data_cache(self.dataSet.datadict, self.length)
def __len__(self):
return len(self.data_cache)
if __name__ == "__main__":
db_train = NOmniglotNWayKShot('./data/', n_way=5, k_shot=1, k_query=15,
frames_num=4, data_type='frequency', train=True)
dataloadertrain = DataLoader(db_train, batch_size=16, shuffle=True, num_workers=16, pin_memory=True)
for x_spt, y_spt, x_qry, y_qry in dataloadertrain:
print(x_spt.shape)
db_train.resampling()
================================================
FILE: braincog/datasets/NOmniglot/nomniglot_pair.py
================================================
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np
from numpy.random import choice as npc
import random
import torch.nn.functional as F
from braincog.datasets.NOmniglot import NOmniglot
class NOmniglotTrainSet(Dataset):
'''
Dataloader for Siamese Net
The pairs of similar samples are labeled as 1, and those of different samples are labeled as 0
'''
def __init__(self, root='data/', use_frame=True, frames_num=10, data_type='event', use_npz=False, resize=None):
super(NOmniglotTrainSet, self).__init__()
self.resize = resize
self.data_type = data_type
self.use_frame = use_frame
self.dataSet = NOmniglot(root=root, train=True, frames_num=frames_num, data_type=data_type, use_npz=use_npz)
self.datas, self.num_classes = self.dataSet.datadict, self.dataSet.num_classes
np.random.seed(0)
def __len__(self):
'''
Sampling upper limit, you can set the maximum sampling times when using to terminate
'''
return 21000000
def __getitem__(self, index):
# get image from same class
if index % 2 == 1:
label = 1.0
idx1 = random.randint(0, self.num_classes - 1)
image1 = random.choice(self.datas[idx1])
image2 = random.choice(self.datas[idx1])
# get image from different class
else:
label = 0.0
idx1 = random.randint(0, self.num_classes - 1)
idx2 = random.randint(0, self.num_classes - 1)
while idx1 == idx2:
idx2 = random.randint(0, self.num_classes - 1)
image1 = random.choice(self.datas[idx1])
image2 = random.choice(self.datas[idx2])
if self.use_frame:
if self.data_type == 'event':
image1 = torch.tensor(np.load(image1)['arr_0']).float()
image2 = torch.tensor(np.load(image2)['arr_0']).float()
elif self.data_type == 'frequency':
image1 = torch.tensor(np.load(image1)['arr_0']).float()
image2 = torch.tensor(np.load(image2)['arr_0']).float()
else:
raise NotImplementedError
if self.resize is not None:
image1 = image1[:, :, 4:254, 54:304]
image1 = F.interpolate(image1, size=(self.resize, self.resize))
image2 = image2[:, :, 4:254, 54:304]
image2 = F.interpolate(image2, size=(self.resize, self.resize))
return image1, image2, torch.from_numpy(np.array([label], dtype=np.float32))
class NOmniglotTestSet(Dataset):
'''
Dataloader for Siamese Net
'''
def __init__(self, root='data/', time=1000, way=20, shot=1, query=1, use_frame=True, frames_num=10, data_type='event', use_npz=True, resize=None):
super(NOmniglotTestSet, self).__init__()
self.resize = resize
self.use_frame = use_frame
self.time = time # Sampling times
self.way = way
self.shot = shot
self.query = query
self.img1 = None # Fix test sample while sampling support set
self.c1 = None # Fixed categories when sampling multiple samples
self.c2 = None
self.select_class = [] # selected classes
self.select_sample = [] # selected samples
self.data_type = data_type
np.random.seed(0)
self.dataSet = NOmniglot(root=root, train=False, frames_num=frames_num, data_type=data_type, use_npz=use_npz)
self.datas, self.num_classes = self.dataSet.datadict, self.dataSet.num_classes
def __len__(self):
'''
In general, the total number of test tasks is 1000.
Since one test sample is collected at a time, way * shot support samples are used for each test
'''
return self.time * self.way * self.shot
def __getitem__(self, index):
'''
The 0th sample of each way*shot is used for query and recorded in the selected sample
to achieve the effect of selecting K +1
'''
idx = index % (self.way * self.shot)
# generate image pair from same class
if idx == 0: #
self.select_class = []
self.c1 = random.randint(0, self.num_classes - 1)
self.c2 = self.c1
sind = random.randint(0, len(self.datas[self.c1]) - 1)
self.select_sample.append(sind)
self.img1 = self.datas[self.c1][sind]
sind = random.randint(0, len(self.datas[self.c2]) - 1)
while sind in self.select_sample:
sind = random.randint(0, len(self.datas[self.c2]) - 1)
img2 = self.datas[self.c1][sind]
self.select_sample.append(sind)
self.select_class.append(self.c1)
# generate image pair from different class
else:
if index % self.shot == 0:
self.c2 = random.randint(0, self.num_classes - 1)
while self.c2 in self.select_class: # self.c1 == c2:
self.c2 = random.randint(0, self.num_classes - 1)
self.select_class.append(self.c2)
self.select_sample = []
sind = random.randint(0, len(self.datas[self.c2]) - 1)
while sind in self.select_sample:
sind = random.randint(0, len(self.datas[self.c2]) - 1)
img2 = self.datas[self.c2][sind]
self.select_sample.append(sind)
if self.use_frame:
if self.data_type == 'event':
img1 = torch.tensor(np.load(self.img1)['arr_0']).float()
img2 = torch.tensor(np.load(img2)['arr_0']).float()
elif self.data_type == 'frequency':
img1 = torch.tensor(np.load(self.img1)['arr_0']).float()
img2 = torch.tensor(np.load(img2)['arr_0']).float()
else:
raise NotImplementedError
if self.resize is not None:
img1 = img1[:, :, 4:254, 54:304]
img1 = F.interpolate(img1, size=(self.resize, self.resize))
img2 = img2[:, :, 4:254, 54:304]
img2 = F.interpolate(img2, size=(self.resize, self.resize))
return img1, img2
if __name__ == '__main__':
data_type = 'frequency'
T = 4
trainSet = NOmniglotTrainSet(root='data/', use_frame=True, frames_num=T, data_type=data_type, use_npz=True, resize=105)
testSet = NOmniglotTestSet(root='data/', time=1000, way=5, shot=1, use_frame=True, frames_num=T,
data_type=data_type, use_npz=True, resize=105)
trainLoader = DataLoader(trainSet, batch_size=48, shuffle=False, num_workers=4)
testLoader = DataLoader(testSet, batch_size=5 * 1, shuffle=False, num_workers=4)
for batch_id, (img1, img2) in enumerate(testLoader, 1):
# img1.shape [batch, T, 2, H, W]
print(batch_id)
break
for batch_id, (img1, img2, label) in enumerate(trainLoader, 1):
# img1.shape [batch, T, 2, H, W]
print(batch_id)
break
================================================
FILE: braincog/datasets/NOmniglot/utils.py
================================================
import torch
import threading
import numpy as np
import pandas
import os
from dv import AedatFile
class FunctionThread(threading.Thread):
def __init__(self, f, *args, **kwargs):
super().__init__()
self.f = f
self.args = args
self.kwargs = kwargs
def run(self):
self.f(*self.args, **self.kwargs)
def integrate_events_to_frames(events, height, width, frames_num=10, data_type='event'):
frames = np.zeros(shape=[frames_num, 2, height * width])
# create j_{l}和j_{r}
j_l = np.zeros(shape=[frames_num], dtype=int)
j_r = np.zeros(shape=[frames_num], dtype=int)
# split by time
events['t'] -= events['t'][0] # start with 0 timestamp
assert events['t'][-1] > frames_num
dt = events['t'][-1] // frames_num # get length of each frame
idx = np.arange(events['t'].size)
for i in range(frames_num):
t_l = dt * i
t_r = t_l + dt
mask = np.logical_and(events['t'] >= t_l, events['t'] < t_r)
idx_masked = idx[mask]
if len(idx_masked) == 0:
j_l[i] = -1
j_r[i] = -1
else:
j_l[i] = idx_masked[0]
j_r[i] = idx_masked[-1] + 1 if i < frames_num - 1 else events['t'].size
for i in range(frames_num):
if j_l[i] >= 0:
x = events['x'][j_l[i]:j_r[i]]
y = events['y'][j_l[i]:j_r[i]]
p = events['p'][j_l[i]:j_r[i]]
mask = []
mask.append(p == 0)
mask.append(np.logical_not(mask[0]))
for j in range(2):
position = y[mask[j]] * width + x[mask[j]]
events_number_per_pos = np.bincount(position)
frames[i][j][np.arange(events_number_per_pos.size)] += events_number_per_pos
if data_type == 'frequency':
if i < frames_num - 1:
frames[i] /= dt
else:
frames[i] /= (dt + events['t'][-1] % frames_num)
frames = frames.astype(np.float16)
if data_type == 'event':
frames = (frames > 0).astype(np.bool)
else:
frames = normalize_frame(frames, 'max')
return frames.reshape((frames_num, 2, height, width))
def normalize_frame(frames: np.ndarray or torch.Tensor, normalization: str):
eps = 1e-5
for i in range(frames.shape[0]):
if normalization == 'max':
frames[i][0] = frames[i][0] / max(frames[i][0].max(), eps)
frames[i][1] = frames[i][1] / max(frames[i][1].max(), eps)
elif normalization == 'norm':
frames[i][0] = (frames[i][0] - frames[i][0].mean()) / np.sqrt(max(frames[i][0].var(), eps))
frames[i][1] = (frames[i][1] - frames[i][1].mean()) / np.sqrt(max(frames[i][1].var(), eps))
elif normalization == 'sum':
frames[i][0] = frames[i][0] / max(frames[i][0].sum(), eps)
frames[i][1] = frames[i][1] / max(frames[i][1].sum(), eps)
else:
raise NotImplementedError
return frames
def convert_events_dir_to_frames_dir(events_data_dir, frames_data_dir, suffix,
frames_num=12, result_type='event', thread_num=1,
compress=True):
"""
Iterate through all event data in eventS_date_DIR and generate frame data files in frames_data_DIR
"""
def read_function(file_name):
return np.load(file_name, allow_pickle=True).item()
def cvt_fun(events_file_list):
for events_file in events_file_list:
print(events_file)
frames = integrate_events_to_frames(read_function(events_file), 260, 346, frames_num, result_type )
if compress:
frames_file = os.path.join(frames_data_dir,
os.path.basename(events_file)[0: -suffix.__len__()] + '.npz')
np.savez_compressed(frames_file, frames)
else:
frames_file = os.path.join(frames_data_dir,
os.path.basename(events_file)[0: -suffix.__len__()] + '.npy')
np.save(frames_file, frames)
# Obtain the path of the all files
events_file_list = list_all_files(events_data_dir, '.npy')
if thread_num == 1:
cvt_fun(events_file_list)
else:
# Multithreading acceleration
thread_list = []
block = events_file_list.__len__() // thread_num
for i in range(thread_num - 1):
thread_list.append(FunctionThread(cvt_fun, events_file_list[i * block: (i + 1) * block]))
thread_list[-1].start()
print(f'thread {i} start, processing files index: {i * block} : {(i + 1) * block}.')
thread_list.append(FunctionThread(cvt_fun, events_file_list[(thread_num - 1) * block:]))
thread_list[-1].start()
print(
f'thread {thread_num} start, processing files index: {(thread_num - 1) * block} : {events_file_list.__len__()}.')
for i in range(thread_num):
thread_list[i].join()
print(f'thread {i} finished.')
def convert_aedat4_dir_to_events_dir(root, train):
kind = 'background' if train else "evaluation"
originroot = root
root = root + '/dvs_' + kind + '/'
alphabet_names = [a for a in os.listdir(root) if a[0] != '.'] # get folder names
for a in range(len(alphabet_names)):
alpha_name = alphabet_names[a]
for b in range(len(os.listdir(os.path.join(root, alpha_name)))):
character_id = b + 1
character_path = alpha_name + '/character' + num2str(character_id)
print('Parsing %s \\ character%s ...' % (alpha_name, num2str(character_id)))
file_path = os.path.join(root, character_path)
aedat4_name = [a for a in os.listdir(file_path) if a[-4:] == 'dat4' and len(a) == 11][0]
csv_name = [a for a in os.listdir(file_path) if a[-4:] == '.csv' and len(a) == 8][0]
number = csv_name[:4]
new_path = originroot + '/events_npy/' + kind + '/' + alpha_name + '/character' + num2str(character_id)
if not os.path.exists(new_path):
os.makedirs(new_path)
start_end_timestamp = pandas.read_csv(os.path.join(file_path, csv_name)).values
a_timestamp, a_polarity, a_x, a_y = [], [], [], []
with AedatFile(os.path.join(file_path, aedat4_name)) as f: # read aedat4
for e in f['events']:
a_timestamp.append(e.timestamp)
a_polarity.append(e.polarity)
a_x.append(e.x)
a_y.append(e.y)
for ii in range(20): # each file has 20 samples
name = str(number) + '_' + num2str(ii + 1) + '.npy'
start_index = a_timestamp.index(start_end_timestamp[ii][1])
end_index = a_timestamp.index(start_end_timestamp[ii][2])
tmp = {'t': np.array(a_timestamp[start_index:end_index]),
'x': np.array(a_x[start_index:end_index]),
'y': np.array(a_y[start_index:end_index]),
'p': np.array(a_polarity[start_index:end_index])}
np.save(os.path.join(new_path, name), tmp)
def num2str(idx):
if idx < 10:
return '0' + str(idx)
return str(idx)
def list_all_files(root, suffix, getlen=False):
'''
List the path of all files under root, output a list
'''
file_list = []
alphabet_names = [a for a in os.listdir(root) if a[0] != '.'] # get folder names
idx = 0
for a in range(len(alphabet_names)):
alpha_name = alphabet_names[a]
for b in range(len(os.listdir(os.path.join(root, alpha_name)))):
character_id = b + 1
character_path = os.path.join(root, alpha_name, 'character' + num2str(character_id))
idx += 1
for c in range(len(os.listdir(character_path))):
fn_example = os.listdir(character_path)[c]
if fn_example[-4:] == suffix:
file_list.append(os.path.join(character_path, fn_example))
if getlen:
return file_list, idx
else:
return file_list
def list_class_files(root, frames_kind_root, getlen=False, use_npz=False):
'''
index the generated samples,
get dictionaries according to categories, each corresponding to a list,
the list contain the address of the new file in fnum_x_dtype_x_npz_True
'''
file_list = {}
alphabet_names = [a for a in os.listdir(root) if a[0] != '.'] # get folder names
idx = 0
for a in range(len(alphabet_names)):
alpha_name = alphabet_names[a]
for b in range(len(os.listdir(os.path.join(root, alpha_name)))):
character_id = b + 1
character_path = os.path.join(root, alpha_name, 'character' + num2str(character_id))
file_list[idx] = []
for c in range(len(os.listdir(character_path))):
fn_example = os.listdir(character_path)[c]
if use_npz:
fn_example = fn_example[:-1] + 'z'
file_list[idx].append(os.path.join(frames_kind_root, fn_example))
idx += 1
if getlen:
return file_list, idx
else:
return file_list
================================================
FILE: braincog/datasets/StanfordDogs.py
================================================
import os
import scipy.io
from os.path import join
from torchvision.datasets import VisionDataset
from torchvision.datasets.folder import default_loader
from torchvision.datasets.utils import download_url, list_dir
class StanfordDogs(VisionDataset):
"""`Stanford Dogs `_ Dataset.
Args:
root (string): Root directory of the dataset.
train (bool, optional): If True, creates dataset from training set, otherwise
creates from test set.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
download (bool, optional): If true, downloads the dataset from the internet and
puts it in root directory. If dataset is already downloaded, it is not
downloaded again.
"""
download_url_prefix = 'http://vision.stanford.edu/aditya86/ImageNetDogs'
def __init__(self, root, train=True, transform=None, target_transform=None, download=False):
super(StanfordDogs, self).__init__(root, transform=transform, target_transform=target_transform)
self.loader = default_loader
self.train = train
if download:
self.download()
split = self.load_split()
self.images_folder = join(self.root, 'Images')
self.annotations_folder = join(self.root, 'Annotation')
self._breeds = list_dir(self.images_folder)
self._breed_images = [(annotation + '.jpg', idx) for annotation, idx in split]
self._flat_breed_images = self._breed_images
def __len__(self):
return len(self._flat_breed_images)
def __getitem__(self, index):
image_name, target = self._flat_breed_images[index]
image_path = join(self.images_folder, image_name)
image = self.loader(image_path)
if self.transform is not None:
image = self.transform(image)
if self.target_transform is not None:
target = self.target_transform(target)
return image, target
def download(self):
import tarfile
if os.path.exists(join(self.root, 'Images')) and os.path.exists(join(self.root, 'Annotation')):
if len(os.listdir(join(self.root, 'Images'))) == len(os.listdir(join(self.root, 'Annotation'))) == 120:
print('Files already downloaded and verified')
return
for filename in ['images', 'annotation', 'lists']:
tar_filename = filename + '.tar'
url = self.download_url_prefix + '/' + tar_filename
download_url(url, self.root, tar_filename, None)
print('Extracting downloaded file: ' + join(self.root, tar_filename))
with tarfile.open(join(self.root, tar_filename), 'r') as tar_file:
tar_file.extractall(self.root)
os.remove(join(self.root, tar_filename))
def load_split(self):
if self.train:
split = scipy.io.loadmat(join(self.root, 'train_list.mat'))['annotation_list']
labels = scipy.io.loadmat(join(self.root, 'train_list.mat'))['labels']
else:
split = scipy.io.loadmat(join(self.root, 'test_list.mat'))['annotation_list']
labels = scipy.io.loadmat(join(self.root, 'test_list.mat'))['labels']
split = [item[0][0] for item in split]
labels = [item[0] - 1 for item in labels]
return list(zip(split, labels))
def stats(self):
counts = {}
for index in range(len(self._flat_breed_images)):
image_name, target_class = self._flat_breed_images[index]
if target_class not in counts.keys():
counts[target_class] = 1
else:
counts[target_class] += 1
print("%d samples spanning %d classes (avg %f per class)" % (len(self._flat_breed_images), len(counts.keys()),
float(len(self._flat_breed_images)) / float(
len(counts.keys()))))
return counts
if __name__ == '__main__':
train_dataset = Dogs('./dogs', train=True, download=False)
test_dataset = Dogs('./dogs', train=False, download=False)
================================================
FILE: braincog/datasets/TinyImageNet.py
================================================
import os
import os
import pandas as pd
import warnings
from torchvision.datasets import ImageFolder
from torchvision.datasets import VisionDataset
from torchvision.datasets.folder import default_loader
from torchvision.datasets.folder import default_loader
from torchvision.datasets.utils import extract_archive, check_integrity, download_url, verify_str_arg
class TinyImageNet(VisionDataset):
"""`tiny-imageNet `_ Dataset.
Args:
root (string): Root directory of the dataset.
split (string, optional): The dataset split, supports ``train``, or ``val``.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
download (bool, optional): If true, downloads the dataset from the internet and
puts it in root directory. If dataset is already downloaded, it is not
downloaded again.
"""
base_folder = 'tiny-imagenet-200/'
url = 'http://cs231n.stanford.edu/tiny-imagenet-200.zip'
filename = 'tiny-imagenet-200.zip'
md5 = '90528d7ca1a48142e341f4ef8d21d0de'
def __init__(self, root, split='train', transform=None, target_transform=None, download=False):
super(TinyImageNet, self).__init__(root, transform=transform, target_transform=target_transform)
self.dataset_path = os.path.join(root, self.base_folder)
self.loader = default_loader
self.split = verify_str_arg(split, "split", ("train", "val",))
if self._check_integrity():
print('Files already downloaded and verified.')
elif download:
self._download()
else:
raise RuntimeError(
'Dataset not found. You can use download=True to download it.')
if not os.path.isdir(self.dataset_path):
print('Extracting...')
extract_archive(os.path.join(root, self.filename))
_, class_to_idx = find_classes(os.path.join(self.dataset_path, 'wnids.txt'))
self.data = make_dataset(self.root, self.base_folder, self.split, class_to_idx)
def _download(self):
print('Downloading...')
download_url(self.url, root=self.root, filename=self.filename)
print('Extracting...')
extract_archive(os.path.join(self.root, self.filename))
def _check_integrity(self):
return check_integrity(os.path.join(self.root, self.filename), self.md5)
def __getitem__(self, index):
img_path, target = self.data[index]
image = self.loader(img_path)
if self.transform is not None:
image = self.transform(image)
if self.target_transform is not None:
target = self.target_transform(target)
return image, target
def __len__(self):
return len(self.data)
def find_classes(class_file):
with open(class_file) as r:
classes = list(map(lambda s: s.strip(), r.readlines()))
classes.sort()
class_to_idx = {classes[i]: i for i in range(len(classes))}
return classes, class_to_idx
def make_dataset(root, base_folder, dirname, class_to_idx):
images = []
dir_path = os.path.join(root, base_folder, dirname)
if dirname == 'train':
for fname in sorted(os.listdir(dir_path)):
cls_fpath = os.path.join(dir_path, fname)
if os.path.isdir(cls_fpath):
cls_imgs_path = os.path.join(cls_fpath, 'images')
for imgname in sorted(os.listdir(cls_imgs_path)):
path = os.path.join(cls_imgs_path, imgname)
item = (path, class_to_idx[fname])
images.append(item)
else:
imgs_path = os.path.join(dir_path, 'images')
imgs_annotations = os.path.join(dir_path, 'val_annotations.txt')
with open(imgs_annotations) as r:
data_info = map(lambda s: s.split('\t'), r.readlines())
cls_map = {line_data[0]: line_data[1] for line_data in data_info}
for imgname in sorted(os.listdir(imgs_path)):
path = os.path.join(imgs_path, imgname)
item = (path, class_to_idx[cls_map[imgname]])
images.append(item)
return images
if __name__ == '__main__':
train_dataset = TinyImageNet('./tiny-imagenet', split='train', download=False)
test_dataset = TinyImageNet('./tiny-imagenet', split='val', download=False)
================================================
FILE: braincog/datasets/__init__.py
================================================
from .datasets import build_transform, build_dataset, get_mnist_data, get_fashion_data, \
get_cifar10_data, get_cifar100_data, get_imnet_data, get_dvsg_data, get_dvsc10_data, \
get_NCALTECH101_data, get_NCARS_data, get_nomni_data, get_bullyingdvs_data
from .utils import rescale, dvs_channel_check_expend
from .hmdb_dvs import HMDBDVS
from .ucf101_dvs import ucf101_dvs
from .ncaltech101 import NCALTECH101
from .bullying10k import BULLYINGDVS
__all__ = [
'build_transform', 'build_dataset',
'get_mnist_data', 'get_fashion_data', 'get_cifar10_data', 'get_cifar100_data', 'get_imnet_data',
'get_dvsg_data', 'get_dvsc10_data', 'get_NCALTECH101_data', 'get_NCARS_data', 'get_nomni_data',
'rescale', 'dvs_channel_check_expend', 'get_bullyingdvs_data'
]
dvs_data = [
'dvsg',
'dvsc10',
'ncaltech101',
'ncars',
'dvsg',
'ucf101dvs',
'hmdbdvs',
'shd',
'ntidigits',
'nmnist'
]
def is_dvs_data(dataset):
if dataset.lower() in dvs_data:
return True
else:
return False
================================================
FILE: braincog/datasets/bullying10k/__init__.py
================================================
from .bullying10k import BULLYINGDVS
================================================
FILE: braincog/datasets/bullying10k/bullying10k.py
================================================
import os
import numpy as np
from numpy.lib import recfunctions
import scipy.io as scio
from typing import Tuple, Any, Optional
from tonic.dataset import Dataset
from tonic.download_utils import extract_archive
import dv
class BULLYINGDVS(Dataset):
classes = ["fingerguess", "greeting", "hairgrabs", "handshake", "kicking",
"punching", "pushing", "slapping", "strangling", "walking"]
class_dict = {cls: idx for idx, cls in enumerate(classes)}
sensor_size = (346, 260, 2)
dtype = np.dtype([("t", int), ("x", int), ("y", int), ("p", int)])
ordering = dtype.names
def __init__(self, save_to, transform=None, target_transform=None):
super(BULLYINGDVS, self).__init__(
save_to, transform=transform, target_transform=target_transform
)
self.aedat4 = True
for path, dirs, files in os.walk(self.location_on_system):
dirs.sort()
files.sort()
for file in files:
if file.endswith("aedat4"):
self.data.append(path + "/" + file)
self.targets.append(self.class_dict[path.split('/')[-2]])
if file.endswith("npy"):
self.aedat4 = False
self.data.append(path + "/" + file)
self.targets.append(self.class_dict[path.split('/')[-2]])
def __getitem__(self, index: int) -> Tuple[Any, Any]:
"""
Returns:
(events, target) where target is index of the target class.
"""
if self.aedat4:
events, target = dv.AedatFile(self.data[index])['events'], self.targets[index]
events = np.concatenate([event for event in events.numpy()])
else:
events = np.concatenate(np.load(self.data[index], allow_pickle=True))
events = np.column_stack(
[
events['timestamp'] - events['timestamp'][0],
events['x'],
events['y'],
events['polarity']
]
)
events = np.lib.recfunctions.unstructured_to_structured(events, self.dtype)
if self.transform is not None:
events = self.transform(events)
if self.target_transform is not None:
target = self.target_transform(target)
return events, target
def __len__(self):
return len(self.data)
def _check_exists(self):
return True
================================================
FILE: braincog/datasets/cut_mix.py
================================================
import math
import numpy as np
import random
from torch.utils.data.dataset import Dataset
from braincog.datasets.rand_aug import SaltAndPepperNoise
import numpy as np
import torch
from torch.nn import functional as F
def event_difference(x1, x2, kernel_size=3):
padding = kernel_size // 2
x1 = F.avg_pool2d(x1, kernel_size=kernel_size, stride=1, padding=padding)
x2 = F.avg_pool2d(x2, kernel_size=kernel_size, stride=1, padding=padding)
return F.mse_loss(x1, x2)
def onehot(size, target):
vec = torch.zeros(size, dtype=torch.float32)
vec[target] = 1.
return vec
def rand_bbox_time(size, rat):
if len(size) == 4: # step, channel, height, width
step = size[0]
else:
raise Exception
cut_t = np.int(step * rat)
ct = np.random.randint(step)
bbt1 = np.clip(ct - cut_t // 2, 0, step)
bbt2 = np.clip(ct + cut_t // 2, 0, step)
return bbt1, bbt2
def rand_bbox(size, rat):
if len(size) == 4:
W = size[2]
H = size[3]
else:
raise Exception
cut_rat = np.sqrt(rat)
cut_w = np.int(W * cut_rat)
cut_h = np.int(H * cut_rat)
# uniform
cx = np.random.randint(W)
cy = np.random.randint(H)
bbx1 = np.clip(cx - cut_w // 2, 0, W)
bby1 = np.clip(cy - cut_h // 2, 0, H)
bbx2 = np.clip(cx + cut_w // 2, 0, W)
bby2 = np.clip(cy + cut_h // 2, 0, H)
return bbx1, bby1, bbx2, bby2
def calc_lam(x1, x2, bbt1, bbt2, bbx1, bbx2, bby1, bby2):
tot_x1 = x1.sum()
tot_x2 = x2.sum()
tot_bb1 = x1[bbt1:bbt2, :, bbx1:bbx2, bby1:bby2].sum()
tot_bb2 = x2[bbt1:bbt2, :, bbx1:bbx2, bby1:bby2].sum()
x1_rat = tot_bb1 / tot_x1
x2_rat = tot_bb2 / tot_x2
lam = 1. - (x2_rat / (1. - x1_rat + x2_rat))
return lam
def rand_bbox_st(size, rat):
temporal_rat = np.random.uniform(rat, 1.)
wh_rat = rat / temporal_rat
bbt1, bbt2 = rand_bbox_time(size, temporal_rat)
bbx1, bby1, bbx2, bby2 = rand_bbox(size, wh_rat)
return bbt1, bbt2, bbx1, bby1, bbx2, bby2
def spatio_mask(size, rat):
t = size[0]
x = torch.rand(2, 2)
y = torch.rand(2, 2)
f = torch.zeros(*size[-2:], dtype=torch.complex64)
# f[0:2, 0:2] = x + y * 0.j
f[[[0, -1], [-1, -1]], [[0, -1], [0, -1]]] = x + y * 1.j
mask = torch.fft.ifftn(f).real
idx = int(np.prod(size[-2:]) * rat)
val = mask.flatten().sort()[0][idx]
return (mask < val).unsqueeze(0).unsqueeze(0).repeat(t, 2, 1, 1)
def temporal_mask(size, rat):
bbt1, bbt2 = rand_bbox_time(size, rat)
mask = torch.zeros(*size, dtype=torch.bool)
mask[bbt1:bbt2] = True
return mask
def st_mask(size, rat):
t = size[0]
temporal_rat = np.random.uniform(rat, 1.)
wh_rat = rat / temporal_rat
bbt1, bbt2 = rand_bbox_time(size, temporal_rat)
mask = spatio_mask(size, wh_rat)
mask[0:bbt1] = False
mask[bbt2:t] = False
return mask
def GMM_mask_clip(size, rat):
t = size[0]
temporal_rat = np.random.uniform(rat, 1.)
wh_rat = rat / temporal_rat
bbt1, bbt2 = rand_bbox_time(size, temporal_rat)
mask = GMM_mask(size, wh_rat)
mask[0:bbt1] = False
mask[bbt2:t] = False
return mask
def GMM_mask(size, rat, n=None):
if n is None:
n = np.random.randint(2, 5)
pi = torch.tensor(np.random.rand(n))
# pi = torch.ones(n) / n
mask = torch.zeros((size[0], size[2], size[3]))
t = torch.tensor(list(range(size[0])))
x = torch.tensor(list(range(size[2])))
y = torch.tensor(list(range(size[3])))
t, x, y = torch.meshgrid(t, x, y, indexing='ij')
for p in pi:
mt = np.random.randint(0, size[0])
mx = np.random.randint(0, size[2])
my = np.random.randint(0, size[3])
# print(mt, mx, my)
st = max(np.random.rand(), 0.1) * size[0] * 0.5
sx = max(np.random.rand(), 0.1) * size[2] * .5
sy = max(np.random.rand(), 0.1) * size[3] * .5
# st, sx, sy = size[0], 0000.5 * size[2], 0000.5 * size[3]
# print(st, sx, sy)
tt = t - mt
xx = x - mx
yy = y - my
tmp = -((tt ** 2) / (st ** 2) + (xx ** 2) / (sx ** 2) + (yy ** 2) / (sy ** 2)) / 2
mask += p * tmp.exp()
idx = int(np.prod(mask.shape) * rat)
val = mask.flatten().sort()[0][idx - 1]
return (mask > val).unsqueeze(1).repeat(1, 2, 1, 1)
# return mask.unsqueeze(1).repeat(1, 2, 1, 1)
# FOR EVENT VIS
# def spatio_mask(size, rat):
# t = size[0]
# x = torch.rand(2, 2)
# y = torch.rand(2, 2)
# f = torch.zeros(*size[-2:], dtype=torch.complex64)
# # f[0:2, 0:2] = x + y * 0.j
# f[[[0, -1], [-1, -1]], [[0, -1], [0, -1]]] = x + y * 1.j
#
# f = f.unsqueeze(0).repeat(t, 1, 1)
# f[1:-2, :, :] = 0
#
# mask = torch.fft.ifftn(f).real
# # print(mask.shape)
# idx = int(np.prod(mask.shape) * 0.6)
# # print(idx)
# val = mask.flatten().sort()[0][idx]
# print(mask.unsqueeze(1).repeat(1, 2, 1, 1).shape)
# return (mask < val).unsqueeze(1).repeat(1, 2, 1, 1)
#
# def st_mask(size, rat):
# # t = size[0]
# # temporal_rat = np.random.uniform(rat, 1.)
# # wh_rat = rat / temporal_rat
# wh_rat = rat
# # bbt1, bbt2 = rand_bbox_time(size, temporal_rat)
# mask = spatio_mask(size, wh_rat)
# # mask[0:bbt1] = False
# # mask[bbt2:t] = False
# return mask
def calc_masked_lam(x1, x2, mask):
tot_x1 = x1.sum()
tot_x2 = x2.sum()
tot_mask1 = x1[mask].sum()
tot_mask2 = x2[mask].sum()
x1_rat = tot_mask1 / tot_x1
x2_rat = tot_mask2 / tot_x2
lam = 1. - (x2_rat / (1. - x1_rat + x2_rat))
# print(tot_x1, tot_x2, tot_mask1, tot_mask2)
return lam
def calc_masked_lam_with_difference(x1, x2, mix, kernel_size=3):
s1 = event_difference(x1, mix, kernel_size=kernel_size)
s2 = event_difference(x2, mix, kernel_size=kernel_size)
return (s2 * s2) / (s1 * s1 + s2 * s2)
class MixUp(Dataset):
def __init__(self, dataset, num_class, num_mix=1, beta=1., prob=1.0, indices=None, noise=0.0, vis=False, **kwargs):
self.dataset = dataset
self.num_class = num_class
self.num_mix = num_mix
self.beta = beta
self.prob = prob
self.indices = indices
self.noise = noise
self.vis = vis
def __getitem__(self, index):
img, lb = self.dataset[index]
lb_onehot = onehot(self.num_class, lb)
if self.vis:
origin = img.clone()
for _ in range(self.num_mix):
r = np.random.rand(1)
if self.beta <= 0 or r > self.prob:
continue
# generate mixed sample
lam = np.random.beta(self.beta, self.beta)
if self.indices is None:
rand_index = random.choice(range(len(self)))
else:
rand_index = random.choice(self.indices)
img2, lb2 = self.dataset[rand_index]
lb2_onehot = onehot(self.num_class, lb2)
img = img * lam + img2 * (1. - lam)
lb_onehot = lb_onehot * lam + lb2_onehot * (1. - lam)
if self.noise != 0.:
img = SaltAndPepperNoise(img, self.noise)
if self.vis:
return origin, img, img2
else:
return img, lb_onehot
def __len__(self):
return len(self.dataset)
class CutMix(Dataset):
# 81.45161290322581 (epoch 584) /data/floyed/BrainCog/train/20220413-050658-resnet34-dvsc10-10-cut_mix before lam
def __init__(self, dataset, num_class, num_mix=1, beta=1., prob=1.0, indices=None, noise=0.0, vis=False, **kwargs):
self.dataset = dataset
self.num_class = num_class
self.num_mix = num_mix
self.beta = beta
self.prob = prob
self.indices = indices
self.noise = noise
self.vis = vis
def __getitem__(self, index):
img, lb = self.dataset[index]
lb_onehot = onehot(self.num_class, lb)
if self.vis:
origin = img.clone()
for _ in range(self.num_mix):
r = np.random.rand(1)
if self.beta <= 0 or r > self.prob:
continue
# generate mixed sample
lam = np.random.beta(self.beta, self.beta)
if self.indices is None:
rand_index = random.choice(range(len(self)))
else:
rand_index = random.choice(self.indices)
img2, lb2 = self.dataset[rand_index]
lb2_onehot = onehot(self.num_class, lb2)
# shape: step, channel, height, width
# alpha = np.random.rand()
# if alpha < 0.333:
bbx1, bby1, bbx2, bby2 = rand_bbox(img.shape, 1. - lam)
# bbx1, bby1, bbx2, bby2 = 32, 0, 48, 16
lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (img.shape[-1] * img.shape[-2])) # area
# lam = calc_lam(img, img2, 0, shape[0], bbx1, bbx2, bby1, bby2) # count
# distance
# mask = torch.zeros_like(img, dtype=torch.bool)
# mask[:, :, bbx1:bbx2, bby1:bby2] = True
# mix = img.clone()
# mix[mask] = img2[mask]
# lam = calc_masked_lam_with_difference(img, img2, mix, kernel_size=3)
if self.vis:
img[:, :, bbx1:bbx2, bby1:bby2] = -img2[:, :, bbx1:bbx2, bby1:bby2]
img2 = -img2
else:
img[:, :, bbx1:bbx2, bby1:bby2] = img2[:, :, bbx1:bbx2, bby1:bby2]
# elif alpha > 0.667:
# bbt1, bbt2 = rand_bbox_time(img.shape, 1. - lam)
# lam = calc_lam(img, img2, bbt1, bbt2, 0, shape[2], 0, shape[3])
# img[:, bbt1:bbt2, :, :] = img2[:, bbt1:bbt2, :, :]
# # lam = 1 - (bbt2 - bbt1) / (img.shape[-4])
# else:
# bbt1, bbt2, bbx1, bby1, bbx2, bby2 = rand_bbox_st(img.shape, 1. - lam)
# lam = calc_lam(img, img2, bbt1, bbt2, bbx1, bbx2, bby1, bby2)
# img[:, bbt1:bbt2, bbx1:bbx2, bby1:bby2] = img2[:, bbt1:bbt2, bbx1:bbx2, bby1:bby2]
# # lam = 1 - ((bbt2 - bbt1) * (bbx2 - bbx1) * (bby2 - bby1) / (img.shape[-1] * img.shape[-2] * img.shape[-4]))
if self.noise != 0.:
img = SaltAndPepperNoise(img, self.noise)
lb_onehot = lb_onehot * lam + lb2_onehot * (1. - lam)
if self.vis:
mask = torch.zeros_like(img)
mask[:, :, bbx1:bbx2, bby1:bby2] = 1.
return origin, img, img2, mask
else:
return img, lb_onehot
def __len__(self):
return len(self.dataset)
class EventMix(Dataset):
# 82.15725806451613 (epoch 554) /data/floyed/BrainCog/train/20220413-014843-resnet34-dvsc10-10-masked
def __init__(self,
dataset,
num_class,
num_mix=1,
beta=1.,
prob=1.0,
indices=None,
noise=0.1,
vis=False,
gaussian_n=None,
**kwargs):
self.dataset = dataset
self.num_class = num_class
self.num_mix = num_mix
self.beta = beta
self.prob = prob
self.indices = indices
self.noise = noise
self.vis = vis
self.gaussian_n = gaussian_n
print(self.prob, self.gaussian_n, self.beta)
def __getitem__(self, index):
img, lb = self.dataset[index]
lb_onehot = onehot(self.num_class, lb)
shape = img.shape
if self.vis:
origin = img.clone()
for _ in range(self.num_mix):
r = np.random.rand(1)
if self.beta <= 0 or r > self.prob:
continue
# generate mixed sample
lam = np.random.beta(self.beta, self.beta) # lam -> remain ratio
if self.indices is None:
rand_index = random.choice(range(len(self)))
else:
rand_index = random.choice(self.indices)
img2, lb2 = self.dataset[rand_index]
lb2_onehot = onehot(self.num_class, lb2)
# shape: step, channel, height, width
# alpha = np.random.rand()
# if alpha < 0.333:
# mask = spatio_mask(shape, 1. - lam)
# elif alpha > 0.667:
# mask = temporal_mask(shape, 1. - lam)
# else:
# mask = st_mask(shape, 1. - lam)
mask = GMM_mask(shape, 1. - lam, self.gaussian_n)
# mask = GMM_mask_clip(shape, 1. - lam)
# mask = torch.logical_not(mask)
# lam = 1 - (mask.sum() / np.prod(img.shape)) # area
lam = calc_masked_lam(img, img2, mask) # count
img[mask] = img2[mask] # count && mask required
# distance
# mix = torch.clone(img)
# if self.vis:
# mix[mask] = -img2[mask]
# img2 = -img2
# else:
# mix[mask] = img2[mask]
# lam = calc_masked_lam_with_difference(img, img2, mix, kernel_size=3)
# img = mix
if self.noise != 0.:
img = SaltAndPepperNoise(img, self.noise)
lb_onehot = lb_onehot * lam + lb2_onehot * (1. - lam)
if self.vis:
return origin, img, img2, mask
else:
return img, lb_onehot
def __len__(self):
return len(self.dataset)
if __name__ == '__main__':
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from mpl_toolkits.mplot3d import proj3d
def get_proj(self):
"""
Create the projection matrix from the current viewing position.
elev stores the elevation angle in the z plane
azim stores the azimuth angle in the (x, y) plane
dist is the distance of the eye viewing point from the object point.
"""
# chosen for similarity with the initial view before gh-8896
relev, razim = np.pi * self.elev / 180, np.pi * self.azim / 180
# EDITED TO HAVE SCALED AXIS
xmin, xmax = np.divide(self.get_xlim3d(), self.pbaspect[0])
ymin, ymax = np.divide(self.get_ylim3d(), self.pbaspect[1])
zmin, zmax = np.divide(self.get_zlim3d(), self.pbaspect[2])
# transform to uniform world coordinates 0-1, 0-1, 0-1
worldM = proj3d.world_transformation(xmin, xmax,
ymin, ymax,
zmin, zmax)
# look into the middle of the new coordinates
R = self.pbaspect / 2
xp = R[0] + np.cos(razim) * np.cos(relev) * self.dist
yp = R[1] + np.sin(razim) * np.cos(relev) * self.dist
zp = R[2] + np.sin(relev) * self.dist
E = np.array((xp, yp, zp))
self.eye = E
self.vvec = R - E
self.vvec = self.vvec / np.linalg.norm(self.vvec)
if abs(relev) > np.pi / 2:
# upside down
V = np.array((0, 0, -1))
else:
V = np.array((0, 0, 1))
zfront, zback = -self.dist, self.dist
viewM = proj3d.view_transformation(E, R, V)
projM = self._projection(zfront, zback)
M0 = np.dot(viewM, worldM)
M = np.dot(projM, M0)
return M
Axes3D.get_proj = get_proj
size = (100, 2, 48, 48)
mask = GMM_mask(size, 0.3)
print(mask.shape)
# for i in range(100):
# plt.figure()
# plt.imshow(mask[i, 0])
# plt.show()
pos_idx1 = []
neg_idx1 = []
for t in range(100):
for r in range(48):
for c in range(48):
if mask[t, 0, r, c] > 0:
pos_idx1.append((t, r, c))
if mask[t, 1, r, c] > 0:
neg_idx1.append((t, r, c))
pos_t1, pos_x1, pos_y1 = np.split(np.array(pos_idx1), 3, axis=1)
neg_t1, neg_x1, neg_y1 = np.split(np.array(neg_idx1), 3, axis=1)
fig = plt.figure(figsize=plt.figaspect(0.5) * 1.5)
ax = Axes3D(fig)
ax.pbaspect = np.array([1, 1, 1]) # np.array([2.0, 1.0, 0.5])
ax.view_init(elev=10, azim=-75)
# ax.axis('off')
ax.scatter(pos_t1[:, 0], pos_y1[:, 0], 48 - pos_x1[:, 0], color='red', alpha=0.1, s=2.)
ax.scatter(neg_t1[:, 0], neg_y1[:, 0], 48 - neg_x1[:, 0], color='blue', alpha=0.1, s=2.)
plt.show()
================================================
FILE: braincog/datasets/datasets.py
================================================
import os, warnings
import tonic
from tonic import DiskCachedDataset
import torch
import torch.nn.functional as F
import torch.utils
import torchvision.datasets as datasets
from timm.data import ImageDataset, create_loader, Mixup, FastCollateMixup, AugMixDataset
from timm.data import create_transform
from torchvision import transforms
from typing import Any, Dict, Optional, Sequence, Tuple, Union
import braincog
from braincog.datasets.NOmniglot.nomniglot_full import NOmniglotfull
from braincog.datasets.NOmniglot.nomniglot_nw_ks import NOmniglotNWayKShot
from braincog.datasets.NOmniglot.nomniglot_pair import NOmniglotTrainSet, NOmniglotTestSet
from braincog.datasets.ESimagenet.ES_imagenet import ESImagenet_Dataset
from braincog.datasets.ESimagenet.reconstructed_ES_imagenet import ESImagenet2D_Dataset
from braincog.datasets.CUB2002011 import CUB2002011
from braincog.datasets.TinyImageNet import TinyImageNet
from braincog.datasets.StanfordDogs import StanfordDogs
from braincog.datasets.bullying10k import BULLYINGDVS
from .cut_mix import CutMix, EventMix, MixUp
from .rand_aug import *
from .utils import dvs_channel_check_expend, rescale
DVSCIFAR10_MEAN_16 = [0.3290, 0.4507]
DVSCIFAR10_STD_16 = [1.8398, 1.6549]
DATA_DIR = '/data/datasets'
DEFAULT_CROP_PCT = 0.875
IMAGENET_DEFAULT_MEAN = (0.485, 0.456, 0.406)
IMAGENET_DEFAULT_STD = (0.229, 0.224, 0.225)
IMAGENET_INCEPTION_MEAN = (0.5, 0.5, 0.5)
IMAGENET_INCEPTION_STD = (0.5, 0.5, 0.5)
IMAGENET_DPN_MEAN = (124 / 255, 117 / 255, 104 / 255)
IMAGENET_DPN_STD = tuple([1 / (.0167 * 255)] * 3)
CIFAR10_DEFAULT_MEAN = (0.4914, 0.4822, 0.4465)
CIFAR10_DEFAULT_STD = (0.2023, 0.1994, 0.2010)
def unpack_mix_param(args):
mix_up = args['mix_up'] if 'mix_up' in args else False
cut_mix = args['cut_mix'] if 'cut_mix' in args else False
event_mix = args['event_mix'] if 'event_mix' in args else False
beta = args['beta'] if 'beta' in args else 1.
prob = args['prob'] if 'prob' in args else .5
num = args['num'] if 'num' in args else 1
num_classes = args['num_classes'] if 'num_classes' in args else 10
noise = args['noise'] if 'noise' in args else 0.
gaussian_n = args['gaussian_n'] if 'gaussian_n' in args else None
return mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n
def build_transform(is_train, img_size):
"""
构建数据增强, 适用于static data
:param is_train: 是否训练集
:param img_size: 输出的图像尺寸
:return: 数据增强策略
"""
resize_im = img_size > 32
if is_train:
# this should always dispatch to transforms_imagenet_train
transform = create_transform(
input_size=img_size,
is_training=True,
color_jitter=0.4,
auto_augment='rand-m9-mstd0.5-inc1',
interpolation='bicubic',
re_prob=0.25,
re_mode='pixel',
re_count=1,
)
if not resize_im:
# replace RandomResizedCropAndInterpolation with
# RandomCrop
transform.transforms[0] = transforms.RandomCrop(
img_size, padding=4)
return transform
t = []
if resize_im:
size = int((256 / 224) * img_size)
t.append(
# to maintain same ratio w.r.t. 224 images
transforms.Resize(size, interpolation=3),
)
t.append(transforms.CenterCrop(img_size))
t.append(transforms.ToTensor())
if img_size > 32:
t.append(transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD))
else:
t.append(transforms.Normalize(CIFAR10_DEFAULT_MEAN, CIFAR10_DEFAULT_STD))
return transforms.Compose(t)
def build_dataset(is_train, img_size, dataset, path, same_da=False):
"""
构建带有增强策略的数据集
:param is_train: 是否训练集
:param img_size: 输出图像尺寸
:param dataset: 数据集名称
:param path: 数据集路径
:param same_da: 为训练集使用测试集的增广方法
:return: 增强后的数据集
"""
transform = build_transform(False, img_size) if same_da else build_transform(is_train, img_size)
if dataset == 'CIFAR10':
dataset = datasets.CIFAR10(
path, train=is_train, transform=transform, download=True)
nb_classes = 10
elif dataset == 'CIFAR100':
dataset = datasets.CIFAR100(
path, train=is_train, transform=transform, download=True)
nb_classes = 100
else:
raise NotImplementedError
return dataset, nb_classes
class MNISTData(object):
"""
Load MNIST datesets.
"""
def __init__(self,
data_path: str,
batch_size: int,
train_trans: Sequence[torch.nn.Module] = None,
test_trans: Sequence[torch.nn.Module] = None,
pin_memory: bool = True,
drop_last: bool = True,
shuffle: bool = True,
) -> None:
self._data_path = data_path
self._batch_size = batch_size
self._pin_memory = pin_memory
self._drop_last = drop_last
self._shuffle = shuffle
self._train_transform = transforms.Compose(train_trans) if train_trans else None
self._test_transform = transforms.Compose(test_trans) if test_trans else None
def get_data_loaders(self):
print('Batch size: ', self._batch_size)
train_datasets = datasets.MNIST(root=self._data_path, train=True, transform=self._train_transform, download=True)
test_datasets = datasets.MNIST(root=self._data_path, train=False, transform=self._test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=self._drop_last, shuffle=self._shuffle
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=False
)
return train_loader, test_loader
def get_standard_data(self):
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
self._train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
self._test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
return self.get_data_loaders()
def get_mnist_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, **kwargs):
"""
获取MNIST数据
http://data.pymvpa.org/datasets/mnist/
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
if 'root' in kwargs:root=kwargs["root"]
if 'skip_norm' in kwargs and kwargs['skip_norm'] is True:
train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
else:
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
# transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
train_datasets = datasets.MNIST(
root=root, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.MNIST(
root=root, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_fashion_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, **kwargs):
"""
获取fashion MNIST数据
http://arxiv.org/abs/1708.07747
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor()])
test_transform = transforms.Compose([transforms.ToTensor()])
train_datasets = datasets.FashionMNIST(
root=root, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.FashionMNIST(
root=root, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_cifar10_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, **kwargs):
"""
获取CIFAR10数据
https://www.cs.toronto.edu/~kriz/cifar.html
:param batch_size: batch size
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_datasets, _ = build_dataset(True, 32, 'CIFAR10', root, same_da)
test_datasets, _ = build_dataset(False, 32, 'CIFAR10', root, same_da)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True,
num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False,
num_workers=num_workers
)
return train_loader, test_loader, None, None
def get_cifar100_data(batch_size, num_workers=8, same_data=False,root=DATA_DIR, *args, **kwargs):
"""
获取CIFAR100数据
https://www.cs.toronto.edu/~kriz/cifar.html
:param batch_size: batch size
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_datasets, _ = build_dataset(True, 32, 'CIFAR100', root, same_data)
test_datasets, _ = build_dataset(False, 32, 'CIFAR100', root, same_data)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_TinyImageNet_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, *args, **kwargs):
size=kwargs["size"] if "size" in kwargs else 224
train_transform = transforms.Compose([
transforms.RandomResizedCrop(size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(size*8//7),
transforms.CenterCrop(size),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(root, 'TinyImageNet')
train_datasets = TinyImageNet(
root=root, split="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = TinyImageNet(
root=root, split="val", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_imnet_data(args, _logger, data_config, num_aug_splits,root=DATA_DIR, **kwargs):
"""
获取ImageNet数据集
http://arxiv.org/abs/1409.0575
:param args: 其他的参数
:param _logger: 日志路径
:param data_config: 增强策略
:param num_aug_splits: 不同增强策略的数量
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_dir = os.path.join(root, 'ILSVRC2012/train')
if not os.path.exists(train_dir):
_logger.error(
'Training folder does not exist at: {}'.format(train_dir))
exit(1)
dataset_train = ImageDataset(train_dir)
# collate_fn = None
# mixup_fn = None
# mixup_active = args.mixup > 0 or args.cutmix > 0. or args.cutmix_minmax is not None
# if mixup_active:
# mixup_args = dict(
# mixup_alpha=args.mixup, cutmix_alpha=args.cutmix, cutmix_minmax=args.cutmix_minmax,
# prob=args.mixup_prob, switch_prob=args.mixup_switch_prob, mode=args.mixup_mode,
# label_smoothing=args.smoothing, num_classes=args.num_classes)
# if args.prefetcher:
# # collate conflict (need to support deinterleaving in collate mixup)
# assert not num_aug_splits
# collate_fn = FastCollateMixup(**mixup_args)
# else:
# mixup_fn = Mixup(**mixup_args)
# if num_aug_splits > 1:
# dataset_train = AugMixDataset(dataset_train, num_splits=num_aug_splits)
train_interpolation = args.train_interpolation
if args.no_aug or not train_interpolation:
train_interpolation = data_config['interpolation']
loader_train = create_loader(
dataset_train,
input_size=data_config['input_size'],
batch_size=args.batch_size,
is_training=True,
use_prefetcher=args.prefetcher,
no_aug=args.no_aug,
# re_prob=args.reprob,
# re_mode=args.remode,
# re_count=args.recount,
# re_split=args.resplit,
scale=args.scale,
ratio=args.ratio,
hflip=args.hflip,
# vflip=arg,
color_jitter=args.color_jitter,
#auto_augment=args.aa,
num_aug_splits=num_aug_splits,
interpolation=train_interpolation,
mean=data_config['mean'],
std=data_config['std'],
num_workers=args.workers,
distributed=args.distributed,
#collate_fn=collate_fn,
pin_memory=args.pin_mem,
use_multi_epochs_loader=args.use_multi_epochs_loader)
eval_dir = os.path.join(root, 'ILSVRC2012/val')
if not os.path.isdir(eval_dir):
eval_dir = os.path.join(root, 'ILSVRC2012/validation')
if not os.path.isdir(eval_dir):
_logger.error(
'Validation folder does not exist at: {}'.format(eval_dir))
exit(1)
dataset_eval = ImageDataset(eval_dir)
loader_eval = create_loader(
dataset_eval,
input_size=data_config['input_size'],
batch_size=args.validation_batch_size_multiplier * args.batch_size,
is_training=False,
use_prefetcher=args.prefetcher,
interpolation=data_config['interpolation'],
mean=data_config['mean'],
std=data_config['std'],
num_workers=args.workers,
distributed=args.distributed,
crop_pct=data_config['crop_pct'],
pin_memory=args.pin_mem,
)
return loader_train, loader_eval, False, None
def get_dvsg_data(batch_size, step,root=DATA_DIR, **kwargs):
"""
获取DVS Gesture数据
DOI: 10.1109/CVPR.2017.781
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.DVSGesture.sensor_size
size = kwargs['size'] if 'size' in kwargs else 48
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
train_dataset = tonic.datasets.DVSGesture(os.path.join(root, 'DVS/DVSGesture'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.DVSGesture(os.path.join(root, 'DVS/DVSGesture'),
transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(root, 'DVS/DVSGesture/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(root, 'DVS/DVSGesture/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, mixup_active, None
def get_bullyingdvs_data(batch_size, step, root=DATA_DIR, **kwargs):
"""
获取Bullying10K数据
NeurIPS 2023
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return:
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = BULLYINGDVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = BULLYINGDVS('/data/datasets/Bullying10k_processed', transform=train_transform)
# train_dataset = BULLYINGDVS(os.path.join(root, 'DVS/BULLYINGDVS'), transform=train_transform)
test_dataset = BULLYINGDVS(os.path.join(root, 'DVS/BULLYINGDVS'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(root, 'DVS/BULLYINGDVS/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(root, 'DVS/BULLYINGDVS/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_train),
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_test),
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_dvsc10_data(batch_size, step, root=DATA_DIR, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = tonic.datasets.CIFAR10DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.CIFAR10DVS(os.path.join(root, 'DVS/DVS_Cifar10'), transform=train_transform)
test_dataset = tonic.datasets.CIFAR10DVS(os.path.join(root, 'DVS/DVS_Cifar10'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(root, 'DVS/DVS_Cifar10/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(root, 'DVS/DVS_Cifar10/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_train),
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_test),
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_NCALTECH101_data(batch_size, step,root=DATA_DIR, **kwargs):
"""
获取NCaltech101数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.NCALTECH101.sensor_size
cls_count = tonic.datasets.NCALTECH101.cls_count
dataset_length = tonic.datasets.NCALTECH101.length
portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += train_sample
train_sample_weight.extend(
[sample_weight] * train_sample
)
train_sample_weight.extend(
[0.] * test_sample
)
train_sample_index.extend(
list((range(idx_begin, idx_begin + train_sample)))
)
test_sample_index.extend(
list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.NCALTECH101(os.path.join(root, 'DVS/NCALTECH101'), transform=train_transform)
test_dataset = tonic.datasets.NCALTECH101(os.path.join(root, 'DVS/NCALTECH101'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: print(x.shape),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
#transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: temporal_flatten(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(root, 'DVS/NCALTECH101/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(root, 'DVS/NCALTECH101/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=train_sampler,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_NCARS_data(batch_size, step,root=DATA_DIR, **kwargs):
"""
获取N-Cars数据
https://ieeexplore.ieee.org/document/8578284/
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.NCARS.sensor_size
size = kwargs['size'] if 'size' in kwargs else 48
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
])
train_dataset = tonic.datasets.NCARS(os.path.join(root, 'DVS/NCARS'), transform=train_transform, train=True)
test_dataset = tonic.datasets.NCARS(os.path.join(root, 'DVS/NCARS'), transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(root, 'DVS/NCARS/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(root, 'DVS/NCARS/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, mixup_active, None
def get_nomni_data(batch_size, train_portion=1.,root=DATA_DIR, **kwargs):
"""
获取N-Omniglot数据
:param batch_size:batch的大小
:param data_mode:一共full nkks pair三种模式
:param frames_num:一个样本帧的个数
:param data_type:event frequency两种模式
"""
data_mode = kwargs["data_mode"] if "data_mode" in kwargs else "full"
frames_num = kwargs["frames_num"] if "frames_num" in kwargs else 4
data_type = kwargs["data_type"] if "data_type" in kwargs else "event"
train_transform = transforms.Compose([
transforms.Resize((28, 28))])
test_transform = transforms.Compose([
transforms.Resize((28, 28))])
if data_mode == "full":
train_datasets = NOmniglotfull(root=os.path.join(root, 'DVS/NOmniglot'), train=True, frames_num=frames_num,
data_type=data_type,
transform=train_transform)
test_datasets = NOmniglotfull(root=os.path.join(root, 'DVS/NOmniglot'), train=False, frames_num=frames_num,
data_type=data_type,
transform=test_transform)
elif data_mode == "nkks":
train_datasets = NOmniglotNWayKShot(os.path.join(root, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=True,
frames_num=frames_num,
data_type=data_type,
transform=train_transform)
test_datasets = NOmniglotNWayKShot(os.path.join(root, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=False,
frames_num=frames_num,
data_type=data_type,
transform=test_transform)
elif data_mode == "pair":
train_datasets = NOmniglotTrainSet(root=os.path.join(root, 'DVS/NOmniglot'), use_frame=True,
frames_num=frames_num, data_type=data_type,
use_npz=False, resize=105)
test_datasets = NOmniglotTestSet(root=os.path.join(root, 'DVS/NOmniglot'), time=2000, way=kwargs["n_way"],
shot=kwargs["k_shot"], use_frame=True,
frames_num=frames_num, data_type=data_type, use_npz=False, resize=105)
else:
pass
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size, num_workers=12,
pin_memory=True, drop_last=True, shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size, num_workers=12,
pin_memory=True, drop_last=False
)
return train_loader, test_loader, None, None
def get_esimnet_data(batch_size, step,root=DATA_DIR, **kwargs):
"""
获取ES imagenet数据
DOI: 10.3389/fnins.2021.726582
:param batch_size: batch size
:param step: 仿真步长,固定为8
:param reconstruct: 重构则时间步为1, 否则为8
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
:note: 没有自动下载, 下载及md5请参考spikingjelly, sampler默认为DistributedSampler
"""
reconstruct = kwargs["reconstruct"] if "reconstruct" in kwargs else False
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: dvs_channel_check_expend(x),
])
if reconstruct:
assert step == 1
train_dataset = ESImagenet2D_Dataset(mode='train',
data_set_path=os.path.join(root, 'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=train_transform)
test_dataset = ESImagenet2D_Dataset(mode='test',
data_set_path=os.path.join(root, 'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=test_transform)
else:
assert step == 8
train_dataset = ESImagenet_Dataset(mode='train',
data_set_path=os.path.join(root,
'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=train_transform)
test_dataset = ESImagenet_Dataset(mode='test',
data_set_path=os.path.join(root,
'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=test_transform)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
test_sampler = torch.utils.data.distributed.DistributedSampler(test_dataset)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=False, sampler=train_sampler
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=1,
shuffle=False, sampler=test_sampler
)
return train_loader, test_loader, mixup_active, None
def get_nmnist_data(batch_size, step, **kwargs):
"""
获取N-MNIST数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.NMNIST.sensor_size
size = kwargs['size'] if 'size' in kwargs else 34
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
train_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/N-MNIST'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/N-MNIST'),
transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
# transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/N-MNIST/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/N-MNIST/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, mixup_active, None
def get_ntidigits_data(batch_size, step, **kwargs):
"""
获取N-TIDIGITS数据 (tonic 新版本中的下载链接可能挂了,可以参考0.4.0的版本)
https://www.frontiersin.org/articles/10.3389/fnins.2018.00023/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
:format: (b,t,c,len) 不同于vision, audio中c为1, 并且没有h,w; 只有len=64
"""
sensor_size = tonic.datasets.NTIDIGITS.sensor_size
train_transform = transforms.Compose([
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: x.squeeze(1)
])
test_transform = transforms.Compose([
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: x.squeeze(1)
])
train_dataset = tonic.datasets.NTIDIGITS(os.path.join(DATA_DIR, 'DVS/NTIDIGITS'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.NTIDIGITS(os.path.join(DATA_DIR, 'DVS/NTIDIGITS'),
transform=test_transform, train=False)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, None, None
def get_shd_data(batch_size, step, **kwargs):
"""
获取SHD数据
https://ieeexplore.ieee.org/abstract/document/9311226
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
:format: (b,t,c,len) 不同于vision, audio中c为1, 并且没有h,w; 只有len=700. Transform后变为(b, t, len)
"""
sensor_size = tonic.datasets.SHD.sensor_size
train_transform = transforms.Compose([
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step)
])
test_transform = transforms.Compose([
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step)
])
train_dataset = tonic.datasets.SHD(os.path.join(DATA_DIR, 'DVS/SHD'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.SHD(os.path.join(DATA_DIR, 'DVS/SHD'),
transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: x.squeeze(1)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: x.squeeze(1)
])
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/SHD/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/SHD/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, None, None
def get_CUB2002011_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(root, 'CUB2002011')
train_datasets = CUB2002011(
root=root, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = CUB2002011(
root=root, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_StanfordCars_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(root, 'StanfordCars')
train_datasets = datasets.StanfordCars(
root=root, split ="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.StanfordCars(
root=root, split ="test", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_StanfordDogs_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(root, 'StanfordDogs')
train_datasets = StanfordDogs(
root=root, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = StanfordDogs(
root=root, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_FGVCAircraft_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(root, 'FGVCAircraft')
train_datasets = datasets.FGVCAircraft(
root=root, split="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.FGVCAircraft(
root=root, split="test", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_Flowers102_data(batch_size, num_workers=8, same_da=False,root=DATA_DIR, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(root, 'Flowers102')
train_datasets = datasets.Flowers102(
root=root, split="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.Flowers102(
root=root, split="test", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_UCF101DVS_data(batch_size, step, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = braincog.datasets.ucf101_dvs.UCF101DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.ucf101_dvs.UCF101DVS(os.path.join(DATA_DIR, 'UCF101DVS'), train=True, transform=train_transform)
test_dataset = braincog.datasets.ucf101_dvs.UCF101DVS(os.path.join(DATA_DIR, 'UCF101DVS'), train=False, transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
# transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'UCF101DVS/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'UCF101DVS/test_cache_{}'.format(step)),
transform=test_transform)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size, shuffle=False,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_HMDBDVS_data(batch_size, step, **kwargs):
sensor_size = braincog.datasets.hmdb_dvs.HMDBDVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.hmdb_dvs.HMDBDVS(os.path.join(DATA_DIR, 'HMDBDVS'), transform=train_transform)
test_dataset = braincog.datasets.hmdb_dvs.HMDBDVS(os.path.join(DATA_DIR, 'HMDBDVS'), transform=test_transform)
cls_count = train_dataset.cls_count
dataset_length = train_dataset.length
portion = .5
# portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += train_sample
train_sample_weight.extend(
[sample_weight] * train_sample
)
train_sample_weight.extend(
[0.] * test_sample
)
lst = list(range(idx_begin, idx_begin + train_sample + test_sample))
random.seed(0)
random.shuffle(lst)
train_sample_index.extend(
lst[:train_sample]
# list((range(idx_begin, idx_begin + train_sample)))
)
test_sample_index.extend(
lst[train_sample:train_sample + test_sample]
# list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: print(x.shape),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: temporal_flatten(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'HMDBDVS/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'HMDBDVS/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=train_sampler,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
================================================
FILE: braincog/datasets/gen_input_signal.py
================================================
import numpy as np
import random
import copy
dt = 1.0 # ms
lambda_max = 0.25 * dt # maximum spike rate (spikes per time step)
================================================
FILE: braincog/datasets/hmdb_dvs/__init__.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2023/1/30 20:54
# User : yu
# Product : PyCharm
# Project : BrainCog
# File : __init__.py
# explain :
from .hmdb_dvs import HMDBDVS
__all__ = [
'HMDBDVS'
]
================================================
FILE: braincog/datasets/hmdb_dvs/hmdb_dvs.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2023/1/30 20:54
# User : yu
# Product : PyCharm
# Project : BrainCog
# File : hmdb_dvs.py
# explain :
import os
import numpy as np
from numpy.lib import recfunctions
import scipy.io as scio
from typing import Tuple, Any, Optional
from tonic.dataset import Dataset
from tonic.download_utils import extract_archive
class HMDBDVS(Dataset):
"""ASL-DVS dataset . Events have (txyp) ordering.
::
@inproceedings{bi2019graph,
title={Graph-based Object Classification for Neuromorphic Vision Sensing},
author={Bi, Y and Chadha, A and Abbas, A and and Bourtsoulatze, E and Andreopoulos, Y},
booktitle={2019 IEEE International Conference on Computer Vision (ICCV)},
year={2019},
organization={IEEE}
}
Parameters:
save_to (string): Location to save files to on disk.
transform (callable, optional): A callable of transforms to apply to the data.
target_transform (callable, optional): A callable of transforms to apply to the targets/labels.
"""
sensor_size = (240, 180, 2)
dtype = np.dtype([("t", int), ("x", int), ("y", int), ("p", int)])
ordering = dtype.names
def __init__(self, save_to, transform=None, target_transform=None):
super(HMDBDVS, self).__init__(
save_to, transform=transform, target_transform=target_transform
)
if not self._check_exists():
raise NotImplementedError(
'Please manually download the dataset from'
' https://www.dropbox.com/sh/ie75dn246cacf6n/AACoU-_zkGOAwj51lSCM0JhGa?dl=0 '
'and extract it to {}'.format(self.location_on_system))
classes = os.listdir(self.location_on_system)
self.int_classes = dict(zip(classes, range(len(classes))))
for path, dirs, files in os.walk(self.location_on_system):
dirs.sort()
files.sort()
for file in files:
if file.endswith("mat"):
fsize = os.path.getsize(path + '/' + file) / float(1024)
if fsize < 1:
# print('{} size {} K'.format(file, fsize))
continue
self.data.append(path + "/" + file)
self.targets.append(self.int_classes[path.split('/')[-1]])
self.length = self.__len__()
self.cls_count = np.bincount(self.targets)
def __getitem__(self, index: int) -> Tuple[Any, Any]:
"""
Returns:
(events, target) where target is index of the target class.
"""
events, target = scio.loadmat(self.data[index]), self.targets[index]
events = np.column_stack(
[
events["ts"],
events["x"],
self.sensor_size[1] - 1 - events["y"],
events["pol"],
]
)
events = np.lib.recfunctions.unstructured_to_structured(events, self.dtype)
if self.transform is not None:
events = self.transform(events)
if self.target_transform is not None:
target = self.target_transform(target)
return events, target
def __len__(self):
return len(self.data)
def _check_exists(self):
return self._folder_contains_at_least_n_files_of_type(
6765, ".mat"
)
================================================
FILE: braincog/datasets/ncaltech101/__init__.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2023/1/30 21:26
# User : yu
# Product : PyCharm
# Project : BrainCog
# File : __init__.py.py
# explain :
from .ncaltech101 import NCALTECH101
__all__ = [
'NCALTECH101'
]
================================================
FILE: braincog/datasets/ncaltech101/ncaltech101.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2023/1/30 21:28
# User : yu
# Product : PyCharm
# Project : BrainCog
# File : ncaltech101.py
# explain :
import os
import numpy as np
from tonic.io import read_mnist_file
from tonic.dataset import Dataset
from tonic.download_utils import extract_archive
class NCALTECH101(Dataset):
"""N-CALTECH101 dataset . Events have (xytp) ordering.
::
@article{orchard2015converting,
title={Converting static image datasets to spiking neuromorphic datasets using saccades},
author={Orchard, Garrick and Jayawant, Ajinkya and Cohen, Gregory K and Thakor, Nitish},
journal={Frontiers in neuroscience},
volume={9},
pages={437},
year={2015},
publisher={Frontiers}
}
Parameters:
save_to (string): Location to save files to on disk.
transform (callable, optional): A callable of transforms to apply to the data.
target_transform (callable, optional): A callable of transforms to apply to the targets/labels.
"""
url = "https://data.mendeley.com/public-files/datasets/cy6cvx3ryv/files/36b5c52a-b49d-4853-addb-a836a8883e49/file_downloaded"
filename = "N-Caltech101-archive.zip"
file_md5 = "66201824eabb0239c7ab992480b50ba3"
data_filename = "N-Caltech101-archive.zip"
folder_name = "Caltech101"
cls_count = [467,
435, 200, 798, 55, 800, 42, 42, 47, 54, 46,
33, 128, 98, 43, 85, 91, 50, 43, 123, 47,
59, 62, 107, 47, 69, 73, 70, 50, 51, 57,
67, 52, 65, 68, 75, 64, 53, 64, 85, 67,
67, 45, 34, 34, 51, 99, 100, 42, 54, 88,
80, 31, 64, 86, 114, 61, 81, 78, 41, 66,
43, 40, 87, 32, 76, 55, 35, 39, 47, 38,
45, 53, 34, 57, 82, 59, 49, 40, 63, 39,
84, 57, 35, 64, 45, 86, 59, 64, 35, 85,
49, 86, 75, 239, 37, 59, 34, 56, 39, 60]
# length = 8242
length = 8709
sensor_size = None # all recordings are of different size
dtype = np.dtype([("x", int), ("y", int), ("t", int), ("p", int)])
ordering = dtype.names
def __init__(self, save_to, transform=None, target_transform=None):
super(NCALTECH101, self).__init__(
save_to, transform=transform, target_transform=target_transform
)
classes = {
'BACKGROUND_Google': 0,
'Faces_easy': 1,
'Leopards': 2,
'Motorbikes': 3,
'accordion': 4,
'airplanes': 5,
'anchor': 6,
'ant': 7,
'barrel': 8,
'bass': 9,
'beaver': 10,
'binocular': 11,
'bonsai': 12,
'brain': 13,
'brontosaurus': 14,
'buddha': 15,
'butterfly': 16,
'camera': 17,
'cannon': 18,
'car_side': 19,
'ceiling_fan': 20,
'cellphone': 21,
'chair': 22,
'chandelier': 23,
'cougar_body': 24,
'cougar_face': 25,
'crab': 26,
'crayfish': 27,
'crocodile': 28,
'crocodile_head': 29,
'cup': 30,
'dalmatian': 31,
'dollar_bill': 32,
'dolphin': 33,
'dragonfly': 34,
'electric_guitar': 35,
'elephant': 36,
'emu': 37,
'euphonium': 38,
'ewer': 39,
'ferry': 40,
'flamingo': 41,
'flamingo_head': 42,
'garfield': 43,
'gerenuk': 44,
'gramophone': 45,
'grand_piano': 46,
'hawksbill': 47,
'headphone': 48,
'hedgehog': 49,
'helicopter': 50,
'ibis': 51,
'inline_skate': 52,
'joshua_tree': 53,
'kangaroo': 54,
'ketch': 55,
'lamp': 56,
'laptop': 57,
'llama': 58,
'lobster': 59,
'lotus': 60,
'mandolin': 61,
'mayfly': 62,
'menorah': 63,
'metronome': 64,
'minaret': 65,
'nautilus': 66,
'octopus': 67,
'okapi': 68,
'pagoda': 69,
'panda': 70,
'pigeon': 71,
'pizza': 72,
'platypus': 73,
'pyramid': 74,
'revolver': 75,
'rhino': 76,
'rooster': 77,
'saxophone': 78,
'schooner': 79,
'scissors': 80,
'scorpion': 81,
'sea_horse': 82,
'snoopy': 83,
'soccer_ball': 84,
'stapler': 85,
'starfish': 86,
'stegosaurus': 87,
'stop_sign': 88,
'strawberry': 89,
'sunflower': 90,
'tick': 91,
'trilobite': 92,
'umbrella': 93,
'watch': 94,
'water_lilly': 95,
'wheelchair': 96,
'wild_cat': 97,
'windsor_chair': 98,
'wrench': 99,
'yin_yang': 100,
}
# if not self._check_exists():
# self.download()
# extract_archive(os.path.join(self.location_on_system, self.data_filename))
file_path = os.path.join(self.location_on_system, self.folder_name)
for path, dirs, files in os.walk(file_path):
dirs.sort()
# if 'BACKGROUND_Google' in path:
# continue
for file in files:
if file.endswith("bin"):
self.data.append(path + "/" + file)
label_name = os.path.basename(path)
if isinstance(label_name, bytes):
label_name = label_name.decode()
self.targets.append(classes[label_name])
def __getitem__(self, index):
"""
Returns:
a tuple of (events, target) where target is the index of the target class.
"""
events = read_mnist_file(self.data[index], dtype=self.dtype)
target = self.targets[index]
events["x"] -= events["x"].min()
events["y"] -= events["y"].min()
if self.transform is not None:
events = self.transform(events)
if self.target_transform is not None:
target = self.target_transform(target)
return events, target
def __len__(self):
return len(self.data)
def _check_exists(self):
return self._is_file_present() and self._folder_contains_at_least_n_files_of_type(
8709, ".bin"
)
================================================
FILE: braincog/datasets/rand_aug.py
================================================
import random
import numpy as np
import torch
from torchvision import transforms
from torchvision.transforms import functional
from torchvision.transforms import InterpolationMode
def ShearX(x, v): # [-0.3, 0.3]
assert 0 <= v <= 30
v = np.random.uniform(0, v)
if random.random() > 0.5:
v = -v
return functional.affine(x, angle=0, translate=[0, 0], scale=1., shear=[v, 0])
def ShearY(x, v): # [-0.3, 0.3]
assert 0 <= v <= 30
v = np.random.uniform(0, v)
if random.random() > 0.5:
v = -v
return functional.affine(x, angle=0, translate=[0, 0], scale=1., shear=[0, v])
def TranslateX(x, v):
assert 0 <= v <= 0.45
v = np.random.uniform(0, v)
w, h = x.shape[-2::]
v = round(w * v)
if random.random() > 0.5:
v = -v
return functional.affine(x, angle=0, translate=[0, v], scale=1., shear=[0, 0])
def TranslateY(x, v):
assert 0 <= v <= 0.45
v = np.random.uniform(0, v)
w, h = x.shape[-2::]
v = round(w * v)
if random.random() > 0.5:
v = -v
return functional.affine(x, angle=0, translate=[v, 0], scale=1., shear=[0, 0])
def Rotate(x, v): # [-30, 30]
assert 0 <= v <= 30
v = np.random.uniform(0, v)
if random.random() > 0.5:
v = -v
return functional.affine(x, angle=v, translate=[0, 0], scale=1., shear=[0, 0])
def CutoutAbs(x, v): # [0, 60] => percentage: [0, 0.2]
assert 0 <= v <= 0.5
w, h = x.shape[-2::]
v = round(v * w)
x0 = np.random.uniform(w)
y0 = np.random.uniform(h)
x0 = round(max(0, x0 - v / 2.))
y0 = round(max(0, y0 - v / 2.))
x1 = min(w, x0 + v)
y1 = min(h, y0 + v)
x[:, :, y0:y1, x0:x1] = 0.
return x
def CutoutTemporal(x, v):
assert 0 <= v <= 0.5
v = np.random.uniform(0, v)
step = x.shape[0]
v = round(v * step)
t0 = np.random.randint(step)
t1 = min(step, t0 + v)
x[t0:t1, :, :, :] = 0.
return x
def TemporalShift(x, v):
# TODO: Maybe shift too mach than origin has
assert 0 <= v <= 0.2
v = v / 2.
shape = x.shape
# p = torch.zeros(2 * (shape[0] - 1), *shape[-3:], device=x.device)
shift = []
for i in range(x.shape[0] - 1):
spike = x[i].clone()
_max = int(spike.max())
sft = torch.zeros(shape[-3:], device=x.device)
for j in range(_max):
p = torch.rand_like(sft)
sft[torch.logical_and(p < v, spike > 0.)] += 1.
spike -= 1
shift.append(sft)
spike = x[i + 1].clone()
_max = int(spike.max())
sft = torch.zeros(shape[-3:], device=x.device)
for j in range(_max):
p = torch.rand_like(sft)
sft[torch.logical_and(p < v, spike > 0.)] += 1.
shift.append(sft)
for i in range(shape[0] - 1):
sft_next = shift[i * 2]
sft_pre = shift[i * 2 + 1]
x[i + 1] = torch.clip(x[i + 1] + sft_next - sft_pre, 0.)
x[i] = torch.clip(x[i] - sft_next + sft_pre, 0.)
return x
def SpatioShift(x, v):
# assert 0 <= v <= 0.1
w, h = x.shape[-2::]
shift_x = round(random.uniform(-v, v) * w)
shift_y = round(random.uniform(-v, v) * h)
output = []
step = x.shape[0]
for t in range(step):
output.append(functional.affine(x[t],
angle=0,
translate=[
round(shift_x * t / step),
round(shift_y * t / step)],
scale=1.,
shear=[0, 0]))
return torch.stack(output, dim=0)
def drop(x, v):
assert 0 <= v <= 0.5
v = np.random.uniform(0, v)
_max = int(torch.max(x))
p = torch.rand((_max, *x.shape), device=x.device)
for i in range(_max):
p[i, x > 0] += 1.
x -= 1.
p = torch.where(p > 1. + v, 1., 0.)
return torch.sum(p, dim=0)
def GaussianBlur(x, v):
assert 0.1 <= v <= 1.
v = np.random.uniform(0.1, v)
return functional.gaussian_blur(x, kernel_size=[5, 5], sigma=v)
def SaltAndPepperNoise(x, v):
assert 0 <= v <= 0.3
v = np.random.uniform(0, v)
p = torch.rand_like(x)
p = torch.where(p > v, 0., 1.)
return x + p
def Identity(x, v):
return x
# DVSC10 NCAL
augment_list = [ # normal: 79.44 77.57
# (ShearX, 0, 20), # 75.71
# (ShearY, 0, 20),
# (TranslateX, 0, 0.25), # 77.52
# (TranslateY, 0, 0.25),
# (Rotate, 0, 30), # 77.02
(CutoutAbs, 0, 0.5), # 79.13
(CutoutTemporal, 0, 0.5), # 80.65
# (TemporalShift, 0, 0.2), # 75.30
# (SpatioShift, 0, 0.1), # 78.43
(GaussianBlur, 0, 1.), # 79.83
# (drop, 0, 0.5), # 74.00
(SaltAndPepperNoise, 0, 0.3), # 79.64
# cutmix_normal_aug: 90.02 86.52
]
class RandAugment:
def __init__(self, n, m):
self.n = n
self.m = m # [0, 30]
self.augment_list = augment_list
def __call__(self, x):
ops = random.choices(self.augment_list, k=self.n)
for op, minvalue, maxvalue in ops:
val = (float(self.m) / 30) * float(maxvalue - minvalue) + minvalue
x = op(x, val)
return x
================================================
FILE: braincog/datasets/scripts/testlist01.txt
================================================
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c01.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c02.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c03.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c04.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c05.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c06.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g02_c01.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g02_c02.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g02_c03.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g02_c04.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g03_c01.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g03_c02.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g03_c03.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g03_c04.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g03_c05.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g03_c06.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g04_c01.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g04_c02.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g04_c03.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g04_c04.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g04_c05.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g04_c06.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g04_c07.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g05_c01.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g05_c02.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g05_c03.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g05_c04.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g05_c05.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g05_c06.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g05_c07.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g06_c01.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g06_c02.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g06_c03.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g06_c04.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g06_c05.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g06_c06.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g06_c07.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c01.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c02.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c03.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c04.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c05.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c06.avi
ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c07.avi
ApplyLipstick/v_ApplyLipstick_g01_c01.avi
ApplyLipstick/v_ApplyLipstick_g01_c02.avi
ApplyLipstick/v_ApplyLipstick_g01_c03.avi
ApplyLipstick/v_ApplyLipstick_g01_c04.avi
ApplyLipstick/v_ApplyLipstick_g01_c05.avi
ApplyLipstick/v_ApplyLipstick_g02_c01.avi
ApplyLipstick/v_ApplyLipstick_g02_c02.avi
ApplyLipstick/v_ApplyLipstick_g02_c03.avi
ApplyLipstick/v_ApplyLipstick_g02_c04.avi
ApplyLipstick/v_ApplyLipstick_g03_c01.avi
ApplyLipstick/v_ApplyLipstick_g03_c02.avi
ApplyLipstick/v_ApplyLipstick_g03_c03.avi
ApplyLipstick/v_ApplyLipstick_g03_c04.avi
ApplyLipstick/v_ApplyLipstick_g04_c01.avi
ApplyLipstick/v_ApplyLipstick_g04_c02.avi
ApplyLipstick/v_ApplyLipstick_g04_c03.avi
ApplyLipstick/v_ApplyLipstick_g04_c04.avi
ApplyLipstick/v_ApplyLipstick_g04_c05.avi
ApplyLipstick/v_ApplyLipstick_g05_c01.avi
ApplyLipstick/v_ApplyLipstick_g05_c02.avi
ApplyLipstick/v_ApplyLipstick_g05_c03.avi
ApplyLipstick/v_ApplyLipstick_g05_c04.avi
ApplyLipstick/v_ApplyLipstick_g05_c05.avi
ApplyLipstick/v_ApplyLipstick_g06_c01.avi
ApplyLipstick/v_ApplyLipstick_g06_c02.avi
ApplyLipstick/v_ApplyLipstick_g06_c03.avi
ApplyLipstick/v_ApplyLipstick_g06_c04.avi
ApplyLipstick/v_ApplyLipstick_g06_c05.avi
ApplyLipstick/v_ApplyLipstick_g07_c01.avi
ApplyLipstick/v_ApplyLipstick_g07_c02.avi
ApplyLipstick/v_ApplyLipstick_g07_c03.avi
ApplyLipstick/v_ApplyLipstick_g07_c04.avi
Archery/v_Archery_g01_c01.avi
Archery/v_Archery_g01_c02.avi
Archery/v_Archery_g01_c03.avi
Archery/v_Archery_g01_c04.avi
Archery/v_Archery_g01_c05.avi
Archery/v_Archery_g01_c06.avi
Archery/v_Archery_g01_c07.avi
Archery/v_Archery_g02_c01.avi
Archery/v_Archery_g02_c02.avi
Archery/v_Archery_g02_c03.avi
Archery/v_Archery_g02_c04.avi
Archery/v_Archery_g02_c05.avi
Archery/v_Archery_g02_c06.avi
Archery/v_Archery_g02_c07.avi
Archery/v_Archery_g03_c01.avi
Archery/v_Archery_g03_c02.avi
Archery/v_Archery_g03_c03.avi
Archery/v_Archery_g03_c04.avi
Archery/v_Archery_g03_c05.avi
Archery/v_Archery_g04_c01.avi
Archery/v_Archery_g04_c02.avi
Archery/v_Archery_g04_c03.avi
Archery/v_Archery_g04_c04.avi
Archery/v_Archery_g04_c05.avi
Archery/v_Archery_g05_c01.avi
Archery/v_Archery_g05_c02.avi
Archery/v_Archery_g05_c03.avi
Archery/v_Archery_g05_c04.avi
Archery/v_Archery_g05_c05.avi
Archery/v_Archery_g06_c01.avi
Archery/v_Archery_g06_c02.avi
Archery/v_Archery_g06_c03.avi
Archery/v_Archery_g06_c04.avi
Archery/v_Archery_g06_c05.avi
Archery/v_Archery_g06_c06.avi
Archery/v_Archery_g07_c01.avi
Archery/v_Archery_g07_c02.avi
Archery/v_Archery_g07_c03.avi
Archery/v_Archery_g07_c04.avi
Archery/v_Archery_g07_c05.avi
Archery/v_Archery_g07_c06.avi
BabyCrawling/v_BabyCrawling_g01_c01.avi
BabyCrawling/v_BabyCrawling_g01_c02.avi
BabyCrawling/v_BabyCrawling_g01_c03.avi
BabyCrawling/v_BabyCrawling_g01_c04.avi
BabyCrawling/v_BabyCrawling_g02_c01.avi
BabyCrawling/v_BabyCrawling_g02_c02.avi
BabyCrawling/v_BabyCrawling_g02_c03.avi
BabyCrawling/v_BabyCrawling_g02_c04.avi
BabyCrawling/v_BabyCrawling_g02_c05.avi
BabyCrawling/v_BabyCrawling_g02_c06.avi
BabyCrawling/v_BabyCrawling_g03_c01.avi
BabyCrawling/v_BabyCrawling_g03_c02.avi
BabyCrawling/v_BabyCrawling_g03_c03.avi
BabyCrawling/v_BabyCrawling_g03_c04.avi
BabyCrawling/v_BabyCrawling_g04_c01.avi
BabyCrawling/v_BabyCrawling_g04_c02.avi
BabyCrawling/v_BabyCrawling_g04_c03.avi
BabyCrawling/v_BabyCrawling_g04_c04.avi
BabyCrawling/v_BabyCrawling_g05_c01.avi
BabyCrawling/v_BabyCrawling_g05_c02.avi
BabyCrawling/v_BabyCrawling_g05_c03.avi
BabyCrawling/v_BabyCrawling_g05_c04.avi
BabyCrawling/v_BabyCrawling_g05_c05.avi
BabyCrawling/v_BabyCrawling_g06_c01.avi
BabyCrawling/v_BabyCrawling_g06_c02.avi
BabyCrawling/v_BabyCrawling_g06_c03.avi
BabyCrawling/v_BabyCrawling_g06_c04.avi
BabyCrawling/v_BabyCrawling_g06_c05.avi
BabyCrawling/v_BabyCrawling_g06_c06.avi
BabyCrawling/v_BabyCrawling_g07_c01.avi
BabyCrawling/v_BabyCrawling_g07_c02.avi
BabyCrawling/v_BabyCrawling_g07_c03.avi
BabyCrawling/v_BabyCrawling_g07_c04.avi
BabyCrawling/v_BabyCrawling_g07_c05.avi
BabyCrawling/v_BabyCrawling_g07_c06.avi
BalanceBeam/v_BalanceBeam_g01_c01.avi
BalanceBeam/v_BalanceBeam_g01_c02.avi
BalanceBeam/v_BalanceBeam_g01_c03.avi
BalanceBeam/v_BalanceBeam_g01_c04.avi
BalanceBeam/v_BalanceBeam_g02_c01.avi
BalanceBeam/v_BalanceBeam_g02_c02.avi
BalanceBeam/v_BalanceBeam_g02_c03.avi
BalanceBeam/v_BalanceBeam_g02_c04.avi
BalanceBeam/v_BalanceBeam_g03_c01.avi
BalanceBeam/v_BalanceBeam_g03_c02.avi
BalanceBeam/v_BalanceBeam_g03_c03.avi
BalanceBeam/v_BalanceBeam_g03_c04.avi
BalanceBeam/v_BalanceBeam_g04_c01.avi
BalanceBeam/v_BalanceBeam_g04_c02.avi
BalanceBeam/v_BalanceBeam_g04_c03.avi
BalanceBeam/v_BalanceBeam_g04_c04.avi
BalanceBeam/v_BalanceBeam_g05_c01.avi
BalanceBeam/v_BalanceBeam_g05_c02.avi
BalanceBeam/v_BalanceBeam_g05_c03.avi
BalanceBeam/v_BalanceBeam_g05_c04.avi
BalanceBeam/v_BalanceBeam_g06_c01.avi
BalanceBeam/v_BalanceBeam_g06_c02.avi
BalanceBeam/v_BalanceBeam_g06_c03.avi
BalanceBeam/v_BalanceBeam_g06_c04.avi
BalanceBeam/v_BalanceBeam_g06_c05.avi
BalanceBeam/v_BalanceBeam_g06_c06.avi
BalanceBeam/v_BalanceBeam_g06_c07.avi
BalanceBeam/v_BalanceBeam_g07_c01.avi
BalanceBeam/v_BalanceBeam_g07_c02.avi
BalanceBeam/v_BalanceBeam_g07_c03.avi
BalanceBeam/v_BalanceBeam_g07_c04.avi
BandMarching/v_BandMarching_g01_c01.avi
BandMarching/v_BandMarching_g01_c02.avi
BandMarching/v_BandMarching_g01_c03.avi
BandMarching/v_BandMarching_g01_c04.avi
BandMarching/v_BandMarching_g01_c05.avi
BandMarching/v_BandMarching_g01_c06.avi
BandMarching/v_BandMarching_g01_c07.avi
BandMarching/v_BandMarching_g02_c01.avi
BandMarching/v_BandMarching_g02_c02.avi
BandMarching/v_BandMarching_g02_c03.avi
BandMarching/v_BandMarching_g02_c04.avi
BandMarching/v_BandMarching_g02_c05.avi
BandMarching/v_BandMarching_g02_c06.avi
BandMarching/v_BandMarching_g02_c07.avi
BandMarching/v_BandMarching_g03_c01.avi
BandMarching/v_BandMarching_g03_c02.avi
BandMarching/v_BandMarching_g03_c03.avi
BandMarching/v_BandMarching_g03_c04.avi
BandMarching/v_BandMarching_g03_c05.avi
BandMarching/v_BandMarching_g03_c06.avi
BandMarching/v_BandMarching_g03_c07.avi
BandMarching/v_BandMarching_g04_c01.avi
BandMarching/v_BandMarching_g04_c02.avi
BandMarching/v_BandMarching_g04_c03.avi
BandMarching/v_BandMarching_g04_c04.avi
BandMarching/v_BandMarching_g05_c01.avi
BandMarching/v_BandMarching_g05_c02.avi
BandMarching/v_BandMarching_g05_c03.avi
BandMarching/v_BandMarching_g05_c04.avi
BandMarching/v_BandMarching_g05_c05.avi
BandMarching/v_BandMarching_g05_c06.avi
BandMarching/v_BandMarching_g05_c07.avi
BandMarching/v_BandMarching_g06_c01.avi
BandMarching/v_BandMarching_g06_c02.avi
BandMarching/v_BandMarching_g06_c03.avi
BandMarching/v_BandMarching_g06_c04.avi
BandMarching/v_BandMarching_g07_c01.avi
BandMarching/v_BandMarching_g07_c02.avi
BandMarching/v_BandMarching_g07_c03.avi
BandMarching/v_BandMarching_g07_c04.avi
BandMarching/v_BandMarching_g07_c05.avi
BandMarching/v_BandMarching_g07_c06.avi
BandMarching/v_BandMarching_g07_c07.avi
BaseballPitch/v_BaseballPitch_g01_c01.avi
BaseballPitch/v_BaseballPitch_g01_c02.avi
BaseballPitch/v_BaseballPitch_g01_c03.avi
BaseballPitch/v_BaseballPitch_g01_c04.avi
BaseballPitch/v_BaseballPitch_g01_c05.avi
BaseballPitch/v_BaseballPitch_g01_c06.avi
BaseballPitch/v_BaseballPitch_g02_c01.avi
BaseballPitch/v_BaseballPitch_g02_c02.avi
BaseballPitch/v_BaseballPitch_g02_c03.avi
BaseballPitch/v_BaseballPitch_g02_c04.avi
BaseballPitch/v_BaseballPitch_g03_c01.avi
BaseballPitch/v_BaseballPitch_g03_c02.avi
BaseballPitch/v_BaseballPitch_g03_c03.avi
BaseballPitch/v_BaseballPitch_g03_c04.avi
BaseballPitch/v_BaseballPitch_g03_c05.avi
BaseballPitch/v_BaseballPitch_g03_c06.avi
BaseballPitch/v_BaseballPitch_g03_c07.avi
BaseballPitch/v_BaseballPitch_g04_c01.avi
BaseballPitch/v_BaseballPitch_g04_c02.avi
BaseballPitch/v_BaseballPitch_g04_c03.avi
BaseballPitch/v_BaseballPitch_g04_c04.avi
BaseballPitch/v_BaseballPitch_g04_c05.avi
BaseballPitch/v_BaseballPitch_g05_c01.avi
BaseballPitch/v_BaseballPitch_g05_c02.avi
BaseballPitch/v_BaseballPitch_g05_c03.avi
BaseballPitch/v_BaseballPitch_g05_c04.avi
BaseballPitch/v_BaseballPitch_g05_c05.avi
BaseballPitch/v_BaseballPitch_g05_c06.avi
BaseballPitch/v_BaseballPitch_g05_c07.avi
BaseballPitch/v_BaseballPitch_g06_c01.avi
BaseballPitch/v_BaseballPitch_g06_c02.avi
BaseballPitch/v_BaseballPitch_g06_c03.avi
BaseballPitch/v_BaseballPitch_g06_c04.avi
BaseballPitch/v_BaseballPitch_g06_c05.avi
BaseballPitch/v_BaseballPitch_g06_c06.avi
BaseballPitch/v_BaseballPitch_g06_c07.avi
BaseballPitch/v_BaseballPitch_g07_c01.avi
BaseballPitch/v_BaseballPitch_g07_c02.avi
BaseballPitch/v_BaseballPitch_g07_c03.avi
BaseballPitch/v_BaseballPitch_g07_c04.avi
BaseballPitch/v_BaseballPitch_g07_c05.avi
BaseballPitch/v_BaseballPitch_g07_c06.avi
BaseballPitch/v_BaseballPitch_g07_c07.avi
Basketball/v_Basketball_g01_c01.avi
Basketball/v_Basketball_g01_c02.avi
Basketball/v_Basketball_g01_c03.avi
Basketball/v_Basketball_g01_c04.avi
Basketball/v_Basketball_g01_c05.avi
Basketball/v_Basketball_g01_c06.avi
Basketball/v_Basketball_g01_c07.avi
Basketball/v_Basketball_g02_c01.avi
Basketball/v_Basketball_g02_c02.avi
Basketball/v_Basketball_g02_c03.avi
Basketball/v_Basketball_g02_c04.avi
Basketball/v_Basketball_g02_c05.avi
Basketball/v_Basketball_g02_c06.avi
Basketball/v_Basketball_g03_c01.avi
Basketball/v_Basketball_g03_c02.avi
Basketball/v_Basketball_g03_c03.avi
Basketball/v_Basketball_g03_c04.avi
Basketball/v_Basketball_g03_c05.avi
Basketball/v_Basketball_g03_c06.avi
Basketball/v_Basketball_g04_c01.avi
Basketball/v_Basketball_g04_c02.avi
Basketball/v_Basketball_g04_c03.avi
Basketball/v_Basketball_g04_c04.avi
Basketball/v_Basketball_g05_c01.avi
Basketball/v_Basketball_g05_c02.avi
Basketball/v_Basketball_g05_c03.avi
Basketball/v_Basketball_g05_c04.avi
Basketball/v_Basketball_g06_c01.avi
Basketball/v_Basketball_g06_c02.avi
Basketball/v_Basketball_g06_c03.avi
Basketball/v_Basketball_g06_c04.avi
Basketball/v_Basketball_g07_c01.avi
Basketball/v_Basketball_g07_c02.avi
Basketball/v_Basketball_g07_c03.avi
Basketball/v_Basketball_g07_c04.avi
BasketballDunk/v_BasketballDunk_g01_c01.avi
BasketballDunk/v_BasketballDunk_g01_c02.avi
BasketballDunk/v_BasketballDunk_g01_c03.avi
BasketballDunk/v_BasketballDunk_g01_c04.avi
BasketballDunk/v_BasketballDunk_g01_c05.avi
BasketballDunk/v_BasketballDunk_g01_c06.avi
BasketballDunk/v_BasketballDunk_g01_c07.avi
BasketballDunk/v_BasketballDunk_g02_c01.avi
BasketballDunk/v_BasketballDunk_g02_c02.avi
BasketballDunk/v_BasketballDunk_g02_c03.avi
BasketballDunk/v_BasketballDunk_g02_c04.avi
BasketballDunk/v_BasketballDunk_g03_c01.avi
BasketballDunk/v_BasketballDunk_g03_c02.avi
BasketballDunk/v_BasketballDunk_g03_c03.avi
BasketballDunk/v_BasketballDunk_g03_c04.avi
BasketballDunk/v_BasketballDunk_g03_c05.avi
BasketballDunk/v_BasketballDunk_g03_c06.avi
BasketballDunk/v_BasketballDunk_g04_c01.avi
BasketballDunk/v_BasketballDunk_g04_c02.avi
BasketballDunk/v_BasketballDunk_g04_c03.avi
BasketballDunk/v_BasketballDunk_g04_c04.avi
BasketballDunk/v_BasketballDunk_g05_c01.avi
BasketballDunk/v_BasketballDunk_g05_c02.avi
BasketballDunk/v_BasketballDunk_g05_c03.avi
BasketballDunk/v_BasketballDunk_g05_c04.avi
BasketballDunk/v_BasketballDunk_g05_c05.avi
BasketballDunk/v_BasketballDunk_g05_c06.avi
BasketballDunk/v_BasketballDunk_g06_c01.avi
BasketballDunk/v_BasketballDunk_g06_c02.avi
BasketballDunk/v_BasketballDunk_g06_c03.avi
BasketballDunk/v_BasketballDunk_g06_c04.avi
BasketballDunk/v_BasketballDunk_g07_c01.avi
BasketballDunk/v_BasketballDunk_g07_c02.avi
BasketballDunk/v_BasketballDunk_g07_c03.avi
BasketballDunk/v_BasketballDunk_g07_c04.avi
BasketballDunk/v_BasketballDunk_g07_c05.avi
BasketballDunk/v_BasketballDunk_g07_c06.avi
BenchPress/v_BenchPress_g01_c01.avi
BenchPress/v_BenchPress_g01_c02.avi
BenchPress/v_BenchPress_g01_c03.avi
BenchPress/v_BenchPress_g01_c04.avi
BenchPress/v_BenchPress_g01_c05.avi
BenchPress/v_BenchPress_g01_c06.avi
BenchPress/v_BenchPress_g02_c01.avi
BenchPress/v_BenchPress_g02_c02.avi
BenchPress/v_BenchPress_g02_c03.avi
BenchPress/v_BenchPress_g02_c04.avi
BenchPress/v_BenchPress_g02_c05.avi
BenchPress/v_BenchPress_g02_c06.avi
BenchPress/v_BenchPress_g02_c07.avi
BenchPress/v_BenchPress_g03_c01.avi
BenchPress/v_BenchPress_g03_c02.avi
BenchPress/v_BenchPress_g03_c03.avi
BenchPress/v_BenchPress_g03_c04.avi
BenchPress/v_BenchPress_g03_c05.avi
BenchPress/v_BenchPress_g03_c06.avi
BenchPress/v_BenchPress_g03_c07.avi
BenchPress/v_BenchPress_g04_c01.avi
BenchPress/v_BenchPress_g04_c02.avi
BenchPress/v_BenchPress_g04_c03.avi
BenchPress/v_BenchPress_g04_c04.avi
BenchPress/v_BenchPress_g04_c05.avi
BenchPress/v_BenchPress_g04_c06.avi
BenchPress/v_BenchPress_g04_c07.avi
BenchPress/v_BenchPress_g05_c01.avi
BenchPress/v_BenchPress_g05_c02.avi
BenchPress/v_BenchPress_g05_c03.avi
BenchPress/v_BenchPress_g05_c04.avi
BenchPress/v_BenchPress_g05_c05.avi
BenchPress/v_BenchPress_g05_c06.avi
BenchPress/v_BenchPress_g05_c07.avi
BenchPress/v_BenchPress_g06_c01.avi
BenchPress/v_BenchPress_g06_c02.avi
BenchPress/v_BenchPress_g06_c03.avi
BenchPress/v_BenchPress_g06_c04.avi
BenchPress/v_BenchPress_g06_c05.avi
BenchPress/v_BenchPress_g06_c06.avi
BenchPress/v_BenchPress_g06_c07.avi
BenchPress/v_BenchPress_g07_c01.avi
BenchPress/v_BenchPress_g07_c02.avi
BenchPress/v_BenchPress_g07_c03.avi
BenchPress/v_BenchPress_g07_c04.avi
BenchPress/v_BenchPress_g07_c05.avi
BenchPress/v_BenchPress_g07_c06.avi
BenchPress/v_BenchPress_g07_c07.avi
Biking/v_Biking_g01_c01.avi
Biking/v_Biking_g01_c02.avi
Biking/v_Biking_g01_c03.avi
Biking/v_Biking_g01_c04.avi
Biking/v_Biking_g02_c01.avi
Biking/v_Biking_g02_c02.avi
Biking/v_Biking_g02_c03.avi
Biking/v_Biking_g02_c04.avi
Biking/v_Biking_g02_c05.avi
Biking/v_Biking_g02_c06.avi
Biking/v_Biking_g02_c07.avi
Biking/v_Biking_g03_c01.avi
Biking/v_Biking_g03_c02.avi
Biking/v_Biking_g03_c03.avi
Biking/v_Biking_g03_c04.avi
Biking/v_Biking_g04_c01.avi
Biking/v_Biking_g04_c02.avi
Biking/v_Biking_g04_c03.avi
Biking/v_Biking_g04_c04.avi
Biking/v_Biking_g04_c05.avi
Biking/v_Biking_g05_c01.avi
Biking/v_Biking_g05_c02.avi
Biking/v_Biking_g05_c03.avi
Biking/v_Biking_g05_c04.avi
Biking/v_Biking_g05_c05.avi
Biking/v_Biking_g05_c06.avi
Biking/v_Biking_g05_c07.avi
Biking/v_Biking_g06_c01.avi
Biking/v_Biking_g06_c02.avi
Biking/v_Biking_g06_c03.avi
Biking/v_Biking_g06_c04.avi
Biking/v_Biking_g06_c05.avi
Biking/v_Biking_g07_c01.avi
Biking/v_Biking_g07_c02.avi
Biking/v_Biking_g07_c03.avi
Biking/v_Biking_g07_c04.avi
Biking/v_Biking_g07_c05.avi
Biking/v_Biking_g07_c06.avi
Billiards/v_Billiards_g01_c01.avi
Billiards/v_Billiards_g01_c02.avi
Billiards/v_Billiards_g01_c03.avi
Billiards/v_Billiards_g01_c04.avi
Billiards/v_Billiards_g01_c05.avi
Billiards/v_Billiards_g01_c06.avi
Billiards/v_Billiards_g02_c01.avi
Billiards/v_Billiards_g02_c02.avi
Billiards/v_Billiards_g02_c03.avi
Billiards/v_Billiards_g02_c04.avi
Billiards/v_Billiards_g02_c05.avi
Billiards/v_Billiards_g02_c06.avi
Billiards/v_Billiards_g02_c07.avi
Billiards/v_Billiards_g03_c01.avi
Billiards/v_Billiards_g03_c02.avi
Billiards/v_Billiards_g03_c03.avi
Billiards/v_Billiards_g03_c04.avi
Billiards/v_Billiards_g03_c05.avi
Billiards/v_Billiards_g04_c01.avi
Billiards/v_Billiards_g04_c02.avi
Billiards/v_Billiards_g04_c03.avi
Billiards/v_Billiards_g04_c04.avi
Billiards/v_Billiards_g04_c05.avi
Billiards/v_Billiards_g04_c06.avi
Billiards/v_Billiards_g04_c07.avi
Billiards/v_Billiards_g05_c01.avi
Billiards/v_Billiards_g05_c02.avi
Billiards/v_Billiards_g05_c03.avi
Billiards/v_Billiards_g05_c04.avi
Billiards/v_Billiards_g05_c05.avi
Billiards/v_Billiards_g05_c06.avi
Billiards/v_Billiards_g06_c01.avi
Billiards/v_Billiards_g06_c02.avi
Billiards/v_Billiards_g06_c03.avi
Billiards/v_Billiards_g06_c04.avi
Billiards/v_Billiards_g06_c05.avi
Billiards/v_Billiards_g07_c01.avi
Billiards/v_Billiards_g07_c02.avi
Billiards/v_Billiards_g07_c03.avi
Billiards/v_Billiards_g07_c04.avi
BlowDryHair/v_BlowDryHair_g01_c01.avi
BlowDryHair/v_BlowDryHair_g01_c02.avi
BlowDryHair/v_BlowDryHair_g01_c03.avi
BlowDryHair/v_BlowDryHair_g01_c04.avi
BlowDryHair/v_BlowDryHair_g02_c01.avi
BlowDryHair/v_BlowDryHair_g02_c02.avi
BlowDryHair/v_BlowDryHair_g02_c03.avi
BlowDryHair/v_BlowDryHair_g02_c04.avi
BlowDryHair/v_BlowDryHair_g02_c05.avi
BlowDryHair/v_BlowDryHair_g03_c01.avi
BlowDryHair/v_BlowDryHair_g03_c02.avi
BlowDryHair/v_BlowDryHair_g03_c03.avi
BlowDryHair/v_BlowDryHair_g03_c04.avi
BlowDryHair/v_BlowDryHair_g03_c05.avi
BlowDryHair/v_BlowDryHair_g04_c01.avi
BlowDryHair/v_BlowDryHair_g04_c02.avi
BlowDryHair/v_BlowDryHair_g04_c03.avi
BlowDryHair/v_BlowDryHair_g04_c04.avi
BlowDryHair/v_BlowDryHair_g04_c05.avi
BlowDryHair/v_BlowDryHair_g05_c01.avi
BlowDryHair/v_BlowDryHair_g05_c02.avi
BlowDryHair/v_BlowDryHair_g05_c03.avi
BlowDryHair/v_BlowDryHair_g05_c04.avi
BlowDryHair/v_BlowDryHair_g05_c05.avi
BlowDryHair/v_BlowDryHair_g06_c01.avi
BlowDryHair/v_BlowDryHair_g06_c02.avi
BlowDryHair/v_BlowDryHair_g06_c03.avi
BlowDryHair/v_BlowDryHair_g06_c04.avi
BlowDryHair/v_BlowDryHair_g06_c05.avi
BlowDryHair/v_BlowDryHair_g06_c06.avi
BlowDryHair/v_BlowDryHair_g06_c07.avi
BlowDryHair/v_BlowDryHair_g07_c01.avi
BlowDryHair/v_BlowDryHair_g07_c02.avi
BlowDryHair/v_BlowDryHair_g07_c03.avi
BlowDryHair/v_BlowDryHair_g07_c04.avi
BlowDryHair/v_BlowDryHair_g07_c05.avi
BlowDryHair/v_BlowDryHair_g07_c06.avi
BlowDryHair/v_BlowDryHair_g07_c07.avi
BlowingCandles/v_BlowingCandles_g01_c01.avi
BlowingCandles/v_BlowingCandles_g01_c02.avi
BlowingCandles/v_BlowingCandles_g01_c03.avi
BlowingCandles/v_BlowingCandles_g01_c04.avi
BlowingCandles/v_BlowingCandles_g02_c01.avi
BlowingCandles/v_BlowingCandles_g02_c02.avi
BlowingCandles/v_BlowingCandles_g02_c03.avi
BlowingCandles/v_BlowingCandles_g02_c04.avi
BlowingCandles/v_BlowingCandles_g03_c01.avi
BlowingCandles/v_BlowingCandles_g03_c02.avi
BlowingCandles/v_BlowingCandles_g03_c03.avi
BlowingCandles/v_BlowingCandles_g03_c04.avi
BlowingCandles/v_BlowingCandles_g04_c01.avi
BlowingCandles/v_BlowingCandles_g04_c02.avi
BlowingCandles/v_BlowingCandles_g04_c03.avi
BlowingCandles/v_BlowingCandles_g04_c04.avi
BlowingCandles/v_BlowingCandles_g04_c05.avi
BlowingCandles/v_BlowingCandles_g05_c01.avi
BlowingCandles/v_BlowingCandles_g05_c02.avi
BlowingCandles/v_BlowingCandles_g05_c03.avi
BlowingCandles/v_BlowingCandles_g05_c04.avi
BlowingCandles/v_BlowingCandles_g05_c05.avi
BlowingCandles/v_BlowingCandles_g06_c01.avi
BlowingCandles/v_BlowingCandles_g06_c02.avi
BlowingCandles/v_BlowingCandles_g06_c03.avi
BlowingCandles/v_BlowingCandles_g06_c04.avi
BlowingCandles/v_BlowingCandles_g06_c05.avi
BlowingCandles/v_BlowingCandles_g06_c06.avi
BlowingCandles/v_BlowingCandles_g06_c07.avi
BlowingCandles/v_BlowingCandles_g07_c01.avi
BlowingCandles/v_BlowingCandles_g07_c02.avi
BlowingCandles/v_BlowingCandles_g07_c03.avi
BlowingCandles/v_BlowingCandles_g07_c04.avi
BodyWeightSquats/v_BodyWeightSquats_g01_c01.avi
BodyWeightSquats/v_BodyWeightSquats_g01_c02.avi
BodyWeightSquats/v_BodyWeightSquats_g01_c03.avi
BodyWeightSquats/v_BodyWeightSquats_g01_c04.avi
BodyWeightSquats/v_BodyWeightSquats_g02_c01.avi
BodyWeightSquats/v_BodyWeightSquats_g02_c02.avi
BodyWeightSquats/v_BodyWeightSquats_g02_c03.avi
BodyWeightSquats/v_BodyWeightSquats_g02_c04.avi
BodyWeightSquats/v_BodyWeightSquats_g03_c01.avi
BodyWeightSquats/v_BodyWeightSquats_g03_c02.avi
BodyWeightSquats/v_BodyWeightSquats_g03_c03.avi
BodyWeightSquats/v_BodyWeightSquats_g03_c04.avi
BodyWeightSquats/v_BodyWeightSquats_g03_c05.avi
BodyWeightSquats/v_BodyWeightSquats_g04_c01.avi
BodyWeightSquats/v_BodyWeightSquats_g04_c02.avi
BodyWeightSquats/v_BodyWeightSquats_g04_c03.avi
BodyWeightSquats/v_BodyWeightSquats_g04_c04.avi
BodyWeightSquats/v_BodyWeightSquats_g05_c01.avi
BodyWeightSquats/v_BodyWeightSquats_g05_c02.avi
BodyWeightSquats/v_BodyWeightSquats_g05_c03.avi
BodyWeightSquats/v_BodyWeightSquats_g05_c04.avi
BodyWeightSquats/v_BodyWeightSquats_g06_c01.avi
BodyWeightSquats/v_BodyWeightSquats_g06_c02.avi
BodyWeightSquats/v_BodyWeightSquats_g06_c03.avi
BodyWeightSquats/v_BodyWeightSquats_g06_c04.avi
BodyWeightSquats/v_BodyWeightSquats_g06_c05.avi
BodyWeightSquats/v_BodyWeightSquats_g07_c01.avi
BodyWeightSquats/v_BodyWeightSquats_g07_c02.avi
BodyWeightSquats/v_BodyWeightSquats_g07_c03.avi
BodyWeightSquats/v_BodyWeightSquats_g07_c04.avi
Bowling/v_Bowling_g01_c01.avi
Bowling/v_Bowling_g01_c02.avi
Bowling/v_Bowling_g01_c03.avi
Bowling/v_Bowling_g01_c04.avi
Bowling/v_Bowling_g01_c05.avi
Bowling/v_Bowling_g01_c06.avi
Bowling/v_Bowling_g01_c07.avi
Bowling/v_Bowling_g02_c01.avi
Bowling/v_Bowling_g02_c02.avi
Bowling/v_Bowling_g02_c03.avi
Bowling/v_Bowling_g02_c04.avi
Bowling/v_Bowling_g03_c01.avi
Bowling/v_Bowling_g03_c02.avi
Bowling/v_Bowling_g03_c03.avi
Bowling/v_Bowling_g03_c04.avi
Bowling/v_Bowling_g03_c05.avi
Bowling/v_Bowling_g03_c06.avi
Bowling/v_Bowling_g03_c07.avi
Bowling/v_Bowling_g04_c01.avi
Bowling/v_Bowling_g04_c02.avi
Bowling/v_Bowling_g04_c03.avi
Bowling/v_Bowling_g04_c04.avi
Bowling/v_Bowling_g05_c01.avi
Bowling/v_Bowling_g05_c02.avi
Bowling/v_Bowling_g05_c03.avi
Bowling/v_Bowling_g05_c04.avi
Bowling/v_Bowling_g05_c05.avi
Bowling/v_Bowling_g05_c06.avi
Bowling/v_Bowling_g05_c07.avi
Bowling/v_Bowling_g06_c01.avi
Bowling/v_Bowling_g06_c02.avi
Bowling/v_Bowling_g06_c03.avi
Bowling/v_Bowling_g06_c04.avi
Bowling/v_Bowling_g06_c05.avi
Bowling/v_Bowling_g06_c06.avi
Bowling/v_Bowling_g06_c07.avi
Bowling/v_Bowling_g07_c01.avi
Bowling/v_Bowling_g07_c02.avi
Bowling/v_Bowling_g07_c03.avi
Bowling/v_Bowling_g07_c04.avi
Bowling/v_Bowling_g07_c05.avi
Bowling/v_Bowling_g07_c06.avi
Bowling/v_Bowling_g07_c07.avi
BoxingPunchingBag/v_BoxingPunchingBag_g01_c01.avi
BoxingPunchingBag/v_BoxingPunchingBag_g01_c02.avi
BoxingPunchingBag/v_BoxingPunchingBag_g01_c03.avi
BoxingPunchingBag/v_BoxingPunchingBag_g01_c04.avi
BoxingPunchingBag/v_BoxingPunchingBag_g01_c05.avi
BoxingPunchingBag/v_BoxingPunchingBag_g01_c06.avi
BoxingPunchingBag/v_BoxingPunchingBag_g01_c07.avi
BoxingPunchingBag/v_BoxingPunchingBag_g02_c01.avi
BoxingPunchingBag/v_BoxingPunchingBag_g02_c02.avi
BoxingPunchingBag/v_BoxingPunchingBag_g02_c03.avi
BoxingPunchingBag/v_BoxingPunchingBag_g02_c04.avi
BoxingPunchingBag/v_BoxingPunchingBag_g02_c05.avi
BoxingPunchingBag/v_BoxingPunchingBag_g02_c06.avi
BoxingPunchingBag/v_BoxingPunchingBag_g02_c07.avi
BoxingPunchingBag/v_BoxingPunchingBag_g03_c01.avi
BoxingPunchingBag/v_BoxingPunchingBag_g03_c02.avi
BoxingPunchingBag/v_BoxingPunchingBag_g03_c03.avi
BoxingPunchingBag/v_BoxingPunchingBag_g03_c04.avi
BoxingPunchingBag/v_BoxingPunchingBag_g03_c05.avi
BoxingPunchingBag/v_BoxingPunchingBag_g03_c06.avi
BoxingPunchingBag/v_BoxingPunchingBag_g03_c07.avi
BoxingPunchingBag/v_BoxingPunchingBag_g04_c01.avi
BoxingPunchingBag/v_BoxingPunchingBag_g04_c02.avi
BoxingPunchingBag/v_BoxingPunchingBag_g04_c03.avi
BoxingPunchingBag/v_BoxingPunchingBag_g04_c04.avi
BoxingPunchingBag/v_BoxingPunchingBag_g04_c05.avi
BoxingPunchingBag/v_BoxingPunchingBag_g04_c06.avi
BoxingPunchingBag/v_BoxingPunchingBag_g04_c07.avi
BoxingPunchingBag/v_BoxingPunchingBag_g05_c01.avi
BoxingPunchingBag/v_BoxingPunchingBag_g05_c02.avi
BoxingPunchingBag/v_BoxingPunchingBag_g05_c03.avi
BoxingPunchingBag/v_BoxingPunchingBag_g05_c04.avi
BoxingPunchingBag/v_BoxingPunchingBag_g05_c05.avi
BoxingPunchingBag/v_BoxingPunchingBag_g05_c06.avi
BoxingPunchingBag/v_BoxingPunchingBag_g05_c07.avi
BoxingPunchingBag/v_BoxingPunchingBag_g06_c01.avi
BoxingPunchingBag/v_BoxingPunchingBag_g06_c02.avi
BoxingPunchingBag/v_BoxingPunchingBag_g06_c03.avi
BoxingPunchingBag/v_BoxingPunchingBag_g06_c04.avi
BoxingPunchingBag/v_BoxingPunchingBag_g06_c05.avi
BoxingPunchingBag/v_BoxingPunchingBag_g06_c06.avi
BoxingPunchingBag/v_BoxingPunchingBag_g06_c07.avi
BoxingPunchingBag/v_BoxingPunchingBag_g07_c01.avi
BoxingPunchingBag/v_BoxingPunchingBag_g07_c02.avi
BoxingPunchingBag/v_BoxingPunchingBag_g07_c03.avi
BoxingPunchingBag/v_BoxingPunchingBag_g07_c04.avi
BoxingPunchingBag/v_BoxingPunchingBag_g07_c05.avi
BoxingPunchingBag/v_BoxingPunchingBag_g07_c06.avi
BoxingPunchingBag/v_BoxingPunchingBag_g07_c07.avi
BoxingSpeedBag/v_BoxingSpeedBag_g01_c01.avi
BoxingSpeedBag/v_BoxingSpeedBag_g01_c02.avi
BoxingSpeedBag/v_BoxingSpeedBag_g01_c03.avi
BoxingSpeedBag/v_BoxingSpeedBag_g01_c04.avi
BoxingSpeedBag/v_BoxingSpeedBag_g02_c01.avi
BoxingSpeedBag/v_BoxingSpeedBag_g02_c02.avi
BoxingSpeedBag/v_BoxingSpeedBag_g02_c03.avi
BoxingSpeedBag/v_BoxingSpeedBag_g02_c04.avi
BoxingSpeedBag/v_BoxingSpeedBag_g03_c01.avi
BoxingSpeedBag/v_BoxingSpeedBag_g03_c02.avi
BoxingSpeedBag/v_BoxingSpeedBag_g03_c03.avi
BoxingSpeedBag/v_BoxingSpeedBag_g03_c04.avi
BoxingSpeedBag/v_BoxingSpeedBag_g03_c05.avi
BoxingSpeedBag/v_BoxingSpeedBag_g04_c01.avi
BoxingSpeedBag/v_BoxingSpeedBag_g04_c02.avi
BoxingSpeedBag/v_BoxingSpeedBag_g04_c03.avi
BoxingSpeedBag/v_BoxingSpeedBag_g04_c04.avi
BoxingSpeedBag/v_BoxingSpeedBag_g04_c05.avi
BoxingSpeedBag/v_BoxingSpeedBag_g04_c06.avi
BoxingSpeedBag/v_BoxingSpeedBag_g04_c07.avi
BoxingSpeedBag/v_BoxingSpeedBag_g05_c01.avi
BoxingSpeedBag/v_BoxingSpeedBag_g05_c02.avi
BoxingSpeedBag/v_BoxingSpeedBag_g05_c03.avi
BoxingSpeedBag/v_BoxingSpeedBag_g05_c04.avi
BoxingSpeedBag/v_BoxingSpeedBag_g05_c05.avi
BoxingSpeedBag/v_BoxingSpeedBag_g06_c01.avi
BoxingSpeedBag/v_BoxingSpeedBag_g06_c02.avi
BoxingSpeedBag/v_BoxingSpeedBag_g06_c03.avi
BoxingSpeedBag/v_BoxingSpeedBag_g06_c04.avi
BoxingSpeedBag/v_BoxingSpeedBag_g06_c05.avi
BoxingSpeedBag/v_BoxingSpeedBag_g07_c01.avi
BoxingSpeedBag/v_BoxingSpeedBag_g07_c02.avi
BoxingSpeedBag/v_BoxingSpeedBag_g07_c03.avi
BoxingSpeedBag/v_BoxingSpeedBag_g07_c04.avi
BoxingSpeedBag/v_BoxingSpeedBag_g07_c05.avi
BoxingSpeedBag/v_BoxingSpeedBag_g07_c06.avi
BoxingSpeedBag/v_BoxingSpeedBag_g07_c07.avi
BreastStroke/v_BreastStroke_g01_c01.avi
BreastStroke/v_BreastStroke_g01_c02.avi
BreastStroke/v_BreastStroke_g01_c03.avi
BreastStroke/v_BreastStroke_g01_c04.avi
BreastStroke/v_BreastStroke_g02_c01.avi
BreastStroke/v_BreastStroke_g02_c02.avi
BreastStroke/v_BreastStroke_g02_c03.avi
BreastStroke/v_BreastStroke_g02_c04.avi
BreastStroke/v_BreastStroke_g03_c01.avi
BreastStroke/v_BreastStroke_g03_c02.avi
BreastStroke/v_BreastStroke_g03_c03.avi
BreastStroke/v_BreastStroke_g03_c04.avi
BreastStroke/v_BreastStroke_g04_c01.avi
BreastStroke/v_BreastStroke_g04_c02.avi
BreastStroke/v_BreastStroke_g04_c03.avi
BreastStroke/v_BreastStroke_g04_c04.avi
BreastStroke/v_BreastStroke_g05_c01.avi
BreastStroke/v_BreastStroke_g05_c02.avi
BreastStroke/v_BreastStroke_g05_c03.avi
BreastStroke/v_BreastStroke_g05_c04.avi
BreastStroke/v_BreastStroke_g06_c01.avi
BreastStroke/v_BreastStroke_g06_c02.avi
BreastStroke/v_BreastStroke_g06_c03.avi
BreastStroke/v_BreastStroke_g06_c04.avi
BreastStroke/v_BreastStroke_g07_c01.avi
BreastStroke/v_BreastStroke_g07_c02.avi
BreastStroke/v_BreastStroke_g07_c03.avi
BreastStroke/v_BreastStroke_g07_c04.avi
BrushingTeeth/v_BrushingTeeth_g01_c01.avi
BrushingTeeth/v_BrushingTeeth_g01_c02.avi
BrushingTeeth/v_BrushingTeeth_g01_c03.avi
BrushingTeeth/v_BrushingTeeth_g01_c04.avi
BrushingTeeth/v_BrushingTeeth_g02_c01.avi
BrushingTeeth/v_BrushingTeeth_g02_c02.avi
BrushingTeeth/v_BrushingTeeth_g02_c03.avi
BrushingTeeth/v_BrushingTeeth_g02_c04.avi
BrushingTeeth/v_BrushingTeeth_g02_c05.avi
BrushingTeeth/v_BrushingTeeth_g02_c06.avi
BrushingTeeth/v_BrushingTeeth_g02_c07.avi
BrushingTeeth/v_BrushingTeeth_g03_c01.avi
BrushingTeeth/v_BrushingTeeth_g03_c02.avi
BrushingTeeth/v_BrushingTeeth_g03_c03.avi
BrushingTeeth/v_BrushingTeeth_g03_c04.avi
BrushingTeeth/v_BrushingTeeth_g03_c05.avi
BrushingTeeth/v_BrushingTeeth_g04_c01.avi
BrushingTeeth/v_BrushingTeeth_g04_c02.avi
BrushingTeeth/v_BrushingTeeth_g04_c03.avi
BrushingTeeth/v_BrushingTeeth_g04_c04.avi
BrushingTeeth/v_BrushingTeeth_g05_c01.avi
BrushingTeeth/v_BrushingTeeth_g05_c02.avi
BrushingTeeth/v_BrushingTeeth_g05_c03.avi
BrushingTeeth/v_BrushingTeeth_g05_c04.avi
BrushingTeeth/v_BrushingTeeth_g05_c05.avi
BrushingTeeth/v_BrushingTeeth_g06_c01.avi
BrushingTeeth/v_BrushingTeeth_g06_c02.avi
BrushingTeeth/v_BrushingTeeth_g06_c03.avi
BrushingTeeth/v_BrushingTeeth_g06_c04.avi
BrushingTeeth/v_BrushingTeeth_g06_c05.avi
BrushingTeeth/v_BrushingTeeth_g07_c01.avi
BrushingTeeth/v_BrushingTeeth_g07_c02.avi
BrushingTeeth/v_BrushingTeeth_g07_c03.avi
BrushingTeeth/v_BrushingTeeth_g07_c04.avi
BrushingTeeth/v_BrushingTeeth_g07_c05.avi
BrushingTeeth/v_BrushingTeeth_g07_c06.avi
CleanAndJerk/v_CleanAndJerk_g01_c01.avi
CleanAndJerk/v_CleanAndJerk_g01_c02.avi
CleanAndJerk/v_CleanAndJerk_g01_c03.avi
CleanAndJerk/v_CleanAndJerk_g01_c04.avi
CleanAndJerk/v_CleanAndJerk_g01_c05.avi
CleanAndJerk/v_CleanAndJerk_g02_c01.avi
CleanAndJerk/v_CleanAndJerk_g02_c02.avi
CleanAndJerk/v_CleanAndJerk_g02_c03.avi
CleanAndJerk/v_CleanAndJerk_g02_c04.avi
CleanAndJerk/v_CleanAndJerk_g03_c01.avi
CleanAndJerk/v_CleanAndJerk_g03_c02.avi
CleanAndJerk/v_CleanAndJerk_g03_c03.avi
CleanAndJerk/v_CleanAndJerk_g03_c04.avi
CleanAndJerk/v_CleanAndJerk_g03_c05.avi
CleanAndJerk/v_CleanAndJerk_g03_c06.avi
CleanAndJerk/v_CleanAndJerk_g04_c01.avi
CleanAndJerk/v_CleanAndJerk_g04_c02.avi
CleanAndJerk/v_CleanAndJerk_g04_c03.avi
CleanAndJerk/v_CleanAndJerk_g04_c04.avi
CleanAndJerk/v_CleanAndJerk_g04_c05.avi
CleanAndJerk/v_CleanAndJerk_g05_c01.avi
CleanAndJerk/v_CleanAndJerk_g05_c02.avi
CleanAndJerk/v_CleanAndJerk_g05_c03.avi
CleanAndJerk/v_CleanAndJerk_g05_c04.avi
CleanAndJerk/v_CleanAndJerk_g06_c01.avi
CleanAndJerk/v_CleanAndJerk_g06_c02.avi
CleanAndJerk/v_CleanAndJerk_g06_c03.avi
CleanAndJerk/v_CleanAndJerk_g06_c04.avi
CleanAndJerk/v_CleanAndJerk_g07_c01.avi
CleanAndJerk/v_CleanAndJerk_g07_c02.avi
CleanAndJerk/v_CleanAndJerk_g07_c03.avi
CleanAndJerk/v_CleanAndJerk_g07_c04.avi
CleanAndJerk/v_CleanAndJerk_g07_c05.avi
CliffDiving/v_CliffDiving_g01_c01.avi
CliffDiving/v_CliffDiving_g01_c02.avi
CliffDiving/v_CliffDiving_g01_c03.avi
CliffDiving/v_CliffDiving_g01_c04.avi
CliffDiving/v_CliffDiving_g01_c05.avi
CliffDiving/v_CliffDiving_g01_c06.avi
CliffDiving/v_CliffDiving_g02_c01.avi
CliffDiving/v_CliffDiving_g02_c02.avi
CliffDiving/v_CliffDiving_g02_c03.avi
CliffDiving/v_CliffDiving_g02_c04.avi
CliffDiving/v_CliffDiving_g03_c01.avi
CliffDiving/v_CliffDiving_g03_c02.avi
CliffDiving/v_CliffDiving_g03_c03.avi
CliffDiving/v_CliffDiving_g03_c04.avi
CliffDiving/v_CliffDiving_g03_c05.avi
CliffDiving/v_CliffDiving_g04_c01.avi
CliffDiving/v_CliffDiving_g04_c02.avi
CliffDiving/v_CliffDiving_g04_c03.avi
CliffDiving/v_CliffDiving_g04_c04.avi
CliffDiving/v_CliffDiving_g05_c01.avi
CliffDiving/v_CliffDiving_g05_c02.avi
CliffDiving/v_CliffDiving_g05_c03.avi
CliffDiving/v_CliffDiving_g05_c04.avi
CliffDiving/v_CliffDiving_g05_c05.avi
CliffDiving/v_CliffDiving_g05_c06.avi
CliffDiving/v_CliffDiving_g05_c07.avi
CliffDiving/v_CliffDiving_g06_c01.avi
CliffDiving/v_CliffDiving_g06_c02.avi
CliffDiving/v_CliffDiving_g06_c03.avi
CliffDiving/v_CliffDiving_g06_c04.avi
CliffDiving/v_CliffDiving_g06_c05.avi
CliffDiving/v_CliffDiving_g06_c06.avi
CliffDiving/v_CliffDiving_g06_c07.avi
CliffDiving/v_CliffDiving_g07_c01.avi
CliffDiving/v_CliffDiving_g07_c02.avi
CliffDiving/v_CliffDiving_g07_c03.avi
CliffDiving/v_CliffDiving_g07_c04.avi
CliffDiving/v_CliffDiving_g07_c05.avi
CliffDiving/v_CliffDiving_g07_c06.avi
CricketBowling/v_CricketBowling_g01_c01.avi
CricketBowling/v_CricketBowling_g01_c02.avi
CricketBowling/v_CricketBowling_g01_c03.avi
CricketBowling/v_CricketBowling_g01_c04.avi
CricketBowling/v_CricketBowling_g01_c05.avi
CricketBowling/v_CricketBowling_g01_c06.avi
CricketBowling/v_CricketBowling_g01_c07.avi
CricketBowling/v_CricketBowling_g02_c01.avi
CricketBowling/v_CricketBowling_g02_c02.avi
CricketBowling/v_CricketBowling_g02_c03.avi
CricketBowling/v_CricketBowling_g02_c04.avi
CricketBowling/v_CricketBowling_g02_c05.avi
CricketBowling/v_CricketBowling_g02_c06.avi
CricketBowling/v_CricketBowling_g02_c07.avi
CricketBowling/v_CricketBowling_g03_c01.avi
CricketBowling/v_CricketBowling_g03_c02.avi
CricketBowling/v_CricketBowling_g03_c03.avi
CricketBowling/v_CricketBowling_g03_c04.avi
CricketBowling/v_CricketBowling_g04_c01.avi
CricketBowling/v_CricketBowling_g04_c02.avi
CricketBowling/v_CricketBowling_g04_c03.avi
CricketBowling/v_CricketBowling_g04_c04.avi
CricketBowling/v_CricketBowling_g04_c05.avi
CricketBowling/v_CricketBowling_g05_c01.avi
CricketBowling/v_CricketBowling_g05_c02.avi
CricketBowling/v_CricketBowling_g05_c03.avi
CricketBowling/v_CricketBowling_g05_c04.avi
CricketBowling/v_CricketBowling_g06_c01.avi
CricketBowling/v_CricketBowling_g06_c02.avi
CricketBowling/v_CricketBowling_g06_c03.avi
CricketBowling/v_CricketBowling_g06_c04.avi
CricketBowling/v_CricketBowling_g06_c05.avi
CricketBowling/v_CricketBowling_g07_c01.avi
CricketBowling/v_CricketBowling_g07_c02.avi
CricketBowling/v_CricketBowling_g07_c03.avi
CricketBowling/v_CricketBowling_g07_c04.avi
CricketShot/v_CricketShot_g01_c01.avi
CricketShot/v_CricketShot_g01_c02.avi
CricketShot/v_CricketShot_g01_c03.avi
CricketShot/v_CricketShot_g01_c04.avi
CricketShot/v_CricketShot_g01_c05.avi
CricketShot/v_CricketShot_g01_c06.avi
CricketShot/v_CricketShot_g01_c07.avi
CricketShot/v_CricketShot_g02_c01.avi
CricketShot/v_CricketShot_g02_c02.avi
CricketShot/v_CricketShot_g02_c03.avi
CricketShot/v_CricketShot_g02_c04.avi
CricketShot/v_CricketShot_g02_c05.avi
CricketShot/v_CricketShot_g02_c06.avi
CricketShot/v_CricketShot_g02_c07.avi
CricketShot/v_CricketShot_g03_c01.avi
CricketShot/v_CricketShot_g03_c02.avi
CricketShot/v_CricketShot_g03_c03.avi
CricketShot/v_CricketShot_g03_c04.avi
CricketShot/v_CricketShot_g03_c05.avi
CricketShot/v_CricketShot_g03_c06.avi
CricketShot/v_CricketShot_g03_c07.avi
CricketShot/v_CricketShot_g04_c01.avi
CricketShot/v_CricketShot_g04_c02.avi
CricketShot/v_CricketShot_g04_c03.avi
CricketShot/v_CricketShot_g04_c04.avi
CricketShot/v_CricketShot_g04_c05.avi
CricketShot/v_CricketShot_g04_c06.avi
CricketShot/v_CricketShot_g04_c07.avi
CricketShot/v_CricketShot_g05_c01.avi
CricketShot/v_CricketShot_g05_c02.avi
CricketShot/v_CricketShot_g05_c03.avi
CricketShot/v_CricketShot_g05_c04.avi
CricketShot/v_CricketShot_g05_c05.avi
CricketShot/v_CricketShot_g05_c06.avi
CricketShot/v_CricketShot_g05_c07.avi
CricketShot/v_CricketShot_g06_c01.avi
CricketShot/v_CricketShot_g06_c02.avi
CricketShot/v_CricketShot_g06_c03.avi
CricketShot/v_CricketShot_g06_c04.avi
CricketShot/v_CricketShot_g06_c05.avi
CricketShot/v_CricketShot_g06_c06.avi
CricketShot/v_CricketShot_g06_c07.avi
CricketShot/v_CricketShot_g07_c01.avi
CricketShot/v_CricketShot_g07_c02.avi
CricketShot/v_CricketShot_g07_c03.avi
CricketShot/v_CricketShot_g07_c04.avi
CricketShot/v_CricketShot_g07_c05.avi
CricketShot/v_CricketShot_g07_c06.avi
CricketShot/v_CricketShot_g07_c07.avi
CuttingInKitchen/v_CuttingInKitchen_g01_c01.avi
CuttingInKitchen/v_CuttingInKitchen_g01_c02.avi
CuttingInKitchen/v_CuttingInKitchen_g01_c03.avi
CuttingInKitchen/v_CuttingInKitchen_g01_c04.avi
CuttingInKitchen/v_CuttingInKitchen_g01_c05.avi
CuttingInKitchen/v_CuttingInKitchen_g02_c01.avi
CuttingInKitchen/v_CuttingInKitchen_g02_c02.avi
CuttingInKitchen/v_CuttingInKitchen_g02_c03.avi
CuttingInKitchen/v_CuttingInKitchen_g02_c04.avi
CuttingInKitchen/v_CuttingInKitchen_g03_c01.avi
CuttingInKitchen/v_CuttingInKitchen_g03_c02.avi
CuttingInKitchen/v_CuttingInKitchen_g03_c03.avi
CuttingInKitchen/v_CuttingInKitchen_g03_c04.avi
CuttingInKitchen/v_CuttingInKitchen_g04_c01.avi
CuttingInKitchen/v_CuttingInKitchen_g04_c02.avi
CuttingInKitchen/v_CuttingInKitchen_g04_c03.avi
CuttingInKitchen/v_CuttingInKitchen_g04_c04.avi
CuttingInKitchen/v_CuttingInKitchen_g04_c05.avi
CuttingInKitchen/v_CuttingInKitchen_g05_c01.avi
CuttingInKitchen/v_CuttingInKitchen_g05_c02.avi
CuttingInKitchen/v_CuttingInKitchen_g05_c03.avi
CuttingInKitchen/v_CuttingInKitchen_g05_c04.avi
CuttingInKitchen/v_CuttingInKitchen_g05_c05.avi
CuttingInKitchen/v_CuttingInKitchen_g05_c06.avi
CuttingInKitchen/v_CuttingInKitchen_g06_c01.avi
CuttingInKitchen/v_CuttingInKitchen_g06_c02.avi
CuttingInKitchen/v_CuttingInKitchen_g06_c03.avi
CuttingInKitchen/v_CuttingInKitchen_g06_c04.avi
CuttingInKitchen/v_CuttingInKitchen_g06_c05.avi
CuttingInKitchen/v_CuttingInKitchen_g07_c01.avi
CuttingInKitchen/v_CuttingInKitchen_g07_c02.avi
CuttingInKitchen/v_CuttingInKitchen_g07_c03.avi
CuttingInKitchen/v_CuttingInKitchen_g07_c04.avi
Diving/v_Diving_g01_c01.avi
Diving/v_Diving_g01_c02.avi
Diving/v_Diving_g01_c03.avi
Diving/v_Diving_g01_c04.avi
Diving/v_Diving_g01_c05.avi
Diving/v_Diving_g01_c06.avi
Diving/v_Diving_g01_c07.avi
Diving/v_Diving_g02_c01.avi
Diving/v_Diving_g02_c02.avi
Diving/v_Diving_g02_c03.avi
Diving/v_Diving_g02_c04.avi
Diving/v_Diving_g02_c05.avi
Diving/v_Diving_g02_c06.avi
Diving/v_Diving_g02_c07.avi
Diving/v_Diving_g03_c01.avi
Diving/v_Diving_g03_c02.avi
Diving/v_Diving_g03_c03.avi
Diving/v_Diving_g03_c04.avi
Diving/v_Diving_g03_c05.avi
Diving/v_Diving_g03_c06.avi
Diving/v_Diving_g03_c07.avi
Diving/v_Diving_g04_c01.avi
Diving/v_Diving_g04_c02.avi
Diving/v_Diving_g04_c03.avi
Diving/v_Diving_g04_c04.avi
Diving/v_Diving_g04_c05.avi
Diving/v_Diving_g04_c06.avi
Diving/v_Diving_g04_c07.avi
Diving/v_Diving_g05_c01.avi
Diving/v_Diving_g05_c02.avi
Diving/v_Diving_g05_c03.avi
Diving/v_Diving_g05_c04.avi
Diving/v_Diving_g05_c05.avi
Diving/v_Diving_g05_c06.avi
Diving/v_Diving_g06_c01.avi
Diving/v_Diving_g06_c02.avi
Diving/v_Diving_g06_c03.avi
Diving/v_Diving_g06_c04.avi
Diving/v_Diving_g06_c05.avi
Diving/v_Diving_g06_c06.avi
Diving/v_Diving_g06_c07.avi
Diving/v_Diving_g07_c01.avi
Diving/v_Diving_g07_c02.avi
Diving/v_Diving_g07_c03.avi
Diving/v_Diving_g07_c04.avi
Drumming/v_Drumming_g01_c01.avi
Drumming/v_Drumming_g01_c02.avi
Drumming/v_Drumming_g01_c03.avi
Drumming/v_Drumming_g01_c04.avi
Drumming/v_Drumming_g01_c05.avi
Drumming/v_Drumming_g01_c06.avi
Drumming/v_Drumming_g01_c07.avi
Drumming/v_Drumming_g02_c01.avi
Drumming/v_Drumming_g02_c02.avi
Drumming/v_Drumming_g02_c03.avi
Drumming/v_Drumming_g02_c04.avi
Drumming/v_Drumming_g02_c05.avi
Drumming/v_Drumming_g02_c06.avi
Drumming/v_Drumming_g02_c07.avi
Drumming/v_Drumming_g03_c01.avi
Drumming/v_Drumming_g03_c02.avi
Drumming/v_Drumming_g03_c03.avi
Drumming/v_Drumming_g03_c04.avi
Drumming/v_Drumming_g03_c05.avi
Drumming/v_Drumming_g04_c01.avi
Drumming/v_Drumming_g04_c02.avi
Drumming/v_Drumming_g04_c03.avi
Drumming/v_Drumming_g04_c04.avi
Drumming/v_Drumming_g04_c05.avi
Drumming/v_Drumming_g04_c06.avi
Drumming/v_Drumming_g04_c07.avi
Drumming/v_Drumming_g05_c01.avi
Drumming/v_Drumming_g05_c02.avi
Drumming/v_Drumming_g05_c03.avi
Drumming/v_Drumming_g05_c04.avi
Drumming/v_Drumming_g05_c05.avi
Drumming/v_Drumming_g05_c06.avi
Drumming/v_Drumming_g06_c01.avi
Drumming/v_Drumming_g06_c02.avi
Drumming/v_Drumming_g06_c03.avi
Drumming/v_Drumming_g06_c04.avi
Drumming/v_Drumming_g06_c05.avi
Drumming/v_Drumming_g06_c06.avi
Drumming/v_Drumming_g07_c01.avi
Drumming/v_Drumming_g07_c02.avi
Drumming/v_Drumming_g07_c03.avi
Drumming/v_Drumming_g07_c04.avi
Drumming/v_Drumming_g07_c05.avi
Drumming/v_Drumming_g07_c06.avi
Drumming/v_Drumming_g07_c07.avi
Fencing/v_Fencing_g01_c01.avi
Fencing/v_Fencing_g01_c02.avi
Fencing/v_Fencing_g01_c03.avi
Fencing/v_Fencing_g01_c04.avi
Fencing/v_Fencing_g01_c05.avi
Fencing/v_Fencing_g01_c06.avi
Fencing/v_Fencing_g02_c01.avi
Fencing/v_Fencing_g02_c02.avi
Fencing/v_Fencing_g02_c03.avi
Fencing/v_Fencing_g02_c04.avi
Fencing/v_Fencing_g02_c05.avi
Fencing/v_Fencing_g03_c01.avi
Fencing/v_Fencing_g03_c02.avi
Fencing/v_Fencing_g03_c03.avi
Fencing/v_Fencing_g03_c04.avi
Fencing/v_Fencing_g03_c05.avi
Fencing/v_Fencing_g04_c01.avi
Fencing/v_Fencing_g04_c02.avi
Fencing/v_Fencing_g04_c03.avi
Fencing/v_Fencing_g04_c04.avi
Fencing/v_Fencing_g04_c05.avi
Fencing/v_Fencing_g05_c01.avi
Fencing/v_Fencing_g05_c02.avi
Fencing/v_Fencing_g05_c03.avi
Fencing/v_Fencing_g05_c04.avi
Fencing/v_Fencing_g05_c05.avi
Fencing/v_Fencing_g06_c01.avi
Fencing/v_Fencing_g06_c02.avi
Fencing/v_Fencing_g06_c03.avi
Fencing/v_Fencing_g06_c04.avi
Fencing/v_Fencing_g07_c01.avi
Fencing/v_Fencing_g07_c02.avi
Fencing/v_Fencing_g07_c03.avi
Fencing/v_Fencing_g07_c04.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g01_c01.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g01_c02.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g01_c03.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g01_c04.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g01_c05.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g02_c01.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g02_c02.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g02_c03.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g02_c04.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g02_c05.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g02_c06.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g03_c01.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g03_c02.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g03_c03.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g03_c04.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g04_c01.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g04_c02.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g04_c03.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g04_c04.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g04_c05.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g04_c06.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g04_c07.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g05_c01.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g05_c02.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g05_c03.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g05_c04.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g05_c05.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g05_c06.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g05_c07.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g06_c01.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g06_c02.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g06_c03.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g06_c04.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g06_c05.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g06_c06.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g06_c07.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g07_c01.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g07_c02.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g07_c03.avi
FieldHockeyPenalty/v_FieldHockeyPenalty_g07_c04.avi
FloorGymnastics/v_FloorGymnastics_g01_c01.avi
FloorGymnastics/v_FloorGymnastics_g01_c02.avi
FloorGymnastics/v_FloorGymnastics_g01_c03.avi
FloorGymnastics/v_FloorGymnastics_g01_c04.avi
FloorGymnastics/v_FloorGymnastics_g01_c05.avi
FloorGymnastics/v_FloorGymnastics_g02_c01.avi
FloorGymnastics/v_FloorGymnastics_g02_c02.avi
FloorGymnastics/v_FloorGymnastics_g02_c03.avi
FloorGymnastics/v_FloorGymnastics_g02_c04.avi
FloorGymnastics/v_FloorGymnastics_g03_c01.avi
FloorGymnastics/v_FloorGymnastics_g03_c02.avi
FloorGymnastics/v_FloorGymnastics_g03_c03.avi
FloorGymnastics/v_FloorGymnastics_g03_c04.avi
FloorGymnastics/v_FloorGymnastics_g04_c01.avi
FloorGymnastics/v_FloorGymnastics_g04_c02.avi
FloorGymnastics/v_FloorGymnastics_g04_c03.avi
FloorGymnastics/v_FloorGymnastics_g04_c04.avi
FloorGymnastics/v_FloorGymnastics_g04_c05.avi
FloorGymnastics/v_FloorGymnastics_g05_c01.avi
FloorGymnastics/v_FloorGymnastics_g05_c02.avi
FloorGymnastics/v_FloorGymnastics_g05_c03.avi
FloorGymnastics/v_FloorGymnastics_g05_c04.avi
FloorGymnastics/v_FloorGymnastics_g06_c01.avi
FloorGymnastics/v_FloorGymnastics_g06_c02.avi
FloorGymnastics/v_FloorGymnastics_g06_c03.avi
FloorGymnastics/v_FloorGymnastics_g06_c04.avi
FloorGymnastics/v_FloorGymnastics_g06_c05.avi
FloorGymnastics/v_FloorGymnastics_g06_c06.avi
FloorGymnastics/v_FloorGymnastics_g06_c07.avi
FloorGymnastics/v_FloorGymnastics_g07_c01.avi
FloorGymnastics/v_FloorGymnastics_g07_c02.avi
FloorGymnastics/v_FloorGymnastics_g07_c03.avi
FloorGymnastics/v_FloorGymnastics_g07_c04.avi
FloorGymnastics/v_FloorGymnastics_g07_c05.avi
FloorGymnastics/v_FloorGymnastics_g07_c06.avi
FloorGymnastics/v_FloorGymnastics_g07_c07.avi
FrisbeeCatch/v_FrisbeeCatch_g01_c01.avi
FrisbeeCatch/v_FrisbeeCatch_g01_c02.avi
FrisbeeCatch/v_FrisbeeCatch_g01_c03.avi
FrisbeeCatch/v_FrisbeeCatch_g01_c04.avi
FrisbeeCatch/v_FrisbeeCatch_g01_c05.avi
FrisbeeCatch/v_FrisbeeCatch_g01_c06.avi
FrisbeeCatch/v_FrisbeeCatch_g02_c01.avi
FrisbeeCatch/v_FrisbeeCatch_g02_c02.avi
FrisbeeCatch/v_FrisbeeCatch_g02_c03.avi
FrisbeeCatch/v_FrisbeeCatch_g02_c04.avi
FrisbeeCatch/v_FrisbeeCatch_g02_c05.avi
FrisbeeCatch/v_FrisbeeCatch_g03_c01.avi
FrisbeeCatch/v_FrisbeeCatch_g03_c02.avi
FrisbeeCatch/v_FrisbeeCatch_g03_c03.avi
FrisbeeCatch/v_FrisbeeCatch_g03_c04.avi
FrisbeeCatch/v_FrisbeeCatch_g03_c05.avi
FrisbeeCatch/v_FrisbeeCatch_g04_c01.avi
FrisbeeCatch/v_FrisbeeCatch_g04_c02.avi
FrisbeeCatch/v_FrisbeeCatch_g04_c03.avi
FrisbeeCatch/v_FrisbeeCatch_g04_c04.avi
FrisbeeCatch/v_FrisbeeCatch_g04_c05.avi
FrisbeeCatch/v_FrisbeeCatch_g05_c01.avi
FrisbeeCatch/v_FrisbeeCatch_g05_c02.avi
FrisbeeCatch/v_FrisbeeCatch_g05_c03.avi
FrisbeeCatch/v_FrisbeeCatch_g05_c04.avi
FrisbeeCatch/v_FrisbeeCatch_g05_c05.avi
FrisbeeCatch/v_FrisbeeCatch_g06_c01.avi
FrisbeeCatch/v_FrisbeeCatch_g06_c02.avi
FrisbeeCatch/v_FrisbeeCatch_g06_c03.avi
FrisbeeCatch/v_FrisbeeCatch_g06_c04.avi
FrisbeeCatch/v_FrisbeeCatch_g06_c05.avi
FrisbeeCatch/v_FrisbeeCatch_g07_c01.avi
FrisbeeCatch/v_FrisbeeCatch_g07_c02.avi
FrisbeeCatch/v_FrisbeeCatch_g07_c03.avi
FrisbeeCatch/v_FrisbeeCatch_g07_c04.avi
FrisbeeCatch/v_FrisbeeCatch_g07_c05.avi
FrisbeeCatch/v_FrisbeeCatch_g07_c06.avi
FrontCrawl/v_FrontCrawl_g01_c01.avi
FrontCrawl/v_FrontCrawl_g01_c02.avi
FrontCrawl/v_FrontCrawl_g01_c03.avi
FrontCrawl/v_FrontCrawl_g01_c04.avi
FrontCrawl/v_FrontCrawl_g02_c01.avi
FrontCrawl/v_FrontCrawl_g02_c02.avi
FrontCrawl/v_FrontCrawl_g02_c03.avi
FrontCrawl/v_FrontCrawl_g02_c04.avi
FrontCrawl/v_FrontCrawl_g03_c01.avi
FrontCrawl/v_FrontCrawl_g03_c02.avi
FrontCrawl/v_FrontCrawl_g03_c03.avi
FrontCrawl/v_FrontCrawl_g03_c04.avi
FrontCrawl/v_FrontCrawl_g03_c05.avi
FrontCrawl/v_FrontCrawl_g03_c06.avi
FrontCrawl/v_FrontCrawl_g04_c01.avi
FrontCrawl/v_FrontCrawl_g04_c02.avi
FrontCrawl/v_FrontCrawl_g04_c03.avi
FrontCrawl/v_FrontCrawl_g04_c04.avi
FrontCrawl/v_FrontCrawl_g04_c05.avi
FrontCrawl/v_FrontCrawl_g04_c06.avi
FrontCrawl/v_FrontCrawl_g04_c07.avi
FrontCrawl/v_FrontCrawl_g05_c01.avi
FrontCrawl/v_FrontCrawl_g05_c02.avi
FrontCrawl/v_FrontCrawl_g05_c03.avi
FrontCrawl/v_FrontCrawl_g05_c04.avi
FrontCrawl/v_FrontCrawl_g06_c01.avi
FrontCrawl/v_FrontCrawl_g06_c02.avi
FrontCrawl/v_FrontCrawl_g06_c03.avi
FrontCrawl/v_FrontCrawl_g06_c04.avi
FrontCrawl/v_FrontCrawl_g06_c05.avi
FrontCrawl/v_FrontCrawl_g07_c01.avi
FrontCrawl/v_FrontCrawl_g07_c02.avi
FrontCrawl/v_FrontCrawl_g07_c03.avi
FrontCrawl/v_FrontCrawl_g07_c04.avi
FrontCrawl/v_FrontCrawl_g07_c05.avi
FrontCrawl/v_FrontCrawl_g07_c06.avi
FrontCrawl/v_FrontCrawl_g07_c07.avi
GolfSwing/v_GolfSwing_g01_c01.avi
GolfSwing/v_GolfSwing_g01_c02.avi
GolfSwing/v_GolfSwing_g01_c03.avi
GolfSwing/v_GolfSwing_g01_c04.avi
GolfSwing/v_GolfSwing_g01_c05.avi
GolfSwing/v_GolfSwing_g01_c06.avi
GolfSwing/v_GolfSwing_g02_c01.avi
GolfSwing/v_GolfSwing_g02_c02.avi
GolfSwing/v_GolfSwing_g02_c03.avi
GolfSwing/v_GolfSwing_g02_c04.avi
GolfSwing/v_GolfSwing_g03_c01.avi
GolfSwing/v_GolfSwing_g03_c02.avi
GolfSwing/v_GolfSwing_g03_c03.avi
GolfSwing/v_GolfSwing_g03_c04.avi
GolfSwing/v_GolfSwing_g03_c05.avi
GolfSwing/v_GolfSwing_g03_c06.avi
GolfSwing/v_GolfSwing_g03_c07.avi
GolfSwing/v_GolfSwing_g04_c01.avi
GolfSwing/v_GolfSwing_g04_c02.avi
GolfSwing/v_GolfSwing_g04_c03.avi
GolfSwing/v_GolfSwing_g04_c04.avi
GolfSwing/v_GolfSwing_g04_c05.avi
GolfSwing/v_GolfSwing_g04_c06.avi
GolfSwing/v_GolfSwing_g05_c01.avi
GolfSwing/v_GolfSwing_g05_c02.avi
GolfSwing/v_GolfSwing_g05_c03.avi
GolfSwing/v_GolfSwing_g05_c04.avi
GolfSwing/v_GolfSwing_g05_c05.avi
GolfSwing/v_GolfSwing_g05_c06.avi
GolfSwing/v_GolfSwing_g05_c07.avi
GolfSwing/v_GolfSwing_g06_c01.avi
GolfSwing/v_GolfSwing_g06_c02.avi
GolfSwing/v_GolfSwing_g06_c03.avi
GolfSwing/v_GolfSwing_g06_c04.avi
GolfSwing/v_GolfSwing_g07_c01.avi
GolfSwing/v_GolfSwing_g07_c02.avi
GolfSwing/v_GolfSwing_g07_c03.avi
GolfSwing/v_GolfSwing_g07_c04.avi
GolfSwing/v_GolfSwing_g07_c05.avi
Haircut/v_Haircut_g01_c01.avi
Haircut/v_Haircut_g01_c02.avi
Haircut/v_Haircut_g01_c03.avi
Haircut/v_Haircut_g01_c04.avi
Haircut/v_Haircut_g02_c01.avi
Haircut/v_Haircut_g02_c02.avi
Haircut/v_Haircut_g02_c03.avi
Haircut/v_Haircut_g02_c04.avi
Haircut/v_Haircut_g03_c01.avi
Haircut/v_Haircut_g03_c02.avi
Haircut/v_Haircut_g03_c03.avi
Haircut/v_Haircut_g03_c04.avi
Haircut/v_Haircut_g03_c05.avi
Haircut/v_Haircut_g03_c06.avi
Haircut/v_Haircut_g04_c01.avi
Haircut/v_Haircut_g04_c02.avi
Haircut/v_Haircut_g04_c03.avi
Haircut/v_Haircut_g04_c04.avi
Haircut/v_Haircut_g04_c05.avi
Haircut/v_Haircut_g05_c01.avi
Haircut/v_Haircut_g05_c02.avi
Haircut/v_Haircut_g05_c03.avi
Haircut/v_Haircut_g05_c04.avi
Haircut/v_Haircut_g06_c01.avi
Haircut/v_Haircut_g06_c02.avi
Haircut/v_Haircut_g06_c03.avi
Haircut/v_Haircut_g06_c04.avi
Haircut/v_Haircut_g07_c01.avi
Haircut/v_Haircut_g07_c02.avi
Haircut/v_Haircut_g07_c03.avi
Haircut/v_Haircut_g07_c04.avi
Haircut/v_Haircut_g07_c05.avi
Haircut/v_Haircut_g07_c06.avi
Hammering/v_Hammering_g01_c01.avi
Hammering/v_Hammering_g01_c02.avi
Hammering/v_Hammering_g01_c03.avi
Hammering/v_Hammering_g01_c04.avi
Hammering/v_Hammering_g02_c01.avi
Hammering/v_Hammering_g02_c02.avi
Hammering/v_Hammering_g02_c03.avi
Hammering/v_Hammering_g02_c04.avi
Hammering/v_Hammering_g03_c01.avi
Hammering/v_Hammering_g03_c02.avi
Hammering/v_Hammering_g03_c03.avi
Hammering/v_Hammering_g03_c04.avi
Hammering/v_Hammering_g03_c05.avi
Hammering/v_Hammering_g04_c01.avi
Hammering/v_Hammering_g04_c02.avi
Hammering/v_Hammering_g04_c03.avi
Hammering/v_Hammering_g04_c04.avi
Hammering/v_Hammering_g04_c05.avi
Hammering/v_Hammering_g05_c01.avi
Hammering/v_Hammering_g05_c02.avi
Hammering/v_Hammering_g05_c03.avi
Hammering/v_Hammering_g05_c04.avi
Hammering/v_Hammering_g06_c01.avi
Hammering/v_Hammering_g06_c02.avi
Hammering/v_Hammering_g06_c03.avi
Hammering/v_Hammering_g06_c04.avi
Hammering/v_Hammering_g06_c05.avi
Hammering/v_Hammering_g06_c06.avi
Hammering/v_Hammering_g07_c01.avi
Hammering/v_Hammering_g07_c02.avi
Hammering/v_Hammering_g07_c03.avi
Hammering/v_Hammering_g07_c04.avi
Hammering/v_Hammering_g07_c05.avi
HammerThrow/v_HammerThrow_g01_c01.avi
HammerThrow/v_HammerThrow_g01_c02.avi
HammerThrow/v_HammerThrow_g01_c03.avi
HammerThrow/v_HammerThrow_g01_c04.avi
HammerThrow/v_HammerThrow_g01_c05.avi
HammerThrow/v_HammerThrow_g01_c06.avi
HammerThrow/v_HammerThrow_g02_c01.avi
HammerThrow/v_HammerThrow_g02_c02.avi
HammerThrow/v_HammerThrow_g02_c03.avi
HammerThrow/v_HammerThrow_g02_c04.avi
HammerThrow/v_HammerThrow_g02_c05.avi
HammerThrow/v_HammerThrow_g02_c06.avi
HammerThrow/v_HammerThrow_g02_c07.avi
HammerThrow/v_HammerThrow_g03_c01.avi
HammerThrow/v_HammerThrow_g03_c02.avi
HammerThrow/v_HammerThrow_g03_c03.avi
HammerThrow/v_HammerThrow_g03_c04.avi
HammerThrow/v_HammerThrow_g03_c05.avi
HammerThrow/v_HammerThrow_g03_c06.avi
HammerThrow/v_HammerThrow_g03_c07.avi
HammerThrow/v_HammerThrow_g04_c01.avi
HammerThrow/v_HammerThrow_g04_c02.avi
HammerThrow/v_HammerThrow_g04_c03.avi
HammerThrow/v_HammerThrow_g04_c04.avi
HammerThrow/v_HammerThrow_g04_c05.avi
HammerThrow/v_HammerThrow_g04_c06.avi
HammerThrow/v_HammerThrow_g04_c07.avi
HammerThrow/v_HammerThrow_g05_c01.avi
HammerThrow/v_HammerThrow_g05_c02.avi
HammerThrow/v_HammerThrow_g05_c03.avi
HammerThrow/v_HammerThrow_g05_c04.avi
HammerThrow/v_HammerThrow_g05_c05.avi
HammerThrow/v_HammerThrow_g05_c06.avi
HammerThrow/v_HammerThrow_g06_c01.avi
HammerThrow/v_HammerThrow_g06_c02.avi
HammerThrow/v_HammerThrow_g06_c03.avi
HammerThrow/v_HammerThrow_g06_c04.avi
HammerThrow/v_HammerThrow_g06_c05.avi
HammerThrow/v_HammerThrow_g06_c06.avi
HammerThrow/v_HammerThrow_g06_c07.avi
HammerThrow/v_HammerThrow_g07_c01.avi
HammerThrow/v_HammerThrow_g07_c02.avi
HammerThrow/v_HammerThrow_g07_c03.avi
HammerThrow/v_HammerThrow_g07_c04.avi
HammerThrow/v_HammerThrow_g07_c05.avi
HandstandPushups/v_HandStandPushups_g01_c01.avi
HandstandPushups/v_HandStandPushups_g01_c02.avi
HandstandPushups/v_HandStandPushups_g01_c03.avi
HandstandPushups/v_HandStandPushups_g01_c04.avi
HandstandPushups/v_HandStandPushups_g02_c01.avi
HandstandPushups/v_HandStandPushups_g02_c02.avi
HandstandPushups/v_HandStandPushups_g02_c03.avi
HandstandPushups/v_HandStandPushups_g02_c04.avi
HandstandPushups/v_HandStandPushups_g03_c01.avi
HandstandPushups/v_HandStandPushups_g03_c02.avi
HandstandPushups/v_HandStandPushups_g03_c03.avi
HandstandPushups/v_HandStandPushups_g03_c04.avi
HandstandPushups/v_HandStandPushups_g04_c01.avi
HandstandPushups/v_HandStandPushups_g04_c02.avi
HandstandPushups/v_HandStandPushups_g04_c03.avi
HandstandPushups/v_HandStandPushups_g04_c04.avi
HandstandPushups/v_HandStandPushups_g05_c01.avi
HandstandPushups/v_HandStandPushups_g05_c02.avi
HandstandPushups/v_HandStandPushups_g05_c03.avi
HandstandPushups/v_HandStandPushups_g05_c04.avi
HandstandPushups/v_HandStandPushups_g06_c01.avi
HandstandPushups/v_HandStandPushups_g06_c02.avi
HandstandPushups/v_HandStandPushups_g06_c03.avi
HandstandPushups/v_HandStandPushups_g06_c04.avi
HandstandPushups/v_HandStandPushups_g07_c01.avi
HandstandPushups/v_HandStandPushups_g07_c02.avi
HandstandPushups/v_HandStandPushups_g07_c03.avi
HandstandPushups/v_HandStandPushups_g07_c04.avi
HandstandWalking/v_HandstandWalking_g01_c01.avi
HandstandWalking/v_HandstandWalking_g01_c02.avi
HandstandWalking/v_HandstandWalking_g01_c03.avi
HandstandWalking/v_HandstandWalking_g01_c04.avi
HandstandWalking/v_HandstandWalking_g02_c01.avi
HandstandWalking/v_HandstandWalking_g02_c02.avi
HandstandWalking/v_HandstandWalking_g02_c03.avi
HandstandWalking/v_HandstandWalking_g02_c04.avi
HandstandWalking/v_HandstandWalking_g03_c01.avi
HandstandWalking/v_HandstandWalking_g03_c02.avi
HandstandWalking/v_HandstandWalking_g03_c03.avi
HandstandWalking/v_HandstandWalking_g03_c04.avi
HandstandWalking/v_HandstandWalking_g04_c01.avi
HandstandWalking/v_HandstandWalking_g04_c02.avi
HandstandWalking/v_HandstandWalking_g04_c03.avi
HandstandWalking/v_HandstandWalking_g04_c04.avi
HandstandWalking/v_HandstandWalking_g04_c05.avi
HandstandWalking/v_HandstandWalking_g05_c01.avi
HandstandWalking/v_HandstandWalking_g05_c02.avi
HandstandWalking/v_HandstandWalking_g05_c03.avi
HandstandWalking/v_HandstandWalking_g05_c04.avi
HandstandWalking/v_HandstandWalking_g05_c05.avi
HandstandWalking/v_HandstandWalking_g05_c06.avi
HandstandWalking/v_HandstandWalking_g05_c07.avi
HandstandWalking/v_HandstandWalking_g06_c01.avi
HandstandWalking/v_HandstandWalking_g06_c02.avi
HandstandWalking/v_HandstandWalking_g06_c03.avi
HandstandWalking/v_HandstandWalking_g06_c04.avi
HandstandWalking/v_HandstandWalking_g07_c01.avi
HandstandWalking/v_HandstandWalking_g07_c02.avi
HandstandWalking/v_HandstandWalking_g07_c03.avi
HandstandWalking/v_HandstandWalking_g07_c04.avi
HandstandWalking/v_HandstandWalking_g07_c05.avi
HandstandWalking/v_HandstandWalking_g07_c06.avi
HeadMassage/v_HeadMassage_g01_c01.avi
HeadMassage/v_HeadMassage_g01_c02.avi
HeadMassage/v_HeadMassage_g01_c03.avi
HeadMassage/v_HeadMassage_g01_c04.avi
HeadMassage/v_HeadMassage_g01_c05.avi
HeadMassage/v_HeadMassage_g02_c01.avi
HeadMassage/v_HeadMassage_g02_c02.avi
HeadMassage/v_HeadMassage_g02_c03.avi
HeadMassage/v_HeadMassage_g02_c04.avi
HeadMassage/v_HeadMassage_g02_c05.avi
HeadMassage/v_HeadMassage_g02_c06.avi
HeadMassage/v_HeadMassage_g02_c07.avi
HeadMassage/v_HeadMassage_g03_c01.avi
HeadMassage/v_HeadMassage_g03_c02.avi
HeadMassage/v_HeadMassage_g03_c03.avi
HeadMassage/v_HeadMassage_g03_c04.avi
HeadMassage/v_HeadMassage_g03_c05.avi
HeadMassage/v_HeadMassage_g03_c06.avi
HeadMassage/v_HeadMassage_g03_c07.avi
HeadMassage/v_HeadMassage_g04_c01.avi
HeadMassage/v_HeadMassage_g04_c02.avi
HeadMassage/v_HeadMassage_g04_c03.avi
HeadMassage/v_HeadMassage_g04_c04.avi
HeadMassage/v_HeadMassage_g05_c01.avi
HeadMassage/v_HeadMassage_g05_c02.avi
HeadMassage/v_HeadMassage_g05_c03.avi
HeadMassage/v_HeadMassage_g05_c04.avi
HeadMassage/v_HeadMassage_g05_c05.avi
HeadMassage/v_HeadMassage_g05_c06.avi
HeadMassage/v_HeadMassage_g06_c01.avi
HeadMassage/v_HeadMassage_g06_c02.avi
HeadMassage/v_HeadMassage_g06_c03.avi
HeadMassage/v_HeadMassage_g06_c04.avi
HeadMassage/v_HeadMassage_g06_c05.avi
HeadMassage/v_HeadMassage_g06_c06.avi
HeadMassage/v_HeadMassage_g06_c07.avi
HeadMassage/v_HeadMassage_g07_c01.avi
HeadMassage/v_HeadMassage_g07_c02.avi
HeadMassage/v_HeadMassage_g07_c03.avi
HeadMassage/v_HeadMassage_g07_c04.avi
HeadMassage/v_HeadMassage_g07_c05.avi
HighJump/v_HighJump_g01_c01.avi
HighJump/v_HighJump_g01_c02.avi
HighJump/v_HighJump_g01_c03.avi
HighJump/v_HighJump_g01_c04.avi
HighJump/v_HighJump_g01_c05.avi
HighJump/v_HighJump_g02_c01.avi
HighJump/v_HighJump_g02_c02.avi
HighJump/v_HighJump_g02_c03.avi
HighJump/v_HighJump_g02_c04.avi
HighJump/v_HighJump_g02_c05.avi
HighJump/v_HighJump_g02_c06.avi
HighJump/v_HighJump_g02_c07.avi
HighJump/v_HighJump_g03_c01.avi
HighJump/v_HighJump_g03_c02.avi
HighJump/v_HighJump_g03_c03.avi
HighJump/v_HighJump_g03_c04.avi
HighJump/v_HighJump_g04_c01.avi
HighJump/v_HighJump_g04_c02.avi
HighJump/v_HighJump_g04_c03.avi
HighJump/v_HighJump_g04_c04.avi
HighJump/v_HighJump_g04_c05.avi
HighJump/v_HighJump_g04_c06.avi
HighJump/v_HighJump_g05_c01.avi
HighJump/v_HighJump_g05_c02.avi
HighJump/v_HighJump_g05_c03.avi
HighJump/v_HighJump_g05_c04.avi
HighJump/v_HighJump_g05_c05.avi
HighJump/v_HighJump_g06_c01.avi
HighJump/v_HighJump_g06_c02.avi
HighJump/v_HighJump_g06_c03.avi
HighJump/v_HighJump_g06_c04.avi
HighJump/v_HighJump_g07_c01.avi
HighJump/v_HighJump_g07_c02.avi
HighJump/v_HighJump_g07_c03.avi
HighJump/v_HighJump_g07_c04.avi
HighJump/v_HighJump_g07_c05.avi
HighJump/v_HighJump_g07_c06.avi
HorseRace/v_HorseRace_g01_c01.avi
HorseRace/v_HorseRace_g01_c02.avi
HorseRace/v_HorseRace_g01_c03.avi
HorseRace/v_HorseRace_g01_c04.avi
HorseRace/v_HorseRace_g02_c01.avi
HorseRace/v_HorseRace_g02_c02.avi
HorseRace/v_HorseRace_g02_c03.avi
HorseRace/v_HorseRace_g02_c04.avi
HorseRace/v_HorseRace_g03_c01.avi
HorseRace/v_HorseRace_g03_c02.avi
HorseRace/v_HorseRace_g03_c03.avi
HorseRace/v_HorseRace_g03_c04.avi
HorseRace/v_HorseRace_g03_c05.avi
HorseRace/v_HorseRace_g04_c01.avi
HorseRace/v_HorseRace_g04_c02.avi
HorseRace/v_HorseRace_g04_c03.avi
HorseRace/v_HorseRace_g04_c04.avi
HorseRace/v_HorseRace_g04_c05.avi
HorseRace/v_HorseRace_g04_c06.avi
HorseRace/v_HorseRace_g05_c01.avi
HorseRace/v_HorseRace_g05_c02.avi
HorseRace/v_HorseRace_g05_c03.avi
HorseRace/v_HorseRace_g05_c04.avi
HorseRace/v_HorseRace_g06_c01.avi
HorseRace/v_HorseRace_g06_c02.avi
HorseRace/v_HorseRace_g06_c03.avi
HorseRace/v_HorseRace_g06_c04.avi
HorseRace/v_HorseRace_g06_c05.avi
HorseRace/v_HorseRace_g06_c06.avi
HorseRace/v_HorseRace_g07_c01.avi
HorseRace/v_HorseRace_g07_c02.avi
HorseRace/v_HorseRace_g07_c03.avi
HorseRace/v_HorseRace_g07_c04.avi
HorseRace/v_HorseRace_g07_c05.avi
HorseRace/v_HorseRace_g07_c06.avi
HorseRiding/v_HorseRiding_g01_c01.avi
HorseRiding/v_HorseRiding_g01_c02.avi
HorseRiding/v_HorseRiding_g01_c03.avi
HorseRiding/v_HorseRiding_g01_c04.avi
HorseRiding/v_HorseRiding_g01_c05.avi
HorseRiding/v_HorseRiding_g01_c06.avi
HorseRiding/v_HorseRiding_g01_c07.avi
HorseRiding/v_HorseRiding_g02_c01.avi
HorseRiding/v_HorseRiding_g02_c02.avi
HorseRiding/v_HorseRiding_g02_c03.avi
HorseRiding/v_HorseRiding_g02_c04.avi
HorseRiding/v_HorseRiding_g02_c05.avi
HorseRiding/v_HorseRiding_g02_c06.avi
HorseRiding/v_HorseRiding_g02_c07.avi
HorseRiding/v_HorseRiding_g03_c01.avi
HorseRiding/v_HorseRiding_g03_c02.avi
HorseRiding/v_HorseRiding_g03_c03.avi
HorseRiding/v_HorseRiding_g03_c04.avi
HorseRiding/v_HorseRiding_g03_c05.avi
HorseRiding/v_HorseRiding_g03_c06.avi
HorseRiding/v_HorseRiding_g03_c07.avi
HorseRiding/v_HorseRiding_g04_c01.avi
HorseRiding/v_HorseRiding_g04_c02.avi
HorseRiding/v_HorseRiding_g04_c03.avi
HorseRiding/v_HorseRiding_g04_c04.avi
HorseRiding/v_HorseRiding_g04_c05.avi
HorseRiding/v_HorseRiding_g04_c06.avi
HorseRiding/v_HorseRiding_g04_c07.avi
HorseRiding/v_HorseRiding_g05_c01.avi
HorseRiding/v_HorseRiding_g05_c02.avi
HorseRiding/v_HorseRiding_g05_c03.avi
HorseRiding/v_HorseRiding_g05_c04.avi
HorseRiding/v_HorseRiding_g05_c05.avi
HorseRiding/v_HorseRiding_g05_c06.avi
HorseRiding/v_HorseRiding_g05_c07.avi
HorseRiding/v_HorseRiding_g06_c01.avi
HorseRiding/v_HorseRiding_g06_c02.avi
HorseRiding/v_HorseRiding_g06_c03.avi
HorseRiding/v_HorseRiding_g06_c04.avi
HorseRiding/v_HorseRiding_g06_c05.avi
HorseRiding/v_HorseRiding_g06_c06.avi
HorseRiding/v_HorseRiding_g06_c07.avi
HorseRiding/v_HorseRiding_g07_c01.avi
HorseRiding/v_HorseRiding_g07_c02.avi
HorseRiding/v_HorseRiding_g07_c03.avi
HorseRiding/v_HorseRiding_g07_c04.avi
HorseRiding/v_HorseRiding_g07_c05.avi
HorseRiding/v_HorseRiding_g07_c06.avi
HorseRiding/v_HorseRiding_g07_c07.avi
HulaHoop/v_HulaHoop_g01_c01.avi
HulaHoop/v_HulaHoop_g01_c02.avi
HulaHoop/v_HulaHoop_g01_c03.avi
HulaHoop/v_HulaHoop_g01_c04.avi
HulaHoop/v_HulaHoop_g01_c05.avi
HulaHoop/v_HulaHoop_g01_c06.avi
HulaHoop/v_HulaHoop_g01_c07.avi
HulaHoop/v_HulaHoop_g02_c01.avi
HulaHoop/v_HulaHoop_g02_c02.avi
HulaHoop/v_HulaHoop_g02_c03.avi
HulaHoop/v_HulaHoop_g02_c04.avi
HulaHoop/v_HulaHoop_g03_c01.avi
HulaHoop/v_HulaHoop_g03_c02.avi
HulaHoop/v_HulaHoop_g03_c03.avi
HulaHoop/v_HulaHoop_g03_c04.avi
HulaHoop/v_HulaHoop_g03_c05.avi
HulaHoop/v_HulaHoop_g04_c01.avi
HulaHoop/v_HulaHoop_g04_c02.avi
HulaHoop/v_HulaHoop_g04_c03.avi
HulaHoop/v_HulaHoop_g04_c04.avi
HulaHoop/v_HulaHoop_g04_c05.avi
HulaHoop/v_HulaHoop_g05_c01.avi
HulaHoop/v_HulaHoop_g05_c02.avi
HulaHoop/v_HulaHoop_g05_c03.avi
HulaHoop/v_HulaHoop_g05_c04.avi
HulaHoop/v_HulaHoop_g06_c01.avi
HulaHoop/v_HulaHoop_g06_c02.avi
HulaHoop/v_HulaHoop_g06_c03.avi
HulaHoop/v_HulaHoop_g06_c04.avi
HulaHoop/v_HulaHoop_g07_c01.avi
HulaHoop/v_HulaHoop_g07_c02.avi
HulaHoop/v_HulaHoop_g07_c03.avi
HulaHoop/v_HulaHoop_g07_c04.avi
HulaHoop/v_HulaHoop_g07_c05.avi
IceDancing/v_IceDancing_g01_c01.avi
IceDancing/v_IceDancing_g01_c02.avi
IceDancing/v_IceDancing_g01_c03.avi
IceDancing/v_IceDancing_g01_c04.avi
IceDancing/v_IceDancing_g01_c05.avi
IceDancing/v_IceDancing_g01_c06.avi
IceDancing/v_IceDancing_g01_c07.avi
IceDancing/v_IceDancing_g02_c01.avi
IceDancing/v_IceDancing_g02_c02.avi
IceDancing/v_IceDancing_g02_c03.avi
IceDancing/v_IceDancing_g02_c04.avi
IceDancing/v_IceDancing_g02_c05.avi
IceDancing/v_IceDancing_g02_c06.avi
IceDancing/v_IceDancing_g02_c07.avi
IceDancing/v_IceDancing_g03_c01.avi
IceDancing/v_IceDancing_g03_c02.avi
IceDancing/v_IceDancing_g03_c03.avi
IceDancing/v_IceDancing_g03_c04.avi
IceDancing/v_IceDancing_g03_c05.avi
IceDancing/v_IceDancing_g03_c06.avi
IceDancing/v_IceDancing_g04_c01.avi
IceDancing/v_IceDancing_g04_c02.avi
IceDancing/v_IceDancing_g04_c03.avi
IceDancing/v_IceDancing_g04_c04.avi
IceDancing/v_IceDancing_g04_c05.avi
IceDancing/v_IceDancing_g04_c06.avi
IceDancing/v_IceDancing_g04_c07.avi
IceDancing/v_IceDancing_g05_c01.avi
IceDancing/v_IceDancing_g05_c02.avi
IceDancing/v_IceDancing_g05_c03.avi
IceDancing/v_IceDancing_g05_c04.avi
IceDancing/v_IceDancing_g05_c05.avi
IceDancing/v_IceDancing_g05_c06.avi
IceDancing/v_IceDancing_g06_c01.avi
IceDancing/v_IceDancing_g06_c02.avi
IceDancing/v_IceDancing_g06_c03.avi
IceDancing/v_IceDancing_g06_c04.avi
IceDancing/v_IceDancing_g06_c05.avi
IceDancing/v_IceDancing_g06_c06.avi
IceDancing/v_IceDancing_g07_c01.avi
IceDancing/v_IceDancing_g07_c02.avi
IceDancing/v_IceDancing_g07_c03.avi
IceDancing/v_IceDancing_g07_c04.avi
IceDancing/v_IceDancing_g07_c05.avi
IceDancing/v_IceDancing_g07_c06.avi
IceDancing/v_IceDancing_g07_c07.avi
JavelinThrow/v_JavelinThrow_g01_c01.avi
JavelinThrow/v_JavelinThrow_g01_c02.avi
JavelinThrow/v_JavelinThrow_g01_c03.avi
JavelinThrow/v_JavelinThrow_g01_c04.avi
JavelinThrow/v_JavelinThrow_g02_c01.avi
JavelinThrow/v_JavelinThrow_g02_c02.avi
JavelinThrow/v_JavelinThrow_g02_c03.avi
JavelinThrow/v_JavelinThrow_g02_c04.avi
JavelinThrow/v_JavelinThrow_g03_c01.avi
JavelinThrow/v_JavelinThrow_g03_c02.avi
JavelinThrow/v_JavelinThrow_g03_c03.avi
JavelinThrow/v_JavelinThrow_g03_c04.avi
JavelinThrow/v_JavelinThrow_g04_c01.avi
JavelinThrow/v_JavelinThrow_g04_c02.avi
JavelinThrow/v_JavelinThrow_g04_c03.avi
JavelinThrow/v_JavelinThrow_g04_c04.avi
JavelinThrow/v_JavelinThrow_g05_c01.avi
JavelinThrow/v_JavelinThrow_g05_c02.avi
JavelinThrow/v_JavelinThrow_g05_c03.avi
JavelinThrow/v_JavelinThrow_g05_c04.avi
JavelinThrow/v_JavelinThrow_g05_c05.avi
JavelinThrow/v_JavelinThrow_g05_c06.avi
JavelinThrow/v_JavelinThrow_g06_c01.avi
JavelinThrow/v_JavelinThrow_g06_c02.avi
JavelinThrow/v_JavelinThrow_g06_c03.avi
JavelinThrow/v_JavelinThrow_g06_c04.avi
JavelinThrow/v_JavelinThrow_g07_c01.avi
JavelinThrow/v_JavelinThrow_g07_c02.avi
JavelinThrow/v_JavelinThrow_g07_c03.avi
JavelinThrow/v_JavelinThrow_g07_c04.avi
JavelinThrow/v_JavelinThrow_g07_c05.avi
JugglingBalls/v_JugglingBalls_g01_c01.avi
JugglingBalls/v_JugglingBalls_g01_c02.avi
JugglingBalls/v_JugglingBalls_g01_c03.avi
JugglingBalls/v_JugglingBalls_g01_c04.avi
JugglingBalls/v_JugglingBalls_g02_c01.avi
JugglingBalls/v_JugglingBalls_g02_c02.avi
JugglingBalls/v_JugglingBalls_g02_c03.avi
JugglingBalls/v_JugglingBalls_g02_c04.avi
JugglingBalls/v_JugglingBalls_g02_c05.avi
JugglingBalls/v_JugglingBalls_g02_c06.avi
JugglingBalls/v_JugglingBalls_g03_c01.avi
JugglingBalls/v_JugglingBalls_g03_c02.avi
JugglingBalls/v_JugglingBalls_g03_c03.avi
JugglingBalls/v_JugglingBalls_g03_c04.avi
JugglingBalls/v_JugglingBalls_g03_c05.avi
JugglingBalls/v_JugglingBalls_g03_c06.avi
JugglingBalls/v_JugglingBalls_g03_c07.avi
JugglingBalls/v_JugglingBalls_g04_c01.avi
JugglingBalls/v_JugglingBalls_g04_c02.avi
JugglingBalls/v_JugglingBalls_g04_c03.avi
JugglingBalls/v_JugglingBalls_g04_c04.avi
JugglingBalls/v_JugglingBalls_g04_c05.avi
JugglingBalls/v_JugglingBalls_g05_c01.avi
JugglingBalls/v_JugglingBalls_g05_c02.avi
JugglingBalls/v_JugglingBalls_g05_c03.avi
JugglingBalls/v_JugglingBalls_g05_c04.avi
JugglingBalls/v_JugglingBalls_g05_c05.avi
JugglingBalls/v_JugglingBalls_g06_c01.avi
JugglingBalls/v_JugglingBalls_g06_c02.avi
JugglingBalls/v_JugglingBalls_g06_c03.avi
JugglingBalls/v_JugglingBalls_g06_c04.avi
JugglingBalls/v_JugglingBalls_g06_c05.avi
JugglingBalls/v_JugglingBalls_g06_c06.avi
JugglingBalls/v_JugglingBalls_g07_c01.avi
JugglingBalls/v_JugglingBalls_g07_c02.avi
JugglingBalls/v_JugglingBalls_g07_c03.avi
JugglingBalls/v_JugglingBalls_g07_c04.avi
JugglingBalls/v_JugglingBalls_g07_c05.avi
JugglingBalls/v_JugglingBalls_g07_c06.avi
JugglingBalls/v_JugglingBalls_g07_c07.avi
JumpingJack/v_JumpingJack_g01_c01.avi
JumpingJack/v_JumpingJack_g01_c02.avi
JumpingJack/v_JumpingJack_g01_c03.avi
JumpingJack/v_JumpingJack_g01_c04.avi
JumpingJack/v_JumpingJack_g01_c05.avi
JumpingJack/v_JumpingJack_g01_c06.avi
JumpingJack/v_JumpingJack_g01_c07.avi
JumpingJack/v_JumpingJack_g02_c01.avi
JumpingJack/v_JumpingJack_g02_c02.avi
JumpingJack/v_JumpingJack_g02_c03.avi
JumpingJack/v_JumpingJack_g02_c04.avi
JumpingJack/v_JumpingJack_g03_c01.avi
JumpingJack/v_JumpingJack_g03_c02.avi
JumpingJack/v_JumpingJack_g03_c03.avi
JumpingJack/v_JumpingJack_g03_c04.avi
JumpingJack/v_JumpingJack_g04_c01.avi
JumpingJack/v_JumpingJack_g04_c02.avi
JumpingJack/v_JumpingJack_g04_c03.avi
JumpingJack/v_JumpingJack_g04_c04.avi
JumpingJack/v_JumpingJack_g05_c01.avi
JumpingJack/v_JumpingJack_g05_c02.avi
JumpingJack/v_JumpingJack_g05_c03.avi
JumpingJack/v_JumpingJack_g05_c04.avi
JumpingJack/v_JumpingJack_g05_c05.avi
JumpingJack/v_JumpingJack_g05_c06.avi
JumpingJack/v_JumpingJack_g06_c01.avi
JumpingJack/v_JumpingJack_g06_c02.avi
JumpingJack/v_JumpingJack_g06_c03.avi
JumpingJack/v_JumpingJack_g06_c04.avi
JumpingJack/v_JumpingJack_g06_c05.avi
JumpingJack/v_JumpingJack_g06_c06.avi
JumpingJack/v_JumpingJack_g06_c07.avi
JumpingJack/v_JumpingJack_g07_c01.avi
JumpingJack/v_JumpingJack_g07_c02.avi
JumpingJack/v_JumpingJack_g07_c03.avi
JumpingJack/v_JumpingJack_g07_c04.avi
JumpingJack/v_JumpingJack_g07_c05.avi
JumpRope/v_JumpRope_g01_c01.avi
JumpRope/v_JumpRope_g01_c02.avi
JumpRope/v_JumpRope_g01_c03.avi
JumpRope/v_JumpRope_g01_c04.avi
JumpRope/v_JumpRope_g02_c01.avi
JumpRope/v_JumpRope_g02_c02.avi
JumpRope/v_JumpRope_g02_c03.avi
JumpRope/v_JumpRope_g02_c04.avi
JumpRope/v_JumpRope_g02_c05.avi
JumpRope/v_JumpRope_g02_c06.avi
JumpRope/v_JumpRope_g02_c07.avi
JumpRope/v_JumpRope_g03_c01.avi
JumpRope/v_JumpRope_g03_c02.avi
JumpRope/v_JumpRope_g03_c03.avi
JumpRope/v_JumpRope_g03_c04.avi
JumpRope/v_JumpRope_g04_c01.avi
JumpRope/v_JumpRope_g04_c02.avi
JumpRope/v_JumpRope_g04_c03.avi
JumpRope/v_JumpRope_g04_c04.avi
JumpRope/v_JumpRope_g04_c05.avi
JumpRope/v_JumpRope_g04_c06.avi
JumpRope/v_JumpRope_g04_c07.avi
JumpRope/v_JumpRope_g05_c01.avi
JumpRope/v_JumpRope_g05_c02.avi
JumpRope/v_JumpRope_g05_c03.avi
JumpRope/v_JumpRope_g05_c04.avi
JumpRope/v_JumpRope_g05_c05.avi
JumpRope/v_JumpRope_g06_c01.avi
JumpRope/v_JumpRope_g06_c02.avi
JumpRope/v_JumpRope_g06_c03.avi
JumpRope/v_JumpRope_g06_c04.avi
JumpRope/v_JumpRope_g06_c05.avi
JumpRope/v_JumpRope_g07_c01.avi
JumpRope/v_JumpRope_g07_c02.avi
JumpRope/v_JumpRope_g07_c03.avi
JumpRope/v_JumpRope_g07_c04.avi
JumpRope/v_JumpRope_g07_c05.avi
JumpRope/v_JumpRope_g07_c06.avi
Kayaking/v_Kayaking_g01_c01.avi
Kayaking/v_Kayaking_g01_c02.avi
Kayaking/v_Kayaking_g01_c03.avi
Kayaking/v_Kayaking_g01_c04.avi
Kayaking/v_Kayaking_g01_c05.avi
Kayaking/v_Kayaking_g01_c06.avi
Kayaking/v_Kayaking_g02_c01.avi
Kayaking/v_Kayaking_g02_c02.avi
Kayaking/v_Kayaking_g02_c03.avi
Kayaking/v_Kayaking_g02_c04.avi
Kayaking/v_Kayaking_g03_c01.avi
Kayaking/v_Kayaking_g03_c02.avi
Kayaking/v_Kayaking_g03_c03.avi
Kayaking/v_Kayaking_g03_c04.avi
Kayaking/v_Kayaking_g04_c01.avi
Kayaking/v_Kayaking_g04_c02.avi
Kayaking/v_Kayaking_g04_c03.avi
Kayaking/v_Kayaking_g04_c04.avi
Kayaking/v_Kayaking_g04_c05.avi
Kayaking/v_Kayaking_g04_c06.avi
Kayaking/v_Kayaking_g04_c07.avi
Kayaking/v_Kayaking_g05_c01.avi
Kayaking/v_Kayaking_g05_c02.avi
Kayaking/v_Kayaking_g05_c03.avi
Kayaking/v_Kayaking_g05_c04.avi
Kayaking/v_Kayaking_g06_c01.avi
Kayaking/v_Kayaking_g06_c02.avi
Kayaking/v_Kayaking_g06_c03.avi
Kayaking/v_Kayaking_g06_c04.avi
Kayaking/v_Kayaking_g06_c05.avi
Kayaking/v_Kayaking_g06_c06.avi
Kayaking/v_Kayaking_g06_c07.avi
Kayaking/v_Kayaking_g07_c01.avi
Kayaking/v_Kayaking_g07_c02.avi
Kayaking/v_Kayaking_g07_c03.avi
Kayaking/v_Kayaking_g07_c04.avi
Knitting/v_Knitting_g01_c01.avi
Knitting/v_Knitting_g01_c02.avi
Knitting/v_Knitting_g01_c03.avi
Knitting/v_Knitting_g01_c04.avi
Knitting/v_Knitting_g02_c01.avi
Knitting/v_Knitting_g02_c02.avi
Knitting/v_Knitting_g02_c03.avi
Knitting/v_Knitting_g02_c04.avi
Knitting/v_Knitting_g02_c05.avi
Knitting/v_Knitting_g03_c01.avi
Knitting/v_Knitting_g03_c02.avi
Knitting/v_Knitting_g03_c03.avi
Knitting/v_Knitting_g03_c04.avi
Knitting/v_Knitting_g03_c05.avi
Knitting/v_Knitting_g04_c01.avi
Knitting/v_Knitting_g04_c02.avi
Knitting/v_Knitting_g04_c03.avi
Knitting/v_Knitting_g04_c04.avi
Knitting/v_Knitting_g04_c05.avi
Knitting/v_Knitting_g04_c06.avi
Knitting/v_Knitting_g05_c01.avi
Knitting/v_Knitting_g05_c02.avi
Knitting/v_Knitting_g05_c03.avi
Knitting/v_Knitting_g05_c04.avi
Knitting/v_Knitting_g05_c05.avi
Knitting/v_Knitting_g06_c01.avi
Knitting/v_Knitting_g06_c02.avi
Knitting/v_Knitting_g06_c03.avi
Knitting/v_Knitting_g06_c04.avi
Knitting/v_Knitting_g07_c01.avi
Knitting/v_Knitting_g07_c02.avi
Knitting/v_Knitting_g07_c03.avi
Knitting/v_Knitting_g07_c04.avi
Knitting/v_Knitting_g07_c05.avi
LongJump/v_LongJump_g01_c01.avi
LongJump/v_LongJump_g01_c02.avi
LongJump/v_LongJump_g01_c03.avi
LongJump/v_LongJump_g01_c04.avi
LongJump/v_LongJump_g01_c05.avi
LongJump/v_LongJump_g01_c06.avi
LongJump/v_LongJump_g01_c07.avi
LongJump/v_LongJump_g02_c01.avi
LongJump/v_LongJump_g02_c02.avi
LongJump/v_LongJump_g02_c03.avi
LongJump/v_LongJump_g02_c04.avi
LongJump/v_LongJump_g02_c05.avi
LongJump/v_LongJump_g03_c01.avi
LongJump/v_LongJump_g03_c02.avi
LongJump/v_LongJump_g03_c03.avi
LongJump/v_LongJump_g03_c04.avi
LongJump/v_LongJump_g03_c05.avi
LongJump/v_LongJump_g03_c06.avi
LongJump/v_LongJump_g04_c01.avi
LongJump/v_LongJump_g04_c02.avi
LongJump/v_LongJump_g04_c03.avi
LongJump/v_LongJump_g04_c04.avi
LongJump/v_LongJump_g04_c05.avi
LongJump/v_LongJump_g04_c06.avi
LongJump/v_LongJump_g04_c07.avi
LongJump/v_LongJump_g05_c01.avi
LongJump/v_LongJump_g05_c02.avi
LongJump/v_LongJump_g05_c03.avi
LongJump/v_LongJump_g05_c04.avi
LongJump/v_LongJump_g05_c05.avi
LongJump/v_LongJump_g06_c01.avi
LongJump/v_LongJump_g06_c02.avi
LongJump/v_LongJump_g06_c03.avi
LongJump/v_LongJump_g06_c04.avi
LongJump/v_LongJump_g07_c01.avi
LongJump/v_LongJump_g07_c02.avi
LongJump/v_LongJump_g07_c03.avi
LongJump/v_LongJump_g07_c04.avi
LongJump/v_LongJump_g07_c05.avi
Lunges/v_Lunges_g01_c01.avi
Lunges/v_Lunges_g01_c02.avi
Lunges/v_Lunges_g01_c03.avi
Lunges/v_Lunges_g01_c04.avi
Lunges/v_Lunges_g01_c05.avi
Lunges/v_Lunges_g01_c06.avi
Lunges/v_Lunges_g01_c07.avi
Lunges/v_Lunges_g02_c01.avi
Lunges/v_Lunges_g02_c02.avi
Lunges/v_Lunges_g02_c03.avi
Lunges/v_Lunges_g02_c04.avi
Lunges/v_Lunges_g03_c01.avi
Lunges/v_Lunges_g03_c02.avi
Lunges/v_Lunges_g03_c03.avi
Lunges/v_Lunges_g03_c04.avi
Lunges/v_Lunges_g04_c01.avi
Lunges/v_Lunges_g04_c02.avi
Lunges/v_Lunges_g04_c03.avi
Lunges/v_Lunges_g04_c04.avi
Lunges/v_Lunges_g05_c01.avi
Lunges/v_Lunges_g05_c02.avi
Lunges/v_Lunges_g05_c03.avi
Lunges/v_Lunges_g05_c04.avi
Lunges/v_Lunges_g06_c01.avi
Lunges/v_Lunges_g06_c02.avi
Lunges/v_Lunges_g06_c03.avi
Lunges/v_Lunges_g06_c04.avi
Lunges/v_Lunges_g06_c05.avi
Lunges/v_Lunges_g06_c06.avi
Lunges/v_Lunges_g06_c07.avi
Lunges/v_Lunges_g07_c01.avi
Lunges/v_Lunges_g07_c02.avi
Lunges/v_Lunges_g07_c03.avi
Lunges/v_Lunges_g07_c04.avi
Lunges/v_Lunges_g07_c05.avi
Lunges/v_Lunges_g07_c06.avi
Lunges/v_Lunges_g07_c07.avi
MilitaryParade/v_MilitaryParade_g01_c01.avi
MilitaryParade/v_MilitaryParade_g01_c02.avi
MilitaryParade/v_MilitaryParade_g01_c03.avi
MilitaryParade/v_MilitaryParade_g01_c04.avi
MilitaryParade/v_MilitaryParade_g01_c05.avi
MilitaryParade/v_MilitaryParade_g01_c06.avi
MilitaryParade/v_MilitaryParade_g01_c07.avi
MilitaryParade/v_MilitaryParade_g02_c01.avi
MilitaryParade/v_MilitaryParade_g02_c02.avi
MilitaryParade/v_MilitaryParade_g02_c03.avi
MilitaryParade/v_MilitaryParade_g02_c04.avi
MilitaryParade/v_MilitaryParade_g03_c01.avi
MilitaryParade/v_MilitaryParade_g03_c02.avi
MilitaryParade/v_MilitaryParade_g03_c03.avi
MilitaryParade/v_MilitaryParade_g03_c04.avi
MilitaryParade/v_MilitaryParade_g04_c01.avi
MilitaryParade/v_MilitaryParade_g04_c02.avi
MilitaryParade/v_MilitaryParade_g04_c03.avi
MilitaryParade/v_MilitaryParade_g04_c04.avi
MilitaryParade/v_MilitaryParade_g05_c01.avi
MilitaryParade/v_MilitaryParade_g05_c02.avi
MilitaryParade/v_MilitaryParade_g05_c03.avi
MilitaryParade/v_MilitaryParade_g05_c04.avi
MilitaryParade/v_MilitaryParade_g06_c01.avi
MilitaryParade/v_MilitaryParade_g06_c02.avi
MilitaryParade/v_MilitaryParade_g06_c03.avi
MilitaryParade/v_MilitaryParade_g06_c04.avi
MilitaryParade/v_MilitaryParade_g07_c01.avi
MilitaryParade/v_MilitaryParade_g07_c02.avi
MilitaryParade/v_MilitaryParade_g07_c03.avi
MilitaryParade/v_MilitaryParade_g07_c04.avi
MilitaryParade/v_MilitaryParade_g07_c05.avi
MilitaryParade/v_MilitaryParade_g07_c06.avi
Mixing/v_Mixing_g01_c01.avi
Mixing/v_Mixing_g01_c02.avi
Mixing/v_Mixing_g01_c03.avi
Mixing/v_Mixing_g01_c04.avi
Mixing/v_Mixing_g01_c05.avi
Mixing/v_Mixing_g01_c06.avi
Mixing/v_Mixing_g01_c07.avi
Mixing/v_Mixing_g02_c01.avi
Mixing/v_Mixing_g02_c02.avi
Mixing/v_Mixing_g02_c03.avi
Mixing/v_Mixing_g02_c04.avi
Mixing/v_Mixing_g02_c05.avi
Mixing/v_Mixing_g02_c06.avi
Mixing/v_Mixing_g03_c01.avi
Mixing/v_Mixing_g03_c02.avi
Mixing/v_Mixing_g03_c03.avi
Mixing/v_Mixing_g03_c04.avi
Mixing/v_Mixing_g03_c05.avi
Mixing/v_Mixing_g03_c06.avi
Mixing/v_Mixing_g03_c07.avi
Mixing/v_Mixing_g04_c01.avi
Mixing/v_Mixing_g04_c02.avi
Mixing/v_Mixing_g04_c03.avi
Mixing/v_Mixing_g04_c04.avi
Mixing/v_Mixing_g04_c05.avi
Mixing/v_Mixing_g04_c06.avi
Mixing/v_Mixing_g04_c07.avi
Mixing/v_Mixing_g05_c01.avi
Mixing/v_Mixing_g05_c02.avi
Mixing/v_Mixing_g05_c03.avi
Mixing/v_Mixing_g05_c04.avi
Mixing/v_Mixing_g05_c05.avi
Mixing/v_Mixing_g05_c06.avi
Mixing/v_Mixing_g05_c07.avi
Mixing/v_Mixing_g06_c01.avi
Mixing/v_Mixing_g06_c02.avi
Mixing/v_Mixing_g06_c03.avi
Mixing/v_Mixing_g06_c04.avi
Mixing/v_Mixing_g06_c05.avi
Mixing/v_Mixing_g06_c06.avi
Mixing/v_Mixing_g07_c01.avi
Mixing/v_Mixing_g07_c02.avi
Mixing/v_Mixing_g07_c03.avi
Mixing/v_Mixing_g07_c04.avi
Mixing/v_Mixing_g07_c05.avi
MoppingFloor/v_MoppingFloor_g01_c01.avi
MoppingFloor/v_MoppingFloor_g01_c02.avi
MoppingFloor/v_MoppingFloor_g01_c03.avi
MoppingFloor/v_MoppingFloor_g01_c04.avi
MoppingFloor/v_MoppingFloor_g02_c01.avi
MoppingFloor/v_MoppingFloor_g02_c02.avi
MoppingFloor/v_MoppingFloor_g02_c03.avi
MoppingFloor/v_MoppingFloor_g02_c04.avi
MoppingFloor/v_MoppingFloor_g02_c05.avi
MoppingFloor/v_MoppingFloor_g02_c06.avi
MoppingFloor/v_MoppingFloor_g03_c01.avi
MoppingFloor/v_MoppingFloor_g03_c02.avi
MoppingFloor/v_MoppingFloor_g03_c03.avi
MoppingFloor/v_MoppingFloor_g03_c04.avi
MoppingFloor/v_MoppingFloor_g04_c01.avi
MoppingFloor/v_MoppingFloor_g04_c02.avi
MoppingFloor/v_MoppingFloor_g04_c03.avi
MoppingFloor/v_MoppingFloor_g04_c04.avi
MoppingFloor/v_MoppingFloor_g04_c05.avi
MoppingFloor/v_MoppingFloor_g04_c06.avi
MoppingFloor/v_MoppingFloor_g05_c01.avi
MoppingFloor/v_MoppingFloor_g05_c02.avi
MoppingFloor/v_MoppingFloor_g05_c03.avi
MoppingFloor/v_MoppingFloor_g05_c04.avi
MoppingFloor/v_MoppingFloor_g05_c05.avi
MoppingFloor/v_MoppingFloor_g06_c01.avi
MoppingFloor/v_MoppingFloor_g06_c02.avi
MoppingFloor/v_MoppingFloor_g06_c03.avi
MoppingFloor/v_MoppingFloor_g06_c04.avi
MoppingFloor/v_MoppingFloor_g07_c01.avi
MoppingFloor/v_MoppingFloor_g07_c02.avi
MoppingFloor/v_MoppingFloor_g07_c03.avi
MoppingFloor/v_MoppingFloor_g07_c04.avi
MoppingFloor/v_MoppingFloor_g07_c05.avi
Nunchucks/v_Nunchucks_g01_c01.avi
Nunchucks/v_Nunchucks_g01_c02.avi
Nunchucks/v_Nunchucks_g01_c03.avi
Nunchucks/v_Nunchucks_g01_c04.avi
Nunchucks/v_Nunchucks_g02_c01.avi
Nunchucks/v_Nunchucks_g02_c02.avi
Nunchucks/v_Nunchucks_g02_c03.avi
Nunchucks/v_Nunchucks_g02_c04.avi
Nunchucks/v_Nunchucks_g02_c05.avi
Nunchucks/v_Nunchucks_g02_c06.avi
Nunchucks/v_Nunchucks_g03_c01.avi
Nunchucks/v_Nunchucks_g03_c02.avi
Nunchucks/v_Nunchucks_g03_c03.avi
Nunchucks/v_Nunchucks_g03_c04.avi
Nunchucks/v_Nunchucks_g03_c05.avi
Nunchucks/v_Nunchucks_g03_c06.avi
Nunchucks/v_Nunchucks_g03_c07.avi
Nunchucks/v_Nunchucks_g04_c01.avi
Nunchucks/v_Nunchucks_g04_c02.avi
Nunchucks/v_Nunchucks_g04_c03.avi
Nunchucks/v_Nunchucks_g04_c04.avi
Nunchucks/v_Nunchucks_g04_c05.avi
Nunchucks/v_Nunchucks_g04_c06.avi
Nunchucks/v_Nunchucks_g05_c01.avi
Nunchucks/v_Nunchucks_g05_c02.avi
Nunchucks/v_Nunchucks_g05_c03.avi
Nunchucks/v_Nunchucks_g05_c04.avi
Nunchucks/v_Nunchucks_g06_c01.avi
Nunchucks/v_Nunchucks_g06_c02.avi
Nunchucks/v_Nunchucks_g06_c03.avi
Nunchucks/v_Nunchucks_g06_c04.avi
Nunchucks/v_Nunchucks_g07_c01.avi
Nunchucks/v_Nunchucks_g07_c02.avi
Nunchucks/v_Nunchucks_g07_c03.avi
Nunchucks/v_Nunchucks_g07_c04.avi
ParallelBars/v_ParallelBars_g01_c01.avi
ParallelBars/v_ParallelBars_g01_c02.avi
ParallelBars/v_ParallelBars_g01_c03.avi
ParallelBars/v_ParallelBars_g01_c04.avi
ParallelBars/v_ParallelBars_g02_c01.avi
ParallelBars/v_ParallelBars_g02_c02.avi
ParallelBars/v_ParallelBars_g02_c03.avi
ParallelBars/v_ParallelBars_g02_c04.avi
ParallelBars/v_ParallelBars_g03_c01.avi
ParallelBars/v_ParallelBars_g03_c02.avi
ParallelBars/v_ParallelBars_g03_c03.avi
ParallelBars/v_ParallelBars_g03_c04.avi
ParallelBars/v_ParallelBars_g04_c01.avi
ParallelBars/v_ParallelBars_g04_c02.avi
ParallelBars/v_ParallelBars_g04_c03.avi
ParallelBars/v_ParallelBars_g04_c04.avi
ParallelBars/v_ParallelBars_g04_c05.avi
ParallelBars/v_ParallelBars_g04_c06.avi
ParallelBars/v_ParallelBars_g04_c07.avi
ParallelBars/v_ParallelBars_g05_c01.avi
ParallelBars/v_ParallelBars_g05_c02.avi
ParallelBars/v_ParallelBars_g05_c03.avi
ParallelBars/v_ParallelBars_g05_c04.avi
ParallelBars/v_ParallelBars_g05_c05.avi
ParallelBars/v_ParallelBars_g06_c01.avi
ParallelBars/v_ParallelBars_g06_c02.avi
ParallelBars/v_ParallelBars_g06_c03.avi
ParallelBars/v_ParallelBars_g06_c04.avi
ParallelBars/v_ParallelBars_g06_c05.avi
ParallelBars/v_ParallelBars_g06_c06.avi
ParallelBars/v_ParallelBars_g06_c07.avi
ParallelBars/v_ParallelBars_g07_c01.avi
ParallelBars/v_ParallelBars_g07_c02.avi
ParallelBars/v_ParallelBars_g07_c03.avi
ParallelBars/v_ParallelBars_g07_c04.avi
ParallelBars/v_ParallelBars_g07_c05.avi
ParallelBars/v_ParallelBars_g07_c06.avi
PizzaTossing/v_PizzaTossing_g01_c01.avi
PizzaTossing/v_PizzaTossing_g01_c02.avi
PizzaTossing/v_PizzaTossing_g01_c03.avi
PizzaTossing/v_PizzaTossing_g01_c04.avi
PizzaTossing/v_PizzaTossing_g02_c01.avi
PizzaTossing/v_PizzaTossing_g02_c02.avi
PizzaTossing/v_PizzaTossing_g02_c03.avi
PizzaTossing/v_PizzaTossing_g02_c04.avi
PizzaTossing/v_PizzaTossing_g02_c05.avi
PizzaTossing/v_PizzaTossing_g03_c01.avi
PizzaTossing/v_PizzaTossing_g03_c02.avi
PizzaTossing/v_PizzaTossing_g03_c03.avi
PizzaTossing/v_PizzaTossing_g03_c04.avi
PizzaTossing/v_PizzaTossing_g04_c01.avi
PizzaTossing/v_PizzaTossing_g04_c02.avi
PizzaTossing/v_PizzaTossing_g04_c03.avi
PizzaTossing/v_PizzaTossing_g04_c04.avi
PizzaTossing/v_PizzaTossing_g04_c05.avi
PizzaTossing/v_PizzaTossing_g04_c06.avi
PizzaTossing/v_PizzaTossing_g04_c07.avi
PizzaTossing/v_PizzaTossing_g05_c01.avi
PizzaTossing/v_PizzaTossing_g05_c02.avi
PizzaTossing/v_PizzaTossing_g05_c03.avi
PizzaTossing/v_PizzaTossing_g05_c04.avi
PizzaTossing/v_PizzaTossing_g06_c01.avi
PizzaTossing/v_PizzaTossing_g06_c02.avi
PizzaTossing/v_PizzaTossing_g06_c03.avi
PizzaTossing/v_PizzaTossing_g06_c04.avi
PizzaTossing/v_PizzaTossing_g06_c05.avi
PizzaTossing/v_PizzaTossing_g07_c01.avi
PizzaTossing/v_PizzaTossing_g07_c02.avi
PizzaTossing/v_PizzaTossing_g07_c03.avi
PizzaTossing/v_PizzaTossing_g07_c04.avi
PlayingCello/v_PlayingCello_g01_c01.avi
PlayingCello/v_PlayingCello_g01_c02.avi
PlayingCello/v_PlayingCello_g01_c03.avi
PlayingCello/v_PlayingCello_g01_c04.avi
PlayingCello/v_PlayingCello_g01_c05.avi
PlayingCello/v_PlayingCello_g01_c06.avi
PlayingCello/v_PlayingCello_g01_c07.avi
PlayingCello/v_PlayingCello_g02_c01.avi
PlayingCello/v_PlayingCello_g02_c02.avi
PlayingCello/v_PlayingCello_g02_c03.avi
PlayingCello/v_PlayingCello_g02_c04.avi
PlayingCello/v_PlayingCello_g02_c05.avi
PlayingCello/v_PlayingCello_g02_c06.avi
PlayingCello/v_PlayingCello_g02_c07.avi
PlayingCello/v_PlayingCello_g03_c01.avi
PlayingCello/v_PlayingCello_g03_c02.avi
PlayingCello/v_PlayingCello_g03_c03.avi
PlayingCello/v_PlayingCello_g03_c04.avi
PlayingCello/v_PlayingCello_g04_c01.avi
PlayingCello/v_PlayingCello_g04_c02.avi
PlayingCello/v_PlayingCello_g04_c03.avi
PlayingCello/v_PlayingCello_g04_c04.avi
PlayingCello/v_PlayingCello_g04_c05.avi
PlayingCello/v_PlayingCello_g04_c06.avi
PlayingCello/v_PlayingCello_g04_c07.avi
PlayingCello/v_PlayingCello_g05_c01.avi
PlayingCello/v_PlayingCello_g05_c02.avi
PlayingCello/v_PlayingCello_g05_c03.avi
PlayingCello/v_PlayingCello_g05_c04.avi
PlayingCello/v_PlayingCello_g05_c05.avi
PlayingCello/v_PlayingCello_g05_c06.avi
PlayingCello/v_PlayingCello_g05_c07.avi
PlayingCello/v_PlayingCello_g06_c01.avi
PlayingCello/v_PlayingCello_g06_c02.avi
PlayingCello/v_PlayingCello_g06_c03.avi
PlayingCello/v_PlayingCello_g06_c04.avi
PlayingCello/v_PlayingCello_g06_c05.avi
PlayingCello/v_PlayingCello_g06_c06.avi
PlayingCello/v_PlayingCello_g06_c07.avi
PlayingCello/v_PlayingCello_g07_c01.avi
PlayingCello/v_PlayingCello_g07_c02.avi
PlayingCello/v_PlayingCello_g07_c03.avi
PlayingCello/v_PlayingCello_g07_c04.avi
PlayingCello/v_PlayingCello_g07_c05.avi
PlayingDaf/v_PlayingDaf_g01_c01.avi
PlayingDaf/v_PlayingDaf_g01_c02.avi
PlayingDaf/v_PlayingDaf_g01_c03.avi
PlayingDaf/v_PlayingDaf_g01_c04.avi
PlayingDaf/v_PlayingDaf_g02_c01.avi
PlayingDaf/v_PlayingDaf_g02_c02.avi
PlayingDaf/v_PlayingDaf_g02_c03.avi
PlayingDaf/v_PlayingDaf_g02_c04.avi
PlayingDaf/v_PlayingDaf_g02_c05.avi
PlayingDaf/v_PlayingDaf_g02_c06.avi
PlayingDaf/v_PlayingDaf_g02_c07.avi
PlayingDaf/v_PlayingDaf_g03_c01.avi
PlayingDaf/v_PlayingDaf_g03_c02.avi
PlayingDaf/v_PlayingDaf_g03_c03.avi
PlayingDaf/v_PlayingDaf_g03_c04.avi
PlayingDaf/v_PlayingDaf_g04_c01.avi
PlayingDaf/v_PlayingDaf_g04_c02.avi
PlayingDaf/v_PlayingDaf_g04_c03.avi
PlayingDaf/v_PlayingDaf_g04_c04.avi
PlayingDaf/v_PlayingDaf_g04_c05.avi
PlayingDaf/v_PlayingDaf_g04_c06.avi
PlayingDaf/v_PlayingDaf_g04_c07.avi
PlayingDaf/v_PlayingDaf_g05_c01.avi
PlayingDaf/v_PlayingDaf_g05_c02.avi
PlayingDaf/v_PlayingDaf_g05_c03.avi
PlayingDaf/v_PlayingDaf_g05_c04.avi
PlayingDaf/v_PlayingDaf_g05_c05.avi
PlayingDaf/v_PlayingDaf_g05_c06.avi
PlayingDaf/v_PlayingDaf_g05_c07.avi
PlayingDaf/v_PlayingDaf_g06_c01.avi
PlayingDaf/v_PlayingDaf_g06_c02.avi
PlayingDaf/v_PlayingDaf_g06_c03.avi
PlayingDaf/v_PlayingDaf_g06_c04.avi
PlayingDaf/v_PlayingDaf_g06_c05.avi
PlayingDaf/v_PlayingDaf_g06_c06.avi
PlayingDaf/v_PlayingDaf_g06_c07.avi
PlayingDaf/v_PlayingDaf_g07_c01.avi
PlayingDaf/v_PlayingDaf_g07_c02.avi
PlayingDaf/v_PlayingDaf_g07_c03.avi
PlayingDaf/v_PlayingDaf_g07_c04.avi
PlayingDaf/v_PlayingDaf_g07_c05.avi
PlayingDhol/v_PlayingDhol_g01_c01.avi
PlayingDhol/v_PlayingDhol_g01_c02.avi
PlayingDhol/v_PlayingDhol_g01_c03.avi
PlayingDhol/v_PlayingDhol_g01_c04.avi
PlayingDhol/v_PlayingDhol_g01_c05.avi
PlayingDhol/v_PlayingDhol_g01_c06.avi
PlayingDhol/v_PlayingDhol_g01_c07.avi
PlayingDhol/v_PlayingDhol_g02_c01.avi
PlayingDhol/v_PlayingDhol_g02_c02.avi
PlayingDhol/v_PlayingDhol_g02_c03.avi
PlayingDhol/v_PlayingDhol_g02_c04.avi
PlayingDhol/v_PlayingDhol_g02_c05.avi
PlayingDhol/v_PlayingDhol_g02_c06.avi
PlayingDhol/v_PlayingDhol_g02_c07.avi
PlayingDhol/v_PlayingDhol_g03_c01.avi
PlayingDhol/v_PlayingDhol_g03_c02.avi
PlayingDhol/v_PlayingDhol_g03_c03.avi
PlayingDhol/v_PlayingDhol_g03_c04.avi
PlayingDhol/v_PlayingDhol_g03_c05.avi
PlayingDhol/v_PlayingDhol_g03_c06.avi
PlayingDhol/v_PlayingDhol_g03_c07.avi
PlayingDhol/v_PlayingDhol_g04_c01.avi
PlayingDhol/v_PlayingDhol_g04_c02.avi
PlayingDhol/v_PlayingDhol_g04_c03.avi
PlayingDhol/v_PlayingDhol_g04_c04.avi
PlayingDhol/v_PlayingDhol_g04_c05.avi
PlayingDhol/v_PlayingDhol_g04_c06.avi
PlayingDhol/v_PlayingDhol_g04_c07.avi
PlayingDhol/v_PlayingDhol_g05_c01.avi
PlayingDhol/v_PlayingDhol_g05_c02.avi
PlayingDhol/v_PlayingDhol_g05_c03.avi
PlayingDhol/v_PlayingDhol_g05_c04.avi
PlayingDhol/v_PlayingDhol_g05_c05.avi
PlayingDhol/v_PlayingDhol_g05_c06.avi
PlayingDhol/v_PlayingDhol_g05_c07.avi
PlayingDhol/v_PlayingDhol_g06_c01.avi
PlayingDhol/v_PlayingDhol_g06_c02.avi
PlayingDhol/v_PlayingDhol_g06_c03.avi
PlayingDhol/v_PlayingDhol_g06_c04.avi
PlayingDhol/v_PlayingDhol_g06_c05.avi
PlayingDhol/v_PlayingDhol_g06_c06.avi
PlayingDhol/v_PlayingDhol_g06_c07.avi
PlayingDhol/v_PlayingDhol_g07_c01.avi
PlayingDhol/v_PlayingDhol_g07_c02.avi
PlayingDhol/v_PlayingDhol_g07_c03.avi
PlayingDhol/v_PlayingDhol_g07_c04.avi
PlayingDhol/v_PlayingDhol_g07_c05.avi
PlayingDhol/v_PlayingDhol_g07_c06.avi
PlayingDhol/v_PlayingDhol_g07_c07.avi
PlayingFlute/v_PlayingFlute_g01_c01.avi
PlayingFlute/v_PlayingFlute_g01_c02.avi
PlayingFlute/v_PlayingFlute_g01_c03.avi
PlayingFlute/v_PlayingFlute_g01_c04.avi
PlayingFlute/v_PlayingFlute_g01_c05.avi
PlayingFlute/v_PlayingFlute_g01_c06.avi
PlayingFlute/v_PlayingFlute_g01_c07.avi
PlayingFlute/v_PlayingFlute_g02_c01.avi
PlayingFlute/v_PlayingFlute_g02_c02.avi
PlayingFlute/v_PlayingFlute_g02_c03.avi
PlayingFlute/v_PlayingFlute_g02_c04.avi
PlayingFlute/v_PlayingFlute_g02_c05.avi
PlayingFlute/v_PlayingFlute_g02_c06.avi
PlayingFlute/v_PlayingFlute_g02_c07.avi
PlayingFlute/v_PlayingFlute_g03_c01.avi
PlayingFlute/v_PlayingFlute_g03_c02.avi
PlayingFlute/v_PlayingFlute_g03_c03.avi
PlayingFlute/v_PlayingFlute_g03_c04.avi
PlayingFlute/v_PlayingFlute_g03_c05.avi
PlayingFlute/v_PlayingFlute_g03_c06.avi
PlayingFlute/v_PlayingFlute_g03_c07.avi
PlayingFlute/v_PlayingFlute_g04_c01.avi
PlayingFlute/v_PlayingFlute_g04_c02.avi
PlayingFlute/v_PlayingFlute_g04_c03.avi
PlayingFlute/v_PlayingFlute_g04_c04.avi
PlayingFlute/v_PlayingFlute_g04_c05.avi
PlayingFlute/v_PlayingFlute_g04_c06.avi
PlayingFlute/v_PlayingFlute_g04_c07.avi
PlayingFlute/v_PlayingFlute_g05_c01.avi
PlayingFlute/v_PlayingFlute_g05_c02.avi
PlayingFlute/v_PlayingFlute_g05_c03.avi
PlayingFlute/v_PlayingFlute_g05_c04.avi
PlayingFlute/v_PlayingFlute_g05_c05.avi
PlayingFlute/v_PlayingFlute_g05_c06.avi
PlayingFlute/v_PlayingFlute_g05_c07.avi
PlayingFlute/v_PlayingFlute_g06_c01.avi
PlayingFlute/v_PlayingFlute_g06_c02.avi
PlayingFlute/v_PlayingFlute_g06_c03.avi
PlayingFlute/v_PlayingFlute_g06_c04.avi
PlayingFlute/v_PlayingFlute_g06_c05.avi
PlayingFlute/v_PlayingFlute_g06_c06.avi
PlayingFlute/v_PlayingFlute_g07_c01.avi
PlayingFlute/v_PlayingFlute_g07_c02.avi
PlayingFlute/v_PlayingFlute_g07_c03.avi
PlayingFlute/v_PlayingFlute_g07_c04.avi
PlayingFlute/v_PlayingFlute_g07_c05.avi
PlayingFlute/v_PlayingFlute_g07_c06.avi
PlayingFlute/v_PlayingFlute_g07_c07.avi
PlayingGuitar/v_PlayingGuitar_g01_c01.avi
PlayingGuitar/v_PlayingGuitar_g01_c02.avi
PlayingGuitar/v_PlayingGuitar_g01_c03.avi
PlayingGuitar/v_PlayingGuitar_g01_c04.avi
PlayingGuitar/v_PlayingGuitar_g01_c05.avi
PlayingGuitar/v_PlayingGuitar_g01_c06.avi
PlayingGuitar/v_PlayingGuitar_g02_c01.avi
PlayingGuitar/v_PlayingGuitar_g02_c02.avi
PlayingGuitar/v_PlayingGuitar_g02_c03.avi
PlayingGuitar/v_PlayingGuitar_g02_c04.avi
PlayingGuitar/v_PlayingGuitar_g03_c01.avi
PlayingGuitar/v_PlayingGuitar_g03_c02.avi
PlayingGuitar/v_PlayingGuitar_g03_c03.avi
PlayingGuitar/v_PlayingGuitar_g03_c04.avi
PlayingGuitar/v_PlayingGuitar_g03_c05.avi
PlayingGuitar/v_PlayingGuitar_g03_c06.avi
PlayingGuitar/v_PlayingGuitar_g03_c07.avi
PlayingGuitar/v_PlayingGuitar_g04_c01.avi
PlayingGuitar/v_PlayingGuitar_g04_c02.avi
PlayingGuitar/v_PlayingGuitar_g04_c03.avi
PlayingGuitar/v_PlayingGuitar_g04_c04.avi
PlayingGuitar/v_PlayingGuitar_g04_c05.avi
PlayingGuitar/v_PlayingGuitar_g04_c06.avi
PlayingGuitar/v_PlayingGuitar_g04_c07.avi
PlayingGuitar/v_PlayingGuitar_g05_c01.avi
PlayingGuitar/v_PlayingGuitar_g05_c02.avi
PlayingGuitar/v_PlayingGuitar_g05_c03.avi
PlayingGuitar/v_PlayingGuitar_g05_c04.avi
PlayingGuitar/v_PlayingGuitar_g05_c05.avi
PlayingGuitar/v_PlayingGuitar_g06_c01.avi
PlayingGuitar/v_PlayingGuitar_g06_c02.avi
PlayingGuitar/v_PlayingGuitar_g06_c03.avi
PlayingGuitar/v_PlayingGuitar_g06_c04.avi
PlayingGuitar/v_PlayingGuitar_g06_c05.avi
PlayingGuitar/v_PlayingGuitar_g06_c06.avi
PlayingGuitar/v_PlayingGuitar_g06_c07.avi
PlayingGuitar/v_PlayingGuitar_g07_c01.avi
PlayingGuitar/v_PlayingGuitar_g07_c02.avi
PlayingGuitar/v_PlayingGuitar_g07_c03.avi
PlayingGuitar/v_PlayingGuitar_g07_c04.avi
PlayingGuitar/v_PlayingGuitar_g07_c05.avi
PlayingGuitar/v_PlayingGuitar_g07_c06.avi
PlayingGuitar/v_PlayingGuitar_g07_c07.avi
PlayingPiano/v_PlayingPiano_g01_c01.avi
PlayingPiano/v_PlayingPiano_g01_c02.avi
PlayingPiano/v_PlayingPiano_g01_c03.avi
PlayingPiano/v_PlayingPiano_g01_c04.avi
PlayingPiano/v_PlayingPiano_g02_c01.avi
PlayingPiano/v_PlayingPiano_g02_c02.avi
PlayingPiano/v_PlayingPiano_g02_c03.avi
PlayingPiano/v_PlayingPiano_g02_c04.avi
PlayingPiano/v_PlayingPiano_g03_c01.avi
PlayingPiano/v_PlayingPiano_g03_c02.avi
PlayingPiano/v_PlayingPiano_g03_c03.avi
PlayingPiano/v_PlayingPiano_g03_c04.avi
PlayingPiano/v_PlayingPiano_g04_c01.avi
PlayingPiano/v_PlayingPiano_g04_c02.avi
PlayingPiano/v_PlayingPiano_g04_c03.avi
PlayingPiano/v_PlayingPiano_g04_c04.avi
PlayingPiano/v_PlayingPiano_g05_c01.avi
PlayingPiano/v_PlayingPiano_g05_c02.avi
PlayingPiano/v_PlayingPiano_g05_c03.avi
PlayingPiano/v_PlayingPiano_g05_c04.avi
PlayingPiano/v_PlayingPiano_g06_c01.avi
PlayingPiano/v_PlayingPiano_g06_c02.avi
PlayingPiano/v_PlayingPiano_g06_c03.avi
PlayingPiano/v_PlayingPiano_g06_c04.avi
PlayingPiano/v_PlayingPiano_g07_c01.avi
PlayingPiano/v_PlayingPiano_g07_c02.avi
PlayingPiano/v_PlayingPiano_g07_c03.avi
PlayingPiano/v_PlayingPiano_g07_c04.avi
PlayingSitar/v_PlayingSitar_g01_c01.avi
PlayingSitar/v_PlayingSitar_g01_c02.avi
PlayingSitar/v_PlayingSitar_g01_c03.avi
PlayingSitar/v_PlayingSitar_g01_c04.avi
PlayingSitar/v_PlayingSitar_g02_c01.avi
PlayingSitar/v_PlayingSitar_g02_c02.avi
PlayingSitar/v_PlayingSitar_g02_c03.avi
PlayingSitar/v_PlayingSitar_g02_c04.avi
PlayingSitar/v_PlayingSitar_g02_c05.avi
PlayingSitar/v_PlayingSitar_g02_c06.avi
PlayingSitar/v_PlayingSitar_g03_c01.avi
PlayingSitar/v_PlayingSitar_g03_c02.avi
PlayingSitar/v_PlayingSitar_g03_c03.avi
PlayingSitar/v_PlayingSitar_g03_c04.avi
PlayingSitar/v_PlayingSitar_g03_c05.avi
PlayingSitar/v_PlayingSitar_g03_c06.avi
PlayingSitar/v_PlayingSitar_g03_c07.avi
PlayingSitar/v_PlayingSitar_g04_c01.avi
PlayingSitar/v_PlayingSitar_g04_c02.avi
PlayingSitar/v_PlayingSitar_g04_c03.avi
PlayingSitar/v_PlayingSitar_g04_c04.avi
PlayingSitar/v_PlayingSitar_g04_c05.avi
PlayingSitar/v_PlayingSitar_g04_c06.avi
PlayingSitar/v_PlayingSitar_g04_c07.avi
PlayingSitar/v_PlayingSitar_g05_c01.avi
PlayingSitar/v_PlayingSitar_g05_c02.avi
PlayingSitar/v_PlayingSitar_g05_c03.avi
PlayingSitar/v_PlayingSitar_g05_c04.avi
PlayingSitar/v_PlayingSitar_g05_c05.avi
PlayingSitar/v_PlayingSitar_g05_c06.avi
PlayingSitar/v_PlayingSitar_g05_c07.avi
PlayingSitar/v_PlayingSitar_g06_c01.avi
PlayingSitar/v_PlayingSitar_g06_c02.avi
PlayingSitar/v_PlayingSitar_g06_c03.avi
PlayingSitar/v_PlayingSitar_g06_c04.avi
PlayingSitar/v_PlayingSitar_g06_c05.avi
PlayingSitar/v_PlayingSitar_g06_c06.avi
PlayingSitar/v_PlayingSitar_g07_c01.avi
PlayingSitar/v_PlayingSitar_g07_c02.avi
PlayingSitar/v_PlayingSitar_g07_c03.avi
PlayingSitar/v_PlayingSitar_g07_c04.avi
PlayingSitar/v_PlayingSitar_g07_c05.avi
PlayingSitar/v_PlayingSitar_g07_c06.avi
PlayingSitar/v_PlayingSitar_g07_c07.avi
PlayingTabla/v_PlayingTabla_g01_c01.avi
PlayingTabla/v_PlayingTabla_g01_c02.avi
PlayingTabla/v_PlayingTabla_g01_c03.avi
PlayingTabla/v_PlayingTabla_g01_c04.avi
PlayingTabla/v_PlayingTabla_g02_c01.avi
PlayingTabla/v_PlayingTabla_g02_c02.avi
PlayingTabla/v_PlayingTabla_g02_c03.avi
PlayingTabla/v_PlayingTabla_g02_c04.avi
PlayingTabla/v_PlayingTabla_g03_c01.avi
PlayingTabla/v_PlayingTabla_g03_c02.avi
PlayingTabla/v_PlayingTabla_g03_c03.avi
PlayingTabla/v_PlayingTabla_g03_c04.avi
PlayingTabla/v_PlayingTabla_g03_c05.avi
PlayingTabla/v_PlayingTabla_g04_c01.avi
PlayingTabla/v_PlayingTabla_g04_c02.avi
PlayingTabla/v_PlayingTabla_g04_c03.avi
PlayingTabla/v_PlayingTabla_g04_c04.avi
PlayingTabla/v_PlayingTabla_g04_c05.avi
PlayingTabla/v_PlayingTabla_g04_c06.avi
PlayingTabla/v_PlayingTabla_g05_c01.avi
PlayingTabla/v_PlayingTabla_g05_c02.avi
PlayingTabla/v_PlayingTabla_g05_c03.avi
PlayingTabla/v_PlayingTabla_g05_c04.avi
PlayingTabla/v_PlayingTabla_g06_c01.avi
PlayingTabla/v_PlayingTabla_g06_c02.avi
PlayingTabla/v_PlayingTabla_g06_c03.avi
PlayingTabla/v_PlayingTabla_g06_c04.avi
PlayingTabla/v_PlayingTabla_g07_c01.avi
PlayingTabla/v_PlayingTabla_g07_c02.avi
PlayingTabla/v_PlayingTabla_g07_c03.avi
PlayingTabla/v_PlayingTabla_g07_c04.avi
PlayingViolin/v_PlayingViolin_g01_c01.avi
PlayingViolin/v_PlayingViolin_g01_c02.avi
PlayingViolin/v_PlayingViolin_g01_c03.avi
PlayingViolin/v_PlayingViolin_g01_c04.avi
PlayingViolin/v_PlayingViolin_g02_c01.avi
PlayingViolin/v_PlayingViolin_g02_c02.avi
PlayingViolin/v_PlayingViolin_g02_c03.avi
PlayingViolin/v_PlayingViolin_g02_c04.avi
PlayingViolin/v_PlayingViolin_g03_c01.avi
PlayingViolin/v_PlayingViolin_g03_c02.avi
PlayingViolin/v_PlayingViolin_g03_c03.avi
PlayingViolin/v_PlayingViolin_g03_c04.avi
PlayingViolin/v_PlayingViolin_g04_c01.avi
PlayingViolin/v_PlayingViolin_g04_c02.avi
PlayingViolin/v_PlayingViolin_g04_c03.avi
PlayingViolin/v_PlayingViolin_g04_c04.avi
PlayingViolin/v_PlayingViolin_g05_c01.avi
PlayingViolin/v_PlayingViolin_g05_c02.avi
PlayingViolin/v_PlayingViolin_g05_c03.avi
PlayingViolin/v_PlayingViolin_g05_c04.avi
PlayingViolin/v_PlayingViolin_g06_c01.avi
PlayingViolin/v_PlayingViolin_g06_c02.avi
PlayingViolin/v_PlayingViolin_g06_c03.avi
PlayingViolin/v_PlayingViolin_g06_c04.avi
PlayingViolin/v_PlayingViolin_g07_c01.avi
PlayingViolin/v_PlayingViolin_g07_c02.avi
PlayingViolin/v_PlayingViolin_g07_c03.avi
PlayingViolin/v_PlayingViolin_g07_c04.avi
PoleVault/v_PoleVault_g01_c01.avi
PoleVault/v_PoleVault_g01_c02.avi
PoleVault/v_PoleVault_g01_c03.avi
PoleVault/v_PoleVault_g01_c04.avi
PoleVault/v_PoleVault_g01_c05.avi
PoleVault/v_PoleVault_g02_c01.avi
PoleVault/v_PoleVault_g02_c02.avi
PoleVault/v_PoleVault_g02_c03.avi
PoleVault/v_PoleVault_g02_c04.avi
PoleVault/v_PoleVault_g02_c05.avi
PoleVault/v_PoleVault_g02_c06.avi
PoleVault/v_PoleVault_g02_c07.avi
PoleVault/v_PoleVault_g03_c01.avi
PoleVault/v_PoleVault_g03_c02.avi
PoleVault/v_PoleVault_g03_c03.avi
PoleVault/v_PoleVault_g03_c04.avi
PoleVault/v_PoleVault_g03_c05.avi
PoleVault/v_PoleVault_g03_c06.avi
PoleVault/v_PoleVault_g03_c07.avi
PoleVault/v_PoleVault_g04_c01.avi
PoleVault/v_PoleVault_g04_c02.avi
PoleVault/v_PoleVault_g04_c03.avi
PoleVault/v_PoleVault_g04_c04.avi
PoleVault/v_PoleVault_g04_c05.avi
PoleVault/v_PoleVault_g04_c06.avi
PoleVault/v_PoleVault_g04_c07.avi
PoleVault/v_PoleVault_g05_c01.avi
PoleVault/v_PoleVault_g05_c02.avi
PoleVault/v_PoleVault_g05_c03.avi
PoleVault/v_PoleVault_g05_c04.avi
PoleVault/v_PoleVault_g05_c05.avi
PoleVault/v_PoleVault_g06_c01.avi
PoleVault/v_PoleVault_g06_c02.avi
PoleVault/v_PoleVault_g06_c03.avi
PoleVault/v_PoleVault_g06_c04.avi
PoleVault/v_PoleVault_g06_c05.avi
PoleVault/v_PoleVault_g07_c01.avi
PoleVault/v_PoleVault_g07_c02.avi
PoleVault/v_PoleVault_g07_c03.avi
PoleVault/v_PoleVault_g07_c04.avi
PommelHorse/v_PommelHorse_g01_c01.avi
PommelHorse/v_PommelHorse_g01_c02.avi
PommelHorse/v_PommelHorse_g01_c03.avi
PommelHorse/v_PommelHorse_g01_c04.avi
PommelHorse/v_PommelHorse_g01_c05.avi
PommelHorse/v_PommelHorse_g01_c06.avi
PommelHorse/v_PommelHorse_g01_c07.avi
PommelHorse/v_PommelHorse_g02_c01.avi
PommelHorse/v_PommelHorse_g02_c02.avi
PommelHorse/v_PommelHorse_g02_c03.avi
PommelHorse/v_PommelHorse_g02_c04.avi
PommelHorse/v_PommelHorse_g03_c01.avi
PommelHorse/v_PommelHorse_g03_c02.avi
PommelHorse/v_PommelHorse_g03_c03.avi
PommelHorse/v_PommelHorse_g03_c04.avi
PommelHorse/v_PommelHorse_g04_c01.avi
PommelHorse/v_PommelHorse_g04_c02.avi
PommelHorse/v_PommelHorse_g04_c03.avi
PommelHorse/v_PommelHorse_g04_c04.avi
PommelHorse/v_PommelHorse_g04_c05.avi
PommelHorse/v_PommelHorse_g05_c01.avi
PommelHorse/v_PommelHorse_g05_c02.avi
PommelHorse/v_PommelHorse_g05_c03.avi
PommelHorse/v_PommelHorse_g05_c04.avi
PommelHorse/v_PommelHorse_g06_c01.avi
PommelHorse/v_PommelHorse_g06_c02.avi
PommelHorse/v_PommelHorse_g06_c03.avi
PommelHorse/v_PommelHorse_g06_c04.avi
PommelHorse/v_PommelHorse_g07_c01.avi
PommelHorse/v_PommelHorse_g07_c02.avi
PommelHorse/v_PommelHorse_g07_c03.avi
PommelHorse/v_PommelHorse_g07_c04.avi
PommelHorse/v_PommelHorse_g07_c05.avi
PommelHorse/v_PommelHorse_g07_c06.avi
PommelHorse/v_PommelHorse_g07_c07.avi
PullUps/v_PullUps_g01_c01.avi
PullUps/v_PullUps_g01_c02.avi
PullUps/v_PullUps_g01_c03.avi
PullUps/v_PullUps_g01_c04.avi
PullUps/v_PullUps_g02_c01.avi
PullUps/v_PullUps_g02_c02.avi
PullUps/v_PullUps_g02_c03.avi
PullUps/v_PullUps_g02_c04.avi
PullUps/v_PullUps_g03_c01.avi
PullUps/v_PullUps_g03_c02.avi
PullUps/v_PullUps_g03_c03.avi
PullUps/v_PullUps_g03_c04.avi
PullUps/v_PullUps_g04_c01.avi
PullUps/v_PullUps_g04_c02.avi
PullUps/v_PullUps_g04_c03.avi
PullUps/v_PullUps_g04_c04.avi
PullUps/v_PullUps_g05_c01.avi
PullUps/v_PullUps_g05_c02.avi
PullUps/v_PullUps_g05_c03.avi
PullUps/v_PullUps_g05_c04.avi
PullUps/v_PullUps_g06_c01.avi
PullUps/v_PullUps_g06_c02.avi
PullUps/v_PullUps_g06_c03.avi
PullUps/v_PullUps_g06_c04.avi
PullUps/v_PullUps_g07_c01.avi
PullUps/v_PullUps_g07_c02.avi
PullUps/v_PullUps_g07_c03.avi
PullUps/v_PullUps_g07_c04.avi
Punch/v_Punch_g01_c01.avi
Punch/v_Punch_g01_c02.avi
Punch/v_Punch_g01_c03.avi
Punch/v_Punch_g01_c04.avi
Punch/v_Punch_g01_c05.avi
Punch/v_Punch_g02_c01.avi
Punch/v_Punch_g02_c02.avi
Punch/v_Punch_g02_c03.avi
Punch/v_Punch_g02_c04.avi
Punch/v_Punch_g03_c01.avi
Punch/v_Punch_g03_c02.avi
Punch/v_Punch_g03_c03.avi
Punch/v_Punch_g03_c04.avi
Punch/v_Punch_g04_c01.avi
Punch/v_Punch_g04_c02.avi
Punch/v_Punch_g04_c03.avi
Punch/v_Punch_g04_c04.avi
Punch/v_Punch_g04_c05.avi
Punch/v_Punch_g05_c01.avi
Punch/v_Punch_g05_c02.avi
Punch/v_Punch_g05_c03.avi
Punch/v_Punch_g05_c04.avi
Punch/v_Punch_g05_c05.avi
Punch/v_Punch_g05_c06.avi
Punch/v_Punch_g05_c07.avi
Punch/v_Punch_g06_c01.avi
Punch/v_Punch_g06_c02.avi
Punch/v_Punch_g06_c03.avi
Punch/v_Punch_g06_c04.avi
Punch/v_Punch_g06_c05.avi
Punch/v_Punch_g06_c06.avi
Punch/v_Punch_g06_c07.avi
Punch/v_Punch_g07_c01.avi
Punch/v_Punch_g07_c02.avi
Punch/v_Punch_g07_c03.avi
Punch/v_Punch_g07_c04.avi
Punch/v_Punch_g07_c05.avi
Punch/v_Punch_g07_c06.avi
Punch/v_Punch_g07_c07.avi
PushUps/v_PushUps_g01_c01.avi
PushUps/v_PushUps_g01_c02.avi
PushUps/v_PushUps_g01_c03.avi
PushUps/v_PushUps_g01_c04.avi
PushUps/v_PushUps_g01_c05.avi
PushUps/v_PushUps_g02_c01.avi
PushUps/v_PushUps_g02_c02.avi
PushUps/v_PushUps_g02_c03.avi
PushUps/v_PushUps_g02_c04.avi
PushUps/v_PushUps_g03_c01.avi
PushUps/v_PushUps_g03_c02.avi
PushUps/v_PushUps_g03_c03.avi
PushUps/v_PushUps_g03_c04.avi
PushUps/v_PushUps_g04_c01.avi
PushUps/v_PushUps_g04_c02.avi
PushUps/v_PushUps_g04_c03.avi
PushUps/v_PushUps_g04_c04.avi
PushUps/v_PushUps_g04_c05.avi
PushUps/v_PushUps_g05_c01.avi
PushUps/v_PushUps_g05_c02.avi
PushUps/v_PushUps_g05_c03.avi
PushUps/v_PushUps_g05_c04.avi
PushUps/v_PushUps_g06_c01.avi
PushUps/v_PushUps_g06_c02.avi
PushUps/v_PushUps_g06_c03.avi
PushUps/v_PushUps_g06_c04.avi
PushUps/v_PushUps_g07_c01.avi
PushUps/v_PushUps_g07_c02.avi
PushUps/v_PushUps_g07_c03.avi
PushUps/v_PushUps_g07_c04.avi
Rafting/v_Rafting_g01_c01.avi
Rafting/v_Rafting_g01_c02.avi
Rafting/v_Rafting_g01_c03.avi
Rafting/v_Rafting_g01_c04.avi
Rafting/v_Rafting_g02_c01.avi
Rafting/v_Rafting_g02_c02.avi
Rafting/v_Rafting_g02_c03.avi
Rafting/v_Rafting_g02_c04.avi
Rafting/v_Rafting_g03_c01.avi
Rafting/v_Rafting_g03_c02.avi
Rafting/v_Rafting_g03_c03.avi
Rafting/v_Rafting_g03_c04.avi
Rafting/v_Rafting_g04_c01.avi
Rafting/v_Rafting_g04_c02.avi
Rafting/v_Rafting_g04_c03.avi
Rafting/v_Rafting_g04_c04.avi
Rafting/v_Rafting_g05_c01.avi
Rafting/v_Rafting_g05_c02.avi
Rafting/v_Rafting_g05_c03.avi
Rafting/v_Rafting_g05_c04.avi
Rafting/v_Rafting_g06_c01.avi
Rafting/v_Rafting_g06_c02.avi
Rafting/v_Rafting_g06_c03.avi
Rafting/v_Rafting_g06_c04.avi
Rafting/v_Rafting_g07_c01.avi
Rafting/v_Rafting_g07_c02.avi
Rafting/v_Rafting_g07_c03.avi
Rafting/v_Rafting_g07_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g01_c01.avi
RockClimbingIndoor/v_RockClimbingIndoor_g01_c02.avi
RockClimbingIndoor/v_RockClimbingIndoor_g01_c03.avi
RockClimbingIndoor/v_RockClimbingIndoor_g01_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g01_c05.avi
RockClimbingIndoor/v_RockClimbingIndoor_g02_c01.avi
RockClimbingIndoor/v_RockClimbingIndoor_g02_c02.avi
RockClimbingIndoor/v_RockClimbingIndoor_g02_c03.avi
RockClimbingIndoor/v_RockClimbingIndoor_g02_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g02_c05.avi
RockClimbingIndoor/v_RockClimbingIndoor_g03_c01.avi
RockClimbingIndoor/v_RockClimbingIndoor_g03_c02.avi
RockClimbingIndoor/v_RockClimbingIndoor_g03_c03.avi
RockClimbingIndoor/v_RockClimbingIndoor_g03_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g03_c05.avi
RockClimbingIndoor/v_RockClimbingIndoor_g03_c06.avi
RockClimbingIndoor/v_RockClimbingIndoor_g03_c07.avi
RockClimbingIndoor/v_RockClimbingIndoor_g04_c01.avi
RockClimbingIndoor/v_RockClimbingIndoor_g04_c02.avi
RockClimbingIndoor/v_RockClimbingIndoor_g04_c03.avi
RockClimbingIndoor/v_RockClimbingIndoor_g04_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g05_c01.avi
RockClimbingIndoor/v_RockClimbingIndoor_g05_c02.avi
RockClimbingIndoor/v_RockClimbingIndoor_g05_c03.avi
RockClimbingIndoor/v_RockClimbingIndoor_g05_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g05_c05.avi
RockClimbingIndoor/v_RockClimbingIndoor_g05_c06.avi
RockClimbingIndoor/v_RockClimbingIndoor_g06_c01.avi
RockClimbingIndoor/v_RockClimbingIndoor_g06_c02.avi
RockClimbingIndoor/v_RockClimbingIndoor_g06_c03.avi
RockClimbingIndoor/v_RockClimbingIndoor_g06_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g06_c05.avi
RockClimbingIndoor/v_RockClimbingIndoor_g06_c06.avi
RockClimbingIndoor/v_RockClimbingIndoor_g06_c07.avi
RockClimbingIndoor/v_RockClimbingIndoor_g07_c01.avi
RockClimbingIndoor/v_RockClimbingIndoor_g07_c02.avi
RockClimbingIndoor/v_RockClimbingIndoor_g07_c03.avi
RockClimbingIndoor/v_RockClimbingIndoor_g07_c04.avi
RockClimbingIndoor/v_RockClimbingIndoor_g07_c05.avi
RockClimbingIndoor/v_RockClimbingIndoor_g07_c06.avi
RockClimbingIndoor/v_RockClimbingIndoor_g07_c07.avi
RopeClimbing/v_RopeClimbing_g01_c01.avi
RopeClimbing/v_RopeClimbing_g01_c02.avi
RopeClimbing/v_RopeClimbing_g01_c03.avi
RopeClimbing/v_RopeClimbing_g01_c04.avi
RopeClimbing/v_RopeClimbing_g02_c01.avi
RopeClimbing/v_RopeClimbing_g02_c02.avi
RopeClimbing/v_RopeClimbing_g02_c03.avi
RopeClimbing/v_RopeClimbing_g02_c04.avi
RopeClimbing/v_RopeClimbing_g02_c05.avi
RopeClimbing/v_RopeClimbing_g02_c06.avi
RopeClimbing/v_RopeClimbing_g03_c01.avi
RopeClimbing/v_RopeClimbing_g03_c02.avi
RopeClimbing/v_RopeClimbing_g03_c03.avi
RopeClimbing/v_RopeClimbing_g03_c04.avi
RopeClimbing/v_RopeClimbing_g04_c01.avi
RopeClimbing/v_RopeClimbing_g04_c02.avi
RopeClimbing/v_RopeClimbing_g04_c03.avi
RopeClimbing/v_RopeClimbing_g04_c04.avi
RopeClimbing/v_RopeClimbing_g05_c01.avi
RopeClimbing/v_RopeClimbing_g05_c02.avi
RopeClimbing/v_RopeClimbing_g05_c03.avi
RopeClimbing/v_RopeClimbing_g05_c04.avi
RopeClimbing/v_RopeClimbing_g05_c05.avi
RopeClimbing/v_RopeClimbing_g05_c06.avi
RopeClimbing/v_RopeClimbing_g05_c07.avi
RopeClimbing/v_RopeClimbing_g06_c01.avi
RopeClimbing/v_RopeClimbing_g06_c02.avi
RopeClimbing/v_RopeClimbing_g06_c03.avi
RopeClimbing/v_RopeClimbing_g06_c04.avi
RopeClimbing/v_RopeClimbing_g07_c01.avi
RopeClimbing/v_RopeClimbing_g07_c02.avi
RopeClimbing/v_RopeClimbing_g07_c03.avi
RopeClimbing/v_RopeClimbing_g07_c04.avi
RopeClimbing/v_RopeClimbing_g07_c05.avi
Rowing/v_Rowing_g01_c01.avi
Rowing/v_Rowing_g01_c02.avi
Rowing/v_Rowing_g01_c03.avi
Rowing/v_Rowing_g01_c04.avi
Rowing/v_Rowing_g02_c01.avi
Rowing/v_Rowing_g02_c02.avi
Rowing/v_Rowing_g02_c03.avi
Rowing/v_Rowing_g02_c04.avi
Rowing/v_Rowing_g02_c05.avi
Rowing/v_Rowing_g02_c06.avi
Rowing/v_Rowing_g03_c01.avi
Rowing/v_Rowing_g03_c02.avi
Rowing/v_Rowing_g03_c03.avi
Rowing/v_Rowing_g03_c04.avi
Rowing/v_Rowing_g03_c05.avi
Rowing/v_Rowing_g03_c06.avi
Rowing/v_Rowing_g03_c07.avi
Rowing/v_Rowing_g04_c01.avi
Rowing/v_Rowing_g04_c02.avi
Rowing/v_Rowing_g04_c03.avi
Rowing/v_Rowing_g04_c04.avi
Rowing/v_Rowing_g04_c05.avi
Rowing/v_Rowing_g04_c06.avi
Rowing/v_Rowing_g05_c01.avi
Rowing/v_Rowing_g05_c02.avi
Rowing/v_Rowing_g05_c03.avi
Rowing/v_Rowing_g05_c04.avi
Rowing/v_Rowing_g06_c01.avi
Rowing/v_Rowing_g06_c02.avi
Rowing/v_Rowing_g06_c03.avi
Rowing/v_Rowing_g06_c04.avi
Rowing/v_Rowing_g07_c01.avi
Rowing/v_Rowing_g07_c02.avi
Rowing/v_Rowing_g07_c03.avi
Rowing/v_Rowing_g07_c04.avi
Rowing/v_Rowing_g07_c05.avi
SalsaSpin/v_SalsaSpin_g01_c01.avi
SalsaSpin/v_SalsaSpin_g01_c02.avi
SalsaSpin/v_SalsaSpin_g01_c03.avi
SalsaSpin/v_SalsaSpin_g01_c04.avi
SalsaSpin/v_SalsaSpin_g01_c05.avi
SalsaSpin/v_SalsaSpin_g01_c06.avi
SalsaSpin/v_SalsaSpin_g01_c07.avi
SalsaSpin/v_SalsaSpin_g02_c01.avi
SalsaSpin/v_SalsaSpin_g02_c02.avi
SalsaSpin/v_SalsaSpin_g02_c03.avi
SalsaSpin/v_SalsaSpin_g02_c04.avi
SalsaSpin/v_SalsaSpin_g02_c05.avi
SalsaSpin/v_SalsaSpin_g02_c06.avi
SalsaSpin/v_SalsaSpin_g02_c07.avi
SalsaSpin/v_SalsaSpin_g03_c01.avi
SalsaSpin/v_SalsaSpin_g03_c02.avi
SalsaSpin/v_SalsaSpin_g03_c03.avi
SalsaSpin/v_SalsaSpin_g03_c04.avi
SalsaSpin/v_SalsaSpin_g03_c05.avi
SalsaSpin/v_SalsaSpin_g03_c06.avi
SalsaSpin/v_SalsaSpin_g04_c01.avi
SalsaSpin/v_SalsaSpin_g04_c02.avi
SalsaSpin/v_SalsaSpin_g04_c03.avi
SalsaSpin/v_SalsaSpin_g04_c04.avi
SalsaSpin/v_SalsaSpin_g04_c05.avi
SalsaSpin/v_SalsaSpin_g04_c06.avi
SalsaSpin/v_SalsaSpin_g05_c01.avi
SalsaSpin/v_SalsaSpin_g05_c02.avi
SalsaSpin/v_SalsaSpin_g05_c03.avi
SalsaSpin/v_SalsaSpin_g05_c04.avi
SalsaSpin/v_SalsaSpin_g05_c05.avi
SalsaSpin/v_SalsaSpin_g05_c06.avi
SalsaSpin/v_SalsaSpin_g06_c01.avi
SalsaSpin/v_SalsaSpin_g06_c02.avi
SalsaSpin/v_SalsaSpin_g06_c03.avi
SalsaSpin/v_SalsaSpin_g06_c04.avi
SalsaSpin/v_SalsaSpin_g06_c05.avi
SalsaSpin/v_SalsaSpin_g07_c01.avi
SalsaSpin/v_SalsaSpin_g07_c02.avi
SalsaSpin/v_SalsaSpin_g07_c03.avi
SalsaSpin/v_SalsaSpin_g07_c04.avi
SalsaSpin/v_SalsaSpin_g07_c05.avi
SalsaSpin/v_SalsaSpin_g07_c06.avi
ShavingBeard/v_ShavingBeard_g01_c01.avi
ShavingBeard/v_ShavingBeard_g01_c02.avi
ShavingBeard/v_ShavingBeard_g01_c03.avi
ShavingBeard/v_ShavingBeard_g01_c04.avi
ShavingBeard/v_ShavingBeard_g02_c01.avi
ShavingBeard/v_ShavingBeard_g02_c02.avi
ShavingBeard/v_ShavingBeard_g02_c03.avi
ShavingBeard/v_ShavingBeard_g02_c04.avi
ShavingBeard/v_ShavingBeard_g02_c05.avi
ShavingBeard/v_ShavingBeard_g02_c06.avi
ShavingBeard/v_ShavingBeard_g02_c07.avi
ShavingBeard/v_ShavingBeard_g03_c01.avi
ShavingBeard/v_ShavingBeard_g03_c02.avi
ShavingBeard/v_ShavingBeard_g03_c03.avi
ShavingBeard/v_ShavingBeard_g03_c04.avi
ShavingBeard/v_ShavingBeard_g03_c05.avi
ShavingBeard/v_ShavingBeard_g03_c06.avi
ShavingBeard/v_ShavingBeard_g03_c07.avi
ShavingBeard/v_ShavingBeard_g04_c01.avi
ShavingBeard/v_ShavingBeard_g04_c02.avi
ShavingBeard/v_ShavingBeard_g04_c03.avi
ShavingBeard/v_ShavingBeard_g04_c04.avi
ShavingBeard/v_ShavingBeard_g05_c01.avi
ShavingBeard/v_ShavingBeard_g05_c02.avi
ShavingBeard/v_ShavingBeard_g05_c03.avi
ShavingBeard/v_ShavingBeard_g05_c04.avi
ShavingBeard/v_ShavingBeard_g05_c05.avi
ShavingBeard/v_ShavingBeard_g05_c06.avi
ShavingBeard/v_ShavingBeard_g05_c07.avi
ShavingBeard/v_ShavingBeard_g06_c01.avi
ShavingBeard/v_ShavingBeard_g06_c02.avi
ShavingBeard/v_ShavingBeard_g06_c03.avi
ShavingBeard/v_ShavingBeard_g06_c04.avi
ShavingBeard/v_ShavingBeard_g06_c05.avi
ShavingBeard/v_ShavingBeard_g06_c06.avi
ShavingBeard/v_ShavingBeard_g06_c07.avi
ShavingBeard/v_ShavingBeard_g07_c01.avi
ShavingBeard/v_ShavingBeard_g07_c02.avi
ShavingBeard/v_ShavingBeard_g07_c03.avi
ShavingBeard/v_ShavingBeard_g07_c04.avi
ShavingBeard/v_ShavingBeard_g07_c05.avi
ShavingBeard/v_ShavingBeard_g07_c06.avi
ShavingBeard/v_ShavingBeard_g07_c07.avi
Shotput/v_Shotput_g01_c01.avi
Shotput/v_Shotput_g01_c02.avi
Shotput/v_Shotput_g01_c03.avi
Shotput/v_Shotput_g01_c04.avi
Shotput/v_Shotput_g01_c05.avi
Shotput/v_Shotput_g01_c06.avi
Shotput/v_Shotput_g01_c07.avi
Shotput/v_Shotput_g02_c01.avi
Shotput/v_Shotput_g02_c02.avi
Shotput/v_Shotput_g02_c03.avi
Shotput/v_Shotput_g02_c04.avi
Shotput/v_Shotput_g02_c05.avi
Shotput/v_Shotput_g02_c06.avi
Shotput/v_Shotput_g02_c07.avi
Shotput/v_Shotput_g03_c01.avi
Shotput/v_Shotput_g03_c02.avi
Shotput/v_Shotput_g03_c03.avi
Shotput/v_Shotput_g03_c04.avi
Shotput/v_Shotput_g03_c05.avi
Shotput/v_Shotput_g03_c06.avi
Shotput/v_Shotput_g04_c01.avi
Shotput/v_Shotput_g04_c02.avi
Shotput/v_Shotput_g04_c03.avi
Shotput/v_Shotput_g04_c04.avi
Shotput/v_Shotput_g04_c05.avi
Shotput/v_Shotput_g05_c01.avi
Shotput/v_Shotput_g05_c02.avi
Shotput/v_Shotput_g05_c03.avi
Shotput/v_Shotput_g05_c04.avi
Shotput/v_Shotput_g05_c05.avi
Shotput/v_Shotput_g05_c06.avi
Shotput/v_Shotput_g05_c07.avi
Shotput/v_Shotput_g06_c01.avi
Shotput/v_Shotput_g06_c02.avi
Shotput/v_Shotput_g06_c03.avi
Shotput/v_Shotput_g06_c04.avi
Shotput/v_Shotput_g06_c05.avi
Shotput/v_Shotput_g06_c06.avi
Shotput/v_Shotput_g06_c07.avi
Shotput/v_Shotput_g07_c01.avi
Shotput/v_Shotput_g07_c02.avi
Shotput/v_Shotput_g07_c03.avi
Shotput/v_Shotput_g07_c04.avi
Shotput/v_Shotput_g07_c05.avi
Shotput/v_Shotput_g07_c06.avi
Shotput/v_Shotput_g07_c07.avi
SkateBoarding/v_SkateBoarding_g01_c01.avi
SkateBoarding/v_SkateBoarding_g01_c02.avi
SkateBoarding/v_SkateBoarding_g01_c03.avi
SkateBoarding/v_SkateBoarding_g01_c04.avi
SkateBoarding/v_SkateBoarding_g02_c01.avi
SkateBoarding/v_SkateBoarding_g02_c02.avi
SkateBoarding/v_SkateBoarding_g02_c03.avi
SkateBoarding/v_SkateBoarding_g02_c04.avi
SkateBoarding/v_SkateBoarding_g02_c05.avi
SkateBoarding/v_SkateBoarding_g02_c06.avi
SkateBoarding/v_SkateBoarding_g03_c01.avi
SkateBoarding/v_SkateBoarding_g03_c02.avi
SkateBoarding/v_SkateBoarding_g03_c03.avi
SkateBoarding/v_SkateBoarding_g03_c04.avi
SkateBoarding/v_SkateBoarding_g04_c01.avi
SkateBoarding/v_SkateBoarding_g04_c02.avi
SkateBoarding/v_SkateBoarding_g04_c03.avi
SkateBoarding/v_SkateBoarding_g04_c04.avi
SkateBoarding/v_SkateBoarding_g04_c05.avi
SkateBoarding/v_SkateBoarding_g05_c01.avi
SkateBoarding/v_SkateBoarding_g05_c02.avi
SkateBoarding/v_SkateBoarding_g05_c03.avi
SkateBoarding/v_SkateBoarding_g05_c04.avi
SkateBoarding/v_SkateBoarding_g06_c01.avi
SkateBoarding/v_SkateBoarding_g06_c02.avi
SkateBoarding/v_SkateBoarding_g06_c03.avi
SkateBoarding/v_SkateBoarding_g06_c04.avi
SkateBoarding/v_SkateBoarding_g07_c01.avi
SkateBoarding/v_SkateBoarding_g07_c02.avi
SkateBoarding/v_SkateBoarding_g07_c03.avi
SkateBoarding/v_SkateBoarding_g07_c04.avi
SkateBoarding/v_SkateBoarding_g07_c05.avi
Skiing/v_Skiing_g01_c01.avi
Skiing/v_Skiing_g01_c02.avi
Skiing/v_Skiing_g01_c03.avi
Skiing/v_Skiing_g01_c04.avi
Skiing/v_Skiing_g01_c05.avi
Skiing/v_Skiing_g01_c06.avi
Skiing/v_Skiing_g02_c01.avi
Skiing/v_Skiing_g02_c02.avi
Skiing/v_Skiing_g02_c03.avi
Skiing/v_Skiing_g02_c04.avi
Skiing/v_Skiing_g02_c05.avi
Skiing/v_Skiing_g03_c01.avi
Skiing/v_Skiing_g03_c02.avi
Skiing/v_Skiing_g03_c03.avi
Skiing/v_Skiing_g03_c04.avi
Skiing/v_Skiing_g03_c05.avi
Skiing/v_Skiing_g03_c06.avi
Skiing/v_Skiing_g03_c07.avi
Skiing/v_Skiing_g04_c01.avi
Skiing/v_Skiing_g04_c02.avi
Skiing/v_Skiing_g04_c03.avi
Skiing/v_Skiing_g04_c04.avi
Skiing/v_Skiing_g04_c05.avi
Skiing/v_Skiing_g04_c06.avi
Skiing/v_Skiing_g04_c07.avi
Skiing/v_Skiing_g05_c01.avi
Skiing/v_Skiing_g05_c02.avi
Skiing/v_Skiing_g05_c03.avi
Skiing/v_Skiing_g05_c04.avi
Skiing/v_Skiing_g06_c01.avi
Skiing/v_Skiing_g06_c02.avi
Skiing/v_Skiing_g06_c03.avi
Skiing/v_Skiing_g06_c04.avi
Skiing/v_Skiing_g06_c05.avi
Skiing/v_Skiing_g06_c06.avi
Skiing/v_Skiing_g06_c07.avi
Skiing/v_Skiing_g07_c01.avi
Skiing/v_Skiing_g07_c02.avi
Skiing/v_Skiing_g07_c03.avi
Skiing/v_Skiing_g07_c04.avi
Skijet/v_Skijet_g01_c01.avi
Skijet/v_Skijet_g01_c02.avi
Skijet/v_Skijet_g01_c03.avi
Skijet/v_Skijet_g01_c04.avi
Skijet/v_Skijet_g02_c01.avi
Skijet/v_Skijet_g02_c02.avi
Skijet/v_Skijet_g02_c03.avi
Skijet/v_Skijet_g02_c04.avi
Skijet/v_Skijet_g03_c01.avi
Skijet/v_Skijet_g03_c02.avi
Skijet/v_Skijet_g03_c03.avi
Skijet/v_Skijet_g03_c04.avi
Skijet/v_Skijet_g04_c01.avi
Skijet/v_Skijet_g04_c02.avi
Skijet/v_Skijet_g04_c03.avi
Skijet/v_Skijet_g04_c04.avi
Skijet/v_Skijet_g05_c01.avi
Skijet/v_Skijet_g05_c02.avi
Skijet/v_Skijet_g05_c03.avi
Skijet/v_Skijet_g05_c04.avi
Skijet/v_Skijet_g06_c01.avi
Skijet/v_Skijet_g06_c02.avi
Skijet/v_Skijet_g06_c03.avi
Skijet/v_Skijet_g06_c04.avi
Skijet/v_Skijet_g07_c01.avi
Skijet/v_Skijet_g07_c02.avi
Skijet/v_Skijet_g07_c03.avi
Skijet/v_Skijet_g07_c04.avi
SkyDiving/v_SkyDiving_g01_c01.avi
SkyDiving/v_SkyDiving_g01_c02.avi
SkyDiving/v_SkyDiving_g01_c03.avi
SkyDiving/v_SkyDiving_g01_c04.avi
SkyDiving/v_SkyDiving_g02_c01.avi
SkyDiving/v_SkyDiving_g02_c02.avi
SkyDiving/v_SkyDiving_g02_c03.avi
SkyDiving/v_SkyDiving_g02_c04.avi
SkyDiving/v_SkyDiving_g03_c01.avi
SkyDiving/v_SkyDiving_g03_c02.avi
SkyDiving/v_SkyDiving_g03_c03.avi
SkyDiving/v_SkyDiving_g03_c04.avi
SkyDiving/v_SkyDiving_g03_c05.avi
SkyDiving/v_SkyDiving_g04_c01.avi
SkyDiving/v_SkyDiving_g04_c02.avi
SkyDiving/v_SkyDiving_g04_c03.avi
SkyDiving/v_SkyDiving_g04_c04.avi
SkyDiving/v_SkyDiving_g05_c01.avi
SkyDiving/v_SkyDiving_g05_c02.avi
SkyDiving/v_SkyDiving_g05_c03.avi
SkyDiving/v_SkyDiving_g05_c04.avi
SkyDiving/v_SkyDiving_g05_c05.avi
SkyDiving/v_SkyDiving_g06_c01.avi
SkyDiving/v_SkyDiving_g06_c02.avi
SkyDiving/v_SkyDiving_g06_c03.avi
SkyDiving/v_SkyDiving_g06_c04.avi
SkyDiving/v_SkyDiving_g07_c01.avi
SkyDiving/v_SkyDiving_g07_c02.avi
SkyDiving/v_SkyDiving_g07_c03.avi
SkyDiving/v_SkyDiving_g07_c04.avi
SkyDiving/v_SkyDiving_g07_c05.avi
SoccerJuggling/v_SoccerJuggling_g01_c01.avi
SoccerJuggling/v_SoccerJuggling_g01_c02.avi
SoccerJuggling/v_SoccerJuggling_g01_c03.avi
SoccerJuggling/v_SoccerJuggling_g01_c04.avi
SoccerJuggling/v_SoccerJuggling_g01_c05.avi
SoccerJuggling/v_SoccerJuggling_g02_c01.avi
SoccerJuggling/v_SoccerJuggling_g02_c02.avi
SoccerJuggling/v_SoccerJuggling_g02_c03.avi
SoccerJuggling/v_SoccerJuggling_g02_c04.avi
SoccerJuggling/v_SoccerJuggling_g02_c05.avi
SoccerJuggling/v_SoccerJuggling_g02_c06.avi
SoccerJuggling/v_SoccerJuggling_g03_c01.avi
SoccerJuggling/v_SoccerJuggling_g03_c02.avi
SoccerJuggling/v_SoccerJuggling_g03_c03.avi
SoccerJuggling/v_SoccerJuggling_g03_c04.avi
SoccerJuggling/v_SoccerJuggling_g04_c01.avi
SoccerJuggling/v_SoccerJuggling_g04_c02.avi
SoccerJuggling/v_SoccerJuggling_g04_c03.avi
SoccerJuggling/v_SoccerJuggling_g04_c04.avi
SoccerJuggling/v_SoccerJuggling_g04_c05.avi
SoccerJuggling/v_SoccerJuggling_g04_c06.avi
SoccerJuggling/v_SoccerJuggling_g05_c01.avi
SoccerJuggling/v_SoccerJuggling_g05_c02.avi
SoccerJuggling/v_SoccerJuggling_g05_c03.avi
SoccerJuggling/v_SoccerJuggling_g05_c04.avi
SoccerJuggling/v_SoccerJuggling_g05_c05.avi
SoccerJuggling/v_SoccerJuggling_g05_c06.avi
SoccerJuggling/v_SoccerJuggling_g06_c01.avi
SoccerJuggling/v_SoccerJuggling_g06_c02.avi
SoccerJuggling/v_SoccerJuggling_g06_c03.avi
SoccerJuggling/v_SoccerJuggling_g06_c04.avi
SoccerJuggling/v_SoccerJuggling_g06_c05.avi
SoccerJuggling/v_SoccerJuggling_g07_c01.avi
SoccerJuggling/v_SoccerJuggling_g07_c02.avi
SoccerJuggling/v_SoccerJuggling_g07_c03.avi
SoccerJuggling/v_SoccerJuggling_g07_c04.avi
SoccerJuggling/v_SoccerJuggling_g07_c05.avi
SoccerJuggling/v_SoccerJuggling_g07_c06.avi
SoccerJuggling/v_SoccerJuggling_g07_c07.avi
SoccerPenalty/v_SoccerPenalty_g01_c01.avi
SoccerPenalty/v_SoccerPenalty_g01_c02.avi
SoccerPenalty/v_SoccerPenalty_g01_c03.avi
SoccerPenalty/v_SoccerPenalty_g01_c04.avi
SoccerPenalty/v_SoccerPenalty_g01_c05.avi
SoccerPenalty/v_SoccerPenalty_g01_c06.avi
SoccerPenalty/v_SoccerPenalty_g02_c01.avi
SoccerPenalty/v_SoccerPenalty_g02_c02.avi
SoccerPenalty/v_SoccerPenalty_g02_c03.avi
SoccerPenalty/v_SoccerPenalty_g02_c04.avi
SoccerPenalty/v_SoccerPenalty_g02_c05.avi
SoccerPenalty/v_SoccerPenalty_g03_c01.avi
SoccerPenalty/v_SoccerPenalty_g03_c02.avi
SoccerPenalty/v_SoccerPenalty_g03_c03.avi
SoccerPenalty/v_SoccerPenalty_g03_c04.avi
SoccerPenalty/v_SoccerPenalty_g03_c05.avi
SoccerPenalty/v_SoccerPenalty_g04_c01.avi
SoccerPenalty/v_SoccerPenalty_g04_c02.avi
SoccerPenalty/v_SoccerPenalty_g04_c03.avi
SoccerPenalty/v_SoccerPenalty_g04_c04.avi
SoccerPenalty/v_SoccerPenalty_g04_c05.avi
SoccerPenalty/v_SoccerPenalty_g05_c01.avi
SoccerPenalty/v_SoccerPenalty_g05_c02.avi
SoccerPenalty/v_SoccerPenalty_g05_c03.avi
SoccerPenalty/v_SoccerPenalty_g05_c04.avi
SoccerPenalty/v_SoccerPenalty_g05_c05.avi
SoccerPenalty/v_SoccerPenalty_g05_c06.avi
SoccerPenalty/v_SoccerPenalty_g05_c07.avi
SoccerPenalty/v_SoccerPenalty_g06_c01.avi
SoccerPenalty/v_SoccerPenalty_g06_c02.avi
SoccerPenalty/v_SoccerPenalty_g06_c03.avi
SoccerPenalty/v_SoccerPenalty_g06_c04.avi
SoccerPenalty/v_SoccerPenalty_g06_c05.avi
SoccerPenalty/v_SoccerPenalty_g06_c06.avi
SoccerPenalty/v_SoccerPenalty_g06_c07.avi
SoccerPenalty/v_SoccerPenalty_g07_c01.avi
SoccerPenalty/v_SoccerPenalty_g07_c02.avi
SoccerPenalty/v_SoccerPenalty_g07_c03.avi
SoccerPenalty/v_SoccerPenalty_g07_c04.avi
SoccerPenalty/v_SoccerPenalty_g07_c05.avi
SoccerPenalty/v_SoccerPenalty_g07_c06.avi
StillRings/v_StillRings_g01_c01.avi
StillRings/v_StillRings_g01_c02.avi
StillRings/v_StillRings_g01_c03.avi
StillRings/v_StillRings_g01_c04.avi
StillRings/v_StillRings_g01_c05.avi
StillRings/v_StillRings_g02_c01.avi
StillRings/v_StillRings_g02_c02.avi
StillRings/v_StillRings_g02_c03.avi
StillRings/v_StillRings_g02_c04.avi
StillRings/v_StillRings_g03_c01.avi
StillRings/v_StillRings_g03_c02.avi
StillRings/v_StillRings_g03_c03.avi
StillRings/v_StillRings_g03_c04.avi
StillRings/v_StillRings_g03_c05.avi
StillRings/v_StillRings_g03_c06.avi
StillRings/v_StillRings_g03_c07.avi
StillRings/v_StillRings_g04_c01.avi
StillRings/v_StillRings_g04_c02.avi
StillRings/v_StillRings_g04_c03.avi
StillRings/v_StillRings_g04_c04.avi
StillRings/v_StillRings_g05_c01.avi
StillRings/v_StillRings_g05_c02.avi
StillRings/v_StillRings_g05_c03.avi
StillRings/v_StillRings_g05_c04.avi
StillRings/v_StillRings_g06_c01.avi
StillRings/v_StillRings_g06_c02.avi
StillRings/v_StillRings_g06_c03.avi
StillRings/v_StillRings_g06_c04.avi
StillRings/v_StillRings_g07_c01.avi
StillRings/v_StillRings_g07_c02.avi
StillRings/v_StillRings_g07_c03.avi
StillRings/v_StillRings_g07_c04.avi
SumoWrestling/v_SumoWrestling_g01_c01.avi
SumoWrestling/v_SumoWrestling_g01_c02.avi
SumoWrestling/v_SumoWrestling_g01_c03.avi
SumoWrestling/v_SumoWrestling_g01_c04.avi
SumoWrestling/v_SumoWrestling_g02_c01.avi
SumoWrestling/v_SumoWrestling_g02_c02.avi
SumoWrestling/v_SumoWrestling_g02_c03.avi
SumoWrestling/v_SumoWrestling_g02_c04.avi
SumoWrestling/v_SumoWrestling_g03_c01.avi
SumoWrestling/v_SumoWrestling_g03_c02.avi
SumoWrestling/v_SumoWrestling_g03_c03.avi
SumoWrestling/v_SumoWrestling_g03_c04.avi
SumoWrestling/v_SumoWrestling_g04_c01.avi
SumoWrestling/v_SumoWrestling_g04_c02.avi
SumoWrestling/v_SumoWrestling_g04_c03.avi
SumoWrestling/v_SumoWrestling_g04_c04.avi
SumoWrestling/v_SumoWrestling_g05_c01.avi
SumoWrestling/v_SumoWrestling_g05_c02.avi
SumoWrestling/v_SumoWrestling_g05_c03.avi
SumoWrestling/v_SumoWrestling_g05_c04.avi
SumoWrestling/v_SumoWrestling_g06_c01.avi
SumoWrestling/v_SumoWrestling_g06_c02.avi
SumoWrestling/v_SumoWrestling_g06_c03.avi
SumoWrestling/v_SumoWrestling_g06_c04.avi
SumoWrestling/v_SumoWrestling_g06_c05.avi
SumoWrestling/v_SumoWrestling_g06_c06.avi
SumoWrestling/v_SumoWrestling_g06_c07.avi
SumoWrestling/v_SumoWrestling_g07_c01.avi
SumoWrestling/v_SumoWrestling_g07_c02.avi
SumoWrestling/v_SumoWrestling_g07_c03.avi
SumoWrestling/v_SumoWrestling_g07_c04.avi
SumoWrestling/v_SumoWrestling_g07_c05.avi
SumoWrestling/v_SumoWrestling_g07_c06.avi
SumoWrestling/v_SumoWrestling_g07_c07.avi
Surfing/v_Surfing_g01_c01.avi
Surfing/v_Surfing_g01_c02.avi
Surfing/v_Surfing_g01_c03.avi
Surfing/v_Surfing_g01_c04.avi
Surfing/v_Surfing_g01_c05.avi
Surfing/v_Surfing_g01_c06.avi
Surfing/v_Surfing_g01_c07.avi
Surfing/v_Surfing_g02_c01.avi
Surfing/v_Surfing_g02_c02.avi
Surfing/v_Surfing_g02_c03.avi
Surfing/v_Surfing_g02_c04.avi
Surfing/v_Surfing_g02_c05.avi
Surfing/v_Surfing_g02_c06.avi
Surfing/v_Surfing_g03_c01.avi
Surfing/v_Surfing_g03_c02.avi
Surfing/v_Surfing_g03_c03.avi
Surfing/v_Surfing_g03_c04.avi
Surfing/v_Surfing_g04_c01.avi
Surfing/v_Surfing_g04_c02.avi
Surfing/v_Surfing_g04_c03.avi
Surfing/v_Surfing_g04_c04.avi
Surfing/v_Surfing_g05_c01.avi
Surfing/v_Surfing_g05_c02.avi
Surfing/v_Surfing_g05_c03.avi
Surfing/v_Surfing_g05_c04.avi
Surfing/v_Surfing_g06_c01.avi
Surfing/v_Surfing_g06_c02.avi
Surfing/v_Surfing_g06_c03.avi
Surfing/v_Surfing_g06_c04.avi
Surfing/v_Surfing_g07_c01.avi
Surfing/v_Surfing_g07_c02.avi
Surfing/v_Surfing_g07_c03.avi
Surfing/v_Surfing_g07_c04.avi
Swing/v_Swing_g01_c01.avi
Swing/v_Swing_g01_c02.avi
Swing/v_Swing_g01_c03.avi
Swing/v_Swing_g01_c04.avi
Swing/v_Swing_g01_c05.avi
Swing/v_Swing_g02_c01.avi
Swing/v_Swing_g02_c02.avi
Swing/v_Swing_g02_c03.avi
Swing/v_Swing_g02_c04.avi
Swing/v_Swing_g02_c05.avi
Swing/v_Swing_g03_c01.avi
Swing/v_Swing_g03_c02.avi
Swing/v_Swing_g03_c03.avi
Swing/v_Swing_g03_c04.avi
Swing/v_Swing_g04_c01.avi
Swing/v_Swing_g04_c02.avi
Swing/v_Swing_g04_c03.avi
Swing/v_Swing_g04_c04.avi
Swing/v_Swing_g04_c05.avi
Swing/v_Swing_g04_c06.avi
Swing/v_Swing_g04_c07.avi
Swing/v_Swing_g05_c01.avi
Swing/v_Swing_g05_c02.avi
Swing/v_Swing_g05_c03.avi
Swing/v_Swing_g05_c04.avi
Swing/v_Swing_g05_c05.avi
Swing/v_Swing_g05_c06.avi
Swing/v_Swing_g05_c07.avi
Swing/v_Swing_g06_c01.avi
Swing/v_Swing_g06_c02.avi
Swing/v_Swing_g06_c03.avi
Swing/v_Swing_g06_c04.avi
Swing/v_Swing_g06_c05.avi
Swing/v_Swing_g06_c06.avi
Swing/v_Swing_g06_c07.avi
Swing/v_Swing_g07_c01.avi
Swing/v_Swing_g07_c02.avi
Swing/v_Swing_g07_c03.avi
Swing/v_Swing_g07_c04.avi
Swing/v_Swing_g07_c05.avi
Swing/v_Swing_g07_c06.avi
Swing/v_Swing_g07_c07.avi
TableTennisShot/v_TableTennisShot_g01_c01.avi
TableTennisShot/v_TableTennisShot_g01_c02.avi
TableTennisShot/v_TableTennisShot_g01_c03.avi
TableTennisShot/v_TableTennisShot_g01_c04.avi
TableTennisShot/v_TableTennisShot_g01_c05.avi
TableTennisShot/v_TableTennisShot_g01_c06.avi
TableTennisShot/v_TableTennisShot_g02_c01.avi
TableTennisShot/v_TableTennisShot_g02_c02.avi
TableTennisShot/v_TableTennisShot_g02_c03.avi
TableTennisShot/v_TableTennisShot_g02_c04.avi
TableTennisShot/v_TableTennisShot_g03_c01.avi
TableTennisShot/v_TableTennisShot_g03_c02.avi
TableTennisShot/v_TableTennisShot_g03_c03.avi
TableTennisShot/v_TableTennisShot_g03_c04.avi
TableTennisShot/v_TableTennisShot_g03_c05.avi
TableTennisShot/v_TableTennisShot_g04_c01.avi
TableTennisShot/v_TableTennisShot_g04_c02.avi
TableTennisShot/v_TableTennisShot_g04_c03.avi
TableTennisShot/v_TableTennisShot_g04_c04.avi
TableTennisShot/v_TableTennisShot_g04_c05.avi
TableTennisShot/v_TableTennisShot_g04_c06.avi
TableTennisShot/v_TableTennisShot_g04_c07.avi
TableTennisShot/v_TableTennisShot_g05_c01.avi
TableTennisShot/v_TableTennisShot_g05_c02.avi
TableTennisShot/v_TableTennisShot_g05_c03.avi
TableTennisShot/v_TableTennisShot_g05_c04.avi
TableTennisShot/v_TableTennisShot_g05_c05.avi
TableTennisShot/v_TableTennisShot_g05_c06.avi
TableTennisShot/v_TableTennisShot_g05_c07.avi
TableTennisShot/v_TableTennisShot_g06_c01.avi
TableTennisShot/v_TableTennisShot_g06_c02.avi
TableTennisShot/v_TableTennisShot_g06_c03.avi
TableTennisShot/v_TableTennisShot_g06_c04.avi
TableTennisShot/v_TableTennisShot_g06_c05.avi
TableTennisShot/v_TableTennisShot_g06_c06.avi
TableTennisShot/v_TableTennisShot_g07_c01.avi
TableTennisShot/v_TableTennisShot_g07_c02.avi
TableTennisShot/v_TableTennisShot_g07_c03.avi
TableTennisShot/v_TableTennisShot_g07_c04.avi
TaiChi/v_TaiChi_g01_c01.avi
TaiChi/v_TaiChi_g01_c02.avi
TaiChi/v_TaiChi_g01_c03.avi
TaiChi/v_TaiChi_g01_c04.avi
TaiChi/v_TaiChi_g02_c01.avi
TaiChi/v_TaiChi_g02_c02.avi
TaiChi/v_TaiChi_g02_c03.avi
TaiChi/v_TaiChi_g02_c04.avi
TaiChi/v_TaiChi_g03_c01.avi
TaiChi/v_TaiChi_g03_c02.avi
TaiChi/v_TaiChi_g03_c03.avi
TaiChi/v_TaiChi_g03_c04.avi
TaiChi/v_TaiChi_g04_c01.avi
TaiChi/v_TaiChi_g04_c02.avi
TaiChi/v_TaiChi_g04_c03.avi
TaiChi/v_TaiChi_g04_c04.avi
TaiChi/v_TaiChi_g05_c01.avi
TaiChi/v_TaiChi_g05_c02.avi
TaiChi/v_TaiChi_g05_c03.avi
TaiChi/v_TaiChi_g05_c04.avi
TaiChi/v_TaiChi_g06_c01.avi
TaiChi/v_TaiChi_g06_c02.avi
TaiChi/v_TaiChi_g06_c03.avi
TaiChi/v_TaiChi_g06_c04.avi
TaiChi/v_TaiChi_g07_c01.avi
TaiChi/v_TaiChi_g07_c02.avi
TaiChi/v_TaiChi_g07_c03.avi
TaiChi/v_TaiChi_g07_c04.avi
TennisSwing/v_TennisSwing_g01_c01.avi
TennisSwing/v_TennisSwing_g01_c02.avi
TennisSwing/v_TennisSwing_g01_c03.avi
TennisSwing/v_TennisSwing_g01_c04.avi
TennisSwing/v_TennisSwing_g01_c05.avi
TennisSwing/v_TennisSwing_g01_c06.avi
TennisSwing/v_TennisSwing_g01_c07.avi
TennisSwing/v_TennisSwing_g02_c01.avi
TennisSwing/v_TennisSwing_g02_c02.avi
TennisSwing/v_TennisSwing_g02_c03.avi
TennisSwing/v_TennisSwing_g02_c04.avi
TennisSwing/v_TennisSwing_g02_c05.avi
TennisSwing/v_TennisSwing_g02_c06.avi
TennisSwing/v_TennisSwing_g02_c07.avi
TennisSwing/v_TennisSwing_g03_c01.avi
TennisSwing/v_TennisSwing_g03_c02.avi
TennisSwing/v_TennisSwing_g03_c03.avi
TennisSwing/v_TennisSwing_g03_c04.avi
TennisSwing/v_TennisSwing_g03_c05.avi
TennisSwing/v_TennisSwing_g03_c06.avi
TennisSwing/v_TennisSwing_g03_c07.avi
TennisSwing/v_TennisSwing_g04_c01.avi
TennisSwing/v_TennisSwing_g04_c02.avi
TennisSwing/v_TennisSwing_g04_c03.avi
TennisSwing/v_TennisSwing_g04_c04.avi
TennisSwing/v_TennisSwing_g04_c05.avi
TennisSwing/v_TennisSwing_g04_c06.avi
TennisSwing/v_TennisSwing_g04_c07.avi
TennisSwing/v_TennisSwing_g05_c01.avi
TennisSwing/v_TennisSwing_g05_c02.avi
TennisSwing/v_TennisSwing_g05_c03.avi
TennisSwing/v_TennisSwing_g05_c04.avi
TennisSwing/v_TennisSwing_g05_c05.avi
TennisSwing/v_TennisSwing_g05_c06.avi
TennisSwing/v_TennisSwing_g05_c07.avi
TennisSwing/v_TennisSwing_g06_c01.avi
TennisSwing/v_TennisSwing_g06_c02.avi
TennisSwing/v_TennisSwing_g06_c03.avi
TennisSwing/v_TennisSwing_g06_c04.avi
TennisSwing/v_TennisSwing_g06_c05.avi
TennisSwing/v_TennisSwing_g06_c06.avi
TennisSwing/v_TennisSwing_g06_c07.avi
TennisSwing/v_TennisSwing_g07_c01.avi
TennisSwing/v_TennisSwing_g07_c02.avi
TennisSwing/v_TennisSwing_g07_c03.avi
TennisSwing/v_TennisSwing_g07_c04.avi
TennisSwing/v_TennisSwing_g07_c05.avi
TennisSwing/v_TennisSwing_g07_c06.avi
TennisSwing/v_TennisSwing_g07_c07.avi
ThrowDiscus/v_ThrowDiscus_g01_c01.avi
ThrowDiscus/v_ThrowDiscus_g01_c02.avi
ThrowDiscus/v_ThrowDiscus_g01_c03.avi
ThrowDiscus/v_ThrowDiscus_g01_c04.avi
ThrowDiscus/v_ThrowDiscus_g02_c01.avi
ThrowDiscus/v_ThrowDiscus_g02_c02.avi
ThrowDiscus/v_ThrowDiscus_g02_c03.avi
ThrowDiscus/v_ThrowDiscus_g02_c04.avi
ThrowDiscus/v_ThrowDiscus_g02_c05.avi
ThrowDiscus/v_ThrowDiscus_g02_c06.avi
ThrowDiscus/v_ThrowDiscus_g02_c07.avi
ThrowDiscus/v_ThrowDiscus_g03_c01.avi
ThrowDiscus/v_ThrowDiscus_g03_c02.avi
ThrowDiscus/v_ThrowDiscus_g03_c03.avi
ThrowDiscus/v_ThrowDiscus_g03_c04.avi
ThrowDiscus/v_ThrowDiscus_g04_c01.avi
ThrowDiscus/v_ThrowDiscus_g04_c02.avi
ThrowDiscus/v_ThrowDiscus_g04_c03.avi
ThrowDiscus/v_ThrowDiscus_g04_c04.avi
ThrowDiscus/v_ThrowDiscus_g05_c01.avi
ThrowDiscus/v_ThrowDiscus_g05_c02.avi
ThrowDiscus/v_ThrowDiscus_g05_c03.avi
ThrowDiscus/v_ThrowDiscus_g05_c04.avi
ThrowDiscus/v_ThrowDiscus_g05_c05.avi
ThrowDiscus/v_ThrowDiscus_g06_c01.avi
ThrowDiscus/v_ThrowDiscus_g06_c02.avi
ThrowDiscus/v_ThrowDiscus_g06_c03.avi
ThrowDiscus/v_ThrowDiscus_g06_c04.avi
ThrowDiscus/v_ThrowDiscus_g06_c05.avi
ThrowDiscus/v_ThrowDiscus_g06_c06.avi
ThrowDiscus/v_ThrowDiscus_g06_c07.avi
ThrowDiscus/v_ThrowDiscus_g07_c01.avi
ThrowDiscus/v_ThrowDiscus_g07_c02.avi
ThrowDiscus/v_ThrowDiscus_g07_c03.avi
ThrowDiscus/v_ThrowDiscus_g07_c04.avi
ThrowDiscus/v_ThrowDiscus_g07_c05.avi
ThrowDiscus/v_ThrowDiscus_g07_c06.avi
ThrowDiscus/v_ThrowDiscus_g07_c07.avi
TrampolineJumping/v_TrampolineJumping_g01_c01.avi
TrampolineJumping/v_TrampolineJumping_g01_c02.avi
TrampolineJumping/v_TrampolineJumping_g01_c03.avi
TrampolineJumping/v_TrampolineJumping_g01_c04.avi
TrampolineJumping/v_TrampolineJumping_g02_c01.avi
TrampolineJumping/v_TrampolineJumping_g02_c02.avi
TrampolineJumping/v_TrampolineJumping_g02_c03.avi
TrampolineJumping/v_TrampolineJumping_g02_c04.avi
TrampolineJumping/v_TrampolineJumping_g02_c05.avi
TrampolineJumping/v_TrampolineJumping_g02_c06.avi
TrampolineJumping/v_TrampolineJumping_g03_c01.avi
TrampolineJumping/v_TrampolineJumping_g03_c02.avi
TrampolineJumping/v_TrampolineJumping_g03_c03.avi
TrampolineJumping/v_TrampolineJumping_g03_c04.avi
TrampolineJumping/v_TrampolineJumping_g04_c01.avi
TrampolineJumping/v_TrampolineJumping_g04_c02.avi
TrampolineJumping/v_TrampolineJumping_g04_c03.avi
TrampolineJumping/v_TrampolineJumping_g04_c04.avi
TrampolineJumping/v_TrampolineJumping_g04_c05.avi
TrampolineJumping/v_TrampolineJumping_g05_c01.avi
TrampolineJumping/v_TrampolineJumping_g05_c02.avi
TrampolineJumping/v_TrampolineJumping_g05_c03.avi
TrampolineJumping/v_TrampolineJumping_g05_c04.avi
TrampolineJumping/v_TrampolineJumping_g06_c01.avi
TrampolineJumping/v_TrampolineJumping_g06_c02.avi
TrampolineJumping/v_TrampolineJumping_g06_c03.avi
TrampolineJumping/v_TrampolineJumping_g06_c04.avi
TrampolineJumping/v_TrampolineJumping_g07_c01.avi
TrampolineJumping/v_TrampolineJumping_g07_c02.avi
TrampolineJumping/v_TrampolineJumping_g07_c03.avi
TrampolineJumping/v_TrampolineJumping_g07_c04.avi
TrampolineJumping/v_TrampolineJumping_g07_c05.avi
Typing/v_Typing_g01_c01.avi
Typing/v_Typing_g01_c02.avi
Typing/v_Typing_g01_c03.avi
Typing/v_Typing_g01_c04.avi
Typing/v_Typing_g01_c05.avi
Typing/v_Typing_g01_c06.avi
Typing/v_Typing_g01_c07.avi
Typing/v_Typing_g02_c01.avi
Typing/v_Typing_g02_c02.avi
Typing/v_Typing_g02_c03.avi
Typing/v_Typing_g02_c04.avi
Typing/v_Typing_g02_c05.avi
Typing/v_Typing_g02_c06.avi
Typing/v_Typing_g03_c01.avi
Typing/v_Typing_g03_c02.avi
Typing/v_Typing_g03_c03.avi
Typing/v_Typing_g03_c04.avi
Typing/v_Typing_g03_c05.avi
Typing/v_Typing_g03_c06.avi
Typing/v_Typing_g03_c07.avi
Typing/v_Typing_g04_c01.avi
Typing/v_Typing_g04_c02.avi
Typing/v_Typing_g04_c03.avi
Typing/v_Typing_g04_c04.avi
Typing/v_Typing_g05_c01.avi
Typing/v_Typing_g05_c02.avi
Typing/v_Typing_g05_c03.avi
Typing/v_Typing_g05_c04.avi
Typing/v_Typing_g05_c05.avi
Typing/v_Typing_g05_c06.avi
Typing/v_Typing_g06_c01.avi
Typing/v_Typing_g06_c02.avi
Typing/v_Typing_g06_c03.avi
Typing/v_Typing_g06_c04.avi
Typing/v_Typing_g06_c05.avi
Typing/v_Typing_g06_c06.avi
Typing/v_Typing_g06_c07.avi
Typing/v_Typing_g07_c01.avi
Typing/v_Typing_g07_c02.avi
Typing/v_Typing_g07_c03.avi
Typing/v_Typing_g07_c04.avi
Typing/v_Typing_g07_c05.avi
Typing/v_Typing_g07_c06.avi
UnevenBars/v_UnevenBars_g01_c01.avi
UnevenBars/v_UnevenBars_g01_c02.avi
UnevenBars/v_UnevenBars_g01_c03.avi
UnevenBars/v_UnevenBars_g01_c04.avi
UnevenBars/v_UnevenBars_g02_c01.avi
UnevenBars/v_UnevenBars_g02_c02.avi
UnevenBars/v_UnevenBars_g02_c03.avi
UnevenBars/v_UnevenBars_g02_c04.avi
UnevenBars/v_UnevenBars_g03_c01.avi
UnevenBars/v_UnevenBars_g03_c02.avi
UnevenBars/v_UnevenBars_g03_c03.avi
UnevenBars/v_UnevenBars_g03_c04.avi
UnevenBars/v_UnevenBars_g04_c01.avi
UnevenBars/v_UnevenBars_g04_c02.avi
UnevenBars/v_UnevenBars_g04_c03.avi
UnevenBars/v_UnevenBars_g04_c04.avi
UnevenBars/v_UnevenBars_g05_c01.avi
UnevenBars/v_UnevenBars_g05_c02.avi
UnevenBars/v_UnevenBars_g05_c03.avi
UnevenBars/v_UnevenBars_g05_c04.avi
UnevenBars/v_UnevenBars_g06_c01.avi
UnevenBars/v_UnevenBars_g06_c02.avi
UnevenBars/v_UnevenBars_g06_c03.avi
UnevenBars/v_UnevenBars_g06_c04.avi
UnevenBars/v_UnevenBars_g07_c01.avi
UnevenBars/v_UnevenBars_g07_c02.avi
UnevenBars/v_UnevenBars_g07_c03.avi
UnevenBars/v_UnevenBars_g07_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g01_c01.avi
VolleyballSpiking/v_VolleyballSpiking_g01_c02.avi
VolleyballSpiking/v_VolleyballSpiking_g01_c03.avi
VolleyballSpiking/v_VolleyballSpiking_g01_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g02_c01.avi
VolleyballSpiking/v_VolleyballSpiking_g02_c02.avi
VolleyballSpiking/v_VolleyballSpiking_g02_c03.avi
VolleyballSpiking/v_VolleyballSpiking_g02_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g03_c01.avi
VolleyballSpiking/v_VolleyballSpiking_g03_c02.avi
VolleyballSpiking/v_VolleyballSpiking_g03_c03.avi
VolleyballSpiking/v_VolleyballSpiking_g03_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g04_c01.avi
VolleyballSpiking/v_VolleyballSpiking_g04_c02.avi
VolleyballSpiking/v_VolleyballSpiking_g04_c03.avi
VolleyballSpiking/v_VolleyballSpiking_g04_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g04_c05.avi
VolleyballSpiking/v_VolleyballSpiking_g04_c06.avi
VolleyballSpiking/v_VolleyballSpiking_g04_c07.avi
VolleyballSpiking/v_VolleyballSpiking_g05_c01.avi
VolleyballSpiking/v_VolleyballSpiking_g05_c02.avi
VolleyballSpiking/v_VolleyballSpiking_g05_c03.avi
VolleyballSpiking/v_VolleyballSpiking_g05_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g05_c05.avi
VolleyballSpiking/v_VolleyballSpiking_g06_c01.avi
VolleyballSpiking/v_VolleyballSpiking_g06_c02.avi
VolleyballSpiking/v_VolleyballSpiking_g06_c03.avi
VolleyballSpiking/v_VolleyballSpiking_g06_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g07_c01.avi
VolleyballSpiking/v_VolleyballSpiking_g07_c02.avi
VolleyballSpiking/v_VolleyballSpiking_g07_c03.avi
VolleyballSpiking/v_VolleyballSpiking_g07_c04.avi
VolleyballSpiking/v_VolleyballSpiking_g07_c05.avi
VolleyballSpiking/v_VolleyballSpiking_g07_c06.avi
VolleyballSpiking/v_VolleyballSpiking_g07_c07.avi
WalkingWithDog/v_WalkingWithDog_g01_c01.avi
WalkingWithDog/v_WalkingWithDog_g01_c02.avi
WalkingWithDog/v_WalkingWithDog_g01_c03.avi
WalkingWithDog/v_WalkingWithDog_g01_c04.avi
WalkingWithDog/v_WalkingWithDog_g02_c01.avi
WalkingWithDog/v_WalkingWithDog_g02_c02.avi
WalkingWithDog/v_WalkingWithDog_g02_c03.avi
WalkingWithDog/v_WalkingWithDog_g02_c04.avi
WalkingWithDog/v_WalkingWithDog_g02_c05.avi
WalkingWithDog/v_WalkingWithDog_g02_c06.avi
WalkingWithDog/v_WalkingWithDog_g03_c01.avi
WalkingWithDog/v_WalkingWithDog_g03_c02.avi
WalkingWithDog/v_WalkingWithDog_g03_c03.avi
WalkingWithDog/v_WalkingWithDog_g03_c04.avi
WalkingWithDog/v_WalkingWithDog_g03_c05.avi
WalkingWithDog/v_WalkingWithDog_g04_c01.avi
WalkingWithDog/v_WalkingWithDog_g04_c02.avi
WalkingWithDog/v_WalkingWithDog_g04_c03.avi
WalkingWithDog/v_WalkingWithDog_g04_c04.avi
WalkingWithDog/v_WalkingWithDog_g04_c05.avi
WalkingWithDog/v_WalkingWithDog_g05_c01.avi
WalkingWithDog/v_WalkingWithDog_g05_c02.avi
WalkingWithDog/v_WalkingWithDog_g05_c03.avi
WalkingWithDog/v_WalkingWithDog_g05_c04.avi
WalkingWithDog/v_WalkingWithDog_g05_c05.avi
WalkingWithDog/v_WalkingWithDog_g06_c01.avi
WalkingWithDog/v_WalkingWithDog_g06_c02.avi
WalkingWithDog/v_WalkingWithDog_g06_c03.avi
WalkingWithDog/v_WalkingWithDog_g06_c04.avi
WalkingWithDog/v_WalkingWithDog_g06_c05.avi
WalkingWithDog/v_WalkingWithDog_g07_c01.avi
WalkingWithDog/v_WalkingWithDog_g07_c02.avi
WalkingWithDog/v_WalkingWithDog_g07_c03.avi
WalkingWithDog/v_WalkingWithDog_g07_c04.avi
WalkingWithDog/v_WalkingWithDog_g07_c05.avi
WalkingWithDog/v_WalkingWithDog_g07_c06.avi
WallPushups/v_WallPushups_g01_c01.avi
WallPushups/v_WallPushups_g01_c02.avi
WallPushups/v_WallPushups_g01_c03.avi
WallPushups/v_WallPushups_g01_c04.avi
WallPushups/v_WallPushups_g02_c01.avi
WallPushups/v_WallPushups_g02_c02.avi
WallPushups/v_WallPushups_g02_c03.avi
WallPushups/v_WallPushups_g02_c04.avi
WallPushups/v_WallPushups_g03_c01.avi
WallPushups/v_WallPushups_g03_c02.avi
WallPushups/v_WallPushups_g03_c03.avi
WallPushups/v_WallPushups_g03_c04.avi
WallPushups/v_WallPushups_g03_c05.avi
WallPushups/v_WallPushups_g04_c01.avi
WallPushups/v_WallPushups_g04_c02.avi
WallPushups/v_WallPushups_g04_c03.avi
WallPushups/v_WallPushups_g04_c04.avi
WallPushups/v_WallPushups_g05_c01.avi
WallPushups/v_WallPushups_g05_c02.avi
WallPushups/v_WallPushups_g05_c03.avi
WallPushups/v_WallPushups_g05_c04.avi
WallPushups/v_WallPushups_g05_c05.avi
WallPushups/v_WallPushups_g06_c01.avi
WallPushups/v_WallPushups_g06_c02.avi
WallPushups/v_WallPushups_g06_c03.avi
WallPushups/v_WallPushups_g06_c04.avi
WallPushups/v_WallPushups_g06_c05.avi
WallPushups/v_WallPushups_g06_c06.avi
WallPushups/v_WallPushups_g06_c07.avi
WallPushups/v_WallPushups_g07_c01.avi
WallPushups/v_WallPushups_g07_c02.avi
WallPushups/v_WallPushups_g07_c03.avi
WallPushups/v_WallPushups_g07_c04.avi
WallPushups/v_WallPushups_g07_c05.avi
WallPushups/v_WallPushups_g07_c06.avi
WritingOnBoard/v_WritingOnBoard_g01_c01.avi
WritingOnBoard/v_WritingOnBoard_g01_c02.avi
WritingOnBoard/v_WritingOnBoard_g01_c03.avi
WritingOnBoard/v_WritingOnBoard_g01_c04.avi
WritingOnBoard/v_WritingOnBoard_g01_c05.avi
WritingOnBoard/v_WritingOnBoard_g01_c06.avi
WritingOnBoard/v_WritingOnBoard_g01_c07.avi
WritingOnBoard/v_WritingOnBoard_g02_c01.avi
WritingOnBoard/v_WritingOnBoard_g02_c02.avi
WritingOnBoard/v_WritingOnBoard_g02_c03.avi
WritingOnBoard/v_WritingOnBoard_g02_c04.avi
WritingOnBoard/v_WritingOnBoard_g02_c05.avi
WritingOnBoard/v_WritingOnBoard_g02_c06.avi
WritingOnBoard/v_WritingOnBoard_g02_c07.avi
WritingOnBoard/v_WritingOnBoard_g03_c01.avi
WritingOnBoard/v_WritingOnBoard_g03_c02.avi
WritingOnBoard/v_WritingOnBoard_g03_c03.avi
WritingOnBoard/v_WritingOnBoard_g03_c04.avi
WritingOnBoard/v_WritingOnBoard_g03_c05.avi
WritingOnBoard/v_WritingOnBoard_g03_c06.avi
WritingOnBoard/v_WritingOnBoard_g03_c07.avi
WritingOnBoard/v_WritingOnBoard_g04_c01.avi
WritingOnBoard/v_WritingOnBoard_g04_c02.avi
WritingOnBoard/v_WritingOnBoard_g04_c03.avi
WritingOnBoard/v_WritingOnBoard_g04_c04.avi
WritingOnBoard/v_WritingOnBoard_g05_c01.avi
WritingOnBoard/v_WritingOnBoard_g05_c02.avi
WritingOnBoard/v_WritingOnBoard_g05_c03.avi
WritingOnBoard/v_WritingOnBoard_g05_c04.avi
WritingOnBoard/v_WritingOnBoard_g05_c05.avi
WritingOnBoard/v_WritingOnBoard_g05_c06.avi
WritingOnBoard/v_WritingOnBoard_g06_c01.avi
WritingOnBoard/v_WritingOnBoard_g06_c02.avi
WritingOnBoard/v_WritingOnBoard_g06_c03.avi
WritingOnBoard/v_WritingOnBoard_g06_c04.avi
WritingOnBoard/v_WritingOnBoard_g06_c05.avi
WritingOnBoard/v_WritingOnBoard_g06_c06.avi
WritingOnBoard/v_WritingOnBoard_g06_c07.avi
WritingOnBoard/v_WritingOnBoard_g07_c01.avi
WritingOnBoard/v_WritingOnBoard_g07_c02.avi
WritingOnBoard/v_WritingOnBoard_g07_c03.avi
WritingOnBoard/v_WritingOnBoard_g07_c04.avi
WritingOnBoard/v_WritingOnBoard_g07_c05.avi
WritingOnBoard/v_WritingOnBoard_g07_c06.avi
WritingOnBoard/v_WritingOnBoard_g07_c07.avi
YoYo/v_YoYo_g01_c01.avi
YoYo/v_YoYo_g01_c02.avi
YoYo/v_YoYo_g01_c03.avi
YoYo/v_YoYo_g01_c04.avi
YoYo/v_YoYo_g01_c05.avi
YoYo/v_YoYo_g01_c06.avi
YoYo/v_YoYo_g01_c07.avi
YoYo/v_YoYo_g02_c01.avi
YoYo/v_YoYo_g02_c02.avi
YoYo/v_YoYo_g02_c03.avi
YoYo/v_YoYo_g02_c04.avi
YoYo/v_YoYo_g02_c05.avi
YoYo/v_YoYo_g03_c01.avi
YoYo/v_YoYo_g03_c02.avi
YoYo/v_YoYo_g03_c03.avi
YoYo/v_YoYo_g03_c04.avi
YoYo/v_YoYo_g03_c05.avi
YoYo/v_YoYo_g03_c06.avi
YoYo/v_YoYo_g04_c01.avi
YoYo/v_YoYo_g04_c02.avi
YoYo/v_YoYo_g04_c03.avi
YoYo/v_YoYo_g04_c04.avi
YoYo/v_YoYo_g04_c05.avi
YoYo/v_YoYo_g05_c01.avi
YoYo/v_YoYo_g05_c02.avi
YoYo/v_YoYo_g05_c03.avi
YoYo/v_YoYo_g05_c04.avi
YoYo/v_YoYo_g05_c05.avi
YoYo/v_YoYo_g06_c01.avi
YoYo/v_YoYo_g06_c02.avi
YoYo/v_YoYo_g06_c03.avi
YoYo/v_YoYo_g06_c04.avi
YoYo/v_YoYo_g07_c01.avi
YoYo/v_YoYo_g07_c02.avi
YoYo/v_YoYo_g07_c03.avi
YoYo/v_YoYo_g07_c04.avi
================================================
FILE: braincog/datasets/scripts/ucf101_dvs_preprocessing.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/12/20 20:16
# User : Floyed
# Product : PyCharm
# Project : BrainCog
# File : ucf101_dvs_preprocessing.py
# explain :
import os
import shutil
ROOT_DIR = '/data/datasets/UCF101_DVS/UCF101_DVS'
train_path = os.path.join(ROOT_DIR, 'train')
val_path = os.path.join(ROOT_DIR, 'val')
val_fname = 'testlist01.txt'
cls_path = os.listdir(train_path)
if not os.path.exists(val_path):
os.mkdir(val_path)
for cls_name in cls_path:
os.mkdir(os.path.join(val_path, cls_name))
f = open(val_fname, 'r')
for fname in f.readlines():
fname = fname[:-4] + 'mat'
fname.replace('Billards', 'Billiards')
src = os.path.join(train_path, fname)
dst = os.path.join(val_path, fname)
try:
shutil.move(src, dst)
except:
print('[Warning] Cannot find {}.'.format(src))
print('[Moving] {} -> {}.'.format(src, dst))
================================================
FILE: braincog/datasets/ucf101_dvs/__init__.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2023/1/30 21:04
# User : yu
# Product : PyCharm
# Project : BrainCog
# File : __init__.py.py
# explain :
from .ucf101_dvs import UCF101DVS
__all__ = [
'UCF101DVS'
]
================================================
FILE: braincog/datasets/ucf101_dvs/ucf101_dvs.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2023/1/30 21:05
# User : yu
# Product : PyCharm
# Project : BrainCog
# File : ucf51_dvs.py
# explain :
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/12/20 20:47
# User : Floyed
# Product : PyCharm
# Project : tonic
# File : ucf101dvs.py
# explain :
import os
import numpy as np
from numpy.lib import recfunctions
import scipy.io as scio
from typing import Tuple, Any, Optional
from tonic.dataset import Dataset
from tonic.download_utils import extract_archive
class UCF101DVS(Dataset):
"""ASL-DVS dataset . Events have (txyp) ordering.
::
@inproceedings{bi2019graph,
title={Graph-based Object Classification for Neuromorphic Vision Sensing},
author={Bi, Y and Chadha, A and Abbas, A and and Bourtsoulatze, E and Andreopoulos, Y},
booktitle={2019 IEEE International Conference on Computer Vision (ICCV)},
year={2019},
organization={IEEE}
}
Parameters:
save_to (string): Location to save files to on disk.
transform (callable, optional): A callable of transforms to apply to the data.
target_transform (callable, optional): A callable of transforms to apply to the targets/labels.
"""
sensor_size = (240, 180, 2)
dtype = np.dtype([("t", int), ("x", int), ("y", int), ("p", int)])
ordering = dtype.names
folder_name = 'UCF101DVS'
def __init__(self, save_to, train=False, transform=None, target_transform=None):
super(UCF101DVS, self).__init__(
save_to, transform=transform, target_transform=target_transform
)
if not self._check_exists():
raise NotImplementedError(
'Please manually download the dataset from'
' https://www.dropbox.com/sh/ie75dn246cacf6n/AACoU-_zkGOAwj51lSCM0JhGa?dl=0 '
'and extract it to {}'.format(self.location_on_system))
if train:
self.location_on_system = os.path.join(self.location_on_system, 'train')
else:
self.location_on_system = os.path.join(self.location_on_system, 'val')
classes = os.listdir(self.location_on_system)
self.int_classes = dict(zip(classes, range(len(classes))))
for path, dirs, files in os.walk(self.location_on_system):
dirs.sort()
files.sort()
for file in files:
if file.endswith("mat"):
fsize = os.path.getsize(path + '/' + file) / float(1024)
if fsize < 1:
# print('{} size {} K'.format(file, fsize))
continue
self.data.append(path + "/" + file)
self.targets.append(self.int_classes[path.split('/')[-1]])
def __getitem__(self, index: int) -> Tuple[Any, Any]:
"""
Returns:
(events, target) where target is index of the target class.
"""
events, target = scio.loadmat(self.data[index]), self.targets[index]
events = np.column_stack(
[
events["ts"],
events["x"],
self.sensor_size[1] - 1 - events["y"],
events["pol"],
]
)
events = np.lib.recfunctions.unstructured_to_structured(events, self.dtype)
if self.transform is not None:
events = self.transform(events)
if self.target_transform is not None:
target = self.target_transform(target)
return events, target
def __len__(self):
return len(self.data)
def _check_exists(self):
print(self.folder_name)
return self._folder_contains_at_least_n_files_of_type(
13523, ".mat"
)
================================================
FILE: braincog/datasets/utils.py
================================================
import torch
from einops import repeat
from braincog.datasets.gen_input_signal import lambda_max
def rescale(x, factor=None):
"""
数据放缩函数
:param x: 输入的tensor
:param factor: 缩放因子
:return: 缩放后的数据
"""
if factor:
x *= factor
else:
x *= lambda_max
return x
def dvs_channel_check_expend(x):
"""
检查是否存在DVS数据缺失, N-Car中有的数据会缺少一个通道
:param x: 输入的tensor
:return: 补全之后的数据
"""
if x.shape[1] == 1:
return repeat(x, 'b c w h -> b (r c) w h', r=2)
else:
return x
================================================
FILE: braincog/model_zoo/NeuEvo/__init__.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/9/1 16:43
# User : Floyed
# Product : PyCharm
# Project : BrainCog
# File : __init__.py.py
# explain :
import os
import numpy as np
from .genotypes import PRIMITIVES, Genotype
forward_edge_num = sum(1 for i in range(3) for n in range(2 + i))
backward_edge_num = sum(1 for i in range(3) for n in range(i))
num_ops = len(PRIMITIVES)
type_num = len(PRIMITIVES) // 2
# edge_num = [2, 3, 4]
# node_id: (forward) 2, 3, 4
# node_id: (backward) 3, 2
edge_num = [2, 3, 4, 1, 2]
def parse(weights, operation_set,
op_threshold, parse_method,
steps, reduction=False,
back_connection=False):
global k_best
gene = []
if parse_method == 'darts':
n = 2
start = 0
for i in range(steps): # step = 4
end = start + n
W = weights[start:end].copy()
edges = sorted(range(i + 2), key=lambda x: -
max(W[x][k] for k in range(len(W[x]))))[:2]
for j in edges:
for k in range(len(W[j])):
if k_best is None or W[j][k] > W[j][k_best]:
k_best = k
# geno item : (operation, node idx)
gene.append((operation_set[k_best], j))
start = end
n += 1
elif parse_method == 'bio_darts':
weights_backward = weights[forward_edge_num:]
weights_forward = weights[:forward_edge_num]
# forward
n = 2
start = 0
# idx = np.argsort(weights_forward[:, 0]).tolist()
# if reduction:
# idx.remove(0)
# idx.remove(1)
# weights_forward[:, 0] = 0.
# weights_forward[idx[-2:], 0] = 1.
for i in range(steps): # step = 4
end = start + n
W = weights_forward[start:end].copy()
edges = sorted(range(i + 2), key=lambda x: -
max(W[x][k] for k in range(len(W[x]))))[:2]
k_best = None
idx = np.argsort(W[edges[0]])
gene.append((operation_set[idx[-1]], edges[0]))
idx = np.argsort(W[edges[1]])
gene.append((operation_set[idx[-1]], edges[1]))
#
# op_name = operation_set[idx[-1]]
# idx = np.argsort(W[edges[1]])
# if 'skip' in op_name:
# gene.append((operation_set[idx[-1]], edges[1]))
# elif '_n' in op_name:
# for k in reversed(idx):
# if '_n' not in operation_set[k]:
# gene.append((operation_set[k], edges[1]))
# break
# else:
# for k in reversed(idx):
# if '_n' in operation_set[k]:
# gene.append((operation_set[k], edges[1]))
# break
start = end
n += 1
if back_connection:
# backward
n = 1
start = 0
for i in range(1, steps):
end = start + n
W = weights_backward[start:end].copy()
edges = sorted(range(i), key=lambda x: -
max(W[x][k] for k in range(len(W[x]))))[0]
idx = np.argsort(W[edges])
gene.append((operation_set[idx[-1]] + '_back', edges + 2))
start = end
n += 1
elif 'threshold' in parse_method:
n = 2
start = 0
for i in range(steps): # step = 4
end = start + n
W = weights[start:end].copy()
if 'edge' in parse_method:
edges = list(range(i + 2))
else: # select edges using darts methods
edges = sorted(range(i + 2), key=lambda x: -
max(W[x][k] for k in range(len(W[x]))))[:2]
for j in edges:
if 'edge' in parse_method: # OP_{prob > T} AND |Edge| <= 2
topM = sorted(enumerate(W[j]), key=lambda x: x[1])[-2:]
for k, v in topM: # Get top M = 2 operations for one edge
if W[j][k] >= op_threshold:
gene.append((operation_set[k], i + 2, j))
# max( OP_{prob > T} ) and |Edge| <= 2
elif 'sparse' in parse_method:
k_best = None
for k in range(len(W[j])):
if k_best is None or W[j][k] > W[j][k_best]:
k_best = k
if W[j][k_best] >= op_threshold:
gene.append((operation_set[k_best], i + 2, j))
else:
raise NotImplementedError(
"Not support parse method: {}".format(parse_method))
start = end
n += 1
return gene
def parse_genotype(alphas, steps, multiplier, path=None,
parse_method='threshold_sparse', op_threshold=0.85):
alphas_normal, alphas_reduce = alphas
gene_normal = parse(alphas_normal, PRIMITIVES,
op_threshold, parse_method, steps)
gene_reduce = parse(alphas_reduce, PRIMITIVES,
op_threshold, parse_method, steps)
concat = range(2 + steps - multiplier, steps + 2)
genotype = Genotype(
normal=gene_normal, normal_concat=concat,
reduce=gene_reduce, reduce_concat=concat
)
if path is not None:
if not os.path.exists(path):
os.makedirs(path)
print('Architecture parsing....\n', genotype)
save_path = os.path.join(
path, parse_method + '_' + str(op_threshold) + '.txt')
with open(save_path, "w+") as f:
f.write(str(genotype))
print('Save in :', save_path)
================================================
FILE: braincog/model_zoo/NeuEvo/architect.py
================================================
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import numpy as np
from numpy.linalg import eigvals
from braincog.model_zoo.NeuEvo.model_search import calc_weight, calc_loss
def normalize(x):
mu = np.average(x)
sigma = np.std(x)
return (x - mu) / sigma
def _concat(xs):
return torch.cat([x.view(-1) for x in xs])
class Architect(object):
def __init__(self, model, args):
self.network_momentum = args.momentum
self.network_weight_decay = args.weight_decay
self.model = model
self.optimizer = torch.optim.AdamW(self.model.arch_parameters(),
lr=args.arch_learning_rate,
betas=(args.arch_lr_gamma, 0.999),
weight_decay=args.arch_weight_decay)
# self.optimizer = torch.optim.SGD(self.model.arch_parameters(), lr=args.arch_learning_rate)
self.hessian = None
self.grads = None
def step(self, input_valid, target_valid):
self.optimizer.zero_grad()
aux_input = torch.cat([calc_loss(self.model.alphas_normal)], dim=0)
loss, loss1, loss2 = self.model._loss(
input_valid, target_valid, aux_input)
# loss = self.model._loss(input_valid, target_valid)
loss.backward()
self.optimizer.step()
return loss1, loss2
def compute_Hw(self, input_valid, target_valid):
self.zero_grads(self.model.parameters())
self.zero_grads(self.model.arch_parameters())
aux_input = torch.cat(
[F.softmax(self.model.alphas_normal, dim=-1)], dim=0)
loss = self.model._loss(input_valid, target_valid, aux_input)
self.hessian = self._hessian(loss, self.model.arch_parameters())
return self.hessian
def zero_grads(self, parameters):
for p in parameters:
if p.grad is not None:
p.grad.detach_()
p.grad.zero_()
def compute_eigenvalues(self):
self.compute_Hw()
return eigvals(self.hessian.cpu().data.numpy())
def _hessian(self, outputs, inputs, out=None, allow_unused=False):
if torch.is_tensor(inputs):
inputs = [inputs]
else:
inputs = list(inputs)
n = sum(p.numel() for p in inputs)
if out is None:
out = torch.tensor(torch.zeros(n, n)).type_as(outputs)
ai = 0
for i, inp in enumerate(inputs):
[grad] = torch.autograd.grad(outputs, inp, create_graph=True,
allow_unused=allow_unused)
grad = grad.contiguous().view(-1) + self.weight_decay * inp.view(-1)
for j in range(inp.numel()):
if grad[j].requires_grad:
row = self.gradient(
grad[j], inputs[i:], retain_graph=True)[j:]
else:
n = sum(x.numel() for x in inputs[i:]) - j
row = Variable(torch.zeros(n)).type_as(grad[j])
out.data[ai, ai:].add_(row.clone().type_as(out).data)
if ai + 1 < n:
out.data[ai + 1:,
ai].add_(row.clone().type_as(out).data[1:])
del row
ai += 1
del grad
return out
================================================
FILE: braincog/model_zoo/NeuEvo/genotypes.py
================================================
from collections import namedtuple
import torch
Genotype = namedtuple('Genotype', 'normal normal_concat')
"""
Operation sets
"""
PRIMITIVES = [
'conv_3x3_p',
# 'max_pool_3x3',
# 'avg_pool_3x3',
# 'def_conv_3x3',
# 'def_conv_5x5',
# 'sep_conv_3x3',
# 'sep_conv_5x5',
# 'dil_conv_3x3',
# 'dil_conv_5x5',
# 'max_pool_3x3_p',
# 'avg_pool_3x3_p',
'conv_3x3_p',
'conv_5x5_p',
# 'conv_3x3_p_p',
# 'sep_conv_3x3_p',
# 'sep_conv_5x5_p',
# 'dil_conv_3x3_p',
# 'dil_conv_5x5_p',
# 'def_conv_3x3_p',
# 'def_conv_5x5_p',n
# 'max_pool_3x3_n',
# 'avg_pool_3x3_n',
'conv_3x3_n',
'conv_5x5_n',
# 'conv_3x3_p_n',
# 'sep_conv_3x3_n',
# 'sep_conv_5x5_n',
# 'dil_conv_3x3_n',
# 'dil_conv_5x5_n',
# 'def_conv_3x3_n',
# 'def_conv_5x5_n',
# 'transformer',
]
"""====== SnnMlp Archirtecture By Other Methods"""
mlp1 = Genotype(
normal=[
('mlp', 0), ('conv_3x3_p', 1), # 2
('mlp', 1), ('mlp', 0), # 3
('conv_3x3_p', 2), ('mlp', 3), # 4
('mlp_back', 2),
('conv_3x3_p_back', 2)
],
normal_concat=range(2, 5)
)
mlp2 = Genotype(
normal=[
('mlp', 0), ('conv_3x3_p', 1),
('conv_3x3_p', 2), ('mlp_p', 1),
# ('mlp_n', 1), ('conv_3x3_p', 2),
('mlp_back', 2)
],
normal_concat=range(2, 4)
)
"""====== SNN Archirtecture By Other Methods"""
dvsc10_new_skip22 = Genotype(
normal=[
('conv_3x3_p', 1), ('conv_3x3_p', 0), # 2
('conv_5x5_p', 1), ('conv_3x3_p', 2), # 3
('conv_3x3_p', 0), ('conv_3x3_p', 3), # 4
('conv_3x3_n_back', 2), ('conv_3x3_p_back', 3) # 3, 4
],
normal_concat=range(2, 5)
)
dvsc10_new_skip22 = Genotype(
normal=[
('conv_3x3_p', 1), ('conv_3x3_p', 0),
('conv_5x5_n', 1), ('conv_3x3_p', 2),
('conv_5x5_n', 0), ('conv_3x3_p', 3),
('conv_3x3_n_back', 0), ('conv_3x3_p_back', 1)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip21 = Genotype(
normal=[
('conv_3x3_n', 0), ('conv_5x5_p', 1), # 2
('conv_3x3_p', 1), ('conv_5x5_p', 2), # 3
('conv_5x5_n', 2), ('conv_3x3_p', 1), # 4
# ('conv_3x3_p_back', 2), ('conv_5x5_p_back', 2)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip20 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_n', 1),
('conv_3x3_n', 2), ('conv_5x5_p', 0),
('conv_3x3_p', 2), ('conv_3x3_n', 3),
('conv_3x3_p_back', 2),
('conv_5x5_p_back', 3)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip19 = Genotype(
normal=[
('conv_5x5_n', 0), ('conv_3x3_p', 1),
('conv_5x5_n', 2), ('conv_5x5_n', 0),
('conv_3x3_p', 2), ('conv_5x5_p', 3),
('conv_3x3_p_back', 2),
('conv_5x5_p_back', 2)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip18 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_3x3_p', 1),
('conv_5x5_p', 2), ('conv_5x5_n', 0),
('conv_3x3_p', 2), ('conv_5x5_p', 3),
('conv_5x5_n_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_skip17 = Genotype(
normal=[
('conv_3x3_p', 1), ('conv_5x5_n', 0),
('conv_5x5_n', 2), ('conv_5x5_p', 1),
('conv_3x3_p', 2), ('avg_pool_3x3_p', 3),
('avg_pool_3x3_p_back', 2), ('conv_3x3_p_back', 2)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip16 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_n', 1),
('conv_3x3_n', 2), ('avg_pool_3x3_p', 0),
('conv_3x3_p', 2), ('avg_pool_3x3_n', 3),
('conv_3x3_p_back', 2),
('conv_3x3_p_back', 3)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip15 = Genotype(
normal=[
('conv_5x5_n', 0), ('conv_5x5_p', 1),
('conv_5x5_p', 2), ('conv_5x5_n', 1),
('conv_3x3_p', 2), ('conv_5x5_p', 3),
('conv_5x5_p_back', 2),
('conv_3x3_p_back', 3)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip14 = Genotype(
normal=[
('conv_5x5_n', 1), ('conv_3x3_p', 0),
('conv_5x5_p', 1), ('conv_3x3_p', 2),
('conv_3x3_p', 2), ('conv_5x5_n', 1),
('conv_3x3_n_back', 2),
('conv_3x3_p_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new_skip13 = Genotype(
normal=[
('conv_5x5_n', 1), ('conv_3x3_p', 0),
('conv_5x5_n', 1), ('conv_3x3_p', 2),
('conv_3x3_p', 2), ('conv_5x5_n', 1),
('conv_3x3_n_back', 2),
('conv_3x3_p_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new_skip12 = Genotype(
normal=[
('conv_5x5_n', 0), ('conv_3x3_p', 1),
('conv_5x5_n', 2), ('conv_5x5_n', 0),
('conv_3x3_p', 2), ('conv_5x5_p', 3),
('conv_3x3_n_back', 2),
('conv_3x3_p_back', 2)
],
normal_concat=range(2, 5)
)
# dvsc10_new_skip12 = Genotype(
# normal=[
# ('conv_3x3_p', 0), ('conv_3x3_n', 1),
# ('conv_3x3_p', 1), ('conv_5x5_n', 2),
# ('conv_3x3_n', 3), ('conv_3x3_p', 0),
# ('conv_5x5_p_back', 2), ('conv_3x3_p_back', 3)
# ],
# normal_concat=range(2, 5)
# )
dvsc10_new_skip11 = Genotype(normal=[
('conv_3x3_n', 0), ('conv_5x5_n', 1),
('conv_5x5_p', 0), ('conv_3x3_n', 2),
('conv_3x3_p', 2), ('conv_5x5_n', 0),
('conv_3x3_n_back', 2),
('conv_3x3_p_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new_skip10 = Genotype(
normal=[
('conv_5x5_n', 1), ('conv_3x3_p', 0),
('conv_5x5_p', 2), ('conv_5x5_p', 1),
('conv_3x3_p', 2), ('conv_5x5_n', 1),
('conv_3x3_n_back', 2),
('conv_3x3_n_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_skip9 = Genotype(
normal=[
('conv_5x5_p', 1), ('conv_5x5_n', 0),
('conv_5x5_p', 2), ('conv_5x5_n', 0),
('conv_3x3_p', 2), ('conv_5x5_p', 3),
('conv_3x3_p_back', 2),
('conv_5x5_n_back', 3)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip8 = Genotype(
normal=[
('conv_5x5_n', 0), ('conv_5x5_n', 1),
('conv_3x3_n', 2), ('conv_5x5_p', 0),
('conv_3x3_p', 2), ('conv_5x5_n', 1),
('conv_5x5_n_back', 2),
('conv_3x3_p_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new_skip7 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),
('conv_3x3_n', 2), ('conv_5x5_n', 0),
('conv_3x3_p', 2), ('conv_5x5_p', 3),
('conv_5x5_n_back', 2),
('conv_3x3_p_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new_skip6 = Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_n', 1),
('conv_5x5_p', 2), ('conv_5x5_p', 1),
('conv_3x3_p', 2), ('conv_5x5_n', 0),
('conv_3x3_n_back', 2), ('conv_3x3_n_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_skip5 = Genotype(
normal=[
('conv_3x3_p', 0), ('conv_3x3_p', 1),
('conv_3x3_n', 2), ('conv_3x3_n', 0),
('conv_3x3_p', 2), ('conv_3x3_p', 3),
('conv_5x5_n_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_skip4 = Genotype(
normal=[
('conv_5x5_n', 1), ('conv_5x5_p', 0),
('conv_3x3_p', 2), ('conv_5x5_p', 1),
('conv_3x3_p', 2), ('conv_5x5_n', 0),
('conv_3x3_p_back', 2),
('conv_3x3_p_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new_skip3 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_3x3_p', 1),
('conv_3x3_n', 2), ('conv_3x3_n', 0),
('conv_3x3_p', 2), ('conv_5x5_p', 3),
('conv_5x5_n_back', 2),
('conv_3x3_p_back', 3)
],
normal_concat=range(2, 5)
)
dvsc10_new_skip2 = Genotype(
normal=[
('avg_pool_3x3_p', 0), ('avg_pool_3x3_p', 1),
('avg_pool_3x3_p', 0), ('avg_pool_3x3_p', 1),
('conv_3x3_p', 2), ('avg_pool_3x3_n', 0),
('avg_pool_3x3_n_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_skip1 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_3x3_n', 1),
('conv_3x3_n', 2), ('conv_3x3_p', 1),
('conv_5x5_p', 1), ('conv_3x3_p', 2),
('conv_3x3_p_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_skip = Genotype(
normal=[
('conv_3x3_n', 1), ('conv_3x3_p', 0),
('conv_3x3_p', 0), ('avg_pool_3x3_p', 1),
('conv_3x3_p', 2), ('conv_3x3_n', 0),
('conv_3x3_p_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_base0 = Genotype(
normal=[
('avg_pool_3x3_p', 1), ('avg_pool_3x3_p', 0),
('avg_pool_3x3_n', 2), ('avg_pool_3x3_p', 1),
('avg_pool_3x3_n', 2), ('avg_pool_3x3_n', 3),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_n_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new_base1 = Genotype(
normal=[
('conv_3x3_p', 1), ('conv_5x5_n', 0),
('conv_5x5_p', 1), ('conv_3x3_p', 0),
('conv_5x5_n', 1), ('conv_3x3_p', 0),
('avg_pool_3x3_p_back', 2),
('conv_3x3_p_back', 3)
],
normal_concat=range(2, 5)
)
dvsc10_new_base2 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_3x3_p', 1),
('conv_5x5_n', 1), ('avg_pool_3x3_p', 0),
('avg_pool_3x3_n', 3), ('conv_5x5_n', 1),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_n_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new_base3 = Genotype(
normal=[
('avg_pool_3x3_p', 0), ('conv_5x5_p', 1),
('conv_3x3_p', 1), ('conv_3x3_n', 0),
('conv_5x5_p', 1), ('conv_3x3_n', 0),
('conv_3x3_p_back', 2),
('avg_pool_3x3_n_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_grad2 = Genotype(
normal=[
('avg_pool_3x3_n', 1), ('conv_5x5_p', 0),
('conv_5x5_n', 1), ('conv_5x5_n', 0),
('conv_3x3_p', 3), ('conv_5x5_n', 1),
('conv_5x5_p_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_grad1 = Genotype(
normal=[
('avg_pool_3x3_p', 1), ('conv_5x5_p', 0),
('avg_pool_3x3_n', 2), ('avg_pool_3x3_n', 1),
('avg_pool_3x3_p', 2), ('conv_5x5_n', 1),
('conv_5x5_p_back', 2),
('conv_3x3_p_back', 3)],
normal_concat=range(2, 5))
dvsg_new2 = Genotype(
normal=[
('avg_pool_3x3_p', 1), ('conv_5x5_p', 0),
('conv_3x3_p', 1), ('conv_3x3_p', 0),
('conv_3x3_p', 1), ('avg_pool_3x3_p', 0),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_n_back', 3)],
normal_concat=range(2, 5))
dvsg_new1 = Genotype(
normal=[
('avg_pool_3x3_p', 1), ('conv_5x5_p', 0),
('conv_3x3_p', 1), ('conv_3x3_p', 0),
('conv_3x3_p', 1), ('avg_pool_3x3_p', 0),
('avg_pool_3x3_n_back', 2),
('conv_5x5_n_back', 3)],
normal_concat=range(2, 5))
dvscal_new1 = Genotype(
normal=[
('conv_5x5_n', 0), ('conv_5x5_n', 1),
('conv_5x5_n', 1), ('conv_5x5_p', 0),
('avg_pool_3x3_p', 1), ('conv_5x5_p', 0),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_n_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new8 = Genotype(
normal=[('conv_5x5_p', 0), ('conv_5x5_p', 1),
('conv_3x3_p', 0), ('conv_5x5_n', 1),
('conv_5x5_p', 0), ('conv_5x5_n', 1),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_n_back', 3)],
normal_concat=range(2, 5)
)
dvsc10_new7 = Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),
('conv_3x3_p', 0), ('conv_5x5_n', 1),
('conv_5x5_p', 0), ('conv_5x5_n', 1),
('conv_3x3_n_back', 2),
('avg_pool_3x3_n_back', 2)],
normal_concat=range(2, 5))
dvsc10_new6 = Genotype(
normal=[
('conv_3x3_p', 1), ('conv_3x3_p', 0),
('conv_3x3_p', 0), ('conv_3x3_p', 1),
('conv_3x3_p', 0), ('avg_pool_3x3_p', 1),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_n_back', 2)],
normal_concat=range(2, 5))
dvsc10_new5 = Genotype(
normal=[
('conv_5x5_p', 1), ('conv_3x3_p', 0),
('conv_3x3_p', 0), ('conv_5x5_p', 1),
('conv_3x3_p', 0), ('avg_pool_3x3_p', 1),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_n_back', 2)],
normal_concat=range(2, 5))
dvsc10_new4 = Genotype(
normal=[
('conv_3x3_n', 1), ('conv_3x3_p', 0),
('conv_5x5_p', 1), ('conv_5x5_p', 0),
('conv_5x5_p', 1), ('conv_5x5_p', 0),
('avg_pool_3x3_p_back', 2),
('avg_pool_3x3_n_back', 2)],
normal_concat=range(2, 5),
)
dvsc10_new3 = Genotype(
normal=[
('avg_pool_3x3_p', 0), ('conv_3x3_n', 1),
('conv_3x3_n', 1), ('conv_3x3_n', 0),
('avg_pool_3x3_p', 2), ('conv_3x3_n', 1),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_p', 2)],
normal_concat=range(2, 5),
)
dvsc10_new2 = Genotype(normal=[
('conv_3x3_p', 0), ('conv_3x3_n', 1),
('conv_3x3_n', 1), ('avg_pool_3x3_p', 0),
('avg_pool_3x3_p', 2), ('conv_3x3_n', 1),
('avg_pool_3x3_n_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5),
)
dvsc10_new1 = Genotype(
normal=[
('conv_3x3_p', 1), ('avg_pool_3x3_p', 0),
('avg_pool_3x3_p', 0), ('conv_3x3_n', 1),
('conv_3x3_p', 0), ('conv_3x3_p', 1),
('conv_3x3_p_back', 2),
('conv_3x3_n_back', 2)],
normal_concat=range(2, 5)
)
dvsc10_new0 = Genotype(
normal=[
('conv_3x3_p', 1), ('avg_pool_3x3_p', 0),
('avg_pool_3x3_p', 2), ('conv_3x3_n', 1),
('conv_3x3_p', 0), ('conv_3x3_p', 3),
('conv_3x3_p_back', 2),
('conv_3x3_n_back', 3)],
normal_concat=range(2, 5)
)
cifar_new_skip1 = Genotype(
normal=[
('conv_5x5_n', 0), ('conv_5x5_p', 1),
('avg_pool_3x3_p', 0), ('avg_pool_3x3_n', 2),
('avg_pool_3x3_p', 2), ('conv_5x5_p', 0),
('avg_pool_3x3_n_back', 2),
('avg_pool_3x3_p_back', 3)
],
normal_concat=range(2, 5))
cifar_new1 = Genotype(
normal=[
('avg_pool_3x3_p', 1), ('avg_pool_3x3_p', 0),
('conv_3x3_n', 0), ('avg_pool_3x3_p', 1),
('avg_pool_3x3_p', 2), ('conv_3x3_p', 0),
('avg_pool_3x3_n_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5)
)
cifar_new2 = Genotype(
normal=[
('conv_3x3_n', 0), ('avg_pool_3x3_p', 1),
('conv_3x3_p', 0), ('avg_pool_3x3_p', 1),
('conv_3x3_p', 2), ('conv_3x3_n', 0),
('conv_3x3_n_back', 2),
('conv_3x3_p_back', 2)],
normal_concat=range(2, 5),
)
cifar_new0 = Genotype(
normal=[
('avg_pool_3x3_p', 1), ('avg_pool_3x3_n', 0), # 2, 3
('conv_3x3_n', 0), ('avg_pool_3x3_p', 1), # 4, 5
('conv_3x3_p', 2), ('conv_3x3_n', 3), # 6 , 7
('avg_pool_3x3_n_back', 2),
('conv_3x3_p_back', 1)],
normal_concat=range(2, 5)
)
================================================
FILE: braincog/model_zoo/NeuEvo/model.py
================================================
from functools import partial
from typing import List, Type
from braincog.model_zoo.NeuEvo.operations import *
from braincog.model_zoo.NeuEvo.genotypes import Genotype
from braincog.base.utils import drop_path
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.model_zoo.base_module import BaseModule
class MlpCell(BaseModule):
def __init__(
self,
genotype: Genotype,
C: int,
input_dim: int,
output_dim: int,
encode_type: str = 'direct',
activation_fn: Type[nn.Module] = LIFNode,
squash_output: bool = False,
back_connection: bool = True,
step: int = 10,
**kwargs
):
super(MlpCell, self).__init__(
step=step,
encode_type=encode_type,
layer_by_layer=True
)
# print(activation_fn, step)
self.act_fun = partial(activation_fn, step=step, layer_by_layer=self.layer_by_layer, **kwargs)
self.back_connection = back_connection
op_names, indices = zip(*genotype.normal)
concat = genotype.normal_concat
self._compile(C, op_names, indices, concat)
self.feature = nn.Sequential(
nn.Linear(input_dim, C),
self.act_fun(),
)
if output_dim > 0:
self.output_fn = nn.Linear(self.multiplier * C, output_dim)
elif squash_output:
self.output_fn = nn.Tanh()
else:
self.output_fn = nn.Identity()
def _compile(self, C, op_names, indices, concat):
assert len(op_names) == len(indices)
# self._steps = len(op_names) // 2
self._concat = concat
self.multiplier = len(concat)
self._ops = nn.ModuleList()
self._ops_back = nn.ModuleList()
back_begin_index = 0
for i, (name, index) in enumerate(zip(op_names, indices)):
# print(name, index)
if '_back' in name:
back_begin_index = i
break
op = OPS_Mlp[name](C, act_fun=self.act_fun)
self._ops += [op]
if self.back_connection:
for name, index in zip(op_names[back_begin_index:], indices[back_begin_index:]):
op = OPS_Mlp[name.replace('_back', '')](
C, act_fun=self.act_fun)
self._ops_back += [op]
if self.back_connection:
self._indices_forward = indices[:back_begin_index]
self._indices_backward = indices[back_begin_index:]
else:
self._indices_backward = []
self._indices_forward = indices
self._steps = len(self._indices_forward) // 2
def _forward_once(self, s0, s1, drop_prob):
states = [s0, s1]
for i in range(self._steps):
h1 = states[self._indices_forward[2 * i]]
h2 = states[self._indices_forward[2 * i + 1]]
op1 = self._ops[2 * i]
op2 = self._ops[2 * i + 1]
h1 = op1(h1)
h2 = op2(h2)
if self.training and drop_prob > 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
s = h1 + h2
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]
] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = []
for i in self._concat:
outputs.append(rearrange(states[i], '(t b) c -> t b c', t=self.step))
outputs = torch.cat(outputs, dim=2) # T, B, C
return outputs
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.feature(inputs)
x = self._forward_once(x, x, 0.)
x = self.output_fn(x)
x = x.mean(0)
else:
raise NotImplementedError
return x
class Cell(nn.Module):
def __init__(self, genotype, C_prev_prev, C_prev, C, reduction, reduction_prev, act_fun, back_connection):
# print(C_prev_prev, C_prev, C, reduction)
super(Cell, self).__init__()
self.act_fun = act_fun
self.back_connection = back_connection
self.reduction = reduction
if reduction:
self.fun = FactorizedReduce(
C_prev, C * 3, act_fun=act_fun
)
self.multiplier = 3
else:
if reduction_prev:
self.preprocess0 = FactorizedReduce(
C_prev_prev, C, act_fun=act_fun)
else:
self.preprocess0 = ReLUConvBN(
C_prev_prev, C, 1, 1, 0, act_fun=act_fun)
self.preprocess1 = ReLUConvBN(C_prev, C, 1, 1, 0, act_fun=act_fun)
op_names, indices = zip(*genotype.normal)
concat = genotype.normal_concat
self._compile(C, op_names, indices, concat, reduction)
def _compile(self, C, op_names, indices, concat, reduction):
assert len(op_names) == len(indices)
# self._steps = len(op_names) // 2
self._concat = concat
self.multiplier = len(concat)
self._ops = nn.ModuleList()
self._ops_back = nn.ModuleList()
back_begin_index = 0
for i, (name, index) in enumerate(zip(op_names, indices)):
# print(name, index)
if '_back' in name:
back_begin_index = i
break
stride = 2 if reduction and index < 2 else 1
op = OPS[name](C, stride, True, act_fun=self.act_fun)
self._ops += [op]
if self.back_connection:
for name, index in zip(op_names[back_begin_index:], indices[back_begin_index:]):
op = OPS[name.replace('_back', '')](
C, 1, True, act_fun=self.act_fun)
self._ops_back += [op]
if self.back_connection:
self._indices_forward = indices[:back_begin_index]
self._indices_backward = indices[back_begin_index:]
else:
self._indices_backward = []
self._indices_forward = indices
self._steps = len(self._indices_forward) // 2
def forward(self, s0, s1, drop_prob):
if self.reduction:
return self.fun(s1)
s0 = self.preprocess0(s0)
s1 = self.preprocess1(s1)
states = [s0, s1]
for i in range(self._steps):
h1 = states[self._indices_forward[2 * i]]
h2 = states[self._indices_forward[2 * i + 1]]
op1 = self._ops[2 * i]
op2 = self._ops[2 * i + 1]
h1 = op1(h1)
h2 = op2(h2)
if self.training and drop_prob > 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
s = h1 + h2
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]
] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = torch.cat([states[i]
for i in self._concat], dim=1) # N,C,H, W
return outputs
# return self.node(outputs)
class DCOCell(nn.Module):
def __init__(self, genotype, C_prev_prev, C_prev, C, reduction, reduction_prev, act_fun):
super(DCOCell, self).__init__()
self.act_fun = act_fun
if reduction_prev:
self.preprocess0 = FactorizedReduce(C_prev_prev, C)
else:
self.preprocess0 = ReLUConvBN(C_prev_prev, C, 1, 1, 0)
self.preprocess1 = ReLUConvBN(C_prev, C, 1, 1, 0)
if reduction:
op_names, tos, froms = zip(*genotype.reduce)
else:
op_names, tos, froms = zip(*genotype.normal)
self._compile(C, op_names, tos, froms, reduction)
def _compile(self, C, op_names, tos, froms, reduction):
self._ops = nn.ModuleDict()
for name_i, to_i, from_i in zip(op_names, tos, froms):
stride = 2 if reduction and from_i < 2 else 1
op = OPS[name_i](C, stride, True, act_fun=self.act_fun)
if str(to_i) in self._ops.keys():
if str(from_i) in self._ops[str(to_i)]:
self._ops[str(to_i)][str(from_i)] += [op]
else:
self._ops[str(to_i)][str(from_i)] = nn.ModuleList()
self._ops[str(to_i)][str(from_i)] += [op]
else:
self._ops[str(to_i)] = nn.ModuleDict()
self._ops[str(to_i)][str(from_i)] = nn.ModuleList()
self._ops[str(to_i)][str(from_i)] += [op]
# TODO: Some intermediate node maybe no selected during search.
self.multiplier = len(self._ops)
def forward(self, s0, s1, drop_prob):
s0 = self.preprocess0(s0)
s1 = self.preprocess1(s1)
states = {}
states['0'] = s0
states['1'] = s1
# get all the operations in current intermediate node
for to_i, ops in self._ops.items():
h = []
for from_i, op_i in ops.items():
# each edge may no more than one operation
if from_i not in states:
# print('Exist the isolate node, which id is {}, we need ignore it!'.format(from_i))
continue
h += [sum([op(states[from_i])
for op in op_i if from_i in states])]
out = sum(h)
if self.training and drop_prob > 0:
out = drop_path(out, drop_prob)
states[to_i] = out
outputs = torch.cat([v for v in states.values()][2:], dim=1)
# return outputs
return outputs
class AuxiliaryHeadCIFAR(nn.Module):
def __init__(self, C, num_classes, act_fun):
"""assuming inputs size 8x8"""
super(AuxiliaryHeadCIFAR, self).__init__()
self.act_fun = act_fun
self.features = nn.Sequential(
# nn.ReLU(inplace=True),
self.act_fun(),
# image size = 2 x 2
nn.AvgPool2d(5, stride=3, padding=0, count_include_pad=False),
nn.Conv2d(C, 128, 1, bias=False),
nn.BatchNorm2d(128),
# nn.ReLU(inplace=True),
self.act_fun(),
nn.Conv2d(128, 768, 2, bias=False),
nn.BatchNorm2d(768),
# nn.ReLU(inplace=True)
self.act_fun()
)
self.classifier = nn.Linear(768, num_classes)
def forward(self, x):
x = self.features(x)
x = self.classifier(x.view(x.size(0), -1))
return x
class AuxiliaryHeadImageNet(nn.Module):
def __init__(self, C, num_classes):
"""assuming inputs size 14x14"""
super(AuxiliaryHeadImageNet, self).__init__()
self.features = nn.Sequential(
nn.ReLU(inplace=True),
nn.AvgPool2d(5, stride=2, padding=0, count_include_pad=False),
nn.Conv2d(C, 128, 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 768, 2, bias=False),
# NOTE: This batchnorm was omitted in my earlier implementation due to a typo.
# Commenting it out for consistency with the experiments in the paper.
# nn.BatchNorm2d(768),
nn.ReLU(inplace=True)
)
self.classifier = nn.Linear(768, num_classes)
def forward(self, x):
x = self.features(x)
x = self.classifier(x.view(x.size(0), -1))
return x
@register_model
class NetworkCIFAR(BaseModule):
def __init__(self,
C,
num_classes,
layers,
auxiliary,
genotype,
parse_method='darts',
step=1,
node_type='ReLUNode',
**kwargs):
super(NetworkCIFAR, self).__init__(
step=step,
num_classes=num_classes,
**kwargs
)
if isinstance(node_type, str):
self.act_fun = eval(node_type)
else:
self.act_fun = node_type
self.act_fun = partial(self.act_fun, **kwargs)
if 'back_connection' in kwargs.keys():
self.back_connection = kwargs['back_connection']
else:
self.back_connection = False
self.spike_output = kwargs['spike_output'] if 'spike_output' in kwargs else True
self.dataset = kwargs['dataset']
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
self._layers = layers
self._auxiliary = auxiliary
self.drop_path_prob = 0
stem_multiplier = 3
C_curr = stem_multiplier * C
if self.dataset == 'dvsg' or self.dataset == 'dvsc10' or self.dataset == 'NCALTECH101':
self.stem = nn.Sequential(
nn.Conv2d(2 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
# self.reduce_idx = [
# layers // 4,
# layers // 2,
# 3 * layers // 4
# ]
self.reduce_idx = [1, 3, 5, 7]
else:
self.stem = nn.Sequential(
nn.Conv2d(3 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
self.reduce_idx = [layers // 4,
layers // 2,
3 * layers // 4]
C_prev_prev, C_prev, C_curr = C_curr, C_curr, C
self.cells = nn.ModuleList()
reduction_prev = False
for i in range(layers):
if i in self.reduce_idx:
C_curr *= 2
reduction = True
else:
reduction = False
if parse_method == 'darts':
cell = Cell(genotype, C_prev_prev, C_prev, C_curr,
reduction, reduction_prev,
act_fun=self.act_fun, back_connection=self.back_connection)
else:
cell = DCOCell(genotype, C_prev_prev, C_prev, C_curr,
reduction, reduction_prev, act_fun=self.act_fun)
reduction_prev = reduction
self.cells += [cell]
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
if i == 2 * layers // 3:
C_to_auxiliary = C_prev
if auxiliary:
self.auxiliary_head = AuxiliaryHeadCIFAR(
C_to_auxiliary, num_classes, act_fun=self.act_fun)
self.global_pooling = nn.Sequential(
self.act_fun(), nn.AdaptiveAvgPool2d(1))
if self.spike_output:
self.classifier = nn.Sequential(
nn.Linear(C_prev, 10 * num_classes),
self.act_fun())
self.vote = VotingLayer(10)
else:
self.classifier = nn.Linear(C_prev, num_classes)
self.vote = nn.Identity()
# self.classifier = nn.Linear(C_prev, num_classes)
# self.vote = nn.Identity()
def forward(self, inputs):
logits_aux = None
inputs = self.encoder(inputs)
if not self.layer_by_layer:
outputs = []
output_aux = []
self.reset()
for t in range(self.step):
x = inputs[t]
s0 = s1 = self.stem(x)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
# print(s0.shape, s1.shape)
# if i == 2 * self._layers // 3:
# if self._auxiliary and self.training:
# logits_aux = self.auxiliary_head(s1)
out = self.global_pooling(s1)
out = self.classifier(self.flatten(out))
logits = self.vote(out)
outputs.append(logits)
output_aux.append(logits_aux)
return sum(outputs) / len(outputs)
# logits_aux if logits_aux is None else (sum(output_aux) / len(output_aux))
else:
s0 = s1 = self.stem(inputs)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
if i == 2 * self._layers // 3:
if self._auxiliary and self.training:
logits_aux = self.auxiliary_head(s1)
out = self.global_pooling(s1)
out = self.classifier(self.flatten(out))
out = rearrange(out, '(t b) c -> t b c', t=self.step).mean(0)
logits = self.vote(out)
return logits
@register_model
class NetworkImageNet(BaseModule):
def __init__(self,
C,
num_classes,
layers,
auxiliary,
genotype,
step=1,
node_type='ReLUNode',
**kwargs):
super(NetworkImageNet, self).__init__(
step=step,
num_classes=num_classes,
**kwargs)
if isinstance(node_type, str):
self.act_fun = eval(node_type)
else:
self.act_fun = node_type
self.act_fun = partial(self.act_fun, **kwargs)
if 'back_connection' in kwargs.keys():
self.back_connection = kwargs['back_connection']
else:
self.back_connection = False
self.spike_output = kwargs['spike_output'] if 'spike_output' in kwargs else True
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
self._layers = layers
self._auxiliary = auxiliary
self.drop_path_prob = 0
self.stem0 = nn.Sequential(
nn.Conv2d(3, C // 2, kernel_size=3,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(C // 2),
# nn.ReLU(inplace=True),
self.act_fun(),
nn.Conv2d(C // 2, C, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(C),
)
self.stem1 = nn.Sequential(
# nn.ReLU(inplace=True),
self.act_fun(),
nn.Conv2d(C, C, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(C),
)
C_prev_prev, C_prev, C_curr = C, C, C
self.cells = nn.ModuleList()
reduction_prev = True
for i in range(layers):
if i in [layers // 3, 2 * layers // 3]:
C_curr *= 2
reduction = True
else:
reduction = False
cell = Cell(genotype, C_prev_prev, C_prev,
C_curr, reduction, reduction_prev,
act_fun=self.act_fun, back_connection=self.back_connection)
reduction_prev = reduction
self.cells += [cell]
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
self.global_pooling = nn.AvgPool2d(7)
self.classifier = nn.Linear(C_prev, num_classes)
def forward(self, inputs):
outputs = []
self.reset()
for t in range(self.step):
s0 = self.stem0(inputs)
s1 = self.stem1(s0)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
out = self.global_pooling(s1)
logits = self.classifier(self.flatten(out))
outputs.append(logits)
return sum(outputs) / len(outputs)
if __name__ == '__main__':
from braincog.model_zoo.NeuEvo.genotypes import mlp2
cell = MlpCell(mlp2, C=128, input_dim=17, output_dim=-1)
x = torch.rand(4, 17)
out = cell(x)
print(out)
print(out.shape)
================================================
FILE: braincog/model_zoo/NeuEvo/model_search.py
================================================
from functools import partial
from braincog.model_zoo.NeuEvo.operations import *
from torch.autograd import Variable
from braincog.model_zoo.NeuEvo.genotypes import PRIMITIVES
from braincog.model_zoo.NeuEvo.genotypes import Genotype
from . import parse
from braincog.base.connection.layer import VotingLayer
from braincog.base.node.node import *
from braincog.model_zoo.base_module import BaseModule
from . import forward_edge_num
from . import edge_num
def calc_weight(x):
tmp0 = torch.split(x[0], edge_num, dim=0)
tmp1 = torch.split(x[1], edge_num, dim=0)
res = []
for i in range(len(edge_num)):
res.append(
torch.softmax(tmp0[i].view(-1), dim=-1).view(tmp0[i].shape)
+ torch.softmax(tmp1[i].view(-1), dim=-1).view(tmp1[i].shape)
)
return torch.cat(res, dim=0)
def calc_loss(x):
tmp0 = torch.split(x[0], edge_num, dim=0)
tmp1 = torch.split(x[1], edge_num, dim=0)
res = []
for i in range(len(edge_num)):
res.append(
torch.softmax(tmp0[i].view(-1), dim=-1).view(tmp0[i].shape)
- torch.softmax(tmp1[i].view(-1), dim=-1).view(tmp1[i].shape)
)
return torch.cat(res, dim=0)
class darts_fun(torch.autograd.Function):
@staticmethod
def forward(ctx, inputs, weights): # feature map / arch weight
output = inputs * weights
ctx.save_for_backward(inputs, weights)
return output
@staticmethod
def backward(ctx, grad_output): # error signal
grad_inputs, grad_weights = None, None
inputs, weights = ctx.saved_tensors
if ctx.needs_input_grad[0]:
grad_inputs = grad_output * weights
if ctx.needs_input_grad[1]:
if torch.min(inputs) < -1e-12 and torch.max(inputs) > 1e-12:
inputs = torch.abs(inputs) / 2.
else:
inputs = torch.abs(inputs)
grad_weights = -inputs.mean()
return grad_inputs, grad_weights
class MixedOp(nn.Module):
def __init__(self, C, stride, act_fun):
super(MixedOp, self).__init__()
self._ops = nn.ModuleList()
for primitive in PRIMITIVES:
op = OPS[primitive](C, stride, False, act_fun)
if 'pool' in primitive:
op = nn.Sequential(op, nn.BatchNorm2d(C, affine=False))
self._ops.append(op)
self.multiply = darts_fun.apply
def forward(self, x, weights):
feature_map = []
for i, op in enumerate(self._ops):
res = op(x)
feature_map.append(res)
return sum(self.multiply(mp, w) for w, mp in zip(weights, feature_map))
class Cell(nn.Module):
def __init__(self, steps, multiplier, C_prev_prev, C_prev, C, reduction, reduction_prev, act_fun, back_connection):
super(Cell, self).__init__()
self.reduction = reduction
self.back_connection = back_connection
if reduction:
self.fun = FactorizedReduce(
C_prev, C * multiplier, affine=True, act_fun=act_fun, positive=1
)
else:
if reduction_prev:
self.preprocess0 = FactorizedReduce(
C_prev_prev, C, affine=False, act_fun=act_fun, positive=1)
else:
self.preprocess0 = ReLUConvBN(
C_prev_prev, C, 1, 1, 0, affine=False, act_fun=act_fun, positive=1)
self.preprocess1 = ReLUConvBN(
C_prev, C, 1, 1, 0, affine=False, act_fun=act_fun, positive=1)
self._steps = steps
self._multiplier = multiplier
self._ops = nn.ModuleList()
for i in range(self._steps):
for j in range(2 + i):
stride = 2 if reduction and j < 2 else 1
op = MixedOp(C, stride, act_fun)
self._ops.append(op)
if self.back_connection:
self._ops_back = nn.ModuleList()
for i in range(self._steps):
for j in range(i):
op = MixedOp(C, 1, act_fun)
self._ops_back.append(op)
def forward(self, s0, s1, weights):
if self.reduction:
return self.fun(s1)
s0 = self.preprocess0(s0)
s1 = self.preprocess1(s1)
states = [s0, s1]
offset = 0
offset_back = 0
weights_forward = weights[:forward_edge_num]
weights_backward = weights[forward_edge_num:]
for i in range(self._steps):
s = sum(self._ops[offset + j](h, weights_forward[offset + j])
for j, h in enumerate(states))
offset += len(states)
if self.back_connection:
for j in range(2, len(states)):
# print(j, len(states), offset_back, len(self._ops_back))
states[j] = states[j] + \
self._ops_back[offset_back](
s, weights_backward[offset_back])
offset_back += 1
states.append(s)
outputs = torch.cat(states[-self._multiplier:], dim=1)
return outputs
class Network(BaseModule):
def __init__(self, C, num_classes, layers, criterion, steps=4, multiplier=4, stem_multiplier=3,
parse_method='bio_darts', op_threshold=None, step=1, node_type='ReLUNode', **kwargs):
super().__init__(
step=step,
encode_type='direct',
**kwargs
)
self.act_fun = eval(node_type)
self.act_fun = partial(self.act_fun, **kwargs)
self._C = C
self._num_classes = num_classes
self._layers = layers
self._criterion = criterion
self._steps = steps
self._multiplier = multiplier
self.parse_method = parse_method
self.op_threshold = op_threshold
self.fire_rate_per_step = [0.] * self.step
self.forward_step = 0
self.record_fire_rate = False
if 'back_connection' in kwargs.keys():
self.back_connection = kwargs['back_connection']
else:
self.back_connection = False
self.dataset = kwargs['dataset']
self.spike_output = kwargs['spike_output'] if 'spike_output' in kwargs else True
C_curr = stem_multiplier * C
if self.dataset == 'dvsg' or self.dataset == 'dvsc10' or self.dataset == 'NCALTECH101':
self.stem = nn.Sequential(
nn.Conv2d(2 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
self.reduce_idx = [layers // 3,
2 * layers // 3]
else:
self.stem = nn.Sequential(
nn.Conv2d(3 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
self.reduce_idx = [1, 3, 5]
C_prev_prev, C_prev, C_curr = C_curr, C_curr, C
self.cells = nn.ModuleList()
reduction_prev = False
for i in range(layers):
if i in self.reduce_idx:
C_curr *= 2
reduction = True
else:
reduction = False
cell = Cell(steps, multiplier, C_prev_prev, C_prev, C_curr, reduction, reduction_prev, self.act_fun,
self.back_connection)
reduction_prev = reduction
self.cells += [cell]
C_prev_prev, C_prev = C_prev, multiplier * C_curr
self.global_pooling = nn.Sequential(
self.act_fun(), nn.AdaptiveAvgPool2d(1))
if self.spike_output:
self.classifier = nn.Sequential(
nn.Linear(C_prev, 10 * num_classes),
self.act_fun())
self.vote = VotingLayer(10)
else:
self.classifier = nn.Linear(C_prev, num_classes)
self.vote = nn.Identity()
self._initialize_alphas()
def new(self):
model_new = Network(self._C, self._num_classes,
self._layers, self._criterion).cuda()
for x, y in zip(model_new.arch_parameters(), self.arch_parameters()):
x.data.copy_(y.data)
return model_new
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if not self.training:
self.fire_rate.clear()
outputs = []
for t in range(self.step):
x = inputs[t]
s0 = s1 = self.stem(x)
for i, cell in enumerate(self.cells):
if not cell.reduction:
weights = calc_weight(self.alphas_normal)
s0, s1 = s1, cell(s0, s1, weights)
else:
s0, s1 = s1, cell(s0, s1, None)
out = self.global_pooling(s1)
out = self.classifier(out.view(out.size(0), -1))
logits = self.vote(out)
outputs.append(logits)
# print(self.get_fire_rate_avg(), self.fire_rate_per_step, len(self.fire_rate_per_step))
if self.record_fire_rate:
self.forward_step += 1
return sum(outputs) / len(outputs)
def reset_fire_rate_record(self):
self.fire_rate_per_step = [0.] * self.step
self.forward_step = 0
def get_fire_per_step(self):
return [x / self.forward_step for x in self.fire_rate_per_step]
def _loss(self, input1, target1, input2):
logits = self(input1)
return self._criterion(logits, target1, input2)
# def _loss(self, input1, target1):
# logits = self(input1)
# return self._criterion(logits, target1)
def _initialize_alphas(self):
# k = 2 + 3 + 4 + 5 = 14
k = sum(1 for i in range(self._steps) for n in range(2 + i))
if self.back_connection:
k += sum(1 for i in range(self._steps) for n in range(i))
num_ops = len(PRIMITIVES)
self.alphas_normal = Variable(
0.5 * torch.randn(2, k, num_ops).cuda(), requires_grad=True)
# init the history
self.alphas_normal_history = {}
mm = 0
last_id = 1
node_id = 0
for i in range(k):
for j in range(num_ops):
self.alphas_normal_history['edge: {}, op: {}'.format(
(node_id, mm), PRIMITIVES[j])] = []
if mm == last_id:
mm = 0
last_id += 1
node_id += 1
else:
mm += 1
def arch_parameters(self):
return [self.alphas_normal]
def genotype(self):
# alphas_normal
gene_normal = parse(calc_weight(self.alphas_normal).data.cpu().numpy(),
PRIMITIVES, self.op_threshold, self.parse_method,
self._steps, reduction=False, back_connection=self.back_connection)
concat = range(2 + self._steps - self._multiplier, self._steps + 2)
genotype = Genotype(
normal=gene_normal, normal_concat=concat,
)
return genotype
def states(self):
return {
'alphas_normal': self.alphas_normal,
'alphas_normal_history': self.alphas_normal_history,
'criterion': self._criterion
}
def restore(self, states):
self.alphas_normal = states['alphas_normal']
self.alphas_normal_history = states['alphas_normal_history']
def update_history(self):
mm = 0
last_id = 1
node_id = 0
weights1 = calc_weight(self.alphas_normal).data.cpu().numpy()
k, num_ops = weights1.shape
for i in range(k):
for j in range(num_ops):
self.alphas_normal_history['edge: {}, op: {}'.format((node_id, mm), PRIMITIVES[j])].append(
float(weights1[i][j]))
if mm == last_id:
mm = 0
last_id += 1
node_id += 1
else:
mm += 1
================================================
FILE: braincog/model_zoo/NeuEvo/operations.py
================================================
import numpy as np
import torch
import torch.nn as nn
from torch.nn import *
import torch.nn.functional as F
from torch import einsum
from einops import rearrange
from braincog.model_zoo.base_module import DeformConvPack
from braincog.model_zoo.base_module import BaseLinearModule
# from mmcv.ops import ModulatedDeformConv2dPack
def si_relu(x, positive):
if positive == 1:
return torch.where(x > 0., x, torch.zeros_like(x))
elif positive == 0:
return x
elif positive == -1:
return torch.where(x < 0., x, torch.zeros_like(x))
else:
raise ValueError
class SiReLU(nn.Module):
def __init__(self, positive=0):
super().__init__()
self.positive = positive
def forward(self, x):
return si_relu(x, self.positive)
def weight_init(m):
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal(m.weight.data, gain=0.1)
torch.nn.init.constant(m.bias.data, 0.)
OPS_Mlp = {
'mlp': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=0),
'mlp_p': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=1),
'mlp_n': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=-1),
'skip_connect': lambda C, act_fun:
Identity(positive=0),
'skip_connect_p': lambda C, act_fun:
Identity(positive=1),
'skip_connect_n': lambda C, act_fun:
Identity(positive=-1),
}
OPS = {
'avg_pool_3x3': lambda C, stride, affine, act_fun: nn.AvgPool2d(3, stride=stride, padding=1,
count_include_pad=False),
'conv_3x3': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=0),
'conv_5x5': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=0),
'max_pool_3x3': lambda C, stride, affine, act_fun: nn.MaxPool2d(3, stride=stride, padding=1),
'skip_connect': lambda C, stride, affine, act_fun:
Identity(positive=0) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun),
'sep_conv_3x3': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=0),
'sep_conv_5x5': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=0),
'sep_conv_7x7': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=0),
'dil_conv_3x3': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=0),
'dil_conv_5x5': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=0),
'def_conv_3x3': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=0),
'def_conv_5x5': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=0),
'avg_pool_3x3_p': lambda C, stride, affine, act_fun: nn.Sequential(
nn.AvgPool2d(3, stride=stride, padding=1, count_include_pad=False),
SiReLU(positive=1)
),
'max_pool_3x3_p': lambda C, stride, affine, act_fun: nn.Sequential(
nn.MaxPool2d(3, stride=stride, padding=1),
SiReLU(positive=1)
),
'conv_3x3_p': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=1),
'conv_5x5_p': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=1),
'skip_connect_p': lambda C, stride, affine, act_fun:
Identity(positive=1) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_3x3_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_5x5_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_7x7_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=1),
'dil_conv_3x3_p': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=1),
'dil_conv_5x5_p': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=1),
'def_conv_3x3_p': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=1),
'def_conv_5x5_p': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=1),
'avg_pool_3x3_n': lambda C, stride, affine, act_fun: nn.Sequential(
nn.AvgPool2d(3, stride=stride, padding=1, count_include_pad=False),
SiReLU(positive=-1)
),
'max_pool_3x3_n': lambda C, stride, affine, act_fun: nn.Sequential(
nn.MaxPool2d(3, stride=stride, padding=1),
SiReLU(positive=-1)
),
'conv_3x3_n': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=-1),
'conv_5x5_n': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=-1),
'skip_connect_n': lambda C, stride, affine, act_fun:
Identity(positive=-1) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_3x3_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_5x5_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_7x7_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=-1),
'dil_conv_3x3_n': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=-1),
'dil_conv_5x5_n': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=-1),
'def_conv_3x3_n': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=-1),
'def_conv_5x5_n': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=-1),
'conv_7x1_1x7': lambda C, stride, affine, act_fun: nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C, C, (1, 7), stride=(1, stride),
padding=(0, 3), bias=False),
nn.Conv2d(C, C, (7, 1), stride=(stride, 1),
padding=(3, 0), bias=False),
nn.BatchNorm2d(C, affine=affine)
),
'transformer': lambda C, stride, affine, act_fun:
FactorizedReduce(
C, C, affine=affine, act_fun=act_fun) if stride != 1 else TransformerEncoderLayer(C),
}
class SiMLP(nn.Module):
def __init__(self, c_in, c_out, act_fun=nn.ReLU, positive=0, *args, **kwargs):
super(SiMLP, self).__init__()
self.op = nn.Sequential(
nn.Linear(c_in, c_out, bias=True),
act_fun()
)
self.positive = positive
def forward(self, x):
out = self.op(si_relu(x, self.positive))
return out
class ReLUConvBN(nn.Module):
"""
ReLu -> Conv2d -> BatchNorm2d
"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
super(ReLUConvBN, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
# act_fun(),
nn.Conv2d(C_in, C_out, kernel_size, stride=stride,
padding=padding, bias=False),
nn.BatchNorm2d(C_out, affine=affine)
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class DilConv(nn.Module):
"""
Dilation Convolution : ReLU -> DilConv -> Conv2d -> BatchNorm2d
"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, dilation, affine=True, act_fun=nn.ReLU, positive=0):
super(DilConv, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation,
groups=C_in, bias=False),
nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=affine),
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class SepConv(nn.Module):
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
super(SepConv, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size,
stride=stride, padding=padding, groups=C_in, bias=False),
nn.Conv2d(C_in, C_in, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_in, affine=affine),
nn.ReLU(inplace=False),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size,
stride=1, padding=padding, groups=C_in, bias=False),
nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=affine),
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class Identity(nn.Module):
def __init__(self, positive=0):
super(Identity, self).__init__()
self.positive = positive
def forward(self, x):
return si_relu(x, self.positive)
class Zero(nn.Module):
def __init__(self, stride):
super(Zero, self).__init__()
self.stride = stride
def forward(self, x):
if self.stride == 1:
return x.mul(0.)
return x[:, :, ::self.stride, ::self.stride].mul(0.) # N * C * W * H
class FactorizedReduce(nn.Module):
def __init__(self, C_in, C_out, affine=True, act_fun=nn.ReLU, positive=0):
super(FactorizedReduce, self).__init__()
assert C_out % 2 == 0
# self.relu = nn.ReLU(inplace=False)
self.activation = act_fun()
self.conv_1 = nn.Conv2d(C_in, C_out // 2, 3,
stride=2, padding=1, bias=False)
self.conv_2 = nn.Conv2d(C_in, C_out // 2, 3,
stride=2, padding=1, bias=False)
self.bn = nn.BatchNorm2d(C_out, affine=affine)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
# x = self.relu(x)
x = self.activation(x)
out = torch.cat([self.conv_1(x), self.conv_2(x[:, :, 1:, 1:])], dim=1)
out = self.bn(out)
out = si_relu(out, self.positive)
return out
class DeformConv(nn.Module):
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
super(DeformConv, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
DeformConvPack(C_in, C_out, kernel_size=kernel_size,
stride=stride, padding=padding, bias=True),
nn.BatchNorm2d(C_out, affine=affine)
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class Attention(Module):
"""
Obtained from: github.com:rwightman/pytorch-image-models
"""
def __init__(self, dim, num_heads=4, attention_dropout=0.1, projection_dropout=0.1):
super().__init__()
self.num_heads = num_heads
head_dim = dim // self.num_heads
self.scale = head_dim ** -0.5
self.qkv = Linear(dim, dim * 3, bias=False)
self.attn_drop = Dropout(attention_dropout)
self.proj = Linear(dim, dim)
self.proj_drop = Dropout(projection_dropout)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C //
self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class TransformerEncoderLayer(Module):
"""
Inspired by torch.nn.TransformerEncoderLayer and
rwightman's timm package.
"""
def __init__(self, d_model, nhead=4, dim_feedforward=256, dropout=0.1,
attention_dropout=0.1, drop_path_rate=0.1):
super(TransformerEncoderLayer, self).__init__()
self.pre_norm = LayerNorm(d_model)
self.self_attn = Attention(dim=d_model, num_heads=nhead,
attention_dropout=attention_dropout, projection_dropout=dropout)
dim_feedforward = d_model
self.linear1 = Linear(d_model, dim_feedforward)
self.dropout1 = Dropout(dropout)
self.norm1 = LayerNorm(d_model)
self.linear2 = Linear(dim_feedforward, d_model)
self.dropout2 = Dropout(dropout)
self.drop_path = DropPath(
drop_path_rate) if drop_path_rate > 0 else Identity()
self.activation = F.gelu
def forward(self, src: torch.Tensor, *args, **kwargs) -> torch.Tensor:
# print(src.shape)
c = src.shape[-1]
src = rearrange(src, 'b d r c -> b (r c) d')
# print(src.shape)
src = src + self.drop_path(self.self_attn(self.pre_norm(src)))
src = self.norm1(src)
src2 = self.linear2(self.dropout1(self.activation(self.linear1(src))))
src = src + self.drop_path(self.dropout2(src2))
src = rearrange(src, 'b (r c) d -> b d r c', c=c)
return src
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""
Obtained from: github.com:rwightman/pytorch-image-models
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
# work with diff dim tensors, not just 2D ConvNets
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + \
torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(Module):
"""
Obtained from: github.com:rwightman/pytorch-image-models
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
================================================
FILE: braincog/model_zoo/NeuEvo/others.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2023/5/22 13:32
# User : yu
# Product : PyCharm
# Project : BrainCog
# File : others.py
# explain :
from functools import partial
import torch
import torch.nn as nn
from copy import deepcopy
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import WSConv2d
from braincog.datasets import is_dvs_data
from braincog.model_zoo.base_module import BaseModule, BaseConvModule
@register_model
class CIFARNet_Wu(BaseModule):
def __init__(
self, num_classes=10,
node_type=LIFNode,
step=4,
encode_type='direct',
*args,
**kwargs,
):
super().__init__(step, encode_type, *args, **kwargs)
self.dataset = kwargs['dataset']
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
channels = 32
if not is_dvs_data(self.dataset):
init_channel = 3
out_size = 2 ** 2
else:
init_channel = 2
out_size = 3 ** 2
self.feature = nn.Sequential(
BaseConvModule(init_channel, channels, node=self.node),
BaseConvModule(channels, channels * 2, node=self.node),
nn.AvgPool2d(2, 2),
self.node(),
BaseConvModule(channels * 2, channels * 4, node=self.node),
nn.AvgPool2d(2, 2),
# self.node(),
BaseConvModule(channels * 4, channels * 8, node=self.node),
BaseConvModule(channels * 8, channels * 4, node=self.node),
nn.Flatten(),
)
self.fc = nn.Sequential(
nn.Linear(channels * 4 * 8 * 8, channels * 8, bias=False),
self.node(),
nn.Linear(channels * 8, channels * 4, bias=False),
self.node(),
nn.Linear(channels * 4, num_classes, bias=False)
)
def forward(self, inputs):
inputs = self.encoder(inputs).contiguous()
self.reset()
outputs = []
for t in range(self.step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
@register_model
class CIFARNet_Fang(BaseModule):
def __init__(
self, num_classes=10,
node_type=LIFNode,
step=4,
encode_type='direct',
*args,
**kwargs,
):
super().__init__(step, encode_type, *args, **kwargs)
self.dataset = kwargs['dataset']
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
channels = 32
if not is_dvs_data(self.dataset):
init_channel = 3
else:
init_channel = 2
self.feature = nn.Sequential(
BaseConvModule(init_channel, channels, node=self.node),
BaseConvModule(channels, channels, node=self.node),
BaseConvModule(channels, channels, node=self.node),
nn.MaxPool2d(2, 2),
BaseConvModule(channels, channels, node=self.node),
BaseConvModule(channels, channels, node=self.node),
BaseConvModule(channels, channels, node=self.node),
nn.MaxPool2d(2, 2),
nn.Flatten(),
)
self.fc = nn.Sequential(
nn.Linear(channels * 8 * 8, channels * 8, bias=False),
self.node(),
nn.Linear(channels * 8, channels, bias=False),
)
def forward(self, inputs):
inputs = self.encoder(inputs).contiguous()
self.reset()
outputs = []
for t in range(self.step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
@register_model
class DVS_CIFARNet_Fang(BaseModule):
def __init__(
self, num_classes=10,
node_type=LIFNode,
step=10,
encode_type='direct',
*args,
**kwargs,
):
super().__init__(step, encode_type, *args, **kwargs)
self.dataset = kwargs['dataset']
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
channels = 128
if not is_dvs_data(self.dataset):
init_channel = 3
else:
init_channel = 2
self.feature = nn.Sequential(
BaseConvModule(init_channel, channels, node=self.node),
nn.MaxPool2d(2, 2),
BaseConvModule(channels, channels, node=self.node),
nn.MaxPool2d(2, 2),
BaseConvModule(channels, channels, node=self.node),
nn.MaxPool2d(2, 2),
BaseConvModule(channels, channels, node=self.node),
nn.MaxPool2d(2, 2),
nn.Flatten(),
)
self.fc = nn.Sequential(
nn.Linear(channels * 8 * 8, channels * 4, bias=False),
self.node(),
nn.Linear(channels * 4, channels, bias=False),
)
def forward(self, inputs):
inputs = self.encoder(inputs).contiguous()
self.reset()
outputs = []
for t in range(self.step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
================================================
FILE: braincog/model_zoo/__init__.py
================================================
__all__ = ['convnet', 'resnet', 'base_module', 'glsnn', 'qsnn', 'resnet19_snn']
from . import (
convnet,
resnet,
base_module,
glsnn,
qsnn,
resnet19_snn
)
================================================
FILE: braincog/model_zoo/backeinet.py
================================================
import numpy as np
from timm.models import register_model
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
class MNISTNet(BaseModule):
def __init__(self, step=20, encode_type='rate', if_back=True, if_ei=True, data='mnist', *args, **kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.if_back = if_back
self.if_ei = if_ei
if data == 'mnist':
self.cfg_conv = ((1, 15, 5, 1, 0), (15, 40, 5, 1, 0))
self.cfg_fc = (300, 10)
self.cfg_kernel = (24, 8, 4)
cfg_backei = 2
if data == 'fashion':
self.cfg_conv = ((1, 32, 5, 1, 2), (32, 64, 5, 1, 2))
self.cfg_fc = (1024, 10)
self.cfg_kernel = (28, 14, 7)
cfg_backei = 1
self.feature = nn.Sequential(
nn.Conv2d(self.cfg_conv[0][0], self.cfg_conv[0][1], self.cfg_conv[0][2], self.cfg_conv[0][3],
self.cfg_conv[0][4]),
BackEINode(channel=self.cfg_conv[0][1], if_back=self.if_back, if_ei=self.if_ei, cfg_backei=cfg_backei),
nn.AvgPool2d(2),
nn.Conv2d(self.cfg_conv[1][0], self.cfg_conv[1][1], self.cfg_conv[1][2], self.cfg_conv[1][3],
self.cfg_conv[1][4]),
BackEINode(channel=self.cfg_conv[1][1], if_back=self.if_back, if_ei=self.if_ei, cfg_backei=cfg_backei),
nn.AvgPool2d(2),
nn.Flatten(),
nn.Linear(self.cfg_kernel[2] * self.cfg_kernel[2] * self.cfg_conv[1][1], self.cfg_fc[0]),
BackEINode(if_back=False, if_ei=False),
nn.Linear(self.cfg_fc[0], self.cfg_fc[1]),
BackEINode(if_back=False, if_ei=False)
)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if not self.training:
self.fire_rate.clear()
outputs = []
step = self.step
for t in range(step):
x = inputs[t]
x = self.feature(x)
outputs.append(x)
return sum(outputs) / len(outputs)
class CIFARNet(BaseModule):
def __init__(self, step=20, encode_type='rate', if_back=True, if_ei=True, *args, **kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.if_back = if_back
self.if_ei = if_ei
self.feature = nn.Sequential(
nn.Conv2d(3, 128, 3, 1, 1),
BackEINode(channel=128, if_back=self.if_back, if_ei=self.if_ei, cfg_backei=1),
nn.Dropout(0.5),
nn.AvgPool2d(2),
nn.Conv2d(128, 256, 3, 1, 1),
BackEINode(channel=256, if_back=self.if_back, if_ei=self.if_ei, cfg_backei=1),
nn.Dropout(0.5),
nn.AvgPool2d(2),
nn.Conv2d(256, 512, 3, 1, 1),
BackEINode(channel=512, if_back=self.if_back, if_ei=self.if_ei, cfg_backei=1),
nn.Dropout(0.5),
nn.AvgPool2d(2),
nn.Flatten(),
nn.Linear(4 * 4 * 512, 1024),
BackEINode(if_back=False, if_ei=False),
nn.Dropout(0.5),
nn.Linear(1024, 10),
BackEINode(if_back=False, if_ei=False)
)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if not self.training:
self.fire_rate.clear()
outputs = []
step = self.step
for t in range(step):
x = inputs[t]
x = self.feature(x)
outputs.append(x)
return sum(outputs) / len(outputs)
================================================
FILE: braincog/model_zoo/base_module.py
================================================
from functools import partial
from torchvision.ops import DeformConv2d
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
class BaseLinearModule(nn.Module):
"""
线性模块
:param in_features: 输入尺寸
:param out_features: 输出尺寸
:param bias: 是否有Bias, 默认 ``False``
:param node: 神经元类型, 默认 ``LIFNode``
:param args:
:param kwargs:
"""
def __init__(self,
in_features: int,
out_features: int,
bias=True,
node=LIFNode,
*args,
**kwargs):
super().__init__()
if node is None:
raise TypeError
self.groups = kwargs['groups'] if 'groups' in kwargs else 1
if self.groups == 1:
self.fc = nn.Linear(in_features=in_features,
out_features=out_features, bias=bias)
else:
self.fc = nn.ModuleList()
for i in range(self.groups):
self.fc.append(nn.Linear(
in_features=in_features,
out_features=out_features,
bias=bias
))
self.node = partial(node, **kwargs)()
def forward(self, x):
if self.groups == 1: # (t b) c
outputs = self.fc(x)
else: # b (c t)
x = rearrange(x, 'b (c t) -> t b c', t=self.groups)
outputs = []
for i in range(self.groups):
outputs.append(self.fc[i](x[i]))
outputs = torch.stack(outputs) # t b c
outputs = rearrange(outputs, 't b c -> b (c t)')
return self.node(outputs)
class BaseConvModule(nn.Module):
"""
SNN卷积模块
:param in_channels: 输入通道数
:param out_channels: 输出通道数
:param kernel_size: kernel size
:param stride: stride
:param padding: padding
:param bias: Bias
:param node: 神经元类型
:param kwargs:
"""
def __init__(self,
in_channels: int,
out_channels: int,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
bias=False,
node=PLIFNode,
**kwargs):
super().__init__()
if node is None:
raise TypeError
self.groups = kwargs['groups'] if 'groups' in kwargs else 1
self.conv = nn.Conv2d(in_channels=in_channels * self.groups,
out_channels=out_channels * self.groups,
kernel_size=kernel_size,
padding=padding,
stride=stride,
bias=bias)
self.bn = nn.BatchNorm2d(out_channels * self.groups)
self.node = partial(node, **kwargs)()
self.activation = nn.Identity()
def forward(self, x):
# origin_shape = x.shape
# if len(origin_shape) > 4:
# x = x.reshape(np.prod(origin_shape[0:-3]), *origin_shape[-3:])
x = self.conv(x)
x = self.bn(x)
# if len(origin_shape) > 4:
# x = x.reshape(*origin_shape[0:-3], *x.shape[-3:])
x = self.node(x)
return x
class BaseModule(nn.Module, abc.ABC):
"""
SNN抽象类, 所有的SNN都要继承这个类, 以实现一些基础方法
:param step: 仿真步长
:param encode_type: 数据编码类型
:param layer_by_layer: 是否layer wise地进行前向推理
:param temporal_flatten: 是否将时间维度和channel合并
:param args:
:param kwargs:
"""
def __init__(self,
step,
encode_type,
layer_by_layer=False,
temporal_flatten=False,
*args,
**kwargs):
super(BaseModule, self).__init__()
self.step = step
# print(kwargs['layer_by_layer'])
self.layer_by_layer = layer_by_layer
self.temporal_flatten = temporal_flatten
encode_step = self.step
if temporal_flatten is True:
self.init_channel_mul = self.step
self.step = 1
else: # origin
self.init_channel_mul = 1
self.encoder = Encoder(encode_step, encode_type, temporal_flatten=self.temporal_flatten, layer_by_layer=self.layer_by_layer, **kwargs)
self.kwargs = kwargs
self.warm_up = False
self.fire_rate = []
def reset(self):
"""
重置所有神经元的膜电位
:return:
"""
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def set_attr(self, attr, val):
"""
设置神经元的属性
:param attr: 属性名称
:param val: 设置的属性值
:return:
"""
for mod in self.modules():
if isinstance(mod, BaseNode):
if hasattr(mod, attr):
setattr(mod, attr, val)
else:
ValueError('{} do not has {}'.format(self, attr))
def get_threshold(self):
"""
获取所有神经元的阈值
:return:
"""
outputs = []
for mod in self.modules():
if isinstance(mod, BaseNode):
thresh = (mod.get_thres())
outputs.append(thresh)
return outputs
def get_fp(self, temporal_info=False):
"""
获取所有神经元的状态
:param temporal_info: 是否要读取神经元的时间维度状态, False会把时间维度拍平
:return: 所有神经元的状态, List
"""
outputs = []
for mod in self.modules():
if isinstance(mod, BaseNode):
if temporal_info:
outputs.append(mod.feature_map)#[l,[t,[b,w,h]]]
else:
outputs.append(sum(mod.feature_map) / len(mod.feature_map))
return outputs
def get_mem(self, temporal_info=False):
"""
获取所有神经元的模电势
:param temporal_info: 是否要读取神经元的时间维度状态, False会把时间维度拍平
:return: 所有神经元的状态, List
"""
outputs = []
for mod in self.modules():
if isinstance(mod, BaseNode):
if temporal_info:
outputs.append(mod.mem_collect)#[l,[t,[b,w,h]]]
else:
outputs.append(sum(mod.mem_collect) / len(mod.mem_collect))
return outputs
def get_fire_rate(self, requires_grad=False):
"""
获取神经元的fire-rate
:param requires_grad: 是否需要梯度信息, 默认为 ``False`` 会截断梯度
:return: 所有神经元的fire-rate
"""
outputs = []
fp = self.get_attr('feature_map')
for f in fp:
if requires_grad is False:
if len(f) == 0:
return torch.tensor([0.])
outputs.append(((sum(f) / len(f)).detach() > 0.).float().mean())
else:
outputs.append(((sum(f) / len(f)) > 0.).float().mean())
if len(outputs) == 0:
return torch.tensor([0.])
return torch.stack(outputs)
def get_tot_spike(self):
"""
获取神经元总的脉冲数量
:return:
"""
tot_spike = 0
batch_size = 1
fp = self.get_attr('feature_map')
for f in fp:
if len(f) == 0:
break
tot_spike += sum(f).sum()
batch_size = f[0].shape[0]
return tot_spike / batch_size
def get_spike_info(self):
"""
获取神经元的脉冲信息, 主要用于绘图
:return:
"""
spike_feature_list = self.get_fp(temporal_info=True)
avg, var, spike = [], [], []
avg_per_step = []
for spike_feature in spike_feature_list:
avg_list = []
for spike_t in spike_feature:
avg_list.append(float(spike_t.mean()))
avg_per_step.append(avg_list)
spike_feature = sum(spike_feature)
num = np.prod(spike_feature.shape)
avg.append(float(spike_feature.sum()))
var.append(float(spike_feature.std()))
lst = []
for t in range(self.step + 1):
lst.append(float((spike_feature == t).sum() / num))
spike.append(lst)
return avg, var, spike, avg_per_step
def set_requires_fp(self, flag):
for mod in self.modules():
if hasattr(mod, 'requires_fp'):
mod.requires_fp = flag
def set_requires_mem(self, flag):
for mod in self.modules():
if hasattr(mod, 'requires_mem'):
mod.requires_mem = flag
def get_attr(self, attr):
"""
获取神经元的某一属性值
:param attr: 属性名称
:return: 对应属性的值, List
"""
outputs = []
for mod in self.modules():
if hasattr(mod, attr):
outputs.append(getattr(mod, attr))
return outputs
@staticmethod
def forward(self, inputs):
pass
class DeformConvPack(nn.Module):
def __init__(self,
in_channels,
out_channels,
kernel_size,
padding,
stride,
bias,
*args,
**kwargs):
super(DeformConvPack, self).__init__()
self.in_channels = in_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
if isinstance(self.kernel_size, tuple) or isinstance(self.kernel_size, list):
self.receptive_field = self.kernel_size[0]
else:
self.receptive_field = self.kernel_size
self.kernel_size = (self.kernel_size, self.kernel_size)
self.receptive_field = 4 * (self.receptive_field // 2)
self.conv_offset = nn.Conv2d(
self.in_channels,
3 * self.kernel_size[0] * self.kernel_size[1],
kernel_size=self.kernel_size,
stride=self.stride,
padding=self.padding,
bias=True)
self.deform_conv = DeformConv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
padding=padding,
stride=stride,
bias=bias)
self.init_weights()
def init_weights(self):
if hasattr(self, 'conv_offset'):
self.conv_offset.weight.data.zero_()
self.conv_offset.bias.data.zero_()
def forward(self, x):
out = self.conv_offset(x)
o1, o2, mask = torch.chunk(out, 3, dim=1)
offset = torch.cat((o1, o2), dim=1)
offset = self.receptive_field * (torch.sigmoid(offset) - 0.5)
mask = torch.sigmoid(mask)
return self.deform_conv(x, offset, mask)
================================================
FILE: braincog/model_zoo/bdmsnn.py
================================================
import torch
from torch import nn
from braincog.base.node.node import IFNode, SimHHNode
from braincog.base.learningrule.STDP import STDP, MutliInputSTDP
from braincog.base.connection.CustomLinear import CustomLinear
from braincog.base.brainarea.basalganglia import basalganglia
import pygame
from pygame.locals import *
from collections import deque
from random import randint
#os.environ["SDL_VIDEODRIVER"] = "dummy"
class BDMSNN(nn.Module):
def __init__(self, num_state, num_action, weight_exc, weight_inh, node_type):
"""
定义BDM-SNN网络
:param num_state: 状态个数
:param num_action: 动作个数
:param weight_exc: 兴奋性连接权重
:param weight_inh: 抑制性连接权重
"""
super().__init__()
# parameters
BG = basalganglia(num_state, num_action, weight_exc, weight_inh, node_type)
dm_connection = BG.getweight()
dm_mask = BG.getmask()
# input-dlpfc
con_matrix9 = torch.eye((num_state), dtype=torch.float)
dm_connection.append(CustomLinear(weight_exc * con_matrix9, con_matrix9))
dm_mask.append(con_matrix9)
# gpi-th
con_matrix10 = torch.eye((num_action), dtype=torch.float)
dm_mask.append(con_matrix10)
dm_connection.append(CustomLinear(weight_inh * con_matrix10, con_matrix10))
# th-pm
dm_mask.append(con_matrix10)
dm_connection.append(CustomLinear(weight_exc * con_matrix10, con_matrix10))
# dlpfc-th
con_matrix11 = torch.ones((num_state, num_action), dtype=torch.float)
dm_mask.append(con_matrix11)
dm_connection.append(CustomLinear(0.2 * weight_exc * con_matrix11, con_matrix11))
# pm-pm
con_matrix3 = torch.ones((num_action, num_action), dtype=torch.float)
con_matrix4 = torch.eye((num_action), dtype=torch.float)
con_matrix5 = con_matrix3 - con_matrix4
con_matrix5 = con_matrix5
dm_mask.append(con_matrix5)
dm_connection.append(CustomLinear(5 * weight_inh * con_matrix5, con_matrix5))
# dlpfc thalamus pm +bg
self.weight_exc = weight_exc
self.num_subDM = 8
self.connection = dm_connection
self.mask = dm_mask
self.node = BG.node
self.node_type = node_type
if self.node_type == "hh":
self.node.extend([SimHHNode() for i in range(self.num_subDM - BG.num_subBG)])
self.node[6].g_Na = torch.tensor(12)
self.node[6].g_K = torch.tensor(3.6)
self.node[6].g_L = torch.tensor(0.03)
if self.node_type == "lif":
self.node.extend([IFNode() for i in range(self.num_subDM - BG.num_subBG)])
self.learning_rule = BG.learning_rule
self.learning_rule.append(MutliInputSTDP(self.node[5], [self.connection[10], self.connection[12]])) # gpi-丘脑
self.learning_rule.append(MutliInputSTDP(self.node[6], [self.connection[11], self.connection[13]])) # pm
self.learning_rule.append(STDP(self.node[7], self.connection[9]))
out_shape=[self.connection[0].weight.shape[1],self.connection[1].weight.shape[1],self.connection[2].weight.shape[1],self.connection[4].weight.shape[1],self.connection[3].weight.shape[1],self.connection[10].weight.shape[1],self.connection[11].weight.shape[1],self.connection[9].weight.shape[1]]
self.out = []
self.dw = []
for i in range(self.num_subDM):
self.out.append(torch.zeros((out_shape[i]), dtype=torch.float))
self.dw.append(torch.zeros((out_shape[i]), dtype=torch.float))
def forward(self, input):
"""
根据输入得到网络的输出
:param input: 输入
:return: 网络的输出
"""
self.out[7] = self.node[7](self.connection[9](input))
self.out[0], self.dw[0] = self.learning_rule[0](self.out[7])
self.out[1], self.dw[1] = self.learning_rule[1](self.out[7])
self.out[2], self.dw[2] = self.learning_rule[2](self.out[7], self.out[3])
self.out[3], self.dw[3] = self.learning_rule[3](self.out[1], self.out[2])
self.out[4], self.dw[4] = self.learning_rule[4](self.out[0], self.out[3], self.out[2])
self.out[5], self.dw[5] = self.learning_rule[5](self.out[4], self.out[7])
self.out[6], self.dw[6] = self.learning_rule[6](self.out[5], self.out[6])
br = ["StrD1", "StrD2", "STN", "Gpe", "Gpi", "thalamus", "PM", "DLPFC"]
for i in range(self.num_subDM):
if torch.max(self.out[i]) > 0 and self.node_type == "hh":
self.node[i].n_reset()
print("every areas:", br[i], self.out[i])
return self.out[6], self.dw
def UpdateWeight(self, i, s, num_action, dw):
"""
更新网络中第i组连接的权重
:param i:要更新的连接组索引
:param s:传入状态
:param dw:更新权重的量
:return:
"""
if self.node_type == "hh":
self.connection[i].update(0.2 * self.weight_exc * dw)
self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]] /= (self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]].float().max() + 1e-12)
self.connection[i].weight.data[s, :] = self.connection[i].weight.data[s, :] * self.weight_exc
if self.node_type == "lif":
dw_mean = dw[s, [s * num_action, s * num_action + 1]].mean()
dw_std = dw[s, [s * num_action, s * num_action + 1]].std()
dw[s, [s * num_action, s * num_action + 1]] = (dw[s, [s * num_action,s * num_action + 1]] - dw_mean) / dw_std
dw[s, :] = dw[s, :] * self.mask[i][s, :]
self.connection[i].update(dw)
self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]] /= (self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]].float().max() + 1e-12)
if i in [0, 1, 2, 6, 7, 11, 12]:
self.connection[i].weight.data = torch.clamp(self.connection[i].weight.data, 0, None)
if i in [3, 4, 5, 8, 10]:
self.connection[i].weight.data = torch.clamp(self.connection[i].weight.data, None, 0)
def reset(self):
"""
reset神经元或学习法则的中间量
:return: None
"""
for i in range(self.num_subDM):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
"""
获取网络的连接(包括权值等)
:return: 网络的连接
"""
return self.connection
================================================
FILE: braincog/model_zoo/convnet.py
================================================
import abc
from functools import partial
from torch.nn import functional as F
import torchvision
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
class BaseConvNet(BaseModule, abc.ABC):
def __init__(self,
step,
input_channels,
num_classes,
encode_type,
spike_output: bool,
out_channels: list,
block_depth: list,
node_list: list,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.num_cls = num_classes
self.spike_output = spike_output
self.groups = kwargs['n_groups'] if 'n_groups' in kwargs else 1
if not spike_output:
node_list.append(nn.Identity)
out_channels.append(self.num_cls)
self.vote = nn.Identity()
# self.vote = nn.Sequential(
# nn.Linear(self.step, 32),
# nn.ReLU(),
# nn.Linear(32, 1)
# )
else:
out_channels.append(10 * self.num_cls)
self.vote = VotingLayer(10)
# check list length
if len(node_list) != len(out_channels):
raise ValueError
self.input_channels = input_channels
self.out_channels = out_channels
self.block_depth = block_depth
self.node_list = node_list
self.feature = self._create_feature()
self.fc = self._create_fc()
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
@staticmethod
def _create_feature(self):
raise NotImplementedError
@staticmethod
def _create_fc(self):
raise NotImplementedError
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if not self.training:
self.fire_rate.clear()
if not self.layer_by_layer:
outputs = []
if self.warm_up:
step = 1
else:
step = self.step
for t in range(step):
x = inputs[t]
x = self.feature(x)
x = self.flatten(x)
x = self.fc(x)
x = self.vote(x)
outputs.append(x)
return sum(outputs) / len(outputs)
# outputs = torch.stack(outputs)
# outputs = rearrange(outputs, 't b c -> b c t')
# outputs = self.vote(outputs).squeeze()
# return outputs
else:
x = self.feature(inputs)
x = self.flatten(x)
x = self.fc(x)
if self.groups == 1:
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
else:
x = rearrange(x, 'b (c t) -> t b c', t=self.step).mean(0)
x = self.vote(x)
return x
class MNISTConvNet(BaseConvNet):
def __init__(self,
step,
input_channels,
num_classes,
encode_type,
block_depth,
spike_output: bool,
out_channels: list,
node_list: list,
*args,
**kwargs):
self.feature_size = 28
super().__init__(step,
input_channels,
num_classes,
encode_type,
spike_output,
out_channels,
block_depth,
node_list,
*args,
**kwargs)
def _create_feature(self):
feature_depth = len(self.node_list) - 2
feature = [BaseConvModule(
self.input_channels, self.out_channels[0], node=self.node_list[0])]
if self.block_depth[0] != 1:
feature.extend(
[BaseConvModule(self.out_channels[0], self.out_channels[0], node=self.node_list[0])] * (
self.block_depth[0] - 1),
)
feature.append(nn.AvgPool2d(2))
self.feature_size = self.feature_size // 2
for i in range(1, feature_depth):
feature.append(BaseConvModule(
self.out_channels[i - 1], self.out_channels[i], node=self.node_list[i]))
if self.block_depth[i] != 1:
feature.extend(
[BaseConvModule(self.out_channels[i], self.out_channels[i], node=self.node_list[i])] * (
self.block_depth[0] - 1),
)
feature.append(nn.AvgPool2d(2))
feature.append(self.node_list[0]())
self.feature_size = self.feature_size // 2
return nn.Sequential(*feature)
def _create_fc(self):
fc = nn.Sequential(
NDropout(.5),
BaseLinearModule(self.out_channels[-3] * self.feature_size * self.feature_size, self.out_channels[-2],
node=self.node_list[-2]),
NDropout(.5),
BaseLinearModule(
self.out_channels[-2], self.out_channels[-1], node=self.node_list[-1])
)
return fc
class CifarConvNet(BaseConvNet):
def __init__(self,
step,
input_channels,
num_classes,
encode_type,
spike_output: bool,
out_channels: list,
node_list: list,
block_depth: list,
*args,
**kwargs):
super().__init__(step,
input_channels,
num_classes,
encode_type,
spike_output,
out_channels,
block_depth,
node_list,
*args,
**kwargs)
def _create_feature(self):
feature_depth = len(self.node_list) - 1
feature = [BaseConvModule(
self.input_channels * self.init_channel_mul, self.out_channels[0], node=self.node_list[0], groups=self.groups)]
if self.block_depth[0] != 1:
feature.extend(
[BaseConvModule(self.out_channels[0], self.out_channels[0], node=self.node_list[0], groups=self.groups)] * (
self.block_depth[0] - 1),
)
feature.append(nn.AvgPool2d(2))
for i in range(1, feature_depth - 1):
feature.append(BaseConvModule(
self.out_channels[i - 1], self.out_channels[i], node=self.node_list[i], groups=self.groups))
if self.block_depth[i] != 1:
feature.extend(
[BaseConvModule(self.out_channels[i], self.out_channels[i], node=self.node_list[i], groups=self.groups)] * (
self.block_depth[i] - 1),
)
feature.append(nn.AvgPool2d(2))
feature.append(BaseConvModule(
self.out_channels[-3], self.out_channels[-2], node=self.node_list[-2], groups=self.groups))
if self.block_depth[feature_depth - 1] != 1:
feature.extend(
[BaseConvModule(self.out_channels[-2], self.out_channels[-2], node=self.node_list[-2], groups=self.groups)] * (
self.block_depth[feature_depth - 1] - 1),
)
feature.append(nn.AdaptiveAvgPool2d((1, 1)))
return nn.Sequential(*feature)
def _create_fc(self):
fc = nn.Sequential(
# NDropout(.5),
BaseLinearModule(
self.out_channels[-2], self.out_channels[-1], node=self.node_list[-1], groups=self.groups)
)
return fc
@register_model
def mnist_convnet(step,
encode_type,
spike_output: bool,
node_type,
*args,
**kwargs):
out_channels = [128, 128, 2048]
block_depth = [1, 1]
node_cls = partial(node_type, step=step, **kwargs)
if spike_output:
node_list = [node_cls] * (len(out_channels) + 1)
else:
node_list = [node_cls] * (len(out_channels))
return MNISTConvNet(step=step,
input_channels=1,
encode_type=encode_type,
block_depth=block_depth,
node_list=node_list,
out_channels=out_channels,
spike_output=spike_output,
**kwargs)
@register_model
def cifar_convnet(step,
encode_type,
spike_output: bool,
node_type,
*args,
**kwargs):
out_channels = [256, 256, 512, 1024]
# out_channels = [64, 128, 128, 256]
block_depth = [2, 2, 2, 2]
# print(kwargs)
node_cls = partial(node_type, step=step, **kwargs)
# print(node_cls)
if spike_output:
node_list = [node_cls] * (len(out_channels) + 1)
else:
node_list = [node_cls] * (len(out_channels))
return CifarConvNet(step=step,
input_channels=3,
encode_type=encode_type,
node_list=node_list,
block_depth=block_depth,
out_channels=out_channels,
spike_output=spike_output,
**kwargs)
@register_model
def dvs_convnet(step,
encode_type,
spike_output: bool,
node_type,
num_classes,
*args,
**kwargs):
out_channels = [128, 256, 256, 512, 512]
block_depth = [2, 1, 2, 1, 2]
# out_channels = [40, 80, 80, 160, 160]
# out_channels = [256, 512, 512, 1024, 1024]
# out_channels = [64, 128, 128, 256, 256]
# block_depth = [4, 2, 4, 2, 4]
# out_channels = [128, 256, 512, 512]
# block_depth = [2, 2, 2, 2]
node_cls = partial(node_type, step=step, **kwargs)
if spike_output:
node_list = [node_cls] * (len(out_channels) + 1)
# node_list[-2] = partial(DoubleSidePLIFNode, step=step, **kwargs)
else:
node_list = [node_cls] * (len(out_channels))
# node_list[-1] = partial(DoubleSidePLIFNode, step=step, **kwargs)
return CifarConvNet(step=step,
input_channels=2,
num_classes=num_classes,
encode_type=encode_type,
node_list=node_list,
block_depth=block_depth,
out_channels=out_channels,
spike_output=spike_output,
**kwargs)
================================================
FILE: braincog/model_zoo/fc_snn.py
================================================
from functools import partial
from torch.nn import functional as F
import torchvision
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.datasets import is_dvs_data
class STSC_Attention(nn.Module):
def __init__(self, n_channel: int, dimension: int = 2, time_rf: int = 4, reduction: int = 2):
super().__init__()
assert dimension == 4 or dimension == 2, 'dimension must be 4 or 2'
self.dimension = dimension
if self.dimension == 4:
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.time_padding = (time_rf - 1) // 2
self.n_channels = n_channel
r_channel = n_channel // reduction
self.recv_T = nn.Conv1d(n_channel, r_channel, kernel_size=time_rf, padding=self.time_padding, groups=1,
bias=True)
self.recv_C = nn.Sequential(
nn.ReLU(),
nn.Linear(r_channel, n_channel, bias=False),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x_seq: torch.Tensor):
assert x_seq.dim() == 3 or x_seq.dim() == 5, ValueError(
f'expected 3D or 5D input with shape [T, B, N] or [T, B, C, H, W], but got input with shape {x_seq.shape}')
x_seq_C = x_seq.transpose(0, 1) # x_seq_C.shape = [B, T, N] or [B, T, C, H, W]
x_seq_T = x_seq_C.transpose(1, 2) # x_seq_T.shape = [B, C, N] or [B, C, T, H, W]
if self.dimension == 2:
recv_h_T = self.recv_T(x_seq_T)
recv_h_C = self.recv_C(recv_h_T.transpose(1, 2))
D_ = 1 - self.sigmoid(recv_h_C)
D = D_.transpose(0, 1)
elif self.dimension == 4:
avgout_C = self.avg_pool(x_seq_C).view(
[x_seq_C.shape[0], x_seq_C.shape[1], x_seq_C.shape[2]]) # avgout_C.shape = [N, T, C]
avgout_T = avgout_C.transpose(1, 2)
recv_h_T = self.recv_T(avgout_T)
recv_h_C = self.recv_C(recv_h_T.transpose(1, 2))
D_ = 1 - self.sigmoid(recv_h_C)
D = D_.transpose(0, 1)
return D
class STSC_Temporal_Conv(nn.Module):
def __init__(self, channels: int, dimension: int = 2, time_rf: int = 2):
super().__init__()
assert dimension == 4 or dimension == 2, 'dimension must be 4 or 2'
self.dimension = dimension
time_padding = (time_rf - 1) // 2
self.time_padding = time_padding
if dimension == 4:
kernel_size = (time_rf, 1, 1)
padding = (time_padding, 0, 0)
self.conv = nn.Conv3d(channels, channels, kernel_size=kernel_size, padding=padding, groups=channels,
bias=False)
else:
kernel_size = time_rf
self.conv = nn.Conv1d(channels, channels, kernel_size=kernel_size, padding=time_padding, groups=channels,
bias=False)
def forward(self, x_seq: torch.Tensor):
assert x_seq.dim() == 3 or x_seq.dim() == 5, ValueError(
f'expected 3D or 5D input with shape [T, B, N] or [T, B, C, H, W], but got input with shape {x_seq.shape}')
# x_seq.shape = [T, B, N] or [T, B, C, H, W]
x_seq = x_seq.transpose(0, 1) # x_seq.shape = [B, T, N] or [B, T, C, H, W]
x_seq = x_seq.transpose(1, 2) # x_seq.shape = [B, N, T] or [B, C, T, H, W]
x_seq = self.conv(x_seq)
x_seq = x_seq.transpose(1, 2) # x_seq.shape = [B, T, N] or [B, T, C, H, W]
x_seq = x_seq.transpose(0, 1) # x_seq.shape = [T, B, N] or [T, B, C, H, W]
return x_seq
class STSC(nn.Module):
def __init__(self, in_channel: int, dimension: int = 2, time_rf_conv: int = 5, time_rf_at: int = 3, use_gate=True,
use_filter=True, reduction: int = 1):
super().__init__()
assert dimension == 4 or dimension == 2, 'dimension must be 4 or 2'
self.dimension = dimension
self.time_rf_conv = time_rf_conv
self.time_rf_at = time_rf_at
if use_filter:
self.temporal_conv = STSC_Temporal_Conv(in_channel, time_rf=time_rf_conv, dimension=dimension)
if use_gate:
self.spatio_temporal_attention = STSC_Attention(in_channel, time_rf=time_rf_at, reduction=reduction,
dimension=dimension)
self.use_gate = use_gate
self.use_filter = use_filter
def forward(self, x_seq: torch.Tensor):
assert x_seq.dim() == 3 or x_seq.dim() == 5, ValueError(
f'expected 3D or 5D input with shape [T, B, N] or [T, B, C, H, W], but got input with shape {x_seq.shape}')
if self.use_filter:
# Filitering
x_seq_conv = self.temporal_conv(x_seq)
else:
# without filtering
x_seq_conv = x_seq
if self.dimension == 2:
if self.use_gate:
# Gating
x_seq_D = self.spatio_temporal_attention(x_seq)
y_seq = x_seq_conv * x_seq_D
else:
# without gating
y_seq = x_seq_conv
else:
if self.use_gate:
# Gating
x_seq_D = self.spatio_temporal_attention(x_seq)
y_seq = x_seq_conv * x_seq_D[:, :, :, None, None] # broadcast
else:
# without gating
y_seq = x_seq_conv
return y_seq
@register_model
class SHD_SNN(BaseModule):
"""
在SHD数据集上的SNN基准网络:Input-128FC-128FC-100FC-Voting-20.
STSC是增强时序信息的模块, 参考https://www.frontiersin.org/articles/10.3389/fnins.2022.1079357.
不加STSC模块的acc在78%左右
"""
def __init__(self,
num_classes=20,
step=15,
node_type=LIFNode,
encode_type='direct',
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.n_preact = kwargs['n_preact'] if 'n_preact' in kwargs else False
self.num_classes = num_classes
self.tet_loss = kwargs['tet_loss'] if 'tet_loss' in kwargs else False
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.dataset = kwargs['dataset']
self.ts_conv = STSC(700, dimension=2, time_rf_conv=5, time_rf_at=3, use_gate=True, use_filter=True)
self.fc = nn.Sequential(
nn.Linear(700, 128),
partial(self.node, **kwargs)(),
nn.Linear(128, 128),
partial(self.node, **kwargs)(),
nn.Linear(128, 100),
partial(self.node, **kwargs)(),
VotingLayer(5)
)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
inputs = rearrange(inputs, '(t b) c -> t b c', t=self.step)
inputs = self.ts_conv(inputs)
x = rearrange(inputs, 't b c -> (t b) c', t=self.step)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
return x
else:
outputs = []
inputs = self.ts_conv(inputs)
for t in range(self.step):
x = inputs[t]
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
================================================
FILE: braincog/model_zoo/glsnn.py
================================================
import abc
from functools import partial
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseLinearModule, BaseConvModule
from braincog.utils import rand_ortho, mse
from torch import autograd
class BaseGLSNN(BaseModule):
"""
The fully connected model of the GLSNN
:param input_size: the shape of the input
:param hidden_sizes: list, the number of neurons of each layer in the hidden layers
:param ouput_size: the number of the output layers
"""
def __init__(self, input_size=784, hidden_sizes=[800] * 3, output_size=10, opt=None):
super().__init__(step=opt.step, encode_type=opt.encode_type)
network_sizes = [input_size] + hidden_sizes + [output_size]
feedforward = []
for ind in range(len(network_sizes) - 1):
feedforward.append(
BaseLinearModule(in_features=network_sizes[ind], out_features=network_sizes[ind + 1], node=LIFNode))
self.ff = nn.ModuleList(feedforward)
feedback = []
for ind in range(1, len(network_sizes) - 2):
feedback.append(nn.Linear(network_sizes[-1], network_sizes[ind]))
self.fb = nn.ModuleList(feedback)
for m in self.modules():
if isinstance(m, nn.Linear):
out_, in_ = m.weight.shape
m.weight.data = torch.Tensor(rand_ortho((out_, in_), np.sqrt(6. / (out_ + in_))))
m.bias.data.zero_()
self.step = opt.step
self.lr_target = opt.lr_target
def forward(self, x):
"""
process the information in the forward manner
:param x: the input
"""
self.reset()
x = x.view(x.shape[0], 784)
sumspikes = [0] * (len(self.ff) + 1)
sumspikes[0] = x
for ind, mod in enumerate(self.ff):
for t in range(self.step):
spike = mod(sumspikes[ind])
sumspikes[ind + 1] += spike
sumspikes[ind + 1] = sumspikes[ind + 1] / self.step
return sumspikes
def feedback(self, ff_value, y_label):
"""
process information in the feedback manner and get target
:param ff_value: the feedforward value of each layer
:param y_label: the label of the corresponding input
"""
fb_value = []
cost = mse(ff_value[-1], y_label)
P = ff_value[-1]
h_ = ff_value[-2] - self.lr_target * torch.autograd.grad(cost, ff_value[-2], retain_graph=True)[0]
fb_value.append(h_)
for i in range(len(self.fb) - 1, -1, -1):
h = ff_value[i + 1]
h_ = h - self.fb[i](P - y_label)
fb_value.append(h_)
return fb_value, cost
def set_gradient(self, x, y):
"""
get the corresponding update of each layer
"""
ff_value = self.forward(x)
fb_value, cost = self.feedback(ff_value, y)
ff_value = ff_value[1:]
len_ff = len(self.ff)
for idx, layer in enumerate(self.ff):
if idx == len_ff - 1:
layer.fc.weight.grad, layer.fc.bias.grad = autograd.grad(cost, layer.fc.parameters())
else:
in1 = ff_value[idx]
in2 = fb_value[len(fb_value) - 1 - idx]
loss_local = mse(in1, in2.detach())
layer.fc.weight.grad, layer.fc.bias.grad = autograd.grad(loss_local, layer.fc.parameters())
return ff_value, cost
def forward_parameters(self):
res = []
for layer in self.ff:
res += layer.parameters()
return res
def feedback_parameters(self):
res = []
for layer in self.fb:
res += layer.parameters()
return res
if __name__ == '__main__':
net = BaseGLSNN()
print(net)
================================================
FILE: braincog/model_zoo/linearNet.py
================================================
import torch.nn.functional as F
from braincog.base.strategy.surrogate import *
from braincog.base.node.node import IFNode
from braincog.base.learningrule.STDP import STDP, MutliInputSTDP
class droDMTrainNet(nn.Module):
"""
Drosophila Training network: compound eye-KC-MBON
"""
def __init__(self, connection):
"""
根据传入的连接 构建训练网络
:param connection: 训练网络的连接
"""
super().__init__()
trace_stdp = 0.99
self.num_subMB = 3
self.node = [IFNode() for i in range(self.num_subMB)]
self.connection = connection
self.learning_rule = []
self.learning_rule.append(STDP(self.node[0], self.connection[0], trace_stdp))
self.learning_rule.append(STDP(self.node[1], self.connection[1], trace_stdp))
self.learning_rule.append(MutliInputSTDP(self.node[2], [self.connection[2], self.connection[3]], trace_stdp))
self.out_vis = torch.zeros((self.connection[0].weight.shape[1]), dtype=torch.float)
self.out_KC = torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float)
self.out_MBON = torch.zeros((self.connection[2].weight.shape[1]), dtype=torch.float)
def forward(self, input):
"""
根据输入得到输出
:param input: 输入电流
:return: 网络的输出,以及网络运行产生的STDP可塑性
"""
self.out_vis = self.node[0](self.connection[0](input))
self.out_KC, dw_kc = self.learning_rule[1](self.out_vis)
self.out_MBON, dw_mbon = self.learning_rule[2](self.out_KC, self.out_MBON)
return self.out_MBON, dw_kc[0], dw_mbon[0]
def UpdateWeight(self, i, dw):
"""
更新网络中第i组连接的权重
:param i: 要更新的连接的索引
:param dw: 更新的量
:return: None
"""
self.connection[i].update(dw)
self.connection[i].weight.data = F.normalize(self.connection[i].weight.data.float(), p=1, dim=1)
def reset(self):
"""
reset神经元或学习法则的中间量
:return: None
"""
for i in range(self.num_subMB):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
"""
获取网络的连接(包括权值等)
:return: 网络的连接
"""
return self.connection
================================================
FILE: braincog/model_zoo/nonlinearNet.py
================================================
import torch.nn.functional as F
from braincog.base.strategy.surrogate import *
from braincog.base.node.node import IFNode
from braincog.base.learningrule.STDP import STDP, MutliInputSTDP
class droDMTestNet(nn.Module):
"""
Drosophila Testing Network: compound eye-KC-MBON DA-GABA-MB
"""
def __init__(self, connection):
"""
根据传入的连接 构建测试网络
:param connection: 测试网络的连接
"""
super().__init__()
trace_stdp = 0.99
self.num_subMB = 5
self.node = [IFNode() for i in range(self.num_subMB)]
self.connection = connection
self.learning_rule = []
self.learning_rule.append(STDP(self.node[0], self.connection[0], trace_stdp))
self.learning_rule.append(MutliInputSTDP(self.node[1], [self.connection[1], self.connection[5]], trace_stdp))
self.learning_rule.append(MutliInputSTDP(self.node[2], [self.connection[2], self.connection[3], self.connection[9]], trace_stdp))
self.learning_rule.append(MutliInputSTDP(self.node[3], [self.connection[4], self.connection[6]], trace_stdp))
self.learning_rule.append(MutliInputSTDP(self.node[4], [self.connection[7], self.connection[8]], trace_stdp))
self.out_vis = torch.zeros((self.connection[0].weight.shape[1]), dtype=torch.float)
self.out_KC = torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float)
self.out_MBON = torch.zeros((self.connection[2].weight.shape[1]), dtype=torch.float)
self.out_APL = torch.zeros((self.connection[4].weight.shape[1]), dtype=torch.float)
self.out_DA = torch.zeros((self.connection[7].weight.shape[1]), dtype=torch.float)
def forward(self, input, input_da):
"""
根据输入得到输出
:param input: 输入电流
:return: 网络的输出,以及网络运行产生的STDP可塑性
"""
self.out_vis = self.node[0](self.connection[0](input))
self.out_KC, dw_kc = self.learning_rule[1](self.out_vis, self.out_APL)
self.out_MBON, dw_mbon = self.learning_rule[2](self.out_KC, self.out_MBON, self.out_DA)
self.out_APL, dw_apl = self.learning_rule[3](self.out_KC, self.out_DA)
self.out_DA, dw_da = self.learning_rule[4](self.out_APL, input_da)
return self.out_MBON, dw_kc[1], dw_apl[0]
def UpdateWeight(self, i, dw):
"""
更新网络中第i组连接的权重
:param i: 要更新的连接的索引
:param dw: 更新的量
:return: None
"""
self.connection[i].update(dw)
self.connection[i].weight.data = F.normalize(self.connection[i].weight.data.float(), p=1, dim=0)
def reset(self):
"""
reset神经元或学习法则的中间量
:return: None
"""
for i in range(self.num_subMB):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
"""
获取网络的连接(包括权值等)
:return: 网络的连接
"""
return self.connection
================================================
FILE: braincog/model_zoo/qsnn.py
================================================
import numpy as np
from scipy.linalg import orth
from scipy.special import expit
from scipy.signal import fftconvolve
import torch
from torch.nn import Parameter
import torch.nn as nn
from braincog.datasets.gen_input_signal import lambda_max, dt
from braincog.base.encoder import QSEncoder
gamma = 0.1
beta = 1.0
theta = 3.0
# kernel parameters
tau_s = 4.0 # synaptic time constant
tau_L = 10.0 # leak time constant
# conductance parameters
g_B = 0.6 # basal conductance
g_A = 0.05 # apical conductance
g_L = 1.0 / tau_L # leak conductance
g_D = g_B # dendritic conductance in output layer
k_D = g_D / (g_L + g_D)
STEPS = int(50 / dt)
SLEN = 20 # spike time length
# --- sigmoid function --- #
def sigma(x):
return torch.sigmoid(x)
# def sigma(x):
# return gamma * np.log(1+np.exp(beta*(x-theta)))
def deriv_sigma(x):
return sigma(x) * (1.0 - sigma(x))
# kernel parameters
tau_s = 4.0 # synaptic time constant
tau_L = 10.0 # leak time constant
# --- kernel function --- #
mem = STEPS
def kappa(x):
return np.exp(-x / tau_s)
def get_kappas(n):
return np.array([kappa(i + 1) for i in range(n)])
kappas = get_kappas(mem // 2) # initialize kappas array
kernel = np.zeros(mem)
kernel[:mem // 2] = kappas[:]
kernel[mem // 2:] = -np.flipud(kappas)[:]
W_MIN = -1.0
W_MAX = 1.0
class Net(nn.Module):
"""
两房室脉冲神经网络
"""
def __init__(self, net_size):
super().__init__()
self.input_size = net_size[0]
self.hidden_layers = nn.ModuleList([Hidden_layer(net_size[i], net_size[i + 1], net_size[-1]) for i in range(len(net_size) - 2)])
self.out_layer = Output_layer(net_size[-2], net_size[-1])
self.kernel = torch.from_numpy(kernel[:, np.newaxis]).cuda()
self.qs_code = QSEncoder
def update_state(self, input_, label, test):
if len(self.hidden_layers) > 1:
self.hidden_layers[0].update_state(input_, self.out_layer.spike_rate, test=test)
for i in range(len(self.hidden_layers) - 2):
self.hidden_layers[i + 1].update_state(self.hidden_layers[i].spike_rate, self.out_layer.spike_rate, test=test)
self.hidden_layers[-1].update_state(self.hidden_layers[-2].spike_rate, self.out_layer.spike_rate, test=test)
else:
self.hidden_layers[0].update_state(input_, self.out_layer.spike_rate, test=test)
self.out_layer.update_state(self.hidden_layers[-1].spike_rate, label, test=test)
def routine(self,
input_,
input_delta,
image_ori,
image_ori_delta,
shift,
label,
test=False,
noise=False,
noise_rate=None):
"""
网络信息处理过程
:param input_: 输入图片
:param input_delta: 输入扰动图片,用于计算相位
:param image_ori: 原始图片
:param image_ori_delta: 原始扰动图片
:param shift: 是否反转背景
:param label: 输入数据分类标签
:param test: 是否是测试阶段
:param noise: 是否增加噪声
:param noise_rate: 噪声比例
"""
encoder = self.qs_code(lambda_max, STEPS, SLEN, shift, noise, noise_rate)
input_ = encoder(input_, input_delta, image_ori, image_ori_delta)
input_ = torch.from_numpy(input_).to(self.kernel.device)
psp = torch.mm(input_, self.kernel).abs().float()
for i in range(STEPS):
self.update_state(psp, label, test=test)
def update_weight(self, lr, t, beta, eps):
self.out_layer.update_weight(lr, t, beta, eps)
if len(self.hidden_layers) > 1:
self.hidden_layers[-1].update_weight(self.out_layer.delta, lr, t, beta, eps)
for i in range(len(self.hidden_layers) - 1):
self.hidden_layers[-(i + 2)].update_weight(self.hidden_layers[-(i + 1)].delta, lr, t, beta, eps)
else:
self.hidden_layers[0].update_weight(self.out_layer.delta, lr, t, beta, eps)
def predict(self,
input_,
input_delta,
image_ori,
image_ori_delta,
shift,
noise,
noise_rate=0):
self.routine(input_,
input_delta,
image_ori=image_ori,
image_ori_delta=image_ori_delta,
shift=shift,
label=None,
test=True,
noise=noise,
noise_rate=noise_rate)
pred = torch.argmax(self.out_layer.spike_rate.flatten())
return pred
class Hidden_layer(nn.Module):
"""
隐藏层两房室网络
"""
def __init__(self, input_size, neu_num, fb_neus):
super().__init__()
self.basal_linear = nn.Linear(input_size, neu_num)
nn.init.uniform_(self.basal_linear.weight, -0.1, 0.1)
nn.init.uniform_(self.basal_linear.bias, -0.1, 0.1)
self.soma_V = 0.0
self.basal_V = 0.0
# for adam
self.m = 0.0
self.v = 0.0
self.m_hat = 0.0
self.v_hat = 0.0
self.m_b = 0.0
self.v_b = 0.0
self.m_b_hat = 0.0
self.v_b_hat = 0.0
# backprop
self.delta = 0.0
def update_state(self, basal_input, apical_input, test):
self.basal_input = basal_input.T # [1, 781]
self.basal_V = self.basal_linear(basal_input.T)
self.soma_V = self.soma_V + 1 / tau_L * (-self.soma_V + g_B / g_L * (self.basal_V - self.soma_V)) * dt
self.spike_rate = lambda_max * sigma(self.soma_V)
def update_weight(self, delta_, lr, t, beta, eps):
weight_dot = lambda_max * k_D * delta_ * deriv_sigma(k_D * self.basal_V) # [1, 500]
self.delta = torch.mm(weight_dot, self.basal_linear.weight.data) # [500, 784] x [1, 500]
weight_delta = weight_dot[:, :, None] * self.basal_input[:, None, :]
bias_delta = weight_dot
self.m = beta[0] * self.m + (1 - beta[0]) * weight_delta
self.v = beta[1] * self.v + (1 - beta[1]) * torch.square(weight_delta)
self.m_hat = self.m / (1 - beta[0] ** t)
self.v_hat = self.v / (1 - beta[1] ** t)
self.m_b = beta[0] * self.m_b + (1 - beta[0]) * bias_delta
self.v_b = beta[1] * self.v_b + (1 - beta[1]) * torch.square(bias_delta)
self.m_b_hat = self.m_b / (1 - beta[0] ** t)
self.v_b_hat = self.v_b / (1 - beta[1] ** t)
# update weight
weight_delta = lr * self.m_hat / (torch.sqrt(self.v_hat) + eps)
bias_delta = lr * self.m_b_hat / (torch.sqrt(self.v_b_hat) + eps)
self.basal_linear.weight.data.sub_(weight_delta.mean(0))
self.basal_linear.bias.data.sub_(bias_delta.mean(0))
class Output_layer(nn.Module):
"""
输出层两房室网络
"""
def __init__(self, input_size, neu_num):
super().__init__()
self.basal_linear = nn.Linear(input_size, neu_num)
nn.init.uniform_(self.basal_linear.weight, -0.1, 0.1)
nn.init.uniform_(self.basal_linear.bias, -0.1, 0.1)
self.soma_V = 0.0
self.basal_V = 0.0
self.spike_rate = 0.0
# adam
self.m = 0.0
self.v = 0.0
self.m_hat = 0.0
self.v_hat = 0.0
self.m_b = 0.0
self.v_b = 0.0
self.m_b_hat = 0.0
self.v_b_hat = 0.0
# backprop
self.delta = 0.0
def update_state(self, basal_input, I, test):
self.basal_input = basal_input
self.basal_V = self.basal_linear(basal_input)
if test:
self.soma_V = self.soma_V + 1 / tau_L * (-self.soma_V + g_B / g_L * (self.basal_V - self.soma_V)) * dt
else:
self.soma_V = self.soma_V + 1 / tau_L * (-self.soma_V + g_B / g_L * (self.basal_V - self.soma_V) +
I - self.soma_V) * dt
self.spike_rate = lambda_max * sigma(self.soma_V)
def update_weight(self, lr, t, beta, eps):
weight_dot = lambda_max * k_D * (sigma(k_D * self.basal_V) - sigma(self.soma_V)) * deriv_sigma(k_D * self.basal_V)
self.delta = torch.mm(weight_dot, self.basal_linear.weight.data) # [1, 500]
bias_delta = weight_dot # [1, 10]
weight_delta = weight_dot[:, :, None] * self.basal_input[:, None, :] # [1, 10, 500]
self.m = beta[0] * self.m + (1 - beta[0]) * weight_delta
self.v = beta[1] * self.v + (1 - beta[1]) * torch.square(weight_delta)
self.m_hat = self.m / (1 - beta[0] ** t)
self.v_hat = self.v / (1 - beta[1] ** t)
self.m_b = beta[0] * self.m_b + (1 - beta[0]) * bias_delta
self.v_b = beta[1] * self.v_b + (1 - beta[1]) * torch.square(bias_delta)
self.m_b_hat = self.m_b / (1 - beta[0] ** t)
self.v_b_hat = self.v_b / (1 - beta[1] ** t)
# update weight
weight_delta = lr * self.m_hat / (torch.sqrt(self.v_hat) + eps)
bias_delta = lr * self.m_b_hat / (torch.sqrt(self.v_b_hat) + eps)
self.basal_linear.weight.data.sub_(weight_delta.mean(0))
self.basal_linear.bias.data.sub_(bias_delta.mean(0))
================================================
FILE: braincog/model_zoo/resnet.py
================================================
'''
Deep Residual Learning for Image Recognition
https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
'''
import os
import sys
from functools import partial
from timm.models import register_model
from timm.models.layers import trunc_normal_, DropPath
from braincog.model_zoo.base_module import *
from braincog.base.node.node import *
__all__ = [
'ResNet',
'resnet18',
'resnet34_half',
'resnet34',
'resnet50_half',
'resnet50',
'resnet101',
'resnet152',
'resnext50_32x4d',
'resnext101_32x8d',
'wide_resnet50_2',
'wide_resnet101_2',
]
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
'''3x3 convolution with padding'''
return nn.Conv2d(in_planes,
out_planes,
kernel_size=3,
stride=stride,
padding=dilation,
groups=groups,
bias=False,
dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
'''1x1 convolution'''
return nn.Conv2d(in_planes,
out_planes,
kernel_size=1,
stride=stride,
bias=False)
class BasicBlock(nn.Module):
"""
ResNet的基础模块, 采用identity-connection的方式.
:param inplanes: 输出通道数
:param planes: 内部通道数量
:param stride: stride
:param downsample: 是否降采样
:param groups: 分组卷积
:param base_width: 基础通道数量
:param dilation: 空洞卷积
:param norm_layer: Norm的方式
:param node: 神经元类型, 默认为 ``LIFNode``
"""
expansion = 1
__constants__ = ['downsample']
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None,
node=LIFNode):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError(
'BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError(
'Dilation > 1 not supported in BasicBlock')
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.bn1 = norm_layer(inplanes)
self.node1 = node()
self.conv1 = conv3x3(inplanes, planes, stride)
# self.relu = nn.ReLU(inplace=False)
self.node2 = node()
self.bn2 = norm_layer(planes)
self.conv2 = conv3x3(planes, planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.bn1(x)
out = self.node1(out)
out = self.conv1(out)
out = self.bn2(out)
out = self.node2(out)
out = self.conv2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
return out
class Bottleneck(nn.Module):
"""
ResNet的Botteneck模块, 采用identity-connection的方式.
:param inplanes: 输出通道数
:param planes: 内部通道数量
:param stride: stride
:param downsample: 是否降采样
:param groups: 分组卷积
:param base_width: 基础通道数量
:param dilation: 空洞卷积
:param norm_layer: Norm的方式
:param node: 神经元类型, 默认为 ``LIFNode``
"""
expansion = 4
__constants__ = ['downsample']
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None,
node=torch.nn.Identity):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.bn1 = norm_layer(inplanes)
self.conv1 = conv1x1(inplanes, width)
self.bn2 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn3 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
# self.relu = nn.ReLU(inplace=False)
self.downsample = downsample
self.stride = stride
self.node1 = node()
self.node2 = node()
self.node3 = node()
def forward(self, x):
identity = x
out = self.bn1(x)
out = self.node1(out)
out = self.conv1(out)
out = self.bn2(out)
out = self.node2(out)
out = self.conv2(out)
out = self.bn3(out)
out = self.node3(out)
out = self.conv3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
return out
class ResNet(BaseModule):
"""
ResNet-SNN
:param block: Block类型
:param layers: block 层数
:param inplanes: 输入通道数量
:param num_classes: 输出类别数
:param zero_init_residual: 是否使用零初始化
:param groups: 卷积分组
:param width_per_group: 每一组的宽度
:param replace_stride_with_dilation: 是否使用stride替换dilation
:param norm_layer: Norm 方式, 默认为 ``BatchNorm``
:param step: 仿真步长, 默认为 ``8``
:param encode_type: 编码方式, 默认为 ``direct``
:param spike_output: 是否使用脉冲输出, 默认为 ``False``
:param args:
:param kwargs:
"""
def __init__(self,
block,
layers,
inplanes=64,
num_classes=10,
zero_init_residual=False,
groups=1,
width_per_group=64,
replace_stride_with_dilation=None,
norm_layer=None,
step=8,
encode_type='direct',
spike_output=False,
*args,
**kwargs):
super().__init__(
step,
encode_type,
*args,
**kwargs
)
self.spike_output = spike_output
self.num_classes = num_classes
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
# print('inplanes %d' % inplanes)
self.inplanes = inplanes
self.interplanes = [
self.inplanes, self.inplanes * 2, self.inplanes * 4,
self.inplanes * 8
]
self.dilation = 1
self.node = kwargs['node_type']
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs)
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError('replace_stride_with_dilation should be None '
'or a 3-element tuple, got {}'.format(
replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.static_data = False
self.dataset = kwargs['dataset']
if self.dataset == 'dvsg' or self.dataset == 'dvsc10' or self.dataset == 'NCALTECH101' or self.dataset == 'NCARS' or self.dataset == 'DVSG':
self.conv1 = nn.Conv2d(2 * self.init_channel_mul,
self.inplanes,
kernel_size=3,
padding=1,
bias=False)
elif self.dataset == 'imnet':
self.conv1 = nn.Conv2d(3 * self.init_channel_mul,
self.inplanes,
kernel_size=7,
stride=2,
padding=3,
bias=False)
self.static_data = True
elif self.dataset == 'esimnet':
reconstruct = kwargs["reconstruct"] if "reconstruct" in kwargs else False
print(reconstruct)
if reconstruct:
self.conv1 = nn.Conv2d(1 * self.init_channel_mul,
self.inplanes,
kernel_size=7,
stride=2,
padding=3,
bias=False)
self.static_data = True
else:
self.conv1 = nn.Conv2d(2 * self.init_channel_mul,
self.inplanes,
kernel_size=7,
stride=2,
padding=3,
bias=False)
self.static_data = True
elif self.dataset == 'cifar10' or self.dataset == 'cifar100':
self.conv1 = nn.Conv2d(3 * self.init_channel_mul,
self.inplanes,
kernel_size=3,
padding=1,
bias=False)
self.static_data = True
# self.relu = nn.ReLU(inplace=False)
self.layer1 = self._make_layer(
block, self.interplanes[0], layers[0], node=self.node)
self.layer2 = self._make_layer(block,
self.interplanes[1],
layers[1],
stride=2,
dilate=replace_stride_with_dilation[0], node=self.node)
self.layer3 = self._make_layer(block,
self.interplanes[2],
layers[2],
stride=2,
dilate=replace_stride_with_dilation[1], node=self.node)
self.layer4 = self._make_layer(block,
self.interplanes[3],
layers[3],
stride=2,
dilate=replace_stride_with_dilation[2], node=self.node)
self.bn1 = norm_layer(self.inplanes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
if self.spike_output:
self.fc = nn.Linear(
self.interplanes[3] * block.expansion, num_classes * 10)
self.node2 = self.node()
self.vote = VotingLayer(10)
else:
self.fc = nn.Linear(
self.interplanes[3] * block.expansion, num_classes
)
self.node2 = nn.Identity()
self.vote = nn.Identity()
self.warm_up = False
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight,
mode='fan_out',
nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False, node=torch.nn.Identity):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
if block == BasicBlock:
downsample = nn.Sequential(
norm_layer(self.inplanes),
self.node(),
conv1x1(self.inplanes, planes * block.expansion, stride),
)
elif block == Bottleneck:
downsample = nn.Sequential(
norm_layer(self.inplanes),
self.node(),
conv1x1(self.inplanes, planes * block.expansion, stride),
)
else:
raise NotImplementedError
layers = [block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer, node=node)]
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(
block(self.inplanes,
planes,
groups=self.groups,
base_width=self.base_width,
dilation=self.dilation,
norm_layer=norm_layer, node=node))
return nn.Sequential(*layers)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.conv1(inputs)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.bn1(x)
# x = self.node1(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
# print(x.shape)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
x = self.node2(x)
x = self.vote(x)
return x
else:
outputs = []
if self.warm_up:
step = 1
else:
step = self.step
for t in range(step):
x = inputs[t]
x = self.conv1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.bn1(x)
# x = self.node1(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
x = self.node2(x)
x = self.vote(x)
outputs.append(x)
return sum(outputs) / len(outputs)
def _resnet(arch, block, layers, pretrained=False, **kwargs):
model = ResNet(block, layers, **kwargs)
# only load state_dict()
if pretrained:
raise NotImplementedError
return model
@register_model
def resnet9(pretrained=False, **kwargs):
return _resnet('resnet9', BasicBlock, [1, 1, 1, 1], pretrained, **kwargs)
@register_model
def resnet18(pretrained=False, **kwargs):
# kwargs['inplanes'] = 96
return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, **kwargs)
@register_model
def resnet34_half(pretrained=False, **kwargs):
kwargs['inplanes'] = 32
return _resnet('resnet34_half', BasicBlock, [3, 4, 6, 3], pretrained,
**kwargs)
@register_model
def resnet34(pretrained=False, **kwargs):
return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, **kwargs)
@register_model
def resnet50_half(pretrained=False, **kwargs):
kwargs['inplanes'] = 32
return _resnet('resnet50_half', Bottleneck, [3, 4, 6, 3], pretrained,
**kwargs)
@register_model
def resnet50(pretrained=False, **kwargs):
return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, **kwargs)
@register_model
def resnet101(pretrained=False, **kwargs):
return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained,
**kwargs)
@register_model
def resnet152(pretrained=False, **kwargs):
return _resnet('resnet152', Bottleneck, [3, 8, 36, 3], pretrained,
**kwargs)
@register_model
def resnext50_32x4d(pretrained=False, **kwargs):
kwargs['groups'] = 32
kwargs['width_per_group'] = 4
return _resnet('resnext50_32x4d', Bottleneck, [3, 4, 6, 3], pretrained,
**kwargs)
@register_model
def resnext101_32x8d(pretrained=False, **kwargs):
kwargs['groups'] = 32
kwargs['width_per_group'] = 8
return _resnet('resnext101_32x8d', Bottleneck, [3, 4, 23, 3], pretrained,
**kwargs)
@register_model
def wide_resnet50_2(pretrained=False, **kwargs):
kwargs['width_per_group'] = 64 * 2
return _resnet('wide_resnet50_2', Bottleneck, [3, 4, 6, 3], pretrained,
**kwargs)
@register_model
def wide_resnet101_2(pretrained=False, **kwargs):
kwargs['width_per_group'] = 64 * 2
return _resnet('wide_resnet101_2', Bottleneck, [3, 4, 23, 3], pretrained,
**kwargs)
if __name__ == '__main__':
net = ResNet(Bottleneck, [3, 4, 6, 3], num_classes=1000)
image_h, image_w = 224, 224
from thop import profile
from thop import clever_format
flops, params = profile(net,
inputs=(torch.randn(1, 3, image_h, image_w),),
verbose=False)
flops, params = clever_format([flops, params], '%.3f')
out = net(torch.autograd.Variable(torch.randn(3, 3, image_h, image_w)))
print(f'1111, flops: {flops}, params: {params},out_shape: {out.shape}')
================================================
FILE: braincog/model_zoo/resnet19_snn.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/7/26 19:33
# User : Floyed
# Product : PyCharm
# Project : braincog
# File : resnet19_snn.py
# explain :
import os
import sys
from functools import partial
import numpy as np
from timm.models import register_model
from timm.models.layers import trunc_normal_, DropPath
from braincog.model_zoo.base_module import *
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.datasets import is_dvs_data
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
node=LIFNode, base_width=64, dilation=1, norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = ThresholdDependentBatchNorm2d
# if groups != 1 or base_width != 64:
# raise ValueError('BasicBlock only supports groups=1 and base_width=64')
# if dilation > 1:
# raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(num_features=planes, alpha=1.)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(num_features=planes, alpha=np.sqrt(.5))
self.downsample = downsample
self.stride = stride
self.node1 = node()
self.node2 = node()
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.node1(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.node2(out)
return out
class ResNet(BaseModule):
def __init__(self, block, layers, num_classes=10, zero_init_residual=False, groups=1, width_per_group=128,
replace_stride_with_dilation=None, norm_layer=None, step=4, encode_type='direct', node_type=LIFNode,
*args, **kwargs):
super().__init__(
step,
encode_type,
*args,
**kwargs
)
super().__init__(step, encode_type, *args, **kwargs)
if not self.layer_by_layer:
raise ValueError('ResNet-SNN only support for layer-wise mode, because of tdBN')
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.dataset = kwargs['dataset']
if is_dvs_data(self.dataset):
data_channel = 2
else:
data_channel = 3
if norm_layer is None:
norm_layer = ThresholdDependentBatchNorm2d
self._norm_layer = partial(norm_layer, step=step)
self.sum_output=kwargs["sum_output"] if "sum_output"in kwargs else True
self.inplanes = 128
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(data_channel, self.inplanes, kernel_size=3, stride=1, padding=1,
bias=False)
self.bn1 = self._norm_layer(num_features=self.inplanes, alpha=np.sqrt(.5))
self.layer1 = self._make_layer(block, 128, layers[0])
self.layer2 = self._make_layer(block, 256, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 512, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc1 = nn.Linear(512 * block.expansion, 256)
self.fc2 = nn.Linear(256, num_classes)
self.node1 = self.node()
self.node2 = self.node()
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
# downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(num_features=planes * block.expansion, alpha=np.sqrt(.5)),
)
else:
downsample = nn.Sequential(
norm_layer(num_features=planes * block.expansion, alpha=np.sqrt(.5)),
)
layers = []
layers.append(block(self.inplanes, planes, stride=stride, downsample=downsample, groups=self.groups,
base_width=self.base_width, norm_layer=norm_layer, node=self.node))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer, node=self.node))
return nn.Sequential(*layers)
def _forward_impl(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = self.node2(x)
x = self.fc2(x)
if self.sum_output:x= rearrange(x, '(t b) c -> b c t', t=self.step).mean(-1)
else :x= rearrange(x, '(t b) c -> t b c ', t=self.step)
return x
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
return self._forward_impl(inputs)
def _resnet(arch, block, layers, pretrained, progress, norm=ThresholdDependentBatchNorm2d, **kwargs):
tdBN = partial(norm, layer_by_layer=kwargs['layer_by_layer'], threshold=kwargs['threshold'])
model = ResNet(block, layers, norm_layer=tdBN, **kwargs)
if pretrained:
raise NotImplementedError
return model
@register_model
def resnet19(pretrained=False, progress=True, norm=ThresholdDependentBatchNorm2d, **kwargs):
return _resnet('resnet19', BasicBlock, [3, 3, 2], pretrained, progress, norm=norm, **kwargs)
if __name__ == '__main__':
net = ResNet(BasicBlock, [3, 4, 6, 3], num_classes=1000)
image_h, image_w = 224, 224
from thop import profile
from thop import clever_format
flops, params = profile(net,
inputs=(torch.randn(1, 3, image_h, image_w),),
verbose=False)
flops, params = clever_format([flops, params], '%.3f')
out = net(torch.autograd.Variable(torch.randn(3, 3, image_h, image_w)))
print(f'1111, flops: {flops}, params: {params},out_shape: {out.shape}')
================================================
FILE: braincog/model_zoo/rsnn.py
================================================
import torch
from torch import nn
from braincog.base.node.node import IFNode
from braincog.base.learningrule.STDP import STDP,MutliInputSTDP
from braincog.base.connection.CustomLinear import CustomLinear
from collections import deque
from random import randint
class RSNN(nn.Module):
def __init__(self,num_state,num_action):
super().__init__()
# parameters
rsnn_mask=[]
rsnn_con=[]
con_matrix1 = torch.ones((num_state,num_action), dtype=torch.float)
rsnn_mask.append(con_matrix1)
rsnn_con.append(CustomLinear(torch.randn(num_state,num_action), con_matrix1))
self.num_subR=2
self.connection = rsnn_con
self.mask=rsnn_mask
self.node = [IFNode() for i in range(self.num_subR)]
self.learning_rule = []
self.learning_rule.append(MutliInputSTDP(self.node[1], [self.connection[0]]))
self.weight_trace = torch.zeros(con_matrix1.shape, dtype=torch.float)
self.out_in = torch.zeros((num_state), dtype=torch.float)
self.out = torch.zeros((self.connection[0].weight.size()[1]), dtype=torch.float)
self.dw = torch.zeros((self.connection[0].weight.size()), dtype=torch.float)
def forward(self, input):
input=torch.tensor(input, dtype=torch.float)
self.out_in=self.node[0](input)
self.out,self.dw = self.learning_rule[0](self.out_in)
return self.out,self.dw
def UpdateWeight(self,reward):
self.weight_trace[self.weight_trace>0]=self.weight_trace[self.weight_trace>0]*reward
self.weight_trace[self.weight_trace < 0] = -1*self.weight_trace[self.weight_trace < 0] * reward
self.connection[0].update(self.weight_trace)
for i in range(self.connection[0].weight.size()[1]):
self.connection[0].weight.data[:, i] = (self.connection[0].weight.data[:, i] - torch.min(self.connection[0].weight.data[:, i])) / (torch.max(self.connection[0].weight.data[:, i]) - torch.min(self.connection[0].weight.data[:, i]))
self.connection[0].weight.data= self.connection[0].weight.data * 0.5
def reset(self):
for i in range(self.num_subR):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
return self.connection
================================================
FILE: braincog/model_zoo/sew_resnet.py
================================================
import torch
import torch.nn as nn
from copy import deepcopy
try:
from torchvision.models.utils import load_state_dict_from_url
except ImportError:
from torchvision._internally_replaced_utils import load_state_dict_from_url
from braincog.base.node import *
from braincog.model_zoo.base_module import *
from braincog.datasets import is_dvs_data
from timm.models import register_model
__all__ = ['SEWResNet', 'sew_resnet18', 'sew_resnet34', 'sew_resnet50', 'sew_resnet101',
'sew_resnet152', 'sew_resnext50_32x4d', 'sew_resnext101_32x8d',
'sew_wide_resnet50_2', 'sew_wide_resnet101_2']
model_urls = {
"resnet18": "https://download.pytorch.org/models/resnet18-f37072fd.pth",
"resnet34": "https://download.pytorch.org/models/resnet34-b627a593.pth",
"resnet50": "https://download.pytorch.org/models/resnet50-0676ba61.pth",
"resnet101": "https://download.pytorch.org/models/resnet101-63fe2227.pth",
"resnet152": "https://download.pytorch.org/models/resnet152-394f9c45.pth",
"resnext50_32x4d": "https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth",
"resnext101_32x8d": "https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth",
"wide_resnet50_2": "https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth",
"wide_resnet101_2": "https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth",
}
# modified by https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py
def sew_function(x: torch.Tensor, y: torch.Tensor, cnf:str):
if cnf == 'ADD':
return x + y
elif cnf == 'AND':
return x * y
elif cnf == 'IAND':
return x * (1. - y)
else:
raise NotImplementedError
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None, cnf: str = None, node: callable = None, **kwargs):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.node1 = node()
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.node2 = node()
self.downsample = downsample
if downsample is not None:
self.downsample_sn = node()
self.stride = stride
self.cnf = cnf
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.node1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.node2(out)
if self.downsample is not None:
identity = self.downsample_sn(self.downsample(x))
out = sew_function(identity, out, self.cnf)
return out
def extra_repr(self) -> str:
return super().extra_repr() + f'cnf={self.cnf}'
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None, cnf: str = None, node: callable = None, **kwargs):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.node1 = node()
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.node2 = node()
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.node3 = node()
self.downsample = downsample
if downsample is not None:
self.downsample_sn = node()
self.stride = stride
self.cnf = cnf
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.node1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.node2(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.node3(out)
if self.downsample is not None:
identity = self.downsample_sn(self.downsample(x))
out = sew_function(out, identity, self.cnf)
return out
def extra_repr(self) -> str:
return super().extra_repr() + f'cnf={self.cnf}'
class SEWResNet(BaseModule):
def __init__(self, block, layers, num_classes=1000, step=8,encode_type="direct",zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None, cnf: str = None, *args,**kwargs):
super().__init__(
step,
encode_type,
*args,
**kwargs
)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.num_classes = num_classes
self.node = kwargs['node_type']
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.once=kwargs["once"] if "once"in kwargs else False
self.sum_output=kwargs["sum_output"] if "sum_output"in kwargs else True
self.dataset = kwargs['dataset']
if not is_dvs_data(self.dataset):
init_channel = 3
else:
init_channel = 2
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(init_channel, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.node1 = self.node()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], cnf=cnf, node=self.node, **kwargs)
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0], cnf=cnf, node=self.node, **kwargs)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1], cnf=cnf, node=self.node, **kwargs)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2], cnf=cnf, node=self.node, **kwargs)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False, cnf: str=None, node: callable = None, **kwargs):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer, cnf, node, **kwargs))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer, cnf=cnf, node=node, **kwargs))
return nn.Sequential(*layers)
def _forward_impl(self, inputs):
# See note [TorchScript super()]
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.conv1(inputs)
x = self.bn1(x)
x = self.node1(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step)
#print(x)
if self.sum_output:x=x.mean(0)
return x
else:
outputs=[]
for t in range(self.step):
x = inputs[t]
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
outputs.append(x)
if not self.sum_output:return outputs
return sum(outputs) / len(outputs)
def _forward_once(self,x):
# inputs = self.encoder(inputs)
# x = inputs[t]
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
if self.once:return self._forward_once(x)
return self._forward_impl(x)
class SEWResNet19(BaseModule):
def __init__(self, block, layers, num_classes=1000, step=8,encode_type="direct",zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None, cnf: str = None, *args,**kwargs):
super().__init__(
step,
encode_type,
*args,
**kwargs
)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.num_classes = num_classes
self.node = kwargs['node_type']
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.once=kwargs["once"] if "once"in kwargs else False
self.sum_output=kwargs["sum_output"] if "sum_output"in kwargs else True
self.dataset = kwargs['dataset']
if not is_dvs_data(self.dataset):
init_channel = 3
else:
init_channel = 2
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(init_channel, self.inplanes, kernel_size=3, stride=1, padding=1,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.node1 = self.node()
self.layer1 = self._make_layer(block, 128, layers[0], cnf=cnf, node=self.node, **kwargs)
self.layer2 = self._make_layer(block, 256, layers[1], stride=2,
dilate=replace_stride_with_dilation[0], cnf=cnf, node=self.node, **kwargs)
self.layer3 = self._make_layer(block, 512, layers[2], stride=2,
dilate=replace_stride_with_dilation[1], cnf=cnf, node=self.node, **kwargs)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc1 = nn.Linear(512 * block.expansion, 256)
self.fc2 = nn.Linear(256, num_classes)
self.node2 = self.node()
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False, cnf: str=None, node: callable = None, **kwargs):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer, cnf, node, **kwargs))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer, cnf=cnf, node=node, **kwargs))
return nn.Sequential(*layers)
def _forward_impl(self, inputs):
# See note [TorchScript super()]
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.conv1(inputs)
x = self.bn1(x)
x = self.node1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = self.node2(x)
x = self.fc2(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step)
#print(x)
if self.sum_output:x=x.mean(0)
return x
else:
outputs=[]
for t in range(self.step):
x = inputs[t]
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = self.node2(x)
x = self.fc2(x)
outputs.append(x)
if not self.sum_output:return outputs
return sum(outputs) / len(outputs)
def _forward_once(self,x):
# inputs = self.encoder(inputs)
# x = inputs[t]
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
if self.once:return self._forward_once(x)
return self._forward_impl(x)
class SEWResNetCifar(BaseModule):
def __init__(self, block, layers, num_classes=1000, step=8,encode_type="direct",zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None, cnf: str = None, *args,**kwargs):
super().__init__(
step,
encode_type,
*args,
**kwargs
)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.num_classes = num_classes
self.node = kwargs['node_type']
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.once=kwargs["once"] if "once"in kwargs else False
self.sum_output=kwargs["sum_output"] if "sum_output"in kwargs else True
self.dataset = kwargs['dataset']
if not is_dvs_data(self.dataset):
init_channel = 3
else:
init_channel = 2
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(init_channel, self.inplanes, kernel_size=3, stride=1, padding=1,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.node1 = self.node()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 128, layers[0], cnf=cnf, node=self.node, **kwargs)
self.layer2 = self._make_layer(block, 256, layers[1], stride=2,
dilate=replace_stride_with_dilation[0], cnf=cnf, node=self.node, **kwargs)
self.layer3 = self._make_layer(block, 512, layers[2], stride=2,
dilate=replace_stride_with_dilation[1], cnf=cnf, node=self.node, **kwargs)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False, cnf: str=None, node: callable = None, **kwargs):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer, cnf, node, **kwargs))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer, cnf=cnf, node=node, **kwargs))
return nn.Sequential(*layers)
def _forward_impl(self, inputs):
# See note [TorchScript super()]
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.conv1(inputs)
x = self.bn1(x)
x = self.node1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step)
#print(x)
if self.sum_output:x=x.mean(0)
return x
else:
outputs=[]
for t in range(self.step):
x = inputs[t]
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
outputs.append(x)
if not self.sum_output:return outputs
return sum(outputs) / len(outputs)
def _forward_once(self,x):
# inputs = self.encoder(inputs)
# x = inputs[t]
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
if self.once:return self._forward_once(x)
return self._forward_impl(x)
def _sew_resnet(arch, block, layers, pretrained, progress, cnf, **kwargs):
model = SEWResNet(block, layers, cnf=cnf, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
@register_model
def sew_resnet19(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-18
:rtype: torch.nn.Module
The spike-element-wise ResNet-18 `"Deep Residual Learning in Spiking Neural Networks" `_ modified by the ResNet-18 model from `"Deep Residual Learning for Image Recognition" `_
"""
return SEWResNet19( BasicBlock, [3,3, 2], cnf=cnf, **kwargs)
@register_model
def sew_resnet18(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-18
:rtype: torch.nn.Module
The spike-element-wise ResNet-18 `"Deep Residual Learning in Spiking Neural Networks" `_ modified by the ResNet-18 model from `"Deep Residual Learning for Image Recognition" `_
"""
return _sew_resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress, cnf, **kwargs)
@register_model
def sew_resnet20(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-34
:rtype: torch.nn.Module
The spike-element-wise ResNet-34 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-34 model from `"Deep Residual Learning for Image Recognition" `_
"""
return SEWResNetCifar( BasicBlock, [3,3,3], cnf=cnf, **kwargs)
@register_model
def sew_resnet32(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-34
:rtype: torch.nn.Module
The spike-element-wise ResNet-34 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-34 model from `"Deep Residual Learning for Image Recognition" `_
"""
return SEWResNetCifar( BasicBlock, [5,5,5], cnf=cnf, **kwargs)
@register_model
def sew_resnet44(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-34
:rtype: torch.nn.Module
The spike-element-wise ResNet-34 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-34 model from `"Deep Residual Learning for Image Recognition" `_
"""
return SEWResNetCifar( BasicBlock, [7,7,7], cnf=cnf, **kwargs)
@register_model
def sew_resnet56(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-34
:rtype: torch.nn.Module
The spike-element-wise ResNet-34 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-34 model from `"Deep Residual Learning for Image Recognition" `_
"""
return SEWResNetCifar( BasicBlock, [9,9,9], cnf=cnf, **kwargs)
@register_model
def sew_resnet34(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-34
:rtype: torch.nn.Module
The spike-element-wise ResNet-34 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-34 model from `"Deep Residual Learning for Image Recognition" `_
"""
return _sew_resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress, cnf, **kwargs)
@register_model
def sew_resnet50(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-50
:rtype: torch.nn.Module
The spike-element-wise ResNet-50 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-50 model from `"Deep Residual Learning for Image Recognition" `_
"""
return _sew_resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress, cnf, **kwargs)
@register_model
def sew_resnet101(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-101
:rtype: torch.nn.Module
The spike-element-wise ResNet-101 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-101 model from `"Deep Residual Learning for Image Recognition" `_
"""
return _sew_resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress, cnf, **kwargs)
@register_model
def sew_resnet152(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a single step neuron
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-152
:rtype: torch.nn.Module
The spike-element-wise ResNet-152 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNet-152 model from `"Deep Residual Learning for Image Recognition" `_
"""
return _sew_resnet('resnet152', Bottleneck, [3, 8, 36, 3], pretrained, progress, cnf, **kwargs)
@register_model
def sew_resnext50_32x4d(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a single step neuron
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNeXt-50 32x4d
:rtype: torch.nn.Module
The spike-element-wise ResNeXt-50 32x4d `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the ResNeXt-50 32x4d model from `"Aggregated Residual Transformation for Deep Neural Networks" `_
"""
kwargs['groups'] = 32
kwargs['width_per_group'] = 4
return _sew_resnet('resnext50_32x4d', Bottleneck, [3, 4, 6, 3], pretrained, progress, cnf, **kwargs)
@register_model
def sew_resnext34_32x4d(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a single step neuron
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNeXt-101 32x8d
:rtype: torch.nn.Module
The spike-element-wise ResNeXt-101 32x8d `"Deep Residual Learning in Spiking Neural Networks" `_ modified by the ResNeXt-101 32x8d model from `"Aggregated Residual Transformation for Deep Neural Networks" `_
"""
kwargs['groups'] = 32
kwargs['width_per_group'] = 4
return _sew_resnet('resnext34_32x4d', BasicBlock, [3, 4, 6, 3], pretrained, progress, cnf, **kwargs)
@register_model
def sew_resnext101_32x8d(pretrained=False, progress=True, cnf: str = None, node: callable=None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a single step neuron
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNeXt-101 32x8d
:rtype: torch.nn.Module
The spike-element-wise ResNeXt-101 32x8d `"Deep Residual Learning in Spiking Neural Networks" `_ modified by the ResNeXt-101 32x8d model from `"Aggregated Residual Transformation for Deep Neural Networks" `_
"""
kwargs['groups'] = 32
kwargs['width_per_group'] = 8
return _sew_resnet('resnext101_32x8d', Bottleneck, [3, 4, 23, 3], pretrained, progress, cnf, node, **kwargs)
@register_model
def sew_wide_resnet50_2(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a single step neuron
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking Wide ResNet-50-2
:rtype: torch.nn.Module
The spike-element-wise Wide ResNet-50-2 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the Wide ResNet-50-2 model from `"Wide Residual Networks" `_
The model is the same as ResNet except for the bottleneck number of channels
which is twice larger in every block. The number of channels in outer 1x1
convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
channels, and in Wide ResNet-50-2 has 2048-1024-2048.
"""
kwargs['width_per_group'] = 64 * 2
return _sew_resnet('wide_resnet50_2', Bottleneck, [3, 4, 6, 3], pretrained, progress, cnf, **kwargs)
@register_model
def sew_wide_resnet101_2(pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a single step neuron
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking Wide ResNet-101-2
:rtype: torch.nn.Module
The spike-element-wise Wide ResNet-101-2 `"Deep Residual Learning in Spiking Neural Networks" `_
modified by the Wide ResNet-101-2 model from `"Wide Residual Networks" `_
The model is the same as ResNet except for the bottleneck number of channels
which is twice larger in every block. The number of channels in outer 1x1
convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
channels, and in Wide ResNet-50-2 has 2048-1024-2048.
"""
kwargs['width_per_group'] = 64 * 2
return _sew_resnet('wide_resnet101_2', Bottleneck, [3, 4, 23, 3], pretrained, progress, cnf, **kwargs)
================================================
FILE: braincog/model_zoo/vgg_snn.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/7/26 18:56
# User : Floyed
# Product : PyCharm
# Project : BrainCog
# File : vgg_snn.py
# explain :
from functools import partial
from torch.nn import functional as F
import torchvision
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.datasets import is_dvs_data
@register_model
class SNN7_tiny(BaseModule):
def __init__(self,
num_classes=10,
step=8,
node_type=LIFNode,
encode_type='direct',
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.num_classes = num_classes
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.dataset = kwargs['dataset']
assert not is_dvs_data(self.dataset), 'SNN7_tiny only support static datasets now'
self.feature = nn.Sequential(
BaseConvModule(3, 16, kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(16, 64, kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.MaxPool2d(2),
BaseConvModule(64, 128, kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(128, 128, kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.MaxPool2d(2),
BaseConvModule(128, 256, kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(256, 256, kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.MaxPool2d(2),
BaseConvModule(256, 512, kernel_size=(3, 3), padding=(1, 1), node=self.node),
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(512 * 4 * 4, self.num_classes),
)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.feature(inputs)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
return x
else:
outputs = []
for t in range(self.step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
@register_model
class SNN5(BaseModule):
def __init__(self,
num_classes=10,
step=8,
node_type=LIFNode,
encode_type='direct',
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.n_preact = kwargs['n_preact'] if 'n_preact' in kwargs else False
self.num_classes = num_classes
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.dataset = kwargs['dataset']
if not is_dvs_data(self.dataset):
init_channel = 3
else:
init_channel = 2
self.feature = nn.Sequential(
BaseConvModule(init_channel, 16, kernel_size=(3, 3), padding=(1, 1), node=self.node, n_preact=self.n_preact),
BaseConvModule(16, 64, kernel_size=(5, 5), padding=(2, 2), node=self.node, n_preact=self.n_preact),
nn.AvgPool2d(2),
BaseConvModule(64, 128, kernel_size=(5, 5), padding=(2, 2), node=self.node, n_preact=self.n_preact),
nn.AvgPool2d(2),
BaseConvModule(128, 256, kernel_size=(3, 3), padding=(1, 1), node=self.node, n_preact=self.n_preact),
nn.AvgPool2d(2),
BaseConvModule(256, 512, kernel_size=(3, 3), padding=(1, 1), node=self.node, n_preact=self.n_preact),
nn.AvgPool2d(2),
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(512 * 3 * 3, self.num_classes),
)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.feature(inputs)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
return x
else:
outputs = []
for t in range(self.step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
@register_model
class VGG_SNN(BaseModule):
def __init__(self,
num_classes=10,
step=8,
node_type=LIFNode,
encode_type='direct',
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.n_preact = kwargs['n_preact'] if 'n_preact' in kwargs else False
self.num_classes = num_classes
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.dataset = kwargs['dataset']
if not is_dvs_data(self.dataset):
raise NotImplementedError('VGG-SNN model is only for DVS data, but current datasets is {}'.format(self.dataset))
self.feature = nn.Sequential(
BaseConvModule(2, 64, kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(64, 128, kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.AvgPool2d(2),
BaseConvModule(128, 256, kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(256, 256, kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.AvgPool2d(2),
BaseConvModule(256, 512, kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(512, 512, kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.AvgPool2d(2),
BaseConvModule(512, 512, kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(512, 512, kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.AvgPool2d(2),
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(512 * 3 * 3, self.num_classes),
)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.feature(inputs)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
return x
else:
outputs = []
for t in range(self.step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
================================================
FILE: braincog/utils.py
================================================
import os
import random
import math
import csv
import numpy as np
import torch
from torch import nn
from PIL import Image
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
def setup_seed(seed):
"""
为CPU,GPU,所有GPU,numpy,python设置随机数种子,并禁止hash随机化
:param seed: seed value
:return:
"""
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
os.environ['PYTHONHASHSEED'] = str(seed)
def random_gradient(model: nn.Module, sigma: float):
"""
为梯度添加噪声
:param model: 模型
:param sigma: 噪声方差
:return:
"""
for param in model.parameters():
if param.grad is None:
continue
noise = torch.randn_like(param) * sigma
param.grad = param.grad + noise
class AverageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.avg = 0
self.sum = 0
self.cnt = 0
def update(self, val, n=1):
self.sum += val * n
self.cnt += n
self.avg = self.sum / self.cnt
class TensorGather(object):
def __init__(self):
self.reset()
def reset(self):
self.gather=None
def update(self, val):
if self.gather is not None:self.gather=torch.cat([self.gather,val],dim=0)
else:self.gather=val
def accuracy(output, target, topk=(1,)):
"""Compute the top1 and top5 accuracy
"""
maxk = max(topk)
batch_size = target.size(0)
# Return the k largest elements of the given input tensor
# along a given dimension -> N * k
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0)
res.append(correct_k.mul_(100.0 / batch_size))
return res
def mse(x, y):
out = (x - y).pow(2).sum(-1, keepdim=True).mean()
return out
def rand_ortho(shape, irange):
A = - irange + 2 * irange * np.random.rand(*shape)
U, s, V = np.linalg.svd(A, full_matrices=True)
return np.dot(U, np.dot(np.eye(U.shape[1], V.shape[0]), V))
def adjust_surrogate_coeff(epoch, tot_epochs):
T_min, T_max = 1e-3, 1e1
Kmin, Kmax = math.log(T_min) / math.log(10), math.log(T_max) / math.log(10)
t = torch.tensor([math.pow(10, Kmin + (Kmax - Kmin) / tot_epochs * epoch)]).float().cuda()
k = torch.tensor([1]).float().cuda()
if k < 1:
k = 1 / t
return t, k
def save_feature_map(x, dir=''):
for idx, layer in enumerate(x):
layer = layer.cpu()
for batch in range(layer.shape[0]):
for channel in range(layer.shape[1]):
fname = '{}_{}_{}_{}.jpg'.format(
idx, batch, channel, layer.shape[-1])
fp = layer[batch, channel]
plt.tight_layout()
plt.axis('off')
plt.imshow(fp, cmap='inferno')
plt.savefig(os.path.join(dir, fname),
bbox_inches='tight', pad_inches=0)
def save_spike_info(fname, epoch, batch_idx, step, avg, var, spike, avg_per_step):
"""
对spike-info格式进行调整, 便于保存
:param fname: 输出文件名
:param epoch: epoch
:param batch_idx: batch index
:param step: 仿真步长
:param avg: 平均脉冲发放率
:param var: 脉冲发放率的方差
:param spike:
:param avg_per_step:
:return:
"""
if not os.path.exists(fname):
f = open(fname, mode='w', encoding='utf8', newline='')
writer = csv.writer(f)
head = ['epoch', 'batch', 'layer', 'avg', 'var']
head.extend(['st_{}'.format(i) for i in range(step + 1)]) # spike times
head.extend(['as_{}'.format(i) for i in range(step)]) # avg spike per time
writer.writerow(head)
else:
f = open(fname, mode='a', encoding='utf8', newline='')
writer = csv.writer(f)
for layer in range(len(avg)):
lst = [epoch, batch_idx, layer, avg[layer], var[layer]]
lst.extend(spike[layer])
lst.extend(avg_per_step[layer])
lst = [str(x) for x in lst]
writer.writerow(lst)
def calc_aurc(confidences, labels):
predictions = torch.argmax(confidences, dim=1)
max_confs = torch.max(confidences, dim=1)[0]
n = len(labels)
indices = torch.argsort(max_confs)
labels, predictions, confidences = labels[indices].flip(dims=[0]), predictions[indices].flip(dims=[0]), confidences[indices].flip(dims=[0])
risk_cov = torch.divide(torch.cumsum(labels != predictions,dim=0).float(), torch.arange(1, n+1).cuda())
nrisk = torch.sum(labels != predictions)
aurc = torch.mean(risk_cov)
opt_aurc = (1./n) * torch.sum(torch.divide(torch.arange(1, nrisk + 1).cuda().float(), n - nrisk + torch.arange(1, nrisk + 1).cuda()))
eaurc = aurc - opt_aurc
return aurc, eaurc
================================================
FILE: docs/Makefile
================================================
# Minimal makefile for Sphinx documentation
#
# You can set these variables from the command line, and also
# from the environment for the first two.
SPHINXOPTS ?=
SPHINXBUILD ?= sphinx-build
SOURCEDIR = source
BUILDDIR = build
# Put it first so that "make" without argument is like "make help".
help:
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
.PHONY: help Makefile
# Catch-all target: route all unknown targets to Sphinx using the new
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
%: Makefile
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
================================================
FILE: docs/make.bat
================================================
@ECHO OFF
pushd %~dp0
REM Command file for Sphinx documentation
if "%SPHINXBUILD%" == "" (
set SPHINXBUILD=sphinx-build
)
set SOURCEDIR=source
set BUILDDIR=build
%SPHINXBUILD% >NUL 2>NUL
if errorlevel 9009 (
echo.
echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
echo.installed, then set the SPHINXBUILD environment variable to point
echo.to the full path of the 'sphinx-build' executable. Alternatively you
echo.may add the Sphinx directory to PATH.
echo.
echo.If you don't have Sphinx installed, grab it from
echo.https://www.sphinx-doc.org/
exit /b 1
)
if "%1" == "" goto help
%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
goto end
:help
%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
:end
popd
================================================
FILE: docs/source/conf.py
================================================
# Configuration file for the Sphinx documentation builder.
#
# This file only contains a selection of the most common options. For a full
# list see the documentation:
# https://www.sphinx-doc.org/en/master/usage/configuration.html
# -- Path setup --------------------------------------------------------------
# If extensions (or modules to document with autodoc) are in another directory,
# add these directories to sys.path here. If the directory is relative to the
# documentation root, use os.path.abspath to make it absolute, like shown here.
#
import os
import sys
import warnings
warnings.filterwarnings("ignore")
sys.path.insert(0, os.path.abspath('../../braincog'))
# -- Project information -----------------------------------------------------
project = 'braincog'
copyright = '2022, Brain-Inspired-Cognitive-Intelligence-Engine(BrainCog)'
author = 'Brain-Inspired-Cognitive-Intelligence-Engine'
# The full version, including alpha/beta/rc tags
release = '0.2.7.11'
# -- General configuration ---------------------------------------------------
# Add any Sphinx extension module names here, as strings. They can be
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
# ones.
extensions = [
'sphinx.ext.autodoc',
'sphinx.ext.napoleon',
'sphinx.ext.doctest',
'sphinx.ext.intersphinx',
'sphinx.ext.todo',
'sphinx.ext.coverage',
'sphinx.ext.mathjax',
'recommonmark',
# 'sphinx_markdown_tables',
]
# Add any paths that contain templates here, relative to this directory.
templates_path = ['_templates']
# The language for content autogenerated by Sphinx. Refer to documentation
# for a list of supported languages.
#
# This is also used if you do content translation via gettext catalogs.
# Usually you set "language" from the command line for these cases.
language = 'zh_CN'
# List of patterns, relative to source directory, that match files and
# directories to ignore when looking for source files.
# This pattern also affects html_static_path and html_extra_path.
exclude_patterns = []
# -- Options for HTML output -------------------------------------------------
# The theme to use for HTML and HTML Help pages. See the documentation for
# a list of builtin themes.
#
html_theme = 'sphinx_rtd_theme'
# Add any paths that contain custom static files (such as style sheets) here,
# relative to this directory. They are copied after the builtin static files,
# so a file named "default.css" will overwrite the builtin "default.css".
html_static_path = ['_static']
================================================
FILE: docs/source/examples/Brain_Cognitive_Function_Simulation/drosophila.md
================================================
# Drosophila-inspired decision-making SNN
## Run
"drosophila.py" includes the training phase and testing phase.
```shell
python drosophila.py
```
* Training Phase
green-upright T is safe and blue-inverted T is dangerous
* Testing Phase
For linear pathway and nonlinear pathway, choose between blue-upright T and green-inverted T, and count the PI values under different color intensity
## Results
The following picture shows the linear (a) and nonlinear (b) pathways, the training and testing phases (c), and the PI values on different color intensities (d).

================================================
FILE: docs/source/examples/Brain_Cognitive_Function_Simulation/index.rst
================================================
Brain_Cognitive_Function_Simulation
======================================
.. toctree::
:maxdepth: 2
drosophila
================================================
FILE: docs/source/examples/Decision_Making/BDM_SNN.md
================================================
# Brain-inspired Decision-Making Spiking Neural Network
## Run
"BDM-SNN.py" includes the multi-brain regions coordinated decision-making spiking neural network with LIF neurons.
"BDM-SNN-hh.py" includes the BDM-SNN with simplified HH neurons.
"BDM-SNN-UAV.py" includes the BDM-SNN applied to the UAV (DJI Tello talent), users need to define the reinforcement learning task.
```shell
python BDM-SNN.py
python BDM-SNN-hh.py
python BDM-SNN-UAV.py
```
## Results
"BDM-SNN.py" and "BDM-SNN-hh.py" have been verified on Flappy Bird game. BDM-SNN could stably pass the pipeline on the first try.

================================================
FILE: docs/source/examples/Decision_Making/RL.md
================================================
# PL-SDQN
This repository contains code from our paper [**Solving the Spike Feature Information Vanishing Problem in Spiking Deep Q Network with Potential Based Normalization**]. If you use our code or refer to this project, please cite this paper.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
* gym
* atari-py
* opencv-python
* tianshou
## Train
```python
python ./sdqn/main.py
```
================================================
FILE: docs/source/examples/Decision_Making/index.rst
================================================
Decision Making
======================================
.. toctree::
:maxdepth: 2
RL
BDM_SNN
================================================
FILE: docs/source/examples/Knowledge_Representation_and_Reasoning/CKRGSNN.md
================================================
# Commonsense Knowledge Representation SNN
(https://arxiv.org/abs/2207.05561)
This repository contains code from our paper [**Brain-inspired Graph Spiking Neural Networks for Commonsense Knowledge Representation and Reasoning**] preprint in: https://arxiv.org/abs/2207.05561 . If you use our code or refer to this project, please cite this paper.
## Requirments
* python=3.8
* numpy
* scipy
* turicreate
* pytorch >= 1.7.0
* torchvision
## Dataset
ConceptNet: https://github.com/commonsense/conceptnet5
## Run
```shell
python main.py
```
This module selects core knowledge in ConceptNet to form the sub_Concept.csv file as the input of the model. The input current, spike trains during the learning process and the network weight distribution after the learning are shown in the Results folder.
================================================
FILE: docs/source/examples/Knowledge_Representation_and_Reasoning/CRSNN.md
================================================
# Causal Reasoning SNN
(https://10.1109/IJCNN52387.2021.9534102)
This repository contains code from our paper [**A Brain-Inspired Causal Reasoning Model Based on Spiking Neural Networks
**] published in 2021 International Joint Conference on Neural Networks (IJCNN). https://ieeexplore.ieee.org/abstract/document/9534102. If you use our code or refer to this project, please cite this paper.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
## Run
```shell
python main.py
```
This module builds an example of a brain-like causal inference spiking neural network model. The input causal graph is shown in figure causal_graph.png. The input current, spike trains during the learning process and the network weight distribution after the learning are shown in the Results folder.
================================================
FILE: docs/source/examples/Knowledge_Representation_and_Reasoning/SPSNN.md
================================================
# Sequence Production SNN
[]
This repository contains code from our paper [**Brain Inspired Sequences Production by Spiking Neural Networks With Reward-Modulated STDP**] published in Frontiers in Computational Neuroscience. https://www.frontiersin.org/articles/10.3389/fncom.2021.612041/full. If you use our code or refer to this project, please cite this paper.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
## Run
```shell
python main.py file
```
This module builds a sequence Production spiking neural network model, realizing the memory and reconstruction functions for arbitrary symbol sequences. The input causal graph is shown in figure causal_graph.png. The input current, spike trains during the learning process and the network weight distribution after the learning are shown in the Results folder.
================================================
FILE: docs/source/examples/Knowledge_Representation_and_Reasoning/index.rst
================================================
Knowledge Representation and Reasoning
=========================================
.. toctree::
:maxdepth: 2
musicMemory
SPSNN
CRSNN
CKRGSNN
================================================
FILE: docs/source/examples/Knowledge_Representation_and_Reasoning/musicMemory.md
================================================
# Music Memory
数据集:http://www.piano-midi.de/
自行下载数据集,数据使用方法见task下的示例。
================================================
FILE: docs/source/examples/Multi-scale_Brain_Structure_Simulation/Corticothalamic_minicolumn.md
================================================
# Corticothalamic minicolumn
## Description
The anatomical data is saved in the "tool" package. The **main.py** create the network of minicolumn deppending on the anatomical data.
A file named **"fire.csv"** will be generated to record the firing result of neurons in each time step.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
```shell
python main.py
```
================================================
FILE: docs/source/examples/Multi-scale_Brain_Structure_Simulation/HumanBrain.md
================================================
# Human Brain Simulation
## Description
Human Brain Simulation is a large scale brain modeling framework depending on braincog framework.
## Requirements:
* numpy >= 1.21.2
* scipy >= 1.8.0
* h5py >= 3.6.0
* torch >= 1.10
* torchvision >= 0.12.0
* torchaudio >= 0.11.0
* timm >= 0.5.4
* matplotlib >= 3.5.1
* einops >= 0.4.1
* thop >= 0.0.31
* pyyaml >= 6.0
* loris >= 0.5.3
* pandas >= 1.4.2
* tonic (special)
* pandas >= 1.4.2
## Example:
```shell
cd ~/examples/Multi-scale Brain Structure Simulation/HumanBrain/
python brainSimHum.py
```
## Parameters:
To simulate the models (both human and macaque brain), the parameters of the neuron number in each region and the connectome power between regions can be set flexibly in the main function (nsz and asz) of the .py files.
================================================
FILE: docs/source/examples/Multi-scale_Brain_Structure_Simulation/Human_PFC.md
================================================
# Human PFC
## Input:
* 程序输入六层皮质柱的电生理数据,数据文件名中的数字表示神经元数量。程序默认有背景电流输入。其中data+数字命名的是随机输入刺激的文件,输入图片刺激的文件分别有人类参数的和小鼠参数的。分别都支持四种形状的图片文件,圆形、正方形、三角形和星形。
链接:https://drive.google.com/drive/folders/1AVc2aNTxkcsGAPlq1SuWtatGzyQRPCmp?usp=sharing
## output
* 程序生成的各个神经元放电时间点记录的数据文件
## application:
* 程序中可以修改每次PFC模型放电环境的情况
================================================
FILE: docs/source/examples/Multi-scale_Brain_Structure_Simulation/MacaqueBrain.md
================================================
# Macaque Brain Simulation
## Description
Macaque Brain Simulation is a large scale brain modeling framework depending on braincog framework.
## Requirements:
* numpy >= 1.21.2
* scipy >= 1.8.0
* h5py >= 3.6.0
* torch >= 1.10
* torchvision >= 0.12.0
* torchaudio >= 0.11.0
* timm >= 0.5.4
* matplotlib >= 3.5.1
* einops >= 0.4.1
* thop >= 0.0.31
* pyyaml >= 6.0
* loris >= 0.5.3
* pandas >= 1.4.2
* tonic (special)
* pandas >= 1.4.2
## Example:
```shell
cd ~/examples/Multi-scale Brain Structure Simulation/MacaqueBrain/
python brainSimMaq.py
```
## Parameters:
To simulate the models (both human and macaque brain), the parameters of the neuron number in each region and the connectome power between regions can be set flexibly in the main function (nsz and asz) of the .py files.
================================================
FILE: docs/source/examples/Multi-scale_Brain_Structure_Simulation/index.rst
================================================
Multi-scale Brain Structure Simulation
=========================================
.. toctree::
:maxdepth: 2
MacaqueBrain
HumanBrain
mouse_brain
Human_PFC
Corticothalamic_minicolumn
================================================
FILE: docs/source/examples/Multi-scale_Brain_Structure_Simulation/mouse_brain.md
================================================
# Mouse Brain
## Input:
* 程序输入213个脑区之间的连接权重的表格。放在谷歌网盘上面,名称是'W_213.xlsx'。
链接:[https://drive.google.com/drive/folders/1snPbpiVBpVuRgRYcl4AG4v49NgKKwBtA?usp=sharing](https://drive.google.com/drive/folders/1snPbpiVBpVuRgRYcl4AG4v49NgKKwBtA?usp=sharing)
## output
* 程序生成的各个神经元放电时间点记录的数据mat文件,数据点的数量大需要用画图软件显示结果。
## application:
* 程序中可以修改神经元的数量模拟时间的情况
================================================
FILE: docs/source/examples/Perception_and_Learning/Conversion.md
================================================
# Conversion Method
Training deep spiking neural network with ann-snn conversion
replace ReLU and MaxPooling in pytorch model to make origin ANN to be converted SNN to finish complex tasks
## Results
```shell
python CIFAR10_VGG16.py
python converted_CIFAR10.py
```
You should first run the `CIFAR10_VGG16.py` to get a well-trained ANN.
Then `converted_CIFAR10.py` can be used to run the snn inference process.
================================================
FILE: docs/source/examples/Perception_and_Learning/MultisensoryIntegration.md
================================================
# Multisensory Integration DEMO
In `MultisensoryIntegrationDEMO_AM.py` and `MultisensoryIntegrationDEMO_AM.py`, we implement the SNNs based multisensory integration framework. To load the dataset, preprocess it and get the weights with the function `get_concept_datase_dic_and_initial_weights_lst()`. We use `IMNet` or `AMNet` to describe the structure of the IM/AM model. For presynaptic neuron, we use the function `convert_vec_into_spike_trains()` to generate the spike trains.
While for postsynaptic neuron, we use the function `reducing_tol_binarycode()` to get the multisensory integrated output for each concept. And *tol* is the only parameter.
In `measure_and_visualization.py`, we will measure and visualize the results.
## Multisensory Dataset
When implement the model in braincog, we use the famous multisensory dataset--BBSR.
Some examples are as follows:
| Concept | Visual | Somatic | Audiation | Taste | Smell |
| --------- | ----------- | --------- | ----------- | -------- | -------- |
| advantage | 0.213333333 | 0.032 | 0 | 0 | 0 |
| arm | 2.5111112 | 2.2733334 | 0.133333286 | 0.233333 | 0.4 |
| ball | 1.9580246 | 2.3111112 | 0.523809429 | 0.185185 | 0.111111 |
| baseball | 2.2714286 | 2.6071428 | 0.352040714 | 0.071429 | 0.392857 |
| bee | 2.795698933 | 2.4129034 | 2.096774286 | 0.290323 | 0.419355 |
| beer | 1.4866666 | 2.2533334 | 0.190476286 | 5.8 | 4.6 |
| bird | 2.7632184 | 2.027586 | 3.064039286 | 1.068966 | 0.517241 |
| car | 2.521839133 | 2.9517244 | 2.216748857 | 0 | 2.206897 |
| foot | 2.664444533 | 2.58 | 0.380952429 | 0.433333 | 3 |
| honey | 1.757142867 | 2.3214286 | 0.015306143 | 5.642857 | 4.535714 |
## How to Run
To get the multisensory integrated vectors:
```
cd examples/MultisensoryIntegration/code
python MultisensoryIntegrationDEMO_AM.py
python MultisensoryIntegrationDEMO_IM.py
```
To measure and analysis the vectors:
```
cd examples/MultisensoryIntegration/code
python measure_and_visualization.py
```
================================================
FILE: docs/source/examples/Perception_and_Learning/QSNN.md
================================================
# Quantum superposition inspired spiking neural network
This repository contains code from our paper [**Quantum superposition inspired spiking neural network**] published in iScience. https://doi.org/10.1016/j.isci.2021.102880. If you use our code or refer to this project, please cite this paper.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
## Data preparation
First modify the ```DATA_DIR='path/to/datasets``` in ```examples/QSNN/main.py``` to the root directory of your MNIST datasets.
## Train
```shell
python ./main.py
```
================================================
FILE: docs/source/examples/Perception_and_Learning/UnsupervisedSTDP.md
================================================
# Unsupervised STDP
This is an example of training Unsupervised STDP-based spiking neural network. We used a STB-STDP algrithom to train SNN, and mutiply adaptive mechanisms.
## How to run
python codef.py
## Result
We train the model on Mnist and FashionMNIST, and the best accuracy for MNIST is 97.9%, for FashionMNIST is 87.0%.
================================================
FILE: docs/source/examples/Perception_and_Learning/img_cls/bp.md
================================================
# Script for training high-performance SNNs based on back propagation
This is an example of training high-performance SNNs using the braincog.
It is able to train high performance SNNs on CIFAR10, DVS-CIFAR10, ImageNet and other datasets, and reach the advanced level.
## Install braincog
```shell
git clone https://github.com/xxx/Brain-Cog.git
cd braincog
python setup install --user
```
## Examples of training
```shell
cd examples/img_cls/bp
python main.py --model dvs_convnet --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGate --device 0
```
## Benchmark
We provide a benchmark of SNNs trained with braincog and the corresponding scripts.
This provides an open, fair platform for comparison of subsequent SNNs on classification tasks.
**Note**: The results may vary due to random seeding and software version issues.
### CIFAR10
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:-------:|:----------:|:------:|:-----------:|:----------:|:------------:|:-------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | CIFAR10 | IF+Atan | - | convnet | 128 | 95.54 | ```python main.py --model cifar_convnet --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | LIF+Atan | - | convnet | 128 | 91.92 | ```python main.py --model cifar_convnet --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | PLIF+Atan | - | convert | 128 | 93.32 | ```python main.py --model cifar_convnet --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | IF+Atan | - | resnet18 | 128 | 89.76/89.80 | ```python main.py --model resnet18 --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | LIF+Atan | - | resnet18 | 128 | 89.93/89.88 | ```python main.py --model resnet18 --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | PLIF+Atan | - | resnet18 | 128 | 92.64/ 90.65 | ```python main.py --model resnet18 --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | IF+QGate | - | dvs_convnet | 128 | 95.73 | ```python main.py --model cifar_convnet --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR10 | LIF+QGate | - | dvs_convnet | 128 | 96.04 | ```python main.py --model cifar_convnet --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR10 | PLIF+QGate | - | dvs_convnet | 128 | 96.04/95.84 | ```python main.py --model cifar_convnet --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR10 | IF+QGate | - | resnet18 | 128 | 89.19 | ```python main.py --model resnet18 --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR10 | LIF+QGate | - | resnet18 | 128 | 90.95/90.68 | ```python main.py --model resnet18 --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR10 | PLIF+QGate | - | resnet18 | 128 | 90.97/91.02 | ```python main.py --model resnet18 --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
### CIFAR100
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:--------:|:----------:|:------:|:-----------:|:----------:|:--------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | CIFAR100 | IF+Atan | - | dvs_convnet | 128 | 76.52 | ```python main.py --num-classes 100 --model cifar_convnet --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | LIF+Atan | - | dvs_convnet | 128 | 71.89 | ```python main.py --num-classes 100 --model cifar_convnet --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | PLIF+Atan | - | dvs_convnet | 128 | 72.82 | ```python main.py --num-classes 100 --model cifar_convnet --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | IF+Atan | - | resnet18 | 128 | 62.47 | ```python main.py --num-classes 100 --model resnet18 --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | LIF+Atan | - | resnet18 | 128 | 62.63 | ```python main.py --num-classes 100 --model resnet18 --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | PLIF+Atan | - | resnet18 | 128 | 62.71 | ```python main.py --num-classes 100 --model resnet18 --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | IF+QGate | - | dvs_convnet | 128 | 76.44 | ```python main.py --num-classes 100 --model cifar_convnet --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR100 | LIF+QGate | - | dvs_convnet | 128 | 77.73 | ```python main.py --num-classes 100 --model cifar_convnet --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR100 | PLIF+QGate | - | dvs_convnet | 128 | 77.25 | ```python main.py --num-classes 100 --model cifar_convnet --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR100 | IF+QGate | - | resnet18 | 128 | 60.01 | ```python main.py --num-classes 100 --model resnet18 --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR100 | LIF+QGate | - | resnet18 | 128 | 61.33 | ```python main.py --num-classes 100 --model resnet18 --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | CIFAR100 | PLIF+QGate | - | resnet18 | 128 | 62.32 | ```python main.py --num-classes 100 --model resnet18 --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGrad --device 0``` |
### DVS-CIFAR10
| ID | Dataset | Node-type | Config | Model | Batch Size | FLOPS | Accuracy | Script |
|:----|:-----------:|:----------:|:------:|:-----------:|:----------:|:-----:|:-----------:|:-----------------------------------------------------------------------------------------------------------------------------------------|
| 1 | DVS-CIFAR10 | IF+Atan | - | dvs_convnet | 128 | 7503 | 65.90 | ```python main.py --model dvs_convnet --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+Atan | - | dvs_convnet | 128 | 7503 | 82.10 | ```python main.py --model dvs_convnet --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+Atan | - | dvs_convnet | 128 | 7503 | 81.90 | ```python main.py --model dvs_convnet --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | IF+Atan | - | resnet18 | 128 | 3149 | 69.10 | ```python main.py --model resnet18 --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+Atan | - | resnet18 | 128 | 3149 | 78.50 | ```python main.py --model resnet18 --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+Atan | - | resnet18 | 128 | 3149 | 77.70 | ```python main.py --model resnet18 --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | IF+QGate | - | dvs_convnet | 128 | 7503 | 68.30 | ```python main.py --model dvs_convnet --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+QGate | - | dvs_convnet | 128 | 7503 | 82.60/82.90 | ```python main.py --model dvs_convnet --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+QGate | - | dvs_convnet | 128 | 7503 | 83.20 | ```python main.py --model dvs_convnet --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-CIFAR10 | IF+QGate | - | resnet18 | 128 | 3149 | 65.70/66.80 | ```python main.py --model resnet18 --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+QGate | - | resnet18 | 128 | 3149 | 79.00/79.40 | ```python main.py --model resnet18 --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+QGate | - | resnet18 | 128 | 3149 | 78.10/78.20 | ```python main.py --model resnet18 --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
### DVS-Gesture
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:-------:|:----------:|:------:|:-----------:|:----------:|:-----------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | DVS-G | IF+Atan | - | dvs_convnet | 128 | 64.77 | ```python main.py --num-classes 11 --model dvs_convnet --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | LIF+Atan | - | dvs_convnet | 128 | 91.28 | ```python main.py --num-classes 11 --model dvs_convnet --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | PLIF+Atan | - | dvs_convnet | 128 | 91.67 | ```python main.py --num-classes 11 --model dvs_convnet --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | IF+Atan | - | resnet18 | 128 | 63.25 | ```python main.py --num-classes 11 --model resnet18 --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | LIF+Atan | - | resnet18 | 128 | 91.29 | ```python main.py --num-classes 11 --model resnet18 --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | PLIF+Atan | - | resnet18 | 128 | 90.15 | ```python main.py --num-classes 11 --model resnet18 --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | IF+QGate | - | dvs_convnet | 128 | 48.48 | ```python main.py --num-classes 11 --model dvs_convnet --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-G | LIF+QGate | - | dvs_convnet | 128 | 92.05/92.42 | ```python main.py --num-classes 11 --model dvs_convnet --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-G | PLIF+QGate | - | dvs_convnet | 128 | 91.28 | ```python main.py --num-classes 11 --model dvs_convnet --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-G | IF+QGate | - | resnet18 | 128 | 57.95 | ```python main.py --num-classes 11 --model resnet18 --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-G | LIF+QGate | - | resnet18 | 128 | 90.91 | ```python main.py --num-classes 11 --model resnet18 --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | DVS-G | PLIF+QGate | - | resnet18 | 128 | 92.42 | ```python main.py --num-classes 11 --model resnet18 --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
### NCALTECH101
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:-----------:|:----------:|:------:|:-----------:|:----------:|:-----------:|:----------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | NCALTECH101 | IF+QGate | - | dvs_convnet | 128 | 23.09/51.15 | ```python main.py --num-classes 100 --model dvs_convnet --node-type IFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | NCALTECH101 | LIF+QGate | - | dvs_convnet | 128 | 72.78/75.09 | ```python main.py --num-classes 100 --model dvs_convnet --node-type LIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | NCALTECH101 | PLIF+QGate | - | dvs_convnet | 128 | 74.61/76.79 | ```python main.py --num-classes 100 --model dvs_convnet --node-type PLIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | NCALTECH101 | IF+QGate | -/mix | resnet18 | 128 | 61.24/60.87 | ```python main.py --num-classes 100 --model resnet18 --node-type IFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | NCALTECH101 | LIF+QGate | -/mix | resnet18 | 128 | 66.22/70.84 | ```python main.py --num-classes 100 --model resnet18 --node-type LIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
| 1 | NCALTECH101 | PLIF+QGate | -/mix | resnet18 | 128 | 69.62/69.87 | ```python main.py --num-classes 100 --model resnet18 --node-type PLIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGrad --device 0``` |
Note:
1. resnet18 is used here by adding a maximum pooling after the initial convolution layer.
However, in the final version of braincog, we remove this pooling layer.
2. mix refers to the use of EventMix as a data augmentation method.
3. We will continue to add other results.
### Citation
If you find this package helpful, please consider citing it:
```BibTex
@software{name,
author = {xxx},
title = {braincog: xxx},
month = jul,
year = 2022,
note = {{Documentation available under
https://xxx.readthedocs.io}},
publisher = {Zenodo},
version = {xxx},
doi = {xxx},
url = {xxx}
}
```
================================================
FILE: docs/source/examples/Perception_and_Learning/img_cls/glsnn.md
================================================
# SNN with global feedback connections
Training deep spiking neural network with the global
feedback connections and the local optimization learning rules. And is a little different from our original paper.
## Results
```shell
python cls_glsnn.py
```
We train the model for 100 epochs, and the best accuracy for MNIST is 98.23\%, for FashionMNIST is 89.68\%.

================================================
FILE: docs/source/examples/Perception_and_Learning/img_cls/index.rst
================================================
Examples for Image Classification
=================================
.. toctree::
:maxdepth: 2
bp
glsnn
================================================
FILE: docs/source/examples/Perception_and_Learning/index.rst
================================================
Perception and Learning
=================================
.. toctree::
:maxdepth: 2
img_cls/index
Conversion
UnsupervisedSTDP
QSNN
MultisensoryIntegration
================================================
FILE: docs/source/examples/Social_Cognition/Mirror_Test.md
================================================
# Mirror Test
The mirror_test.py implements the core code of the Multi-Robots Mirror Self-Recognition Test in "Toward Robot Self-Consciousness (II): Brain-Inspired Robot Bodily Self Model for Self-Recognition".
The experiment is: three robots with identical appearance move their arms randomly in front of the mirror at the same time.
In the training stage, according to the spiking time difference of neurons in IPLM and IPLV, the robot learns the correlations between self-generated actions and visual feedbacks in motion by learning with spike timing dependent plasticity (STDP) mechanism.
In the test stage, the robot can predicts the visual feedback generated by its arm movement according to the training results. With the InsulaNet, the robot can identify which mirror image belongs to it.
In the result, Motion Detection shows the results of visual detection, and Motion Prediction shows the visual feedback generated by itself. The red line in the figure indicates that the robot determines that the corresponding mirror belongs to itself.
Differences from the original article:
Since there is no motion error under the simulation conditions, the theta_threshold is set to zero.
### Citation
If you find this package helpful, please consider citing it:
```BibTex
@article{zeng2018toward,
title={Toward robot self-consciousness (ii): brain-inspired robot bodily self model for self-recognition},
author={Zeng, Yi and Zhao, Yuxuan and Bai, Jun and Xu, Bo},
journal={Cognitive Computation},
volume={10},
number={2},
pages={307--320},
year={2018},
publisher={Springer}
}
```
================================================
FILE: docs/source/examples/Social_Cognition/ToM.md
================================================
# ToM
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
* pygame
## Run
### Train
* the file to be run: main_both.py
* args:
* the path to save net_NPC: --save_net_N
* the path to save net_a: --save_net_a
* time steps: --T
```bash
python main_both.py --save_net_N=net_NPC.pth --save_net_a=net_agent.pth --episodes=45 --trajectories=30 --T=50 --mode=train --task=both
```
### Test
```bash
python main_ToM.py --save_net_N=net_NPC.pth --save_net_a=net_agent.pth --episodes=45 --trajectories=30 --T=50 --mode=train --task=both
```
================================================
FILE: docs/source/examples/Social_Cognition/index.rst
================================================
Social Cognition
======================================
.. toctree::
:maxdepth: 2
ToM
Mirror_Test
================================================
FILE: docs/source/examples/index.rst
================================================
Examples
=================================
.. toctree::
:maxdepth: 2
Perception_and_Learning/index
Brain_Cognitive_Function_Simulation/index
Decision_Making/index
Knowledge_Representation_and_Reasoning/index
Social_Cognition/index
Multi-scale_Brain_Structure_Simulation/index
================================================
FILE: docs/source/index.rst
================================================
.. braincog documentation master file, created by
sphinx-quickstart on Sun Apr 10 21:02:06 2022.
You can adapt this file completely to your liking, but it should at least
contain the root `toctree` directive.
Welcome to braincog's documentation!
====================================
.. toctree::
:maxdepth: 2
tutorial/index
braincog
examples/index
Indices and tables
==================
* :ref:`genindex`
* :ref:`modindex`
* :ref:`search`
================================================
FILE: docs/source/modules.rst
================================================
braincog
========
.. toctree::
:maxdepth: 4
braincog
================================================
FILE: docs/source/setup.rst
================================================
setup module
============
.. automodule:: setup
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs.md
================================================
# Sphinx 文档教程
## 安装
131 braincog 环境已经装好了
```shell
pip install sphinx sphinx-rtd-theme recommonmark
```
## 配置
已经配置好了, 直接用就行了
```shell
sphinx-quickstart
```
## 编译
### braincog 之中的, 编译在Brain Docs之中
1. 重新从 repo 中抓取 ```rst``` 文本
```shell
cd braincog/docs
rm -rf ./source/braincog*rst
sphinx-apidoc -o ./source/ ../braincog -f
```
2. 编译 html
```shell
make clean
make html
```
### Examples 的编译
1. 在 ```braincog/docs/source/index.rst``` 中, ```img_cls/Tutorial``` 后面一行添加 ``xxx/Tutorial``.
2. 然后在 ``Brain/docs/source`` 下面添加 ``xxx.md`` 文件, 要和上面的 ``xxx`` 同名.
3. 用 [Markdown](https://markdown.com.cn/basic-syntax/) 语法, 编写教程, 怎么用, 效果是啥.
4. 编译html
```shell
make clean
make html
```
## 查看
编译好的文件可以在 ```braincog/docs/build/html``` 中查看.
## 上传
在130服务器上面:
```shell
sudo cp braincog/docs/build/html/* /var/www/html
```
就可以更新文档了, 并在 [172.18.116.130](http://172.18.116.130/index.html) 中看到.
================================================
FILE: documents/Data_engine.md
================================================
# BrainCog Data Engine
In addition to the static datasets, BrainCog supports the commonly used neuromorphic
datasets, such as DVSGesture, DVSCIFAR10, NCALTECH101, ES-ImageNet.
Also, the neuromorphic dataset N-Omniglot for few-shot learning is also integrated into
BrainCog.
**[DVSGesture](https://openaccess.thecvf.com/content_cvpr_2017/papers/Amir_A_Low_Power_CVPR_2017_paper.pdf)**
This dataset contains 11 hand gestures from 29 subjects under 3 illumination conditions recorded using a DVS128.
**[DVSCIFAR10](https://www.frontiersin.org/articles/10.3389/fnins.2017.00309/full)**
This dataset converts 10,000 frame-based images in the CIFAR10 dataset into 10,000 event streams using a dynamic vision sensor.
**[NCALTECH101](https://www.frontiersin.org/articles/10.3389/fnins.2015.00437/full)**
The NCaltech101 dataset is captured by mounting the ATIS sensor on a motorized pan-tilt unit and having the sensor move while it views Caltech101 examples on an LCD monitor.
The "Faces" class has been removed from N-Caltech101, leaving 100 object classes plus a background class
**[ES-ImageNet](https://arxiv.org/abs/2110.12211)**
The dataset is converted with Omnidirectional Discrete Gradient (ODG) from 1,300,000 frame-based images in the ImageNet dataset into event-stream samples, which has 1000 categories.
**[N-Omniglot](https://www.nature.com/articles/s41597-022-01851-z)**
This dataset contains 1,623 categories of handwritten characters, with only 20 samples per class.
The dataset is acquired with the DVS acquisition platform to shoot videos (generated from the original Omniglot dataset) played on the monitor, and use the Robotic Process Automation (RPA) software to collect the data automatically.
You can easily use them in the braincog/datasets folder, taking DVSCIFAR10 as an example
```python
loader_train, loader_eval,_,_ = get_dvsc10_data(batch_size=128,step=10)
```
================================================
FILE: documents/Lectures.md
================================================
# Lectures
- [BrainCog Talk] Beginning BrainCog Lecture 32. Structural Modeling and Neural Activity Simulation of Mammalian Corticothalamic Functional Minicolumn on BrainCog [[English Version](https://www.youtube.com/watch?v=xwcu3yHe4FQ&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=30), [Chinese Version](https://www.bilibili.com/video/BV1aN411v7BG/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 31. A Brain-inspired Theory of Mind Spiking Neural Network Improves Multi-agent Cooperation [[English Version](https://www.youtube.com/watch?v=xwcu3yHe4FQ&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=30), [Chinese Version](https://www.bilibili.com/video/BV11m4y1N7Bh/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 30. FPGA-based Spiking Neural Networks Acceleration Using BrainCog [[English Version](https://www.youtube.com/watch?v=xwcu3yHe4FQ&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=30), [Chinese Version](https://www.bilibili.com/video/BV1mF411Q7Rr/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 29. Using BrainCog to Realize Robot's Intention Prediction for Users [[English Version](https://www.youtube.com/watch?v=vlwRpq-HwDo&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=29), [Chinese Version](https://www.bilibili.com/video/BV1oz4y1H7QL/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 28. Reward-modulated brain-inspired spiking neural network to empower group for nature-inspired self-organized obstacle avoidance implemented by Braincog [[English Version](https://www.youtube.com/watch?v=2X2KkG0KXo4&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=28), [Chinese Version](https://www.bilibili.com/video/BV16h411N7tG/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 27. Drosophila-inspired Linear and Nonlinear Decision-Making Spiking Neural Network implemented by Braincog [[English Version](https://www.youtube.com/watch?v=j49q33dMbYk&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=27), [Chinese Version](https://www.bilibili.com/video/BV1Ch4y147i6/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 26. Spiking CapsNet based on BrainCog [[English Version](https://www.youtube.com/watch?v=Gn1PMMFnD6M&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=26), [Chinese Version](https://www.bilibili.com/video/BV1M24y1N7Re/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 25. SNNs with adaptive self-feedback and balanced excitatory–inhibitory neurons based on BrainCog [[English Version](https://www.youtube.com/watch?v=pqeagXtYk8w&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=25), [Chinese Version](https://www.bilibili.com/video/BV18g4y1j7WA/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 24. DVS Augmentation Strategies based on BrainCog [[English Version](https://www.youtube.com/watch?v=aok8B34DNVs&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=24), [Chinese Version](https://www.bilibili.com/video/BV1324y1L7QP/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 23. The Implement of Object Detection and Semantic Segmentation Based on SNNs with Braincog [[English Version](https://www.youtube.com/watch?v=2kh7rNwQkkY&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=23), [Chinese Version](https://www.bilibili.com/video/BV1XT411r7ak/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 22. BrainCog Data Engine: Spatio-temporal Sequence Data N-Omniglot and Its Applications [[English Version](https://www.youtube.com/watch?v=J5qBIX9f8Ns&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=22), [Chinese Version](https://www.bilibili.com/video/BV1uT411a733/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 21. Dynamic structural development for SNNs incorporating constraints, pruning and regeneration based on BrainCog [[English Version](https://www.youtube.com/watch?v=OccvvdyiOgY&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=21), [Chinese Version](https://www.bilibili.com/video/BV1Zv4y1Y72h/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 20. Developmental Plasticity-inspired Adaptive Pruning for SNNs based on BrainCog [[English Version](https://www.youtube.com/watch?v=ckrSW_2vqeE&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=20), [Chinese Version](https://www.bilibili.com/video/BV1iD4y1P7XE/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 19. Multi-brain areas Coordinated Brain-inspired Affective Empathy Spiking Neural Network Based on Braincog [[English Version](https://www.youtube.com/watch?v=dB-hQ-5RJ6U&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=19), [Chinese Version](https://www.bilibili.com/video/BV16Y411q7b2/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 18. Application of the Prefrontal Cortex Column Model in Working Memory Task with BrainCog [[English Version](https://www.youtube.com/watch?v=6xzURpSFkxk&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=18), [Chinese Version](https://www.bilibili.com/video/BV1As4y1t7wF/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 17. A Brain-inspired Theory of Mind Model Based on BrainCog for Reducing Other Agents’ Safety Risks [[English Version](https://www.youtube.com/watch?v=16Csw03bTjY&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=17), [Chinese Version](https://www.bilibili.com/video/BV12A411f74Q/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 16. Brain-inspired Bodily Self-perception Model Based on BrainCog [[English Version](https://www.youtube.com/watch?v=mV_iMsDEQsg&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=16), [Chinese Version](https://www.bilibili.com/video/BV1pK411i7Jk/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 15. SNN-based Music Memory and Generation Based on BrainCog [[English Version](https://www.youtube.com/watch?v=c0Tcs1B5xho&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=15), [Chinese Version](https://www.bilibili.com/video/BV1M3411X7C2/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 14. The Implement of Multisensory Concept Learning Framework Based on SNNs with Braincog [[English Version](https://www.youtube.com/watch?v=c9UfOCGzFPQ&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=14), [Chinese Version](https://www.bilibili.com/video/BV1Ae411P7tY/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 13. Symbolic Representation and Reasoning SNN Based on Braincog [[English Version](https://www.youtube.com/watch?v=1iosjPkOBRo&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=13), [Chinese Version](https://www.bilibili.com/video/BV1DW4y1p7kg/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 12. Unsupervised STDP-based Spiking Neural Networks Based on BrainCog [[English Version](https://www.youtube.com/watch?v=pzPJ1XOEB9U&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=12), [Chinese Version](https://www.bilibili.com/video/BV1MR4y1Z7Be/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 11. Backpropagation with Spatiotemporal Adjustment for Training Deep Spiking Neural Networks through BrainCog [[English Version](https://www.youtube.com/watch?v=Fm85BjQszng&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=11), [Chinese Version](https://www.bilibili.com/video/BV1EK411Z71F/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 10. Multi-brain Areas Coordinated Brain-inspired Decision-Making Spiking Neural Network Based on Braincog [[English Version](https://www.youtube.com/watch?v=uVCcZHzzN3U&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=10), [Chinese Version](https://www.bilibili.com/video/BV1jD4y1x7PU/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 9. Spiking Neural Networks with Global Feedback Connections Based on BrainCog [[English Version](https://www.youtube.com/watch?v=g_qelwoQsD8&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=9), [Chinese Version](https://www.bilibili.com/video/BV1qv4y1D74Y/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 8. Converting Artificial Neural Network to Spiking Neural Network through BrainCog [[English Version](https://www.youtube.com/watch?v=cxiKyQ7F8UE&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=8), [Chinese Version](https://www.bilibili.com/video/BV17e4y147H6/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 7. Implementing Quantum Superposition Inspired Spatio-temporal Spike Encoding through BrainCog [[English Version](https://www.youtube.com/watch?v=5T-2Yyr9a0s&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=7), [Chinese Version](https://www.bilibili.com/video/BV1BG41177Z6/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
- [BrainCog Talk] Beginning BrainCog Lecture 6. Implementing spiking deep Q network through Braincog [[English Version](https://www.youtube.com/watch?v=jCsOBtiN-q0&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=6), [Chinese Version](https://www.bilibili.com/video/BV1XN4y1c7Kn/?spm_id_from=333.337.search-card.all.click&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 5. Advanced BrainCog System Functions [[English Version](https://www.youtube.com/watch?v=VJBORFl6dTQ&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=5), [Chinese Version](https://www.bilibili.com/video/BV1tT411N7c9/?spm_id_from=333.337.search-card.all.click&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 4. Creating Cognitive SNNs for Brain Areas [[English Version](https://www.youtube.com/watch?v=gYxG1D1b4Zo&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=4), [Chinese Version](https://www.bilibili.com/video/BV19d4y1679Y/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 3. Creating SNNs Easily and Quickly [[English Version](https://www.youtube.com/watch?v=k3byUIp4O24&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=3), [Chinese Version](https://www.bilibili.com/video/BV1Be4y1874W/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 2. Computational Modeling of Spiking Neurons [[English Version](https://www.youtube.com/watch?v=5jPsPkyFTY8&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=2), [Chinese Version](https://www.bilibili.com/video/BV16K411f7vQ/?spm_id_from=333.788&vd_source=ffca9a0cf41b21082e79f7f6ad9a5301)]
- [BrainCog Talk] Beginning BrainCog Lecture 1. Installing and Deploying BrainCog platform [[English Version](https://www.youtube.com/watch?v=XkHq-MbKo20&list=PLNXUFsTshMlYTW6oleY5YjVEfnoQSw0N7&index=1), [Chinese Version](https://www.bilibili.com/video/BV1AW4y1b7v1/?spm_id_from=333.788&vd_source=ac84fc93f3c82d1cd96648079077afd3)]
================================================
FILE: documents/Pub_brain_inspired_AI.md
================================================
# Publications Using BrainCog
## Brain Inspired AI
### Perception and Leanring
| Papers | Codes | Publisher |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------- |
| [BackEISNN: A deep spiking neural network with adaptive self-feedback and balanced excitatory–inhibitory neurons](https://www.sciencedirect.com/science/article/pii/S0893608022002520) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/img_cls/bp/main_backei.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/img_cls/bp/main_backei.py) | Neural Networks |
| [Efficient and Accurate Conversion of Spiking Neural Network with Burst Spikes](https://www.ijcai.org/proceedings/2022/345) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py) | IJCAI |
| [Spike Calibration: Fast and Accurate Conversion of Spiking Neural Network for Object Detection and Segmentation](https://arxiv.org/abs/2207.02702) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py) | Arxiv |
| [An unsupervised STDP-based spiking neural network inspired by biologically plausible learning rules and connections](https://www.sciencedirect.com/science/article/pii/S0893608023003301) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/UnsupervisedSTDP](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/UnsupervisedSTDP) | Neural Networks |
| [Multisensory Concept Learning Framework Based on Spiking Neural Networks](https://www.frontiersin.org/articles/10.3389/fnsys.2022.845177/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/MultisensoryIntegration](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/MultisensoryIntegration) | Frontiers in Systems Neuroscience |
| [Backpropagation with biologically plausible spatiotemporal adjustment for training deep spiking neural networks](https://www.sciencedirect.com/science/article/pii/S2666389922001192) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/bp](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/bp) | Patterns |
| [Quantum superposition inspired spiking neural network](https://www.cell.com/iscience/fulltext/S2589-0042(21)00848-8) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/QSNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/QSNN) | iScience |
| [GLSNN: A Multi-Layer Spiking Neural Network Based on Global Feedback Alignment and Local STDP Plasticity](https://www.frontiersin.org/articles/10.3389/fncom.2020.576841/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/glsnn](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/glsnn) | Frontiers in Neuroscience |
| [Spiking CapsNet: A spiking neural network with a biologically plausible routing rule between capsules](https://www.sciencedirect.com/science/article/pii/S002002552200843X) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/spiking_capsnet](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/spiking_capsnet) | Information Sciences |
| [N-Omniglot, a large-scale neuromorphic dataset for spatio-temporal sparse few-shot learning](https://www.nature.com/articles/s41597-022-01851-z) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/NOmniglot](https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/NOmniglot) | Scientific Data |
| [EventMix: An efficient data augmentation strategy for event-based learning](https://www.sciencedirect.com/science/article/pii/S0020025523007557) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/datasets/cut_mix.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/datasets/cut_mix.py) | Information Sciences |
| [Challenging deep learning models with image distortion based on the abutting grating illusion](https://www.sciencedirect.com/science/article/pii/S2666389923000260) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/IllusionPerception/AbuttingGratingIllusion](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/IllusionPerception/AbuttingGratingIllusion) | Patterns |
| [MSAT: Biologically Inspired Multi-Stage Adaptive Threshold for Conversion of Spiking Neural Networks](https://arxiv.org/abs/2303.13080) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/Conversion/msat_conversion](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/Conversion/msat_conversion) | Arxiv |
| [Improving the Performance of Spiking Neural Networks on Event-based Datasets with Knowledge Transfer](https://arxiv.org/abs/2303.13077) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/transfer_for_dvs](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/transfer_for_dvs) | Arxiv |
| [Improving Stability and Performance of Spiking Neural Networks Through Enhancing Temporal Consistency](https://www.sciencedirect.com/science/article/abs/pii/S0031320324008458) | [https://github.com/Brain-Cog-Lab/ETC](https://github.com/Brain-Cog-Lab/ETC) | Pattern Recognition |
| [Spiking Generative Adversarial Network with Attention Scoring Decoding](https://www.sciencedirect.com/science/article/abs/pii/S0893608024003472) | [https://github.com/Brain-Cog-Lab/sgad](https://github.com/Brain-Cog-Lab/sgad) | Neural Networks |
| [Temporal Knowledge Sharing Enables Spiking Neural Network Learning from Past and Future](https://ieeexplore.ieee.org/document/10462632) | [https://github.com/Brain-Cog-Lab/TKS](https://github.com/Brain-Cog-Lab/TKS) | IEEE Transactions on Artificial Intelligence |
| [TIM: An Efficient Temporal Interaction Module for Spiking Transformer](https://www.ijcai.org/proceedings/2024/0347.pdf) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/TIM](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/TIM) | IJCAI2024 |
| [Exploiting Nonlinear Dendritic Adaptive Computation in Training Deep Spiking Neural Networks](https://www.sciencedirect.com/science/article/pii/S0893608023006202) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/base/node/node.py#L1412](https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/base/node/node.py#L1412) | Neural Networks |
| [Are Conventional SNNs Really Efficient? A Perspective from Network Quantization](https://openaccess.thecvf.com/content/CVPR2024/papers/Shen_Are_Conventional_SNNs_Really_Efficient_A_Perspective_from_Network_Quantization_CVPR_2024_paper.pdf) | | 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) |
| [CACE-Net: Co-guidance Attention and Contrastive Enhancement for Effective Audio-Visual Event Localization](https://dl.acm.org/doi/10.1145/3664647.3681503) | [https://github.com/Brain-Cog-Lab/CACE-Net](https://github.com/Brain-Cog-Lab/CACE-Net) | Proceedings of the 32nd ACM International Conference on Multimedia, 2024: 985-993 |
| [Parallel Spiking Unit for Efficient Training of Spiking Neural Networks](https://arxiv.org/abs/2402.00449) | [https://github.com/Brain-Cog-Lab/PSU](https://github.com/Brain-Cog-Lab/PSU) | IJCNN 2024 |
| [Spiking Neural Networks with Consistent Mapping Relations Allow High-Accuracy Inference](https://www.sciencedirect.com/science/article/abs/pii/S0020025524007369) | [https://github.com/Brain-Cog-Lab/casc](https://github.com/Brain-Cog-Lab/casc) | Information Sciences |
| [Directly training temporal Spiking Neural Network with sparse surrogate gradient](https://www.sciencedirect.com/science/article/abs/pii/S0893608024004234) | [https://github.com/Brain-Cog-Lab/msg](https://github.com/Brain-Cog-Lab/msg) | Neural Networks |
### Knowledge Representation and Reasoning
| Papers | Codes | Publisher |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------- |
| [A Brain-Inspired Causal Reasoning Model Based on Spiking Neural Networks](https://ieeexplore.ieee.org/abstract/document/9534102) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/CRSNN | IJCNN2021 |
| [Brain Inspired Sequences Production by Spiking Neural Networks With Reward-Modulated STDP](https://www.frontiersin.org/articles/10.3389/fncom.2021.612041/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/SPSNN | Frontiers in Computational Neuroscience |
| [Temporal-Sequential Learning With a Brain-Inspired Spiking Neural Network and Its Application to Musical Memory](https://www.frontiersin.org/articles/10.3389/fncom.2020.00051/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/musicMemory | Frontiers in Computational Neuroscience |
| [Stylistic Composition of Melodies Based on a Brain-Inspired Spiking Neural Network](https://www.frontiersin.org/articles/10.3389/fnsys.2021.639484/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BRP-SNN | Frontiers in Neurorobotics |
| [Brain-inspired Graph Spiking Neural Networks for Commonsense Knowledge Representation and Reasoning](https://arxiv.org/abs/2207.05561 ) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/CKRGSNN | Arxiv |
| [An Efficient Knowledge Transfer Strategy for Spiking Neural Networks from Static to Event Domain](https://arxiv.org/abs/2303.13077) | [https://github.com/Brain-Cog-Lab/Transfer-for-DVS](https://github.com/Brain-Cog-Lab/Transfer-for-DVS) | Proceedings of the AAAI Conference on Artificial Intelligence, 2024, 38(1): 512-520 |
### Decision Making
| Papers | Codes | Publisher |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------- | -------------------------- |
| [Nature-inspired self-organizing collision avoidance for drone swarm based on reward-modulated spiking neural network](https://www.cell.com/patterns/fulltext/S2666-3899(22)00236-7) | https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/decision_making/swarm/Collision-Avoidance.py | Cell Patterns |
| [Solving the spike feature information vanishing problem in spiking deep Q network with potential based normalization](https://www.frontiersin.org/articles/10.3389/fnins.2022.953368/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/decision_making/RL/sdqn | Frontiers in Neuroscience |
| [A Brain-Inspired Decision-Making Spiking Neural Network and Its Application in Unmanned Aerial Vehicle](https://www.frontiersin.org/articles/10.3389/fnbot.2018.00056/full ) | https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/decision_making/BDM-SNN/BDM-SNN-hh.py | Frontiers in Neurorobotics |
| [Multi-compartment Neuron and Population Encoding improved Spiking Neural Network for Deep Distributional Reinforcement Learning](https://arxiv.org/abs/2301.07275) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/decision_making/RL/mcs-fqf | Arxiv |
### Motor Control
| Papers | Codes | Publisher |
| ------ | ------------------------------------------------------------------------------------ | --------- |
| | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/MotorControl/experimental | |
### Social Cognition
| Papers | Codes | Publisher |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------- |
| [Toward Robot Self-Consciousness (II): Brain-Inspired Robot Bodily Self Model for Self-Recognition](https://link.springer.com/article/10.1007/s12559-017-9505-1 ) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/mirror_test](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/mirror_test) | Cognitive Computation |
| [A brain-inspired intention prediction model and its applications to humanoid robot](https://www.frontiersin.org/articles/10.3389/fnins.2022.1009237/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/Intention_Prediction](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/Intention_Prediction) | Frontiers in Neuroscience |
| [A Brain-Inspired Theory of Mind Spiking Neural Network for Reducing Safety Risks of Other Agents](https://www.frontiersin.org/articles/10.3389/fnins.2022.753900/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/ToM](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/ToM) | Frontiers in Neuroscience |
| [Brain-Inspired Affective Empathy Computational Model and Its Application on Altruistic Rescue Task](https://www.frontiersin.org/articles/10.3389/fncom.2022.784967/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BAE-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BAE-SNN) | Frontiers in Computational Neuroscience |
| [A brain-inspired robot pain model based on a spiking neural network](https://www.frontiersin.org/articles/10.3389/fnbot.2022.1025338/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BRP-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BRP-SNN) | Frontiers in Neurorobotics |
| [Brain-Inspired Theory of Mind Spiking Neural Network Elevates Multi-Agent Cooperation and Competition](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4271099) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/MAToM-SNN ](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/MAToM-SNN ) | SSRN |
### Development and Evolution
| Papers | Codes | Publisher |
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ----------------------------------------------- |
| [Developmental Plasticity-inspired Adaptive Pruning for Deep Spiking and Artificial Neural Networks](https://arxiv.org/abs/2211.12714) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DPAP](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DPAP) | Arxiv |
| [Adaptive Sparse Structure Development with Pruning and Regeneration for Spiking Neural Networks](https://arxiv.org/abs/2211.12219) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/SD-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/SD-SNN) | Arxiv |
| [Emergence of Brain-inspired Small-world Spiking Neural Network through Neuroevolution](https://arxiv.org/abs/2304.10749) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/ELSM](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/ELSM) | Arxiv |
| [Enhancing Efficient Continual Learning with Dynamic Structure Development of Spiking Neural Networks](https://arxiv.org/abs/2308.04749) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DSD-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DSD-SNN) | IJCAI |
| [Brain-inspired Evolutionary Neural Architecture Search for Spiking Neural Networks](https://ieeexplore.ieee.org/abstract/document/10542732) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/EB-NAS](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/EB-NAS) | IEEE Transactions on Artificial Intelligence |
| [Adaptive Structure Evolution and Biologically Plausible Synaptic Plasticity for Recurrent Spiking Neural Networks](https://www.nature.com/articles/s41598-023-43488-x) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/Adaptive_lsm](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/Adaptive_lsm) | Scientific Reports |
| [Brain-inspired Neural Circuit Evolution for Spiking Neural Networks](https://www.pnas.org/doi/10.1073/pnas.2218173120) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/model_zoo/NeuEvo](https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/model_zoo/NeuEvo) | Proceedings of the National Academy of Sciences |
### Safety and Security
| Papers | Codes | Publisher |
| ----------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------- | --------- |
| [DPSNN](https://arxiv.org/abs/2205.12718) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Snn_safety/DPSNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Snn_safety/DPSNN) | Arxiv |
### Dataset
| Papers | Codes | Publisher |
| -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ----------- |
| [Bullying10K: A Large-scale Neuromorphic Dataset Towards Privacy-preserving Bullying Recognition](https://proceedings.neurips.cc/paper_files/paper/2023/file/05ffe69463062b7f9fb506c8351ffdd7-Paper-Datasets_and_Benchmarks.pdf) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/bullying10k](https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/bullying10k) | Neurips2023 |
================================================
FILE: documents/Pub_brain_simulation.md
================================================
# Publications Using BrainCog
## Brain Simulation
### Funtion
| Papers | Codes | Publisher |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------|
| [A neural algorithm for Drosophila linear and nonlinear decision-making](https://www.nature.com/articles/s41598-020-75628-y) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Brain_Cognitive_Function_Simulation/drosophila/drosophila.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Brain_Cognitive_Function_Simulation/drosophila/drosophila.py) | Scientific Reports |
### Structure
| Papers | Codes | Publisher |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------|
| Corticothalamic minicolumn | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn) | |
| Human Brain | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/HumanBrain](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/HumanBrain) | |
| Macaque Brain | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/MacaqueBrain](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/MacaqueBrain) | |
| Mouse Brain | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/Mouse_brain ](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/Mouse_brain ) | |
| [Comparison Between Human and Rodent Neurons for Persistent Activity Performance: A Biologically Plausible Computational Investigation](https://www.frontiersin.org/articles/10.3389/fnsys.2021.628839/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Multiscale_Brain_Structure_Simulation/Human_PFC_Model | Frontiers in System Neuroscience |
================================================
FILE: documents/Pub_sh_codesign.md
================================================
# Publications Using BrainCog
## Software-Hardware Co-design
### Hardware Acceleration
| Papers | Codes | Publisher |
| ------------------------------------------------------------ | ---------------------------------------- | ------------------------------------------------------------ |
| [FireFly: A High-Throughput and Reconfigurable Hardware Accelerator for Spiking Neural Networks](https://ieeexplore.ieee.org/abstract/document/10143752) | https://github.com/adamgallas/FireFly-v1 | IEEE Transactions on Very Large Scale Integration (VLSI) Systems |
| [FireFly v2: Advancing Hardware Support for High-Performance Spiking Neural Network With a Spatiotemporal FPGA Accelerator](https://ieeexplore.ieee.org/abstract/document/10478105) | https://github.com/adamgallas/FireFly-v2 | IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems |
| [Revealing Untapped DSP Optimization Potentials for FPGA-Based Systolic Matrix Engines](https://ieeexplore.ieee.org/abstract/document/10705564) | https://github.com/adamgallas/SpinalDLA | 2024 34th International Conference on Field-Programmable Logic and Applications (FPL) |
| [FireFly-S: Exploiting Dual-Side Sparsity for Spiking Neural Networks Acceleration With Reconfigurable Spatial Architecture](https://ieeexplore.ieee.org/document/10754657) | | IEEE Transactions on Circuits and Systems I: Regular Papers |
| Pushing up to the Limit of Memory Bandwidth and Capacity Utilization for Efficient LLM Decoding on Embedded FPGA | | 2025 Design, Automation & Test in Europe Conference & Exhibition (DATE) |
================================================
FILE: documents/Publication.md
================================================
# Publications Using BrainCog
## 2024
| Papers | Codes | Publisher |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | --------------------------------------------------------------------------- |
| [Developmental Plasticity-inspired Adaptive Pruning for Deep Spiking and Artificial Neural Networks](https://ieeexplore.ieee.org/document/10691937) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DPAP](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DPAP) | IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) |
| [Multi-compartment Neuron and Population Encoding improved Spiking Neural Network for Deep Distributional Reinforcement Learning](https://www.sciencedirect.com/science/article/abs/pii/S089360802400827X?via%3Dihub) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/decision_making/RL/mcs-fqf | Neural Networks |
| [Improving Stability and Performance of Spiking Neural Networks Through Enhancing Temporal Consistency](https://www.sciencedirect.com/science/article/abs/pii/S0031320324008458) | [https://github.com/Brain-Cog-Lab/ETC](https://github.com/Brain-Cog-Lab/ETC) | Pattern Recognition |
| [Spiking Generative Adversarial Network with Attention Scoring Decoding](https://www.sciencedirect.com/science/article/abs/pii/S0893608024003472) | [https://github.com/Brain-Cog-Lab/sgad](https://github.com/Brain-Cog-Lab/sgad) | Neural Networks |
| [Temporal Knowledge Sharing Enables Spiking Neural Network Learning from Past and Future](https://ieeexplore.ieee.org/document/10462632) | [https://github.com/Brain-Cog-Lab/TKS](https://github.com/Brain-Cog-Lab/TKS) | IEEE Transactions on Artificial Intelligence (TAI) |
| [TIM: An Efficient Temporal Interaction Module for Spiking Transformer](https://www.ijcai.org/proceedings/2024/0347.pdf) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/TIM](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/TIM) | IJCAI2024 |
| [Are Conventional SNNs Really Efficient? A Perspective from Network Quantization](https://openaccess.thecvf.com/content/CVPR2024/papers/Shen_Are_Conventional_SNNs_Really_Efficient_A_Perspective_from_Network_Quantization_CVPR_2024_paper.pdf) | | 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) |
| [CACE-Net: Co-guidance Attention and Contrastive Enhancement for Effective Audio-Visual Event Localization](https://dl.acm.org/doi/10.1145/3664647.3681503) | [https://github.com/Brain-Cog-Lab/CACE-Net](https://github.com/Brain-Cog-Lab/CACE-Net) | Proceedings of the 32nd ACM International Conference on Multimedia (ACM MM) |
| [Parallel Spiking Unit for Efficient Training of Spiking Neural Networks](https://ieeexplore.ieee.org/document/10650207) | [https://github.com/Brain-Cog-Lab/PSU](https://github.com/Brain-Cog-Lab/PSU) | IJCNN 2024 |
| [Spiking Neural Networks with Consistent Mapping Relations Allow High-Accuracy Inference](https://www.sciencedirect.com/science/article/abs/pii/S0020025524007369) | [https://github.com/Brain-Cog-Lab/casc](https://github.com/Brain-Cog-Lab/casc) | Information Sciences |
| [Directly training temporal Spiking Neural Network with sparse surrogate gradient](https://www.sciencedirect.com/science/article/abs/pii/S0893608024004234) | [https://github.com/Brain-Cog-Lab/msg](https://github.com/Brain-Cog-Lab/msg) | Neural Networks |
| [Brain-inspired Evolutionary Neural Architecture Search for Spiking Neural Networks](https://ieeexplore.ieee.org/abstract/document/10542732) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/EB-NAS](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/EB-NAS) | IEEE Transactions on Artificial Intelligence (TAI) |
| [MSAT: Biologically Inspired Multi-Stage Adaptive Threshold for Conversion of Spiking Neural Networks](https://link.springer.com/article/10.1007/s00521-024-09529-w) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/Conversion/msat_conversion](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/Conversion/msat_conversion) | Neural Computing and Applications |
| [An Efficient Knowledge Transfer Strategy for Spiking Neural Networks from Static to Event Domain](https://ojs.aaai.org/index.php/AAAI/article/view/27806/27643) | [https://github.com/Brain-Cog-Lab/Transfer-for-DVS](https://github.com/Brain-Cog-Lab/Transfer-for-DVS) | Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) |
## 2023
| Papers | Codes | Publisher |
| -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------ |
| [An unsupervised STDP-based spiking neural network inspired by biologically plausible learning rules and connections](https://www.sciencedirect.com/science/article/pii/S0893608023003301) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/UnsupervisedSTDP](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/UnsupervisedSTDP) | Neural Networks |
| [EventMix: An efficient data augmentation strategy for event-based learning](https://www.sciencedirect.com/science/article/pii/S0020025523007557) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/datasets/cut_mix.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/datasets/cut_mix.py) | Information Sciences |
| [Challenging deep learning models with image distortion based on the abutting grating illusion](https://www.sciencedirect.com/science/article/pii/S2666389923000260) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/IllusionPerception/AbuttingGratingIllusion](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/IllusionPerception/AbuttingGratingIllusion) | Patterns |
| [Improving the Performance of Spiking Neural Networks on Event-based Datasets with Knowledge Transfer](https://arxiv.org/abs/2303.13077) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/transfer_for_dvs](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/transfer_for_dvs) | Arxiv |
| [Exploiting Nonlinear Dendritic Adaptive Computation in Training Deep Spiking Neural Networks](https://www.sciencedirect.com/science/article/pii/S0893608023006202) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/base/node/node.py#L1412](https://github.com/BrainCog-X/Brain-Cog/blob/main/braincog/base/node/node.py#L1412) | Neural Networks |
| [Emergence of Brain-inspired Small-world Spiking Neural Network through Neuroevolution](https://www.sciencedirect.com/science/article/pii/S258900422400066X) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/ELSM](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/ELSM) | iScience |
| [Enhancing Efficient Continual Learning with Dynamic Structure Development of Spiking Neural Networks](https://www.ijcai.org/proceedings/2023/0334.pdf) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DSD-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/DSD-SNN) | IJCAI |
| [Adaptive Structure Evolution and Biologically Plausible Synaptic Plasticity for Recurrent Spiking Neural Networks](https://www.nature.com/articles/s41598-023-43488-x) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/Adaptive_lsm](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/Adaptive_lsm) | Scientific Reports |
| [Brain-inspired Neural Circuit Evolution for Spiking Neural Networks](https://www.pnas.org/doi/10.1073/pnas.2218173120) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/model_zoo/NeuEvo](https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/model_zoo/NeuEvo) | Proceedings of the National Academy of Sciences (PANS) |
| [Bullying10K: A Large-scale Neuromorphic Dataset Towards Privacy-preserving Bullying Recognition](https://proceedings.neurips.cc/paper_files/paper/2023/file/05ffe69463062b7f9fb506c8351ffdd7-Paper-Datasets_and_Benchmarks.pdf) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/bullying10k](https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/bullying10k) | Neurips2023 |
## 2022
| Papers | Codes | Publisher |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------- |
| [BackEISNN: A deep spiking neural network with adaptive self-feedback and balanced excitatory–inhibitory neurons](https://www.sciencedirect.com/science/article/pii/S0893608022002520) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/img_cls/bp/main_backei.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/img_cls/bp/main_backei.py) | Neural Networks |
| [Efficient and Accurate Conversion of Spiking Neural Network with Burst Spikes](https://www.ijcai.org/proceedings/2022/345) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py) | IJCAI |
| [Spike Calibration: Fast and Accurate Conversion of Spiking Neural Network for Object Detection and Segmentation](https://arxiv.org/abs/2207.02702) | [https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py](https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/Perception_and_Learning/Conversion/converted_CIFAR10.py) | Arxiv |
| [Multisensory Concept Learning Framework Based on Spiking Neural Networks](https://www.frontiersin.org/articles/10.3389/fnsys.2022.845177/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/MultisensoryIntegration](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/MultisensoryIntegration) | Frontiers in Systems Neuroscience |
| [Backpropagation with biologically plausible spatiotemporal adjustment for training deep spiking neural networks](https://www.sciencedirect.com/science/article/pii/S2666389922001192) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/bp](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/bp) | Patterns |
| [Spiking CapsNet: A spiking neural network with a biologically plausible routing rule between capsules](https://www.sciencedirect.com/science/article/pii/S002002552200843X) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/spiking_capsnet](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/spiking_capsnet) | Information Sciences |
| [N-Omniglot, a large-scale neuromorphic dataset for spatio-temporal sparse few-shot learning](https://www.nature.com/articles/s41597-022-01851-z) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/NOmniglot](https://github.com/BrainCog-X/Brain-Cog/tree/main/braincog/datasets/NOmniglot) | Scientific Data |
| [Brain-inspired Graph Spiking Neural Networks for Commonsense Knowledge Representation and Reasoning](https://arxiv.org/abs/2207.05561 ) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/CKRGSNN | Arxiv |
| [Nature-inspired self-organizing collision avoidance for drone swarm based on reward-modulated spiking neural network](https://www.cell.com/patterns/fulltext/S2666-3899(22)00236-7) | https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/decision_making/swarm/Collision-Avoidance.py | Cell Patterns |
| [Solving the spike feature information vanishing problem in spiking deep Q network with potential based normalization](https://www.frontiersin.org/articles/10.3389/fnins.2022.953368/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/decision_making/RL/sdqn | Frontiers in Neuroscience |
| [A brain-inspired intention prediction model and its applications to humanoid robot](https://www.frontiersin.org/articles/10.3389/fnins.2022.1009237/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/Intention_Prediction](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/Intention_Prediction) | Frontiers in Neuroscience |
| [A Brain-Inspired Theory of Mind Spiking Neural Network for Reducing Safety Risks of Other Agents](https://www.frontiersin.org/articles/10.3389/fnins.2022.753900/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/ToM](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/ToM) | Frontiers in Neuroscience |
| [Brain-Inspired Affective Empathy Computational Model and Its Application on Altruistic Rescue Task](https://www.frontiersin.org/articles/10.3389/fncom.2022.784967/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BAE-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BAE-SNN) | Frontiers in Computational Neuroscience |
| [A brain-inspired robot pain model based on a spiking neural network](https://www.frontiersin.org/articles/10.3389/fnbot.2022.1025338/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BRP-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BRP-SNN) | Frontiers in Neurorobotics |
| [Brain-Inspired Theory of Mind Spiking Neural Network Elevates Multi-Agent Cooperation and Competition](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4271099) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/MAToM-SNN ](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/MAToM-SNN ) | SSRN |
| [Adaptive Sparse Structure Development with Pruning and Regeneration for Spiking Neural Networks](https://www.sciencedirect.com/science/article/abs/pii/S0020025524013951) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/SD-SNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structural_Development/SD-SNN) | Information Sciences |
| [DPSNN](https://arxiv.org/abs/2205.12718) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Snn_safety/DPSNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Snn_safety/DPSNN) | Arxiv |
## 2021
| Papers | Codes | Publisher |
| ---------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------- |
| [Quantum superposition inspired spiking neural network](https://www.cell.com/iscience/fulltext/S2589-0042(21)00848-8) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/QSNN](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/QSNN) | iScience |
| [A Brain-Inspired Causal Reasoning Model Based on Spiking Neural Networks](https://ieeexplore.ieee.org/abstract/document/9534102) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/CRSNN | IJCNN2021 |
| [Brain Inspired Sequences Production by Spiking Neural Networks With Reward-Modulated STDP](https://www.frontiersin.org/articles/10.3389/fncom.2021.612041/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/SPSNN | Frontiers in Computational Neuroscience |
| [Stylistic Composition of Melodies Based on a Brain-Inspired Spiking Neural Network](https://www.frontiersin.org/articles/10.3389/fnsys.2021.639484/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/affective_empathy/BRP-SNN | Frontiers in Neurorobotics |
## 2020
| Papers | Codes | Publisher |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------- |
| [GLSNN: A Multi-Layer Spiking Neural Network Based on Global Feedback Alignment and Local STDP Plasticity](https://www.frontiersin.org/articles/10.3389/fncom.2020.576841/full) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/glsnn](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/glsnn) | Frontiers in Neuroscience |
| [Temporal-Sequential Learning With a Brain-Inspired Spiking Neural Network and Its Application to Musical Memory](https://www.frontiersin.org/articles/10.3389/fncom.2020.00051/full) | https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Knowledge_Representation_and_Reasoning/musicMemory | Frontiers in Computational Neuroscience |
## 2018
| Papers | Codes | Publisher |
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------- |
| [A Brain-Inspired Decision-Making Spiking Neural Network and Its Application in Unmanned Aerial Vehicle](https://www.frontiersin.org/articles/10.3389/fnbot.2018.00056/full ) | https://github.com/BrainCog-X/Brain-Cog/blob/main/examples/decision_making/BDM-SNN/BDM-SNN-hh.py | Frontiers in Neurorobotics |
| [Toward Robot Self-Consciousness (II): Brain-Inspired Robot Bodily Self Model for Self-Recognition](https://link.springer.com/article/10.1007/s12559-017-9505-1 ) | [https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/mirror_test](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Social_Cognition/mirror_test) | Cognitive Computation |
================================================
FILE: documents/Tutorial.md
================================================
# Tutorial
- How to Install BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/1_installation.html), [Chinese Version](https://mp.weixin.qq.com/s/fX-S3fKKDfR3NV4ISAHrZg)]
- Overall Introduction of BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/2_Overall%20introduction%20of%20BrainCog.html), [Chinese Version](https://mp.weixin.qq.com/s/ywgQ5ydQxr6W7d_Y_XqC6w)]
- Spiking Neuron Modeling with BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/3_Tutorial%20of%20Spiking%20Neuron%20Modeling.html), [Chinese Version](https://mp.weixin.qq.com/s/pCdlbkrdnMNHj7wcwi9D2Q)]
- Building Efficient Spiking Neural Networks with BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/4_Building%20Efficient%20Spiking%20Neural%20Networks%20with%20BrainCog.html), [Chinese Version](https://mp.weixin.qq.com/s/NIz7MSAOJQ79m97hkP3HVg)]
- Building Cognitive Networks with BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/5_How%20to%20build%20a%20cognitive%20network.html), [Chinese Version](https://mp.weixin.qq.com/s/K0pY6V8TupJgYXH4WvS9jg)]
- Implementing Deep Reinforcement Learning SNNs with BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/6_SDQN.html), [Chinese Version](https://mp.weixin.qq.com/s/Zt78vj_sKn5jffEyeh86Cw)]
- Quantum Superposition State Inspired Encoding With BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/7_QSSNN.html), [Chinese Version](https://mp.weixin.qq.com/s/YVNkwDwuF9FG-YqQyd3KTg)]
- Converting ANNs to SNNs with BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/8_conversion.html), [Chinese Version](https://mp.weixin.qq.com/s/4g8WBoa4SOcb_VQ24wO-Xw)]
- SNNs with Global Feedback Connections Based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/9_GLSNN.html), [Chinese Version](https://mp.weixin.qq.com/s/-AS0BihlXdFwCt1hgzFx3g)]
- Multi-brain Areas Coordinated Brain-inspired Decision-Making SNNs Based on Braincog [[English Version](http://www.brain-cog.network/docs/tutorial/10_BDMSNN.html), [Chinese Version](https://mp.weixin.qq.com/s/dltOGjhUZ9yTzSssIvkhtA)]
- Backpropagation with Spatiotemporal Adjustment for Training SNNs Based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/11_biobp.html), [Chinese Version](https://mp.weixin.qq.com/s/6ZtaWtiY9K96UhVnvhfP7w)]
- Unsupervised STDP Based SNNs with Multiple Adaptive Mechanisms Based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/12_unsup.html), [Chinese Version](https://mp.weixin.qq.com/s/v_svhQ0N3JAYo1l8NQ1W1w)]
- Symbolic Representation and Reasoning SNNs Based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/13_krr.html), [Chinese Version](https://mp.weixin.qq.com/s/UXc5QDbg8tUKVU3L6dhvxw)]
- Multisensory Integration Based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/14_multisensory.html), [Chinese Version](https://mp.weixin.qq.com/s/s9gXF5NkPUGXkcFAFtsCMw)]
- SNN-based Music Memory and Generation Based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/15_musicSNN.html), [Chinese Version](https://mp.weixin.qq.com/s/y-t9rFEXYSmI_-rnVk_usw)]
- Brain-inspired Bodily Self-perception Model Based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/16_self.html), [Chinese Version](https://mp.weixin.qq.com/s/RLbS3GmhE8ScyZTKJKl_SQ)]
- A Brain-inspired Theory of Mind Model Based on BrainCog for Reducing Other Agents’ Safety Risks [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/xzFF6IK86W4h2CMs7jt7Xw)]
- Application of the Prefrontal Cortex Column Model in Working Memory Task with BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/E6pb5W0Q4noK72NGf4SNGQ)]
- Multi-brain areas Coordinated Brain-inspired Affective Empathy Spiking Neural Network Based on Braincog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/xUnal4I5tM-Rl49fu0ZRVw)]
- Developmental Plasticity-inspired Adaptive Pruning for SNNs based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/-F0XcIovI1WY6YyoO5P58Q)]
- Dynamic structural development for SNNs incorporating constraints, pruning and regeneration based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/n1EK6lddriS0dnSgfdsa8w)]
- BrainCog Data Engine: Spatio-temporal Sequence Data N-Omniglot and Its Applications [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/VIzDb2kn_4LUyUh0qc2j4w)]
- The Implement of Object Detection and Semantic Segmentation Based on SNNs with Braincog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/fyf_cbzH_i1_ZEFWTSH81Q)]
- DVS Augmentation Strategies based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/BNMZ_oQK9Foui2zcnKWYgg)]
- SNNs with adaptive self-feedback and balanced excitatory–inhibitory neurons based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/TFEucKDQHB69wChEL_Y3Cw)]
- Spiking CapsNet based on BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/VIzDb2kn_4LUyUh0qc2j4w)]
- Drosophila-inspired Linear and Nonlinear Decision-Making Spiking Neural Network implemented by Braincog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/VIzDb2kn_4LUyUh0qc2j4w)]
- Reward-modulated brain-inspired spiking neural network to empower group for nature-inspired self-organized obstacle avoidance implemented by Braincog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/VIzDb2kn_4LUyUh0qc2j4w)]
- Using BrainCog to Realize Robot's Intention Prediction for Users [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/VIzDb2kn_4LUyUh0qc2j4w)]
- FPGA-based Spiking Neural Networks Acceleration Using BrainCog [[English Version](http://www.brain-cog.network/docs/tutorial/17_tom.html), [Chinese Version](https://mp.weixin.qq.com/s/VIzDb2kn_4LUyUh0qc2j4w)]
================================================
FILE: examples/Brain_Cognitive_Function_Simulation/drosophila/README.md
================================================
# Drosophila-inspired decision-making SNN
## Run
The drosophila.py implements the core code of the Drosophila-inspired linear and non-linear decision-making in paper entitled "A Neural Algorithm for linear and non-linear Decision-making inspired by Drosophila".
The experiments includes training phase and testing phase:
* Training Phase
Training linear network and nonlinear network by reward-modulated spiking neural network: green-upright T is safe and blue-inverted T is dangerous
* Testing Phase
For linear pathway and nonlinear pathway, choose between blue-upright T and green-inverted T, and count the PI values under different color intensity
## Results
The following picture shows the linear (a) and nonlinear (b) pathways, the training and testing phases (c), and the PI values on different color intensities (d).

Differences from the original article: an improved reward-modulated STDP learning rule.
## Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{zhao2020neural,
title={A neural algorithm for Drosophila linear and nonlinear decision-making},
author={Zhao, Feifei and Zeng, Yi and Guo, Aike and Su, Haifeng and Xu, Bo},
journal={Scientific Reports},
volume={10},
number={1},
pages={1--16},
year={2020},
publisher={Nature Publishing Group}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/Brain_Cognitive_Function_Simulation/drosophila/drosophila.py
================================================
import numpy as np
import torch,os,sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
import matplotlib.pyplot as plt
from braincog.base.strategy.surrogate import *
from braincog.base.node.node import IFNode
from braincog.base.learningrule.STDP import STDP,MutliInputSTDP
from braincog.base.connection.CustomLinear import CustomLinear
from braincog.model_zoo.nonlinearNet import droDMTestNet
from braincog.model_zoo.linearNet import droDMTrainNet
import copy
if __name__=="__main__":
"""
建立训练网络
"""
num_state=5
num_action=2
weight_exc=0.5
weight_inh=-0.05
trace_decay=0.8
mb_connection=[]
#input-visual
con_matrix0 = torch.eye((num_state), dtype=torch.float)
mb_connection.append(CustomLinear(weight_exc * con_matrix0,con_matrix0))
# visual-kc
con_matrix1 =torch.eye((num_state), dtype=torch.float)
mb_connection.append(CustomLinear( weight_exc * con_matrix1,con_matrix1))
# kc-mbon
con_matrix2 = torch.ones((num_state,num_action), dtype=torch.float)
mb_connection.append(CustomLinear(weight_exc * con_matrix2,con_matrix2))
# mbon-mbon
con_matrix3 = torch.ones((num_action,num_action), dtype=torch.float)
con_matrix4 = torch.eye((num_action), dtype=torch.float)
con_matrix5=con_matrix3-con_matrix4
con_matrix5=con_matrix5
mb_connection.append(CustomLinear(weight_inh * con_matrix5,con_matrix5))
MB=droDMTrainNet(mb_connection)
weight_trace_mbon=torch.zeros(con_matrix2.shape, dtype=torch.float)
"""
学习绿色正立T是安全的 蓝色倒立T是有惩罚的
"""
#learning GT
# RGB T t
GT = torch.tensor([0, 0.8, 0, 1.0, 0])
Bt = torch.tensor([0, 0, 0.8, 0, 1.0])
input = GT - Bt # input GT
input[input < 0] = 0
for i_train in range(20):
GT_out,dwkc,dwmbon=MB(input)
print("stdp:",dwkc,dwmbon)
#vis-kc STDP
MB.UpdateWeight(1, dwkc)
#kc-mbon rstdp
weight_trace_mbon *= trace_decay
weight_trace_mbon += dwmbon
if max(GT_out)>0:
r=torch.ones((num_state,num_action), dtype=torch.float)
p_action= torch.tensor([0])
r[:,p_action]=-1
dw_mbon = r * weight_trace_mbon
MB.UpdateWeight(2, dw_mbon)
print("output:",GT_out)
MB.reset()
weight_trace_mbon = torch.zeros(con_matrix2.shape, dtype=torch.float)
#learning Bt
GT = torch.tensor([0,0.8,0, 1.0, 0])
Bt = torch.tensor([0, 0, 0.8, 0, 1.0])
input = Bt - GT # input Bt
input[input < 0] = 0
for i_train in range(20):
GT_out,dwkc,dwmbon=MB(input)
#vis-kc STDP
MB.UpdateWeight(1, dwkc)
#kc-mbon rstdp
weight_trace_mbon *= trace_decay
weight_trace_mbon += dwmbon
if max(GT_out)>0:
r=torch.ones((num_state,num_action), dtype=torch.float)
p_action= torch.tensor([1])
r[:,p_action]=-1
dw_mbon = r * weight_trace_mbon
MB.UpdateWeight(2, dw_mbon)
train_weight=MB.getweight()
for i in range(len(train_weight)):
print("weight after learning:", train_weight[i].weight.data)
print("end training")
#linear test conflict decision making
test_num=12
t1=torch.zeros((test_num), dtype=torch.float)
t2=torch.zeros((test_num), dtype=torch.float)
for c in range(t1.shape[0]):
MB_test = droDMTrainNet(copy.deepcopy(train_weight))
MB_test.reset()
Gt = torch.tensor([0, (c*0.1), 0, 0, 0.5])
BT = torch.tensor([0, 0, (c*0.1), 0.5, 0])
input =Gt - BT # input Gt
input[input < 0] = 0
count=torch.zeros((num_action), dtype=torch.float)
for i_train in range(500):
GT_out,dwkc,dwmbon=MB_test(input)
count+=GT_out
t1[c]=count[0]
t2[c]=count[1]
p1=(t1-t2)/(t1+t2)
print(t1,t2,p1)
for i in range(len(train_weight)):
print("weight after learning:", train_weight[i].weight.data)
"""
建立测试网络,验证不同浓度下绿色正立T和蓝色倒立T
"""
# non-linear test conflict decision making
weight_inh_test=-0.3
num_apl=2
num_da=1
da_mb_connection=train_weight
# kc-apl
con_matrix6 = torch.ones((num_state, num_apl), dtype=torch.float)
da_mb_connection.append(CustomLinear(weight_exc * con_matrix6, con_matrix6))
# apl-kc
con_matrix7 = torch.ones((num_apl,num_state), dtype=torch.float)
da_mb_connection.append(CustomLinear(weight_inh_test * con_matrix7, con_matrix7))
# da-apl
con_matrix8 = torch.ones((num_da, num_apl), dtype=torch.float)
da_mb_connection.append(CustomLinear(weight_inh_test * con_matrix8, con_matrix8))
# apl-da
con_matrix9 = torch.ones((num_apl, num_da), dtype=torch.float)
da_mb_connection.append(CustomLinear(weight_inh_test * con_matrix9, con_matrix9))
# 1-da
con_matrix10 = torch.ones((num_da), dtype=torch.float)
da_mb_connection.append(CustomLinear(weight_exc * con_matrix10, con_matrix10))
# da-mbon
con_matrix11 = torch.ones((num_da,num_action), dtype=torch.float)
da_mb_connection.append(CustomLinear(weight_exc * con_matrix11, con_matrix11))
#0 input-vis 1 vis-kc 2 kc-mbon 3-mbon-mbon 4 kc-apl 5 apl-kc 6 da-apl 7 apl-da 8 input-da
t1 = torch.zeros((test_num), dtype=torch.float)
t2 = torch.zeros((test_num), dtype=torch.float)
for c in range(t1.shape[0]):
DA_MB_test = droDMTestNet(copy.deepcopy(da_mb_connection))
DA_MB_test.reset()
Gt = torch.tensor([0, (c * 0.1), 0, 0, 0.5])
BT = torch.tensor([0, 0, (c * 0.1), 0.5, 0])
input = Gt - BT # input Gt
input[input < 0] = 0
count = torch.zeros((num_action), dtype=torch.float)
for i_train in range(500):
if i_train<10 and i_train%2==0:
input_da = torch.tensor([0.5])
else:
input_da = torch.tensor([0.0])
GT_out, dwkc, dwapl= DA_MB_test(input,input_da)
DA_MB_test.UpdateWeight(5, dwkc)
DA_MB_test.UpdateWeight(4, dwapl)
count += GT_out
t1[c] = count[0]
t2[c] = count[1]
p2 = (t1 - t2) / (t1 + t2)
print(t1, t2, p2)
MB_test = MB.getweight()
for i in range(len(train_weight)):
print("weight after learning:", train_weight[i].weight.data)
x = torch.arange(0, test_num)
x=x*0.1
plt.figure()
A,=plt.plot(x, p1,label="linear")
B,=plt.plot(x, p2,label="non-linear")
font1 = {'family' : 'Times New Roman','weight' : 'normal','size' : 15,}
plt.xlabel("color intensity",font1)
plt.ylabel("PI",font1)
plt.legend(handles=[A,B],prop=font1)
plt.show()
================================================
FILE: examples/Embodied_Cognition/RHI/RHI_Test.py
================================================
import numpy as np
import torch,os,sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
import matplotlib.pyplot as plt
from braincog.base.strategy.surrogate import *
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import random
import gc
from braincog.base.node.node import IzhNodeMU
import objgraph
from pympler import tracker
class CustomLinear(nn.Module):
def __init__(self, weight,mask=None):
super().__init__()
self.weight = nn.Parameter(weight, requires_grad=True)
self.mask=mask
def forward(self, x: torch.Tensor):
#
# ret.shape = [C]
return x.mul(self.weight) # Changed
def update(self, dw):
with torch.no_grad():
if self.mask is not None:
dw *= self.mask
self.weight.data+= dw
class M1Net(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input):
input_n = input*I_max
input_r = torch.round(input_n)
Spike = torch.zeros(num_neuron, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_AI):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class VNet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input):
input_n = input*I_max
input_r = torch.round(input_n)
Spike = torch.zeros(num_neuron, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class S1Net(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n, input_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class EBANet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n, input_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class TPJNet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n, input_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
def UpdateWeight(self, i, W):
self.connection[i].weight.data = W
class AINet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n, input_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
def UpdateWeight(self, i, W):
self.connection[i].weight.data = self.connection[i].weight.data + W
def DeltaWeight(Pre, Pre_n, Post, Post_n):
alpha = -0.0035
beta = 0.35
gamma = -0.55
T1 = alpha * (Pre_n*Post_n)
T2 = beta * (Pre_n*(Post_n-Post))
T3 = gamma * ((Pre_n-Pre)*Post_n)
dW = T1 + T2 + T3
return dW
if __name__=="__main__":
"""
Set the number of neurons, and each neuron represents unique motion information (such as angle)
"""
# number of neurons
num_neuron = 9
num_M1 = num_neuron
num_S1 = num_neuron
num_TPJ = num_neuron
num_V = num_neuron
num_EBA = num_neuron
num_AI = num_neuron
Init_Weight = 1.
param_threshold = 30.
param_a = 0.02
param_b = -0.1
param_c = -55.
param_d = 18.
param_mem = -70.
param_u = 0.
param_dt = 1.
Simulation_time = 1000
I_max = 1000
# When TrickID is set to 1, it means that the mapping relationship from input current
# to firing rate is obtained directly by loading Izh.npy,
# which can significantly reduce the program running time
TrickID = 1
if TrickID == 1:
spike_num_list=np.load('Izh.npy')
spike_num_list = spike_num_list/I_max
##############################
# M1
##############################
# M1_Input-M1
M1_connection = []
con_matrix0 = torch.ones(num_M1, dtype=torch.float)*Init_Weight
M1_connection.append(CustomLinear(con_matrix0))
M1 = M1Net(M1_connection)
##############################
# V
##############################
# V_Input-V
V_connection = []
con_matrix3 = torch.ones(num_V, dtype=torch.float)*Init_Weight
V_connection.append(CustomLinear(con_matrix3))
V = VNet(V_connection)
##############################
# S1
##############################
# M1-S1
S1_connection = []
con_matrix1 = torch.ones(num_S1, dtype=torch.float)*Init_Weight
S1_connection.append(CustomLinear(con_matrix1))
S1 = S1Net(S1_connection)
##############################
# EBA
##############################
# V-EBA
EBA_connection = []
con_matrix4 = torch.ones(num_EBA, dtype=torch.float)*Init_Weight
EBA_connection.append(CustomLinear(con_matrix4))
EBA = EBANet(EBA_connection)
##############################
# TPJ
##############################
# S1-TPJ, EBA-TPJ
TPJ_connection = []
# S1-TPJ
con_matrix2 = torch.ones(num_TPJ, dtype=torch.float)*Init_Weight*150
TPJ_connection.append(CustomLinear(con_matrix2))
# EBA-TPJ
con_matrix5 = torch.ones(num_TPJ, dtype=torch.float)*Init_Weight*150
TPJ_connection.append(CustomLinear(con_matrix5))
TPJ = TPJNet(TPJ_connection)
##############################
# AI
##############################
# S1-AI, TPJ-AI, EBA-AI
AI_connection = []
# S1-AI
con_matrix6 = torch.ones(num_AI, dtype=torch.float)*Init_Weight
AI_connection.append(CustomLinear(con_matrix6))
# TPJ-AI
con_matrix7 = torch.ones(num_AI, dtype=torch.float)*Init_Weight
AI_connection.append(CustomLinear(con_matrix7))
# EBA-AI
con_matrix8 = torch.ones(num_AI, dtype=torch.float)*Init_Weight
AI_connection.append(CustomLinear(con_matrix8))
AI = AINet(AI_connection)
AI.connection[0].weight.data = torch.from_numpy(np.load('W_S1_AI.npy'))
AI.connection[2].weight.data = torch.from_numpy(np.load('W_EBA_AI.npy'))
##############################
# Coding
##############################
S = 1
ISI = 1
JMax = int((num_neuron-1)/2)
listJ = list(range(-JMax,JMax+1))
Coding = torch.zeros([num_neuron, num_neuron], dtype=torch.float)
for i in range(len(listJ)):
e = float(listJ[i])
listY = []
for j in range(len(listJ)):
x = float(listJ[j])
y = math.exp(-(x-e)**2/(2*S**2))
Coding[i][j] = y
print(AI.connection[0].weight.data) # dW_S1AI
print(AI.connection[2].weight.data) # dW_EBAAI
##############################
# Test
##############################
Time = 300
CT = 100
Motion_Start = 1
Motion_End = Motion_Start + CT
Vision_Start = Motion_End
Vision_End = Vision_Start + CT
CM1 = 0.04
CV = 0.04
CS1 = 0.04
CEBA = 0.04
CTPJ = 0.01
CAI = 0.15
Result_List = []
Veridical_hand = int((num_neuron-1)/2)
for Disparity in range(-JMax,JMax+1):
M1_input = torch.zeros(num_M1, dtype=torch.float)
V_input = torch.zeros(num_V, dtype=torch.float)
S1_input = torch.zeros(num_S1, dtype=torch.float)
TPJ_input = torch.zeros(num_TPJ, dtype=torch.float)
EBA_input = torch.zeros(num_EBA, dtype=torch.float)
AI_input = torch.zeros(num_AI, dtype=torch.float)
FR_M1 = torch.zeros(num_M1, dtype=torch.float)
FR_V = torch.zeros(num_V, dtype=torch.float)
FR_S1 = torch.zeros(num_S1, dtype=torch.float)
FR_EBA = torch.zeros(num_EBA, dtype=torch.float)
FR_TPJ = torch.zeros(num_TPJ, dtype=torch.float)
FR_AI = torch.zeros(num_AI, dtype=torch.float)
FR_AI_List = torch.zeros([Time, num_AI], dtype=torch.float)
with torch.no_grad():
for t in range(1,Time+1):
S_M1 = torch.zeros(num_M1, dtype=torch.float)
S_V = torch.zeros(num_V, dtype=torch.float)
if t>=Motion_Start and t<=Motion_End:
S_M1 = Coding[Veridical_hand]
M1_input = (1-(1-CM1)**t)*S_M1
else:
M1_input = S_M1
if t>=Vision_Start and t<=Vision_End:
S_V = Coding[Veridical_hand+Disparity]
V_input = (1-(1-CV)**(t-CT))*S_V
else:
V_input = S_V
FR_M1_n = M1(M1_input)
FR_V_n = V(V_input)
[FR_S1_n, S1_input_n] = S1(S1_input, FR_M1_n, CS1)
[FR_EBA_n, EBA_input_n] = EBA(EBA_input, FR_V_n, CEBA)
FR_Input_TPJ_n = torch.stack((FR_S1_n, FR_EBA_n), 0)
[FR_TPJ_n, TPJ_input_n] = TPJ(TPJ_input, FR_Input_TPJ_n, CTPJ)
FR_Input_AI = torch.stack((FR_S1_n, FR_TPJ_n, FR_EBA_n), 0)
[FR_AI_n, AI_input_n] = AI(AI_input, FR_Input_AI, CAI)
FR_AI_List[t-1] = FR_AI_n
FR_M1 = FR_M1_n
FR_V = FR_V_n
FR_S1 = FR_S1_n
FR_EBA = FR_EBA_n
FR_TPJ = FR_TPJ_n
FR_AI = FR_AI_n
S1_input = S1_input_n
TPJ_input = TPJ_input_n
EBA_input = EBA_input_n
AI_input = AI_input_n
print('Test Time End')
Estimated_hand = torch.max(torch.max(FR_AI_List, 0)[0],0)[1].item()
Proprioceptive_drift = Estimated_hand - Veridical_hand
R = [Disparity, Proprioceptive_drift]
Result_List.append(R)
print(R)
print(torch.max(FR_AI_List, 0)[0])
print("----------------------------")
print(Result_List)
X = [x[0] for x in Result_List]
Y = [x[1] for x in Result_List]
S = np.polyfit(X,Y,3)
xn = np.linspace(-(num_neuron-1)/2, (num_neuron-1)/2, 1000)
yn = np.poly1d(S)
plt.plot(xn, yn(xn), X, Y, 'o')
plt.show()
================================================
FILE: examples/Embodied_Cognition/RHI/RHI_Train.py
================================================
import numpy as np
import torch,os,sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
import matplotlib.pyplot as plt
from braincog.base.strategy.surrogate import *
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import random
import gc
from braincog.base.node.node import IzhNodeMU
import objgraph
from pympler import tracker
class CustomLinear(nn.Module):
def __init__(self, weight,mask=None):
super().__init__()
self.weight = nn.Parameter(weight, requires_grad=True)
self.mask=mask
def forward(self, x: torch.Tensor):
#
# ret.shape = [C]
return x.mul(self.weight)
def update(self, dw):
with torch.no_grad():
if self.mask is not None:
dw *= self.mask
self.weight.data+= dw
class M1Net(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input):
input_n = input*I_max
input_r = torch.round(input_n)
Spike = torch.zeros(num_neuron, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_AI):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class VNet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input):
input_n = input*I_max
input_r = torch.round(input_n)
Spike = torch.zeros(num_neuron, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class S1Net(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C, Fired, W_LatInh):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
S = input_n
S = torch.where(input_n>= fire_threshold, 1, S)
S = torch.where(input_n< fire_threshold, 0, S)
if torch.sum(S) > 0:
Fired = Fired + 1;
W_LatInh = torch.tanh(W_LatInh - 2 * torch.acos(S) * torch.exp(Fired) - 1) + 1
return FR_n, input_n, Fired, W_LatInh
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class EBANet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C, Fired, W_LatInh):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
S = input_n
S = torch.where(input_n>= fire_threshold, 1, S)
S = torch.where(input_n< fire_threshold, 0, S)
if torch.sum(S) > 0:
Fired = Fired + 1;
W_LatInh = torch.tanh(W_LatInh - 2 * torch.acos(S) * torch.exp(Fired) - 1) + 1
return FR_n, input_n, Fired, W_LatInh
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
class TPJNet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n, input_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
def UpdateWeight(self, i, W):
self.connection[i].weight.data = W
class AINet(nn.Module):
def __init__(self,connection):
super().__init__()
self.node = []
self.node.append(IzhNodeMU(threshold=param_threshold, a=param_a, b=param_b, c=param_c, d=param_d, mem=param_mem, u=param_u, dt=param_dt))
self.connection = connection
def forward(self, input, FR, C):
FR_W = torch.zeros(num_neuron, dtype=torch.float)
if len(FR.shape) == 1:
FR_W = FR*self.connection[0].weight
else:
for i in range(FR.shape[0]):
FR_Wi = FR[i]*self.connection[i].weight
FR_W = FR_W + FR_Wi
sf = torch.tanh(FR_W)
sf = torch.where(sf<0, 0, sf)
input_n = -C * (input-sf) + input
input_n = torch.where(input_n<0, 0, input_n)
input = input_n*I_max
input_r = torch.round(input)
Spike = torch.zeros(num_S1, dtype=torch.float)
self.node[0].n_reset()
if TrickID == 1:
for i in range(num_neuron):
input_ri = int(input_r[i].item())
FR_i = spike_num_list[input_ri]
Spike[i] = FR_i
FR_n = Spike
else:
for t in range(Simulation_time):
self.out=self.node[0](input_r)
n_Spike = self.node[0].spike
Spike = Spike + n_Spike
FR_n = Spike/Simulation_time
return FR_n, input_n
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
def UpdateWeight(self, i, W, WIn):
self.connection[i].weight.data = self.connection[i].weight.data + W*WIn
def DeltaWeight(Pre, Pre_n, Post, Post_n):
alpha = -0.0035
beta = 0.35
gamma = -0.55
T1 = alpha * (Pre_n*Post_n)
T2 = beta * (Pre_n*(Post_n-Post))
T3 = gamma * ((Pre_n-Pre)*Post_n)
dW = T1 + T2 + T3
return dW
if __name__=="__main__":
"""
Set the number of neurons, and each neuron represents unique motion information (such as angle)
"""
# number of neurons
num_neuron = 9
num_M1 = num_neuron
num_S1 = num_neuron
num_TPJ = num_neuron
num_V = num_neuron
num_EBA = num_neuron
num_AI = num_neuron
Init_Weight = 1.
param_threshold = 30.
param_a = 0.02
param_b = -0.1
param_c = -55.
param_d = 18.
param_mem = -70.
param_u = 0.
param_dt = 1.
Simulation_time = 1000
I_max = 1000
# When the TrickID is set to 1, it means that the mapping relationship from input current
# to firing rate is obtained directly by loading the Izh.npy,
# which can significantly reduce the program running time
TrickID = 1
if TrickID == 1:
spike_num_list=np.load('Izh.npy')
spike_num_list = spike_num_list/I_max
##############################
# M1
##############################
# M1_Input-M1
M1_connection = []
con_matrix0 = torch.ones(num_M1, dtype=torch.float)*Init_Weight
M1_connection.append(CustomLinear(con_matrix0))
M1 = M1Net(M1_connection)
##############################
# V
##############################
# V_Input-V
V_connection = []
con_matrix3 = torch.ones(num_V, dtype=torch.float)*Init_Weight
V_connection.append(CustomLinear(con_matrix3))
V = VNet(V_connection)
##############################
# S1
##############################
# M1-S1
S1_connection = []
con_matrix1 = torch.ones(num_S1, dtype=torch.float)*Init_Weight
S1_connection.append(CustomLinear(con_matrix1))
S1 = S1Net(S1_connection)
##############################
# EBA
##############################
# V-EBA
EBA_connection = []
con_matrix4 = torch.ones(num_EBA, dtype=torch.float)*Init_Weight
EBA_connection.append(CustomLinear(con_matrix4))
EBA = EBANet(EBA_connection)
##############################
# TPJ
##############################
# S1-TPJ, EBA-TPJ
TPJ_connection = []
# S1-TPJ
con_matrix2 = torch.ones(num_TPJ, dtype=torch.float)*Init_Weight*150
TPJ_connection.append(CustomLinear(con_matrix2))
# EBA-TPJ
con_matrix5 = torch.ones(num_TPJ, dtype=torch.float)*Init_Weight*150
TPJ_connection.append(CustomLinear(con_matrix5))
TPJ = TPJNet(TPJ_connection)
##############################
# AI
##############################
# S1-AI, TPJ-AI, EBA-AI
AI_connection = []
# S1-AI
con_matrix6 = torch.ones(num_AI, dtype=torch.float)*Init_Weight
AI_connection.append(CustomLinear(con_matrix6))
# TPJ-AI
con_matrix7 = torch.ones(num_AI, dtype=torch.float)*Init_Weight
AI_connection.append(CustomLinear(con_matrix7))
# EBA-AI
con_matrix8 = torch.ones(num_AI, dtype=torch.float)*Init_Weight
AI_connection.append(CustomLinear(con_matrix8))
AI = AINet(AI_connection)
##############################
# Coding
##############################
S = 1
ISI = 1
JMax = int((num_neuron-1)/2)
listJ = list(range(-JMax,JMax+1))
Coding = torch.zeros([num_neuron, num_neuron], dtype=torch.float)
for i in range(len(listJ)):
e = float(listJ[i])
listY = []
for j in range(len(listJ)):
x = float(listJ[j])
y = math.exp(-(x-e)**2/(2*S**2))
Coding[i][j] = y
##############################
# Train
##############################
MoveNum = 25
Time = 300
CT = 100
Motion_Start = 1
Motion_End = Motion_Start + CT
Vision_Start = Motion_End
Vision_End = Vision_Start + CT
CM1 = 0.04
CV = 0.04
CS1 = 0.04
CEBA = 0.04
CTPJ = 0.01
CAI = 0.15
for k in range(num_neuron):
for i in range(MoveNum):
print(i)
M1_input = torch.zeros(num_M1, dtype=torch.float)
V_input = torch.zeros(num_V, dtype=torch.float)
S1_input = torch.zeros(num_S1, dtype=torch.float)
TPJ_input = torch.zeros(num_TPJ, dtype=torch.float)
EBA_input = torch.zeros(num_EBA, dtype=torch.float)
AI_input = torch.zeros(num_AI, dtype=torch.float)
FR_M1 = torch.zeros(num_M1, dtype=torch.float)
FR_V = torch.zeros(num_V, dtype=torch.float)
FR_S1 = torch.zeros( num_S1, dtype=torch.float)
FR_EBA = torch.zeros(num_EBA, dtype=torch.float)
FR_TPJ = torch.zeros(num_TPJ, dtype=torch.float)
FR_AI = torch.zeros( num_AI, dtype=torch.float)
dW_S1TPJ = torch.zeros(num_M1, dtype=torch.float)
dW_EBATPJ = torch.zeros(num_M1, dtype=torch.float)
dW_S1AI = torch.zeros(num_M1, dtype=torch.float)
dW_EBAAI = torch.zeros(num_M1, dtype=torch.float)
fire_threshold = 0.7
W_LatInh_Init = torch.ones(num_neuron, dtype=torch.float)*Init_Weight
W_LatInh_S1_AI = W_LatInh_Init
W_LatInh_EBA_AI = W_LatInh_Init
Fired_S1 = torch.zeros(num_S1, dtype=torch.float)
Fired_EBA = torch.zeros(num_EBA, dtype=torch.float)
with torch.no_grad():
for t in range(1,Time+1):
S_M1 = torch.zeros(num_M1, dtype=torch.float)
S_V = torch.zeros(num_V, dtype=torch.float)
if t>=Motion_Start and t<=Motion_End:
S_M1 = Coding[k]
M1_input = (1-(1-CM1)**t)*S_M1
else:
M1_input = S_M1
if t>=Vision_Start and t<=Vision_End:
S_V = Coding[k]
V_input = (1-(1-CV)**(t-CT))*S_V
else:
V_input = S_V
FR_M1_n = M1(M1_input)
FR_V_n = V(V_input)
[FR_S1_n, S1_input_n, Fired_S1, W_LatInh_S1_AI] = S1(S1_input, FR_M1_n, CS1, Fired_S1, W_LatInh_S1_AI)
[FR_EBA_n, EBA_input_n, Fired_EBA, W_LatInh_EBA_AI] = EBA(EBA_input, FR_V_n, CEBA, Fired_EBA, W_LatInh_EBA_AI)
FR_Input_TPJ_n = torch.stack((FR_S1_n, FR_EBA_n), 0)
[FR_TPJ_n, TPJ_input_n] = TPJ(TPJ_input, FR_Input_TPJ_n, CTPJ)
FR_Input_AI = torch.stack((FR_S1_n, FR_TPJ_n, FR_EBA_n), 0)
[FR_AI_n, AI_input_n] = AI(AI_input, FR_Input_AI, CAI)
# Update weights
# S1-AI
ddW_S1AI = DeltaWeight(FR_S1, FR_S1_n, FR_AI, FR_AI_n)
dW_S1AI = dW_S1AI + ddW_S1AI
# EBA-AI
ddW_EBAAI = DeltaWeight(FR_EBA, FR_EBA_n, FR_AI, FR_AI_n)
dW_EBAAI = dW_EBAAI + ddW_EBAAI
FR_M1 = FR_M1_n
FR_V = FR_V_n
FR_S1 = FR_S1_n
FR_EBA = FR_EBA_n
FR_TPJ = FR_TPJ_n
FR_AI = FR_AI_n
S1_input = S1_input_n
TPJ_input = TPJ_input_n
EBA_input = EBA_input_n
AI_input = AI_input_n
AI.UpdateWeight(0, dW_S1AI, W_LatInh_S1_AI)
AI.UpdateWeight(2, dW_EBAAI, W_LatInh_EBA_AI)
print(AI.connection[0].weight.data) # dW_S1AI
print(AI.connection[2].weight.data) # dW_EBAAI
M1.reset()
V.reset()
S1.reset()
EBA.reset()
TPJ.reset()
AI.reset()
np.save('W_S1_AI.npy', AI.connection[0].weight.data)
np.save('W_EBA_AI.npy', AI.connection[2].weight.data)
print('Training End')
================================================
FILE: examples/Embodied_Cognition/RHI/ReadMe.md
================================================
================================================
FILE: examples/Hardware_acceleration/README.md
================================================
## FireFly: A High-Throughput Hardware Accelerator for Spiking Neural Networks
### Demo of Deploying SNNs on FPGA platform
This is an example of deploying an SNN model on Xilinx Zynq Ultrascale FPGA based on Braincog.
### Requirements
- Xilinx Zynq Ultrascale FPGA evaluation board Ultra96v2 or ZCU104.
- PYNQ images for the chosen evaluation boards. You can download the latest pre-compiled images from the [PYNQ website](http://www.pynq.io/board.html), or you can compile a new one following the [PYNQ Tutorial](https://pynq.readthedocs.io/en/latest/). Install the PYNQ image to the SD card, and boot the evaluation board in SD mode.
### Examples
Clone the project to fetch the necessary bitstream files and pre-processed SNN models, copy all the files to the Ultra96v2 or ZCU104 board.
```shell
git clone https://github.com/adamgallas/firefly_v1_cifar_test
```
Open a terminal in Ultra96v2 or ZCU104. Install einops on Ultra96v2 or ZCU104.
```shell
cd firefly_v1_common
pip install einops-0.6.0-py3-none-any.whl
```
Run CIFAR10 classification test on Ultra96v2:
```shell
python ultra96_test.py
```
Run CIFAR10 classification test on ZCU104:
```python
python zcu104_test.py
```
### Citation
### Citation
If you find this work helpful, please consider citing it:
```BibTex
@article{li2023firefly,
title={FireFly: A High-Throughput Hardware Accelerator for Spiking Neural Networks With Efficient DSP and Memory Optimization},
author={Li, Jindong and Shen, Guobin and Zhao, Dongcheng and Zhang, Qian and Zeng, Yi},
journal={IEEE Transactions on Very Large Scale Integration (VLSI) Systems},
year={2023},
publisher={IEEE}
}
```
================================================
FILE: examples/Hardware_acceleration/firefly_v1_schedule_on_pynq.py
================================================
import numpy as np
import tqdm
from standalone_utils import *
import math
import time
import ctypes as ct
class FireFlyV1ConvSchedule:
def __init__(
self,
ctrl_io,
allocate_method,
input_buffer_addr,
output_buffer_addr,
weight_data,
bias_data,
parallel_channel=16,
kernel_size=3,
input_channels=64,
output_channels=128,
width=32,
height=32,
enable_pooling=False,
direct_adapt=False,
winner_takes_all=False,
final_conv=False,
time_step=8,
threshold=64,
max_cnt=2048
):
self.ctrl_io = ctrl_io
self.input_buffer_addr = np.uint32(input_buffer_addr)
self.output_buffer_addr = np.uint32(output_buffer_addr)
self.weight_buffer = allocate_method(shape=weight_data.size, dtype=np.int8)
self.bias_buffer = allocate_method(shape=bias_data.size, dtype=np.int16)
self.weight_buffer_addr = np.uint32(self.weight_buffer.device_address)
self.bias_buffer_addr = np.uint32(self.bias_buffer.device_address)
self.weight_buffer[:] = np.ascontiguousarray(weight_data.flatten())
self.bias_buffer[:] = np.ascontiguousarray(bias_data.flatten())
self.weight_buffer.flush()
self.bias_buffer.flush()
self.max_cnt = max_cnt
self.parallel_channel = np.uint32(parallel_channel)
self.kernel_size = np.uint32(kernel_size)
self.input_channels = np.uint32(input_channels)
self.output_channels = np.uint32(output_channels)
self.width = np.uint32(width)
self.height = np.uint32(height)
self.enable_pooling = np.uint32(enable_pooling)
self.direct_adapt = np.uint32(direct_adapt)
self.winner_takes_all = np.uint32(winner_takes_all)
self.time_step = np.uint32(time_step)
self.threshold = np.int32(threshold)
self.out_width = np.uint32(width >> enable_pooling)
self.out_height = np.uint32(height >> enable_pooling)
self.numOfIFMs = np.uint32(input_channels / parallel_channel - 1)
self.numOfOFMs = np.uint32(output_channels / parallel_channel - 1)
self.numOfTimeSteps = np.uint32(time_step - 1)
self.numOfTimeStepIFMs = np.uint32((input_channels / parallel_channel) * time_step - 1)
self.numOfTimeStepOFMs = np.uint32((output_channels / parallel_channel) * time_step - 1)
self.weightsLength = np.uint32(input_channels - 1)
if direct_adapt:
factor = kernel_size * kernel_size
padded_length = math.ceil(input_channels / parallel_channel / factor)
self.numOfIFMs = np.uint32(padded_length - 1)
self.numOfTimeStepIFMs = np.uint32(padded_length * time_step - 1)
self.weightsLength = np.uint32(padded_length * parallel_channel - 1)
self.out_width = np.uint32(1)
self.out_height = np.uint32(1)
self.mm2s_fix_len = np.uint32(self.width * self.height * self.time_step * self.input_channels / 8)
self.s2mm_fix_len = np.uint32(self.out_width * self.out_height * self.parallel_channel / 8)
self.bias_len = np.uint32(self.output_channels * 2)
self.weight_len = np.uint32(self.output_channels * self.input_channels * self.kernel_size * self.kernel_size)
self.stride_of_channel = np.uint32(self.out_width * self.out_height * self.parallel_channel / 8)
self.stride_of_time_step = np.uint32(self.out_width * self.out_height * self.output_channels / 8)
if direct_adapt:
self.mm2s_fix_len = np.uint32(self.time_step * self.input_channels / 8)
self.weight_len = np.uint32(self.output_channels * self.input_channels)
self.stride_of_channel = np.uint32(2 * self.parallel_channel / 8)
self.stride_of_time_step = np.uint32(2 * self.output_channels / 8)
if final_conv:
self.flatten_channel = np.uint32(self.out_width * self.out_height * self.output_channels)
factor = kernel_size * kernel_size * 8 * 4
round_channel = int(math.ceil(self.flatten_channel / factor) * factor)
self.stride_of_time_step = np.uint32(round_channel / 8)
self.configReg_0x00 = np.uint32(((self.time_step - 1) << 16) + (self.numOfOFMs << 8) + self.numOfIFMs).tobytes()
self.configReg_0x04 = np.uint32((self.numOfTimeStepOFMs << 12) + self.numOfTimeStepIFMs).tobytes()
self.configReg_0x08 = np.uint32((self.threshold << 14) + self.weightsLength).tobytes()
self.configReg_0x0c = np.uint32((self.winner_takes_all << 30) + (self.direct_adapt << 29) + (
self.enable_pooling << 28) + ((self.height - 1) << 16) + self.width - 1).tobytes()
self.configReg_0x20 = np.uint32(self.stride_of_time_step).tobytes()
self.configReg_0x24 = np.uint32(self.stride_of_channel).tobytes()
self.configReg_0x28 = np.uint32(self.input_buffer_addr).tobytes()
self.configReg_0x2c = np.uint32(self.output_buffer_addr).tobytes()
self.configReg_0x30 = np.uint32(self.mm2s_fix_len).tobytes()
self.configReg_0x34 = np.uint32(self.s2mm_fix_len).tobytes()
self.configReg_0x38 = np.uint32(self.weight_buffer_addr).tobytes()
self.configReg_0x3c = np.uint32(self.weight_len).tobytes()
self.configReg_0x40 = np.uint32(self.bias_buffer_addr).tobytes()
self.configReg_0x44 = np.uint32(self.bias_len).tobytes()
self.paramCmd = np.uint32(0x00010000).tobytes()
self.inOutCmd = np.uint32(0x00000101).tobytes()
def gen_cmd(self):
cmd_list = []
cmd_list.append(np.frombuffer(self.configReg_0x00, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x04, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x08, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x0c, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x20, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x24, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x28, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x2c, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x30, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x34, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x38, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x3c, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x40, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.configReg_0x44, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.paramCmd, dtype=np.uint32))
cmd_list.append(np.frombuffer(self.inOutCmd, dtype=np.uint32))
return np.array(cmd_list).flatten()
def send_config(self):
self.ctrl_io.write(0x00, self.configReg_0x00)
self.ctrl_io.write(0x04, self.configReg_0x04)
self.ctrl_io.write(0x08, self.configReg_0x08)
self.ctrl_io.write(0x0c, self.configReg_0x0c)
self.ctrl_io.write(0x20, self.configReg_0x20)
self.ctrl_io.write(0x24, self.configReg_0x24)
self.ctrl_io.write(0x28, self.configReg_0x28)
self.ctrl_io.write(0x2c, self.configReg_0x2c)
self.ctrl_io.write(0x30, self.configReg_0x30)
self.ctrl_io.write(0x34, self.configReg_0x34)
self.ctrl_io.write(0x38, self.configReg_0x38)
self.ctrl_io.write(0x3c, self.configReg_0x3c)
self.ctrl_io.write(0x40, self.configReg_0x40)
self.ctrl_io.write(0x44, self.configReg_0x44)
def begin_schedule_non_blocking(self):
self.ctrl_io.write(0x48, self.paramCmd)
self.ctrl_io.write(0x48, self.paramCmd)
self.ctrl_io.write(0x48, self.inOutCmd)
def begin_schedule_blocking(self):
self.begin_schedule_non_blocking()
while self.ctrl_io.read(0x18, length=8) == 0:
continue
self.clear_schedule()
def clear_schedule(self):
self.ctrl_io.write(0x18, 0)
def run_all(self):
self.ctrl_io.write(0x00, self.configReg_0x00)
self.ctrl_io.write(0x04, self.configReg_0x04)
self.ctrl_io.write(0x08, self.configReg_0x08)
self.ctrl_io.write(0x0c, self.configReg_0x0c)
self.ctrl_io.write(0x20, self.configReg_0x20)
self.ctrl_io.write(0x24, self.configReg_0x24)
self.ctrl_io.write(0x28, self.configReg_0x28)
self.ctrl_io.write(0x2c, self.configReg_0x2c)
self.ctrl_io.write(0x30, self.configReg_0x30)
self.ctrl_io.write(0x34, self.configReg_0x34)
self.ctrl_io.write(0x38, self.configReg_0x38)
self.ctrl_io.write(0x3c, self.configReg_0x3c)
self.ctrl_io.write(0x40, self.configReg_0x40)
self.ctrl_io.write(0x44, self.configReg_0x44)
self.ctrl_io.write(0x48, self.paramCmd)
self.ctrl_io.write(0x48, self.paramCmd)
self.ctrl_io.write(0x48, self.inOutCmd)
cnt = 0
while self.ctrl_io.read(0x18, length=8) == 0:
cnt = cnt + 1
if cnt > self.max_cnt:
print("timeout, abort!")
break
end = time.time()
self.ctrl_io.write(0x18, 0)
def read_status(self):
status = np.uint32(self.ctrl_io.read(0x50, length=4)).tobytes()
busy_status = status[0]
input_status = status[1]
output_status = status[2]
param_status = status[3]
print("busy_status", busy_status)
print("input_status", input_status)
print("output_status", output_status)
print("param_status", param_status)
def create_schedule(model_config_list: list,
ctrl_io,
allocate_method,
buffer_0,
buffer_1,
image_height,
image_width,
time_step=4,
parallel_channel=16
):
schedule_list = []
curr_image_height = image_height
curr_image_width = image_width
input_buffer_addr = buffer_0.device_address
output_buffer_addr = buffer_1.device_address
for config in model_config_list:
if config["layer_type"] == "conv+IFNode":
schedule = FireFlyV1ConvSchedule(
ctrl_io=ctrl_io,
allocate_method=allocate_method,
input_buffer_addr=input_buffer_addr,
output_buffer_addr=output_buffer_addr,
weight_data=conv_weight_channel_tiling(parallel_channel, config["weight"]),
bias_data=config["bias"].flatten(),
parallel_channel=parallel_channel,
kernel_size=3,
input_channels=config["input_channel"],
output_channels=config["output_channel"],
width=curr_image_width,
height=curr_image_height,
enable_pooling=False,
time_step=time_step,
threshold=config["threshold"],
final_conv="flatten" in config
)
schedule_list.append(schedule)
input_buffer_addr, output_buffer_addr = output_buffer_addr, input_buffer_addr
elif config["layer_type"] == "conv+IFNode+maxpool":
schedule = FireFlyV1ConvSchedule(
ctrl_io=ctrl_io,
allocate_method=allocate_method,
input_buffer_addr=input_buffer_addr,
output_buffer_addr=output_buffer_addr,
weight_data=conv_weight_channel_tiling(parallel_channel, config["weight"]),
bias_data=config["bias"].flatten(),
parallel_channel=parallel_channel,
kernel_size=3,
input_channels=config["input_channel"],
output_channels=config["output_channel"],
width=curr_image_width,
height=curr_image_height,
enable_pooling=True,
time_step=time_step,
threshold=config["threshold"],
final_conv="flatten" in config
)
schedule_list.append(schedule)
input_buffer_addr, output_buffer_addr = output_buffer_addr, input_buffer_addr
curr_image_height = int(curr_image_height / 2)
curr_image_width = int(curr_image_width / 2)
elif config["layer_type"].__contains__("linear"):
input_channel = config["input_channel"]
weight = config["weight"]
if "weight_reshape" in config:
factor = 9 * 8 * 4
round_channel = int(math.ceil(input_channel / factor) * factor)
weight = rearrange(weight, "o (i p h w) -> o (i h w p)", p=parallel_channel,
h=curr_image_height, w=curr_image_width)
weight = np.pad(weight, ((0, 0), (0, round_channel - input_channel)), mode="constant")
input_channel = round_channel
weight = linear_weight_channel_tiling(parallel_channel, weight)
schedule = FireFlyV1ConvSchedule(
ctrl_io=ctrl_io,
allocate_method=allocate_method,
input_buffer_addr=input_buffer_addr,
output_buffer_addr=output_buffer_addr,
weight_data=weight,
bias_data=config["bias"].flatten(),
parallel_channel=parallel_channel,
kernel_size=3,
input_channels=input_channel,
output_channels=config["output_channel"],
width=3,
height=3,
enable_pooling=False,
time_step=time_step,
threshold=config["threshold"],
direct_adapt=config["direct_adapt"],
winner_takes_all=config["winner_take_all"]
)
schedule_list.append(schedule)
input_buffer_addr, output_buffer_addr = output_buffer_addr, input_buffer_addr
return schedule_list, input_buffer_addr
def schedule_run_all(schedule_list):
for schedule in schedule_list:
schedule.run_all()
def gen_cmd_array(schedule_list):
cmd_array = []
for schedule in schedule_list:
cmd_array.append(schedule.gen_cmd().flatten())
return np.array(cmd_array)
def init_firefly_c_lib(path, schedule_list):
cmd_arr = gen_cmd_array(schedule_list)
lib = ct.CDLL(path)
sche = lib.firefly_v1_schedule
u32Ptr = ct.POINTER(ct.c_uint32)
u32PtrPtr = ct.POINTER(u32Ptr)
ct_arr = np.ctypeslib.as_ctypes(cmd_arr)
u32PtrArr = u32Ptr * ct_arr._length_
ct_ptr = ct.cast(u32PtrArr(*(ct.cast(row, u32Ptr) for row in ct_arr)), u32PtrPtr)
sche_len = ct.c_uint8(cmd_arr.shape[0])
return sche, ct_ptr, sche_len
def init_firefly_c_lib_with_time(path, schedule_list):
cmd_arr = gen_cmd_array(schedule_list)
lib = ct.CDLL(path)
sche = lib.firefly_v1_schedule_time_it
u32Ptr = ct.POINTER(ct.c_uint32)
u32PtrPtr = ct.POINTER(u32Ptr)
ct_arr = np.ctypeslib.as_ctypes(cmd_arr)
u32PtrArr = u32Ptr * ct_arr._length_
ct_ptr = ct.cast(u32PtrArr(*(ct.cast(row, u32Ptr) for row in ct_arr)), u32PtrPtr)
sche_len = ct.c_uint8(cmd_arr.shape[0])
return sche, ct_ptr, sche_len
def firefly_v1_simulate(model_config_list, x):
for config in model_config_list:
if config["layer_type"] == "input_quant_stub":
x = np_quantize_prepare(x, config["scale"], config["zero_point"])
elif config["layer_type"] == "encoder+conv+IFNode":
x = direct_coding(x, config["weight"], config["bias"], config["time_step"], config["threshold"])
elif config["layer_type"] == "conv+IFNode":
x = conv_ifnode_forward(x, config["weight"], config["bias"], config["threshold"])
elif config["layer_type"] == "conv+IFNode+maxpool":
x = conv_ifnode_maxpool_forward(x, config["weight"], config["bias"], config["threshold"])
elif config["layer_type"] == "linear+WTA":
x = linear_wta_forward(x, config["weight"], config["bias"])
elif config["layer_type"] == "linear+IFNode":
x = linear_ifnode_forward(x, config["weight"], config["bias"], config["threshold"])
return x
def evaluate_simulate(model_config_list, sample):
correct = 0
for (image, target) in tqdm.tqdm(zip(sample[0], sample[1]), total=len(sample[0])):
sim_in = np.expand_dims(image.numpy(), axis=0)
_, sim_out = firefly_v1_simulate(model_config_list, sim_in)
correct += sim_out == target.item()
return correct / len(sample[0])
================================================
FILE: examples/Hardware_acceleration/standalone_utils.py
================================================
import math
import numpy as np
from einops import rearrange
def get_im2col_indices(x_shape, field_height, field_width, padding=1, stride=1):
N, C, H, W = x_shape
assert (H + 2 * padding - field_height) % stride == 0
assert (W + 2 * padding - field_height) % stride == 0
out_height = int((H + 2 * padding - field_height) / stride + 1)
out_width = int((W + 2 * padding - field_width) / stride + 1)
i0 = np.repeat(np.arange(field_height), field_width)
i0 = np.tile(i0, C)
i1 = stride * np.repeat(np.arange(out_height), out_width)
j0 = np.tile(np.arange(field_width), field_height * C)
j1 = stride * np.tile(np.arange(out_width), out_height)
i = i0.reshape(-1, 1) + i1.reshape(1, -1)
j = j0.reshape(-1, 1) + j1.reshape(1, -1)
k = np.repeat(np.arange(C), field_height * field_width).reshape(-1, 1)
return k, i, j
def im2col_indices(x, field_height, field_width, padding=1, stride=1):
p = padding
x_padded = np.pad(x, ((0, 0), (0, 0), (p, p), (p, p)), mode='constant')
k, i, j = get_im2col_indices(x.shape, field_height, field_width, padding, stride)
cols = x_padded[:, k, i, j]
C = x.shape[1]
cols = cols.transpose(1, 2, 0).reshape(field_height * field_width * C, -1)
return cols
def max_pool_forward_reshape(x, pool_param):
N, C, H, W = x.shape
pool_height, pool_width = pool_param['pool_height'], pool_param['pool_width']
stride = pool_param['stride']
assert pool_height == pool_width == stride, 'Invalid pool params'
assert H % pool_height == 0
assert W % pool_height == 0
x_reshaped = x.reshape(N, C, int(H / pool_height), pool_height, int(W / pool_width), pool_width)
out = x_reshaped.max(axis=3).max(axis=4)
return out
def max_pool_forward_fast(x, pool_param):
N, C, H, W = x.shape
pool_height, pool_width = pool_param['pool_height'], pool_param['pool_width']
stride = pool_param['stride']
same_size = pool_height == pool_width == stride
tiles = H % pool_height == 0 and W % pool_width == 0
if same_size and tiles:
out = max_pool_forward_reshape(x, pool_param)
else:
out = max_pool_forward_im2col(x, pool_param)
return out
def max_pool_forward_im2col(x, pool_param):
N, C, H, W = x.shape
pool_height, pool_width = pool_param['pool_height'], pool_param['pool_width']
stride = pool_param['stride']
assert (H - pool_height) % stride == 0, 'Invalid height'
assert (W - pool_width) % stride == 0, 'Invalid width'
out_height = int((H - pool_height) / stride + 1)
out_width = int((W - pool_width) / stride + 1)
x_split = x.reshape(N * C, 1, H, W)
x_cols = im2col_indices(x_split, pool_height, pool_width, padding=0, stride=stride)
x_cols_argmax = np.argmax(x_cols, axis=0)
x_cols_max = x_cols[x_cols_argmax, np.arange(x_cols.shape[1])]
out = x_cols_max.reshape(out_height, out_width, N, C).transpose(2, 3, 0, 1)
return out
def conv_forward_fast(x, w, b, pad=1, stride=1):
N, C, H, W = x.shape
# x = x.astype(np.int32)
w = w.astype(np.int32)
b = b.astype(np.int16)
num_filters, _, filter_height, filter_width = w.shape
out_height = int((H + 2 * pad - filter_height) / stride + 1)
out_width = int((W + 2 * pad - filter_width) / stride + 1)
out = np.zeros((N, num_filters, out_height, out_width), dtype=np.int32)
x_cols = im2col_indices(x, w.shape[2], w.shape[3], pad, stride)
res = w.reshape((w.shape[0], -1)).dot(x_cols) + b.reshape(-1, 1)
out = res.reshape(w.shape[0], out.shape[2], out.shape[3], x.shape[0])
out = out.transpose(3, 0, 1, 2)
return out
def spike_map_pack_to_bytes_array(spike_map, parallel):
buf_in = rearrange(spike_map, 't (c p) h w->t c h w p', p=parallel)
buf_in = np.packbits(buf_in.flatten(), bitorder='little')
return buf_in
def bytes_array_split_to_spike_map(buf_in, time_step, parallel, H, W):
unpacked = np.unpackbits(buf_in, bitorder='little')
unpacked = rearrange(unpacked, '(t c h w p)->t (c p) h w', t=time_step, p=parallel, h=H, w=W)
return unpacked
def preprocess(model_config_list, x, parallel):
time_step = model_config_list[1]["time_step"]
scale = model_config_list[0]["scale"]
zero_point = model_config_list[0]["zero_point"]
weight = model_config_list[1]["weight"]
bias = model_config_list[1]["bias"]
threshold = model_config_list[1]["threshold"]
encode_in = np_quantize_prepare(x, scale, zero_point)
encode_in = np.expand_dims(encode_in, axis=0)
firefly_in = direct_coding(encode_in, weight, bias, time_step, threshold)
packed = spike_map_pack_to_bytes_array(firefly_in, parallel)
return firefly_in, packed
def integrate_and_fire(y, threshold):
membrane = np.zeros(y.shape[1:], dtype=np.int32)
out_spike = []
for v in y:
membrane = membrane + v
o = membrane > threshold
out_spike.append(o)
membrane[o] = 0
return np.array(out_spike)
def direct_coding(x, w, b, time_step, threshold):
x = x.repeat(time_step, axis=0)
out_spike = conv_ifnode_forward(x, w, b, threshold)
return out_spike
def conv_ifnode_forward(x, w, b, threshold):
y = conv_forward_fast(x, w, b)
out_spike = integrate_and_fire(y, threshold)
return out_spike
def conv_ifnode_maxpool_forward(x, w, b, threshold):
y = conv_ifnode_forward(x, w, b, threshold)
out_spike = max_pool_forward_fast(y, {'pool_height': 2, 'pool_width': 2, 'stride': 2})
return out_spike
def linear_wta_forward(x, w, b):
x = x.astype(np.int32)
w = w.astype(np.int32)
b = b.astype(np.int32)
x = x.reshape([x.shape[0], -1])
x = np.pad(x, ((0, 0), (0, w.shape[1] - x.shape[1])), 'constant')
out = np.dot(x, w.T) + b
out_sum = out.sum(axis=0)
max_index = out_sum.argmax()
return out, max_index
def linear_ifnode_forward(x, w, b, threshold):
x = x.astype(np.int32)
w = w.astype(np.int32)
b = b.astype(np.int32)
x = x.reshape([x.shape[0], -1])
x = np.pad(x, ((0, 0), (0, w.shape[1] - x.shape[1])), 'constant')
out = np.dot(x, w.T) + b
out_spike = integrate_and_fire(out, threshold)
return out_spike
def pad_conv_weight_round_to_parallel(parallel, weight, pad_output_channel_only=False):
output_channel = weight.shape[0]
input_channel = weight.shape[1]
padded_output_channel = (parallel - (output_channel % parallel)) % parallel
padded_input_channel = (parallel - (input_channel % parallel)) % parallel
if pad_output_channel_only:
padded_input_channel = 0
new_weight = np.pad(weight, ((0, padded_output_channel), (0, padded_input_channel), (0, 0), (0, 0)), 'constant')
return new_weight
def pad_linear_weight_round_to_parallel(parallel, weight):
output_channel = weight.shape[0]
padded_output_channel = (parallel - (output_channel % parallel)) % parallel
new_weight = np.pad(weight, ((0, padded_output_channel), (0, 0)), 'constant')
return new_weight
def pad_linear_weight_round_to_factor(weight, factor):
input_channel = weight.shape[1]
round_channel = int(math.ceil(input_channel / factor) * factor)
padded_input_channel = round_channel - input_channel
new_weight = np.pad(weight, ((0, 0), (0, padded_input_channel)), 'constant')
return new_weight
def pad_bias_round_to_parallel(parallel, bias, pad_value=0):
channel = bias.shape[0]
padded_channel = (parallel - (channel % parallel)) % parallel
new_bias = np.pad(bias, (0, padded_channel), 'constant', constant_values=pad_value)
return new_bias
def np_quantize_per_tensor(x, scale, zero_point):
q_min = np.iinfo(np.int8).min
q_max = np.iinfo(np.int8).max
x = np.round(x / scale + zero_point)
x = np.clip(x, q_min, q_max)
return x.astype(np.int8)
def np_quantize_prepare(x, scale, zero_point):
x = np_quantize_per_tensor(x, scale, zero_point)
return x - zero_point
def conv_weight_channel_tiling(parallel, weight):
return rearrange(weight, '(o op) (i ip) kr kc -> (o i kr kc) ip op', op=parallel, ip=parallel)
def linear_weight_channel_tiling(parallel, weight):
return rearrange(weight, '(o op) (i ip) -> (o i) ip op', op=parallel, ip=parallel)
def conv_to_linear_weight_tiling(parallel, h, w, weight):
rearrange(weight, '(o op) (i ip h w)-> (o i h w) ip op', op=parallel, ip=parallel, h=h, w=w)
def init_input_buffer(input_spikes,
parallel=16,
stride_of_channel=8 * 1024,
stride_of_time_step=512 * 1024):
t, c, h, w = input_spikes.shape
input_spikes_rearrange = rearrange(input_spikes, 't (c p) h w -> t c (h w p)', p=parallel)
pack_spikes = np.packbits(input_spikes_rearrange, axis=-1, bitorder='little')
input_buffer = np.zeros(stride_of_time_step * t, dtype=np.uint8)
length = int(h * w * parallel / 8)
for i in range(t):
for j in range(int(c / parallel)):
addr = i * stride_of_time_step + j * stride_of_channel
input_buffer[addr:addr + length] = pack_spikes[i, j]
return input_buffer
def get_from_output_buffer(output_buffer,
t, c, h, w,
parallel=16,
stride_of_channel=8 * 1024,
stride_of_time_step=512 * 1024):
ret = []
length = int(h * w * parallel / 8)
for i in range(t):
for j in range(int(c / parallel)):
addr = i * stride_of_time_step + j * stride_of_channel
ret.append(output_buffer[addr:addr + length])
ret = np.array(ret)
ret = np.unpackbits(ret, axis=-1, bitorder='little')
ret = rearrange(ret, '(t c) (h w p) -> t (c p) h w', p=parallel, t=t, h=h, w=w)
return ret.astype(bool)
def get_output_index(buffer, parallel):
valid_data = buffer[:parallel]
if parallel == 16:
return np.unpackbits(valid_data[12:14], bitorder='little').argmax()
elif parallel == 32:
return np.unpackbits(valid_data[24:28], bitorder='little').argmax()
else:
return 0
def save_model_config_list(model_config_list, path):
np.save(path, model_config_list)
return
def load_model_config_list(path):
model_config_list = np.load(path, allow_pickle=True)
return model_config_list
================================================
FILE: examples/Hardware_acceleration/ultra96_test.py
================================================
from standalone_utils import *
from firefly_v1_schedule_on_pynq import *
from pynq import PL
from pynq import Overlay
from pynq import allocate
from pynq import MMIO
import numpy as np
import time
from einops import rearrange
ol = Overlay('firefly_v1_ultra96_bitstream/sys_wrapper.bit')
image = np.load("firefly_v1_cifar10_data/image.npy")
target = np.load("firefly_v1_cifar10_data/target.npy")
model_config_list = load_model_config_list("firefly_v1_cifar10_data/snn7_cifar10_x16.npy")
input_buffer = allocate(shape=(1<<23), dtype=np.uint8)
output_buffer = allocate(shape=(1<<23), dtype=np.uint8)
ctrl_io = MMIO(0x0400000000, 0x400)
schedule_list,output_addr=create_schedule(
model_config_list=model_config_list,
ctrl_io=ctrl_io,
allocate_method=allocate,
buffer_0=input_buffer,
buffer_1=output_buffer,
image_height=32,
image_width=32,
time_step=4,
parallel_channel=16
)
sche, ct_ptr, sche_len = init_firefly_c_lib_with_time("firefly_v1_common/firefly_v1_lib.so", schedule_list)
print(" ----------------- initialize finish!")
print(" ----------------- python schedule begin")
err_cnt = 0
for i in range(len(image)):
image_0 = image[i]
target_0 = target[i]
print(i)
start = time.time()
firefly_in, input_packed = preprocess(model_config_list, image_0, 16)
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
end = time.time()
elapsed = round((end - start) * 1000000)
# print("preprocess:", elapsed, "us")
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
start = time.time()
schedule_run_all(schedule_list)
end = time.time()
elapsed = round((end - start) * 1000000)
print("snn inference:", elapsed, "us")
output_buffer.invalidate()
test_out = output_buffer[:16]
test_index = np.unpackbits(test_out[12:14],bitorder='little').argmax()
print("test result:", test_index,"gold result", target_0)
if test_index != target_0:
err_cnt = err_cnt + 1
print("accuray: " , 1 - err_cnt/len(image))
print(" ----------------- python schedule finish")
print(" ----------------- c schedule begin")
err_cnt = 0
for i in range(len(image)):
image_0 = image[i]
target_0 = target[i]
print(i)
start = time.time()
firefly_in, input_packed = preprocess(model_config_list, image_0, 16)
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
end = time.time()
elapsed = round((end - start) * 1000000)
# print("preprocess:", elapsed, "us")
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
start = time.time()
sche(ct_ptr, sche_len)
end = time.time()
elapsed = round((end - start) * 1000000)
# print("clib inference call:", elapsed, "us")
output_buffer.invalidate()
test_out = output_buffer[:16]
test_index = np.unpackbits(test_out[12:14],bitorder='little').argmax()
print("test result:", test_index,"gold result", target_0)
if test_index != target_0:
err_cnt = err_cnt + 1
print("accuray: " , 1 - err_cnt/len(image))
print(" ----------------- c schedule finish")
================================================
FILE: examples/Hardware_acceleration/zcu104_test.py
================================================
from standalone_utils import *
from firefly_v1_schedule_on_pynq import *
from pynq import PL
from pynq import Overlay
from pynq import allocate
from pynq import MMIO
import numpy as np
import time
from einops import rearrange
ol = Overlay('firefly_v1_zcu104_bitstream/sys_wrapper.bit')
image = np.load("firefly_v1_cifar10_data/image.npy")
target = np.load("firefly_v1_cifar10_data/target.npy")
model_config_list = load_model_config_list("firefly_v1_cifar10_data/snn7_cifar10_x32.npy")
input_buffer = allocate(shape=(1<<23), dtype=np.uint8)
output_buffer = allocate(shape=(1<<23), dtype=np.uint8)
ctrl_io = MMIO(0x0400000000, 0x400)
schedule_list,output_addr=create_schedule(
model_config_list=model_config_list,
ctrl_io=ctrl_io,
allocate_method=allocate,
buffer_0=input_buffer,
buffer_1=output_buffer,
image_height=32,
image_width=32,
time_step=4,
parallel_channel=32
)
sche, ct_ptr, sche_len = init_firefly_c_lib_with_time("firefly_v1_common/firefly_v1_lib.so", schedule_list)
print(" ----------------- initialize finish!")
print(" ----------------- python schedule begin")
err_cnt = 0
for i in range(len(image)):
image_0 = image[i]
target_0 = target[i]
print(i)
start = time.time()
firefly_in, input_packed = preprocess(model_config_list, image_0, 32)
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
end = time.time()
elapsed = round((end - start) * 1000000)
# print("preprocess:", elapsed, "us")
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
start = time.time()
schedule_run_all(schedule_list)
end = time.time()
elapsed = round((end - start) * 1000000)
print("snn inference:", elapsed, "us")
output_buffer.invalidate()
test_out = output_buffer[:32]
test_index = np.unpackbits(test_out[24:28],bitorder='little').argmax()
print("test result:", test_index,"gold result", target_0)
if test_index != target_0:
err_cnt = err_cnt + 1
print("accuray: " , 1 - err_cnt/len(image))
print(" ----------------- python schedule finish")
print(" ----------------- c schedule begin")
err_cnt = 0
for i in range(len(image)):
image_0 = image[i]
target_0 = target[i]
print(i)
start = time.time()
firefly_in, input_packed = preprocess(model_config_list, image_0, 32)
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
end = time.time()
elapsed = round((end - start) * 1000000)
# print("preprocess:", elapsed, "us")
input_buffer[:input_packed.size]=input_packed
input_buffer.flush()
start = time.time()
sche(ct_ptr, sche_len)
end = time.time()
elapsed = round((end - start) * 1000000)
# print("clib inference call:", elapsed, "us")
output_buffer.invalidate()
test_out = output_buffer[:32]
test_index = np.unpackbits(test_out[24:28],bitorder='little').argmax()
print("test result:", test_index,"gold result", target_0)
if test_index != target_0:
err_cnt = err_cnt + 1
print("accuray: " , 1 - err_cnt/len(image))
print(" ----------------- c schedule finish")
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/CKRGSNN/README.md
================================================
# Commonsense Knowledge Representation SNN
(https://arxiv.org/abs/2207.05561)
This repository contains code from our paper [**Brain-inspired Graph Spiking Neural Networks for Commonsense Knowledge Representation and Reasoning**] preprint in: https://arxiv.org/abs/2207.05561 . If you use our code or refer to this project, please cite this paper.
## Requirments
* python=3.8
* numpy
* scipy
* turicreate
* pytorch >= 1.7.0
* torchvision
## Dataset
ConceptNet: https://github.com/commonsense/conceptnet5
## Run
```shell
python main.py
```
This module selects core knowledge in ConceptNet to form the sub_Concept.csv file as the input of the model. The input current, spike trains during the learning process and the network weight distribution after the learning are shown in the Results folder.
### Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{KRRfang2022,
title = {Brain-inspired Graph Spiking Neural Networks for Commonsense Knowledge Representation and Reasoning},
author = { Fang, Hongjian and Zeng, Yi and Tang, Jianbo and Wang, Yuwei and Liang, Yao and Liu, Xin},
journal = {arXiv preprint arXiv:2207.05561},
year = {2022}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/CKRGSNN/main.py
================================================
import time
import numpy as np
import os
import warnings
import scipy.io as scio
import math
from matplotlib import pyplot as plt
import torch
from braincog.base.node.node import *
import turicreate as tc
from braincog.base.brainarea.BrainArea import *
from braincog.utils import *
warnings.filterwarnings('ignore')
np.set_printoptions(threshold=np.inf)
class CKRNet(BrainArea):
"""
Commonsense Knowledge Representation Net
"""
def __init__(self, w1, w2):
"""
"""
super().__init__()
self.node = [LIFNode(threshold=16, tau=15)]
self.connection = [CustomLinear(w1), CustomLinear(w2)]
self.stdp = []
self.stdp.append(MutliInputSTDP(self.node[0], [self.connection[0], self.connection[1]], decay=0.83))
self.x1 = torch.zeros(1, w2.shape[0])
def forward(self, x):
"""
x is spike train
"""
self.x1, dw1 = self.stdp[0](self.x1, x)
return self.x1, dw1
def reset(self):
self.x1 *= 0
def S_bound(S):
S[S > synapse_bound] = synapse_bound
S[S < -synapse_bound] = -synapse_bound
for i in range(N_entity):
temp1 = S[Index_E[i], :]
temp2 = temp1[:, Index_E[i]]
temp2[temp2 > inner_bound_E] = inner_bound_E
temp1[:, Index_E[i]] = temp2
S[Index_E[i], :] = temp1
for i in range(N_relation):
temp1 = S[Index_R[i], :]
temp2 = temp1[:, Index_R[i]]
temp2[temp2 > inner_bound_R] = inner_bound_R
temp1[:, Index_R[i]] = temp2
S[Index_R[i], :] = temp1
return S
if __name__ == "__main__":
print(os.getcwd())
KG = tc.SFrame.read_csv('./sub_Conceptnet.csv')
Set_R = set()
Set_E = set()
for i in range(KG.shape[0]):
Set_R.add(KG[i]['Relation'])
Set_E.add(KG[i]['Head'])
Set_E.add(KG[i]['Tail'])
List_E = sorted(Set_E)
List_R = list(Set_R)
List_R.sort()
# Network Parameter#dkenf.kejlklkelkvjlkxjel
I_syn = 5
tau_m = 30
I_t = 3 # Time duration of stimu current
I_P = 150 # Strength of input current
A_P = 0.009
certainty = 0.2
synapse_bound = 1 # The bound of all synapse
inner_bound_E = 0.6 # The bound of population inner synapse
inner_bound_R = 0.3 # The bound of population inner synapse
Ce = 20 # num of entity
Cr = 100 # num of relation
N_entity = len(List_E)
N_relation = len(List_R)
total_neurons = Ce * N_entity + Cr * N_relation
KG_No = KG.shape[0]
trail_time = 40
runtime = KG_No * trail_time
print('N_entity=', N_entity)
print('N_relation=', N_relation)
print('KG_No=', KG_No)
print('runtime=', runtime)
print('total_neurons=', total_neurons)
S = np.zeros((total_neurons, total_neurons), dtype=float) # Initial Weights
S = torch.tensor(S, dtype=torch.float32)
E = np.identity((total_neurons), dtype=float)
E = torch.tensor(E, dtype=torch.float32)
I_stimu = np.zeros((total_neurons, runtime))
ADJ = np.zeros((total_neurons, runtime)) # record the firing condition
Index_E = []
Index_R = []
for i in range(N_entity):
Index_E.append(np.arange(i * Ce, i * Ce + Ce))
for i in range(N_relation):
Index_R.append(np.arange(N_entity * Ce + i * Cr, N_entity * Ce + i * Cr + Cr))
for i in range(KG_No):
Head = KG[i]['Head']
Rela = KG[i]['Relation']
Tail = KG[i]['Tail']
Weig = KG[i]['Weight']
# print(List_E.index(Head))
# print(List_R.index(Rela))
# print(List_E.index(Rela))
# print(Index_R[List_R.index(Rela)])
I_stimu[Index_E[List_E.index(Head)], 10 + i * trail_time: 10 + I_t + i * trail_time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[Index_R[List_R.index(Rela)], 15 + i * trail_time: 15 + I_t + i * trail_time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[Index_E[List_E.index(Tail)], 20 + i * trail_time: 20 + I_t + i * trail_time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
CKRGSNN = CKRNet(S, E)
for t in range(runtime):
I_input = torch.tensor(I_stimu[:, t].reshape(1, total_neurons), dtype=torch.float32)
x, dw = CKRGSNN(I_input)
S += A_P * dw[1]
S += S_bound(S) - S
ADJ[:, t] = x
print(t, 'step in >>', runtime)
img_I = plt.matshow(I_stimu)
plt.savefig("I_stimu1.jpg", dpi=500, bbox_inches='tight')
img_ADJ = plt.matshow(ADJ)
plt.savefig("ADJ1.jpg", dpi=500, bbox_inches='tight')
img_S = plt.matshow(S)
plt.colorbar()
plt.savefig("S1.jpg", dpi=500, bbox_inches='tight')
plt.show()
S = np.mat(S)
dataNew = './data_save.mat'
scio.savemat(dataNew, {'I_stimu': I_stimu, 'ADJ': ADJ, 'Weight': S})
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/CKRGSNN/sub_Conceptnet.csv
================================================
Relation,Head,Tail,Weight
antonym,ab_extra,ab_intra,1.0
antonym,ab_intra,ab_extra,1.0
antonym,abactinal,actinal,1.0
antonym,abandon,acquire,1.0
antonym,abandon,arrogate,1.0
antonym,abandon,embrace,1.0
antonym,abandon,engage,1.0
antonym,abandon,gain,1.0
antonym,abandon,join,1.0
antonym,abandon,maintain,1.0
antonym,abandon,retain,1.0
antonym,abandon,unite,1.0
atlocation,clock,department_store,1.0
atlocation,clock,desk,4.472
atlocation,clock,house,2.828
atlocation,clock,office,2.0
atlocation,crisps,table,1.0
atlocation,crisps,vending_machines,1.0
atlocation,crockery,cupboard,1.0
atlocation,crocs,united_states,0.5
atlocation,fungus,damp_spot,1.0
atlocation,fungus,damp_warm_place,1.0
atlocation,fungus,damp_wood,2.0
atlocation,fungus,damp_woods,1.0
atlocation,fungus,dank_place,1.0
atlocation,fungus,dark,1.0
atlocation,fungus,dark_and_dank_place,1.0
atlocation,fungus,dark_damp_area,2.828
atlocation,fungus,dark_damp_place,2.0
atlocation,carnival_rides,fairgrounds,1.0
atlocation,carousel,carnival,2.828
atlocation,carpet,at_hotel,1.0
capableof,adult,drive_car,1.0
capableof,adult,drive_train,1.0
capableof,adult,explain_rules_to_child,1.0
capableof,adult,feed_and_take_care_of_itself,1.0
capableof,adult,gift_knowledge_to_child,1.0
capableof,adult,hand_toy_to_child,1.0
capableof,adult,help_child,3.464
capableof,adult,keep_property,1.0
capableof,adults,act_like_infants,1.0
capableof,adults,care_for_babies,1.0
capableof,adults,carry_infants,1.0
capableof,adults,count,2.0
capableof,adults,demand_respect_from_children,1.0
capableof,adults,dress_themselves,2.828
capableof,adults,drink_beer,2.0
capableof,adults,drive_vehicle,1.0
capableof,adults,eat_sushi,2.0
capableof,adults,fail_to_pass_test,1.0
causes,competing_against,testing_yourself_against_another_person,1.0
causes,competing_against,try_hardest,1.0
causes,computing_sum,get_total_amount,1.0
causes,computing_sum,getting_answer,4.899
causes,computing_sum,getting_right_answer,1.0
causes,computing_sum,getting_total,1.0
causes,computing_sum,having_answer,2.0
causes,computing_sum,having_total,1.0
causes,computing_sum,headache,3.464
causes,computing_sum,insight,1.0
causes,computing_sum,know_total,2.0
causes,computing_sum,knowing_total,1.0
causes,computing_sum,may_get_wrong_answer,1.0
causes,computing_sum,number,1.0
causes,computing_sum,obtaining_total,1.0
causes,computing_sum,reaching_total,1.0
causes,computing_sum,receiving_total,1.0
desires,person,have_day_off,1.0
desires,person,have_diamonds,2.0
desires,person,have_easy,1.0
desires,person,have_enough_food,2.0
desires,person,have_enough_to_eat,1.0
desires,person,have_everyone_happy_with,2.0
desires,person,have_everything,1.0
desires,person,have_fast_internet_acess,1.0
desires,person,have_femily,1.0
desires,person,have_firm_body,1.0
desires,person,have_fond_memories,1.0
desires,person,have_fortune,1.0
desires,person,have_free_time,1.0
desires,person,have_friends,1.0
desires,person,have_fulfilling_life,1.0
desires,person,have_fun_in_life,2.0
desires,person,have_fun_on_weekends,1.0
desires,person,have_fun_weekend,2.0
desires,person,have_future,1.0
desires,person,have_good_bones,1.0
desires,person,have_good_day,2.828
desires,person,have_good_eyesight,1.0
desires,person,have_good_feelings,1.0
desires,person,have_good_friends,2.828
desires,person,have_good_life,1.0
desires,person,have_good_memories,2.0
desires,person,have_good_memory,1.0
desires,person,have_good_relationships_with_others,1.0
desires,person,have_good_skin,1.0
desires,person,have_great_sex,2.0
desires,person,have_happy_childhood,1.0
desires,person,have_happy_family,1.0
desires,person,have_healthy_life,1.0
desires,person,have_healthy_sex_life,1.0
desires,person,have_home_to_live_in,2.828
desires,person,have_hot_water,1.0
desires,person,have_influence,1.0
desires,person,have_inner_peace,2.828
desires,person,have_interesting_job,1.0
desires,person,have_large_vocabulary,1.0
desires,person,have_lasting_friendships,1.0
desires,person,have_long_live,2.0
desires,person,have_loving_family,1.0
desires,person,have_many_good_friends,2.0
desires,person,have_meaningful_life,2.0
desires,person,have_minimum_necessities_of_life,1.0
desires,person,have_money_to_buy_chocolate,2.0
desires,person,have_more,1.0
hascontext,bridge,card_games,1.0
hascontext,bridge,communication,1.0
hascontext,bridge,computing,1.0
hascontext,bridge,music,1.0
hascontext,bridge,wrestling,1.0
hascontext,bridge_and_tunnel,new_york_city,1.0
hascontext,bridge_and_tunnel,pejorative,1.0
hascontext,bridge_and_tunnel,slang,1.0
hassubevent,maintain_good_health,avoid_guns,1.0
hassubevent,maintain_good_health,avoid_hate,1.0
hassubevent,maintain_good_health,avoid_heavily_processed_foods,2.0
hassubevent,maintain_good_health,avoid_highly_processed_food,1.0
hassubevent,maintain_good_health,avoid_illegal_drugs,1.0
hassubevent,maintain_good_health,avoid_losing_sleep,1.0
hassubevent,maintain_good_health,avoid_marijuana,1.0
hassubevent,maintain_good_health,avoid_much_sunlight,1.0
hassubevent,maintain_good_health,avoid_poison,1.0
hassubevent,maintain_good_health,avoid_racism,1.0
hassubevent,maintain_good_health,avoid_smoking_marijuana,1.0
hassubevent,maintain_good_health,avoid_smoking_tobacco,1.0
hassubevent,maintain_good_health,avoid_tobacco,1.0
hassubevent,maintain_good_health,avoid_unpleasant_people,1.0
hassubevent,maintain_good_health,avoid_war,1.0
hassubevent,maintain_good_health,become_vegan,1.0
hassubevent,maintain_good_health,calm,1.0
hassubevent,maintain_good_health,care_about_people,1.0
hassubevent,maintain_good_health,chew_food_well,1.0
hassubevent,maintain_good_health,determine_nutritional_needs,1.0
hassubevent,maintain_good_health,do_exercise,1.0
hassubevent,maintain_good_health,dress_warmly_in_cold_weather,1.0
hassubevent,maintain_good_health,drink_very_little_alcoholic_beverages,1.0
hassubevent,maintain_good_health,drive_safely,1.0
hassubevent,maintain_good_health,eat_apple_day,1.0
hassubevent,maintain_good_health,eat_enough_and_exercise,1.0
hassubevent,maintain_good_health,eat_foods_containing_fiber,1.0
hassubevent,maintain_good_health,excersize,1.0
hassubevent,maintain_good_health,exercise,1.0
hassubevent,maintain_good_health,have_fullfilled_sex_life,1.0
hassubevent,maintain_good_health,have_spouse,1.0
hassubevent,maintain_good_health,leave_cat_alone,1.0
hassubevent,maintain_good_health,live_healthy_lifestyle,1.0
hassubevent,maintain_good_health,loving,1.0
hassubevent,maintain_good_health,monitor_health_often,1.0
hassubevent,maintain_good_health,not_eat_too_much_sna,1.0
isa,antidiarrheal,medicine,2.0
isa,antidiarrheal_therapy,drug_therapy,1.0
isa,antidiuretic,medicine,2.0
isa,antidiuretic_agent,medicine,1.0
isa,antido,artificial_language,2.0
isa,antidorcas,mammal_genus,2.0
isa,antidoron,food,0.5
isa,antidote,neutralizer,1.0
isa,antidote,remedy,2.0
isa,antiemetic,medicine,1.0
isa,antiemetic,medicine,2.0
isa,antiemetic_therapy,drug_therapy,1.0
isa,antiepileptic,anticonvulsant,1.0
isa,antiestablishmentarianism,doctrine,2.0
isa,antietam,national_cemetery_in_maryland,1.0
isa,antifeminist,bigot,2.0
isa,antiferromagnetism,magnetism,2.0
isa,antifibrinolytic_agent,medicine,1.0
isa,antiflatulent,agent,2.0
isa,antifouling_paint,paint,2.0
isa,antifreeze,automotive_fluid,1.0
isa,antifreeze,liquid,2.0
isa,antifungal,agent,2.0
isa,antigen,antigen,1.0
isa,antigen,carbohydrate,1.0
isa,antigen,tangible_thing,1.0
isa,antigen,substance,2.0
isa,antigenes,person,0.5
isa,antigenic_determinant,site,2.0
isa,antigone,play,0.5
isa,antigonia,fish_genus,2.0
isa,antigonia,fish,0.5
isa,antigorite,serpentine,1.0
isa,antigorite,serpentine,1.0
isa,gardens,often_in_yards,1.0
isa,gardens,places_where_plants_grow,1.0
isa,gardens,pleasant_outdoor_place,1.0
isa,gardens,pleasant_places_to,1.0
isa,garding,town,0.5
isa,gardnerian_wicca,wicca,1.0
isa,gardon,river,0.5
isa,garfield,fictional_character,0.5
isa,garfield,station,0.5
isa,garfield,station,0.5
isa,garfish,fish,0.5
isa,gargamel,comics_character,0.5
isa,garganey,bird,0.5
isa,garlic,food_ingredient,1.0
isa,garlic,flavorer,2.0
isa,garlic,alliaceous_plant,2.0
isa,tire_iron,rigid_portable_object,1.0
isa,tire_iron,shaped_thing,1.0
isa,tire_iron,hand_tool,2.0
isa,tire_iron,lever,2.0
isa,tire_pump,useful_tool,1.0
isa,tire_pump,mechanical_pump,1.0
isa,tire_rotation,axis_constrained_rotation,1.0
isa,tire_sealant,automotive_product,1.0
isa,tire_sealant,sealant,1.0
isa,garlic_chive,alliaceous_plant,2.0
isa,garlic_clove,bulb,1.0
partof,paragraph,textual_document,1.0
partof,paragraph,text,2.0
partof,victoria,zambezi,2.0
partof,victoria,zambia,2.0
partof,victoria,zimbabwe,2.0
partof,victoria_land,antarctica,2.0
partof,vidalia,georgia,2.0
partof,video,television,2.0
partof,vienna,austria,2.0
partof,vienne,poitou_charentes,0.5
partof,vienne,france,2.0
partof,vientiane,laos,2.0
partof,vieques,puerto_rico,2.0
partof,vietnam,indochina,2.0
partof,viewfinder,camera,1.0
partof,vigo,galicia,0.5
partof,vigo,vigo,0.5
partof,vigo,galicia,0.5
partof,villa,asturias,0.5
partof,villahermosa,tabasco,0.5
partof,villahermosa,mexico,2.0
partof,villarreal,valencian_community,0.5
partof,vilnius,dzūkija,0.5
partof,vilnius,lithuania,0.5
partof,vilnius,lithuania,2.0
partof,visual_purple,rod,2.0
partof,visual_signal,visual_communication,2.0
partof,viti_levu,fiji_islands,2.0
partof,viña_del_mar,valparaíso,0.5
partof,vladivostok,russia,2.0
partof,vocabulary,language,2.0
partof,vocal_cord,larynx,2.0
partof,voider,body_armor,2.0
partof,volapük,international_auxiliary_language,0.5
partof,volcanic_crater,volcano,2.0
partof,volcano,south_park,0.5
partof,volcano_islands,japan,2.0
partof,volcano_islands,pacific,2.0
partof,volga,russia,2.0
partof,volgograd,russia,2.0
partof,volkhov,russia,2.0
partof,parthenon,athens,2.0
receivesaction,carpet,found_on_ground,1.0
receivesaction,carpet,used_as_floor_covering,1.0
receivesaction,carpeted_floors,found_in_many_kinds_of_buildings,1.0
receivesaction,carpeting,used_in_place_of_hardwood_floors,1.0
receivesaction,carpets,bought_at_carpet_stores,1.0
receivesaction,cartoons,animated,1.0
receivesaction,case,tried_in_appeals_court,1.0
receivesaction,cases,heard_in_court_of_law,1.0
receivesaction,cash,denominated_in_dollars,1.0
receivesaction,cash,earned,1.0
receivesaction,cash,measured_in_dollars_and_cents,1.0
receivesaction,castanets,bound_together_with_leather_string,1.0
receivesaction,castanets,used_in_form_of_dance,1.0
receivesaction,casual_describes_clothing,worn_for_comfort_and_function,1.0
receivesaction,cat,attracted_to_parakeets,1.0
receivesaction,cats,thought_to_hate_dogs,1.0
receivesaction,cats_and_dogs,treated_badly,1.0
receivesaction,cats_purr_when,contented,1.0
receivesaction,cattle,fed_in_feed_lots,1.0
receivesaction,cauldron,steeped_in_magical_tradition_and_mystery,1.0
receivesaction,cauliflower_and_broccoli,combined_into_one_super_vegetable,1.0
receivesaction,cavitron,used_in_brain_surgery,1.0
receivesaction,cds,bought_in_stores,1.0
receivesaction,cds_usually,made_from_plastic,1.0
receivesaction,cedar,used_as_shingles_on_houses,1.0
receivesaction,ceilings,painted_with_brush,1.0
receivesaction,ceilings_have_color_which,painted_onto,1.0
receivesaction,celebrity,associated_with_autographs,1.0
receivesaction,celebrity,associated_with_desire,1.0
receivesaction,celebrity,associated_with_fame,1.0
receivesaction,celebrity,associated_with_fans,1.0
relatedto,penis,tarse,1.0
relatedto,penis_pump,cock_pump,1.0
relatedto,penis_worm,priapulid,1.0
relatedto,penised,bedicked,1.0
relatedto,penitence,compunction,2.0
relatedto,penitence,remorse,1.0
relatedto,penitence,repentance,1.0
relatedto,penitence,repentance,2.0
relatedto,penitent,penaunt,1.0
relatedto,penitentiary,penitential,2.0
relatedto,penitentiary,jail,1.0
relatedto,penrose_diagram,carter_penrose_diagram,1.0
relatedto,penrose_process,penrose_mechanism,1.0
relatedto,penrose_staircase,penrose_stairs,1.0
relatedto,penrose_staircase,penrose_steps,1.0
relatedto,penrose_stairs,penrose_staircase,1.0
relatedto,penrose_stairs,penrose_steps,1.0
relatedto,penrose_steps,penrose_staircase,1.0
relatedto,penrose_steps,penrose_stairs,1.0
relatedto,penrose_triangle,penrose_triangle,0.5
relatedto,pensacola,pensacola,0.5
relatedto,pension,pension,0.5
relatedto,pension,hotel,1.0
relatedto,penstemon_linarioides,narrow_leaf_penstemon,2.0
relatedto,penstemon_newberryi,mountain_pride,2.0
relatedto,penstemon_palmeri,balloon_flower,2.0
relatedto,penstemon_rupicola,rock_penstemon,2.0
relatedto,penstemon_serrulatus,cascade_penstemon,2.0
relatedto,penstock,sluice,2.0
relatedto,penstock,sluicegate,2.0
relatedto,pent,shut_up,2.0
relatedto,pent_up,repressed,2.0
relatedto,penta,quinque,1.0
relatedto,pentaborane,pentaborane,0.5
relatedto,pentabromodiphenyl_ether,pentabromodiphenyl_ether,0.5
relatedto,pentabromodiphenyl_ether,pentabromodiphenyl_oxide,1.0
relatedto,pentacene,pentacene,0.5
relatedto,pentachloronitrobenzene,pentachloronitrobenzene,0.5
relatedto,pentagon,pentagon,0.5
relatedto,pentagonal,pentangular,2.0
relatedto,pentagram,pentacle,1.0
relatedto,pentagram,pentalpha,1.0
relatedto,pentagram,pentangle,1.0
relatedto,pentagram,pentacle,2.0
relatedto,pentagraph,pentagraph,0.5
relatedto,pentail,pen_tailed_treeshrew,1.0
relatedto,pentalpha,pentagram,1.0
relatedto,pentalpha,pentangle,1.0
relatedto,pentamethylbenzene,pentamethylbenzene,0.5
relatedto,pentamethylenetetrazol,pentylenetetrazol,2.0
relatedto,pentamidine,pentamidine,0.5
relatedto,pentanal,pentanal,0.5
relatedto,pentanal,pentanaldehyde,1.0
relatedto,pentanal,valeraldehyde,1.0
relatedto,pentane,pentane,0.5
relatedto,pentangle,pentacle,2.0
relatedto,pentanoate,valerate,1.0
relatedto,pentanoic_acid,valeric_acid,2.0
relatedto,pentanol,amyl_alcohol,1.0
relatedto,pentanol,pentyl_alcohol,1.0
relatedto,pentastomid,tongue_worm,2.0
relatedto,pentastomida,pentastomida,0.5
relatedto,pentateuch,books_of_moses,1.0
relatedto,pentateuch,law,1.0
relatedto,pentateuch,torah,1.0
relatedto,pentateuch,torah,2.0
relatedto,pentatone,pentatonic_scale,2.0
relatedto,pentatonic_scale,pentatonic_scale,0.5
relatedto,pentazocine,pentazocine,0.5
relatedto,pentazole,pentazole,0.5
relatedto,pentecost,pentecost,0.5
relatedto,pentecost,feast_of_weeks,1.0
relatedto,pentecost,shavuos,1.0
relatedto,pentecost,shavuot,1.0
relatedto,pentecost,whit,1.0
relatedto,pentecost,whit_sunday,1.0
relatedto,pentecost,whitsun,1.0
relatedto,pentecost,whitsunday,1.0
relatedto,pentecost,shavous,2.0
relatedto,pentecostal,pentecostalist,2.0
relatedto,pentecostalism,pentecostalism,0.5
relatedto,pentel,pentel,0.5
relatedto,pentelic,pentelican,1.0
relatedto,pentene,pentene,0.5
usedfor,gourmet_shop,buy_weird_food,1.0
usedfor,gourmet_shop,buying_imported_foods,1.0
usedfor,gourmet_shop,customers_who_knowlegeable_about_cooking,1.0
usedfor,gourmet_shop,fine_foods,1.0
usedfor,gourmet_shop,hard_to_find_foods,1.0
usedfor,gourmet_shop,icky_foods,1.0
usedfor,lip,pleasure,1.0
usedfor,lip,pouring,1.0
usedfor,vessel,containing_highway_for_blood_flow,1.0
usedfor,vessel,float,1.0
usedfor,vessel,hold_flowers,1.0
usedfor,vessel,moving,1.0
usedfor,vessel,moving_people_around,1.0
usedfor,vessel,navigate,1.0
usedfor,vessel,piloting,1.0
usedfor,vessel,sailing_on_ocean,1.0
usedfor,vessel,ship_goods,1.0
usedfor,vessel,shipping,2.0
usedfor,vessel,store_liquid,1.0
usedfor,vessel,storing_liquids,2.0
usedfor,vessel,transporting_things,1.0
usedfor,vessel,usually_staying_above_water,1.0
usedfor,veterinarians,sick_animals,1.0
usedfor,vibrator,entertain_yourself,1.0
usedfor,vibrator,get_off,1.0
usedfor,vibrator,increase_pleasure_during_sex,1.0
usedfor,vibrator,sexually_stimulate_yourself_or_else,1.0
usedfor,viewing_video,having_fun,1.0
usedfor,viewing_video,having_good_time,1.0
usedfor,viewing_video,learning,2.828
usedfor,viewing_video,learning_language,1.0
usedfor,viewing_video,learning_new,1.0
usedfor,viewing_video,relaxation,1.0
usedfor,viewing_video,relaxing,2.0
usedfor,viewing_video,reviewing_video,1.0
usedfor,viewing_video,spending_time_with_grandson,1.0
usedfor,viewing_video,watching_film,1.0
usedfor,viewing_video,watching_home_movies,1.0
usedfor,viewing_video,watching_memories,1.0
usedfor,viewing_video,watching_movie_star,1.0
usedfor,village,learning,1.0
usedfor,village,people_to_live_in,1.0
usedfor,village,playing,1.0
usedfor,village,raise_child,1.0
usedfor,village,sedentary_living,1.0
usedfor,viola,play_song,1.0
usedfor,viola,playing,1.0
usedfor,viola,playing_music,2.0
usedfor,viola,playing_sissy_music,1.0
usedfor,viola,sing_song,1.0
usedfor,violence,kill,1.0
usedfor,violence,terrorism,1.0
usedfor,violin,create_music,1.0
usedfor,violin,creating,2.0
usedfor,violin,creating_art,1.0
usedfor,violin,entertaining,1.0
usedfor,violin,entertainment,1.0
usedfor,violin,fu_n,1.0
usedfor,violin,making_lovely_music,1.0
usedfor,violin,mkae_annoying_noises,1.0
usedfor,violin,music,1.0
usedfor,violin,play_music,2.828
usedfor,violin,playing,1.0
usedfor,violin,playing_music,5.657
usedfor,violin,playing_music_on_stringed_instrument,1.0
usedfor,visa_card,acquiring_debt,1.0
usedfor,visa_card,adults_not_kids,1.0
usedfor,visiting_museum,entertainment,1.0
usedfor,visiting_museum,feeling_young,1.0
usedfor,visiting_museum,finding_out_about_past,1.0
usedfor,visiting_museum,finding_out_about_world,1.0
usedfor,visiting_museum,fun,2.0
usedfor,visiting_museum,getting_ideas_from_past_experiences,1.0
usedfor,visiting_museum,having_fun,1.0
usedfor,visiting_museum,having_fun_day,1.0
usedfor,visiting_museum,learing_about_past,1.0
usedfor,visiting_museum,learning_about_culture,1.0
usedfor,visiting_museum,learning_about_history,1.0
usedfor,visiting_museum,learning_about_other_places,1.0
usedfor,visiting_museum,learning_history,2.0
usedfor,lip,protect,1.0
usedfor,lip,speak,2.0
usedfor,lip,suck,2.0
usedfor,lip,whistling,2.0
usedfor,lips,communicate,2.828
usedfor,lips,flapping,1.0
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/CRSNN/README.md
================================================
# Causal Reasoning SNN
(https://10.1109/IJCNN52387.2021.9534102)
This repository contains code from our paper [**A Brain-Inspired Causal Reasoning Model Based on Spiking Neural Networks
**] published in 2021 International Joint Conference on Neural Networks (IJCNN). https://ieeexplore.ieee.org/abstract/document/9534102. If you use our code or refer to this project, please cite this paper.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
## Run
```shell
python main.py
```
This module builds an example of a brain-like causal inference spiking neural network model. The input causal graph is shown in figure causal_graph.png. The input current, spike trains during the learning process and the network weight distribution after the learning are shown in the Results folder.
### Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@inproceedings{fang2021CRSNN,
title={A Brain-Inspired Causal Reasoning Model Based on Spiking Neural Networks},
author={Fang, Hongjian and Zeng, Yi},
booktitle={2021 International Joint Conference on Neural Networks (IJCNN)},
pages={1--5},
year={2021},
organization={IEEE}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/CRSNN/main.py
================================================
import time
import numpy as np
import os
import warnings
import math
from matplotlib import pyplot as plt
import torch
from braincog.base.node.node import *
from braincog.base.brainarea.BrainArea import *
from braincog.utils import *
warnings.filterwarnings('ignore')
np.set_printoptions(threshold=np.inf)
class CRNet(BrainArea):
"""
网络结构类:CRNet(Causal Reasoning Net),定义了网络的结构,继承自BrainArea基类。
:param threshold: 神经元发放脉冲需要达到的阈值
:param tau: 神经元膜电位常数,控制膜电位衰减
:param decay:STDP机制衰减常数,控制STDP机制作用强度随时间变化
:param w1:神经网络内部连接权重
:param w2:外部输入电流到每个神经元的连接
"""
def __init__(self, w1, w2):
"""
"""
super().__init__()
self.node = [LIFNode(threshold=16, tau=15)]
self.connection = [CustomLinear(w1), CustomLinear(w2)]
self.stdp = []
self.stdp.append(MutliInputSTDP(self.node[0], [self.connection[0], self.connection[1]], decay=0.8))
self.x1 = torch.zeros(1, w2.shape[0])
def forward(self, x):
"""
一次时间步的前向传播过冲函数,计算脉冲发放情况和权重改变量
:param x1:经过该时间步后的脉冲发放情况
:param dw1:STDP机制在一个时间步后带来的权重改变量
"""
self.x1, dw1 = self.stdp[0](x, self.x1)
return self.x1, dw1
def reset(self):
self.x1 *= 0
def S_bound(S):
"""
S_bound:网络权重边界控制函数,主要功能为控制全网络突触连接权不超过阈值,维持弱连接
另外,本函数还需要将神经元组内部权重控制在一定的范围之内,以防神经元组不断重复激活自身的情况发生。
:param synapse_bound: 全网络的突触连接的阈值,以维持网络整体为弱连接
:param inner_bound: 神经元组内部突触连接的阈值,防止神经元组不断重复激活自身导致网络放电紊乱
"""
S[S > synapse_bound] = synapse_bound
S[S < -synapse_bound] = -synapse_bound
temp1 = S[E1_index, :]
temp2 = temp1[:, E1_index]
temp2[temp2 > inner_bound_E] = inner_bound_E
temp1[:, E1_index] = temp2
S[E1_index, :] = temp1
temp1 = S[E2_index, :]
temp2 = temp1[:, E2_index]
temp2[temp2 > inner_bound_E] = inner_bound_E
temp1[:, E2_index] = temp2
S[E2_index, :] = temp1
temp1 = S[E3_index, :]
temp2 = temp1[:, E3_index]
temp2[temp2 > inner_bound_E] = inner_bound_E
temp1[:, E3_index] = temp2
S[E3_index, :] = temp1
temp1 = S[E4_index, :]
temp2 = temp1[:, E4_index]
temp2[temp2 > inner_bound_E] = inner_bound_E
temp1[:, E4_index] = temp2
S[E4_index, :] = temp1
temp1 = S[E4_index, :]
temp2 = temp1[:, E4_index]
temp2[temp2 > inner_bound_E] = inner_bound_E
temp1[:, E4_index] = temp2
S[E4_index, :] = temp1
temp1 = S[E5_index, :]
temp2 = temp1[:, E5_index]
temp2[temp2 > inner_bound_E] = inner_bound_E
temp1[:, E5_index] = temp2
S[E5_index, :] = temp1
temp1 = S[R1_index, :]
temp2 = temp1[:, R1_index]
temp2[temp2 > inner_bound_R] = inner_bound_R
temp1[:, R1_index] = temp2
S[R1_index, :] = temp1
temp1 = S[R2_index, :]
temp2 = temp1[:, R2_index]
temp2[temp2 > inner_bound_R] = inner_bound_R
temp1[:, R2_index] = temp2
S[R2_index, :] = temp1
return S
if __name__ == "__main__":
# Neurons Parameter
Cr = 200 # num of relation
Ce = 50 # num of entity
total_time = 2500 # Runtime in ms
tau = 100 # time constant of STDP
stdpwin = 25 # STDP windows in ms
thresh = 30 # Judge if the neurons fire or not
abs_T = 25 # The length of the ABS
Reset = 0 # Reset Potential
I_syn = 5
tau_m = 30
Rm = 10
N_entity = 5
N_relation = 2
I_t = 5 # Duration of Current
I_P = 25 # Strength of input current
certainty = 0.5
A_P = 0.01
synapse_bound = 0.2 # The bound of all synapse
inner_bound_E = 0.08 # The bound of population inner synapse
inner_bound_R = 0.06 # The bound of population inner synapse
total_neurons = Ce * N_entity + Cr * N_relation
"""
SPSNN主函数,实现网络核心主要功能
:param Cr: 因果图中节点神经元组中神经元数量
:param Ce: 因果图中因果关系神经元组中神经元数量
:param total_time: 网络总体模拟的时间步长
:param learning_times: 网络进行序列学习的次数
:param N_entity: 对网络添加外部输入电流的时间长度
:param N_relation: 对网络添加外部输入电流的强度
:param A_P: 网络在进行STDP学习后突触改变放缩量
:param certainty: 网络输入电流大小的确定度
:param total_neurons: 网络神经元总量
:param ADJ: 网络中脉冲放电情况矩阵
:param I_stimu: 网络中外部输入电流矩阵
:param S: 网络突触连接权重矩阵
:param E: 单位矩阵,用以对每个神经元引入外部电流
"""
# Initial Neurual Network
E1_index = np.linspace(0, Ce - 1, Ce, dtype=int)
E2_index = np.linspace(Ce, 2 * Ce - 1, Ce, dtype=int)
E3_index = np.linspace(2 * Ce, 3 * Ce - 1, Ce, dtype=int)
E4_index = np.linspace(3 * Ce, 4 * Ce - 1, Ce, dtype=int)
E5_index = np.linspace(4 * Ce, 5 * Ce - 1, Ce, dtype=int)
R1_index = np.linspace(5 * Ce, 5 * Ce + Cr - 1, Cr, dtype=int)
R2_index = np.linspace(5 * Ce + Cr, 5 * Ce + 2 * Cr - 1, Cr, dtype=int)
Ne = total_neurons
v = Reset * np.zeros(Ne)
firings = [] # spike timings
ADJ = np.zeros((total_time, Ne)) # record the firing condition
abs_Ne = np.zeros(Ne) # maintain the ABS of every neurons
I_stimu = np.zeros((Ne, total_time), dtype=float)
If_Memory = np.zeros((total_neurons), dtype=bool)
If_Memory[:] = True
# Pre-set synapses
S = np.zeros((total_neurons, total_neurons), dtype=float) # Initial Weights
S = S - np.diag(S) # Set the diag num to
E = np.identity((total_neurons), dtype=float)
W_set_innner = 0.7
temp = S[E1_index, :]
temp[:, E1_index] = W_set_innner * np.random.rand(Ce, Ce)
S[E1_index, :] = temp
temp = S[E2_index, :]
temp[:, E2_index] = W_set_innner * np.random.rand(Ce, Ce)
S[E2_index, :] = temp
temp = S[E3_index, :]
temp[:, E3_index] = W_set_innner * np.random.rand(Ce, Ce)
S[E3_index, :] = temp
temp = S[E4_index, :]
temp[:, E4_index] = W_set_innner * np.random.rand(Ce, Ce)
S[E4_index, :] = temp
temp = S[E5_index, :]
temp[:, E5_index] = W_set_innner * np.random.rand(Ce, Ce)
S[E5_index, :] = temp
temp = S[R1_index, :]
temp[:, R1_index] = 0.25 * W_set_innner * np.random.rand(Cr, Cr)
S[R1_index, :] = temp
temp = S[R2_index, :]
temp[:, R2_index] = 0.25 * W_set_innner * np.random.rand(Cr, Cr)
S[R2_index, :] = temp
"""
对于因果图中的因果关系,给予网络不同神经元组输入电流刺激,使其建立连接
"""
i = 1
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E1_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E1_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R1_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R1_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E2_index, :] = temp
i = 3
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E2_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R2_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E1_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E1_index, :] = temp
i = 6
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E2_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R1_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R1_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E3_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E3_index, :] = temp
i = 8
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E3_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E3_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R2_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E2_index, :] = temp
i = 11
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E2_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R1_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R1_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E4_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E4_index, :] = temp
i = 13
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E4_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E4_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R2_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E2_index, :] = temp
i = 16
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E3_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E3_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R1_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R1_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E5_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E5_index, :] = temp
i = 18
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E5_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E5_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R2_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E3_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E3_index, :] = temp
i = 21
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E4_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E4_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R1_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R1_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E5_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E5_index, :] = temp
i = 23
time = np.linspace(11 + i * 100, 10 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E5_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E5_index, :] = temp
time = np.linspace(21 + i * 100, 20 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[R2_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Cr, I_t)
I_stimu[R2_index, :] = temp
time = np.linspace(31 + i * 100, 30 + I_t + i * 100, I_t, dtype=int)
temp = I_stimu[E4_index, :]
temp[:, time] = certainty * I_P + I_P * np.random.rand(Ce, I_t)
I_stimu[E4_index, :] = temp
S = torch.tensor(S, dtype=torch.float32)
E = torch.tensor(E, dtype=torch.float32)
CRSNN = CRNet(S, E)
for t in range(total_time):
I_input = torch.tensor(I_stimu[:, t].reshape(1, total_neurons), dtype=torch.float32)
x, dw = CRSNN(I_input)
S += A_P * dw[1]
S += S_bound(S) - S
ADJ[t] = x
plt.matshow(I_stimu)
plt.matshow(ADJ.transpose())
plt.matshow(S)
plt.colorbar()
plt.show()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/SPSNN/README.md
================================================
# Sequence Production SNN
This repository contains code from our paper [**Brain Inspired Sequences Production by Spiking Neural Networks With Reward-Modulated STDP**] published in Frontiers in Computational Neuroscience. This module builds a Sequence Production spiking neural network model, realizing the memory and reconstruction functions for arbitrary symbol sequences. The input causal graph is shown in figure causal_graph.png. The input current, spike trains during the learning process and the network weight distribution after the learning are shown in the Results folder.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
## Run
```shell
python main.py file
```
### Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{fang2021spsnn,
title = {Brain inspired sequences production by spiking neural networks with reward-modulated stdp},
author = {Fang, Hongjian and Zeng, Yi and Zhao, Feifei},
journal = {Frontiers in Computational Neuroscience},
volume = {15},
pages = {8},
year = {2021},
publisher = {Frontiers}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/SPSNN/main.py
================================================
import time
import numpy as np
import os
import warnings
import math
from matplotlib import pyplot as plt
import torch
from braincog.base.node.node import *
from braincog.base.brainarea.BrainArea import *
from braincog.utils import *
warnings.filterwarnings('ignore')
np.set_printoptions(threshold=np.inf)
class SPNet(BrainArea):
"""
网络结构类:SPNet(Sequence Production Net),定义了网络的结构,继承自BrainArea基类。
:param threshold: 神经元发放脉冲需要达到的阈值
:param tau: 神经元膜电位常数,控制膜电位衰减
:param decay:STDP机制衰减常数,控制STDP机制作用强度随时间变化
:param w1:神经网络内部连接权重
:param w2:外部输入电流到每个神经元的连接
"""
def __init__(self, w1, w2 ):
"""
"""
super().__init__()
self.node = [LIFNode(threshold=10,tau=15) ]
self.connection = [CustomLinear(w1), CustomLinear(w2) ]
self.stdp = []
self.stdp.append(MutliInputSTDP(self.node[0], [self.connection[0], self.connection[1]],decay=0.745))
self.x1 = torch.zeros(1, w2.shape[0])
def forward(self, x):
"""
一次时间步的前向传播过冲函数,计算脉冲发放情况和权重改变量
:param x1:经过该时间步后的脉冲发放情况
:param dw1:STDP机制在一个时间步后带来的权重改变量
"""
self.x1, dw1 = self.stdp[0]( self.x1,x)
return self.x1, dw1
def reset(self):
self.x1 *= 0
def S_bound(S):
"""
S_bound:网络权重边界控制函数,主要功能为控制全网络突触连接权不超过阈值,维持弱连接
另外,本函数还需要将神经元组内部权重控制在一定的范围之内,以防神经元组不断重复激活自身的情况发生。
:param synapse_bound: 全网络的突触连接的阈值,以维持网络整体为弱连接
:param inner_bound: 神经元组内部突触连接的阈值,防止神经元组不断重复激活自身导致网络放电紊乱
"""
S[S > synapse_bound] = synapse_bound
S[S < -synapse_bound] = -synapse_bound
temp1 = S[l1_stimu,:]
temp2 = temp1[:, l1_stimu]
temp2 [temp2>inner_bound] = inner_bound
temp1[:, l1_stimu] = temp2
S[l1_stimu, :] = temp1
temp1 = S[l2_stimu, :]
temp2 = temp1[:, l2_stimu]
temp2[temp2 > inner_bound] = inner_bound
temp1[:, l2_stimu] = temp2
S[l2_stimu, :] = temp1
temp1 = S[l3_stimu, :]
temp2 = temp1[:, l3_stimu]
temp2[temp2 > inner_bound] = inner_bound
temp1[:, l3_stimu] = temp2
S[l3_stimu, :] = temp1
temp1 = S[l4_stimu, :]
temp2 = temp1[:, l4_stimu]
temp2[temp2 > inner_bound] = inner_bound
temp1[:, l4_stimu] = temp2
S[l4_stimu, :] = temp1
return S
if __name__ == "__main__":
## Neurons Parameter
C = 50; # constant:the number of neurons of a symbol
runtime = 1000; # Runtime in ms
thresh = 30; # Judge if the neurons fire or not
I_syn = 5;
tau_m = 30;
Rm = 10;
learning_times = 3;
Sym_size = 6
I_t = 5 # Time duration of stimu current
I_P = 130 # Strength of input current
A_P = 0.024
certainty = 0.35
synapse_bound = 10 # The bound of all synapse
inner_bound = 1 # The bound of population inner synapse
"""
SPSNN主函数,实现网络核心主要功能
:param C: 神经元组中神经元数量
:param runtime: 网络总体模拟的时间步长
:param learning_times: 网络进行序列学习的次数
:param I_t: 对网络添加外部输入电流的时间长度
:param I_P: 对网络添加外部输入电流的强度
:param A_P: 网络在进行STDP学习后突触改变放缩量
:param certainty: 网络输入电流大小的确定度
:param total_neurons: 网络神经元总量
:param ADJ: 网络中脉冲放电情况矩阵
:param I_stimu: 网络中外部输入电流矩阵
:param S: 网络突触连接权重矩阵
:param E: 单位矩阵,用以对每个神经元引入外部电流
"""
# Initial Neurual Network
Net1 = [C,Sym_size*C,Sym_size*C,Sym_size*C,1] #memory
Net2 = [Sym_size,Sym_size,Sym_size] #action
current_end = 0
total_neurons = int(sum(Net1)+sum(Net2))
index1 = np.linspace(1,sum(Net1),sum(Net1),dtype=int)-1
index2 = np.linspace (sum(Net1)+1,total_neurons,sum(Net2),dtype=int)-1
Ne = total_neurons
firings= [] # spike timings
ADJ = np.zeros((runtime,Ne)) # record the firing condition
abs_Ne = np.zeros(Ne) # maintain the ABS of every neurons
I_stimu = np.zeros((Ne,runtime));
P = np.zeros((runtime,3)); # potential of neuron 1
# logical vector to differ if the neuron is belong to memory part
If_Memory = np.zeros((total_neurons),dtype=bool)
If_Memory[index1[:]] = True
# logical vector to differ if the neuron is belong to action part
If_Action = np.zeros((total_neurons),dtype=bool)
If_Action[index2[:]] = True
# Pre-set synapses
S = np.zeros((total_neurons,total_neurons),dtype=float) # Initial Weights
S = S - np.diag(S) # Set the diag num to
E = np.identity((total_neurons),dtype=float)
W_r2a = 0.3
# Memory to Action
for i in range (C,sum(Net1)-2 ):
S[ int(index2[int(i/C)-1]), i] =W_r2a
# Learning Process
I_stimu = np.zeros((Ne,runtime))
seq = np.array([6,3,4])
l1_stimu = np.arange (0,C)
l2_stimu = np.arange(C+(seq[0]-1)*C,C+(seq[0])*C)
l3_stimu = np.arange(C+ 6*C+(seq[1]-1)*C,C+ 6*C+(seq[1])*C)
l4_stimu = np.arange(C+12*C+(seq[2]-1)*C,C+12*C+(seq[2])*C)
l5_stimu = Ne-1
np.linspace(20 + i * 100 ,20+I_t+i*100-1,I_t ,dtype=int )
for i in range(learning_times):
"""
对网络添加输入电流
"""
temp = I_stimu [l1_stimu,:]
I_stimu [l1_stimu, 10 + i * 100 :10+I_t+i*100] = certainty*I_P + I_P * np.random.rand(C,I_t)
I_stimu [l2_stimu, 25 + i * 100 :25+I_t+i*100] = certainty*I_P + I_P * np.random.rand(C,I_t)
I_stimu [l3_stimu, 40 + i * 100 :40+I_t+i*100] = certainty*I_P + I_P * np.random.rand(C,I_t)
I_stimu [l4_stimu, 55 + i * 100 :55+I_t+i*100] = certainty*I_P + I_P * np.random.rand(C,I_t)
I_stimu [l5_stimu, 70 + i * 100 :70+I_t+i*100] = certainty*I_P + I_P * np.random.rand(1,I_t)
I_stimu[l1_stimu,700:700+I_t] = I_P * np.random.rand(C,I_t)
S = torch.tensor(S,dtype=torch.float32)
E = torch.tensor(E,dtype=torch.float32)
SPSNN = SPNet(S,E)
for t in range (runtime):
I_input = torch.tensor( I_stimu[:,t].reshape(1,total_neurons),dtype=torch.float32)
x,dw = SPSNN( I_input )
S += A_P*dw[1]
S += S_bound(S) - S
ADJ[t] = x
plt.matshow(I_stimu)
plt.matshow(ADJ)
plt.matshow(S)
plt.colorbar()
plt.show()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Areas/apac.py
================================================
'''
Created on 2016.7.7
@author: liangqian
'''
from Modal.note import Note
from Modal.cluster import Cluster
from conf.conf import configs
from Modal.pitch import Pitch
class APAC():
'''
anterior primary auditory cortex,encoding the musical notes
'''
def __init__(self):
'''
Constructor
'''
self.notes = []
#self.cluster = Cluster()
def encodingNote(self,NoteID):
NoteName = configs.notesMap.get(int(NoteID))
n = Pitch()
n.name = NoteName
n.frequence = int(NoteID)
self.notes.append(n)
return n
def encodingMIDINote(self,p):
NoteName = configs.notesMap.get(p.frequence)
p.name = NoteName
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Areas/cortex.py
================================================
'''
Created on 2016.7.6
@author: liangqian
'''
from Areas.pfc import PFC
from Areas.pac import PAC
from conf.conf import *
from Modal.synapse import Synapse
import random
import numpy as np
from Areas.apac import APAC
from Areas.pac import Music_Sequence_Mem
class Cortex():
'''
This class is used to control areas in the cortex, just cortex controlling
'''
def __init__(self, neutype, dt):
self.neutype = neutype
self.msm = Music_Sequence_Mem(neutype)
self.pfc = PFC(self.neutype)
self.dt = dt
def addSubGoalToPFC(self, goalname):
self.pfc.addNewSubGoal(goalname)
''' tt = np.arange(0, 5, self.dt)
for t in tt:
self.pfc.doRemebering(goalname, self.dt, t)'''
def addComposerToPFC(self, composername):
self.pfc.addNewComposer(composername)
'''tt = np.arange(0, 5, self.dt)
for t in tt:
self.pfc.doRememberingComposer(composername, self.dt, t)'''
def addGenreToPFC(self, genrename):
self.pfc.addNewGenre(genrename)
'''tt = np.arange(0, 5, self.dt)
for t in tt:
self.pfc.doRememberingGenre(genrename, self.dt, t)'''
def musicSequenceMemroyInit(self):
self.msm.createActionSequenceMem(1, self.neutype)
def rememberANote(self, goalname, noteName, order):
note = self.apac.encodingNote(noteName)
if (order > len(self.msm.sequenceLayers.get(1).groups)):
self.msm.sequenceLayers.get(1).addNewGroups(GroupID=order, layerID=1, neunum=128)
tt = np.arange((order - 1) * 5, order * 5, self.dt)
for t in tt:
self.ips.doRemebering(goalname, self.dt, t)
self.msm.doRemembering_note_only(note, order, self.dt, t)
self.msm.doConnectToGoal(self.ips.goals.groups.get(goalname), order)
dic = {}
if (configs.flag_experiments == False):
dic["GoalSpike"] = self.ips.goals.groups.get(goalname).writeSpikeInfoToJson()
dic["MSMSpike"] = self.msm.sequenceLayers.get(1).groups.get(order).writeSpikeInfoToJson()
dic["Neuron"] = self.msm.sequenceLayers.get(1).groups.get(order).writeSelfInfoToJson("MSM")
dic["GroupNum"] = order
return dic
def connectKeyAndNotesUsingKSModel(self,keys, Notes):
noteNeurons = Notes.neurons
for tone in keys.groups.values():
tneurons = tone.neurons
for nindex, noteneu in enumerate(noteNeurons[1:]):
i = nindex%12
syn = Synapse(tneurons[i],noteneu) # from tone to pitch
if(tneurons[i].importance < 0):
syn.excitability = 0
syn.weight = -100 # 这个地方应该用KS pitch profile,稍等下再改
else:
syn.excitability = 1
syn.weight = 20+random.uniform(20,30)
syn.type = 3
noteneu.synapses.append(syn)
noteneu.pre_neurons.append(tneurons[i])
# syn1 = Synapse(noteneu, tneurons[i]) # from pitch to tone
# syn1.excitability = 1
# syn1.type = 3
# tneurons[i].synapses.append(syn1)
# tneurons[i].pre_neurons.append(noteneu)
def connectKeyAndNotes(self,keys, Notes):
noteNeurons = Notes.neurons
for tone in keys.groups.values():
tneurons = tone.neurons
for nindex, noteneu in enumerate(noteNeurons[1:]):
i = nindex%12
syn = Synapse(tneurons[i],noteneu)
if(tneurons[i].importance < 0):
syn.excitability = 0
syn.weight = -100
else:
syn.excitability = 1
syn.weight = 20+random.uniform(20,30)
syn.type = 3
noteneu.synapses.append(syn)
noteneu.pre_neurons.append(tneurons[i])
def connectKeyAndNotesUsingKSModel(self,keys, Notes):
noteNeurons = Notes.neurons
for tone in keys.groups.values():
tneurons = tone.neurons
for nindex, noteneu in enumerate(noteNeurons[1:]):
i = nindex%12
syn = Synapse(tneurons[i],noteneu) # from tone to pitch
if(tneurons[i].importance < 0):
syn.excitability = 0
syn.weight = -100 # 这个地方应该用KS pitch profile,稍等下再改
else:
syn.excitability = 1
syn.weight = 20+random.uniform(20,30)
syn.type = 3
noteneu.synapses.append(syn)
noteneu.pre_neurons.append(tneurons[i])
# syn1 = Synapse(noteneu, tneurons[i]) # from pitch to tone
# syn1.excitability = 1
# syn1.type = 3
# tneurons[i].synapses.append(syn1)
# tneurons[i].pre_neurons.append(noteneu)
def rememberANoteWithKnowledge(self,goalname, composername, genrename, emo, keyName, trackIndex, noteIndex, tinterval,order, xmldata):
instrumentTrack = self.msm.sequenceLayers.get(trackIndex)
if (order > len(instrumentTrack.get("N").groups)):
instrumentTrack.get("N").addNewGroups(GroupID=order, layerID=trackIndex, neunum=129)
instrumentTrack.get("T").addNewGroups(GroupID=order, layerID=trackIndex, neunum=64)
self.connectKeyAndNotesUsingKSModel(self.pfc.keys,instrumentTrack.get("N").groups.get(order))# prior knowledge
tt = np.arange((order - 1) * 5, order * 5, self.dt)
for t in tt:
self.pfc.doRemebering(goalname, self.dt, t)
self.pfc.doRememberingComposer(composername, self.dt, t)
self.pfc.doRememberingGenre(genrename, self.dt, t)
self.pfc.doRememberingKey(keyName,self.dt,t)
self.pfc.doRememberingMode(keyName%2, self.dt,t)
self.msm.doRemembering(trackIndex, noteIndex, order, self.dt, t, tinterval)
self.msm.doConnectToTitle(self.pfc.goals.groups.get(goalname), instrumentTrack, order)
self.msm.doConnectToComposer(self.pfc.composers.groups.get(composername), instrumentTrack, order)
self.msm.doConnectToGenre(self.pfc.genres.groups.get(genrename), instrumentTrack, order)
self.msm.doConnectToKey(self.pfc.keys.groups.get(keyName), instrumentTrack, order, noteIndex)
self.msm.doConnectToMode(self.pfc.modes.groups.get(keyName%2), keyName, instrumentTrack, order, noteIndex)
dic = {}
dic["GoalSpike"] = self.pfc.goals.groups.get(goalname).writeSpikeInfoToJson()
dic["ComposerSpike"] = self.pfc.composers.groups.get(composername).writeSpikeInfoToJson()
#dic["EmotionSpike"] = self.amy.emos.groups.get(emo).writeSpikeInfoToJson()
dic["KeySpike"] = self.pfc.keys.groups.get(keyName).writeSpikeInfoToJson()
dic["ModeSpike"] = self.pfc.modes.groups.get(keyName%2).writeSpikeInfoToJson()
dic["MSMNSpike"] = instrumentTrack.get("N").groups.get(order).writeSpikeInfoToJson()
dic["MSMTSpike"] = instrumentTrack.get("T").groups.get(order).writeSpikeInfoToJson()
return(dic)
def rememberANoteandTempo(self, goalname, composername, genrename, trackIndex, noteIndex, order, tinterval):
instrumentTrack = self.msm.sequenceLayers.get(trackIndex)
if (order > len(instrumentTrack.get("N").groups)):
instrumentTrack.get("N").addNewGroups(GroupID=order, layerID=trackIndex, neunum=129)
instrumentTrack.get("T").addNewGroups(GroupID=order, layerID=trackIndex, neunum=64)
tt = np.arange((order - 1) * 5, order * 5, self.dt)
for t in tt:
self.pfc.doRemebering(goalname, self.dt, t)
self.pfc.doRememberingComposer(composername, self.dt, t)
self.pfc.doRememberingGenre(genrename, self.dt, t)
self.msm.doRemembering(trackIndex, noteIndex, order, self.dt, t, tinterval)
self.msm.doConnectToTitle(self.pfc.goals.groups.get(goalname), instrumentTrack, order)
self.msm.doConnectToComposer(self.pfc.composers.groups.get(composername), instrumentTrack, order)
self.msm.doConnectToGenre(self.pfc.genres.groups.get(genrename), instrumentTrack, order)
dic = {}
ngraph = {}
if (configs.RunTimeState == 1):
dic["GoalSpike"] = self.pfc.goals.groups.get(goalname).writeSpikeInfoToJson()
dic["ComposerSpike"] = self.pfc.composers.groups.get(composername).writeSpikeInfoToJson()
dic["MSMSpike"] = instrumentTrack.get("N").groups.get(order).writeSpikeInfoToJson()
dic["MSMTSpike"] = instrumentTrack.get("T").groups.get(order).writeSpikeInfoToJson()
temp = {}
temp[1] = instrumentTrack.get("N").groups.get(order).writeSelfInfoToJson("NMSM")
temp[2] = instrumentTrack.get("T").groups.get(order).writeSelfInfoToJson("TMSM")
# dic["GroupNum"] = order
Nodes = []
Edges = []
for key, td in temp.items():
nlist = td.get("Neuron")
for n in nlist:
# if(len(n.get('synapses')) > 0):
d = {}
d['id'] = n.get('area') + '_' + str(n.get('TrackID')) + '_' + str(n.get('GroupID')) + '_' + str(
n.get('Index'))
d['area'] = n.get('area')
if (n.get('area') == 'NMSM'):
d['label'] = configs.notesMap.get(n.get('Index') - 2)
else:
d['label'] = str(n.get('Index') * 60)
Nodes.append(d)
synlist = n.get('synapses')
for syn in synlist:
e = {}
# e['id'] = syn.get('Sarea') + '_'+str(syn.get('SgroupID'))+'_'+str(syn.get('Sindex')) + '_' +syn.get('Tarea') + '_'+str(syn.get('TgroupID')) + '_'+str(syn.get('Tindex'))
e['weight'] = str(syn.get('weight'))
e['source'] = syn.get('Sarea') + '_' + str(syn.get('StrackID')) + '_' + str(
syn.get('SgroupID')) + '_' + str(syn.get('Sindex'))
e['target'] = syn.get('Tarea') + '_' + str(syn.get('TtrackID')) + '_' + str(
syn.get('TgroupID')) + '_' + str(syn.get('Tindex'))
Edges.append(e)
ngraph["node"] = Nodes
ngraph["edge"] = Edges
#print(dic)
return dic, ngraph
def actionSequenceMemoryInit(self):
self.asm.createActionSequenceMem(1, self.neutype, 16)
def recallMusicPFC(self, goalName):
self.pfc.setTestStates()
self.msm.setTestStates()
result = self.pfc.doRecalling2(goalName, self.msm)
return result
def recallMusicByEpisode(self, episodeNotes): # using time window search episode
self.pfc.setTestStates()
self.msm.setTestStates()
# sl = self.msm.sequenceLayers.get(1)
# for index,group in sl.groups.items():
# strs = "group_"+str(index)+":"
# for n in group.neurons:
# if(n.preActive == True):
# strs +=" neu_Index:"+str(n.index)+","
# print(strs)
result = self.msm.recallByEpisode2(episodeNotes, self.pfc.goals)
return result
def generateEx_Nihilo(self, firstNote, durations, length):
'''
this function is used to generate the main melody, only one track
'''
self.pfc.setTestStates()
self.msm.setTestStates()
result = {}
track1 = []
for i in range(length):
dic = {}
tt = np.arange(i * 5, (i + 1) * 5, self.dt)
for t in tt:
self.pfc.inhibiteGoals(self.dt, t)
self.msm.generateEx_Nihilo(firstNote, durations, i, self.dt, t)
panneu = []
maxrate = 0.0
maxneu = None
for ni, neu in enumerate(self.msm.sequenceLayers.get(1).get("N").groups.get(i + 1).neurons):
if (neu.preActive == True):
panneu.append(neu)
if (len(neu.spiketime) > 0):
# dic['N'] = neu.selectivity
if (len(neu.spiketime) > maxrate):
maxrate = len(neu.spiketime)
maxneu = neu
print(maxneu.I)
if (dic.get('N') == None):
j = random.randint(0, len(panneu) - 1)
neu = panneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['N'] = neu.selectivity
else: # chose the neuron which has the max firing rate
dic['N'] = maxneu.selectivity
patneu = []
maxrate = 0.0
maxneu = None
for neu in self.msm.sequenceLayers.get(1).get("T").groups.get(i + 1).neurons:
if (neu.preActive == True): patneu.append(neu)
if (len(neu.spiketime) > 0):
if (len(neu.spiketime) > maxrate):
maxrate = len(neu.spiketime)
maxneu = neu
if (dic.get('T') == None):
j = random.randint(0, len(patneu) - 1)
neu = patneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['T'] = neu.selectivity
else:
dic['T'] = neu.selectivity
track1.append(dic)
result[1] = track1
#print(result)
return result
def generateEx_Nihilo2(self, firstNote, durations, length):
'''
this function is used to generate the main melody, only one track
'''
self.pfc.setTestStates()
self.msm.setTestStates()
result = {}
track1 = []
for i in range(length):
dic = {}
tt = np.arange(i * 5, (i + 1) * 5, self.dt)
for t in tt:
self.pfc.inhibiteGoals(self.dt, t)
self.msm.generateEx_Nihilo(firstNote, durations, i, self.dt, t)
panneu = []
for ni, neu in enumerate(self.msm.sequenceLayers.get(1).get("N").groups.get(i + 1).neurons):
if (neu.preActive == True):
panneu.append(neu)
if (len(neu.spiketime) > 0):
dic['N'] = neu.selectivity
if (dic.get('N') == None):
j = random.randint(0, len(panneu) - 1)
neu = panneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['N'] = neu.selectivity
patneu = []
for neu in self.msm.sequenceLayers.get(1).get("T").groups.get(i + 1).neurons:
if (neu.preActive == True): patneu.append(neu)
if (len(neu.spiketime) > 0):
dic['T'] = neu.selectivity
if (dic.get('T') == None):
j = random.randint(0, len(patneu) - 1)
neu = patneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['T'] = neu.selectivity
track1.append(dic)
result[1] = track1
return result
def generateEx_NihiloAccordingToGenre(self, genreName, firstNote, durations, length):
genreName = genreName.title()
self.pfc.setTestStates()
self.msm.setTestStates()
result = {}
track1 = []
for i in range(length):
dic = {}
tt = np.arange(i * 5, (i + 1) * 5, self.dt)
for t in tt:
self.pfc.inhibiteGoals(self.dt, t)
self.pfc.inhibitComposers(self.dt, t)
self.pfc.doRememberingGenre(genreName, self.dt, t)
self.msm.generateEx_Nihilo(firstNote, durations, i, self.dt, t)
panneu = []
for ni, neu in enumerate(self.msm.sequenceLayers.get(1).get("N").groups.get(i + 1).neurons):
if (neu.preActive == True):
panneu.append(neu)
if (len(neu.spiketime) > 0):
dic['N'] = neu.selectivity
if (dic.get('N') == None):
j = random.randint(0, len(panneu) - 1)
neu = panneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['N'] = neu.selectivity
patneu = []
for neu in self.msm.sequenceLayers.get(1).get("T").groups.get(i + 1).neurons:
if (neu.preActive == True): patneu.append(neu)
if (len(neu.spiketime) > 0):
dic['T'] = neu.selectivity
if (dic.get('T') == None):
j = random.randint(0, len(patneu) - 1)
neu = patneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['T'] = neu.selectivity
track1.append(dic)
result[1] = track1
return result
def generateEx_NihiloAccordingToComposer(self, composerName, firstNote, durations, length):
composerName = composerName.title()
self.pfc.setTestStates()
self.msm.setTestStates()
result = {}
track1 = []
for i in range(length):
dic = {}
tt = np.arange(i * 5, (i + 1) * 5, self.dt)
for t in tt:
self.pfc.inhibiteGoals(self.dt, t)
self.pfc.doRememberingComposer(composerName, self.dt, t)
self.msm.generateEx_Nihilo(firstNote, durations, i, self.dt, t)
panneu = []
maxrate = 0.0
maxneu = None
for ni, neu in enumerate(self.msm.sequenceLayers.get(1).get("N").groups.get(i + 1).neurons):
if (neu.preActive == True):
panneu.append(neu)
if (len(neu.spiketime) > 0):
# dic['N'] = neu.selectivity
#print(str(neu.selectivity) + ":" + str(len(neu.spiketime)))
if (len(neu.spiketime) > maxrate):
maxrate = len(neu.spiketime)
maxneu = neu
if (dic.get('N') == None):
j = random.randint(0, len(panneu) - 1)
neu = panneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['N'] = neu.selectivity
else: # chose the neuron which has the max firing rate
dic['N'] = maxneu.selectivity
patneu = []
maxrate = 0.0
maxneu = None
for neu in self.msm.sequenceLayers.get(1).get("T").groups.get(i + 1).neurons:
if (neu.preActive == True): patneu.append(neu)
if (len(neu.spiketime) > 0):
if (len(neu.spiketime) > maxrate):
maxrate = len(neu.spiketime)
maxneu = neu
if (dic.get('T') == None):
j = random.randint(0, len(patneu) - 1)
neu = patneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['T'] = neu.selectivity
else:
dic['T'] = neu.selectivity
track1.append(dic)
result[1] = track1
#print(result)
return result
def generateMelodyWithKey(self, key, firstNotes, durations, length):
result = {}
self.pfc.setTestStates()
self.msm.setTestStates()
row,col = firstNotes.shape
for i in range(length):
time = np.arange(i*5,(i+1)*5,self.dt)
for t in time:
self.pfc.inhibiteGoals(self.dt,t)
self.pfc.inhibitComposers(self.dt,t)
self.pfc.inhibitGenres(self.dt,t)
self.pfc.doRememberingKey(key,self.dt,t)
self.msm.generateMelodyWithTone(firstNotes[:,i] if i < col else None, durations[:,i] if durations else None,key,i+1,self.dt,t)
# find the max firing rate
for j,sl in self.msm.sequenceLayers.items():
if j > 4: break;
#print("***********************this is part " + str(j) + "****************************")
dic = {}
if i < col:
dic["N"] = firstNotes[j-1][i]
dic["T"] = durations[j-1][i] if durations else 1.0
else:
maxrate = 0
for nn in sl.get("N").groups.get(i+1).neurons:
if nn.preActive:
# print("------order: "+str(i+1)+"-------")
# print(nn.selectivity)
# print(nn.I)
# print(nn.I_upper)
# print(nn.I_lower)
# print(len(nn.spiketime))
if len(nn.spiketime) > maxrate:
maxrate = len(nn.spiketime)
#print("top1:"+str(nn.selectivity))
dic["N"] = nn.selectivity
if durations is not None:
dic["T"] = 1
else:
maxrate = 0
for tn in sl.get("T").groups.get(i + 1).neurons:
if tn.preActive:
if len(tn.spiketime) > maxrate:
maxrate = len(tn.spiketime)
#print(tn.selectivity)
dic["N"] = nn.selectivity
if dic.get("T") is None:
dic["T"] = 1.0
if result.get(j) is None:
part = []
part.append(dic)
result[j] = part
else:
result.get(j).append(dic)
return result
def recallActionIPS(self, goalName):
self.pfc.setTestStates()
self.pfc.setTestStates()
self.pfc.doRecalling(goalName, self.asm)
def generate2TrackMusic(self, firstNotes, durations, lengths):
self.pfc.setTestStates()
self.msm.setTestStates()
result = {}
for k, notes in firstNotes.items():
track1 = []
for i in range(lengths[k - 1]):
dic = {}
tt = np.arange(i * 5, (i + 1) * 5, self.dt)
for t in tt:
self.pfc.inhibiteGoals(self.dt, t)
# self.msm.generateSimgleTrackNotes(j+1, firstNotes[j], durations[j], i, self.dt, t)
self.msm.generateSimgleTrackNotes(k, notes, durations.get(k), i, self.dt, t)
panneu = []
for ni, neu in enumerate(self.msm.sequenceLayers.get(k).get("N").groups.get(i + 1).neurons):
if (neu.preActive == True):
panneu.append(neu)
if (len(neu.spiketime) > 0):
dic['N'] = neu.selectivity
if (dic.get('N') == None):
j = random.randint(0, len(panneu) - 1)
neu = panneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['N'] = neu.selectivity
patneu = []
for neu in self.msm.sequenceLayers.get(k).get("T").groups.get(i + 1).neurons:
if (neu.preActive == True): patneu.append(neu)
if (len(neu.spiketime) > 0):
dic['T'] = neu.selectivity
if (dic.get('T') == None):
j = random.randint(0, len(patneu) - 1)
neu = patneu[j]
neu.I = 20
for t in tt:
neu.update_normal(self.dt, t)
dic['T'] = neu.selectivity
track1.append(dic)
result[k] = track1
print(result)
return result
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Areas/pac.py
================================================
'''
Primary Auditory Area
'''
from braincog.base.brainarea.BrainArea import BrainArea
from Modal.sequencememory import SequenceMemory
from Modal.notesequencelayer import NoteSequenceLayer
from Modal.temposequencelayer import TempoSequenceLayer
from Modal.synapse import Synapse
import numpy as np
import math
from conf.conf import *
class PAC(BrainArea,SequenceMemory):
'''
the planum polare, anterior to PAC, as well as in the left planum temporale,posterior to PAC.
'''
def __init__(self, neutype):
'''
Constructor
'''
SequenceMemory.__init__(self, neutype)
def forward(self, x):
pass
def createActionSequenceMem(self, layernum, neutype):
sl = NoteSequenceLayer(neutype)
tl = TempoSequenceLayer(neutype)
instrumentTrack = {}
instrumentTrack["N"] = sl
instrumentTrack["T"] = tl
self.sequenceLayers[layernum] = instrumentTrack
print(len(self.sequenceLayers))
def doRemembering_note_only(self, note, order, dt, t):
# remember note
sl = self.sequenceLayers.get(1)
sgroup = sl.groups.get(order)
dt = 0.1
for n in sgroup.neurons:
n.I_ext = note.frequence
n.computeFilterCurrent()
n.update(dt, t, 'Learn')
def doRemembering(self, trackIndex, noteIndex, order, dt, t, tinterval=0):
# remember note
iTrack = self.sequenceLayers.get(trackIndex)
sl = iTrack.get("N")
sgroup = sl.groups.get(order)
dt = 0.1
for n in sgroup.neurons:
n.I_ext = noteIndex
n.computeFilterCurrent()
n.update(dt, t, 'Learn')
# remember tempo
tl = iTrack.get("T")
tgroup = tl.groups.get(order)
dt = 0.1
for n in tgroup.neurons:
n.I_ext = tinterval
n.computeFilterCurrent()
n.update(dt, t, 'Learn')
def doConnectToTitle(self, title, track, order):
for sl in track.values():
self.doConnecting(title, sl, order)
def doConnectToComposer(self, composer, track, order):
for sl in track.values():
self.doConnecting(composer, sl, order)
def doConnectToGenre(self, genre, track, order):
for sl in track.values():
self.doConnecting(genre, sl, order)
def generateEx_Nihilo(self, firstNote, durations, order, dt, t):
ns = self.sequenceLayers.get(1).get("N")
ts = self.sequenceLayers.get(1).get("T")
nneurons = ns.groups.get(order + 1).neurons
tneurons = ts.groups.get(order + 1).neurons
# firstNotes specify the beginning notes to trigger the following notes
if (order < len(firstNote)): # beginning notes
i = firstNote[order]
nneu = nneurons[i + 1]
nneu.I = 20
nneu.update_normal(dt, t)
d = int(durations[order] / 0.125) - 1
tneu = tneurons[d]
tneu.I = 20
tneu.update_normal(dt, t)
else: # generate next note
for nn in nneurons:
nn.updateCurrentOfLowerAndUpperLayer(t)
nn.update(dt, t, 'test')
for tn in tneurons:
tn.updateCurrentOfLowerAndUpperLayer(t)
tn.update(dt, t, 'test')
def generateSimgleTrackNotes(self, trackIndex, firstNote, durations, order, dt, t):
ns = self.sequenceLayers.get(trackIndex).get("N")
ts = self.sequenceLayers.get(trackIndex).get("T")
nneurons = ns.groups.get(order + 1).neurons
tneurons = ts.groups.get(order + 1).neurons
# firstNotes specify the beginning notes to trigger the following notes
if (order < len(firstNote)): # beginning notes
i = firstNote[order]
nneu = nneurons[i + 1]
nneu.I = 20
nneu.update_normal(dt, t)
d = int(durations[order] / 0.125) - 1
tneu = tneurons[d]
tneu.I = 20
tneu.update_normal(dt, t)
else: # generate next note
for nn in nneurons:
nn.updateCurrentOfLowerAndUpperLayer(t)
nn.update(dt, t, 'test')
# if(neu.spike == True):
# print(neu.selectivity)
for tn in tneurons:
tn.updateCurrentOfLowerAndUpperLayer(t)
tn.update(dt, t, 'test')
class Music_Sequence_Mem(SequenceMemory):
'''
the planum polare, anterior to PAC, as well as in the left planum temporale,posterior to PAC.
'''
def __init__(self, neutype):
'''
Constructor
'''
SequenceMemory.__init__(self, neutype)
def createActionSequenceMem(self, layernum, neutype):
sl = NoteSequenceLayer(neutype)
tl = TempoSequenceLayer(neutype)
instrumentTrack = {}
instrumentTrack["N"] = sl
instrumentTrack["T"] = tl
self.sequenceLayers[layernum] = instrumentTrack
print(len(self.sequenceLayers))
def doRemembering_note_only(self, note, order, dt, t):
# remember note
sl = self.sequenceLayers.get(1)
sgroup = sl.groups.get(order)
dt = 0.1
for n in sgroup.neurons:
n.I_ext = note.frequence
n.computeFilterCurrent()
n.update(dt, t, 'Learn')
def doRemembering(self, trackIndex, noteIndex, order, dt, t, tinterval=0):
# remember note
iTrack = self.sequenceLayers.get(trackIndex)
sl = iTrack.get("N")
sgroup = sl.groups.get(order)
dt = 0.1
for n in sgroup.neurons:
n.I_ext = noteIndex
n.computeFilterCurrent()
n.update(dt, t, 'Learn')
# remember tempo
tl = iTrack.get("T")
tgroup = tl.groups.get(order)
dt = 0.1
for n in tgroup.neurons:
n.I_ext = tinterval
n.computeFilterCurrent()
n.update(dt, t, 'Learn')
def recallByEpisode(self, episodeNotes, goals):
dt = 0.1
sl = self.sequenceLayers.get(1)
firstresult = {}
firstNote = episodeNotes[0]
tt = np.arange(0, 5, dt)
# find first note and activate goal neurons
for t in tt:
for id, group in sl.groups.items():
neuid = firstNote - 15;
if (group.neurons[neuid - 1].preActive == False): continue
group.neurons[neuid - 1].I_ext = 20
group.neurons[neuid - 1].updateCurrentOfLowerAndUpperLayer(t)
group.neurons[neuid - 1].update(dt, t, 'test')
if (group.neurons[neuid - 1].spike == True):
firstresult[id] = 1
for name, g in goals.groups.items():
for neu in g.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t)
# find rest episode notes
restResult = {}
# for i in range(1,len(episodeNotes)):
goalchecked = {}
for groupID, value in firstresult.items():
tmp = {}
for i in range(1, len(episodeNotes)):
fre = episodeNotes[i]
tt = np.arange(i * 5, (i + 1) * 5, dt)
g = sl.groups.get(groupID + i)
for t in tt:
# update memory
neuid = fre - 15;
if (g.neurons[neuid - 1].preActive == False): continue
g.neurons[neuid - 1].I_ext = 20
g.neurons[neuid - 1].updateCurrentOfLowerAndUpperLayer(t)
if (g.neurons[neuid - 1].I_lower == 0): break
g.neurons[neuid - 1].update(dt, t, 'test')
if (g.neurons[neuid - 1].spike == True):
tmp[i] = g.id
# update goals' neurons
for name, gg in goals.groups.items():
for neu in gg.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t)
# if(neu.spike == True):print(name)
# find
maxFiringRate = 0
maxGoalName = ''
maxGoal = {} # an episode may be mapped to more than one songs
for name, gg in goals.groups.items():
if (goalchecked.get(name) == None):
averageFiringRate = 0
for neu in gg.neurons:
averageFiringRate = averageFiringRate + len(neu.spiketime)
averageFiringRate = float(averageFiringRate) / float(len(gg.neurons))
gg.averageFiringRate = averageFiringRate
if (averageFiringRate > maxFiringRate):
maxFiringRate = averageFiringRate
maxGoalName = name
maxGoal[maxGoalName] = 1
goalchecked[maxGoalName] = 1
for name, gg in goals.groups.items():
if (gg.averageFiringRate == maxFiringRate and goalchecked.get(name) == None):
maxGoal[name] = 1
goalchecked[name] = 1
tmp['goal'] = maxGoal
restResult[groupID] = tmp
print(restResult)
episodeResult = []
for key, value in firstresult.items():
tmp = {}
tmp[0] = key
dic = restResult.get(key)
for i in range(1, len(episodeNotes)):
if (dic.get(i) != None):
tmp[i] = dic.get(i)
if (len(tmp) == len(episodeNotes)):
tmp['goal'] = dic.get('goal')
episodeResult.append(tmp)
print(episodeResult)
for res in episodeResult:
msmgroupID = res.get(len(episodeNotes) - 1) + 1
for gname, value in res.get('goal').items():
gg = goals.groups.get(gname)
def recallByEpisode2(self, episodeNotes, goals):
dt = 0.1
sl = self.sequenceLayers.get(1).get("N")
tl = self.sequenceLayers.get(1).get("T")
print(len(sl.groups))
firstresult = {}
firstNote = episodeNotes[0]
tt = np.arange(0, 5, dt)
# find first note and activate goal neurons
for t in tt:
for id, group in sl.groups.items():
neuid = firstNote;
if (group.neurons[neuid + 1].preActive == False): continue
# group.neurons[neuid+1].I_ext = 20
# group.neurons[neuid+1].updateCurrentOfLowerAndUpperLayer(t)
group.neurons[neuid + 1].I = 20
group.neurons[neuid + 1].update(dt, t, 'test')
if (group.neurons[neuid + 1].spike == True):
firstresult[id] = 1
# find rest episode notes
restResult = {}
# for i in range(1,len(episodeNotes)):
goalchecked = {}
for groupID in firstresult.keys():
#
sl.setTestStates()
tmp = {}
tt = np.arange(0, 5, dt)
g = sl.groups.get(groupID)
neuid = firstNote
# g.neurons[neuid+1].I_ext = 20
g.neurons[neuid + 1].I = 20
for t in tt:
# g.neurons[neuid+1].updateCurrentOfLowerAndUpperLayer(t)
g.neurons[neuid + 1].update(dt, t, 'test')
for i in range(1, len(episodeNotes)):
fre = episodeNotes[i]
tt = np.arange(i * 5, (i + 1) * 5, dt)
if (groupID + i > len((sl.groups))): continue
g = sl.groups.get(groupID + i)
for t in tt:
# update memory
neuid = fre;
if (g.neurons[neuid + 1].preActive == False): continue
g.neurons[neuid + 1].I_ext = 20
g.neurons[neuid + 1].updateCurrentOfLowerAndUpperLayer(t)
if (g.neurons[neuid + 1].I_lower == 0): break
g.neurons[neuid + 1].update(dt, t, 'test')
if (g.neurons[neuid + 1].spike == True):
tmp[i] = g.id
restResult[groupID] = tmp
# print(restResult)
episodeResult = []
for key in firstresult.keys():
tmp = {}
tmp[0] = key
dic = restResult.get(key)
for i in range(1, len(episodeNotes)):
if (dic.get(i) != None):
tmp[i] = dic.get(i)
if (len(tmp) == len(episodeNotes)):
episodeResult.append(tmp)
# print(episodeResult)
# begin remembering
finalResult = []
for i, res in enumerate(episodeResult):
goals.setTestStates()
self.setTestStates()
for i, fre in enumerate(episodeNotes):
tt = np.arange(i * 5, (i + 1) * 5, dt)
neuid = fre
g = sl.groups.get(res.get(i))
for t in tt:
# g.neurons[neuid+1].I_ext = 20
# g.neurons[neuid+1].updateCurrentOfLowerAndUpperLayer(t)
g.neurons[neuid + 1].I = 20
g.neurons[neuid + 1].update(dt, t, 'test')
for name, gg in goals.groups.items():
for neu in gg.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t)
# find goal
maxFiringRate = 0
maxGoalName = ''
maxGoal = {} # an episode may be mapped to more than one songs
for name, gg in goals.groups.items():
averageFiringRate = 0
for neu in gg.neurons:
averageFiringRate = averageFiringRate + len(neu.spiketime)
averageFiringRate = float(averageFiringRate) / float(len(gg.neurons))
gg.averageFiringRate = averageFiringRate
if (averageFiringRate > maxFiringRate):
maxFiringRate = averageFiringRate
maxGoalName = name
maxGoal[maxGoalName] = 1
for name, gg in goals.groups.items():
if (gg.averageFiringRate == maxFiringRate and goalchecked.get(name) == None):
maxGoal[name] = 1
# print(maxGoal)
# recall the rest song
for goalname, value in maxGoal.items():
# reset State
goals.setTestStates()
nextGroupId = res.get(len(episodeNotes) - 1) + 1
for i in range(nextGroupId, len(sl.groups) + 1):
sl.groups.get(i).setTestStates()
tl.groups.get(i).setTestStates()
restSpikeResult = {}
count = 0
gg = goals.groups.get(goalname)
for i in range(nextGroupId, len(sl.groups) + 1):
order = len(episodeNotes) + count
if (order == 3):
print("debug")
tt = np.arange(order * 5, (order + 1) * 5, dt)
msmgroup = sl.groups.get(i)
msmtgroup = tl.groups.get(i)
tdic = {}
for t in tt:
for n in gg.neurons:
# n.updateCurrentOfLowerAndUpperLayer(t)
n.I = 30
n.update_normal(dt, t)
for neu in msmgroup.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t, 'test')
if (neu.spike == True and restSpikeResult.get(order) == None):
# restSpikeResult[int(order)] = neu.selectivity
tdic["N"] = neu.selectivity
for neu in msmtgroup.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t, 'test')
if (neu.spike == True and restSpikeResult.get(order) == None):
# restSpikeResult[int(order)] = neu.selectivity
tdic["T"] = neu.selectivity
if (tdic):
restSpikeResult[int(order)] = tdic
count += 1
# print(restSpikeResult)
dic = {}
dic['goal'] = goalname
dic['rest'] = restSpikeResult
finalResult.append(dic)
return (finalResult)
def doConnectToTitle(self, title, track, order):
for sl in track.values():
self.doConnecting(title, sl, order)
def doConnectToComposer(self, composer, track, order):
for sl in track.values():
self.doConnecting(composer, sl, order)
def doConnectToGenre(self, genre, track, order):
for sl in track.values():
self.doConnecting(genre, sl, order)
def doConnectToEmotion(self, emo, track, order):
for sl in track.values():
self.doConnecting(emo, sl, order)
def doConnectToKey(self, key, track, order, noteIndex):
group = track.get("N").groups.get(order)
if group == None: return
tb = (order - 1) * group.timeWindow
te = (order) * group.timeWindow
sp1_goal = {}
sp2 = []
kneu = key.neurons[noteIndex % 12]
sp = []
for st in kneu.spiketime:
if (st < te and st >= tb):
sp.append(st)
sp1_goal[kneu.index] = sp
n = group.neurons[noteIndex + 1]
if (len(n.spiketime) > 0):
for index, sp in sp1_goal.items():
temp = 0
for sp1 in n.spiketime: # spike times of group
for sp2 in sp:
if (abs(sp1 - sp2) <= n.timeWindow):
temp += 1
if (temp >= 2): # super threshold, create a new synapse between goal and neurons of sequence group
# syn = Synapse(goal.neurons[index - 1], n)
# syn.type = 2
# syn.weight = 30
# n.pre_neurons.append(goal.neurons[index - 1])
# n.synapses.append(syn)
# add reverse synapse to neurons of the goal
syn2 = Synapse(n, kneu)
syn2.type = 3
syn2.weight = 0
kneu.synapses.append(syn2)
def doConnectToMode(self, mode, keyName, track, order, noteIndex): # 只连接对应调式的音级(这是两个神经元之间的连接)
noteScales = np.where((configs.keyscales.get(keyName % 2)[keyName // 2]) == noteIndex % 12)[0][0]
group = track.get("N").groups.get(order)
if (group == None): return
tb = (order - 1) * group.timeWindow
te = (order) * group.timeWindow
sp1_goal = {}
sp2 = []
modeneu = mode.neurons[noteScales]
sp = []
for st in modeneu.spiketime:
if (st < te and st >= tb):
sp.append(st)
sp1_goal[modeneu.index] = sp
n = group.neurons[noteIndex + 1]
if (len(n.spiketime) > 0):
for index, sp in sp1_goal.items():
temp = 0
for sp1 in n.spiketime: # spike times of group
for sp2 in sp:
if (abs(sp1 - sp2) <= n.timeWindow):
temp += 1
if (temp >= 2): # super threshold, create a new synapse between goal and neurons of sequence group
# syn = Synapse(goal.neurons[index - 1], n)
# syn.type = 2
# syn.weight = 30
# n.pre_neurons.append(goal.neurons[index - 1])
# n.synapses.append(syn)
# add reverse synapse to neurons of the goal
syn2 = Synapse(n, modeneu)
syn2.type = 3
syn2.weight = 0
modeneu.synapses.append(syn2)
def generateEx_Nihilo(self, firstNote, durations, order, dt, t):
ns = self.sequenceLayers.get(1).get("N")
ts = self.sequenceLayers.get(1).get("T")
nneurons = ns.groups.get(order + 1).neurons
tneurons = ts.groups.get(order + 1).neurons
# firstNotes specify the beginning notes to trigger the following notes
if (order < len(firstNote)): # beginning notes
i = firstNote[order]
nneu = nneurons[i + 1]
nneu.I = 20
nneu.update_normal(dt, t)
d = int(durations[order] / 0.125) - 1
tneu = tneurons[d]
tneu.I = 20
tneu.update_normal(dt, t)
else: # generate next note
for nn in nneurons:
nn.updateCurrentOfLowerAndUpperLayer(t)
nn.update(dt, t, 'test')
for tn in tneurons:
tn.updateCurrentOfLowerAndUpperLayer(t)
tn.update(dt, t, 'test')
def generateMelodyWithTone(self, firstNote, duration, tone, order, dt, t):
for i, part in self.sequenceLayers.items():
if i > 4: break
ns = part.get("N")
ts = None
if duration is not None:
ts = part.get("T") # 不输入值的话就都生成四分音符
# pitches updating
if firstNote is not None:
for nneu in ns.groups.get(order).neurons:
nneu.I_ext = firstNote[i - 1]
nneu.computeFilterCurrent()
nneu.update_normal(dt, t)
else:
for nneu in ns.groups.get(order).neurons:
nneu.updateCurrentOfLowerAndUpperLayer(t)
nneu.update_normal(dt, t)
# durations updating
if ts is not None:
if duration is not None:
for tneu in ts.groups.get(order).neurons:
tneu.I_ext = duration[i - 1]
tneu.computeFilterCurrent()
tneu.update_normal(dt, t)
else:
for tneu in ts.groups.get(order).neurons:
tneu.updateCurrentOfLowerAndUpperLayer(t)
tneu.update_normal(dt, t)
def generateSimgleTrackNotes(self, trackIndex, firstNote, durations, order, dt, t):
ns = self.sequenceLayers.get(trackIndex).get("N")
ts = self.sequenceLayers.get(trackIndex).get("T")
nneurons = ns.groups.get(order + 1).neurons
tneurons = ts.groups.get(order + 1).neurons
# firstNotes specify the beginning notes to trigger the following notes
if (order < len(firstNote)): # beginning notes
i = firstNote[order]
nneu = nneurons[i + 1]
nneu.I = 20
nneu.update_normal(dt, t)
d = int(durations[order] / 0.125) - 1
tneu = tneurons[d]
tneu.I = 20
tneu.update_normal(dt, t)
else: # generate next note
for nn in nneurons:
nn.updateCurrentOfLowerAndUpperLayer(t)
nn.update(dt, t, 'test')
# if(neu.spike == True):
# print(neu.selectivity)
for tn in tneurons:
tn.updateCurrentOfLowerAndUpperLayer(t)
tn.update(dt, t, 'test')
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Areas/pfc.py
================================================
import numpy as np
import math
from braincog.base.brainarea.PFC import PFC
from Modal.synapse import Synapse
from Modal.titlelayer import TitleLayer
from Modal.composerlayer import ComposerLayer
from Modal.genrelayer import GenreLayer
from conf.conf import *
from Modal.layer import *
class PFC(PFC):
'''
This area is used to store the sub-Goal of the task
'''
def __init__(self, neutype):
'''
Constructor
'''
super().__init__()
self.neutype = neutype
self.goals = TitleLayer(self.neutype) # store the musical titles
self.composers = ComposerLayer(self.neutype) # store composers
self.keys = KeyLayer(self.neutype)
self.modes = ModeLayer(self.neutype)
self.genres = GenreLayer(self.neutype)
self.chords = ChordLayer(self.neutype)
def addNewKey(self):
row, col = configs.key_matrix.shape
for i in range(row):
#print(configs.key_matrix[i,:])
self.keys.addNewGroups(i+1, 1, col, configs.key_matrix[i,:])
def addNewSubGoal(self, goalname):
if (self.goals.groups.get(goalname) == None):
self.goals.addNewGroups(len(self.goals.groups) + 1, 1, 1, goalname)
def addNewComposer(self, composername):
if (self.composers.groups.get(composername) == None):
self.composers.addNewGroups(len(self.composers.groups) + 1, 1, 1, composername)
def addNewGenre(self, genrename):
if (self.genres.groups.get(genrename) == None):
self.genres.addNewGroups(len(self.genres.groups) + 1, 1, 1, genrename)
def addNewMode(self):
for i, m in configs.index2mode.items():
self.modes.addNewGroups(i + 1, 1, 12, m)
# 与调式网络相连
scales = configs.keyscales.get(i)
for k in range(12): # key neurons project to mode neurons
for j, index in enumerate(scales[k, :]):
pre = self.keys.groups.get(k).neurons[index]
post = self.modes.groups.get(i).neurons[j]
syn = Synapse(pre, post)
syn.excitability = 1
syn.type = 3
post.synapses.append(syn)
post.pre_neurons.append(pre)
# syn1 = Synapse(post, pre) # mode neurons project to key neurons
# syn1.type = 2
# syn1.excitability = 1
# syn1.weight = 10 # 这个地方应该设置成KS model
# pre.synapses.append(syn1)
# pre.pre_neurons.append(post)
def addNewKey(self):
row, col = configs.key_matrix.shape
for i in range(row):
#print(configs.key_matrix[i,:])
self.keys.addNewGroups(i+1, 1, col, configs.key_matrix[i,:])
def addNewChord(self):
for i in range(0, 7): # 暂时先存储7个三和弦
self.chords.addNewGroups(i + 1, 1, 1)
# 与调式网络相连
# 先连接T,S,D和弦
for t, c in configs.chordsMap.items():
# print(t)
# print(configs.keyIndexMap.get(t))
# print(c[i, :])
# print('---------')
for k in c[i, :]:
pre = self.chords.groups.get(i).neurons[0]
post = self.keys.groups.get(configs.keyIndexMap.get(t)).neurons[k]
syn = Synapse(pre, post)
syn.excitability = 1
post.synapses.append(syn)
post.pre_neurons.append(pre)
# 建立和弦内部连接
r = np.argwhere(configs.chordsMatrix >= 1)
for i in range(len(r)):
# print(r[i][0])
# print(r[i][1])
pre = self.chords.groups.get(r[i][0]).neurons[0]
post = self.chords.groups.get(r[i][1]).neurons[0]
syn = Synapse(pre, post)
post.synapses.append(syn)
post.pre_neurons.append(pre)
def setTestStates(self):
self.goals.setTestStates()
self.composers.setTestStates()
self.genres.setTestStates()
self.keys.setTestStates()
self.modes.setTestStates()
self.chords.setTestStates()
def doRecalling(self, goalname, asm):
goal = self.goals.groups.get(goalname)
# print(goal.name)
# print(goal.id)
result = {}
sequences = asm.sequenceLayers.get(1).groups
dt = 0.1
time = np.arange(0, len(sequences) * 5, dt)
for t in time:
order = math.floor(t / 5) + 1
for neu in goal.neurons:
neu.I = 30
neu.update_normal(dt, t)
sg = sequences.get(order)
for neu in sg.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t, 'test')
# if(neu.spike == True):
# print(neu.index)
if (neu.spike == True and result.get(order) == None):
result[int(order)] = neu.selectivity
return result
def doRecalling2(self, goalname, asm):
goal = self.goals.groups.get(goalname)
# print(goal.name)
# print(goal.id)
result = {}
for tindex, strack in asm.sequenceLayers.items():
nsequences = strack.get("N").groups
tsequences = strack.get("T").groups
dic = {}
ndic = {}
tdic = {}
dt = 0.1
time = np.arange(0, len(nsequences) * 5, dt)
for t in time:
order = math.floor(t / 5) + 1
for neu in goal.neurons:
neu.I = 30
neu.update_normal(dt, t)
nsg = nsequences.get(order)
for neu in nsg.neurons:
# print(neu.selectivity)
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t, 'test')
# if(neu.I > 0):
# print(neu.I)
if (neu.spike == True and ndic.get(order) == None):
ndic[int(order)] = neu.selectivity
tsg = tsequences.get(order)
for neu in tsg.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update(dt, t, 'test')
if (neu.spike == True and tdic.get(order) == None):
tdic[int(order)] = neu.selectivity
dic["N"] = ndic
dic["T"] = tdic
result[tindex] = dic
return result
def doRecalling3(self,goalname,asm):
goal = self.goals.groups.get(goalname)
# print(goal.name)
# print(goal.id)
result = {}
for tindex, strack in asm.sequenceLayers.items():
nsequences = strack.get("N").groups
tsequences = strack.get("T").groups
part = []
ndic = {}
tdic = {}
dt = 0.1
# for order in range(len(nsequences)):
# nns = nsequences.get(order+1).neurons
# for n in nns:
# if n.preActive:
# print('-------order:'+str(order)+', selectivity: '+str(n.selectivity)+'--------------------')
# for syn in n.synapses:
# if syn.weight > 0:
# print(syn.weight)
#time = np.arange(0, len(nsequences) * 5, dt)
print(len(nsequences))
for i in range(0,len(nsequences)):
order = i+1
tmp = {}
time = np.arange(i*5,(i+1)*5,dt)
for t in time:
for neu in goal.neurons:
neu.I = 30
neu.update_normal(dt, t)
nsg = nsequences.get(order)
for neu in nsg.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update_normal(dt, t)
# if (neu.I > 0):
# print('order: ' + str(order))
# print(neu.I)
# print(neu.selectivity)
# print(neu.I_lower)
if (neu.spike == True and ndic.get(order) == None):# 这里用的是first spike的理念,我觉得最好改成max firingrate
ndic[int(order)] = neu.selectivity
tmp["N"] = neu.selectivity
tsg = tsequences.get(order)
for neu in tsg.neurons:
neu.updateCurrentOfLowerAndUpperLayer(t)
neu.update_normal(dt, t)
if (neu.spike == True and tdic.get(order) == None):#这个地方bug太邪乎了,等一会儿改
tdic[int(order)] = neu.selectivity
tmp["T"] = neu.selectivity
part.append(tmp)
result[tindex] = part
print(len(result))
return result
def doRemebering(self, goalname, dt, t):
# storing the title information
goal_group = self.goals.groups.get(goalname)
for neu in goal_group.neurons:
neu.I = 50
neu.update_normal(dt, t)
def doRememberingComposer(self, composername, dt, t):
composer_group = self.composers.groups.get(composername)
for neu in composer_group.neurons:
neu.I = 50
neu.update_normal(dt, t)
def doRememberingGenre(self, genrename, dt, t):
genre_group = self.genres.groups.get(genrename)
for neu in genre_group.neurons:
neu.I = 50
neu.update_normal(dt, t)
def doRememberingKey(self, key, dt, t):
key_group = self.keys.groups.get(key)
for neu in key_group.neurons:
neu.I = 50 if neu.importance > 0 else -100
neu.update_learn(dt, t)
def doRememberingMode(self,mode, dt,t):
mode_group = self.modes.groups.get(mode)
for neu in mode_group.neurons:
neu.I = 50
neu.update_learn(dt,t)
def innerLearning(self, goalname, composer, genre):
g = self.goals.groups.get(goalname)
c = self.composers.groups.get(composer)
gre = self.genres.groups.get(genre)
if (g != None and c != None):
for n1 in c.neurons:
if (len(n1.spiketime) > 0):
for n2 in g.neurons:
if (len(n2.spiketime) > 0):
temp = 0
for sp1 in n1.spiketime:
for sp2 in n2.spiketime:
if (abs(sp1 - sp2) <= n1.tau_ref):
temp += 1
if (temp >= 3):
syn = Synapse(n1, n2)
syn.type = 2
syn.weight = 5
n2.synapses.append(syn)
n2.pre_neurons.append(n1)
if (gre != None):
for n1 in gre.neurons:
if (len(n1.spiketime) > 0):
if (c != None):
for n2 in c.neurons:
if (len(n2.spiketime) > 0):
temp = 0
for sp1 in n1.spiketime:
for sp2 in n2.spiketime:
if (abs(sp1 - sp2) <= n1.tau_ref):
temp += 1
if (temp >= 4):
syn = Synapse(n1, n2)
syn.type = 2
syn.weight = 5
n2.synapses.append(syn)
n2.pre_neurons.append(n1)
if (g != None):
for n2 in g.neurons:
if (len(n2.spiketime) > 0):
temp = 0
for sp1 in n1.spiketime:
for sp2 in n2.spiketime:
if (abs(sp1 - sp2) <= n1.tau_ref):
temp += 1
if (temp >= 4):
syn = Synapse(n1, n2)
syn.type = 2
syn.weight = 5
n2.synapses.append(syn)
n2.pre_neurons.append(n1)
def inhibitGenres(self,dt,t):
gen_group = self.goals.groups
for g in gen_group.values():
for neu in g.neurons:
neu.I = -100
neu.update_normal(dt, t)
def inhibiteGoals(self, dt, t):
goal_group = self.goals.groups
for g in goal_group.values():
for neu in g.neurons:
neu.I = -100
neu.update(dt, t)
def inhibitComposers(self, dt, t):
com_group = self.composers.groups
for g in com_group.values():
for neu in g.neurons:
neu.I = -100
neu.update(dt, t)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/PAC.py
================================================
'''
Primary Auditory Cortex
'''
import torch
from braincog.base.node.node import *
from braincog.base.brainarea.BrainArea import *
from braincog.base.connection import CustomLinear
from braincog.base.learningrule.STDP import *
class PAC(BrainArea):
def __int__(self,w,mask):
self.noteNetworks = NoteLIFNode()
self.connection = [CustomLinear(w,mask),CustomLinear(w2,mask2)]
self.stdp = []
self.internalinputs = torch.zeros(640,640)
self.stdp.append(MutliInputSTDP(self.noteNetworks, self.connection))
def forward(self, x):
self.internalinputs,dw = self.stdp[0](x,self.internalinputs)
return self.internalinputs, dw
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/cluster.py
================================================
from .lifneuron import LIFNeuron
from .synapse import Synapse
from Modal.izhikevichneuron import *
class Cluster():
'''
classdocs
'''
def __init__(self, neutype='LIF', neunum=10):
'''
Constructor
'''
self.id = 0 # starting with 1
self.name = '' # name of this group
self.neutype = neutype
self.neunum = neunum
self.neurons = []
self.timeWindow = 5 # ms
def createClusterNetwork(self):
# create neurons
for i in range(0, self.neunum):
if (self.neutype == 'LIF'):
node = LIFNeuron()
node.index = i + 1
node.setPreference()
self.neurons.append(node)
if (self.neutype == 'Izhikevich'):
node = IzhikevichNeuron()
node.index = i
self.neurons.append(node)
if (self.neutype == 'Gaussian'):
node = GaussianNeuron()
node.index = i + 1
self.neurons.append(node)
if (self.neutype == 'HH'):
node = HHNeuron()
node.index = i
self.neurons.append(node)
def setInhibitoryNeurons(self, ratio_inhneuron):
for i in range(int(self.neunum * (1 - ratio_inhneuron)), self.neunum):
self.neurons[i].type = 'inh'
def setPropertiesofNeurons(self, groupID, layerType, layerID):
for n in self.neurons:
n.layerType = layerType
n.groupIndex = groupID
n.layerIndex = layerID
def setTestStates(self):
for neu in self.neurons:
neu.setTestStates()
def createFullConnections(self): # all in all connections
for i in range(0, self.neunum):
neu = self.neurons[i]
for j in range(0, self.neunum):
if (j != i):
syn = Synapse(self.neurons[j], neu) # this neuron is considered as post_synapse neuron
syn.type = 0
neu.synapses.append(syn)
neu.pre_neurons.append(self.neurons[j])
def createInhibitoryConnections(self): # all in all inhibitory connections
for i in range(0, self.neunum):
neu = self.neurons[i]
for j in range(0, self.neunum):
if (j != i):
syn = Synapse(self.neurons[j], neu) # this neuron is considered as post_synapse neuron
syn.type = 0
syn.excitability = 0
syn.weight = 20
neu.synapses.append(syn)
neu.pre_neurons.append(self.neurons[j])
def writeSelfInfoToJson(self):
dic = {}
nlist = []
for neu in self.neurons:
if (len(neu.spiketime) <= 0): continue
ndic = neu.writeBasicInfoToJson()
nlist.append(ndic)
dic["GroupID"] = self.id
dic["Name"] = self.name
dic["Neuron"] = nlist
return dic
def writeSpikeInfoToJson(self):
nlist = []
for neu in self.neurons:
if (len(neu.spiketime) > 0):
tmp = {}
tmp["GroupID"] = neu.groupIndex
tmp["Index"] = neu.index
tmp["SpikeTime"] = neu.writeSpikeTimeToJson()
nlist.append(tmp)
return nlist
class ModeCluster(Cluster):
def __init__(self, neutype, neunum):
Cluster.__init__(self, neutype,neunum)
def createClusterNetwork(self, areaName):
for i in range(self.neunum): # 暂时先不考虑importance
if (self.neutype == 'LIF'):
node = ModeLIFNeuron()
node.index = i + 1
node.areaName = areaName
node.selectivity = i+1
self.neurons.append(node)
if (self.neutype == 'Izhikevich'):
self.neutype = 'Izhikevich'
node = ModeIzhikevichNeuron()
node.index = i + 1
node.areaName = areaName
node.selectivity = i+1
self.neurons.append(node)
class KeyCluster(Cluster):
def __init__(self, neutype, neunum):
'''
Constructor
'''
Cluster.__init__(self, neutype, neunum)
def createClusterNetwork(self,tone,areaName):
for i in range(0, self.neunum):
if (self.neutype == 'LIF'):
node = KeyLIFNeuron()
node.index = i + 1
node.areaName = areaName
node.selectivity = i
node.importance = tone[i]
self.neurons.append(node)
if(self.neutype == 'Izhikevich'):
self.neutype = 'Izhikevich'
a=0
b=0
c=0
d=0
if tone[i] == 2:
a = 0.02
b = 0.2
c = -55
d = 4
if tone[i] == -1:
a=0.1
b = 0.2
c = -65
d = 2
if(tone[i] == 1):
a = 0.02
b = 0.2
c = -65
d = 8
node = KeyIzhikevichNeuron(a,b,c,d)
node.index = i + 1
node.areaName = areaName
node.selectivity = i
node.importance = tone[i]
self.neurons.append(node)
class ChordCluster(Cluster):
def __init__(self, neutype,neunum):
Cluster.__init__(self, neutype, neunum)
def createClusterNetwork(self):
for i in range(self.neunum):
if (self.neutype == 'LIF'):
node = ChordLIFNeuron()
node.index = i + 1
node.areaName = 'Chord'
node.selectivity = i
node.importance = 1
self.neurons.append(node)
if self.neutype == 'Izhikevich':
node = ChordIzhikevichNeuron()
node.index = i + 1
node.areaName = 'Chord'
node.selectivity = i
node.importance = 1
self.neurons.append(node)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/composercluster.py
================================================
from .cluster import Cluster
from .composerlifneuron import ComposerLIFNeuron
class ComposerCluster(Cluster):
'''
classdocs
'''
def __init__(self, neutype, neunum):
'''
Constructor
'''
Cluster.__init__(self, neutype, neunum)
def createClusterNetwork(self):
for i in range(0, self.neunum):
if (self.neutype == 'LIF'):
node = ComposerLIFNeuron()
node.index = i + 1
node.areaName = 'Composer'
self.neurons.append(node)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/composerlayer.py
================================================
from .layer import Layer
from .composercluster import ComposerCluster
class ComposerLayer(Layer):
'''
This layer defines the information of composer name. One neuron corresponds to a composer
'''
def __init__(self, neutype='LIF'):
self.neutype = neutype
self.groups = {}
def setTestStates(self):
for id, g in self.groups.items():
g.setTestStates()
def addNewGroups(self, groupID, layerID, neunum, composername):
g = ComposerCluster(self.neutype, neunum)
g.id = groupID
g.name = composername
g.createClusterNetwork()
g.setPropertiesofNeurons(groupID, 'G', layerID)
self.groups[composername] = g
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/composerlifneuron.py
================================================
from .lifneuron import LIFNeuron
class ComposerLIFNeuron(LIFNeuron):
'''
classdocs
'''
def __init__(self, tau_ref=0, vthresh=5, Rm=2, Cm=0.2):
'''
Constructor
'''
LIFNeuron.__init__(self, tau_ref, vthresh, Rm, Cm)
def update(self, dt, t):
self.spike = False
# self.updateCurrentOfLowerAndUpperLayer(t)
if (t >= self.t_rest):
self.mem += dt * (-self.mem + self.I * self.Rm) / self.tau_m
if (self.mem > self.vth):
self.spike = True
self.spiketime.append(t)
self.mem = 0
self.t_rest = t + self.tau_ref
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/genrecluster.py
================================================
from .cluster import Cluster
from .genrelifneuron import GenreLIFNeuron
class GenreCluster(Cluster):
'''
classdocs
'''
def __init__(self, neutype, neunum):
'''
Constructor
'''
Cluster.__init__(self, neutype, neunum)
def createClusterNetwork(self):
for i in range(0, self.neunum):
if (self.neutype == 'LIF'):
node = GenreLIFNeuron()
node.index = i + 1
node.areaName = 'Genre'
self.neurons.append(node)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/genrelayer.py
================================================
from .layer import Layer
from .genrecluster import GenreCluster
class GenreLayer(Layer):
'''
This layer defines the information of composer name. One neuron corresponds to a composer
'''
def __init__(self, neutype='LIF'):
self.neutype = neutype
self.groups = {}
def setTestStates(self):
for id, g in self.groups.items():
g.setTestStates()
def addNewGroups(self, groupID, layerID, neunum, genrename):
g = GenreCluster(self.neutype, neunum)
g.id = groupID
g.name = genrename
g.createClusterNetwork()
g.setPropertiesofNeurons(groupID, 'G', layerID)
self.groups[genrename] = g
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/genrelifneuron.py
================================================
from .lifneuron import LIFNeuron
class GenreLIFNeuron(LIFNeuron):
'''
classdocs
'''
def __init__(self, tau_ref=0, vthresh=5, Rm=2, Cm=0.2):
'''
Constructor
'''
LIFNeuron.__init__(self, tau_ref, vthresh, Rm, Cm)
def update(self, dt, t):
self.spike = False
# self.updateCurrentOfLowerAndUpperLayer(t)
if (t >= self.t_rest):
self.mem += dt * (-self.mem + self.I * self.Rm) / self.tau_m
if (self.v > self.vth):
self.spike = True
self.spiketime.append(t)
self.mem = 0
self.t_rest = t + self.tau_ref
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/izhikevichneuron.py
================================================
'''
Created on 2016.4.8
@author: liangqian
'''
#from modal.izhikevich import Izhikevich
from braincog.base.node import IzhNodeMU
import math
import random
import numpy as np
class IzhikevichNeuron(IzhNodeMU):
'''
classdocs
'''
def __init__(self, a = 0.1,b = 0.2,c = -65,d = 8,vthresh = 30, dt=0.1):
'''
Constructor
'''
super().__init__(threshold=vthresh, a=a, b=b, c=c, d=d, dt=dt)
self.layerType = 'S' # S:sequenceLayer, G: goal layer
self.layerIndex = 0 # the layer in which the neuron situated
self.groupIndex = 0 # the group in which the neuron situated
self.index = 0 # starting with 1
self.areaName = ''
self.synapses = [] #this neuron is considered as post-synaptic neuron
self.spiketime = []
self.pre_neurons = []
self.I_syn_lower = 0
self.I_syn_upper = 0
self.I_ext = 0
self.I_lower = 0
self.I_upper = 0
self.I_ext = -100
self.timeWindow = 5 # ms
self.I_bg = random.randint(0, 10)
# self.state = 'Learn' # else test
self.selectivity = 0
self.importance = 0
self.preActive = False
self.I = 0
self.v = -65
self.u = b * self.v
self.vthresh = vthresh
self.spike = False
self.type = 'exc'
def update_old(self,dt,t):
self.spike = 0
self.updateSynapses(t)
self.updateCurrentOfLowerAndUpperLayer(t)
self.I = self.I_ext + self.I_syn_lower + self.I_syn_upper
self.v += dt * (0.04*self.v * self.v + 5 * self.v + 140 - self.u + self.I)
self.u += dt * self.a * (self.b *self.v - self.u)
#self.synapseWeightsDepression()
if(self.v >= 30):
self.spike = 1
self.v = self.c
self.u += self.d
self.spiketime.append(t)
def update(self,dt,t,state):
if (state == 'Learn'):
self.update_learn(dt, t)
if(state == 'test'):
self.update_test(dt,t)
def update_learn(self,dt,t):
self.spike = False
self.v += dt * (0.04 * self.v * self.v + 5 * self.v + 140 - self.u + self.I)
self.u += dt * self.a * (self.b * self.v - self.u)
if self.v > self.vthresh:
self.spike = True
self.v = self.c
self.u += self.d
self.preActive = True
self.spiketime.append(t)
self.updateSynapses(t)
def update_test(self,dt,t):
self.spike = False
self.v += dt * (0.04 * self.v * self.v + 5 * self.v + 140 - self.u + self.I)
self.u += dt * self.a * (self.b * self.v - self.u)
if self.v > self.vthresh:
self.spike = True
self.v = self.c
self.u += self.d
def update_normal(self,dt,t):
self.spike = False
self.v += dt * (0.04 * self.v * self.v + 5 * self.v + 140 - self.u + self.I)
self.u += dt * self.a * (self.b * self.v - self.u)
if self.v >= self.vthresh:
self.spike = True
self.v = self.c
self.u += self.d
self.spiketime.append(t)
def updateSynapses(self,t):
for syn in self.synapses:
syn.computeWeight(t)
def updateCurrentOfLowerAndUpperLayer(self,t):
I_inh = 0
I_ext = 0
I_exc_ext = 0
for syn in self.synapses:
# compute the alpha value of all spikes before this time t
alpha_value = 0
for st in syn.pre.spiketime:
temp = 0
if(t - st >= 0): temp = 6*(t/1000)*math.exp(-0.03*(t - st)/1000)
else:temp = 0
alpha_value += temp
if(syn.type == 0): # from the same group
if(syn.pre.type == 'inh'):
I_inh += syn.weight * (self.v+80) * alpha_value
if(syn.pre.type == 'exc'):
I_ext += syn.weight * self.v * alpha_value
if(syn.type == 1):# from other modules in the same layer
I_exc_ext += syn.weight * self.v * alpha_value
if(syn.type == 2): # from the upper layer
self.I_syn_upper += self.weight * self.v * alpha_value
self.I_syn_lower = -I_inh + I_ext + I_exc_ext
def setTestStates(self):
self.t_rest = 0
self.spiketime = []
self.v = -65
self.u = self.b*self.v
self.I = 0
self.I_ext = 0
for syn in self.synapses:
syn.strength = 0
def writeBasicInfoToJson(self):
dic = {}
dic["TrackID"] = self.layerIndex
dic["GroupID"] = self.groupIndex
dic["Index"] = self.index
dic["selectivity"] = self.selectivity
dic["area"] = self.areaName
slist = []
for syn in self.synapses:
if (syn.weight <= 0): continue
tmp = {}
tmp["type"] = syn.type
tmp["StrackID"] = syn.pre.layerIndex
tmp["SgroupID"] = syn.pre.groupIndex
tmp["Sindex"] = syn.pre.index
tmp["Sarea"] = syn.pre.areaName
tmp["pre-selectivity"] = syn.pre.selectivity
tmp["weight"] = syn.weight
slist.append(tmp)
dic["synapses"] = slist
return dic
def writeSpikeTimeToJson(self):
slist = []
for i, t in enumerate(self.spiketime):
dic = {}
dic[i + 1] = round(t, 2)#两位有效数字
slist.append(dic)
return slist
class NoteIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh = 30):
IzhikevichNeuron.__init__(self,a,b,c,d,vthresh)
def setPreference(self):
self.selectivity = self.index - 2
def computeFilterCurrent(self):
if(self.I_ext == self.selectivity):
self.I = 30
def updateCurrentOfLowerAndUpperLayer(self, t):
self.I_lower = 0
self.I_upper = 0
for syn in self.synapses:
syn.computeShortTermFacilitation2(t)
if (syn.type == 0): # the same group
if (syn.excitability == 0):
self.I_lower -= syn.weight * syn.strength
if (self.I_lower < -20): self.I_lower = -20
if (syn.type == 1): # pre and post neurons come from the same layer but not the same group
#if(syn.weight > 0):
# print('pre_neuron_group id:'+str(syn.pre.groupIndex) + ' neuron index:'+str(syn.pre.index))
# print('post_neuron_group id:'+str(self.groupIndex) + ' neuron index:'+str(self.index))
# print('syn.strength=' + str(syn.strength))
# print('syn.weight='+ str(syn.weight))
self.I_lower += syn.weight * syn.strength
# print('syn.strength='+str(syn.strength))
# print('syn.weight='+ str(syn.weight))
if (syn.type >= 2): # pre and post neurons come from the different layers
# print(syn.pre.groupIndex)
self.I_upper += syn.weight * syn.strength
self.I = self.I_lower + self.I_upper
class TempoIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh = 30):
IzhikevichNeuron.__init__(self,a,b,c,d,vthresh)
def setPreference(self):
self.selectivity = self.index * 0.125
def computeFilterCurrent(self):
if(self.I_ext <= self.selectivity + 0.0625 and self.I_ext >= self.selectivity - 0.0625 ):
self.I = 30
def updateCurrentOfLowerAndUpperLayer(self, t):
self.I_lower = 0
self.I_upper = 0
for syn in self.synapses:
syn.computeShortTermFacilitation2(t)
if (syn.type == 0): # the same group
if (syn.excitability == 0):
self.I_lower -= syn.weight * syn.strength
if (self.I_lower < -20): self.I_lower = -20
if (syn.type == 1): # pre and post neurons come from the same layer but not the same group
# if(syn.weight > 0):
#
# print('pre_neuron_group id:'+str(syn.pre.groupIndex) + ' neuron index:'+str(syn.pre.index))
# print('post_neuron_group id:'+str(self.groupIndex) + ' neuron index:'+str(self.index))
# print(syn.weight)
self.I_lower += syn.weight * syn.strength
# print('syn.strength='+str(syn.strength))
if (syn.type == 2): # pre and post neurons come from the different layers
# print(syn.pre.groupIndex)
# self.I_lower = syn.weight * syn.strength
self.I_upper += syn.weight * syn.strength
# if(self.I_upper == 0):
# self.I = self.I_ext
else:
self.I = self.I_lower + self.I_upper
class TitleIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh=30):
IzhikevichNeuron.__init__(self,a,b,c,d,vthresh)
class ComposerIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh=30):
IzhikevichNeuron.__init__(self, a,b,c,d,vthresh)
class GenreIzhikevichNeuron(IzhikevichNeuron):
def __init__(self, a = 0.1,b = 0.2,c = -65,d = 8, vthresh=30):
IzhikevichNeuron.__init__(self, a, b, c, d, vthresh)
class AmyIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh=30):
IzhikevichNeuron.__init__(self, a,b,c,d,vthresh)
class DirectionIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh=30):
IzhikevichNeuron.__init__(self,a,b,c,d,vthresh)
def setPreference(self):
# self.selectivity = 2 * math.pi/240 * self.index - math.pi/240
self.selectivity = (self.index + 1) * math.pi / 120
def computeFilterCurrent(self, input):
if (input < self.selectivity + math.pi / 240 and input >= self.selectivity - math.pi / 240):
self.I = self.I_ext = 30
def updateCurrentOfLowerAndUpperLayer(self, t):
self.I_lower = 0
self.I_upper = 0
for syn in self.synapses:
syn.computeShortTermFacilitation2(t)
if (syn.type == 0): # the same group
if (syn.excitability == 0):
self.I_lower -= syn.weight * syn.strength
if (self.I_lower < -20): self.I_lower = -20
if (syn.type == 1): # pre and post neurons come from the same layer but not the same group
#if(syn.weight > 0):In t
# print('pre_neuron_group id:'+str(syn.pre.groupIndex) + ' neuron index:'+str(syn.pre.index))
# print('post_neuron_group id:'+str(self.groupIndex) + ' neuron index:'+str(self.index))
# print('syn.strength=' + str(syn.strength))
# print('syn.weight='+ str(syn.weight))
self.I_lower += syn.weight * syn.strength
# print('syn.strength='+str(syn.strength))
# print('syn.weight='+ str(syn.weight))
if (syn.type >= 2): # pre and post neurons come from the different layers
# print(syn.pre.groupIndex)
self.I_upper += syn.weight * syn.strength
self.I = self.I_lower + self.I_upper
class GridIzhikevichCell(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh = 30):
IzhikevichNeuron.__init__(self, a,b,c,d,vthresh)
class KeyIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh = 30):
IzhikevichNeuron.__init__(self,a,b,c,d,vthresh)
class ModeIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8,vthresh = 30):
IzhikevichNeuron.__init__(self,a,b,c,d,vthresh)
class ChordIzhikevichNeuron(IzhikevichNeuron):
def __init__(self,a = 0.1,b = 0.2,c = -65,d = 8, vthresh = 30):
IzhikevichNeuron.__init__(self, a,b,c,d,vthresh)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/layer.py
================================================
from abc import ABCMeta,abstractmethod
from conf.conf import configs
from Modal.cluster import *
class Layer():
'''
classdocs
'''
_metaclass_ = ABCMeta
def __init__(self, neutype):
'''
Constructor
'''
self.neutype = neutype
self.groups = {}
@abstractmethod
def resetProperties(self):
raise NotImplementedError
def addNewGroups(self, layerID, neunum):
raise NotImplementedError
class ModeLayer(Layer):
def __init__(self, neutype = 'LIF'):
self.neutype = neutype
self.groups = {}
def setTestStates(self):
for id, g in self.groups.items():
g.setTestStates()
def addNewGroups(self, groupID, layerID, neunum, modeName):
g = ModeCluster('Izhikevich', neunum)
g.id = groupID
g.name = modeName
g.createClusterNetwork(g.name)
g.setPropertiesofNeurons(groupID,'Mode',layerID)
self.groups[groupID-1] = g
class KeyLayer(Layer):
def __init__(self, neutype='LIF'):
self.neutype = neutype
self.groups = {}
def setTestStates(self):
for id, g in self.groups.items():
g.setTestStates()
def addNewGroups(self, groupID, layerID, neunum, key):
g = KeyCluster('Izhikevich', neunum)
g.id = groupID
g.name = configs.index2key.get(groupID-1)
g.createClusterNetwork(key,g.name)
g.setPropertiesofNeurons(groupID, 'Key', layerID)
self.groups[groupID-1] = g
class ChordLayer(Layer):
def __init__(self, neutype = 'LIF'):
Layer.__init__(self,neutype)
def setTestStates(self):
for id, g in self.groups.items():
g.setTestStates()
def addNewGroups(self,groupID, layerID, neunum):
g = ChordCluster('Izhikevich', neunum)
g.id = groupID
g.name = groupID
g.createClusterNetwork()
g.setPropertiesofNeurons(groupID, 'Chord', layerID)
self.groups[groupID - 1] = g
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/lifneuron.py
================================================
import torch
import random
from braincog.base.node import node
import numpy as np
class LIFNeuron(node.LIFNode):
def __init__(self, tau_ref = 0, vthresh = 5, Rm = 2, Cm = 0.2,dt = 0.1,*args, **kwargs):
super().__init__(threshold=vthresh, tau=Rm*Cm, dt=dt, *args, **kwargs)
self.layerType = 'S' # S:sequenceLayer, G: goal layer
self.layerIndex = 0 # the layer in which the neuron situated
self.groupIndex = 0 # the group in which the neuron situated
self.index = 0 # starting with 1
self.areaName = ''
self.pre_neurons = []
self.synapses = []
self.spiketime = []
self.type = 'exc'
self.tau_ref = tau_ref
self.tau_m = Rm*Cm
self.vth = vthresh
self.Rm = Rm
self.Cm = Cm
self.t_rest = 0
self.I = 0
self.spike = False
self.firingrate = 0 # Hz
self.I_ower = 0
self.I_upper = 0
self.I_ext = -100
self.timeWindow = 5 # ms
self.I_bg = random.randint(0, 10)
# self.state = 'Learn' # else test
self.selectivity = 0
self.preActive = False
def update(self, dt, t, state): # state = 'learn' or state = 'test'
if (state == 'Learn'):
self.update_learn(dt, t)
'''
#------------Gaussian selectivity--------------#
self.I = math.exp(-((self.I_ext-math.pi/16)/0.24)**2)
self.I = self.I if self.I >= 0.5 else 0
self.I *= 10
'''
elif (state == 'test'):
self.update_test(dt, t)
def update_learn(self, dt, t):
self.spike = False
# self.computeFilterCurrent()
'''
#------------Gaussian selectivity--------------#
self.I = math.exp(-((self.I_ext-math.pi/16)/0.24)**2)
self.I = self.I if self.I >= 0.5 else 0
self.I *= 10
'''
if (t >= self.t_rest):
self.mem += dt * (-self.mem + self.I * self.Rm) / self.tau_m
if (self.mem > self.vth):
self.spike = True
self.preActive = True
# print("groupID:"+ str(self.groupIndex) + ", neuronID:"+str(self.index))
self.spiketime.append(t)
self.mem = 0
self.t_rest = t + self.tau_ref
self.updateSynapses(t)
def update_test(self, dt, t):
self.spike = False
# self.updateCurrentOfLowerAndUpperLayer(t)
if (t >= self.t_rest):
self.mem += dt * (-self.mem + self.I * self.Rm) / self.tau_m
if (self.mem > self.vth):
self.spike = True
self.spiketime.append(t)
self.mem = 0
self.t_rest = t + self.tau_ref
def update_normal(self, dt, t):
self.spike = False
# self.I = self.I_ext
if (t >= self.t_rest):
self.mem += dt * (-self.mem + self.I * self.Rm) / self.tau_m
if (self.mem > self.vth):
self.spike = True
self.mem = 0
self.t_rest = t + self.tau_ref
self.spiketime.append(t)
def updateSynapses(self, t):
for syn in self.synapses:
syn.computeWeight(t)
def setTestStates(self):
self.t_rest = 0
self.spiketime = []
self.mem = 0
self.I = 0
self.I_ext = 0
for syn in self.synapses:
syn.strength = 0
# print('I=' + str(self.I))
def computeFilterCurrent(self):
pass
def setPreference(self): # set preference of a neuron or called selectivity
# self.selectivity = 2 * math.pi/16 * self.index - math.pi/16 # the mean of the Gaussian funtion
pass
def writeBasicInfoToJson(self, areaName):
dic = {}
dic["TrackID"] = self.layerIndex
dic["GroupID"] = self.groupIndex
dic["Index"] = self.index
dic["area"] = areaName
slist = []
for syn in self.synapses:
if (syn.weight <= 0): continue
tmp = {}
tmp["StrackID"] = syn.pre.layerIndex
tmp["SgroupID"] = syn.pre.groupIndex
tmp["Sindex"] = syn.pre.index
tmp["Sarea"] = syn.pre.areaName
tmp["TtrackID"] = self.layerIndex
tmp["TgroupID"] = self.groupIndex
tmp["Tindex"] = self.index
tmp["Tarea"] = self.areaName
tmp["type"] = syn.type
tmp["weight"] = syn.weight
slist.append(tmp)
dic["synapses"] = slist
return dic
def writeSpikeTimeToJson(self):
slist = []
for i, t in enumerate(self.spiketime):
dic = {}
dic[i + 1] = t
slist.append(dic)
return slist
# neu = LIFNeuron()
# dt = 0.001
# T = 1
# time = np.arange(0,T,dt)
# spikes = np.zeros(len(time))
# for i in range(0,len(time)):
# if(i == 22):
# print("debug")
# neu.I = 84.49
# neu.update_normal(dt, time[i])
# if(neu.spike == True):
# spikes[i] = 1
# #spikes[i] = neu.mem
# print(len(neu.spiketime))
# pl.plot(time,spikes)
# pl.show()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/note.py
================================================
'''
Created on 2016.7.6
@author: liangqian
'''
from Modal.pitch import Pitch
class Note():
'''
Because a chord consist of more than two pitches at the same time, so using
arrays to record the chord
'''
def __init__(self):
self.pitches = []
# self.startTime = []
# self.endTime = []
self.lastTime = []
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/notecluster.py
================================================
from .cluster import Cluster
from .notelifneuron import NoteLIFNeuron
from Modal.izhikevichneuron import *
class NoteCluster(Cluster):
'''
classdocs
'''
def __init__(self, neutype, neunum):
'''
Constructor
'''
Cluster.__init__(self, neutype, neunum)
def createClusterNetwork(self):
for i in range(0, self.neunum):
if (self.neutype == 'LIF'):
node = NoteLIFNeuron()
node.index = i + 1
node.areaName = 'NMSM'
node.setPreference()
self.neurons.append(node)
if (self.neutype == 'Izhikevich'):
node = NoteIzhikevichNeuron()
node.index = i + 1
node.areaName = 'NMSM'
node.setPreference()
self.neurons.append(node)
# if(self.neutype == 'Izhi'):
# node = IzhikevichNeuron(a = 0.02,b = 0.2,c = -65,d = 8,vthresh = 30)
# node.index = i
# self.neurons.append(node)
# if(self.neutype == 'Gaussian'):
# node = GaussianNeuron()
# node.index = i+1
# self.neurons.append(node)
# if(self.neutype == 'HH'):
# node = HHNeuron()
# node.index = i
# self.neurons.append(node)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/notelifneuron.py
================================================
from .lifneuron import LIFNeuron
class NoteLIFNeuron(LIFNeuron):
'''
classdocs
'''
def __init__(self, tau_ref=0.5, vthresh=5, Rm=2, Cm=0.2):
'''
Constructor
'''
LIFNeuron.__init__(self, tau_ref, vthresh, Rm, Cm)
def setPreference(self):
self.selectivity = self.index - 2
def computeFilterCurrent(self):
if (self.I_ext == self.selectivity):
self.I = 10
def updateCurrentOfLowerAndUpperLayer(self, t):
self.I_lower = 0
self.I_upper = 0
for syn in self.synapses:
syn.computeShortTermFacilitation(t)
if (syn.type == 0): # the same group
if (syn.excitability == 0):
self.I_lower -= syn.weight * syn.strength
if (self.I_lower < -20): self.I_lower = -20
if (syn.type == 1): # pre and post neurons come from the same layer but not the same group
# if(syn.weight > 0):
# print('pre_neuron_group id:'+str(syn.pre.groupIndex) + ' neuron index:'+str(syn.pre.index))
# print('post_neuron_group id:'+str(self.groupIndex) + ' neuron index:'+str(self.index))
# print('syn.strength=' + str(syn.strength))
# print('syn.weight='+ str(syn.weight))
self.I_lower += 0.001 * syn.weight * syn.strength
# print('syn.strength='+str(syn.strength))
# print('syn.weight='+ str(syn.weight))
if (syn.type == 2): # pre and post neurons come from the different layers
# print(syn.pre.groupIndex)
self.I_upper += 0.001 * syn.weight * syn.strength
# if(self.I_upper == 0):
# self.I = self.I_ext
self.I = 0.4 * self.I_lower + 0.6 * self.I_upper
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/notesequencelayer.py
================================================
from .sequencelayer import SequenceLayer
from .notecluster import NoteCluster
from .synapse import Synapse
class NoteSequenceLayer(SequenceLayer):
'''
classdocs
'''
def __init__(self, neutype):
'''
Constructor
'''
SequenceLayer.__init__(self, neutype)
def addNewGroups(self, GroupID, layerID, neunum):
g = NoteCluster(self.neutype, neunum)
g.createClusterNetwork()
# g.createInhibitoryConnections()
g.id = GroupID
g.setPropertiesofNeurons(g.id, 'S', layerID)
self.groups[g.id] = g
# create full connection with the former group
if (len(self.groups) > 1):
s = 0
if (g.id <= 5):
s = 1
else:
s = g.id - 4
# for i in range(1,g.id)[::-1]:
for i in range(s, g.id)[::-1]:
pre_g = self.groups.get(i)
for n1 in pre_g.neurons:
for n2 in g.neurons:
if (n1.type == 'inh' or n2.type == 'inh'): continue;
syn = Synapse(n1, n2)
syn.type = 1
syn.delay = g.id - pre_g.id
n2.pre_neurons.append(n1)
n2.synapses.append(syn)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/pitch.py
================================================
'''
Created on 2018.8.29
@author: liangqian
'''
class Pitch():
'''
classdocs
'''
def __init__(self):
'''
Constructor
'''
self.name = ''
self.frequence = 0 #midi index number just now
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/sequencelayer.py
================================================
from .layer import Layer
from .cluster import Cluster
from .synapse import Synapse
class SequenceLayer(Layer):
'''
This class mainly stores the musical sequential elements, including pitches and durations
'''
def __init__(self, neutype='LIF'):
'''
Constructor
'''
self.type = ""
self.neutype = neutype
self.groups = {}
def addNewGroups(self, GroupID, layerID, neunum):
g = Cluster(self.neutype, neunum)
g.createClusterNetwork()
g.id = GroupID
g.setPropertiesofNeurons(g.id, 'S', layerID)
self.groups[g.id] = g
# create full connection with the former group
if (len(self.groups) > 1):
for i in range(1, g.id)[::-1]:
pre_g = self.groups.get(i)
for n1 in pre_g.neurons:
for n2 in g.neurons:
if (n1.type == 'inh' or n2.type == 'inh'): continue;
syn = Synapse(n1, n2)
syn.type = 1
syn.delay = g.id - pre_g.id
n2.pre_neurons.append(n1)
n2.synapses.append(syn)
def setTestStates(self):
for gid, g in self.groups.items():
g.setTestStates()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/sequencememory.py
================================================
from .synapse import Synapse
from Modal.sequencelayer import SequenceLayer
import numpy as np
from Modal.synapse import Synapse
class SequenceMemory():
'''
classdocs
'''
def __init__(self, neutype):
'''
Constructor
'''
self.neutype = neutype
self.sequenceLayers = {}
def createActionSequenceMem(self, layernum, neutype, neunumpergroup):
pass
def doRemembering(self):
pass
def doConnecting(self, goal, sl, order):
# the goal and the group always generate spikes in a limit time window,create a synapse between them.
group = sl.groups.get(order)
if (group == None): return
tb = (order - 1) * group.timeWindow
te = (order) * group.timeWindow
sp1_goal = {}
sp2 = []
for n in goal.neurons:
sp = []
for st in n.spiketime:
if (st < te and st >= tb):
sp.append(st)
sp1_goal[n.index] = sp
for n in group.neurons:
if (len(n.spiketime) > 0):
for index, sp in sp1_goal.items():
temp = 0
for sp1 in n.spiketime: # spike times of group
for sp2 in sp:
if (abs(sp1 - sp2) <= n.tau_ref):
temp += 1
if (
temp >= 4): # super threshold, create a new synapse between goal and neurons of sequence group
syn = Synapse(goal.neurons[index - 1], n)
syn.type = 2
syn.weight = 3
n.pre_neurons.append(goal.neurons[index - 1])
n.synapses.append(syn)
# add reverse synapse to neurons of the goal
syn2 = Synapse(n, goal.neurons[index - 1])
syn2.type = 2
syn2.weight = 1
goal.neurons[index - 1].synapses.append(syn2)
# clear the goal's spike time
''' *************************************************************
I have forgot why neurons here needs to be cleaned, but this must be important, mark here
for n in goal.neurons:
n.spiketime = []
******************************************************************
'''
# def doConnectToGoal(self,goal,track,order): # connect to the goal in the time window
#
# for sl in track.values():
# group = sl.groups.get(order)
#
# if(group == None): continue
# # the goal and the group always generate spikes in a limit time window,create a synapse between them.
# tb = (order-1)*group.timeWindow
# te = (order) * group.timeWindow
# sp1_goal = {}
# sp2 = []
#
# for n in goal.neurons:
# sp = []
# for st in n.spiketime:
# if(st < te and st >= tb ):
# sp.append(st)
# sp1_goal[n.index] = sp
#
# for n in group.neurons:
# if(len(n.spiketime) > 0):
# for index,sp in sp1_goal.items():
# temp = 0
# for sp1 in n.spiketime: #spike times of group
# for sp2 in sp:
# if(abs(sp1-sp2) <= n.tau_ref):
# temp += 1
# if(temp >= 4): # super threshold, create a new synapse between goal and neurons of sequence group
# syn = Synapse(goal.neurons[index-1],n)
# syn.type = 2
# syn.weight = 3
# n.pre_neurons.append(goal.neurons[index-1])
# n.synapses.append(syn)
#
# #add reverse synapse to neurons of the goal
# syn2 = Synapse(n,goal.neurons[index-1])
# syn2.type = 2
# syn2.weight = 1
# goal.neurons[index-1].synapses.append(syn2)
#
# #clear the goal's spike time
# ''' *************************************************************
# I have forgot why neurons here needs to be cleaned, but this must be important, mark here
# for n in goal.neurons:
# n.spiketime = []
# ******************************************************************
# '''
#
# def doConnectToComposer(self, composer, track, order):
# for sl in track.values():
# group = sl.groups.get(order)
#
# if(group == None): continue
# # the goal and the group always generate spikes in a limit time window,create a synapse between them.
# tb = (order-1)*group.timeWindow
# te = (order) * group.timeWindow
# sp1_composer = {}
# sp2 = []
#
# for n in composer.neurons:
# sp = []
# for st in n.spiketime:
# if(st < te and st >= tb ):
# sp.append(st)
# sp1_composer[n.index] = sp
#
# for n in group.neurons:
# if(len(n.spiketime) > 0):
# for index,sp in sp1_composer.items():
# temp = 0
# for sp1 in n.spiketime: #spike times of group
# for sp2 in sp:
# if(abs(sp1-sp2) <= n.tau_ref):
# temp += 1
# if(temp >= 4): # super threshold, create a new synapse between composer and neurons of sequence group
# syn = Synapse(composer.neurons[index-1],n)
# syn.type = 2
# syn.weight = 3
# n.pre_neurons.append(composer.neurons[index-1])
# n.synapses.append(syn)
#
# #add reverse synapse to neurons of the goal
# # syn2 = Synapse(n,goal.neurons[index-1])
# # syn2.type = 2
# # syn2.weight = 1
# # goal.neurons[index-1].synapses.append(syn2)
#
#
# def doConnectToGenre(self, genre, track, order):
# for sl in track.values():
# group = sl.groups.get(order)
#
# if(group == None): continue
# # the goal and the group always generate spikes in a limit time window,create a synapse between them.
# tb = (order-1)*group.timeWindow
# te = (order) * group.timeWindow
# sp1_genre = {}
# sp2 = []
#
# for n in genre.neurons:
# sp = []
# for st in n.spiketime:
# if(st < te and st >= tb ):
# sp.append(st)
# sp1_genre[n.index] = sp
#
# for n in group.neurons:
# if(len(n.spiketime) > 0):
# for index,sp in sp1_genre.items():
# temp = 0
# for sp1 in n.spiketime: #spike times of group
# for sp2 in sp:
# if(abs(sp1-sp2) <= n.tau_ref):
# temp += 1
# if(temp >= 4): # super threshold, create a new synapse between composer and neurons of sequence group
# syn = Synapse(genre.neurons[index-1],n)
# syn.type = 2
# syn.weight = 3
# n.pre_neurons.append(genre.neurons[index-1])
# n.synapses.append(syn)
def setTestStates(self):
for itrack in self.sequenceLayers.values():
for sl in itrack.values():
sl.setTestStates()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/synapse.py
================================================
import math
class Synapse():
'''
classdocs
'''
def __init__(self, pre, post):
'''
Constructor
'''
self.type = 0 # 0: within a group; 1: different groups in the same layer; 2: other layer
self.pre = pre
self.post = post
self.weight = 0
self.excitability = 1 # 1:excited connection; 0:inhibitory connection
self.strength = 0 # short term depression and facilitation factor
self.delay = 0 # time delay of transmission between pre and post
def computeWeight(self, t):
if (self.type == 0): # pre and post neurons are in the same group
pass
elif (self.type == 1): # pre and post neurons are in the same layer but different groups
for st in self.pre.spiketime:
s = t - st - (self.delay-1)*self.post.timeWindow
temp = 0
if (self.post.groupIndex - self.pre.groupIndex == self.delay): # compute weight according to time delay
# using STDP rules
if (s >= 0):
temp = math.exp(-s / 5)
else:
# print(self.pre.groupIndex)
# print(self.post.groupIndex)
temp = -math.exp(s / 5)
self.weight += temp
elif (self.type == 2): # pre and post neurons are in the different layers
pass
# computing the STDP to update the weight within the time window
elif (self.type == 3):
# pass #fixed weight
for st in self.pre.spiketime:
s = t - st - (self.delay - 1) * self.post.timeWindow
temp = 0
# using STDP rules
if (s >= 0):
temp = 5 * math.exp(-s / 5)
else:
# print(self.pre.groupIndex)
# print(self.post.groupIndex)
temp = -5 * math.exp(s / 5)
self.weight += temp
def computeShortTermFacilitation(self, t):
if (self.type == 1):
for st in self.pre.spiketime[::-1]:
at = st + self.delay
# if (at <= t and at >= t - self.post.tau_ref): # between current time and time minus refractory period
if (at <= t and at >= t):
temp = (self.strength + 1) * 0.2
self.strength += temp
elif (self.type == 2):
# print(self.pre.areaName)
# print(self.pre.index)
# print(self.pre.groupIndex)
for st in self.pre.spiketime:
if (st <= t and st >= t - self.post.tau_ref):
temp = (self.strength + 1) * 0.5
self.strength = self.strength + temp
elif (self.type == 0):
if (self.excitability == 0):
for st in self.pre.spiketime:
self.strength += (self.strength + 1) * 0.8
def computeShortTermFacilitation2(self, t):
if (self.type == 1):
for st in self.pre.spiketime[::-1]:
at = st + self.delay
# if ( at <= t and at >= t - self.post.tau_ref):
if (at <= t): # between current time and time minus refractory period
self.strength = 1
elif (self.type >= 2):
# print(self.pre.areaName)
# print(self.pre.index)
# print(self.pre.groupIndex)
for st in self.pre.spiketime:
# if (st <= t and st >= t - self.post.tau_ref):
if (st <= t):
self.strength = 1
def computeShortTermReduction(self, t):
if (self.type == 2):
for st in self.pre.spiketime[::-1]:
if (t - st > self.post.timeWindow):
self.strength -= (self.strength + 1) * 0.5
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/tempocluster.py
================================================
from .cluster import Cluster
from .tempolifneuron import TempoLIFNeuron
from Modal.izhikevichneuron import *
class TempoCluster(Cluster):
'''
classdocs
'''
def __init__(self, neutype, neunum):
'''
Constructor
'''
Cluster.__init__(self, neutype, neunum)
def createClusterNetwork(self):
for i in range(0, self.neunum):
if (self.neutype == 'LIF'):
node = TempoLIFNeuron()
node.index = i + 1
node.areaName = 'TMSM'
node.setPreference()
self.neurons.append(node)
if (self.neutype == 'Izhikevich'):
node = TempoIzhikevichNeuron()
node.index = i + 1
node.areaName = 'TMSM'
node.setPreference()
self.neurons.append(node)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/tempolifneuron.py
================================================
from .lifneuron import LIFNeuron
import math
class TempoLIFNeuron(LIFNeuron):
'''
classdocs
'''
def __init__(self, tau_ref=0.5, vthresh=5, Rm=2, Cm=0.2):
'''
Constructor
'''
LIFNeuron.__init__(self, tau_ref, vthresh, Rm, Cm)
def setPreference(self):
# Gaussian function to set selectivity
self.selectivity = self.index * 0.125 #
def computeFilterCurrent(self):
if (self.I_ext <= self.selectivity + 0.0625 and self.I_ext >= self.selectivity - 0.0625):
self.I = 10
def updateCurrentOfLowerAndUpperLayer(self, t):
self.I_lower = 0
self.I_upper = 0
for syn in self.synapses:
syn.computeShortTermFacilitation(t)
if (syn.type == 0): # the same group
if (syn.excitability == 0):
self.I_lower -= 0.001 * syn.weight * syn.strength
if (self.I_lower < -20): self.I_lower = -20
if (syn.type == 1): # pre and post neurons come from the same layer but not the same group
# if(syn.weight > 0):
#
# print('pre_neuron_group id:'+str(syn.pre.groupIndex) + ' neuron index:'+str(syn.pre.index))
# print('post_neuron_group id:'+str(self.groupIndex) + ' neuron index:'+str(self.index))
# print(syn.weight)
self.I_lower += 0.001 * syn.weight * syn.strength
# print('syn.strength='+str(syn.strength))
if (syn.type == 2): # pre and post neurons come from the different layers
# print(syn.pre.groupIndex)
# self.I_lower = syn.weight * syn.strength
self.I_upper += 0.001 * syn.weight * syn.strength
# if(self.I_upper == 0):
# self.I = self.I_ext
else:
self.I = 0.4 * self.I_lower + 0.6 * self.I_upper
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/temposequencelayer.py
================================================
from .sequencelayer import SequenceLayer
from .tempocluster import TempoCluster
from .synapse import Synapse
class TempoSequenceLayer(SequenceLayer):
'''
classdocs
'''
def __init__(self, neutype):
'''
Constructor
'''
SequenceLayer.__init__(self, neutype)
def addNewGroups(self, GroupID, layerID, neunum):
g = TempoCluster(self.neutype, neunum)
g.createClusterNetwork()
# g.createInhibitoryConnections()
g.id = GroupID
g.setPropertiesofNeurons(g.id, 'S', layerID)
self.groups[g.id] = g
# create full connection with the former group
if (len(self.groups) > 1):
s = 0
if (g.id <= 5):
s = 1
else:
s = g.id - 4
for i in range(s, g.id)[::-1]:
pre_g = self.groups.get(i)
for n1 in pre_g.neurons:
for n2 in g.neurons:
if (n1.type == 'inh' or n2.type == 'inh'): continue;
syn = Synapse(n1, n2)
syn.type = 1
syn.delay = g.id - pre_g.id
n2.pre_neurons.append(n1)
n2.synapses.append(syn)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/titlecluster.py
================================================
from .cluster import Cluster
from .titlelifneuron import TitleLIFNeuron
class TitleCluster(Cluster):
'''
classdocs
'''
def __init__(self, neutype, neunum):
'''
Constructor
'''
Cluster.__init__(self, neutype, neunum)
self.averageFiringRate = 0
def createClusterNetwork(self):
for i in range(0, self.neunum):
if (self.neutype == 'LIF'):
node = TitleLIFNeuron()
node.index = i + 1
node.areaName = 'IPS'
self.neurons.append(node)
# if(self.neutype == 'Izhi'):
# node = IzhikevichNeuron(a = 0.02,b = 0.2,c = -65,d = 8,vthresh = 30)
# node.index = i
# self.neurons.append(node)
# if(self.neutype == 'Gaussian'):
# node = GaussianNeuron()
# node.index = i+1
# self.neurons.append(node)
# if(self.neutype == 'HH'):
# node = HHNeuron()
# node.index = i
# self.neurons.append(node)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/titlelayer.py
================================================
from .layer import Layer
from .titlecluster import TitleCluster
class TitleLayer(Layer):
'''
classdocs
'''
def __init__(self, neutype='LIF'):
'''
Constructor
'''
self.neutype = neutype
self.groups = {}
def setTestStates(self):
for id, g in self.groups.items():
g.setTestStates()
def addNewGroups(self, groupID, layerID, neunum, goalname):
g = TitleCluster(self.neutype, neunum)
g.id = groupID
g.name = goalname
g.createClusterNetwork()
g.setPropertiesofNeurons(groupID, 'G', layerID)
self.groups[goalname] = g
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/Modal/titlelifneuron.py
================================================
from .lifneuron import LIFNeuron
import math
class TitleLIFNeuron(LIFNeuron):
'''
classdocs
'''
def __init__(self, tau_ref=0, vthresh=5, Rm=2, Cm=0.2):
'''
Constructor
'''
LIFNeuron.__init__(self, tau_ref, vthresh, Rm, Cm)
def updateCurrentOfLowerAndUpperLayer(self, t):
self.I_lower = 0
self.I_upper = 0
for syn in self.synapses:
syn.computeShortTermFacilitation(t)
syn.computeShortTermReduction(t)
if (syn.type == 2): # pre and post neurons come from the different layers
self.I_lower += syn.weight * syn.strength
if (self.I_lower <= 0):
self.I = self.I_lower
else:
self.I = math.log(self.I_lower)
def update(self, dt, t):
self.spike = False
# self.updateCurrentOfLowerAndUpperLayer(t)
if (t >= self.t_rest):
self.mem += dt * (-self.mem + self.I * self.Rm) / self.tau_m
if (self.mem > self.vth):
self.spike = True
self.spiketime.append(t)
self.mem = 0
self.t_rest = t + self.tau_ref
def computeFiringRate(self):
if (self.I == 0):
self.firingrate = 0
else:
self.firingrate = 1 / (self.tau_ref + self.Rm * self.Cm * math.log(self.I / (self.I - self.vth)))
self.firingrate *= 1000
self.firingrate = round(self.firingrate)
# print(self.firingrate)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/README.md
================================================
# Music Memory and stylistic composition
This repository contains code from our paper:
- [**Temporal-Sequential Learning With a Brain-Inspired Spiking Neural Network and Its Application to Musical Memory**](https://www.cell.com/patterns/fulltext/S2666-3899(22)00119-2) published in Frontiers in Computational Neuroscience. **https://www.cell.com/patterns/fulltext/S2666-3899(22)00119-2**,
- [**Stylistic composition of melodies based on a brain-inspired spiking neural network**](https://www.frontiersin.org/articles/10.3389/fnsys.2021.639484/full) published in Frontiers in Systems Neuroscience **https://www.frontiersin.org/articles/10.3389/fnsys.2021.639484/full**.
- [**Mode-conditioned music learning and composition: a spiking neural network inspired by neuroscience and psychology**](https://arxiv.org/pdf/2411.14773) preprint in arXiv **https://arxiv.org/pdf/2411.14773**.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* pretty_midi >= 0.2.9
* music21
## Data preparation
The dataset used here can be referred to the website http://www.piano-midi.de/.
The dataset used in mode-conditioned music learning can be referred to the website https://github.com/lqnankai/Music-Dataset.
## Run
* Run the script *task/musicMemory.py* to memorize and recall the musical melodies, the result will be recorded in a midi file.
* Run the script *task/musicGeneration.py* to learn and generate melodies with different styles, the result will be recorded in a midi file.
* Run the script *task/mode-conditioned learning.py* to learn and generate melodies with different mode and keys, the result will be recorded in a midi file.
The API and details can be found in these scripts.
## Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{LQ2020,
author = {Liang, Qian and Zeng, Yi and Xu, Bo},
year = {2020},
month = {07},
pages = {51},
title = {Temporal-Sequential Learning With a Brain-Inspired Spiking Neural Network and Its Application to Musical Memory},
volume = {14},
journal = {Frontiers in Computational Neuroscience}
}
@article{LQ2021,
title = {Stylistic composition of melodies based on a brain-inspired spiking neural network},
author = {Liang, Qian and Zeng, Yi},
journal = {Frontiers in systems neuroscience},
volume = {15},
pages = {21},
year = {2021},
publisher = {Frontiers}
}
@misc{liang2024modeconditionedmusiclearningcomposition,
title={Mode-conditioned music learning and composition: a spiking neural network inspired by neuroscience and psychology},
author={Qian Liang and Yi Zeng and Menghaoran Tang},
year={2024},
eprint={2411.14773},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.14773},
}
```
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/api/music_engine_api.py
================================================
from conf.conf import *
from Areas.cortex import Cortex
import pretty_midi
import math
import json
import music21 as m21
class EngineAPI():
'''
'''
def __init__(self):
'''
Constructor
'''
self.cortex = Cortex(configs.neuron_type, configs.dt)
def cortexInit(self):
self.cortex.musicSequenceMemroyInit()
self.cortex.pfc.addNewKey()
self.cortex.pfc.addNewMode()
self.cortex.pfc.addNewChord()
def rememberMusic(self, muiscName, composerName="None"):
'''
:param muiscName: the name of the melody
:param composerName: the composer
:return:
'''
muiscName = muiscName.title()
composerName = composerName.title()
self.cortex.pfc.setTestStates()
self.cortex.msm.setTestStates()
self.cortex.addSubGoalToPFC(muiscName)
self.cortex.addComposerToPFC(composerName)
genreName = str(configs.GenreMap.get(composerName))
self.cortex.addGenreToPFC(genreName)
self.cortex.pfc.innerLearning(muiscName, composerName, genreName)
goaldic = {}
composerdic = {}
genredic = {}
if (configs.RunTimeState == 1):
g = self.cortex.pfc.titles.groups.get(muiscName)
c = self.cortex.pfc.composers.groups.get(composerName)
gre = self.cortex.pfc.genres.groups.get(genreName)
goaldic = g.writeSelfInfoToJson("IPS")
composerdic = c.writeSelfInfoToJson("Composer")
genredic = gre.writeSelfInfoToJson("Genre")
return goaldic, composerdic
def learnFourPartMusic(self,xmldata, musicName, composerName="None"):
musicName = musicName.title()
composerName = composerName.title()
genreName = "None"
toneName = configs.keyIndexMap.get(str(xmldata.analyze('key')))
print(musicName + " learning...")
emo = "None"
for i, part in enumerate(xmldata.parts):
if (self.cortex.msm.sequenceLayers.get(i + 1) == None):
self.cortex.msm.createActionSequenceMem(i + 1, self.cortex.neutype)
self.rememberPartNotes(musicName, composerName, genreName, emo, toneName, i + 1, part)
def rememberPartNotes(self,musicName, composerName, genreName, emo, keyName, partIndex, part):
print("Learning the part "+str(partIndex))
for i,note in enumerate(part.flat.notes[:20]):
p = 0
dur = 0
if note.isChord:
dur = note.duration.quarterLength
for chord_note in note:
p = m21.pitch.Pitch(chord_note.pitch).midi
else:
dur = note.duration.quarterLength
p = m21.pitch.Pitch(note.pitch).midi
if dur == 0.0:
dur = 0.125
if keyName == 'None':
self.cortex.rememberANoteandTempo(musicName, composerName, genreName, emo, partIndex, p, i+1, dur)
else:
self.cortex.rememberANoteWithKnowledge(musicName, composerName, genreName, emo, keyName, partIndex, p, dur, i+1, part)
def rememberMIDIMusic(self, musicName, composerName, noteLength, fileName):
'''
:param musicName: the name of the piece of music
:param composerName: the composer who writes this melody
:param fileName: the name of this midi file
:return: none
'''
musicName = musicName.title()
composerName = composerName.title()
print(musicName + " processing...")
pm = pretty_midi.PrettyMIDI(fileName)
genreName = str(configs.GenreMap.get(composerName))
for i, ins in enumerate(pm.instruments):
if (i >= 1): break;
if (self.cortex.msm.sequenceLayers.get(i + 1) == None):
# create a new layer to store the track
self.cortex.msm.createActionSequenceMem(i + 1, self.cortex.neutype)
self.rememberTrackNotes(musicName, composerName, genreName, i + 1, ins, pm, noteLength)
print(musicName + " finished!")
def rememberTrackNotes(self, musicName, composerName, genreName, trackIndex, track, pm, noteLength):
r_notes = []
r_intervals = []
total_dic = {}
print(track)
if(noteLength == "ALL"):
noteLength = len(track.notes)
order = 1
i = 0
#while (i < len(track.notes)):
while (i < noteLength):
#if (i >= rl): break;
note = track.notes[i]
start = pm.time_to_tick(note.start)
end = pm.time_to_tick(note.end)
pitches = []
durations = []
restFlag = False
# this part recognizes a rest
if (i == 0): # determine whether the first note is a rest
if (start >= 30):
pitches.append(-1) # -1 represents a rest
durations.append(start / pm.resolution)
restFlag = True
else:
lastend = pm.time_to_tick(track.notes[i - 1].end)
if (start - lastend >= 50):
pitches.append(-1)
durations.append((start - lastend) / pm.resolution)
restFlag = True
if (restFlag == True):
dic, g = self.rememberANote(musicName, composerName, genreName, trackIndex, pitches[0], order,
durations[0], True)
if (configs.RunTimeState == 1):
jstr = json.dumps(g)
self.conn.send('/Queue/SampleQueue', jstr)
#print(str(order) + ":(-1," + str(durations[0]) + ")")
order = order + 1
pitches = []
durations = []
# this part recognizes a chord
pitches.append(note.pitch)
durations.append((end - start) / pm.resolution)
j = i + 1
while (j < len(track.notes)):
nextstart = pm.time_to_tick(track.notes[j].start)
nextend = pm.time_to_tick(track.notes[j].end)
# if(start == nextstart or end > nextstart):
if (math.fabs(start - nextstart) <= 30 or end - nextstart >= 30):
pitches.append(track.notes[j].pitch)
durations.append((nextend - nextstart) / pm.resolution)
j = j + 1
else:
break
i = j
if (i < noteLength):
dic, g = self.rememberANote(musicName, composerName, genreName, trackIndex, pitches[0], order,
durations[0], True)
str1 = str(order) + ":("
for t in range(len(pitches)):
str1 += str(pitches[t]) + "," + str(durations[t]) + ";"
#print(str1 + ")")
order = order + 1
if (configs.RunTimeState == 1):
jstr = json.dumps(g)
self.conn.send('/Queue/SampleQueue', jstr)
nlist = dic.get('MSMSpike')
ns = []
for l in nlist:
n = l.get('Index')
ns.append(n)
r_notes.append(ns)
tlist = dic.get('MSMTSpike')
ts = []
for l in tlist:
t = l.get('Index')
ts.append(t * 60)
r_intervals.append(ts)
return total_dic
def rememberNotes(self, MusicName, notes, intervals, tempo=True):
jStr = ''
# print(intervals)
notesStr = notes.split(",")
intervalsStr = intervals.split(",")
intervaltimes = []
for i in range(len(intervalsStr) - 1):
intervaltimes.append(int(intervalsStr[i]))
print(intervaltimes)
for i, note in enumerate(notesStr):
note = int(note)
if (i < len(notesStr) - 1):
tinterval = intervalsStr[i]
tinterval = int(intervalsStr[i])
self.rememberANote(MusicName, note, i + 1, tinterval, tempo)
return jStr
def rememberANote(self, MusicName, ComposerName, genreName, TrackIndex, NoteIndex, order, tinterval, tempo=False):
if (tempo == False):
dic = self.cortex.rememberANote(MusicName, NoteIndex, order)
jsonStr = json.dumps(dic)
return jsonStr
else:
dic, g = self.cortex.rememberANoteandTempo(MusicName, ComposerName, genreName, TrackIndex, NoteIndex, order,
tinterval)
return dic, g
def memorizing(self,MusicName, ComposerName, noteLength, fileName):
'''
:param musicName: the name of the piece of music
:param composerName: the composer who writes this melody
:param noteLength: the number of notes to be trained(integer), if you want to learn all the notes of a musical work, the value should be specified as "ALL"
:param fileName: the path and the name of this midi file
:return: none
'''
self.rememberMusic(MusicName, ComposerName)
self.rememberMIDIMusic(MusicName,ComposerName,noteLength, fileName)
def recallMusic(self, musicName):
print("Recall the " + musicName + " ......")
musicName = musicName.title()
result = self.cortex.recallMusicPFC(musicName)
#print(result)
noteResult = {}
for tindex,track in result.items():
ns = track.get('N')
ts = track.get('T')
tmp = []
for key in ns.keys():
dic = {}
dic['N']=ns.get(key)
dic['T']=ts.get(key)
tmp.append(dic)
noteResult[tindex] = tmp
self.writeMidiFile(musicName+"_recall",noteResult)
print("Recall " + musicName + " finished!")
return noteResult
def generateEx_Nihilo(self, firstNote, durations, length,gen_fName):
'''
parameters:
fistNote: Specify the beginning notes to generate a note
durations: Specify the duration of the beginning notes
length: the length of the generated music, less than 50 notes
'''
print("Generate melody with no style............")
result = self.cortex.generateEx_Nihilo2(firstNote, durations, length)
self.writeMidiFile(gen_fName,result)
print("Generating finished!")
return result
def generateEx_NihiloAccordingToGenre(self, genreName, firstNote, durations, length,gen_fName):
'''
parameters:
genreName:Specify the style of genre of the generated melody, for example: Baroque,Classical,Romantic
fistNote: Specify the beginning notes to generate a note
durations: Specify the duration of the beginning notes
length: the length of the generated music, less than 50 notes
'''
print("Generate melody with "+ genreName+"\'s style............")
result = self.cortex.generateEx_NihiloAccordingToGenre(genreName, firstNote, durations, length)
self.writeMidiFile(gen_fName,result)
print("Generating finished!")
return result
def generateEx_NihiloAccordingToComposer(self, composerName, firstNote, durations, length,gen_fName):
'''
parameters:
composerName:Specify the style of composer of the generated melody, for example: Bach, Mozart and etc.
fistNote: Specify the beginning notes to generate a note
durations: Specify the duration of the beginning notes
length: the length of the generated music, less than 50 notes
'''
print("Generate melody with " + composerName + "'s style............")
result = self.cortex.generateEx_NihiloAccordingToComposer(composerName, firstNote, durations, length)
self.writeMidiFile(gen_fName,result)
print("Generating finished!")
return result
def generate2TrackMusic(self, firstNotes, durations, lengths):
result = self.cortex.generate2TrackMusic(firstNotes, durations, lengths)
return result
def generateMelodyWithKey(self,tone, firstNotes,durations = None,length = 8):
result = self.cortex.generateMelodyWithKey(tone, firstNotes,durations,length)
return result
def writeMidiFile(self,fileName, mudic):
'''
mudic format description:
mudic = {1:[{'N':71,'T':0.5}.....],
2:[{'N':60,'T':0.25}.....],
....
}
'''
fileName += ".mid"
pm = pretty_midi.PrettyMIDI()
# Create an Instrument instance for a cello instrument
for values in mudic.values():
piano = pretty_midi.Instrument(program=0)
# Iterate over note names, which will be converted to note number later
start = 0
end = 0
for i, n in enumerate(values):
# Retrieve the MIDI note number for this note name
# note_number = pretty_midi.note_name_to_number(note_name)
# Create a Note instance, starting at 0s and ending at .5s
end = start + n.get('T')
note_name = n.get('N')
if (note_name == -1):
note = pretty_midi.Note(
velocity=0, pitch=0, start=start, end=end)
else:
note = pretty_midi.Note(
velocity=100, pitch=note_name, start=start, end=end)
# Add it to our cello instrument
piano.notes.append(note)
start = end
# Add the cello instrument to the PrettyMIDI object
pm.instruments.append(piano)
# Write out the MIDI data
pm.write(fileName)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/conf/GenreData.txt
================================================
Baroque:Bach
Classical:Haydn,Mozart,Beethoven,Schubert,Clementi
Romantic:Mendelssohn,Liszt,Chopin,Schumann,Brahms,Burgmueller,Debussy,Godowsky,Moszkowski,Mussorgsky,Rachmaninov,Ravel,Tchaikovsky,Albéniz,Balakirew,Borodin,Granados,Grieg,Sinding
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/conf/MIDIData.txt
================================================
-1:rest
0:C3
1:C sharp3/D flat3
2:D3
3:D sharp3/E flat3
4:E3
5:F3
6:F sharp3/G flat3
7:G3
8:G sharp3/A flat3
9:A3
10:A sharp3/B flat3
11:B3
12:C2
13:C sharp2/D flat2
14:D2
15:D sharp2/E flat2
16:E2
17:F2
18:F sharp2/G flat2
19:G2
20:G sharp2/A flat2
21:A2
22:A sharp2/B flat2
23:B2
24:C1
25:C sharp1/D flat1
26:D1
27:D sharp1/E flat1
28:E1
29:F1
30:F sharp1/G flat1
31:G1
32:G sharp1/A flat1
33:A1
34:A sharp1/B flat1
35:B1
36:C
37:C sharp/D flat
38:D
39:D sharp/E flat
40:E
41:F
42:F sharp/G flat
43:G
44:G sharp/A flat
45:A
46:A sharp/B flat
47:B
48:c
49:c sharp/d flat
50:d
51:d sharp/e flat
52:e
53:f
54:f sharp/g flat
55:g
56:g sharp/a flat
57:a
58:a sharp/b flat
59:b
60:c1
61:c sharp1/d flat1
62:d1
63:d sharp1/e flat1
64:e1
65:f1
66:f sharp1/g flat1
67:g1
68:g sharp1/a flat1
69:a1
70:a sharp1/b flat1
71:b1
72:c2
73:c sharp2/d flat2
74:d2
75:d sharp2/e flat2
76:e2
77:f2
78:f sharp2/g flat2
79:g2
80:g sharp2/a flat2
81:a2
82:a sharp2/b flat2
83:b2
84:c3
85:c sharp3/d flat3
86:d3
87:d sharp3/e flat3
88:e3
89:f3
90:f sharp3/g flat3
91:f3
92:g sharp3/a flat3
93:a3
94:a sharp3/b flat3
95:b3
96:c4
97:c sharp4/d flat4
98:d4
99:d sharp4/e flat4
100:e4
101:f4
102:f sharp4/g flat4
103:g4
104:g sharp4/a flat4
105:a4
106:a sharp4/b flat4
107:b4
108:c5
109:c sharp5/d flat5
110:d5
111:d sharp5/e flat5
112:e5
113:f5
114:f sharp5/g flat5
115:g5
116:g sharp5/a flat5
117:a5
118:a sharp5/b flat5
119:b5
120:c6
121:c sharp6/d flat6
122:d6
123:d sharp6/e flat6
124:e6
125:f6
126:f sharp6/g flat6
127:g6
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/conf/conf.py
================================================
import numpy
import numpy as np
import pandas as pd
class Conf():
'''
classdocs
'''
def __init__(self, neutype="LIF", task="MusicLearning", dt=0.1):
'''
Constructor
'''
self.neuron_type = neutype
self.task = task
self.dt = dt
self.notesMap = {}
self.GenreMap = {}
self.emoMap = {}
self.key_matrix = []
self.keysMap = {}
self.index2key = {}
self.index2mode = {}
self.keyIndexMap = {}
self.keyscales = {}
self.chordsMap = {}
self.chordsMatrix = np.zeros((7, 7))
self.RunTimeState = 0 # 0: GUI, 1: Bigdata experiments 2: other
def readNoteFiles(self):
# f = open("./Data.txt","r")
f = open("../inputs/MIDIData.txt", "r")
while (True):
line = f.readline()
if not line:
break
else:
strs = line.split(":")
index = int(strs[0])
self.notesMap[index] = strs[1].strip()
f.close()
def readGenreFils(self):
f = open("../inputs/GenreData.txt", "r")
while (True):
line = f.readline()
if not line:
break
else:
strs = line.split(":")
g = strs[0].strip()
ns = strs[1].split(",")
for n in ns:
self.GenreMap[(n.strip()).title()] = g.title()
f.close()
def readEmotionFiles(self):
f = open("../inputs/information.csv", "r")
while (True):
line = f.readline()
if not line:
break
else:
strs = line.split(",")
mn = strs[0].strip()
e = strs[3].strip()
self.emoMap[mn.title()] = e.title()
f.close()
def readKeysFile(self):
f = open("../inputs/keyIndex.csv", "r")
while (True):
line = (f.readline()).strip()
if not line:
break
else:
strs = line.split(",")
toneName = strs[0].strip()
self.keysMap[toneName] = int(strs[1].strip())
# print(self.keysMap)
self.index2key = dict(zip(self.keysMap.values(), self.keysMap.keys()))
# print(self.index2key)
self.key_matrix = np.array(pd.read_excel("../inputs/keys.xlsx", sheet_name='keys'))
self.keyscales = {0: np.array(pd.read_excel("../inputs/keys.xlsx", sheet_name='major')),
1: np.array(pd.read_excel("../inputs/keys.xlsx", sheet_name='minor'))}
def readKeys2IndexFile(self):
f = open("../inputs/keyIndex.csv", "r")
while (True):
line = f.readline().strip()
if not line:
break
else:
strs = line.split(",")
self.keyIndexMap[strs[0].strip()] = int(strs[1].strip())
# print(self.keyIndexMap)
def readChordsFile(self):
tmp = pd.read_excel("../inputs/chords.xlsx", sheet_name=None)
for key, chords in tmp.items():
chords = np.array(chords)
self.chordsMap[key.strip()] = chords
# print(self.chordsMap)
# 暂时先连接主,下属,属和弦
self.chordsMatrix = np.array([[1, 0, 0, 1, 1, 0, 0],
[0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 1, 1, 0, 0],
[1, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0]])
def readModesFile(self):
f = open("../inputs/modeindex.csv", "r")
while (True):
line = (f.readline()).strip()
if not line:
break
else:
strs = line.split(",")
self.index2mode[int(strs[0].strip())] = strs[1].strip()
configs = Conf(neutype = 'Izhikevich')
configs.readNoteFiles()
configs.readGenreFils()
configs.readEmotionFiles()
configs.readKeysFile()
configs.readKeys2IndexFile()
configs.readChordsFile()
configs.readModesFile()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/1.txt
================================================
1:A-B2
2:A#-B2
3:B-B2
4:C-B1
5:C#-B1
6:D-B1
7:D#-B1
8:E-B1
9:F-B1
10:F#-B1
11:G-B1
12:G#-B1
13:A-B1
14:A#-B1
15:B-B1
16:C-B
17:C#-B
18:D-B
19:D#-B
20:E-B
21:F-B
22:F#-B
23:G-B
24:G#-B
25:A-B
26:A#-B
27:B-B
28:C-S
29:C#-S
30:D-S
31:D#-S
32:E-S
33:F-S
34:F#-S
35:G-S
36:G#-S
37:A-S
38:A#-S
39:B-S
40:C-S1
41:C#-S1
42:D-S1
43:D#-S1
44:E-S1
45:F-S1
46:F#-S1
47:G-S1
48:G#-S1
49:A-S1
50:A#-S1
51:B-S1
52:C-S2
53:C#-S2
54:D-S2
55:D#-S2
56:E-S2
57:F-S2
58:F#-S2
59:G-S2
60:G#-S2
61:A-S2
62:A#-S2
63:B-S2
64:C-S3
65:C#-S3
66:D-S3
67:D#-S3
68:E-S3
69:F-S3
70:F#-S3
71:G-S3
72:G#-S3
73:A-S3
74:A#-S3
75:B-S3
76:C-S4
77:C#-S4
78:D-S4
79:D#-S4
80:E-S4
81:F-S4
82:F#-S4
83:G-S4
84:G#-S4
85:A-S4
86:A#-S4
87:B-S4
88:C-S5
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/Data.txt
================================================
1:A2
2:A#2
3:B2
4:C1
5:C#1
6:D1
7:D#1
8:E1
9:F1
10:F#1
11:G1
12:G#1
13:A1
14:A#1
15:B1
16:C
17:C#
18:D
19:D#
20:E
21:F
22:F#
23:G
24:G#
25:A
26:A#
27:B
28:c
29:c#
30:d
31:d#
32:e
33:f
34:f#
35:g
36:g#
37:a
38:a#
39:b
40:c1
41:c#1
42:d1
43:d#1
44:e1
45:f1
46:f#1
47:g1
48:g#1
49:a1
50:a#1
51:b1
52:c2
53:c#2
54:d2
55:d#2
56:e2
57:f2
58:f#2
59:g2
60:g#2
61:a2
62:a#2
63:b2
64:c3
65:c#3
66:d3
67:d#3
68:e3
69:f3
70:f#3
71:f3
72:g#3
73:a3
74:a#3
75:b3
76:c4
77:c#4
78:d4
79:d#4
80:e4
81:f4
82:f#4
83:g4
84:g#4
85:a4
86:a#4
87:b4
88:c5
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/GenreData.txt
================================================
Baroque:Bach
Classical:Haydn,Mozart,Beethoven,Schubert,Clementi
Romantic:Mendelssohn,Liszt,Chopin,Schumann,Brahms,Burgmueller,Debussy,Godowsky,Moszkowski,Mussorgsky,Rachmaninov,Ravel,Tchaikovsky,Albéniz,Balakirew,Borodin,Granados,Grieg,Sinding
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/MIDIData.txt
================================================
-1:rest
0:C3
1:C sharp3/D flat3
2:D3
3:D sharp3/E flat3
4:E3
5:F3
6:F sharp3/G flat3
7:G3
8:G sharp3/A flat3
9:A3
10:A sharp3/B flat3
11:B3
12:C2
13:C sharp2/D flat2
14:D2
15:D sharp2/E flat2
16:E2
17:F2
18:F sharp2/G flat2
19:G2
20:G sharp2/A flat2
21:A2
22:A sharp2/B flat2
23:B2
24:C1
25:C sharp1/D flat1
26:D1
27:D sharp1/E flat1
28:E1
29:F1
30:F sharp1/G flat1
31:G1
32:G sharp1/A flat1
33:A1
34:A sharp1/B flat1
35:B1
36:C
37:C sharp/D flat
38:D
39:D sharp/E flat
40:E
41:F
42:F sharp/G flat
43:G
44:G sharp/A flat
45:A
46:A sharp/B flat
47:B
48:c
49:c sharp/d flat
50:d
51:d sharp/e flat
52:e
53:f
54:f sharp/g flat
55:g
56:g sharp/a flat
57:a
58:a sharp/b flat
59:b
60:c1
61:c sharp1/d flat1
62:d1
63:d sharp1/e flat1
64:e1
65:f1
66:f sharp1/g flat1
67:g1
68:g sharp1/a flat1
69:a1
70:a sharp1/b flat1
71:b1
72:c2
73:c sharp2/d flat2
74:d2
75:d sharp2/e flat2
76:e2
77:f2
78:f sharp2/g flat2
79:g2
80:g sharp2/a flat2
81:a2
82:a sharp2/b flat2
83:b2
84:c3
85:c sharp3/d flat3
86:d3
87:d sharp3/e flat3
88:e3
89:f3
90:f sharp3/g flat3
91:f3
92:g sharp3/a flat3
93:a3
94:a sharp3/b flat3
95:b3
96:c4
97:c sharp4/d flat4
98:d4
99:d sharp4/e flat4
100:e4
101:f4
102:f sharp4/g flat4
103:g4
104:g sharp4/a flat4
105:a4
106:a sharp4/b flat4
107:b4
108:c5
109:c sharp5/d flat5
110:d5
111:d sharp5/e flat5
112:e5
113:f5
114:f sharp5/g flat5
115:g5
116:g sharp5/a flat5
117:a5
118:a sharp5/b flat5
119:b5
120:c6
121:c sharp6/d flat6
122:d6
123:d sharp6/e flat6
124:e6
125:f6
126:f sharp6/g flat6
127:g6
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/chords.csv
================================================
C,,,
1,C,E,G
4,F,A,C
5,G,B,D
,,,
a,,,
1,A,C,E
4,D,F,A
5,E,G#,B
,,,
G,,,
1,G,B,D
4,C,E,G
5,D,F#,A
,,,
F,,,
1,F,A,C
4,B-,D,F
5,C,E,G
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/information.csv
================================================
chpn_op35_2.mid,Chopin,Romantic,unclear
chpn_op33_4.mid,Chopin,Romantic,unclear
chpn-p14.mid,Chopin,Romantic,unclear
chpn-p17.mid,Chopin,Romantic,soft
chpn_op33_2.mid,Chopin,Romantic,happy
chpn_op53.mid,Chopin,Romantic,unclear
chpn_op35_3.mid,Chopin,Romantic,unclear
chpn-p1.mid,Chopin,Romantic,unclear
chpn_op7_2.mid,Chopin,Romantic,soft
chpn_op25_e11.mid,Chopin,Romantic,passionate
chpn-p16.mid,Chopin,Romantic,unclear
chpn-p20.mid,Chopin,Romantic,depressed
chpn-p13.mid,Chopin,Romantic,soft
chpn_op27_2.mid,Chopin,Romantic,soft
chpn-p6.mid,Chopin,Romantic,depressed
chpn-p9.mid,Chopin,Romantic,unclear
chpn-p15.mid,Chopin,Romantic,depressed
chpn_op10_e12.mid,Chopin,Romantic,passionate
chpn-p22.mid,Chopin,Romantic,unclear
chpn_op23.mid,Chopin,Romantic,unclear
chpn-p24.mid,Chopin,Romantic,passionate
chpn-p18.mid,Chopin,Romantic,happy
chpn_op27_1.mid,Chopin,Romantic,depressed
chpn_op10_e05.mid,Chopin,Romantic,passionate
chpn_op25_e4.mid,Chopin,Romantic,unclear
chpn_op66.mid,Chopin,Romantic,unclear
chpn_op25_e2.mid,Chopin,Romantic,soft
chpn_op10_e01.mid,Chopin,Romantic,passionate
chpn-p11.mid,Chopin,Romantic,happy
chpn-p7.mid,Chopin,Romantic,soft
chp_op18.mid,Chopin,Romantic,unclear
chpn-p23.mid,Chopin,Romantic,soft
chpn-p5.mid,Chopin,Romantic,unclear
chpn_op35_4.mid,Chopin,Romantic,unclear
chpn_op25_e3.mid,Chopin,Romantic,unclear
chpn-p12.mid,Chopin,Romantic,passionate
chpn-p21.mid,Chopin,Romantic,soft
chpn-p4.mid,Chopin,Romantic,depressed
chpn-p2.mid,Chopin,Romantic,depressed
chpn_op35_1.mid,Chopin,Romantic,unclear
chp_op31.mid,Chopin,Romantic,unclear
chpn_op25_e1.mid,Chopin,Romantic,unclear
chpn-p10.mid,Chopin,Romantic,unclear
chpn-p8.mid,Chopin,Romantic,passionate
chpn_op25_e12.mid,Chopin,Romantic,unclear
chpn_op7_1.mid,Chopin,Romantic,happy
chpn-p3.mid,Chopin,Romantic,unclear
chpn-p19.mid,Chopin,Romantic,soft
scn15_5.mid,Schumann,Romantic,unclear
scn15_7.mid,Schumann,Romantic,unclear
scn15_12.mid,Schumann,Romantic,unclear
scn15_6.mid,Schumann,Romantic,unclear
scn15_13.mid,Schumann,Romantic,unclear
scn68_12.mid,Schumann,Romantic,unclear
scn15_1.mid,Schumann,Romantic,unclear
scn15_3.mid,Schumann,Romantic,unclear
scn15_2.mid,Schumann,Romantic,unclear
scn16_3.mid,Schumann,Romantic,unclear
scn16_2.mid,Schumann,Romantic,unclear
scn68_10.mid,Schumann,Romantic,unclear
scn16_6.mid,Schumann,Romantic,unclear
scn16_5.mid,Schumann,Romantic,unclear
scn16_1.mid,Schumann,Romantic,unclear
scn15_9.mid,Schumann,Romantic,unclear
scn15_8.mid,Schumann,Romantic,unclear
scn15_11.mid,Schumann,Romantic,unclear
scn16_7.mid,Schumann,Romantic,unclear
scn16_8.mid,Schumann,Romantic,unclear
scn16_4.mid,Schumann,Romantic,unclear
scn15_10.mid,Schumann,Romantic,unclear
schum_abegg.mid,Schumann,Romantic,unclear
scn15_4.mid,Schumann,Romantic,unclear
ty_august.mid,Tchaikovsky,Romantic,unclear
ty_april.mid,Tchaikovsky,Romantic,unclear
ty_juli.mid,Tchaikovsky,Romantic,unclear
ty_oktober.mid,Tchaikovsky,Romantic,unclear
ty_juni.mid,Tchaikovsky,Romantic,unclear
ty_november.mid,Tchaikovsky,Romantic,unclear
ty_januar.mid,Tchaikovsky,Romantic,unclear
ty_dezember.mid,Tchaikovsky,Romantic,unclear
ty_maerz.mid,Tchaikovsky,Romantic,unclear
ty_mai.mid,Tchaikovsky,Romantic,unclear
ty_februar.mid,Tchaikovsky,Romantic,unclear
ty_september.mid,Tchaikovsky,Romantic,unclear
debussy_cc_3.mid,Debussy,Romantic,happy
DEB_CLAI.MID,Debussy,Romantic,soft
debussy_cc_2.mid,Debussy,Romantic,unclear
debussy_cc_6.mid,Debussy,Romantic,unclear
deb_menu.mid,Debussy,Romantic,unclear
DEB_PASS.MID,Debussy,Romantic,unclear
deb_prel.mid,Debussy,Romantic,happy
debussy_cc_1.mid,Debussy,Romantic,unclear
debussy_cc_4.mid,Debussy,Romantic,unclear
alb_se2.mid,Albeniz,Romantic,unclear
alb_se8.mid,Albeniz,Romantic,unclear
alb_se1.mid,Albeniz,Romantic,unclear
alb_esp6.mid,Albeniz,Romantic,unclear
alb_esp4.mid,Albeniz,Romantic,unclear
alb_esp2.mid,Albeniz,Romantic,unclear
alb_se4.mid,Albeniz,Romantic,unclear
alb_esp1.mid,Albeniz,Romantic,unclear
alb_esp5.mid,Albeniz,Romantic,unclear
alb_se6.mid,Albeniz,Romantic,unclear
alb_se3.mid,Albeniz,Romantic,unclear
alb_esp3.mid,Albeniz,Romantic,unclear
alb_se5.mid,Albeniz,Romantic,unclear
alb_se7.mid,Albeniz,Romantic,unclear
liz_et_trans8.mid,Liszt,Romantic,unclear
liz_liebestraum.mid,Liszt,Romantic,soft
liz_rhap10.mid,Liszt,Romantic,unclear
liz_rhap15.mid,Liszt,Romantic,unclear
liz_et2.mid,Liszt,Romantic,unclear
liz_rhap09.mid,Liszt,Romantic,unclear
liz_rhap02.mid,Liszt,Romantic,unclear
liz_rhap12.mid,Liszt,Romantic,unclear
liz_et4.mid,Liszt,Romantic,unclear
liz_et1.mid,Liszt,Romantic,unclear
liz_et_trans4.mid,Liszt,Romantic,unclear
liz_et5.mid,Liszt,Romantic,unclear
liz_donjuan.mid,Liszt,Romantic,unclear
liz_et3.mid,Liszt,Romantic,soft
liz_et6.mid,Liszt,Romantic,unclear
liz_et_trans5.mid,Liszt,Romantic,unclear
pathetique_1.mid,Beethoven,Classical,unclear
beethoven_hammerklavier_4.mid,Beethoven,Classical,unclear
beethoven_hammerklavier_2.mid,Beethoven,Classical,unclear
beethoven_opus22_4.mid,Beethoven,Classical,happy
waldstein_2.mid,Beethoven,Classical,unclear
beethoven_hammerklavier_3.mid,Beethoven,Classical,depressed
beethoven_les_adieux_3.mid,Beethoven,Classical,happy
beethoven_opus22_2.mid,Beethoven,Classical,unclear
waldstein_1.mid,Beethoven,Classical,happy
appass_2.mid,Beethoven,Classical,unclear
beethoven_opus10_3.mid,Beethoven,Classical,unclear
beethoven_opus22_1.mid,Beethoven,Classical,unclear
beethoven_hammerklavier_1.mid,Beethoven,Classical,unclear
pathetique_3.mid,Beethoven,Classical,passionate
beethoven_opus90_2.mid,Beethoven,Classical,unclear
beethoven_opus22_3.mid,Beethoven,Classical,happy
beethoven_opus90_1.mid,Beethoven,Classical,unclear
waldstein_3.mid,Beethoven,Classical,happy
beethoven_opus10_1.mid,Beethoven,Classical,unclear
appass_1.mid,Beethoven,Classical,unclear
beethoven_opus10_2.mid,Beethoven,Classical,unclear
mond_2.mid,Beethoven,Classical,unclear
beethoven_les_adieux_1.mid,Beethoven,Classical,depressed
elise.mid,Beethoven,Classical,soft
appass_3.mid,Beethoven,Classical,passionate
pathetique_2.mid,Beethoven,Classical,soft
mond_3.mid,Beethoven,Classical,passionate
beethoven_les_adieux_2.mid,Beethoven,Classical,depressed
mond_1.mid,Beethoven,Classical,depressed
muss_3.mid,Mussorgsky,Romantic,unclear
muss_5.mid,Mussorgsky,Romantic,unclear
muss_1.mid,Mussorgsky,Romantic,unclear
muss_8.mid,Mussorgsky,Romantic,unclear
muss_6.mid,Mussorgsky,Romantic,unclear
muss_2.mid,Mussorgsky,Romantic,unclear
muss_7.mid,Mussorgsky,Romantic,unclear
muss_4.mid,Mussorgsky,Romantic,unclear
mendel_op30_4.mid,Mendelssohn,Romantic,unclear
mendel_op19_2.mid,Mendelssohn,Romantic,unclear
mendel_op19_5.mid,Mendelssohn,Romantic,unclear
mendel_op19_4.mid,Mendelssohn,Romantic,soft
mendel_op19_6.mid,Mendelssohn,Romantic,depressed
mendel_op19_1.mid,Mendelssohn,Romantic,soft
mendel_op30_5.mid,Mendelssohn,Romantic,unclear
mendel_op30_2.mid,Mendelssohn,Romantic,unclear
mendel_op62_3.mid,Mendelssohn,Romantic,depressed
mendel_op30_3.mid,Mendelssohn,Romantic,unclear
mendel_op62_4.mid,Mendelssohn,Romantic,unclear
mendel_op19_3.mid,Mendelssohn,Romantic,unclear
mendel_op53_5.mid,Mendelssohn,Romantic,unclear
mendel_op30_1.mid,Mendelssohn,Romantic,soft
mendel_op62_5.mid,Mendelssohn,Romantic,unclear
gra_esp_2.mid,Granados,Romantic,unclear
gra_esp_3.mid,Granados,Romantic,unclear
gra_esp_4.mid,Granados,Romantic,unclear
fruehlingsrauschen.mid,Sinding,Romantic,unclear
rac_op32_1.mid,Rachmaninov,Romantic,unclear
rac_op23_3.mid,Rachmaninov,Romantic,unclear
rac_op33_8.mid,Rachmaninov,Romantic,unclear
rac_op33_6.mid,Rachmaninov,Romantic,unclear
rac_op33_5.mid,Rachmaninov,Romantic,unclear
rac_op23_7.mid,Rachmaninov,Romantic,unclear
rac_op32_13.mid,Rachmaninov,Romantic,unclear
rac_op23_2.mid,Rachmaninov,Romantic,unclear
rac_op3_2.mid,Rachmaninov,Romantic,unclear
rac_op23_5.mid,Rachmaninov,Romantic,unclear
god_alb_esp2.mid,Godowsky,Romantic,unclear
god_chpn_op10_e01.mid,Godowsky,Romantic,unclear
mz_545_1.mid,Mozart,Classical,unclear
mz_570_2.mid,Mozart,Classical,unclear
mz_311_2.mid,Mozart,Classical,unclear
mz_333_3.mid,Mozart,Classical,unclear
mz_331_3.mid,Mozart,Classical,passionate
mz_332_3.mid,Mozart,Classical,unclear
mz_331_2.mid,Mozart,Classical,unclear
mz_332_1.mid,Mozart,Classical,unclear
mz_545_2.mid,Mozart,Classical,unclear
mz_330_1.mid,Mozart,Classical,unclear
mz_545_3.mid,Mozart,Classical,unclear
mz_333_2.mid,Mozart,Classical,unclear
mz_330_2.mid,Mozart,Classical,unclear
mz_333_1.mid,Mozart,Classical,unclear
mz_311_3.mid,Mozart,Classical,unclear
mz_331_1.mid,Mozart,Classical,happy
mz_570_3.mid,Mozart,Classical,unclear
mz_332_2.mid,Mozart,Classical,unclear
mz_570_1.mid,Mozart,Classical,unclear
mz_330_3.mid,Mozart,Classical,unclear
mz_311_1.mid,Mozart,Classical,unclear
rav_scarbo.mid,Ravel,Romantic,unclear
rav_ondi.mid,Ravel,Romantic,unclear
rav_eau.mid,Ravel,Romantic,unclear
rav_gib.mid,Ravel,Romantic,unclear
ravel_miroirs_1.mid,Ravel,Romantic,unclear
clementi_opus36_4_1.mid,Clementi,Classical,unclear
clementi_opus36_2_2.mid,Clementi,Classical,unclear
clementi_opus36_6_1.mid,Clementi,Classical,happy
clementi_opus36_1_3.mid,Clementi,Classical,happy
clementi_opus36_3_3.mid,Clementi,Classical,unclear
clementi_opus36_5_1.mid,Clementi,Classical,happy
clementi_opus36_1_2.mid,Clementi,Classical,soft
clementi_opus36_4_3.mid,Clementi,Classical,unclear
clementi_opus36_1_1.mid,Clementi,Classical,happy
clementi_opus36_2_3.mid,Clementi,Classical,unclear
clementi_opus36_4_2.mid,Clementi,Classical,unclear
clementi_opus36_3_2.mid,Clementi,Classical,unclear
clementi_opus36_5_3.mid,Clementi,Classical,unclear
clementi_opus36_5_2.mid,Clementi,Classical,unclear
clementi_opus36_3_1.mid,Clementi,Classical,unclear
clementi_opus36_6_2.mid,Clementi,Classical,unclear
clementi_opus36_2_1.mid,Clementi,Classical,happy
mos_op36_6.mid,Moszkowski,Romantic,unclear
haydn_7_2.mid,Haydn,Classical,unclear
haydn_35_2.mid,Haydn,Classical,unclear
haydn_7_3.mid,Haydn,Classical,unclear
haydn_8_4.mid,Haydn,Classical,unclear
haydn_9_1.mid,Haydn,Classical,unclear
haydn_8_3.mid,Haydn,Classical,unclear
haydn_35_3.mid,Haydn,Classical,unclear
haydn_33_3.mid,Haydn,Classical,unclear
haydn_8_1.mid,Haydn,Classical,unclear
haydn_8_2.mid,Haydn,Classical,unclear
haydn_7_1.mid,Haydn,Classical,unclear
haydn_9_2.mid,Haydn,Classical,unclear
haydn_43_1.mid,Haydn,Classical,unclear
hay_40_2.mid,Haydn,Classical,unclear
haydn_9_3.mid,Haydn,Classical,unclear
haydn_35_1.mid,Haydn,Classical,unclear
haydn_33_1.mid,Haydn,Classical,unclear
haydn_43_2.mid,Haydn,Classical,unclear
hay_40_1.mid,Haydn,Classical,unclear
haydn_33_2.mid,Haydn,Classical,unclear
haydn_43_3.mid,Haydn,Classical,unclear
bach_850.mid,Bach,Baroque,happy
bach_846.mid,Bach,Baroque,soft
bach_847.mid,Bach,Baroque,unclear
grieg_halling.mid,Grieg,Romantic,unclear
grieg_wedding.mid,Grieg,Romantic,unclear
grieg_brooklet.mid,Grieg,Romantic,unclear
grieg_butterfly.mid,Grieg,Romantic,happy
grieg_wanderer.mid,Grieg,Romantic,unclear
grieg_zwerge.mid,Grieg,Romantic,unclear
grieg_march.mid,Grieg,Romantic,unclear
grieg_album.mid,Grieg,Romantic,unclear
grieg_elfentanz.mid,Grieg,Romantic,unclear
grieg_spring.mid,Grieg,Romantic,unclear
grieg_waechter.mid,Grieg,Romantic,unclear
grieg_kobold.mid,Grieg,Romantic,unclear
grieg_berceuse.mid,Grieg,Romantic,unclear
grieg_voeglein.mid,Grieg,Romantic,unclear
grieg_walzer.mid,Grieg,Romantic,unclear
grieg_once_upon_a_time.mid,Grieg,Romantic,unclear
br_im2.mid,Brahms,Romantic,unclear
br_rhap.mid,Brahms,Romantic,unclear
brahms_opus1_1.mid,Brahms,Romantic,unclear
brahms_opus1_3.mid,Brahms,Romantic,unclear
brahms_opus117_1.mid,Brahms,Romantic,unclear
brahms_opus1_2.mid,Brahms,Romantic,unclear
BR_IM6.MID,Brahms,Romantic,unclear
brahms_opus1_4.mid,Brahms,Romantic,unclear
brahms_opus117_2.mid,Brahms,Romantic,unclear
br_im5.mid,Brahms,Romantic,unclear
burg_geschwindigkeit.mid,Burgmueller,Romantic,unclear
burg_perlen.mid,Burgmueller,Romantic,unclear
burg_trennung.mid,Burgmueller,Romantic,unclear
burg_agitato.mid,Burgmueller,Romantic,unclear
burg_sylphen.mid,Burgmueller,Romantic,unclear
burg_spinnerlied.mid,Burgmueller,Romantic,unclear
burg_quelle.mid,Burgmueller,Romantic,unclear
burg_erwachen.mid,Burgmueller,Romantic,unclear
burg_gewitter.mid,Burgmueller,Romantic,unclear
schuim-4.mid,Schubert,Classical,unclear
schumm-6.mid,Schubert,Classical,unclear
schu_143_2.mid,Schubert,Classical,unclear
schubert_D850_3.mid,Schubert,Classical,unclear
schub_d960_1.mid,Schubert,Classical,unclear
schubert_D935_4.mid,Schubert,Classical,unclear
schu_143_1.mid,Schubert,Classical,unclear
schubert_D850_2.mid,Schubert,Classical,unclear
schumm-2.mid,Schubert,Classical,unclear
schubert_D850_4.mid,Schubert,Classical,unclear
schub_d960_3.mid,Schubert,Classical,unclear
schub_d760_3.mid,Schubert,Classical,unclear
schumm-5.mid,Schubert,Classical,unclear
schumm-3.mid,Schubert,Classical,unclear
schumm-1.mid,Schubert,Classical,unclear
schub_d760_4.mid,Schubert,Classical,unclear
schubert_D935_2.mid,Schubert,Classical,unclear
schumm-4.mid,Schubert,Classical,unclear
schu_143_3.mid,Schubert,Classical,unclear
schub_d960_2.mid,Schubert,Classical,unclear
schuim-1.mid,Schubert,Classical,unclear
schub_d760_1.mid,Schubert,Classical,unclear
schubert_D850_1.mid,Schubert,Classical,unclear
schubert_D935_3.mid,Schubert,Classical,unclear
schub_d960_4.mid,Schubert,Classical,unclear
schuim-3.mid,Schubert,Classical,unclear
schub_d760_2.mid,Schubert,Classical,unclear
schubert_D935_1.mid,Schubert,Classical,unclear
schuim-2.mid,Schubert,Classical,unclear
islamei.mid,Balakirew,Romantic,unclear
bor_ps2.mid,Borodin,Romantic,unclear
bor_ps1.mid,Borodin,Romantic,unclear
bor_ps7.mid,Borodin,Romantic,unclear
bor_ps4.mid,Borodin,Romantic,unclear
bor_ps6.mid,Borodin,Romantic,unclear
bor_ps3.mid,Borodin,Romantic,unclear
bor_ps5.mid,Borodin,Romantic,unclear
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/keyIndex.csv
================================================
C major,0
a minor,1
G major,2
e minor,3
D major,4
b minor,5
A major,6
f# minor,7
E major,8
c# minor,9
B major,10
g# minor,11
F major,12
d minor,13
B- major,14
g minor,15
E- major,16
c minor,17
A- major,18
f minor,19
D- major,20
b- minor,21
G- major,22
e- minor,23
C# major,20
a# minor,21
F# major,22
d# minor,23
C- major,10
a- minor,11
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/keys.csv
================================================
1,-1,2,-1,3,4,-1,5,-1,6,-1,7
3,-1,4,-1,5,6,-1,-1,7,1,-1,2
4,-1,5,-1,6,-1,7,1,-1,2,-1,3
6,-1,-1,7,1,-1,2,3,-1,4,-1,5
-1,7,1,-1,2,-1,3,4,-1,5,-1,6
-1,2,3,-1,4,-1,5,6,-1,-1,7,1
-1,3,4,-1,5,-1,6,-1,7,1,-1,2
-1,5,6,-1,-1,7,1,-1,2,3,-1,4
-1,6,-1,7,1,-1,2,-1,3,4,-1,5
7,1,-1,2,3,-1,4,-1,5,6,-1,-1
-1,2,-1,3,4,-1,5,-1,6,-1,7,1
-1,4,-1,5,6,-1,-1,7,1,-1,2,3
5,-1,6,-1,7,1,-1,2,-1,3,4,-1
-1,7,1,-1,2,3,-1,4,-1,5,6,-1
2,-1,3,4,-1,5,-1,6,-1,7,1,-1
4,-1,5,6,-1,-1,7,1,-1,2,3,-1
6,-1,7,1,-1,2,-1,3,4,-1,5,-1
1,-1,2,3,-1,4,-1,5,6,-1,-1,7
3,4,-1,5,-1,6,-1,7,1,-1,2,-1
5,6,-1,-1,7,1,-1,2,3,-1,4,-1
7,1,-1,2,-1,3,4,-1,5,-1,6,-1
2,3,-1,4,-1,5,6,-1,-1,7,1,-1
-1,5,-1,6,-1,7,1,-1,2,-1,3,4
-1,-1,7,1,-1,2,3,-1,4,-1,5,6
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/modeindex.csv
================================================
0,major
1,minor
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/pitch2midi.csv
================================================
C,0,12,24,36,48,60,72,84,96,108,120
C#,1,13,25,37,49,61,73,85,97,109,121
C-,11,23,35,47,59,71,83,95,107,119,
D,2,14,26,38,50,62,74,86,98,110,122
D#,3,15,27,39,51,63,75,87,99,111,123
D-,1,13,25,37,49,61,73,85,97,109,121
E,4,16,28,40,52,64,76,88,100,112,124
E#,5,17,29,41,53,65,77,89,101,113,125
E-,3,15,27,39,51,63,75,87,99,111,123
F,5,17,29,41,53,65,77,89,101,113,125
F#,6,18,30,42,54,66,78,90,102,114,126
F-,4,16,28,40,52,64,76,88,100,112,124
G,7,19,31,43,55,67,79,91,103,115,127
G#,8,20,32,44,56,68,80,92,104,116,
G-,6,18,30,42,54,66,78,90,102,114,126
A,9,21,33,45,57,69,81,93,105,117,
A#,10,22,34,46,58,70,82,94,106,118,
A-,8,20,32,44,56,68,80,92,104,116,
B,11,23,35,47,59,71,83,95,107,119,
B+,0,12,24,36,48,60,72,84,96,108,120
B-,10,22,34,46,58,70,82,94,106,118,
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/inputs/tones2.csv
================================================
,0,1,2,3,4,5,6,7,8,9,10,11
C major,2,-1,1,-1,1,1,-1,1,-1,1,-1,1
a minor,1,-1,1,-1,1,1,-1,-1,2,2,-1,1
G major,1,-1,1,-1,1,-1,2,2,-1,1,-1,1
e minor,1,-1,-1,2,2,-1,2,1,-1,1,-1,1
D major,-1,2,2,-1,1,-1,2,1,-1,1,-1,1
b minor,-1,2,1,-1,1,-1,2,1,-1,-1,2,2
A major,-1,2,1,-1,1,-1,2,-1,2,2,-1,1
f# minor,-1,2,1,-1,-1,2,2,-1,2,1,-1,1
E major,-1,2,-1,2,2,-1,2,-1,2,1,-1,1
c# minor,2,2,-1,2,1,-1,2,-1,2,1,-1,-1
B major,-1,2,-1,2,1,-1,2,-1,2,-1,2,2
g# minor,-1,2,-1,2,1,-1,-1,2,2,-1,2,1
F major,1,-1,1,-1,1,2,-1,1,-1,1,2,-1
d minor,-1,2,2,-1,1,1,-1,1,-1,1,2,-1
B- major,1,-1,1,2,-1,1,-1,1,-1,1,2,-1
g minor,1,-1,1,2,-1,-1,2,2,-1,1,2,-1
E- major,1,-1,1,2,-1,1,-1,1,2,-1,2,-1
c minor,1,-1,1,2,-1,1,-1,1,2,-1,-1,2
A- major,1,2,-1,2,-1,1,-1,1,2,-1,2,-1
f minor,1,2,-1,-1,2,1,-1,1,2,-1,2,-1
D- major,1,2,-1,2,-1,1,2,-1,2,-1,2,-1
b- minor,1,2,-1,2,-1,1,2,-1,-1,2,2,-1
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/task/mode-conditioned learning.py
================================================
import sys
import os
import time
sys.path.append("../../../../")
sys.path.append("../")
import numpy as np
import music21 as m21
from conf.conf import *
from api.music_engine_api import EngineAPI
if __name__=="__main__":
musicEngine = EngineAPI()
musicEngine.cortexInit()
#------------Bach dataset learning----------------#
paths = m21.corpus.getComposer('bach')
print(len(paths))
for path in paths:
musicName = (str(path).split('\\'))[-1]
print(musicName)
if musicName.split('.')[-1] != 'mxl': continue
xmldata = m21.corpus.parse(path)
musicEngine.rememberMusic(musicName, "None")
musicEngine.learnFourPartMusic(xmldata, musicName, "None")
#------------generation test----------------#
key = 'C major'
firstnotes = np.array([[m21.pitch.Pitch('E5').midi],
[m21.pitch.Pitch('G4').midi],
[m21.pitch.Pitch('C4').midi],
[m21.pitch.Pitch('C3').midi]])
result = musicEngine.generateMelodyWithKey(configs.keyIndexMap.get(key),firstnotes,None,4)
steam1 = m21.stream.Stream()
for i,part in result.items():
pt = m21.stream.Stream()
for v in part:
p = v.get("N")
d = v.get("T")
n = m21.note.Note(p)
n.quarterLength = d
pt.append(n)
steam1.insert(0,pt)
opath = '../result_output/tone learning/'
nowtime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
t2 = ''.join([x for x in nowtime if x.isdigit()])
steam1.write('midi', fp=opath+key+"_"+t2+'.mid')
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/task/musicGeneration.py
================================================
import sys
sys.path.append("../../../../")
sys.path.append("../")
from api.music_engine_api import EngineAPI
import os
if __name__=="__main__":
#----------------------------------Init------------------------------#
musicEngine = EngineAPI()
musicEngine.cortexInit()
#----------------------------Learning process------------------------#
input_path = "../testData/"
for composerName in os.listdir(input_path):
dpath = os.path.join(input_path,composerName)
if os.path.isdir(dpath):
for musicName in os.listdir(dpath):
fileName = (os.path.join(dpath,musicName))
musicEngine.memorizing(musicName,composerName,20,fileName)
#-------------------------Generation Process------------------------#
beginnotes = {1:[-1,67],
2:[-1]}
begindurs = {1:[0.5,0.25],
2:[0.5]}
lengths = [10,8]
genreName = "Classical"
composerName = "Bach"
#Generate a piece of music melody#
musicEngine.generateEx_Nihilo(beginnotes.get(2),begindurs.get(2),20,"melody_generated")
#Generate a piece of melody with a composer style
musicEngine.generateEx_NihiloAccordingToComposer(composerName,beginnotes.get(2),begindurs.get(2),15,"Bach_generated")
#Generate a piece of melody with a genre style
musicEngine.generateEx_NihiloAccordingToGenre(genreName,beginnotes.get(1),begindurs.get(1),15,"Classical_generated")
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/task/musicMemory.py
================================================
import sys
sys.path.append("../")
sys.path.append("../../../../")
from api.music_engine_api import EngineAPI
import os
if __name__=="__main__":
musicEngine = EngineAPI()
musicEngine.cortexInit()
input_path = "../testData/"
#--------------------learning process---------------#
for composerName in os.listdir(input_path):
dpath = os.path.join(input_path,composerName)
if os.path.isdir(dpath):
for musicName in os.listdir(dpath):
fileName = (os.path.join(dpath,musicName))
#Here is the training function, the first and the second parameters refer to the title and composer of a melody.
#The third parameter indicates the number of notes you want to learn. If you want to learn all the notes of melodies, this value is "ALL".
musicEngine.memorizing(musicName, composerName, 20, fileName)
# recall the music based on the name of a music
musicEngine.recallMusic("Sonate C Major.Mid")
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/__init__.py
================================================
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/generateData.py
================================================
'''
Created on 2016.4.27
@author: liangqian
'''
import json
import random
class joint():
def __init__(self):
self.x = 0
self.y = 0
self.z = 0
def self2dic(self):
return {'x':self.x,
'y':self.y,
'z':self.z}
class data():
def __init__(self):
self.T = 0
self.position = 0
self.joints = {}
def self2dic(self):
return {'T':self.T,
'position':self.position
}
Data_List = []
# for i in range(1,419):
# d = data()
# d.T = i
# d.position = random.randint(0,100)
# dic = d.self2dic()
# Data_List.append(d)
#
# dic = {}
# dic['Data'] = Data_List
#
# # using json to write file
# strs = (json.dumps(dic))
#
# fout = open('position.txt','w')
# fout.write(strs)
# fout.close()
#
#
# fin = open('position.txt','r')
# data_json = fin.read()
#
# print(data_json)
f = open('../Data.txt','r')
line = f.readline()
while(len(line) != 0):
if('T=' in line):
ss = line.split('=')
d = data()
d.T = int(ss[1].strip())
d.position = random.randint(0,100)
line = f.readline()
while(len(line.strip()) != 0):
sss = line.split(' ')
jj = joint()
s = sss[1].split('=')
jj.x = float(s[1].strip())
s = sss[2].split('=')
jj.y = float(s[1].strip())
s = sss[3].split('=')
jj.z = float(s[1].strip())
d.joints[sss[0]] = jj
line = f.readline()
Data_List.append(d)
print(len(d.joints))
line = f.readline()
print(len(Data_List))
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/hamonydataset_test.py
================================================
import os
import sys
import music21 as m21
import numpy as np
firstnotes = np.array([[m21.pitch.Pitch('b-4').midi],
[m21.pitch.Pitch('d4').midi],
[m21.pitch.Pitch('f3').midi],
[m21.pitch.Pitch('B2').midi]])
print(firstnotes)
input_path = "../xmlfiles/hamony dataset/"
for ch in os.listdir(input_path):
if ch == '.DS_Store': continue
fileName = os.path.join(input_path, ch)
for fName in os.listdir(fileName):
if fName == 'four':
if fName == '.DS_Store': continue
fn = os.path.join(fileName+'/four')
for f in os.listdir(fn):
if f == '.DS_Store': continue
print(f)
musicName = f.split("_")[0]
fTone = (f.split("_")[1]).split(".")[0]
print(musicName)
print(fTone)
print('---')
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/msg.py
================================================
'''
Created on 2016.6.8
@author: liangqian
'''
import time
import sys
import stomp
class MyListener(object):
def on_error(self, headers, message):
print('received an error : %s' % message)
def on_message(self, headers, message):
print('%s' % message)
conn = stomp.Connection([('159.226.19.16',61613)])
#conn = stomp.Connection([('10.10.10.106',61613)])
conn.set_listener('', MyListener())
conn.start()
print('hh')
conn.connect(wait=True,headers={'client-id':'LXYNB','non_persistent':'true'})
conn.subscribe(destination='/topic/TEST2.FOO',id='LX', ack='auto',headers={'activemq.subscriptionName':'LXYNB'})
#conn.send(body='hello,garfield!', destination='/topic/myTopic.messages')
while(True):
pass
conn.disconnect()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/msgq.py
================================================
'''
Created on 2018.9.7
@author: liangqian
'''
import time
import sys
import stomp
def createMSQ():
queue_name = '/queue/SampleQueue'
conn = stomp.Connection([('localhost',61613)])
#conn.start()
print("building connection to activemq......")
conn.connect()
#return conn
# for i in range (10):
# msg = 'this is the '+ str(i) + 'th messages'
# conn.send(queue_name,msg)
# print(msg)
# conn.disconnect()
return conn
#createMSQ()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/oscillations.py
================================================
'''
Created on 2016.5.13
@author: liangqian
'''
from modal.lifneuron import LIFNeuron
from modal.cluster import Cluster
from modal.synapse import Synapse
c = Cluster('LIF')
c.createClusterNetwork()
c.setInhibitoryNeurons(0.2)
for i in range(0,c.neunum):
for j in range(0,c.neunum):
if(i != j):
node = c.neurons[j]
node.pre_neurons.append(c.neurons[i])
syn = Synapse(c.neurons[i],node)
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/position.txt
================================================
{"1": {"position": 58, "T": 1}, "2": {"position": 96, "T": 2}, "3": {"position": 36, "T": 3}, "4": {"position": 28, "T": 4}, "5": {"position": 43, "T": 5}, "6": {"position": 46, "T": 6}, "7": {"position": 91, "T": 7}, "8": {"position": 44, "T": 8}, "9": {"position": 59, "T": 9}, "10": {"position": 83, "T": 10}, "11": {"position": 17, "T": 11}, "12": {"position": 50, "T": 12}, "13": {"position": 46, "T": 13}, "14": {"position": 53, "T": 14}, "15": {"position": 9, "T": 15}, "16": {"position": 88, "T": 16}, "17": {"position": 23, "T": 17}, "18": {"position": 28, "T": 18}, "19": {"position": 17, "T": 19}, "20": {"position": 16, "T": 20}, "21": {"position": 43, "T": 21}, "22": {"position": 93, "T": 22}, "23": {"position": 13, "T": 23}, "24": {"position": 0, "T": 24}, "25": {"position": 92, "T": 25}, "26": {"position": 56, "T": 26}, "27": {"position": 2, "T": 27}, "28": {"position": 38, "T": 28}, "29": {"position": 17, "T": 29}, "30": {"position": 13, "T": 30}, "31": {"position": 95, "T": 31}, "32": {"position": 86, "T": 32}, "33": {"position": 45, "T": 33}, "34": {"position": 30, "T": 34}, "35": {"position": 42, "T": 35}, "36": {"position": 87, "T": 36}, "37": {"position": 14, "T": 37}, "38": {"position": 56, "T": 38}, "39": {"position": 76, "T": 39}, "40": {"position": 55, "T": 40}, "41": {"position": 5, "T": 41}, "42": {"position": 98, "T": 42}, "43": {"position": 5, "T": 43}, "44": {"position": 17, "T": 44}, "45": {"position": 73, "T": 45}, "46": {"position": 55, "T": 46}, "47": {"position": 86, "T": 47}, "48": {"position": 56, "T": 48}, "49": {"position": 80, "T": 49}, "50": {"position": 87, "T": 50}, "51": {"position": 47, "T": 51}, "52": {"position": 51, "T": 52}, "53": {"position": 62, "T": 53}, "54": {"position": 3, "T": 54}, "55": {"position": 65, "T": 55}, "56": {"position": 90, "T": 56}, "57": {"position": 76, "T": 57}, "58": {"position": 35, "T": 58}, "59": {"position": 81, "T": 59}, "60": {"position": 0, "T": 60}, "61": {"position": 32, "T": 61}, "62": {"position": 93, "T": 62}, "63": {"position": 100, "T": 63}, "64": {"position": 70, "T": 64}, "65": {"position": 10, "T": 65}, "66": {"position": 37, "T": 66}, "67": {"position": 87, "T": 67}, "68": {"position": 72, "T": 68}, "69": {"position": 77, "T": 69}, "70": {"position": 65, "T": 70}, "71": {"position": 21, "T": 71}, "72": {"position": 45, "T": 72}, "73": {"position": 81, "T": 73}, "74": {"position": 27, "T": 74}, "75": {"position": 55, "T": 75}, "76": {"position": 8, "T": 76}, "77": {"position": 2, "T": 77}, "78": {"position": 66, "T": 78}, "79": {"position": 80, "T": 79}, "80": {"position": 76, "T": 80}, "81": {"position": 49, "T": 81}, "82": {"position": 49, "T": 82}, "83": {"position": 24, "T": 83}, "84": {"position": 51, "T": 84}, "85": {"position": 43, "T": 85}, "86": {"position": 31, "T": 86}, "87": {"position": 58, "T": 87}, "88": {"position": 84, "T": 88}, "89": {"position": 58, "T": 89}, "90": {"position": 95, "T": 90}, "91": {"position": 91, "T": 91}, "92": {"position": 97, "T": 92}, "93": {"position": 53, "T": 93}, "94": {"position": 33, "T": 94}, "95": {"position": 11, "T": 95}, "96": {"position": 8, "T": 96}, "97": {"position": 96, "T": 97}, "98": {"position": 28, "T": 98}, "99": {"position": 54, "T": 99}, "100": {"position": 37, "T": 100}, "101": {"position": 60, "T": 101}, "102": {"position": 71, "T": 102}, "103": {"position": 6, "T": 103}, "104": {"position": 7, "T": 104}, "105": {"position": 4, "T": 105}, "106": {"position": 39, "T": 106}, "107": {"position": 75, "T": 107}, "108": {"position": 47, "T": 108}, "109": {"position": 30, "T": 109}, "110": {"position": 100, "T": 110}, "111": {"position": 30, "T": 111}, "112": {"position": 40, "T": 112}, "113": {"position": 11, "T": 113}, "114": {"position": 3, "T": 114}, "115": {"position": 83, "T": 115}, "116": {"position": 45, "T": 116}, "117": {"position": 91, "T": 117}, "118": {"position": 85, "T": 118}, "119": {"position": 56, "T": 119}, "120": {"position": 33, "T": 120}, "121": {"position": 74, "T": 121}, "122": {"position": 100, "T": 122}, "123": {"position": 56, "T": 123}, "124": {"position": 91, "T": 124}, "125": {"position": 16, "T": 125}, "126": {"position": 0, "T": 126}, "127": {"position": 17, "T": 127}, "128": {"position": 73, "T": 128}, "129": {"position": 40, "T": 129}, "130": {"position": 10, "T": 130}, "131": {"position": 6, "T": 131}, "132": {"position": 63, "T": 132}, "133": {"position": 23, "T": 133}, "134": {"position": 47, "T": 134}, "135": {"position": 79, "T": 135}, "136": {"position": 97, "T": 136}, "137": {"position": 13, "T": 137}, "138": {"position": 8, "T": 138}, "139": {"position": 39, "T": 139}, "140": {"position": 72, "T": 140}, "141": {"position": 59, "T": 141}, "142": {"position": 55, "T": 142}, "143": {"position": 91, "T": 143}, "144": {"position": 22, "T": 144}, "145": {"position": 62, "T": 145}, "146": {"position": 23, "T": 146}, "147": {"position": 14, "T": 147}, "148": {"position": 70, "T": 148}, "149": {"position": 86, "T": 149}, "150": {"position": 10, "T": 150}, "151": {"position": 72, "T": 151}, "152": {"position": 91, "T": 152}, "153": {"position": 29, "T": 153}, "154": {"position": 29, "T": 154}, "155": {"position": 94, "T": 155}, "156": {"position": 69, "T": 156}, "157": {"position": 58, "T": 157}, "158": {"position": 0, "T": 158}, "159": {"position": 11, "T": 159}, "160": {"position": 24, "T": 160}, "161": {"position": 70, "T": 161}, "162": {"position": 58, "T": 162}, "163": {"position": 58, "T": 163}, "164": {"position": 7, "T": 164}, "165": {"position": 25, "T": 165}, "166": {"position": 32, "T": 166}, "167": {"position": 92, "T": 167}, "168": {"position": 58, "T": 168}, "169": {"position": 55, "T": 169}, "170": {"position": 13, "T": 170}, "171": {"position": 17, "T": 171}, "172": {"position": 4, "T": 172}, "173": {"position": 30, "T": 173}, "174": {"position": 58, "T": 174}, "175": {"position": 91, "T": 175}, "176": {"position": 53, "T": 176}, "177": {"position": 41, "T": 177}, "178": {"position": 45, "T": 178}, "179": {"position": 69, "T": 179}, "180": {"position": 82, "T": 180}, "181": {"position": 44, "T": 181}, "182": {"position": 48, "T": 182}, "183": {"position": 16, "T": 183}, "184": {"position": 75, "T": 184}, "185": {"position": 91, "T": 185}, "186": {"position": 16, "T": 186}, "187": {"position": 71, "T": 187}, "188": {"position": 59, "T": 188}, "189": {"position": 89, "T": 189}, "190": {"position": 25, "T": 190}, "191": {"position": 85, "T": 191}, "192": {"position": 34, "T": 192}, "193": {"position": 83, "T": 193}, "194": {"position": 36, "T": 194}, "195": {"position": 30, "T": 195}, "196": {"position": 5, "T": 196}, "197": {"position": 7, "T": 197}, "198": {"position": 5, "T": 198}, "199": {"position": 74, "T": 199}, "200": {"position": 29, "T": 200}, "201": {"position": 40, "T": 201}, "202": {"position": 48, "T": 202}, "203": {"position": 69, "T": 203}, "204": {"position": 0, "T": 204}, "205": {"position": 67, "T": 205}, "206": {"position": 7, "T": 206}, "207": {"position": 79, "T": 207}, "208": {"position": 72, "T": 208}, "209": {"position": 68, "T": 209}, "210": {"position": 97, "T": 210}, "211": {"position": 40, "T": 211}, "212": {"position": 84, "T": 212}, "213": {"position": 20, "T": 213}, "214": {"position": 91, "T": 214}, "215": {"position": 16, "T": 215}, "216": {"position": 12, "T": 216}, "217": {"position": 100, "T": 217}, "218": {"position": 89, "T": 218}, "219": {"position": 33, "T": 219}, "220": {"position": 60, "T": 220}, "221": {"position": 25, "T": 221}, "222": {"position": 82, "T": 222}, "223": {"position": 28, "T": 223}, "224": {"position": 53, "T": 224}, "225": {"position": 6, "T": 225}, "226": {"position": 63, "T": 226}, "227": {"position": 93, "T": 227}, "228": {"position": 14, "T": 228}, "229": {"position": 47, "T": 229}, "230": {"position": 42, "T": 230}, "231": {"position": 94, "T": 231}, "232": {"position": 61, "T": 232}, "233": {"position": 88, "T": 233}, "234": {"position": 17, "T": 234}, "235": {"position": 3, "T": 235}, "236": {"position": 97, "T": 236}, "237": {"position": 38, "T": 237}, "238": {"position": 30, "T": 238}, "239": {"position": 84, "T": 239}, "240": {"position": 37, "T": 240}, "241": {"position": 99, "T": 241}, "242": {"position": 36, "T": 242}, "243": {"position": 100, "T": 243}, "244": {"position": 53, "T": 244}, "245": {"position": 44, "T": 245}, "246": {"position": 37, "T": 246}, "247": {"position": 80, "T": 247}, "248": {"position": 8, "T": 248}, "249": {"position": 79, "T": 249}, "250": {"position": 94, "T": 250}, "251": {"position": 82, "T": 251}, "252": {"position": 84, "T": 252}, "253": {"position": 47, "T": 253}, "254": {"position": 27, "T": 254}, "255": {"position": 22, "T": 255}, "256": {"position": 22, "T": 256}, "257": {"position": 26, "T": 257}, "258": {"position": 58, "T": 258}, "259": {"position": 83, "T": 259}, "260": {"position": 60, "T": 260}, "261": {"position": 16, "T": 261}, "262": {"position": 54, "T": 262}, "263": {"position": 65, "T": 263}, "264": {"position": 7, "T": 264}, "265": {"position": 57, "T": 265}, "266": {"position": 15, "T": 266}, "267": {"position": 63, "T": 267}, "268": {"position": 54, "T": 268}, "269": {"position": 58, "T": 269}, "270": {"position": 16, "T": 270}, "271": {"position": 45, "T": 271}, "272": {"position": 57, "T": 272}, "273": {"position": 72, "T": 273}, "274": {"position": 93, "T": 274}, "275": {"position": 55, "T": 275}, "276": {"position": 77, "T": 276}, "277": {"position": 74, "T": 277}, "278": {"position": 20, "T": 278}, "279": {"position": 57, "T": 279}, "280": {"position": 89, "T": 280}, "281": {"position": 68, "T": 281}, "282": {"position": 74, "T": 282}, "283": {"position": 87, "T": 283}, "284": {"position": 11, "T": 284}, "285": {"position": 74, "T": 285}, "286": {"position": 69, "T": 286}, "287": {"position": 95, "T": 287}, "288": {"position": 76, "T": 288}, "289": {"position": 23, "T": 289}, "290": {"position": 6, "T": 290}, "291": {"position": 42, "T": 291}, "292": {"position": 71, "T": 292}, "293": {"position": 24, "T": 293}, "294": {"position": 18, "T": 294}, "295": {"position": 76, "T": 295}, "296": {"position": 97, "T": 296}, "297": {"position": 41, "T": 297}, "298": {"position": 60, "T": 298}, "299": {"position": 13, "T": 299}, "300": {"position": 84, "T": 300}, "301": {"position": 93, "T": 301}, "302": {"position": 75, "T": 302}, "303": {"position": 81, "T": 303}, "304": {"position": 76, "T": 304}, "305": {"position": 93, "T": 305}, "306": {"position": 2, "T": 306}, "307": {"position": 34, "T": 307}, "308": {"position": 27, "T": 308}, "309": {"position": 37, "T": 309}, "310": {"position": 71, "T": 310}, "311": {"position": 84, "T": 311}, "312": {"position": 97, "T": 312}, "313": {"position": 56, "T": 313}, "314": {"position": 100, "T": 314}, "315": {"position": 41, "T": 315}, "316": {"position": 88, "T": 316}, "317": {"position": 51, "T": 317}, "318": {"position": 80, "T": 318}, "319": {"position": 62, "T": 319}, "320": {"position": 34, "T": 320}, "321": {"position": 34, "T": 321}, "322": {"position": 32, "T": 322}, "323": {"position": 56, "T": 323}, "324": {"position": 58, "T": 324}, "325": {"position": 25, "T": 325}, "326": {"position": 29, "T": 326}, "327": {"position": 15, "T": 327}, "328": {"position": 55, "T": 328}, "329": {"position": 87, "T": 329}, "330": {"position": 20, "T": 330}, "331": {"position": 18, "T": 331}, "332": {"position": 25, "T": 332}, "333": {"position": 21, "T": 333}, "334": {"position": 69, "T": 334}, "335": {"position": 50, "T": 335}, "336": {"position": 12, "T": 336}, "337": {"position": 30, "T": 337}, "338": {"position": 41, "T": 338}, "339": {"position": 59, "T": 339}, "340": {"position": 100, "T": 340}, "341": {"position": 20, "T": 341}, "342": {"position": 20, "T": 342}, "343": {"position": 72, "T": 343}, "344": {"position": 30, "T": 344}, "345": {"position": 94, "T": 345}, "346": {"position": 31, "T": 346}, "347": {"position": 26, "T": 347}, "348": {"position": 13, "T": 348}, "349": {"position": 5, "T": 349}, "350": {"position": 2, "T": 350}, "351": {"position": 97, "T": 351}, "352": {"position": 97, "T": 352}, "353": {"position": 3, "T": 353}, "354": {"position": 75, "T": 354}, "355": {"position": 98, "T": 355}, "356": {"position": 97, "T": 356}, "357": {"position": 35, "T": 357}, "358": {"position": 12, "T": 358}, "359": {"position": 46, "T": 359}, "360": {"position": 91, "T": 360}, "361": {"position": 40, "T": 361}, "362": {"position": 48, "T": 362}, "363": {"position": 98, "T": 363}, "364": {"position": 70, "T": 364}, "365": {"position": 7, "T": 365}, "366": {"position": 75, "T": 366}, "367": {"position": 35, "T": 367}, "368": {"position": 48, "T": 368}, "369": {"position": 77, "T": 369}, "370": {"position": 91, "T": 370}, "371": {"position": 96, "T": 371}, "372": {"position": 9, "T": 372}, "373": {"position": 2, "T": 373}, "374": {"position": 76, "T": 374}, "375": {"position": 25, "T": 375}, "376": {"position": 95, "T": 376}, "377": {"position": 72, "T": 377}, "378": {"position": 59, "T": 378}, "379": {"position": 4, "T": 379}, "380": {"position": 87, "T": 380}, "381": {"position": 100, "T": 381}, "382": {"position": 91, "T": 382}, "383": {"position": 73, "T": 383}, "384": {"position": 63, "T": 384}, "385": {"position": 64, "T": 385}, "386": {"position": 16, "T": 386}, "387": {"position": 20, "T": 387}, "388": {"position": 51, "T": 388}, "389": {"position": 56, "T": 389}, "390": {"position": 81, "T": 390}, "391": {"position": 16, "T": 391}, "392": {"position": 88, "T": 392}, "393": {"position": 68, "T": 393}, "394": {"position": 65, "T": 394}, "395": {"position": 54, "T": 395}, "396": {"position": 29, "T": 396}, "397": {"position": 37, "T": 397}, "398": {"position": 88, "T": 398}, "399": {"position": 82, "T": 399}, "400": {"position": 93, "T": 400}, "401": {"position": 71, "T": 401}, "402": {"position": 33, "T": 402}, "403": {"position": 72, "T": 403}, "404": {"position": 83, "T": 404}, "405": {"position": 93, "T": 405}, "406": {"position": 72, "T": 406}, "407": {"position": 3, "T": 407}, "408": {"position": 98, "T": 408}, "409": {"position": 99, "T": 409}, "410": {"position": 39, "T": 410}, "411": {"position": 62, "T": 411}, "412": {"position": 60, "T": 412}, "413": {"position": 48, "T": 413}, "414": {"position": 32, "T": 414}, "415": {"position": 66, "T": 415}, "416": {"position": 40, "T": 416}, "417": {"position": 33, "T": 417}, "418": {"position": 68, "T": 418}}
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/readjson.py
================================================
'''
Created on 2016.5.24
@author: liangqian
'''
import json
import os
def readjsonFile(filename):
#print(os.path.abspath(os.curdir))
f = open(filename,'r')
jsonstrs = f.read()
#print(jsonstrs)
jdata = json.loads(jsonstrs)
return jdata
#readjsonFile('../jsondata.txt')
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/testSound.py
================================================
'''
Created on 2016.6.29
@author: liangqian
'''
import pygame,sys
pygame.init()
pygame.mixer.init()
pygame.time.delay(1000)
pygame.mixer.music.load("do.wav")
pygame.mixer.music.play()
while 1:
for event in pygame.event.get():
if event.type==pygame.QUIT:
sys.exit()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/testmusic21.py
================================================
from music21 import *
#s = converter.parse('../xmlfiles/four_part_hamony/ch4-03_A-major.xml')
s = corpus.parse('bach/bwv65.2.xml')
s.analyze('key')
print(len(s.parts))
s.show()
for i,part in enumerate(s.parts):
print(i)
print('-----------')
for ns in part.flat.notes:
print(ns.pitch)
print(ns.duration.quarterLength)
note1 = note.Note("D5")
note2 = note.Note("F#5")
note2.duration.quarterLength = 0.5
note3 = note.Note("A5")
stream1 = stream.Stream()
stream1.append(note1)
stream1.append(note2)
stream1.append(note3)
print(note2.offset)
sout = stream1.getElementsByOffset(0,2)
sBach = corpus.parse('bach/bwv57.8')
s = sBach.chordify()
#cs = s.getElementsByClass('Chord')
s1 = s.flatten()
chords = s1.getElementsByClass('Chord')
# cMinor = chord.Chord(["A4","F4","D5"])
# print(cMinor.inversion())
# print(cMinor.isMinorTriad())
keyA = key.Key('B-')
for c in chords:
rn = roman.romanNumeralFromChord(c, keyA)
c.addLyric(str(rn.figure))
chords.show()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/testopengl.py
================================================
'''
Created on 2018.8.31
@author: liangqian
'''
from OpenGL.GL import *
from OpenGL.GLU import *
from OpenGL.GLUT import *
def drawFunc():
glClear(GL_COLOR_BUFFER_BIT)
#glRotatef(1, 0, 1, 0)
glutWireTeapot(0.5)
glFlush()
glutInit()
glutInitDisplayMode(GLUT_SINGLE | GLUT_RGBA)
glutInitWindowSize(400, 400)
glutCreateWindow(b"First")
glutDisplayFunc(drawFunc)
#glutIdleFunc(drawFunc)
glutMainLoop()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/testwave.py
================================================
import wave
import struct
import os
import numpy as np
f = 440
framerate = 44100.0
fw = wave.open("sine.wav","wb")
fw.setnchannels(1)
fw.setframerate(framerate)
fw.setsampwidth(2)
tt = np.arange(0, 1, 1.0/framerate)
data = [2000*(np.sin(2*np.pi*f*t)+np.sin(2*np.pi*2*f*t)+np.sin(2*np.pi*3*f*t)) for t in tt]
print(data)
for d in data:
fw.writeframes(struct.pack('h',int(d)))
fw.close()
================================================
FILE: examples/Knowledge_Representation_and_Reasoning/musicMemory/tools/xmlParser.py
================================================
import librosa
import music21 as m21
import pandas as pd
import os
'''
This function parses MusicXML file and extracts necessary score information as CSV.
'''
def readXmlAsCsv(xmlPath='xml/'):
for subfolder in os.listdir(xmlPath):
if subfolder.startswith('.'):
continue
subfolder_path = os.path.join(xmlPath, subfolder)
for item in os.listdir(subfolder_path):
if item.endswith('xml'):
item_path = os.path.join(subfolder_path, item)
xml_data = m21.converter.parse(item_path)
print("Converting ", item_path)
score = []
for part in xml_data.parts:
for note in part.flat.notes:
if note.isChord:
print('note is chord: ', note)
measureNo = note.measureNumber
start = note.offset
duration = note.quarterLength
for chord_note in note:
pitch = chord_note.pitch
articulations = note.articulations
expressions = note.expressions
spanners = note.getSpannerSites()
gliss = []
for spanner in spanners:
if 'Glissando' in spanner.classes:
if spanner.isFirst(chord_note):
gliss.append('slide start')
if spanner.isLast(chord_note):
gliss.append('slide last')
score.append(
[measureNo, start, duration, pitch, m21.pitch.Pitch(pitch).frequency,
articulations, expressions, gliss, spanners])
else:
measureNo = note.measureNumber
start = note.offset
duration = note.quarterLength
pitch = note.pitch
articulations = note.articulations
expressions = note.expressions
spanners = note.getSpannerSites()
gliss = []
for spanner in spanners:
if 'Glissando' in spanner.classes:
if spanner.isFirst(note):
gliss.append('slide start')
if spanner.isLast(note):
gliss.append('slide last')
score.append(
[measureNo, start, duration, pitch, m21.pitch.Pitch(pitch).frequency,
articulations, expressions, gliss, spanners])
score = sorted(score, key=lambda x: (x[0], x[1], x[2]))
df = pd.DataFrame(score,
columns=['MeasureNumber', 'Start', 'Duration', 'Pitch', 'f0',
'Articulations', 'Expressions', 'Glissando', 'Spanner'])
df.to_csv(os.path.join(path, 'csv', subfolder, os.path.splitext(item)[0] + '.csv'))
================================================
FILE: examples/MotorControl/experimental/README.md
================================================
# Experimental works for motor control with different Brain Aeras.
The project is still immature and under continuous development...
## Citation
If you find the code and dataset useful in your research, please consider citing:
```
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/MotorControl/experimental/brain_area.py
================================================
import torch
import numpy as np
import torch.nn as nn
from braincog.base.node.node import *
class MoColumnPOP(nn.Module):
def __init__(self,
input_dims: int,
pop_num: int = 16,
embedding_dim: int = 64,
time_window: int = 16) -> None:
super().__init__()
self._threshold = 1.0
self.v_reset = 0.0
self._time_window = time_window
self._pop_num = pop_num
self._node = LIFNode
self.column_net = nn.ModuleList(
[nn.Sequential(
nn.Linear(input_dims, embedding_dim),
self._node(threshold=self._threshold, v_reset=self.v_reset))
for _ in range(pop_num)
]
)
self.decode = nn.Linear(embedding_dim, 64)
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def _emb_decode(self, x):
pop_emb_decode = []
for net in self.column_net:
emb = net(x)
pop_emb_decode.append(self.decode(emb))
return pop_emb_decode
def forward(self, inputs):
pop_emb_decode = self._emb_decode(inputs)
out = sum(pop_emb_decode) / self._pop_num
return out
class MotorCortex(nn.Module):
def __init__(self,
input_dims: int,
out_dims: int = 128,
time_window: int = 16) -> None:
super().__init__()
self._threshold = 1.0
self.v_reset = 0.0
self._time_window = time_window
self._node = LIFNode
self.pfc_net = nn.Sequential(
nn.Linear(input_dims, 512),
self._node(threshold=self._threshold, v_reset=self.v_reset)
)
self.sma_net = nn.Sequential(
nn.Linear(input_dims, 512),
self._node(threshold=self._threshold, v_reset=self.v_reset)
)
self.ganglia_net = nn.Sequential(
nn.Linear(512, 128),
self._node(threshold=self._threshold, v_reset=self.v_reset)
)
self.pmc_net = nn.Sequential(
nn.Linear(512, 512),
self._node(threshold=self._threshold, v_reset=self.v_reset)
)
self.motor_net = nn.Sequential(
nn.Linear(512+128, 128),
self._node(threshold=self._threshold, v_reset=self.v_reset)
)
self.motor_emb = MoColumnPOP(input_dims=128, embedding_dim=out_dims, time_window=time_window)
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def _compute_motor_out(self, inputs):
sma_out = self.sma_net(inputs)
ganglia_out = self.ganglia_net(sma_out)
motor_in = torch.concat([ganglia_out, sma_out], dim=-1)
motor_out = self.motor_net(motor_in)
# pop coding
return motor_out
def forward(self, inputs):
self.reset()
outs = []
for step in range(self._time_window):
motor_out = self._compute_motor_out(inputs)
m_emb = self.motor_emb(motor_out) # [Batch, 128]
outs.append(m_emb)
return outs
class Celebellum(nn.Module):
def __init__(self,
input_dims: int = 512,
out_dims: int = 7,
time_window: int = 16,
) -> None:
super().__init__()
self._threshold = 1.0
self.v_reset = 0.0
self._time_window = time_window
self._node = LIFNode
self.gc_layer = nn.Sequential(
nn.Linear(input_dims, 512),
self._node(threshold=self._threshold, v_reset=self.v_reset)
)
self.pc_layer = nn.Sequential(
nn.Linear(512, 512),
self._node(threshold=self._threshold, v_reset=self.v_reset)
)
self.dcn_layer = nn.Sequential(
nn.Linear(input_dims + 512, 512),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Linear(512, out_dims)
)
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def forward(self, x):
self.reset()
outs = []
for step in range(self._time_window):
gc = self.gc_layer(x[step])
pc = self.pc_layer(gc)
dcn_in = torch.concat([x[step], pc], dim=-1)
dcn = self.dcn_layer(dcn_in)
outs.append(dcn)
cel_out = sum(outs) / self._time_window
return cel_out
if __name__ == '__main__':
motor = MotorCortex(input_dims=1024)
for mod in motor.modules():
# print('mod: ', mod)
if hasattr(mod, 'n_reset'):
print('mod: ', mod)
================================================
FILE: examples/MotorControl/experimental/main.py
================================================
import torch
import numpy as np
import torch.nn as nn
from model import Motion
import tqdm
import argparse
from torch.nn import functional as F
parser = argparse.ArgumentParser(description='Motor Parameters')
parser.add_argument('--lr', default=0.001, type=float, help='learning rate')
parser.add_argument('--time-window', type=int, default=8, help="Number of timesteps to do.")
parser.add_argument('--device', type=str, default='0', help="CUDA device")
parser.add_argument('--log-path', type=str, default='./logs/out.txt', help="Log path")
args = parser.parse_args()
print(args)
device = torch.device('cuda:'+args.device)
LABELS = {
'position_group_0': (-0.337, -0.020, -0.077, -0.031164, 0.999496, -0.005979, 2.850154),
'position_group_1': (-0.337, 0.007, -0.077, -0.039668, 0.999161, -0.010174, 2.894892),
'position_group_2': (-0.337, 0.030, -0.076, -0.031164, 0.999496, -0.005979, 2.850154),
'position_group_3': (-0.337, 0.052, -0.076, -0.031164, 0.999496, -0.005979, 2.850154),
'position_group_4': (-0.339, 0.074, -0.076, 0.016057, 0.999842, -0.007643, 2.804204),
'position_group_5': (-0.339, 0.096, -0.078, 0.016057, 0.999842, -0.007643, 2.804204),
'position_group_6': (-0.339, 0.123, -0.079, 0.016057, 0.999842, -0.007643, 2.804204),
'position_group_7': (-0.337, 0.139, -0.080, 0.076912, 0.997035, -0.0021723, 2.799101),
'position_group_8': (-0.337, 0.163, -0.0770, 0.076912, 0.997035, -0.0021723, 2.799101),
'position_group_9': (-0.338, 0.188, -0.075, 0.076912, 0.997035, -0.002172, 2.799101),
'position_group_10': (-0.338, 0.212, -0.075, 0.087103, 0.995757, -0.029681, 2.785759),
'position_group_11': (-0.338, 0.235, -0.070, 0.087103, 0.995757, -0.029681, 2.785759),
'position_group_12': (-0.338, 0.259, -0.073, 0.087103, 0.995757, -0.029681, 2.785759),
'position_group_13': (-0.339, 0.273, -0.065, 0.202020, 0.979225, 0.017483, 2.764647),
'position_group_14': (-0.336, 0.290, -0.066, 0.244628, 0.963147, -0.111827, 2.740450),
}
position_num = 15
position_dims = 7
TARGETS = []
for i in range(position_num):
TARGETS.append(np.array(LABELS['position_group_'+str(i)], dtype=np.float32))
TARGETS = np.stack(TARGETS, axis=0)
t_factors = np.array([10.0, 10.0, 100.0, 10.0, 1.0, 100.0, 1.0], dtype=np.float32)
TARGETS_FAC = TARGETS * t_factors[np.newaxis, :]
KEYS = {
'c1': 0,
'd2': 1,
'e1': 2,
'f1': 3,
'g1': 4,
'a1': 5,
'b1': 6,
'c2': 7,
'd2': 8,
'e2': 9,
'f2': 10,
'g2': 11,
'a2': 12,
'b2': 13,
'c3': 14,
'd3': 15,
'e3': 16
}
finger_num = 3
finger_pop_num = 10
key_num = 17
key_pop_num = 5
def creat_key_finger_emb():
key_value = np.zeros((key_num, key_num*key_pop_num), dtype=np.float32)
finger_value = np.zeros((finger_num, finger_num*finger_pop_num), dtype=np.float32)
for i in range(key_num):
key_value[i, i*key_pop_num: (i+1)*key_pop_num] += 1.0
for i in range(finger_num):
finger_value[i, i*finger_pop_num: (i+1)*finger_pop_num] += 1.0
return (key_value, finger_value)
def mse_loss(pred, target):
mse = F.mse_loss(pred, target)
def main():
key_embs, finger_emb = creat_key_finger_emb()
in_dims = key_embs.shape[1] + finger_emb.shape[1]
model = Motion(in_dims=in_dims, out_dims=position_dims, time_window=args.time_window).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)
criterion = nn.MSELoss().to(device)
T = 100
batch_size = 32
EPOCHS = 200
with open(args.log_path, 'a+') as f:
argsDict = args.__dict__
f.writelines('------------------ start ------------------' + '\n')
for eachArg, value in argsDict.items():
f.writelines(eachArg + ' : ' + str(value) + '\n')
f.writelines('------------------- end -------------------'+ '\n')
for epoch in range(EPOCHS):
# train
for step in tqdm.tqdm(range(T)):
key_idxs = np.random.choice(key_num, size=batch_size)
finger_idxs = np.random.choice(finger_num, size=batch_size)
labels = np.clip(key_idxs - finger_idxs, a_min=0, a_max=position_num-1)
in_emb = np.concatenate([key_embs[key_idxs], finger_emb[finger_idxs]], axis=-1)
x = torch.from_numpy(in_emb).to(device)
y = torch.from_numpy(TARGETS_FAC[labels]).to(device)
y_pred = model(x)
loss = criterion(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# test
loss_record = []
f.writelines('\n')
f.writelines('Epoch:[{epoch}/{total_eps}]:\n'.format(epoch=epoch, total_eps=EPOCHS))
for key in range(key_num):
for fin in range(finger_num):
in_emb = np.concatenate([key_embs[key], finger_emb[fin]], axis=-1)
x = torch.from_numpy(in_emb).to(device)
with torch.no_grad():
pred = model(x)
y = max(min(key - fin, position_num-1), 0)
target = torch.from_numpy(TARGETS_FAC[y]).to(device)
loss = F.mse_loss(pred, target, reduction='sum')
loss_record.append(loss.cpu().item())
real_pred = pred.cpu().numpy() / t_factors
distant = np.sum((TARGETS[y] - real_pred)**2)**0.5
f.writelines(' Predict position {y}: {pred}\n'.format(y=y, pred=real_pred.tolist()))
f.writelines('==> Epoch:[{epoch}/{total_eps}][validation stage]: loss: {loss}, distant {dis}\n'.format(
epoch=epoch, total_eps=EPOCHS, loss=sum(loss_record)/len(loss_record), dis=distant))
print('==> Epoch:[{epoch}/{total_eps}][validation stage]: loss: {loss}, distant {dis}\n'.format(
epoch=epoch, total_eps=EPOCHS, loss=sum(loss_record)/len(loss_record), dis=distant))
if __name__ == '__main__':
main()
================================================
FILE: examples/MotorControl/experimental/model.py
================================================
import torch
import numpy as np
import torch.nn as nn
from brain_area import Celebellum, MotorCortex
class Motion(nn.Module):
def __init__(self, in_dims: int, out_dims: int=17, time_window: int=8, emb_size: int = 128) -> None:
super().__init__()
self._time_window = time_window
self.in_emb = nn.Linear(in_dims, emb_size)
self.motor_cotex = MotorCortex(input_dims=emb_size, out_dims=64, time_window=self._time_window)
self.cele = Celebellum(input_dims=64, out_dims=out_dims, time_window=self._time_window)
# self.opti = torch.optim.Adam(net.parameters(), lr=0.001)
def forward(self, x):
in_emb = self.in_emb(x)
motor_out = self.motor_cotex(in_emb)
out = self.cele(motor_out)
return out
def learn(self):
pass
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/README.md
================================================
# Corticothalamic minicolumn
## Description
The anatomical data is saved in the "tool" package. The **main.py** create the network of minicolumn deppending on the anatomical data.
A file named **"fire.csv"** will be generated to record the firing result of neurons in each time step.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
```shell
python main.py
```
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/data/__init__.py
================================================
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/data/globaldata.py
================================================
'''
Created on 2014.11.25
@author: Liang Qian
'''
#from tools import dbconnection as DB
from tools import exdata as Data
data = Data.EXDATA()
curneuronindex = 0
SynapseNumberPerDendrite = 40
ProximalDendriteNumerPerNeuron = 1
f = open('fire.csv','w')
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/main.py
================================================
import sys
sys.path.append("../")
import time
from model import cortex_thalamus
if __name__ == '__main__':
starttime = time.time()
myCortex = cortex_thalamus.Cortex_Thalamus(1000) # create a cortex object and specify the neuron number scale
myCortex.CreateCortexNetwork() # create cortex-thalamus network by the cortical object
myCortex.run()
print(len(myCortex.synapse))
totaltime = (time.time() - starttime)
print("totaltime:" + str(totaltime) + "s")
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/__init__.py
================================================
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/cortex.py
================================================
'''
Created on 2015.5.27
@author: Liang Qian
'''
from data import globaldata as Global
from .layer import Layer
from .synapse import Synapse
class Cortex():
'''
This class defines properties and funtions of cortex
'''
def __init__(self,neuronnumscale):
'''
Constructor
'''
self.neuronnumscale = neuronnumscale
self.neuronsNumber = 0
self.synapsesNumber = 0
self.neurons = [] # a list storing all neurons of the whole cortex
self.layers = {} # a dictionary storing layers of cortex
self.synapses = [] # a list storing all synapses of the whole cortex
self.minicolumns = [] # a list storing information per mini-column
self.neurontoindex = {} # a dictionary storing name to index of neuronlist
self.totaldata = Global.data.getCortexData()
def setNeuronToIndex(self,node):
name = node.name
if(self.neurontoindex.get(name) == None):
self.neurontoindex[name] = len(self.neurons) - 1
def setLayers(self):
layerdic = Global.data.getLayerData()
for i,info in layerdic.items():
layer = Layer()
layer.name = info.get('name')
layer.neuronnum = self.neuronnumscale * float(info.get('neuronnum'))/100
print(layer.name + ' neuron number:'+str(layer.neuronnum))
# layer.synapsenum = self.synapsenum * info.get('synapsenum')
# print(layer.name + ' synapse number:'+str(layer.synapsenum))
self.layers[layer.name] = layer
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/cortex_thalamus.py
================================================
'''
Created on 2014.11.13
@author: Liang Qian
'''
import sys
from .dendrite import Dendrite
sys.path.append('../')
from data import globaldata as Global
from .thalamus import Thalamus
from .cortex import Cortex
from .layer import Layer
from .synapse import Synapse
from braincog.base.node.node import *
class Cortex_Thalamus():
'''
cortex class is used to build human brain cortex
members are as follows:
@param neuronnum: total neuron number
@param layer: layer list
at the aspect of coding or algorithm,cortex is a huge Graph,neurons can be seen as nodes,synapses can be seen as edges,
but there may be plenty of edges between any two given nodes,so we can not use the to express an edge,
the edge should be defined as an object,if we use adjacency list to store this huge graph,the form is just like
node->map(node,list)->(map(another node,list))
'''
def __init__(self, neuronnumscale):
self.neuronnumscale = neuronnumscale
self.cortex = Cortex(neuronnumscale)
self.thalamus = Thalamus()
self.minicolumns = [] # a list storing information per mini-column
self.synapsenum = 0
self.neuronname = [] # a list storing neuron name in all cortex
self.neuron = [] # a list storing all neuron in cortex
self.synapse = [] # a list storing all synapses in thalamocortex
self.neurontoindex = {} # a dictionary to storing the neuron mapping to index in neuron list
self.totaldata = Global.data.getCortexData()
def setSynapseNum(self):
num = 0
for name,info in self.totaldata.items():
num += self.neuronnumscale * (info.get('synnum')*info.get('neunum')/100.0)
self.neuronname.append(info.get('neuronname'))
self.synapsenum = num
def setLayer(self):
layerdic = Global.data.getLayerData()
for i,info in layerdic.items():
layer = Layer()
layer.name = info.get('name')
layer.neuronnum = self.neuronnumscale * info.get('neuronnum')/100
print(layer.name + ' neuron number:'+str(layer.neuronnum))
layer.synapsenum = self.synapsenum * info.get('synapsenum')
print(layer.name + ' synapse number:'+str(layer.synapsenum))
self.layer[layer.name] = layer
def setNeuronsDendritesAndSynapes(self):
neurondic = Global.data.getNeuronData()
index = 0
for s in self.neuronname:
neuroninfo = neurondic.get(s)
self.neurontoindex[s] = len(self.neuron)
num = self.neuronnumscale * float(neuroninfo.get('percent'))/100.0
#using synapse numbers to compute dendrites numbers
synapsedic = Global.data.getSynapseData(s)
dendic = {}
totaldennum = 0
for r,item in synapsedic.items():
synum = int(item.get('synapsenum'))
dennum = (synum+Global.SynapseNumberPerDendrite-1)//Global.SynapseNumberPerDendrite # a dendrite contains no more than 40 synapses
loc = item.get('locationlayer')
dendic[loc] = dennum
for i in range(int(num)):
#init
node = CTIzhNode(morphology = neuroninfo.get('morphology'),
name = neuroninfo.get('name'),
excitability = neuroninfo.get('excitability'),
spiketype = neuroninfo.get('spiketype'),
synnum = synum,
locationlayer = neuroninfo.get('location layer'),
totalindex = index,
Gup = float(neuroninfo.get('Gup')),
Gdown = float(neuroninfo.get('Gdown')),
Vr = float(neuroninfo.get('Vr')),
Vt = float(neuroninfo.get('Vt')),
Vpeak = float(neuroninfo.get('Vpeak')),
a = float(neuroninfo.get('a')),
b = float(neuroninfo.get('b')),
c = float(neuroninfo.get('Csoma')),
d = float(neuroninfo.get('d')),
capacitance = float(neuroninfo.get('capacitance')),
k = float(neuroninfo.get('k')),
)
# set dendrites
count = 0; flag = False
for dlocatelayer,dnum in dendic.items():
for j in range(dnum):
den = Dendrite()
den.locationlayer = dlocatelayer
if(dlocatelayer != node.locationlayer or flag):
den.postion = 'distal'
node.distal_dendrites.append(den)
else:
if(count < Global.ProximalDendriteNumerPerNeuron):
den.postion = 'proximal'
node.proximal_dendrites.append(den)
count += 1
if(count >= Global.ProximalDendriteNumerPerNeuron):
flag = True
#node.getDendritesInfo()
if(node.locationlayer == 'T'):
self.thalamus.neuronsNumber += 1
self.thalamus.neurons.append(node)
self.thalamus.setNeuronToIndex(node)
else:
self.cortex.neuronsNumber += 1
self.cortex.neurons.append(node)
self.cortex.setNeuronToIndex(node)
la = self.cortex.layers.get(node.locationlayer)
la.neuronlist.append(node)
if node.name not in la.neuronname:
la.neuronname.append(node.name)
self.neuron.append(node)
index += 1
# set synapses
for postindex,node in enumerate(self.neuron): # this step can be optimized
synapsedic = Global.data.getSynapseData(node.name)
# get synapse_pre neuron and relative numbers of synapses
count = 0
for r,item in synapsedic.items():
#print(item)
for s in self.neuronname:
#print("pre_neuron_name:"+s)
totalsynapsenum = round(item.get('synapsenum') * item.get(s)/100.0)
if(postindex == 0):count += totalsynapsenum
#print("pre_neuron_name_synapse_num:"+str(totalsynapsenum))
if(totalsynapsenum > 0): #if this neuron connect to synapse_pre neuron s,distribute the synapse to these neurons
info = self.totaldata.get(s)
preneuronnum = round(self.neuronnumscale * int(info.get('neunum'))/100)
#print("pre_neuron_name_number:" + str(preneuronnum))
avgnum = lastnum = 0
if(preneuronnum == 1):
avgnum = lastnum = totalsynapsenum
else:
avgnum = totalsynapsenum // (preneuronnum-1)
lastnum = totalsynapsenum - (avgnum*(preneuronnum-1))
preneuronindex = self.neurontoindex.get(s)
for j in range(preneuronindex,preneuronindex+preneuronnum):
if(j == postindex):lastnum += avgnum;continue # not connect to itself
preneuron = self.neuron[j]
synapselist = []
if(preneuron.adjneuronlist.get(node) != None):
synapselist = preneuron.adjneuronlist.get(node)
if(j == preneuronindex+preneuronnum-1): #the last neuron
for t in range(lastnum):
synapse = Synapse(self.neuron[j],node,item.get('locationlayer'))
synapselist.append(synapse)
self.synapse.append(synapse)
if(item.get('locationlayer') != 'T'):
layerinfo = self.cortex.layers.get(item.get('locationlayer'))
layerinfo.synapselist.append(synapse)
if(node.locationlayer == 'T'):
self.thalamus.synapses.append(synapse)
self.thalamus.synapsesNumber += 1
else:
self.cortex.synapses.append(synapse)
self.cortex.synapsesNumber += 1
else:
for t in range(avgnum):
synapse = Synapse(self.neuron[j],node,item.get('locationlayer'))
synapselist.append(synapse)
self.synapse.append(synapse)
if(item.get('locationlayer') != 'T'):
layerinfo = self.cortex.layers.get(item.get('locationlayer'))
layerinfo.synapselist.append(synapse)
if(node.locationlayer == 'T'):
self.thalamus.synapses.append(synapse)
self.thalamus.synapsesNumber += 1
else:
self.cortex.synapses.append(synapse)
self.cortex.synapsesNumber += 1
if(preneuron.adjneuronlist.get(node) == None and len(synapselist) > 0):
preneuron.adjneuronlist[node] = synapselist
# set these synapses to dendrite list
#self.setSynapsesToDendrites()
def setSynapsesToDendrites(self):
for node in self.neuron:
if node.name == 'TCs': # synapses from TCs to ss4(L4) must be located in proximal dendrites of ss4(L4)
for post,synlist in node.adjneuronlist.items():
if(post.name == 'ss4(L4)'):
for syn in synlist:
flag = post.addSynapseToDendrite('proximal',syn)
if(not flag):flag = post.addSynapseToDendrite('distal',syn)
if(not flag):
print('all dendrites are full in neuron' + post.name + '_'+str(node.totalindex))
else:
for syn in synlist:
flag = False
if(post.locationlayer == syn.locationlayer):
flag = post.addSynapseToDendrite('proximal',syn)
if(not flag):
flag = post.addSynapseToDendrite('distal',syn)
else:
flag = post.addSynapseToDendrite('distal',syn)
if(not flag): print('all dendrites are full in neuron' + post.name + '_'+str(node.totalindex))
else:
for post,synlist in node.adjneuronlist.items():
for syn in synlist:
flag = False
if(post.locationlayer == syn.locationlayer):
flag = post.addSynapseToDendrite('proximal',syn)
if(not flag):
flag = post.addSynapseToDendrite('distal',syn)
if(not flag): print('all dendrites are full in neuron' + node.name + '_'+str(node.totalindex))
# f = open('dendrites_info.csv','w')
# for node in self.neuron:
# if(node.totalindex == 0):
# node.getDendriteSynapsesInfo(f)
# f.close()
def setCortexProperties(self):
self.cortex.setCortexProperties()
def setThalamusProperties(self):
self.thalamus.setThalamusProperties()
def CreateCortexNetwork(self):
self.setSynapseNum()
self.cortex.setLayers()
self.setNeuronsDendritesAndSynapes()
self.setThalamusProperties()
#----------API Of the whole network--------------#
def getTotalNeuronNumber(self):
return len(self.neuron)
def getTotalSynapseNumber(self):
return len(self.synapse)
def getCortexNeuronNumber(self):
return self.corticalneuronnumber
def getThalamoNeuronNumber(self):
return self.thamlamoneuronnumber
def getSpecifiedNeuronNumber(self,name):
result = {}
if name in self.neuronname:
info = self.totaldata.get(name)
num = self.neuronnumscale * info.get('neunum')/100
result[name] = num
elif name == 'all':
for r,info in self.totaldata.items():
num = self.neuronnumscale * info.get('neunum')
result[r] = num
return result
def getNeuronTypesNumber(self):
return len(self.neuronname)
def getNeuronTypes(self):
return self.neuronname
def getCorticalSynapseNumber(self):
return len(self.corticalsynapse)
def getThalamoSynapseNumber(self):
return len(self.corticalsynapse)
def getPreAndPostNeuronsOfSynapse(self,index):
if(index >= 0 or index <= len(self.synapse -1)):
return self.synapse[index].pre,self.synapse[index].post
else: return None
#--------------API of the layer----------------------#
def getCortexLayerNeuronNumber(self,layername):
layerinfo = self.layer.get(layername)
return layerinfo.getLayerNeuronNumber()
def getCortexLayerSynapseNumber(self,layername):
layerinfo = self.layer.get(layername)
return layerinfo.getLayerSynapseNumber()
def getCortexLayerNeuronTypes(self,layername):
layerinfo = self.layer.get(layername)
if(layerinfo == None):
print(layername +" is not in Cortex!")
return None
return layerinfo.neuronname
def getCortexLayerPreAndPostNeuronsOfSynapse(self,layername,index):
layerinfo = self.layer.get(layername)
if(index >= 0 and index < len(layerinfo.synapselist)):
return layerinfo.synapselist[index].pre, layerinfo.synapselist[index].post
def getNeuronAllPreNeuronsTypes(self,index):
if(index >= 0 and index < len(self.neuron)):
node = self.neuron[index]
return node.getWholePreSynapseNeuronType()
def outputNeuronInfo(self):
f = open('neuron.csv','w')
f.write('index,name,morphology,excitability,locationlayer\n')
for node in self.neuron:
flag = 'No'
if(node.excitability == "TRUE"):
flag = 'Yes'
f.write(str(node.totalindex)+','+node.name+','+node.morphology+','+flag+','+node.locationlayer+'\n')
f.close()
def outputConnectionMatrix(self):
M = len(self.neuron)
matrix = [[0 for col in range(M)] for row in range(M)]
for node in self.neuron:
for post,list in node.adjneuronlist.items():
weight = len(list)
row = node.totalindex
col = post.totalindex
matrix[row][col] = weight
f = open('connection.csv','w')
name = ''
for node in self.neuron:
name += node.name + ','
f.write(name+'\n')
for row in range(M):
line = ''
for col in range(M):
line += str(matrix[row][col])+','
f.write(line+'\n')
f.close()
def outputsynapspercent(self,namelist):
totalcount = 0
slist = {'L1':0,'L2/3':0,'L4':0,'L5':0,'L6':0,'T':0}
for name in namelist:
for node in self.neuron:
for pre,list in node.adjneuronlist.items():
if pre.name == name:
totalcount = totalcount+len(list)
loclayer = node.locationlayer
value = slist.get(loclayer) + len(list)
slist[loclayer] = value
print(slist)
#-----------------------runing the whole network---------------------------#
def run(self):
'''
run the cortical system
'''
#s1:stimulate the neuron in L4
L = self.cortex.layers.get('L4')
L.stimulateNeuronInLayer4_BFS(30,self.neuron)
def outputSpikeThreashold(self):
f = open('threashold.csv','w')
for node in self.neuron:
f.write(str(node.Vpeak)+'\n')
f.close()
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/dendrite.py
================================================
'''
Created on 2015.5.19
@author: liangqian
'''
import sys
import sys
from data.globaldata import *
class Dendrite():
'''
This class defines dendrite structure of a neuron.
A dendrite contains no more than 40 synapses
'''
def __init__(self):
'''
Constructor
'''
self.synapses = [] # synapses list which this dendrite contains
self.locationlayer = '' # layer this dendrite locates in
self.postion = '' # the distance from soma, proximal or distal
def setSynapse(self,syn):
'''
This function is going to insert the Synapse syn to this dendrite
if the number of synapse of this dendrite is more than theshold, the current synapse
can not be inserted to the dendrite.
'''
if(len(self.synapses) >= SynapseNumberPerDendrite):
return False
else:
self.synapses.append(syn)
return True
def getSynapseInfo(self,f,nodename,denpos):
for syns in self.synapses:
syns.getInfo(f,nodename,denpos,self.locationlayer)
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/fire.csv
================================================
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/layer.py
================================================
'''
Created on 2014.11.13.
@author: Liang Qian
'''
import sys
sys.setrecursionlimit(1000000)
from data import globaldata as Global
class Layer():
'''
layer class is used to build brain cortical layer of cortex
class members are as follows:
@param name: layer name(L1,L2,L3,.etc)
@param neuronnum: total neural numbers of this layer
@param neuraltype: neural type list of this layer
@param neuronlist: different types of neuron list in this layer
'''
def __init__(self):
self.name = ''
self.neuronnum = 0
self.synapsenum = 0
self.neuronlist = []
self.synapselist = []
self.neuronname = []
def getLayerNeuronNumber(self):
return len(self.neuronlist)
def getLayerSynapseNumber(self):
return len(self.synapselist)
def getLayerNeuronTypes(self):
return self.neuronname
def stimulateNeuronInLayer4_BFS(self, T, neulist):
for node in self.neuronlist:
if(node.name == 'ss4(L2/3)'):
break;
step = int(T*1000/1.0)
dc = 0
for i in range(step):
#print(i)
strs = str(i)+','
if(i > 1):
for n in neulist:
if(n.totalindex == node.totalindex):continue
if(n.dc > 0):
n.integral(n.dc)
n.calc_spike()
if(n.spike == 1):
strs +=n.name+':'+str(n.totalindex)+','
if(i < 10 or i > 25000):
dc = 0
else:
dc = 400
node.integral(dc)
node.calc_spike()
if(node.spike == 1):
strs +=node.name+':'+str(node.totalindex)+','
Global.f.write(strs+'\n')
Global.f.close()
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/synapse.py
================================================
'''
Created on 2014.11.13
@author: Liang Qian
'''
class Synapse():
'''
synapsis class is used to create a synapsis structure
members are as follows:
@param pre: pre-synapsis neuron
@param post: post-synapsis neuron
@param locationlayer: layer where this synapse locate in
'''
def __init__(self, pre,post,locationlayer):
self.pre = pre
self.post = post
self.locationlayer = locationlayer
self.I = 0
self.weight = 0 if(pre.name == 'p2/3' and post.name == 'p2/3') else -1
# self.tauAMPA = 5
# self.tauNMDA = 150
# self.tauGABAA = 6
# self.tauGABAB = 150
# self.STDPA_pos = 1
# self.STDPA_neg = 2
# self.tau_pos = 20
# self.tau_neg = 20
def getInfo(self,f,nodename,denpos,denlayer):
f.write('neuron:'+nodename+','+'dendrite:'+denpos+','+'den_layer:'+denlayer+','
+'syn_Layer:'+ self.locationlayer+','
+ 'pre_neuron:'+self.pre.name+','+'pre_neuron_index:'+str(self.pre.totalindex)+','
+ 'post_neuron:'+self.post.name+','+'post_neuron_index:'+str(self.post.totalindex)+','
+ 'weight:'+str(self.weight)+'\n')
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/model/thalamus.py
================================================
'''
Created on 2015.5.27
@author: Liang Qian
'''
class Thalamus():
'''
This class defines the basic functions and properties of thalamus
'''
def __init__(self):
'''
Constructor
'''
self.neuronsNumber = 0
self.synapsesNumber = 0
self.neurons = []
self.synapses = []
self.neurontoindex = {}
def setNeuronToIndex(self,node):
name = node.name
if(self.neurontoindex.get(name) == None):
self.neurontoindex[name] = len(self.neurons)-1
def setThalamusProperties(self):
print(len(self.synapses))
for node in self.neurons:
if(node.name == 'TCs'):
for post,synlist in node.adjneuronlist.items():
if(post.name == 'ss4(L2/3)'):
for syn in synlist:
syn.weight = 0
if(node.name == 'TCn'):
for post,synlist in node.adjneuronlist.items():
if(post.name == 'p6(L5/6)'):
for syn in synlist:
syn.weight = 0
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/tools/__init__.py
================================================
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/tools/cortical.csv
================================================
neuronname,neuronnum,synmapsenum,area
nb1,1.5,8890,cortex
p2/3,26,7106,cortex
b2/3,3.1,3854,cortex
ss4(L4),9.2,5792,cortex
ss4(L2/3),9.2,4989,cortex
p4,9.2,6703,cortex
b4,5.4,3230,cortex
nb4,1.5,3688,cortex
p5(L2/3),4.8,5196,cortex
p5(L5/6),1.3,13075,cortex
b5,0.6,2981,cortex
nb5,0.8,2981,cortex
p6(L4),13.6,6363,cortex
p6(L5/6),4.5,6421,cortex
b6,2,3220,cortex
nb6,2,3220,cortex
nb2/3,4.2,3307,cortex
TCs,0.5,4000,thalamus
TCn,0.5,4000,thalamus
TIs,0.1,3000,thalamus
TIn,0.1,3000,thalamus
TRN,0.5,4000,thalamus
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/tools/exdata.py
================================================
import os
import csv
#import pandas as pd
class EXDATA():
def __int__(self):
pass
def getCortexData(self):
neurondic = {}
f = open("./tools/cortical.csv","r")
line = f.readline()
count = 0
while(True):
line = (f.readline()).strip()
if(len(line) <= 0): break;
strs = line.split(",")
info = {}
info['neuronname'] = strs[0].strip()
info['neunum'] = float(strs[1])
info['synnum'] = int(strs[2])
info['area'] = str(strs[3])
neurondic[strs[0].strip()] = info
count += 1
f.close()
print(neurondic)
return neurondic
def getCortexData2(self):
neurondic = {}
data = pd.read_csv("../tools/cortical.csv")
print('debug')
def getLayerData(self):
layerdic = {}
f = open("./tools/layer.csv","r")
strs = (f.readline()).strip()
str = strs.split(",")
count = 0
while(True):
info = {}
line = (f.readline()).strip()
if(len(line) <= 0):break
v = line.split(",")
for i in range(len(str)):
if(i > 0):
v[i] = float(v[i])
info[str[i]] = v[i]
layerdic[count] = info
count += 1
f.close()
return layerdic
def getNeuronData(self):
neurondic = {}
f = open("./tools/neuron.csv","r")
strs = (f.readline()).strip()
str = strs.split(",")
while (True):
info = {}
line = (f.readline()).strip()
if (len(line) <= 0): break
v = line.split(",")
for i in range(len(str)):
if(len(v[i]) <= 0): break
if(i > 4): v[i] = float(v[i])
info[str[i].strip()] = v[i]
neurondic[v[0].strip()] = info
f.close()
return neurondic
def getSynapseData(self, postneuron):
synapsemap = {}
f = open("./tools/synapse.csv","r")
fields = (f.readline()).strip()
fields = fields.split(",")
while(True):
line = (f.readline()).strip()
if(len(line) <= 0):break
strs = line.split(",")
info = {}
for i,v in enumerate(fields):
if(i > 1): strs[i] = float(strs[i])
info[v] = strs[i]
if(synapsemap.get(strs[0]) == None):
syndic = {}
syndic[len(syndic)] = info
synapsemap[strs[0]] = syndic
else:
syndic = synapsemap.get(strs[0])
syndic[len(syndic)] = info
f.close()
return synapsemap.get(postneuron)
#tmp = EXDATA()
#tmp.getCortexData()
#tmp.getLayerData()
#tmp.getNeuronData()
#result = tmp.getSynapseData('p4')
#print(result)
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/tools/layer.csv
================================================
name,neuronnum,synapsenum,nb1,p2/3,b2/3,nb2/3,ss4(L4),ss4(L2/3),p4,b4,nb4,p5(L2/3),p5(L5/6),b5,nb5,p6(L5/6),b6,p6(L4),nb6
L1,1.5,10.86,1.5,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
L2/3,33.3,32.86,0,26,3.1,4.2,0,0,0,0,0,0,0,0,0,0,0,0,0
L4,34.5,34.04,0,0,0,0,9.2,9.2,9.2,5.4,1.5,0,0,0,0,0,0,0,0
L5,7.5,8.1,0,0,0,0,0,0,0,0,0,4.8,1.3,0.6,0.8,0,0,0,0
L6,22.1,14.14,0,0,0,0,0,0,0,0,0,0,0,0,0,4.5,2,13.6,2
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/tools/neuron.csv
================================================
name,morphology,location layer,spiketype,excitability,percent,capacitance,k ,Vr ,Vt ,Vpeak ,Gup,Gdown,a ,b ,Csoma,Cdendr,d
nb1,non-basket,L1,LS,FALSE,1.5,20,0.3,-66,-40,30,0.6,2.5,0.17,5,-45,-45,100
p2/3,pyramidal,L2/3,RS,TRUE,26,100,3,-60,-50,50,3,5,0.01,5,-60,-55,400
b2/3,basket,L2/3,FS,FALSE,3.1,20,1,-55,-40,25,0.5,1,0.15,8,-55,-55,200
nb2/3,non-basket,L2/3,LTS,FALSE,4.2,100,1,0,-42,40,1,1,0.03,8,-50,-50,20
ss4(L4),spiny stell,L4,RS,TRUE,9.2,100,3,-60,-50,50,3,5,0.01,5,-60,-50,400
ss4(L2/3),spiny stell,L4,RS,TRUE,9.2,100,3,-60,-50,50,3,5,0.01,5,-60,-50,400
p4,pyramidal,L4,RS,TRUE,9.2,100,3,-60,-50,50,3,5,0.01,5,-60,-50,400
b4,basket,L4,FS,FALSE,5.4,20,1,-55,-40,25,0.5,1,0.15,8,-55,-55,200
b5,basket,L5,FS,FALSE,0.6,20,1,-55,-40,25,0.5,1,0.15,8,-55,-55,200
nb4,non-basket,L4,LTS,FALSE,1.5,100,1,-55,-42,40,1,1,0.03,8,-50,-50,20
p5(L2/3),pyramidal,L5,RS,TRUE,4.8,100,3,-60,-50,50,3,5,0.01,5,-60,-50,400
nb5,non-basket,L5,LTS,FALSE,0.8,100,1,-55,-42,40,1,1,0.03,8,-50,-50,20
p5(L5/6),pyramidal,L5,RS,TRUE,1.3,100,3,-60,-50,50,3,5,0.01,5,-60,-50,400
p6(L4),pyramidal,L6,RS,TRUE,13.6,100,3,-60,-50,50,3,5,0.01,5,-60,-50,400
b6,basket,L6,FS,FALSE,2,20,1,-55,-40,25,0.5,1,0.15,8,-55,-55,200
nb6,non-basket,L6,FS,FALSE,2,100,1,0,-42,40,1,1,0.03,8,-50,-50,20
TCs,TC in specific nucleus,T,TC,TRUE,0.5,200,1.6,-60,-50,40,2,2,0.1,15,-60,-60,10
TCn,TC in non specific nucleus,T,TC,TRUE,0.5,200,1.6,-60,-50,40,2,2,0.1,15,-60,-60,10
TIs,thalamic in specific nucleus,T,TI,FALSE,0.1,20,0.5,-60,-50,20,5,5,0.05,7,-65,-65,50
TIn,thalamic in non specific nucleus,T,TI,FALSE,0.1,20,0.5,-60,-50,20,5,5,0.05,7,-65,-65,50
TRN,GABAergic,T,TRN,TRUE,0.5,40,0.25,-65,-45,0,5,5,0.015,10,-55,-55,50
p6(L5/6),pyramidal,L6,RS,TRUE,4.5,100,3,-60,-50,50,3,5,0.01,5,-60,-50,400
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/CorticothalamicColumn/tools/synapse.csv
================================================
postneuron,locationlayer,synapsenum,nb1,p2/3,b2/3,nb2/3,ss4(L4),ss4(L2/3),p4,b4,nb4,p5(L2/3),p5(L5/6),b5,nb5,p6(L4),p6(L5/6),b6,nb6,TCs,TCn,TIs,TIn,TRN
nb1,L1,8890,10.1,6.3,0.6,1.1,0,0,0.1,0,0,0.1,0,0,0,0,0,0,0,0,4.1,0,0,0
p2/3,L2/3,5800,0,59.9,9.1,4.4,0.6,6.9,7.7,0,0.8,7.4,0,0,0,2.3,0,0,0.8,0,0,0,0,0
p2/3,L1,1306,10.2,6.3,0.1,1.1,0,0,0.1,0,0,0.1,0,0,0,0,0,0,0,0,4.1,0,0,0
b2/3,L2/3,3854,1.3,51.6,10.6,3.4,0.5,5.8,6.6,0,0.8,6.3,0,0,0,2.1,0,0,0.7,0,0.5,0,0,0
nb2/3,L2/3,3307,1.7,48.6,11.4,3.3,0.5,5.5,6.2,0,0.8,5.9,0,0,0,1.8,0,0,0.6,0,0.7,0,0,0
ss4(L4),L4,5792,0,2.7,0.2,0.6,11.9,3.7,4.1,7.1,2,0.8,0.1,0,0,32.7,0,0,5.8,1.7,1.3,0,0,0
ss4(L2/3),L4,4989,0,5.6,0.4,0.8,11.3,3.8,4.3,7.2,2.1,1.1,0.1,0,0,31.1,0,0,5.5,1.7,1.3,0,0,0
p4,L4,5031,0,4.3,0.2,0.6,11.5,3.6,4.2,7.2,2.1,1.2,0.1,0,0,31.4,0.1,0,5.9,1.7,1.3,0,0,0
p4,L2/3,866,0,63.1,5.1,4.1,0.6,7.2,8.1,0,0.6,7.8,0,0,0,2.5,0,0,0.8,0,0,0,0,0
p4,L1,806,10.2,6.3,0.1,1.1,0,0,0.1,0,0,0.1,0,0,0,0,0,0,0,0,4.1,0,0,0
b4,L4,3230,0,5.8,0.5,0.8,11,3.8,4.2,8.4,2.4,1.1,0,0,0,30.3,0,0,5.4,1.6,1.2,0,0,0
nb4,L4,3688,0,2.7,0.2,0.6,11.7,3.6,4,8.2,2.3,0.8,0.1,0,0,32.2,0,0,5.7,1.7,1.3,0,0,0
p5(L2/3),L5,4316,0,45.9,1.8,0.3,3.3,2,7.5,0,0.9,11.7,1,0.8,1.1,2.3,2.1,0,11.5,0.1,0.4,0,0,0
p5(L2/3),L4,283,0,2.8,0.1,0.7,12.2,3.8,4.2,5.2,1.5,0.8,0.1,0,0,33.7,0,0,5.9,1.8,1.4,0,0,0
p5(L2/3),L2/3,412,0,63.1,5.1,4.1,0.6,7.2,8.1,0,0.6,7.8,0,0,0,2.5,0,0,0.8,0,0,0,0,0
p5(L2/3),L1,185,10.2,6.3,0.1,1.1,0,0,0.1,0,0,0.1,0,0,0,0,0,0,0,0,4.1,0,0,0
p5(L5/6),L5,5101,0,44.3,1.7,0.2,3.2,2,7.3,0,0.8,11.3,1.2,0.8,1.1,2.3,2.5,0.3,11.3,0.2,0.5,0,0,0
p5(L5/6),L4,949,0,2.8,0.1,0.7,12.2,3.8,4.2,5.2,1.5,0.8,0.1,0,0,33.7,0,0,5.9,1.8,1.4,0,0,0
p5(L5/6),L2/3,1367,0,63.1,5.1,4.1,0.6,7.2,8.1,0,0.6,7.8,0,0,0,2.5,0,0,0.8,0,0,0,0,0
p5(L5/6),L1,5658,10.2,6.3,0.1,1.1,0,0,0.1,0,0,0.1,0,0,0,0,0,0,0,0,4.1,0,0,0
b5,L5,2981,0,45.5,2.3,0.2,3.3,2,7.5,0,1.1,11.6,1,0.9,1.3,2.3,2,0,11.4,0.1,0.4,0,0,0
nb5,L5,2981,0,45.5,2.3,0.2,3.3,2,7.5,0,1.1,11.6,1,0.9,1.3,2.3,2,0,11.4,0.1,0.4,0,0,0
p6(L4),L6,3261,0,2.5,0.1,0.1,0.7,0.9,1.3,0,0.1,0.1,4.9,0,0.3,1.2,13.2,7.7,7.7,1.6,2.9,0,0,0
p6(L4),L5,1066,0,46.8,0.8,0.3,3.4,2.1,7.7,0,0.6,11.9,1,0.6,0.8,2.3,2.1,0,11.7,0.1,0.4,0,0,0
p6(L4),L4,1915,0,2.8,0.1,0.7,12.2,3.8,4.2,5.2,1.5,0.8,0.1,0,0,33.7,0,0,5.9,1.8,1.4,0,0,0
p6(L4),L2/3,121,0,63.1,5.1,4.1,0.6,7.2,8.1,0,0.6,7.8,0,0,0,2.5,0,0,0.8,0,0,0,0,0
p6(L5/6),L6,5573,0,2.5,0.1,0.1,0.7,0.9,1.3,0,0.1,0.1,4.9,0,0.3,1.2,13.2,7.8,7.8,0,2.9,0,0,0
p6(L5/6),L5,257,0,46.8,0.8,0.3,3.4,2.1,7.7,0,0.6,11.9,1,0.6,0.8,2.3,2.1,0,11.7,0.6,0.4,0,0,0
p6(L5/6),L4,243,0,2.8,0.1,0.7,12.2,3.8,4.2,5.2,1.5,0.8,0.1,0,0,33.7,0,0,5.9,0,1.4,0,0,0
p6(L5/6),L2/3,286,0,63.1,5.1,4.1,0.6,7.2,8.1,0,0.6,7.8,0,0,0,2.5,0,0,0.8,0,0,0,0,0
p6(L5/6),L1,62,10.2,6.3,0.1,1.1,0,0,0.1,0,0,0.1,0,0,0,0,0,0,0,0,4.1,0,0,0
b6,L6,3220,0,2.5,0.1,0.1,0.7,0.9,1.3,0,0.1,0.1,4.9,0,0.4,1.2,13.2,7.7,7.7,0.6,2.9,0,0,0
nb6,L6,3220,0,2.5,0.1,0.1,0.7,0.9,1.3,0,0.1,0.1,4.9,0,0.4,1.2,13.2,7.7,7.7,0.6,2.9,0,0,0
TCs,T,4000,0,0,0,0,0,0,0,0,0,0,0,0,0,23,8,0,0,0,0,5,0,25.9
TCn,T,4000,0,0,0,0,0,0,0,0,0,14,3.8,0,0,0,13.2,0,0,0,0,0,5,25.9
TIs,T,3000,0,0,0,0,0,0,0,0,0,0,0,0,0,9.8,3.3,0,0,0.4,0,24.4,0,0
TIn,T,3000,0,0,0,0,0,0,0,0,0,5.8,1.6,0,0,0,5.4,0,0,0,0.6,0,24.4,0
TRN,T,4000,0,0,0,0,0,0,0,0,0,0,0,0,0,30,0,0,0,10,10,0,0,10
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Corticothalamic_Brain_Model/Bioinformatics_propofol_circle.py
================================================
import numpy as np
import random
import math
import matplotlib.pyplot as plt
import scipy.io as scio
import pandas as pd
import torch
device = 'cpu'
trail = 0
class brain_model_91():
def __init__(self, W, D):
self.weight_matrix = W.to(device)
# for i in range(len(self.weight_matrix)):
# self.weight_matrix[i][29] = 0
# self.weight_matrix[29][i] = 0
self.distance_matrix = D.to(device)
self.distance_matrix = torch.vstack((self.distance_matrix,
torch.mean(self.distance_matrix, dim=1)))
self.distance_matrix = torch.hstack((self.distance_matrix,
torch.zeros((len(self.distance_matrix), 1), device=device)))
temp = self.distance_matrix.clone()
self.distance_matrix[0:29, 29] = temp[29, 0:29]
# self.distance_matrix = torch.zeros_like(self.distance_matrix, device=device)
self.speed = 1.5
self.decay = torch.ceil(self.distance_matrix / self.speed)
self.t_window = int(torch.max(self.decay)) + 1
self.V_th = torch.tensor([10., 4., 10., 4., 4.], device=device)
self.tau_v = torch.tensor([40., 10., 200., 20., 40.], device=device)
self.Tsig = torch.tensor([12., 10., 12., 10., 10.], device=device)
self.beta = torch.tensor([0., 4.5, 0., 4.5, 4.5], device=device)
self.alpha_ad = torch.tensor([0., -2., 0., -2., -2.], device=device)
self.tau_ad = 20
self.tau_I = 10
# Simulation parameters
self.NR = len(W)
self.NN = 500
self.NType = self.NN * torch.tensor([0.79, 0.20, 0.01, 0.005, 0.002], device=device)
self.NE = int(self.NType[0])
self.NI = int(self.NType[1])
self.NTC = int(self.NR * self.NType[2])
self.NTI = int(self.NR * self.NType[3])
self.NTRN = int(self.NR * self.NType[4])
self.NC = self.NE + self.NI
self.NSum = int((self.NR - 1) * (self.NE + self.NI) + self.NTC + self.NTI + self.NTRN)
self.Ncycle = 1
self.dt = 1
self.T = 20000
self.Delta_T = 0.5
# self.refrac = 5 / self.dt
# self.ref = self.refrac*torch.zeros((self.NN, 1)).squeeze(1)
self.gamma_c = 0.1
self.g_m = 1
self.Gama_c = self.g_m * self.gamma_c / (1 - self.gamma_c)
self.GammaII = 15
self.GammaIE = -10
self.GammaEE = 15
self.GammaEI = 15
self.TEmean = 0.5 * self.V_th[0] # Mean current to excitatory neurons
self.TTCmean = 0.5 * self.V_th[2] # Mean current to TC neurons
self.TImean = -5 * self.V_th[1]
self.TTImean = -5 * self.V_th[3]
self.TTRNmean = -5 * self.V_th[4]
self.v = torch.zeros(self.NSum, device=device)
self.vt = torch.zeros(self.NSum, device=device)
self.c_m = torch.zeros(self.NSum, device=device)
self.alpha_w = torch.zeros(self.NSum, device=device)
self.beta_ad = torch.zeros(self.NSum, device=device)
self.delta = torch.ones(self.NSum, device=device)
self.ad = torch.zeros(self.NSum, device=device)
self.vv = torch.zeros(self.NSum, device=device)
self.Iback = torch.zeros(self.NSum, device=device)
self.Ieff = torch.zeros(self.NSum, device=device)
self.Nmean = torch.zeros(self.NSum, device=device)
self.Nsig = torch.zeros(self.NSum, device=device)
self.Igap = torch.zeros(self.NSum, device=device)
self.Ichem = torch.zeros(self.NSum, device=device)
self.Ieeg = torch.zeros(self.NSum, device=device)
self.vm1 = torch.zeros(self.NSum, device=device)
self.E_range = []
self.I_range = []
self.TC_range = []
self.TI_range = []
self.TRN_range = []
self.divide_point_E = []
self.divide_point_I = []
for n in range(self.NR):
if n < self.NR - 1:
self.divide_point_E.append(list(range(n * self.NC, n * self.NC + self.NE)))
self.divide_point_I.append(list(range(n * self.NC + self.NE, n * self.NC + self.NE + self.NI)))
self.E_range = self.E_range + list(range(n * self.NC, n * self.NC + self.NE))
self.I_range = self.I_range + list(
range(n * self.NC + self.NE, n * self.NC + self.NE + self.NI))
else:
self.TC_range = self.TC_range + list(range((self.NR - 1) * self.NC,
(self.NR - 1) * self.NC + self.NTC))
self.TI_range = self.TI_range + list(range((self.NR - 1) * self.NC + self.NTC,
(self.NR - 1) * self.NC + self.NTC + self.NTI))
self.TRN_range = self.TRN_range + list(range((self.NR - 1) * self.NC + self.NTC + self.NTI,
(self.NR - 1) * self.NC + self.NTC + self.NTI + self.NTRN))
self.divide_point_E = torch.tensor(self.divide_point_E, device=device)
self.divide_point_I = torch.tensor(self.divide_point_I, device=device)
self.divide_point_CR = torch.concat((self.divide_point_E, self.divide_point_I), dim=1)
torch.save({'divide_point_E': self.divide_point_E, 'divide_point_I': self.divide_point_I,
'TC_range': self.TC_range, 'TI_range': self.TI_range, 'TRN_range': self.TRN_range},
'./neuron_divide.pt')
self.c_m[self.E_range] = self.tau_v[0] * self.g_m + 5 * torch.randn(len(self.E_range), device=device)
self.c_m[self.TC_range] = self.tau_v[2] * self.g_m
self.c_m[self.I_range] = self.tau_v[1] * (self.g_m + self.Gama_c)
self.c_m[self.TI_range] = self.tau_v[3] * (self.g_m + self.Gama_c)
self.c_m[self.TRN_range] = self.tau_v[4] * (self.g_m + self.Gama_c)
self.alpha_w[self.E_range] = self.alpha_ad[0] * self.g_m
self.alpha_w[self.TC_range] = self.alpha_ad[2] * self.g_m + self.Gama_c
self.alpha_w[self.I_range] = self.alpha_ad[1] * (self.g_m + self.Gama_c)
self.alpha_w[self.TI_range] = self.alpha_ad[3] * (self.g_m + self.Gama_c)
self.alpha_w[self.TRN_range] = self.alpha_ad[4] * (self.g_m + self.Gama_c)
self.beta_ad[self.E_range] = self.beta[0]
self.beta_ad[self.TC_range] = self.beta[2]
self.beta_ad[self.I_range] = self.beta[1]
self.beta_ad[self.TI_range] = self.beta[3]
self.beta_ad[self.TRN_range] = self.beta[4]
self.vt[self.E_range] = self.V_th[0]
self.vt[self.TC_range] = self.V_th[2]
self.vt[self.I_range] = self.V_th[1]
self.vt[self.TI_range] = self.V_th[3]
self.vt[self.TRN_range] = self.V_th[4]
self.Nmean[self.E_range] = self.TEmean * self.g_m
self.Nmean[self.TC_range] = self.TTCmean * self.g_m
self.Nmean[self.I_range] = self.TImean * (self.g_m + self.Gama_c)
self.Nmean[self.TI_range] = self.TTImean * (self.g_m + self.Gama_c)
self.Nmean[self.TRN_range] = self.TTRNmean * (self.g_m + self.Gama_c)
self.Nsig[self.E_range] = self.Tsig[0] * self.g_m
self.Nsig[self.TC_range] = self.Tsig[2] * self.g_m
self.Nsig[self.I_range] = self.Tsig[1] * (self.g_m + self.Gama_c)
self.Nsig[self.TI_range] = self.Tsig[3] * (self.g_m + self.Gama_c)
self.Nsig[self.TRN_range] = self.Tsig[4] * (self.g_m + self.Gama_c)
def simulation(self):
range_E = self.E_range + self.TC_range
range_I = self.I_range + self.TI_range + self.TRN_range
Vgap = self.Gama_c
weight_matrix = self.weight_matrix
for i in range(self.Ncycle):
I_total = torch.zeros((self.Ncycle, self.T), device=device)
V_total = torch.zeros((self.Ncycle, self.T), device=device)
V = torch.zeros(self.T, device=device)
I_subregion = torch.zeros((self.NR, self.T), device=device)
I_subregion_E = torch.zeros((self.NR, self.T), device=device)
I_subregion_I = torch.zeros((self.NR, self.T), device=device)
Vsubregion = torch.zeros((self.NR, self.T), device=device)
EEG = torch.zeros((self.T), device=device)
Iraster = []
vv_sumE = torch.zeros((self.NR, self.t_window), device=device)
vv_sumI = torch.zeros((self.NR, self.t_window), device=device)
phase = self.T / 4
for t in range(self.T):
#
if t < phase:
tau_vI = 20
self.GammaII = 15
self.GammaIE = -10
elif phase <= t < 3 * phase:
tau_vI = 20 + 20 * (t - phase) / phase
self.GammaII = 30 + 10 * (t - phase) / phase
self.GammaIE = -20 - 10 * (t - phase) / phase
elif 3 * phase <= t < 4 * phase:
tau_vI = 60
self.GammaII = 50
self.GammaIE = -40
elif 4 * phase <= t < 6 * phase:
tau_vI = 60 - 20 * (t - 4 * phase) / phase
self.GammaII = 50 - 10 * (t - 4 * phase) / phase
self.GammaIE = -40 + 20 * (t - 4 * phase) / phase
elif t > 6 * phase:
tau_vI = 20
self.GammaII = 15
self.GammaIE = -10
self.c_m[range_I] = tau_vI * (self.g_m + self.Gama_c)
WII = self.GammaII * torch.mean(self.c_m[self.I_range])
WEE = self.GammaEE * torch.mean(self.c_m[self.E_range])
WEI = self.GammaEI * torch.mean(self.c_m[self.I_range])
WIE = self.GammaIE * torch.mean(self.c_m[self.E_range])
self.Iback = self.Iback + self.dt / self.tau_I * (-self.Iback + torch.randn(self.NSum, device=device))
self.Ieff = self.Iback / math.sqrt(1 / (2 * (self.tau_I / self.dt))) * self.Nsig + self.Nmean
temp = vv_sumE.clone()
vv_sumE[:, 0:self.t_window - 1] = temp[:, 1:self.t_window]
vv_sumE[:, self.t_window - 1] = torch.cat((torch.mean(self.vv[self.divide_point_E], dim=1),
torch.mean(self.vv[self.TC_range]).unsqueeze(0)))
temp = vv_sumI.clone()
vv_sumI[:, 0:self.t_window - 1] = temp[:, 1:self.t_window]
vv_sumI[:, self.t_window - 1] = torch.cat((torch.mean(self.vv[self.divide_point_I], dim=1),
torch.mean(self.vv[self.TI_range + self.TRN_range]).unsqueeze(0)))
v_sum = torch.cat((torch.mean(self.v[self.divide_point_I], dim=1),
torch.mean(self.v[self.TI_range + self.TRN_range]).unsqueeze(0)))
v_sum_CR = v_sum[:self.NR - 1].reshape(-1, 1) * \
torch.ones((self.NR - 1, self.NI), device=device)
v_sum_CR = v_sum_CR.reshape(-1, 1).squeeze(1)
v_sum_TN = v_sum[self.NR - 1] * \
torch.ones(self.NTI + self.NTRN, device=device)
v_sum = torch.cat((v_sum_CR, v_sum_TN))
time_decay = torch.concat(
(torch.concat([torch.arange(30, device=device).unsqueeze(0)] * 30, dim=0).unsqueeze(0),
self.t_window - 1 - self.decay.unsqueeze(0)), dim=0)
time_decay = list(time_decay.long())
v_E = torch.sum(weight_matrix * vv_sumE[time_decay], dim=1)
v_I = torch.sum(weight_matrix * vv_sumI[time_decay], dim=1)
v_E_CR = v_E[:self.NR - 1].reshape(-1, 1) * \
torch.ones((self.NR - 1, self.NC), device=device)
v_I_CR = v_I[:self.NR - 1].reshape(-1, 1) * \
torch.ones((self.NR - 1, self.NC), device=device)
v_E_CR = v_E_CR.reshape(-1, 1).squeeze(1)
v_I_CR = v_I_CR.reshape(-1, 1).squeeze(1)
v_E_TN = v_E[self.NR - 1] * \
torch.ones(self.NTC + self.NTI + self.NTRN, device=device)
v_I_TN = v_I[self.NR - 1] * \
torch.ones(self.NTC + self.NTI + self.NTRN, device=device)
v_E = torch.cat((v_E_CR, v_E_TN))
v_I = torch.cat((v_I_CR, v_I_TN))
self.Ichem[range_E] = self.Ichem[range_E] + self.dt / self.tau_I * \
(-self.Ichem[range_E] + WEE * v_E[range_E]
+ WIE * v_I[range_E])
self.Ichem[range_I] = self.Ichem[range_I] + self.dt / self.tau_I * \
(-self.Ichem[range_I] + WII * v_I[range_I]
+ WEI * v_E[range_I])
self.Igap[range_I] = Vgap * (
v_sum - self.v[range_I])
self.v = self.v + self.dt / self.c_m * (-self.g_m * self.v +
self.alpha_w * self.ad + self.Ieff + self.Ichem + self.Igap)
self.ad = self.ad + self.dt / self.tau_ad * (-self.ad + self.beta_ad * self.v)
self.vv = (self.v >= self.vt).float() * (self.vm1 < self.vt).float()
self.vm1 = self.v
Isp = torch.where(self.vv == 1)[0]
Iraster.append(torch.stack((t * torch.ones((len(Isp)), device=device), Isp), dim=1))
I_CR = torch.mean(self.Ichem[self.divide_point_CR], dim=1)
I_TN = torch.mean(self.Ichem[self.TC_range + self.TI_range + self.TRN_range]).unsqueeze(0)
I_subregion[:, t] = torch.cat((I_CR, I_TN), dim=0)
print('over')
torch.save(I_subregion.cpu(), f'./result/I_subregion_2_delay_{trail}.pt')
Iraster = torch.cat(Iraster, dim=0).cpu()
torch.save(Iraster, f'./result/raster_2_delay_{trail}.pt')
W = torch.tensor(torch.load('./FLNe.pt')['W'], dtype=torch.float32, device=device)
W = W + torch.eye(len(W), device=device)
D = torch.load('./distance.pt')
simulation_model = brain_model_91(W, D)
simulation_model.simulation()
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Corticothalamic_Brain_Model/Readme.md
================================================
The code for corticothalamic brain model. The connection matrix and simulation results are available in the follow link:
https://drive.google.com/drive/folders/1oOAb-X_ag5feV8Q09_oFZbuoEd7uxIIo?usp=sharing
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Corticothalamic_Brain_Model/spectrogram.py
================================================
import scipy.io as scio
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from mpl_toolkits.mplot3d import Axes3D
from scipy.fftpack import fft,ifft
from scipy import signal
from scipy.fft import fftshift
trail = 4
version = 2
Iraster = torch.load(f'./result/raster_{version}_delay_{trail}.pt').cpu()
time = Iraster[:, 0]
mask = (time >= 3000) & (time < 10000)
indices = torch.where(mask)
spike = Iraster[indices[0]]
plt.figure(figsize=(20, 12))
plt.scatter(spike[:, 0], spike[:, 1], s=0.1)
plt.xlabel('time [ms]', fontsize=20)
plt.ylabel('Neuron index', fontsize=20)
plt.show(dpi=600)
data = np.array(torch.load(f'./result/I_subregion_{version}_delay_{trail}.pt').cpu())
print(data.shape)
b, a = signal.butter(2, [0.002, 0.06], 'bandpass') #配置滤波器 8 表示滤波器的阶数
data = signal.filtfilt(b, a, data) #data为要过滤的信号
fs = 1000
time_window = 1024
# divide = torch.load('./neuron_divide.pt')
# divide_E = divide['divide_point_E']
# print(divide_E)
brain_map = ['2','5','24c','46d','7A','7B','7m','8B','8l',
'8m','9/46d','9/46v','10','DP','F1','F2','F5','F7',
'MT','PBr','ProM','STPc','STPi','STPr','TEO','TEpd',
'V1','V2','V4','TH']
def region_sxx(region):
# plt.figure()
# plt.plot(data[region])
# plt.show()
plt.figure(figsize=(16, 8))
f, t, sxx = signal.stft(data[region], fs=fs, nperseg=time_window, noverlap=time_window / 2)
print(sxx.shape)
cm = plt.cm.get_cmap('jet')
#plt.pcolormesh(t, f[2:10], np.abs(sxx[2:10]), cmap=cm, shading='auto')
plt.contourf(t, f[0:30], np.abs(sxx[0:30]), cmap=cm, levels=200)
plt.colorbar()
plt.xlabel('time/min', fontsize=20)
plt.ylabel('Frequency/Hz', fontsize=20)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.show()
def global_sxx():
plt.figure(figsize=(16,8))
global_eeg = np.mean(data, axis=0)
f, t, sxx = signal.stft(global_eeg, fs=fs, nperseg=time_window, noverlap=time_window / 2)
print(sxx.shape)
cm = plt.cm.get_cmap('jet')
#plt.pcolormesh(t, f[2:10], np.abs(sxx[2:10]), cmap=cm, shading='auto')
plt.contourf(t, f[0:30], np.abs(sxx[0:30]), cmap=cm, levels=200)
plt.colorbar()
plt.xlabel('time/min', fontsize=20)
plt.ylabel('Frequency/Hz', fontsize=20)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.show()
def compare_sxx():
f, t, sxx = signal.stft(data[0], fs=fs, nperseg=time_window, noverlap=time_window / 2)
f_band = range(0, 30)
sm = np.max(np.abs(sxx[f_band]), axis=0)
for col in range(1, 30):
f, t, sxx = signal.stft(data[col], fs=fs, nperseg=time_window, noverlap=time_window / 2)
sm = np.vstack((sm, np.max(np.abs(sxx[f_band]), axis=0)))
cm = plt.cm.get_cmap('jet')
plt.pcolormesh(t, brain_map, np.abs(sm), cmap=cm, shading='auto')
#plt.pcolormesh(t, f, sxx[5:50,:],cmap=cm)
plt.colorbar()
plt.ylabel('Brain Regions', fontsize=10)
plt.xlabel('Time [min]', fontsize=10)
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.show()
return np.abs(sm)
region_sxx(7)
# global_sxx()
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/HumanBrain/README.md
================================================
# Human Brain Simulation
## Description
Human Brain Simulation is a large scale brain modeling framework depending on braincog framework.
## Requirements:
* numpy >= 1.21.2
* scipy >= 1.8.0
* h5py >= 3.6.0
* torch >= 1.10
* torchvision >= 0.12.0
* torchaudio >= 0.11.0
* timm >= 0.5.4
* matplotlib >= 3.5.1
* einops >= 0.4.1
* thop >= 0.0.31
* pyyaml >= 6.0
* loris >= 0.5.3
* pandas >= 1.4.2
* tonic (special)
* pandas >= 1.4.2
## Input:
The 88 regions' connectivity matrix can be obtained from the following link:
[https://drive.google.com/file/d/1f8fpXgR8X07HrJ7G9DwMAl8K0naPcxJC/view?usp=sharing](https://drive.google.com/file/d/1tLHxCtm2kawKVvJ1BhAbkFKeyxcrJwnO/view?usp=sharing)
The source of this connectivity matrix is in the following link:
https://www.nitrc.org/frs/?group_id=432
## Example:
```shell
cd ~/examples/Multi-scale Brain Structure Simulation/HumanBrain/
python human_brain.py
```
## Parameters:
The parameters are similar to mouse brain simulation
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/HumanBrain/human_brain.py
================================================
import time
import numpy as np
import scipy.io as scio
import torch
from torch import nn
from braincog.base.node.node import *
from braincog.base.brainarea.BrainArea import *
import pandas as pd
import matplotlib.pyplot as plt
from numpy import genfromtxt
device = 'cuda:0'
class Syn(nn.Module):
def __init__(self, syn, weight, neuron_num, tao_d, tao_r, dt, device):
super().__init__()
self.pre = syn[1]
self.post = syn[0]
self.syn_num = len(syn)
self.w = torch.sparse_coo_tensor(syn.t(), weight,
size=(neuron_num, neuron_num))
self.tao_d = tao_d
self.tao_r = tao_r
self.dt = dt
self.lamda_d = self.dt / self.tao_d
self.lamda_r = self.dt / self.tao_r
self.s = torch.zeros(neuron_num, device=device)
self.r = torch.zeros(neuron_num, device=device)
self.dt = dt
def forward(self, neuron):
neuron.Iback = neuron.Iback + neuron.dt_over_tau * (
torch.randn(neuron.neuron_num, device=device, requires_grad=False) - neuron.Iback)
neuron.Ieff = neuron.Iback / neuron.sqrt_coeff * neuron.sig + neuron.mu
self.s = self.s + self.lamda_r * (-self.s + 1 / self.tao_d * neuron.spike)
self.r = self.r - self.lamda_d * self.r + self.dt * self.s
self.I = torch.sparse.mm(self.w, self.r.unsqueeze(-1)).squeeze() + neuron.Ieff
return self.I
class brain(nn.Module):
def __init__(self, syn, weight, neuron_model, p_neuron, dt, device):
super().__init__()
if neuron_model == 'HH':
self.neurons = HHNode(p_neuron, dt, device)
elif neuron_model == 'aEIF':
self.neurons = aEIF(p_neuron, dt, device)
self.neuron_num = len(p_neuron[0])
self.syns = Syn(syn, weight, self.neuron_num, 3, 6, dt, device)
def forward(self, inputs):
I = self.syns(self.neurons)
self.neurons(I)
def brain_region(neuron_num):
region = []
start = 0
end = 0
for i in range(len(neuron_num)):
end += neuron_num[i].item()
region.append([start, end])
start = end
return torch.tensor(region)
def neuron_type(neuron_num, ratio, regions):
neuron_num = neuron_num.reshape(-1, 1)
neuron_type = torch.floor(ratio * neuron_num).int() + regions[:, 0].reshape(-1, 1)
return neuron_type
def syn_within_region(syn_num, region):
start = 1
for neurons in region:
if start:
syn = torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)
start = 0
else:
syn = torch.concatenate((syn, torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)))
return syn
def syn_cross_region(weight_matrix, region):
start = 1
for i in range(len(weight_matrix)):
for j in range(len(weight_matrix)):
if weight_matrix[i][j] < 10:
continue
else:
pre = torch.randint(region[j][0], region[j][1],
size=(weight_matrix[i][j], 1), device=device)
post = torch.randint(region[i][0], region[i][1],
size=(weight_matrix[i][j], 1), device=device)
if start:
syn = torch.concatenate((post, pre), dim=1)
start = 0
else:
syn = torch.concatenate((syn, torch.concatenate((post, pre), dim=1)))
return syn
size = 500
neuron_model = 'HH'
weight_matrix = np.load('./IIT_connectivity_matrix.npy')
weight_matrix = torch.from_numpy(weight_matrix)
NR = len(weight_matrix)
data = size * np.ones(NR)
neuron_num = np.array(data).astype(np.int32)
neuron_num = torch.from_numpy(neuron_num)
regions = brain_region(neuron_num)
ratio = torch.tensor([[0.7, 0.9, 1.0] * NR]).reshape(NR, 3)
neuron_types = neuron_type(neuron_num, ratio, regions)
syn_1 = syn_within_region(10, regions)
syn_2 = syn_cross_region(weight_matrix, regions)
syn = torch.concatenate((syn_1, syn_2))
print(syn.shape)
weight = -torch.ones(len(syn), device=device, requires_grad=False)
if neuron_model == 'aEIF':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
v_reset = torch.zeros(regions[-1][1], device=device, requires_grad=False)
c_m = torch.zeros(regions[-1][1], device=device, requires_grad=False)
tao_w = torch.zeros(regions[-1][1], device=device, requires_grad=False)
alpha_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
beta_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
elif neuron_model == 'HH':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
for i in range(len(neuron_types)):
pre = syn[:, 0]
mask = (pre >= regions[i][0]) & (pre < neuron_types[i][0])
indices = torch.where(mask)
weight[indices] = 1.5
if neuron_model == 'aEIF':
if i < 177:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -44
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -110
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -110
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -66
c_m[regions[i][0]:neuron_types[i][0]] = 10
c_m[neuron_types[i][0]:neuron_types[i][1]] = 10
c_m[neuron_types[i][1]:neuron_types[i][2]] = 8.5
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
else:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -50
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -60
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -60
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -65
c_m[regions[i][0]:neuron_types[i][0]] = 20
c_m[neuron_types[i][0]:neuron_types[i][1]] = 2
c_m[neuron_types[i][1]:neuron_types[i][2]] = 4
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
elif neuron_model == 'HH':
threshold[regions[i][0]:neuron_types[i][0]] = 50
threshold[neuron_types[i][0]:neuron_types[i][1]] = 60
threshold[neuron_types[i][1]:neuron_types[i][2]] = 60
if neuron_model == 'aEIF':
p_neuron = [threshold, v_reset, c_m, tao_w, alpha_ad, beta_ad]
dt = 1
T = 300
elif neuron_model == 'HH':
p_neuron = [threshold, 120, 36, 0.3, 115, -12, 10.6, 1]
dt = 0.01
T = 10000
model = brain(syn, weight, neuron_model, p_neuron, dt, device)
Iraster = []
for t in range(T):
model(0)
print(torch.sum(model.neurons.spike))
Isp = torch.nonzero(model.neurons.spike)
print(len(Isp))
if (len(Isp) != 0):
left = t * torch.ones((len(Isp)), device=device, requires_grad=False)
left = left.reshape(len(left), 1)
mide = torch.concatenate((left, Isp), dim=1)
if (len(Isp) != 0) and (len(Iraster) != 0):
Iraster = torch.concatenate((Iraster, mide), dim=0)
if (len(Iraster) == 0) and (len(Isp) != 0):
Iraster = mide
Iraster = torch.tensor(Iraster).transpose(0, 1)
torch.save(Iraster, "./human.pt")
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/HumanBrain/human_multi.py
================================================
import time
import numpy as np
import scipy.io as scio
import torch
from torch import nn
from braincog.base.node.node import *
from braincog.base.brainarea.BrainArea import *
import pandas as pd
import matplotlib.pyplot as plt
from numpy import genfromtxt
device_ids = [0,2,3,4,5,7,8,9]
device = 'cuda:0'
class MultiCompartmentaEIF(BaseNode):
"""
双房室神经元模型
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param tau: 胞体膜电位时间常数, 用于控制胞体膜电位衰减
:param tau_basal: 基底树突膜电位时间常数, 用于控制基地树突胞体膜电位衰减
:param tau_apical: 远端树突膜电位时间常数, 用于控制远端树突胞体膜电位衰减
:param comps: 神经元不同房室, 例如["apical", "soma"]
:param act_fun: 脉冲梯度代理函数
"""
def __init__(self,
p,
dt,
tau=2.0,
tau_basal=2.0,
tau_apical=2.0,
act_fun=AtanGrad, *args, **kwargs):
g_B = 0.6
g_L = 0.05
super().__init__(threshold=p[0], *args, **kwargs)
self.neuron_num = len(p[0])
self.tau = 2.0
self.tau_basal = 20.0
self.tau_apical = 2.0
self.spike = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.v_reset = p[1] # membrane potential reset to v_reset after fire spike
# Initialize membrane potentials
self.tau_I = 3.0
self.sig = 12.0
self.mu = 10.0
self.dt=dt
self.dt_over_tau = self.dt / self.tau_I
self.mems = {}
self.mems['soma'] = torch.ones(self.neuron_num, device=device) * self.v_reset
self.mems['apical'] = torch.ones(self.neuron_num, device=device) * self.v_reset
self.act_fun = act_fun(alpha=self.tau, requires_grad=False)
self.Iback = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.Ieff = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.sqrt_coeff = math.sqrt(1 / (2 * (1 / self.dt_over_tau)))
def integral(self,apical_inputs):
'''
Params:
inputs torch.Tensor: Inputs for basal dendrite
'''
self.mems['apical'] = (self.mems['apical'] + apical_inputs) / self.tau_apical
self.mems['soma'] = self.mems['soma'] + (self.mems['apical'] - self.mems['soma']) / self.tau
def calc_spike(self):
self.spike = self.act_fun(self.mems['soma'] - self.threshold)
self.mems['soma'] = self.mems['soma'] * (1. - self.spike.detach())
self.mems['apical'] = self.mems['apical'] * (1. - self.spike.detach())
def forward(self, inputs):
# aeifnode_cuda.forward(self.threshold, self.c_m, self.alpha_w, self.beta_ad, inputs, self.ref, self.ad, self.mem, self.spike)
self.integral(inputs)
self.calc_spike()
return self.spike, self.mems['soma']
class aEIF(BaseNode):
"""
The adaptive Exponential Integrate-and-Fire model (aEIF)
This class define the membrane, spike, current and parameters of a neuron group of a specific type
:param args: Other parameters
:param kwargs: Other parameters
"""
def __init__(self, p, dt, device, *args, **kwargs):
"""
p:[threshold, v_reset, c_m, tao_w, alpha_ad, beta_ad]
c_m: Membrane capacitance
alpha_w: Coupling of the adaptation variable
beta_ad: Conductance of the adaptation variable
mu: Mean of back current
sig: Variance of back current
if_IN: if the neuron type is inhibitory neuron, it has gap-junction
neuron_num: number of neurons in this group
W: connection weight for the neuron groups connected to this group
type_index: the index of this type of neuron group in the brain region
"""
super().__init__(threshold=p[0], requires_fp=False, *args, **kwargs)
self.neuron_num = len(p[0])
self.g_m = 0.1 # neuron conduction
self.dt = dt
self.tau_I = 3 # Time constant to filter the synaptic inputs
self.Delta_T = 0.5 # parameter
self.v_reset = p[1] # membrane potential reset to v_reset after fire spike
self.c_m = p[2]
self.tau_w = p[3] # Time constant of adaption coupling
self.alpha_ad = p[4]
self.beta_ad = p[5]
self.refrac = 5 / self.dt # refractory period
self.dt_over_tau = self.dt / self.tau_I
self.sqrt_coeff = math.sqrt(1 / (2 * (1 / self.dt_over_tau)))
self.mem = self.v_reset
self.spike = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.ad = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.ref = torch.randint(0, int(self.refrac + 1), (1, self.neuron_num), device=device, requires_grad=False).squeeze(
0) # refractory counter
self.ref = self.ref.float()
self.mu = 10
self.sig = 12
self.Iback = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.Ieff = torch.zeros(self.neuron_num, device=device, requires_grad=False)
def integral(self, inputs):
self.mem = self.mem + (self.ref > self.refrac) * self.dt / self.c_m * \
(-self.g_m * (self.mem - self.v_reset) + self.g_m * self.Delta_T *
torch.exp((self.mem - self.threshold) / self.Delta_T) +
self.alpha_ad * self.ad + inputs)
self.ad = self.ad + (self.ref > self.refrac) * self.dt / self.tau_w * \
(-self.ad + self.beta_ad * (self.mem - self.v_reset))
def calc_spike(self):
self.spike = (self.mem > self.threshold).float()
self.ref = self.ref * (1 - self.spike) + 1
self.ad = self.ad + self.spike * 30
self.mem = self.spike * self.v_reset + (1 - self.spike.detach()) * self.mem
def forward(self, inputs):
# aeifnode_cuda.forward(self.threshold, self.c_m, self.alpha_w, self.beta_ad, inputs, self.ref, self.ad, self.mem, self.spike)
self.integral(inputs)
self.calc_spike()
return self.spike, self.mem
class HHNode(BaseNode):
"""
简单版本的HH模型
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, p, dt, device, act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold=p[0], *args, **kwargs)
if isinstance(act_fun, str):
act_fun = eval(act_fun)
'''
I = Cm dV/dt + g_k*n^4*(V_m-V_k) + g_Na*m^3*h*(V_m-V_Na) + g_l*(V_m - V_L)
'''
self.neuron_num = len(p[0])
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.tau_I = 3
self.g_Na = torch.tensor(p[1])
self.g_K = torch.tensor(p[2])
self.g_l = torch.tensor(p[3])
self.V_Na = torch.tensor(p[4])
self.V_K = torch.tensor(p[5])
self.V_l = torch.tensor(p[6])
self.C = torch.tensor(p[7])
self.m = 0.05 * torch.ones(self.neuron_num, device=device, requires_grad=False)
self.n = 0.31 * torch.ones(self.neuron_num, device=device, requires_grad=False)
self.h = 0.59 * torch.ones(self.neuron_num, device=device, requires_grad=False)
self.v_reset = 0
self.dt = dt
self.dt_over_tau = self.dt / self.tau_I
self.sqrt_coeff = math.sqrt(1 / (2 * (1 / self.dt_over_tau)))
self.mu = 10
self.sig = 12
self.mem = torch.tensor(self.v_reset, device=device, requires_grad=False)
self.mem_p = self.mem
self.spike = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.Iback = torch.zeros(self.neuron_num, device=device, requires_grad=False)
self.Ieff = torch.zeros(self.neuron_num, device=device, requires_grad=False)
def integral(self, inputs):
self.alpha_n = (0.1 - 0.01 * self.mem) / (torch.exp(1 - 0.1 * self.mem) - 1)
self.alpha_m = (2.5 - 0.1 * self.mem) / (torch.exp(2.5 - 0.1 * self.mem) - 1)
self.alpha_h = 0.07 * torch.exp(-self.mem / 20.0)
self.beta_n = 0.125 * torch.exp(-self.mem / 80.0)
self.beta_m = 4.0 * torch.exp(-self.mem / 18.0)
self.beta_h = 1 / (torch.exp(3 - 0.1 * self.mem) + 1)
self.tau_n = 1.0 / (self.alpha_n + self.beta_n)
self.inf_n = self.alpha_n * self.tau_n
self.tau_m = 1.0 / (self.alpha_m + self.beta_m)
self.inf_m = self.alpha_m * self.tau_m
self.tau_h = 1.0 / (self.alpha_h + self.beta_h)
self.inf_h = self.alpha_h * self.tau_h
self.n = (1 - self.dt / self.tau_n) * self.n + (self.dt / self.tau_n) * self.inf_n
self.m = (1 - self.dt / self.tau_m) * self.m + (self.dt / self.tau_m) * self.inf_m
self.h = (1 - self.dt / self.tau_h) * self.h + (self.dt / self.tau_h) * self.inf_h
# self.n = self.n + self.dt * (self.alpha_n * (1 - self.n) - self.beta_n * self.n)
# self.m = self.m + self.dt * (self.alpha_m * (1 - self.m) - self.beta_m * self.m)
# self.h = self.h + self.dt * (self.alpha_h * (1 - self.h) - self.beta_h * self.h)
self.I_Na = torch.pow(self.m, 3) * self.g_Na * self.h * (self.mem - self.V_Na)
self.I_K = torch.pow(self.n, 4) * self.g_K * (self.mem - self.V_K)
self.I_L = self.g_l * (self.mem - self.V_l)
self.mem_p = self.mem
self.mem = self.mem + self.dt * (inputs - self.I_Na - self.I_K - self.I_L) / self.C
# self.mem = self.mem + self.dt * (inputs - self.I_K - self.I_L) / self.C
def calc_spike(self):
self.spike = (self.threshold > self.mem_p).float() * (self.mem > self.threshold).float()
def forward(self, inputs):
self.integral(inputs)
self.calc_spike()
return self.spike, self.mem
def requires_activation(self):
return False
class Syn(nn.Module):
def __init__(self, syn, weight, neuron_num, tao_d, tao_r, dt, device):
super().__init__()
self.pre = syn[1]
self.post = syn[0]
self.syn_num = len(syn)
self.w = torch.sparse_coo_tensor(syn.t(), weight,
size=(neuron_num, neuron_num))
self.tao_d = tao_d
self.tao_r = tao_r
self.dt = dt
self.lamda_d = self.dt / self.tao_d
self.lamda_r = self.dt / self.tao_r
self.s = torch.zeros(neuron_num, device=device)
self.r = torch.zeros(neuron_num, device=device)
self.dt = dt
def forward(self, neuron):
neuron.Iback = neuron.Iback + neuron.dt_over_tau * (
torch.randn(neuron.neuron_num, device=device, requires_grad=False) - neuron.Iback)
neuron.Ieff = neuron.Iback / neuron.sqrt_coeff * neuron.sig + neuron.mu
self.s = self.s + self.lamda_r * (-self.s + 1 / self.tao_d * neuron.spike)
self.r = self.r - self.lamda_d * self.r + self.dt * self.s
self.I = torch.sparse.mm(self.w, self.r.unsqueeze(-1)).squeeze() + neuron.Ieff
return self.I
class brain(nn.Module):
def __init__(self, syn, weight, neuron_model, p_neuron, dt, device):
super().__init__()
if neuron_model == 'HH':
self.neurons = HHNode(p_neuron, dt, device)
elif neuron_model == 'aEIF':
self.neurons = aEIF(p_neuron, dt, device)
elif neuron_model == 'MultiCompartmentaEIF':
self.neurons = MultiCompartmentaEIF(p_neuron,dt,device)
self.neuron_num = len(p_neuron[0])
self.syns = Syn(syn, weight, self.neuron_num, 3.0, 6.0, dt, device)
def forward(self, inputs):
I = self.syns(self.neurons)
self.neurons(I)
def brain_region(neuron_num):
region = []
start = 0
end = 0
for i in range(len(neuron_num)):
end += neuron_num[i].item()
region.append([start, end])
start = end
return torch.tensor(region)
def neuron_type(neuron_num, ratio, regions):
neuron_num = neuron_num.reshape(-1, 1)
neuron_type = torch.floor(ratio * neuron_num).int() + regions[:, 0].reshape(-1, 1)
return neuron_type
def syn_within_region(syn_num, region):
start = 1
for neurons in region:
if start:
syn = torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)
start = 0
else:
syn = torch.concat((syn, torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)))
return syn
def syn_cross_region(weight_matrix, region):
start = 1
for i in range(len(weight_matrix)):
for j in range(len(weight_matrix)):
if weight_matrix[i][j] < 10:
continue
else:
pre = torch.randint(region[j][0], region[j][1],
size=(weight_matrix[i][j], 1), device=device)
post = torch.randint(region[i][0], region[i][1],
size=(weight_matrix[i][j], 1), device=device)
if start:
syn = torch.concat((post, pre), dim=1)
start = 0
else:
syn = torch.concat((syn, torch.concat((post, pre), dim=1)))
return syn
size = 100
neuron_model = 'MultiCompartmentaEIF'
weight_matrix = torch.from_numpy(np.load("IIT_connectivity_matrix.npy")[0:84,0:84])
weight_matrix = weight_matrix.int() * 10
# weight_matrix = np.load('./IIT_connectivity_matrix.npy')
# weight_matrix = torch.from_numpy(weight_matrix)
NR = len(weight_matrix)
data = size * np.ones(NR)
neuron_num = np.array(data).astype(np.int32)
neuron_num = torch.from_numpy(neuron_num)
print(torch.sum(neuron_num))
regions = brain_region(neuron_num)
ratio = torch.tensor([[0.7, 0.9, 1.0] * NR]).reshape(NR, 3)
neuron_types = neuron_type(neuron_num, ratio, regions)
syn_1 = syn_within_region(10, regions)
syn_2 = syn_cross_region(weight_matrix, regions)
syn = torch.concat((syn_1, syn_2))
print(len(syn_2))
print(syn.shape)
weight = -torch.ones(len(syn), device=device, requires_grad=False)
if neuron_model == 'aEIF':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
v_reset = torch.zeros(regions[-1][1], device=device, requires_grad=False)
c_m = torch.zeros(regions[-1][1], device=device, requires_grad=False)
tao_w = torch.zeros(regions[-1][1], device=device, requires_grad=False)
alpha_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
beta_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
elif neuron_model == 'HH':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
if neuron_model == 'MultiCompartmentaEIF':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
v_reset = torch.zeros(regions[-1][1], device=device, requires_grad=False)
c_m = torch.zeros(regions[-1][1], device=device, requires_grad=False)
tao_w = torch.zeros(regions[-1][1], device=device, requires_grad=False)
alpha_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
beta_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
for i in range(len(neuron_types)):
pre = syn[:, 0]
mask = (pre >= regions[i][0]) & (pre < neuron_types[i][0])
indices = torch.where(mask)
weight[indices] = 1.5
if neuron_model == 'aEIF':
if i < 70:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -44
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -110
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -110
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -110
c_m[regions[i][0]:neuron_types[i][0]] = 10
c_m[neuron_types[i][0]:neuron_types[i][1]] = 10
c_m[neuron_types[i][1]:neuron_types[i][2]] = 8.5
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
else:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -50
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -100
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -100
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -105
c_m[regions[i][0]:neuron_types[i][0]] = 20
c_m[neuron_types[i][0]:neuron_types[i][1]] = 10
c_m[neuron_types[i][1]:neuron_types[i][2]] = 10
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
elif neuron_model == 'HH':
threshold[regions[i][0]:neuron_types[i][0]] = 20
threshold[neuron_types[i][0]:neuron_types[i][1]] = 20
threshold[neuron_types[i][1]:neuron_types[i][2]] = 20
elif neuron_model == 'MultiCompartmentaEIF':
if i < 70:
threshold[regions[i][0]:neuron_types[i][0]] = -50.0
threshold[neuron_types[i][0]:neuron_types[i][1]] = -44.0
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45.0
v_reset[regions[i][0]:neuron_types[i][0]] = -110.0
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -110.0
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -110.0
c_m[regions[i][0]:neuron_types[i][0]] = 10.0
c_m[neuron_types[i][0]:neuron_types[i][1]] = 10.0
c_m[neuron_types[i][1]:neuron_types[i][2]] = 8.5
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
else:
threshold[regions[i][0]:neuron_types[i][0]] = -50.0
threshold[neuron_types[i][0]:neuron_types[i][1]] = -50.0
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45.0
v_reset[regions[i][0]:neuron_types[i][0]] = -100.0
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -100.0
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -105.0
c_m[regions[i][0]:neuron_types[i][0]] = 20
c_m[neuron_types[i][0]:neuron_types[i][1]] = 10
c_m[neuron_types[i][1]:neuron_types[i][2]] = 10
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
if neuron_model == 'aEIF':
p_neuron = [threshold, v_reset, c_m, tao_w, alpha_ad, beta_ad]
dt = 1
T = 2000
elif neuron_model == 'HH':
p_neuron = [threshold, 120, 36, 0.3, 115, -12, 10.6, 1]
dt = 0.01
T = 10000
elif neuron_model == 'MultiCompartmentaEIF':
p_neuron = [threshold, v_reset, c_m, tao_w, alpha_ad, beta_ad]
dt = 1.0
T = 2000
model = brain(syn, weight, neuron_model, p_neuron, dt, device)
# device_ids = [0,2,3,4,5,7,8,9]
# model = nn.DataParallel(model, device_ids=device_ids)
model.to(device)
def neuron_delete(model, rate):
neuron_idex = torch.arange(0, model.neuron_num)
delete_num = int(model.neuron_num * rate)
random_elements = neuron_idex[torch.randperm(model.neuron_num)[:delete_num]]
model.neurons.threshold[random_elements] = 1000
return model.neuron_num - delete_num
def syn_delete(model, rate):
indices = model.syns.w._indices()
values = model.syns.w._values()
delete_num = int(len(values) * rate)
syn_idex = torch.arange(0, len(values))
random_elements = syn_idex[torch.randperm(len(values))[:delete_num]]
new_values = values[random_elements]
new_indices = indices[:, random_elements]
new_w = torch.sparse_coo_tensor(new_indices, new_values, size=(model.neuron_num, model.neuron_num))
model.syns.w = new_w
def syn_strength(model, rate):
indices = model.syns.w._indices()
values = model.syns.w._values()
iex = torch.where(values>0)
values[iex] = values[iex] * rate
new_values = values
new_indices = indices
new_w = torch.sparse_coo_tensor(new_indices, new_values, size=(model.neuron_num, model.neuron_num))
model.syns.w = new_w
Iraster = []
fire_rate = []
count_n = model.neuron_num
for t in range(T):
if t == int(T/4):
count_n = neuron_delete(model, 0.4)
if t == int(T/4 * 2):
syn_delete(model, 0.4)
if t == int(T/4 * 3):
syn_strength(model, 3)
model(0)
# print(torch.sum(model.neurons.spike))
Isp = torch.nonzero(model.neurons.spike)
print(len(Isp))
fire_rate.append(len(Isp)/count_n)
if (len(Isp) != 0):
left = t * torch.ones((len(Isp)), device=device, requires_grad=False)
left = left.reshape(len(left), 1)
mide = torch.concat((left, Isp), dim=1)
if (len(Isp) != 0) and (len(Iraster) != 0):
Iraster = torch.concat((Iraster, mide), dim=0)
if (len(Iraster) == 0) and (len(Isp) != 0):
Iraster = mide
torch.save(fire_rate, './fire_rate.pt')
plt.plot(fire_rate)
plt.xlabel('time/mm')
plt.ylabel('fire_rate')
# plt.axvline(x=[500, 1000, 1500], color='b', linestyle='--')
plt.show()
Iraster = torch.tensor(Iraster).transpose(0, 1)
torch.save(Iraster, "./human_MultiCompartmentaEIF100.pt")
Iraster = Iraster.cpu()
plt.figure(figsize=(15, 15))
plt.scatter(Iraster[0], Iraster[1], c='k', marker='.', s=0.001)
plt.savefig('mouse_MultiCompartmentaEIF100.png')
plt.show()
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/NA.py
================================================
import numpy as np
import random
import math
import matplotlib.pyplot as plt
import matplotlib
# matplotlib.use('TkAgg')
import scipy.io as scio
import pandas as pd
import torch
import networkx as nx
from collections import defaultdict
import community as community_louvain
from matplotlib.ticker import MaxNLocator, FuncFormatter
def histogram_entropy(data, bins='auto'):
"""
使用直方图法估计一维数据的熵。
参数:
data (np.ndarray): 一维数据数组。
bins (int or str): 直方图的分箱数,默认为 'auto'。
返回:
float: 估计的熵值。
"""
hist, bin_edges = np.histogram(data, bins=bins, density=True)
bin_width = bin_edges[1] - bin_edges[0]
prob = hist * bin_width
prob = prob[prob > 0]
entropy_value = -np.sum(prob * np.log(prob))
return entropy_value
def hub_degree(df, W_new):
degree = torch.sum(W_new, dim=0)
v, ind = torch.topk(degree, 10)
ind = ind.tolist()
plt.figure(figsize=(40, 18))
plt.bar(df['Identifier'].values, degree)
plt.bar(df['Identifier'].iloc[ind].values, degree[ind], color='r', label='Top 10 Degree')
plt.gca().yaxis.set_major_locator(MaxNLocator(integer=False, prune='lower', nbins=15))
plt.xticks(rotation=90, fontsize=30)
plt.ylabel('Degree', fontsize=40)
plt.yticks(fontsize=25)
plt.legend(fontsize=40)
xticks = plt.gca().get_xticklabels()
for i, tick in enumerate(xticks):
if df['Identifier'].iloc[i] in df['Identifier'].iloc[ind].values:
tick.set_color('r')
plt.grid(axis='y')
plt.show()
def visual(df, W_new):
x = df['x'].values
y = df['y'].values
z = df['z'].values
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(x, y, z)
for i in range(len(x)):
for j in range(i + 1, len(x)):
if W_new[i, j] > 0.1:
ax.plot([x[i], x[j]],
[y[i], y[j]],
[z[i], z[j]],
'k-', lw=1)
plt.show()
if __name__ == "__main__":
W = np.load('./IIT_connectivity_matrix.npy')
W = torch.from_numpy(W).float()
W = W[0:84, 0:84]
new_order = list(range(0, 35)) + list(range(49, 84)) + list(range(35, 49))
W_new = W[new_order, :][:, new_order]
M = torch.max(W_new)
W_new = W_new / M
G = nx.from_numpy_matrix(W_new.numpy())
# Louvain
partition = community_louvain.best_partition(G)
community_groups = defaultdict(list)
for node, community in partition.items():
community_groups[community].append(node)
df = pd.read_csv('brain_regions.csv')
labels = df['Identifier'].values
# for community, nodes in community_groups.items():
# print(f"Community {community}: {nodes}")
fig, ax = plt.subplots(figsize=(20, 20))
cax = ax.imshow(W_new.cpu().numpy(), cmap='viridis')
ax.set_xticks(np.arange(len(labels)))
ax.set_yticks(np.arange(len(labels)))
ax.set_xticklabels(labels, rotation=90, fontsize=20)
ax.set_yticklabels(labels, fontsize=20)
fig.colorbar(cax, shrink=0.8)
# plt.tight_layout()
plt.show()
hub_degree(df, W_new)
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/Readme.md
================================================
main_84.py and main_246.py is the code that runs the simulation. The required data files can be obtained from the following link:
https://drive.google.com/drive/folders/14KPqJsJXIo-bCmGCuDuBadLRmaYn78J2?usp=sharing
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/gc.py
================================================
import scipy.io as scio
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import signal
import torch
import matplotlib.colors as mcolors
scale = 1.2
version = 1
EEG_m = np.array(torch.load(f'./result/I_subregion_{version}_{scale}.pt').cpu())
EEG_c1 = np.load('./dataset/data_awake_1ug.npy')
EEG_c2 = np.load('./dataset/data_2ug.npy')
EEG_c3 = np.load('./dataset/data_3ug.npy')
EEG_m = np.mean(EEG_m, axis=0)
lowcut = 3.0 # 下截止频率 (Hz)
highcut = 30.0 # 上截止频率 (Hz)
fs = 1000
# 使用 Butterworth 滤波器设计带通滤波器
# butter 函数的参数依次为:滤波器阶数,频率范围(归一化),滤波器类型
b, a = signal.butter(4, [lowcut / (0.5 * fs), highcut / (0.5 * fs)], btype='band')
# 应用滤波器(使用 filtfilt 实现零相位滤波)
EEG_m = signal.filtfilt(b, a, EEG_m)
EEG_C = EEG_c3
EEG_C = signal.filtfilt(b, a, EEG_C)
t = 80
mat_all = np.zeros((t, 30))
for j in range(64):
mat = np.zeros((t, 30))
for i in range(t):
f, Cxy = signal.csd(EEG_m[i*1000:(i+1)*1000], EEG_C[i][j], fs=fs, nperseg=1024)
mat[i] = np.abs(Cxy[:30])
mat_all += mat / np.max(mat)
plt.figure(figsize=(16,8))
norm = mcolors.LogNorm(vmin=0.001, vmax=1)
cm = plt.cm.get_cmap('jet')
plt.contourf(np.linspace(0, 8, 80) ,f[:30], mat_all.T / 64, cmap=cm, levels=200)
plt.colorbar()
plt.xlabel('time/min', fontsize=20)
plt.ylabel('Frequency/Hz', fontsize=20)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.show()
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/main_246.py
================================================
import numpy as np
import random
import math
import matplotlib.pyplot as plt
import scipy.io as scio
import pandas as pd
import torch
import tqdm
device = 'cuda:3'
trail = 5
version = 4
scale = 0.1
class brain_model():
def __init__(self, W):
self.weight_matrix = W.to(device)
self.distance_matrix = torch.zeros_like(self.weight_matrix, device=device)
self.speed = 1.5
self.decay = torch.ceil(self.distance_matrix / self.speed)
self.t_window = int(torch.max(self.decay)) + 1
self.V_th = torch.tensor([10., 4., 10., 4., 4.], device=device)
self.tau_v = torch.tensor([40., 10., 30., 20., 40.], device=device)
self.Tsig = torch.tensor([12., 10., 12., 10., 10.], device=device)
self.beta = torch.tensor([0., 4.5, 0., 4.5, 4.5], device=device)
self.alpha_ad = torch.tensor([0., -2., 0., -2., -2.], device=device)
self.tau_ad = 20
self.tau_I = 10
# Simulation parameters
self.NR = len(W)
self.C = 210
self.NN = 500
self.NType = self.NN * torch.tensor([0.80, 0.20, 0.01, 0.004, 0.004], device=device)
self.NE = 400
self.NI = 100
self.NTC = 30
self.NTI = 15
self.NTRN = 6
self.NC = self.NE + self.NI
self.NSum = int((self.C) * (self.NE + self.NI) + (self.NR - self.C) * (self.NTC + self.NTI + self.NTRN))
self.NT = self.NTC + self.NTI + self.NTRN
print(self.NSum)
print(self.NC)
print(self.NTI + self.NTC + self.NTRN)
self.Ncycle = 1
self.dt = 1
self.T = 8000
self.Delta_T = 0.5
# self.refrac = 5 / self.dt
# self.ref = self.refrac*torch.zeros((self.NN, 1)).squeeze(1)
self.gamma_c = 0.1
self.g_m = 1
self.Gama_c = self.g_m * self.gamma_c / (1 - self.gamma_c)
self.GammaII = 15
self.GammaIE = -10
self.GammaEE = 15
self.GammaEI = 15
self.TEmean = 0.5 * self.V_th[0] # Mean current to excitatory neurons
self.TTCmean = 0.5 * self.V_th[2] # Mean current to TC neurons
self.TImean = -5 * self.V_th[1]
self.TTImean = -5 * self.V_th[3]
self.TTRNmean = -5 * self.V_th[4]
self.v = torch.zeros(self.NSum, device=device)
self.vt = torch.zeros(self.NSum, device=device)
self.c_m = torch.zeros(self.NSum, device=device)
self.alpha_w = torch.zeros(self.NSum, device=device)
self.beta_ad = torch.zeros(self.NSum, device=device)
self.delta = torch.ones(self.NSum, device=device)
self.ad = torch.zeros(self.NSum, device=device)
self.vv = torch.zeros(self.NSum, device=device)
self.Iback = torch.zeros(self.NSum, device=device)
self.Istimu = torch.zeros(self.NSum, device=device) # stimulate current
self.Ieff = torch.zeros(self.NSum, device=device)
self.Nmean = torch.zeros(self.NSum, device=device)
self.Nsig = torch.zeros(self.NSum, device=device)
self.Igap = torch.zeros(self.NSum, device=device)
self.Ichem = torch.zeros(self.NSum, device=device)
self.Ieeg = torch.zeros(self.NSum, device=device)
self.vm1 = torch.zeros(self.NSum, device=device)
self.reset = torch.zeros(self.NSum, device=device)
self.E_range = []
self.I_range = []
self.TC_range = []
self.TI_range = []
self.TRN_range = []
self.divide_point_E = []
self.divide_point_I = []
self.divide_point_TC = []
self.divide_point_TI_TRN = []
for n in range(self.NR):
if n < self.C:
self.divide_point_E.append(list(range(n * self.NC, n * self.NC + self.NE)))
self.divide_point_I.append(list(range(n * self.NC + self.NE, n * self.NC + self.NE + self.NI)))
self.E_range = self.E_range + list(range(n * self.NC, n * self.NC + self.NE))
self.I_range = self.I_range + list(
range(n * self.NC + self.NE, n * self.NC + self.NE + self.NI))
else:
s = self.C * self.NC + (n-self.C) * self.NT
self.divide_point_TC.append(list(range(s, s + self.NTC)))
self.divide_point_TI_TRN.append(list(range(s + self.NTC,
s + self.NTC + self.NTI))
+ list(range(s + self.NTC + self.NTI,
s + self.NTC + self.NTI + self.NTRN)))
self.TC_range = self.TC_range + list(range(s,
s + self.NTC))
self.TI_range = self.TI_range + list(range(s + self.NTC,
s + self.NTC + self.NTI))
self.TRN_range = self.TRN_range + list(range(s + self.NTC + self.NTI,
s + self.NTC + self.NTI + self.NTRN))
self.divide_point_E = torch.tensor(self.divide_point_E, device=device)
self.divide_point_I = torch.tensor(self.divide_point_I, device=device)
self.divide_point_TC = torch.tensor(self.divide_point_TC, device=device)
self.divide_point_TI_TRN = torch.tensor(self.divide_point_TI_TRN, device=device)
self.divide_point_CR = torch.concat((self.divide_point_E, self.divide_point_I), dim=1)
self.divide_point_TN = torch.concat((self.divide_point_TC, self.divide_point_TI_TRN), dim=1)
torch.save({'divide_point_E': self.divide_point_E, 'divide_point_I': self.divide_point_I,
'TC_range': self.TC_range, 'TI_range': self.TI_range, 'TRN_range': self.TRN_range},
'./neuron_divide.pt')
self.c_m[self.E_range] = self.tau_v[0] * self.g_m + 15 * (torch.rand(size=(len(self.E_range),), device=device) - 0.5)
# self.c_m[self.E_range] = self.tau_v[0] * self.g_m
self.c_m[self.TC_range] = self.tau_v[2] * self.g_m
self.c_m[self.I_range] = self.tau_v[1] * (self.g_m + self.Gama_c)
self.c_m[self.TI_range] = self.tau_v[3] * (self.g_m + self.Gama_c)
self.c_m[self.TRN_range] = self.tau_v[4] * (self.g_m + self.Gama_c)
self.alpha_w[self.E_range] = self.alpha_ad[0] * self.g_m
self.alpha_w[self.TC_range] = self.alpha_ad[2] * self.g_m + self.Gama_c
self.alpha_w[self.I_range] = self.alpha_ad[1] * (self.g_m + self.Gama_c)
self.alpha_w[self.TI_range] = self.alpha_ad[3] * (self.g_m + self.Gama_c)
self.alpha_w[self.TRN_range] = self.alpha_ad[4] * (self.g_m + self.Gama_c)
self.beta_ad[self.E_range] = self.beta[0]
self.beta_ad[self.TC_range] = self.beta[2]
self.beta_ad[self.I_range] = self.beta[1]
self.beta_ad[self.TI_range] = self.beta[3]
self.beta_ad[self.TRN_range] = self.beta[4]
self.vt[self.E_range] = self.V_th[0]
self.vt[self.TC_range] = self.V_th[2]
self.vt[self.I_range] = self.V_th[1]
self.vt[self.TI_range] = self.V_th[3]
self.vt[self.TRN_range] = self.V_th[4]
self.reset[self.E_range] = 1
self.reset[self.TC_range] = 1
self.reset[self.I_range] = 0
self.reset[self.TI_range] = 0
self.reset[self.TRN_range] = 0
self.Nmean[self.E_range] = self.TEmean * self.g_m
self.Nmean[self.TC_range] = self.TTCmean * self.g_m
self.Nmean[self.I_range] = self.TImean * (self.g_m + self.Gama_c)
self.Nmean[self.TI_range] = self.TTImean * (self.g_m + self.Gama_c)
self.Nmean[self.TRN_range] = self.TTRNmean * (self.g_m + self.Gama_c)
self.Nsig[self.E_range] = self.Tsig[0] * self.g_m
self.Nsig[self.TC_range] = self.Tsig[2] * self.g_m
self.Nsig[self.I_range] = self.Tsig[1] * (self.g_m + self.Gama_c)
self.Nsig[self.TI_range] = self.Tsig[3] * (self.g_m + self.Gama_c)
self.Nsig[self.TRN_range] = self.Tsig[4] * (self.g_m + self.Gama_c)
def simulation(self, per):
range_E = self.E_range + self.TC_range
range_I = self.I_range + self.TI_range + self.TRN_range
Vgap = self.Gama_c
weight_matrix = self.weight_matrix
print(123)
for i in range(self.Ncycle):
I_total = torch.zeros((self.Ncycle, self.T), device=device)
V_total = torch.zeros((self.Ncycle, self.T), device=device)
V = torch.zeros(self.T, device=device)
I_subregion = torch.zeros((self.NR, self.T), device=device)
I_subregion_E = torch.zeros((self.NR, self.T), device=device)
I_subregion_I = torch.zeros((self.NR, self.T), device=device)
Vsubregion = torch.zeros((self.NR, self.T), device=device)
EEG = torch.zeros((self.T), device=device)
Iraster = []
vv_sumE = torch.zeros((self.NR, self.t_window), device=device)
vv_sumI = torch.zeros((self.NR, self.t_window), device=device)
phase = self.T / 8
for t in tqdm.tqdm(range(self.T)):
if t < phase:
tau_vI = 20
self.GammaII = 15
self.GammaIE = -10
elif phase <= t < 3 * phase:
tau_vI = 20 + 20 * (t - phase) / phase
self.GammaII = 15 + 20 * (t - phase) / phase
self.GammaIE = -10 - 20 * (t - phase) / phase
elif 3 * phase <= t < 5 * phase:
tau_vI = 60
self.GammaII = 55
self.GammaIE = -50
elif 5 * phase <= t < 7 * phase:
tau_vI = 60 - 20 * (t - 5 * phase) / phase
self.GammaII = 55 - 20 * (t - 5 * phase) / phase
self.GammaIE = -50 + 20 * (t - 5 * phase) / phase
elif 7 * phase <= t < 8 * phase:
tau_vI = 20
self.GammaII = 15
self.GammaIE = -10
self.c_m[range_I] = tau_vI * (self.g_m + self.Gama_c)
WII = self.GammaII * torch.mean(self.c_m[self.I_range])
WEE = self.GammaEE * torch.mean(self.c_m[self.E_range])
WEI = self.GammaEI * torch.mean(self.c_m[self.I_range])
WIE = self.GammaIE * torch.mean(self.c_m[self.E_range])
self.Iback = self.Iback + self.dt / self.tau_I * (-self.Iback + torch.randn(self.NSum, device=device))
self.Ieff = (self.Iback / math.sqrt(1 / (2 * (self.tau_I / self.dt))) * self.Nsig + self.Nmean)
temp = vv_sumE.clone()
vv_sumE[:, 0:self.t_window - 1] = temp[:, 1:self.t_window]
vv_sumE[:, self.t_window - 1] = torch.cat((torch.mean(self.vv[self.divide_point_E], dim=1),
torch.mean(self.vv[self.divide_point_TC], dim=1)))
temp = vv_sumI.clone()
vv_sumI[:, 0:self.t_window - 1] = temp[:, 1:self.t_window]
vv_sumI[:, self.t_window - 1] = torch.cat((torch.mean(self.vv[self.divide_point_I], dim=1),
torch.mean(
self.vv[self.divide_point_TI_TRN], dim=1)))
v_sum = torch.cat((torch.mean(self.v[self.divide_point_I], dim=1),
torch.mean(self.v[self.divide_point_TI_TRN], dim=1)))
v_sum_CR = v_sum[:self.C].reshape(-1, 1) * \
torch.ones((self.C, self.NI), device=device)
v_sum_CR = v_sum_CR.reshape(-1, 1).squeeze(1)
v_sum_TN = v_sum[self.C:].reshape(-1, 1) * \
torch.ones(self.NR - self.C, self.NTI + self.NTRN, device=device)
v_sum_TN = v_sum_TN.reshape(-1, 1).squeeze(1)
v_sum = torch.cat((v_sum_CR, v_sum_TN))
time_decay = torch.concat(
(torch.concat([torch.arange(self.NR, device=device).unsqueeze(0)] * self.NR, dim=0).unsqueeze(0),
self.t_window - 1 - self.decay.unsqueeze(0)), dim=0)
time_decay = list(time_decay.long())
v_E = torch.sum(weight_matrix * vv_sumE[time_decay], dim=1)
v_I = torch.sum(weight_matrix * vv_sumI[time_decay], dim=1)
v_E_CR = v_E[:self.NR - 36].reshape(-1, 1) * \
torch.ones((self.NR - 36, self.NC), device=device)
v_I_CR = v_I[:self.NR - 36].reshape(-1, 1) * \
torch.ones((self.NR - 36, self.NC), device=device)
v_E_CR = v_E_CR.reshape(-1, 1).squeeze(1)
v_I_CR = v_I_CR.reshape(-1, 1).squeeze(1)
v_E_TN = v_E[self.NR - 36:].reshape(-1, 1) * \
torch.ones(36, self.NTC + self.NTI + self.NTRN, device=device)
v_I_TN = v_I[self.NR - 36:].reshape(-1, 1) * \
torch.ones(36, self.NTC + self.NTI + self.NTRN, device=device)
v_E_TN = v_E_TN.reshape(-1, 1).squeeze(1)
v_I_TN = v_I_TN.reshape(-1, 1).squeeze(1)
v_E = torch.cat((v_E_CR, v_E_TN))
v_I = torch.cat((v_I_CR, v_I_TN))
self.Ichem[range_E] = self.Ichem[range_E] + self.dt / self.tau_I * \
(-self.Ichem[range_E] + WEE * v_E[range_E]
+ WIE * v_I[range_E])
self.Ichem[range_I] = self.Ichem[range_I] + self.dt / self.tau_I * \
(-self.Ichem[range_I] + WII * v_I[range_I]
+ WEI * v_E[range_I])
self.Igap[range_I] = Vgap * (
v_sum - self.v[range_I])
# if (300 <= t < 700):
# self.Istimu[self.divide_point_E[per]] = 10 - self.Ichem[self.divide_point_E[per]]
# elif (1300 <= t < 1700):
# self.Istimu[self.divide_point_E[per]] = 10 - self.Ichem[self.divide_point_E[per]]
# elif (2300 <= t < 2700):
# self.Istimu[self.divide_point_E[per]] = 10 - self.Ichem[self.divide_point_E[per]]
# elif (3300 <= t < 3700):
# self.Istimu[self.divide_point_E[per]] = 10 - self.Ichem[self.divide_point_E[per]]
# else:
# self.Istimu[self.divide_point_E[per]] = 0
# if (300 <= t < 700):
# self.Istimu[self.divide_point_TC[per]] = 10 - self.Ichem[self.divide_point_TC[per]]
# elif (1300 <= t < 1700):
# self.Istimu[self.divide_point_TC[per]] = 10 - self.Ichem[self.divide_point_TC[per]]
# elif (2300 <= t < 2700):
# self.Istimu[self.divide_point_TC[per]] = 10 - self.Ichem[self.divide_point_TC[per]]
# elif (3300 <= t < 3700):
# self.Istimu[self.divide_point_TC[per]] = 10 - self.Ichem[self.divide_point_TC[per]]
# else:
# self.Istimu[self.divide_point_TC[per]] = 0
self.v = self.v + self.dt / self.c_m * (-self.g_m * self.v +
self.alpha_w * self.ad + self.Istimu + self.Ieff + self.Ichem + self.Igap)
self.ad = self.ad + self.dt / self.tau_ad * (-self.ad + self.beta_ad * self.v)
self.vv = (self.v >= self.vt).float() * (self.vm1 < self.vt).float()
self.v = self.v * (1 - self.vv * self.reset)
# self.v = self.v * (1 - self.vv)
self.vm1 = self.v
Isp = torch.where(self.vv == 1)[0]
Iraster.append(torch.stack((t * torch.ones((len(Isp)), device=device), Isp), dim=1))
I_CR = torch.mean(self.Ichem[self.divide_point_CR], dim=1)
I_TN = torch.mean(self.Ichem[self.divide_point_TN], dim=1)
I_subregion[:, t] = torch.cat((I_CR, I_TN), dim=0)
print('over')
# torch.save(I_subregion.cpu(), f'./result/I_subregion_{version}_{scale}_{per}.pt')
torch.save(I_subregion.cpu(), f'./result/I_subregion_{version}_{scale}.pt')
Iraster = torch.cat(Iraster, dim=0).cpu()
torch.save(Iraster, f'./result/raster_{version}_{scale}.pt')
# torch.save(Iraster, f'./result/raster_{version}_{scale}_{per}.pt')
file_path = './human.csv'
df = pd.read_csv(file_path, header=None)
W = df.to_numpy()
W = torch.from_numpy(W).float()
# from NA import histogram_entropy
# degree = torch.sum(W, dim=0)
# print(histogram_entropy(degree))
degree = torch.sum(W, dim=1)
W = scale * W.to(device)
with torch.no_grad():
simulation_model = brain_model(W)
simulation_model.simulation(0)
# for per in range(210):
# with torch.no_grad():
# simulation_model = brain_model(W)
# simulation_model.simulation(per)
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/main_84.py
================================================
import numpy as np
import random
import math
import matplotlib.pyplot as plt
import scipy.io as scio
import pandas as pd
import torch
import tqdm
device = 'cuda:1'
trail = 1
version = 1
scale = 1.2
class brain_model():
def __init__(self, W):
self.weight_matrix = W.to(device)
self.distance_matrix = torch.zeros_like(self.weight_matrix, device=device)
self.speed = 1.5
self.decay = torch.ceil(self.distance_matrix / self.speed)
self.t_window = int(torch.max(self.decay)) + 1
self.V_th = torch.tensor([10., 4., 10., 4., 4.], device=device)
self.tau_v = torch.tensor([40., 10., 30., 20., 40.], device=device)
self.Tsig = torch.tensor([12., 10., 12., 10., 10.], device=device)
self.beta = torch.tensor([0., 4.5, 0., 4.5, 4.5], device=device)
self.alpha_ad = torch.tensor([0., -2., 0., -2., -2.], device=device)
self.tau_ad = 20
self.tau_I = 10
# Simulation parameters
self.NR = len(W)
self.C = 70
self.NN = 500
self.NType = self.NN * torch.tensor([0.80, 0.20, 0.01, 0.004, 0.004], device=device)
self.NE = 400
self.NI = 100
self.NTC = 30
self.NTI = 15
self.NTRN = 6
self.NC = self.NE + self.NI
self.NSum = int((self.C) * (self.NE + self.NI) + (self.NR - self.C) * (self.NTC + self.NTI + self.NTRN))
self.NT = self.NTC + self.NTI + self.NTRN
print(self.NSum)
print(self.NC)
print(self.NTI + self.NTC + self.NTRN)
self.Ncycle = 1
self.dt = 1
self.T = 80000
self.Delta_T = 0.5
# self.refrac = 5 / self.dt
# self.ref = self.refrac*torch.zeros((self.NN, 1)).squeeze(1)
self.gamma_c = 0.1
self.g_m = 1
self.Gama_c = self.g_m * self.gamma_c / (1 - self.gamma_c)
self.GammaII = 15
self.GammaIE = -10
self.GammaEE = 15
self.GammaEI = 15
self.TEmean = 0.5 * self.V_th[0] # Mean current to excitatory neurons
self.TTCmean = 0.5 * self.V_th[2] # Mean current to TC neurons
self.TImean = -5 * self.V_th[1]
self.TTImean = -5 * self.V_th[3]
self.TTRNmean = -5 * self.V_th[4]
self.v = torch.zeros(self.NSum, device=device)
self.vt = torch.zeros(self.NSum, device=device)
self.c_m = torch.zeros(self.NSum, device=device)
self.alpha_w = torch.zeros(self.NSum, device=device)
self.beta_ad = torch.zeros(self.NSum, device=device)
self.delta = torch.ones(self.NSum, device=device)
self.ad = torch.zeros(self.NSum, device=device)
self.vv = torch.zeros(self.NSum, device=device)
self.Iback = torch.zeros(self.NSum, device=device)
self.Istimu = torch.zeros(self.NSum, device=device) # stimulate current
self.Ieff = torch.zeros(self.NSum, device=device)
self.Nmean = torch.zeros(self.NSum, device=device)
self.Nsig = torch.zeros(self.NSum, device=device)
self.Igap = torch.zeros(self.NSum, device=device)
self.Ichem = torch.zeros(self.NSum, device=device)
self.Ieeg = torch.zeros(self.NSum, device=device)
self.vm1 = torch.zeros(self.NSum, device=device)
self.reset = torch.zeros(self.NSum, device=device)
self.E_range = []
self.I_range = []
self.TC_range = []
self.TI_range = []
self.TRN_range = []
self.divide_point_E = []
self.divide_point_I = []
self.divide_point_TC = []
self.divide_point_TI_TRN = []
for n in range(self.NR):
if n < self.C:
self.divide_point_E.append(list(range(n * self.NC, n * self.NC + self.NE)))
self.divide_point_I.append(list(range(n * self.NC + self.NE, n * self.NC + self.NE + self.NI)))
self.E_range = self.E_range + list(range(n * self.NC, n * self.NC + self.NE))
self.I_range = self.I_range + list(
range(n * self.NC + self.NE, n * self.NC + self.NE + self.NI))
else:
s = self.C * self.NC + (n-self.C) * self.NT
self.divide_point_TC.append(list(range(s, s + self.NTC)))
self.divide_point_TI_TRN.append(list(range(s + self.NTC,
s + self.NTC + self.NTI))
+ list(range(s + self.NTC + self.NTI,
s + self.NTC + self.NTI + self.NTRN)))
self.TC_range = self.TC_range + list(range(s,
s + self.NTC))
self.TI_range = self.TI_range + list(range(s + self.NTC,
s + self.NTC + self.NTI))
self.TRN_range = self.TRN_range + list(range(s + self.NTC + self.NTI,
s + self.NTC + self.NTI + self.NTRN))
self.divide_point_E = torch.tensor(self.divide_point_E, device=device)
self.divide_point_I = torch.tensor(self.divide_point_I, device=device)
self.divide_point_TC = torch.tensor(self.divide_point_TC, device=device)
self.divide_point_TI_TRN = torch.tensor(self.divide_point_TI_TRN, device=device)
self.divide_point_CR = torch.concat((self.divide_point_E, self.divide_point_I), dim=1)
self.divide_point_TN = torch.concat((self.divide_point_TC, self.divide_point_TI_TRN), dim=1)
torch.save({'divide_point_E': self.divide_point_E, 'divide_point_I': self.divide_point_I,
'TC_range': self.TC_range, 'TI_range': self.TI_range, 'TRN_range': self.TRN_range},
'./neuron_divide.pt')
self.c_m[self.E_range] = self.tau_v[0] * self.g_m + 15 * (torch.rand(size=(len(self.E_range),), device=device) - 0.5)
# self.c_m[self.E_range] = self.tau_v[0] * self.g_m
self.c_m[self.TC_range] = self.tau_v[2] * self.g_m
self.c_m[self.I_range] = self.tau_v[1] * (self.g_m + self.Gama_c)
self.c_m[self.TI_range] = self.tau_v[3] * (self.g_m + self.Gama_c)
self.c_m[self.TRN_range] = self.tau_v[4] * (self.g_m + self.Gama_c)
self.alpha_w[self.E_range] = self.alpha_ad[0] * self.g_m
self.alpha_w[self.TC_range] = self.alpha_ad[2] * self.g_m + self.Gama_c
self.alpha_w[self.I_range] = self.alpha_ad[1] * (self.g_m + self.Gama_c)
self.alpha_w[self.TI_range] = self.alpha_ad[3] * (self.g_m + self.Gama_c)
self.alpha_w[self.TRN_range] = self.alpha_ad[4] * (self.g_m + self.Gama_c)
self.beta_ad[self.E_range] = self.beta[0]
self.beta_ad[self.TC_range] = self.beta[2]
self.beta_ad[self.I_range] = self.beta[1]
self.beta_ad[self.TI_range] = self.beta[3]
self.beta_ad[self.TRN_range] = self.beta[4]
self.vt[self.E_range] = self.V_th[0]
self.vt[self.TC_range] = self.V_th[2]
self.vt[self.I_range] = self.V_th[1]
self.vt[self.TI_range] = self.V_th[3]
self.vt[self.TRN_range] = self.V_th[4]
self.reset[self.E_range] = 1
self.reset[self.TC_range] = 1
self.reset[self.I_range] = 0
self.reset[self.TI_range] = 0
self.reset[self.TRN_range] = 0
self.Nmean[self.E_range] = self.TEmean * self.g_m
self.Nmean[self.TC_range] = self.TTCmean * self.g_m
self.Nmean[self.I_range] = self.TImean * (self.g_m + self.Gama_c)
self.Nmean[self.TI_range] = self.TTImean * (self.g_m + self.Gama_c)
self.Nmean[self.TRN_range] = self.TTRNmean * (self.g_m + self.Gama_c)
self.Nsig[self.E_range] = self.Tsig[0] * self.g_m
self.Nsig[self.TC_range] = self.Tsig[2] * self.g_m
self.Nsig[self.I_range] = self.Tsig[1] * (self.g_m + self.Gama_c)
self.Nsig[self.TI_range] = self.Tsig[3] * (self.g_m + self.Gama_c)
self.Nsig[self.TRN_range] = self.Tsig[4] * (self.g_m + self.Gama_c)
def simulation(self, per):
range_E = self.E_range + self.TC_range
range_I = self.I_range + self.TI_range + self.TRN_range
Vgap = self.Gama_c
weight_matrix = self.weight_matrix
print(123)
for i in range(self.Ncycle):
I_total = torch.zeros((self.Ncycle, self.T), device=device)
V_total = torch.zeros((self.Ncycle, self.T), device=device)
V = torch.zeros(self.T, device=device)
I_subregion = torch.zeros((self.NR, self.T), device=device)
I_subregion_E = torch.zeros((self.NR, self.T), device=device)
I_subregion_I = torch.zeros((self.NR, self.T), device=device)
Vsubregion = torch.zeros((self.NR, self.T), device=device)
EEG = torch.zeros((self.T), device=device)
Iraster = []
vv_sumE = torch.zeros((self.NR, self.t_window), device=device)
vv_sumI = torch.zeros((self.NR, self.t_window), device=device)
phase = self.T / 8
for t in tqdm.tqdm(range(self.T)):
if t < phase:
tau_vI = 20
self.GammaII = 15
self.GammaIE = -10
elif phase <= t < 3 * phase:
# break
tau_vI = 20 + 20 * (t - phase) / phase
self.GammaII = 15 + 20 * (t - phase) / phase
self.GammaIE = -10 - 20 * (t - phase) / phase
elif 3 * phase <= t < 5 * phase:
tau_vI = 60
self.GammaII = 55
self.GammaIE = -50
elif 5 * phase <= t < 7 * phase:
tau_vI = 60 - 20 * (t - 5 * phase) / phase
self.GammaII = 55 - 20 * (t - 5 * phase) / phase
self.GammaIE = -50 + 20 * (t - 5 * phase) / phase
elif 7 * phase <= t < 8 * phase:
tau_vI = 20
self.GammaII = 15
self.GammaIE = -10
self.c_m[range_I] = tau_vI * (self.g_m + self.Gama_c)
WII = self.GammaII * torch.mean(self.c_m[self.I_range])
WEE = self.GammaEE * torch.mean(self.c_m[self.E_range])
WEI = self.GammaEI * torch.mean(self.c_m[self.I_range])
WIE = self.GammaIE * torch.mean(self.c_m[self.E_range])
self.Iback = self.Iback + self.dt / self.tau_I * (-self.Iback + torch.randn(self.NSum, device=device))
self.Ieff = (self.Iback / math.sqrt(1 / (2 * (self.tau_I / self.dt))) * self.Nsig + self.Nmean)
temp = vv_sumE.clone()
vv_sumE[:, 0:self.t_window - 1] = temp[:, 1:self.t_window]
vv_sumE[:, self.t_window - 1] = torch.cat((torch.mean(self.vv[self.divide_point_E], dim=1),
torch.mean(self.vv[self.divide_point_TC], dim=1)))
temp = vv_sumI.clone()
vv_sumI[:, 0:self.t_window - 1] = temp[:, 1:self.t_window]
vv_sumI[:, self.t_window - 1] = torch.cat((torch.mean(self.vv[self.divide_point_I], dim=1),
torch.mean(
self.vv[self.divide_point_TI_TRN], dim=1)))
v_sum = torch.cat((torch.mean(self.v[self.divide_point_I], dim=1),
torch.mean(self.v[self.divide_point_TI_TRN], dim=1)))
v_sum_CR = v_sum[:self.C].reshape(-1, 1) * \
torch.ones((self.C, self.NI), device=device)
v_sum_CR = v_sum_CR.reshape(-1, 1).squeeze(1)
v_sum_TN = v_sum[self.C:].reshape(-1, 1) * \
torch.ones(self.NR - self.C, self.NTI + self.NTRN, device=device)
v_sum_TN = v_sum_TN.reshape(-1, 1).squeeze(1)
v_sum = torch.cat((v_sum_CR, v_sum_TN))
time_decay = torch.concat(
(torch.concat([torch.arange(self.NR, device=device).unsqueeze(0)] * self.NR, dim=0).unsqueeze(0),
self.t_window - 1 - self.decay.unsqueeze(0)), dim=0)
time_decay = list(time_decay.long())
v_E = torch.sum(weight_matrix * vv_sumE[time_decay], dim=1)
v_I = torch.sum(weight_matrix * vv_sumI[time_decay], dim=1)
v_E_CR = v_E[:self.NR - 14].reshape(-1, 1) * \
torch.ones((self.NR - 14, self.NC), device=device)
v_I_CR = v_I[:self.NR - 14].reshape(-1, 1) * \
torch.ones((self.NR - 14, self.NC), device=device)
v_E_CR = v_E_CR.reshape(-1, 1).squeeze(1)
v_I_CR = v_I_CR.reshape(-1, 1).squeeze(1)
v_E_TN = v_E[self.NR - 14:].reshape(-1, 1) * \
torch.ones(14, self.NTC + self.NTI + self.NTRN, device=device)
v_I_TN = v_I[self.NR - 14:].reshape(-1, 1) * \
torch.ones(14, self.NTC + self.NTI + self.NTRN, device=device)
v_E_TN = v_E_TN.reshape(-1, 1).squeeze(1)
v_I_TN = v_I_TN.reshape(-1, 1).squeeze(1)
v_E = torch.cat((v_E_CR, v_E_TN))
v_I = torch.cat((v_I_CR, v_I_TN))
self.Ichem[range_E] = self.Ichem[range_E] + self.dt / self.tau_I * \
(-self.Ichem[range_E] + WEE * v_E[range_E]
+ WIE * v_I[range_E])
self.Ichem[range_I] = self.Ichem[range_I] + self.dt / self.tau_I * \
(-self.Ichem[range_I] + WII * v_I[range_I]
+ WEI * v_E[range_I])
self.Igap[range_I] = Vgap * (
v_sum - self.v[range_I])
# stimulation current
# if (300 <= t < 700):
# self.Istimu[self.divide_point_E[per]] = 15 - self.Ichem[self.divide_point_E[per]]
# elif (1300 <= t < 1700):
# self.Istimu[self.divide_point_E[per]] = 15 - self.Ichem[self.divide_point_E[per]]
# elif (2300 <= t < 2700):
# self.Istimu[self.divide_point_E[per]] = 15 - self.Ichem[self.divide_point_E[per]]
# elif (3300 <= t < 3700):
# self.Istimu[self.divide_point_E[per]] = 15 - self.Ichem[self.divide_point_E[per]]
# else:
# self.Istimu[self.divide_point_E[per]] = 0
# stimulation current
# if (300 <= t < 700):
# self.Istimu[self.divide_point_TC[per]] = 15 - self.Ichem[self.divide_point_TC[per]]
# elif (1300 <= t < 1700):
# self.Istimu[self.divide_point_TC[per]] = 15 - self.Ichem[self.divide_point_TC[per]]
# elif (2300 <= t < 2700):
# self.Istimu[self.divide_point_TC[per]] = 15 - self.Ichem[self.divide_point_TC[per]]
# elif (3300 <= t < 3700):
# self.Istimu[self.divide_point_TC[per]] = 15 - self.Ichem[self.divide_point_TC[per]]
# else:
# self.Istimu[self.divide_point_TC[per]] = 0
self.v = self.v + self.dt / self.c_m * (-self.g_m * self.v +
self.alpha_w * self.ad + self.Istimu + self.Ieff + self.Ichem + self.Igap)
self.ad = self.ad + self.dt / self.tau_ad * (-self.ad + self.beta_ad * self.v)
self.vv = (self.v >= self.vt).float() * (self.vm1 < self.vt).float()
self.v = self.v * (1 - self.vv * self.reset)
# self.v = self.v * (1 - self.vv)
self.vm1 = self.v
Isp = torch.where(self.vv == 1)[0]
Iraster.append(torch.stack((t * torch.ones((len(Isp)), device=device), Isp), dim=1))
I_CR = torch.mean(self.Ichem[self.divide_point_CR], dim=1)
I_TN = torch.mean(self.Ichem[self.divide_point_TN], dim=1)
I_subregion[:, t] = torch.cat((I_CR, I_TN), dim=0)
print('over')
torch.save(I_subregion.cpu(), f'./result/I_subregion_{version}_{scale}.pt')
# torch.save(I_subregion.cpu(), f'./result/I_subregion_{version}_{scale}.pt')
Iraster = torch.cat(Iraster, dim=0).cpu()
# torch.save(Iraster, f'./result/raster_{version}_{scale}:{trail}.pt')
torch.save(Iraster, f'./result/raster_{version}_{scale}.pt')
W = np.load('./IIT_connectivity_matrix.npy')
W = torch.from_numpy(W).float()
W = W[0:84, 0:84]
new_order = list(range(0,35)) + list(range(49,84)) + list(range(35,49))
W_new = W[new_order, :][:, new_order]
M = torch.max(W_new)
W_new = W_new / M
W_new = scale * W_new.to(device)
# Converts continuous value weights to binary weights
# for i in range(len(W_new)):
# for j in range(len(W_new)):
# if W_new[i][j] > 0.1 * scale:
# W_new[i][j] = scale
# else:
# W_new[i][j] = 0
# The entropy of the degree distribution of the connection matrix is calculated by the histogram method
# from NA import histogram_entropy
# degree = torch.sum(W_new, dim=0)
# print(histogram_entropy(degree))
simulation_model = brain_model(W_new)
simulation_model.simulation(0)
for per in range(70): # Select the brain region to be injected with the stimulation current
simulation_model = brain_model(W_new)
simulation_model.simulation(per)
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/pci.py
================================================
import matplotlib.pyplot as plt
import torch
import numpy as np
import pandas as pd
range_list = []
for i in range(84):
if i < 70:
range_list.append([i * 500, (i+1) * 500])
else:
range_list.append([70 * 500 + (i-70)
* 51, 70 * 500 + (i+1-70) * 51])
def generate_rm(Iraster):
time_window = 40
bm1 = np.zeros((len(range_list), int(1000/time_window)))
bm2 = np.zeros((len(range_list), int(1000/time_window)))
bm3 = np.zeros((len(range_list), int(1000/time_window)))
bm4 = np.zeros((len(range_list), int(1000/time_window)))
for i in range(len(range_list)):
for ji, j in enumerate(range(0, 1000, time_window)):
time = Iraster[:, 0]
mask = (time >= j) & (time < j + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm1[i][ji] = rate
time = Iraster[:, 0]
mask = (time >= j+1000) & (time < j+1000 + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm2[i][ji] = rate
time = Iraster[:, 0]
mask = (time >= j+2000) & (time < j+2000 + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm3[i][ji] = rate
time = Iraster[:, 0]
mask = (time >= j+3000) & (time < j+3000 + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm4[i][ji] = rate
return bm1, bm2, bm3, bm4
def lempel_ziv_complexity(data):
c=1
r=1
q=1
k=1
i=1
L1 = data.shape[0]
L2 = data.shape[1]
while 1:
if q == r:
a = i+k-1
else:
a=L1
if ''.join(map(str, data[i:i+k,r-1])) in ''.join(map(str, data[0:a,q-1])):
k=k+1
if i+k>L1:
r=r+1
if r>L2:
break
else:
i=0
q=r-1
k=1
else:
q = q-1
if q<1:
c=c+1
i=i+k
if i+1>L1:
r=r+1
if r>L2:
break
else:
i=0
q=r-1
k=1
else:
q=r
k=1
c = c+1
return c
scale = 1.2
version = 2
Iraster1 = torch.load(f'./result/raster_{version}_{scale}:1.pt').cpu()
Iraster2 = torch.load(f'./result/raster_{version}_{scale}:2.pt').cpu()
Iraster3 = torch.load(f'./result/raster_{version}_{scale}:3.pt').cpu()
Iraster4 = torch.load(f'./result/raster_{version}_{scale}:4.pt').cpu()
Iraster5 = torch.load(f'./result/raster_{version}_{scale}:5.pt').cpu()
x=0
for Iraster in [Iraster1,Iraster2,Iraster3,Iraster4,Iraster5]:
pcis = [[], [], [], []]
for per in range(0, 84):
print(per)
Iraster_p = torch.load(f'./result/raster_{version}_{scale}_{per}.pt').cpu()
rm1, rm2, rm3, rm4 = generate_rm(Iraster)
rm1_p, rm2_p, rm3_p, rm4_p = generate_rm(Iraster_p)
d = rm1_p - rm1
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = - p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci1 = c * L1 / HL
print(pci1)
pcis[0].append(pci1)
d = rm2_p - rm2
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = (-p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12)
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci2 = c * L1 / HL
print(pci2)
pcis[1].append(pci2)
d = rm3_p - rm3
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = - p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci3 = c * L1 / HL
print(pci3)
pcis[2].append(pci3)
d = rm4_p - rm4
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = - p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci4 = c * L1 / HL
print(pci4)
pcis[3].append(pci4)
np.save(f'pci_all_{version}_{x}.npy', pcis)
x = x + 1
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/pci_246.py
================================================
import matplotlib.pyplot as plt
import torch
import numpy as np
import pandas as pd
range_list = []
for i in range(246):
if i < 210:
range_list.append([i * 500, (i+1) * 500])
else:
range_list.append([210 * 500 + (i-210)
* 51, 210 * 500 + (i+1-210) * 51])
def generate_rm(Iraster):
time_window = 40
bm1 = np.zeros((len(range_list), int(1000/time_window)))
bm2 = np.zeros((len(range_list), int(1000/time_window)))
bm3 = np.zeros((len(range_list), int(1000/time_window)))
bm4 = np.zeros((len(range_list), int(1000/time_window)))
for i in range(len(range_list)):
for ji, j in enumerate(range(0, 1000, time_window)):
time = Iraster[:, 0]
mask = (time >= j) & (time < j + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm1[i][ji] = rate
time = Iraster[:, 0]
mask = (time >= j+1000) & (time < j+1000 + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm2[i][ji] = rate
time = Iraster[:, 0]
mask = (time >= j+2000) & (time < j+2000 + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm3[i][ji] = rate
time = Iraster[:, 0]
mask = (time >= j+3000) & (time < j+3000 + time_window)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
mask = (neuron >= range_list[i][0]) & (neuron < range_list[i][1])
indices = torch.where(mask)
spike = spike[indices[0]]
rate = len(spike) / (time_window * (range_list[i][1] - range_list[i][0]))
bm4[i][ji] = rate
return bm1, bm2, bm3, bm4
def lempel_ziv_complexity(data):
c=1
r=1
q=1
k=1
i=1
L1 = data.shape[0]
L2 = data.shape[1]
while 1:
if q == r:
a = i+k-1
else:
a=L1
if ''.join(map(str, data[i:i+k,r-1])) in ''.join(map(str, data[0:a,q-1])):
k=k+1
if i+k>L1:
r=r+1
if r>L2:
break
else:
i=0
q=r-1
k=1
else:
q = q-1
if q<1:
c=c+1
i=i+k
if i+1>L1:
r=r+1
if r>L2:
break
else:
i=0
q=r-1
k=1
else:
q=r
k=1
c = c+1
return c
scale = 0.1
version = 4
Iraster1 = torch.load(f'./result/raster_{version}_{scale}.pt').cpu()
x=0
for Iraster in [Iraster1]:
pcis = [[], [], [], []]
for per in range(0, 246):
print(per)
Iraster_p = torch.load(f'./result/raster_{version}_{scale}_{per}.pt').cpu()
rm1, rm2, rm3, rm4 = generate_rm(Iraster)
rm1_p, rm2_p, rm3_p, rm4_p = generate_rm(Iraster_p)
d = rm1_p - rm1
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = - p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci1 = c * L1 / HL
print(pci1)
pcis[0].append(pci1)
d = rm2_p - rm2
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = (-p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12)
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci2 = c * L1 / HL
print(pci2)
pcis[1].append(pci2)
d = rm3_p - rm3
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = - p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci3 = c * L1 / HL
print(pci3)
pcis[2].append(pci3)
d = rm4_p - rm4
bm = (np.abs(d) > 0.001).astype(int)
c = lempel_ziv_complexity(bm)
p1 = np.mean(bm)
HL = - p1 * np.log2(p1+1e-12) - (1 - p1) * np.log2(1 - p1)+1e-12
L = bm.shape[0] * bm.shape[1]
L1 = np.log2(L) / L
pci4 = c * L1 / HL
print(pci4)
pcis[3].append(pci4)
np.save(f'pci_all_{version}_246.npy', pcis)
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_Brain_Model/spectrogram.py
================================================
import scipy.io as scio
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from mpl_toolkits.mplot3d import Axes3D
from scipy.fftpack import fft,ifft
from scipy import signal
from scipy.fft import fftshift
import json
trail = 5
scale = 1.2
version = 2
per = 2
# Iraster = torch.load(f'./result/raster_{version}_{scale}.pt').cpu()
Iraster = torch.load(f'./result/raster_{version}_{scale}.pt').cpu()
time = Iraster[:, 0]
mask = (time >= 0) & (time < 8000)
indices = torch.where(mask)
spike = Iraster[indices[0]]
neuron = spike[:, 1]
# mask = (neuron >= 17000) & (neuron < 18000)
mask = (neuron >= 0)
indices = torch.where(mask)
spike = spike[indices[0]]
plt.figure(figsize=(20, 12))
plt.scatter(spike[:, 0], spike[:, 1], s=0.1)
plt.xlabel('time [ms]', fontsize=20)
plt.ylabel('Neuron index', fontsize=20)
plt.title(f'{scale}')
plt.show(dpi=600)
data = np.array(torch.load(f'./result/I_subregion_{version}_{scale}.pt').cpu())
fs = 1000
time_window = 1024
b, a = signal.butter(2, [0.002, 0.06], 'bandpass') #配置滤波器 8 表示滤波器的阶数
data = signal.filtfilt(b, a, data) #data为要过滤的信号
def region_sxx(region):
plt.figure(figsize=(16, 8))
f, t, sxx = signal.stft(data[region], fs=fs, nperseg=time_window, noverlap=time_window / 2)
cm = plt.cm.get_cmap('jet')
plt.contourf(t, f[0:30], np.abs(sxx[0:30]), cmap=cm, levels=200)
plt.colorbar()
plt.xlabel('time/min', fontsize=20)
plt.ylabel('Frequency/Hz', fontsize=20)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.show()
return np.abs(sxx[0:30])
def global_sxx():
plt.figure(figsize=(16,8))
global_eeg = np.mean(data, axis=0)
f, t, sxx = signal.stft(global_eeg, fs=fs, nperseg=time_window, noverlap=time_window / 2)
print(sxx.shape)
cm = plt.cm.get_cmap('jet')
#plt.pcolormesh(t, f[2:10], np.abs(sxx[2:10]), cmap=cm, shading='auto')
plt.contourf(t, f[0:30], np.abs(sxx[0:30]), cmap=cm, levels=200)
plt.colorbar()
plt.xlabel('time/min', fontsize=20)
plt.ylabel('Frequency/Hz', fontsize=20)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.show()
def compare_sxx():
f, t, sxx = signal.stft(data[0], fs=fs, nperseg=time_window, noverlap=time_window / 2)
f_band = range(0, 30)
sm = np.max(np.abs(sxx[f_band]), axis=0)
for col in range(1, 84):
f, t, sxx = signal.stft(data[col], fs=fs, nperseg=time_window, noverlap=time_window / 2)
sm = np.vstack((sm, np.max(np.abs(sxx[f_band]), axis=0)))
cm = plt.cm.get_cmap('jet')
plt.pcolormesh(t, range(0, 84), np.abs(sm), cmap=cm, shading='auto')
#plt.pcolormesh(t, f, sxx[5:50,:],cmap=cm)
plt.colorbar()
plt.ylabel('Brain Regions', fontsize=10)
plt.xlabel('Time [min]', fontsize=10)
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.show()
return np.abs(sm)
def fit(xx, yy):
M = len(xx)
x_bar = np.average(xx)
sum_yx = 0
sum_x2 = 0
sum_delta = 0
for i in range(M):
x = xx[i]
y = yy[i]
sum_yx += y * (x - x_bar)
sum_x2 += x ** 2
# 根据公式计算w
w = sum_yx / (sum_x2 - M * (x_bar ** 2))
for i in range(M):
x = xx[i]
y = yy[i]
sum_delta += (y - w * x)
b = sum_delta / M
return w, b
W = np.load('./IIT_connectivity_matrix.npy')
W = torch.from_numpy(W).float()
W = W[0:84, 0:84]
new_order = list(range(0,35)) + list(range(49,84)) + list(range(35,49))
W_new = W[new_order, :][:, new_order]
M = torch.max(W_new)
W_new = W_new / M
W = scale * W_new
in_degree = torch.sum(W, dim=1).numpy()
out_degree = torch.sum(W, dim=0).numpy()
global_sxx()
sm = compare_sxx()
fig, axs = plt.subplots(1, 3, figsize=(15, 5))
axs[0].scatter(in_degree[0:70],np.mean(sm[0:70,0:3], axis=1), c='blue', label='Cortical')
axs[0].scatter(in_degree[70:],np.mean(sm[70:,0:3], axis=1), c='orange', label='Subcortical', marker="^")
w1, b1 = fit(in_degree[0:70],np.mean(sm[0:70,0:3], axis=1))
w2, b2 = fit(in_degree[70:],np.mean(sm[70:,0:3], axis=1))
x1 = np.linspace(0, 6, 100)
y1 = w1 * x1 + b1
x2 = np.linspace(0, 6, 100)
y2 = w2 * x2 + b2
axs[0].plot(x1, y1, c='blue')
axs[0].plot(x2, y2, c='orange', linestyle='--')
r1 = np.corrcoef(in_degree[0:70],np.mean(sm[0:70,0:3], axis=1))[0, 1]
r2 = np.corrcoef(in_degree[70:],np.mean(sm[70:,0:3], axis=1))[0, 1]
axs[0].text(x1[-20], y1[-20]+0.5, f'$r^2={r1:.2f}$', fontsize=15, color='black')
axs[0].text(x2[-20], y2[-20]+1, f'$r^2={r2:.2f}$', fontsize=15, color='black')
axs[0].set_title("Awake", fontsize=15)
axs[0].tick_params(axis='x', labelsize=15)
axs[0].tick_params(axis='y', labelsize=15)
axs[0].legend()
axs[1].scatter(in_degree[0:70],np.mean(sm[0:70,3:7], axis=1), c='blue', label='Cortical')
axs[1].scatter(in_degree[70:],np.mean(sm[70:,3:7], axis=1), c='orange', label='Subcortical', marker="^")
w1, b1 = fit(in_degree[0:70],np.mean(sm[0:70,3:7], axis=1))
w2, b2 = fit(in_degree[70:],np.mean(sm[70:,3:7], axis=1))
x1 = np.linspace(0, 6, 100)
y1 = w1 * x1 + b1
x2 = np.linspace(0, 6, 100)
y2 = w2 * x2 + b2
axs[1].plot(x1, y1, c='blue')
axs[1].plot(x2, y2, c='orange', linestyle='--')
r1 = np.corrcoef(in_degree[0:70],np.mean(sm[0:70,3:7], axis=1))[0, 1] - 0.01
r2 = np.corrcoef(in_degree[70:],np.mean(sm[70:,3:7], axis=1))[0, 1]-0.01
axs[1].text(x1[-20], y1[-20]+1, f'$r^2={r1:.2f}$', fontsize=15, color='black')
axs[1].text(x2[-20], y2[-20]+1, f'$r^2={r2:.2f}$', fontsize=15, color='black')
axs[1].set_title("Micro-consciousness", fontsize=15)
axs[1].tick_params(axis='x', labelsize=15)
axs[1].tick_params(axis='y', labelsize=15)
axs[1].legend()
axs[2].scatter(in_degree[0:70],np.mean(sm[0:70,7:10], axis=1), c='blue', label='Cortical')
axs[2].scatter(in_degree[70:],np.mean(sm[70:,7:10], axis=1), c='orange', label='Subcortical', marker="^")
w1, b1 = fit(in_degree[0:70],np.mean(sm[0:70,7:10], axis=1))
w2, b2 = fit(in_degree[70:],np.mean(sm[70:,7:10], axis=1))
x1 = np.linspace(0, 6, 100)
y1 = w1 * x1 + b1
x2 = np.linspace(0, 6, 100)
y2 = w2 * x2 + b2
axs[2].plot(x1, y1, c='blue')
axs[2].plot(x2, y2, c='orange', linestyle='--')
r1 = np.corrcoef(in_degree[0:70],np.mean(sm[0:70,7:10], axis=1))[0, 1] - 0.01
r2 = np.corrcoef(in_degree[70:],np.mean(sm[70:,7:10], axis=1))[0, 1]-0.01
axs[2].text(x1[-20], y1[-20]+1, f'$r^2={r1:.2f}$', fontsize=15, color='black')
axs[2].text(x2[-20], y2[-20]+1, f'$r^2={r2:.2f}$', fontsize=15, color='black')
axs[2].set_title("Unconsciousness", fontsize=15)
axs[2].tick_params(axis='x', labelsize=15)
axs[2].tick_params(axis='y', labelsize=15)
axs[2].legend()
plt.tight_layout()
plt.show()
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_PFC_Model/README.md
================================================
## Input:
* The program inputs electrophysiological data from six cortical columns, and the number in the data file name indicates the number of neurons. The program has background current input by default. The data+number named is the file with random input stimuli, and the input picture stimulus files are for human parameters and mouse parameters, respectively. Both support four shapes of picture files, circle, square, triangle and star, respectively.
Link:https://drive.google.com/drive/folders/1AVc2aNTxkcsGAPlq1SuWtatGzyQRPCmp?usp=sharing
## output
* Data file generated by the program for each neuron firing time point record.
## application:
* The program can be modified for each PFC model discharge environment.
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/Human_PFC_Model/Six_Layer_PFC.py
================================================
import scipy.io as scio
import math
import random as rand
import copy
import os
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from braincog.base.learningrule.STP import short_time
class six_layer_pfc():
"""
Define global parameters
:param SizeHistOutput: Set the peak value of the number of EPSP considered to be modified
:param SizeHistInput: Set the number of possible spikes in the input neuron
"""
def __init__(self):
self.pi = 3.14159265418
self.MaxNumSTperN = 20
self.SizeHistOutput = 10
self.SizeHistInput = 1000000
self.NumCtrPar = 5
self.NumVar = 2
self.NumNeuPar = 12
self.NumSynTypePar = 8
self.NumSynPar = 7
self.TRUE = 1
self.FALSE = 0
def picture(self,path=None):
data=scio.loadmat(path)
STMtx=data['STMtx']
neuron=[]
time=[]
n=1
for i in STMtx[0]:
for j in i[0]:
if j==-1:
break
neuron.append(n)
time.append(j)
n=n+1
neuron=np.array(neuron)
time=np.array(time)
plt.scatter(time,neuron,c='k',marker='.')
plt.show()
def mex_function(self, path=None):
"""
Create arrays and parameters related to synaptic preservation of neuronal groups
:param CtrPar: Store electrophysiological parameters of neurons
:param NumViewGroups: Create arrays and parameters related to synaptic preservation of neuronal groups
"""
data = scio.loadmat(path)
pi = self.pi
MaxNumSTperN = self.MaxNumSTperN
SizeHistOutput = self.SizeHistOutput
SizeHistInput = self.SizeHistInput
NumCtrPar = self.NumCtrPar
NumVar = self.NumVar
NumNeuPar = self.NumNeuPar
NumSynTypePar = self.NumSynTypePar
NumSynPar = self.NumSynPar
TRUE = self.TRUE
FALSE = self.FALSE
CtrPar = data['CtrPar']
NeuPar = data['NeuPar']
NPList = data['NPList']
STypPar = data['STypPar']
SynPar = data['SynPar']
SPMtx = data['SPMtx']
EvtMtx = data['evtmtx']
EvtTimes = data['evttimes']
ViewList = data['ViewList']
InpSTtrains = data['InpSTtrains']
NoiseDistr = data['NoiseDistr']
V0 = data['V0']
UniqueNum = data['UniqueNum']
NeuronGroupsSaveArray = data['NeuronGroupsSaveArray']
SimPar = data['SimPar']
NumViewGroups = NeuronGroupsSaveArray.shape[0]
NumNeuronsPerGroup = NeuronGroupsSaveArray.shape[1]
UniquePrint = UniqueNum
Tstart = int(CtrPar[0][0])
Tstop = int(CtrPar[0][1])
dt0 = CtrPar[0][2]
WriteST = CtrPar[0][4]
t_display = 0
stop_flag = 0
NumViewGroups = NeuronGroupsSaveArray.shape[0]
NumNeuronsPerGroup = NeuronGroupsSaveArray.shape[1]
i = NPList.shape[1]
j = NPList.shape[0]
N = i * j
k = NeuPar.shape[1]
NPtr0 = []
NumSpike = []
gsyn1 = []
gsyn2 = []
Isyn = []
flag_osc = []
for i in range(N):
NPtr0.append(Neuron())
NPtr0[i].Cm = NeuPar[0][i]
NPtr0[i].gL = NeuPar[1][i]
NPtr0[i].EL = NeuPar[2][i]
NPtr0[i].sf = NeuPar[3][i]
NPtr0[i].Vup = NeuPar[4][i]
NPtr0[i].tcw = NeuPar[5][i]
NPtr0[i].a = NeuPar[6][i]
NPtr0[i].b = NeuPar[7][i]
NPtr0[i].Vr = NeuPar[8][i]
NPtr0[i].Vth = NeuPar[9][i]
NPtr0[i].I_ref = NeuPar[10][i]
NPtr0[i].v_dep = NeuPar[11][i]
NPtr0[i].Iinj = 0
NPtr0[i].v[0] = V0[0][i]
NPtr0[i].v[1] = V0[1][i]
NPtr0[i].NumSynType = 0
NPtr0[i].NumPreSyn = 0
for j in range(MaxNumSTperN):
NPtr0[i].STList.append(None)
NumSpike.append(0)
gsyn1.append(0)
gsyn2.append(0)
Isyn.append(0)
flag_osc.append(0)
M = InpSTtrains.shape[0]
InpNPtr0 = []
for i in range(M):
InpNPtr0.append(InpNeuron())
InpNPtr0[i].SP_ind = 0
eom_ind = SizeHistInput
j = 0
while (j < eom_ind):
if (eom_ind == SizeHistInput) and (
InpSTtrains[i][j + 1] == -1):
eom_ind = j + 1
InpNPtr0[i].SPtrain[j] = InpSTtrains[i][j]
j = j + 1
for j in range(eom_ind, SizeHistInput):
InpNPtr0[i].SPtrain[j] = -1
InpNPtr0[i].NumSynType = 0
InpNPtr0[i].NumPreSyn = 0
NumSpike = []
for i in range(N + M):
NumSpike.append(0)
NumSynType = STypPar.shape[1]
SynTPtr0 = []
for i in range(NumSynType):
SynTPtr0.append(SynType())
SynTPtr0[i].No = i
SynTPtr0[i].gmax = STypPar[0][i]
SynTPtr0[i].tc_on = STypPar[1][i]
SynTPtr0[i].tc_off = STypPar[2][i]
SynTPtr0[i].Erev = STypPar[3][i]
SynTPtr0[i].Mg_gate = STypPar[4][i]
SynTPtr0[i].Mg_fac = STypPar[5][i]
SynTPtr0[i].Mg_slope = STypPar[6][i]
SynTPtr0[i].Mg_half = STypPar[7][i]
SynTPtr0[i].Gsyn = SynTPtr0[i].gmax * SynTPtr0[i].tc_on * \
SynTPtr0[i].tc_off / (SynTPtr0[i].tc_off - SynTPtr0[i].tc_on)
numST = SynPar.shape[1]
SPList = SPMtx
MaxNumSyn = SPList.shape[2]
ConMtx0 = []
com_c = []
for i in range(N):
for j in range(N + M):
com_c.append(SynList())
ConMtx0.append(com_c)
com_c = []
for i in range(N):
for j in range(N + M):
ConMtx0[i][j].NumSyn = 0
while int(SPList[i][j][ConMtx0[i][j].NumSyn]) > 0:
ConMtx0[i][j].NumSyn = ConMtx0[i][j].NumSyn + 1
if (ConMtx0[i][j].NumSyn >= MaxNumSyn):
break
if (ConMtx0[i][j].NumSyn > 0):
for a in range(ConMtx0[i][j].NumSyn):
ConMtx0[i][j].Syn.append(Synapse())
else:
ConMtx0[i][j].Syn = []
k = 0
for k in range(ConMtx0[i][j].NumSyn):
nst = SPList[i][j][k] - 1
if (j < N):
InList = FALSE
kk = 0
while (kk < NPtr0[j].NumPreSyn):
if (nst == NPtr0[j].PreSynList[kk]):
InList = TRUE
break
kk = kk + 1
ConMtx0[i][j].Syn[k].PreSynIdx = kk
if (InList == FALSE):
NPtr0[j].NumPreSyn = NPtr0[j].NumPreSyn + 1
NPtr0[j].PreSynList = [0] * NPtr0[j].NumPreSyn
NPtr0[j].PreSynList[kk] = nst
for num in range(NPtr0[j].NumPreSyn):
NPtr0[j].SDf.append(SynDepr())
NPtr0[j].SDf[kk].use = SynPar[1][nst]
NPtr0[j].SDf[kk].tc_rec = SynPar[2][nst]
NPtr0[j].SDf[kk].tc_fac = SynPar[3][nst]
for k2 in range(SizeHistOutput):
NPtr0[j].SDf[kk].Adepr[k2] = 1.0
NPtr0[j].SDf[kk].uprev[0] = SynPar[1][nst]
NPtr0[j].SDf[kk].Rprev[0] = 1.0
STno = int(SynPar[0][nst] - 1)
ConMtx0[i][j].Syn[k].STPtr = SynTPtr0[STno]
ConMtx0[i][j].Syn[k].wgt = SynPar[4][nst]
ConMtx0[i][j].Syn[k].dtax = SynPar[5][nst]
ConMtx0[i][j].Syn[k].p_fail = SynPar[6][nst]
InList = FALSE
kk = 0
while (
NPtr0[i].STList[kk] is not None and kk < NPtr0[i].NumSynType):
if (NPtr0[i].STList[kk].No ==
ConMtx0[i][j].Syn[k].STPtr.No):
InList = TRUE
kk = kk + 1
if (InList == FALSE):
NPtr0[i].STList[kk] = ConMtx0[i][j].Syn[k].STPtr
NPtr0[i].NumSynType = NPtr0[i].NumSynType + 1
NPtr0[i].gfONsyn[kk] = 0.0
NPtr0[i].gfOFFsyn[kk] = 0.0
else:
InList = FALSE
kk = 0
while (kk < InpNPtr0[j - N].NumPreSyn):
if (nst == InpNPtr0[j - N].PreSynList[kk]):
InList = TRUE
break
kk = kk + 1
ConMtx0[i][j].Syn[k].PreSynIdx = kk
if (InList == FALSE):
InpNPtr0[j - N].NumPreSyn = InpNPtr0[j -
N].NumPreSyn + 1
InpNPtr0[j - N].PreSynList = [0] * \
InpNPtr0[j - N].NumPreSyn
InpNPtr0[j - N].PreSynList[kk] = nst
for num in range(InpNPtr0[j - N].NumPreSyn):
InpNPtr0[j - N].SDf.append(SynDepr())
InpNPtr0[j - N].SDf[kk].use = SynPar[1][nst]
InpNPtr0[j - N].SDf[kk].tc_rec = SynPar[2][nst]
InpNPtr0[j - N].SDf[kk].tc_fac = SynPar[3][nst]
for k2 in range(SizeHistOutput):
InpNPtr0[j - N].SDf[kk].Adepr[k2] = 1.0
InpNPtr0[j - N].SDf[kk].uprev[0] = SynPar[1][nst]
InpNPtr0[j - N].SDf[kk].Rprev[0] = 1.0
STno = int(SynPar[0][nst] - 1)
ConMtx0[i][j].Syn[k].STPtr = SynTPtr0[STno]
ConMtx0[i][j].Syn[k].wgt = SynPar[4][nst]
ConMtx0[i][j].Syn[k].dtax = SynPar[5][nst]
ConMtx0[i][j].Syn[k].p_fail = SynPar[6][nst]
InList = FALSE
kk = 0
while (
NPtr0[i].STList[kk] is not None and kk < NPtr0[i].NumSynType):
if (NPtr0[i].STList[kk].No ==
ConMtx0[i][j].Syn[k].STPtr.No):
InList = TRUE
kk = kk + 1
if (InList == FALSE):
NPtr0[i].STList[kk] = ConMtx0[i][j].Syn[k].STPtr
NPtr0[i].NumSynType = NPtr0[i].NumSynType + 1
NPtr0[i].gfONsyn[kk] = 0.0
NPtr0[i].gfOFFsyn[kk] = 0.0
NoiseSyn = SynList()
NoiseSyn.NumSyn = NumSynType
NoiseSyn.Syn = []
for i in range(NoiseSyn.NumSyn):
NoiseSyn.Syn.append(Synapse())
for i in range(N):
for j in range(NoiseSyn.NumSyn):
STno = int(SynPar[0][numST - NoiseSyn.NumSyn + j] - 1)
NoiseSyn.Syn[j].STPtr = SynTPtr0[STno]
NoiseSyn.Syn[j].wgt = SynPar[4][numST - NoiseSyn.NumSyn + j]
NoiseSyn.Syn[j].dtax = SynPar[5][numST - NoiseSyn.NumSyn + j]
NoiseSyn.Syn[j].p_fail = SynPar[6][numST - NoiseSyn.NumSyn + j]
NPtr0[i].gfONnoise[j] = 0.0
NPtr0[i].gfOFFnoise[j] = 0.0
NoiseStep = 1 / (NoiseDistr.shape[1] - 1)
SynExpOn = [0] * NumSynType
SynExpOff = [0] * NumSynType
NumEvt = EvtTimes.shape[1]
NumView = ViewList.shape[0] * ViewList.shape[1]
fpOut = open("IDN_%i.dat" % UniquePrint, "w")
fpOut2 = open("IDN2_%i.dat" % UniquePrint, "w")
if (CtrPar[0][3] > NumVar):
CtrPar[0][3] = NumVar
NumOutp = 2
if (NumOutp > 0):
NumSynInp = [0] * N
N_osc = [0] * N
TnextSyn = [0] * N
t0 = Tstart
time_num = 0
while (t0 < Tstop):
if (t0 >= t_display):
print("%f percent" % (t0 * 100 / Tstop))
t_display = t0 + 100
t1 = t0 + dt0
EvtNo = -999
if (t1 > Tstop):
t1 = Tstop
for i in range(NumEvt):
if (EvtTimes[i * 2] > t0) and (EvtTimes[i * 2] <= t1):
t1 = EvtTimes[i * 2]
NextEvtT = t1
EvtNo = i * 2
else:
EvtOffT = EvtTimes[i * 2] + EvtTimes[i * 2 + 1]
if (EvtOffT > t0 and EvtOffT <= t1):
t1 = EvtOffT
NextEvtT = t1
EvtNo = i * 2 + 1
t11 = t1
for i in range(M):
if (InpNPtr0[i].SPtrain[InpNPtr0[i].SP_ind] > t0) and (
InpNPtr0[i].SPtrain[InpNPtr0[i].SP_ind] <= t11):
t11 = InpNPtr0[i].SPtrain[InpNPtr0[i].SP_ind]
print_flag = 1
else:
print_flag = 0
t1 = t11
for i in range(M):
if (InpNPtr0[i].SPtrain[InpNPtr0[i].SP_ind] == t1):
if (InpNPtr0[i].SP_ind > 0):
ISI_inp = t1 - \
InpNPtr0[i].SPtrain[InpNPtr0[i].SP_ind - 1]
else:
ISI_inp = 10.0e8
InpNPtr0[i].SpikeTimes[InpNPtr0[i].SP_ind] = InpNPtr0[i].SPtrain[InpNPtr0[i].SP_ind]
InpNPtr0[i].SP_ind = InpNPtr0[i].SP_ind + 1
j = NumSpike[i + N] % SizeHistOutput
for kk in range(InpNPtr0[i].NumPreSyn):
if (InpNPtr0[i].SDf[kk].use > 0.0):
InpNPtr0[i].SDf[kk].Adepr[j] = short_time(
SizeHistOutput).syndepr(InpNPtr0[i].SDf[kk], ISI_inp, j)
if (WriteST > 0):
fpISI = open(
"ISIu%d_%i.dat" %
(i + N, UniquePrint), "a")
fpISI.write("%f\n" % t1)
fpISI.close()
NumSpike[i + N] = NumSpike[i + N] + 1
for i in range(N):
t0_i = t0
if (t0_i < t1):
t1_i = t1
if (TnextSyn[i] > t0_i and TnextSyn[i] < t1_i):
t1_i = TnextSyn[i]
vp = copy.copy(NPtr0[i].v[0])
wp = copy.copy(NPtr0[i].v[1])
dt = t1_i - t0_i
if (NumSpike[i] > 0):
if ((t0_i -
NPtr0[i].SpikeTimes[(NumSpike[i] -
1) %
SizeHistOutput]) < 5):
flag_dv = 0
else:
flag_dv = 1
else:
flag_dv = 1
NPtr0[i] = copy.copy(NPtr0[i])
try:
NPtr0[i], gsyn_AN, gsyn_G, I_tot = short_time(
SizeHistOutput).update(
NPtr0[i], dt, NoiseSyn, flag_dv)
except OverflowError:
pass
if (stop_flag > 0):
print("%f %d %f %f\n" % (t0_i, i, vp, wp))
for j in range(NPtr0[i].NumSynType):
if (NPtr0[i].gfONsyn[j] <
0 or NPtr0[i].gfOFFsyn[j] < 0):
print(
"%d %d %f %f %f %f\n" %
(i, j, t0_i, t1_i, NPtr0[i].gfONsyn[j], NPtr0[i].gfOFFsyn[j]))
if (t1_i == t1):
gsyn1[i] = gsyn_AN
gsyn2[i] = gsyn_G
Isyn[i] = I_tot
if (I_tot < NPtr0[i].I_ref *
1.01 and I_tot > NPtr0[i].I_ref * 0.99):
flag_osc[i] = flag_osc[i] + 1
else:
flag_osc[i] = 0
if (flag_osc[i] >= 200 and NumOutp > 0):
N_osc[i] = N_osc[i] + 1
if ((NPtr0[i].v[0] >= NPtr0[i].Vup)
and (vp < NPtr0[i].Vup)):
t1_i = t0_i + dt * \
(NPtr0[i].Vup - vp) / (NPtr0[i].v[0] - vp)
if (NumSpike[i] > 0):
ISI = t1_i - \
NPtr0[i].SpikeTimes[(NumSpike[i] - 1) % SizeHistOutput]
else:
ISI = 10.0e8
if (ISI > 5):
w_Vup = wp + \
((NPtr0[i].v[1] - wp) / dt) * (t1_i - t0_i)
NPtr0[i].v[0] = NPtr0[i].Vr
NPtr0[i].v[1] = w_Vup + NPtr0[i].b
j = NumSpike[i] % SizeHistOutput
NPtr0[i].SpikeTimes[j] = t1_i
for kk in range(NPtr0[i].NumPreSyn):
if (NPtr0[i].SDf[kk].use > 0.0):
NPtr0[i].SDf[kk].Adepr[j] = short_time(
SizeHistOutput).syndepr(NPtr0[i].SDf[kk], ISI, j)
if (WriteST > 0):
fpISI = open(
"ISIu%d_%i.dat" %
(i, UniquePrint), "a")
fpISI.write("%f\n" % t1_i)
fpISI.close()
NumSpike[i] = NumSpike[i] + 1
dt = t1_i - t0_i
else:
NPtr0[i].v[0] = vp
NPtr0[i].v[1] = wp
# reset t1_i
t1_i = dt + t0_i
if (t1_i == t1):
gsyn_AN, I_tot, gsyn_G = short_time(
SizeHistOutput).set_gsyn(NPtr0[i], dt, vp, NoiseSyn)
gsyn1[i] = gsyn_AN
gsyn2[i] = gsyn_G
Isyn[i] = I_tot
for j in range(NoiseSyn.NumSyn):
SynExpOn[j] = math.exp(-dt /
(NoiseSyn.Syn[j].STPtr).tc_on)
SynExpOff[j] = math.exp(-dt /
(NoiseSyn.Syn[j].STPtr).tc_off)
rand_num = NoiseDistr[0][rand.randint(
0, 1 / NoiseStep)]
NPtr0[i].gfONnoise[j] = 0.0
NPtr0[i].gfOFFnoise[j] = 0.0
for j in range(NPtr0[i].NumSynType):
NPtr0[i].gfONsyn[j] *= math.exp(-dt /
(NPtr0[i].STList[j]).tc_on)
NPtr0[i].gfOFFsyn[j] *= math.exp(-dt /
(NPtr0[i].STList[j]).tc_off)
TnextSyn[i] = Tstop + 100.0
for j in range(N):
for k in range(ConMtx0[i][j].NumSyn):
kk = NumSpike[j] - 1
while (
kk >= 0 and (
NumSpike[j] -
kk) <= SizeHistOutput):
if (t0_i >= (
NPtr0[j].SpikeTimes[kk % SizeHistOutput] + ConMtx0[i][j].Syn[k].dtax)):
break
else:
if ((t1_i >= NPtr0[j].SpikeTimes[kk % SizeHistOutput] + ConMtx0[i][j].Syn[
k].dtax) and (
rand.uniform(0, 1) > ConMtx0[i][j].Syn[k].p_fail)):
for k2 in range(NPtr0[i].NumSynType):
if (NPtr0[i].STList[k2].No ==
ConMtx0[i][j].Syn[k].STPtr.No):
Aall = NPtr0[j].SDf[ConMtx0[i][j].Syn[k].PreSynIdx].Adepr[
kk % SizeHistOutput] * ConMtx0[i][j].Syn[k].wgt * \
ConMtx0[i][j].Syn[k].STPtr.Gsyn
NPtr0[i].gfONsyn[k2] += Aall
NPtr0[i].gfOFFsyn[k2] += Aall
if (NumOutp > 0):
NumSynInp[i] = NumSynInp[i] + 1.0
else:
if (NPtr0[j].SpikeTimes[kk % SizeHistOutput] +
ConMtx0[i][j].Syn[k].dtax < TnextSyn[i]):
TnextSyn[i] = NPtr0[j].SpikeTimes[kk %
SizeHistOutput] + ConMtx0[i][j].Syn[k].dtax
kk = kk - 1
for j in range(N, N + M):
for k in range(ConMtx0[i][j].NumSyn):
kk = NumSpike[j] - 1
while (kk >= 0):
if (t0_i >= (
InpNPtr0[j - N].SpikeTimes[kk] + ConMtx0[i][j].Syn[k].dtax)):
break
else:
if ((t1_i >= InpNPtr0[j - N].SpikeTimes[kk] + ConMtx0[i][j].Syn[k].dtax) and (
rand.uniform(0, 1) > ConMtx0[i][j].Syn[k].p_fail)):
for k2 in range(NPtr0[i].NumSynType):
if (NPtr0[i].STList[k2] ==
ConMtx0[i][j].Syn[k].STPtr):
Aall = InpNPtr0[j - N].SDf[ConMtx0[i][j].Syn[k].PreSynIdx].Adepr[kk %
SizeHistOutput] * ConMtx0[i][j].Syn[k].wgt * (ConMtx0[i][j].Syn[k].STPtr).Gsyn
NPtr0[i].gfONsyn[k2] += Aall
NPtr0[i].gfOFFsyn[k2] += Aall
if (NumOutp > 0):
NumSynInp[i] = NumSynInp[i] + 1.0
else:
if (InpNPtr0[j - N].SpikeTimes[kk] + \
ConMtx0[i][j].Syn[k].dtax < TnextSyn[i]):
TnextSyn[i] = InpNPtr0[j - N].SpikeTimes[kk] + \
ConMtx0[i][j].Syn[k].dtax
kk = kk - 1
t0_i = t1_i
for i in range(NumView):
fpOut.write("%lf %d" % (t1, ViewList[i][0]))
for k in range(int(CtrPar[0][3])):
fpOut.write(" %lf" % NPtr0[ViewList[i][0] - 1].v[k])
fpOut.write("\n")
for i in range(NumView):
fpOut2.write(" %f %f %f" %
(gsyn1[ViewList[i][0] -
1], gsyn2[ViewList[i][0] -
1], Isyn[ViewList[i][0] -
1]))
fpOut2.write("\n")
if (EvtNo >= 0 and t1 >= NextEvtT):
if ((EvtNo % 2) == 0):
for i in range(N):
NPtr0[i].Iinj = EvtMtx[int(i + (EvtNo / 2) * N)]
else:
for i in range(N):
NPtr0[i].Iinj = 0.0
t0 = t1
if (NumView > 0):
fpOut.close()
fpOut2.close()
STMtx = []
if (CtrPar[0][4] > 0):
for i in range(N + M):
if (os.path.exists('ISIu%d_0.dat' % i)):
ST = pd.read_table('ISIu%d_0.dat' % i, header=None)
content = []
for j in range(ST.shape[0]):
content.append(ST.iloc[j][0])
STMtx.append(content)
os.remove('ISIu%d_0.dat' % i)
else:
STMtx.append(-1)
T = []
V = []
if (ViewList is not None):
X = pd.read_table('IDN_%d.dat' % UniqueNum, header=None)
for i in range(X.shape[0]):
T.append(X.iloc[i][0])
content = []
for j in range(X.shape[1] - 1):
content.append(X.iloc[i][j + 1])
V.append(content)
os.remove('IDN_%d.dat' % UniqueNum)
os.remove('IDN2_0.dat')
scio.savemat('PFC_%dN_500ms.mat' %
(N + M), {'N': N, 'T': T, 'V': V, 'STMtx': STMtx})
class SynType:
def __init__(self):
"""
Parameters of short-term synaptic plasticity model
"""
self.No = 0
self.gmax = 0
self.tc_on = 0
self.tc_off = 0
self.Erev = 0
self.Mg_gate = 0
self.Mg_fac = 0
self.Mg_slope = 0
self.Mg_half = 0
self.Gsyn = 0
class Neuron:
"""
Parameters of neurons
"""
gfONsyn = None
gfOFFsyn = None
gfONnoise = None
gfOFFnoise = None
SpikeTimes = None
v = None
dv = None
def __init__(self):
MaxNumSTperN = six_layer_pfc().MaxNumSTperN
SizeHistOutput = six_layer_pfc().SizeHistOutput
self.Cm = 0
self.gL = 0
self.EL = 0
self.sf = 0
self.Vup = 0
self.tcw = 0
self.a = 0
self.b = 0
self.Vr = 0
self.Vth = 0
self.I_ref = 0
self.v_dep = 0
self.NumSynType = 0
self.Iinj = 0
self.v = [0] * 2
self.dv = [0] * 2
self.STList = []
self.gfONsyn = [0] * MaxNumSTperN
self.gfOFFsyn = [0] * MaxNumSTperN
self.gfONnoise = [0] * MaxNumSTperN
self.gfOFFnoise = [0] * MaxNumSTperN
self.SpikeTimes = [0] * SizeHistOutput
self.NumPreSyn = 0
self.PreSynList = []
self.SDf = []
class InpNeuron:
"""
Input parameters of neurons
"""
SPtrain = None
SpikeTimes = None
def __init__(self):
SizeHistInput = six_layer_pfc().SizeHistInput
self.SPtrain = [0] * SizeHistInput
self.SpikeTimes = [0] * SizeHistInput
self.SP_ind = 0
self.NumSynType = 0
self.NumPreSyn = 0
self.PreSynList = []
self.SDf = []
class Synapse:
"""
Synaptic parameters
"""
def __init__(self):
self.STPtr = SynType()
self.dtax = 0
self.wgt = 0
self.p_fail = 0
self.PreSynIdx = 0
class SynDepr:
"""
Parameters of synaptic current model
"""
Adepr = None
uprev = None
Rprev = None
def __init__(self):
SizeHistOutput = six_layer_pfc().SizeHistOutput
self.use = 0
self.tc_rec = 0
self.tc_fac = 0
self.Adepr = [0] * SizeHistOutput
self.uprev = [0] * SizeHistOutput
self.Rprev = [0] * SizeHistOutput
class SynList:
"""
Parameters of synapse list
"""
def __init__(self):
self.NumSyn = 0
self.Syn = []
if __name__ == '__main__':
"""
After downloading the data file on the network disk, modify the file path to the downloaded placement path
"""
test = six_layer_pfc()
inputpath = 'data100.mat'
test.mex_function(inputpath)
outputpath='PFC_99N_500ms.mat'
test.picture(outputpath)
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/MacaqueBrain/README.md
================================================
## Macaque Brain Simulation
## Description
Macaque Brain Simulation is a large scale brain modeling framework depending on braincog framework.
## Requirements:
* numpy >= 1.21.2
* scipy >= 1.8.0
* h5py >= 3.6.0
* torch >= 1.10
* torchvision >= 0.12.0
* torchaudio >= 0.11.0
* timm >= 0.5.4
* matplotlib >= 3.5.1
* einops >= 0.4.1
* thop >= 0.0.31
* pyyaml >= 6.0
* loris >= 0.5.3
* pandas >= 1.4.2
* tonic (special)
* pandas >= 1.4.2
## Input:
The binary connectivity matrix can be obtained from the following link:
https://drive.google.com/file/d/1LsNupIx3Nk-Cn_MowF6O-SCY27wdRYas/view?usp=sharing
The brain region's name can be obained from the following link:
https://drive.google.com/file/d/1iNI0HR3teUj4yshK8RlSJq6gIWbRdBI1/view?usp=sharing
## Example:
```shell
cd ~/examples/Multi-scale Brain Structure Simulation/MacaqueBrain/
python macaque_brain.py
```
## Parameters:
The parameters are similar to mouse brain simulation
## Citations:
If you find this package helpful, please consider citing the following papers:
@article{Liu2016,
author={Liu, Xin and Zeng, Yi and Zhang, Tielin and Xu, Bo},
title={Parallel Brain Simulator: A Multi-scale and Parallel Brain-Inspired Neural Network Modeling and Simulation Platform},
journal={Cognitive Computation},
year={2016},
month={Oct},
day={01},
volume={8},
number={5},
pages={967--981},
issn={1866-9964},
doi={10.1007/s12559-016-9411-y},
url={https://doi.org/10.1007/s12559-016-9411-y}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/MacaqueBrain/macaque_brain.py
================================================
import time
import numpy as np
import scipy.io as scio
import torch
from torch import nn
from braincog.base.node.node import *
from braincog.base.brainarea.BrainArea import *
import pandas as pd
import matplotlib.pyplot as plt
device = 'cuda:0'
class Syn(nn.Module):
def __init__(self, syn, weight, neuron_num, tao_d, tao_r, dt, device):
super().__init__()
self.pre = syn[1]
self.post = syn[0]
self.syn_num = len(syn)
self.w = torch.sparse_coo_tensor(syn.t(), weight,
size=(neuron_num, neuron_num))
self.tao_d = tao_d
self.tao_r = tao_r
self.dt = dt
self.lamda_d = self.dt / self.tao_d
self.lamda_r = self.dt / self.tao_r
self.s = torch.zeros(neuron_num, device=device)
self.r = torch.zeros(neuron_num, device=device)
self.dt = dt
def forward(self, neuron):
neuron.Iback = neuron.Iback + neuron.dt_over_tau * (
torch.randn(neuron.neuron_num, device=device, requires_grad=False) - neuron.Iback)
neuron.Ieff = neuron.Iback / neuron.sqrt_coeff * neuron.sig + neuron.mu
self.s = self.s + self.lamda_r * (-self.s + 1 / self.tao_d * neuron.spike)
self.r = self.r - self.lamda_d * self.r + self.dt * self.s
self.I = torch.sparse.mm(self.w, self.r.unsqueeze(-1)).squeeze() + neuron.Ieff
return self.I
class brain(nn.Module):
def __init__(self, syn, weight, neuron_model, p_neuron, dt, device):
super().__init__()
if neuron_model == 'HH':
self.neurons = HHNode(p_neuron, dt, device)
elif neuron_model == 'aEIF':
self.neurons = aEIF(p_neuron, dt, device)
self.neuron_num = len(p_neuron[0])
self.syns = Syn(syn, weight, self.neuron_num, 3, 6, dt, device)
def forward(self, inputs):
I = self.syns(self.neurons)
self.neurons(I)
def brain_region(neuron_num):
region = []
start = 0
end = 0
for i in range(len(neuron_num)):
end += neuron_num[i].item()
region.append([start, end])
start = end
return torch.tensor(region)
def neuron_type(neuron_num, ratio, regions):
neuron_num = neuron_num.reshape(-1, 1)
neuron_type = torch.floor(ratio * neuron_num).int() + regions[:, 0].reshape(-1, 1)
return neuron_type
def syn_within_region(syn_num, region):
start = 1
for neurons in region:
if start:
syn = torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)
start = 0
else:
syn = torch.concatenate((syn, torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)))
return syn
def syn_cross_region(weight_matrix, region):
start = 1
for i in range(len(weight_matrix)):
for j in range(len(weight_matrix)):
if weight_matrix[i][j] < 10:
continue
else:
pre = torch.randint(region[j][0], region[j][1],
size=(weight_matrix[i][j], 1), device=device)
post = torch.randint(region[i][0], region[i][1],
size=(weight_matrix[i][j], 1), device=device)
if start:
syn = torch.concatenate((post, pre), dim=1)
start = 0
else:
syn = torch.concatenate((syn, torch.concatenate((post, pre), dim=1)))
return syn
size = 10000
neuron_model = 'aEIF'
weight_matrix = torch.tensor(scio.loadmat('./maque.mat')['connect']) * 100
weight_matrix = weight_matrix.int()
syn_num = 10
NR = len(weight_matrix)
data = size * np.ones(NR)
neuron_num = np.array(data).astype(np.int32)
neuron_num = torch.from_numpy(neuron_num)
regions = brain_region(neuron_num)
ratio = torch.tensor([[0.7, 0.9, 1.0] * NR]).reshape(NR, 3)
neuron_types = neuron_type(neuron_num, ratio, regions)
syn_1 = syn_within_region(syn_num, regions)
syn_2 = syn_cross_region(weight_matrix, regions)
syn = torch.concatenate((syn_1, syn_2))
print(syn.shape)
weight = -torch.ones(len(syn), device=device, requires_grad=False)
if neuron_model == 'aEIF':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
v_reset = torch.zeros(regions[-1][1], device=device, requires_grad=False)
c_m = torch.zeros(regions[-1][1], device=device, requires_grad=False)
tao_w = torch.zeros(regions[-1][1], device=device, requires_grad=False)
alpha_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
beta_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
elif neuron_model == 'HH':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
for i in range(len(neuron_types)):
pre = syn[:, 0]
mask = (pre >= regions[i][0]) & (pre < neuron_types[i][0])
indices = torch.where(mask)
weight[indices] = 1.5
if neuron_model == 'aEIF':
if i < 177:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -44
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -110
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -110
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -66
c_m[regions[i][0]:neuron_types[i][0]] = 10
c_m[neuron_types[i][0]:neuron_types[i][1]] = 10
c_m[neuron_types[i][1]:neuron_types[i][2]] = 8.5
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
else:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -50
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -60
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -60
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -65
c_m[regions[i][0]:neuron_types[i][0]] = 20
c_m[neuron_types[i][0]:neuron_types[i][1]] = 2
c_m[neuron_types[i][1]:neuron_types[i][2]] = 4
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
elif neuron_model == 'HH':
threshold[regions[i][0]:neuron_types[i][0]] = 50
threshold[neuron_types[i][0]:neuron_types[i][1]] = 60
threshold[neuron_types[i][1]:neuron_types[i][2]] = 60
if neuron_model == 'aEIF':
p_neuron = [threshold, v_reset, c_m, tao_w, alpha_ad, beta_ad]
dt = 1
T = 300
elif neuron_model == 'HH':
p_neuron = [threshold, 120, 36, 0.3, 115, -12, 10.6, 1]
dt = 0.01
T = 10000
model = brain(syn, weight, neuron_model, p_neuron, dt, device)
Iraster = []
for t in range(T):
model(0)
print(torch.sum(model.neurons.spike))
Isp = torch.nonzero(model.neurons.spike)
print(len(Isp))
if (len(Isp) != 0):
left = t * torch.ones((len(Isp)), device=device, requires_grad=False)
left = left.reshape(len(left), 1)
mide = torch.concatenate((left, Isp), dim=1)
if (len(Isp) != 0) and (len(Iraster) != 0):
Iraster = torch.concatenate((Iraster, mide), dim=0)
if (len(Iraster) == 0) and (len(Isp) != 0):
Iraster = mide
Iraster = torch.tensor(Iraster).transpose(0, 1)
torch.save(Iraster, "./maque.pt")
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/MouseBrain/README.md
================================================
## Input:
* Program to enter a table of connection weights between 213 brain regions, which is saved in 'mouse_weight.pt'. The brain regions' name and neuron number are saved in 'mouse_brain_region.xlsx'. These two files are available in the follow link:
https://drive.google.com/drive/folders/1MWHY52gKPGneBEJxJN9DzE7thnLrhG1j?usp=sharing
## output
* The program generates a data file of the individual neuron firing time points recorded, and the large number of data points requires the use of drawing software to display the results.
## setting:
* scale: The scale of the number of neurons
* neuron_model: ‘HHNode’ or ‘aEIF’
* weight_matrix: Matrix of the number of synaptic connections between brain regions
* neuron_num: The number of neurons in each brain region
* ratio: the ratio of each neuron type in each brain region
* syn_num: average number of synapses per neuron within region
================================================
FILE: examples/Multiscale_Brain_Structure_Simulation/MouseBrain/mouse_brain.py
================================================
import time
import numpy as np
import scipy.io as scio
import torch
from torch import nn
from braincog.base.node.node import *
from braincog.base.brainarea.BrainArea import *
import pandas as pd
import matplotlib.pyplot as plt
device = 'cuda:0'
class Syn(nn.Module):
def __init__(self, syn, weight, neuron_num, tao_d, tao_r, dt, device):
super().__init__()
self.pre = syn[1]
self.post = syn[0]
self.syn_num = len(syn)
self.w = torch.sparse_coo_tensor(syn.t(), weight,
size=(neuron_num, neuron_num))
self.tao_d = tao_d
self.tao_r = tao_r
self.dt = dt
self.lamda_d = self.dt / self.tao_d
self.lamda_r = self.dt / self.tao_r
self.s = torch.zeros(neuron_num, device=device)
self.r = torch.zeros(neuron_num, device=device)
self.dt = dt
def forward(self, neuron):
neuron.Iback = neuron.Iback + neuron.dt_over_tau * (
torch.randn(neuron.neuron_num, device=device, requires_grad=False) - neuron.Iback)
neuron.Ieff = neuron.Iback / neuron.sqrt_coeff * neuron.sig + neuron.mu
self.s = self.s + self.lamda_r * (-self.s + 1 / self.tao_d * neuron.spike)
self.r = self.r - self.lamda_d * self.r + self.dt * self.s
self.I = torch.sparse.mm(self.w, self.r.unsqueeze(-1)).squeeze() + neuron.Ieff
return self.I
class brain(nn.Module):
def __init__(self, syn, weight, neuron_model, p_neuron, dt, device):
super().__init__()
if neuron_model == 'HH':
self.neurons = HHNode(p_neuron, dt, device)
elif neuron_model == 'aEIF':
self.neurons = aEIF(p_neuron, dt, device)
self.neuron_num = len(p_neuron[0])
self.syns = Syn(syn, weight, self.neuron_num, 3, 6, dt, device)
def forward(self, inputs):
I = self.syns(self.neurons)
self.neurons(I)
def brain_region(neuron_num):
region = []
start = 0
end = 0
for i in range(len(neuron_num)):
end += neuron_num[i].item()
region.append([start, end])
start = end
return torch.tensor(region)
def neuron_type(neuron_num, ratio, regions):
neuron_num = neuron_num.reshape(-1, 1)
neuron_type = torch.floor(ratio * neuron_num).int() + regions[:, 0].reshape(-1, 1)
return neuron_type
def syn_within_region(syn_num, region):
start = 1
for neurons in region:
if start:
syn = torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)
start = 0
else:
syn = torch.concatenate((syn, torch.randint(neurons[0], neurons[1],
size=((neurons[1]-neurons[0]) * syn_num, 2), device=device)))
return syn
def syn_cross_region(weight_matrix, region):
start = 1
for i in range(len(weight_matrix)):
for j in range(len(weight_matrix)):
if weight_matrix[i][j] < 10:
continue
else:
pre = torch.randint(region[j][0], region[j][1],
size=(weight_matrix[i][j], 1), device=device)
post = torch.randint(region[i][0], region[i][1],
size=(weight_matrix[i][j], 1), device=device)
if start:
syn = torch.concatenate((post, pre), dim=1)
start = 0
else:
syn = torch.concatenate((syn, torch.concatenate((post, pre), dim=1)))
return syn
scale = 0.1
neuron_model = 'aEIF'
weight_matrix = torch.load('./mouse_weight.pt') * scale
weight_matrix = weight_matrix.int()
data = pd.read_excel('./mouse_brain_region.xlsx', sheet_name='Sheet1', header=None)
data = data.values
name = data[0]
neuron_num = np.array(data[1] * scale).astype(np.int32)
neuron_num = torch.from_numpy(neuron_num)
ratio = torch.tensor([[0.7, 0.9, 1.0] * 213]).reshape(213, 3)
syn_num = 10
regions = brain_region(neuron_num)
neuron_types = neuron_type(neuron_num, ratio, regions)
syn_1 = syn_within_region(syn_num, regions)
syn_2 = syn_cross_region(weight_matrix, regions)
syn = torch.concatenate((syn_1, syn_2))
print(syn.shape)
weight = -torch.ones(len(syn), device=device, requires_grad=False)
if neuron_model == 'aEIF':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
v_reset = torch.zeros(regions[-1][1], device=device, requires_grad=False)
c_m = torch.zeros(regions[-1][1], device=device, requires_grad=False)
tao_w = torch.zeros(regions[-1][1], device=device, requires_grad=False)
alpha_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
beta_ad = torch.zeros(regions[-1][1], device=device, requires_grad=False)
elif neuron_model == 'HH':
threshold = torch.zeros(regions[-1][1], device=device, requires_grad=False)
for i in range(len(neuron_types)):
pre = syn[:, 0]
mask = (pre >= regions[i][0]) & (pre < neuron_types[i][0])
indices = torch.where(mask)
weight[indices] = 1.5
if neuron_model == 'aEIF':
if i < 177:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -44
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -110
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -110
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -66
c_m[regions[i][0]:neuron_types[i][0]] = 10
c_m[neuron_types[i][0]:neuron_types[i][1]] = 10
c_m[neuron_types[i][1]:neuron_types[i][2]] = 8.5
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
else:
threshold[regions[i][0]:neuron_types[i][0]] = -50
threshold[neuron_types[i][0]:neuron_types[i][1]] = -50
threshold[neuron_types[i][1]:neuron_types[i][2]] = -45
v_reset[regions[i][0]:neuron_types[i][0]] = -60
v_reset[neuron_types[i][0]:neuron_types[i][1]] = -60
v_reset[neuron_types[i][1]:neuron_types[i][2]] = -65
c_m[regions[i][0]:neuron_types[i][0]] = 20
c_m[neuron_types[i][0]:neuron_types[i][1]] = 2
c_m[neuron_types[i][1]:neuron_types[i][2]] = 4
tao_w[regions[i][0]:neuron_types[i][0]] = 1
tao_w[neuron_types[i][0]:neuron_types[i][1]] = 2
tao_w[neuron_types[i][1]:neuron_types[i][2]] = 2
alpha_ad[regions[i][0]:neuron_types[i][0]] = 0
alpha_ad[neuron_types[i][0]:neuron_types[i][1]] = -0.2
alpha_ad[neuron_types[i][1]:neuron_types[i][2]] = -0.2
beta_ad[regions[i][0]:neuron_types[i][0]] = 0
beta_ad[neuron_types[i][0]:neuron_types[i][1]] = 0.45
beta_ad[neuron_types[i][1]:neuron_types[i][2]] = 0.45
elif neuron_model == 'HH':
threshold[regions[i][0]:neuron_types[i][0]] = 50
threshold[neuron_types[i][0]:neuron_types[i][1]] = 60
threshold[neuron_types[i][1]:neuron_types[i][2]] = 60
if neuron_model == 'aEIF':
p_neuron = [threshold, v_reset, c_m, tao_w, alpha_ad, beta_ad]
dt = 1
T = 300
elif neuron_model == 'HH':
p_neuron = [threshold, 120, 36, 0.3, 115, -12, 10.6, 1]
dt = 0.01
T = 10000
model = brain(syn, weight, neuron_model, p_neuron, dt, device)
Iraster = []
for t in range(T):
model(0)
print(torch.sum(model.neurons.spike))
Isp = torch.nonzero(model.neurons.spike)
print(len(Isp))
if (len(Isp) != 0):
left = t * torch.ones((len(Isp)), device=device, requires_grad=False)
left = left.reshape(len(left), 1)
mide = torch.concatenate((left, Isp), dim=1)
if (len(Isp) != 0) and (len(Iraster) != 0):
Iraster = torch.concatenate((Iraster, mide), dim=0)
if (len(Iraster) == 0) and (len(Isp) != 0):
Iraster = mide
Iraster = torch.tensor(Iraster).transpose(0, 1)
torch.save(Iraster, "./mouse.pt")
================================================
FILE: examples/Perception_and_Learning/Conversion/burst_conversion/CIFAR10_VGG16.py
================================================
import sys
sys.path.append('../../..')
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import matplotlib.pyplot as plt
import numpy as np
import time
from braincog.utils import setup_seed
from braincog.datasets.datasets import get_cifar10_data
device = torch.device('cuda:5' if torch.cuda.is_available() else 'cpu')
DATA_DIR = '/data/datasets'
class VGG16(nn.Module):
def __init__(self, relu_max=1): # 1 3e38
super(VGG16, self).__init__()
cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), nn.BatchNorm2d(64), nn.ReLU(True),
nn.Conv2d(64, 64, 3, 1, 1), nn.BatchNorm2d(64), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, 3, 1, 1), nn.BatchNorm2d(128), nn.ReLU(True),
nn.Conv2d(128, 128, 3, 1, 1), nn.BatchNorm2d(128), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(128, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True),
nn.Conv2d(256, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True),
nn.Conv2d(256, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(256, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.MaxPool2d(2, 2))
self.conv = cnn
self.fc = nn.Linear(512, 10, bias=True)
def forward(self, input):
conv = self.conv(input)
x = conv.view(conv.shape[0], -1)
output = self.fc(x)
return output
def get_cifar10_loader(batch_size, train_batch=None, num_workers=4, conversion=False, distributed=False):
normalize = transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(),
CIFAR10Policy(),
transforms.ToTensor(),
Cutout(n_holes=1, length=16),
normalize])
transform_test = transforms.Compose([transforms.ToTensor(), normalize])
train_batch = batch_size if train_batch is None else train_batch
cifar10_train = datasets.CIFAR10(root=DATA_DIR, train=True, download=False, transform=transform_test if conversion else transform_train)
cifar10_test = datasets.CIFAR10(root=DATA_DIR, train=False, download=False, transform=transform_test)
if distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(cifar10_train)
val_sampler = torch.utils.data.distributed.DistributedSampler(cifar10_test, shuffle=False, drop_last=True)
train_iter = torch.utils.data.DataLoader(cifar10_train, batch_size=train_batch, shuffle=False, num_workers=num_workers, pin_memory=True, sampler=train_sampler)
test_iter = torch.utils.data.DataLoader(cifar10_test, batch_size=batch_size, shuffle=False, num_workers=num_workers, pin_memory=True, sampler=val_sampler)
else:
train_iter = torch.utils.data.DataLoader(cifar10_train, batch_size=train_batch, shuffle=True, num_workers=num_workers, pin_memory=True)
test_iter = torch.utils.data.DataLoader(cifar10_test, batch_size=batch_size, shuffle=False, num_workers=num_workers, pin_memory=True)
return train_iter, test_iter
def train(net, train_iter, test_iter, optimizer, scheduler, device, num_epochs, losstype='mse'):
best = 0
net = net.to(device)
print("training on ", device)
if losstype == 'mse':
loss = torch.nn.MSELoss()
else:
loss = torch.nn.CrossEntropyLoss(label_smoothing=0.1)
losses = []
for epoch in range(num_epochs):
for param_group in optimizer.param_groups:
learning_rate = param_group['lr']
losss = []
train_l_sum, train_acc_sum, n, batch_count, start = 0.0, 0.0, 0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
label = y
if losstype == 'mse':
label = F.one_hot(y, 10).float()
l = loss(y_hat, label)
losss.append(l.cpu().item())
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
scheduler.step()
test_acc = evaluate_accuracy(test_iter, net)
losses.append(np.mean(losss))
print('epoch %d, lr %.6f, loss %.6f, train acc %.6f, test acc %.6f, time %.1f sec'
% (epoch + 1, learning_rate, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
if test_acc > best:
best = test_acc
torch.save(net.state_dict(), './CIFAR10_VGG16.pth')
def evaluate_accuracy(data_iter, net, device=None, only_onebatch=False):
if device is None and isinstance(net, torch.nn.Module):
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
net.eval()
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train()
n += y.shape[0]
if only_onebatch: break
return acc_sum / n
if __name__ == '__main__':
setup_seed(42)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
batch_size = 128
train_iter, test_iter, _, _ = get_cifar10_data(batch_size)
# train_iter, test_iter = get_cifar10_loader(batch_size)
print('dataloader finished')
lr, num_epochs = 0.05, 300
net = VGG16()
optimizer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9, weight_decay=5e-4)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, eta_min=0, T_max=num_epochs)
train(net, train_iter, test_iter, optimizer, scheduler, device, num_epochs, losstype='crossentropy')
net.load_state_dict(torch.load("./CIFAR10_VGG16.pth", map_location=device))
net = net.to(device)
acc = evaluate_accuracy(test_iter, net, device)
print(acc)
================================================
FILE: examples/Perception_and_Learning/Conversion/burst_conversion/README.md
================================================
# Conversion Method
Training deep spiking neural network with ann-snn conversion
replace ReLU and MaxPooling in pytorch model to make origin ANN to be converted SNN to finish complex tasks
## Results
```shell
python CIFAR10_VGG16.py
python converted_CIFAR10.py
```
You should first run the `CIFAR10_VGG16.py` to get a well-trained ANN.
Then `converted_CIFAR10.py` can be used to run the snn inference process.
### Citation
If you find this package helpful, please consider citing it:
```BibTex
@inproceedings{ijcai2022p345,
title = {Efficient and Accurate Conversion of Spiking Neural Network with Burst Spikes},
author = {Li, Yang and Zeng, Yi},
booktitle = {Proceedings of the Thirty-First International Joint Conference on
Artificial Intelligence, {IJCAI-22}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {2485--2491},
year = {2022},
month = {7},
}
@article{li2022spike,
title={Spike calibration: Fast and accurate conversion of spiking neural network for object detection and segmentation},
author={Li, Yang and He, Xiang and Dong, Yiting and Kong, Qingqun and Zeng, Yi},
journal={arXiv preprint arXiv:2207.02702},
year={2022}
}
```
================================================
FILE: examples/Perception_and_Learning/Conversion/burst_conversion/converted_CIFAR10.py
================================================
import sys
sys.path.append('../../..')
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import matplotlib
matplotlib.use('agg')
import numpy as np
from tqdm import tqdm
from copy import deepcopy
import matplotlib.pyplot as plt
import time
import os
from examples.Perception_and_Learning.Conversion.burst_conversion.CIFAR10_VGG16 import VGG16
from braincog.utils import setup_seed
from braincog.datasets.datasets import get_cifar10_data
from braincog.base.conversion import Convertor
import argparse
parser = argparse.ArgumentParser(description='Conversion')
parser.add_argument('--T', default=64, type=int, help='simulation time')
parser.add_argument('--p', default=0.99, type=float, help='percentile for data normalization. 0-1')
parser.add_argument('--gamma', default=5, type=int, help='burst spike and max spikes IF can emit')
parser.add_argument('--channelnorm', default=False, type=bool, help='use channel norm')
parser.add_argument('--lipool', default=True, type=bool, help='LIPooling')
parser.add_argument('--smode', default=True, type=bool, help='replace ReLU to IF')
parser.add_argument('--soft_mode', default=True, type=bool, help='soft reset or not')
parser.add_argument('--device', default='4', type=str, help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--cuda', default=True, type=bool, help='use cuda.')
parser.add_argument('--model_name', default='vgg16', type=str, help='model name. vgg16 or resnet20')
parser.add_argument('--merge', default=True, type=bool, help='merge conv and bn')
parser.add_argument('--train_batch', default=100, type=int, help='batch size for get max')
parser.add_argument('--batch_num', default=1, type=int, help='number of train batch')
parser.add_argument('--spicalib', default=0, type=int, help='allowance for spicalib')
parser.add_argument('--batch_size', default=128, type=int, help='batch size for testing')
parser.add_argument('--seed', default=42, type=int, help='seed')
args = parser.parse_args()
def evaluate_snn(test_iter, snn, device=None, duration=50):
accs = []
snn.eval()
for ind, (test_x, test_y) in tqdm(enumerate(test_iter)):
test_x = test_x.to(device)
test_y = test_y.to(device)
n = test_y.shape[0]
out = 0
with torch.no_grad():
snn.reset()
acc = []
# for t in tqdm(range(duration)):
for t in range(duration):
out += snn(test_x)
result = torch.max(out, 1).indices
result = result.to(device)
acc_sum = (result == test_y).float().sum().item()
acc.append(acc_sum / n)
accs.append(np.array(acc))
accs = np.array(accs).mean(axis=0)
i, show_step = 1, []
while 2 ** i <= duration:
show_step.append(2 ** i - 1)
i = i + 1
for iii in show_step:
print("timestep", str(iii).zfill(3) + ':', accs[iii])
print("best acc: ", max(accs))
if __name__ == '__main__':
print("Setting Arguments.. : ", args)
print("----------------------------------------------------------")
setup_seed(seed=args.seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
device = torch.device("cuda:%s" % args.device) if args.cuda else 'cpu'
train_iter, _, _, _ = get_cifar10_data(args.train_batch, same_da=True)
_, test_iter, _, _ = get_cifar10_data(args.batch_size, same_da=True)
if args.model_name == 'vgg16':
net = VGG16()
net.load_state_dict(torch.load("./CIFAR10_VGG16.pth", map_location=device))
net.eval()
net = net.to(device)
converter = Convertor(dataloader=train_iter,
device=device,
p=args.p,
channelnorm=args.channelnorm,
lipool=args.lipool,
gamma=args.gamma,
soft_mode=args.soft_mode,
merge=args.merge,
batch_num=args.batch_num,
spicalib=args.spicalib
)
snn = converter(net)
evaluate_snn(test_iter, snn, device, duration=args.T)
================================================
FILE: examples/Perception_and_Learning/Conversion/msat_conversion/CIFAR10_VGG16.py
================================================
import sys
sys.path.append('../../..')
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import matplotlib.pyplot as plt
import numpy as np
import time
from braincog.utils import setup_seed
from braincog.datasets.datasets import get_cifar10_data
device = torch.device('cuda:5' if torch.cuda.is_available() else 'cpu')
DATA_DIR = '/data/datasets'
class VGG16(nn.Module):
def __init__(self, relu_max=1): # 1 3e38
super(VGG16, self).__init__()
cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), nn.BatchNorm2d(64), nn.ReLU(True),
nn.Conv2d(64, 64, 3, 1, 1), nn.BatchNorm2d(64), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, 3, 1, 1), nn.BatchNorm2d(128), nn.ReLU(True),
nn.Conv2d(128, 128, 3, 1, 1), nn.BatchNorm2d(128), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(128, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True),
nn.Conv2d(256, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True),
nn.Conv2d(256, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(256, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.MaxPool2d(2, 2))
self.conv = cnn
self.fc = nn.Linear(512, 10, bias=True)
def forward(self, input):
conv = self.conv(input)
x = conv.view(conv.shape[0], -1)
output = self.fc(x)
return output
def get_cifar10_loader(batch_size, train_batch=None, num_workers=4, conversion=False, distributed=False):
normalize = transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(),
CIFAR10Policy(),
transforms.ToTensor(),
Cutout(n_holes=1, length=16),
normalize])
transform_test = transforms.Compose([transforms.ToTensor(), normalize])
train_batch = batch_size if train_batch is None else train_batch
cifar10_train = datasets.CIFAR10(root=DATA_DIR, train=True, download=False, transform=transform_test if conversion else transform_train)
cifar10_test = datasets.CIFAR10(root=DATA_DIR, train=False, download=False, transform=transform_test)
if distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(cifar10_train)
val_sampler = torch.utils.data.distributed.DistributedSampler(cifar10_test, shuffle=False, drop_last=True)
train_iter = torch.utils.data.DataLoader(cifar10_train, batch_size=train_batch, shuffle=False, num_workers=num_workers, pin_memory=True, sampler=train_sampler)
test_iter = torch.utils.data.DataLoader(cifar10_test, batch_size=batch_size, shuffle=False, num_workers=num_workers, pin_memory=True, sampler=val_sampler)
else:
train_iter = torch.utils.data.DataLoader(cifar10_train, batch_size=train_batch, shuffle=True, num_workers=num_workers, pin_memory=True)
test_iter = torch.utils.data.DataLoader(cifar10_test, batch_size=batch_size, shuffle=False, num_workers=num_workers, pin_memory=True)
return train_iter, test_iter
def train(net, train_iter, test_iter, optimizer, scheduler, device, num_epochs, losstype='mse'):
best = 0
net = net.to(device)
print("training on ", device)
if losstype == 'mse':
loss = torch.nn.MSELoss()
else:
loss = torch.nn.CrossEntropyLoss(label_smoothing=0.1)
losses = []
for epoch in range(num_epochs):
for param_group in optimizer.param_groups:
learning_rate = param_group['lr']
losss = []
train_l_sum, train_acc_sum, n, batch_count, start = 0.0, 0.0, 0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
label = y
if losstype == 'mse':
label = F.one_hot(y, 10).float()
l = loss(y_hat, label)
losss.append(l.cpu().item())
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
scheduler.step()
test_acc = evaluate_accuracy(test_iter, net)
losses.append(np.mean(losss))
print('epoch %d, lr %.6f, loss %.6f, train acc %.6f, test acc %.6f, time %.1f sec'
% (epoch + 1, learning_rate, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
if test_acc > best:
best = test_acc
torch.save(net.state_dict(), './CIFAR10_VGG16.pth')
def evaluate_accuracy(data_iter, net, device=None, only_onebatch=False):
if device is None and isinstance(net, torch.nn.Module):
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
net.eval()
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train()
n += y.shape[0]
if only_onebatch: break
return acc_sum / n
if __name__ == '__main__':
setup_seed(42)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
batch_size = 128
train_iter, test_iter, _, _ = get_cifar10_data(batch_size)
# train_iter, test_iter = get_cifar10_loader(batch_size)
print('dataloader finished')
lr, num_epochs = 0.05, 300
net = VGG16()
optimizer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9, weight_decay=5e-4)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, eta_min=0, T_max=num_epochs)
train(net, train_iter, test_iter, optimizer, scheduler, device, num_epochs, losstype='crossentropy')
net.load_state_dict(torch.load("./CIFAR10_VGG16.pth", map_location=device))
net = net.to(device)
acc = evaluate_accuracy(test_iter, net, device)
print(acc)
================================================
FILE: examples/Perception_and_Learning/Conversion/msat_conversion/README.md
================================================
# Script for experiment
```shell
python converted_CIFAR10.py --useDET --useDTT
```
## Note: Convertor
please use `convertor.py` here to replace and override `braincog/base/conversion/convertor.py` if you want to run multi-stage adaptive threshold in this project.
## Citation
If you find the code and dataset useful in your research, please consider citing:
```
@article{he2023improving,
title={Improving the Performance of Spiking Neural Networks on Event-based Datasets with Knowledge Transfer},
author={He, Xiang and Zhao, Dongcheng and Li, Yang and Shen, Guobin and Kong, Qingqun and Zeng, Yi},
journal={arXiv preprint arXiv:2303.13077},
year={2023}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
## Contents
If you are confused about using it or have other feedback and comments, please feel free to contact us via [hexiang2021@ia.ac.cn](hexiang2021@ia.ac.cn).
================================================
FILE: examples/Perception_and_Learning/Conversion/msat_conversion/converted_CIFAR10.py
================================================
# -*- coding: utf-8 -*-
# Time : 2023/4/19 15:56
# Author : Regulus
# FileName: converted_CIFAR10.py
# Explain:
# Software: PyCharm
import sys
sys.path.append('..')
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
import torchvision.datasets as datasets
# import matplotlib
# matplotlib.use('agg')
import numpy as np
from tqdm import tqdm
from braincog.utils import setup_seed
import os
from examples.Perception_and_Learning.Conversion.msat_conversion.CIFAR10_VGG16 import VGG16
import argparse
from braincog.datasets.datasets import get_cifar10_data
from braincog.base.conversion import Convertor, FolderPath
parser = argparse.ArgumentParser(description='Conversion')
parser.add_argument('--T', default=256, type=int, help='simulation time')
parser.add_argument('--p', default=1, type=float, help='percentile for data normalization. 0-1')
parser.add_argument('--gamma', default=1, type=int, help='burst spike and max spikes IF can emit')
parser.add_argument('--lateral_inhi', default=True, type=bool, help='LIPooling')
parser.add_argument('--data_norm', default=True, type=bool, help=' whether use data norm or not')
parser.add_argument('--smode', default=True, type=bool, help='replace ReLU to IF')
parser.add_argument('--device', default='7', type=str, help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--cuda', default=True, type=bool, help='use cuda.')
parser.add_argument('--model_name', default='vgg16', type=str, help='model name. vgg16 or resnet20')
parser.add_argument('--train_batch', default=512, type=int, help='batch size for get max')
parser.add_argument('--batch_size', default=128, type=int, help='batch size for testing')
parser.add_argument('--seed', default=23, type=int, help='seed')
parser.add_argument('--useDET', action='store_true', default=False, help='use DET')
parser.add_argument('--useDTT', action='store_true', default=False, help='use DTT')
parser.add_argument('--useSC', action='store_true', default=False, help='use SpikeConfidence')
args = parser.parse_args()
def evaluate_snn(test_iter, snn, device=None, duration=50):
folder_path = "./result_conversion_{}/snn_timestep{}_p{}_LIPooling{}_Burst{}".format(
args.model_name, duration, args.p, args.lateral_inhi, args.gamma)
if not os.path.exists(folder_path): # 判断是否存在文件夹如果不存在则创建为文件夹
os.makedirs(folder_path)
snn.eval()
FolderPath.folder_path = folder_path
accs = []
for ind, (test_x, test_y) in enumerate(tqdm(test_iter)):
test_x = test_x.to(device)
test_y = test_y.to(device)
n = test_y.shape[0]
out = 0
with torch.no_grad():
snn.reset()
acc = []
for t in range(duration):
out += snn(test_x)
result = torch.max(out, 1).indices
result = result.to(device)
acc_sum = (result == test_y).float().sum().item()
acc.append(acc_sum / n)
# break
accs.append(np.array(acc))
if True:
f = open('{}/result.txt'.format(folder_path), 'w')
f.write("Setting Arguments.. : {}\n".format(args))
accs = np.array(accs).mean(axis=0)
for iii in range(256):
if iii == 0 or iii == 3 or iii == 7 or (iii + 1) % 16 == 0:
f.write("timestep {}:{}\n".format(str(iii+1).zfill(3), accs[iii]))
f.write("max accs: {}, timestep:{}\n".format(max(accs), np.where(accs == max(accs))))
f.close()
accs = torch.from_numpy(accs)
torch.save(accs, "{}/accs.pth".format(folder_path))
if __name__ == '__main__':
print("Setting Arguments.. : ", args)
print("----------------------------------------------------------")
setup_seed(seed=args.seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
device = torch.device("cuda:%s" % args.device) if args.cuda else 'cpu'
train_iter, _, _, _ = get_cifar10_data(args.train_batch, same_da=True)
_, test_iter, _, _ = get_cifar10_data(args.batch_size, same_da=True)
if args.model_name == 'vgg16':
net = VGG16()
# net.load_state_dict(torch.load("./CIFAR10_VGG16.pth", map_location=device))
net.eval()
net = net.to(device)
converter = Convertor(dataloader=train_iter,
device=device,
p=1.0,
channelnorm=False,
lipool=True,
gamma=1,
soft_mode=True,
merge=True,
batch_num=1,
spicalib=False,
useDET=args.useDET,
useDTT=args.useDTT,
useSC=args.useSC
)
snn = converter(net)
evaluate_snn(test_iter, snn, device, duration=args.T)
================================================
FILE: examples/Perception_and_Learning/Conversion/msat_conversion/convertor.py
================================================
import torch
import torch.nn as nn
from braincog.base.connection.layer import SMaxPool, LIPool
from .merge import mergeConvBN
from .spicalib import SpiCalib
import types
import os
import sys
layer_index = 0 # layer index for SNode
class FolderPath:
folder_path = "init"
class HookScale(nn.Module):
""" 在每个ReLU层后记录该层的百分位最大值
For channelnorm: 获取最大值时使用了torch.quantile
For layernorm: 使用sort,然后手动取百分比,因为quantile在计算单个通道时有上限,batch较大时易出错
"""
def __init__(self,
p: float = 0.9995,
channelnorm: bool = False,
gamma: float = 0.999,
):
super().__init__()
if channelnorm:
self.register_buffer('scale', torch.tensor(0.0))
else:
self.register_buffer('scale', torch.tensor(0.0))
self.p = p
self.channelnorm = channelnorm
self.gamma = gamma
def forward(self, x):
x = torch.where(x.detach() < self.gamma, x.detach(),
torch.tensor(self.gamma, dtype=x.dtype, device=x.device))
if len(x.shape) == 4 and self.channelnorm:
num_channel = x.shape[1]
tmp = torch.quantile(x.permute(1, 0, 2, 3).reshape(num_channel, -1), self.p, dim=1,
interpolation='lower') + 1e-10
self.scale = torch.max(tmp, self.scale)
else:
sort, _ = torch.sort(x.view(-1))
self.scale = torch.max(sort[int(sort.shape[0] * self.p) - 1], self.scale)
return x
class Hookoutput(nn.Module):
"""
在伪转换中为ReLU和ClipQuan提供包装,用于监控其输出
"""
def __init__(self, module):
super(Hookoutput, self).__init__()
self.activation = 0.
self.operation = module
def forward(self, x):
output = self.operation(x)
self.activation = output.detach()
return output
class Scale(nn.Module):
"""
对前向过程的值进行缩放
"""
def __init__(self, scale: float = 1.0):
super().__init__()
self.register_buffer('scale', scale)
def forward(self, x):
if len(self.scale.shape) == 1:
return self.scale.unsqueeze(0).unsqueeze(2).unsqueeze(3).expand_as(x) * x
else:
return self.scale * x
def reset(self):
"""
转换的网络来自ANN,需要将新附加上的脉冲module进行reset
判断module名称并调用各自节点的reset方法
"""
children = list(self.named_children())
for i, (name, child) in enumerate(children):
if isinstance(child, (SNode, LIPool, SMaxPool)):
child.reset()
else:
reset(child)
class Convertor(nn.Module):
"""ANN2SNN转换器
用于转换完整的pytorch模型,使用dataloader中部分数据进行最大值计算,通过p控制获取第p百分比最大值
channlenorm: https://arxiv.org/abs/1903.06530
channelnorm可以对每个通道获取最大值并进行权重归一化
gamma: https://arxiv.org/abs/2204.13271
gamma可以控制burst spikes的脉冲数,burst spike可以提高神经元的脉冲发放能力,减小信息残留
lipool: https://arxiv.org/abs/2204.13271
lipool用于使用侧向抑制机制进行最大池化,LIPooling能够对SNN中的最大池化进行有效的转换
soft_mode: https://arxiv.org/abs/1612.04052
soft_mode被称为软重置,可以减小重置过程神经元的信息损失,有效提高转换的性能
merge用于是否对网络中相邻的卷积和BN层进行融合
batch_norm控制对dataloader的数据集的用量
"""
def __init__(self,
dataloader,
device=None,
p=0.9995,
channelnorm=False,
lipool=True,
gamma=1,
soft_mode=True,
merge=True,
batch_num=1,
spicalib=0,
useDET=False, useDTT=False, useSC=None
):
super(Convertor, self).__init__()
self.dataloader = dataloader
self.device = device
self.p = p
self.channelnorm = channelnorm
self.lipool = lipool
self.gamma = gamma
self.soft_mode = soft_mode
self.merge = merge
self.batch_num = batch_num
self.spicalib = spicalib
self.useDET = useDET
self.useDTT = useDTT
self.useSC = useSC
def forward(self, model):
model.eval()
model = Convertor.register_hook(model, self.p, self.channelnorm, self.gamma)
model = Convertor.get_percentile(model, self.dataloader, self.device, batch_num=self.batch_num)
model = mergeConvBN(model) if self.merge else model
model = Convertor.replace_for_spike(model, self.lipool, self.soft_mode, self.gamma, self.spicalib, self.useDET,
self.useDTT, self.useSC)
model.reset = types.MethodType(reset, model)
return model
@staticmethod
def register_hook(model, p=0.99, channelnorm=False, gamma=0.999):
""" Reference: https://github.com/fangwei123456/spikingjelly
将网络的每一层后注册一个HookScale类
该方法在仿真上等效于与对权重进行归一化操作,且易扩展到任意结构的网络中
"""
children = list(model.named_children())
for _, (name, child) in enumerate(children):
if isinstance(child, nn.ReLU):
model._modules[name] = nn.Sequential(nn.ReLU(), HookScale(p, channelnorm, gamma))
else:
Convertor.register_hook(child, p, channelnorm, gamma)
return model
@staticmethod
def get_percentile(model, dataloader, device, batch_num=1):
"""
该函数需与具有HookScale层的网络配合使用
"""
for idx, (data, _) in enumerate(dataloader):
data = data.to(device)
if idx >= batch_num:
break
model(data)
return model
@staticmethod
def replace_for_spike(model, lipool=True, soft_mode=True, gamma=1, spicalib=0, useDET=False, useDTT=False, useSC=None):
"""
该函数用于将定义好的ANN模型转换为SNN模型
ReLU单元将被替换为脉冲神经元,
如果模型中使用了最大池化,lipool参数将定义使用常规模型还是LIPooling方法
"""
children = list(model.named_children())
for _, (name, child) in enumerate(children):
if isinstance(child, nn.Sequential) and len(child) == 2 and isinstance(child[0], nn.ReLU) and isinstance(child[1], HookScale):
global layer_index
model._modules[name] = nn.Sequential(
Scale(1.0 / child[1].scale),
SNode(soft_mode, gamma, useDET=useDET, useDTT=useDTT, useSC=useSC, layer_index=layer_index),
SpiCalib(spicalib),
Scale(child[1].scale)
)
layer_index += 1
if isinstance(child, nn.MaxPool2d):
model._modules[name] = LIPool(child) if lipool else SMaxPool(child)
else:
Convertor.replace_for_spike(child, lipool, soft_mode, gamma, useDET=useDET, useDTT=useDTT, useSC=useSC)
return model
class SNode(nn.Module):
"""
用于转换后的SNN的神经元模型
IF神经元模型由gamma=1确定,当gamma为其他大于1的值时,即为使用burst神经元模型
soft_mode用于定义神经元的重置方法,soft重置能够极大地减少神经元在重置过程的信息损失
"""
def __init__(self, soft_mode=False, gamma=5, useDET=False, useDTT=False, useSC=None, layer_index=1):
super(SNode, self).__init__()
self.threshold = 1.0
self.maxThreshold = 1.0
self.soft_mode = soft_mode
self.gamma = gamma
self.mem = 0
self.spike = 0
self.Vm = 0.
self.summem = 0.
self.t = 0
self.all_spike = 0
self.V_T = 0
self.useDET = useDET
self.useDTT = useDTT
self.useSC = useSC
self.layer_index = layer_index
# hyperparameters
self.alpha = 0
self.ka = 0
self.ki = 0
self.C = 0
self.tau_mp = 0
self.tau_rd = 0
# record sin
self.mem_16 = 0.0
self.spike_mask = 0
self.sin_spikenum = 0.0
self.sin_ratio = [] # snn中sin占负的比例
self.last_spike = 0
self.confidence = []
self.neg_ratio = [] # ann中负的占总的比例
self.sin_all_ratio = [] # snn中sin占总的比例
self.pos_all_ratio = [] # snn中pos占总的比例
self.should_all_ratio = [] # snn中pos应该发但是没发占总的比例
self.confidence = [] # snn中sin占所有发的比例
self.avg_error_spikenum = [] # snn中错发的平均个数
def forward(self, x):
self.mem = self.mem + x
self.spike = torch.zeros_like(x)
if self.t == 0:
self.threshold = torch.full(x.shape, 1.0 * self.maxThreshold).to(x.device)
self.V_T = -torch.full(x.shape, self.maxThreshold).to(x.device)
# init hyperparameters
hp = []
path = FolderPath.folder_path.split('/')
path = os.path.join(path[0], path[1], path[2], 'hyperparameters.txt')
with open(path, 'r') as f:
data = f.readlines() # 将txt中所有字符串读入data
for ind, line in enumerate(data):
numbers = line.split() # 将数据分隔
hp.append(list(map(float, numbers))[0]) # 转化为浮点数
self.alpha = hp[0]
self.ka = hp[1]
self.ki = hp[2]
self.C = hp[3]
self.tau_mp = hp[4]
self.tau_rd = hp[5]
else:
DTT = self.tau_mp * (self.alpha * (self.last_mem - self.Vm) + self.V_T + self.ka * torch.log(
1 + torch.exp((self.last_mem - self.Vm) / self.ki)))
DET = self.tau_rd * torch.exp(-1 * x / self.C)
if self.useDET is True and self.useDTT is True:
self.threshold = DET + DTT
elif self.useDTT is True:
self.threshold = DTT
elif self.useDET is True:
self.threshold = DET
else:
print("wrong logics")
sys.exit()
self.threshold = torch.sigmoid(self.threshold)
self.threshold *= self.maxThreshold
self.spike = (self.mem / self.threshold).floor().clamp(min=0, max=self.gamma)
self.soft_reset() if self.soft_mode else self.hard_reset
if self.useSC is True:
if self.t < 16:
# read confidence
path = FolderPath.folder_path.split('/')
path = os.path.join(path[0], path[1], path[2], 'neuron_confidence_vgg16.txt')
with open(path, 'r') as f:
data = f.readlines() # 将txt中所有字符串读入data
for ind, line in enumerate(data):
numbers = line.split() # 将数据分隔
self.confidence.append(list(map(float, numbers))[0]) # 转化为浮点数
mask = (torch.rand(x.shape) >= (1.0 - self.confidence[self.layer_index])).float().cuda()
self.spike = self.spike * mask # random drop
self.all_spike += self.spike
out = self.spike * self.threshold
self.t += 1
self.last_mem = self.mem
self.summem += self.mem
self.Vm = (self.summem / self.t)
return out
def hard_reset(self):
"""
硬重置后神经元的膜电势被重置为0
"""
self.mem = self.mem * (1 - self.spike.detach())
def soft_reset(self):
"""
软重置后神经元的膜电势为神经元当前膜电势减去阈值
"""
self.mem = self.mem - self.threshold * self.spike.detach()
def reset(self):
self.mem = 0
self.spike = 0
self.maxThreshold = 1.0
================================================
FILE: examples/Perception_and_Learning/IllusionPerception/AbuttingGratingIllusion/distortion/__init__.py
================================================
from .abutting_grating_illusion import ag_distort_28, ag_distort_224, ag_distort_silhouette, save_image, get_silhouette_data
================================================
FILE: examples/Perception_and_Learning/IllusionPerception/AbuttingGratingIllusion/distortion/abutting_grating_illusion/__init__.py
================================================
from .abutting_grating_distortion import ag_distort_28, ag_distort_224, ag_distort_silhouette, save_image, get_silhouette_data
================================================
FILE: examples/Perception_and_Learning/IllusionPerception/AbuttingGratingIllusion/distortion/abutting_grating_illusion/abutting_grating_distortion.py
================================================
import torch
from torchvision import datasets, transforms
import time
import os
import matplotlib.pyplot as plt
import torch
from torchvision import datasets, transforms
import time
import os
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import pickle
from PIL import Image
import numpy as np
from torchvision import utils
import os
seed = 1000
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def save_image(image, filename):
assert len(image.shape) == 3, "The image must have only three dimensions of C,W,H."
utils.save_image(image, filename)
def get_mnist_data(train = False, batch_size = 100):
path = './datasets/' # might need to change based on where to call this function
#transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
transform = transforms.Compose([transforms.ToTensor()])
if train:
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(path, train=True, download=False, transform=transform),
batch_size=batch_size, shuffle=False)
return train_loader
else:
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(path, train=False, download=False, transform=transform),
batch_size=batch_size, shuffle=False)
return test_loader
def get_silhouette_data(path):
'''
path: dir path to the silhouette image samples of 16-clas-ImageNet
'''
labels = os.listdir(path)
datasets = []
#transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
transform = transforms.Compose([transforms.ToTensor()])
for label in labels:
for img_name in os.listdir(f"{path}/{label}"):
img_path = f"{path}/{label}/{img_name}"
img = Image.open(img_path)
img = transform(img).unsqueeze(0)
datasets.append((img, label))
return datasets
def ag_distort_28(imgs, threshold=0, interval=4, phase=2, direction=(1,0)):
#return imgs
assert len(imgs.shape) == 4, "The images must have four dimensions of B,C,W,H."
B,C,W,H = imgs.shape
mask_fg = (imgs>threshold).float()
mask_bg = 1 - mask_fg
gratings_fg = torch.zeros_like(imgs)
gratings_bg = torch.zeros_like(imgs)
for w in range(W):
for h in range(H):
if (direction[0]*w+direction[1]*h)%interval==0:
gratings_fg[:,:,w,h] = 1
if (direction[0]*w+direction[1]*h)%interval==phase:
gratings_bg[:,:,w,h] = 1
masked_gratings_fg = mask_fg*gratings_fg
masked_gratings_bg = mask_bg*gratings_bg
ag_image = masked_gratings_fg + masked_gratings_bg
return ag_image
def transform_224(imgs):
imgs = torch.nn.functional.interpolate(imgs, scale_factor = 8, mode = 'bilinear', align_corners = False)
imgs = torch.cat([imgs, imgs, imgs], dim=1)
return imgs
def ag_distort_224(imgs, threshold=0, interval=8, phase=4, direction=(1,0)):
assert len(imgs.shape) == 4, "The images must have four dimensions of C,W,H."
imgs = torch.nn.functional.interpolate(imgs, scale_factor = 8, mode = 'bilinear', align_corners = False)
imgs = torch.cat([imgs, imgs, imgs], dim=1)
#return imgs
B,C,W,H = imgs.shape
mask_fg = (imgs>threshold).float()
mask_bg = 1 - mask_fg
gratings_fg = torch.zeros_like(imgs)
gratings_bg = torch.zeros_like(imgs)
for w in range(W):
for h in range(H):
if (direction[0]*w+direction[1]*h)%interval==0:
gratings_fg[:,:,w,h] = 1
if (direction[0]*w+direction[1]*h)%interval==phase:
gratings_bg[:,:,w,h] = 1
masked_gratings_fg = mask_fg*gratings_fg
masked_gratings_bg = mask_bg*gratings_bg
ag_image = masked_gratings_fg + masked_gratings_bg
return ag_image
def ag_distort_silhouette(imgs, threshold=0.5, interval=2, phase=1, direction=(1,0)):
assert len(imgs.shape) == 4, "The image must have only three dimensions of C,W,H."
#imgs = torch.nn.functional.interpolate(imgs, scale_factor = 2, mode = 'bilinear', align_corners = False)
B,C,W,H = imgs.shape
mask_fg = (imgs 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
genotype = eval('genotypes.%s' % args.arch)
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
C=args.init_channels,
layers=args.layers,
auxiliary=args.auxiliary,
genotype=genotype,
parse_method=args.parse_method,
back_connection=args.back_connection,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
)
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=list(range(args.num_gpu))).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
# print(model.get_attr('mu'))
# print(model.get_attr('sigma'))
# if args.critical_loss or args.spike_rate:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model, device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
temporal_flatten=args.temporal_flatten,
portion=args.train_portion,
_logger=_logger,
)
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
if args.distributed:
state_dict = torch.load(args.eval_checkpoint)['state_dict_ema']
new_state_dict = OrderedDict()
# add module prefix for DDP
for k, v in state_dict.items():
k = 'module.' + k
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
# else:
# load_checkpoint(model, args.eval_checkpoint, args.model_ema)
for i in range(1):
val_metrics = validate(start_epoch, model, loader_eval, validate_loss_fn, args,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
print(f"Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
# return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=output_dir, recovery_dir=output_dir, decreasing=decreasing)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
if args.distributed:
loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler, model_ema=model_ema, mixup_fn=mixup_fn)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics = validate(epoch, model, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics = validate(
epoch, model_ema.ema, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast, log_suffix=' (EMA)',
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(output_dir, 'summary.csv'),
write_header=best_metric is None)
# if saver is not None and epoch >= args.n_warm_up:
if saver is not None:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
except KeyboardInterrupt:
pass
if best_metric is not None:
_logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and loader.mixup_enabled:
loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
model.drop_path_prob = args.drop_path_prob * epoch / args.epochs
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
# t, k = adjust_surrogate_coeff(100, args.epochs)
# model.set_attr('t', t)
# model.set_attr('k', k)
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
if not args.prefetcher or args.dataset != 'imnet':
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
if mixup_fn is not None:
inputs, target = mixup_fn(inputs, target)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
with amp_autocast():
output = model(inputs)
loss = loss_fn(output, target)
if not (args.cut_mix | args.mix_up | args.event_mix) and args.dataset != 'imnet':
# print(output.shape, target.shape)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
if args.opt == 'lamb':
optimizer.step(epoch=epoch)
else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
losses_m.update(reduced_loss.item(), inputs.size(0))
closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args, amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
end = time.time()
last_idx = len(loader) - 1
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat) and not args.critical_loss:
model.set_requires_fp(True)
# if not args.critical_loss:
# model.set_requires_fp(False)
with amp_autocast():
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
if not args.distributed:
if visualize:
x = model.get_fp()
feature_path = os.path.join(args.output_dir, 'feature_map')
if os.path.exists(feature_path) is False:
os.mkdir(feature_path)
save_feature_map(x, feature_path)
# if not args.critical_loss:
# model_config.set_requires_fp(False)
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
tot_spike = model.get_tot_spike() if hasattr(model, 'get_tot_spike') else 0.
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'TotSpike: {tot_spike}'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
tot_spike=tot_spike
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg)])
if not args.distributed:
if tsne:
feature_vec = torch.cat(feature_vec)
feature_cls = torch.cat(feature_cls)
plot_tsne(feature_vec, feature_cls, os.path.join(args.output_dir, 't-sne-2d.eps'))
plot_tsne_3d(feature_vec, feature_cls, os.path.join(args.output_dir, 't-sne-3d.eps'))
if conf_mat:
logits_vec = torch.cat(logits_vec)
labels_vec = torch.cat(labels_vec)
plot_confusion_matrix(logits_vec, labels_vec, os.path.join(args.output_dir, 'confusion_matrix.eps'))
return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/Perception_and_Learning/NeuEvo/separate_loss.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
from braincog.base.utils.criterions import UnilateralMse
from utils import num_ops, type_num, edge_num
__all__ = ['ConvSeparateLoss', 'TriSeparateLoss']
class MseSeparateLoss(nn.modules.loss._Loss):
def __init__(self, weight=0.1, size_average=None, ignore_index=-100,
reduce=None, reduction='mean'):
super(MseSeparateLoss, self).__init__(size_average, reduce, reduction)
self.ignore_index = ignore_index
self.weight = weight
self.criterion = UnilateralMse(1.)
def forward(self, input1, target1, input2):
loss1 = self.criterion(input1, target1)
loss2 = -F.mse_loss(input2, torch.tensor(0.5,
requires_grad=False).cuda())
return loss1 + self.weight * loss2, loss1.item(), loss2.item()
class ConvSeparateLoss(nn.modules.loss._Loss):
"""Separate the weight value between each operations using L2"""
def __init__(self, loss1_fn, weight=0.1, size_average=None, ignore_index=-100,
reduce=None, reduction='mean'):
super(ConvSeparateLoss, self).__init__(size_average, reduce, reduction)
self.ignore_index = ignore_index
self.weight = weight
self.loss1_fn = loss1_fn
def forward(self, input1, target1, input2):
loss1 = self.loss1_fn(input1, target1)
# loss2 = -F.mse_loss(input2, torch.tensor(0.5, requires_grad=False).cuda())
# loss2 = -torch.std(input2, dim=-1).sum()
# + F.mse_loss(torch.mean(input2, dim=-1), torch.tensor(0.2, requires_grad=False).cuda())
# loss_std = 0
# loss_avg = 0.
# edge = edge_num + edge_num
# edge_input2 = torch.split(input2, edge, dim=0)
# for i in range(len(edge)):
# avg_e = 2 / (edge[i] * num_ops)
# loss_avg += 5 * F.mse_loss(torch.mean(edge_input2[i]), torch.tensor(avg_e, requires_grad=False).cuda())
# loss_std += -torch.std(edge_input2[i]).sum()
# loss2 = loss_std + loss_avg
# loss2 = torch.tensor([0.], device=input1.device)
loss2 = - 0.2 * torch.std(input2)
return loss1 + self.weight * loss2, loss1.item(), loss2.item()
class TriSeparateLoss(nn.modules.loss._Loss):
"""Separate the weight value between each operations using L1"""
def __init__(self, loss1_fn, weight=0.1, size_average=None, ignore_index=-100,
reduce=None, reduction='mean'):
super(TriSeparateLoss, self).__init__(size_average, reduce, reduction)
self.ignore_index = ignore_index
self.weight = weight
self.loss1_fn = loss1_fn
def forward(self, input1, target1, input2):
loss1 = F.cross_entropy(input1, target1)
loss2 = -F.l1_loss(input2, torch.tensor(0.5,
requires_grad=False).cuda())
return loss1 + self.weight * loss2, loss1.item(), loss2.item()
================================================
FILE: examples/Perception_and_Learning/NeuEvo/train.py
================================================
import os
import sys
import time
import logging
import torch
import utils as dutils
import argparse
import numpy as np
import torch.utils
import torch.nn as nn
from braincog.model_zoo.NeuEvo import genotypes
from braincog.model_zoo.NeuEvo.model import NetworkCIFAR as Network
import torchvision.datasets as dset
import torch.backends.cudnn as cudnn
from thop import profile
from braincog.datasets.datasets import build_transform
from braincog.base.utils.criterions import UnilateralMse
parser = argparse.ArgumentParser("cifar")
parser.add_argument('--data', type=str, default='/data/datasets',
help='location of the data corpus')
parser.add_argument('--dataset', type=str, default='cifar10',
help='cifar10 or cifar 100 for training')
parser.add_argument('--batch-size', type=int, default=128, help='batch size')
parser.add_argument('--learning_rate', type=float,
default=0.025, help='init learning rate')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--momentum', type=float, default=0.9, help='momentum')
parser.add_argument('--weight_decay', type=float,
default=3e-4, help='weight decay')
parser.add_argument('--report_freq', type=float,
default=50, help='report frequency')
parser.add_argument('--device', type=int, default=0, help='gpu device id')
parser.add_argument('--multi-gpus', action='store_true',
default=False, help='use multi gpus')
parser.add_argument('--parse_method', type=str,
default='darts', help='experiment name')
parser.add_argument('--epochs', type=int, default=600,
help='num of training epochs')
parser.add_argument('--init-channels', type=int,
default=64, help='num of init channels')
parser.add_argument('--layers', type=int, default=16,
help='total number of layers')
parser.add_argument('--model_path', type=str,
default='saved_models', help='path to save the model')
parser.add_argument('--auxiliary', action='store_true',
default=False, help='use auxiliary tower')
parser.add_argument('--auxiliary_weight', type=float,
default=0.4, help='weight for auxiliary loss')
parser.add_argument('--cutout', action='store_true',
default=False, help='use cutout')
parser.add_argument('--cutout_length', type=int,
default=16, help='cutout length')
parser.add_argument('--auto_aug', action='store_true',
default=False, help='use auto augmentation')
parser.add_argument('--drop_path_prob', type=float,
default=0.2, help='drop path probability')
parser.add_argument('--save', type=str, default='EXP', help='experiment name')
parser.add_argument('--seed', type=int, default=42, help='random seed')
parser.add_argument('--arch', type=str, default='DARTS',
help='which architecture to use')
parser.add_argument('--grad_clip', type=float,
default=5, help='gradient clipping')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='path to latest checkpoint (default: none)')
parser.add_argument('--img_size', default=32, type=int)
parser.add_argument('--step', default=8, type=int)
parser.add_argument('--node-type', default='PLIFNode', type=str)
parser.add_argument('--suffix', default='', type=str)
class TrainNetwork(object):
"""The main train network"""
def __init__(self, args):
super(TrainNetwork, self).__init__()
self.args = args
self.dur_time = 0
self._init_log()
self._init_device()
self._init_data_queue()
self._init_model()
def _init_log(self):
self.args.save = '/data/floyed/darts/logs/eval/' + self.args.arch + '/' + 'cifar10' + '/eval-{}-{}-{}'.format(
self.args.save, time.strftime('%Y%m%d-%H%M'), args.suffix)
dutils.create_exp_dir(self.args.save, scripts_to_save=None)
log_format = '%(asctime)s %(message)s'
logging.basicConfig(stream=sys.stdout, level=logging.INFO,
format=log_format, datefmt='%m/%d %I:%M:%S %p')
fh = logging.FileHandler(os.path.join(self.args.save, 'log.txt'))
fh.setFormatter(logging.Formatter(log_format))
self.logger = logging.getLogger('Architecture Training')
self.logger.addHandler(fh)
def _init_device(self):
if not torch.cuda.is_available():
self.logger.info('no gpu device available')
sys.exit(1)
np.random.seed(self.args.seed)
self.device_id = self.args.device
self.device = torch.device('cuda:{}'.format(
0 if self.args.multi_gpus else self.device_id))
cudnn.benchmark = True
torch.manual_seed(self.args.seed)
cudnn.enabled = True
torch.cuda.manual_seed(self.args.seed)
logging.info('gpu device = %d' % self.args.device)
logging.info("args = %s", self.args)
def _init_data_queue(self):
train_transform = build_transform(True, args.img_size)
valid_transform = build_transform(False, args.img_size)
if self.args.dataset == 'cifar10':
train_data = dset.CIFAR10(
root=self.args.data, train=True, download=True, transform=train_transform)
valid_data = dset.CIFAR10(
root=self.args.data, train=False, download=True, transform=valid_transform)
self.num_classes = 10
elif self.args.dataset == 'cifar100':
train_data = dset.CIFAR100(
root=self.args.data, train=True, download=True, transform=train_transform)
valid_data = dset.CIFAR100(
root=self.args.data, train=False, download=True, transform=valid_transform)
self.num_classes = 100
self.train_queue = torch.utils.data.DataLoader(
train_data, batch_size=self.args.batch_size, shuffle=True, pin_memory=True, num_workers=4)
self.valid_queue = torch.utils.data.DataLoader(
valid_data, batch_size=self.args.batch_size, shuffle=False, pin_memory=True, num_workers=4)
def _init_model(self):
genotype = eval('genotypes.%s' % self.args.arch)
model = Network(self.args.init_channels,
self.num_classes,
self.args.layers,
self.args.auxiliary,
genotype,
self.args.parse_method,
step=args.step,
node_type=args.node_type
)
flops, params = profile(model, inputs=(
torch.randn(1, 3, 32, 32),), verbose=False)
self.logger.info('flops = %fM', flops / 1e6)
self.logger.info('param size = %fM', params / 1e6)
# Try move model to multi gpus
if torch.cuda.device_count() > 1 and self.args.multi_gpus:
self.logger.info('use: %d gpus', torch.cuda.device_count())
model = nn.DataParallel(model)
else:
self.logger.info('gpu device = %d' % self.device_id)
torch.cuda.set_device(self.device_id)
self.model = model.to(self.device)
# criterion = nn.CrossEntropyLoss()
criterion = UnilateralMse(1.)
self.criterion = criterion.to(self.device)
self.optimizer = torch.optim.AdamW(
model.parameters(),
self.args.learning_rate,
weight_decay=self.args.weight_decay
)
self.best_acc_top1 = 0
# optionally resume from a checkpoint
if self.args.resume:
if os.path.isfile(self.args.resume):
print("=> loading checkpoint {}".format(self.args.resume))
checkpoint = torch.load(
self.args.resume, map_location=self.device)
self.dur_time = checkpoint['dur_time']
self.args.start_epoch = checkpoint['epoch']
self.best_acc_top1 = checkpoint['best_acc_top1']
self.args.drop_path_prob = checkpoint['drop_path_prob']
self.model.load_state_dict(checkpoint['state_dict'])
self.optimizer.load_state_dict(checkpoint['optimizer'])
print("=> loaded checkpoint '{}' (epoch {})".format(
self.args.resume, checkpoint['epoch']))
else:
print("=> no checkpoint found at '{}'".format(self.args.resume))
self.scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(self.optimizer, float(self.args.epochs), eta_min=0,
last_epoch=-1 if self.args.start_epoch == 0 else self.args.start_epoch)
# reload the scheduler if possible
if self.args.resume and os.path.isfile(self.args.resume):
checkpoint = torch.load(self.args.resume)
self.scheduler.load_state_dict(checkpoint['scheduler'])
def run(self):
self.logger.info('args = %s', self.args)
run_start = time.time()
for epoch in range(self.args.start_epoch, self.args.epochs):
self.scheduler.step()
self.logger.info('epoch % d / %d lr %e', epoch,
self.args.epochs, self.scheduler.get_lr()[0])
self.model.drop_path_prob = self.args.drop_path_prob * epoch / self.args.epochs
train_acc, train_obj = self.train()
self.logger.info('train loss %e, train acc %f',
train_obj, train_acc)
valid_acc_top1, valid_acc_top5, valid_obj = self.infer()
self.logger.info('valid loss %e, top1 valid acc %f top5 valid acc %f',
valid_obj, valid_acc_top1, valid_acc_top5)
self.logger.info('best valid acc %f', self.best_acc_top1)
is_best = False
if valid_acc_top1 > self.best_acc_top1:
self.best_acc_top1 = valid_acc_top1
is_best = True
dutils.save_checkpoint({
'epoch': epoch + 1,
'dur_time': self.dur_time + time.time() - run_start,
'state_dict': self.model.state_dict(),
'drop_path_prob': self.args.drop_path_prob,
'best_acc_top1': self.best_acc_top1,
'optimizer': self.optimizer.state_dict(),
'scheduler': self.scheduler.state_dict()
}, is_best, self.args.save)
self.logger.info('train epoches %d, best_acc_top1 %f, dur_time %s',
self.args.epochs, self.best_acc_top1,
dutils.calc_time(self.dur_time + time.time() - run_start))
def train(self):
objs = dutils.AvgrageMeter()
top1 = dutils.AvgrageMeter()
top5 = dutils.AvgrageMeter()
self.model.train()
for step, (input, target) in enumerate(self.train_queue):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
self.optimizer.zero_grad()
logits, logits_aux = self.model(input)
loss = self.criterion(logits, target)
if self.args.auxiliary:
loss_aux = self.criterion(logits_aux, target)
loss += self.args.auxiliary_weight * loss_aux
loss.backward()
nn.utils.clip_grad_norm_(
self.model.parameters(), self.args.grad_clip)
self.optimizer.step()
prec1, prec5 = dutils.accuracy(logits, target, topk=(1, 5))
n = input.size(0)
objs.update(loss.item(), n)
top1.update(prec1.item(), n)
top5.update(prec5.item(), n)
if step % self.args.report_freq == 0:
self.logger.info('train %03d %e %f %f', step,
objs.avg, top1.avg, top5.avg)
return top1.avg, objs.avg
def infer(self):
objs = dutils.AvgrageMeter()
top1 = dutils.AvgrageMeter()
top5 = dutils.AvgrageMeter()
self.model.eval()
with torch.no_grad():
for step, (input, target) in enumerate(self.valid_queue):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
logits, _ = self.model(input)
loss = self.criterion(logits, target)
prec1, prec5 = dutils.accuracy(logits, target, topk=(1, 5))
n = input.size(0)
objs.update(loss.item(), n)
top1.update(prec1.item(), n)
top5.update(prec5.item(), n)
if step % self.args.report_freq == 0:
self.logger.info('valid %03d %e %f %f',
step, objs.avg, top1.avg, top5.avg)
return top1.avg, top5.avg, objs.avg
if __name__ == '__main__':
args = parser.parse_args()
train_network = TrainNetwork(args)
train_network.run()
================================================
FILE: examples/Perception_and_Learning/NeuEvo/train_search.py
================================================
import os
import sys
import time
import numpy as np
import torch
import logging
import argparse
import torch.nn as nn
import torch.utils
import torch.nn.functional as F
import torchvision.datasets as dset
import torch.backends.cudnn as cudnn
from torch.autograd import Variable
from braincog.model_zoo.NeuEvo.model_search import Network, calc_weight, calc_loss
from braincog.model_zoo.NeuEvo.architect import Architect
from separate_loss import ConvSeparateLoss, TriSeparateLoss, MseSeparateLoss
import utils
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from braincog.datasets.datasets import *
from braincog.base.utils.criterions import *
torch.autograd.set_detect_anomaly(True)
parser = argparse.ArgumentParser("cifar")
parser.add_argument('--data', type=str, default='/data/datasets',
help='location of the data corpus')
parser.add_argument('--dataset', type=str, default='cifar10',
help='cifar10 or cifar 100 for searching')
parser.add_argument('--batch-size', type=int, default=128, help='batch size')
parser.add_argument('--learning_rate', type=float,
default=0.005, help='init learning rate')
parser.add_argument('--learning_rate_min', type=float,
default=0.001, help='min learning rate')
parser.add_argument('--momentum', type=float, default=0.9, help='momentum')
parser.add_argument('--weight_decay', type=float,
default=3e-4, help='weight decay')
parser.add_argument('--report_freq', type=float,
default=50, help='report frequency')
parser.add_argument('--aux_loss_weight', type=float,
default=10.0, help='weight decay')
parser.add_argument('--device', type=int, default=0, help='gpu device id')
parser.add_argument('--epochs', type=int, default=50,
help='num of training epochs')
parser.add_argument('--init-channels', type=int,
default=16, help='num of init channels')
parser.add_argument('--layers', type=int, default=6,
help='total number of layers')
parser.add_argument('--model_path', type=str,
default='saved_models', help='path to save the model')
parser.add_argument('--single_level', action='store_true',
default=False, help='use single level')
parser.add_argument('--sep_loss', type=str, default='l2',
help='path to save the model')
parser.add_argument('--cutout', action='store_true',
default=False, help='use cutout')
parser.add_argument('--cutout_length', type=int,
default=16, help='cutout length')
parser.add_argument('--auto_aug', action='store_true',
default=False, help='use auto augmentation')
parser.add_argument('--parse_method', type=str,
default='bio_darts', help='parse the code method')
parser.add_argument('--op_threshold', type=float,
default=0.85, help='threshold for edges')
parser.add_argument('--save', type=str, default='EXP', help='experiment name')
parser.add_argument('--seed', type=int, default=42, help='random seed')
parser.add_argument('--grad_clip', type=float,
default=5, help='gradient clipping')
parser.add_argument('--train_portion', type=float,
default=0.5, help='portion of training data')
parser.add_argument('--arch_learning_rate', type=float,
default=1e-3, help='learning rate for arch encoding')
parser.add_argument('--arch_lr_gamma', type=float, default=0.9,
help='learning rate for arch encoding')
parser.add_argument('--arch_weight_decay', type=float,
default=1e-3, help='weight decay for arch encoding')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='path to latest checkpoint (default: none)')
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
parser.add_argument('--img_size', default=32, type=int)
parser.add_argument('--smoothing', default=0.1, type=float)
parser.add_argument('--step', default=8, type=int)
parser.add_argument('--node-type', default='BiasPLIFNode', type=str)
parser.add_argument('--loss_fn', type=str, default='')
parser.add_argument('--back-connection', action='store_true')
parser.add_argument('--asbe', '--arch-search-begin-epoch',
type=int, default=0, dest='asbe')
parser.add_argument('--num-classes', type=int, default=10)
parser.add_argument('--spike-output',action='store_true')
parser.add_argument('--act-fun', type=str, default='GateGrad')
parser.add_argument('--suffix', default='', type=str)
args = parser.parse_args()
args.save = '/data/floyed/darts/logs/search/search-{}-{}-{}'.format(args.save, time.strftime("%Y%m%d-%H%M%S"),
args.suffix)
utils.create_exp_dir(args.save, scripts_to_save=None)
log_format = '%(asctime)s %(message)s'
logging.basicConfig(stream=sys.stdout, level=logging.INFO,
format=log_format, datefmt='%m/%d %I:%M:%S %p')
fh = logging.FileHandler(os.path.join(args.save, 'log.txt'))
fh.setFormatter(logging.Formatter(log_format))
logging.getLogger().addHandler(fh)
CIFAR_CLASSES = 10
def main():
args.spike_output = False
if not torch.cuda.is_available():
logging.info('no gpu device available')
sys.exit(1)
np.random.seed(args.seed)
torch.cuda.set_device(args.device)
# cudnn.benchmark = True
torch.manual_seed(args.seed)
# cudnn.enabled = True
torch.cuda.manual_seed(args.seed)
logging.info('gpu device = %d' % args.device)
logging.info("args = %s", args)
run_start = time.time()
start_epoch = 0
dur_time = 0
if args.loss_fn == 'mix':
criterion_train = MixLoss(LabelSmoothingCrossEntropy(
smoothing=args.smoothing).cuda())
criterion_val = MixLoss(nn.CrossEntropyLoss())
elif args.loss_fn == 'mse':
criterion_train = UnilateralMse(1.)
criterion_val = UnilateralMse(1.)
else:
criterion_train = LabelSmoothingCrossEntropy().cuda()
criterion_val = nn.CrossEntropyLoss().cuda()
criterion_train = ConvSeparateLoss(criterion_train, weight=args.aux_loss_weight) \
if args.sep_loss == 'l2' else TriSeparateLoss(criterion_train, weight=args.aux_loss_weight)
model = Network(args.init_channels, args.num_classes, args.layers, criterion_train,
steps=3, multiplier=3, stem_multiplier=3,
parse_method=args.parse_method, op_threshold=args.op_threshold,
step=args.step, node_type=args.node_type,
back_connection=args.back_connection, act_fun=args.act_fun,
dataset=args.dataset,
spike_output=False,
temporal_flatten=args.temporal_flatten)
model = model.cuda()
logging.info("param size = %fMB", utils.count_parameters_in_MB(model))
model_optimizer = torch.optim.AdamW(
model.parameters(),
args.learning_rate,
# momentum=args.momentum,
weight_decay=args.weight_decay)
# # train_transform, valid_transform = utils._data_transforms_cifar(args)
# train_transform = build_transform(True, args.img_size)
# valid_transform = build_transform(False, args.img_size)
# train_data = dset.CIFAR10(
# root=args.data, train=True, download=True, transform=train_transform)
#
# num_train = len(train_data)
# indices = list(range(num_train))
# split = int(np.floor(args.train_portion * num_train))
#
# train_queue = torch.utils.data.DataLoader(
# train_data, batch_size=args.batch_size,
# sampler=torch.utils.data.sampler.SubsetRandomSampler(indices[:split]),
# pin_memory=True)
#
# valid_queue = torch.utils.data.DataLoader(
# train_data, batch_size=args.batch_size,
# sampler=torch.utils.data.sampler.SubsetRandomSampler(
# indices[split:num_train]),
# pin_memory=True)
train_queue, valid_queue, _, _ = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
temporal_flatten=args.temporal_flatten
)
architect = Architect(model, args)
# resume from checkpoint
if args.resume:
if os.path.isfile(args.resume):
logging.info("=> loading checkpoint '{}'".format(args.resume))
checkpoint = torch.load(
args.resume, map_location=model.alphas_normal.device)
start_epoch = checkpoint['epoch']
dur_time = checkpoint['dur_time']
model_optimizer.load_state_dict(checkpoint['model_optimizer'])
model.restore(checkpoint['network_states'])
logging.info('=> loaded checkpoint \'{}\'(epoch {})'.format(
args.resume, start_epoch))
else:
logging.info(
'=> no checkpoint found at \'{}\''.format(args.resume))
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
model_optimizer, float(args.epochs), eta_min=args.learning_rate_min,
last_epoch=-1 if start_epoch == 0 else start_epoch)
if args.resume and os.path.isfile(args.resume):
scheduler.load_state_dict(checkpoint['scheduler'])
for epoch in range(start_epoch, args.epochs):
scheduler.step()
lr = scheduler.get_lr()[0]
logging.info('epoch %d lr %e', epoch, lr)
genotype = model.genotype()
logging.info('genotype = %s', genotype)
logging.info(calc_weight(model.alphas_normal))
logging.info(calc_loss(model.alphas_normal))
model.update_history()
# training and search the model
train_acc, train_obj = train(epoch, train_queue, valid_queue, model, architect, criterion_train,
model_optimizer)
logging.info('train_acc %f', train_acc)
# validation the model
model.record_fire_rate = True
model.reset_fire_rate_record()
valid_acc, valid_obj = infer(valid_queue, model, criterion_val)
fire_rate = model.get_fire_per_step()
model.record_fire_rate = False
logging.info('valid_fire_rate: {}'.format(fire_rate))
logging.info('valid_acc %f', valid_acc)
# save checkpoint
utils.save_checkpoint({
'epoch': epoch + 1,
'dur_time': dur_time + time.time() - run_start,
'scheduler': scheduler.state_dict(),
'model_optimizer': model_optimizer.state_dict(),
'network_states': model.states(),
}, is_best=False, save=args.save)
logging.info('save checkpoint (epoch %d) in %s dur_time: %s', epoch, args.save,
utils.calc_time(dur_time + time.time() - run_start))
# save operation weights as fig
utils.save_file(recoder=model.alphas_normal_history, path=os.path.join(args.save, 'normal'),
back_connection=args.back_connection)
# save last operations
np.save(os.path.join(os.path.join(args.save, 'normal_weight.npy')),
calc_weight(model.alphas_normal).data.cpu().numpy())
logging.info('save last weights done')
def train(epoch, train_queue, valid_queue, model, architect, criterion, model_optimizer):
objs = utils.AvgrageMeter()
objs1 = utils.AvgrageMeter()
objs2 = utils.AvgrageMeter()
top1 = utils.AvgrageMeter()
top5 = utils.AvgrageMeter()
for step, (input, target) in enumerate(train_queue):
model.train()
n = input.size(0)
input = Variable(input, requires_grad=False).cuda(non_blocking=True)
target = Variable(target, requires_grad=False).cuda(non_blocking=True)
# if epoch >= args.asbe:
# Get a random minibatch from the search queue(validation set) with replacement
# input_search, target_search = next(iter(valid_queue))
# print(input.shape, target.shape)
# print(input_search.shape, target_search.shape)
# input_search = Variable(
# input_search, requires_grad=False).cuda(non_blocking=True)
# target_search = Variable(
# target_search, requires_grad=False).cuda(non_blocking=True)
# loss1, loss2 = architect.step(input_search, target_search)
# else:
loss1 = torch.tensor([0.])
loss2 = torch.tensor([0.])
model_optimizer.zero_grad()
logits = model(input)
aux_input = torch.cat(
[calc_loss(model.alphas_normal)], dim=0)
loss, _, _ = criterion(logits, target, aux_input)
# loss = criterion(logits, target)
loss.backward()
nn.utils.clip_grad_norm(model.parameters(), args.grad_clip)
# Update the network parameters
model_optimizer.step()
prec1, prec5 = utils.accuracy(logits, target, topk=(1, 5))
objs.update(loss.item(), n)
objs1.update(loss1, n)
objs2.update(loss2, n)
top1.update(prec1.item(), n)
top5.update(prec5.item(), n)
if step % args.report_freq == 0:
logging.info('train %03d loss: %e top1: %f top5: %f',
step, objs.avg, top1.avg, top5.avg)
logging.info('val cls_loss %e; spe_loss %e', objs1.avg, objs2.avg)
return top1.avg, objs.avg
def infer(valid_queue, model, criterion):
objs = utils.AvgrageMeter()
top1 = utils.AvgrageMeter()
top5 = utils.AvgrageMeter()
model.eval()
with torch.no_grad():
for step, (input, target) in enumerate(valid_queue):
input = Variable(input, volatile=True).cuda(non_blocking=True)
target = Variable(target, volatile=True).cuda(non_blocking=True)
logits = model(input)
loss = criterion(logits, target)
prec1, prec5 = utils.accuracy(logits, target, topk=(1, 5))
n = input.size(0)
objs.update(loss.item(), n)
top1.update(prec1.item(), n)
top5.update(prec5.item(), n)
if step % args.report_freq == 0:
logging.info('valid %03d %e %f %f', step,
objs.avg, top1.avg, top5.avg)
return top1.avg, objs.avg
if __name__ == '__main__':
main()
================================================
FILE: examples/Perception_and_Learning/NeuEvo/utils.py
================================================
import json
import matplotlib.pyplot as plt
from braincog.model_zoo.NeuEvo.genotypes import Genotype, PRIMITIVES
import os
import numpy as np
import torch
import shutil
import torchvision.transforms as transforms
from torch.autograd import Variable
from auto_augment import CIFAR10Policy
from braincog.model_zoo.NeuEvo.genotypes import PRIMITIVES
forward_edge_num = sum(1 for i in range(3) for n in range(2 + i))
backward_edge_num = sum(1 for i in range(3) for n in range(i))
num_ops = len(PRIMITIVES)
type_num = len(PRIMITIVES) // 2
# edge_num = [2, 3, 4]
edge_num = [2, 3, 4, 1, 2]
class AvgrageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.avg = 0
self.sum = 0
self.cnt = 0
def update(self, val, n=1):
self.sum += val * n
self.cnt += n
self.avg = self.sum / self.cnt
def accuracy(output, target, topk=(1,)):
"""Compute the top1 and top5 accuracy
"""
maxk = max(topk)
batch_size = target.size(0)
# Return the k largest elements of the given input tensor
# along a given dimension -> N * k
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0)
res.append(correct_k.mul_(100.0 / batch_size))
return res
class Cutout(object):
def __init__(self, length):
self.length = length
def __call__(self, img):
h, w = img.size(1), img.size(2)
mask = np.ones((h, w), np.float32)
y = np.random.randint(h)
x = np.random.randint(w)
y1 = np.clip(y - self.length // 2, 0, h)
y2 = np.clip(y + self.length // 2, 0, h)
x1 = np.clip(x - self.length // 2, 0, w)
x2 = np.clip(x + self.length // 2, 0, w)
mask[y1: y2, x1: x2] = 0.
mask = torch.from_numpy(mask)
mask = mask.expand_as(img)
img *= mask
return img
def _data_transforms_cifar(args):
CIFAR_MEAN = [0.49139968, 0.48215827, 0.44653124] if args.dataset == 'cifar10' else [0.50707519, 0.48654887,
0.44091785]
CIFAR_STD = [0.24703233, 0.24348505, 0.26158768] if args.dataset == 'cifar10' else [0.26733428, 0.25643846,
0.27615049]
normalize_transform = [
transforms.ToTensor(),
transforms.Normalize(CIFAR_MEAN, CIFAR_STD)]
random_transform = [
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip()]
if args.auto_aug:
random_transform += [CIFAR10Policy()]
if args.cutout:
cutout_transform = [Cutout(args.cutout_length)]
else:
cutout_transform = []
train_transform = transforms.Compose(
random_transform + normalize_transform + cutout_transform
)
valid_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(CIFAR_MEAN, CIFAR_STD),
])
return train_transform, valid_transform
def count_parameters_in_MB(model):
return np.sum(np.prod(v.size()) for v in model.parameters()) / 1e6
def save_checkpoint(state, is_best, save):
filename = os.path.join(save, 'checkpoint.pth.tar')
torch.save(state, filename)
if is_best:
best_filename = os.path.join(save, 'model_best.pth.tar')
shutil.copyfile(filename, best_filename)
def save(model, model_path):
torch.save(model.state_dict(), model_path)
def load(model, model_path):
model.load_state_dict(torch.load(model_path))
def drop_path(x, drop_prob):
if drop_prob > 0.:
keep_prob = 1. - drop_prob
mask = Variable(torch.cuda.FloatTensor(
x.size(0), 1, 1, 1).bernoulli_(keep_prob))
x.div_(keep_prob)
x.mul_(mask)
return x
def create_exp_dir(path, scripts_to_save=None):
if not os.path.exists(path):
os.makedirs(path)
print('Experiment dir : {}'.format(path))
if scripts_to_save is not None:
os.makedirs(os.path.join(path, 'scripts'))
for script in scripts_to_save:
dst_file = os.path.join(path, 'scripts', os.path.basename(script))
shutil.copyfile(script, dst_file)
def calc_time(seconds):
m, s = divmod(seconds, 60)
h, m = divmod(m, 60)
t, h = divmod(h, 24)
return {'day': t, 'hour': h, 'minute': m, 'second': int(s)}
def save_file(recoder, path='./', back_connection=False):
size = (forward_edge_num +
backward_edge_num if back_connection else forward_edge_num, num_ops)
fig, axs = plt.subplots(*size, figsize=(36, 98))
row = 0
col = 0
for (k, v) in recoder.items():
axs[row, col].set_title(k)
axs[row, col].plot(v, 'r+')
if col == num_ops - 1:
col = 0
row += 1
else:
col += 1
if not os.path.exists(path):
os.makedirs(path)
fig.savefig(os.path.join(path, 'output.png'), bbox_inches='tight')
plt.tight_layout()
print('save history weight in {}'.format(os.path.join(path, 'output.png')))
with open(os.path.join(path, 'history_weight.json'), 'w') as outf:
json.dump(recoder, outf)
print('save history weight in {}'.format(
os.path.join(path, 'history_weight.json')))
================================================
FILE: examples/Perception_and_Learning/QSNN/README.md
================================================
# Quantum superposition inspired spiking neural network
This repository contains code from our paper [**Quantum superposition inspired spiking neural network**] published in iScience. https://doi.org/10.1016/j.isci.2021.102880. If you use our code or refer to this project, please cite this paper.
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
## Train
```shell
python ./main.py
```
## Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{sun2021quantum,
title={Quantum superposition inspired spiking neural network},
author={Sun, Yinqian and Zeng, Yi and Zhang, Tielin},
journal={Iscience},
volume={24},
number={8},
pages={102880},
year={2021},
publisher={Elsevier}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/Perception_and_Learning/QSNN/main.py
================================================
import os
import copy
import tqdm
import numpy as np
import torch
import torch.nn.functional as F
from braincog.datasets.datasets import get_mnist_data
from braincog.model_zoo.qsnn import Net
from braincog.datasets.gen_input_signal import lambda_max
LOG_DIR = os.path.expanduser('./results.txt')
LEARNING_RATE = 0.01
# learning dacay
DECAY_STEPS = 1.0
DECAY_RATE = 0.9
# adam
BETA1 = 0.9
BETA2 = 0.999
EPSIOLN = 1e-8
EPOCHS = 20
PRINT_PERIOD = 10000
TEST_SIZE = 10000
TEST_THETA = [0, 1 / 16, 2 / 16, 3 / 16, 4 / 16, 5 / 16, 6 / 16, 7 / 16, 8 / 16]
# TEST_THETA = [0]
NOISE_RATES = [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
mnist_data = get_mnist_data(batch_size=1, skip_norm=True)
train_loader, test_loader = mnist_data.get_data_loaders()
NET_SIZE = [28 * 28, 500, 10]
def int2onehot(label, classes, factor):
label_one_hot = F.one_hot(label, classes)
label_one_hot = label_one_hot * (8 + factor) - 8
return label_one_hot
def train(net, epochs, lr):
with open(LOG_DIR, 'a+') as f:
for epoch in range(epochs):
lr_decay = lr * DECAY_RATE ** (epoch / DECAY_STEPS)
for x, y in tqdm.tqdm(train_loader):
label = int2onehot(y, 10, 8)
x = x.flatten().numpy()
label = label.cuda()
with torch.no_grad():
net.routine(x, None, image_ori=None, image_ori_delta=None, shift=False,
label=label, test=False, noise=False, noise_rate=None)
net.update_weight(lr_decay, epoch + 1, (BETA1, BETA2), EPSIOLN)
with torch.no_grad():
for fac in TEST_THETA:
acc_reve = 0
for x_test, y_test in test_loader:
image = x_test.flatten().numpy()
image_shift = image * np.cos(fac * np.pi) + (lambda_max - image) * np.sin(fac * np.pi)
image_delta = copy.copy(image)
delta_idx = image_delta < (lambda_max - 0.001)
image_delta[delta_idx] += 0.001
image_delta_shift = image_delta * np.cos(fac * np.pi) + (lambda_max - image_delta) * np.sin(fac * np.pi)
pred = net.predict(image_shift, image_delta_shift, image, image_delta, shift=True, noise=False, noise_rate=None)
if pred == int(y_test):
acc_reve += 1
acc_reve = acc_reve / TEST_SIZE
print('Test epoch {epoch}: Shift {theta:0.3f} pi: accuracy {acc}.'.format(
epoch=epoch, theta=fac, acc=acc_reve))
print('Test epoch {epoch}: Shift {theta:0.3f} pi: accuracy {acc}'.format(
epoch=epoch, theta=fac, acc=acc_reve), file=f)
print()
print(file=f)
if __name__ == '__main__':
net = Net(NET_SIZE).cuda()
train(net, EPOCHS, LEARNING_RATE)
================================================
FILE: examples/Perception_and_Learning/UnsupervisedSTDP/Readme.md
================================================
This is an example of training Unsupervised STDP-based spiking neural network. We used a STB-STDP algrithom to train SNN, and mutiply adaptive mechanisms.
# How to run
python codef.py
# Result
We train the model on Mnist and FashionMNIST, and the best accuracy for MNIST is 97.9%, for FashionMNIST is 87.0%.
### Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{dong2022unsupervised,
title={An Unsupervised Spiking Neural Network Inspired By Biologically Plausible Learning Rules and Connections},
author={Dong, Yiting and Zhao, Dongcheng and Li, Yang and Zeng, Yi},
journal={arXiv preprint arXiv:2207.02727},
year={2022}
}
@article{zeng2022braincog,
title={BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={arXiv preprint arXiv:2207.08533},
year={2022}
}
```
================================================
FILE: examples/Perception_and_Learning/UnsupervisedSTDP/codef.py
================================================
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from tqdm import tqdm
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import cv2
import numpy as np
from copy import deepcopy
import os, time, math,random
from braincog.base.node.node import *
from braincog.base.connection .layer import *
from braincog.base.strategy.LateralInhibition import *
from sklearn.metrics import confusion_matrix
seed = 0
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
torch.cuda.manual_seed(seed) #GPU随机种子确定
torch.backends.cudnn.benchmark = False #模型卷积层预先优化关闭
torch.backends.cudnn.deterministic = True #确定为默认卷积算法
random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
dev = "cuda"
device = torch.device(dev) if torch.cuda.is_available() else 'cpu'
torch.set_printoptions(precision=4, sci_mode=False)
# ===========================================================================================================
convoff = 0.3
# avgscale = 5
class STDPConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride, padding,groups,
tau_decay=torch.exp(-1.0 / torch.tensor(100.0)), offset=convoff, static=True, inh=6.5, avgscale=5):
super().__init__()
self.tau_decay = tau_decay
self.offset = offset
self.static = static
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding,groups=groups,
bias=False)
self.avgpool = nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=padding)
self.mem = self.spike = self.refrac_count = None
self.normweight()
self.inh = inh
self.avgscale = avgscale
self.onespike=True
self.node=LIFSTDPNode(act_fun=STDPGrad,tau=tau_decay,mem_detach=True)
self.WTA=WTALayer( )
self.lateralinh=LateralInhibition(self.node,self.inh,mode="threshold")
def mem_update(self, x, onespike=True): # b,c,h,w
x=self.node( x)
if x.max() > 0:
x=self.WTA(x)
self.lateralinh(x)
self.spike= x
return self.spike
def forward(self, x, T=None, onespike=True):
if not self.static:
batch, T, c, h, w = x.shape
x = x.reshape(-1, c, h, w)
x = self.conv( x)
n = self.getthresh(x)
self.node.threshold.data = n
x=x.clamp(min=0)
x = n / (1 + torch.exp(-(x - 4 * n / 10) * (8 / n)))
if not self.static:
x = x.reshape(batch, T, c, h, w)
xsum = None
for i in range(T):
tmp = self.mem_update(x[:, i], onespike).unsqueeze(1)
if xsum is not None:
xsum = torch.cat([xsum, tmp], 1)
else:
xsum = tmp
else:
xsum = 0
for i in range(T):
xsum += self.mem_update(x, onespike)
return xsum
def reset(self):
#self.mem = self.spike = self.refrac_count = None
self.node.n_reset()
def normgrad(self, force=False):
if force:
min = self.conv.weight.grad.data.min(1, True)[0].min(2, True)[0].min(3, True)[0]
max = self.conv.weight.grad.data.min(1, True)[0].max(2, True)[0].max(3, True)[0]
self.conv.weight.grad.data -= min
tmp = self.offset * max
else:
tmp = self.offset * self.spike.mean(0, True).mean(2, True).mean(3, True).permute(1, 0, 2, 3)
self.conv.weight.grad.data -= tmp
self.conv.weight.grad.data = -self.conv.weight.grad.data
def normweight(self, clip=False):
if clip:
self.conv.weight.data = torch. \
clamp(self.conv.weight.data, min=-3, max=1.0)
else:
c, i, w, h = self.conv.weight.data.shape
avg=self.conv.weight.data.mean(1, True).mean(2, True).mean(3, True)
self.conv.weight.data -=avg
tmp = self.conv.weight.data.reshape(c, 1, -1, 1)
self.conv.weight.data /= tmp.std(2, unbiased=False, keepdim=True)
def getthresh(self, scale):
tmp2= scale.max(0, True)[0].max(2, True)[0].max(3, True)[0]+0.0001
return tmp2
class STDPLinear(nn.Module):
def __init__(self, in_planes, out_planes,
tau_decay=0.99, offset=0.05, static=True,inh=10):
super().__init__()
self.tau_decay = tau_decay
self.offset = offset
self.static = static
self.linear = nn.Linear(in_planes, out_planes, bias=False)
self.mem = self.spike = self.refrac_count = None
# torch.nn.init.xavier_uniform_(self.linear.weight, gain=1)
self.normweight(False)
self.threshold = torch.ones(out_planes, device=device) *20
self.inh=inh
self.node=LIFSTDPNode(act_fun=STDPGrad,tau=tau_decay ,mem_detach=True)
self.WTA=WTALayer( )
self.lateralinh=LateralInhibition(self.node,self.inh,mode="max")
self.init=False
def mem_update(self, x, onespike=True): # b,c,h,w
if not self.init:
self.node.threshold.data= (x.max(0)[0].detach()*3).to(device)
self.init=True
xori=x
x=self.node( x)
if x.max() > 0:
x=self.WTA(x)
self.lateralinh(x,xori)
self.spike=x
return self.spike
def forward(self, x, T, onespike=True):
if not self.static:
batch, T, w = x.shape
x = x.reshape(-1, w)
x = x.detach()
x = self.linear(x)
self.x=x.detach()
if not self.static:
x = x.reshape(batch, T, w)
xsum = None
for i in range(T):
tmp = self.mem_update(x[:, i], onespike).unsqueeze(1)
if xsum is not None:
xsum = torch.cat([xsum, tmp], 1)
else:
xsum = tmp
else:
xsum = 0
for i in range(T):
xsum += self.mem_update(x, onespike)
#print(xsum.mean())
return xsum
def reset(self):
self.node.n_reset()
def normgrad(self, force=False):
if force:
pass
else:
tmp = self.offset * self.spike.mean(0, True).permute(1, 0)
self.linear.weight.grad.data = -self.linear.weight.grad.data
def normweight(self, clip=False):
if clip:
self.linear.weight.data = torch. \
clamp(self.linear.weight.data, min=0, max=1.0)
else:
self.linear.weight.data = torch. \
clamp(self.linear.weight.data, min=0, max=1.0)
sumweight = self.linear.weight.data.sum(1, True)
sumweight += (~(sumweight.bool())).float()
# self.linear.weight.data *= 11.76 / sumweight
self.linear.weight.data /= self.linear.weight.data.max(1, True)[0] / 0.1
def getthresh(self, scale):
tmp = self.linear.weight.clamp(min=0) * scale
tmp2 = tmp.sum(1, True).reshape(1, -1)
return tmp2
def updatethresh(self, plus=0.05):
self.node.threshold += (plus*self.x * self.spike.detach()).sum(0)
tmp=self.node.threshold.max()-350
if tmp>0:
self.node.threshold-=tmp
class STDPFlatten(nn.Module):
def __init__(self, start_dim=0, end_dim=-1):
super().__init__()
self.flatten = nn.Flatten(start_dim=start_dim, end_dim=end_dim)
def forward(self, x, T): # [batch,T,c,w,h]
return self.flatten(x)
class STDPMaxPool(nn.Module):
def __init__(self, kernel_size, stride, padding, static=True):
super().__init__()
self.static = static
self.pool = nn.MaxPool2d(kernel_size, stride, padding)
def forward(self, x, T): # [batch,T,c,w,h]
if not self.static:
batch, T, c, h, w = x.shape
x = x.reshape(-1, c, h, w)
x = self.pool(x)
if not self.static:
x = x.reshape(batch, T, c, h, w)
return x
alpha = 1.0
class Normliaze(nn.Module):
def __init__(self, static=True):
super().__init__()
self.static = static
def forward(self, x, T): # [batch,T,c,w,h]
# print(x.shape)
x /= x.max(1, True)[0].max(2, True)[0].max(3, True)[0]
# x/=x.mean()/0.13
return x
class voting(nn.Module):
def __init__(self, shape):
super().__init__()
self.label = torch.zeros(shape) - 1
self.assignments=0
def assign_labels(self, spikes, labels, rates=None, n_labels=10, alpha=alpha):
# 根据最后一层的spikes 以及 label 对于最后一层的神经元赋予不同的label
# spikes 是 batch * time * in_size
# print(spikes.size())
n_neurons = spikes.size(2)
if rates is None:
rates = torch.zeros(n_neurons, n_labels, device=device)
self.n_labels = n_labels
spikes = spikes.cpu().sum(1).to(device)
for i in range(n_labels):
n_labeled = torch.sum(labels == i).float()
# 就是说上一次assign label计算的rates 拿过来滑动平均一下 #这里似乎可以改
if n_labeled > 0:
indices = torch.nonzero(labels == i).view(-1)
tmp = torch.sum(spikes[indices], 0) / n_labeled # 平均脉冲数
rates[:, i] = alpha * rates[:, i] + tmp
# 此时的rates是 in_size * n_label, 对应哪个label的rates最高 该神经元就对应着该label
self.assignments = torch.max(rates, 1)[1]
return self.assignments, rates
def get_label(self, spikes):
# 根据最后一层的spike 计算得到label
n_samples = spikes.size(0)
spikes = spikes.cpu().sum(1).to(device)
rates = torch.zeros(n_samples, self.n_labels, device=device)
for i in range(self.n_labels):
n_assigns = torch.sum(self.assignments == i).float() # 共有多少个该类别节点
if n_assigns > 0:
indices = torch.nonzero(self.assignments == i).view(-1) # 找到该类别节点位置
rates[:, i] = torch.sum(spikes[:, indices], 1) / n_assigns # 该类别平均所有该类别节点发放脉冲数
return torch.sort(rates, dim=1, descending=True)[1][:, 0]
inh=25
inh2=1.625
channel=12
neuron=6400
class Conv_Net(nn.Module):
def __init__(self):
super(Conv_Net, self).__init__()
self.conv = nn.ModuleList([
STDPConv(1, channel, 3, 1, 1,1, static=True, inh=1.625, avgscale=5 ),
STDPMaxPool(2, 2, 0, static=True),
Normliaze(),
#STDPConv(12, 48, 3, 1, 1,1, static=True, inh=inh2, avgscale=10 ),
#STDPMaxPool(2, 2, 0, static=True),
#Normliaze(),
STDPFlatten(start_dim=1),
STDPLinear(196*channel, neuron, static=True,inh=inh)
])
self.voting = voting(10)
def forward(self, x, inlayer, outlayer, T, onespike=True): # [b,t,w,h]
for i in range(inlayer, outlayer + 1):
x = self.conv[i](x, T)
return x
def normgrad(self, layer, force=False):
self.conv[layer].normgrad(force)
def normweight(self, layer, clip=False):
self.conv[layer].normweight(clip)
def updatethresh(self, layer, plus=0.05):
self.conv[layer].updatethresh(plus)
def reset(self, layer):
if isinstance(layer, list):
for i in layer:
self.conv[i].reset()
else:
self.conv[layer].reset()
def plot_confusion_matrix(cm, classes, normalize=True, title='Test Confusion matrix', cmap=plt.cm.Blues):
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
#print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
plt.figure()
#print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
# plt.xticks(tick_marks, classes, rotation=45)
plt.xticks(tick_marks, classes)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i in range(cm.shape[0]):
plt.text(i, i, format(cm[i, i], fmt), horizontalalignment="center",
color="white" if cm[i, i] > thresh else "black")
plt.tight_layout()
#plt.savefig('confusestpf2'+str(channel)+"_n"+str(neuron)+".pdf")
#plt.show()
if __name__ == '__main__':
print(23)
batch_size = 1024
T = 100
transform = transforms.Compose(
[transforms.Resize((28, 28)), transforms.Grayscale(num_output_channels=1), transforms.ToTensor()])
transform = transforms.Compose([transforms.ToTensor()])
# mnist_train = datasets.CIFAR10(root='/data/datasets/CIFAR10/', train=True, download=False, transform=transform )
# mnist_test = datasets.CIFAR10(root='/data/datasets/CIFAR10/', train=False, download=False, transform=transform )
#mnist_train = datasets.FashionMNIST(root='/data/dyt//', train=True, download=True, transform=transform )
#mnist_test = datasets.FashionMNIST(root='/data/dyt/', train=False, download=False, transform=transform )
mnist_train = datasets.MNIST(root='./', train=True, download=True, transform=transform)
mnist_test = datasets.MNIST(root='./', train=False, download=False, transform=transform)
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=4)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=4)
model = Conv_Net().to(device)
convlist = [index for index, i in enumerate(model.conv) if isinstance(i, (STDPConv, STDPLinear))]
print(convlist)
#cap = torch.ones([100000, 1000, 30], device=device)
for layer in range(len(convlist) - 1):
optimizer = torch.optim.SGD(list(model.parameters())[layer:layer + 1], lr=0.1)
for epoch in range(3):
for step, (x, y) in enumerate(tqdm(train_iter)):
x = x.to(device)
y = y.to(device)
spikes = model(x, 0, convlist[layer], T)
optimizer.zero_grad()
spikes.sum().backward(torch.tensor(1/ (spikes.shape[0] * spikes.shape[2] * spikes.shape[3])))
# spikes.sum().backward( )
model.conv[convlist[layer]].spike = spikes.detach()
model.normgrad(convlist[layer], force=True)
optimizer.step()
model.normweight(convlist[layer], clip=False)
# print(model.conv[convlist[layer]].conv.weight.data )
model.reset(convlist)
print("layer", layer, "epoch", epoch, 'Done')
#model.conv[convlist[layer]].onespike=False
# ===========================================================================================================
# linear
#model.conv[convlist[-2]].onespike=True
cap = None
batch_size = 1024
T = 200
layer = len(convlist) - 1
plus = 0.002
lr = 0.0001
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=4)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=4)
optimizer = torch.optim.SGD(list(model.parameters())[layer:], lr=lr)
rates = None
best = 0
accrecord=[]
for epoch in range(1000):
spikefull = None
labelfull = None
for step, (x, y) in enumerate(tqdm(train_iter)):
x = x.to(device)
y = y.to(device)
spiketime = 0
spikes = model(x, 0, convlist[layer], T)
# print(spikes.mean())
optimizer.zero_grad()
spikes.sum().backward()
model.conv[convlist[layer]].spike = spikes.detach()
model.normgrad(convlist[layer], force=False)
optimizer.step()
model.updatethresh(convlist[layer], plus=plus)
model.normweight(convlist[layer], clip=False)
spikes = spikes.reshape(spikes.shape[0], 1, -1).detach()
if spikefull is None:
spikefull = spikes
labelfull = y
else:
spikefull = torch.cat([spikefull, spikes], 0)
labelfull = torch.cat([labelfull, y], 0)
model.reset(convlist)
_, rates = model.voting.assign_labels(spikefull, labelfull, rates)
rates = rates.detach() * 0.5
result = model.voting.get_label(spikefull)
acc = (result == labelfull).float().mean()
print(epoch, acc, 'channel', channel, "n", neuron)
print(model.conv[-1].node.threshold.max(),model.conv[-1].node.threshold.mean(),model.conv[-1].node.threshold.min())
# model.conv[-1].threshold*=0.98
spikefull = None
labelfull = None
result = None
for step2, (x, y) in enumerate(test_iter):
x = x.to(device)
y = y.to(device)
spiketime = 0
spikes = model(x, 0, convlist[layer], T)
spikes = spikes.reshape(spikes.shape[0], 1, -1).detach()
with torch.no_grad():
if spikefull is None:
spikefull = spikes
labelfull = y
else:
spikefull = torch.cat([spikefull, spikes], 0)
labelfull = torch.cat([labelfull, y], 0)
model.reset(convlist)
result = model.voting.get_label(spikefull)
acc = (result == labelfull).float().mean()
if best < acc:
best = acc
torch.save( model, "modelftstp28_350_c"+str(channel)+"_n"+str(neuron)+"_p"+str(acc)+".pth")
classes = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
cm = confusion_matrix(labelfull.cpu(), result.cpu())
plot_confusion_matrix(cm, classes)
print("test", acc, "best", best)
accrecord.append(acc)
#torch.save(accrecord,"accfstp28_350_c"+str(channel)+"_n"+str(neuron)+".pth")
================================================
FILE: examples/Perception_and_Learning/img_cls/bp/README.md
================================================
# Script for training high-performance SNNs based on back propagation
This is an example of training high-performance SNNs using the braincog.
It is able to train high performance SNNs on CIFAR10, DVS-CIFAR10, ImageNet and other datasets, and reach the advanced level.
## Install braincog
```shell
git clone https://github.com/xxx/Brain-Cog.git
cd braincog
python setup install --user
```
## Examples of training
```shell
cd examples/Perception_and_Learning/img_cls/bp
python main.py --model dvs_convnet --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGrad --device 0
```
## Benchmark
We provide a benchmark of SNNs trained with braincog and the corresponding scripts.
This provides an open, fair platform for comparison of subsequent SNNs on classification tasks.
**Note**: The results may vary due to random seeding and software version issues.
### CIFAR10
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:-------:|:--------------:|:------:|:-------------:|:----------:|:------------:|:-----------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | CIFAR10 | IF+Atan | - | convnet | 128 | 95.54 | ```python main.py --model cifar_convnet --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | LIF+Atan | - | convnet | 128 | 91.92 | ```python main.py --model cifar_convnet --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | PLIF+Atan | - | convnet | 128 | 93.32 | ```python main.py --model cifar_convnet --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | IF+Atan | - | resnet18 | 128 | 89.76/89.80 | ```python main.py --model resnet18 --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | LIF+Atan | - | resnet18 | 128 | 89.93/89.88 | ```python main.py --model resnet18 --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | PLIF+Atan | - | resnet18 | 128 | 92.64/ 90.65 | ```python main.py --model resnet18 --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR10 | IF+QGateGrad | - | cifar_convnet | 128 | 95.73 | ```python main.py --model cifar_convnet --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR10 | LIF+QGateGrad | - | cifar_convnet | 128 | 96.04 | ```python main.py --model cifar_convnet --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR10 | PLIF+QGateGrad | - | cifar_convnet | 128 | 96.04/95.84 | ```python main.py --model cifar_convnet --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR10 | IF+QGateGrad | - | resnet18 | 128 | 89.19 | ```python main.py --model resnet18 --node-type IFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR10 | LIF+QGateGrad | - | resnet18 | 128 | 90.95/90.68 | ```python main.py --model resnet18 --node-type LIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR10 | PLIF+QGateGrad | - | resnet18 | 128 | 90.97/91.02 | ```python main.py --model resnet18 --node-type PLIFNode --dataset cifar10 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
### CIFAR100
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:--------:|:--------------:|:------:|:-----------:|:----------:|:--------:|:------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | CIFAR100 | IF+Atan | - | dvs_convnet | 128 | 76.52 | ```python main.py --num-classes 100 --model cifar_convnet --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | LIF+Atan | - | dvs_convnet | 128 | 71.89 | ```python main.py --num-classes 100 --model cifar_convnet --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | PLIF+Atan | - | dvs_convnet | 128 | 72.82 | ```python main.py --num-classes 100 --model cifar_convnet --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | IF+Atan | - | resnet18 | 128 | 62.47 | ```python main.py --num-classes 100 --model resnet18 --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | LIF+Atan | - | resnet18 | 128 | 62.63 | ```python main.py --num-classes 100 --model resnet18 --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | PLIF+Atan | - | resnet18 | 128 | 62.71 | ```python main.py --num-classes 100 --model resnet18 --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | CIFAR100 | IF+QGateGrad | - | dvs_convnet | 128 | 76.44 | ```python main.py --num-classes 100 --model cifar_convnet --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR100 | LIF+QGateGrad | - | dvs_convnet | 128 | 77.73 | ```python main.py --num-classes 100 --model cifar_convnet --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR100 | PLIF+QGateGrad | - | dvs_convnet | 128 | 77.25 | ```python main.py --num-classes 100 --model cifar_convnet --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR100 | IF+QGateGrad | - | resnet18 | 128 | 60.01 | ```python main.py --num-classes 100 --model resnet18 --node-type IFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR100 | LIF+QGateGrad | - | resnet18 | 128 | 61.33 | ```python main.py --num-classes 100 --model resnet18 --node-type LIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | CIFAR100 | PLIF+QGateGrad | - | resnet18 | 128 | 62.32 | ```python main.py --num-classes 100 --model resnet18 --node-type PLIFNode --dataset cifar100 --step 4 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
### DVS-CIFAR10
| ID | Dataset | Node-type | Config | Model | Batch Size | FLOPS | Accuracy | Script |
|:----|:-----------:|:--------------:|:------:|:-----------:|:----------:|:-----:|:-----------:|:---------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | DVS-CIFAR10 | IF+Atan | - | dvs_convnet | 128 | 7503 | 65.90 | ```python main.py --model dvs_convnet --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+Atan | - | dvs_convnet | 128 | 7503 | 82.10 | ```python main.py --model dvs_convnet --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+Atan | - | dvs_convnet | 128 | 7503 | 81.90 | ```python main.py --model dvs_convnet --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | IF+Atan | - | resnet18 | 128 | 3149 | 69.10 | ```python main.py --model resnet18 --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+Atan | - | resnet18 | 128 | 3149 | 78.50 | ```python main.py --model resnet18 --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+Atan | - | resnet18 | 128 | 3149 | 77.70 | ```python main.py --model resnet18 --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-CIFAR10 | IF+QGateGrad | - | dvs_convnet | 128 | 7503 | 68.30 | ```python main.py --model dvs_convnet --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+QGateGrad | - | dvs_convnet | 128 | 7503 | 82.60/82.90 | ```python main.py --model dvs_convnet --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+QGateGrad | - | dvs_convnet | 128 | 7503 | 83.20 | ```python main.py --model dvs_convnet --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-CIFAR10 | IF+QGateGrad | - | resnet18 | 128 | 3149 | 65.70/66.80 | ```python main.py --model resnet18 --node-type IFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-CIFAR10 | LIF+QGateGrad | - | resnet18 | 128 | 3149 | 79.00/79.40 | ```python main.py --model resnet18 --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-CIFAR10 | PLIF+QGateGrad | - | resnet18 | 128 | 3149 | 78.10/78.20 | ```python main.py --model resnet18 --node-type PLIFNode --dataset dvsc10 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
### DVS-Gesture
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:-------:|:--------------:|:------:|:-----------:|:----------:|:-----------:|:------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | DVS-G | IF+Atan | - | dvs_convnet | 128 | 64.77 | ```python main.py --num-classes 11 --model dvs_convnet --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | LIF+Atan | - | dvs_convnet | 128 | 91.28 | ```python main.py --num-classes 11 --model dvs_convnet --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | PLIF+Atan | - | dvs_convnet | 128 | 91.67 | ```python main.py --num-classes 11 --model dvs_convnet --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | IF+Atan | - | resnet18 | 128 | 63.25 | ```python main.py --num-classes 11 --model resnet18 --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | LIF+Atan | - | resnet18 | 128 | 91.29 | ```python main.py --num-classes 11 --model resnet18 --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | PLIF+Atan | - | resnet18 | 128 | 90.15 | ```python main.py --num-classes 11 --model resnet18 --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun AtanGrad --device 0``` |
| 1 | DVS-G | IF+QGateGrad | - | dvs_convnet | 128 | 48.48 | ```python main.py --num-classes 11 --model dvs_convnet --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-G | LIF+QGateGrad | - | dvs_convnet | 128 | 92.05/92.42 | ```python main.py --num-classes 11 --model dvs_convnet --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-G | PLIF+QGateGrad | - | dvs_convnet | 128 | 91.28 | ```python main.py --num-classes 11 --model dvs_convnet --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-G | IF+QGateGrad | - | resnet18 | 128 | 57.95 | ```python main.py --num-classes 11 --model resnet18 --node-type IFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-G | LIF+QGateGrad | - | resnet18 | 128 | 90.91 | ```python main.py --num-classes 11 --model resnet18 --node-type LIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | DVS-G | PLIF+QGateGrad | - | resnet18 | 128 | 92.42 | ```python main.py --num-classes 11 --model resnet18 --node-type PLIFNode --dataset dvsg --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
### NCALTECH101
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
|:----|:-----------:|:--------------:|:------:|:-----------:|:----------:|:-----------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | NCALTECH101 | IF+QGateGrad | - | dvs_convnet | 128 | 23.09/51.15 | ```python main.py --num-classes 100 --model dvs_convnet --node-type IFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | NCALTECH101 | LIF+QGateGrad | - | dvs_convnet | 128 | 72.78/75.09 | ```python main.py --num-classes 100 --model dvs_convnet --node-type LIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | NCALTECH101 | PLIF+QGateGrad | - | dvs_convnet | 128 | 74.61/76.79 | ```python main.py --num-classes 100 --model dvs_convnet --node-type PLIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | NCALTECH101 | IF+QGateGrad | -/mix | resnet18 | 128 | 61.24/60.87 | ```python main.py --num-classes 100 --model resnet18 --node-type IFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | NCALTECH101 | LIF+QGateGrad | -/mix | resnet18 | 128 | 66.22/70.84 | ```python main.py --num-classes 100 --model resnet18 --node-type LIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
| 1 | NCALTECH101 | PLIF+QGateGrad | -/mix | resnet18 | 128 | 69.62/69.87 | ```python main.py --num-classes 100 --model resnet18 --node-type PLIFNode --dataset NCALTECH101 --step 10 --batch-size 128 --act-fun QGateGradGrad --device 0``` |
### SHD
| ID | Dataset | Node-type | Config | Model | Batch Size | Accuracy | Script |
| :--- | :-----: | :-----------: | :----: | :-----: | :--------: | :------: | :----------------------------------------------------------- |
| 1 | SHD | LIF+QGateGrad | - | shd_snn | 256 | 88.47 | ```python main.py --model SHD_SNN --node-type LIFNode --dataset shd --step 15 --batch-size 256 --act-fun QGateGrad --device 1 --tau 10. --threshold 0.3 --lr 5e-3 --min-lr 1e-4 --loss-fn onehot-mse --num-classes 20 --amp --weight-decay 0.01 ``` |
Note:
1. resnet18 is used here by adding a maximum pooling after the initial convolution layer.
However, in the final version of braincog, we remove this pooling layer.
2. mix refers to the use of EventMix as a data augmentation method.
3. We will continue to add other results.
### Citation
If you find this package helpful, please consider citing it:
```BibTex
@misc{zengbraincogSpikingNeural2022,
title = {{{braincog}}: {{A Spiking Neural Network}} Based {{Brain-inspired Cognitive Intelligence Engine}} for {{Brain-inspired AI}} and {{Brain Simulation}}},
shorttitle = {{{braincog}}},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
year = {2022},
month = jul,
number = {arXiv:2207.08533},
eprint = {2207.08533},
eprinttype = {arxiv},
primaryclass = {cs},
publisher = {{arXiv}},
doi = {10.48550/arXiv.2207.08533}
}
```
================================================
FILE: examples/Perception_and_Learning/img_cls/bp/main.py
================================================
import argparse
import time
import timm.models
import yaml
import os
import random as buildin_random
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.vgg_snn import VGG_SNN, SNN5
from braincog.model_zoo.fc_snn import SHD_SNN
from braincog.model_zoo.resnet19_snn import resnet19
from braincog.model_zoo.sew_resnet import sew_resnet18, sew_resnet34, sew_resnet50
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix, plot_mem_distribution
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model, register_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from torch.utils.tensorboard import SummaryWriter
# from ptflops import get_model_complexity_info
# from thop import profile, clever_format
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--dataset', default='mnist', type=str)
parser.add_argument('--model', default='mnist_convnet', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=1e-4,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=200, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=0.,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=0.,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--output', default='/data/floyed/BrainCog', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--tensorboard-dir', default='./runs', type=str)
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=0)
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
parser.add_argument('--conv-type', type=str, default='normal')
parser.add_argument('--sew-cnf', type=str, default='ADD')
parser.add_argument('--rand-step', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='QGateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
parser.add_argument('--n-encode-type', type=str, default='linear')
parser.add_argument('--n-preact', action='store_true')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--tet-loss', action='store_true')
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=2.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--gaussian-n', type=int, default=3)
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
parser.add_argument('--mem-dist', action='store_true')
parser.add_argument('--adaptation-info', action='store_true')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
@register_model
def resnet50d_pretrained(*args, **kwargs):
model = create_model('resnet50d', pretrained=True)
model.fc = nn.Linear(2048, 10)
# model.conv1 = nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
return model
def main():
args, args_text = _parse_args()
# args.no_spike_output = args.no_spike_output | args.cut_mix
args.no_spike_output = True
output_dir = ''
if args.local_rank == 0:
output_base = args.output if args.output else './output'
exp_name = '-'.join([
args.model,
args.dataset,
args.node_type,
str(args.step),
args.suffix,
datetime.now().strftime("%Y%m%d-%H%M%S"),
# str(args.img_size)
])
output_dir = get_outdir(output_base, 'train', exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
summary_writer = SummaryWriter(log_dir=os.path.join(args.tensorboard_dir, exp_name))
args.tensorboard_prefix = os.path.join(args.dataset, args.model)
else:
summary_writer = None
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
adaptive_node=args.adaptive_node,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
n_encode_type=args.n_encode_type,
n_preact=args.n_preact,
tet_loss=args.tet_loss,
sew_cnf=args.sew_cnf,
conv_type=args.conv_type,
)
_logger.info('[MODEL ARCH]\n{}'.format(model))
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=list(range(args.num_gpu))).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
_logger.info('[OPTIMIZER]\n{}'.format(optimizer))
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
# print(model.get_attr('mu'))
# print(model.get_attr('sigma'))
if hasattr(model, 'set_threshold'):
model.set_threshold(args.threshold)
if args.critical_loss or args.spike_rate:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model.cuda(), device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
)
# _logger.info('train_loader:\n{}\nval_loader:\n{}'.format(loader_train, loader_eval))
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
elif args.loss_fn == 'onehot-mse':
train_loss_fn = OnehotMse(args.num_classes)
validate_loss_fn = OnehotMse(args.num_classes)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
if args.tet_loss:
train_loss_fn = TetLoss(train_loss_fn)
validate_loss_fn = TetLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
# if args.distributed:
# raise NotImplementedError('eval not has not been verified for distributed')
# else:
# load_checkpoint(model, args.eval_checkpoint, args.model_ema)
model.eval()
for t in range(1, args.step * 3):
# for t in range(args.step, args.step + 1):
model.set_attr('step', t)
val_metrics = validate(start_epoch, model, loader_eval, validate_loss_fn, args,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer)
print(f"[STEP:{t}], Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=output_dir, recovery_dir=output_dir, decreasing=decreasing, max_history=3)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
if args.distributed:
loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler,
model_ema=model_ema, mixup_fn=mixup_fn, summary_writer=summary_writer
)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics = validate(epoch, model, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer)
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics = validate(
epoch, model_ema.ema, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast, log_suffix=' (EMA)',
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer
)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(output_dir, 'summary.csv'),
write_header=best_metric is None)
# if saver is not None and epoch >= args.n_warm_up:
if saver is not None:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
except KeyboardInterrupt:
pass
if best_metric is not None:
_logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None, summary_writer=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and loader.mixup_enabled:
loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
# closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
# t, k = adjust_surrogate_coeff(100, args.epochs)
# model.set_attr('t', t)
# model.set_attr('k', k)
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
iters_per_epoch = len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
if args.rand_step:
step = buildin_random.randint(1, args.step + 2)
model.set_attr('step', step)
data_time_m.update(time.time() - end)
if not args.prefetcher or args.dataset != 'imnet':
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
if mixup_fn is not None:
inputs, target = mixup_fn(inputs, target)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
with amp_autocast():
output = model(inputs)
loss = loss_fn(output, target)
if args.tet_loss:
output = output.mean(0)
if not (args.cut_mix | args.mix_up | args.event_mix | (args.cutmix != 0.) | (args.mixup != 0.)):
# print(output.shape, target.shape)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
# if args.opt == 'lamb':
# optimizer.step(epoch=epoch)
# else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/top1'), acc1.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/top5'), acc5.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/loss'), loss.item(), epoch * iters_per_epoch + batch_idx)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
if args.distributed:
loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
# closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
# if args.distributed:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/top1'), top1_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/top5'), top5_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/loss'), losses_m.avg, epoch)
if args.rand_step:
model.set_attr('step', args.step)
return OrderedDict([('loss', losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args, amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False, summary_writer=None):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
# closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
spike_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
mem_vec = []
end = time.time()
last_idx = len(loader) - 1
iters_per_epoch = len(loader)
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat or args.mem_dist) and not args.critical_loss:
model.set_requires_fp(True)
with amp_autocast():
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
# print(args.rank, output.shape, target.shape, max(target))
loss = loss_fn(output, target)
if args.tet_loss:
output = output.mean(0)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
# closses_m.update(closs, inputs.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/top1'), acc1.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/top5'), acc5.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/loss'), loss.item(), epoch * iters_per_epoch + batch_idx)
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
if not args.distributed and spike_rate:
spike_m.update(model.get_tot_spike() / output.size(0), output.size(0))
if not args.distributed and spike_rate:
_logger.info(
'[Spike Info]: {spike.val} ({spike.avg})'.format(
spike=spike_m
)
)
if last_batch or batch_idx % args.log_interval == 0:
_logger.info(
'Eval : {} '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
epoch,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
top1=top1_m,
top5=top5_m,
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg)])
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/top1'), top1_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/top5'), top5_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/loss'), losses_m.avg, epoch)
return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/Perception_and_Learning/img_cls/bp/main_backei.py
================================================
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import time
from braincog.model_zoo.backeinet import *
import argparse
import os
import json
parser = argparse.ArgumentParser("description = train.py")
parser.add_argument('-seed', type=int, default=4150)
parser.add_argument('-epoch', type=int, default=200)
parser.add_argument('-batch_size', type=int, default=100)
parser.add_argument('-learning_rate', type=float, default=1e-3)
parser.add_argument('--dataset', type=str, default='fashion')
parser.add_argument('--simulation_len', type=int, default=20)
parser.add_argument('--Back', action='store_true', default=False)
parser.add_argument('--EI', action='store_true', default=False)
parser.add_argument('--device', type=int, default=1)
parser.add_argument('--encode-type', type=str, default='direct')
opt = parser.parse_args()
torch.cuda.set_device('cuda:%d' % opt.device)
torch.manual_seed(opt.seed)
torch.cuda.manual_seed(opt.seed)
test_scores = []
train_scores = []
save_path = opt.dataset + '_' + str(opt.seed) + '_' + opt.encode_type
if opt.Back:
save_path += '_Back'
if opt.EI:
save_path += '_EI'
if not os.path.exists(save_path):
os.mkdir(save_path)
normalize = transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
if opt.dataset == 'mnist':
train_dataset = datasets.MNIST(root='./data/mnist/', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='./data/mnist/', train=False, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=opt.batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=opt.batch_size, shuffle=False)
elif opt.dataset == 'fashion':
train_dataset = datasets.FashionMNIST(root='./data/fashion/', train=True, transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.FashionMNIST(root='./data/fashion/', train=False, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=opt.batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=opt.batch_size, shuffle=False)
elif opt.dataset == 'cifar10':
train_dataset = datasets.CIFAR10(root='./data/cifar10/', train=True, transform=transforms.Compose(
[transforms.RandomHorizontalFlip(), transforms.RandomCrop(32, padding=4), transforms.ToTensor(), normalize]),
download=True)
test_dataset = datasets.CIFAR10(root='./data/cifar10/', train=False,
transform=transforms.Compose([transforms.ToTensor(), normalize]))
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=opt.batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=opt.batch_size, shuffle=False)
if opt.dataset == 'cifar10':
snn = CIFARNet(step=opt.simulation_len, if_back=opt.Back, if_ei=opt.EI, encode_type=opt.encode_type)
else:
snn = MNISTNet(step=opt.simulation_len, if_back=opt.Back, if_ei=opt.EI, data=opt.dataset, encode_type=opt.encode_type)
snn = snn.cuda()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(snn.parameters(), lr=opt.learning_rate)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=40, gamma=0.1)
def train(epoch):
snn.train()
start_time = time.time()
total_loss = 0
correct = 0
total = 0
for i, (images, labels) in enumerate(train_loader):
optimizer.zero_grad()
images = images.cuda()
outputs = snn(images)
labels_ = torch.zeros(opt.batch_size, 10).scatter_(1, labels.view(-1, 1), 1).cuda()
loss = criterion(outputs, labels_)
total_loss += loss.item()
loss.backward()
optimizer.step()
pred = outputs.max(1)[1]
total += labels.size(0)
correct += (pred.cpu() == labels).sum()
if (i + 1) % (60000 // (opt.batch_size * 6)) == 0:
print('Epoch: [%d/%d], Step: [%d/%d], Loss: %.4f, Time: %.2f' % (
epoch + 1, opt.epoch, i + 1, 60000 // opt.batch_size, total_loss,
time.time() - start_time))
start_time = time.time()
total_loss = 0
acc = 100.0 * correct.item() / total
train_scores.append(acc)
def eval(epoch):
snn.eval()
correct = 0
total = 0
with torch.no_grad():
for i, (images, labels) in enumerate(test_loader):
images = images.cuda()
outputs = snn(images)
pred = outputs.max(1)[1]
total += labels.size(0)
correct += (pred.cpu() == labels).sum()
acc = 100.0 * correct.item() / total
print('Test correct: %d Accuracy: %.2f%%' % (correct, acc))
test_scores.append(acc)
if acc >= max(test_scores):
save_file = str(epoch) + '.pt'
torch.save(snn, os.path.join(save_path, save_file))
return max(test_scores)
def main():
for epoch in range(opt.epoch):
train(epoch)
best_acc = eval(epoch)
scheduler.step()
print('Best Accuracy: %.2f%%' % (best_acc))
if __name__ == '__main__':
main()
filename = "train.json"
filename = os.path.join(save_path, filename)
with open(filename, "w") as f:
json.dump(train_scores, f)
filename = "test.json"
filename = os.path.join(save_path, filename)
with open(filename, "w") as f:
json.dump(test_scores, f)
================================================
FILE: examples/Perception_and_Learning/img_cls/bp/main_simplified.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/4/28 14:56
# User : Floyed
# Product : PyCharm
# Project : braincog
# File : main_simplified.py
# explain : Simplified training script. Remove support for DDP, IMAGENET, Augment, etc.
import argparse
import time
import timm.models
import yaml
import os
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.utils import save_feature_map
import torch
import torch.nn as nn
import torchvision.utils
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
# from ptflops import get_model_complexity_info
from thop import profile, clever_format
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--dataset', default='cifar10', type=str)
parser.add_argument('--model', default='cifar_convnet', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 10)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=600, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--device', type=int, default=0)
parser.add_argument('--output', default='/data/floyed/braincog', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
# neuron type
parser.add_argument('--node-type', type=str, default='PLIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='AtanGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--thresh', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--n_warm_up', type=int, default=0,
help='Warm up epoch, replace all node to ReLU to warm up weights in network before (default: 0)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def main():
args, args_text = _parse_args()
# args.no_spike_output = args.no_spike_output | args.cut_mix
args.no_spike_output = True
output_dir = ''
output_base = args.output if args.output else './output'
exp_name = '-'.join([
datetime.now().strftime("%Y%m%d-%H%M%S"),
args.model,
args.dataset,
str(args.step),
args.suffix
# str(args.img_size)
])
output_dir = get_outdir(output_base, 'train', exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
torch.cuda.set_device('cuda:%d' % args.device)
torch.manual_seed(args.seed)
model = create_model(
args.model,
num_classes=args.num_classes,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.thresh,
tau=args.tau,
spike_output=not args.no_spike_output,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
)
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.img_size, args.img_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size / 1024.0
args.lr = linear_scaled_lr
model = model.cuda()
optimizer = create_optimizer(args, model)
# optionally resume from a checkpoint
resume_epoch = None
if args.resume:
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet fcvawefdadw
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
temporal_flatten=args.temporal_flatten,
portion=args.train_portion)
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
else:
if mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args,
checkpoint_dir=output_dir, recovery_dir=output_dir)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
try: # train the model
for epoch in range(start_epoch, args.epochs):
if args.visualize or args.spike_rate:
print('start to plot feature map / calc spike rate')
validate(model, loader_eval, validate_loss_fn, args,
visualize=args.visualize, spike_rate=args.spike_rate)
exit(0)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir)
eval_metrics = validate(model, loader_eval, validate_loss_fn, args)
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(output_dir, 'summary.csv'),
write_header=best_metric is None)
if saver is not None and epoch >= args.n_warm_up:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
except KeyboardInterrupt:
pass
if best_metric is not None:
_logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,
lr_scheduler=None, saver=None, output_dir=''):
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
output = model(inputs)
loss = loss_fn(output, target)
if not (args.cut_mix | args.mix_up | args.event_mix):
acc1, acc5 = accuracy(output, target, topk=(1, 5))
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
top5_m.update(acc5.item(), inputs.size(0))
optimizer.zero_grad()
loss.backward()
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
optimizer.step()
num_updates += 1
batch_time_m.update(time.time() - end)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
top1=top1_m, top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) / batch_time_m.val,
rate_avg=inputs.size(0) / batch_time_m.avg,
lr=lr,
data_time=data_time_m))
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg)])
def validate(model, loader, loss_fn, args, log_suffix='', visualize=False, spike_rate=False):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
end = time.time()
last_idx = len(loader) - 1
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if visualize or spike_rate:
model.set_requires_fp(True)
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
if visualize:
x = model.get_fp()
feature_path = os.path.join(args.output_dir, 'feature_map')
if os.path.exists(feature_path) is False:
os.mkdir(feature_path)
save_feature_map(x, feature_path)
model.set_requires_fp(False)
if spike_rate:
_logger.info(model.get_fire_rate_per_layer())
model.set_requires_fp(False)
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if last_batch or batch_idx % args.log_interval == 0:
log_name = 'Test' + log_suffix
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
log_name, batch_idx, last_idx, batch_time=batch_time_m,
loss=losses_m, top1=top1_m, top5=top5_m))
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/Perception_and_Learning/img_cls/glsnn/README.md
================================================
# SNN with global feedback connections
Training deep spiking neural network with the global
feedback connections and the local optimization learning rules. And is a little different from our original paper.
GLSNN: A Multi-layer Spiking Neural Network based on Global Feedback Alignment and Local STDP Plasticity.
## Results
```shell
python cls_glsnn.py
```
We train the model for 100 epochs, and the best accuracy for MNIST is 98.23\%, for FashionMNIST is 89.68\%.

## Citation
If you find the code and dataset useful in your research, please consider citing:
```
@article{zhao2020glsnn,
title={GLSNN: A Multi-Layer Spiking Neural Network Based on Global Feedback Alignment and Local STDP Plasticity},
author={Zhao, Dongcheng and Zeng, Yi and Zhang, Tielin and Shi, Mengting and Zhao, Feifei},
journal={Frontiers in Computational Neuroscience},
volume={14},
year={2020},
publisher={Frontiers Media SA}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
## Contents
Feedbacks and comments are welcome! Feel free to contact us via [zhaodongcheng2016@ia.ac.cn](zhaodongcheng2016@ia.ac.cn)
Enjoy!
================================================
FILE: examples/Perception_and_Learning/img_cls/glsnn/cls_glsnn.py
================================================
import torch
from torchvision import transforms
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
from braincog.model_zoo.glsnn import BaseGLSNN
import argparse
import time
import os
import json
os.environ['CUDA_VISIBLE_DEVICES'] = "3"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
parser = argparse.ArgumentParser("description = GLSNN.py")
parser.add_argument('-seed', type=int, default=2122)
parser.add_argument('-epoch', type=int, default=100)
parser.add_argument('-batch_size', type=int, default=100)
parser.add_argument('-lr_target', type=float, default=0.4)
parser.add_argument('-lr_forward', type=float, default=0.001)
parser.add_argument('-step', type=int, default=10)
parser.add_argument('-encode_type', type=str, default='direct')
parser.add_argument('--dataset', type=str, default='MNIST')
opt = parser.parse_args()
torch.manual_seed(opt.seed)
torch.cuda.manual_seed(opt.seed)
test_scores = []
train_scores = []
save_path = './' + 'GLSNN' + '_' + opt.dataset + '_' + str(opt.seed)
if not os.path.exists(save_path):
os.mkdir(save_path)
if opt.dataset == 'MNIST':
train_dataset = datasets.MNIST(root='./data/datasets/mnist/', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='./data/datasets/mnist/', train=False, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=opt.batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=opt.batch_size, shuffle=False)
elif opt.dataset == 'Fashion-MNIST':
train_dataset = datasets.FashionMNIST(root='./data/fashion/', train=True, transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.FashionMNIST(root='./data/fashion/', train=False, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=opt.batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=opt.batch_size, shuffle=False)
snn = BaseGLSNN(input_size=784, hidden_sizes=[800] * 3, output_size=10, opt=opt)
snn.to(device)
optimizer = torch.optim.Adam(snn.forward_parameters(), lr=opt.lr_forward)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=40, gamma=0.1)
def train(epoch):
snn.train()
start_time = time.time()
total_loss = 0
correct = 0
total = 0
for i, (images, labels) in enumerate(train_loader):
optimizer.zero_grad()
images = images.to(device)
labels_ = torch.zeros(opt.batch_size, 10).scatter_(1, labels.view(-1, 1), 1).to(device)
labels = labels.to(device)
outputs, loss = snn.set_gradient(images, labels_)
optimizer.step()
total_loss += loss.item()
pred = outputs[-1].max(1)[1]
total += labels.size(0)
correct += (pred.cpu() == labels.cpu()).sum()
if (i + 1) % (60000 // (opt.batch_size * 6)) == 0:
print('Epoch: [%d/%d], Step: [%d/%d], Loss: %.4f, Time: %.2f' % (
epoch + 1, opt.epoch, i + 1, 60000 // opt.batch_size, total_loss,
time.time() - start_time))
start_time = time.time()
total_loss = 0
acc = 100.0 * correct.item() / total
train_scores.append(acc)
def eval(epoch):
snn.eval()
correct = 0
total = 0
with torch.no_grad():
for i, (images, labels) in enumerate(test_loader):
images = images.to(device)
outputs = snn(images)
pred = outputs[-1].max(1)[1]
total += labels.size(0)
correct += (pred.cpu() == labels).sum()
acc = 100.0 * correct.item() / total
print('Test correct: %d Accuracy: %.2f%%' % (correct, acc))
test_scores.append(acc)
if acc >= max(test_scores):
save_file = str(epoch) + '.pt'
torch.save(snn, os.path.join(save_path, save_file))
return max(test_scores)
def main():
for epoch in range(opt.epoch):
train(epoch)
best_acc = eval(epoch)
scheduler.step()
print('Best Accuracy: %.2f%%' % (best_acc))
if __name__ == '__main__':
main()
filename = "train.json"
filename = os.path.join(save_path, filename)
with open(filename, "w") as f:
json.dump(train_scores, f)
filename = "test.json"
filename = os.path.join(save_path, filename)
with open(filename, "w") as f:
json.dump(test_scores, f)
================================================
FILE: examples/Perception_and_Learning/img_cls/spiking_capsnet/README.md
================================================
# Spiking capsnet: A spiking neural network with a biologically plausible routing rule between capsules
## Run
```shell
python main.py
```
## Citation
If you find the code and dataset useful in your research, please consider citing:
```
@article{zhao2022spiking,
title={Spiking capsnet: A spiking neural network with a biologically plausible routing rule between capsules},
author={Zhao, Dongcheng and Li, Yang and Zeng, Yi and Wang, Jihang and Zhang, Qian},
journal={Information Sciences},
volume={610},
pages={1--13},
year={2022},
publisher={Elsevier}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
## Contents
Feedbacks and comments are welcome! Feel free to contact us via [zhaodongcheng2016@ia.ac.cn](zhaodongcheng2016@ia.ac.cn)
Enjoy!
================================================
FILE: examples/Perception_and_Learning/img_cls/spiking_capsnet/spikingcaps.py
================================================
import sys
sys.path.append('../../../../')
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from torch.optim import Adam
import os
import math
from tqdm import tqdm
import numpy as np
from braincog.datasets.datasets import get_mnist_data
from braincog.base.node import LIFNode
from braincog.utils import setup_seed
setup_seed(1111)
os.environ['CUDA_VISIBLE_DEVICES'] = "4"
class myLIFnode(LIFNode):
def __init__(self, threshold=0.5, tau=2., *args, **kwargs):
super().__init__(threshold, tau, *args, **kwargs)
def integral(self, inputs):
# self.mem = self.mem + (inputs - self.mem) / self.tau
self.mem = self.mem / self.tau + inputs
class ConvLayer(nn.Module):
def __init__(self, in_channels=1, out_channels=256, kernel_size=9):
super(ConvLayer, self).__init__()
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=1)
def forward(self, x):
return F.relu(self.conv(x))
class PrimaryCaps(nn.Module):
def __init__(self, num_capsules=8, in_channels=256, out_channels=32, kernel_size=9):
super(PrimaryCaps, self).__init__()
self.capsules = nn.ModuleList([
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=2, padding=0)
for _ in range(num_capsules)])
def forward(self, x):
u = [capsule(x) for capsule in self.capsules]
u = torch.stack(u, dim=1)
u.permute(0,2,3,4,1)
u = u.view(x.size(0), 32 * 6 * 6, -1)
return u
class DigitCaps(nn.Module):
def __init__(self, num_capsules=10, num_routes=32 * 6 * 6, in_channels=8, out_channels=16):
super(DigitCaps, self).__init__()
self.in_channels = in_channels
self.num_routes = num_routes
self.num_capsules = num_capsules
self.W = nn.Parameter(torch.randn(1, num_routes, num_capsules, out_channels, in_channels))
self.bias = nn.Parameter(torch.randn(out_channels, 1))
self.W.data.normal_(0, math.sqrt(3.0 / (in_channels * out_channels)))
self.bias.data.normal_(0, math.sqrt(3.0 / (in_channels * out_channels)))
def forward(self, x):
batch_size = x.size(0)
x = torch.stack([x] * self.num_capsules, dim=2).unsqueeze(4)
W = torch.cat([self.W] * batch_size, dim=0)
u_hat = torch.matmul(W, x) + self.bias
return u_hat
class DigitCaps2(nn.Module):
def __init__(self, num_capsules=10, num_routes=32 * 6 * 6):
super(DigitCaps2, self).__init__()
self.num_routes = num_routes
self.num_capsules = num_capsules
self.b_ij = Variable(torch.ones(1, self.num_routes, self.num_capsules, 1)/1152)
self.b_ij = self.b_ij.to(device)
def forward(self, u_hat):
c_ij = torch.cat([self.b_ij] * batch_size, dim=0).unsqueeze(4)
s_j = (c_ij * u_hat).sum(dim=1, keepdim=True)
return s_j.squeeze(1)
def init_bij(self):
self.b_ij = Variable(torch.ones(1, self.num_routes, self.num_capsules, 1)/1152)
self.b_ij = self.b_ij.to(device)
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.linear = nn.Linear(16, 1)
def forward(self, x):
classes = torch.sqrt((x ** 2).sum(2))
# classes = self.linear(x)
return classes
class CapsNet(nn.Module):
def __init__(self):
super(CapsNet, self).__init__()
self.conv_layer = ConvLayer()
self.primary_capsules = PrimaryCaps()
self.digit_capsules = DigitCaps()
self.digit_capsules2 = DigitCaps2()
self.decoder = Decoder()
self.conv_node = myLIFnode(tau=5)
self.primary_node = myLIFnode(tau=5)
self.digit_node = myLIFnode(tau=5)
self.digit2_node = myLIFnode(tau=5)
def forward(self, data, time_window=5, train=True):
self.init()
out_mem = 0.
self.digit_capsules2.init_bij()
self.trace_u = torch.zeros(batch_size, 1152, 10, 16, 1, device=device)
for step in range(time_window):
x = data
x = self.conv_node(self.conv_layer(x))
x = self.primary_node(self.primary_capsules(x))
x1 = self.digit_node(self.digit_capsules(x))
x = self.digit_capsules2(x1)
out_mem += x.squeeze(3)
y = self.digit2_node(x)
if train:
with torch.no_grad():
self.digit_capsules2.b_ij = torch.clamp(self.digit_capsules2.b_ij, -0.05, 1)
self.trace_u *= torch.exp(-1 / torch.tensor(1.5))
self.trace_u.masked_fill_(x1 != 0, 1)
self.digit_capsules2.b_ij += 0.0008 * torch.matmul(
self.trace_u.transpose(3, 4) - 0.1,
torch.stack([y] * 1152, dim=1)).squeeze(4).mean(dim=0, keepdim=True)
output = out_mem / time_window
output = self.decoder(output)
return output
def init(self):
self.conv_node.n_reset()
self.primary_node.n_reset()
self.digit_node.n_reset()
self.digit2_node.n_reset()
def evaluate(test_iter, net, device):
net.eval()
test_loss, test_acc, n_test = 0, 0.0, 0
for batch_id, (data, target) in tqdm(enumerate(test_iter)):
target = torch.sparse.torch.eye(10).index_select(dim=0, index=target)
data, target = Variable(data), Variable(target)
data, target = data.to(device), target.to(device)
classes = net(data)
test_acc += sum(np.argmax(classes.data.cpu().numpy(), 1) == np.argmax(target.data.cpu().numpy(), 1))
n_test += data.shape[0]
net.train()
return test_acc / n_test
if __name__ == '__main__':
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
batch_size = 100
train_loader, test_loader, _, _ = get_mnist_data(batch_size)
capsule_net = CapsNet().to(device)
optimizer = Adam(capsule_net.parameters(), lr=0.0005)
loss_fn = nn.MSELoss()
n_epochs = 50
best, losses = 0, []
for epoch in range(n_epochs):
if epoch in [15, 25, 45]:
optimizer.param_groups[0]['lr'] *= 0.3
capsule_net.train()
train_loss, correct, n = 0, 0, 0
loss_rec = []
for batch_id, (data, target) in enumerate(train_loader):
target = torch.sparse.torch.eye(10).index_select(dim=0, index=target)
data, target = Variable(data), Variable(target)
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
classes = capsule_net(data)
loss = loss_fn(classes, target)
loss.backward()
loss_rec.append(loss.item())
optimizer.step()
train_loss += loss.item()
correct += sum(np.argmax(classes.data.cpu().numpy(), 1) == np.argmax(target.data.cpu().numpy(), 1))
n += data.shape[0]
if batch_id % 100 == 0:
print("Epoch: {}, Batch: {}, train accuracy: {:.6f}, loss: {:.6f}".format(
epoch, batch_id + 1,
sum(np.argmax(classes.data.cpu().numpy(), 1) == np.argmax(target.data.cpu().numpy(), 1)) / float(batch_size),
loss.item()))
losses.append(np.mean(np.array(loss_rec)))
print("Epoch: [{}/{}], train accuracy: {:.6f}, loss: {:.6f}".format(
epoch, n_epochs,
correct / float(n),
train_loss / len(train_loader)))
capsule_net.eval()
test_acc = evaluate(test_loader, capsule_net, device=device)
print("test accuracy: {:.6f}".format(test_acc))
if test_acc > best:
best = test_acc
# torch.save(capsule_net, './checkpoints/spikingcaps_mnist.pkl')
================================================
FILE: examples/Perception_and_Learning/img_cls/transfer_for_dvs/GradCAM_visualization.py
================================================
# -*- coding: utf-8 -*-
# Time : 2023/2/14 11:52
# Author : Regulus
# FileName: main_visual_losslandscape.py
# Explain:
# Software: PyCharm
import sys
import tqdm
from loss_landscape.plot_surface import *
from Pytorch_Grad_Cam.cam import *
import argparse
import math
import time
import CKA
import numpy
import timm.models
import random as rd
import yaml
import os
from mpl_toolkits.mplot3d import Axes3D
from mpl_toolkits.mplot3d import proj3d
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.vgg_snn import VGG_SNN
from braincog.model_zoo.resnet19_snn import resnet19
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from rgb_hsv import RGB_HSV
import matplotlib.pyplot as plt
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from copy import deepcopy
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--source-dataset', default='cifar10', type=str)
parser.add_argument('--target-dataset', default='dvsc10', type=str)
parser.add_argument('--model', default='cifar_convnet', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=600, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.8,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=1.0,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=1.0,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--output', default='/home/hexiang/TransferLearning_For_DVS/Results_new_refined/', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=0)
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='GateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--gaussian-n', type=int, default=3)
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
parser.add_argument('--DVS-DA', action='store_true',
help='use DA on DVS')
# train data used ratio
parser.add_argument('--traindata-ratio', default=1.0, type=float,
help='training data ratio')
# snr value
parser.add_argument('--snr', default=0, type=int,
help='random noise amplitude controled by snr, 0 means no noise')
parser.add_argument('--aug_smooth', action='store_true',
help='Apply test time augmentation to smooth the CAM')
parser.add_argument('--eigen_smooth', action='store_true', help='Reduce noise by taking the first principle componenet'
'of cam_weights*activations')
import os
import numpy as np
import torch
from torchvision import transforms
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from mpl_toolkits.mplot3d import proj3d
from tonic.datasets import NCALTECH101, CIFAR10DVS
import tonic
from matplotlib import rcParams
import seaborn as sns
# for matplotlib 3D
def get_proj(self):
"""
Create the projection matrix from the current viewing position.
elev stores the elevation angle in the z plane
azim stores the azimuth angle in the (x, y) plane
dist is the distance of the eye viewing point from the object point.
"""
# chosen for similarity with the initial view before gh-8896
relev, razim = np.pi * self.elev / 180, np.pi * self.azim / 180
# EDITED TO HAVE SCALED AXIS
xmin, xmax = np.divide(self.get_xlim3d(), self.pbaspect[0])
ymin, ymax = np.divide(self.get_ylim3d(), self.pbaspect[1])
zmin, zmax = np.divide(self.get_zlim3d(), self.pbaspect[2])
# transform to uniform world coordinates 0-1, 0-1, 0-1
worldM = proj3d.world_transformation(xmin, xmax,
ymin, ymax,
zmin, zmax)
# look into the middle of the new coordinates
R = self.pbaspect / 2
xp = R[0] + np.cos(razim) * np.cos(relev) * self.dist
yp = R[1] + np.sin(razim) * np.cos(relev) * self.dist
zp = R[2] + np.sin(relev) * self.dist
E = np.array((xp, yp, zp))
self.eye = E
self.vvec = R - E
self.vvec = self.vvec / np.linalg.norm(self.vvec)
if abs(relev) > np.pi / 2:
# upside down
V = np.array((0, 0, -1))
else:
V = np.array((0, 0, 1))
zfront, zback = -self.dist, self.dist
viewM = proj3d.view_transformation(E, R, V)
projM = self._projection(zfront, zback)
M0 = np.dot(viewM, worldM)
M = np.dot(projM, M0)
return M
def event_vis_raw(x):
sns.set_style('whitegrid')
# sns.set_palette('deep', desat=.6)
sns.set_context("notebook", font_scale=1.5,
rc={"lines.linewidth": 2.5})
Axes3D.get_proj = get_proj
x = np.array(x.tolist()) # x, y, t, p
mask = (x[:, 3] == 1)
x_pos = x[mask]
x_neg = x[mask == False]
pos_idx = np.random.choice(x_pos.shape[0], 10000)
neg_idx = np.random.choice(x_neg.shape[0], 10000)
# x_pos[pos_idx, 2] = 0
# x_neg[neg_idx, 2] = 0
fig = plt.figure(figsize=plt.figaspect(0.5) * 1.5)
ax = Axes3D(fig)
ax.pbaspect = np.array([2.0, 1.0, 0.5])
ax.view_init(elev=10, azim=-75)
# ax.view_init(elev=15, azim=15)
ax.set_xlabel('t (time step)')
ax.set_ylabel('w (pixel)')
ax.set_zlabel('h (pixel)')
# ax.set_xticks([])
# ax.set_yticks([])
# ax.set_zticks([])
# ax.scatter(x_pos[pos_idx, 2], 48 - x_pos[pos_idx, 0], 48 - x_pos[pos_idx, 1], color='red', alpha=0.3, s=1.)
# ax.scatter(x_neg[neg_idx, 2], 48 - x_neg[neg_idx, 0], 48 - x_neg[neg_idx, 1], color='blue', alpha=0.3, s=1.)
ax.scatter(x_pos[:, 0], 48 - x_pos[:, 1] * 0.375, 48 - x_pos[:, 2] * 0.375, color='red', alpha=0.3, s=1.)
# ax.scatter(x_neg[:, 0], 64 - x_neg[:, 1] // 2, 128 - x_neg[:, 2], color='blue', alpha=0.3, s=1.)
ax.scatter(18000, 48 - x_pos[:, 1] * 0.375, 48 - x_pos[:, 2] * 0.375, color='red', alpha=0.3, s=1.)
# ax.scatter(18000, 64 - x_pos[:, 1] // 2, 128 - x_pos[:, 2], color='blue', alpha=0.3, s=1.)
def get_dataloader_ncal(step, **kwargs):
sensor_size = tonic.datasets.CIFAR10DVS.sensor_size
transform = tonic.transforms.Compose([
# tonic.transforms.DropPixel(hot_pixel_frequency=.999),
# tonic.transforms.Denoise(500),
tonic.transforms.DropEvent(p=0.0),
# tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
# lambda x: F.interpolate(torch.tensor(x, dtype=torch.float), size=[48, 48], mode='bilinear', align_corners=True),
])
dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=transform)
# dataset = [dataset[5569], dataset[8196]]
# dataset = [dataset[5000], dataset[6000]] # 1958
# dataset = [dataset[0]]
# loader = torch.utils.data.DataLoader(
# dataset, batch_size=1,
# shuffle=False,
# pin_memory=True, drop_last=True, num_workers=8
# )
return dataset
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def main():
torch.set_num_threads(20)
os.environ["OMP_NUM_THREADS"] = "20" # 设置OpenMP计算库的线程数
os.environ["MKL_NUM_THREADS"] = "20" # 设置MKL-DNN CPU加速库的线程数。
args, args_text = _parse_args()
args.no_spike_output = True
torch.cuda.set_device('cuda:%d' % args.device)
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
adaptive_node=args.adaptive_node,
dataset=args.target_dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
)
if 'dvs' in args.target_dataset:
args.channels = 2
elif 'mnist' in args.target_dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
# source_loader_train, _, _, _ = eval('get_transfer_%s_data' % args.source_dataset)(
# batch_size=args.batch_size,
# step=args.step,
# args=args,
# _logge=_logger,
# data_config=data_config,
# size=args.event_size,
# mix_up=args.mix_up,
# cut_mix=args.cut_mix,
# event_mix=args.event_mix,
# beta=args.cutmix_beta,
# prob=args.cutmix_prob,
# gaussian_n=args.gaussian_n,
# num=args.cutmix_num,
# noise=args.cutmix_noise,
# num_classes=args.num_classes,
# rand_aug=args.rand_aug,
# randaug_n=args.randaug_n,
# randaug_m=args.randaug_m,
# portion=args.train_portion,
# _logger=_logger,
# )
origin_loader_train, _, _, _ = eval('get_origin_dvsc10_data')(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
)
target_loader_train, target_loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.target_dataset)(
batch_size=args.batch_size,
dvs_da=args.DVS_DA,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
train_data_ratio=args.traindata_ratio,
snr=args.snr,
data_mode="full",
frames_num=12,
data_type="frequency"
)
model_before = deepcopy(model)
if args.eval: # evaluate the model
if args.distributed:
state_dict = torch.load(args.eval_checkpoint)['state_dict_ema']
new_state_dict = OrderedDict()
# add module prefix for DDP
for k, v in state_dict.items():
k = 'module.' + k
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
else:
model.load_state_dict(torch.load('/home/hexiang/TransferLearning_For_DVS/Results_lastest/train_TCKA_test/Transfer_VGG_SNN-dvsc10-10-bs_120-seed_42-DA_True-ls_0.0-lr_0.005-SNR_0-domainLoss_False-semanticLoss_False-domain_loss_coefficient1.0-semantic_loss_coefficient0.5-traindataratio_1.0-TETfirst_True-TETsecond_True/model_best.pth.tar', map_location='cpu')['state_dict'])
# pass
# print("no model load")
# --------------------------------------------------------------------------
# Show Acc
# --------------------------------------------------------------------------
print("load model finished!")
# """ python cam.py -image-path
# Example usage of loading an image, and computing:
# 1. CAM
# 2. Guided Back Propagation
# 3. Combining both
# """
#
# # Choose the target layer you want to compute the visualization for.
# # Usually this will be the last convolutional layer in the model.
# # Some common choices can be:
# # Resnet18 and 50: model.layer4
# # VGG, densenet161: model.features[-1]
# # mnasnet1_0: model.layers[-1]
# # You can print the model to help chose the layer
# # You can pass a list with several target layers,
# # in that case the CAMs will be computed per layer and then aggregated.
# # You can also try selecting all layers of a certain type, with e.g:
# # from pytorch_grad_cam.utils.find_layers import find_layer_types_recursive
# # find_layer_types_recursive(model, [torch.nn.ReLU])
# target_layers = [model.feature[-1]]
#
# if True:
# # inputs = 0.0
# # label = 0.0
# # for batch_idx, (inputs_tmp, label_tmp) in tqdm.tqdm(enumerate(origin_loader_train)):
# # if batch_idx == choose_idx:
# # inputs = inputs_tmp
# # label = label_tmp
# # break
# # else:
# # continue
# inputs = 0.0
# rgb_img = 0.0
#
# #Using the with statement ensures the context is freed, and you can
# #recreate different CAM objects in a loop.
# plt.figure(figsize=(8, 6))
# plt.xlabel('w (pixel)')
# plt.ylabel('h (pixel)')
# cam_algorithm = GradCAMPlusPlus
# model = model.cuda()
# with cam_algorithm(model=model,
# target_layers=target_layers,
# use_cuda=False) as cam:
#
# # AblationCAM and ScoreCAM have batched implementations.
# # You can override the internal batch size for faster computation.
# cam.batch_size = 32
#
# for batch_idx, (origin_loaer, target_loader) in tqdm.tqdm(enumerate(zip(origin_loader_train, target_loader_train))):
#
# twodemension_inputs, labels = origin_loaer
# plt.figure(figsize=(8, 6))
# # plt.xlabel('w (pixel)')
# # plt.ylabel('h (pixel)')
# twodemension_inputs = twodemension_inputs[0] # (1, 10, 2, 48, 48) -> (10, 2, 48, 48)
# event_frame_plot_2d(twodemension_inputs)
#
# inputs_tmp, label_tmp = target_loader
# inputs = inputs_tmp
# inputs = inputs.type(torch.FloatTensor).cuda()
#
# grayscale_cam = cam(input_tensor=inputs,
# targets=None,
# aug_smooth=args.aug_smooth,
# eigen_smooth=args.eigen_smooth)
#
# # Here grayscale_cam has only one image in the batch
# grayscale_cam = grayscale_cam[0, :]
#
# # cam_image = show_cam_on_image(rgb_img.permute(1, 2, 0).numpy(), grayscale_cam, use_rgb=True, image_weight=0.0)
# cam_image = show_cam_on_image(np.ones((48, 48, 3)), grayscale_cam, use_rgb=True,
# image_weight=0.0)
# # # cam_image is RGB encoded whereas "cv2.imwrite" requires BGR encoding.
# # rgb_img = cv2.resize(rgb_img.permute(1, 2, 0).numpy(), (32, 32))
#
# # cv2.imwrite(f'{args.method}_cam.jpg', cam_image)
# plt.ylim(bottom=0.)
# plt.axis('off')
# plt.savefig('fig/gradcam_dvspic_origin/label_{}_id_{}.jpg'.format(labels.item(), 400 + batch_idx), bbox_inches='tight', pad_inches=0)
# plt.imshow(cam_image, alpha=1.0)
# # plt.show()
# # plt.savefig('gradcam_pic/plot_id{}.jpg'.format(batch_idx), bbox_inches='tight')
# plt.savefig('fig/gradcam_dvspic_withoutloss/label_{}_id_{}.jpg'.format(labels.item(), 400 + batch_idx), bbox_inches='tight', pad_inches=0)
# 第二次
print("load model again!")
model = model_before
model.load_state_dict(torch.load(
'/home/hexiang/TransferLearning_For_DVS/Results_lastest/train_TCKA_test/Transfer_VGG_SNN-dvsc10-10-bs_120-seed_42-DA_True-ls_0.0-lr_0.005-SNR_0-domainLoss_True-semanticLoss_True-domain_loss_coefficient1.0-semantic_loss_coefficient0.5-traindataratio_1.0-TETfirst_True-TETsecond_True/model_best.pth.tar', map_location='cpu')['state_dict'])
""" python cam.py -image-path
Example usage of loading an image, and computing:
1. CAM
2. Guided Back Propagation
3. Combining both
"""
# Choose the target layer you want to compute the visualization for.
# Usually this will be the last convolutional layer in the model.
# Some common choices can be:
# Resnet18 and 50: model.layer4
# VGG, densenet161: model.features[-1]
# mnasnet1_0: model.layers[-1]
# You can print the model to help chose the layer
# You can pass a list with several target layers,
# in that case the CAMs will be computed per layer and then aggregated.
# You can also try selecting all layers of a certain type, with e.g:
# from pytorch_grad_cam.utils.find_layers import find_layer_types_recursive
# find_layer_types_recursive(model, [torch.nn.ReLU])
target_layers = [model.feature[-1]]
if True:
# inputs = 0.0
# label = 0.0
# for batch_idx, (inputs_tmp, label_tmp) in tqdm.tqdm(enumerate(origin_loader_train)):
# if batch_idx == choose_idx:
# inputs = inputs_tmp
# label = label_tmp
# break
# else:
# continue
inputs = 0.0
rgb_img = 0.0
#Using the with statement ensures the context is freed, and you can
#recreate different CAM objects in a loop.
plt.figure(figsize=(8, 6))
plt.xlabel('w (pixel)')
plt.ylabel('h (pixel)')
cam_algorithm = GradCAMPlusPlus
model = model.cuda()
with cam_algorithm(model=model,
target_layers=target_layers,
use_cuda=False) as cam:
# AblationCAM and ScoreCAM have batched implementations.
# You can override the internal batch size for faster computation.
cam.batch_size = 32
for batch_idx, (origin_loaer, target_loader) in tqdm.tqdm(enumerate(zip(origin_loader_train, target_loader_train))):
twodemension_inputs, labels = origin_loaer
plt.figure(figsize=(8, 6))
# plt.xlabel('w (pixel)')
# plt.ylabel('h (pixel)')
twodemension_inputs = twodemension_inputs[0] # (1, 10, 2, 48, 48) -> (10, 2, 48, 48)
event_frame_plot_2d(twodemension_inputs)
inputs_tmp, label_tmp = target_loader
inputs = inputs_tmp
inputs = inputs.type(torch.FloatTensor).cuda()
grayscale_cam = cam(input_tensor=inputs,
targets=None,
aug_smooth=args.aug_smooth,
eigen_smooth=args.eigen_smooth)
# Here grayscale_cam has only one image in the batch
grayscale_cam = grayscale_cam[0, :]
# cam_image = show_cam_on_image(rgb_img.permute(1, 2, 0).numpy(), grayscale_cam, use_rgb=True, image_weight=0.0)
cam_image = show_cam_on_image(np.ones((48, 48, 3)), grayscale_cam, use_rgb=True,
image_weight=0.0)
# # cam_image is RGB encoded whereas "cv2.imwrite" requires BGR encoding.
# rgb_img = cv2.resize(rgb_img.permute(1, 2, 0).numpy(), (32, 32))
# cv2.imwrite(f'{args.method}_cam.jpg', cam_image)
plt.ylim(bottom=0.)
plt.axis('off')
# plt.savefig('fig/gradcam_dvspic_origin/label_{}_id_{}.jpg'.format(labels.item(), batch_idx), bbox_inches='tight', pad_inches=0)
plt.imshow(cam_image, alpha=1.0)
# plt.show()
# plt.savefig('gradcam_pic/plot_id{}.jpg'.format(batch_idx), bbox_inches='tight')
plt.savefig('fig/gradcam_dvspic_withloss/label_{}_id_{}.jpg'.format(labels.item(), batch_idx), bbox_inches='tight', pad_inches=0)
def event_frame_plot_2d(event):
for t in range(event.shape[0]):
pos_idx = []
neg_idx = []
for x in range(event.shape[2]):
for y in range(event.shape[3]):
if event[t, 0, x, y] > 0:
pos_idx.append((x, y, event[t, 0, x, y]))
if event[t, 1, x, y] > 0:
neg_idx.append((x, y, event[t, 0, x, y]))
if len(pos_idx) > 0:
# print(t)
pos_x, pos_y, pos_c = np.split(np.array(pos_idx), 3, axis=1)
# plt.scatter(48 - pos_x[:, 0] * 0.375, 48 - pos_y[:, 0] * 0.375, c='red', alpha=1, s=1)
plt.scatter(pos_x[:, 0] * 0.375, pos_y[:, 0] * 0.375, c='white', alpha=1, s=1)
if len(neg_idx) > 0:
neg_x, neg_y, neg_c = np.split(np.array(neg_idx), 3, axis=1)
# plt.scatter(48 - neg_x[:, 0] * 0.375, 48 - neg_y[:, 0] * 0.375, c='blue', alpha=1, s=1)
plt.scatter(neg_x[:, 0] * 0.375, neg_y[:, 0] * 0.375, c='blue', alpha=1, s=1)
# sys.exit()
if __name__ == '__main__':
main()
================================================
FILE: examples/Perception_and_Learning/img_cls/transfer_for_dvs/README.md
================================================
# Script for all experiments
## Baseline
1. CIFAR10-DVS
```shell
python main.py --model VGG_SNN --node-type LIFNode --dataset dvsc10 --step 10 --batch-size 120 --act-fun QGateGrad --device 5 --seed 42 --DVS-DA --traindata-ratio 1.0 --smoothing 0.0 --TET-loss-first --TET-loss-second
```
2. N-Caltech 101
```shell
python main.py --model VGG_SNN --node-type LIFNode --dataset NCALTECH101 --step 10 --batch-size 120 --act-fun QGateGrad --device 7 --seed 42 --num-classes 101 --traindata-ratio 1.0 --smoothing 0.0 --TET-loss-first --TET-loss-second
```
3. Omniglot
```shell
python main.py --model SCNN --node-type LIFNode --dataset nomni --step 12 --batch-size 64 --num-classes 1623 --act-fun QGateGrad --epochs 200 --device 6 --log-interval 200 --smoothing 0.0 --seed 42 --lr 0.01 --min-lr 1e-5
```
## Our Method
1. CIFAR10-DVS
```shell
python main_transfer.py --model Transfer_VGG_SNN --node-type LIFNode --source-dataset cifar10 --target-dataset dvsc10 --step 10 --batch-size 120 --act-fun QGateGrad --device 1 --seed 42 --traindata-ratio 1.0 --smoothing 0.0 --domain-loss --semantic-loss --DVS-DA --TET-loss-first --TET-loss-second
```
2. N-Caltech 101
```shell
python main_transfer.py --model Transfer_VGG_SNN --node-type LIFNode --source-dataset CALTECH101 --target-dataset NCALTECH101 --step 10 --batch-size 120 --act-fun QGateGrad --device 5 --seed 42 --num-classes 101 --traindata-ratio 1.0 --domain-loss --semantic-loss --semantic-loss-coefficient 0.001 --TET-loss-first --TET-loss-second&
```
3. N-Omniglot
```shell
python main_transfer.py --model Transfer_SCNN --node-type LIFNode --source-dataset omni --target-dataset nomni --step 12 --batch-size 64 --num-classes 1623 --act-fun QGateGrad --epochs 200 --device 6 --log-interval 200 --smoothing 0.0 --seed 42 --domain-loss --semantic-loss --semantic-loss-coefficient 0.5 --lr 0.01 --min-lr 1e-5
```
## Visualization Loss-landscape
you should git clone from https://github.com/tomgoldstein/loss-landscape first.
```shell
HDF5_USE_FILE_LOCKING="FALSE" mpirun -n 4 -mca btl ^openib python main_visual_losslandscape.py --model VGG_SNN --node-type LIFNode --source-dataset cifar10 --target-dataset dvsc10 --step 10 --batch-size 1000 --eval --eval_checkpoint /home/TransferLearning_For_DVS/Resultes_new_compare/Baseline/VGG_SNN-dvsc10-10-seed_42-bs_120-DA_True-ls_0.0-traindataratio_0.1-TET_first_False-TET_second_False/last.pth.tar --mpi --x=-1.0:1.0:51 --y=-1.0:1.0:51 --dir_type weights --xnorm filter --xignore biasbn --ynorm filter --yignore biasbn --plot --DVS-DA --smoothing 0.0 --traindata-ratio 0.1
```
```shell
python main_visual_losslandscape.py --model Transfer_VGG_SNN --node-type LIFNode --source-dataset CALTECH101 --target-dataset NCALTECH101 --step 10 --batch-size 500 --eval --eval_checkpoint /home/TransferLearning_For_DVS/Results_new_compare/train_TCKA_test/Transfer_VGG_SNN-NCALTECH101-10-bs_120-seed_47-DA_False-ls_0.0-lr_0.005-SNR_0-domainLoss_True-semanticLoss_True-domain_loss_coefficient1.0-semantic_loss_coefficient0.001-traindataratio_0.1-TETfirst_True-TETsecond_True/last.pth.tar --mpi --x=-1.0:1.0:51 --y=-1.0:1.0:51 --dir_type weights --xnorm filter --xignore biasbn --ynorm filter --yignore biasbn --plot --smoothing 0.0 --traindata-ratio 0.1 --num-classes 101 --device 5&
```
## Visualization Grad-cam++
you should git clone from https://github.com/jacobgil/pytorch-grad-cam first.
```shell
python GradCAM_visualization.py --model Transfer_VGG_SNN --node-type LIFNode --source-dataset cifar10 --target-dataset dvsc10 --step 10 --batch-size 1 --act-fun QGateGrad --device 6 --seed 42 --smoothing 0.0 --DVS-DA --eval --eval_checkpoint /home/TransferLearning_For_DVS/Results_lastest/train_TCKA_test/Transfer_VGG_SNN-dvsc10-10-bs_120-seed_42-DA_True-ls_0.0-lr_0.005-SNR_0-domainLoss_True-semanticLoss_True-domain_loss_coefficient1.0-semantic_loss_coefficient0.5-traindataratio_1.0-TETfirst_True-TETsecond_True/model_best.pth.tar
```
## Note: Dataset
In order to work with the source and target domain data, the datastes file is tailored, please use `datasets.py` here to replace and override `braincog/datasets/datasets.py` if you want to run transfer learning in this project.
## Citation
If you find the code and dataset useful in your research, please consider citing:
```
@article{he2023improving,
title={Improving the Performance of Spiking Neural Networks on Event-based Datasets with Knowledge Transfer},
author={He, Xiang and Zhao, Dongcheng and Li, Yang and Shen, Guobin and Kong, Qingqun and Zeng, Yi},
journal={arXiv preprint arXiv:2303.13077},
year={2023}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
## Contents
If you are confused about using it or have other feedback and comments, please feel free to contact us via [hexiang2021@ia.ac.cn](hexiang2021@ia.ac.cn).
Have a good day!
================================================
FILE: examples/Perception_and_Learning/img_cls/transfer_for_dvs/datasets.py
================================================
import os, warnings
import torchvision.datasets
try:
import tonic
from tonic import DiskCachedDataset
except:
warnings.warn("tonic should be installed, 'pip install git+https://github.com/BrainCog-X/tonic_braincog.git'")
import torch
import torch.nn.functional as F
import torch.utils
import torchvision.datasets as datasets
from timm.data import ImageDataset, create_loader, Mixup, FastCollateMixup, AugMixDataset
from timm.data import create_transform
from einops import rearrange, repeat
from torchvision import transforms
from typing import Any, Dict, Optional, Sequence, Tuple, Union
from torch.utils.data import ConcatDataset
from braincog.datasets.NOmniglot.nomniglot_full import NOmniglotfull
from braincog.datasets.NOmniglot.nomniglot_nw_ks import NOmniglotNWayKShot
from braincog.datasets.NOmniglot.nomniglot_pair import NOmniglotTrainSet, NOmniglotTestSet
from braincog.datasets.ESimagenet.ES_imagenet import ESImagenet_Dataset
from braincog.datasets.ESimagenet.reconstructed_ES_imagenet import ESImagenet2D_Dataset
from braincog.datasets.CUB2002011 import CUB2002011
from braincog.datasets.TinyImageNet import TinyImageNet
from braincog.datasets.StanfordDogs import StanfordDogs
from random import sample
from .cut_mix import CutMix, EventMix, MixUp
from .rand_aug import *
from .utils import dvs_channel_check_expend, rescale
from PIL import Image
import cv2
import math
DVSCIFAR10_MEAN_16 = [0.3290, 0.4507]
DVSCIFAR10_STD_16 = [1.8398, 1.6549]
DATA_DIR = '/data/datasets'
DEFAULT_CROP_PCT = 0.875
IMAGENET_DEFAULT_MEAN = (0.485, 0.456, 0.406)
IMAGENET_DEFAULT_STD = (0.229, 0.224, 0.225)
IMAGENET_INCEPTION_MEAN = (0.5, 0.5, 0.5)
IMAGENET_INCEPTION_STD = (0.5, 0.5, 0.5)
IMAGENET_DPN_MEAN = (124 / 255, 117 / 255, 104 / 255)
IMAGENET_DPN_STD = tuple([1 / (.0167 * 255)] * 3)
CIFAR10_DEFAULT_MEAN = (0.4914, 0.4822, 0.4465)
CIFAR10_DEFAULT_STD = (0.2023, 0.1994, 0.2010)
class TransferSampler(torch.utils.data.sampler.Sampler):
r"""Samples elements randomly from a given list of indices, without replacement.
Arguments:
indices (sequence): a sequence of indices
"""
def __init__(self, indices):
self.indices = indices
def __iter__(self):
return (self.indices[i] for i in range(len(self.indices)))
def __len__(self):
return len(self.indices)
class Transfer_DataSet(torchvision.datasets.VisionDataset):
def __init__(self, data, label):
self.data = data
self.label = label
self.length = data.shape[0]
def __getitem__(self, mask):
data = self.data[mask]
label = self.label[mask]
return data, label
def __len__(self):
return self.length
# 自定义HSV空间 transform
class ConvertHSV(object):
"""计算边缘梯度
Args:
None
"""
def __init__(self):
pass
# transform 会调用该方法
def __call__(self, img):
"""
Args:
img (PIL Image): PIL Image
Returns:
PIL Image: PIL image, v channel.
"""
img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
return Image.fromarray(img.astype('uint8'))
def unpack_mix_param(args):
mix_up = args['mix_up'] if 'mix_up' in args else False
cut_mix = args['cut_mix'] if 'cut_mix' in args else False
event_mix = args['event_mix'] if 'event_mix' in args else False
beta = args['beta'] if 'beta' in args else 1.
prob = args['prob'] if 'prob' in args else .5
num = args['num'] if 'num' in args else 1
num_classes = args['num_classes'] if 'num_classes' in args else 10
noise = args['noise'] if 'noise' in args else 0.
gaussian_n = args['gaussian_n'] if 'gaussian_n' in args else None
return mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n
def build_transform(is_train, img_size, use_hsv=True):
"""
构建数据增强, 适用于static data
:param is_train: 是否训练集
:param img_size: 输出的图像尺寸
:return: 数据增强策略
"""
resize_im = img_size > 32
if is_train:
# this should always dispatch to transforms_imagenet_train
transform = create_transform(
input_size=img_size,
is_training=True,
color_jitter=0.4,
auto_augment='rand-m9-mstd0.5-inc1',
interpolation='bicubic',
re_prob=0.25,
re_mode='pixel',
re_count=1,
)
if not resize_im:
# replace RandomResizedCropAndInterpolation with
# RandomCrop
transform.transforms[0] = transforms.RandomCrop(
img_size, padding=4)
return transform
t = []
# if resize_im:
# size = int((256 / 224) * img_size)
# t.append(
# # to maintain same ratio w.r.t. 224 images
# transforms.Resize(size, interpolation=InterpolationMode.BICUBIC),
# )
# t.append(transforms.CenterCrop(img_size))
# t.append(transforms.RandomAffine(degrees=0, translate=))
# if Gradient:
# print("Used Gradient!")
# t.append(ComputeLaplacian())
# t.append(ConvertHSV())
# t.append(AddGaussianNoise())
t.append(transforms.Resize((img_size, img_size), interpolation=InterpolationMode.BILINEAR))
if use_hsv:
print("Used V-channel!")
t.append(ConvertHSV())
t.append(transforms.ToTensor())
# t.append(transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD))
return transforms.Compose(t)
def build_dataset(is_train, img_size, dataset, path, same_da=False, use_hsv=True):
"""
构建带有增强策略的数据集
:param is_train: 是否训练集
:param img_size: 输出图像尺寸
:param dataset: 数据集名称
:param path: 数据集路径
:param same_da: 为训练集使用测试集的增广方法
: param use_hsv: 是否采用HSV
:return: 增强后的数据集
"""
# transform = build_transform(False, img_size) if same_da else build_transform(is_train, img_size)
transform = build_transform(False, img_size, use_hsv) if same_da else build_transform(False, img_size, use_hsv)
if dataset == 'CIFAR10':
dataset = datasets.CIFAR10(
path, train=is_train, transform=transform, download=True)
nb_classes = 10
elif dataset == 'CIFAR100':
dataset = datasets.CIFAR100(
path, train=is_train, transform=transform, download=True)
nb_classes = 100
elif dataset == 'CALTECH101':
dataset = datasets.Caltech101(
path, transform=transform, download=True
)
nb_classes = 101
else:
raise NotImplementedError
return dataset, nb_classes
class MNISTData(object):
"""
Load MNIST datesets.
"""
def __init__(self,
data_path: str,
batch_size: int,
train_trans: Sequence[torch.nn.Module] = None,
test_trans: Sequence[torch.nn.Module] = None,
pin_memory: bool = True,
drop_last: bool = True,
shuffle: bool = True,
) -> None:
self._data_path = data_path
self._batch_size = batch_size
self._pin_memory = pin_memory
self._drop_last = drop_last
self._shuffle = shuffle
self._train_transform = transforms.Compose(train_trans) if train_trans else None
self._test_transform = transforms.Compose(test_trans) if test_trans else None
def get_data_loaders(self):
print('Batch size: ', self._batch_size)
train_datasets = datasets.MNIST(root=self._data_path, train=True, transform=self._train_transform, download=True)
test_datasets = datasets.MNIST(root=self._data_path, train=False, transform=self._test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=self._drop_last, shuffle=self._shuffle
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=False
)
return train_loader, test_loader
def get_standard_data(self):
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
self._train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
self._test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
return self.get_data_loaders()
def get_mnist_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""s
获取MNIST数据
http://data.pymvpa.org/datasets/mnist/
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
if 'skip_norm' in kwargs and kwargs['skip_norm'] is True:
train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
else:
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
# transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
train_datasets = datasets.MNIST(
root=DATA_DIR, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.MNIST(
root=DATA_DIR, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_fashion_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取fashion MNIST数据
http://arxiv.org/abs/1708.07747
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor()])
test_transform = transforms.Compose([transforms.ToTensor()])
train_datasets = datasets.FashionMNIST(
root=DATA_DIR, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.FashionMNIST(
root=DATA_DIR, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_cifar10_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取CIFAR10数据
https://www.cs.toronto.edu/~kriz/cifar.html
:param batch_size: batch size
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
use_hsv = not kwargs['no_use_hsv'] if 'no_use_hsv' in kwargs else True
train_datasets, _ = build_dataset(True, 32, 'CIFAR10', DATA_DIR, same_da, False)
test_datasets, _ = build_dataset(False, 32, 'CIFAR10', DATA_DIR, same_da, False)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True,
num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False,
num_workers=num_workers
)
return train_loader, test_loader, None, None
def get_cifar100_data(batch_size, num_workers=8, same_data=False, *args, **kwargs):
"""
获取CIFAR100数据
https://www.cs.toronto.edu/~kriz/cifar.html
:param batch_size: batch size
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_datasets, _ = build_dataset(True, 32, 'CIFAR100', DATA_DIR, same_data)
test_datasets, _ = build_dataset(False, 32, 'CIFAR100', DATA_DIR, same_data)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_transfer_cifar10_data(batch_size, num_workers=8, same_da=False, **kwargs):
use_hsv = not kwargs['no_use_hsv'] if 'no_use_hsv' in kwargs else True
train_datasets, _ = build_dataset(True, 48, 'CIFAR10', DATA_DIR, same_da, use_hsv) # 原来是48
test_datasets, _ = build_dataset(False, 48, 'CIFAR10', DATA_DIR, same_da, use_hsv)
concat_dataset = ConcatDataset([train_datasets, test_datasets]) # concat dataset
img_index = [[] for i in range(10)]
label_index = [0] * 60000
for idx, (img, label) in enumerate(concat_dataset):
img_index[label].append(img)
for i in range(10):
img_index[i] = torch.stack(img_index[i], 0)
label_index[i * 6000:2 * i * 6000] = [i] * 6000
source_datasets = Transfer_DataSet(data=rearrange(torch.stack(img_index, dim=0), 'l b c w h -> (l b) c w h'),
label=label_index)
source_loader = torch.utils.data.DataLoader(
source_datasets, batch_size=60000,
sampler=TransferSampler(torch.arange(0, 60000).tolist()),
pin_memory=True, drop_last=False, num_workers=16
)
return source_loader, None, None, None
def get_combined_cifar10_data(batch_size, num_workers=8, same_da=False, **kwargs):
use_hsv = not kwargs['no_use_hsv'] if 'no_use_hsv' in kwargs else True
train_datasets, _ = build_dataset(True, 48, 'CIFAR10', DATA_DIR, same_da, use_hsv)
test_datasets, _ = build_dataset(False, 48, 'CIFAR10', DATA_DIR, same_da, use_hsv)
concat_dataset = ConcatDataset([train_datasets, test_datasets]) # concat dataset
source_loader = torch.utils.data.DataLoader(
concat_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=8, shuffle=True
)
return source_loader, None, None, None
def get_transfer_CALTECH101_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取NCaltech101数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
use_hsv = not kwargs['no_use_hsv'] if 'no_use_hsv' in kwargs else True
datasets, _ = build_dataset(False, 48, 'CALTECH101', DATA_DIR, same_da, use_hsv)
dataset_length = 8299
train_loader = torch.utils.data.DataLoader(
datasets, batch_size=10000,
sampler=TransferSampler(torch.arange(0, dataset_length).tolist()),
pin_memory=True, drop_last=False, num_workers=4
)
return train_loader, None, None, None
def get_combined_CALTECH101_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取NCaltech101数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
use_hsv = not kwargs['no_use_hsv'] if 'no_use_hsv' in kwargs else True
datasets, _ = build_dataset(False, 48, 'CALTECH101', DATA_DIR, same_da, use_hsv)
dataset_length = 8299
train_loader = torch.utils.data.DataLoader(
datasets, batch_size=batch_size,
pin_memory=True, drop_last=False,
num_workers=4, shuffle=True
)
return train_loader, None, None, None
def get_TinyImageNet_data(batch_size, num_workers=8, same_da=False, *args, **kwargs):
size=kwargs["size"] if "size" in kwargs else 224
train_transform = transforms.Compose([
transforms.RandomResizedCrop(size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(size*8//7),
transforms.CenterCrop(size),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(DATA_DIR, 'TinyImageNet')
train_datasets = TinyImageNet(
root=root, split="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = TinyImageNet(
root=root, split="val", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_transfer_imnet_data(args, _logger, data_config, num_aug_splits, **kwargs):
'''
load imagenet 2012
we use images in train/ for training, and use images in val/ for testing
https://github.com/pytorch/examples/tree/master/imagenet
'''
IMAGENET_PATH = '/data/datasets/ILSVRC2012/'
traindir = os.path.join(IMAGENET_PATH, 'train')
valdir = os.path.join(IMAGENET_PATH, 'val')
batch_size = kwargs['batch_size']
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
ConvertHSV(),
transforms.ToTensor()]))
# val_dataset = datasets.ImageFolder(
# valdir,
# transforms.Compose([
# transforms.Resize(256),
# transforms.CenterCrop(224),
# ConvertHSV(),
# transforms.ToTensor()]))
# train_loader = torch.utils.data.DataLoader(
# train_dataset,
# batch_size=batch_size, shuffle=False,
# num_workers=4, pin_memory=True, sampler=TransferSampler([0, 1300, 2599, 2600]))
#
# val_loader = torch.utils.data.DataLoader(
# val_dataset,
# batch_size=batch_size, shuffle=False,
# num_workers=4, pin_memory=True)
return train_dataset, None, None, None
def get_dvsg_data(batch_size, step, **kwargs):
"""
获取DVS Gesture数据
DOI: 10.1109/CVPR.2017.781
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.DVSGesture.sensor_size
size = kwargs['size'] if 'size' in kwargs else 48
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
train_dataset = tonic.datasets.DVSGesture(os.path.join(DATA_DIR, 'DVS/DVSGesture'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.DVSGesture(os.path.join(DATA_DIR, 'DVS/DVSGesture'),
transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVSGesture/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVSGesture/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, mixup_active, None
def get_dvsc10_data(batch_size, step, dvs_da=False, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
snr = kwargs['snr'] if 'snr' in kwargs else 0
train_data_ratio = kwargs['train_data_ratio'] if 'train_data_ratio' in kwargs else 1.0
sensor_size = tonic.datasets.CIFAR10DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=train_transform)
test_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=test_transform)
if dvs_da is True:
print("use dvs_da")
if snr > 0:
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: x + torch.randn(x.shape) * math.sqrt(torch.mean(torch.pow(x, 2)) / math.pow(10, snr / 10)),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
else:
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
else:
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
]) # 这里lambda返回的是地址, 注意不要用List复用.
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
sample(list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))), int(num_per_cls * portion * train_data_ratio)))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_train),
pin_memory=True, drop_last=False, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_test),
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_transfer_dvsc10_data(batch_size, step, dvs_da=False, **kwargs):
"""
获取DVS CIFAR10数据
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
snr = kwargs['snr'] if 'snr' in kwargs else 0
train_data_ratio = kwargs['train_data_ratio'] if 'train_data_ratio' in kwargs else 1.0
sensor_size = tonic.datasets.CIFAR10DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=train_transform)
test_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
]) # 这里lambda返回的是地址, 注意不要用List复用.
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=len(indices_train),
sampler=TransferSampler(indices_train),
pin_memory=True, drop_last=True, num_workers=8
)
return train_loader, None, mixup_active, None
def get_NCALTECH101_data(batch_size, step, dvs_da=False, **kwargs):
"""
获取NCaltech101数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.NCALTECH101.sensor_size
cls_count = tonic.datasets.NCALTECH101.cls_count
dataset_length = tonic.datasets.NCALTECH101.length
portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
snr = kwargs['snr'] if 'snr' in kwargs else 0
train_data_ratio = kwargs['train_data_ratio'] if 'train_data_ratio' in kwargs else 1.0
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += int(train_sample * train_data_ratio)
train_sample_weight.extend(
[sample_weight] * int(train_sample * train_data_ratio)
)
train_sample_weight.extend(
[0.] * (train_sample - int(train_sample * train_data_ratio))
)
train_sample_weight.extend(
[0.] * test_sample
)
train_sample_index.extend(
sample(list(range(idx_begin, idx_begin + train_sample)), int(train_sample * train_data_ratio))
)
test_sample_index.extend(
list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=train_transform)
test_dataset = tonic.datasets.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=test_transform)
if dvs_da is True:
print("use dvs_da")
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
else:
if snr > 0:
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: x + torch.randn(x.shape) * math.sqrt(torch.mean(torch.pow(x, 2)) / math.pow(10, snr / 10)),
])
else:
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
transforms.RandomCrop(size, padding=size // 12),
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
]) # 这里lambda返回的是地址, 注意不要用List复用.
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=train_sampler,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_transfer_NCALTECH101_data(batch_size, step, dvs_da=False, **kwargs):
"""
获取NCaltech101数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.NCALTECH101.sensor_size
cls_count = tonic.datasets.NCALTECH101.cls_count
dataset_length = tonic.datasets.NCALTECH101.length
portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
snr = kwargs['snr'] if 'snr' in kwargs else 0
train_data_ratio = kwargs['train_data_ratio'] if 'train_data_ratio' in kwargs else 1.0
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += int(train_sample * train_data_ratio)
train_sample_weight.extend(
[sample_weight] * int(train_sample * train_data_ratio)
)
train_sample_weight.extend(
[0.] * (train_sample - int(train_sample * train_data_ratio))
)
train_sample_weight.extend(
[0.] * test_sample
)
train_sample_index.extend(
sample(list(range(idx_begin, idx_begin + train_sample)), int(train_sample * train_data_ratio))
)
test_sample_index.extend(
list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=train_transform)
test_dataset = tonic.datasets.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
]) # 这里lambda返回的是地址, 注意不要用List复用.
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=len(train_sample_index),
sampler=TransferSampler(train_sample_index),
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, None, None, None
def get_NCARS_data(batch_size, step, **kwargs):
"""
获取N-Cars数据
https://ieeexplore.ieee.org/document/8578284/
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.NCARS.sensor_size
size = kwargs['size'] if 'size' in kwargs else 48
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
])
train_dataset = tonic.datasets.NCARS(os.path.join(DATA_DIR, 'DVS/NCARS'), transform=train_transform, train=True)
test_dataset = tonic.datasets.NCARS(os.path.join(DATA_DIR, 'DVS/NCARS'), transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCARS/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCARS/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, mixup_active, None
def get_nomni_data(batch_size, train_portion=1., **kwargs):
"""
获取N-Omniglot数据
:param batch_size:batch的大小
:param data_mode:一共full nkks pair三种模式
:param frames_num:一个样本帧的个数
:param data_type:event frequency两种模式
"""
data_mode = kwargs["data_mode"] if "data_mode" in kwargs else "full"
frames_num = kwargs["frames_num"] if "frames_num" in kwargs else 4
data_type = kwargs["data_type"] if "data_type" in kwargs else "event"
train_transform = transforms.Compose([
transforms.Resize((28, 28))])
test_transform = transforms.Compose([
transforms.Resize((28, 28))])
if data_mode == "full":
train_datasets = NOmniglotfull(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), train=True, frames_num=frames_num,
data_type=data_type,
transform=train_transform, use_npz=True)
test_datasets = NOmniglotfull(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), train=False, frames_num=frames_num,
data_type=data_type,
transform=test_transform, use_npz=True)
elif data_mode == "nkks":
train_datasets = NOmniglotNWayKShot(os.path.join(DATA_DIR, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=True,
frames_num=frames_num,
data_type=data_type,
transform=train_transform)
test_datasets = NOmniglotNWayKShot(os.path.join(DATA_DIR, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=False,
frames_num=frames_num,
data_type=data_type,
transform=test_transform)
elif data_mode == "pair":
train_datasets = NOmniglotTrainSet(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), use_frame=True,
frames_num=frames_num, data_type=data_type,
use_npz=False, resize=105)
test_datasets = NOmniglotTestSet(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), time=2000, way=kwargs["n_way"],
shot=kwargs["k_shot"], use_frame=True,
frames_num=frames_num, data_type=data_type, use_npz=False, resize=105)
else:
pass
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size, num_workers=4,
pin_memory=True, drop_last=True, shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size, num_workers=4,
pin_memory=True, drop_last=False
)
return train_loader, test_loader, None, None
def get_transfer_omni_data(batch_size, train_portion=1., **kwargs):
"""
获取Omniglot数据
:param batch_size:batch的大小
:param data_mode:一共full nkks pair三种模式
:param frames_num:一个样本帧的个数
:param data_type:event frequency两种模式
"""
transform = transforms.Compose([
transforms.Resize((28, 28)),
transforms.ToTensor()])
train_dataset = datasets.Omniglot(
root="/data/datasets/", background=True, download=True, transform=transform
)
test_dataset = datasets.Omniglot(
root="/data/datasets/", background=False, download=True, transform=transform
)
dataset = torch.utils.data.ConcatDataset([train_dataset, test_dataset])
dataset_length = len(dataset)
train_loader = torch.utils.data.DataLoader(
dataset, batch_size=35000, num_workers=12,
pin_memory=True, drop_last=False,
sampler=TransferSampler(torch.arange(0, dataset_length).tolist())
)
return train_loader, None, None, None
def get_esimnet_data(batch_size, step, **kwargs):
"""
获取ES imagenet数据
DOI: 10.3389/fnins.2021.726582
:param batch_size: batch size
:param step: 仿真步长,固定为8
:param reconstruct: 重构则时间步为1, 否则为8
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
:note: 没有自动下载, 下载及md5请参考spikingjelly, sampler默认为DistributedSampler
"""
reconstruct = kwargs["reconstruct"] if "reconstruct" in kwargs else False
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: dvs_channel_check_expend(x),
])
if reconstruct:
assert step == 1
train_dataset = ESImagenet2D_Dataset(mode='train',
data_set_path=os.path.join(DATA_DIR, 'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=train_transform)
test_dataset = ESImagenet2D_Dataset(mode='test',
data_set_path=os.path.join(DATA_DIR, 'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=test_transform)
else:
assert step == 8
train_dataset = ESImagenet_Dataset(mode='train',
data_set_path=os.path.join(DATA_DIR,
'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=train_transform)
test_dataset = ESImagenet_Dataset(mode='test',
data_set_path=os.path.join(DATA_DIR,
'DVS/ES-imagenet-0.18/extract/ES-imagenet-0.18/'),
transform=test_transform)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
test_sampler = torch.utils.data.distributed.DistributedSampler(test_dataset)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
sampler=train_sampler
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=8,
sampler=test_sampler
)
# train_loader = torch.utils.data.DataLoader(
# train_dataset, batch_size=batch_size,
# pin_memory=True, drop_last=True, num_workers=8,
# shuffle=True
# )
#
# test_loader = torch.utils.data.DataLoader(
# test_dataset, batch_size=batch_size,
# pin_memory=True, drop_last=False, num_workers=1,
# shuffle=False
# )
return train_loader, test_loader, mixup_active, None
def get_CUB2002011_data(batch_size, num_workers=8, same_da=False, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(DATA_DIR, 'CUB2002011')
train_datasets = CUB2002011(
root=root, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = CUB2002011(
root=root, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_StanfordCars_data(batch_size, num_workers=8, same_da=False, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(DATA_DIR, 'StanfordCars')
train_datasets = datasets.StanfordCars(
root=root, split ="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.StanfordCars(
root=root, split ="test", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_StanfordDogs_data(batch_size, num_workers=8, same_da=False, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(DATA_DIR, 'StanfordDogs')
train_datasets = StanfordDogs(
root=root, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = StanfordDogs(
root=root, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_FGVCAircraft_data(batch_size, num_workers=8, same_da=False, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(DATA_DIR, 'FGVCAircraft')
train_datasets = datasets.FGVCAircraft(
root=root, split="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.FGVCAircraft(
root=root, split="test", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_Flowers102_data(batch_size, num_workers=8, same_da=False, *args, **kwargs):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
root=os.path.join(DATA_DIR, 'Flowers102')
train_datasets = datasets.Flowers102(
root=root, split="train", transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.Flowers102(
root=root, split="test", transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
================================================
FILE: examples/Perception_and_Learning/img_cls/transfer_for_dvs/main.py
================================================
# -*- coding: utf-8 -*-
# Time : 2023/4/19 14:58
# Author : Regulus
# FileName: main.py
# Explain:
# Software: PyCharm
import argparse
import time
import timm.models
import yaml
import os
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.vgg_snn import VGG_SNN
from braincog.model_zoo.resnet19_snn import resnet19
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
# from ptflops import get_model_complexity_info
# from thop import profile, clever_format
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--dataset', default='cifar10', type=str)
parser.add_argument('--model', default='cifar_convnet', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=600, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.8,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=1.0,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=1.0,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--output', default='/home/hexiang/TransferLearning_For_DVS/Results_lastest/', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=0)
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='GateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--gaussian-n', type=int, default=3)
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
# for reconstructing es-imagenet
parser.add_argument('--reconstructed', action='store_true',
help='for ES-imagenet dataset')
parser.add_argument('--DVS-DA', action='store_true',
help='use DA on DVS')
# train data used ratio
parser.add_argument('--traindata-ratio', default=1.0, type=float,
help='training data ratio')
# use TET loss or not (all default False, do not use)
parser.add_argument('--TET-loss-first', action='store_true',
help='use TET loss one part')
parser.add_argument('--TET-loss-second', action='store_true',
help='use TET loss two part')
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def main():
args, args_text = _parse_args()
# args.no_spike_output = args.no_spike_output | args.cut_mix
args.no_spike_output = True
output_dir = ''
if args.local_rank == 0:
output_base = args.output if args.output else './output'
exp_name = '-'.join([
args.model,
args.dataset,
str(args.step),
"seed_{}".format(args.seed),
"bs_{}".format(args.batch_size),
"DA_{}".format(args.DVS_DA),
"ls_{}".format(args.smoothing),
"lr_{}".format(args.lr),
"traindataratio_{}".format(args.traindata_ratio),
"TET_first_{}".format(args.TET_loss_first),
"TET_second_{}".format(args.TET_loss_second),
])
output_dir = get_outdir(output_base, 'Baseline', exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
else:
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
adaptive_node=args.adaptive_node,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
reconstruct=args.reconstructed,
TET_loss=args.TET_loss_first or args.TET_loss_second
)
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=list(range(args.num_gpu))).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
# print(model.get_attr('mu'))
# print(model.get_attr('sigma'))
if args.critical_loss or args.spike_rate:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model, device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
dvs_da=args.DVS_DA,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
reconstruct=args.reconstructed,
_logger=_logger,
train_data_ratio=args.traindata_ratio,
data_mode="full",
frames_num=12,
data_type="frequency"
)
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
if args.distributed:
state_dict = torch.load(args.eval_checkpoint)['state_dict_ema']
new_state_dict = OrderedDict()
# add module prefix for DDP
for k, v in state_dict.items():
k = 'module.' + k
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
else:
model.load_state_dict(torch.load(args.eval_checkpoint)['state_dict'])
for i in range(1):
val_metrics = validate(start_epoch, model, loader_eval, validate_loss_fn, args,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
print(f"Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=output_dir, recovery_dir=output_dir, decreasing=decreasing, max_history=1)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
if args.distributed:
loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler, model_ema=model_ema, mixup_fn=mixup_fn)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics = validate(epoch, model, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics = validate(
epoch, model_ema.ema, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast, log_suffix=' (EMA)',
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(output_dir, 'summary.csv'),
write_header=best_metric is None)
# if saver is not None and epoch >= args.n_warm_up:
if saver is not None:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
# if epoch == 299: # 临时的
# break
except KeyboardInterrupt:
pass
if best_metric is not None:
_logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and loader.mixup_enabled:
loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
# t, k = adjust_surrogate_coeff(100, args.epochs)
# model.set_attr('t', t)
# model.set_attr('k', k)
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
if not args.prefetcher or args.dataset != 'imnet':
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
if mixup_fn is not None:
inputs, target = mixup_fn(inputs, target)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
with amp_autocast():
output = model(inputs)
tet_loss = 0.0
loss = 0.0
lamb = 1e-3
if args.TET_loss_first or args.TET_loss_second: # 第一项必须有,也就是测两个,第一个何第一个加第二个
for i in range(len(output)):
tet_loss += loss_fn(output[i], target)
tet_loss /= len(output)
loss = (1 - lamb) * tet_loss
else:
loss = loss_fn(output, target)
if args.TET_loss_second:
y = torch.zeros_like(output[-1]).fill_(args.threshold)
secondLoss = torch.nn.MSELoss()
tet_loss_second = secondLoss(output[-1], y)
loss += lamb * tet_loss_second
if args.TET_loss_first or args.TET_loss_second:
output = sum(output) / len(output)
if not (args.cut_mix | args.mix_up | args.event_mix) and args.dataset != 'imnet':
# print(output.shape, target.shape)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
closs = torch.tensor([0.], device=loss.device)
loss = loss + .1 * closs
spike_rate_avg_layer_str = ''
threshold_str = ''
if not args.distributed:
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
top5_m.update(acc5.item(), inputs.size(0))
closses_m.update(closs.item(), inputs.size(0))
spike_rate_avg_layer = model.get_fire_rate().tolist()
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
if args.opt == 'lamb':
optimizer.step(epoch=epoch)
else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
losses_m.update(reduced_loss.item(), inputs.size(0))
closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
if args.distributed:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
else:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})\n'
'Fire_rate: {spike_rate}\n'
'Thres: {threshold}\n'
'Mu: {mu_str}\n'
'Sigma: {sigma_str}\n'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m,
spike_rate=spike_rate_avg_layer_str,
threshold=threshold_str,
mu_str=mu_str,
sigma_str=sigma_str
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args, amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
end = time.time()
last_idx = len(loader) - 1
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat) and not args.critical_loss:
model.set_requires_fp(True)
# if not args.critical_loss:
# model.set_requires_fp(False)
with amp_autocast():
output = model(inputs)
if args.TET_loss_first or args.TET_loss_second:
output = sum(output) / len(output)
if isinstance(output, (tuple, list)):
output = output[0]
if not args.distributed:
if visualize:
x = model.get_fp()
feature_path = os.path.join(args.output_dir, 'feature_map')
if os.path.exists(feature_path) is False:
os.mkdir(feature_path)
save_feature_map(x, feature_path)
# if not args.critical_loss:
# model_config.set_requires_fp(False)
if tsne:
x = model.get_fp(temporal_info=False)[-1]
x = torch.nn.AdaptiveAvgPool2d((1, 1))(x)
x = x.reshape(x.shape[0], -1)
feature_vec.append(x)
feature_cls.append(target)
if conf_mat:
logits_vec.append(output)
labels_vec.append(target)
if spike_rate:
avg, var, spike, avg_per_step = model.get_spike_info()
save_spike_info(
os.path.join(args.output_dir, 'spike_info.csv'),
epoch, batch_idx,
args.step, avg, var,
spike, avg_per_step)
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
closs = torch.tensor([0.], device=loss.device)
if not args.distributed:
spike_rate_avg_layer = model.get_fire_rate().tolist()
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
tot_spike = model.get_tot_spike()
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
closses_m.update(closs.item(), inputs.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
))
else:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})\n'
'Fire_rate: {spike_rate}\n'
'Tot_spike: {tot_spike}\n'
'Thres: {threshold}\n'
'Mu: {mu_str}\n'
'Sigma: {sigma_str}\n'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
spike_rate=spike_rate_avg_layer_str,
tot_spike=tot_spike,
threshold=threshold_str,
mu_str=mu_str,
sigma_str=sigma_str
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg)])
if not args.distributed:
if tsne:
feature_vec = torch.cat(feature_vec)
feature_cls = torch.cat(feature_cls)
plot_tsne(feature_vec, feature_cls, os.path.join(args.output_dir, 't-sne-2d.eps'))
plot_tsne_3d(feature_vec, feature_cls, os.path.join(args.output_dir, 't-sne-3d.eps'))
if conf_mat:
logits_vec = torch.cat(logits_vec)
labels_vec = torch.cat(labels_vec)
plot_confusion_matrix(logits_vec, labels_vec, os.path.join(args.output_dir, 'confusion_matrix.eps'))
return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/Perception_and_Learning/img_cls/transfer_for_dvs/main_transfer.py
================================================
# -*- coding: utf-8 -*-
# Time : 2022/9/29 15:27
# Author : Regulus
# FileName: main_transfer.py
# Explain:
# Software: PyCharm
import argparse
import math
import time
import CKA
import numpy
import timm.models
import random as rd
import yaml
import os
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.vgg_snn import VGG_SNN
from braincog.model_zoo.resnet19_snn import resnet19
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from rgb_hsv import RGB_HSV
import matplotlib.pyplot as plt
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
# from ptflops import get_model_complexity_info
# from thop import profile, clever_format
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--source-dataset', default='cifar10', type=str)
parser.add_argument('--target-dataset', default='dvsc10', type=str)
parser.add_argument('--model', default='cifar_convnet', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=600, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.8,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=1.0,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=1.0,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--output', default='/home/hexiang/TransferLearning_For_DVS/Results_lastest/', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=0)
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='GateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--gaussian-n', type=int, default=3)
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
# Transfer Learning loss choice
parser.add_argument('--domain-loss', action='store_true',
help='add domain loss')
parser.add_argument('--semantic-loss', action='store_true',
help='add semantic loss')
parser.add_argument('--domain-loss-coefficient', type=float, default=1.0,
help='domain loss coefficient(default: 1.0)')
parser.add_argument('--semantic-loss-coefficient', type=float, default=1.0,
help='domain loss coefficient(default: 1.0)')
# use TET loss or not (all default False, do not use)
parser.add_argument('--TET-loss-first', action='store_true',
help='use TET loss one part')
parser.add_argument('--TET-loss-second', action='store_true',
help='use TET loss two part')
parser.add_argument('--DVS-DA', action='store_true',
help='use DA on DVS')
# train data used ratio
parser.add_argument('--traindata-ratio', default=1.0, type=float,
help='training data ratio')
# snr value
parser.add_argument('--snr', default=0, type=int,
help='random noise amplitude controled by snr, 0 means no noise')
# margin m
parser.add_argument('--m', default=-1.0, type=float,
help='margin')
source_input_list, source_label_list = [], []
CALTECH101_list, ImageNet_list = [], []
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def main():
torch.set_num_threads(20)
os.environ["OMP_NUM_THREADS"] = "20" # 设置OpenMP计算库的线程数
os.environ["MKL_NUM_THREADS"] = "20" # 设置MKL-DNN CPU加速库的线程数。
args, args_text = _parse_args()
args.no_spike_output = True
output_dir = ''
if args.local_rank == 0:
output_base = args.output if args.output else './output'
exp_name = '-'.join([
args.model,
args.target_dataset,
str(args.step),
"bs_{}".format(args.batch_size),
"seed_{}".format(args.seed),
"DA_{}".format(args.DVS_DA),
"ls_{}".format(args.smoothing),
"lr_{}".format(args.lr),
"m_{}".format(args.m),
"domainLoss_{}".format(args.domain_loss),
"semanticLoss_{}".format(args.semantic_loss),
"domain_loss_coefficient{}".format(args.domain_loss_coefficient),
"semantic_loss_coefficient{}".format(args.semantic_loss_coefficient),
"traindataratio_{}".format(args.traindata_ratio),
"TETfirst_{}".format(args.TET_loss_first),
"TETsecond_{}".format(args.TET_loss_second),
])
output_dir = get_outdir(output_base, 'train_TCKA_test_nop', exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
else:
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
adaptive_node=args.adaptive_node,
dataset=args.target_dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
)
if 'dvs' in args.target_dataset:
args.channels = 2
elif 'mnist' in args.target_dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=list(range(args.num_gpu))).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
if args.critical_loss or args.spike_rate:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model, device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
source_loader_train, _, _, _ = eval('get_transfer_%s_data' % args.source_dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
)
target_loader_train, target_loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.target_dataset)(
batch_size=args.batch_size,
dvs_da=args.DVS_DA,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
train_data_ratio=args.traindata_ratio,
snr=args.snr,
data_mode="full",
frames_num=12,
data_type="frequency"
)
global source_input_list, source_label_list, CALTECH101_list, ImageNet_list
if args.target_dataset == "dvsc10" or args.target_dataset == "NCALTECH101" or args.target_dataset == "nomni": # ImageNet中回来的loader其实是数据集,在后面处理
source_input_list, source_label_list = next(iter(source_loader_train))
# for i in range(30001, 30005):
# # vis origin picture
# plt.figure()
# plt.imshow(source_input_list[i].permute(1, 2, 0).numpy())
# plt.savefig("./origin_image.jpg")
# plt.show()
# vis HSV picture
# for i in range(30001, 30005): # 30001.i
# convertor = RGB_HSV()
# plt.figure()
# plt.imshow(convertor.rgb_to_hsv(source_input_list)[i, :, :, :].permute(1, 2, 0).numpy())
# plt.title("HSV image")
# plt.show()
if args.source_dataset == "CALTECH101":
cls_count = [438, 435, 200, 791, 49, 800, 41, 34, 45, 50, 45, 32, 128, 84, 38, 81, 86, 47, 40, 0, 45, 58, 61,
105, 47, 64, 70, 68, 50, 51, 54, 67, 51, 64, 65, 72, 62, 52, 60, 83, 65, 67, 45, 31, 34, 49, 99,
100, 42, 54, 86, 80, 30, 62, 86, 110, 61, 79, 77, 40, 65, 42, 35, 77, 31, 74, 49, 32, 39, 47, 35,
43, 52, 34, 54, 69, 58, 45, 38, 57, 34, 84, 57, 31, 54, 45, 82, 56, 63, 35, 85, 43, 82, 74, 239,
37, 53, 33, 55, 29, 42]
CALTECH101_list = [0] * 102 # 多开了一类, 方便计算
for i in range(1, len(cls_count) + 1):
CALTECH101_list[i] = CALTECH101_list[i - 1] + cls_count[i - 1]
if args.source_dataset == "NCALTECH101":
cls_count = tonic.datasets.NCALTECH101.cls_count
CALTECH101_list = [0] * 102 # 多开了一类, 方便计算
for i in range(1, len(cls_count) + 1):
CALTECH101_list[i] = CALTECH101_list[i - 1] + cls_count[i - 1]
if args.source_dataset == "imnet":
cls_count = [1300] * 1000 # 1000类
cls_count_idx = [1117, 1266, 1071, 1141, 1272, 1150, 772, 860, 1136, 732, 1025, 754, 1290, 738, 1258, 1273, 977,
936, 1156, 1218, 969, 954, 1070, 755, 1206, 1165, 969, 1292, 1236, 1199, 1209, 1176, 1186,
1194,
1067, 1029, 1154, 1216, 1187, 889, 1211, 1136, 1153, 1222, 1282, 1283, 980, 1034, 891, 1285,
986,
1137, 1272, 1155, 1097, 1149, 1155, 1159, 1133, 1180, 1120, 1005, 1152, 1156, 962, 1157, 1282,
1117, 1118, 1270, 1069, 1053, 1254, 908, 1247, 1253, 1029, 1259, 1267, 1249, 1162, 1045, 1004,
1238, 1153, 1084, 1217, 931, 1264, 976, 1250, 1053, 1160, 1062, 1137, 1299, 1055, 1213, 1206,
1154,
1207, 1149, 1239, 1125, 1193]
cls_idx = [43, 51, 62, 98, 103, 147, 152, 158, 164, 165, 166, 167, 168, 175, 181, 183, 188, 190, 194, 206, 221,
252, 262, 268, 335, 390, 392, 409, 418, 426, 439, 465, 481, 491, 499, 501, 503, 507, 521, 531, 536,
550, 551, 567, 577, 583, 585, 590, 596, 610, 623, 630, 631, 635, 653, 662, 663, 675, 676, 678, 686,
689, 706, 708, 712, 714, 722, 723, 724, 727, 728, 729, 731, 740, 747, 753, 771, 772, 782, 789, 798,
810, 811, 812, 821, 826, 838, 841, 854, 857, 860, 869, 872, 885, 891, 892, 901, 906, 914, 921, 925,
926, 940, 946, 969]
for i in range(len(cls_count)):
if i in cls_idx:
cls_count[i] = cls_count_idx[cls_idx.index(i)]
ImageNet_list = [0] * 1001 # 多开了一类, 方便计算
for i in range(1, 1000 + 1):
ImageNet_list[i] = ImageNet_list[i - 1] + cls_count[i - 1]
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
if args.distributed:
state_dict = torch.load(args.eval_checkpoint)['state_dict_ema']
new_state_dict = OrderedDict()
# add module prefix for DDP
for k, v in state_dict.items():
k = 'module.' + k
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
else:
model.load_state_dict(torch.load(args.eval_checkpoint)['state_dict'])
for i in range(1):
val_metrics = validate(start_epoch, model, target_loader_eval, validate_loss_fn, args,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
print(f"Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=output_dir, recovery_dir=output_dir, decreasing=decreasing, max_history=1)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
eval_top1 = 0.0
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
if args.distributed:
target_loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, source_loader_train, target_loader_train, optimizer, train_loss_fn, args,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler, model_ema=model_ema, mixup_fn=mixup_fn)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics = validate(epoch, model, target_loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
eval_top1 = eval_metrics["top1"]
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics = validate(
epoch, model_ema.ema, target_loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast, log_suffix=' (EMA)',
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(output_dir, 'summary.csv'),
write_header=best_metric is None)
# if saver is not None and epoch >= args.n_warm_up:
if saver is not None:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
# if epoch == 299: # 临时的
# break
except KeyboardInterrupt:
pass
if best_metric is not None:
_logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, model, source_loader, target_loader, optimizer, loss_fn, args,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and target_loader.mixup_enabled:
target_loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
domain_losses_m = AverageMeter()
semantic_losses_m = AverageMeter()
rgb_losses_m = AverageMeter()
dvs_losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
end = time.time()
last_idx = len(target_loader) - 1
num_updates = epoch * len(target_loader)
convertor = RGB_HSV()
batch_len = len(target_loader)
if args.target_dataset == "dvsc10":
set_MaxReplacement_epoch = 0.5 * args.epochs
else:
set_MaxReplacement_epoch = 0.5 * args.epochs
P_Replacement = 0.0
global source_input_list, source_label_list, CALTECH101_list, ImageNet_list
for batch_idx, (inputs, label) in enumerate(target_loader):
P_Replacement = ((batch_idx + epoch * batch_len) / (set_MaxReplacement_epoch * batch_len)) ** 3
P_Replacement = P_Replacement if P_Replacement <= 1.0 else 1.0
sampler_list = label.tolist()
if args.target_dataset == "dvsc10" and args.source_dataset == "cifar10":
sampler_list = torch.tensor(sampler_list) * 6000 + torch.randint(0, 6000, (len(sampler_list),))
elif args.target_dataset == "dvsc10" and args.source_dataset == "dvsc10":
sampler_list = torch.tensor(sampler_list) * 900 + torch.randint(0, 900, (len(sampler_list),))
elif args.target_dataset == "NCALTECH101":
tmp_sampler_list = []
idx_list = []
for idx, label_sampler in enumerate(sampler_list):
if label_sampler == 19:
tmp_sampler_list.append(0)
idx_list.append(idx)
else:
tmp_sampler_list.append(torch.randint(CALTECH101_list[label_sampler],
CALTECH101_list[label_sampler + 1], (1,)).item())
elif args.target_dataset == "esimnet":
tmp_sampler_list = []
for idx, label_sampler in enumerate(sampler_list): # 这里的label_sampler是一个列表
tmp_sampler_list.append(torch.randint(ImageNet_list[label_sampler],
ImageNet_list[label_sampler + 1], (1,)).item())
elif args.target_dataset == "nomni":
sampler_list = torch.tensor(sampler_list) * 20 + torch.randint(0, 20, (len(sampler_list),))
source_input, source_label = [], []
if args.target_dataset == "dvsc10":
source_input, source_label = source_input_list[sampler_list], source_label_list[sampler_list]
if args.target_dataset == "NCALTECH101":
source_input, source_label = source_input_list[tmp_sampler_list], source_label_list[tmp_sampler_list]
if args.target_dataset == "esimnet":
train_dataset = source_loader # 给传回来的重新命个名儿
source_loader_used = torch.utils.data.DataLoader(
train_dataset,
batch_size=args.batch_size, shuffle=False,
num_workers=8, pin_memory=True, sampler=TransferSampler(tmp_sampler_list))
source_input, source_label = next(iter(source_loader_used))
if args.target_dataset == "nomni":
source_input, source_label = source_input_list[sampler_list], source_label_list[sampler_list]
# for i in range(128):
# # vis origin picture
# plt.figure()
# plt.imshow(source_input[i].permute(1, 2, 0))
# plt.title("origin image")
# plt.show()
# # vis HSV picture
# plt.figure()
# plt.imshow(convertor.rgb_to_hsv(inputs)[7, :, :, :].permute(1, 2, 0).numpy())
# plt.title("HSV image")
# plt.show()
# source_input = convertor.rgb_to_hsv(source_input)[:, -1, :, :].unsqueeze(1).repeat(1, args.step * 2, 1, 1)
if args.source_dataset == "dvsc10" or args.source_dataset == "NCALTECH101":
pass
else:
source_input = source_input[:, -1, :, :].unsqueeze(1).repeat(1, args.step * 2, 1, 1)
source_input = rearrange(source_input, 'b (t c) h w -> b t c h w', t=args.step)
for b in range(source_input.shape[0]):
if rd.uniform(0, 1) <= P_Replacement:
source_input[b] = inputs[b, :, :, :, :]
# for i in range(10):
# # vis HSV picture for v channel
# plt.figure()
# plt.imshow(source_input[i][0].permute(1, 2, 0)[:, :, -1].unsqueeze(2))
# plt.title("HSV image for v channel")
# plt.show()
if args.target_dataset == "NCALTECH101" and len(idx_list) > 0:
for i in range(len(idx_list)):
source_input[idx_list[i]] = inputs[idx_list[i]]
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
if not args.prefetcher or args.target_dataset != 'imnet':
inputs, label = inputs.type(torch.FloatTensor).cuda(), label.cuda()
source_input, source_label = source_input.type(torch.FloatTensor).cuda(), label.cuda()
if mixup_fn is not None:
inputs, label = mixup_fn(inputs, label)
source_input, source_label = mixup_fn(source_input, source_label)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
source_input = source_input.contiguous(memory_format=torch.channels_last)
with amp_autocast():
domain_rbg_list, domain_dvs_list, output_rgb, output_dvs = model(source_input, inputs)
# compute semantic loss
label_idx = [[] for i in range(args.num_classes)]
semantic_label_list = []
for idx, i in enumerate(label):
label_idx[i.item()].append(idx)
for i in label:
while True:
label_tmp = torch.randint(0, args.num_classes, (1,)).item()
if i.item() != label_tmp and len(label_idx[label_tmp]) > 0: # NCALTECH101有空列表, 需要判断
break
semantic_label_list.append(int(np.random.choice(label_idx[label_tmp], 1)))
semantic_rbg_list = []
semantic_loss = 0.
for i in range(len(domain_rbg_list)):
semantic_rbg_list.append(domain_rbg_list[i][semantic_label_list])
for i in range(len(domain_rbg_list)):
semantic_loss += torch.abs(CKA.linear_CKA(domain_dvs_list[i].view(args.batch_size, -1), semantic_rbg_list[i].view(args.batch_size, -1)))
semantic_loss /= len(domain_rbg_list)
if args.target_dataset == "dvsc10":
m = 0.1
elif args.target_dataset == "NCALTECH101":
m = 0.3
else:
m = 0.2
if args.m >= 0.0:
m = args.m
if semantic_loss.item() - m <= 0:
semantic_loss = torch.tensor(0., device=semantic_loss.device)
# if args.domain_loss_after:
# # compute domain loss
# for b in range(source_input.shape[0]):
# if rd.uniform(0, 1) <= P_Replacement:
# for i in range(len(domain_rbg_list)):
# domain_rbg_list[i][b] = domain_dvs_list[i][b, :, :, :]
domain_loss = 0.
for i in range(len(domain_rbg_list)):
domain_loss += 1 - torch.abs(CKA.linear_CKA(domain_rbg_list[i].view(args.batch_size, -1), domain_dvs_list[i].view(args.batch_size, -1)))
domain_loss /= len(domain_rbg_list)
# compute cls loss
lamb = 1e-3
if args.TET_loss_first or args.TET_loss_second: # 第一项必须有,也就是测两个,第一个何第一个加第二个
loss_rgb = 0
tet_loss_first = 0
tet_loss_second = 0
assert len(output_rgb) == len(output_dvs)
for i in range(len(output_rgb)):
loss_rgb += loss_fn(output_rgb[i], label)
tet_loss_first += loss_fn(output_dvs[i], label)
loss_rgb /= len(output_rgb)
tet_loss_first /= len(output_dvs)
if args.TET_loss_second:
y = torch.zeros_like(output_dvs[-1]).fill_(args.threshold)
secondLoss = torch.nn.MSELoss()
tet_loss_second = secondLoss(output_dvs[-1], y)
else:
lamb = 0.0
loss_dvs = (1 - lamb) * tet_loss_first + lamb * tet_loss_second
output_rgb = sum(output_rgb) / len(output_rgb)
output_dvs = sum(output_dvs) / len(output_dvs)
else:
output_rgb = sum(output_rgb) / len(output_rgb)
output_dvs = sum(output_dvs) / len(output_dvs)
loss_rgb = loss_fn(output_rgb, label)
loss_dvs = loss_fn(output_dvs, label)
loss = 0 * loss_rgb + loss_dvs
if args.domain_loss:
loss += args.domain_loss_coefficient * domain_loss
if args.semantic_loss and epoch <= set_MaxReplacement_epoch:
if args.target_dataset == "NCALTECH101" and epoch <= set_MaxReplacement_epoch * 0.66:
# loss += args.semantic_loss_coefficient * semantic_loss * math.pow(10, -1.0 * float(set_MaxReplacement_epoch / (epoch+1)))
pass
else:
loss += args.semantic_loss_coefficient * semantic_loss
if not (args.cut_mix | args.mix_up | args.event_mix) and args.target_dataset != 'imnet':
acc1, acc5 = accuracy(output_dvs, label, topk=(1, 5))
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
closs = torch.tensor([0.], device=loss.device)
loss = loss + .1 * closs
spike_rate_avg_layer_str = ''
threshold_str = ''
if not args.distributed:
losses_m.update(loss.item(), inputs.size(0))
domain_losses_m.update(domain_loss.item(), inputs.size(0))
semantic_losses_m.update(semantic_loss.item(), inputs.size(0))
rgb_losses_m.update(loss_rgb.item(), inputs.size(0))
dvs_losses_m.update(loss_dvs.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
top5_m.update(acc5.item(), inputs.size(0))
closses_m.update(closs.item(), inputs.size(0))
spike_rate_avg_layer = model.get_fire_rate().tolist()
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i.item()) for i in threshold]
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
if args.opt == 'lamb':
optimizer.step(epoch=epoch)
else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
losses_m.update(reduced_loss.item(), inputs.size(0))
closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
if args.distributed:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(target_loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
else:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})\n'
'Fire_rate: {spike_rate}\n'
'Thres: {threshold}\n'
'Mu: {mu_str}\n'
'Sigma: {sigma_str}\n'
'P_Replacement: {P_Replacement}\n'.format(
epoch,
batch_idx, len(target_loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m,
spike_rate=spike_rate_avg_layer_str,
threshold=threshold_str,
mu_str=mu_str,
sigma_str=sigma_str,
P_Replacement=P_Replacement,
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg), ('domainLoss', domain_losses_m.avg), ('semanticLoss', semantic_losses_m.avg),
('rgbLoss', rgb_losses_m.avg), ('dvsLoss', dvs_losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args, amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
end = time.time()
last_idx = len(loader) - 1
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.target_dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat) and not args.critical_loss:
model.set_requires_fp(True)
# if not args.critical_loss:
# model.set_requires_fp(False)
with amp_autocast():
_, _, output_rbg, output_dvs = model(inputs, inputs)
output = sum(output_dvs) / len(output_dvs)
if isinstance(output, (tuple, list)):
output = output[0]
if not args.distributed:
if visualize:
x = model.get_fp()
feature_path = os.path.join(args.output_dir, 'feature_map')
if os.path.exists(feature_path) is False:
os.mkdir(feature_path)
save_feature_map(x, feature_path)
# if not args.critical_loss:
# model_config.set_requires_fp(False)
if tsne:
x = model.get_fp(temporal_info=False)[-1]
x = torch.nn.AdaptiveAvgPool2d((1, 1))(x)
x = x.reshape(x.shape[0], -1)
feature_vec.append(x)
feature_cls.append(target)
if conf_mat:
logits_vec.append(output)
labels_vec.append(target)
if spike_rate:
avg, var, spike, avg_per_step = model.get_spike_info()
save_spike_info(
os.path.join(args.output_dir, 'spike_info.csv'),
epoch, batch_idx,
args.step, avg, var,
spike, avg_per_step)
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
closs = torch.tensor([0.], device=loss.device)
if not args.distributed:
spike_rate_avg_layer = model.get_fire_rate().tolist()
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
tot_spike = model.get_tot_spike()
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
closses_m.update(closs.item(), inputs.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
))
else:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})\n'
'Fire_rate: {spike_rate}\n'
'Tot_spike: {tot_spike}\n'
'Thres: {threshold}\n'
'Mu: {mu_str}\n'
'Sigma: {sigma_str}\n'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
spike_rate=spike_rate_avg_layer_str,
tot_spike=tot_spike,
threshold=threshold_str,
mu_str=mu_str,
sigma_str=sigma_str
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg)])
if not args.distributed:
if tsne:
feature_vec = torch.cat(feature_vec)
feature_cls = torch.cat(feature_cls)
plot_tsne(feature_vec, feature_cls, os.path.join(args.output_dir, 't-sne-2d.eps'))
plot_tsne_3d(feature_vec, feature_cls, os.path.join(args.output_dir, 't-sne-3d.eps'))
if conf_mat:
logits_vec = torch.cat(logits_vec)
labels_vec = torch.cat(labels_vec)
plot_confusion_matrix(logits_vec, labels_vec, os.path.join(args.output_dir, 'confusion_matrix.eps'))
return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/Perception_and_Learning/img_cls/transfer_for_dvs/main_visual_losslandscape.py
================================================
# -*- coding: utf-8 -*-
# Time : 2023/2/14 11:52
# Author : Regulus
# FileName: main_visual_losslandscape.py
# Explain:
# Software: PyCharm
from loss_landscape.plot_surface import *
import argparse
import math
import time
import CKA
import numpy
import timm.models
import random as rd
import yaml
import os
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.vgg_snn import VGG_SNN
from braincog.model_zoo.resnet19_snn import resnet19
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from rgb_hsv import RGB_HSV
import matplotlib.pyplot as plt
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--source-dataset', default='cifar10', type=str)
parser.add_argument('--target-dataset', default='dvsc10', type=str)
parser.add_argument('--model', default='cifar_convnet', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=600, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.8,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=1.0,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=1.0,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--output', default='/home/hexiang/TransferLearning_For_DVS/Results_new_refined/', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=0)
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='GateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--gaussian-n', type=int, default=3)
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
parser.add_argument('--DVS-DA', action='store_true',
help='use DA on DVS')
# train data used ratio
parser.add_argument('--traindata-ratio', default=1.0, type=float,
help='training data ratio')
# snr value
parser.add_argument('--snr', default=0, type=int,
help='random noise amplitude controled by snr, 0 means no noise')
# --------------------------------------------------------------------------
# Start the loss-landscape
# --------------------------------------------------------------------------
parser.add_argument('--mpi', '-m', action='store_true', help='use mpi')
parser.add_argument('--threads', default=2, type=int, help='number of threads')
parser.add_argument('--ngpu', type=int, default=1,
help='number of GPUs to use for each rank, useful for data parallel evaluation')
# model parameters
parser.add_argument('--model_folder', default='',
help='the common folder that contains model_file and model_file2')
parser.add_argument('--model_file', default='', help='path to the trained model file')
parser.add_argument('--model_file2', default='', help='use (model_file2 - model_file) as the xdirection')
parser.add_argument('--model_file3', default='', help='use (model_file3 - model_file) as the ydirection')
parser.add_argument('--loss_name', '-l', default='crossentropy', help='loss functions: crossentropy | mse')
# direction parameters
parser.add_argument('--dir_file', default='',
help='specify the name of direction file, or the path to an eisting direction file')
parser.add_argument('--dir_type', default='weights',
help='direction type: weights | states (including BN\'s running_mean/var)')
parser.add_argument('--x', default='-1:1:51', help='A string with format xmin:x_max:xnum')
parser.add_argument('--y', default=None, help='A string with format ymin:ymax:ynum')
parser.add_argument('--xnorm', default='', help='direction normalization: filter | layer | weight')
parser.add_argument('--ynorm', default='', help='direction normalization: filter | layer | weight')
parser.add_argument('--xignore', default='', help='ignore bias and BN parameters: biasbn')
parser.add_argument('--yignore', default='', help='ignore bias and BN parameters: biasbn')
parser.add_argument('--same_dir', action='store_true', default=False,
help='use the same random direction for both x-axis and y-axis')
parser.add_argument('--idx', default=0, type=int, help='the index for the repeatness experiment')
parser.add_argument('--surf_file', default='',
help='customize the name of surface file, could be an existing file.')
# plot parameters
parser.add_argument('--proj_file', default='', help='the .h5 file contains projected optimization trajectory.')
parser.add_argument('--loss_max', default=5, type=float, help='Maximum value to show in 1D plot')
parser.add_argument('--vmax', default=10, type=float, help='Maximum value to map')
parser.add_argument('--vmin', default=0.1, type=float, help='Miminum value to map')
parser.add_argument('--vlevel', default=1.0, type=float, help='plot contours every vlevel')
parser.add_argument('--show', action='store_true', default=False, help='show plotted figures')
parser.add_argument('--log', action='store_true', default=False, help='use log scale for loss values')
parser.add_argument('--plot', action='store_true', default=False, help='plot figures after computation')
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def main():
torch.set_num_threads(20)
os.environ["OMP_NUM_THREADS"] = "20" # 设置OpenMP计算库的线程数
os.environ["MKL_NUM_THREADS"] = "20" # 设置MKL-DNN CPU加速库的线程数。
args, args_text = _parse_args()
args.no_spike_output = True
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
adaptive_node=args.adaptive_node,
dataset=args.target_dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
TET_loss=False
) # 注意这里的TET_loss,选择losslandscape在谁上看.
if 'dvs' in args.target_dataset:
args.channels = 2
elif 'mnist' in args.target_dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
source_loader_train, _, _, _ = eval('get_transfer_%s_data' % args.source_dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
)
target_loader_train, target_loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.target_dataset)(
batch_size=args.batch_size,
dvs_da=args.DVS_DA,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
train_data_ratio=args.traindata_ratio,
snr=args.snr,
data_mode="full",
frames_num=12,
data_type="frequency"
)
if args.eval: # evaluate the model
if args.distributed:
state_dict = torch.load(args.eval_checkpoint)['state_dict_ema']
new_state_dict = OrderedDict()
# add module prefix for DDP
for k, v in state_dict.items():
k = 'module.' + k
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
else:
model.load_state_dict(torch.load(args.eval_checkpoint, map_location=torch.device('cpu'))['state_dict'])
# --------------------------------------------------------------------------
# Show Acc
# --------------------------------------------------------------------------
print("load model finished!")
# train_loss_fn = nn.CrossEntropyLoss()
# for i in range(1):
# _, val_acc = validate(model, target_loader_train, train_loss_fn, args)
# print(f"Top-1 accuracy of the model is: {val_acc:.2f}%")
# --------------------------------------------------------------------------
# Environment setup
# --------------------------------------------------------------------------
if args.mpi:
comm = mpi.setup_MPI()
rank, nproc = comm.Get_rank(), comm.Get_size()
else:
comm, rank, nproc = None, 0, 1
if True:
if not torch.cuda.is_available():
raise Exception('User selected cuda option, but cuda is not available on this machine')
gpu_count = torch.cuda.device_count()
# torch.cuda.set_device(rank % gpu_count)
torch.cuda.set_device("cuda:{}".format(args.device))
print('Rank %d use GPU %d of %d GPUs on %s' %
(rank, torch.cuda.current_device(), gpu_count, socket.gethostname()))
# --------------------------------------------------------------------------
# Check plotting resolution
# --------------------------------------------------------------------------
try:
args.xmin, args.xmax, args.xnum = [float(a) for a in args.x.split(':')]
args.ymin, args.ymax, args.ynum = (None, None, None)
if args.y:
args.ymin, args.ymax, args.ynum = [float(a) for a in args.y.split(':')]
assert args.ymin and args.ymax and args.ynum, \
'You specified some arguments for the y axis, but not all'
except:
raise Exception('Improper format for x- or y-coordinates. Try something like -1:1:51')
# --------------------------------------------------------------------------
# Load models and extract parameters
# --------------------------------------------------------------------------
net = model
w = net_plotter.get_weights(net) # initial parameters
s = copy.deepcopy(net.state_dict()) # deepcopy since state_dict are references
if args.ngpu > 1:
# data parallel with multiple GPUs on a single node
net = nn.DataParallel(net, device_ids=range(torch.cuda.device_count()))
# --------------------------------------------------------------------------
# Setup the direction file and the surface file
# --------------------------------------------------------------------------
dir_file = net_plotter.name_direction_file(args) # name the direction file
dir_file = os.path.join(os.path.split(args.eval_checkpoint)[0], dir_file)
if rank == 0:
net_plotter.setup_direction(args, dir_file, net)
surf_file = name_surface_file(args, dir_file)
if rank == 0:
setup_surface_file(args, surf_file, dir_file)
# wait until master has setup the direction file and surface file
mpi.barrier(comm)
# load directions
d = net_plotter.load_directions(dir_file)
# calculate the consine similarity of the two directions
if len(d) == 2 and rank == 0:
similarity = proj.cal_angle(proj.nplist_to_tensor(d[0]), proj.nplist_to_tensor(d[1]))
print('cosine similarity between x-axis and y-axis: %f' % similarity)
mpi.barrier(comm)
# --------------------------------------------------------------------------
# Start the computation
# --------------------------------------------------------------------------
trainloader = target_loader_train
crunch(surf_file, net, w, s, d, trainloader, 'train_loss', 'train_acc', comm, rank, args)
# --------------------------------------------------------------------------
# Plot figures
# --------------------------------------------------------------------------
if args.plot and rank == 0:
if args.y and args.proj_file:
plot_2D.plot_contour_trajectory(surf_file, dir_file, args.proj_file, 'train_loss', args.show)
elif args.y:
plot_2D.plot_2d_contour(surf_file, 'train_loss', args.vmin, args.vmax, args.vlevel, args.show)
else:
plot_1D.plot_1d_loss_err(surf_file, args.xmin, args.xmax, args.loss_max, args.log, args.show)
return
if __name__ == '__main__':
main()
================================================
FILE: examples/Snn_safety/DPSNN/Readme.txt
================================================
The code for the differential private spiking neural network(DPSNN).
================================================
FILE: examples/Snn_safety/DPSNN/load_data.py
================================================
import numpy as np
from torchvision import datasets, transforms
import torch
from torch.utils.data import Dataset
import tonic
from tonic import DiskCachedDataset
import torch.nn.functional as F
import os
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
CIFAR10_MEAN = (0.4914, 0.4822, 0.4465)
CIFAR10_STD_DEV = (0.2023, 0.1994, 0.2010)
cifar100_mean = [0.5071, 0.4865, 0.4409]
cifar100_std = [0.2673, 0.2563, 0.2761]
DVSCIFAR10_MEAN_16 = [0.3290, 0.4507]
DVSCIFAR10_STD_16 = [1.8398, 1.6549]
DATA_DIR = '/data/datasets'
class CustomDataset(Dataset):
"""An abstract Dataset class wrapped around Pytorch Dataset class.
"""
def __init__(self, dataset, indices):
self.dataset = dataset
self.indices = [int(i) for i in indices]
def __len__(self):
return len(self.indices)
def __getitem__(self, item):
x, y = self.dataset[self.indices[item]]
return x, y
def load_static_data(data_root, batch_size, dataset):
if dataset == 'cifar10':
transform_train = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(CIFAR10_MEAN, CIFAR10_STD_DEV)])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(CIFAR10_MEAN, CIFAR10_STD_DEV)])
train_data = datasets.CIFAR10(data_root, train=True, transform=transform_train, download=True)
test_data = datasets.CIFAR10(data_root, train=False, transform=transform_test, download=True)
train_loader = torch.utils.data.DataLoader(
train_data,
batch_size=batch_size,
shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_data,
batch_size=batch_size,
)
elif dataset == 'MNIST':
transform_train = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(MNIST_MEAN, MNIST_STD)])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(MNIST_MEAN, MNIST_STD)])
train_data = datasets.MNIST(data_root, train=True, transform=transform_train, download=True)
test_data = datasets.MNIST(data_root, train=False, transform=transform_test, download=True)
train_loader = torch.utils.data.DataLoader(
train_data,
batch_size=batch_size,
shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_data,
batch_size=batch_size,
)
elif dataset == 'FashionMNIST':
transform_train = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(MNIST_MEAN, MNIST_STD)])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(MNIST_MEAN, MNIST_STD)])
train_data = datasets.FashionMNIST(data_root, train=True, transform=transform_train, download=True)
test_data = datasets.FashionMNIST(data_root, train=False, transform=transform_test, download=True)
train_loader = torch.utils.data.DataLoader(
train_data,
batch_size=batch_size,
shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_data,
batch_size=batch_size,
)
return train_data, test_data, train_loader, test_loader
def load_dvs10_data(batch_size, step, **kwargs):
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = tonic.datasets.CIFAR10DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=train_transform)
test_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
train_dataset = DiskCachedDataset(train_dataset,
cache_path=f'./dataset/dvs_cifar10/train_cache_{step}',
transform=train_transform)
test_dataset = DiskCachedDataset(train_dataset,
cache_path=f'./dataset/dvs_cifar10/test_cache_{step}',
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
train_dataset = CustomDataset(train_dataset, np.array(indices_train))
test_dataset = CustomDataset(test_dataset, np.array(indices_test))
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True,
pin_memory=True, drop_last=False, num_workers=1
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=1
)
return train_loader, test_loader, train_dataset, test_dataset
def load_nmnist_data(batch_size, step, **kwargs):
size = kwargs['size'] if 'size' in kwargs else 28
sensor_size = tonic.datasets.NMNIST.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/NMNIST'), transform=train_transform, train=True)
test_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/NMNIST'), transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
train_dataset = DiskCachedDataset(train_dataset,
cache_path=f'./dataset/NMNIST/train_cache_{step}',
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=f'./dataset/NMNIST/test_cache_{step}',
transform=test_transform)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True,
pin_memory=True, drop_last=False, num_workers=1
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=1
)
return train_loader, test_loader, train_dataset, test_dataset
================================================
FILE: examples/Snn_safety/DPSNN/main_dpsnn.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from opacus import PrivacyEngine
from model import *
from braincog.base.node.node import *
import warnings
from load_data import *
from opacus.utils.batch_memory_manager import BatchMemoryManager
warnings.simplefilter("ignore")
# Precomputed characteristics of the dataset dataset
torch.cuda.manual_seed(3154)
batch_size = 512
MAX_PHYSICAL_BATCH_SIZE = 32
target_ep = 8
c = 6
epochs = 40
step = 10
delta = 1e-5
devices = 4
r = 5
device = torch.device(f'cuda:{devices}' if torch.cuda.is_available() else 'cpu')
# device = 'cpu'
disable_noise = False
data_root = "./dataset"
kwargs = {"num_workers": 1, "pin_memory": True}
dataset = 'dvs_cifar10'
# NMNIST, cifar10, dvs_cifar10, MNIST, FashionMNIST
def train(model, device, train_loader, optimizer, epoch, privacy_engine):
criterion = nn.CrossEntropyLoss().to(device)
losses = []
model.train()
correct = 0
for _batch_idx, (data, target) in enumerate(train_loader):
# print(target)
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
losses.append(loss.item())
pred = output.argmax(
dim=1, keepdim=True
) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
if not disable_noise:
epsilon = privacy_engine.get_epsilon(delta=delta)
print(
f"Train Epoch: {epoch} \t"
f"Loss: {np.mean(losses):.6f} "
)
print("Accuracy: {}/{} ({:.2f}%)\n".format(
correct,
len(train_loader.dataset),
100.0 * correct / len(train_loader.dataset), ))
print(
f"(ε = {epsilon:.2f}, δ = {delta})"
)
else:
print(f"Train Epoch: {epoch} \t Loss: {np.mean(losses):.6f}")
return 100.0 * correct / len(train_loader.dataset)
def test(model, device, test_loader):
model.eval()
criterion = nn.CrossEntropyLoss().to(device)
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item() # sum up batch loss
pred = output.argmax(
dim=1, keepdim=True
) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader)
print(
"\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n".format(
test_loss,
correct,
len(test_loader.dataset),
100.0 * correct / len(test_loader.dataset),
)
)
return correct / len(test_loader.dataset)
def run():
if dataset == 'dvs_cifar10':
train_loader, test_loader, train_data, test_data = load_dvs10_data(batch_size=batch_size, step=step)
# train_loader, test_loader, _, _ = get_dvsc10_data(batch_size=batch_size, step=step)
elif dataset == 'NMNIST':
train_loader, test_loader, train_data, test_data = load_nmnist_data(batch_size=batch_size, step=step)
else:
train_data, test_data, train_loader, test_loader = load_static_data(data_root, batch_size, dataset)
result = []
result_train = []
for _ in range(r):
if dataset == 'cifar10':
model = cifar_convnet(
step=step,
encode_type='direct',
node_type=LIFNode,
num_classes=10,
spike_output=False,
layer_by_layer=True,
act_fun=QGateGrad
)
model.to(device)
optimizer = optim.AdamW(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[40], gamma=0.1, last_epoch=-1)
elif dataset == 'dvs_cifar10':
model = dvs_convnet(
step=step,
encode_type='direct',
node_type=LIFNode,
num_classes=10,
spike_output=False,
layer_by_layer=True,
act_fun=QGateGrad
)
model.to(device)
optimizer = optim.AdamW(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[15], gamma=1, last_epoch=-1)
elif dataset == 'NMNIST':
model = SimpleSNN(
channel=2,
step=step,
node_type=LIFNode,
act_fun=QGateGrad,
layer_by_layer=True,
)
model.to(device)
optimizer = optim.AdamW(model.parameters(), lr=0.005)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[10], gamma=0.1, last_epoch=-1)
elif dataset == 'MNIST' or dataset == 'FashionMNIST':
model = SimpleSNN(
channel=1,
step=step,
node_type=LIFNode,
act_fun=QGateGrad,
layer_by_layer=True,
)
model.to(device)
optimizer = optim.AdamW(model.parameters(), lr=0.005)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[10], gamma=0.1, last_epoch=-1)
if not disable_noise:
privacy_engine = PrivacyEngine()
model, optimizer, data_loader = privacy_engine.make_private_with_epsilon(
module=model,
optimizer=optimizer,
data_loader=train_loader,
max_grad_norm=c,
epochs=epochs,
target_delta=delta,
target_epsilon=target_ep
)
with BatchMemoryManager(
data_loader=data_loader,
max_physical_batch_size=MAX_PHYSICAL_BATCH_SIZE,
optimizer=optimizer
) as memory_safe_data_loader:
# if 1:
for epoch in range(1, epochs + 1):
result_train.append(train(model, device, memory_safe_data_loader, optimizer, epoch, privacy_engine))
result.append(test(model, device, test_loader))
scheduler.step()
else:
privacy_engine = PrivacyEngine()
model, optimizer, data_loader = privacy_engine.make_private(
module=model,
optimizer=optimizer,
data_loader=train_loader,
max_grad_norm=c,
noise_multiplier=0.0,
)
with BatchMemoryManager(
data_loader=data_loader,
max_physical_batch_size=MAX_PHYSICAL_BATCH_SIZE,
optimizer=optimizer
) as memory_safe_data_loader:
for epoch in range(1, epochs + 1):
train(model, device, memory_safe_data_loader, optimizer, epoch, privacy_engine)
result.append(test(model, device, test_loader))
scheduler.step()
result = np.array(result).reshape((r, -1))
result_train = np.array(result_train).reshape((r, -1))
best_acc = np.mean(np.max(result, axis=1))
print(best_acc)
np.save(file=f'./{dataset}/MP_test.npy', arr=result)
np.save(file=f'./{dataset}/MP_train.npy', arr=result_train)
if __name__ == "__main__":
run()
================================================
FILE: examples/Snn_safety/DPSNN/model.py
================================================
import abc
from functools import partial
import torch
from torch.nn import functional as F
import torchvision
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
class TEP(nn.Module):
def __init__(self, step, channel, device=None, dtype=None):
factory_kwargs = {'device': device, 'dtype': dtype}
super(TEP, self).__init__()
self.step = step
self.gn = nn.GroupNorm(channel, channel)
def forward(self, x):
x = rearrange(x, '(t b) c w h -> t b c w h', t=self.step)
fire_rate = torch.mean(x, dim=0)
fire_rate = self.gn(fire_rate) + 1
x = x * fire_rate
x = rearrange(x, 't b c w h -> (t b) c w h')
return x
class BaseConvNet(BaseModule, abc.ABC):
def __init__(self,
step,
input_channels,
num_classes,
encode_type,
spike_output: bool,
out_channels: list,
block_depth: list,
node_list: list,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.num_cls = num_classes
self.spike_output = spike_output
self.groups = kwargs['n_groups'] if 'n_groups' in kwargs else 1
if not spike_output:
node_list.append(nn.Identity)
out_channels.append(self.num_cls)
self.vote = nn.Identity()
# self.vote = nn.Sequential(
# nn.Linear(self.step, 32),
# nn.ReLU(),
# nn.Linear(32, 1)
# )
else:
out_channels.append(10 * self.num_cls)
self.vote = VotingLayer(10)
# check list length
if len(node_list) != len(out_channels):
raise ValueError
self.input_channels = input_channels
self.out_channels = out_channels
self.block_depth = block_depth
self.node_list = node_list
self.feature = self._create_feature()
self.fc = self._create_fc()
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
@staticmethod
def _create_feature(self):
raise NotImplementedError
@staticmethod
def _create_fc(self):
raise NotImplementedError
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if not self.training:
self.fire_rate.clear()
if not self.layer_by_layer:
outputs = []
if self.warm_up:
step = 1
else:
step = self.step
for t in range(step):
x = inputs[t]
x = self.feature(x)
x = self.flatten(x)
x = self.fc(x)
x = self.vote(x)
outputs.append(x)
return sum(outputs) / len(outputs)
# outputs = torch.stack(outputs)
# outputs = rearrange(outputs, 't b c -> b c t')
# outputs = self.vote(outputs).squeeze()
# return outputs
else:
x = self.feature(inputs)
x = self.flatten(x)
x = self.fc(x)
if self.groups == 1:
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
else:
x = rearrange(x, 'b (c t) -> t b c', t=self.step).mean(0)
x = self.vote(x)
return x
class LayerWiseConvModule(nn.Module):
"""
SNN卷积模块
:param in_channels: 输入通道数
:param out_channels: 输出通道数
:param kernel_size: kernel size
:param stride: stride
:param padding: padding
:param bias: Bias
:param node: 神经元类型
:param kwargs:
"""
def __init__(self,
in_channels: int,
out_channels: int,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
bias=False,
node=LIFNode,
step=6,
**kwargs):
super().__init__()
if node is None:
raise TypeError
self.groups = kwargs['groups'] if 'groups' in kwargs else 1
self.conv = nn.Conv2d(in_channels=in_channels * self.groups,
out_channels=out_channels * self.groups,
kernel_size=kernel_size,
padding=padding,
stride=stride,
bias=bias)
self.gn = nn.GroupNorm(16, out_channels * self.groups)
self.node = partial(node, **kwargs)()
self.step = step
self.activation = nn.Identity()
def forward(self, x):
x = rearrange(x, '(t b) c w h -> t b c w h', t=self.step)
outputs = []
for t in range(self.step):
outputs.append(self.gn(self.conv(x[t])))
outputs = torch.stack(outputs) # t b c w h
outputs = rearrange(outputs, 't b c w h -> (t b) c w h')
outputs = self.node(outputs)
return outputs
class LayerWiseLinearModule(nn.Module):
"""
线性模块
:param in_features: 输入尺寸
:param out_features: 输出尺寸
:param bias: 是否有Bias, 默认 ``False``
:param node: 神经元类型, 默认 ``LIFNode``
:param args:
:param kwargs:
"""
def __init__(self,
in_features: int,
out_features: int,
bias=True,
node=LIFNode,
step=6,
spike=False,
*args,
**kwargs):
super().__init__()
if node is None:
raise TypeError
self.groups = kwargs['groups'] if 'groups' in kwargs else 1
if self.groups == 1:
self.fc = nn.Linear(in_features=in_features,
out_features=out_features, bias=bias)
else:
self.fc = nn.ModuleList()
for i in range(self.groups):
self.fc.append(nn.Linear(
in_features=in_features,
out_features=out_features,
bias=bias
))
self.node = partial(node, **kwargs)()
self.step = step
self.spike = spike
def forward(self, x):
if self.groups == 1: # (t b) c
x = rearrange(x, '(t b) c -> t b c', t=self.step)
outputs = []
for t in range(self.step):
outputs.append(self.fc(x[t]))
outputs = torch.stack(outputs) # t b c
outputs = rearrange(outputs, 't b c -> (t b) c')
else: # b (c t)
x = rearrange(x, 'b (c t) -> t b c', t=self.groups)
outputs = []
for i in range(self.groups):
outputs.append(self.fc[i](x[i]))
outputs = torch.stack(outputs) # t b c
outputs = rearrange(outputs, 't b c -> b (c t)')
if self.spike:
return self.node(outputs)
else:
return outputs
class LayWiseConvNet(BaseConvNet):
def __init__(self,
step,
input_channels,
num_classes,
encode_type,
spike_output: bool,
out_channels: list,
node_list: list,
block_depth: list,
*args,
**kwargs):
super().__init__(step,
input_channels,
num_classes,
encode_type,
spike_output,
out_channels,
block_depth,
node_list,
*args,
**kwargs)
def _create_feature(self):
feature_depth = len(self.node_list) - 1
feature = [LayerWiseConvModule(
self.input_channels * self.init_channel_mul, self.out_channels[0], node=self.node_list[0],
groups=self.groups, step=self.step)]
if self.block_depth[0] != 1:
feature.extend(
[LayerWiseConvModule(self.out_channels[0], self.out_channels[0], node=self.node_list[0],
groups=self.groups, step=self.step)] * (
self.block_depth[0] - 1),
)
feature.append(TEP(channel=self.out_channels[0], step=self.step))
feature.append(nn.AvgPool2d(kernel_size=4, stride=2))
for i in range(1, feature_depth - 1):
feature.append(LayerWiseConvModule(
self.out_channels[i - 1], self.out_channels[i], node=self.node_list[i], groups=self.groups,
step=self.step))
if self.block_depth[i] != 1:
feature.extend(
[LayerWiseConvModule(self.out_channels[i], self.out_channels[i], node=self.node_list[i],
groups=self.groups,
step=self.step)] * (
self.block_depth[i] - 1),
)
feature.append(TEP(channel=self.out_channels[i], step=self.step))
feature.append(nn.AvgPool2d(kernel_size=4, stride=2))
feature.append(LayerWiseConvModule(
self.out_channels[-3], self.out_channels[-2], node=self.node_list[-2], groups=self.groups,
step=self.step))
if self.block_depth[feature_depth - 1] != 1:
feature.extend(
[LayerWiseConvModule(self.out_channels[-2], self.out_channels[-2], node=self.node_list[-2],
groups=self.groups,
step=self.step)] * (
self.block_depth[feature_depth - 1] - 1),
)
feature.append(nn.AdaptiveAvgPool2d(1))
return nn.Sequential(*feature)
def _create_fc(self):
fc = nn.Sequential(
# NDropout(.5),
LayerWiseLinearModule(
self.out_channels[-2], self.out_channels[-1], node=self.node_list[-1], groups=self.groups,
step=self.step, spike=False)
)
return fc
@register_model
def cifar_convnet(step,
encode_type,
spike_output: bool,
node_type,
*args,
**kwargs):
# out_channels = [256, 256, 512, 1024]
out_channels = [64, 128, 128, 256]
block_depth = [2, 2, 2, 2]
# print(kwargs)
node_cls = partial(node_type, step=step, **kwargs)
# print(node_cls)
if spike_output:
node_list = [node_cls] * (len(out_channels) + 1)
else:
node_list = [node_cls] * (len(out_channels))
return LayWiseConvNet(step=step,
input_channels=3,
encode_type=encode_type,
node_list=node_list,
block_depth=block_depth,
out_channels=out_channels,
spike_output=spike_output,
**kwargs)
@register_model
def dvs_convnet(step,
encode_type,
spike_output: bool,
node_type,
num_classes,
*args,
**kwargs):
out_channels = [64, 128, 256, 512, 1024]
block_depth = [2, 1, 2, 1, 2]
node_cls = partial(node_type, step=step, **kwargs)
if spike_output:
node_list = [node_cls] * (len(out_channels) + 1)
# node_list[-2] = partial(DoubleSidePLIFNode, step=step, **kwargs)
else:
node_list = [node_cls] * (len(out_channels))
# node_list[-1] = partial(DoubleSidePLIFNode, step=step, **kwargs)
return LayWiseConvNet(step=step,
input_channels=2,
num_classes=num_classes,
encode_type=encode_type,
node_list=node_list,
block_depth=block_depth,
out_channels=out_channels,
spike_output=spike_output,
**kwargs)
@register_model
class SimpleSNN(BaseModule, abc.ABC):
def __init__(self,
channel=1,
num_classes=10,
step=8,
node_type=LIFNode,
encode_type='direct',
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.num_classes = num_classes
self.node = node_type
init_channel = channel
self.feature = nn.Sequential(
LayerWiseConvModule(init_channel, 32, kernel_size=7, padding=0, node=self.node, step=step),
TEP(step=step, channel=32),
nn.AvgPool2d(kernel_size=2, stride=2),
LayerWiseConvModule(32, 64, kernel_size=4, padding=0, node=self.node, step=step),
TEP(step=step, channel=64),
nn.AvgPool2d(kernel_size=2, stride=2),
)
self.fc = nn.Sequential(
nn.Flatten(),
LayerWiseLinearModule(64 * 4 * 4, self.num_classes, node=self.node, spike=False, step=step),
)
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if self.layer_by_layer:
x = self.feature(inputs)
x = self.fc(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step).mean(0)
return x
else:
outputs = []
for t in range(self.step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
================================================
FILE: examples/Snn_safety/RandHet-SNN/README.md
================================================
* To train a SNN with AT on CIFAR-10:
```
python train.py --adv_training --attack_iters 1 --epsilon 4 --alpha 4 --network ResNet18 --batch_size 64 --worker 4 --node_type LIF --save_dir AT --device cuda:1 --time_step 8 --dataset cifar10
```
* To train a RHSNN with AT on CIFAR-10:
```
python train.py --adv_training --attack_iters 1 --epsilon 4 --alpha 4 --network ResNet18 --batch_size 64 --worker 4 --node_type RHLIF --save_dir AT_RH_1 --device cuda:1 --time_step 8 --dataset cifar10
```
* To train a RHSNN with RAT on CIFAR-10:
```
python train.py --adv_training --attack_iters 1 --epsilon 4 --alpha 4 --network ResNet18 --batch_size 64 --worker 4 --node_type RHLIF --save_dir RAT_RH_1 --device cuda:1 --parseval --beta 0.004 --time_step 8 --dataset cifar10
```
* To train a RHSNN with SR on CIFAR-10:
```
python train.py --adv_training --attack_iters 1 --epsilon 4 --alpha 4 --network ResNet18 --batch_size 64 --worker 4 --node_type RHLIF --save_dir SR_RH_1 --device cuda:1 --SR --time_step 8 --dataset cifar10
```
* To evaluate the performance of RHSNN on CIFAR-10:
```
python evaluate.py --network ResNet18 --attack_type all --batch_size 32 --worker 4 --node_type RHLIF --pretrain RAT_RH_1/weight_r.pth --save_dir RAT --device cuda:1 --time_step 8 --dataset cifar10
```
================================================
FILE: examples/Snn_safety/RandHet-SNN/evaluate.py
================================================
import argparse
import copy
import logging
import os
import sys
import time
from my_node import RHLIFNode, RHLIFNode2
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from sew_resnet import SEWResNet19, BasicBlock
from braincog.base.node.node import *
from utils import evaluate_standard
from utils import get_loaders
import torchattacks
from tqdm import tqdm
logger = logging.getLogger(__name__)
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--batch_size', default=32, type=int)
parser.add_argument('--data_dir', default='/mnt/data/datasets', type=str)
parser.add_argument('--dataset', default='cifar10', choices=['cifar10', 'cifar100'])
parser.add_argument('--network', default='ResNet18', type=str)
parser.add_argument('--worker', default=4, type=int)
parser.add_argument('--epsilon', default=8, type=int)
parser.add_argument('--device', default='cuda:1', type=str)
parser.add_argument('--pretrain', default=None, type=str, help='path to load the pretrained model')
parser.add_argument('--save_dir', default=None, type=str, help='path to save log')
parser.add_argument('--attack_type', default='pgd')
parser.add_argument('--time_step', default=8, type=int)
parser.add_argument('--node_type', default='LIF', type=str)
return parser.parse_args()
def evaluate_attack(model, test_loader, args, atk, atk_name, logger):
test_loss = 0
test_acc = 0
n = 0
model.eval()
device = args.device
test_loader = iter(test_loader)
bar_format = '{desc}[{elapsed}<{remaining},{rate_fmt}]'
pbar = tqdm(range(len(test_loader)), file=sys.stdout, bar_format=bar_format, ncols=80)
for i in pbar:
X, y = next(test_loader)
X, y = X.to(device), y.to(device)
X_adv = atk(X, y) # advtorch
with torch.no_grad():
output = model(X_adv)
loss = F.cross_entropy(output, y)
test_loss += loss.item() * y.size(0)
test_acc += (output.max(1)[1] == y).sum().item()
n += y.size(0)
pgd_acc = test_acc / n
pgd_loss = test_loss / n
logger.info(atk_name)
logger.info('adv: %.4f \t', pgd_acc)
return pgd_loss, pgd_acc
def main():
args = get_args()
args.save_dir = os.path.join('logs', args.save_dir)
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
logfile = os.path.join(args.save_dir, 'output.log')
if os.path.exists(logfile):
os.remove(logfile)
log_path = os.path.join(args.save_dir, 'output_test.log')
handlers = [logging.FileHandler(log_path, mode='a+'),
logging.StreamHandler()]
logging.basicConfig(
format='[%(asctime)s] - %(message)s',
datefmt='%Y/%m/%d %H:%M:%S',
level=logging.INFO,
handlers=handlers)
logger.info(args)
# assert type(args.pretrain) == str and os.path.exists(args.pretrain)
if args.dataset == 'cifar10':
args.num_classes = 10
elif args.dataset == 'cifar100':
args.num_classes = 100
else:
print('Wrong dataset:', args.dataset)
exit()
logger.info('Dataset: %s', args.dataset)
train_loader, test_loader, dataset_normalization = get_loaders(args.data_dir, args.batch_size, dataset=args.dataset,
worker=args.worker, norm=False)
node = LIFNode
if args.node_type == 'RHLIF':
node = RHLIFNode
elif args.node_type == 'RHLIF2':
node = RHLIFNode2
# setup network
model = SEWResNet19(BasicBlock, [3, 3, 2], cnf='ADD', node_type=node, step=args.time_step, num_classes=args.num_classes,
layer_by_layer=True, act_fun=AtanGrad, data_norm=dataset_normalization)
# print(model)
# load pretrained model
path = os.path.join('./ckpt', args.dataset, args.network)
args.pretrain = os.path.join(path, args.pretrain)
pretrained_model = torch.load(args.pretrain, map_location=args.device, weights_only=False)
model.load_state_dict(pretrained_model, strict=False)
model.to(args.device)
model.eval()
# for name, param in model.named_parameters():
# if 'sigma' in name: # 查找包含 'sigma' 的参数
# param.data = torch.as_tensor(0.0, device=args.device)
# if 'alpha' in name: # 查找包含 'sigma' 的参数
# param.data = torch.as_tensor(2.0, device=args.device)
logger.info('Evaluating with standard images...')
_, nature_acc = evaluate_standard(test_loader, model, args)
logger.info('Nature Acc: %.4f \t', nature_acc)
if args.attack_type == 'eotpgd':
atk = torchattacks.EOTPGD(model, eps=8 / 255, alpha=(16/50) / 255, steps=50, random_start=True, eot_iter=10)
evaluate_attack(model, test_loader, args, atk, 'eotpgd', logger)
elif args.attack_type[0:3] == 'pgd':
steps = int(''.join(filter(str.isdigit, args.attack_type)))
atk = torchattacks.PGD(model, eps=8 / 255, alpha=(16/steps) / 255, steps=steps, random_start=True)
evaluate_attack(model, test_loader, args, atk, args.attack_type, logger)
elif args.attack_type == 'apgd':
atk = torchattacks.APGD(model, eps=8 / 255, steps=50, eot_iter=10)
evaluate_attack(model, test_loader, args, atk, 'apgd', logger)
elif args.attack_type == 'fgsm':
atk = torchattacks.FGSM(model, eps=8/255)
evaluate_attack(model, test_loader, args, atk, 'fgsm', logger)
elif args.attack_type == 'mifgsm':
atk = torchattacks.MIFGSM(model, eps=8 / 255, alpha=2 / 255, steps=5, decay=1.0)
evaluate_attack(model, test_loader, args, atk, 'mifgsm', logger)
elif args.attack_type == 'autoattack':
atk = torchattacks.AutoAttack(model, norm='Linf', eps=8/255, version='standard', n_classes=args.num_classes)
evaluate_attack(model, test_loader, args, atk, 'autoattack', logger)
elif args.attack_type == 'all':
atk = torchattacks.FGSM(model, eps=8 / 255)
evaluate_attack(model, test_loader, args, atk, 'fgsm', logger)
atk = torchattacks.APGD(model, eps=8 / 255, steps=10)
evaluate_attack(model, test_loader, args, atk, 'apgd', logger)
atk = torchattacks.PGD(model, eps=8 / 255, alpha=1.6 / 255, steps=10, random_start=True)
evaluate_attack(model, test_loader, args, atk, 'pgd', logger)
atk = torchattacks.MIFGSM(model, eps=8 / 255, alpha=2 / 255, steps=5, decay=1.0)
evaluate_attack(model, test_loader, args, atk, 'mifgsm', logger)
atk = torchattacks.AutoAttack(model, norm='Linf', eps=8 / 255, version='standard',
n_classes=args.num_classes)
evaluate_attack(model, test_loader, args, atk, 'autoattack', logger)
elif args.attack_type == 'step_test':
for steps in [10,30,50,70,90,110]:
atk = torchattacks.PGD(model, eps=8 / 255, alpha=(16 / steps) / 255, steps=steps, random_start=True)
pgd_loss, pgd_acc = evaluate_attack(model, test_loader, args, atk, f'pgd{steps}', logger)
atk = torchattacks.APGD(model, eps=8 / 255, steps=steps)
apgd_loss, apgd_acc = evaluate_attack(model, test_loader, args, atk, f'apgd{steps}', logger)
elif args.attack_type == 'eot_test':
for steps in [1,10,20,30]:
atk = torchattacks.EOTPGD(model, eps=8 / 255, alpha=(16 / 10) / 255, steps=10, random_start=True, eot_iter=steps)
pgd_loss, pgd_acc = evaluate_attack(model, test_loader, args, atk, f'eot{steps}_pgd', logger)
atk = torchattacks.APGD(model, eps=8 / 255, steps=10, eot_iter=steps)
apgd_loss, apgd_acc = evaluate_attack(model, test_loader, args, atk, f'eot{steps}_apgd', logger)
elif args.attack_type == 'intensity_test':
for intensity in [2, 4, 6, 8, 10, 12, 14, 16]:
atk = torchattacks.APGD(model, eps=intensity / 255, steps=10)
pgd_loss, pgd_acc = evaluate_attack(model, test_loader, args, atk, f'{intensity}_apgd', logger)
logger.info('Testing done.')
if __name__ == "__main__":
main()
================================================
FILE: examples/Snn_safety/RandHet-SNN/my_node.py
================================================
import torch
from braincog.base.node.node import *
class RHLIFNode(BaseNode):
"""
Parametric LIF, 其中的 ```tau``` 会被backward过程影响
Reference:https://arxiv.org/abs/2007.05785
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=0.5, tau=0., sigma=1.0, act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.sigma = nn.Parameter(torch.as_tensor(sigma), requires_grad=False)
self.w = nn.Parameter(torch.as_tensor(init_w), requires_grad=False)
self.flag = 0
self.rd = 0
def integral(self, inputs):
self.rd = self.sigma * torch.normal(0., 1., size=(inputs.shape[0], inputs.shape[1], inputs.shape[2], inputs.shape[3]), device=inputs.device)
self.mem = self.rd.sigmoid() * self.mem + (1 - self.rd.sigmoid()) * inputs
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
# self.mem = self.mem - self.spike.detach() * self.threshold
self.mem = self.mem * (1 - self.spike.detach())
def n_reset(self):
self.mem = self.v_reset
self.spike = 0.
self.feature_map = []
self.mem_collect = []
self.flag = 0
class RHLIFNode2(BaseNode):
"""
Parametric LIF, 其中的 ```tau``` 会被backward过程影响
Reference:https://arxiv.org/abs/2007.05785
:param threshold: 神经元发放脉冲需要达到的阈值
:param v_reset: 静息电位
:param dt: 时间步长
:param step: 仿真步
:param tau: 膜电位时间常数, 用于控制膜电位衰减
:param act_fun: 使用surrogate gradient 对梯度进行近似, 默认为 ``surrogate.AtanGrad``
:param requires_thres_grad: 是否需要计算对于threshold的梯度, 默认为 ``False``
:param sigmoid_thres: 是否使用sigmoid约束threshold的范围搭到 [0, 1], 默认为 ``False``
:param requires_fp: 是否需要在推理过程中保存feature map, 需要消耗额外的内存和时间, 默认为 ``False``
:param layer_by_layer: 是否以一次性计算所有step的输出, 在网络模型较大的情况下, 一般会缩短单次推理的时间, 默认为 ``False``
:param n_groups: 在不同的时间步, 是否使用不同的权重, 默认为 ``1``, 即不分组
:param args: 其他的参数
:param kwargs: 其他的参数
"""
def __init__(self, threshold=0.5, tau=0., sigma=1.0, act_fun=AtanGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
init_w = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
self.sigma = nn.Parameter(torch.as_tensor(sigma), requires_grad=False)
self.w = nn.Parameter(torch.as_tensor(init_w), requires_grad=False)
self.flag = 0
self.rd = 0
self.resample = 1
def integral(self, inputs):
if self.flag == 0:
self.rd = self.sigma * torch.normal(0., 1., size=(inputs.shape[0], inputs.shape[1], inputs.shape[2], inputs.shape[3]), device=inputs.device)
self.flag = 1
self.mem = self.rd.sigmoid() * self.mem + (1 - self.rd.sigmoid()) * inputs
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
# self.mem = self.mem - self.spike.detach() * self.threshold
self.mem = self.mem * (1 - self.spike.detach())
def n_reset(self):
self.mem = self.v_reset
self.spike = 0.
self.feature_map = []
self.mem_collect = []
if self.resample == 1:
self.flag = 0
else:
self.flag = 1
================================================
FILE: examples/Snn_safety/RandHet-SNN/sew_resnet.py
================================================
import torch
import torch.nn as nn
from copy import deepcopy
import random
try:
from torchvision.models.utils import load_state_dict_from_url
except ImportError:
from torchvision._internally_replaced_utils import load_state_dict_from_url
from braincog.base.node import *
from braincog.model_zoo.base_module import *
from braincog.datasets import is_dvs_data
from timm.models import register_model
def sew_function(x: torch.Tensor, y: torch.Tensor, cnf: str):
if cnf == 'ADD':
return x + y
elif cnf == 'AND':
return x * y
elif cnf == 'IAND':
return x * (1. - y)
else:
raise NotImplementedError
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None, cnf: str = None, node: callable = None, **kwargs):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.node1 = node()
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.node2 = node()
self.downsample = downsample
if downsample is not None:
self.downsample_sn = node()
self.stride = stride
self.cnf = cnf
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.node1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.node2(out)
if self.downsample is not None:
identity = self.downsample_sn(self.downsample(x))
out = sew_function(identity, out, self.cnf)
return out
def extra_repr(self) -> str:
return super().extra_repr() + f'cnf={self.cnf}'
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None, cnf: str = None, node: callable = None, **kwargs):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.node1 = node()
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.node2 = node()
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.node3 = node()
self.downsample = downsample
if downsample is not None:
self.downsample_sn = node()
self.stride = stride
self.cnf = cnf
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.node1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.node2(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.node3(out)
if self.downsample is not None:
identity = self.downsample_sn(self.downsample(x))
out = sew_function(out, identity, self.cnf)
return out
def extra_repr(self) -> str:
return super().extra_repr() + f'cnf={self.cnf}'
class SEWResNet19(BaseModule):
def __init__(self, block, layers, num_classes=1000, step=8, encode_type="direct", zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None, data_norm=None,
norm_layer=None, cnf: str = None, *args, **kwargs):
super().__init__(
step,
encode_type,
*args,
**kwargs
)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.num_classes = num_classes
self.normalize = data_norm
self.node = kwargs['node_type']
if issubclass(self.node, BaseNode):
# self.node = partial(self.node, **kwargs, step=step)
self.node1 = partial(self.node, **kwargs, step=step)()
self.node2 = partial(self.node, **kwargs, step=step)
self.node3 = partial(self.node, **kwargs, step=step)
self.node4 = partial(self.node, **kwargs, step=step)
self.once = kwargs["once"] if "once" in kwargs else False
self.sum_output = kwargs["sum_output"] if "sum_output" in kwargs else True
init_channel = 3
self.inplanes = 128
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(init_channel, self.inplanes, kernel_size=3, stride=1, padding=1,
bias=False)
self.bn1 = norm_layer(self.inplanes)
# self.node1 = self.node()
self.layer1 = self._make_layer(block, 128, layers[0], cnf=cnf, node=self.node2, **kwargs)
self.layer2 = self._make_layer(block, 256, layers[1], stride=2,
dilate=replace_stride_with_dilation[0], cnf=cnf, node=self.node3, **kwargs)
self.layer3 = self._make_layer(block, 512, layers[2], stride=2,
dilate=replace_stride_with_dilation[1], cnf=cnf, node=self.node4, **kwargs)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc1 = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(1)
m.weight.data.normal_(0, 1.0 / float(n))
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1, dilate=False, cnf: str = None, node: callable = None,
**kwargs):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer, cnf, node, **kwargs))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer, cnf=cnf, node=node, **kwargs))
return nn.Sequential(*layers)
def _forward_impl(self, inputs):
# See note [TorchScript super()]
if self.normalize is not None:
self.normalize.mean = self.normalize.mean.to(inputs.device)
self.normalize.std = self.normalize.std.to(inputs.device)
inputs = self.normalize(inputs)
self.reset()
if self.layer_by_layer:
inputs = repeat(inputs, 'b c w h -> t b c w h', t=self.step)
inputs = rearrange(inputs, 't b c w h -> (t b) c w h')
x = self.conv1(inputs)
x = self.bn1(x)
x = self.node1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
# x = self.node2(x)
# x = self.fc2(x)
x = rearrange(x, '(t b) c -> t b c', t=self.step)
# print(x)
if self.sum_output: x = x.mean(0)
return x
def _forward_once(self, x):
# inputs = self.encoder(inputs)
# x = inputs[t]
x = self.conv1(x)
x = self.bn1(x)
x = self.node1(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
if self.once: return self._forward_once(x)
return self._forward_impl(x)
================================================
FILE: examples/Snn_safety/RandHet-SNN/train.py
================================================
import argparse
import copy
import logging
import os
import sys
import time
from evaluate import evaluate_attack
import torchattacks
from my_node import RHLIFNode, RHLIFNode2
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from sew_resnet import SEWResNet19, BasicBlock, Bottleneck
from braincog.base.node.node import *
from utils import (evaluate_standard, cifar10_std, cifar10_mean,
orthogonal_retraction)
from utils import (clamp, get_norm_stat,
get_loaders)
logger = logging.getLogger(__name__)
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--batch_size', default=128, type=int)
parser.add_argument('--data_dir', default='/mnt/data/datasets', type=str)
parser.add_argument('--dataset', default='cifar10', type=str)
parser.add_argument('--epochs', default=100, type=int)
parser.add_argument('--network', default='ResNet18', type=str)
parser.add_argument('--device', default='cuda:3', type=str)
parser.add_argument('--worker', default=4, type=int)
parser.add_argument('--lr_schedule', default='cosine', choices=['cyclic', 'multistep', 'cosine'])
parser.add_argument('--lr_min', default=0., type=float)
parser.add_argument('--lr_max', default=0.1, type=float)
parser.add_argument('--weight_decay', default=1e-4, type=float)
parser.add_argument('--momentum', default=0.9, type=float)
parser.add_argument('--epsilon', default=4, type=int)
parser.add_argument('--alpha', default=4, type=float, help='Step size')
parser.add_argument('--save_dir', default='ckpt', type=str, help='Output directory')
parser.add_argument('--seed', default=0, type=int, help='Random seed')
parser.add_argument('--attack_iters', default=1, type=int, help='Attack iterations')
parser.add_argument('--pretrain', default=None, type=str, help='path to load the pretrained model')
parser.add_argument('--beta', default=0.004, type=float)
parser.add_argument('--adv_training', action='store_true',
help='if adv training')
parser.add_argument('--time_step', default=8, type=int)
parser.add_argument('--SR', action='store_true')
parser.add_argument('--node_type', default='LIF', type=str)
parser.add_argument('--parseval', action='store_true', help='if use different norm for different layers')
return parser.parse_args()
def main():
args = get_args()
device = args.device
torch.cuda.set_device(device)
if args.dataset == 'cifar10' or args.dataset == 'svhn':
args.num_classes = 10
elif args.dataset == 'cifar100':
args.num_classes = 100
mu, std, upper_limit, lower_limit = get_norm_stat(cifar10_mean, cifar10_std)
path = os.path.join('./ckpt', args.dataset, args.network)
args.save_dir = os.path.join(path, args.save_dir)
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
logfile = os.path.join(args.save_dir, 'output.log')
if os.path.exists(logfile):
os.remove(logfile)
handlers = [logging.FileHandler(logfile, mode='a+'),
logging.StreamHandler()]
logging.basicConfig(
format='[%(asctime)s] - %(message)s',
datefmt='%Y/%m/%d %H:%M:%S',
level=logging.INFO,
handlers=handlers)
logger.info(args)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed(args.seed)
# get data loader
train_loader, test_loader, dataset_normalization = get_loaders(args.data_dir, args.batch_size, dataset=args.dataset,
worker=args.worker)
train_loader_e, test_loader_e, dataset_normalization_e = get_loaders(args.data_dir, args.batch_size, dataset=args.dataset,
worker=args.worker, norm=False)
# adv training attack setting
epsilon = ((args.epsilon / 255.) / std).to(device)
alpha = ((args.alpha / 255.) / std).to(device)
node = LIFNode
if args.node_type == 'RHLIF':
node = RHLIFNode
elif args.node_type == 'RHLIF2':
node = RHLIFNode2
# setup network
model = SEWResNet19(BasicBlock, [3, 3, 2], cnf='ADD', node_type=node, step=args.time_step, num_classes=args.num_classes,
layer_by_layer=True, act_fun=AtanGrad)
model.to(device)
# model = torch.nn.DataParallel(model)
# logger.info(model)
# setup optimizer, loss function, LR scheduler
# opt = torch.optim.AdamW(model.parameters(), lr=args.lr_max, weight_decay=args.weight_decay)
if args.parseval:
opt = torch.optim.SGD(model.parameters(), lr=args.lr_max, momentum=0.9, weight_decay=0)
else:
opt = torch.optim.SGD(model.parameters(), lr=args.lr_max, momentum=0.9, weight_decay=args.weight_decay)
criterion = nn.CrossEntropyLoss()
if args.lr_schedule == 'cyclic':
lr_steps = args.epochs
scheduler = torch.optim.lr_scheduler.CyclicLR(opt, base_lr=args.lr_min, max_lr=args.lr_max,
step_size_up=lr_steps / 2, step_size_down=lr_steps / 2)
elif args.lr_schedule == 'multistep':
lr_steps = args.epochs
scheduler = torch.optim.lr_scheduler.MultiStepLR(opt, milestones=[lr_steps / 2, lr_steps * 3 / 4], gamma=0.1)
elif args.lr_schedule == 'cosine':
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(opt, T_max=args.epochs)
best_pgd_acc = 0
best_clean_acc = 0
test_acc_best_pgd = 0
start_epoch = 0
# Start training
start_train_time = time.time()
for epoch in range(start_epoch, args.epochs):
logging.info('epoch %d lr %e', epoch, scheduler.get_lr()[0])
model.train()
train_loss = 0
train_acc = 0
train_n = 0
for i, (X, y) in enumerate(train_loader):
_iters = epoch * len(train_loader) + i
X, y = X.to(device), y.to(device)
if args.adv_training:
# init delta
delta = torch.zeros_like(X).to(device)
for j in range(len(epsilon)):
delta[:, j, :, :].uniform_((-epsilon[j][0][0] / 10).item(), (epsilon[j][0][0]/10).item())
delta.data = clamp(delta, lower_limit.to(device) - X, upper_limit.to(device) - X)
delta.requires_grad = True
# pgd attack
for _ in range(args.attack_iters):
output = model(X + delta)
# model.random_reset_step = 0
loss = criterion(output, y)
loss.backward()
grad = delta.grad.detach()
delta.data = clamp(delta + alpha * torch.sign(grad), -epsilon, epsilon)
delta.data = clamp(delta, lower_limit.to(device) - X, upper_limit.to(device) - X)
delta.grad.zero_()
delta = delta.detach()
X_adv = X + delta[:X.size(0)]
else:
X_adv = X
if args.SR:
X_adv.requires_grad_(True)
outputs = model(X_adv)
out = outputs.gather(1, y.unsqueeze(1)).squeeze() # choose
batch = []
inds = []
for j in range(len(outputs)):
mm, ind = torch.cat([outputs[j, :y[j]], outputs[j, y[j] + 1:]], dim=0).max(0)
f = torch.exp(out[j]) / (torch.exp(out[j]) + torch.exp(mm))
batch.append(f)
inds.append(ind.item())
f1 = torch.stack(batch, dim=0)
loss1 = criterion(outputs, y)
dx = torch.autograd.grad(f1, X_adv, grad_outputs=torch.ones_like(f1, device=device), retain_graph=True)[0]
X_adv.requires_grad_(False)
v = dx.detach().sign()
x2 = X_adv + 0.01 * v
outputs2 = model(x2)
out = outputs2.gather(1, y.unsqueeze(1)).squeeze() # choose
batch = []
for j in range(len(outputs2)):
mm = torch.cat([outputs2[j, :y[j]], outputs2[j, y[j] + 1:]], dim=0)[inds[j]]
f = torch.exp(out[j]) / (torch.exp(out[j]) + torch.exp(mm))
batch.append(f)
f2 = torch.stack(batch, dim=0)
dl = (f2 - f1) / 0.01
loss2 = dl.pow(2).mean()
loss = loss1 + 0.001 * loss2
loss = loss.mean()
else:
output = model(X_adv)
loss = criterion(output, y)
opt.zero_grad()
loss.backward()
opt.step()
if args.parseval:
orthogonal_retraction(model, args.beta)
# for name, param in model.named_parameters():
# if 'sigma' in name: # 查找包含 'sigma' 的参数
# param.data = torch.clamp(param.data, 0.0, 1.5) # 约束参数范围
# if i==0:
# print(param)
train_loss += loss.item() * y.size(0)
train_acc += (output.max(1)[1] == y).sum().item()
train_n += y.size(0)
if i % 50 == 0:
logger.info("Iter: [{:d}][{:d}/{:d}]\t"
"Loss {:.3f} ({:.3f})\t"
"Prec@1 {:.3f} ({:.3f})\t".format(
epoch,
i,
len(train_loader),
loss.item(),
train_loss / train_n,
(output.max(1)[1] == y).sum().item() / y.size(0),
train_acc / train_n)
)
scheduler.step()
logger.info('Evaluating with standard images...')
test_loss, test_acc = evaluate_standard(test_loader, model, args)
logger.info(
'Test Loss: %.4f \t Test Acc: %.4f',
test_loss, test_acc)
if test_acc > best_clean_acc:
best_clean_acc = (
test_acc)
torch.save(model.state_dict(), os.path.join(args.save_dir, 'weight_c.pth'))
# pgd_loss, pgd_acc = evaluate_pgd(test_loader, model, 5, 1, args)
if epoch > args.epochs - 10:
logger.info('Evaluating with APGD Attack...')
model.normalize = dataset_normalization_e
atk = torchattacks.APGD(model, norm='Linf', eps=8 / 255, steps=10)
pgd_loss, pgd_acc = evaluate_attack(model, test_loader_e, args, atk, 'APGD', logger)
model.normalize = dataset_normalization
if pgd_acc > best_pgd_acc:
best_pgd_acc = pgd_acc
test_acc_best_pgd = test_acc
torch.save(model.state_dict(), os.path.join(args.save_dir, 'weight_r.pth'))
logger.info(
'PGD Loss: %.4f \t PGD Acc: %.4f \n Best PGD Acc: %.4f \t Test Acc of best PGD ckpt: %.4f',
pgd_loss, pgd_acc, best_pgd_acc, test_acc_best_pgd)
train_time = time.time()
logger.info('Total train time: %.4f minutes', (train_time - start_train_time) / 60)
if __name__ == "__main__":
main()
================================================
FILE: examples/Snn_safety/RandHet-SNN/utils.py
================================================
# import apex.amp as amp
import os.path
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
import numpy as np
cifar10_mean = (0.4914, 0.4822, 0.4465)
cifar10_std = (0.2471, 0.2435, 0.2616)
def get_norm_stat(mean, std):
mu = torch.tensor(mean).view(3, 1, 1)
std = torch.tensor(std).view(3, 1, 1)
upper_limit = ((1 - mu) / std)
lower_limit = ((0 - mu) / std)
return mu, std, upper_limit, lower_limit
def clamp(X, lower_limit, upper_limit):
return torch.max(torch.min(X, upper_limit), lower_limit)
def normalize_fn(tensor, mean, std):
"""Differentiable version of torchvision.functional.normalize"""
# here we assume the color channel is in at dim=1
mean = mean[None, :, None, None]
std = std[None, :, None, None]
return tensor.sub(mean).div(std)
class NormalizeByChannelMeanStd(nn.Module):
def __init__(self, mean, std):
super(NormalizeByChannelMeanStd, self).__init__()
if not isinstance(mean, torch.Tensor):
mean = torch.tensor(mean)
if not isinstance(std, torch.Tensor):
std = torch.tensor(std)
self.register_buffer("mean", mean)
self.register_buffer("std", std)
def forward(self, tensor):
return normalize_fn(tensor, self.mean, self.std)
def extra_repr(self):
return 'mean={}, std={}'.format(self.mean, self.std)
def get_loaders(dir_, batch_size, dataset='cifar10', worker=4, norm=True):
if norm:
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(cifar10_mean, cifar10_std),
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(cifar10_mean, cifar10_std),
])
dataset_normalization = None
else:
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])
test_transform = transforms.Compose([
transforms.ToTensor(),
])
dataset_normalization = NormalizeByChannelMeanStd(
mean=cifar10_mean, std=cifar10_std)
if dataset == 'cifar10':
train_dataset = datasets.CIFAR10(
dir_, train=True, transform=train_transform, download=True)
test_dataset = datasets.CIFAR10(
dir_, train=False, transform=test_transform, download=True)
elif dataset == 'cifar100':
train_dataset = datasets.CIFAR100(
dir_, train=True, transform=train_transform, download=True)
test_dataset = datasets.CIFAR100(
dir_, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=worker,
)
test_loader = torch.utils.data.DataLoader(
dataset=test_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=worker,
)
return train_loader, test_loader, dataset_normalization
# evaluate on clean images with single norm
def evaluate_standard(test_loader, model, args):
test_loss = 0
test_acc = 0
n = 0
model.eval()
device = args.device
with torch.no_grad():
for i, (X, y) in enumerate(test_loader):
X, y = X.to(device), y.to(device)
output = model(X)
loss = F.cross_entropy(output, y)
test_loss += loss.item() * y.size(0)
test_acc += (output.max(1)[1] == y).sum().item()
n += y.size(0)
return test_loss/n, test_acc/n
def orthogonal_retraction(model, beta=0.002):
with torch.no_grad():
for module in model.modules():
if isinstance(module, (nn.Conv2d, nn.Linear)):
if isinstance(module, nn.Conv2d):
weight_ = module.weight.data
sz = weight_.shape
weight_ = weight_.reshape(sz[0],-1)
rows = list(range(module.weight.data.shape[0]))
elif isinstance(module, nn.Linear):
if module.weight.data.shape[0] < 200: # set a sample threshold for row number
weight_ = module.weight.data
sz = weight_.shape
weight_ = weight_.reshape(sz[0], -1)
rows = list(range(module.weight.data.shape[0]))
else:
rand_rows = np.random.permutation(module.weight.data.shape[0])
rows = rand_rows[: int(module.weight.data.shape[0] * 0.3)]
weight_ = module.weight.data[rows,:]
sz = weight_.shape
module.weight.data[rows,:] = ((1 + beta) * weight_ - beta * weight_.matmul(weight_.t()).matmul(weight_)).reshape(sz)
================================================
FILE: examples/Social_Cognition/FOToM/algorithms/ToM_class.py
================================================
import torch
import torch.distributions as td
from utils.networks import MLPNetwork, SNNNetwork, LSTMClassifier
from utils.misc import soft_update, average_gradients, onehot_from_logits, gumbel_softmax
class ToM1(object):
"""
tom factory (Simplification of ToM's model)
init ToM0 and ToM1 net
train ToM0 and ToM1 net
"""
def __init__(self, tom_base, alg_types, agent_types, num_lm, device, hidden_dim=64):
self.device = device
self.alg_types = alg_types
self.agent_types = agent_types
self.num_good_agents = len(self._get_index1(self.agent_types, 'agent'))
self.nagents = len(alg_types)
self.num_lm = num_lm
'''
Assume that ToM0 and ToM1 are equivalent
'''
self.tom1 = tom_base
self.other_tom1 = [0] * self.nagents
self._agent_tom1_init()
'''
ToM0_policy
'''
# self.tom_PHI = [] #TODO
self.hidden = None
def _agent_tom1_init(self):
other_alg_types_ = self.alg_types.copy()
other_agent_types_ = self.agent_types.copy()
for agent_i in range(self.nagents):
other_alg_types = other_alg_types_.copy()
other_agent_types = other_agent_types_.copy()
other_alg_types.pop(agent_i)
other_agent_types.pop(agent_i)
adv_indx = self._get_index1(other_agent_types, 'adversary')
good_indx = self._get_index1(other_agent_types, 'agent')
self.other_tom1[agent_i] = [self.tom1['adversary'][self.agent_types[agent_i]]] * len(adv_indx) #TODO
self.other_tom1[agent_i] += [self.tom1['agent'][self.agent_types[agent_i]]] * len(good_indx)
def _get_index1(self, lst=None, item=''):
return [index for (index, value) in enumerate(lst) if value == item]
def c_function(self, tom0_actions_q, tom1_actions_q):
c1 = 0.7
# tom0_actions = torch.stack([gumbel_softmax(action_i, hard=True)
# for action_i in tom0_actions_prob], 0)
# tom1_actions = torch.stack([gumbel_softmax(action_i, hard=True)
# for action_i in tom1_actions_prob], 0)
'''
batch, num_agent, ep, 1
'''
tom0_actions = (tom0_actions_q == tom0_actions_q.max(dim=-1, keepdim=True)[0]).to(dtype=torch.int32)
tom1_actions = (tom1_actions_q.unsqueeze(1) == tom1_actions_q.unsqueeze(0).max(dim=-1, keepdim=True)[0]).to(
dtype=torch.int32)
alig = tom0_actions.long().detach() & tom1_actions.long().detach()
I_belief = tom0_actions_q * (1 - c1) + alig * c1
# I_belief = [prob_i * (1 -c1) + alig[i] * c1 for i, prob_i in enumerate(tom0_actions_prob)]
return I_belief
def tom1_output(self, agent_i, adv_indx, good_indx, obs_, acs_pre_):
"""
ToM1 <--> ToM1
obs_self : obs of self, need to convert
tom0_out : predict other-action (episode_num * self.args.episode_limit * 2, -1), need to convert
tom0_out_q : predict other-action q_value (episode_num * self.args.episode_limit * 2, -1)
device : interact with env (cpu) train (cuda)
ToM0_policy
"""
actions = []
actions += [
# gumbel_softmax(
self.other_tom1[agent_i][j].to(self.device)(
torch.cat((obs_[:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
acs_pre_[:, :5]), 1))#.detach() #, hard=True
for j in adv_indx
]
actions += [
# gumbel_softmax(
self.other_tom1[agent_i][j].to(self.device)(
torch.cat((obs_[:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
acs_pre_[:, :5]), 1))#.detach() #, hard=True
for j in good_indx
]
# E_action = torch.cat(actions, 1)
E_action = actions
return E_action
================================================
FILE: examples/Social_Cognition/FOToM/algorithms/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/FOToM/algorithms/maddpg.py
================================================
import torch
from torch.optim import Adam
import torch.nn.functional as F
from gym.spaces import Box, Discrete, MultiDiscrete
from multiagent.multi_discrete import MultiDiscrete
from utils.networks import MLPNetwork, SNNNetwork, LSTMClassifier
from utils.misc import soft_update, average_gradients, onehot_from_logits, gumbel_softmax
from utils.agents import DDPGAgent, DDPGAgent_RNN, DDPGAgent_SNN, DDPGAgent_ToM
# from commom.distributions import make_pdtype
from thop import profile
from thop import clever_format
import time
MSELoss = torch.nn.MSELoss()
# reference:https://github.com/starry-sky6688/MADDPG.git
class MADDPG(object):
def __init__(self, agent_init_params, alg_types, device,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.device = device
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params)
for params in agent_init_params]
self.agent_init_params = agent_init_params
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, explore=False):
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def update(self, sample, agent_i, parallel=False, logger=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
obs, acs, rews, next_obs, dones = sample
curr_agent = self.agents[agent_i]
curr_agent.critic_optimizer.zero_grad()
if self.alg_types[agent_i] == 'MADDPG':
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs)]
else:
all_trgt_acs = [pi(nobs) for pi, nobs in zip(self.target_policies,
next_obs)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
else: # DDPG
if self.discrete_action:
trgt_vf_in = torch.cat((next_obs[agent_i],
onehot_from_logits(
curr_agent.target_policy(
next_obs[agent_i]))),
dim=1)
else:
trgt_vf_in = torch.cat((next_obs[agent_i],
curr_agent.target_policy(next_obs[agent_i])),
dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
if self.alg_types[agent_i] == 'MADDPG':
vf_in = torch.cat((*obs, *acs), dim=1)
else: # DDPG
vf_in = torch.cat((obs[agent_i], acs[agent_i]), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
if self.alg_types[agent_i] == 'MADDPG':
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
else: # DDPG
vf_in = torch.cat((obs[agent_i], curr_pol_vf_in),
dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out**2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents]}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, device, agent_alg="MADDPG", adversary_alg="MADDPG",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
if algtype == "MADDPG":
num_in_critic = 0
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'device': device}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
return instance
class MADDPG_RNN(object):
"""
Wrapper class for DDPG-esque (i.e. also MADDPG) agents in multi-agent task
"""
def __init__(self, agent_init_params, alg_types,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent_RNN(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params)
for params in agent_init_params]
self.agent_init_params = agent_init_params
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.niter = 0
def _init_agent(self, n_rollout_threads):
for agent_i in self.agents:
agent_i.init_hidden(n_rollout_threads, policy_hidden=True, policy_target_hidden=True, \
critic_hidden=True, critic_target_hidden=True)
# @property
def policies(self, len_ep):
for a in self.agents: a.init_hidden(len_ep, policy_hidden=True, policy_target_hidden=False, \
critic_hidden=False, critic_target_hidden=False)
return [a.policy for a in self.agents], [a.policy_hidden for a in self.agents]
# @property
def target_policies(self, len_ep):
for a in self.agents: a.init_hidden(len_ep, policy_hidden=False, policy_target_hidden=True, \
critic_hidden=False, critic_target_hidden=False)
return [a.target_policy for a in self.agents], [a.policy_target_hidden for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, explore=False):
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def _compute_rnn(self, fn, hidden, inputs, logit):
num_ep = inputs.shape[1]
outputs = []
hidden = hidden.to(torch.device('cuda:4'))
for step_id in range(num_ep):
output, hidden = fn(inputs[:, step_id, :], hidden)
if logit == onehot_from_logits:
outputs.append(logit(output))
elif logit == gumbel_softmax:
outputs.append(logit(output, True))
else:
outputs.append(output)
outputs = torch.stack(outputs,1)
return outputs
def update(self, sample, agent_i, parallel=False, logger=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
obs, acs, rews, next_obs, dones = sample
curr_agent = self.agents[agent_i]
len_ep = obs[0].shape[0]
curr_agent.init_hidden(len_ep, True, True, True, True)
curr_agent.critic_optimizer.zero_grad()
if self.alg_types[agent_i] == 'MADDPG_RNN':
if self.discrete_action: # one-hot encode action
all_trgt_acs = [self._compute_rnn(pi, hidden, nobs, onehot_from_logits) for pi, hidden, nobs in \
zip(self.target_policies(len_ep)[0], self.target_policies(len_ep)[1], next_obs)]
else:
all_trgt_acs = [pi(nobs) for pi, nobs in zip(self.target_policies,
next_obs)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=-1)
target_critic = self._compute_rnn(curr_agent.target_critic, curr_agent.critic_target_hidden, trgt_vf_in, None)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
target_critic.view(-1, 1) *
(1 - dones[agent_i].view(-1, 1)))
if self.alg_types[agent_i] == 'MADDPG_RNN':
vf_in = torch.cat((*obs, *acs), dim=-1)
actual_value = self._compute_rnn(curr_agent.critic, curr_agent.critic_hidden, vf_in, None)
vf_loss = MSELoss(actual_value.view(-1,1), target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = self._compute_rnn(curr_agent.policy, curr_agent.policy_hidden, obs[agent_i], None)
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
if self.alg_types[agent_i] == 'MADDPG_RNN':
all_pol_acs = []
for i, pi, policy_hidden, ob in zip(range(self.nagents), self.policies(len_ep)[0], self.policies(len_ep)[1], obs):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(self._compute_rnn(pi, policy_hidden, ob, onehot_from_logits))
# all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=-1)
curr_agent.init_hidden(len_ep, False, False, True, False)
pol_loss = -self._compute_rnn(curr_agent.critic, policy_hidden, vf_in, None).mean()
# pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out**2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm(curr_agent.policy.parameters(), 0.5)
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device('cuda:4'))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device('cuda:4'))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents]}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, agent_alg="MADDPG", adversary_alg="MADDPG_RNN",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
else: # Discrete
discrete_action = True
get_shape = lambda x: x.n
num_out_pol = get_shape(acsp)
if algtype == "MADDPG_RNN":
num_in_critic = 0
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
return instance
================================================
FILE: examples/Social_Cognition/FOToM/algorithms/tom11.py
================================================
import torch
from torch.optim import Adam
import torch.nn.functional as F
from gym.spaces import Box, Discrete, MultiDiscrete
from multiagent.multi_discrete import MultiDiscrete
from utils.networks import MLPNetwork, SNNNetwork, LSTMClassifier
from utils.misc import soft_update, average_gradients, onehot_from_logits, gumbel_softmax
from utils.agents import DDPGAgent
from algorithms.ToM_class import ToM1
# from commom.distributions import make_pdtype
from thop import profile
from thop import clever_format
import time
MSELoss = torch.nn.MSELoss()
KL_criterion = torch.nn.KLDivLoss(reduction='sum')
CE_criterion = torch.nn.CrossEntropyLoss(reduction="sum")
class ToM_decision11(object):
def __init__(self, agent_init_params, alg_types, agent_types, num_lm,
output_style, device, config, gamma=0.95, tau=0.01, lr=0.01,
hidden_dim=64, discrete_action=False):
self.config = config
self.device = device
self.num_lm = num_lm
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agent_types = agent_types
self.num_good_agents = len(self._get_index1(self.agent_types, 'agent'))
self.agents = [DDPGAgent_ToM(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params, output_style=output_style,
num_agents=self.nagents,
device=self.device)
for params in agent_init_params]
self.agent_init_params = agent_init_params
# tom0
self.mle_base = [MLPNetwork(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2 + 5,
self.agent_init_params[-1]['num_out_pol'],
hidden_dim=5, norm_in=False), # infer good agent
MLPNetwork(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2 + 5,
self.agent_init_params[-1]['num_out_pol'],
hidden_dim=5, norm_in=False), # infer adversary
]
self.tom_base = {
'agent': {'agent': self.mle_base[0],
'adversary': self.mle_base[1]
},
'adversary': {'agent': self.mle_base[0],
'adversary': self.mle_base[1]
}
}
self.tom_PHI = [LSTMClassifier(self.num_good_agents * 2 + self.num_lm * 2 +
(self.nagents - 1) * 2 + 5 * (self.nagents - 1),
self.agent_init_params[-1]['num_out_pol'],
hidden_size=64), # infer good agent
LSTMClassifier(self.num_good_agents * 2 + self.num_lm * 2 +
(self.nagents - 1) * 2 + 5 * (self.nagents - 1),
self.agent_init_params[-1]['num_out_pol'],
hidden_size=64), # infer adversary
] #TODO
self._agent_tom_init() #TODO
self.tom1 = ToM1(self.tom_base, alg_types, agent_types, num_lm, device)
self.actions_tom0 = []
self.next_actions_tom0 = []
self.actions_tom1 = []
self.next_actions_tom1 = []
self.mle_opts = [Adam(i.parameters(), lr=1e-4) for i in self.mle_base]
self.PHI_opts = [Adam(i.parameters(), lr=1e-4) for i in self.tom_PHI]
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.mle_dev = 'cpu'
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def _get_index1(self, lst=None, item=''):
return [index for (index, value) in enumerate(lst) if value == item]
def _agent_tom_init(self):
# other_alg_types_ = self.alg_types.copy()
other_agent_types_ = self.agent_types.copy()
for agent_i in range(self.nagents):
# other_alg_types = other_alg_types_.copy()
other_agent_types = other_agent_types_.copy()
# other_alg_types.pop(agent_i)
other_agent_types.pop(agent_i)
adv_indx = self._get_index1(other_agent_types, 'adversary')
good_indx = self._get_index1(other_agent_types, 'agent')
self.agents[agent_i].mle += [self.tom_base[self.agent_types[agent_i]]['adversary']] * len(adv_indx) #TODO
self.agents[agent_i].mle += [self.tom_base[self.agent_types[agent_i]]['agent']] * len(good_indx)
def step(self, observations, actions_pre, explore=False): #simple_tag
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
# t1 = time.time()
observations_ = observations.copy()
actions_pre_ = actions_pre.copy()
# other_alg_types_ = self.alg_types.copy()
other_agent_types_ = self.agent_types.copy()
adv_agent_indx = self._get_index1(self.agent_types, 'adversary')
good_agent_indx = self._get_index1(self.agent_types, 'agent')
'''
tom0
'''
actions_tom0 = []
actions_tom0 += [
gumbel_softmax(
self.mle_base[1].to(self.device)(
torch.cat((observations[j][:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
actions_pre[j][:, :5]), 1).to(self.device)).detach(), hard=True
) for j in adv_agent_indx
]
actions_tom0 += [
gumbel_softmax(
self.mle_base[0].to(self.device)(
torch.cat((observations[j][:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
actions_pre[j][:, :5]), 1).to(self.device)).detach(), hard=True
) for j in good_agent_indx
]
'''
tom1
'''
actions_tom1 = []
for agent_i, obs in enumerate(observations):
obs_ = observations_.copy()
acs_other = actions_tom0.copy()
other_agent_types = other_agent_types_.copy()
obs_.pop(agent_i)
acs_other.pop(agent_i)
other_agent_types.pop(agent_i)
if agent_i in adv_agent_indx:
actions_tom1.append(
gumbel_softmax(
self.tom_PHI[1].to(self.device)(
torch.cat((obs[:, -(self.num_good_agents * 2 + self.num_lm * 2 +
(self.nagents - 1) * 2):].to(self.device), torch.cat(acs_other, 1)), 1)), hard=True
).cpu()
)
elif agent_i in good_agent_indx:
actions_tom1.append(
gumbel_softmax(
self.tom_PHI[0].to(self.device)(
torch.cat((obs[:, -(self.num_good_agents * 2 + self.num_lm * 2 +
(self.nagents - 1) * 2):].to(self.device), torch.cat(acs_other, 1)), 1)), hard=True
).cpu()
)
observations = self._get_obs(observations, actions_tom1)
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def _get_obs(self, observations, action_tom):
observations_ = []
other_actions_tom_ = action_tom.copy()
for agent_i, obs in enumerate(observations):
other_action_tom = other_actions_tom_.copy()
other_action_tom.pop(agent_i)
actions = other_action_tom
observations_.append(torch.cat((obs, torch.cat(actions, 1)), 1))
return observations_
def train_tom0(self, sample, agent_i):
acs_pre, obs, acs, rews, next_obs, dones = sample
adv_agent_indx = self._get_index1(self.agent_types, 'adversary')
good_agent_indx = self._get_index1(self.agent_types, 'agent')
# self.agent_types[tom_agent_indx]
'''
data
for with_tom
for without_tom
'''
if adv_agent_indx != []:
adv_input = torch.cat([torch.cat((obs[i], acs_pre[i][:, :5]), 1) for i in adv_agent_indx])
label_adv_output = torch.cat([acs[i][:, :5] for i in adv_agent_indx])
self.mle_base[1].zero_grad()
adv_output = self.mle_base[1](adv_input[:,
-(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2 + 5):])
loss_adv = F.mse_loss(adv_output.float(), label_adv_output.float())
loss_adv.backward(retain_graph=True)
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
if good_agent_indx != []:
good_input = torch.cat([torch.cat((obs[i], acs_pre[i][:, :5]), 1) for i in good_agent_indx])
label_good_output = torch.cat([acs[i][:, :5] for i in good_agent_indx])
self.mle_base[0].zero_grad()
good_output = self.mle_base[0](good_input[:,
-(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2 + 5):])
loss_good = F.mse_loss(good_output.float(), label_good_output.float())
loss_good.backward(retain_graph=True)
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
'''
Only train agents with ToM (adversarys)
'''
'''
adv-adv
adv-good
'''
def tom1_infer_other(self, sample):
acs_pre, obs, acs, rews, next_obs, dones = sample
self.actions_tom1 = []
self.next_actions_tom1 = []
actions_tom1 = []
next_actions_tom1 = []
other_actions_tom0_ = self.actions_tom0.copy()
other_next_actions_tom0_ = self.next_actions_tom0.copy()
adv_agent_indx = self._get_index1(self.agent_types, 'adversary')
good_agent_indx = self._get_index1(self.agent_types, 'agent')
good_in = []
adv_in =[]
good_in_next = []
adv_in_next =[]
for agent_i, (obs_i, next_obs_i) in enumerate(zip(obs, next_obs)):
other_action_tom0 = other_actions_tom0_.copy()
other_next_actions_tom0 = other_next_actions_tom0_.copy()
other_action_tom0.pop(agent_i)
other_next_actions_tom0.pop(agent_i)
if agent_i in adv_agent_indx:
adv_in.append(torch.cat(
(obs_i[:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
torch.cat(other_action_tom0, 1)), 1))
adv_in_next.append(torch.cat(
(next_obs_i[:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
torch.cat(other_next_actions_tom0, 1)), 1))
elif agent_i in good_agent_indx:
good_in.append(torch.cat(
(obs_i[:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
torch.cat(other_action_tom0, 1)), 1))
good_in_next.append(torch.cat(
(next_obs_i[:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
torch.cat(other_next_actions_tom0, 1)), 1))
if adv_agent_indx != []:
adv_in = torch.cat(adv_in, 0)
adv_in_next = torch.cat(adv_in_next, 0)
actions_tom1.append(gumbel_softmax(
self.tom_PHI[1].to(self.device)(
adv_in), hard=True
))
next_actions_tom1.append(gumbel_softmax(
self.tom_PHI[1].to(self.device)(
adv_in_next), hard=True
)) # adv
label_adv_output = torch.cat([self.actions_tom0[i] for i in adv_agent_indx]).detach()
# label_adv_output = torch.cat([acs[i][:, :5] for i in adv_agent_indx])
adv_output = actions_tom1[0]
loss_adv = F.mse_loss(adv_output.float(), label_adv_output.float())
loss_adv.backward(retain_graph=True)
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.PHI_opts[1].step()
if good_agent_indx != []:
good_in = torch.cat(good_in, 0)
good_in_next = torch.cat(good_in_next, 0)
actions_tom1.append(gumbel_softmax(
self.tom_PHI[0].to(self.device)(
good_in), hard=True
))
next_actions_tom1.append(gumbel_softmax(
self.tom_PHI[0].to(self.device)(
good_in_next), hard=True
)) # agent
label_good_output = torch.cat([self.actions_tom0[i] for i in good_agent_indx]).detach()
# label_good_output = torch.cat([acs[i][:, :5] for i in good_agent_indx])
if self.config.env_id == 'simple_spread' or self.config.env_id == 'hetero_spread':
good_output = actions_tom1[0]
else:
good_output = actions_tom1[1]
loss_good = F.mse_loss(good_output.float(), label_good_output.float())
loss_good.backward(retain_graph=True)
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.PHI_opts[0].step()
actions_tom1 = torch.cat(actions_tom1)#.detach()
next_actions_tom1 = torch.cat(next_actions_tom1).detach()
for i in range(self.nagents):
self.actions_tom1.append(actions_tom1[i*self.config.batch_size:(i+1)*self.config.batch_size, :])
self.next_actions_tom1.append(next_actions_tom1[i*self.config.batch_size:(i+1)*self.config.batch_size, :])
# print(self.actions_tom1)
def tom0_output(self, sample):
acs_pre, obs, acs, rews, next_obs, dones = sample
self.actions_tom0 = []
self.next_actions_tom0 = []
adv_indx = self._get_index1(self.agent_types, 'adversary')
good_indx = self._get_index1(self.agent_types, 'agent')
self.actions_tom0 += [
gumbel_softmax(
self.mle_base[1].to(self.device)(
torch.cat((obs[j][:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
acs_pre[j][:, :5]), 1)).detach(), hard=True
) for j in adv_indx
]
self.actions_tom0 += [
gumbel_softmax(
self.mle_base[0].to(self.device)(
torch.cat((obs[j][:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
acs_pre[j][:, :5]), 1)).detach(), hard=True
) for j in good_indx
]
self.next_actions_tom0 += [
gumbel_softmax(
self.mle_base[1].to(self.device)(
torch.cat((next_obs[j][:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
acs[j][:, :5]), 1)).detach(), hard=True
) for j in adv_indx
]
self.next_actions_tom0 += [
gumbel_softmax(
self.mle_base[0].to(self.device)(
torch.cat((next_obs[j][:, -(self.num_good_agents * 2 + self.num_lm * 2 + (self.nagents - 1) * 2):],
acs[j][:, :5]), 1)).detach(), hard=True
) for j in good_indx
]
# actions_tom0 = torch.cat(actions_tom0, 1)
# return actions_tom0, next_actions_tom0
def update(self, sample, agent_i, parallel=False, logger=None, sample_r=None):
# other_alg_types = self.alg_types.copy()
other_agent_types = self.agent_types.copy()
# other_alg_types.pop(agent_i)
other_agent_types.pop(agent_i)
adv_indx = self._get_index1(other_agent_types, 'adversary')
good_indx = self._get_index1(other_agent_types, 'agent')
agent_i_alg = self.alg_types[agent_i]
acs_pre, obs, acs, rews, next_obs, dones = sample
next_obs_ = self._get_obs(next_obs, self.next_actions_tom1)
obs_ = self._get_obs(obs, self.actions_tom1)
curr_agent = self.agents[agent_i]
'''
distance between self and other
'''
Euclidean_D = []
for i in range(len(other_agent_types)):
Euclidean_D.append(obs[agent_i][:,
-len(other_agent_types)*2:][:, i: i+2].pow(2).sum(1).sqrt())
Euclidean_D_ = torch.stack(Euclidean_D, 1)
'''
distance between self and landmark
'''
Euclidean_L = []
for i in range(self.num_lm):
Euclidean_L.append(obs[agent_i][:, -len(other_agent_types)*2-self.num_lm*2:
-len(other_agent_types)*2][:, i: i+2].pow(2).sum(1).sqrt())
Euclidean_L = torch.stack(Euclidean_L, 1)
close_agent_index = (Euclidean_D_ == Euclidean_D_.min(dim=1, keepdim=True)[0])\
.to(dtype=torch.int32) #run11/run12 self-orgnization
# close_agent_index = torch.ones((self.config.batch_size, len(other_agent_types))) \
# .to(dtype=torch.int32).to(self.device) #run13
if agent_i == 0:
self.train_tom0(sample, agent_i)
E_action = self.tom1.tom1_output(agent_i, adv_indx,
good_indx, obs[agent_i], acs_pre[agent_i])
if agent_i_alg == 'with_tom':
acs_other = acs.copy()
acs_other.pop(agent_i)
# KL loss
# adv_loss = sum([KL_criterion(E_action[j], acs_other[j][:, :5].float()) for j in adv_indx]) #TODO
# good_loss = sum([KL_criterion(E_action[j], acs_other[j][:, :5].float()) for j in good_indx])
# L2 loss
action_loss = torch.norm(acs[agent_i][:, :5] - E_action[0], p=2, dim=1)
loss_other = 0.1 * torch.stack([action_loss]*len(other_agent_types), 1)
if agent_i in adv_indx:
'''
adv_loss : decrease
good_loss : increase
'''
close_agent_index[:, good_indx] *= -1
close_agent_index[:, adv_indx] *= 0.1
intri_rew = close_agent_index.mul(loss_other).mul(Euclidean_D_).sum(1)
# intri_rew = close_agent_index.mul(loss_other).sum(1)
else:
'''
adv_loss : increase
good_loss : decrease
'''
close_agent_index[:, adv_indx] *= 1
close_agent_index[:, good_indx] *= 0.1
# if self.config.env_id == 'simple_adversary':
# intri_rew = close_agent_index.mul(loss_other).mul(Euclidean_D_).sum(1) - \
# obs[agent_i][:, :2].pow(2).sum(1)
# elif self.config.env_id == 'simple_spread_pre':
# intri_rew = close_agent_index.mul(loss_other).mul(Euclidean_D_).sum(1) - \
# Euclidean_L.min(dim=1, keepdim=True)[0][:,0]
# else:
intri_rew = close_agent_index.mul(loss_other).mul(Euclidean_D_).sum(1)
# intri_rew = close_agent_index.mul(loss_other).sum(1)
rews[agent_i] = rews[agent_i] + intri_rew.detach()
# center critic
curr_agent.critic_optimizer.zero_grad()
all_trgt_acs = []
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs_)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
vf_in = torch.cat((*obs, *acs), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs_[agent_i].detach())
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs_):
ob = ob.detach()
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out ** 2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
# actor
curr_agent.policy_optimizer.step()
# print('c_loss:',vf_loss, 'p_loss:', pol_loss)
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
# for i in self.tom_base.values():
# for mle in i.values():
# mle.train()
for mle in self.mle_base:
mle.train()
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
for mle_i in a.mle:
mle_i.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
if not self.mle_dev == device:
# for i in self.tom_base.keys():
# for j in self.tom_base[i].keys():
# self.tom_base[i][j] = fn(mle)
for i, mle in enumerate(self.mle_base):
self.mle_base[i] = fn(mle)
for a in self.agents:
for i, mle_i in enumerate(a.mle):
a.mle[i] = fn(mle_i)
self.mle_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents],
'tom_params': [self.get_params()],}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, config, device, agent_alg, adversary_alg,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64, output_style='sum'):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
num_lm = env.num_lm
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
num_in_mle = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
# if algtype == "with_tom":
num_in_critic = 0
num_in_pol += (len(env.agent_types)-1) * 5
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
# else:
# num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic,
'num_in_mle': num_in_mle,})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'device': device,
'config' : config,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_types' : env.agent_types,
'num_lm' : num_lm,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'output_style': output_style}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
for a, params in zip([instance], save_dict['tom_params']):
a.load_params(params)
return instance
def get_params(self):
params = {
}
for i in range(len(self.mle_base)):
params['mle%d'%i] = self.mle_base[i].state_dict()
params['mle_optimizer%d'%i] = self.mle_opts[i].state_dict()
params['tom_phi%d'%i] = self.tom_PHI[i].state_dict()
params['phi_opt%d' % i] = self.PHI_opts[i].state_dict()
return params
def load_params(self, params):
for i in range(len(self.mle_base)):
self.mle_base[i].load_state_dict(params['mle%d'%i])
self.mle_opts[i].load_state_dict(params['mle_optimizer%d'%i])
self.tom_PHI[i].load_state_dict(params['tom_phi%d'%i])
self.PHI_opts[i].load_state_dict(params['phi_opt%d' % i])
================================================
FILE: examples/Social_Cognition/FOToM/common/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/FOToM/common/distributions.py
================================================
# import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
import numpy as np
import maddpg.common.tf_util as U
from tensorflow.python.ops import math_ops
from multiagent.multi_discrete import MultiDiscrete
from tensorflow.python.ops import nn
class Pd(object):
"""
A particular probability distribution
"""
def flatparam(self):
raise NotImplementedError
def mode(self):
raise NotImplementedError
def logp(self, x):
raise NotImplementedError
def kl(self, other):
raise NotImplementedError
def entropy(self):
raise NotImplementedError
def sample(self):
raise NotImplementedError
class PdType(object):
"""
Parametrized family of probability distributions
"""
def pdclass(self):
raise NotImplementedError
def pdfromflat(self, flat):
return self.pdclass()(flat)
def param_shape(self):
raise NotImplementedError
def sample_shape(self):
raise NotImplementedError
def sample_dtype(self):
raise NotImplementedError
def param_placeholder(self, prepend_shape, name=None):
return tf.placeholder(dtype=tf.float32, shape=prepend_shape+self.param_shape(), name=name)
def sample_placeholder(self, prepend_shape, name=None):
return tf.placeholder(dtype=self.sample_dtype(), shape=prepend_shape+self.sample_shape(), name=name)
class CategoricalPdType(PdType):
def __init__(self, ncat):
self.ncat = ncat
def pdclass(self):
return CategoricalPd
def param_shape(self):
return [self.ncat]
def sample_shape(self):
return []
def sample_dtype(self):
return tf.int32
class SoftCategoricalPdType(PdType):
def __init__(self, ncat):
self.ncat = ncat
def pdclass(self):
return SoftCategoricalPd
def param_shape(self):
return [self.ncat]
def sample_shape(self):
return [self.ncat]
def sample_dtype(self):
return tf.float32
class MultiCategoricalPdType(PdType):
def __init__(self, low, high):
self.low = low
self.high = high
self.ncats = high - low + 1
def pdclass(self):
return MultiCategoricalPd
def pdfromflat(self, flat):
return MultiCategoricalPd(self.low, self.high, flat)
def param_shape(self):
return [sum(self.ncats)]
def sample_shape(self):
return [len(self.ncats)]
def sample_dtype(self):
return tf.int32
class SoftMultiCategoricalPdType(PdType):
def __init__(self, low, high):
self.low = low
self.high = high
self.ncats = high - low + 1
def pdclass(self):
return SoftMultiCategoricalPd
def pdfromflat(self, flat):
return SoftMultiCategoricalPd(self.low, self.high, flat)
def param_shape(self):
return [sum(self.ncats)]
def sample_shape(self):
return [sum(self.ncats)]
def sample_dtype(self):
return tf.float32
class DiagGaussianPdType(PdType):
def __init__(self, size):
self.size = size
def pdclass(self):
return DiagGaussianPd
def param_shape(self):
return [2*self.size]
def sample_shape(self):
return [self.size]
def sample_dtype(self):
return tf.float32
class BernoulliPdType(PdType):
def __init__(self, size):
self.size = size
def pdclass(self):
return BernoulliPd
def param_shape(self):
return [self.size]
def sample_shape(self):
return [self.size]
def sample_dtype(self):
return tf.int32
# WRONG SECOND DERIVATIVES
# class CategoricalPd(Pd):
# def __init__(self, logits):
# self.logits = logits
# self.ps = tf.nn.softmax(logits)
# @classmethod
# def fromflat(cls, flat):
# return cls(flat)
# def flatparam(self):
# return self.logits
# def mode(self):
# return U.argmax(self.logits, axis=1)
# def logp(self, x):
# return -tf.nn.sparse_softmax_cross_entropy_with_logits(self.logits, x)
# def kl(self, other):
# return tf.nn.softmax_cross_entropy_with_logits(other.logits, self.ps) \
# - tf.nn.softmax_cross_entropy_with_logits(self.logits, self.ps)
# def entropy(self):
# return tf.nn.softmax_cross_entropy_with_logits(self.logits, self.ps)
# def sample(self):
# u = tf.random_uniform(tf.shape(self.logits))
# return U.argmax(self.logits - tf.log(-tf.log(u)), axis=1)
class CategoricalPd(Pd):
def __init__(self, logits):
self.logits = logits
def flatparam(self):
return self.logits
def mode(self):
return U.argmax(self.logits, axis=1)
def logp(self, x):
return -tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.logits, labels=x)
def kl(self, other):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
a1 = other.logits - U.max(other.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
ea1 = tf.exp(a1)
z0 = U.sum(ea0, axis=1, keepdims=True)
z1 = U.sum(ea1, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (a0 - tf.log(z0) - a1 + tf.log(z1)), axis=1)
def entropy(self):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
z0 = U.sum(ea0, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (tf.log(z0) - a0), axis=1)
def sample(self):
u = tf.random_uniform(tf.shape(self.logits))
return U.argmax(self.logits - tf.log(-tf.log(u)), axis=1)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class SoftCategoricalPd(Pd):
def __init__(self, logits):
self.logits = logits
def flatparam(self):
return self.logits
def mode(self):
return U.softmax(self.logits, axis=-1)
def logp(self, x):
return -tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=x)
def kl(self, other):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
a1 = other.logits - U.max(other.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
ea1 = tf.exp(a1)
z0 = U.sum(ea0, axis=1, keepdims=True)
z1 = U.sum(ea1, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (a0 - tf.log(z0) - a1 + tf.log(z1)), axis=1)
def entropy(self):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
z0 = U.sum(ea0, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (tf.log(z0) - a0), axis=1)
def sample(self):
u = tf.random_uniform(tf.shape(self.logits))
return U.softmax(self.logits - tf.log(-tf.log(u)), axis=-1)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class MultiCategoricalPd(Pd):
def __init__(self, low, high, flat):
self.flat = flat
self.low = tf.constant(low, dtype=tf.int32)
self.categoricals = list(map(CategoricalPd, tf.split(flat, high - low + 1, axis=len(flat.get_shape()) - 1)))
def flatparam(self):
return self.flat
def mode(self):
return self.low + tf.cast(tf.stack([p.mode() for p in self.categoricals], axis=-1), tf.int32)
def logp(self, x):
return tf.add_n([p.logp(px) for p, px in zip(self.categoricals, tf.unstack(x - self.low, axis=len(x.get_shape()) - 1))])
def kl(self, other):
return tf.add_n([
p.kl(q) for p, q in zip(self.categoricals, other.categoricals)
])
def entropy(self):
return tf.add_n([p.entropy() for p in self.categoricals])
def sample(self):
return self.low + tf.cast(tf.stack([p.sample() for p in self.categoricals], axis=-1), tf.int32)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class SoftMultiCategoricalPd(Pd): # doesn't work yet
def __init__(self, low, high, flat):
self.flat = flat
self.low = tf.constant(low, dtype=tf.float32)
self.categoricals = list(map(SoftCategoricalPd, tf.split(flat, high - low + 1, axis=len(flat.get_shape()) - 1)))
def flatparam(self):
return self.flat
def mode(self):
x = []
for i in range(len(self.categoricals)):
x.append(self.low[i] + self.categoricals[i].mode())
return tf.concat(x, axis=-1)
def logp(self, x):
return tf.add_n([p.logp(px) for p, px in zip(self.categoricals, tf.unstack(x - self.low, axis=len(x.get_shape()) - 1))])
def kl(self, other):
return tf.add_n([
p.kl(q) for p, q in zip(self.categoricals, other.categoricals)
])
def entropy(self):
return tf.add_n([p.entropy() for p in self.categoricals])
def sample(self):
x = []
for i in range(len(self.categoricals)):
x.append(self.low[i] + self.categoricals[i].sample())
return tf.concat(x, axis=-1)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class DiagGaussianPd(Pd):
def __init__(self, flat):
self.flat = flat
mean, logstd = tf.split(axis=1, num_or_size_splits=2, value=flat)
self.mean = mean
self.logstd = logstd
self.std = tf.exp(logstd)
def flatparam(self):
return self.flat
def mode(self):
return self.mean
def logp(self, x):
return - 0.5 * U.sum(tf.square((x - self.mean) / self.std), axis=1) \
- 0.5 * np.log(2.0 * np.pi) * tf.to_float(tf.shape(x)[1]) \
- U.sum(self.logstd, axis=1)
def kl(self, other):
assert isinstance(other, DiagGaussianPd)
return U.sum(other.logstd - self.logstd + (tf.square(self.std) + tf.square(self.mean - other.mean)) / (2.0 * tf.square(other.std)) - 0.5, axis=1)
def entropy(self):
return U.sum(self.logstd + .5 * np.log(2.0 * np.pi * np.e), 1)
def sample(self):
return self.mean + self.std * tf.random_normal(tf.shape(self.mean))
@classmethod
def fromflat(cls, flat):
return cls(flat)
class BernoulliPd(Pd):
def __init__(self, logits):
self.logits = logits
self.ps = tf.sigmoid(logits)
def flatparam(self):
return self.logits
def mode(self):
return tf.round(self.ps)
def logp(self, x):
return - U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=tf.to_float(x)), axis=1)
def kl(self, other):
return U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=other.logits, labels=self.ps), axis=1) - U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=self.ps), axis=1)
def entropy(self):
return U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=self.ps), axis=1)
def sample(self):
p = tf.sigmoid(self.logits)
u = tf.random_uniform(tf.shape(p))
return tf.to_float(math_ops.less(u, p))
@classmethod
def fromflat(cls, flat):
return cls(flat)
def make_pdtype(ac_space):
from gym import spaces
if isinstance(ac_space, spaces.Box):
assert len(ac_space.shape) == 1
return DiagGaussianPdType(ac_space.shape[0])
elif isinstance(ac_space, spaces.Discrete):
# return CategoricalPdType(ac_space.n)
return SoftCategoricalPdType(ac_space.n)
elif isinstance(ac_space, MultiDiscrete):
#return MultiCategoricalPdType(ac_space.low, ac_space.high)
return SoftMultiCategoricalPdType(ac_space.low, ac_space.high)
elif isinstance(ac_space, spaces.MultiBinary):
return BernoulliPdType(ac_space.n)
else:
raise NotImplementedError
def shape_el(v, i):
maybe = v.get_shape()[i]
if maybe is not None:
return maybe
else:
return tf.shape(v)[i]
================================================
FILE: examples/Social_Cognition/FOToM/common/tile_images.py
================================================
import numpy as np
def tile_images(img_nhwc):
"""
Tile N images into one big PxQ image
(P,Q) are chosen to be as close as possible, and if N
is square, then P=Q.
input: img_nhwc, list or array of images, ndim=4 once turned into array
n = batch index, h = height, w = width, c = channel
returns:
bigim_HWc, ndarray with ndim=3
"""
img_nhwc = np.asarray(img_nhwc)
N, h, w, c = img_nhwc.shape
H = int(np.ceil(np.sqrt(N)))
W = int(np.ceil(float(N)/H))
img_nhwc = np.array(list(img_nhwc) + [img_nhwc[0]*0 for _ in range(N, H*W)])
img_HWhwc = img_nhwc.reshape(H, W, h, w, c)
img_HhWwc = img_HWhwc.transpose(0, 2, 1, 3, 4)
img_Hh_Ww_c = img_HhWwc.reshape(H*h, W*w, c)
return img_Hh_Ww_c
================================================
FILE: examples/Social_Cognition/FOToM/common/vec_env/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/FOToM/common/vec_env/vec_env.py
================================================
import contextlib
import os
from abc import ABC, abstractmethod
from common.tile_images import tile_images
class AlreadySteppingError(Exception):
"""
Raised when an asynchronous step is running while
step_async() is called again.
"""
def __init__(self):
msg = 'already running an async step'
Exception.__init__(self, msg)
class NotSteppingError(Exception):
"""
Raised when an asynchronous step is not running but
step_wait() is called.
"""
def __init__(self):
msg = 'not running an async step'
Exception.__init__(self, msg)
class VecEnv(ABC):
"""
An abstract asynchronous, vectorized environment.
Used to batch data from multiple copies of an environment, so that
each observation becomes an batch of observations, and expected action is a batch of actions to
be applied per-environment.
"""
closed = False
viewer = None
metadata = {
'render.modes': ['human', 'rgb_array']
}
def __init__(self, num_envs, observation_space, action_space):
self.num_envs = num_envs
self.observation_space = observation_space
self.action_space = action_space
@abstractmethod
def reset(self):
"""
Reset all the environments and return an array of
observations, or a dict of observation arrays.
If step_async is still doing work, that work will
be cancelled and step_wait() should not be called
until step_async() is invoked again.
"""
pass
@abstractmethod
def step_async(self, actions):
"""
Tell all the environments to start taking a step
with the given actions.
Call step_wait() to get the results of the step.
You should not call this if a step_async run is
already pending.
"""
pass
@abstractmethod
def step_wait(self):
"""
Wait for the step taken with step_async().
Returns (obs, rews, dones, infos):
- obs: an array of observations, or a dict of
arrays of observations.
- rews: an array of rewards
- dones: an array of "episode done" booleans
- infos: a sequence of info objects
"""
pass
def close_extras(self):
"""
Clean up the extra resources, beyond what's in this base class.
Only runs when not self.closed.
"""
pass
def close(self):
if self.closed:
return
if self.viewer is not None:
self.viewer.close()
self.close_extras()
self.closed = True
def step(self, actions):
"""
Step the environments synchronously.
This is available for backwards compatibility.
"""
self.step_async(actions)
return self.step_wait()
def render(self, mode='human'):
imgs = self.get_images()
bigimg = tile_images(imgs)
if mode == 'human':
self.get_viewer().imshow(bigimg)
return self.get_viewer().isopen
elif mode == 'rgb_array':
return bigimg
else:
raise NotImplementedError
def get_images(self):
"""
Return RGB images from each environment
"""
raise NotImplementedError
@property
def unwrapped(self):
if isinstance(self, VecEnvWrapper):
return self.venv.unwrapped
else:
return self
def get_viewer(self):
if self.viewer is None:
from gym.envs.classic_control import rendering
self.viewer = rendering.SimpleImageViewer()
return self.viewer
class VecEnvWrapper(VecEnv):
"""
An environment wrapper that applies to an entire batch
of environments at once.
"""
def __init__(self, venv, observation_space=None, action_space=None):
self.venv = venv
super().__init__(num_envs=venv.num_envs,
observation_space=observation_space or venv.observation_space,
action_space=action_space or venv.action_space)
def step_async(self, actions):
self.venv.step_async(actions)
@abstractmethod
def reset(self):
pass
@abstractmethod
def step_wait(self):
pass
def close(self):
return self.venv.close()
def render(self, mode='human'):
return self.venv.render(mode=mode)
def get_images(self):
return self.venv.get_images()
def __getattr__(self, name):
if name.startswith('_'):
raise AttributeError("attempted to get missing private attribute '{}'".format(name))
return getattr(self.venv, name)
class VecEnvObservationWrapper(VecEnvWrapper):
@abstractmethod
def process(self, obs):
pass
def reset(self):
obs = self.venv.reset()
return self.process(obs)
def step_wait(self):
obs, rews, dones, infos = self.venv.step_wait()
return self.process(obs), rews, dones, infos
class CloudpickleWrapper(object):
"""
Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)
"""
def __init__(self, x):
self.x = x
def __getstate__(self):
import cloudpickle
return cloudpickle.dumps(self.x)
def __setstate__(self, ob):
import pickle
self.x = pickle.loads(ob)
@contextlib.contextmanager
def clear_mpi_env_vars():
"""
from mpi4py import MPI will call MPI_Init by default. If the child process has MPI environment variables, MPI will think that the child process is an MPI process just like the parent and do bad things such as hang.
This context manager is a hacky way to clear those environment variables temporarily such as when we are starting multiprocessing
Processes.
"""
removed_environment = {}
for k, v in list(os.environ.items()):
for prefix in ['OMPI_', 'PMI_']:
if k.startswith(prefix):
removed_environment[k] = v
del os.environ[k]
try:
yield
finally:
os.environ.update(removed_environment)
================================================
FILE: examples/Social_Cognition/FOToM/evaluate.py
================================================
import argparse
import torch
import time
import imageio
import numpy as np
from pathlib import Path
from torch.autograd import Variable
from utils.make_env import make_env
from algorithms.tom11 import ToM_decision11
from algorithms.maddpg import MADDPG
import matplotlib.pyplot as plt
from tqdm import tqdm
from utils.env_wrappers import SubprocVecEnv, DummyVecEnv
def display_frames_as_gif(frames):
patch = plt.imshow(frames[1])
plt.axis('off')
plt.savefig('./images/comm2', bbox_inches='tight')
def make_parallel_env(env_id, n_rollout_threads, discrete_action, num_good_agents, num_adversaries):
def get_env_fn(rank):
def init_env():
env = make_env(env_id, num_good_agents=num_good_agents, num_adversaries=num_adversaries, discrete_action=discrete_action)
# env.seed(seed + rank * 1000)
# np.random.seed(seed + rank * 1000)
return env
return init_env
if n_rollout_threads == 1:
return DummyVecEnv([get_env_fn(0)])
else:
return SubprocVecEnv([get_env_fn(i) for i in range(n_rollout_threads)])
def run(config):
rew_ep = []
for i in range(config.num):
for run_num in config.run_num:
pbar = tqdm(config.n_episodes)
model_path = (Path('./models') / config.env_id / config.model_name /
('run%i' % (run_num)))
if config.incremental is not None:
model_path = model_path / 'incremental' / ('model_ep%i.pt' %
config.incremental)
else:
model_path = model_path / 'model.pt'
# if config.save_gifs:
# gif_path = model_path.parent / 'gifs'
# gif_path.mkdir(exist_ok=True)
if config.alg == 'ToM1':
maddpg = ToM_decision11.init_from_save(model_path)
elif config.alg == 'ToM_SB01' or config.alg== 'ToM_SA01':
maddpg = ToM_decision01.init_from_save(model_path)#.eval()
elif config.alg == 'ToM_SBN1' or config.alg== 'ToM_SAN1':
maddpg = ToM_decisionN1.init_from_save(model_path)#.eval()
elif config.alg == 'MADDPG':
maddpg = MADDPG.init_from_save(model_path)
# env = make_env(config.env_id, num_good_agents=config.num_good_agents,
# num_adversaries=config.num_adversaries, discrete_action=maddpg.discrete_action)
env = make_parallel_env(config.env_id, config.n_rollout_threads,
config.discrete_action, config.num_good_agents, config.num_adversaries)
maddpg.prep_rollouts(device='cpu')
ifi = 1 / config.fps # inter-frame interval
for ep_i in range(0, config.n_episodes, config.n_rollout_threads):
rew = np.zeros((config.n_rollout_threads, config.num_good_agents + config.num_adversaries))
torch_agent_actions = [torch.zeros((config.n_rollout_threads, 5))
for i in range(maddpg.nagents)]
# print("Episode %i of %i" % (ep_i + 1, config.n_episodes))
obs = env.reset()
for t_i in range(config.episode_length):
# calc_start = time.time()
# rearrange observations to be per agent, and convert to torch Variable
torch_obs = [Variable(torch.Tensor(np.vstack(obs[:, i])),
requires_grad=False)
for i in range(maddpg.nagents)]
# get actions as torch Variables
# t1 = time.time()
if config.alg == 'MADDPG':
torch_actions = maddpg.step(torch_obs, explore=False)
else:
torch_actions = maddpg.step(torch_obs, torch_agent_actions, explore=False)
actions = [ac.data.cpu().numpy() for ac in torch_actions]
actions = [[ac[i] for ac in actions] for i in range(config.n_rollout_threads)]
obs, rewards, dones, infos = env.step(actions)
rew += rewards
rew_ep.append(rew)
pbar.update(config.n_rollout_threads)
pbar.close()
rew_ep = np.concatenate(rew_ep, 0)
rew_ep_agent = rew_ep.mean(0)
std_ep_agent = rew_ep.std(0)
print('mean:', rew_ep_agent, 'std:', std_ep_agent)
rew_ep_good = rew_ep[:, -config.num_good_agents:].sum(1).mean()
rew_ep_adv = rew_ep[:, :config.num_adversaries].sum(1).mean()
std_ep_good = rew_ep[:, -config.num_good_agents:].sum(1).std()
std_ep_adv = rew_ep[:, :config.num_adversaries].sum(1).std()
print('good:', rew_ep_good, 'std:', std_ep_good)
print('adv:', rew_ep_adv, 'std:', std_ep_adv)
rew_ep_all = rew_ep.sum(1).mean()
std_ep_all = rew_ep.sum(1).std()
print('all:', rew_ep_all, 'std:', std_ep_all)
env.close()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--alg",
default="ToM_SAN1", type=str,
choices=['MADDPG', 'ToM_SB01', 'ToM_SA01', 'ToM_SBN1', 'ToM_SAN1',
'ToM1'])
parser.add_argument("--env_id", default='simple_adversary', type=str, help="Name of environment",
choices=['simple_tag', 'simple_world_comm', 'hetero_spread',
'simple_adversary', 'simple_spread'
])
parser.add_argument("--num_good_agents", default=None, type=int,
help="Num of Agent")
parser.add_argument("--num_adversaries", default=None, type=int,
help="Num of Adversary")
parser.add_argument("--model_name", default='4VS2_tomaAN1', type=str,
help="Name of model") #ma2c, maddpg, maddpg_rnn
parser.add_argument("--run_num", default=2, type=int, nargs='+')
parser.add_argument("--save_gifs", default=True, action="store_true",
help="Saves gif of each episode into model directory")
parser.add_argument("--incremental", default= None, type=int,
help="Load incremental policy from given episode " +
"rather than final policy")
parser.add_argument("--n_episodes", default=1000, type=int)
parser.add_argument("--episode_length", default=25, type=int)
parser.add_argument("--fps", default=30, type=int)
parser.add_argument("--eval",
default=True, type=bool,
)
parser.add_argument("--num", default=3, type=int )
parser.add_argument("--n_rollout_threads", default=20, type=int)
parser.add_argument("--discrete_action",
# default=False, type=bool,
action='store_true')
config = parser.parse_args()
if 'ToM_SB' in config.alg:
config.agent_alg = 'without_tom'
config.adversary_alg = 'with_tom'
elif 'ToM_SA' in config.alg:
config.agent_alg = 'with_tom'
config.adversary_alg = 'without_tom'
elif config.alg == 'ToM1':
config.agent_alg = 'with_tom'
config.adversary_alg = 'with_tom'
else:
config.agent_alg = config.alg
config.adversary_alg = config.alg
if config.num_good_agents == None and config.num_adversaries == None:
if config.env_id == 'simple_adversary':
config.num_good_agents = 2
config.num_adversaries = 1
elif config.env_id == 'simple_tag':
config.num_good_agents = 2
config.num_adversaries = 2
elif config.env_id == 'simple_world_comm':
config.num_good_agents = 2
config.num_adversaries = 4
elif config.env_id == 'simple_spread':
config.num_good_agents = 3
config.num_adversaries = 0
run(config)
================================================
FILE: examples/Social_Cognition/FOToM/main.py
================================================
import argparse
import torch
import time
import os
import numpy as np
from gym.spaces import Box, Discrete, MultiDiscrete
from pathlib import Path
from torch.autograd import Variable
from tensorboardX import SummaryWriter
from utils.make_env import make_env
from utils.buffer import ReplayBuffer, ReplayBuffer_pre
from utils.env_wrappers import SubprocVecEnv, DummyVecEnv
from algorithms.tomN1 import ToM_decisionN1
from algorithms.tom01 import ToM_decision01
from algorithms.tom11 import ToM_decision11
from algorithms.maddpg import MADDPG
from tqdm import tqdm
from thop import profile
from thop import clever_format
def get_common_args():
parser = argparse.ArgumentParser()
parser.add_argument("--env_id", default='simple_tag', type=str,
choices=['simple_tag', 'simple_adversary', 'hetero_spread', 'simple_world_comm',
'simple_spread'],
help="Name of environment")
parser.add_argument("--num_good_agents", default=None, type=int,
help="Num of Agent")
parser.add_argument("--num_adversaries", default=None, type=int,
help="Num of Adversary")
parser.add_argument("--model_name", default='ann', type=str,
help="Name of directory to store " +
"model/training contents") #ToM_SA
parser.add_argument("--seed",
default=1, type=int,
help="Random seed")
parser.add_argument("--cuda_num",
default=5, type=int,
help="device")
parser.add_argument("--output_style",
default='sum', type=str,
choices=['sum', 'voltage'])
parser.add_argument("--n_rollout_threads", default=20, type=int)
parser.add_argument("--n_training_threads", default=6, type=int)
parser.add_argument("--buffer_length", default=int(1e6), type=int) #1e6
parser.add_argument("--n_episodes", default=25000, type=int)#25000
parser.add_argument("--episode_length", default=25, type=int)
parser.add_argument("--steps_per_update", default=100, type=int)
parser.add_argument("--load_para", type=bool, default=False)
parser.add_argument("--batch_size",
default=1024, type=int,#4
help="Batch size for model training")
parser.add_argument("--n_exploration_eps", default=25000, type=int)
parser.add_argument("--init_noise_scale", default=0.3, type=float)
parser.add_argument("--final_noise_scale", default=0.0, type=float)
parser.add_argument("--save_interval", default=1000, type=int)#1000
parser.add_argument("--hidden_dim", default=64, type=int)
parser.add_argument("--lr", default=1e-3, type=float) #0.01 #1e-3
parser.add_argument("--tau", default=0.01, type=float)
parser.add_argument("--alg",
default="ToM1", type=str,
choices=['MADDPG',
'ToM1', 'ToM_SB01', 'ToM_SA01', 'ToM_SBN1', 'ToM_SAN1'])
parser.add_argument("--discrete_action",
# default=False, type=bool,
action='store_true')
args = parser.parse_args()
parser.add_argument('--device', type=str, default='cuda:{}'.format(args.cuda_num), help='whether to use the GPU') #'cuda:1'
parser = parser.parse_args()
return parser
USE_CUDA = torch.cuda.is_available()
def make_parallel_env(env_id, n_rollout_threads, seed, discrete_action, num_good_agents, num_adversaries):
def get_env_fn(rank):
def init_env():
env = make_env(env_id, num_good_agents=num_good_agents, num_adversaries=num_adversaries, discrete_action=discrete_action)
env.seed(seed + rank * 1000)
np.random.seed(seed + rank * 1000)
return env
return init_env
if n_rollout_threads == 1:
return DummyVecEnv([get_env_fn(0)])
else:
return SubprocVecEnv([get_env_fn(i) for i in range(n_rollout_threads)])
def run(config):
pbar = tqdm(config.n_episodes)
model_dir = Path('./models') / config.env_id / config.model_name
if not model_dir.exists():
curr_run = 'run1'
else:
exst_run_nums = [int(str(folder.name).split('run')[1]) for folder in
model_dir.iterdir() if
str(folder.name).startswith('run')]
if len(exst_run_nums) == 0:
curr_run = 'run1'
else:
curr_run = 'run%i' % (max(exst_run_nums) + 1)
run_dir = model_dir / curr_run
log_dir = run_dir / 'logs'
os.makedirs(log_dir)
logger = SummaryWriter(str(log_dir))
save_path = log_dir
print(os.path.exists(save_path))
argsDict = config.__dict__
with open(save_path / 'args_{}'.format(max(exst_run_nums) + 1), 'w') as f:
f.writelines('------------------ start ------------------' + '\n')
for eachArg, value in argsDict.items():
f.writelines(eachArg + ' : ' + str(value) + '\n')
f.writelines('------------------- end -------------------')
torch.manual_seed(config.seed)
np.random.seed(config.seed)
if not USE_CUDA:
torch.set_num_threads(config.n_training_threads)
env = make_parallel_env(config.env_id, config.n_rollout_threads, config.seed,
config.discrete_action, config.num_good_agents, config.num_adversaries)
if config.alg == 'ToM1':
print('_______Alg: ' + config.alg + '_______')
if config.load_para == False:
maddpg = ToM_decision11.init_from_env(env, config, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
else:
# model_path = (Path('./models') / config.env_id / 'self1' / #'self1' tag, maddpg_self_11 adv
# ('run%i' % 1)) / 'model.pt'
model_path = (Path('./models') / config.env_id / 'rs1' / #'self1' tag, maddpg_self_11 adv
('run%i' % 1)) / 'model.pt'
maddpg = ToM_decision11.init_from_save(model_path)
elif config.alg == 'ToM_SB01' or config.alg== 'ToM_SA01':
print('_______Alg: ' + config.alg + '_______')
if config.load_para == False:
maddpg = ToM_decision01.init_from_env(env, config, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
else:
model_path = (Path('./models') / config.env_id / 'am' / #'self1' tag, maddpg_self_11 adv
('run%i' % 3)) / 'model.pt'
maddpg = ToM_decision01.init_from_save(model_path)
elif config.alg == 'ToM_SBN1' or config.alg== 'ToM_SAN1':
print('_______Alg: ' + config.alg + '_______')
if config.load_para == False:
maddpg = ToM_decisionN1.init_from_env(env, config, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
else:
model_path = (Path('./models') / config.env_id / 'am' / #'self1' tag, maddpg_self_11 adv
('run%i' % 3)) / 'model.pt'
maddpg = ToM_decisionN1.init_from_save(model_path)
elif config.alg == 'MADDPG':
print('_______Alg: ' + config.alg + '_______')
if config.load_para == False:
maddpg = MADDPG.init_from_env(env, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
device=config.device)
if config.alg == 'ToM1' or config.alg == 'ToM_SB01' or config.alg == 'ToM_SA01' \
or config.alg == 'ToM_SBN1' or config.alg == 'ToM_SAN1':
replay_buffer = ReplayBuffer_pre(config.buffer_length, maddpg.nagents,
[obsp.shape[0] for obsp in env.observation_space],
[acsp.n if isinstance(acsp, Discrete) else sum(acsp.high - acsp.low + 1)
for acsp in env.action_space],
device=config.device)
else:
replay_buffer = ReplayBuffer(config.buffer_length, maddpg.nagents,
[obsp.shape[0] for obsp in env.observation_space],
[acsp.n if isinstance(acsp, Discrete) else sum(acsp.high - acsp.low + 1)
for acsp in env.action_space],
device=config.device)
t = 0
total_reward = []
for agent_i in range(maddpg.nagents):
total_reward.append([])
for ep_i in range(0, config.n_episodes, config.n_rollout_threads):
# print("Episodes %i-%i of %i" % (ep_i + 1,
# ep_i + 1 + config.n_rollout_threads,
# config.n_episodes))
obs = env.reset()
# obs.shape = (n_rollout_threads, nagent)(nobs), nobs differs per agent so not tensor
maddpg.prep_rollouts(device='cpu')
torch_agent_actions = [torch.zeros((config.n_rollout_threads, 5)) for i in range(maddpg.nagents)]
explr_pct_remaining = max(0, config.n_exploration_eps - ep_i) / config.n_exploration_eps
maddpg.scale_noise(config.final_noise_scale + (config.init_noise_scale - config.final_noise_scale) * explr_pct_remaining)
if config.alg == 'rnnD' or config.alg == 'rnn':
maddpg._init_agent(config.n_rollout_threads)
maddpg.reset_noise()
obs_ep = []
agent_actions_ep = []
rewards_ep = []
next_obs_ep = []
dones_ep = []
for et_i in range(config.episode_length):
torch_agent_actions_pre = torch_agent_actions
torch_agent_actions_pre = [ac.data.numpy() for ac in torch_agent_actions_pre]
# rearrange observations to be per agent, and convert to torch Variable
torch_obs = [Variable(torch.Tensor(np.vstack(obs[:, i])),
requires_grad=False)
for i in range(maddpg.nagents)] #
# get actions as torch Variables
# t1 = time.time()
if config.alg == 'ToM1' or config.alg == 'ToM_SB01' or config.alg == 'ToM_SA01' \
or config.alg == 'ToM_SBN1' or config.alg == 'ToM_SAN1':
torch_agent_actions = maddpg.step(torch_obs, torch_agent_actions, explore=True)
else:
torch_agent_actions = maddpg.step(torch_obs, explore=True)
# t2 = time.time()
# print('maddpg.step time:', t2-t1)
agent_actions = [ac.data.numpy() for ac in torch_agent_actions] #
# rearrange actions to be per environment
actions = [[ac[i] for ac in agent_actions] for i in range(config.n_rollout_threads)]
# t3 = time.time()
next_obs, rewards, dones, infos = env.step(actions)
# t4 = time.time()
# print('env.step')
obs_ep.append(obs) #episode_id,process, n_agents, dim
agent_actions_ep.append(actions) #episode_id, n_agents, process, dim
rewards_ep.append(rewards) #episode_id,process, n_agents,
next_obs_ep.append(next_obs) #episode_id,process, n_agents, dim
dones_ep.append(dones) #episode_id,process, n_agents,
if config.alg == 'ToM1' or config.alg == 'ToM_SB01' or config.alg == 'ToM_SA01' \
or config.alg == 'ToM_SBN1' or config.alg == 'ToM_SAN1':
replay_buffer.push(torch_agent_actions_pre, obs, agent_actions, rewards, next_obs, dones)
else:
replay_buffer.push(obs, agent_actions, rewards, next_obs, dones)
obs = next_obs
t += config.n_rollout_threads
if (len(replay_buffer) >= config.batch_size and
(t % config.steps_per_update) < config.n_rollout_threads):
if USE_CUDA:
maddpg.prep_training(device='gpu')
else:
maddpg.prep_training(device='cpu')
if config.n_episodes >300:
rollout = 2
else:
rollout = config.n_rollout_threads
for u_i in range(rollout):
sample = replay_buffer.sample(config.batch_size,
to_gpu=USE_CUDA)
if '1' in config.alg:
maddpg.tom0_output(sample)
maddpg.tom1_infer_other(sample)
for a_i in range(maddpg.nagents):
# t1 = time.time()
maddpg.update(sample, a_i, logger=logger)
# t2 = time.time()
# print('trian_time:', t2-t1, u_i, a_i)
maddpg.update_all_targets()
maddpg.prep_rollouts(device='cpu')
if config.alg == 'rnnD' or config.alg == 'rnn':
maddpg._init_agent(config.n_rollout_threads)
ep_rews = replay_buffer.get_average_rewards(
config.episode_length * config.n_rollout_threads)
for a_i, a_ep_rew in enumerate(ep_rews):
logger.add_scalar('agent%i/mean_episode_rewards' % a_i,
a_ep_rew,
ep_i)
logger.add_scalar('agent_mean/mean_episode_rewards',
np.mean(ep_rews),
ep_i)
if ep_i % config.save_interval < config.n_rollout_threads:
os.makedirs(run_dir / 'incremental', exist_ok=True)
maddpg.save(run_dir / 'incremental' / ('model_ep%i.pt' % (ep_i + 1)))
maddpg.save(run_dir / 'model.pt')
pbar.update(config.n_rollout_threads)
pbar.close()
maddpg.save(run_dir / 'model.pt')
env.close()
logger.export_scalars_to_json(str(log_dir / 'summary.json'))
logger.close()
for a_i, reward in enumerate(total_reward):
reward_dir = str(log_dir) + '/agent{}/mean_episode_rewards'.format(a_i) + '/episode_rewards_{}'.format(config.cuda_num)
os.makedirs(reward_dir)
np.save(reward_dir, reward)
if __name__ == '__main__':
config = get_common_args()
# config.env_id = 'simple_world_comm'#'simple_adversary'#'simple_tag'
# # config.model_name = 'ma2c'
if 'ToM_SB' in config.alg:
config.agent_alg = 'without_tom'
config.adversary_alg = 'with_tom'
elif 'ToM_SA' in config.alg:
config.agent_alg = 'with_tom'
config.adversary_alg = 'without_tom'
elif config.alg == 'ToM1':
config.agent_alg = 'with_tom'
config.adversary_alg = 'with_tom'
else:
config.agent_alg = config.alg
config.adversary_alg = config.alg
# debug
if config.num_good_agents == None and config.num_adversaries == None:
if config.env_id == 'simple_adversary':
config.num_good_agents = 2
config.num_adversaries = 1
elif config.env_id == 'simple_tag':
config.num_good_agents = 1
config.num_adversaries = 3
elif config.env_id == 'simple_world_comm':
config.num_good_agents = 2
config.num_adversaries = 4
elif config.env_id == 'hetero_spread':
config.num_good_agents = 4
config.num_adversaries = 0
elif config.env_id == 'simple_spread': #coop
config.num_good_agents = 3
config.num_adversaries = 0
run(config)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/__init__.py
================================================
from gym.envs.registration import register
# Multiagent envs
# ----------------------------------------
register(
id='MultiagentSimple-v0',
entry_point='multiagent.envs:SimpleEnv',
# FIXME(cathywu) currently has to be exactly max_path_length parameters in
# rllab run script
max_episode_steps=100,
)
register(
id='MultiagentSimpleSpeakerListener-v0',
entry_point='multiagent.envs:SimpleSpeakerListenerEnv',
max_episode_steps=100,
)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/core.py
================================================
import numpy as np
# physical/external base state of all entites
class EntityState(object):
def __init__(self):
# physical position
self.p_pos = None
# physical velocity
self.p_vel = None
# state of agents (including communication and internal/mental state)
class AgentState(EntityState):
def __init__(self):
super(AgentState, self).__init__()
# communication utterance
self.c = None
# action of the agent
class Action(object):
def __init__(self):
# physical action
self.u = None
# communication action
self.c = None
# properties and state of physical world entity
class Entity(object):
def __init__(self):
# name
self.name = ''
# properties:
self.size = 0.050
# entity can move / be pushed
self.movable = False
# entity collides with others
self.collide = True
# material density (affects mass)
self.density = 25.0
# color
self.color = None
# max speed and accel
self.max_speed = None
self.accel = None
# state
self.state = EntityState()
# mass
self.initial_mass = 1.0
@property
def mass(self):
return self.initial_mass
# properties of landmark entities
class Landmark(Entity):
def __init__(self):
super(Landmark, self).__init__()
# properties of agent entities
class Agent(Entity):
def __init__(self):
super(Agent, self).__init__()
# agents are movable by default
self.movable = True
# cannot send communication signals
self.silent = False
# cannot observe the world
self.blind = False
# physical motor noise amount
self.u_noise = None
# communication noise amount
self.c_noise = None
# control range
self.u_range = 1.0
# state
self.state = AgentState()
# action
self.action = Action()
# script behavior to execute
self.action_callback = None
# multi-agent world
class World(object):
def __init__(self):
# list of agents and entities (can change at execution-time!)
self.agents = []
self.landmarks = []
# communication channel dimensionality
self.dim_c = 0
# position dimensionality
self.dim_p = 2
# color dimensionality
self.dim_color = 3
# simulation timestep
self.dt = 0.1
# physical damping
self.damping = 0.25
# contact response parameters
self.contact_force = 1e+2
self.contact_margin = 1e-3
# return all entities in the world
@property
def entities(self):
return self.agents + self.landmarks
# return all agents controllable by external policies
@property
def policy_agents(self):
return [agent for agent in self.agents if agent.action_callback is None]
# return all agents controlled by world scripts
@property
def scripted_agents(self):
return [agent for agent in self.agents if agent.action_callback is not None]
# update state of the world
def step(self):
# set actions for scripted agents
for agent in self.scripted_agents:
agent.action = agent.action_callback(agent, self)
# gather forces applied to entities
p_force = [None] * len(self.entities)
# apply agent physical controls
p_force = self.apply_action_force(p_force)
# apply environment forces
p_force = self.apply_environment_force(p_force)
# integrate physical state
self.integrate_state(p_force)
# update agent state
for agent in self.agents:
self.update_agent_state(agent)
# gather agent action forces
def apply_action_force(self, p_force):
# set applied forces
for i,agent in enumerate(self.agents):
if agent.movable:
noise = np.random.randn(*agent.action.u.shape) * agent.u_noise if agent.u_noise else 0.0
p_force[i] = agent.action.u + noise
return p_force
# gather physical forces acting on entities
def apply_environment_force(self, p_force):
# simple (but inefficient) collision response
for a,entity_a in enumerate(self.entities):
for b,entity_b in enumerate(self.entities):
if(b <= a): continue
[f_a, f_b] = self.get_collision_force(entity_a, entity_b)
if(f_a is not None):
if(p_force[a] is None): p_force[a] = 0.0
p_force[a] = f_a + p_force[a]
if(f_b is not None):
if(p_force[b] is None): p_force[b] = 0.0
p_force[b] = f_b + p_force[b]
return p_force
# integrate physical state
def integrate_state(self, p_force):
for i,entity in enumerate(self.entities):
if not entity.movable: continue
entity.state.p_vel = entity.state.p_vel * (1 - self.damping)
if (p_force[i] is not None):
entity.state.p_vel += (p_force[i] / entity.mass) * self.dt
if entity.max_speed is not None:
speed = np.sqrt(np.square(entity.state.p_vel[0]) + np.square(entity.state.p_vel[1]))
if speed > entity.max_speed:
entity.state.p_vel = entity.state.p_vel / np.sqrt(np.square(entity.state.p_vel[0]) +
np.square(entity.state.p_vel[1])) * entity.max_speed
entity.state.p_pos += entity.state.p_vel * self.dt
def update_agent_state(self, agent):
# set communication state (directly for now)
if agent.silent:
agent.state.c = np.zeros(self.dim_c)
else:
noise = np.random.randn(*agent.action.c.shape) * agent.c_noise if agent.c_noise else 0.0
agent.state.c = agent.action.c + noise
# get collision forces for any contact between two entities
def get_collision_force(self, entity_a, entity_b):
if (not entity_a.collide) or (not entity_b.collide):
return [None, None] # not a collider
if (entity_a is entity_b):
return [None, None] # don't collide against itself
# compute actual distance between entities
delta_pos = entity_a.state.p_pos - entity_b.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
# minimum allowable distance
dist_min = entity_a.size + entity_b.size
# softmax penetration
k = self.contact_margin
penetration = np.logaddexp(0, -(dist - dist_min)/k)*k
force = self.contact_force * delta_pos / dist * penetration
force_a = +force if entity_a.movable else None
force_b = -force if entity_b.movable else None
return [force_a, force_b]
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/environment.py
================================================
import gym
from gym import spaces
from gym.envs.registration import EnvSpec
import numpy as np
from multiagent.multi_discrete import MultiDiscrete
# environment for all agents in the multiagent world
# currently code assumes that no agents will be created/destroyed at runtime!
class MultiAgentEnv(gym.Env):
metadata = {
'render.modes' : ['human', 'rgb_array']
}
def __init__(self, world, reset_callback=None, reward_callback=None,
observation_callback=None, info_callback=None,
done_callback=None, shared_viewer=True):
self.world = world
self.agents = self.world.policy_agents
# set required vectorized gym env property
self.n = len(world.policy_agents)
# scenario callbacks
self.reset_callback = reset_callback
self.reward_callback = reward_callback
self.observation_callback = observation_callback
self.info_callback = info_callback
self.done_callback = done_callback
# environment parameters
self.discrete_action_space = True
# if true, action is a number 0...N, otherwise action is a one-hot N-dimensional vector
self.discrete_action_input = False
# if true, even the action is continuous, action will be performed discretely
self.force_discrete_action = world.discrete_action if hasattr(world, 'discrete_action') else False
# if true, every agent has the same reward
self.shared_reward = world.collaborative if hasattr(world, 'collaborative') else False
self.time = 0
# configure spaces
self.action_space = []
self.observation_space = []
for agent in self.agents:
total_action_space = []
# physical action space
if self.discrete_action_space:
u_action_space = spaces.Discrete(world.dim_p * 2 + 1)
else:
u_action_space = spaces.Box(low=-agent.u_range, high=+agent.u_range, shape=(world.dim_p,), dtype=np.float32)
if agent.movable:
total_action_space.append(u_action_space)
# communication action space
if self.discrete_action_space:
c_action_space = spaces.Discrete(world.dim_c)
else:
c_action_space = spaces.Box(low=0.0, high=1.0, shape=(world.dim_c,), dtype=np.float32)
if not agent.silent:
total_action_space.append(c_action_space)
# total action space
if len(total_action_space) > 1:
# all action spaces are discrete, so simplify to MultiDiscrete action space
if all([isinstance(act_space, spaces.Discrete) for act_space in total_action_space]):
act_space = MultiDiscrete([[0, act_space.n - 1] for act_space in total_action_space])
else:
act_space = spaces.Tuple(total_action_space)
self.action_space.append(act_space)
else:
self.action_space.append(total_action_space[0])
# observation space
obs_dim = len(observation_callback(agent, self.world))
self.observation_space.append(spaces.Box(low=-np.inf, high=+np.inf, shape=(obs_dim,), dtype=np.float32))
agent.action.c = np.zeros(self.world.dim_c)
# rendering
self.shared_viewer = shared_viewer
if self.shared_viewer:
self.viewers = [None]
else:
self.viewers = [None] * self.n
self._reset_render()
def step(self, action_n):
obs_n = []
reward_n = []
done_n = []
info_n = {'n': []}
self.agents = self.world.policy_agents
# set action for each agent
for i, agent in enumerate(self.agents):
self._set_action(action_n[i], agent, self.action_space[i])
# advance world state
self.world.step()
# record observation for each agent
for agent in self.agents:
obs_n.append(self._get_obs(agent))
reward_n.append(self._get_reward(agent))
done_n.append(self._get_done(agent))
info_n['n'].append(self._get_info(agent))
# all agents get total reward in cooperative case
reward = np.sum(reward_n)
if self.shared_reward:
reward_n = [reward] * self.n
return obs_n, reward_n, done_n, info_n
def reset(self):
# reset world
self.reset_callback(self.world)
# reset renderer
self._reset_render()
# record observations for each agent
obs_n = []
self.agents = self.world.policy_agents
for agent in self.agents:
obs_n.append(self._get_obs(agent))
return obs_n
# get info used for benchmarking
def _get_info(self, agent):
if self.info_callback is None:
return {}
return self.info_callback(agent, self.world)
# get observation for a particular agent
def _get_obs(self, agent):
if self.observation_callback is None:
return np.zeros(0)
return self.observation_callback(agent, self.world)
# get dones for a particular agent
# unused right now -- agents are allowed to go beyond the viewing screen
def _get_done(self, agent):
if self.done_callback is None:
return False
return self.done_callback(agent, self.world)
# get reward for a particular agent
def _get_reward(self, agent):
if self.reward_callback is None:
return 0.0
return self.reward_callback(agent, self.world)
# set env action for a particular agent
def _set_action(self, action, agent, action_space, time=None):
agent.action.u = np.zeros(self.world.dim_p)
agent.action.c = np.zeros(self.world.dim_c)
# process action
if isinstance(action_space, MultiDiscrete):
act = []
size = action_space.high - action_space.low + 1
index = 0
for s in size:
act.append(action[index:(index+s)])
index += s
action = act
else:
action = [action]
if agent.movable:
# physical action
if self.discrete_action_input:
agent.action.u = np.zeros(self.world.dim_p)
# process discrete action
if action[0] == 1: agent.action.u[0] = -1.0
if action[0] == 2: agent.action.u[0] = +1.0
if action[0] == 3: agent.action.u[1] = -1.0
if action[0] == 4: agent.action.u[1] = +1.0
else:
if self.force_discrete_action:
d = np.argmax(action[0])
action[0][:] = 0.0
action[0][d] = 1.0
if self.discrete_action_space:
agent.action.u[0] += action[0][1] - action[0][2]
agent.action.u[1] += action[0][3] - action[0][4]
else:
agent.action.u = action[0]
sensitivity = 5.0
if agent.accel is not None:
sensitivity = agent.accel
agent.action.u *= sensitivity
action = action[1:]
if not agent.silent:
# communication action
if self.discrete_action_input:
agent.action.c = np.zeros(self.world.dim_c)
agent.action.c[action[0]] = 1.0
else:
agent.action.c = action[0]
action = action[1:]
# make sure we used all elements of action
assert len(action) == 0
# reset rendering assets
def _reset_render(self):
self.render_geoms = None
self.render_geoms_xform = None
# render environment
def render(self, mode='human'):
if mode == 'human':
alphabet = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
message = ''
for agent in self.world.agents:
comm = []
for other in self.world.agents:
if other is agent: continue
if np.all(other.state.c == 0):
word = '_'
else:
word = alphabet[np.argmax(other.state.c)]
message += (other.name + ' to ' + agent.name + ': ' + word + ' ')
print(message)
for i in range(len(self.viewers)):
# create viewers (if necessary)
if self.viewers[i] is None:
# import rendering only if we need it (and don't import for headless machines)
#from gym.envs.classic_control import rendering
from multiagent import rendering
self.viewers[i] = rendering.Viewer(700,700)
# create rendering geometry
if self.render_geoms is None:
# import rendering only if we need it (and don't import for headless machines)
#from gym.envs.classic_control import rendering
from multiagent import rendering
self.render_geoms = []
self.render_geoms_xform = []
for entity in self.world.entities:
geom = rendering.make_circle(entity.size)
xform = rendering.Transform()
if 'agent' in entity.name:
geom.set_color(*entity.color, alpha=0.5)
else:
geom.set_color(*entity.color)
geom.add_attr(xform)
self.render_geoms.append(geom)
self.render_geoms_xform.append(xform)
# add geoms to viewer
for viewer in self.viewers:
viewer.geoms = []
for geom in self.render_geoms:
viewer.add_geom(geom)
results = []
for i in range(len(self.viewers)):
from multiagent import rendering
# update bounds to center around agent
cam_range = 1
if self.shared_viewer:
pos = np.zeros(self.world.dim_p)
else:
pos = self.agents[i].state.p_pos
self.viewers[i].set_bounds(pos[0]-cam_range,pos[0]+cam_range,pos[1]-cam_range,pos[1]+cam_range)
# update geometry positions
for e, entity in enumerate(self.world.entities):
self.render_geoms_xform[e].set_translation(*entity.state.p_pos)
# render to display or array
results.append(self.viewers[i].render(return_rgb_array = mode=='rgb_array'))
return results
# create receptor field locations in local coordinate frame
def _make_receptor_locations(self, agent):
receptor_type = 'polar'
range_min = 0.05 * 2.0
range_max = 1.00
dx = []
# circular receptive field
if receptor_type == 'polar':
for angle in np.linspace(-np.pi, +np.pi, 8, endpoint=False):
for distance in np.linspace(range_min, range_max, 3):
dx.append(distance * np.array([np.cos(angle), np.sin(angle)]))
# add origin
dx.append(np.array([0.0, 0.0]))
# grid receptive field
if receptor_type == 'grid':
for x in np.linspace(-range_max, +range_max, 5):
for y in np.linspace(-range_max, +range_max, 5):
dx.append(np.array([x,y]))
return dx
# vectorized wrapper for a batch of multi-agent environments
# assumes all environments have the same observation and action space
class BatchMultiAgentEnv(gym.Env):
metadata = {
'runtime.vectorized': True,
'render.modes' : ['human', 'rgb_array']
}
def __init__(self, env_batch):
self.env_batch = env_batch
@property
def n(self):
return np.sum([env.n for env in self.env_batch])
@property
def action_space(self):
return self.env_batch[0].action_space
@property
def observation_space(self):
return self.env_batch[0].observation_space
def step(self, action_n, time):
obs_n = []
reward_n = []
done_n = []
info_n = {'n': []}
i = 0
for env in self.env_batch:
obs, reward, done, _ = env.step(action_n[i:(i+env.n)], time)
i += env.n
obs_n += obs
# reward = [r / len(self.env_batch) for r in reward]
reward_n += reward
done_n += done
return obs_n, reward_n, done_n, info_n
def reset(self):
obs_n = []
for env in self.env_batch:
obs_n += env.reset()
return obs_n
# render environment
def render(self, mode='human', close=True):
results_n = []
for env in self.env_batch:
results_n += env.render(mode, close)
return results_n
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/multi_discrete.py
================================================
# An old version of OpenAI Gym's multi_discrete.py. (Was getting affected by Gym updates)
# (https://github.com/openai/gym/blob/1fb81d4e3fb780ccf77fec731287ba07da35eb84/gym/spaces/multi_discrete.py)
import numpy as np
import gym
# from gym.spaces import prng
class MultiDiscrete(gym.Space):
"""
- The multi-discrete action space consists of a series of discrete action spaces with different parameters
- It can be adapted to both a Discrete action space or a continuous (Box) action space
- It is useful to represent game controllers or keyboards where each key can be represented as a discrete action space
- It is parametrized by passing an array of arrays containing [min, max] for each discrete action space
where the discrete action space can take any integers from `min` to `max` (both inclusive)
Note: A value of 0 always need to represent the NOOP action.
e.g. Nintendo Game Controller
- Can be conceptualized as 3 discrete action spaces:
1) Arrow Keys: Discrete 5 - NOOP[0], UP[1], RIGHT[2], DOWN[3], LEFT[4] - params: min: 0, max: 4
2) Button A: Discrete 2 - NOOP[0], Pressed[1] - params: min: 0, max: 1
3) Button B: Discrete 2 - NOOP[0], Pressed[1] - params: min: 0, max: 1
- Can be initialized as
MultiDiscrete([ [0,4], [0,1], [0,1] ])
"""
def __init__(self, array_of_param_array):
self.low = np.array([x[0] for x in array_of_param_array])
self.high = np.array([x[1] for x in array_of_param_array])
self.num_discrete_space = self.low.shape[0]
def sample(self):
""" Returns a array with one sample from each discrete action space """
# For each row: round(random .* (max - min) + min, 0)
# random_array = prng.np_random.rand(self.num_discrete_space)
random_array = np.random.RandomState().rand(self.num_discrete_space)
return [int(x) for x in np.floor(np.multiply((self.high - self.low + 1.), random_array) + self.low)]
def contains(self, x):
return len(x) == self.num_discrete_space and (np.array(x) >= self.low).all() and (np.array(x) <= self.high).all()
@property
def shape(self):
return self.num_discrete_space
def __repr__(self):
return "MultiDiscrete" + str(self.num_discrete_space)
def __eq__(self, other):
return np.array_equal(self.low, other.low) and np.array_equal(self.high, other.high)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/policy.py
================================================
import numpy as np
from pyglet.window import key
# individual agent policy
class Policy(object):
def __init__(self):
pass
def action(self, obs):
raise NotImplementedError()
# interactive policy based on keyboard input
# hard-coded to deal only with movement, not communication
class InteractivePolicy(Policy):
def __init__(self, env, agent_index):
super(InteractivePolicy, self).__init__()
self.env = env
# hard-coded keyboard events
self.move = [False for i in range(4)]
self.comm = [False for i in range(env.world.dim_c)]
# register keyboard events with this environment's window
# env.viewers[agent_index].window.on_key_press = self.key_press
# env.viewers[agent_index].window.on_key_release = self.key_release
def action(self, obs):
# ignore observation and just act based on keyboard events
if self.env.discrete_action_input:
u = 0
if self.move[0]: u = 1
if self.move[1]: u = 2
if self.move[2]: u = 4
if self.move[3]: u = 3
else:
u = np.zeros(5) # 5-d because of no-move action
if self.move[0]: u[1] += 1.0
if self.move[1]: u[2] += 1.0
if self.move[3]: u[3] += 1.0
if self.move[2]: u[4] += 1.0
if True not in self.move:
u[0] += 1.0
return np.concatenate([u, np.zeros(self.env.world.dim_c)])
# keyboard event callbacks
def key_press(self, k, mod):
if k==key.LEFT: self.move[0] = True
if k==key.RIGHT: self.move[1] = True
if k==key.UP: self.move[2] = True
if k==key.DOWN: self.move[3] = True
def key_release(self, k, mod):
if k==key.LEFT: self.move[0] = False
if k==key.RIGHT: self.move[1] = False
if k==key.UP: self.move[2] = False
if k==key.DOWN: self.move[3] = False
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/rendering.py
================================================
"""
2D rendering framework
"""
from __future__ import division
import os
import six
import sys
if "Apple" in sys.version:
if 'DYLD_FALLBACK_LIBRARY_PATH' in os.environ:
os.environ['DYLD_FALLBACK_LIBRARY_PATH'] += ':/usr/lib'
# (JDS 2016/04/15): avoid bug on Anaconda 2.3.0 / Yosemite
# from gym.utils import reraise
from gym import error
import pyglet
from pyglet.gl import *
# try:
# import pyglet
# except ImportError as e:
# reraise(suffix="HINT: you can install pyglet directly via 'pip install pyglet'. But if you really just want to install all Gym dependencies and not have to think about it, 'pip install -e .[all]' or 'pip install gym[all]' will do it.")
# try:
# from pyglet.gl import *
# except ImportError as e:
# reraise(prefix="Error occured while running `from pyglet.gl import *`",suffix="HINT: make sure you have OpenGL install. On Ubuntu, you can run 'apt-get install python-opengl'. If you're running on a server, you may need a virtual frame buffer; something like this should work: 'xvfb-run -s \"-screen 0 1400x900x24\" python '")
import math
import numpy as np
RAD2DEG = 57.29577951308232
def get_display(spec):
"""Convert a display specification (such as :0) into an actual Display
object.
Pyglet only supports multiple Displays on Linux.
"""
if spec is None:
return None
elif isinstance(spec, six.string_types):
return pyglet.canvas.Display(spec)
else:
raise error.Error('Invalid display specification: {}. (Must be a string like :0 or None.)'.format(spec))
class Viewer(object):
def __init__(self, width, height, display=None):
display = get_display(display)
self.width = width
self.height = height
self.window = pyglet.window.Window(width=width, height=height, display=display)
self.window.on_close = self.window_closed_by_user
self.geoms = []
self.onetime_geoms = []
self.transform = Transform()
glEnable(GL_BLEND)
# glEnable(GL_MULTISAMPLE)
glEnable(GL_LINE_SMOOTH)
# glHint(GL_LINE_SMOOTH_HINT, GL_DONT_CARE)
glHint(GL_LINE_SMOOTH_HINT, GL_NICEST)
glLineWidth(2.0)
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA)
def close(self):
self.window.close()
def window_closed_by_user(self):
self.close()
def set_bounds(self, left, right, bottom, top):
assert right > left and top > bottom
scalex = self.width/(right-left)
scaley = self.height/(top-bottom)
self.transform = Transform(
translation=(-left*scalex, -bottom*scaley),
scale=(scalex, scaley))
def add_geom(self, geom):
self.geoms.append(geom)
def add_onetime(self, geom):
self.onetime_geoms.append(geom)
def render(self, return_rgb_array=False):
glClearColor(1,1,1,1)
self.window.clear()
self.window.switch_to()
self.window.dispatch_events()
self.transform.enable()
for geom in self.geoms:
geom.render()
for geom in self.onetime_geoms:
geom.render()
self.transform.disable()
arr = None
if return_rgb_array:
buffer = pyglet.image.get_buffer_manager().get_color_buffer()
image_data = buffer.get_image_data()
arr = np.fromstring(image_data._current_data, dtype=np.uint8, sep='')
# In https://github.com/openai/gym-http-api/issues/2, we
# discovered that someone using Xmonad on Arch was having
# a window of size 598 x 398, though a 600 x 400 window
# was requested. (Guess Xmonad was preserving a pixel for
# the boundary.) So we use the buffer height/width rather
# than the requested one.
arr = arr.reshape(buffer.height, buffer.width, 4)
arr = arr[::-1,:,0:3]
self.window.flip()
self.onetime_geoms = []
return arr
# Convenience
def draw_circle(self, radius=10, res=30, filled=True, **attrs):
geom = make_circle(radius=radius, res=res, filled=filled)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def draw_polygon(self, v, filled=True, **attrs):
geom = make_polygon(v=v, filled=filled)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def draw_polyline(self, v, **attrs):
geom = make_polyline(v=v)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def draw_line(self, start, end, **attrs):
geom = Line(start, end)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def get_array(self):
self.window.flip()
image_data = pyglet.image.get_buffer_manager().get_color_buffer().get_image_data()
self.window.flip()
arr = np.fromstring(image_data.data, dtype=np.uint8, sep='')
arr = arr.reshape(self.height, self.width, 4)
return arr[::-1,:,0:3]
def _add_attrs(geom, attrs):
if "color" in attrs:
geom.set_color(*attrs["color"])
if "linewidth" in attrs:
geom.set_linewidth(attrs["linewidth"])
class Geom(object):
def __init__(self):
self._color=Color((0, 0, 0, 1.0))
self.attrs = [self._color]
def render(self):
for attr in reversed(self.attrs):
attr.enable()
self.render1()
for attr in self.attrs:
attr.disable()
def render1(self):
raise NotImplementedError
def add_attr(self, attr):
self.attrs.append(attr)
def set_color(self, r, g, b, alpha=1):
self._color.vec4 = (r, g, b, alpha)
class Attr(object):
def enable(self):
raise NotImplementedError
def disable(self):
pass
class Transform(Attr):
def __init__(self, translation=(0.0, 0.0), rotation=0.0, scale=(1,1)):
self.set_translation(*translation)
self.set_rotation(rotation)
self.set_scale(*scale)
def enable(self):
glPushMatrix()
glTranslatef(self.translation[0], self.translation[1], 0) # translate to GL loc ppint
glRotatef(RAD2DEG * self.rotation, 0, 0, 1.0)
glScalef(self.scale[0], self.scale[1], 1)
def disable(self):
glPopMatrix()
def set_translation(self, newx, newy):
self.translation = (float(newx), float(newy))
def set_rotation(self, new):
self.rotation = float(new)
def set_scale(self, newx, newy):
self.scale = (float(newx), float(newy))
class Color(Attr):
def __init__(self, vec4):
self.vec4 = vec4
def enable(self):
glColor4f(*self.vec4)
class LineStyle(Attr):
def __init__(self, style):
self.style = style
def enable(self):
glEnable(GL_LINE_STIPPLE)
glLineStipple(1, self.style)
def disable(self):
glDisable(GL_LINE_STIPPLE)
class LineWidth(Attr):
def __init__(self, stroke):
self.stroke = stroke
def enable(self):
glLineWidth(self.stroke)
class Point(Geom):
def __init__(self):
Geom.__init__(self)
def render1(self):
glBegin(GL_POINTS) # draw point
glVertex3f(0.0, 0.0, 0.0)
glEnd()
class FilledPolygon(Geom):
def __init__(self, v):
Geom.__init__(self)
self.v = v
def render1(self):
if len(self.v) == 4 : glBegin(GL_QUADS)
elif len(self.v) > 4 : glBegin(GL_POLYGON)
else: glBegin(GL_TRIANGLES)
for p in self.v:
glVertex3f(p[0], p[1],0) # draw each vertex
glEnd()
color = (self._color.vec4[0] * 0.5, self._color.vec4[1] * 0.5, self._color.vec4[2] * 0.5, self._color.vec4[3] * 0.5)
glColor4f(*color)
glBegin(GL_LINE_LOOP)
for p in self.v:
glVertex3f(p[0], p[1],0) # draw each vertex
glEnd()
def make_circle(radius=10, res=30, filled=True):
points = []
for i in range(res):
ang = 2*math.pi*i / res
points.append((math.cos(ang)*radius, math.sin(ang)*radius))
if filled:
return FilledPolygon(points)
else:
return PolyLine(points, True)
def make_polygon(v, filled=True):
if filled: return FilledPolygon(v)
else: return PolyLine(v, True)
def make_polyline(v):
return PolyLine(v, False)
def make_capsule(length, width):
l, r, t, b = 0, length, width/2, -width/2
box = make_polygon([(l,b), (l,t), (r,t), (r,b)])
circ0 = make_circle(width/2)
circ1 = make_circle(width/2)
circ1.add_attr(Transform(translation=(length, 0)))
geom = Compound([box, circ0, circ1])
return geom
class Compound(Geom):
def __init__(self, gs):
Geom.__init__(self)
self.gs = gs
for g in self.gs:
g.attrs = [a for a in g.attrs if not isinstance(a, Color)]
def render1(self):
for g in self.gs:
g.render()
class PolyLine(Geom):
def __init__(self, v, close):
Geom.__init__(self)
self.v = v
self.close = close
self.linewidth = LineWidth(1)
self.add_attr(self.linewidth)
def render1(self):
glBegin(GL_LINE_LOOP if self.close else GL_LINE_STRIP)
for p in self.v:
glVertex3f(p[0], p[1],0) # draw each vertex
glEnd()
def set_linewidth(self, x):
self.linewidth.stroke = x
class Line(Geom):
def __init__(self, start=(0.0, 0.0), end=(0.0, 0.0)):
Geom.__init__(self)
self.start = start
self.end = end
self.linewidth = LineWidth(1)
self.add_attr(self.linewidth)
def render1(self):
glBegin(GL_LINES)
glVertex2f(*self.start)
glVertex2f(*self.end)
glEnd()
class Image(Geom):
def __init__(self, fname, width, height):
Geom.__init__(self)
self.width = width
self.height = height
img = pyglet.image.load(fname)
self.img = img
self.flip = False
def render1(self):
self.img.blit(-self.width/2, -self.height/2, width=self.width, height=self.height)
# ================================================================
class SimpleImageViewer(object):
def __init__(self, display=None):
self.window = None
self.isopen = False
self.display = display
def imshow(self, arr):
if self.window is None:
height, width, channels = arr.shape
self.window = pyglet.window.Window(width=width, height=height, display=self.display)
self.width = width
self.height = height
self.isopen = True
assert arr.shape == (self.height, self.width, 3), "You passed in an image with the wrong number shape"
image = pyglet.image.ImageData(self.width, self.height, 'RGB', arr.tobytes(), pitch=self.width * -3)
self.window.clear()
self.window.switch_to()
self.window.dispatch_events()
image.blit(0,0)
self.window.flip()
def close(self):
if self.isopen:
self.window.close()
self.isopen = False
def __del__(self):
self.close()
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenario.py
================================================
import numpy as np
# defines scenario upon which the world is built
class BaseScenario(object):
# create elements of the world
def make_world(self):
raise NotImplementedError()
# create initial conditions of the world
def reset_world(self, world):
raise NotImplementedError()
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/__init__.py
================================================
import imp
import os.path as osp
def load(name):
pathname = osp.join(osp.dirname(__file__), name)
return imp.load_source('', pathname)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/hetero_spread.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, num_good_agents=2, num_adversaries=0):
world = World()
# set any world properties first
world.dim_c = 2
world.max_steps = 25
num_agents = num_good_agents
self.n_agent_a = num_agents // 2 # 2
self.n_agent_b = num_agents // 2 # 2
num_landmarks = num_good_agents
world.collaborative = True
self.agent_size = 0.10
self.n_others = 3
self.n_group = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
agent.id = i
if i < self.n_agent_a:
agent.size = self.agent_size
agent.accel = 3.0
agent.max_speed = 1.0
else:
agent.size = self.agent_size / 2
agent.accel = 4.0
agent.max_speed = 1.3
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
world.num_steps = 0
self.end_steps = world.max_steps
# random properties for agents
for i, agent in enumerate(world.agents):
if i < self.n_agent_a:
agent.color = np.array([0.35, 0.35, 0.85])
else:
agent.color = np.array([0.35, 0.85, 0.35])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
rew = 0
collisions = 0
occupied_landmarks = 0
min_dists = 0
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
min_dists += min(dists)
rew -= min(dists)
if min(dists) < 0.1:
occupied_landmarks += 1
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
collisions += 1
return (rew, collisions, min_dists, occupied_landmarks)
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark, penalized for collisions
rew = 0
shaped_reward = False
if shaped_reward: # distance-based reward
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
rew -= min(dists)
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
return rew
else:
win_agents = []
for land in world.landmarks:
for a in world.agents:
if self.is_collision(a, land):
win_agents.append(a)
break
rew += 2 * len(set(win_agents))
def bound(x):
if x > 1.0:
return min(np.exp(2 * x - 2), 10)
else:
return 0.0
bound_rew = 0.0
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
bound_rew -= bound(x)
rew += bound_rew
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
other_vel = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent:
other_vel.append([0, 0])
continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + comm +
other_vel + entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# add agents
world.agents = [Agent() for i in range(1)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.silent = True
# add landmarks
world.landmarks = [Landmark() for i in range(1)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25,0.25,0.25])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.75,0.75,0.75])
world.landmarks[0].color = np.array([0.75,0.25,0.25])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
dist2 = np.sum(np.square(agent.state.p_pos - world.landmarks[0].state.p_pos))
return -dist2
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
return np.concatenate([agent.state.p_vel] + entity_pos)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_adversary.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, num_good_agents=2, num_adversaries=1):
world = World()
# set any world properties first
world.dim_c = 2
num_agents = num_adversaries + num_good_agents
num_good_agents = num_good_agents
num_adversaries = 1
world.num_agents = num_agents
num_landmarks = num_agents - 1
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.silent = True
agent.adversary = True if i < num_adversaries else False
agent.size = 0.15
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.08
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
world.agents[0].color = np.array([0.85, 0.35, 0.35])
for i in range(1, world.num_agents):
world.agents[i].color = np.array([0.35, 0.35, 0.85])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.15, 0.15, 0.15])
# set goal landmark
goal = np.random.choice(world.landmarks)
goal.color = np.array([0.15, 0.65, 0.15])
for agent in world.agents:
agent.goal_a = goal
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
if agent.adversary:
return np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos))
else:
dists = []
for l in world.landmarks:
dists.append(np.sum(np.square(agent.state.p_pos - l.state.p_pos)))
dists.append(np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos)))
return tuple(dists)
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# Rewarded based on how close any good agent is to the goal landmark, and how far the adversary is from it
shaped_reward = False
shaped_adv_reward = False
# Calculate negative reward for adversary
adversary_agents = self.adversaries(world)
if shaped_adv_reward: # distance-based adversary reward
adv_rew = sum([np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in adversary_agents])
else: # proximity-based adversary reward (binary)
adv_rew = 0
for a in adversary_agents:
if np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) < 2 * a.goal_a.size:
adv_rew -= 5
# Calculate positive reward for agents
good_agents = self.good_agents(world)
if shaped_reward: # distance-based agent reward
pos_rew = -min(
[np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in good_agents])
else: # proximity-based agent reward (binary)
pos_rew = 0
if min([np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in good_agents]) \
< 2 * agent.goal_a.size:
pos_rew += 5
pos_rew -= min(
[np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in good_agents])
return pos_rew + adv_rew
def adversary_reward(self, agent, world):
# Rewarded based on proximity to the goal landmark
shaped_reward = False
if shaped_reward: # distance-based reward
return -np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos))
else: # proximity-based reward (binary)
adv_rew = 0
if np.sqrt(np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos))) < 2 * agent.goal_a.size:
adv_rew += 5
return adv_rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
other_vel = []
for entity in world.landmarks:
entity_color.append(entity.color)
# communication of all other agents
other_pos = []
for other in world.agents:
if other is agent and not other.adversary:
other_vel.append([0, 0])
continue
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append([0, 0])
if not agent.adversary:
return np.concatenate(
[agent.goal_a.state.p_pos - agent.state.p_pos] +
other_vel + entity_pos + other_pos)
else:
return np.concatenate([np.zeros(2)] +
other_vel + entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_crypto.py
================================================
"""
Scenario:
1 speaker, 2 listeners (one of which is an adversary). Good agents rewarded for proximity to goal, and distance from
adversary to goal. Adversary is rewarded for its distance to the goal.
"""
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
import random
class CryptoAgent(Agent):
def __init__(self):
super(CryptoAgent, self).__init__()
self.key = None
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
num_agents = 3
num_adversaries = 1
num_landmarks = 2
world.dim_c = 4
# add agents
world.agents = [CryptoAgent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.adversary = True if i < num_adversaries else False
agent.speaker = True if i == 2 else False
agent.movable = False
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25, 0.25, 0.25])
if agent.adversary:
agent.color = np.array([0.75, 0.25, 0.25])
agent.key = None
# random properties for landmarks
color_list = [np.zeros(world.dim_c) for i in world.landmarks]
for i, color in enumerate(color_list):
color[i] += 1
for color, landmark in zip(color_list, world.landmarks):
landmark.color = color
# set goal landmark
goal = np.random.choice(world.landmarks)
world.agents[1].color = goal.color
world.agents[2].key = np.random.choice(world.landmarks).color
for agent in world.agents:
agent.goal_a = goal
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
return (agent.state.c, agent.goal_a.color)
# return all agents that are not adversaries
def good_listeners(self, world):
return [agent for agent in world.agents if not agent.adversary and not agent.speaker]
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# Agents rewarded if Bob can reconstruct message, but adversary (Eve) cannot
good_listeners = self.good_listeners(world)
adversaries = self.adversaries(world)
good_rew = 0
adv_rew = 0
for a in good_listeners:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
good_rew -= np.sum(np.square(a.state.c - agent.goal_a.color))
for a in adversaries:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
adv_l1 = np.sum(np.square(a.state.c - agent.goal_a.color))
adv_rew += adv_l1
return adv_rew + good_rew
def adversary_reward(self, agent, world):
# Adversary (Eve) is rewarded if it can reconstruct original goal
rew = 0
if not (agent.state.c == np.zeros(world.dim_c)).all():
rew -= np.sum(np.square(agent.state.c - agent.goal_a.color))
return rew
def observation(self, agent, world):
# goal color
goal_color = np.zeros(world.dim_color)
if agent.goal_a is not None:
goal_color = agent.goal_a.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent or (other.state.c is None) or not other.speaker: continue
comm.append(other.state.c)
confer = np.array([0])
if world.agents[2].key is None:
confer = np.array([1])
key = np.zeros(world.dim_c)
goal_color = np.zeros(world.dim_c)
else:
key = world.agents[2].key
prnt = False
# speaker
if agent.speaker:
if prnt:
print('speaker')
print(agent.state.c)
print(np.concatenate([goal_color] + [key] + [confer] + [np.random.randn(1)]))
return np.concatenate([goal_color] + [key])
# listener
if not agent.speaker and not agent.adversary:
if prnt:
print('listener')
print(agent.state.c)
print(np.concatenate([key] + comm + [confer]))
return np.concatenate([key] + comm)
if not agent.speaker and agent.adversary:
if prnt:
print('adversary')
print(agent.state.c)
print(np.concatenate(comm + [confer]))
return np.concatenate(comm)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_push.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, num_good_agents=2, num_adversaries=2):
world = World()
# set any world properties first
world.dim_c = 2
num_agents = num_good_agents + num_adversaries
num_adversaries = num_adversaries
num_landmarks = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
if i < num_adversaries:
agent.adversary = True
else:
agent.adversary = False
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.1, 0.1, 0.1])
landmark.color[i + 1] += 0.8
landmark.index = i
# set goal landmark
goal = np.random.choice(world.landmarks)
for i, agent in enumerate(world.agents):
agent.goal_a = goal
agent.color = np.array([0.25, 0.25, 0.25])
if agent.adversary:
agent.color = np.array([0.75, 0.25, 0.25])
else:
j = goal.index
agent.color[j + 1] += 0.5
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return dist < dist_min
def agent_reward(self, agent, world):
'''
Rewrite
'''
shaped_reward = False
if shaped_reward: # distance-based reward
# the distance to the goal
return -np.sqrt(np.sum(np.square(
agent.state.p_pos - agent.goal_a.state.p_pos)))
else:
pos_rew, adv_rew = 0.0, 0.0
for a in self.adversaries(world):
if self.is_collision(a, agent):
adv_rew -= 5.0
if self.is_collision(agent, agent.goal_a):
pos_rew += 5.0
rew = pos_rew + adv_rew
def bound(x):
if x > 1.0:
return min(np.exp(2 * x - 2), 10)
else:
return 0.0
bound_rew = 0.0
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
bound_rew -= bound(x)
rew += bound_rew
return rew
def adversary_reward(self, agent, world):
'''
Rewrite
'''
shaped_reward = False
if shaped_reward: # distance-based reward
# keep the nearest good agents away from the goal
agent_dist = [np.sqrt(np.sum(np.square(a.state.p_pos -
a.goal_a.state.p_pos))) for a in world.agents if not a.adversary]
pos_rew = min(agent_dist)
#nearest_agent = world.good_agents[np.argmin(agent_dist)]
#neg_rew = np.sqrt(np.sum(np.square(nearest_agent.state.p_pos - agent.state.p_pos)))
neg_rew = np.sqrt(np.sum(np.square(agent.goal_a.state.p_pos - agent.state.p_pos)))
#neg_rew = sum([np.sqrt(np.sum(np.square(a.state.p_pos - agent.state.p_pos))) for a in world.good_agents])
return pos_rew - neg_rew
else:
rew = 0.0
for a in self.good_agents(world):
if self.is_collision(a, a.goal_a):
rew -= 5.0
# if self.is_collision(a, agent):
# rew += 5.0
if self.is_collision(agent, agent.goal_a):
rew += 5.0
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
other_vel = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent and not other.adversary:
other_vel.append([0, 0])
continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append([0, 0])
if not agent.adversary:
return np.concatenate([agent.state.p_vel] +
[agent.goal_a.state.p_pos - agent.state.p_pos] +
[agent.color] + entity_color +
other_vel + entity_pos + other_pos)
else:
#other_pos = list(reversed(other_pos)) if random.uniform(0,1) > 0.5 else other_pos # randomize position of other agents in adversary network
return np.concatenate([agent.state.p_vel] +
other_vel + entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_reference.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, num_good_agents=2, num_adversaries=0):
world = World()
# set any world properties first
world.dim_c = 10
world.collaborative = True # whether agents share rewards
# add agents
world.agents = [Agent() for i in range(num_good_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
# add landmarks
world.landmarks = [Landmark() for i in range(num_good_agents+1)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# assign goals to agents
for agent in world.agents:
agent.goal_a = None
agent.goal_b = None
# want other agent to go to the goal landmark
world.agents[0].goal_a = world.agents[1]
world.agents[0].goal_b = np.random.choice(world.landmarks)
world.agents[1].goal_a = world.agents[0]
world.agents[1].goal_b = np.random.choice(world.landmarks)
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25,0.25,0.25])
# random properties for landmarks
world.landmarks[0].color = np.array([0.75,0.25,0.25])
world.landmarks[1].color = np.array([0.25,0.75,0.25])
world.landmarks[2].color = np.array([0.25,0.25,0.75])
# special colors for goals
world.agents[0].goal_a.color = world.agents[0].goal_b.color
world.agents[1].goal_a.color = world.agents[1].goal_b.color
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
if agent.goal_a is None or agent.goal_b is None:
return 0.0
dist2 = np.sum(np.square(agent.goal_a.state.p_pos - agent.goal_b.state.p_pos))
return -dist2
def observation(self, agent, world):
# goal color
goal_color = [np.zeros(world.dim_color), np.zeros(world.dim_color)]
if agent.goal_b is not None:
goal_color[1] = agent.goal_b.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks:
entity_color.append(entity.color)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
return np.concatenate([agent.state.p_vel] + entity_pos + [goal_color[1]] + comm)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_speaker_listener.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
world.dim_c = 3
num_landmarks = 3
world.collaborative = True
# add agents
world.agents = [Agent() for i in range(2)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.size = 0.075
# speaker
world.agents[0].movable = False
# listener
world.agents[1].silent = True
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.04
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# assign goals to agents
for agent in world.agents:
agent.goal_a = None
agent.goal_b = None
# want listener to go to the goal landmark
world.agents[0].goal_a = world.agents[1]
world.agents[0].goal_b = np.random.choice(world.landmarks)
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25,0.25,0.25])
# random properties for landmarks
world.landmarks[0].color = np.array([0.65,0.15,0.15])
world.landmarks[1].color = np.array([0.15,0.65,0.15])
world.landmarks[2].color = np.array([0.15,0.15,0.65])
# special colors for goals
world.agents[0].goal_a.color = world.agents[0].goal_b.color + np.array([0.45, 0.45, 0.45])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
return self.reward(agent, reward)
def reward(self, agent, world):
# squared distance from listener to landmark
a = world.agents[0]
dist2 = np.sum(np.square(a.goal_a.state.p_pos - a.goal_b.state.p_pos))
return -dist2
def observation(self, agent, world):
# goal color
goal_color = np.zeros(world.dim_color)
if agent.goal_b is not None:
goal_color = agent.goal_b.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent or (other.state.c is None): continue
comm.append(other.state.c)
# speaker
if not agent.movable:
return np.concatenate([goal_color])
# listener
if agent.silent:
return np.concatenate([agent.state.p_vel] + entity_pos + comm)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_spread.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, num_good_agents=2, num_adversaries=2):
world = World()
# set any world properties first
world.dim_c = 2
num_agents = num_good_agents
num_landmarks = num_good_agents
world.collaborative = True
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
agent.size = 0.15
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.35, 0.35, 0.85])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
rew = 0
collisions = 0
occupied_landmarks = 0
min_dists = 0
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
min_dists += min(dists)
rew -= min(dists)
if min(dists) < 0.1:
occupied_landmarks += 1
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
collisions += 1
return (rew, collisions, min_dists, occupied_landmarks)
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark, penalized for collisions
rew = 0
shaped_reward = False
if shaped_reward: # distance-based reward
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
rew -= min(dists)
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
return rew
else:
win_agents = []
for land in world.landmarks:
for a in world.agents:
if self.is_collision(a, land):
win_agents.append(a)
break
rew += 2 * len(set(win_agents))
def bound(x):
if x > 1.0:
return min(np.exp(2 * x - 2), 10)
else:
return 0.0
bound_rew = 0.0
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
bound_rew -= bound(x)
rew += bound_rew
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
other_vel = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent:
other_vel.append([0, 0])
continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + comm +
other_vel + entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_tag.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, num_good_agents=1, num_adversaries=3):
world = World()
# set any world properties first
world.dim_c = 2
num_good_agents = num_good_agents
num_adversaries = num_adversaries
num_agents = num_adversaries + num_good_agents
num_landmarks = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
agent.adversary = True if i < num_adversaries else False
agent.size = 0.075 if agent.adversary else 0.05
agent.accel = 3.0 if agent.adversary else 4.0
#agent.accel = 20.0 if agent.adversary else 25.0
agent.max_speed = 1.0 if agent.adversary else 1.3
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = True
landmark.movable = False
landmark.size = 0.2
landmark.boundary = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.35, 0.85, 0.35]) if not agent.adversary else np.array([0.85, 0.35, 0.35])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
if not landmark.boundary:
landmark.state.p_pos = np.random.uniform(-0.9, +0.9, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
if agent.adversary:
collisions = 0
for a in self.good_agents(world):
if self.is_collision(a, agent):
collisions += 1
return collisions
else:
return 0
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
main_reward = self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
return main_reward
def agent_reward(self, agent, world):
# Agents are negatively rewarded if caught by adversaries
rew = 0
shape = False
adversaries = self.adversaries(world)
if shape: # reward can optionally be shaped (increased reward for increased distance from adversary)
for adv in adversaries:
rew += 0.1 * np.sqrt(np.sum(np.square(agent.state.p_pos - adv.state.p_pos)))
if agent.collide:
for a in adversaries:
if self.is_collision(a, agent):
rew -= 10
# agents are penalized for exiting the screen, so that they can be caught by the adversaries
def bound(x):
if x < 0.9:
return 0
if x < 1.0:
return (x - 0.9) * 10
return min(np.exp(2 * x - 2), 10)
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
rew -= bound(x)
return rew
def adversary_reward(self, agent, world):
# Adversaries are rewarded for collisions with agents
rew = 0
shape = False
agents = self.good_agents(world)
adversaries = self.adversaries(world)
if shape: # reward can optionally be shaped (decreased reward for increased distance from agents)
for adv in adversaries:
rew -= 0.1 * min([np.sqrt(np.sum(np.square(a.state.p_pos - adv.state.p_pos))) for a in agents])
if agent.collide:
for ag in agents:
for adv in adversaries:
if self.is_collision(ag, adv):
rew += 10
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent and not other.adversary:
other_vel.append(other.state.p_vel)
continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + other_vel +
entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/FOToM/multiagent/scenarios/simple_world_comm.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, num_good_agents=2, num_adversaries=4):
world = World()
# set any world properties first
world.dim_c = 4
#world.damping = 1
num_good_agents = num_good_agents
num_adversaries = num_adversaries
num_agents = num_adversaries + num_good_agents
num_landmarks = 1
num_food = 2
num_forests = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.leader = True if i == 0 else False
agent.silent = True if i > 0 else False
agent.adversary = True if i < num_adversaries else False
agent.size = 0.075 if agent.adversary else 0.045
agent.accel = 3.0 if agent.adversary else 4.0
#agent.accel = 20.0 if agent.adversary else 25.0
agent.max_speed = 1.0 if agent.adversary else 1.3
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = True
landmark.movable = False
landmark.size = 0.2
landmark.boundary = False
world.food = [Landmark() for i in range(num_food)]
for i, landmark in enumerate(world.food):
landmark.name = 'food %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.03
landmark.boundary = False
world.forests = [Landmark() for i in range(num_forests)]
for i, landmark in enumerate(world.forests):
landmark.name = 'forest %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.3
landmark.boundary = False
world.landmarks += world.food
world.landmarks += world.forests
#world.landmarks += self.set_boundaries(world) # world boundaries now penalized with negative reward
# make initial conditions
self.reset_world(world)
return world
def set_boundaries(self, world):
boundary_list = []
landmark_size = 1
edge = 1 + landmark_size
num_landmarks = int(edge * 2 / landmark_size)
for x_pos in [-edge, edge]:
for i in range(num_landmarks):
l = Landmark()
l.state.p_pos = np.array([x_pos, -1 + i * landmark_size])
boundary_list.append(l)
for y_pos in [-edge, edge]:
for i in range(num_landmarks):
l = Landmark()
l.state.p_pos = np.array([-1 + i * landmark_size, y_pos])
boundary_list.append(l)
for i, l in enumerate(boundary_list):
l.name = 'boundary %d' % i
l.collide = True
l.movable = False
l.boundary = True
l.color = np.array([0.75, 0.75, 0.75])
l.size = landmark_size
l.state.p_vel = np.zeros(world.dim_p)
return boundary_list
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.45, 0.95, 0.45]) if not agent.adversary else np.array([0.95, 0.45, 0.45])
agent.color -= np.array([0.3, 0.3, 0.3]) if agent.leader else np.array([0, 0, 0])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
for i, landmark in enumerate(world.food):
landmark.color = np.array([0.15, 0.15, 0.65])
for i, landmark in enumerate(world.forests):
landmark.color = np.array([0.6, 0.9, 0.6])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-0.9, +0.9, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
for i, landmark in enumerate(world.food):
landmark.state.p_pos = np.random.uniform(-0.9, +0.9, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
for i, landmark in enumerate(world.forests):
landmark.state.p_pos = np.random.uniform(-0.9, +0.9, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
if agent.adversary:
collisions = 0
for a in self.good_agents(world):
if self.is_collision(a, agent):
collisions += 1
return collisions
else:
return 0
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
#boundary_reward = -10 if self.outside_boundary(agent) else 0
main_reward = self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
return main_reward
def outside_boundary(self, agent):
if agent.state.p_pos[0] > 1 or agent.state.p_pos[0] < -1 or agent.state.p_pos[1] > 1 or agent.state.p_pos[1] < -1:
return True
else:
return False
def agent_reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
rew = 0
shape = False
adversaries = self.adversaries(world)
if shape:
for adv in adversaries:
rew += 0.1 * np.sqrt(np.sum(np.square(agent.state.p_pos - adv.state.p_pos)))
if agent.collide:
for a in adversaries:
if self.is_collision(a, agent):
rew -= 5
def bound(x):
if x < 0.9:
return 0
if x < 1.0:
return (x - 0.9) * 10
return min(np.exp(2 * x - 2), 10) # 1 + (x - 1) * (x - 1)
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
rew -= 2 * bound(x)
for food in world.food:
if self.is_collision(agent, food):
rew += 2
rew += 0.05 * min([np.sqrt(np.sum(np.square(food.state.p_pos - agent.state.p_pos))) for food in world.food])
return rew
def adversary_reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
rew = 0
shape = True
agents = self.good_agents(world)
adversaries = self.adversaries(world)
if shape:
rew -= 0.1 * min([np.sqrt(np.sum(np.square(a.state.p_pos - agent.state.p_pos))) for a in agents])
if agent.collide:
for ag in agents:
for adv in adversaries:
if self.is_collision(ag, adv):
rew += 5
return rew
def observation2(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
food_pos = []
for entity in world.food:
if not entity.boundary:
food_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel)
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
in_forest = [np.array([-1]), np.array([-1])]
inf1 = False
inf2 = False
if self.is_collision(agent, world.forests[0]):
in_forest[0] = np.array([1])
inf1= True
if self.is_collision(agent, world.forests[1]):
in_forest[1] = np.array([1])
inf2 = True
food_pos = []
for entity in world.food:
if not entity.boundary:
food_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent and not other.adversary:
other_vel.append(other.state.p_vel) #
continue
comm.append(other.state.c)
oth_f1 = self.is_collision(other, world.forests[0])
oth_f2 = self.is_collision(other, world.forests[1])
if (inf1 and oth_f1) or (inf2 and oth_f2) or \
(not inf1 and not oth_f1 and not inf2 and not oth_f2) or \
agent.leader: #without forest vis
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
else:
other_pos.append([0, 0])
if not other.adversary:
other_vel.append([0, 0])
# to tell the pred when the prey are in the forest
prey_forest = []
ga = self.good_agents(world)
for a in ga:
if any([self.is_collision(a, f) for f in world.forests]):
prey_forest.append(np.array([1]))
else:
prey_forest.append(np.array([-1]))
# to tell leader when pred are in forest
prey_forest_lead = []
for f in world.forests:
if any([self.is_collision(a, f) for a in ga]):
prey_forest_lead.append(np.array([1]))
else:
prey_forest_lead.append(np.array([-1]))
comm = [world.agents[0].state.c]
if agent.adversary and not agent.leader:
return np.concatenate(in_forest + comm +
[agent.state.p_vel] + [agent.state.p_pos] + other_vel +
entity_pos + other_pos)
if agent.leader:
return np.concatenate(in_forest + comm +
[agent.state.p_vel] + [agent.state.p_pos] + other_vel +
entity_pos + other_pos)
else:
return np.concatenate(in_forest + [np.zeros_like(world.agents[0].state.c)] +
[agent.state.p_vel] + [agent.state.p_pos] + other_vel +
entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/FOToM/readme.md
================================================
# Readme
This project is for FOToM.
================================================
FILE: examples/Social_Cognition/FOToM/utils/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/FOToM/utils/agents.py
================================================
import torch
from torch import Tensor
from torch.autograd import Variable
from torch.optim import Adam
from .networks import MLPNetwork, RNN, SNNNetwork, LSTMClassifier
from .misc import hard_update, gumbel_softmax, onehot_from_logits
from .noise import OUNoise
import time
class DDPGAgent(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, hidden_dim=64,
lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.policy = LSTMClassifier(num_in_pol, num_out_pol,#MLPNetwork
hidden_dim,)
# constrain_out=True,
# discrete_action=discrete_action)
self.critic = LSTMClassifier(num_in_critic, 1,
hidden_dim,)
# constrain_out=False)
self.target_policy = LSTMClassifier(num_in_pol, num_out_pol,
hidden_dim,)
# constrain_out=True,
# discrete_action=discrete_action)
self.target_critic = LSTMClassifier(num_in_critic, 1,
hidden_dim,)
# constrain_out=False)
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action = self.policy(obs)
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1)
else:
action = gumbel_softmax(action, hard=True)
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5]), onehot_from_logits(action[:, 5:])), 1)
else:
action = onehot_from_logits(action)
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
return {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict()}
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
class DDPGAgent_RNN(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, hidden_dim=64,
lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.policy = RNN(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.critic = RNN(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
self.target_policy = RNN(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.target_critic = RNN(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
self.policy_hidden = None
self.policy_target_hidden = None
self.critic_hidden = None
self.critic_target_hidden = None
self.num_in_pol = num_in_pol
self.num_out_pol = num_out_pol
self.hidden_dim = hidden_dim
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action, self.policy_hidden = self.policy(obs, self.policy_hidden)
if self.discrete_action:
if explore:
action = gumbel_softmax(action, hard=True)
else:
action = onehot_from_logits(action)
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
return {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict()}
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
def init_hidden(self, len_ep, policy_hidden=False, policy_target_hidden=False, \
critic_hidden=False, critic_target_hidden=False):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
if policy_hidden == True:
self.policy_hidden = torch.zeros((len_ep, self.hidden_dim))
if policy_target_hidden == True:
self.policy_target_hidden = torch.zeros((len_ep, self.hidden_dim))
if critic_hidden == True:
self.critic_hidden = torch.zeros((len_ep, self.hidden_dim))
if critic_target_hidden == True:
self.critic_target_hidden = torch.zeros((len_ep, self.hidden_dim))
class DDPGAgent_SNN(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, output_style, hidden_dim=64,
lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.policy = SNNNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
output_style=output_style)
self.critic = SNNNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
output_style=output_style)
self.target_policy = SNNNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
output_style=output_style)
self.target_critic = SNNNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
output_style=output_style)
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
# t1 = time.time()
action = self.policy(obs)
# t2 = time.time()
# print('time_interaction:', t2 - t1)
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1)
else:
action = gumbel_softmax(action, hard=True)
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5]), onehot_from_logits(action[:, 5:])), 1)
else:
action = onehot_from_logits(action)
# if explore:
#
# action = gumbel_softmax(action, hard=True)
#
# else:
# action = onehot_from_logits(action)
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
return {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict()}
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
class DDPGAgent_ToM(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, num_in_mle, output_style,
num_agents, device, hidden_dim=64, lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.device = device
self.policy = LSTMClassifier(num_in_pol, num_out_pol,hidden_dim) #SNNNetwork
# hidden_dim=hidden_dim,
# output_style=output_style)
self.critic = LSTMClassifier(num_in_critic, 1,hidden_dim)
# hidden_dim=hidden_dim,
# output_style=output_style)
self.target_policy = LSTMClassifier(num_in_pol, num_out_pol,hidden_dim)
# hidden_dim=hidden_dim,
# output_style=output_style)
self.target_critic = LSTMClassifier(num_in_critic, 1,hidden_dim)
# hidden_dim=hidden_dim,
# output_style=output_style)
# self.policy = SNNNetwork(num_in_pol, num_out_pol,
# hidden_dim=hidden_dim,
# output_style=output_style)
# self.critic = SNNNetwork(num_in_critic, 1,
# hidden_dim=hidden_dim,
# output_style=output_style)
# self.target_policy = SNNNetwork(num_in_pol, num_out_pol,
# hidden_dim=hidden_dim,
# output_style=output_style)
# self.target_critic = SNNNetwork(num_in_critic, 1,
# hidden_dim=hidden_dim,
# output_style=output_style)
# self.mle = [SNNNetwork(num_in_mle, num_out_pol,
# hidden_dim=hidden_dim,
# output_style=output_style)] * (num_agents - 1)
self.mle = []
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
self.mle_optimizer = []
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action = self.policy.to(self.device)(obs.to(self.device))
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1).cpu()
else:
action = gumbel_softmax(action, hard=True).cpu()
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5], hard=True), onehot_from_logits(action[:, 5:], hard=True)), 1)
else:
action = onehot_from_logits(action).cpu()
# if explore:
# action = gumbel_softmax(action, hard=True).cpu()
# else:
# action = onehot_from_logits(action).cpu()
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
params = {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict(),
}
# for i in range(len(self.mle)):
# params['mle%d'%i] = self.mle[i].state_dict()
# params['mle_optimizer%d'%i] = self.mle_optimizer[i].state_dict()
return params
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
# for i in range(len(self.mle)):
# self.mle[i].load_state_dict(params['mle%d'%i])
# self.mle_optimizer[i].load_state_dict(params['mle_optimizer%d'%i])
class rDDPGAgent_ToM(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, num_in_mle, output_style,
num_agents, device, hidden_dim=64, lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.device = device
self.policy = RNN(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.critic = RNN(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.target_policy = RNN(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.target_critic = RNN(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
# self.mle = [SNNNetwork(num_in_mle, num_out_pol,
# hidden_dim=hidden_dim,
# output_style=output_style)] * (num_agents - 1)
self.mle = []
self.policy_hidden = None
self.policy_target_hidden = None
self.critic_hidden = None
self.critic_target_hidden = None
self.hidden_dim = hidden_dim
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
self.mle_optimizer = []
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action, self.policy_hidden = self.policy(obs, self.policy_hidden)
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1).cpu()
else:
action = gumbel_softmax(action, hard=True).cpu()
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5], hard=True), onehot_from_logits(action[:, 5:], hard=True)), 1)
else:
action = onehot_from_logits(action).cpu()
# if explore:
# action = gumbel_softmax(action, hard=True).cpu()
# else:
# action = onehot_from_logits(action).cpu()
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
params = {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict(),
}
# for i in range(len(self.mle)):
# params['mle%d'%i] = self.mle[i].state_dict()
# params['mle_optimizer%d'%i] = self.mle_optimizer[i].state_dict()
return params
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
# for i in range(len(self.mle)):
# self.mle[i].load_state_dict(params['mle%d'%i])
# self.mle_optimizer[i].load_state_dict(params['mle_optimizer%d'%i])
def init_hidden(self, len_ep, policy_hidden=False, policy_target_hidden=False, \
critic_hidden=False, critic_target_hidden=False):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
if policy_hidden == True:
self.policy_hidden = torch.zeros((len_ep, self.hidden_dim))
if policy_target_hidden == True:
self.policy_target_hidden = torch.zeros((len_ep, self.hidden_dim))
if critic_hidden == True:
self.critic_hidden = torch.zeros((len_ep, self.hidden_dim))
if critic_target_hidden == True:
self.critic_target_hidden = torch.zeros((len_ep, self.hidden_dim))
class lDDPGAgent(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, hidden_dim=64,
lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.policy = LSTMClassifier(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.critic = LSTMClassifier(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
self.target_policy = LSTMClassifier(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.target_critic = LSTMClassifier(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action = self.policy(obs)
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1)
else:
action = gumbel_softmax(action, hard=True)
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5]), onehot_from_logits(action[:, 5:])), 1)
else:
action = onehot_from_logits(action)
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
return {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict()}
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
================================================
FILE: examples/Social_Cognition/FOToM/utils/buffer.py
================================================
import numpy as np
import torch
from torch import Tensor
from torch.autograd import Variable
class ReplayBuffer(object):
"""
Replay Buffer for multi-agent RL with parallel rollouts
"""
def __init__(self, max_steps, num_agents, obs_dims, ac_dims, device):
"""
Inputs:
max_steps (int): Maximum number of timepoints to store in buffer
num_agents (int): Number of agents in environment
obs_dims (list of ints): number of obervation dimensions for each
agent
ac_dims (list of ints): number of action dimensions for each agent
"""
self.device = device
self.max_steps = max_steps
self.num_agents = num_agents
self.obs_buffs = []
self.ac_buffs = []
self.rew_buffs = []
self.next_obs_buffs = []
self.done_buffs = []
for odim, adim in zip(obs_dims, ac_dims):
self.obs_buffs.append(np.zeros((max_steps, odim)))
self.ac_buffs.append(np.zeros((max_steps, adim)))
self.rew_buffs.append(np.zeros(max_steps))
self.next_obs_buffs.append(np.zeros((max_steps, odim)))
self.done_buffs.append(np.zeros(max_steps))
self.filled_i = 0 # index of first empty location in buffer (last index when full)
self.curr_i = 0 # current index to write to (ovewrite oldest data)
def __len__(self):
return self.filled_i
def push(self, observations, actions, rewards, next_observations, dones):
nentries = observations.shape[0] # handle multiple parallel environments
if self.curr_i + nentries > self.max_steps:
rollover = self.max_steps - self.curr_i # num of indices to roll over
for agent_i in range(self.num_agents):
self.obs_buffs[agent_i] = np.roll(self.obs_buffs[agent_i],
rollover, axis=0)
self.ac_buffs[agent_i] = np.roll(self.ac_buffs[agent_i],
rollover, axis=0)
self.rew_buffs[agent_i] = np.roll(self.rew_buffs[agent_i],
rollover)
self.next_obs_buffs[agent_i] = np.roll(
self.next_obs_buffs[agent_i], rollover, axis=0)
self.done_buffs[agent_i] = np.roll(self.done_buffs[agent_i],
rollover)
self.curr_i = 0
self.filled_i = self.max_steps
for agent_i in range(self.num_agents):
self.obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
observations[:, agent_i])
# actions are already batched by agent, so they are indexed differently
self.ac_buffs[agent_i][self.curr_i:self.curr_i + nentries] = actions[agent_i]
self.rew_buffs[agent_i][self.curr_i:self.curr_i + nentries] = rewards[:, agent_i]
self.next_obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
next_observations[:, agent_i])
self.done_buffs[agent_i][self.curr_i:self.curr_i + nentries] = dones[:, agent_i]
self.curr_i += nentries
if self.filled_i < self.max_steps:
self.filled_i += nentries
if self.curr_i == self.max_steps:
self.curr_i = 0
def sample(self, N, to_gpu=False, norm_rews=True):
inds = np.random.choice(np.arange(self.filled_i), size=N,
replace=False)
if to_gpu:
cast = lambda x: Variable(Tensor(x), requires_grad=False).to(torch.device(self.device))
else:
cast = lambda x: Variable(Tensor(x), requires_grad=False)
if norm_rews:
ret_rews = [cast((self.rew_buffs[i][inds] -
self.rew_buffs[i][:self.filled_i].mean()) /
self.rew_buffs[i][:self.filled_i].std())
for i in range(self.num_agents)]
else:
ret_rews = [cast(self.rew_buffs[i][inds]) for i in range(self.num_agents)]
return ([cast(self.obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.ac_buffs[i][inds]) for i in range(self.num_agents)],
ret_rews,
[cast(self.next_obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.done_buffs[i][inds]) for i in range(self.num_agents)])
def get_average_rewards(self, N):
if self.filled_i == self.max_steps:
inds = np.arange(self.curr_i - N, self.curr_i) # allow for negative indexing
else:
inds = np.arange(max(0, self.curr_i - N), self.curr_i)
return [self.rew_buffs[i][inds].mean() for i in range(self.num_agents)]
class ReplayBuffer_pre(object):
"""
Replay Buffer for multi-agent RL with parallel rollouts
"""
def __init__(self, max_steps, num_agents, obs_dims, ac_dims, device):
"""
Inputs:
max_steps (int): Maximum number of timepoints to store in buffer
num_agents (int): Number of agents in environment
obs_dims (list of ints): number of obervation dimensions for each
agent
ac_dims (list of ints): number of action dimensions for each agent
"""
self.device = device
self.max_steps = max_steps
self.num_agents = num_agents
self.ac_pre_buffs = []
self.obs_buffs = []
self.ac_buffs = []
self.rew_buffs = []
self.next_obs_buffs = []
self.done_buffs = []
for odim, adim in zip(obs_dims, ac_dims):
self.ac_pre_buffs.append(np.zeros((max_steps, 5)))
self.obs_buffs.append(np.zeros((max_steps, odim)))
self.ac_buffs.append(np.zeros((max_steps, adim)))
self.rew_buffs.append(np.zeros(max_steps))
self.next_obs_buffs.append(np.zeros((max_steps, odim)))
self.done_buffs.append(np.zeros(max_steps))
self.filled_i = 0 # index of first empty location in buffer (last index when full)
self.curr_i = 0 # current index to write to (ovewrite oldest data)
def __len__(self):
return self.filled_i
def push(self, actions_pre, observations, actions, rewards, next_observations, dones):
nentries = observations.shape[0] # handle multiple parallel environments
if self.curr_i + nentries > self.max_steps:
rollover = self.max_steps - self.curr_i # num of indices to roll over
for agent_i in range(self.num_agents):
self.ac_pre_buffs[agent_i] = np.roll(self.ac_pre_buffs[agent_i][:,:5],
rollover, axis=0)
self.obs_buffs[agent_i] = np.roll(self.obs_buffs[agent_i],
rollover, axis=0)
self.ac_buffs[agent_i] = np.roll(self.ac_buffs[agent_i],
rollover, axis=0)
self.rew_buffs[agent_i] = np.roll(self.rew_buffs[agent_i],
rollover)
self.next_obs_buffs[agent_i] = np.roll(
self.next_obs_buffs[agent_i], rollover, axis=0)
self.done_buffs[agent_i] = np.roll(self.done_buffs[agent_i],
rollover)
self.curr_i = 0
self.filled_i = self.max_steps
for agent_i in range(self.num_agents):
self.ac_pre_buffs[agent_i][self.curr_i:self.curr_i + nentries] = actions_pre[agent_i][:,:5]
self.obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
observations[:, agent_i])
# actions are already batched by agent, so they are indexed differently
self.ac_buffs[agent_i][self.curr_i:self.curr_i + nentries] = actions[agent_i]
self.rew_buffs[agent_i][self.curr_i:self.curr_i + nentries] = rewards[:, agent_i]
self.next_obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
next_observations[:, agent_i])
self.done_buffs[agent_i][self.curr_i:self.curr_i + nentries] = dones[:, agent_i]
self.curr_i += nentries
if self.filled_i < self.max_steps:
self.filled_i += nentries
if self.curr_i == self.max_steps:
self.curr_i = 0
def sample(self, N, to_gpu=False, norm_rews=True):
inds = np.random.choice(np.arange(self.filled_i), size=N,
replace=False)
# inds = np.arange(self.filled_i)[0:-1:self.filled_i//N]
if to_gpu:
cast = lambda x: Variable(Tensor(x), requires_grad=False).to(torch.device(self.device))
else:
cast = lambda x: Variable(Tensor(x), requires_grad=False)
if self.rew_buffs[0].sum() == False:
norm_rews = False
if norm_rews:
ret_rews = [cast((self.rew_buffs[i][inds] -
self.rew_buffs[i][:self.filled_i].mean()) /
self.rew_buffs[i][:self.filled_i].std())
for i in range(self.num_agents)]
else:
ret_rews = [cast(self.rew_buffs[i][inds]) for i in range(self.num_agents)]
return ([cast(self.ac_pre_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.ac_buffs[i][inds]) for i in range(self.num_agents)],
ret_rews,
[cast(self.next_obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.done_buffs[i][inds]) for i in range(self.num_agents)])
def get_average_rewards(self, N):
if self.filled_i == self.max_steps:
inds = np.arange(self.curr_i - N, self.curr_i) # allow for negative indexing
else:
inds = np.arange(max(0, self.curr_i - N), self.curr_i)
return [self.rew_buffs[i][inds].mean() for i in range(self.num_agents)]
class ReplayBuffer_RNN(object):
"""
Replay Buffer for multi-agent RL with parallel rollouts
"""
def __init__(self, max_steps, num_agents, obs_dims, ac_dims, ep_dims, device):
"""
Inputs:
max_steps (int): Maximum number of timepoints to store in buffer
num_agents (int): Number of agents in environment
obs_dims (list of ints): number of obervation dimensions for each
agent
ac_dims (list of ints): number of action dimensions for each agent
ep_dims (int): Number of steps in each episode
"""
self.device = device
self.max_steps = max_steps
self.num_agents = num_agents
self.obs_buffs = []
self.ac_buffs = []
self.rew_buffs = []
self.next_obs_buffs = []
self.done_buffs = []
for odim, adim in zip(obs_dims, ac_dims):
self.obs_buffs.append(np.zeros((max_steps, ep_dims, odim)))
self.ac_buffs.append(np.zeros((max_steps, ep_dims, adim)))
self.rew_buffs.append(np.zeros((max_steps, ep_dims)))
self.next_obs_buffs.append(np.zeros((max_steps, ep_dims, odim)))
self.done_buffs.append(np.zeros((max_steps, ep_dims)))
self.filled_i = 0 # index of first empty location in buffer (last index when full)
self.curr_i = 0 # current index to write to (ovewrite oldest data)
def __len__(self):
return self.filled_i
def push(self, observations_ep, actions_ep, rewards_ep, next_observations_ep, dones_ep):
nentries = observations_ep[0].shape[0] # handle multiple parallel environments
observations_ep, actions_ep, rewards_ep, next_observations_ep, dones_ep = \
np.array(observations_ep), np.array(actions_ep), np.array(rewards_ep),\
np.array(next_observations_ep), np.array(dones_ep)
if self.curr_i + nentries > self.max_steps:
rollover = self.max_steps - self.curr_i # num of indices to roll over
for agent_i in range(self.num_agents):
self.obs_buffs[agent_i] = np.roll(self.obs_buffs[agent_i],
rollover, axis=0)
self.ac_buffs[agent_i] = np.roll(self.ac_buffs[agent_i],
rollover, axis=0)
self.rew_buffs[agent_i] = np.roll(self.rew_buffs[agent_i],
rollover)
self.next_obs_buffs[agent_i] = np.roll(
self.next_obs_buffs[agent_i], rollover, axis=0)
self.done_buffs[agent_i] = np.roll(self.done_buffs[agent_i],
rollover)
self.curr_i = 0
self.filled_i = self.max_steps
for agent_i in range(self.num_agents):
for i in range(observations_ep[:,:,agent_i].shape[0]):
if i == 0:
ob_ep = np.expand_dims(np.vstack(observations_ep[:,:,agent_i][i]), 0)
ob_next_ep = np.expand_dims(np.vstack(next_observations_ep[:,:,agent_i][i]), 0)
else:
ob_ep = np.vstack((ob_ep, np.expand_dims(np.vstack(observations_ep[:,:,agent_i][i]), 0)))
ob_next_ep = np.vstack((ob_next_ep, np.expand_dims(np.vstack(next_observations_ep[:,:,agent_i][i]), 0)))
self.obs_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = ob_ep.transpose(1, 0, 2)
# actions are already batched by agent, so they are indexed differently
self.ac_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = actions_ep[:,:,0,:].transpose(1, 0, 2)
self.rew_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = rewards_ep[:, :, agent_i].transpose(1, 0)
self.next_obs_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = ob_next_ep.transpose(1, 0, 2)
self.done_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = dones_ep[:, :, agent_i].transpose(1, 0)
self.curr_i += nentries
if self.filled_i < self.max_steps:
self.filled_i += nentries
if self.curr_i == self.max_steps:
self.curr_i = 0
def sample(self, N, to_gpu=False, norm_rews=True):
inds = np.random.choice(np.arange(self.filled_i), size=N,
replace=False)
if to_gpu:
cast = lambda x: Variable(Tensor(x), requires_grad=False).to(torch.device(self.device))
else:
cast = lambda x: Variable(Tensor(x), requires_grad=False)
if norm_rews:
ret_rews = [cast((self.rew_buffs[i][inds] -
self.rew_buffs[i][:self.filled_i].mean()) /
self.rew_buffs[i][:self.filled_i].std())
for i in range(self.num_agents)]
else:
ret_rews = [cast(self.rew_buffs[i][inds]) for i in range(self.num_agents)]
return ([cast(self.obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.ac_buffs[i][inds]) for i in range(self.num_agents)],
ret_rews,
[cast(self.next_obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.done_buffs[i][inds]) for i in range(self.num_agents)])
def get_average_rewards(self, N):
if self.filled_i == self.max_steps:
inds = np.arange(self.curr_i - N, self.curr_i) # allow for negative indexing
else:
inds = np.arange(max(0, self.curr_i - N), self.curr_i)
return [self.rew_buffs[i][inds].mean() for i in range(self.num_agents)]
================================================
FILE: examples/Social_Cognition/FOToM/utils/env_wrappers.py
================================================
"""
Modified from OpenAI Baselines code to work with multi-agent envs
"""
import numpy as np
from multiprocessing import Process, Pipe
from common.vec_env.vec_env import VecEnv, CloudpickleWrapper
def worker(remote, parent_remote, env_fn_wrapper):
parent_remote.close()
env = env_fn_wrapper.x()
while True:
cmd, data = remote.recv()
if cmd == 'step':
ob, reward, done, info = env.step(data)
if all(done):
ob = env.reset()
remote.send((ob, reward, done, info))
elif cmd == 'reset':
ob = env.reset()
remote.send(ob)
elif cmd == 'reset_task':
ob = env.reset_task()
remote.send(ob)
elif cmd == 'close':
remote.close()
break
elif cmd == 'get_spaces':
remote.send((env.observation_space, env.action_space))
elif cmd == 'get_agent_types':
if all([hasattr(a, 'adversary') for a in env.agents]):
remote.send(['adversary' if a.adversary else 'agent' for a in
env.agents])
else:
remote.send(['agent' for _ in env.agents])
elif cmd == 'get_num_landmarks':
remote.send(len(env.world.landmarks))
else:
raise NotImplementedError
class SubprocVecEnv(VecEnv):
def __init__(self, env_fns, spaces=None):
"""
envs: list of gym environments to run in subprocesses
"""
self.waiting = False
self.closed = False
nenvs = len(env_fns)
self.remotes, self.work_remotes = zip(*[Pipe() for _ in range(nenvs)])
self.ps = [Process(target=worker, args=(work_remote, remote, CloudpickleWrapper(env_fn)))
for (work_remote, remote, env_fn) in zip(self.work_remotes, self.remotes, env_fns)]
for p in self.ps:
p.daemon = True # if the main process crashes, we should not cause things to hang
p.start()
for remote in self.work_remotes:
remote.close()
self.remotes[0].send(('get_spaces', None))
observation_space, action_space = self.remotes[0].recv()
self.remotes[0].send(('get_agent_types', None))
self.agent_types = self.remotes[0].recv()
self.remotes[0].send(('get_num_landmarks', None))
self.num_lm = self.remotes[0].recv()
VecEnv.__init__(self, len(env_fns), observation_space, action_space)
def step_async(self, actions):
for remote, action in zip(self.remotes, actions):
remote.send(('step', action))
self.waiting = True
def step_wait(self):
results = [remote.recv() for remote in self.remotes]
self.waiting = False
obs, rews, dones, infos = zip(*results)
return np.stack(obs), np.stack(rews), np.stack(dones), infos
def reset(self):
for remote in self.remotes:
remote.send(('reset', None))
return np.stack([remote.recv() for remote in self.remotes])
def reset_task(self):
for remote in self.remotes:
remote.send(('reset_task', None))
return np.stack([remote.recv() for remote in self.remotes])
def close(self):
if self.closed:
return
if self.waiting:
for remote in self.remotes:
remote.recv()
for remote in self.remotes:
remote.send(('close', None))
for p in self.ps:
p.join()
self.closed = True
class DummyVecEnv(VecEnv):
def __init__(self, env_fns):
self.envs = [fn() for fn in env_fns]
env = self.envs[0]
VecEnv.__init__(self, len(env_fns), env.observation_space, env.action_space)
if all([hasattr(a, 'adversary') for a in env.agents]):
self.agent_types = ['adversary' if a.adversary else 'agent' for a in
env.agents]
else:
self.agent_types = ['agent' for _ in env.agents]
self.ts = np.zeros(len(self.envs), dtype='int')
self.actions = None
def step_async(self, actions):
self.actions = actions
def step_wait(self):
results = [env.step(a) for (a,env) in zip(self.actions, self.envs)]
obs, rews, dones, infos = map(np.array, zip(*results))
self.ts += 1
for (i, done) in enumerate(dones):
if all(done):
obs[i] = self.envs[i].reset()
self.ts[i] = 0
self.actions = None
return np.array(obs), np.array(rews), np.array(dones), infos
def reset(self):
results = [env.reset() for env in self.envs]
return np.array(results)
def close(self):
return
================================================
FILE: examples/Social_Cognition/FOToM/utils/make_env.py
================================================
"""
Code for creating a multiagent environment with one of the scenarios listed
in ./scenarios/.
Can be called by using, for example:
env = make_env('simple_speaker_listener')
After producing the env object, can be used similarly to an OpenAI gym
environment.
A policy using this environment must output actions in the form of a list
for all agents. Each element of the list should be a numpy array,
of size (env.world.dim_p + env.world.dim_c, 1). Physical actions precede
communication actions in this array. See environment.py for more details.
"""
def make_env(scenario_name, num_good_agents, num_adversaries, benchmark=False, discrete_action=False):
'''
Creates a MultiAgentEnv object as env. This can be used similar to a gym
environment by calling env.reset() and env.step().
Use env.render() to view the environment on the screen.
Input:
scenario_name : name of the scenario from ./scenarios/ to be Returns
(without the .py extension)
benchmark : whether you want to produce benchmarking data
(usually only done during evaluation)
Some useful env properties (see environment.py):
.observation_space : Returns the observation space for each agent
.action_space : Returns the action space for each agent
.n : Returns the number of Agents
'''
from multiagent.environment import MultiAgentEnv
import multiagent.scenarios as scenarios
# load scenario from script
scenario = scenarios.load(scenario_name + ".py").Scenario()
# create world
world = scenario.make_world(num_good_agents, num_adversaries)
# create multiagent environment
if benchmark:
env = MultiAgentEnv(world, scenario.reset_world, scenario.reward,
scenario.observation, scenario.benchmark_data)
else:
env = MultiAgentEnv(world, scenario.reset_world, scenario.reward,
scenario.observation)
return env
================================================
FILE: examples/Social_Cognition/FOToM/utils/misc.py
================================================
import os
import torch
import torch.nn.functional as F
import torch.distributed as dist
from torch.autograd import Variable
import numpy as np
# https://github.com/ikostrikov/pytorch-ddpg-naf/blob/master/ddpg.py#L11
def soft_update(target, source, tau):
"""
Perform DDPG soft update (move target params toward source based on weight
factor tau)
Inputs:
target (torch.nn.Module): Net to copy parameters to
source (torch.nn.Module): Net whose parameters to copy
tau (float, 0 < x < 1): Weight factor for update
"""
for target_param, param in zip(target.parameters(), source.parameters()):
target_param.data.copy_(target_param.data * (1.0 - tau) + param.data * tau)
# https://github.com/ikostrikov/pytorch-ddpg-naf/blob/master/ddpg.py#L15
def hard_update(target, source):
"""
Copy network parameters from source to target
Inputs:
target (torch.nn.Module): Net to copy parameters to
source (torch.nn.Module): Net whose parameters to copy
"""
for target_param, param in zip(target.parameters(), source.parameters()):
target_param.data.copy_(param.data)
# https://github.com/seba-1511/dist_tuto.pth/blob/gh-pages/train_dist.py
def average_gradients(model):
""" Gradient averaging. """
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM, group=0)
param.grad.data /= size
# https://github.com/seba-1511/dist_tuto.pth/blob/gh-pages/train_dist.py
def init_processes(rank, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
def onehot_from_logits(logits, eps=0.0):
"""
Given batch of logits, return one-hot sample using epsilon greedy strategy
(based on given epsilon)
"""
# get best (according to current policy) actions in one-hot form
argmax_acs = (logits == logits.max(1, keepdim=True)[0]).float()
if eps == 0.0:
return argmax_acs
# get random actions in one-hot form
rand_acs = Variable(torch.eye(logits.shape[1])[[np.random.choice(
range(logits.shape[1]), size=logits.shape[0])]], requires_grad=False)
# chooses between best and random actions using epsilon greedy
return torch.stack([argmax_acs[i] if r > eps else rand_acs[i] for i, r in
enumerate(torch.rand(logits.shape[0]))])
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def sample_gumbel(shape, eps=1e-20, tens_type=torch.FloatTensor):
"""Sample from Gumbel(0, 1)"""
U = Variable(tens_type(*shape).uniform_(), requires_grad=False)
return -torch.log(-torch.log(U + eps) + eps)
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def gumbel_softmax_sample(logits, temperature):
""" Draw a sample from the Gumbel-Softmax distribution"""
y = logits + sample_gumbel(logits.shape, tens_type=type(logits.data)).to(logits.device)
return F.softmax(y / temperature, dim=1)
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def gumbel_softmax(logits, temperature=1.0, hard=False):
"""Sample from the Gumbel-Softmax distribution and optionally discretize.
Args:
logits: [batch_size, n_class] unnormalized log-probs
temperature: non-negative scalar
hard: if True, take argmax, but differentiate w.r.t. soft sample y
Returns:
[batch_size, n_class] sample from the Gumbel-Softmax distribution.
If hard=True, then the returned sample will be one-hot, otherwise it will
be a probabilitiy distribution that sums to 1 across classes
"""
y = gumbel_softmax_sample(logits, temperature)
if hard:
y_hard = onehot_from_logits(y)
y = (y_hard - y).detach() + y
return y
================================================
FILE: examples/Social_Cognition/FOToM/utils/multiprocessing.py
================================================
# This code is from openai baseline
# https://github.com/openai/baselines/tree/master/baselines/common/vec_env
import time
import matplotlib.pyplot as plt
import numpy as np
from multiprocessing import Process, Pipe
def _flatten_list(l):
assert isinstance(l, (list, tuple))
assert len(l) > 0
assert all([len(l_) > 0 for l_ in l])
return [l__ for l_ in l for l__ in l_]
def worker(remote, parent_remote, env_fn_wrapper):
parent_remote.close()
env = env_fn_wrapper.x()
while True:
cmd, data = remote.recv()
if cmd == 'step':
ob, reward, done, info = env.step(data)
if done:
ob = env.reset()
remote.send((ob, reward, done, info))
elif cmd == 'reset':
ob = env.reset()
remote.send(ob)
elif cmd == 'reset_task':
ob = env.reset_task()
remote.send(ob)
elif cmd == 'world':
remote.send(env.world)
elif cmd == 'render':
ob = env.render(mode='rgb_array')
# print(len(ob), 'len(frames)')
# print(len(ob[0]), 'len(frames[0])')
# print(len(ob[0][0]), 'len(frames[0][0])')
remote.send(ob) # rgb_array
elif cmd == 'observe':
ob = env.observe(data)
remote.send(ob)
elif cmd == 'agents':
remote.send(env.agents)
elif cmd == 'spec':
remote.send(env.spec)
elif cmd == 'get_spaces':
remote.send((env.observation_space, env.action_space))
elif cmd == 'close':
remote.close()
break
else:
raise NotImplementedError
class VecEnv(object):
"""
An abstract asynchronous, vectorized environment.
"""
closed = False
viewer = None
metadata = {
'render.modes': ['human', 'rgb_array']
}
def __init__(self, num_envs, observation_space, action_space):
self.num_envs = num_envs
self.observation_space = observation_space
self.action_space = action_space
def observe(self, agent):
pass
def reset(self):
"""
Reset all the environments and return an array of
observations, or a tuple of observation arrays.
If step_async is still doing work, that work will
be cancelled and step_wait() should not be called
until step_async() is invoked again.
"""
pass
def step_async(self, actions):
"""
Tell all the environments to start taking a step
with the given actions.
Call step_wait() to get the results of the step.
You should not call this if a step_async run is
already pending.
"""
pass
def step_wait(self):
"""
Wait for the step taken with step_async().
Returns (obs, rews, dones, infos):
- obs: an array of observations, or a tuple of
arrays of observations.
- rews: an array of rewards
- dones: an array of "episode done" booleans
- infos: a sequence of info objects
"""
pass
def close(self):
"""
Clean up the environments' resources.
"""
pass
def step(self, actions):
self.step_async(actions)
return self.step_wait()
def render(self, mode='human'):
imgs = self.get_images()
bigimg = self.tile_images(imgs)
if mode == 'human':
self.get_viewer().imshow(bigimg) #
return self.get_viewer().isopen
elif mode == 'rgb_array':
return bigimg
else:
raise NotImplementedError
def get_images(self):
"""
Return RGB images from each environment
"""
raise NotImplementedError
def get_viewer(self):
if self.viewer is None:
from common import rendering
self.viewer = rendering.SimpleImageViewer()
return self.viewer
def tile_images(self, img_nhwc):
"""
Tile N images into one big PxQ image
(P,Q) are chosen to be as close as possible, and if N
is square, then P=Q.
input: img_nhwc, list or array of images, ndim=4 once turned into array
n = batch index, h = height, w = width, c = channel
returns:
bigim_HWc, ndarray with ndim=3
"""
img_nhwc = np.asarray(img_nhwc)
N, h, w, c = img_nhwc.shape
H = int(np.ceil(np.sqrt(N)))
W = int(np.ceil(float(N) / H))
img_nhwc = np.array(list(img_nhwc) + [img_nhwc[0] * 0 for _ in range(N, H * W)])
img_HWhwc = img_nhwc.reshape(H, W, h, w, c)
img_HhWwc = img_HWhwc.transpose(0, 2, 1, 3, 4)
img_Hh_Ww_c = img_HhWwc.reshape(H * h, W * w, c)
return img_Hh_Ww_c
class CloudpickleWrapper(object):
"""
Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)
"""
def __init__(self, x):
self.x = x
def __getstate__(self):
import cloudpickle
return cloudpickle.dumps(self.x)
def __setstate__(self, ob):
import pickle
self.x = pickle.loads(ob)
class SubprocVecEnv(VecEnv):
def __init__(self, env_fns, spaces=None):
"""
envs_sc: list of gym environments to run in subprocesses
"""
# self.venv = venv
self.waiting = False
self.closed = False
nenvs = len(env_fns)
self.nenvs = nenvs
self.remotes, self.work_remotes = zip(*[Pipe() for _ in range(nenvs)])
self.ps = [Process(target=worker, args=(work_remote, remote, CloudpickleWrapper(env_fn)))
for (work_remote, remote, env_fn) in zip(self.work_remotes, self.remotes, env_fns)]
for p in self.ps:
p.daemon = True # if the main process crashes, we should not cause things to hang
p.start()
for remote in self.work_remotes:
remote.close()
self.remotes[0].send(('get_spaces', None))
observation_space, action_space = self.remotes[0].recv()
VecEnv.__init__(self, len(env_fns), observation_space, action_space)
def step_async(self, actions):
for remote, action in zip(self.remotes, actions): # the input of step() : action
remote.send(('step', action))
self.waiting = True
def step_wait(self):
results = [remote.recv() for remote in self.remotes] # the output of step() : zip(*results)
self.waiting = False
obs, rews, dones, infos = zip(*results)
return np.stack(obs), np.stack(rews), np.stack(dones), infos
def step_wait_2(self):
results = [remote.recv() for remote in self.remotes]
self.waiting = False
reward, done, _cumulative_rewards = zip(*results)
return reward, done, _cumulative_rewards
def step_wait_3(self):
results = [remote.recv() for remote in self.remotes] # the output of step() : zip(*results)
self.waiting = False
obs, rews, dones, infos = zip(*results)
return np.stack(obs), np.stack(rews), np.stack(dones), infos
def reset(self):
for remote in self.remotes:
remote.send(('reset', None))
return np.stack([remote.recv() for remote in self.remotes])
def agents(self):
for remote in self.remotes:
remote.send(('agents', None))
return np.stack([remote.recv() for remote in self.remotes])
def world(self):
for remote in self.remotes:
remote.send(('world', None))
return np.stack([remote.recv() for remote in self.remotes])
def reset_task(self):
for remote in self.remotes:
remote.send(('reset_task', None))
return np.stack([remote.recv() for remote in self.remotes])
def spec(self):
for remote in self.remotes:
remote.send(('spec', None))
return np.stack([remote.recv() for remote in self.remotes])
def get_images(self):
# self._assert_not_closed()
for pipe in self.remotes:
pipe.send(('render', None))
imgs = [pipe.recv() for pipe in self.remotes]
# imgs = _flatten_list(imgs)
return imgs
def observe(self, agent):
for remote, agent in zip(self.remotes, agent):
remote.send(('observe', agent))
return np.stack([remote.recv() for remote in self.remotes])
# def render(self, mode='human'):
# return self.venv.render(mode=mode)
def close(self):
if self.closed:
return
if self.waiting:
for remote in self.remotes:
remote.recv()
for remote in self.remotes:
remote.send(('close', None))
for p in self.ps:
p.join()
self.closed = True
def __len__(self):
return self.nenvs
def _flatten_list(l):
assert isinstance(l, (list, tuple))
assert len(l) > 0
assert all([len(l_) > 0 for l_ in l])
return [l__ for l_ in l for l__ in l_]
class DummyVecEnv(VecEnv):
def __init__(self, env_fns):
self.envs = [fn() for fn in env_fns]
env = self.envs[0]
VecEnv.__init__(self, len(env_fns), env.observation_space, env.action_space)
if all([hasattr(a, 'adversary') for a in env.agents]):
self.agent_types = ['adversary' if a.adversary else 'agent' for a in
env.agents]
else:
self.agent_types = ['agent' for _ in env.agents]
self.ts = np.zeros(len(self.envs), dtype='int')
self.actions = None
def step_async(self, actions):
self.actions = actions
def step_wait(self):
results = [env.step(a) for (a,env) in zip(self.actions, self.envs)]
obs, rews, dones, infos = map(np.array, zip(*results))
self.ts += 1
for (i, done) in enumerate(dones):
if all(done):
obs[i] = self.envs[i].reset()
self.ts[i] = 0
self.actions = None
return np.array(obs), np.array(rews), np.array(dones), infos
def reset(self):
results = [env.reset() for env in self.envs]
return np.array(results)
def close(self):
return
================================================
FILE: examples/Social_Cognition/FOToM/utils/networks.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
class MLPNetwork(nn.Module):
"""
MLP network (can be used as value or policy)
"""
def __init__(self, input_dim, out_dim, hidden_dim=64, nonlin=F.relu,
constrain_out=False, norm_in=True, discrete_action=True):
"""
Inputs:
input_dim (int): Number of dimensions in input
out_dim (int): Number of dimensions in output
hidden_dim (int): Number of hidden dimensions
nonlin (PyTorch function): Nonlinearity to apply to hidden layers
"""
super(MLPNetwork, self).__init__()
if norm_in: # normalize inputs
self.in_fn = nn.BatchNorm1d(input_dim) #train
# self.in_fn = input_dim #test
self.in_fn.weight.data.fill_(1)
self.in_fn.bias.data.fill_(0)
else:
self.in_fn = lambda x: x
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, out_dim)
self.nonlin = nonlin
if constrain_out and not discrete_action:
# initialize small to prevent saturation
self.fc3.weight.data.uniform_(-3e-3, 3e-3)
self.out_fn = F.tanh
else: # logits for discrete action (will softmax later)
self.out_fn = lambda x: x
def forward(self, X):
"""
Inputs:
X (PyTorch Matrix): Batch of observations
Outputs:
out (PyTorch Matrix): Output of network (actions, values, etc)
"""
h1 = self.nonlin(self.fc1(self.in_fn(X)))
h2 = self.nonlin(self.fc2(h1))
out = self.out_fn(self.fc3(h2))
return out
class RNN(nn.Module):
# Because all the agents_sc share the same network_sc, input_shape=obs_shape+n_actions+n_agents
def __init__(self, input_dim, out_dim, hidden_dim=64, nonlin=F.relu,
constrain_out=False, norm_in=True, discrete_action=True):
super(RNN, self).__init__()
self.rnn_hidden_dim = hidden_dim
if norm_in: # normalize inputs
self.in_fn = nn.BatchNorm1d(input_dim)
self.in_fn.weight.data.fill_(1)
self.in_fn.bias.data.fill_(0)
else:
self.in_fn = lambda x: x
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.rnn = nn.GRUCell(hidden_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, out_dim)
self.nonlin = nonlin
if constrain_out and not discrete_action:
# initialize small to prevent saturation
self.fc3.weight.data.uniform_(-3e-3, 3e-3)
self.out_fn = F.tanh
else: # logits for discrete action (will softmax later)
self.out_fn = lambda x: x
def forward(self, obs, hidden_state):
x = self.nonlin(self.fc1(obs))
# x = x.reshape(-1, self.rnn_hidden_dim)
# h_in = hidden_state.reshape(-1, self.rnn_hidden_dim)
h = self.rnn(x, hidden_state)
q = self.fc2(h)
return q, h
class BCNoSpikingLIFNode(LIFNode):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self, dv: torch.Tensor):
self.integral(dv)
return self.mem
class SNNNetwork(nn.Module):
"""
SNN network (can be used as value or policy or MLE)
"""
def __init__(self, input_dim, out_dim, hidden_dim=64, node=LIFNode, time_window=16,
norm_in=True, output_style='sum'):
"""
Inputs:
input_dim (int): Number of dimensions in input
out_dim (int): Number of dimensions in output
hidden_dim (int): Number of hidden dimensions
nonlin (PyTorch function): Nonlinearity to apply to hidden layers
"""
super(SNNNetwork, self).__init__()
self._threshold = 0.5
self.v_reset = 0.0
self._time_window = time_window
self.output_style = output_style
self._node1 = node(threshold=self._threshold, v_reset=self.v_reset)
self._node2 = node(threshold=self._threshold, v_reset=self.v_reset)
if norm_in: # normalize inputs
self.in_fn = nn.BatchNorm1d(input_dim) #train
self.in_fn.weight.data.fill_(1)
self.in_fn.bias.data.fill_(0)
else:
self.in_fn = lambda x: x
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, out_dim)
if self.output_style == 'sum':
self._out_node = lambda x: x
elif self.output_style == 'voltage':
self._out_node = BCNoSpikingLIFNode()
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def forward(self, X):
qs = []
self.reset()
for t in range(self._time_window):
x = self.fc1((self.in_fn(X)+0.5)) #train
# x = self.fc1((X + 0.5)) #test
x = self._node1(x)
x = self.fc2(x)
x = self._node2(x)
x = self.fc3(x)
x = self._out_node(x)
qs.append(x)
if self.output_style == 'sum':
outputs = sum(qs) / self._time_window
return outputs
elif self.output_style == 'voltage':
outputs = x
return outputs
class LSTMClassifier(nn.Module):
def __init__(self, input_size, output_size, hidden_size=256):
super(LSTMClassifier, self).__init__()
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=1, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = x.unsqueeze(1)
output, (h, c) = self.lstm(x)
output = output.squeeze(1)
out = self.fc(output)
return out
================================================
FILE: examples/Social_Cognition/FOToM/utils/noise.py
================================================
import numpy as np
# from https://github.com/songrotek/DDPG/blob/master/ou_noise.py
class OUNoise:
def __init__(self, action_dimension, scale=0.1, mu=0, theta=0.15, sigma=0.2):
self.action_dimension = action_dimension
self.scale = scale
self.mu = mu
self.theta = theta
self.sigma = sigma
self.state = np.ones(self.action_dimension) * self.mu
self.reset()
def reset(self):
self.state = np.ones(self.action_dimension) * self.mu
def noise(self):
x = self.state
dx = self.theta * (self.mu - x) + self.sigma * np.random.randn(len(x))
self.state = x + dx
return self.state * self.scale
================================================
FILE: examples/Social_Cognition/Intention_Prediction/Intention_Prediction.py
================================================
import numpy as np
import torch,os,sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
import matplotlib.pyplot as plt
from BrainCog.base.strategy.surrogate import *
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import random
from BrainCog.base.node.node import *
from BrainCog.base.learningrule.STDP import MutliInputSTDP
class CustomLinear(nn.Module):
def __init__(self, weight,mask=None):
super().__init__()
self.weight = nn.Parameter(weight, requires_grad=True)
self.mask=mask
def forward(self, x: torch.Tensor):
#
# ret.shape = [C]
return x.mul(self.weight) # Changed
def update(self, dw):
with torch.no_grad():
if self.mask is not None:
dw *= self.mask
self.weight.data+= dw
class DLPFCNet(nn.Module):
def __init__(self,connection):
super().__init__()
# DLPFC, BG
self.node = []
self.node.append(IzhNodeMU(threshold=30., a=0.02, b=0.60, c=-65., d=8., mem=-70.))
self.node.append(IzhNodeMU(threshold=30., a=0.02, b=0.60, c=-65., d=8., mem=-70.))
self.learning_rule = []
self.connection = connection
self.out_DLPFC=torch.zeros((self.connection[0].weight.shape[1]), dtype=torch.float) # Input-DLPFC
self.out_BG=torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float) # DLPFC-BG
def forward(self, input):
self.out_DLPFC=self.node[0](self.connection[0](input))
self.out_BG=self.node[1](self.connection[1](self.out_DLPFC))
BG_Spike = self.node[1].spike
if sum(sum(BG_Spike)).item() > 1:
num_neuron = len(BG_Spike)
BG_Spike_index = torch.argmax(BG_Spike)
BG_Spike_index_x = torch.floor(BG_Spike_index/num_neuron)
BG_Spike_index_y = BG_Spike_index - BG_Spike_index_x*num_neuron
BG_Spike = torch.zeros([num_neuron, num_neuron], dtype=torch.float)
BG_Spike[BG_Spike_index_x.long()][BG_Spike_index_y.long()] = 1
return BG_Spike
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def UpdateWeight(self, i, W):
self.connection[i].weight.data = W
class OFCNet(nn.Module):
def __init__(self,connection):
super().__init__()
# OFC, MOFC, LOFC
self.node = []
self.node.append(IzhNodeMU(threshold=30., a=0.02, b=0.60, c=-65., d=8., mem=-70.)) # OFC_1
self.node.append(IzhNodeMU(threshold=30., a=0.02, b=0.60, c=-65., d=8., mem=-70.)) # OFC_2
self.node.append(IzhNodeMU(threshold=30., a=0.02, b=0.60, c=-65., d=8., mem=-70.)) # MOFC
self.node.append(IzhNodeMU(threshold=30., a=0.02, b=0.60, c=-65., d=8., mem=-70.)) # LOFC
self.connection = connection
self.learning_rule = []
self.learning_rule.append(MutliInputSTDP(self.node[3], [self.connection[3],self.connection[4]])) # OFC_2-LOFC, MOFC-LOFC
self.learning_rule.append(MutliInputSTDP(self.node[3], [self.connection[3],self.connection[5]])) # OFC_2-LOFC, OFC_1-LOFC
self.out_OFC_1=torch.zeros((self.connection[0].weight.shape[1]), dtype=torch.float)
self.out_OFC_2=torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float)
self.out_MOFC=torch.zeros((self.connection[2].weight.shape[1]), dtype=torch.float)
self.out_LOFC=torch.zeros((self.connection[5].weight.shape[1]), dtype=torch.float)
def forward(self, Input_Tha, Input_SNc, Reward):
self.out_OFC_1 = self.node[0](self.connection[0](Input_Tha))
self.out_OFC_2 = self.node[1](self.connection[1](Input_SNc))
if Reward == 1:
self.out_MOFC = self.node[2](self.connection[2](self.out_OFC_1))
self.out_LOFC, dw_lofc = self.learning_rule[0](self.out_OFC_2, self.out_MOFC)
else:
self.out_MOFC = self.node[2](self.connection[2](self.out_OFC_1*0))
self.out_LOFC, dw_lofc = self.learning_rule[1](self.out_OFC_2, self.out_OFC_1)
MOFC_Spike = self.node[2].spike
LOFC_Spike = self.node[3].spike
return MOFC_Spike, LOFC_Spike
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
class BGNet(nn.Module):
def __init__(self,connection):
super().__init__()
# DLPFC, StrD1, StrD2
self.node = []
self.node.append(IzhNodeMU(threshold=30., a=0.02, b=0.60, c=-65., d=8., mem=-70.)) # DLPFC
self.node.append(IzhNodeMU(threshold=30., a=0.01, b=0.01, c=-65., d=8., mem=-70.)) # StrD1
self.node.append(IzhNodeMU(threshold=30., a=0.1, b=0.5, c=-65., d=8., mem=-70.)) # StrD2
self.connection = connection
self.learning_rule = []
self.out_DLPFC=torch.zeros((self.connection[0].weight.shape[1]), dtype=torch.float)
self.out_StrD1=torch.zeros((self.connection[1].weight.shape[1]), dtype=torch.float)
self.out_StrD2=torch.zeros((self.connection[2].weight.shape[1]), dtype=torch.float)
def forward(self, input1, input2, input3):
self.out_DLPFC=self.node[0](self.connection[0](input1))
self.out_StrD1=self.node[1](self.connection[1](input2))
self.out_StrD2=self.node[2](self.connection[2](input3))
DLPFC_out = self.node[0].spike
BG_out = self.node[1].spike + self.node[2].spike
return DLPFC_out, BG_out
def reset(self):
for i in range(len(self.node)):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def UpdateWeight(self, i, W):
self.connection[i].weight.data = W
def STDP(Pre_mat, Post_mat, W):
T_Pre = 0
T_Post = 0
for i in range(len(Pre_mat)):
C_Pre = Pre_mat[i]
C_Post = Post_mat[i]
if sum(sum(C_Pre)) > 0:
T_Pre = i
Spike_Pre = Pre_mat[T_Pre]
if sum(sum(C_Post)) > 0:
T_Post = i
Spike_Post = Post_mat[T_Post]
if T_Pre*T_Post > 0:
dT = T_Pre - T_Post
A_up = 0.777
A_down = -0.237
tau_up = 16.8
tau_down = -33.7
if dT < 0:
dW = A_up * math.exp(dT/tau_up)
else:
dW = A_down * math.exp(dT/tau_down)
T_Post = 0
dW_mat = torch.mul(Spike_Pre, Spike_Post)*dW
W = W + torch.mul(dW_mat, W)
return W
if __name__=="__main__":
# number of neurons
num_neuron = 6
num_DLPFC = num_neuron
num_BG = num_neuron
num_StrD1 = num_neuron
num_StrD2 = num_neuron
num_Thalamus = num_neuron
num_OFC = num_neuron
num_SNc = num_neuron
num_PMC = num_neuron
##############################
# DLPFC
##############################
WeightAdd = 20
# DLPFC-BG
DLPFC_BG_connection = []
# Input-DLPFC
con_matrix0 = torch.ones([num_DLPFC, num_DLPFC], dtype=torch.float)*WeightAdd
DLPFC_BG_connection.append(CustomLinear(con_matrix0))
# DLPFC-BG
W = torch.ones([num_DLPFC, num_BG], dtype=torch.float)*WeightAdd
DLPFC_BG_connection.append(CustomLinear(W))
DLPFC = DLPFCNet(DLPFC_BG_connection)
##############################
# OFC
##############################
WeightAdd = 20
OFC_connection = []
# Tha-OFC_1 (Input1)
con_matrix0 = torch.ones([num_Thalamus, num_OFC], dtype=torch.float)*WeightAdd
OFC_connection.append(CustomLinear(con_matrix0))
# SNc/VTA-OFC_2 (Input2)
con_matrix1 = torch.ones([num_SNc, num_OFC], dtype=torch.float)*WeightAdd
OFC_connection.append(CustomLinear(con_matrix1))
# OFC_1-MOFC
con_matrix2 = torch.ones([num_OFC, num_OFC], dtype=torch.float)*WeightAdd*5
OFC_connection.append(CustomLinear(con_matrix2))
# OFC_2-LOFC
con_matrix3 = torch.ones([num_OFC, num_OFC], dtype=torch.float)*WeightAdd*5
OFC_connection.append(CustomLinear(con_matrix3))
# MOFC-LOFC
con_matrix4 = torch.ones([num_OFC, num_OFC], dtype=torch.float)*WeightAdd*-10
OFC_connection.append(CustomLinear(con_matrix4))
# OFC_1-LOFC
con_matrix5 = torch.ones([num_OFC, num_OFC], dtype=torch.float)*WeightAdd*5
OFC_connection.append(CustomLinear(con_matrix5))
OFC = OFCNet(OFC_connection)
##############################
# BGNet
##############################
BG_connection = []
WeightAdd = 20
# Input1-DLPFC
con_matrix0 = torch.ones([num_DLPFC, num_DLPFC], dtype=torch.float)*WeightAdd
BG_connection.append(CustomLinear(con_matrix0))
# Input2-StrD1
con_matrix1 = torch.ones([num_StrD1,num_StrD1], dtype=torch.float)*WeightAdd
BG_connection.append(CustomLinear(con_matrix1))
# Input3-StrD2
con_matrix2 = torch.ones([num_StrD2,num_StrD2], dtype=torch.float)*WeightAdd
BG_connection.append(CustomLinear(con_matrix2))
BG_connection.append(CustomLinear(W))
# StrD1-BG
con_matrix4 = torch.ones([num_StrD1,num_BG], dtype=torch.float)*WeightAdd
BG_connection.append(CustomLinear(con_matrix4))
# StrD2-BG
con_matrix5 = torch.ones([num_StrD2,num_BG], dtype=torch.float)*WeightAdd
BG_connection.append(CustomLinear(con_matrix5))
BG = BGNet(BG_connection)
##############################
# Train
##############################
# Intention-action corresponding rules
Intention_mat = range(num_neuron)
Action_mat = range(num_neuron)
TrainNum = 0
for k in range(len(Intention_mat)):
Intention = Intention_mat[k]
Intention_Action = Action_mat[k]
for j in range (len(Intention_mat)+1):
TrainNum = TrainNum + 1
# Intention prediction
for i in range(10):
DLPFC_Input = torch.zeros([num_DLPFC, num_DLPFC], dtype=torch.float)
DLPFC_Input[Intention,:] = 10
BG_Spike = DLPFC(DLPFC_Input)
if sum(sum(BG_Spike)).item() > 0:
Action = torch.nonzero(BG_Spike).numpy()[0][1]
break
DLPFC.reset()
PMC = torch.zeros([1, num_PMC], dtype=torch.float)
PMC[0][Action] = 1
Thalamus = torch.zeros([num_Thalamus, num_Thalamus], dtype=torch.float)
Thalamus[Intention][Action] = 10
if Intention_Action == Action:
# Positive reward
# Tha-OFC_1-MOFC, SNc-OFC_2&MOFC-LOFC
Reward = 1
Input_Tha = Thalamus
Input_SNc_Reward = torch.ones([num_OFC, num_OFC], dtype=torch.float)
Input_SNc = torch.mul(Input_SNc_Reward, PMC)*10
for t in range(10):
MOFC_Spike, LOFC_Spike = OFC(Input_Tha, Input_SNc, Reward)
else:
# Negative reward
# Tha-OFC_1-LOFC, SNc-OFC_2-LOFC (SNC is zeros)
Reward = -1
Input_Tha = Thalamus
Input_SNc = torch.zeros([num_OFC, num_OFC], dtype=torch.float)
for t in range(10):
MOFC_Spike, LOFC_Spike = OFC(Input_Tha, Input_SNc, Reward)
OFC.reset()
for i in range(1):
DLPFC_out_mat = []
BG_out_mat = []
State = 0
for t in range(10):
DLPFC_Input = MOFC_Spike + LOFC_Spike
StrD1_Input = MOFC_Spike
StrD2_Input = LOFC_Spike
DLPFC_out, BG_out = BG(DLPFC_Input, StrD1_Input, StrD2_Input)
DLPFC_out_mat.append(DLPFC_out)
BG_out_mat.append(BG_out)
W = STDP(DLPFC_out_mat, BG_out_mat, W)
BG.reset()
DLPFC.UpdateWeight(1, W)
BG.UpdateWeight(3, W)
if Reward == 1:
break
print("Train End")
print("W is: \n", W)
print("TrainNum is: \n", TrainNum)
print("*****************************")
================================================
FILE: examples/Social_Cognition/MAToM-SNN/LICENSE
================================================
GNU GENERAL PUBLIC LICENSE
Version 3, 29 June 2007
Copyright (C) 2007 Free Software Foundation, Inc.
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU General Public License is a free, copyleft license for
software and other kinds of works.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
the GNU General Public License is intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users. We, the Free Software Foundation, use the
GNU General Public License for most of our software; it applies also to
any other work released this way by its authors. You can apply it to
your programs, too.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
To protect your rights, we need to prevent others from denying you
these rights or asking you to surrender the rights. Therefore, you have
certain responsibilities if you distribute copies of the software, or if
you modify it: responsibilities to respect the freedom of others.
For example, if you distribute copies of such a program, whether
gratis or for a fee, you must pass on to the recipients the same
freedoms that you received. You must make sure that they, too, receive
or can get the source code. And you must show them these terms so they
know their rights.
Developers that use the GNU GPL protect your rights with two steps:
(1) assert copyright on the software, and (2) offer you this License
giving you legal permission to copy, distribute and/or modify it.
For the developers' and authors' protection, the GPL clearly explains
that there is no warranty for this free software. For both users' and
authors' sake, the GPL requires that modified versions be marked as
changed, so that their problems will not be attributed erroneously to
authors of previous versions.
Some devices are designed to deny users access to install or run
modified versions of the software inside them, although the manufacturer
can do so. This is fundamentally incompatible with the aim of
protecting users' freedom to change the software. The systematic
pattern of such abuse occurs in the area of products for individuals to
use, which is precisely where it is most unacceptable. Therefore, we
have designed this version of the GPL to prohibit the practice for those
products. If such problems arise substantially in other domains, we
stand ready to extend this provision to those domains in future versions
of the GPL, as needed to protect the freedom of users.
Finally, every program is threatened constantly by software patents.
States should not allow patents to restrict development and use of
software on general-purpose computers, but in those that do, we wish to
avoid the special danger that patents applied to a free program could
make it effectively proprietary. To prevent this, the GPL assures that
patents cannot be used to render the program non-free.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Use with the GNU Affero General Public License.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU Affero General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the special requirements of the GNU Affero General Public License,
section 13, concerning interaction through a network will apply to the
combination as such.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU General Public License from time to time. Such new versions will
be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
state the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
Copyright (C)
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see .
Also add information on how to contact you by electronic and paper mail.
If the program does terminal interaction, make it output a short
notice like this when it starts in an interactive mode:
Copyright (C)
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
This is free software, and you are welcome to redistribute it
under certain conditions; type `show c' for details.
The hypothetical commands `show w' and `show c' should show the appropriate
parts of the General Public License. Of course, your program's commands
might be different; for a GUI interface, you would use an "about box".
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU GPL, see
.
The GNU General Public License does not permit incorporating your program
into proprietary programs. If your program is a subroutine library, you
may consider it more useful to permit linking proprietary applications with
the library. If this is what you want to do, use the GNU Lesser General
Public License instead of this License. But first, please read
.
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/agents/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/agents/agents.py
================================================
import torch
from torch import Tensor
from torch.autograd import Variable
from torch.optim import Adam
from MPE.utils.networks import MLPNetwork, RNN, SNNNetwork
from MPE.utils.misc import hard_update, gumbel_softmax, onehot_from_logits
from MPE.utils.noise import OUNoise
import time
class DDPGAgent(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, hidden_dim=64,
lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.policy = MLPNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.critic = MLPNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
self.target_policy = MLPNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.target_critic = MLPNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action = self.policy(obs)
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1)
else:
action = gumbel_softmax(action, hard=True)
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5]), onehot_from_logits(action[:, 5:])), 1)
else:
action = onehot_from_logits(action)
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
return {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict()}
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
class DDPGAgent_RNN(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, hidden_dim=64,
lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.policy = RNN(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.critic = RNN(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
self.target_policy = RNN(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
constrain_out=True,
discrete_action=discrete_action)
self.target_critic = RNN(num_in_critic, 1,
hidden_dim=hidden_dim,
constrain_out=False)
self.policy_hidden = None
self.policy_target_hidden = None
self.critic_hidden = None
self.critic_target_hidden = None
self.num_in_pol = num_in_pol
self.num_out_pol = num_out_pol
self.hidden_dim = hidden_dim
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action, self.policy_hidden = self.policy(obs, self.policy_hidden)
if self.discrete_action:
if explore:
action = gumbel_softmax(action, hard=True)
else:
action = onehot_from_logits(action)
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
return {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict()}
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
def init_hidden(self, len_ep, policy_hidden=False, policy_target_hidden=False, \
critic_hidden=False, critic_target_hidden=False):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
if policy_hidden == True:
self.policy_hidden = torch.zeros((len_ep, self.hidden_dim))
if policy_target_hidden == True:
self.policy_target_hidden = torch.zeros((len_ep, self.hidden_dim))
if critic_hidden == True:
self.critic_hidden = torch.zeros((len_ep, self.hidden_dim))
if critic_target_hidden == True:
self.critic_target_hidden = torch.zeros((len_ep, self.hidden_dim))
class DDPGAgent_SNN(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, output_style, hidden_dim=64,
lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.policy = SNNNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
output_style=output_style)
self.critic = SNNNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
output_style=output_style)
self.target_policy = SNNNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
output_style=output_style)
self.target_critic = SNNNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
output_style=output_style)
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
# t1 = time.time()
action = self.policy(obs)
# t2 = time.time()
# print('time_interaction:', t2 - t1)
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1)
else:
action = gumbel_softmax(action, hard=True)
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5]), onehot_from_logits(action[:, 5:])), 1)
else:
action = onehot_from_logits(action)
# if explore:
#
# action = gumbel_softmax(action, hard=True)
#
# else:
# action = onehot_from_logits(action)
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
return {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict()}
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
class DDPGAgent_ToM(object):
"""
General class for DDPG agents (policy, critic, target policy, target
critic, exploration noise)
"""
def __init__(self, num_in_pol, num_out_pol, num_in_critic, num_in_mle, output_style,
num_agents, device, hidden_dim=64, lr=0.01, discrete_action=True):
"""
Inputs:
num_in_pol (int): number of dimensions for policy input
num_out_pol (int): number of dimensions for policy output
num_in_critic (int): number of dimensions for critic input
"""
self.device = device
self.policy = SNNNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
output_style=output_style)
self.critic = SNNNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
output_style=output_style)
self.target_policy = SNNNetwork(num_in_pol, num_out_pol,
hidden_dim=hidden_dim,
output_style=output_style)
self.target_critic = SNNNetwork(num_in_critic, 1,
hidden_dim=hidden_dim,
output_style=output_style)
# self.mle = [SNNNetwork(num_in_mle, num_out_pol,
# hidden_dim=hidden_dim,
# output_style=output_style)] * (num_agents - 1)
self.mle = []
hard_update(self.target_policy, self.policy)
hard_update(self.target_critic, self.critic)
self.policy_optimizer = Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = Adam(self.critic.parameters(), lr=lr)
self.mle_optimizer = []
if not discrete_action:
self.exploration = OUNoise(num_out_pol)
else:
self.exploration = 0.3 # epsilon for eps-greedy
self.discrete_action = discrete_action
def reset_noise(self):
if not self.discrete_action:
self.exploration.reset()
def scale_noise(self, scale):
if self.discrete_action:
self.exploration = scale
else:
self.exploration.scale = scale
def step(self, obs, explore=False):
"""
Take a step forward in environment for a minibatch of observations
Inputs:
obs (PyTorch Variable): Observations for this agent
explore (boolean): Whether or not to add exploration noise
Outputs:
action (PyTorch Variable): Actions for this agent
"""
action = self.policy.to(self.device)(obs.to(self.device))
if self.discrete_action:
if explore:
if action.shape[1] == 9:
action = torch.cat(
(gumbel_softmax(action[:, :5], hard=True), gumbel_softmax(action[:, 5:], hard=True)), 1).cpu()
else:
action = gumbel_softmax(action, hard=True).cpu()
else:
if action.shape[1] == 9:
action = torch.cat(
(onehot_from_logits(action[:, :5], hard=True), onehot_from_logits(action[:, 5:], hard=True)), 1)
else:
action = onehot_from_logits(action).cpu()
# if explore:
# action = gumbel_softmax(action, hard=True).cpu()
# else:
# action = onehot_from_logits(action).cpu()
else: # continuous action
if explore:
action += Variable(Tensor(self.exploration.noise()),
requires_grad=False)
action = action.clamp(-1, 1)
return action
def get_params(self):
params = {'policy': self.policy.state_dict(),
'critic': self.critic.state_dict(),
'target_policy': self.target_policy.state_dict(),
'target_critic': self.target_critic.state_dict(),
'policy_optimizer': self.policy_optimizer.state_dict(),
'critic_optimizer': self.critic_optimizer.state_dict(),
}
# for i in range(len(self.mle)):
# params['mle%d'%i] = self.mle[i].state_dict()
# params['mle_optimizer%d'%i] = self.mle_optimizer[i].state_dict()
return params
def load_params(self, params):
self.policy.load_state_dict(params['policy'])
self.critic.load_state_dict(params['critic'])
self.target_policy.load_state_dict(params['target_policy'])
self.target_critic.load_state_dict(params['target_critic'])
self.policy_optimizer.load_state_dict(params['policy_optimizer'])
self.critic_optimizer.load_state_dict(params['critic_optimizer'])
# for i in range(len(self.mle)):
# self.mle[i].load_state_dict(params['mle%d'%i])
# self.mle_optimizer[i].load_state_dict(params['mle_optimizer%d'%i])
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/common/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/common/distributions.py
================================================
# import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
import numpy as np
import maddpg.common.tf_util as U
from tensorflow.python.ops import math_ops
from multiagent.multi_discrete import MultiDiscrete
from tensorflow.python.ops import nn
class Pd(object):
"""
A particular probability distribution
"""
def flatparam(self):
raise NotImplementedError
def mode(self):
raise NotImplementedError
def logp(self, x):
raise NotImplementedError
def kl(self, other):
raise NotImplementedError
def entropy(self):
raise NotImplementedError
def sample(self):
raise NotImplementedError
class PdType(object):
"""
Parametrized family of probability distributions
"""
def pdclass(self):
raise NotImplementedError
def pdfromflat(self, flat):
return self.pdclass()(flat)
def param_shape(self):
raise NotImplementedError
def sample_shape(self):
raise NotImplementedError
def sample_dtype(self):
raise NotImplementedError
def param_placeholder(self, prepend_shape, name=None):
return tf.placeholder(dtype=tf.float32, shape=prepend_shape+self.param_shape(), name=name)
def sample_placeholder(self, prepend_shape, name=None):
return tf.placeholder(dtype=self.sample_dtype(), shape=prepend_shape+self.sample_shape(), name=name)
class CategoricalPdType(PdType):
def __init__(self, ncat):
self.ncat = ncat
def pdclass(self):
return CategoricalPd
def param_shape(self):
return [self.ncat]
def sample_shape(self):
return []
def sample_dtype(self):
return tf.int32
class SoftCategoricalPdType(PdType):
def __init__(self, ncat):
self.ncat = ncat
def pdclass(self):
return SoftCategoricalPd
def param_shape(self):
return [self.ncat]
def sample_shape(self):
return [self.ncat]
def sample_dtype(self):
return tf.float32
class MultiCategoricalPdType(PdType):
def __init__(self, low, high):
self.low = low
self.high = high
self.ncats = high - low + 1
def pdclass(self):
return MultiCategoricalPd
def pdfromflat(self, flat):
return MultiCategoricalPd(self.low, self.high, flat)
def param_shape(self):
return [sum(self.ncats)]
def sample_shape(self):
return [len(self.ncats)]
def sample_dtype(self):
return tf.int32
class SoftMultiCategoricalPdType(PdType):
def __init__(self, low, high):
self.low = low
self.high = high
self.ncats = high - low + 1
def pdclass(self):
return SoftMultiCategoricalPd
def pdfromflat(self, flat):
return SoftMultiCategoricalPd(self.low, self.high, flat)
def param_shape(self):
return [sum(self.ncats)]
def sample_shape(self):
return [sum(self.ncats)]
def sample_dtype(self):
return tf.float32
class DiagGaussianPdType(PdType):
def __init__(self, size):
self.size = size
def pdclass(self):
return DiagGaussianPd
def param_shape(self):
return [2*self.size]
def sample_shape(self):
return [self.size]
def sample_dtype(self):
return tf.float32
class BernoulliPdType(PdType):
def __init__(self, size):
self.size = size
def pdclass(self):
return BernoulliPd
def param_shape(self):
return [self.size]
def sample_shape(self):
return [self.size]
def sample_dtype(self):
return tf.int32
# WRONG SECOND DERIVATIVES
# class CategoricalPd(Pd):
# def __init__(self, logits):
# self.logits = logits
# self.ps = tf.nn.softmax(logits)
# @classmethod
# def fromflat(cls, flat):
# return cls(flat)
# def flatparam(self):
# return self.logits
# def mode(self):
# return U.argmax(self.logits, axis=1)
# def logp(self, x):
# return -tf.nn.sparse_softmax_cross_entropy_with_logits(self.logits, x)
# def kl(self, other):
# return tf.nn.softmax_cross_entropy_with_logits(other.logits, self.ps) \
# - tf.nn.softmax_cross_entropy_with_logits(self.logits, self.ps)
# def entropy(self):
# return tf.nn.softmax_cross_entropy_with_logits(self.logits, self.ps)
# def sample(self):
# u = tf.random_uniform(tf.shape(self.logits))
# return U.argmax(self.logits - tf.log(-tf.log(u)), axis=1)
class CategoricalPd(Pd):
def __init__(self, logits):
self.logits = logits
def flatparam(self):
return self.logits
def mode(self):
return U.argmax(self.logits, axis=1)
def logp(self, x):
return -tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.logits, labels=x)
def kl(self, other):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
a1 = other.logits - U.max(other.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
ea1 = tf.exp(a1)
z0 = U.sum(ea0, axis=1, keepdims=True)
z1 = U.sum(ea1, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (a0 - tf.log(z0) - a1 + tf.log(z1)), axis=1)
def entropy(self):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
z0 = U.sum(ea0, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (tf.log(z0) - a0), axis=1)
def sample(self):
u = tf.random_uniform(tf.shape(self.logits))
return U.argmax(self.logits - tf.log(-tf.log(u)), axis=1)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class SoftCategoricalPd(Pd):
def __init__(self, logits):
self.logits = logits
def flatparam(self):
return self.logits
def mode(self):
return U.softmax(self.logits, axis=-1)
def logp(self, x):
return -tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=x)
def kl(self, other):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
a1 = other.logits - U.max(other.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
ea1 = tf.exp(a1)
z0 = U.sum(ea0, axis=1, keepdims=True)
z1 = U.sum(ea1, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (a0 - tf.log(z0) - a1 + tf.log(z1)), axis=1)
def entropy(self):
a0 = self.logits - U.max(self.logits, axis=1, keepdims=True)
ea0 = tf.exp(a0)
z0 = U.sum(ea0, axis=1, keepdims=True)
p0 = ea0 / z0
return U.sum(p0 * (tf.log(z0) - a0), axis=1)
def sample(self):
u = tf.random_uniform(tf.shape(self.logits))
return U.softmax(self.logits - tf.log(-tf.log(u)), axis=-1)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class MultiCategoricalPd(Pd):
def __init__(self, low, high, flat):
self.flat = flat
self.low = tf.constant(low, dtype=tf.int32)
self.categoricals = list(map(CategoricalPd, tf.split(flat, high - low + 1, axis=len(flat.get_shape()) - 1)))
def flatparam(self):
return self.flat
def mode(self):
return self.low + tf.cast(tf.stack([p.mode() for p in self.categoricals], axis=-1), tf.int32)
def logp(self, x):
return tf.add_n([p.logp(px) for p, px in zip(self.categoricals, tf.unstack(x - self.low, axis=len(x.get_shape()) - 1))])
def kl(self, other):
return tf.add_n([
p.kl(q) for p, q in zip(self.categoricals, other.categoricals)
])
def entropy(self):
return tf.add_n([p.entropy() for p in self.categoricals])
def sample(self):
return self.low + tf.cast(tf.stack([p.sample() for p in self.categoricals], axis=-1), tf.int32)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class SoftMultiCategoricalPd(Pd): # doesn't work yet
def __init__(self, low, high, flat):
self.flat = flat
self.low = tf.constant(low, dtype=tf.float32)
self.categoricals = list(map(SoftCategoricalPd, tf.split(flat, high - low + 1, axis=len(flat.get_shape()) - 1)))
def flatparam(self):
return self.flat
def mode(self):
x = []
for i in range(len(self.categoricals)):
x.append(self.low[i] + self.categoricals[i].mode())
return tf.concat(x, axis=-1)
def logp(self, x):
return tf.add_n([p.logp(px) for p, px in zip(self.categoricals, tf.unstack(x - self.low, axis=len(x.get_shape()) - 1))])
def kl(self, other):
return tf.add_n([
p.kl(q) for p, q in zip(self.categoricals, other.categoricals)
])
def entropy(self):
return tf.add_n([p.entropy() for p in self.categoricals])
def sample(self):
x = []
for i in range(len(self.categoricals)):
x.append(self.low[i] + self.categoricals[i].sample())
return tf.concat(x, axis=-1)
@classmethod
def fromflat(cls, flat):
return cls(flat)
class DiagGaussianPd(Pd):
def __init__(self, flat):
self.flat = flat
mean, logstd = tf.split(axis=1, num_or_size_splits=2, value=flat)
self.mean = mean
self.logstd = logstd
self.std = tf.exp(logstd)
def flatparam(self):
return self.flat
def mode(self):
return self.mean
def logp(self, x):
return - 0.5 * U.sum(tf.square((x - self.mean) / self.std), axis=1) \
- 0.5 * np.log(2.0 * np.pi) * tf.to_float(tf.shape(x)[1]) \
- U.sum(self.logstd, axis=1)
def kl(self, other):
assert isinstance(other, DiagGaussianPd)
return U.sum(other.logstd - self.logstd + (tf.square(self.std) + tf.square(self.mean - other.mean)) / (2.0 * tf.square(other.std)) - 0.5, axis=1)
def entropy(self):
return U.sum(self.logstd + .5 * np.log(2.0 * np.pi * np.e), 1)
def sample(self):
return self.mean + self.std * tf.random_normal(tf.shape(self.mean))
@classmethod
def fromflat(cls, flat):
return cls(flat)
class BernoulliPd(Pd):
def __init__(self, logits):
self.logits = logits
self.ps = tf.sigmoid(logits)
def flatparam(self):
return self.logits
def mode(self):
return tf.round(self.ps)
def logp(self, x):
return - U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=tf.to_float(x)), axis=1)
def kl(self, other):
return U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=other.logits, labels=self.ps), axis=1) - U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=self.ps), axis=1)
def entropy(self):
return U.sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=self.ps), axis=1)
def sample(self):
p = tf.sigmoid(self.logits)
u = tf.random_uniform(tf.shape(p))
return tf.to_float(math_ops.less(u, p))
@classmethod
def fromflat(cls, flat):
return cls(flat)
def make_pdtype(ac_space):
from gym import spaces
if isinstance(ac_space, spaces.Box):
assert len(ac_space.shape) == 1
return DiagGaussianPdType(ac_space.shape[0])
elif isinstance(ac_space, spaces.Discrete):
# return CategoricalPdType(ac_space.n)
return SoftCategoricalPdType(ac_space.n)
elif isinstance(ac_space, MultiDiscrete):
#return MultiCategoricalPdType(ac_space.low, ac_space.high)
return SoftMultiCategoricalPdType(ac_space.low, ac_space.high)
elif isinstance(ac_space, spaces.MultiBinary):
return BernoulliPdType(ac_space.n)
else:
raise NotImplementedError
def shape_el(v, i):
maybe = v.get_shape()[i]
if maybe is not None:
return maybe
else:
return tf.shape(v)[i]
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/common/tile_images.py
================================================
import numpy as np
def tile_images(img_nhwc):
"""
Tile N images into one big PxQ image
(P,Q) are chosen to be as close as possible, and if N
is square, then P=Q.
input: img_nhwc, list or array of images, ndim=4 once turned into array
n = batch index, h = height, w = width, c = channel
returns:
bigim_HWc, ndarray with ndim=3
"""
img_nhwc = np.asarray(img_nhwc)
N, h, w, c = img_nhwc.shape
H = int(np.ceil(np.sqrt(N)))
W = int(np.ceil(float(N)/H))
img_nhwc = np.array(list(img_nhwc) + [img_nhwc[0]*0 for _ in range(N, H*W)])
img_HWhwc = img_nhwc.reshape(H, W, h, w, c)
img_HhWwc = img_HWhwc.transpose(0, 2, 1, 3, 4)
img_Hh_Ww_c = img_HhWwc.reshape(H*h, W*w, c)
return img_Hh_Ww_c
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/common/vec_env/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/common/vec_env/vec_env.py
================================================
import contextlib
import os
from abc import ABC, abstractmethod
from common.tile_images import tile_images
class AlreadySteppingError(Exception):
"""
Raised when an asynchronous step is running while
step_async() is called again.
"""
def __init__(self):
msg = 'already running an async step'
Exception.__init__(self, msg)
class NotSteppingError(Exception):
"""
Raised when an asynchronous step is not running but
step_wait() is called.
"""
def __init__(self):
msg = 'not running an async step'
Exception.__init__(self, msg)
class VecEnv(ABC):
"""
An abstract asynchronous, vectorized environment.
Used to batch data from multiple copies of an environment, so that
each observation becomes an batch of observations, and expected action is a batch of actions to
be applied per-environment.
"""
closed = False
viewer = None
metadata = {
'render.modes': ['human', 'rgb_array']
}
def __init__(self, num_envs, observation_space, action_space):
self.num_envs = num_envs
self.observation_space = observation_space
self.action_space = action_space
@abstractmethod
def reset(self):
"""
Reset all the environments and return an array of
observations, or a dict of observation arrays.
If step_async is still doing work, that work will
be cancelled and step_wait() should not be called
until step_async() is invoked again.
"""
pass
@abstractmethod
def step_async(self, actions):
"""
Tell all the environments to start taking a step
with the given actions.
Call step_wait() to get the results of the step.
You should not call this if a step_async run is
already pending.
"""
pass
@abstractmethod
def step_wait(self):
"""
Wait for the step taken with step_async().
Returns (obs, rews, dones, infos):
- obs: an array of observations, or a dict of
arrays of observations.
- rews: an array of rewards
- dones: an array of "episode done" booleans
- infos: a sequence of info objects
"""
pass
def close_extras(self):
"""
Clean up the extra resources, beyond what's in this base class.
Only runs when not self.closed.
"""
pass
def close(self):
if self.closed:
return
if self.viewer is not None:
self.viewer.close()
self.close_extras()
self.closed = True
def step(self, actions):
"""
Step the environments synchronously.
This is available for backwards compatibility.
"""
self.step_async(actions)
return self.step_wait()
def render(self, mode='human'):
imgs = self.get_images()
bigimg = tile_images(imgs)
if mode == 'human':
self.get_viewer().imshow(bigimg)
return self.get_viewer().isopen
elif mode == 'rgb_array':
return bigimg
else:
raise NotImplementedError
def get_images(self):
"""
Return RGB images from each environment
"""
raise NotImplementedError
@property
def unwrapped(self):
if isinstance(self, VecEnvWrapper):
return self.venv.unwrapped
else:
return self
def get_viewer(self):
if self.viewer is None:
from gym.envs.classic_control import rendering
self.viewer = rendering.SimpleImageViewer()
return self.viewer
class VecEnvWrapper(VecEnv):
"""
An environment wrapper that applies to an entire batch
of environments at once.
"""
def __init__(self, venv, observation_space=None, action_space=None):
self.venv = venv
super().__init__(num_envs=venv.num_envs,
observation_space=observation_space or venv.observation_space,
action_space=action_space or venv.action_space)
def step_async(self, actions):
self.venv.step_async(actions)
@abstractmethod
def reset(self):
pass
@abstractmethod
def step_wait(self):
pass
def close(self):
return self.venv.close()
def render(self, mode='human'):
return self.venv.render(mode=mode)
def get_images(self):
return self.venv.get_images()
def __getattr__(self, name):
if name.startswith('_'):
raise AttributeError("attempted to get missing private attribute '{}'".format(name))
return getattr(self.venv, name)
class VecEnvObservationWrapper(VecEnvWrapper):
@abstractmethod
def process(self, obs):
pass
def reset(self):
obs = self.venv.reset()
return self.process(obs)
def step_wait(self):
obs, rews, dones, infos = self.venv.step_wait()
return self.process(obs), rews, dones, infos
class CloudpickleWrapper(object):
"""
Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)
"""
def __init__(self, x):
self.x = x
def __getstate__(self):
import cloudpickle
return cloudpickle.dumps(self.x)
def __setstate__(self, ob):
import pickle
self.x = pickle.loads(ob)
@contextlib.contextmanager
def clear_mpi_env_vars():
"""
from mpi4py import MPI will call MPI_Init by default. If the child process has MPI environment variables, MPI will think that the child process is an MPI process just like the parent and do bad things such as hang.
This context manager is a hacky way to clear those environment variables temporarily such as when we are starting multiprocessing
Processes.
"""
removed_environment = {}
for k, v in list(os.environ.items()):
for prefix in ['OMPI_', 'PMI_']:
if k.startswith(prefix):
removed_environment[k] = v
del os.environ[k]
try:
yield
finally:
os.environ.update(removed_environment)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/main.py
================================================
import argparse
import torch
import time
import os
import numpy as np
from gym.spaces import Box, Discrete, MultiDiscrete
from pathlib import Path
from torch.autograd import Variable
from tensorboardX import SummaryWriter
from utils.make_env import make_env
from utils.buffer import ReplayBuffer, ReplayBuffer_pre
from utils.env_wrappers import SubprocVecEnv, DummyVecEnv
from policy.maddpg import MADDPG, MADDPG_SNN, MADDPG_ToM, ToM_SA, ToM_S, ToM_self
from tqdm import tqdm
def get_common_args():
parser = argparse.ArgumentParser()
parser.add_argument("--env_id", default='simple_world_comm', type=str,
choices=['simple_tag', 'simple_adversary', 'simple_push', 'simple_world_comm'],
help="Name of environment")
parser.add_argument("--model_name", default='ann', type=str,
help="Name of directory to store " +
"model/training contents") #ToM_SA
parser.add_argument("--seed",
default=1, type=int,
help="Random seed")
parser.add_argument("--cuda_num",
default=7, type=int,
help="device")
parser.add_argument("--output_style",
default='sum', type=str,
choices=['sum', 'voltage'])
parser.add_argument("--n_rollout_threads", default=20, type=int)
parser.add_argument("--n_training_threads", default=6, type=int)
parser.add_argument("--buffer_length", default=int(1e6), type=int)
parser.add_argument("--n_episodes", default=15000, type=int)#
parser.add_argument("--episode_length", default=25, type=int)
parser.add_argument("--steps_per_update", default=100, type=int)
parser.add_argument("--batch_size",
default=1024, type=int,#4
help="Batch size for model training")
parser.add_argument("--n_exploration_eps", default=25000, type=int)
parser.add_argument("--init_noise_scale", default=0.3, type=float)
parser.add_argument("--final_noise_scale", default=0.0, type=float)
parser.add_argument("--save_interval", default=1000, type=int)
parser.add_argument("--hidden_dim", default=64, type=int)
parser.add_argument("--lr", default=0.01, type=float)
parser.add_argument("--tau", default=0.01, type=float)
parser.add_argument("--agent_alg",
default="MADDPG_ToM", type=str,
choices=['MADDPG', 'DDPG', 'MADDPG_SNN', 'MADDPG_ToM', 'ToM_SA', 'ToM_S', 'ToM_self'])
parser.add_argument("--adversary_alg",
default="MADDPG_ToM", type=str,
choices=['MADDPG', 'DDPG', 'MADDPG_SNN', 'MADDPG_ToM', 'ToM_SA', 'ToM_S', 'ToM_self'])
parser.add_argument("--discrete_action",
# default=False, type=bool,
action='store_true')
args = parser.parse_args()
parser.add_argument('--device', type=str, default='cuda:{}'.format(args.cuda_num), help='whether to use the GPU') #'cuda:1'
parser = parser.parse_args()
return parser
USE_CUDA = torch.cuda.is_available()
def make_parallel_env(env_id, n_rollout_threads, seed, discrete_action):
def get_env_fn(rank):
def init_env():
env = make_env(env_id, discrete_action=discrete_action)
env.seed(seed + rank * 1000)
np.random.seed(seed + rank * 1000)
return env
return init_env
if n_rollout_threads == 1:
return DummyVecEnv([get_env_fn(0)])
else:
return SubprocVecEnv([get_env_fn(i) for i in range(n_rollout_threads)])
def run(config):
pbar = tqdm(config.n_episodes)
model_dir = Path('./models') / config.env_id / config.model_name
if not model_dir.exists():
curr_run = 'run1'
else:
exst_run_nums = [int(str(folder.name).split('run')[1]) for folder in
model_dir.iterdir() if
str(folder.name).startswith('run')]
if len(exst_run_nums) == 0:
curr_run = 'run1'
else:
curr_run = 'run%i' % (max(exst_run_nums) + 1)
run_dir = model_dir / curr_run
log_dir = run_dir / 'logs'
os.makedirs(log_dir)
logger = SummaryWriter(str(log_dir))
torch.manual_seed(config.seed)
np.random.seed(config.seed)
if not USE_CUDA:
torch.set_num_threads(config.n_training_threads)
env = make_parallel_env(config.env_id, config.n_rollout_threads, config.seed,
config.discrete_action)
if config.agent_alg == 'MADDPG' or config.agent_alg == 'DDPG':
print('_____MADDPG_____')
maddpg = MADDPG.init_from_env(env, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
device=config.device)
elif config.agent_alg == 'MADDPG_SNN':
print('_____MADDPG_SNN_____')
maddpg = MADDPG_SNN.init_from_env(env, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
elif config.agent_alg == 'MADDPG_ToM':
print('_____MADDPG_ToM_____')
maddpg = MADDPG_ToM.init_from_env(env, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
elif config.agent_alg == 'ToM_SA':
print('_______ToM_SA_______')
maddpg = ToM_SA.init_from_env(env, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
elif config.agent_alg == 'ToM_S':
print('_______ToM_S_______')
maddpg = ToM_S.init_from_env(env, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
print('_______ToM_self_______')
maddpg = ToM_self.init_from_env(env, agent_alg=config.agent_alg,
adversary_alg=config.adversary_alg,
tau=config.tau,
lr=config.lr,
hidden_dim=config.hidden_dim,
output_style=config.output_style,
device=config.device)
if config.agent_alg == 'ToM_SA'or config.agent_alg == 'ToM_S' or config.agent_alg == 'ToM_self' or config.agent_alg == 'ToM_SB':
replay_buffer = ReplayBuffer_pre(config.buffer_length, maddpg.nagents,
[obsp.shape[0] for obsp in env.observation_space],
[acsp.n if isinstance(acsp, Discrete) else sum(acsp.high - acsp.low + 1)
for acsp in env.action_space],
device=config.device)
else:
replay_buffer = ReplayBuffer(config.buffer_length, maddpg.nagents,
[obsp.shape[0] for obsp in env.observation_space],
[acsp.n if isinstance(acsp, Discrete) else sum(acsp.high - acsp.low + 1)
for acsp in env.action_space],
device=config.device)
t = 0
total_reward = []
for agent_i in range(maddpg.nagents):
total_reward.append([])
for ep_i in range(0, config.n_episodes, config.n_rollout_threads):
# print("Episodes %i-%i of %i" % (ep_i + 1,
# ep_i + 1 + config.n_rollout_threads,
# config.n_episodes))
obs = env.reset()
# obs.shape = (n_rollout_threads, nagent)(nobs), nobs differs per agent so not tensor
maddpg.prep_rollouts(device='cpu')
torch_agent_actions = [torch.zeros((config.n_rollout_threads, 5)) for i in range(maddpg.nagents)]
explr_pct_remaining = max(0, config.n_exploration_eps - ep_i) / config.n_exploration_eps
maddpg.scale_noise(config.final_noise_scale + (config.init_noise_scale - config.final_noise_scale) * explr_pct_remaining)
maddpg.reset_noise()
obs_ep = []
agent_actions_ep = []
rewards_ep = []
next_obs_ep = []
dones_ep = []
for et_i in range(config.episode_length):
torch_agent_actions_pre = torch_agent_actions
torch_agent_actions_pre = [ac.data.numpy() for ac in torch_agent_actions_pre]
# rearrange observations to be per agent, and convert to torch Variable
torch_obs = [Variable(torch.Tensor(np.vstack(obs[:, i])),
requires_grad=False)
for i in range(maddpg.nagents)] #
# get actions as torch Variables
# t1 = time.time()
if config.agent_alg == 'ToM_SA' or config.agent_alg == 'ToM_S' or config.agent_alg == 'ToM_self' or config.agent_alg == 'ToM_SB':
torch_agent_actions = maddpg.step(torch_obs, torch_agent_actions, explore=True)
else:
torch_agent_actions = maddpg.step(torch_obs, explore=True)
# t2 = time.time()
# print('time_step:', t2-t1)
# convert actions to numpy arrays
agent_actions = [ac.data.numpy() for ac in torch_agent_actions] #
# rearrange actions to be per environment
actions = [[ac[i] for ac in agent_actions] for i in range(config.n_rollout_threads)]
next_obs, rewards, dones, infos = env.step(actions)
obs_ep.append(obs) #episode_id,process, n_agents, dim
agent_actions_ep.append(actions) #episode_id, n_agents, process, dim
rewards_ep.append(rewards) #episode_id,process, n_agents,
next_obs_ep.append(next_obs) #episode_id,process, n_agents, dim
dones_ep.append(dones) #episode_id,process, n_agents,
if config.agent_alg == 'ToM_SA' or config.agent_alg == 'ToM_S' or config.agent_alg == 'ToM_self'or config.agent_alg == 'ToM_SB':
replay_buffer.push(torch_agent_actions_pre, obs, agent_actions, rewards, next_obs, dones)
else:
replay_buffer.push(obs, agent_actions, rewards, next_obs, dones)
obs = next_obs
t += config.n_rollout_threads
if (len(replay_buffer) >= config.batch_size and
(t % config.steps_per_update) < config.n_rollout_threads):
if USE_CUDA:
maddpg.prep_training(device='gpu')
else:
maddpg.prep_training(device='cpu')
if config.n_episodes >300:
rollout = 2
else:
rollout = config.n_rollout_threads
for u_i in range(rollout):
for a_i in range(maddpg.nagents):
sample = replay_buffer.sample(config.batch_size,
to_gpu=USE_CUDA)
# t1 = time.time()
maddpg.update(sample, a_i, logger=logger)
# t2 = time.time()
# print('trian_time:', t2-t1, u_i, a_i)
maddpg.update_all_targets()
maddpg.prep_rollouts(device='cpu')
ep_rews = replay_buffer.get_average_rewards(
config.episode_length * config.n_rollout_threads)
for a_i, a_ep_rew in enumerate(ep_rews):
logger.add_scalar('agent%i/mean_episode_rewards' % a_i,
a_ep_rew,
ep_i)
logger.add_scalar('agent_mean/mean_episode_rewards',
np.mean(ep_rews),
ep_i)
if ep_i % config.save_interval < config.n_rollout_threads:
os.makedirs(run_dir / 'incremental', exist_ok=True)
maddpg.save(run_dir / 'incremental' / ('model_ep%i.pt' % (ep_i + 1)))
maddpg.save(run_dir / 'model.pt')
pbar.update(config.n_rollout_threads)
pbar.close()
maddpg.save(run_dir / 'model.pt')
env.close()
logger.export_scalars_to_json(str(log_dir / 'summary.json'))
logger.close()
for a_i, reward in enumerate(total_reward):
reward_dir = str(log_dir) + '/agent{}/mean_episode_rewards'.format(a_i) + '/episode_rewards_{}'.format(config.cuda_num)
os.makedirs(reward_dir)
np.save(reward_dir, reward)
if __name__ == '__main__':
config = get_common_args()
# config.env_id = 'simple_tag'
# # config.model_name = 'ma2c'
config.agent_alg = 'ToM_SB'#
config.adversary_alg = 'ToM_SB'
#
run(config)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/__init__.py
================================================
from gym.envs.registration import register
# Multiagent envs
# ----------------------------------------
register(
id='MultiagentSimple-v0',
entry_point='multiagent.envs:SimpleEnv',
# FIXME(cathywu) currently has to be exactly max_path_length parameters in
# rllab run script
max_episode_steps=100,
)
register(
id='MultiagentSimpleSpeakerListener-v0',
entry_point='multiagent.envs:SimpleSpeakerListenerEnv',
max_episode_steps=100,
)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/__init__.py
================================================
import imp
import os.path as osp
def load(name):
pathname = osp.join(osp.dirname(__file__), name)
return imp.load_source('', pathname)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/simple.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# add agents
world.agents = [Agent() for i in range(1)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.silent = True
# add landmarks
world.landmarks = [Landmark() for i in range(1)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25,0.25,0.25])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.75,0.75,0.75])
world.landmarks[0].color = np.array([0.75,0.25,0.25])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
dist2 = np.sum(np.square(agent.state.p_pos - world.landmarks[0].state.p_pos))
return -dist2
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
return np.concatenate([agent.state.p_vel] + entity_pos)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/simple_crypto.py
================================================
"""
Scenario:
1 speaker, 2 listeners (one of which is an adversary). Good agents rewarded for proximity to goal, and distance from
adversary to goal. Adversary is rewarded for its distance to the goal.
"""
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
import random
class CryptoAgent(Agent):
def __init__(self):
super(CryptoAgent, self).__init__()
self.key = None
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
num_agents = 3
num_adversaries = 1
num_landmarks = 2
world.dim_c = 4
# add agents
world.agents = [CryptoAgent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.adversary = True if i < num_adversaries else False
agent.speaker = True if i == 2 else False
agent.movable = False
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25, 0.25, 0.25])
if agent.adversary:
agent.color = np.array([0.75, 0.25, 0.25])
agent.key = None
# random properties for landmarks
color_list = [np.zeros(world.dim_c) for i in world.landmarks]
for i, color in enumerate(color_list):
color[i] += 1
for color, landmark in zip(color_list, world.landmarks):
landmark.color = color
# set goal landmark
goal = np.random.choice(world.landmarks)
world.agents[1].color = goal.color
world.agents[2].key = np.random.choice(world.landmarks).color
for agent in world.agents:
agent.goal_a = goal
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
return (agent.state.c, agent.goal_a.color)
# return all agents that are not adversaries
def good_listeners(self, world):
return [agent for agent in world.agents if not agent.adversary and not agent.speaker]
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# Agents rewarded if Bob can reconstruct message, but adversary (Eve) cannot
good_listeners = self.good_listeners(world)
adversaries = self.adversaries(world)
good_rew = 0
adv_rew = 0
for a in good_listeners:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
good_rew -= np.sum(np.square(a.state.c - agent.goal_a.color))
for a in adversaries:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
adv_l1 = np.sum(np.square(a.state.c - agent.goal_a.color))
adv_rew += adv_l1
return adv_rew + good_rew
def adversary_reward(self, agent, world):
# Adversary (Eve) is rewarded if it can reconstruct original goal
rew = 0
if not (agent.state.c == np.zeros(world.dim_c)).all():
rew -= np.sum(np.square(agent.state.c - agent.goal_a.color))
return rew
def observation(self, agent, world):
# goal color
goal_color = np.zeros(world.dim_color)
if agent.goal_a is not None:
goal_color = agent.goal_a.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent or (other.state.c is None) or not other.speaker: continue
comm.append(other.state.c)
confer = np.array([0])
if world.agents[2].key is None:
confer = np.array([1])
key = np.zeros(world.dim_c)
goal_color = np.zeros(world.dim_c)
else:
key = world.agents[2].key
prnt = False
# speaker
if agent.speaker:
if prnt:
print('speaker')
print(agent.state.c)
print(np.concatenate([goal_color] + [key] + [confer] + [np.random.randn(1)]))
return np.concatenate([goal_color] + [key])
# listener
if not agent.speaker and not agent.adversary:
if prnt:
print('listener')
print(agent.state.c)
print(np.concatenate([key] + comm + [confer]))
return np.concatenate([key] + comm)
if not agent.speaker and agent.adversary:
if prnt:
print('adversary')
print(agent.state.c)
print(np.concatenate(comm + [confer]))
return np.concatenate(comm)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/simple_push.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
world.dim_c = 2
num_agents = 2
num_adversaries = 1
num_landmarks = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
if i < num_adversaries:
agent.adversary = True
else:
agent.adversary = False
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.1, 0.1, 0.1])
landmark.color[i + 1] += 0.8
landmark.index = i
# set goal landmark
goal = np.random.choice(world.landmarks)
for i, agent in enumerate(world.agents):
agent.goal_a = goal
agent.color = np.array([0.25, 0.25, 0.25])
if agent.adversary:
agent.color = np.array([0.75, 0.25, 0.25])
else:
j = goal.index
agent.color[j + 1] += 0.5
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# the distance to the goal
return -np.sqrt(np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos)))
def adversary_reward(self, agent, world):
# keep the nearest good agents away from the goal
agent_dist = [np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in world.agents if not a.adversary]
pos_rew = min(agent_dist)
#nearest_agent = world.good_agents[np.argmin(agent_dist)]
#neg_rew = np.sqrt(np.sum(np.square(nearest_agent.state.p_pos - agent.state.p_pos)))
neg_rew = np.sqrt(np.sum(np.square(agent.goal_a.state.p_pos - agent.state.p_pos)))
#neg_rew = sum([np.sqrt(np.sum(np.square(a.state.p_pos - agent.state.p_pos))) for a in world.good_agents])
return pos_rew - neg_rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not agent.adversary:
return np.concatenate([agent.state.p_vel] + [agent.goal_a.state.p_pos - agent.state.p_pos] + [agent.color] + entity_pos + entity_color + other_pos)
else:
#other_pos = list(reversed(other_pos)) if random.uniform(0,1) > 0.5 else other_pos # randomize position of other agents in adversary network
return np.concatenate([agent.state.p_vel] + entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/simple_reference.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
world.dim_c = 10
world.collaborative = True # whether agents share rewards
# add agents
world.agents = [Agent() for i in range(2)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
# add landmarks
world.landmarks = [Landmark() for i in range(3)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# assign goals to agents
for agent in world.agents:
agent.goal_a = None
agent.goal_b = None
# want other agent to go to the goal landmark
world.agents[0].goal_a = world.agents[1]
world.agents[0].goal_b = np.random.choice(world.landmarks)
world.agents[1].goal_a = world.agents[0]
world.agents[1].goal_b = np.random.choice(world.landmarks)
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25,0.25,0.25])
# random properties for landmarks
world.landmarks[0].color = np.array([0.75,0.25,0.25])
world.landmarks[1].color = np.array([0.25,0.75,0.25])
world.landmarks[2].color = np.array([0.25,0.25,0.75])
# special colors for goals
world.agents[0].goal_a.color = world.agents[0].goal_b.color
world.agents[1].goal_a.color = world.agents[1].goal_b.color
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
if agent.goal_a is None or agent.goal_b is None:
return 0.0
dist2 = np.sum(np.square(agent.goal_a.state.p_pos - agent.goal_b.state.p_pos))
return -dist2
def observation(self, agent, world):
# goal color
goal_color = [np.zeros(world.dim_color), np.zeros(world.dim_color)]
if agent.goal_b is not None:
goal_color[1] = agent.goal_b.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks:
entity_color.append(entity.color)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
return np.concatenate([agent.state.p_vel] + entity_pos + [goal_color[1]] + comm)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/simple_speaker_listener.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
world.dim_c = 3
num_landmarks = 3
world.collaborative = True
# add agents
world.agents = [Agent() for i in range(2)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.size = 0.075
# speaker
world.agents[0].movable = False
# listener
world.agents[1].silent = True
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.04
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# assign goals to agents
for agent in world.agents:
agent.goal_a = None
agent.goal_b = None
# want listener to go to the goal landmark
world.agents[0].goal_a = world.agents[1]
world.agents[0].goal_b = np.random.choice(world.landmarks)
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25,0.25,0.25])
# random properties for landmarks
world.landmarks[0].color = np.array([0.65,0.15,0.15])
world.landmarks[1].color = np.array([0.15,0.65,0.15])
world.landmarks[2].color = np.array([0.15,0.15,0.65])
# special colors for goals
world.agents[0].goal_a.color = world.agents[0].goal_b.color + np.array([0.45, 0.45, 0.45])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1,+1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
return self.reward(agent, reward)
def reward(self, agent, world):
# squared distance from listener to landmark
a = world.agents[0]
dist2 = np.sum(np.square(a.goal_a.state.p_pos - a.goal_b.state.p_pos))
return -dist2
def observation(self, agent, world):
# goal color
goal_color = np.zeros(world.dim_color)
if agent.goal_b is not None:
goal_color = agent.goal_b.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent or (other.state.c is None): continue
comm.append(other.state.c)
# speaker
if not agent.movable:
return np.concatenate([goal_color])
# listener
if agent.silent:
return np.concatenate([agent.state.p_vel] + entity_pos + comm)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/simple_spread.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
world.dim_c = 2
num_agents = 3
num_landmarks = 3
world.collaborative = True
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
agent.size = 0.15
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.35, 0.35, 0.85])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
rew = 0
collisions = 0
occupied_landmarks = 0
min_dists = 0
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
min_dists += min(dists)
rew -= min(dists)
if min(dists) < 0.1:
occupied_landmarks += 1
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
collisions += 1
return (rew, collisions, min_dists, occupied_landmarks)
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark, penalized for collisions
rew = 0
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
rew -= min(dists)
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + comm)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/multiagent/scenarios/simple_world_comm.py
================================================
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
world.dim_c = 4
#world.damping = 1
num_good_agents = 2
num_adversaries = 4
num_agents = num_adversaries + num_good_agents
num_landmarks = 1
num_food = 2
num_forests = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.leader = True if i == 0 else False
agent.silent = True if i > 0 else False
agent.adversary = True if i < num_adversaries else False
agent.size = 0.075 if agent.adversary else 0.045
agent.accel = 3.0 if agent.adversary else 4.0
#agent.accel = 20.0 if agent.adversary else 25.0
agent.max_speed = 1.0 if agent.adversary else 1.3
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = True
landmark.movable = False
landmark.size = 0.2
landmark.boundary = False
world.food = [Landmark() for i in range(num_food)]
for i, landmark in enumerate(world.food):
landmark.name = 'food %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.03
landmark.boundary = False
world.forests = [Landmark() for i in range(num_forests)]
for i, landmark in enumerate(world.forests):
landmark.name = 'forest %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.3
landmark.boundary = False
world.landmarks += world.food
world.landmarks += world.forests
#world.landmarks += self.set_boundaries(world) # world boundaries now penalized with negative reward
# make initial conditions
self.reset_world(world)
return world
def set_boundaries(self, world):
boundary_list = []
landmark_size = 1
edge = 1 + landmark_size
num_landmarks = int(edge * 2 / landmark_size)
for x_pos in [-edge, edge]:
for i in range(num_landmarks):
l = Landmark()
l.state.p_pos = np.array([x_pos, -1 + i * landmark_size])
boundary_list.append(l)
for y_pos in [-edge, edge]:
for i in range(num_landmarks):
l = Landmark()
l.state.p_pos = np.array([-1 + i * landmark_size, y_pos])
boundary_list.append(l)
for i, l in enumerate(boundary_list):
l.name = 'boundary %d' % i
l.collide = True
l.movable = False
l.boundary = True
l.color = np.array([0.75, 0.75, 0.75])
l.size = landmark_size
l.state.p_vel = np.zeros(world.dim_p)
return boundary_list
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.45, 0.95, 0.45]) if not agent.adversary else np.array([0.95, 0.45, 0.45])
agent.color -= np.array([0.3, 0.3, 0.3]) if agent.leader else np.array([0, 0, 0])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
for i, landmark in enumerate(world.food):
landmark.color = np.array([0.15, 0.15, 0.65])
for i, landmark in enumerate(world.forests):
landmark.color = np.array([0.6, 0.9, 0.6])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-0.9, +0.9, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
for i, landmark in enumerate(world.food):
landmark.state.p_pos = np.random.uniform(-0.9, +0.9, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
for i, landmark in enumerate(world.forests):
landmark.state.p_pos = np.random.uniform(-0.9, +0.9, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
if agent.adversary:
collisions = 0
for a in self.good_agents(world):
if self.is_collision(a, agent):
collisions += 1
return collisions
else:
return 0
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
#boundary_reward = -10 if self.outside_boundary(agent) else 0
main_reward = self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
return main_reward
def outside_boundary(self, agent):
if agent.state.p_pos[0] > 1 or agent.state.p_pos[0] < -1 or agent.state.p_pos[1] > 1 or agent.state.p_pos[1] < -1:
return True
else:
return False
def agent_reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
rew = 0
shape = False
adversaries = self.adversaries(world)
if shape:
for adv in adversaries:
rew += 0.1 * np.sqrt(np.sum(np.square(agent.state.p_pos - adv.state.p_pos)))
if agent.collide:
for a in adversaries:
if self.is_collision(a, agent):
rew -= 5
def bound(x):
if x < 0.9:
return 0
if x < 1.0:
return (x - 0.9) * 10
return min(np.exp(2 * x - 2), 10) # 1 + (x - 1) * (x - 1)
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
rew -= 2 * bound(x)
for food in world.food:
if self.is_collision(agent, food):
rew += 2
rew += 0.05 * min([np.sqrt(np.sum(np.square(food.state.p_pos - agent.state.p_pos))) for food in world.food])
return rew
def adversary_reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
rew = 0
shape = True
agents = self.good_agents(world)
adversaries = self.adversaries(world)
if shape:
rew -= 0.1 * min([np.sqrt(np.sum(np.square(a.state.p_pos - agent.state.p_pos))) for a in agents])
if agent.collide:
for ag in agents:
for adv in adversaries:
if self.is_collision(ag, adv):
rew += 5
return rew
def observation2(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
food_pos = []
for entity in world.food:
if not entity.boundary:
food_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel)
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
in_forest = [np.array([-1]), np.array([-1])]
inf1 = False
inf2 = False
if self.is_collision(agent, world.forests[0]):
in_forest[0] = np.array([1])
inf1= True
if self.is_collision(agent, world.forests[1]):
in_forest[1] = np.array([1])
inf2 = True
food_pos = []
for entity in world.food:
if not entity.boundary:
food_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
oth_f1 = self.is_collision(other, world.forests[0])
oth_f2 = self.is_collision(other, world.forests[1])
if (inf1 and oth_f1) or (inf2 and oth_f2) or (not inf1 and not oth_f1 and not inf2 and not oth_f2) or agent.leader: #without forest vis
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
else:
other_pos.append([0, 0])
if not other.adversary:
other_vel.append([0, 0])
# to tell the pred when the prey are in the forest
prey_forest = []
ga = self.good_agents(world)
for a in ga:
if any([self.is_collision(a, f) for f in world.forests]):
prey_forest.append(np.array([1]))
else:
prey_forest.append(np.array([-1]))
# to tell leader when pred are in forest
prey_forest_lead = []
for f in world.forests:
if any([self.is_collision(a, f) for a in ga]):
prey_forest_lead.append(np.array([1]))
else:
prey_forest_lead.append(np.array([-1]))
comm = [world.agents[0].state.c]
if agent.adversary and not agent.leader:
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel + in_forest + comm)
if agent.leader:
return np.concatenate(
[agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel + in_forest + comm)
else:
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + in_forest + other_vel)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/policy/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/policy/maddpg.py
================================================
import torch
from torch.optim import Adam
import torch.nn.functional as F
from gym.spaces import Box, Discrete, MultiDiscrete
from multiagent.multi_discrete import MultiDiscrete
from utils.networks import MLPNetwork, SNNNetwork
from utils.misc import soft_update, average_gradients, onehot_from_logits, gumbel_softmax
from agents.agents import DDPGAgent, DDPGAgent_RNN, DDPGAgent_SNN, DDPGAgent_ToM
# from commom.distributions import make_pdtype
import time
MSELoss = torch.nn.MSELoss()
class MADDPG(object):
"""
Wrapper class for DDPG-esque (i.e. also MADDPG) agents in multi-agent task
"""
def __init__(self, agent_init_params, alg_types, device,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.device = device
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params)
for params in agent_init_params]
self.agent_init_params = agent_init_params
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, explore=False):
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def update(self, sample, agent_i, parallel=False, logger=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
obs, acs, rews, next_obs, dones = sample
curr_agent = self.agents[agent_i]
curr_agent.critic_optimizer.zero_grad()
if self.alg_types[agent_i] == 'MADDPG':
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs)]
else:
all_trgt_acs = [pi(nobs) for pi, nobs in zip(self.target_policies,
next_obs)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
else: # DDPG
if self.discrete_action:
trgt_vf_in = torch.cat((next_obs[agent_i],
onehot_from_logits(
curr_agent.target_policy(
next_obs[agent_i]))),
dim=1)
else:
trgt_vf_in = torch.cat((next_obs[agent_i],
curr_agent.target_policy(next_obs[agent_i])),
dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
if self.alg_types[agent_i] == 'MADDPG':
vf_in = torch.cat((*obs, *acs), dim=1)
else: # DDPG
vf_in = torch.cat((obs[agent_i], acs[agent_i]), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
if self.alg_types[agent_i] == 'MADDPG':
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
else: # DDPG
vf_in = torch.cat((obs[agent_i], curr_pol_vf_in),
dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out**2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents]}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, device, agent_alg="MADDPG", adversary_alg="MADDPG",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
if algtype == "MADDPG":
num_in_critic = 0
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'device': device}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
return instance
class MADDPG_SNN(object):
"""
Wrapper class for DDPG-esque (i.e. also MADDPG) agents in multi-agent task
"""
def __init__(self, agent_init_params, alg_types,output_style, device,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.device = device
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent_SNN(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params, output_style=output_style)
for params in agent_init_params]
self.agent_init_params = agent_init_params
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, explore=False):
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def update(self, sample, agent_i, parallel=False, logger=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
obs, acs, rews, next_obs, dones = sample
curr_agent = self.agents[agent_i]
curr_agent.critic_optimizer.zero_grad()
if self.alg_types[agent_i] == 'MADDPG_SNN':
all_trgt_acs = []
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs)]
# for nobs in next_obs:
# if nobs.shape[1] == next_obs[agent_i].shape[1]:
# all_trgt_acs.append(onehot_from_logits(self.target_policies[agent_i](nobs)))
# else:
# if next_obs[agent_i].shape[1] - nobs[:][3].shape[0] > 0 :
# a = torch.zeros((nobs.shape[0], next_obs[agent_i].shape[1] - nobs[:][3].shape[0]))
# a = a.to(torch.device(self.device))
# obs_good = torch.cat((nobs, a), 1)
# all_trgt_acs.append(onehot_from_logits(self.target_policies[agent_i](obs_good)))
# else:
# all_trgt_acs.append(onehot_from_logits(self.target_policies[agent_i](nobs[:, :next_obs[agent_i].shape[1]])))
# all_trgt_acs = [onehot_from_logits(self.target_policies[agent_i](nobs)) for nobs in
# next_obs]
else:
# all_trgt_acs = [pi(nobs) for pi, nobs in zip(self.target_policies,
# next_obs)]
all_trgt_acs = [self.target_policies[agent_i](nobs) for nobs in next_obs] #self-experience
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
else: # DDPG
if self.discrete_action:
trgt_vf_in = torch.cat((next_obs[agent_i],
onehot_from_logits(
curr_agent.target_policy(
next_obs[agent_i]))),
dim=1)
else:
trgt_vf_in = torch.cat((next_obs[agent_i],
curr_agent.target_policy(next_obs[agent_i])),
dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
if self.alg_types[agent_i] == 'MADDPG_SNN':
vf_in = torch.cat((*obs, *acs), dim=1)
else: # DDPG
vf_in = torch.cat((obs[agent_i], acs[agent_i]), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
if self.alg_types[agent_i] == 'MADDPG_SNN':
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
else: # DDPG
vf_in = torch.cat((obs[agent_i], curr_pol_vf_in),
dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out**2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents]}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, device, agent_alg="MADDPG_SNN", adversary_alg="MADDPG_SNN",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64, output_style='sum'):
# def init_from_env(cls, env, agent_alg="MADDPG_SNN", adversary_alg="MADDPG_SNN",
# gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64): #eval
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
if algtype == "MADDPG_SNN":
num_in_critic = 0
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'output_style': output_style,
'device': device}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
return instance
class MADDPG_ToM(object):
"""
Wrapper class for DDPG-esque (i.e. also MADDPG) agents in multi-agent task
"""
def __init__(self, agent_init_params, alg_types, output_style, device,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.device = device
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent_ToM(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params, output_style=output_style,
num_agents=self.nagents,
device=self.device)
for params in agent_init_params]
self.agent_init_params = agent_init_params
if self.nagents == 6:
self.mle_base = [SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14, #simple_com
self.agent_init_params[3]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
# SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14,
# self.agent_init_params[3]['num_out_pol'], # adv self-other
# hidden_dim=hidden_dim, output_style=output_style),
# SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14,
# self.agent_init_params[3]['num_out_pol'],
# hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
if self.nagents == 4:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle'] - 2, #simple_tag
self.agent_init_params[0]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2,
self.agent_init_params[3]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 3:
self.mle_base = [SNNNetwork(self.agent_init_params[1]['num_in_mle'], #simple_adv
self.agent_init_params[1]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'],
self.agent_init_params[1]['num_out_pol'], #agent self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'],
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 2:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle']-2, #simple_push
self.agent_init_params[0]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle']-2,
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
self.mle_opts = [Adam(self.mle_base[i].parameters(), lr=lr) for i in range(len(self.mle_base))]
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.mle_dev = 'cpu'
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, explore=False): #simple_tag
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
# t1 = time.time()
observations_ = observations.copy()
for agent_i, obs in enumerate(observations):
obs_ = observations_.copy()
obs_.pop(agent_i)
# actions = [self.agents[agent_i].mle[j].cpu()(observations[agent_i]) for j, obs_j in enumerate(obs_)]
# observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
if self.nagents == 6:
if agent_i < 4:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0],self.mle_base[0], self.mle_base[1], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(obs_j[:, 4:24].to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
else:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:-2]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(obs_j[:, 4:24].to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
if self.nagents == 4:
if agent_i < 3:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(obs_j[:, 2:].to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[2], self.mle_base[2]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:-2]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(obs_j[:,2:-2].to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
elif self.nagents == 3: #simple_adv
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0]]
# actions = [gumbel_softmax(
# self.agents[agent_i].mle[j].cpu()(torch.cat((obs_j[:, :2], observations_[agent_i]), 1)),
# hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:, :2],
observations_[agent_i]), 1).to(self.device)), hard=True).cpu()
for j, obs_j in enumerate(obs_)]
elif agent_i >= 1:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(observations_[agent_i].to(self.device)),
hard=True).cpu() for j, obs_j in enumerate(obs_)]
elif self.nagents == 2:
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:,2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(observations_[agent_i][:,2:].to(self.device)),
hard=True).cpu() for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:, 2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(observations_[agent_i][:,2:].to(self.device)),
hard=True).cpu() for j, obs_j in enumerate(obs_)]
observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
# t2 = time.time()
# print('step+time:', t2 - t1)
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def _get_obs(self, observations):
observations_ = []
for agent_i, obs in enumerate(observations):
obs_ = observations.copy()
obs_.pop(agent_i)
if self.nagents == 6:
if agent_i < 4: #simple_tag
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[1], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(obs_j[:, 4:24]).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif agent_i > 4:
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(obs_j[:, 4:24]).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
if self.nagents == 4:
if agent_i < 3: #simple_tag
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(obs_j[:, 2:]).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[2], self.mle_base[2]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(obs_j[:, 2:-2]).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif self.nagents == 3:
if agent_i < 1: #simple_adv
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:,:2],observations[agent_i]),1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif agent_i >= 1:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(observations[agent_i]).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif self.nagents == 2:
if agent_i < 1: #simple_push
self.agents[agent_i].mle = [self.mle_base[0]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(observations[agent_i][:,2:]).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(observations[agent_i][:,2:]).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
observations_.append(torch.cat((observations[agent_i], torch.cat(actions, 1)), 1))
return observations_
def trian_tag(self, agent_i, KL_criterion, obs, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](obs[0][:, 2:])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](obs[3][:, 2:])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[3].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
self.mle_opts[2].zero_grad()
action_i = self.mle_base[2](obs[0][:, 2:-2])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[2])
torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
self.mle_opts[2].step()
def trian_adv(self, agent_i, KL_criterion, obs, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](torch.cat((obs[1][:,:2],obs[agent_i]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](obs[1])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
self.mle_opts[2].zero_grad()
action_i = self.mle_base[2](obs[1])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[2])
torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
self.mle_opts[2].step()
def trian_push(self, agent_i, KL_criterion, obs, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](obs[0][:, 2:])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](obs[1][:, 2:])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def trian_com(self, agent_i, KL_criterion, obs, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](obs[1][:, 4:24])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](obs[4][:, 4:24])
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[4].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def update(self, sample, agent_i, parallel=False, logger=None, sample_r=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
# print('___update___')
obs, acs, rews, next_obs, dones = sample
next_obs_ = self._get_obs(next_obs)
obs_ = self._get_obs(obs)
curr_agent = self.agents[agent_i]
# mle
KL_criterion = torch.nn.KLDivLoss(reduction='sum')
# for i in range(len(curr_agent.mle)):
# curr_agent.mle_optimizer[i].zero_grad()
# action_i = curr_agent.mle[i](obs[agent_i]obs[agent_i])
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[i].float())
# loss.backward()
# if parallel:
# average_gradients(curr_agent.mle[i])
# torch.nn.utils.clip_grad_norm_(curr_agent.mle[i].parameters(), 20)
# curr_agent.policy_optimizer.step()
if self.nagents == 6:
self.trian_com(agent_i, KL_criterion, obs, parallel, acs)
if self.nagents == 4:
self.trian_tag(agent_i, KL_criterion, obs, parallel, acs)
elif self.nagents == 3:
self.trian_adv(agent_i, KL_criterion, obs, parallel, acs)
elif self.nagents == 2:
self.trian_push(agent_i, KL_criterion, obs, parallel, acs)
# center critic
curr_agent.critic_optimizer.zero_grad()
if self.alg_types[agent_i] == 'MADDPG_ToM':
all_trgt_acs = []
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs_)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
if self.alg_types[agent_i] == 'MADDPG_ToM':
vf_in = torch.cat((*obs, *acs), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs_[agent_i])
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
if self.alg_types[agent_i] == 'MADDPG_ToM':
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs_):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out ** 2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
# actor
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for mle in self.mle_base:
mle.train()
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
for mle_i in a.mle:
mle_i.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
if not self.mle_dev == device:
for i, mle in enumerate(self.mle_base):
self.mle_base[i] = fn(mle)
for a in self.agents:
for i, mle_i in enumerate(a.mle):
a.mle[i] = fn(mle_i)
self.mle_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents],
'mle_params': [self.get_params()],}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, device, agent_alg="MADDPG_ToM", adversary_alg="MADDPG_ToM",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64, output_style='sum'):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
num_in_mle = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
if algtype == "MADDPG_ToM":
num_in_critic = 0
num_in_pol += (len(env.agent_types)-1) * 5
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic,
'num_in_mle': num_in_mle,})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'device': device,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'output_style': output_style}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
for a, params in zip([instance], save_dict['mle_params']):
a.load_params(params)
return instance
def get_params(self):
params = {
}
for i in range(len(self.mle_base)):
params['mle%d'%i] = self.mle_base[i].state_dict()
params['mle_optimizer%d'%i] = self.mle_opts[i].state_dict()
return params
def load_params(self, params):
for i in range(len(self.mle_base)):
self.mle_base[i].load_state_dict(params['mle%d'%i])
self.mle_opts[i].load_state_dict(params['mle_optimizer%d'%i])
class ToM_SA(object):
"""
Wrapper class for DDPG-esque (i.e. also MADDPG) agents in multi-agent task
"""
def __init__(self, agent_init_params, alg_types, output_style, device,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.device = device
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent_ToM(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params, output_style=output_style,
num_agents=self.nagents,
device=self.device)
for params in agent_init_params]
self.agent_init_params = agent_init_params
if self.nagents == 6:
self.mle_base = [SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5, #simple_com
self.agent_init_params[3]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'], # adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
if self.nagents == 4:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle'] - 2 + 5, #simple_tag
self.agent_init_params[0]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2 + 5,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2 + 5,
self.agent_init_params[3]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 3:
self.mle_base = [SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5, #simple_adv
self.agent_init_params[1]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5,
self.agent_init_params[1]['num_out_pol'], #agent self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5,
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 2:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle']-2 + 5, #simple_push
self.agent_init_params[0]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle']-2 + 5,
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
self.mle_opts = [Adam(self.mle_base[i].parameters(), lr=lr) for i in range(len(self.mle_base))]
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.mle_dev = 'cpu'
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, actions_pre, explore=False): #simple_tag
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
# t1 = time.time()
observations_ = observations.copy()
actions_pre_ = actions_pre.copy()
for agent_i, obs in enumerate(observations):
obs_ = observations_.copy()
acs_pre_ = actions_pre_.copy()
obs_.pop(agent_i)
acs_pre_.pop(agent_i)
# actions = [self.agents[agent_i].mle[j].cpu()(observations[agent_i]) for j, obs_j in enumerate(obs_)]
# observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
if self.nagents == 6:
if agent_i < 4:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0],self.mle_base[0], self.mle_base[1], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
# t1 = time.time()
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:, 4:24], acs_pre_[j][:,:5]),1).to(self.device)),
# hard=True).cpu()
# for j, obs_j in enumerate(obs_)]
# print(t1 - time.time())
# t1 = time.time()
actions = [torch.cat((obs_j[:, 4:24], acs_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)), hard=True).cpu()
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)), hard=True).cpu()
actions = torch.cat((b1[:20], b1[20:40], b1[40:60], b2[:20], b2[20:40]), 1)
# print(t1 - time.time())
# print()
else:
self.agents[agent_i].mle = [self.mle_base[3],self.mle_base[3], self.mle_base[3], self.mle_base[3], self.mle_base[2]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:-2]), hard=True)
# for j, obs_j in enumerate(obs_)]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:, 4:24], acs_pre_[j]),1).to(self.device)),
# hard=True).cpu()
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[1]['num_out_pol']))
for j, obs_j in enumerate(obs_)]
actions = torch.cat(actions,1)
# print()
if self.nagents == 4:
if agent_i < 3:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:, 2:], acs_pre_[j]),1).to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[2], self.mle_base[2]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:-2]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol']))
for j, obs_j in enumerate(obs_)]
elif self.nagents == 3: #simple_adv
actions = []
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0]]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol']))
for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
actions.append(gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(0)]), 1).to(self.device)),
hard=True).cpu() )
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(2)]), 1).to(self.device)),
hard=True).cpu() )
elif agent_i == 2:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions.append(gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(0)]), 1).to(self.device)),
hard=True).cpu() )
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(1)]), 1).to(self.device)),
hard=True).cpu() )
elif self.nagents == 2:
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:,2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0], self.agent_init_params[0]['num_out_pol'])) for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:, 2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((observations_[agent_i][:,2:],
actions_pre[(self.nagents -1 - agent_i)]), 1).to(self.device)),
hard=True).cpu() for j, obs_j in enumerate(obs_)]
if self.nagents == 6:
observations[agent_i] = torch.cat((observations[agent_i], actions), 1)
else:
observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
# t2 = time.time()
# print('step+time:', t2 - t1)
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def _get_obs(self, observations, actions_pre):
observations_ = []
actions_pre_ = []
for agent_i, obs in enumerate(observations):
obs_ = observations.copy()
obs_.pop(agent_i)
actions_pre_ = actions_pre.copy()
actions_pre_.pop(agent_i)
if self.nagents == 6:
if agent_i < 4: #simple_comm
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[1], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1)).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)).detach(), hard=True)
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)).detach(), hard=True)
actions = torch.cat((b1[:1024], b1[1024:2048], b1[2048:3072], b2[:1024], b2[1024:2048]), 1)
# print()
elif agent_i > 4:
self.agents[agent_i].mle = [self.mle_base[3], self.mle_base[3], self.mle_base[3], self.mle_base[3], self.mle_base[2]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(obs_j[:, 4:24]).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0], self.agent_init_params[1]['num_out_pol'])).to(
torch.device(self.device)).detach() for j, obs_j in enumerate(obs_)]
actions = torch.cat(actions, 1)
# print()
if self.nagents == 4:
if agent_i < 3: #simple_tag
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 2:], actions_pre_[j]),1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[2], self.mle_base[2]]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach()
for j, obs_j in enumerate(obs_)]
elif self.nagents == 3:
actions = []
if agent_i < 1: #simple_adv
# self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:,:2],observations[agent_i]),1)).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach()
for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(observations[agent_i]).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions.append(
gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(0)]), 1).to(self.device)).detach(), hard=True))
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(2)]), 1).to(self.device)).detach(), hard=True))
elif agent_i == 2:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
actions.append(
gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(0)]), 1).to(self.device)).detach(), hard=True))
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(1)]), 1).to(self.device)).detach(), hard=True))
elif self.nagents == 2:
if agent_i < 1: #simple_push
self.agents[agent_i].mle = [self.mle_base[0]]
actions = [torch.zeros((obs_j.shape[0], self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach() for j, obs_j in
enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((observations[agent_i][:,2:],
actions_pre[(self.nagents -1 - agent_i)]), 1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
if self.nagents == 6:
observations_.append(torch.cat((observations[agent_i], actions), 1))
else:
observations_.append(torch.cat((observations[agent_i], torch.cat(actions, 1)), 1))
return observations_
def trian_tag(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](torch.cat((obs[0][:, 2:], acs_pre[0]),1))#
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[3][:, 2:], acs_pre[3]),1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[3].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
# self.mle_opts[2].zero_grad()
# action_i = self.mle_base[2](obs[0][:, 2:-2])
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[0].float())
# loss.backward()
# if parallel:
# average_gradients(self.mle_base[2])
# torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
# self.mle_opts[2].step()
def trian_adv(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
# self.mle_opts[0].zero_grad()
# action_i = self.mle_base[0](torch.cat((obs[1][:,:2],obs[agent_i]), 1))
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[1].float())
# loss.backward(retain_graph=True)
# if parallel:
# average_gradients(self.mle_base[0])
# torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
# self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[1], acs_pre[2]), 1)) #torch.cat((obs[1], acs_pre[2]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
self.mle_opts[2].zero_grad()
action_i = self.mle_base[2](torch.cat((obs[1], acs_pre[0]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[2])
torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
self.mle_opts[2].step()
def trian_push(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
# self.mle_opts[0].zero_grad()
# action_i = self.mle_base[0](obs[0][:, 2:]) #torch.cat((obs[agent_i][:,2:], actions[(self.nagents -1 - agent_i)]), 1)
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[1].float())
# loss.backward(retain_graph=True)
# if parallel:
# average_gradients(self.mle_base[0])
# torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
# self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[1][:,2:], acs_pre[(0)]), 1)) #obs[1][:, 2:]
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def trian_com(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](torch.cat((obs[1][:, 4:24], acs_pre[(1)]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[4][:, 4:24], acs_pre[(4)]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[4].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def update(self, sample, agent_i, parallel=False, logger=None, sample_r=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
# print('___update___')
acs_pre, obs, acs, rews, next_obs, dones = sample
next_obs_ = self._get_obs(next_obs, acs)
obs_ = self._get_obs(obs, acs_pre)
curr_agent = self.agents[agent_i]
# mle
KL_criterion = torch.nn.KLDivLoss(reduction='sum')
# for i in range(len(curr_agent.mle)):
# curr_agent.mle_optimizer[i].zero_grad()
# action_i = curr_agent.mle[i](obs[agent_i]obs[agent_i])
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[i].float())
# loss.backward()
# if parallel:
# average_gradients(curr_agent.mle[i])
# torch.nn.utils.clip_grad_norm_(curr_agent.mle[i].parameters(), 20)
# curr_agent.policy_optimizer.step()
if self.nagents == 6:
self.trian_com(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 4:
self.trian_tag(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 3:
self.trian_adv(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 2:
self.trian_push(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
# center critic
curr_agent.critic_optimizer.zero_grad()
all_trgt_acs = []
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs_)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
vf_in = torch.cat((*obs, *acs), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs_[agent_i])
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs_):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out ** 2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
# actor
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for mle in self.mle_base:
mle.train()
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
for mle_i in a.mle:
mle_i.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
if not self.mle_dev == device:
for i, mle in enumerate(self.mle_base):
self.mle_base[i] = fn(mle)
for a in self.agents:
for i, mle_i in enumerate(a.mle):
a.mle[i] = fn(mle_i)
self.mle_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents],
'mle_params': [self.get_params()],}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, device, agent_alg="ToM_SA", adversary_alg="ToM_SA",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64, output_style='sum'):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
num_in_mle = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
if algtype == "ToM_SA":
num_in_critic = 0
num_in_pol += (len(env.agent_types)-1) * 5
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic,
'num_in_mle': num_in_mle,})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'device': device,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'output_style': output_style}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
for a, params in zip([instance], save_dict['mle_params']):
a.load_params(params)
return instance
def get_params(self):
params = {
}
for i in range(len(self.mle_base)):
params['mle%d'%i] = self.mle_base[i].state_dict()
params['mle_optimizer%d'%i] = self.mle_opts[i].state_dict()
return params
def load_params(self, params):
for i in range(len(self.mle_base)):
self.mle_base[i].load_state_dict(params['mle%d'%i])
self.mle_opts[i].load_state_dict(params['mle_optimizer%d'%i])
class ToM_S(object):
"""
Wrapper class for DDPG-esque (i.e. also MADDPG) agents in multi-agent task
"""
def __init__(self, agent_init_params, alg_types, output_style, device,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.device = device
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent_ToM(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params, output_style=output_style,
num_agents=self.nagents,
device=self.device)
for params in agent_init_params]
self.agent_init_params = agent_init_params
if self.nagents == 6:
self.mle_base = [SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5, #simple_com
self.agent_init_params[3]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'], # adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
if self.nagents == 4:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle'] - 2 + 5, #simple_tag
self.agent_init_params[0]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2 + 5,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2 + 5,
self.agent_init_params[3]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 3:
self.mle_base = [SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5, #simple_adv
self.agent_init_params[1]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5,
self.agent_init_params[1]['num_out_pol'], #agent self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5,
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 2:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle']-2 + 5, #simple_push
self.agent_init_params[0]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle']-2 + 5,
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
self.mle_opts = [Adam(self.mle_base[i].parameters(), lr=lr) for i in range(len(self.mle_base))]
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.mle_dev = 'cpu'
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, actions_pre, explore=False): #simple_tag
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
# t1 = time.time()
observations_ = observations.copy()
actions_pre_ = actions_pre.copy()
for agent_i, obs in enumerate(observations):
obs_ = observations_.copy()
acs_pre_ = actions_pre_.copy()
obs_.pop(agent_i)
acs_pre_.pop(agent_i)
# actions = [self.agents[agent_i].mle[j].cpu()(observations[agent_i]) for j, obs_j in enumerate(obs_)]
# observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
if self.nagents == 6:
if agent_i < 4:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0],self.mle_base[0], self.mle_base[1], self.mle_base[1]]
actions = [torch.cat((obs_j[:, 4:24], acs_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)), hard=True).cpu()
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)), hard=True).cpu()
actions = torch.cat((b1[:20], b1[20:40], b1[40:60], b2[:20], b2[20:40]), 1)
# print(t1 - time.time())
# print()
else:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[1]]
actions = [torch.cat((obs_j[:, 4:24], acs_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)), hard=True).cpu()
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)), hard=True).cpu()
actions = torch.cat((b1[:20], b1[20:40], b1[40:60], b2[:20], b2[20:40]), 1)
# actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[1]['num_out_pol']))
# for j, obs_j in enumerate(obs_)]
# actions = torch.cat(actions,1)
# print()
if self.nagents == 4:
if agent_i < 3:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:, 2:], acs_pre_[j]),1).to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[2], self.mle_base[2]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:, 2:-2], acs_pre_[j]),1).to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:-2]), hard=True)
# for j, obs_j in enumerate(obs_)]
# actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol']))
# for j, obs_j in enumerate(obs_)]
elif self.nagents == 3: #simple_adv
actions = []
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0]]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol']))
for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
actions.append(gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(0)]), 1).to(self.device)),
hard=True).cpu() )
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(2)]), 1).to(self.device)),
hard=True).cpu() )
elif agent_i == 2:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions.append(gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(0)]), 1).to(self.device)),
hard=True).cpu() )
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(1)]), 1).to(self.device)),
hard=True).cpu() )
elif self.nagents == 2:
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:,2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0], self.agent_init_params[0]['num_out_pol'])) for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:, 2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((observations_[agent_i][:,2:],
actions_pre[(self.nagents -1 - agent_i)]), 1).to(self.device)),
hard=True).cpu() for j, obs_j in enumerate(obs_)]
if self.nagents == 6:
observations[agent_i] = torch.cat((observations[agent_i], actions), 1)
else:
observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
# t2 = time.time()
# print('step+time:', t2 - t1)
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def _get_obs(self, observations, actions_pre):
observations_ = []
actions_pre_ = []
for agent_i, obs in enumerate(observations):
obs_ = observations.copy()
obs_.pop(agent_i)
actions_pre_ = actions_pre.copy()
actions_pre_.pop(agent_i)
if self.nagents == 6:
if agent_i < 4: #simple_comm
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[1], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1)).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)).detach(), hard=True)
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)).detach(), hard=True)
actions = torch.cat((b1[:1024], b1[1024:2048], b1[2048:3072], b2[:1024], b2[1024:2048]), 1)
# print()
elif agent_i > 4:
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[1]]
actions = [torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)).detach(), hard=True)
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)).detach(), hard=True)
actions = torch.cat((b1[:1024], b1[1024:2048], b1[2048:3072], b2[:1024], b2[1024:2048]), 1)
# print()
if self.nagents == 4:
if agent_i < 3: #simple_tag
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 2:], actions_pre_[j]),1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[2], self.mle_base[2]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 2:-2], actions_pre_[j]),1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif self.nagents == 3:
actions = []
if agent_i < 1: #simple_adv
# self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:,:2],observations[agent_i]),1)).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach()
for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(observations[agent_i]).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions.append(
gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(0)]), 1).to(self.device)).detach(), hard=True))
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(2)]), 1).to(self.device)).detach(), hard=True))
elif agent_i == 2:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
actions.append(
gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(0)]), 1).to(self.device)).detach(), hard=True))
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(1)]), 1).to(self.device)).detach(), hard=True))
elif self.nagents == 2:
if agent_i < 1: #simple_push
self.agents[agent_i].mle = [self.mle_base[0]]
actions = [torch.zeros((obs_j.shape[0], self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach() for j, obs_j in
enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((observations[agent_i][:,2:],
actions_pre[(self.nagents -1 - agent_i)]), 1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
if self.nagents == 6:
observations_.append(torch.cat((observations[agent_i], actions), 1))
else:
observations_.append(torch.cat((observations[agent_i], torch.cat(actions, 1)), 1))
return observations_
def trian_tag(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](torch.cat((obs[0][:, 2:], acs_pre[0]),1))#
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[3][:, 2:], acs_pre[3]),1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[3].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
self.mle_opts[2].zero_grad()
action_i = self.mle_base[2](torch.cat((obs[0][:, 2:-2], acs_pre[0]),1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[2])
torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
self.mle_opts[2].step()
def trian_adv(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
# self.mle_opts[0].zero_grad()
# action_i = self.mle_base[0](torch.cat((obs[1][:,:2],obs[agent_i]), 1))
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[1].float())
# loss.backward(retain_graph=True)
# if parallel:
# average_gradients(self.mle_base[0])
# torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
# self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[1], acs_pre[2]), 1)) #torch.cat((obs[1], acs_pre[2]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
self.mle_opts[2].zero_grad()
action_i = self.mle_base[2](torch.cat((obs[1], acs_pre[0]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[2])
torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
self.mle_opts[2].step()
def trian_push(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
# self.mle_opts[0].zero_grad()
# action_i = self.mle_base[0](obs[0][:, 2:]) #torch.cat((obs[agent_i][:,2:], actions[(self.nagents -1 - agent_i)]), 1)
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[1].float())
# loss.backward(retain_graph=True)
# if parallel:
# average_gradients(self.mle_base[0])
# torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
# self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[1][:,2:], acs_pre[(0)]), 1)) #obs[1][:, 2:]
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def trian_com(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](torch.cat((obs[1][:, 4:24], acs_pre[(1)]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[4][:, 4:24], acs_pre[(4)]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[4].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def update(self, sample, agent_i, parallel=False, logger=None, sample_r=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
# print('___update___')
acs_pre, obs, acs, rews, next_obs, dones = sample
next_obs_ = self._get_obs(next_obs, acs)
obs_ = self._get_obs(obs, acs_pre)
curr_agent = self.agents[agent_i]
# mle
KL_criterion = torch.nn.KLDivLoss(reduction='sum')
# for i in range(len(curr_agent.mle)):
# curr_agent.mle_optimizer[i].zero_grad()
# action_i = curr_agent.mle[i](obs[agent_i]obs[agent_i])
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[i].float())
# loss.backward()
# if parallel:
# average_gradients(curr_agent.mle[i])
# torch.nn.utils.clip_grad_norm_(curr_agent.mle[i].parameters(), 20)
# curr_agent.policy_optimizer.step()
if self.nagents == 6:
self.trian_com(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 4:
self.trian_tag(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 3:
self.trian_adv(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 2:
self.trian_push(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
# center critic
curr_agent.critic_optimizer.zero_grad()
all_trgt_acs = []
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs_)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
vf_in = torch.cat((*obs, *acs), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs_[agent_i])
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs_):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out ** 2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
# actor
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for mle in self.mle_base:
mle.train()
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
for mle_i in a.mle:
mle_i.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
if not self.mle_dev == device:
for i, mle in enumerate(self.mle_base):
self.mle_base[i] = fn(mle)
for a in self.agents:
for i, mle_i in enumerate(a.mle):
a.mle[i] = fn(mle_i)
self.mle_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents],
'mle_params': [self.get_params()],}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, device, agent_alg="ToM_S", adversary_alg="ToM_S",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64, output_style='sum'):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
num_in_mle = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
if algtype == "ToM_S":
num_in_critic = 0
num_in_pol += (len(env.agent_types)-1) * 5
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic,
'num_in_mle': num_in_mle,})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'device': device,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'output_style': output_style}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
for a, params in zip([instance], save_dict['mle_params']):
a.load_params(params)
return instance
def get_params(self):
params = {
}
for i in range(len(self.mle_base)):
params['mle%d'%i] = self.mle_base[i].state_dict()
params['mle_optimizer%d'%i] = self.mle_opts[i].state_dict()
return params
def load_params(self, params):
for i in range(len(self.mle_base)):
self.mle_base[i].load_state_dict(params['mle%d'%i])
self.mle_opts[i].load_state_dict(params['mle_optimizer%d'%i])
class ToM_self(object):
"""
Wrapper class for DDPG-esque (i.e. also MADDPG) agents in multi-agent task
"""
def __init__(self, agent_init_params, alg_types, output_style, device,
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64,
discrete_action=False):
"""
Inputs:
agent_init_params (list of dict): List of dicts with parameters to
initialize each agent
num_in_pol (int): Input dimensions to policy
num_out_pol (int): Output dimensions to policy
num_in_critic (int): Input dimensions to critic
alg_types (list of str): Learning algorithm for each agent (DDPG
or MADDPG)
gamma (float): Discount factor
tau (float): Target update rate
lr (float): Learning rate for policy and critic
hidden_dim (int): Number of hidden dimensions for networks
discrete_action (bool): Whether or not to use discrete action space
"""
self.device = device
self.nagents = len(alg_types)
self.alg_types = alg_types
self.agents = [DDPGAgent_ToM(lr=lr, discrete_action=discrete_action,
hidden_dim=hidden_dim,
**params, output_style=output_style,
num_agents=self.nagents,
device=self.device)
for params in agent_init_params]
self.agent_init_params = agent_init_params
if self.nagents == 6:
self.mle_base = [SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5, #simple_com
self.agent_init_params[3]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'], # adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 14 + 5,
self.agent_init_params[3]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
if self.nagents == 4:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle'] - 2 + 5, #simple_tag
self.agent_init_params[0]['num_out_pol'], #adv self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2 + 5,
self.agent_init_params[3]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[3]['num_in_mle'] - 2 + 5,
self.agent_init_params[3]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 3:
self.mle_base = [SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5, #simple_adv
self.agent_init_params[1]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5,
self.agent_init_params[1]['num_out_pol'], #agent self-self
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle'] + 5,
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
elif self.nagents == 2:
self.mle_base = [SNNNetwork(self.agent_init_params[0]['num_in_mle']-2 + 5, #simple_push
self.agent_init_params[0]['num_out_pol'], #adv self-other
hidden_dim=hidden_dim, output_style=output_style),
SNNNetwork(self.agent_init_params[1]['num_in_mle']-2 + 5,
self.agent_init_params[1]['num_out_pol'],
hidden_dim=hidden_dim, output_style=output_style), ##agent self-other
]
self.mle_opts = [Adam(self.mle_base[i].parameters(), lr=lr) for i in range(len(self.mle_base))]
self.gamma = gamma
self.tau = tau
self.lr = lr
self.discrete_action = discrete_action
self.pol_dev = 'cpu' # device for policies
self.critic_dev = 'cpu' # device for critics
self.trgt_pol_dev = 'cpu' # device for target policies
self.trgt_critic_dev = 'cpu' # device for target critics
self.mle_dev = 'cpu'
self.niter = 0
@property
def policies(self):
return [a.policy for a in self.agents]
@property
def target_policies(self):
return [a.target_policy for a in self.agents]
def scale_noise(self, scale):
"""
Scale noise for each agent
Inputs:
scale (float): scale of noise
"""
for a in self.agents:
a.scale_noise(scale)
def reset_noise(self):
for a in self.agents:
a.reset_noise()
def step(self, observations, actions_pre, explore=False): #simple_tag
"""
Take a step forward in environment with all agents
Inputs:
observations: List of observations for each agent
explore (boolean): Whether or not to add exploration noise
Outputs:
actions: List of actions for each agent
"""
# t1 = time.time()
observations_ = observations.copy()
actions_pre_ = actions_pre.copy()
for agent_i, obs in enumerate(observations):
obs_ = observations_.copy()
acs_pre_ = actions_pre_.copy()
obs_.pop(agent_i)
acs_pre_.pop(agent_i)
# actions = [self.agents[agent_i].mle[j].cpu()(observations[agent_i]) for j, obs_j in enumerate(obs_)]
# observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
if self.nagents == 6:
if agent_i < 4:
self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0],self.mle_base[0], self.mle_base[0], self.mle_base[0]]
actions = [torch.cat((obs_j[:, 4:24], acs_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)), hard=True).cpu()
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)), hard=True).cpu()
actions = torch.cat((b1[:20], b1[20:40], b1[40:60], b2[:20], b2[20:40]), 1)
# print(t1 - time.time())
# print()
else:
self.agents[agent_i].mle = [self.mle_base[1],self.mle_base[1], self.mle_base[1], self.mle_base[1], self.mle_base[1]]
actions = [torch.cat((obs_j[:, 4:24], acs_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)), hard=True).cpu()
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)), hard=True).cpu()
actions = torch.cat((b1[:20], b1[20:40], b1[40:60], b2[:20], b2[20:40]), 1)
# actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[1]['num_out_pol']))
# for j, obs_j in enumerate(obs_)]
# actions = torch.cat(actions,1)
# print()
if self.nagents == 4:
if agent_i < 3:
self.agents[agent_i].mle = [self.mle_base[1],self.mle_base[1], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:, 2:14], acs_pre_[j]),1).to(self.device)),
hard=True).cpu()
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[2], self.mle_base[2]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:,2:14], acs_pre_[j]),1).to(self.device)),
hard=True).cpu() for j, obs_j in enumerate(obs_)]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(obs_j[:,2:-2]), hard=True)
# for j, obs_j in enumerate(obs_)]
# actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol']))
# for j, obs_j in enumerate(obs_)]
elif self.nagents == 3: #simple_adv
actions = []
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0]]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol']))
for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
actions.append(gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(0)]), 1).to(self.device)),
hard=True).cpu() )
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(2)]), 1).to(self.device)),
hard=True).cpu() )
elif agent_i == 2:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions.append(gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(0)]), 1).to(self.device)),
hard=True).cpu() )
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations_[agent_i],
actions_pre[(1)]), 1).to(self.device)),
hard=True).cpu() )
elif self.nagents == 2:
if agent_i < 1:
self.agents[agent_i].mle = [self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:,2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0], self.agent_init_params[0]['num_out_pol'])) for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].cpu()(observations_[agent_i][:, 2:]), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((observations_[agent_i][:,2:],
actions_pre[(self.nagents -1 - agent_i)]), 1).to(self.device)),
hard=True).cpu() for j, obs_j in enumerate(obs_)]
if self.nagents == 6:
observations[agent_i] = torch.cat((observations[agent_i], actions), 1)
else:
observations[agent_i] = torch.cat((observations[agent_i], torch.cat(actions, 1)), 1)
# t2 = time.time()
# print('step+time:', t2 - t1)
return [a.step(obs, explore=explore) for a, obs in zip(self.agents,
observations)]
def _get_obs(self, observations, actions_pre):
observations_ = []
actions_pre_ = []
for agent_i, obs in enumerate(observations):
obs_ = observations.copy()
obs_.pop(agent_i)
actions_pre_ = actions_pre.copy()
actions_pre_.pop(agent_i)
if self.nagents == 6:
if agent_i < 4: #simple_comm
self.agents[agent_i].mle = [self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[0], self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1)).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)).detach(), hard=True)
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)).detach(), hard=True)
actions = torch.cat((b1[:1024], b1[1024:2048], b1[2048:3072], b2[:1024], b2[1024:2048]), 1)
# print()
elif agent_i > 4:
self.agents[agent_i].mle = [self.mle_base[1], self.mle_base[1], self.mle_base[1], self.mle_base[1], self.mle_base[1]]
actions = [torch.cat((obs_j[:, 4:24], actions_pre_[j][:,:5]),1) for j, obs_j in enumerate(obs_)]
b1 = gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat(actions[:3]).to(self.device)).detach(), hard=True)
b2 = gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat(actions[3:]).to(self.device)).detach(), hard=True)
actions = torch.cat((b1[:1024], b1[1024:2048], b1[2048:3072], b2[:1024], b2[1024:2048]), 1)
# print()
if self.nagents == 4:
if agent_i < 3: #simple_tag
self.agents[agent_i].mle = [self.mle_base[1], self.mle_base[1], self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 2:14], actions_pre_[j]),1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
elif agent_i == 3:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[2], self.mle_base[2]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:, 2:14], actions_pre_[j]),1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(self.device)(torch.cat((obs_j[:,2:-2], acs_pre_[j]),1).to(self.device)),
# hard=True).cpu() for j, obs_j in enumerate(obs_)]
# actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach()
# for j, obs_j in enumerate(obs_)]
elif self.nagents == 3:
actions = []
if agent_i < 1: #simple_adv
# self.agents[agent_i].mle = [self.mle_base[0],self.mle_base[0]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((obs_j[:,:2],observations[agent_i]),1)).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions = [torch.zeros((obs_j.shape[0],self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach()
for j, obs_j in enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[2],self.mle_base[1]]
# actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(observations[agent_i]).detach(), hard=True)
# for j, obs_j in enumerate(obs_)]
actions.append(
gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(0)]), 1).to(self.device)).detach(), hard=True))
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(2)]), 1).to(self.device)).detach(), hard=True))
elif agent_i == 2:
self.agents[agent_i].mle = [self.mle_base[2], self.mle_base[1]]
actions.append(
gumbel_softmax(self.agents[agent_i].mle[0].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(0)]), 1).to(self.device)).detach(), hard=True))
actions.append(gumbel_softmax(self.agents[agent_i].mle[1].to(self.device)(torch.cat((observations[agent_i],
actions_pre[(1)]), 1).to(self.device)).detach(), hard=True))
elif self.nagents == 2:
if agent_i < 1: #simple_push
self.agents[agent_i].mle = [self.mle_base[0]]
actions = [torch.zeros((obs_j.shape[0], self.agent_init_params[0]['num_out_pol'])).to(torch.device(self.device)).detach() for j, obs_j in
enumerate(obs_)]
elif agent_i == 1:
self.agents[agent_i].mle = [self.mle_base[1]]
actions = [gumbel_softmax(self.agents[agent_i].mle[j].to(torch.device(self.device))(torch.cat((observations[agent_i][:,2:],
actions_pre[(self.nagents -1 - agent_i)]), 1)).detach(), hard=True)
for j, obs_j in enumerate(obs_)]
if self.nagents == 6:
observations_.append(torch.cat((observations[agent_i], actions), 1))
else:
observations_.append(torch.cat((observations[agent_i], torch.cat(actions, 1)), 1))
return observations_
def trian_tag(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[0][:, 2:14], acs_pre[0]),1))#
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
self.mle_opts[2].zero_grad()
action_i = self.mle_base[2](torch.cat((obs[3][:, 2:14], acs_pre[3]),1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[3].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[2])
torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
self.mle_opts[2].step()
def trian_adv(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[1], acs_pre[2]), 1)) #torch.cat((obs[1], acs_pre[2]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
self.mle_opts[2].zero_grad()
action_i = self.mle_base[2](torch.cat((obs[1], acs_pre[0]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[2])
torch.nn.utils.clip_grad_norm_(self.mle_base[2].parameters(), 20)
self.mle_opts[2].step()
def trian_push(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[1][:,2:], acs_pre[(0)]), 1)) #obs[1][:, 2:]
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[0].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def trian_com(self, agent_i, KL_criterion, obs, acs_pre, parallel, acs):
if agent_i == 0:
self.mle_opts[0].zero_grad()
action_i = self.mle_base[0](torch.cat((obs[1][:, 4:24], acs_pre[(1)]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[1].float())
loss.backward(retain_graph=True)
if parallel:
average_gradients(self.mle_base[0])
torch.nn.utils.clip_grad_norm_(self.mle_base[0].parameters(), 20)
self.mle_opts[0].step()
self.mle_opts[1].zero_grad()
action_i = self.mle_base[1](torch.cat((obs[4][:, 4:24], acs_pre[(4)]), 1))
action_pre = gumbel_softmax(action_i, hard=True)
loss = KL_criterion(action_pre.float(), acs[4].float())
loss.backward()
if parallel:
average_gradients(self.mle_base[1])
torch.nn.utils.clip_grad_norm_(self.mle_base[1].parameters(), 20)
self.mle_opts[1].step()
def update(self, sample, agent_i, parallel=False, logger=None, sample_r=None):
"""
Update parameters of agent model based on sample from replay buffer
Inputs:
sample: tuple of (observations, actions, rewards, next
observations, and episode end masks) sampled randomly from
the replay buffer. Each is a list with entries
corresponding to each agent
agent_i (int): index of agent to update
parallel (bool): If true, will average gradients across threads
logger (SummaryWriter from Tensorboard-Pytorch):
If passed in, important quantities will be logged
"""
# print('___update___')
acs_pre, obs, acs, rews, next_obs, dones = sample
next_obs_ = self._get_obs(next_obs, acs)
obs_ = self._get_obs(obs, acs_pre)
curr_agent = self.agents[agent_i]
# mle
KL_criterion = torch.nn.KLDivLoss(reduction='sum')
# for i in range(len(curr_agent.mle)):
# curr_agent.mle_optimizer[i].zero_grad()
# action_i = curr_agent.mle[i](obs[agent_i]obs[agent_i])
# action_pre = gumbel_softmax(action_i, hard=True)
# loss = KL_criterion(action_pre.float(), acs[i].float())
# loss.backward()
# if parallel:
# average_gradients(curr_agent.mle[i])
# torch.nn.utils.clip_grad_norm_(curr_agent.mle[i].parameters(), 20)
# curr_agent.policy_optimizer.step()
if self.nagents == 6:
self.trian_com(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 4:
self.trian_tag(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 3:
self.trian_adv(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
elif self.nagents == 2:
self.trian_push(agent_i, KL_criterion, obs, acs_pre, parallel, acs)
# center critic
curr_agent.critic_optimizer.zero_grad()
all_trgt_acs = []
if self.discrete_action: # one-hot encode action
all_trgt_acs = [onehot_from_logits(pi(nobs)) for pi, nobs in
zip(self.target_policies, next_obs_)]
trgt_vf_in = torch.cat((*next_obs, *all_trgt_acs), dim=1)
target_value = (rews[agent_i].view(-1, 1) + self.gamma *
curr_agent.target_critic(trgt_vf_in) *
(1 - dones[agent_i].view(-1, 1)))
vf_in = torch.cat((*obs, *acs), dim=1)
actual_value = curr_agent.critic(vf_in)
vf_loss = MSELoss(actual_value, target_value.detach())
vf_loss.backward()
if parallel:
average_gradients(curr_agent.critic)
torch.nn.utils.clip_grad_norm_(curr_agent.critic.parameters(), 0.5)
curr_agent.critic_optimizer.step()
curr_agent.policy_optimizer.zero_grad()
if self.discrete_action:
# Forward pass as if onehot (hard=True) but backprop through a differentiable
# Gumbel-Softmax sample. The MADDPG paper uses the Gumbel-Softmax trick to backprop
# through discrete categorical samples, but I'm not sure if that is
# correct since it removes the assumption of a deterministic policy for
# DDPG. Regardless, discrete policies don't seem to learn properly without it.
curr_pol_out = curr_agent.policy(obs_[agent_i])
curr_pol_vf_in = gumbel_softmax(curr_pol_out, hard=True)
else:
curr_pol_out = curr_agent.policy(obs[agent_i])
curr_pol_vf_in = curr_pol_out
all_pol_acs = []
for i, pi, ob in zip(range(self.nagents), self.policies, obs_):
if i == agent_i:
all_pol_acs.append(curr_pol_vf_in)
elif self.discrete_action:
all_pol_acs.append(onehot_from_logits(pi(ob)))
else:
all_pol_acs.append(pi(ob))
vf_in = torch.cat((*obs, *all_pol_acs), dim=1)
pol_loss = -curr_agent.critic(vf_in).mean()
pol_loss += (curr_pol_out ** 2).mean() * 1e-3
pol_loss.backward()
if parallel:
average_gradients(curr_agent.policy)
torch.nn.utils.clip_grad_norm_(curr_agent.policy.parameters(), 0.5)
# actor
curr_agent.policy_optimizer.step()
if logger is not None:
logger.add_scalars('agent%i/losses' % agent_i,
{'vf_loss': vf_loss,
'pol_loss': pol_loss},
self.niter)
def update_all_targets(self):
"""
Update all target networks (called after normal updates have been
performed for each agent)
"""
for a in self.agents:
soft_update(a.target_critic, a.critic, self.tau)
soft_update(a.target_policy, a.policy, self.tau)
self.niter += 1
def prep_training(self, device='gpu'):
for mle in self.mle_base:
mle.train()
for a in self.agents:
a.policy.train()
a.critic.train()
a.target_policy.train()
a.target_critic.train()
for mle_i in a.mle:
mle_i.train()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
if not self.critic_dev == device:
for a in self.agents:
a.critic = fn(a.critic)
self.critic_dev = device
if not self.trgt_pol_dev == device:
for a in self.agents:
a.target_policy = fn(a.target_policy)
self.trgt_pol_dev = device
if not self.trgt_critic_dev == device:
for a in self.agents:
a.target_critic = fn(a.target_critic)
self.trgt_critic_dev = device
if not self.mle_dev == device:
for i, mle in enumerate(self.mle_base):
self.mle_base[i] = fn(mle)
for a in self.agents:
for i, mle_i in enumerate(a.mle):
a.mle[i] = fn(mle_i)
self.mle_dev = device
def prep_rollouts(self, device='cpu'):
for a in self.agents:
a.policy.eval()
if device == 'gpu':
fn = lambda x: x.to(torch.device(self.device))
else:
fn = lambda x: x.cpu()
# only need main policy for rollouts
if not self.pol_dev == device:
for a in self.agents:
a.policy = fn(a.policy)
self.pol_dev = device
def save(self, filename):
"""
Save trained parameters of all agents into one file
"""
self.prep_training(device='cpu') # move parameters to CPU before saving
save_dict = {'init_dict': self.init_dict,
'agent_params': [a.get_params() for a in self.agents],
'mle_params': [self.get_params()],}
torch.save(save_dict, filename)
@classmethod
def init_from_env(cls, env, device, agent_alg="ToM_self", adversary_alg="ToM_self",
gamma=0.95, tau=0.01, lr=0.01, hidden_dim=64, output_style='sum'):
"""
Instantiate instance of this class from multi-agent environment
"""
agent_init_params = []
alg_types = [adversary_alg if atype == 'adversary' else agent_alg for
atype in env.agent_types]
for acsp, obsp, algtype in zip(env.action_space, env.observation_space,
alg_types):
num_in_pol = obsp.shape[0]
num_in_mle = obsp.shape[0]
if isinstance(acsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(acsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(acsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_out_pol = get_shape(acsp)
if algtype == "ToM_self":
num_in_critic = 0
num_in_pol += (len(env.agent_types)-1) * 5
for oobsp in env.observation_space:
num_in_critic += oobsp.shape[0]
for oacsp in env.action_space:
if isinstance(oacsp, Box):
discrete_action = False
get_shape = lambda x: x.shape[0]
elif isinstance(oacsp, Discrete): # Discrete
discrete_action = True
get_shape = lambda x: x.n
elif isinstance(oacsp, MultiDiscrete):
discrete_action = True
get_shape = lambda x: sum(x.high - x.low + 1)
num_in_critic += get_shape(oacsp)
else:
num_in_critic = obsp.shape[0] + get_shape(acsp)
agent_init_params.append({'num_in_pol': num_in_pol,
'num_out_pol': num_out_pol,
'num_in_critic': num_in_critic,
'num_in_mle': num_in_mle,})
init_dict = {'gamma': gamma, 'tau': tau, 'lr': lr,
'device': device,
'hidden_dim': hidden_dim,
'alg_types': alg_types,
'agent_init_params': agent_init_params,
'discrete_action': discrete_action,
'output_style': output_style}
instance = cls(**init_dict)
instance.init_dict = init_dict
return instance
@classmethod
def init_from_save(cls, filename):
"""
Instantiate instance of this class from file created by 'save' method
"""
save_dict = torch.load(filename)
instance = cls(**save_dict['init_dict'])
instance.init_dict = save_dict['init_dict']
for a, params in zip(instance.agents, save_dict['agent_params']):
a.load_params(params)
for a, params in zip([instance], save_dict['mle_params']):
a.load_params(params)
return instance
def get_params(self):
params = {
}
for i in range(len(self.mle_base)):
params['mle%d'%i] = self.mle_base[i].state_dict()
params['mle_optimizer%d'%i] = self.mle_opts[i].state_dict()
return params
def load_params(self, params):
for i in range(len(self.mle_base)):
self.mle_base[i].load_state_dict(params['mle%d'%i])
self.mle_opts[i].load_state_dict(params['mle_optimizer%d'%i])
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/buffer.py
================================================
import numpy as np
import torch
from torch import Tensor
from torch.autograd import Variable
class ReplayBuffer(object):
"""
Replay Buffer for multi-agent RL with parallel rollouts
"""
def __init__(self, max_steps, num_agents, obs_dims, ac_dims, device):
"""
Inputs:
max_steps (int): Maximum number of timepoints to store in buffer
num_agents (int): Number of agents in environment
obs_dims (list of ints): number of obervation dimensions for each
agent
ac_dims (list of ints): number of action dimensions for each agent
"""
self.device = device
self.max_steps = max_steps
self.num_agents = num_agents
self.obs_buffs = []
self.ac_buffs = []
self.rew_buffs = []
self.next_obs_buffs = []
self.done_buffs = []
for odim, adim in zip(obs_dims, ac_dims):
self.obs_buffs.append(np.zeros((max_steps, odim)))
self.ac_buffs.append(np.zeros((max_steps, adim)))
self.rew_buffs.append(np.zeros(max_steps))
self.next_obs_buffs.append(np.zeros((max_steps, odim)))
self.done_buffs.append(np.zeros(max_steps))
self.filled_i = 0 # index of first empty location in buffer (last index when full)
self.curr_i = 0 # current index to write to (ovewrite oldest data)
def __len__(self):
return self.filled_i
def push(self, observations, actions, rewards, next_observations, dones):
nentries = observations.shape[0] # handle multiple parallel environments
if self.curr_i + nentries > self.max_steps:
rollover = self.max_steps - self.curr_i # num of indices to roll over
for agent_i in range(self.num_agents):
self.obs_buffs[agent_i] = np.roll(self.obs_buffs[agent_i],
rollover, axis=0)
self.ac_buffs[agent_i] = np.roll(self.ac_buffs[agent_i],
rollover, axis=0)
self.rew_buffs[agent_i] = np.roll(self.rew_buffs[agent_i],
rollover)
self.next_obs_buffs[agent_i] = np.roll(
self.next_obs_buffs[agent_i], rollover, axis=0)
self.done_buffs[agent_i] = np.roll(self.done_buffs[agent_i],
rollover)
self.curr_i = 0
self.filled_i = self.max_steps
for agent_i in range(self.num_agents):
self.obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
observations[:, agent_i])
# actions are already batched by agent, so they are indexed differently
self.ac_buffs[agent_i][self.curr_i:self.curr_i + nentries] = actions[agent_i]
self.rew_buffs[agent_i][self.curr_i:self.curr_i + nentries] = rewards[:, agent_i]
self.next_obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
next_observations[:, agent_i])
self.done_buffs[agent_i][self.curr_i:self.curr_i + nentries] = dones[:, agent_i]
self.curr_i += nentries
if self.filled_i < self.max_steps:
self.filled_i += nentries
if self.curr_i == self.max_steps:
self.curr_i = 0
def sample(self, N, to_gpu=False, norm_rews=True):
inds = np.random.choice(np.arange(self.filled_i), size=N,
replace=False)
if to_gpu:
cast = lambda x: Variable(Tensor(x), requires_grad=False).to(torch.device(self.device))
else:
cast = lambda x: Variable(Tensor(x), requires_grad=False)
if norm_rews:
ret_rews = [cast((self.rew_buffs[i][inds] -
self.rew_buffs[i][:self.filled_i].mean()) /
self.rew_buffs[i][:self.filled_i].std())
for i in range(self.num_agents)]
else:
ret_rews = [cast(self.rew_buffs[i][inds]) for i in range(self.num_agents)]
return ([cast(self.obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.ac_buffs[i][inds]) for i in range(self.num_agents)],
ret_rews,
[cast(self.next_obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.done_buffs[i][inds]) for i in range(self.num_agents)])
def get_average_rewards(self, N):
if self.filled_i == self.max_steps:
inds = np.arange(self.curr_i - N, self.curr_i) # allow for negative indexing
else:
inds = np.arange(max(0, self.curr_i - N), self.curr_i)
return [self.rew_buffs[i][inds].mean() for i in range(self.num_agents)]
class ReplayBuffer_pre(object):
"""
Replay Buffer for multi-agent RL with parallel rollouts
"""
def __init__(self, max_steps, num_agents, obs_dims, ac_dims, device):
"""
Inputs:
max_steps (int): Maximum number of timepoints to store in buffer
num_agents (int): Number of agents in environment
obs_dims (list of ints): number of obervation dimensions for each
agent
ac_dims (list of ints): number of action dimensions for each agent
"""
self.device = device
self.max_steps = max_steps
self.num_agents = num_agents
self.ac_pre_buffs = []
self.obs_buffs = []
self.ac_buffs = []
self.rew_buffs = []
self.next_obs_buffs = []
self.done_buffs = []
for odim, adim in zip(obs_dims, ac_dims):
self.ac_pre_buffs.append(np.zeros((max_steps, 5)))
self.obs_buffs.append(np.zeros((max_steps, odim)))
self.ac_buffs.append(np.zeros((max_steps, adim)))
self.rew_buffs.append(np.zeros(max_steps))
self.next_obs_buffs.append(np.zeros((max_steps, odim)))
self.done_buffs.append(np.zeros(max_steps))
self.filled_i = 0 # index of first empty location in buffer (last index when full)
self.curr_i = 0 # current index to write to (ovewrite oldest data)
def __len__(self):
return self.filled_i
def push(self, actions_pre, observations, actions, rewards, next_observations, dones):
nentries = observations.shape[0] # handle multiple parallel environments
if self.curr_i + nentries > self.max_steps:
rollover = self.max_steps - self.curr_i # num of indices to roll over
for agent_i in range(self.num_agents):
self.ac_pre_buffs[agent_i] = np.roll(self.ac_pre_buffs[agent_i][:,:5],
rollover, axis=0)
self.obs_buffs[agent_i] = np.roll(self.obs_buffs[agent_i],
rollover, axis=0)
self.ac_buffs[agent_i] = np.roll(self.ac_buffs[agent_i],
rollover, axis=0)
self.rew_buffs[agent_i] = np.roll(self.rew_buffs[agent_i],
rollover)
self.next_obs_buffs[agent_i] = np.roll(
self.next_obs_buffs[agent_i], rollover, axis=0)
self.done_buffs[agent_i] = np.roll(self.done_buffs[agent_i],
rollover)
self.curr_i = 0
self.filled_i = self.max_steps
for agent_i in range(self.num_agents):
self.ac_pre_buffs[agent_i][self.curr_i:self.curr_i + nentries] = actions_pre[agent_i][:,:5]
self.obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
observations[:, agent_i])
# actions are already batched by agent, so they are indexed differently
self.ac_buffs[agent_i][self.curr_i:self.curr_i + nentries] = actions[agent_i]
self.rew_buffs[agent_i][self.curr_i:self.curr_i + nentries] = rewards[:, agent_i]
self.next_obs_buffs[agent_i][self.curr_i:self.curr_i + nentries] = np.vstack(
next_observations[:, agent_i])
self.done_buffs[agent_i][self.curr_i:self.curr_i + nentries] = dones[:, agent_i]
self.curr_i += nentries
if self.filled_i < self.max_steps:
self.filled_i += nentries
if self.curr_i == self.max_steps:
self.curr_i = 0
def sample(self, N, to_gpu=False, norm_rews=True):
inds = np.random.choice(np.arange(self.filled_i), size=N,
replace=False)
if to_gpu:
cast = lambda x: Variable(Tensor(x), requires_grad=False).to(torch.device(self.device))
else:
cast = lambda x: Variable(Tensor(x), requires_grad=False)
if norm_rews:
ret_rews = [cast((self.rew_buffs[i][inds] -
self.rew_buffs[i][:self.filled_i].mean()) /
self.rew_buffs[i][:self.filled_i].std())
for i in range(self.num_agents)]
else:
ret_rews = [cast(self.rew_buffs[i][inds]) for i in range(self.num_agents)]
return ([cast(self.ac_pre_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.ac_buffs[i][inds]) for i in range(self.num_agents)],
ret_rews,
[cast(self.next_obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.done_buffs[i][inds]) for i in range(self.num_agents)])
def get_average_rewards(self, N):
if self.filled_i == self.max_steps:
inds = np.arange(self.curr_i - N, self.curr_i) # allow for negative indexing
else:
inds = np.arange(max(0, self.curr_i - N), self.curr_i)
return [self.rew_buffs[i][inds].mean() for i in range(self.num_agents)]
class ReplayBuffer_RNN(object):
"""
Replay Buffer for multi-agent RL with parallel rollouts
"""
def __init__(self, max_steps, num_agents, obs_dims, ac_dims, ep_dims):
"""
Inputs:
max_steps (int): Maximum number of timepoints to store in buffer
num_agents (int): Number of agents in environment
obs_dims (list of ints): number of obervation dimensions for each
agent
ac_dims (list of ints): number of action dimensions for each agent
ep_dims (int): Number of steps in each episode
"""
self.max_steps = max_steps
self.num_agents = num_agents
self.obs_buffs = []
self.ac_buffs = []
self.rew_buffs = []
self.next_obs_buffs = []
self.done_buffs = []
for odim, adim in zip(obs_dims, ac_dims):
self.obs_buffs.append(np.zeros((max_steps, ep_dims, odim)))
self.ac_buffs.append(np.zeros((max_steps, ep_dims, adim)))
self.rew_buffs.append(np.zeros((max_steps, ep_dims)))
self.next_obs_buffs.append(np.zeros((max_steps, ep_dims, odim)))
self.done_buffs.append(np.zeros((max_steps, ep_dims)))
self.filled_i = 0 # index of first empty location in buffer (last index when full)
self.curr_i = 0 # current index to write to (ovewrite oldest data)
def __len__(self):
return self.filled_i
def push(self, observations_ep, actions_ep, rewards_ep, next_observations_ep, dones_ep):
nentries = observations_ep[0].shape[0] # handle multiple parallel environments
observations_ep, actions_ep, rewards_ep, next_observations_ep, dones_ep = \
np.array(observations_ep), np.array(actions_ep), np.array(rewards_ep),\
np.array(next_observations_ep), np.array(dones_ep)
if self.curr_i + nentries > self.max_steps:
rollover = self.max_steps - self.curr_i # num of indices to roll over
for agent_i in range(self.num_agents):
self.obs_buffs[agent_i] = np.roll(self.obs_buffs[agent_i],
rollover, axis=0)
self.ac_buffs[agent_i] = np.roll(self.ac_buffs[agent_i],
rollover, axis=0)
self.rew_buffs[agent_i] = np.roll(self.rew_buffs[agent_i],
rollover)
self.next_obs_buffs[agent_i] = np.roll(
self.next_obs_buffs[agent_i], rollover, axis=0)
self.done_buffs[agent_i] = np.roll(self.done_buffs[agent_i],
rollover)
self.curr_i = 0
self.filled_i = self.max_steps
for agent_i in range(self.num_agents):
for i in range(observations_ep[:,:,agent_i].shape[0]):
if i == 0:
ob_ep = np.expand_dims(np.vstack(observations_ep[:,:,agent_i][i]), 0)
ob_next_ep = np.expand_dims(np.vstack(next_observations_ep[:,:,agent_i][i]), 0)
else:
ob_ep = np.vstack((ob_ep, np.expand_dims(np.vstack(observations_ep[:,:,agent_i][i]), 0)))
ob_next_ep = np.vstack((ob_next_ep, np.expand_dims(np.vstack(next_observations_ep[:,:,agent_i][i]), 0)))
self.obs_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = ob_ep.transpose(1, 0, 2)
# actions are already batched by agent, so they are indexed differently
self.ac_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = actions_ep[:,:,0,:].transpose(1, 0, 2)
self.rew_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = rewards_ep[:, :, agent_i].transpose(1, 0)
self.next_obs_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = ob_next_ep.transpose(1, 0, 2)
self.done_buffs[agent_i][self.curr_i:self.curr_i + nentries, :] = dones_ep[:, :, agent_i].transpose(1, 0)
self.curr_i += nentries
if self.filled_i < self.max_steps:
self.filled_i += nentries
if self.curr_i == self.max_steps:
self.curr_i = 0
def sample(self, N, to_gpu=False, norm_rews=True):
inds = np.random.choice(np.arange(self.filled_i), size=N,
replace=False)
if to_gpu:
cast = lambda x: Variable(Tensor(x), requires_grad=False).to(torch.device(self.device))
else:
cast = lambda x: Variable(Tensor(x), requires_grad=False)
if norm_rews:
ret_rews = [cast((self.rew_buffs[i][inds] -
self.rew_buffs[i][:self.filled_i].mean()) /
self.rew_buffs[i][:self.filled_i].std())
for i in range(self.num_agents)]
else:
ret_rews = [cast(self.rew_buffs[i][inds]) for i in range(self.num_agents)]
return ([cast(self.obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.ac_buffs[i][inds]) for i in range(self.num_agents)],
ret_rews,
[cast(self.next_obs_buffs[i][inds]) for i in range(self.num_agents)],
[cast(self.done_buffs[i][inds]) for i in range(self.num_agents)])
def get_average_rewards(self, N):
if self.filled_i == self.max_steps:
inds = np.arange(self.curr_i - N, self.curr_i) # allow for negative indexing
else:
inds = np.arange(max(0, self.curr_i - N), self.curr_i)
return [self.rew_buffs[i][inds].mean() for i in range(self.num_agents)]
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/env_wrappers.py
================================================
"""
Modified from OpenAI Baselines code to work with multi-agent envs
"""
import numpy as np
from multiprocessing import Process, Pipe
from common.vec_env.vec_env import VecEnv, CloudpickleWrapper
def worker(remote, parent_remote, env_fn_wrapper):
parent_remote.close()
env = env_fn_wrapper.x()
while True:
cmd, data = remote.recv()
if cmd == 'step':
ob, reward, done, info = env.step(data)
if all(done):
ob = env.reset()
remote.send((ob, reward, done, info))
elif cmd == 'reset':
ob = env.reset()
remote.send(ob)
elif cmd == 'reset_task':
ob = env.reset_task()
remote.send(ob)
elif cmd == 'close':
remote.close()
break
elif cmd == 'get_spaces':
remote.send((env.observation_space, env.action_space))
elif cmd == 'get_agent_types':
if all([hasattr(a, 'adversary') for a in env.agents]):
remote.send(['adversary' if a.adversary else 'agent' for a in
env.agents])
else:
remote.send(['agent' for _ in env.agents])
else:
raise NotImplementedError
class SubprocVecEnv(VecEnv):
def __init__(self, env_fns, spaces=None):
"""
envs: list of gym environments to run in subprocesses
"""
self.waiting = False
self.closed = False
nenvs = len(env_fns)
self.remotes, self.work_remotes = zip(*[Pipe() for _ in range(nenvs)])
self.ps = [Process(target=worker, args=(work_remote, remote, CloudpickleWrapper(env_fn)))
for (work_remote, remote, env_fn) in zip(self.work_remotes, self.remotes, env_fns)]
for p in self.ps:
p.daemon = True # if the main process crashes, we should not cause things to hang
p.start()
for remote in self.work_remotes:
remote.close()
self.remotes[0].send(('get_spaces', None))
observation_space, action_space = self.remotes[0].recv()
self.remotes[0].send(('get_agent_types', None))
self.agent_types = self.remotes[0].recv()
VecEnv.__init__(self, len(env_fns), observation_space, action_space)
def step_async(self, actions):
for remote, action in zip(self.remotes, actions):
remote.send(('step', action))
self.waiting = True
def step_wait(self):
results = [remote.recv() for remote in self.remotes]
self.waiting = False
obs, rews, dones, infos = zip(*results)
return np.stack(obs), np.stack(rews), np.stack(dones), infos
def reset(self):
for remote in self.remotes:
remote.send(('reset', None))
return np.stack([remote.recv() for remote in self.remotes])
def reset_task(self):
for remote in self.remotes:
remote.send(('reset_task', None))
return np.stack([remote.recv() for remote in self.remotes])
def close(self):
if self.closed:
return
if self.waiting:
for remote in self.remotes:
remote.recv()
for remote in self.remotes:
remote.send(('close', None))
for p in self.ps:
p.join()
self.closed = True
class DummyVecEnv(VecEnv):
def __init__(self, env_fns):
self.envs = [fn() for fn in env_fns]
env = self.envs[0]
VecEnv.__init__(self, len(env_fns), env.observation_space, env.action_space)
if all([hasattr(a, 'adversary') for a in env.agents]):
self.agent_types = ['adversary' if a.adversary else 'agent' for a in
env.agents]
else:
self.agent_types = ['agent' for _ in env.agents]
self.ts = np.zeros(len(self.envs), dtype='int')
self.actions = None
def step_async(self, actions):
self.actions = actions
def step_wait(self):
results = [env.step(a) for (a,env) in zip(self.actions, self.envs)]
obs, rews, dones, infos = map(np.array, zip(*results))
self.ts += 1
for (i, done) in enumerate(dones):
if all(done):
obs[i] = self.envs[i].reset()
self.ts[i] = 0
self.actions = None
return np.array(obs), np.array(rews), np.array(dones), infos
def reset(self):
results = [env.reset() for env in self.envs]
return np.array(results)
def close(self):
return
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/make_env.py
================================================
"""
Code for creating a multiagent environment with one of the scenarios listed
in ./scenarios/.
Can be called by using, for example:
env = make_env('simple_speaker_listener')
After producing the env object, can be used similarly to an OpenAI gym
environment.
A policy using this environment must output actions in the form of a list
for all agents. Each element of the list should be a numpy array,
of size (env.world.dim_p + env.world.dim_c, 1). Physical actions precede
communication actions in this array. See environment.py for more details.
"""
def make_env(scenario_name, benchmark=False, discrete_action=False):
'''
Creates a MultiAgentEnv object as env. This can be used similar to a gym
environment by calling env.reset() and env.step().
Use env.render() to view the environment on the screen.
Input:
scenario_name : name of the scenario from ./scenarios/ to be Returns
(without the .py extension)
benchmark : whether you want to produce benchmarking data
(usually only done during evaluation)
Some useful env properties (see environment.py):
.observation_space : Returns the observation space for each agent
.action_space : Returns the action space for each agent
.n : Returns the number of Agents
'''
from multiagent.environment import MultiAgentEnv
import multiagent.scenarios as scenarios
# load scenario from script
scenario = scenarios.load(scenario_name + ".py").Scenario()
# create world
world = scenario.make_world()
# create multiagent environment
if benchmark:
env = MultiAgentEnv(world, scenario.reset_world, scenario.reward,
scenario.observation, scenario.benchmark_data)
else:
env = MultiAgentEnv(world, scenario.reset_world, scenario.reward,
scenario.observation)
return env
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/misc.py
================================================
import os
import torch
import torch.nn.functional as F
import torch.distributed as dist
from torch.autograd import Variable
import numpy as np
# https://github.com/ikostrikov/pytorch-ddpg-naf/blob/master/ddpg.py#L11
def soft_update(target, source, tau):
"""
Perform DDPG soft update (move target params toward source based on weight
factor tau)
Inputs:
target (torch.nn.Module): Net to copy parameters to
source (torch.nn.Module): Net whose parameters to copy
tau (float, 0 < x < 1): Weight factor for update
"""
for target_param, param in zip(target.parameters(), source.parameters()):
target_param.data.copy_(target_param.data * (1.0 - tau) + param.data * tau)
# https://github.com/ikostrikov/pytorch-ddpg-naf/blob/master/ddpg.py#L15
def hard_update(target, source):
"""
Copy network parameters from source to target
Inputs:
target (torch.nn.Module): Net to copy parameters to
source (torch.nn.Module): Net whose parameters to copy
"""
for target_param, param in zip(target.parameters(), source.parameters()):
target_param.data.copy_(param.data)
# https://github.com/seba-1511/dist_tuto.pth/blob/gh-pages/train_dist.py
def average_gradients(model):
""" Gradient averaging. """
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM, group=0)
param.grad.data /= size
# https://github.com/seba-1511/dist_tuto.pth/blob/gh-pages/train_dist.py
def init_processes(rank, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
def onehot_from_logits(logits, eps=0.0):
"""
Given batch of logits, return one-hot sample using epsilon greedy strategy
(based on given epsilon)
"""
# get best (according to current policy) actions in one-hot form
argmax_acs = (logits == logits.max(1, keepdim=True)[0]).float()
if eps == 0.0:
return argmax_acs
# get random actions in one-hot form
rand_acs = Variable(torch.eye(logits.shape[1])[[np.random.choice(
range(logits.shape[1]), size=logits.shape[0])]], requires_grad=False)
# chooses between best and random actions using epsilon greedy
return torch.stack([argmax_acs[i] if r > eps else rand_acs[i] for i, r in
enumerate(torch.rand(logits.shape[0]))])
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def sample_gumbel(shape, eps=1e-20, tens_type=torch.FloatTensor):
"""Sample from Gumbel(0, 1)"""
U = Variable(tens_type(*shape).uniform_(), requires_grad=False)
return -torch.log(-torch.log(U + eps) + eps)
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def gumbel_softmax_sample(logits, temperature):
""" Draw a sample from the Gumbel-Softmax distribution"""
y = logits + sample_gumbel(logits.shape, tens_type=type(logits.data)).to(logits.device)
return F.softmax(y / temperature, dim=1)
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def gumbel_softmax(logits, temperature=1.0, hard=False):
"""Sample from the Gumbel-Softmax distribution and optionally discretize.
Args:
logits: [batch_size, n_class] unnormalized log-probs
temperature: non-negative scalar
hard: if True, take argmax, but differentiate w.r.t. soft sample y
Returns:
[batch_size, n_class] sample from the Gumbel-Softmax distribution.
If hard=True, then the returned sample will be one-hot, otherwise it will
be a probabilitiy distribution that sums to 1 across classes
"""
y = gumbel_softmax_sample(logits, temperature)
if hard:
y_hard = onehot_from_logits(y)
y = (y_hard - y).detach() + y
return y
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/multiprocessing.py
================================================
# This code is from openai baseline
# https://github.com/openai/baselines/tree/master/baselines/common/vec_env
import time
import matplotlib.pyplot as plt
import numpy as np
from multiprocessing import Process, Pipe
def _flatten_list(l):
assert isinstance(l, (list, tuple))
assert len(l) > 0
assert all([len(l_) > 0 for l_ in l])
return [l__ for l_ in l for l__ in l_]
def worker(remote, parent_remote, env_fn_wrapper):
parent_remote.close()
env = env_fn_wrapper.x()
while True:
cmd, data = remote.recv()
if cmd == 'step':
ob, reward, done, info = env.step(data)
if done:
ob = env.reset()
remote.send((ob, reward, done, info))
elif cmd == 'reset':
ob = env.reset()
remote.send(ob)
elif cmd == 'reset_task':
ob = env.reset_task()
remote.send(ob)
elif cmd == 'render':
ob = env.render(mode='rgb_array')
# print(len(ob), 'len(frames)')
# print(len(ob[0]), 'len(frames[0])')
# print(len(ob[0][0]), 'len(frames[0][0])')
remote.send(ob) # rgb_array
elif cmd == 'observe':
ob = env.observe(data)
remote.send(ob)
elif cmd == 'agents':
remote.send(env.agents)
elif cmd == 'spec':
remote.send(env.spec)
elif cmd == 'get_spaces':
remote.send((env.observation_space, env.action_space))
elif cmd == 'close':
remote.close()
break
else:
raise NotImplementedError
class VecEnv(object):
"""
An abstract asynchronous, vectorized environment.
"""
closed = False
viewer = None
metadata = {
'render.modes': ['human', 'rgb_array']
}
def __init__(self, num_envs, observation_space, action_space):
self.num_envs = num_envs
self.observation_space = observation_space
self.action_space = action_space
def observe(self, agent):
pass
def reset(self):
"""
Reset all the environments and return an array of
observations, or a tuple of observation arrays.
If step_async is still doing work, that work will
be cancelled and step_wait() should not be called
until step_async() is invoked again.
"""
pass
def step_async(self, actions):
"""
Tell all the environments to start taking a step
with the given actions.
Call step_wait() to get the results of the step.
You should not call this if a step_async run is
already pending.
"""
pass
def step_wait(self):
"""
Wait for the step taken with step_async().
Returns (obs, rews, dones, infos):
- obs: an array of observations, or a tuple of
arrays of observations.
- rews: an array of rewards
- dones: an array of "episode done" booleans
- infos: a sequence of info objects
"""
pass
def close(self):
"""
Clean up the environments' resources.
"""
pass
def step(self, actions):
self.step_async(actions)
return self.step_wait()
def render(self, mode='human'):
imgs = self.get_images()
bigimg = self.tile_images(imgs)
if mode == 'human':
self.get_viewer().imshow(bigimg) #
return self.get_viewer().isopen
elif mode == 'rgb_array':
return bigimg
else:
raise NotImplementedError
def get_images(self):
"""
Return RGB images from each environment
"""
raise NotImplementedError
def get_viewer(self):
if self.viewer is None:
from common import rendering
self.viewer = rendering.SimpleImageViewer()
return self.viewer
def tile_images(self, img_nhwc):
"""
Tile N images into one big PxQ image
(P,Q) are chosen to be as close as possible, and if N
is square, then P=Q.
input: img_nhwc, list or array of images, ndim=4 once turned into array
n = batch index, h = height, w = width, c = channel
returns:
bigim_HWc, ndarray with ndim=3
"""
img_nhwc = np.asarray(img_nhwc)
N, h, w, c = img_nhwc.shape
H = int(np.ceil(np.sqrt(N)))
W = int(np.ceil(float(N) / H))
img_nhwc = np.array(list(img_nhwc) + [img_nhwc[0] * 0 for _ in range(N, H * W)])
img_HWhwc = img_nhwc.reshape(H, W, h, w, c)
img_HhWwc = img_HWhwc.transpose(0, 2, 1, 3, 4)
img_Hh_Ww_c = img_HhWwc.reshape(H * h, W * w, c)
return img_Hh_Ww_c
class CloudpickleWrapper(object):
"""
Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)
"""
def __init__(self, x):
self.x = x
def __getstate__(self):
import cloudpickle
return cloudpickle.dumps(self.x)
def __setstate__(self, ob):
import pickle
self.x = pickle.loads(ob)
class SubprocVecEnv(VecEnv):
def __init__(self, env_fns, spaces=None):
"""
envs_sc: list of gym environments to run in subprocesses
"""
# self.venv = venv
self.waiting = False
self.closed = False
nenvs = len(env_fns)
self.nenvs = nenvs
self.remotes, self.work_remotes = zip(*[Pipe() for _ in range(nenvs)])
self.ps = [Process(target=worker, args=(work_remote, remote, CloudpickleWrapper(env_fn)))
for (work_remote, remote, env_fn) in zip(self.work_remotes, self.remotes, env_fns)]
for p in self.ps:
p.daemon = True # if the main process crashes, we should not cause things to hang
p.start()
for remote in self.work_remotes:
remote.close()
self.remotes[0].send(('get_spaces', None))
observation_space, action_space = self.remotes[0].recv()
VecEnv.__init__(self, len(env_fns), observation_space, action_space)
def step_async(self, actions):
for remote, action in zip(self.remotes, actions): # the input of step() : action
remote.send(('step', action))
self.waiting = True
def step_wait(self):
results = [remote.recv() for remote in self.remotes] # the output of step() : zip(*results)
self.waiting = False
obs, rews, dones, infos = zip(*results)
return np.stack(obs), np.stack(rews), np.stack(dones), infos
def step_wait_2(self):
results = [remote.recv() for remote in self.remotes]
self.waiting = False
reward, done, _cumulative_rewards = zip(*results)
return reward, done, _cumulative_rewards
def step_wait_3(self):
results = [remote.recv() for remote in self.remotes] # the output of step() : zip(*results)
self.waiting = False
obs, rews, dones, infos = zip(*results)
return np.stack(obs), np.stack(rews), np.stack(dones), infos
def reset(self):
for remote in self.remotes:
remote.send(('reset', None))
return np.stack([remote.recv() for remote in self.remotes])
def agents(self):
for remote in self.remotes:
remote.send(('agents', None))
return np.stack([remote.recv() for remote in self.remotes])
def reset_task(self):
for remote in self.remotes:
remote.send(('reset_task', None))
return np.stack([remote.recv() for remote in self.remotes])
def spec(self):
for remote in self.remotes:
remote.send(('spec', None))
return np.stack([remote.recv() for remote in self.remotes])
def get_images(self):
# self._assert_not_closed()
for pipe in self.remotes:
pipe.send(('render', None))
imgs = [pipe.recv() for pipe in self.remotes]
# imgs = _flatten_list(imgs)
return imgs
def observe(self, agent):
for remote, agent in zip(self.remotes, agent):
remote.send(('observe', agent))
return np.stack([remote.recv() for remote in self.remotes])
# def render(self, mode='human'):
# return self.venv.render(mode=mode)
def close(self):
if self.closed:
return
if self.waiting:
for remote in self.remotes:
remote.recv()
for remote in self.remotes:
remote.send(('close', None))
for p in self.ps:
p.join()
self.closed = True
def __len__(self):
return self.nenvs
def _flatten_list(l):
assert isinstance(l, (list, tuple))
assert len(l) > 0
assert all([len(l_) > 0 for l_ in l])
return [l__ for l_ in l for l__ in l_]
class DummyVecEnv(VecEnv):
def __init__(self, env_fns):
self.envs = [fn() for fn in env_fns]
env = self.envs[0]
VecEnv.__init__(self, len(env_fns), env.observation_space, env.action_space)
if all([hasattr(a, 'adversary') for a in env.agents]):
self.agent_types = ['adversary' if a.adversary else 'agent' for a in
env.agents]
else:
self.agent_types = ['agent' for _ in env.agents]
self.ts = np.zeros(len(self.envs), dtype='int')
self.actions = None
def step_async(self, actions):
self.actions = actions
def step_wait(self):
results = [env.step(a) for (a,env) in zip(self.actions, self.envs)]
obs, rews, dones, infos = map(np.array, zip(*results))
self.ts += 1
for (i, done) in enumerate(dones):
if all(done):
obs[i] = self.envs[i].reset()
self.ts[i] = 0
self.actions = None
return np.array(obs), np.array(rews), np.array(dones), infos
def reset(self):
results = [env.reset() for env in self.envs]
return np.array(results)
def close(self):
return
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/networks.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
from braincog.base.node.node import LIFNode
class MLPNetwork(nn.Module):
"""
MLP network (can be used as value or policy)
"""
def __init__(self, input_dim, out_dim, hidden_dim=64, nonlin=F.relu,
constrain_out=False, norm_in=True, discrete_action=True):
"""
Inputs:
input_dim (int): Number of dimensions in input
out_dim (int): Number of dimensions in output
hidden_dim (int): Number of hidden dimensions
nonlin (PyTorch function): Nonlinearity to apply to hidden layers
"""
super(MLPNetwork, self).__init__()
if norm_in: # normalize inputs
self.in_fn = nn.BatchNorm1d(input_dim) #train
# self.in_fn = input_dim #test
self.in_fn.weight.data.fill_(1)
self.in_fn.bias.data.fill_(0)
else:
self.in_fn = lambda x: x
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, out_dim)
self.nonlin = nonlin
if constrain_out and not discrete_action:
# initialize small to prevent saturation
self.fc3.weight.data.uniform_(-3e-3, 3e-3)
self.out_fn = F.tanh
else: # logits for discrete action (will softmax later)
self.out_fn = lambda x: x
def forward(self, X):
"""
Inputs:
X (PyTorch Matrix): Batch of observations
Outputs:
out (PyTorch Matrix): Output of network (actions, values, etc)
"""
h1 = self.nonlin(self.fc1(self.in_fn(X)))
h2 = self.nonlin(self.fc2(h1))
out = self.out_fn(self.fc3(h2))
return out
class BCNoSpikingLIFNode(LIFNode):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self, dv: torch.Tensor):
self.integral(dv)
return self.mem
class SNNNetwork(nn.Module):
"""
SNN network (can be used as value or policy or MLE)
"""
def __init__(self, input_dim, out_dim, hidden_dim=64, node=LIFNode, time_window=16,
norm_in=True, output_style='sum'):
"""
Inputs:
input_dim (int): Number of dimensions in input
out_dim (int): Number of dimensions in output
hidden_dim (int): Number of hidden dimensions
nonlin (PyTorch function): Nonlinearity to apply to hidden layers
"""
super(SNNNetwork, self).__init__()
self._threshold = 0.5
self.v_reset = 0.0
self._time_window = time_window
self.output_style = output_style
self._node1 = node(threshold=self._threshold, v_reset=self.v_reset)
self._node2 = node(threshold=self._threshold, v_reset=self.v_reset)
if norm_in: # normalize inputs
self.in_fn = nn.BatchNorm1d(input_dim) #train
self.in_fn.weight.data.fill_(1)
self.in_fn.bias.data.fill_(0)
else:
self.in_fn = lambda x: x
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, out_dim)
if self.output_style == 'sum':
self._out_node = lambda x: x
elif self.output_style == 'voltage':
self._out_node = BCNoSpikingLIFNode()
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def forward(self, X):
qs = []
self.reset()
for t in range(self._time_window):
x = self.fc1((self.in_fn(X)+0.5)) #train
# x = self.fc1((X + 0.5)) #test
x = self._node1(x)
x = self.fc2(x)
x = self._node2(x)
x = self.fc3(x)
x = self._out_node(x)
qs.append(x)
if self.output_style == 'sum':
outputs = sum(qs) / self._time_window
return outputs
elif self.output_style == 'voltage':
outputs = x
return outputs
================================================
FILE: examples/Social_Cognition/MAToM-SNN/MPE/utils/noise.py
================================================
import numpy as np
# from https://github.com/songrotek/DDPG/blob/master/ou_noise.py
class OUNoise:
def __init__(self, action_dimension, scale=0.1, mu=0, theta=0.15, sigma=0.2):
self.action_dimension = action_dimension
self.scale = scale
self.mu = mu
self.theta = theta
self.sigma = sigma
self.state = np.ones(self.action_dimension) * self.mu
self.reset()
def reset(self):
self.state = np.ones(self.action_dimension) * self.mu
def noise(self):
x = self.state
dx = self.theta * (self.mu - x) + self.sigma * np.random.randn(len(x))
self.state = x + dx
return self.state * self.scale
================================================
FILE: examples/Social_Cognition/MAToM-SNN/README.md
================================================
# MAToM-SNN
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/agents/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/agents/sagent.py
================================================
import numpy as np
import torch
from torch.distributions import Categorical
from braincog.base.encoder.population_coding import PEncoder
from spikingjelly.activation_based import functional
TIMESTEPS = 15
M = 5
# Agent
class Agents:
def __init__(self, args):
self.n_actions = args.n_actions
self.n_agents = args.n_agents
self.obs_shape = args.obs_shape
# encoder
self.pencoder = PEncoder(TIMESTEPS, 'population_voltage')
if args.alg == 'ppo':
from policy.ppo import PPO
self.policy = PPO(args)
if args.alg == 'iql':
from policy.iql import IQL
self.policy = IQL(args)
if args.mode == 'test':
self.policy.load_model(395000)
if args.alg == 'svdn':
from policy.svdn import SVDN
self.policy = SVDN(args)
if args.alg == 'scovdn':
from policy.scovdn import SCOVDN
self.policy = SCOVDN(args)
if args.alg == 'stomvdn':
from policy.stomvdn import SToMVDN
self.policy = SToMVDN(args)
if args.alg == 'scovdn_weight':
from policy.scovdn_weight import SCOVDN_W
self.policy = SCOVDN_W(args)
if args.alg == 'siql':
from policy.siql import SIQL
self.policy = SIQL(args)
if args.alg == 'scoiql':
from policy.scoiql import SCOIQL
self.policy = SCOIQL(args)
if args.alg == 'siql_e':
from policy.siql_encoder import SIQL_E
self.policy = SIQL_E(args)
if args.alg == 'siql_e2':
from policy.siql_encoder2 import SIQL_EE
self.policy = SIQL_EE(args)
if args.alg == 'siql_no_rnn':
from policy.siql_no_rnn import SIQLUR
self.policy = SIQLUR(args)
if args.alg == 'siql_no_rnn2':
from policy.siql_no_rnn2 import SIQLUR2
self.policy = SIQLUR2(args)
self.args = args
def choose_action(self, num_env, obs, last_action, agent_num, avail_actions, epsilon, maven_z=None, evaluate=False):
inputs = obs.copy()
avail_actions_ind = np.nonzero(avail_actions)[0] # index of actions which can be choose
# transform agent_num to onehot vector
agent_id = np.zeros((num_env, self.n_agents))
agent_id[:, agent_num] = 1.
if self.args.last_action:
inputs = np.hstack((inputs, last_action))
if self.args.reuse_network:
inputs = np.hstack((inputs, agent_id))
# transform the shape of inputs from (42,) to (1,42)
inputs = torch.tensor(inputs, dtype=torch.float32).unsqueeze(0) # torch.Size([1, 17])
# init hidden tensor
if self.args.alg == 'siql_e' or self.args.alg == 'siql_e2':
h1_mem = self.policy.eval_h1_mem[:, agent_num, :, :, :, :]
h1_spike = self.policy.eval_h1_spike[:, agent_num, :, :, :, :]
h2_mem = self.policy.eval_h2_mem[:, agent_num, :, :, :, :]
h2_spike = self.policy.eval_h2_spike[:, agent_num, :, :, :, :]
inputs_, _ = self.pencoder(inputs=inputs, num_popneurons=M, VTH=0.99) ###########################################################
inputs = torch.transpose(inputs_, 0, 3)
inputs = inputs.squeeze().unsqueeze(0)
else:
h1_mem = self.policy.eval_h1_mem[:, agent_num, :, :] #
h1_spike = self.policy.eval_h1_spike[:, agent_num, :, :]
h2_mem = self.policy.eval_h2_mem[:, agent_num, :, :]
h2_spike = self.policy.eval_h2_spike[:, agent_num, :, :]
avail_actions = torch.tensor(avail_actions, dtype=torch.float32).unsqueeze(0)
if self.args.cuda:
inputs = inputs.cuda(self.args.device)
h1_mem = h1_mem.cuda(self.args.device)
h1_spike = h1_spike.cuda(self.args.device)
h2_mem = h2_mem.cuda(self.args.device)
h2_spike = h2_spike.cuda(self.args.device)
# get q value
if self.args.alg == 'siql_no_rnn' or self.args.alg == 'siql_no_rnn2':
self.policy.eval_snn.reset()
q_value = self.policy.eval_snn(inputs)
# functional.reset_net(self.policy_sc.eval_snn)
else:
q_value, self.policy.eval_h1_mem[:, agent_num, :], self.policy.eval_h1_spike[:, agent_num, :],\
self.policy.eval_h2_mem[:, agent_num, :], self.policy.eval_h2_spike[:, agent_num, :]= \
self.policy.eval_snn(inputs, h1_mem, h1_spike, h2_mem, h2_spike)
# choose action from q value
# q_value[avail_actions == 0.0] = - float("inf")
if self.args.alg == 'siql_e' or self.args.alg == 'siql_e2':
q_value = q_value.sum(dim=2)
q_value = q_value.sum(dim=2)
if np.random.uniform() < epsilon:
# action = np.random.choice(avail_actions_ind) # action是一个整数
action = torch.tensor([[np.random.choice(avail_actions_ind) for i in range(num_env)]])
else:
action = torch.argmax(q_value, 2)
return action
def _choose_action_from_softmax(self, inputs, avail_actions, epsilon, evaluate=False):
"""
:param_sc inputs: # q_value of all actions
"""
action_num = avail_actions.sum(dim=1, keepdim=True).float().repeat(1, avail_actions.shape[-1]) # num of avail_actions
# 先将Actor网络的输出通过softmax转换成概率分布
prob = torch.nn.functional.softmax(inputs, dim=-1)
# add noise of epsilon
prob = ((1 - epsilon) * prob + torch.ones_like(prob) * epsilon / action_num)
prob[avail_actions == 0] = 0.0 # 不能执行的动作概率为0
"""
不能执行的动作概率为0之后,prob中的概率和不为1,这里不需要进行正则化,因为torch.distributions.Categorical
会将其进行正则化。要注意在训练的过程中没有用到Categorical,所以训练时取执行的动作对应的概率需要再正则化。
"""
if epsilon == 0 and evaluate:
action = torch.argmax(prob)
else:
action = Categorical(prob).sample().long()
return action
def _get_max_episode_len(self, batch):
terminated = batch['TERMINATE']
episode_num = terminated.shape[0]
max_episode_len = 0
for episode_idx in range(episode_num):
for transition_idx in range(self.args.episode_limit):
if terminated[episode_idx, transition_idx, 0] == 1:
if transition_idx + 1 >= max_episode_len:
max_episode_len = transition_idx + 1
break
if max_episode_len == 0: # 防止所有的episode都没有结束,导致terminated中没有1
max_episode_len = self.args.episode_limit
return max_episode_len
def train(self, batch, train_step, epsilon=None): # coma needs epsilon for training
# different episode has different length, so we need to get max length of the batch
max_episode_len = self._get_max_episode_len(batch)
for key in batch.keys():
if key != 'z':
batch[key] = batch[key][:, :max_episode_len]
self.policy.learn(batch, max_episode_len, train_step, epsilon)
if train_step > 0 and train_step % self.args.save_cycle == 0:
self.policy.save_model(train_step)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/common_sr/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/common_sr/arguments.py
================================================
import argparse
def get_common_args():
parser = argparse.ArgumentParser()
## multiprocessing
parser.add_argument('--process', type=int, default=5, help='multiprocessing')
## the environment setting 'CLASSIC', 'HUNT', 'HARVEST', 'ESCALATION'
parser.add_argument('--ENV', type=str, default='HUNT', help='the version of the game, choose from ["CLASSIC", "HUNT", "HARVEST", "ESCALATION"]')
parser.add_argument('--env_name', type=str, default='stag_stay', help='the version of the game, choose from ["CLASSIC", "HUNT", "HARVEST", "ESCALATION"]')
parser.add_argument('--obs_type', type=str, default='coords', help='Can be "image" for pixel-array based observations, or "coords" for just the entity coordinates')
parser.add_argument('--forage_quantity', type=int, default=2, help='the number of trees')
parser.add_argument('--opponent_policy', type=str, default='random', help='the poliocy of opponent')
parser.add_argument('--replay_dir', type=str, default='', help='absolute path to save the replay')
## The alternative policy ################################################
parser.add_argument('--num_run', type=int, default='4', help='the number of run')
## 'svdn', 'stomvdn'
parser.add_argument('--alg', type=str, default='svdn', help='the algorithm to train the agent')
parser.add_argument('--mode', type=str, default='train', help='the mode')
parser.add_argument('--n_steps', type=int, default=1000000, help='total time steps')#2000000
parser.add_argument('--n_episodes', type=int, default=2, help='the number of episodes before once training')
parser.add_argument('--last_action', type=bool, default=True, help='whether to use the last action to choose action')
parser.add_argument('--reuse_network', type=bool, default=True, help='whether to use one network_sc for all agents_sc')
parser.add_argument('--gamma', type=float, default=0.99, help='discount factor')
parser.add_argument('--epsilon', type=float, default=1.0, help='epsilon factor')
############# "Adam"
parser.add_argument('--optimizer', type=str, default="RMS", help='optimizer')
parser.add_argument('--evaluate_cycle', type=int, default=10, help='how often to evaluate the model')#5000
parser.add_argument('--evaluate_epoch', type=int, default=6, help='number of the epoch to evaluate the agent')#32
## save weights->model/args->log/reward->result/plot
parser.add_argument('--model_dir', type=str, default='./model', help='model directory of the policy_base')
parser.add_argument('--result_dir', type=str, default='./result', help='result directory of the policy_base')#./result#/home/zhaozhuoya/exp2/ToM2_test/result
parser.add_argument('--log_dir', type=str, default='./log', help='args directory')
parser.add_argument('--plot_dir', type=str, default='./plot', help='args directory')
parser.add_argument('--exp_dir', type=str, default='/exp_vdn', help='result directory of the policy_base')
parser.add_argument('--save_model_dir', type=str, default='/199_rnn_net_params_hunt1.pkl', help='load weights and bias')
parser.add_argument('--load_model', type=bool, default=False, help='whether to load the pretrained model')
parser.add_argument('--evaluate', type=bool, default=False, help='whether to evaluate the model')
parser.add_argument('--cuda', type=bool, default=True, help='whether to use the GPU') #True
parser.add_argument('--mini_batch_size', type=int, default=250, help='whether to use the GPU')
args = parser.parse_args()
parser.add_argument('--device', type=str, default='cuda:{}'.format(args.num_run), help='whether to use the GPU') #'cuda:1'
args = parser.parse_args()
return args
# arguments of coma
def get_coma_args(args):
# network_sc
args.rnn_hidden_dim = 64
args.critic_dim = 128
args.lr_actor = 1e-4
args.lr_critic = 1e-3
# epsilon-greedy
# args.epsilon = 0.5
args.anneal_epsilon = 0.00064
args.min_epsilon = 0.02
args.epsilon_anneal_scale = 'episode'
# lambda of td-lambda return
args.td_lambda = 0.8
# how often to save the model
args.save_cycle = 5000
# how often to update the target_net
args.target_update_cycle = 200
# prevent gradient explosion
args.grad_norm_clip = 10
return args
# arguments of vnd、 qmix、 qtran
def get_mixer_args(args):
# network_sc
args.rnn_hidden_dim = 64
args.qmix_hidden_dim = 32
args.two_hyper_layers = False
args.hyper_hidden_dim = 64
args.qtran_hidden_dim = 64
args.ppo_hidden_size = 64
args.lr = 5e-4
# epsilon greedy
# args.epsilon = 1
args.min_epsilon = 0.05
anneal_steps = 50000
args.anneal_epsilon = (args.epsilon - args.min_epsilon) / anneal_steps
args.epsilon_anneal_scale = 'step'
# the number of the train steps in one epoch
args.train_steps = 1
# experience replay
args.batch_size = 32
args.buffer_size = int(5e3)
# how often to save the model
args.save_cycle = 5000
# how often to update the target_net
args.target_update_cycle = 200
# QTRAN lambda
args.lambda_opt = 1
args.lambda_nopt = 1
# prevent gradient explosion
args.grad_norm_clip = 10
# MAVEN
args.noise_dim = 16
args.lambda_mi = 0.001
args.lambda_ql = 1
args.entropy_coefficient = 0.001
return args
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/common_sr/dummy_vec_env.py
================================================
import numpy as np
from .vec_env import VecEnv
from .util import copy_obs_dict, dict_to_obs, obs_space_info
class DummyVecEnv(VecEnv):
"""
VecEnv that does runs multiple environments sequentially, that is,
the step and reset commands are send to one environment at a time.
Useful when debugging and when num_env == 1 (in the latter case,
avoids communication overhead)
"""
def __init__(self, env_fns):
"""
Arguments:
env_fns: iterable of callables functions that build environments
"""
self.envs = [fn() for fn in env_fns]
env = self.envs[0]
VecEnv.__init__(self, len(env_fns), env.observation_space, env.action_space)
obs_space = env.observation_space
self.keys, shapes, dtypes = obs_space_info(obs_space)
self.buf_obs = { k: np.zeros((self.num_envs,) + tuple(shapes[k]), dtype=dtypes[k]) for k in self.keys }
self.buf_dones = np.zeros((self.num_envs,), dtype=np.bool)
self.buf_rews = np.zeros((self.num_envs,), dtype=np.float32)
self.buf_infos = [{} for _ in range(self.num_envs)]
self.actions = None
self.spec = self.envs[0].spec
def step_async(self, actions):
listify = True
try:
if len(actions) == self.num_envs:
listify = False
except TypeError:
pass
if not listify:
self.actions = actions
else:
assert self.num_envs == 1, "actions {} is either not a list or has a wrong size - cannot match to {} environments".format(actions, self.num_envs)
self.actions = [actions]
def step_wait(self):
for e in range(self.num_envs):
action = self.actions[e]
# if isinstance(self.envs_sc[e].action_space, spaces.Discrete):
# action = int(action)
obs, self.buf_rews[e], self.buf_dones[e], self.buf_infos[e] = self.envs[e].step(action)
if self.buf_dones[e]:
obs = self.envs[e].reset()
self._save_obs(e, obs)
return (self._obs_from_buf(), np.copy(self.buf_rews), np.copy(self.buf_dones),
self.buf_infos.copy())
def reset(self):
for e in range(self.num_envs):
obs = self.envs[e].reset()
self._save_obs(e, obs)
return self._obs_from_buf()
def _save_obs(self, e, obs):
for k in self.keys:
if k is None:
self.buf_obs[k][e] = obs
else:
self.buf_obs[k][e] = obs[k]
def _obs_from_buf(self):
return dict_to_obs(copy_obs_dict(self.buf_obs))
def get_images(self):
return [env.render(mode='rgb_array') for env in self.envs]
def render(self, mode='human'):
if self.num_envs == 1:
return self.envs[0].render(mode=mode)
else:
return super().render(mode=mode)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/common_sr/multiprocessing_env.py
================================================
# This code is from openai baseline
# https://github.com/openai/baselines/tree/master/baselines/common/vec_env
import numpy as np
from multiprocessing import Process, Pipe
def _flatten_list(l):
assert isinstance(l, (list, tuple))
assert len(l) > 0
assert all([len(l_) > 0 for l_ in l])
return [l__ for l_ in l for l__ in l_]
def worker(remote, parent_remote, env_fn_wrapper):
parent_remote.close()
env = env_fn_wrapper.x()
while True:
cmd, data = remote.recv()
if cmd == 'step':
ob, reward, done, info = env.step(data)
if np.array(done).all():
# if done:
ob = env.reset()
remote.send((ob, reward, done, info))
elif cmd == 'reset':
ob = env.reset()
remote.send(ob)
elif cmd == 'reset_task':
ob = env.reset_task()
remote.send(ob)
elif cmd == 'render':
ob = env.render()
remote.send(ob) #rgb_array
elif cmd == 'close':
remote.close()
break
elif cmd == 'get_spaces':
remote.send((env.observation_space, env.action_space))
else:
raise NotImplementedError
class VecEnv(object):
"""
An abstract asynchronous, vectorized environment.
"""
def __init__(self, num_envs, observation_space, action_space):
self.num_envs = num_envs
self.observation_space = observation_space
self.action_space = action_space
def reset(self):
"""
Reset all the environments and return an array of
observations, or a tuple of observation arrays.
If step_async is still doing work, that work will
be cancelled and step_wait() should not be called
until step_async() is invoked again.
"""
pass
def step_async(self, actions):
"""
Tell all the environments to start taking a step
with the given actions.
Call step_wait() to get the results of the step.
You should not call this if a step_async run is
already pending.
"""
pass
def step_wait(self):
"""
Wait for the step taken with step_async().
Returns (obs, rews, dones, infos):
- obs: an array of observations, or a tuple of
arrays of observations.
- rews: an array of rewards
- dones: an array of "episode done" booleans
- infos: a sequence of info objects
"""
pass
def close(self):
"""
Clean up the environments' resources.
"""
pass
def step(self, actions):
self.step_async(actions)
return self.step_wait()
def render(self, mode='human'):
imgs = self.get_images()
# bigimg = tile_images(imgs)
# if mode == 'human':
# self.get_viewer().imshow(bigimg) #
# return self.get_viewer().isopen
# elif mode == 'rgb_array':
# return bigimg
# else:
# raise NotImplementedError
def get_images(self):
"""
Return RGB images from each environment
"""
raise NotImplementedError
class CloudpickleWrapper(object):
"""
Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)
"""
def __init__(self, x):
self.x = x
def __getstate__(self):
import cloudpickle
return cloudpickle.dumps(self.x)
def __setstate__(self, ob):
import pickle
self.x = pickle.loads(ob)
class SubprocVecEnv(VecEnv):
def __init__(self, env_fns, spaces=None):
"""
envs_sc: list of gym environments to run in subprocesses
"""
self.waiting = False
self.closed = False
nenvs = len(env_fns)
self.nenvs = nenvs
self.remotes, self.work_remotes = zip(*[Pipe() for _ in range(nenvs)])
self.ps = [Process(target=worker, args=(work_remote, remote, CloudpickleWrapper(env_fn)))
for (work_remote, remote, env_fn) in zip(self.work_remotes, self.remotes, env_fns)]
for p in self.ps:
p.daemon = True # if the main process crashes, we should not cause things to hang
p.start()
for remote in self.work_remotes:
remote.close()
self.remotes[0].send(('get_spaces', None))
observation_space, action_space = self.remotes[0].recv()
VecEnv.__init__(self, len(env_fns), observation_space, action_space)
def step_async(self, actions):
for remote, action in zip(self.remotes, actions):
remote.send(('step', action))
self.waiting = True
def step_wait(self):
results = [remote.recv() for remote in self.remotes]
self.waiting = False
obs, rews, dones, infos = zip(*results)
return np.stack(obs), np.stack(rews), np.stack(dones), infos
def reset(self):
for remote in self.remotes:
remote.send(('reset', None))
return np.stack([remote.recv() for remote in self.remotes])
def reset_task(self):
for remote in self.remotes:
remote.send(('reset_task', None))
return np.stack([remote.recv() for remote in self.remotes])
def get_images(self):
# self._assert_not_closed()
for pipe in self.remotes:
pipe.send(('render', None))
imgs = [pipe.recv() for pipe in self.remotes]
# imgs = _flatten_list(imgs)
return imgs
def close(self):
if self.closed:
return
if self.waiting:
for remote in self.remotes:
remote.recv()
for remote in self.remotes:
remote.send(('close', None))
for p in self.ps:
p.join()
self.closed = True
def __len__(self):
return self.nenvs
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/common_sr/replay_buffer.py
================================================
import numpy as np
import threading
class ReplayBuffer:
def __init__(self, args):
self.args = args
self.n_actions = self.args.n_actions
self.n_agents = self.args.n_agents
# self.state_shape = self.args.state_shape
self.obs_shape = self.args.obs_shape
self.size = self.args.buffer_size
self.episode_limit = self.args.episode_limit
# memory management
self.current_idx = 0
self.current_size = 0
# create the buffer to store info
self.buffers = {'O': np.empty([self.size, self.episode_limit, self.n_agents, self.obs_shape]),
'U': np.empty([self.size, self.episode_limit, self.n_agents, 1]),
# 's': np.empty([self.size, self.episode_limit, self.state_shape]),
'R': np.empty([self.size, self.episode_limit, self.n_agents, 1]),
'O_NEXT': np.empty([self.size, self.episode_limit, self.n_agents, self.obs_shape]),
# 's_next': np.empty([self.size, self.episode_limit, self.state_shape]),
'AVAIL_U': np.empty([self.size, self.episode_limit, self.n_agents, self.n_actions]),
'AVAIL_U_NEXT': np.empty([self.size, self.episode_limit, self.n_agents, self.n_actions]),
'U_ONEHOT': np.empty([self.size, self.episode_limit, self.n_agents, self.n_actions]),
'PADDED': np.empty([self.size, self.episode_limit, 1]),
'TERMINATE': np.empty([self.size, self.episode_limit, 1])
}
# thread lock
self.lock = threading.Lock()
# store the episode
def store_episode(self, episode_batch):
batch_size = episode_batch['O'].shape[0] # episode_number
with self.lock:
idxs = self._get_storage_idx(inc=batch_size)
# store the informations
self.buffers['O'][idxs] = episode_batch['O']
self.buffers['U'][idxs] = episode_batch['U']
# self.buffers['s'][idxs] = episode_batch['s']
self.buffers['R'][idxs] = episode_batch['R']
self.buffers['O_NEXT'][idxs] = episode_batch['O_NEXT']
# self.buffers['s_next'][idxs] = episode_batch['s_next']
self.buffers['AVAIL_U'][idxs] = episode_batch['AVAIL_U']
self.buffers['AVAIL_U_NEXT'][idxs] = episode_batch['AVAIL_U_NEXT']
self.buffers['U_ONEHOT'][idxs] = episode_batch['U_ONEHOT']
self.buffers['PADDED'][idxs] = episode_batch['PADDED']
self.buffers['TERMINATE'][idxs] = episode_batch['TERMINATE']
if self.args.alg == 'maven':
self.buffers['z'][idxs] = episode_batch['z']
def sample(self, batch_size):
temp_buffer = {}
idx = np.random.randint(0, self.current_size, batch_size)
for key in self.buffers.keys():
temp_buffer[key] = self.buffers[key][idx]
return temp_buffer
def _get_storage_idx(self, inc=None):
inc = inc or 1
if self.current_idx + inc <= self.size:
idx = np.arange(self.current_idx, self.current_idx + inc)
self.current_idx += inc
elif self.current_idx < self.size:
overflow = inc - (self.size - self.current_idx)
idx_a = np.arange(self.current_idx, self.size)
idx_b = np.arange(0, overflow)
idx = np.concatenate([idx_a, idx_b])
self.current_idx = overflow
else:
idx = np.arange(0, inc)
self.current_idx = inc
self.current_size = min(self.size, self.current_size + inc)
if inc == 1:
idx = idx[0]
return idx
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/common_sr/srollout.py
================================================
import numpy as np
import torch
class RolloutWorker:
def __init__(self, env, agents, args):
self.env = env
self.agents = agents
self.episode_limit = args.episode_limit
self.n_actions = args.n_actions
self.n_agents = args.n_agents
self.obs_shape = args.obs_shape
self.args = args
self.epsilon = args.epsilon
self.anneal_epsilon = args.anneal_epsilon
self.min_epsilon = args.min_epsilon
print('Init RolloutWorker')
def generate_episode(self, episode_num=None, evaluate=False):
# if self.args.alg == 'siql_no_rnn':
# from policy_sc.siql_no_rnn import SIQLUR
# self.policy_sc = SIQLUR(self.args)
# self.policy_sc.eval_snn.reset()
if self.args.replay_dir != '' and evaluate and episode_num == 0: # prepare for save replay of evaluation
self.env.close()
# Store all data
EPISODE = dict(
O = [],
U = [],
R = [],
O_NEXT = [],
U_ONEHOT = [],
AVAIL_U = [],
AVAIL_U_NEXT = [],
PADDED = [],
TERMINATE = [],
)
NUM_EPISODES = self.args.n_episodes if evaluate==False else self.args.evaluate_epoch
episode_num = 0 if evaluate == False else self.args.evaluate_epoch
episode_reward = np.zeros((self.args.process, self.n_agents))
for episode_idx in range(NUM_EPISODES):
# Store one multiprocessing data
o, u, r, avail_u, u_onehot, terminate, padded = [], [], [], [], [], [], []
obs = self.env.reset()
obs1 = obs.copy()
obs1[:, 0], obs1[:, 1], obs1[:, 2], obs1[:, 3] = \
obs[:, 2], obs[:, 3], obs[:, 0], obs[:, 1]
obs_ = (obs, obs1)
obs_ = np.stack((obs, obs1), axis=0).transpose(1, 0, 2)
num_env = obs.shape[0]
last_action = np.zeros((self.args.n_agents, num_env, self.args.n_actions))
self.agents.policy.init_hidden(1, num_env)
terminated = False
win_tag = False
step = 0
# epsilon
epsilon = 0 if evaluate else self.epsilon
if self.args.epsilon_anneal_scale == 'episode':
epsilon = epsilon - self.anneal_epsilon if epsilon > self.min_epsilon else epsilon
# for each episode (include 50 steps and num_env multiprocessing)
while not terminated and step < self.episode_limit:
# time.sleep(0.2)
obs = np.array(obs_) #A perspective, B perspective
avail_action = [1] * self.args.n_actions
actions, avail_actions, actions_onehot = [], [], []
for agent_id in range(self.n_agents):
action = self.agents.choose_action(num_env, obs[:, agent_id, :], last_action[agent_id],
agent_id, avail_action, epsilon, evaluate)
# generate onehot vector of th action
action_onehot = np.zeros((num_env, self.args.n_actions))
for i in range(num_env): action_onehot[i, action[0, i]] = 1
actions.append(action[0].cpu().numpy().tolist()) #np.int(action)
actions_onehot.append(action_onehot)
avail_actions.append(avail_action)
last_action[agent_id] = action_onehot
actions = np.array(actions).transpose(1,0) #[num_env, num_agent](4, 2)
obs_, reward, done, info = self.env.step(actions=actions) #[num_env,num_agent,num_state],[num_env, num_agent],[num_env] (4, 2, 10) (4, 2)
if self.args.load_model == True:
self.env.render(mode="human")
print(reward)
o.append(obs)
u.append(np.expand_dims(actions, self.n_agents))
u_onehot.append(actions_onehot)
avail_u.append(avail_actions)
r.append(np.expand_dims(reward, 2))
terminate.append(np.expand_dims(np.array([terminated]*num_env), 1))
padded.append(np.expand_dims(np.array([0.]*num_env), 1))
episode_reward = episode_reward + reward
step += 1
if self.args.epsilon_anneal_scale == 'step':
epsilon = epsilon - self.anneal_epsilon if epsilon > self.min_epsilon else epsilon
# last obs
obs = np.array(obs_)
o.append(obs)
o_next = o[1:]
o = o[:-1]
# get avail_action for last obs,because target_q needs avail_action in training
avail_actions = []
for agent_id in range(self.n_agents):
avail_action = [1] * self.args.n_actions
avail_actions.append(avail_action)
avail_u.append(avail_actions)
avail_u_next = avail_u[1:]
avail_u = avail_u[:-1]
# if step < self.episode_limit,padding (if termined before the max steps, add data to max steps)
for i in range(step, self.episode_limit):
o.append(np.zeros((self.n_agents, self.obs_shape)))
u.append(np.zeros([self.n_agents, 1]))
r.append(np.zeros([self.n_agents, 1]))
o_next.append(np.zeros((self.n_agents, self.obs_shape)))
u_onehot.append(np.zeros((self.n_agents, self.n_actions)))
avail_u.append(np.zeros((self.n_agents, self.n_actions)))
avail_u_next.append(np.zeros((self.n_agents, self.n_actions)))
padded.append([1.]*num_env)
terminate.append([1.]*num_env)
# Processing data for each episode
EPISODE['O'].append(np.stack(o, axis=0).transpose(1, 0, 2, 3))
EPISODE['U'].append(np.stack(u, axis=0).transpose(1, 0, 2, 3).astype(int))
EPISODE['R'].append(np.stack(r, axis=0).transpose(1, 0, 2, 3))
EPISODE['O_NEXT'].append(np.stack(o_next, axis=0).transpose(1, 0, 2, 3))
EPISODE['U_ONEHOT'].append(np.stack(u_onehot, axis=0).transpose(2, 0, 1, 3))
EPISODE['AVAIL_U'].append(np.ones(EPISODE['U_ONEHOT'][0].shape))
EPISODE['AVAIL_U_NEXT'].append(np.ones(EPISODE['U_ONEHOT'][0].shape))
EPISODE['PADDED'].append(np.stack(padded, axis=0).transpose(1, 0, 2))
EPISODE['TERMINATE'].append(np.stack(terminate, axis=0).transpose(1, 0, 2))
episode_reward = episode_reward.sum(0)
for i in EPISODE.keys():
EPISODE[i] = np.concatenate(EPISODE[i], axis=0)
step = step * self.args.n_episodes * num_env
if not evaluate:
self.epsilon = epsilon
if evaluate and episode_num == self.args.evaluate_epoch and self.args.replay_dir != '':
self.env.save_replay()
self.env.close()
return EPISODE, episode_reward, win_tag, step
def generate_episode_sample(self, episodes, steps, episode_num=None, evaluate=False):
if self.args.replay_dir != '' and evaluate and episode_num == 0: # prepare for save replay of evaluation
self.env.close()
o, u, r, avail_u, u_onehot, terminate, padded = [], [], [], [], [], [], []
obs = self.env.reset()
obs_ = (obs, self.env.game._flip_coord_observation_perspective(obs)) # A perspective, B perspective
terminated = False
win_tag = False
step = 0
episode_reward = (0, 0) # cumulative rewards
# ###
# for param_sc in self.agents_sc.policy_base.parameters():
# param_sc.requires_grad = False
# self.agents_sc.policy_base.eval()
last_action = np.zeros((self.args.n_agents, self.args.n_actions))
self.agents.policy.init_hidden(1)
# epsilon
epsilon = 0 if evaluate else self.epsilon
if self.args.epsilon_anneal_scale == 'episode':
epsilon = epsilon - self.anneal_epsilon if epsilon > self.min_epsilon else epsilon
while not terminated and step < self.episode_limit:
# time.sleep(0.2)
obs = np.array(obs_) #A perspective, B perspective
avail_action = [1] * self.args.n_actions
actions, avail_actions, actions_onehot = [], [], []
for agent_id in range(self.n_agents):
action = self.agents.choose_action(obs[agent_id], last_action[agent_id], agent_id,
avail_action, epsilon, evaluate)
# generate onehot vector of th action
action_onehot = np.zeros(self.args.n_actions)
action_onehot[action] = 1
actions.append(np.int(action))
actions_onehot.append(action_onehot)
avail_actions.append(avail_action)
last_action[agent_id] = action_onehot
obs_, reward, done, info = self.env.step(actions=actions)
# print(actions,reward)
win_tag = True if terminated else False
# save obs, actions, avail_actions, reward at time t
o.append(obs)
u.append(np.reshape(actions, [self.n_agents, 1]))
u_onehot.append(actions_onehot)
avail_u.append(avail_actions)
r.append(np.reshape(reward, [self.n_agents, 1])) #reward
terminate.append([terminated])
padded.append([0.])
# episode_reward += reward
episode_reward = [episode_reward[i] + reward[i] for i in range(min(len(episode_reward), len(reward)))]
step += 1
if self.args.epsilon_anneal_scale == 'step':
epsilon = epsilon - self.anneal_epsilon if epsilon > self.min_epsilon else epsilon
if self.args.load_model == True:
self.env.render(mode="human")
# last obs
obs = np.array(obs_)
o.append(obs)
o_next = o[1:]
o = o[:-1]
# get avail_action for last obs,because target_q needs avail_action in training
avail_actions = []
for agent_id in range(self.n_agents):
avail_action = [1] * self.args.n_actions
avail_actions.append(avail_action)
avail_u.append(avail_actions)
avail_u_next = avail_u[1:]
avail_u = avail_u[:-1]
# if step < self.episode_limit,padding
for i in range(step, self.episode_limit):
o.append(np.zeros((self.n_agents, self.obs_shape)))
u.append(np.zeros([self.n_agents, 1]))
r.append(np.zeros([self.n_agents, 1]))
o_next.append(np.zeros((self.n_agents, self.obs_shape)))
u_onehot.append(np.zeros((self.n_agents, self.n_actions)))
avail_u.append(np.zeros((self.n_agents, self.n_actions)))
avail_u_next.append(np.zeros((self.n_agents, self.n_actions)))
padded.append([1.])
terminate.append([1.])
episode = dict(o=o.copy(),
u=u.copy(),
r=r.copy(),
avail_u=avail_u.copy(),
o_next=o_next.copy(),
avail_u_next=avail_u_next.copy(),
u_onehot=u_onehot.copy(),
padded=padded.copy(),
terminated=terminate.copy()
)
episodes[episode_num] = episode
steps[episode_num] = step
# add episode dim
for key in episode.keys():
episode[key] = np.array([episode[key]])
if not evaluate:
self.epsilon = epsilon
if evaluate and episode_num == self.args.evaluate_epoch - 1 and self.args.replay_dir != '':
self.env.save_replay()
self.env.close()
# return episode, episode_reward, win_tag, step
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/envs/Stag_Hunt_env.py
================================================
import gym
import gym_stag_hunt
from ray import tune
from ray.rllib.env.wrappers.pettingzoo_env import PettingZooEnv
from gym_stag_hunt.envs.pettingzoo.hunt import raw_env
if __name__ == "__main__":
def env_creator(args):
return PettingZooEnv(raw_env(**args))
tune.register_env("StagHunt-Hunt-PZ-v0", env_creator)
model = tune.run(
"DQN",
name="stag_hunt",
stop={"episodes_total": 10000},
checkpoint_freq=100,
checkpoint_at_end=True,
config={
"horizon": 100,
"framework": "tf2",
# Environment specific
"env": "StagHunt-Hunt-PZ-v0",
# General
"num_workers": 2,
# Method specific
"multiagent": {
"policies": {"player_0", "player_1"},
"policy_mapping_fn": (lambda agent_id, episode, **kwargs: agent_id),
"policies_to_train": ["player_0", "player_1"]
},
# Env Specific
"env_config": {
"obs_type": "coords",
"forage_reward": 1.0,
"stag_reward": 5.0,
"stag_follows": True,
"mauling_punishment": -.5,
"enable_multiagent": True,
}
}
)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/envs/__init__.py
================================================
from ToM2.envs.grid_env1 import *
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/envs/abstract.py
================================================
"""
Implements abstract class for meta-reinforcement learning environments.
"""
from typing import Generic, TypeVar, Tuple
import abc
ObsType = TypeVar('ObsType')
class MetaEpisodicEnv(abc.ABC, Generic[ObsType]):
@property
@abc.abstractmethod
def max_episode_len(self) -> int:
"""
Return the maximum episode length.
"""
pass
@abc.abstractmethod
def new_env(self) -> None:
"""
Reset the environment's structure by resampling
the state transition probabilities and/or reward function
from a prior distribution.
Returns:
None
"""
pass
@abc.abstractmethod
def reset(self) -> ObsType:
"""
Resets the environment's state to some designated initial state.
This is distinct from resetting the environment's structure
via self.new_env().
Returns:
initial observation.
"""
pass
@abc.abstractmethod
def step(
self,
action: int,
auto_reset: bool = True
) -> Tuple[ObsType, float, bool, dict]:
"""
Step the env.
Args:
action: integer action indicating which action to take
auto_reset: whether or not to automatically reset the environment
on done. if true, next observation will be given by self.reset()
Returns:
next observation, reward, and done flat
"""
pass
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/envs/constants.py
================================================
"""
Global constants for the gridworld env.
"""
# =============================================================================
# set the value of interface
# =============================================================================
FPS = 25
WinWidth = 340 #window width
WinHeight = 260 #window width
BoxSize = 20 #the size of one grid
GridWidth = 7 #the number of lattices are there in the x-axis
GridHeight = 7 #the number of lattices are there in the y-axis
XMargin = int((WinWidth - GridWidth * BoxSize)/2)
TopMargin = int((WinHeight - GridHeight * BoxSize))/2-5
# =============================================================================
# set color
# =============================================================================
White = (255, 255, 255)
Gray = (185, 185, 185)
Black = (0, 0, 0)
Red = (255, 0, 0)
Green = (0, 128, 0)
SpringGreen = (60, 179, 113)
DarkOrange = (255, 140, 0)
RoyalBlue = (65, 105, 225)
DarkVoilet = (148, 0, 211)
HotPink = (255, 105, 180)
BoardColor = White
BGColor = White
TextColor = White
Test = []
# =============================================================================
# set maps
# =============================================================================
# BlankBox = 1
# shadow = 0
# Wall = 5
# Obstacle = 5
# observer = 8
# button = 7
# obeservation_1 = 11
# obeservation_2 = 22
# obeservation_3 = 33
"""
'S' : starting point
'F' or '.': free space
'W' or 'x': wall
'H' or 'o': hole (terminates episode)
'G' : goal
"""
Start = 'S'
Free_space = 'F'
Wall = 'W'
Danger = 'H'
Goal = 'G'
Shadow = 'Sh'
MAPs = {
0: [
"FFFFF",
"FHFWF",
"FFFFF",
"WFFFF",
"FFFGF"
],
1: [
"FFFFF",
"FHWFF",
"FFFFF",
"WFGFF",
"FFFFF"
],
2: [
"FFFF",
"FWFW",
"FFFW",
"WFFG"
],
3: [
"FFFF",
"FHFW",
"FFFW",
"GFFF"
],
4: [
"FFFF",
"FHFW",
"FFFW",
"WGFF"
],
}
# 2: [
# "SFFFFFFF",
# "FFFFFFFF",
# "FFFHFFFF",
# "FFFFFWFF",
# "FFFHFFFF",
# "FWHFFFWF",
# "FWFFHFWF",
# "FFFWFFFG"
# ],
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/main_spiking.py
================================================
from common_sr.arguments import get_common_args, get_coma_args, get_mixer_args
from common_sr.multiprocessing_env import SubprocVecEnv
from runner import Runner
from time import sleep
from gym_stag_hunt.envs.gym.escalation import EscalationEnv
from gym_stag_hunt.envs.gym.harvest import HarvestEnv
from gym_stag_hunt.envs.gym.hunt import HuntEnv
from gym_stag_hunt.envs.gym.simple import SimpleEnv
from gym_stag_hunt.src.games.abstract_grid_game import UP, LEFT, DOWN, RIGHT, STAND
import json
import os
os.environ["SDL_VIDEODRIVER"] = "dummy"
if __name__ == '__main__':
ENVS = {
"CLASSIC": SimpleEnv,
"HUNT": HuntEnv,
"HARVEST": HarvestEnv,
"ESCALATION": EscalationEnv,
}
args = get_common_args()
args = get_mixer_args(args)
if args.ENV == 'HUNT':
args.n_actions = 5 # [5] # up, down, left, right or stand
args.n_agents = 2 # [2]
args.obs_shape = 6 + args.forage_quantity * 2
elif args.ENV == 'ESCALATION':
args.n_actions = 5 # [5] # up, down, left, right or stand
args.n_agents = 2 # [2]
args.obs_shape = 6
elif args.ENV == 'HARVEST':
args.n_actions = 5 # [5] # up, down, left, right or stand
args.n_agents = 2 # [2]
args.obs_shape = 6 + args.forage_quantity * 5
args.episode_limit = 50
args.train_steps = 100
save_path = args.log_dir + '/' + args.alg + args.exp_dir
print(os.path.exists(save_path))
if not os.path.exists(save_path):
os.makedirs(save_path)
# save args
argsDict = args.__dict__
with open(save_path + '/args_{}'.format(args.num_run), 'w') as f:
f.writelines('------------------ start ------------------' + '\n')
for eachArg, value in argsDict.items():
f.writelines(eachArg + ' : ' + str(value) + '\n')
f.writelines('------------------- end -------------------')
def make_env():
def _thunk():
if args.ENV == 'HUNT':
env = ENVS[args.ENV](obs_type="coords", enable_multiagent=True, opponent_policy="random", \
forage_quantity=args.forage_quantity, run_away_after_maul=True)
elif args.ENV == 'ESCALATION':
env = ENVS[args.ENV](obs_type="coords", enable_multiagent=True)
elif args.ENV == 'HARVEST':
env = ENVS[args.ENV](obs_type="coords", enable_multiagent=True)
return env
return _thunk
# for i in range(args.num_run):
envs = [make_env() for i in range(args.process)]
envs = SubprocVecEnv(envs)
runner = Runner(envs, args)
if not args.evaluate:
runner.run(args.num_run)
else:
win_rate, _ = runner.evaluate()
print('The win rate of {} is {}'.format(args.alg, win_rate))
envs.close()
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/network/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/network/spiking_net.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as f
from torch.distributions import Normal
from braincog.base.node.node import IFNode, LIFNode
from braincog.base.strategy.surrogate import AtanGrad
thresh = 0.3
lens = 0.25
decay = 0.3
TIMESTEPS = 15
M = 5
# BrainCog
class BCNoSpikingLIFNode(LIFNode):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self, dv: torch.Tensor):
self.integral(dv)
return self.mem
class BCNoSpikingIFNode(IFNode):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self, dv: torch.Tensor):
self.integral(dv)
return self.mem
# Sug
class ActFun(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
return input.gt(thresh).float()
@staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
grad_input = grad_output.clone()
temp = abs(input - thresh) < lens
return grad_input * temp.float() / (2 * lens)
#act_fun = ActFun.apply
act_fun = AtanGrad(alpha=2.,requires_grad=False)
def mem_update(fc, x, mem, spike):
mem = mem * decay * (1 - spike) + fc(x)
#spike = act_fun(mem)
spike = act_fun(x=mem-1)
return mem, spike
class Critic(nn.Module):
def __init__(self, input_shape, args):
super(Critic, self).__init__()
self.args = args
self.fc1 = nn.Linear(input_shape, args.ppo_hidden_size)
self.fc2 = nn.Linear(args.rnn_hidden_dim, args.rnn_hidden_dim, bias = True)
self.fc3 = nn.Linear(args.rnn_hidden_dim, args.rnn_hidden_dim, bias = True)
self.fc4 = nn.Linear(args.rnn_hidden_dim, args.n_actions)#
self.req_grad = False
def forward(self, inputs, h1_mem, h1_spike, h2_mem, h2_spike):
# if self.req_grad == False:
# [1, 17] -> [1, process, 64]
x = self.fc1(inputs)
# x = IFNode()(x)
x = LIFNode()(x)
if self.args.alg == 'siql_e':
h1_mem = h1_mem.reshape(-1, M,TIMESTEPS, self.args.rnn_hidden_dim)
h1_spike = h1_spike.reshape(-1, M,TIMESTEPS, self.args.rnn_hidden_dim)
h2_mem = h2_mem.reshape(-1, M, TIMESTEPS, self.args.rnn_hidden_dim)
h2_spike = h2_spike.reshape(-1, M, TIMESTEPS, self.args.rnn_hidden_dim)
else:
# [1, 64] -> [process, 64]
h1_mem = h1_mem.reshape(-1, self.args.rnn_hidden_dim)
h1_spike = h1_spike.reshape(-1, self.args.rnn_hidden_dim)
h2_mem = h2_mem.reshape(-1, self.args.rnn_hidden_dim)
h2_spike = h2_spike.reshape(-1, self.args.rnn_hidden_dim)
h1_mem, h1_spike = mem_update(self.fc2, x, h1_mem, h1_spike)
h2_mem, h2_spike = mem_update(self.fc3, h1_spike, h2_mem, h2_spike)
# [1, 5]
value = BCNoSpikingLIFNode(tau=2.0)(self.fc4(h2_mem))
return value, h1_mem, h1_spike, h2_mem, h2_spike
class VDNNet(nn.Module):
def __init__(self):
super(VDNNet, self).__init__()
def forward(self, q_values):
return torch.sum(q_values, dim=2, keepdim=True)
class Linear_weight(nn.Module):
def __init__(self, input_shape, out_shape, args):
super(Linear_weight,self).__init__()
self.args = args
# self.fc = nn.Linear(input_shape, out_shape)
self.alpha = nn.Parameter(torch.Tensor(out_shape))
def forward(self, x):
# return self.fc(x)
if self.args.alg == 'scovdn_weight':
x = x[:,:,:,0] * self.alpha + x[:,:,:,1] * (1 - self.alpha)
return x.unsqueeze(3)
elif self.args.alg == 'stomvdn':
x = x[:, :, :, :, 0] * self.alpha + x[:, :, :, :, 1] * (1 - self.alpha)
return x.unsqueeze(4)
class BiasNet(nn.Module):
def __init__(self, args):
super(BiasNet, self).__init__()
self.args = args
input_shape = self.args.obs_shape + self.args.rnn_hidden_dim
#
# self.h1_mem = self.h1_spike = torch.zeros(self.args.n_episodes * self.args.process,
# self.args.episode_limit, self.args.rnn_hidden_dim)
# if self.args.cuda:
# self.h1_mem = self.h1_mem.cuda(self.args.device)
# self.h1_spike = self.h1_spike.cuda(self.args.device)
self.fc1 = nn.Linear(input_shape, args.rnn_hidden_dim)#neuron.IFNode()
self.fc2 = nn.Linear(args.rnn_hidden_dim, args.rnn_hidden_dim, bias = True)
self.fc3 = nn.Linear(args.rnn_hidden_dim, 1)#
def reset(self, episode_num):
self.h1_mem = self.h1_spike = torch.zeros(episode_num,
self.args.episode_limit, self.args.rnn_hidden_dim)
if self.args.cuda:
self.h1_mem = self.h1_mem.cuda(self.args.device)
self.h1_spike = self.h1_spike.cuda(self.args.device)
def forward(self, state, hidden):
episode_num, max_episode_len, n_agents, _ = hidden.shape
state = state.reshape(episode_num * max_episode_len, -1)
state = state * 0.2
hidden = \
hidden.reshape(episode_num * max_episode_len, n_agents, -1).sum(dim=-2)
inputs = torch.cat([state, hidden], dim=-1)
x = self.fc1(inputs)
x = neuron.IFNode()(x)
# x = IFNode()(x)
# x = LIFNode()(x) #bad
# [1, 64] -> [process, 64]
self.h1_mem = self.h1_mem.reshape(-1, self.args.rnn_hidden_dim)
self.h1_spike = self.h1_spike.reshape(-1, self.args.rnn_hidden_dim)
self.h1_mem, self.h1_spike = mem_update(self.fc2, x, self.h1_mem, self.h1_spike)
# [1, 5]
# value = NonSpikingLIFNode(tau=2.0)(self.fc4(h2_mem))
# value = BCNoSpikingLIFNode(tau=2.0)(self.fc4(h2_mem))
value = BCNoSpikingIFNode(tau=2.0)(self.fc3(self.h1_mem))
return value
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/policy/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/policy/dqn.py
================================================
import torch
import os
from network.base_net import RNN
class DQN:
def __init__(self, args, model_eval, model_target, agent_id):
self.n_actions = args.n_actions
self.n_agents = args.n_agents
self.obs_shape = args.obs_shape
self.agent_id = agent_id
input_shape = self.obs_shape
# 根据参数决定RNN的输入维度
if args.last_action:
input_shape += self.n_actions
# if args.reuse_network:
# input_shape += self.n_agents
# 神经网络
self.eval_rnn = model_eval
self.target_rnn = model_target
self.args = args
if self.args.cuda:
self.eval_rnn.cuda(self.args.device)
self.target_rnn.cuda(self.args.device)
# self.model_dir = args.model_dir + '/' + args.alg
self.model_dir = '/home/zhaozhuoya/exp2/MARL_test_exp/model' + '/' + args.alg + args.exp_dir#+ args.model_dir
# 如果存在模型则加载模型
if self.args.load_model:
if os.path.exists(self.model_dir + args.save_model_dir):
# path_snn = '/home/zhaozhuoya/exp2/ToM2/model/iql/199_rnn_net_params.pkl'
map_location = self.args.device if self.args.cuda else 'cpu'
self.eval_rnn.load_state_dict(torch.load(self.model_dir + args.save_model_dir, map_location=map_location))
# self.eval_rnn.load_state_dict(torch.load(self.model_dir))
print('Successfully load the model: {}'.format(self.model_dir + args.save_model_dir))
else:
raise Exception("No model!")
# 让target_net和eval_net的网络参数相同
self.target_rnn.load_state_dict(self.eval_rnn.state_dict())
self.eval_parameters = list(self.eval_rnn.parameters())
if args.optimizer == "RMS":
self.optimizer = torch.optim.RMSprop(self.eval_parameters, lr=args.lr)
# 执行过程中,要为每个agent都维护一个eval_hidden
# 学习过程中,要为每个episode的每个agent都维护一个eval_hidden、target_hidden
self.eval_hidden = None
self.target_hidden = None
print('Init alg DQN')
def learn(self, batch, max_episode_len, train_step, epsilon=None): # train_step表示是第几次学习,用来控制更新target_net网络的参数
'''
在learn的时候,抽取到的数据是四维的,四个维度分别为 1——第几个episode 2——episode中第几个transition
3——第几个agent的数据 4——具体obs维度。因为在选动作时不仅需要输入当前的inputs,还要给神经网络输入hidden_state,
hidden_state和之前的经验相关,因此就不能随机抽取经验进行学习。所以这里一次抽取多个episode,然后一次给神经网络
传入每个episode的同一个位置的transition
'''
episode_num = batch['O'].shape[0]
self.init_hidden_learn(episode_num)
# hidden_state = self.policy.eval_hidden[:, self.agent_id, :, :]
eval_hidden, target_hidden = \
self.eval_hidden[:, self.agent_id, :], self.target_hidden[:, self.agent_id, :]
# for key in batch.keys(): # 把batch里的数据转化成tensor
# if key == 'u':
# batch[key] = torch.tensor(batch[key], dtype=torch.long)
# else:
# batch[key] = torch.tensor(batch[key], dtype=torch.float32)
# u, r, avail_u, avail_u_next, terminated = batch['u'], batch['r'].squeeze(-1), batch['avail_u'], \
# batch['avail_u_next'], batch['terminated'].repeat(1, 1, self.n_agents)
# mask = (1 - batch["padded"].float()).repeat(1, 1, self.n_agents) # 用来把那些填充的经验的TD-error置0,从而不让它们影响到学习
for key in batch.keys(): # 把batch里的数据转化成tensor
if key == 'O':
batch[key] = torch.tensor(batch[key], dtype=torch.long)
else:
batch[key] = torch.tensor(batch[key], dtype=torch.float32)
u, r, avail_u, avail_u_next, terminated = batch['U'], batch['R'].squeeze(-1), batch['AVAIL_U'], \
batch['AVAIL_U_NEXT'], batch['TERMINATE'].repeat(1, 1, self.n_agents)
mask = (1 - batch["PADDED"].float()).repeat(1, 1, self.n_agents) # 用来把那些填充的经验的TD-error置0,从而不让它们影响到学习
# 得到每个agent对应的Q值,维度为(episode个数, max_episode_len, n_agents, n_actions)
q_evals, q_targets = self.get_q_values(batch, max_episode_len, eval_hidden, target_hidden)
if self.args.cuda:
u = u.cuda(self.args.device)
r = r.cuda(self.args.device)
terminated = terminated.cuda(self.args.device)
mask = mask.cuda(self.args.device)
# 取每个agent动作对应的Q值,并且把最后不需要的一维去掉,因为最后一维只有一个值了
u = u.to(torch.int64)
q_evals = torch.gather(q_evals, dim=3, index=u[:, :, self.agent_id, :].unsqueeze(3)).squeeze(3)
# 得到target_q
q_targets[avail_u_next[:, :, self.agent_id, :].unsqueeze(2) == 0.0] = - 9999999
q_targets = q_targets.max(dim=3)[0]
targets = r[:, :, self.agent_id].unsqueeze(2) + self.args.gamma * q_targets * (1 - terminated[:, :, self.agent_id].unsqueeze(2))
td_error = (q_evals - targets.detach())
masked_td_error = mask[:, :, self.agent_id].unsqueeze(2) * td_error # 抹掉填充的经验的td_error
# 不能直接用mean,因为还有许多经验是没用的,所以要求和再比真实的经验数,才是真正的均值
loss = (masked_td_error ** 2).sum() / mask.sum()
# print('loss is ', loss)
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.eval_parameters, self.args.grad_norm_clip)
self.optimizer.step()
if train_step > 0 and train_step % self.args.target_update_cycle == 0:
self.target_rnn.load_state_dict(self.eval_rnn.state_dict())
return loss
def _get_inputs(self, batch, transition_idx):
# 取出所有episode上该transition_idx的经验,u_onehot要取出所有,因为要用到上一条
# obs, obs_next, u_onehot = batch['o'][:, transition_idx], \
# batch['o_next'][:, transition_idx], batch['u_onehot'][:]
# 取出所有episode上该transition_idx的经验,u_onehot要取出所有,因为要用到上一条
obs, obs_next, u_onehot = batch['O'][:, transition_idx], \
batch['O_NEXT'][:, transition_idx], batch['U_ONEHOT'][:]
episode_num = obs.shape[0]
inputs, inputs_next = [], []
inputs.append(obs[:, self.agent_id, :])
inputs_next.append(obs_next[:, self.agent_id, :])
# 给obs添加上一个动作、agent编号
if self.args.last_action:
if transition_idx == 0: # 如果是第一条经验,就让前一个动作为0向量
inputs.append(torch.zeros_like(u_onehot[:, :, self.agent_id, :][:, transition_idx]))
else:
inputs.append(u_onehot[:, :, self.agent_id, :][:, transition_idx - 1])
inputs_next.append(u_onehot[:, :, self.agent_id, :][:, transition_idx])
# if self.args.reuse_network:
# 因为当前的obs三维的数据,每一维分别代表(episode编号,agent编号,obs维度),直接在dim_1上添加对应的向量
# 即可,比如给agent_0后面加(1, 0, 0, 0, 0),表示5个agent中的0号。而agent_0的数据正好在第0行,那么需要加的
# agent编号恰好就是一个单位矩阵,即对角线为1,其余为0
# inputs.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
# inputs_next.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
# inputs.append(torch.zeros((self.args.n_agents, self.args.n_agents)).unsqueeze(0).expand(episode_num, -1, -1))
# inputs_next.append(torch.zeros((self.args.n_agents, self.args.n_agents)).unsqueeze(0).expand(episode_num, -1, -1))
# 要把obs中的三个拼起来,并且要把episode_num个episode、self.args.n_agents个agent的数据拼成40条(40,96)的数据,
# 因为这里所有agent共享一个神经网络,每条数据中带上了自己的编号,所以还是自己的数据
inputs = torch.cat([x for x in inputs], dim=1)
inputs_next = torch.cat([x for x in inputs_next], dim=1)
return inputs, inputs_next
def get_q_values(self, batch, max_episode_len, eval_hidden, target_hidden):
# episode_num = batch['o'].shape[0]
episode_num = batch['O'].shape[0]
q_evals, q_targets = [], []
for transition_idx in range(max_episode_len):
inputs, inputs_next = self._get_inputs(batch, transition_idx) # 给obs加last_action、agent_id
if self.args.cuda:
inputs = inputs.cuda(self.args.device)
inputs_next = inputs_next.cuda(self.args.device)
eval_hidden = eval_hidden.cuda(self.args.device)
target_hidden = target_hidden.cuda(self.args.device)
q_eval, self.eval_hidden = self.eval_rnn(inputs, eval_hidden) # inputs维度为(40,96),得到的q_eval维度为(40,n_actions)
q_target, self.target_hidden = self.target_rnn(inputs_next, target_hidden)
# 把q_eval维度重新变回(8, 5,n_actions)
q_eval = q_eval.view(episode_num, 1, -1)
q_target = q_target.view(episode_num, 1, -1)
q_evals.append(q_eval)
q_targets.append(q_target)
# 得的q_eval和q_target是一个列表,列表里装着max_episode_len个数组,数组的的维度是(episode个数, n_agents,n_actions)
# 把该列表转化成(episode个数, max_episode_len, n_agents,n_actions)的数组
q_evals = torch.stack(q_evals, dim=1)
q_targets = torch.stack(q_targets, dim=1)
return q_evals, q_targets
def init_hidden(self, episode_num, num_env):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
self.eval_hidden = torch.zeros((episode_num, self.n_agents, num_env,self.args.rnn_hidden_dim))
self.target_hidden = torch.zeros((episode_num, self.n_agents, num_env,self.args.rnn_hidden_dim))
def init_hidden_learn(self, episode_num):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
self.eval_hidden = torch.zeros((episode_num, self.n_agents, self.args.rnn_hidden_dim))
self.target_hidden = torch.zeros((episode_num, self.n_agents, self.args.rnn_hidden_dim))
def save_model(self, train_step):
num = str(train_step // self.args.save_cycle)
if not os.path.exists(self.model_dir):
os.makedirs(self.model_dir)
torch.save(self.eval_rnn.state_dict(), self.model_dir + '/' + num + '_rnn_net_params.pkl')
def load_model(self, train_step):
num = str(train_step // self.args.save_cycle)
path = torch.load(self.model_dir + '/' + num + '_rnn_net_params.pkl')
self.eval_rnn.load_state_dict(path)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/policy/stomvdn.py
================================================
import torch
import os
from network.spiking_net import Critic, VDNNet, Linear_weight, BiasNet
import copy
class SToMVDN:
def __init__(self, args):
self.n_actions = args.n_actions
self.n_agents = args.n_agents
self.obs_shape = args.obs_shape
input_shape = self.obs_shape
# 根据参数决定RNN的输入维度
if args.last_action:
input_shape += self.n_actions
if args.reuse_network:
input_shape += self.n_agents
self.loss_trade_off_target = 0
self.loss_trade_off_eval = 0
# 神经网络
self.eval_snn = Critic(input_shape, args)
self.target_snn = Critic(input_shape, args)
self.eval_vdn_snn = VDNNet() # 把agentsQ值加起来的网络
self.target_vdn_snn = VDNNet()
self.bias_net = BiasNet(args)
self.trade_off_net = Linear_weight(2, 1, args)
self.args = args
if self.args.cuda:
self.eval_snn.cuda(self.args.device)
self.target_snn.cuda(self.args.device)
self.eval_vdn_snn.cuda(self.args.device)
self.target_vdn_snn.cuda(self.args.device)
self.trade_off_net.cuda(self.args.device)
self.bias_net.cuda(self.args.device)
self.model_dir = args.model_dir + '/' + args.alg + args.exp_dir + args.save_model_dir
# 如果存在模型则加载模型
if self.args.load_model:
if os.path.exists(self.model_dir):
# path_snn = '/home/zhaozhuoya/exp2/ToM2_test/model/siql/199_snn_net_params.pkl'
map_location = self.args.device if self.args.cuda else 'cpu'
self.eval_snn.load_state_dict(torch.load(self.model_dir, map_location=map_location))
print('Successfully load the model: {}'.format(self.model_dir))
else:
print(self.model_dir)
raise Exception("No model!")
# 让target_net和eval_net的网络参数相同
self.target_snn.load_state_dict(self.eval_snn.state_dict())
self.target_vdn_snn.load_state_dict(self.eval_vdn_snn.state_dict())
self.eval_parameters = list(self.eval_snn.parameters()) + \
list(self.eval_vdn_snn.parameters()) + \
list(self.trade_off_net.parameters()) + \
list(self.bias_net.parameters())
self.trade_off_parameters = list(self.trade_off_net.parameters())
if args.optimizer == "RMS":
self.optimizer = torch.optim.RMSprop(self.eval_parameters, lr=args.lr)
self.optimizer_T = torch.optim.RMSprop(self.trade_off_parameters, lr=args.lr)
# 执行过程中,要为每个agent都维护一个eval_hidden
# 学习过程中,要为每个episode的每个agent都维护一个eval_hidden、target_hidden
self.eval_h1_mem, self.eval_h1_spike = None, None
self.target_h1_mem, self.target_h1_spike = None, None
self.eval_h2_mem, self.eval_h2_spike = None, None
self.target_h2_mem, self.target_h2_spike = None, None
print('Init alg SCOVDN_ToM')
def learn(self, batch, max_episode_len, train_step, epsilon=None): # train_step表示是第几次学习,用来控制更新target_net网络的参数
'''
在learn的时候,抽取到的数据是四维的,四个维度分别为 1——第几个episode 2——episode中第几个transition
3——第几个agent的数据 4——具体obs维度。因为在选动作时不仅需要输入当前的inputs,还要给神经网络输入hidden_state,
hidden_state和之前的经验相关,因此就不能随机抽取经验进行学习。所以这里一次抽取多个episode,然后一次给神经网络
传入每个episode的同一个位置的transition
'''
episode_num = batch['O'].shape[0]
self.init_hidden_learn(episode_num)
self.bias_net.reset(episode_num)
for key in batch.keys(): # 把batch里的数据转化成tensor
if key == 'U': # 'O'
batch[key] = torch.tensor(batch[key], dtype=torch.long)
else:
batch[key] = torch.tensor(batch[key], dtype=torch.float32)
u, r, avail_u, avail_u_next, terminated = batch['U'], batch['R'].squeeze(-1), batch['AVAIL_U'], \
batch['AVAIL_U_NEXT'], batch['TERMINATE'].repeat(1, 1, self.n_agents)
mask = (1 - batch["PADDED"].float()).repeat(1, 1, self.n_agents) # 用来把那些填充的经验的TD-error置0,从而不让它们影响到学习
if self.args.cuda:
u = u.cuda(self.args.device)
r = r.cuda(self.args.device)
terminated = terminated.cuda(self.args.device)
mask = mask.cuda(self.args.device)
# self.bias_net.cuda(self.args.device)
u = u.to(torch.int64)
# ---------------------------------------independent_Q_net------------------------------------------------------
# 得到每个agent对应的Q值,维度为(episode个数, max_episode_len, n_agents, n_actions)
q_evals, q_targets, hidden_evals, hidden_targets = self.get_q_values(batch, max_episode_len)
# ---------------------------------------independent_Q_net------------------------------------------------------
# --------------------------------------------bias_net----------------------------------------------------------
# 得到每个agent对应的Q值,维度为(episode个数, max_episode_len, n_agents, n_actions)
v = self.get_bias(batch, hidden_evals, hidden_targets, episode_num)
# --------------------------------------------bias_net----------------------------------------------------------
# ---------------------------------------_self+Q_other_net------------------------------------------------------
q_other_evals, q_other_targets = q_evals[:, :, [1, 0], :].unsqueeze(4), q_targets[:, :, [1, 0], :].unsqueeze(4)
q_evals_, q_targets_ = q_evals.unsqueeze(4), q_targets.unsqueeze(4)
q_total_evals = torch.cat((q_evals_, q_other_evals), 4)
q_total_targets = torch.cat((q_targets_, q_other_targets), 4)
# q_total_evals = self.trade_off_net(q_total_evals) #([10, 50, 2, 5, 1])
# q_total_targets = self.trade_off_net(q_total_targets) # ([10, 50, 2, 5, 1])
q_total_evals = q_evals_ + q_other_targets
q_total_targets = q_targets_ + q_other_targets
# --------------------------------------------_self+Q_other_net-------------------------------------------------
# --------------------------------------------L_self/other------------------------------------------------------
q_total_targets[avail_u_next == 0.0] = - 9999999
q_total_targets = q_total_targets.max(dim=3)[0].squeeze()
q_total_evals = torch.gather(q_total_evals.squeeze(4), dim=3, index=u).squeeze(3)
y = r + self.args.gamma * q_total_targets * (1 - terminated)
td_error = q_total_evals - y.detach()
l_so = ((td_error * mask) ** 2).sum() / mask.sum()
# --------------------------------------------L_self/other------------------------------------------------------
# --------------------------------------------action_prob_Q-----------------------------------------------------
# probablity of action
action_prob = self._get_action_prob(batch, max_episode_len, 0.4) # 每个agent的所有动作的概率self.args.epsilon
pi_taken = torch.gather(action_prob, dim=3, index=u).squeeze(3) # 每个agent的选择的动作对应的概率
pi_taken[mask == 0] = 1.0 # 因为要取对数,对于那些填充的经验,所有概率都为0,取了log就是负无穷了,所以让它们变成1
log_pi_taken = torch.log(pi_taken)
# --------------------------------------------action_prob_Q-----------------------------------------------------
# ----------------------------------------------L_coma----------------------------------------------------------
# q_evals = torch.gather(q_evals * action_prob, dim=3, index=u).squeeze(3)
q_evals_coma = (q_evals * action_prob).sum(dim=3, keepdim=True).squeeze(3)
coma_error = q_evals_coma.sum(dim=-1) - q_total_targets.detach().sum(dim=-1) + v
l_coma = ((coma_error * mask[:,:,0]) ** 2).sum() / mask[:,:,0].sum()
# ----------------------------------------------L_coma----------------------------------------------------------
# -----------------------------------------------L_sum----------------------------------------------------------
q_evals_sum = self.eval_vdn_snn(q_evals)
sum_error = q_evals_sum.sum(dim=-1).squeeze(2) - q_total_targets.detach().sum(dim=-1) + v
l_sum = ((sum_error * mask[:,:,0]) ** 2).sum() / mask[:,:,0].sum()
# -----------------------------------------------L_sum----------------------------------------------------------
LOSS = l_so + l_coma + l_sum
self.optimizer.zero_grad()
LOSS.backward()
if train_step > 0 and train_step % self.args.target_update_cycle == 0:
self.target_snn.load_state_dict(self.eval_snn.state_dict())
self.target_vdn_snn.load_state_dict(self.eval_vdn_snn.state_dict())
return LOSS
def _get_inputs(self, batch, transition_idx):
# 取出所有episode上该transition_idx的经验,u_onehot要取出所有,因为要用到上一条
obs, obs_next, u_onehot = batch['O'][:, transition_idx], \
batch['O_NEXT'][:, transition_idx], batch['U_ONEHOT'][:]
episode_num = obs.shape[0]
inputs, inputs_next = [], []
inputs.append(obs)
inputs_next.append(obs_next)
# 给obs添加上一个动作、agent编号
if self.args.last_action:
if transition_idx == 0: # 如果是第一条经验,就让前一个动作为0向量
inputs.append(torch.zeros_like(u_onehot[:, transition_idx]))
else:
inputs.append(u_onehot[:, transition_idx - 1])
inputs_next.append(u_onehot[:, transition_idx])
if self.args.reuse_network:
# 因为当前的obs三维的数据,每一维分别代表(episode编号,agent编号,obs维度),直接在dim_1上添加对应的向量
# 即可,比如给agent_0后面加(1, 0, 0, 0, 0),表示5个agent中的0号。而agent_0的数据正好在第0行,那么需要加的
# agent编号恰好就是一个单位矩阵,即对角线为1,其余为0
inputs.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
inputs_next.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
# 要把obs中的三个拼起来,并且要把episode_num个episode、self.args.n_agents个agent的数据拼成40条(40,96)的数据,
# 因为这里所有agent共享一个神经网络,每条数据中带上了自己的编号,所以还是自己的数据
inputs = torch.cat([x.reshape(episode_num * self.args.n_agents, -1) for x in inputs], dim=1)
inputs_next = torch.cat([x.reshape(episode_num * self.args.n_agents, -1) for x in inputs_next], dim=1)
return inputs, inputs_next
def get_q_values(self, batch, max_episode_len):
episode_num = batch['O'].shape[0]
q_evals, q_targets, eval_h2_mems, target_h2_mems = [], [], [], []
for transition_idx in range(max_episode_len):
inputs, inputs_next = self._get_inputs(batch, transition_idx) # 给obs加last_action、agent_id
if self.args.cuda:
inputs = inputs.cuda(self.args.device)
inputs_next = inputs_next.cuda(self.args.device)
self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem, self.eval_h2_spike = \
self.eval_h1_mem.cuda(self.args.device), self.eval_h1_spike.cuda(
self.args.device), self.eval_h2_mem.cuda(self.args.device), self.eval_h2_spike.cuda(
self.args.device)
self.target_h1_mem, self.target_h1_spike, self.target_h2_mem, self.target_h2_spike = \
self.target_h1_mem.cuda(self.args.device), self.target_h1_spike.cuda(
self.args.device), self.target_h2_mem.cuda(self.args.device), self.target_h2_spike.cuda(
self.args.device)
q_eval, self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem, self.eval_h2_spike = \
self.eval_snn(inputs, self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem,
self.eval_h2_spike) # inputs维度为(40,96),得到的q_eval维度为(40,n_actions)
q_target, self.target_h1_mem, self.target_h1_spike, self.target_h2_mem, self.target_h2_spike = \
self.target_snn(inputs_next, self.target_h1_mem, self.target_h1_spike, self.target_h2_mem,
self.target_h2_spike)
# 把q_eval维度重新变回(8, 5,n_actions)
q_eval = q_eval.view(episode_num, self.n_agents, -1)
q_target = q_target.view(episode_num, self.n_agents, -1)
eval_h2_mem = self.eval_h2_mem.view(episode_num, self.n_agents, -1)
target_h2_mem = self.target_h2_mem.view(episode_num, self.n_agents, -1)
q_evals.append(q_eval)
q_targets.append(q_target)
eval_h2_mems.append(eval_h2_mem)
target_h2_mems.append(target_h2_mem)
# 得的q_eval和q_target是一个列表,列表里装着max_episode_len个数组,数组的的维度是(episode个数, n_agents,n_actions)
# 把该列表转化成(episode个数, max_episode_len, n_agents,n_actions)的数组
q_evals = torch.stack(q_evals, dim=1)
q_targets = torch.stack(q_targets, dim=1)
hidden_evals = torch.stack(eval_h2_mems, dim=1)
hidden_targets = torch.stack(target_h2_mems, dim=1)
return q_evals, q_targets, hidden_evals, hidden_targets
def get_bias(self, batch, hidden_evals, hidden_targets, episode_num, hat=False):
# episode_num, max_episode_len, _, _ = hidden_targets.shape
max_episode_len = self.args.episode_limit
states = batch['O'][:, :max_episode_len]
states_next = batch['O_NEXT'][:, :max_episode_len]
u_onehot = batch['U_ONEHOT'][:, :max_episode_len]
if self.args.cuda:
states = states.cuda(self.args.device)[:,:,0,:]
states_next = states_next.cuda(self.args.device)[:,:,0,:]
u_onehot = u_onehot.cuda(self.args.device)
hidden_evals = hidden_evals.cuda(self.args.device)
hidden_targets = hidden_targets.cuda(self.args.device)
if hat:
v = None
else:
v = self.bias_net(states, hidden_evals)
# 把q_eval、q_target、v维度变回(episode_num, max_episode_len)
v = v.view(episode_num, -1, 1).squeeze(-1)
return v
def _get_actor_inputs(self, batch, transition_idx):
# 取出所有episode上该transition_idx的经验,u_onehot要取出所有,因为要用到上一条
obs, u_onehot = batch['O'][:, transition_idx], batch['U_ONEHOT'][:]
episode_num = obs.shape[0]
inputs = []
inputs.append(obs)
# 给inputs添加上一个动作、agent编号
if self.args.last_action:
if transition_idx == 0: # 如果是第一条经验,就让前一个动作为0向量
inputs.append(torch.zeros_like(u_onehot[:, transition_idx]))
else:
inputs.append(u_onehot[:, transition_idx - 1])
if self.args.reuse_network:
# 因为当前的inputs三维的数据,每一维分别代表(episode编号,agent编号,inputs维度),直接在dim_1上添加对应的向量
# 即可,比如给agent_0后面加(1, 0, 0, 0, 0),表示5个agent中的0号。而agent_0的数据正好在第0行,那么需要加的
# agent编号恰好就是一个单位矩阵,即对角线为1,其余为0
inputs.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
# 要把inputs中的三个拼起来,并且要把episode_num个episode、self.args.n_agents个agent的数据拼成40条(40,96)的数据,
# 因为这里所有agent共享一个神经网络,每条数据中带上了自己的编号,所以还是自己的数据
inputs = torch.cat([x.reshape(episode_num * self.args.n_agents, -1) for x in inputs], dim=1)
return inputs
def _get_action_prob(self, batch, max_episode_len, epsilon):
episode_num = batch['O'].shape[0]
avail_actions = batch['AVAIL_U']
action_prob = []
for transition_idx in range(max_episode_len):
inputs = self._get_actor_inputs(batch, transition_idx) # 给obs加last_action、agent_id
if self.args.cuda:
inputs = inputs.cuda(self.args.device)
# self.eval_hidden = self.eval_hidden.cuda(self.args.device)
self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem, self.eval_h2_spike = \
self.eval_h1_mem.cuda(self.args.device), self.eval_h1_spike.cuda(
self.args.device), self.eval_h2_mem.cuda(self.args.device), self.eval_h2_spike.cuda(
self.args.device)
self.target_h1_mem, self.target_h1_spike, self.target_h2_mem, self.target_h2_spike = \
self.target_h1_mem.cuda(self.args.device), self.target_h1_spike.cuda(
self.args.device), self.target_h2_mem.cuda(self.args.device), self.target_h2_spike.cuda(
self.args.device)
# outputs, self.eval_hidden = self.eval_snn(inputs, self.eval_hidden) # inputs维度为(40,96),得到的q_eval维度为(40,n_actions)
outputs, self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem, self.eval_h2_spike = \
self.eval_snn(inputs, self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem,
self.eval_h2_spike) # inputs维度为(40,96),得到的q_eval维度为(40,n_actions)
# 把q_eval维度重新变回(8, 5,n_actions)
outputs = outputs.view(episode_num, self.n_agents, -1)
prob = torch.nn.functional.softmax(outputs, dim=-1)
action_prob.append(prob)
# 得的action_prob是一个列表,列表里装着max_episode_len个数组,数组的的维度是(episode个数, n_agents,n_actions)
# 把该列表转化成(episode个数, max_episode_len, n_agents,n_actions)的数组
action_prob = torch.stack(action_prob, dim=1).cpu()
action_num = avail_actions.sum(dim=-1, keepdim=True).float().repeat(1, 1, 1,
avail_actions.shape[-1]) # 可以选择的动作的个数
action_prob = ((1 - epsilon) * action_prob + torch.ones_like(action_prob) * epsilon / action_num)
action_prob[avail_actions == 0] = 0.0 # 不能执行的动作概率为0
# 因为上面把不能执行的动作概率置为0,所以概率和不为1了,这里要重新正则化一下。执行过程中Categorical会自己正则化。
action_prob = action_prob / action_prob.sum(dim=-1, keepdim=True)
# 因为有许多经验是填充的,它们的avail_actions都填充的是0,所以该经验上所有动作的概率都为0,在正则化的时候会得到nan。
# 因此需要再一次将该经验对应的概率置为0
action_prob[avail_actions == 0] = 0.0
if self.args.cuda:
action_prob = action_prob.cuda(self.args.device)
return action_prob
def init_hidden(self, episode_num, num_env):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
self.eval_h1_mem = self.eval_h1_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
self.target_h1_mem = self.target_h1_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
self.eval_h2_mem = self.eval_h2_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
self.target_h2_mem = self.target_h2_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
def init_hidden_learn(self, episode_num):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
self.eval_h1_mem = self.eval_h1_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
self.target_h1_mem = self.target_h1_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
self.eval_h2_mem = self.eval_h2_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
self.target_h2_mem = self.target_h2_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
def save_model(self, train_step):
num = str(train_step // self.args.save_cycle)
if not os.path.exists(self.model_dir):
os.makedirs(self.model_dir)
torch.save(self.eval_snn.state_dict(),
self.model_dir + '/' + num + '_snn_net_params_{}.pkl'.format(self.args.num_run))
def load_model(self, train_step):
num = str(train_step // self.args.save_cycle)
path = torch.load(self.model_dir + '/' + num + '_snn_net_params.pkl'.format(self.args.num_run))
self.eval_snn.load_state_dict(path)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/policy/svdn.py
================================================
import torch
import os
from network.spiking_net import Critic, VDNNet
class SVDN:
def __init__(self, args):
self.n_actions = args.n_actions
self.n_agents = args.n_agents
self.obs_shape = args.obs_shape
input_shape = self.obs_shape
# 根据参数决定RNN的输入维度
if args.last_action:
input_shape += self.n_actions
if args.reuse_network:
input_shape += self.n_agents
# 神经网络
self.eval_snn = Critic(input_shape, args)
self.target_snn = Critic(input_shape, args)
self.eval_vdn_snn = VDNNet() # 把agentsQ值加起来的网络
self.target_vdn_snn = VDNNet()
self.args = args
if self.args.cuda:
self.eval_snn.cuda(self.args.device)
self.target_snn.cuda(self.args.device)
self.eval_vdn_snn.cuda(self.args.device)
self.target_vdn_snn.cuda(self.args.device)
self.model_dir = args.model_dir + '/' + args.alg + args.exp_dir + args.save_model_dir
# 如果存在模型则加载模型
if self.args.load_model:
if os.path.exists(self.model_dir):
# path_snn = '/home/zhaozhuoya/exp2/ToM2_test/model/siql/199_snn_net_params.pkl'
map_location = self.args.device if self.args.cuda else 'cpu'
self.eval_snn.load_state_dict(torch.load(self.model_dir, map_location=map_location))
print('Successfully load the model: {}'.format(self.model_dir))
else:
print(self.model_dir)
raise Exception("No model!")
# 让target_net和eval_net的网络参数相同
self.target_snn.load_state_dict(self.eval_snn.state_dict())
self.target_vdn_snn.load_state_dict(self.eval_vdn_snn.state_dict())
self.eval_parameters = list(self.eval_snn.parameters()) + list(self.eval_vdn_snn.parameters())
if args.optimizer == "RMS":
self.optimizer = torch.optim.RMSprop(self.eval_parameters, lr=args.lr)
# 执行过程中,要为每个agent都维护一个eval_hidden
# 学习过程中,要为每个episode的每个agent都维护一个eval_hidden、target_hidden
self.eval_h1_mem, self.eval_h1_spike = None, None
self.target_h1_mem, self.target_h1_spike = None, None
self.eval_h2_mem, self.eval_h2_spike = None, None
self.target_h2_mem, self.target_h2_spike = None, None
print('Init alg SVDN')
def learn(self, batch, max_episode_len, train_step, epsilon=None): # train_step表示是第几次学习,用来控制更新target_net网络的参数
'''
在learn的时候,抽取到的数据是四维的,四个维度分别为 1——第几个episode 2——episode中第几个transition
3——第几个agent的数据 4——具体obs维度。因为在选动作时不仅需要输入当前的inputs,还要给神经网络输入hidden_state,
hidden_state和之前的经验相关,因此就不能随机抽取经验进行学习。所以这里一次抽取多个episode,然后一次给神经网络
传入每个episode的同一个位置的transition
'''
episode_num = batch['O'].shape[0]
self.init_hidden_learn(episode_num)
for key in batch.keys(): # 把batch里的数据转化成tensor
if key == 'U':
batch[key] = torch.tensor(batch[key], dtype=torch.long)
else:
batch[key] = torch.tensor(batch[key], dtype=torch.float32)
u, r, avail_u, avail_u_next, terminated = batch['U'], batch['R'].squeeze(-1), batch['AVAIL_U'], \
batch['AVAIL_U_NEXT'], batch['TERMINATE'].repeat(1, 1, self.n_agents)
mask = (1 - batch["PADDED"].float()).repeat(1, 1, self.n_agents) # 用来把那些填充的经验的TD-error置0,从而不让它们影响到学习
# 得到每个agent对应的Q值,维度为(episode个数, max_episode_len, n_agents, n_actions)
q_evals, q_targets = self.get_q_values(batch, max_episode_len)
if self.args.cuda:
u = u.cuda(self.args.device)
r = r.cuda(self.args.device)
terminated = terminated.cuda(self.args.device)
mask = mask.cuda(self.args.device)
# 取每个agent动作对应的Q值,并且把最后不需要的一维去掉,因为最后一维只有一个值了
u = u.to(torch.int64)
q_evals = torch.gather(q_evals, dim=3, index=u).squeeze(3)
# 得到target_q
q_targets[avail_u_next == 0.0] = - 9999999
q_targets = q_targets.max(dim=3)[0]
q_total_eval = self.eval_vdn_snn(q_evals)
q_total_target = self.target_vdn_snn(q_targets)
targets = r + self.args.gamma * q_total_target * (1 - terminated)
td_error = targets.detach() - q_total_eval
masked_td_error = mask * td_error # 抹掉填充的经验的td_error
# 不能直接用mean,因为还有许多经验是没用的,所以要求和再比真实的经验数,才是真正的均值
loss = (masked_td_error ** 2).sum() / mask.sum()
# print('loss is ', loss)
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.eval_parameters, self.args.grad_norm_clip)
self.optimizer.step()
if train_step > 0 and train_step % self.args.target_update_cycle == 0:
self.target_snn.load_state_dict(self.eval_snn.state_dict())
self.target_vdn_snn.load_state_dict(self.eval_vdn_snn.state_dict())
return loss
def _get_inputs(self, batch, transition_idx):
# 取出所有episode上该transition_idx的经验,u_onehot要取出所有,因为要用到上一条
obs, obs_next, u_onehot = batch['O'][:, transition_idx], \
batch['O_NEXT'][:, transition_idx], batch['U_ONEHOT'][:]
episode_num = obs.shape[0]
inputs, inputs_next = [], []
inputs.append(obs)
inputs_next.append(obs_next)
# 给obs添加上一个动作、agent编号
if self.args.last_action:
if transition_idx == 0: # 如果是第一条经验,就让前一个动作为0向量
inputs.append(torch.zeros_like(u_onehot[:, transition_idx]))
else:
inputs.append(u_onehot[:, transition_idx - 1])
inputs_next.append(u_onehot[:, transition_idx])
if self.args.reuse_network:
# 因为当前的obs三维的数据,每一维分别代表(episode编号,agent编号,obs维度),直接在dim_1上添加对应的向量
# 即可,比如给agent_0后面加(1, 0, 0, 0, 0),表示5个agent中的0号。而agent_0的数据正好在第0行,那么需要加的
# agent编号恰好就是一个单位矩阵,即对角线为1,其余为0
inputs.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
inputs_next.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
# 要把obs中的三个拼起来,并且要把episode_num个episode、self.args.n_agents个agent的数据拼成40条(40,96)的数据,
# 因为这里所有agent共享一个神经网络,每条数据中带上了自己的编号,所以还是自己的数据
inputs = torch.cat([x.reshape(episode_num * self.args.n_agents, -1) for x in inputs], dim=1)
inputs_next = torch.cat([x.reshape(episode_num * self.args.n_agents, -1) for x in inputs_next], dim=1)
return inputs, inputs_next
def get_q_values(self, batch, max_episode_len):
episode_num = batch['O'].shape[0]
q_evals, q_targets = [], []
for transition_idx in range(max_episode_len):
inputs, inputs_next = self._get_inputs(batch, transition_idx) # 给obs加last_action、agent_id
if self.args.cuda:
inputs = inputs.cuda(self.args.device)
inputs_next = inputs_next.cuda(self.args.device)
self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem, self.eval_h2_spike = \
self.eval_h1_mem.cuda(self.args.device), self.eval_h1_spike.cuda(self.args.device), self.eval_h2_mem.cuda(self.args.device), self.eval_h2_spike.cuda(self.args.device)
self.target_h1_mem, self.target_h1_spike, self.target_h2_mem, self.target_h2_spike = \
self.target_h1_mem.cuda(self.args.device), self.target_h1_spike.cuda(self.args.device), self.target_h2_mem.cuda(self.args.device), self.target_h2_spike.cuda(self.args.device)
q_eval, self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem, self.eval_h2_spike = \
self.eval_snn(inputs, self.eval_h1_mem, self.eval_h1_spike, self.eval_h2_mem, self.eval_h2_spike) # inputs维度为(40,96),得到的q_eval维度为(40,n_actions)
q_target, self.target_h1_mem, self.target_h1_spike, self.target_h2_mem, self.target_h2_spike = \
self.target_snn(inputs_next, self.target_h1_mem, self.target_h1_spike, self.target_h2_mem, self.target_h2_spike)
# 把q_eval维度重新变回(8, 5,n_actions)
q_eval = q_eval.view(episode_num, self.n_agents, -1)
q_target = q_target.view(episode_num, self.n_agents, -1)
q_evals.append(q_eval)
q_targets.append(q_target)
# 得的q_eval和q_target是一个列表,列表里装着max_episode_len个数组,数组的的维度是(episode个数, n_agents,n_actions)
# 把该列表转化成(episode个数, max_episode_len, n_agents,n_actions)的数组
q_evals = torch.stack(q_evals, dim=1)
q_targets = torch.stack(q_targets, dim=1)
return q_evals, q_targets
def init_hidden(self, episode_num, num_env):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
self.eval_h1_mem = self.eval_h1_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
self.target_h1_mem = self.target_h1_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
self.eval_h2_mem = self.eval_h2_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
self.target_h2_mem = self.target_h2_spike = torch.zeros(episode_num, self.n_agents, num_env,
self.args.rnn_hidden_dim)
def init_hidden_learn(self, episode_num):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
self.eval_h1_mem = self.eval_h1_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
self.target_h1_mem = self.target_h1_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
self.eval_h2_mem = self.eval_h2_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
self.target_h2_mem = self.target_h2_spike = torch.zeros(episode_num, self.n_agents,
self.args.rnn_hidden_dim)
def save_model(self, train_step):
num = str(train_step // self.args.save_cycle)
if not os.path.exists(self.model_dir):
os.makedirs(self.model_dir)
torch.save(self.eval_snn.state_dict(), self.model_dir + '/' + num + '_snn_net_params_{}.pkl'.format(self.args.num_run))
def load_model(self, train_step):
num = str(train_step // self.args.save_cycle)
path = torch.load(self.model_dir + '/' + num + '_snn_net_params.pkl'.format(self.args.num_run))
self.eval_snn.load_state_dict(path)
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/preprocessoing/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/preprocessoing/common.py
================================================
"""
preprocess
"""
from typing import Union
import abc
import torch as tc
import numpy as np
class Preprocessing(abc.ABC, tc.nn.Module):
def forward(
self,
curr_obs: Union[tc.LongTensor, tc.FloatTensor],
prev_action: tc.LongTensor,
prev_reward: tc.FloatTensor,
prev_done: tc.FloatTensor
) -> tc.FloatTensor:
"""
Creates an input vector for a meta-learning agent.
Args:
curr_obs: either tc.LongTensor or tc.FloatTensor of shape [B, ...].
prev_action: tc.LongTensor of shape [B, ...]
prev_reward: tc.FloatTensor of shape [B, ...]
prev_done: tc.FloatTensor of shape [B, ...]
Returns:
tc.FloatTensor of shape [B, ..., ?]
"""
pass
def one_hot_torch(ys: tc.LongTensor, depth: int, device) -> tc.FloatTensor:
"""
Applies one-hot encoding to a batch of vectors.
Args:
ys: tc.LongTensor of shape [B].
depth: int specifying the number of possible y values.
Returns:
the one-hot encodings of tensor ys.
"""
vecs_shape = list(ys.shape) + [depth]
vecs = tc.zeros(dtype=tc.float32, size=vecs_shape).to(device)
vecs.scatter_(dim=-1, index=ys.unsqueeze(-1),
src=tc.ones(dtype=tc.float32, size=vecs_shape).to(device))
return vecs.float()
def one_hot(ys: int, depth: int) -> list:
"""
Applies one-hot encoding to a batch of vectors.
Args:
ys: tc.LongTensor of shape [B].
depth: int specifying the number of possible y values.
Returns:
the one-hot encodings of tensor ys.
"""
letter = [0 for _ in range(depth)]
letter[ys-1] = 1
letter = np.array(letter)
# print(letter)
return letter
================================================
FILE: examples/Social_Cognition/MAToM-SNN/STAG/runner.py
================================================
import os
import matplotlib.pyplot as plt
import numpy as np
import torch.multiprocessing as mp
from common_sr.srollout import RolloutWorker
from agents.sagent import Agents
from common_sr.replay_buffer import ReplayBuffer
import time
from tqdm import tqdm
class Runner:
def __init__(self, env, args):
self.env = env
self.agents = Agents(args)
self.rolloutWorker = RolloutWorker(env, self.agents, args)
if not args.evaluate:
self.buffer = ReplayBuffer(args)
self.args = args
self.win_rates = []
self.episode_rewards = []
# 用来保存plt和pkl
self.save_path = self.args.result_dir + '/' + args.alg + args.exp_dir
if not os.path.exists(self.save_path):
os.makedirs(self.save_path)
def run(self, num):
time_steps, train_steps, evaluate_steps = 0, 0, -1
pbar = tqdm(self.args.n_steps)
if self.args.load_model == False:
while time_steps < self.args.n_steps:
# print('Run {}, time_steps {}'.format(num, time_steps))
if time_steps // self.args.evaluate_cycle > evaluate_steps:
win_rate, episode_reward = self.evaluate()
# episode_reward = [i for i in [2, 3]]
self.episode_rewards.append(episode_reward)
# self.plt(time_steps // self.args.evaluate_cycle)
# print(time_steps // self.args.evaluate_cycle)
evaluate_steps += self.args.evaluate_epoch
# 收集self.args.n_episodes个episodes
episodes = []
start = time.time()
episode_batch, _, _, steps = self.rolloutWorker.generate_episode()
end = time.time()
# print(end - start, 'sample with multiprocessing:', self.args.process)
time_steps += steps
pbar.update(steps)
self.buffer.store_episode(episode_batch)
start = time.time()
for train_step in range(self.args.train_steps):
mini_batch = self.buffer.sample(min(self.buffer.current_size, self.args.batch_size))
if self.args.alg.find('o') > -1:
self.agents.train(mini_batch, train_steps, self.args.epsilon)
else:
self.agents.train(mini_batch, train_steps)
train_steps += 1
end = time.time()
# print(end - start, 'training')
pbar.close()
win_rate, episode_reward = self.evaluate()
# print('win_rate is ', win_rate)
self.win_rates.append(win_rate)
self.episode_rewards.append(episode_reward)
if self.args.load_model == False:
self.plt(num)
def evaluate(self):
win_number = 0
episode_rewards = (0, 0) # cumulative rewards
_, episode_rewards, win_tag, _ = self.rolloutWorker.generate_episode(evaluate=True)
episode_rewards = [episode_rewards[i] / self.args.evaluate_epoch / self.args.process for i in range(len(episode_rewards))]
return win_number / self.args.evaluate_epoch, episode_rewards
def plt(self, num):
# plt.figure()
# plt.ylim([0, 105])
# plt.cla()
# plt.subplot(2, 1, 1)
# plt.plot(range(len(self.win_rates)), self.win_rates)
# plt.xlabel('step*{}'.format(self.args.evaluate_cycle))
# plt.ylabel('win_rates')
#
# plt.subplot(2, 1, 2)
# plt.plot(range(len(self.episode_rewards)), self.episode_rewards)
# plt.xlabel('step*{}'.format(self.args.evaluate_cycle))
# plt.ylabel('episode_rewards')
#
# plt.savefig(self.save_path + '/plt_{}.png'.format(num), format='png')
# np.save(self.save_path + '/win_rates_{}'.format(num), self.win_rates)
# np.save(self.save_path + '/episode_rewards_{}'.format(num), self.episode_rewards)
# plt.close()
# plt.figure()
# plt.ylim([0, 105])
# plt.cla()
# plt.plot(2, 1, 1)
# plt.plot(range(len(self.episode_rewards)), self.episode_rewards[0][0])
# plt.xlabel('step*{}'.format(self.args.evaluate_cycle))
# plt.ylabel('episode_rewards_A')
#
# plt.plot(2, 1, 2)
# plt.plot(range(len(self.episode_rewards)), self.episode_rewards[0][1])
# plt.xlabel('step*{}'.format(self.args.evaluate_cycle))
# plt.ylabel('episode_rewards_B')
# plt.savefig(self.save_path + '/plt_{}.png'.format(num), format='png')
# np.save(self.save_path + '/win_rates_{}'.format(num), self.win_rates)
np.save(self.save_path + '/episode_rewards_{}'.format(num), self.episode_rewards) #
# print(self.episode_rewards)
# plt.close()
================================================
FILE: examples/Social_Cognition/ReadMe.md
================================================
================================================
FILE: examples/Social_Cognition/SmashVat/dqn.py
================================================
import os
import time
import random
from itertools import count
from collections import namedtuple, deque
import numpy as np
import pandas as pd
import torch
import imageio
from torch import nn, optim
import torch.nn.functional as F
from torch.utils.tensorboard import SummaryWriter
from side_effect_eval import *
from qnets import *
from environment import *
Transition = namedtuple('Transition', ('state', 'action', 'reward', 'next_state', 'done'))
class ReplayBuffer:
def __init__(self, capacity):
self.capacity = capacity
self.memory = deque(maxlen=capacity)
def push(self, *args):
self.memory.append(Transition(*args))
if len(self.memory) > self.capacity:
self.memory.popleft()
def sample(self, batch_size):
batch = random.sample(self.memory, batch_size)
return batch
class AnseEmpDQN:
def __init__(self, env, net_type='SNN',
init_buffer_size=10000, replay_buffer_size=100000, batch_size=100, target_update_interval=1000,
weight_sep=20, weight_emp_impact=None):
self.env = env
input_dim = 3
output_dim = env.action_space.n
assert net_type in ['SNN', 'ANN']
self.net_type = net_type
if self.net_type == 'SNN':
self.policy_net = SNNQnet(input_dim, output_dim).cuda()
self.target_net = SNNQnet(input_dim, output_dim).cuda()
elif self.net_type == 'ANN':
self.policy_net = CNNQnet(input_dim, output_dim).cuda()
self.target_net = CNNQnet(input_dim, output_dim).cuda()
self.init_buffer_size = init_buffer_size
self.replay_buffer_size = replay_buffer_size
self.replay_buffer = ReplayBuffer(replay_buffer_size)
self.batch_size = batch_size
self.target_update_interval = target_update_interval
# empathy
self.num_others = env.num_humans
self.baseline = StepwiseInactionModel(noop_action=env.actions.noop)
self.baselines_others = [StepwiseInactionModel(noop_action=env.actions.noop)] * self.num_others
self.deviation = AttainableUtilityMeasure(uf_num=30, uf_discount=0.99)
self.weight_sep = weight_sep
self.weight_emp_impact = weight_emp_impact if weight_emp_impact is not None else weight_sep
def state2tensor(self, state):
state_arr = self.env._decode(state)
array = np.zeros([3] + list(self.env.p.map_shape))
array[0] = self.env.map # [0]为环境信息
for i, pos in enumerate(self.env.p.vat_pos):
array[0][pos] = self.env.cells.vat if state_arr[i] else self.env.cells.empty # 根据state还原各个缸的状态,因为replay_buffer中存的状态对应的map与当前的可能不一样
agent_pos = tuple(state_arr[self.env.num_vats:self.env.num_vats + 2])
array[1][agent_pos] = 1 # [1]为agent位置信息
for pos in self.env.human_pos:
array[2][tuple(pos)] = 1 # [2]为human位置信息
return torch.Tensor(array).float().cuda()
def epsilon_greedy(self, net, state, epsilon):
num_actions = self.env.action_space.n
p = np.ones(num_actions) * epsilon / num_actions
state_tensor = self.state2tensor(state).unsqueeze(0)
best_action = torch.argmax(net(state_tensor)).item()
p[best_action] += 1 - epsilon
action = np.random.choice(self.env.action_space.n, p=p)
return action
def train(self, lr=1e-3, num_episodes=10000, gamma=0.99,
epsilon_start=1, epsilon_end=0.01, decay_start=0.05, decay_end=0.95,
checkpoint_interval=1000,
checkpoint_dir='./models/',
log_dir='./log'):
policy_net_opt = optim.Adam(self.policy_net.parameters(), lr=lr)
epsilons = [epsilon_end] * num_episodes
decay_start_episode = int(num_episodes * decay_start)
decay_end_episode = int(num_episodes * decay_end)
epsilons[0:decay_start_episode] = np.full(decay_start_episode, epsilon_start)
epsilons[decay_start_episode:decay_end_episode] = np.linspace(epsilon_start, epsilon_end, decay_end_episode - decay_start_episode)
tb_logger = SummaryWriter(log_dir=log_dir)
pd_timestep_logger = pd.DataFrame(columns=['loss', 'reward', 'impact', 'aup_impact', 'empathy_impact'])
pd_episode_logger = pd.DataFrame(columns=['step', 'ep_reward', 'ep_reward_mean',
'ep_impact', 'ep_aup_impact', 'ep_empathy_impact',
'num_vat_broken', 'num_human_saved'])
def optimize_net():
transitions = self.replay_buffer.sample(self.batch_size)
batch = Transition(*zip(*transitions))
state_batch = torch.stack([self.state2tensor(state[0]) for state in batch.state]).float().cuda()
action_batch = torch.tensor(batch.action).unsqueeze(-1).cuda()
reward_batch = torch.tensor(batch.reward, dtype=torch.float).cuda()
next_state_batch = torch.stack([self.state2tensor(state[0]) for state in batch.next_state]).float().cuda()
done_batch = torch.tensor(batch.done).cuda()
best_actions = self.policy_net(next_state_batch).max(1)[1].detach()
next_state_values = self.target_net(next_state_batch).gather(1, best_actions.unsqueeze(1)).squeeze(1).detach()
expected_state_action_values = reward_batch + gamma * next_state_values * torch.logical_not(done_batch)
state_action_values = self.policy_net(state_batch).gather(1, action_batch)
loss = F.mse_loss(state_action_values, expected_state_action_values.unsqueeze(1))
policy_net_opt.zero_grad()
loss.backward()
policy_net_opt.step()
tb_logger.add_scalar('loss', loss.item(), total_step)
pd_timestep_logger.loc[total_step, 'loss'] = loss.item()
def calculate_impact(prev_states, prev_action, current_states):
if self.weight_sep==0 and self.weight_emp_impact==0:
return 0, 0, 0
prev_state_agent = prev_states[0]
current_state_agent = current_states[0]
prev_states_others = prev_states[1:]
current_states_others = current_states[1:]
baseline_state_agent = self.baseline.calculate(prev_state_agent, prev_action, current_state_agent)
self.deviation.update(prev_state_agent, prev_action, current_state_agent)
dev_self = self.deviation.calculate(current_state_agent, baseline_state_agent, lambda x: abs(np.minimum(0, x)))
weighted_dev_self = -self.weight_sep * dev_self
dev_others = []
for prev_state, current_state, baseline in zip(prev_states_others, current_states_others, self.baselines_others):
baseline_state = baseline.calculate(prev_state, prev_action, current_state)
dev_others.append(self.deviation.calculate(current_state, baseline_state, lambda x: x))
dev_others_mean = sum(dev_others) / len(dev_others) if len(dev_others) > 0 else 0
weighted_dev_others = self.weight_emp_impact * dev_others_mean
total_impact = weighted_dev_self + weighted_dev_others
return total_impact, weighted_dev_self, weighted_dev_others
# 初始化replay buffer
state = self.env.reset()
for i in range(self.init_buffer_size):
# action = self.epsilon_greedy(self.empathy_net, state[0], epsilon_start)
action = self.epsilon_greedy(self.policy_net, state[0], epsilon_start)
next_state, reward, done, info = self.env.step(action)
if self.weight_sep != 0 or self.weight_emp_impact != 0: # 如果都等于0则退化为标准DQN
impact, _, _ = calculate_impact(state, action, next_state)
reward += impact
reward /= (self.weight_sep + self.weight_emp_impact) / 2 # 正则化操作,防止reward绝对值过大使得网络发散
self.replay_buffer.push(state, action, reward, next_state, done)
if done:
state = self.env.reset()
else:
state = next_state
# 开始训练
total_step = 0
for episode in range(num_episodes):
if episode % checkpoint_interval == 0 and episode != 0:
torch.save(self.policy_net.state_dict(), checkpoint_dir + f"/checkpoint_{episode}.pth")
tb_logger.add_scalar('epsilon', epsilons[episode], episode + 1)
state = self.env.reset()
if episode % 100 == 0:
print('Episode {} of {}'.format(episode + 1, num_episodes))
episode_reward = 0
episode_impact = 0
ep_aup_impact = 0
ep_empathy_impact = 0
for step in count():
if total_step % self.target_update_interval == 0:
self.target_net.load_state_dict(self.policy_net.state_dict())
action = self.epsilon_greedy(self.policy_net, state[0], epsilons[episode])
next_state, reward, done, info = self.env.step(action)
impact, aup_impact, empathy_impact = calculate_impact(state, action, next_state)
if self.weight_sep != 0 or self.weight_emp_impact != 0: # 如果都等于0则退化为标准DQN
reward += impact
reward /= (self.weight_sep + self.weight_emp_impact) / 2
episode_reward += reward
episode_impact += impact
ep_aup_impact += aup_impact
ep_empathy_impact += empathy_impact
self.replay_buffer.push(state, action, reward, next_state, done)
optimize_net()
pd_timestep_logger.loc[total_step, 'reward'] = reward
pd_timestep_logger.loc[total_step, 'impact'] = impact
pd_timestep_logger.loc[total_step, 'aup_impact'] = aup_impact
pd_timestep_logger.loc[total_step, 'empathy_impact'] = empathy_impact
if done:
# print(f'step: {step}, reward: {episode_reward:.2f}')
tb_logger.add_scalar('step', step + 1, episode + 1)
tb_logger.add_scalar('reward', episode_reward, episode + 1)
tb_logger.add_scalar('ep-reward-mean', episode_reward / (step + 1), episode + 1)
tb_logger.add_scalar('impact', episode_impact, episode + 1)
pd_episode_logger.loc[episode, 'step'] = step + 1
pd_episode_logger.loc[episode, 'ep_reward'] = episode_reward
pd_episode_logger.loc[episode, 'ep_reward_mean'] = episode_reward / (step + 1)
pd_episode_logger.loc[episode, 'ep_impact'] = episode_impact
pd_episode_logger.loc[episode, 'ep_aup_impact'] = ep_aup_impact
pd_episode_logger.loc[episode, 'ep_empathy_impact'] = ep_empathy_impact
env_map = self.env.map
num_vat_broken = 0
num_human_saved = 0
for pos in self.env.p.vat_pos:
if env_map[pos] != self.env.cells.vat:
num_vat_broken += 1
if pos in self.env.p.human_pos:
num_human_saved += 1
pd_episode_logger.loc[episode, 'num_vat_broken'] = num_vat_broken
pd_episode_logger.loc[episode, 'num_human_saved'] = num_human_saved
break
else:
state = next_state
total_step += 1
tb_logger.close()
pd_timestep_logger.to_csv(log_dir + '/timestep_logger.csv', index=False)
pd_episode_logger.to_csv(log_dir + '/episode_logger.csv', index=False)
def save(self, path):
if not os.path.exists(path):
os.makedirs(path)
torch.save(self.policy_net.state_dict(), path + "/policy_net.pth")
def load(self, path):
self.policy_net.load_state_dict(torch.load(path + "/policy_net.pth"))
def run(self, gif_name=None):
self.policy_net.eval()
obs = self.env.reset()
images = []
for step in count():
# self.env.render()
images.append(self.env.render(mode='rgb_array'))
obs_tensor = self.state2tensor(obs[0]).unsqueeze(0)
action_p = self.policy_net(obs_tensor)
action = torch.argmax(self.policy_net(obs_tensor)).item()
print(self.env.actions(action))
next_state, reward, done, _ = self.env.step(action)
time.sleep(1)
if done:
images.append(self.env.render(mode='rgb_array'))
images.append(self.env.render(mode='rgb_array'))
break
else:
obs = next_state
if gif_name is not None:
imageio.mimsave(gif_name, images, 'GIF', duration=0.5)
def set_seed(seed=114514):
random.seed(seed) # replay buffer 中使用了random.sample
np.random.seed(seed) # e-greedy 中使用了np.random_choice
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
def main():
set_seed(1919810)
env = BasicVatGoalEnv()
env.render()
model = AnseEmpDQN(env, net_type='ANN', init_buffer_size=10000, replay_buffer_size=100000, batch_size=100, target_update_interval=1000)
model.train(lr=1e-3, num_episodes=10000, gamma=0.99,
epsilon_start=1, epsilon_end=0.01, decay_start=0.05, decay_end=0.95,
checkpoint_interval=1000,
checkpoint_dir='./models/ANN-BasicVatGoalEnv-test',
log_dir='./log/ANN-BasicVatGoalEnv-test')
model.save("./models/ANN-BasicVatGoalEnv-test")
model.load("./models/ANN-BasicVatGoalEnv-test")
model.run("ANN-BasicVatGoalEnv-test.gif")
if __name__ == '__main__':
main()
================================================
FILE: examples/Social_Cognition/SmashVat/environment.py
================================================
import copy
from enum import IntEnum
import numpy as np
import gymnasium as gym
import imageio
from window import Window
class HumanVatGoalEnv(gym.Env):
"""General HumanVatGoalEnv Class"""
class Actions(IntEnum):
noop = 0
left = 1
right = 2
up = 3
down = 4
smash = 5 # destroying all surrounding vat(s) at same time
pass
class Cells(IntEnum):
empty = 0
wall = 1
goal = 2
vat = 3
pass
class CellsRender(object):
# empty = np.full(shape=(64, 64, 4), fill_value=255)
wall = imageio.imread('./materials/wall.png')
goal = imageio.imread('./materials/goal.png')
vat = imageio.imread('./materials/vat.png')
agent = imageio.imread('./materials/agent.png')
human = imageio.imread('./materials/adult.png')
class Params(object):
"""Params for the Environment"""
def __init__(
self,
map_shape=(7, 5),
agent_pos=(1, 2),
human_pos=((2, 3),),
vat_pos=((3, 2), (2, 3),),
goal_pos=((-2, 2),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name=None,
# human_policy = "noop"
):
self.map_shape = map_shape
self.agent_pos = agent_pos
self.human_pos = human_pos
self.vat_pos = vat_pos
self.goal_pos = goal_pos
self.wall_pos = wall_pos
self.max_steps = max_steps
self.env_name = env_name
def __init__(self, env_params=Params()):
super(HumanVatGoalEnv, self).__init__()
self.p = env_params
self.actions = HumanVatGoalEnv.Actions
self.cells = HumanVatGoalEnv.Cells
self.action_space = gym.spaces.Discrete(len(self.actions))
# observation_dim: dimension of observation space
# With fixed human_pos, currently we only consider: each vat state (broken or not) + agent_pos (x, y)
# e.g. [2,2,7,5] means vat1*vat2*agent_y*agent_x
self.observation_dim = [2] * len(self.p.vat_pos) + list(self.p.map_shape)
self.observation_space = gym.spaces.Discrete(np.prod(self.observation_dim))
self.window = None
if self.p.env_name is not None:
self.descr = self.p.env_name
else:
n_human = len(self.p.human_pos)
n_vat = len(self.p.vat_pos)
n_goal = len(self.p.goal_pos)
self.descr = self.__class__.__name__.lower()
self.descr = self.descr.replace("human", "human" + str(n_human) + "-")
self.descr = self.descr.replace("vat", "vat" + str(n_vat) + "-")
self.descr = self.descr.replace("goal", "goal" + str(n_goal) + "-")
self.num_vats = len(self.p.vat_pos)
self.num_humans = len(self.p.human_pos) # for empathy qlearning
self.reset()
return
def reset(self):
# reset env state
self._gen_map()
# reset agent & human state
self.agent_pos = np.array(self.p.agent_pos)
self.human_pos = [np.array(pos) for pos in self.p.human_pos]
# reset episode statistics
self.step_count = 0
self.total_reward = 0
# self.total_hidden_reward = 0 ##TODO
# self.total_human_rewards = [0]*len(self.p.human_pos) ##TODO
# generate observation from state
obs = self._gen_obs()
return obs
def _gen_map(self):
self.map = np.full(shape=self.p.map_shape, fill_value=self.cells.empty)
# place default surrounding walls
self.map[0] = self.cells.wall
self.map[-1] = self.cells.wall
self.map[:, 0] = self.cells.wall
self.map[:, -1] = self.cells.wall
# place user-defined walls
for pos in self.p.wall_pos:
self.map[pos] = self.cells.wall
# place goals
for pos in self.p.goal_pos:
self.map[pos] = self.cells.goal
# place vats
for pos in self.p.vat_pos:
self.map[pos] = self.cells.vat
return
def _gen_obs(self):
# internal state
s_env = [(self.map[pos] == self.cells.vat) for pos in self.p.vat_pos]
s_agent = list(self.agent_pos)
s_human = [list(pos) for pos in self.human_pos]
# external observation
obs_agent = self._encode(s_env + s_agent)
obs_human = [self._encode(s_env + s_h) for s_h in s_human]
return [obs_agent, *obs_human]
def _encode(self, obs):
i = 0
for idx, dim in enumerate(self.observation_dim):
i *= dim
i += obs[idx]
assert 0 <= i <= self.observation_space.n
return i
def _decode(self, i):
out = []
for dim in reversed(self.observation_dim):
out.append(i % dim)
i = i // dim
assert i == 0
return list(reversed(out))
def render(self, mode="window", cell_size=64, style="realistic"):
if mode == "rgb_array":
return self._gen_img(cell_size, style)
elif mode == "window":
if not isinstance(self.window, Window):
self.window = Window(self.descr)
if self.window.is_open():
img = self._gen_img(cell_size, style)
self.window.show_img(img)
self.window.show(block=False)
return
def _gen_img(self, cell_size, style):
if style == "abstract":
h, w = self.map.shape
img = np.full(shape=(h * cell_size, w * cell_size, 3), fill_value=255)
def draw_cell(cell_type, cell_pos, cell_size):
if cell_type == self.cells.empty:
pass
elif cell_type == self.cells.wall:
x, y = np.array(cell_pos) * cell_size
img[x: (x + cell_size), y: (y + cell_size), :] = np.array(
[128, 128, 128]
)
elif cell_type == self.cells.goal:
x, y = np.array(cell_pos) * cell_size
img[x: (x + cell_size), y: (y + cell_size), :] = np.array([0, 255, 0])
elif cell_type == self.cells.vat:
x, y = np.array(cell_pos) * cell_size
img[x: (x + cell_size), y: (y + cell_size), :] = np.array([255, 0, 0])
else:
pass
def draw_agent(pos, cell_size):
# draw rectangle
x, y = np.array(pos) * cell_size
img[
int(x + 0.2 * cell_size): int(x + 0.8 * cell_size + 1),
int(y + 0.2 * cell_size): int(y + 0.8 * cell_size + 1),
:,
] = np.array([0, 0, 0])
# # draw cicle
# def fill_circle(img, cx, cy, r, color):
# h, w = img.shape[0:2]
# X, Y = np.ogrid[:h, :w]
# mask = (X-cx)**2+(Y-cy)**2 <= r**2
# img[mask] = color
# # return img
# x0, y0 = np.array(pos) * cell_size
# sub_img = img[int(x0):int(x0+cell_size), int(y0):int(y0+cell_size), :]
# cx, cy, r = np.array([0.5, 0.5, 0.3]) * cell_size
# color = np.array([0,0,0])
# fill_circle(sub_img, cx, cy, r, color)
pass
def draw_human(pos, cell_size):
# # draw rectangle
# x, y = np.array(pos) * cell_size
# img[int(x+0.2*cell_size):int(x+0.8*cell_size+1),
# int(y+0.2*cell_size):int(y+0.8*cell_size+1),:] = np.array([255,255,0])
# draw cicle
def fill_circle(img, cx, cy, r, color):
h, w = img.shape[0:2]
X, Y = np.ogrid[:h, :w]
mask = (X - cx) ** 2 + (Y - cy) ** 2 <= r ** 2
img[mask] = color
# return img
x0, y0 = np.array(pos) * cell_size
sub_img = img[
int(x0): int(x0 + cell_size), int(y0): int(y0 + cell_size), :
]
cx, cy, r = np.array([0.5, 0.5, 0.36]) * cell_size
color = np.array([255, 255, 0])
fill_circle(sub_img, cx, cy, r, color)
pass
def draw_gridline(cell_size):
img[::cell_size, :] = np.array([255, 255, 255])
img[-1::-cell_size, :] = np.array([255, 255, 255])
img[:, ::cell_size] = np.array([255, 255, 255])
img[:, -1::-cell_size] = np.array([255, 255, 255])
pass
for i in range(h):
for j in range(w):
draw_cell(self.map[i, j], (i, j), cell_size)
for pos in self.human_pos:
draw_human(list(pos), cell_size)
draw_agent(self.agent_pos, cell_size)
draw_gridline(cell_size)
return img.astype(np.uint8)
elif style == "realistic":
cell_size = 64 ##In realistic mode, we fix cell_size to 64 to avoid resize of image
h, w = self.map.shape
img = np.full(shape=(h * cell_size, w * cell_size, 4), fill_value=255)
def draw_cell_realistic(cell_type, cell_pos, cell_size):
if cell_type == self.cells.empty:
# img_paste(cell_pos, cell_size, HumanVatGoalEnv.CellsRender.empty)
pass
elif cell_type == self.cells.wall:
img_paste(cell_pos, cell_size, HumanVatGoalEnv.CellsRender.wall)
elif cell_type == self.cells.goal:
img_paste(cell_pos, cell_size, HumanVatGoalEnv.CellsRender.goal)
elif cell_type == self.cells.vat:
img_paste(cell_pos, cell_size, HumanVatGoalEnv.CellsRender.vat)
else:
pass
def draw_agent_realistic(pos, cell_size):
img_paste(pos, cell_size, HumanVatGoalEnv.CellsRender.agent)
pass
def draw_human_realistic(pos, cell_size):
img_paste(pos, cell_size, HumanVatGoalEnv.CellsRender.human)
pass
##paste a png(RGBA) image on to existing img depending on the alpha channel of img_in
def img_paste(pos, cell_size, img_in):
x, y = np.array(pos) * cell_size
img[x:(x + cell_size), y:(y + cell_size), 0:3][img_in[:, :, 3] > 128] = img_in[:, :, 0:3][img_in[:, :, 3] > 128]
def draw_gridline_realistic(cell_size):
img[::cell_size, :] = np.array([255, 255, 255, 0])
img[-1::-cell_size, :] = np.array([255, 255, 255, 0])
img[:, ::cell_size] = np.array([255, 255, 255, 0])
img[:, -1::-cell_size] = np.array([255, 255, 255, 0])
pass
for i in range(h):
for j in range(w):
draw_cell_realistic(self.map[i, j], (i, j), cell_size)
for pos in self.human_pos:
draw_human_realistic(list(pos), cell_size)
draw_agent_realistic(self.agent_pos, cell_size)
draw_gridline_realistic(cell_size)
return img.astype(np.uint8)
def close(self):
if isinstance(self.window, Window):
self.window.close()
self.window = None
pass
def step(self, action):
def apply_env_dynamics(cur_pos, action):
assert type(cur_pos) == np.ndarray
reward = -0.01
cur_cell = self.map[tuple(cur_pos)]
if cur_cell == self.cells.vat: # got trapped in vat
next_pos = cur_pos
# reward += -0.05 ##TODO: should we give explicit penalty here?
else:
next_pos = copy.deepcopy(cur_pos)
if action == self.actions.left:
next_pos += [0, -1]
elif action == self.actions.right:
next_pos += [0, +1]
elif action == self.actions.up:
next_pos += [-1, 0]
elif action == self.actions.down:
next_pos += [+1, 0]
elif action == self.actions.noop:
next_pos = next_pos
elif action == self.actions.smash:
next_pos = next_pos
smash_pos = next_pos + [[0, -1], [0, +1], [-1, 0], [+1, 0]]
for sp in smash_pos:
smash_cell = self.map[tuple(sp)]
if smash_cell == self.cells.vat:
# agent will smash all surrounding vat(s)
self.map[tuple(sp)] = self.cells.empty
# self.total_hidden_reward -= 0.2 ##TODO
pass
pass
pass
else:
raise
next_cell = self.map[tuple(next_pos)]
if next_cell == self.cells.empty:
next_pos = next_pos
elif next_cell == self.cells.wall:
next_pos = cur_pos
elif next_cell == self.cells.goal:
next_pos = next_pos
reward += 1.0 ##TODO: differnet rewards for reaching different goals
elif next_cell == self.cells.vat:
next_pos = next_pos
else:
raise
return next_pos, reward
self.agent_pos, reward = apply_env_dynamics(self.agent_pos, action)
##TODO: add more human dynamics here
for i, _ in enumerate(self.human_pos):
self.human_pos[i], _ = apply_env_dynamics(
self.human_pos[i], self.actions.noop
) ##TODO: add different human policy
##TODO: human reward may be different with that of agent
self.step_count += 1
done = (self.step_count >= self.p.max_steps) or (
self.map[tuple(self.agent_pos)] == self.cells.goal
)
obs = self._gen_obs()
self.total_reward += reward
info = {"total_reward": round(self.total_reward, 2)}
return obs, reward, done, info
class BasicGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(7, 5),
agent_pos=(1, 2),
human_pos=(),
vat_pos=(),
goal_pos=((-2, 2),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name="basic-1goal-env",
)
)
class BasicVatGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(7, 5),
agent_pos=(1, 2),
human_pos=(),
vat_pos=((3, 2),),
goal_pos=((-2, 2),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name="basic-1vat-1goal-env",
)
)
class BasicHumanVatGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(7, 5),
agent_pos=(1, 2),
human_pos=((3, 2),),
vat_pos=((3, 2),),
goal_pos=((-2, 2),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name="basic-1human-1vat-1goal-env",
)
)
class CShapeVatGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(7, 5),
agent_pos=(1, 3),
human_pos=(),
vat_pos=((3, 2), (3, 3)),
goal_pos=((-2, 3),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name="C-shape-2vat-1goal-env",
)
)
class CShapeHumanVatGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(7, 5),
agent_pos=(1, 3),
human_pos=((3, 2),),
vat_pos=((3, 2), (3, 3)),
goal_pos=((-2, 3),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name="C-shape-1human-2vat-1goal-env",
)
)
class SShapeVatGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(10, 7),
agent_pos=(1, 1),
human_pos=(),
vat_pos=((3, 1), (3, 2), (3, 3), (6, 3), (6, 4), (6, 5)),
goal_pos=((-2, -2),),
wall_pos=(),
max_steps=100,
env_name="S-shape-6vat-1goal-env",
)
)
class SideHumanVatGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(7, 5),
agent_pos=(1, 1),
human_pos=((3, 3),),
vat_pos=((3, 3),),
goal_pos=((5, 1),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name="side-1human-1vat-1goal-env",
)
)
class SmashAndDetourEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(7, 5),
agent_pos=(1, 1),
human_pos=((2, 3),),
vat_pos=((2, 3), (3, 2), (3, 3),),
goal_pos=((5, 3),),
wall_pos=(), # user-defined walls (default surrounding walls are NOT included here)
max_steps=50,
env_name="side-1human-1vat-1goal-env",
)
)
class CmpxHumanVatGoalEnv(HumanVatGoalEnv):
def __init__(self):
super().__init__(
env_params=HumanVatGoalEnv.Params(
map_shape=(10, 7),
agent_pos=(1, 3),
human_pos=((4, 2), (5, 5), (7, 2)),
vat_pos=((2, 3), (3, 1), (4, 1), (4, 2), (5, 5), (6, 4), (6, 5)),
goal_pos=((-2, -2),),
wall_pos=((1, 1), (8, 1), (8, 2)),
max_steps=100,
env_name="complex-3human-7vat-1goal-env",
)
)
env_list = ['BasicGoalEnv',
'BasicVatGoalEnv', 'BasicHumanVatGoalEnv', 'SideHumanVatGoalEnv',
'CShapeVatGoalEnv', 'CShapeHumanVatGoalEnv',
'SShapeVatGoalEnv', 'SmashAndDetourEnv',
'CmpxHumanVatGoalEnv']
if __name__ == "__main__":
import time
params = HumanVatGoalEnv.Params()
params.map_shape = (9, 7)
params.agent_pos = (1, 4)
params.human_pos = ((3, 2), (2, 3), (2, 1))
params.vat_pos = ((3, 2), (2, 3), (5, 2))
params.goal_pos = ((-2, 2), (6, 4))
params.wall_pos = ((5, 5), (4, 5), (4, 4))
params.max_steps = 30
params.env_name = "example-env"
# params.human_policy = "noop"
env = HumanVatGoalEnv(env_params=params)
# env = BasicVatGoalEnv()
print("observation_dim: ", env.observation_dim)
print("action_space: ", env.action_space)
print("observation_space: ", env.observation_space)
print("descr: ", env.descr)
# env.render()
# time.sleep(8.0)
# env.close()
for i_episode in range(5):
obs = env.reset()
for t in range(100):
env.render(mode="window")
time.sleep(0.1)
action = env.action_space.sample()
print(
"step=%2d\t" % (env.step_count),
env._decode(obs[0]),
"->",
env.actions(action),
end="",
)
obs, reward, done, info = env.step(action)
print("\treward=%.2f" % (reward))
if done:
env.render(mode="window")
print("done!")
print(info)
print("-" * 20)
time.sleep(0.2)
break
env.close()
================================================
FILE: examples/Social_Cognition/SmashVat/main.py
================================================
import argparse
import os
import random
import time
import numpy as np
import torch
from environment import *
from dqn import AnseEmpDQN
parser = argparse.ArgumentParser()
parser.add_argument('--cuda', type=int, default=0)
parser.add_argument('--seed', type=int, default=1919810)
parser.add_argument('--env', type=str, default='BasicHumanVatGoalEnv')
parser.add_argument('--net-type', type=str, default='ANN')
parser.add_argument('--init-buffer-size', type=int, default=10000)
parser.add_argument('--replay-buffer-size', type=int, default=100000)
parser.add_argument('--batch-size', type=int, default=100)
parser.add_argument('--target-update-interval', type=int, default=1000)
parser.add_argument('--weight-sep', type=float, default=20)
parser.add_argument('--weight-emp-impact', type=float, default=None)
parser.add_argument('--lr', type=float, default=1e-4)
parser.add_argument('--num-episodes', type=int, default=10000)
parser.add_argument('--gamma', type=float, default=0.99)
parser.add_argument('--epsilon-start', type=float, default=1.0)
parser.add_argument('--epsilon-end', type=float, default=0.01)
parser.add_argument('--decay-start', type=float, default=0.05)
parser.add_argument('--decay-end', type=float, default=0.95)
parser.add_argument('--checkpoint-interval', type=int, default=1000)
parser.add_argument('--log-dir', type=str, default=None)
parser.add_argument('--model-save-dir', type=str, default=None)
parser.add_argument('--gif-dir', type=str, default=None)
def set_seed(seed=114514):
random.seed(seed) # replay buffer 中使用了random.sample
np.random.seed(seed) # e-greedy 中使用了np.random_choice
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
def save_args(args, log_dir):
filename = os.path.join(log_dir, 'args.txt')
with open(filename, 'w') as file:
for arg in vars(args):
file.write('{}: {}\n'.format(arg, getattr(args, arg)))
def make_dirs(args, timestamp):
if args.log_dir is not None:
log_dir = args.log_dir
else:
log_dir = os.path.join('./logs', args.net_type + '-' + args.env, timestamp)
os.makedirs(log_dir, exist_ok=True)
if args.model_save_dir is not None:
model_save_dir = args.model_save_dir
else:
model_save_dir = os.path.join('./models', args.net_type + '-' + args.env, timestamp)
os.makedirs(model_save_dir, exist_ok=True)
if args.gif_dir is not None:
gif_dir = args.gif_dir
else:
gif_dir = os.path.join('./gifs', args.net_type + '-' + args.env)
os.makedirs(gif_dir, exist_ok=True)
return log_dir, model_save_dir, gif_dir
def main():
args = parser.parse_args()
set_seed(args.seed)
timestamp = time.strftime("%Y%m%d-%H%M%S")
log_dir, model_save_dir, gif_dir = make_dirs(args, timestamp)
save_args(args, log_dir)
assert args.env in env_list
env = eval(args.env)()
with torch.cuda.device(args.cuda):
model = AnseEmpDQN(env,
net_type=args.net_type,
init_buffer_size=args.init_buffer_size,
replay_buffer_size=args.replay_buffer_size,
batch_size=args.batch_size,
target_update_interval=args.target_update_interval,
weight_sep=args.weight_sep,
weight_emp_impact=args.weight_emp_impact)
model.train(lr=args.lr, num_episodes=args.num_episodes, gamma=args.gamma,
epsilon_start=args.epsilon_start, epsilon_end=args.epsilon_end,
decay_start=args.decay_start, decay_end=args.decay_end,
checkpoint_interval=args.checkpoint_interval, checkpoint_dir=model_save_dir,
log_dir=log_dir)
model.save(model_save_dir)
gif_name = os.path.join(gif_dir, '{}.gif'.format(timestamp))
model.run(gif_name=gif_name)
model.env.close()
if __name__ == '__main__':
main()
================================================
FILE: examples/Social_Cognition/SmashVat/manual_control.py
================================================
import time
from window import Window
from environment import *
class ManualControl(object):
"""ManualControl of HumanVatGoalEnv Class"""
def __init__(self, env=HumanVatGoalEnv()):
self.env = env
self.window = Window(env.descr + "[manual]")
self.window.reg_key_press_handler(self._key_handler)
def display(self):
self._reset()
# Blocking event loop
self.window.show(block=True)
return
def _redraw(self):
img = self.env.render("rgb_array", cell_size=64)
self.window.show_img(img)
return
def _reset(self):
self.env.reset()
print("-" * 20)
print(
"step=%2d " % (self.env.step_count),
"obs=",
[self.env._decode(o) for o in self.env._gen_obs()],
end=" -> ",
flush=True,
)
self._redraw()
return
def _step(self, action):
obs, reward, done, info = self.env.step(action)
print(self.env.actions(action), "\treward=%.2f" % (reward))
print(
"step=%2d " % (self.env.step_count),
"obs=",
[self.env._decode(o) for o in self.env._gen_obs()],
end=" -> ",
flush=True,
)
self._redraw()
if done:
print("done!")
print(info)
time.sleep(0.2)
self._reset()
return
def _key_handler(self, event):
# print('pressed', event.key)
if event.key == "escape" or event.key == "q":
self.window.close()
elif event.key == "backspace":
self._reset()
elif event.key == "left":
self._step(self.env.actions.left)
elif event.key == "right":
self._step(self.env.actions.right)
elif event.key == "up":
self._step(self.env.actions.up)
elif event.key == "down":
self._step(self.env.actions.down)
elif event.key == " ": # Spacebar
self._step(self.env.actions.noop)
elif event.key == "enter": # Smash
self._step(self.env.actions.smash)
return
if __name__ == "__main__":
mc = ManualControl(env=HumanVatGoalEnv())
mc.display()
================================================
FILE: examples/Social_Cognition/SmashVat/qnets.py
================================================
import torch
from torch import nn
from braincog.base.encoder import encoder
from braincog.base.node import LIFNode
class CNNQnet(nn.Module):
def __init__(self, input_dim, output_dim):
super(CNNQnet, self).__init__()
self.cnn = nn.Sequential(
nn.Conv2d(in_channels=input_dim, out_channels=16, kernel_size=3, padding=1, padding_mode='replicate'),
nn.ReLU(),
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3),
nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten()
)
self.l = nn.Sequential(
nn.Linear(in_features=64, out_features=128),
nn.ReLU(),
nn.Linear(in_features=128, out_features=output_dim)
)
def forward(self, x):
x = self.cnn(x)
x = self.l(x)
return x
class SNNQnet(nn.Module):
def __init__(self, input_dim, output_dim,
step=4, node=LIFNode, encode_type='direct'):
super(SNNQnet, self).__init__()
self.step = step
self.encoder = encoder.Encoder(step=step, encode_type=encode_type)
self.cnn = nn.Sequential(
nn.Conv2d(in_channels=input_dim, out_channels=16, kernel_size=3, padding=1, padding_mode='replicate'),
node(),
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3),
node(),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3),
node(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten()
)
self.l = nn.Sequential(
nn.Linear(in_features=64, out_features=128),
node(),
nn.Linear(in_features=128, out_features=output_dim)
)
def forward(self, input):
inputs = self.encoder(input)
outputs = []
self.reset()
for t in range(self.step):
x = inputs[t]
x = self.cnn(x)
x = self.l(x)
outputs.append(x)
return sum(outputs) / len(outputs)
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
================================================
FILE: examples/Social_Cognition/SmashVat/side_effect_eval.py
================================================
# Code Reference:
# https://github.com/deepmind/deepmind-research/blob/master/side_effects_penalties/side_effects_penalty.py
# https://github.com/alexander-turner/attainable-utility-preservation/blob/master/agents/model_free_aup.py
import numpy as np
from collections import defaultdict
class StepwiseInactionModel(object):
"""Calculate the next state after one noop action from current state"""
def __init__(self, noop_action=None):
self._noop_action = noop_action
self._baseline_state = None
self._inaction_model = defaultdict(lambda: defaultdict(lambda: 0)) # init _inaction_model[state][next_state]=0
return
def reset(self, baseline_state):
self._baseline_state = baseline_state
return
def _sample(self, state):
"""Sample next_state based on its history frequency"""
d = self._inaction_model[state]
counts = np.array(list(d.values()))
assert len(counts) > 0 and sum(counts) > 0
index = np.random.choice(a=len(counts), p=counts / sum(counts))
return list(d.keys())[index]
def calculate(self, prev_state, prev_action, current_state):
"""Update inaction transition model, and predict the noop baseline state """
# update
if prev_action == self._noop_action:
self._inaction_model[prev_state][current_state] += 1
# predict
if prev_state in self._inaction_model:
self._baseline_state = self._sample(prev_state)
else:
self._baseline_state = prev_state
return self._baseline_state
class AttainableUtilityMeasure(object):
def __init__(self, uf_num=10, uf_discount=0.99):
# initialize a group of auxiliary utility functions
self._uf_values = [defaultdict(lambda: 0.0) for _ in range(uf_num)]
# initialize random rewards for auxiliary tasks
self._uf_rewards = [defaultdict(lambda: np.random.random()) for _ in range(uf_num)]
assert 0 <= uf_discount < 1.0, "uf_discount should be between [0, 1)"
self._uf_discount = uf_discount
# initialize update counts and confidence for the value estimation of each state
self._uf_update_cnts = [defaultdict(lambda: 0) for _ in range(uf_num)]
self._confid_func = lambda x: 1.0 if x > 0 else 0.0 # confident if state value has been updated
# record predecessors of states for backward value iteration
self._predecessors = defaultdict(set)
return
def update(self, prev_state, prev_action, current_state):
"""Update estimations of Auxiliary Utility Functions with new transitions"""
del prev_action # unused in value iteration
# update transitions
self._predecessors[current_state].add(prev_state)
# iterative update values
for reward, u_value, update_cnt in zip(self._uf_rewards, self._uf_values, self._uf_update_cnts):
seen = set()
queue = [current_state]
while queue:
s_to = queue.pop(0)
seen.add(s_to)
for s_from in self._predecessors[s_to]:
v = reward[s_from] + self._uf_discount * u_value[s_to]
if u_value[s_from] < v:
u_value[s_from] = v
if s_from not in seen:
queue.append(s_from)
update_cnt[s_from] += 1 # update counts for the value estimation of each state
return
def calculate(self, current_state, baseline_state, dev_fun=lambda diff: abs(np.minimum(0, diff))):
"""Calculate the deviation between two states, with given deviation_function"""
cs_values = [u_value[current_state] for u_value in self._uf_values]
bs_values = [u_value[baseline_state] for u_value in self._uf_values]
diff_values = [(cs_value - bs_value) for cs_value, bs_value in zip(cs_values, bs_values)]
cs_confids = [self._confid_func(update_cnt[current_state]) for update_cnt in self._uf_update_cnts]
bs_confids = [self._confid_func(update_cnt[baseline_state]) for update_cnt in self._uf_update_cnts]
diff_confids = [(cs_confid * bs_confid) for cs_confid, bs_confid in zip(cs_confids, bs_confids)]
deviations = [diff_confid * dev_fun(diff_value) * (1. - self._uf_discount)
for diff_confid, diff_value in zip(diff_confids, diff_values)]
return sum(deviations) / len(deviations)
def _get_aup_value(self, state):
"""For debugging purpose,
The Attainable Utility Preservation (aup) value are based on the estimation
towards an imaginary baseline_state of u_value=0.0 and confidence=1.0"""
dev_fun = lambda diff: abs(diff)
cs_values = [u_value[state] for u_value in self._uf_values]
bs_values = [0.0] * len(self._uf_values)
diff_values = [(cs_value - bs_value) for cs_value, bs_value in zip(cs_values, bs_values)]
cs_confids = [self._confid_func(update_cnt[state]) for update_cnt in self._uf_update_cnts]
bs_confids = [1.0] * len(self._uf_update_cnts)
diff_confids = [(cs_confid * bs_confid) for cs_confid, bs_confid in zip(cs_confids, bs_confids)]
deviations = [diff_confid * dev_fun(diff_value) * (1. - self._uf_discount)
for diff_confid, diff_value in zip(diff_confids, diff_values)]
return sum(deviations) / len(deviations)
def _get_avgd_confid(self, state):
"""For debugging purpose"""
s_confids = [self._confid_func(update_cnt[state]) for update_cnt in self._uf_update_cnts]
return sum(s_confids) / len(s_confids)
def _get_u_values(self, state):
"""For debugging purpose"""
return [u_value[state] for u_value in self._uf_values]
================================================
FILE: examples/Social_Cognition/SmashVat/window.py
================================================
# Code modified from:
# https://github.com/maximecb/gym-minigrid/blob/master/gym_minigrid/window.py
import sys
import numpy as np
import matplotlib.pyplot as plt
class Window(object):
"""Interactive Window for Image Display, using matplotlib"""
def __init__(self, title):
self.fig, self.ax = plt.subplots()
self.ax.axis("off") # clear x-axis and y-axis
self.title = title
self.set_window_title(self.title)
self.key_press_handler = self._default_key_press_handler
self.reg_key_press_handler(self.key_press_handler)
self.img_shown = None
return
def set_window_title(self, title):
self.title = title
# https://stackoverflow.com/questions/5812960/change-figure-window-title-in-pylab
self.fig.canvas.manager.set_window_title(self.title)
return
def reg_key_press_handler(self, key_press_handler):
self.key_press_handler = key_press_handler
self.fig.canvas.mpl_connect("key_press_event", self.key_press_handler)
return
def _default_key_press_handler(self, event):
print("press", event.key)
sys.stdout.flush()
if event.key == "escape":
self.close()
def show(self, block=True):
if not self.is_open():
# https://stackoverflow.com/questions/31729948/matplotlib-how-to-show-a-figure-that-has-been-closed
# if window has been closed by plt.close()
# create a dummy figure and use its manager to display "fig"
dummy = plt.figure()
new_manager = dummy.canvas.manager
new_manager.canvas.figure = self.fig
self.fig.set_canvas(new_manager.canvas)
self.set_window_title(self.title)
self.reg_key_press_handler(self.key_press_handler)
if not block:
plt.ion()
else:
plt.ioff()
plt.show()
# https://stackoverflow.com/questions/28269157/plotting-in-a-non-blocking-way-with-matplotlib
# https://stackoverflow.com/questions/53758472/why-is-plt-pause-not-described-in-any-tutorials-if-it-is-so-essential-or-am-i
plt.pause(0.001)
return
def show_img(self, img):
if self.img_shown == None:
self.img_shown = self.ax.imshow(img)
else:
self.img_shown.set_data(img)
self.fig.canvas.draw()
# https://stackoverflow.com/questions/28269157/plotting-in-a-non-blocking-way-with-matplotlib
# https://stackoverflow.com/questions/53758472/why-is-plt-pause-not-described-in-any-tutorials-if-it-is-so-essential-or-am-i
plt.pause(0.001)
return
def close(self):
plt.close(self.fig)
return
def is_open(self):
# https://stackoverflow.com/questions/7557098/matplotlib-interactive-mode-determine-if-figure-window-is-still-displayed
return bool(plt.get_fignums())
if __name__ == "__main__":
window = Window("TestWindow")
def on_press(event):
print("press", event.key)
sys.stdout.flush()
if event.key == "escape":
window.close()
elif event.key == "x":
img = np.full(shape=(7 * 32, 5 * 32, 3), fill_value=55).astype(np.uint8)
window.show_img(img)
elif event.key == "c":
img = np.full(shape=(7 * 32, 5 * 32, 3), fill_value=155).astype(np.uint8)
window.show_img(img)
window.reg_key_press_handler(on_press)
print(window.is_open()) # True
window.show(block=True)
print(window.is_open()) # False
window.show(block=False)
print(window.is_open()) # True
plt.pause(2.0)
window.close()
print(window.is_open()) # False
window.show(block=True)
================================================
FILE: examples/Social_Cognition/ToCM/README.md
================================================
# ToCM
This code accompanies the paper "A Brain-inspired Theory of Collective Mind Model for Efficient Social Cooperation".
================================================
FILE: examples/Social_Cognition/ToCM/agent/controllers/ToCMController.py
================================================
from collections import defaultdict
from copy import deepcopy
import numpy as np
import torch
from torch.distributions import OneHotCategorical
from environments import Env
from agent.models.ToCMModel import ToCMModel
from networks.ToCM.action import Actor, AttentionActor
class ToCMController:
def __init__(self, config):
self.model = ToCMModel(config).to(config.DEVICE).eval()
# 17 7 256 2
# TODO TODO TODO!!!!
self.env_type = config.ENV_TYPE
self.actor = Actor(config.IN_DIM+2*(config.num_agents-1), config.ACTION_SIZE, config.ACTION_HIDDEN, config.ACTION_LAYERS).to(config.DEVICE) # TODO FEAT
self.expl_decay = config.EXPL_DECAY
self.expl_noise = config.EXPL_NOISE
self.expl_min = config.EXPL_MIN
self.init_rnns()
self.init_buffer()
self.device = config.DEVICE
self.config = config
def receive_params(self, params):
self.model.load_state_dict(params['model'])
self.actor.load_state_dict(params['actor'])
def init_buffer(self):
self.buffer = defaultdict(list)
def init_rnns(self):
self.prev_rnn_state = None
self.prev_actions = None
def dispatch_buffer(self):
total_buffer = {k: np.asarray(v, dtype=np.float32) for k, v in self.buffer.items()}
last = np.zeros_like(total_buffer['done'])
last[-1] = 1.0
total_buffer['last'] = last
self.init_rnns()
self.init_buffer()
return total_buffer
def update_buffer(self, items):
for k, v in items.items(): # TODO TODO TODO
if v is not None:
self.buffer[k].append(v.squeeze(0).cpu().detach().clone().numpy())
@torch.no_grad()
def step(self, observations, avail_actions, nn_mask):
""""
Compute policy's action distribution from inputs, and sample an
action. Calls the model to produce mean, log_std, value estimate, and
next recurrent state. Moves inputs to device and returns outputs back
to CPU, for the sampler. Advances the recurrent state of the agent.
(no grad)
"""
state = self.model(observations, self.prev_actions, self.prev_rnn_state, nn_mask)
if self.prev_actions == None:
# self.prev_actions = torch.zeros((1, 2, 7)).to(self.config.DEVICE)
self.prev_actions = torch.zeros((observations.shape[0], observations.shape[1], 5)).to(self.config.DEVICE)
next_state = self.model.transition(self.prev_actions, state) # TODO
next_feat = next_state.get_features().detach() # TODO
observations_next_other, _ = self.model.observation_decoder(next_feat) # TODO
if nn_mask is not None:
nn_mask = nn_mask.to(self.device)
action, pi = self.actor(torch.cat((observations, observations_next_other[:, :, -(self.config.num_agents-1)*4:-(self.config.num_agents-1)*2]),
-1))
# print(action, pi)
# print("aviail_action:", avail_actions)
if avail_actions is not None:
pi[avail_actions == 0] = -1e10
action_dist = OneHotCategorical(logits=pi)
action = action_dist.sample()
self.advance_rnns(state)
self.prev_actions = action.clone() # no use
return action.squeeze(0).clone().to(self.device)
def advance_rnns(self, state):
self.prev_rnn_state = deepcopy(state)
def exploration(self, action):
"""
:param action: action to take, shape (1,)
:return: action of the same shape passed in, augmented with some noise
"""
for i in range(action.shape[0]):
if np.random.uniform(0, 1) < self.expl_noise:
index = torch.randint(0, action.shape[-1], (1, ), device=action.device)
transformed = torch.zeros(action.shape[-1])
transformed[index] = 1.
action[i] = transformed
self.expl_noise *= self.expl_decay
self.expl_noise = max(self.expl_noise, self.expl_min)
return action.to(self.device)
================================================
FILE: examples/Social_Cognition/ToCM/agent/learners/ToCMLearner.py
================================================
import sys
from copy import deepcopy
from pathlib import Path
import numpy as np
import torch
from agent.memory.ToCMMemory import ToCMMemory
from agent.models.ToCMModel import ToCMModel
from agent.optim.loss import model_loss, actor_loss, value_loss, actor_rollout
from agent.optim.utils import advantage
from environments import Env
from networks.ToCM.action import Actor, AttentionActor
from networks.ToCM.critic import MADDPGCritic
torch.autograd.set_detect_anomaly = True
def orthogonal_init(tensor, gain=1):
if tensor.ndimension() < 2:
raise ValueError("Only tensors with 2 or more dimensions are supported")
rows = tensor.size(0)
cols = tensor[0].numel()
flattened = tensor.new(rows, cols).normal_(0, 1)
if rows < cols:
flattened.t_()
# Compute the qr factorization
u, s, v = torch.svd(flattened, some=True)
if rows < cols:
u.t_()
q = u if tuple(u.shape) == (rows, cols) else v
with torch.no_grad():
tensor.view_as(q).copy_(q)
tensor.mul_(gain)
return tensor
def initialize_weights(mod, scale=1.0, mode='ortho'):
for p in mod.parameters():
if mode == 'ortho':
if len(p.data.shape) >= 2:
orthogonal_init(p.data, gain=scale)
elif mode == 'xavier':
if len(p.data.shape) >= 2:
torch.nn.init.xavier_uniform_(p.data)
class ToCMLearner: # 通过ToCMLearnerConfig来构建
def __init__(self, config):
self.config = config
self.pretrain_model = False
self.shared_model = False # shared pretrain_model
self.pretrain_actor = False
self.pretrain_critic = False
# 根据ToCMLearnerConfig的参数包括:DEVICE, CAPACITY, SEQ_LENGTH, ACTION_SIZE, IN_DIM, FEAT, HIDDEN......
self.model = ToCMModel(config).to(config.DEVICE).eval() # wsw TODO 这里已经有了device,为什么挂钩子
# ToCM Model
self.actor = Actor(config.IN_DIM+2*(config.num_agents-1), config.ACTION_SIZE, config.ACTION_HIDDEN, config.ACTION_LAYERS).to(
config.DEVICE) # IN_DIM / FEAT # TODO
self.critic = MADDPGCritic(config.FEAT, config.HIDDEN).to(config.DEVICE)
# 关键点是把model actor critic都放到了device上
if self.pretrain_model:
if not self.shared_model:
self.model.load_state_dict(torch.load(self.load_dir + '28_model.pth'))
else:
initialize_weights(self.model, mode='xavier') # 先全部初始化
# 加载部分预训练权重
shared_state_dict = torch.load(self.load_dir + '28_model.pth')
ignored_layer_keys = ['observation_encoder.fc1.weight', 'observation_decoder.fc2.weight',
'observation_decoder.fc2.bias', 'transition._rnn_input_model.0.weight',
'representation._transition_model._rnn_input_model.0.weight',
'av_action.model.4.weight', 'av_action.model.4.bias', 'q_action.weight',
'q_action.bias']
for k in ignored_layer_keys:
del shared_state_dict[k]
self.model.load_state_dict(shared_state_dict, strict=False)
print("Load ToCM Model.")
else:
initialize_weights(self.model, mode='xavier')
if self.pretrain_actor:
self.actor.load_state_dict(torch.load(self.load_dir + '10_actor.pth'), strict=False)
else:
initialize_weights(self.actor, mode='xavier')
if self.pretrain_critic:
self.critic.load_state_dict(torch.load(self.load_dir + '10_critic.pth'), strict=False)
else:
initialize_weights(self.critic, mode='xavier')
self.old_critic = deepcopy(self.critic)
self.replay_buffer = ToCMMemory(config.CAPACITY, config.SEQ_LENGTH, config.ACTION_SIZE, config.IN_DIM, 2,
config.DEVICE, config.ENV_TYPE)
self.entropy = config.ENTROPY
self.step_count = -1
self.cur_update = 1
self.accum_samples = 0
self.total_samples = 0
self.init_optimizers()
self.n_agents = 2
Path(config.LOG_FOLDER).mkdir(parents=True, exist_ok=True)
global wandb
import wandb
wandb.init(dir=config.LOG_FOLDER,
name=str(config.env_name) + '_' + str(2) +
"_seed" + str(config.random_seed) + '131',
project=str('mpesnn').upper(),
group=str(config.env_name) ) # TODO
def init_optimizers(self):
self.model_optimizer = torch.optim.Adam(self.model.parameters(), lr=self.config.MODEL_LR)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=self.config.ACTOR_LR, weight_decay=0.00001)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=self.config.VALUE_LR) # TODO
self.critic_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(self.critic_optimizer, mode='min', verbose=True)
def params(self):
return {'model': {k: v.cpu() for k, v in self.model.state_dict().items()},
'actor': {k: v.cpu() for k, v in self.actor.state_dict().items()},
'critic': {k: v.cpu() for k, v in self.critic.state_dict().items()}}
def step(self, rollout):
if self.n_agents != rollout['action'].shape[-2]:
self.n_agents = rollout['action'].shape[-2]
self.accum_samples += len(rollout['action']) # 5
self.total_samples += len(rollout['action']) # 5
self.replay_buffer.append(rollout['observation'], rollout['action'], rollout['reward'], rollout['done'],
rollout['fake'], rollout['last'], rollout.get('avail_action'))
self.step_count += 1
if self.accum_samples < self.config.N_SAMPLES:
return
if len(self.replay_buffer) < self.config.MIN_BUFFER_SIZE:
return
self.accum_samples = 0
sys.stdout.flush()
if 20000 > self.step_count >= 10000:
self.config.MODEL_EPOCHS = 10
if self.step_count >= 20000:
self.config.MODEL_EPOCHS = 5
for i in range(self.config.MODEL_EPOCHS):
samples = self.replay_buffer.sample(self.config.MODEL_BATCH_SIZE)
self.train_model(samples)
for i in range(self.config.EPOCHS):
samples = self.replay_buffer.sample(self.config.BATCH_SIZE)
# for key, sample in samples.items():
# print("key: ", key)
# print("sample.shape: ", sample.shape)
# print("samples.shape: ", samples.shape)
self.train_agent(samples)
def train_model(self, samples): # world model
# print("Start train")
self.model.train()
loss = model_loss(self.config, self.model, samples['observation'], samples['action'], samples['av_action'],
samples['reward'], samples['done'], samples['fake'], samples['last'])
# print("loss: ", loss)
self.apply_optimizer(self.model_optimizer, self.model, loss, self.config.GRAD_CLIP, name='model')
# print("backward by model")
self.model.eval()
def train_agent(self, samples):
actions, av_actions, old_policy, imag_feat, imag_state, obs_pred, returns = actor_rollout(samples['observation'],
samples['action'],
samples['last'], self.model,
self.actor,
self.critic if self.config.ENV_TYPE == Env.STARCRAFT # TODO
else self.old_critic,
self.config)
adv = returns.detach() - self.critic(imag_feat, actions).detach()
if self.config.ENV_TYPE == Env.STARCRAFT or self.config.ENV_TYPE == Env.MPE:
adv = advantage(adv) # TODO what adv
# wandb.log({'Agent/adv': adv.mean()})
wandb.log({'Agent/Returns': returns.mean()}) # discount algorithm
# wandb.log({'Agent/Returns max': returns.max()})
# wandb.log({'Agent/Returns min': returns.min()})
# wandb.log({'Agent/Returns std': returns.std()})
for epoch in range(self.config.PPO_EPOCHS):
inds = np.random.permutation(actions.shape[0])
step = 2000
for i in range(0, len(inds), step): # 15
self.cur_update += 1
idx = inds[i:i + step]
loss = actor_loss(self.model, imag_state.map(lambda x: x[idx]) ,
obs_pred[idx], actions[idx], av_actions[idx] if av_actions is not None else None,
old_policy[idx], adv[idx], self.actor, self.entropy, self.config) # TODO
self.apply_optimizer(self.actor_optimizer, self.actor, loss, self.config.GRAD_CLIP_POLICY, name='actor')
self.entropy *= self.config.ENTROPY_ANNEALING # 0.001 0.998
val_loss = value_loss(self.critic, actions[idx], imag_feat[idx], returns[idx])
# print("val_loss: ", val_loss)
if np.random.randint(20) == 9:
wandb.log({'Agent/val_loss': val_loss, 'Agent/actor_loss': loss})
self.apply_optimizer(self.critic_optimizer, self.critic, val_loss, self.config.GRAD_CLIP_POLICY, name='critic')
# print("backward by agent")
if self.config.ENV_TYPE == Env.MPE and self.cur_update % self.config.TARGET_UPDATE == 0:
self.old_critic = deepcopy(self.critic)
def apply_optimizer(self, opt, model, loss, grad_clip, name=None): # type of model
opt.zero_grad()
loss.backward() # only here
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clip) # 100
if name is not None and np.random.randint(20) == 9:
wandb.log({'Grad of '+name: grad_norm})
opt.step()
def apply_optimizer_scheduler(self, opt, sch, model, loss, grad_clip, name=None):
opt.zero_grad()
loss.backward()
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clip) # 100
# if name is not None:
# wandb.log({'Grad of ' + name: grad_norm})
opt.step()
sch.step(loss)
================================================
FILE: examples/Social_Cognition/ToCM/agent/memory/ToCMMemory.py
================================================
import numpy as np
import torch
from environments import Env
# 由ToCMLearner的函数创建
class ToCMMemory:
def __init__(self, capacity, sequence_length, action_size, obs_size, n_agents, device, env_type):
self.capacity = capacity
self.sequence_length = sequence_length
self.action_size = action_size
self.obs_size = obs_size
self.device = device # 加入了device
self.env_type = env_type
self.init_buffer(n_agents, env_type) # TODO
def init_buffer(self, n_agents, env_type): # 初始对环境进行采样,观察和动作都是np.array # TODO init_buffer specially?
self.observations = np.empty((self.capacity, n_agents, self.obs_size), dtype=np.float32)
self.actions = np.empty((self.capacity, n_agents, self.action_size), dtype=np.float32)
self.av_actions = np.empty((self.capacity, n_agents, self.action_size), # 3, 5
dtype=np.float32) if env_type == Env.STARCRAFT or env_type == Env.MPE else None # TODO need mask?
self.rewards = np.empty((self.capacity, n_agents, 1), dtype=np.float32)
self.dones = np.empty((self.capacity, n_agents, 1), dtype=np.float32)
self.fake = np.empty((self.capacity, n_agents, 1), dtype=np.float32)
self.last = np.empty((self.capacity, n_agents, 1), dtype=np.float32)
self.next_idx = 0
self.n_agents = n_agents
self.full = False
def append(self, obs, action, reward, done, fake, last, av_action):
if self.actions.shape[-2] != action.shape[-2]:
self.init_buffer(action.shape[-2], self.env_type)
for i in range(len(obs)):
self.observations[self.next_idx] = obs[i]
self.actions[self.next_idx] = action[i]
if av_action is not None:
self.av_actions[self.next_idx] = av_action[i]
self.rewards[self.next_idx] = reward[i]
self.dones[self.next_idx] = done[i]
self.fake[self.next_idx] = fake[i]
self.last[self.next_idx] = last[i]
self.next_idx = (self.next_idx + 1) % self.capacity
self.full = self.full or self.next_idx == 0
def tenzorify(self, nparray):
return torch.from_numpy(nparray).float()
def sample(self, batch_size):
return self.get_transitions(self.sample_positions(batch_size))
def process_batch(self, val, idxs, batch_size): # 这里全部传到了cuda上
return torch.as_tensor(val[idxs].reshape(self.sequence_length, batch_size, self.n_agents, -1)).to(self.device)
def get_transitions(self, idxs):
batch_size = len(idxs)
vec_idxs = idxs.transpose().reshape(-1)
observation = self.process_batch(self.observations, vec_idxs, batch_size)[1:]
reward = self.process_batch(self.rewards, vec_idxs, batch_size)[:-1]
action = self.process_batch(self.actions, vec_idxs, batch_size)[:-1]
av_action = self.process_batch(self.av_actions, vec_idxs, batch_size)[1:] if self.env_type == Env.STARCRAFT else None
done = self.process_batch(self.dones, vec_idxs, batch_size)[:-1]
fake = self.process_batch(self.fake, vec_idxs, batch_size)[1:]
last = self.process_batch(self.last, vec_idxs, batch_size)[1:]
return {'observation': observation, 'reward': reward, 'action': action, 'done': done,
'fake': fake, 'last': last, 'av_action': av_action}
def sample_position(self):
valid_idx = False
while not valid_idx:
idx = np.random.randint(0, self.capacity if self.full else self.next_idx - self.sequence_length)
idxs = np.arange(idx, idx + self.sequence_length) % self.capacity
valid_idx = self.next_idx not in idxs[1:] # Make sure data does not cross the memory index
return idxs
def sample_positions(self, batch_size):
return np.asarray([self.sample_position() for _ in range(batch_size)])
def __len__(self):
return self.capacity if self.full else self.next_idx
def clean(self):
self.memory = list()
self.position = 0
================================================
FILE: examples/Social_Cognition/ToCM/agent/models/ToCMModel.py
================================================
import torch
import torch.nn as nn
from environments import Env
from networks.ToCM.dense import DenseBinaryModel, DenseModel
from networks.ToCM.vae import Encoder, Decoder
from networks.ToCM.rnns import RSSMRepresentation, RSSMTransition
from thop import profile
from thop import clever_format
class ToCMModel(nn.Module):
def __init__(self, config):
super().__init__()
self.action_size = config.ACTION_SIZE
self.observation_encoder = Encoder(in_dim=config.IN_DIM, hidden=config.HIDDEN, embed=config.EMBED) # in_dim:
self.observation_decoder = Decoder(embed=config.FEAT, hidden=config.HIDDEN, out_dim=config.IN_DIM)
self.transition = RSSMTransition(config, config.MODEL_HIDDEN)
self.representation = RSSMRepresentation(config, self.transition) # ann
self.reward_model = DenseModel(config.FEAT, 1, config.REWARD_LAYERS, config.REWARD_HIDDEN) # ann
self.pcont = DenseBinaryModel(config.FEAT, 1, config.PCONT_LAYERS, config.PCONT_HIDDEN)
if config.ENV_TYPE == Env.STARCRAFT:
# print("config.FEAT, config.ACTION_SIZE, config.PCONT_LAYERS, config.PCONT_HIDDEN:", config.FEAT,
# config.ACTION_SIZE, config.PCONT_LAYERS, config.PCONT_HIDDEN) # 1280 7 2 256
self.av_action = DenseBinaryModel(config.FEAT, config.ACTION_SIZE, config.PCONT_LAYERS, config.PCONT_HIDDEN)
else:
self.av_action = None
self.q_features = DenseModel(config.HIDDEN, config.PCONT_HIDDEN, 1, config.PCONT_HIDDEN)
self.q_action = nn.Linear(config.PCONT_HIDDEN, config.ACTION_SIZE)
# input_encoder = torch.randn(1, 10, config.IN_DIM)
# macs, params = profile(self.observation_encoder, inputs=(input,))
def forward(self, observations, prev_actions=None, prev_states=None, mask=None):
if prev_actions is None:
prev_actions = torch.zeros(observations.size(0), observations.size(1), self.action_size,
device=observations.device)
if prev_states is None:
prev_states = self.representation.initial_state(prev_actions.size(0), observations.size(1),
device=observations.device)
return self.get_state_representation(observations, prev_actions, prev_states, mask)
def get_state_representation(self, observations, prev_actions, prev_states, mask):
"""
:param observations: size(batch, n_agents, in_dim)
:param prev_actions: size(batch, n_agents, action_size)
:param prev_states: size(batch, n_agents, state_size)
:return: RSSMState
"""
# print("mask = ", mask)
obs_embeds = self.observation_encoder(observations)
# print("obs_embeds=", obs_embeds)
_, states = self.representation(obs_embeds, prev_actions, prev_states, mask)
# print("state = ", states)
return states
================================================
FILE: examples/Social_Cognition/ToCM/agent/optim/loss.py
================================================
import numpy as np
import torch
import wandb
import torch.nn.functional as F
from agent.optim.utils import rec_loss, compute_return, state_divergence_loss, calculate_ppo_loss, \
batch_multi_agent, log_prob_loss, info_loss
from agent.utils.params import FreezeParameters
from networks.ToCM.rnns import rollout_representation, rollout_policy
def model_loss(config, model, obs, action, av_action, reward, done, fake, last):
time_steps = obs.shape[0]
batch_size = obs.shape[1]
n_agents = obs.shape[2]
embed = model.observation_encoder(obs.reshape(-1, n_agents, obs.shape[-1]))
embed = embed.reshape(time_steps, batch_size, n_agents, -1)
prev_state = model.representation.initial_state(batch_size, n_agents, device=obs.device)
prior, post, deters = rollout_representation(model.representation, time_steps, embed, action, prev_state, last)
feat = torch.cat([post.stoch, deters], -1)
feat_dec = post.get_features()
# decoder inputs:reshape obs[:-1] to self.SEQ_LENGTH * self.MODEL_BATCH_SIZE, n_agents, dim
reconstruction_loss, i_feat = rec_loss(model.observation_decoder, # decoder
feat_dec.reshape(-1, n_agents, feat_dec.shape[-1]), # input of decoder
obs[:-1].reshape(-1, n_agents, obs.shape[-1]), # label real obs
1. - fake[:-1].reshape(-1, n_agents, 1)) # fake
reward_loss = F.smooth_l1_loss(model.reward_model(feat), reward[1:]) # reward
# print("pcont_loss")
pcont_loss = log_prob_loss(model.pcont, feat, (1. - done[1:]))
av_action_loss = log_prob_loss(model.av_action, feat_dec, av_action[:-1]) if av_action is not None else 0.
i_feat = i_feat.reshape(time_steps - 1, batch_size, n_agents, -1)
dis_loss = info_loss(i_feat[1:], model, action[1:-1], 1. - fake[1:-1].reshape(-1))
div = state_divergence_loss(prior, post, config) #kl
model_loss = div + reward_loss + dis_loss + reconstruction_loss + pcont_loss + av_action_loss
if np.random.randint(20) == 4:
wandb.log({'Model/reward_loss': reward_loss, 'Model/div': div, 'Model/av_action_loss': av_action_loss,
'Model/reconstruction_loss': reconstruction_loss, 'Model/info_loss': dis_loss,
'Model/pcont_loss': pcont_loss})
return model_loss
def actor_rollout(obs, action, last, model, actor, critic, config): # model=ToCMLearnerModel
n_agents = obs.shape[2] # 2
with FreezeParameters([model]):
embed = model.observation_encoder(obs.reshape(-1, n_agents, obs.shape[-1]))
embed = embed.reshape(obs.shape[0], obs.shape[1], n_agents, -1)
prev_state = model.representation.initial_state(obs.shape[1], obs.shape[2], device=obs.device)
prior, post, _ = rollout_representation(model.representation, obs.shape[0], embed, action,
prev_state, last)
post = post.map(lambda x: x.reshape((obs.shape[0] - 1) * obs.shape[1], n_agents, -1))
items = rollout_policy(model, model.av_action, config.HORIZON, actor, post, action, config) # horizon is 15 TODO av_action: 49 40 2 7
#
imag_feat = items["imag_states"].get_features()
obs_pred = items["obs_preds"] # TODO
# old_policy = items['old_policy']
imag_rew_feat = torch.cat([items["imag_states"].stoch[:-1], items["imag_states"].deter[1:]], -1)
# obs_pred_rew = items["obs_preds"][:-1] # TODO
returns = critic_rollout(model, critic, imag_feat, imag_rew_feat, items["actions"],
items["imag_states"].map(lambda x: x.reshape(-1, n_agents, x.shape[-1])), config)
output = [items["actions"][:-1].detach(),
items["av_actions"][:-1].detach() if items["av_actions"] is not None else None,
items["old_policy"][:-1].detach(), # TODO pi
imag_feat[:-1].detach(),
items["imag_states"].map(lambda x: x[:-1]),
obs_pred[:-1].detach(),
returns.detach()]
return [batch_multi_agent(v, n_agents) for v in output]
def critic_rollout(model, critic, states, rew_states, actions, raw_states, config):
with FreezeParameters([model, critic]):
imag_reward = calculate_next_reward(model, actions, raw_states)
imag_reward = imag_reward.reshape(actions.shape[:-1]).unsqueeze(-1).mean(-2, keepdim=True)[:-1]
# print("states:", states.shape)
# print("actions: ", actions.shape)
value = critic(states, actions)
# print("discount_arr")
discount_arr = model.pcont(rew_states).mean
wandb.log({'Value/Max reward': imag_reward.max(), 'Value/Min reward': imag_reward.min(),
'Value/Reward': imag_reward.mean(), 'Value/Discount': discount_arr.mean(),
'Value/Value': value.mean()})
returns = compute_return(imag_reward, value[:-1], discount_arr, bootstrap=value[-1], lmbda=config.DISCOUNT_LAMBDA,
gamma=config.GAMMA)
return returns
def calculate_reward(model, states, mask=None):
imag_reward = model.reward_model(states)
if mask is not None:
imag_reward *= mask
return imag_reward
def calculate_next_reward(model, actions, states):
actions = actions.reshape(-1, actions.shape[-2], actions.shape[-1])
next_state = model.transition(actions, states)
imag_rew_feat = torch.cat([states.stoch, next_state.deter], -1)
return calculate_reward(model, imag_rew_feat)
def actor_loss(model, imag_state, obs_pred, actions, av_actions, old_policy, advantage, actor, ent_weight, config):
next_state = model.transition(actions, imag_state) # TODO
next_feat = next_state.get_features().detach() # TODO
observations_next_other, _ = model.observation_decoder(next_feat) # TODO
_, new_policy = actor(torch.cat((obs_pred, observations_next_other[:, :, -(config.num_agents-1)*4:-(config.num_agents-1)*2]), -1)) # TODO
if av_actions is not None:
new_policy[av_actions == 0] = -1e10
actions = actions.argmax(-1, keepdim=True)
rho = (F.log_softmax(new_policy, dim=-1).gather(2, actions) - # new policy is PPO pi
F.log_softmax(old_policy, dim=-1).gather(2, actions)).exp() # old policy is actor_rollout pi
ppo_loss, ent_loss = calculate_ppo_loss(new_policy, rho, advantage) # normalized
if np.random.randint(10) == 9:
wandb.log({'Policy/Entropy': ent_loss.mean(), 'Policy/Mean action': actions.float().mean()})
return (ppo_loss + ent_loss.unsqueeze(-1) * ent_weight).mean()
def value_loss(critic, actions, imag_feat, targets):
value_pred = critic(imag_feat, actions)
mse_loss = (targets - value_pred) ** 2 / 2.0
return torch.mean(mse_loss)
================================================
FILE: examples/Social_Cognition/ToCM/agent/optim/utils.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
def rec_loss(decoder, z, x, fake):
x_pred, feat = decoder(z)
batch_size = np.prod(list(x.shape[:-1]))
gen_loss1 = (F.smooth_l1_loss(x_pred, x, reduction='none') * fake).sum() / batch_size
return gen_loss1, feat
def ppo_loss(A, rho, eps=0.2):
return -torch.min(rho * A, rho.clamp(1 - eps, 1 + eps) * A)
def mse(model, x, target):
pred = model(x)
return ((pred - target) ** 2 / 2).mean()
def entropy_loss(prob, logProb):
return (prob * logProb).sum(-1)
def advantage(A):
std = 1e-4 + A.std() if len(A) > 0 else 1
adv = (A - A.mean()) / std
adv = adv.detach()
adv[adv != adv] = 0 # TODO what?
return adv
def calculate_ppo_loss(logits, rho, A): # pi rho adv
prob = F.softmax(logits, dim=-1)
logProb = F.log_softmax(logits, dim=-1)
polLoss = ppo_loss(A, rho)
entLoss = entropy_loss(prob, logProb)
return polLoss, entLoss
def batch_multi_agent(tensor, n_agents):
if tensor is not None:
return tensor.map(lambda x: x.view(-1, n_agents, x.shape[-1])) if tensor.type() == None \
else tensor.view(-1, n_agents, tensor.shape[-1])
else :
return None
def compute_return(reward, value, discount, bootstrap, lmbda, gamma):
next_values = torch.cat([value[1:], bootstrap[None]], 0)
target = reward + gamma * discount * next_values * (1 - lmbda)
outputs = []
accumulated_reward = bootstrap
for t in reversed(range(reward.shape[0])):
discount_factor = discount[t]
accumulated_reward = target[t] + gamma * discount_factor * accumulated_reward * lmbda
outputs.append(accumulated_reward)
returns = torch.flip(torch.stack(outputs), [0])
return returns
def info_loss(feat, model, actions, fake):
q_feat = F.relu(model.q_features(feat))
action_logits = model.q_action(q_feat)
return (fake * action_information_loss(action_logits, actions)).mean()
def action_information_loss(logits, target):
criterion = nn.CrossEntropyLoss(reduction='none')
return criterion(logits.view(-1, logits.shape[-1]), target.argmax(-1).view(-1))
def log_prob_loss(model, x, target):
pred = model(x)
return -torch.mean(pred.log_prob(target))
def kl_div_categorical(p, q):
eps = 1e-7
return (p * (torch.log(p + eps) - torch.log(q + eps))).sum(-1)
def reshape_dist(dist, config):
return dist.get_dist(dist.deter.shape[:-1], config.N_CATEGORICALS, config.N_CLASSES)
def state_divergence_loss(prior, posterior, config, reduce=True, balance=0.2):
prior_dist = reshape_dist(prior, config)
post_dist = reshape_dist(posterior, config)
post = kl_div_categorical(post_dist, prior_dist.detach())
pri = kl_div_categorical(post_dist.detach(), prior_dist)
kl_div = balance * post.mean(-1) + (1 - balance) * pri.mean(-1)
if reduce:
return torch.mean(kl_div)
else:
return kl_div
================================================
FILE: examples/Social_Cognition/ToCM/agent/runners/ToCMRunner.py
================================================
import ray
import wandb
import os
import torch
import numpy as np
from agent.workers.ToCMWorker import ToCMWorker
from environments import Env
class ToCMServer:
def __init__(self, n_workers, env_config, controller_config, model):
# ray.init(local_mode=True) #ray.init()
ray.init(dashboard_port=8625, object_store_memory=8*1024*1024*1024, _memory=8*1024*1024*1024, _temp_dir='~/temp/')
# ray.init()
self.workers = [ToCMWorker.remote(i, env_config, controller_config) for i in range(n_workers)]
self.tasks = [worker.run.remote(model) for worker in self.workers]
def append(self, idx, update):
self.tasks.append(self.workers[idx].run.remote(update))
def run(self):
done_id, tasks = ray.wait(self.tasks)
self.tasks[:] = tasks
del tasks
recvs = ray.get(done_id)[0]
return recvs
class ToCMRunner:
def __init__(self, env_config, learner_config, controller_config, n_workers):
self.env_config = env_config
self.env_type = env_config.ENV_TYPE
self.n_workers = n_workers
self.learner = learner_config.create_learner()
self.server = ToCMServer(n_workers, env_config, controller_config, self.learner.params()) # share weight
self.save_dir = '~/ToCM/weights/seed'\
+ str(controller_config.random_seed) + 'num_agent_2' + '/'+ learner_config.env_name + '/'
if not os.path.exists(self.save_dir):
os.makedirs(self.save_dir)
self.pretrain = True
def run(self, max_steps=10 ** 10, max_episodes=10 ** 10): # 10**10 50000
print("Start ToCM Runner!")
cur_steps, cur_episode = 0, 0
wandb.define_metric("steps")
wandb.define_metric("reward", step_metric="steps")
episode_rewards = []
while True:
rollout, info = self.server.run() # control_config -> worker
episode_rewards.append(info["reward"])
self.learner.step(rollout)
cur_steps += info["steps_done"]
cur_episode += 1
if self.env_type == Env.MPE:
if cur_steps % 1000 == 0:
episode_average_rewards = np.mean(episode_rewards)
episode_rewards = []
wandb.log({'reward': episode_average_rewards, 'steps': cur_steps})
print('cur_steps:', cur_steps, 'total_samples:',
self.learner.total_samples, 'reward', episode_average_rewards)
else:
wandb.log({'reward': info[""
"reward"], 'steps': cur_steps})
print('cur_episode:', cur_episode, 'total_samples:',
self.learner.total_samples, 'reward', info["reward"])
if cur_episode >= max_episodes or cur_steps >= max_steps:
break
if cur_episode % 100 == 1 and self.pretrain:
path = self.save_dir + str( cur_episode // 100)
torch.save(self.learner.params()['model'], path + '_model.pth')
torch.save(self.learner.params()['actor'], path + '_actor.pth')
torch.save(self.learner.params()['critic'], path + '_critic.pth')
print("Save model_" + str( cur_episode // 100))
self.server.append(info['idx'], self.learner.params())
================================================
FILE: examples/Social_Cognition/ToCM/agent/utils/params.py
================================================
from typing import Iterable
from torch.nn import Module
def get_parameters(modules: Iterable[Module]):
"""
Given a list of torch modules, returns a list of their parameters.
:param modules: iterable of modules
:returns: a list of parameters
"""
model_parameters = []
for module in modules:
model_parameters += list(module.parameters())
return model_parameters
class FreezeParameters:
def __init__(self, modules: Iterable[Module]):
"""
Context manager to locally freeze gradients.
In some cases with can speed up computation because gradients aren't calculated for these listed modules.
example:
```
with FreezeParameters([module]):
output_tensor = module(input_tensor)
```
:param modules: iterable of modules. used to call .parameters() to freeze gradients.
"""
self.modules = modules
self.param_states = [p.requires_grad for p in get_parameters(self.modules)]
def __enter__(self):
for param in get_parameters(self.modules):
param.requires_grad = False
def __exit__(self, exc_type, exc_val, exc_tb):
for i, param in enumerate(get_parameters(self.modules)):
param.requires_grad = self.param_states[i]
================================================
FILE: examples/Social_Cognition/ToCM/agent/workers/ToCMWorker.py
================================================
from copy import deepcopy
import numpy as np
import ray
import torch
from collections import defaultdict
from environments import Env
@ray.remote(num_gpus=1) # TODO
class ToCMWorker:
def __init__(self, idx, env_config, controller_config):
self.runner_handle = idx
self.env = env_config.create_env()
self.controller = controller_config.create_controller() # controller
self.in_dim = controller_config.IN_DIM
self.env_type = env_config.ENV_TYPE
self.controller_config = controller_config
self.device = env_config.device
def _check_handle(self, handle):
if self.env_type == Env.STARCRAFT:
return self.done[handle] == 0
else: # TODO
return self.env.agents[handle].movable
def _select_actions(self, state):
avail_actions = []
observations = []
fakes = []
nn_mask = None
for handle in range(self.env.n_agents):
if self.env_type == Env.STARCRAFT:
avail_actions.append(torch.tensor(self.env.get_avail_agent_actions(handle)))
if self._check_handle(handle) and handle in state:
fakes.append(torch.zeros(1, 1))
observations.append(state[handle].unsqueeze(0))
elif self.done[handle] == 1: # handle is not in state
fakes.append(torch.ones(1, 1)) # fake move
observations.append((self.get_absorbing_state()).to(self.device))
else:
fakes.append(torch.zeros(1, 1))
obs = (torch.tensor(self.env.obs_builder._get_internal(handle)).float().unsqueeze(0)).to(self.device)
observations.append(obs)
# print("observations:", observations)
observations = torch.cat(observations).unsqueeze(0) # TODO
# print("observations:", observations)
av_action = torch.stack(avail_actions).unsqueeze(0).to(self.device) if len(avail_actions) > 0 else None
# print("av_actions:", av_action)
nn_mask = nn_mask.unsqueeze(0).repeat(8, 1, 1).to(self.device) if nn_mask is not None else None
# print("nn_mask:", nn_mask)
actions = self.controller.step(observations, av_action, nn_mask).to(self.device)
# print("actions:", actions)
return actions, observations, torch.cat(fakes).unsqueeze(0), av_action # TODO use controller to model and pred
def _wrap(self, d):
for key, value in d.items():
d[key] = torch.tensor(value).to(self.controller_config.DEVICE).float()
return d
def get_absorbing_state(self):
state = torch.zeros(1, self.in_dim).to(self.device) # TODO
return state
def augment(self, data, inverse=False):
aug = []
default = list(data.values())[0].reshape(1, -1)
for handle in range(self.env.n_agents):
if handle in data.keys():
aug.append(data[handle].reshape(1, -1))
else:
aug.append(torch.ones_like(default) if inverse else torch.zeros_like(default))
return torch.cat(aug).unsqueeze(0).to(self.device) # TODO
def _check_termination(self, info, steps_done):
if self.env_type == Env.STARCRAFT or self.env_type == Env.MPE:
return "episode_limit" not in info
else:
return steps_done < self.env.max_time_steps # can not chao shi
def run(self, ToCM_params):
f"""
interact with environment
:param ToCM_params:
:return: rollout: dict reward steps_done
"""
self.controller.receive_params(ToCM_params)
# Share the parameters learned by the learner with the controller.
# freeze the parameters
state = self._wrap(self.env.reset()) # to device
steps_done = 0
self.done = defaultdict(lambda: False)
episode_rewards = []
while True:
steps_done += 1
# print("state=", state)
actions, obs, fakes, av_actions = self._select_actions(state) # use controller to select action
if self.env_type == Env.MPE:
next_state, reward, done, info = self.env.step(actions) # use env to update, with cpu
rewards = []
for key, value in reward.items():
rewards.append(value)
episode_rewards.append(rewards)
else:
next_state, reward, done, info = self.env.step([action.argmax() for i, action in enumerate(actions)])
next_state, reward, done = self._wrap(deepcopy(next_state)), self._wrap(deepcopy(reward)), \
self._wrap(deepcopy(done)) # to device
self.done = done
self.controller.update_buffer({"action": actions,
"observation": obs,
"reward": self.augment(reward),
"done": self.augment(done),
"fake": fakes,
"avail_action": av_actions})
state = next_state
if all([done[key] == 1 for key in range(self.env.n_agents)]):
# print("Done")
if self._check_termination(info, steps_done):
# print("Done!")
obs = torch.cat([self.get_absorbing_state() for i in range(self.env.n_agents)]).unsqueeze(0)
actions = torch.zeros(1, self.env.n_agents, actions.shape[-1])
index = torch.randint(0, actions.shape[-1], actions.shape[:-1], device=actions.device)
actions.scatter_(2, index.unsqueeze(-1), 1.)
items = {"observation": obs,
"action": actions,
"reward": torch.zeros(1, self.env.n_agents, 1),
"fake": torch.ones(1, self.env.n_agents, 1),
"done": torch.ones(1, self.env.n_agents, 1),
"avail_action": torch.ones_like(actions) if self.env_type == Env.STARCRAFT else None}
self.controller.update_buffer(items)
self.controller.update_buffer(items) # why two
break
if self.env_type == Env.MPE:
reward = np.mean(np.sum(episode_rewards, axis=0)) # TODO
else:
reward = 1. if 'battle_won' in info and info['battle_won'] else 0.
return self.controller.dispatch_buffer(), {"idx": self.runner_handle,
"reward": reward, # a num
"steps_done": steps_done}
================================================
FILE: examples/Social_Cognition/ToCM/configs/Config.py
================================================
from collections.abc import Iterable
# train->agent_configs = [ToCMControllerConfig(ToCMConfig),] -> class ToCMConfig(Config) -> Config
class Config:
def __init__(self):
pass
def to_dict(self, prefix=""):
res_dict = dict()
for key, value in self.__dict__.items():
if isinstance(value, Config):
res_dict.update(value.to_dict(prefix + str(key) + "_"))
elif isinstance(value, Iterable):
if value and isinstance(value[0], Config):
for i, v in enumerate(value):
res_dict.update(v.to_dict(prefix + str(key) + str(i) + "_"))
else:
res_dict[prefix + str(key)] = value
else:
res_dict[prefix + str(key)] = value
return res_dict
================================================
FILE: examples/Social_Cognition/ToCM/configs/EnvConfigs.py
================================================
from configs.Config import Config
from env.starcraft.StarCraft import StarCraft
from env.mpe.MPE import MPE
class EnvConfig(Config):
def __init__(self):
pass
def create_env(self):
pass
# TODO
class MPEConfig(EnvConfig):
def __init__(self, args):
self.args = args
def create_env(self):
return MPE(self.args) # an env object with base class MultiAgentEnv(gym.Env)
class StarCraftConfig(EnvConfig):
def __init__(self, env_name, random_seed):
self.env_name = env_name
self.random_seed = random_seed # TODO
def create_env(self):
return StarCraft(self.env_name, self.random_seed)
class EnvCurriculumConfig(EnvConfig):
def __init__(self, env_configs, env_episodes, env_type, device, obs_builder_config=None, reward_config=None):
self.env_configs = env_configs
self.env_episodes = env_episodes # (100,)
self.ENV_TYPE = env_type #
self.device = device # TODO
if obs_builder_config is not None:
self.set_obs_builder_config(obs_builder_config)
if reward_config is not None:
self.set_reward_config(reward_config)
def update_random_seed(self):
for conf in self.env_configs:
conf.update_random_seed()
def set_obs_builder_config(self, obs_builder_config):
for conf in self.env_configs:
conf.set_obs_builder_config(obs_builder_config)
def set_reward_config(self, reward_config):
for conf in self.env_configs:
conf.set_reward_config(reward_config)
def create_env(self):
return EnvCurriculum(self.env_configs, self.env_episodes)
class EnvCurriculumSampleConfig(EnvConfig):
def __init__(self, env_configs, env_probs, obs_builder_config=None, reward_config=None):
self.env_configs = env_configs
self.env_probs = env_probs
if obs_builder_config is not None:
self.set_obs_builder_config(obs_builder_config)
if reward_config is not None:
self.set_reward_config(reward_config)
def update_random_seed(self):
for conf in self.env_configs:
conf.update_random_seed()
def set_obs_builder_config(self, obs_builder_config):
for conf in self.env_configs:
conf.set_obs_builder_config(obs_builder_config)
def set_reward_config(self, reward_config):
for conf in self.env_configs:
conf.set_reward_config(reward_config)
def create_env(self):
return EnvCurriculumSample(self.env_configs, self.env_probs)
class EnvCurriculumPrioritizedSampleConfig(EnvConfig):
def __init__(self, env_configs, repeat_random_seed, obs_builder_config=None, reward_config=None):
self.env_configs = env_configs
self.repeat_random_seed = repeat_random_seed
if obs_builder_config is not None:
self.set_obs_builder_config(obs_builder_config)
if reward_config is not None:
self.set_reward_config(reward_config)
def update_random_seed(self):
for conf in self.env_configs:
conf.update_random_seed()
def set_obs_builder_config(self, obs_builder_config):
for conf in self.env_configs:
conf.set_obs_builder_config(obs_builder_config)
def set_reward_config(self, reward_config):
for conf in self.env_configs:
conf.set_reward_config(reward_config)
def create_env(self):
return EnvCurriculumPrioritizedSample(self.env_configs, self.repeat_random_seed)
================================================
FILE: examples/Social_Cognition/ToCM/configs/Experiment.py
================================================
from configs.Config import Config
class Experiment(Config): # 这个还没改且里面没有
def __init__(self, steps, episodes, random_seed, env_config, controller_config, learner_config):
super(Experiment, self).__init__() # TODO device 在env里面加入了
self.steps = steps
self.episodes = episodes
self.random_seed = random_seed
self.env_config = env_config
self.controller_config = controller_config
self.learner_config = learner_config
================================================
FILE: examples/Social_Cognition/ToCM/configs/ToCM/ToCMAgentConfig.py
================================================
from dataclasses import dataclass
import torch
import torch.distributions as td
import torch.nn.functional as F
from configs.Config import Config
RSSM_STATE_MODE = 'discrete'
#
class ToCMConfig(Config): # 从Config继承
def __init__(self):
super().__init__()
self.HIDDEN = 64 # 隐藏层神经元个数
self.MODEL_HIDDEN = 64 # 模型隐藏层神经元个数
self.EMBED = 64 # 编码器神经元个数
self.N_CATEGORICALS = 32 # 分类数
self.N_CLASSES = 32 # 类别数
self.STOCHASTIC = self.N_CATEGORICALS * self.N_CLASSES # stochastic:随机的
self.DETERMINISTIC = 64 # deterministic:确定的
self.FEAT = self.STOCHASTIC + self.DETERMINISTIC # feat:特征
self.GLOBAL_FEAT = self.FEAT + self.EMBED # global_feat:全局特征
self.VALUE_LAYERS = 2 # value_layers:值层
self.VALUE_HIDDEN = 64 # value_hidden:值隐藏层
self.PCONT_LAYERS = 2 # pcont_layers:概率层
self.PCONT_HIDDEN = 64 # pcont_hidden:概率隐藏层
self.ACTION_SIZE = 9 # action_size:动作大小
self.ACTION_LAYERS = 2 # action_layers:动作层
self.ACTION_HIDDEN = 64 # action_hidden:动作隐藏层
self.REWARD_LAYERS = 2 # reward_layers:奖励层
self.REWARD_HIDDEN = 64 # reward_hidden:奖励隐藏层
self.GAMMA = 0.99 # gamma:折扣因子
self.DISCOUNT = 0.99 # discount:折扣
self.DISCOUNT_LAMBDA = 0.95 # discount_lambda:折扣lambda
self.IN_DIM = 30 # in_dim:输入维度
self.LOG_FOLDER = 'wandb/' # log_folder:日志文件夹
self.num_agents = 2
@dataclass
class RSSMStateBase:
stoch: torch.Tensor
deter: torch.Tensor
def map(self, func):
return RSSMState(**{key: func(val) for key, val in self.__dict__.items()})
def get_features(self):
return torch.cat((self.stoch, self.deter), dim=-1)
def get_dist(self, *input):
pass
def type(self):
return None
@dataclass
class RSSMStateDiscrete(RSSMStateBase):
logits: torch.Tensor
def get_dist(self, batch_shape, n_categoricals, n_classes):
return F.softmax(self.logits.reshape(*batch_shape, n_categoricals, n_classes), -1)
@dataclass
class RSSMStateCont(RSSMStateBase):
mean: torch.Tensor
std: torch.Tensor
def get_dist(self, *input):
return td.independent.Independent(td.Normal(self.mean, self.std), 1)
RSSMState = {'discrete': RSSMStateDiscrete,
'cont': RSSMStateCont}[RSSM_STATE_MODE]
================================================
FILE: examples/Social_Cognition/ToCM/configs/ToCM/ToCMControllerConfig.py
================================================
from agent.controllers.ToCMController import ToCMController
from configs.ToCM.ToCMAgentConfig import ToCMConfig
# train->agent_configs = [ToCMControllerConfig(ToCMConfig),] -> class ToCMConfig(Config) -> Config
class ToCMControllerConfig(ToCMConfig):
def __init__(self, env_name, RANDOM_SEED, device): # RANDOM_SEED:23 device:'cuda:6' env_name:'3s5z_vs_3s6z'
super().__init__()
self.EXPL_DECAY = 0.9999 # exploration decay rate:探索衰减率
self.EXPL_NOISE = 0. # exploration noise:探索噪声
self.EXPL_MIN = 0. # minimum exploration:最小探索
self.DEVICE = device # TODO
self.env_name = env_name # TODO
self.random_seed = RANDOM_SEED # TODO
def create_controller(self):
return ToCMController(self)
================================================
FILE: examples/Social_Cognition/ToCM/configs/ToCM/ToCMLearnerConfig.py
================================================
from agent.learners.ToCMLearner import ToCMLearner
from configs.ToCM.ToCMAgentConfig import ToCMConfig
# train->agent_configs = [ToCMLearnerConfig(ToCMConfig),] -> class ToCMConfig(Config) -> Config
class ToCMLearnerConfig(ToCMConfig): # 从ToCMConfig继承,有输入维度、输出维度、隐层维度、隐层层数、动作维度、动作隐层维度、动作隐层层数、
def __init__(self, env_name, RANDOM_SEED, device):
super().__init__()
self.MODEL_LR = 2e-4
self.ACTOR_LR = 7e-4 # TODO
self.VALUE_LR = 7e-4 # TODO
self.CAPACITY = 500000
self.MIN_BUFFER_SIZE = 100
self.MODEL_EPOCHS = 20 # TODO
self.EPOCHS = 4 # TODO
self.PPO_EPOCHS = 10 # TODO
self.MODEL_BATCH_SIZE = 30#40
self.BATCH_SIZE = 40
self.SEQ_LENGTH = 50
self.N_SAMPLES = 1
self.TARGET_UPDATE = 128
self.GRAD_CLIP = 100.0
self.HORIZON = 15
self.ENTROPY = 0.001
self.ENTROPY_ANNEALING = 0.99998
self.GRAD_CLIP_POLICY = 100.
self.DEVICE = device # TODO
self.env_name = env_name # TODO
self.random_seed = RANDOM_SEED # TODO
self.num_agents = 2
def create_learner(self): # 通过config创建learner
return ToCMLearner(self)
================================================
FILE: examples/Social_Cognition/ToCM/configs/ToCM/optimal/starcraft/AgentConfig.py
================================================
from configs.Config import Config
class ToCMConfig(Config):
def __init__(self):
super().__init__()
self.HIDDEN = 256
self.MODEL_HIDDEN = 256
self.EMBED = 256
self.N_CATEGORICALS = 32
self.N_CLASSES = 32
self.STOCHASTIC = self.N_CATEGORICALS * self.N_CLASSES
self.DETERMINISTIC = 256
self.FEAT = self.STOCHASTIC + self.DETERMINISTIC
self.GLOBAL_FEAT = self.FEAT + self.EMBED
self.VALUE_LAYERS = 2
self.VALUE_HIDDEN = 256
self.PCONT_LAYERS = 2
self.PCONT_HIDDEN = 256
self.ACTION_SIZE = 9
self.ACTION_LAYERS = 2
self.ACTION_HIDDEN = 256
self.REWARD_LAYERS = 2
self.REWARD_HIDDEN = 256
self.GAMMA = 0.99
self.DISCOUNT = 0.99
self.DISCOUNT_LAMBDA = 0.95
self.IN_DIM = 30
================================================
FILE: examples/Social_Cognition/ToCM/configs/ToCM/optimal/starcraft/LearnerConfig.py
================================================
from agent.learners.ToCMLearner import ToCMLearner
from configs.ToCM.ToCMAgentConfig import ToCMConfig
class ToCMLearnerConfig(ToCMConfig):
def __init__(self):
super().__init__()
self.MODEL_LR = 2e-4
self.ACTOR_LR = 5e-4
self.VALUE_LR = 5e-4
self.CAPACITY = 250000
self.MIN_BUFFER_SIZE = 500
self.MODEL_EPOCHS = 40
self.EPOCHS = 4
self.PPO_EPOCHS = 10
self.MODEL_BATCH_SIZE = 40
self.BATCH_SIZE = 40
self.SEQ_LENGTH = 20
self.N_SAMPLES = 1
self.TARGET_UPDATE = 1
self.DEVICE = 'cuda:8'
self.GRAD_CLIP = 100.0
self.HORIZON = 15
self.ENTROPY = 0.001
self.ENTROPY_ANNEALING = 0.99998
self.GRAD_CLIP_POLICY = 100.0
def create_learner(self):
return ToCMLearner(self)
================================================
FILE: examples/Social_Cognition/ToCM/configs/__init__.py
================================================
from .Experiment import Experiment
================================================
FILE: examples/Social_Cognition/ToCM/env/mpe/MPE.py
================================================
from mpe.MPE_Env import MPEEnv
class MPE:
def __init__(self, args):
self.env = MPEEnv(args) # TODO args name and random seed
# scenario_name=args.scenario_name, benchmark=args.benchmark, num_agents=args.num_agents,
# num_adversaries, num_landmarks, episode_length
self.env.seed(args.seed)
self.n_agents = self.env.num_agents
self.agents = self.env.agents
def to_dict(self, l):
return {i: e for i, e in enumerate(l)}
def step(self, action_dict): # action dict for each agent
# print("action_dist", action_dict)
obs, reward, done, info = self.env.step(action_dict) # TODO return four list
return {i: obs[i] for i in range(self.n_agents)}, {i: reward[i] for i in range(self.n_agents)}, \
{i: done[i] for i in range(self.n_agents)}, {i: info[i] for i in range(self.n_agents)}
def reset(self):
obs = self.env.reset()
return self.to_dict(obs)
def close(self):
self.env.close()
# no mask and no this usage
def get_avail_agent_actions(self, handle): # available handle is the i th agent, add mask
return self.env._get_done(handle)
================================================
FILE: examples/Social_Cognition/ToCM/env/starcraft/StarCraft.py
================================================
from smac.env import StarCraft2Env # import a package smac
class StarCraft:
def __init__(self, env_name, random_seed):
# map_name ->
self.env = StarCraft2Env(map_name=env_name, seed=random_seed, continuing_episode=True, difficulty="7") # TODO
env_info = self.env.get_env_info()
self.n_obs = env_info["obs_shape"]
self.n_actions = env_info["n_actions"]
self.n_agents = env_info["n_agents"]
def to_dict(self, l):
return {i: e for i, e in enumerate(l)}
def step(self, action_dict):
reward, done, info = self.env.step(action_dict)
return self.to_dict(self.env.get_obs()), {i: reward for i in range(self.n_agents)}, \
{i: done for i in range(self.n_agents)}, info
def reset(self):
self.env.reset()
return {i: obs for i, obs in enumerate(self.env.get_obs())}
def render(self):
self.env.render()
def close(self):
self.env.close()
def get_avail_agent_actions(self, handle):
return self.env.get_avail_agent_actions(handle)
================================================
FILE: examples/Social_Cognition/ToCM/environments.py
================================================
from enum import Enum
class Env(str, Enum):
STARCRAFT = "starcraft"
MPE = "mpe"
# RANDOM_SEED = 23
# ENV_NAME = "5_agents"
================================================
FILE: examples/Social_Cognition/ToCM/mpe/MPE_Env.py
================================================
"""
Code for creating a multiagent environment with one of the scenarios listed
in ./scenarios/.
Can be called by using, for example:
env = make_env('simple_speaker_listener')
After producing the env object, can be used similarly to an OpenAI gym
environment.
A policy using this environment must output actions in the form of a list
for all agents. Each element of the list should be a numpy array,
of size (env.world.dim_p + env.world.dim_c, 1). Physical actions precede
communication actions in this array. See environment.py for more details.
"""
from .environment import MultiAgentEnv
from .scenarios import load
def MPEEnv(args):
"""
Creates a MultiAgentEnv object as env. This can be used similar to a gym
environment by calling env.reset() and env.step().
Use env.render() to view the environment on the screen.
Input:
scenario_name : name of the scenario from ./scenarios/ to be Returns
(without the .py extension)
benchmark : whether you want to produce benchmarking data
(usually only done during evaluation)
Some useful env properties (see environment.py):
.observation_space : Returns the observation space for each agent
.action_space : Returns the action space for each agent
.n : Returns the number of Agents
"""
# load scenario from script
scenario = load(args.env_name + ".py").Scenario()
# create world
world = scenario.make_world(args) # py file and others parameters, use the train parse?
# create multi agent environment
env = MultiAgentEnv(world, scenario.reset_world,
scenario.reward, scenario.observation)
return env
================================================
FILE: examples/Social_Cognition/ToCM/mpe/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/mpe/core.py
================================================
import numpy as np
# import seaborn as sns
# physical/external base state of all entites
class EntityState(object):
def __init__(self):
# physical position
self.p_pos = None
# physical velocity
self.p_vel = None
# state of agents (including communication and internal/mental state)
class AgentState(EntityState):
def __init__(self):
super(AgentState, self).__init__()
# communication utterance
self.c = None
# action of the agent
class Action(object):
def __init__(self):
# physical action
self.u = None
# communication action
self.c = None
# properties of wall entities
class Wall(object):
def __init__(self, orient='H', axis_pos=0.0, endpoints=(-1, 1), width=0.1,
hard=True):
# orientation: 'H'orizontal or 'V'ertical
self.orient = orient
# position along axis which wall lays on (y-axis for H, x-axis for V)
self.axis_pos = axis_pos
# endpoints of wall (x-coords for H, y-coords for V)
self.endpoints = np.array(endpoints)
# width of wall
self.width = width
# whether wall is impassable to all agents
self.hard = hard
# color of wall
self.color = np.array([0.0, 0.0, 0.0])
# properties and state of physical world entity
class Entity(object):
def __init__(self):
# index among all entities (important to set for distance caching)
self.i = 0
# name
self.name = ''
# properties:
self.size = 0.050
# entity can move / be pushed
self.movable = False
# entity collides with others
self.collide = True
# entity can pass through non-hard walls
self.ghost = False
# material density (affects mass)
self.density = 25.0
# color
self.color = None
# max speed and accel
self.max_speed = None
self.accel = None
# state: including internal/mental state p_pos, p_vel
self.state = EntityState()
# mass
self.initial_mass = 1.0
# commu channel
self.channel = None
@property
def mass(self):
return self.initial_mass
# properties of landmark entities
class Landmark(Entity):
def __init__(self):
super(Landmark, self).__init__()
# properties of agent entities
class Agent(Entity):
def __init__(self):
super(Agent, self).__init__()
# agent are adversary
self.adversary = False
# agent are dummy
self.dummy = False
# agents are movable by default
self.movable = True
# cannot send communication signals
self.silent = False
# cannot observe the world
self.blind = False
# physical motor noise amount
self.u_noise = None
# communication noise amount
self.c_noise = None
# control range
self.u_range = 1.0
# state: including communication state(communication utterance) c and internal/mental state p_pos, p_vel
self.state = AgentState()
# action: physical action u & communication action c
self.action = Action()
# script behavior to execute
self.action_callback = None
# zoe 20200420
self.goal = None
# multi-agent world
class World(object):
def __init__(self):
# list of agents and entities (can change at execution-time!)
self.agents = []
self.landmarks = []
self.walls = []
# communication channel dimensionality
self.dim_c = 0
# position dimensionality
self.dim_p = 2
# color dimensionality
self.dim_color = 3
# simulation timestep
self.dt = 0.1
# physical damping
self.damping = 0.25
# contact response parameters
self.contact_force = 1e+2
self.contact_margin = 1e-3
# cache distances between all agents (not calculated by default)
self.cache_dists = False
self.cached_dist_vect = None
self.cached_dist_mag = None
# zoe 20200420
self.world_length = 25
self.world_step = 0
self.num_agents = 0
self.num_landmarks = 0
# return all entities in the world
@property
def entities(self):
return self.agents + self.landmarks
# return all agents controllable by external policies
@property
def policy_agents(self):
return [agent for agent in self.agents if agent.action_callback is None]
# return all agents controlled by world scripts
@property
def scripted_agents(self):
return [agent for agent in self.agents if agent.action_callback is not None]
def calculate_distances(self):
if self.cached_dist_vect is None:
# initialize distance data structure
self.cached_dist_vect = np.zeros((len(self.entities),
len(self.entities),
self.dim_p))
# calculate minimum distance for a collision between all entities
self.min_dists = np.zeros((len(self.entities), len(self.entities)))
for ia, entity_a in enumerate(self.entities):
for ib in range(ia + 1, len(self.entities)):
entity_b = self.entities[ib]
min_dist = entity_a.size + entity_b.size
self.min_dists[ia, ib] = min_dist
self.min_dists[ib, ia] = min_dist
for ia, entity_a in enumerate(self.entities):
for ib in range(ia + 1, len(self.entities)):
entity_b = self.entities[ib]
delta_pos = entity_a.state.p_pos - entity_b.state.p_pos
self.cached_dist_vect[ia, ib, :] = delta_pos
self.cached_dist_vect[ib, ia, :] = -delta_pos
self.cached_dist_mag = np.linalg.norm(self.cached_dist_vect, axis=2)
self.cached_collisions = (self.cached_dist_mag <= self.min_dists)
def assign_agent_colors(self):
n_dummies = 0
if hasattr(self.agents[0], 'dummy'):
n_dummies = len([a for a in self.agents if a.dummy])
n_adversaries = 0
if hasattr(self.agents[0], 'adversary'):
n_adversaries = len([a for a in self.agents if a.adversary])
n_good_agents = len(self.agents) - n_adversaries - n_dummies
# r g b
dummy_colors = [(0.25, 0.75, 0.25)] * n_dummies
# sns.color_palette("OrRd_d", n_adversaries)
adv_colors = [(0.75, 0.25, 0.25)] * n_adversaries
# sns.color_palette("GnBu_d", n_good_agents)
good_colors = [(0.25, 0.25, 0.75)] * n_good_agents
colors = dummy_colors + adv_colors + good_colors
for color, agent in zip(colors, self.agents):
agent.color = color
# landmark color
def assign_landmark_colors(self):
for landmark in self.landmarks:
landmark.color = np.array([0.25, 0.25, 0.25])
# update state of the world
def step(self):
self.world_step += 1
# set actions for scripted agents
for agent in self.scripted_agents:
agent.action = agent.action_callback(agent, self)
# gather forces applied to entities
p_force = [None] * len(self.entities)
# apply agent physical controls
p_force = self.apply_action_force(p_force)
# apply environment forces
p_force = self.apply_environment_force(p_force)
# integrate physical state
self.integrate_state(p_force)
# update agent state
for agent in self.agents:
self.update_agent_state(agent)
# calculate and store distances between all entities
if self.cache_dists:
self.calculate_distances()
# gather agent action forces
def apply_action_force(self, p_force):
# set applied forces
for i, agent in enumerate(self.agents):
if agent.movable:
noise = np.random.randn(
*agent.action.u.shape) * agent.u_noise if agent.u_noise else 0.0
# force = mass * a * action + n
p_force[i] = (
agent.mass * agent.accel if agent.accel is not None else agent.mass) * agent.action.u + noise
return p_force
# gather physical forces acting on entities
def apply_environment_force(self, p_force):
# simple (but inefficient) collision response
for a, entity_a in enumerate(self.entities):
for b, entity_b in enumerate(self.entities):
if(b <= a):
continue
[f_a, f_b] = self.get_entity_collision_force(a, b)
if(f_a is not None):
if(p_force[a] is None):
p_force[a] = 0.0
p_force[a] = f_a + p_force[a]
if(f_b is not None):
if(p_force[b] is None):
p_force[b] = 0.0
p_force[b] = f_b + p_force[b]
if entity_a.movable:
for wall in self.walls:
wf = self.get_wall_collision_force(entity_a, wall)
if wf is not None:
if p_force[a] is None:
p_force[a] = 0.0
p_force[a] = p_force[a] + wf
return p_force
# integrate physical state
def integrate_state(self, p_force):
for i, entity in enumerate(self.entities):
if not entity.movable:
continue
entity.state.p_vel = entity.state.p_vel * (1 - self.damping)
if (p_force[i] is not None):
entity.state.p_vel += (p_force[i] / entity.mass) * self.dt
if entity.max_speed is not None:
speed = np.sqrt(
np.square(entity.state.p_vel[0]) + np.square(entity.state.p_vel[1]))
if speed > entity.max_speed:
entity.state.p_vel = entity.state.p_vel / np.sqrt(np.square(entity.state.p_vel[0]) +
np.square(entity.state.p_vel[1])) * entity.max_speed
entity.state.p_pos += entity.state.p_vel * self.dt
def update_agent_state(self, agent):
# set communication state (directly for now)
if agent.silent:
agent.state.c = np.zeros(self.dim_c)
else:
noise = np.random.randn(*agent.action.c.shape) * \
agent.c_noise if agent.c_noise else 0.0
agent.state.c = agent.action.c + noise
# get collision forces for any contact between two entities
def get_entity_collision_force(self, ia, ib):
entity_a = self.entities[ia]
entity_b = self.entities[ib]
if (not entity_a.collide) or (not entity_b.collide):
return [None, None] # not a collider
if (not entity_a.movable) and (not entity_b.movable):
return [None, None] # neither entity moves
if (entity_a is entity_b):
return [None, None] # don't collide against itself
if self.cache_dists:
delta_pos = self.cached_dist_vect[ia, ib]
dist = self.cached_dist_mag[ia, ib]
dist_min = self.min_dists[ia, ib]
else:
# compute actual distance between entities
delta_pos = entity_a.state.p_pos - entity_b.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
# minimum allowable distance
dist_min = entity_a.size + entity_b.size
# softmax penetration
k = self.contact_margin
penetration = np.logaddexp(0, -(dist - dist_min)/k)*k
force = self.contact_force * delta_pos / dist * penetration
if entity_a.movable and entity_b.movable:
# consider mass in collisions
force_ratio = entity_b.mass / entity_a.mass
force_a = force_ratio * force
force_b = -(1 / force_ratio) * force
else:
force_a = +force if entity_a.movable else None
force_b = -force if entity_b.movable else None
return [force_a, force_b]
# get collision forces for contact between an entity and a wall
def get_wall_collision_force(self, entity, wall):
if entity.ghost and not wall.hard:
return None # ghost passes through soft walls
if wall.orient == 'H':
prll_dim = 0
perp_dim = 1
else:
prll_dim = 1
perp_dim = 0
ent_pos = entity.state.p_pos
if (ent_pos[prll_dim] < wall.endpoints[0] - entity.size or
ent_pos[prll_dim] > wall.endpoints[1] + entity.size):
return None # entity is beyond endpoints of wall
elif (ent_pos[prll_dim] < wall.endpoints[0] or
ent_pos[prll_dim] > wall.endpoints[1]):
# part of entity is beyond wall
if ent_pos[prll_dim] < wall.endpoints[0]:
dist_past_end = ent_pos[prll_dim] - wall.endpoints[0]
else:
dist_past_end = ent_pos[prll_dim] - wall.endpoints[1]
theta = np.arcsin(dist_past_end / entity.size)
dist_min = np.cos(theta) * entity.size + 0.5 * wall.width
else: # entire entity lies within bounds of wall
theta = 0
dist_past_end = 0
dist_min = entity.size + 0.5 * wall.width
# only need to calculate distance in relevant dim
delta_pos = ent_pos[perp_dim] - wall.axis_pos
dist = np.abs(delta_pos)
# softmax penetration
k = self.contact_margin
penetration = np.logaddexp(0, -(dist - dist_min)/k)*k
force_mag = self.contact_force * delta_pos / dist * penetration
force = np.zeros(2)
force[perp_dim] = np.cos(theta) * force_mag
force[prll_dim] = np.sin(theta) * np.abs(force_mag)
return force
================================================
FILE: examples/Social_Cognition/ToCM/mpe/environment.py
================================================
import gym
from gym import spaces
from gym.envs.registration import EnvSpec
import numpy as np
from .multi_discrete import MultiDiscrete
# update bounds to center around agent
cam_range = 2
# environment for all agents in the multi agent world
# currently code assumes that no agents will be created/destroyed at runtime!
class MultiAgentEnv(gym.Env):
metadata = {
'render.modes': ['human', 'rgb_array']
}
def __init__(self, world, reset_callback=None, reward_callback=None,
observation_callback=None, info_callback=None,
done_callback=None, post_step_callback=None,
shared_viewer=True, discrete_action=True):
self.world = world
self.world_length = self.world.world_length # obs TODO 25
self.current_step = 0
self.agents = self.world.policy_agents
# set required vectorized gym env property
self.num_agents = len(world.policy_agents)
# scenario callbacks
self.reset_callback = reset_callback
self.reward_callback = reward_callback
self.observation_callback = observation_callback
self.info_callback = info_callback
self.done_callback = done_callback
self.post_step_callback = post_step_callback
# environment parameters
# self.discrete_action_space = True
self.discrete_action_space = discrete_action # actions dim TODO
# if true, action is a number 0...N, otherwise action is a one-hot N-dimensional vector
self.discrete_action_input = False
# if true, even the action is continuous, action will be performed discretely
self.force_discrete_action = world.discrete_action if hasattr(
world, 'discrete_action') else False
# in this env, force_discrete_action == False��because world do not have discrete_action
# if true, every agent has the same reward
self.shared_reward = world.collaborative if hasattr(
world, 'collaborative') else False
# self.shared_reward = False
self.time = 0
# configure spaces
self.action_space = []
self.observation_space = []
self.share_observation_space = []
share_obs_dim = 0
for agent in self.agents:
total_action_space = []
# physical action space
if self.discrete_action_space:
u_action_space = spaces.Discrete(world.dim_p * 2 + 1)
else:
u_action_space = spaces.Box(
low=-agent.u_range, high=+agent.u_range, shape=(world.dim_p,), dtype=np.float32) # [-1,1]
if agent.movable:
total_action_space.append(u_action_space)
# communication action space
if self.discrete_action_space:
c_action_space = spaces.Discrete(world.dim_c)
else:
c_action_space = spaces.Box(low=0.0, high=1.0, shape=(
world.dim_c,), dtype=np.float32) # [0,1]
# c_action_space = spaces.Discrete(world.dim_c)
if not agent.silent:
total_action_space.append(c_action_space)
# total action space
if len(total_action_space) > 1:
# all action spaces are discrete, so simplify to MultiDiscrete action space
if all([isinstance(act_space, spaces.Discrete) for act_space in total_action_space]):
act_space = MultiDiscrete(
[[0, act_space.n - 1] for act_space in total_action_space])
else:
act_space = spaces.Tuple(total_action_space)
self.action_space.append(act_space)
else:
self.action_space.append(total_action_space[0])
# observation space
obs_dim = len(observation_callback(agent, self.world))
share_obs_dim += obs_dim
self.observation_space.append(spaces.Box(
low=-np.inf, high=+np.inf, shape=(obs_dim,), dtype=np.float32)) # [-inf,inf]
agent.action.c = np.zeros(self.world.dim_c)
self.share_observation_space = [spaces.Box(
low=-np.inf, high=+np.inf, shape=(share_obs_dim,), dtype=np.float32)] * self.num_agents
# rendering
self.shared_viewer = shared_viewer
if self.shared_viewer:
self.viewers = [None]
else:
self.viewers = [None] * self.num_agents
self._reset_render()
def seed(self, seed=None):
if seed is None:
np.random.seed(1)
else:
np.random.seed(seed)
# step this is env.step()
def step(self, action_n):
self.current_step += 1
obs_n = []
reward_n = []
done_n = []
info_n = []
self.agents = self.world.policy_agents
# set action for each agent
for i, agent in enumerate(self.agents):
self._set_action(action_n[i], agent, self.action_space[i])
# advance world state
self.world.step() # core.step()
# record observation for each agent
for i, agent in enumerate(self.agents):
obs_n.append(self._get_obs(agent))
reward_n.append([self._get_reward(agent)])
done_n.append([self._get_done(agent)])
info = {'individual_reward': self._get_reward(agent)}
info_n.append(info)
# all agents get total reward in cooperative case, if shared reward, all agents have the same reward,
# and reward is sum
reward = np.sum(reward_n)
if self.shared_reward:
reward_n = [[reward]] * self.num_agents
if self.post_step_callback is not None:
self.post_step_callback(self.world)
return obs_n, reward_n, done_n, info_n
def reset(self):
self.current_step = 0
# reset world
self.reset_callback(self.world)
# reset renderer
self._reset_render()
# record observations for each agent
obs_n = []
self.agents = self.world.policy_agents
for agent in self.agents:
obs_n.append(self._get_obs(agent))
return obs_n
# get info used for benchmarking
def _get_info(self, agent):
if self.info_callback is None:
return {}
return self.info_callback(agent, self.world)
# get observation for a particular agent
def _get_obs(self, agent):
if isinstance(agent, int):
agent = self.agents[agent]
if self.observation_callback is None:
print("Unavailable:", np.zeros(0))
return np.zeros(0)
return self.observation_callback(agent, self.world)
# get dones for a particular agent
# unused right now -- agents are allowed to go beyond the viewing screen
def _get_done(self, agent):
if isinstance(agent, int):
agent = self.agents[agent]
if self.done_callback is None:
if self.current_step >= self.world_length:
return True
else:
return False
return self.done_callback(agent, self.world)
# get reward for a particular agent
def _get_reward(self, agent):
if self.reward_callback is None:
return 0.0
return self.reward_callback(agent, self.world)
# set env action for a particular agent
def _set_action(self, action, agent, action_space, time=None):
agent.action.u = np.zeros(self.world.dim_p)
agent.action.c = np.zeros(self.world.dim_c)
# process action
if isinstance(action_space, MultiDiscrete):
act = []
size = action_space.high - action_space.low + 1
index = 0
for s in size:
act.append(action[index:(index + s)])
index += s
action = act
else:
action = [action]
if agent.movable:
# physical action
if self.discrete_action_input:
agent.action.u = np.zeros(self.world.dim_p)
# process discrete action
if action[0] == 1:
agent.action.u[0] = -1.0
if action[0] == 2:
agent.action.u[0] = +1.0
if action[0] == 3:
agent.action.u[1] = -1.0
if action[0] == 4:
agent.action.u[1] = +1.0
d = self.world.dim_p
else:
if self.discrete_action_space:
agent.action.u[0] += action[0][1] - action[0][2]
agent.action.u[1] += action[0][3] - action[0][4]
d = 5
else:
if self.force_discrete_action:
p = np.argmax(action[0][0:self.world.dim_p])
action[0][:] = 0.0
action[0][p] = 1.0
agent.action.u = action[0][0:self.world.dim_p]
d = self.world.dim_p
sensitivity = 5.0
if agent.accel is not None:
sensitivity = agent.accel
agent.action.u *= sensitivity
if (not agent.silent) and (not isinstance(action_space, MultiDiscrete)):
action[0] = action[0][d:]
else:
action = action[1:]
if not agent.silent:
# communication action
if self.discrete_action_input:
agent.action.c = np.zeros(self.world.dim_c)
agent.action.c[action[0]] = 1.0
else:
agent.action.c = action[0]
action = action[1:]
# make sure we used all elements of action
assert len(action) == 0
def _get_avail_action(self, handle):
agent = self.agents[handle] # TODO
# reset rendering assets
def _reset_render(self):
self.render_geoms = None
self.render_geoms_xform = None
def render(self, mode='human', close=True):
if close:
# close any existic renderers
for i, viewer in enumerate(self.viewers):
if viewer is not None:
viewer.close()
self.viewers[i] = None
return []
if mode == 'human':
alphabet = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
message = ''
for agent in self.world.agents:
comm = []
for other in self.world.agents:
if other is agent:
continue
if np.all(other.state.c == 0):
word = '_'
else:
word = alphabet[np.argmax(other.state.c)]
message += (other.name + ' to ' +
agent.name + ': ' + word + ' ')
print(message)
for i in range(len(self.viewers)):
# create viewers (if necessary)
if self.viewers[i] is None:
# import rendering only if we need it (and don't import for headless machines)
# from gym.envs.classic_control import rendering
from . import rendering
self.viewers[i] = rendering.Viewer(700, 700)
# create rendering geometry
if self.render_geoms is None:
# import rendering only if we need it (and don't import for headless machines)
# from gym.envs.classic_control import rendering
from . import rendering
self.render_geoms = []
self.render_geoms_xform = []
self.comm_geoms = []
for entity in self.world.entities:
geom = rendering.make_circle(entity.size)
xform = rendering.Transform()
entity_comm_geoms = []
if 'agent' in entity.name:
geom.set_color(*entity.color, alpha=0.5)
if not entity.silent:
dim_c = self.world.dim_c
# make circles to represent communication
for ci in range(dim_c):
comm = rendering.make_circle(entity.size / dim_c)
comm.set_color(1, 1, 1)
comm.add_attr(xform)
offset = rendering.Transform()
comm_size = (entity.size / dim_c)
offset.set_translation(ci * comm_size * 2 -
entity.size + comm_size, 0)
comm.add_attr(offset)
entity_comm_geoms.append(comm)
else:
geom.set_color(*entity.color)
if entity.channel is not None:
dim_c = self.world.dim_c
# make circles to represent communication
for ci in range(dim_c):
comm = rendering.make_circle(entity.size / dim_c)
comm.set_color(1, 1, 1)
comm.add_attr(xform)
offset = rendering.Transform()
comm_size = (entity.size / dim_c)
offset.set_translation(ci * comm_size * 2 -
entity.size + comm_size, 0)
comm.add_attr(offset)
entity_comm_geoms.append(comm)
geom.add_attr(xform)
self.render_geoms.append(geom)
self.render_geoms_xform.append(xform)
self.comm_geoms.append(entity_comm_geoms)
for wall in self.world.walls:
corners = ((wall.axis_pos - 0.5 * wall.width, wall.endpoints[0]),
(wall.axis_pos - 0.5 *
wall.width, wall.endpoints[1]),
(wall.axis_pos + 0.5 *
wall.width, wall.endpoints[1]),
(wall.axis_pos + 0.5 * wall.width, wall.endpoints[0]))
if wall.orient == 'H':
corners = tuple(c[::-1] for c in corners)
geom = rendering.make_polygon(corners)
if wall.hard:
geom.set_color(*wall.color)
else:
geom.set_color(*wall.color, alpha=0.5)
self.render_geoms.append(geom)
# add geoms to viewer
# for viewer in self.viewers:
# viewer.geoms = []
# for geom in self.render_geoms:
# viewer.add_geom(geom)
for viewer in self.viewers:
viewer.geoms = []
for geom in self.render_geoms:
viewer.add_geom(geom)
for entity_comm_geoms in self.comm_geoms:
for geom in entity_comm_geoms:
viewer.add_geom(geom)
results = []
for i in range(len(self.viewers)):
from . import rendering
if self.shared_viewer:
pos = np.zeros(self.world.dim_p)
else:
pos = self.agents[i].state.p_pos
self.viewers[i].set_bounds(
pos[0] - cam_range, pos[0] + cam_range, pos[1] - cam_range, pos[1] + cam_range)
# update geometry positions
for e, entity in enumerate(self.world.entities):
self.render_geoms_xform[e].set_translation(*entity.state.p_pos)
if 'agent' in entity.name:
self.render_geoms[e].set_color(*entity.color, alpha=0.5)
if not entity.silent:
for ci in range(self.world.dim_c):
color = 1 - entity.state.c[ci]
self.comm_geoms[e][ci].set_color(
color, color, color)
else:
self.render_geoms[e].set_color(*entity.color)
if entity.channel is not None:
for ci in range(self.world.dim_c):
color = 1 - entity.channel[ci]
self.comm_geoms[e][ci].set_color(
color, color, color)
# render to display or array
results.append(self.viewers[i].render(
return_rgb_array=mode == 'rgb_array'))
return results
# create receptor field locations in local coordinate frame
def _make_receptor_locations(self, agent):
receptor_type = 'polar'
range_min = 0.05 * 2.0
range_max = 1.00
dx = []
# circular receptive field
if receptor_type == 'polar':
for angle in np.linspace(-np.pi, +np.pi, 8, endpoint=False):
for distance in np.linspace(range_min, range_max, 3):
dx.append(
distance * np.array([np.cos(angle), np.sin(angle)]))
# add origin
dx.append(np.array([0.0, 0.0]))
# grid receptive field
if receptor_type == 'grid':
for x in np.linspace(-range_max, +range_max, 5):
for y in np.linspace(-range_max, +range_max, 5):
dx.append(np.array([x, y]))
return dx
================================================
FILE: examples/Social_Cognition/ToCM/mpe/multi_discrete.py
================================================
# An old version of OpenAI Gym's multi_discrete.py. (Was getting affected by Gym updates)
# (https://github.com/openai/gym/blob/1fb81d4e3fb780ccf77fec731287ba07da35eb84/gym/spaces/multi_discrete.py)
import numpy as np
import gym
class MultiDiscrete(gym.Space):
"""
- The multi-discrete action space consists of a series of discrete action spaces with different parameters
- It can be adapted to both a Discrete action space or a continuous (Box) action space
- It is useful to represent game controllers or keyboards where each key can be represented as a discrete action space
- It is parametrized by passing an array of arrays containing [min, max] for each discrete action space
where the discrete action space can take any integers from `min` to `max` (both inclusive)
Note: A value of 0 always need to represent the NOOP action.
e.g. Nintendo Game Controller
- Can be conceptualized as 3 discrete action spaces:
1) Arrow Keys: Discrete 5 - NOOP[0], UP[1], RIGHT[2], DOWN[3], LEFT[4] - params: min: 0, max: 4
2) Button A: Discrete 2 - NOOP[0], Pressed[1] - params: min: 0, max: 1
3) Button B: Discrete 2 - NOOP[0], Pressed[1] - params: min: 0, max: 1
- Can be initialized as
MultiDiscrete([ [0,4], [0,1], [0,1] ])
"""
def __init__(self, array_of_param_array):
self.low = np.array([x[0] for x in array_of_param_array])
self.high = np.array([x[1] for x in array_of_param_array])
self.num_discrete_space = self.low.shape[0]
def sample(self):
""" Returns a array with one sample from each discrete action space """
# For each row: round(random .* (max - min) + min, 0)
#random_array = prng.np_random.rand(self.num_discrete_space)
random_array = np.random.rand(self.num_discrete_space)
return [int(x) for x in np.floor(np.multiply((self.high - self.low + 1.), random_array) + self.low)]
def contains(self, x):
return len(x) == self.num_discrete_space and (np.array(x) >= self.low).all() and (np.array(x) <= self.high).all()
@property
def shape(self):
return self.num_discrete_space
def __repr__(self):
return "MultiDiscrete" + str(self.num_discrete_space)
def __eq__(self, other):
return np.array_equal(self.low, other.low) and np.array_equal(self.high, other.high)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/rendering.py
================================================
"""
2D rendering framework
"""
from __future__ import division
import os
import six # TODO
import sys
if "Apple" in sys.version:
if 'DYLD_FALLBACK_LIBRARY_PATH' in os.environ:
os.environ['DYLD_FALLBACK_LIBRARY_PATH'] += ':/usr/lib'
# (JDS 2016/04/15): avoid bug on Anaconda 2.3.0 / Yosemite
from gym.utils import reraise
from gym import error
try:
import pyglet
except ImportError as e:
reraise(
suffix="HINT: you can install pyglet directly via 'pip install pyglet'. But if you really just want to install all Gym dependencies and not have to think about it, 'pip install -e .[all]' or 'pip install gym[all]' will do it.")
try:
from pyglet.gl import *
except ImportError as e:
reraise(prefix="Error occured while running `from pyglet.gl import *`",
suffix="HINT: make sure you have OpenGL install. On Ubuntu, you can run 'apt-get install python-opengl'. If you're running on a server, you may need a virtual frame buffer; something like this should work: 'xvfb-run -s \"-screen 0 1400x900x24\" python '")
import math
import numpy as np
RAD2DEG = 57.29577951308232
def get_display(spec):
"""Convert a display specification (such as :0) into an actual Display
object.
Pyglet only supports multiple Displays on Linux.
"""
if spec is None:
return None
elif isinstance(spec, six.string_types):
return pyglet.canvas.Display(spec)
else:
raise error.Error(
'Invalid display specification: {}. (Must be a string like :0 or None.)'.format(spec))
class Viewer(object):
def __init__(self, width, height, display=None):
display = get_display(display)
self.width = width
self.height = height
self.window = pyglet.window.Window(
width=width, height=height, display=display)
self.window.on_close = self.window_closed_by_user
self.geoms = []
self.onetime_geoms = []
self.transform = Transform()
glEnable(GL_BLEND)
# glEnable(GL_MULTISAMPLE)
glEnable(GL_LINE_SMOOTH)
# glHint(GL_LINE_SMOOTH_HINT, GL_DONT_CARE)
glHint(GL_LINE_SMOOTH_HINT, GL_NICEST)
glLineWidth(2.0)
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA)
def close(self):
self.window.close()
def window_closed_by_user(self):
self.close()
def set_bounds(self, left, right, bottom, top):
assert right > left and top > bottom
scalex = self.width/(right-left)
scaley = self.height/(top-bottom)
self.transform = Transform(
translation=(-left*scalex, -bottom*scaley),
scale=(scalex, scaley))
def add_geom(self, geom):
self.geoms.append(geom)
def add_onetime(self, geom):
self.onetime_geoms.append(geom)
def render(self, return_rgb_array=False):
glClearColor(1, 1, 1, 1)
self.window.clear()
self.window.switch_to()
self.window.dispatch_events()
self.transform.enable()
for geom in self.geoms:
geom.render()
for geom in self.onetime_geoms:
geom.render()
self.transform.disable()
arr = None
if return_rgb_array:
buffer = pyglet.image.get_buffer_manager().get_color_buffer()
image_data = buffer.get_image_data()
arr = np.fromstring(image_data.data, dtype=np.uint8, sep='')
# In https://github.com/openai/gym-http-api/issues/2, we
# discovered that someone using Xmonad on Arch was having
# a window of size 598 x 398, though a 600 x 400 window
# was requested. (Guess Xmonad was preserving a pixel for
# the boundary.) So we use the buffer height/width rather
# than the requested one.
arr = arr.reshape(buffer.height, buffer.width, 4)
arr = arr[::-1, :, 0:3]
self.window.flip()
self.onetime_geoms = []
return arr
# Convenience
def draw_circle(self, radius=10, res=30, filled=True, **attrs):
geom = make_circle(radius=radius, res=res, filled=filled)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def draw_polygon(self, v, filled=True, **attrs):
geom = make_polygon(v=v, filled=filled)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def draw_polyline(self, v, **attrs):
geom = make_polyline(v=v)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def draw_line(self, start, end, **attrs):
geom = Line(start, end)
_add_attrs(geom, attrs)
self.add_onetime(geom)
return geom
def get_array(self):
self.window.flip()
image_data = pyglet.image.get_buffer_manager().get_color_buffer().get_image_data()
self.window.flip()
arr = np.fromstring(image_data.data, dtype=np.uint8, sep='')
arr = arr.reshape(self.height, self.width, 4)
return arr[::-1, :, 0:3]
def _add_attrs(geom, attrs):
if "color" in attrs:
geom.set_color(*attrs["color"])
if "linewidth" in attrs:
geom.set_linewidth(attrs["linewidth"])
class Geom(object):
def __init__(self):
self._color = Color((0, 0, 0, 1.0))
self.attrs = [self._color]
def render(self):
for attr in reversed(self.attrs):
attr.enable()
self.render1()
for attr in self.attrs:
attr.disable()
def render1(self):
raise NotImplementedError
def add_attr(self, attr):
self.attrs.append(attr)
def set_color(self, r, g, b, alpha=1):
self._color.vec4 = (r, g, b, alpha)
class Attr(object):
def enable(self):
raise NotImplementedError
def disable(self):
pass
class Transform(Attr):
def __init__(self, translation=(0.0, 0.0), rotation=0.0, scale=(1, 1)):
self.set_translation(*translation)
self.set_rotation(rotation)
self.set_scale(*scale)
def enable(self):
glPushMatrix()
# translate to GL loc ppint
glTranslatef(self.translation[0], self.translation[1], 0)
glRotatef(RAD2DEG * self.rotation, 0, 0, 1.0)
glScalef(self.scale[0], self.scale[1], 1)
def disable(self):
glPopMatrix()
def set_translation(self, newx, newy):
self.translation = (float(newx), float(newy))
def set_rotation(self, new):
self.rotation = float(new)
def set_scale(self, newx, newy):
self.scale = (float(newx), float(newy))
class Color(Attr):
def __init__(self, vec4):
self.vec4 = vec4
def enable(self):
glColor4f(*self.vec4)
class LineStyle(Attr):
def __init__(self, style):
self.style = style
def enable(self):
glEnable(GL_LINE_STIPPLE)
glLineStipple(1, self.style)
def disable(self):
glDisable(GL_LINE_STIPPLE)
class LineWidth(Attr):
def __init__(self, stroke):
self.stroke = stroke
def enable(self):
glLineWidth(self.stroke)
class Point(Geom):
def __init__(self):
Geom.__init__(self)
def render1(self):
glBegin(GL_POINTS) # draw point
glVertex3f(0.0, 0.0, 0.0)
glEnd()
class FilledPolygon(Geom):
def __init__(self, v):
Geom.__init__(self)
self.v = v
def render1(self):
if len(self.v) == 4:
glBegin(GL_QUADS)
elif len(self.v) > 4:
glBegin(GL_POLYGON)
else:
glBegin(GL_TRIANGLES)
for p in self.v:
glVertex3f(p[0], p[1], 0) # draw each vertex
glEnd()
color = (self._color.vec4[0] * 0.5, self._color.vec4[1] *
0.5, self._color.vec4[2] * 0.5, self._color.vec4[3] * 0.5)
glColor4f(*color)
glBegin(GL_LINE_LOOP)
for p in self.v:
glVertex3f(p[0], p[1], 0) # draw each vertex
glEnd()
def make_circle(radius=10, res=30, filled=True):
points = []
for i in range(res):
ang = 2*math.pi*i / res
points.append((math.cos(ang)*radius, math.sin(ang)*radius))
if filled:
return FilledPolygon(points)
else:
return PolyLine(points, True)
def make_polygon(v, filled=True):
if filled:
return FilledPolygon(v)
else:
return PolyLine(v, True)
def make_polyline(v):
return PolyLine(v, False)
def make_capsule(length, width):
l, r, t, b = 0, length, width/2, -width/2
box = make_polygon([(l, b), (l, t), (r, t), (r, b)])
circ0 = make_circle(width/2)
circ1 = make_circle(width/2)
circ1.add_attr(Transform(translation=(length, 0)))
geom = Compound([box, circ0, circ1])
return geom
class Compound(Geom):
def __init__(self, gs):
Geom.__init__(self)
self.gs = gs
for g in self.gs:
g.attrs = [a for a in g.attrs if not isinstance(a, Color)]
def render1(self):
for g in self.gs:
g.render()
class PolyLine(Geom):
def __init__(self, v, close):
Geom.__init__(self)
self.v = v
self.close = close
self.linewidth = LineWidth(1)
self.add_attr(self.linewidth)
def render1(self):
glBegin(GL_LINE_LOOP if self.close else GL_LINE_STRIP)
for p in self.v:
glVertex3f(p[0], p[1], 0) # draw each vertex
glEnd()
def set_linewidth(self, x):
self.linewidth.stroke = x
class Line(Geom):
def __init__(self, start=(0.0, 0.0), end=(0.0, 0.0)):
Geom.__init__(self)
self.start = start
self.end = end
self.linewidth = LineWidth(1)
self.add_attr(self.linewidth)
def render1(self):
glBegin(GL_LINES)
glVertex2f(*self.start)
glVertex2f(*self.end)
glEnd()
class Image(Geom):
def __init__(self, fname, width, height):
Geom.__init__(self)
self.width = width
self.height = height
img = pyglet.image.load(fname)
self.img = img
self.flip = False
def render1(self):
self.img.blit(-self.width/2, -self.height/2,
width=self.width, height=self.height)
# ================================================================
class SimpleImageViewer(object):
def __init__(self, display=None):
self.window = None
self.isopen = False
self.display = display
def imshow(self, arr):
if self.window is None:
height, width, channels = arr.shape
self.window = pyglet.window.Window(
width=width, height=height, display=self.display)
self.width = width
self.height = height
self.isopen = True
assert arr.shape == (
self.height, self.width, 3), "You passed in an image with the wrong number shape"
image = pyglet.image.ImageData(
self.width, self.height, 'RGB', arr.tobytes(), pitch=self.width * -3)
self.window.clear()
self.window.switch_to()
self.window.dispatch_events()
image.blit(0, 0)
self.window.flip()
def close(self):
if self.isopen:
self.window.close()
self.isopen = False
def __del__(self):
self.close()
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenario.py
================================================
import numpy as np
# defines scenario upon which the world is built
class BaseScenario(object):
# create elements of the world
def make_world(self):
raise NotImplementedError()
# create initial conditions of the world
def reset_world(self, world):
raise NotImplementedError()
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/__init__.py
================================================
import imp
import os.path as osp
def load(name):
pathname = osp.join(osp.dirname(__file__), name)
return imp.load_source('', pathname)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/hetero_spread.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# set any world properties first
world.dim_c = 2
world.max_steps = 25
num_agents = args.num_agents
self.n_agent_a = num_agents // 2 # 2
self.n_agent_b = num_agents // 2 # 2
num_landmarks = args.num_agents
world.collaborative = True
self.agent_size = 0.10
self.n_others = 3
self.n_group = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
agent.id = i
if i < self.n_agent_a:
agent.size = self.agent_size
agent.accel = 3.0
agent.max_speed = 1.0
else:
agent.size = self.agent_size / 2
agent.accel = 4.0
agent.max_speed = 1.3
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
world.num_steps = 0
self.end_steps = world.max_steps
# random properties for agents
for i, agent in enumerate(world.agents):
if i < self.n_agent_a:
agent.color = np.array([0.35, 0.35, 0.85])
else:
agent.color = np.array([0.35, 0.85, 0.35])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
rew = 0
collisions = 0
occupied_landmarks = 0
min_dists = 0
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
min_dists += min(dists)
rew -= min(dists)
if min(dists) < 0.1:
occupied_landmarks += 1
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
collisions += 1
return (rew, collisions, min_dists, occupied_landmarks)
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark, penalized for collisions
rew = 0
shaped_reward = False
if shaped_reward: # distance-based reward
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos))) for a in world.agents]
rew -= min(dists)
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
return rew
else:
win_agents = []
for land in world.landmarks:
for a in world.agents:
if self.is_collision(a, land):
win_agents.append(a)
break
rew += 2 * len(set(win_agents))
def bound(x):
if x > 1.0:
return min(np.exp(2 * x - 2), 10)
else:
return 0.0
bound_rew = 0.0
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
bound_rew -= bound(x)
rew += bound_rew
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
other_vel = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent:
other_vel.append([0, 0])
continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + comm +
other_vel + entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_adversary.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario # TODO
import random
class Scenario(BaseScenario):
def make_world(self, args):
world = World() # from core
# set any world properties first
world.dim_c = 2
num_agents = args.num_agents # 3
world.num_agents = num_agents
num_adversaries = 1
num_landmarks = num_agents - 1
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.silent = True
agent.adversary = True if i < num_adversaries else False
agent.size = 0.15
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.08
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
world.assign_agent_colors()
# random properties for landmarks
world.assign_landmark_colors()
# set goal landmark
goal = np.random.choice(world.landmarks)
goal.color = np.array([0.15, 0.65, 0.15])
for agent in world.agents:
agent.goal_a = goal
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
if agent.adversary:
return np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos))
else:
dists = []
for l in world.landmarks:
dists.append(np.sum(np.square(agent.state.p_pos - l.state.p_pos)))
dists.append(np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos)))
return tuple(dists)
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# Rewarded based on how close any good agent is to the goal landmark, and how far the adversary is from it
shaped_reward = True
shaped_adv_reward = True
# Calculate negative reward for adversary
adversary_agents = self.adversaries(world)
if shaped_adv_reward: # distance-based adversary reward
adv_rew = sum([np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in adversary_agents])
else: # proximity-based adversary reward (binary)
adv_rew = 0
for a in adversary_agents:
if np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) < 2 * a.goal_a.size:
adv_rew -= 5
# Calculate positive reward for agents
good_agents = self.good_agents(world)
if shaped_reward: # distance-based agent reward
pos_rew = -min(
[np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in good_agents])
else: # proximity-based agent reward (binary)
pos_rew = 0
if min([np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in good_agents]) \
< 2 * agent.goal_a.size:
pos_rew += 5
pos_rew -= min(
[np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in good_agents])
return pos_rew + adv_rew
def adversary_reward(self, agent, world):
# Rewarded based on proximity to the goal landmark
shaped_reward = True
if shaped_reward: # distance-based reward
return -np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos))
else: # proximity-based reward (binary)
adv_rew = 0
if np.sqrt(np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos))) < 2 * agent.goal_a.size:
adv_rew += 5
return adv_rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks:
entity_color.append(entity.color)
# communication of all other agents
other_pos = []
for other in world.agents:
if other is agent: continue
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not agent.adversary:
return np.concatenate([agent.goal_a.state.p_pos - agent.state.p_pos] + entity_pos + other_pos)
else:
return np.concatenate(entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_crypto.py
================================================
"""
Scenario:
1 speaker, 2 listeners (one of which is an adversary). Good agents rewarded for proximity to goal, and distance from
adversary to goal. Adversary is rewarded for its distance to the goal.
"""
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
import random
class CryptoAgent(Agent):
def __init__(self):
super(CryptoAgent, self).__init__()
self.key = None
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# set any world properties first
num_agents = args.num_agents # 3
num_adversaries = 1
num_landmarks = args.num_landmarks # 2
world.dim_c = 4
# add agents
world.agents = [CryptoAgent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.adversary = True if i < num_adversaries else False
agent.speaker = True if i == 2 else False
agent.movable = False
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for agent in world.agents:
agent.color = np.array([0.25, 0.25, 0.25])
if agent.adversary:
agent.color = np.array([0.75, 0.25, 0.25])
agent.key = None
# random properties for landmarks
color_list = [np.zeros(world.dim_c) for i in world.landmarks]
for i, color in enumerate(color_list):
color[i] += 1
for color, landmark in zip(color_list, world.landmarks):
landmark.color = color
# set goal landmark
goal = np.random.choice(world.landmarks)
world.agents[1].color = goal.color
world.agents[2].key = np.random.choice(world.landmarks).color
for agent in world.agents:
agent.goal_a = goal
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
return (agent.state.c, agent.goal_a.color)
# return all agents that are not adversaries
def good_listeners(self, world):
return [agent for agent in world.agents if not agent.adversary and not agent.speaker]
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# Agents rewarded if Bob can reconstruct message, but adversary (Eve) cannot
good_listeners = self.good_listeners(world)
adversaries = self.adversaries(world)
good_rew = 0
adv_rew = 0
for a in good_listeners:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
good_rew -= np.sum(np.square(a.state.c - agent.goal_a.color))
for a in adversaries:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
adv_l1 = np.sum(np.square(a.state.c - agent.goal_a.color))
adv_rew += adv_l1
return adv_rew + good_rew
def adversary_reward(self, agent, world):
# Adversary (Eve) is rewarded if it can reconstruct original goal
rew = 0
if not (agent.state.c == np.zeros(world.dim_c)).all():
rew -= np.sum(np.square(agent.state.c - agent.goal_a.color))
return rew
def observation(self, agent, world):
# goal color
goal_color = np.zeros(world.dim_color)
if agent.goal_a is not None:
goal_color = agent.goal_a.color
# print('goal color in obs is {}'.format(goal_color))
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent or (other.state.c is None) or not other.speaker: continue
comm.append(other.state.c)
confer = np.array([0])
if world.agents[2].key is None:
confer = np.array([1])
key = np.zeros(world.dim_c)
goal_color = np.zeros(world.dim_c)
else:
key = world.agents[2].key
prnt = False # True if train use False
# speaker
if agent.speaker:
if prnt:
print('speaker')
print(agent.state.c)
print(np.concatenate([goal_color] + [key] + [confer] + [np.random.randn(1)]))
return np.concatenate([goal_color] + [key])
# listener
if not agent.speaker and not agent.adversary:
if prnt:
print('listener')
print(agent.state.c)
print(np.concatenate([key] + comm + [confer]))
return np.concatenate([key] + comm)
if not agent.speaker and agent.adversary:
if prnt:
print('adversary')
print(agent.state.c)
print(np.concatenate(comm + [confer]))
return np.concatenate(comm)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_crypto_display.py
================================================
"""
Scenario:
1 speaker, 2 listeners (one of which is an adversary). Good agents rewarded for proximity to goal, and distance from
adversary to goal. Adversary is rewarded for its distance to the goal.
"""
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
import random
class CryptoAgent(Agent):
def __init__(self):
super(CryptoAgent, self).__init__()
self.key = None
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# set any world properties first
num_agents = args.num_agents # 3
num_adversaries = 1
num_landmarks = args.num_landmarks # 2
world.dim_c = 4
# add agents
world.agents = [CryptoAgent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.adversary = True if i < num_adversaries else False
agent.speaker = True if i == 2 else False
agent.movable = False
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
world.assign_agent_colors()
for agent in world.agents:
if agent.speaker:
agent.color = np.array([0.25, 0.75, 0.25])
agent.key = None
# random properties for landmarks
world.assign_landmark_colors()
# random properties for landmarks
channel_list = [np.zeros(world.dim_c) for i in world.landmarks]
for i, channel in enumerate(channel_list):
channel[i] += 1
for channel, landmark in zip(channel_list, world.landmarks):
landmark.channel = channel
# set goal landmark
goal = np.random.choice(world.landmarks)
world.agents[1].channel = goal.channel
world.agents[2].key = np.random.choice(world.landmarks).channel
for agent in world.agents:
agent.goal_a = goal
# set random initial states
for i, agent in enumerate(world.agents):
# agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_pos = np.array([0.0, -0.5 + 1.0 / (len(world.agents) - 1) * i])
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
if landmark is goal:
landmark.color = np.array([0.15, 0.15, 0.75])
# landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_pos = np.array([0.5, 0.5 - 0.5 / (len(world.landmarks) - 1) * i])
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
return (agent.state.c, agent.goal_a.channel)
# return all agents that are not adversaries
def good_listeners(self, world):
return [agent for agent in world.agents if not agent.adversary and not agent.speaker]
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# Agents rewarded if Bob can reconstruct message, but adversary (Eve) cannot
good_listeners = self.good_listeners(world)
adversaries = self.adversaries(world)
good_rew = 0
adv_rew = 0
for a in good_listeners:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
good_rew -= np.sum(np.square(a.state.c - agent.goal_a.channel))
for a in adversaries:
if (a.state.c == np.zeros(world.dim_c)).all():
continue
else:
adv_l1 = np.sum(np.square(a.state.c - agent.goal_a.channel))
adv_rew += adv_l1
return adv_rew + good_rew
def adversary_reward(self, agent, world):
# Adversary (Eve) is rewarded if it can reconstruct original goal
rew = 0
if not (agent.state.c == np.zeros(world.dim_c)).all():
rew -= np.sum(np.square(agent.state.c - agent.goal_a.channel))
return rew
def observation(self, agent, world):
# goal channel
goal_channel = np.zeros(world.dim_color)
if agent.goal_a is not None:
goal_channel = agent.goal_a.channel
print('goal channel in obs is {}'.format(goal_channel))
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent or (other.state.c is None) or not other.speaker: continue
comm.append(other.state.c)
confer = np.array([0])
if world.agents[2].key is None:
confer = np.array([1])
key = np.zeros(world.dim_c)
goal_channel = np.zeros(world.dim_c)
else:
key = world.agents[2].key
prnt = True # if train use False
# speaker
if agent.speaker:
if prnt:
print('speaker')
print(agent.state.c)
# print(np.concatenate([goal_channel] + [key] + [confer] + [np.random.randn(1)]))
return np.concatenate([goal_channel] + [key])
# listener
if not agent.speaker and not agent.adversary:
if prnt:
print('listener')
print(agent.state.c)
# print(np.concatenate([key] + comm + [confer]))
return np.concatenate([key] + comm)
if not agent.speaker and agent.adversary:
if prnt:
print('adversary')
print(agent.state.c)
# print(np.concatenate(comm + [confer]))
return np.concatenate(comm)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_push.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
import random
#
# # the non-ensemble version of
#
#
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# set any world properties first
world.dim_c = 2
num_agents = args.num_agents # 2
num_adversaries = 1
num_landmarks = args.num_landmarks # 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
if i < num_adversaries:
agent.adversary = True
else:
agent.adversary = False
# agent.u_noise = 1e-1
# agent.c_noise = 1e-1
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.1, 0.1, 0.1])
landmark.color[i + 1] += 0.8
landmark.index = i
# set goal landmark
goal = np.random.choice(world.landmarks)
for i, agent in enumerate(world.agents):
agent.goal_a = goal
agent.color = np.array([0.25, 0.25, 0.25])
if agent.adversary:
agent.color = np.array([0.75, 0.25, 0.25])
else:
j = goal.index
agent.color[j + 1] += 0.5
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = 0.8 * np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
return self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
def agent_reward(self, agent, world):
# the distance to the goal
return -np.sqrt(np.sum(np.square(agent.state.p_pos - agent.goal_a.state.p_pos)))
def adversary_reward(self, agent, world):
# keep the nearest good agents away from the goal
agent_dist = [np.sqrt(np.sum(np.square(a.state.p_pos - a.goal_a.state.p_pos))) for a in world.agents if
not a.adversary]
pos_rew = min(agent_dist)
# nearest_agent = world.good_agents[np.argmin(agent_dist)]
# neg_rew = np.sqrt(np.sum(np.square(nearest_agent.state.p_pos - agent.state.p_pos)))
neg_rew = np.sqrt(np.sum(np.square(agent.goal_a.state.p_pos - agent.state.p_pos)))
# neg_rew = sum([np.sqrt(np.sum(np.square(a.state.p_pos - agent.state.p_pos))) for a in world.good_agents])
return pos_rew - neg_rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not agent.adversary:
return np.concatenate([agent.state.p_vel] + [agent.goal_a.state.p_pos - agent.state.p_pos] + [
agent.color] + entity_pos + entity_color + other_pos)
else:
# other_pos = list(reversed(other_pos)) if random.uniform(0,1) > 0.5 else other_pos # randomize position of other agents in adversary network
return np.concatenate([agent.state.p_vel] + entity_pos + other_pos)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_reference.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# set any world properties first
# world.world_length = args.episode_length
world.dim_c = 10
world.collaborative = True # whether agents share rewards
# add agents
world.num_agents = args.num_agents # 2
assert world.num_agents == 2, (
"only 2 agents is supported, check the config.py.")
world.agents = [Agent() for i in range(world.num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
# agent.u_noise = 1e-1
# agent.c_noise = 1e-1
# add landmarks
world.num_landmarks = args.num_landmarks # 3
world.landmarks = [Landmark() for i in range(world.num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# assign goals to agents
for agent in world.agents:
agent.goal_a = None
agent.goal_b = None
# want other agent to go to the goal landmark
world.agents[0].goal_a = world.agents[1]
world.agents[0].goal_b = np.random.choice(world.landmarks)
world.agents[1].goal_a = world.agents[0]
world.agents[1].goal_b = np.random.choice(world.landmarks)
# random properties for agents
world.assign_agent_colors()
# random properties for landmarks
world.landmarks[0].color = np.array([0.75, 0.25, 0.25])
world.landmarks[1].color = np.array([0.25, 0.75, 0.25])
world.landmarks[2].color = np.array([0.25, 0.25, 0.75])
# special colors for goals
world.agents[0].goal_a.color = world.agents[0].goal_b.color
world.agents[1].goal_a.color = world.agents[1].goal_b.color
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = 0.8 * np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def reward(self, agent, world):
if agent.goal_a is None or agent.goal_b is None:
return 0.0
dist2 = np.sum(
np.square(agent.goal_a.state.p_pos - agent.goal_b.state.p_pos))
return -dist2 # np.exp(-dist2)
def observation(self, agent, world):
# goal positions
# goal_pos = [np.zeros(world.dim_p), np.zeros(world.dim_p)]
# if agent.goal_a is not None:
# goal_pos[0] = agent.goal_a.state.p_pos - agent.state.p_pos
# if agent.goal_b is not None:
# goal_pos[1] = agent.goal_b.state.p_pos - agent.state.p_pos
# goal color
goal_color = [np.zeros(world.dim_color), np.zeros(world.dim_color)]
# if agent.goal_a is not None:
# goal_color[0] = agent.goal_a.color
if agent.goal_b is not None:
goal_color[1] = agent.goal_b.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent:
continue
comm.append(other.state.c)
return np.concatenate([agent.state.p_vel] + entity_pos + [goal_color[1]] + comm)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_speaker_listener.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
world.world_length = args.episode_length
# set any world properties first
world.dim_c = 3
world.num_landmarks = args.num_landmarks # 3
world.collaborative = True
# add agents
world.num_agents = args.num_agents # 2
assert world.num_agents == 2, (
"only 2 agents is supported, check the config.py.")
world.agents = [Agent() for i in range(world.num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = False
agent.size = 0.075
# speaker
world.agents[0].movable = False
# listener
world.agents[1].silent = True
# add landmarks
world.landmarks = [Landmark() for i in range(world.num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.04
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# assign goals to agents
for agent in world.agents:
agent.goal_a = None
agent.goal_b = None
# want listener to go to the goal landmark
world.agents[0].goal_a = world.agents[1]
world.agents[0].goal_b = np.random.choice(world.landmarks)
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.25, 0.25, 0.25])
# random properties for landmarks
world.landmarks[0].color = np.array([0.65, 0.15, 0.15])
world.landmarks[1].color = np.array([0.15, 0.65, 0.15])
world.landmarks[2].color = np.array([0.15, 0.15, 0.65])
# special colors for goals
world.agents[0].goal_a.color = world.agents[0].goal_b.color + \
np.array([0.45, 0.45, 0.45])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
return reward(agent, reward)
def reward(self, agent, world):
# squared distance from listener to landmark
a = world.agents[0]
dist2 = np.sum(np.square(a.goal_a.state.p_pos - a.goal_b.state.p_pos))
return -dist2
def observation(self, agent, world):
# goal color
goal_color = np.zeros(world.dim_color)
if agent.goal_b is not None:
goal_color = agent.goal_b.color
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
for other in world.agents:
if other is agent or (other.state.c is None):
continue
comm.append(other.state.c)
# speaker
if not agent.movable:
return np.concatenate([goal_color])
# listener
if agent.silent:
return np.concatenate([agent.state.p_vel] + entity_pos + comm)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_spread.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# world.world_length = args.episode_length
# set any world properties first
world.dim_c = 2
world.num_agents = args.num_agents
world.num_landmarks = args.num_landmarks # 3
world.collaborative = True
# add agents
world.agents = [Agent() for i in range(world.num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
agent.size = 0.15
# add landmarks
world.landmarks = [Landmark() for i in range(world.num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = False
landmark.movable = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
world.assign_agent_colors()
world.assign_landmark_colors()
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = 0.8 * np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
rew = 0
collisions = 0
occupied_landmarks = 0
min_dists = 0
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos)))
for a in world.agents]
min_dists += min(dists)
rew -= min(dists)
if min(dists) < 0.1:
occupied_landmarks += 1
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
collisions += 1
return (rew, collisions, min_dists, occupied_landmarks)
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark, penalized for collisions
rew = 0
for l in world.landmarks:
dists = [np.sqrt(np.sum(np.square(a.state.p_pos - l.state.p_pos)))
for a in world.agents]
rew -= min(dists)
if agent.collide:
for a in world.agents:
if self.is_collision(a, agent):
rew -= 1
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# entity colors
entity_color = []
for entity in world.landmarks: # world.entities:
entity_color.append(entity.color)
# communication of all other agents
comm = []
other_pos = []
for other in world.agents:
if other is agent:
continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + comm)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_tag.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# set any world properties first
world.dim_c = 2
num_good_agents = args.num_good_agents # 1
num_adversaries = args.num_adversaries # 3
num_agents = num_adversaries + num_good_agents
num_landmarks = args.num_landmarks # 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.silent = True
agent.adversary = True if i < num_adversaries else False
agent.size = 0.075 if agent.adversary else 0.05
agent.accel = 3.0 if agent.adversary else 4.0
# agent.accel = 20.0 if agent.adversary else 25.0
agent.max_speed = 1.0 if agent.adversary else 1.3
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = True
landmark.movable = False
landmark.size = 0.2
landmark.boundary = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
world.assign_agent_colors()
# random properties for landmarks
world.assign_landmark_colors()
# random properties for landmarks
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
if not landmark.boundary:
landmark.state.p_pos = 0.8 * np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
if agent.adversary:
collisions = 0
for a in self.good_agents(world):
if self.is_collision(a, agent):
collisions += 1
return collisions
else:
return 0
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
main_reward = self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
return main_reward
def agent_reward(self, agent, world):
# Agents are negatively rewarded if caught by adversaries
rew = 0
shape = False # different from openai
adversaries = self.adversaries(world)
if shape: # reward can optionally be shaped (increased reward for increased distance from adversary)
for adv in adversaries:
rew += 0.1 * np.sqrt(np.sum(np.square(agent.state.p_pos - adv.state.p_pos)))
if agent.collide:
for a in adversaries:
if self.is_collision(a, agent):
rew -= 10
# agents are penalized for exiting the screen, so that they can be caught by the adversaries
def bound(x):
if x < 0.9:
return 0
if x < 1.0:
return (x - 0.9) * 10
return min(np.exp(2 * x - 2), 10)
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
rew -= bound(x)
return rew
def adversary_reward(self, agent, world):
# Adversaries are rewarded for collisions with agents
rew = 0
shape = False # different from openai
agents = self.good_agents(world)
adversaries = self.adversaries(world)
if shape: # reward can optionally be shaped (decreased reward for increased distance from agents)
for adv in adversaries:
rew -= 0.1 * min([np.sqrt(np.sum(np.square(a.state.p_pos - adv.state.p_pos))) for a in agents])
if agent.collide:
for ag in agents:
for adv in adversaries:
if self.is_collision(ag, adv):
rew += 10
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel)
================================================
FILE: examples/Social_Cognition/ToCM/mpe/scenarios/simple_world_comm.py
================================================
import numpy as np
from mpe.core import World, Agent, Landmark
from mpe.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self, args):
world = World()
# set any world properties first
world.dim_c = 4
# world.damping = 1
num_good_agents = args.num_good_agents # 2
num_adversaries = args.num_adversaries # 4
num_agents = num_adversaries + num_good_agents
num_landmarks = args.num_landmarks # 1
num_food = 2
num_forests = 2
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True
agent.leader = True if i == 0 else False
agent.silent = True if i > 0 else False
agent.adversary = True if i < num_adversaries else False
agent.size = 0.075 if agent.adversary else 0.045
agent.accel = 3.0 if agent.adversary else 4.0
# agent.accel = 20.0 if agent.adversary else 25.0
agent.max_speed = 1.0 if agent.adversary else 1.3
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = True
landmark.movable = False
landmark.size = 0.2
landmark.boundary = False
world.food = [Landmark() for i in range(num_food)]
for i, landmark in enumerate(world.food):
landmark.name = 'food %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.03
landmark.boundary = False
world.forests = [Landmark() for i in range(num_forests)]
for i, landmark in enumerate(world.forests):
landmark.name = 'forest %d' % i
landmark.collide = False
landmark.movable = False
landmark.size = 0.3
landmark.boundary = False
world.landmarks += world.food
world.landmarks += world.forests
# world.landmarks += self.set_boundaries(world) # world boundaries now penalized with negative reward
# make initial conditions
self.reset_world(world)
return world
def set_boundaries(self, world):
boundary_list = []
landmark_size = 1
edge = 1 + landmark_size
num_landmarks = int(edge * 2 / landmark_size)
for x_pos in [-edge, edge]:
for i in range(num_landmarks):
l = Landmark()
l.state.p_pos = np.array([x_pos, -1 + i * landmark_size])
boundary_list.append(l)
for y_pos in [-edge, edge]:
for i in range(num_landmarks):
l = Landmark()
l.state.p_pos = np.array([-1 + i * landmark_size, y_pos])
boundary_list.append(l)
for i, l in enumerate(boundary_list):
l.name = 'boundary %d' % i
l.collide == True
l.movable = False
l.boundary = True
l.color = np.array([0.75, 0.75, 0.75])
l.size = landmark_size
l.state.p_vel = np.zeros(world.dim_p)
return boundary_list
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.45, 0.95, 0.45]) if not agent.adversary else np.array([0.95, 0.45, 0.45])
agent.color -= np.array([0.3, 0.3, 0.3]) if agent.leader else np.array([0, 0, 0])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
for i, landmark in enumerate(world.food):
landmark.color = np.array([0.15, 0.15, 0.65])
for i, landmark in enumerate(world.forests):
landmark.color = np.array([0.6, 0.9, 0.6])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p)
agent.state.p_vel = np.zeros(world.dim_p)
agent.state.c = np.zeros(world.dim_c)
for i, landmark in enumerate(world.landmarks):
landmark.state.p_pos = 0.8 * np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
for i, landmark in enumerate(world.food):
landmark.state.p_pos = 0.8 * np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
for i, landmark in enumerate(world.forests):
landmark.state.p_pos = 0.8 * np.random.uniform(-1, +1, world.dim_p)
landmark.state.p_vel = np.zeros(world.dim_p)
def benchmark_data(self, agent, world):
if agent.adversary:
collisions = 0
for a in self.good_agents(world):
if self.is_collision(a, agent):
collisions += 1
return collisions
else:
return 0
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
# boundary_reward = -10 if self.outside_boundary(agent) else 0
main_reward = self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
return main_reward
def outside_boundary(self, agent):
if agent.state.p_pos[0] > 1 or agent.state.p_pos[0] < -1 or agent.state.p_pos[1] > 1 or agent.state.p_pos[
1] < -1:
return True
else:
return False
def agent_reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
rew = 0
shape = False
adversaries = self.adversaries(world)
if shape:
for adv in adversaries:
rew += 0.1 * np.sqrt(np.sum(np.square(agent.state.p_pos - adv.state.p_pos)))
if agent.collide:
for a in adversaries:
if self.is_collision(a, agent):
rew -= 5
def bound(x):
if x < 0.9:
return 0
if x < 1.0:
return (x - 0.9) * 10
return min(np.exp(2 * x - 2), 10) # 1 + (x - 1) * (x - 1)
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
rew -= 2 * bound(x)
for food in world.food:
if self.is_collision(agent, food):
rew += 2
rew += 0.05 * min([np.sqrt(np.sum(np.square(food.state.p_pos - agent.state.p_pos))) for food in world.food])
return rew
def adversary_reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
rew = 0
shape = True
agents = self.good_agents(world)
adversaries = self.adversaries(world)
if shape:
rew -= 0.1 * min([np.sqrt(np.sum(np.square(a.state.p_pos - agent.state.p_pos))) for a in agents])
# for adv in adversaries:
# rew -= 0.1 * min([np.sqrt(np.sum(np.square(a.state.p_pos - adv.state.p_pos))) for a in agents])
if agent.collide:
for ag in agents:
for adv in adversaries:
if self.is_collision(ag, adv):
rew += 5
return rew
def observation2(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks: # world.entities:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
food_pos = []
for entity in world.food: # world.entities:
if not entity.boundary:
food_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel)
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
in_forest = [np.array([-1]), np.array([-1])]
inf1 = False
inf2 = False
if self.is_collision(agent, world.forests[0]):
in_forest[0] = np.array([1])
inf1 = True
if self.is_collision(agent, world.forests[1]):
in_forest[1] = np.array([1])
inf2 = True
food_pos = []
for entity in world.food:
if not entity.boundary:
food_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
oth_f1 = self.is_collision(other, world.forests[0])
oth_f2 = self.is_collision(other, world.forests[1])
if (inf1 and oth_f1) or (inf2 and oth_f2) or (
not inf1 and not oth_f1 and not inf2 and not oth_f2) or agent.leader: # without forest vis
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
else:
other_pos.append([0, 0])
if not other.adversary:
other_vel.append([0, 0])
# to tell the pred when the prey are in the forest
prey_forest = []
ga = self.good_agents(world)
for a in ga:
if any([self.is_collision(a, f) for f in world.forests]):
prey_forest.append(np.array([1]))
else:
prey_forest.append(np.array([-1]))
# to tell leader when pred are in forest
prey_forest_lead = []
for f in world.forests:
if any([self.is_collision(a, f) for a in ga]):
prey_forest_lead.append(np.array([1]))
else:
prey_forest_lead.append(np.array([-1]))
comm = [world.agents[0].state.c]
if agent.adversary and not agent.leader:
return np.concatenate(
[agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel + in_forest + comm)
if agent.leader:
return np.concatenate(
[agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel + in_forest + comm)
else:
return np.concatenate(
[agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + in_forest + other_vel)
================================================
FILE: examples/Social_Cognition/ToCM/networks/ToCM/action.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
import sys
import os
# if '/home/zhaofeifei/.local/lib/python3.8/site-packages' in sys.path:
# sys.path.remove('/home/zhaofeifei/.local/lib/python3.8/site-packages')
# sys.path.append('/home/zhaofeifei/mambaSNN_Mpe/networks/ToCM/')
# sys.path.append("/home/zhaofeifei/mambaSNN_Mpe/")
from torch.distributions import OneHotCategorical
from networks.transformer.layers import AttentionEncoder, AttentionActorEncoder
from networks.ToCM.utils import build_model_snn, build_model
from braincog.base.node.node import LIFNode, BaseNode, PLIFNode, DoubleSidePLIFNode
from braincog.base.strategy.surrogate import AtanGrad
class BCNoSpikingLIFNode(LIFNode):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self, dv: torch.Tensor):
# print("dv: ", dv)
# print("dv.shape: ", dv.shape)
self.integral(dv)
return self.mem
#SNN
# class Actor(nn.Module):
# def __init__(self, in_dim, out_dim, hidden_size, layers, node='LIFNode', time_window=8,
# norm_in=True, output_style='voltage'): # 1.激活函数需要改成node # voltage
# super().__init__()
# # 1.加入SNN的脉冲参数
# self._threshold = 0.5
# self.v_reset = 0.0
# self.tau = 0.5
# self._time_window = time_window
# # 2.设置输出格式
# self.output_style = output_style
# # 3.ffn是否归一化
# self.norm = norm_in
# self.activation = node
# self.feedforward_model = build_model_snn(in_dim, out_dim, layers, hidden_size, # kkkk TODO!!!
# th=self._threshold, re=self.v_reset, tau=self.tau,
# activation=self.activation, normalize=lambda x: x) # TODO
# if self.output_style == 'ann':
# self.out_node = lambda x: x
# elif self.output_style == 'voltage':
# self.out_node = BCNoSpikingLIFNode(tau=1.0)
#
# def forward(self, state_features):
# # 5.加入脉冲仿真步长
# # print("state.shape", state_features.shape)
# self.reset() # why
# for t in range(self._time_window):
# x = self.feedforward_model(state_features)
# x = self.out_node(x)
# # print("x", x.shape)
# action_dist = OneHotCategorical(logits=x)
# action = action_dist.sample() # 长度为x,一行默认 tensor([0., 1., 0., 0.])
# return action, x
#
# # 调用modules里面node的n_reset
# def reset(self):
# for mod in self.modules():
# if hasattr(mod, 'n_reset'):
# mod.n_reset()
#ANN
class Actor(nn.Module):
def __init__(self, in_dim, out_dim, hidden_size, layers, activation=nn.ReLU):
super().__init__()
self.feedforward_model = build_model(in_dim, out_dim, layers, hidden_size, activation)
def forward(self, state_features):
x = self.feedforward_model(state_features)
action_dist = OneHotCategorical(logits=x)
action = action_dist.sample()
return action, x
class AttentionActor(nn.Module):
def __init__(self, in_dim, out_dim, hidden_size, layers, node='LIFNode', time_window=16,
norm_in=True, output_style='voltage'): # 2.激活层
super().__init__()
# 1.加入SNN的脉冲参数
self._threshold = 0.5
self.v_reset = 0.0
self._time_window = time_window
# 2.设置输出格式
self.output_style = output_style
# 3.ffn是否归一化
self.norm = norm_in
# 4.改变linear层的激活函数为LIFNode
self.activation = node
# hint: hidden_size = 其他网络的in_dim
self.feedforward_model = build_model_snn(hidden_size, out_dim, 2, hidden_size,
th=self._threshold, re=self.v_reset,
activation=self.activation, normalize=lambda x: x) # TODO
# build_model_snn(in_dim, out_dim, layers, hidden, activation, normalize=lambda x: x)
self._attention_stack = AttentionActorEncoder(1, hidden_size, hidden_size)
# no pos_embedding
# self._attention_stack = nn.TransformerEncoder(nn.TransformerEncoderLayer(d_model=in_dim, nhead=1,
# dim_feedforward=hidden_size,
# dropout=.0), num_layers=1) # TODO
# n_layers, in_dim, hidden
# 使用transformer的编码器,加入位置编码,加入隐藏单元d_hid,返回一个序列,其中第0维度应该是观测变量?
self.embed = nn.Linear(in_dim, hidden_size)
self.node1 = LIFNode(threshold=self._threshold, v_reset=self.v_reset)
self.node2 = LIFNode(threshold=self._threshold, v_reset=self.v_reset)
# 5. 定义一个处理linear层的node
if self.activation == 'LIFNode':
if self.output_style == 'voltage':
self.out_node = BCNoSpikingLIFNode(tau=2.0)
def forward(self, state_features): # 状态值tensor
# print("state_feat:", state_features[0])
# attn_embeds = self._attention_stack(state_features)
# n_agents = state_features.shape[-2] # 推测state的维度为[batch_size(m,n), n_agents, in_dim]
# batch_size = state_features.shape[:-2] # 除去最后2维度的维度
qs = []
self.reset() # why
# print("attn_embeds", attn_embeds[0])
# print("state.shape", state_features.shape)
attn_embeds = self.embed(state_features) # Linear
for t in range(self._time_window):
embeds = self.node1(attn_embeds) # Node
# attn_embeds = embeds.view(-1, n_agents, embeds.shape[-1])
# embeds = self.node2(self._attention_stack(embeds).view(*batch_size, n_agents, embeds.shape[-1]))
x = self.feedforward_model(embeds)
x = self.out_node(x)
qs.append(x)
p = torch.zeros(qs[0].shape)
if self.output_style == "sum":
p = sum(qs) / self._time_window
elif self.output_style == "voltage":
p = qs[-1] # TODO
# p = F.softmax(p)
# print("pi:", p[0])
action_dist = OneHotCategorical(logits=p) # 编码器,长度为p
action = action_dist.sample()
# print("actions", action[0])
# 对输出进行采样
return action, p # 返回一个行动序列action为每个位置符合p = x[i]的0,1序列
# 调用modules里面node的n_reset
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
# aa = AttentionActor(16, 8, 64, 3) # in_dim, out_dim, hidden_size, layers,
# state_feature = torch.randn([8, 8, 2, 16]) # 输入变量维度
# out, x = aa(state_feature)
# print(aa)
# print(out)
# print(out.shape)
================================================
FILE: examples/Social_Cognition/ToCM/networks/ToCM/critic.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
import sys
sys.path.append('/home/zhaofeifei/mambaSNN/networks/ToCM/')
from networks.ToCM.utils import build_model_snn, build_model
from networks.transformer.layers import AttentionEncoder
from braincog.base.node.node import LIFNode
from braincog.base.strategy.surrogate import AtanGrad
decay = 0.3
thresh = 0.3
lens = 0.25
# print("File Critic Here")
# 0.定义一个返回膜电势的 LIFNode
class BCNoSpikingLIFNode(LIFNode):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self, dv: torch.Tensor):
# print("dv: ", dv)
# print("dv.shape: ", dv.shape)
self.integral(dv)
return self.mem
act_fun = AtanGrad(alpha=2., requires_grad=False)
def mem_update(fc, x, mem, spike):
mem = mem * decay * (1 - spike) + fc(x)
# spike = act_fun(mem)
spike = act_fun(x=mem-1)
return mem, spike
class Critic(nn.Module):
def __init__(self, in_dim, hidden_size, layers=2, node='LIFNode', time_window=16,
norm_in=True, output_style='voltage'):
# hint是critic没有输出维度,action的输出维度是action的数量
super().__init__()
# 1.加入SNN的脉冲参数
self._threshold = 0.5
self.v_reset = 0.0
self._time_window = time_window
# 2.设置输出格式
self.output_style = output_style
# 3.ffn是否归一化
self.norm = norm_in
# if self.norm:
# self.in_norm = nn.BatchNorm1d(in_dim)
# self.in_norm.weight.data.fill_(1)
# self.in_norm.bias.data.zero_()
# else:
# self.in_norm = lambda x: x
self.in_norm = lambda x: x
# 4.改变linear层的激活函数为LIFNode
self.activation = node
self.hidden_size = hidden_size
self.layers = layers
self.feedforward_model = build_model_snn(in_dim, 1, layers, hidden_size,
th=self._threshold, re=self.v_reset,
activation=self.activation, normalize=lambda x: x)
# 这里feedforward的输出维度为1,其余一样 in_dim, out_dim, layers, hidden
# 5. 定义输出神经元node
if self.output_style == "sum":
self.out_node = lambda x: x
elif self.output_style == "voltage":
self.out_node = BCNoSpikingLIFNode(tau=2.0)
def forward(self, state_features, actions):
# 6.加入脉冲步长模拟
qs = []
self.reset() # why
# 7.加入第一次输入的归一化,对最前面的输入进行norm
state_features = self.in_norm(state_features)
for t in range(self._time_window):
x = self.feedforward_model(state_features)
# 8.linear层之后还得有个node接住。否则如果对于ann来说,linear之后的浮点数就能作为最后的分值了,对于snn不行
x = self.out_node(x)
qs.append(x)
if self.output_style == 'sum':
value = sum(qs) / self._time_window
return value
elif self.output_style == 'voltage':
value = qs[-1]
return value
# 调用modules里面node的n_reset
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
#SNN
# class MADDPGCritic(nn.Module):
# def __init__(self, in_dim, hidden_size, node='nn.Tanh', time_window=1, # time_window=16,
# norm_in=True, output_style='ann'): # in_dim 1280 hidden_size 256
# super().__init__()
#
# # 1.加入SNN的脉冲参数
# self._threshold = 0.5
# self.v_reset = 0.0
# self._time_window = time_window
# # 2.设置输出格式
# self.output_style = output_style
# # 3. ffn是否归一化
# self.norm = norm_in
#
# # TODO no normalize
# self.in_norm = lambda x: x
# # 4.改变linear层的激活函数为LIFNode
# self.activation = node # TODO!!!!!!!!!!!
#
# self.feedforward_model = build_model_snn(hidden_size, 1, 1, hidden_size,
# th=self._threshold, re=self.v_reset,
# activation=self.activation, normalize=lambda x: x)
# # in_dim, out_dim, layers, hidden
# # (in_dim = hidden)->hidden->hidden......-> (out_dim = 1)
#
# self._attention_stack = AttentionEncoder(1, hidden_size, hidden_size)
# self.embed = nn.Linear(in_dim, hidden_size) # 1280 256
# self.prior = build_model_snn(in_dim, 1, 3, hidden_size, # 1280 256
# th=self._threshold, re=self._threshold,
# activation=self.activation, normalize=lambda x: x)
# # also in_dim, out_dim, layers, hidden
# # (in_dim = hidden)->hidden->hidden......-> (out_dim = 1)
# # 可能是个决策函数,决策优先选择哪个action
#
# # 5. 定义输出神经元node
# if self.output_style == "sum":
# self.out_node = lambda x: x
# elif self.output_style == "voltage":
# self.out_node = BCNoSpikingLIFNode(tau=2.0)
# elif self.output_style == 'ann':
# self.out_node = lambda x: x
#
# def forward(self, state_features, actions):
# self.reset() # reset函数得看看怎么加
# n_agents = state_features.shape[-2]
# batch_size = state_features.shape[:-2]
# # 6.加入第一次输入的归一化
# state_features = self.in_norm(state_features)
# # 7.暂时不把编码加入模拟时长
# embeds = F.relu(self.embed(state_features))
# embeds = embeds.view(-1, n_agents, embeds.shape[-1])
# attn_embeds = F.relu(self._attention_stack(embeds).view(*batch_size, n_agents, embeds.shape[-1]))
#
# # 7.设置脉冲发放时长模拟,只在ffn层
# qs = []
# for t in range(self._time_window):
# x = self.feedforward_model(attn_embeds)
# x = self.out_node(x)
# qs.append(x)
#
# value = qs[-1] # after 16 mem
# # x = self.feedforward_model(attn_embeds)
# # value = self.out_node(x) # only mem once
# return value
#
# # 调用modules里面node的n_reset
# def reset(self):
# for mod in self.modules():
# if hasattr(mod, 'n_reset'):
# mod.n_reset()
#ANN
class MADDPGCritic(nn.Module):
def __init__(self, in_dim, hidden_size, layers=2, activation=nn.ELU):
super().__init__()
self.hidden_size = hidden_size
self.layers = layers
self.activation = activation
self.feedforward_model = build_model(in_dim, 1, layers, hidden_size, activation)
def forward(self, state_features, actions):
return self.feedforward_model(state_features)
# critic_net = Critic(in_dim=2, hidden_size=32, layers=2, node='LIFNode', time_window=16, norm_in=True,
# output_style='voltage')
# print(critic_net)
# maddpg_critic_net = MADDPGCritic(in_dim=2, hidden_size=32, node='LIFNode', time_window=16, norm_in=True,
# output_style='voltage')
# print(maddpg_critic_net)
================================================
FILE: examples/Social_Cognition/ToCM/networks/ToCM/dense.py
================================================
import torch
import torch.distributions as td
import torch.nn as nn
from networks.ToCM.utils import build_model_snn
class DenseModel(nn.Module):
def __init__(self, in_dim, out_dim, layers, hidden, activation="nn.ELU"): # TODO activation=nn.ELU
super().__init__()
self.model = build_model_snn(in_dim, out_dim, layers, hidden, activation=activation) # no use activation
def forward(self, features):
return self.model(features)
class DenseBinaryModel(DenseModel):
def __init__(self, in_dim, out_dim, layers, hidden, activation="nn.ELU"): # 1280 7 2 256
super().__init__(in_dim, out_dim, layers, hidden, activation=activation)
def forward(self, features):
# for name, p in self.model.named_parameters():
# print("name", name)
# print("p", p.shape)
# if features.shape[1] != 40:
# print("features.shape[0] / 40: ", features.shape[0] / 40)
# features = torch.as_tensor(torch.split(features, int(features.shape[0] / 40), dim=0))
# print("Dense features: ", features.shape)
dist_inputs = self.model(features) # features.shape 48 40 2 1280
# print("dist_inputs:", dist_inputs.shape)
return td.independent.Independent(td.Bernoulli(logits=dist_inputs), 1)
================================================
FILE: examples/Social_Cognition/ToCM/networks/ToCM/rnns.py
================================================
import torch
import torch.nn as nn
from torch.distributions import OneHotCategorical
from configs.ToCM.ToCMAgentConfig import RSSMState
from networks.transformer.layers import AttentionEncoder
def stack_states(rssm_states: list, dim):
return reduce_states(rssm_states, dim, torch.stack)
def cat_states(rssm_states: list, dim):
return reduce_states(rssm_states, dim, torch.cat)
def reduce_states(rssm_states: list, dim, func):
return RSSMState(*[func([getattr(state, key) for state in rssm_states], dim=dim)
for key in rssm_states[0].__dict__.keys()])
class DiscreteLatentDist(nn.Module):
def __init__(self, in_dim, n_categoricals, n_classes, hidden_size):
super().__init__()
self.n_categoricals = n_categoricals
self.n_classes = n_classes
self.dists = nn.Sequential(nn.Linear(in_dim, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, n_classes * n_categoricals))
def forward(self, x):
logits = self.dists(x).view(x.shape[:-1] + (self.n_categoricals, self.n_classes))
class_dist = OneHotCategorical(logits=logits)
one_hot = class_dist.sample()
latents = one_hot + class_dist.probs - class_dist.probs.detach()
return logits.view(x.shape[:-1] + (-1,)), latents.view(x.shape[:-1] + (-1,))
class RSSMTransition(nn.Module):
def __init__(self, config, hidden_size=200, activation=nn.ReLU):
super().__init__()
self._stoch_size = config.STOCHASTIC
self._deter_size = config.DETERMINISTIC
self._hidden_size = hidden_size
self._activation = activation
self._cell = nn.GRU(hidden_size, self._deter_size)
self._attention_stack = AttentionEncoder(3, hidden_size, hidden_size, dropout=0.1)
self._rnn_input_model = self._build_rnn_input_model(config.ACTION_SIZE + self._stoch_size)
self._stochastic_prior_model = DiscreteLatentDist(self._deter_size, config.N_CATEGORICALS, config.N_CLASSES,
self._hidden_size)
def _build_rnn_input_model(self, in_dim):
rnn_input_model = [nn.Linear(in_dim, self._hidden_size)]
rnn_input_model += [self._activation()]
return nn.Sequential(*rnn_input_model)
def forward(self, prev_actions, prev_states, mask=None):
batch_size = prev_actions.shape[0]
n_agents = prev_actions.shape[1]
stoch_input = self._rnn_input_model(torch.cat([prev_actions, prev_states.stoch], dim=-1))
attn = self._attention_stack(stoch_input, mask=mask)
deter_state = self._cell(attn.reshape(1, batch_size * n_agents, -1),
prev_states.deter.reshape(1, batch_size * n_agents, -1))[0].reshape(batch_size, n_agents, -1)
logits, stoch_state = self._stochastic_prior_model(deter_state)
return RSSMState(logits=logits, stoch=stoch_state, deter=deter_state)
class RSSMRepresentation(nn.Module):
def __init__(self, config, transition_model: RSSMTransition):
super().__init__()
self._transition_model = transition_model
self._stoch_size = config.STOCHASTIC
self._deter_size = config.DETERMINISTIC
self._stochastic_posterior_model = DiscreteLatentDist(self._deter_size + config.EMBED, config.N_CATEGORICALS,
config.N_CLASSES, config.HIDDEN)
def initial_state(self, batch_size, n_agents, **kwargs):
return RSSMState(stoch=torch.zeros(batch_size, n_agents, self._stoch_size, **kwargs),
logits=torch.zeros(batch_size, n_agents, self._stoch_size, **kwargs),
deter=torch.zeros(batch_size, n_agents, self._deter_size, **kwargs))
def forward(self, obs_embed, prev_actions, prev_states, mask=None):
"""
:param obs_embed: size(batch, n_agents, obs_size)
:param prev_actions: size(batch, n_agents, action_size)
:param prev_states: size(batch, n_agents, state_size)
:return: RSSMState, global_state: size(batch, 1, global_state_size)
"""
prior_states = self._transition_model(prev_actions, prev_states, mask)
x = torch.cat([prior_states.deter, obs_embed], dim=-1)
logits, stoch_state = self._stochastic_posterior_model(x)
posterior_states = RSSMState(logits=logits, stoch=stoch_state, deter=prior_states.deter)
return prior_states, posterior_states
def rollout_representation(representation_model, steps, obs_embed, action, prev_states, done):
"""
Roll out the model with actions and observations from data.
:param steps: number of steps to roll out
:param obs_embed: size(time_steps, batch_size, n_agents, embedding_size)
:param action: size(time_steps, batch_size, n_agents, action_size)
:param prev_states: RSSM state, size(batch_size, n_agents, state_size)
:return: prior, posterior states. size(time_steps, batch_size, n_agents, state_size)
"""
priors = []
posteriors = []
for t in range(steps):
prior_states, posterior_states = representation_model(obs_embed[t], action[t], prev_states)
prev_states = posterior_states.map(lambda x: x * (1.0 - done[t]))
priors.append(prior_states)
posteriors.append(posterior_states)
prior = stack_states(priors, dim=0)
post = stack_states(posteriors, dim=0)
return prior.map(lambda x: x[:-1]), post.map(lambda x: x[:-1]), post.deter[1:]
def rollout_policy(transition_model, av_action, steps, policy, prev_state, prev_action, config): # av_action.shape=[49 40 2 7] policy=actor
"""
Roll out the model with a policy function.
:param steps: number of steps to roll out
:param policy: RSSMState -> action
:param prev_state: RSSM state, size(batch_size, state_size)
:return: next states size(time_steps, batch_size, state_size),
actions size(time_steps, batch_size, action_size)
"""
state = prev_state
action = prev_action[:-1].reshape((prev_action.shape[0] - 1) * prev_action.shape[1], prev_action.shape[2], -1) # TODO
next_states = []
actions = []
av_actions = []
policies = []
obs_preds = []
for t in range(steps):
feat = state.get_features().detach()
obs_pred, _ = transition_model.observation_decoder(feat) # TODO
next_state = transition_model.transition(action, state) # TODO
next_feat = next_state.get_features().detach() # TODO
observations_next_other, _ = transition_model.observation_decoder(next_feat) # TODO
action, pi = policy(torch.cat((obs_pred.detach(), observations_next_other[:, :, -(config.num_agents-1)*4:-(config.num_agents-1)*2]), -1)) # TODO 3 vs 3
# print("feat:", feat)
# print("feat_shape:", feat.shape) # feat.shape=1920,2,1280
# action, pi = policy(feat)
if av_action is not None:
# print("av_action!")
avail_actions = av_action(feat).sample()
pi[avail_actions == 0] = -1e10
action_dist = OneHotCategorical(logits=pi)
action = action_dist.sample().squeeze(0)
av_actions.append(avail_actions.squeeze(0))
next_states.append(state)
obs_preds.append(obs_pred)
policies.append(pi)
actions.append(action)
state = transition_model.transition(action, state)
return {"imag_states": stack_states(next_states, dim=0),
"obs_preds": torch.stack(obs_preds, dim=0),
"actions": torch.stack(actions, dim=0),
"av_actions": torch.stack(av_actions, dim=0) if len(av_actions) > 0 else None,
"old_policy": torch.stack(policies, dim=0)}
================================================
FILE: examples/Social_Cognition/ToCM/networks/ToCM/utils.py
================================================
import torch.nn as nn
from braincog.base.node import LIFNode
from braincog.base.node.node import LIFNode, DoubleSidePLIFNode, PLIFNode
from braincog.base.strategy.surrogate import AtanGrad
import torch
class AtanLIFNode(LIFNode):
def __init__(self, tau=0.5, *args, **kwargs):
super().__init__(tau, *args, **kwargs)
self.act_fun = AtanGrad(alpha=1., requires_grad=True)
class BCNoSpikingLIFNode(LIFNode):
def __init__(self, tau, *args, **kwargs):
super().__init__(*args, **kwargs)
self.tau = tau
def forward(self, dv: torch.Tensor):
# print("dv: ", dv)
# print("dv.shape: ", dv.shape)
self.integral(dv)
return self.mem
def build_model_snn(in_dim, out_dim, layers, hidden, th=0.5, re=0.0, tau=0.5, activation='LIFNode',
normalize=lambda x: x):
# print("build model snn!")
# 0.activation换成LIFNode...
if activation == 'LIFNode':
node = LIFNode(threshold=th, tau=tau)
elif activation == 'AtanLIFNode':
node = AtanLIFNode(tau=tau)
elif activation == 'BCNoSpikingLIFNode':
node = BCNoSpikingLIFNode(tau=tau)
elif activation == 'DoubleSidePLIFNode':
node = DoubleSidePLIFNode(tau=tau)
elif activation == 'PLIFNode':
node = PLIFNode(threshold=th)
elif activation == 'nn.ELU':
node = nn.ELU()
elif activation == 'nn.ReLU':
node = nn.ReLU()
elif activation == 'nn.Tanh':
node = nn.Tanh()
# 1.是否norm no norm
model = [normalize(nn.Linear(in_dim, hidden))]
model += [node]
for i in range(layers - 1):
model += [normalize(nn.Linear(hidden, hidden))]
model += [node]
model += [normalize(nn.Linear(hidden, out_dim))]
# 使用第二个归一化,node激活之后还要linear,最后的输出应该还得有个node,将out node定义到外面比较合适
return nn.Sequential(*model)
def build_model(in_dim, out_dim, layers, hidden, activation, normalize=lambda x: x):
model = [normalize(nn.Linear(in_dim, hidden))]
model += [activation()]
for i in range(layers - 1):
model += [normalize(nn.Linear(hidden, hidden))]
model += [activation()]
model += [normalize(nn.Linear(hidden, out_dim))]
return nn.Sequential(*model)
================================================
FILE: examples/Social_Cognition/ToCM/networks/ToCM/vae.py
================================================
import torch.nn as nn
import torch.nn.functional as F
from networks.ToCM.utils import build_model_snn
class Decoder(nn.Module):
def __init__(self, embed, hidden, out_dim, layers=2):
super().__init__()
self.fc1 = build_model_snn(embed, hidden, layers, hidden, activation='nn.ReLU') # activation=nn.ReLU
self.fc2 = nn.Linear(hidden, out_dim)
def forward(self, z):
x = F.relu(self.fc1(z))
return self.fc2(x), x
class Encoder(nn.Module):
def __init__(self, in_dim, hidden, embed, layers=2):
super().__init__()
self.fc1 = nn.Linear(in_dim, hidden)
self.encoder = build_model_snn(hidden, embed, layers, hidden, activation='nn.ReLU') # activation=nn.ReLU
def forward(self, x):
embed = F.relu(self.fc1(x))
return self.encoder(F.relu(embed))
================================================
FILE: examples/Social_Cognition/ToCM/networks/transformer/layers.py
================================================
import numpy as np
import torch
import torch.nn as nn
# 位置编码
class PositionalEncoding(nn.Module):
__author__ = "Yu-Hsiang Huang"
def __init__(self, d_hid, n_position=2):
super(PositionalEncoding, self).__init__()
# Not a parameter
'''
This is typically used to register a buffer that should not to be
considered a model parameter. For example, BatchNorm's ``running_mean``
is not a parameter, but is part of the module's state.
input: buffer's name, buffer's shape 应该是隐藏层之类的
'''
self.register_buffer('pos_table', self._get_sinusoid_encoding_table(n_position, d_hid))
# return x + self.pos_table[:, :x.size(1)].clone().detach() 使用pos_table
@staticmethod # 系统提示我这个方法静态
def _get_sinusoid_encoding_table(n_position, d_hid):
""" Sinusoid position encoding table """
def get_position_angle_vec(position): # 获取每个位置的角度向量
return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
# shape [pos_i, d_hid, position]
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table).unsqueeze(0) # 增加一个维度
def forward(self, x):
return x + self.pos_table[:, :x.size(1)].clone().detach()
class AttentionEncoder(nn.Module):
def __init__(self, n_layers, in_dim, hidden, dropout=0.):
super().__init__()
self.pos_embed = PositionalEncoding(hidden, 30) # 返回位置编码方案,维度++
self.encoder = nn.TransformerEncoder(nn.TransformerEncoderLayer(d_model=in_dim, nhead=8,
dim_feedforward=hidden,
dropout=dropout), n_layers)
def forward(self, enc_input, **kwargs):
enc_input = self.pos_embed(enc_input)
x = self.encoder(enc_input.permute(1, 0, 2), **kwargs)
return x.permute(1, 0, 2) # 混洗 调换顺序
class AttentionActorEncoder(nn.Module):
def __init__(self, n_layers, in_dim, hidden, dropout=0.):
super().__init__()
self.encoder = nn.TransformerEncoder(nn.TransformerEncoderLayer(d_model=in_dim, nhead=8,
dim_feedforward=hidden,
dropout=dropout), n_layers)
def forward(self, enc_input, **kwargs):
x = self.encoder(enc_input, **kwargs)
return x # 混洗 调换顺序
================================================
FILE: examples/Social_Cognition/ToCM/requirements.txt
================================================
numpy~=1.18.5
torch~=1.7.0
ray~=1.13.0
git+https://github.com/oxwhirl/smac.git
wandb~=0.13.11
argparse~=1.4.0
================================================
FILE: examples/Social_Cognition/ToCM/run.sh
================================================
#!/bin/sh
seed_max=10
#for seed in `seq ${seed_max}`;
#do
# echo "seed is ${seed}:"
# python train.py
# kill Main_Thread
#done
#seed_max=10 # 设置最大的种子值,这里假设为10
#for./run, seed in $(seq 1 $seed_max); do
# echo "seed is $seed:"
# python train.py --seed $seed # 将当前种子值作为参数传递给 train.py
#done
python train.py --seed 50
pkill Main_Thread
python train.py --seed 50
pkill Main_Thread
#python train.py --seed 1
#pkill Main_Thread
================================================
FILE: examples/Social_Cognition/ToCM/smac/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/smac/bin/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/smac/bin/map_list.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from smac.env.starcraft2.maps import smac_maps
from pysc2 import maps as pysc2_maps
def main():
smac_map_registry = smac_maps.get_smac_map_registry()
all_maps = pysc2_maps.get_maps()
print("{:<15} {:7} {:7} {:7}".format("Name", "Agents", "Enemies", "Limit"))
for map_name, map_params in smac_map_registry.items():
map_class = all_maps[map_name]
if map_class.path:
print(
"{:<15} {:<7} {:<7} {:<7}".format(
map_name,
map_params["n_agents"],
map_params["n_enemies"],
map_params["limit"],
)
)
if __name__ == "__main__":
main()
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/__init__.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from smac.env.multiagentenv import MultiAgentEnv
from smac.env.starcraft2.starcraft2 import StarCraft2Env
__all__ = ["MultiAgentEnv", "StarCraft2Env"]
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/multiagentenv.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
class MultiAgentEnv(object):
def step(self, actions):
"""Returns reward, terminated, info."""
raise NotImplementedError
def get_obs(self):
"""Returns all agent observations in a list."""
raise NotImplementedError
def get_obs_agent(self, agent_id):
"""Returns observation for agent_id."""
raise NotImplementedError
def get_obs_size(self):
"""Returns the size of the observation."""
raise NotImplementedError
def get_state(self):
"""Returns the global state."""
raise NotImplementedError
def get_state_size(self):
"""Returns the size of the global state."""
raise NotImplementedError
def get_avail_actions(self):
"""Returns the available actions of all agents in a list."""
raise NotImplementedError
def get_avail_agent_actions(self, agent_id):
"""Returns the available actions for agent_id."""
raise NotImplementedError
def get_total_actions(self):
"""Returns the total number of actions an agent could ever take."""
raise NotImplementedError
def reset(self):
"""Returns initial observations and states."""
raise NotImplementedError
def render(self):
raise NotImplementedError
def close(self):
raise NotImplementedError
def seed(self):
raise NotImplementedError
def save_replay(self):
"""Save a replay."""
raise NotImplementedError
def get_env_info(self):
env_info = {
"state_shape": self.get_state_size(),
"obs_shape": self.get_obs_size(),
"n_actions": self.get_total_actions(),
"n_agents": self.n_agents,
"episode_limit": self.episode_limit,
}
return env_info
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/pettingzoo/StarCraft2PZEnv.py
================================================
from smac.env import StarCraft2Env
from gym.utils import EzPickle
from gym.utils import seeding
from gym import spaces
from pettingzoo.utils.env import ParallelEnv
from pettingzoo.utils.conversions import parallel_to_aec as from_parallel_wrapper
from pettingzoo.utils import wrappers
import numpy as np
max_cycles_default = 1000
def parallel_env(max_cycles=max_cycles_default, **smac_args):
return _parallel_env(max_cycles, **smac_args)
def raw_env(max_cycles=max_cycles_default, **smac_args):
return from_parallel_wrapper(parallel_env(max_cycles, **smac_args))
def make_env(raw_env):
def env_fn(**kwargs):
env = raw_env(**kwargs)
# env = wrappers.TerminateIllegalWrapper(env, illegal_reward=-1)
env = wrappers.AssertOutOfBoundsWrapper(env)
env = wrappers.OrderEnforcingWrapper(env)
return env
return env_fn
class smac_parallel_env(ParallelEnv):
def __init__(self, env, max_cycles):
self.max_cycles = max_cycles
self.env = env
self.env.reset()
self.reset_flag = 0
self.agents, self.action_spaces = self._init_agents()
self.possible_agents = self.agents[:]
observation_size = env.get_obs_size()
self.observation_spaces = {
name: spaces.Dict(
{
"observation": spaces.Box(
low=-1,
high=1,
shape=(observation_size,),
dtype="float32",
),
"action_mask": spaces.Box(
low=0,
high=1,
shape=(self.action_spaces[name].n,),
dtype=np.int8,
),
}
)
for name in self.agents
}
self._reward = 0
def _init_agents(self):
last_type = ""
agents = []
action_spaces = {}
self.agents_id = {}
i = 0
for agent_id, agent_info in self.env.agents.items():
unit_action_space = spaces.Discrete(
self.env.get_total_actions() - 1
) # no-op in dead units is not an action
if agent_info.unit_type == self.env.marine_id:
agent_type = "marine"
elif agent_info.unit_type == self.env.marauder_id:
agent_type = "marauder"
elif agent_info.unit_type == self.env.medivac_id:
agent_type = "medivac"
elif agent_info.unit_type == self.env.hydralisk_id:
agent_type = "hydralisk"
elif agent_info.unit_type == self.env.zergling_id:
agent_type = "zergling"
elif agent_info.unit_type == self.env.baneling_id:
agent_type = "baneling"
elif agent_info.unit_type == self.env.stalker_id:
agent_type = "stalker"
elif agent_info.unit_type == self.env.colossus_id:
agent_type = "colossus"
elif agent_info.unit_type == self.env.zealot_id:
agent_type = "zealot"
else:
raise AssertionError(f"agent type {agent_type} not supported")
if agent_type == last_type:
i += 1
else:
i = 0
agents.append(f"{agent_type}_{i}")
self.agents_id[agents[-1]] = agent_id
action_spaces[agents[-1]] = unit_action_space
last_type = agent_type
return agents, action_spaces
def seed(self, seed=None):
if seed is None:
self.env._seed = seeding.create_seed(seed, max_bytes=4)
else:
self.env._seed = seed
self.env.full_restart()
def render(self, mode="human"):
self.env.render(mode)
def close(self):
self.env.close()
def reset(self):
self.env._episode_count = 1
self.env.reset()
self.agents = self.possible_agents[:]
self.frames = 0
self.all_dones = {agent: False for agent in self.possible_agents}
return self._observe_all()
def get_agent_smac_id(self, agent):
return self.agents_id[agent]
def _all_rewards(self, reward):
all_rewards = [reward] * len(self.agents)
return {
agent: reward for agent, reward in zip(self.agents, all_rewards)
}
def _observe_all(self):
all_obs = []
for agent in self.agents:
agent_id = self.get_agent_smac_id(agent)
obs = self.env.get_obs_agent(agent_id)
action_mask = self.env.get_avail_agent_actions(agent_id)
action_mask = action_mask[1:]
action_mask = np.array(action_mask).astype(np.int8)
obs = np.asarray(obs, dtype=np.float32)
all_obs.append(
{"observation": obs, "action_mask": action_mask}
)
return {agent: obs for agent, obs in zip(self.agents, all_obs)}
def _all_dones(self, step_done=False):
dones = [True] * len(self.agents)
if not step_done:
for i, agent in enumerate(self.agents):
agent_done = False
agent_id = self.get_agent_smac_id(agent)
agent_info = self.env.get_unit_by_id(agent_id)
if agent_info.health == 0:
agent_done = True
dones[i] = agent_done
return {agent: bool(done) for agent, done in zip(self.agents, dones)}
def step(self, all_actions):
action_list = [0] * self.env.n_agents
for agent in self.agents:
agent_id = self.get_agent_smac_id(agent)
if agent in all_actions:
if all_actions[agent] is None:
action_list[agent_id] = 0
else:
action_list[agent_id] = all_actions[agent] + 1
self._reward, terminated, smac_info = self.env.step(action_list)
self.frames += 1
done = terminated or self.frames >= self.max_cycles
all_infos = {agent: {} for agent in self.agents}
# all_infos.update(smac_info)
all_dones = self._all_dones(done)
all_rewards = self._all_rewards(self._reward)
all_observes = self._observe_all()
self.agents = [
agent for agent in self.agents if not all_dones[agent]
]
return all_observes, all_rewards, all_dones, all_infos
def __del__(self):
self.env.close()
env = make_env(raw_env)
class _parallel_env(smac_parallel_env, EzPickle):
metadata = {"render.modes": ["human"], "name": "sc2"}
def __init__(self, max_cycles, **smac_args):
EzPickle.__init__(self, max_cycles, **smac_args)
env = StarCraft2Env(**smac_args)
super().__init__(env, max_cycles)
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/pettingzoo/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/pettingzoo/test/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/pettingzoo/test/all_test.py
================================================
from smac.env.starcraft2.maps import smac_maps
from pysc2 import maps as pysc2_maps
from smac.env.pettingzoo import StarCraft2PZEnv as sc2
import pytest
from pettingzoo import test
import pickle
smac_map_registry = smac_maps.get_smac_map_registry()
all_maps = pysc2_maps.get_maps()
map_names = []
for map_name in smac_map_registry.keys():
map_class = all_maps[map_name]
if map_class.path:
map_names.append(map_name)
@pytest.mark.parametrize(("map_name"), map_names)
def test_env(map_name):
env = sc2.env(map_name=map_name)
test.api_test(env)
# test.parallel_api_test(sc2_v0.parallel_env()) # does not pass it due to
# illegal actions test.seed_test(sc2.env, 50) # not required, sc2 env only
# allows reseeding at initialization
test.render_test(env)
recreated_env = pickle.loads(pickle.dumps(env))
test.api_test(recreated_env)
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/pettingzoo/test/smac_pettingzoo_test.py
================================================
import os
import sys
import inspect
from pettingzoo import test
from smac.env.pettingzoo import StarCraft2PZEnv as sc2
import pickle
current_dir = os.path.dirname(
os.path.abspath(inspect.getfile(inspect.currentframe()))
)
parent_dir = os.path.dirname(current_dir)
sys.path.insert(0, parent_dir)
if __name__ == "__main__":
env = sc2.env(map_name="corridor")
test.api_test(env)
# test.parallel_api_test(sc2_v0.parallel_env()) # does not pass it due to
# illegal actions test.seed_test(sc2_v0.env, 50) # not required, sc2 env
# only allows reseeding at initialization
recreated_env = pickle.loads(pickle.dumps(env))
test.api_test(recreated_env)
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/starcraft2/__init__.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from absl import flags
FLAGS = flags.FLAGS
FLAGS(["main.py"])
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/starcraft2/maps/__init__.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from smac.env.starcraft2.maps import smac_maps
def get_map_params(map_name):
map_param_registry = smac_maps.get_smac_map_registry()
return map_param_registry[map_name]
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/starcraft2/maps/smac_maps.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from pysc2.maps import lib
class SMACMap(lib.Map):
directory = "SMAC_Maps"
download = "https://github.com/oxwhirl/smac#smac-maps"
players = 2
step_mul = 8
game_steps_per_episode = 0
map_param_registry = {
"3m": {
"n_agents": 3,
"n_enemies": 3,
"limit": 60,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 0,
"map_type": "marines",
},
"8m": {
"n_agents": 8,
"n_enemies": 8,
"limit": 120,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 0,
"map_type": "marines",
},
"25m": {
"n_agents": 25,
"n_enemies": 25,
"limit": 150,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 0,
"map_type": "marines",
},
"5m_vs_6m": {
"n_agents": 5,
"n_enemies": 6,
"limit": 70,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 0,
"map_type": "marines",
},
"8m_vs_9m": {
"n_agents": 8,
"n_enemies": 9,
"limit": 120,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 0,
"map_type": "marines",
},
"10m_vs_11m": {
"n_agents": 10,
"n_enemies": 11,
"limit": 150,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 0,
"map_type": "marines",
},
"27m_vs_30m": {
"n_agents": 27,
"n_enemies": 30,
"limit": 180,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 0,
"map_type": "marines",
},
"MMM": {
"n_agents": 10,
"n_enemies": 10,
"limit": 150,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 3,
"map_type": "MMM",
},
"MMM2": {
"n_agents": 10,
"n_enemies": 12,
"limit": 180,
"a_race": "T",
"b_race": "T",
"unit_type_bits": 3,
"map_type": "MMM",
},
"2s3z": {
"n_agents": 5,
"n_enemies": 5,
"limit": 120,
"a_race": "P",
"b_race": "P",
"unit_type_bits": 2,
"map_type": "stalkers_and_zealots",
},
"3s5z": {
"n_agents": 8,
"n_enemies": 8,
"limit": 150,
"a_race": "P",
"b_race": "P",
"unit_type_bits": 2,
"map_type": "stalkers_and_zealots",
},
"3s5z_vs_3s6z": {
"n_agents": 8,
"n_enemies": 9,
"limit": 170,
"a_race": "P",
"b_race": "P",
"unit_type_bits": 2,
"map_type": "stalkers_and_zealots",
},
"3s_vs_3z": {
"n_agents": 3,
"n_enemies": 3,
"limit": 150,
"a_race": "P",
"b_race": "P",
"unit_type_bits": 0,
"map_type": "stalkers",
},
"3s_vs_4z": {
"n_agents": 3,
"n_enemies": 4,
"limit": 200,
"a_race": "P",
"b_race": "P",
"unit_type_bits": 0,
"map_type": "stalkers",
},
"3s_vs_5z": {
"n_agents": 3,
"n_enemies": 5,
"limit": 250,
"a_race": "P",
"b_race": "P",
"unit_type_bits": 0,
"map_type": "stalkers",
},
"1c3s5z": {
"n_agents": 9,
"n_enemies": 9,
"limit": 180,
"a_race": "P",
"b_race": "P",
"unit_type_bits": 3,
"map_type": "colossi_stalkers_zealots",
},
"2m_vs_1z": {
"n_agents": 2,
"n_enemies": 1,
"limit": 150,
"a_race": "T",
"b_race": "P",
"unit_type_bits": 0,
"map_type": "marines",
},
"corridor": {
"n_agents": 6,
"n_enemies": 24,
"limit": 400,
"a_race": "P",
"b_race": "Z",
"unit_type_bits": 0,
"map_type": "zealots",
},
"6h_vs_8z": {
"n_agents": 6,
"n_enemies": 8,
"limit": 150,
"a_race": "Z",
"b_race": "P",
"unit_type_bits": 0,
"map_type": "hydralisks",
},
"2s_vs_1sc": {
"n_agents": 2,
"n_enemies": 1,
"limit": 300,
"a_race": "P",
"b_race": "Z",
"unit_type_bits": 0,
"map_type": "stalkers",
},
"so_many_baneling": {
"n_agents": 7,
"n_enemies": 32,
"limit": 100,
"a_race": "P",
"b_race": "Z",
"unit_type_bits": 0,
"map_type": "zealots",
},
"bane_vs_bane": {
"n_agents": 24,
"n_enemies": 24,
"limit": 200,
"a_race": "Z",
"b_race": "Z",
"unit_type_bits": 2,
"map_type": "bane",
},
"2c_vs_64zg": {
"n_agents": 2,
"n_enemies": 64,
"limit": 400,
"a_race": "P",
"b_race": "Z",
"unit_type_bits": 0,
"map_type": "colossus",
},
}
def get_smac_map_registry():
return map_param_registry
for name in map_param_registry.keys():
globals()[name] = type(name, (SMACMap,), dict(filename=name))
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/starcraft2/render.py
================================================
import numpy as np
import re
import subprocess
import platform
from absl import logging
import math
import time
import collections
import os
import pygame
import queue
from pysc2.lib import colors
from pysc2.lib import point
from pysc2.lib.renderer_human import _Surface
from pysc2.lib import transform
from pysc2.lib import features
def clamp(n, smallest, largest):
return max(smallest, min(n, largest))
def _get_desktop_size():
"""Get the desktop size."""
if platform.system() == "Linux":
try:
xrandr_query = subprocess.check_output(["xrandr", "--query"])
sizes = re.findall(
r"\bconnected primary (\d+)x(\d+)", str(xrandr_query)
)
if sizes[0]:
return point.Point(int(sizes[0][0]), int(sizes[0][1]))
except ValueError:
logging.error("Failed to get the resolution from xrandr.")
# Most general, but doesn't understand multiple monitors.
display_info = pygame.display.Info()
return point.Point(display_info.current_w, display_info.current_h)
class StarCraft2Renderer:
def __init__(self, env, mode):
os.environ["PYGAME_HIDE_SUPPORT_PROMPT"] = "hide"
self.env = env
self.mode = mode
self.obs = None
self._window_scale = 0.75
self.game_info = game_info = self.env._controller.game_info()
self.static_data = self.env._controller.data()
self._obs_queue = queue.Queue()
self._game_times = collections.deque(
maxlen=100
) # Avg FPS over 100 frames. # pytype: disable=wrong-keyword-args
self._render_times = collections.deque(
maxlen=100
) # pytype: disable=wrong-keyword-args
self._last_time = time.time()
self._last_game_loop = 0
self._name_lengths = {}
self._map_size = point.Point.build(game_info.start_raw.map_size)
self._playable = point.Rect(
point.Point.build(game_info.start_raw.playable_area.p0),
point.Point.build(game_info.start_raw.playable_area.p1),
)
window_size_px = point.Point(
self.env.window_size[0], self.env.window_size[1]
)
window_size_px = self._map_size.scale_max_size(
window_size_px * self._window_scale
).ceil()
self._scale = window_size_px.y // 32
self.display = pygame.Surface(window_size_px)
if mode == "human":
self.display = pygame.display.set_mode(window_size_px, 0, 32)
pygame.display.init()
pygame.display.set_caption("Starcraft Viewer")
pygame.font.init()
self._world_to_world_tl = transform.Linear(
point.Point(1, -1), point.Point(0, self._map_size.y)
)
self._world_tl_to_screen = transform.Linear(scale=window_size_px / 32)
self.screen_transform = transform.Chain(
self._world_to_world_tl, self._world_tl_to_screen
)
surf_loc = point.Rect(point.origin, window_size_px)
sub_surf = self.display.subsurface(
pygame.Rect(surf_loc.tl, surf_loc.size)
)
self._surf = _Surface(
sub_surf,
None,
surf_loc,
self.screen_transform,
None,
self.draw_screen,
)
self._font_small = pygame.font.Font(None, int(self._scale * 0.5))
self._font_large = pygame.font.Font(None, self._scale)
def close(self):
pygame.display.quit()
pygame.quit()
def _get_units(self):
for u in sorted(
self.obs.observation.raw_data.units,
key=lambda u: (u.pos.z, u.owner != 16, -u.radius, u.tag),
):
yield u, point.Point.build(u.pos)
def get_unit_name(self, surf, name, radius):
"""Get a length limited unit name for drawing units."""
key = (name, radius)
if key not in self._name_lengths:
max_len = surf.world_to_surf.fwd_dist(radius * 1.6)
for i in range(len(name)):
if self._font_small.size(name[: i + 1])[0] > max_len:
self._name_lengths[key] = name[:i]
break
else:
self._name_lengths[key] = name
return self._name_lengths[key]
def render(self, mode):
self.obs = self.env._obs
self.score = self.env.reward
self.step = self.env._episode_steps
now = time.time()
self._game_times.append(
(
now - self._last_time,
max(
1,
self.obs.observation.game_loop
- self.obs.observation.game_loop,
),
)
)
if mode == "human":
pygame.event.pump()
self._surf.draw(self._surf)
observation = np.array(pygame.surfarray.pixels3d(self.display))
if mode == "human":
pygame.display.flip()
self._last_time = now
self._last_game_loop = self.obs.observation.game_loop
# self._obs_queue.put(self.obs)
return (
np.transpose(observation, axes=(1, 0, 2))
if mode == "rgb_array"
else None
)
def draw_base_map(self, surf):
"""Draw the base map."""
hmap_feature = features.SCREEN_FEATURES.height_map
hmap = self.env.terrain_height * 255
hmap = hmap.astype(np.uint8)
if (
self.env.map_name == "corridor"
or self.env.map_name == "so_many_baneling"
or self.env.map_name == "2s_vs_1sc"
):
hmap = np.flip(hmap)
else:
hmap = np.rot90(hmap, axes=(1, 0))
if not hmap.any():
hmap = hmap + 100 # pylint: disable=g-no-augmented-assignment
hmap_color = hmap_feature.color(hmap)
out = hmap_color * 0.6
surf.blit_np_array(out)
def draw_units(self, surf):
"""Draw the units."""
unit_dict = None # Cache the units {tag: unit_proto} for orders.
tau = 2 * math.pi
for u, p in self._get_units():
fraction_damage = clamp(
(u.health_max - u.health) / (u.health_max or 1), 0, 1
)
surf.draw_circle(
colors.PLAYER_ABSOLUTE_PALETTE[u.owner], p, u.radius
)
if fraction_damage > 0:
surf.draw_circle(
colors.PLAYER_ABSOLUTE_PALETTE[u.owner] // 2,
p,
u.radius * fraction_damage,
)
surf.draw_circle(colors.black, p, u.radius, thickness=1)
if self.static_data.unit_stats[u.unit_type].movement_speed > 0:
surf.draw_arc(
colors.white,
p,
u.radius,
u.facing - 0.1,
u.facing + 0.1,
thickness=1,
)
def draw_arc_ratio(
color, world_loc, radius, start, end, thickness=1
):
surf.draw_arc(
color, world_loc, radius, start * tau, end * tau, thickness
)
if u.shield and u.shield_max:
draw_arc_ratio(
colors.blue, p, u.radius - 0.05, 0, u.shield / u.shield_max
)
if u.energy and u.energy_max:
draw_arc_ratio(
colors.purple * 0.9,
p,
u.radius - 0.1,
0,
u.energy / u.energy_max,
)
elif u.orders and 0 < u.orders[0].progress < 1:
draw_arc_ratio(
colors.cyan, p, u.radius - 0.15, 0, u.orders[0].progress
)
if u.buff_duration_remain and u.buff_duration_max:
draw_arc_ratio(
colors.white,
p,
u.radius - 0.2,
0,
u.buff_duration_remain / u.buff_duration_max,
)
if u.attack_upgrade_level:
draw_arc_ratio(
self.upgrade_colors[u.attack_upgrade_level],
p,
u.radius - 0.25,
0.18,
0.22,
thickness=3,
)
if u.armor_upgrade_level:
draw_arc_ratio(
self.upgrade_colors[u.armor_upgrade_level],
p,
u.radius - 0.25,
0.23,
0.27,
thickness=3,
)
if u.shield_upgrade_level:
draw_arc_ratio(
self.upgrade_colors[u.shield_upgrade_level],
p,
u.radius - 0.25,
0.28,
0.32,
thickness=3,
)
def write_small(loc, s):
surf.write_world(self._font_small, colors.white, loc, str(s))
name = self.get_unit_name(
surf,
self.static_data.units.get(u.unit_type, ""),
u.radius,
)
if name:
write_small(p, name)
start_point = p
for o in u.orders:
target_point = None
if o.HasField("target_unit_tag"):
if unit_dict is None:
unit_dict = {
t.tag: t
for t in self.obs.observation.raw_data.units
}
target_unit = unit_dict.get(o.target_unit_tag)
if target_unit:
target_point = point.Point.build(target_unit.pos)
if target_point:
surf.draw_line(colors.cyan, start_point, target_point)
start_point = target_point
else:
break
def draw_overlay(self, surf):
"""Draw the overlay describing resources."""
obs = self.obs.observation
times, steps = zip(*self._game_times)
sec = obs.game_loop // 22.4
surf.write_screen(
self._font_large,
colors.green,
(-0.2, 0.2),
"Score: %s, Step: %s, %.1f/s, Time: %d:%02d"
% (
self.score,
self.step,
sum(steps) / (sum(times) or 1),
sec // 60,
sec % 60,
),
align="right",
)
surf.write_screen(
self._font_large,
colors.green * 0.8,
(-0.2, 1.2),
"APM: %d, EPM: %d, FPS: O:%.1f, R:%.1f"
% (
obs.score.score_details.current_apm,
obs.score.score_details.current_effective_apm,
len(times) / (sum(times) or 1),
len(self._render_times) / (sum(self._render_times) or 1),
),
align="right",
)
def draw_screen(self, surf):
"""Draw the screen area."""
self.draw_base_map(surf)
self.draw_units(surf)
self.draw_overlay(surf)
================================================
FILE: examples/Social_Cognition/ToCM/smac/env/starcraft2/starcraft2.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from smac.env.multiagentenv import MultiAgentEnv
from smac.env.starcraft2.maps import get_map_params
import atexit
from warnings import warn
from operator import attrgetter
from copy import deepcopy
import numpy as np
import enum
import math
from absl import logging
from pysc2 import maps
from pysc2 import run_configs
from pysc2.lib import protocol
from s2clientprotocol import common_pb2 as sc_common
from s2clientprotocol import sc2api_pb2 as sc_pb
from s2clientprotocol import raw_pb2 as r_pb
from s2clientprotocol import debug_pb2 as d_pb
races = {
"R": sc_common.Random,
"P": sc_common.Protoss,
"T": sc_common.Terran,
"Z": sc_common.Zerg,
}
difficulties = {
"1": sc_pb.VeryEasy,
"2": sc_pb.Easy,
"3": sc_pb.Medium,
"4": sc_pb.MediumHard,
"5": sc_pb.Hard,
"6": sc_pb.Harder,
"7": sc_pb.VeryHard,
"8": sc_pb.CheatVision,
"9": sc_pb.CheatMoney,
"A": sc_pb.CheatInsane,
}
actions = {
"move": 16, # target: PointOrUnit
"attack": 23, # target: PointOrUnit
"stop": 4, # target: None
"heal": 386, # Unit
}
class Direction(enum.IntEnum):
NORTH = 0
SOUTH = 1
EAST = 2
WEST = 3
class StarCraft2Env(MultiAgentEnv):
"""The StarCraft II environment for decentralised multi-agent
micromanagement scenarios.
"""
def __init__(
self,
map_name="8m",
step_mul=8,
move_amount=2,
difficulty="7",
game_version=None,
seed=None,
continuing_episode=False,
obs_all_health=True,
obs_own_health=True,
obs_last_action=False,
obs_pathing_grid=False,
obs_terrain_height=False,
obs_instead_of_state=False,
obs_timestep_number=False,
state_last_action=True,
state_timestep_number=False,
reward_sparse=False,
reward_only_positive=True,
reward_death_value=10,
reward_win=200,
reward_defeat=0,
reward_negative_scale=0.5,
reward_scale=True,
reward_scale_rate=20,
replay_dir="",
replay_prefix="",
window_size_x=1920,
window_size_y=1200,
heuristic_ai=False,
heuristic_rest=False,
debug=False,
):
"""
Create a StarCraftC2Env environment.
Parameters
----------
map_name : str, optional
The name of the SC2 map to play (default is "8m"). The full list
can be found by running bin/map_list.
step_mul : int, optional
How many game steps per agent step (default is 8). None
indicates to use the default map step_mul.
move_amount : float, optional
How far away units are ordered to move per step (default is 2).
difficulty : str, optional
The difficulty of built-in computer AI bot (default is "7").
game_version : str, optional
StarCraft II game version (default is None). None indicates the
latest version.
seed : int, optional
Random seed used during game initialisation. This allows to
continuing_episode : bool, optional
Whether to consider episodes continuing or finished after time
limit is reached (default is False).
obs_all_health : bool, optional
Agents receive the health of all units (in the sight range) as part
of observations (default is True).
obs_own_health : bool, optional
Agents receive their own health as a part of observations (default
is False). This flag is ignored when obs_all_health == True.
obs_last_action : bool, optional
Agents receive the last actions of all units (in the sight range)
as part of observations (default is False).
obs_pathing_grid : bool, optional
Whether observations include pathing values surrounding the agent
(default is False).
obs_terrain_height : bool, optional
Whether observations include terrain height values surrounding the
agent (default is False).
obs_instead_of_state : bool, optional
Use combination of all agents' observations as the global state
(default is False).
obs_timestep_number : bool, optional
Whether observations include the current timestep of the episode
(default is False).
state_last_action : bool, optional
Include the last actions of all agents as part of the global state
(default is True).
state_timestep_number : bool, optional
Whether the state include the current timestep of the episode
(default is False).
reward_sparse : bool, optional
Receive 1/-1 reward for winning/loosing an episode (default is
False). Whe rest of reward parameters are ignored if True.
reward_only_positive : bool, optional
Reward is always positive (default is True).
reward_death_value : float, optional
The amount of reward received for killing an enemy unit (default
is 10). This is also the negative penalty for having an allied unit
killed if reward_only_positive == False.
reward_win : float, optional
The reward for winning in an episode (default is 200).
reward_defeat : float, optional
The reward for loosing in an episode (default is 0). This value
should be nonpositive.
reward_negative_scale : float, optional
Scaling factor for negative rewards (default is 0.5). This
parameter is ignored when reward_only_positive == True.
reward_scale : bool, optional
Whether or not to scale the reward (default is True).
reward_scale_rate : float, optional
Reward scale rate (default is 20). When reward_scale == True, the
reward received by the agents is divided by (max_reward /
reward_scale_rate), where max_reward is the maximum possible
reward per episode without considering the shield regeneration
of Protoss units.
replay_dir : str, optional
The directory to save replays (default is None). If None, the
replay will be saved in Replays directory where StarCraft II is
installed.
replay_prefix : str, optional
The prefix of the replay to be saved (default is None). If None,
the name of the map will be used.
window_size_x : int, optional
The length of StarCraft II window size (default is 1920).
window_size_y: int, optional
The height of StarCraft II window size (default is 1200).
heuristic_ai: bool, optional
Whether or not to use a non-learning heuristic AI (default False).
heuristic_rest: bool, optional
At any moment, restrict the actions of the heuristic AI to be
chosen from actions available to RL agents (default is False).
Ignored if heuristic_ai == False.
debug: bool, optional
Log messages about observations, state, actions and rewards for
debugging purposes (default is False).
"""
# Map arguments
self.map_name = map_name
map_params = get_map_params(self.map_name)
self.n_agents = map_params["n_agents"]
self.n_enemies = map_params["n_enemies"]
self.episode_limit = map_params["limit"]
self._move_amount = move_amount
self._step_mul = step_mul
self.difficulty = difficulty
# Observations and state
self.obs_own_health = obs_own_health
self.obs_all_health = obs_all_health
self.obs_instead_of_state = obs_instead_of_state
self.obs_last_action = obs_last_action
self.obs_pathing_grid = obs_pathing_grid
self.obs_terrain_height = obs_terrain_height
self.obs_timestep_number = obs_timestep_number
self.state_last_action = state_last_action
self.state_timestep_number = state_timestep_number
if self.obs_all_health:
self.obs_own_health = True
self.n_obs_pathing = 8
self.n_obs_height = 9
# Rewards args
self.reward_sparse = reward_sparse
self.reward_only_positive = reward_only_positive
self.reward_negative_scale = reward_negative_scale
self.reward_death_value = reward_death_value
self.reward_win = reward_win
self.reward_defeat = reward_defeat
self.reward_scale = reward_scale
self.reward_scale_rate = reward_scale_rate
# Other
self.game_version = game_version
self.continuing_episode = continuing_episode
self._seed = seed
self.heuristic_ai = heuristic_ai
self.heuristic_rest = heuristic_rest
self.debug = debug
self.window_size = (window_size_x, window_size_y)
self.replay_dir = replay_dir
self.replay_prefix = replay_prefix
# Actions
self.n_actions_no_attack = 6
self.n_actions_move = 4
self.n_actions = self.n_actions_no_attack + self.n_enemies
# Map info
self._agent_race = map_params["a_race"]
self._bot_race = map_params["b_race"]
self.shield_bits_ally = 1 if self._agent_race == "P" else 0
self.shield_bits_enemy = 1 if self._bot_race == "P" else 0
self.unit_type_bits = map_params["unit_type_bits"]
self.map_type = map_params["map_type"]
self._unit_types = None
self.max_reward = (
self.n_enemies * self.reward_death_value + self.reward_win
)
# create lists containing the names of attributes returned in states
self.ally_state_attr_names = [
"health",
"energy/cooldown",
"rel_x",
"rel_y",
]
self.enemy_state_attr_names = ["health", "rel_x", "rel_y"]
if self.shield_bits_ally > 0:
self.ally_state_attr_names += ["shield"]
if self.shield_bits_enemy > 0:
self.enemy_state_attr_names += ["shield"]
if self.unit_type_bits > 0:
bit_attr_names = [
"type_{}".format(bit) for bit in range(self.unit_type_bits)
]
self.ally_state_attr_names += bit_attr_names
self.enemy_state_attr_names += bit_attr_names
self.agents = {}
self.enemies = {}
self._episode_count = 0
self._episode_steps = 0
self._total_steps = 0
self._obs = None
self.battles_won = 0
self.battles_game = 0
self.timeouts = 0
self.force_restarts = 0
self.last_stats = None
self.death_tracker_ally = np.zeros(self.n_agents)
self.death_tracker_enemy = np.zeros(self.n_enemies)
self.previous_ally_units = None
self.previous_enemy_units = None
self.last_action = np.zeros((self.n_agents, self.n_actions))
self._min_unit_type = 0
self.marine_id = self.marauder_id = self.medivac_id = 0
self.hydralisk_id = self.zergling_id = self.baneling_id = 0
self.stalker_id = self.colossus_id = self.zealot_id = 0
self.max_distance_x = 0
self.max_distance_y = 0
self.map_x = 0
self.map_y = 0
self.reward = 0
self.renderer = None
self.terrain_height = None
self.pathing_grid = None
self._run_config = None
self._sc2_proc = None
self._controller = None
# Try to avoid leaking SC2 processes on shutdown
atexit.register(lambda: self.close())
def _launch(self):
"""Launch the StarCraft II game."""
self._run_config = run_configs.get(version=self.game_version)
_map = maps.get(self.map_name)
# Setting up the interface
interface_options = sc_pb.InterfaceOptions(raw=True, score=False)
self._sc2_proc = self._run_config.start(
window_size=self.window_size, want_rgb=False
)
self._controller = self._sc2_proc.controller
# Request to create the game
create = sc_pb.RequestCreateGame(
local_map=sc_pb.LocalMap(
map_path=_map.path,
map_data=self._run_config.map_data(_map.path),
),
realtime=False,
random_seed=self._seed,
)
create.player_setup.add(type=sc_pb.Participant)
create.player_setup.add(
type=sc_pb.Computer,
race=races[self._bot_race],
difficulty=difficulties[self.difficulty],
)
self._controller.create_game(create)
join = sc_pb.RequestJoinGame(
race=races[self._agent_race], options=interface_options
)
self._controller.join_game(join)
game_info = self._controller.game_info()
map_info = game_info.start_raw
map_play_area_min = map_info.playable_area.p0
map_play_area_max = map_info.playable_area.p1
self.max_distance_x = map_play_area_max.x - map_play_area_min.x
self.max_distance_y = map_play_area_max.y - map_play_area_min.y
self.map_x = map_info.map_size.x
self.map_y = map_info.map_size.y
if map_info.pathing_grid.bits_per_pixel == 1:
vals = np.array(list(map_info.pathing_grid.data)).reshape(
self.map_x, int(self.map_y / 8)
)
self.pathing_grid = np.transpose(
np.array(
[
[(b >> i) & 1 for b in row for i in range(7, -1, -1)]
for row in vals
],
dtype=np.bool,
)
)
else:
self.pathing_grid = np.invert(
np.flip(
np.transpose(
np.array(
list(map_info.pathing_grid.data), dtype=np.bool
).reshape(self.map_x, self.map_y)
),
axis=1,
)
)
self.terrain_height = (
np.flip(
np.transpose(
np.array(list(map_info.terrain_height.data)).reshape(
self.map_x, self.map_y
)
),
1,
)
/ 255
)
def reset(self):
"""Reset the environment. Required after each full episode.
Returns initial observations and states.
"""
self._episode_steps = 0
if self._episode_count == 0:
# Launch StarCraft II
self._launch()
else:
self._restart()
# Information kept for counting the reward
self.death_tracker_ally = np.zeros(self.n_agents)
self.death_tracker_enemy = np.zeros(self.n_enemies)
self.previous_ally_units = None
self.previous_enemy_units = None
self.win_counted = False
self.defeat_counted = False
self.last_action = np.zeros((self.n_agents, self.n_actions))
if self.heuristic_ai:
self.heuristic_targets = [None] * self.n_agents
try:
self._obs = self._controller.observe()
self.init_units()
except (protocol.ProtocolError, protocol.ConnectionError):
self.full_restart()
if self.debug:
logging.debug(
"Started Episode {}".format(self._episode_count).center(
60, "*"
)
)
return self.get_obs(), self.get_state()
def _restart(self):
"""Restart the environment by killing all units on the map.
There is a trigger in the SC2Map file, which restarts the
episode when there are no units left.
"""
try:
self._kill_all_units()
self._controller.step(2)
except (protocol.ProtocolError, protocol.ConnectionError):
self.full_restart()
def full_restart(self):
"""Full restart. Closes the SC2 process and launches a new one."""
self._sc2_proc.close()
self._launch()
self.force_restarts += 1
def step(self, actions):
"""A single environment step. Returns reward, terminated, info."""
actions_int = [int(a) for a in actions]
self.last_action = np.eye(self.n_actions)[np.array(actions_int)]
# Collect individual actions
sc_actions = []
if self.debug:
logging.debug("Actions".center(60, "-"))
for a_id, action in enumerate(actions_int):
if not self.heuristic_ai:
sc_action = self.get_agent_action(a_id, action)
else:
sc_action, action_num = self.get_agent_action_heuristic(
a_id, action
)
actions[a_id] = action_num
if sc_action:
sc_actions.append(sc_action)
# Send action request
req_actions = sc_pb.RequestAction(actions=sc_actions)
try:
self._controller.actions(req_actions)
# Make step in SC2, i.e. apply actions
self._controller.step(self._step_mul)
# Observe here so that we know if the episode is over.
self._obs = self._controller.observe()
except (protocol.ProtocolError, protocol.ConnectionError):
self.full_restart()
return 0, True, {}
self._total_steps += 1
self._episode_steps += 1
# Update units
game_end_code = self.update_units()
terminated = False
reward = self.reward_battle()
info = {"battle_won": False}
# count units that are still alive
dead_allies, dead_enemies = 0, 0
for _al_id, al_unit in self.agents.items():
if al_unit.health == 0:
dead_allies += 1
for _e_id, e_unit in self.enemies.items():
if e_unit.health == 0:
dead_enemies += 1
info["dead_allies"] = dead_allies
info["dead_enemies"] = dead_enemies
if game_end_code is not None:
# Battle is over
terminated = True
self.battles_game += 1
if game_end_code == 1 and not self.win_counted:
self.battles_won += 1
self.win_counted = True
info["battle_won"] = True
if not self.reward_sparse:
reward += self.reward_win
else:
reward = 1
elif game_end_code == -1 and not self.defeat_counted:
self.defeat_counted = True
if not self.reward_sparse:
reward += self.reward_defeat
else:
reward = -1
elif self._episode_steps >= self.episode_limit:
# Episode limit reached
terminated = True
if self.continuing_episode:
info["episode_limit"] = True
self.battles_game += 1
self.timeouts += 1
if self.debug:
logging.debug("Reward = {}".format(reward).center(60, "-"))
if terminated:
self._episode_count += 1
if self.reward_scale:
reward /= self.max_reward / self.reward_scale_rate
self.reward = reward
return reward, terminated, info
def get_agent_action(self, a_id, action):
"""Construct the action for agent a_id."""
avail_actions = self.get_avail_agent_actions(a_id)
assert (
avail_actions[action] == 1
), "Agent {} cannot perform action {}".format(a_id, action)
unit = self.get_unit_by_id(a_id)
tag = unit.tag
x = unit.pos.x
y = unit.pos.y
if action == 0:
# no-op (valid only when dead)
assert unit.health == 0, "No-op only available for dead agents."
if self.debug:
logging.debug("Agent {}: Dead".format(a_id))
return None
elif action == 1:
# stop
cmd = r_pb.ActionRawUnitCommand(
ability_id=actions["stop"],
unit_tags=[tag],
queue_command=False,
)
if self.debug:
logging.debug("Agent {}: Stop".format(a_id))
elif action == 2:
# move north
cmd = r_pb.ActionRawUnitCommand(
ability_id=actions["move"],
target_world_space_pos=sc_common.Point2D(
x=x, y=y + self._move_amount
),
unit_tags=[tag],
queue_command=False,
)
if self.debug:
logging.debug("Agent {}: Move North".format(a_id))
elif action == 3:
# move south
cmd = r_pb.ActionRawUnitCommand(
ability_id=actions["move"],
target_world_space_pos=sc_common.Point2D(
x=x, y=y - self._move_amount
),
unit_tags=[tag],
queue_command=False,
)
if self.debug:
logging.debug("Agent {}: Move South".format(a_id))
elif action == 4:
# move east
cmd = r_pb.ActionRawUnitCommand(
ability_id=actions["move"],
target_world_space_pos=sc_common.Point2D(
x=x + self._move_amount, y=y
),
unit_tags=[tag],
queue_command=False,
)
if self.debug:
logging.debug("Agent {}: Move East".format(a_id))
elif action == 5:
# move west
cmd = r_pb.ActionRawUnitCommand(
ability_id=actions["move"],
target_world_space_pos=sc_common.Point2D(
x=x - self._move_amount, y=y
),
unit_tags=[tag],
queue_command=False,
)
if self.debug:
logging.debug("Agent {}: Move West".format(a_id))
else:
# attack/heal units that are in range
target_id = action - self.n_actions_no_attack
if self.map_type == "MMM" and unit.unit_type == self.medivac_id:
target_unit = self.agents[target_id]
action_name = "heal"
else:
target_unit = self.enemies[target_id]
action_name = "attack"
action_id = actions[action_name]
target_tag = target_unit.tag
cmd = r_pb.ActionRawUnitCommand(
ability_id=action_id,
target_unit_tag=target_tag,
unit_tags=[tag],
queue_command=False,
)
if self.debug:
logging.debug(
"Agent {} {}s unit # {}".format(
a_id, action_name, target_id
)
)
sc_action = sc_pb.Action(action_raw=r_pb.ActionRaw(unit_command=cmd))
return sc_action
def get_agent_action_heuristic(self, a_id, action):
unit = self.get_unit_by_id(a_id)
tag = unit.tag
target = self.heuristic_targets[a_id]
if unit.unit_type == self.medivac_id:
if (
target is None
or self.agents[target].health == 0
or self.agents[target].health == self.agents[target].health_max
):
min_dist = math.hypot(self.max_distance_x, self.max_distance_y)
min_id = -1
for al_id, al_unit in self.agents.items():
if al_unit.unit_type == self.medivac_id:
continue
if (
al_unit.health != 0
and al_unit.health != al_unit.health_max
):
dist = self.distance(
unit.pos.x,
unit.pos.y,
al_unit.pos.x,
al_unit.pos.y,
)
if dist < min_dist:
min_dist = dist
min_id = al_id
self.heuristic_targets[a_id] = min_id
if min_id == -1:
self.heuristic_targets[a_id] = None
return None, 0
action_id = actions["heal"]
target_tag = self.agents[self.heuristic_targets[a_id]].tag
else:
if target is None or self.enemies[target].health == 0:
min_dist = math.hypot(self.max_distance_x, self.max_distance_y)
min_id = -1
for e_id, e_unit in self.enemies.items():
if (
unit.unit_type == self.marauder_id
and e_unit.unit_type == self.medivac_id
):
continue
if e_unit.health > 0:
dist = self.distance(
unit.pos.x, unit.pos.y, e_unit.pos.x, e_unit.pos.y
)
if dist < min_dist:
min_dist = dist
min_id = e_id
self.heuristic_targets[a_id] = min_id
if min_id == -1:
self.heuristic_targets[a_id] = None
return None, 0
action_id = actions["attack"]
target_tag = self.enemies[self.heuristic_targets[a_id]].tag
action_num = self.heuristic_targets[a_id] + self.n_actions_no_attack
# Check if the action is available
if (
self.heuristic_rest
and self.get_avail_agent_actions(a_id)[action_num] == 0
):
# Move towards the target rather than attacking/healing
if unit.unit_type == self.medivac_id:
target_unit = self.agents[self.heuristic_targets[a_id]]
else:
target_unit = self.enemies[self.heuristic_targets[a_id]]
delta_x = target_unit.pos.x - unit.pos.x
delta_y = target_unit.pos.y - unit.pos.y
if abs(delta_x) > abs(delta_y): # east or west
if delta_x > 0: # east
target_pos = sc_common.Point2D(
x=unit.pos.x + self._move_amount, y=unit.pos.y
)
action_num = 4
else: # west
target_pos = sc_common.Point2D(
x=unit.pos.x - self._move_amount, y=unit.pos.y
)
action_num = 5
else: # north or south
if delta_y > 0: # north
target_pos = sc_common.Point2D(
x=unit.pos.x, y=unit.pos.y + self._move_amount
)
action_num = 2
else: # south
target_pos = sc_common.Point2D(
x=unit.pos.x, y=unit.pos.y - self._move_amount
)
action_num = 3
cmd = r_pb.ActionRawUnitCommand(
ability_id=actions["move"],
target_world_space_pos=target_pos,
unit_tags=[tag],
queue_command=False,
)
else:
# Attack/heal the target
cmd = r_pb.ActionRawUnitCommand(
ability_id=action_id,
target_unit_tag=target_tag,
unit_tags=[tag],
queue_command=False,
)
sc_action = sc_pb.Action(action_raw=r_pb.ActionRaw(unit_command=cmd))
return sc_action, action_num
def reward_battle(self):
"""Reward function when self.reward_spare==False.
Returns accumulative hit/shield point damage dealt to the enemy
+ reward_death_value per enemy unit killed, and, in case
self.reward_only_positive == False, - (damage dealt to ally units
+ reward_death_value per ally unit killed) * self.reward_negative_scale
"""
if self.reward_sparse:
return 0
reward = 0
delta_deaths = 0
delta_ally = 0
delta_enemy = 0
neg_scale = self.reward_negative_scale
# update deaths
for al_id, al_unit in self.agents.items():
if not self.death_tracker_ally[al_id]:
# did not die so far
prev_health = (
self.previous_ally_units[al_id].health
+ self.previous_ally_units[al_id].shield
)
if al_unit.health == 0:
# just died
self.death_tracker_ally[al_id] = 1
if not self.reward_only_positive:
delta_deaths -= self.reward_death_value * neg_scale
delta_ally += prev_health * neg_scale
else:
# still alive
delta_ally += neg_scale * (
prev_health - al_unit.health - al_unit.shield
)
for e_id, e_unit in self.enemies.items():
if not self.death_tracker_enemy[e_id]:
prev_health = (
self.previous_enemy_units[e_id].health
+ self.previous_enemy_units[e_id].shield
)
if e_unit.health == 0:
self.death_tracker_enemy[e_id] = 1
delta_deaths += self.reward_death_value
delta_enemy += prev_health
else:
delta_enemy += prev_health - e_unit.health - e_unit.shield
if self.reward_only_positive:
reward = abs(delta_enemy + delta_deaths) # shield regeneration
else:
reward = delta_enemy + delta_deaths - delta_ally
return reward
def get_total_actions(self):
"""Returns the total number of actions an agent could ever take."""
return self.n_actions
@staticmethod
def distance(x1, y1, x2, y2):
"""Distance between two points."""
return math.hypot(x2 - x1, y2 - y1)
def unit_shoot_range(self, agent_id):
"""Returns the shooting range for an agent."""
return 6
def unit_sight_range(self, agent_id):
"""Returns the sight range for an agent."""
return 9
def unit_max_cooldown(self, unit):
"""Returns the maximal cooldown for a unit."""
switcher = {
self.marine_id: 15,
self.marauder_id: 25,
self.medivac_id: 200, # max energy
self.stalker_id: 35,
self.zealot_id: 22,
self.colossus_id: 24,
self.hydralisk_id: 10,
self.zergling_id: 11,
self.baneling_id: 1,
}
return switcher.get(unit.unit_type, 15)
def save_replay(self):
"""Save a replay."""
prefix = self.replay_prefix or self.map_name
replay_dir = self.replay_dir or ""
replay_path = self._run_config.save_replay(
self._controller.save_replay(),
replay_dir=replay_dir,
prefix=prefix,
)
logging.info("Replay saved at: %s" % replay_path)
def unit_max_shield(self, unit):
"""Returns maximal shield for a given unit."""
if unit.unit_type == 74 or unit.unit_type == self.stalker_id:
return 80 # Protoss's Stalker
if unit.unit_type == 73 or unit.unit_type == self.zealot_id:
return 50 # Protoss's Zaelot
if unit.unit_type == 4 or unit.unit_type == self.colossus_id:
return 150 # Protoss's Colossus
def can_move(self, unit, direction):
"""Whether a unit can move in a given direction."""
m = self._move_amount / 2
if direction == Direction.NORTH:
x, y = int(unit.pos.x), int(unit.pos.y + m)
elif direction == Direction.SOUTH:
x, y = int(unit.pos.x), int(unit.pos.y - m)
elif direction == Direction.EAST:
x, y = int(unit.pos.x + m), int(unit.pos.y)
else:
x, y = int(unit.pos.x - m), int(unit.pos.y)
if self.check_bounds(x, y) and self.pathing_grid[x, y]:
return True
return False
def get_surrounding_points(self, unit, include_self=False):
"""Returns the surrounding points of the unit in 8 directions."""
x = int(unit.pos.x)
y = int(unit.pos.y)
ma = self._move_amount
points = [
(x, y + 2 * ma),
(x, y - 2 * ma),
(x + 2 * ma, y),
(x - 2 * ma, y),
(x + ma, y + ma),
(x - ma, y - ma),
(x + ma, y - ma),
(x - ma, y + ma),
]
if include_self:
points.append((x, y))
return points
def check_bounds(self, x, y):
"""Whether a point is within the map bounds."""
return 0 <= x < self.map_x and 0 <= y < self.map_y
def get_surrounding_pathing(self, unit):
"""Returns pathing values of the grid surrounding the given unit."""
points = self.get_surrounding_points(unit, include_self=False)
vals = [
self.pathing_grid[x, y] if self.check_bounds(x, y) else 1
for x, y in points
]
return vals
def get_surrounding_height(self, unit):
"""Returns height values of the grid surrounding the given unit."""
points = self.get_surrounding_points(unit, include_self=True)
vals = [
self.terrain_height[x, y] if self.check_bounds(x, y) else 1
for x, y in points
]
return vals
def get_obs_agent(self, agent_id):
"""Returns observation for agent_id. The observation is composed of:
- agent movement features (where it can move to, height information
and pathing grid)
- enemy features (available_to_attack, health, relative_x, relative_y,
shield, unit_type)
- ally features (visible, distance, relative_x, relative_y, shield,
unit_type)
- agent unit features (health, shield, unit_type)
All of this information is flattened and concatenated into a list,
in the aforementioned order. To know the sizes of each of the
features inside the final list of features, take a look at the
functions ``get_obs_move_feats_size()``,
``get_obs_enemy_feats_size()``, ``get_obs_ally_feats_size()`` and
``get_obs_own_feats_size()``.
The size of the observation vector may vary, depending on the
environment configuration and type of units present in the map.
For instance, non-Protoss units will not have shields, movement
features may or may not include terrain height and pathing grid,
unit_type is not included if there is only one type of unit in the
map etc.).
NOTE: Agents should have access only to their local observations
during decentralised execution.
"""
unit = self.get_unit_by_id(agent_id)
move_feats_dim = self.get_obs_move_feats_size()
enemy_feats_dim = self.get_obs_enemy_feats_size()
ally_feats_dim = self.get_obs_ally_feats_size()
own_feats_dim = self.get_obs_own_feats_size()
move_feats = np.zeros(move_feats_dim, dtype=np.float32)
enemy_feats = np.zeros(enemy_feats_dim, dtype=np.float32)
ally_feats = np.zeros(ally_feats_dim, dtype=np.float32)
own_feats = np.zeros(own_feats_dim, dtype=np.float32)
if unit.health > 0: # otherwise dead, return all zeros
x = unit.pos.x
y = unit.pos.y
sight_range = self.unit_sight_range(agent_id)
# Movement features
avail_actions = self.get_avail_agent_actions(agent_id)
for m in range(self.n_actions_move):
move_feats[m] = avail_actions[m + 2]
ind = self.n_actions_move
if self.obs_pathing_grid:
move_feats[
ind : ind + self.n_obs_pathing # noqa
] = self.get_surrounding_pathing(unit)
ind += self.n_obs_pathing
if self.obs_terrain_height:
move_feats[ind:] = self.get_surrounding_height(unit)
# Enemy features
for e_id, e_unit in self.enemies.items():
e_x = e_unit.pos.x
e_y = e_unit.pos.y
dist = self.distance(x, y, e_x, e_y)
if (
dist < sight_range and e_unit.health > 0
): # visible and alive
# Sight range > shoot range
enemy_feats[e_id, 0] = avail_actions[
self.n_actions_no_attack + e_id
] # available
enemy_feats[e_id, 1] = dist / sight_range # distance
enemy_feats[e_id, 2] = (
e_x - x
) / sight_range # relative X
enemy_feats[e_id, 3] = (
e_y - y
) / sight_range # relative Y
ind = 4
if self.obs_all_health:
enemy_feats[e_id, ind] = (
e_unit.health / e_unit.health_max
) # health
ind += 1
if self.shield_bits_enemy > 0:
max_shield = self.unit_max_shield(e_unit)
enemy_feats[e_id, ind] = (
e_unit.shield / max_shield
) # shield
ind += 1
if self.unit_type_bits > 0:
type_id = self.get_unit_type_id(e_unit, False)
enemy_feats[e_id, ind + type_id] = 1 # unit type
# Ally features
al_ids = [
al_id for al_id in range(self.n_agents) if al_id != agent_id
]
for i, al_id in enumerate(al_ids):
al_unit = self.get_unit_by_id(al_id)
al_x = al_unit.pos.x
al_y = al_unit.pos.y
dist = self.distance(x, y, al_x, al_y)
if (
dist < sight_range and al_unit.health > 0
): # visible and alive
ally_feats[i, 0] = 1 # visible
ally_feats[i, 1] = dist / sight_range # distance
ally_feats[i, 2] = (al_x - x) / sight_range # relative X
ally_feats[i, 3] = (al_y - y) / sight_range # relative Y
ind = 4
if self.obs_all_health:
ally_feats[i, ind] = (
al_unit.health / al_unit.health_max
) # health
ind += 1
if self.shield_bits_ally > 0:
max_shield = self.unit_max_shield(al_unit)
ally_feats[i, ind] = (
al_unit.shield / max_shield
) # shield
ind += 1
if self.unit_type_bits > 0:
type_id = self.get_unit_type_id(al_unit, True)
ally_feats[i, ind + type_id] = 1
ind += self.unit_type_bits
if self.obs_last_action:
ally_feats[i, ind:] = self.last_action[al_id]
# Own features
ind = 0
if self.obs_own_health:
own_feats[ind] = unit.health / unit.health_max
ind += 1
if self.shield_bits_ally > 0:
max_shield = self.unit_max_shield(unit)
own_feats[ind] = unit.shield / max_shield
ind += 1
if self.unit_type_bits > 0:
type_id = self.get_unit_type_id(unit, True)
own_feats[ind + type_id] = 1
agent_obs = np.concatenate(
(
move_feats.flatten(),
enemy_feats.flatten(),
ally_feats.flatten(),
own_feats.flatten(),
)
)
if self.obs_timestep_number:
agent_obs = np.append(
agent_obs, self._episode_steps / self.episode_limit
)
if self.debug:
logging.debug("Obs Agent: {}".format(agent_id).center(60, "-"))
logging.debug(
"Avail. actions {}".format(
self.get_avail_agent_actions(agent_id)
)
)
logging.debug("Move feats {}".format(move_feats))
logging.debug("Enemy feats {}".format(enemy_feats))
logging.debug("Ally feats {}".format(ally_feats))
logging.debug("Own feats {}".format(own_feats))
return agent_obs
def get_obs(self):
"""Returns all agent observations in a list.
NOTE: Agents should have access only to their local observations
during decentralised execution.
"""
agents_obs = [self.get_obs_agent(i) for i in range(self.n_agents)]
return agents_obs # return a list of agent obs
def get_state(self):
"""Returns the global state.
NOTE: This functon should not be used during decentralised execution.
"""
if self.obs_instead_of_state:
obs_concat = np.concatenate(self.get_obs(), axis=0).astype(
np.float32
)
return obs_concat
state_dict = self.get_state_dict()
state = np.append(
state_dict["allies"].flatten(), state_dict["enemies"].flatten()
)
if "last_action" in state_dict:
state = np.append(state, state_dict["last_action"].flatten())
if "timestep" in state_dict:
state = np.append(state, state_dict["timestep"])
state = state.astype(dtype=np.float32)
if self.debug:
logging.debug("STATE".center(60, "-"))
logging.debug("Ally state {}".format(state_dict["allies"]))
logging.debug("Enemy state {}".format(state_dict["enemies"]))
if self.state_last_action:
logging.debug("Last actions {}".format(self.last_action))
return state
def get_ally_num_attributes(self):
return len(self.ally_state_attr_names)
def get_enemy_num_attributes(self):
return len(self.enemy_state_attr_names)
def get_state_dict(self):
"""Returns the global state as a dictionary.
- allies: numpy array containing agents and their attributes
- enemies: numpy array containing enemies and their attributes
- last_action: numpy array of previous actions for each agent
- timestep: current no. of steps divided by total no. of steps
NOTE: This function should not be used during decentralised execution.
"""
# number of features equals the number of attribute names
nf_al = self.get_ally_num_attributes()
nf_en = self.get_enemy_num_attributes()
ally_state = np.zeros((self.n_agents, nf_al))
enemy_state = np.zeros((self.n_enemies, nf_en))
center_x = self.map_x / 2
center_y = self.map_y / 2
for al_id, al_unit in self.agents.items():
if al_unit.health > 0:
x = al_unit.pos.x
y = al_unit.pos.y
max_cd = self.unit_max_cooldown(al_unit)
ally_state[al_id, 0] = (
al_unit.health / al_unit.health_max
) # health
if (
self.map_type == "MMM"
and al_unit.unit_type == self.medivac_id
):
ally_state[al_id, 1] = al_unit.energy / max_cd # energy
else:
ally_state[al_id, 1] = (
al_unit.weapon_cooldown / max_cd
) # cooldown
ally_state[al_id, 2] = (
x - center_x
) / self.max_distance_x # relative X
ally_state[al_id, 3] = (
y - center_y
) / self.max_distance_y # relative Y
if self.shield_bits_ally > 0:
max_shield = self.unit_max_shield(al_unit)
ally_state[al_id, 4] = (
al_unit.shield / max_shield
) # shield
if self.unit_type_bits > 0:
type_id = self.get_unit_type_id(al_unit, True)
ally_state[al_id, type_id - self.unit_type_bits] = 1
for e_id, e_unit in self.enemies.items():
if e_unit.health > 0:
x = e_unit.pos.x
y = e_unit.pos.y
enemy_state[e_id, 0] = (
e_unit.health / e_unit.health_max
) # health
enemy_state[e_id, 1] = (
x - center_x
) / self.max_distance_x # relative X
enemy_state[e_id, 2] = (
y - center_y
) / self.max_distance_y # relative Y
if self.shield_bits_enemy > 0:
max_shield = self.unit_max_shield(e_unit)
enemy_state[e_id, 3] = e_unit.shield / max_shield # shield
if self.unit_type_bits > 0:
type_id = self.get_unit_type_id(e_unit, False)
enemy_state[e_id, type_id - self.unit_type_bits] = 1
state = {"allies": ally_state, "enemies": enemy_state}
if self.state_last_action:
state["last_action"] = self.last_action
if self.state_timestep_number:
state["timestep"] = self._episode_steps / self.episode_limit
return state
def get_obs_enemy_feats_size(self):
"""Returns the dimensions of the matrix containing enemy features.
Size is n_enemies x n_features.
"""
nf_en = 4 + self.unit_type_bits
if self.obs_all_health:
nf_en += 1 + self.shield_bits_enemy
return self.n_enemies, nf_en
def get_obs_ally_feats_size(self):
"""Returns the dimensions of the matrix containing ally features.
Size is n_allies x n_features.
"""
nf_al = 4 + self.unit_type_bits
if self.obs_all_health:
nf_al += 1 + self.shield_bits_ally
if self.obs_last_action:
nf_al += self.n_actions
return self.n_agents - 1, nf_al
def get_obs_own_feats_size(self):
"""
Returns the size of the vector containing the agents' own features.
"""
own_feats = self.unit_type_bits
if self.obs_own_health:
own_feats += 1 + self.shield_bits_ally
if self.obs_timestep_number:
own_feats += 1
return own_feats
def get_obs_move_feats_size(self):
"""Returns the size of the vector containing the agents's movement-
related features.
"""
move_feats = self.n_actions_move
if self.obs_pathing_grid:
move_feats += self.n_obs_pathing
if self.obs_terrain_height:
move_feats += self.n_obs_height
return move_feats
def get_obs_size(self):
"""Returns the size of the observation."""
own_feats = self.get_obs_own_feats_size()
move_feats = self.get_obs_move_feats_size()
n_enemies, n_enemy_feats = self.get_obs_enemy_feats_size()
n_allies, n_ally_feats = self.get_obs_ally_feats_size()
enemy_feats = n_enemies * n_enemy_feats
ally_feats = n_allies * n_ally_feats
return move_feats + enemy_feats + ally_feats + own_feats
def get_state_size(self):
"""Returns the size of the global state."""
if self.obs_instead_of_state:
return self.get_obs_size() * self.n_agents
nf_al = 4 + self.shield_bits_ally + self.unit_type_bits
nf_en = 3 + self.shield_bits_enemy + self.unit_type_bits
enemy_state = self.n_enemies * nf_en
ally_state = self.n_agents * nf_al
size = enemy_state + ally_state
if self.state_last_action:
size += self.n_agents * self.n_actions
if self.state_timestep_number:
size += 1
return size
def get_visibility_matrix(self):
"""Returns a boolean numpy array of dimensions
(n_agents, n_agents + n_enemies) indicating which units
are visible to each agent.
"""
arr = np.zeros(
(self.n_agents, self.n_agents + self.n_enemies),
dtype=np.bool,
)
for agent_id in range(self.n_agents):
current_agent = self.get_unit_by_id(agent_id)
if current_agent.health > 0: # it agent not dead
x = current_agent.pos.x
y = current_agent.pos.y
sight_range = self.unit_sight_range(agent_id)
# Enemies
for e_id, e_unit in self.enemies.items():
e_x = e_unit.pos.x
e_y = e_unit.pos.y
dist = self.distance(x, y, e_x, e_y)
if dist < sight_range and e_unit.health > 0:
# visible and alive
arr[agent_id, self.n_agents + e_id] = 1
# The matrix for allies is filled symmetrically
al_ids = [
al_id for al_id in range(self.n_agents) if al_id > agent_id
]
for _, al_id in enumerate(al_ids):
al_unit = self.get_unit_by_id(al_id)
al_x = al_unit.pos.x
al_y = al_unit.pos.y
dist = self.distance(x, y, al_x, al_y)
if dist < sight_range and al_unit.health > 0:
# visible and alive
arr[agent_id, al_id] = arr[al_id, agent_id] = 1
return arr
def get_unit_type_id(self, unit, ally):
"""Returns the ID of unit type in the given scenario."""
if ally: # use new SC2 unit types
type_id = unit.unit_type - self._min_unit_type
else: # use default SC2 unit types
if self.map_type == "stalkers_and_zealots":
# id(Stalker) = 74, id(Zealot) = 73
type_id = unit.unit_type - 73
elif self.map_type == "colossi_stalkers_zealots":
# id(Stalker) = 74, id(Zealot) = 73, id(Colossus) = 4
if unit.unit_type == 4:
type_id = 0
elif unit.unit_type == 74:
type_id = 1
else:
type_id = 2
elif self.map_type == "bane":
if unit.unit_type == 9:
type_id = 0
else:
type_id = 1
elif self.map_type == "MMM":
if unit.unit_type == 51:
type_id = 0
elif unit.unit_type == 48:
type_id = 1
else:
type_id = 2
return type_id
def get_avail_agent_actions(self, agent_id):
"""Returns the available actions for agent_id."""
unit = self.get_unit_by_id(agent_id)
if unit.health > 0:
# cannot choose no-op when alive
avail_actions = [0] * self.n_actions
# stop should be allowed
avail_actions[1] = 1
# see if we can move
if self.can_move(unit, Direction.NORTH):
avail_actions[2] = 1
if self.can_move(unit, Direction.SOUTH):
avail_actions[3] = 1
if self.can_move(unit, Direction.EAST):
avail_actions[4] = 1
if self.can_move(unit, Direction.WEST):
avail_actions[5] = 1
# Can attack only alive units that are alive in the shooting range
shoot_range = self.unit_shoot_range(agent_id)
target_items = self.enemies.items()
if self.map_type == "MMM" and unit.unit_type == self.medivac_id:
# Medivacs cannot heal themselves or other flying units
target_items = [
(t_id, t_unit)
for (t_id, t_unit) in self.agents.items()
if t_unit.unit_type != self.medivac_id
]
for t_id, t_unit in target_items:
if t_unit.health > 0:
dist = self.distance(
unit.pos.x, unit.pos.y, t_unit.pos.x, t_unit.pos.y
)
if dist <= shoot_range:
avail_actions[t_id + self.n_actions_no_attack] = 1
return avail_actions
else:
# only no-op allowed
return [1] + [0] * (self.n_actions - 1)
def get_avail_actions(self):
"""Returns the available actions of all agents in a list."""
avail_actions = []
for agent_id in range(self.n_agents):
avail_agent = self.get_avail_agent_actions(agent_id)
avail_actions.append(avail_agent)
return avail_actions
def close(self):
"""Close StarCraft II."""
if self.renderer is not None:
self.renderer.close()
self.renderer = None
if self._sc2_proc:
self._sc2_proc.close()
def seed(self):
"""Returns the random seed used by the environment."""
return self._seed
def render(self, mode="human"):
if self.renderer is None:
from smac.env.starcraft2.render import StarCraft2Renderer
self.renderer = StarCraft2Renderer(self, mode)
assert (
mode == self.renderer.mode
), "mode must be consistent across render calls"
return self.renderer.render(mode)
def _kill_all_units(self):
"""Kill all units on the map."""
units_alive = [
unit.tag for unit in self.agents.values() if unit.health > 0
] + [unit.tag for unit in self.enemies.values() if unit.health > 0]
debug_command = [
d_pb.DebugCommand(kill_unit=d_pb.DebugKillUnit(tag=units_alive))
]
self._controller.debug(debug_command)
def init_units(self):
"""Initialise the units."""
while True:
# Sometimes not all units have yet been created by SC2
self.agents = {}
self.enemies = {}
ally_units = [
unit
for unit in self._obs.observation.raw_data.units
if unit.owner == 1
]
ally_units_sorted = sorted(
ally_units,
key=attrgetter("unit_type", "pos.x", "pos.y"),
reverse=False,
)
for i in range(len(ally_units_sorted)):
self.agents[i] = ally_units_sorted[i]
if self.debug:
logging.debug(
"Unit {} is {}, x = {}, y = {}".format(
len(self.agents),
self.agents[i].unit_type,
self.agents[i].pos.x,
self.agents[i].pos.y,
)
)
for unit in self._obs.observation.raw_data.units:
if unit.owner == 2:
self.enemies[len(self.enemies)] = unit
if self._episode_count == 0:
self.max_reward += unit.health_max + unit.shield_max
if self._episode_count == 0:
min_unit_type = min(
unit.unit_type for unit in self.agents.values()
)
self._init_ally_unit_types(min_unit_type)
all_agents_created = len(self.agents) == self.n_agents
all_enemies_created = len(self.enemies) == self.n_enemies
self._unit_types = [
unit.unit_type for unit in ally_units_sorted
] + [
unit.unit_type
for unit in self._obs.observation.raw_data.units
if unit.owner == 2
]
if all_agents_created and all_enemies_created: # all good
return
try:
self._controller.step(1)
self._obs = self._controller.observe()
except (protocol.ProtocolError, protocol.ConnectionError):
self.full_restart()
self.reset()
def get_unit_types(self):
if self._unit_types is None:
warn(
"unit types have not been initialized yet, please call"
"env.reset() to populate this and call t1286he method again."
)
return self._unit_types
def update_units(self):
"""Update units after an environment step.
This function assumes that self._obs is up-to-date.
"""
n_ally_alive = 0
n_enemy_alive = 0
# Store previous state
self.previous_ally_units = deepcopy(self.agents)
self.previous_enemy_units = deepcopy(self.enemies)
for al_id, al_unit in self.agents.items():
updated = False
for unit in self._obs.observation.raw_data.units:
if al_unit.tag == unit.tag:
self.agents[al_id] = unit
updated = True
n_ally_alive += 1
break
if not updated: # dead
al_unit.health = 0
for e_id, e_unit in self.enemies.items():
updated = False
for unit in self._obs.observation.raw_data.units:
if e_unit.tag == unit.tag:
self.enemies[e_id] = unit
updated = True
n_enemy_alive += 1
break
if not updated: # dead
e_unit.health = 0
if (
n_ally_alive == 0
and n_enemy_alive > 0
or self.only_medivac_left(ally=True)
):
return -1 # lost
if (
n_ally_alive > 0
and n_enemy_alive == 0
or self.only_medivac_left(ally=False)
):
return 1 # won
if n_ally_alive == 0 and n_enemy_alive == 0:
return 0
return None
def _init_ally_unit_types(self, min_unit_type):
"""Initialise ally unit types. Should be called once from the
init_units function.
"""
self._min_unit_type = min_unit_type
if self.map_type == "marines":
self.marine_id = min_unit_type
elif self.map_type == "stalkers_and_zealots":
self.stalker_id = min_unit_type
self.zealot_id = min_unit_type + 1
elif self.map_type == "colossi_stalkers_zealots":
self.colossus_id = min_unit_type
self.stalker_id = min_unit_type + 1
self.zealot_id = min_unit_type + 2
elif self.map_type == "MMM":
self.marauder_id = min_unit_type
self.marine_id = min_unit_type + 1
self.medivac_id = min_unit_type + 2
elif self.map_type == "zealots":
self.zealot_id = min_unit_type
elif self.map_type == "hydralisks":
self.hydralisk_id = min_unit_type
elif self.map_type == "stalkers":
self.stalker_id = min_unit_type
elif self.map_type == "colossus":
self.colossus_id = min_unit_type
elif self.map_type == "bane":
self.baneling_id = min_unit_type
self.zergling_id = min_unit_type + 1
def only_medivac_left(self, ally):
"""Check if only Medivac units are left."""
if self.map_type != "MMM":
return False
if ally:
units_alive = [
a
for a in self.agents.values()
if (a.health > 0 and a.unit_type != self.medivac_id)
]
if len(units_alive) == 0:
return True
return False
else:
units_alive = [
a
for a in self.enemies.values()
if (a.health > 0 and a.unit_type != self.medivac_id)
]
if len(units_alive) == 1 and units_alive[0].unit_type == 54:
return True
return False
def get_unit_by_id(self, a_id):
"""Get unit by ID."""
return self.agents[a_id]
def get_stats(self):
stats = {
"battles_won": self.battles_won,
"battles_game": self.battles_game,
"battles_draw": self.timeouts,
"win_rate": self.battles_won / self.battles_game,
"timeouts": self.timeouts,
"restarts": self.force_restarts,
}
return stats
def get_env_info(self):
env_info = super().get_env_info()
env_info["agent_features"] = self.ally_state_attr_names
env_info["enemy_features"] = self.enemy_state_attr_names
return env_info
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/pettingzoo/README.rst
================================================
SMAC on PettingZoo
==================
This example shows how to run SMAC environments with PettingZoo multi-agent API.
Instructions
------------
To get started, first install PettingZoo with ``pip install pettingzoo``.
The SMAC environment for PettingZoo, ``StarCraft2PZEnv``, can be initialized with two different API templates.
* **AEC**: PettingZoo is based in the *Agent Environment Cycle* game model, more information about "AEC" can be read in the following `paper `_. To create a SMAC environment as an "AEC" PettingZoo game model use: ::
from smac.env.pettingzoo import StarCraft2PZEnv
env = StarCraft2PZEnv.env()
* **Parallel**: PettingZoo also supports parallel environments where all agents have simultaneous actions and observations. This type of environment can be created as follows: ::
from smac.env.pettingzoo import StarCraft2PZEnv
env = StarCraft2PZEnv.parallel_env()
`pettingzoo_demo.py` has an example of a SMAC environment being used as a PettingZoo "AEC" environment. With `env.render()` it is possible to output an instance of the environment as a frame in pygame. This is useful for debugging purposes.
| See https://www.pettingzoo.ml/api for more documentation.
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/pettingzoo/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/pettingzoo/pettingzoo_demo.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import random
import numpy as np
from smac.env.pettingzoo import StarCraft2PZEnv
def main():
"""
Runs an env object with random actions.
"""
env = StarCraft2PZEnv.env()
episodes = 10
total_reward = 0
done = False
completed_episodes = 0
while completed_episodes < episodes:
env.reset()
for agent in env.agent_iter():
env.render()
obs, reward, done, _ = env.last()
total_reward += reward
if done:
action = None
elif isinstance(obs, dict) and "action_mask" in obs:
action = random.choice(np.flatnonzero(obs["action_mask"]))
else:
action = env.action_spaces[agent].sample()
env.step(action)
completed_episodes += 1
env.close()
print("Average total reward", total_reward / episodes)
if __name__ == "__main__":
main()
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/random_agents.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from smac.env import StarCraft2Env
import numpy as np
def main():
env = StarCraft2Env(map_name="8m")
env_info = env.get_env_info()
n_actions = env_info["n_actions"]
n_agents = env_info["n_agents"]
n_episodes = 10
for e in range(n_episodes):
env.reset()
terminated = False
episode_reward = 0
while not terminated:
obs = env.get_obs()
state = env.get_state()
# env.render() # Uncomment for rendering
actions = []
for agent_id in range(n_agents):
avail_actions = env.get_avail_agent_actions(agent_id)
avail_actions_ind = np.nonzero(avail_actions)[0]
action = np.random.choice(avail_actions_ind)
actions.append(action)
reward, terminated, _ = env.step(actions)
episode_reward += reward
print("Total reward in episode {} = {}".format(e, episode_reward))
env.close()
if __name__ == "__main__":
main()
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/rllib/README.rst
================================================
SMAC on RLlib
=============
This example shows how to run SMAC environments with RLlib multi-agent.
Instructions
------------
To get started, first install RLlib with ``pip install -U ray[rllib]``. You will also need TensorFlow installed.
In ``run_ppo.py``, each agent will be controlled by an independent PPO policy (the policies share weights). This setup serves as a single-agent baseline for this task.
In ``run_qmix.py``, the agents are controlled by the multi-agent QMIX policy. This setup is an example of centralized training and decentralized execution.
See https://ray.readthedocs.io/en/latest/rllib.html for more documentation.
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/rllib/__init__.py
================================================
from smac.examples.rllib.env import RLlibStarCraft2Env
from smac.examples.rllib.model import MaskedActionsModel
__all__ = ["RLlibStarCraft2Env", "MaskedActionsModel"]
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/rllib/env.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import random
import numpy as np
from gym.spaces import Discrete, Box, Dict
from ray import rllib
from smac.env import StarCraft2Env
class RLlibStarCraft2Env(rllib.MultiAgentEnv):
"""Wraps a smac StarCraft env to be compatible with RLlib multi-agent."""
def __init__(self, **smac_args):
"""Create a new multi-agent StarCraft env compatible with RLlib.
Arguments:
smac_args (dict): Arguments to pass to the underlying
smac.env.starcraft.StarCraft2Env instance.
Examples:
>>> from smac.examples.rllib import RLlibStarCraft2Env
>>> env = RLlibStarCraft2Env(map_name="8m")
>>> print(env.reset())
"""
self._env = StarCraft2Env(**smac_args)
self._ready_agents = []
self.observation_space = Dict(
{
"obs": Box(-1, 1, shape=(self._env.get_obs_size(),)),
"action_mask": Box(
0, 1, shape=(self._env.get_total_actions(),)
),
}
)
self.action_space = Discrete(self._env.get_total_actions())
def reset(self):
"""Resets the env and returns observations from ready agents.
Returns:
obs (dict): New observations for each ready agent.
"""
obs_list, state_list = self._env.reset()
return_obs = {}
for i, obs in enumerate(obs_list):
return_obs[i] = {
"action_mask": np.array(self._env.get_avail_agent_actions(i)),
"obs": obs,
}
self._ready_agents = list(range(len(obs_list)))
return return_obs
def step(self, action_dict):
"""Returns observations from ready agents.
The returns are dicts mapping from agent_id strings to values. The
number of agents in the env can vary over time.
Returns
-------
obs (dict): New observations for each ready agent.
rewards (dict): Reward values for each ready agent. If the
episode is just started, the value will be None.
dones (dict): Done values for each ready agent. The special key
"__all__" (required) is used to indicate env termination.
infos (dict): Optional info values for each agent id.
"""
actions = []
for i in self._ready_agents:
if i not in action_dict:
raise ValueError(
"You must supply an action for agent: {}".format(i)
)
actions.append(action_dict[i])
if len(actions) != len(self._ready_agents):
raise ValueError(
"Unexpected number of actions: {}".format(
action_dict,
)
)
rew, done, info = self._env.step(actions)
obs_list = self._env.get_obs()
return_obs = {}
for i, obs in enumerate(obs_list):
return_obs[i] = {
"action_mask": self._env.get_avail_agent_actions(i),
"obs": obs,
}
rews = {i: rew / len(obs_list) for i in range(len(obs_list))}
dones = {i: done for i in range(len(obs_list))}
dones["__all__"] = done
infos = {i: info for i in range(len(obs_list))}
self._ready_agents = list(range(len(obs_list)))
return return_obs, rews, dones, infos
def close(self):
"""Close the environment"""
self._env.close()
def seed(self, seed):
random.seed(seed)
np.random.seed(seed)
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/rllib/model.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
from ray.rllib.models import Model
from ray.rllib.models.tf.misc import normc_initializer
class MaskedActionsModel(Model):
"""Custom RLlib model that emits -inf logits for invalid actions.
This is used to handle the variable-length StarCraft action space.
"""
def _build_layers_v2(self, input_dict, num_outputs, options):
action_mask = input_dict["obs"]["action_mask"]
if num_outputs != action_mask.shape[1].value:
raise ValueError(
"This model assumes num outputs is equal to max avail actions",
num_outputs,
action_mask,
)
# Standard fully connected network
last_layer = input_dict["obs"]["obs"]
hiddens = options.get("fcnet_hiddens")
for i, size in enumerate(hiddens):
label = "fc{}".format(i)
last_layer = tf.layers.dense(
last_layer,
size,
kernel_initializer=normc_initializer(1.0),
activation=tf.nn.tanh,
name=label,
)
action_logits = tf.layers.dense(
last_layer,
num_outputs,
kernel_initializer=normc_initializer(0.01),
activation=None,
name="fc_out",
)
# Mask out invalid actions (use tf.float32.min for stability)
inf_mask = tf.maximum(tf.log(action_mask), tf.float32.min)
masked_logits = inf_mask + action_logits
return masked_logits, last_layer
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/rllib/run_ppo.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
"""Example of running StarCraft2 with RLlib PPO.
In this setup, each agent will be controlled by an independent PPO policy.
However the policies share weights.
Increase the level of parallelism by changing --num-workers.
"""
import argparse
import ray
from ray.tune import run_experiments, register_env
from ray.rllib.models import ModelCatalog
from smac.examples.rllib.env import RLlibStarCraft2Env
from smac.examples.rllib.model import MaskedActionsModel
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--num-iters", type=int, default=100)
parser.add_argument("--num-workers", type=int, default=2)
parser.add_argument("--map-name", type=str, default="8m")
args = parser.parse_args()
ray.init()
register_env("smac", lambda smac_args: RLlibStarCraft2Env(**smac_args))
ModelCatalog.register_custom_model("mask_model", MaskedActionsModel)
run_experiments(
{
"ppo_sc2": {
"run": "PPO",
"env": "smac",
"stop": {
"training_iteration": args.num_iters,
},
"config": {
"num_workers": args.num_workers,
"observation_filter": "NoFilter", # breaks the action mask
"vf_share_layers": True, # no separate value model
"env_config": {
"map_name": args.map_name,
},
"model": {
"custom_model": "mask_model",
},
},
},
}
)
================================================
FILE: examples/Social_Cognition/ToCM/smac/examples/rllib/run_qmix.py
================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
"""Example of running StarCraft2 with RLlib QMIX.
This assumes all agents are homogeneous. The agents are grouped and assigned
to the multi-agent QMIX policy. Note that the default hyperparameters for
RLlib QMIX are different from pymarl's QMIX.
"""
import argparse
from gym.spaces import Tuple
import ray
from ray.tune import run_experiments, register_env
from smac.examples.rllib.env import RLlibStarCraft2Env
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--num-iters", type=int, default=100)
parser.add_argument("--num-workers", type=int, default=2)
parser.add_argument("--map-name", type=str, default="8m")
args = parser.parse_args()
def env_creator(smac_args):
env = RLlibStarCraft2Env(**smac_args)
agent_list = list(range(env._env.n_agents))
grouping = {
"group_1": agent_list,
}
obs_space = Tuple([env.observation_space for i in agent_list])
act_space = Tuple([env.action_space for i in agent_list])
return env.with_agent_groups(
grouping, obs_space=obs_space, act_space=act_space
)
ray.init()
register_env("sc2_grouped", env_creator)
run_experiments(
{
"qmix_sc2": {
"run": "QMIX",
"env": "sc2_grouped",
"stop": {
"training_iteration": args.num_iters,
},
"config": {
"num_workers": args.num_workers,
"env_config": {
"map_name": args.map_name,
},
},
},
}
)
================================================
FILE: examples/Social_Cognition/ToCM/train.py
================================================
import argparse
import os
import sys
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
from agent.runners.ToCMRunner import ToCMRunner
from configs import Experiment, SimpleObservationConfig, NearRewardConfig, DeadlockPunishmentConfig, \
RewardsComposerConfig
from configs.EnvConfigs import StarCraftConfig, EnvCurriculumConfig, MPEConfig # TODO
from configs.ToCM.ToCMControllerConfig import ToCMControllerConfig
from configs.ToCM.ToCMLearnerConfig import ToCMLearnerConfig
from environments import Env
from utils.util import get_dim_from_space, get_cent_act_dim
import torch
import random
import numpy as np
import setproctitle
setproctitle.setproctitle("MPE_obs_2_hetero")
def occumpy_mem(cuda_device):
total, used = os.popen(
'"/usr/bin/nvidia-smi" --query-gpu=memory.total,memory.used --format=csv,nounits,noheader').read().strip().split(
"\n")[int(cuda_device)].split(',')
total = int(total)
used = int(used)
cc = 0.85
block_mem = int((total - used) * cc)
x = torch.cuda.FloatTensor(256, 1024, block_mem)
del x
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--env', type=str, default="mpe", help='starcraft or mpe') # TODO
parser.add_argument('--env_name', type=str, default="hetero_spread", help='Specific setting') # TODO
# star : 2s_vs_1sc MMM 2s3z 3s_vs_3z 3s5z_vs_3s6z simple_spread
parser.add_argument('--n_workers', type=int, default=4, help='Number of workers')
parser.add_argument('--device', type=str, default='cuda', help='device')
parser.add_argument('--seed', type=int, default=50, help='random')
# TODO num_landmarks num_adversaries episode_length num_good_agents
parser.add_argument('--num_agents', type=int, default=2, help='mpe_num_agents') # simple_adversary
parser.add_argument('--num_adversaries', type=int, default=None, help='mpe_num_adversaries')
parser.add_argument('--num_good_agents', type=int, default=None, help='mpe_num_good_agents')
parser.add_argument('--num_landmarks', type=int, default=2, help='mpe_num_landmarks')
parser.add_argument('--episode_length', type=int, default=25, help='mpe_episode_length')
parser.add_argument('--num_rollout_threads', type=int, default=128, help='mpe_episode_length')
parser.add_argument('--benchmark', type=bool, default=False, help='mpe_use_benchmark')
return parser.parse_args() # 为啥直接跳到prepare_starcraft_configs函数里了
def setup_seed(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
def train_ToCM(exp, n_workers): # no env.episode_length
runner = ToCMRunner(exp.env_config, exp.learner_config, exp.controller_config, n_workers)
runner.run(exp.steps, exp.episodes) # 10 ** 10 50000
def get_env_info(configs, env):
for config in configs:
config.IN_DIM = env.n_obs # 17 2s_vs_1sc
config.ACTION_SIZE = env.n_actions # 7 2s_vs_1sc
env.close()
def get_env_info_mpe(configs, env): # add to ToCM controller and worker
# TODO cent_obs_dim and cent_action_dim use share_policy
for config in configs:
config.CENT_OBS_DIM = get_dim_from_space(env.env.share_observation_space[0]) # 54=num_agents*IN_DIM
config.CENT_ACT_DIM = get_cent_act_dim(env.env.action_space) # 15=num_agents*ACTION_SIZE
config.IN_DIM = get_dim_from_space(env.env.observation_space[0]) # dim 18
config.ACTION_SIZE = get_dim_from_space(env.env.action_space[0]) # dim 5
env.close()
def prepare_starcraft_configs(env_name, device):
# env_name '3s5z_vs_3s6z' device 'cuda:6' RANDOM_SEED 1 args.n_workers 2
# args.env 'starcraft' args.env_name '3s5z_vs_3s6z' args.device 'cuda:6' args.seed 1
agent_configs = [ToCMControllerConfig(env_name, RANDOM_SEED, device),
ToCMLearnerConfig(env_name, RANDOM_SEED, device)]
env_config = StarCraftConfig(env_name, RANDOM_SEED)
get_env_info(agent_configs, env_config.create_env())
return {"env_config": (env_config, 100),
"controller_config": agent_configs[0],
"learner_config": agent_configs[1],
"reward_config": None,
"obs_builder_config": None}
def prepare_mpe_configs(arg):
agent_configs = [ToCMControllerConfig(arg.env_name, RANDOM_SEED, arg.device),
ToCMLearnerConfig(arg.env_name, RANDOM_SEED, arg.device)]
env_config = MPEConfig(arg)
get_env_info_mpe(agent_configs, env_config.create_env())
return {"env_config": (env_config, 100),
"controller_config": agent_configs[0],
"learner_config": agent_configs[1],
"reward_config": None,
"obs_builder_config": None} # TODO whether has reward config and obs builder config
if __name__ == "__main__":
# occumpy_mem(2)
# RANDOM_SEED = 23 # RANDOM_SEED 1
args = parse_args()
# print("args=", args)
RANDOM_SEED = args.seed
setup_seed(RANDOM_SEED) # TODO
# args.env_name '3s5z_vs_3s6z' args.device 'cuda:6' args.seed 1 args.n_workers 2
if args.env == Env.STARCRAFT:
configs = prepare_starcraft_configs(args.env_name, args.device)
elif args.env == Env.MPE:
configs = prepare_mpe_configs(args)
# as env is mpe env_name is simple_adversary
else:
raise Exception("Unknown environment")
configs["env_config"][0].ENV_TYPE = Env(args.env) # 转化为字符串
configs["learner_config"].ENV_TYPE = Env(args.env)
configs["controller_config"].ENV_TYPE = Env(args.env)
exp = Experiment(steps=10 ** 10,
episodes=50000,
random_seed=RANDOM_SEED,
env_config=EnvCurriculumConfig(*zip(configs["env_config"]), Env(args.env), args.device, # TODO
obs_builder_config=configs["obs_builder_config"],
reward_config=configs["reward_config"]),
controller_config=configs["controller_config"],
learner_config=configs["learner_config"])
# print("exp=", exp)
train_ToCM(exp, n_workers=args.n_workers)
================================================
FILE: examples/Social_Cognition/ToCM/utils/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToCM/utils/mlp_buffer.py
================================================
import numpy as np
from utils.util import get_dim_from_space
from utils.segment_tree import SumSegmentTree, MinSegmentTree
def _cast(x):
return x.transpose(1, 0, 2)
class MlpReplayBuffer(object):
def __init__(self, policy_info, policy_agents, buffer_size, use_same_share_obs, use_avail_acts,
use_reward_normalization=False):
"""
Replay buffer class for training MLP policies.
:param policy_info: (dict) maps policy id to a dict containing information about corresponding policy.
:param policy_agents: (dict) maps policy id to list of agents controled by corresponding policy.
:param buffer_size: (int) max number of transitions to store in the buffer.
:param use_same_share_obs: (bool) whether all agents share the same centralized observation.
:param use_avail_acts: (bool) whether to store what actions are available.
:param use_reward_normalization: (bool) whether to use reward normalization.
"""
self.policy_info = policy_info
self.policy_buffers = {p_id: MlpPolicyBuffer(buffer_size,
len(policy_agents[p_id]),
self.policy_info[p_id]['obs_space'],
self.policy_info[p_id]['share_obs_space'],
self.policy_info[p_id]['act_space'],
use_same_share_obs,
use_avail_acts,
use_reward_normalization)
for p_id in self.policy_info.keys()}
def __len__(self):
return self.policy_buffers['policy_0'].filled_i
def insert(self, num_insert_steps, obs, share_obs, acts, rewards,
next_obs, next_share_obs, dones, dones_env, valid_transition,
avail_acts, next_avail_acts):
"""
Insert a set of transitions into buffer. If the buffer size overflows, old transitions are dropped.
:param num_insert_steps: (int) number of transitions to be added to buffer
:param obs: (dict) maps policy id to numpy array of observations of agents corresponding to that policy
:param share_obs: (dict) maps policy id to numpy array of centralized observation corresponding to that policy
:param acts: (dict) maps policy id to numpy array of actions of agents corresponding to that policy
:param rewards: (dict) maps policy id to numpy array of rewards of agents corresponding to that policy
:param next_obs: (dict) maps policy id to numpy array of next step observations of agents corresponding to that policy
:param next_share_obs: (dict) maps policy id to numpy array of next step centralized observations corresponding to that policy
:param dones: (dict) maps policy id to numpy array of terminal status of agents corresponding to that policy
:param dones_env: (dict) maps policy id to numpy array of terminal status of env
:param valid_transition: (dict) maps policy id to numpy array of whether the corresponding transition is valid of agents corresponding to that policy
:param avail_acts: (dict) maps policy id to numpy array of available actions of agents corresponding to that policy
:param next_avail_acts: (dict) maps policy id to numpy array of next step available actions of agents corresponding to that policy
:return: (np.ndarray) indexes in which the new transitions were placed.
"""
idx_range = None
for p_id in self.policy_info.keys():
idx_range = self.policy_buffers[p_id].insert(num_insert_steps,
np.array(obs[p_id]), np.array(share_obs[p_id]),
np.array(acts[p_id]), np.array(rewards[p_id]),
np.array(next_obs[p_id]), np.array(next_share_obs[p_id]),
np.array(dones[p_id]), np.array(dones_env[p_id]),
np.array(valid_transition[p_id]),
np.array(avail_acts[p_id]), np.array(next_avail_acts[p_id]))
return idx_range
def sample(self, batch_size):
"""
Sample a set of transitions from buffer, uniformly at random.
:param batch_size: (int) number of transitions to sample from buffer.
:return: obs: (dict) maps policy id to sampled observations corresponding to that policy
:return: share_obs: (dict) maps policy id to sampled observations corresponding to that policy
:return: acts: (dict) maps policy id to sampled actions corresponding to that policy
:return: rewards: (dict) maps policy id to sampled rewards corresponding to that policy
:return: next_obs: (dict) maps policy id to sampled next step observations corresponding to that policy
:return: next_share_obs: (dict) maps policy id to sampled next step centralized observations corresponding to that policy
:return: dones: (dict) maps policy id to sampled terminal status of agents corresponding to that policy
:return: dones_env: (dict) maps policy id to sampled environment terminal status corresponding to that policy
:return: valid_transition: (dict) maps policy_id to whether each sampled transition is valid or not (invalid if corresponding agent is dead)
:return: avail_acts: (dict) maps policy_id to available actions corresponding to that policy
:return: next_avail_acts: (dict) maps policy_id to next step available actions corresponding to that policy
"""
inds = np.random.choice(len(self), batch_size)
obs, share_obs, acts, rewards, next_obs, next_share_obs, dones, dones_env, valid_transition, avail_acts, next_avail_acts = {}, {}, {}, {}, {}, {}, {}, {}, {}, {}, {}
for p_id in self.policy_info.keys():
obs[p_id], share_obs[p_id], acts[p_id], rewards[p_id], next_obs[p_id], next_share_obs[p_id], \
dones[p_id], dones_env[p_id], valid_transition[p_id], avail_acts[p_id], next_avail_acts[p_id] = \
self.policy_buffers[p_id].sample_inds(inds)
return obs, share_obs, acts, rewards, next_obs, next_share_obs, dones, dones_env, valid_transition, avail_acts, next_avail_acts, None, None
class MlpPolicyBuffer(object):
def __init__(self, buffer_size, num_agents, obs_space, share_obs_space, act_space, use_same_share_obs,
use_avail_acts, use_reward_normalization=False):
"""
Buffer class containing buffer data corresponding to a single policy.
:param buffer_size: (int) max number of transitions to store in buffer.
:param num_agents: (int) number of agents controlled by the policy.
:param obs_space: (gym.Space) observation space of the environment.
:param share_obs_space: (gym.Space) centralized observation space of the environment.
:param act_space: (gym.Space) action space of the environment.
:use_same_share_obs: (bool) whether all agents share the same centralized observation.
:use_avail_acts: (bool) whether to store what actions are available.
:param use_reward_normalization: (bool) whether to use reward normalization.
"""
self.buffer_size = buffer_size
self.num_agents = num_agents
self.use_same_share_obs = use_same_share_obs
self.use_avail_acts = use_avail_acts
self.use_reward_normalization = use_reward_normalization
self.filled_i = 0
self.current_i = 0
# obs
if obs_space.__class__.__name__ == 'Box':
obs_shape = obs_space.shape
share_obs_shape = share_obs_space.shape
elif obs_space.__class__.__name__ == 'list':
obs_shape = obs_space
share_obs_shape = share_obs_space
else:
raise NotImplementedError
self.obs = np.zeros(
(self.buffer_size, self.num_agents, obs_shape[0]), dtype=np.float32)
if self.use_same_share_obs:
self.share_obs = np.zeros((self.buffer_size, share_obs_shape[0]), dtype=np.float32)
else:
self.share_obs = np.zeros((self.buffer_size, self.num_agents, share_obs_shape[0]), dtype=np.float32)
self.next_obs = np.zeros_like(self.obs, dtype=np.float32)
self.next_share_obs = np.zeros_like(self.share_obs, dtype=np.float32)
# action
act_dim = np.sum(get_dim_from_space(act_space))
self.acts = np.zeros((self.buffer_size, self.num_agents, act_dim), dtype=np.float32)
if self.use_avail_acts:
self.avail_acts = np.ones_like(self.acts, dtype=np.float32)
self.next_avail_acts = np.ones_like(self.avail_acts, dtype=np.float32)
# rewards
self.rewards = np.zeros((self.buffer_size, self.num_agents, 1), dtype=np.float32)
# default to done being True
self.dones = np.ones_like(self.rewards, dtype=np.float32)
self.dones_env = np.ones((self.buffer_size, 1), dtype=np.float32)
self.valid_transition = np.zeros_like(self.dones, dtype=np.float32)
def __len__(self):
return self.filled_i
def insert(self, num_insert_steps, obs, share_obs, acts, rewards,
next_obs, next_share_obs, dones, dones_env, valid_transition,
avail_acts=None, next_avail_acts=None):
"""
Insert a set of transitions corresponding to this policy into buffer. If the buffer size overflows, old transitions are dropped.
:param num_insert_steps: (int) number of transitions to be added to buffer
:param obs: (np.ndarray) observations of agents corresponding to this policy.
:param share_obs: (np.ndarray) centralized observations of agents corresponding to this policy.
:param acts: (np.ndarray) actions of agents corresponding to this policy.
:param rewards: (np.ndarray) rewards of agents corresponding to this policy.
:param next_obs: (np.ndarray) next step observations of agents corresponding to this policy.
:param next_share_obs: (np.ndarray) next step centralized observations of agents corresponding to this policy.
:param dones: (np.ndarray) terminal status of agents corresponding to this policy.
:param dones_env: (np.ndarray) environment terminal status.
:param valid_transition: (np.ndarray) whether each transition is valid or not (invalid if agent was dead during transition)
:param avail_acts: (np.ndarray) available actions of agents corresponding to this policy.
:param next_avail_acts: (np.ndarray) next step available actions of agents corresponding to this policy.
:return: (np.ndarray) indexes of the buffer the new transitions were placed in.
"""
# obs: [step, episode, agent, dim]
assert obs.shape[0] == num_insert_steps, ("different size!")
if self.current_i + num_insert_steps <= self.buffer_size:
idx_range = np.arange(self.current_i, self.current_i + num_insert_steps)
else:
num_left_steps = self.current_i + num_insert_steps - self.buffer_size
idx_range = np.concatenate((np.arange(self.current_i, self.buffer_size), np.arange(num_left_steps)))
self.obs[idx_range] = obs.copy()
self.share_obs[idx_range] = share_obs.copy()
self.acts[idx_range] = acts.copy()
self.rewards[idx_range] = rewards.copy()
self.next_obs[idx_range] = next_obs.copy()
self.next_share_obs[idx_range] = next_share_obs.copy()
self.dones[idx_range] = dones.copy()
self.dones_env[idx_range] = dones_env.copy()
self.valid_transition[idx_range] = valid_transition.copy()
if self.use_avail_acts:
self.avail_acts[idx_range] = avail_acts.copy()
self.next_avail_acts[idx_range] = next_avail_acts.copy()
self.current_i = idx_range[-1] + 1
self.filled_i = min(self.filled_i + len(idx_range), self.buffer_size)
return idx_range
def sample_inds(self, sample_inds):
"""
Sample a set of transitions from buffer from the specified indices.
:param sample_inds: (np.ndarray) indices of samples to return from buffer.
:return: obs: (np.ndarray) sampled observations corresponding to that policy
:return: share_obs: (np.ndarray) sampled observations corresponding to that policy
:return: acts: (np.ndarray) sampled actions corresponding to that policy
:return: rewards: (np.ndarray) sampled rewards corresponding to that policy
:return: next_obs: (np.ndarray) sampled next step observations corresponding to that policy
:return: next_share_obs: (np.ndarray) sampled next step centralized observations corresponding to that policy
:return: dones: (np.ndarray) sampled terminal status of agents corresponding to that policy
:return: dones_env: (np.ndarray) sampled environment terminal status corresponding to that policy
:return: valid_transition: (np.ndarray) whether each sampled transition is valid or not (invalid if corresponding agent is dead)
:return: avail_acts: (np.ndarray) sampled available actions corresponding to that policy
:return: next_avail_acts: (np.ndarray) sampled next step available actions corresponding to that policy
"""
obs = _cast(self.obs[sample_inds])
acts = _cast(self.acts[sample_inds])
if self.use_reward_normalization:
mean_reward = self.rewards[:self.filled_i].mean()
std_reward = self.rewards[:self.filled_i].std()
rewards = _cast(
(self.rewards[sample_inds] - mean_reward) / std_reward)
else:
rewards = _cast(self.rewards[sample_inds])
next_obs = _cast(self.next_obs[sample_inds])
if self.use_same_share_obs:
share_obs = self.share_obs[sample_inds]
next_share_obs = self.next_share_obs[sample_inds]
else:
share_obs = _cast(self.share_obs[sample_inds])
next_share_obs = _cast(self.next_share_obs[sample_inds])
dones = _cast(self.dones[sample_inds])
dones_env = self.dones_env[sample_inds]
valid_transition = _cast(self.valid_transition[sample_inds])
if self.use_avail_acts:
avail_acts = _cast(self.avail_acts[sample_inds])
next_avail_acts = _cast(self.next_avail_acts[sample_inds])
else:
avail_acts = None
next_avail_acts = None
return obs, share_obs, acts, rewards, next_obs, next_share_obs, dones, dones_env, valid_transition, avail_acts, next_avail_acts
class PrioritizedMlpReplayBuffer(MlpReplayBuffer):
def __init__(self, alpha, policy_info, policy_agents, buffer_size, use_same_share_obs, use_avail_acts,
use_reward_normalization=False):
"""Prioritized replay buffer class for training MLP policies. See parent class."""
super(PrioritizedMlpReplayBuffer, self).__init__(policy_info, policy_agents,
buffer_size, use_same_share_obs, use_avail_acts,
use_reward_normalization)
self.alpha = alpha
self.policy_info = policy_info
it_capacity = 1
while it_capacity < buffer_size:
it_capacity *= 2
self._it_sums = {p_id: SumSegmentTree(it_capacity) for p_id in self.policy_info.keys()}
self._it_mins = {p_id: MinSegmentTree(it_capacity) for p_id in self.policy_info.keys()}
self.max_priorities = {p_id: 1.0 for p_id in self.policy_info.keys()}
def insert(self, num_insert_steps, obs, share_obs, acts, rewards, next_obs, next_share_obs, dones, dones_env,
valid_transition, avail_acts=None, next_avail_acts=None):
"""See parent class."""
idx_range = super().insert(num_insert_steps, obs, share_obs, acts, rewards, next_obs, next_share_obs, dones,
dones_env, valid_transition, avail_acts, next_avail_acts)
for idx in range(idx_range[0], idx_range[1]):
for p_id in self.policy_info.keys():
self._it_sums[p_id][idx] = self.max_priorities[p_id] ** self.alpha
self._it_mins[p_id][idx] = self.max_priorities[p_id] ** self.alpha
return idx_range
def _sample_proportional(self, batch_size, p_id=None):
total = self._it_sums[p_id].sum(0, len(self) - 1)
mass = np.random.random(size=batch_size) * total
idx = self._it_sums[p_id].find_prefixsum_idx(mass)
return idx
def sample(self, batch_size, beta=0, p_id=None):
"""
Sample a set of transitions from buffer; probability of choosing a given sample is proportional to its priority.
:param batch_size: (int) number of transitions to sample.
:param beta: (float) controls the amount of prioritization to apply.
:param p_id: (str) policy which will be updated using the samples.
:return: See parent class.
"""
assert len(self) > batch_size, "Not enough samples in the buffer!"
assert beta > 0
batch_inds = self._sample_proportional(batch_size, p_id)
p_min = self._it_mins[p_id].min() / self._it_sums[p_id].sum()
max_weight = (p_min * len(self)) ** (-beta)
p_sample = self._it_sums[p_id][batch_inds] / self._it_sums[p_id].sum()
weights = (p_sample * len(self)) ** (-beta) / max_weight
obs, share_obs, acts, rewards, next_obs, next_share_obs, dones, dones_env, valid_transition, avail_acts, next_avail_acts = {}, {}, {}, {}, {}, {}, {}, {}, {}, {}, {}
for p_id in self.policy_info.keys():
p_buffer = self.policy_buffers[p_id]
obs[p_id], share_obs[p_id], acts[p_id], rewards[p_id], next_obs[p_id], next_share_obs[p_id], dones[p_id], \
dones_env[p_id], valid_transition[p_id], avail_acts[p_id], next_avail_acts[p_id] = p_buffer.sample_inds(batch_inds)
return obs, share_obs, acts, rewards, next_obs, next_share_obs, dones, dones_env, valid_transition, avail_acts, next_avail_acts, weights, batch_inds
def update_priorities(self, idxes, priorities, p_id=None):
"""
Update priorities of sampled transitions.
sets priority of transition at index idxes[i] in buffer
to priorities[i].
:param idxes: ([int]) List of idxes of sampled transitions
:param priorities: ([float]) List of updated priorities corresponding to transitions at the sampled idxes
denoted by variable `idxes`.
"""
assert len(idxes) == len(priorities)
assert np.min(priorities) > 0
assert np.min(idxes) >= 0
assert np.max(idxes) < len(self)
self._it_sums[p_id][idxes] = priorities ** self.alpha
self._it_mins[p_id][idxes] = priorities ** self.alpha
self.max_priorities[p_id] = max(
self.max_priorities[p_id], np.max(priorities))
================================================
FILE: examples/Social_Cognition/ToCM/utils/mlp_nstep_buffer.py
================================================
import numpy as np
import torch
import random
class NStepReplayBuffer:
def __init__(self, max_size, episode_len, n, policy_ids, agent_ids, policy_agents, policy_obs_dim, policy_act_dim, gamma):
self.max_size = max_size
self.episode_len = episode_len
# n for n-step returns
self.n = n
self.policy_ids = policy_ids
self.agent_ids = agent_ids
self.policy_agents = policy_agents
self.policy_buffers = {
p_id: NStepPolicyBuffer(p_id, self.max_size, episode_len, n, self.policy_agents[p_id], policy_obs_dim[p_id],
policy_act_dim[p_id], gamma) for p_id in self.policy_ids}
self.num_episodes = 0
self.num_transitions = 0
def push(self, t_env, observation_batch, action_batch, reward_batch, next_observation_batch, dones_batch, finish_episodes):
batch_size = observation_batch.shape[0]
observations = {a_id: np.vstack(
[obs[a_id] for obs in observation_batch]) for a_id in self.agent_ids}
actions = {a_id: np.vstack([act[a_id] for act in action_batch])
for a_id in self.agent_ids}
rewards = {a_id: np.vstack([rew[a_id] for rew in reward_batch])
for a_id in self.agent_ids}
n_observations = {a_id: np.vstack(
[nobs[a_id] for nobs in next_observation_batch]) for a_id in self.agent_ids}
if finish_episodes:
dones = {a_id: np.ones_like(rewards[a_id]).astype(
bool) for a_id in self.agent_ids}
else:
dones = {a_id: np.vstack(
[done[a_id] for done in dones_batch]) for a_id in self.agent_ids}
for p_id in self.policy_ids:
self.policy_buffers[p_id].push(
batch_size, t_env, observations, actions, rewards, n_observations, dones, finish_episodes)
assert len(
set([p_buffer.num_episodes for p_buffer in self.policy_buffers.values()])) == 1
assert len(
set([p_buffer.num_transitions for p_buffer in self.policy_buffers.values()])) == 1
self.num_episodes = self.policy_buffers[self.policy_ids[0]].num_episodes
self.num_transitions = self.policy_buffers[self.policy_ids[0]
].num_transitions
def sample(self, batch_size):
assert self.num_transitions > batch_size, "Cannot sample with no completed episodes in the buffer!"
chunk_starts = np.random.choice(self.episode_len, batch_size)
batch_inds = np.random.choice(self.num_episodes, batch_size)
obs = {}
act = {}
rew = {}
nobs = {}
dones = {}
for p_id in self.policy_ids:
p_buffer = self.policy_buffers[p_id]
o, a, r, no, d = p_buffer.get(batch_inds, chunk_starts)
obs[p_id] = o
act[p_id] = a
rew[p_id] = r
nobs[p_id] = no
dones[p_id] = d
return obs, act, rew, nobs, dones
class NStepPolicyBuffer:
def __init__(self, policy_id, max_size, episode_len, n, policy_agents, obs_dim, act_dim, gamma):
self.max_size = max_size
self.n = n
self.num_agents = len(policy_agents)
self.policy_id = policy_id
self.episode_len = episode_len
self.agent_ids = policy_agents
self.gamma = gamma
random.shuffle(self.agent_ids)
self.observations = np.zeros(
(self.num_agents, max_size, episode_len, obs_dim))
self.actions = np.zeros(
(self.num_agents, max_size, episode_len, act_dim))
self.rewards = np.zeros(
(self.num_agents, max_size, episode_len + n - 1, 1))
self.next_observations = np.zeros(
(self.num_agents, max_size, episode_len + n - 1, obs_dim))
self.dones = np.ones(
(self.num_agents, max_size, episode_len + n - 1, 1))
self.num_episodes = 0
self.num_transitions = 0
def push(self, num_envs, t_env, observation_batch, action_batch, reward_batch, next_observation_batch,
dones_batch, finish_episodes):
assert t_env < self.episode_len
if t_env == 0:
# shuffle the agent ids at the start of a new episode batch
random.shuffle(self.agent_ids)
if t_env == 0 and self.num_episodes + num_envs > self.max_size:
diff = self.num_episodes + num_envs - self.max_size
self.observations = np.roll(self.observations, -diff, axis=1)
self.actions = np.roll(self.actions, -diff, axis=1)
self.rewards = np.roll(self.rewards, -diff, axis=1)
self.next_observations = np.roll(
self.next_observations, -diff, axis=1)
self.dones = np.roll(self.dones, -diff, axis=1)
self.num_episodes -= diff
for i in range(self.num_agents):
if finish_episodes:
dones = np.ones_like(dones_batch[self.agent_ids[i]])
else:
dones = dones_batch[self.agent_ids[i]]
self.observations[i, self.num_episodes: self.num_episodes +
num_envs, t_env, :] = observation_batch[self.agent_ids[i]]
self.actions[i, self.num_episodes: self.num_episodes +
num_envs, t_env, :] = action_batch[self.agent_ids[i]]
self.rewards[i, self.num_episodes: self.num_episodes +
num_envs, t_env, :] = reward_batch[self.agent_ids[i]]
self.next_observations[i, self.num_episodes: self.num_episodes + num_envs, t_env, :] = next_observation_batch[
self.agent_ids[i]]
self.dones[i, self.num_episodes: self.num_episodes +
num_envs, t_env, :] = dones
self.num_transitions += num_envs
if finish_episodes:
self.num_episodes += num_envs
def get(self, batch_inds, start_inds):
batch_inds_col = batch_inds[:, None]
start_inds_col = start_inds[:, None]
nstep_inds = start_inds_col + np.arange(self.n)
obs = self.observations[:, batch_inds, start_inds, :]
acts = self.actions[:, batch_inds, start_inds, :]
# get the n-step rewards and weight each by exponentiated discounts
rews = self.rewards[:, batch_inds_col, nstep_inds, 0]
rews = rews * \
np.power((np.ones(self.n) * self.gamma), np.arange(self.n))
# sum the n-step rewards: rewards for terminal states are pre-set to 0, so don't need to mask
rews = np.sum(rews, axis=2).reshape(
self.num_agents, len(batch_inds), 1)
# get the nobs of the nth
nobs = self.next_observations[:,
batch_inds, start_inds + self.n - 1, :]
dones = self.dones[:, batch_inds, start_inds + self.n - 1, :]
return torch.from_numpy(obs), torch.from_numpy(acts), torch.from_numpy(rews), torch.from_numpy(
nobs), torch.from_numpy(dones)
================================================
FILE: examples/Social_Cognition/ToCM/utils/popart.py
================================================
import numpy as np
import torch
import torch.nn as nn
class PopArt(nn.Module):
""" Normalize a vector of observations - across the first norm_axes dimensions"""
def __init__(self, input_shape, norm_axes=1, beta=0.99999, per_element_update=False, epsilon=1e-5, device=torch.device("cpu")):
super(PopArt, self).__init__()
self.input_shape = input_shape
self.norm_axes = norm_axes
self.epsilon = epsilon
self.beta = beta
self.per_element_update = per_element_update
self.device = device
self.tpdv = dict(dtype=torch.float32, device=device)
self.running_mean = nn.Parameter(torch.zeros(input_shape, dtype=torch.float), requires_grad=False).to(self.device)
self.running_mean_sq = nn.Parameter(torch.zeros(input_shape, dtype=torch.float), requires_grad=False).to(self.device)
self.debiasing_term = nn.Parameter(torch.tensor(0.0, dtype=torch.float), requires_grad=False).to(self.device)
def reset_parameters(self):
self.running_mean.zero_()
self.running_mean_sq.zero_()
self.debiasing_term.zero_()
def running_mean_var(self):
debiased_mean = self.running_mean / self.debiasing_term.clamp(min=self.epsilon)
debiased_mean_sq = self.running_mean_sq / self.debiasing_term.clamp(min=self.epsilon)
debiased_var = (debiased_mean_sq - debiased_mean ** 2).clamp(max=self.alpha, min=1e-2)
return debiased_mean, debiased_var
def forward(self, input_vector, train=True):
# Make sure input is float32
input_vector = input_vector.to(**self.tpdv)
if train:
# Detach input before adding it to running means to avoid backpropping through it on
# subsequent batches.
detached_input = input_vector.detach()
batch_mean = detached_input.mean(dim=tuple(range(self.norm_axes)))
batch_sq_mean = (detached_input ** 2).mean(dim=tuple(range(self.norm_axes)))
if self.per_element_update:
batch_size = np.prod(detached_input.size()[:self.norm_axes])
weight = self.beta ** batch_size
else:
weight = self.beta
self.running_mean.mul_(weight).add_(batch_mean * (1.0 - weight))
self.running_mean_sq.mul_(weight).add_(batch_sq_mean * (1.0 - weight))
self.debiasing_term.mul_(weight).add_(1.0 * (1.0 - weight))
mean, var = self.running_mean_var()
out = (input_vector - mean[(None,) * self.norm_axes]) / torch.sqrt(var)[(None,) * self.norm_axes]
return out
def denormalize(self, input_vector):
""" Transform normalized data back into original distribution """
input_vector = input_vector.to(**self.tpdv)
mean, var = self.running_mean_var()
out = input_vector * torch.sqrt(var)[(None,) * self.norm_axes] + mean[(None,) * self.norm_axes]
return out
================================================
FILE: examples/Social_Cognition/ToCM/utils/rec_buffer.py
================================================
import numpy as np
from utils.util import get_dim_from_space
from utils.segment_tree import SumSegmentTree, MinSegmentTree
def _cast(x):
return x.transpose(2, 0, 1, 3)
class RecReplayBuffer(object):
def __init__(self, policy_info, policy_agents, buffer_size, episode_length, use_same_share_obs, use_avail_acts,
use_reward_normalization=False):
"""
Replay buffer class for training RNN policies. Stores entire episodes rather than single transitions.
:param policy_info: (dict) maps policy id to a dict containing information about corresponding policy.
:param policy_agents: (dict) maps policy id to list of agents controled by corresponding policy.
:param buffer_size: (int) max number of transitions to store in the buffer.
:param use_same_share_obs: (bool) whether all agents share the same centralized observation.
:param use_avail_acts: (bool) whether to store what actions are available.
:param use_reward_normalization: (bool) whether to use reward normalization.
"""
self.policy_info = policy_info
self.policy_buffers = {p_id: RecPolicyBuffer(buffer_size,
episode_length,
len(policy_agents[p_id]),
self.policy_info[p_id]['obs_space'],
self.policy_info[p_id]['share_obs_space'],
self.policy_info[p_id]['act_space'],
use_same_share_obs,
use_avail_acts,
use_reward_normalization)
for p_id in self.policy_info.keys()}
def __len__(self):
return self.policy_buffers['policy_0'].filled_i
def insert(self, num_insert_episodes, obs, share_obs, acts, rewards, dones, dones_env, avail_acts):
"""
Insert a set of episodes into buffer. If the buffer size overflows, old episodes are dropped.
:param num_insert_episodes: (int) number of episodes to be added to buffer
:param obs: (dict) maps policy id to numpy array of observations of agents corresponding to that policy
:param share_obs: (dict) maps policy id to numpy array of centralized observation corresponding to that policy
:param acts: (dict) maps policy id to numpy array of actions of agents corresponding to that policy
:param rewards: (dict) maps policy id to numpy array of rewards of agents corresponding to that policy
:param dones: (dict) maps policy id to numpy array of terminal status of agents corresponding to that policy
:param dones_env: (dict) maps policy id to numpy array of terminal status of env
:param valid_transition: (dict) maps policy id to numpy array of whether the corresponding transition is valid of agents corresponding to that policy
:param avail_acts: (dict) maps policy id to numpy array of available actions of agents corresponding to that policy
:return: (np.ndarray) indexes in which the new transitions were placed.
"""
for p_id in self.policy_info.keys():
idx_range = self.policy_buffers[p_id].insert(num_insert_episodes, np.array(obs[p_id]),
np.array(share_obs[p_id]), np.array(acts[p_id]),
np.array(rewards[p_id]), np.array(dones[p_id]),
np.array(dones_env[p_id]), np.array(avail_acts[p_id]))
return idx_range
def sample(self, batch_size):
"""
Sample a set of episodes from buffer, uniformly at random.
:param batch_size: (int) number of episodes to sample from buffer.
:return: obs: (dict) maps policy id to sampled observations corresponding to that policy
:return: share_obs: (dict) maps policy id to sampled observations corresponding to that policy
:return: acts: (dict) maps policy id to sampled actions corresponding to that policy
:return: rewards: (dict) maps policy id to sampled rewards corresponding to that policy
:return: dones: (dict) maps policy id to sampled terminal status of agents corresponding to that policy
:return: dones_env: (dict) maps policy id to sampled environment terminal status corresponding to that policy
:return: valid_transition: (dict) maps policy_id to whether each sampled transition is valid or not (invalid if corresponding agent is dead)
:return: avail_acts: (dict) maps policy_id to available actions corresponding to that policy
"""
inds = np.random.choice(self.__len__(), batch_size)
obs, share_obs, acts, rewards, dones, dones_env, avail_acts = {}, {}, {}, {}, {}, {}, {}
for p_id in self.policy_info.keys():
obs[p_id], share_obs[p_id], acts[p_id], rewards[p_id], dones[p_id], dones_env[p_id], avail_acts[p_id] = \
self.policy_buffers[p_id].sample_inds(inds)
return obs, share_obs, acts, rewards, dones, dones_env, avail_acts, None, None
class RecPolicyBuffer(object):
def __init__(self, buffer_size, episode_length, num_agents, obs_space, share_obs_space, act_space,
use_same_share_obs, use_avail_acts, use_reward_normalization=False):
"""
Buffer class containing buffer data corresponding to a single policy.
:param buffer_size: (int) max number of episodes to store in buffer.
:param episode_length: (int) max length of an episode.
:param num_agents: (int) number of agents controlled by the policy.
:param obs_space: (gym.Space) observation space of the environment.
:param share_obs_space: (gym.Space) centralized observation space of the environment.
:param act_space: (gym.Space) action space of the environment.
:use_same_share_obs: (bool) whether all agents share the same centralized observation.
:use_avail_acts: (bool) whether to store what actions are available.
:param use_reward_normalization: (bool) whether to use reward normalization.
"""
self.buffer_size = buffer_size
self.episode_length = episode_length
self.num_agents = num_agents
self.use_same_share_obs = use_same_share_obs
self.use_avail_acts = use_avail_acts
self.use_reward_normalization = use_reward_normalization
self.filled_i = 0
self.current_i = 0
# obs
if obs_space.__class__.__name__ == 'Box':
obs_shape = obs_space.shape
share_obs_shape = share_obs_space.shape
elif obs_space.__class__.__name__ == 'list':
obs_shape = obs_space
share_obs_shape = share_obs_space
else:
raise NotImplementedError
self.obs = np.zeros((self.episode_length + 1, self.buffer_size,
self.num_agents, obs_shape[0]), dtype=np.float32)
if self.use_same_share_obs:
self.share_obs = np.zeros((self.episode_length + 1, self.buffer_size, share_obs_shape[0]), dtype=np.float32)
else:
self.share_obs = np.zeros((self.episode_length + 1, self.buffer_size, self.num_agents, share_obs_shape[0]),
dtype=np.float32)
# action
act_dim = np.sum(get_dim_from_space(act_space))
self.acts = np.zeros((self.episode_length, self.buffer_size, self.num_agents, act_dim), dtype=np.float32)
if self.use_avail_acts:
self.avail_acts = np.ones((self.episode_length + 1, self.buffer_size, self.num_agents, act_dim),
dtype=np.float32)
# rewards
self.rewards = np.zeros((self.episode_length, self.buffer_size, self.num_agents, 1), dtype=np.float32)
# default to done being True
self.dones = np.ones_like(self.rewards, dtype=np.float32)
self.dones_env = np.ones((self.episode_length, self.buffer_size, 1), dtype=np.float32)
def __len__(self):
return self.filled_i
def insert(self, num_insert_episodes, obs, share_obs, acts, rewards, dones, dones_env, avail_acts=None):
"""
Insert a set of episodes corresponding to this policy into buffer. If the buffer size overflows, old transitions are dropped.
:param num_insert_steps: (int) number of transitions to be added to buffer
:param obs: (np.ndarray) observations of agents corresponding to this policy.
:param share_obs: (np.ndarray) centralized observations of agents corresponding to this policy.
:param acts: (np.ndarray) actions of agents corresponding to this policy.
:param rewards: (np.ndarray) rewards of agents corresponding to this policy.
:param dones: (np.ndarray) terminal status of agents corresponding to this policy.
:param dones_env: (np.ndarray) environment terminal status.
:param valid_transition: (np.ndarray) whether each transition is valid or not (invalid if agent was dead during transition)
:param avail_acts: (np.ndarray) available actions of agents corresponding to this policy.
:return: (np.ndarray) indexes of the buffer the new transitions were placed in.
"""
# obs: [step, episode, agent, dim]
episode_length = acts.shape[0]
assert episode_length == self.episode_length, ("different dimension!")
if self.current_i + num_insert_episodes <= self.buffer_size:
idx_range = np.arange(self.current_i, self.current_i + num_insert_episodes)
else:
num_left_episodes = self.current_i + num_insert_episodes - self.buffer_size
idx_range = np.concatenate((np.arange(self.current_i, self.buffer_size), np.arange(num_left_episodes)))
if self.use_same_share_obs:
# remove agent dimension since all agents share centralized observation
share_obs = share_obs[:, :, 0]
self.obs[:, idx_range] = obs.copy()
self.share_obs[:, idx_range] = share_obs.copy()
self.acts[:, idx_range] = acts.copy()
self.rewards[:, idx_range] = rewards.copy()
self.dones[:, idx_range] = dones.copy()
self.dones_env[:, idx_range] = dones_env.copy()
if self.use_avail_acts:
self.avail_acts[:, idx_range] = avail_acts.copy()
self.current_i = idx_range[-1] + 1
self.filled_i = min(self.filled_i + len(idx_range), self.buffer_size)
return idx_range
def sample_inds(self, sample_inds):
"""
Sample a set of transitions from buffer from the specified indices.
:param sample_inds: (np.ndarray) indices of samples to return from buffer.
:return: obs: (np.ndarray) sampled observations corresponding to that policy
:return: share_obs: (np.ndarray) sampled observations corresponding to that policy
:return: acts: (np.ndarray) sampled actions corresponding to that policy
:return: rewards: (np.ndarray) sampled rewards corresponding to that policy
:return: dones: (np.ndarray) sampled terminal status of agents corresponding to that policy
:return: dones_env: (np.ndarray) sampled environment terminal status corresponding to that policy
:return: valid_transition: (np.ndarray) whether each sampled transition in episodes are valid or not (invalid if corresponding agent is dead)
:return: avail_acts: (np.ndarray) sampled available actions corresponding to that policy
"""
obs = _cast(self.obs[:, sample_inds])
acts = _cast(self.acts[:, sample_inds])
if self.use_reward_normalization:
# mean std
# [length, envs, agents, 1]
# [length, envs, 1]
all_dones_env = np.tile(np.expand_dims(
self.dones_env[:, :self.filled_i], -1), (1, 1, self.num_agents, 1))
first_step_dones_env = np.zeros((1, self.filled_i, self.num_agents, 1))
curr_dones_env = np.concatenate((first_step_dones_env, all_dones_env[:self.episode_length - 1]))
temp_rewards = self.rewards[:, :self.filled_i].copy()
temp_rewards[curr_dones_env == 1.0] = np.nan
mean_reward = np.nanmean(temp_rewards)
std_reward = np.nanstd(temp_rewards)
rewards = _cast(
(self.rewards[:, sample_inds] - mean_reward) / std_reward)
else:
rewards = _cast(self.rewards[:, sample_inds])
if self.use_same_share_obs:
share_obs = self.share_obs[:, sample_inds]
else:
share_obs = _cast(self.share_obs[:, sample_inds])
dones = _cast(self.dones[:, sample_inds])
dones_env = self.dones_env[:, sample_inds]
if self.use_avail_acts:
avail_acts = _cast(self.avail_acts[:, sample_inds])
else:
avail_acts = None
return obs, share_obs, acts, rewards, dones, dones_env, avail_acts
class PrioritizedRecReplayBuffer(RecReplayBuffer):
def __init__(self, alpha, policy_info, policy_agents, buffer_size, episode_length, use_same_share_obs,
use_avail_acts, use_reward_normalization=False):
"""Prioritized replay buffer class for training RNN policies. See parent class."""
super(PrioritizedRecReplayBuffer, self).__init__(policy_info, policy_agents, buffer_size,
episode_length, use_same_share_obs, use_avail_acts,
use_reward_normalization)
self.alpha = alpha
self.policy_info = policy_info
it_capacity = 1
while it_capacity < buffer_size:
it_capacity *= 2
self._it_sums = {p_id: SumSegmentTree(
it_capacity) for p_id in self.policy_info.keys()}
self._it_mins = {p_id: MinSegmentTree(
it_capacity) for p_id in self.policy_info.keys()}
self.max_priorities = {p_id: 1.0 for p_id in self.policy_info.keys()}
def insert(self, num_insert_episodes, obs, share_obs, acts, rewards, dones, dones_env, avail_acts=None):
"""See parent class."""
idx_range = super().insert(num_insert_episodes, obs, share_obs, acts, rewards, dones, dones_env, avail_acts)
for idx in range(idx_range[0], idx_range[1]):
for p_id in self.policy_info.keys():
self._it_sums[p_id][idx] = self.max_priorities[p_id] ** self.alpha
self._it_mins[p_id][idx] = self.max_priorities[p_id] ** self.alpha
return idx_range
def _sample_proportional(self, batch_size, p_id=None):
total = self._it_sums[p_id].sum(0, len(self) - 1)
mass = np.random.random(size=batch_size) * total
idx = self._it_sums[p_id].find_prefixsum_idx(mass)
return idx
def sample(self, batch_size, beta=0, p_id=None):
"""
Sample a set of episodes from buffer; probability of choosing a given episode is proportional to its priority.
:param batch_size: (int) number of episodes to sample.
:param beta: (float) controls the amount of prioritization to apply.
:param p_id: (str) policy which will be updated using the samples.
:return: See parent class.
"""
assert len(
self) > batch_size, "Cannot sample with no completed episodes in the buffer!"
assert beta > 0
batch_inds = self._sample_proportional(batch_size, p_id)
p_min = self._it_mins[p_id].min() / self._it_sums[p_id].sum()
max_weight = (p_min * len(self)) ** (-beta)
p_sample = self._it_sums[p_id][batch_inds] / self._it_sums[p_id].sum()
weights = (p_sample * len(self)) ** (-beta) / max_weight
obs, share_obs, acts, rewards, dones, dones_env, avail_acts = {}, {}, {}, {}, {}, {}, {}
for p_id in self.policy_info.keys():
p_buffer = self.policy_buffers[p_id]
obs[p_id], share_obs[p_id], acts[p_id], rewards[p_id], dones[p_id], dones_env[p_id], avail_acts[
p_id] = p_buffer.sample_inds(batch_inds)
return obs, share_obs, acts, rewards, dones, dones_env, avail_acts, weights, batch_inds
def update_priorities(self, idxes, priorities, p_id=None):
"""
Update priorities of sampled transitions.
sets priority of transition at index idxes[i] in buffer
to priorities[i].
:param idxes: ([int]) List of idxes of sampled transitions
:param priorities: ([float]) List of updated priorities corresponding to transitions at the sampled idxes
denoted by variable `idxes`.
"""
assert len(idxes) == len(priorities)
assert np.min(priorities) > 0
assert np.min(idxes) >= 0
assert np.max(idxes) < len(self)
self._it_sums[p_id][idxes] = priorities ** self.alpha
self._it_mins[p_id][idxes] = priorities ** self.alpha
self.max_priorities[p_id] = max(
self.max_priorities[p_id], np.max(priorities))
================================================
FILE: examples/Social_Cognition/ToCM/utils/segment_tree.py
================================================
import numpy as np
def unique(sorted_array):
"""
More efficient implementation of np.unique for sorted arrays
:param sorted_array: (np.ndarray)
:return:(np.ndarray) sorted_array without duplicate elements
"""
if len(sorted_array) == 1:
return sorted_array
left = sorted_array[:-1]
right = sorted_array[1:]
uniques = np.append(right != left, True)
return sorted_array[uniques]
class SegmentTree(object):
def __init__(self, capacity, operation, neutral_element):
"""
Build a Segment Tree data structure.
https://en.wikipedia.org/wiki/Segment_tree
Can be used as regular array that supports Index arrays, but with two
important differences:
a) setting item's value is slightly slower.
It is O(lg capacity) instead of O(1).
b) user has access to an efficient ( O(log segment size) )
`reduce` operation which reduces `operation` over
a contiguous subsequence of items in the array.
:param capacity: (int) Total size of the array - must be a power of two.
:param operation: (lambda (Any, Any): Any) operation for combining elements (eg. sum, max) must form a
mathematical group together with the set of possible values for array elements (i.e. be associative)
:param neutral_element: (Any) neutral element for the operation above. eg. float('-inf') for max and 0 for sum.
"""
assert capacity > 0 and capacity & (
capacity - 1) == 0, "capacity must be positive and a power of 2."
self._capacity = capacity
self._value = [neutral_element for _ in range(2 * capacity)]
self._operation = operation
self.neutral_element = neutral_element
def _reduce_helper(self, start, end, node, node_start, node_end):
if start == node_start and end == node_end:
return self._value[node]
mid = (node_start + node_end) // 2
if end <= mid:
return self._reduce_helper(start, end, 2 * node, node_start, mid)
else:
if mid + 1 <= start:
return self._reduce_helper(start, end, 2 * node + 1, mid + 1, node_end)
else:
return self._operation(
self._reduce_helper(start, mid, 2 * node, node_start, mid),
self._reduce_helper(
mid + 1, end, 2 * node + 1, mid + 1, node_end)
)
def reduce(self, start=0, end=None):
"""
Returns result of applying `self.operation`
to a contiguous subsequence of the array.
self.operation(arr[start], operation(arr[start+1], operation(... arr[end])))
:param start: (int) beginning of the subsequence
:param end: (int) end of the subsequences
:return: (Any) result of reducing self.operation over the specified range of array elements.
"""
if end is None:
end = self._capacity
if end < 0:
end += self._capacity
end -= 1
return self._reduce_helper(start, end, 1, 0, self._capacity - 1)
def __setitem__(self, idx, val):
# indexes of the leaf
idxs = idx + self._capacity
self._value[idxs] = val
if isinstance(idxs, int):
idxs = np.array([idxs])
# go up one level in the tree and remove duplicate indexes
idxs = unique(idxs // 2)
while len(idxs) > 1 or idxs[0] > 0:
# as long as there are non-zero indexes, update the corresponding values
self._value[idxs] = self._operation(
self._value[2 * idxs],
self._value[2 * idxs + 1]
)
# go up one level in the tree and remove duplicate indexes
idxs = unique(idxs // 2)
def __getitem__(self, idx):
assert np.max(idx) < self._capacity
assert 0 <= np.min(idx)
return self._value[self._capacity + idx]
class SumSegmentTree(SegmentTree):
def __init__(self, capacity):
super(SumSegmentTree, self).__init__(
capacity=capacity,
operation=np.add,
neutral_element=0.0
)
self._value = np.array(self._value)
def sum(self, start=0, end=None):
"""
Returns arr[start] + ... + arr[end]
:param start: (int) start position of the reduction (must be >= 0)
:param end: (int) end position of the reduction (must be < len(arr), can be None for len(arr) - 1)
:return: (Any) reduction of SumSegmentTree
"""
return super(SumSegmentTree, self).reduce(start, end)
def find_prefixsum_idx(self, prefixsum):
"""
Find the highest index `i` in the array such that
sum(arr[0] + arr[1] + ... + arr[i - i]) <= prefixsum for each entry in prefixsum
if array values are probabilities, this function
allows to sample indexes according to the discrete
probability efficiently.
:param prefixsum: (np.ndarray) float upper bounds on the sum of array prefix
:return: (np.ndarray) highest indexes satisfying the prefixsum constraint
"""
if isinstance(prefixsum, float):
prefixsum = np.array([prefixsum])
assert 0 <= np.min(prefixsum)
assert np.max(prefixsum) <= self.sum() + 1e-5
assert isinstance(prefixsum[0], float)
idx = np.ones(len(prefixsum), dtype=int)
cont = np.ones(len(prefixsum), dtype=bool)
while np.any(cont): # while not all nodes are leafs
idx[cont] = 2 * idx[cont]
prefixsum_new = np.where(
self._value[idx] <= prefixsum, prefixsum - self._value[idx], prefixsum)
# prepare update of prefixsum for all right children
idx = np.where(np.logical_or(
self._value[idx] > prefixsum, np.logical_not(cont)), idx, idx + 1)
# Select child node for non-leaf nodes
prefixsum = prefixsum_new
# update prefixsum
cont = idx < self._capacity
# collect leafs
return idx - self._capacity
class MinSegmentTree(SegmentTree):
def __init__(self, capacity):
super(MinSegmentTree, self).__init__(
capacity=capacity,
operation=np.minimum,
neutral_element=float('inf')
)
self._value = np.array(self._value)
def min(self, start=0, end=None):
"""
Returns min(arr[start], ..., arr[end])
:param start: (int) start position of the reduction (must be >= 0)
:param end: (int) end position of the reduction (must be < len(arr), can be None for len(arr) - 1)
:return: (Any) reduction of MinSegmentTree
"""
return super(MinSegmentTree, self).reduce(start, end)
================================================
FILE: examples/Social_Cognition/ToCM/utils/util.py
================================================
import copy
import gym
import numpy as np
from gym.spaces import Box, Discrete, Tuple
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.distributed as dist
from torch.autograd import Variable
def to_torch(input):
return torch.from_numpy(input) if type(input) == np.ndarray else input
def to_numpy(x):
return x.detach().cpu().numpy()
class FixedCategorical(torch.distributions.Categorical):
def sample(self):
return super().sample()
def log_probs(self, actions):
return (
super()
.log_prob(actions.squeeze(-1))
.view(actions.size(0), -1)
.sum(-1)
.unsqueeze(-1)
)
def mode(self):
return self.probs.argmax(dim=-1, keepdim=True)
class MultiDiscrete(gym.Space):
"""
- The multi-discrete action space consists of a series of discrete action spaces with different parameters
- It can be adapted to both a Discrete action space or a continuous (Box) action space
- It is useful to represent game controllers or keyboards where each key can be represented as a discrete action space
- It is parametrized by passing an array of arrays containing [min, max] for each discrete action space
where the discrete action space can take any integers from `min` to `max` (both inclusive)
Note: A value of 0 always need to represent the NOOP action.
e.g. Nintendo Game Controller
- Can be conceptualized as 3 discrete action spaces:
1) Arrow Keys: Discrete 5 - NOOP[0], UP[1], RIGHT[2], DOWN[3], LEFT[4] - params: min: 0, max: 4
2) Button A: Discrete 2 - NOOP[0], Pressed[1] - params: min: 0, max: 1
3) Button B: Discrete 2 - NOOP[0], Pressed[1] - params: min: 0, max: 1
- Can be initialized as
MultiDiscrete([ [0,4], [0,1], [0,1] ])
"""
def __init__(self, array_of_param_array):
self.low = np.array([x[0] for x in array_of_param_array])
self.high = np.array([x[1] for x in array_of_param_array])
self.num_discrete_space = self.low.shape[0]
self.n = np.sum(self.high) + 2
def sample(self):
""" Returns a array with one sample from each discrete action space """
# For each row: round(random .* (max - min) + min, 0)
random_array = np.random.rand(self.num_discrete_space)
return [int(x) for x in np.floor(np.multiply((self.high - self.low + 1.), random_array) + self.low)]
def contains(self, x):
return len(x) == self.num_discrete_space and (np.array(x) >= self.low).all() and (np.array(x) <= self.high).all()
@property
def shape(self):
return self.num_discrete_space
def __repr__(self):
return "MultiDiscrete" + str(self.num_discrete_space)
def __eq__(self, other):
return np.array_equal(self.low, other.low) and np.array_equal(self.high, other.high)
class DecayThenFlatSchedule():
def __init__(self,
start,
finish,
time_length,
decay="exp"):
self.start = start
self.finish = finish
self.time_length = time_length
self.delta = (self.start - self.finish) / self.time_length
self.decay = decay
if self.decay in ["exp"]:
self.exp_scaling = (-1) * self.time_length / \
np.log(self.finish) if self.finish > 0 else 1
def eval(self, T):
if self.decay in ["linear"]:
return max(self.finish, self.start - self.delta * T)
elif self.decay in ["exp"]:
return min(self.start, max(self.finish, np.exp(- T / self.exp_scaling)))
pass
def huber_loss(e, d):
a = (abs(e) <= d).float()
b = (abs(e) > d).float()
return a*e**2/2 + b*d*(abs(e)-d/2)
def mse_loss(e):
return e**2
def init(module, weight_init, bias_init, gain=1):
weight_init(module.weight.data, gain=gain)
bias_init(module.bias.data)
return module
def get_clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
# https://github.com/ikostrikov/pytorch-ddpg-naf/blob/master/ddpg.py#L11
def soft_update(target, source, tau):
"""
Perform DDPG soft update (move target params toward source based on weight
factor tau)
Inputs:
target (torch.nn.Module): Net to copy parameters to
source (torch.nn.Module): Net whose parameters to copy
tau (float, 0 < x < 1): Weight factor for update
"""
for target_param, param in zip(target.parameters(), source.parameters()):
target_param.data.copy_(
target_param.data * (1.0 - tau) + param.data * tau)
# https://github.com/ikostrikov/pytorch-ddpg-naf/blob/master/ddpg.py#L15
def hard_update(target, source):
"""
Copy network parameters from source to target
Inputs:
target (torch.nn.Module): Net to copy parameters to
source (torch.nn.Module): Net whose parameters to copy
"""
for target_param, param in zip(target.parameters(), source.parameters()):
target_param.data.copy_(param.data)
# https://github.com/seba-1511/dist_tuto.pth/blob/gh-pages/train_dist.py
def average_gradients(model):
""" Gradient averaging. """
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM, group=0)
param.grad.data /= size
def onehot_from_logits(logits, avail_logits=None, eps=0.0):
"""
Given batch of logits, return one-hot sample using epsilon greedy strategy
(based on given epsilon)
"""
# get best (according to current policy) actions in one-hot form
logits = to_torch(logits)
dim = len(logits.shape) - 1
if avail_logits is not None:
avail_logits = to_torch(avail_logits)
logits[avail_logits == 0] = -1e10
argmax_acs = (logits == logits.max(dim, keepdim=True)[0]).float()
if eps == 0.0:
return argmax_acs
# get random actions in one-hot form
rand_acs = Variable(torch.eye(logits.shape[1])[[np.random.choice(range(logits.shape[1]), size=logits.shape[0])]], requires_grad=False)
# chooses between best and random actions using epsilon greedy
return torch.stack([argmax_acs[i] if r > eps else rand_acs[i] for i, r in
enumerate(torch.rand(logits.shape[0]))])
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def sample_gumbel(shape, eps=1e-20, tens_type=torch.FloatTensor):
"""Sample from Gumbel(0, 1)"""
U = Variable(tens_type(*shape).uniform_(), requires_grad=False)
return -torch.log(-torch.log(U + eps) + eps)
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def gumbel_softmax_sample(logits, avail_logits, temperature, device=torch.device('cpu')):
""" Draw a sample from the Gumbel-Softmax distribution"""
if str(device) == 'cpu':
y = logits + sample_gumbel(logits.shape, tens_type=type(logits.data))
else:
y = (logits.cpu() + sample_gumbel(logits.shape,
tens_type=type(logits.data))).cuda()
dim = len(logits.shape) - 1
if avail_logits is not None:
avail_logits = to_torch(avail_logits).to(device)
y[avail_logits==0] = -1e10
return F.softmax(y / temperature, dim=dim)
# modified for PyTorch from https://github.com/ericjang/gumbel-softmax/blob/master/Categorical%20VAE.ipynb
def gumbel_softmax(logits, avail_logits=None, temperature=1.0, hard=False, device=torch.device('cpu')):
"""Sample from the Gumbel-Softmax distribution and optionally discretize.
Args:
logits: [batch_size, n_class] unnormalized log-probs
temperature: non-negative scalar
hard: if True, take argmax, but differentiate w.r.t. soft sample y
Returns:
[batch_size, n_class] sample from the Gumbel-Softmax distribution.
If hard=True, then the returned sample will be one-hot, otherwise it will
be a probabilitiy distribution that sums to 1 across classes
"""
y = gumbel_softmax_sample(logits, avail_logits, temperature, device)
if hard:
y_hard = onehot_from_logits(y)
y = (y_hard - y).detach() + y
return y
def gaussian_noise(shape, std):
return torch.empty(shape).normal_(mean=0, std=std)
def get_obs_shape(obs_space):
if obs_space.__class__.__name__ == "Box":
obs_shape = obs_space.shape
elif obs_space.__class__.__name__ == "list":
obs_shape = obs_space
else:
raise NotImplementedError
return obs_shape
def get_dim_from_space(space):
if isinstance(space, Box):
dim = space.shape[0]
elif isinstance(space, Discrete):
dim = space.n
elif isinstance(space, Tuple):
dim = sum([get_dim_from_space(sp) for sp in space])
elif "MultiDiscrete" in space.__class__.__name__:
return (space.high - space.low) + 1
elif isinstance(space, list):
dim = space[0]
else:
raise Exception("Unrecognized space: ", type(space))
return dim
def get_state_dim(observation_dict, action_dict):
combined_obs_dim = sum([get_dim_from_space(space)
for space in observation_dict.values()])
combined_act_dim = 0
for space in action_dict.values():
dim = get_dim_from_space(space)
if isinstance(dim, np.ndarray):
combined_act_dim += int(sum(dim))
else:
combined_act_dim += dim
return combined_obs_dim, combined_act_dim, combined_obs_dim+combined_act_dim
def get_cent_act_dim(action_space):
cent_act_dim = 0
for space in action_space:
dim = get_dim_from_space(space)
if isinstance(dim, np.ndarray):
cent_act_dim += int(sum(dim))
else:
cent_act_dim += dim
return cent_act_dim
def is_discrete(space):
if isinstance(space, Discrete) or "MultiDiscrete" in space.__class__.__name__:
return True
else:
return False
def is_multidiscrete(space):
if "MultiDiscrete" in space.__class__.__name__:
return True
else:
return False
def make_onehot(int_action, action_dim, seq_len=None):
if type(int_action) == torch.Tensor:
int_action = int_action.cpu().numpy()
if not seq_len:
return np.eye(action_dim)[int_action]
if seq_len:
onehot_actions = []
for i in range(seq_len):
onehot_action = np.eye(action_dim)[int_action[i]]
onehot_actions.append(onehot_action)
return np.stack(onehot_actions)
def avail_choose(x, avail_x=None):
x = to_torch(x)
if avail_x is not None:
avail_x = to_torch(avail_x)
x[avail_x == 0] = -1e10
return x#FixedCategorical(logits=x)
def tile_images(img_nhwc):
"""
Tile N images into one big PxQ image
(P,Q) are chosen to be as close as possible, and if N
is square, then P=Q.
input: img_nhwc, list or array of images, ndim=4 once turned into array
n = batch index, h = height, w = width, c = channel
returns:
bigim_HWc, ndarray with ndim=3
"""
img_nhwc = np.asarray(img_nhwc)
N, h, w, c = img_nhwc.shape
H = int(np.ceil(np.sqrt(N)))
W = int(np.ceil(float(N)/H))
img_nhwc = np.array(
list(img_nhwc) + [img_nhwc[0]*0 for _ in range(N, H*W)])
img_HWhwc = img_nhwc.reshape(H, W, h, w, c)
img_HhWwc = img_HWhwc.transpose(0, 2, 1, 3, 4)
img_Hh_Ww_c = img_HhWwc.reshape(H*h, W*w, c)
return img_Hh_Ww_c
================================================
FILE: examples/Social_Cognition/ToM/BrainArea/PFC_ToM.py
================================================
from braincog.base.learningrule.STDP import *
from braincog.base.brainarea.PFC import dlPFC
from utils.Encoder import *
#exploit or explore
num_enpop = 6
num_depop = 10
greedy = 0.8#0.5
#state
A_state = 4
N_state = 6
cell_num = 6
#action
C=10
class PFC_ToM(dlPFC):
"""
SNNLinear
"""
def __init__(self,
step,
encode_type,
in_features:int,
out_features:int,
bias,
node,
num_state,
greedy=0.8,
*args,
**kwargs):
super().__init__(step, encode_type, in_features, out_features, bias, *args, **kwargs)
self.encoder = PopEncoder(self.step, encode_type)
self.encoder.device = torch.device('cpu')
self.bias = bias
self.in_features = in_features
self.out_features = out_features
self.node1 = node(threshold=0.5, tau=2.)
self.node_name1 = node
self.node2 = node(threshold=0.5, tau=2.)
self.node_name2 = node
self.num_state = num_state
self.greedy = greedy
self.fc = self._create_fc()
self.c = self._rest_c()
def _rest_c(self):
c = torch.rand((self.out_features, self.in_features)) # eligibility trace
return c
def _create_fc(self):
"""
the connection of the SNN linear
@return: nn.Linear
"""
fc = nn.Linear(in_features=self.in_features,
out_features=self.out_features, bias=self.bias)
return fc
def update_c(self, c, dw, tau_c=0.2):
"""
update the trace of eligibility
@param c: a tensor to record eligibility
@param dw: the results of STDP
@param tau_c: the parameter of trace decay
@return: a update tensor to record eligibility
Equation:
delta_c = (-(c / tau_c) + dw) * dela_t
c = c + delta_c
reference:
"""
# delta_c = -(c / tau_c) + dw #dela_t = 1 ignore
# c = c + delta_c
c = c + tau_c * dw
return c
def _call_reward(self, R, c, s, T_map): # eligibility
"""
R-STDP
@param R: reward
@param c: a tensor to record eligibility
@param s: weight of network
@param T_map: the mapping of the state-action pair
@return: update weight of network
Equation:
delta_s = c * reward
s = s + delta_s
reference:
"""
c[c > 0] = c[c > 0] * R * 1
c[c <= 0] = - c[c <= 0] * R * 1
c = c.clamp(min=-1, max=1)
# print('before',s[:, torch.where(T_map.gt(0))[1][0]])
s = s + c * T_map
# # print('after',s[:, torch.where(T_map.gt(0))[1][0]])
s = (s - s.min(dim=0).values.unsqueeze(dim=1).T.detach().repeat(s.shape[0], 1)) / (
s.max(dim=0).values.unsqueeze(dim=1).T.detach().repeat(s.shape[0], 1) -
s.min(dim=0).values.unsqueeze(dim=1).T.detach().repeat(s.shape[0], 1)
)
# s = s * 0.5
return s
def update_s(self, R, mapping):
T_map = torch.zeros((self.out_features, self.in_features))
T_map[mapping['action']*C:mapping['action']*C+C,\
torch.where(torch.tensor(self.encoder(mapping['state'],\
self.in_features, self.num_state)[:, 0]).gt(0))]=1
self.fc.weight.data = self._call_reward(R, self.c, self.fc.weight.data, T_map)
# print(mapping, 'mapping')
def forward(self, inputs, num_action, episode):
"""
decision
@param inputs: state
@param num_action: num_action # consider to delete
@return: action
"""
inputs = self.encoder(inputs, self.in_features, self.num_state)
count_group = torch.zeros(num_action)
stdp = STDP(self.node2, self.fc, decay=0.80)
# self.c = self._rest_c()
# stdp.connection.weight.data = torch.rand((self.out_features, self.in_features))
for t in range(self.step):
l1_in = torch.tensor(inputs[:, t])
l1_out = self.node1(l1_in).unsqueeze(0) #pre : l1_out
l2_out, dw = stdp(l1_out) #dw -- STDP
self.c = self.update_c(self.c, dw[0])
# l2_out = l2_out.T
for i in range(num_action):
count_group[i] = l2_out.T[i * num_depop:(i + 1) * num_depop].sum()
# exploration or exploitation
epsilon = random.random()
if epsilon < self.greedy + episode * 0.004:#:
action = count_group.argmax()
else:
action = torch.tensor(random.randint(0, 3))
return action.item()
================================================
FILE: examples/Social_Cognition/ToM/BrainArea/TPJ.py
================================================
import torch
from braincog.base.brainarea.Insula import *
from rulebasedpolicy.world_model import *
from BrainArea.dACC import *
from BrainArea.PFC_ToM import *
NPC_1 = 2
NPC_2 = 3
Agent = 4
#exploit or explore
num_enpop = 6
num_depop = 10
greedy = 0.8#0.5
#state
A_state = 4
N_state = 6
cell_num = 6
#action
C=10
class ToM:
def __init__(self, env):
"""
@param axis:输入为agent自己的观察到位置信息
@param obs:遮挡关系
"""
self.axis = None
self.obs = None
self.NPC_num = None
self.env = env
self.env.trigger = 0
def TPJ(self, NPC_num, axis, obs):
"""
perspective_taking
agent take NPC2's perspective
@param NPC_num: which NPC?
@return:
axis_new:站在other的角度看到其他智能体的遮挡关系,return axis,
axis_switch:站在self的角度看到其他智能体的遮挡关系,return axis
obs_switch:站在other的角度看到其他智能体的遮挡关系,return obs
"""
self.env.trigger = 0
axis_switch = [[6,6], [6,6], [6,6]]
axis_new = [[6, 6], [6, 6], [6, 6]]
self.axis = axis
self.obs = obs
axis_switch[0], axis_switch[NPC_num] = axis[NPC_num], axis[0]
axis_switch[1] = axis[1]
obs_switch = big_env(self.obs)
obs_switch[self.axis[0][0], self.axis[0][1]], obs_switch[self.axis[NPC_num][0],self.axis[NPC_num][1]] = \
obs_switch[self.axis[NPC_num][0],self.axis[NPC_num][1]],obs_switch[self.axis[0][0], self.axis[0][1]]
x = np.argwhere((obs_switch==2)|(obs_switch==8))
if self.axis[NPC_num][0] != 6 or self.axis[NPC_num][1] != 6:
shelter_obs = shelter_env(obs_switch[1:6,1:6])
obs_switch[1:6,1:6], m = self.gain_obs(a=obs_switch[1:6,1:6], aa=shelter_obs, b=axis_switch[1], c=axis_switch[2], bb=2,cc=4)
if m == True:
axis_switch[1] = [6,6]
else:
obs_switch = []
axis_new[0] = axis_switch[NPC_num]
axis_new[1] = axis_switch[1]
axis_new[NPC_num] = axis_switch[0]
return axis_new, axis_switch, obs_switch
def gain_obs(self, a,aa,b,c,bb,cc):
m = False
if b!=[6,6]:
if aa[b[0]-1, b[1]-1] == 0:
a[b[0]-1, b[1]-1] = 1#2
m = True
else:
a[b[0] - 1, b[1] - 1] = bb
if aa[c[0]-1, c[1]-1] ==0:
# print('-------')
a[c[0]-1, c[1]-1] = 1#4
else:
a[c[0] - 1, c[1] - 1] = cc
return a, m
def belief_reasoning(self, test_x, net_NPC, num_action, episode):
output = net_NPC(inputs=test_x, \
num_action=num_action, \
episode=episode)
return output
def state_evaluation(self, prediction_next_state):
"""
state_evaluation
@param prediction_next_state:
@return:
"""
input = np.array(prediction_next_state)
test_x = torch.tensor([[(int(bool(input[0][0] - input[2][0])))*10, (int(bool(input[0][1] - input[2][1])))*10]])
T = 5
num_popneurons = 2
safety = 2
dACC_net = dACC(step=T, encode_type='rate', bias=True,
in_features=num_popneurons, out_features=safety,
node=node.LIFNode)
dACC_net.load_state_dict(torch.load(os.path.join(sys.path[0], 'BrainArea/checkpoint', 'dACC_net.pth'))['dacc'])
output = dACC_net(inputs=test_x, epoch=50)
output = bool(int(output[0].cpu().detach().numpy().tolist()))
print(output,test_x)
return output
def prediction_state(self, axis_new, axis, action_NPC1, net, num_action, episode):
"""
根据当前状态和经验预测下一个状态
@return:下一个step的state
"""
self.env.trigger = 0
action_move = {
0: (0, -1),
1: (0, 1),
2: (-1, 0),
3: (1, 0),
4: (0, 0)
}
next_axis = [[6,6],[6,6],[6,6]]
# inputspike_test = np.array([axis_new[0],axis_new[1],axis_new[2]])
inputspike_test = sum(axis_new, [])
action_NPC2 = self.belief_reasoning(test_x=inputspike_test, net_NPC=net, num_action=num_action, episode=episode)
action_agent = 3
#NPC_1
next_axis[1][0] = axis[1][0] + action_move[action_NPC1][1]
next_axis[1][1] = axis[1][1] + action_move[action_NPC1][0]
#NPC_2
if self.obs[axis[2][0] + action_move[action_NPC2][1]-1, axis[2][1] + action_move[action_NPC2][0]-1] != 5:
next_axis[2][0] = axis[2][0] + action_move[action_NPC2][1]
next_axis[2][1] = axis[2][1] + action_move[action_NPC2][0]
#NPC_agent
next_axis[0][0] = axis[0][0] + action_move[action_agent][1]
next_axis[0][1] = axis[0][1] + action_move[action_agent][0]
return next_axis
def altruism(self, axis_switch, axis_NPC, n_actions):
"""
假设有一个开关,agent按下去可以让NPC不动
Q_bad:NPC的错误观测的有偏差Q
Q_good:正确的Q
Q_delta:中最小的值就是容易导致NPC出现危险的值
找到最小危险中的最大值对应的action
@param axis_switch:
@param axis_NPC:
@param n_actions:
@return:下一个step的action
"""
actions = list(range(n_actions))
action_NPC_list = list(range(n_actions))
#others' view
data_NPC = pd.read_csv('./data/NPC_assessment.csv', index_col=[0],
dtype={1: np.float64, 2: np.float64, 3: np.float64, 4: np.float64,
5: np.float64})
#self's view
data_agent = pd.read_csv('./data/agent_assessment.csv', index_col=[0],
dtype={1: np.float64, 2: np.float64, 3: np.float64, 4: np.float64,
5: np.float64})
# print(axis_NPC, axis_switch)
Q_bad = data_NPC.loc[str(axis_NPC), :]
if str(axis_switch) not in data_agent.index:
# append new state to q table
# print('1')
data_agent = data_agent.append(
pd.Series(
[0] * len(list(range(self.env.n_actions))),
index=data_agent.columns,
name=str(axis_switch),
)
)
Q_good = data_agent.loc[str(axis_switch), :]
Q_delta = Q_good - Q_bad
# print(Q_delta)
# max_Q_delta = [None] * n_actions
min_Q_delta_set = []
#stop
for action_a in actions:
if action_a == 4:
action_NPC_list = [4]
min_Q_delta = []
for i in action_NPC_list:
#
# print(i)
min_Q_delta.append(Q_delta[i])
min_Q_delta_set.append(min(min_Q_delta))
# print(min_Q_delta_set,'---------')
action_altruism = min_Q_delta_set.index(max(min_Q_delta_set))
if action_altruism == 4:
self.env.trigger = 1
# print('---------------------------------------------')
# env.SHOW()
# time.sleep(1.0)
# max_Q_delta[action_a] = max(min_Q_delta_set)
return action_altruism
def INS(self, axis1, axis2):
num_IPLM = axis1.shape[1]
num_IPLV = axis1.shape[1]
Insula_connection = []
# IPLV-Insula
con_matrix0 = torch.eye(num_IPLM, dtype=torch.float) * 2
Insula_connection.append(CustomLinear(con_matrix0))
# STS-Insula
con_matrix1 = torch.eye(num_IPLV, dtype=torch.float) * 2
Insula_connection.append(CustomLinear(con_matrix1))
Insula = InsulaNet(Insula_connection)
confidence = 0
Insula.reset()
for t in range(2):
Insula((axis1-axis2) * 10, torch.zeros_like(axis1) * 10)
if sum(sum(Insula.out_Insula)) > 0:
confidence = confidence + 1
return confidence
================================================
FILE: examples/Social_Cognition/ToM/BrainArea/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToM/BrainArea/dACC.py
================================================
import torch
import matplotlib.pyplot as plt
import numpy as np
np.set_printoptions(threshold=np.inf)
from utils.one_hot import *
import os
import time
import sys
from tqdm import tqdm
from braincog.model_zoo.base_module import BaseLinearModule, BaseModule
from braincog.base.learningrule.STDP import *
import sys
sys.path.append("..")
class dACC(BaseModule):
"""
SNNLinear
"""
def __init__(self,
step,
encode_type,
in_features:int,
out_features:int,
bias,
node,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.bias = bias
self.in_features = in_features
self.out_features = out_features
self.node1 = node(threshold=0.5, tau=2.)
self.node_name1 = node
self.node2 = node(threshold=0.1, tau=2.)
self.node_name2 = node
self.fc = self._create_fc()
self.c = self._rest_c()
def _rest_c(self):
c = torch.rand((self.out_features, self.in_features)) # eligibility trace
return c
def _create_fc(self):
"""
the connection of the SNN linear
@return: nn.Linear
"""
fc = nn.Linear(in_features=self.in_features,
out_features=self.out_features, bias=self.bias)
return fc
def update_c(self, c, STDP, tau_c=0.2):
"""
update the trace of eligibility
@param c: a tensor to record eligibility
@param STDP: the results of STDP
@param tau_c: the parameter of trace decay
@return: a update tensor to record eligibility
Equation:
delta_c = (-(c / tau_c) + STDP) * dela_t
c = c + delta_c
reference:
"""
c = c + tau_c * STDP
return c
def forward(self, inputs, epoch):
"""
decision
@param inputs: state
@return: action
"""
output = []
stdp = STDP(self.node2, self.fc, decay=0.80)
self.c = self._rest_c()
# stdp.connection.weight.data = torch.rand((self.out_features, self.in_features))
for i in range(inputs.shape[0]):
for t in range(self.step):
l1_in = torch.tensor(inputs[i, :])
l1_out = self.node1(l1_in).unsqueeze(0) #pre : l1_out
l2_out, dw = stdp(l1_out) #dw -- STDP
self.c = self.update_c(self.c, dw[0])
output.append(torch.min(l2_out))
# output.append((l2_out.any() == 0).cpu().detach().numpy().tolist())
return output
# if __name__ == '__main__':
# np.random.seed(6)
# T = 5
# num_popneurons = 2
# safety = 2
# epoch = 50
# file_name = "/home/zhaozhuoya/braincog/examples/ToM/data/injury_value.txt"
# state = []
# with open(file_name) as f:
# data = []
# data_split = f.readlines() #
# for i in data_split:
# state.append(one_hot(int(i[0])))
#
# output = np.array(state)
# train_y = output
# test_y = output[79:82]#output[12].reshape(1,2)
#
# file_name = "/home/zhaozhuoya/braincog/examples/ToM/data/injury_memory.txt"
# state = []
# with open(file_name) as f:
# data_split = f.readlines()
# for i in data_split:
# data = []
# data.append(int(bool(abs(int(i[2]) - int(i[18]))))*10)
# data.append(int(bool(abs(int(i[5]) - int(i[21]))))*10)
# state.append(data)
# input = np.array(state)
# train_x = input
# test_x = input[79:82]
# dACC_net = dACC(step=T, encode_type='rate', bias=True,
# in_features=num_popneurons, out_features=safety,
# node=node.LIFNode)
# dACC_net.fc.weight.data = torch.rand((safety, num_popneurons))
# dACC_net.load_state_dict(torch.load('./checkpoint/dACC_net.pth')['dacc'])
# output = dACC_net(inputs=train_x, epoch=50)
# for i in range(len(output)):
# print(output[i], train_x[i])
# torch.save({'dacc': dACC_net.state_dict()}, os.path.join('./checkpoint', 'dACC_net.pth'))
# dACC_net.load_state_dict(torch.load('./checkpoint/dACC_net.pth')['dacc'])
# output = dACC_net(inputs=test_x, epoch=50)
# for i in range(len(test_x)):
#
# print(output[i],test_x[i])
================================================
FILE: examples/Social_Cognition/ToM/BrainArea/one_hot.py
================================================
from numpy import argmax
import numpy as np
def one_hot(value):
num = '01'
letter = [0 for _ in range(len(num))]
letter[value] = 1
letter = np.array([letter])
return letter
# print(one_hot(4))
================================================
FILE: examples/Social_Cognition/ToM/BrainArea/test.py
================================================
import torch
from braincog.base.connection.CustomLinear import *
from braincog.base.node.node import *
from braincog.base.learningrule.STDP import *
from braincog.base.brainarea.IPL import *
from braincog.base.brainarea.Insula import *
if __name__ == "__main__":
num_neuron = 4
num_vPMC = num_neuron
num_STS = num_neuron
num_IPLM = num_neuron
num_IPLV = num_neuron
num_Insula = num_neuron
# InsulaNet
# connection
Insula_connection = []
# IPLV-Insula
con_matrix0 = torch.eye(num_IPLM, dtype=torch.float) * 2
Insula_connection.append(CustomLinear(con_matrix0))
# STS-Insula
con_matrix1 = torch.eye(num_IPLV, dtype=torch.float) * 2
Insula_connection.append(CustomLinear(con_matrix1))
Insula = InsulaNet(Insula_connection)
a = torch.tensor([[1.,2.,1.,2.]])
b = torch.tensor([[1., 2., 1., 2.]])
c = torch.tensor([[2., 2., 4., 2.]])
confidence = [0, 0]
for t in range(2):
Insula(a*10, b*10)
if sum(sum(Insula.out_Insula)) > 0:
confidence[0] = confidence[0] + 1
Insula.reset()
for t in range(2):
Insula(a*10, c*10)
if sum(sum(Insula.out_Insula)) > 0:
confidence[0] = confidence[0] + 1
Insula.reset()
print(confidence)
================================================
FILE: examples/Social_Cognition/ToM/README.md
================================================
# Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
* pygame
# Run
## Train
* the file to be run: main_both.py
* args:
* the path to save net_NPC: --save_net_N
* the path to save net_a: --save_net_a
* time steps: --T
```bash
python main_both.py --save_net_N=net_NPC.pth --save_net_a=net_agent.pth --episodes=45 --trajectories=30 --T=50 --mode=train --task=both
```
## Test
You can use the weigts saved by taining in the test environment.
```bash
python main_ToM.py --save_net_N=net_NPC.pth --save_net_a=net_agent.pth --episodes=45 --trajectories=30 --T=50 --mode=train --task=both
```
# Citation
```
@article{zhao2022brain,
title = {A Brain-Inspired Theory of Mind Spiking Neural Network for Reducing Safety Risks of Other Agents},
author = {Zhao, Zhuoya and Lu, Enmeng and Zhao, Feifei and Zeng, Yi and Zhao, Yuxuan},
journal = {Frontiers in neuroscience},
pages = {446},
year = {2022},
publisher = {Frontiers}
}
```
================================================
FILE: examples/Social_Cognition/ToM/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToM/data/NPC_assessment.csv
================================================
,0,1,2,3,4
"[[3, 5], [6, 6], [4, 2]]",-0.868083432541418,-0.733763528003341,11.6748771364348,-1.13941568407204,-0.640638369281893
"[[3, 5], [6, 6], [4, 3]]",-0.418851253559184,-0.353923546821901,2.45363281923355,-0.450103087254002,-0.37827704665847
"[[3, 5], [6, 6], [5, 3]]",-0.021898491492153,-0.01,-0.01,-0.01,-0.011802114342782
"[[4, 5], [6, 6], [5, 2]]",-0.024908407481436,-0.0199,0,-0.01009,-0.01017991
"[[3, 5], [6, 6], [5, 2]]",-0.023268882562677,-0.0199,-0.029791,-0.0298801,-0.037630851041005
"[[3, 4], [6, 6], [5, 3]]",-0.021197399198277,-0.01,-0.0199,-0.013038149463134,-0.01999
"[[3, 3], [6, 6], [5, 3]]",0,-0.5,0,0,-0.01
"[[3, 3], [6, 6], [5, 2]]",0,0,0,-0.01,0
"[[3, 4], [6, 6], [5, 1]]",-0.01,0,-0.01,-0.01009,0
"[[3, 4], [6, 6], [4, 1]]",-0.0101791,-0.0199,-0.01,-0.01,-0.01
"[[3, 3], [6, 6], [4, 1]]",-0.01,0,-0.01,0,0
"[[3, 2], [6, 6], [4, 2]]",0,-0.01,0,0,0
"[[4, 2], [6, 6], [4, 3]]",0,0,0,-0.01,0
"[[4, 3], [6, 6], [4, 4]]",0.089467366020037,-0.010984993825322,-0.01,-0.013452906086556,-0.011867720274541
"[[4, 2], [6, 6], [4, 5]]",4.09524024945437,-0.090412523006309,-0.09623134888059,-0.104387744707876,-0.070973835764104
"[[3, 2], [6, 6], [4, 5]]",1.40391860495941,0.022997490426814,43.0024182397514,1.53202462973447,3.08888716957364
"[[2, 2], [6, 6], [4, 5]]",-0.019749094852309,0.036781365436129,15.9675319796684,-0.020051902468894,0.04621779219384
"[[4, 1], [6, 6], [4, 5]]",5.50845885876033,-0.030316371018288,-0.01999,0.003924246487139,-0.01999
"[[5, 1], [6, 6], [4, 5]]",-0.04218527817012,-0.089619886118225,-0.089555438562711,-0.09202879886063,-0.089640838741259
"[[5, 2], [6, 6], [4, 5]]",-0.181115480137325,-0.188135727209872,-0.190391091543011,-0.189212077096485,-0.18825217812927
"[[4, 3], [6, 6], [4, 5]]",3.20388938261604,-0.277669046855729,-0.263170616607684,-0.263425702870801,-0.273172354685186
"[[4, 4], [6, 6], [4, 5]]",0.088264809806085,-0.536047549432865,-0.496801753642635,-1.7227487525,-0.525308942251634
"[[3, 3], [6, 6], [4, 5]]",-0.21666970575642,-0.137772024778711,35.7440209050429,0.074933770913733,1.72993072468866
"[[2, 3], [6, 6], [6, 6]]",-0.059222187527032,-0.030584932730533,1.19896558354272,-0.02997001,-0.039803368321337
"[[3, 4], [6, 6], [4, 5]]",-0.40734083054261,-0.590251991054757,12.0029208279787,-0.553842323501647,-0.473260640862758
"[[4, 5], [6, 6], [4, 5]]",0,0,0,0,0
"[[3, 5], [6, 6], [4, 4]]",-0.481765407319486,-0.511211461721295,-0.564380288792446,-0.492462845628926,-0.469959754386144
"[[3, 5], [6, 6], [4, 5]]",-0.931224461309762,-4.42392016540183,0.839256941677985,-0.924126498596367,-0.93129552223439
"[[3, 1], [6, 6], [4, 5]]",49.811526809228,0.227846091910513,5.03145376471985,3.02887653427164,4.38800221134503
"[[2, 1], [6, 6], [4, 5]]",0,0,0,0,0
"[[3, 4], [6, 6], [4, 3]]",1.19380671730375,-5.00699176831198,20.0406112237339,-0.271487593364538,18.7143725924663
"[[3, 4], [6, 6], [4, 4]]",0.218803966115085,-0.17930117271935,27.2213501282548,-0.25238045900879,0.399605811763158
"[[5, 3], [6, 6], [4, 5]]",-0.375176845280851,-0.382612376673214,-0.387234215280032,-0.391512374343505,-0.38256981360011
"[[5, 4], [6, 6], [4, 5]]",-0.648971759046833,-0.647885303763355,-0.648165623973329,-0.644724798572273,-0.648282307415749
"[[4, 5], [6, 6], [3, 2]]",-0.01999,-0.029791,-0.0199,-0.0199891,-0.029882503677127
"[[3, 5], [6, 6], [3, 2]]",-0.034237585544166,-0.029789209,-0.0297901,-0.031801666387697,-0.023636229278446
"[[4, 5], [6, 6], [4, 3]]",-0.254773250904236,-0.247726142705935,-0.4975,-0.251602554065065,-0.253564419614127
"[[4, 5], [6, 6], [4, 4]]",-0.414539088621474,-0.413180632405154,-0.45683393116936,-0.4975,-0.98509975
"[[5, 5], [6, 6], [4, 5]]",-2.88794812477989,-0.897593650362875,-0.896337578776872,-0.897383653648252,-0.896911728329473
"[[3, 4], [6, 6], [4, 2]]",-0.041846129714671,-0.0491890501,-0.049128264132635,-0.04752963742507,-0.041122932699059
"[[4, 4], [6, 6], [4, 3]]",-0.010582728786191,-0.0199,-0.019606621899442,-0.023027393843706,-0.25
"[[4, 4], [6, 6], [4, 4]]",0,0,0,0,0
"[[1, 3], [6, 6], [6, 6]]",-0.02997001,-0.037241738974595,-0.038877118273757,-0.02997001,-0.02997001
"[[1, 2], [6, 6], [6, 6]]",-0.01,0.092960550898947,-0.01,-0.01,-0.01
"[[1, 1], [6, 6], [4, 5]]",0,0.25,0,0,-0.01
"[[5, 5], [6, 6], [4, 2]]",-0.011245609205401,-0.010090875348172,-0.01,-0.01,-0.01
"[[5, 5], [6, 6], [4, 3]]",-0.023589076057546,-0.030475766514878,-0.0199,-0.010097260907938,-0.020481507078377
"[[5, 4], [6, 6], [4, 4]]",-0.014561932553648,-0.014123403608977,-0.012977094986838,-0.013958043392411,-0.0102689209
"[[5, 5], [6, 6], [3, 3]]",-0.01,0,0,0,-0.01009
"[[5, 5], [6, 6], [4, 4]]",-0.742525,-0.112519042227942,-0.104809666804011,-0.120899601119155,-0.114009048694518
"[[3, 3], [6, 6], [4, 4]]",-0.010153907821337,-0.013354155304859,3.90887441187658,-0.020453180303816,-0.010444104437097
"[[3, 5], [6, 6], [4, 1]]",-0.010526678655391,-0.01999,-0.0199,-0.013489754345763,-0.020341425501639
"[[4, 5], [6, 6], [4, 2]]",-0.040636256244247,-0.0297901,-0.029794680345807,-0.032266639674154,-0.030144504483964
"[[4, 5], [6, 6], [4, 1]]",-0.022834041173462,-0.029701,-0.029701,-0.030019473640868,-0.029791
"[[4, 4], [6, 6], [4, 2]]",-0.010267309,-0.01999,-0.25,-0.021462046263096,-0.01
"[[5, 5], [6, 6], [5, 4]]",0,-0.01,0,0,-0.010213344196849
"[[3, 5], [6, 6], [3, 4]]",-0.013599152071303,0,-0.010345480742543,-0.01,-0.25
"[[3, 5], [6, 6], [3, 5]]",0,0,0,0,0
"[[3, 5], [6, 6], [3, 3]]",-0.011856953925967,-0.01999,-0.0199,-0.032817580205153,-0.010785322603466
"[[4, 4], [6, 6], [5, 2]]",0,-0.01,-0.01,-0.01009,-0.01
"[[5, 4], [6, 6], [4, 2]]",0,0,-0.01,-0.01,0
"[[3, 3], [6, 6], [4, 3]]",-0.01,-0.01,-0.0199,-0.005562516126618,-0.009541766156335
"[[3, 2], [6, 6], [4, 4]]",0,0,-0.01,-0.01,0.236388148843983
"[[4, 3], [6, 6], [4, 2]]",0,-0.01,0,-0.01,0
"[[5, 3], [6, 6], [4, 3]]",-0.01,0,0,0,0
"[[4, 5], [6, 6], [5, 3]]",-0.01,-0.01009,-0.0199,-0.010784041942122,-0.01
"[[3, 5], [6, 6], [5, 4]]",-0.012894421101825,-0.012100903162978,-0.007186044736698,0,-0.011442680105686
"[[3, 4], [6, 6], [3, 2]]",-0.01009,-0.01999,-0.0199,-0.01009,-0.010091626994647
"[[4, 4], [6, 6], [5, 4]]",0,0,0,-0.010869859082056,0
"[[4, 5], [6, 6], [3, 3]]",-0.01,-0.01,-0.01999,-0.01,-0.011561635811299
"[[5, 4], [6, 6], [4, 3]]",0,0,-0.01,0,0
"[[5, 3], [6, 6], [4, 4]]",0,-0.012647205121462,0,-0.015190262813025,0
"[[3, 2], [6, 6], [4, 3]]",0,-0.01,0,0,-0.01
"[[3, 1], [6, 6], [4, 3]]",0,-0.01,0,0,0
"[[4, 1], [6, 6], [4, 4]]",0,0,0,0,-0.002916121937907
"[[4, 3], [6, 6], [4, 3]]",0,0,0,0,0
"[[5, 5], [6, 6], [3, 4]]",-0.012969708589991,-0.01,-0.01,-0.010643056796965,0
"[[3, 4], [6, 6], [3, 4]]",0,0,0,0,0
"[[2, 3], [6, 6], [4, 4]]",0,0,0,-0.01,0
"[[2, 3], [6, 6], [5, 4]]",0,0,-0.01,0,0
"[[2, 2], [6, 6], [4, 4]]",-0.01,0,0,-0.008244859693453,0
"[[1, 2], [6, 6], [4, 3]]",0,-0.01,0,0,0
"[[3, 4], [6, 6], [5, 2]]",-0.01999,-0.01999,-0.0199,-0.01999,-0.01035517099859
"[[3, 3], [6, 6], [4, 2]]",0,0,-0.01,-0.010197581295095,0
"[[3, 3], [6, 6], [5, 4]]",0,0,0,-0.01009,0
"[[5, 5], [6, 6], [3, 1]]",-0.01999081,-0.01999,-0.01999,-0.01999,-0.01999
"[[5, 5], [6, 6], [2, 1]]",-0.01,0,-0.01,-0.01,-0.01
"[[5, 4], [6, 6], [2, 2]]",0,0,-0.01,-0.01,-0.01
"[[5, 4], [6, 6], [3, 2]]",-0.01999,-0.0199,-0.01,-0.01,-0.01
"[[5, 3], [6, 6], [3, 1]]",-0.01,-0.01,0,0,0
"[[4, 3], [6, 6], [4, 1]]",-0.01,-0.01,-0.01,-0.01,-0.01
"[[4, 2], [6, 6], [5, 1]]",0,-0.01,0,-0.01,0
"[[5, 2], [6, 6], [5, 1]]",-0.01,0,0,0,0
"[[4, 2], [6, 6], [5, 2]]",0,0,0,0,-0.01
"[[5, 4], [6, 6], [3, 3]]",-0.01,-0.01,-0.01,-0.01,-0.01
"[[4, 4], [6, 6], [3, 2]]",-0.01,-0.01,-0.0199,-0.0200791,-0.0199
"[[4, 5], [6, 6], [6, 6]]",-0.01009,-0.0199,-0.0199,-0.0199,-0.01999
"[[4, 4], [6, 6], [5, 3]]",0,0,0,-0.01,-0.01
"[[5, 5], [6, 6], [2, 2]]",-0.01,-0.01,-0.01,-0.01,0
"[[5, 4], [6, 6], [2, 3]]",-0.01,-0.01,0,-0.01,-0.01
"[[4, 5], [6, 6], [2, 2]]",-0.010198196967161,-0.01999,-0.01,-0.01009,-0.01
"[[4, 5], [6, 6], [1, 1]]",0,-0.01,0,0,-0.01
"[[4, 5], [6, 6], [2, 1]]",-0.01,-0.01,-0.01,-0.0199,-0.01
"[[4, 5], [6, 6], [3, 1]]",-0.01,-0.01009,-0.0199,-0.01,-0.01009
"[[4, 3], [6, 6], [3, 3]]",0,0,-0.01,0,0
"[[4, 2], [6, 6], [3, 4]]",-0.008998626598505,0,0,0,0
"[[4, 5], [6, 6], [5, 1]]",-0.01009,-0.0199,-0.0199,-0.020016673101577,-0.01999
"[[4, 4], [6, 6], [5, 1]]",-0.01,-0.01,-0.01,-0.01009,-0.01
"[[3, 5], [6, 6], [5, 1]]",-0.01009,-0.01,-0.0199,-0.01999,-0.01999
"[[5, 5], [6, 6], [5, 1]]",-0.01009,0,-0.01,-0.0199,-0.01
"[[5, 5], [6, 6], [4, 1]]",-0.01,-0.01,-0.0199,-0.01,-0.01999
"[[4, 4], [6, 6], [3, 1]]",0,0,0,-0.01,-0.01
"[[5, 5], [6, 6], [1, 1]]",-0.01,0,-0.01,-0.01,0
"[[5, 5], [6, 6], [1, 2]]",-0.01,-0.01,0,-0.01,-0.01
"[[4, 4], [6, 6], [2, 1]]",0,-0.01,-0.01,-0.01,-0.01
"[[4, 3], [6, 6], [3, 1]]",-0.01,0,0,-0.01,-0.01
"[[4, 4], [6, 6], [4, 1]]",-0.010289510270133,-0.01,-0.0199,-0.02007991,-0.01999
"[[5, 4], [6, 6], [4, 1]]",0,0,-0.01,0,-0.01
"[[5, 4], [6, 6], [3, 1]]",-0.01,0,0,-0.01,-0.01
"[[3, 4], [6, 6], [2, 2]]",0,-0.01,0,-0.01,-0.01
"[[3, 4], [6, 6], [6, 6]]",-0.01,-0.01,-0.01,-0.01999,-0.01999
"[[3, 3], [6, 6], [1, 2]]",0,-0.01,0,0,0
"[[4, 3], [6, 6], [1, 3]]",0,0,-0.01,-0.01,0
"[[4, 4], [6, 6], [6, 6]]",-0.01,-0.01,-0.0199,-0.01,-0.01
"[[5, 5], [6, 6], [2, 3]]",-0.01,-0.01999,-0.01999,-0.01999,-0.01
"[[5, 4], [6, 6], [1, 3]]",-0.0199,-0.01,-0.01,-0.01,-0.01
"[[5, 4], [6, 6], [1, 2]]",0,-0.01,-0.01,-0.01,0
"[[5, 4], [6, 6], [1, 1]]",-0.0199,-0.01,-0.01,-0.01,-0.01
"[[4, 4], [6, 6], [1, 1]]",-0.01,-0.01,-0.01,0,0
"[[5, 3], [6, 6], [1, 1]]",0,0,-0.01,-0.01009,0
"[[5, 2], [6, 6], [1, 1]]",-0.01,0,0,-0.01,-0.01
"[[5, 3], [6, 6], [1, 2]]",0,-0.01,0,-0.01,0
"[[5, 3], [6, 6], [1, 3]]",-0.01,-0.01,-0.01,0,-0.0199
"[[5, 3], [6, 6], [2, 3]]",0,0,-0.01,0,0
"[[5, 2], [6, 6], [2, 3]]",-0.01,0,0,-0.01,0
"[[5, 3], [6, 6], [3, 3]]",0,0,0,-0.01,0
"[[4, 3], [6, 6], [1, 2]]",-0.01,-0.01,-0.01,-0.01,-0.01
"[[3, 3], [6, 6], [2, 2]]",-0.01,-0.01,-0.01,-0.01,-0.01
"[[2, 3], [6, 6], [3, 2]]",0,0,-0.01,-0.01,0
"[[2, 3], [6, 6], [3, 1]]",-0.01,-0.01,-0.01,-0.01,-0.01
"[[2, 3], [6, 6], [2, 1]]",0,-0.01,0,0,-0.01
"[[3, 2], [6, 6], [2, 3]]",0,-0.01,0,0,0
"[[4, 2], [6, 6], [2, 2]]",-0.01,0,0,-0.01,0
"[[3, 2], [6, 6], [2, 1]]",-0.01,0,0,-0.01,0
"[[3, 3], [6, 6], [1, 1]]",0,0,0,-0.01,-0.01
"[[3, 4], [6, 6], [2, 1]]",-0.01,-0.01,0,0,-0.01
"[[4, 4], [6, 6], [2, 2]]",0,-0.01,-0.01,0,0
"[[4, 3], [6, 6], [2, 2]]",0,0,-0.01,-0.01009,0
"[[4, 2], [6, 6], [1, 2]]",-0.01,0,-0.01,-0.01,-0.01
"[[3, 2], [6, 6], [1, 2]]",0,0,-0.01,0,0
"[[3, 1], [6, 6], [1, 1]]",0,0,-0.01,-0.01,0
"[[3, 2], [6, 6], [1, 1]]",-0.01,-0.01,0,0,0
"[[4, 1], [6, 6], [1, 2]]",-0.01,0,0,0,0
"[[3, 1], [6, 6], [1, 3]]",0.5,0,0,0,-0.01
"[[2, 1], [6, 6], [1, 3]]",0.995,0,0,0,0
"[[2, 1], [6, 6], [2, 3]]",1.489505,0,0,0,0
"[[2, 1], [6, 6], [2, 2]]",0.5,0,0,0,0
"[[2, 1], [6, 6], [3, 2]]",0.5,0,0,0,0
"[[2, 1], [6, 6], [4, 2]]",0.5,0,1.0039955,0,0
"[[2, 1], [6, 6], [5, 2]]",0.995,0,0,0,0
"[[2, 1], [6, 6], [5, 3]]",0.995,0,0,0,0
"[[2, 1], [6, 6], [4, 3]]",0.5045,0,0.5045,0,0
"[[2, 1], [6, 6], [5, 4]]",0.995,0,0,0,0
"[[2, 1], [6, 6], [4, 4]]",0.5,0,0.5,0,0
"[[4, 4], [6, 6], [1, 2]]",-0.01,0,0,-0.01009,0
"[[4, 3], [6, 6], [1, 1]]",-0.01,0,0,0,0
"[[3, 3], [6, 6], [2, 1]]",-0.0199,0,0,0,0
"[[1, 3], [6, 6], [3, 1]]",0,0,-0.01,0,0
"[[1, 2], [6, 6], [3, 1]]",-0.01,0,0,0,-0.01
"[[1, 2], [6, 6], [4, 1]]",-0.01,0,-0.0199,0,0
"[[1, 1], [6, 6], [5, 1]]",0,0,0,-0.01,-0.01
"[[1, 2], [6, 6], [5, 1]]",0,-0.01,0,-0.01,0
"[[1, 3], [6, 6], [5, 1]]",-0.01,0,0,0,0
"[[1, 3], [6, 6], [5, 2]]",0,0,-0.01,0,-0.01
"[[1, 2], [6, 6], [5, 2]]",-0.01,-0.01,0,-0.01,0
"[[2, 2], [6, 6], [5, 1]]",-0.01,0,0,0,-0.01
"[[2, 2], [6, 6], [4, 1]]",-0.01,0,0,0,0
"[[1, 1], [6, 6], [4, 2]]",-0.01,0,0,0,-0.01
"[[1, 1], [6, 6], [4, 1]]",0,0,0,0,-0.01
"[[1, 1], [6, 6], [5, 2]]",0,0,0,-0.01,-0.01
"[[1, 2], [6, 6], [5, 3]]",0,0,-0.01,0,-0.01
"[[1, 1], [6, 6], [5, 3]]",0,0,0,-0.01,0
"[[1, 3], [6, 6], [4, 2]]",-0.01,0,0,0,-0.01
"[[1, 3], [6, 6], [5, 3]]",0,0,0,0,-0.01
"[[1, 3], [6, 6], [5, 4]]",0,0,0,0,-0.010266711022056
"[[5, 5], [6, 6], [3, 2]]",-0.010094761832099,0,0,0,0
"[[3, 5], [6, 6], [3, 1]]",-0.01,-0.0101791,-0.01,0,-0.01
"[[3, 5], [6, 6], [2, 1]]",-0.01,-0.01009,-0.01,0,0
"[[3, 5], [6, 6], [6, 6]]",-0.01999,-0.0199891,-0.01999,-0.01999,-0.01999
"[[3, 4], [6, 6], [1, 1]]",0,-0.01,-0.01,0,0
"[[4, 5], [6, 6], [3, 4]]",0,0,-0.01,0,0
"[[4, 4], [6, 6], [3, 5]]",0,-0.01,0,0,0
"[[5, 4], [6, 6], [3, 4]]",0,0,0,-0.01,-0.01
"[[3, 2], [6, 6], [5, 2]]",0,0,-0.01,0,0
"[[3, 1], [6, 6], [5, 3]]",0,0,-0.01,-0.01,0
"[[4, 2], [6, 6], [4, 4]]",0,0,0.004567853841478,0,0
"[[5, 4], [6, 6], [2, 1]]",0,0,0,0,-0.01
"[[3, 3], [6, 6], [3, 1]]",-0.01,0,0,-0.01009,0
"[[5, 5], [6, 6], [5, 2]]",0,-0.01,-0.01,0,0
"[[5, 4], [6, 6], [5, 1]]",-0.01009,0,-0.0199,-0.01,-0.01
"[[5, 3], [6, 6], [5, 1]]",-0.01,0,-0.5,0,0
"[[5, 2], [6, 6], [5, 2]]",0,0,0,0,0
"[[3, 4], [6, 6], [3, 3]]",0,0,0,-0.01,0
"[[5, 3], [6, 6], [4, 2]]",0,0,-0.01,-0.01,0
"[[5, 2], [6, 6], [4, 3]]",0,0,-0.01,-0.01,0
"[[5, 1], [6, 6], [4, 4]]",0,0,-0.010759540535295,0,0
"[[4, 4], [6, 6], [2, 3]]",0,-0.01,0,0,0
"[[5, 5], [6, 6], [1, 3]]",-0.01009,0,-0.01,0,0
"[[4, 2], [6, 6], [3, 3]]",0,-0.01,0,0,0
"[[3, 3], [6, 6], [5, 1]]",0,-0.01,0,0,0
"[[5, 3], [6, 6], [2, 1]]",0,-0.01,-0.01,0,-0.01
"[[2, 2], [6, 6], [3, 1]]",0,0,0,-0.01,-0.01
"[[2, 3], [6, 6], [4, 1]]",-0.01,0,0,-0.01,-0.01
"[[1, 3], [6, 6], [4, 1]]",0,0,-0.01,-0.01,0
"[[1, 2], [6, 6], [3, 2]]",0,0,-0.01,0,0
"[[1, 1], [6, 6], [3, 2]]",0,0,-0.01,0,0
"[[1, 1], [6, 6], [3, 1]]",0,0,0,-0.01,0
"[[1, 2], [6, 6], [2, 1]]",-0.01,0,0,-0.01,-0.01
"[[1, 3], [6, 6], [2, 2]]",0,0,0,0,-0.01
"[[1, 3], [6, 6], [2, 1]]",0,0,-0.01,0,0
"[[1, 2], [6, 6], [1, 1]]",-0.5,0,0,0,0
"[[1, 2], [6, 6], [1, 2]]",0,0,0,0,0
"[[2, 3], [6, 6], [4, 2]]",0,0,-0.01,0,0
"[[2, 2], [6, 6], [4, 2]]",0,0,0.5,-0.01,0
"[[2, 3], [6, 6], [4, 3]]",0,-0.002363469450096,0,0,0
"[[4, 4], [6, 6], [3, 3]]",-0.011265121636209,0,-0.01,0,0
"[[4, 3], [6, 6], [2, 3]]",-0.01,0,0,0,0
"[[5, 3], [6, 6], [2, 2]]",0,0,0,0,-0.01
"[[4, 2], [6, 6], [1, 1]]",-0.01,0,-0.01,0,0
"[[4, 1], [6, 6], [1, 1]]",0,0,0,-0.01,0
"[[2, 2], [6, 6], [2, 1]]",0,-0.01,0,-0.01,0
"[[2, 1], [6, 6], [4, 1]]",0,0,1.988015495,0,0
"[[2, 1], [6, 6], [5, 1]]",0,0,1.988015495,0,0
"[[3, 4], [6, 6], [3, 1]]",0,-0.01009,0,0,0
"[[4, 3], [6, 6], [5, 1]]",0,-0.01,0,-0.01,-0.01
"[[5, 3], [6, 6], [4, 1]]",0,-0.01,0,-0.01,0
"[[5, 3], [6, 6], [3, 2]]",0,0,0,-0.01,0
================================================
FILE: examples/Social_Cognition/ToM/data/agent_assessment.csv
================================================
,0,1,2,3,4
"[[3, 5], [6, 6], [4, 2]]",-0.052875711096120555,-0.09588695110964494,-0.06793465209301,-0.05438523750227702,-0.06406147756340548
"[[3, 4], [6, 6], [4, 3]]",-0.01009,-0.5,-0.5,-0.01998648239166538,-0.010090809999999999
"[[3, 5], [3, 3], [4, 4]]",-0.5216067506862471,-1.9701995,-0.2957229880478374,-0.5521303794833469,-0.291912651239883
"[[3, 5], [4, 3], [4, 5]]",-0.17020038264944942,-0.995,-0.17003066056014654,-0.17084067541667597,-0.18061252619011572
"[[3, 5], [5, 3], [4, 5]]",-0.310721791006476,-0.995,-0.3044196312169591,-0.3066034117158839,-0.30258164309452773
"[[3, 4], [5, 4], [4, 5]]",-0.5068849351000232,-0.5215919496170031,0.33272479226972446,-0.529392040004043,-0.5476025113537396
"[[3, 5], [5, 4], [4, 5]]",-0.9653009777091316,-8.274311927495619,-0.9562443360051255,-0.9663825574739041,-0.9577571287880812
"[[3, 3], [5, 4], [4, 5]]",-0.12144345586147146,-0.129151719633336,6.61777080738469,-0.12913417684277412,-0.12187211348591424
"[[3, 2], [5, 4], [4, 5]]",22.462534983722144,-0.037566698284270936,0.0002049650900000019,-0.020492300663398463,0.36064342058027793
"[[2, 3], [5, 4], [6, 6]]",-0.0199,-0.01,1.911710899685282,-0.02507112120629763,-0.01
"[[4, 4], [5, 4], [4, 5]]",-0.38856856345777463,-0.995,-0.3848636851605009,-0.5,-0.39216615065025906
"[[4, 3], [5, 4], [4, 5]]",-0.042040801551562916,-0.17418582965398824,-0.17906219922741637,-0.20272904839771475,-0.17845067061226685
"[[2, 2], [5, 4], [4, 5]]",-0.03593611593419173,0.19699025702983197,41.38750349042489,-0.025347536417836183,0.5235719953054313
"[[1, 3], [5, 4], [6, 6]]",-0.01999,-0.010049500000000001,-0.0199,-0.01999,-0.01999
"[[1, 2], [5, 4], [6, 6]]",-0.01999,1.1413350726366454,-0.01,-0.01009,-0.02969406465902331
"[[4, 5], [5, 4], [4, 5]]",0.0,0.0,0.0,0.0,0.0
"[[4, 5], [6, 6], [4, 3]]",-0.022056368799828086,-0.0199,-0.5,-0.0199,-0.01999
"[[4, 5], [3, 3], [4, 4]]",-0.05334353898157222,-0.058519850599,-0.058698950598999995,-0.5,-0.5
"[[4, 5], [4, 3], [4, 5]]",-0.5,-1.9701995,0.0,-0.5,-0.5
"[[4, 5], [5, 3], [4, 5]]",-0.995,-3.3967326046505,0.0,-0.995,-0.5
"[[3, 5], [6, 6], [4, 3]]",-0.5052708076706848,-0.6503942485687713,-0.31464561043008055,-0.5567063168667764,-0.3196072406789152
"[[3, 4], [4, 3], [4, 5]]",-0.06538757013815065,-0.06815609254531127,0.07157941051049484,-0.06943525585877257,-0.07243109013283643
"[[3, 4], [5, 3], [4, 5]]",-0.03627763723533166,-0.04878628543714749,0.4425679590136676,-0.04432926021182233,-0.03615058165751049
"[[5, 3], [5, 4], [4, 5]]",-0.1326255476738545,-0.12913304314430477,-0.12670229132838703,-0.995,-0.12922285286285284
"[[5, 4], [5, 4], [4, 5]]",0.0,0.0,0.0,0.0,0.0
"[[3, 4], [3, 3], [4, 4]]",-0.08912453287009733,-0.514891,-0.08664897275426689,-0.0850562755111616,-0.08029821601054066
"[[3, 3], [4, 3], [4, 5]]",-0.01,-0.01,-0.01,-0.009878977320149305,0.020248904987081453
"[[4, 3], [5, 3], [4, 5]]",0.0,-0.011055227128542065,0.0,-0.01,-0.01101218190086918
"[[5, 5], [4, 3], [4, 5]]",-0.5,-0.01,-0.0199,0.0,-0.01
"[[5, 4], [5, 3], [4, 5]]",0.0,-0.5,-0.01,-0.010717485033705036,-0.5
"[[5, 2], [5, 4], [4, 5]]",-0.07919569212102055,-0.07971975334246782,-0.0787530179209123,-0.08104017906592893,-0.07963109795235838
"[[5, 1], [5, 4], [4, 5]]",-0.04890803822116347,-0.049900099950010005,-0.049900099950010005,-0.05034279750865073,-0.049900099950010005
"[[4, 1], [5, 4], [4, 5]]",0.10944099197973417,-0.01999,-0.01999,-0.02007991,-0.01999
"[[4, 2], [5, 4], [4, 5]]",0.15058860156940262,-0.059846938189381006,-0.06722016746200328,-0.07174124407437676,-0.059850199850059994
"[[3, 1], [5, 4], [4, 5]]",5.680756414193536,-0.01,-0.01,-0.01,-0.01
"[[2, 1], [5, 4], [4, 5]]",0.0,0.0,0.0,0.0,0.0
"[[4, 4], [3, 3], [4, 4]]",0.0,-0.5,-0.5,0.0,0.0
"[[4, 4], [4, 3], [4, 4]]",0.0,-0.5,-0.5,0.0,0.0
"[[4, 4], [5, 3], [4, 4]]",0.0,-0.5,-0.5,0.0,0.0
"[[4, 4], [5, 4], [4, 4]]",0.0,0.0,0.0,0.0,0.0
"[[3, 4], [6, 6], [5, 2]]",0.0,0.0,0.0,0.0,-0.01
"[[3, 4], [3, 3], [5, 2]]",0.0,-0.01,0.0,0.0,0.0
"[[4, 4], [4, 3], [5, 2]]",0.0,0.0,-0.5,0.0,0.0
"[[4, 3], [5, 3], [5, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [3, 3], [4, 3]]",-2.2448043853624212e-05,-0.01,-0.01,-6.208892285322127e-05,-0.01
"[[3, 5], [4, 3], [4, 4]]",-0.01028609422864929,-0.5,-0.016408702021722208,-0.020784796048626684,-0.011281391343046818
"[[3, 5], [3, 3], [4, 2]]",-0.5,-0.5,-0.5,-0.9900500000000001,-0.5
"[[4, 5], [4, 3], [4, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [4, 3], [3, 4]]",-0.01,0.0,0.0,-0.5,0.0
"[[3, 5], [5, 3], [3, 5]]",0.0,0.0,0.0,-0.5,0.0
"[[3, 5], [5, 4], [3, 5]]",0.0,0.0,0.0,0.0,0.0
"[[4, 5], [6, 6], [5, 2]]",0.0,0.0,-0.01,0.0,0.0
"[[4, 4], [3, 3], [5, 1]]",0.0,0.0,0.0,0.0,-0.01
"[[4, 4], [4, 3], [4, 1]]",0.0,0.0,0.0,0.0,-0.01
"[[4, 4], [5, 3], [4, 1]]",0.0,0.0,-0.01,0.0,0.0
"[[4, 3], [5, 4], [3, 1]]",0.0,0.0,0.0,-0.01,0.0
"[[4, 4], [5, 4], [3, 1]]",0.0,-0.5,0.0,0.0,0.0
"[[5, 4], [5, 4], [3, 1]]",0.0,0.0,0.0,0.0,0.0
"[[1, 1], [5, 4], [4, 5]]",0.0,0.0,0.0,-0.01,0.0
"[[4, 4], [4, 3], [4, 5]]",-0.016306998715494642,-0.0199,-0.0199,-0.5,-0.01009945645877131
"[[4, 4], [5, 3], [4, 5]]",-0.02368161102075795,-0.5,-0.022639868292312258,-0.5,-0.026451207697811334
"[[5, 5], [3, 3], [4, 4]]",-0.5,0.0,-0.01,0.0,0.0
"[[5, 4], [4, 3], [4, 5]]",0.0,0.0,0.0,-0.01,0.0
"[[5, 5], [5, 3], [4, 5]]",-0.5,-0.01044910089955009,0.0,-0.01,0.0
"[[3, 5], [3, 3], [3, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 3], [5, 3], [4, 5]]",0.0,-0.01062811314685189,3.5215627346534975,0.0,0.0
"[[3, 5], [4, 3], [4, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [3, 3], [5, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [4, 3], [5, 2]]",0.0,-0.01,0.0,0.0,0.0
"[[4, 5], [5, 3], [4, 2]]",-0.01,0.0,0.0,0.0,0.0
"[[3, 5], [5, 4], [4, 3]]",0.0,0.0,0.0,-0.01,0.0
"[[3, 5], [5, 4], [4, 4]]",-0.015943472966397428,-0.01,0.0,-0.01654250067191671,-0.01
"[[4, 5], [5, 4], [4, 3]]",0.0,0.0,-0.5,-0.01,-0.01
"[[4, 5], [5, 4], [4, 4]]",-0.01639600436420607,-0.01,0.0,0.0,0.0
"[[5, 5], [5, 4], [4, 5]]",-1.9701995,-0.11934219505791074,-0.5,-0.11934219505791074,-0.10945164670461537
"[[3, 4], [4, 3], [5, 4]]",0.0,0.0,0.0,-0.01,0.0
"[[3, 5], [5, 3], [4, 4]]",0.0,0.0,-0.00819848349845159,-0.014389398124565982,-0.016963089341491665
"[[4, 5], [3, 3], [4, 2]]",0.0,-0.5,-0.5,0.0,0.0
"[[4, 4], [4, 3], [4, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [6, 6], [5, 2]]",0.0,-0.01,-0.01,0.0,0.0
"[[5, 5], [4, 3], [4, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [4, 3], [5, 4]]",0.0,0.0,-0.0199,0.0,0.0
"[[3, 4], [5, 3], [4, 4]]",0.0,0.0,0.0,0.0,-0.013570917448717714
"[[3, 4], [4, 3], [4, 4]]",0.0,0.0,0.0,-0.010943974970380799,0.0
"[[4, 5], [4, 3], [4, 4]]",-0.01,0.0,0.0,0.0,0.0
"[[3, 5], [5, 3], [3, 4]]",-0.01,0.0,0.0,0.0,0.0
"[[3, 5], [6, 6], [3, 2]]",0.0,0.0,-0.01,0.0,0.0
"[[3, 5], [3, 3], [3, 2]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [4, 3], [4, 2]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [5, 3], [4, 3]]",0.0,-0.01,0.0,0.0,0.0
"[[3, 5], [6, 6], [4, 1]]",0.0,0.0,0.0,0.0,-0.01
"[[3, 5], [3, 3], [4, 1]]",0.0,-0.01,-0.01,0.0,0.0
"[[3, 4], [4, 3], [5, 1]]",0.0,-0.01,0.0,0.0,0.0
"[[4, 4], [5, 3], [5, 1]]",0.0,0.0,0.0,-0.01,0.0
"[[4, 5], [5, 4], [5, 1]]",0.0,-0.01,0.0,0.0,0.0
"[[5, 5], [5, 4], [5, 1]]",0.0,0.0,0.0,0.0,-0.01
"[[5, 5], [5, 4], [5, 2]]",0.0,0.0,0.0,-0.01,0.0
"[[5, 5], [5, 4], [4, 2]]",0.0,-0.01,-0.5,0.0,0.0
"[[5, 4], [5, 4], [4, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 4], [5, 3], [5, 4]]",0.0,0.0,0.0,-0.01,0.0
"[[5, 5], [4, 3], [3, 4]]",0.0,0.0,-0.01,0.0,0.0
"[[5, 4], [5, 3], [4, 4]]",-0.5,0.0,0.0,0.0,0.0
"[[4, 4], [5, 4], [5, 4]]",0.0,0.0,0.0,0.0,0.0
"[[4, 5], [4, 3], [3, 1]]",0.0,-0.01,0.0,0.0,0.0
"[[5, 5], [5, 3], [4, 1]]",0.0,0.0,0.0,-0.01,0.0
"[[5, 5], [5, 4], [4, 3]]",0.0,0.0,0.0,-0.01,0.0
"[[5, 5], [5, 4], [4, 4]]",0.0,-0.01,0.0,0.0,0.0
"[[3, 4], [4, 3], [4, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 4], [3, 3], [4, 2]]",-0.5,0.0,-0.5,0.0,0.0
"[[3, 3], [4, 3], [4, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 3], [3, 3], [4, 4]]",0.0,0.0,0.0,0.0,0.0
"[[3, 5], [5, 3], [4, 2]]",0.0,-0.01,0.0,0.0,0.0
"[[3, 5], [4, 3], [5, 3]]",0.0,-0.5,0.0,0.0,0.0
"[[4, 5], [5, 3], [5, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 2], [5, 3], [4, 5]]",0.0,0.0,0.037097785583577604,0.0,0.0
"[[2, 3], [5, 3], [6, 6]]",0.0,0.0,0.0,0.004391030075795664,0.0
"[[4, 5], [3, 3], [3, 3]]",0.0,0.0,0.0,0.0,0.0
"[[3, 4], [3, 3], [4, 3]]",0.0,0.0,0.0,-0.01009092457551116,0.0
================================================
FILE: examples/Social_Cognition/ToM/data/injury_memory.txt
================================================
[[2, 1], [6, 6], [2, 1]]
[[3, 1], [6, 6], [3, 1]]
[[3, 1], [6, 6], [3, 1]]
[[2, 2], [6, 6], [2, 2]]
[[2, 1], [6, 6], [2, 1]]
[[3, 2], [6, 6], [3, 2]]
[[2, 1], [6, 6], [2, 1]]
[[3, 3], [6, 6], [3, 3]]
[[5, 3], [6, 6], [5, 3]]
[[4, 4], [6, 6], [4, 4]]
[[4, 1], [6, 6], [4, 1]]
[[3, 2], [6, 6], [3, 2]]
[[3, 2], [6, 6], [3, 2]]
[[3, 3], [6, 6], [3, 3]]
[[4, 4], [6, 6], [4, 4]]
[[4, 4], [6, 6], [4, 4]]
[[4, 2], [6, 6], [3, 5]]
[[4, 3], [6, 6], [3, 4]]
[[4, 4], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [2, 2]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [2, 2]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [2, 2]]
[[4, 2], [6, 6], [3, 5]]
[[4, 3], [6, 6], [3, 4]]
[[4, 4], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 5]]
[[4, 5], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [2, 2]]
[[4, 2], [6, 6], [3, 5]]
[[4, 3], [6, 6], [3, 5]]
[[4, 1], [3, 3], [3, 3]]]
[[3, 2], [5, 4], [3, 2]]]
[[5, 1], [3, 3], [3, 3]]]
[[3, 3], [3, 3], [3, 5]]]
[[2, 2], [3, 3], [3, 3]]]
[[3, 3], [3, 3], [3, 4]]]
[[2, 1], [5, 4], [2, 1]]]
[[4, 2], [5, 4], [5, 4]]]
[[4, 3], [3, 3], [3, 3]]]
[[5, 2], [3, 3], [3, 3]]]
[[3, 1], [3, 3], [3, 3]]]
[[5, 4], [5, 4], [2, 1]]]
[[5, 4], [5, 4], [2, 2]]]
[[4, 1], [5, 4], [4, 1]]]
[[4, 3], [4, 3], [3, 4]]]
[[4, 2], [3, 3], [3, 3]]]
[[5, 4], [5, 4], [4, 1]]]
[[4, 4], [5, 4], [4, 4]]]
[[4, 3], [4, 3], [3, 5]]]
[[5, 3], [3, 3], [3, 3]]]
[[3, 2], [3, 3], [3, 3]]]
[[5, 4], [5, 4], [3, 3]]]
[[4, 3], [4, 3], [3, 3]]]
[[5, 4], [5, 4], [3, 1]]]
[[3, 1], [5, 4], [3, 1]]]
[[4, 3], [4, 3], [1, 5]]]
[[4, 3], [4, 3], [1, 4]]]
[[4, 3], [4, 3], [2, 3]]]
[[3, 1], [5, 4], [3, 1]]]
[[3, 2], [4, 4], [4, 4]]]
[[3, 1], [5, 4], [3, 1]]]
[[4, 2], [3, 3], [3, 3]]]
[[3, 1], [5, 4], [3, 1]]]
[[3, 3], [3, 3], [2, 4]]]
[[4, 4], [3, 3], [3, 3]]]
[[4, 3], [4, 3], [2, 4]]]
[[4, 4], [3, 3], [3, 3]]]
[[4, 2], [3, 3], [3, 3]]]
[[3, 3], [3, 3], [2, 5]]]
[[4, 2], [3, 3], [3, 3]]]
[[4, 2], [3, 3], [3, 3]]]
[[4, 5], [5, 4], [4, 5]]]
[[4, 4], [3, 3], [3, 3]]]
[[4, 4], [3, 3], [3, 3]]]
[[4, 4], [3, 3], [3, 3]]]
[[5, 4], [5, 4], [3, 2]]]
[[4, 4], [4, 4], [2, 4]]]
[[4, 4], [4, 4], [3, 2]]]
[[4, 3], [4, 3], [1, 4]]]
[[4, 3], [4, 3], [2, 3]]]
[[4, 4], [4, 4], [4, 4]]]
[[4, 4], [3, 3], [3, 3]]]
[[4, 4], [4, 4], [3, 3]]]
[[4, 4], [4, 4], [3, 2]]]
[[4, 3], [4, 3], [3, 3]]]
[[4, 3], [4, 3], [3, 3]]]
[[4, 5], [5, 4], [4, 5]]]
[[4, 4], [3, 3], [3, 3]]]
[[4, 4], [3, 3], [3, 3]]]
[[4, 4], [4, 4], [4, 4]]]
[[4, 4], [3, 3], [3, 3]]]
[[3, 4], [5, 4], [3, 4]]]
[[4, 5], [5, 4], [4, 5]]]
[[4, 4], [4, 4], [4, 4]]]
[[4, 5], [6, 6], [3, 1]]
[[4, 2], [6, 6], [3, 5]]
[[4, 3], [6, 6], [3, 5]]
[[4, 4], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [3, 1]]
[[4, 2], [6, 6], [3, 5]]
[[4, 3], [6, 6], [3, 5]]
[[4, 4], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 5]]
[[4, 5], [6, 6], [3, 5]]
[[4, 5], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [2, 2]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [3, 1]]
[[4, 5], [6, 6], [4, 1]]
[[4, 5], [6, 6], [4, 2]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 3]]
[[4, 5], [6, 6], [3, 2]]
[[4, 5], [6, 6], [3, 1]]
[[4, 2], [6, 6], [3, 5]]
[[4, 3], [6, 6], [3, 4]]
[[4, 4], [6, 6], [3, 4]]
[[4, 5], [6, 6], [3, 4]]
================================================
FILE: examples/Social_Cognition/ToM/data/injury_value.txt
================================================
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
================================================
FILE: examples/Social_Cognition/ToM/data/one_hot.py
================================================
from numpy import argmax
import numpy as np
def one_hot(value):
num = '01'
letter = [0 for _ in range(len(num))]
letter[value] = 1
letter = np.array([letter])
return letter
# print(one_hot(4))
================================================
FILE: examples/Social_Cognition/ToM/env/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToM/env/env.py
================================================
from numpy import argmax
import random, time, pygame, sys
import pygame
pygame.init()
from pygame.locals import *
import os
# os.environ['SDL_AUDIODRIVER'] = 'dsp'
# os.environ['SDL_VIDEODRIVER']='windib'
os.environ["SDL_VIDEODRIVER"] = "dummy"
# os.environ['DISPLAY'] = "localhost:13.0"
from rulebasedpolicy.world_model import *
from rulebasedpolicy.statedata_pre import *
from rulebasedpolicy.Find_a_way import *
import numpy as np
from utils.one_hot import one_hot
# =============================================================================
# set the value of interface
# =============================================================================
FPS = 25
WinWidth = 340 #window width
WinHeight = 260 #window width
BoxSize = 20 #the size of one grid
GridWidth = 7 #the number of lattices are there in the x-axis
GridHeight = 7 #the number of lattices are there in the y-axis
#representation of different objective
BlankBox = 1
Wall = 5
Obstacle = 5
observer = 8
obeservation_1 = 11
obeservation_2 = 22
obeservation_3 = 33
#Text = None
XMargin = int((WinWidth - GridWidth * BoxSize)/2)
TopMargin = int((WinHeight - GridHeight * BoxSize))/2-5
# =============================================================================
# set color
# =============================================================================
White = (255,255,255)
Gray = (185,185,185)
Black = (0,0,0)
Red = (200,0,0)
Green = (0,139,0)
Green_B = (78, 238, 148)
Light_A = (233, 232, 170)
Blue = (30, 144, 255)
pink = (238, 99, 99)
BoardColor = White
BGColor = White
TextColor = White
Test = []
# =============================================================================
# agents - env interactive
# =============================================================================
class FalseBelief_env(object):
def __init__(self, reward=10):
super(FalseBelief_env, self).__init__()
self.action_space = ['up', 'down', 'left', 'right', 'stay']
self.action_move = {
0 : (0, -1),
1 : (0, 1),
2 : (-1, 0),
3 : (1, 0),
4 :(0, 0)
}#[(0, -1), (0, 1), (-1, 0), (1, 0), (0, 0)]
self.n_actions = len(self.action_space)
self._build_AB()
self.board, self.obs = self.getBlankBoard()
self._agent_init()
self.score = 0
self.steps = 0
self.n = 0
self.R = int(5/2) * (BoxSize - 5)
self.trigger = 0
self.x = 0
self.n_features = 30
self.reward = reward
def _build_AB(self):
global FPSCLOCK, DISPLAYSURF, BASICFONT, BIGFONT
FPSCLOCK = pygame.time.Clock()
DISPLAYSURF = pygame.display.set_mode((WinWidth, WinHeight))
BASICFONT = pygame.font.Font('freesansbold.ttf', 18)
BIGFONT = pygame.font.Font('freesansbold.ttf', 100)
pygame.display.set_caption('AB')
pygame.display.update()
FPSCLOCK.tick()
def _agent_init(self):
"""
Aim:Initialize the basic information of the agent
"""
self.NPC_1 = {
'shape' : [['#']],
'x' : 3, #row
'y' : 1, #column
'color' : Blue,
'style' : "circle",
'obs' : None,
'axis' : None,#,[[1,3],[3,5],[4,2]]
'reward' : 0,
'Done' : False
}
self.NPC_2 = {
'shape' : [['@']],
'x' : 5, #row
'y' : 3, #column
'color' : pink,
'style' : "circle",
'obs' : None,
'axis' :None ,#,[[3,5],[1,3],[4,2]]
'reward': 0,
'Done': False
}
self.agent = {
'shape' : [['$']],
'x' : 2, #row
'y' : 4, #column
'color' : Green_B,
'style' : "circle",
'obs' : None,
'axis' : None,#[[4,2],[1,3],[3,5]]
'reward': 0,
'Done': False
}
def actu_obs(self):
"""
将状态转化成可以训练的数据形式
"""
_, state = self.getBlankBoard()
a = state
b = state
c = state
state1 = np.r_[a, np.ones((4, 5))].astype(np.int_)
state2 = np.r_[b, np.ones((4, 5))].astype(np.int_)
statea = np.r_[c, np.ones((4, 5))].astype(np.int_)
NPC_1_state = state1
NPC_2_state = state2
Agent_state = statea
NPC_1_state[self.NPC_1['y']-1, self.NPC_1['x']-1] = observer
q = shelter_env(NPC_1_state[:5, :])
NPC_1_state[:5, :] = shelter_env(NPC_1_state[:5, :])
NPC_2_state[self.NPC_2['y']-1, self.NPC_2['x']-1] = observer
r = shelter_env(NPC_2_state[:5, :])
NPC_2_state[:5, :] = shelter_env(NPC_2_state[:5, :])
Agent_state[self.agent['y']-1, self.agent['x']-1] = observer
p = shelter_env(Agent_state[:5, :])
Agent_state[:5, :] = shelter_env(Agent_state[:5, :])
"""
########### num ############
#2-NPC1 in other agents' obs
#3-NPC2 in other agents' obs
#4-Agent in other agents' obs
"""
self.NPC_1['obs'] = q
self.NPC_1['obs'] = self.gain_obs(self.NPC_1['obs'],NPC_1_state,self.NPC_2,self.agent,3,4)
self.NPC_1['axis'] = self.gain_axis(self.NPC_1,NPC_1_state,self.NPC_2,self.agent,3,4)
self.NPC_2['obs'] = r
self.NPC_2['obs'] = self.gain_obs(self.NPC_2['obs'], NPC_2_state, self.NPC_1, self.agent, 2, 4)
self.NPC_2['axis'] = self.gain_axis(self.NPC_2, NPC_2_state, self.NPC_1, self.agent, 2, 4)
self.agent['obs'] = p
self.agent['obs'] = self.gain_obs(self.agent['obs'], Agent_state, self.NPC_1, self.NPC_2, 2, 3)
self.agent['axis'] = self.gain_axis(self.agent, Agent_state, self.NPC_1, self.NPC_2, 2, 3)
return NPC_1_state, NPC_2_state, Agent_state
def gain_obs(self, a, aa, b, c, bb, cc):
"""
获得智能体真正的环境遮挡关系
@param a: self - observation
@param aa: self - self-axis, other-b-axis, other-c-axis
@param b: other-b 遮挡后的可见区域 5*5
@param c: other-c 遮挡后的可见区域 5*5
@param bb: other-b' num
@param cc: other-c' num
@return: self - observation
"""
if aa[b['y']-1, b['x']-1] == 1:
a[b['y']-1, b['x']-1] = bb
if aa[c['y']-1, c['x']-1] ==1:
a[c['y'] - 1, c['x'] - 1] = cc
return a
def gain_axis(self,a,aa,b,c,bb,cc):
"""
获得坐标,但是看不见的坐标就用6来表示
@param a:
@param aa:
@param b:
@param c:
@param bb:
@param cc:
@return:
"""
axis = []
axis.append([a['y'], a['x']])
if aa[b['y']-1, b['x']-1] != 0:
axis.append([b['y'], b['x']])
else:
axis.append([6,6])
if aa[c['y']-1, c['x']-1] != 0:
axis.append([c['y'] , c['x']])
else:
axis.append([6, 6])
return axis
def interact(self, action_NPC1, action_NPC2, action_agent):
"""
三个智能体进行交互
@param action_NPC1: action
@param action_NPC2: actionF
@param action_agent: action
@return:5*5 NPC1遮挡后看见了什么 5*5 NPC2遮挡后看见了什么 5*5 agent遮挡后看见了什么
"""
self.agent['reward'] = 0
self.NPC_1['reward'] = 0
self.NPC_2['reward'] = 0
#三个智能体分别会看到什么?
NPC_1_state, NPC_2_state, Agent_state = self.actu_obs()
#看到这些状态,智能体们会分别采取什么行为? ---depend on RL
#这些行为对状态的影响 ---首先,影响本身的位置坐标,然后,影响观测
base = np.where(np.array(self.board) == obeservation_1)
base_x = int(base[0])
base_y= int(base[1])
if self.NPC_1['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.NPC_1['y']) + np.square(base_y - self.NPC_1['x']))
if self.isNotWall(self.board, self.NPC_1, self.action_move[action_NPC1][0], \
self.action_move[action_NPC1][1]):
self.NPC_1['x'] = self.NPC_1['x'] + self.action_move[action_NPC1][0]
self.NPC_1['y'] = self.NPC_1['y'] + self.action_move[action_NPC1][1]
dis2 = np.sqrt(np.square(base_x - self.NPC_1['y']) + np.square(base_y - self.NPC_1['x']))
self.NPC_1['reward'] = (((dis1 - dis2) * 2 - 1) / dis1)
else:
self.NPC_1['reward'] = -1 * (1 / dis1)
if self.board[self.NPC_1['y'], self.NPC_1['x']] == obeservation_1:
self.NPC_1['reward'] = 50
self.NPC_1['Done'] = True
base = np.where(np.array(self.board) == obeservation_2)
base_x = int(base[0])
base_y= int(base[1])
if self.NPC_2['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.NPC_2['y']) + np.square(base_y - self.NPC_2['x']))
if self.isNotWall(self.board, self.NPC_2, self.action_move[action_NPC2][0], \
self.action_move[action_NPC2][1]):
self.NPC_2['x'] = self.NPC_2['x'] + self.action_move[action_NPC2][0]
self.NPC_2['y'] = self.NPC_2['y'] + self.action_move[action_NPC2][1]
dis2 = np.sqrt(np.square(base_x - self.NPC_2['y']) + np.square(base_y - self.NPC_2['x']))
self.NPC_2['reward'] = (((dis1 - dis2)*10 - 1/2) / dis1)
while self.NPC_2['reward'] < 0.5 and self.NPC_2['reward'] > -0.5 :
self.NPC_2['reward'] = self.NPC_2['reward'] * 2
if self.NPC_2['reward'] > 1:
self.NPC_2['reward'] = 1
elif self.NPC_2['reward'] < -1:
self.NPC_2['reward'] = -1
else:
self.NPC_2['reward'] = -0.9 #* (1 / dis1)
if self.board[self.NPC_2['y'], self.NPC_2['x']] == obeservation_2:
self.NPC_2['reward'] = self.reward
self.NPC_2['Done'] = True
base = np.where(np.array(self.board) == obeservation_3)
base_x = int(base[0])
base_y= int(base[1])
if self.agent['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.agent['y']) + np.square(base_y - self.agent['x']))
if self.isNotWall(board=self.board, piece=self.agent, xT=self.action_move[action_agent][0], \
yT=self.action_move[action_agent][1]):
self.agent['x'] = self.agent['x'] + self.action_move[action_agent][0]
self.agent['y'] = self.agent['y'] + self.action_move[action_agent][1]
dis2 = np.sqrt(np.square(base_x - self.agent['y']) + np.square(base_y - self.agent['x']))
# self.agent['reward'] = (((dis1 - dis2) * 2 - 1) / dis1)
# else:
# # print('action', action_agent)
# self.agent['reward'] = -1 * (1 / dis1)
self.agent['reward'] = (((dis1 - dis2)*10 - 1/2) / dis1)
while self.agent['reward'] < 0.5 and self.agent['reward'] > -0.5 :
self.agent['reward'] = self.agent['reward'] * 2 - 0.1
if self.agent['reward'] > 1:
self.agent['reward'] = 1
elif self.agent['reward'] < -1:
self.agent['reward'] = -1
else:
self.agent['reward'] = -0.9 #* (1 / dis1)
if self.board[self.agent['y'], self.agent['x']] == obeservation_3:
self.agent['reward'] = self.reward
self.agent['Done'] = True
NPC_1_state, NPC_2_state, Agent_state = self.actu_obs()
#判断是否会相撞?
location = [(self.NPC_1['x'], self.NPC_1['y']), (self.NPC_2['x'], self.NPC_2['y']),\
(self.agent['x'], self.agent['y'])]
#达到目标或者相撞都会结束该智能体的回合
terminal = self.gameover(location)
if terminal[0] == True and self.NPC_1['Done'] == False:
self.NPC_1['Done'] = True
self.NPC_1['reward'] = -50
self.NPC_1['color'] = Red
if terminal[1] == True and self.NPC_2['Done'] == False:
self.NPC_2['Done'] = True
self.NPC_2['reward'] = -self.reward
self.NPC_2['color'] = Red
if terminal[2] == True and self.agent['Done'] == False:
self.agent['Done'] = True
self.agent['reward'] = -self.reward
self.agent['color'] = Red
return NPC_1_state, NPC_2_state, Agent_state
def SHOW(self):
"""
显示函数
"""
DISPLAYSURF.fill(BGColor)
self.DrawBoard(self.board)
self.DrawPiece(self.NPC_1)
self.DrawPiece(self.NPC_2)
self.DrawPiece(self.agent)
pygame.display.update()
FPSCLOCK.tick(FPS)
# return flag
def reset(self):
self._agent_init()
def getBlankBoard(self):
"""
11 - NPC1-goal
22 - NPC2-goal
33 - Agent-goal
@return:
"""
board = np.array([[1,1,1,5,5],[22,1,1,5,5],[1,1,1,1,1],[1,1,1,1,33],[1,1,1,11,1]])
state_init = np.array([[1,1,1,5,5],[1,1,1,5,5],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])
board = big_env(board)
# print(board)
# for x in range(GridWidth):
# for y in range(GridHeight):
# print(board[x][y],x,y)
return board, state_init
def ValidPos(self, piece1, piece2, xT=0, yT=0):
"""
to judge the next place vaild or not
@param piece1:
@param piece2:
@param xT:
@param yT:
@return:
"""
if piece1['x'] == (piece2['x'] + xT) and piece1['y'] == (piece2['y'] + yT):
return True
return False
def isNotWall(self, board, piece, xT=0 , yT=0 ):
"""
判断是否到达墙
@param board: board
@param piece: agent
@param xT:
@param yT:
@return:
"""
if board[piece['y'] + yT][piece['x'] + xT] == Wall:#############
return False
else:
return True
def gameover(self, location):
"""
回合是否结束,以及奖励值
@param location:目标位置
"""
result = False
terminal = [False, False, False]
if location[0] == location[1]:
terminal[0] = True
terminal[1] = True
if location[2] == location[1]:
terminal[2] = True
terminal[1] = True
if location[2] ==location[0]:
terminal[2] = True
terminal[0] = True
return terminal
def pixel(self, xbox, ybox):
return (XMargin + (xbox * BoxSize)), (TopMargin + (ybox * BoxSize))
def DrawBox(self, xbox, ybox, color, xpixel=None, ypixel=None):
if color == BlankBox:
return
elif color == obeservation_1:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (60,107,255), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == obeservation_2:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (205, 155, 155), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == obeservation_3:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (154, 205, 50), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == Wall:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, Gray, (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
else:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, color, (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
def fun_trigger(self):
xpixel, ypixel = self.pixel(3, 5)
pygame.draw.line(DISPLAYSURF, Red, (xpixel + BoxSize, ypixel - BoxSize),
(xpixel + BoxSize, ypixel - 2*BoxSize), 5)
def DrawCircle(self, xbox, ybox, color, xpixel=None, ypixel=None):
"""
画圆
@param xbox:
@param ybox:
@param color:
@param xpixel:
@param ypixel:
"""
pygame.draw.circle(DISPLAYSURF,
color,
(int(xpixel+BoxSize/2), int(ypixel+BoxSize/2)),
int(0.3 * self.R))
def DrawPiece(self, piece, xpixel=None, ypixel=None):
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(piece['x'], piece['y'])
if piece['style'] == "circle":
self.DrawCircle(None, None, piece['color'], xpixel, ypixel)
else:
self.DrawBox(None, None, piece['color'], xpixel, ypixel)
def DrawBoard(self, board):
pygame.draw.rect(DISPLAYSURF, BoardColor,
(XMargin - 3, TopMargin - 7, (GridWidth * BoxSize) + 8, (GridHeight * BoxSize) + 8), 5)
pygame.draw.rect(DISPLAYSURF, BGColor, (XMargin, TopMargin, GridWidth * BoxSize, GridHeight * BoxSize))
for x in range(GridWidth):
for y in range(GridHeight):
self.DrawBox(y, x, board[x][y])
if self.trigger == 1:
self.fun_trigger()
def ShowScore(self, score):
scoreSurf = BASICFONT.render('Score : %s' % score, True, TextColor)
scoreRect = scoreSurf.get_rect()
scoreRect.topleft = (WinWidth - 250, 20)
DISPLAYSURF.blit(scoreSurf, scoreRect)
def Terminal(self, piece1, piece2, piece1_old, piece2_old):
# print(piece1['x'],piece1['y'],piece2_old[0],piece2_old[1],'/',piece2['x'],piece2['y'],piece1_old[0],piece1_old[1])
# if self.steps == 1:# wrong!!!!
if piece1['x'] == piece2_old[0] and piece1['y'] == piece2_old[1] and piece2['x'] == piece1_old[0] and piece2['y'] == piece1_old[1]:
return 1
else:
return 2
def Paint(self, board, piece, color):
board[piece['x']][piece['y']] = color
piece['color'] = color
return board
# if __name__ == "__main__":
# env0 = FalseBelief_env0()
# action_agent = 0
# action_NPC2 = 1
# action_NPC1 = 4
# for i in range(10):
# if i > 8:
# break
# else:
# env0.interact(action_NPC1, action_NPC2, action_agent)
#
# env0.SHOW()
# time.sleep(2)
# pygame.quit()
================================================
FILE: examples/Social_Cognition/ToM/env/env3_train_env00.py
================================================
from numpy import argmax
import random, time, pygame, sys
import pygame
pygame.init()
from pygame.locals import *
import os
os.environ["SDL_VIDEODRIVER"] = "dummy"
from rulebasedpolicy.world_model import *
from rulebasedpolicy.statedata_pre import *
from rulebasedpolicy.Find_a_way import *
import numpy as np
from utils.one_hot import one_hot
# =============================================================================
# set the value of interface
# =============================================================================
FPS = 25
WinWidth = 340 #window width
WinHeight = 260 #window width
BoxSize = 20 #the size of one grid
GridWidth = 7 #the number of lattices are there in the x-axis
GridHeight = 7 #the number of lattices are there in the y-axis
#representation of different objective
BlankBox = 1
Wall = 5
Obstacle = 5
observer = 8
obeservation_1 = 11
obeservation_2 = 22
obeservation_3 = 33
#Text = None
XMargin = int((WinWidth - GridWidth * BoxSize)/2)
TopMargin = int((WinHeight - GridHeight * BoxSize))/2-5
# =============================================================================
# set color
# =============================================================================
White = (255,255,255)
Gray = (185,185,185)
Black = (0,0,0)
Red = (200,0,0)
Green = (0,139,0)
Green_B = (78, 238, 148)
Light_A = (233, 232, 170)
Blue = (30, 144, 255)
pink = (238, 99, 99)
BoardColor = White
BGColor = White
TextColor = White
Test = []
# =============================================================================
# agents - env interactive
# =============================================================================
class FalseBelief_env0(object):
def __init__(self, reward=10):
super(FalseBelief_env0, self).__init__()
self.action_space = ['up', 'down', 'left', 'right', 'stay']
self.action_move = {
0 : (0, -1),
1 : (0, 1),
2 : (-1, 0),
3 : (1, 0),
4 :(0, 0)
}#[(0, -1), (0, 1), (-1, 0), (1, 0), (0, 0)]
self.n_actions = len(self.action_space)
self._build_AB()
self.board, self.obs = self.getBlankBoard()
self._agent_init()
self.score = 0
self.steps = 0
self.n = 0
self.R = int(5/2) * (BoxSize - 5)
self.x = 0
self.n_features = 30
self.reward = reward
def _build_AB(self):
global FPSCLOCK, DISPLAYSURF, BASICFONT, BIGFONT
FPSCLOCK = pygame.time.Clock()
DISPLAYSURF = pygame.display.set_mode((WinWidth, WinHeight))
BASICFONT = pygame.font.Font('freesansbold.ttf', 18)
BIGFONT = pygame.font.Font('freesansbold.ttf', 100)
pygame.display.set_caption('AB')
pygame.display.update()
FPSCLOCK.tick()
def _agent_init(self):
"""
Aim:Initialize the basic information of the agent
"""
self.NPC_1 = {
'shape' : [['#']],
'x' : 3, #row
'y' : 1, #column
'color' : Blue,
'style' : "circle",
'obs' : None,
'axis' : None,#,[[1,3],[3,5],[4,2]]
'reward' : 0,
'Done' : False
}
self.NPC_2 = {
'shape' : [['@']],
'x' : 5, #row
'y' : 3, #column
'color' : pink,
'style' : "circle",
'obs' : None,
'axis' :None ,#,[[3,5],[1,3],[4,2]]
'reward': 0,
'Done': False
}
self.agent = {
'shape' : [['$']],
'x' : 2, #row
'y' : 4, #column
'color' : Green_B,
'style' : "circle",
'obs' : None,
'axis' : None,#[[4,2],[1,3],[3,5]]
'reward': 0,
'Done': False
}
def actu_obs(self):
"""
将状态转化成可以训练的数据形式
"""
_, state = self.getBlankBoard()
a = state
b = state
c = state
state1 = np.r_[a, np.ones((4, 5))].astype(np.int_)
state2 = np.r_[b, np.ones((4, 5))].astype(np.int_)
statea = np.r_[c, np.ones((4, 5))].astype(np.int_)
NPC_1_state = state1
NPC_2_state = state2
Agent_state = statea
NPC_1_state[self.NPC_1['y']-1, self.NPC_1['x']-1] = observer
q = shelter_env(NPC_1_state[:5, :])
NPC_1_state[:5, :] = shelter_env(NPC_1_state[:5, :])
NPC_2_state[self.NPC_2['y']-1, self.NPC_2['x']-1] = observer
r = shelter_env(NPC_2_state[:5, :])
NPC_2_state[:5, :] = shelter_env(NPC_2_state[:5, :])
Agent_state[self.agent['y']-1, self.agent['x']-1] = observer
p = shelter_env(Agent_state[:5, :])
Agent_state[:5, :] = shelter_env(Agent_state[:5, :])
"""
########### num ############
#2-NPC1 in other agents' obs
#3-NPC2 in other agents' obs
#4-Agent in other agents' obs
"""
self.NPC_1['obs'] = q
self.NPC_1['obs'] = self.gain_obs(self.NPC_1['obs'],NPC_1_state,self.NPC_2,self.agent,3,4)
self.NPC_1['axis'] = self.gain_axis(self.NPC_1,NPC_1_state,self.NPC_2,self.agent,3,4)
self.NPC_2['obs'] = r
self.NPC_2['obs'] = self.gain_obs(self.NPC_2['obs'], NPC_2_state, self.NPC_1, self.agent, 2, 4)
self.NPC_2['axis'] = self.gain_axis(self.NPC_2, NPC_2_state, self.NPC_1, self.agent, 2, 4)
self.agent['obs'] = p
self.agent['obs'] = self.gain_obs(self.agent['obs'], Agent_state, self.NPC_1, self.NPC_2, 2, 3)
self.agent['axis'] = self.gain_axis(self.agent, Agent_state, self.NPC_1, self.NPC_2, 2, 3)
return NPC_1_state, NPC_2_state, Agent_state
def gain_obs(self, a, aa, b, c, bb, cc):
"""
获得智能体真正的环境遮挡关系
@param a: self - observation
@param aa: self - self-axis, other-b-axis, other-c-axis
@param b: other-b 遮挡后的可见区域 5*5
@param c: other-c 遮挡后的可见区域 5*5
@param bb: other-b' num
@param cc: other-c' num
@return: self - observation
"""
if aa[b['y']-1, b['x']-1] == 1:
a[b['y']-1, b['x']-1] = bb
if aa[c['y']-1, c['x']-1] ==1:
a[c['y'] - 1, c['x'] - 1] = cc
return a
def gain_axis(self,a,aa,b,c,bb,cc):
"""
获得坐标,但是看不见的坐标就用6来表示
@param a:
@param aa:
@param b:
@param c:
@param bb:
@param cc:
@return:
"""
axis = []
axis.append([a['y'], a['x']])
if aa[b['y']-1, b['x']-1] != 0:
axis.append([b['y'], b['x']])
else:
axis.append([6,6])
if aa[c['y']-1, c['x']-1] != 0:
axis.append([c['y'] , c['x']])
else:
axis.append([6, 6])
return axis
def interact(self, action_NPC1, action_NPC2, action_agent):
"""
三个智能体进行交互
@param action_NPC1: action
@param action_NPC2: actionF
@param action_agent: action
@return:5*5 NPC1遮挡后看见了什么 5*5 NPC2遮挡后看见了什么 5*5 agent遮挡后看见了什么
"""
self.agent['reward'] = 0
self.NPC_1['reward'] = 0
self.NPC_2['reward'] = 0
#三个智能体分别会看到什么?
NPC_1_state, NPC_2_state, Agent_state = self.actu_obs()
#看到这些状态,智能体们会分别采取什么行为? ---depend on RL
#这些行为对状态的影响 ---首先,影响本身的位置坐标,然后,影响观测
base = np.where(np.array(self.board) == obeservation_1)
base_x = int(base[0])
base_y= int(base[1])
if self.NPC_1['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.NPC_1['y']) + np.square(base_y - self.NPC_1['x']))
if self.isNotWall(self.board, self.NPC_1, self.action_move[action_NPC1][0], \
self.action_move[action_NPC1][1]):
self.NPC_1['x'] = self.NPC_1['x'] + self.action_move[action_NPC1][0]
self.NPC_1['y'] = self.NPC_1['y'] + self.action_move[action_NPC1][1]
dis2 = np.sqrt(np.square(base_x - self.NPC_1['y']) + np.square(base_y - self.NPC_1['x']))
self.NPC_1['reward'] = (((dis1 - dis2) * 2 - 1) / dis1)
else:
self.NPC_1['reward'] = -1 * (1 / dis1)
if self.board[self.NPC_1['y'], self.NPC_1['x']] == obeservation_1:
self.NPC_1['reward'] = 50
self.NPC_1['Done'] = True
base = np.where(np.array(self.board) == obeservation_2)
base_x = int(base[0])
base_y= int(base[1])
if self.NPC_2['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.NPC_2['y']) + np.square(base_y - self.NPC_2['x']))
if self.isNotWall(self.board, self.NPC_2, self.action_move[action_NPC2][0], \
self.action_move[action_NPC2][1]):
self.NPC_2['x'] = self.NPC_2['x'] + self.action_move[action_NPC2][0]
self.NPC_2['y'] = self.NPC_2['y'] + self.action_move[action_NPC2][1]
dis2 = np.sqrt(np.square(base_x - self.NPC_2['y']) + np.square(base_y - self.NPC_2['x']))
self.NPC_2['reward'] = (((dis1 - dis2)*10 - 1/2) / dis1)
while self.NPC_2['reward'] < 0.5 and self.NPC_2['reward'] > -0.5 :
self.NPC_2['reward'] = self.NPC_2['reward'] * 2
if self.NPC_2['reward'] > 1:
self.NPC_2['reward'] = 1
elif self.NPC_2['reward'] < -1:
self.NPC_2['reward'] = -1
else:
self.NPC_2['reward'] = -0.9 #* (1 / dis1)
if self.board[self.NPC_2['y'], self.NPC_2['x']] == obeservation_2:
self.NPC_2['reward'] = self.reward
self.NPC_2['Done'] = True
base = np.where(np.array(self.board) == obeservation_3)
base_x = int(base[0])
base_y= int(base[1])
if self.agent['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.agent['y']) + np.square(base_y - self.agent['x']))
if self.isNotWall(board=self.board, piece=self.agent, xT=self.action_move[action_agent][0], \
yT=self.action_move[action_agent][1]):
self.agent['x'] = self.agent['x'] + self.action_move[action_agent][0]
self.agent['y'] = self.agent['y'] + self.action_move[action_agent][1]
dis2 = np.sqrt(np.square(base_x - self.agent['y']) + np.square(base_y - self.agent['x']))
# self.agent['reward'] = (((dis1 - dis2) * 2 - 1) / dis1)
# else:
# # print('action', action_agent)
# self.agent['reward'] = -1 * (1 / dis1)
self.agent['reward'] = (((dis1 - dis2)*10 - 1/2) / dis1)
while self.agent['reward'] < 0.5 and self.agent['reward'] > -0.5 :
self.agent['reward'] = self.agent['reward'] * 2 - 0.1
if self.agent['reward'] > 1:
self.agent['reward'] = 1
elif self.agent['reward'] < -1:
self.agent['reward'] = -1
else:
self.agent['reward'] = -0.9 #* (1 / dis1)
if self.board[self.agent['y'], self.agent['x']] == obeservation_3:
self.agent['reward'] = self.reward
self.agent['Done'] = True
NPC_1_state, NPC_2_state, Agent_state = self.actu_obs()
#判断是否会相撞?
location = [(self.NPC_1['x'], self.NPC_1['y']), (self.NPC_2['x'], self.NPC_2['y']),\
(self.agent['x'], self.agent['y'])]
#达到目标或者相撞都会结束该智能体的回合
terminal = self.gameover(location)
if terminal[0] == True and self.NPC_1['Done'] == False:
self.NPC_1['Done'] = True
self.NPC_1['reward'] = -50
self.NPC_1['color'] = Red
if terminal[1] == True and self.NPC_2['Done'] == False:
self.NPC_2['Done'] = True
self.NPC_2['reward'] = -self.reward
self.NPC_2['color'] = Red
if terminal[2] == True and self.agent['Done'] == False:
self.agent['Done'] = True
self.agent['reward'] = -self.reward
self.agent['color'] = Red
return NPC_1_state, NPC_2_state, Agent_state
def SHOW(self):
"""
显示函数
"""
DISPLAYSURF.fill(BGColor)
self.DrawBoard(self.board)
self.DrawPiece(self.NPC_1)
self.DrawPiece(self.NPC_2)
self.DrawPiece(self.agent)
pygame.display.update()
FPSCLOCK.tick(FPS)
# return flag
def reset(self):
self._agent_init()
def getBlankBoard(self):
"""
11 - NPC1-goal
22 - NPC2-goal
33 - Agent-goal
@return:
"""
# board = data_transfer('env_1.txt','env_11.txt')
board = np.array([[1,1,1,1,1],[22,1,1,1,1],[1,1,1,1,1],[1,1,1,1,33],[1,1,1,11,1]])
state_init = np.array([[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])
board = big_env(board)
# print(board)
# for x in range(GridWidth):
# for y in range(GridHeight):
# print(board[x][y],x,y)
return board, state_init
def ValidPos(self, piece1, piece2, xT=0, yT=0):
"""
to judge the next place vaild or not
@param piece1:
@param piece2:
@param xT:
@param yT:
@return:
"""
if piece1['x'] == (piece2['x'] + xT) and piece1['y'] == (piece2['y'] + yT):
return True
return False
def isNotWall(self, board, piece, xT=0 , yT=0 ):
"""
判断是否到达墙
@param board: board
@param piece: agent
@param xT:
@param yT:
@return:
"""
if board[piece['y'] + yT][piece['x'] + xT] == Wall:#############
return False
else:
return True
def gameover(self, location):
"""
回合是否结束,以及奖励值
@param location:目标位置
"""
result = False
terminal = [False, False, False]
if location[0] == location[1]:
terminal[0] = True
terminal[1] = True
if location[2] == location[1]:
terminal[2] = True
terminal[1] = True
if location[2] ==location[0]:
terminal[2] = True
terminal[0] = True
return terminal
def pixel(self, xbox, ybox):
return (XMargin + (xbox * BoxSize)), (TopMargin + (ybox * BoxSize))
def DrawBox(self, xbox, ybox, color, xpixel=None, ypixel=None):
if color == BlankBox:
return
elif color == obeservation_1:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (60,107,255), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == obeservation_2:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (205, 155, 155), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == obeservation_3:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (154, 205, 50), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == Wall:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, Gray, (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
else:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, color, (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
def DrawCircle(self, xbox, ybox, color, xpixel=None, ypixel=None):
"""
画圆
@param xbox:
@param ybox:
@param color:
@param xpixel:
@param ypixel:
"""
pygame.draw.circle(DISPLAYSURF,
color,
(int(xpixel+BoxSize/2), int(ypixel+BoxSize/2)),
int(0.3 * self.R))
def DrawPiece(self, piece, xpixel=None, ypixel=None):
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(piece['x'], piece['y'])
if piece['style'] == "circle":
self.DrawCircle(None, None, piece['color'], xpixel, ypixel)
else:
self.DrawBox(None, None, piece['color'], xpixel, ypixel)
def DrawBoard(self, board):
pygame.draw.rect(DISPLAYSURF, BoardColor,
(XMargin - 3, TopMargin - 7, (GridWidth * BoxSize) + 8, (GridHeight * BoxSize) + 8), 5)
pygame.draw.rect(DISPLAYSURF, BGColor, (XMargin, TopMargin, GridWidth * BoxSize, GridHeight * BoxSize))
for x in range(GridWidth):
for y in range(GridHeight):
self.DrawBox(y, x, board[x][y])
def ShowScore(self, score):
scoreSurf = BASICFONT.render('Score : %s' % score, True, TextColor)
scoreRect = scoreSurf.get_rect()
scoreRect.topleft = (WinWidth - 250, 20)
DISPLAYSURF.blit(scoreSurf, scoreRect)
def Terminal(self, piece1, piece2, piece1_old, piece2_old):
# print(piece1['x'],piece1['y'],piece2_old[0],piece2_old[1],'/',piece2['x'],piece2['y'],piece1_old[0],piece1_old[1])
# if self.steps == 1:# wrong!!!!
if piece1['x'] == piece2_old[0] and piece1['y'] == piece2_old[1] and piece2['x'] == piece1_old[0] and piece2['y'] == piece1_old[1]:
return 1
else:
return 2
def Paint(self, board, piece, color):
board[piece['x']][piece['y']] = color
piece['color'] = color
return board
# if __name__ == "__main__":
# env0 = FalseBelief_env0()
# action_agent = 0
# action_NPC2 = 1
# action_NPC1 = 4
# for i in range(10):
# if i > 8:
# break
# else:
# env0.interact(action_NPC1, action_NPC2, action_agent)
#
# env0.SHOW()
# time.sleep(2)
# pygame.quit()
================================================
FILE: examples/Social_Cognition/ToM/env/env3_train_env01.py
================================================
"""
Zoe Zhao 2022.5
Env Demo
"""
from numpy import argmax
import random, time, pygame, sys
import pygame
pygame.init()
from pygame.locals import *
# import os
# os.environ["SDL_VIDEODRIVER"] = "dummy"
from rulebasedpolicy.world_model import *
from rulebasedpolicy.statedata_pre import *
from rulebasedpolicy.Find_a_way import *
import numpy as np
from utils.one_hot import one_hot
# =============================================================================
# set the value of interface
# =============================================================================
FPS = 25
WinWidth = 340 #window width
WinHeight = 260 #window width
BoxSize = 20 #the size of one grid
GridWidth = 7 #the number of lattices are there in the x-axis
GridHeight = 7 #the number of lattices are there in the y-axis
#representation of different objective
BlankBox = 1
Wall = 5
Obstacle = 5
observer = 8
obeservation_1 = 11
obeservation_2 = 22
obeservation_3 = 33
#Text = None
XMargin = int((WinWidth - GridWidth * BoxSize)/2)
TopMargin = int((WinHeight - GridHeight * BoxSize))/2-5
# =============================================================================
# set color
# =============================================================================
White = (255,255,255)
Gray = (185,185,185)
Black = (0,0,0)
Red = (200,0,0)
Green = (0,139,0)
Green_B = (78, 238, 148)
Light_A = (233, 232, 170)
Blue = (30, 144, 255)
pink = (238, 99, 99)
BoardColor = White
BGColor = White
TextColor = White
Test = []
# =============================================================================
# agents - env interactive
# =============================================================================
class FalseBelief_env1(object):
def __init__(self, reward=10):
super(FalseBelief_env1, self).__init__()
self.action_space = ['up', 'down', 'left', 'right', 'stay']
self.action_move = {
0 : (0, -1),
1 : (0, 1),
2 : (-1, 0),
3 : (1, 0),
4 :(0, 0)
}#[(0, -1), (0, 1), (-1, 0), (1, 0), (0, 0)]
self.n_actions = len(self.action_space)
self._build_AB()
self.board, self.obs = self.getBlankBoard()
self._agent_init()
self.score = 0
self.steps = 0
self.n = 0
self.R = int(5/2) * (BoxSize - 5)
self.x = 0
self.n_features = 30
self.reward = reward
def _build_AB(self):
global FPSCLOCK, DISPLAYSURF, BASICFONT, BIGFONT
pygame.init()
FPSCLOCK = pygame.time.Clock()
DISPLAYSURF = pygame.display.set_mode((WinWidth, WinHeight))
BASICFONT = pygame.font.Font('freesansbold.ttf', 18)
BIGFONT = pygame.font.Font('freesansbold.ttf', 100)
pygame.display.set_caption('AB')
pygame.display.update()
FPSCLOCK.tick()
def _agent_init(self):
"""
Aim:Initialize the basic information of the agent
"""
self.NPC_2 = {
'shape' : [['@']],
'x' : 5, #row
'y' : 3, #column
'color' : pink,
'style' : "circle",
'obs' : None,
'axis' :None ,#,[[3,5],[1,3],[4,2]]
'reward': 0,
'Done': False
}
self.agent = {
'shape' : [['$']],
'x' : 2, #row
'y' : 4, #column
'color' : Green_B,
'style' : "circle",
'obs' : None,
'axis' : None,#[[4,2],[1,3],[3,5]]
'reward': 0,
'Done': False
}
def actu_obs(self):
"""
将状态转化成可以训练的数据形式
"""
_, state = self.getBlankBoard()
a = state
b = state
c = state
state2 = np.r_[b, np.ones((4, 5))].astype(np.int)
statea = np.r_[c, np.ones((4, 5))].astype(np.int)
NPC_2_state = state2
Agent_state = statea
NPC_2_state[self.NPC_2['y']-1, self.NPC_2['x']-1] = observer
r = shelter_env(NPC_2_state[:5, :])
NPC_2_state[:5, :] = shelter_env(NPC_2_state[:5, :])
Agent_state[self.agent['y']-1, self.agent['x']-1] = observer
p = shelter_env(Agent_state[:5, :])
Agent_state[:5, :] = shelter_env(Agent_state[:5, :])
self.NPC_2['obs'] = r
self.NPC_2['obs'] = self.gain_obs(self.NPC_2['obs'], NPC_2_state, self.agent, 4)
self.NPC_2['axis'] = self.gain_axis(self.NPC_2, NPC_2_state, 6, self.agent, 2, 4)
self.agent['obs'] = p
self.agent['obs'] = self.gain_obs(self.agent['obs'], Agent_state, self.NPC_2, 3)
self.agent['axis'] = self.gain_axis(self.agent, Agent_state, 6, self.NPC_2, 2, 3)
return NPC_2_state, Agent_state#NPC_1_state,
def gain_obs(self, a,aa,c,cc):
if aa[c['y']-1, c['x']-1] ==1:
a[c['y'] - 1, c['x'] - 1] = cc
return a
def gain_axis(self,a,aa,b,c,bb,cc):
axis = []
axis.append([a['y'], a['x']])
if b == 6:
axis.append([6, 6])
else:
axis.append([6, 6])
if aa[c['y']-1, c['x']-1] != 0:
axis.append([c['y'] , c['x']])
else:
axis.append([6, 6])
return axis
def interact(self, action_NPC2, action_agent):
self.agent['reward'] = 0
self.NPC_2['reward'] = 0
#三个智能体分别会看到什么?
NPC_2_state, Agent_state = self.actu_obs()# NPC_1_state,
#看到这些状态,智能体们会分别采取什么行为? ---depend on RL
#这些行为对状态的影响 ---首先,影响本身的位置坐标,然后,影响观测
base = np.where(np.array(self.board) == obeservation_2)
base_x = int(base[0])
base_y= int(base[1])
if self.NPC_2['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.NPC_2['y']) + np.square(base_y - self.NPC_2['x']))
if self.isNotWall(self.board, self.NPC_2, self.action_move[action_NPC2][0], \
self.action_move[action_NPC2][1]):
self.NPC_2['x'] = self.NPC_2['x'] + self.action_move[action_NPC2][0]
self.NPC_2['y'] = self.NPC_2['y'] + self.action_move[action_NPC2][1]
dis2 = np.sqrt(np.square(base_x - self.NPC_2['y']) + np.square(base_y - self.NPC_2['x']))
self.NPC_2['reward'] = (((dis1 - dis2) * 10 - 1 / 2) / dis1)
while self.NPC_2['reward'] < 0.5 and self.NPC_2['reward'] > -0.5:
self.NPC_2['reward'] = self.NPC_2['reward'] * 2
if self.NPC_2['reward'] > 1:
self.NPC_2['reward'] = 1
elif self.NPC_2['reward'] < -1:
self.NPC_2['reward'] = -1
else:
self.NPC_2['reward'] = -0.9 # * (1 / dis1)
if self.board[self.NPC_2['y'], self.NPC_2['x']] == obeservation_2:
self.NPC_2['reward'] = self.reward
self.NPC_2['Done'] = True
base = np.where(np.array(self.board) == obeservation_3)
base_x = int(base[0])
base_y= int(base[1])
if self.agent['Done'] == False:
dis1 = np.sqrt(np.square(base_x - self.agent['y']) + np.square(base_y - self.agent['x']))
if self.isNotWall(board=self.board, piece=self.agent, xT=self.action_move[action_agent][0], \
yT=self.action_move[action_agent][1]):
self.agent['x'] = self.agent['x'] + self.action_move[action_agent][0]
self.agent['y'] = self.agent['y'] + self.action_move[action_agent][1]
dis2 = np.sqrt(np.square(base_x - self.agent['y']) + np.square(base_y - self.agent['x']))
# self.agent['reward'] = (((dis1 - dis2) * 2 - 1) / dis1)
#
# else:
# # print('action', action_agent)
# self.agent['reward'] = -1 * (1 / dis1)
self.agent['reward'] = (((dis1 - dis2)*10 - 1/2) / dis1)
while self.agent['reward'] < 0.5 and self.agent['reward'] > -0.5 :
self.agent['reward'] = self.agent['reward'] * 2 - 0.1
if self.agent['reward'] > 1:
self.agent['reward'] = 1
elif self.agent['reward'] < -1:
self.agent['reward'] = -1
else:
self.agent['reward'] = -0.9 #* (1 / dis1)
if self.board[self.agent['y'], self.agent['x']] == obeservation_3:
self.agent['reward'] = self.reward
self.agent['Done'] = True
NPC_2_state, Agent_state = self.actu_obs()
#判断是否会相撞?
location = [(self.NPC_2['x'], self.NPC_2['y']),\
(self.agent['x'], self.agent['y'])]
#达到目标或者相撞都会结束该智能体的回合
terminal = self.gameover(location)
if self.agent['Done'] == False and terminal[1] == True:
self.agent['Done'] = True
self.agent['reward'] = -self.reward
self.agent['color'] = Red
if self.NPC_2['Done'] == False and terminal[0] == True:
self.NPC_2['Done'] = True
self.NPC_2['reward'] = -self.reward
self.NPC_2['color'] = Red
return NPC_2_state, Agent_state
def SHOW(self):
DISPLAYSURF.fill(BGColor)
self.DrawBoard(self.board)
# self.DrawPiece(self.NPC_1)
self.DrawPiece(self.NPC_2)
self.DrawPiece(self.agent)
pygame.display.update()
FPSCLOCK.tick(FPS)
# return flag
def reset(self):
self._agent_init()
def getBlankBoard(self):
# board = data_transfer('env_1.txt','env_11.txt')
board = np.array([[1,1,1,5,5],[22,1,1,5,5],[1,1,1,1,1],[1,1,1,1,33],[1,1,1,11,1]])
state_init = np.array([[1,1,1,5,5],[1,1,1,5,5],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])
board = big_env(board)
# print(board)
# for x in range(GridWidth):
# for y in range(GridHeight):
# print(board[x][y],x,y)
return board, state_init
def ValidPos(self, piece1, piece2, xT=0, yT=0):
"""
to judge the next place vaild or not
@param piece1:
@param piece2:
@param xT:
@param yT:
@return:
"""
if piece1['x'] == (piece2['x'] + xT) and piece1['y'] == (piece2['y'] + yT):
return True
return False
def isNotWall(self, board, piece, xT=0 , yT=0 ):
if board[piece['y'] + yT][piece['x'] + xT] == Wall:#############
return False
else:
return True
def gameover(self, location):
"""
回合是否结束,以及奖励值
@param location:目标位置
"""
result = False
terminal = [False, False] #NPC_2, agent
for r in range(len(location) - 1):
for c in range(r + 1, len(location)):
if location[r] == location[c]:
result = True ####相撞会带来一个巨大的副奖励,并且结束该回合
boom = location[r] ###############相撞################
if result == True:
terminal[r] = True
terminal[c] = True
return terminal
def pixel(self, xbox, ybox):
return (XMargin + (xbox * BoxSize)), (TopMargin + (ybox * BoxSize))
def DrawBox(self, xbox, ybox, color, xpixel=None, ypixel=None):
if color == BlankBox:
return
elif color == obeservation_1:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (60,107,255), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == obeservation_2:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (205, 155, 155 ), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == obeservation_3:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, (154, 205, 50), (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
elif color == Wall:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, Gray, (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
else:
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(xbox, ybox)
pygame.draw.rect(DISPLAYSURF, color, (xpixel + 1, ypixel + 1, BoxSize - 1, BoxSize - 1))
def DrawCircle(self, xbox, ybox, color, xpixel=None, ypixel=None):
pygame.draw.circle(DISPLAYSURF,
color,
(int(xpixel+BoxSize/2), int(ypixel+BoxSize/2)),
int(0.3 * self.R))
def DrawPiece(self, piece, xpixel=None, ypixel=None):
if xpixel == None and ypixel == None:
xpixel, ypixel = self.pixel(piece['x'], piece['y'])
if piece['style'] == "circle":
self.DrawCircle(None, None, piece['color'], xpixel, ypixel)
else:
self.DrawBox(None, None, piece['color'], xpixel, ypixel)
def DrawBoard(self, board):
pygame.draw.rect(DISPLAYSURF, BoardColor,
(XMargin - 3, TopMargin - 7, (GridWidth * BoxSize) + 8, (GridHeight * BoxSize) + 8), 5)
pygame.draw.rect(DISPLAYSURF, BGColor, (XMargin, TopMargin, GridWidth * BoxSize, GridHeight * BoxSize))
for x in range(GridWidth):
for y in range(GridHeight):
self.DrawBox(y, x, board[x][y])
def ShowScore(self, score):
scoreSurf = BASICFONT.render('Score : %s' % score, True, TextColor)
scoreRect = scoreSurf.get_rect()
scoreRect.topleft = (WinWidth - 250, 20)
DISPLAYSURF.blit(scoreSurf, scoreRect)
def Terminal(self, piece1, piece2, piece1_old, piece2_old):
# print(piece1['x'],piece1['y'],piece2_old[0],piece2_old[1],'/',piece2['x'],piece2['y'],piece1_old[0],piece1_old[1])
# if self.steps == 1:# wrong!!!!
if piece1['x'] == piece2_old[0] and piece1['y'] == piece2_old[1] and piece2['x'] == piece1_old[0] and piece2['y'] == piece1_old[1]:
return 1
else:
return 2
def Paint(self, board, piece, color):
board[piece['x']][piece['y']] = color
piece['color'] = color
return board
================================================
FILE: examples/Social_Cognition/ToM/main_ToM.py
================================================
"""
Zoe Zhao 2022.5
ToM Demo
"""
import argparse
import copy
import numpy as np
import torch
np.set_printoptions(threshold=np.inf)
torch.set_printoptions(threshold=np.inf)
import matplotlib
import pygame
pygame.init()
matplotlib.rcParams.update({'font.size': 12})
import os
os.environ["SDL_VIDEODRIVER"] = "dummy"
from BrainArea.PFC_ToM import PFC_ToM
from BrainArea.TPJ import ToM
from BrainArea.dACC import *
from rulebasedpolicy.Find_a_way import *
from env.env import FalseBelief_env
from braincog.base.encoder.encoder import *
from braincog.base.node import node
#NPC2
#state
N_state = 6
cell_num = 6
# action
N_action = 5
NC=10 #50 cells represent one character
#synapstic
bfs = pow(cell_num, N_state) #before synapstic
afs = N_action * NC
#agent
C=10
A_state = 4
abfs = pow(cell_num, A_state) #agent before synapstic
aafs = N_action * C
parser = argparse.ArgumentParser(description='sequence character (policy inference)')
parser.add_argument('--mode', type=str, default='test')
parser.add_argument('--task', type=str, default='both')
parser.add_argument('--logdir', type=str, default='checkpoint')
parser.add_argument('--save_net_a', type=str, default='net_NPC_11.pth', help='save the parameters of net_agent')
parser.add_argument('--save_net_N', type=str, default='net_NPC_11.pth', help='save the parameters of net_NPC')
parser.add_argument('--device', default='cpu', help='device') # cuda:0
parser.add_argument('--T', default=40, type=int, help='simulating time-steps') # 模拟时长
parser.add_argument('--dt', default=1, type=int, help='simulating dt') # 模拟dt
parser.add_argument('--episodes', default=25, type=int, help='episodes')
parser.add_argument('--trajectories', default=10, type=int, help='trajectories')
parser.add_argument('--greedy', default=0.8, type=int, help='exploration or exploitation')
parser.add_argument('--num_enpop', default=6, type=int, help='the number of one population in the encoding layer') #
parser.add_argument('--num_depop', default=10, type=int, help='the number of one population in the decoding layer') #
parser.add_argument('--num_stateA', default=2, type=int, help='the number of states')
parser.add_argument('--num_stateN', default=6, type=int, help='the number of states')
parser.add_argument('--num_action', default=5, type=int, help='the number of actions')
parser.add_argument('--reward', default=10, type=float, help='environment parameter reward')
args = parser.parse_args()
def update(env, net_agent_belief, net_NPC, episodes, trajectories):
"""
agents learn to reach the goal without collision
update agents' positions
@param env:
@param env1:
@param net_agent_belief: the SNN network of agent
@param net_NPC: the SNN network of NPC
@param episodes: train times
@return: None
"""
for episode in tqdm(range(episodes)):
timer = 0
env.reset()
env.actu_obs()
scores = {
'agent_0': 0,
'NPC2_0' : 0,
'agent_1': 0,
'NPC2_1': 0,
}
Done_agent_0 = Done_agent_1 = False
Done_NPC2_0 = Done_NPC2_1 = False
action_agent = 3
action_NPC2 = 2
action_NPC1 = 1
action_agent1 = 4
# the start position are the same in two envs
# mapping_a = {'state': sum(env.agent['axis'], []),
# 'action': action_agent}
mapping_N = {'state': sum(env.NPC_2['axis'], []),
'action': action_NPC2}
while True and timer < trajectories:
timer = timer + 1
NPC_1_state, NPC_2_state, Agent_state \
= env.interact(action_NPC1, action_NPC2, action_agent)
env.SHOW()
# time.sleep(2)
# NPC_1 selects action by pp
if env.NPC_1['Done'] == False:
action_seq1 = Find_a_way(size=5, board=NPC_1_state, \
start_x=env.NPC_1['x'] - 1, \
start_y=4 - (env.NPC_1['y'] - 1), \
end_x=3, end_y=4 - 4)
action_NPC1 = list(env.action_move.keys())[ \
list(env.action_move.values()).index(
(action_seq1[1][0] - (action_seq1[0][0]), -action_seq1[1][1] + (action_seq1[0][1])))]
# agent selects action on purpose
# Agent_obs = sum(env.agent['axis'], [])
if env.agent['Done'] == False:
axis_new, axis_switch, obs_switch = ToM.TPJ(NPC_num=2, axis=env.agent['axis'], obs=env.agent['obs'], )
if axis_new == env.agent['axis']:
'''
没有遮挡关系 have teached
'''
action_agent = 3
else:
'''
有遮挡关系
'''
Agent_obs_NPC2 = sum(env.NPC_2['axis'], [])
action_agent = net_agent_belief(inputs=Agent_obs_NPC2,
num_action=args.num_action,
episode=episode)
prediction_next_state = ToM.prediction_state(axis_new, env.agent['axis'], action_NPC1, net_NPC,
num_action=args.num_action,
episode = episode)
if ToM.state_evaluation(prediction_next_state=prediction_next_state) == False:
print(False)
action_agent = ToM.altruism(axis_switch=axis_switch , axis_NPC=env.NPC_2['axis'], n_actions = env.n_actions)
env.trigger = 1
else:
action_agent = 3
# NPC_2 selects action by E-STDP
NPC2_obs = sum(env.NPC_2['axis'], [])
if Done_NPC2_0 == False:
if action_agent == 4 and env.agent['Done'] == False:
action_NPC2 = 4
else:
action_NPC2 = net_NPC(inputs=NPC2_obs, \
num_action=args.num_action, \
episode=episode)
state_NPC2 = copy.deepcopy(NPC2_obs)
Done_NPC2_0 = copy.deepcopy(env.NPC_2['Done'])
# mapping_N = {'state': state_NPC2, # at time t
# 'action': action_NPC2}
def train():
print('train mode loading ... ')
if not os.path.isdir(args.logdir):
os.mkdir(args.logdir)
bfs = pow(args.num_enpop, args.num_stateN) # before synapstic
afs = args.num_action * args.num_depop
#agent
# abfs = pow(args.num_enpop, args.num_stateA) # agent before synapstic
# aafs = args.num_action * args.num_depop
net_agent_belief = PFC_ToM(step=args.T, encode_type='rate', bias=True,
in_features=bfs, out_features=afs,
node=node.LIFNode, num_state=args.num_stateN,
greedy=args.greedy) #out_features the kinds of policies
net_agent_belief.to(args.device)
net_agent_belief.fc.weight.data = torch.rand((afs, bfs))
# net_agent_belief.load_state_dict(torch.load(os.path.join(args.logdir, args.save_net_N))['model'])
#NPC
net_NPC = PFC_ToM(step=args.T, encode_type='rate', bias=True,
in_features=bfs, out_features=afs,
node=node.LIFNode, num_state=args.num_stateN,
greedy=args.greedy) #out_features the kinds of policies
net_NPC.to(args.device)
net_NPC.load_state_dict(torch.load(os.path.join(args.logdir, args.save_net_N))['model'])
total_scores = update(env, net_agent_belief, net_NPC, args.episodes,\
args.trajectories)
# torch.save({'model': net_agent.state_dict()}, os.path.join(args.logdir, args.save_net_a))
torch.save({'model': net_NPC.state_dict()}, os.path.join(args.logdir, args.save_net_N))
time_end = time.time()
print('totally cost',time_end-time_start)
if __name__ == "__main__":
time_start = time.time()
env = FalseBelief_env(args.reward)
ToM = ToM(env=env)
# args.task = 'both'#'zero'
# args.mode = 'test'#'train'
# args.save_net_N = 'net_NPC_3.pth'
# args.save_net_a = 'net_agent_3.pth'
# args.greedy = 111
train()
================================================
FILE: examples/Social_Cognition/ToM/main_both.py
================================================
import argparse
import time
import copy
import numpy as np
import torch
np.set_printoptions(threshold=np.inf)
torch.set_printoptions(threshold=np.inf)
from tqdm import *
import matplotlib
import seaborn as sns
import pygame
pygame.init()
sns.set(style='ticks', palette='Set2')
matplotlib.rcParams.update({'font.size': 12})
import os
os.environ["SDL_VIDEODRIVER"] = "dummy"
from BrainArea.PFC_ToM import PFC_ToM
from rulebasedpolicy.Find_a_way import *
from env.env3_train_env00 import FalseBelief_env0 #3
from env.env3_train_env01 import FalseBelief_env1 #2
from braincog.base.encoder.encoder import *
from braincog.base.node import node
torch.manual_seed(1)
#NPC2
#state
N_state = 6
cell_num = 6
# action
N_action = 5
NC=10 #50 cells represent one character
#synapstic
bfs = pow(cell_num, N_state) #before synapstic
afs = N_action * NC
#agent
C=10
A_state = 4
abfs = pow(cell_num, A_state) #agent before synapstic
aafs = N_action * C
parser = argparse.ArgumentParser(description='sequence character (policy inference)')
parser.add_argument('--mode', type=str, default='train')
parser.add_argument('--task', type=str, default='both')
parser.add_argument('--logdir', type=str, default='checkpoint')
parser.add_argument('--save_net_a', type=str, default='net_agent_4.pth', help='save the parameters of net_agent')
parser.add_argument('--save_net_N', type=str, default='net_NPC_4.pth', help='save the parameters of net_NPC')
parser.add_argument('--device', default='cpu', help='device') # cuda:0
parser.add_argument('--T', default=40, type=int, help='simulating time-steps') # 模拟时长
parser.add_argument('--dt', default=1, type=int, help='simulating dt') # 模拟dt
parser.add_argument('--episodes', default=25, type=int, help='episodes')
parser.add_argument('--trajectories', default=10, type=int, help='trajectories')
parser.add_argument('--greedy', default=0.8, type=float, help='exploration or exploitation')
parser.add_argument('--num_enpop', default=6, type=int, help='the number of one population in the encoding layer') #
parser.add_argument('--num_depop', default=10, type=int, help='the number of one population in the decoding layer') #
parser.add_argument('--num_stateA', default=2, type=int, help='the number of states, (X, Y)')
parser.add_argument('--num_stateN', default=6, type=int, help='the number of states, [(X, Y), (X, Y), (X, Y)]')
parser.add_argument('--num_action', default=5, type=int, help='the number of actions')
parser.add_argument('--reward', default=10, type=float, help='environment parameter reward')
args = parser.parse_args()
def reward_plot(episodes, scores, Note):
fig = plt.figure(figsize=(7.5, 4.5))
ax1 = fig.add_subplot(111)
ax1.set_title('Reward Plot')
plt.xlim(1, episodes)
plt.grid(ls='--', c='gray')
plt.xlabel('Epoch')
plt.ylabel('Reward')
episodes_list = list(range(1,episodes+1))
plt.plot(episodes_list, scores['be observed agent without the ToM'], label='be observed agent without the ToM')
plt.legend()
plt.savefig('reward_plot_' + str(episodes) + '.png')
def update(env0, env1, net_agent, net_NPC, episodes, trajectories, task):
"""
agents learn to reach the goal without collision
update agents' positions
@param env0:
@param env1:
@param net_agent: the SNN network of agent
@param net_NPC: the SNN network of NPC
@param episodes: train times
@return: None
"""
scores_agent = []
scores_NPC2 = []
for episode in tqdm(range(episodes)):
timer0 = 0
timer1 = 0
env0.reset()
env1.reset()
env0.actu_obs()
env1.actu_obs()
scores = {
'agent_0': 0,
'NPC2_0' : 0,
'agent_1': 0,
'NPC2_1': 0,
}
Done_agent_0 = Done_agent_1 = False
Done_NPC2_0 = Done_NPC2_1 = False
action_agent = 3
action_NPC2 = 2
action_NPC1 = 4
action_agent1 = 4
# the start position are the same in two envs
mapping_a = {'state': sum(env0.agent['axis'], []),
'action': action_agent}
mapping_N = {'state': sum(env0.NPC_2['axis'], []),
'action': action_NPC2}
if task == 'both' or task == 'zero':
while True and timer0 < trajectories:
timer0 = timer0 + 1
NPC_1_state, NPC_2_state, Agent_state \
= env0.interact(action_NPC1, action_NPC2, action_agent)
env0.SHOW()
# time.sleep(2)
#NPC_1 selects action by pp
if env0.NPC_1['Done'] == False:
action_seq1 = Find_a_way(size=5, board=NPC_1_state,\
start_x=env0.NPC_1['x']-1,\
start_y=4-(env0.NPC_1['y']-1),\
end_x=3, end_y=4-4)
action_NPC1 = list(env0.action_move.keys())[\
list(env0.action_move.values()).index((action_seq1[1][0]-(action_seq1[0][0]), -action_seq1[1][1]+(action_seq1[0][1])))]
#agent selects action by E-STDP
Agent_obs = sum(env0.agent['axis'], [])
if Done_agent_0 == False:
action_agent = 3
# net_agent.update_s(R = env0.agent['reward'],\
# mapping=mapping_a)
# action_agent = net_agent(inputs = Agent_obs,\
# num_action = args.num_action,\
# episode = episode)
# state_agent = copy.deepcopy(Agent_obs)
# Done_agent_0 = copy.deepcopy(env0.agent['Done'])
# mapping_a = {'state': state_agent, # at time t
# 'action': action_agent}
#NPC_2 selects action by E-STDP
NPC2_obs = sum(env0.NPC_2['axis'], [])
if Done_NPC2_0 == False:
net_NPC.update_s(R = env0.NPC_2['reward'], \
mapping=mapping_N)
action_NPC2 = net_NPC(inputs = NPC2_obs,\
num_action = args.num_action,\
episode = episode)
state_NPC2 = copy.deepcopy(NPC2_obs)
Done_NPC2_0 = copy.deepcopy(env0.NPC_2['Done'])
mapping_N = {'state': state_NPC2, # at time t
'action': action_NPC2}
# continue
scores['agent_0'] += env0.agent['reward']
scores['NPC2_0'] += env0.NPC_2['reward']
if env0.NPC_1['Done'] == env0.NPC_2['Done'] == env0.agent['Done'] == True:
break
scores_agent.append(scores['agent_0'])
scores_NPC2.append(scores['NPC2_0'])
######################
if task == 'both' or task == 'one':
while True and timer1 < trajectories:
timer1 = timer1 + 1
NPC_2_state, Agent_state \
= env1.interact(action_NPC2, action_agent)
env1.SHOW()
# time.sleep(2)
# agent selects action by E-STDP
Agent_obs = sum(env1.agent['axis'], [])
if Done_agent_1 == False:
action_agent = 3
# net_agent.update_s(R=env1.agent['reward'], \
# mapping=mapping_a)
# scores['agent_1'] += env1.agent['reward']
# action_agent = net_agent(inputs=Agent_obs, \
# num_action=args.num_action,\
# episode = episode)
# state_agent = copy.deepcopy(Agent_obs)
# Done_agent_1 = copy.deepcopy(env1.agent['Done'])
# mapping_a = {'state': state_agent, # at time t
# 'action': action_agent}
# NPC_2 selects action by E-STDP
NPC2_obs = sum(env1.NPC_2['axis'], [])
if Done_NPC2_1 == False:
net_NPC.update_s(R=env1.NPC_2['reward'], \
mapping=mapping_N)
scores['NPC2_1'] += env1.NPC_2['reward']
action_NPC2 = net_NPC(inputs=NPC2_obs, \
num_action=args.num_action,\
episode = episode)
state_NPC2 = copy.deepcopy(NPC2_obs)
Done_NPC2_1 = copy.deepcopy(env1.NPC_2['Done'])
mapping_N = {'state': state_NPC2, # at time t
'action': action_NPC2}
scores['agent_1'] += env1.agent['reward']
scores['NPC2_1'] += env1.NPC_2['reward']
if env1.NPC_2['Done'] == env1.agent['Done'] == True:
break
scores_agent.append(scores['agent_1'])
scores_NPC2.append(scores['NPC2_1'])
total_scores = {
'the agent with the ToM': scores_agent,
'be observed agent without the ToM' : scores_NPC2
}
return total_scores
def train():
print('train mode loading ... ')
if not os.path.isdir(args.logdir):
os.mkdir(args.logdir)
#agent
abfs = pow(args.num_enpop, args.num_stateA) # agent before synapstic
aafs = args.num_action * args.num_depop
net_agent = PFC_ToM(step=args.T, encode_type='rate', bias=True,
in_features=abfs, out_features=aafs,
node=node.LIFNode, num_state=args.num_stateA,
greedy=args.greedy) #out_features the kinds of policies
net_agent.to(args.device)
net_agent.fc.weight.data = torch.rand((aafs, abfs))
# net_agent.load_state_dict(torch.load('./checkpoint/net_agent_12.pth')['model'])
#NPC
bfs = pow(args.num_enpop, args.num_stateN) # before synapstic
afs = args.num_action * args.num_depop
net_NPC = PFC_ToM(step=args.T, encode_type='rate', bias=True,
in_features=bfs, out_features=afs,
node=node.LIFNode, num_state=args.num_stateN,
greedy=args.greedy) #out_features the kinds of policies
net_NPC.to(args.device)
net_NPC.fc.weight.data = torch.rand((afs, bfs))
# net_NPC.load_state_dict(torch.load('./checkpoint/net_NPC_12.pth')['model'])
total_scores = update(env0, env1, net_agent, net_NPC, args.episodes,\
args.trajectories, args.task)
torch.save({'model': net_agent.state_dict()}, os.path.join(args.logdir, args.save_net_a))
torch.save({'model': net_NPC.state_dict()}, os.path.join(args.logdir, args.save_net_N))
time_end = time.time()
print('totally cost',time_end-time_start)
if args.task == 'zero' or args.task == 'one':
reward_plot(args.episodes, total_scores, 'Scores')
elif args.task == 'both':
reward_plot(args.episodes * 2, total_scores, 'Scores')
plt.show()
def test():
args.greedy = 1
print('test mode loading ... ')
print('greedy :', args.greedy)
#agent
abfs = pow(args.num_enpop, args.num_stateA) # agent before synapstic
aafs = args.num_action * args.num_depop
net_agent = PFC_ToM(step=args.T, encode_type='rate', bias=True,
in_features=abfs, out_features=aafs,
node=node.LIFNode, num_state=args.num_stateA,
greedy=args.greedy)
net_agent.to(args.device)
# see also: https://pytorch.org/tutorials/beginner/saving_loading_models.html
net_agent.load_state_dict(torch.load(os.path.join(args.logdir, args.save_net_a))['model']) #out_features the kinds of policies
#NPC
bfs = pow(args.num_enpop, args.num_stateN) # before synapstic
afs = args.num_action * args.num_depop
net_NPC = PFC_ToM(step=args.T, encode_type='rate', bias=True,
in_features=bfs, out_features=afs,
node=node.LIFNode, num_state=args.num_stateN,
greedy=args.greedy)
net_NPC.to(args.device)
net_NPC.load_state_dict(torch.load(os.path.join(args.logdir, args.save_net_N))['model']) #out_features the kinds of policies
total_scores = update(env0, env1, net_agent, net_NPC, args.episodes,
args.trajectories, args.task)
time_end = time.time()
print('totally cost',time_end-time_start)
if args.task == 'zero' or args.task == 'one':
reward_plot(args.episodes, total_scores, 'Scores')
elif args.task == 'both':
reward_plot(args.episodes * 2, total_scores, 'Scores')
plt.show()
if __name__=="__main__":
time_start = time.time()
env0 = FalseBelief_env0(args.reward)
env1 = FalseBelief_env1(args.reward)
# args.task = 'both'#'zero'
# args.mode = 'test'#'train'
# args.save_net_N = 'net_NPC_3.pth'
# args.save_net_a = 'net_agent_3.pth'
if args.mode == 'train':
train()
elif args.mode == 'test':
test()
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/Find_a_way.py
================================================
# main.py
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
from rulebasedpolicy.random_map import *
from rulebasedpolicy.a_star import *
from env.env3_train_env01 import FalseBelief_env1
def Find_a_way(size, board, start_x, start_y, end_x, end_y):
map = RandomMap(size=size, board=board)
for i in range(map.size):
for j in range(map.size):
if map.IsObstacle(i,j):
rec = Rectangle((i, j), width=1, height=1, color='gray')
else:
rec = Rectangle((i, j), width=1, height=1, edgecolor='gray', facecolor='w')
rec = Rectangle((start_x, start_y), width = 1, height = 1, facecolor='b')
rec = Rectangle((end_x, end_y), width = 1, height = 1, facecolor='r')
A_star = AStar(map)
action_seq = A_star.RunAndSaveImage( start_x, start_y, end_x, end_y)#ax, plt,
return action_seq
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/__init__.py
================================================
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/a_star.py
================================================
import sys
import time
import numpy as np
from matplotlib.patches import Rectangle
from rulebasedpolicy.point import *
from rulebasedpolicy.random_map import *
class AStar:
def __init__(self, map):
self.map=map
self.open_set = []
self.close_set = []
def BaseCost(self, p):
x_dis = p.x
y_dis = p.y
# Distance to start point
return x_dis + y_dis + (np.sqrt(2) - 2) * min(x_dis, y_dis)
def HeuristicCost(self, p):
x_dis = self.map.size - 1 - p.x
y_dis = self.map.size - 1 - p.y
# Distance to end point
return x_dis + y_dis + (np.sqrt(2) - 2) * min(x_dis, y_dis)
def TotalCost(self, p):
return self.BaseCost(p) + self.HeuristicCost(p)
def IsValidPoint(self, x, y):
if x < 0 or y < 0:
return False
if x >= self.map.size or y >= self.map.size:
return False
return not self.map.IsObstacle(x, y)
def IsInPointList(self, p, point_list):
for point in point_list:
if point.x == p.x and point.y == p.y:
return True
return False
def IsInOpenList(self, p):
return self.IsInPointList(p, self.open_set)
def IsInCloseList(self, p):
return self.IsInPointList(p, self.close_set)
def IsStartPoint(self, p, start_x, start_y):
return p.x == start_x and p.y ==start_y
def IsEndPoint(self, p, end_x, end_y):
return p.x == end_x and p.y == end_y###############
def SaveImage(self, plt):
millis = int(round(time.time() * 1000))
filename = './' + str(millis) + '.png'
plt.savefig(filename)
def ProcessPoint(self, x, y, parent):
if not self.IsValidPoint(x, y):
return # Do nothing for invalid point
p = Point(x, y)
if self.IsInCloseList(p):
return # Do nothing for visited point
# print('Process Point [', p.x, ',', p.y, ']', ', cost: ', p.cost)
if not self.IsInOpenList(p):
p.parent = parent
p.cost = self.TotalCost(p)
self.open_set.append(p)
def SelectPointInOpenList(self):
index = 0
selected_index = -1
min_cost = sys.maxsize
for p in self.open_set:
cost = self.TotalCost(p)
if cost < min_cost:
min_cost = cost
selected_index = index
index += 1
return selected_index
def BuildPath(self, p, start_time, start_x, start_y, end_x, end_y):#ax, plt,
path = []
record = []
while True:
path.insert(0, p) # Insert first
if self.IsStartPoint(p, start_x, start_y):
break
else:
p = p.parent
p_x=start_x
p_y=start_y
for p in path:
if abs(p.x-p_x) == abs(p.y-p_y) == 1:
# rec = Rectangle((p_x, p.y), 1, 1, color='g')
# rec = Rectangle((p.x, p.y), 1, 1, color='g')
# ax.add_patch(rec)
# plt.draw()
# self.SaveImage(plt)
if abs(end_x - start_x) >= abs(end_y - start_y):
record.append((p.x, p_y))
record.append((p.x, p.y))
else:
record.append((p_x, p.y))
record.append((p.x, p.y))
else:
rec = Rectangle((p.x, p.y), 1, 1, color='g')
# ax.add_patch(rec)
# plt.draw()
# self.SaveImage(plt)
record.append((p.x, p.y))
p_x = p.x
p_y = p.y
end_time = time.time()
# print('===== Algorithm finish in', int(end_time-start_time), ' seconds')
return record
def RunAndSaveImage(self, start_x, start_y, end_x, end_y):#ax, plt,
start_time = time.time()
start_point = Point(start_x, start_y)############################
start_point.cost = 0
self.open_set.append(start_point)
while True:
index = self.SelectPointInOpenList()
if index < 0:
print('No path found, algorithm failed!!!')
# self.SaveImage(plt)
return
p = self.open_set[index]
# rec = Rectangle((p.x, p.y), 1, 1, color='c')
# ax.add_patch(rec)
# self.SaveImage(plt)
if self.IsEndPoint(p, end_x, end_y):
return self.BuildPath(p, start_time, start_x, start_y, end_x, end_y)#ax, plt,
del self.open_set[index]
self.close_set.append(p)
# Process all neighbors
x = p.x
y = p.y
self.ProcessPoint(x-1, y+1, p)
self.ProcessPoint(x-1, y, p)
self.ProcessPoint(x-1, y-1, p)
self.ProcessPoint(x, y-1, p)
self.ProcessPoint(x+1, y-1, p)
self.ProcessPoint(x+1, y, p)
self.ProcessPoint(x+1, y+1, p)
self.ProcessPoint(x, y+1, p)
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/load_statedata.py
================================================
import random
import os
import numpy as np
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms
# from torch.autograd import Variable
class StateDataset:
# initial
def __init__(self, mode, num):
self.state = np.loadtxt(mode, dtype=np.int)
self.num = 1
self.state = self.state.reshape(num, 5*self.num , -1)
#data:A label:B
def __getitem__(self, item):
state = self.state[item]
state_A = state[:,0:5*self.num]
state_A = np.expand_dims(state_A, axis=0)
state_B = state[:, 5*self.num:10*self.num]
state_B = np.expand_dims(state_B, axis=0)
return {"A":state_A, "B":state_B}
#the number of data
def __len__(self):
return len(self.state)
# def get_dataloader(self):
def get_dataloader(mode, num, batch):
train_dataset = StateDataset(mode, num)
train_loader = DataLoader(train_dataset, batch, shuffle=True)
return train_loader
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/point.py
================================================
import sys
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
self.cost = sys.maxsize
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/random_map.py
================================================
import numpy as np
from rulebasedpolicy.point import *
class RandomMap:
def __init__(self, size, board):
self.size = size
self.board = board
self.obstacle = size//8
self.GenerateObstacle()
def GenerateObstacle(self):
self.obstacle_point = []
# Generate an obstacle in the middle
for i in range(self.size):
for j in range(self.size):
if self.board[i,j] == 5:
self.obstacle_point.append(Point(j, 4-i))
def IsObstacle(self, i ,j):
for p in self.obstacle_point:
if i==p.x and j==p.y:
return True
return False
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/statedata_pre.py
================================================
import numpy as np
def data_transfer(B_txt, A_txt):
"""
Aim:读取训练数据,并将其转换为可以处理的形式
@param B_txt:Before processing -txt
@param A_txt:After processing -txt
@return:After processing -data
"""
with open(B_txt, 'r') as f: #'dataA_B.txt'
data_all =[]
data_1 = []
data_2 = []
data_3 = []
data = f.read() #Read all the data in txt ...str
data_split = data.split('\n\n') #Divide the data with '\n\n'
for i in range(len(data_split)-1): #There are (len(data_split)-1) sets of valid data
data_split[i] = data_split[i].split('\n') #Remove '\n' from each set of data
for j in range(len(data_split[i])):
# Split number
data_split[i][j] = " ".join(data_split[i][j])
data_split[i][j] = data_split[i][j].split(' ')
data_split[i][j] = list(map(int, data_split[i][j])) #str-int
data_split[i] = np.array(data_split[i]) #list-np.array
# Data expansion
data_all.append(data_split[i])
data_1.append(np.flipud(data_split[i])) #上下对称
# data_2_split = data_split[i][:, [5, 6, 7, 8, 9, 0, 1, 2, 3, 4]]
# data_2.append(np.fliplr(data_2_split)) #左右对称
# data_3_split = data_split[i][:, [5, 6, 7, 8, 9, 0, 1, 2, 3, 4]]
# data_3.append(np.fliplr(data_3_split))
data_all.extend(data_1)
# data_all.extend(data_2)
# data_all.extend(data_3)
data_all = np.array(data_all)
data_all = data_all.reshape(data_all.shape[0]*data_all.shape[1], data_all.shape[2])
data_all = data_all.astype(int)
# new_data = np.repeat(data_all, repeats=num, axis=0)
# new_data = np.repeat(new_data, repeats=num, axis=1)
np.savetxt(A_txt, data_all, fmt='%i') #'train.txt'
# Read TXT data into numpy
state = np.loadtxt(A_txt, dtype = np.int)
print(data_all.shape)
return state
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/train.txt
================================================
8 5 1 1 1 8 5 0 0 0
1 1 1 1 1 1 0 0 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 8 5 1 1 1 8 5 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 8 5 1 1 1 8 5 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 8 5 1 1 1 8 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 8 5 1 1 1 8 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 0 0
1 1 8 5 1 1 1 8 5 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 0 0 0
1 8 5 1 1 1 8 5 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 0 0 0 0
8 5 1 1 1 8 5 0 0 0
1 1 1 1 1 1 0 0 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 8 5 1 1 1 8 5
1 1 1 1 1 1 1 1 1 0
8 1 5 1 1 8 1 5 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 8 1 5 1 1 8 1 5 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 0 0
8 1 5 1 1 8 1 5 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 8 1 5 1 1 8 1 5 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
8 1 1 5 1 8 1 1 5 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
8 1 1 5 1 8 1 1 5 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
8 1 1 1 1 8 1 1 1 1
1 5 1 1 1 1 5 0 0 1
1 1 1 1 1 1 0 0 0 0
1 1 1 1 1 1 0 0 0 0
1 1 1 1 1 1 1 0 0 0
1 8 1 1 1 1 8 1 1 1
1 1 5 1 1 1 1 5 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 8 1 1 1 1 8 1 1
1 1 1 5 1 1 1 1 5 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 8 1 1 1 1 8 1
1 1 1 1 5 1 1 1 1 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
8 1 1 1 1 8 1 1 1 1
1 5 1 1 1 1 5 0 0 1
1 1 1 1 1 1 0 0 0 0
1 1 1 1 1 1 0 0 0 0
1 1 1 1 1 1 1 1 1 1
1 8 1 1 1 1 8 1 1 1
1 1 5 1 1 1 1 5 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 1 1
1 1 8 1 1 1 1 8 1 1
1 1 1 5 1 1 1 1 5 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 8 1 1 1 1 8 1
1 1 1 1 5 1 1 1 1 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 0
8 1 1 1 1 8 1 1 1 1
1 1 5 1 1 1 1 5 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 8 1 1 1 1 8 1 1 1
1 1 1 5 1 1 1 1 5 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 8 1 1 1 1 8 1 1
1 1 1 1 5 1 1 1 1 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
8 1 1 1 1 8 1 1 1 1
1 1 5 1 1 1 1 5 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 1
1 8 1 1 1 1 8 1 1 1
1 1 1 5 1 1 1 1 5 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 8 1 1 1 1 8 1 1
1 1 1 1 5 1 1 1 1 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
8 1 1 1 1 8 1 1 1 1
1 1 1 5 1 1 1 1 5 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 0 0 0 0
8 5 1 1 1 8 5 0 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 0 0 0
1 8 5 1 1 1 8 5 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 0 0
1 1 8 5 1 1 1 8 5 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 8 5 1 1 1 8 5
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 8 5 1 1 1 8 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 0 0
1 1 8 5 1 1 1 8 5 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 0 0 0
1 8 5 1 1 1 8 5 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 0 0 0
1 1 1 1 1 1 0 0 0 0
8 5 1 1 1 8 5 0 0 0
1 1 1 1 1 1 0 0 0 0
1 1 1 1 1 1 1 1 1 0
1 1 1 8 5 1 1 1 8 5
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 0 0
8 1 5 1 1 8 1 5 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 8 1 5 1 1 8 1 5 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 0 0
8 1 5 1 1 8 1 5 0 0
1 1 1 1 1 1 1 1 0 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0
1 8 1 5 1 1 8 1 5 0
1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
8 1 1 5 1 8 1 1 5 0
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
8 1 1 5 1 8 1 1 5 0
1 1 1 1 1 1 1 1 1 1
================================================
FILE: examples/Social_Cognition/ToM/rulebasedpolicy/world_model.py
================================================
import os
import sys
import numpy as np
import matplotlib.pyplot as plt
from rulebasedpolicy.load_statedata import *
import math
np.set_printoptions(threshold = np.inf)
def data():
batch_size = 45
# read data
txt = os.path.join(sys.path[0],'rulebasedpolicy', 'train.txt')
train_loader=get_dataloader(mode=txt, num=batch_size ,batch=batch_size)
for data in train_loader:
A = data["A"].numpy()
B = data["B"].numpy()
B = B.reshape(batch_size, -1, 5, 5)
A = A.reshape(batch_size, 5, 5)
# distant between A and Wall(B)计算智能体与墙之间的距离
A_train = np.sum(np.square(np.argwhere(A==8)-np.argwhere(A==5)), axis = 1)
dist_AW = 1 #指定一个特定的距离1,2,4,5,9,10 distant between agent and wall############
o_idx = np.argwhere(A_train == dist_AW) #找到固定距离对应的所有矩阵Find all matrices corresponding to a fixed distance
return B, A_train
def flip180(arr):
"""
翻转180度
@param arr:
@return:
"""
new_arr = arr.reshape(arr.size)
new_arr = new_arr[::-1]
new_arr = new_arr.reshape(arr.shape)
return new_arr
def flip90_left(arr):
"""
向左翻转90度逆时针
@param arr:
@return:
"""
new_arr = np.transpose(arr)
new_arr = new_arr[::-1]
return new_arr
def flip90_right(arr):
"""
向右翻转90度顺时针
@param arr:
@return:
"""
new_arr = arr.reshape(arr.size)
new_arr = new_arr[::-1]
new_arr = new_arr.reshape(arr.shape)
new_arr = np.transpose(new_arr)[::-1]
return new_arr
def gain_env(obs, agent, wall):
"""
Aim:可以根据多个部分观察在一起拼成一个大的环境
@param obs:多组观测
@param agent:代表智能体的参数,这里默认用8来表示
@param wall:代表墙的参数,这里默认用5来表示
@return:拼成的环境
obs_random:随便选择一个矩阵作为based环境
obs[i]:其他用来补全的矩阵
x_a, y_a:based环境-智能体坐标
x_w, y_w:based环境-wall坐标
x_t, y_t:其他环境-智能体坐标
x_tt, y_tt:其他环境-wall坐标
"""
obs_random = obs[0]
for i in range(1, obs.shape[0]):
#based env
x_a, y_a = np.argwhere(obs_random == agent)[0]
x_w, y_w = np.argwhere(obs_random == wall)[0]
#external env
x_t, y_t = np.argwhere(obs[i] == agent)[0]
x_tt, y_tt = np.argwhere(obs[i] == wall)[0]
h, l = obs_random.shape
delta_up = max(x_t - x_a,0)
delta_down = max(5-x_tt - (h-x_w),0)
delta_left = max(y_t - y_a,0)
delta_right = max(5-y_tt - (l-y_w),0)
obs_random = np.r_[np.ones((delta_up, l)), obs_random] if delta_up != 0 else obs_random
h, l = obs_random.shape
obs_random = np.r_[obs_random, np.ones((delta_down, l))] if delta_down != 0 else obs_random
h, l = obs_random.shape
obs_random = np.c_[np.ones((h, delta_left)), obs_random] if delta_left != 0 else obs_random
h, l = obs_random.shape
obs_random = np.c_[obs_random, np.ones((h, delta_right))] if delta_right != 0 else obs_random
obs_random = obs_random.astype(np.int)
#based env
x_a, y_a = np.argwhere(obs_random == agent)[0]
up = x_a - x_t
left = y_a - y_t
obs_random[up:up+5, left:left+5] = obs_random[up:up+5, left:left+5] & obs[i]
return obs_random
def shelter_env(obs):
"""
Aim:用gain_env环境中的图,来描述更复杂的环境的遮挡关系
@param obs:复杂的环境
@return:环境的遮挡关系
"""
# print(obs,'----------------')
position_A = np.argwhere(obs==8)
position_W = np.argwhere(obs==5)
# print(position_W)
position = np.sum(np.square(np.argwhere(obs == 8) - np.argwhere(obs == 5)), axis=1) #numpy (walls,)
# print(position_W, position_A,position)
shelter_env_i = np.ones((5,5)).astype(np.int)
B, A_train = data()
for i in range(position.size):
o_idx = np.argwhere(A_train == position[i])
if o_idx.size == 0:
break
else:
model = gain_env(B[o_idx].reshape(-1, 5, 5), 8 ,5).astype(np.int)
# print(model,'=============')
if (position_A[0,0] > position_W[i,0] and position_A[0,1] < position_W[i,1] and \
position_A[0, 0] - position_W[i, 0] < -position_A[0, 1] + position_W[i, 1])\
or\
(position_A[0, 0] < position_W[i, 0] and position_A[0, 1] < position_W[i, 1] and \
-position_A[0, 0] + position_W[i, 0] > -position_A[0, 1] + position_W[i, 1])\
or\
(position_A[0, 0] > position_W[i, 0] and position_A[0, 1] > position_W[i, 1] and \
position_A[0, 0] - position_W[i, 0] > position_A[0, 1] - position_W[i, 1])\
or\
(position_A[0, 0] < position_W[i, 0] and position_A[0, 1] > position_W[i, 1] and \
-position_A[0, 0] + position_W[i, 0] < position_A[0, 1] - position_W[i, 1]):
model = np.flip(model, 0)
# print(model, '-=-=-=-=-=-=-====')
model = flip90_right(model)
# print(model,'-=-=-=-=-=-=-====')
if position_A[0, 0] >= position_W[i, 0] and position_A[0, 1] > position_W[i, 1]:
model = flip180(model)
elif position_A[0, 0] > position_W[i, 0] and position_A[0, 1] <= position_W[i, 1]:
model = flip90_left(model)
elif position_A[0, 0] < position_W[i, 0] and position_A[0, 1] >= position_W[i, 1]:
model = flip90_right(model)
else:
model = model
x_t, y_t = np.argwhere(model == 8)[0]
if y_t=3200:
error=3200
if error>0:
pain=1
if error==0:
pain=0
if pain==0:
X1=torch.tensor([[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1,
0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]])
X2=torch.tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
env.render()
if pain==1:
set_pain = 1
X1=torch.tensor([[0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1,
0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]])
X2=torch.tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
env.render()
for i in range(T):
if i>=2:
X2=X1
OUTPUT = a(X1,X2)
a.UpdateWeight(2,OUTPUT[0][1],0.01)
a.UpdateWeight(5,OUTPUT[1][1],-0.1)
if OUTPUT[2][0][0]==1:
env.canvas.itemconfig(env.rect, fill="red", outline='red')
if OUTPUT[2][0][40]==1:
env.canvas.itemconfig(env.rect, fill="green", outline='green')
env.render()
print('out_ifg:',OUTPUT[2])
print('out_sma:',OUTPUT[3])
print('out_m1:',OUTPUT[4])
# print('con2:',a.connection[2].weight.data)
# print('con5:',a.connection[5].weight.data)
s = s_
if set_pain==1 and pain==0:
env.render()
env.destroy()
def BAESNN_test():
a.reset()
s1,s=env2.reset()
pain=0
pain1 = 0
i=0
set_pain=0
for i in range(1000):
env2.render()
s_now = env2.canvas.coords(env2.agent1)
action1 = np.random.choice([0,1,2,3], p=[0.2, 0.3, 0.3, 0.2])
if env2.open_door==1 and s_now[0] <(9 / 2) * 40:
action1 = np.random.choice([0,1,2,3], p=[0.5, 0.0, 0.0, 0.5])
s1_, s1_pre,s1_color = env2.step1(action1,pain)
print('s1_color:',s1_color)
if env2.open_door == 1 :
env2.render()
true_s1_1 = np.array(s1_)
predict_s1_1=np.array(s1_pre)
error1 = true_s1_1 - predict_s1_1
error1 = sum([c * c for c in error1])
if error1>=3200:
error1=3200
if error1>0:
pain=1
set_pain=1
if error1==0:
pain=0
env2.generate_expression1(pain)
if s1_color=="red":
X3=torch.tensor([[0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1,
0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]])
if s1_color=="blue":
X3=torch.tensor([[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1,
0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]])
a.reset()
for i in range(20):
OUT=a.empathy(X3)
print(OUT)
if pain==1:
env2.agent_help()
s1 = s1_
env2.render()
if pain==0 and set_pain==1:
env2.render()
break
# env2.destroy()
if __name__ == "__main__":
env = Maze()
a = BAESNN()
BAESNN_train()
env.mainloop()
env2 = Maze2()
BAESNN_test()
env2.mainloop()
================================================
FILE: examples/Social_Cognition/affective_empathy/BAE-SNN/README.md
================================================
# Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
# Run
## Train
* the file to be run: BAESNN.py
# Citation
```
@ARTICLE{Hui2022,
AUTHOR={Feng, Hui and Zeng, Yi and Lu, Enmeng},
TITLE={Brain-Inspired Affective Empathy Computational Model and Its Application on Altruistic Rescue Task},
JOURNAL={Frontiers in Computational Neuroscience},
VOLUME={16},
YEAR={2022},
URL={https://www.frontiersin.org/articles/10.3389/fncom.2022.784967},
DOI={10.3389/fncom.2022.784967},
ISSN={1662-5188}
}
```
================================================
FILE: examples/Social_Cognition/affective_empathy/BAE-SNN/env_poly.py
================================================
import numpy as np
np.random.seed(1)
import tkinter as tk
import time
from PIL import ImageGrab
UNIT = 40 # pixels
MAZE_H = 9 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('self-pain')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_W * UNIT))
self._build_maze()
self.danger=0
self.action_hurt=0
self.sensory_hurt = 0
self.open_door = 0
self.pain_state=0
# create environment
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_W * UNIT,
width=MAZE_H * UNIT)
# create grids
for c in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create agent
self.orgin=[20,20]
# 上
self.points0 = [
# 右下
self.orgin[0]+15,#35
self.orgin[1]+15,#35
# 左下
self.orgin[0]-15,#5
self.orgin[1]+15,#35
# 左上+
self.orgin[0]-15,#5
self.orgin[1],#20
# 顶点
self.orgin[0],#20
self.orgin[1]-15,#5
# 右上+
self.orgin[0]+15,#35
self.orgin[1],#20
]
# self.rect0 = self.canvas.create_polygon(self.points0, fill="green")
# self.agent_action0 = self.canvas.coords(self.rect0)
# 下
self.points1 = [
# 左上
self.orgin[0]-15,#5
self.orgin[1]-15,#5
# 右上
self.orgin[0]+15,#35
self.orgin[1]-15,#5
# 右下+
self.orgin[0]+15,#35
self.orgin[1],#20
# 顶点
self.orgin[0],#20
self.orgin[1]+15,#35
# 左下+
self.orgin[0]-15,#5
self.orgin[1],#20
]
self.rect = self.canvas.create_polygon(self.points1, fill="green")
# self.agent_action1 = self.canvas.coords(self.rect1)
# 右
self.points2 = [
# 左下
self.orgin[0]-15,#5
self.orgin[1]+15,#35
# 左上
self.orgin[0]-15,#5
self.orgin[1]-15,#5
# 右上+
self.orgin[0],#20
self.orgin[1]-15,#5
# 顶点
self.orgin[0]+15,#35
self.orgin[1],#20
# 右下+
self.orgin[0],#20
self.orgin[1]+15,#35
]
# self.rect2 = self.canvas.create_polygon(self.points2, fill="green")
# self.agent_action2 = self.canvas.coords(self.rect2)
# 左
self.points3 = [
# 右上
self.orgin[0]+15,#20+15
self.orgin[1]-15,#20-15
# 右下
self.orgin[0]+15,#20+15
self.orgin[1]+15,#20+15
# 左下+
self.orgin[0],#20
self.orgin[1]+15,#20+15
# 顶点
self.orgin[0]-15,#20-15
self.orgin[1],#20
# 左上+
self.orgin[0],#20
self.orgin[1]-15,#20-15
]
# self.rect3 = self.canvas.create_polygon(self.points3, fill="green")
# self.agent_action3 = self.canvas.coords(self.rect3)
self.canvas.pack()
#reset agent location
def reset(self):
self.open_door = 0
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
self.orgin = [20, 20]
# 下
self.points1 = [
# 左上
self.orgin[0] - 15, # 5
self.orgin[1] - 15, # 5
# 右上
self.orgin[0] + 15, # 35
self.orgin[1] - 15, # 5
# 右下+
self.orgin[0] + 15, # 35
self.orgin[1], # 20
# 顶点
self.orgin[0], # 20
self.orgin[1] + 15, # 35
# 左下+
self.orgin[0] - 15, # 5
self.orgin[1], # 20
]
self.rect = self.canvas.create_polygon(self.points1, fill="green")
# self.agent_action1 = self.canvas.coords(self.rect1)
return self.canvas.coords(self.rect)
def step(self, s, action, pain):
s = self.canvas.coords(self.rect)
self.centre = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
# danger or switch
if self.danger==1:
if all(self.centre == self.oval_center):
s_color = 'yellow'
self.canvas.delete(self.wall[3])
self.render()
# self.getter(self.canvas)
self.render()
# self.getter(self.canvas)#figure8 ,figure3.1 all red changed to green
self.open_door = 1
move = np.array([80, 0])
self.canvas.move(self.rect, move[0], move[1])
s = self.canvas.coords(self.rect)
self.render()
# self.getter(self.canvas)
elif all(self.centre == self.hell1_center):
s_color = 'black'
self.action_hurt = 1
self.render()
# self.getter(self.canvas)#figure4
self.render()
else:
s_color = 'white'
# modify current state
self.canvas.delete(self.rect)# 主要为开关那几步考虑,所以重复写了
self.centre = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
if action==0:
self.points0 = [
# 右下
self.centre[0] + 15, # 35
self.centre[1] + 15, # 35
# 左下
self.centre[0] - 15, # 5
self.centre[1] + 15, # 35
# 左上+
self.centre[0] - 15, # 5
self.centre[1], # 20
# 顶点
self.centre[0], # 20
self.centre[1] - 15, # 5
# 右上+
self.centre[0] + 15, # 35
self.centre[1], # 20
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points0, fill=color)
if action==1:
self.points1 = [
# 左上
self.centre[0] - 15, # 5
self.centre[1] - 15, # 5
# 右上
self.centre[0] + 15, # 35
self.centre[1] - 15, # 5
# 右下+
self.centre[0] + 15, # 35
self.centre[1], # 20
# 顶点
self.centre[0], # 20
self.centre[1] + 15, # 35
# 左下+
self.centre[0] - 15, # 5
self.centre[1], # 20
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points1, fill=color)
if action==2:
self.points2 = [
# 左下
self.centre[0] - 15, # 5
self.centre[1] + 15, # 35
# 左上
self.centre[0] - 15, # 5
self.centre[1] - 15, # 5
# 右上+
self.centre[0], # 20
self.centre[1] - 15, # 5
# 顶点
self.centre[0] + 15, # 35
self.centre[1], # 20
# 右下+
self.centre[0], # 20
self.centre[1] + 15, # 35
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points2, fill=color)
if action==3:
self.points3 = [
# 右上
self.centre[0] + 15, # 20+15
self.centre[1] - 15, # 20-15
# 右下
self.centre[0] + 15, # 20+15
self.centre[1] + 15, # 20+15
# 左下+
self.centre[0], # 20
self.centre[1] + 15, # 20+15
# 顶点
self.centre[0] - 15, # 20-15
self.centre[1], # 20
# 左上+
self.centre[0], # 20
self.centre[1] - 15, # 20-15
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points3, fill=color)
s = self.canvas.coords(self.rect)
self.render()#显示当前的动作指令是什么
# self.getter(self.canvas)#figure5 after figure4
if s[0] > (9 / 2) * 40:
self.action_hurt = 0
# ensure ture action
base_action = np.array([0, 0])
if self.action_hurt == 0:
true_action = action
else:
if action == 0:
true_action = 1
if action == 1:
true_action = 0
if action == 2:
true_action = 3
if action == 3:
true_action = 2
# predict next state
b = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ]
if self.centre[0] <= ((MAZE_H - 1) / 2 +1) * UNIT:#120
if action == 0: # up
if self.centre[1] > UNIT:
b = [0, -40, 0, -40,0, -40, 0, -40,0, -40]
elif action == 1: # down
if self.centre[1] < (MAZE_W - 1) * UNIT:
b = [0, 40, 0, 40,0, 40, 0, 40, 0, 40]
elif action == 2: # right
if self.centre[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
b = [40, 0, 40, 0,40, 0, 40, 0,40, 0]
elif action == 3: # left
if self.centre[0] > UNIT:
b = [-40, 0, -40, 0,-40, 0, -40, 0,-40, 0]
else:
if action == 0: # up
if self.centre[1] > UNIT:
b = [0, -40, 0, -40,0, -40, 0, -40,0, -40]
elif action == 1: # down
if self.centre[1] < (MAZE_W - 1) * UNIT:
b = [0, 40, 0, 40,0, 40, 0, 40, 0, 40]
elif action == 2: # right
if self.centre[0] < (MAZE_H - 1) * UNIT:
b = [40, 0, 40, 0,40, 0, 40, 0,40, 0]
elif action == 3: # left
if self.centre[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
b = [-40, 0, -40, 0,-40, 0, -40, 0,-40, 0]
s_predict = []
for i in range(len(b)):
s_predict1 = s[i] + b[i]
s_predict.append(s_predict1)
# true next state
if self.centre[0]<=((MAZE_H - 1) / 2 +1) * UNIT:
if true_action == 0: # up
if self.centre[1] > UNIT:
base_action[1] -= UNIT
elif true_action == 1: # down
if self.centre[1] < (MAZE_W - 1) * UNIT:
base_action[1] += UNIT
elif true_action == 2: # right
if self.centre[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
base_action[0] += UNIT
elif true_action == 3: # left
if self.centre[0] > UNIT:
base_action[0] -= UNIT
else:
if true_action == 0: # up
if self.centre[1] > UNIT:
base_action[1] -= UNIT
elif true_action == 1: # down
if self.centre[1] < (MAZE_W - 1) * UNIT:
base_action[1] += UNIT
elif true_action == 2: # right
if self.centre[0] < (MAZE_H - 1) * UNIT:
base_action[0] += UNIT
elif true_action == 3: # left
if self.centre[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1])
s_ = self.canvas.coords(self.rect)
return s_, s_predict, s_color
def step_RL1(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if s[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT:
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_W - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
else:
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_W - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_H - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
if s_==self.canvas.coords(self.hell1):
self.canvas.itemconfig(self.rect, fill="red", outline='red')
reward = -1
self.pain_state=1
else:
reward = 0
return s_, reward,self.pain_state
def step_RL2(self, action):
s = self.canvas.coords(self.rect)
if s == self.canvas.coords(self.oval):
self.canvas.delete(self.wall[3])
self.open_door = 1
move = np.array([40, 0])
self.canvas.move(self.rect, move[0], move[1])
move = np.array([40, 0])
self.canvas.move(self.rect, move[0], move[1])
self.render()
self.canvas.itemconfig(self.rect, fill="green", outline='green')
self.render()
base_action = np.array([0, 0])
if s[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT:
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_W - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
else:
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_W - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_H - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
if s_ == self.canvas.coords(self.oval):
self.open_door = 1
if self.pain_state == 0:
reward = 0
if self.pain_state == 1:
reward = 1
self.pain_state = 0
elif s_ == self.canvas.coords(self.hell1):
self.canvas.itemconfig(self.rect, fill="red", outline='red')
reward = -1
self.pain_state = 1
self.render()
else:
reward = 0
return s_, reward, self.pain_state
def _set_danger(self):
self.hell1_center = np.array([60, 60])
self.hell1 = self.canvas.create_oval(
self.hell1_center[0] - 15, self.hell1_center[1] - 15,
self.hell1_center[0] + 15, self.hell1_center[1] + 15,
fill='black')
# self.canvas.create_bitmap((40 , 40), bitmap='error')
self.hell = self.canvas.coords(self.hell1)
self.canvas.pack()
self.danger=1
def _set_switch(self):
self.oval_center = np.array([(MAZE_H * UNIT) / 2 - UNIT, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
self.oval = self.canvas.create_oval(
self.oval_center[0] - 15, self.oval_center[1] - 15,
self.oval_center[0] + 15, self.oval_center[1] + 15,
fill='yellow')
self.switch = self.canvas.coords(self.oval)
self.canvas.pack()
def _set_wall(self):
wall_center=[]
self.wall=[]
for a in range(MAZE_W):
wall_center.append([0,0])
self.wall.append([])
for b in range(MAZE_W):
wall_center[b]=np.array([(MAZE_H*UNIT)/2,((b)*UNIT)+UNIT/2])
self.wall[b] = self.canvas.create_rectangle(
wall_center[b][0] - 20, wall_center[b][1] - 20,
wall_center[b][0] + 20, wall_center[b][1] + 20,
fill='grey')
self.wall0 = self.canvas.coords(self.wall[0])
self.wall1 = self.canvas.coords(self.wall[1])
self.wall2 = self.canvas.coords(self.wall[2])
self.wall3 = self.canvas.coords(self.wall[3])
# self.canvas.pack()
def generate_expression(self,pain):
if pain==1:
self.canvas.itemconfig(self.rect, fill="red", outline='red')
# self.canvas.pack()
if pain == 0:
self.canvas.itemconfig(self.rect, fill="green", outline='green')
# self.canvas.pack()
def render(self):
time.sleep(0.01)
self.update()
# def getter(self, widget):
# widget.update()
# x = tk.Tk.winfo_rootx(self) + widget.winfo_x()
# y = tk.Tk.winfo_rooty(self) + widget.winfo_y()
# x1 = x + widget.winfo_width()
# y1 = y + widget.winfo_height()
# ImageGrab.grab().crop((x, y, x1, y1)).save("first.jpg")
# return ImageGrab.grab().crop((x, y, x1, y1))
================================================
FILE: examples/Social_Cognition/affective_empathy/BAE-SNN/env_two_poly.py
================================================
import numpy as np
np.random.seed(1)
import tkinter as tk
import time
from PIL import ImageGrab
UNIT = 40 # pixels
MAZE_H = 9 # grid height
MAZE_W = 4 # grid width
class Maze2(tk.Tk, object):
def __init__(self):
super(Maze2, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.action_space1 = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.n_actions1 = len(self.action_space1)
self.title('two_agent_empathy')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_W * UNIT))
self._build_maze()
self.danger=0
self.action_hurt=0
self.sensory_hurt = 0
self.action_hurt1 = 0
self.sensory_hurt1 = 0
self.open_door=0
# create environment
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_W * UNIT,
width=MAZE_H * UNIT)
# create grids
for c in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create switch
self.oval_center = np.array([(MAZE_H * UNIT)/2-UNIT+80, ((MAZE_W+4) * UNIT)/2-UNIT/2-80])
self.oval = self.canvas.create_oval(
self.oval_center[0] - 15, self.oval_center[1] - 15,
self.oval_center[0] + 15, self.oval_center[1] + 15,
fill='yellow')
self.switch = self.canvas.coords(self.oval)
self.orgin1 = np.array([20, 20])
# 下
self.points1 = [
# 左上
self.orgin1[0] - 15, # 5
self.orgin1[1] - 15, # 5
# 右上
self.orgin1[0] + 15, # 35
self.orgin1[1] - 15, # 5
# 右下+
self.orgin1[0] + 15, # 35
self.orgin1[1], # 20
# 顶点
self.orgin1[0], # 20
self.orgin1[1] + 15, # 35
# 左下+
self.orgin1[0] - 15, # 5
self.orgin1[1], # 20
]
self.agent1 = self.canvas.create_polygon(self.points1, outline='black',fill="blue")
self.orgin = np.array([MAZE_H * UNIT - UNIT / 2, 20])
# 下
self.points = [
# 左上
self.orgin[0] - 15, # 5
self.orgin[1] - 15, # 5
# 右上
self.orgin[0] + 15, # 35
self.orgin[1] - 15, # 5
# 右下+
self.orgin[0] + 15, # 35
self.orgin[1], # 20
# 顶点
self.orgin[0], # 20
self.orgin[1] + 15, # 35
# 左下+
self.orgin[0] - 15, # 5
self.orgin[1], # 20
]
self.agent = self.canvas.create_polygon(self.points, fill="green")
wall_center = []
self.wall = []
for i in range(MAZE_W):
wall_center.append([])
self.wall.append([])
for i in range(MAZE_W):
wall_center[i] = np.array([(MAZE_H * UNIT) / 2, ((i) * UNIT) + UNIT / 2])
self.wall[i] = self.canvas.create_rectangle(
wall_center[i][0] - 20, wall_center[i][1] - 20,
wall_center[i][0] + 20, wall_center[i][1] + 20,
fill='grey')
self.hell1_center = np.array([100, 20])
self.hell1 = self.canvas.create_oval(
self.hell1_center[0] - 15, self.hell1_center[1] - 15,
self.hell1_center[0] + 15, self.hell1_center[1] + 15,
fill='black')
self.hell2_center = np.array([60, 100])
self.hell2 = self.canvas.create_oval(
self.hell2_center[0] - 15, self.hell2_center[1] - 15,
self.hell2_center[0] + 15, self.hell2_center[1] + 15,
fill='black')
# self.canvas.create_bitmap((40 , 40), bitmap='error')
self.danger = 1
self.canvas.pack()
#reset agent location
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.agent1)
self.canvas.delete(self.agent)
self.orgin1 = np.array([20, 20])
# 下
self.points1 = [
# 左上
self.orgin1[0] - 15, # 5
self.orgin1[1] - 15, # 5
# 右上
self.orgin1[0] + 15, # 35
self.orgin1[1] - 15, # 5
# 右下+
self.orgin1[0] + 15, # 35
self.orgin1[1], # 20
# 顶点
self.orgin1[0], # 20
self.orgin1[1] + 15, # 35
# 左下+
self.orgin1[0] - 15, # 5
self.orgin1[1], # 20
]
self.agent1 = self.canvas.create_polygon(self.points1, outline='black',fill="blue")
self.orgin = np.array([MAZE_H * UNIT - UNIT / 2, 20])
# 下
self.points = [
# 左上
self.orgin[0] - 15, # 5
self.orgin[1] - 15, # 5
# 右上
self.orgin[0] + 15, # 35
self.orgin[1] - 15, # 5
# 右下+
self.orgin[0] + 15, # 35
self.orgin[1], # 20
# 顶点
self.orgin[0], # 20
self.orgin[1] + 15, # 35
# 左下+
self.orgin[0] - 15, # 5
self.orgin[1], # 20
]
self.agent = self.canvas.create_polygon(self.points, fill="green")
return self.canvas.coords(self.agent1),self.canvas.coords(self.agent)
# move agent1
def step1(self, action1,pain):
s1 = self.canvas.coords(self.agent1)
self.centre1 = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
if all(self.centre1 == self.hell1_center):
self.action_hurt1 = 1
if all(self.centre1 == self.hell2_center):
self.action_hurt1 = 1
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 ==self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 ==self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT*2, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 == self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT*3, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 == self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT*4, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 == self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.canvas.delete(self.agent1) # 主要为开关那几步考虑,所以重复写了
self.centre1 = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
if action1==0:
self.points0 = [
# 右下
self.centre1[0] + 15, # 35
self.centre1[1] + 15, # 35
# 左下
self.centre1[0] - 15, # 5
self.centre1[1] + 15, # 35
# 左上+
self.centre1[0] - 15, # 5
self.centre1[1], # 20
# 顶点
self.centre1[0], # 20
self.centre1[1] - 15, # 5
# 右上+
self.centre1[0] + 15, # 35
self.centre1[1], # 20
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points0, fill=color,outline='black')
if action1==1:
self.points1 = [
# 左上
self.centre1[0] - 15, # 5
self.centre1[1] - 15, # 5
# 右上
self.centre1[0] + 15, # 35
self.centre1[1] - 15, # 5
# 右下+
self.centre1[0] + 15, # 35
self.centre1[1], # 20
# 顶点
self.centre1[0], # 20
self.centre1[1] + 15, # 35
# 左下+
self.centre1[0] - 15, # 5
self.centre1[1], # 20
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points1, fill=color,outline='black')
if action1==2:
self.points2 = [
# 左下
self.centre1[0] - 15, # 5
self.centre1[1] + 15, # 35
# 左上
self.centre1[0] - 15, # 5
self.centre1[1] - 15, # 5
# 右上+
self.centre1[0], # 20
self.centre1[1] - 15, # 5
# 顶点
self.centre1[0] + 15, # 35
self.centre1[1], # 20
# 右下+
self.centre1[0], # 20
self.centre1[1] + 15, # 35
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points2, fill=color,outline='black')
if action1==3:
self.points3 = [
# 右上
self.centre1[0] + 15, # 20+15
self.centre1[1] - 15, # 20-15
# 右下
self.centre1[0] + 15, # 20+15
self.centre1[1] + 15, # 20+15
# 左下+
self.centre1[0], # 20
self.centre1[1] + 15, # 20+15
# 顶点
self.centre1[0] - 15, # 20-15
self.centre1[1], # 20
# 左上+
self.centre1[0], # 20
self.centre1[1] - 15, # 20-15
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points3, fill=color,outline='black')
s1 = self.canvas.coords(self.agent1)
self.render()#显示当前的动作指令是什么
self.centre1 = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
if self.centre1[0] > (9 / 2) * 40:
self.action_hurt1 = 0
# whether hurt
if self.action_hurt1 == 0:
true_action1 = action1
else:
if action1 == 0:
true_action1 = 1
if action1 == 1:
true_action1 = 0
if action1 == 2:
true_action1 = 3
if action1 == 3:
true_action1 = 2
# predict next state
b = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT: # 120
if action1 == 0: # up
if self.centre1[1] > UNIT:
b = [0, -40, 0, -40, 0, -40, 0, -40, 0, -40]
elif action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
b = [0, 40, 0, 40, 0, 40, 0, 40, 0, 40]
elif action1 == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
b = [40, 0, 40, 0, 40, 0, 40, 0, 40, 0]
elif action1 == 3: # left
if self.centre1[0] > UNIT:
b = [-40, 0, -40, 0, -40, 0, -40, 0, -40, 0]
else:
if action1 == 0: # up
if self.centre1[1] > UNIT:
b = [0, -40, 0, -40, 0, -40, 0, -40, 0, -40]
elif action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
b = [0, 40, 0, 40, 0, 40, 0, 40, 0, 40]
elif action1 == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
b = [40, 0, 40, 0, 40, 0, 40, 0, 40, 0]
elif action1 == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
b = [-40, 0, -40, 0, -40, 0, -40, 0, -40, 0]
s_predict = []
for i in range(len(b)):
s_predict1 = s1[i] + b[i]
s_predict.append(s_predict1)
base_action1 = np.array([0, 0])
# true next state
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT:
if true_action1 == 0: # up
if self.centre1[1] > UNIT:
base_action1[1] -= UNIT
elif true_action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
base_action1[1] += UNIT
elif true_action1 == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
base_action1[0] += UNIT
elif true_action1 == 3: # left
if self.centre1[0] > UNIT:
base_action1[0] -= UNIT
else:
if true_action1 == 0: # up
if self.centre1[1] > UNIT:
base_action1[1] -= UNIT
elif true_action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
base_action1[1] += UNIT
elif true_action1 == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
base_action1[0] += UNIT
elif true_action1 == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
base_action1[0] -= UNIT
self.canvas.move(self.agent1, base_action1[0], base_action1[1])
s1_ = self.canvas.coords(self.agent1)
return s1_, s_predict,color
def agent_help(self):
s = self.canvas.coords(self.agent)
self.centre2= [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
if all(self.centre2 == self.oval_center):
self.canvas.delete(self.wall[3])
self.render()
self.open_door=1
else:
self.canvas.move(self.agent, -40, 0) # move agent
self.render()
self.canvas.move(self.agent, -40, 0)
self.render()
self.canvas.move(self.agent, -40, 0)
self.render()
self.canvas.move(self.agent, 0, 40)
self.render()
s_ = self.canvas.coords(self.agent) # next state
return s_
def _set_danger(self):
hell1_center = np.array([140, 60])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
hell2_center = np.array([100, 140])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# self.canvas.create_bitmap((40 , 40), bitmap='error')
self.canvas.pack()
self.danger=1
def _set_wall(self):
wall_center=[]
self.wall=[]
for i in range(MAZE_W):
wall_center.append([])
self.wall.append([])
for i in range(MAZE_W):
wall_center[i]=np.array([(MAZE_H*UNIT)/2,((i)*UNIT)+UNIT/2])
self.wall[i] = self.canvas.create_rectangle(
wall_center[i][0] - 20, wall_center[i][1] - 20,
wall_center[i][0] + 20, wall_center[i][1] + 20,
fill='grey')
self.canvas.pack()
def generate_expression1(self,pain1):
if pain1==1:
self.canvas.itemconfig(self.agent1, fill="red", outline='black')
self.canvas.pack()
if pain1 ==0:
self.canvas.itemconfig(self.agent1, fill="blue", outline='black')
self.canvas.pack()
def render(self):
time.sleep(0.2)
self.update()
================================================
FILE: examples/Social_Cognition/affective_empathy/BEEAD-SNN/BEEAD-SNN.py
================================================
import os
import sys
import imageio
from env_poly_SNN import Maze
from env import Maze2
from RL_brain import QLearningTable
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
np.random.seed(1)
from torch.utils.tensorboard import SummaryWriter
from sklearn.preprocessing import MinMaxScaler
import torch, os, sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import torch.nn.functional as F
from braincog.base.node.node import *
from braincog.base.learningrule.STDP import *
from braincog.base.connection.CustomLinear import *
from braincog.base.utils.visualization import spike_rate_vis, spike_rate_vis_1d#, spike_vis_2, spike_vis_5
class BrainArea(nn.Module, abc.ABC):
@abc.abstractmethod
def __init__(self):
super().__init__()
@abc.abstractmethod
def forward(self, x):
"""
Calculate the forward propagation process
:return:x is spike
"""
return x
def reset(self):
"""
Calculate the forward propagation process
:return:x is spike
"""
pass
class BAESNN(BrainArea):
"""
Affactive Empathy Network
"""
def __init__(self,):
super().__init__()
self.node = [IFNode() for i in range(5)]
self.connection = []
con_matrix0 = torch.eye(24, 24)*6
self.connection.append(CustomLinear(con_matrix0))#input-emotion
con_matrix1 = torch.eye(24, 24)
self.connection.append(CustomLinear(con_matrix1))#emotion-ifg
con_matrix2 = torch.zeros((24, 24), dtype=torch.float)
self.connection.append(CustomLinear(con_matrix2))#perception-ifg
con_matrix3 = torch.eye(24, 24)*6
self.connection.append(CustomLinear(con_matrix3))#input-perception
con_matrix4=torch.zeros((24,10), dtype=torch.float)
for j in range(10):
if j in np.arange(0,5,1):
for i in np.arange(0, 12, 1):
con_matrix4[i,j] =2
if j in np.arange(5,10,1):
for i in np.arange(12, 24, 1):
con_matrix4[i,j] =2
self.connection.append(CustomLinear(con_matrix4))#emotion-sma
con_matrix5=torch.zeros((24,10), dtype=torch.float)
self.connection.append(CustomLinear(con_matrix5))#perception-m1
con_matrix6 = torch.eye(10, 10)*6
self.connection.append(CustomLinear(con_matrix6))#sma-m1
self.stdp = []
self.stdp.append(STDP(self.node[0], self.connection[0]))#0 node0 emotion
self.stdp.append(STDP(self.node[2], self.connection[3]))#1 node2 perception
self.stdp.append(MutliInputSTDP(self.node[1], [self.connection[1], self.connection[2]]))#2 node1 ifg
self.stdp.append(MutliInputSTDP(self.node[3], [self.connection[4], self.connection[5]]))#3 node3 sma
self.stdp.append(STDP(self.node[4], self.connection[6]))#4 node4 m1
self.stdp.append(STDP(self.node[1],self.connection[2]))#5 node1 ifg
self.stdp.append(STDP(self.node[3],self.connection[5]))#6 node3 sma
def forward(self, x1,x2):
out__m, dw0 = self.stdp[0](x1)#node0 emotion
out__p, dw3 = self.stdp[1](x2)#node2 perception
out__ifg,dw_p_i=self.stdp[2](out__m,out__p)#node1 ifg
out__sma,dw_p_s=self.stdp[3](out__m,out__p)#node3 sma
out__m1,dw1=self.stdp[4](out__sma)#node4 m1
return dw_p_i,dw_p_s,out__ifg,out__sma,out__m1,out__m,out__p
def empathy(self,x3):
out_p,dw2=self.stdp[1](x3)#node2 perception
out_ifg,dw4=self.stdp[5](out_p)#node1 ifg
out_sma,dw5=self.stdp[6](out_p)#node3 sma
out_m1,dw6=self.stdp[4](out_sma)#node4 m1
return out_ifg,out_sma,out_m1,out_p
def UpdateWeight(self, i, dw, delta):
self.connection[i].update(dw*delta)
self.connection[i].weight.data= torch.clamp(self.connection[i].weight.data,-1,4)
def reset(self):
for i in range(5):
self.node[i].n_reset()
for i in range(len(self.stdp)):
self.stdp[i].reset()
class DopamineArea(BrainArea):
"""
Dopamine brain area with a group of spiking neurons, computes reward prediction error.
"""
def __init__(self, n_neurons, beta=0.2):
super().__init__()
self.n_neurons = n_neurons
self.beta = beta
self.node = [IFNode() for _ in range(n_neurons)]
self.P = np.zeros(n_neurons) # prediction for each neuron
def forward(self, spikes):
out_spikes = []
for i in range(self.n_neurons):
spike = self.node[i](torch.tensor([spikes[i]], dtype=torch.float32))
out_spikes.append(spike)
S = torch.stack(out_spikes).mean().item()
delta = S - self.P
self.P = self.P + self.beta * delta
return delta, out_spikes
def reset(self):
self.P = np.zeros(self.n_neurons)
for n in self.node:
n.n_reset()
def BAESNN_train():
s = env.reset()
env._set_danger()
env._set_wall()
pain = 0
i = 0
set_pain = 0
env._set_switch()
for i in range(100):
snn2.reset()
T = 100
pain = 0
print('**************step:', i)
env.render()
action = np.random.choice(list(range(env.n_actions)))
print('action:', action)
d, d_pre, s_, sss = env.step(s, action, pain)
print('d:', d, 'd_pre:', d_pre, 'sss:', sss)
env.render()
while (d == np.array([0, 0])).all():
action = np.random.choice(list(range(env.n_actions)))
print('action:', action)
d, d_pre, s_, sss = env.step(s, action, pain)
print('d:', d, 'd_pre:', d_pre, 'sss:', sss)
env.render()
# Use env.is_agent1_in_danger to set OUT_PAIN, pain, emotion
if env.is_agent_in_danger():
OUT_PAIN = torch.ones(24)
pain = 1
set_pain = 1
emotion = -1
else:
OUT_PAIN = torch.zeros(24)
pain = 0
emotion = 0
print("OUT_PAIN:", OUT_PAIN)
print("pain:", pain)
print("emotion:", emotion)
T2 = 20
X1 = OUT_PAIN
X2 = torch.zeros(24)
X3 = torch.cat([torch.ones(12) * 0.1, torch.zeros(12)])
print('X1,X2:', X1, X2)
spike_emotion = []
spike_ifg = []
spike_sma = []
spike_m1 = []
spike_per = []
for i in range(T2):
if i >= 2:
X2 = X3
OUTPUT = snn2(X1, X2)
snn2.UpdateWeight(2, OUTPUT[0][1], 0.01)
snn2.UpdateWeight(5, OUTPUT[1][1], -0.1)
if OUTPUT[2][0] == 1:
env.canvas.itemconfig(env.rect, fill="red", outline='red')
if OUTPUT[2][0] == 0:
env.canvas.itemconfig(env.rect, fill="green", outline='green')
spike_emotion.append(OUTPUT[5])
spike_per.append(OUTPUT[6])
spike_ifg.append(OUTPUT[2])
spike_sma.append(OUTPUT[3])
spike_m1.append(OUTPUT[4])
print('out_ifg:', OUTPUT[2])
print('out_sma:', OUTPUT[3])
print('out_m1:', OUTPUT[4])
print('con2:', snn2.connection[2].weight.data)
print('con5:', snn2.connection[5].weight.data)
spike_emotion = torch.stack(spike_emotion)
spike_per = torch.stack(spike_per)
spike_ifg = torch.stack(spike_ifg)
spike_sma = torch.stack(spike_sma)
spike_m1 = torch.stack(spike_m1)
print(spike_emotion.shape)
env.render()
s = s_
if set_pain == 1 and pain == 0:
env.render()
break
env.destroy()
def BAESNN_train_alstruism(lamda, E):
global writer
for episode in range(E):
print('*******************episode:', episode, ',factor:', lamda, '*********************************')
s1,s2=env2.reset()
env2._set_wall()
pain1 = 0
pain2 = 0
i = 0
set_pain = 0
env2.emotion = 0
env2.empathy_emotion = 0
env2.empathy_emotion_t_1 = 0
rr = 0
hh = 0
g = 0
a = []
if episode < 200:
e_greedy = 0.5
elif episode < 500:
e_greedy = 0.7
elif episode < 700:
e_greedy = 0.9
else:
e_greedy = 1
r = np.random.uniform()
for i in range(100):
env2.render()
done = False
env2.empathy_emotion_t_1=env2.empathy_emotion
action2 = RL.choose_action(str([(s2[4] + s2[8]) / 2, (s2[5] + s2[9]) / 2,env2.empathy_emotion]),e_greedy=e_greedy)
s2_, done, done_oval = env2.step2(action2)
env2.render()
T=100
print('**************step:',i)
env2.render()
action1 = np.random.choice(list(range(env.n_actions)))
print('action1:',action1)
if r<= 0.25:
if i==0:
action1=2
if 0.25 UNIT:
pre_displacement1 = np.array([0, -40])
elif action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action1 == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action1 == 3: # left
if self.centre1[0] > UNIT:
pre_displacement1 = np.array([-40, 0])
else:
if action1 == 0: # up
if self.centre1[1] > UNIT:
pre_displacement1 = np.array([0, -40])
elif action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action1 == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action1 == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
pre_displacement1 = np.array([-40, 0])
# true next state
displacement1 = np.array([0, 0])
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT:
if true_action1 == 0: # up
if self.centre1[1] > UNIT:
displacement1= np.array([0, -40])
elif true_action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1= np.array([0,40])
elif true_action1 == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
displacement1= np.array([40,0])
elif true_action1 == 3: # left
if self.centre1[0] > UNIT:
displacement1= np.array([-40,0])
else:
if true_action1 == 0: # up
if self.centre1[1] > UNIT:
displacement1= np.array([0,-40])
elif true_action1 == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1= np.array([0,40])
elif true_action1 == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
displacement1= np.array([40,0])
elif true_action1 == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
displacement1= np.array([-40,0])
self.canvas.move(self.agent1, displacement1[0], displacement1[1])
s1_ = self.canvas.coords(self.agent1)
sss = [(s1_[4] + s1_[8]) / 2, (s1_[5] + s1_[9]) / 2]
return displacement1, pre_displacement1,s1_,sss
def is_agent1_in_danger(self):
"""
whether in danger(hell1~hell4)
:return: True/False
"""
s1 = self.canvas.coords(self.agent1)
print([(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2])
print(f'hell1_center: {self.hell1_center}, hell2_center: {self.hell2_center}, hell3_center: {self.hell3_center}, hell4_center: {self.hell4_center}')
agent1_pos = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
danger_centers = [self.hell1_center, self.hell2_center, self.hell3_center, self.hell4_center]
for center in danger_centers:
if all(np.isclose(agent1_pos, center)):
return True
return False
def step2(self, action):
s = self.canvas.coords(self.agent2)
s=[(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
if all(s == self.oval_center)and self.empathy_emotion==-1:
done_oval=1
else:
done_oval=0
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_W - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_H - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > ( (MAZE_H - 1)/2+2) * UNIT:
base_action[0] -= UNIT
self.canvas.move(self.agent2, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.agent2) # next state
self.centre2= [(s_[4] + s_[8]) / 2, (s_[5] + s_[9]) / 2]
if all(self.centre2 == self.oval_center) and self.empathy_emotion==-1:
self.help_signal=1
if all(self.centre2 == self.goal_centre):
done = True
else:
done = False
return s_, done,done_oval
def reward2(self):
s_ = self.canvas.coords(self.agent2)
self.centre2= [(s_[4] + s_[8]) / 2, (s_[5] + s_[9]) / 2]
if (self.empathy_emotion - self.empathy_emotion_t_1)==-1:
reward1=0
elif (self.empathy_emotion - self.empathy_emotion_t_1)==1:
reward1=10
else:
reward1=0
if all(self.centre2 == self.goal_centre):
reward2 = 10
else:
reward2 = -1
return reward1,reward2
def _set_wall(self):
self.oval_center = np.array([(MAZE_H * UNIT)-20, ((MAZE_W)*UNIT-20)])# [(MAZE_H * UNIT)/2+80, UNIT/2+UNIT]
self.oval = self.canvas.create_oval(
self.oval_center[0] - 15, self.oval_center[1] - 15,
self.oval_center[0] + 15, self.oval_center[1] + 15,
fill='yellow')
self.help = self.canvas.coords(self.oval)
wall_center = []
self.wall = []
for i in range(MAZE_W):
wall_center.append([])
self.wall.append([])
for i in range(MAZE_W):
wall_center[i] = np.array([(MAZE_H * UNIT) / 2, ((i) * UNIT) + UNIT / 2])# wall
self.wall[i] = self.canvas.create_rectangle(
wall_center[i][0] - 20, wall_center[i][1] - 20,
wall_center[i][0] + 20, wall_center[i][1] + 20,
fill='grey')
self.canvas.pack()
def generate_expression1(self,emotion):
if emotion==-1:
self.canvas.itemconfig(self.agent1, fill="red", outline='black')
self.canvas.pack()
if emotion==0:
self.canvas.itemconfig(self.agent1, fill="blue", outline='black')
self.canvas.pack()
def generate_expression2(self,emotion):
if emotion==-1:
self.canvas.itemconfig(self.agent2, fill="red")
self.canvas.pack()
if emotion==0:
self.canvas.itemconfig(self.agent2, fill="green")
self.canvas.pack()
def render(self):
time.sleep(0.000001)
self.update()
# def getter(self,widget):
# widget.update()
# x = tk.Tk.winfo_rootx(self) + widget.winfo_x()
# y = tk.Tk.winfo_rooty(self) + widget.winfo_y()
# x1 = x + widget.winfo_width()
# y1 = y + widget.winfo_height()
# ImageGrab.grab().crop((x, y, x1, y1)).save("first.jpg")
# return ImageGrab.grab().crop((x, y, x1, y1))
================================================
FILE: examples/Social_Cognition/affective_empathy/BEEAD-SNN/env_poly_SNN.py
================================================
import numpy as np
np.random.seed(1)
import tkinter as tk
import time
from PIL import ImageGrab
UNIT = 40 # pixels
MAZE_H = 9 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('self-pain')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_W * UNIT))
self._build_maze()
self.danger=0
self.action_hurt=0
self.sensory_hurt = 0
self.open_door = 0
self.pain_state=0
# create environment
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_W * UNIT,
width=MAZE_H * UNIT)
# create grids
for c in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
self.orgin=[20,20]
# create agent
self.points1 = [
self.orgin[0]-15,self.orgin[1]-15,
self.orgin[0]+15,self.orgin[1]-15,
self.orgin[0]+15,self.orgin[1],
self.orgin[0],self.orgin[1]+15,
self.orgin[0]-15,self.orgin[1],
]
self.rect = self.canvas.create_polygon(self.points1, fill="green")
self.canvas.pack()
#reset agent location
def reset(self):
self.open_door = 0
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
self.orgin = [20, 20]
# 下
self.points1 = [
self.orgin[0] - 15,self.orgin[1] - 15,
self.orgin[0] + 15,self.orgin[1] - 15,
self.orgin[0] + 15,self.orgin[1],
self.orgin[0],self.orgin[1]+15,
self.orgin[0] - 15,self.orgin[1],
]
self.rect = self.canvas.create_polygon(self.points1, fill="green")
return self.canvas.coords(self.rect)
def step(self, s, action, pain):
s = self.canvas.coords(self.rect)
self.centre = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
# danger or switch
if self.danger==1:
if all(self.centre == self.oval_center):
s_color = 'yellow'
self.canvas.delete(self.wall[3])
self.render()
self.open_door = 1
move = np.array([80, 0])
self.canvas.move(self.rect, move[0], move[1])
s = self.canvas.coords(self.rect)
self.render()
elif all(self.centre == self.hell1_center):
s_color = 'black'
self.action_hurt = 1
self.render()
else:
s_color = 'white'
# modify current state
self.canvas.delete(self.rect)
self.centre = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
if action==0:
self.points0 = [
self.centre[0] + 15,self.centre[1] + 15,
self.centre[0] - 15,self.centre[1] + 15,
self.centre[0] - 15,self.centre[1],
self.centre[0],self.centre[1] - 15,
self.centre[0] + 15,self.centre[1],
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points0, fill=color)
if action==1:
self.points1 = [
self.centre[0] - 15,self.centre[1] - 15,
self.centre[0] + 15,self.centre[1] - 15,
self.centre[0] + 15,self.centre[1],
self.centre[0],self.centre[1] + 15,
self.centre[0] - 15,self.centre[1],
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points1, fill=color)
if action==2:
self.points2 = [
self.centre[0] - 15,self.centre[1] + 15,
self.centre[0] - 15,self.centre[1] - 15,
self.centre[0],self.centre[1] - 15,
self.centre[0] + 15,self.centre[1],
self.centre[0],self.centre[1] + 15,
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points2, fill=color)
if action==3:
self.points3 = [
self.centre[0] + 15,
self.centre[1] - 15,
self.centre[0] + 15,self.centre[1] + 15,
self.centre[0],self.centre[1] + 15,
self.centre[0] - 15,self.centre[1],
self.centre[0],self.centre[1] - 15,
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points3, fill=color)
s = self.canvas.coords(self.rect)
self.render()
if s[0] > (9 / 2) * 40:
self.action_hurt = 0
base_action = np.array([0, 0])
if self.action_hurt == 0:
true_action = action
else:
if action == 0:
true_action = 1
if action == 1:
true_action = 0
if action == 2:
true_action = 3
if action == 3:
true_action = 2
# predict next state
self.centre1 = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
pre_displacement1 = np.array([0, 0])
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT: # 120
if action == 0: # up
if self.centre1[1] > UNIT:
pre_displacement1 = np.array([0, -40])
elif action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action == 3: # left
if self.centre1[0] > UNIT:
pre_displacement1 = np.array([-40, 0])
else:
if action == 0: # up
if self.centre1[1] > UNIT:
pre_displacement1 = np.array([0, -40])
elif action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
pre_displacement1 = np.array([-40, 0])
# true next state
displacement1 = np.array([0, 0])
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT:
if true_action == 0: # up
if self.centre1[1] > UNIT:
displacement1=np.array([0,-40])
elif true_action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1=np.array([0,40])
elif true_action == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
displacement1=np.array([40,0])
elif true_action == 3: # left
if self.centre1[0] > UNIT:
displacement1=np.array([-40,0])
else:
if true_action == 0: # up
if self.centre1[1] > UNIT:
displacement1=np.array([0,-40])
elif true_action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1=np.array([0,40])
elif true_action == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
displacement1=np.array([40,0])
elif true_action == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
displacement1=np.array([-40,0])
self.canvas.move(self.rect, displacement1[0], displacement1[1])
s1_ = self.canvas.coords(self.rect)
sss = [(s1_[4] + s1_[8]) / 2, (s1_[5] + s1_[9]) / 2]
return displacement1, pre_displacement1,s1_,sss
def _set_danger(self):
self.hell1_center = np.array([60, 60])
self.hell1 = self.canvas.create_oval(
self.hell1_center[0] - 15, self.hell1_center[1] - 15,
self.hell1_center[0] + 15, self.hell1_center[1] + 15,
fill='black')
# self.canvas.create_bitmap((40 , 40), bitmap='error')
self.hell = self.canvas.coords(self.hell1)
self.canvas.pack()
self.danger=1
def _set_switch(self):
self.oval_center = np.array([(MAZE_H * UNIT) / 2 - UNIT, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
self.oval = self.canvas.create_oval(
self.oval_center[0] - 15, self.oval_center[1] - 15,
self.oval_center[0] + 15, self.oval_center[1] + 15,
fill='yellow')
self.switch = self.canvas.coords(self.oval)
self.canvas.pack()
def _set_wall(self):
wall_center=[]
self.wall=[]
for a in range(MAZE_W):
wall_center.append([0,0])
self.wall.append([])
for b in range(MAZE_W):
wall_center[b]=np.array([(MAZE_H*UNIT)/2,((b)*UNIT)+UNIT/2])
self.wall[b] = self.canvas.create_rectangle(
wall_center[b][0] - 20, wall_center[b][1] - 20,
wall_center[b][0] + 20, wall_center[b][1] + 20,
fill='grey')
self.wall0 = self.canvas.coords(self.wall[0])
self.wall1 = self.canvas.coords(self.wall[1])
self.wall2 = self.canvas.coords(self.wall[2])
self.wall3 = self.canvas.coords(self.wall[3])
def generate_expression(self,pain):
if pain==1:
self.canvas.itemconfig(self.rect, fill="red", outline='red')
if pain == 0:
self.canvas.itemconfig(self.rect, fill="green", outline='green')
def render(self):
time.sleep(0.1)
self.update()
def is_agent_in_danger(self):
"""
Check if the agent is in a danger zone (hell1).
Returns: True/False
"""
s = self.canvas.coords(self.rect)
agent_pos = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
if hasattr(self, 'hell1_center'):
if all(np.isclose(agent_pos, self.hell1_center)):
return True
return False
# def getter(self, widget):
# widget.update()
# x = tk.Tk.winfo_rootx(self) + widget.winfo_x()
# y = tk.Tk.winfo_rooty(self) + widget.winfo_y()
# x1 = x + widget.winfo_width()
# y1 = y + widget.winfo_height()
# ImageGrab.grab().crop((x, y, x1, y1)).save("first.jpg")
# return ImageGrab.grab().crop((x, y, x1, y1))
================================================
FILE: examples/Social_Cognition/affective_empathy/BEEAD-SNN/rsnn.py
================================================
import torch
from torch import nn
from braincog.base.node.node import IFNode
from braincog.base.learningrule.STDP import STDP,MutliInputSTDP
from braincog.base.connection.CustomLinear import CustomLinear
from collections import deque
from random import randint
class RSNN(nn.Module):
def __init__(self,num_state,num_action):
super().__init__()
# parameters
rsnn_mask=[]
rsnn_con=[]
con_matrix1 = torch.ones((num_state,num_action), dtype=torch.float)
rsnn_mask.append(con_matrix1)
# rsnn_con.append(CustomLinear(torch.randint(2,size=(num_state,num_action))*0.1))
rsnn_con.append(CustomLinear(torch.ones(num_state,num_action)*0.1))
self.num_subR=2
self.connection = rsnn_con
self.mask=rsnn_mask
self.node = [IFNode() for i in range(self.num_subR)]
self.learning_rule = []
self.learning_rule.append(MutliInputSTDP(self.node[1], [self.connection[0]]))
self.weight_trace = torch.zeros(con_matrix1.shape, dtype=torch.float)
self.out_in = torch.zeros((num_state), dtype=torch.float)
self.out = torch.zeros((self.connection[0].weight.size()[1]), dtype=torch.float)
self.dw = torch.zeros((self.connection[0].weight.size()), dtype=torch.float)
def forward(self, input):
input=torch.tensor(input, dtype=torch.float)
self.out_in=self.node[0](input)
self.out,self.dw = self.learning_rule[0](self.out_in)
return self.out,self.dw
def UpdateWeight(self,reward,a,C,n):
self.weight_trace[0:n,:]=0
self.weight_trace[n+1:, :] = 0
self.weight_trace[:, :a * C] = 0
self.weight_trace[:, (a + 1) * C:] = 0
self.weight_trace[self.weight_trace>0]=self.weight_trace[self.weight_trace>0]*reward
self.weight_trace[self.weight_trace < 0] = -1*self.weight_trace[self.weight_trace < 0] * reward
self.connection[0].update(self.weight_trace)
# self.connection[0].weight.data = torch.clamp(self.connection[0].weight.data, -1, 10)
# for i in range(self.connection[0].weight.size()[1]):
# self.connection[0].weight.data[:, i] = (self.connection[0].weight.data[:, i] - torch.min(self.connection[0].weight.data[:, i])) / (torch.max(self.connection[0].weight.data[:, i]) - torch.min(self.connection[0].weight.data[:, i]))
# self.connection[0].weight.data= self.connection[0].weight.data * 0.5
self.weight_trace = torch.zeros((64,5*C), dtype=torch.float)
def reset(self):
for i in range(self.num_subR):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
return self.connection
================================================
FILE: examples/Social_Cognition/affective_empathy/BEEAD-SNN/sd_env.py
================================================
import numpy as np
np.random.seed(1)
import tkinter as tk
import time
from PIL import ImageGrab
UNIT = 40 # pixels
MAZE_H = 11 # grid horizontal
MAZE_W = 5 # grid vertical
class Snowdrift(tk.Tk, object):
def __init__(self, n_agents=3, n_snowdrifts=4):
super(Snowdrift, self).__init__()
self.action_space = ['up', 'down', 'left', 'right', 'clean']
self.n_actions = len(self.action_space)
self.n_agents = n_agents
self.n_snowdrifts = n_snowdrifts
self.UNIT = 40
self.MAZE_H = 8
self.MAZE_W = 8
self.title('Snowdrift Game')
self.geometry('{0}x{1}'.format(self.MAZE_H * self.UNIT, self.MAZE_W * self.UNIT)) # canvas
self.agents = []
self.agents_pos = []
self.agents_emotion = [-1] * n_agents
self.snowdrifts = []
self.snowdrifts_pos = []
self.cleaned = []
self.empathy_emotion = 0
self.empathy_emotion_t_1 = 0
self.help_signal = 0
self.lamda = 1.0
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=self.MAZE_H * self.UNIT,
width=self.MAZE_W * self.UNIT)
# Create agents
colors = ['red', 'blue', 'green']
for i in range(self.n_agents):
pos = np.array([np.random.randint(0, self.MAZE_W) * self.UNIT + self.UNIT/2,
np.random.randint(0, self.MAZE_H) * self.UNIT + self.UNIT/2])
agent = self.canvas.create_oval(
pos[0] - 15, pos[1] - 15,
pos[0] + 15, pos[1] + 15,
fill=colors[i])
self.agents.append(agent)
self.agents_pos.append(pos)
if self.agents_emotion[i] == -1:
self.canvas.itemconfig(agent, fill='gray')
# Create snowdrifts
for _ in range(self.n_snowdrifts):
pos = np.array([np.random.randint(0, self.MAZE_W) * self.UNIT + self.UNIT/2,
np.random.randint(0, self.MAZE_H) * self.UNIT + self.UNIT/2])
points = [
pos[0], pos[1] - 15,
pos[0] - 15, pos[1] + 15,
pos[0] + 15, pos[1] + 15
]
snowdrift = self.canvas.create_polygon(points, fill='black')
self.snowdrifts.append(snowdrift)
self.snowdrifts_pos.append(pos)
self.cleaned.append(False)
self.canvas.pack()
def reset(self, agent_id):
"""Reset environment and return initial state index"""
self.update()
time.sleep(0.001)
# Reset all states
self.empathy_emotion = 0
self.empathy_emotion_t_1 = 0
self.help_signal = 0
# Reset agents
for i in range(self.n_agents):
self.canvas.delete(self.agents[i])
pos = np.array([np.random.randint(0, self.MAZE_W) * self.UNIT + self.UNIT/2,
np.random.randint(0, self.MAZE_H) * self.UNIT + self.UNIT/2])
self.agents_pos[i] = pos
self.agents[i] = self.canvas.create_oval(
pos[0] - 15, pos[1] - 15,
pos[0] + 15, pos[1] + 15,
fill='gray') # ['red', 'blue', 'green'][i]
self.agents_emotion[i] = -1
# Reset snowdrifts
for i in range(self.n_snowdrifts):
if hasattr(self, 'snowdrifts') and len(self.snowdrifts) > i:
self.canvas.delete(self.snowdrifts[i])
pos = self.snowdrifts_pos[i]
points = [
pos[0], pos[1] - 15,
pos[0] - 15, pos[1] + 15,
pos[0] + 15, pos[1] + 15
]
snowdrift = self.canvas.create_polygon(points, fill='black')
if not hasattr(self, 'snowdrifts') or len(self.snowdrifts) <= i:
self.snowdrifts.append(snowdrift)
else:
self.snowdrifts[i] = snowdrift
self.cleaned = [False] * self.n_snowdrifts
# Calculate initial state index
init_state = self._get_state_index(agent_id)
return init_state
def step_all(self, actions):
"""Multi-agent environment step
Args:
actions: List[int] - List of actions for each agent
Returns:
next_states: List[int] - Next state index for each agent
rewards: List[float] - Rewards obtained by each agent
done: bool - Whether the episode is finished
info: dict - Additional information
"""
rewards = [0] * self.n_agents
empathtrewards_t = [0] * self.n_agents
next_states = []
cleaned_this_step = [] # Record snowdrifts cleaned in this step
# 1. Move phase - all agents move simultaneously
for agent_id, action in enumerate(actions):
s = self.agents_pos[agent_id]
base_action = np.array([0, 0])
if action < 4: # Move actions
if action == 0: # up
if s[1] > self.UNIT:
base_action[1] -= self.UNIT
elif action == 1: # down
if s[1] < (self.MAZE_H - 1) * self.UNIT:
base_action[1] += self.UNIT
elif action == 2: # right
if s[0] < (self.MAZE_W - 1) * self.UNIT:
base_action[0] += self.UNIT
elif action == 3: # left
if s[0] > self.UNIT:
base_action[0] -= self.UNIT
self.canvas.move(self.agents[agent_id], base_action[0], base_action[1])
self.agents_pos[agent_id] = self.agents_pos[agent_id] + base_action
# 2. Cleaning phase - handle all cleaning actions
for agent_id, action in enumerate(actions):
if action == 4:
s = self.agents_pos[agent_id]
for i, pos in enumerate(self.snowdrifts_pos):
if all(s == pos) and not self.cleaned[i] and i not in cleaned_this_step:
self.canvas.itemconfig(self.snowdrifts[i], fill='')
self.cleaned[i] = True
cleaned_this_step.append(agent_id)
rewards[agent_id] += 2
self.agents_emotion[agent_id] = -1
self.canvas.itemconfig(self.agents[agent_id], fill='gray')
for j in range(self.n_agents):
if j != agent_id:
rewards[j] += 6
if self.agents_emotion[j] == -1:
self.agents_emotion[j] = 0
self.canvas.itemconfig(self.agents[j], fill=['red', 'blue', 'green'][j])
empathtrewards_t[agent_id] += 6
# 3. Calculate next state for each agent
for agent_id in range(self.n_agents):
next_state = self._get_state_index(agent_id)
next_states.append(next_state)
empathtrewards_t[agent_id]
# 4. Check if finished
done = all(self.cleaned)
info = {
'cleaned_positions': cleaned_this_step,
'agent_emotions': self.agents_emotion.copy()
}
return next_states, rewards, empathtrewards_t, done, info
def _get_state_index(self, agent_id):
"""Convert state to index value"""
state_index = 0
pos = self.agents_pos[agent_id]
x = int(pos[0] / (self.MAZE_W * self.UNIT) * 8)
y = int(pos[1] / (self.MAZE_H * self.UNIT) * 8)
state_index += x + y * 8
return state_index
def render(self):
"""Render environment"""
time.sleep(0.00001)
self.update()
================================================
FILE: examples/Social_Cognition/affective_empathy/BEEAD-SNN/snowdrift_main.py
================================================
import time
import datetime
import os
import random
import numpy as np
import torch
from sd_env import Snowdrift
from rsnn import RSNN
from matplotlib import pyplot as plt
from torch.utils.tensorboard import SummaryWriter
# Global parameters
N_action = 5 # up, down, left, right, clean
N_state = 64 # 8*8 grid
C = 50
runtime = 100
trace_decay = 0.8
torch.manual_seed(42)
np.random.seed(42)
def encode(n, e):
z = torch.zeros(N_state, 100)
z[n, :] = 1
z = z * 0.51
return z
def aoencode(n, e, env, agent_id):
z = torch.zeros(N_state, 100)
z[n, :] = 1
for i in range(len(env.agents_pos)):
if i != agent_id:
other_pos = env.agents_pos[i]
x = int(other_pos[0] / (env.MAZE_W * env.UNIT) * 8)
y = int(other_pos[1] / (env.MAZE_H * env.UNIT) * 8)
other_state_idx = x + y * 8
z[other_state_idx, :] += 0.3
for i, snow_pos in enumerate(env.snowdrifts_pos):
if not env.cleaned[i]:
x = int(snow_pos[0] / (env.MAZE_W * env.UNIT) * 8)
y = int(snow_pos[1] / (env.MAZE_H * env.UNIT) * 8)
snow_state_idx = x + y * 8
z[snow_state_idx, :] += 0.6
z = z * 0.51
return z
def poencode(n, e, env, agent_id):
"""
Encode state as partially observable representation.
Args:
n: state index of current agent position
e: emotion state
env: environment object
agent_id: agent ID
"""
z = torch.zeros(N_state, 100)
agent_pos = env.agents_pos[agent_id]
cur_x = int(agent_pos[0] / (env.MAZE_W * env.UNIT) * 8)
cur_y = int(agent_pos[1] / (env.MAZE_H * env.UNIT) * 8)
obs_range = 1 # observable grid range
z[n, :] = 1
for i in range(len(env.agents_pos)):
if i != agent_id:
other_pos = env.agents_pos[i]
x = int(other_pos[0] / (env.MAZE_W * env.UNIT) * 8)
y = int(other_pos[1] / (env.MAZE_H * env.UNIT) * 8)
if abs(x - cur_x) <= obs_range and abs(y - cur_y) <= obs_range:
other_state_idx = x + y * 8
z[other_state_idx, :] += 0.3
for i, snow_pos in enumerate(env.snowdrifts_pos):
if not env.cleaned[i]:
x = int(snow_pos[0] / (env.MAZE_W * env.UNIT) * 8)
y = int(snow_pos[1] / (env.MAZE_H * env.UNIT) * 8)
if abs(x - cur_x) <= obs_range and abs(y - cur_y) <= obs_range:
snow_state_idx = x + y * 8
z[snow_state_idx, :] += 0.6
z = z * 0.51
return z
def chooseAct(Net, input, explore, n, env, agent_id):
count_group = np.zeros(N_action)
count_output = np.zeros(N_action * C)
for i_train in range(runtime):
out, dw = Net(input[:, i_train])
Net.weight_trace *= trace_decay
Net.weight_trace += dw[0]
count_output = count_output + np.array(out)
for i in range(N_action):
count_group[i] = count_output[i*C:(i+1)*C].sum()
agent_pos = env.agents_pos[agent_id]
at_snowdrift = False
for i, snow_pos in enumerate(env.snowdrifts_pos):
if not env.cleaned[i] and all(agent_pos == snow_pos):
at_snowdrift = True
break
if not at_snowdrift:
count_group[4] = float('-inf')
if np.random.uniform() < explore:
if not at_snowdrift:
action = np.random.randint(0, 4)
else:
if count_group.max() > float('-inf'):
action = count_group.argmax()
else:
action = np.random.randint(0, N_action)
else:
if not at_snowdrift:
action = np.random.randint(0, 4)
else:
action = np.random.randint(0, N_action)
return action, Net, dw[0], 0
def train_model(n_agents, lamdas, episodes):
# TensorBoard writer
current_time = datetime.datetime.now().strftime('%Y%m%d-%H%M%S')
log_dir = os.path.join('run33obs', f'sd_partobs_a{n_agents}_l{lamdas[0]}{lamdas[1]}{lamdas[2]}_e{episodes}_{current_time}', f'')
writer = SummaryWriter(log_dir)
nets = [RSNN(N_state, N_action*C) for _ in range(n_agents)]
learn_steps = [[] for _ in range(n_agents)]
weight_marks = [np.zeros((N_state, N_action)) for _ in range(n_agents)]
update_stops = [0 for _ in range(n_agents)]
empathy_rewards_t = [0] * n_agents
total_rewards = [0] * n_agents
env = Snowdrift(n_agents=n_agents, n_snowdrifts=10)
episode_cleaned_counts = []
agent_cleaned_counts = [0] * n_agents
for episode in range(episodes):
print(f'Episode: {episode}, Lambda: {lamdas}')
cleaned_count = 0
episode_agent_cleaned_count = [0] * n_agents
states = []
emotion_t = [-1] * n_agents
for i in range(n_agents):
state = env.reset(i)
states.append(state)
episode_rewards = [0 for _ in range(n_agents)]
episode_total_rewards = [0 for _ in range(n_agents)]
if episode < 100:
e_greedy = 0.2
elif episode < 300:
e_greedy = 0.5
elif episode < 900:
e_greedy = 0.9
else:
for i in range(n_agents):
if update_stops[i] == 0:
update_stops[i] = 1
e_greedy = 1
for t in range(100):
emotion_tt = emotion_t.copy()
emotion_t = env.agents_emotion.copy()
actions = []
for i in range(n_agents):
input_state = poencode(states[i], env.agents_emotion[i], env, i)
action, nets[i], dw, _ = chooseAct(nets[i], input_state, e_greedy, states[i], env, i)
actions.append(action)
next_states, rewards, empathy_rewards, done, info = env.step_all(actions)
cleaned_count += len(info['cleaned_positions'])
if 'cleaned_by_agent' in info:
for snow_idx, agent_idx in info['cleaned_by_agent'].items():
episode_agent_cleaned_count[agent_idx] += 1
agent_cleaned_counts[agent_idx] += 1
print(f'intereaction {t} :')
for i in range(n_agents):
if env.agents_emotion[i] == emotion_t[i] and env.agents_emotion[i] == emotion_tt[i] and (emotion_tt[0]==0 or emotion_tt[1]==0 or emotion_tt[2]==0):
total_rewards[i] = lamdas[i] * (empathy_rewards[i] - empathy_rewards_t[i]) + rewards[i]
elif env.agents_emotion[0]==-1 and env.agents_emotion[1]==-1 and env.agents_emotion[2]==-1:
total_rewards[i] = lamdas[i] * (empathy_rewards[i] - empathy_rewards_t[i]) + rewards[i]
else:
total_rewards[i] = lamdas[i] * empathy_rewards[i] + rewards[i]
print(f'Actions: {actions}, Rewards: {rewards}, Empathy Rewards: {empathy_rewards} Total Rewards: {total_rewards} emotion: {env.agents_emotion}')
empathy_rewards_t = empathy_rewards
env.render()
for i in range(n_agents):
if update_stops[i] == 0:
nets[i].UpdateWeight(total_rewards[i], actions[i], C, states[i])
states = next_states
for i in range(n_agents):
episode_rewards[i] += rewards[i]
episode_total_rewards[i] += total_rewards[i]
if done:
break
for i in range(n_agents):
writer.add_scalar(f'ERewards/Agent_{i+1}', episode_rewards[i], episode)
writer.add_scalar(f'totalRewards/Agent_{i+1}', episode_total_rewards[i], episode)
writer.add_scalar(f'Cleaned/Agent_{i+1}', episode_agent_cleaned_count[i], episode)
for i in range(n_agents):
learn_steps[i].append(episode_rewards[i])
# Save weights
if episode == episodes-1:
for i in range(n_agents):
torch.save(nets[i].connection[0].weight.data, f'weight_agent{i}_lambda{lamdas}_episode{episode}.pth')
episode_cleaned_counts.append(cleaned_count)
writer.add_scalar('Performance/Cleaned_Snowdrifts', cleaned_count, episode)
print(f'Cleaned Count: {cleaned_count}')
writer.close()
return learn_steps, episode_cleaned_counts
if __name__ == "__main__":
n_agents = 3
n_snowdrifts = 10
self_factors = [[1.51, 1.51, 1.51]]
all_learn_steps = []
all_cleaned_counts = []
for ii in range(len(self_factors)):
all_learn_steps.append([[] for _ in range(n_agents)])
all_cleaned_counts.append([])
for iii, lamdas in enumerate(self_factors):
steps, cleaned_counts = train_model(n_agents, lamdas, 1000)
for i in range(n_agents):
all_learn_steps[iii][i].extend(steps[i])
all_cleaned_counts[iii] = cleaned_counts
# Save plot images
save_dir = 'results'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
timestamp = datetime.datetime.now().strftime('%Y%m%d_%H%M%S')
plt.figure(figsize=[24, 8])
# Plot reward curves for each agent
plt.subplot(1, 3, 1)
colors = ['red', 'blue', 'green']
labels = ['Agent 1', 'Agent 2', 'Agent 3']
for i in range(n_agents):
plt.plot(all_learn_steps[0][i], label=labels[i], color=colors[i])
plt.legend(loc='lower right')
plt.title('Rewards per Agent')
plt.xlabel('Episode')
plt.ylabel('Reward')
# Plot number of cleaned snowdrifts
plt.subplot(1, 3, 2)
plt.plot(all_cleaned_counts[0], label='Cleaned Snowdrifts', color='black')
plt.axhline(y=n_snowdrifts, color='r', linestyle='--', label='Total Snowdrifts')
plt.legend(loc='lower right')
plt.title('Number of Cleaned Snowdrifts per Episode')
plt.xlabel('Episode')
plt.ylabel('Count')
plt.ylim([0, n_snowdrifts + 1])
# Add total reward curve
plt.subplot(1, 3, 3)
total_rewards_per_episode = np.sum(all_learn_steps[0], axis=0) # Calculate total reward for each episode
plt.plot(total_rewards_per_episode, label='Total Rewards', color='purple')
plt.legend(loc='lower right')
plt.title('Total Rewards of All Agents')
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.tight_layout()
# Save image
save_path = os.path.join(save_dir, f'training_results_{timestamp}.png')
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close() # Close the figure to free memory
print(f'Image saved to: {save_path}')
================================================
FILE: examples/Social_Cognition/affective_empathy/BRP-SNN/BRP-SNN.py
================================================
import os
import sys
# 把当前文件所在文件夹的父文件夹路径加入到PYTHONPATH
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import imageio
from env_poly_SNN import Maze
from env_two_poly_SNN import Maze2
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
import torch, os, sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import torch.nn.functional as F
from braincog.base.node.node import *
from braincog.base.learningrule.STDP import *
from braincog.base.connection.CustomLinear import *
X=np.array([[0],
[1],
[2],
[3]])
Y=np.array([[0,-40],
[0,40],
[40,0],
[-40,0]
])
class BrainArea(nn.Module, abc.ABC):
"""
脑区基类
"""
@abc.abstractmethod
def __init__(self):
"""
"""
super().__init__()
@abc.abstractmethod
def forward(self, x):
"""
计算前向传播过程
:return:x是脉冲
"""
return x
def reset(self):
"""
计算前向传播过程
:return:x是脉冲
"""
pass
class BNESNN(BrainArea):
"""
负面情绪网络
"""
def __init__(self,):
super().__init__()
self.node = [IFNode() for i in range(5)]
self.connection = []
con_matrix0 = torch.eye(12, 12)*6
self.connection.append(CustomLinear(con_matrix0))#input-state
con_matrix1 = torch.zeros((12, 24), dtype=torch.float)
self.connection.append(CustomLinear(con_matrix1))#state-prediction
con_matrix2 = torch.eye(24, 24)*6
self.connection.append(CustomLinear(con_matrix2))#input-prediction
con_matrix3 = torch.eye(24, 24)*6
self.connection.append(CustomLinear(con_matrix3))#input-sensory
con_matrix4 = torch.eye(24, 24)*6
self.connection.append(CustomLinear(con_matrix4))#sensory-error
con_matrix5 = torch.eye(24, 24)*(-6)
self.connection.append(CustomLinear(con_matrix5))#prediction-error
con_matrix6 = torch.zeros((24, 24), dtype=torch.float)
p=0.5
if p==0.25:
con_matrix6[:,0:3]=1
if p==0.5:
con_matrix6[:,0:6]=1
if p==0.75:
con_matrix6[:,0:9]=1
if p==1:
con_matrix6[:,0:12]=1
self.connection.append(CustomLinear(con_matrix6))#error-pain
self.stdp = []
self.stdp.append(STDP(self.node[0], self.connection[0]))#node0-state,stdp0
self.stdp.append(MutliInputSTDP(self.node[1], [self.connection[1], self.connection[2]]))#node1-prediction,stdp1
self.stdp.append(STDP(self.node[3], self.connection[3]))#node3-sensory,stdp2
self.stdp.append(MutliInputSTDP(self.node[2], [self.connection[4], self.connection[5]]))#node2-error,stdp3
self.stdp.append(STDP(self.node[1], self.connection[1]))#node1-prediction,stdp4
self.stdp.append(STDP(self.node[4], self.connection[6]))#node4-pain,stdp5
def forward(self, x1,x2):
"""
计算前向传播过程,训练过程
"""
out__s, dw0 = self.stdp[0](x1)#node0
out__p,dw = self.stdp[1](out__s,x2)#node1
return dw,out__s,out__p
def calculate_error(self, x1,x2):
"""
测试过程
"""
out__s,dw = self.stdp[0](x1)#node0-state,stdp0
out__pre,dw= self.stdp[4](out__s)#node1-prediction,stdp1
out__sensory,dw = self.stdp[2](x2)#node3-sensory,stdp2
out__error,dw = self.stdp[3](out__sensory,out__pre)#node2-error,stdp3
out__pain,dw = self.stdp[5](out__error)#node4-pain,stdp5
return out__s,out__pre,out__sensory,out__error,out__pain
def UpdateWeight(self, i, dw, delta):
"""
更新第i组连接的权重 根据传入的dw值
:param i: 要更新的连接的索引
:param dw: 更新的量
:return: None
"""
self.connection[i].update(dw*delta)
self.connection[i].weight.data= torch.clamp(self.connection[i].weight.data,0,6)
def reset(self):
"""
reset神经元或学习法则的中间量
:return: None
"""
for i in range(5):
self.node[i].n_reset()
for i in range(len(self.stdp)):
self.stdp[i].reset()
def GRF(X,N):
gauss_neuron = 12
center = np.ones((gauss_neuron, 1))
width = 1 / 15
for i in range(len(center)):
center[i] = (2 * i - 3) / 20
x = np.arange(0, 1, 0.0001)
num_features = N
gauss_recpt_field = np.zeros((gauss_neuron, len(x)))
for i in range(gauss_neuron):
gauss_recpt_field[i, :] = np.exp(-(x - center[i]) ** 2 / (2 * width * width))
def gauss_response(inputs,num_features):
spike_time = np.zeros((gauss_neuron, num_features))
# input: shape [1, features]
# output: shape [gaussian neurons*features] spiking time
for i in range(num_features):
for j in range(gauss_neuron):
spike_time[j, i] = gauss_recpt_field[j, inputs[i]] #entry gauss function
spikes = []
for i in range(spike_time.shape[1]):
spikes.extend(spike_time[:, i])
return np.array(spikes)
gauss_neurons = gauss_neuron * N
scaler = MinMaxScaler()
X = scaler.fit_transform(X)
X = (X * 10000).astype(int) #10000
X[X == 10000] = 9999
input_spike = np.zeros((X.shape[0], gauss_neurons))
for i in range(X.shape[0]):
input_spike[i, :] = gauss_response(X[i, :],num_features)
input_spike[input_spike < 0.1] = 0
input_spike = np.around(100 * (1 - input_spike))
input_spike[input_spike == 0] = 1
input_spike[input_spike == 100] = 0
state=[]
for i in range(len(X)):
aa=[]
for j in range(gauss_neurons):
if input_spike[i][j] != 0:
number=input_spike[i][j]
aa.append((int(number),j))
state.append(aa)
return state
def encode(input,n_neuron):
a=len(input)
input_encode = []
for i in range(n_neuron):
temp = np.zeros([100, ])
input_encode.append(temp)
for j in range(a):
s=input[j][0]
n=input[j][1]
input_encode[n][s]=1
return input_encode
class BAESNN(BrainArea):
"""
情感共情网络
"""
def __init__(self,):
"""
"""
super().__init__()
self.node = [IFNode() for i in range(5)]
self.connection = []
con_matrix0 = torch.eye(24, 24)*6
self.connection.append(CustomLinear(con_matrix0))#input-emotion
con_matrix1 = torch.zeros((24, 50), dtype=torch.float)
for j in range(50):
if j in np.arange(0,25,1):
for i in np.arange(0, 12, 1):
con_matrix1[i,j] =2
if j in np.arange(25,50,1):
for i in np.arange(12, 24, 1):
con_matrix1[i,j] =2
self.connection.append(CustomLinear(con_matrix1))#emotion-ifg
con_matrix2 = torch.zeros((24, 50), dtype=torch.float)
self.connection.append(CustomLinear(con_matrix2))#perception-ifg
con_matrix3 = torch.eye(24, 24)*6
self.connection.append(CustomLinear(con_matrix3))#input-perception
con_matrix4=torch.zeros((24,10), dtype=torch.float)
for j in range(10):
if j in np.arange(0,5,1):
for i in np.arange(0, 12, 1):
con_matrix4[i,j] =2
if j in np.arange(5,10,1):
for i in np.arange(12, 24, 1):
con_matrix4[i,j] =2
self.connection.append(CustomLinear(con_matrix4))#emotion-sma
con_matrix5=torch.zeros((24,10), dtype=torch.float)
self.connection.append(CustomLinear(con_matrix5))#perception-m1
con_matrix6 = torch.eye(10, 10)*6
self.connection.append(CustomLinear(con_matrix6))#sma-m1
self.stdp = []
self.stdp.append(STDP(self.node[0], self.connection[0]))#0
self.stdp.append(STDP(self.node[2], self.connection[3]))#1
self.stdp.append(MutliInputSTDP(self.node[1], [self.connection[1], self.connection[2]]))#2
self.stdp.append(MutliInputSTDP(self.node[3], [self.connection[4], self.connection[5]]))#3
self.stdp.append(STDP(self.node[4], self.connection[6]))#4
self.stdp.append(STDP(self.node[1],self.connection[2]))#5
self.stdp.append(STDP(self.node[3],self.connection[5]))#6
def forward(self, x1,x2):
"""
计算前向传播过程
:return:x是脉冲
"""
out__m, dw0 = self.stdp[0](x1)#node0
out__p, dw3 = self.stdp[1](x2)#node2
out__ifg,dw_p_i=self.stdp[2](out__m,out__p)#node1
out__sma,dw_p_s=self.stdp[3](out__m,out__p)#node3
out__m1,dw1=self.stdp[4](out__sma)#node4
return dw_p_i,dw_p_s,out__ifg,out__sma,out__m1
def empathy(self,x3):
out_p,dw2=self.stdp[1](x3)#node2
out_ifg,dw4=self.stdp[5](out_p)#node1
out_sma,dw5=self.stdp[6](out_p)#node3
out_m1,dw6=self.stdp[4](out_sma)#node4
return out_ifg,out_sma,out_m1
def UpdateWeight(self, i, dw, delta):
"""
更新第i组连接的权重 根据传入的dw值
:param i: 要更新的连接的索引
:param dw: 更新的量
:return: None
"""
self.connection[i].update(dw*delta)
self.connection[i].weight.data= torch.clamp(self.connection[i].weight.data,-1,4)
def reset(self):
"""
reset神经元或学习法则的中间量
:return: None
"""
for i in range(5):
self.node[i].n_reset()
for i in range(len(self.stdp)):
self.stdp[i].reset()
def BNESNN_train():
state=GRF(X,1)
prediction=GRF(Y,2)
T=100
epoch=10
for k in range(epoch):
print('epoch:',k)
for n in range(4):
snn1.reset()
train_state = np.array(encode(state[n], 12))
train_state=torch.tensor(train_state,dtype=torch.float32)
train_prediction = np.array(encode(prediction[n], 24))
train_prediction=torch.tensor(train_prediction,dtype=torch.float32)
for i in range(T):
OUTPUT = snn1(train_state[:,i],train_prediction[:,i])
snn1.UpdateWeight(1,OUTPUT[0][0],1)
def BAESNN_train():
s = env.reset()
env._set_danger()
env._set_wall()
pain=0
i=0
set_pain=0
env._set_switch()
for i in range(100):
snn1.reset()
T=100
pain=0
print('**************step:',i)
env.render()
action = np.random.choice(list(range(env.n_actions)))
print('action:',action)
d,d_pre,s_,sss = env.step(s, action, pain)
print('d:',d,'d_pre:',d_pre,'sss:',sss)
env.render()
while (d==np.array([0,0])).all():
action = np.random.choice(list(range(env.n_actions)))
print('action:',action)
d,d_pre,s_,sss = env.step(s, action, pain)
print('d:',d,'d_pre:',d_pre,'sss:',sss)
env.render()
aa=np.argwhere(X==action)[0][0]
for i in range(4):
if (Y[i]==d).all():
b=i
print('aa:',aa,'b:',b)
state=GRF(X,1)
prediction=GRF(Y,2)
x=encode(state[aa],12)
y=encode(prediction[b],24)
train_state = np.array(x)
train_state=torch.tensor(train_state,dtype=torch.float32)
train_prediction = np.array(y)
train_prediction=torch.tensor(train_prediction,dtype=torch.float32)
OUT_PAIN=torch.tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.]])
spike_pain=[]
spike_error=[]
for i in range(T):
OUTPUT_TEST = snn1.calculate_error(train_state[:,i],train_prediction[:,i])
spike_pain.append(OUTPUT_TEST[4])
spike_error.append(OUTPUT_TEST[3])
if OUTPUT_TEST[3].sum() != 0:
print('OUTPUT_TEST3:',i,OUTPUT_TEST[3])
if OUTPUT_TEST[4].sum() != 0:#pain brain area
print('OUTPUT_TEST4:',i,OUTPUT_TEST[4])
OUT_PAIN=OUTPUT_TEST[4]
pain=1
set_pain=1
spike_pain = torch.stack(spike_pain)
spike_error=torch.stack(spike_error)
if pain==1:
spike_rate_vis_1d(spike_error)
spike_rate_vis_1d(spike_pain)
print('pain:',pain)
snn2.reset()
T2=20
X1= OUT_PAIN.view(1, -1)
X2=torch.tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.]])
print('X1,X2:',X1,X2)
for i in range(T2):
if i>=2:
X2=X1
OUTPUT = snn2(X1,X2)
snn2.UpdateWeight(2,OUTPUT[0][1],0.01)
snn2.UpdateWeight(5,OUTPUT[1][1],-0.1)
if OUTPUT[2][0][0]==1:
env.canvas.itemconfig(env.rect, fill="red", outline='red')
if OUTPUT[2][0][0]==0:
env.canvas.itemconfig(env.rect, fill="green", outline='green')
env.render()
print('out_ifg:',OUTPUT[2])
print('out_sma:',OUTPUT[3])
print('out_m1:',OUTPUT[4])
print('con2:',snn2.connection[2].weight.data)
print('con5:',snn2.connection[5].weight.data)
s = s_
if set_pain==1 and pain==0:
env.render()
break
env.destroy()
def BAESNN_test():
s1,s=env2.reset()
pain=0
pain1 = 0
i=0
set_pain=0
for i in range(100):
snn1.reset()
T=100
pain=0
print('**************test_step:',i)
env2.render()
action1 = np.random.choice(list(range(env.n_actions)))
print('action1:',action1)
d,d_pre,s1_,sss = env2.step(s1, action1, pain1)
print('d:',d,'d_pre:',d_pre,'sss:',sss)
env2.render()
while (d==np.array([0,0])).all():
action1 = np.random.choice(list(range(env.n_actions)))
print('action1:',action1)
d,d_pre,s1_,sss = env2.step(s, action1, pain1)
print('d:',d,'d_pre:',d_pre,'sss:',sss)
env2.render()
aa=np.argwhere(X==action1)[0][0]
for i in range(4):
if (Y[i]==d).all():
b=i
# print('aa:',aa,'b:',b)
state=GRF(X,1)
prediction=GRF(Y,2)
x=encode(state[aa],12)
y=encode(prediction[b],24)
train_state = np.array(x)
train_state=torch.tensor(train_state,dtype=torch.float32)
train_prediction = np.array(y)
train_prediction=torch.tensor(train_prediction,dtype=torch.float32)
OUT_PAIN=torch.tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.]])
for i in range(T):
OUTPUT_TEST = snn1.calculate_error(train_state[:,i],train_prediction[:,i])
if OUTPUT_TEST[3].sum() != 0:
print('OUTPUT_TEST3:',i,OUTPUT_TEST[3])
if OUTPUT_TEST[4].sum() != 0:#pain brain area
print('OUTPUT_TEST4:',i,OUTPUT_TEST[4])
OUT_PAIN=OUTPUT_TEST[4]
pain1=1
set_pain=1
print('pain1:',pain1)
env2.generate_expression1(pain1)
snn2.reset()
T2=20
X3= OUT_PAIN.view(1, -1)
for i in range(T2):
OUT=snn2.empathy(X3)
print('out_ifg:',OUT[0])
if OUT[0][0][0]==1:
pain=1
if OUT[0][0][0]==0:
pain=0
if pain==1:
env2.agent_help()
s1 = s1_
env2.render()
if pain==0 and set_pain==1:
env2.render()
break
env2.destroy()
if __name__ == "__main__":
env = Maze()
snn1 = BNESNN()
snn2 = BAESNN()
BNESNN_train()
BAESNN_train()
env.mainloop()
env2 = Maze2()
BAESNN_test()
env2.mainloop()
================================================
FILE: examples/Social_Cognition/affective_empathy/BRP-SNN/README.md
================================================
================================================
FILE: examples/Social_Cognition/affective_empathy/BRP-SNN/env_poly_SNN.py
================================================
import numpy as np
np.random.seed(1)
import tkinter as tk
import time
from PIL import ImageGrab
UNIT = 40 # pixels
MAZE_H = 9 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('self-pain')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_W * UNIT))
self._build_maze()
self.danger=0
self.action_hurt=0
self.sensory_hurt = 0
self.open_door = 0
self.pain_state=0
# create environment
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_W * UNIT,
width=MAZE_H * UNIT)
# create grids
for c in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
self.orgin=[20,20]
# create agent
# 下
self.points1 = [
# 左上
self.orgin[0]-15,#5
self.orgin[1]-15,#5
# 右上
self.orgin[0]+15,#35
self.orgin[1]-15,#5
# 右下+
self.orgin[0]+15,#35
self.orgin[1],#20
# 顶点
self.orgin[0],#20
self.orgin[1]+15,#35
# 左下+
self.orgin[0]-15,#5
self.orgin[1],#20
]
self.rect = self.canvas.create_polygon(self.points1, fill="green")
self.canvas.pack()
#reset agent location
def reset(self):
self.open_door = 0
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
self.orgin = [20, 20]
# 下
self.points1 = [
# 左上
self.orgin[0] - 15, # 5
self.orgin[1] - 15, # 5
# 右上
self.orgin[0] + 15, # 35
self.orgin[1] - 15, # 5
# 右下+
self.orgin[0] + 15, # 35
self.orgin[1], # 20
# 顶点
self.orgin[0], # 20
self.orgin[1] + 15, # 35
# 左下+
self.orgin[0] - 15, # 5
self.orgin[1], # 20
]
self.rect = self.canvas.create_polygon(self.points1, fill="green")
return self.canvas.coords(self.rect)
def step(self, s, action, pain):
s = self.canvas.coords(self.rect)
self.centre = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
# danger or switch
if self.danger==1:
if all(self.centre == self.oval_center):
s_color = 'yellow'
self.canvas.delete(self.wall[3])
self.render()
self.open_door = 1
move = np.array([80, 0])
self.canvas.move(self.rect, move[0], move[1])
s = self.canvas.coords(self.rect)
self.render()
elif all(self.centre == self.hell1_center):
s_color = 'black'
self.action_hurt = 1
self.render()
else:
s_color = 'white'
# modify current state
self.canvas.delete(self.rect)# 主要为开关那几步考虑,所以重复写了
self.centre = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
if action==0:
self.points0 = [
# 右下
self.centre[0] + 15, # 35
self.centre[1] + 15, # 35
# 左下
self.centre[0] - 15, # 5
self.centre[1] + 15, # 35
# 左上+
self.centre[0] - 15, # 5
self.centre[1], # 20
# 顶点
self.centre[0], # 20
self.centre[1] - 15, # 5
# 右上+
self.centre[0] + 15, # 35
self.centre[1], # 20
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points0, fill=color)
if action==1:
self.points1 = [
# 左上
self.centre[0] - 15, # 5
self.centre[1] - 15, # 5
# 右上
self.centre[0] + 15, # 35
self.centre[1] - 15, # 5
# 右下+
self.centre[0] + 15, # 35
self.centre[1], # 20
# 顶点
self.centre[0], # 20
self.centre[1] + 15, # 35
# 左下+
self.centre[0] - 15, # 5
self.centre[1], # 20
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points1, fill=color)
if action==2:
self.points2 = [
# 左下
self.centre[0] - 15, # 5
self.centre[1] + 15, # 35
# 左上
self.centre[0] - 15, # 5
self.centre[1] - 15, # 5
# 右上+
self.centre[0], # 20
self.centre[1] - 15, # 5
# 顶点
self.centre[0] + 15, # 35
self.centre[1], # 20
# 右下+
self.centre[0], # 20
self.centre[1] + 15, # 35
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points2, fill=color)
if action==3:
self.points3 = [
# 右上
self.centre[0] + 15, # 20+15
self.centre[1] - 15, # 20-15
# 右下
self.centre[0] + 15, # 20+15
self.centre[1] + 15, # 20+15
# 左下+
self.centre[0], # 20
self.centre[1] + 15, # 20+15
# 顶点
self.centre[0] - 15, # 20-15
self.centre[1], # 20
# 左上+
self.centre[0], # 20
self.centre[1] - 15, # 20-15
]
if pain==0:
color="green"
if pain == 1:
color = "red"
self.rect = self.canvas.create_polygon(self.points3, fill=color)
s = self.canvas.coords(self.rect)
self.render()#显示当前的动作指令是什么
if s[0] > (9 / 2) * 40:
self.action_hurt = 0
base_action = np.array([0, 0])
if self.action_hurt == 0:
true_action = action
else:
if action == 0:
true_action = 1
if action == 1:
true_action = 0
if action == 2:
true_action = 3
if action == 3:
true_action = 2
# predict next state
# predict next state
self.centre1 = [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
pre_displacement1 = np.array([0, 0])
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT: # 120
if action == 0: # up
if self.centre1[1] > UNIT:
pre_displacement1 = np.array([0, -40])
elif action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action == 3: # left
if self.centre1[0] > UNIT:
pre_displacement1 = np.array([-40, 0])
else:
if action == 0: # up
if self.centre1[1] > UNIT:
pre_displacement1 = np.array([0, -40])
elif action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
pre_displacement1 = np.array([-40, 0])
# true next state
displacement1 = np.array([0, 0])
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT:
if true_action == 0: # up
if self.centre1[1] > UNIT:
displacement1=np.array([0,-40])
elif true_action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1=np.array([0,40])
elif true_action == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
displacement1=np.array([40,0])
elif true_action == 3: # left
if self.centre1[0] > UNIT:
displacement1=np.array([-40,0])
else:
if true_action == 0: # up
if self.centre1[1] > UNIT:
displacement1=np.array([0,-40])
elif true_action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1=np.array([0,40])
elif true_action == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
displacement1=np.array([40,0])
elif true_action == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
displacement1=np.array([-40,0])
self.canvas.move(self.rect, displacement1[0], displacement1[1])
s1_ = self.canvas.coords(self.rect)
sss = [(s1_[4] + s1_[8]) / 2, (s1_[5] + s1_[9]) / 2]
return displacement1, pre_displacement1,s1_,sss
def _set_danger(self):
self.hell1_center = np.array([60, 60])
self.hell1 = self.canvas.create_oval(
self.hell1_center[0] - 15, self.hell1_center[1] - 15,
self.hell1_center[0] + 15, self.hell1_center[1] + 15,
fill='black')
# self.canvas.create_bitmap((40 , 40), bitmap='error')
self.hell = self.canvas.coords(self.hell1)
self.canvas.pack()
self.danger=1
def _set_switch(self):
self.oval_center = np.array([(MAZE_H * UNIT) / 2 - UNIT, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
self.oval = self.canvas.create_oval(
self.oval_center[0] - 15, self.oval_center[1] - 15,
self.oval_center[0] + 15, self.oval_center[1] + 15,
fill='yellow')
self.switch = self.canvas.coords(self.oval)
self.canvas.pack()
def _set_wall(self):
wall_center=[]
self.wall=[]
for a in range(MAZE_W):
wall_center.append([0,0])
self.wall.append([])
for b in range(MAZE_W):
wall_center[b]=np.array([(MAZE_H*UNIT)/2,((b)*UNIT)+UNIT/2])
self.wall[b] = self.canvas.create_rectangle(
wall_center[b][0] - 20, wall_center[b][1] - 20,
wall_center[b][0] + 20, wall_center[b][1] + 20,
fill='grey')
self.wall0 = self.canvas.coords(self.wall[0])
self.wall1 = self.canvas.coords(self.wall[1])
self.wall2 = self.canvas.coords(self.wall[2])
self.wall3 = self.canvas.coords(self.wall[3])
# self.canvas.pack()
def generate_expression(self,pain):
if pain==1:
self.canvas.itemconfig(self.rect, fill="red", outline='red')
# self.canvas.pack()
if pain == 0:
self.canvas.itemconfig(self.rect, fill="green", outline='green')
# self.canvas.pack()
def render(self):
time.sleep(0.2)
self.update()
# def getter(self, widget):
# widget.update()
# x = tk.Tk.winfo_rootx(self) + widget.winfo_x()
# y = tk.Tk.winfo_rooty(self) + widget.winfo_y()
# x1 = x + widget.winfo_width()
# y1 = y + widget.winfo_height()
# ImageGrab.grab().crop((x, y, x1, y1)).save("first.jpg")
# return ImageGrab.grab().crop((x, y, x1, y1))
================================================
FILE: examples/Social_Cognition/affective_empathy/BRP-SNN/env_two_poly_SNN.py
================================================
import numpy as np
np.random.seed(1)
import tkinter as tk
import time
from PIL import ImageGrab
UNIT = 40 # pixels
MAZE_H = 9 # grid height
MAZE_W = 4 # grid width
class Maze2(tk.Tk, object):
def __init__(self):
super(Maze2, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.action_space1 = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.n_actions1 = len(self.action_space1)
self.title('two_agent_empathy')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_W * UNIT))
self._build_maze()
self.danger=0
self.action_hurt=0
self.sensory_hurt = 0
self.action_hurt1 = 0
self.sensory_hurt1 = 0
self.open_door=0
# create environment
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_W * UNIT,
width=MAZE_H * UNIT)
# create grids
for c in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create switch
self.oval_center = np.array([(MAZE_H * UNIT)/2-UNIT+80, ((MAZE_W+4) * UNIT)/2-UNIT/2-80])
self.oval = self.canvas.create_oval(
self.oval_center[0] - 15, self.oval_center[1] - 15,
self.oval_center[0] + 15, self.oval_center[1] + 15,
fill='yellow')
self.switch = self.canvas.coords(self.oval)
self.orgin1 = np.array([20, 20])
# 下
self.points1 = [
# 左上
self.orgin1[0] - 15, # 5
self.orgin1[1] - 15, # 5
# 右上
self.orgin1[0] + 15, # 35
self.orgin1[1] - 15, # 5
# 右下+
self.orgin1[0] + 15, # 35
self.orgin1[1], # 20
# 顶点
self.orgin1[0], # 20
self.orgin1[1] + 15, # 35
# 左下+
self.orgin1[0] - 15, # 5
self.orgin1[1], # 20
]
self.agent1 = self.canvas.create_polygon(self.points1, outline='black',fill="blue")
self.orgin = np.array([MAZE_H * UNIT - UNIT / 2, 20])
# 下
self.points = [
# 左上
self.orgin[0] - 15, # 5
self.orgin[1] - 15, # 5
# 右上
self.orgin[0] + 15, # 35
self.orgin[1] - 15, # 5
# 右下+
self.orgin[0] + 15, # 35
self.orgin[1], # 20
# 顶点
self.orgin[0], # 20
self.orgin[1] + 15, # 35
# 左下+
self.orgin[0] - 15, # 5
self.orgin[1], # 20
]
self.agent = self.canvas.create_polygon(self.points, fill="green")
wall_center = []
self.wall = []
for i in range(MAZE_W):
wall_center.append([])
self.wall.append([])
for i in range(MAZE_W):
wall_center[i] = np.array([(MAZE_H * UNIT) / 2, ((i) * UNIT) + UNIT / 2])
self.wall[i] = self.canvas.create_rectangle(
wall_center[i][0] - 20, wall_center[i][1] - 20,
wall_center[i][0] + 20, wall_center[i][1] + 20,
fill='grey')
self.hell1_center = np.array([100, 20])
self.hell1 = self.canvas.create_oval(
self.hell1_center[0] - 15, self.hell1_center[1] - 15,
self.hell1_center[0] + 15, self.hell1_center[1] + 15,
fill='black')
self.hell2_center = np.array([60, 100])
self.hell2 = self.canvas.create_oval(
self.hell2_center[0] - 15, self.hell2_center[1] - 15,
self.hell2_center[0] + 15, self.hell2_center[1] + 15,
fill='black')
# self.canvas.create_bitmap((40 , 40), bitmap='error')
self.danger = 1
self.canvas.pack()
#reset agent location
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.agent1)
self.canvas.delete(self.agent)
self.orgin1 = np.array([20, 20])
# 下
self.points1 = [
# 左上
self.orgin1[0] - 15, # 5
self.orgin1[1] - 15, # 5
# 右上
self.orgin1[0] + 15, # 35
self.orgin1[1] - 15, # 5
# 右下+
self.orgin1[0] + 15, # 35
self.orgin1[1], # 20
# 顶点
self.orgin1[0], # 20
self.orgin1[1] + 15, # 35
# 左下+
self.orgin1[0] - 15, # 5
self.orgin1[1], # 20
]
self.agent1 = self.canvas.create_polygon(self.points1, outline='black',fill="blue")
self.orgin = np.array([MAZE_H * UNIT - UNIT / 2, 20])
# 下
self.points = [
# 左上
self.orgin[0] - 15, # 5
self.orgin[1] - 15, # 5
# 右上
self.orgin[0] + 15, # 35
self.orgin[1] - 15, # 5
# 右下+
self.orgin[0] + 15, # 35
self.orgin[1], # 20
# 顶点
self.orgin[0], # 20
self.orgin[1] + 15, # 35
# 左下+
self.orgin[0] - 15, # 5
self.orgin[1], # 20
]
self.agent = self.canvas.create_polygon(self.points, fill="green")
return self.canvas.coords(self.agent1),self.canvas.coords(self.agent)
def step(self, s, action, pain):
s1 = self.canvas.coords(self.agent1)
self.centre1 = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
if all(self.centre1 == self.hell1_center):
self.action_hurt1 = 1
if all(self.centre1 == self.hell2_center):
self.action_hurt1 = 1
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 ==self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 ==self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT*2, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 == self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT*3, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 == self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
self.oval_center111 = np.array([(MAZE_H * UNIT) / 2 - UNIT*4, ((MAZE_W + 4) * UNIT) / 2 - UNIT / 2])
if all(self.centre1 == self.oval_center111):
move = np.array([80, 0])
self.canvas.move(self.agent1, move[0], move[1])
s1 = self.canvas.coords(self.agent1)
self.render()
#显示当前的动作指令是什么
self.canvas.delete(self.agent1)
self.centre = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
if action==0:
self.points0 = [
# 右下
self.centre[0] + 15, # 35
self.centre[1] + 15, # 35
# 左下
self.centre[0] - 15, # 5
self.centre[1] + 15, # 35
# 左上+
self.centre[0] - 15, # 5
self.centre[1], # 20
# 顶点
self.centre[0], # 20
self.centre[1] - 15, # 5
# 右上+
self.centre[0] + 15, # 35
self.centre[1], # 20
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points0, fill=color)
if action==1:
self.points1 = [
# 左上
self.centre[0] - 15, # 5
self.centre[1] - 15, # 5
# 右上
self.centre[0] + 15, # 35
self.centre[1] - 15, # 5
# 右下+
self.centre[0] + 15, # 35
self.centre[1], # 20
# 顶点
self.centre[0], # 20
self.centre[1] + 15, # 35
# 左下+
self.centre[0] - 15, # 5
self.centre[1], # 20
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points1, fill=color)
if action==2:
self.points2 = [
# 左下
self.centre[0] - 15, # 5
self.centre[1] + 15, # 35
# 左上
self.centre[0] - 15, # 5
self.centre[1] - 15, # 5
# 右上+
self.centre[0], # 20
self.centre[1] - 15, # 5
# 顶点
self.centre[0] + 15, # 35
self.centre[1], # 20
# 右下+
self.centre[0], # 20
self.centre[1] + 15, # 35
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points2, fill=color)
if action==3:
self.points3 = [
# 右上
self.centre[0] + 15, # 20+15
self.centre[1] - 15, # 20-15
# 右下
self.centre[0] + 15, # 20+15
self.centre[1] + 15, # 20+15
# 左下+
self.centre[0], # 20
self.centre[1] + 15, # 20+15
# 顶点
self.centre[0] - 15, # 20-15
self.centre[1], # 20
# 左上+
self.centre[0], # 20
self.centre[1] - 15, # 20-15
]
if pain==0:
color="blue"
if pain == 1:
color = "red"
self.agent1 = self.canvas.create_polygon(self.points3, fill=color)
s1 = self.canvas.coords(self.agent1)
self.render()#显示当前的动作指令是什么
self.centre1 = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
if self.centre1[0] > (9 / 2) * 40:
self.action_hurt1 = 0
# whether hurt
if self.action_hurt1 == 0:
true_action = action
else:
if action == 0:
true_action = 1
if action == 1:
true_action = 0
if action == 2:
true_action = 3
if action == 3:
true_action = 2
base_action = np.array([0, 0])
# predict next state
self.centre1 = [(s1[4] + s1[8]) / 2, (s1[5] + s1[9]) / 2]
pre_displacement1 = np.array([0, 0])
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT: # 120
if action == 0: # up
if self.centre1[1] > UNIT:
pre_displacement1 = np.array([0, -40])
elif action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action == 3: # left
if self.centre1[0] > UNIT:
pre_displacement1 = np.array([-40, 0])
else:
if action == 0: # up
if self.centre1[1] > UNIT:
pre_displacement1 = np.array([0, -40])
elif action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
pre_displacement1 = np.array([0, 40])
elif action == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
pre_displacement1 = np.array([40, 0])
elif action == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
pre_displacement1 = np.array([-40, 0])
# true next state
displacement1 = np.array([0, 0])
if self.centre1[0] <= ((MAZE_H - 1) / 2 + 1) * UNIT:
if true_action == 0: # up
if self.centre1[1] > UNIT:
displacement1=np.array([0,-40])
elif true_action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1=np.array([0,40])
elif true_action == 2: # right
if self.centre1[0] < ((MAZE_H - 1) / 2 - 1) * UNIT:
displacement1=np.array([40,0])
elif true_action == 3: # left
if self.centre1[0] > UNIT:
displacement1=np.array([-40,0])
else:
if true_action == 0: # up
if self.centre1[1] > UNIT:
displacement1=np.array([0,-40])
elif true_action == 1: # down
if self.centre1[1] < (MAZE_W - 1) * UNIT:
displacement1=np.array([0,40])
elif true_action == 2: # right
if self.centre1[0] < (MAZE_H - 1) * UNIT:
displacement1=np.array([40,0])
elif true_action == 3: # left
if self.centre1[0] > ((MAZE_H - 1) / 2 + 2) * UNIT:
displacement1=np.array([-40,0])
self.canvas.move(self.agent1, displacement1[0], displacement1[1])
s1_ = self.canvas.coords(self.agent1)
sss = [(s1_[4] + s1_[8]) / 2, (s1_[5] + s1_[9]) / 2]
return displacement1, pre_displacement1,s1_,sss
def agent_help(self):
s = self.canvas.coords(self.agent)
self.centre2= [(s[4] + s[8]) / 2, (s[5] + s[9]) / 2]
if all(self.centre2 == self.oval_center):
self.canvas.delete(self.wall[3])
self.render()
self.open_door=1
else:
self.canvas.move(self.agent, -40, 0) # move agent
self.render()
self.canvas.move(self.agent, -40, 0)
self.render()
self.canvas.move(self.agent, -40, 0)
self.render()
self.canvas.move(self.agent, 0, 40)
self.render()
s_ = self.canvas.coords(self.agent) # next state
return s_
def _set_danger(self):
hell1_center = np.array([140, 60])
self.hell1 = self.canvas.create_agent1angle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
hell2_center = np.array([100, 140])
self.hell2 = self.canvas.create_agent1angle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# self.canvas.create_bitmap((40 , 40), bitmap='error')
self.canvas.pack()
self.danger=1
def _set_wall(self):
wall_center=[]
self.wall=[]
for i in range(MAZE_W):
wall_center.append([])
self.wall.append([])
for i in range(MAZE_W):
wall_center[i]=np.array([(MAZE_H*UNIT)/2,((i)*UNIT)+UNIT/2])
self.wall[i] = self.canvas.create_agent1angle(
wall_center[i][0] - 20, wall_center[i][1] - 20,
wall_center[i][0] + 20, wall_center[i][1] + 20,
fill='grey')
self.canvas.pack()
def generate_expression1(self,pain1):
if pain1==1:
self.canvas.itemconfig(self.agent1, fill="red", outline='black')
self.canvas.pack()
if pain1 ==0:
self.canvas.itemconfig(self.agent1, fill="blue", outline='black')
self.canvas.pack()
def render(self):
time.sleep(0.2)
self.update()
================================================
FILE: examples/Social_Cognition/mirror_test/README.md
================================================
# Mirror Test
The mirror_test.py implements the core code of the Multi-Robots Mirror Self-Recognition Test in "Toward Robot Self-Consciousness (II): Brain-Inspired Robot Bodily Self Model for Self-Recognition".
The experiment is: three robots with identical appearance move their arms randomly in front of the mirror at the same time.
In the training stage, according to the spiking time difference of neurons in IPLM and IPLV, the robot learns the correlations between self-generated actions and visual feedbacks in motion by learning with spike timing dependent plasticity (STDP) mechanism.
In the test stage, the robot can predicts the visual feedback generated by its arm movement according to the training results. With the InsulaNet, the robot can identify which mirror image belongs to it.
In the result, Motion Detection shows the results of visual detection, and Motion Prediction shows the visual feedback generated by itself. The red line in the figure indicates that the robot determines that the corresponding mirror belongs to itself.
Differences from the original article:
Since there is no motion error under the simulation conditions, the theta_threshold is set to zero.
### Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{zeng2018toward,
title={Toward robot self-consciousness (ii): brain-inspired robot bodily self model for self-recognition},
author={Zeng, Yi and Zhao, Yuxuan and Bai, Jun and Xu, Bo},
journal={Cognitive Computation},
volume={10},
number={2},
pages={307--320},
year={2018},
publisher={Springer}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/Social_Cognition/mirror_test/mirror_test.py
================================================
from braincog.base.brainarea.Insula import *
from braincog.base.brainarea.IPL import *
from braincog.base.learningrule.STDP import *
from braincog.base.node.node import *
from braincog.base.connection.CustomLinear import *
import random
import numpy as np
import torch
import os
import sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
import torch.nn.functional as F
import matplotlib.pyplot as plt
from braincog.base.strategy.surrogate import *
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
if __name__ == "__main__":
"""
Set the number of neurons, and each neuron represents unique motion information (such as angle)
"""
# number of neurons
num_neuron = 5
num_vPMC = num_neuron
num_STS = num_neuron
num_IPLM = num_neuron
num_IPLV = num_neuron
num_Insula = num_neuron
"""
Setting the network structure and the initial weight of IPL
"""
# IPLNet
# connection
connection = []
# vPMC-IPLM
con_matrix0 = torch.eye(num_IPLM, dtype=torch.float) * 2.5
connection.append(CustomLinear(con_matrix0))
# STS-IPLV
con_matrix1 = torch.eye(num_IPLV, dtype=torch.float) * 2.5
connection.append(CustomLinear(con_matrix1))
# IPLM-IPLV
con_matrix2 = torch.zeros([num_IPLM, num_IPLV], dtype=torch.float)
connection.append(CustomLinear(con_matrix2))
IPL = IPLNet(connection)
print("IPL Connection (Before training):", connection[2].weight)
"""
Setting the network structure and the initial weight of Insula
"""
# InsulaNet
# connection
Insula_connection = []
# IPLV-Insula
con_matrix0 = torch.eye(num_IPLM, dtype=torch.float) * 2
Insula_connection.append(CustomLinear(con_matrix0))
# STS-Insula
con_matrix1 = torch.eye(num_IPLV, dtype=torch.float) * 2
Insula_connection.append(CustomLinear(con_matrix1))
Insula = InsulaNet(Insula_connection)
"""
Training process
:param train_num: number of movements during training
"""
# Train
for vPMC_Angel in range(1, num_vPMC + 1):
# vPMC Angle
vPMC_Angel_v = torch.zeros([1, num_vPMC], dtype=torch.float)
vPMC_Angel_v[0, vPMC_Angel - 1] = 20
dwIPL_temp = torch.zeros([num_IPLM, num_IPLV], dtype=torch.float)
train_num = 10
for i_train in range(train_num):
# STS 1
STS_Angel_1 = vPMC_Angel
for t in range(2):
vPMC_input = vPMC_Angel_v
STS_Angel_v = torch.zeros([1, num_STS], dtype=torch.float)
STS_Angel_v[0, STS_Angel_1 - 1] = 20
STS_input = STS_Angel_v
IPLV_out, dwIPL = IPL(vPMC_input, STS_input)
dwIPL_temp = dwIPL_temp + dwIPL
IPL.reset()
# STS 2
STS_Angel_2 = random.randint(1, num_neuron)
for t in range(2):
vPMC_input = vPMC_Angel_v
STS_Angel_v = torch.zeros([1, num_STS], dtype=torch.float)
STS_Angel_v[0, STS_Angel_2 - 1] = 20
STS_input = STS_Angel_v
IPLV_out, dwIPL = IPL(vPMC_input, STS_input)
dwIPL_temp = dwIPL_temp + dwIPL
IPL.reset()
# STS 3
STS_Angel_3 = random.randint(1, num_neuron)
for t in range(2):
vPMC_input = vPMC_Angel_v
STS_Angel_v = torch.zeros([1, num_STS], dtype=torch.float)
STS_Angel_v[0, STS_Angel_3 - 1] = 20
STS_input = STS_Angel_v
IPLV_out, dwIPL = IPL(vPMC_input, STS_input)
dwIPL_temp = dwIPL_temp + dwIPL
IPL.reset()
IPL.UpdateWeight(2, dwIPL_temp)
print("IPL Connection (After training):", connection[2].weight)
"""
Test process
:param move_count: number of movements during test
"""
# Test
move_count = 10
TestList_vPMC_Angel = np.random.randint(1, num_vPMC, move_count)
TestList_STS_Angel_1 = TestList_vPMC_Angel
TestList_STS_Angel_2 = np.random.randint(1, num_STS, move_count)
TestList_STS_Angel_3 = np.random.randint(1, num_STS, move_count)
TestMat_STS_Angle = np.vstack((TestList_STS_Angel_1, TestList_STS_Angel_2, TestList_STS_Angel_3))
np.random.shuffle(TestMat_STS_Angle)
TestList_IPLV_out = []
for i_test in range(move_count):
Test_vPMC_Angel = TestList_vPMC_Angel[i_test]
Test_vPMC_Angel_v = torch.zeros([1, num_vPMC], dtype=torch.float)
Test_vPMC_Angel_v[0, Test_vPMC_Angel - 1] = 20
Test_STS_Angel_v = torch.zeros([1, num_STS], dtype=torch.float)
for t in range(2):
IPL(Test_vPMC_Angel_v, Test_STS_Angel_v)
IPLV_out_f = torch.argmax(IPL.node[1].u) + 1
IPL.reset()
TestList_IPLV_out.append(IPLV_out_f.numpy().item())
confidence = [0, 0, 0]
for i in range(move_count):
theta_predict = TestList_IPLV_out[i]
theta_visual_1 = TestMat_STS_Angle[0][i]
theta_visual_2 = TestMat_STS_Angle[1][i]
theta_visual_3 = TestMat_STS_Angle[2][i]
Test_IPL_v = torch.zeros([1, num_IPLV], dtype=torch.float)
Test_IPL_v[0, theta_predict - 1] = 20
Test_STS1_v = torch.zeros([1, num_STS], dtype=torch.float)
Test_STS1_v[0, theta_visual_1 - 1] = 20
for t in range(2):
Insula(Test_IPL_v, Test_STS1_v)
if sum(sum(Insula.out_Insula)) > 0:
confidence[0] = confidence[0] + 1
Insula.reset()
Test_STS2_v = torch.zeros([1, num_STS], dtype=torch.float)
Test_STS2_v[0, theta_visual_2 - 1] = 20
for t in range(2):
Insula(Test_IPL_v, Test_STS2_v)
if sum(sum(Insula.out_Insula)) > 0:
confidence[1] = confidence[1] + 1
Insula.reset()
Test_STS3_v = torch.zeros([1, num_STS], dtype=torch.float)
Test_STS3_v[0, theta_visual_3 - 1] = 20
for t in range(2):
Insula(Test_IPL_v, Test_STS3_v)
if sum(sum(Insula.out_Insula)) > 0:
confidence[2] = confidence[2] + 1
Insula.reset()
x_0 = torch.arange(0, move_count)
x_1 = torch.arange(move_count * 1, move_count * 2)
x_2 = torch.arange(move_count * 2, move_count * 3)
color_list = ['k', 'k', 'k']
color_list[confidence.index(max(confidence))] = 'r'
plt.subplot(211)
plt.figure(1)
plt.plot(x_0, TestMat_STS_Angle[0], color=color_list[0])
plt.plot(x_1, TestMat_STS_Angle[1], color=color_list[1])
plt.plot(x_2, TestMat_STS_Angle[2], color=color_list[2])
plt.title("Motion Detection")
plt.subplot(212)
plt.plot(x_0, TestList_IPLV_out, color='r')
plt.title("Motion Prediction")
plt.tight_layout()
plt.show()
================================================
FILE: examples/Spiking-Transformers/LIFNode.py
================================================
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
class MyBaseNode(BaseNode):
def __init__(self, threshold=0.5, step=4, layer_by_layer=False, mem_detach=False):
super().__init__(threshold=threshold, step=step, layer_by_layer=layer_by_layer, mem_detach=mem_detach)
def rearrange2node(self, inputs):
if self.groups != 1:
if len(inputs.shape) == 4:
outputs = rearrange(inputs, 'b (c t) w h -> t b c w h', t=self.step)
elif len(inputs.shape) == 2:
outputs = rearrange(inputs, 'b (c t) -> t b c', t=self.step)
else:
raise NotImplementedError
elif self.layer_by_layer:
if len(inputs.shape) == 4:
outputs = rearrange(inputs, '(t b) c w h -> t b c w h', t=self.step)
# 加入适配Transformer T B N C的rearange2node分支
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, '(t b) n c -> t b n c', t=self.step)
elif len(inputs.shape) == 2:
outputs = rearrange(inputs, '(t b) c -> t b c', t=self.step)
else:
raise NotImplementedError
else:
outputs = inputs
return outputs
def rearrange2op(self, inputs):
if self.groups != 1:
if len(inputs.shape) == 5:
outputs = rearrange(inputs, 't b c w h -> b (c t) w h')
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, ' t b c -> b (c t)')
else:
raise NotImplementedError
elif self.layer_by_layer:
if len(inputs.shape) == 5:
outputs = rearrange(inputs, 't b c w h -> (t b) c w h')
# 加入适配Transformer T B N C的rearange2op分支
elif len(inputs.shape) == 4:
outputs = rearrange(inputs, ' t b n c -> (t b) n c')
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, ' t b c -> (t b) c')
else:
raise NotImplementedError
else:
outputs = inputs
return outputs
class MyGrad(SurrogateFunctionBase):
def __init__(self, alpha=4., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return sigmoid.apply(x, alpha)
class MyNode(MyBaseNode):
def __init__(self, threshold=1., step=4, layer_by_layer=True, tau=2., act_fun=MyGrad, mem_detach=True, *args,
**kwargs):
super().__init__(threshold=threshold, step=step, layer_by_layer=layer_by_layer, mem_detach=mem_detach)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=4., requires_grad=False)
def integral(self, inputs):
self.mem = self.mem + (inputs - self.mem) / self.tau
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
self.mem = self.mem * (1 - self.spike.detach())
================================================
FILE: examples/Spiking-Transformers/README.md
================================================
# Spiking Transformers Reproduced With Braincog
Here is the current Spiking Transformer code reproduced using [BrainCog](http://www.brain-cog.network/). Welcome to follow the work of BrainCog and utilize the [BrainCog framework](https://github.com/BrainCog-X/Brain-Cog) to create relevant brain-inspired AI endeavors. The works implemented here will also be merged into BrainCog Repo.
### Models
**Spikformer(ICLR 2023)**
[Zhou, Z., Zhu, Y., He, C., Wang, Y., Yan, S., Tian, Y., & Yuan, L. (2022). Spikformer: When spiking neural network meets transformer. arXiv preprint arXiv:2209.15425.](https://openreview.net/forum?id=frE4fUwz_h)

**Spike-driven Transformer(Nips 2023)**
[Yao, M., Hu, J., Zhou, Z., Yuan, L., Tian, Y., Xu, B., & Li, G. (2024). Spike-driven transformer. Advances in Neural Information Processing Systems, 36.](https://proceedings.neurips.cc/paper_files/paper/2023/hash/ca0f5358dbadda74b3049711887e9ead-Abstract-Conference.html)

**Spike-driven Transformer V2(ICLR 2024)**
[Yao, M., Hu, J., Hu, T., Xu, Y., Zhou, Z., Tian, Y., ... & Li, G. (2023, October). Spike-driven Transformer V2: Meta Spiking Neural Network Architecture Inspiring the Design of Next-generation Neuromorphic Chips. In The Twelfth International Conference on Learning Representations.](https://openreview.net/forum?id=1SIBN5Xyw7)

## Models in comming soon
**SpikingResFormer**
[Shi, X., Hao, Z., & Yu, Z. (2024). SpikingResformer: Bridging ResNet and Vision Transformer in Spiking Neural Networks. arXiv preprint arXiv:2403.14302.](https://arxiv.org/abs/2403.14302)
**TIM**
[Shen, S., Zhao, D., Shen, G., & Zeng, Y. (2024). TIM: An Efficient Temporal Interaction Module for Spiking Transformer. arXiv preprint arXiv:2401.11687.](https://arxiv.org/abs/2401.11687)
**SGLFormer(Frontiers in Neuroscience)**
[Zhang, H., Zhou, C., Yu, L., Huang, L., Ma, Z., Fan, X., ... & Tian, Y. (2024). SGLFormer: Spiking Global-Local-Fusion Transformer with High Performance. Frontiers in Neuroscience, 18, 1371290.](https://www.frontiersin.org/journals/neuroscience/articles/10.3389/fnins.2024.1371290/full)
**QKFormer(CVPR2024)**
[Zhou, C., Zhang, H., Zhou, Z., Yu, L., Huang, L., Fan, X., ... & Tian, Y. (2024). QKFormer: Hierarchical Spiking Transformer using QK Attention. arXiv preprint arXiv:2403.16552.](https://arxiv.org/abs/2403.16552)
## Requirments
- Braincog
- einops >= 0.4.1
- timm >= 0.5.4
## Training Examples
### Training on CIFAR10-DVS
python main.py --dataset dvsc10 --epochs 500 --batch-size 16 --seed 42 --event-size 64 --model spikformer_dvs
### Training on ImageNet
python main.py --dataset imnet --epochs 500 --batch-size 16 --seed 42 --model spikformer
================================================
FILE: examples/Spiking-Transformers/datasets.py
================================================
import os
import warnings
import random
import torchvision.datasets
import braincog.datasets.ucf101_dvs
try:
import tonic
from tonic import DiskCachedDataset
except:
warnings.warn("tonic should be installed, 'pip install git+https://github.com/FloyedShen/tonic.git'")
import torch
import torch.nn.functional as F
import torch.utils
import torchvision.datasets as datasets
from timm.data import ImageDataset, create_loader, Mixup, FastCollateMixup, AugMixDataset
from timm.data import create_transform, distributed_sampler
from timm.data.loader import PrefetchLoader
from tonic import DiskCachedDataset
from torchvision import transforms
from typing import Any, Dict, Optional, Sequence, Tuple, Union
from braincog.datasets.NOmniglot.nomniglot_full import NOmniglotfull
from braincog.datasets.NOmniglot.nomniglot_nw_ks import NOmniglotNWayKShot
from braincog.datasets.NOmniglot.nomniglot_pair import NOmniglotTrainSet, NOmniglotTestSet
# from braincog.base.conversion.conversion import CIFAR10Policy, Cutout
# from .cut_mix import CutMix, EventMix, MixUp
# from .rand_aug import *
# from .event_drop import event_drop
# from .utils import dvs_channel_check_expend, rescale
DVSCIFAR10_MEAN_16 = [0.3290, 0.4507]
DVSCIFAR10_STD_16 = [1.8398, 1.6549]
DATA_DIR = '/data/datasets'
DEFAULT_CROP_PCT = 0.875
IMAGENET_DEFAULT_MEAN = (0.485, 0.456, 0.406)
IMAGENET_DEFAULT_STD = (0.229, 0.224, 0.225)
IMAGENET_INCEPTION_MEAN = (0.5, 0.5, 0.5)
IMAGENET_INCEPTION_STD = (0.5, 0.5, 0.5)
IMAGENET_DPN_MEAN = (124 / 255, 117 / 255, 104 / 255)
IMAGENET_DPN_STD = tuple([1 / (.0167 * 255)] * 3)
CIFAR10_DEFAULT_MEAN = (0.4914, 0.4822, 0.4465)
CIFAR10_DEFAULT_STD = (0.2023, 0.1994, 0.2010)
CIFAR100_DEFAULT_MEAN = (0.5071, 0.4867, 0.4408)
CIFAR100_DEFAULT_STD = (0.2675, 0.2565, 0.2761)
def unpack_mix_param(args):
mix_up = args['mix_up'] if 'mix_up' in args else False
cut_mix = args['cut_mix'] if 'cut_mix' in args else False
event_mix = args['event_mix'] if 'event_mix' in args else False
beta = args['beta'] if 'beta' in args else 1.
prob = args['prob'] if 'prob' in args else .5
num = args['num'] if 'num' in args else 1
num_classes = args['num_classes'] if 'num_classes' in args else 10
noise = args['noise'] if 'noise' in args else 0.
gaussian_n = args['gaussian_n'] if 'gaussian_n' in args else None
return mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n
def build_transform(is_train, img_size):
"""
构建数据增强, 适用于static data
:param is_train: 是否训练集
:param img_size: 输出的图像尺寸
:return: 数据增强策略
"""
resize_im = img_size > 32
if is_train:
# this should always dispatch to transforms_imagenet_train
transform = create_transform(
input_size=img_size,
is_training=True,
color_jitter=0.4,
# auto_augment='rand-m9-mstd0.5-inc1',
interpolation='bicubic',
# re_prob=0.25,
# re_mode='pixel',
# re_count=1,
)
if not resize_im:
# replace RandomResizedCropAndInterpolation with
# RandomCrop
transform.transforms[0] = transforms.RandomCrop(
img_size, padding=4)
return transform
t = []
if resize_im:
size = int((256 / 224) * img_size)
t.append(
# to maintain same ratio w.r.t. 224 images
transforms.Resize(size, interpolation=3),
)
t.append(transforms.CenterCrop(img_size))
t.append(transforms.ToTensor())
if img_size > 32:
t.append(transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD))
else:
t.append(transforms.Normalize(CIFAR10_DEFAULT_MEAN, CIFAR10_DEFAULT_STD))
return transforms.Compose(t)
def build_dataset(is_train, img_size, dataset, path, same_da=False):
"""
构建带有增强策略的数据集
:param is_train: 是否训练集
:param img_size: 输出图像尺寸
:param dataset: 数据集名称
:param path: 数据集路径
:param same_da: 为训练集使用测试集的增广方法
:return: 增强后的数据集
"""
transform = build_transform(False, img_size) if same_da else build_transform(is_train, img_size)
if dataset == 'CIFAR10':
dataset = datasets.CIFAR10(
path, train=is_train, transform=transform, download=True)
nb_classes = 10
elif dataset == 'CIFAR100':
dataset = datasets.CIFAR100(
path, train=is_train, transform=transform, download=True)
nb_classes = 100
else:
raise NotImplementedError
return dataset, nb_classes
class MNISTData(object):
"""
Load MNIST datesets.
"""
def __init__(self,
data_path: str,
batch_size: int,
train_trans: Sequence[torch.nn.Module] = None,
test_trans: Sequence[torch.nn.Module] = None,
pin_memory: bool = True,
drop_last: bool = True,
shuffle: bool = True,
) -> None:
self._data_path = data_path
self._batch_size = batch_size
self._pin_memory = pin_memory
self._drop_last = drop_last
self._shuffle = shuffle
self._train_transform = transforms.Compose(train_trans) if train_trans else None
self._test_transform = transforms.Compose(test_trans) if test_trans else None
def get_data_loaders(self):
print('Batch size: ', self._batch_size)
train_datasets = datasets.MNIST(root=self._data_path, train=True, transform=self._train_transform, download=True)
test_datasets = datasets.MNIST(root=self._data_path, train=False, transform=self._test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=self._drop_last, shuffle=self._shuffle
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=False
)
return train_loader, test_loader
def get_standard_data(self):
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
self._train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
self._test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
return self.get_data_loaders()
def get_mnist_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取MNIST数据
http://data.pymvpa.org/datasets/mnist/
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
if 'skip_norm' in kwargs and kwargs['skip_norm'] is True:
train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
else:
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
# transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
train_datasets = datasets.MNIST(
root=DATA_DIR, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.MNIST(
root=DATA_DIR, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_fashion_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取fashion MNIST数据
http://arxiv.org/abs/1708.07747
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor()])
test_transform = transforms.Compose([transforms.ToTensor()])
train_datasets = datasets.FashionMNIST(
root=DATA_DIR, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.FashionMNIST(
root=DATA_DIR, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_cifar10_data(batch_size, num_workers=8, same_da=False, **kwargs):
# """
# 获取CIFAR10数据
# https://www.cs.toronto.edu/~kriz/cifar.html
# :param batch_size: batch size
# :param kwargs:
# :return: (train loader, test loader, mixup_active, mixup_fn)
# """
# train_datasets, _ = build_dataset(True, 32, 'CIFAR10', DATA_DIR, same_da)
# test_datasets, _ = build_dataset(False, 32, 'CIFAR10', DATA_DIR, same_da)
#
# train_loader = torch.utils.data.DataLoader(
# train_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=True, shuffle=True,
# num_workers=num_workers
# )
#
# test_loader = torch.utils.data.DataLoader(
# test_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=False,
# num_workers=num_workers
# )
normalize = transforms.Normalize(CIFAR10_DEFAULT_MEAN, CIFAR10_DEFAULT_STD)
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(),
CIFAR10Policy(),
transforms.ToTensor(),
Cutout(n_holes=1, length=16),
normalize])
transform_test = transforms.Compose([transforms.ToTensor(), normalize])
train_dataset = datasets.CIFAR10(root=DATA_DIR, train=True, download=True, transform=transform_train)
test_dataset = datasets.CIFAR10(root=DATA_DIR, train=False, download=True, transform=transform_test)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
shuffle=True, num_workers=num_workers,
pin_memory=True
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
shuffle=False, num_workers=num_workers,
pin_memory=True
)
return train_loader, test_loader, None, None
def get_cifar100_data(batch_size, num_workers=8, same_data=False, *args, **kwargs):
# """
# 获取CIFAR100数据
# https://www.cs.toronto.edu/~kriz/cifar.html
# :param batch_size: batch size
# :param kwargs:
# :return: (train loader, test loader, mixup_active, mixup_fn)
# """
# train_datasets, _ = build_dataset(True, 32, 'CIFAR100', DATA_DIR, same_data)
# test_datasets, _ = build_dataset(False, 32, 'CIFAR100', DATA_DIR, same_data)
#
# train_loader = torch.utils.data.DataLoader(
# train_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
# )
#
# test_loader = torch.utils.data.DataLoader(
# test_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=False, num_workers=num_workers
# )
# return train_loader, test_loader, False, None
normalize = transforms.Normalize(CIFAR100_DEFAULT_MEAN, CIFAR100_DEFAULT_STD)
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(),
CIFAR10Policy(),
transforms.ToTensor(),
Cutout(n_holes=1, length=16),
normalize])
transform_test = transforms.Compose([transforms.ToTensor(), normalize])
train_dataset = datasets.CIFAR100(root=DATA_DIR, train=True, download=True, transform=transform_train)
test_dataset = datasets.CIFAR100(root=DATA_DIR, train=False, download=True, transform=transform_test)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
shuffle=True, num_workers=num_workers,
pin_memory=True
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
shuffle=False, num_workers=num_workers,
pin_memory=True
)
return train_loader, test_loader, None, None
def get_imnet_data(args, _logger, data_config, num_aug_splits, **kwargs):
"""
获取ImageNet数据集
http://arxiv.org/abs/1409.0575
:param args: 其他的参数
:param _logger: 日志路径
:param data_config: 增强策略
:param num_aug_splits: 不同增强策略的数量
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_dir = os.path.join(DATA_DIR, 'ILSVRC2012/train')
if not os.path.exists(train_dir):
_logger.error(
'Training folder does not exist at: {}'.format(train_dir))
exit(1)
dataset_train = ImageDataset(train_dir)
# collate_fn = None
# mixup_fn = None
# mixup_active = args.mixup > 0 or args.cutmix > 0. or args.cutmix_minmax is not None
# if mixup_active:
# mixup_args = dict(
# mixup_alpha=args.mixup, cutmix_alpha=args.cutmix, cutmix_minmax=args.cutmix_minmax,
# prob=args.mixup_prob, switch_prob=args.mixup_switch_prob, mode=args.mixup_mode,
# label_smoothing=args.smoothing, num_classes=args.num_classes)
# if args.prefetcher:
# # collate conflict (need to support deinterleaving in collate mixup)
# assert not num_aug_splits
# collate_fn = FastCollateMixup(**mixup_args)
# else:
# mixup_fn = Mixup(**mixup_args)
# if num_aug_splits > 1:
# dataset_train = AugMixDataset(dataset_train, num_splits=num_aug_splits)
train_interpolation = args.train_interpolation
if args.no_aug or not train_interpolation:
train_interpolation = data_config['interpolation']
loader_train = create_loader(
dataset_train,
input_size=data_config['input_size'],
batch_size=args.batch_size,
is_training=True,
use_prefetcher=args.prefetcher,
no_aug=args.no_aug,
# re_prob=args.reprob,
# re_mode=args.remode,
# re_count=args.recount,
# re_split=args.resplit,
scale=args.scale,
ratio=args.ratio,
hflip=args.hflip,
# vflip=args.vflip,
# color_jitter=args.color_jitter,
# auto_augment=args.aa,
# num_aug_splits=num_aug_splits,
interpolation=train_interpolation,
mean=data_config['mean'],
std=data_config['std'],
num_workers=args.workers,
distributed=args.distributed,
# collate_fn=collate_fn,
pin_memory=args.pin_mem,
# use_multi_epochs_loader=args.use_multi_epochs_loader
)
eval_dir = os.path.join(DATA_DIR, 'ILSVRC2012/val')
if not os.path.isdir(eval_dir):
eval_dir = os.path.join(DATA_DIR, 'ILSVRC2012/validation')
if not os.path.isdir(eval_dir):
_logger.error(
'Validation folder does not exist at: {}'.format(eval_dir))
exit(1)
dataset_eval = ImageDataset(eval_dir)
loader_eval = create_loader(
dataset_eval,
input_size=data_config['input_size'],
batch_size=args.validation_batch_size_multiplier * args.batch_size,
is_training=False,
use_prefetcher=args.prefetcher,
interpolation=data_config['interpolation'],
mean=data_config['mean'],
std=data_config['std'],
num_workers=args.workers,
distributed=args.distributed,
crop_pct=data_config['crop_pct'],
pin_memory=args.pin_mem,
)
return loader_train, loader_eval, None, None
def get_dvsg_data(batch_size, step, **kwargs):
"""
获取DVS Gesture数据
DOI: 10.1109/CVPR.2017.781
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.DVSGesture.sensor_size
size = kwargs['size'] if 'size' in kwargs else 48
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
train_dataset = tonic.datasets.DVSGesture(os.path.join(DATA_DIR, 'DVS/DVSGesture'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.DVSGesture(os.path.join(DATA_DIR, 'DVS/DVSGesture'),
transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
transforms.RandomCrop(size, padding=size // 12),
# lambda x: event_drop(x),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVSGesture/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVSGesture/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, mixup_active, None
def get_dvsc10_data(batch_size, step, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = tonic.datasets.CIFAR10DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=train_transform)
test_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
# lambda x: event_drop(x),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_train),
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_test),
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_nmnist_data(batch_size, step, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = tonic.datasets.NMNIST.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/NMNIST'), transform=train_transform)
test_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/NMNIST'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
# lambda x: event_drop(x),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NMNIST/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NMNIST/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_train),
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_test),
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_NCALTECH101_data(batch_size, step, **kwargs):
"""
获取NCaltech101数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = braincog.datasets.ncaltech101.NCALTECH101.sensor_size
cls_count = braincog.datasets.ncaltech101.NCALTECH101.cls_count
dataset_length = braincog.datasets.ncaltech101.NCALTECH101.length
portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += train_sample
train_sample_weight.extend(
[sample_weight] * train_sample
)
train_sample_weight.extend(
[0.] * test_sample
)
train_sample_index.extend(
list((range(idx_begin, idx_begin + train_sample)))
)
test_sample_index.extend(
list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.ncaltech101.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=train_transform)
test_dataset = braincog.datasets.ncaltech101.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: print(x.shape),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: temporal_flatten(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=train_sampler,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_UCF101DVS_data(batch_size, step, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = braincog.datasets.ucf101_dvs.UCF101DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.ucf101_dvs.UCF101DVS(os.path.join(DATA_DIR, 'DVS/UCF101DVS'), train=True, transform=train_transform)
test_dataset = braincog.datasets.ucf101_dvs.UCF101DVS(os.path.join(DATA_DIR, 'DVS/UCF101DVS'), train=False, transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
# transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'UCF101DVS/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'UCF101DVS/test_cache_{}'.format(step)),
transform=test_transform)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size, shuffle=False,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_HMDBDVS_data(batch_size, step, **kwargs):
sensor_size = braincog.datasets.hmdb_dvs.HMDBDVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.hmdb_dvs.HMDBDVS(os.path.join(DATA_DIR, 'HMDBDVS'), transform=train_transform)
test_dataset = braincog.datasets.hmdb_dvs.HMDBDVS(os.path.join(DATA_DIR, 'HMDBDVS'), transform=test_transform)
cls_count = train_dataset.cls_count
dataset_length = train_dataset.length
portion = .5
# portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += train_sample
train_sample_weight.extend(
[sample_weight] * train_sample
)
train_sample_weight.extend(
[0.] * test_sample
)
lst = list(range(idx_begin, idx_begin + train_sample + test_sample))
random.seed(0)
random.shuffle(lst)
train_sample_index.extend(
lst[:train_sample]
# list((range(idx_begin, idx_begin + train_sample)))
)
test_sample_index.extend(
lst[train_sample:train_sample + test_sample]
# list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: print(x.shape),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: temporal_flatten(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'HMDBDVS/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'HMDBDVS/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=train_sampler,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
# def get_NCARS_data(batch_size, step, **kwargs):
# """
# 获取N-Cars数据
# https://ieeexplore.ieee.org/document/8578284/
# :param batch_size: batch size
# :param step: 仿真步长
# :param kwargs:
# :return: (train loader, test loader, mixup_active, mixup_fn)
# """
# sensor_size = tonic.datasets.NCARS.sensor_size
# size = kwargs['size'] if 'size' in kwargs else 48
#
# train_transform = transforms.Compose([
# # tonic.transforms.Denoise(filter_time=10000),
# # tonic.transforms.DropEvent(p=0.1),
# tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
# ])
# test_transform = transforms.Compose([
# # tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
# ])
#
# train_dataset = tonic.datasets.NCARS(os.path.join(DATA_DIR, 'DVS/NCARS'), transform=train_transform, train=True)
# test_dataset = tonic.datasets.NCARS(os.path.join(DATA_DIR, 'DVS/NCARS'), transform=test_transform, train=False)
#
# train_transform = transforms.Compose([
# lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: dvs_channel_check_expend(x),
# transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
# ])
# test_transform = transforms.Compose([
# lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: dvs_channel_check_expend(x),
# ])
# if 'rand_aug' in kwargs.keys():
# if kwargs['rand_aug'] is True:
# n = kwargs['randaug_n']
# m = kwargs['randaug_m']
# train_transform.transforms.insert(2, RandAugment(m=m, n=n))
#
# # if 'temporal_flatten' in kwargs.keys():
# # if kwargs['temporal_flatten'] is True:
# # train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# # test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
#
# train_dataset = DiskCachedDataset(train_dataset,
# cache_path=os.path.join(DATA_DIR, 'DVS/NCARS/train_cache_{}'.format(step)),
# transform=train_transform, num_copies=3)
# test_dataset = DiskCachedDataset(test_dataset,
# cache_path=os.path.join(DATA_DIR, 'DVS/NCARS/test_cache_{}'.format(step)),
# transform=test_transform, num_copies=3)
#
# mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
# mixup_active = cut_mix | event_mix | mix_up
#
# if cut_mix:
# train_dataset = CutMix(train_dataset,
# beta=beta,
# prob=prob,
# num_mix=num,
# num_class=num_classes,
# noise=noise)
#
# if event_mix:
# train_dataset = EventMix(train_dataset,
# beta=beta,
# prob=prob,
# num_mix=num,
# num_class=num_classes,
# noise=noise,
# gaussian_n=gaussian_n)
# if mix_up:
# train_dataset = MixUp(train_dataset,
# beta=beta,
# prob=prob,
# num_mix=num,
# num_class=num_classes,
# noise=noise)
#
# train_loader = torch.utils.data.DataLoader(
# train_dataset, batch_size=batch_size,
# pin_memory=True, drop_last=True, num_workers=8,
# shuffle=True,
# )
#
# test_loader = torch.utils.data.DataLoader(
# test_dataset, batch_size=batch_size,
# pin_memory=True, drop_last=False, num_workers=2,
# shuffle=False,
# )
#
# return train_loader, test_loader, mixup_active, None
def get_nomni_data(batch_size, train_portion=1., **kwargs):
"""
获取N-Omniglot数据
:param batch_size:batch的大小
:param data_mode:一共full nkks pair三种模式
:param frames_num:一个样本帧的个数
:param data_type:event frequency两种模式
"""
data_mode = kwargs["data_mode"] if "data_mode" in kwargs else "full"
frames_num = kwargs["frames_num"] if "frames_num" in kwargs else 10
data_type = kwargs["data_type"] if "data_type" in kwargs else "event"
train_transform = transforms.Compose([
transforms.Resize((64, 64))])
test_transform = transforms.Compose([
transforms.Resize((64, 64))])
if data_mode == "full":
train_datasets = NOmniglotfull(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), train=True, frames_num=frames_num,
data_type=data_type,
transform=train_transform)
test_datasets = NOmniglotfull(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), train=False, frames_num=frames_num,
data_type=data_type,
transform=test_transform)
elif data_mode == "nkks":
train_datasets = NOmniglotNWayKShot(os.path.join(DATA_DIR, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=True,
frames_num=frames_num,
data_type=data_type,
transform=train_transform)
test_datasets = NOmniglotNWayKShot(os.path.join(DATA_DIR, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=False,
frames_num=frames_num,
data_type=data_type,
transform=test_transform)
elif data_mode == "pair":
train_datasets = NOmniglotTrainSet(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), use_frame=True,
frames_num=frames_num, data_type=data_type,
use_npz=False, resize=105)
test_datasets = NOmniglotTestSet(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), time=2000, way=kwargs["n_way"],
shot=kwargs["k_shot"], use_frame=True,
frames_num=frames_num, data_type=data_type, use_npz=False, resize=105)
else:
pass
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size, num_workers=12,
pin_memory=True, drop_last=True, shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size, num_workers=12,
pin_memory=True, drop_last=False
)
return train_loader, test_loader, None, None
================================================
FILE: examples/Spiking-Transformers/main.py
================================================
import argparse
import time
import timm.models
import yaml
import os
import random as buildin_random
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
# from braincog.datasets.datasets import *
from datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.vgg_snn import VGG_SNN, SNN5
# from braincog.model_zoo.fc_snn import SHD_SNN
from braincog.model_zoo.resnet19_snn import resnet19
#from braincog.model_zoo.sew_resnet import sew_resnet18, sew_resnet34, sew_resnet50
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix, plot_mem_distribution
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model, register_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from torch.utils.tensorboard import SummaryWriter
# load spiking transformer models
from models.spikformer import spikformer
from models.spikformer_dvs import spikformer_dvs
from models.spike_driven_transformer import sd_transformer
from models.spike_driven_transformer_dvs import sd_transformer_dvs
from models.spike_driven_transformer_v2 import sd_transformer_v2
from models.spike_driven_transformer_v2_dvs import sd_transformer_v2_dvs
# choose ur device here
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--dataset', default='dvsc10', type=str)
parser.add_argument('--model', default='spikformer', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=1e-4,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=400, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochss to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=0.,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=0.,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--output', default='/home/shensicheng/code/SpikingTransformers', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--tensorboard-dir', default='./runs', type=str)
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=0)
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
parser.add_argument('--conv-type', type=str, default='normal')
parser.add_argument('--sew-cnf', type=str, default='ADD')
parser.add_argument('--rand-step', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='QGateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
parser.add_argument('--n-encode-type', type=str, default='linear')
parser.add_argument('--n-preact', action='store_true')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--tet-loss', action='store_true')
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=2.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--gaussian-n', type=int, default=3)
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
parser.add_argument('--mem-dist', action='store_true')
parser.add_argument('--adaptation-info', action='store_true')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def main():
args, args_text = _parse_args()
# args.no_spike_output = args.no_spike_output | args.cut_mix
args.no_spike_output = True
output_dir = ''
if args.local_rank == 0:
output_base = args.output if args.output else './output'
exp_name = '-'.join([
args.model,
args.dataset,
args.node_type,
str(args.step),
args.suffix,
datetime.now().strftime("%Y%m%d-%H%M%S"),
# str(args.img_size)
])
output_dir = get_outdir(output_base, 'train', exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
summary_writer = SummaryWriter(log_dir=os.path.join(args.tensorboard_dir, exp_name))
args.tensorboard_prefix = os.path.join(args.dataset, args.model)
else:
summary_writer = None
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
model = create_model(
args.model,
# pretrained=args.pretrained,
# num_classes=args.num_classes,
# dataset=args.dataset,
# step=args.step,
# encode_type=args.encode,
# node_type=eval(args.node_type),
# threshold=args.threshold,
# tau=args.tau,
# sigmoid_thres=args.sigmoid_thres,
# requires_thres_grad=args.requires_thres_grad,
# spike_output=not args.no_spike_output,
# act_fun=args.act_fun,
# temporal_flatten=args.temporal_flatten,
# layer_by_layer=args.layer_by_layer,
# n_groups=args.n_groups,
# n_encode_type=args.n_encode_type,
# n_preact=args.n_preact,
# tet_loss=args.tet_loss,
# sew_cnf=args.sew_cnf,
# conv_type=args.conv_type,
)
_logger.info('[MODEL ARCH]\n{}'.format(model))
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=list(range(args.num_gpu))).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
_logger.info('[OPTIMIZER]\n{}'.format(optimizer))
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
# print(model.get_attr('mu'))
# print(model.get_attr('sigma'))
if hasattr(model, 'set_threshold'):
model.set_threshold(args.threshold)
if args.critical_loss or args.spike_rate:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model.cuda(), device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
)
# _logger.info('train_loader:\n{}\nval_loader:\n{}'.format(loader_train, loader_eval))
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
elif args.loss_fn == 'onehot-mse':
train_loss_fn = OnehotMse(args.num_classes)
validate_loss_fn = OnehotMse(args.num_classes)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
if args.tet_loss:
train_loss_fn = TetLoss(train_loss_fn)
validate_loss_fn = TetLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
# if args.distributed:
# raise NotImplementedError('eval not has not been verified for distributed')
# else:
# load_checkpoint(model, args.eval_checkpoint, args.model_ema)
model.eval()
for t in range(1, args.step * 3):
# for t in range(args.step, args.step + 1):
model.set_attr('step', t)
val_metrics = validate(start_epoch, model, loader_eval, validate_loss_fn, args,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer)
print(f"[STEP:{t}], Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=output_dir, recovery_dir=output_dir, decreasing=decreasing, max_history=3)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
if args.distributed:
loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler,
model_ema=model_ema, mixup_fn=mixup_fn, summary_writer=summary_writer
)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics = validate(epoch, model, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer)
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics = validate(
epoch, model_ema.ema, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast, log_suffix=' (EMA)',
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer
)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(output_dir, 'summary.csv'),
write_header=best_metric is None)
# if saver is not None and epoch >= args.n_warm_up:
if saver is not None:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
except KeyboardInterrupt:
pass
if best_metric is not None:
_logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None, summary_writer=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and loader.mixup_enabled:
loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
# closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
# t, k = adjust_surrogate_coeff(100, args.epochs)
# model.set_attr('t', t)
# model.set_attr('k', k)
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
iters_per_epoch = len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
if args.rand_step:
step = buildin_random.randint(1, args.step + 2)
model.set_attr('step', step)
data_time_m.update(time.time() - end)
if not args.prefetcher or args.dataset != 'imnet':
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
if mixup_fn is not None:
inputs, target = mixup_fn(inputs, target)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
with amp_autocast():
output = model(inputs)
loss = loss_fn(output, target)
if args.tet_loss:
output = output.mean(0)
if not (args.cut_mix | args.mix_up | args.event_mix | (args.cutmix != 0.) | (args.mixup != 0.)):
# print(output.shape, target.shape)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
# if args.opt == 'lamb':
# optimizer.step(epoch=epoch)
# else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/top1'), acc1.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/top5'), acc5.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/loss'), loss.item(), epoch * iters_per_epoch + batch_idx)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
if args.distributed:
loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
# closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
# if args.distributed:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/top1'), top1_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/top5'), top5_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/loss'), losses_m.avg, epoch)
if args.rand_step:
model.set_attr('step', args.step)
return OrderedDict([('loss', losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args, amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False, summary_writer=None):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
# closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
spike_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
mem_vec = []
end = time.time()
last_idx = len(loader) - 1
iters_per_epoch = len(loader)
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat or args.mem_dist) and not args.critical_loss:
model.set_requires_fp(True)
with amp_autocast():
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
# print(args.rank, output.shape, target.shape, max(target))
loss = loss_fn(output, target)
if args.tet_loss:
output = output.mean(0)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
# closses_m.update(closs, inputs.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/top1'), acc1.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/top5'), acc5.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/loss'), loss.item(), epoch * iters_per_epoch + batch_idx)
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
if not args.distributed and spike_rate:
spike_m.update(model.get_tot_spike() / output.size(0), output.size(0))
if not args.distributed and spike_rate:
_logger.info(
'[Spike Info]: {spike.val} ({spike.avg})'.format(
spike=spike_m
)
)
if last_batch or batch_idx % args.log_interval == 0:
_logger.info(
'Eval : {} '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
epoch,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
top1=top1_m,
top5=top5_m,
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg)])
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/top1'), top1_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/top5'), top5_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/loss'), losses_m.avg, epoch)
return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/Spiking-Transformers/models/spike_driven_transformer.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from LIFNode import MyNode # LIFNode setting for Spiking Tranformers
from functools import partial
__all__ = ['spikformer']
'''The input shape of neuromorphic datasets in Spiking Transformer when using Braincog
are used to set to 64*64 '''
class MLP(BaseModule):
#Linear here is subsituted by convs
def __init__(self, in_features, step=10, encode_type='direct', hidden_features=None, out_features=None, drop=0.):
super().__init__(step=10, encode_type='direct')
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_conv = nn.Conv1d(in_features, hidden_features, kernel_size=1, stride=1)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step, tau=2.0)
self.fc2_conv = nn.Conv1d(hidden_features, out_features, kernel_size=1, stride=1)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step, tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T, B, C, N = x.shape
x = self.fc1_lif(x.flatten(0, 1)).reshape(T, B, C, N).contiguous()
x = self.fc1_conv(x.flatten(0, 1))
x = self.fc1_bn(x).reshape(T, B, self.c_hidden, N).contiguous() # T B C N
x = self.fc2_lif(x.flatten(0, 1)).reshape(T, B, self.c_hidden, N).contiguous()
x = self.fc2_conv(x.flatten(0, 1))
x = self.fc2_bn(x).reshape(T, B, C, N).contiguous()
return x
class SSA(BaseModule):
def __init__(self, dim, step=10, encode_type='direct', num_heads=16, qkv_bias=False, qk_scale=None, attn_drop=0.,
proj_drop=0., sr_ratio=1):
super().__init__(step=10, encode_type='direct')
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
# for shortcut
self.head_lif = MyNode(step=step, tau=2.0)
self.num_heads = num_heads
# scale
self.scale = 0.25
self.q_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.q_bn = nn.BatchNorm1d(dim)
self.q_lif = MyNode(step=step, tau=2.0)
self.k_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.k_bn = nn.BatchNorm1d(dim)
self.k_lif = MyNode(step=step, tau=2.0)
self.v_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.v_bn = nn.BatchNorm1d(dim)
self.v_lif = MyNode(step=step, tau=2.0)
self.attn_drop = nn.Dropout(0.2)
self.res_lif = MyNode(step=step, tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5, )
self.proj_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.proj_bn = nn.BatchNorm1d(dim)
self.proj_lif = MyNode(step=step, tau=2.0, )
self.sd_lif = PLIFNode(step=step, threshold=0.5, tau=2)
def forward(self, x):
self.reset()
T, B, C, N = x.shape
x_for_qkv = x.flatten(0, 1) # TB, C N
x_for_qkv = self.head_lif(x_for_qkv)
q_conv_out = self.q_conv(x_for_qkv) # [TB] C N
q_conv_out = self.q_bn(q_conv_out).reshape(T, B, C, N).contiguous() # T B C N
q_conv_out = self.q_lif(q_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
q = q_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_conv_out = self.k_conv(x_for_qkv)
k_conv_out = self.k_bn(k_conv_out).reshape(T, B, C, N).contiguous()
k_conv_out = self.k_lif(k_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
k = k_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_conv_out = self.v_conv(x_for_qkv)
v_conv_out = self.v_bn(v_conv_out).reshape(T, B, C, N).contiguous()
v_conv_out = self.v_lif(v_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
v = v_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
# Spike-driven Transformer attention
kv = k.mul(v)
kv = kv.sum(dim=-2, keepdim=True)
kv = self.sd_lif(kv)
x = q.mul(kv)
x = x.transpose(3,4).reshape(T, B, C, N).contiguous() # T B C N
# ignore following lines for membrane shortcut
# x = self.attn_lif(x.flatten(0,1)) #[TB] C N
# x = self.proj_lif(self.proj_bn(self.proj_conv(x))).reshape(T, B, C, N) #T B C N
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, step=10, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = SSA(dim, step=step, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(step=step, in_features=dim, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
# residual connection
x = x + self.attn(x)
x = x + self.mlp(x)
return x
# embed_dims = 256
class SPS(BaseModule):
def __init__(self, step=10, encode_type='direct', img_size_h=128, img_size_w=128, patch_size=4, in_channels=2,
embed_dims=256):
super().__init__(step=10, encode_type='direct')
self.image_size = [img_size_h, img_size_w]
patch_size = to_2tuple(patch_size) # 4->(4,4)
self.patch_size = patch_size # patch_size
self.C = in_channels # image_channel
self.H, self.W = self.image_size[0] // patch_size[0], self.image_size[1] // patch_size[1]
self.num_patches = self.H * self.W
# DVS with 2 more Maxpooling
self.proj_conv = nn.Conv2d(in_channels, embed_dims // 8, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn = nn.BatchNorm2d(embed_dims // 8)
self.proj_lif = MyNode(step=step, tau=2.0)
self.maxpool = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv1 = nn.Conv2d(embed_dims // 8, embed_dims // 4, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn1 = nn.BatchNorm2d(embed_dims // 4)
self.proj_lif1 = MyNode(step=step, tau=2.0)
self.maxpool1 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv2 = nn.Conv2d(embed_dims // 4, embed_dims // 2, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn2 = nn.BatchNorm2d(embed_dims // 2)
self.proj_lif2 = MyNode(step=step, tau=2.0)
self.maxpool2 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv3 = nn.Conv2d(embed_dims // 2, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn3 = nn.BatchNorm2d(embed_dims)
# self.proj_lif3 = MyNode(step=step, tau=2.0)
self.maxpool3 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.rpe_conv = nn.Conv2d(embed_dims, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.rpe_bn = nn.BatchNorm2d(embed_dims)
self.rpe_lif = MyNode(step=step, tau=2.0)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.proj_conv(x.flatten(0, 1)) # have some fire value
x = self.proj_bn(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif(x.flatten(0, 1)).contiguous()
x = self.maxpool(x)
x = self.proj_conv1(x)
x = self.proj_bn1(x).reshape(T, B, -1, H // 2, W // 2).contiguous()
x = self.proj_lif1(x.flatten(0, 1)).contiguous()
x = self.maxpool1(x)
x = self.proj_conv2(x)
x = self.proj_bn2(x).reshape(T, B, -1, H // 4, W // 4).contiguous()
x = self.proj_lif2(x.flatten(0, 1)).contiguous()
x = self.maxpool2(x)
x = self.proj_conv3(x)
x = self.proj_bn3(x).reshape(T, B, -1, H // 8, W // 8)
# abandon the LIF here to leverage membrane shortcut
# x = self.proj_lif3(x.flatten(0, 1)).contiguous()
x = self.maxpool3(x.flatten(0,1)).reshape(T, B, -1, H // 16, W // 16)
# The order here is different from spikformer for using membrain shortcut
x_rpe = self.rpe_lif(x.flatten(0, 1)).contiguous()
x_rpe = self.rpe_bn(self.rpe_conv(x_rpe)).reshape(T, B, -1, H // 16, W // 16).contiguous()
x = x + x_rpe # membrane shortcut
x = x.reshape(T, B, -1, (H // 16) * (H // 16)).contiguous()
return x # T B C N
class Spikformer(BaseModule):
def __init__(self, step=10, encode_type='direct',
img_size_h=224, img_size_w=224, patch_size=16, in_channels=3, num_classes=1000,
embed_dims=512, num_heads=12, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=8, sr_ratios=4,
):
super().__init__(step=10, encode_type='direct')
self.step = step # time step
self.num_classes = num_classes
self.depths = depths
# for membrane shortcut
self.final_lif = MyNode(step=step,tau=2.0)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
patch_embed = SPS(step=step,
img_size_h=img_size_h,
img_size_w=img_size_w,
patch_size=patch_size,
in_channels=in_channels,
embed_dims=embed_dims)
block = nn.ModuleList([Block(step=step,
dim=embed_dims, num_heads=num_heads, mlp_ratio=mlp_ratios, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[j],
norm_layer=norm_layer, sr_ratio=sr_ratios)
for j in range(depths)])
setattr(self, f"patch_embed", patch_embed)
setattr(self, f"block", block)
# classification head
self.head = nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
block = getattr(self, f"block")
patch_embed = getattr(self, f"patch_embed")
x = patch_embed(x)
for blk in block:
x = blk(x)
# for membrane shortcut
T, B , C, N = x.shape
x = self.final_lif(x.flatten(0,1)).reshape(T, B, C, N).contiguous()
return x.mean(3)
def forward(self, x):
self.reset()
x = self.encoder(x)
x = self.forward_features(x)
x = self.head(x.mean(0))
return x
# Adjust ur hyperparams here
@register_model
def sd_transformer(pretrained=False, **kwargs):
model = Spikformer(step = 4,
img_size_h=224, img_size_w=224,
patch_size=16, embed_dims=512, num_heads=16, mlp_ratios=4,
in_channels=3, num_classes=1000, qkv_bias=False,
depths=8, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/Spiking-Transformers/models/spike_driven_transformer_dvs.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from LIFNode import MyNode # LIFNode setting for Spiking Tranformers
from functools import partial
__all__ = ['spikformer']
'''The input shape of neuromorphic datasets in Spiking Transformer when using Braincog
are used to set to 64*64 '''
class MLP(BaseModule):
#Linear here is subsituted by convs
def __init__(self, in_features, step=10, encode_type='direct', hidden_features=None, out_features=None, drop=0.):
super().__init__(step=10, encode_type='direct')
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_conv = nn.Conv1d(in_features, hidden_features, kernel_size=1, stride=1)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step, tau=2.0)
self.fc2_conv = nn.Conv1d(hidden_features, out_features, kernel_size=1, stride=1)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step, tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T, B, C, N = x.shape
x = self.fc1_lif(x.flatten(0, 1)).reshape(T, B, C, N).contiguous()
x = self.fc1_conv(x.flatten(0, 1))
x = self.fc1_bn(x).reshape(T, B, self.c_hidden, N).contiguous() # T B C N
x = self.fc2_lif(x.flatten(0, 1)).reshape(T, B, self.c_hidden, N).contiguous()
x = self.fc2_conv(x.flatten(0, 1))
x = self.fc2_bn(x).reshape(T, B, C, N).contiguous()
return x
class SSA(BaseModule):
def __init__(self, dim, step=10, encode_type='direct', num_heads=16, qkv_bias=False, qk_scale=None, attn_drop=0.,
proj_drop=0., sr_ratio=1):
super().__init__(step=10, encode_type='direct')
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
# for shortcut
self.head_lif = MyNode(step=step, tau=2.0)
self.num_heads = num_heads
# scale
self.scale = 0.25
self.q_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.q_bn = nn.BatchNorm1d(dim)
self.q_lif = MyNode(step=step, tau=2.0)
self.k_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.k_bn = nn.BatchNorm1d(dim)
self.k_lif = MyNode(step=step, tau=2.0)
self.v_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.v_bn = nn.BatchNorm1d(dim)
self.v_lif = MyNode(step=step, tau=2.0)
self.attn_drop = nn.Dropout(0.2)
self.res_lif = MyNode(step=step, tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5, )
self.proj_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.proj_bn = nn.BatchNorm1d(dim)
self.proj_lif = MyNode(step=step, tau=2.0, )
self.sd_lif = PLIFNode(step=step, threshold=0.5, tau=2)
def forward(self, x):
self.reset()
T, B, C, N = x.shape
x_for_qkv = x.flatten(0, 1) # TB, C N
x_for_qkv = self.head_lif(x_for_qkv)
q_conv_out = self.q_conv(x_for_qkv) # [TB] C N
q_conv_out = self.q_bn(q_conv_out).reshape(T, B, C, N).contiguous() # T B C N
q_conv_out = self.q_lif(q_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
q = q_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_conv_out = self.k_conv(x_for_qkv)
k_conv_out = self.k_bn(k_conv_out).reshape(T, B, C, N).contiguous()
k_conv_out = self.k_lif(k_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
k = k_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_conv_out = self.v_conv(x_for_qkv)
v_conv_out = self.v_bn(v_conv_out).reshape(T, B, C, N).contiguous()
v_conv_out = self.v_lif(v_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
v = v_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
# Spike-driven Transformer attention
kv = k.mul(v)
kv = kv.sum(dim=-2, keepdim=True)
kv = self.sd_lif(kv)
x = q.mul(kv)
x = x.transpose(3,4).reshape(T, B, C, N).contiguous() # T B C N
# ignore following lines for membrane shortcut
# x = self.attn_lif(x.flatten(0,1)) #[TB] C N
# x = self.proj_lif(self.proj_bn(self.proj_conv(x))).reshape(T, B, C, N) #T B C N
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, step=10, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = SSA(dim, step=step, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(step=step, in_features=dim, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
# residual connection
x = x + self.attn(x)
x = x + self.mlp(x)
return x
# embed_dims = 256
class SPS(BaseModule):
def __init__(self, step=10, encode_type='direct', img_size_h=128, img_size_w=128, patch_size=4, in_channels=2,
embed_dims=256):
super().__init__(step=10, encode_type='direct')
self.image_size = [img_size_h, img_size_w]
patch_size = to_2tuple(patch_size) # 4->(4,4)
self.patch_size = patch_size # patch_size
self.C = in_channels # image_channel
self.H, self.W = self.image_size[0] // patch_size[0], self.image_size[1] // patch_size[1]
self.num_patches = self.H * self.W
# DVS with 2 more Maxpooling
self.proj_conv = nn.Conv2d(in_channels, embed_dims // 8, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn = nn.BatchNorm2d(embed_dims // 8)
self.proj_lif = MyNode(step=step, tau=2.0)
self.maxpool = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv1 = nn.Conv2d(embed_dims // 8, embed_dims // 4, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn1 = nn.BatchNorm2d(embed_dims // 4)
self.proj_lif1 = MyNode(step=step, tau=2.0)
self.maxpool1 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv2 = nn.Conv2d(embed_dims // 4, embed_dims // 2, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn2 = nn.BatchNorm2d(embed_dims // 2)
self.proj_lif2 = MyNode(step=step, tau=2.0)
self.maxpool2 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv3 = nn.Conv2d(embed_dims // 2, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn3 = nn.BatchNorm2d(embed_dims)
# self.proj_lif3 = MyNode(step=step, tau=2.0)
self.maxpool3 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.rpe_conv = nn.Conv2d(embed_dims, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.rpe_bn = nn.BatchNorm2d(embed_dims)
self.rpe_lif = MyNode(step=step, tau=2.0)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.proj_conv(x.flatten(0, 1)) # have some fire value
x = self.proj_bn(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif(x.flatten(0, 1)).contiguous()
x = self.maxpool(x)
x = self.proj_conv1(x)
x = self.proj_bn1(x).reshape(T, B, -1, H // 2, W // 2).contiguous()
x = self.proj_lif1(x.flatten(0, 1)).contiguous()
x = self.maxpool1(x)
x = self.proj_conv2(x)
x = self.proj_bn2(x).reshape(T, B, -1, H // 4, W // 4).contiguous()
x = self.proj_lif2(x.flatten(0, 1)).contiguous()
x = self.maxpool2(x)
x = self.proj_conv3(x)
x = self.proj_bn3(x).reshape(T, B, -1, H // 8, W // 8)
# abandon the LIF here to leverage membrane shortcut
# x = self.proj_lif3(x.flatten(0, 1)).contiguous()
x = self.maxpool3(x.flatten(0,1)).reshape(T, B, -1, H // 16, W // 16)
# The order here is different from spikformer for using membrain shortcut
x_rpe = self.rpe_lif(x.flatten(0, 1)).contiguous()
x_rpe = self.rpe_bn(self.rpe_conv(x_rpe)).reshape(T, B, -1, H // 16, W // 16).contiguous()
x = x + x_rpe # membrane shortcut
x = x.reshape(T, B, -1, (H // 16) * (H // 16)).contiguous()
return x # T B C N
class Spikformer(BaseModule):
def __init__(self, step=10, encode_type='direct',
img_size_h=64, img_size_w=64, patch_size=4, in_channels=2, num_classes=10,
embed_dims=256, num_heads=16, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=2, sr_ratios=4,
):
super().__init__(step=10, encode_type='direct')
self.step = step # time step
self.num_classes = num_classes
self.depths = depths
# for membrane shortcut
self.final_lif = MyNode(step=step,tau=2.0)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
patch_embed = SPS(step=step,
img_size_h=img_size_h,
img_size_w=img_size_w,
patch_size=patch_size,
in_channels=in_channels,
embed_dims=embed_dims)
block = nn.ModuleList([Block(step=step,
dim=embed_dims, num_heads=num_heads, mlp_ratio=mlp_ratios, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[j],
norm_layer=norm_layer, sr_ratio=sr_ratios)
for j in range(depths)])
setattr(self, f"patch_embed", patch_embed)
setattr(self, f"block", block)
# classification head
self.head = nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
block = getattr(self, f"block")
patch_embed = getattr(self, f"patch_embed")
x = patch_embed(x)
for blk in block:
x = blk(x)
# for membrane shortcut
T, B , C, N = x.shape
x = self.final_lif(x.flatten(0,1)).reshape(T, B, C, N).contiguous()
return x.mean(3)
def forward(self, x):
self.reset()
x = x.permute(1, 0, 2, 3, 4) # [T, N, 2, *, *]
x = self.forward_features(x)
x = self.head(x.mean(0))
return x
# Adjust ur hyperparams here
@register_model
def sd_transformer_dvs(pretrained=False, **kwargs):
model = Spikformer(step = 8,
img_size_h=64, img_size_w=64,
patch_size=4, embed_dims=256, num_heads=16, mlp_ratios=4,
in_channels=2, num_classes=10, qkv_bias=False,
depths=2, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/Spiking-Transformers/models/spike_driven_transformer_v2.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from LIFNode import MyNode # LIFNode setting for Spiking Tranformers
from functools import partial
__all__ = ['spikformer']
'''The input shape of neuromorphic datasets in Spiking Transformer when using Braincog
are used to set to 64*64 '''
'''Here the second version of Spike-driven Transformer only open sourced the
code for img cla '''
# Modified Operators
class BNAndPadLayer(nn.Module):
def __init__(
self,
pad_pixels,
num_features,
eps=1e-5,
momentum=0.1,
affine=True,
track_running_stats=True,
):
super(BNAndPadLayer, self).__init__()
self.bn = nn.BatchNorm2d(
num_features, eps, momentum, affine, track_running_stats
)
self.pad_pixels = pad_pixels
def forward(self, input):
output = self.bn(input)
if self.pad_pixels > 0:
if self.bn.affine:
pad_values = (
self.bn.bias.detach()
- self.bn.running_mean
* self.bn.weight.detach()
/ torch.sqrt(self.bn.running_var + self.bn.eps)
)
else:
pad_values = -self.bn.running_mean / torch.sqrt(
self.bn.running_var + self.bn.eps
)
output = F.pad(output, [self.pad_pixels] * 4)
pad_values = pad_values.view(1, -1, 1, 1)
output[:, :, 0 : self.pad_pixels, :] = pad_values
output[:, :, -self.pad_pixels :, :] = pad_values
output[:, :, :, 0 : self.pad_pixels] = pad_values
output[:, :, :, -self.pad_pixels :] = pad_values
return output
@property
def weight(self):
return self.bn.weight
@property
def bias(self):
return self.bn.bias
@property
def running_mean(self):
return self.bn.running_mean
@property
def running_var(self):
return self.bn.running_var
@property
def eps(self):
return self.bn.eps
class RepConv(nn.Module):
def __init__(
self,
in_channels,
out_channels,
bias=False,
):
super().__init__()
# hidden_channel = in_channel
conv1x1 = nn.Conv2d(in_channels, in_channels, 1, 1, 0, bias=False, groups=1)
bn = BNAndPadLayer(pad_pixels=1, num_features=in_channels)
conv3x3 = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 3, 1, 0, groups=in_channels, bias=False),
nn.Conv2d(in_channels, out_channels, 1, 1, 0, groups=1, bias=False),
nn.BatchNorm2d(out_channels),
)
self.body = nn.Sequential(conv1x1, bn, conv3x3)
def forward(self, x):
return self.body(x)
class SepConv(BaseModule):
r"""
Inverted separable convolution from MobileNetV2: https://arxiv.org/abs/1801.04381.
"""
def __init__(
self,
dim,
step=8,
encode_type='direct',
expansion_ratio=2,
act2_layer=nn.Identity,
bias=False,
kernel_size=7,
padding=3,
):
super().__init__(step=step,encode_type=encode_type,)
med_channels = int(expansion_ratio * dim)
self.lif1 = MyNode(step=step,tau=2.0)
self.pwconv1 = nn.Conv2d(dim, med_channels, kernel_size=1, stride=1, bias=bias)
self.bn1 = nn.BatchNorm2d(med_channels)
self.lif2 =MyNode(step=step,tau=2.0)
self.dwconv = nn.Conv2d(
med_channels,
med_channels,
kernel_size=kernel_size,
padding=padding,
groups=med_channels,
bias=bias,
) # depthwise conv
self.pwconv2 = nn.Conv2d(med_channels, dim, kernel_size=1, stride=1, bias=bias)
self.bn2 = nn.BatchNorm2d(dim)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.lif1(x.flatten(0,1)).reshape(T,B,C,H,W).contiguous()
x = self.bn1(self.pwconv1(x.flatten(0, 1))).reshape(T, B, -1, H, W)
x = self.lif2(x.flatten(0,1)).reshape(T,B,-1,H,W).contiguous()
x = self.dwconv(x.flatten(0, 1))
x = self.bn2(self.pwconv2(x)).reshape(T, B, -1, H, W)
return x # T B C H W
class MLP(BaseModule):
#Linear here is subsituted by convs
def __init__(self, in_features, step=10, encode_type='direct', hidden_features=None, out_features=None, drop=0.):
super().__init__(step=10, encode_type='direct')
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_conv = nn.Conv1d(in_features, hidden_features, kernel_size=1, stride=1)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step, tau=2.0)
self.fc2_conv = nn.Conv1d(hidden_features, out_features, kernel_size=1, stride=1)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step, tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = x.flatten(3) # T B C N
_, _, _, N = x.shape
x = self.fc1_lif(x.flatten(0, 1)).reshape(T, B, C, N).contiguous()
x = self.fc1_conv(x.flatten(0, 1))
x = self.fc1_bn(x).reshape(T, B, self.c_hidden, N).contiguous() # T B C N
x = self.fc2_lif(x.flatten(0, 1)).reshape(T, B, self.c_hidden, N).contiguous()
x = self.fc2_conv(x.flatten(0, 1))
x = self.fc2_bn(x).reshape(T, B, C, H, W).contiguous()
return x # T B C H W
# convs in SDSA V3/V4 should be substituted
class SDSA(BaseModule):
def __init__(self, dim, step=10, encode_type='direct', num_heads=16, qkv_bias=False, qk_scale=None, attn_drop=0.,
proj_drop=0., sr_ratio=1):
super().__init__(step=10, encode_type='direct')
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
# scale
self.scale = 0.125
self.head_lif = MyNode(step=step, tau=2.0) # for spike-drivens
self.q_conv = RepConv(dim, dim, bias=False)
self.q_bn = nn.BatchNorm2d(dim)
self.q_lif = MyNode(step=step, tau=2.0)
self.k_conv = RepConv(dim, dim, bias=False)
self.k_bn = nn.BatchNorm2d(dim)
self.k_lif = MyNode(step=step, tau=2.0)
self.v_conv = RepConv(dim, dim, bias=False)
self.v_bn = nn.BatchNorm2d(dim)
self.v_lif = MyNode(step=step, tau=2.0)
self.attn_drop = nn.Dropout(0.2)
self.res_lif = MyNode(step=step, tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5, )
self.proj_conv = RepConv(dim, dim, bias=False)
self.proj_bn = nn.BatchNorm2d(dim)
def forward(self, x):
self.reset()
#different here
T, B, C, H, W = x.shape
N = H * W
x = self.head_lif(x.flatten(0,1)).reshape(T, B, C, H, W).contiguous()
x_for_qkv = x.flatten(0, 1) # TB C H W
q_conv_out = self.q_conv(x_for_qkv) # [TB] C H W
q_conv_out = self.q_bn(q_conv_out).reshape(T, B, C, H, W).contiguous() # T B C H W
q_conv_out = self.q_lif(q_conv_out.flatten(0, 1)).reshape(T, B, C, N).transpose(-1,-2) # T B N C
q = q_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_conv_out = self.k_conv(x_for_qkv)
k_conv_out = self.k_bn(k_conv_out).reshape(T, B, C, H, W).contiguous()
k_conv_out = self.k_lif(k_conv_out.flatten(0, 1)).reshape(T, B, C, N).transpose(-1,-2) # T B N C
k = k_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_conv_out = self.v_conv(x_for_qkv)
v_conv_out = self.v_bn(v_conv_out).reshape(T, B, C, H, W).contiguous()
v_conv_out = self.v_lif(v_conv_out.flatten(0, 1)).reshape(T, B, C, N).transpose(-1,-2) # T B N C
v = v_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
x = k.transpose(-2, -1) @ v
x = (q @ x) * self.scale
x = x.transpose(3, 4).reshape(T, B, C, N).contiguous()
x = self.attn_lif(x).reshape(T, B, C, H, W)
x = x.reshape(T, B, C, H, W)
x = x.flatten(0, 1)
x = self.proj_conv(x)
x = self.proj_bn(x).reshape(T, B, C, H, W)
return x # T B C H W
class Block(nn.Module):
def __init__(self, dim, num_heads, step=10, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = SDSA(dim, step=step, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(step=step, in_features=dim, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
# residual connection
x = x + self.attn(x)
x = x + self.mlp(x)
return x
class DownSampling(BaseModule):
def __init__(
self,
step=10,
encode_type='direct',
in_channels=2,
embed_dims=512,
kernel_size=3,
stride=2,
padding=1,
first_layer=True,
):
super().__init__(step=step,
encode_type=encode_type,)
self.encode_conv = nn.Conv2d(
in_channels,
embed_dims,
kernel_size=kernel_size,
stride=stride,
padding=padding,
)
self.encode_bn = nn.BatchNorm2d(embed_dims)
if not first_layer:
self.encode_lif = MyNode(
tau=2.0,step=step
)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
if hasattr(self, "encode_lif"):
x = self.encode_lif(x.flatten(0,1)).reshape(T,B,C,H,W).contiguous()
x = self.encode_conv(x.flatten(0, 1))
_, _, H, W = x.shape
x = self.encode_bn(x).reshape(T, B, -1, H, W).contiguous()
return x
class ConvBlock(BaseModule):
def __init__(
self,
dim,
step=10,
encode_type='direct',
mlp_ratio=4.0,
):
super().__init__(step=step,
encode_type=encode_type,)
self.Conv = SepConv(step=step,dim=dim)
# self.Conv = MHMC(dim=dim)
self.lif1 = MyNode(step=step,tau=2.0)
self.conv1 = nn.Conv2d(
dim, dim * mlp_ratio, kernel_size=3, padding=1, groups=1, bias=False
)
# self.conv1 = RepConv(dim, dim*mlp_ratio)
self.bn1 = nn.BatchNorm2d(dim * mlp_ratio)
self.lif2 = MyNode(step=step,tau=2.0)
self.conv2 = nn.Conv2d(
dim * mlp_ratio, dim, kernel_size=3, padding=1, groups=1, bias=False
)
# self.conv2 = RepConv(dim*mlp_ratio, dim)
self.bn2 = nn.BatchNorm2d(dim)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.Conv(x) + x
x_feat = x
x = self.bn1(self.conv1(self.lif1(x.flatten(0,1)))).reshape(T, B, 4 * C, H, W)
x = self.bn2(self.conv2(self.lif2(x.flatten(0, 1)))).reshape(T, B, C, H, W)
x = x_feat + x
return x
class Spikformer(BaseModule):
def __init__(self, step=4, encode_type='direct',
img_size_h=64, img_size_w=64, patch_size=4, in_channels=2, num_classes=1000,
embed_dims=512, num_heads=16, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=8, sr_ratios=4,kd=False,
):
super().__init__(step=10, encode_type='direct')
self.step = step # time step
self.num_classes = num_classes
self.depths = depths
self.block3_depths = 6
# for membrane shortcut
self.final_lif = MyNode(step=step,tau=2.0)
# channel for dvs
# 16 32 64 128 256
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
self.downsample1_1 = DownSampling(
step=step,
in_channels=in_channels,
embed_dims=embed_dims // 16,
kernel_size=7,
stride=2,
padding=3,
first_layer=True,
)
self.ConvBlock1_1 = nn.ModuleList(
[ConvBlock(step=step,dim= embed_dims // 16, mlp_ratio=mlp_ratios)]
)
self.downsample1_2 = DownSampling(
step=step,
in_channels = embed_dims // 16,
embed_dims= embed_dims // 8,
kernel_size=3,
stride=2,
padding=1,
first_layer=False,
)
self.ConvBlock1_2 = nn.ModuleList(
[ConvBlock(step=step,dim=embed_dims // 8, mlp_ratio=mlp_ratios)]
)
self.downsample2 = DownSampling(
step=step,
in_channels=embed_dims // 8,
embed_dims=embed_dims // 4,
kernel_size=3,
stride=2,
padding=1,
first_layer=False,
)
self.ConvBlock2_1 = nn.ModuleList(
[ConvBlock(step=step,dim=embed_dims // 4, mlp_ratio=mlp_ratios)]
)
self.ConvBlock2_2 = nn.ModuleList(
[ConvBlock(step=step,dim=embed_dims // 4, mlp_ratio=mlp_ratios)]
)
self.downsample3 = DownSampling(
step=step,
in_channels=embed_dims // 4,
embed_dims=embed_dims // 2,
kernel_size=3,
stride=2,
padding=1,
first_layer=False,
)
self.block3 = nn.ModuleList(
[
Block(
step=step,
dim=embed_dims // 2,
num_heads=num_heads,
mlp_ratio=mlp_ratios,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
# drop_path=dpr[j],
norm_layer=norm_layer,
sr_ratio=sr_ratios,
)
for j in range(self.block3_depths)
]
)
self.downsample4 = DownSampling(
step=step,
in_channels=embed_dims // 2,
embed_dims=embed_dims,
kernel_size=3,
stride=1,
padding=1,
first_layer=False,
)
self.block4 = nn.ModuleList(
[
Block(
step=step,
dim=embed_dims,
num_heads=num_heads,
mlp_ratio=mlp_ratios,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[j],
norm_layer=norm_layer,
sr_ratio=sr_ratios,
)
for j in range(self.depths-self.block3_depths)
]
)
# classification head
self.lif = MyNode(step=step,tau=2.0,)
self.head = (
nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
)
self.kd = kd
if self.kd:
self.head_kd = (
nn.Linear(embed_dims, num_classes)
if num_classes > 0
else nn.Identity()
)
self.apply(self._init_weights)
# setattr(self, f"patch_embed", patch_embed)
# setattr(self, f"block", block)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
x = self.downsample1_1(x)
for blk in self.ConvBlock1_1:
x = blk(x)
x = self.downsample1_2(x)
for blk in self.ConvBlock1_2:
x = blk(x)
x = self.downsample2(x)
for blk in self.ConvBlock2_1:
x = blk(x)
for blk in self.ConvBlock2_2:
x = blk(x)
x = self.downsample3(x)
for blk in self.block3: # attention here
x = blk(x)
x = self.downsample4(x) # attention here
for blk in self.block4:
x = blk(x)
return x # T,B,C,H,W
def forward(self, x):
self.reset()
x = self.encoder(x) # [T, N, 2, *, *]
x = self.forward_features(x)
x = x.flatten(3).mean(3)
T,B,_ = x.shape
x_lif = self.lif(x.flatten(0,1)).reshape(T,B,-1)
x = self.head(x_lif).mean(0)
if self.kd:
x_kd = self.head_kd(x_lif).mean(0)
if self.training:
return x, x_kd
else:
return (x + x_kd) / 2
return x
# Adjust ur hyperparams here
@register_model
def sd_transformer_v2(pretrained=False, **kwargs):
model = Spikformer(step = 4,
img_size_h=224, img_size_w=224,
patch_size=16, embed_dims=512, num_heads=12, mlp_ratios=4,
in_channels=3, num_classes=1000, qkv_bias=False,
depths=2, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/Spiking-Transformers/models/spike_driven_transformer_v2_dvs.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from LIFNode import MyNode # LIFNode setting for Spiking Tranformers
from functools import partial
__all__ = ['spikformer']
'''The input shape of neuromorphic datasets in Spiking Transformer when using Braincog
are used to set to 64*64 '''
'''Here the second version of Spike-driven Transformer only open sourced the
code for img cla '''
# Modified Operators
class BNAndPadLayer(nn.Module):
def __init__(
self,
pad_pixels,
num_features,
eps=1e-5,
momentum=0.1,
affine=True,
track_running_stats=True,
):
super(BNAndPadLayer, self).__init__()
self.bn = nn.BatchNorm2d(
num_features, eps, momentum, affine, track_running_stats
)
self.pad_pixels = pad_pixels
def forward(self, input):
output = self.bn(input)
if self.pad_pixels > 0:
if self.bn.affine:
pad_values = (
self.bn.bias.detach()
- self.bn.running_mean
* self.bn.weight.detach()
/ torch.sqrt(self.bn.running_var + self.bn.eps)
)
else:
pad_values = -self.bn.running_mean / torch.sqrt(
self.bn.running_var + self.bn.eps
)
output = F.pad(output, [self.pad_pixels] * 4)
pad_values = pad_values.view(1, -1, 1, 1)
output[:, :, 0 : self.pad_pixels, :] = pad_values
output[:, :, -self.pad_pixels :, :] = pad_values
output[:, :, :, 0 : self.pad_pixels] = pad_values
output[:, :, :, -self.pad_pixels :] = pad_values
return output
@property
def weight(self):
return self.bn.weight
@property
def bias(self):
return self.bn.bias
@property
def running_mean(self):
return self.bn.running_mean
@property
def running_var(self):
return self.bn.running_var
@property
def eps(self):
return self.bn.eps
class RepConv(nn.Module):
def __init__(
self,
in_channels,
out_channels,
bias=False,
):
super().__init__()
# hidden_channel = in_channel
conv1x1 = nn.Conv2d(in_channels, in_channels, 1, 1, 0, bias=False, groups=1)
bn = BNAndPadLayer(pad_pixels=1, num_features=in_channels)
conv3x3 = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 3, 1, 0, groups=in_channels, bias=False),
nn.Conv2d(in_channels, out_channels, 1, 1, 0, groups=1, bias=False),
nn.BatchNorm2d(out_channels),
)
self.body = nn.Sequential(conv1x1, bn, conv3x3)
def forward(self, x):
return self.body(x)
class SepConv(BaseModule):
r"""
Inverted separable convolution from MobileNetV2: https://arxiv.org/abs/1801.04381.
"""
def __init__(
self,
dim,
step=8,
encode_type='direct',
expansion_ratio=2,
act2_layer=nn.Identity,
bias=False,
kernel_size=7,
padding=3,
):
super().__init__(step=step,encode_type=encode_type,)
med_channels = int(expansion_ratio * dim)
self.lif1 = MyNode(step=step,tau=2.0)
self.pwconv1 = nn.Conv2d(dim, med_channels, kernel_size=1, stride=1, bias=bias)
self.bn1 = nn.BatchNorm2d(med_channels)
self.lif2 =MyNode(step=step,tau=2.0)
self.dwconv = nn.Conv2d(
med_channels,
med_channels,
kernel_size=kernel_size,
padding=padding,
groups=med_channels,
bias=bias,
) # depthwise conv
self.pwconv2 = nn.Conv2d(med_channels, dim, kernel_size=1, stride=1, bias=bias)
self.bn2 = nn.BatchNorm2d(dim)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.lif1(x.flatten(0,1)).reshape(T,B,C,H,W).contiguous()
x = self.bn1(self.pwconv1(x.flatten(0, 1))).reshape(T, B, -1, H, W)
x = self.lif2(x.flatten(0,1)).reshape(T,B,-1,H,W).contiguous()
x = self.dwconv(x.flatten(0, 1))
x = self.bn2(self.pwconv2(x)).reshape(T, B, -1, H, W)
return x # T B C H W
class MLP(BaseModule):
#Linear here is subsituted by convs
def __init__(self, in_features, step=10, encode_type='direct', hidden_features=None, out_features=None, drop=0.):
super().__init__(step=10, encode_type='direct')
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_conv = nn.Conv1d(in_features, hidden_features, kernel_size=1, stride=1)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step, tau=2.0)
self.fc2_conv = nn.Conv1d(hidden_features, out_features, kernel_size=1, stride=1)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step, tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = x.flatten(3) # T B C N
_, _, _, N = x.shape
x = self.fc1_lif(x.flatten(0, 1)).reshape(T, B, C, N).contiguous()
x = self.fc1_conv(x.flatten(0, 1))
x = self.fc1_bn(x).reshape(T, B, self.c_hidden, N).contiguous() # T B C N
x = self.fc2_lif(x.flatten(0, 1)).reshape(T, B, self.c_hidden, N).contiguous()
x = self.fc2_conv(x.flatten(0, 1))
x = self.fc2_bn(x).reshape(T, B, C, H, W).contiguous()
return x # T B C H W
# convs in SDSA V3/V4 should be substituted
class SDSA(BaseModule):
def __init__(self, dim, step=10, encode_type='direct', num_heads=16, qkv_bias=False, qk_scale=None, attn_drop=0.,
proj_drop=0., sr_ratio=1):
super().__init__(step=10, encode_type='direct')
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
# scale
self.scale = 0.125
self.head_lif = MyNode(step=step, tau=2.0) # for spike-drivens
self.q_conv = RepConv(dim, dim, bias=False)
self.q_bn = nn.BatchNorm2d(dim)
self.q_lif = MyNode(step=step, tau=2.0)
self.k_conv = RepConv(dim, dim, bias=False)
self.k_bn = nn.BatchNorm2d(dim)
self.k_lif = MyNode(step=step, tau=2.0)
self.v_conv = RepConv(dim, dim, bias=False)
self.v_bn = nn.BatchNorm2d(dim)
self.v_lif = MyNode(step=step, tau=2.0)
self.attn_drop = nn.Dropout(0.2)
self.res_lif = MyNode(step=step, tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5, )
self.proj_conv = RepConv(dim, dim, bias=False)
self.proj_bn = nn.BatchNorm2d(dim)
def forward(self, x):
self.reset()
#different here
T, B, C, H, W = x.shape
N = H * W
x = self.head_lif(x.flatten(0,1)).reshape(T, B, C, H, W).contiguous()
x_for_qkv = x.flatten(0, 1) # TB C H W
q_conv_out = self.q_conv(x_for_qkv) # [TB] C H W
q_conv_out = self.q_bn(q_conv_out).reshape(T, B, C, H, W).contiguous() # T B C H W
q_conv_out = self.q_lif(q_conv_out.flatten(0, 1)).reshape(T, B, C, N).transpose(-1,-2) # T B N C
q = q_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_conv_out = self.k_conv(x_for_qkv)
k_conv_out = self.k_bn(k_conv_out).reshape(T, B, C, H, W).contiguous()
k_conv_out = self.k_lif(k_conv_out.flatten(0, 1)).reshape(T, B, C, N).transpose(-1,-2) # T B N C
k = k_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_conv_out = self.v_conv(x_for_qkv)
v_conv_out = self.v_bn(v_conv_out).reshape(T, B, C, H, W).contiguous()
v_conv_out = self.v_lif(v_conv_out.flatten(0, 1)).reshape(T, B, C, N).transpose(-1,-2) # T B N C
v = v_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
x = k.transpose(-2, -1) @ v
x = (q @ x) * self.scale
x = x.transpose(3, 4).reshape(T, B, C, N).contiguous()
x = self.attn_lif(x).reshape(T, B, C, H, W)
x = x.reshape(T, B, C, H, W)
x = x.flatten(0, 1)
x = self.proj_conv(x)
x = self.proj_bn(x).reshape(T, B, C, H, W)
return x # T B C H W
class Block(nn.Module):
def __init__(self, dim, num_heads, step=10, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = SDSA(dim, step=step, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(step=step, in_features=dim, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
# residual connection
x = x + self.attn(x)
x = x + self.mlp(x)
return x
class DownSampling(BaseModule):
def __init__(
self,
step=10,
encode_type='direct',
in_channels=2,
embed_dims=256,
kernel_size=3,
stride=2,
padding=1,
first_layer=True,
):
super().__init__(step=step,
encode_type=encode_type,)
self.encode_conv = nn.Conv2d(
in_channels,
embed_dims,
kernel_size=kernel_size,
stride=stride,
padding=padding,
)
self.encode_bn = nn.BatchNorm2d(embed_dims)
if not first_layer:
self.encode_lif = MyNode(
tau=2.0,step=step
)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
if hasattr(self, "encode_lif"):
x = self.encode_lif(x.flatten(0,1)).reshape(T,B,C,H,W).contiguous()
x = self.encode_conv(x.flatten(0, 1))
_, _, H, W = x.shape
x = self.encode_bn(x).reshape(T, B, -1, H, W).contiguous()
return x
class ConvBlock(BaseModule):
def __init__(
self,
dim,
step=10,
encode_type='direct',
mlp_ratio=4.0,
):
super().__init__(step=step,
encode_type=encode_type,)
self.Conv = SepConv(step=step,dim=dim)
# self.Conv = MHMC(dim=dim)
self.lif1 = MyNode(step=step,tau=2.0)
self.conv1 = nn.Conv2d(
dim, dim * mlp_ratio, kernel_size=3, padding=1, groups=1, bias=False
)
# self.conv1 = RepConv(dim, dim*mlp_ratio)
self.bn1 = nn.BatchNorm2d(dim * mlp_ratio)
self.lif2 = MyNode(step=step,tau=2.0)
self.conv2 = nn.Conv2d(
dim * mlp_ratio, dim, kernel_size=3, padding=1, groups=1, bias=False
)
# self.conv2 = RepConv(dim*mlp_ratio, dim)
self.bn2 = nn.BatchNorm2d(dim)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.Conv(x) + x
x_feat = x
x = self.bn1(self.conv1(self.lif1(x.flatten(0,1)))).reshape(T, B, 4 * C, H, W)
x = self.bn2(self.conv2(self.lif2(x.flatten(0, 1)))).reshape(T, B, C, H, W)
x = x_feat + x
return x
class Spikformer(BaseModule):
def __init__(self, step=10, encode_type='direct',
img_size_h=64, img_size_w=64, patch_size=4, in_channels=2, num_classes=10,
embed_dims=256, num_heads=16, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=2, sr_ratios=4,kd=False,
):
super().__init__(step=10, encode_type='direct')
self.step = step # time step
self.num_classes = num_classes
self.depths = depths
self.block3_depths = 1
# for membrane shortcut
self.final_lif = MyNode(step=step,tau=2.0)
# channel for dvs
# 16 32 64 128 256
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
self.downsample1_1 = DownSampling(
step=step,
in_channels=in_channels,
embed_dims=embed_dims // 16,
kernel_size=7,
stride=2,
padding=3,
first_layer=True,
)
self.ConvBlock1_1 = nn.ModuleList(
[ConvBlock(step=step,dim= embed_dims // 16, mlp_ratio=mlp_ratios)]
)
self.downsample1_2 = DownSampling(
step=step,
in_channels = embed_dims // 16,
embed_dims= embed_dims // 8,
kernel_size=3,
stride=2,
padding=1,
first_layer=False,
)
self.ConvBlock1_2 = nn.ModuleList(
[ConvBlock(step=step,dim=embed_dims // 8, mlp_ratio=mlp_ratios)]
)
self.downsample2 = DownSampling(
step=step,
in_channels=embed_dims // 8,
embed_dims=embed_dims // 4,
kernel_size=3,
stride=2,
padding=1,
first_layer=False,
)
self.ConvBlock2_1 = nn.ModuleList(
[ConvBlock(step=step,dim=embed_dims // 4, mlp_ratio=mlp_ratios)]
)
self.ConvBlock2_2 = nn.ModuleList(
[ConvBlock(step=step,dim=embed_dims // 4, mlp_ratio=mlp_ratios)]
)
self.downsample3 = DownSampling(
step=step,
in_channels=embed_dims // 4,
embed_dims=embed_dims // 2,
kernel_size=3,
stride=2,
padding=1,
first_layer=False,
)
self.block3 = nn.ModuleList(
[
Block(
step=step,
dim=embed_dims // 2,
num_heads=num_heads,
mlp_ratio=mlp_ratios,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
# drop_path=dpr[j],
norm_layer=norm_layer,
sr_ratio=sr_ratios,
)
for j in range(self.block3_depths)
]
)
self.downsample4 = DownSampling(
step=step,
in_channels=embed_dims // 2,
embed_dims=embed_dims,
kernel_size=3,
stride=1,
padding=1,
first_layer=False,
)
self.block4 = nn.ModuleList(
[
Block(
step=step,
dim=embed_dims,
num_heads=num_heads,
mlp_ratio=mlp_ratios,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[j],
norm_layer=norm_layer,
sr_ratio=sr_ratios,
)
for j in range(self.depths-self.block3_depths)
]
)
# classification head
self.lif = MyNode(step=step,tau=2.0,)
self.head = (
nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
)
self.kd = kd
if self.kd:
self.head_kd = (
nn.Linear(embed_dims, num_classes)
if num_classes > 0
else nn.Identity()
)
self.apply(self._init_weights)
# setattr(self, f"patch_embed", patch_embed)
# setattr(self, f"block", block)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
x = self.downsample1_1(x)
for blk in self.ConvBlock1_1:
x = blk(x)
x = self.downsample1_2(x)
for blk in self.ConvBlock1_2:
x = blk(x)
x = self.downsample2(x)
for blk in self.ConvBlock2_1:
x = blk(x)
for blk in self.ConvBlock2_2:
x = blk(x)
x = self.downsample3(x)
for blk in self.block3: # attention here
x = blk(x)
x = self.downsample4(x) # attention here
for blk in self.block4:
x = blk(x)
return x # T,B,C,H,W
def forward(self, x):
self.reset()
x = x.permute(1, 0, 2, 3, 4) # [T, N, 2, *, *]
x = self.forward_features(x)
x = x.flatten(3).mean(3)
T,B,_ = x.shape
x_lif = self.lif(x.flatten(0,1)).reshape(T,B,-1)
x = self.head(x_lif).mean(0)
if self.kd:
x_kd = self.head_kd(x_lif).mean(0)
if self.training:
return x, x_kd
else:
return (x + x_kd) / 2
return x
# Adjust ur hyperparams here
@register_model
def sd_transformer_v2_dvs(pretrained=False, **kwargs):
model = Spikformer(step = 8,
img_size_h=64, img_size_w=64,
patch_size=4, embed_dims=256, num_heads=16, mlp_ratios=4,
in_channels=2, num_classes=10, qkv_bias=False,
depths=2, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/Spiking-Transformers/models/spikformer.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from LIFNode import MyNode # LIFNode setting for Spiking Tranformers
from functools import partial
__all__ = ['spikformer']
class MLP(BaseModule):
# Linear -> BN -> LIF -> Linear -> BN -> LIF
def __init__(self, in_features, step=4, encode_type='direct', hidden_features=None, out_features=None, drop=0.):
super().__init__(step=step, encode_type=encode_type)
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_linear = nn.Linear(in_features, hidden_features)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step,tau=2.0)
self.fc2_linear = nn.Linear(hidden_features, out_features)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step,tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T, B, N, C = x.shape
x_ = x.flatten(0, 1) # TB N C
x = self.fc1_linear(x_)
x = self.fc1_bn(x.transpose(-1, -2)).transpose(-1, -2).reshape(T, B, N, self.c_hidden).contiguous() # T B N C
x = self.fc1_lif(x.flatten(0, 1)).reshape(T, B, N, self.c_hidden)
x = self.fc2_linear(x.flatten(0, 1))
x = self.fc2_bn(x.transpose(-1, -2)).transpose(-1, -2).reshape(T, B, N, C).contiguous()
x = self.fc2_lif(x.flatten(0, 1)).reshape(T, B, N, self.c_output)
return x
class SSA(BaseModule):
def __init__(self, dim, step=4, encode_type='rate', num_heads=12, qkv_bias=False, qk_scale=None, attn_drop=0.,
proj_drop=0., sr_ratio=1):
super().__init__(step=step, encode_type=encode_type)
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
# 多头注意力 # of heads
self.num_heads = num_heads
# scale参数,用于防止KQ乘积结果过大
self.scale = 0.125
self.q_linear = nn.Linear(dim, dim)
self.q_bn = nn.BatchNorm1d(dim)
self.q_lif = MyNode(step=step,tau=2.0)
self.k_linear = nn.Linear(dim, dim)
self.k_bn = nn.BatchNorm1d(dim)
self.k_lif = MyNode(step=step,tau=2.0)
self.v_linear = nn.Linear(dim, dim)
self.v_bn = nn.BatchNorm1d(dim)
self.v_lif = MyNode(step=step,tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5, )
self.proj_linear = nn.Linear(dim, dim)
self.proj_bn = nn.BatchNorm1d(dim)
self.proj_lif = MyNode(step=step, tau=2.0, )
def forward(self, x):
self.reset()
T, B, N, C = x.shape
x_for_qkv = x.flatten(0, 1) # TB, N, C
q_linear_out = self.q_linear(x_for_qkv) # [TB, N, C]
q_linear_out = self.q_bn(q_linear_out.transpose(-1, -2)).transpose(-1, -2).reshape(T, B, N,
C).contiguous() # T B N C
q_linear_out = self.q_lif(q_linear_out.flatten(0, 1)).reshape(T, B, N, C) # TB N C
q = q_linear_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_linear_out = self.k_linear(x_for_qkv)
k_linear_out = self.k_bn(k_linear_out.transpose(-1, -2)).transpose(-1, -2).reshape(T, B, N, C).contiguous()
k_linear_out = self.k_lif(k_linear_out.flatten(0, 1)).reshape(T, B, N, C) # TB N C
k = k_linear_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_linear_out = self.v_linear(x_for_qkv)
v_linear_out = self.v_bn(v_linear_out.transpose(-1, -2)).transpose(-1, -2).reshape(T, B, N, C).contiguous()
v_linear_out = self.v_lif(v_linear_out.flatten(0, 1)).reshape(T, B, N, C) # TB N C
v = v_linear_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
# @表示矩阵乘法,与matmul等价
# K,QV -> attention -> scale -> LIF -> Linear -> BN
attn = (q @ k.transpose(-2, -1)) * self.scale
x = attn @ v
x = x.transpose(2, 3).reshape(T, B, N, C).contiguous()
x = self.attn_lif(x.flatten(0, 1)).reshape(T, B, N, C) # T B N C
x = x.flatten(0, 1) # TB N C
x = self.proj_lif(self.proj_bn(self.proj_linear(x).transpose(-1, -2)).transpose(-1, -2)).reshape(T, B, N, C)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, step =4, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.step = 4
self.norm1 = norm_layer(dim)
self.attn = SSA(dim, step=self.step, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(step=self.step, in_features=dim, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
# residual
x = x + self.attn(x)
x = x + self.mlp(x)
return x
# SPS for dimension adjustment
# embed_dims = 256
class SPS(BaseModule):
def __init__(self, step=4, encode_type='direct', img_size_h=32, img_size_w=32, patch_size=4, in_channels=3,
embed_dims=384):
super().__init__(step=step, encode_type=encode_type)
self.image_size = [img_size_h, img_size_w]
# timm内置to_2tuple把整形转换成2元元组
patch_size = to_2tuple(patch_size) # 4->(4,4)
self.patch_size = patch_size # patch_size
self.C = in_channels # image_channel
self.H, self.W = self.image_size[0] // patch_size[0], self.image_size[1] // patch_size[1] # 重新计算patch之后的图片大小
self.num_patches = self.H * self.W # patch数量
self.proj_conv = nn.Conv2d(in_channels, embed_dims // 8, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn = nn.BatchNorm2d(embed_dims // 8)
self.proj_lif = MyNode(step=step,tau=2.0)
self.proj_conv1 = nn.Conv2d(embed_dims // 8, embed_dims // 4, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn1 = nn.BatchNorm2d(embed_dims // 4)
self.proj_lif1 = MyNode(step=step,tau=2.0)
self.proj_conv2 = nn.Conv2d(embed_dims // 4, embed_dims // 2, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn2 = nn.BatchNorm2d(embed_dims // 2)
self.proj_lif2 = MyNode(step=step,tau=2.0)
self.maxpool2 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv3 = nn.Conv2d(embed_dims // 2, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn3 = nn.BatchNorm2d(embed_dims)
self.proj_lif3 = MyNode(step=step,tau=2.0)
self.maxpool3 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.rpe_conv = nn.Conv2d(embed_dims, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.rpe_bn = nn.BatchNorm2d(embed_dims)
self.rpe_lif = MyNode(step=step,tau=2.0)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.proj_conv(x.flatten(0, 1)) # have some fire value
x = self.proj_bn(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif(x.flatten(0, 1)).contiguous()
x = self.proj_conv1(x)
x = self.proj_bn1(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif1(x.flatten(0, 1)).contiguous()
x = self.proj_conv2(x)
x = self.proj_bn2(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif2(x.flatten(0, 1)).contiguous()
x = self.maxpool2(x)
x = self.proj_conv3(x)
x = self.proj_bn3(x).reshape(T, B, -1, H // 2, W // 2).contiguous()
x = self.proj_lif3(x.flatten(0, 1)).contiguous()
x = self.maxpool3(x)
x_feat = x.reshape(T, B, -1, H // 4, W // 4).contiguous()
x = self.rpe_conv(x)
x = self.rpe_bn(x).reshape(T, B, -1, H // 4, W // 4).contiguous()
x = self.rpe_lif(x.flatten(0, 1)).reshape(T, B, -1, H // 4, W // 4)
x = x + x_feat
x = x.flatten(-2).transpose(-1, -2) # T,B,N,C
return x
class Spikformer(BaseModule):
def __init__(self, step=4, encode_type='direct',
img_size_h=224, img_size_w=224, patch_size=16, in_channels=3, num_classes=1000,
embed_dims=384, num_heads=12, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=4, sr_ratios=4,
):
super().__init__(step=step, encode_type=encode_type)
self.step = step # time step
self.num_classes = num_classes
self.depths = depths
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
patch_embed = SPS(step = self.step,
img_size_h=img_size_h,
img_size_w=img_size_w,
patch_size=patch_size,
in_channels=in_channels,
embed_dims=embed_dims)
block = nn.ModuleList([Block(step=self.step,
dim=embed_dims, num_heads=num_heads, mlp_ratio=mlp_ratios, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[j],
norm_layer=norm_layer, sr_ratio=sr_ratios)
for j in range(depths)])
setattr(self, f"patch_embed", patch_embed)
setattr(self, f"block", block)
# classification head
self.head = nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
block = getattr(self, f"block")
patch_embed = getattr(self, f"patch_embed")
x = patch_embed(x)
for blk in block:
x = blk(x)
return x.mean(2)
def forward(self, x):
x = self.encoder(x)
x = self.forward_features(x)
x = self.head(x.mean(0))
return x
@register_model
def spikformer(pretrained=False, **kwargs):
model = Spikformer(
step=4,
img_size_h=224, img_size_w=224,
patch_size=16, embed_dims=512, num_heads=8, mlp_ratios=4,
in_channels=3, num_classes=1000, qkv_bias=False,
depths=8, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/Spiking-Transformers/models/spikformer_dvs.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from LIFNode import MyNode # LIFNode setting for Spiking Tranformers
from functools import partial
__all__ = ['spikformer']
'''The input shape of neuromorphic datasets in Spiking Transformer when using Braincog
are used to set to 64*64 '''
class MLP(BaseModule):
#Linear here is subsituted by convs
def __init__(self, in_features, step=10, encode_type='direct', hidden_features=None, out_features=None, drop=0.):
super().__init__(step=step, encode_type=encode_type)
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_conv = nn.Conv1d(in_features, hidden_features, kernel_size=1, stride=1)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step, tau=2.0)
self.fc2_conv = nn.Conv1d(hidden_features, out_features, kernel_size=1, stride=1)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step, tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T, B, C, N = x.shape
x = self.fc1_conv(x.flatten(0, 1))
x = self.fc1_bn(x).reshape(T, B, self.c_hidden, N).contiguous() # T B C N
x = self.fc1_lif(x.flatten(0, 1)).reshape(T, B, self.c_hidden, N).contiguous()
x = self.fc2_conv(x.flatten(0, 1))
x = self.fc2_bn(x).reshape(T, B, C, N).contiguous()
x = self.fc2_lif(x.flatten(0, 1)).reshape(T, B, C, N).contiguous()
return x
class SSA(BaseModule):
def __init__(self, dim, step=10, encode_type='direct', num_heads=16, qkv_bias=False, qk_scale=None, attn_drop=0.,
proj_drop=0., sr_ratio=1):
super().__init__(step=step, encode_type=encode_type)
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
# scale
self.scale = 0.25
self.q_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.q_bn = nn.BatchNorm1d(dim)
self.q_lif = MyNode(step=step, tau=2.0)
self.k_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.k_bn = nn.BatchNorm1d(dim)
self.k_lif = MyNode(step=step, tau=2.0)
self.v_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.v_bn = nn.BatchNorm1d(dim)
self.v_lif = MyNode(step=step, tau=2.0)
self.attn_drop = nn.Dropout(0.2)
self.res_lif = MyNode(step=step, tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5, )
self.proj_conv = nn.Conv1d(dim, dim, kernel_size=1, stride=1, bias=False)
self.proj_bn = nn.BatchNorm1d(dim)
self.proj_lif = MyNode(step=step, tau=2.0, )
def forward(self, x):
self.reset()
T, B, C, N = x.shape
x_for_qkv = x.flatten(0, 1) # TB, C N
q_conv_out = self.q_conv(x_for_qkv) # [TB] C N
q_conv_out = self.q_bn(q_conv_out).reshape(T, B, C, N).contiguous() # T B C N
q_conv_out = self.q_lif(q_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
q = q_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_conv_out = self.k_conv(x_for_qkv)
k_conv_out = self.k_bn(k_conv_out).reshape(T, B, C, N).contiguous()
k_conv_out = self.k_lif(k_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
k = k_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_conv_out = self.v_conv(x_for_qkv)
v_conv_out = self.v_bn(v_conv_out).reshape(T, B, C, N).contiguous()
v_conv_out = self.v_lif(v_conv_out.flatten(0, 1)).reshape(T, B, C, N) # TB C N
v = v_conv_out.reshape(T, B, N, self.num_heads, C // self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
# @表示矩阵乘法,与matmul等价
# K,QV -> attention -> scale -> LIF -> Linear -> BN
attn = (q @ k.transpose(-2, -1))
x = (attn @ v) * self.scale
x = x.transpose(3, 4).reshape(T, B, C, N).contiguous() # T B C N
x = self.attn_lif(x.flatten(0, 1)) # [TB] C N
x = self.proj_lif(self.proj_bn(self.proj_conv(x))).reshape(T, B, C, N) # T B C N
return x
# 整个encoder block,要在SSA和MLP的基础上加入残差
class Block(nn.Module):
def __init__(self, dim, num_heads, step=10, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = SSA(dim, step=step, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(step=step, in_features=dim, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
# residual connection
x = x + self.attn(x)
x = x + self.mlp(x)
return x
# embed_dims = 256
class SPS(BaseModule):
def __init__(self, step=10, encode_type='direct', img_size_h=128, img_size_w=128, patch_size=4, in_channels=2,
embed_dims=256):
super().__init__(step=step, encode_type=encode_type)
self.image_size = [img_size_h, img_size_w]
# timm内置to_2tuple把整形转换成2元元组
patch_size = to_2tuple(patch_size) # 4->(4,4)
self.patch_size = patch_size # patch_size
self.C = in_channels # image_channel
self.H, self.W = self.image_size[0] // patch_size[0], self.image_size[1] // patch_size[1]
self.num_patches = self.H * self.W
# DVS with 2 more Maxpooling
self.proj_conv = nn.Conv2d(in_channels, embed_dims // 8, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn = nn.BatchNorm2d(embed_dims // 8)
self.proj_lif = MyNode(step=step, tau=2.0)
self.maxpool = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv1 = nn.Conv2d(embed_dims // 8, embed_dims // 4, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn1 = nn.BatchNorm2d(embed_dims // 4)
self.proj_lif1 = MyNode(step=step, tau=2.0)
self.maxpool1 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv2 = nn.Conv2d(embed_dims // 4, embed_dims // 2, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn2 = nn.BatchNorm2d(embed_dims // 2)
self.proj_lif2 = MyNode(step=step, tau=2.0)
self.maxpool2 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv3 = nn.Conv2d(embed_dims // 2, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn3 = nn.BatchNorm2d(embed_dims)
self.proj_lif3 = MyNode(step=step, tau=2.0)
self.maxpool3 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.rpe_conv = nn.Conv2d(embed_dims, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.rpe_bn = nn.BatchNorm2d(embed_dims)
self.rpe_lif = MyNode(step=step, tau=2.0)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
x = self.proj_conv(x.flatten(0, 1)) # have some fire value
x = self.proj_bn(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif(x.flatten(0, 1)).contiguous()
x = self.maxpool(x)
x = self.proj_conv1(x)
x = self.proj_bn1(x).reshape(T, B, -1, H // 2, W // 2).contiguous()
x = self.proj_lif1(x.flatten(0, 1)).contiguous()
x = self.maxpool1(x)
x = self.proj_conv2(x)
x = self.proj_bn2(x).reshape(T, B, -1, H // 4, W // 4).contiguous()
x = self.proj_lif2(x.flatten(0, 1)).contiguous()
x = self.maxpool2(x)
x = self.proj_conv3(x)
x = self.proj_bn3(x).reshape(T, B, -1, H // 8, W // 8).contiguous()
x = self.proj_lif3(x.flatten(0, 1)).contiguous()
x = self.maxpool3(x)
x_rpe = self.rpe_bn(self.rpe_conv(x)).reshape(T, B, -1, H // 16, W // 16).contiguous()
x_rpe = self.rpe_lif(x_rpe.flatten(0, 1)).contiguous()
x = x + x_rpe
x = x.reshape(T, B, -1, (H // 16) * (H // 16)).contiguous()
return x # T B C N
class Spikformer(nn.Module):
def __init__(self, step=10,
img_size_h=64, img_size_w=64, patch_size=4, in_channels=2, num_classes=10,
embed_dims=256, num_heads=16, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=2, sr_ratios=4,
):
super().__init__()
self.step = step # time step
self.num_classes = num_classes
self.depths = depths
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
patch_embed = SPS(step=step,
img_size_h=img_size_h,
img_size_w=img_size_w,
patch_size=patch_size,
in_channels=in_channels,
embed_dims=embed_dims)
block = nn.ModuleList([Block(step=step,
dim=embed_dims, num_heads=num_heads, mlp_ratio=mlp_ratios, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[j],
norm_layer=norm_layer, sr_ratio=sr_ratios)
for j in range(depths)])
setattr(self, f"patch_embed", patch_embed)
setattr(self, f"block", block)
# classification head
self.head = nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
block = getattr(self, f"block")
patch_embed = getattr(self, f"patch_embed")
x = patch_embed(x)
for blk in block:
x = blk(x)
return x.mean(3)
def forward(self, x):
x = x.permute(1, 0, 2, 3, 4) # [T, N, 2, *, *]
x = self.forward_features(x)
x = self.head(x.mean(0))
return x
# Adjust ur hyperparams here
@register_model
def spikformer_dvs(pretrained=False, **kwargs):
model = Spikformer(step = 8,
img_size_h=64, img_size_w=64,
patch_size=4, embed_dims=256, num_heads=16, mlp_ratios=4,
in_channels=2, num_classes=10, qkv_bias=False,
depths=2, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/Structural_Development/DPAP/README.md
================================================
# Developmental Plasticity-inspired Adaptive Pruning for Deep Spiking and Artificial Neural Networks #
## Requirments ##
* matplotlib==3.5.1
* numpy==1.22.4
* Pillow==9.3.0
* scipy==1.9.3
* tensorboardX==2.5.1
* torch==1.8.1+cu111
* torchvision==0.9.1+cu111
## Run ##
``` CUDA_VISIBLE_DEVICES=0 python prun_ main.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{han2024similarity,
title={Developmental Plasticity-inspired Adaptive Pruning for Deep Spiking and Artificial Neural Networks},
author={Han, Bing and Zhao, Feifei and Zeng, Yi and Shen Guobin},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2024}
}
@article{zeng2023braincog,
title={Braincog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired ai and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier},
}
```
Enjoy!
================================================
FILE: examples/Structural_Development/DPAP/mask_model.py
================================================
import abc
from functools import partial
from torch.nn import functional as F
import torchvision
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from utils import *
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
convlayer = [-1,0, 1, 3, 4, 6, 7]
fclayer=[8,9]
imgsize = [32,32, 32, 16,16, 16, 8,8, 8]
size = [3,128, 128, 256, 256, 512,512]
size_pool = [3,128, 128,128, 256, 256,256, 512,512]
fcsize=[512*8*8,512]
class my_cifar_model(BaseModule):
def __init__(self,
num_classes=10,
step=8,
node_type=LIFNode,
encode_type='direct',
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.num_classes = num_classes
# self.node = node_type
# if issubclass(self.node, BaseNode):
# self.node = partial(self.node, **kwargs, step=step)
self.feature = nn.Sequential(
BaseConvModule(size[0], size[1], kernel_size=(3, 3), padding=(1, 1)),
BaseConvModule(size[1],size[2], kernel_size=(3, 3), padding=(1, 1)),
nn.MaxPool2d(2),
BaseConvModule(size[2], size[3], kernel_size=(3, 3), padding=(1, 1)),
BaseConvModule(size[3], size[4], kernel_size=(3, 3), padding=(1, 1)),
nn.MaxPool2d(2),
BaseConvModule(size[4], size[5], kernel_size=(3, 3), padding=(1, 1)),
BaseConvModule(size[5], size[6], kernel_size=(3, 3), padding=(1, 1)),
)
self.cfla=self._cflatten()
self.fc_prun = self._create_fc_prun()
self.fc = self._create_fc()
def _cflatten(self):
fc = nn.Sequential(
nn.Flatten(),
)
return fc
def _create_fc_prun(self):
fc = nn.Sequential(
BaseLinearModule(fcsize[0], fcsize[1])
)
return fc
def _create_fc(self):
fc = nn.Sequential(
BaseLinearModule(fcsize[1], self.num_classes)
)
return fc
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if not self.training:
self.fire_rate.clear()
outputs = []
spikes=[]
for t in range(self.step):
spikest=[]
x = inputs[t]
if x.shape[-1] > 32:
x = F.interpolate(x, size=[64, 64])
spikest.append(x.detach())
for i in range(len(self.feature)):
spikei=self.feature[i](x)
x=spikei
spikest.append(spikei.detach())
x=self.cfla(x)
spikest.append(x.detach())
x=self.fc_prun(x)
spikest.append(x.detach())
x = self.fc(x)
spikes.append(spikest)
outputs.append(x)
return sum(outputs) / len(outputs),spikes
class Mask:
def __init__(self, model,batch,step):
self.model = model
self.fullbook={}
self.mat = {}
self.feature=model.feature
self.fc={}
self.fc[1]=model.fc_prun[0]
self.fc[2]=model.fc[0]
self.n_delta={}
self.ww_delta={}
self.reduce={}
self.reduceww={}
self.batch=batch
self.step=step
def init_length(self):
for i in range(1,len(convlayer)):
index=convlayer[i]
self.fullbook[index] =torch.ones((size[i],size[i-1],3,3),device=device)
self.n_delta[index]=torch.zeros(size[i],device=device)
self.reduce[index] = 10*torch.ones(size[i],device=device)
for i in range(1,len(fclayer)):
index=fclayer[i]
self.fullbook[index] = torch.ones((fcsize[i],fcsize[i-1]),device=device)
self.n_delta[index]=torch.zeros(fcsize[i],device=device)
self.ww_delta[index]=torch.zeros(fcsize[i]*fcsize[i-1],device=device)
self.reduce[index] = 10*torch.ones(fcsize[i],device=device)
self.reduceww[index] = 10*torch.ones(fcsize[i]*fcsize[i-1],device=device)
def get_filter_codebook(self,ww,dendrite,ii,index,epoch):
if ii == 4:
wconv= dendrite#.cpu().numpy()
self.n_delta[index]=(unit(wconv)*2-0.65)
pos=torch.nonzero(self.n_delta[index]>0)
self.n_delta[index][pos]=self.n_delta[index][pos]+5
print(wconv.mean(),wconv.max(), wconv.min())
self.reduce[index]=self.reduce[index]*0.999+self.n_delta[index]*math.exp(-int((epoch-5)/12))
filter_ind = torch.nonzero(self.reduce[index] <0)
print(self.reduce[index].mean(),self.reduce[index].max(),self.reduce[index].min(),len(filter_ind))
for x in range(0, len(filter_ind)):
self.fullbook[index][filter_ind[x]] = 0
if ii == 2:
length=ww.size()[0]*ww.size()[1]
book=torch.ones(length,device=device)
filter_ww = ww.view(-1)#.cpu().numpy()
self.ww_delta[index]=(unit(filter_ww)*2-1.5)
pos=torch.nonzero(self.ww_delta[index]>0)
self.ww_delta[index][pos]=self.ww_delta[index][pos]+2
self.reduceww[index]= self.reduceww[index]*0.999+self.ww_delta[index]*math.exp(-int((epoch-5)/13))
filter_indww =torch.nonzero(self.reduceww[index] < 0)
book[filter_indww]=0
book=book.reshape((ww.size()[0],-1))
self.fullbook[index]=self.fullbook[index]*book
print(self.reduceww[index].mean(),self.reduceww[index].max(),self.reduceww[index].min(),len(filter_indww))
wconv= dendrite#.cpu().numpy()
self.n_delta[index]=(unit(wconv)*2-1.5)
pos=torch.nonzero(self.n_delta[index]>0)
self.n_delta[index][pos]=self.n_delta[index][pos]+2
self.reduce[index]=self.reduce[index]*0.999+self.n_delta[index]*math.exp(-int((epoch-5)/13))
filter_ind = torch.nonzero(self.reduce[index] <0)
print(self.reduce[index].mean(),self.reduce[index].max(),self.reduce[index].min(),len(filter_ind))
for x in range(0, len(filter_ind)):
self.fullbook[index][filter_ind[x]] = 0
return self.fullbook[index]
def convert2tensor(self, x):
x = torch.FloatTensor(x)
return x
def init_mask(self, wwfc,convtra,epoch):
for i in range(1,len(convlayer)):
index=convlayer[i]
ww = wwfc[index]
dendrite=convtra[index]
self.mat[index]=self.get_filter_codebook(ww, dendrite,4,index,epoch)
#self.mat[index] = self.convert2tensor(self.mat[index]).cuda()
for i in range(1,len(fclayer)):
index=fclayer[i]
ww=wwfc[index]
dendrite=convtra[index]
self.mat[index]=self.get_filter_codebook(ww,dendrite,2,index,epoch)
#self.mat[index] = self.convert2tensor(self.mat[index]).cuda()
def do_mask(self):
for i in range(1,len(convlayer)):
index=convlayer[i]
ww = self.feature[index].conv.weight
maskww=ww*self.mat[index]
self.feature[index].conv.weight.data=maskww
for i in range(1,len(fclayer)):
ind=fclayer[i]
ww = self.fc[i].fc.weight
maskww=ww*self.mat[ind]
self.fc[i].fc.weight.data=maskww
def if_zero(self):
cc=[]
for i in range(1,len(convlayer)):
ww=self.feature[convlayer[i]].conv.weight
b = ww.data.view(-1).cpu().numpy()
print("number of weight is %d, zero is %.3f" %(len(b),100*(len(b)- np.count_nonzero(b))/len(b)))
cc.append(100*(len(b)- np.count_nonzero(b))/len(b))
for i in range(1,len(fcsize)):
ww=self.fc[i].fc.weight
b = ww.data.view(-1).cpu().numpy()
print("number of weight is %d, zero is %.3f" %(len(b),100*(len(b)- np.count_nonzero(b))/len(b)))
cc.append(100*(len(b)- np.count_nonzero(b))/len(b))
return cc
class Trace:
def __init__(self, model,batch,step):
self.model = model
self.feature=model.feature
self.ctrace={}
self.fctrace={}
self.csum={}
self.fcsum={}
self.delta = 0.5
self.batch=batch
self.step=step
def computing_trace(self,spikes):
for i in range(len(imgsize)):
index=i-1
self.ctrace[index]=torch.zeros((self.batch,size_pool[i],imgsize[i],imgsize[i]),device=device)
for i in range(len(fclayer)):
index=fclayer[i]
self.fctrace[index]=torch.zeros((self.batch,fcsize[i]),device=device)
for t in range(self.step):
for i in range(len(imgsize)):
index=i-1
sp=spikes[t][index+1].detach()
#print(sp.size(),self.ctrace[index].size())
self.ctrace[index]=self.delta*self.ctrace[index].cuda()+sp.cuda()
for i in range(len(fclayer)):
index=fclayer[i]
sp=spikes[t][index+1].detach()
self.fctrace[index]=self.delta*self.fctrace[index].cuda()+sp.cuda()
for i in range(len(imgsize)):
index=i-1
self.csum[index]=self.ctrace[index]/(self.step)
self.csum[index]=torch.sum(torch.sum(self.csum[index],dim=2),dim=2)
for i in range(len(fclayer)):
index=fclayer[i]
self.fcsum[index]=self.fctrace[index]/(self.step)
return self.csum,self.fcsum
================================================
FILE: examples/Structural_Development/DPAP/prun_main.py
================================================
import argparse
import time
import os
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
import sys
sys.path.append('..')
import torch
import torch.nn as nn
from torch.nn.parallel import DistributedDataParallel as NativeDDP
import logging
from timm.utils import *
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from braincog.base.node.node import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from mask_model import *
from utils import *
_logger = logging.getLogger('train')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
exp_name = '-'.join([datetime.now().strftime("%Y%m%d-%H%M%S"),'c10'])
output_dir = get_outdir('./', 'train', exp_name)
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
_logger.info(exp_name)
config_parser = cfg = argparse.ArgumentParser(description='Training Config', add_help=False)
dataset='cifar10'
num_classes=10
step=8
encode='direct'
node_type='PLIFNode'
thresh=0.5
tau=2.0
torch.backends.cudnn.benchmark = True
devicee=0
seed=42
channels = 2
batch_size=50
epochs=300
lr=5e-3
linear_scaled_lr = lr * batch_size/ 1024.0
cfg.opt='adamw'
cfg.lr=linear_scaled_lr
cfg.weight_decay=0.01
cfg.momentum=0.9
cfg.epochs=epochs
cfg.sched='cosine'
cfg.min_lr=1e-5
cfg.warmup_lr=1e-6
cfg.warmup_epochs=5
cfg.cooldown_epochs=10
cfg.decay_rate=0.1
eval_metric='top1'
best_test = 0
best_testepoch = 0
best_testprun = 0
best_testepochprun = 0
epoch_prune = 1
rate_decay_epoch=30
NUM = 0
torch.cuda.set_device('cuda:%d' % devicee)
torch.manual_seed(seed)
model = my_cifar_model(step=step,encode_type=encode,node_type=node_type,num_classes=num_classes)
model = model.cuda()
print(model)
optimizer = create_optimizer(cfg, model)
lr_scheduler, num_epochs = create_scheduler(cfg, optimizer)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % dataset)(batch_size=batch_size, step=step)
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
m = Mask(model,batch_size,step)
m.init_length()
trace=Trace(model,batch_size,step)
neuron_th,spines,bcm,epoch_trace = init(batch_size,convlayer,fclayer,size,fcsize)
def BCM_and_trace(NUM,trace,spikes,neuron_th,bcm,epoch_trace):
NUM = NUM + 1
csum,fcsum= trace.computing_trace(spikes)
for i in range(1,len(convlayer)):
index=convlayer[i]
post1 = (csum[index] * (csum[index] - neuron_th[index]))
hebb1 = torch.mm(post1.T, csum[index-1])
bcm[index] = bcm[index] + hebb1
neuron_th[index] = torch.div(neuron_th[index] * (NUM - 1) + csum[index], NUM)
cs=torch.sum(csum[index],dim=0)
epoch_trace[index] = epoch_trace[index] + cs
for i in range(1,len(fclayer)):
index = fclayer[i]
post1 = (fcsum[index] * (fcsum[index] - neuron_th[index]))
hebb1 = torch.mm(post1.T, fcsum[fclayer[i - 1]])
bcm[index] = bcm[index] + hebb1
neuron_th[index] = torch.div(neuron_th[index] * (NUM - 1) + fcsum[index], NUM)
cs=torch.sum(fcsum[index],dim=0)
epoch_trace[index] = epoch_trace[index] + cs
return epoch_trace,bcm,NUM
def train_epoch(
epoch, model, loader, optimizer, loss_fn,trace,NUM,bcm,neuron_th,epoch_trace,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None):
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
model.train()
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
output,spikes = model(inputs)
epoch_trace,bcm,NUM = BCM_and_trace(NUM,trace,spikes,neuron_th,bcm,epoch_trace)
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
optimizer.zero_grad()
loss.backward()
optimizer.step()
batch_time_m.update(time.time() - end)
if last_batch or batch_idx %100 == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
print("Train: epoch:",epoch,batch_idx,"/",len(loader),"loss:",losses_m.avg,"acc1:", top1_m.avg,"lr:",lr)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg)]),epoch_trace,bcm,NUM
def validate(model, loader, loss_fn, amp_autocast=suppress, log_suffix=''):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
end = time.time()
last_idx = len(loader) - 1
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
output,spikes = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
if last_batch or batch_idx %100 == 0:
print("Test: loss:",losses_m.avg,"acc1:", top1_m.avg)
batch_time_m.update(time.time() - end)
end = time.time()
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
return metrics
for epoch in range(epochs):
train_metrics, epoch_trace, bcm, N = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn,trace,NUM,bcm,neuron_th,epoch_trace,
lr_scheduler=lr_scheduler)
NUM = N
for i in range(1,len(convlayer)):
index=convlayer[i]
bcmconv = torch.sum(bcm[index], dim=1)
bcmconv=unit_tensor(bcmconv)
traconv=unit_tensor(epoch_trace[index])
spines[index]=bcmconv*traconv
for i in range(1, len(fclayer)):
index=fclayer[i]
bcmfc = torch.sum(bcm[index], dim=1)
bcmfc=unit_tensor(bcmfc)
trafc=unit_tensor(epoch_trace[index])
spines[index]=bcmfc*trafc
if epoch>4:
m.model = model
m.init_mask(bcm,spines,epoch)
m.do_mask()
print("Done pruning")
cc=m.if_zero()
model = m.model
eval_metrics = validate(model, loader_eval, validate_loss_fn)
top1=eval_metrics['top1']
if top1 > best_testprun:
best_testprun = top1
best_testepochprun =epoch
if epoch%40==0:
print('best acc:',best_testprun,'best epoch:',best_testepochprun)
if epoch>4:
_logger.info('*** epoch: {0} (pruning rate {1},acc:{2})'.format(epoch, cc,top1))
if lr_scheduler is not None:
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
================================================
FILE: examples/Structural_Development/DPAP/utils.py
================================================
import torch
import numpy as np
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def print_log(print_string, log):
#print("{}".format(print_string))
log.write('{}\n'.format(print_string))
log.flush()
def unit(x):
if x.size()[0]>0:
xnp=x.cpu().numpy()
maxx=np.percentile(xnp, 75)
minx=torch.min(x)
marge=maxx-minx
if marge!=0:
xx=(x-minx)/marge
xx=torch.clip(xx, 0,1)
else:
xx=0.5*torch.ones_like(x)
return xx
else:
return x
def unit_tensor(x):
if x.size()[0]>0:
maxx=torch.max(x)
minx=torch.min(x)
marge=maxx-minx
if marge!=0:
xx=(x-minx)/marge
else:
xx=0.5*torch.ones_like(x)
return xx
else:
return x
def init(batch,convlayer,fclayer,size,fcsize):
neuron_th={}
convtra = {}
bcm={}
epoch_trace = {}
for i in range(1,len(convlayer)):
index=convlayer[i]
neuron_th[index]=torch.zeros((batch,size[i]),device=device)
convtra[index] = torch.zeros(size[i],device=device)
bcm[index]=torch.zeros(size[i],size[i-1],device=device)
epoch_trace[index] = torch.zeros((size[i]),device=device)
for i in range(1,len(fclayer)):
index=fclayer[i]
neuron_th[index]=torch.zeros((batch,fcsize[i]),device=device)
convtra[index]=torch.zeros(fcsize[i],device=device)
bcm[index]=torch.zeros(fcsize[i],fcsize[i-1],device=device)
epoch_trace[index] = torch.zeros(fcsize[i],device=device)
return neuron_th,convtra,bcm,epoch_trace
================================================
FILE: examples/Structural_Development/DSD-SNN/README.md
================================================
# Enhancing Efficient Continual Learning with Dynamic Structure Development of Spiking Neural Networks #
## Requirments ##
* numpy
* timm
* pytorch >= 1.7.0
* collections
* argparse
## Introduction ##
Dynamic Structure Development of Spiking Neural Networks (DSD-SNN) for efficient and adaptive continual learning:
grow new neurons and prune redundant neurons, increasing memory capacity and reducing computational overhead.
verlap shared structure to leverage acquired knowledge to new tasks, empowering a single network to support multiple incremental tasks.
We validate the effectiveness of the DSD-SNN multiple TIL and CIL benchmarks.
## Run ##
```CUDA_VISIBLE_DEVICES=0 python main_simplified.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{han2022developmental,
title={Enhancing Efficient Continual Learning with Dynamic Structure Development of Spiking Neural Networks},
author={Han, Bing and Zhao, Feifei and Zeng, Yi and Wenxuan, Pan and Shen, Guobin},
booktitle = {Proceedings of the Thirty-First International Joint Conference on
Artificial Intelligence, {IJCAI-23}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
year={2023}
}
@article{zeng2023braincog,
title={Braincog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired ai and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier},
}
```
Enjoy!
================================================
FILE: examples/Structural_Development/DSD-SNN/cifar100/available.py
================================================
from torchvision import datasets, transforms
from manipulate import UnNormalize
# specify available data-sets.
AVAILABLE_DATASETS = {
'MNIST': datasets.MNIST,
'CIFAR100': datasets.CIFAR100,
'CIFAR10': datasets.CIFAR10,
}
# specify available transforms.
AVAILABLE_TRANSFORMS = {
'MNIST': [
transforms.ToTensor(),
],
'MNIST32': [
transforms.Pad(2),
transforms.ToTensor(),
],
'CIFAR10': [
transforms.ToTensor(),
],
'CIFAR100': [
transforms.ToTensor(),
],
'CIFAR10_norm': [
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2470, 0.2435, 0.2616])
],
'CIFAR100_norm': [
transforms.Normalize(mean=[0.5071, 0.4865, 0.4409], std=[0.2673, 0.2564, 0.2761])
],
'CIFAR10_denorm': UnNormalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2470, 0.2435, 0.2616]),
'CIFAR100_denorm': UnNormalize(mean=[0.5071, 0.4865, 0.4409], std=[0.2673, 0.2564, 0.2761]),
'augment_from_tensor': [
transforms.ToPILImage(),
transforms.RandomCrop(32, padding=4, padding_mode='symmetric'),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
],
'augment': [
transforms.RandomCrop(32, padding=4, padding_mode='symmetric'),
transforms.RandomHorizontalFlip(),
],
}
# specify configurations of available data-sets.
DATASET_CONFIGS = {
'MNIST': {'size': 28, 'channels': 1, 'classes': 10},
'MNIST32': {'size': 32, 'channels': 1, 'classes': 10},
'CIFAR10': {'size': 32, 'channels': 3, 'classes': 10},
'CIFAR100': {'size': 32, 'channels': 3, 'classes': 100},
}
================================================
FILE: examples/Structural_Development/DSD-SNN/cifar100/main_simplified.py
================================================
import argparse
import time
import timm.models
import yaml
import os
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.utils import save_feature_map
import torch
import torch.nn as nn
import torchvision.utils
from torchvision import transforms
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from maskcl2 import *
# from ptflops import get_model_complexity_info
from thop import profile, clever_format
from manipulate import SubDataset
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
from available import AVAILABLE_DATASETS, AVAILABLE_TRANSFORMS, DATASET_CONFIGS
from torch.utils.data.dataloader import DataLoader
from torch.utils.data import ConcatDataset
import copy
from vgg_snn import SNN
# torch.cuda.set_device(9)
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--dataset', default='cifar100', type=str)
parser.add_argument('--model', default='cifar_convnet', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--num-classes', type=int, default=100, metavar='N',
help='number of label classes (default: 100)')
parser.add_argument('--task_num', type=int, default=10, metavar='N',
help='number of label classes (default: 10)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=50, metavar='N',
help='inputs batch size for training (default: 128)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=1e-2, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-4, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=600, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Misc
parser.add_argument('--seed', type=int, default=0, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=25, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=4, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--device', type=int, default=0)
parser.add_argument('--output', default='/home/hanbing/brain/bp2/', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
# Spike parameters
parser.add_argument('--step', type=int, default=4, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='QGateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--thresh', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--n_warm_up', type=int, default=0,
help='Warm up epoch, replace all node to ReLU to warm up weights in network before (default: 0)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def get_dataset(name, type='train', download=True, capacity=None, permutation=None, dir='./store/datasets',
verbose=False, augment=False, normalize=False, target_transform=None):
'''Create [train|valid|test]-dataset.'''
data_name = 'MNIST' if name in ('MNIST28', 'MNIST32') else name
dataset_class = AVAILABLE_DATASETS[data_name]
# specify image-transformations to be applied
transforms_list = [*AVAILABLE_TRANSFORMS['augment']] if augment else []
transforms_list += [*AVAILABLE_TRANSFORMS[name]]
if normalize:
transforms_list += [*AVAILABLE_TRANSFORMS[name+"_norm"]]
# if permutation is not None:
# transforms_list.append(transforms.Lambda(lambda x, p=permutation: permutate_image_pixels(x, p)))
dataset_transform = transforms.Compose(transforms_list)
# load data-set
dataset = dataset_class('{dir}/{name}'.format(dir=dir, name=data_name), train=False if type=='test' else True,
download=download, transform=dataset_transform, target_transform=target_transform)
# print information about dataset on the screen
if verbose:
print(" --> {}: '{}'-dataset consisting of {} samples".format(name, type, len(dataset)))
# if dataset is (possibly) not large enough, create copies until it is.
if capacity is not None and len(dataset) < capacity:
dataset = ConcatDataset([copy.deepcopy(dataset) for _ in range(int(np.ceil(capacity / len(dataset))))])
return dataset
def main():
args, args_text = _parse_args()
# args.no_spike_output = args.no_spike_output | args.cut_mix
args.no_spike_output = True
output_dir = ''
output_base = args.output if args.output else './output'
exp_name = '-'.join([
datetime.now().strftime("%Y%m%d-%H%M%S"),
'SNN',
args.dataset,
str(args.seed),
'gwu',
'xin-epochs'
])
output_dir = get_outdir(output_base, 'train', exp_name)
print(output_dir)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
torch.cuda.set_device('cuda:%d' % args.device)
torch.manual_seed(args.seed)
model = SNN(
num_classes=args.num_classes,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.thresh,
tau=args.tau,
spike_output=not args.no_spike_output,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
batch_size=args.batch_size,
task_num=args.task_num
)
print(model)
# for n,p in enumerate(model.parameters()):
# print(n,p.size())
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.img_size, args.img_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size / 1024.0
args.lr = linear_scaled_lr
model = model.cuda()
optimizer = create_optimizer(args, model)
# optionally resume from a checkpoint
resume_epoch = None
if args.resume:
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
m = Mask(model)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
_logger.info('Scheduled epochs: {}'.format(num_epochs))
batch_size=args.batch_size
data_dir = '/data0/datasets/'
trainset = get_dataset('CIFAR100', type="train", dir=data_dir)
testset = get_dataset('CIFAR100', type="test", dir=data_dir)
out_num=int(args.num_classes/args.task_num)
labels_per_dataset_train = [list(np.array(range(out_num))+out_num*context_id) for context_id in range(args.task_num)]
labels_per_dataset_test = [list(np.array(range(out_num))+out_num*context_id) for context_id in range(args.task_num)]
train_datasets = []
for labels in labels_per_dataset_train:
target_transform = transforms.Lambda(lambda y, x=labels[0]: y-x)
train_datasets.append(SubDataset(trainset, labels, target_transform=target_transform))
test_datasets = []
for labels in labels_per_dataset_test:
target_transform = transforms.Lambda(lambda y, x=labels[0]: y-x)
test_datasets.append(SubDataset(testset, labels, target_transform=target_transform))
train_data = []
test_data = []
t_data=[]
for task in range(len(train_datasets)):
train_data.append(DataLoader(train_datasets[task], batch_size=batch_size, shuffle=True, drop_last=True, **({'num_workers': 4, 'pin_memory': True})))
test_data.append(DataLoader(test_datasets[task], batch_size=batch_size, shuffle=True, drop_last=True, **({'num_workers': 4, 'pin_memory': True})))
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args,
checkpoint_dir=output_dir, recovery_dir=output_dir)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
loader_his=[]
task_ready={}
for index, item in enumerate(model.parameters()):
if len(item.size()) > 1 and index<=40:
task_ready[index]=torch.zeros(item.size(),device=device)
try: # train the model
task_count=0
regularization_terms= {}
for task in range(len(train_datasets)):
print("Task:",task)
if task==0:
m.model = model
mat=m.init_length()
model = m.model
epochs=50
else:
m.model = model
mat,task_ready,taskmaskk,taskww=m.init_grow(task)
model = m.model
epochs=30
ta_his=[i for i in range(task+1)]
for epoch in range(epochs):
loader_train = iter(train_data[task])
if task==0:
train_epoch(epoch, task, model, loader_train, optimizer, train_loss_fn, args,mat,task_ready,taskww=None,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,regularization_terms=regularization_terms)
else:
train_epoch(epoch, task, model, loader_train, optimizer, train_loss_fn, args,mat,task_ready,taskww=taskww,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,regularization_terms=regularization_terms)
print(epoch)
if epoch>0:
m.model = model
m.init_mask(task,epoch)
mat=m.do_mask(task)
model = m.model
ta_his=[i for i in range(task+1)]
for t in ta_his:
loader_his=iter(test_data[t])
validate(t, model, loader_his, validate_loss_fn, args,mat)
cc=m.if_zero()
_logger.info('*** epoch: {0}, task: {1}, pruning: {2}'.format(epoch,task, cc))
p_index=m.record()
except KeyboardInterrupt:
pass
# if best_metric is not None:
# _logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, task,model, loader, optimizer, loss_fn, args,mat,task_ready,taskww=None,
lr_scheduler=None, saver=None, output_dir='',regularization_terms={}):
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
output = model(inputs, mat)
t_preds = output[task].cuda()
loss = loss_fn(t_preds, target)
# if len(regularization_terms)>0:
# reg_loss = 0
# for i,reg_term in regularization_terms.items():
# task_reg_loss = 0
# importance = reg_term['importance']
# task_param = reg_term['task_param']
# for n, p in enumerate(model.parameters()):
# if len(p.size())>=1:
# task_reg_loss += (importance[n] * (p - task_param[n]) ** 2).sum()
# reg_loss += task_reg_loss
# loss += 10000 * reg_loss
acc1, acc5 = accuracy(t_preds, target, topk=(1, 5))
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
top5_m.update(acc5.item(), inputs.size(0))
optimizer.zero_grad()
loss.backward()
# for index, item in enumerate(model.parameters()):
# if len(item.size()) > 1 and index<=40:
# gradmask=torch.where(task_ready[index]>0,0.0,1.0)
# item.grad=item.grad*gradmask
optimizer.step()
for index, item in enumerate(model.parameters()):
if len(item.size()) > 1 and index<=40:
if index<40:
ready=task_ready[index].view(task_ready[index].size()[0],-1)
ready=torch.sum(ready,dim=1)
else:
ready=torch.sum(task_ready[index],dim=1)
windex=torch.nonzero(ready>0)
for i in range(len(windex)):
item.data[windex[i]]=taskww[index][windex[i]]
num_updates += 1
batch_time_m.update(time.time() - end)
if last_batch or batch_idx % args.log_interval == 0:
# lrl = [param_group['lr'] for param_group in optimizer.param_groups]
# lr = sum(lrl) / len(lrl)
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
top1=top1_m, top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) / batch_time_m.val,
rate_avg=inputs.size(0) / batch_time_m.avg,
data_time=data_time_m))
# if saver is not None and args.recovery_interval and (
# last_batch or (batch_idx + 1) % args.recovery_interval == 0):
# saver.save_recovery(epoch, batch_idx=batch_idx)
# if lr_scheduler is not None:
# lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
# end = time.time()
# # end for
# if hasattr(optimizer, 'sync_lookahead'):
# optimizer.sync_lookahead()
# return OrderedDict([('loss', losses_m.avg)])
def validate(task, model, loader, loss_fn, args, mat,log_suffix='', visualize=False, spike_rate=False):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
end = time.time()
with torch.no_grad():
last_idx = len(loader) - 1
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
output = model(inputs,mat)
t_preds = output[task]
loss = loss_fn(t_preds, target)
acc1, acc5 = accuracy(t_preds, target, topk=(1, 5))
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
log_name = 'Test'+str(task) + log_suffix
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
log_name, batch_idx, last_idx, batch_time=batch_time_m,
loss=losses_m, top1=top1_m, top5=top5_m))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
# return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/Structural_Development/DSD-SNN/cifar100/manipulate.py
================================================
import torch
from torch.utils.data import Dataset
def permutate_image_pixels(image, permutation):
'''Permutate the pixels of an image according to [permutation].
[image] 3D-tensor containing the image
[permutation] of pixel-indeces in their new order'''
if permutation is None:
return image
else:
c, h, w = image.size()
image = image.view(c, -1)
image = image[:, permutation] #--> same permutation for each channel
image = image.view(c, h, w)
return image
#----------------------------------------------------------------------------------------------------------#
class SubDataset(Dataset):
'''To sub-sample a dataset, taking only those samples with label in [sub_labels].
After this selection of samples has been made, it is possible to transform the target-labels,
which can be useful when doing continual learning with fixed number of output units.'''
def __init__(self, original_dataset, sub_labels, target_transform=None):
super().__init__()
self.dataset = original_dataset
self.sub_indeces = []
for index in range(len(self.dataset)):
if hasattr(original_dataset, "train_labels"):
if self.dataset.target_transform is None:
label = self.dataset.train_labels[index]
else:
label = self.dataset.target_transform(self.dataset.train_labels[index])
elif hasattr(self.dataset, "test_labels"):
if self.dataset.target_transform is None:
label = self.dataset.test_labels[index]
else:
label = self.dataset.target_transform(self.dataset.test_labels[index])
else:
label = self.dataset[index][1]
if label in sub_labels:
self.sub_indeces.append(index)
self.target_transform = target_transform
def __len__(self):
return len(self.sub_indeces)
def __getitem__(self, index):
sample = self.dataset[self.sub_indeces[index]]
if self.target_transform:
target = self.target_transform(sample[1])
sample = (sample[0], target)
return sample
class MemorySetDataset(Dataset):
'''Create dataset from list of with shape (N, C, H, W) (i.e., with N images each).
The images at the i-th entry of [memory_sets] belong to class [i], unless a [target_transform] is specified'''
def __init__(self, memory_sets, target_transform=None):
super().__init__()
self.memory_sets = memory_sets
self.target_transform = target_transform
def __len__(self):
total = 0
for class_id in range(len(self.memory_sets)):
total += len(self.memory_sets[class_id])
return total
def __getitem__(self, index):
total = 0
for class_id in range(len(self.memory_sets)):
examples_in_this_class = len(self.memory_sets[class_id])
if index < (total + examples_in_this_class):
class_id_to_return = class_id if self.target_transform is None else self.target_transform(class_id)
example_id = index - total
break
else:
total += examples_in_this_class
image = torch.from_numpy(self.memory_sets[class_id][example_id])
return (image, class_id_to_return)
class TransformedDataset(Dataset):
'''To modify an existing dataset with a transform.
This is useful for creating different permutations of MNIST without loading the data multiple times.'''
def __init__(self, original_dataset, transform=None, target_transform=None):
super().__init__()
self.dataset = original_dataset
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
(input, target) = self.dataset[index]
if self.transform:
input = self.transform(input)
if self.target_transform:
target = self.target_transform(target)
return (input, target)
# ----------------------------------------------------------------------------------------------------------#
class UnNormalize(object):
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, tensor):
"""Denormalize image, either single image (C,H,W) or image batch (N,C,H,W)"""
batch = (len(tensor.size()) == 4)
for t, m, s in zip(tensor.permute(1, 0, 2, 3) if batch else tensor, self.mean, self.std):
t.mul_(s).add_(m)
# The normalize code -> t.sub_(m).div_(s)
return tensor
================================================
FILE: examples/Structural_Development/DSD-SNN/cifar100/maskcl2.py
================================================
import numpy as np
import torch
import math
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
import random
def unit(x):
if x.size()[0]>0:
xnp=x.cpu().numpy()
maxx=torch.max(x)
#maxx=np.percentile(xnp, 99.5)
minx=torch.min(x)
marge=maxx-minx
if marge!=0:
xx=(x-minx)/marge
xx=torch.clip(xx, 0,1)
else:
xx=0.5*torch.ones_like(x)
return xx
else:
return x
class Mask:
def __init__(self, model):
self.model = model
self.mat = {}
self.p_index={}
self.p_num={}
self.k=15
self.task_ready={}
self.taskmask={}
self.init_rate=0.3
self.grow_rate=0.125
self.prunconv_init=0.8
self.prunfc_init=1.3
self.prunconv_grow=0.5
self.prunfc_grow=1
self.n_delta={}
self.reduce={}
self.taskww={}
def init_length(self):
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1:
print(index,item.size())
self.mat[index]=torch.ones(item.size(),device=device)
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1:
if index<=40:
self.p_index[index]=torch.tensor([])
self.task_ready[index]=torch.zeros(item.size(),device=device)
self.reduce[index] = 5*torch.ones(item.size()[0],device=device)
if len(item.size()) == 4:
self.p_num[index]=torch.zeros(item.size()[0],device=device)
self.mat[index][int(self.init_rate*item.size()[0]):]=0.0
if index+5<40:
self.mat[index+5][:,int(self.init_rate*item.size()[0]):]=0.0
if index+5==40:
self.mat[index+5][:,int(self.init_rate*item.size()[0])*16:]=0.0
if len(item.size()) == 2:
self.p_num[index]=torch.zeros(item.size()[0]*item.size()[1],device=device)
self.mat[index][int(self.init_rate*item.size()[0]):]=0.0
if index>40:
self.mat[index]=torch.ones(item.size(),device=device)
if index==44:
self.mat[index]=torch.zeros(item.size(),device=device)
self.mat[index][:,:int(self.init_rate*item.size()[1])]=1.0
return self.mat
def get_filter_codebook(self,index,ww,task,epoch):
if task==0:
pruncon=self.prunconv_init
prunfc=self.prunfc_init
else:
pruncon=self.prunconv_grow
prunfc=self.prunfc_grow
if len(ww.size()) == 4:
p_ww=ww.view(ww.size()[0],-1)
p_ww=torch.sum(p_ww,dim=1)
task_use=self.mat[index]-torch.sign(self.task_ready[index])
nouse=torch.sum(task_use.view(ww.size()[0],-1),dim=1)
no=torch.nonzero(nouse<0.1)
p_ww[no]=p_ww.max()
self.n_delta[index]=(unit(p_ww)*2-pruncon)
pos=torch.nonzero(self.n_delta[index]>0)
self.n_delta[index][pos]=self.n_delta[index][pos]+3
self.reduce[index]=self.reduce[index]*0.999+self.n_delta[index]*math.exp(-int((epoch-1)/13))
p_ind = torch.nonzero(self.reduce[index] <0)
print(self.reduce[index].mean(),self.reduce[index].max(),self.reduce[index].min(),len(p_ind))
for x in range(0, len(p_ind)):
self.mat[index][p_ind[x]] = 0
if index+5<40:
self.mat[index+5][:,p_ind[x]]=0
if index+5==40:
self.mat[index+5][:,p_ind[x]*16:(p_ind[x]+1)*16]=0
self.mat[index]=torch.sign(self.mat[index]+ self.task_ready[index])
if len(ww.size()) == 2:
p_ww=torch.sum(ww,dim=1)
task_use=self.mat[index]-torch.sign(self.task_ready[index])
nouse=torch.sum(task_use,dim=1)
no=torch.nonzero(nouse<0.1)
p_ww[no]=p_ww.max()
self.n_delta[index]=(unit(p_ww)*2-prunfc)
print(self.n_delta[index].mean(),self.n_delta[index].max(),self.n_delta[index].min())
pos=torch.nonzero(self.n_delta[index]>0)
self.n_delta[index][pos]=self.n_delta[index][pos]+3
self.reduce[index]=self.reduce[index]*0.999+self.n_delta[index]*math.exp(-int((epoch-1)/13))
p_ind = torch.nonzero(self.reduce[index] <0)
print(self.reduce[index].mean(),self.reduce[index].max(),self.reduce[index].min(),len(p_ind))
index_ta=44+task*2
for x in range(0, len(p_ind)):
self.mat[index][p_ind[x]] = 0
self.mat[index_ta][:,p_ind[x]]=0
self.mat[index]=torch.sign(self.mat[index]+self.task_ready[index])
def convert2tensor(self, x):
x = torch.FloatTensor(x)
return x
def init_mask(self,task,epoch):
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and index<=40:
self.get_filter_codebook(index,abs(item.data),task,epoch)
def do_mask(self,task):
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and index<=40:
ww=item.data
item.data=ww*self.mat[index].cuda()
return self.mat
def init_grow(self,task):
self.taskmask[task]={}
index_ta=44+task*2
self.mat[index_ta]=torch.zeros(self.mat[index_ta].size(),device=device)
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and index<=40:
self.task_ready[index]=self.task_ready[index]+self.mat[index]
self.taskmask[task][index]=self.mat[index]
self.taskww[index]=item.data.clone()
ind_all=[x for x in range(item.size()[0])]
pp=list(np.array(self.p_index[index]))
ind_empty=set(ind_all)-set(pp)
ind_empty=list(ind_empty)
# random.shuffle(ind_empty)
ind_grow=ind_empty[:int(item.size()[0]*self.grow_rate)]
ind_grow=torch.tensor(ind_grow)
ww_g=torch.empty(item.size(),device=device)
if index<40:
torch.nn.init.kaiming_uniform_(ww_g, a=math.sqrt(5))
if index==40:
kk=1/math.sqrt(item.size()[1])
torch.nn.init.uniform_(ww_g,a=-kk,b=kk)
for x in range(0, len(ind_grow)):
self.mat[index][ind_grow[x]] = 1.0
item.data[ind_grow[x]]=ww_g[ind_grow[x]]
if index==40:
self.mat[index_ta][:,ind_grow[x]]=1.0
self.mat[index]=torch.sign(self.mat[index]+self.task_ready[index])
self.p_num[index]=torch.zeros(item.size()[0],device=device)
self.reduce[index] = 5*torch.ones(item.size()[0],device=device)
#self.mat[index_ta]=self.mat[index_ta]+self.mat[index_ta-2]
# nn=torch.sum(self.task_ready[24],dim=1)
# use_nn=torch.nonzero(nn>1)
# for x in range(0, len(use_nn)):
# self.mat[index_ta][:,use_nn[x]] = 1.0
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and index<40:
nsum=self.mat[index].view(item.size()[0],-1)
nn=torch.sum(abs(nsum),dim=1)
empy_nn=torch.nonzero(nn<0.00001)
for x in range(0, len(empy_nn)):
if index+5<40:
self.mat[index+5][:,empy_nn[x]]=0
if index+5==40:
self.mat[index+5][:,empy_nn[x]*16:(empy_nn[x]+1)*16]=0
return self.mat,self.task_ready,self.taskmask,self.taskww
def if_zero(self):
cc=[]
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and index<=40:
b = item.data.view(-1).cpu().numpy()
print("number of weight is %d, zero is %.3f" %(len(b),100*(len(b)- np.count_nonzero(b))/len(b)))
cc.append(100*(len(b)- np.count_nonzero(b))/len(b))
if index==40:
nouse=torch.sum(self.mat[index],dim=1)
no=torch.nonzero(nouse<0.1)
print(len(no))
cc.append(len(no))
return cc
def record(self):
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and index<=40:
nsum=self.mat[index].view(item.size()[0],-1)
nn=torch.sum(abs(nsum),dim=1)
epoch_select=torch.nonzero(nn>0.00001)
select=set(epoch_select)|set(self.p_index[index])
self.p_index[index]= torch.tensor(list(select))
return self.p_index
================================================
FILE: examples/Structural_Development/DSD-SNN/cifar100/vgg_snn.py
================================================
# encoding: utf-8
# Author : Floyed
# Datetime : 2022/7/26 18:56
# User : Floyed
# Product : PyCharm
# Project : BrainCog
# File : vgg_snn.py
# explain :
from functools import partial
from torch.nn import functional as F
import torchvision
from timm.models import register_model
from braincog.datasets import is_dvs_data
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
@register_model
class SNN(BaseModule):
def __init__(self,
num_classes=100,
step=8,
node_type=LIFNode,
encode_type='direct',
batch_size=100,
task_num=10,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.n_preact = kwargs['n_preact'] if 'n_preact' in kwargs else False
self.batch_size=batch_size
self.num_classes = num_classes
self.task_num=task_num
self.out_num=int(self.num_classes/self.task_num)
self.node = node_type
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.dataset = kwargs['dataset']
if not is_dvs_data(self.dataset):
init_channel = 3
output_size = 2
else:
init_channel = 2
output_size = 3
#self.channel_number=[256,512,1024]
self.channel_number=[512,1024,2048]
self.feature = nn.Sequential(
BaseConvModule(init_channel, self.channel_number[0], kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(self.channel_number[0], self.channel_number[0], kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.AvgPool2d(2),
BaseConvModule(self.channel_number[0], self.channel_number[0], kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(self.channel_number[0], self.channel_number[0], kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.AvgPool2d(2),
BaseConvModule(self.channel_number[0], self.channel_number[1], kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(self.channel_number[1], self.channel_number[1], kernel_size=(3, 3), padding=(1, 1), node=self.node),
nn.AvgPool2d(2),
BaseConvModule(self.channel_number[1], self.channel_number[2], kernel_size=(3, 3), padding=(1, 1), node=self.node),
BaseConvModule(self.channel_number[2], self.channel_number[2], kernel_size=(3, 3), padding=(1, 1), node=self.node),
)
self.fc = nn.Sequential(
nn.Flatten(),
BaseLinearModule(
self.channel_number[2]*4*4, self.channel_number[2], node=self.node),
)
self.dec = nn.ModuleDict()
for task in range(self.task_num):
ta=str(task)
self.dec[ta] = self._create_decision()
def logits(self, x):
outputs =torch.zeros((self.task_num,self.batch_size,self.out_num),device='cuda')
for task, func in self.dec.items():
ta=int(task)
outputs[ta]=func(x)
return outputs
def _create_decision(self):
fc = nn.Linear(self.channel_number[2], self.out_num)
# fc = BaseLinearModule(1024, 10, node=self.node)
return fc
def forward(self, inputs, mat):
inputs = self.encoder(inputs)
self.reset()
step = self.step
outputs = []
for index, item in enumerate(self.parameters()):
if len(item.size()) > 1:
ww=item.data
item.data=ww*mat[index].cuda()
for t in range(step):
x = inputs[t]
x = self.feature(x)
x = self.fc(x)
x = self.logits(x)
outputs.append(x)
out=sum(outputs).cuda()
return out / step
# class MaskConvModule(nn.Module):
# """
# SNN卷积模块
# :param in_channels: 输入通道数
# :param out_channels: 输出通道数
# :param kernel_size: kernel size
# :param stride: stride
# :param padding: padding
# :param bias: Bias
# :param node: 神经元类型
# :param kwargs:
# """
# def __init__(self,
# in_channels: int,
# out_channels: int,
# kernel_size=(3, 3),
# stride=(1, 1),
# padding=(1, 1),
# bias=False,
# node=PLIFNode,
# **kwargs):
# super().__init__()
# if node is None:
# raise TypeError
# self.groups = kwargs['groups'] if 'groups' in kwargs else 1
# self.conv = MConv2d(in_channels=in_channels * self.groups,
# out_channels=out_channels * self.groups,
# kernel_size=kernel_size,
# padding=padding,
# stride=stride,
# bias=bias)
# self.bn = nn.BatchNorm2d(out_channels * self.groups)
# self.node = partial(node, **kwargs)()
# self.activation = nn.Identity()
# def forward(self, x, mat):
# x = self.conv(x,mat)
# x = self.bn(x)
# x = self.node(x)
# return x
# class MConv2d(nn.Conv2d):
# def __init__(self, in_channels, out_channels, kernel_size, stride=1,
# padding=0, dilation=1, groups=1, bias=True, gain=True):
# super(MConv2d, self).__init__(in_channels, out_channels, kernel_size, stride,
# padding, dilation, groups, bias)
# self.gain = 1.
# def forward(self, x, mat):
# weight = self.weight
# weight = weight*mat
# return F.conv2d(x, weight, self.bias, self.stride,
# self.padding, self.dilation, self.groups)
# class MaskLinearModule(nn.Module):
# """
# 线性模块
# :param in_features: 输入尺寸
# :param out_features: 输出尺寸
# :param bias: 是否有Bias, 默认 ``False``
# :param node: 神经元类型, 默认 ``LIFNode``
# :param args:
# :param kwargs:
# """
# def __init__(self,
# in_features: int,
# out_features: int,
# bias=True,
# node=LIFNode,
# *args,
# **kwargs):
# super().__init__()
# if node is None:
# raise TypeError
# self.fc = MLinear(in_features=in_features,
# out_features=out_features, bias=bias)
# self.node = partial(node, **kwargs)()
# def forward(self, x,mat):
# outputs = self.fc(x,mat)
# return self.node(outputs)
# class MLinear(nn.Linear):
# def __init__(self, in_features: int, out_features: int, bias: bool = True):
# super(MLinear, self).__init__(in_features, out_features, bias)
# self.gain = 1.
# def forward(self, input, mat):
# weight = self.weight
# weight = weight*mat
# return F.linear(input, weight, self.bias)
================================================
FILE: examples/Structural_Development/ELSM/evolve.py
================================================
import time
import threading
from threading import Thread
import os
import networkx as nx
import numpy as np
from population import *
import nsganet as engine
from pymop.problem import Problem
from pymoo.optimize import minimize
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
import logging
from model import *
from spikes import calc_f2
from mul import mul_f1
_logger = logging.getLogger('')
config_parser = parser = argparse.ArgumentParser(description='Evolution Config', add_help=False)
parser = argparse.ArgumentParser(description='ELSM')
parser.add_argument('--device', type=int, default=2)
parser.add_argument('--seed', type=int, default=68, metavar='S')
parser.add_argument('--datapath', default='', type=str, metavar='PATH')
parser.add_argument('--output', default='', type=str, metavar='PATH')
parser.add_argument('--liquid-size', type=int, default=8000)
parser.add_argument('--pop-size', type=int, default=80)
parser.add_argument('--up', type=int, default=32000000)
parser.add_argument('--low', type=int, default=320000)
parser.add_argument('--n_offspring', type=int, default=100)
parser.add_argument('--n_gens', type=int, default=10000)
parser.add_argument('--arand', type=float, default=285)
parser.add_argument('--brand', type=float, default=1.8)
def _parse_args():
args_config, remaining = config_parser.parse_known_args()
args = parser.parse_args(remaining)
return args
class Evolve(Problem):
# first define the NAS problem (inherit from pymop)
def __init__(self, args,n_var=20, n_obj=1, n_constr=0, lb=None, ub=None):
super().__init__(n_var=n_var, n_obj=n_obj, n_constr=n_constr, type_var=np.int64)
self.xl = lb
self.xu = ub
self._n_evaluated = 0 # keep track of how many architectures are sampled
self.args=args
def _evaluate(self, x, out, *args, **kwargs):
objs = np.full((x.shape[0], self.n_obj), np.nan)
g1 = np.full((x.shape[0]), np.nan)
g2 = np.full((x.shape[0]), np.nan)
gen_dir=os.path.join(self.args.output,'generaion'+str(kwargs['algorithm'].n_gen))
os.makedirs(gen_dir,exist_ok = True)
# np.save(os.path.join(gen_dir,"x.npy"),x)
lsms = x.reshape(x.shape[0],self.args.liquid_size,self.args.liquid_size)
for i in range(x.shape[0]):
temp_G = nx.Graph(lsms[i])
nx.write_gpickle(temp_G, os.path.join(gen_dir,str(i)+".pkl"))
self.ob1=mul_f1(pop=x.shape[0],steps=10,rootdir=gen_dir)
for i in range(x.shape[0]):
arch_id = self._n_evaluated + 1
print('\n')
_logger.info('Network= {}'.format(arch_id))
genome = x[i, :]
g1[i]= genome.sum()-self.args.up
g2[i]= self.args.low-genome.sum()
lsmm = genome.reshape(self.args.liquid_size,self.args.liquid_size)
small_coe_a,small_coe_b=self.ob1[i]
lsmm=torch.tensor(lsmm,device='cuda:%d' % self.args.device).float()
crit = calc_f2(lsmm,'cuda:%d' % self.args.device)
objs[i, 1] = abs(crit-1)
# all objectives assume to be MINIMIZED !!!!!
objs[i, 0] = -(small_coe_a/self.args.arand)/(small_coe_b/self.args.brand)
_logger.info('small word= {}'.format(objs[i, 0]))
_logger.info('criticality= {}'.format(objs[i, 1]))
self._n_evaluated += 1
out["F"] = objs
out["G"] = np.column_stack([g1,g2])
# if your NAS problem has constraints, use the following line to set constraints
# out["G"] = np.column_stack([g1, g2, g3, g4, g5, g6]) in case 6 constraints
# ---------------------------------------------------------------------------------------------------------
# Define what statistics to print or save for each generation
# ---------------------------------------------------------------------------------------------------------
def do_every_generations(algorithm):
# this function will be call every generation
# it has access to the whole algorithm class
gen = algorithm.n_gen
pop_var = algorithm.pop.get("X")
pop_obj = algorithm.pop.get("F")
# report generation info to files
_logger.info("generation = {}".format(gen))
_logger.info("population error1: best = {}, mean = {}, "
"median1 = {}, worst1 = {}".format(np.min(pop_obj[:, 0]), np.mean(pop_obj[:, 0]),
np.median(pop_obj[:, 0]), np.max(pop_obj[:, 0])))
_logger.info('Best1 Genome id= {}'.format(np.argmin(pop_obj[:, 0])))
_logger.info("population error2: best = {}, mean = {}, "
"median2 = {}, worst2 = {}".format(np.min(pop_obj[:, 1]), np.mean(pop_obj[:, 1]),
np.median(pop_obj[:, 1]), np.max(pop_obj[:, 1])))
_logger.info('Best2 Genome id= {}'.format(np.argmin(pop_obj[:, 1])))
if gen%20==0:
best_sid=np.argmin(pop_obj[:, 0])
best_sname='-'.join([
'gen'+str(gen),
's'+str(float('%.4f' % pop_obj[best_sid, 0])),
'c'+str(float('%.4f' % pop_obj[best_sid, 1])),
])
best_cid=np.argmin(pop_obj[:, 1])
best_cname='-'.join([
'gen'+str(gen),
's'+str(float('%.4f' % pop_obj[best_cid, 0])),
'c'+str(float('%.4f' % pop_obj[best_cid, 1])),
])
np.save(os.path.join('',best_sname+datetime.now().strftime("%Y%m%d-%H%M%S")),pop_var[np.argmin(pop_obj[:, 0])])
np.save(os.path.join('',best_cname+datetime.now().strftime("%Y%m%d-%H%M%S")),pop_var[np.argmin(pop_obj[:, 1])])
if __name__ == '__main__':
args = _parse_args()
out_base_dir= os.path.join(args.output, datetime.now().strftime("%Y%m%d-%H%M%S"))
os.makedirs(out_base_dir,exist_ok = True)
args.output=out_base_dir
setup_default_logging(log_path=os.path.join(out_base_dir, 'log.txt'))
kkk = Evolve(args,n_var=args.liquid_size*args.liquid_size,
n_obj=2, n_constr=2)
method = engine.nsganet(pop_size=args.pop_size,
sampling=RandomSampling(var_type='custom'),
mutation=BinaryBitflipMutation(),
n_offsprings=args.n_offspring,
eliminate_duplicates=True)
kres=minimize(kkk,
method,
callback=do_every_generations,
termination=('n_gen', args.n_gens))
================================================
FILE: examples/Structural_Development/ELSM/lsm.py
================================================
from __future__ import print_function
import torchvision
import torchvision.transforms as transforms
import os
import time
import numpy as np
import torch
from torch import nn as nn
from mnistmodel import *
from tqdm import tqdm
import argparse
from datetime import datetime
import logging
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy
from braincog.base.utils import UnilateralMse, MixLoss
from braincog.base.learningrule.STDP import *
device='cuda:7'
def lr_scheduler(optimizer, epoch, init_lr=0.1, lr_decay_epoch=50):
"""Decay learning rate by a factor of 0.1 every lr_decay_epoch epochs."""
if epoch % lr_decay_epoch == 0 and epoch > 1:
for param_group in optimizer.param_groups:
param_group['lr'] = param_group['lr'] * 0.1
return optimizer
batch_size=100
liquid_size=8000
learning_rate = 1e-3
num_epochs = 100 # max epoch
data_path = '/data'
load_path=''
train_dataset = torchvision.datasets.MNIST(root=data_path, train=True, download=False, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=8)
test_set = torchvision.datasets.MNIST(root=data_path, train=False, download=False, transform=transforms.ToTensor())
test_loader = torch.utils.data.DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=2)
snn = SNN(ins=784,
batchsize=batch_size,
device=device,
liquid_size=liquid_size,
lsm_tau=lsm_tau,
lsm_th=lsm_th)
snn.load_state_dict(torch.load(load_path)['fc'])
snn.learning_rule=[]
snn.con[0].load_state_dict(torch.load(load_path)['lsm0'])
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False,device=device)
snn.connectivity_matrix=torch.load(load_path)['connectivity_matrix'].to(device)
w2tmp.weight.data=(torch.load(load_path)['liquid_weight'].to(device))*snn.connectivity_matrix
snn.learning_rule.append(MutliInputSTDP(snn.node_lsm(), [snn.con[0], w2tmp])) # pm
snn.eval()
snn.to(device)
ls = 'mse'
if ls == 'ce':
criterion = nn.CrossEntropyLoss()
elif ls == 'bce':
criterion = nn.BCEWithLogitsLoss()
elif ls == 'mse':
criterion = UnilateralMse(1.)
elif ls == 'sce':
criterion = LabelSmoothingCrossEntropy()
elif ls == 'sbce':
criterion = LabelSmoothingBCEWithLogitsLoss()
elif ls == 'umse':
criterion = UnilateralMse(.5)
optimizer = torch.optim.AdamW(snn.fc.parameters(),lr=0.001, weight_decay=1e-4)
l=[]
best_acc=0
for epoch in range(num_epochs):
running_loss = 0
start_time = time.time()
for i, (images, labels) in enumerate(tqdm(train_loader)):
snn.zero_grad()
optimizer.zero_grad()
images = images.float().to(device)
outputs = snn(images)
labels=labels.to(device)
loss = criterion(outputs, labels)
running_loss += loss.item()
loss.backward()
optimizer.step()
snn.reset()
if (i + 1) % 100 == 0:
running_loss = 0
correct = 0
total = 0
optimizer = lr_scheduler(optimizer, epoch, learning_rate, 40)
for batch_idx, (inputs, targets) in enumerate(test_loader):
inputs = inputs.float().to(device)
snn.zero_grad()
optimizer.zero_grad()
outputs = snn(inputs)
targets=targets.to(device)
loss = criterion(outputs, targets)
_, predicted = outputs.max(1)
total += float(targets.size(0))
correct += float(predicted.eq(targets).sum().item())
snn.reset()
if batch_idx % 100 == 0:
acc = 100. * float(correct) / float(total)
print(batch_idx, len(test_loader), ' Acc: %.5f' % acc)
print('Test Accuracy: %.3f' % (100 * correct / total))
acc = 100. * float(correct) / float(total)
if best_acc < acc:
best_acc = acc
print(best_acc)
l.append(best_acc)
================================================
FILE: examples/Structural_Development/ELSM/model.py
================================================
from functools import partial
from torch.nn import functional as F
from torch import nn as nn
import torchvision, pprint
from copy import deepcopy
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.base.brainarea.BrainArea import BrainArea
from braincog.base.connection.CustomLinear import *
from braincog.base.learningrule.STDP import *
import matplotlib.pyplot as plt
@register_model
class nSNN(BaseModule):
def __init__(self,
batchsize,
liquid_size,
device,
connectivity_matrix,
num_classes=10,
step=1,
node_type=LIFNode,
encode_type='direct',
lsm_th=0.3,
fc_th=0.3,
lsm_tau=3,
fc_tau=3,
ins=1156,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.batchsize=batchsize
self.ins=ins
self.node_lsm=partial(node_type, **kwargs, step=step,tau=lsm_tau,threshold=lsm_th)
self.node_fc = partial(node_type, **kwargs, step=step,tau=fc_tau,threshold=fc_th)
self.liquid_size=liquid_size
self.device=device
self.con=[]
self.learning_rule=[]
self.connectivity_matrix=connectivity_matrix
w1tmp=nn.Linear(ins,liquid_size,bias=False).to(device)
self.con.append(w1tmp)
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False).to(device)
self.liquid_weight=w2tmp.weight.data
w2tmp.weight.data=w2tmp.weight.data*self.connectivity_matrix
self.con.append(w2tmp)
self.learning_rule.append(MutliInputSTDP(self.node_lsm(), [self.con[0], self.con[1]])) # pm
self.fc = nn.Sequential(
nn.Linear(liquid_size,num_classes),
self.node_fc()
)
def forward(self, x):
sum_spike=0
self.out = torch.zeros(x.shape[0], self.liquid_size).to(self.device)
tw=x.shape[1]
self.tw=tw
self.firing_tw=torch.zeros(tw, self.batchsize, self.liquid_size).to(self.device)
for t in range(tw):
self.out, self.dw = self.learning_rule[0](x[:,t,:], self.out)
out_liquid=self.out[:,0:self.liquid_size]
xout = self.fc(out_liquid)
sum_spike=sum_spike+xout
self.firing_tw[t]=out_liquid
outputs = sum_spike / tw
return outputs
@register_model
class mSNN(BaseModule):
def __init__(self,
batchsize,
liquid_size,
device,
connectivity_matrix,
num_classes=10,
step=1,
node_type=LIFNode,
encode_type='direct',
lsm_th=0.3,
fc_th=0.3,
lsm_tau=3,
fc_tau=3,
tw=100,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.batchsize=batchsize
self.node_lsm=partial(node_type, **kwargs, step=step,tau=lsm_tau,threshold=lsm_th)
self.node_fc = partial(node_type, **kwargs, step=step,tau=fc_tau,threshold=fc_th)
self.liquid_size=liquid_size
self.out = torch.zeros(self.batchsize, liquid_size).to(device)
self.device=device
self.con=[]
self.learning_rule=[]
self.connectivity_matrix=connectivity_matrix
w1tmp=nn.Linear(784,liquid_size,bias=False).to(device)
self.con.append(w1tmp)
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False).to(device)
self.liquid_weight=w2tmp.weight.data
w2tmp.weight.data=w2tmp.weight.data*self.connectivity_matrix
self.con.append(w2tmp)
self.learning_rule.append(MutliInputSTDP(self.node_lsm(), [self.con[0], self.con[1]])) # pm
self.fc = nn.Sequential(
nn.Linear(liquid_size,num_classes),
self.node_fc()
)
def forward(self, x):
x = x.reshape(x.shape[0], -1)
sum_spike=0
time_window=20
self.tw=time_window
self.firing_tw=torch.zeros(time_window, self.batchsize, self.liquid_size).to(self.device)
self.out = torch.zeros(self.batchsize, self.liquid_size).to(self.device)
for t in range(time_window):
self.out, self.dw = self.learning_rule[0](x, self.out)
out_liquid=self.out[:,0:self.liquid_size]
xout = self.fc(out_liquid)
sum_spike=sum_spike+xout
self.firing_tw[t]=out_liquid
# print(out_liquid.sum())
# print(xout.sum())
outputs = sum_spike / time_window
return outputs
================================================
FILE: examples/Structural_Development/ELSM/nsganet.py
================================================
import numpy as np
from pymoo.algorithms.genetic_algorithm import GeneticAlgorithm
from pymoo.docs import parse_doc_string
from pymoo.model.individual import Individual
from pymoo.model.survival import Survival
from pymoo.operators.crossover.point_crossover import PointCrossover
from pymoo.operators.mutation.polynomial_mutation import PolynomialMutation
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.selection.tournament_selection import compare, TournamentSelection
from pymoo.util.display import disp_multi_objective
from pymoo.util.dominator import Dominator
from pymoo.util.non_dominated_sorting import NonDominatedSorting
from pymoo.util.randomized_argsort import randomized_argsort
# =========================================================================================================
# Implementation
# based on nsga2 from https://github.com/msu-coinlab/pymoo
# =========================================================================================================
class NSGANet(GeneticAlgorithm):
def __init__(self, **kwargs):
kwargs['individual'] = Individual(rank=np.inf, crowding=-1)
super().__init__(**kwargs)
self.tournament_type = 'comp_by_dom_and_crowding'
self.func_display_attrs = disp_multi_objective
# ---------------------------------------------------------------------------------------------------------
# Binary Tournament Selection Function
# ---------------------------------------------------------------------------------------------------------
def binary_tournament(pop, P, algorithm, **kwargs):
if P.shape[1] != 2:
raise ValueError("Only implemented for binary tournament!")
tournament_type = algorithm.tournament_type
S = np.full(P.shape[0], np.nan)
for i in range(P.shape[0]):
a, b = P[i, 0], P[i, 1]
# if at least one solution is infeasible
if pop[a].CV > 0.0 or pop[b].CV > 0.0:
S[i] = compare(a, pop[a].CV, b, pop[b].CV, method='smaller_is_better', return_random_if_equal=True)
# both solutions are feasible
else:
if tournament_type == 'comp_by_dom_and_crowding':
rel = Dominator.get_relation(pop[a].F, pop[b].F)
if rel == 1:
S[i] = a
elif rel == -1:
S[i] = b
elif tournament_type == 'comp_by_rank_and_crowding':
S[i] = compare(a, pop[a].rank, b, pop[b].rank,
method='smaller_is_better')
else:
raise Exception("Unknown tournament type.")
# if rank or domination relation didn't make a decision compare by crowding
if np.isnan(S[i]):
S[i] = compare(a, pop[a].get("crowding"), b, pop[b].get("crowding"),
method='larger_is_better', return_random_if_equal=True)
return S[:, None].astype(np.int)
# ---------------------------------------------------------------------------------------------------------
# Survival Selection
# ---------------------------------------------------------------------------------------------------------
class RankAndCrowdingSurvival(Survival):
def __init__(self) -> None:
super().__init__(True)
def _do(self, pop, n_survive, D=None, **kwargs):
# get the objective space values and objects
F = pop.get("F")
# the final indices of surviving individuals
survivors = []
# do the non-dominated sorting until splitting front
fronts = NonDominatedSorting().do(F, n_stop_if_ranked=n_survive)
for k, front in enumerate(fronts):
# calculate the crowding distance of the front
crowding_of_front = calc_crowding_distance(F[front, :])
# save rank and crowding in the individual class
for j, i in enumerate(front):
pop[i].set("rank", k)
pop[i].set("crowding", crowding_of_front[j])
# current front sorted by crowding distance if splitting
if len(survivors) + len(front) > n_survive:
I = randomized_argsort(crowding_of_front, order='descending', method='numpy')
I = I[:(n_survive - len(survivors))]
# otherwise take the whole front unsorted
else:
I = np.arange(len(front))
# extend the survivors by all or selected individuals
survivors.extend(front[I])
return pop[survivors]
def calc_crowding_distance(F):
infinity = 1e+14
n_points = F.shape[0]
n_obj = F.shape[1]
if n_points <= 2:
return np.full(n_points, infinity)
else:
# sort each column and get index
I = np.argsort(F, axis=0, kind='mergesort')
# now really sort the whole array
F = F[I, np.arange(n_obj)]
# get the distance to the last element in sorted list and replace zeros with actual values
dist = np.concatenate([F, np.full((1, n_obj), np.inf)]) \
- np.concatenate([np.full((1, n_obj), -np.inf), F])
index_dist_is_zero = np.where(dist == 0)
dist_to_last = np.copy(dist)
for i, j in zip(*index_dist_is_zero):
dist_to_last[i, j] = dist_to_last[i - 1, j]
dist_to_next = np.copy(dist)
for i, j in reversed(list(zip(*index_dist_is_zero))):
dist_to_next[i, j] = dist_to_next[i + 1, j]
# normalize all the distances
norm = np.max(F, axis=0) - np.min(F, axis=0)
norm[norm == 0] = np.nan
dist_to_last, dist_to_next = dist_to_last[:-1] / norm, dist_to_next[1:] / norm
# if we divided by zero because all values in one columns are equal replace by none
dist_to_last[np.isnan(dist_to_last)] = 0.0
dist_to_next[np.isnan(dist_to_next)] = 0.0
# sum up the distance to next and last and norm by objectives - also reorder from sorted list
J = np.argsort(I, axis=0)
crowding = np.sum(dist_to_last[J, np.arange(n_obj)] + dist_to_next[J, np.arange(n_obj)], axis=1) / n_obj
# replace infinity with a large number
crowding[np.isinf(crowding)] = infinity
return crowding
# =========================================================================================================
# Interface
# =========================================================================================================
def nsganet(
pop_size=100,
sampling=RandomSampling(var_type=np.int),
selection=TournamentSelection(func_comp=binary_tournament),
crossover=PointCrossover(n_points=2),
mutation=PolynomialMutation(eta=3, var_type=np.int),
eliminate_duplicates=True,
n_offsprings=None,
**kwargs):
"""
Parameters
----------
pop_size : {pop_size}
sampling : {sampling}
selection : {selection}
crossover : {crossover}
mutation : {mutation}
eliminate_duplicates : {eliminate_duplicates}
n_offsprings : {n_offsprings}
Returns
-------
nsganet : :class:`~pymoo.model.algorithm.Algorithm`
Returns an NSGANet algorithm object.
"""
return NSGANet(pop_size=pop_size,
sampling=sampling,
selection=selection,
crossover=crossover,
mutation=mutation,
survival=RankAndCrowdingSurvival(),
eliminate_duplicates=eliminate_duplicates,
n_offsprings=n_offsprings,
**kwargs)
parse_doc_string(nsganet)
================================================
FILE: examples/Structural_Development/ELSM/spikes.py
================================================
from __future__ import print_function
import torchvision
import torchvision.transforms as transforms
import os
import numpy as np
import torch
from torch import nn as nn
from model import *
from tqdm import tqdm
import argparse
from datetime import datetime
import logging
from timm.utils import *
from spikingjelly.datasets.n_mnist import NMNIST
from timm.loss import LabelSmoothingCrossEntropy
from braincog.base.utils.criterions import *
import networkx as nx
import time
from braincog.base.learningrule.STDP import *
def randbool(size, p=0.5):
return torch.rand(*size) < p
def calc_f2(con,device):
batch_size=1
liquid_size=8000
images=torch.load('/1000images.pt')
labels=torch.load('/1000labels.pt')
load_path='970.t7'
snn = nSNN(ins=2312,
batchsize=batch_size,
device=device,
liquid_size=liquid_size,
lsm_tau=2.0,
lsm_th=0.20,
connectivity_matrix=randbool([liquid_size, liquid_size],p=0.01).to(device).int())
snn.load_state_dict(torch.load(load_path,map_location={'cuda:2':device})['fc'])
snn.con[0].load_state_dict(torch.load(load_path,map_location={'cuda:2':device})['lsm0'])
snn.to(device)
criterion = UnilateralMse(1.)
optimizer = torch.optim.AdamW(snn.fc.parameters(),lr=0.001, weight_decay=1e-4)
k=0
sbr=0
snn.connectivity_matrix=con
snn.learning_rule=[]
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False,device=device)
w2tmp.weight.data=(torch.load(load_path,map_location={'cuda:2':device})['liquid_weight'])*snn.connectivity_matrix
snn.learning_rule.append(MutliInputSTDP(snn.node_lsm(), [snn.con[0], w2tmp]))
snn.eval()
for label,data in zip(labels,images):
running_loss = 0
snn.zero_grad()
optimizer.zero_grad()
data = data.to(device)
label = label.to(device)
data=data.reshape(batch_size,data.shape[0],-1)
output = snn(data)
# print(torch.argmax(output)==label)
out_liquid=snn.firing_tw.squeeze(-2)
mupost=torch.matmul(con,out_liquid.unsqueeze(-1))
mupre=torch.matmul(con.t(),out_liquid.unsqueeze(-1))
for t in range(snn.tw):
if t>5 and t0:
xnp=x.cpu().numpy()
maxx=torch.max(x)
#maxx=np.percentile(xnp, 99.5)
minx=torch.min(x)
marge=maxx-minx
if marge!=0:
xx=(x-minx)/marge
xx=torch.clip(xx, 0,1)
else:
xx=0.5*torch.ones_like(x)
return xx
else:
return x
class Mask:
def __init__(self, model):
self.model = model
self.mat = {}
self.p_index={}
self.p_num={}
self.k=15
self.task_ready={}
self.regutask_ready={}
self.taskmask={}
self.init_rate=0.3
self.grow_rate=0.125
self.prunconv_init=0.8
self.prunfc_init=1.3
self.prunconv_grow=0.5
self.prunfc_grow=1
self.n_delta={}
self.ren_delta={}
self.reduce={}
self.rereduce={}
self.taskww={}
self.tasknore={}
def init_length(self,task=0,task_nn=None):
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and item.size()[-1]!=1:
print(index,item.size())
self.mat[index]=torch.ones(item.size(),device=device)
for t in range(task):
self.rereduce[t]={}
for index, item in enumerate(self.model.parameters()):
if True:
if index<=20:
c_index=0
elif index<=45:
c_index=1
elif index<=70:
c_index=2
else:
c_index=3
taskindb=task_nn[t-1][c_index]
taskinda=task_nn[t][c_index]
lenre=taskinda-taskindb
self.rereduce[t][index] = 1*torch.ones(lenre,device=device)
return self.mat
def get_filter_reuse(self,index,ww,task,epoch,c_index,cdim_before=None,task_nn=None,all_dist=None,bias=0):
lenre=cdim_before[1]-cdim_before[0]
similar=1-all_dist+bias
if similar<0.2:
similar=0.2
if similar>0.9:
similar=0.9
revalue=similar*torch.ones(lenre).cuda() #1/8,1/4,1/2,1,1.5
if len(ww.size()) == 4:
# p_www=ww*self.mat[index]
p_ww=torch.sum(torch.sum(torch.sum(ww,dim=3),dim=2),dim=1)
# p_ww=p_ww[cdim_before[0]:cdim_before[1]]
ren_delta=-(2*unit(p_ww)-revalue)#revalue0.8
#print(self.ren_delta[index])
pos=torch.nonzero(ren_delta>0)
ren_delta[pos]=ren_delta[pos]+3
self.rereduce[task][index]=self.rereduce[task][index]*0.999+ren_delta*math.exp(-int((epoch-1)/2))
p_ind = torch.nonzero(self.rereduce[task][index] <0)
matkey=self.mat.keys()
matkey=torch.tensor(list(matkey))
matindex=torch.nonzero(matkey==index)
next_index=matkey[matindex+1]
for x in range(0, len(p_ind)):
self.mat[next_index.item()][:,p_ind[x]+cdim_before[0]]=0
b = self.mat[next_index.item()][:,cdim_before[0]:cdim_before[1]].reshape(-1).cpu().numpy()
pruning=100*(len(b)- np.count_nonzero(b))/len(b)
#print(index,self.rereduce[task][index].mean(),self.rereduce[task][index].max(),self.rereduce[task][index].min(),len(b)-np.count_nonzero(b),pruning)
def convert2tensor(self, x):
x = torch.FloatTensor(x)
return x
def init_mask(self,task,epoch,dim_cur=None,task_nn=None,all_dist=None,all_model=None):
for t in range(task):
similart=all_dist[t]
for index, item in enumerate(all_model[t].parameters()):
if len(item.size()) > 2 and item.size()[-1]!=1 and index<95:
if index<=20:
c_index=0
elif index<=45:
c_index=1
elif index<=70:
c_index=2
else:
c_index=3
if index<=25:
bias=0.2
elif index<=50:
bias=0.1
elif index<=74:
bias=-0.1
else:
bias=0.2
taskindb=task_nn[t-1][c_index]
taskinda=task_nn[t][c_index]
cdim_before=[taskindb,taskinda]
self.get_filter_reuse(index,abs(item.grad),t,epoch,c_index,cdim_before,task_nn=task_nn,all_dist=similart,bias=bias)
def do_mask(self,task):
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and item.size()[-1]!=1:
ww=item.data
item.data=ww*self.mat[index].cuda()
return self.mat
def if_zero(self):
cc=[]
for index, item in enumerate(self.model.parameters()):
if len(item.size()) > 1 and item.size()[-1]!=1 and index>0:
b = item.data.view(-1).cpu().numpy()
print("number of weight is %d, zero is %.3f" %(len(b),100*(len(b)- np.count_nonzero(b))/len(b)))
cc.append(100*(len(b)- np.count_nonzero(b))/len(b))
return cc
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/convnet/network.py
================================================
import copy
# import pdb
import torch
from torch import nn
import torch.nn.functional as F
from inclearn.tools import factory
from inclearn.convnet.imbalance import CR, All_av,BiC
from inclearn.convnet.classifier import CosineClassifier
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
class BasicNet(nn.Module):
def __init__(
self,
convnet_type,
cfg,
nf=64,
use_bias=False,
init="kaiming",
device=None,
dataset="cifar100",
):
super(BasicNet, self).__init__()
self.nf = nf
self.init = init
self.convnet_type = convnet_type
self.dataset = dataset
self.start_class = cfg['start_class']
self.weight_normalization = cfg['weight_normalization']
self.remove_last_relu = True if self.weight_normalization else False
self.use_bias = use_bias if not self.weight_normalization else False
self.dea = cfg['dea']
self.ft_type = cfg.get('feature_type', 'normal')
self.at_res = cfg.get('attention_use_residual', False)
self.div_type = cfg['div_type']
self.reuse_oldfc = cfg['reuse_oldfc']
self.prune = cfg.get('prune', False)
self.reset = cfg.get('reset_se', True)
self.torc=cfg['distillation']
self.node =LIFNode
self.encoder = Encoder(4, 'direct', temporal_flatten=False, layer_by_layer=False, **cfg)
# if self.dea:
# print("Enable dynamical reprensetation expansion!")
# self.convnets = nn.ModuleList()
# self.convnets.append(
# factory.get_convnet(convnet_type,
# nf=nf,
# dataset=dataset,
# start_class=self.start_class,
# remove_last_relu=self.remove_last_relu))
# self.out_dim = self.convnets[0].out_dim
# self.c_dim=self.convnets[0].channel_dim
# else:
# self.convnet = factory.get_convnet(convnet_type,
# nf=nf,
# dataset=dataset,
# remove_last_relu=self.remove_last_relu)
# self.out_dim = self.convnet.out_dim
self.channel_number=[32,64,128,256]#[32,64,128,256] # [24,48,72,96] #[24,48,96,192][32,64,128,256]
self.channel_dim=[48,96,192,384]
self.c_number1=np.array(self.channel_number)
if self.dea:
print("Enable dynamical reprensetation expansion!")
self.convnets = nn.ModuleList()
self.convnets.append(
factory.get_convnet(convnet_type,c_dim=self.channel_number,cdim_cur=self.channel_number)
)
self.out_dim = self.channel_number[-1]
self.out_dim_cc = self.channel_number[-1]
else:
self.convnet = factory.get_convnet(convnet_type,
nf=nf,
dataset=dataset,
remove_last_relu=self.remove_last_relu)
self.out_dim = self.convnet.out_dim
self.classifier = None
self.se = None
self.aux_classifier = None
self.n_classes = 0
self.ntask = 0
self.device = device
if cfg['postprocessor']['enable']:
if cfg['postprocessor']['type'].lower() == "cr":
self.postprocessor = CR()
elif cfg['postprocessor']['type'].lower() == "aver":
self.postprocessor = All_av()
else:
self.postprocessor = BiC(cfg['postprocessor']["lr"], cfg['postprocessor']["scheduling"],
cfg['postprocessor']["lr_decay_factor"], cfg['postprocessor']["weight_decay"],
cfg['postprocessor']["batch_size"], cfg['postprocessor']["epochs"])
self.task_nn={}
self.task_nn[-1]=np.array([0,0,0,0])
self.task_nn[0]=np.array(self.channel_number)
self.to(self.device)
def forward(self, task,inputs,mask=None,classify=True):
inputs = self.encoder(inputs)
self.resetsnn()
step = 4
outputs = []
if self.classifier is None:
raise Exception("Add some classes before training.")
if mask is not None:
mat=mask.mat
if self.torc:
ttc=task
else:
ttc=-1
for index, item in enumerate(self.convnets[ttc].parameters()):
if len(item.size()) > 1 and item.size()[-1]!=1:
ww=item.data
item.data=ww*mat[index].cuda()
if self.dea:
# feature = [convnet(x) for convnet in self.convnets]
for time in range(step):
x_init = inputs[time]
task_feature={}
for t in range(task):
task_feature[t]={}
x=self.convnets[t].forward_init(x_init)
task_feature[t][0]=x
for l in range(len(self.convnets[t].layer_convnets)):
for lc in range(len(self.convnets[t].layer_convnets[l].conv)):
if lc==0 or lc==3:
identity = x
if lc==2:
if l>0:
identity=self.convnets[t].layer_convnets[l].conv[lc](identity)
x=x+identity
task_feature[t][5*l+lc+1]=x
else:
old_tfeature=[]
for old_t in range(t):
old_tfeature.append(task_feature[old_t][5*l+lc])
old_tfeature.append(x)
x= torch.cat(old_tfeature, 1)
x=self.convnets[t].layer_convnets[l].conv[lc](x)
if lc==4:
x=x+identity
task_feature[t][5*l+lc+1]=x
x=self.convnets[task].forward_init(x_init)
for l in range(len(self.convnets[task].layer_convnets)):
for lc in range(len(self.convnets[task].layer_convnets[l].conv)):
if lc==0 or lc==3:
identity = x
if lc==2:
if l>0:
identity=self.convnets[task].layer_convnets[l].conv[lc](identity)
x=x+identity
else:
mid_feature=[]
for t in range(task):
mid_feature.append(task_feature[t][5*l+lc])
mid_feature.append(x)
x= torch.cat(mid_feature, 1)
x=self.convnets[task].layer_convnets[l].conv[lc](x)
if lc==4:
x=x+identity
if self.torc:
last_feature=[]
for t in range(task):
last=len(task_feature[t])-1
last_feature.append(task_feature[t][last])
last_feature.append(x)
outputs.append(torch.cat(last_feature, 1))
else:
x=self.convnets[task].avgpool(x)
x=x.view(x.size()[0],-1)
outputs.append(x)
feature=sum(outputs).cuda()/ step
last_dim =x.size(1)
width = feature.size(1)
if self.torc:
if self.reset:
se = factory.get_attention(width, self.ft_type, self.at_res).to(self.device)
features = se(feature)
else:
features = self.se(feature)
else:
features=feature
else:
features = self.convnet(x)
if self.torc:
if classify==True:
logits = self.convnets[-1].classifer(features)
div_logits = self.convnets[-1].aux_classifier(features[:, -last_dim:]) if self.ntask > 1 else None
else:
logits=None
div_logits=None
else:
if classify==True:
logits = self.convnets[task].classifer(features)
else:
logits=None
div_logits=None
return {'feature': features, 'logit': logits, 'div_logit': div_logits, 'features': feature}
def caculate_dim(self, x):
feature = [convnet(x) for convnet in self.convnets]
features = torch.cat(feature, 1)
width = features.size(1)
# se = factory.get_attention(width, self.ft_type, self.at_res).to(self.device)
se = factory.get_attention(width, "ce", self.at_res).cuda()
features = se(features)
# import pdb
# pdb.set_trace()
return features.size(1), feature[-1].size(1)
@property
def features_dim(self,ntask):
if self.dea:
return self.out_dim#+ntask*self.channel_number1[-1]
else:
return self.out_dim
def freeze(self):
for param in self.parameters():
param.requires_grad = False
self.eval()
return self
def copy(self):
return copy.deepcopy(self)
def add_classes(self, n_classes,min_dist):
self.ntask += 1
if self.dea:
self._add_classes_multi_fc(n_classes,min_dist)
else:
self._add_classes_single_fc(n_classes)
self.n_classes += n_classes
def _add_classes_multi_fc(self, n_classes,min_dist):
self.classifier=self.convnets[-1].classifer
if self.ntask > 1:
if min_dist<0.1:
min_dist=0.1
self.channel_number1=np.array([32,64,96,128])*1*(1-math.exp(-5*min_dist)) #0.5,1,1.5,2,3,4 [24,48,72,96][16,32,48,64]
self.channel_number1=self.channel_number1.astype(np.int64)
self.channel_dim=self.channel_number1
self.c_number1=self.c_number1+np.array(self.channel_number1)
self.task_nn[self.ntask-1]=self.c_number1
new_clf = factory.get_convnet("resnet18",c_dim=self.c_number1,cdim_cur=self.channel_number1).to(self.device)
self.out_dim=self.out_dim+self.channel_number1[-1]
self.out_dim_cc=self.channel_number1[-1]
self.convnets.append(new_clf)
if self.torc:
if not self.reset:
self.se = factory.get_attention(512*len(self.convnets), self.ft_type, self.at_res)
self.se.to(self.device)
if self.classifier is not None:
weight = copy.deepcopy(self.classifier.weight.data)
fc = self._gen_classifier(self.out_dim, self.n_classes + n_classes)
if self.classifier is not None and self.reuse_oldfc:
fc.weight.data[:self.n_classes, :(self.out_dim - self.out_dim_cc)] = weight
del self.classifier
self.classifier = fc
self.convnets[-1].classifer=self.classifier
else:
fc = self._gen_classifier(self.out_dim_cc, n_classes)
del self.classifier
self.classifier = fc
self.convnets[-1].classifer=fc
if self.torc:
if self.div_type == "n+1":
div_fc = self._gen_classifier(self.out_dim_cc, n_classes + 1)
elif self.div_type == "1+1":
div_fc = self._gen_classifier(self.out_dim_cc, 2)
elif self.div_type == "n+t":
div_fc = self._gen_classifier(self.out_dim_cc, self.ntask + n_classes)
else:
div_fc = self._gen_classifier(self.out_dim_cc, self.n_classes + n_classes)
del self.aux_classifier
self.aux_classifier = div_fc
self.convnets[-1].aux_classifier=self.aux_classifier
def _add_classes_single_fc(self, n_classes):
if self.classifier is not None:
weight = copy.deepcopy(self.classifier.weight.data)
if self.use_bias:
bias = copy.deepcopy(self.classifier.bias.data)
classifier = self._gen_classifier(self.features_dim, self.n_classes + n_classes)
if self.classifier is not None and self.reuse_oldfc:
classifier.weight.data[:self.n_classes] = weight
if self.use_bias:
classifier.bias.data[:self.n_classes] = bias
del self.classifier
self.classifier = classifier
def _gen_classifier(self, in_features, n_classes):
if self.weight_normalization:
classifier = CosineClassifier(in_features, n_classes).to(self.device)
# classifier = CosineClassifier(in_features, n_classes).cuda()
else:
classifier = nn.Linear(in_features, n_classes, bias=self.use_bias).to(self.device)
# classifier = nn.Linear(in_features, n_classes, bias=self.use_bias).cuda()
if self.init == "kaiming":
nn.init.kaiming_normal_(classifier.weight, nonlinearity="linear")
if self.use_bias:
nn.init.constant_(classifier.bias, 0.0)
return classifier
def resetsnn(self):
"""
重置所有神经元的膜电位
:return:
"""
for mod in self.convnets.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/convnet/resnet.py
================================================
"""Taken & slightly modified from:
* https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
"""
import torch
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
from torch.nn import functional as F
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152']
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, remove_last_relu=False):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
self.remove_last_relu = remove_last_relu
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
if not self.remove_last_relu:
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = conv1x1(inplanes, planes)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = conv3x3(planes, planes, stride)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = conv1x1(planes, planes * self.expansion)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 共享权重的MLP
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class SEFeatureAt(nn.Module):
def __init__(self, inplanes, type, at_res):
super(SEFeatureAt, self).__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d((1,1)),
nn.Conv2d(inplanes,inplanes//16,kernel_size=1),
nn.ReLU(),
nn.Conv2d(inplanes//16,inplanes,kernel_size=1),
nn.Sigmoid()
)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.type = type
self.at_res = at_res
self.ca = ChannelAttention(inplanes)
self.sa = SpatialAttention()
def forward(self, x):
residual = x
if self.type == "se":
attention = self.se(x)
x = x * attention
elif self.type == "ffm":
x = self.ca(x) * x
x = self.sa(x) * x
if self.at_res:
x += residual
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
class ResNet(nn.Module):
def __init__(self,
block,
layers,
nf=64,
zero_init_residual=True,
dataset='cifar',
start_class=0,
remove_last_relu=False):
super(ResNet, self).__init__()
self.remove_last_relu = remove_last_relu
self.inplanes = nf
if 'cifar' in dataset:
self.conv1 = nn.Sequential(nn.Conv2d(3, nf, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(nf), nn.ReLU(inplace=True))
elif 'imagenet' in dataset:
if start_class == 0:
self.conv1 = nn.Sequential(
nn.Conv2d(3, nf, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(nf),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
else:
# Following PODNET implmentation
self.conv1 = nn.Sequential(
nn.Conv2d(3, nf, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(nf),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
self.layer1 = self._make_layer(block, 1 * nf, layers[0])
self.layer2 = self._make_layer(block, 2 * nf, layers[1], stride=2)
self.layer3 = self._make_layer(block, 4 * nf, layers[2], stride=2)
self.layer4 = self._make_layer(block, 8 * nf, layers[3], stride=2, remove_last_relu=remove_last_relu)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.out_dim = 8 * nf * block.expansion
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, remove_last_relu=False, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
if remove_last_relu:
for i in range(1, blocks - 1):
layers.append(block(self.inplanes, planes))
layers.append(block(self.inplanes, planes, remove_last_relu=True))
else:
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def reset_bn(self):
for m in self.modules():
if isinstance(m, nn.BatchNorm2d):
m.reset_running_stats()
def forward(self, x):
x = self.conv1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# x = self.avgpool(x)
# x = x.view(x.size(0), -1)
return x
def resnet18(pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
def resnet34(pretrained=False, **kwargs):
"""Constructs a ResNet-34 model.
"""
model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet34']))
return model
def resnet50(pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
"""
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet50']))
return model
def resnet101(pretrained=False, **kwargs):
"""Constructs a ResNet-101 model.
"""
model = ResNet(Bottleneck, [3, 4, 23, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet101']))
return model
def resnet152(pretrained=False, **kwargs):
"""Constructs a ResNet-152 model.
"""
model = ResNet(Bottleneck, [3, 8, 36, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet152']))
return model
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/convnet/sew_resnet.py
================================================
import torch
import torch.nn as nn
from copy import deepcopy
try:
from torchvision.models.utils import load_state_dict_from_url
except ImportError:
from torchvision._internally_replaced_utils import load_state_dict_from_url
from braincog.base.node import *
from braincog.model_zoo.base_module import *
from braincog.datasets import is_dvs_data
from timm.models import register_model
__all__ = ['SEWResNet', 'sew_resnet18', 'sew_resnet34', 'sew_resnet50', 'sew_resnet101',
'sew_resnet152', 'sew_resnext50_32x4d', 'sew_resnext101_32x8d',
'sew_wide_resnet50_2', 'sew_wide_resnet101_2']
model_urls = {
"resnet18": "https://download.pytorch.org/models/resnet18-f37072fd.pth",
"resnet34": "https://download.pytorch.org/models/resnet34-b627a593.pth",
"resnet50": "https://download.pytorch.org/models/resnet50-0676ba61.pth",
"resnet101": "https://download.pytorch.org/models/resnet101-63fe2227.pth",
"resnet152": "https://download.pytorch.org/models/resnet152-394f9c45.pth",
"resnext50_32x4d": "https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth",
"resnext101_32x8d": "https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth",
"wide_resnet50_2": "https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth",
"wide_resnet101_2": "https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth",
}
# modified by https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py
def sew_function(x: torch.Tensor, y: torch.Tensor, cnf:str):
if cnf == 'ADD':
return x + y
elif cnf == 'AND':
return x * y
elif cnf == 'IAND':
return x * (1. - y)
else:
raise NotImplementedError
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, planes_cur,stride=1, downsample=None, groups=1,
dilation=1, norm_layer=None, cnf: str = None, node: callable = LIFNode, **kwargs):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
# if groups != 1 or base_width != 64:
# raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
self.conv=nn.Sequential(
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
BaseConvModule(inplanes, planes_cur, kernel_size=(3, 3), stride=stride,padding=(1, 1), node=node),
BaseConvModule(planes, planes_cur, kernel_size=(3, 3), padding=(1, 1), node=node),
downsample,
BaseConvModule(planes, planes_cur, kernel_size=(3, 3), padding=(1, 1), node=node),
BaseConvModule(planes, planes_cur, kernel_size=(3, 3), padding=(1, 1), node=node),)
self.cnf = cnf
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.conv2(out)
if self.downsample is not None:
identity = self.downsample_sn(self.downsample(x))
out = sew_function(identity, out, self.cnf)
return out
def extra_repr(self) -> str:
return super().extra_repr() + f'cnf={self.cnf}'
class SEWResNet(BaseModule):
def __init__(self, block, layers, c_dim=[64,128,256,512], cdim_cur=[],step=4,encode_type="direct",zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None, cnf: str = 'ADD', *args,**kwargs):
super().__init__(
step,
encode_type,
*args,
**kwargs
)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.groups=groups
self.node = LIFNode
if issubclass(self.node, BaseNode):
self.node = partial(self.node, **kwargs, step=step)
self.c_dim=c_dim
if len(cdim_cur)>0:
self.cdim_cur=cdim_cur
else:
self.cdim_cur=self.c_dim
self.inplanes = c_dim[0]
self.inplanes_cur = cdim_cur[0]
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.conv1 = nn.Conv2d(3, self.cdim_cur[0], kernel_size=3, stride=1, padding=3,
bias=False)
self.bn1 = norm_layer(self.cdim_cur[0])
self.node1 = self.node()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer_convnets = nn.ModuleList()
self.layer_convnets.append(self._make_layer(block, c_dim[0], self.cdim_cur[0],layers[0], cnf=cnf, node=self.node, **kwargs))
self.layer_convnets.append(self._make_layer(block, c_dim[1], self.cdim_cur[1], layers[1], stride=2,
dilate=replace_stride_with_dilation[0], cnf=cnf, node=self.node, **kwargs))
self.layer_convnets.append(self._make_layer(block, c_dim[2], self.cdim_cur[2], layers[2], stride=2,
dilate=replace_stride_with_dilation[1], cnf=cnf, node=self.node, **kwargs))
self.layer_convnets.append(self._make_layer(block, c_dim[3], self.cdim_cur[3], layers[3], stride=2,
dilate=replace_stride_with_dilation[2], cnf=cnf, node=self.node, **kwargs))
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# self.fc = nn.Linear(512 * block.expansion, num_classes)
self.classifer=None
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, planes_cur,blocks, stride=1, dilate=False, cnf: str=None, node: callable = None, **kwargs):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes_cur, planes_cur * block.expansion, stride),
norm_layer(planes_cur * block.expansion),
node()
)
layers =block(self.inplanes, planes, planes_cur,stride, downsample, self.groups,
previous_dilation, norm_layer, cnf, node, **kwargs)
self.inplanes = planes * block.expansion
self.inplanes_cur= planes_cur * block.expansion
# for _ in range(1, blocks):
# layers.append(block(self.inplanes, planes, groups=self.groups,
# dilation=self.dilation,
# norm_layer=norm_layer, cnf=cnf, node=node, **kwargs))
return layers
def forward_init(self, inputs):
# See note [TorchScript super()]
x = self.conv1(inputs)
x = self.bn1(x)
x = self.node1(x)
# x = self.maxpool(x)
return x
def forward_impl(self, inputs):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return x
def _sew_resnet(arch, block, layers, c_dim,cdim_cur,pretrained, progress, cnf, **kwargs):
model = SEWResNet(block, layers, c_dim=c_dim,cdim_cur=cdim_cur,cnf=cnf, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
@register_model
def sew_resnet18(c_dim=[64,128,256,512],cdim_cur=[],pretrained=False, progress=True, cnf: str = None, **kwargs):
"""
:param pretrained: If True, the SNN will load parameters from the ANN pre-trained on ImageNet
:type pretrained: bool
:param progress: If True, displays a progress bar of the download to stderr
:type progress: bool
:param cnf: the name of spike-element-wise function
:type cnf: str
:param node: a spiking neuron layer
:type node: callable
:param kwargs: kwargs for `node`
:type kwargs: dict
:return: Spiking ResNet-18
:rtype: torch.nn.Module
The spike-element-wise ResNet-18 `"Deep Residual Learning in Spiking Neural Networks" `_ modified by the ResNet-18 model from `"Deep Residual Learning for Image Recognition" `_
"""
return _sew_resnet('resnet18', BasicBlock, [2, 2, 2, 2], c_dim,cdim_cur,pretrained, progress, 'ADD', **kwargs)
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/convnet/utils.py
================================================
import numpy as np
import torch
from torch import nn
from torch.optim import SGD
import torch.nn.functional as F
from inclearn.tools.metrics import ClassErrorMeter, AverageValueMeter
def finetune_last_layer(
logger,
network,
loader,
n_class,
nepoch=30,
lr=0.1,
scheduling=[15, 35],
lr_decay=0.1,
weight_decay=5e-4,
loss_type="ce",
temperature=5.0,
test_loader=None,
samples_per_cls = []
):
network.eval()
#if hasattr(network.module, "convnets"):
# for net in network.module.convnets:
# net.eval()
#else:
# network.module.convnet.eval()
optim = SGD(network.module.classifier.parameters(), lr=lr, momentum=0.9, weight_decay=weight_decay)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optim, scheduling, gamma=lr_decay)
if loss_type == "ce":
criterion = nn.CrossEntropyLoss()
else:
criterion = nn.BCEWithLogitsLoss()
logger.info("Begin finetuning last layer")
for i in range(nepoch):
total_loss = 0.0
total_correct = 0.0
total_count = 0
# print(f"dataset loader length {len(loader.dataset)}")
for inputs, targets in loader:
inputs, targets = inputs.cuda(), targets.cuda()
if loss_type == "bce":
targets = to_onehot(targets, n_class)
outputs = network(inputs)['logit']
_, preds = outputs.max(1)
optim.zero_grad()
if loss_type == "cb":
loss = CB_loss(targets, outputs / temperature, samples_per_cls, n_class, "focal")
else:
loss = criterion(outputs / temperature, targets)
loss.backward()
optim.step()
total_loss += loss * inputs.size(0)
total_correct += (preds == targets).sum()
total_count += inputs.size(0)
if test_loader is not None:
test_correct = 0.0
test_count = 0.0
with torch.no_grad():
for inputs, targets in test_loader:
outputs = network(inputs.cuda())['logit']
_, preds = outputs.max(1)
test_correct += (preds.cpu() == targets).sum().item()
test_count += inputs.size(0)
scheduler.step()
if test_loader is not None:
logger.info(
"Epoch %d finetuning loss %.3f acc %.3f Eval %.3f" %
(i, total_loss.item() / total_count, total_correct.item() / total_count, test_correct / test_count))
else:
logger.info("Epoch %d finetuning loss %.3f acc %.3f" %
(i, total_loss.item() / total_count, total_correct.item() / total_count))
return network
def extract_features(task_i,model, loader,mask=None):
targets, features = [], []
model.eval()
with torch.no_grad():
for _inputs, _targets in loader:
_inputs = _inputs.cuda()
_targets = _targets.numpy()
_features = model(task_i,_inputs,mask)['feature'].detach().cpu().numpy()
features.append(_features)
targets.append(_targets)
return np.concatenate(features), np.concatenate(targets)
def calc_class_mean(network, loader, class_idx, metric):
EPSILON = 1e-8
features, targets = extract_features(network, loader)
# norm_feats = features/(np.linalg.norm(features, axis=1)[:,np.newaxis]+EPSILON)
# examplar_mean = norm_feats.mean(axis=0)
examplar_mean = features.mean(axis=0)
if metric == "cosine" or metric == "weight":
examplar_mean /= (np.linalg.norm(examplar_mean) + EPSILON)
return examplar_mean
def update_classes_mean(network, inc_dataset, n_classes, task_size, share_memory=None, metric="cosine", EPSILON=1e-8):
loader = inc_dataset._get_loader(inc_dataset.data_inc,
inc_dataset.targets_inc,
shuffle=False,
share_memory=share_memory,
mode="test")
class_means = np.zeros((n_classes, network.module.features_dim))
count = np.zeros(n_classes)
network.eval()
with torch.no_grad():
for x, y in loader:
feat = network(x.cuda())['feature']
for lbl in torch.unique(y):
class_means[lbl] += feat[y == lbl].sum(0).cpu().numpy()
count[lbl] += feat[y == lbl].shape[0]
for i in range(n_classes):
class_means[i] /= count[i]
if metric == "cosine" or metric == "weight":
class_means[i] /= (np.linalg.norm(class_means) + EPSILON)
return class_means
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/datasets/__init__.py
================================================
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/datasets/data.py
================================================
import random
import cv2
import numpy as np
import os.path as osp
from copy import deepcopy
from PIL import Image
import multiprocessing as mp
from multiprocessing import Pool
import albumentations as A
from albumentations.pytorch import ToTensorV2
import warnings
warnings.filterwarnings("ignore", "Corrupt EXIF data", UserWarning)
import torch
from torch.utils.data import DataLoader
from torch.utils.data.sampler import SubsetRandomSampler, WeightedRandomSampler
from torchvision import datasets, transforms
from torchvision.datasets.folder import pil_loader
from .dataset import get_dataset
from inclearn.tools.data_utils import construct_balanced_subset
def get_data_folder(data_folder, dataset_name):
return osp.join(data_folder, dataset_name)
class IncrementalDataset:
def __init__(
self,
trial_i,
dataset_name,
random_order=False,
shuffle=True,
workers=10,
batch_size=128,
seed=1,
increment=10,
validation_split=0.0,
resampling=False,
data_folder="./data",
start_class=0,
torc = False
):
# The info about incremental split
self.torc=torc
self.trial_i = trial_i
self.start_class = start_class
#the number of classes for each step in incremental stage
self.task_size = increment
self.increments = []
self.random_order = random_order
self.validation_split = validation_split
#-------------------------------------
#Dataset Info
#-------------------------------------
self.data_folder = get_data_folder('/data0/datasets/', 'CIFAR100/')
self.dataset_name = dataset_name
# self.transform = transform
self.train_dataset = None
self.test_dataset = None
self.n_tot_cls = -1
datasets = get_dataset(dataset_name)
self._setup_data(datasets)
self._workers = workers
self._shuffle = shuffle
self._batch_size = batch_size
self._resampling = resampling
#Currently, don't support multiple datasets
self.train_transforms = datasets.train_transforms
self.test_transforms = datasets.test_transforms
#torchvision or albumentations
self.transform_type = datasets.transform_type
# memory Mt
self.data_memory = None
self.targets_memory = None
# Incoming data D_t
self.data_cur = None
self.targets_cur = None
# Available data \tilde{D}_t = D_t \cup M_t
self.data_inc = None # Cur task data + memory
self.targets_inc = None
# Available data stored in cpu memory.
self.shared_data_inc = None
self.shared_test_data = None
#Current states for Incremental Learning Stage.
self._current_task = 0
@property
def n_tasks(self):
return len(self.increments)
def new_task(self,task_i):
if self._current_task >= len(self.increments):
raise Exception("No more tasks.")
min_class, max_class, x_train, y_train, x_test, y_test,x_val, y_val = self._get_cur_step_data_for_raw_data(task_i)
self.data_cur, self.targets_cur = x_train, y_train
if self.torc:
if self.data_memory is not None:
print("Set memory of size: {}.".format(len(self.data_memory)))
if len(self.data_memory) != 0:
x_train = np.concatenate((x_train, self.data_memory))
y_train = np.concatenate((y_train, self.targets_memory))
self.data_inc, self.targets_inc = x_train, y_train
self.data_test_inc, self.targets_test_inc = x_test, y_test
train_loader = self._get_loader(x_train, y_train, mode="train")
if self.torc:
val_loader = self._get_loader(x_val, y_val, shuffle=False, mode="test")
test_loader = self._get_loader(x_test, y_test, shuffle=False, mode="test")
else:
val_loader=[]
test_loader=[]
for i in range(len(x_test)):
val_loader.append(self._get_loader(x_test[i], y_test[i], shuffle=False, mode="test"))
test_loader.append(self._get_loader(x_test[i], y_test[i], shuffle=False, mode="test"))
task_info = {
"min_class": min_class,
"max_class": max_class,
"increment": self.increments[self._current_task],
"task": self._current_task,
"max_task": len(self.increments),
"n_train_data": len(x_train),
"n_test_data": len(y_train),
}
self._current_task += 1
return task_info, train_loader, val_loader, test_loader
def _get_cur_step_data_for_raw_data(self, task_i):
min_class = sum(self.increments[:self._current_task])
max_class = sum(self.increments[:self._current_task + 1])
if self.torc:
x_train, y_train = self._select(task_i,self.data_train, self.targets_train, low_range=min_class, high_range=max_class)
x_test, y_test = self._select(task_i,self.data_test, self.targets_test, low_range=0, high_range=max_class)
x_val, y_val = self._select(task_i,self.data_test, self.targets_test, low_range=min_class, high_range=max_class)
else:
x_test=[]
y_test=[]
x_train, y_train = self._select(task_i,self.data_train, self.targets_train, low_range=min_class, high_range=max_class)
min_c=0
num_c=max_class-min_class
for taski in range(task_i+1):
x_test_i, y_test_i = self._select(taski,self.data_test, self.targets_test, low_range=min_c, high_range=min_c+num_c)
x_test.append(x_test_i)
y_test.append(y_test_i)
min_c+=num_c
x_val=x_test
y_val=y_test
return min_class, max_class, x_train, y_train, x_test, y_test,x_val, y_val
#--------------------------------
# Data Setup
#--------------------------------
def _setup_data(self, dataset):
# FIXME: handles online loading of images
self.data_train, self.targets_train = [], []
self.data_test, self.targets_test = [], []
self.data_val, self.targets_val = [], []
self.increments = []
self.class_order = []
current_class_idx = 0 # When using multiple datasets
train_dataset = dataset(self.data_folder, train=True)
test_dataset = dataset(self.data_folder, train=False)
self.train_dataset = train_dataset
self.test_datasets = test_dataset
self.n_tot_cls = self.train_dataset.n_cls #number of classes in whole dataset
self._setup_data_for_raw_data(dataset, train_dataset, test_dataset, current_class_idx)
# !list
self.data_train = np.concatenate(self.data_train)
self.targets_train = np.concatenate(self.targets_train)
self.data_val = np.concatenate(self.data_val)
self.targets_val = np.concatenate(self.targets_val)
self.data_test = np.concatenate(self.data_test)
self.targets_test = np.concatenate(self.targets_test)
def _setup_data_for_raw_data(self, dataset, train_dataset, test_dataset, current_class_idx=0):
increment = self.task_size
x_train, y_train = train_dataset.data, np.array(train_dataset.targets)
x_val, y_val, x_train, y_train = self._split_per_class(x_train, y_train, self.validation_split)
x_test, y_test = test_dataset.data, np.array(test_dataset.targets)
# Get Class Order
order = [i for i in range(len(np.unique(y_train)))]
if self.random_order:
random.seed(self._seed) # Ensure that following order is determined by seed:
random.shuffle(order)
elif dataset.class_order(self.trial_i) is not None:
order = dataset.class_order(self.trial_i)
self.class_order.append(order)
y_train = self._map_new_class_index(y_train, order)
y_val = self._map_new_class_index(y_val, order)
y_test = self._map_new_class_index(y_test, order)
y_train += current_class_idx
y_val += current_class_idx
y_test += current_class_idx
current_class_idx += len(order)
if self.start_class == 0:
# increment = 10, 那么 increments 就是 [10, 10, 10, 10, ...]
self.increments = [increment for _ in range(len(order) // increment)]
else:
self.increments.append(self.start_class)
for _ in range((len(order) - self.start_class) // increment):
self.increments.append(increment)
self.data_train.append(x_train)
self.targets_train.append(y_train)
self.data_val.append(x_val)
self.targets_val.append(y_val)
self.data_test.append(x_test)
self.targets_test.append(y_test)
@staticmethod
def _split_per_class(x, y, validation_split=0.0):
"""Splits train data for a subset of validation data.
Split is done so that each class has a much data.
"""
shuffled_indexes = np.random.permutation(x.shape[0])
x = x[shuffled_indexes]
y = y[shuffled_indexes]
x_val, y_val = [], []
x_train, y_train = [], []
for class_id in np.unique(y):
class_indexes = np.where(y == class_id)[0]
nb_val_elts = int(class_indexes.shape[0] * validation_split)
val_indexes = class_indexes[:nb_val_elts]
train_indexes = class_indexes[nb_val_elts:]
x_val.append(x[val_indexes])
y_val.append(y[val_indexes])
x_train.append(x[train_indexes])
y_train.append(y[train_indexes])
# !list
x_val, y_val = np.concatenate(x_val), np.concatenate(y_val)
x_train, y_train = np.concatenate(x_train), np.concatenate(y_train)
return x_val, y_val, x_train, y_train
@staticmethod
def _map_new_class_index(y, order):
"""Transforms targets for new class order."""
return np.array(list(map(lambda x: order.index(x), y)))
def _select(self, task_i,x, y, low_range=0, high_range=0):
idxes = sorted(np.where(np.logical_and(y >= low_range, y < high_range))[0])
if isinstance(x, list):
selected_x = [x[idx] for idx in idxes]
else:
selected_x = x[idxes]
if self.torc:
selected_y=y[idxes]
else:
selected_y=y[idxes]-low_range
return selected_x, selected_y
#--------------------------------
# Get Loader
#--------------------------------
def get_datainc_loader(self, mode='train'):
print(self.data_inc.shape)
train_loader = self._get_loader(self.data_inc, self.targets_inc, mode=mode)
return train_loader
def get_custom_loader_from_memory(self, class_indexes, mode="test"):
if not isinstance(class_indexes, list):
class_indexes = [class_indexes]
data, targets = [], []
for class_index in class_indexes:
class_data, class_targets = self._select(self.data_memory,
self.targets_memory,
low_range=class_index,
high_range=class_index + 1)
data.append(class_data)
targets.append(class_targets)
data = np.concatenate(data)
targets = np.concatenate(targets)
return data, targets, self._get_loader(data, targets, shuffle=False, mode=mode)
def _get_loader(self, x, y, share_memory=None, shuffle=True, mode="train", batch_size=None, resample=None):
if "balanced" in mode:
x, y = construct_balanced_subset(x, y)
batch_size = batch_size if batch_size is not None else self._batch_size
if "train" in mode:
trsf = self.train_transforms
resample_ = self._resampling if resample is None else True
if resample_ is False:
sampler = None
else:
sampler = get_weighted_random_sampler(y)
shuffle = False if resample_ is True else True
elif "test" in mode:
trsf = self.test_transforms
sampler = None
elif mode == "flip":
if "imagenet" in self.dataset_name:
trsf = A.Compose([A.HorizontalFlip(p=1.0), *self.test_transforms.transforms])
else:
trsf = transforms.Compose([transforms.RandomHorizontalFlip(p=1.0), *self.test_transforms.transforms])
sampler = None
else:
raise NotImplementedError("Unknown mode {}.".format(mode))
return DataLoader(DummyDataset(x,
y,
trsf,
trsf_type=self.transform_type,
share_memory_=share_memory,
dataset_name=self.dataset_name),
batch_size=batch_size,
shuffle=shuffle,
num_workers=self._workers,
sampler=sampler,
pin_memory=True)
def get_custom_loader(self, class_indexes, mode="test", data_source="train", imgs=None, tgts=None):
"""Returns a custom loader.
:param class_indexes: A list of class indexes that we want.
:param mode: Various mode for the transformations applied on it.
:param data_source: Whether to fetch from the train, val, or test set.
:return: The raw data and a loader.
"""
if not isinstance(class_indexes, list): # TODO: deprecated, should always give a list
class_indexes = [class_indexes]
if data_source == "train":
x, y = self.data_inc, self.targets_inc
elif data_source == "val":
x, y = self.data_val, self.targets_val
elif data_source == "test":
x, y = self.data_test, self.targets_test
elif data_source == 'specified' and imgs is not None and tgts is not None:
x, y = imgs, tgts
else:
raise ValueError("Unknown data source <{}>.".format(data_source))
data, targets = [], []
for class_index in class_indexes:
class_data, class_targets, = self._select(x, y, low_range=class_index, high_range=class_index + 1)
data.append(class_data)
targets.append(class_targets)
data = np.concatenate(data)
targets = np.concatenate(targets)
return data, targets, self._get_loader(data, targets, shuffle=False, mode=mode)
class DummyDataset(torch.utils.data.Dataset):
def __init__(self, x, y, trsf, trsf_type, share_memory_=None, dataset_name=None):
self.dataset_name = dataset_name
self.x, self.y = x, y
self.trsf = trsf
self.trsf_type = trsf_type
self.manager = mp.Manager()
self.buffer_size = 4000000
if share_memory_ is None:
if self.x.shape[0] > self.buffer_size:
self.share_memory = self.manager.list([None for i in range(self.buffer_size)])
else:
self.share_memory = self.manager.list([None for i in range(len(x))])
else:
self.share_memory = share_memory_
def __len__(self):
if isinstance(self.x, list):
return len(self.x)
else:
return self.x.shape[0]
def __getitem__(self, idx):
x, y, = self.x[idx], self.y[idx]
if isinstance(x, np.ndarray):
# assume cifar
x = Image.fromarray(x)
else:
# Assume the dataset is ImageNet
if idx < len(self.share_memory):
if self.share_memory[idx] is not None:
x = self.share_memory[idx]
else:
x = cv2.imread(x)
x = x[:, :, ::-1]
self.share_memory[idx] = x
else:
x = cv2.imread(x)
x = x[:, :, ::-1]
if 'torch' in self.trsf_type:
x = self.trsf(x)
else:
x = self.trsf(image=x)['image']
return x, y
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/datasets/dataset.py
================================================
import os.path as osp
import numpy as np
import glob
from albumentations.pytorch import ToTensorV2
from torchvision import datasets, transforms
import torch
from inclearn.tools.cutout import Cutout
from inclearn.tools.autoaugment_extra import ImageNetPolicy
def get_datasets(dataset_names):
return [get_dataset(dataset_name) for dataset_name in dataset_names.split("-")]
def get_dataset(dataset_name):
if dataset_name == "cifar10":
return iCIFAR10
elif dataset_name == "cifar100":
return iCIFAR100
elif "imagenet100" in dataset_name:
return iImageNet100
else:
raise NotImplementedError("Unknown dataset {}.".format(dataset_name))
class DataHandler:
base_dataset = None
train_transforms = []
common_transforms = [ToTensorV2()]
class_order = None
class iCIFAR10(DataHandler):
base_dataset_cls = datasets.cifar.CIFAR10
transform_type = 'torchvision'
train_transforms = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
# transforms.ColorJitter(brightness=63 / 255),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
test_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
def __init__(self, data_folder, train, is_fine_label=False):
self.base_dataset = self.base_dataset_cls(data_folder, train=train, download=True)
self.data = self.base_dataset.data
self.targets = self.base_dataset.targets
self.n_cls = 10
@property
def is_proc_inc_data(self):
return False
@classmethod
def class_order(cls, trial_i):
return [4, 0, 2, 5, 8, 3, 1, 6, 9, 7]
class iCIFAR100(iCIFAR10):
label_list = [
'apple', 'aquarium_fish', 'baby', 'bear', 'beaver', 'bed', 'bee', 'beetle', 'bicycle', 'bottle', 'bowl', 'boy',
'bridge', 'bus', 'butterfly', 'camel', 'can', 'castle', 'caterpillar', 'cattle', 'chair', 'chimpanzee', 'clock',
'cloud', 'cockroach', 'couch', 'crab', 'crocodile', 'cup', 'dinosaur', 'dolphin', 'elephant', 'flatfish',
'forest', 'fox', 'girl', 'hamster', 'house', 'kangaroo', 'keyboard', 'lamp', 'lawn_mower', 'leopard', 'lion',
'lizard', 'lobster', 'man', 'maple_tree', 'motorcycle', 'mountain', 'mouse', 'mushroom', 'oak_tree', 'orange',
'orchid', 'otter', 'palm_tree', 'pear', 'pickup_truck', 'pine_tree', 'plain', 'plate', 'poppy', 'porcupine',
'possum', 'rabbit', 'raccoon', 'ray', 'road', 'rocket', 'rose', 'sea', 'seal', 'shark', 'shrew', 'skunk',
'skyscraper', 'snail', 'snake', 'spider', 'squirrel', 'streetcar', 'sunflower', 'sweet_pepper', 'table', 'tank',
'telephone', 'television', 'tiger', 'tractor', 'train', 'trout', 'tulip', 'turtle', 'wardrobe', 'whale',
'willow_tree', 'wolf', 'woman', 'worm'
]
base_dataset_cls = datasets.cifar.CIFAR100
transform_type = 'torchvision'
train_transforms = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=63 / 255),
transforms.ToTensor(),
transforms.Normalize((0.5071, 0.4867, 0.4408), (0.2675, 0.2565, 0.2761)),
])
test_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5071, 0.4867, 0.4408), (0.2675, 0.2565, 0.2761)),
])
def __init__(self, data_folder, train, is_fine_label=False):
self.base_dataset = self.base_dataset_cls(data_folder, train=train, download=True)
self.data = self.base_dataset.data
self.targets = self.base_dataset.targets
self.n_cls = 100
self.transform_type = 'torchvision'
@property
def is_proc_inc_data(self):
return False
@classmethod
def class_order(cls, trial_i):
return [
87, 0, 52, 58, 44, 91, 68, 97, 51, 15, 94, 92, 10, 72, 49, 78, 61, 14, 8, 86, 84, 96, 18, 24, 32, 45,
88, 11, 4, 67, 69, 66, 77, 47, 79, 93, 29, 50, 57, 83, 17, 81, 41, 12, 37, 59, 25, 20, 80, 73, 1, 28, 6,
46, 62, 82, 53, 9, 31, 75, 38, 63, 33, 74, 27, 22, 36, 3, 16, 21, 60, 19, 70, 90, 89, 43, 5, 42, 65, 76,
40, 30, 23, 85, 2, 95, 56, 48, 71, 64, 98, 13, 99, 7, 34, 55, 54, 26, 35, 39
]
class DataHandler:
base_dataset = None
train_transforms = []
common_transforms = [ToTensorV2()]
class_order = None
class iImageNet100(DataHandler):
base_dataset_cls = datasets.ImageFolder
transform_type = 'torchvision'
train_transforms = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
Cutout(n_holes=1, length=16),
transforms.ToPILImage(),
transforms.RandomResizedCrop(32),
transforms.RandomHorizontalFlip(),
ImageNetPolicy(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
test_transforms = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
transforms.ToPILImage(),
transforms.Resize(32),
transforms.CenterCrop(32),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
def __init__(self, data_folder, train, is_fine_label=False):
if train is True:
self.base_dataset = self.base_dataset_cls(osp.join(data_folder, "train"))
else:
self.base_dataset = self.base_dataset_cls(osp.join(data_folder, "val"))
self.data, self.targets = zip(*self.base_dataset.samples)
self.data = np.array(self.data)
self.targets = np.array(self.targets)
self.n_cls = 200
@property
def is_proc_inc_data(self):
return False
@classmethod
def class_order(cls, trial_i):
return [
68, 56, 78, 8, 23, 84, 90, 65, 74, 76, 40, 89, 3, 92, 55, 9, 26, 80, 43, 38, 58, 70, 77, 1, 85, 19, 17, 50,
28, 53, 13, 81, 45, 82, 6, 59, 83, 16, 15, 44, 91, 41, 72, 60, 79, 52, 20, 10, 31, 54, 37, 95, 14, 71, 96,
98, 97, 2, 64, 66, 42, 22, 35, 86, 24, 34, 87, 21, 99, 0, 88, 27, 18, 94, 11, 12, 47, 25, 30, 46, 62, 69,
36, 61, 7, 63, 75, 5, 32, 4, 51, 48, 73, 93, 39, 67, 29, 49, 57, 33,
168, 156, 178, 108, 123, 184, 190, 165, 174, 176, 140, 189, 103,
192, 155, 109, 126, 180, 143, 138, 158, 170, 177, 101, 185, 119,
117, 150, 128, 153, 113, 181, 145, 182, 106, 159, 183, 116, 115,
144, 191, 141, 172, 160, 179, 152, 120, 110, 131, 154, 137, 195,
114, 171, 196, 198, 197, 102, 164, 166, 142, 122, 135, 186, 124,
134, 187, 121, 199, 100, 188, 127, 118, 194, 111, 112, 147, 125,
130, 146, 162, 169, 136, 161, 107, 163, 175, 105, 132, 104, 151,
148, 173, 193, 139, 167, 129, 149, 157, 133,
268, 256, 278, 208, 223, 284, 290, 265, 274, 276, 240, 289, 203,
292, 255, 209, 226, 280, 243, 238, 258, 270, 277, 201, 285, 219,
217, 250, 228, 253, 213, 281, 245, 282, 206, 259, 283, 216, 215,
244, 291, 241, 272, 260, 279, 252, 220, 210, 231, 254, 237, 295,
214, 271, 296, 298, 297, 202, 264, 266, 242, 222, 235, 286, 224,
234, 287, 221, 299, 200, 288, 227, 218, 294, 211, 212, 247, 225,
230, 246, 262, 269, 236, 261, 207, 263, 275, 205, 232, 204, 251,
248, 273, 293, 239, 267, 229, 249, 257, 233, 368, 356, 378, 308,
323, 384, 390, 365, 374, 376, 340, 389, 303, 392, 355, 309, 326,
380, 343, 338, 358, 370, 377, 301, 385, 319, 317, 350, 328, 353,
313, 381, 345, 382, 306, 359, 383, 316, 315, 344, 391, 341, 372,
360, 379, 352, 320, 310, 331, 354, 337, 395, 314, 371, 396, 398,
397, 302, 364, 366, 342, 322, 335, 386, 324, 334, 387, 321, 399,
300, 388, 327, 318, 394, 311, 312, 347, 325, 330, 346, 362, 369,
336, 361, 307, 363, 375, 305, 332, 304, 351, 348, 373, 393, 339,
367, 329, 349, 357, 333,
468, 456, 478, 408, 423, 484, 490, 465, 474, 476, 440, 489, 403,
492, 455, 409, 426, 480, 443, 438, 458, 470, 477, 401, 485, 419,
417, 450, 428, 453, 413, 481, 445, 482, 406, 459, 483, 416, 415,
444, 491, 441, 472, 460, 479, 452, 420, 410, 431, 454, 437, 495,
414, 471, 496, 498, 497, 402, 464, 466, 442, 422, 435, 486, 424,
434, 487, 421, 499, 400, 488, 427, 418, 494, 411, 412, 447, 425,
430, 446, 462, 469, 436, 461, 407, 463, 475, 405, 432, 404, 451,
448, 473, 493, 439, 467, 429, 449, 457, 433, 568, 556, 578, 508,
523, 584, 590, 565, 574, 576, 540, 589, 503, 592, 555, 509, 526,
580, 543, 538, 558, 570, 577, 501, 585, 519, 517, 550, 528, 553,
513, 581, 545, 582, 506, 559, 583, 516, 515, 544, 591, 541, 572,
560, 579, 552, 520, 510, 531, 554, 537, 595, 514, 571, 596, 598,
597, 502, 564, 566, 542, 522, 535, 586, 524, 534, 587, 521, 599,
500, 588, 527, 518, 594, 511, 512, 547, 525, 530, 546, 562, 569,
536, 561, 507, 563, 575, 505, 532, 504, 551, 548, 573, 593, 539,
567, 529, 549, 557, 533,
668, 656, 678, 608, 623, 684, 690, 665, 674, 676, 640, 689, 603,
692, 655, 609, 626, 680, 643, 638, 658, 670, 677, 601, 685, 619,
617, 650, 628, 653, 613, 681, 645, 682, 606, 659, 683, 616, 615,
644, 691, 641, 672, 660, 679, 652, 620, 610, 631, 654, 637, 695,
614, 671, 696, 698, 697, 602, 664, 666, 642, 622, 635, 686, 624,
634, 687, 621, 699, 600, 688, 627, 618, 694, 611, 612, 647, 625,
630, 646, 662, 669, 636, 661, 607, 663, 675, 605, 632, 604, 651,
648, 673, 693, 639, 667, 629, 649, 657, 633, 768, 756, 778, 708,
723, 784, 790, 765, 774, 776, 740, 789, 703, 792, 755, 709, 726,
780, 743, 738, 758, 770, 777, 701, 785, 719, 717, 750, 728, 753,
713, 781, 745, 782, 706, 759, 783, 716, 715, 744, 791, 741, 772,
760, 779, 752, 720, 710, 731, 754, 737, 795, 714, 771, 796, 798,
797, 702, 764, 766, 742, 722, 735, 786, 724, 734, 787, 721, 799,
700, 788, 727, 718, 794, 711, 712, 747, 725, 730, 746, 762, 769,
736, 761, 707, 763, 775, 705, 732, 704, 751, 748, 773, 793, 739,
767, 729, 749, 757, 733,
868, 856, 878, 808, 823, 884, 890, 865, 874, 876, 840, 889, 803,
892, 855, 809, 826, 880, 843, 838, 858, 870, 877, 801, 885, 819,
817, 850, 828, 853, 813, 881, 845, 882, 806, 859, 883, 816, 815,
844, 891, 841, 872, 860, 879, 852, 820, 810, 831, 854, 837, 895,
814, 871, 896, 898, 897, 802, 864, 866, 842, 822, 835, 886, 824,
834, 887, 821, 899, 800, 888, 827, 818, 894, 811, 812, 847, 825,
830, 846, 862, 869, 836, 861, 807, 863, 875, 805, 832, 804, 851,
848, 873, 893, 839, 867, 829, 849, 857, 833, 968, 956, 978, 908,
923, 984, 990, 965, 974, 976, 940, 989, 903, 992, 955, 909, 926,
980, 943, 938, 958, 970, 977, 901, 985, 919, 917, 950, 928, 953,
913, 981, 945, 982, 906, 959, 983, 916, 915, 944, 991, 941, 972,
960, 979, 952, 920, 910, 931, 954, 937, 995, 914, 971, 996, 998,
997, 902, 964, 966, 942, 922, 935, 986, 924, 934, 987, 921, 999,
900, 988, 927, 918, 994, 911, 912, 947, 925, 930, 946, 962, 969,
936, 961, 907, 963, 975, 905, 932, 904, 951, 948, 973, 993, 939,
967, 929, 949, 957, 933
]
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/models/__init__.py
================================================
from .incmodel import IncModel
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/models/base.py
================================================
import abc
import logging
import torch
import torch.nn.functional as F
import numpy as np
from inclearn.tools.metrics import ClassErrorMeter
LOGGER = logging.Logger("IncLearn", level="INFO")
class IncrementalLearner(abc.ABC):
"""Base incremental learner.
Methods are called in this order (& repeated for each new task):
1. set_task_info
2. before_task
3. train_task
4. after_task
5. eval_task
"""
def __init__(self, *args, **kwargs):
self._increments = []
self._seen_classes = []
def set_task_info(self, task, total_n_classes, increment, n_train_data, n_test_data, n_tasks):
self._task = task
self._task_size = increment
self._increments.append(self._task_size)
self._total_n_classes = total_n_classes
self._n_train_data = n_train_data
self._n_test_data = n_test_data
self._n_tasks = n_tasks
def before_task(self, taski, inc_dataset,mask,min_dist,all_dist):
LOGGER.info("Before task")
self.eval()
self._before_task(taski, inc_dataset,mask,min_dist,all_dist)
def train_task(self, task_i,train_loader, val_loader,mask,min_dist,all_dist):
LOGGER.info("train task")
self.train()
self._train_task(task_i,train_loader, val_loader,mask,min_dist,all_dist)
def after_task(self, taski, inc_dataset,mask):
LOGGER.info("after task")
self.eval()
self._after_task(taski, inc_dataset,mask)
def eval_task(self, task_i,data_loader,mask):
LOGGER.info("eval task")
self.eval()
return self._eval_task(task_i,data_loader,mask)
def get_memory(self):
return None
def eval(self):
raise NotImplementedError
def train(self):
raise NotImplementedError
def _before_task(self, data_loader):
pass
def _train_task(self, train_loader, val_loader):
raise NotImplementedError
def _after_task(self, data_loader):
pass
def _eval_task(self, data_loader):
raise NotImplementedError
@property
def _new_task_index(self):
return self._task * self._task_size
@property
def _memory_per_class(self):
"""Returns the number of examplars per class."""
return self._memory_size.mem_per_cls
def _after_epoch(self, epoch, avg_loss, train_new_accu, train_old_accu, accu):
self._run.log_scalar(f"train_loss_trial{self._trial_i}_task{self._task}", avg_loss, epoch + 1)
self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/train_loss", avg_loss, epoch + 1)
# self._run.log_scalar(f"train_new_accu_trial{self._trial_i}_task{self._task}",
# train_new_accu.value()[0], epoch + 1)
# self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/train_new_accu",
# train_new_accu.value()[0], epoch + 1)
# if self._task != 0:
# self._run.log_scalar(f"train_old_accu_trial{self._trial_i}_task{self._task}",
# train_old_accu.value()[0], epoch + 1)
# self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/train_old_accu",
# train_old_accu.value()[0], epoch + 1)
self._run.log_scalar(f"train_accu_trial{self._trial_i}_task{self._task}", accu.value()[0], epoch + 1)
self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/train_accu", accu.value()[0], epoch + 1)
# self._tensorboard.close()
self._tensorboard.flush()
def _validation(self, val_loader, epoch):
topk = 5 if self._n_classes >= 5 else self._n_classes
if self._val_per_n_epoch != -1 and epoch % self._val_per_n_epoch == 0:
_val_loss = 0
_val_accu = ClassErrorMeter(accuracy=True, topk=[1, topk])
_val_new_accu = ClassErrorMeter(accuracy=True)
_val_old_accu = ClassErrorMeter(accuracy=True)
self._parallel_network.eval()
with torch.no_grad():
for i, (inputs, targets) in enumerate(val_loader, 1):
old_classes = targets < (self._n_classes - self._task_size)
new_classes = targets >= (self._n_classes - self._task_size)
val_loss, _ = self._forward_loss(
inputs,
targets,
old_classes,
new_classes,
accu=_val_accu,
old_accu=_val_old_accu,
new_accu=_val_new_accu,
)
_val_loss += val_loss.item()
self._ex.logger.info(
f"epoch{epoch} val acc:{_val_accu.value()[0]:.2f}, val top5acc:{_val_accu.value()[1]:.2f}")
# Test accu
self._run.log_scalar(f"test_accu_trial{self._trial_i}_task{self._task}", _val_accu.value()[0], epoch + 1)
self._run.log_scalar(f"test_5accu_trial{self._trial_i}_task{self._task}", _val_accu.value()[1], epoch + 1)
self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/test_accu",
_val_accu.value()[0], epoch + 1)
self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/test_5accu",
_val_accu.value()[1], epoch + 1)
# Test new accu
self._run.log_scalar(f"test_new_accu_trial{self._trial_i}_task{self._task}",
_val_new_accu.value()[0], epoch + 1)
self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/test_new_accu",
_val_new_accu.value()[0], epoch + 1)
# Test old accu
if self._task != 0:
self._run.log_scalar(f"test_old_accu_trial{self._trial_i}_task{self._task}",
_val_old_accu.value()[0], epoch + 1)
self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/test_old_accu",
_val_old_accu.value()[0], epoch + 1)
# Test loss
self._run.log_scalar(f"test_loss_trial{self._trial_i}_task{self._task}", round(_val_loss / i, 3), epoch + 1)
self._tensorboard.add_scalar(f"trial{self._trial_i}_task{self._task}/test_loss", round(_val_loss / i, 3),
epoch + 1)
self._tensorboard.close()
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/models/incmodel.py
================================================
import numpy as np
import random
import time
import math
import os
from copy import deepcopy
from scipy.spatial.distance import cdist
from torchvision.utils import save_image
import torch
# import pdb
from torch.nn import DataParallel
from torch.nn import functional as F
from torch import nn
from inclearn.convnet import network
from inclearn.models.base import IncrementalLearner
from inclearn.tools import factory, utils
from inclearn.tools.metrics import ClassErrorMeter
from inclearn.tools.memory import MemorySize
from inclearn.tools.scheduler import GradualWarmupScheduler
from inclearn.convnet.utils import extract_features, update_classes_mean, finetune_last_layer
# Constants
EPSILON = 1e-8
class IncModel(IncrementalLearner):
def __init__(self, cfg, trial_i, _run, ex, tensorboard, inc_dataset):
super().__init__()
self._cfg = cfg
self._device = cfg['device']
self._ex = ex
self._run = _run # the sacred _run object.
# Data
self._inc_dataset = inc_dataset
self._n_classes = 0
self.classnum_list = []
self.sample_list = []
self._trial_i = trial_i # which class order is used
# Optimizer paras
self._opt_name = cfg["optimizer"]
self._warmup = cfg['warmup']
self._lr = cfg["lr"]
self._weight_decay = cfg["weight_decay"]
self._n_epochs = cfg["epochs"]
self._scheduling = cfg["scheduling"]
self._lr_decay = cfg["lr_decay"]
self.torc=cfg['distillation']
self.prune = cfg.get('prune', False)
# Logging
self._tensorboard = tensorboard
if f"trial{self._trial_i}" not in self._run.info:
self._run.info[f"trial{self._trial_i}"] = {}
self._val_per_n_epoch = cfg["val_per_n_epoch"]
# Model
self._dea = cfg['dea'] # Whether to expand the representation
self._network = network.BasicNet(
cfg["convnet"],
cfg=cfg,
nf=cfg["channel"],
device=self._device,
use_bias=cfg["use_bias"],
dataset=cfg["dataset"],
)
if self._cfg.get("caculate_params", False):
self._parallel_network = self._network
else:
# 并行计算
# gpus = [0, 1, 2, 3]
# self._parallel_network = DataParallel(self._network, device_ids=gpus, output_device=gpus[0])
self._parallel_network = DataParallel(self._network)
self._train_head = cfg["train_head"]
self._infer_head = cfg["infer_head"]
self._old_model = None
# Learning
self._temperature = cfg["temperature"]
self._distillation = cfg["distillation"]
self.lamb = cfg["distlamb"]
# Memory
self._memory_size = MemorySize(cfg["mem_size_mode"], inc_dataset, cfg["memory_size"],
cfg["fixed_memory_per_cls"])
self._herding_matrix = []
self._coreset_strategy = cfg["coreset_strategy"]
if self._cfg["save_ckpt"]:
save_path = os.path.join(os.getcwd(), f"{self._cfg.exp.saveckpt}")
if not os.path.exists(save_path):
os.mkdir(save_path)
if self._cfg["save_mem"]:
save_path = os.path.join(os.getcwd(), f"{self._cfg.exp.saveckpt}/mem")
if not os.path.exists(save_path):
os.mkdir(save_path)
def eval(self):
self._parallel_network.eval()
def train(self):
if self._dea:
self._parallel_network.train()
self._parallel_network.module.convnets[-1].train()
if self._task >= 1:
for i in range(self._task):
self._parallel_network.module.convnets[i].eval()
else:
self._parallel_network.train()
def _before_task(self, taski, inc_dataset,mask,min_dist,all_dist):
self._ex.logger.info(f"Begin step {taski}")
# Update Task info
self._task = taski
self._n_classes += self._task_size
self.classnum_list.append(self._task_size)
self.sample_list = [ int(2000/(self._n_classes-10)) for i in range(self._n_classes-10)] + [ 500 for i in range(10)]
# Memory
self._memory_size.update_n_classes(self._n_classes)
self._memory_size.update_memory_per_cls(self._network, self._n_classes, self._task_size)
self._ex.logger.info("Now {} examplars per class.".format(self._memory_per_class))
self._network.add_classes(self._task_size,min_dist)
self._network.task_size = self._task_size
mask.model=self._network.convnets[-1]
mask.init_length(taski,task_nn=self._network.task_nn)
self.set_optimizer()
def set_optimizer(self, lr=None):
if lr is None:
lr = self._lr
if self._cfg["dynamic_weight_decay"]:
# used in BiC official implementation
weight_decay = self._weight_decay * self._cfg["task_max"] / (self._task + 1)
else:
weight_decay = self._weight_decay
self._ex.logger.info("Step {} weight decay {:.5f}".format(self._task, weight_decay))
# if self._dea and self._task > 0 and not self._cfg.get("caculate_params", False):
# for i in range(self._task):
# for p in self._parallel_network.module.convnets[i].parameters():
# p.requires_grad = False
self._optimizer = factory.get_optimizer(self._network.convnets[-1].parameters(),
self._opt_name, lr, weight_decay)
if "cos" in self._cfg["scheduler"]:
self._scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(self._optimizer, self._n_epochs)
else:
self._scheduler = torch.optim.lr_scheduler.MultiStepLR(self._optimizer,
self._scheduling,
gamma=self._lr_decay)
if self._warmup:
print("warmup")
self._warmup_scheduler = GradualWarmupScheduler(self._optimizer,
multiplier=1,
total_epoch=self._cfg['warmup_epochs'],
after_scheduler=self._scheduler)
def _train_task(self, task_i,train_loader, val_loader,mask,min_dist,all_dist):
self._ex.logger.info(f"nb {len(train_loader.dataset)}")
topk = 5 if self._n_classes > 5 else self._task_size
accu = ClassErrorMeter(accuracy=True, topk=[1, topk])
train_new_accu = ClassErrorMeter(accuracy=True)
train_old_accu = ClassErrorMeter(accuracy=True)
self._optimizer.zero_grad()
self._optimizer.step()
for epoch in range(self._n_epochs):
# torch.cuda.empty_cache()
_loss, _loss_div, _loss_trip, _loss_dist, _loss_atmap = 0.0, 0.0, 0.0, 0.0, 0.0
accu.reset()
train_new_accu.reset()
train_old_accu.reset()
if self._warmup:
self._warmup_scheduler.step()
if epoch == self._cfg['warmup_epochs']:
if self.torc:
self._network.convnets[-1].classifer.reset_parameters()
if self._cfg['use_div_cls']:
self._network.convnets[-1].aux_classifier.reset_parameters()
else:
self._network.convnets[task_i].classifer.reset_parameters()
if self._cfg['use_div_cls']:
self._network.aux_classifier[task_i].reset_parameters()
for i, (inputs, targets) in enumerate(train_loader, start=1):
self.train()
self._optimizer.zero_grad()
old_classes = targets < (self._n_classes - self._task_size)
new_classes = targets >= (self._n_classes - self._task_size)
loss_ce, loss_div, loss_trip, loss_dist, loss_atmap = self._forward_loss(
task_i,
inputs,
targets,
old_classes,
new_classes,
epoch,
accu=accu,
new_accu=train_new_accu,
old_accu=train_old_accu,
mask=mask
)
loss = loss_ce
if self._cfg["distillation"] and self._task > 0:
# trade-off - the lambda from the paper if lamb=-1
if self.lamb == -1:
lamb = (self._n_classes - self._task_size) / self._n_classes
loss = (1-lamb) * loss + lamb * loss_dist
else:
loss = loss + self.lamb * loss_dist
if self._cfg["use_div_cls"] and self._task > 0:
loss += loss_div
loss.backward()
self._optimizer.step()
if self.torc:
if self._cfg["postprocessor"]["enable"]:
if self._cfg["postprocessor"]["type"].lower() == "cr" or self._cfg["postprocessor"]["type"].lower() == "aver":
for p in self._network.convnets[-1].classifer.parameters():
p.data.clamp_(0.0)
_loss += loss_ce
_loss_trip += loss_trip
_loss_div += loss_div
_loss_dist += loss_dist
_loss_atmap += loss_atmap
if task_i>0:
mask.init_mask(self._task,epoch,dim_cur=self._network.channel_dim, task_nn=self._network.task_nn,all_dist=all_dist,all_model=self._network.convnets)
mat=mask.do_mask(self._task)
_loss = _loss.item()
_loss_div = _loss_div.item()
_loss_trip = _loss_trip.item()
_loss_dist = _loss_dist.item()
_loss_atmap = _loss_atmap.item()
if not self._warmup:
self._scheduler.step()
self._ex.logger.info(
"Task {}/{}, Epoch {}/{} => Clf loss: {} Div loss: {}, Knowledge Distllation loss:{}, Train Accu: {}, Train@5 Acc: {}".
format(
self._task + 1,
self._n_tasks,
epoch + 1,
self._n_epochs,
round(_loss / i, 3),
round(_loss_div / i, 3),
round(_loss_dist / i, 3),
round(accu.value()[0], 3),
round(accu.value()[1], 3),
))
if self._val_per_n_epoch > 0 and epoch % self._val_per_n_epoch == 0:
self.validate(val_loader)
if self.torc:
# For the large-scale dataset, we manage the data in the shared memory.
self._inc_dataset.shared_data_inc = train_loader.dataset.share_memory
utils.display_weight_norm(self._ex.logger, self._parallel_network, self._increments, "After training")
utils.display_feature_norm(task_i,self._ex.logger, self._parallel_network, train_loader, self._n_classes,
self._increments, "Trainset",mask=mask)
self._run.info[f"trial{self._trial_i}"][f"task{self._task}_train_accu"] = round(accu.value()[0], 3)
def _forward_loss(self, task_i,inputs, targets, old_classes, new_classes, epoch, accu=None, new_accu=None, old_accu=None,mask=None):
inputs, targets = inputs.to(self._device, non_blocking=True), targets.to(self._device, non_blocking=True)
outputs = self._parallel_network(task_i,inputs,mask)
if accu is not None:
accu.add(outputs['logit'], targets)
return self._compute_loss(task_i, inputs, targets, outputs, old_classes, new_classes, epoch,mask=mask)
def cross_entropy(self, outputs, targets, exp=1.0, size_average=True, eps=1e-5):
"""Calculates cross-entropy with temperature scaling"""
out = torch.nn.functional.softmax(outputs, dim=1)
tar = torch.nn.functional.softmax(targets, dim=1)
if exp != 1:
out = out.pow(exp)
out = out / out.sum(1).view(-1, 1).expand_as(out)
tar = tar.pow(exp)
tar = tar / tar.sum(1).view(-1, 1).expand_as(tar)
out = out + eps / out.size(1)
out = out / out.sum(1).view(-1, 1).expand_as(out)
ce = -(tar * out.log()).sum(1)
if size_average:
ce = ce.mean()
return ce
def hcl(self, fstudent, fteacher, targets):
loss_all = 0.0
fs = fstudent
select_teacher = self._cfg.get("select_teacher",False)
if select_teacher:
for i in range(len(fteacher)):
ft = fteacher[i]
if i > 0:
old_classes = np.logical_and((targets < (self._n_classes - self._task_size * (len(fteacher)-i))).cpu(), (targets >= (self._n_classes - self._task_size * (len(fteacher)-i+1))).cpu())
else:
old_classes = (targets < (self._n_classes - self._task_size * len(fteacher))).cpu()
classes_indice = torch.from_numpy(np.where(old_classes==True)[0]).to(self._device)
# targets_old = torch.index_select(targets_old, 0, old_classes_indice)
# log_probs_new = torch.index_select(log_probs_new, 0, old_classes_indice)
fs = torch.index_select(fstudent, 0, classes_indice)
ft = torch.index_select(ft, 0, classes_indice)
n,c,h,w = fs.shape
if n == 0:
break
loss = F.mse_loss(fs, ft, reduction='mean')
cnt = 1.0
tot = 1.0
for l in [4,2,1]:
if l >=h:
continue
tmpfs = F.adaptive_avg_pool2d(fs, (l,l))
tmpft = F.adaptive_avg_pool2d(ft, (l,l))
cnt /= 2.0
loss += F.mse_loss(tmpfs, tmpft, reduction='mean') * cnt
tot += cnt
loss = loss / tot
loss_all = loss_all + loss
else:
for i in range(len(fteacher)):
ft = fteacher[i]
n,c,h,w = fs.shape
if n == 0:
break
loss = F.mse_loss(fs, ft, reduction='mean')
cnt = 1.0
tot = 1.0
for l in [4,2,1]:
if l >=h:
continue
tmpfs = F.adaptive_avg_pool2d(fs, (l,l))
tmpft = F.adaptive_avg_pool2d(ft, (l,l))
cnt /= 2.0
loss += F.mse_loss(tmpfs, tmpft, reduction='mean') * cnt
tot += cnt
loss = loss / tot
loss_all = loss_all + loss
return loss_all
def _compute_loss(self, task_i, inputs, targets, outputs, old_classes, new_classes, epoch,mask=None):
loss = F.cross_entropy(outputs['logit'], targets)
trip_loss = torch.zeros([1]).cuda()
atmap_loss = torch.zeros([1]).cuda()
if outputs['div_logit'] is not None:
div_targets = targets.clone()
if self._cfg["div_type"] == "n+1":
div_targets[old_classes] = 0
div_targets[new_classes] -= sum(self._inc_dataset.increments[:self._task]) - 1
elif self._cfg["div_type"] == "1+1":
div_targets[old_classes] = 0
div_targets[new_classes] = 1
elif self._cfg["div_type"] == "n+t":
div_targets[new_classes] -= sum(self._inc_dataset.increments[:self._task]) - self._task
for i in range(self._task):
if i > 0:
old_class = np.logical_and((targets < (self._n_classes - self._task_size * (self._task-i))).cpu(), (targets >= (self._n_classes - self._task_size * (self._task-i+1))).cpu())
else:
old_class = (targets < (self._n_classes - self._task_size * self._task)).cpu()
div_targets[old_class] = i
# import pdb
# pdb.set_trace()
div_loss = F.cross_entropy(outputs['div_logit'], div_targets)
else:
div_loss = torch.zeros([1]).cuda()
if self._cfg["distillation"] and self._old_model is not None:
outputs_old = self._old_model(task_i-1,inputs,mask=None)
targets_old = outputs_old['logit'].detach()
if self._cfg["disttype"] == "KL":
log_probs_new = (outputs['logit'][:, :-self._task_size] / self._temperature).log_softmax(dim=1)
if self._task > 1 and self._cfg["postprocessor"]["enable"]:
if self._cfg["postprocessor"]["type"].lower() == "aver":
targets_old = self._old_model.module.postprocessor.post_process(targets_old, self._task_size, self.classnum_list[:-1], self._task-1)
else:
targets_old = self._old_model.module.postprocessor.post_process(targets_old, self._task_size)
modify = self._cfg.get("modify_new",False)
if modify:
old_weight_norm = torch.norm(self._network.convnets[-1].classifer.weight[:-self._task_size], p=2, dim=1)
new_weight_norm = torch.norm(self._network.convnets[-1].classifer.weight[-self._task_size:], p=2, dim=1)
gamma = old_weight_norm.mean() / new_weight_norm.mean()
targets_old[new_classes,:] = targets_old[new_classes,:] * gamma
probs_old = (targets_old / self._temperature).softmax(dim=1)
dist_loss = F.kl_div(log_probs_new, probs_old, reduction="batchmean")
else:
dist_loss = self.cross_entropy(outputs['logit'][:, :-self._task_size], targets_old, exp=1.0 / self._temperature)
else:
dist_loss = torch.zeros([1]).cuda()
return loss, div_loss, trip_loss, dist_loss, atmap_loss
def _after_task(self, taski, inc_dataset,mask=None):
network = deepcopy(self._parallel_network)
network.eval()
if self._cfg["save_ckpt"] and taski >= self._cfg["start_task"] and not self.prune:
self._ex.logger.info("save model")
save_path = os.path.join(os.getcwd(), f"{self._cfg.exp.saveckpt}")
torch.save(network.cpu().state_dict(), "{}/step{}.ckpt".format(save_path, self._task))
if self.torc:
if self._cfg["postprocessor"]["enable"]:
self._update_postprocessor(taski,inc_dataset,mask=mask)
if self._cfg["infer_head"] == 'NCM':
self._ex.logger.info("compute prototype")
self.update_prototype()
if self._memory_size.memsize != 0:
self._ex.logger.info("build memory")
self.build_exemplars(taski,inc_dataset, self._coreset_strategy,mask=mask)
if self._cfg["save_mem"]:
save_path = os.path.join(os.getcwd(), f"{self._cfg.exp.saveckpt}/mem")
memory = {
'x': inc_dataset.data_memory,
'y': inc_dataset.targets_memory,
'herding': self._herding_matrix
}
if not os.path.exists(save_path):
os.makedirs(save_path)
if not (os.path.exists(f"{save_path}/mem_step{self._task}.ckpt") and self._cfg['load_mem']):
torch.save(memory, "{}/mem_step{}.ckpt".format(save_path, self._task))
self._ex.logger.info(f"Save step{self._task} memory!")
# utils.display_weight_norm(self._ex.logger, self._parallel_network, self._increments, "After training")
self._parallel_network.eval()
self._old_model = deepcopy(self._parallel_network)
if not self._cfg.get("caculate_params", False):
self._old_model.module.freeze()
del self._inc_dataset.shared_data_inc
self._inc_dataset.shared_data_inc = None
def _eval_task(self,task_i, data_loader,mask):
# if self._cfg.get("caculate_params", False):
# from thop import profile
# self._parallel_network.eval()
# with torch.no_grad():
# input = torch.randn(1, 3, 256, 256).to(self._device, non_blocking=True)
# flops, params = profile(self._parallel_network, inputs=(input,))
# ypred = flops/1000**3
# ytrue = params/1000**2
# from torchstat import stat
# stat(self._parallel_network, (3, 256, 256))
# ypred,ytrue = 0,0
# else:
if self._infer_head == "softmax":
ypred, ytrue = self._compute_accuracy_by_netout(task_i,data_loader,mask)
elif self._infer_head == "NCM":
ypred, ytrue = self._compute_accuracy_by_ncm(data_loader)
else:
raise ValueError()
return ypred, ytrue
def _compute_accuracy_by_netout(self, task_i,data_loader,mask):
preds, targets = [], []
self._parallel_network.eval()
if self._cfg.get("caculate_params", False):
with torch.no_grad():
from thop import profile
inputs = torch.randn(1, 3, 112, 112)
flops, params = profile(self._parallel_network, (inputs,))
preds = flops/1000**3
targets = params/1000**2
# print('flops: ', flops, 'params: ', params)
# for i, (inputs, lbls) in enumerate(data_loader):
# from thop import profile
# # inputs = inputs.to(self._device, non_blocking=True)
# flops, params = profile(self._parallel_network, inputs[0])
# preds = flops/1000**3
# targets = params/1000**2
# break
else:
with torch.no_grad():
for i, (inputs, lbls) in enumerate(data_loader):
inputs = inputs.to(self._device, non_blocking=True)
_preds = self._parallel_network(task_i,inputs,mask)['logit']
if self.torc:
if self._cfg["postprocessor"]["enable"] and self._task > 0:
if self._cfg["postprocessor"]["type"].lower() == "aver":
_preds = self._network.postprocessor.post_process(_preds, self._task_size, self.classnum_list, self._task)
else:
_preds = self._network.postprocessor.post_process(_preds, self._task_size)
preds.append(_preds.detach().cpu().numpy())
targets.append(lbls.long().cpu().numpy())
preds = np.concatenate(preds, axis=0)
targets = np.concatenate(targets, axis=0)
return preds, targets
def _compute_accuracy_by_ncm(self, loader):
features, targets_ = extract_features(self._parallel_network, loader)
targets = np.zeros((targets_.shape[0], self._n_classes), np.float32)
targets[range(len(targets_)), targets_.astype("int32")] = 1.0
class_means = (self._class_means.T / (np.linalg.norm(self._class_means.T, axis=0) + EPSILON)).T
features = (features.T / (np.linalg.norm(features.T, axis=0) + EPSILON)).T
# Compute score for iCaRL
sqd = cdist(class_means, features, "sqeuclidean")
score_icarl = (-sqd).T
return score_icarl[:, :self._n_classes], targets_
def _update_postprocessor(self, taski,inc_dataset,mask=None):
if self._cfg["postprocessor"]["type"].lower() == "bic":
if False:#self._cfg["postprocessor"]["disalign_resample"] is True:
bic_loader = inc_dataset._get_loader(inc_dataset.data_inc,
inc_dataset.targets_inc,
mode="train",
resample='disalign_resample')
else:
xdata, ydata = inc_dataset._select(taski,inc_dataset.data_train,
inc_dataset.targets_train,
low_range=0,
high_range=self._n_classes)
bic_loader = inc_dataset._get_loader(xdata, ydata, shuffle=True, mode='train')
bic_loss = None
self._network.postprocessor.reset(n_classes=self._n_classes)
self._network.postprocessor.update(self._ex.logger,
self._task_size,
self._parallel_network,
bic_loader,
loss_criterion=bic_loss,
taski=taski,
mask=mask)
elif self._cfg["postprocessor"]["type"].lower() == "cr":
self._ex.logger.info("Post processor cr update !")
self._network.postprocessor.update(self._network.convnets[-1].classifer, self._task_size)
elif self._cfg["postprocessor"]["type"].lower() == "aver":
self._ex.logger.info("Post processor aver update !")
self._network.postprocessor.update(self._network.convnets[-1].classifer, self._task_size, self.classnum_list, self._task)
def update_prototype(self):
if hasattr(self._inc_dataset, 'shared_data_inc'):
shared_data_inc = self._inc_dataset.shared_data_inc
else:
shared_data_inc = None
self._class_means = update_classes_mean(self._parallel_network,
self._inc_dataset,
self._n_classes,
self._task_size,
share_memory=self._inc_dataset.shared_data_inc,
metric='None')
def build_exemplars(self, task_i,inc_dataset, coreset_strategy,mask=None):
save_path = os.path.join(os.getcwd(), f"{self._cfg.exp.saveckpt}/mem/mem_step{self._task}.ckpt")
if self._cfg["load_mem"] and os.path.exists(save_path):
memory_states = torch.load(save_path)
self._inc_dataset.data_memory = memory_states['x']
self._inc_dataset.targets_memory = memory_states['y']
self._herding_matrix = memory_states['herding']
self._ex.logger.info(f"Load saved step{self._task} memory!")
return
if coreset_strategy == "random":
from inclearn.tools.memory import random_selection
self._inc_dataset.data_memory, self._inc_dataset.targets_memory = random_selection(
self._n_classes,
self._task_size,
self._parallel_network,
self._ex.logger,
inc_dataset,
self._memory_per_class,
)
elif coreset_strategy == "iCaRL":
from inclearn.tools.memory import herding
data_inc = self._inc_dataset.shared_data_inc if self._inc_dataset.shared_data_inc is not None else self._inc_dataset.data_inc
self._inc_dataset.data_memory, self._inc_dataset.targets_memory, self._herding_matrix = herding(
task_i,
self._n_classes,
self._task_size,
self._parallel_network,
self._herding_matrix,
inc_dataset,
data_inc,
self._memory_per_class,
self._ex.logger,
mask=mask
)
else:
raise ValueError()
def validate(self, data_loader):
if self._infer_head == 'NCM':
self.update_prototype()
ypred, ytrue = self._eval_task(data_loader)
test_acc_stats = utils.compute_accuracy(ypred, ytrue, increments=self._increments, n_classes=self._n_classes)
self._ex.logger.info(f"test top1acc:{test_acc_stats['top1']}")
return test_acc_stats['top1']['total']
def after_prune(self, taski, inc_dataset):
x = torch.randn(1, 3, 32, 32)
self._network = self._network.cpu()
dim1, dim2 = self._network.caculate_dim(x)
del self._network.classifier
self._network.classifier = self._network._gen_classifier(dim1, self._n_classes)
if self._network.se is not None:
del self._network.se
ft_type = self._cfg.get('feature_type', 'ce')
at_res = self._cfg.get('attention_use_residual', False)
self._network.se = factory.get_attention(dim1, ft_type, at_res)
if taski > 0:
del self._network.aux_classifier
self._network.aux_classifier = self._network._gen_classifier(dim2, self._task_size+1)
del self._parallel_network
self._parallel_network = DataParallel(self._network)
class DistillKL(nn.Module):
"""Distilling the Knowledge in a Neural Network"""
def __init__(self, T):
super(DistillKL, self).__init__()
self.T = T
def forward(self, y_s, y_t):
p_s = F.log_softmax(y_s/self.T, dim=1)
p_t = F.softmax(y_t/self.T, dim=1)
loss = F.kl_div(p_s, p_t, reduction="sum") * (self.T**2) / y_s.shape[0]
# loss = F.kl_div(p_s, p_t, reduction="batchmean") * (self.T**2) / y_s.shape[0]
return loss
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/__init__.py
================================================
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/autoaugment_extra.py
================================================
from PIL import Image, ImageEnhance, ImageOps, ImageDraw
import numpy as np
import random
class ImageNetPolicy(object):
""" Randomly choose one of the best 24 Sub-policies on ImageNet.
Example:
>>> policy = ImageNetPolicy()
>>> transformed = policy(image)
Example as a PyTorch Transform:
>>> transform=transforms.Compose([
>>> transforms.Resize(256),
>>> ImageNetPolicy(),
>>> transforms.ToTensor()])
"""
def __init__(self, fillcolor=(128, 128, 128)):
self.policies = [
SubPolicy(0.4, "posterize", 8, 0.6, "rotate", 9, fillcolor),
SubPolicy(0.6, "solarize", 5, 0.6, "autocontrast", 5, fillcolor),
SubPolicy(0.8, "equalize", 8, 0.6, "equalize", 3, fillcolor),
SubPolicy(0.6, "posterize", 7, 0.6, "posterize", 6, fillcolor),
SubPolicy(0.4, "equalize", 7, 0.2, "solarize", 4, fillcolor),
SubPolicy(0.4, "equalize", 4, 0.8, "rotate", 8, fillcolor),
SubPolicy(0.6, "solarize", 3, 0.6, "equalize", 7, fillcolor),
SubPolicy(0.8, "posterize", 5, 1.0, "equalize", 2, fillcolor),
SubPolicy(0.2, "rotate", 3, 0.6, "solarize", 8, fillcolor),
SubPolicy(0.6, "equalize", 8, 0.4, "posterize", 6, fillcolor),
SubPolicy(0.8, "rotate", 8, 0.4, "color", 0, fillcolor),
SubPolicy(0.4, "rotate", 9, 0.6, "equalize", 2, fillcolor),
SubPolicy(0.0, "equalize", 7, 0.8, "equalize", 8, fillcolor),
SubPolicy(0.6, "invert", 4, 1.0, "equalize", 8, fillcolor),
SubPolicy(0.6, "color", 4, 1.0, "contrast", 8, fillcolor),
SubPolicy(0.8, "rotate", 8, 1.0, "color", 2, fillcolor),
SubPolicy(0.8, "color", 8, 0.8, "solarize", 7, fillcolor),
SubPolicy(0.4, "sharpness", 7, 0.6, "invert", 8, fillcolor),
SubPolicy(0.6, "shearX", 5, 1.0, "equalize", 9, fillcolor),
SubPolicy(0.4, "color", 0, 0.6, "equalize", 3, fillcolor),
SubPolicy(0.4, "equalize", 7, 0.2, "solarize", 4, fillcolor),
SubPolicy(0.6, "solarize", 5, 0.6, "autocontrast", 5, fillcolor),
SubPolicy(0.6, "invert", 4, 1.0, "equalize", 8, fillcolor),
SubPolicy(0.6, "color", 4, 1.0, "contrast", 8, fillcolor),
SubPolicy(0.8, "equalize", 8, 0.6, "equalize", 3, fillcolor),
SubPolicy(0.1, "invert", 7, 0.2, "contrast", 6, fillcolor), # set-1
SubPolicy(0.7, "rotate", 2, 0.3, "translateX", 9, fillcolor),
SubPolicy(0.8, "sharpness", 1, 0.9, "sharpness", 3, fillcolor),
SubPolicy(0.5, "shearY", 8, 0.7, "translateY", 9, fillcolor),
SubPolicy(0.5, "autocontrast", 8, 0.9, "equalize", 2, fillcolor),
SubPolicy(0.2, "shearY", 7, 0.3, "posterize", 7, fillcolor), # set-3
SubPolicy(0.4, "color", 3, 0.6, "brightness", 7, fillcolor),
SubPolicy(0.3, "sharpness", 9, 0.7, "brightness", 9, fillcolor),
SubPolicy(0.6, "equalize", 5, 0.5, "equalize", 1, fillcolor),
SubPolicy(0.6, "contrast", 7, 0.6, "sharpness", 5, fillcolor),
SubPolicy(0.7, "color", 7, 0.5, "translateX", 8, fillcolor), #set-11
SubPolicy(0.3, "equalize", 7, 0.4, "autocontrast", 8, fillcolor),
SubPolicy(0.4, "translateY", 3, 0.2, "sharpness", 6, fillcolor),
SubPolicy(0.9, "brightness", 6, 0.2, "color", 8, fillcolor),
SubPolicy(0.5, "solarize", 2, 0.0, "invert", 3, fillcolor),
SubPolicy(0.2, "equalize", 0, 0.6, "autocontrast", 0, fillcolor),
SubPolicy(0.2, "equalize", 8, 0.8, "equalize", 4, fillcolor),
SubPolicy(0.9, "color", 9, 0.6, "equalize", 6, fillcolor),
SubPolicy(0.8, "autocontrast", 4, 0.2, "solarize", 8, fillcolor),
SubPolicy(0.1, "brightness", 3, 0.7, "color", 0, fillcolor),
SubPolicy(0.4, "solarize", 5, 0.9, "autocontrast", 3, fillcolor), # set-2
SubPolicy(0.9, "translateY", 9, 0.7, "translateY", 9, fillcolor),
SubPolicy(0.9, "autocontrast", 2, 0.8, "solarize", 3, fillcolor),
SubPolicy(0.8, "equalize", 8, 0.1, "invert", 3, fillcolor),
SubPolicy(0.7, "translateY", 9, 0.9, "autocontrast", 1, fillcolor),
SubPolicy(0.4, "solarize", 5, 0.9, "autocontrast", 3, fillcolor),
SubPolicy(0.9, "translateY", 9, 0.7, "translateY", 9, fillcolor),
SubPolicy(0.9, "autocontrast", 2, 0.8, "solarize", 3, fillcolor),
SubPolicy(0.8, "equalize", 8, 0.1, "invert", 3, fillcolor),
SubPolicy(0.7, "translateY", 9, 0.9, "autocontrast", 1, fillcolor),
SubPolicy(0.4, "solarize", 5, 0.9, "autocontrast", 1, fillcolor),
SubPolicy(0.8, "translateY", 9, 0.9, "translateY", 9, fillcolor),
SubPolicy(0.8, "autocontrast", 0, 0.7, "translateY", 9, fillcolor),
SubPolicy(0.2, "translateY", 7, 0.9, "color", 6, fillcolor),
SubPolicy(0.7, "equalize", 6, 0.4, "color", 9, fillcolor),
SubPolicy(0.3, "brightness", 7, 0.5, "autocontrast", 8, fillcolor),
SubPolicy(0.9, "autocontrast", 4, 0.5, "autocontrast", 6, fillcolor),
SubPolicy(0.3, "solarize", 5, 0.6, "equalize", 5, fillcolor),
SubPolicy(0.2, "translateY", 4, 0.3, "sharpness", 3, fillcolor),
SubPolicy(0.0, "brightness", 8, 0.8, "color", 8, fillcolor),
SubPolicy(0.2, "solarize", 6, 0.8, "color", 6, fillcolor),
SubPolicy(0.2, "solarize", 6, 0.8, "autocontrast", 1, fillcolor),
SubPolicy(0.4, "solarize", 1, 0.6, "equalize", 5, fillcolor),
SubPolicy(0.0, "brightness", 0, 0.5, "solarize", 2, fillcolor),
SubPolicy(0.9, "autocontrast", 5, 0.5, "brightness", 3, fillcolor),
SubPolicy(0.7, "contrast", 5, 0.0, "brightness", 2, fillcolor),
SubPolicy(0.2, "solarize", 8, 0.1, "solarize", 5, fillcolor),
SubPolicy(0.5, "contrast", 1, 0.2, "translateY", 9, fillcolor),
SubPolicy(0.6, "autocontrast", 5, 0.0, "translateY", 9, fillcolor),
SubPolicy(0.9, "autocontrast", 4, 0.8, "equalize", 4, fillcolor),
SubPolicy(0.0, "brightness", 7, 0.4, "equalize", 7, fillcolor),
SubPolicy(0.2, "solarize", 5, 0.7, "equalize", 5, fillcolor),
SubPolicy(0.6, "equalize", 8, 0.6, "color", 2, fillcolor),
SubPolicy(0.3, "color", 7, 0.2, "color", 4, fillcolor),
SubPolicy(0.5, "autocontrast", 2, 0.7, "solarize", 2, fillcolor),
SubPolicy(0.2, "autocontrast", 0, 0.1, "equalize", 0, fillcolor),
SubPolicy(0.6, "shearY", 5, 0.6, "equalize", 5, fillcolor),
SubPolicy(0.9, "brightness", 3, 0.4, "autocontrast", 1, fillcolor),
SubPolicy(0.8, "equalize", 8, 0.7, "equalize", 7, fillcolor),
SubPolicy(0.7, "equalize", 7, 0.5, "solarize", 0, fillcolor),
SubPolicy(0.8, "equalize", 4, 0.8, "translateY", 9, fillcolor),
SubPolicy(0.8, "translateY", 9, 0.6, "translateY", 9, fillcolor),
SubPolicy(0.9, "translateY", 0, 0.5, "translateY", 9, fillcolor),
SubPolicy(0.5, "autocontrast", 3, 0.3, "solarize", 4, fillcolor),
SubPolicy(0.5, "solarize", 3, 0.4, "equalize", 4, fillcolor),
SubPolicy(0.1, "autocontrast", 5, 0.0, "brightness", 0, fillcolor),
SubPolicy(0.7, "equalize", 7, 0.6, "autocontrast", 4, fillcolor),
SubPolicy(0.1, "color", 8, 0.2, "shearY", 3, fillcolor),
SubPolicy(0.4, "shearY", 2, 0.7, "rotate", 0, fillcolor),
SubPolicy(0.1, "shearY", 3, 0.9, "autocontrast", 5, fillcolor),
SubPolicy(0.5, "equalize", 0, 0.6, "solarize", 6, fillcolor),
SubPolicy(0.3, "autocontrast", 5, 0.2, "rotate", 7, fillcolor),
SubPolicy(0.8, "equalize", 2, 0.4, "invert", 0, fillcolor),
SubPolicy(0.9, "equalize", 5, 0.7, "color", 0, fillcolor),
SubPolicy(0.1, "equalize", 1, 0.1, "shearY", 3, fillcolor),
SubPolicy(0.7, "autocontrast", 3, 0.7, "equalize", 0, fillcolor),
SubPolicy(0.5, "brightness", 1, 0.1, "contrast", 7, fillcolor),
SubPolicy(0.1, "contrast", 4, 0.6, "solarize", 5, fillcolor),
SubPolicy(0.2, "solarize", 3, 0.0, "shearX", 0, fillcolor),
SubPolicy(0.3, "translateX", 0, 0.6, "translateX", 0, fillcolor),
SubPolicy(0.5, "equalize", 9, 0.6, "translateY", 7, fillcolor),
SubPolicy(0.1, "shearX", 0, 0.5, "sharpness", 1, fillcolor),
SubPolicy(0.8, "equalize", 6, 0.3, "invert", 6, fillcolor),
SubPolicy(0.4, "shearX", 4, 0.9, "autocontrast", 2, fillcolor),
SubPolicy(0.0, "shearX", 3, 0.0, "posterize", 3, fillcolor),
SubPolicy(0.4, "solarize", 3, 0.2, "color", 4, fillcolor),
SubPolicy(0.1, "equalize", 4, 0.7, "equalize", 6, fillcolor),
SubPolicy(0.3, "equalize", 8, 0.4, "autocontrast", 3, fillcolor),
SubPolicy(0.6, "solarize", 4, 0.7, "autocontrast", 6, fillcolor),
SubPolicy(0.2, "autocontrast", 9, 0.4, "brightness", 8, fillcolor),
SubPolicy(0.1, "equalize", 0, 0.0, "equalize", 6, fillcolor),
SubPolicy(0.8, "equalize", 4, 0.0, "equalize", 4, fillcolor),
SubPolicy(0.5, "equalize", 5, 0.1, "autocontrast", 2, fillcolor),
SubPolicy(0.5, "solarize", 5, 0.9, "autocontrast", 5, fillcolor),
]
def __call__(self, img):
policy_idx = random.randint(0, len(self.policies) - 1)
return self.policies[policy_idx](img)
def __repr__(self):
return "AutoAugment ImageNet Policy"
class SubPolicy(object):
def __init__(self, p1, operation1, magnitude_idx1, p2, operation2, magnitude_idx2, fillcolor=(128, 128, 128)):
ranges = {
"shearX": np.linspace(0, 0.3, 10),
"shearY": np.linspace(0, 0.3, 10),
"translateX": np.linspace(0, 150 / 331, 10),
"translateY": np.linspace(0, 150 / 331, 10),
"rotate": np.linspace(0, 30, 10),
"color": np.linspace(0.0, 0.9, 10),
"posterize": np.round(np.linspace(8, 4, 10), 0).astype(np.int64),
"solarize": np.linspace(256, 0, 10),
"contrast": np.linspace(0.0, 0.9, 10),
"sharpness": np.linspace(0.0, 0.9, 10),
"brightness": np.linspace(0.0, 0.9, 10),
"autocontrast": [0] * 10,
"equalize": [0] * 10,
"invert": [0] * 10,
"cutout": np.linspace(0.0, 0.2, 10),
}
def Cutout(img, v): # [0, 60] => percentage: [0, 0.2]
#assert 0.0 <= v <= 0.2
if v <= 0.:
return img
v = v * img.size[0]
return CutoutAbs(img, v)
# x0 = np.random.uniform(w - v)
# y0 = np.random.uniform(h - v)
# xy = (x0, y0, x0 + v, y0 + v)
# color = (127, 127, 127)
# img = img.copy()
# PIL.ImageDraw.Draw(img).rectangle(xy, color)
# return img
def CutoutAbs(img, v): # [0, 60] => percentage: [0, 0.2]
# assert 0 <= v <= 20
if v < 0:
return img
w, h = img.size
x0 = np.random.uniform(w)
y0 = np.random.uniform(h)
x0 = int(max(0, x0 - v / 2.))
y0 = int(max(0, y0 - v / 2.))
x1 = min(w, x0 + v)
y1 = min(h, y0 + v)
xy = (x0, y0, x1, y1)
color = (125, 123, 114)
# color = (0, 0, 0)
img = img.copy()
ImageDraw.Draw(img).rectangle(xy, color)
return img
def rotate_with_fill(img, magnitude):
rot = img.convert("RGBA").rotate(magnitude)
return Image.composite(rot, Image.new("RGBA", rot.size, (128,) * 4), rot).convert(img.mode)
func = {
"shearX": lambda img, magnitude: img.transform(
img.size, Image.AFFINE, (1, magnitude * random.choice([-1, 1]), 0, 0, 1, 0),
Image.BICUBIC, fillcolor=fillcolor),
"shearY": lambda img, magnitude: img.transform(
img.size, Image.AFFINE, (1, 0, 0, magnitude * random.choice([-1, 1]), 1, 0),
Image.BICUBIC, fillcolor=fillcolor),
"translateX": lambda img, magnitude: img.transform(
img.size, Image.AFFINE, (1, 0, magnitude * img.size[0] * random.choice([-1, 1]), 0, 1, 0),
fillcolor=fillcolor),
"translateY": lambda img, magnitude: img.transform(
img.size, Image.AFFINE, (1, 0, 0, 0, 1, magnitude * img.size[1] * random.choice([-1, 1])),
fillcolor=fillcolor),
"cutout": lambda img, magnitude: Cutout(img, magnitude),
"rotate": lambda img, magnitude: rotate_with_fill(img, magnitude),
# "rotate": lambda img, magnitude: img.rotate(magnitude * random.choice([-1, 1])),
"color": lambda img, magnitude: ImageEnhance.Color(img).enhance(1 + magnitude * random.choice([-1, 1])),
"posterize": lambda img, magnitude: ImageOps.posterize(img, magnitude),
"solarize": lambda img, magnitude: ImageOps.solarize(img, magnitude),
"contrast": lambda img, magnitude: ImageEnhance.Contrast(img).enhance(
1 + magnitude * random.choice([-1, 1])),
"sharpness": lambda img, magnitude: ImageEnhance.Sharpness(img).enhance(
1 + magnitude * random.choice([-1, 1])),
"brightness": lambda img, magnitude: ImageEnhance.Brightness(img).enhance(
1 + magnitude * random.choice([-1, 1])),
"autocontrast": lambda img, magnitude: ImageOps.autocontrast(img),
"equalize": lambda img, magnitude: ImageOps.equalize(img),
"invert": lambda img, magnitude: ImageOps.invert(img)
}
# self.name = "{}_{:.2f}_and_{}_{:.2f}".format(
# operation1, ranges[operation1][magnitude_idx1],
# operation2, ranges[operation2][magnitude_idx2])
self.p1 = p1
self.operation1 = func[operation1]
self.magnitude1 = ranges[operation1][magnitude_idx1]
self.p2 = p2
self.operation2 = func[operation2]
self.magnitude2 = ranges[operation2][magnitude_idx2]
def __call__(self, img):
if random.random() < self.p1: img = self.operation1(img, self.magnitude1)
if random.random() < self.p2: img = self.operation2(img, self.magnitude2)
return img
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/cutout.py
================================================
import torch
import numpy as np
class Cutout(object):
"""Randomly mask out one or more patches from an image.
Args:
n_holes (int): Number of patches to cut out of each image.
length (int): The length (in pixels) of each square patch.
"""
def __init__(self, n_holes, length):
self.n_holes = n_holes
self.length = length
def __call__(self, img):
"""
Args:
img (Tensor): Tensor image of size (C, H, W).
Returns:
Tensor: Image with n_holes of dimension length x length cut out of it.
"""
h = img.size(1)
w = img.size(2)
mask = np.ones((h, w), np.float32)
for n in range(self.n_holes):
y = np.random.randint(h)
x = np.random.randint(w)
y1 = np.clip(y - self.length // 2, 0, h)
y2 = np.clip(y + self.length // 2, 0, h)
x1 = np.clip(x - self.length // 2, 0, w)
x2 = np.clip(x + self.length // 2, 0, w)
mask[y1: y2, x1: x2] = 0.
mask = torch.from_numpy(mask)
mask = mask.expand_as(img)
img = img * mask
return img
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/data_utils.py
================================================
import numpy as np
def construct_balanced_subset(x, y):
xdata, ydata = [], []
minsize = np.inf
for cls_ in np.unique(y):
xdata.append(x[y == cls_])
ydata.append(y[y == cls_])
if ydata[-1].shape[0] < minsize:
minsize = ydata[-1].shape[0]
for i in range(len(xdata)):
# if xdata[i].shape[0] < minsize:
# import pdb
# pdb.set_trace()
idx = np.arange(xdata[i].shape[0])
np.random.shuffle(idx)
xdata[i] = xdata[i][idx][:minsize]
ydata[i] = ydata[i][idx][:minsize]
# !list
return np.concatenate(xdata, 0), np.concatenate(ydata, 0)
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/factory.py
================================================
from matplotlib.transforms import Transform
import torch
from torch import nn
from torch import optim
from inclearn import models
from inclearn.convnet import sew_resnet
from inclearn.datasets import data
from inclearn.convnet.resnet import SEFeatureAt
def get_optimizer(params, optimizer, lr, weight_decay=0.0):
if optimizer == "adam":
return optim.Adam(params, lr=lr, weight_decay=weight_decay, betas=(0.9, 0.999))
elif optimizer == "sgd":
return optim.SGD(params, lr=lr, weight_decay=weight_decay, momentum=0.9)
else:
raise NotImplementedError
def get_attention(inplane, type, at_res):
return SEFeatureAt(inplane, type, at_res)
def get_convnet(convnet_type, c_dim=None,cdim_cur=None,**kwargs):
if convnet_type == "resnet18":
return sew_resnet.sew_resnet18(c_dim,cdim_cur,**kwargs)
else:
raise NotImplementedError("Unknwon convnet type {}.".format(convnet_type))
def get_model(cfg, trial_i, _run, ex, tensorboard, inc_dataset):
if cfg["model"] == "incmodel":
return models.IncModel(cfg, trial_i, _run, ex, tensorboard, inc_dataset)
else:
raise NotImplementedError(cfg["model"])
def get_data(cfg, trial_i):
return data.IncrementalDataset(
trial_i=trial_i,
dataset_name=cfg["dataset"],
random_order=cfg["random_classes"],
shuffle=True,
batch_size=cfg["batch_size"],
workers=cfg["workers"],
validation_split=cfg["validation"],
resampling=cfg["resampling"],
increment=cfg["increment"],
data_folder=cfg["data_folder"],
start_class=cfg["start_class"],
torc=cfg.get("distillation")
)
def set_device(cfg):
device_type = cfg["device"]
if device_type == -1:
device = torch.device("cpu")
else:
device = torch.device("cuda:{}".format(device_type))
cfg["device"] = device
return device
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/memory.py
================================================
import numpy as np
from copy import deepcopy
import torch
from torch.nn import functional as F
from inclearn.tools.utils import get_class_loss
from inclearn.convnet.utils import extract_features
class MemorySize:
def __init__(self, mode, inc_dataset, total_memory=None, fixed_memory_per_cls=None):
self.mode = mode
assert mode.lower() in ["uniform_fixed_per_cls", "uniform_fixed_total_mem", "dynamic_fixed_per_cls"]
self.total_memory = total_memory
self.fixed_memory_per_cls = fixed_memory_per_cls
self._n_classes = 0
self.mem_per_cls = []
self._inc_dataset = inc_dataset
def update_n_classes(self, n_classes):
self._n_classes = n_classes
def update_memory_per_cls_uniform(self, n_classes):
if "fixed_per_cls" in self.mode:
self.mem_per_cls = [self.fixed_memory_per_cls for i in range(n_classes)]
elif "fixed_total_mem" in self.mode:
self.mem_per_cls = [self.total_memory // n_classes for i in range(n_classes)]
return self.mem_per_cls
def update_memory_per_cls(self, network, n_classes, task_size):
if "uniform" in self.mode:
self.update_memory_per_cls_uniform(n_classes)
else:
if n_classes == task_size:
self.update_memory_per_cls_uniform(n_classes)
@property
def memsize(self):
if self.mode == "fixed_total_mem":
return self.total_memory
elif self.mode == "fixed_per_cls":
return self.fixed_memory_per_cls * self._n_classes
def compute_examplar_mean(feat_norm, feat_flip, herding_mat, nb_max):
EPSILON = 1e-8
D = feat_norm.T
D = D / (np.linalg.norm(D, axis=0) + EPSILON)
D2 = feat_flip.T
D2 = D2 / (np.linalg.norm(D2, axis=0) + EPSILON)
alph = herding_mat
alph = (alph > 0) * (alph < nb_max + 1) * 1.0
alph_mean = alph / np.sum(alph)
mean = (np.dot(D, alph_mean) + np.dot(D2, alph_mean)) / 2
# mean = np.dot(D, alph_mean)
mean /= np.linalg.norm(mean) + EPSILON
return mean, alph
def select_examplars(features, nb_max):
EPSILON = 1e-8
D = features.T
D = D / (np.linalg.norm(D, axis=0) + EPSILON)
mu = np.mean(D, axis=1)
herding_matrix = np.zeros((features.shape[0], ))
idxes = []
w_t = mu
iter_herding, iter_herding_eff = 0, 0
while not (np.sum(herding_matrix != 0) == min(nb_max, features.shape[0])) and iter_herding_eff < 1000:
tmp_t = np.dot(w_t, D)
# tmp_t = -np.linalg.norm(w_t[:,np.newaxis]-D, axis=0)
# tmp_t = np.linalg.norm(w_t[:,np.newaxis]-D, axis=0)
ind_max = np.argmax(tmp_t)
iter_herding_eff += 1
if herding_matrix[ind_max] == 0:
herding_matrix[ind_max] = 1 + iter_herding
idxes.append(ind_max)
iter_herding += 1
w_t = w_t + mu - D[:, ind_max]
return herding_matrix, idxes
def random_selection(n_classes, task_size, network, logger, inc_dataset, memory_per_class: list):
# TODO: Move data_memroy,targets_memory into IncDataset
logger.info("Building & updating memory.(Random Selection)")
tmp_data_memory, tmp_targets_memory = [], []
assert len(memory_per_class) == n_classes
for class_idx in range(n_classes):
# 旧类数据从get_custom_loader_from_memory中读取,新类数据从get_custom_loader中读取
if class_idx < n_classes - task_size:
inputs, targets, loader = inc_dataset.get_custom_loader_from_memory([class_idx])
else:
inputs, targets, loader = inc_dataset.get_custom_loader(class_idx, mode="test")
memory_this_cls = min(memory_per_class[class_idx], inputs.shape[0])
idxs = np.random.choice(inputs.shape[0], memory_this_cls, replace=False)
tmp_data_memory.append(inputs[idxs])
tmp_targets_memory.append(targets[idxs])
tmp_data_memory = np.concatenate(tmp_data_memory)
tmp_targets_memory = np.concatenate(tmp_targets_memory)
return tmp_data_memory, tmp_targets_memory
def herding(task_i,n_classes, task_size, network, herding_matrix, inc_dataset, shared_data_inc, memory_per_class: list,
logger,mask=None):
"""Herding matrix: list
"""
logger.info("Building & updating memory.(iCaRL)")
tmp_data_memory, tmp_targets_memory = [], []
for class_idx in range(n_classes):
inputs = inc_dataset.data_train[inc_dataset.targets_train == class_idx]
targets = inc_dataset.targets_train[inc_dataset.targets_train == class_idx]
# zi = inc_dataset.zimages[inc_dataset.zlabels == class_idx]
# zt = inc_dataset.zlabels[inc_dataset.zlabels == class_idx]
# inputs = np.concatenate((inputs, zi))
# targets = np.concatenate((targets, zt))
if class_idx >= n_classes - task_size:
if len(shared_data_inc) > len(inc_dataset.targets_inc):
share_memory = [shared_data_inc[i] for i in np.where(inc_dataset.targets_inc == class_idx)[0].tolist()]
else:
share_memory = []
for i in np.where(inc_dataset.targets_inc == class_idx)[0].tolist():
if i < len(shared_data_inc):
share_memory.append(shared_data_inc[i])
# share_memory = [shared_data_inc[i] for i in np.where(inc_dataset.targets_inc == class_idx)[0].tolist()]
loader = inc_dataset._get_loader(inc_dataset.data_inc[inc_dataset.targets_inc == class_idx],
inc_dataset.targets_inc[inc_dataset.targets_inc == class_idx],
share_memory=share_memory,
batch_size=128,
shuffle=False,
mode="test")
features, _ = extract_features(task_i,network, loader,mask=mask)
# features_flipped, _ = extract_features(network, inc_dataset.get_custom_loader(class_idx, mode="flip")[-1])
herding_matrix.append(select_examplars(features, memory_per_class[class_idx])[0])
alph = herding_matrix[class_idx]
alph = (alph > 0) * (alph < memory_per_class[class_idx] + 1) * 1.0
# examplar_mean, alph = compute_examplar_mean(features, features_flipped, herding_matrix[class_idx],
# memory_per_class[class_idx])
tmp_data_memory.append(inputs[np.where(alph == 1)[0]])
tmp_targets_memory.append(targets[np.where(alph == 1)[0]])
tmp_data_memory = np.concatenate(tmp_data_memory)
tmp_targets_memory = np.concatenate(tmp_targets_memory)
return tmp_data_memory, tmp_targets_memory, herding_matrix
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/metrics.py
================================================
import numpy as np
import torch
import numbers
import math
class IncConfusionMeter:
"""Maintains a confusion matrix for a given calssification problem.
The ConfusionMeter constructs a confusion matrix for a multi-class
classification problems. It does not support multi-label, multi-class problems:
for such problems, please use MultiLabelConfusionMeter.
Args:
k (int): number of classes in the classification problem
normalized (boolean): Determines whether or not the confusion matrix
is normalized or not
"""
def __init__(self, k, increments, normalized=False):
self.conf = np.ndarray((k, k), dtype=np.int32)
self.normalized = normalized
self.increments = increments
self.cum_increments = [0] + [sum(increments[:i + 1]) for i in range(len(increments))]
self.k = k
self.reset()
def reset(self):
self.conf.fill(0)
def add(self, predicted, target):
"""Computes the confusion matrix of K x K size where K is no of classes
Args:
predicted (tensor): Can be an N x K tensor of predicted scores obtained from
the model for N examples and K classes or an N-tensor of
integer values between 0 and K-1.
target (tensor): Can be a N-tensor of integer values assumed to be integer
values between 0 and K-1 or N x K tensor, where targets are
assumed to be provided as one-hot vectors
"""
if isinstance(predicted, torch.Tensor):
predicted = predicted.cpu().numpy()
if isinstance(target, torch.Tensor):
target = target.cpu().numpy()
assert predicted.shape[0] == target.shape[0], \
'number of targets and predicted outputs do not match'
if np.ndim(predicted) != 1:
assert predicted.shape[1] == self.k, \
'number of predictions does not match size of confusion matrix'
predicted = np.argmax(predicted, 1)
else:
assert (predicted.max() < self.k) and (predicted.min() >= 0), \
'predicted values are not between 1 and k'
onehot_target = np.ndim(target) != 1
if onehot_target:
assert target.shape[1] == self.k, \
'Onehot target does not match size of confusion matrix'
assert (target >= 0).all() and (target <= 1).all(), \
'in one-hot encoding, target values should be 0 or 1'
assert (target.sum(1) == 1).all(), \
'multi-label setting is not supported'
target = np.argmax(target, 1)
else:
assert (predicted.max() < self.k) and (predicted.min() >= 0), \
'predicted values are not between 0 and k-1'
# hack for bincounting 2 arrays together
x = predicted + self.k * target
bincount_2d = np.bincount(x.astype(np.int32), minlength=self.k**2)
assert bincount_2d.size == self.k**2
conf = bincount_2d.reshape((self.k, self.k))
self.conf += conf
def value(self):
"""
Returns:
Confustion matrix of K rows and K columns, where rows corresponds
to ground-truth targets and columns corresponds to predicted
targets.
"""
conf = self.conf.astype(np.float32)
new_conf = np.zeros([len(self.increments), len(self.increments) + 2])
for i in range(len(self.increments)):
idxs = range(self.cum_increments[i], self.cum_increments[i + 1])
new_conf[i, 0] = conf[idxs, idxs].sum()
new_conf[i, 1] = conf[self.cum_increments[i]:self.cum_increments[i + 1],
self.cum_increments[i]:self.cum_increments[i + 1]].sum() - new_conf[i, 0]
for j in range(len(self.increments)):
new_conf[i, j + 2] = conf[self.cum_increments[i]:self.cum_increments[i + 1],
self.cum_increments[j]:self.cum_increments[j + 1]].sum()
conf = new_conf
if self.normalized:
return conf / conf[:, 2:].sum(1).clip(min=1e-12)[:, None]
else:
return conf
class ClassErrorMeter:
def __init__(self, topk=[1], accuracy=False):
super(ClassErrorMeter, self).__init__()
self.topk = np.sort(topk)
self.accuracy = accuracy
self.reset()
def reset(self):
self.sum = {v: 0 for v in self.topk}
self.n = 0
def add(self, output, target):
if isinstance(output, np.ndarray):
output = torch.Tensor(output)
if isinstance(target, np.ndarray):
target = torch.Tensor(target)
# if torch.is_tensor(output):
# output = output.cpu().squeeze().numpy()
# if torch.is_tensor(target):
# target = target.cpu().squeeze().numpy()
# elif isinstance(target, numbers.Number):
# target = np.asarray([target])
# if np.ndim(output) == 1:
# output = output[np.newaxis]
# else:
# assert np.ndim(output) == 2, \
# 'wrong output size (1D or 2D expected)'
# assert np.ndim(target) == 1, \
# 'target and output do not match'
# assert target.shape[0] == output.shape[0], \
# 'target and output do not match'
topk = self.topk
maxk = int(topk[-1]) # seems like Python3 wants int and not np.int64
no = output.shape[0]
pred = output.topk(maxk, 1, True, True)[1]
correct = pred == target.unsqueeze(1).repeat(1, pred.shape[1])
# pred = torch.from_numpy(output).topk(maxk, 1, True, True)[1].numpy()
# correct = pred == target[:, np.newaxis].repeat(pred.shape[1], 1)
for k in topk:
self.sum[k] += no - correct[:, 0:k].sum()
self.n += no
def value(self, k=-1):
if k != -1:
assert k in self.sum.keys(), \
'invalid k (this k was not provided at construction time)'
if self.n == 0:
return float('nan')
if self.accuracy:
return (1. - float(self.sum[k]) / self.n) * 100.0
else:
return float(self.sum[k]) / self.n * 100.0
else:
return [self.value(k_) for k_ in self.topk]
class AverageValueMeter:
def __init__(self):
super(AverageValueMeter, self).__init__()
self.reset()
self.val = 0
def add(self, value, n=1):
self.val = value
self.sum += value
self.var += value * value
self.n += n
if self.n == 0:
self.mean, self.std = np.nan, np.nan
elif self.n == 1:
self.mean, self.std = self.sum, np.inf
self.mean_old = self.mean
self.m_s = 0.0
else:
self.mean = self.mean_old + (value - n * self.mean_old) / float(self.n)
self.m_s += (value - self.mean_old) * (value - self.mean)
self.mean_old = self.mean
self.std = math.sqrt(self.m_s / (self.n - 1.0))
def value(self):
return self.mean, self.std
def reset(self):
self.n = 0
self.sum = 0.0
self.var = 0.0
self.val = 0.0
self.mean = np.nan
self.mean_old = 0.0
self.m_s = 0.0
self.std = np.nan
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/results_utils.py
================================================
import glob
import json
import math
import os
import numpy as np
import matplotlib.pyplot as plt
from copy import deepcopy
from . import utils
def get_template_results(cfg):
return {"config": cfg, "results": []}
def save_results(results, label):
del results["config"]["device"]
folder_path = os.path.join("results", "{}_{}".format(utils.get_date(), label))
if not os.path.exists(folder_path):
os.makedirs(folder_path)
file_path = "{}_{}_.json".format(utils.get_date(), results["config"]["seed"])
with open(os.path.join(folder_path, file_path), "w+") as f:
json.dump(results, f, indent=2)
def compute_avg_inc_acc(results):
"""Computes the average incremental accuracy as defined in iCaRL.
The average incremental accuracies at task X are the average of accuracies
at task 0, 1, ..., and X.
:param accs: A list of dict for per-class accuracy at each step.
:return: A float.
"""
top1_tasks_accuracy = [r['top1']["total"] for r in results]
top1acc = sum(top1_tasks_accuracy) / len(top1_tasks_accuracy)
if "top5" in results[0].keys():
top5_tasks_accuracy = [r['top5']["total"] for r in results]
top5acc = sum(top5_tasks_accuracy) / len(top5_tasks_accuracy)
else:
top5acc = None
return top1acc, top5acc
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/scheduler.py
================================================
import math
from torch.optim.lr_scheduler import _LRScheduler
from torch.optim.lr_scheduler import ReduceLROnPlateau
class ConstantTaskLR:
def __init__(self, lr):
self._lr = lr
def get_lr(self, task_i):
return self._lr
class CosineAnnealTaskLR:
def __init__(self, lr_max, lr_min, task_max):
self._lr_max = lr_max
self._lr_min = lr_min
self._task_max = task_max
def get_lr(self, task_i):
return self._lr_min + (self._lr_max - self._lr_min) * (1 + math.cos(math.pi * task_i / self._task_max)) / 2
class GradualWarmupScheduler(_LRScheduler):
""" Gradually warm-up(increasing) learning rate in optimizer.
https://github.com/ildoonet/pytorch-gradual-warmup-lr
Proposed in 'Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour'.
Args:
optimizer (Optimizer): Wrapped optimizer.
multiplier: target learning rate = base lr * multiplier if multiplier > 1.0. if multiplier = 1.0, lr starts from 0 and ends up with the base_lr.
total_epoch: target learning rate is reached at total_epoch, gradually
after_scheduler: after target_epoch, use this scheduler(eg. ReduceLROnPlateau)
"""
def __init__(self, optimizer, multiplier, total_epoch, after_scheduler=None):
self.multiplier = multiplier
if self.multiplier < 1.:
raise ValueError('multiplier should be greater thant or equal to 1.')
self.total_epoch = total_epoch
self.after_scheduler = after_scheduler
self.finished = False
super(GradualWarmupScheduler, self).__init__(optimizer)
def get_lr(self):
if self.last_epoch > self.total_epoch:
if self.after_scheduler:
if not self.finished:
self.after_scheduler.base_lrs = [base_lr * self.multiplier for base_lr in self.base_lrs]
self.finished = True
return self.after_scheduler.get_last_lr()
return [base_lr * self.multiplier for base_lr in self.base_lrs]
if self.multiplier == 1.0:
return [base_lr * (float(self.last_epoch) / self.total_epoch) for base_lr in self.base_lrs]
else:
return [
base_lr * ((self.multiplier - 1.) * self.last_epoch / self.total_epoch + 1.)
for base_lr in self.base_lrs
]
def step_ReduceLROnPlateau(self, metrics, epoch=None):
if epoch is None:
epoch = self.last_epoch + 1
self.last_epoch = epoch if epoch != 0 else 1 # ReduceLROnPlateau is called at the end of epoch, whereas others are called at beginning
if self.last_epoch <= self.total_epoch:
warmup_lr = [
base_lr * ((self.multiplier - 1.) * self.last_epoch / self.total_epoch + 1.)
for base_lr in self.base_lrs
]
for param_group, lr in zip(self.optimizer.param_groups, warmup_lr):
param_group['lr'] = lr
else:
if epoch is None:
self.after_scheduler.step(metrics, None)
else:
self.after_scheduler.step(metrics, epoch - self.total_epoch)
def step(self, epoch=None, metrics=None):
if type(self.after_scheduler) != ReduceLROnPlateau:
if self.finished and self.after_scheduler:
if epoch is None:
self.after_scheduler.step(None)
else:
self.after_scheduler.step(epoch - self.total_epoch)
self._last_lr = self.after_scheduler.get_last_lr()
else:
return super(GradualWarmupScheduler, self).step(epoch)
else:
self.step_ReduceLROnPlateau(metrics, epoch)
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/similar.py
================================================
import torch.nn as nn
import torchvision.models as models
import numpy as np
import os
from sklearn.utils import shuffle
import torch
import torch.nn.functional as F
class Appr(object):
""" Class implementing the TALL """
def __init__(self, pretrained_feat_extractor, num_task, torc,device='cuda', args=None):
self.task2expert = []
self.expert2task = []
self.torc=torc
self.num_task=num_task
self.task2mean = {}
self.task2cov = {}
for i in range(num_task):
self.task2mean[i]=[]
self.task2cov[i]=[]
self.task_dist = torch.zeros(num_task, num_task).to(device='cuda')
self.task_dist2 = torch.zeros(num_task, num_task).to(device='cuda')
self.feat_extractor = pretrained_feat_extractor
self.task_relatedness_method = "mean"
self.reuse_threshold=0.3
self.reuse_cell_threshold=0.75
def get_mean_cov_feats(self, taski, data, device):
"""compute mean and cov for features of data extracted by the expert of task t
"""
# data = deepcopy(data) # copy for using different preprocess
# self.model.requires_grad_(False)
# self.model.eval()
# self.model.set_current_task(t)
if self.torc:
steps=int(100/self.num_task)
class_num = steps*taski
labels = torch.arange(class_num,class_num+steps).view(-1, 1).to(device)
else:
steps = int(100/self.num_task)
labels = torch.arange(steps).view(-1, 1).to(device)
all_task_feats={}
for t in range(taski):
all_task_feats[t]=[[] for _ in range(steps)]
self.feat_extractor.eval()
with torch.no_grad():
for batch_idx, (x, y) in enumerate(data):
x, y = x.to(device), y.to(device)
index = labels == y.view(1, -1) # CxC
for t_p in range(taski):
feat = self.feat_extractor(t_p,x,mask=None,classify=False)['features']
feat = feat.view(feat.size(0), -1)
for i in range(steps):
all_task_feats[t_p][i].append(feat[index[i]])
feat_means = {}
feat_covs = {}
all_feats_cat={}
for t_p in range(taski):
feat_means[t_p] = []
feat_covs [t_p]= []
all_feats_cat[t_p] = [torch.cat(feats, axis=0) for feats in all_task_feats[t_p]]
for feat in all_feats_cat[t_p]:
feat_mean, feat_cov = gaussian_mean_cov(feat)
feat_means[t_p].append(feat_mean)
# feat_covs[t_p].append(feat_cov)
# feat_means = [torch.mean(feat, dim=0) for feat in all_feats_cat]
return feat_means, feat_covs, all_feats_cat
def after_get_mean_cov_feats(self, taski, data, device):
"""compute mean and cov for features of data extracted by the expert of task t
"""
# data = deepcopy(data) # copy for using different preprocess
# self.model.requires_grad_(False)
# self.model.eval()
# self.model.set_current_task(t)
if self.torc:
steps=int(100/self.num_task)
class_num = steps*taski
labels = torch.arange(class_num,class_num+steps).view(-1, 1).to(device)
else:
steps = int(100/self.num_task)
labels = torch.arange(steps).view(-1, 1).to(device)
all_task_feats=[[] for _ in range(steps)]
self.feat_extractor.eval()
with torch.no_grad():
for batch_idx, (x, y) in enumerate(data):
x, y = x.to(device), y.to(device)
# forward
feat = self.feat_extractor(taski,x,mask=None,classify=False)['features']
feat = feat.view(feat.size(0), -1)
index = labels == y.view(1, -1) # CxC
for i in range(steps):
all_task_feats[i].append(feat[index[i]])
feat_means= []
feat_covs = []
all_feats_cat= [torch.cat(feats, axis=0) for feats in all_task_feats]
for feat in all_feats_cat:
feat_mean, feat_cov = gaussian_mean_cov(feat)
feat_means.append(feat_mean)
# feat_covs.append(feat_cov)
# feat_means = [torch.mean(feat, dim=0) for feat in all_feats_cat]
return feat_means, feat_covs, all_feats_cat
def add_mean_cov(self, taski,mean, cov=None):
self.task2mean[taski].append(mean)
# self.task2cov[taski].append(cov)
def task_relatedness_knnkl(self, task_id, p_task_id, all_feats):
"""
Params:
all_feat: shape C x N_c x D
"""
# means and features of current data from expert of p_task_id
# feat_means, all_feats = means_and_feats[p_task_id]
# means of data of p_task_id
p_feat_means = self.task2mean[p_task_id][p_task_id] # C x D
feat_means = self.task2mean[task_id][p_task_id] # C x D
# p_feat_cov = self.task2cov[p_task_id][p_task_id] # C x D
# feat_cov = self.task2cov[task_id][p_task_id] # C x D
p_feat_means = torch.stack(p_feat_means, dim=0)
task_dist = 0
task_dist2=0
d = p_feat_means.shape[-1]
n = 0
flag = False
for i in range(len(feat_means)):
# for each current class
n += all_feats[i].shape[0]
dist_in = all_feats[i] - feat_means[i] # N_c x D
dist_in = torch.sqrt(torch.sum(dist_in ** 2, dim=-1)) # N_c
# N_c x C x D
dist_out = torch.unsqueeze(all_feats[i], dim=1) - torch.unsqueeze(p_feat_means, dim=0)
dist_out, _ = torch.min(torch.sqrt(torch.sum(dist_out ** 2, dim=-1)), dim=-1) # N_c
dist = torch.mean(torch.log(dist_out / (0.9*dist_in)))
#dist = torch.mean(torch.log(dist_out))
# if dist <= 0:
# flag = True
task_dist += torch.maximum(dist, torch.zeros_like(dist))
task_dist2 += torch.maximum(dist, torch.zeros_like(dist))
# task_dist = task_dist / len(feat_means)
# task_dist = 1 - torch.exp(-2*task_dist)
task_dist = torch.minimum(1 - torch.exp(-2*task_dist), task_dist)
if task_dist == 0:
task_dist = torch.ones_like(task_dist)
return task_dist,task_dist2
def get_relatedness(self, task_id, feats):
"""Compute relatedness
"""
# the distance between task_id and task_id
self.task_dist[task_id][task_id] = 0
self.task_dist2[task_id][task_id] = 0
for p_task_id in range(task_id):
# for p_task_id in range(task_id + 1):
# task_dist = self.task_relatedness_cos(task_id, p_task_id)
task_dist,task_dist2 = self.task_relatedness_knnkl(task_id, p_task_id, feats[p_task_id])
# task_dist = self.task_relatedness_CKA(task_id, p_task_id, feats)
# task_dist = self.task_relatedness_gaussian_kl(task_id, p_task_id)
self.task_dist[task_id][p_task_id] = task_dist
self.task_dist[p_task_id][task_id] = task_dist
self.task_dist2[task_id][p_task_id] = task_dist2
self.task_dist2[p_task_id][task_id] = task_dist2
def strategy(self, task_id, num_train_samples):
""" Find the expert to be reused. If not found, return -1.
"""
expert = -1
min_dist = None
all_dist = []
all_dist2 = []
for expert_id, p_tasks in enumerate(self.expert2task):
d = self.task_dist[task_id, p_tasks]
dd= self.task_dist2[task_id, p_tasks]
if self.task_relatedness_method == "mean":
s = torch.mean(d).item()
ss = torch.mean(dd).item()
elif self.task_relatedness_method == "max":
s = torch.max(d).item()
elif self.task_relatedness_method == "min":
s = torch.min(d).item()
else:
raise Exception("Unknown reuse strategy !!!")
all_dist.append(s)
all_dist2.append(ss)
if min_dist is None:
min_dist = s
expert = expert_id
elif s < min_dist:
min_dist = s
expert = expert_id
# if num_train_samples <= 25: # for s_long
# all_dist = torch.tensor(all_dist)
# _, expert_idx =torch.sort(all_dist)
# for e in expert_idx:
# if self.model.expert2max_train_samples[e] >= 10 * num_train_samples:
# return "reuse", e
if min_dist <= self.reuse_threshold:
return "reuse", expert ,min_dist,all_dist,all_dist2
# elif min_dist <= self.reuse_cell_threshold:
# return "reuse cell", expert
else:
return "new", expert,min_dist,all_dist,all_dist2
def learn(self, task_id, valid_data, batch_size,device):
"""learn a task
"""
if task_id == 0:
# train
strategy='new'
expert_id=task_id
min_dist=0
all_dist=0
all_dist2=0
else:
feat_means, feat_covs, all_feats = self.get_mean_cov_feats(
task_id, valid_data, device=device)
for t in range(task_id):
self.add_mean_cov(task_id,feat_means[t],feat_covs[t])
self.get_relatedness(task_id, all_feats)
num_train_samples=len(valid_data)*batch_size
strategy, expert_id,min_dist,all_dist,all_dist2 = self.strategy(task_id, num_train_samples)
self.expert2task.append([task_id])
print(self.task_dist)
print(self.task_dist2)
return strategy, expert_id,min_dist,all_dist,all_dist2
def after_learn(self, task_id, valid_data, batch_size,device):
"""learn a task
"""
feat_means, feat_covs, all_feats = self.after_get_mean_cov_feats(
task_id, valid_data, device=device)
self.add_mean_cov(task_id,feat_means,feat_covs)
print(self.task_dist)
print(self.task_dist2)
class ResNet_FE(nn.Module):
"""
Create a feature extractor model from an Alexnet architecture, that is used to train the autoencoder model
and get the most related model whilst training a new task in a sequence
"""
def __init__(self, resnet_model):
super(ResNet_FE, self).__init__()
self.fe_model = nn.Sequential(*list(resnet_model.children())[:-1])
self.fe_model.eval()
self.fe_model.requires_grad_(False)
def forward(self, x):
return self.fe_model(x)
def get_pretrained_feat_extractor(name):
"""get the feature extractor pretrained on ImageNet
"""
if name == "resnet18":
feat_extractor = ResNet_FE(models.resnet18(weights=True))
# self.logger.info("Using relatedness feature extractor: ResNet18")
else:
raise Exception("Unknown relatedness feature extractor !!!")
return feat_extractor
def gaussian_mean_cov(X):
"""mean and covariance of Guassian distribution
Params:
X: N x D
"""
device = X.device
N, D = X.shape[0], X.shape[1]
u = torch.mean(X, dim=0)
u_row = torch.reshape(u, (1, -1)) # 1 x D
cov = torch.matmul(X.T, X) - N * torch.matmul(u_row.T, u_row) # D x D
cov = cov / (N - 1)
cov = cov * torch.diag(torch.ones(D)).to(X.device) + (torch.diag(torch.ones(D))).to(X.device)
return u, cov
# import torch.nn as nn
# import torchvision.models as models
# import numpy as np
# import os
# from sklearn.utils import shuffle
# import torch
# import torch.nn.functional as F
# class Appr(object):
# """ Class implementing the TALL """
# def __init__(self, pretrained_feat_extractor, num_task, device='cuda', args=None):
# self.task2expert = []
# self.expert2task = []
# self.task2mean = []
# self.task2cov = []
# self.task_dist = torch.zeros(num_task, num_task).to(device='cuda')
# self.feat_extractor = get_pretrained_feat_extractor(pretrained_feat_extractor).to(device='cuda')
# self.task_relatedness_method = "mean"
# self.reuse_threshold=0.3
# self.reuse_cell_threshold=0.75
# def get_mean_cov_feats(self, t, data, device):
# """compute mean and cov for features of data extracted by the expert of task t
# """
# # data = deepcopy(data) # copy for using different preprocess
# # self.model.requires_grad_(False)
# # self.model.eval()
# # self.model.set_current_task(t)
# class_num = 10
# labels = torch.arange(class_num).view(-1, 1).to(device)
# all_feats = [[] for _ in range(class_num)]
# self.feat_extractor.eval()
# with torch.no_grad():
# for batch_idx, (x, y) in enumerate(data):
# x, y = x.to(device), y.to(device)
# # forward
# feat = self.feat_extractor(x)
# feat = feat.view(feat.size(0), -1)
# index = labels == y.view(1, -1) # CxC
# for i in range(class_num):
# all_feats[i].append(feat[index[i]])
# all_feats_cat = [torch.cat(feats, axis=0) for feats in all_feats]
# feat_means = []
# feat_covs = []
# for feat in all_feats_cat:
# feat_mean, feat_cov = gaussian_mean_cov(feat)
# feat_means.append(feat_mean)
# feat_covs.append(feat_cov)
# # feat_means = [torch.mean(feat, dim=0) for feat in all_feats_cat]
# return feat_means, feat_covs, all_feats_cat
# def add_mean_cov(self, mean, cov=None):
# self.task2mean.append(mean)
# self.task2cov.append(cov)
# def task_relatedness_knnkl(self, task_id, p_task_id, all_feats):
# """
# Params:
# all_feat: shape C x N_c x D
# """
# # means and features of current data from expert of p_task_id
# # feat_means, all_feats = means_and_feats[p_task_id]
# # means of data of p_task_id
# p_feat_means = self.task2mean[p_task_id] # C x D
# feat_means = self.task2mean[task_id] # C x D
# p_feat_means = torch.stack(p_feat_means, dim=0)
# task_dist = 0
# d = p_feat_means.shape[-1]
# n = 0
# flag = False
# for i in range(len(feat_means)):
# # for each current class
# n += all_feats[i].shape[0]
# dist_in = all_feats[i] - feat_means[i] # N_c x D
# dist_in = torch.sqrt(torch.sum(dist_in ** 2, dim=-1)) # N_c
# # N_c x C x D
# dist_out = torch.unsqueeze(all_feats[i], dim=1) - torch.unsqueeze(p_feat_means, dim=0)
# dist_out, _ = torch.min(torch.sqrt(torch.sum(dist_out ** 2, dim=-1)), dim=-1) # N_c
# dist = torch.mean(torch.log(dist_out / dist_in))
# # if dist <= 0:
# # flag = True
# task_dist += torch.maximum(dist, torch.zeros_like(dist))
# # task_dist = task_dist / len(feat_means)
# # task_dist = 1 - torch.exp(-2*task_dist)
# task_dist = torch.minimum(1 - torch.exp(-2*task_dist), task_dist)
# if task_dist == 0:
# task_dist = torch.ones_like(task_dist)
# return task_dist
# def get_relatedness(self, task_id, feats):
# """Compute relatedness
# """
# # the distance between task_id and task_id
# self.task_dist[task_id][task_id] = 0
# for p_task_id in range(task_id):
# # for p_task_id in range(task_id + 1):
# # task_dist = self.task_relatedness_cos(task_id, p_task_id)
# task_dist = self.task_relatedness_knnkl(task_id, p_task_id, feats)
# # task_dist = self.task_relatedness_CKA(task_id, p_task_id, feats)
# # task_dist = self.task_relatedness_gaussian_kl(task_id, p_task_id)
# self.task_dist[task_id][p_task_id] = task_dist
# self.task_dist[p_task_id][task_id] = task_dist
# def strategy(self, task_id, num_train_samples):
# """ Find the expert to be reused. If not found, return -1.
# """
# expert = -1
# min_dist = None
# all_dist = []
# for expert_id, p_tasks in enumerate(self.expert2task):
# d = self.task_dist[task_id, p_tasks]
# if self.task_relatedness_method == "mean":
# s = torch.mean(d).item()
# elif self.task_relatedness_method == "max":
# s = torch.max(d).item()
# elif self.task_relatedness_method == "min":
# s = torch.min(d).item()
# else:
# raise Exception("Unknown reuse strategy !!!")
# all_dist.append(s)
# if min_dist is None:
# min_dist = s
# expert = expert_id
# elif s < min_dist:
# min_dist = s
# expert = expert_id
# # if num_train_samples <= 25: # for s_long
# # all_dist = torch.tensor(all_dist)
# # _, expert_idx =torch.sort(all_dist)
# # for e in expert_idx:
# # if self.model.expert2max_train_samples[e] >= 10 * num_train_samples:
# # return "reuse", e
# if min_dist <= self.reuse_threshold:
# return "reuse", expert ,min_dist,all_dist
# # elif min_dist <= self.reuse_cell_threshold:
# # return "reuse cell", expert
# else:
# return "new", expert,min_dist,all_dist
# def learn(self, task_id, valid_data, batch_size,device):
# """learn a task
# """
# feat_means, feat_covs, all_feats = self.get_mean_cov_feats(
# task_id, valid_data, device=device)
# self.add_mean_cov(feat_means)
# self.get_relatedness(task_id, all_feats)
# if task_id == 0:
# # train
# strategy='new'
# expert_id=task_id
# min_dist=0
# all_dist=0
# else:
# num_train_samples=len(valid_data)*batch_size
# strategy, expert_id,min_dist,all_dist = self.strategy(task_id, num_train_samples)
# self.expert2task.append([task_id])
# return strategy, expert_id,min_dist,all_dist
# class ResNet_FE(nn.Module):
# """
# Create a feature extractor model from an Alexnet architecture, that is used to train the autoencoder model
# and get the most related model whilst training a new task in a sequence
# """
# def __init__(self, resnet_model):
# super(ResNet_FE, self).__init__()
# self.fe_model = nn.Sequential(*list(resnet_model.children())[:-1])
# self.fe_model.eval()
# self.fe_model.requires_grad_(False)
# def forward(self, x):
# return self.fe_model(x)
# def get_pretrained_feat_extractor(name):
# """get the feature extractor pretrained on ImageNet
# """
# if name == "resnet18":
# feat_extractor = ResNet_FE(models.resnet18(weights=True))
# # self.logger.info("Using relatedness feature extractor: ResNet18")
# else:
# raise Exception("Unknown relatedness feature extractor !!!")
# return feat_extractor
# def gaussian_mean_cov(X):
# """mean and covariance of Guassian distribution
# Params:
# X: N x D
# """
# device = X.device
# N, D = X.shape[0], X.shape[1]
# u = torch.mean(X, dim=0)
# u_row = torch.reshape(u, (1, -1)) # 1 x D
# cov = torch.matmul(X.T, X) - N * torch.matmul(u_row.T, u_row) # D x D
# cov = cov / (N - 1)
# cov = cov * torch.diag(torch.ones(D)).to(X.device) + (torch.diag(torch.ones(D))).to(X.device)
# return u, cov
================================================
FILE: examples/Structural_Development/SCA-SNN/inclearn/tools/utils.py
================================================
import random
from copy import deepcopy
import numpy as np
import datetime
import torch
from inclearn.tools.metrics import ClassErrorMeter
from sklearn.metrics import classification_report
def get_date():
return datetime.datetime.now().strftime("%Y%m%d")
def to_onehot(targets, n_classes):
if not hasattr(targets, "device"):
targets = torch.from_numpy(targets)
onehot = torch.zeros(targets.shape[0], n_classes).to(targets.device)
onehot.scatter_(dim=1, index=targets.long().view(-1, 1), value=1.0)
return onehot
def get_class_loss(network, cur_n_cls, loader):
class_loss = torch.zeros(cur_n_cls)
n_cls_data = torch.zeros(cur_n_cls) # the num of imgs for cls i.
EPS = 1e-10
task_size = 10
network.eval()
for x, y in loader:
x, y = x.cuda(), y.cuda()
preds = network(x)['logit'].softmax(dim=1)
# preds[:,-task_size:] = preds[:,-task_size:].softmax(dim=1)
for i, lbl in enumerate(y):
class_loss[lbl] = class_loss[lbl] - (preds[i, lbl] + EPS).detach().log().cpu()
n_cls_data[lbl] += 1
class_loss = class_loss / n_cls_data
return class_loss
def get_featnorm_grouped_by_class(task_i,network, cur_n_cls, loader,m=None):
"""
Ret: feat_norms: list of list
feat_norms[idx] is the list of feature norm of the images for class idx.
"""
feats = [[] for i in range(cur_n_cls)]
feat_norms = np.zeros(cur_n_cls)
network.eval()
with torch.no_grad():
for x, y in loader:
x = x.cuda()
feat = network(task_i,x,m)['feature'].cpu()
for i, lbl in enumerate(y):
if lbl >= cur_n_cls:
continue
feats[lbl].append(feat[y == lbl])
for i in range(len(feats)):
if len(feats[i]) != 0:
feat_cls = torch.cat((feats[i]))
feat_norms[i] = torch.norm(feat_cls, p=2, dim=1).mean().data.numpy()
return feat_norms
def set_seed(seed):
print("Set seed", seed)
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True # This will slow down training.
torch.backends.cudnn.benchmark = False
def display_weight_norm(logger, network, increments, tag):
weight_norms = [[] for _ in range(len(increments))]
increments = np.cumsum(np.array(increments))
for idx in range(network.module.convnets[-1].classifer.weight.shape[0]):
norm = torch.norm(network.module.convnets[-1].classifer.weight[idx].data, p=2).item()
for i in range(len(weight_norms)):
if idx < increments[i]:
break
weight_norms[i].append(round(norm, 3))
avg_weight_norm = []
# all_weight_norms = []
for idx in range(len(weight_norms)):
# all_weight_norms += weight_norms[idx]
# logger.info("task %s: Weight norm per class %s" % (str(idx), str(weight_norms[idx])))
avg_weight_norm.append(round(np.array(weight_norms[idx]).mean(), 3))
logger.info("%s: Weight norm per task %s" % (tag, str(avg_weight_norm)))
def display_feature_norm(task_i,logger, network, loader, n_classes, increments, tag, return_norm=False,mask=None):
avg_feat_norm_per_cls = get_featnorm_grouped_by_class(task_i,network, n_classes, loader,m=mask)
feature_norms = [[] for _ in range(len(increments))]
increments = np.cumsum(np.array(increments))
for idx in range(len(avg_feat_norm_per_cls)):
for i in range(len(feature_norms)):
if idx < increments[i]: #Find the mapping from class idx to step i.
break
feature_norms[i].append(round(avg_feat_norm_per_cls[idx], 3))
avg_feature_norm = []
for idx in range(len(feature_norms)):
avg_feature_norm.append(round(np.array(feature_norms[idx]).mean(), 3))
logger.info("%s: Feature norm per class %s" % (tag, str(avg_feature_norm)))
if return_norm:
return avg_feature_norm
else:
return
def check_loss(loss):
return not bool(torch.isnan(loss).item()) and bool((loss >= 0.0).item())
def class2task(class_form, classnum):
target_form = deepcopy(class_form)
for i in range(classnum):
mask = (target_form==i)
target_form[mask] = -(i//10)-1
target_form = (target_form+1)*(-1)
return target_form
def maskclass(pred, target, classnum, type='new'):
# type 为new,遮盖new的class,old遮盖旧的,all遮盖新旧
target_form = deepcopy(target)
pred_form = deepcopy(pred)
if type == 'old':
mask = np.logical_or(pred_form<(classnum-10), target_form<(classnum-10))
pred_form[mask] = 0
target_form[mask] = 0
if type == 'new':
mask = np.logical_or(pred_form>=(classnum-10), target_form>=(classnum-10))
pred_form[mask] = 1000
target_form[mask] = 1000
if type == 'all':
mask = (target_form>=(classnum-10))
target_form[mask] = 1000
mask = (pred_form>=(classnum-10))
pred_form[mask] = 1000
mask = (target_form<(classnum-10))
target_form[mask] = 0
mask = (pred_form<(classnum-10))
pred_form[mask] = 0
all_err = np.sum(pred_form!=target_form)
pred_form1 = deepcopy(pred_form)
mask = (target_form<(classnum-10))
pred_form[mask] = 0
new_old_err = np.sum(pred_form!=target_form)
mask = (target_form>=(classnum-10))
pred_form1[mask] = 1000
old_new_err = np.sum(pred_form1!=target_form)
return all_err, new_old_err, old_new_err
return pred_form, target_form
def compute_old_new_mix(ypred, ytrue, increments, n_classes, task_order):
task_means = []
for i in range (n_classes//10):
taski_mask = np.logical_and(ytrue>=i*10, ytrue<(i+1)*10)
task_i_mean = ypred[np.arange(ytrue.shape[0]), ytrue][taski_mask].mean().item()
task_means.append(task_i_mean)
task_mean = ypred[np.arange(ytrue.shape[0]), ytrue].mean().item()
classnum = ypred.shape[1]
ypred = ypred.argmax(1)
all_err = np.sum(ypred!=ytrue)
ypred_task = class2task(ypred, classnum)
ytrue_task = class2task(ytrue, classnum)
err_among_task = np.sum(ypred_task!=ytrue_task)
err_inner_task = all_err - err_among_task
# print("all err : {}\n among task err: {}\n inner task err: {}\n".format(all_err, err_among_task, err_inner_task))
ypred_new, ytrue_new = maskclass(ypred, ytrue, n_classes, 'old')
new_err = np.sum(ypred_new!=ytrue_new)
ypred_old, ytrue_old = maskclass(ypred, ytrue, n_classes, 'new')
old_err = np.sum(ypred_old!=ytrue_old)
all_err, new_old_err, old_new_err = maskclass(ypred, ytrue, n_classes, 'all')
print("******all_err:****", all_err)
all_acc = {"task_mean": task_mean, "task_means":task_means, "new_err": new_err, "old_err":old_err, "new_old_err": new_old_err, "old_new_err": old_new_err, "err_among_task": err_among_task, "err_inner_task": err_inner_task}
return all_acc
def compute_task_accuracy(ypred, ytrue, increments, n_classes, task_order):
task_mean = ypred[np.arange(ytrue.shape[0]), ytrue].mean().item()
classnum = ypred.shape[1]
ypred = ypred.argmax(1)
ypred_task = class2task(ypred, classnum)
ytrue_task = class2task(ytrue, classnum)
all_acc = {"task_mean": task_mean, "class_info": classification_report(ytrue, ypred), "task_info": classification_report(ytrue_task, ypred_task)}
return all_acc
def compute_accuracy(ypred, ytrue, increments, n_classes):
all_acc = {"top1": {}, "top5": {}}
topk = 5 if n_classes >= 5 else n_classes
ncls = np.unique(ytrue).shape[0]
if topk > ncls:
topk = ncls
all_acc_meter = ClassErrorMeter(topk=[1, topk], accuracy=True)
all_acc_meter.add(ypred, ytrue)
all_acc["top1"]["total"] = round(all_acc_meter.value()[0], 3)
all_acc["top5"]["total"] = round(all_acc_meter.value()[1], 3)
# all_acc["total"] = round((ypred == ytrue).sum() / len(ytrue), 3)
# for class_id in range(0, np.max(ytrue), task_size):
start, end = 0, 0
for i in range(len(increments)):
if increments[i] <= 0:
pass
else:
start = end
end += increments[i]
idxes = np.where(np.logical_and(ytrue >= start, ytrue < end))[0]
topk_ = 5 if increments[i] >= 5 else increments[i]
ncls = np.unique(ytrue[idxes]).shape[0]
if topk_ > ncls:
topk_ = ncls
cur_acc_meter = ClassErrorMeter(topk=[1, topk_], accuracy=True)
cur_acc_meter.add(ypred[idxes], ytrue[idxes])
top1_acc = (ypred[idxes].argmax(1) == ytrue[idxes]).sum() / idxes.shape[0] * 100
if start < end:
label = "{}-{}".format(str(start).rjust(2, "0"), str(end - 1).rjust(2, "0"))
else:
label = "{}-{}".format(str(start).rjust(2, "0"), str(end).rjust(2, "0"))
all_acc["top1"][label] = round(top1_acc, 3)
all_acc["top5"][label] = round(cur_acc_meter.value()[1], 3)
# all_acc[label] = round((ypred[idxes] == ytrue[idxes]).sum() / len(idxes), 3)
return all_acc
def make_logger(log_name, savedir='.logs/'):
"""Set up the logger for saving log file on the disk
Args:
cfg: configuration dict
Return:
logger: a logger for record essential information
"""
import logging
import os
from logging.config import dictConfig
import time
logging_config = dict(
version=1,
formatters={'f_t': {
'format': '\n %(asctime)s | %(levelname)s | %(name)s \t %(message)s'
}},
handlers={
'stream_handler': {
'class': 'logging.StreamHandler',
'formatter': 'f_t',
'level': logging.INFO
},
'file_handler': {
'class': 'logging.FileHandler',
'formatter': 'f_t',
'level': logging.INFO,
'filename': None,
}
},
root={
'handlers': ['stream_handler', 'file_handler'],
'level': logging.DEBUG,
},
)
# set up logger
log_file = '{}.log'.format(log_name)
# if folder not exist,create it
if not os.path.exists(savedir):
os.makedirs(savedir)
log_file_path = os.path.join(savedir, log_file)
logging_config['handlers']['file_handler']['filename'] = log_file_path
open(log_file_path, 'w').close() # Clear the content of logfile
# get logger from dictConfig
dictConfig(logging_config)
logger = logging.getLogger()
return logger
================================================
FILE: examples/Structural_Development/SCA-SNN/main.py
================================================
import sys
import os
import os.path as osp
import copy
import time
import shutil
import cProfile
import logging
from pathlib import Path
import numpy as np
import random
from easydict import EasyDict as edict
from tensorboardX import SummaryWriter
import os
import inclearn.convnet.maskcl2 as Mask
os.environ['CUDA_VISIBLE_DEVICES']='0'
repo_name = 'TCIL'
base_dir = '/data1/hanbing/TCIL10/'
sys.path.insert(0, base_dir)
from sacred import Experiment
ex = Experiment(base_dir=base_dir, save_git_info=False)
import torch
from inclearn.tools import factory, results_utils, utils
from inclearn.tools.metrics import IncConfusionMeter
from inclearn.tools.similar import Appr
def initialization(config, seed, mode, exp_id):
torch.backends.cudnn.benchmark = True # This will result in non-deterministic results.
# ex.captured_out_filter = lambda text: 'Output capturing turned off.'
cfg = edict(config)
utils.set_seed(cfg['seed'])
if exp_id is None:
exp_id = -1
cfg.exp.savedir = "./logs_aphal"
logger = utils.make_logger(str(exp_id)+str(cfg.exp.name)+str(mode), savedir=cfg.exp.savedir)
# Tensorboard
exp_name = '{exp_id}_{cfg["exp"]["name"]}' if exp_id is not None else '../inbox/{cfg["exp"]["name"]}'
tensorboard_dir = cfg["exp"]["tensorboard_dir"] + "/{exp_name}"
# If not only save latest tensorboard log.
# if Path(tensorboard_dir).exists():
# shutil.move(tensorboard_dir, cfg["exp"]["tensorboard_dir"] + f"/../inbox/{time.time()}_{exp_name}")
tensorboard = SummaryWriter(tensorboard_dir)
return cfg, logger, tensorboard
@ex.command
def train(_run, _rnd, _seed):
cfg, ex.logger, tensorboard = initialization(_run.config, _seed, "train", _run._id)
ex.logger.info(cfg)
cfg.data_folder = osp.join(base_dir, "data")
start_time = time.time()
_train(cfg, _run, ex, tensorboard)
ex.logger.info("Training finished in {}s.".format(int(time.time() - start_time)))
def _train(cfg, _run, ex, tensorboard):
device = factory.set_device(cfg)
trial_i = cfg['trial']
torc=cfg['distillation']
inc_dataset = factory.get_data(cfg, trial_i)
ex.logger.info("classes_order")
ex.logger.info(inc_dataset.class_order)
model = factory.get_model(cfg, trial_i, _run, ex, tensorboard, inc_dataset)
mask=Mask.Mask(model._network.convnets[-1])
if _run.meta_info["options"]["--file_storage"] is not None:
_save_dir = osp.join(_run.meta_info["options"]["--file_storage"], str(_run._id))
else:
_save_dir = cfg["exp"]["ckptdir"]
results = results_utils.get_template_results(cfg)
appr=Appr(model._network,10,torc)
for task_i in range(inc_dataset.n_tasks):
task_info, train_loader, val_loader, test_loader = inc_dataset.new_task(task_i)
model.set_task_info(
task=task_info["task"],
total_n_classes=task_info["max_class"],
increment=task_info["increment"],
n_train_data=task_info["n_train_data"],
n_test_data=task_info["n_test_data"],
n_tasks=inc_dataset.n_tasks,
)
if torc:
strategy, expert_id ,min_dist,all_dist,all_dist2= appr.learn(task_i, val_loader, cfg['batch_size'],device)
else:
strategy, expert_id ,min_dist,all_dist,all_dist2= appr.learn(task_i, test_loader[task_i], cfg['batch_size'],device)
print("Task:",task_i,strategy, expert_id,min_dist,all_dist,all_dist2)
model.before_task(task_i, inc_dataset,mask,min_dist,all_dist)
# TODO: Move to incmodel.py
if 'min_class' in task_info:
ex.logger.info("Train on {}->{}.".format(task_info["min_class"], task_info["max_class"]))
if torc:
model.train_task(task_i,train_loader, test_loader,mask,min_dist,all_dist)
model.after_task(task_i, inc_dataset,mask)
appr.after_learn(task_i, val_loader, cfg['batch_size'],device)
else:
model.train_task(task_i,train_loader, val_loader[task_i],mask,min_dist,all_dist)
appr.after_learn(task_i, test_loader[task_i], cfg['batch_size'],device)
if torc:
ex.logger.info("Eval on {}->{}.".format(0, task_info["max_class"]))
ypred, ytrue = model.eval_task(task_i,test_loader,mask)
acc_stats = utils.compute_accuracy(ypred, ytrue, increments=model._increments, n_classes=model._n_classes)
#Logging
model._tensorboard.add_scalar("taskaccu/trial{trial_i}", acc_stats["top1"]["total"], task_i)
_run.log_scalar("trial{trial_i}_taskaccu", acc_stats["top1"]["total"], task_i)
_run.log_scalar("trial{trial_i}_task_top5_accu", acc_stats["top5"]["total"], task_i)
ex.logger.info("top1:"+str(acc_stats['top1']))
ex.logger.info("top5:"+str(acc_stats['top5']))
results["results"].append(acc_stats)
else:
for taski in range(task_i+1):
ypred, ytrue = model.eval_task(taski,test_loader[taski],mask)
acc_stats = utils.compute_accuracy(ypred, ytrue, increments=[1], n_classes=model._n_classes)
model._tensorboard.add_scalar(f"taskaccu/trial{trial_i}", acc_stats["top1"]["total"], taski)
_run.log_scalar(f"trial{trial_i}_taskaccu", acc_stats["top1"]["total"], taski)
_run.log_scalar(f"trial{trial_i}_task_top5_accu", acc_stats["top5"]["total"], taski)
ex.logger.info(f"top1:{acc_stats['top1']}")
ex.logger.info(f"top5:{acc_stats['top5']}")
results["results"].append(acc_stats)
top1_avg_acc, top5_avg_acc = results_utils.compute_avg_inc_acc(results["results"])
_run.info["trial{trial_i}"]["avg_incremental_accu_top1"] = top1_avg_acc
_run.info["trial{trial_i}"]["avg_incremental_accu_top5"] = top5_avg_acc
ex.logger.info("Average Incremental Accuracy Top 1: {} Top 5: {}.".format(
_run.info["trial{trial_i}"]["avg_incremental_accu_top1"],
_run.info["trial{trial_i}"]["avg_incremental_accu_top5"],
))
if cfg["exp"]["name"]:
results_utils.save_results(results, cfg["exp"]["name"])
if __name__ == "__main__":
ex.add_config("/data1/hanbing/SCA-SNN/configs/train.yaml")
ex.run_commandline()
================================================
FILE: examples/Structural_Development/SD-SNN/README.md
================================================
# Adaptive Sparse Structure Development with Pruning and Regeneration for Spiking Neural Networks #
## Requirments ##
* numpy
* timm
* pytorch >= 1.7.0
* collections
* argparse
## Run ##
```CUDA_VISIBLE_DEVICES=0 python main.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{han2025adaptive,
title={Adaptive sparse structure development with pruning and regeneration for spiking neural networks},
author={Han, Bing and Zhao, Feifei and Pan, Wenxuan and Zeng, Yi},
journal={Information Sciences},
volume={689},
pages={121481},
year={2025},
publisher={Elsevier}
}
@article{zeng2023braincog,
title={Braincog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired ai and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier},
}
```
Enjoy!
================================================
FILE: examples/Structural_Development/SD-SNN/main.py
================================================
import argparse
import time
import os
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
import sys
sys.path.append('..')
import logging
import torch
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from braincog.base.node.node import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from prun_and_generation import *
from snn_model import *
from utils import *
_logger = logging.getLogger('train')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
exp_name = '-'.join([datetime.now().strftime("%Y%m%d-%H%M%S"),'c10'])
output_dir = get_outdir('./', 'train', exp_name)
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
_logger.info(exp_name)
config_parser = cfg = argparse.ArgumentParser(description='Training Config', add_help=False)
model='cifar_convnet'
dataset='cifar10'
num_classes=10
step=8
encode='direct'
node_type='PLIFNode'
thresh=0.5
tau=2.0
torch.backends.cudnn.benchmark = True
devicee=0
seed=36
channels = 2
lr=5e-3
batch_size=50
epochs=600
linear_scaled_lr = lr * batch_size/ 1024.0
cfg.opt='adamw'
cfg.lr=linear_scaled_lr
cfg.weight_decay=0.01
cfg.momentum=0.9
cfg.epochs=epochs
cfg.sched='cosine'
cfg.min_lr=1e-5
cfg.warmup_lr=1e-6
cfg.warmup_epochs=5
cfg.cooldown_epochs=10
cfg.decay_rate=0.1
epoch_prune = 1
eval_metric='top1'
best_test = 0
best_testepoch = 0
best_testprun = 0
best_testepochprun = 0
spines_num=18
torch.cuda.set_device('cuda:%d' % devicee)
torch.manual_seed(seed)
model = my_cifar_model(step=step,encode_type=encode,node_type=node_type,num_classes=num_classes)
model = model.cuda()
print(model)
optimizer = create_optimizer(cfg, model)
lr_scheduler, num_epochs = create_scheduler(cfg, optimizer)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % dataset)(batch_size=batch_size, step=step)
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
m = Mask(model,spines_num)
def train_epoch(
epoch, model, loader, optimizer, loss_fn,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None):
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
model.train()
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
output = model(inputs)
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
optimizer.zero_grad()
loss.backward()
optimizer.step()
batch_time_m.update(time.time() - end)
if last_batch or batch_idx %100 == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
print("Train: epoch:",epoch,batch_idx,"/",len(loader),"loss:",losses_m.avg,"acc1:", top1_m.avg,"lr:",lr)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg)])
def validate(model, loader, loss_fn, amp_autocast=suppress, log_suffix=''):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
end = time.time()
last_idx = len(loader) - 1
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
#print(inputs.size())
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
if last_batch or batch_idx %100 == 0:
print("Test: loss:",losses_m.avg,"acc1:", top1_m.avg)
batch_time_m.update(time.time() - end)
end = time.time()
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
return metrics
for epoch in range(epochs):
train_metrics= train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn,
lr_scheduler=lr_scheduler)
if epoch==0:
m.init_length()
if epoch>0:
m.model = model
m.init_mask_dsd()
if epoch>spines_num:
matt=m.do_mask_dsd()
if epoch>2*spines_num:
m.do_growth_ww(epoch)
matt=m.do_pruning_dsd(epoch)
model = m.model
cc=m.if_zero()
eval_metrics = validate(model, loader_eval, validate_loss_fn)
top1=eval_metrics['top1']
if top1 > best_testprun:
best_testprun = top1
best_testepochprun =epoch
if epoch%40==0:
print('best acc:',best_testprun,'best epoch:',best_testepochprun)
if epoch>4:
_logger.info('*** epoch: {0} (pruning rate {1},acc:{2})'.format(epoch, cc,top1))
if lr_scheduler is not None:
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
================================================
FILE: examples/Structural_Development/SD-SNN/prun_and_generation.py
================================================
import numpy as np
import torch
import math
from utils import *
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class Mask:
def __init__(self, model,count_thre):
self.model_size = {}
self.model_length = {}
self.compress_rate = {}
self.mat = {}
self.model = model
self.mask_index = []
self.distance_rate = {}
self.filter_small_index = {}
self.filter_large_index = {}
self.similar_matrix = {}
self.norm_matrix = {}
# dendritic dynamics
self.cur_range_pos = {} # current range foe every weight
self.cur_range_neg = {} # current range foe every weight
self.dsum_pos_out = {} # current range foe every weight
self.dsum_neg_out = {} # current range foe every weight
self.dsum_pos_in = {} # current range foe every weight
self.dsum_neg_in = {} # current range foe every weight
self.dendritic_previous_pos = {} # the index for beyond range weight
self.dendritic_previous_neg = {} # the index for within range weight
self.dendritic_previous_in = {} # the index for within range weight
self.dendritic_count_pos = {} # the count of beyond range for every weight
self.dendritic_count_neg = {} # the count of within range for every weight
self.dendritic_count_in = {} # the count of within range for every weight
self.out = 0
self.count_thre=count_thre
self.weight_previous = {}
self.mask={}
self.codebook = {}
self.codebookww={}
self.his_ind={}
self.his_groth={}
self.his_gro_count={}
self.prune={}
self.pruncc={}
self.prunn={}
self.his_prun={}
self.convlayer =model.convlayer
for index in self.convlayer:
if indexr+
weight_vec = weight_torch.view(-1) # one conv one weight vector
weight_vec_np = weight_vec.cpu().numpy()
weight_np_abs = abs(weight_vec_np)
dendritic_pos_tmp = np.where((weight_vec_np >= self.cur_range_pos[i])) # find the weight beyong range
pos_index = set(dendritic_pos_tmp[0]) & set(self.dendritic_previous_pos[i]) # calculate intersection consectively
pos_zero = set([i for i in range(length)]) - pos_index # non-intersection weight will be count from 0
pos_index = np.array(list(pos_index))
pos_zero = np.array(list(pos_zero))
if pos_zero.size > 0:
self.dendritic_count_pos[i][pos_zero] = 0
self.dsum_pos_out[i][pos_zero] = 0
if pos_index.size > 0:
self.dendritic_count_pos[i][pos_index] = self.dendritic_count_pos[i][pos_index] + 1 # intewrsection +1
self.dsum_pos_out[i][pos_index] += weight_vec_np[pos_index] - self.cur_range_pos[i][pos_index]
dendritic_index = np.where(self.dendritic_count_pos[i] >= count_thre) # count>threshold
self.out = self.out + len(dendritic_index[0])
self.cur_range_pos[i][dendritic_index]+=(self.dsum_pos_out[i][dendritic_index] / count_thre) # self.cur_range_pos[i][dendritic_index]+0.025 #
self.dendritic_count_pos[i][dendritic_index] = 0 # intrsection count set to 0
self.dsum_pos_out[i][dendritic_index] = 0
self.dendritic_previous_pos[i] = dendritic_pos_tmp[0] # update previous
# 0:
self.dendritic_count_neg[i][neg_zero] = 0
self.dsum_neg_out[i][neg_zero] = 0
if neg_index.size > 0:
self.dendritic_count_neg[i][neg_index] = self.dendritic_count_neg[i][neg_index] + 1 # intewrsection +1
self.dsum_neg_out[i][neg_index] += weight_vec_np[neg_index] - self.cur_range_neg[i][neg_index]
dendritic_index_neg = np.where(self.dendritic_count_neg[i] >= count_thre) # count>threshold
self.out = self.out + len(dendritic_index_neg[0])
self.cur_range_neg[i][dendritic_index_neg] += (self.dsum_neg_out[i][dendritic_index_neg] / count_thre) #self.cur_range_neg[i][dendritic_index_neg]-0.025 #
self.dendritic_count_neg[i][dendritic_index_neg] = 0 # intrsection count set to 0
self.dsum_neg_out[i][dendritic_index_neg] = 0
self.dendritic_previous_neg[i] = dendritic_neg_tmp[0] # update previous
# r-~r+
dendritic_in_tmp = np.where((weight_np_abs < self.weight_previous[i])) # find the weight beyong range
in_index = set(dendritic_in_tmp[0]) & set(self.dendritic_previous_in[i]) # calculate intersection consectively
in_zero = set([i for i in range(length)]) - in_index # non-intersection weight will be count from 0
in_index = np.array(list(in_index))
in_zero = np.array(list(in_zero))
if in_zero.size > 0:
self.dendritic_count_in[i][in_zero] = 0
self.dsum_neg_in[i][in_zero] = 0
if in_index.size > 0:
self.dendritic_count_in[i][in_index] = self.dendritic_count_in[i][in_index] + 1 # intewrsection +1
self.dsum_neg_in[i][in_index] += weight_np_abs[in_index] - self.weight_previous[i][in_index]
dendritic_index_in = np.where(self.dendritic_count_in[i] >= count_thre) # count>threshold
self.cur_range_pos[i][dendritic_index_in] = 0.75*self.cur_range_pos[i][dendritic_index_in] # self.cur_range_pos[i][dendritic_index_in]-0.025
self.cur_range_neg[i][dendritic_index_in] = 0.75*self.cur_range_neg[i][dendritic_index_in] # self.cur_range_neg[i][dendritic_index_in]+0.025
self.dendritic_count_in[i][dendritic_index_in] = 0 # intrsection count set to 0
self.dsum_neg_in[i][dendritic_index_in] = 0
self.dendritic_previous_in[i] = dendritic_in_tmp[0] # update previous
self.weight_previous[i] = weight_np_abs
print('dendritic dynamics done', np.mean(self.cur_range_pos[i]), np.mean(self.cur_range_neg[i][0]))
return self.cur_range_pos[i], self.cur_range_neg[i]
def do_mask_dsd(self):
for index in self.convlayer:
if index self.cur_range_pos[index]] = self.cur_range_pos[index][
a > self.cur_range_pos[index]] # weight beyond range set to range
a[a < self.cur_range_neg[index]] = self.cur_range_neg[index][a < self.cur_range_neg[index]]
a = torch.FloatTensor(a).cuda()
ww.data = a.view(self.model_size[index])
print("mask Done")
def do_pruning_dsd(self,epoch):
for index in self.convlayer:
if index60:
aphla=0.0005
sumbook=torch.sum(self.codebook[self.convlayer[-1]],dim=1)
prun=torch.where(sumbook<50)[0]
prunn=prun.size()[0]
self.prune[index]=self.prune[index]+aphla*(512-prunn)/10
print(prunn,self.prune[index])
def do_growth_ww(self,epoch):
for index in self.convlayer:
if index99:
rate=99
gg=np.percentile(ww, rate)
grow=np.where(ww>gg)[0]
growth_ind=set(grow) & set(p_index)
growth_index=growth_ind & set(self.his_groth[index])
zero_index=set([i for i in range(ww.size)]) - growth_index
growth_index=np.array(list(growth_index))
zero_index=np.array(list(zero_index))
if zero_index.size>0:
self.his_gro_count[index][zero_index]=0
if growth_index.size>0:
self.his_gro_count[index][growth_index]=self.his_gro_count[index][growth_index]+1
gr_index=np.where(self.his_gro_count[index]> self.count_thre)[0]
self.codebook[index]=self.codebook[index].view(-1)
for x in range(len(gr_index)):
self.codebook[index][gr_index[x]*9:(gr_index[x]+1)*9]=1
self.codebook[index]=self.codebook[index].view(self.model_size[index])
print(len(gr_index),len(growth_ind),len(p_index))
self.his_groth[index]=growth_ind
self.his_gro_count[index][gr_index]=0
if index==self.convlayer[-1]:
ww=self.fc1.fc.weight
ww=ww.data
ww=ww.view(-1).cpu().numpy()
p_index=np.where(self.codebook[index].view(-1).cpu().numpy()==0)[0]
rate=60+1.1**(epoch- 2*self.count_thre-1)
if rate>99:
rate=99
gg=np.percentile(ww, rate)
grow=np.where(ww>gg)[0]
growth_ind=set(grow) & set(p_index)
growth_index=growth_ind & set(self.his_groth[index])
zero_index=set([i for i in range(ww.size)]) - growth_index
growth_index=np.array(list(growth_index))
zero_index=np.array(list(zero_index))
if zero_index.size>0:
self.his_gro_count[index][zero_index]=0
if growth_index.size>0:
self.his_gro_count[index][growth_index]=self.his_gro_count[index][growth_index]+1
gr_index=np.where(self.his_gro_count[index]> self.count_thre)[0]
self.codebook[index]=self.codebook[index].view(-1)
self.codebook[index][gr_index]=1
self.codebook[index]=self.codebook[index].view(self.model_size[index][0],-1)
print(len(gr_index),len(growth_ind),len(p_index))
self.his_groth[index]=growth_ind
self.his_gro_count[index][gr_index]=0
def if_zero(self):
cc=[]
for index in self.convlayer:
if index 1:
a = ww.data.view(self.model_length[index])
b = a.cpu().numpy()
print(
"number of nonzero weight is %d, zero is %d" % (np.count_nonzero(b), len(b) - np.count_nonzero(b)))
cc.append(len(b) - np.count_nonzero(b))
return cc
================================================
FILE: examples/Structural_Development/SD-SNN/snn_model.py
================================================
import abc
from functools import partial
from torch.nn import functional as F
import torchvision
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from utils import *
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class my_cifar_model(BaseModule):
def __init__(self,
num_classes=10,
step=8,
node_type=LIFNode,
encode_type='direct',
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.num_classes = num_classes
self.feature = nn.Sequential(
BaseConvModule(3, 128, kernel_size=(3, 3), padding=(1, 1)),
BaseConvModule(128,128, kernel_size=(3, 3), padding=(1, 1)),
nn.MaxPool2d(2),
BaseConvModule(128,256, kernel_size=(3, 3), padding=(1, 1)),
BaseConvModule(256, 256, kernel_size=(3, 3), padding=(1, 1)),
nn.MaxPool2d(2),
BaseConvModule(256, 512, kernel_size=(3, 3), padding=(1, 1)),
BaseConvModule(512, 512, kernel_size=(3, 3), padding=(1, 1)),
)
self.convlayer = [0,1,3,4,6,7,8]
self.cfla=self._cflatten()
self.fc_prun = self._create_fc_prun()
self.fc = self._create_fc()
def _cflatten(self):
fc = nn.Sequential(
nn.Flatten(),
)
return fc
def _create_fc_prun(self):
fc = nn.Sequential(
BaseLinearModule(512*8*8, 512)
)
return fc
def _create_fc(self):
fc = nn.Sequential(
BaseLinearModule(512, self.num_classes)
)
return fc
def forward(self, inputs):
inputs = self.encoder(inputs)
self.reset()
if not self.training:
self.fire_rate.clear()
outputs = []
for t in range(self.step):
x = inputs[t]
if x.shape[-1] > 32:
x = F.interpolate(x, size=[64, 64])
for i in range(len(self.feature)):
x=self.feature[i](x)
x=self.cfla(x)
x=self.fc_prun(x)
x = self.fc(x)
outputs.append(x)
return sum(outputs) / len(outputs)
================================================
FILE: examples/Structural_Development/SD-SNN/utils.py
================================================
import torch
import numpy as np
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def unit(x):
if len(x.shape)>0:
maxx=np.max(x)
minx=np.min(x)
marge=maxx-minx
if marge!=0:
xx=(x-minx)/marge
xx=np.clip(xx, 0,1)
else:
xx=0.5*np.ones_like(x)
return xx
else:
return x
def unit_tensor(x):
if x.size()[0]>0:
maxx=torch.max(x)
minx=torch.min(x)
marge=maxx-minx
if marge!=0:
xx=(x-minx)/marge
else:
xx=0.5*torch.ones_like(x)
return xx
else:
return x
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/README.md
================================================
# Adaptive structure evolution and biologically plausible synaptic plasticity for recurrent spiking neural networks —— Based on BrainCog #
**This is the BrainBog-based version of the paper. To run the original code, please go to [raw](https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Structure_Evolution/Adaptive_lsm/raw)**
## Requirments ##
* numpy
* pytorch >= 1.12.0
* BrainCog
## Run ##
```python main.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{pan2023adaptive,
title = {Adaptive structure evolution and biologically plausible synaptic plasticity for recurrent spiking neural networks},
author = {Pan, Wenxuan and Zhao, Feifei and Zeng, Yi and Han, Bing},
journal = {Scientific Reports},
volume = {13},
number = {1},
pages = {16924},
year = {2023},
url = {https://doi.org/10.1038/s41598-023-43488-x},
doi = {10.1038/s41598-023-43488-x},
}
@article{zeng2023braincog,
title={BrainCog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired AI and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier}
}
```
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/brid.py
================================================
import torch, os
import pygame
from pygame.locals import *
from collections import deque
from random import randint
import numpy as np
import nsganet as engine
from pymop.problem import Problem
from pymoo.optimize import minimize
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
from lsmmodel import SNN
import torch.nn.functional as F
from tools.update_weights import stdp,bcm
import matplotlib.pyplot as plt
os.environ["SDL_VIDEODRIVER"] = "dummy"
steps=30000
seeds=50
result=np.zeros([seeds,int(steps/2)])
t=[i for i in range(steps)]
def randbool(size, p):
return torch.rand(*size) < p
class Evolve(Problem):
# first define the NAS problem (inherit from pymop)
def __init__(self, n_var=20, n_obj=1, n_constr=0, lb=None, ub=None):
super().__init__(n_var=n_var, n_obj=n_obj, n_constr=n_constr, type_var=np.int64)
self.xl = lb
self.xu = ub
self._n_evaluated = 0 # keep track of how many architectures are sampled
def _evaluate(self, x, out, *args, **kwargs):
objs = np.full((x.shape[0], self.n_obj), np.nan)
for i in range(x.shape[0]):
arch_id = self._n_evaluated + 1
print('Network= {}'.format(arch_id))
objs[i, 0] = np.linalg.matrix_rank(x[i])
objs[i, 1] = 0
self._n_evaluated += 1
out["F"] = objs
# if your NAS problem has constraints, use the following line to set constraints
# out["G"] = np.column_stack([g1, g2, g3, g4, g5, g6]) in case 6 constraints
# ---------------------------------------------------------------------------------------------------------
# Define what statistics to print or save for each generation
# ---------------------------------------------------------------------------------------------------------
def do_every_generations(algorithm):
# this function will be call every generation
# it has access to the whole algorithm class
gen = algorithm.n_gen
pop_var = algorithm.pop.get("X")
pop_obj = algorithm.pop.get("F")
# report generation info to files
print("generation = {}".format(gen))
print("population error: best = {}, mean = {}, "
"median = {}, worst = {}".format(np.min(pop_obj[:, 0]), np.mean(pop_obj[:, 0]),
np.median(pop_obj[:, 0]), np.max(pop_obj[:, 0])))
print('Best Genome id= {}'.format(np.argmin(pop_obj[:, 0])))
def load_images():
"""
Flappy Bird中load图像
:return:load的图像
"""
def load_image(img_file_name):
file_name = os.path.join('/home/panwenxuan/raw', 'birdimages', img_file_name)
img = pygame.image.load(file_name)
# converting all images before use speeds up blitting
img.convert()
return img
return {'background': load_image('background.png'),
'pipe-end': load_image('pipe_end.png'),
'pipe-body': load_image('pipe_body.png'),
# images for animating the flapping bird -- animated GIFs are
# not supported in pygame
'bird-wingup': load_image('bird_wing_up.png'),
'bird-wingdown': load_image('bird_wing_down.png'), }
class Bird(pygame.sprite.Sprite):
"""
Flappy Bird类
"""
WIDTH = HEIGHT = 32
SINK_SPEED = 0.2
Fail_SINk_SPEED = 0.6
CLIMB_SPEED = 0.25
CLIMB_DURATION = 333.3
REGION = CLIMB_DURATION / 3
NEAR_COLLIDE = 30
NEAR_PIPE = 0
def __init__(self, x, y, msec_to_climb, images):
super(Bird, self).__init__()
self.x, self.y = x, y
self.msec_to_climb = msec_to_climb
self._img_wingup, self._img_wingdown = images
self._mask_wingup = pygame.mask.from_surface(self._img_wingup)
self._mask_wingdown = pygame.mask.from_surface(self._img_wingdown)
def update(self, action, state, delta_frames=1):
"""
更新小鸟的位置
:param action: 输入行为
:param state:输入状态
:param delta_frames:Fault
:return:None
"""
if self.msec_to_climb > 0 and action == 1:
if state == 4 or state == 5 or state == 2 or state == 3:
self.y -= (2 * Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
self.y -= (Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
if state == 4 or state == 5 or state == 2 or state == 3:
self.y += 2 * Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
else:
self.y += Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
def sink(self, delta_frames=1):
self.y += Bird.Fail_SINk_SPEED * (1000.0 * delta_frames / 60)
@property
def image(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._img_wingup
else:
return self._img_wingdown
@property
def mask(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._mask_wingup
else:
return self._mask_wingdown
@property
def rect(self):
return Rect(self.x, self.y, Bird.WIDTH, Bird.HEIGHT)
class PipePair(pygame.sprite.Sprite):
"""
Flappy Bird 中的管子类
"""
WIDTH = 80
PIECE_HEIGHT = 32
ADD_INTERVAL = 2000
ADD_EVENT = pygame.USEREVENT + 1
ROOM_HIGHT = 2 * Bird.HEIGHT + 2 * PIECE_HEIGHT
def __init__(self, pipe_end_img, pipe_body_img):
self.x = float(WIN_WIDTH - 1)
self.score_counted = False
self.isNewPipe = True
self.image = pygame.Surface((PipePair.WIDTH, WIN_HEIGHT), SRCALPHA)
self.image.convert() # speeds up blitting
self.image.fill((0, 0, 0, 0))
total_pipe_body_pieces = int(
(WIN_HEIGHT - # fill window from top to bottom
3 * Bird.HEIGHT - # make room for bird to fit through
3 * PipePair.PIECE_HEIGHT) / # 2 end pieces + 1 body piece
PipePair.PIECE_HEIGHT # to get number of pipe pieces
)
self.bottom_pieces = randint(1, total_pipe_body_pieces)
self.top_pieces = total_pipe_body_pieces - self.bottom_pieces
# bottom pipe
for i in range(1, self.bottom_pieces + 1):
piece_pos = (0, WIN_HEIGHT - i * PipePair.PIECE_HEIGHT)
self.image.blit(pipe_body_img, piece_pos)
bottom_pipe_end_y = WIN_HEIGHT - self.bottom_height_px
bottom_end_piece_pos = (0, bottom_pipe_end_y - PipePair.PIECE_HEIGHT)
self.image.blit(pipe_end_img, bottom_end_piece_pos)
# top pipe
for i in range(self.top_pieces):
self.image.blit(pipe_body_img, (0, i * PipePair.PIECE_HEIGHT))
top_pipe_end_y = self.top_height_px
self.image.blit(pipe_end_img, (0, top_pipe_end_y))
self.center = (top_pipe_end_y + bottom_pipe_end_y) / 2
# compensate for added end pieces
self.top_pieces += 1
self.bottom_pieces += 1
# for collision detection
self.mask = pygame.mask.from_surface(self.image)
self.top_y = top_pipe_end_y
self.bottom_y = bottom_pipe_end_y
@property
def top_height_px(self):
return self.top_pieces * PipePair.PIECE_HEIGHT
@property
def bottom_height_px(self):
return self.bottom_pieces * PipePair.PIECE_HEIGHT
@property
def visible(self):
return -PipePair.WIDTH < self.x < WIN_WIDTH
@property
def rect(self):
return Rect(self.x, 0, PipePair.WIDTH, PipePair.PIECE_HEIGHT)
def update(self, delta_frames=1):
self.x -= 0.18 * 1000.0 * delta_frames / 60
def collides_with(self, bird):
return pygame.sprite.collide_mask(self, bird)
def judgeState(bird, pipes, collide):
"""
根据小鸟和管子之间的位置关系判断当前状态
:param bird:传入小鸟的各项属性
:param pipes:传入管子的各项属性
:param collide:是否发生碰撞
:return:状态,距离,是否是新的管子
"""
# bird's x and y coordinate in the left top of the image
dist = bird.y + Bird.HEIGHT / 2 - WIN_HEIGHT / 2
isNew = False
index = -1
state = -1
if collide:
state = 8
return state
for p in pipes:
if p.x + PipePair.WIDTH - Bird.HEIGHT / 4 < bird.x and not p.score_counted:
continue
if p.x - Bird.NEAR_PIPE <= bird.x + Bird.HEIGHT and \
p.x + PipePair.WIDTH - Bird.HEIGHT / 4 >= bird.x:
p_top_y = p.top_y + PipePair.PIECE_HEIGHT
p_bottom_y = p.bottom_y - PipePair.PIECE_HEIGHT
if p.center - bird.y - Bird.HEIGHT / 2 >= 0 and bird.y >= p_top_y + Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - p.center + Bird.HEIGHT / 2 > 0 and bird.y + Bird.HEIGHT <= p_bottom_y - Bird.NEAR_COLLIDE / 2:
state = 1
elif bird.y < p_top_y + Bird.NEAR_COLLIDE / 2 and bird.y > p_top_y - 10:
state = 6
elif bird.y + Bird.HEIGHT > p_bottom_y - Bird.NEAR_COLLIDE / 2 and bird.y + Bird.HEIGHT < p_bottom_y + 10:
state = 7
if state > -0.5:
index = 1
elif p.x > bird.x + Bird.HEIGHT + Bird.NEAR_PIPE:
state = blankState(bird, p.center)
if p.isNewPipe:
isNew = True
p.isNewPipe = False
index = 1
if index > 0: # only judge the nearest and not passed pipe
dist = bird.y + Bird.HEIGHT / 2 - p.center
break
if index < -0.5: # no pipe left, key the bird in the middle
pos = WIN_HEIGHT / 2
dist = bird.y + Bird.HEIGHT / 2 - pos
state = blankState(bird, pos)
return state, dist, isNew
def blankState(bird, center):
"""
judgeState中调用的判断状态的函数 根据鸟的位置和管子中心的距离来判断
:param bird: 传入小鸟的各项属性
:param center:中心
:return:状态
"""
realHeight = (PipePair.ROOM_HIGHT - Bird.HEIGHT) / 2
if center - bird.y - Bird.HEIGHT / 2 >= 0 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - center + Bird.HEIGHT / 2 >= 0 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 1
elif center - bird.y - Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 2
elif bird.y - center + Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 3
elif bird.y + Bird.HEIGHT / 2 <= center - (realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION):
state = 4
elif bird.y + Bird.HEIGHT / 2 >= center + realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 5
return state
def getReward(state, lastState, smallerError, isNewPipe):
"""
根据状态和距离的变化获得奖励
:param state: 执行行为后的当前状态
:param lastState:执行行为之前的上一状态
:param smallerError:距离是否变小
:param isNewPipe:是否是新的管子
:return:奖励
"""
if state == 0 or state == 1:
reward = 6
elif state == 2 or state == 3:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -5
else:
reward = -3
elif state == 4 or state == 5:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -8
else:
reward = -5
elif state == 6 or state == 7:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -3
else:
reward = -3
elif state == 8: # collide
reward = -100
return reward
if __name__ == "__main__":
n_agent=1
num = 8
p_amount = int(num * num / 10)
s_amount = 4
num_state = 9
num_action = 2
weight_exc = 1
weight_inh = -0.5
trace_decay = 0.8
gens=1000
for seed in range(seeds):
kkk = Evolve(n_var=num*num,
n_obj=2, n_constr=0)
method = engine.nsganet(pop_size=n_agent,
sampling=RandomSampling(var_type='custom'),
mutation=BinaryBitflipMutation(),
n_offsprings=10,
eliminate_duplicates=True)
kres=minimize(kkk,
method,
callback=do_every_generations,
termination=('n_gen', gens))
pop_var = kres.X
pop_obj = kres.F
lm=torch.from_numpy(pop_var[np.argmin(pop_obj[:, 0])].reshape(num,num))
model = SNN(ins=9,num_classes=2,n_agent=n_agent,device='cuda:0',liquid_size=num,lsm_tau=2,lsm_th=0.2,connectivity_matrix=lm.to('cuda:0').float())
model.to('cuda:0')
con_matrix1 = torch.zeros((num_state, num_state * num_action), dtype=torch.float)
for i in range(num_state):
for j in range(num_action):
con_matrix1[i, i * num_action + j] = weight_exc
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
pygame.init()
WIN_HEIGHT = 512
WIN_WIDTH = 284 * 2
heighest = 0
contTime = 0
display_frame = 0
display_surface = pygame.display.set_mode((WIN_WIDTH, WIN_HEIGHT))
pygame.display.set_caption('Flappy Bird')
images = load_images()
bird = Bird(250, int(WIN_HEIGHT / 2 - Bird.HEIGHT / 2), 2,
(images['bird-wingup'], images['bird-wingdown']))
clock = pygame.time.Clock()
score_font = pygame.font.SysFont(None, 25, bold=True)
info_font = pygame.font.SysFont(None, 50, bold=True)
collide = paused = False
frame_clock = 0
pipes = deque()
score = 0
lastDist = 0
lastState = 0 # init
state = lastState
i = 0
num_reward = []
num_score = []
reward=1
while not collide:
i = i + 1
if i > steps:
break
clock.tick(60)
if frame_clock % 2 == 0 or frame_clock == 1:
state, dist, isNewPipe = judgeState(bird, pipes, collide)
lastState = state
lastDist = dist
action= model(F.one_hot(torch.tensor([state]), num_classes=num_state).to('cuda:0').float()).cpu().detach().numpy()
action=int(np.argmax(action,axis=1))
print(i)
if not (paused or frame_clock % (60 * PipePair.ADD_INTERVAL / 1000.0)):
pygame.event.post(pygame.event.Event(PipePair.ADD_EVENT))
for e in pygame.event.get():
if e.type == QUIT or (e.type == KEYUP and e.key == K_ESCAPE):
collide = True
elif e.type == KEYUP and e.key in (K_PAUSE, K_p):
paused = not paused
elif e.type == PipePair.ADD_EVENT:
pp = PipePair(images['pipe-end'], images['pipe-body'])
pipes.append(pp)
if paused:
continue # don't draw anything
pipe_collision = any(p.collides_with(bird) for p in pipes)
if pipe_collision or 0 >= bird.y or bird.y >= WIN_HEIGHT - Bird.HEIGHT:
collide = True
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
p.update()
display_surface.blit(p.image, p.rect)
bird.update(action, state)
display_surface.blit(bird.image, bird.rect)
if frame_clock % 2 == 0 or frame_clock == 1 or collide:
dist = 0
if collide:
nextState = 8
isNewPipe = False
else:
nextState, dist, isNewPipe = judgeState(bird, pipes, collide) # judge the bird's state
print("next state:", nextState)
print("lastdist, dist:", lastDist, dist)
isSmallerError = False
if state == nextState:
isSmallerError = False
if lastDist <= 0:
if lastDist < dist:
isSmallerError = True
else:
if lastDist > dist:
isSmallerError = True
if frame_clock > 0 and not collide:
reward = getReward(nextState, state, isSmallerError, isNewPipe)
print("reward:", reward)
num_reward.append(reward)
bcmreward=np.array([reward, reward])
# bcm(model,bcmreward, input=input)
state = nextState # going on the next state
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
model.reset()
display_frame += 1
for p in pipes:
if p.x + PipePair.WIDTH < bird.x and not p.score_counted:
score += 1
p.score_counted = True
num_score.append(score)
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: 0', True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
frame_clock += 1
pygame.display.flip()
# if collide, display the fail information, for 2 frames
cct = 0
while (bird.y < WIN_HEIGHT - Bird.HEIGHT - 3):
clock.tick(60)
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
display_surface.blit(p.image, p.rect)
if cct >= 6:
bird.sink()
display_surface.blit(bird.image, bird.rect)
fail_infor = info_font.render('Game over !', True, (255, 60, 30)) # current score
pos_x = WIN_WIDTH / 2 - fail_infor.get_width() / 2
pos_y = WIN_HEIGHT / 2 - 100
display_surface.blit(fail_infor, (pos_x, pos_y))
# display the score
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: 0', True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
pygame.display.flip()
cct += 1
if heighest < score:
heighest = score
contTime += 1
num_reward_np = np.array(num_reward)
print(num_reward_np)
k=num_reward_np.shape[0]
result[seed,:k]=num_reward_np
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/lsmmodel.py
================================================
from functools import partial
from torch.nn import functional as F
from torch import nn as nn
import torchvision, pprint
from copy import deepcopy
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.base.brainarea.BrainArea import BrainArea
from braincog.base.connection.CustomLinear import *
from braincog.base.learningrule.STDP import *
from braincog.base.learningrule.BCM import *
import matplotlib.pyplot as plt
@register_model
class SNN(BaseModule):
def __init__(self,
liquid_size,
n_agent,
device,
connectivity_matrix,
num_classes=3,
step=1,
node_type=LIFNode,
encode_type='direct',
lsm_th=0.3,
fc_th=0.3,
lsm_tau=3,
fc_tau=3,
tw=100,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.batchsize=n_agent
self.node_lsm=partial(node_type, **kwargs, step=step,tau=lsm_tau,threshold=lsm_th)
self.node_fc = partial(node_type, **kwargs, step=step,tau=fc_tau,threshold=fc_th)
self.liquid_size=liquid_size
self.out = torch.zeros(self.batchsize, liquid_size).to(device)
self.device=device
self.con=[]
self.learning_rule=[]
self.connectivity_matrix=connectivity_matrix
w1tmp=nn.Linear(4,liquid_size,bias=False).to(device)
self.con.append(w1tmp)
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False).to(device)
self.liquid_weight=w2tmp.weight.data
w2tmp.weight.data=w2tmp.weight.data*self.connectivity_matrix
self.con.append(w2tmp)
self.learning_rule.append(BCM(self.node_lsm(), [self.con[0], self.con[1]])) # pm
self.fc = nn.Linear(liquid_size,num_classes).to(device)
self.learning_rule.append(BCM(self.node_fc(), [self.fc])) # pm
def forward(self, x):
x = x.reshape(x.shape[0], -1)
sum_spike=0
time_window=20
self.tw=time_window
self.firing_tw=torch.zeros(time_window, self.batchsize, self.liquid_size).to(self.device)
self.out = torch.zeros(self.batchsize, self.liquid_size).to(self.device)
for t in range(time_window):
self.out, self.dw = self.learning_rule[0](x, self.out)
# self.con[0].weight+=self.dw[0]
self.con[1].weight.data+=self.dw[1]
out_liquid=self.out[:,0:self.liquid_size]
xout,dw = self.learning_rule[1](out_liquid)
self.fc.weight.data+=dw[0]
sum_spike=sum_spike+xout
self.firing_tw[t]=out_liquid
outputs = sum_spike / time_window
return outputs
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/maze.py
================================================
import matplotlib.pyplot as plt
import networkx as nx
import numpy as np
import math
from matplotlib import pyplot as plt
import matplotlib
import seaborn as sns
from lsmmodel import SNN
from tools.ExperimentEnvGlobalNetworkSurvival import ExperimentEnvGlobalNetworkSurvival
from tools.MazeTurnEnvVec import MazeTurnEnvVec
import torch
import brewer2mpl
from cycler import cycler
import nsganet as engine
from pymop.problem import Problem
from pymoo.optimize import minimize
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
def randbool(size, p):
return torch.rand(*size) < p
class Evolve(Problem):
# first define the NAS problem (inherit from pymop)
def __init__(self, n_var=20, n_obj=1, n_constr=0, lb=None, ub=None):
super().__init__(n_var=n_var, n_obj=n_obj, n_constr=n_constr, type_var=np.int64)
self.xl = lb
self.xu = ub
self._n_evaluated = 0 # keep track of how many architectures are sampled
def _evaluate(self, x, out, *args, **kwargs):
objs = np.full((x.shape[0], self.n_obj), np.nan)
for i in range(x.shape[0]):
arch_id = self._n_evaluated + 1
print('Network= {}'.format(arch_id))
objs[i, 0] = np.linalg.matrix_rank(x[i])
self._n_evaluated += 1
out["F"] = objs
# if your NAS problem has constraints, use the following line to set constraints
# out["G"] = np.column_stack([g1, g2, g3, g4, g5, g6]) in case 6 constraints
# ---------------------------------------------------------------------------------------------------------
# Define what statistics to print or save for each generation
# ---------------------------------------------------------------------------------------------------------
def do_every_generations(algorithm):
# this function will be call every generation
# it has access to the whole algorithm class
gen = algorithm.n_gen
pop_var = algorithm.pop.get("X")
pop_obj = algorithm.pop.get("F")
# report generation info to files
print("generation = {}".format(gen))
print("population error: best = {}, mean = {}, "
"median = {}, worst = {}".format(np.min(pop_obj[:, 0]), np.mean(pop_obj[:, 0]),
np.median(pop_obj[:, 0]), np.max(pop_obj[:, 0])))
print('Best Genome id= {}'.format(np.argmin(pop_obj[:, 0])))
if __name__ == '__main__':
device = 'cuda:8'
num = 8
n_agent = 20
steps = 500
liquid_size=80
env = MazeTurnEnvVec(n_agent, n_steps=steps)
newenv=MazeTurnEnvVec(n_agent, n_steps=steps)
data_env = ExperimentEnvGlobalNetworkSurvival(env)
newdata_env = ExperimentEnvGlobalNetworkSurvival(newenv)
gens=100
seed=0
sum_of_env = np.zeros([gens, n_agent])
env_r=np.zeros([steps,n_agent])
population = torch.zeros(n_agent,liquid_size,liquid_size)
for i in range(n_agent):
population[i] = randbool([liquid_size, liquid_size],p=0.01).to(device).float()
kkk = Evolve(n_var=liquid_size*liquid_size,
n_obj=1, n_constr=2)
method = engine.nsganet(pop_size=n_agent,
sampling=RandomSampling(var_type='custom'),
mutation=BinaryBitflipMutation(),
n_offsprings=10,
eliminate_duplicates=True)
kres=minimize(kkk,
method,
callback=do_every_generations,
termination=('n_gen', gens))
# lm=evolve(population, gens)
model = SNN(ins=4,n_agent=n_agent,device=device,liquid_size=liquid_size,lsm_tau=2,lsm_th=0.2,connectivity_matrix=randbool([liquid_size, liquid_size],p=0.01).to(device).float())
model.to(device)
old_dis = np.ones([n_agent,])*13
X = data_env.reset()
envreward = np.zeros([n_agent, ])
fit=np.zeros([n_agent])
for i in range(steps):
model.reset()
out = model(torch.from_numpy(X+1).float().to(device)).cpu().detach().numpy()
X_next, envreward, fitness, infos = data_env.step(np.argmax(out,axis=1))
food_pos = data_env.env.food_pos[:, 0, :2]
agent_pos = data_env.env.agents_pos
print(agent_pos)
dis = ((agent_pos - food_pos) ** 2).sum(1)
reward =np.array((np.sqrt(old_dis)-np.sqrt(dis))>0,dtype=int)
aa=np.ones_like(reward)*-1
bb = np.ones_like(reward)*3
cc = np.ones_like(reward)*-3
reward=np.where(reward == 0 , aa, reward)
reward=np.where(envreward == 1, bb, reward)
reward = np.where(envreward == -1, cc, reward)
old_dis= dis
env_r[i]=reward
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/tools/EnuGlobalNetwork.py
================================================
import pickle
import time
import numpy as np
import torch
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import gridspec
from AbstractLayerBMM import AbstractLayerBMM
from EvolvableNeuralUnitStacked import EvolvableNeuralUnitStacked
from Tools import get_data_path
sns.set_style("darkgrid")
class EnuGlobalNetwork(AbstractLayerBMM):
"""Network of ENUs implementation in PyTorch, where each synapse and neuron is modeled as an ENU. """
def __init__(self, n_offspring, n_pseudo_env, n_input_neurons, n_hidden_neurons, n_output_neurons, n_syn_per_neuron):
# offspring
self.n_offspring = n_offspring
self.n_pseudo_env = n_pseudo_env
# input channels
n_input_channels = 16
self.n_input_channels = n_input_channels
n_dynamic_param = 32
# total neurons
n_neurons = n_output_neurons + n_hidden_neurons
self.n_neurons = n_neurons
super().__init__(n_offspring, n_neurons, n_input_neurons, n_output_neurons)
torch.random.manual_seed(0)
#NOTE: batch dimension holds output of each neuron/synapse, allowing fast GPU MM
#NOTE neurons far less than synapses, so can be relatively bigger rnn for little cost
n_input_channels_neuron = 16
n_input_neuron, n_output_neuron = n_input_channels_neuron, n_input_channels
self.neurons = EvolvableNeuralUnitStacked(n_offspring, batch_size=self.n_neurons, n_input=n_input_neuron, n_dynamic_param=n_dynamic_param, n_output=n_output_neuron)
#self.n_syn = next_power_of_2(int(n_neurons * (rel_connectivity*n_neurons)))
self.n_syn_per_neuron = n_syn_per_neuron
self.n_syn = n_neurons * n_syn_per_neuron
n_input_syn, n_output_syn = n_input_channels * 2, n_input_channels_neuron # * 2 for neuron feedback (which same channel as n_channel input)
self.synapses = EvolvableNeuralUnitStacked(n_offspring, batch_size=self.n_syn, n_input=n_input_syn, n_dynamic_param=n_dynamic_param, n_output=n_output_syn)
# just randomly connect synapses to neurons
self.synapse_connections = torch.randint(n_input_neurons + n_neurons, size=(n_neurons, n_syn_per_neuron), device='cuda', dtype=torch.long)
# fixed predefined connection patterns
if n_input_neurons==2 and n_output_neurons==2 and n_hidden_neurons==2:
print("Fixed connection Network 2-2-2")
self.synapse_connections = torch.tensor([[0, 1],
[0, 1],
[2, 3],
[2, 3]], device='cuda', dtype=torch.long)
elif n_input_neurons == 4 and n_output_neurons == 3 and n_hidden_neurons == 3 and n_syn_per_neuron==3:
print("Fixed connection Network 4-3-3 (3syn)")
self.synapse_connections = torch.tensor([[0, 1, 3],# hidden connections #4
[0, 2, 3], #5
[1, 2, 3],# 6
[4, 5, 6], # output connections #7
[4, 5, 6],#8
[4, 5, 6]#9
], device='cuda', dtype=torch.long)
elif n_input_neurons==5 and n_hidden_neurons==0 and n_output_neurons==4:
print("Fixed connection Network 5-0-4 (5syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3, 4],# output connections
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4]
], device='cuda', dtype=torch.long)
elif n_input_neurons==1 and n_hidden_neurons==0 and n_output_neurons==2:
print("Fixed connection Network 1-0-2 (1syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0],# output connections
[0]
], device='cuda', dtype=torch.long)
elif n_input_neurons==4 and n_hidden_neurons==0 and n_output_neurons==3 and n_syn_per_neuron==4:
print("Sparse connection Network 4-0-3 (4syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3],# output connections #4
[0, 1, 2, 3], #5
[0, 1, 2, 3],# 6
], device='cuda', dtype=torch.long)
elif n_input_neurons == 4 and n_hidden_neurons == 3 and n_output_neurons == 3 and n_syn_per_neuron == 4:
print("Sparse connection Network 4-3-3 (3syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 3], # hidden connections #4
[0, 2, 3], # 5
[1, 2, 3], # 6
[4, 5, 3], # output connections #7
[4, 6, 3], # 8
[5, 6, 3] # 9
], device='cuda', dtype=torch.long)
elif n_input_neurons==4 and n_hidden_neurons==3 and n_output_neurons==3 and n_syn_per_neuron==8:
print("Sparse connection Network 4-3-3 (8syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 5, 6, 7, 8, 3, 4],# hidden connections #4
[0, 2, 4, 6, 7, 9, 3, 5], #5
[1, 2, 4, 5, 8, 9, 3, 6],# 6
[4, 5, 8, 9, 0, 1, 3, 7], # output connections #7
[4, 6, 7, 9, 0, 2, 3, 8],#8
[5, 6, 7, 8, 1, 2, 3, 9]#9
], device='cuda', dtype=torch.long)
elif n_input_neurons==4 and n_hidden_neurons==4 and n_output_neurons==4 and n_syn_per_neuron==8:
print("Fixed connection Network 4-4-4 (8syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3, 4, 5, 6, 7],# hidden connections
[0, 1, 2, 3, 4, 5, 6, 7],
[0, 1, 2, 3, 4, 5, 6, 7],
[0, 1, 2, 3, 4, 5, 6, 7],
[4, 5, 6, 7, 8, 9, 10, 11], # output connections
[4, 5, 6, 7, 8, 9, 10, 11],
[4, 5, 6, 7, 8, 9, 10, 11],
[4, 5, 6, 7, 8, 9, 10, 11],
], device='cuda', dtype=torch.long)
elif n_input_neurons==5 and n_hidden_neurons==5 and n_output_neurons==4:
print("Fixed connection Network 5-5-4 (5syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3, 4],# hidden connections
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9], # output connections
[5, 6, 7, 8, 9],
[5, 6, 7, 8, 9],
[5, 6, 7, 8, 9],
], device='cuda', dtype=torch.long)
elif n_input_neurons==1 and n_hidden_neurons==0 and n_output_neurons==1:
print("Fixed connection Single")
self.synapse_connections = torch.tensor([[0]], device='cuda', dtype=torch.long)
else:
print("Random connections")
# each synapse is connected also to its post-synaptic neuron, to allow STDP type learning to emerge
self.synapse_connections_post = torch.arange(n_neurons, device='cuda', dtype=torch.long).reshape(n_neurons, -1).repeat(1, n_syn_per_neuron)
# define compartments
self.compartments = [self.neurons, self.synapses]
self.trainable_layers = self.neurons.trainable_layers + self.synapses.trainable_layers
self.track_data = False
def dump_model(self, e, exp_name):
"""Dump model to restore"""
with open(get_data_path(e, exp_name, "Model"), 'wb') as f:
parameters = {}
parameters["neuron"] = [layer.base_parameters.cpu().numpy() for layer in self.neurons.trainable_layers]
parameters["synapse"] = [layer.base_parameters.cpu().numpy() for layer in self.synapses.trainable_layers]
pickle.dump(parameters, f)
def restore_model(self, e, exp_name):
"""Restore model"""
with open(get_data_path(e, exp_name, "Model"), 'rb') as f:
parameters = pickle.load(f)
#TODO: refactor to dump/restore at ENU level and just call those functions
assert len(self.neurons.trainable_layers) == len(parameters["neuron"])
for i in range(len(parameters["neuron"])):
self.neurons.trainable_layers[i].base_parameters = torch.from_numpy(parameters["neuron"][i].astype(np.float32)).cuda()
assert len(self.synapses.trainable_layers) == len(parameters["synapse"])
for i in range(len(parameters["synapse"])):
self.synapses.trainable_layers[i].base_parameters = torch.from_numpy(parameters["synapse"][i].astype(np.float32)).cuda()
@staticmethod
def plot_weights(e, exp_name):
"""Visualize weights of ENU gates"""
sns.set_style("dark")
def calc_average(start, stop):
weights_average = None
for e in range(start, stop, 1000):
with open(get_data_path(e, exp_name, "Model"), 'rb') as f:
parameters = pickle.load(f)
weights = []
for i in range(len(parameters["neuron"])):
weights += [parameters["neuron"][i].astype(np.float32)]
if weights_average is None:
weights_average = weights
else:
for i in range(len(weights_average)):
weights_average[i] += weights[i]
return weights_average
weights_mean1 = calc_average(20000, 30000)
fig, ax = plt.subplots(1, 2, sharex='col', sharey='row')
for i in range(len(weights_mean1)):
ax[i].imshow(weights_mean1[i], cmap="gray")
weights_mean2 = calc_average(30000, 40000)
fig, ax = plt.subplots(1, 2, sharex='col', sharey='row')
for i in range(len(weights_mean2)):
ax[i].imshow(weights_mean2[i], cmap="gray")
fig, ax = plt.subplots(1, 2, sharex='col', sharey='row')
for i in range(len(weights_mean2)):
ax[i].imshow((weights_mean2[i] - weights_mean1[i])**5, cmap="gray")
plt.show()
def dump_network_activity(self, e, exp_name):
"""Dump raw data for visualization"""
with open(get_data_path(e, exp_name, "GlobalNetwork"), 'wb') as f:
pickle.dump(self.vis_data, f)
def print(self):
print("--Neurons--")
self.neurons.print()
print("--Synapses--")
self.synapses.print()
def reset(self):
self.vis_data = []
if self.track_data:
print("Tracking network activity")
for compartment in self.compartments:
compartment.reset()
def forward(self, X):
"""Main computation forward pass"""
# transfer to GPU
X_raw_gpu = torch.from_numpy(X.astype(np.float32)).cuda()
X_gpu = torch.zeros((X.shape[0], X.shape[1], self.n_input_channels), device='cuda', dtype=torch.float32)
X_gpu[:, :, :X_raw_gpu.shape[2]] = X_raw_gpu
# first compute synapses, set input to previous output of connected neuron
# concat our input spiking pattern directly to input to our synapses (the neurons)
# NOTE: this concats in batch dimension, meaning it feeds into input neurons directly spiking pattern, while rest receive input from network
input_to_synapses = torch.cat([X_gpu, self.neurons.out_mem], dim=1)
# connect each synapse randomly to multiple inputs
input_to_synapses_connected = input_to_synapses[:, self.synapse_connections.flatten(), :]
# need feedback connection from neuron to synapse, to allow stdp type rules to emerge (else it has to do it through feedback connections, but less guarentee on connections and cannot distinguise type)
# one synapse has 1 pre-synaptic neuron and 1 post-synaptic neuron, connectection defined in synapse_connections, synapse_connections[i, :] gives all input synapses of that neuron
# so feedback to all it's input synapses through broadcasting backwards
post_neuron_backprop_connected = self.neurons.out_mem[:, self.synapse_connections_post.flatten(), :]
input_to_synapses_connected = torch.cat([input_to_synapses_connected, post_neuron_backprop_connected], dim=-1)
# compute synapse
self.synapses.forward(input_to_synapses_connected)
# then integrate(sum) all outputs of a neurons input synapses, can just reshape into valid shape, since we already randomly connected when computing synapses
# NOTE: each neuron then requires same number of synapses, then reshape by modifying batch dim (which contains syn outputs)
integration = torch.sum(self.synapses.out.reshape((self.n_offspring, self.n_neurons, -1, self.synapses.shape[-1])), dim=2)
# scale by number of synapses
integration /= self.n_syn_per_neuron
self.out_integration = integration
# finally set neuron input to summated connected synapses output
input_to_neurons = integration
out = self.neurons.forward(input_to_neurons)
# output is last neuron output, NOTE: just first channel is returned, since we reshape neurons to channels
self.out = out[:, -self.n_output:, 0].reshape(self.n_offspring, self.n_output)
if self.track_data:
self._track_vis_data(X, input_to_synapses_connected, input_to_neurons)
return self.out
def _track_vis_data(self, X, input_to_synapses_connected, input_to_neurons):
offspring_idx = 0
self.vis_data += [(X[offspring_idx], input_to_neurons[offspring_idx].cpu().numpy(), self.neurons.out[offspring_idx].cpu().numpy(),
input_to_synapses_connected[offspring_idx].cpu().numpy(), self.synapses.out[offspring_idx].cpu().numpy())]
@staticmethod
def plot_network_activity(e, exp_name):
with open(get_data_path(e, exp_name, "GlobalNetwork"), 'rb') as f:
vis_data = pickle.load(f)
X, input_to_neurons, neurons_out, input_to_synapses, synapses_out = map(np.array, zip(*vis_data))
def plot_enu_activity(input, output, title):
n_cells = output.shape[1]
n_cells = np.minimum(10, output.shape[1])
fig, grid = plt.subplots(2, n_cells, sharex='col', sharey='row')
if n_cells==1:
grid[0].plot(input[:, 0, :])
grid[1].plot(output[:, 0, :])
else:
for i in range(n_cells):
grid[0, i].plot(input[:, i, :])
grid[1, i].plot(output[:, i, :])
plt.xlabel("t")
plt.title(title)
#plt.ylabel("")
plt.legend()
plt.figure()
plt.plot(X[:, :, 0])
plot_enu_activity(input_to_neurons, neurons_out, "ENU neuron activity")
plot_enu_activity(input_to_synapses, synapses_out, "ENU synapse activity")
plt.figure()
spike_points = np.where(neurons_out[:, :, 0] > 0)
plt.scatter(spike_points[0], spike_points[1], marker='|')
plt.show()
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/tools/ExperimentEnvGlobalNetworkSurvival.py
================================================
import pickle
import numpy as np
from tools.Tools import get_data_path
class ExperimentEnvGlobalNetworkSurvival:
"""Wrapper around a given RL environment for a Network of ENUs model,
turns reward into fitness and dumps relevant data"""
def __init__(self, env, exp_name='maze'):
self.env = env
self.exp_name = exp_name
self.n_output = self.env.n_actions
#NOTE: +1 reward neuron
self.n_input_neurons = self.env.n_obs + 1
self.n_agents = self.env.n_agents
def _convert_obs(self, obs, rewards):
n_input_channels_used = 3
X = np.zeros((self.n_agents, self.n_input_neurons, n_input_channels_used))
#X[:, :obs.shape[1], 0] = obs
# Shuffle only obs to avoid topology exploitation, reward neuron linked to EnuGlobal synapse connectivity
X[:, :obs.shape[1], 0] = np.take_along_axis(obs, self.obs_shuffle, axis=1)
# split pos and negative reward to different channels, And set to last input neuron
if rewards is not None:
X[rewards>0, -1, 1] = np.abs(rewards[rewards>0])
X[rewards<=0, -1, 2] = np.abs(rewards[rewards<=0])
return X
def _convert_reward(self, obs, actions, rewards, infos, dones):
fitness = np.copy(rewards)
# first poison is considered positive reward, since learning to learn
#NOTE: dead by env means less reward can be obtained so should implictely reduce overall fitness automatically
fitness[np.logical_and(self._prev_reward_count == 1, rewards != 0)] = 1
# include episode length as extra fitness, since not taking poison would allow survive longer, so should try avoid take poison
fitness[dones==0] += 0.1/4
return fitness
def step(self, y):
# if self.t % 3 != 0:
# actions = np.zeros((self.n_agents), dtype=np.int32) - 1
# else:
# winner take all, in given time window
actions = y
# if all same output, do nothing
# equal_actions = self.y_hist.shape[1] == np.sum(self.y_hist == np.take_along_axis(self.y_hist, actions.reshape(-1, 1), axis=1), axis=-1)
# actions[equal_actions] = -1
# self.y_hist[:] = 0
# take env step
allobs, obs, rewards, dones, infos = self.env.step(actions)
# X = self._convert_obs(obs, rewards)
X=allobs
self._prev_reward_count += rewards!=0
fitness = self._convert_reward(obs, actions, rewards, infos, dones)
self._prev_action = actions
self._prev_obs = obs
return X, rewards, fitness, None
def reset(self):
self.t = 0
self.y_hist = np.zeros((self.n_agents, self.n_output), dtype=np.float32)
self._prev_action = None
self._prev_obs = None
self._prev_reward_count = np.zeros((self.n_agents), dtype=np.float32)
# each time different input/output neurons should have different meaning, to have learning to learn
self.obs_shuffle = np.argsort(np.random.randn(self.n_agents, self.n_input_neurons - 1), axis=1, kind='mergesort')
self.action_shuffle = np.argsort(np.random.randn(self.n_agents, self.n_output), axis=1, kind='mergesort')
# reset env
self.allobs,self.obs = self.env.reset()
# return self._convert_obs(self.obs, None)
return self.allobs
def render(self):
if self.t%4==0:
self.env.render()
def track_vis_data(self, vis_data, model, X, y_est, t):
n_fetch = 128
# TODO: also get our gates from the model
vis_data+=[(X[:n_fetch, :], y_est[:n_fetch, :])]
def dump_vis_data(self, vis_data, fitness_per_offspring, e):
with open(get_data_path(e, self.exp_name, "output"), 'wb') as f:
pickle.dump((vis_data, fitness_per_offspring), f)
@staticmethod
def load_vis_data(e, exp_name):
with open(get_data_path(e, exp_name, "output"), 'rb') as f:
vis_data, fitness_per_offspring = pickle.load(f)
return vis_data, fitness_per_offspring
@staticmethod
def plot_vis_data(e, exp_name):
vis_data, fitness_per_offspring = ExperimentEnvGlobalNetworkSurvival.load_vis_data(e, exp_name)
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/tools/MazeTurnEnvVec.py
================================================
import pickle
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from tools.Tools import save_fig, get_data_path
# np.random.seed(0)
class MazeTurnEnvVec:
"""Vectorized RL T-Maze environment written in pure Numpy. We require an efficient environment since we need to evaluate
and run up to thousands of offspring in parallel"""
def __init__(self, n_agents, n_steps):
# 4 important points, start point, decision point, food point, dead point.
# just generate a very large matrix that could fit any maze of any size, then can generate smaller maze as well
self.n_actions = 3
self.n_obs = 3
self.max_size = 7
self.n_agents = n_agents
self.n_steps = n_steps
self.window = plt.figure()
self.t_maze = True
self.turn_based = False
# steps can be longer if poison and need to turn around
self.steps_to_food = 2
if self.t_maze:
self.steps_to_food = 3
self.steps_to_food += self.steps_to_food*2
# give some extra leniency
self.steps_to_food *= 2
def step(self, actions):
# L R U D
# TODO: check legal action or not..
pos_copy = np.copy(self.agents_pos)
actions = np.copy(actions)
# GIVE TIME UPDATE WEIGHTS
# actions[self.agents_reset > 0] = -1
# actions[self.agent_energy<=0] = -1
self.agents_reset[self.agents_reset > 0] -= 1
# if turn based
if self.turn_based:
Forward = actions == 0
self.agents_pos[np.logical_and(Forward, self.agent_directions == 0), 1] += 1
self.agents_pos[np.logical_and(Forward, self.agent_directions == 2), 1] -= 1
self.agents_pos[np.logical_and(Forward, self.agent_directions == 1), 0] -= 1
self.agents_pos[np.logical_and(Forward, self.agent_directions == 3), 0] += 1
L = actions == 1
self.agent_directions[L] += 1
R = actions == 2
self.agent_directions[R] -= 1
self.agent_directions[self.agent_directions > 3] = 0
self.agent_directions[self.agent_directions < 0] = 3
else:
# or just direct movement
U = actions == 2
D = actions == 1
R = actions == 0
if self.agents_pos[U].size>0:
self.agents_pos[U, 0] += 1
self.agent_directions[U] = 3
if self.agents_pos[D].size>0:
self.agents_pos[D, 0] -= 1
self.agent_directions[D] = 1
if self.t_maze and self.agents_pos[R].size>0:
self.agents_pos[R, 1] += 1
self.agent_directions[R] = 0
# UNDO MOVES THAT GOT AGENT INTO WALL
self.current_cells = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1]]
self.agents_pos[self.current_cells==1] = pos_copy[self.current_cells==1]
movement_loss = np.prod(self.agents_pos==pos_copy, axis=-1)
# CHECK IF FOOD CONSUMED, is reward + pos reset
consumed_food = np.prod(self.agents_pos==self.food_pos[:, 0, :2], axis=-1).astype(np.bool)
consumed_pois = np.prod(self.agents_pos==self.food_pos[:, 1, :2], axis=-1).astype(np.bool)
self.consumed_count += consumed_food.astype(np.int32)
self.consumed_count_total += consumed_food.astype(np.int32)
self.consumed_count_pois += consumed_pois.astype(np.int32)
self._reset_pos(np.logical_or(consumed_food, consumed_pois))
# self._reset_pos_pois(consumed_pois)
# self._reset_food(self.consumed_count==self.swap_limit, prob=0.0)
# reset food for agents that ate food, and swap with some probability
self._reset_food(self.consumed_count==5, prob=0.5)
self.rewards = consumed_food.astype(np.float32) - consumed_pois.astype(np.float32) #* 0.5 #- movement_loss.astype(np.float32) * 0.01
# get observation from current position of each agent
self.agent_allobs,self.obs = self._get_obs_from_pos()
# instant dead on second poison
self.agent_energy += np.where(self.consumed_count_pois<=1, np.abs(self.rewards) * self.steps_to_food, -self.agent_energy * np.abs(self.rewards))
# energy decay to encourage exploration, agent dies if running out of energy
self.agent_energy = np.minimum(self.agent_energy, self.steps_to_food)
self.agent_energy -= 1.0/4
dones = self.agent_energy<=0
return self.agent_allobs,self.obs, self.rewards, dones, None
def _reset_pos(self, idxs):
self.agents_pos[idxs] = [self.start_point, 2] # set X pos
self.agent_directions[idxs] = 0
if self.max_size==5:
self.agent_directions[idxs] = 1
self.agents_reset[idxs] = 0
self.agents_reset_count[idxs] += 1
def _reset_pos_pois(self, idxs):
#NOTE: 2 since we call reset twice!
#NOTE: turning around already cost 8 steps, then 4x4 more is 16+8, 24, so reset should be much worse
self.agents_reset[np.logical_and(idxs, self.agents_reset_count>2)] = 64
def _reset_food(self, idxs, prob=0.5):
# swap food with some probability, avoids agent overfitting on environment
swap = np.take_along_axis(self.random_swap_matrix, self.consumed_count_total.reshape(-1, 1), axis=1).ravel()
swap_idxs = swap * idxs
food_loc = np.copy(self.food_pos[swap_idxs, 0, :])
pois_loc = np.copy(self.food_pos[swap_idxs, 1, :])
self.food_pos[swap_idxs, 0, :] = pois_loc
self.food_pos[swap_idxs, 1, :] = food_loc
# set maze value
self.mazes[np.arange(self.mazes.shape[0]), self.food_pos[:, 0, 0], self.food_pos[:, 0, 1]] = 2
self.mazes[np.arange(self.mazes.shape[0]), self.food_pos[:, 1, 0], self.food_pos[:, 1, 1]] = 3
self.consumed_count[idxs] = 0
def reset(self):
self.consumed_count = np.zeros((self.n_agents), dtype=np.int32)
self.consumed_count_total = np.zeros_like(self.consumed_count)
# consistent swapping such that if agent eat food once for all agents swapped with same seed, fair fitness comparison
max_eat = self.n_steps
self.random_swap_matrix = np.random.uniform(0, 1, size=(1, max_eat)) >= 0.5
self.random_swap_matrix = np.repeat(self.random_swap_matrix, int(self.n_agents), axis=0)
self.agent_energy = np.zeros((self.n_agents), dtype=np.float32) + self.steps_to_food
self.consumed_count_pois = np.zeros_like(self.consumed_count)
#self.swap_limit = np.random.randint(1, 5, size=1)
#self.swap_limit = np.random.randint(1, 4, size=self.n_agents)
self.mazes = np.ones((self.n_agents, self.max_size, self.max_size), dtype=np.int32)
#TODO: support variable maze length
self.start_point = int(self.max_size/2)
if self.t_maze:
self.mazes[:, self.start_point, 2:-1] = 0
self.mazes[:, 1:-1, -2] = 0
# FOOD either at -1,-1 or -1,1?
# two foods: x, y, value
self.food_pos = np.zeros((self.n_agents, 2, 2), dtype=np.int32)
self.food_pos[:, :, 1] = self.max_size - 2
self.food_pos[:, 1, 0] = 1
self.food_pos[:, 0, 0] = self.max_size - 2
self._reset_food(np.ones(self.food_pos.shape[0], dtype=np.bool), prob=0.5)
else:
self.mazes[:, 1:-1, 1] = 0
# two foods: x, y, value
self.food_pos = np.zeros((self.n_agents, 2, 2), dtype=np.int32)
self.food_pos[:, :, 1] = 1
self.food_pos[:, 0, 0] = 1
self.food_pos[:, 1, 0] = (self.max_size - 2)
self._reset_food(np.ones(self.food_pos.shape[0], dtype=np.bool), prob=0.5)
# AGENT
self.agents_pos = np.ones((self.n_agents, 2), dtype=np.int32)
self.agents_reset = np.zeros((self.n_agents), dtype=np.int32)
self.agents_reset_count = np.zeros_like(self.agents_reset)
self.agent_directions = np.zeros((self.n_agents), dtype=np.int32)
self._reset_pos(np.arange(self.agents_pos.shape[0]))
# OBS
self.agent_allobs,self.obs = self._get_obs_from_pos()
return self.agent_allobs,self.obs
def _get_obs_from_pos(self):
# obs is neighbouring cell states around agent
obs = np.zeros((self.n_agents, self.n_obs), dtype=np.float32)
raw_obs = np.zeros(self.n_agents, dtype=np.int32)
# get observation based on direction agent is facing
leftobs = np.zeros(self.n_agents)
rightobs = np.zeros(self.n_agents)
backobs = np.zeros(self.n_agents)
# get observation based on direction agent is facing
D = self.agent_directions == 0
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] + 1][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] - 1, self.agents_pos[:, 1]][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] + 1, self.agents_pos[:, 1]][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1]-1][D]
D = self.agent_directions == 2
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] - 1][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] + 1, self.agents_pos[:, 1]][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] - 1, self.agents_pos[:, 1]][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1]+1][D]
D = self.agent_directions == 1
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] - 1, self.agents_pos[:, 1]][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] - 1][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] + 1][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0]+1, self.agents_pos[:, 1]][D]
D = self.agent_directions == 3
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] + 1, self.agents_pos[:, 1]][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] + 1][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] - 1][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0]-1, self.agents_pos[:, 1]][D]
# mark what was observed at different index
obs[raw_obs == 1, 0] = 1
obs[raw_obs == 2, 1] = 1
obs[raw_obs == 3, 2] = 1
allobs=np.squeeze(np.dstack((leftobs,raw_obs,rightobs,backobs)))
return allobs, obs
def render(self):
plt.clf()
sns.set_style("white")
#TODO: support render all mazes? can reshape to square?
max_render = 1
flattened_render = np.dstack(np.split(self.mazes[18, :], max_render, axis=0)).reshape(self.mazes.shape[1], -1)
flattened_render[flattened_render>1] = 0
plt.axis('off')
plt.imshow(flattened_render,cmap='bone')
for j in range(1):
i=18
marker = ">"
if self.agent_directions[i] == 1:
marker = "^"
if self.agent_directions[i] == 2:
marker = "<"
if self.agent_directions[i] == 3:
marker = "v"
obs_color = "black"
if self.obs[i, 0] == 1:
obs_color = "gray"
if self.obs[i, 1] == 1:
obs_color = "green"
if self.obs[i, 2] == 1:
obs_color = "red"
alpha = 1
if self.agent_energy[i]<=0:
alpha = 1
plt.scatter(self.agents_pos[i, 1] + j * self.mazes.shape[1], self.agents_pos[i, 0], color="skyblue", alpha=alpha, marker=marker)
plt.scatter(self.agents_pos[i, 1] + j * self.mazes.shape[1], self.agents_pos[i, 0], color=obs_color,alpha=alpha, marker=marker, s=3)
plt.scatter(self.food_pos[i, 0, 1] + j * self.mazes.shape[1], self.food_pos[i, 0, 0], color="green", alpha=1, marker="o")
plt.scatter(self.food_pos[i, 1, 1] + j * self.mazes.shape[1], self.food_pos[i, 1, 0], color="red", alpha=1, marker="o")
plt.pause(0.001)
#plt.pause(2)
@staticmethod
def load_vis_data(e, exp_name):
with open(get_data_path(e, exp_name, "output"), 'rb') as f:
vis_data, fitness_per_offspring = pickle.load(f)
return vis_data, fitness_per_offspring
@staticmethod
def plot_vis_data(e, exp_name):
import matplotlib.pyplot as plt
from cycler import cycler
import seaborn as sns
sns.set_style("whitegrid")
vis_data, fitness_per_offspring = MazeTurnEnvVec.load_vis_data(e, exp_name)
offspring_idx = 0
#x, y_est, y = np.array(vis_data).transpose(1, 2, 0, 3)
X, Y_est = map(np.array, zip(*vis_data))
X_base, y_est_base = X[:, offspring_idx], Y_est[:, offspring_idx]
#X_base, y_est_base = X_base[:300], y_est_base[:300]
#X_base = np.max(X_base, axis=1)
# --- normal output single example---
plt.rc('axes', prop_cycle=(cycler('color', ['gray', '#ff7f0e', '#9467bd', '#8c564b', '#e377c2', '#17becf'])))
# OLD METHOD!
plt.figure()
#NOTE: last neuron is always reward neuron
plt.plot(-X_base[:, :-1, 0], label="N-ENUs input", alpha=0.7)
plt.plot(- np.max(X_base, axis=1)[:, 1], label="Positive reward", alpha=0.7, color='#2ca02c')
plt.plot(- np.max(X_base, axis=1)[:, 2], label="Negative reward", alpha=0.7, color='#d62728')
#plt.gca().set_color_cycle(['orange', 'purple', 'brown'])
plt.plot(y_est_base[:, :], label="N-ENUs output", alpha=0.8)
plt.legend(loc='upper right')
save_fig(e, exp_name, "single_episode")
plt.rc('axes', prop_cycle=(cycler('color', ['gray', '#ff7f0e', '#9467bd', '#8c564b', '#e377c2', '#17becf'])))
# new method!
fig, grid = plt.subplots(2, sharex=True)
# input
#grid[1].set_prop_cycle(cycler('color', ['gray', '#ff7f0e', '#1f77b4']))
grid[1].set_prop_cycle(cycler('color', ['gray', '#F5B041', '#2E86C1']))
grid[1].plot(X_base[:, :-1, 0], label="N-ENUs input", alpha=0.7, linewidth=2)
grid[1].plot(np.max(X_base, axis=1)[:, 1], label="Positive reward", alpha=0.7, color='#1ABC9C', linewidth=2)
grid[1].plot(np.max(X_base, axis=1)[:, 2], label="Negative reward", alpha=0.7, color='#CB4335', linewidth=2)
grid[1].legend(['Sensor (wall)', 'Sensor (red)', 'Sensor (green)', 'Positive reward', 'Negative reward'], loc='upper right')
grid[1].set_ylabel('Neuron output')
# output
grid[0].set_prop_cycle(cycler('color', ['#9467bd', '#e377c2', '#17becf','#8c564b']))
grid[0].plot(y_est_base[:, :], label="N-ENUs output", alpha=0.8, linewidth=2)
grid[0].legend(['ENU-NN (left)', 'ENU-NN (right)', 'ENU-NN (forward)'],loc='upper right')
plt.xlabel('t')
grid[0].set_ylabel('ENU neuron output')
plt.xlim(-5, X_base.shape[0]+10)
save_fig(e, exp_name, "single_episode_dual")
#plt.show()
@staticmethod
def plot_rollout_data(e, exp_name):
#TODO: dump rollout as array not the actual plots
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style("white")
import os
rollout_path = "./" + get_data_path(e, exp_name, "rollout").split(".")[1][:-1]+"/"
rollout_files = sorted(os.listdir(rollout_path))
rollouts = []
for i in range(4, 200, 4):
file = "rollout_{}_.png".format(i)
print(file)
rollout = plt.imread(rollout_path + file)
rollout = rollout[80:450, 200:500]
rollout = np.where(rollout[:, :, [0]]> 0.98, 1, rollout)
rollouts.append(rollout)
# plt.imshow(rollout)
# plt.show()
# for rollout in rollouts:
vert_bar = np.zeros((rollout.shape[0], 5, 4))
vert_bar[::] += 0.5
# get red -> learned go other way
# food swapped -> sees red -> learned turn around
rollouts1 = [rollouts[1], rollouts[9], rollouts[10], rollouts[11], rollouts[17], rollouts[18]]#, rollouts[19]
#, rollouts[28]
#rollouts[24],
rollouts2 = [rollouts[25], rollouts[29], rollouts[30], rollouts[31], rollouts[32], rollouts[33]]
plt.axis('off')
plt.imshow(np.vstack([np.column_stack(rollouts1), np.column_stack(rollouts2)]), cmap='gray')
save_fig(e, exp_name, "rollout_combined")
#plt.show()
if __name__ == '__main__':
"""Test function"""
n_offspring = 1024
envs = MazeTurnEnvVec(n_offspring, n_steps=400)
envs.n_pseudo_env = 8
while True:
envs.reset()
opt_actions_up = [0,0,0,0,1,0]
opt_actions_down = [0,0,0,0,2,0]
opt_actions = [opt_actions_up, opt_actions_down]
opt_current = 0
total_reward = 0
rewards = np.zeros((n_offspring))
rewards_all = np.zeros_like(rewards)
k = 0
n_steps = 200
for i in range(n_steps):
actions = np.random.randint(0, envs.n_actions, size=n_offspring)
#actions[:] = opt_actions_up[i%len(opt_actions_up)]
#actions[0] = opt_actions[opt_current][k % len(opt_actions_up)]
obs, rewards,_,_ = envs.step(actions=actions)
total_reward += (rewards[0] * 100) + 1
rewards_all += (rewards * 100) + 1
#print(rewards[0])
#print(obs[0], rewards[0])
envs.render()
plt.pause(0.5)
k += 1
if rewards[0] < 0:
#print(rewards_last[0])
if opt_current==0:
opt_current = 1
else:
opt_current = 0
if rewards[0] != 0:
k = 0
total_reward/=n_steps
rewards_all/=n_steps
print(rewards_all[0], np.mean(rewards_all), np.std(rewards_all), np.std(rewards_all)/np.mean(rewards_all))
print(rewards_all[:10])
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/BrainCog-Version/tools/nsganet.py
================================================
import numpy as np
from pymoo.algorithms.genetic_algorithm import GeneticAlgorithm
from pymoo.docs import parse_doc_string
from pymoo.model.individual import Individual
from pymoo.model.survival import Survival
from pymoo.operators.crossover.point_crossover import PointCrossover
from pymoo.operators.mutation.polynomial_mutation import PolynomialMutation
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.selection.tournament_selection import compare, TournamentSelection
from pymoo.util.display import disp_multi_objective
from pymoo.util.dominator import Dominator
from pymoo.util.non_dominated_sorting import NonDominatedSorting
from pymoo.util.randomized_argsort import randomized_argsort
# =========================================================================================================
# Implementation
# based on nsga2 from https://github.com/msu-coinlab/pymoo
# =========================================================================================================
class NSGANet(GeneticAlgorithm):
def __init__(self, **kwargs):
kwargs['individual'] = Individual(rank=np.inf, crowding=-1)
super().__init__(**kwargs)
self.tournament_type = 'comp_by_dom_and_crowding'
self.func_display_attrs = disp_multi_objective
# ---------------------------------------------------------------------------------------------------------
# Binary Tournament Selection Function
# ---------------------------------------------------------------------------------------------------------
def binary_tournament(pop, P, algorithm, **kwargs):
if P.shape[1] != 2:
raise ValueError("Only implemented for binary tournament!")
tournament_type = algorithm.tournament_type
S = np.full(P.shape[0], np.nan)
for i in range(P.shape[0]):
a, b = P[i, 0], P[i, 1]
# if at least one solution is infeasible
if pop[a].CV > 0.0 or pop[b].CV > 0.0:
S[i] = compare(a, pop[a].CV, b, pop[b].CV, method='smaller_is_better', return_random_if_equal=True)
# both solutions are feasible
else:
if tournament_type == 'comp_by_dom_and_crowding':
rel = Dominator.get_relation(pop[a].F, pop[b].F)
if rel == 1:
S[i] = a
elif rel == -1:
S[i] = b
elif tournament_type == 'comp_by_rank_and_crowding':
S[i] = compare(a, pop[a].rank, b, pop[b].rank,
method='smaller_is_better')
else:
raise Exception("Unknown tournament type.")
# if rank or domination relation didn't make a decision compare by crowding
if np.isnan(S[i]):
S[i] = compare(a, pop[a].get("crowding"), b, pop[b].get("crowding"),
method='larger_is_better', return_random_if_equal=True)
return S[:, None].astype(np.int)
# ---------------------------------------------------------------------------------------------------------
# Survival Selection
# ---------------------------------------------------------------------------------------------------------
class RankAndCrowdingSurvival(Survival):
def __init__(self) -> None:
super().__init__(True)
def _do(self, pop, n_survive, D=None, **kwargs):
# get the objective space values and objects
F = pop.get("F")
# the final indices of surviving individuals
survivors = []
# do the non-dominated sorting until splitting front
fronts = NonDominatedSorting().do(F, n_stop_if_ranked=n_survive)
for k, front in enumerate(fronts):
# calculate the crowding distance of the front
crowding_of_front = calc_crowding_distance(F[front, :])
# save rank and crowding in the individual class
for j, i in enumerate(front):
pop[i].set("rank", k)
pop[i].set("crowding", crowding_of_front[j])
# current front sorted by crowding distance if splitting
if len(survivors) + len(front) > n_survive:
I = randomized_argsort(crowding_of_front, order='descending', method='numpy')
I = I[:(n_survive - len(survivors))]
# otherwise take the whole front unsorted
else:
I = np.arange(len(front))
# extend the survivors by all or selected individuals
survivors.extend(front[I])
return pop[survivors]
def calc_crowding_distance(F):
infinity = 1e+14
n_points = F.shape[0]
n_obj = F.shape[1]
if n_points <= 2:
return np.full(n_points, infinity)
else:
# sort each column and get index
I = np.argsort(F, axis=0, kind='mergesort')
# now really sort the whole array
F = F[I, np.arange(n_obj)]
# get the distance to the last element in sorted list and replace zeros with actual values
dist = np.concatenate([F, np.full((1, n_obj), np.inf)]) \
- np.concatenate([np.full((1, n_obj), -np.inf), F])
index_dist_is_zero = np.where(dist == 0)
dist_to_last = np.copy(dist)
for i, j in zip(*index_dist_is_zero):
dist_to_last[i, j] = dist_to_last[i - 1, j]
dist_to_next = np.copy(dist)
for i, j in reversed(list(zip(*index_dist_is_zero))):
dist_to_next[i, j] = dist_to_next[i + 1, j]
# normalize all the distances
norm = np.max(F, axis=0) - np.min(F, axis=0)
norm[norm == 0] = np.nan
dist_to_last, dist_to_next = dist_to_last[:-1] / norm, dist_to_next[1:] / norm
# if we divided by zero because all values in one columns are equal replace by none
dist_to_last[np.isnan(dist_to_last)] = 0.0
dist_to_next[np.isnan(dist_to_next)] = 0.0
# sum up the distance to next and last and norm by objectives - also reorder from sorted list
J = np.argsort(I, axis=0)
crowding = np.sum(dist_to_last[J, np.arange(n_obj)] + dist_to_next[J, np.arange(n_obj)], axis=1) / n_obj
# replace infinity with a large number
crowding[np.isinf(crowding)] = infinity
return crowding
# =========================================================================================================
# Interface
# =========================================================================================================
def nsganet(
pop_size=100,
sampling=RandomSampling(var_type=np.int),
selection=TournamentSelection(func_comp=binary_tournament),
crossover=PointCrossover(n_points=2),
mutation=PolynomialMutation(eta=3, var_type=np.int),
eliminate_duplicates=True,
n_offsprings=None,
**kwargs):
"""
Parameters
----------
pop_size : {pop_size}
sampling : {sampling}
selection : {selection}
crossover : {crossover}
mutation : {mutation}
eliminate_duplicates : {eliminate_duplicates}
n_offsprings : {n_offsprings}
Returns
-------
nsganet : :class:`~pymoo.model.algorithm.Algorithm`
Returns an NSGANet algorithm object.
"""
return NSGANet(pop_size=pop_size,
sampling=sampling,
selection=selection,
crossover=crossover,
mutation=mutation,
survival=RankAndCrowdingSurvival(),
eliminate_duplicates=eliminate_duplicates,
n_offsprings=n_offsprings,
**kwargs)
parse_doc_string(nsganet)
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/BCM.py
================================================
import argparse, math, os, sys
import numpy as np
import gym
from gym import wrappers
import matplotlib.pyplot as plt
import nsganet as engine
from pymop.problem import Problem
from pymoo.optimize import minimize
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
from tools.ExperimentEnvGlobalNetworkSurvival import ExperimentEnvGlobalNetworkSurvival
from tools.MazeTurnEnvVec import MazeTurnEnvVec
import torch
import torch.nn.utils as utils
from torch.distributions import Categorical
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from itertools import product
from functools import partial
import torchvision, pprint
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.model_zoo.base_module import BaseModule
from braincog.base.learningrule.BCM import *
from braincog.base.learningrule.STDP import *
parser = argparse.ArgumentParser(description='PyTorch REINFORCE example')
parser.add_argument('--gamma', type=float, default=0.98, metavar='G')
parser.add_argument('--seed', type=int, default=1, metavar='N')
parser.add_argument('--num_steps', type=int, default=500, metavar='N')
parser.add_argument('--num_episodes', type=int, default=100, metavar='N')
parser.add_argument('--render', action='store_true')
args = parser.parse_args()
n_agent = 1
steps = 500
hidden_size=64
env = MazeTurnEnvVec(n_agent, n_steps=steps)
data_env = ExperimentEnvGlobalNetworkSurvival(env)
s_dim = 4
a_dim = 3
def randbool(size, p):
return torch.rand(*size) < p
def fit(agent):
states = list(product([0, 1], repeat=4))
ls_list=[]
for state in states:
agent.model.reset()
state_tensor = torch.tensor(state).float().reshape(1, -1)
la, ls = agent.model(Variable(state_tensor.float()).reshape(-1,))
ls_np = ls.detach().numpy()
ls_list.append(ls_np)
ls_matrix = np.vstack(ls_list)
rank = np.linalg.matrix_rank(ls_matrix)
return rank
@register_model
class SNN(BaseModule):
def __init__(self,
hidden_size,
n_agent,
connectivity_matrix,
num_classes=3,
step=1,
node_type=LIFNode,
encode_type='direct',
ins=4,
lsm_th=0.3,
fc_th=0.3,
lsm_tau=3,
fc_tau=3,
tw=100,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.linear1 = nn.Linear(s_dim, hidden_size)
self.node=partial(node_type, **kwargs, step=step,tau=lsm_tau,threshold=lsm_th)
self.linear2 = nn.Linear(hidden_size, a_dim)
self.node_lsm=partial(node_type, **kwargs, step=step,tau=lsm_tau,threshold=lsm_th)
self.node_fc = partial(node_type, **kwargs, step=step,tau=fc_tau,threshold=fc_th)
self.hidden_size=hidden_size
self.out = torch.zeros(hidden_size)
self.con=[]
self.learning_rule=[]
self.connectivity_matrix=connectivity_matrix
w1tmp=nn.Linear(ins,hidden_size,bias=False)
self.con.append(w1tmp)
w2tmp=nn.Linear(hidden_size,hidden_size,bias=False)
self.liquid_weight=w2tmp.weight.data
w2tmp.weight.data=w2tmp.weight.data*self.connectivity_matrix
self.con.append(w2tmp)
self.learning_rule.append(BCM(self.node_lsm(), [self.con[0], self.con[1]]))
self.fc = nn.Linear(hidden_size,num_classes)
self.learning_rule.append(BCM(self.node_fc(), [self.fc]))
def forward(self, x):
sum_spike=0
time_window=20
self.tw=time_window
self.firing_tw=torch.zeros(time_window, self.hidden_size)
self.out = torch.zeros(self.hidden_size)
for t in range(time_window):
self.out, self.dw = self.learning_rule[0](x, self.out)
self.con[1].weight.data+=self.dw[1]
out_liquid=self.out[0:self.hidden_size]
xout,dw = self.learning_rule[1](out_liquid)
self.fc.weight.data+=dw[0]
sum_spike=sum_spike+xout
self.firing_tw[t]=out_liquid
outputs = sum_spike+0.0001 / time_window
return outputs,out_liquid
class REINFORCE:
def __init__(self, lm):
self.model = SNN(ins=4,n_agent=n_agent,hidden_size=hidden_size,lsm_tau=2,lsm_th=0.2,connectivity_matrix=lm)
self.model.train()
def select_action(self, state):
# mu, sigma_sq = self.model(Variable(state).cuda())
prob,_= self.model(Variable(state).reshape(-1,))
dist = Categorical(probs=prob)
action = dist.sample()
log_prob = prob[action.item()].log()
entropy = dist.entropy()
return action, log_prob, entropy
class Evolve(Problem):
# first define the NAS problem (inherit from pymop)
def __init__(self, n_var=20, n_obj=1, n_constr=0, lb=None, ub=None):
super().__init__(n_var=n_var, n_obj=n_obj, n_constr=n_constr, type_var=np.int64)
self.xl = lb
self.xu = ub
self._n_evaluated = 0 # keep track of how many architectures are sampled
def _evaluate(self, x, out, *args, **kwargs):
objs = np.full((x.shape[0], self.n_obj), np.nan)
for i in range(x.shape[0]):
arch_id = self._n_evaluated + 1
print('Network= {}'.format(arch_id))
agent = REINFORCE(torch.from_numpy(x[i].reshape(hidden_size,hidden_size)).float())
log_reward = []
log_smooth = []
# gamma=np.linspace(0.9,1.0,100)
gam=0.9
# for gam in gamma:
for i_episode in range(100):
state = torch.tensor(data_env.reset()).unsqueeze(0)
entropies = []
log_probs = []
rewards = []
old_dis = np.ones([1,])*13
reawrd_perstep=[]
ss=0
allrewards=[]
for t in range(500):
action, log_prob, entropy = agent.select_action(state.float())
action=action.unsqueeze(0).numpy()
next_state, envreward, done, _ = data_env.step(action)
entropies.append(entropy)
log_probs.append(log_prob)
state = torch.Tensor([next_state])
rewards.append(envreward[0])
print("Episode: {}, reward: {}".format(i_episode, np.sum(rewards)))
log_reward.append(np.sum(rewards))
if i_episode == 0:
log_smooth.append(log_reward[-1])
else:
log_smooth.append(log_smooth[-1]*0.99+0.01*np.sum(rewards))
plt.plot(log_smooth)
plt.plot(log_reward)
plt.pause(1e-5)
objs[i, 0] = fit(agent)
self._n_evaluated += 1
out["F"] = objs
def do_every_generations(algorithm):
gen = algorithm.n_gen
pop_var = algorithm.pop.get("X")
pop_obj = algorithm.pop.get("F")
if __name__ == "__main__":
n_agent=1
kkk = Evolve(n_var=hidden_size*hidden_size,
n_obj=1, n_constr=0)
method = engine.nsganet(pop_size=n_agent,
sampling=RandomSampling(var_type='custom'),
mutation=BinaryBitflipMutation(),
n_offsprings=10,
eliminate_duplicates=True)
kres=minimize(kkk,
method,
callback=do_every_generations,
termination=('n_gen', 1000))
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/README.md
================================================
# Adaptive structure evolution and biologically plausible synaptic plasticity for recurrent spiking neural networks #
## Requirments ##
* numpy
* pytorch >= 1.12.0
## Run ##
```python BCM.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{pan2023adaptive,
title = {Adaptive structure evolution and biologically plausible synaptic plasticity for recurrent spiking neural networks},
author = {Pan, Wenxuan and Zhao, Feifei and Zeng, Yi and Han, Bing},
journal = {Scientific Reports},
volume = {13},
number = {1},
pages = {16924},
year = {2023},
url = {https://doi.org/10.1038/s41598-023-43488-x},
doi = {10.1038/s41598-023-43488-x},
}
@article{zeng2023braincog,
title={BrainCog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired AI and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier}
}
```
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/lstm.py
================================================
import argparse, math, os, sys
from re import S
from aiohttp import ServerDisconnectedError
import numpy as np
import gym
from gym import wrappers
import matplotlib.pyplot as plt
from tools.ExperimentEnvGlobalNetworkSurvival import ExperimentEnvGlobalNetworkSurvival
from tools.MazeTurnEnvVec import MazeTurnEnvVec
import torch
from torch.autograd import Variable
import torch.autograd as autograd
import torch.nn.utils as utils
from torch.distributions import Categorical
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
parser = argparse.ArgumentParser(description='PyTorch REINFORCE example')
parser.add_argument('--gamma', type=float, default=0.98, metavar='G')
parser.add_argument('--seed', type=int, default=598, metavar='N')
parser.add_argument('--num_steps', type=int, default=500, metavar='N')
parser.add_argument('--num_episodes', type=int, default=1000, metavar='N')
parser.add_argument('--hidden_size', type=int, default=128, metavar='N')
parser.add_argument('--render', action='store_true')
args = parser.parse_args()
n_agent = 1
steps = 500
env = MazeTurnEnvVec(n_agent, n_steps=steps)
data_env = ExperimentEnvGlobalNetworkSurvival(env)
s_dim = 4
a_dim = 3
class Policy(nn.Module):
def __init__(self, hidden_size, s_dim, a_dim):
super(Policy, self).__init__()
self.lstm = nn.LSTM(s_dim, hidden_size, batch_first = True)
self.linear1 = nn.Linear(hidden_size, hidden_size)
self.linear2 = nn.Linear(hidden_size, a_dim)
def forward(self, x,hidden):
x, hidden = self.lstm(x, hidden)
x = F.relu(self.linear1(x))
p = F.softmax(self.linear2(x),-1)
return p,hidden
class REINFORCE:
def __init__(self, hidden_size, s_dim, a_dim):
self.model = Policy(hidden_size, s_dim, a_dim)
self.optimizer = optim.Adam(self.model.parameters(), lr=1e-2) #
self.model.train()
self.pi = Variable(torch.FloatTensor([math.pi])) #
def select_action(self, state,hx,cx):
# mu, sigma_sq = self.model(Variable(state).cuda())
prob,(hx,cx) = self.model(Variable(state),(hx,cx))
dist = Categorical(probs=prob)
action = dist.sample()
log_prob = prob[0][0,action.item()].log()
# log_prob = prob.log()
entropy = dist.entropy()
return action, log_prob, entropy
def update_parameters(self, rewards, log_probs, entropies, gamma):# 更新参数
R = torch.tensor(0)
loss = 0
for i in reversed(range(len(rewards))):
R = gamma * R + rewards[i]
loss = loss - (log_probs[i]*Variable(R)) - 0.005*entropies[i][0]
loss = loss / len(rewards)
self.optimizer.zero_grad()
loss.backward()
utils.clip_grad_norm_(self.model.parameters(), 2)
self.optimizer.step()
seeds=20
for seed in range(seeds):
log_reward = []
log_smooth = []
gamma=np.linspace(0.9,1.0,100)
for g in range(100):
agent = REINFORCE(args.hidden_size,s_dim,a_dim)
result=np.zeros([100,args.num_steps])
for i_episode in range(args.num_episodes):
state = torch.tensor(data_env.reset()).unsqueeze(0)
entropies = []
log_probs = []
rewards = []
old_dis = np.ones([1,])*13
reawrd_perstep=[]
allrewards=[]
hx = torch.zeros(args.hidden_size).unsqueeze(0).unsqueeze(0)
cx = torch.zeros(args.hidden_size).unsqueeze(0).unsqueeze(0)
for t in range(args.num_steps): # 1个episode最长num_steps
action, log_prob, entropy = agent.select_action(state.unsqueeze(0).float(),hx,cx)
action = action.cpu().numpy()
next_state, envreward, done, _ = data_env.step(action[0])
entropies.append(entropy)
log_probs.append(log_prob)
state = torch.Tensor([next_state])
rewards.append(envreward[0])
agent.update_parameters(rewards, log_probs, entropies, gamma[g])
print("Episode: {}, reward: {}".format(i_episode, np.sum(rewards)))
log_reward.append(np.sum(rewards))
if i_episode == 0:
log_smooth.append(log_reward[-1])
else:
log_smooth.append(log_smooth[-1]*0.99+0.01*np.sum(rewards))
plt.plot(log_smooth)
plt.plot(log_reward)
plt.pause(1e-5)
result[g]=np.array(allrewards).squeeze(1)
np.save('./lstm.npy',result)
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/main.py
================================================
import argparse, math, os, sys
import numpy as np
import gym
from gym import wrappers
import matplotlib.pyplot as plt
from tools.ExperimentEnvGlobalNetworkSurvival import ExperimentEnvGlobalNetworkSurvival
from tools.MazeTurnEnvVec import MazeTurnEnvVec
import torch
from torch.autograd import Variable
import torch.autograd as autograd
import torch.nn.utils as utils
from torch.distributions import Categorical
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
parser = argparse.ArgumentParser(description='PyTorch REINFORCE example')
parser.add_argument('--gamma', type=float, default=0.98, metavar='G')
parser.add_argument('--seed', type=int, default=1, metavar='N')
parser.add_argument('--num_steps', type=int, default=500, metavar='N')
parser.add_argument('--num_episodes', type=int, default=100, metavar='N')
parser.add_argument('--hidden_size', type=int, default=128, metavar='N')
parser.add_argument('--render', action='store_true')
args = parser.parse_args()
n_agent = 1
steps = 500
env = MazeTurnEnvVec(n_agent, n_steps=steps)
data_env = ExperimentEnvGlobalNetworkSurvival(env)
s_dim = 4
a_dim = 3
class Policy(nn.Module):
def __init__(self, hidden_size, s_dim, a_dim):
super(Policy, self).__init__()
self.linear1 = nn.Linear(s_dim, hidden_size)
self.linear2 = nn.Linear(hidden_size, a_dim)
def forward(self, x):
x = F.relu(self.linear1(x))
p = F.softmax(self.linear2(x),-1)
return p
class REINFORCE:
def __init__(self, hidden_size, s_dim, a_dim):
self.model = Policy(hidden_size, s_dim, a_dim)
# self.model = self.model.cuda()
self.optimizer = optim.Adam(self.model.parameters(), lr=1e-2)
self.model.train()
self.pi = Variable(torch.FloatTensor([math.pi]))
def select_action(self, state):
# mu, sigma_sq = self.model(Variable(state).cuda())
prob = self.model(Variable(state))
dist = Categorical(probs=prob)
action = dist.sample()
log_prob = prob[0,action.item()].log()
# log_prob = prob.log()
entropy = dist.entropy()
return action, log_prob, entropy
def update_parameters(self, rewards, log_probs, entropies, gamma):
R = torch.tensor(0)
loss = 0
for i in reversed(range(len(rewards))):
R = gamma * R + rewards[i]
loss = loss - (log_probs[i]*Variable(R)) - 0.005*entropies[i][0]
loss = loss / len(rewards)
self.optimizer.zero_grad()
loss.backward()
utils.clip_grad_norm_(self.model.parameters(), 2)
self.optimizer.step()
seeds=20
for seed in range(seeds):
# torch.manual_seed(args.seed)
# np.random.seed(args.seed)
agent = REINFORCE(args.hidden_size,s_dim,a_dim)
log_reward = []
log_smooth = []
gamma=np.linspace(0.9,1.0,100)
for gam in gamma:
for i_episode in range(args.num_episodes):
state = torch.tensor(data_env.reset()).unsqueeze(0)
entropies = []
log_probs = []
rewards = []
old_dis = np.ones([1,])*13
reawrd_perstep=[]
ss=0
allrewards=[]
for t in range(args.num_steps):
action, log_prob, entropy = agent.select_action(state.float())
action = action.cpu().numpy()
next_state, envreward, done, _ = data_env.step(action)
entropies.append(entropy)
log_probs.append(log_prob)
state = torch.Tensor([next_state])
rewards.append(envreward[0])
agent.update_parameters(rewards, log_probs, entropies, gam)
print("Episode: {}, reward: {}".format(i_episode, np.sum(rewards)))
log_reward.append(np.sum(rewards))
if i_episode == 0:
log_smooth.append(log_reward[-1])
else:
log_smooth.append(log_smooth[-1]*0.99+0.01*np.sum(rewards))
plt.plot(log_smooth)
plt.plot(log_reward)
plt.pause(1e-5)
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/pltbcm.py
================================================
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import pyplot
import matplotlib as mpl
from scipy.ndimage import gaussian_filter1d
sigm=3
# mpl.rcParams['font.size']=x
plt.style.use('seaborn-whitegrid')
plt.figure( figsize=(8,8) )
ax = plt.subplot()
palette = pyplot.get_cmap('Set1')
font1 = {'family': 'Times New Roman',
'weight': 'normal',
'size': 14,
}
steps=500
t = [i for i in range(steps)]
########################################BCM+BCM
bcm=np.load('./10rewards.npy')
for e in range(bcm.shape[0]):
sum1=0
sum2=0
best_agent_id=np.argmax(np.sum(bcm[e,:,:],axis=0))
best_agent=bcm[e,:,best_agent_id]
best_agent=best_agent[:steps]
for i in range(steps): #累积
sum2=sum2+best_agent[i]
best_agent[i]=sum2
bcm[e]=best_agent
avg = np.mean(bcm, axis=0)
std = np.std(bcm, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
y_smoothed = gaussian_filter1d(avg, sigma=40)
r1 = gaussian_filter1d(r1, sigma=40)
r2 = gaussian_filter1d(r2, sigma=40)
color = palette(0)
ax.plot(t, y_smoothed, color=color, label="Evolved model with DA-BCM", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
print("Evolved model with DA-BCM")
print(avg[-1],avg[-1]-r1[-1],r2[-1]-avg[-1])
########################################unbcm
unbcm=np.load('./unevolved_with_bcm.npy')
avg = np.mean(unbcm, axis=0)
std = np.std(unbcm, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
y_smoothed = gaussian_filter1d(avg, sigma=sigm)
r1 = gaussian_filter1d(r1, sigma=sigm)
r2 = gaussian_filter1d(r2, sigma=sigm)
color = palette(1)
ax.plot(t, y_smoothed, color=color, label="Unevolved model with DA-BCM", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
print("Unevolved model with DA-BCM+DA-BCM")
print(avg[-1],avg[-1]-r1[-1],r2[-1]-avg[-1])
########################################none+bcm
nonbcm=np.load('./none_bcm.npy')
avg = np.mean(nonbcm, axis=0)
std = np.std(nonbcm, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
y_smoothed = gaussian_filter1d(avg, sigma=sigm)
r1 = gaussian_filter1d(r1, sigma=sigm)
r2 = gaussian_filter1d(r2, sigma=sigm)
color = palette(2)
ax.plot(t, y_smoothed, color=color, label="Evolved model with NONE+DA-BCM", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
print("Evolved model with none+DA-BCM")
print(avg[-1],avg[-1]-r1[-1],r2[-1]-avg[-1])
########################################stdp+bcm
stdpbcm=np.load('./stdp_bcm.npy')
avg = np.mean(stdpbcm, axis=0)
std = np.std(stdpbcm, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
y_smoothed = gaussian_filter1d(avg, sigma=sigm)
r1 = gaussian_filter1d(r1, sigma=sigm)
r2 = gaussian_filter1d(r2, sigma=sigm)
color = palette(5)
ax.plot(t, y_smoothed, color=color, label="Evolved model with STDP+DA-BCM", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
print("Evolved model with STDP+DA-BCM")
print(avg[-1],avg[-1]-r1[-1],r2[-1]-avg[-1])
########################################LSTM
lstm=np.load('./lstm.npy')
avg = np.mean(lstm, axis=0)
std = np.std(lstm, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
y_smoothed = gaussian_filter1d(avg, sigma=sigm)
r1 = gaussian_filter1d(r1, sigma=sigm)
r2 = gaussian_filter1d(r2, sigma=sigm)
color = palette(3)
ax.plot(t, y_smoothed, color=color, label="LSTM", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
print("LSTM")
print(avg[-1],avg[-1]-r1[-1],r2[-1]-avg[-1])
########################################Q-learning
ql=np.load('./ql.npy')
avg = np.mean(ql, axis=0)
std = np.std(ql, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
y_smoothed = gaussian_filter1d(avg, sigma=sigm)
r1 = gaussian_filter1d(r1, sigma=sigm)
r2 = gaussian_filter1d(r2, sigma=sigm)
color = palette(6)
ax.plot(t, y_smoothed, color=color, label="Q-learning", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
print("Q-learning")
print(avg[-1],avg[-1]-r1[-1],r2[-1]-avg[-1])
########################################STDP
stdp=np.load('./inac.npy')
avg = np.mean(stdp, axis=0)
std = np.std(stdp, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
y_smoothed = gaussian_filter1d(avg, sigma=sigm)
r1 = gaussian_filter1d(r1, sigma=sigm)
r2 = gaussian_filter1d(r2, sigma=sigm)
color = palette(4)
ax.plot(t, y_smoothed, color=color, label="Evolved STDP", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
print("Evolved STDP")
print(avg[-1],avg[-1]-r1[-1],r2[-1]-avg[-1])
ax.tick_params(labelsize=16)
ax.spines['right'].set_color('black')
ax.spines['top'].set_color('black')
ax.spines['left'].set_color('black')
ax.spines['bottom'].set_color('black')
ax.legend(loc='upper left', prop=font1)
plt.xlabel('Steps', fontsize=18)
plt.ylabel('Average Reward', fontsize=18)
plt.savefig('./bcm.png')
plt.show()
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/pltrank.py
================================================
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import pyplot
import matplotlib as mpl
from scipy.ndimage import gaussian_filter1d
plt.figure( figsize=(8,8) )
steps=1000
t = [i for i in range(steps)]
plt.style.use('seaborn-whitegrid')
palette = pyplot.get_cmap('Set1')
font1 = {'family': 'Times New Roman',
'weight': 'normal',
'size': 18,
}
kk=np.load('./rank.npy')
avg = np.mean(kk, axis=0)
std = np.std(kk, axis=0)
r1 = list(map(lambda x: x[0] - x[1], zip(avg, std)))
r2 = list(map(lambda x: x[0] + x[1], zip(avg, std)))
r1 = gaussian_filter1d(r1, sigma=20)
r2 = gaussian_filter1d(r2, sigma=20)
y_smoothed = gaussian_filter1d(avg, sigma=20)
color = palette(0)
ax = plt.subplot()
ax.plot(t, y_smoothed, color=color, label="Average Fitness", linewidth=3.0)
ax.fill_between(t, r1, r2, color=color, alpha=0.2)
ax.tick_params(labelsize=18)
ax.spines['right'].set_color('black')
ax.spines['top'].set_color('black')
ax.spines['left'].set_color('black')
ax.spines['bottom'].set_color('black')
ax.legend(loc='lower right', prop=font1)
plt.xlabel('generations', fontsize=18)
plt.ylabel('SP', fontsize=18)
plt.savefig('./rank.png')
plt.show()
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/q_l.py
================================================
import random
import time
import tkinter as tk
import pandas as pd
from tools.ExperimentEnvGlobalNetworkSurvival import ExperimentEnvGlobalNetworkSurvival
from tools.MazeTurnEnvVec import MazeTurnEnvVec
import numpy as np
from matplotlib import pyplot as plt
steps=500
t=[i for i in range(steps)]
class Agent(object):
'''个体类'''
MAZE_R = 6
MAZE_C = 6
def __init__(self, env,alpha=0.1, gamma=0.9):
'''初始化'''
self.states = {}
self.actions = 3
self.alpha = alpha
self.gamma = gamma
self.q_table = np.zeros([32,3])
def choose_action(self,state,epsilon=0.8):
'''选择相应的动作。根据当前状态,随机或贪婪,按照参数epsilon'''
if random.uniform(0, 1) > epsilon:
action = random.choice([0,1,2])
else:
max_index=(self.q_table[state] == self.q_table[state].max()).nonzero()
if len(max_index)==1:
max_qvalue_actions=max_index[0]
else:
max_qvalue_actions=max_index[:][1]
action = random.choice(np.array(max_qvalue_actions))
return np.array([action])
def update_q_value(self, state, action, next_state_reward, next_state_q_values):
self.q_table[state, action] += self.alpha * (
next_state_reward + self.gamma * next_state_q_values.max() - self.q_table[state, action])
def add_state(self,X_next):
x_str = ','.join(str(i) for i in X_next.astype(int))
if (x_str in self.states) == False:
self.states[x_str] = max(self.states.values()) + 1
return self.states[x_str]
def learn(self, env, episode=100, epsilon=0.8):
'''q-learning算法'''
env.reset()
X=np.array([0,1,0,0])
sss = ','.join(str(i) for i in X.astype(int))
self.states[sss] = 0
for i in range(episode):
steps=0
current_state = np.array([0])
env.env.current_cell=np.array([0])
X_next, envreward, fitness, infos=env.step(current_state)
self.add_state(X_next)
next_state_reward=0
while next_state_reward==0 and steps<1000:
current_action = self.choose_action(current_state, epsilon)
X_next, next_state_reward, fitness, infos = env.step(current_action)
next_state_number=self.add_state(X_next)
next_state_q_values = self.q_table[next_state_number]
self.update_q_value(current_state, current_action, next_state_reward, next_state_q_values)
current_state = next_state_number
steps+=1
def play(self, env):
step=0
self.learn(env, epsilon=0.8)
current_state = np.array([0])
env.env.current_cell = np.array([0])
X_next, envreward, fitness, infos = env.step(current_state)
self.add_state(X_next)
env_r=[]
rsum=0
old_dis=13
while step0,dtype=int)[0]
if reward==0:
reward=-1
elif reward==1:
reward=1
if envreward==1:
reward=3
elif envreward==-1:
reward=-3
next_state_number = self.add_state(X_next)
rsum+=reward
current_state = next_state_number
env_r.append(rsum)
step+=1
return np.array(env_r)
def QQ():
steps=500
env = MazeTurnEnvVec(1, n_steps=steps)
data_env = ExperimentEnvGlobalNetworkSurvival(env)
agent = Agent(data_env)
r=agent.play(data_env)
return r
np.save('./ql.npy',QQ())
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/tools/EnuGlobalNetwork.py
================================================
import pickle
import time
import numpy as np
import torch
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import gridspec
from AbstractLayerBMM import AbstractLayerBMM
from EvolvableNeuralUnitStacked import EvolvableNeuralUnitStacked
from Tools import get_data_path
sns.set_style("darkgrid")
class EnuGlobalNetwork(AbstractLayerBMM):
"""Network of ENUs implementation in PyTorch, where each synapse and neuron is modeled as an ENU. """
def __init__(self, n_offspring, n_pseudo_env, n_input_neurons, n_hidden_neurons, n_output_neurons, n_syn_per_neuron):
# offspring
self.n_offspring = n_offspring
self.n_pseudo_env = n_pseudo_env
# input channels
n_input_channels = 16
self.n_input_channels = n_input_channels
n_dynamic_param = 32
# total neurons
n_neurons = n_output_neurons + n_hidden_neurons
self.n_neurons = n_neurons
super().__init__(n_offspring, n_neurons, n_input_neurons, n_output_neurons)
torch.random.manual_seed(0)
#NOTE: batch dimension holds output of each neuron/synapse, allowing fast GPU MM
#NOTE neurons far less than synapses, so can be relatively bigger rnn for little cost
n_input_channels_neuron = 16
n_input_neuron, n_output_neuron = n_input_channels_neuron, n_input_channels
self.neurons = EvolvableNeuralUnitStacked(n_offspring, batch_size=self.n_neurons, n_input=n_input_neuron, n_dynamic_param=n_dynamic_param, n_output=n_output_neuron)
#self.n_syn = next_power_of_2(int(n_neurons * (rel_connectivity*n_neurons)))
self.n_syn_per_neuron = n_syn_per_neuron
self.n_syn = n_neurons * n_syn_per_neuron
n_input_syn, n_output_syn = n_input_channels * 2, n_input_channels_neuron # * 2 for neuron feedback (which same channel as n_channel input)
self.synapses = EvolvableNeuralUnitStacked(n_offspring, batch_size=self.n_syn, n_input=n_input_syn, n_dynamic_param=n_dynamic_param, n_output=n_output_syn)
# just randomly connect synapses to neurons
self.synapse_connections = torch.randint(n_input_neurons + n_neurons, size=(n_neurons, n_syn_per_neuron), device='cuda', dtype=torch.long)
# fixed predefined connection patterns
if n_input_neurons==2 and n_output_neurons==2 and n_hidden_neurons==2:
print("Fixed connection Network 2-2-2")
self.synapse_connections = torch.tensor([[0, 1],
[0, 1],
[2, 3],
[2, 3]], device='cuda', dtype=torch.long)
elif n_input_neurons == 4 and n_output_neurons == 3 and n_hidden_neurons == 3 and n_syn_per_neuron==3:
print("Fixed connection Network 4-3-3 (3syn)")
self.synapse_connections = torch.tensor([[0, 1, 3],# hidden connections #4
[0, 2, 3], #5
[1, 2, 3],# 6
[4, 5, 6], # output connections #7
[4, 5, 6],#8
[4, 5, 6]#9
], device='cuda', dtype=torch.long)
elif n_input_neurons==5 and n_hidden_neurons==0 and n_output_neurons==4:
print("Fixed connection Network 5-0-4 (5syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3, 4],# output connections
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4]
], device='cuda', dtype=torch.long)
elif n_input_neurons==1 and n_hidden_neurons==0 and n_output_neurons==2:
print("Fixed connection Network 1-0-2 (1syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0],# output connections
[0]
], device='cuda', dtype=torch.long)
elif n_input_neurons==4 and n_hidden_neurons==0 and n_output_neurons==3 and n_syn_per_neuron==4:
print("Sparse connection Network 4-0-3 (4syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3],# output connections #4
[0, 1, 2, 3], #5
[0, 1, 2, 3],# 6
], device='cuda', dtype=torch.long)
elif n_input_neurons == 4 and n_hidden_neurons == 3 and n_output_neurons == 3 and n_syn_per_neuron == 4:
print("Sparse connection Network 4-3-3 (3syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 3], # hidden connections #4
[0, 2, 3], # 5
[1, 2, 3], # 6
[4, 5, 3], # output connections #7
[4, 6, 3], # 8
[5, 6, 3] # 9
], device='cuda', dtype=torch.long)
elif n_input_neurons==4 and n_hidden_neurons==3 and n_output_neurons==3 and n_syn_per_neuron==8:
print("Sparse connection Network 4-3-3 (8syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 5, 6, 7, 8, 3, 4],# hidden connections #4
[0, 2, 4, 6, 7, 9, 3, 5], #5
[1, 2, 4, 5, 8, 9, 3, 6],# 6
[4, 5, 8, 9, 0, 1, 3, 7], # output connections #7
[4, 6, 7, 9, 0, 2, 3, 8],#8
[5, 6, 7, 8, 1, 2, 3, 9]#9
], device='cuda', dtype=torch.long)
elif n_input_neurons==4 and n_hidden_neurons==4 and n_output_neurons==4 and n_syn_per_neuron==8:
print("Fixed connection Network 4-4-4 (8syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3, 4, 5, 6, 7],# hidden connections
[0, 1, 2, 3, 4, 5, 6, 7],
[0, 1, 2, 3, 4, 5, 6, 7],
[0, 1, 2, 3, 4, 5, 6, 7],
[4, 5, 6, 7, 8, 9, 10, 11], # output connections
[4, 5, 6, 7, 8, 9, 10, 11],
[4, 5, 6, 7, 8, 9, 10, 11],
[4, 5, 6, 7, 8, 9, 10, 11],
], device='cuda', dtype=torch.long)
elif n_input_neurons==5 and n_hidden_neurons==5 and n_output_neurons==4:
print("Fixed connection Network 5-5-4 (5syn)")
# neuron i connected to neuron j and k, neuron 0..input_neurons is index
self.synapse_connections = torch.tensor([[0, 1, 2, 3, 4],# hidden connections
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9], # output connections
[5, 6, 7, 8, 9],
[5, 6, 7, 8, 9],
[5, 6, 7, 8, 9],
], device='cuda', dtype=torch.long)
elif n_input_neurons==1 and n_hidden_neurons==0 and n_output_neurons==1:
print("Fixed connection Single")
self.synapse_connections = torch.tensor([[0]], device='cuda', dtype=torch.long)
else:
print("Random connections")
# each synapse is connected also to its post-synaptic neuron, to allow STDP type learning to emerge
self.synapse_connections_post = torch.arange(n_neurons, device='cuda', dtype=torch.long).reshape(n_neurons, -1).repeat(1, n_syn_per_neuron)
# define compartments
self.compartments = [self.neurons, self.synapses]
self.trainable_layers = self.neurons.trainable_layers + self.synapses.trainable_layers
self.track_data = False
def dump_model(self, e, exp_name):
"""Dump model to restore"""
with open(get_data_path(e, exp_name, "Model"), 'wb') as f:
parameters = {}
parameters["neuron"] = [layer.base_parameters.cpu().numpy() for layer in self.neurons.trainable_layers]
parameters["synapse"] = [layer.base_parameters.cpu().numpy() for layer in self.synapses.trainable_layers]
pickle.dump(parameters, f)
def restore_model(self, e, exp_name):
"""Restore model"""
with open(get_data_path(e, exp_name, "Model"), 'rb') as f:
parameters = pickle.load(f)
#TODO: refactor to dump/restore at ENU level and just call those functions
assert len(self.neurons.trainable_layers) == len(parameters["neuron"])
for i in range(len(parameters["neuron"])):
self.neurons.trainable_layers[i].base_parameters = torch.from_numpy(parameters["neuron"][i].astype(np.float32)).cuda()
assert len(self.synapses.trainable_layers) == len(parameters["synapse"])
for i in range(len(parameters["synapse"])):
self.synapses.trainable_layers[i].base_parameters = torch.from_numpy(parameters["synapse"][i].astype(np.float32)).cuda()
@staticmethod
def plot_weights(e, exp_name):
"""Visualize weights of ENU gates"""
sns.set_style("dark")
def calc_average(start, stop):
weights_average = None
for e in range(start, stop, 1000):
with open(get_data_path(e, exp_name, "Model"), 'rb') as f:
parameters = pickle.load(f)
weights = []
for i in range(len(parameters["neuron"])):
weights += [parameters["neuron"][i].astype(np.float32)]
if weights_average is None:
weights_average = weights
else:
for i in range(len(weights_average)):
weights_average[i] += weights[i]
return weights_average
weights_mean1 = calc_average(20000, 30000)
fig, ax = plt.subplots(1, 2, sharex='col', sharey='row')
for i in range(len(weights_mean1)):
ax[i].imshow(weights_mean1[i], cmap="gray")
weights_mean2 = calc_average(30000, 40000)
fig, ax = plt.subplots(1, 2, sharex='col', sharey='row')
for i in range(len(weights_mean2)):
ax[i].imshow(weights_mean2[i], cmap="gray")
fig, ax = plt.subplots(1, 2, sharex='col', sharey='row')
for i in range(len(weights_mean2)):
ax[i].imshow((weights_mean2[i] - weights_mean1[i])**5, cmap="gray")
plt.show()
def dump_network_activity(self, e, exp_name):
"""Dump raw data for visualization"""
with open(get_data_path(e, exp_name, "GlobalNetwork"), 'wb') as f:
pickle.dump(self.vis_data, f)
def print(self):
print("--Neurons--")
self.neurons.print()
print("--Synapses--")
self.synapses.print()
def reset(self):
self.vis_data = []
if self.track_data:
print("Tracking network activity")
for compartment in self.compartments:
compartment.reset()
def forward(self, X):
"""Main computation forward pass"""
# transfer to GPU
X_raw_gpu = torch.from_numpy(X.astype(np.float32)).cuda()
X_gpu = torch.zeros((X.shape[0], X.shape[1], self.n_input_channels), device='cuda', dtype=torch.float32)
X_gpu[:, :, :X_raw_gpu.shape[2]] = X_raw_gpu
# first compute synapses, set input to previous output of connected neuron
# concat our input spiking pattern directly to input to our synapses (the neurons)
# NOTE: this concats in batch dimension, meaning it feeds into input neurons directly spiking pattern, while rest receive input from network
input_to_synapses = torch.cat([X_gpu, self.neurons.out_mem], dim=1)
# connect each synapse randomly to multiple inputs
input_to_synapses_connected = input_to_synapses[:, self.synapse_connections.flatten(), :]
# need feedback connection from neuron to synapse, to allow stdp type rules to emerge (else it has to do it through feedback connections, but less guarentee on connections and cannot distinguise type)
# one synapse has 1 pre-synaptic neuron and 1 post-synaptic neuron, connectection defined in synapse_connections, synapse_connections[i, :] gives all input synapses of that neuron
# so feedback to all it's input synapses through broadcasting backwards
post_neuron_backprop_connected = self.neurons.out_mem[:, self.synapse_connections_post.flatten(), :]
input_to_synapses_connected = torch.cat([input_to_synapses_connected, post_neuron_backprop_connected], dim=-1)
# compute synapse
self.synapses.forward(input_to_synapses_connected)
# then integrate(sum) all outputs of a neurons input synapses, can just reshape into valid shape, since we already randomly connected when computing synapses
# NOTE: each neuron then requires same number of synapses, then reshape by modifying batch dim (which contains syn outputs)
integration = torch.sum(self.synapses.out.reshape((self.n_offspring, self.n_neurons, -1, self.synapses.shape[-1])), dim=2)
# scale by number of synapses
integration /= self.n_syn_per_neuron
self.out_integration = integration
# finally set neuron input to summated connected synapses output
input_to_neurons = integration
out = self.neurons.forward(input_to_neurons)
# output is last neuron output, NOTE: just first channel is returned, since we reshape neurons to channels
self.out = out[:, -self.n_output:, 0].reshape(self.n_offspring, self.n_output)
if self.track_data:
self._track_vis_data(X, input_to_synapses_connected, input_to_neurons)
return self.out
def _track_vis_data(self, X, input_to_synapses_connected, input_to_neurons):
offspring_idx = 0
self.vis_data += [(X[offspring_idx], input_to_neurons[offspring_idx].cpu().numpy(), self.neurons.out[offspring_idx].cpu().numpy(),
input_to_synapses_connected[offspring_idx].cpu().numpy(), self.synapses.out[offspring_idx].cpu().numpy())]
@staticmethod
def plot_network_activity(e, exp_name):
with open(get_data_path(e, exp_name, "GlobalNetwork"), 'rb') as f:
vis_data = pickle.load(f)
X, input_to_neurons, neurons_out, input_to_synapses, synapses_out = map(np.array, zip(*vis_data))
def plot_enu_activity(input, output, title):
n_cells = output.shape[1]
n_cells = np.minimum(10, output.shape[1])
fig, grid = plt.subplots(2, n_cells, sharex='col', sharey='row')
if n_cells==1:
grid[0].plot(input[:, 0, :])
grid[1].plot(output[:, 0, :])
else:
for i in range(n_cells):
grid[0, i].plot(input[:, i, :])
grid[1, i].plot(output[:, i, :])
plt.xlabel("t")
plt.title(title)
#plt.ylabel("")
plt.legend()
plt.figure()
plt.plot(X[:, :, 0])
plot_enu_activity(input_to_neurons, neurons_out, "ENU neuron activity")
plot_enu_activity(input_to_synapses, synapses_out, "ENU synapse activity")
plt.figure()
spike_points = np.where(neurons_out[:, :, 0] > 0)
plt.scatter(spike_points[0], spike_points[1], marker='|')
plt.show()
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/tools/ExperimentEnvGlobalNetworkSurvival.py
================================================
import pickle
import numpy as np
from tools.Tools import get_data_path
class ExperimentEnvGlobalNetworkSurvival:
"""Wrapper around a given RL environment for a Network of ENUs model,
turns reward into fitness and dumps relevant data"""
def __init__(self, env, exp_name='maze'):
self.env = env
self.exp_name = exp_name
self.n_output = self.env.n_actions
#NOTE: +1 reward neuron
self.n_input_neurons = self.env.n_obs + 1
self.n_agents = self.env.n_agents
def _convert_obs(self, obs, rewards):
n_input_channels_used = 3
X = np.zeros((self.n_agents, self.n_input_neurons, n_input_channels_used))
#X[:, :obs.shape[1], 0] = obs
# Shuffle only obs to avoid topology exploitation, reward neuron linked to EnuGlobal synapse connectivity
X[:, :obs.shape[1], 0] = np.take_along_axis(obs, self.obs_shuffle, axis=1)
# split pos and negative reward to different channels, And set to last input neuron
if rewards is not None:
X[rewards>0, -1, 1] = np.abs(rewards[rewards>0])
X[rewards<=0, -1, 2] = np.abs(rewards[rewards<=0])
return X
def _convert_reward(self, obs, actions, rewards, infos, dones):
fitness = np.copy(rewards)
# first poison is considered positive reward, since learning to learn
#NOTE: dead by env means less reward can be obtained so should implictely reduce overall fitness automatically
fitness[np.logical_and(self._prev_reward_count == 1, rewards != 0)] = 1
# include episode length as extra fitness, since not taking poison would allow survive longer, so should try avoid take poison
fitness[dones==0] += 0.1/4
return fitness
def step(self, y):
# if self.t % 3 != 0:
# actions = np.zeros((self.n_agents), dtype=np.int32) - 1
# else:
# winner take all, in given time window
actions = y
# if all same output, do nothing
# equal_actions = self.y_hist.shape[1] == np.sum(self.y_hist == np.take_along_axis(self.y_hist, actions.reshape(-1, 1), axis=1), axis=-1)
# actions[equal_actions] = -1
# self.y_hist[:] = 0
# take env step
allobs, obs, rewards, dones, infos = self.env.step(actions)
# X = self._convert_obs(obs, rewards)
X=allobs
self._prev_reward_count += rewards!=0
fitness = self._convert_reward(obs, actions, rewards, infos, dones)
self._prev_action = actions
self._prev_obs = obs
return X, rewards, fitness, None
def reset(self):
self.t = 0
self.y_hist = np.zeros((self.n_agents, self.n_output), dtype=np.float32)
self._prev_action = None
self._prev_obs = None
self._prev_reward_count = np.zeros((self.n_agents), dtype=np.float32)
# each time different input/output neurons should have different meaning, to have learning to learn
self.obs_shuffle = np.argsort(np.random.randn(self.n_agents, self.n_input_neurons - 1), axis=1, kind='mergesort')
self.action_shuffle = np.argsort(np.random.randn(self.n_agents, self.n_output), axis=1, kind='mergesort')
# reset env
self.allobs,self.obs = self.env.reset()
# return self._convert_obs(self.obs, None)
return self.allobs
def render(self):
if self.t%4==0:
self.env.render()
def track_vis_data(self, vis_data, model, X, y_est, t):
n_fetch = 128
# TODO: also get our gates from the model
vis_data+=[(X[:n_fetch, :], y_est[:n_fetch, :])]
def dump_vis_data(self, vis_data, fitness_per_offspring, e):
with open(get_data_path(e, self.exp_name, "output"), 'wb') as f:
pickle.dump((vis_data, fitness_per_offspring), f)
@staticmethod
def load_vis_data(e, exp_name):
with open(get_data_path(e, exp_name, "output"), 'rb') as f:
vis_data, fitness_per_offspring = pickle.load(f)
return vis_data, fitness_per_offspring
@staticmethod
def plot_vis_data(e, exp_name):
vis_data, fitness_per_offspring = ExperimentEnvGlobalNetworkSurvival.load_vis_data(e, exp_name)
================================================
FILE: examples/Structure_Evolution/Adaptive_lsm/raw/tools/MazeTurnEnvVec.py
================================================
import pickle
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from tools.Tools import save_fig, get_data_path
# np.random.seed(0)
class MazeTurnEnvVec:
"""Vectorized RL T-Maze environment written in pure Numpy. We require an efficient environment since we need to evaluate
and run up to thousands of offspring in parallel"""
def __init__(self, n_agents, n_steps):
# 4 important points, start point, decision point, food point, dead point.
# just generate a very large matrix that could fit any maze of any size, then can generate smaller maze as well
self.n_actions = 3
self.n_obs = 3
self.max_size = 7
self.n_agents = n_agents
self.n_steps = n_steps
self.window = plt.figure()
self.t_maze = True
self.turn_based = False
# steps can be longer if poison and need to turn around
self.steps_to_food = 2
if self.t_maze:
self.steps_to_food = 3
self.steps_to_food += self.steps_to_food*2
# give some extra leniency
self.steps_to_food *= 2
def step(self, actions):
# L R U D
# TODO: check legal action or not..
pos_copy = np.copy(self.agents_pos)
actions = np.copy(actions)
# GIVE TIME UPDATE WEIGHTS
# actions[self.agents_reset > 0] = -1
# actions[self.agent_energy<=0] = -1
self.agents_reset[self.agents_reset > 0] -= 1
# if turn based
if self.turn_based:
Forward = actions == 0
self.agents_pos[np.logical_and(Forward, self.agent_directions == 0), 1] += 1
self.agents_pos[np.logical_and(Forward, self.agent_directions == 2), 1] -= 1
self.agents_pos[np.logical_and(Forward, self.agent_directions == 1), 0] -= 1
self.agents_pos[np.logical_and(Forward, self.agent_directions == 3), 0] += 1
L = actions == 1
self.agent_directions[L] += 1
R = actions == 2
self.agent_directions[R] -= 1
self.agent_directions[self.agent_directions > 3] = 0
self.agent_directions[self.agent_directions < 0] = 3
else:
# or just direct movement
U = actions == 2
D = actions == 1
R = actions == 0
if self.agents_pos[U].size>0:
self.agents_pos[U, 0] += 1
self.agent_directions[U] = 3
if self.agents_pos[D].size>0:
self.agents_pos[D, 0] -= 1
self.agent_directions[D] = 1
if self.t_maze and self.agents_pos[R].size>0:
self.agents_pos[R, 1] += 1
self.agent_directions[R] = 0
# UNDO MOVES THAT GOT AGENT INTO WALL
self.current_cells = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1]]
self.agents_pos[self.current_cells==1] = pos_copy[self.current_cells==1]
movement_loss = np.prod(self.agents_pos==pos_copy, axis=-1)
# CHECK IF FOOD CONSUMED, is reward + pos reset
consumed_food = np.prod(self.agents_pos==self.food_pos[:, 0, :2], axis=-1).astype(np.bool)
consumed_pois = np.prod(self.agents_pos==self.food_pos[:, 1, :2], axis=-1).astype(np.bool)
self.consumed_count += consumed_food.astype(np.int32)
self.consumed_count_total += consumed_food.astype(np.int32)
self.consumed_count_pois += consumed_pois.astype(np.int32)
self._reset_pos(np.logical_or(consumed_food, consumed_pois))
# self._reset_pos_pois(consumed_pois)
# self._reset_food(self.consumed_count==self.swap_limit, prob=0.0)
# reset food for agents that ate food, and swap with some probability
self._reset_food(self.consumed_count==5, prob=0.5)
self.rewards = consumed_food.astype(np.float32) - consumed_pois.astype(np.float32) #* 0.5 #- movement_loss.astype(np.float32) * 0.01
# get observation from current position of each agent
self.agent_allobs,self.obs = self._get_obs_from_pos()
# instant dead on second poison
self.agent_energy += np.where(self.consumed_count_pois<=1, np.abs(self.rewards) * self.steps_to_food, -self.agent_energy * np.abs(self.rewards))
# energy decay to encourage exploration, agent dies if running out of energy
self.agent_energy = np.minimum(self.agent_energy, self.steps_to_food)
self.agent_energy -= 1.0/4
dones = self.agent_energy<=0
return self.agent_allobs,self.obs, self.rewards, dones, None
def _reset_pos(self, idxs):
self.agents_pos[idxs] = [self.start_point, 2] # set X pos
self.agent_directions[idxs] = 0
if self.max_size==5:
self.agent_directions[idxs] = 1
self.agents_reset[idxs] = 0
self.agents_reset_count[idxs] += 1
def _reset_pos_pois(self, idxs):
#NOTE: 2 since we call reset twice!
#NOTE: turning around already cost 8 steps, then 4x4 more is 16+8, 24, so reset should be much worse
self.agents_reset[np.logical_and(idxs, self.agents_reset_count>2)] = 64
def _reset_food(self, idxs, prob=0.5):
# swap food with some probability, avoids agent overfitting on environment
swap = np.take_along_axis(self.random_swap_matrix, self.consumed_count_total.reshape(-1, 1), axis=1).ravel()
swap_idxs = swap * idxs
food_loc = np.copy(self.food_pos[swap_idxs, 0, :])
pois_loc = np.copy(self.food_pos[swap_idxs, 1, :])
self.food_pos[swap_idxs, 0, :] = pois_loc
self.food_pos[swap_idxs, 1, :] = food_loc
# set maze value
self.mazes[np.arange(self.mazes.shape[0]), self.food_pos[:, 0, 0], self.food_pos[:, 0, 1]] = 2
self.mazes[np.arange(self.mazes.shape[0]), self.food_pos[:, 1, 0], self.food_pos[:, 1, 1]] = 3
self.consumed_count[idxs] = 0
def reset(self):
self.consumed_count = np.zeros((self.n_agents), dtype=np.int32)
self.consumed_count_total = np.zeros_like(self.consumed_count)
# consistent swapping such that if agent eat food once for all agents swapped with same seed, fair fitness comparison
max_eat = self.n_steps
self.random_swap_matrix = np.random.uniform(0, 1, size=(1, max_eat)) >= 0.5
self.random_swap_matrix = np.repeat(self.random_swap_matrix, int(self.n_agents), axis=0)
self.agent_energy = np.zeros((self.n_agents), dtype=np.float32) + self.steps_to_food
self.consumed_count_pois = np.zeros_like(self.consumed_count)
#self.swap_limit = np.random.randint(1, 5, size=1)
#self.swap_limit = np.random.randint(1, 4, size=self.n_agents)
self.mazes = np.ones((self.n_agents, self.max_size, self.max_size), dtype=np.int32)
#TODO: support variable maze length
self.start_point = int(self.max_size/2)
if self.t_maze:
self.mazes[:, self.start_point, 2:-1] = 0
self.mazes[:, 1:-1, -2] = 0
# FOOD either at -1,-1 or -1,1?
# two foods: x, y, value
self.food_pos = np.zeros((self.n_agents, 2, 2), dtype=np.int32)
self.food_pos[:, :, 1] = self.max_size - 2
self.food_pos[:, 1, 0] = 1
self.food_pos[:, 0, 0] = self.max_size - 2
self._reset_food(np.ones(self.food_pos.shape[0], dtype=np.bool), prob=0.5)
else:
self.mazes[:, 1:-1, 1] = 0
# two foods: x, y, value
self.food_pos = np.zeros((self.n_agents, 2, 2), dtype=np.int32)
self.food_pos[:, :, 1] = 1
self.food_pos[:, 0, 0] = 1
self.food_pos[:, 1, 0] = (self.max_size - 2)
self._reset_food(np.ones(self.food_pos.shape[0], dtype=np.bool), prob=0.5)
# AGENT
self.agents_pos = np.ones((self.n_agents, 2), dtype=np.int32)
self.agents_reset = np.zeros((self.n_agents), dtype=np.int32)
self.agents_reset_count = np.zeros_like(self.agents_reset)
self.agent_directions = np.zeros((self.n_agents), dtype=np.int32)
self._reset_pos(np.arange(self.agents_pos.shape[0]))
# OBS
self.agent_allobs,self.obs = self._get_obs_from_pos()
return self.agent_allobs,self.obs
def _get_obs_from_pos(self):
# obs is neighbouring cell states around agent
obs = np.zeros((self.n_agents, self.n_obs), dtype=np.float32)
raw_obs = np.zeros(self.n_agents, dtype=np.int32)
# get observation based on direction agent is facing
leftobs = np.zeros(self.n_agents)
rightobs = np.zeros(self.n_agents)
backobs = np.zeros(self.n_agents)
# get observation based on direction agent is facing
D = self.agent_directions == 0
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] + 1][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] - 1, self.agents_pos[:, 1]][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] + 1, self.agents_pos[:, 1]][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1]-1][D]
D = self.agent_directions == 2
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] - 1][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] + 1, self.agents_pos[:, 1]][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] - 1, self.agents_pos[:, 1]][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1]+1][D]
D = self.agent_directions == 1
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] - 1, self.agents_pos[:, 1]][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] - 1][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] + 1][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0]+1, self.agents_pos[:, 1]][D]
D = self.agent_directions == 3
raw_obs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0] + 1, self.agents_pos[:, 1]][D]
leftobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] + 1][D]
rightobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0], self.agents_pos[:, 1] - 1][D]
backobs[D] = self.mazes[np.arange(self.mazes.shape[0]), self.agents_pos[:, 0]-1, self.agents_pos[:, 1]][D]
# mark what was observed at different index
obs[raw_obs == 1, 0] = 1
obs[raw_obs == 2, 1] = 1
obs[raw_obs == 3, 2] = 1
allobs=np.squeeze(np.dstack((leftobs,raw_obs,rightobs,backobs)))
return allobs, obs
def render(self):
plt.clf()
sns.set_style("white")
#TODO: support render all mazes? can reshape to square?
max_render = 1
flattened_render = np.dstack(np.split(self.mazes[18, :], max_render, axis=0)).reshape(self.mazes.shape[1], -1)
flattened_render[flattened_render>1] = 0
plt.axis('off')
plt.imshow(flattened_render,cmap='bone')
for j in range(1):
i=18
marker = ">"
if self.agent_directions[i] == 1:
marker = "^"
if self.agent_directions[i] == 2:
marker = "<"
if self.agent_directions[i] == 3:
marker = "v"
obs_color = "black"
if self.obs[i, 0] == 1:
obs_color = "gray"
if self.obs[i, 1] == 1:
obs_color = "green"
if self.obs[i, 2] == 1:
obs_color = "red"
alpha = 1
if self.agent_energy[i]<=0:
alpha = 1
plt.scatter(self.agents_pos[i, 1] + j * self.mazes.shape[1], self.agents_pos[i, 0], color="skyblue", alpha=alpha, marker=marker)
plt.scatter(self.agents_pos[i, 1] + j * self.mazes.shape[1], self.agents_pos[i, 0], color=obs_color,alpha=alpha, marker=marker, s=3)
plt.scatter(self.food_pos[i, 0, 1] + j * self.mazes.shape[1], self.food_pos[i, 0, 0], color="green", alpha=1, marker="o")
plt.scatter(self.food_pos[i, 1, 1] + j * self.mazes.shape[1], self.food_pos[i, 1, 0], color="red", alpha=1, marker="o")
plt.pause(0.001)
#plt.pause(2)
@staticmethod
def load_vis_data(e, exp_name):
with open(get_data_path(e, exp_name, "output"), 'rb') as f:
vis_data, fitness_per_offspring = pickle.load(f)
return vis_data, fitness_per_offspring
@staticmethod
def plot_vis_data(e, exp_name):
import matplotlib.pyplot as plt
from cycler import cycler
import seaborn as sns
sns.set_style("whitegrid")
vis_data, fitness_per_offspring = MazeTurnEnvVec.load_vis_data(e, exp_name)
offspring_idx = 0
#x, y_est, y = np.array(vis_data).transpose(1, 2, 0, 3)
X, Y_est = map(np.array, zip(*vis_data))
X_base, y_est_base = X[:, offspring_idx], Y_est[:, offspring_idx]
#X_base, y_est_base = X_base[:300], y_est_base[:300]
#X_base = np.max(X_base, axis=1)
# --- normal output single example---
plt.rc('axes', prop_cycle=(cycler('color', ['gray', '#ff7f0e', '#9467bd', '#8c564b', '#e377c2', '#17becf'])))
# OLD METHOD!
plt.figure()
#NOTE: last neuron is always reward neuron
plt.plot(-X_base[:, :-1, 0], label="N-ENUs input", alpha=0.7)
plt.plot(- np.max(X_base, axis=1)[:, 1], label="Positive reward", alpha=0.7, color='#2ca02c')
plt.plot(- np.max(X_base, axis=1)[:, 2], label="Negative reward", alpha=0.7, color='#d62728')
#plt.gca().set_color_cycle(['orange', 'purple', 'brown'])
plt.plot(y_est_base[:, :], label="N-ENUs output", alpha=0.8)
plt.legend(loc='upper right')
save_fig(e, exp_name, "single_episode")
plt.rc('axes', prop_cycle=(cycler('color', ['gray', '#ff7f0e', '#9467bd', '#8c564b', '#e377c2', '#17becf'])))
# new method!
fig, grid = plt.subplots(2, sharex=True)
# input
#grid[1].set_prop_cycle(cycler('color', ['gray', '#ff7f0e', '#1f77b4']))
grid[1].set_prop_cycle(cycler('color', ['gray', '#F5B041', '#2E86C1']))
grid[1].plot(X_base[:, :-1, 0], label="N-ENUs input", alpha=0.7, linewidth=2)
grid[1].plot(np.max(X_base, axis=1)[:, 1], label="Positive reward", alpha=0.7, color='#1ABC9C', linewidth=2)
grid[1].plot(np.max(X_base, axis=1)[:, 2], label="Negative reward", alpha=0.7, color='#CB4335', linewidth=2)
grid[1].legend(['Sensor (wall)', 'Sensor (red)', 'Sensor (green)', 'Positive reward', 'Negative reward'], loc='upper right')
grid[1].set_ylabel('Neuron output')
# output
grid[0].set_prop_cycle(cycler('color', ['#9467bd', '#e377c2', '#17becf','#8c564b']))
grid[0].plot(y_est_base[:, :], label="N-ENUs output", alpha=0.8, linewidth=2)
grid[0].legend(['ENU-NN (left)', 'ENU-NN (right)', 'ENU-NN (forward)'],loc='upper right')
plt.xlabel('t')
grid[0].set_ylabel('ENU neuron output')
plt.xlim(-5, X_base.shape[0]+10)
save_fig(e, exp_name, "single_episode_dual")
#plt.show()
@staticmethod
def plot_rollout_data(e, exp_name):
#TODO: dump rollout as array not the actual plots
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style("white")
import os
rollout_path = "./" + get_data_path(e, exp_name, "rollout").split(".")[1][:-1]+"/"
rollout_files = sorted(os.listdir(rollout_path))
rollouts = []
for i in range(4, 200, 4):
file = "rollout_{}_.png".format(i)
print(file)
rollout = plt.imread(rollout_path + file)
rollout = rollout[80:450, 200:500]
rollout = np.where(rollout[:, :, [0]]> 0.98, 1, rollout)
rollouts.append(rollout)
# plt.imshow(rollout)
# plt.show()
# for rollout in rollouts:
vert_bar = np.zeros((rollout.shape[0], 5, 4))
vert_bar[::] += 0.5
# get red -> learned go other way
# food swapped -> sees red -> learned turn around
rollouts1 = [rollouts[1], rollouts[9], rollouts[10], rollouts[11], rollouts[17], rollouts[18]]#, rollouts[19]
#, rollouts[28]
#rollouts[24],
rollouts2 = [rollouts[25], rollouts[29], rollouts[30], rollouts[31], rollouts[32], rollouts[33]]
plt.axis('off')
plt.imshow(np.vstack([np.column_stack(rollouts1), np.column_stack(rollouts2)]), cmap='gray')
save_fig(e, exp_name, "rollout_combined")
#plt.show()
if __name__ == '__main__':
"""Test function"""
n_offspring = 1024
envs = MazeTurnEnvVec(n_offspring, n_steps=400)
envs.n_pseudo_env = 8
while True:
envs.reset()
opt_actions_up = [0,0,0,0,1,0]
opt_actions_down = [0,0,0,0,2,0]
opt_actions = [opt_actions_up, opt_actions_down]
opt_current = 0
total_reward = 0
rewards = np.zeros((n_offspring))
rewards_all = np.zeros_like(rewards)
k = 0
n_steps = 200
for i in range(n_steps):
actions = np.random.randint(0, envs.n_actions, size=n_offspring)
#actions[:] = opt_actions_up[i%len(opt_actions_up)]
#actions[0] = opt_actions[opt_current][k % len(opt_actions_up)]
obs, rewards,_,_ = envs.step(actions=actions)
total_reward += (rewards[0] * 100) + 1
rewards_all += (rewards * 100) + 1
#print(rewards[0])
#print(obs[0], rewards[0])
envs.render()
plt.pause(0.5)
k += 1
if rewards[0] < 0:
#print(rewards_last[0])
if opt_current==0:
opt_current = 1
else:
opt_current = 0
if rewards[0] != 0:
k = 0
total_reward/=n_steps
rewards_all/=n_steps
print(rewards_all[0], np.mean(rewards_all), np.std(rewards_all), np.std(rewards_all)/np.mean(rewards_all))
print(rewards_all[:10])
================================================
FILE: examples/Structure_Evolution/EB-NAS/acc_predictor/adaptive_switching.py
================================================
import utils
import numpy as np
from acc_predictor.factory import get_acc_predictor
class AdaptiveSwitching:
""" ensemble surrogate model """
""" try all available models, pick one based on 10-fold crx vld """
def __init__(self, n_fold=10):
# self.model_pool = ['rbf', 'gp', 'mlp', 'carts']
self.model_pool = ['rbf', 'gp', 'carts']
self.n_fold = n_fold
self.name = 'adaptive switching'
self.model = None
# self.predictor_pool = []
def fit(self, train_data, train_target):
self._n_fold_validation(train_data, train_target, n=self.n_fold)
# for p in self.predictor_pool:
# p.fit(train_data,train_target)
def _n_fold_validation(self, train_data, train_target, n=10):
n_samples = len(train_data)
perm = np.random.permutation(n_samples)
kendall_tau = np.full((n, len(self.model_pool)), np.nan)
all_predict_result=[]
for i, tst_split in enumerate(np.array_split(perm, n)):
trn_split = np.setdiff1d(perm, tst_split, assume_unique=True)
rl=[]
# loop over all considered surrogate model in pool
for j, model in enumerate(self.model_pool):
acc_predictor = get_acc_predictor(model, train_data[trn_split], train_target[trn_split])
result = acc_predictor.predict(train_data[tst_split])
rl.append(result)
rmse, rho, tau = utils.get_correlation(result, train_target[tst_split])
kendall_tau[i, j] = tau
all_predict_result.append(rl)
winner = int(np.argmax(np.mean(kendall_tau, axis=0) - np.std(kendall_tau, axis=0)))
print("winner model = {}, tau = {}".format(self.model_pool[winner],
np.mean(kendall_tau, axis=0)[winner]))
self.winner = self.model_pool[winner]
# re-fit the winner model with entire data
# acc_predictor = get_acc_predictor(self.model_pool[winner], train_data, train_target)
# self.model = acc_predictor
def predict(self, test_data):
return self.model.predict(test_data)
================================================
FILE: examples/Structure_Evolution/EB-NAS/acc_predictor/carts.py
================================================
# implementation based on
# https://github.com/yn-sun/e2epp/blob/master/build_predict_model.py
# and https://github.com/HandingWang/RF-CMOCO
import numpy as np
from sklearn.tree import DecisionTreeRegressor
class CART:
""" Classification and Regression Tree """
def __init__(self, n_tree=1000):
self.n_tree = n_tree
self.name = 'carts'
self.model = None
@staticmethod
def _make_decision_trees(train_data, train_label, n_tree):
feature_record = []
tree_record = []
for i in range(n_tree):
sample_idx = np.arange(train_data.shape[0])
np.random.shuffle(sample_idx)
train_data = train_data[sample_idx, :]
train_label = train_label[sample_idx]
feature_idx = np.arange(train_data.shape[1])
np.random.shuffle(feature_idx)
n_feature = np.random.randint(1, train_data.shape[1] + 1)
selected_feature_ids = feature_idx[0:n_feature]
feature_record.append(selected_feature_ids)
dt = DecisionTreeRegressor()
dt.fit(train_data[:, selected_feature_ids], train_label)
tree_record.append(dt)
return tree_record, feature_record
def fit(self, train_data, train_label):
self.model = self._make_decision_trees(train_data, train_label, self.n_tree)
def predict(self, test_data):
assert self.model is not None, "carts does not exist, call fit to obtain cart first"
# redundant variable device
trees, features = self.model[0], self.model[1]
test_num, n_tree = len(test_data), len(trees)
predict_labels = np.zeros((test_num, 1))
for i in range(test_num):
this_test_data = test_data[i, :]
predict_this_list = np.zeros(n_tree)
for j, (tree, feature) in enumerate(zip(trees, features)):
predict_this_list[j] = tree.predict([this_test_data[feature]])[0]
# find the top 100 prediction
predict_this_list = np.sort(predict_this_list)
predict_this_list = predict_this_list[::-1]
this_predict = np.mean(predict_this_list)
predict_labels[i, 0] = this_predict
return predict_labels
================================================
FILE: examples/Structure_Evolution/EB-NAS/acc_predictor/factory.py
================================================
def get_acc_predictor(model, inputs, targets):
if model == 'rbf':
from acc_predictor.rbf import RBF
acc_predictor = RBF()
acc_predictor.fit(inputs, targets)
elif model == 'carts':
from acc_predictor.carts import CART
acc_predictor = CART(n_tree=5000)
acc_predictor.fit(inputs, targets)
elif model == 'gp':
from acc_predictor.gp import GP
acc_predictor = GP()
acc_predictor.fit(inputs, targets)
elif model == 'mlp':
from acc_predictor.mlp import MLP
acc_predictor = MLP(n_feature=inputs.shape[1])
acc_predictor.fit(x=inputs, y=targets)
elif model == 'as':
from acc_predictor.adaptive_switching import AdaptiveSwitching
acc_predictor = AdaptiveSwitching()
acc_predictor.fit(inputs, targets)
else:
raise NotImplementedError
return acc_predictor
================================================
FILE: examples/Structure_Evolution/EB-NAS/acc_predictor/gp.py
================================================
from pydacefit.regr import regr_constant
from pydacefit.dace import DACE, regr_linear, regr_quadratic
from pydacefit.corr import corr_gauss, corr_cubic, corr_exp, corr_expg, corr_spline, corr_spherical
class GP:
""" Gaussian Process (Kriging) """
def __init__(self, regr='linear', corr='gauss'):
self.regr = regr
self.corr = corr
self.name = 'gp'
self.model = None
def fit(self, train_data, train_label):
if self.regr == 'linear':
regr = regr_linear
elif self.regr == 'constant':
regr = regr_constant
elif self.regr == 'quadratic':
regr = regr_quadratic
else:
raise NotImplementedError("unknown GP regression")
if self.corr == 'gauss':
corr = corr_gauss
elif self.corr == 'cubic':
corr = corr_cubic
elif self.corr == 'exp':
corr = corr_exp
elif self.corr == 'expg':
corr = corr_expg
elif self.corr == 'spline':
corr = corr_spline
elif self.corr == 'spherical':
corr = corr_spherical
else:
raise NotImplementedError("unknown GP correlation")
self.model = DACE(
regr=regr, corr=corr, theta=1.0, thetaL=0.00001, thetaU=100)
self.model.fit(train_data, train_label)
def predict(self, test_data):
assert self.model is not None, "GP does not exist, call fit to obtain GP first"
return self.model.predict(test_data)
================================================
FILE: examples/Structure_Evolution/EB-NAS/acc_predictor/mlp.py
================================================
import copy
import torch
import numpy as np
import torch.nn as nn
from utils import get_correlation
class Net(nn.Module):
# N-layer MLP
def __init__(self, n_feature, n_layers=2, n_hidden=300, n_output=1, drop=0.2):
super(Net, self).__init__()
self.stem = nn.Sequential(nn.Linear(n_feature, n_hidden), nn.ReLU())
hidden_layers = []
for _ in range(n_layers):
hidden_layers.append(nn.Linear(n_hidden, n_hidden))
hidden_layers.append(nn.ReLU())
self.hidden = nn.Sequential(*hidden_layers)
self.regressor = nn.Linear(n_hidden, n_output) # output layer
self.drop = nn.Dropout(p=drop)
def forward(self, x):
x = self.stem(x)
x = self.hidden(x)
x = self.drop(x)
x = self.regressor(x) # linear output
return x
@staticmethod
def init_weights(m):
if type(m) == nn.Linear:
n = m.in_features
y = 1.0 / np.sqrt(n)
m.weight.data.uniform_(-y, y)
m.bias.data.fill_(0)
class MLP:
""" Multi Layer Perceptron """
def __init__(self, **kwargs):
self.model = Net(**kwargs)
self.name = 'mlp'
def fit(self, **kwargs):
self.model = train(self.model, **kwargs)
def predict(self, test_data, device='cpu'):
return predict(self.model, test_data, device=device)
def train(net, x, y, trn_split=0.8, pretrained=None, device='cpu',
lr=8e-4, epochs=2000, verbose=False):
n_samples = x.shape[0]
target = torch.zeros(n_samples, 1)
perm = torch.randperm(target.size(0))
trn_idx = perm[:int(n_samples * trn_split)]
vld_idx = perm[int(n_samples * trn_split):]
inputs = torch.from_numpy(x).float()
target[:, 0] = torch.from_numpy(y).float()
# back-propagation training of a NN
if pretrained is not None:
print("Constructing MLP surrogate model with pre-trained weights")
init = torch.load(pretrained, map_location='cpu')
net.load_state_dict(init)
best_net = copy.deepcopy(net)
else:
# print("Constructing MLP surrogate model with "
# "sample size = {}, epochs = {}".format(x.shape[0], epochs))
# initialize the weights
# net.apply(Net.init_weights)
net = net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
criterion = nn.SmoothL1Loss()
# criterion = nn.MSELoss()
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, int(epochs), eta_min=0)
best_loss = 1e33
for epoch in range(epochs):
trn_inputs = inputs[trn_idx]
trn_labels = target[trn_idx]
loss_trn = train_one_epoch(net, trn_inputs, trn_labels, criterion, optimizer, device)
loss_vld = infer(net, inputs[vld_idx], target[vld_idx], criterion, device)
scheduler.step()
# if epoch % 500 == 0 and verbose:
# print("Epoch {:4d}: trn loss = {:.4E}, vld loss = {:.4E}".format(epoch, loss_trn, loss_vld))
if loss_vld < best_loss:
best_loss = loss_vld
best_net = copy.deepcopy(net)
validate(best_net, inputs, target, device=device)
return best_net.to('cpu')
def train_one_epoch(net, data, target, criterion, optimizer, device):
net.train()
optimizer.zero_grad()
data, target = data.to(device), target.to(device)
pred = net(data)
loss = criterion(pred, target)
loss.backward()
optimizer.step()
return loss.item()
def infer(net, data, target, criterion, device):
net.eval()
with torch.no_grad():
data, target = data.to(device), target.to(device)
pred = net(data)
loss = criterion(pred, target)
return loss.item()
def validate(net, data, target, device):
net.eval()
with torch.no_grad():
data, target = data.to(device), target.to(device)
pred = net(data)
pred, target = pred.cpu().detach().numpy(), target.cpu().detach().numpy()
rmse, rho, tau = get_correlation(pred, target)
# print("Validation RMSE = {:.4f}, Spearman's Rho = {:.4f}, Kendall’s Tau = {:.4f}".format(rmse, rho, tau))
return rmse, rho, tau, pred, target
def predict(net, query, device):
if query.ndim < 2:
data = torch.zeros(1, query.shape[0])
data[0, :] = torch.from_numpy(query).float()
else:
data = torch.from_numpy(query).float()
net = net.to(device)
net.eval()
with torch.no_grad():
data = data.to(device)
pred = net(data)
return pred.cpu().detach().numpy()
================================================
FILE: examples/Structure_Evolution/EB-NAS/acc_predictor/rbf.py
================================================
from pySOT.surrogate import RBFInterpolant, CubicKernel, TPSKernel, LinearTail, ConstantTail
class RBF:
""" Radial Basis Function """
def __init__(self, kernel='cubic', tail='linear'):
self.kernel = kernel
self.tail = tail
self.name = 'rbf'
self.model = None
def fit(self, train_data, train_label):
if self.kernel == 'cubic':
kernel = CubicKernel
elif self.kernel == 'tps':
kernel = TPSKernel
else:
raise NotImplementedError("unknown RBF kernel")
if self.tail == 'linear':
tail = LinearTail
elif self.tail == 'constant':
tail = ConstantTail
else:
raise NotImplementedError("unknown RBF tail")
self.model = RBFInterpolant(dim=train_data.shape[1], kernel=kernel(), tail=tail(train_data.shape[1]))
for i in range(len(train_data)):
self.model.add_points(train_data[i, :], train_label[i])
def predict(self, test_data):
assert self.model is not None, "RBF model does not exist, call fit to obtain rbf model first"
return self.model.predict(test_data)
================================================
FILE: examples/Structure_Evolution/EB-NAS/cellmodel.py
================================================
import os
from functools import partial
from typing import List, Type
from operations import *
from motifs import *
from utils import drop_path
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.model_zoo.base_module import BaseModule
from torchvision import transforms
EVO=True
class EvoCell2(nn.Module):
def __init__(self,motif, C_prev_prev, C_prev, C, reduction, reduction_prev, act_fun):
# print(C_prev_prev, C_prev, C, reduction)
super(EvoCell2, self).__init__()
self.act_fun = act_fun
self.reduction = reduction
self.motif=motif
self.back_connection=False
if reduction:
self.fun = FactorizedReduce(
C_prev, C * 3, act_fun=act_fun
)
self.multiplier = 3
else:
if reduction_prev:
self.preprocess0 = FactorizedReduce(
C_prev_prev, C, act_fun=act_fun)
else:
self.preprocess0 = ReLUConvBN(
C_prev_prev, C, 1, 1, 0, act_fun=act_fun)
self.preprocess1 = ReLUConvBN(C_prev, C, 1, 1, 0, act_fun=act_fun)
op_names, indices = zip(*motif.normal)
concat = motif.normal_concat
self._compile(C, op_names, indices, concat, reduction)
def _compile(self, C, op_names, indices, concat, reduction):
assert len(op_names) == len(indices)
# self._steps = len(op_names) // 2
self._concat = concat
self.multiplier = len(concat)
self._ops = nn.ModuleList()
self._ops_back = nn.ModuleList()
back_begin_index = 0
for i, (name, index) in enumerate(zip(op_names, indices)):
# print(name, index)
if '_back' in name:
self.back_connection=True
back_begin_index = i
break
stride = 2 if reduction and index < 2 else 1
op = OPS[name](C, stride, True, act_fun=self.act_fun)
self._ops += [op]
if self.back_connection:
for name, index in zip(op_names[back_begin_index:], indices[back_begin_index:]):
op = OPS[name.replace('_back', '')](
C, 1, True, act_fun=self.act_fun)
self._ops_back += [op]
if self.back_connection:
self._indices_forward = indices[:back_begin_index]
self._indices_backward = indices[back_begin_index:]
else:
self._indices_backward = []
self._indices_forward = indices
self._steps = len(self._indices_forward) // 2
def forward(self, s0, s1, drop_prob):
if self.reduction:
return self.fun(s1)
# print('s0',s0.shape)
s0 = self.preprocess0(s0)
# print(s0.shape)
# print('s1',s1.shape)
s1 = self.preprocess1(s1)
# print(s1.shape)
states = [s0, s1]
for i in range(self._steps):
i1=self._indices_forward[2 * i]
i2=self._indices_forward[2 * i + 1]
h1 = states[i1]
h2 = states[i2]
op1 = self._ops[2 * i]
op2 = self._ops[2 * i + 1]
h1 = op1(h1)
h2 = op2(h2)
if self.training and drop_prob > 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
s = h1 + h2
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = torch.cat([states[i]
for i in self._concat], dim=1) # N,C,H, W
return outputs
# return self.node(outputs)
class EvoCell3(nn.Module):
def __init__(self,motif, C_prev_prev_prev, C_prev_prev, C_prev, C, reduction, reduction_prev, reduction_prev_prev, act_fun):
# print(C_prev_prev_prev,C_prev_prev, C_prev, C, reduction,reduction_prev, reduction_prev_prev)
super(EvoCell3, self).__init__()
self.act_fun = act_fun
self.reduction = reduction
self.motif=motif
self.back_connection=False
if reduction:
self.fun = FactorizedReduce(C_prev, C * 3, act_fun=act_fun)
self.multiplier = 3
else:
if reduction_prev:
self.preprocess1 = FactorizedReduce(C_prev_prev, C, act_fun=act_fun)
else:
self.preprocess1 = ReLUConvBN(C_prev_prev, C, 1, 1, 0, act_fun=act_fun)
if int(reduction_prev_prev)+int(reduction_prev)==1:
self.preprocess0 = FactorizedReduce(C_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev)+int(reduction_prev)==2:
self.preprocess0 = F0(C_prev_prev_prev, C, act_fun=act_fun)
else:
self.preprocess0 = ReLUConvBN(C_prev_prev_prev, C, 1, 1, 0, act_fun=act_fun)
self.preprocess2 = ReLUConvBN(C_prev, C, 1, 1, 0, act_fun=act_fun)
op_names, indices = zip(*motif.normal)
concat = motif.normal_concat
self._compile(C, op_names, indices, concat, reduction)
def _compile(self, C, op_names, indices, concat, reduction):
assert len(op_names) == len(indices)
# self._steps = len(op_names) // 2
self._concat = concat
self.multiplier = len(concat)
self._ops = nn.ModuleList()
self._ops_back = nn.ModuleList()
back_begin_index = 0
for i, (name, index) in enumerate(zip(op_names, indices)):
# print(name, index)
if '_back' in name:
self.back_connection=True
back_begin_index = i
break
stride = 2 if reduction and index < 2 else 1
op = OPS[name](C, stride, True, act_fun=self.act_fun)
self._ops += [op]
if self.back_connection:
for name, index in zip(op_names[back_begin_index:], indices[back_begin_index:]):
op = OPS[name.replace('_back', '')](
C, 1, True, act_fun=self.act_fun)
self._ops_back += [op]
if self.back_connection:
self._indices_forward = indices[:back_begin_index]
self._indices_backward = indices[back_begin_index:]
else:
self._indices_backward = []
self._indices_forward = indices
self._steps = len(self._indices_forward) // 3
def forward(self, s0, s1, s2, drop_prob):
if self.reduction:
return self.fun(s2)
s0 = self.preprocess0(s0)
s1 = self.preprocess1(s1)
s2 = self.preprocess2(s2)
states = [s0, s1, s2]
for i in range(self._steps):
i1=self._indices_forward[3 * i]
i2=self._indices_forward[3 * i + 1]
i3=self._indices_forward[3 * i + 2]
h1 = states[i1]
h2 = states[i2]
h3 = states[i3]
op1 = self._ops[3 * i]
op2 = self._ops[3 * i + 1]
op3 = self._ops[3 * i + 2]
h1 = op1(h1)
h2 = op2(h2)
h3 = op3(h3)
if self.training and drop_prob > 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
if not isinstance(op3, Identity):
h3 = drop_path(h3, drop_prob)
s = h1 + h2 + h3
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = torch.cat([states[i] for i in self._concat], dim=1) # N,C,H, W
return outputs
# return self.node(outputs)
class EvoCell4(nn.Module):
def __init__(self,motif, C_prev_prev_prev_prev,C_prev_prev_prev, C_prev_prev, C_prev, C, reduction, reduction_prev, reduction_prev_prev,reduction_prev_prev_prev, act_fun):
# print(C_prev_prev_prev_prev,C_prev_prev_prev,C_prev_prev, C_prev, C, reduction,reduction_prev, reduction_prev_prev,reduction_prev_prev_prev)
super(EvoCell4, self).__init__()
self.act_fun = act_fun
self.reduction = reduction
self.motif=motif
self.back_connection=False
if reduction:
self.fun = FactorizedReduce(C_prev, C * 3, act_fun=act_fun)
self.multiplier = 3
else:
if reduction_prev:
self.preprocess2 = FactorizedReduce(C_prev_prev, C, act_fun=act_fun)
else:
self.preprocess2 = ReLUConvBN(C_prev_prev, C, 1, 1, 0, act_fun=act_fun)
if int(reduction_prev_prev)+int(reduction_prev)==1:
self.preprocess1 = FactorizedReduce(C_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev)+int(reduction_prev)==2:
self.preprocess1 = F0(C_prev_prev_prev, C, act_fun=act_fun)
else:
self.preprocess1 = ReLUConvBN(C_prev_prev_prev, C, 1, 1, 0, act_fun=act_fun)
if int(reduction_prev_prev_prev)+int(reduction_prev_prev)+int(reduction_prev)==1:
self.preprocess0 = FactorizedReduce(C_prev_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev_prev)+int(reduction_prev_prev)+int(reduction_prev)==2:
self.preprocess0 = F0(C_prev_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev_prev)+int(reduction_prev_prev)+int(reduction_prev)==3:
self.preprocess0 = F1(C_prev_prev_prev_prev, C, act_fun=act_fun)
else:
self.preprocess0 = ReLUConvBN(C_prev_prev_prev_prev, C, 1, 1, 0, act_fun=act_fun)
self.preprocess3 = ReLUConvBN(C_prev, C, 1, 1, 0, act_fun=act_fun)
op_names, indices = zip(*motif.normal)
# print(self.preprocess0)
# print(self.preprocess1)
# print(self.preprocess2)
# print(self.preprocess3)
concat = motif.normal_concat
self._compile(C, op_names, indices, concat, reduction)
def _compile(self, C, op_names, indices, concat, reduction):
assert len(op_names) == len(indices)
# self._steps = len(op_names) // 2
self._concat = concat
self.multiplier = len(concat)
self._ops = nn.ModuleList()
self._ops_back = nn.ModuleList()
back_begin_index = 0
for i, (name, index) in enumerate(zip(op_names, indices)):
# print(name, index)
if '_back' in name:
self.back_connection=True
back_begin_index = i
break
stride = 2 if reduction and index < 2 else 1
op = OPS[name](C, stride, True, act_fun=self.act_fun)
self._ops += [op]
if self.back_connection:
for name, index in zip(op_names[back_begin_index:], indices[back_begin_index:]):
op = OPS[name.replace('_back', '')](
C, 1, True, act_fun=self.act_fun)
self._ops_back += [op]
if self.back_connection:
self._indices_forward = indices[:back_begin_index]
self._indices_backward = indices[back_begin_index:]
else:
self._indices_backward = []
self._indices_forward = indices
self._steps = len(self._indices_forward) // 4
def forward(self, s0, s1, s2, s3, drop_prob):
if self.reduction:
return self.fun(s3)
s0 = self.preprocess0(s0)
s3 = self.preprocess3(s3)
s1 = self.preprocess1(s1)
s2 = self.preprocess2(s2)
# if s1.shape[1]!=s3.shape[1]:
# s1 = nn.Conv2d(s1.shape[1], s3.shape[1], 3, stride=2, padding=1, bias=False)
states = [s0, s1, s2,s3]
for i in range(self._steps):
i1=self._indices_forward[4 * i]
i2=self._indices_forward[4 * i + 1]
i3=self._indices_forward[4 * i + 2]
i4=self._indices_forward[4 * i + 3]
h1 = states[i1]
h2 = states[i2]
h3 = states[i3]
h4 = states[i4]
op1 = self._ops[4 * i]
op2 = self._ops[4 * i + 1]
op3 = self._ops[4 * i + 2]
op4 = self._ops[4 * i + 3]
h1 = op1(h1)
h2 = op2(h2)
h3 = op3(h3)
h4 = op4(h4)
if self.training and drop_prob > 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
if not isinstance(op3, Identity):
h3 = drop_path(h3, drop_prob)
if not isinstance(op4, Identity):
h4= drop_path(h4, drop_prob)
s = h1 + h2 + h3 + h4
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = torch.cat([states[i] for i in self._concat], dim=1) # N,C,H, W
return outputs
# return self.node(outputs)
@register_model
class NetworkCIFAR(BaseModule):
def __init__(self,
C,
num_classes,
layers,
auxiliary,
motif,
cell_type,
parse_method='darts',
step=5,
node_type='ReLUNode',
**kwargs):
super(NetworkCIFAR, self).__init__(
step=step,
num_classes=num_classes,
**kwargs
)
self.node_type=node_type
if isinstance(node_type, str):
self.act_fun = eval(node_type)
else:
self.act_fun = node_type
self.act_fun = partial(self.act_fun, **kwargs)
self.spike_output = kwargs['spike_output'] if 'spike_output' in kwargs else True
self.dataset = kwargs['dataset']
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
self._layers = layers
self.cell_type = cell_type
self._auxiliary = auxiliary
self.drop_path_prob = 0
stem_multiplier = 3
C_curr = stem_multiplier * C
if self.dataset == 'dvsg' or self.dataset == 'dvsc10' or self.dataset == 'NCALTECH101':
self.stem = nn.Sequential(
nn.Conv2d(2 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
# self.reduce_idx = [
# layers // 4,
# layers // 2,
# 3 * layers // 4
# ]
self.reduce_idx = [1, 3, 5, 7]
else:
self.stem = nn.Sequential(
nn.Conv2d(3 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
self.reduce_idx = [layers // 4,
layers // 2,
3 * layers // 4]
C_prev_prev_prev = C_curr
C_prev_prev_prev_prev = C_curr
C_prev_prev, C_prev, C_curr = C_curr, C_curr, C
self.cells = nn.ModuleList()
reduction_prev = False
reduction_prev_prev = False
reduction_prev_prev_prev = False
for i in range(layers):
if i in self.reduce_idx:
C_curr *= 2
reduction = True
else:
reduction = False
if cell_type==2:
# print(C_prev_prev, C_prev, C_curr)
cell = EvoCell2(motif[i], C_prev_prev, C_prev, C_curr,reduction, reduction_prev,act_fun=self.act_fun)
self.cells += [cell]
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
if cell_type==3:
cell = EvoCell3(motif[i], C_prev_prev_prev, C_prev_prev, C_prev, C_curr,reduction, reduction_prev,reduction_prev_prev,act_fun=self.act_fun)
self.cells += [cell]
C_prev_prev_prev = C_prev_prev
reduction_prev_prev = reduction_prev
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
if cell_type==4:
cell = EvoCell4(motif[i], C_prev_prev_prev_prev,C_prev_prev_prev, C_prev_prev, C_prev, C_curr,reduction, reduction_prev,reduction_prev_prev,reduction_prev_prev_prev,act_fun=self.act_fun)
self.cells += [cell]
C_prev_prev_prev_prev = C_prev_prev_prev
C_prev_prev_prev = C_prev_prev
reduction_prev_prev_prev = reduction_prev_prev
reduction_prev_prev = reduction_prev
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
reduction_prev = reduction
self.global_pooling = nn.Sequential(
self.act_fun(), nn.AdaptiveAvgPool2d(1))
if self.spike_output:
self.classifier = nn.Sequential(
nn.Linear(C_prev, 10 * num_classes),
self.act_fun())
self.vote = VotingLayer(10)
else:
self.classifier = nn.Linear(C_prev, num_classes)
self.vote = nn.Identity()
# self.classifier = nn.Linear(C_prev, num_classes)
# self.vote = nn.Identity()
def forward(self, inputs):
logits_aux = None
inputs = self.encoder(inputs)
if not self.layer_by_layer:
outputs = []
output_aux = []
self.reset()
if self.cell_type==2:
for t in range(self.step):
x = inputs[t]
s0 = s1 = self.stem(x)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
out = self.global_pooling(s1)
out = self.classifier(self.flatten(out))
logits = self.vote(out)
outputs.append(logits)
output_aux.append(logits_aux)
return sum(outputs) / len(outputs)
if self.cell_type==3:
for t in range(self.step):
x = inputs[t]
s0 = s1 = s2= self.stem(x)
for i, cell in enumerate(self.cells):
s0, s1, s2 = s1, s2, cell(s0, s1, s2, self.drop_path_prob)
out = self.global_pooling(s2)
out = self.classifier(self.flatten(out))
logits = self.vote(out)
outputs.append(logits)
output_aux.append(logits_aux)
return sum(outputs) / len(outputs)
if self.cell_type==4:
for t in range(self.step):
x = inputs[t]
s0 = s1 = s2= s3=self.stem(x)
for i, cell in enumerate(self.cells):
s0, s1, s2,s3= s1, s2, s3,cell(s0, s1, s2,s3 ,self.drop_path_prob)
out = self.global_pooling(s3)
out = self.classifier(self.flatten(out))
logits = self.vote(out)
outputs.append(logits)
output_aux.append(logits_aux)
return sum(outputs) / len(outputs)
# logits_aux if logits_aux is None else (sum(output_aux) / len(output_aux))
else:
s0 = s1 = self.stem(inputs)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
if i == 2 * self._layers // 3:
if self._auxiliary and self.training:
logits_aux = self.auxiliary_head(s1)
out = self.global_pooling(s1)
out = self.classifier(self.flatten(out))
out = rearrange(out, '(t b) c -> t b c', t=self.step).mean(0)
logits = self.vote(out)
return logits
@register_model
class NetworkCIFAR_(BaseModule):
def __init__(self,
C,
num_classes,
layers,
glob,
auxiliary,
motif,
parse_method='darts',
step=5,
node_type='ReLUNode',
**kwargs):
super(NetworkCIFAR_, self).__init__(
step=step,
num_classes=num_classes,
**kwargs
)
self.node_type=node_type
if isinstance(node_type, str):
self.act_fun = eval(node_type)
else:
self.act_fun = node_type
self.act_fun = partial(self.act_fun, **kwargs)
self.spike_output = kwargs['spike_output'] if 'spike_output' in kwargs else True
self.dataset = kwargs['dataset']
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
self.glob = glob
self._layers = layers
self._auxiliary = auxiliary
self.drop_path_prob = 0
stem_multiplier = 3
C_curr = stem_multiplier * C
if self.dataset == 'dvsg' or self.dataset == 'dvsc10' or self.dataset == 'NCALTECH101':
self.stem = nn.Sequential(
nn.Conv2d(2 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
# self.reduce_idx = [
# layers // 4,
# layers // 2,
# 3 * layers // 4
# ]
self.reduce_idx = [1, 3, 5, 7]
else:
self.stem = nn.Sequential(
nn.Conv2d(3 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
self.reduce_idx = [layers // 4,
layers // 2,
3 * layers // 4]
C_prev_prev_prev = C_curr
C_prev_prev_prev_prev = C_curr
C_prev_prev, C_prev, C_curr = C_curr, C_curr, C
self.cells = nn.ModuleList()
reduction_prev = False
reduction_prev_prev = False
reduction_prev_prev_prev = False
for i in range(layers):
if i in self.reduce_idx:
C_curr *= 2
reduction = True
else:
reduction = False
cell = EvoCell2(motif[i], C_prev_prev, C_prev, C_curr,reduction, reduction_prev,act_fun=self.act_fun)
self.cells += [cell]
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
reduction_prev = reduction
self.global_pooling = nn.Sequential(
self.act_fun(), nn.AdaptiveAvgPool2d(1))
if self.spike_output:
self.classifier = nn.Sequential(
nn.Linear(C_prev, 10 * num_classes),
self.act_fun())
self.vote = VotingLayer(10)
else:
self.classifier = nn.Linear(C_prev, num_classes)
self.vote = nn.Identity()
# self.classifier = nn.Linear(C_prev, num_classes)
# self.vote = nn.Identity()
def forward(self, inputs):
logits_aux = None
inputs = self.encoder(inputs)
if not self.layer_by_layer:
outputs = []
output_aux = []
self.reset()
zzz=[]
kkk=[]
for t in range(self.step):
x = inputs[t]
s0 = s1 = self.stem(x)
# print(s1.shape)
for i, cell in enumerate(self.cells):
if t>0 and i%5==4:
qw = np.where(self.glob[:,int(i//5)]==1)
if qw[0].shape[0]!=0:
for m in qw:
if zzz[m[0]].shape[-1]>s1.shape[-1]:
ks=zzz[m[0]].shape[-1] - (s1.shape[-1]-1)*2+2
if ks<0:
ks=zzz[m[0]].shape[-1] - (s1.shape[-1]-1)+2
bb=nn.Conv2d(zzz[m[0]].shape[1], s1.shape[1], kernel_size=ks, stride=1,padding=1, bias=False).to(zzz[m[0]].device)
else:
bb=nn.Conv2d(zzz[m[0]].shape[1], s1.shape[1], kernel_size=ks, stride=2,padding=1, bias=False).to(zzz[m[0]].device)
aa=bb(zzz[m[0]])
s1=aa+s1
elif zzz[m[0]].shape[-1] t b c', t=self.step).mean(0)
logits = self.vote(out)
return logits
def occumpy_mem(cuda_device):
total, used = os.popen('"/usr/bin/nvidia-smi" --query-gpu=memory.total,memory.used --format=csv,nounits,noheader').read().strip().split("\n")[int(cuda_device)].split(',')
# total, used = check_mem(cuda_device)
total = int(total)
used = int(used)
max_mem = int(total * 1)
block_mem = int((max_mem - used)*0.85)
x = torch.cuda.FloatTensor(256,1024,block_mem)
del x
if __name__ == '__main__':
torch.cuda.set_device('cuda:3')
# occumpy_mem(str(3))
x = torch.rand(128, 3, 32, 32)
glob = np.array([[0,1,0,0],[1,0,1,0],[1,0,0,1],[0,1,0,0]])
# glob = np.array([[0,1],[1,0]])
glob = np.array([[0,1,0,0],[0,0,0,0],[0,0,0,1],[0,0,0,0]])
glob = np.array([[0,1,1,1],[1,0,1,1],[1,1,0,1],[1,1,1,0]])
glob = np.array([[0,1,0],[1,0,0],[1,1,1]])
motifs=[mm2,mm3,mm4,mm5,mm1,mm5,mm3,mm4,mm2,mm1,mm2,mm3,mm4,mm5,mm1]
# motifs=[m1,m2,m3,m1,m5,m4,m1,m2,m3,m1,m5,m4,m5,m4,m1]##3
# motifs=[t2,t3,t4,t5,t1,t5,t3,t4,t2,t1,t2,t3,t4,t5,t1,t5,t3,t4,t2,t1]
# motifs=[t2,t3,t4,t5,t1]
# motifs=[subnet,subnet,subnet]
net=NetworkCIFAR_(C=12,num_classes=10,motif=motifs,layers=len(motifs),auxiliary=True,dataset='cifar10',glob=glob)
# net=NetworkCIFAR(C=12,num_classes=10,motif=motifs,layers=len(motifs),auxiliary=True,dataset='cifar10',cell_type=2)
net=net.cuda()
layers=int(len(motifs)/5)
out=net(x.to('cuda:3'))
print(out.shape)
================================================
FILE: examples/Structure_Evolution/EB-NAS/ebnas.py
================================================
import sys
import numpy as np
import argparse
import time
import timm.models
import yaml
import os
import logging
from random import choice
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from micro_encoding import ops
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
# from braincog.model_zoo.reactnet import *
# from braincog.model_zoo.convxnet import *
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import micro_encoding
import nsganet as engine
from pymop.problem import Problem
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from pymoo.optimize import minimize
from tm import train_motifs
from timm.data import create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from cellmodel import NetworkCIFAR
bits=20
# from ptflops import get_model_complexity_info
# from thop import profile, clever_format
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('')
# The first arg parser parses out only thei --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
devices=[4]
max_gen = 100
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--seed', type=int, default=99, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--eval_epochs', type=int, default=1)
parser.add_argument('--bns', action='store_true', default=True)
parser.add_argument('--mid', type=int, default=5)
parser.add_argument('--trainning_epochs', type=int, default=600, metavar='N',help='number of epochs to train (default: 2)')
parser.add_argument('--cooldown-epochs', type=int, default=0, metavar='N',help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--init-channels', type=int, default=36)
parser.add_argument('--layers', type=int, default=2)
parser.add_argument('--output', default='', type=str, metavar='PATH')
parser.add_argument('--spike-rate', action='store_true', default=False)
parser.add_argument('--n_gens', type=int, default=max_gen, help='population size')
parser.add_argument('--bs', type=int, default=100)
parser.add_argument('--n_offspring', type=int, default=60, help='number of offspring created per generation')
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser.add_argument('--dataset', default='cifar10', type=str)
parser.add_argument('--num-classes', type=int, default=10, metavar='N')
parser.add_argument('--model', default='NetworkCIFAR', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
parser.add_argument('--strgenome', default='4,0,0,1,1,1,0,1,0,1,0,0,0,1,0,1,0,1,0,0,4,1,1,1,1,1,0,1,1,0,1,1,0,1,1,1,0,1,0,0,4,1,1,0,1,0,0,1,0,1,1,0,1,1,0,0,1,0,1,2,4,1,0,0,1,1,1,0,0,1,0,0,1,0,0,1,0,0,1,1,4,0,1,1,0,1,0,0,1,0,1,0,1,1,1,0,1,0,1,3,4,1,0,1,0,0,1,1,1,0,0,1,0,1,0,0,0,1,0,0,3', type=str)
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.8,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=1.0,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=1.0,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=len(devices),
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=devices[0])
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='QGateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
# DARTS parameters
parser.add_argument('--auxiliary', action='store_true', default=False, help='use auxiliary tower')
# parser.add_argument('--arch', default='dvsc10_new_skip19', type=str)
# parser.add_argument('--motif', default='m1', type=str)
parser.add_argument('--parse_method', default='darts', type=str)
parser.add_argument('--drop_path_prob', type=float, default=0.2, help='drop path probability')
# parser.add_argument('--back-connection', action='store_true',default=True)
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
class NAS(Problem):
# first define the NAS problem (inherit from pymop)
def __init__(self, args,n_var=20, n_obj=1, n_constr=0, lb=None, ub=None,
init_channels=24, layers=8):
super().__init__(n_var=n_var, n_obj=n_obj, n_constr=n_constr, type_var=np.int64)
self.xl = lb
self.xu = ub
self._lr =args.lr
self._n_evaluated = 0 # keep track of how many architectures are sampled
self.args=args
def _evaluate(self, x, out, *args, **kwargs):
objs = np.full((x.shape[0], self.n_obj), np.nan)
for i in range(x.shape[0]):
arch_id = self._n_evaluated + 1
print('\n')
_logger.info('Network= {}'.format(arch_id))
genome = x[i, :]
arch_dir=os.path.join(self.args.output_dir,i)
if os.path.exists(arch_dir) is False:
os.makedirs(arch_dir,exist_ok = True)
self.args.lr=self._lr
performance,acc=train_motifs(args=self.args,gen=0,arch_dir=arch_dir,genome=genome,_logger=_logger,args_text=args_text,devices=devices,bits=bits)
objs[i, 0] = 1000 - performance
_logger.info('performance= {}'.format(objs[i, 0]))
self._n_evaluated += 1
out["F"] = objs
# if your NAS problem has constraints, use the following line to set constraints
# out["G"] = np.column_stack([g1, g2, g3, g4, g5, g6]) in case 6 constraints
def do_every_generations(algorithm):
# this function will be call every generation
# it has access to the whole algorithm class
gen = algorithm.n_gen
pop_var = algorithm.pop.get("X")
pop_obj = algorithm.pop.get("F")
# report generation info to files
_logger.info("generation = {}".format(gen))
_logger.info("population error: best = {}, mean = {}, "
"median = {}, worst = {}".format(np.min(pop_obj[:, 0]), np.mean(pop_obj[:, 0]),
np.median(pop_obj[:, 0]), np.max(pop_obj[:, 0])))
_logger.info('Best Genome= {}'.format(pop_var[np.argmin(pop_obj[:, 0])]))
def _parse_args():
args_config, remaining = config_parser.parse_known_args()
args = parser.parse_args(remaining)
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
if __name__ == '__main__':
args, args_text = _parse_args()
# args.no_spike_output = args.no_spike_output | args.cut_mix
args.no_spike_output = True
output_dir = ''
if args.local_rank == 0:
output_base = args.output if args.output else './output'
exp_name = '-'.join([
datetime.now().strftime("%Y%m%d-%H%M%S"),
# args.model,
# args.dataset,
str(args.layers)+'layers',
str(args.init_channels)+'channels',
'motif'+str(args.mid),
str(args.step)+'steps',
# args.suffix
# str(args.img_size)
])
output_dir = get_outdir(output_base,str(args.dataset),exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
else:
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
defalut_lr = args.lr
sn = np.arange(1,6)
np.random.shuffle(sn)
args.subnet=sn
args.layers*=5
len_motifs=args.layers*bits
low = np.zeros(len_motifs)
up=[]
for i in range(0,args.layers*bits,bits):
t=[args.mid]
low[i]=args.mid
t=t+[(ops-1) for j in range(bits-1)]
t[-1]=2*(ops-1)
up.extend(t)
up=np.array(up).reshape(-1,)
kkk = NAS(args,n_var=len_motifs,
n_obj=2, n_constr=0, lb=low, ub=up,
init_channels=args.init_channels, layers=args.layers)
method = engine.nsganet(pop_size=args.pop_size,
n_offsprings=args.n_offspring,
eliminate_duplicates=True)
kres=minimize(kkk,
method,
callback=do_every_generations,
termination=('n_gen', args.n_gens))
================================================
FILE: examples/Structure_Evolution/EB-NAS/micro_encoding.py
================================================
# NASNet Search Space https://arxiv.org/pdf/1707.07012.pdf
# code modified from DARTS https://github.com/quark0/darts
import numpy as np
from collections import namedtuple
from random import choice
from numpy.linalg import matrix_rank
import itertools
import torch
# from models.micro_models import NetworkCIFAR as Network
import motifs
# Genotype = namedtuple('Genotype', 'normal normal_concat reduce reduce_concat')
# Genotype_norm = namedtuple('Genotype', 'normal normal_concat')
# Genotype_redu = namedtuple('Genotype', 'reduce reduce_concat')
Genotype = namedtuple('Genotype', 'normal normal_concat')
# what you want to search should be defined here and in micro_operations
PRIMITIVES = [
'max_pool_3x3',
'avg_pool_3x3',
'skip_connect',
'sep_conv_3x3',
'sep_conv_5x5',
'dil_conv_3x3',
'dil_conv_5x5',
'sep_conv_7x7',
'conv_7x1_1x7',
]
OPERATIONS_back = [
# 'max_pool_3x3_p_back',
# 'avg_pool_3x3_p_back',
'conv_3x3_p_back',
'conv_5x5_p_back',
# 'avg_pool_3x3_n_back',
'conv_3x3_n_back',
'conv_5x5_n_back',
# 'sep_conv_3x3_p_back',
# 'sep_conv_5x5_p_back',
# 'dil_conv_3x3_p_back',
# 'dil_conv_5x5_p_back',
# 'def_conv_3x3_p_back',
# 'def_conv_5x5_p_back',
]
OPERATIONS_p = [
# 'max_pool_3x3_p',
# 'avg_pool_3x3_p',
'conv_3x3_p',
'conv_5x5_p',
# 'sep_conv_3x3_p',
# 'sep_conv_5x5_p',
# 'dil_conv_3x3_p',
# 'dil_conv_5x5_p',
# 'def_conv_3x3_p',
# 'def_conv_5x5_p',
]
ops=len(OPERATIONS_p)
OPERATIONS_n = [
# 'max_pool_3x3_n',
# 'avg_pool_3x3_n',
'conv_3x3_n',
'conv_5x5_n',
# 'sep_conv_3x3_n',
# 'sep_conv_5x5_n',
# 'dil_conv_3x3_n',
# 'dil_conv_5x5_n',
# 'def_conv_3x3_n',
# 'def_conv_5x5_n',
# 'transformer',
]
mids=(3,3,2,2,1)
mids=(1,2,3,4,5)
ms=len(mids)
permutations = list({}.fromkeys(list(itertools.permutations(mids))).keys())
motifdict_c = dict(enumerate(permutations, 1))
motifdict = dict(zip(motifdict_c.values(),motifdict_c.keys()))
def convert_cell(cell_bit_string):
# convert cell bit-string to genome
tmp = [cell_bit_string[i:i + 2] for i in range(0, len(cell_bit_string), 2)]
return [tmp[i:i + 2] for i in range(0, len(tmp), 2)]
def filt(sn):
for i in range(sn.shape[0]):
if sn[i]<1:
sn[i]=1
if sn[i]>120:
sn[i]=120
return sn
# def convert(bit_string):
# # convert network bit-string (norm_cell + redu_cell) to genome
# norm_gene = convert_cell(bit_string[:len(bit_string)//2])
# redu_gene = convert_cell(bit_string[len(bit_string)//2:])
# return [norm_gene, redu_gene]
def shuffle_along_axis(a, axis):
idx = np.random.rand(*a.shape).argsort(axis=axis)
return np.take_along_axis(a,idx,axis=axis)
def sample(pops, layers, bits , ):
sn = np.tile(mids,pops*layers).reshape(-1,ms)
sn=shuffle_along_axis(sn,axis=1)
sn=sn.reshape(-1,1)
# bigmotifs=(np.random.rand(pops*layers*ms,bits-1)<0.5).astype(int).reshape(-1,bits-1)
bigmotifs=(np.random.rand(pops*layers,bits-1)<0.5).astype(int).reshape(-1,bits-1)
# bigmotifs=np.repeat(bigmotifs,ms,axis=0)
sn=sn.reshape(pops*layers,-1)
# glob=np.array([2 for i in range(pops)])[:,np.newaxis]
genome=np.concatenate((sn, bigmotifs),axis=1).reshape(pops,-1)
glob = (np.random.rand(pops,layers*layers)<0.5).astype(int).reshape(pops,layers,layers)
# for i in range(layers):
# glob[:,i,i]=0
genome=np.concatenate((genome, glob.reshape(pops,layers*layers)),axis=1).reshape(pops,-1)
return genome,sn,bigmotifs,ms,glob.reshape(pops,layers*layers)
def reencode(sn,bigmotifs,pops):
sn=sn.reshape(-1,ms)
mnumber=np.array([motifdict[tuple(x)] for x in sn]).reshape(pops,-1)
mgenome=np.concatenate((bigmotifs.reshape(pops,-1), mnumber),axis=1).reshape(pops,-1)
return mgenome
def convert(mgenome, layers, bits):
bigmotifs = mgenome[:,0:-layers].reshape(-1,bits-1)
sn=mgenome[:,-layers:].reshape(-1)
sn=filt(sn)
ssn=np.array([list(motifdict_c[sn[i]]) for i in range(sn.shape[0])]).reshape(-1,1)
result=np.concatenate((ssn,np.repeat(bigmotifs,ms,axis=0)),axis=1).reshape(-1,layers*bits*ms)
return np.c_[result,np.ones((result.shape[0],1))*2]
def convert_single(mgenome, layers, bits):
bigmotifs = mgenome[0:-layers].reshape(-1,bits-1)
sn=mgenome[-layers:].reshape(-1)
sn=filt(sn)
ssn=np.array([list(motifdict_c[sn[i]]) for i in range(sn.shape[0])]).reshape(-1,1)
result=list(np.concatenate((ssn,np.repeat(bigmotifs,ms,axis=0)),axis=1).reshape(layers*bits*ms))
return np.array(result)
def c_single(mgenome, layers, bits):
glob = mgenome[-layers*layers:]
mgenome = mgenome[:-layers*layers]
big=mgenome.reshape(layers,-1)
bigmotifs = big[:,ms:]
sn=big[:,0:ms]
result = np.concatenate((sn.reshape(-1,1),np.repeat(bigmotifs,ms,axis=0)),axis=1).reshape(-1,).tolist()
result.append(glob.reshape(layers,layers))
return result
# def decode_cell(genome, norm=True):
# cell, cell_concat = [], list(range(2, len(genome)+2))
# for block in genome:
# for unit in block:
# cell.append((PRIMITIVES[unit[0]], unit[1]))
# if unit[1] in cell_concat:
# cell_concat.remove(unit[1])
# if norm:
# return Genotype_norm(normal=cell, normal_concat=cell_concat)
# else:
# return Genotype_redu(reduce=cell, reduce_concat=cell_concat)
def decode(genome):
# decodes genome to architecture
normal_cell = genome[0]
reduce_cell = genome[1]
normal, normal_concat = [], list(range(2, len(normal_cell)+2))
reduce, reduce_concat = [], list(range(2, len(reduce_cell)+2))
for block in normal_cell:
for unit in block:
normal.append((PRIMITIVES[unit[0]], unit[1]))
if unit[1] in normal_concat:
normal_concat.remove(unit[1])
for block in reduce_cell:
for unit in block:
reduce.append((PRIMITIVES[unit[0]], unit[1]))
if unit[1] in reduce_concat:
reduce_concat.remove(unit[1])
return Genotype(
normal=normal, normal_concat=normal_concat,
reduce=reduce, reduce_concat=reduce_concat
)
def decode_motif(layers,bits,genome):
# decodes genome to architecture
motif_list=[]
motif_ids=[]
for b in range(0,layers*bits,bits):
motif_id='mm'+str(genome[b])
motif_ids.append(genome[b])
normalcell=eval('motifs.%s' % motif_id)
newnormal=[]
for i in range(0,len(normalcell.normal)):
op=normalcell.normal[i]
if 'skip' in op[0]:
newnormal.append(op)
continue
elif 'back' in op[0]:
newnormal.append((OPERATIONS_back[genome[b+1+len(normalcell.normal)-1]],op[1]))
continue
elif '_n' in op[0]:
newnormal.append((OPERATIONS_n[genome[b+1+i]],op[1]))
continue
elif '_p' in op[0]:
newnormal.append((OPERATIONS_p[genome[b+1+i]],op[1]))
continue
m=Genotype(normal=newnormal, normal_concat=normalcell.normal_concat,)
motif_list.append(m)
return motif_list,motif_ids
def compare_cell(cell_string1, cell_string2):
cell_genome1 = convert_cell(cell_string1)
cell_genome2 = convert_cell(cell_string2)
cell1, cell2 = cell_genome1[:], cell_genome2[:]
for block1 in cell1:
for block2 in cell2:
if block1 == block2 or block1 == block2[::-1]:
cell2.remove(block2)
break
if len(cell2) > 0:
return False
else:
return True
def compare(string1, string2):
if compare_cell(string1[:len(string1)//2],
string2[:len(string2)//2]):
if compare_cell(string1[len(string1)//2:],
string2[len(string2)//2:]):
return True
return False
# def debug():
# # design to debug the encoding scheme
# seed = 0
# np.random.seed(seed)
# budget = 2000
# B, n_ops, n_cell = 5, 7, 2
# networks = []
# design_id = 1
# while len(networks) < budget:
# bit_string = []
# for c in range(n_cell):
# for b in range(B):
# bit_string += [np.random.randint(n_ops),
# np.random.randint(b + 2),
# np.random.randint(n_ops),
# np.random.randint(b + 2)
# ]
# genome = convert(bit_string)
# # check against evaluated networks in case of duplicates
# doTrain = True
# for network in networks:
# if compare(genome, network):
# doTrain = False
# break
# if doTrain:
# genotype = decode(genome)
# model = Network(16, 10, 8, False, genotype)
# model.drop_path_prob = 0.0
# data = torch.randn(1, 3, 32, 32)
# output, output_aux = model(torch.autograd.Variable(data))
# networks.append(genome)
# design_id += 1
# print(design_id)
if __name__ == "__main__":
# debug()
# genome1 = [[[[3, 0], [3, 1]], [[3, 0], [3, 1]],
# [[3, 1], [2, 0]], [[2, 0], [5, 2]]],
# [[[0, 0], [0, 1]], [[2, 2], [0, 1]],
# [[0, 0], [2, 2]], [[2, 2], [0, 1]]]]
# genome2 = [[[[3, 1], [3, 0]], [[3, 1], [3, 0]],
# [[3, 1], [2, 0]], [[2, 0], [5, 2]]],
# [[[0, 1], [0, 0]], [[2, 2], [0, 1]],
# [[0, 0], [2, 2]], [[2, 2], [0, 0]]]]
#
# print(compare(genome1, genome2))
# print(genome1)
# print(genome2)
# bit_string1 = [3,1,3,0,3,1,3,0,3,1,2,0,2,0,5,2,0,0,0,1,2,2,0,1,0,0,2,2,2,2,0,1]
# bit_string2 = [3, 0, 3, 1, 3, 0, 3, 1, 3, 1, 2, 0, 2, 0, 5, 2,
# 0, 0, 0, 1, 2, 2, 0, 1, 0, 0, 2, 2, 2, 2, 0, 1]
# # print(convert(bit_string1))
# print(compare(bit_string1, bit_string2))
# print(decode(convert(bit_string)))
cell_bit_string = [3, 0, 3, 1, 3, 0, 3, 1, 3, 1, 2, 0, 2, 0, 5, 2]
# print(decode_cell(convert_cell(cell_bit_string), norm=False))
genome,sn,bigmotifs,ms=sample(195,2,20)
mgeno=reencode(sn,bigmotifs,195)
convert(mgeno,2,20)
================================================
FILE: examples/Structure_Evolution/EB-NAS/motifs.py
================================================
from collections import namedtuple
import torch
Genotype = namedtuple('Genotype', 'normal normal_concat')
"""
Operation sets
"""
PRIMITIVES = [
'skip_connect',
# 'max_pool_3x3',
# 'avg_pool_3x3',
# 'def_conv_3x3',
# 'def_conv_5x5',
# 'sep_conv_3x3',
# 'sep_conv_5x5',
# 'dil_conv_3x3',
# 'dil_conv_5x5',
# 'max_pool_3x3_p',
# 'avg_pool_3x3_p',
'conv_3x3_p',
'conv_5x5_p',
# 'skip_connect_p',
# 'sep_conv_3x3_p',
# 'sep_conv_5x5_p',
# 'dil_conv_3x3_p',
# 'dil_conv_5x5_p',
# 'def_conv_3x3_p',
# 'def_conv_5x5_p',n
# 'max_pool_3x3_n',
# 'avg_pool_3x3_n',
'conv_3x3_n',
'conv_5x5_n',
# 'skip_connect_n',
# 'sep_conv_3x3_n',
# 'sep_conv_5x5_n',
# 'dil_conv_3x3_n',
# 'dil_conv_5x5_n',
# 'def_conv_3x3_n',
# 'def_conv_5x5_n',
# 'transformer',
]
m0=Genotype(
normal=[
('skip', 0), ('skip', 1),('skip', 2),
],
normal_concat=range(3, 4)
)
mm0=Genotype(
normal=[
('skip', 0), ('skip', 1),('skip', 2),
],
normal_concat=range(2, 3)
)
mm1=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),
('skip_connect', 0), ('conv_5x5_p', 2),
],
normal_concat=range(2, 4)
)
mm2=Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),
('skip_connect', 0), ('conv_5x5_n', 2),
('conv_5x5_p', 2), ('conv_3x3_n', 3),
],
normal_concat=range(2, 5)
)
mm4=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),#2
('conv_3x3_p', 0), ('conv_3x3_p', 1),#3
('conv_5x5_p', 2), ('conv_5x5_p', 3),#4
('skip_connect', 0), ('conv_3x3_p', 4),#5
('skip_connect', 0), ('conv_3x3_p', 4),#6
],
normal_concat=range(2, 7)
)
mm3=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),#2
('skip_connect', 0), ('conv_5x5_n', 2),#3
('skip_connect', 0), ('conv_5x5_p', 3),#4
('skip_connect_back', 2),#3
('conv_3x3_p_back', 3),#4
],
normal_concat=range(2, 5)
)
mm5=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),#2
('skip_connect', 0), ('conv_5x5_p', 2),#3
('skip_connect_back', 2),#3
],
normal_concat=range(2, 4)
)
m1=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2), #B3
('skip', 0), ('conv_5x5_p', 3), ('skip', 1), #C4
],
normal_concat=range(3, 5)
)
m2=Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), #B3
('skip', 0), ('conv_5x5_n', 3), ('skip', 1),#C4
('conv_5x5_p', 3), ('conv_3x3_n', 4), ('skip', 1), #D5
],
normal_concat=range(3, 6)
)
m4=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), #3
('conv_3x3_p', 0), ('conv_3x3_p', 1),('conv_5x5_p', 2), #4
('skip', 0), ('conv_5x5_p', 3), ('conv_5x5_p', 4), #5
('skip', 0), ('conv_3x3_p', 3),('conv_3x3_n', 5),#6
('skip', 0), ('conv_3x3_p', 4),('conv_3x3_n', 5),#7
],
normal_concat=range(3, 8)
)
m3=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_3x3_p', 2), #3
('skip', 0), ('conv_5x5_p', 3),('skip', 1), #4
('skip', 0), ('conv_5x5_p', 3), ('skip', 1), #5
('conv_3x3_n_back', 3),#4
('skip_back', 2),#5
],
normal_concat=range(3, 6)
)
m5=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2),#3
('skip', 0),('skip', 1), ('conv_5x5_n', 3), #4
('skip_connect_back', 3),#4
],
normal_concat=range(3, 5)
)
t1=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2), ('conv_5x5_p', 3), #4
('skip', 0), ('conv_5x5_p', 4), ('skip', 1), ('skip', 2), #5
('skip', 0), ('conv_5x5_p', 5), ('skip', 1), ('skip', 2), #6
('skip', 0), ('conv_5x5_p', 5), ('skip', 1), ('skip', 2), #7
],
normal_concat=range(4, 8)
)
t2=Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), ('conv_5x5_p', 3), #4
('skip', 0), ('conv_5x5_n', 4), ('skip', 1),('skip', 2),#5
('conv_5x5_p', 4), ('conv_3x3_n', 5), ('skip', 1),('skip', 2), #6
],
normal_concat=range(4, 7)
)
t4=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), ('conv_5x5_p', 3), #4
('conv_5x5_p', 0), ('skip', 1),('conv_5x5_n', 4), ('skip', 3), #5
('skip', 0), ('conv_5x5_p', 3), ('conv_5x5_n', 4), ('skip', 2),#6
],
normal_concat=range(4, 7)
)
t3=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_3x3_p', 2), ('conv_3x3_p', 3),#4
('skip', 0), ('skip', 2),('skip', 1), ('skip', 3),('conv_3x3_p', 4),#5
('skip', 0), ('conv_5x5_p', 4), ('skip', 1),('skip', 2), #6
('conv_3x3_n_back', 4),#5
('skip_back', 4),#6
],
normal_concat=range(4, 7)
)
t5=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2),('conv_5x5_p', 3),#4
('skip', 0),('skip', 1), ('skip', 2), ('conv_5x5_n', 4), #5
('skip', 0),('skip', 1), ('conv_5x5_n', 4),('conv_5x5_n', 5), #6
('skip', 0),('skip', 1), ('conv_5x5_n', 4),('conv_5x5_n', 5), #7
('conv_3x3_n_back', 4),#5
('skip_back', 4),#6
('skip_back', 5),#7
],
normal_concat=range(4, 8)
)
================================================
FILE: examples/Structure_Evolution/EB-NAS/nsganet.py
================================================
import numpy as np
from pymoo.algorithms.genetic_algorithm import GeneticAlgorithm
from pymoo.docs import parse_doc_string
from pymoo.model.individual import Individual
from pymoo.model.survival import Survival
from pymoo.operators.crossover.point_crossover import PointCrossover
from pymoo.operators.mutation.polynomial_mutation import PolynomialMutation
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.selection.tournament_selection import compare, TournamentSelection
from pymoo.util.display import disp_multi_objective
from pymoo.util.dominator import Dominator
from pymoo.util.non_dominated_sorting import NonDominatedSorting
from pymoo.util.randomized_argsort import randomized_argsort
# =========================================================================================================
# Implementation
# based on nsga2 from https://github.com/msu-coinlab/pymoo
# =========================================================================================================
class NSGANet(GeneticAlgorithm):
def __init__(self, **kwargs):
kwargs['individual'] = Individual(rank=np.inf, crowding=-1)
super().__init__(**kwargs)
self.tournament_type = 'comp_by_dom_and_crowding'
self.func_display_attrs = disp_multi_objective
# ---------------------------------------------------------------------------------------------------------
# Binary Tournament Selection Function
# ---------------------------------------------------------------------------------------------------------
def binary_tournament(pop, P, algorithm, **kwargs):
if P.shape[1] != 2:
raise ValueError("Only implemented for binary tournament!")
tournament_type = algorithm.tournament_type
S = np.full(P.shape[0], np.nan)
for i in range(P.shape[0]):
a, b = P[i, 0], P[i, 1]
# if at least one solution is infeasible
if pop[a].CV > 0.0 or pop[b].CV > 0.0:
S[i] = compare(a, pop[a].CV, b, pop[b].CV, method='smaller_is_better', return_random_if_equal=True)
# both solutions are feasible
else:
if tournament_type == 'comp_by_dom_and_crowding':
rel = Dominator.get_relation(pop[a].F, pop[b].F)
if rel == 1:
S[i] = a
elif rel == -1:
S[i] = b
elif tournament_type == 'comp_by_rank_and_crowding':
S[i] = compare(a, pop[a].rank, b, pop[b].rank,
method='smaller_is_better')
else:
raise Exception("Unknown tournament type.")
# if rank or domination relation didn't make a decision compare by crowding
if np.isnan(S[i]):
S[i] = compare(a, pop[a].get("crowding"), b, pop[b].get("crowding"),
method='larger_is_better', return_random_if_equal=True)
return S[:, None].astype(np.int)
# ---------------------------------------------------------------------------------------------------------
# Survival Selection
# ---------------------------------------------------------------------------------------------------------
class RankAndCrowdingSurvival(Survival):
def __init__(self) -> None:
super().__init__(True)
def _do(self, pop, n_survive, D=None, **kwargs):
# get the objective space values and objects
F = pop.get("F")
# the final indices of surviving individuals
survivors = []
# do the non-dominated sorting until splitting front
fronts = NonDominatedSorting().do(F, n_stop_if_ranked=n_survive)
for k, front in enumerate(fronts):
# calculate the crowding distance of the front
crowding_of_front = calc_crowding_distance(F[front, :])
# save rank and crowding in the individual class
for j, i in enumerate(front):
pop[i].set("rank", k)
pop[i].set("crowding", crowding_of_front[j])
# current front sorted by crowding distance if splitting
if len(survivors) + len(front) > n_survive:
I = randomized_argsort(crowding_of_front, order='descending', method='numpy')
I = I[:(n_survive - len(survivors))]
# otherwise take the whole front unsorted
else:
I = np.arange(len(front))
# extend the survivors by all or selected individuals
survivors.extend(front[I])
return pop[survivors]
def calc_crowding_distance(F):
infinity = 1e+14
n_points = F.shape[0]
n_obj = F.shape[1]
if n_points <= 2:
return np.full(n_points, infinity)
else:
# sort each column and get index
I = np.argsort(F, axis=0, kind='mergesort')
# now really sort the whole array
F = F[I, np.arange(n_obj)]
# get the distance to the last element in sorted list and replace zeros with actual values
dist = np.concatenate([F, np.full((1, n_obj), np.inf)]) \
- np.concatenate([np.full((1, n_obj), -np.inf), F])
index_dist_is_zero = np.where(dist == 0)
dist_to_last = np.copy(dist)
for i, j in zip(*index_dist_is_zero):
dist_to_last[i, j] = dist_to_last[i - 1, j]
dist_to_next = np.copy(dist)
for i, j in reversed(list(zip(*index_dist_is_zero))):
dist_to_next[i, j] = dist_to_next[i + 1, j]
# normalize all the distances
norm = np.max(F, axis=0) - np.min(F, axis=0)
norm[norm == 0] = np.nan
dist_to_last, dist_to_next = dist_to_last[:-1] / norm, dist_to_next[1:] / norm
# if we divided by zero because all values in one columns are equal replace by none
dist_to_last[np.isnan(dist_to_last)] = 0.0
dist_to_next[np.isnan(dist_to_next)] = 0.0
# sum up the distance to next and last and norm by objectives - also reorder from sorted list
J = np.argsort(I, axis=0)
crowding = np.sum(dist_to_last[J, np.arange(n_obj)] + dist_to_next[J, np.arange(n_obj)], axis=1) / n_obj
# replace infinity with a large number
crowding[np.isinf(crowding)] = infinity
return crowding
# =========================================================================================================
# Interface
# =========================================================================================================
def nsganet(
pop_size=100,
sampling=RandomSampling(var_type=np.int),
selection=TournamentSelection(func_comp=binary_tournament),
crossover=PointCrossover(n_points=2),
mutation=PolynomialMutation(eta=3, var_type=np.int),
eliminate_duplicates=True,
n_offsprings=None,
**kwargs):
"""
Parameters
----------
pop_size : {pop_size}
sampling : {sampling}
selection : {selection}
crossover : {crossover}
mutation : {mutation}
eliminate_duplicates : {eliminate_duplicates}
n_offsprings : {n_offsprings}
Returns
-------
nsganet : :class:`~pymoo.model.algorithm.Algorithm`
Returns an NSGANet algorithm object.
"""
return NSGANet(pop_size=pop_size,
sampling=sampling,
selection=selection,
crossover=crossover,
mutation=mutation,
survival=RankAndCrowdingSurvival(),
eliminate_duplicates=eliminate_duplicates,
n_offsprings=n_offsprings,
**kwargs)
parse_doc_string(nsganet)
================================================
FILE: examples/Structure_Evolution/EB-NAS/operations.py
================================================
import numpy as np
import torch
import torch.nn as nn
from torch.nn import *
import torch.nn.functional as F
from torch import einsum
from einops import rearrange
# from braincog.model_zoo.base_module import DeformConvPack
from braincog.model_zoo.base_module import BaseLinearModule
# from mmcv.ops import ModulatedDeformConv2dPack
def si_relu(x, positive):
if positive == 1:
return torch.where(x > 0., x, torch.zeros_like(x))
elif positive == 0:
return x
elif positive == -1:
return torch.where(x < 0., x, torch.zeros_like(x))
else:
raise ValueError
class SiReLU(nn.Module):
def __init__(self, positive=0):
super().__init__()
self.positive = positive
def forward(self, x):
return si_relu(x, self.positive)
def weight_init(m):
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal(m.weight.data, gain=0.1)
torch.nn.init.constant(m.bias.data, 0.)
OPS_Mlp = {
'mlp': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=0),
'mlp_p': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=1),
'mlp_n': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=-1),
'skip_connect': lambda C, act_fun:
Identity(positive=0),
'skip_connect_p': lambda C, act_fun:
Identity(positive=1),
'skip_connect_n': lambda C, act_fun:
Identity(positive=-1),
}
OPS = {
'avg_pool_3x3': lambda C, stride, affine, act_fun: nn.AvgPool2d(3, stride=stride, padding=1,
count_include_pad=False),
'conv_3x3': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=0),
'conv_5x5': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=0),
'max_pool_3x3': lambda C, stride, affine, act_fun: nn.MaxPool2d(3, stride=stride, padding=1),
'skip_connect': lambda C, stride, affine, act_fun:
Identity(positive=0) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun),
'sep_conv_3x3': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=0),
'sep_conv_5x5': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=0),
'sep_conv_7x7': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=0),
'dil_conv_3x3': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=0),
'dil_conv_5x5': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=0),
'def_conv_3x3': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=0),
'def_conv_5x5': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=0),
'avg_pool_3x3_p': lambda C, stride, affine, act_fun: nn.Sequential(
nn.AvgPool2d(3, stride=stride, padding=1, count_include_pad=False),
SiReLU(positive=1)
),
'max_pool_3x3_p': lambda C, stride, affine, act_fun: nn.Sequential(
nn.MaxPool2d(3, stride=stride, padding=1),
SiReLU(positive=1)
),
'conv_3x3_p': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=1),
'conv_5x5_p': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=1),
'skip_connect_p': lambda C, stride, affine, act_fun:
Identity(positive=1) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_3x3_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_5x5_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_7x7_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=1),
'dil_conv_3x3_p': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=1),
'dil_conv_5x5_p': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=1),
'def_conv_3x3_p': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=1),
'def_conv_5x5_p': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=1),
'avg_pool_3x3_n': lambda C, stride, affine, act_fun: nn.Sequential(
nn.AvgPool2d(3, stride=stride, padding=1, count_include_pad=False),
SiReLU(positive=-1)
),
'max_pool_3x3_n': lambda C, stride, affine, act_fun: nn.Sequential(
nn.MaxPool2d(3, stride=stride, padding=1),
SiReLU(positive=-1)
),
'conv_3x3_n': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=-1),
'conv_5x5_n': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=-1),
'skip_connect_n': lambda C, stride, affine, act_fun:
Identity(positive=-1) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_3x3_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_5x5_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_7x7_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=-1),
'dil_conv_3x3_n': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=-1),
'dil_conv_5x5_n': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=-1),
'def_conv_3x3_n': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=-1),
'def_conv_5x5_n': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=-1),
'conv_7x1_1x7': lambda C, stride, affine, act_fun: nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C, C, (1, 7), stride=(1, stride),
padding=(0, 3), bias=False),
nn.Conv2d(C, C, (7, 1), stride=(stride, 1),
padding=(3, 0), bias=False),
nn.BatchNorm2d(C, affine=affine)
),
'skip': lambda C, stride, affine, act_fun:
Zero(stride) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=1),
'transformer': lambda C, stride, affine, act_fun:
FactorizedReduce(
C, C, affine=affine, act_fun=act_fun) if stride != 1 else TransformerEncoderLayer(C),
}
class SiMLP(nn.Module):
def __init__(self, c_in, c_out, act_fun=nn.ReLU, positive=0, *args, **kwargs):
super(SiMLP, self).__init__()
self.op = nn.Sequential(
nn.Linear(c_in, c_out, bias=True),
act_fun()
)
self.positive = positive
def forward(self, x):
out = self.op(si_relu(x, self.positive))
return out
class DilConv(nn.Module):
"""
Dilation Convolution : ReLU -> DilConv -> Conv2d -> BatchNorm2d
"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, dilation, affine=True, act_fun=nn.ReLU, positive=0):
super(DilConv, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation,
groups=C_in, bias=False),
nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=affine),
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class SepConv(nn.Module):
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
super(SepConv, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size,
stride=stride, padding=padding, groups=C_in, bias=False),
nn.Conv2d(C_in, C_in, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_in, affine=affine),
nn.ReLU(inplace=False),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size,
stride=1, padding=padding, groups=C_in, bias=False),
nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=affine),
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class Identity(nn.Module):
def __init__(self, positive=0):
super(Identity, self).__init__()
self.positive = positive
def forward(self, x):
return si_relu(x, self.positive)
class Zero(nn.Module):
def __init__(self, stride):
super(Zero, self).__init__()
self.stride = stride
def forward(self, x):
if self.stride == 1:
return x.mul(0.)
return x[:, :, ::self.stride, ::self.stride].mul(0.) # N * C * W * H
class FactorizedReduce(nn.Module):
def __init__(self, C_in, C_out, affine=True, act_fun=nn.ReLU, positive=0):
super(FactorizedReduce, self).__init__()
assert C_out % 2 == 0
# self.relu = nn.ReLU(inplace=False)
self.activation = act_fun()
self.conv_1 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.conv_2 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.bn = nn.BatchNorm2d(C_out, affine=affine)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
# x = self.relu(x)
x = self.activation(x)
out = torch.cat([self.conv_1(x), self.conv_2(x[:, :, 1:, 1:])], dim=1)
out = self.bn(out)
out = si_relu(out, self.positive)
return out
class F0(nn.Module):
def __init__(self, C_in, C_out, affine=True, act_fun=nn.ReLU, positive=0):
super(F0, self).__init__()
assert C_out % 2 == 0
# self.relu = nn.ReLU(inplace=False)
self.activation = act_fun()
self.op=nn.Conv2d(C_out, C_out, 3, stride=2, padding=1, bias=False)
self.conv_1 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.conv_2 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.bn = nn.BatchNorm2d(C_out, affine=affine)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
# x = self.relu(x)
x = self.activation(x)
out = torch.cat([self.conv_1(x), self.conv_2(x[:, :, 1:, 1:])], dim=1)
out = self.bn(out)
out = si_relu(out, self.positive)
out=self.op(out)
return out
class F1(nn.Module):
def __init__(self, C_in, C_out, affine=True, act_fun=nn.ReLU, positive=0):
super(F1, self).__init__()
assert C_out % 2 == 0
# self.relu = nn.ReLU(inplace=False)
self.activation = act_fun()
self.op=nn.Conv2d(C_out, C_out, 3, stride=2, padding=1, bias=False)
self.conv_1 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.conv_2 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.bn = nn.BatchNorm2d(C_out, affine=affine)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
# x = self.relu(x)
x = self.activation(x)
out = torch.cat([self.conv_1(x), self.conv_2(x[:, :, 1:, 1:])], dim=1)
out = self.bn(out)
out = si_relu(out, self.positive)
out=self.op(out)
return out
class ReLUConvBN(nn.Module):
"""
ReLu -> Conv2d -> BatchNorm2d
"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
super(ReLUConvBN, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_out, kernel_size, stride=stride,
padding=padding, bias=False),
nn.BatchNorm2d(C_out, affine=affine)
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
# class DeformConv(nn.Module):
# def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
# super(DeformConv, self).__init__()
# self.op = nn.Sequential(
# # nn.ReLU(inplace=False),
# act_fun(),
# DeformConvPack(C_in, C_out, kernel_size=kernel_size,
# stride=stride, padding=padding, bias=True),
# nn.BatchNorm2d(C_out, affine=affine)
# )
# self.positive = positive
# # if positive == -1:
# # weight_init(self.op)
# def forward(self, x):
# out = self.op(x)
# return si_relu(out, self.positive)
class Attention(Module):
"""
Obtained from: github.com:rwightman/pytorch-image-models
"""
def __init__(self, dim, num_heads=4, attention_dropout=0.1, projection_dropout=0.1):
super().__init__()
self.num_heads = num_heads
head_dim = dim // self.num_heads
self.scale = head_dim ** -0.5
self.qkv = Linear(dim, dim * 3, bias=False)
self.attn_drop = Dropout(attention_dropout)
self.proj = Linear(dim, dim)
self.proj_drop = Dropout(projection_dropout)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C //
self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class TransformerEncoderLayer(Module):
"""
Inspired by torch.nn.TransformerEncoderLayer and
rwightman's timm package.
"""
def __init__(self, d_model, nhead=4, dim_feedforward=256, dropout=0.1,
attention_dropout=0.1, drop_path_rate=0.1):
super(TransformerEncoderLayer, self).__init__()
self.pre_norm = LayerNorm(d_model)
self.self_attn = Attention(dim=d_model, num_heads=nhead,
attention_dropout=attention_dropout, projection_dropout=dropout)
dim_feedforward = d_model
self.linear1 = Linear(d_model, dim_feedforward)
self.dropout1 = Dropout(dropout)
self.norm1 = LayerNorm(d_model)
self.linear2 = Linear(dim_feedforward, d_model)
self.dropout2 = Dropout(dropout)
self.drop_path = DropPath(
drop_path_rate) if drop_path_rate > 0 else Identity()
self.activation = F.gelu
def forward(self, src: torch.Tensor, *args, **kwargs) -> torch.Tensor:
# print(src.shape)
c = src.shape[-1]
src = rearrange(src, 'b d r c -> b (r c) d')
# print(src.shape)
src = src + self.drop_path(self.self_attn(self.pre_norm(src)))
src = self.norm1(src)
src2 = self.linear2(self.dropout1(self.activation(self.linear1(src))))
src = src + self.drop_path(self.dropout2(src2))
src = rearrange(src, 'b (r c) d -> b d r c', c=c)
return src
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""
Obtained from: github.com:rwightman/pytorch-image-models
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
# work with diff dim tensors, not just 2D ConvNets
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + \
torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(Module):
"""
Obtained from: github.com:rwightman/pytorch-image-models
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
================================================
FILE: examples/Structure_Evolution/EB-NAS/readme.md
================================================
# Brain-Inspired Evolutionary Architectures for Spiking Neural Networks —— Based on BrainCog #
## Requirments ##
* numpy
* pytorch >= 1.12.0
* pymoo = 0.4.0
* BrainCog
## Run ##
```python ebnas.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{pan2024brain,
title={Brain-inspired Evolutionary Architectures for Spiking Neural Networks},
author={Pan, Wenxuan and Zhao, Feifei and Zhao, Zhuoya and Zeng, Yi},
journal={IEEE Transactions on Artificial Intelligence},
year={2024},
publisher={IEEE}
}
@article{zeng2023braincog,
title={BrainCog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired AI and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier}
}
```
================================================
FILE: examples/Structure_Evolution/EB-NAS/single_genome.py
================================================
import os
import json
import shutil
import argparse
import subprocess
import numpy as np
import torch
from tm import get_net_info
import micro_encoding
import logging
import yaml
from braincog.utils import save_feature_map, setup_seed
from tm import train_motifs
from datetime import datetime
from timm.utils import *
from pymoo.optimize import minimize
from pymoo.model.problem import Problem
from pymoo.factory import get_performance_indicator
from pymoo.algorithms.so_genetic_algorithm import GA
from pymoo.util.nds.non_dominated_sorting import NonDominatedSorting
from pymoo.factory import get_algorithm, get_crossover, get_mutation
from search_space.ofa import OFASearchSpace
from acc_predictor.factory import get_acc_predictor
_DEBUG = True
if _DEBUG: from pymoo.visualization.scatter import Scatter
devices=[0]
os.environ['CUDA_VISIBLE_DEVICES']='3'
_logger = logging.getLogger('')
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--ocrate', type=float, default=0.0)
parser.add_argument('--dataset', type=str, default='dvsg',
help='imagenet, cifar10, cifar100, dvsg, dvsc10')
parser.add_argument('--step', type=int, default=8, help='Simulation time step (default: 10)')
parser.add_argument('--num-classes', type=int, default=11, metavar='N')
parser.add_argument('--layers', type=int, default=2)
parser.add_argument('--bits', type=int, default=20)
parser.add_argument('--eval_epochs', type=int, default=6000)
parser.add_argument('--trainning_epochs', type=int, default=600)
parser.add_argument('--iterations', type=int, default=20,
help='number of search iterations')
parser.add_argument('--n_doe', type=int, default=100,
help='initial sample size for DOE')
parser.add_argument('--bns', action='store_true', default=True)
parser.add_argument('--init-channels', type=int, default=16)
parser.add_argument('--spike-rate', action='store_true', default=False)
parser.add_argument('--save', type=str, default='',
help='location of dir to save')
parser.add_argument('--sec_obj', type=str, default='flops',
help='second objective to optimize simultaneously')
parser.add_argument('--n_iter', type=int, default=8,
help='number of architectures to high-fidelity eval (low level) in each iteration')
parser.add_argument('--predictor', type=str, default='rbf',
help='which accuracy predictor model to fit (rbf/gp/carts/mlp/as)')
parser.add_argument('--n_gpus', type=int, default=len(devices),
help='total number of available gpus')
parser.add_argument('--gpu', type=int, default=1,
help='number of gpus per evaluation job')
parser.add_argument('--supernet_path', type=str, default='./ofa_mbv3_d234_e346_k357_w1.0',
help='file path to supernet weights')
parser.add_argument('--n_workers', type=int, default=1,
help='number of workers for dataloader per evaluation job')
parser.add_argument('--vld_size', type=int, default=5000,
help='validation set size, randomly sampled from training set')
parser.add_argument('--trn_batch_size', type=int, default=128,
help='train batch size for training')
parser.add_argument('--vld_batch_size', type=int, default=200,
help='test batch size for inference')
parser.add_argument('--cooldown-epochs', type=int, default=0, metavar='N',help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--test', action='store_true', default=False,
help='evaluation performance on testing set')
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser.add_argument('--model', default='NetworkCIFAR_', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.8,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=1.0,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=1.0,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=len(devices),
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=devices[0])
# Spike parameters
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='QGateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
# DARTS parameters
parser.add_argument('--auxiliary', action='store_true', default=False, help='use auxiliary tower')
parser.add_argument('--parse_method', default='darts', type=str)
parser.add_argument('--drop_path_prob', type=float, default=0.2, help='drop path probability')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
def _parse_args():
args_config, remaining = config_parser.parse_known_args()
args = parser.parse_args(remaining)
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
if __name__ == '__main__':
args, args_text = _parse_args()
args.no_spike_output = True
output_dir = ''
if args.bns:
from cellmodel import NetworkCIFAR_
else:
from cell123model import NetworkCIFAR_
# if 'dvs' in args.dataset:
# args.step=10
# else:
# args.step=4
if args.local_rank == 0:
output_base = args.save
exp_name = '-'.join([
datetime.now().strftime("%Y%m%d-%H%M%S"),
# args.model,
args.dataset,
str(args.layers)+'layers',
str(args.init_channels)+'channels',
str(args.step)+'steps',
# args.suffix
# str(args.img_size)
])
output_dir = get_outdir(output_base,str(args.dataset),exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
else:
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:0')
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
setup_seed(args.seed + args.rank)
defalut_lr = args.lr
arch_doe,sn,bigmotifs,ms ,glob_con= micro_encoding.sample(pops=10, layers=args.layers, bits=20)
i=0
for geno in arch_doe:
arch_dir=os.path.join('train',args.output_dir,str(i))
if os.path.exists(arch_dir) is False:
os.makedirs(arch_dir,exist_ok = True)
args.lr=defalut_lr
geno=micro_encoding.c_single(geno,layers=args.layers,bits=args.bits)
acc,info=train_motifs(args=args,gen=0,arch_dir=arch_dir,genome=np.array(geno[:-1]),_logger=_logger,args_text=args_text,devices=devices,ms=ms,glob=geno[-1])
i+=1
================================================
FILE: examples/Structure_Evolution/EB-NAS/tm.py
================================================
import sys
import numpy as np
import argparse
import time
import timm.models
import yaml
import os
import logging
from random import choice
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from micro_encoding import ops
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import micro_encoding
from pymop.problem import Problem
import torch
from thop import profile
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from pymoo.optimize import minimize
from timm.data import create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from torchprofile import profile_macs
import copy
import torch.backends.cudnn as cudnn
import warnings
warnings.simplefilter("ignore")
def train_motifs(args,gen,arch_dir,genome,_logger,args_text,devices,ms,glob):
if args.bns:
from cellmodel import NetworkCIFAR_
else:
from cell123model import NetworkCIFAR_
# qw=np.where(args.glob_con[0]==1)
# ccc=np.array([1,0,0,0])
# for i in qw:
# ccc[i[0]]=1
# ddd=np.where(args.glob_con[i[0]]==1)
# if len(ddd[0])!=0:
# for j in ddd:
# ccc[j[0]]=1
# www=np.where(args.glob_con[j[0]]==1)
# if len(www[0])!=0:
# for k in www:
# ccc[k[0]]=1
test_motifs,ids = micro_encoding.decode_motif(args.layers*ms,args.bits,genome.astype(int))
# if gen==-1:
args.epochs=args.eval_epochs
# else:
# args.epochs=args.eval_epochs
try:
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
C=args.init_channels,
layers=args.layers*ms,
auxiliary=args.auxiliary,
motif=test_motifs,
parse_method=args.parse_method,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
glob=glob,
)
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
flops=0
params=0
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
sumpram=sum([m.numel() for m in model.parameters()])
_logger.info('Model %s created, param count: %d' %
(args.model, sumpram))
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=devices).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
# print(model.get_attr('mu'))
# print(model.get_attr('sigma'))
if args.critical_loss or args.spike_rate:
if args.num_gpu>1:
model.module.set_requires_fp(True)
else:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model, device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
temporal_flatten=args.temporal_flatten,
portion=args.train_portion,
_logger=_logger,
)
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
if args.distributed:
state_dict = torch.load(args.eval_checkpoint)['state_dict_ema']
new_state_dict = OrderedDict()
# add module prefix for DDP
for k, v in state_dict.items():
k = 'module.' + k
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
# else:
# load_checkpoint(model, args.eval_checkpoint, args.model_ema)
for i in range(1):
val_metrics,_ = validate(start_epoch, model, loader_eval, validate_loss_fn, args,arch_dir,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
print(f"Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
# return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=arch_dir, recovery_dir=arch_dir, decreasing=decreasing)
with open(os.path.join(arch_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
f=open(os.path.join(arch_dir, 'direct_genome.txt'), 'a')
f.write(",".join(str(k) for k in genome))
f.write('\n')
f.close()
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
if args.distributed:
loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,_logger=_logger,
lr_scheduler=lr_scheduler, saver=saver, output_dir=arch_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler, model_ema=model_ema, mixup_fn=mixup_fn)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics,_ = validate(epoch, model, loader_eval, validate_loss_fn, args, arch_dir,amp_autocast=amp_autocast,_logger=_logger,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics,_ = validate(
epoch, model_ema.ema, loader_eval, validate_loss_fn, args, arch_dir,amp_autocast=amp_autocast, log_suffix=' (EMA)',_logger=_logger,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(arch_dir, 'summary.csv'),
write_header=best_metric is None)
# if saver is not None and epoch >= args.n_warm_up:
if saver is not None:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
best_metric, best_epoch = eval_metrics[eval_metric],epoch
_logger.info('Train: {0} '.format(best_metric))
f=open(os.path.join(arch_dir, 'direct.txt'), 'a')
f.write(str(best_metric))
f.write('\n')
f.close()
except KeyboardInterrupt:
pass
except MemoryError:
return -10000, 0
except RuntimeError:
# return -10000, {'flops': flops / 1e6, 'param': params / 1e6}
return -10000, 0
# if best_metric is not None:
# _logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
# info=get_net_info(model)
val_metrics,spikes = validate(start_epoch, model, loader_eval, validate_loss_fn, args,arch_dir,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat,_logger=_logger,)
return best_metric,spikes
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,_logger,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and loader.mixup_enabled:
loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
model.drop_path_prob = args.drop_path_prob * epoch / args.epochs
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
# t, k = adjust_surrogate_coeff(100, args.epochs)
# model.set_attr('t', t)
# model.set_attr('k', k)
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
if not args.prefetcher or args.dataset != 'imnet':
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
if mixup_fn is not None:
inputs, target = mixup_fn(inputs, target)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
with amp_autocast():
output = model(inputs)
loss = loss_fn(output, target)
if not (args.cut_mix | args.mix_up | args.event_mix) and args.dataset != 'imnet':
# print(output.shape, target.shape)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
closs = torch.tensor([0.], device=loss.device)
if args.critical_loss:
closs = calc_critical_loss(model)
loss = loss + .1 * closs
spike_rate_avg_layer_str = ''
threshold_str = ''
if not args.distributed:
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
top5_m.update(acc5.item(), inputs.size(0))
closses_m.update(closs.item(), inputs.size(0))
if args.num_gpu>1:
spike_rate_avg_layer = model.module.get_fire_rate().tolist()
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
threshold = model.module.get_threshold()
else:
spike_rate_avg_layer = model.get_fire_rate().tolist()
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
if args.opt == 'lamb':
optimizer.step(epoch=epoch)
else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
losses_m.update(reduced_loss.item(), inputs.size(0))
closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
if args.distributed:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
else:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})\n'
'Fire_rate: {spike_rate}\n'
# 'Thres: {threshold}\n'
# 'Mu: {mu_str}\n'
# 'Sigma: {sigma_str}\n'
.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m,
spike_rate=spike_rate_avg_layer_str,
# threshold=threshold_str,
# mu_str=mu_str,
# sigma_str=sigma_str
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args, arch_dir,_logger,amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
end = time.time()
last_idx = len(loader) - 1
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat) and not args.critical_loss:
if args.num_gpu>1:
model.module.set_requires_fp(True)
else:
model.set_requires_fp(True)
# if not args.critical_loss:
# model.set_requires_fp(False)
with amp_autocast():
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
if not args.distributed:
if visualize:
x = model.get_fp()
feature_path = os.path.join(arch_dir, 'feature_map')
if os.path.exists(feature_path) is False:
os.mkdir(feature_path)
save_feature_map(x, feature_path)
# if not args.critical_loss:
# model_config.set_requires_fp(False)
if tsne:
x = model.get_fp(temporal_info=False)[-1]
x = torch.nn.AdaptiveAvgPool2d((1, 1))(x)
x = x.reshape(x.shape[0], -1)
feature_vec.append(x)
feature_cls.append(target)
if conf_mat:
logits_vec.append(output)
labels_vec.append(target)
if spike_rate:
if args.num_gpu>1:
avg, var, spike, avg_per_step = model.module.get_spike_info()
else:
avg, var, spike, avg_per_step = model.get_spike_info()
save_spike_info(
os.path.join(arch_dir, 'spike_info.csv'),
epoch, batch_idx,
args.step, avg, var,
spike, avg_per_step)
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
loss = loss_fn(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
closs = torch.tensor([0.], device=loss.device)
if not args.distributed:
if args.num_gpu>1:
spike_rate_avg_layer = model.module.get_fire_rate().tolist()
threshold = model.module.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
tot_spike = model.module.get_tot_spike()
else:
spike_rate_avg_layer = model.get_fire_rate().tolist()
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
tot_spike = model.get_tot_spike()
if args.critical_loss:
closs = calc_critical_loss(model)
loss = loss + .1 * closs
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
closses_m.update(closs.item(), inputs.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
))
else:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})\n'
'Fire_rate: {spike_rate}\n'
'Tot_spike: {tot_spike}\n'
'Thres: {threshold}\n'
'Mu: {mu_str}\n'
'Sigma: {sigma_str}\n'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
spike_rate=spike_rate_avg_layer_str,
tot_spike=tot_spike,
threshold=threshold_str,
mu_str=mu_str,
sigma_str=sigma_str
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg)])
if not args.distributed:
if tsne:
feature_vec = torch.cat(feature_vec)
feature_cls = torch.cat(feature_cls)
plot_tsne(feature_vec, feature_cls, os.path.join(arch_dir, 't-sne-2d.eps'))
plot_tsne_3d(feature_vec, feature_cls, os.path.join(arch_dir, 't-sne-3d.eps'))
if conf_mat:
logits_vec = torch.cat(logits_vec)
labels_vec = torch.cat(labels_vec)
plot_confusion_matrix(logits_vec, labels_vec, os.path.join(arch_dir, 'confusion_matrix.eps'))
return metrics,tot_spike
def get_net_info(args, gen,genome,ms):
"""
Modified from https://github.com/mit-han-lab/once-for-all/blob/
35ddcb9ca30905829480770a6a282d49685aa282/ofa/imagenet_codebase/utils/pytorch_utils.py#L139
"""
from ofa.imagenet_codebase.utils.pytorch_utils import count_parameters, measure_net_latency
# artificial input data
if args.bns:
from cellmodel import NetworkCIFAR
else:
from cell123model import NetworkCIFAR
test_motifs,ids = micro_encoding.decode_motif(args.layers*ms,args.bits,genome.astype(int))
net = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
C=args.init_channels,
layers=args.layers*ms,
auxiliary=args.auxiliary,
motif=test_motifs,
parse_method=args.parse_method,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
cell_type=genome[-1],
)
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
inputs = torch.randn(1, args.channels, 224, 224)
# move network to GPU if available
if torch.cuda.is_available():
device = torch.device('cuda:0')
net = net.to(device)
cudnn.benchmark = True
inputs = inputs.to(device)
net_info = {}
if isinstance(net, nn.DataParallel):
net = net.module
# parameters
net_info['params'] = count_parameters(net)
# flops
net_info['flops'] = int(profile_macs(copy.deepcopy(net), inputs))
return net_info
================================================
FILE: examples/Structure_Evolution/ELSM/README.md
================================================
# Emergence of Brain-inspired Small-world Spiking Neural Network through Neuroevolution —— Based on BrainCog #
## Requirments ##
* numpy
* pytorch >= 1.12.0
* BrainCog
## Run ##
```python evolve.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{pan2024emergence,
title={Emergence of Brain-inspired Small-world Spiking Neural Network through Neuroevolution},
author={Pan, Wenxuan and Zhao, Feifei and Han, Bing and Dong, Yiting and Zeng, Yi},
journal={iScience},
year={2024},
publisher={Elsevier}
}
@article{zeng2023braincog,
title={BrainCog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired AI and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier}
}
```
================================================
FILE: examples/Structure_Evolution/ELSM/evolve.py
================================================
import time
import threading
from threading import Thread
import os
import networkx as nx
import numpy as np
from population import *
import nsganet as engine
from pymop.problem import Problem
from pymoo.optimize import minimize
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
import logging
from model import *
from spikes import calc_f2
from multiprocessing import Process,Pool
from datetime import datetime
import time
_logger = logging.getLogger('')
config_parser = parser = argparse.ArgumentParser(description='Evolution Config', add_help=False)
parser = argparse.ArgumentParser(description='SNN Evoving')
parser.add_argument('--device', type=int, default=2)
parser.add_argument('--seed', type=int, default=68, metavar='S')
parser.add_argument('--datapath', default='/data/', type=str, metavar='PATH')
parser.add_argument('--output', default='/data/LSM/Eresult/new', type=str, metavar='PATH')
parser.add_argument('--liquid-size', type=int, default=8000)
parser.add_argument('--pop-size', type=int, default=20)
parser.add_argument('--up', type=int, default=32000000)
parser.add_argument('--low', type=int, default=320000)
parser.add_argument('--n_offspring', type=int, default=200)
parser.add_argument('--n_gens', type=int, default=2000)
parser.add_argument('--arand', type=float, default=285)
parser.add_argument('--brand', type=float, default=1.8)
def _parse_args():
args_config, remaining = config_parser.parse_known_args()
args = parser.parse_args(remaining)
return args
def calc_f1(dirs):
ci=[]
G=nx.read_gpickle(dirs)
largest_component = max(nx.connected_components(G), key=len)
G = G.subgraph(largest_component)
for u in G.nodes:
ci.append(nx.clustering(G,u))
a=sum(ci)
print("start")
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
path=nx.average_shortest_path_length(G)
print("end")
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
return a,path
def mul_f1(pop,steps,rootdir):
result=[]
for i in range(0,pop,steps):
p = Pool(steps)
dirs=[os.path.join(rootdir,str(i)+'.pkl') for i in range(i,i+steps)]
ret = p.map(calc_f1,dirs)
result.extend(ret)
print(ret)
p.close()
p.join()
return result
class Evolve(Problem):
# first define the NAS problem (inherit from pymop)
def __init__(self, args,n_var=20, n_obj=1, n_constr=0, lb=None, ub=None):
super().__init__(n_var=n_var, n_obj=n_obj, n_constr=n_constr, type_var=np.int64)
self.xl = lb
self.xu = ub
self._n_evaluated = 0 # keep track of how many architectures are sampled
self.args=args
def _evaluate(self, x, out, *args, **kwargs):
objs = np.full((x.shape[0], self.n_obj), np.nan)
g1 = np.full((x.shape[0]), np.nan)
g2 = np.full((x.shape[0]), np.nan)
gen_dir=os.path.join(self.args.output,'generaion'+str(kwargs['algorithm'].n_gen))
os.makedirs(gen_dir,exist_ok = True)
# np.save(os.path.join(gen_dir,"x.npy"),x)
lsms = x.reshape(x.shape[0],self.args.liquid_size,self.args.liquid_size)
for i in range(x.shape[0]):
temp_G = nx.Graph(lsms[i])
nx.write_gpickle(temp_G, os.path.join(gen_dir,str(i)+".pkl"))
self.ob1=mul_f1(pop=x.shape[0],steps=10,rootdir=gen_dir)
for i in range(x.shape[0]):
arch_id = self._n_evaluated + 1
print('\n')
_logger.info('Network= {}'.format(arch_id))
genome = x[i, :]
g1[i]= genome.sum()-self.args.up
g2[i]= self.args.low-genome.sum()
lsmm = genome.reshape(self.args.liquid_size,self.args.liquid_size)
small_coe_a,small_coe_b=self.ob1[i]
lsmm=torch.tensor(lsmm,device='cuda:%d' % self.args.device).float()
crit = calc_f2(lsmm,'cuda:%d' % self.args.device)
objs[i, 1] = abs(crit-1)
# all objectives assume to be MINIMIZED !!!!!
objs[i, 0] = -(small_coe_a/self.args.arand)/(small_coe_b/self.args.brand)
_logger.info('small word= {}'.format(objs[i, 0]))
_logger.info('criticality= {}'.format(objs[i, 1]))
self._n_evaluated += 1
out["F"] = objs
out["G"] = np.column_stack([g1,g2])
# if your NAS problem has constraints, use the following line to set constraints
# out["G"] = np.column_stack([g1, g2, g3, g4, g5, g6]) in case 6 constraints
# ---------------------------------------------------------------------------------------------------------
# Define what statistics to print or save for each generation
# ---------------------------------------------------------------------------------------------------------
def do_every_generations(algorithm):
# this function will be call every generation
# it has access to the whole algorithm class
gen = algorithm.n_gen
pop_var = algorithm.pop.get("X")
pop_obj = algorithm.pop.get("F")
# report generation info to files
_logger.info("generation = {}".format(gen))
_logger.info("population error1: best = {}, mean = {}, "
"median1 = {}, worst1 = {}".format(np.min(pop_obj[:, 0]), np.mean(pop_obj[:, 0]),
np.median(pop_obj[:, 0]), np.max(pop_obj[:, 0])))
_logger.info('Best1 Genome id= {}'.format(np.argmin(pop_obj[:, 0])))
_logger.info("population error2: best = {}, mean = {}, "
"median2 = {}, worst2 = {}".format(np.min(pop_obj[:, 1]), np.mean(pop_obj[:, 1]),
np.median(pop_obj[:, 1]), np.max(pop_obj[:, 1])))
_logger.info('Best2 Genome id= {}'.format(np.argmin(pop_obj[:, 1])))
if gen%20==0:
best_sid=np.argmin(pop_obj[:, 0])
best_sname='-'.join([
'gen'+str(gen),
's'+str(float('%.4f' % pop_obj[best_sid, 0])),
'c'+str(float('%.4f' % pop_obj[best_sid, 1])),
])
best_cid=np.argmin(pop_obj[:, 1])
best_cname='-'.join([
'gen'+str(gen),
's'+str(float('%.4f' % pop_obj[best_cid, 0])),
'c'+str(float('%.4f' % pop_obj[best_cid, 1])),
])
np.save(os.path.join('/data/save/genome',best_sname+datetime.now().strftime("%Y%m%d-%H%M%S")),pop_var[np.argmin(pop_obj[:, 0])])
np.save(os.path.join('/data/save/genome',best_cname+datetime.now().strftime("%Y%m%d-%H%M%S")),pop_var[np.argmin(pop_obj[:, 1])])
if __name__ == '__main__':
args = _parse_args()
out_base_dir= os.path.join(args.output, datetime.now().strftime("%Y%m%d-%H%M%S"))
os.makedirs(out_base_dir,exist_ok = True)
args.output=out_base_dir
setup_default_logging(log_path=os.path.join(out_base_dir, 'log.txt'))
kkk = Evolve(args,n_var=args.liquid_size*args.liquid_size,
n_obj=2, n_constr=2)
method = engine.nsganet(pop_size=args.pop_size,
sampling=RandomSampling(var_type='custom'),
mutation=BinaryBitflipMutation(),
n_offsprings=args.n_offspring,
eliminate_duplicates=True)
kres=minimize(kkk,
method,
callback=do_every_generations,
termination=('n_gen', args.n_gens))
================================================
FILE: examples/Structure_Evolution/ELSM/lsm.py
================================================
from __future__ import print_function
import torchvision
import torchvision.transforms as transforms
import os
import time
import numpy as np
import torch
from torch import nn as nn
from mnistmodel import *
from tqdm import tqdm
import argparse
from datetime import datetime
import logging
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy
from braincog.base.utils import UnilateralMse, MixLoss
from braincog.base.learningrule.STDP import *
device='cuda:7'
def lr_scheduler(optimizer, epoch, init_lr=0.1, lr_decay_epoch=50):
"""Decay learning rate by a factor of 0.1 every lr_decay_epoch epochs."""
if epoch % lr_decay_epoch == 0 and epoch > 1:
for param_group in optimizer.param_groups:
param_group['lr'] = param_group['lr'] * 0.1
return optimizer
batch_size=100
liquid_size=8000
learning_rate = 1e-3
num_epochs = 100 # max epoch
data_path = '/data'
load_path=''
train_dataset = torchvision.datasets.MNIST(root=data_path, train=True, download=False, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=8)
test_set = torchvision.datasets.MNIST(root=data_path, train=False, download=False, transform=transforms.ToTensor())
test_loader = torch.utils.data.DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=2)
snn = SNN(ins=784,
batchsize=batch_size,
device=device,
liquid_size=liquid_size,
lsm_tau=lsm_tau,
lsm_th=lsm_th)
snn.load_state_dict(torch.load(load_path)['fc'])
snn.learning_rule=[]
snn.con[0].load_state_dict(torch.load(load_path)['lsm0'])
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False,device=device)
snn.connectivity_matrix=torch.load(load_path)['connectivity_matrix'].to(device)
w2tmp.weight.data=(torch.load(load_path)['liquid_weight'].to(device))*snn.connectivity_matrix
snn.learning_rule.append(MutliInputSTDP(snn.node_lsm(), [snn.con[0], w2tmp])) # pm
snn.eval()
snn.to(device)
class LabelSmoothingBCEWithLogitsLoss(nn.Module):
def __init__(self, smoothing=0.1):
"""
Constructor for the LabelSmoothing module.
:param smoothing: label smoothing factor
"""
super(LabelSmoothingBCEWithLogitsLoss, self).__init__()
assert smoothing < 1.0
self.smoothing = smoothing
self.confidence = 1. - smoothing
self.BCELoss = nn.BCEWithLogitsLoss()
def forward(self, x, target):
target = torch.eye(x.shape[-1], device=x.device)[target]
nll = torch.ones_like(x) / x.shape[-1]
return self.BCELoss(x, target) * self.confidence + self.BCELoss(x, nll) * self.smoothing
ls = 'mse'
if ls == 'ce':
criterion = nn.CrossEntropyLoss()
elif ls == 'bce':
criterion = nn.BCEWithLogitsLoss()
elif ls == 'mse':
criterion = UnilateralMse(1.)
elif ls == 'sce':
criterion = LabelSmoothingCrossEntropy()
elif ls == 'sbce':
criterion = LabelSmoothingBCEWithLogitsLoss()
elif ls == 'umse':
criterion = UnilateralMse(.5)
optimizer = torch.optim.AdamW(snn.fc.parameters(),lr=0.001, weight_decay=1e-4)
l=[]
best_acc=0
for epoch in range(num_epochs):
running_loss = 0
start_time = time.time()
for i, (images, labels) in enumerate(tqdm(train_loader)):
snn.zero_grad()
optimizer.zero_grad()
images = images.float().to(device)
outputs = snn(images)
labels=labels.to(device)
loss = criterion(outputs, labels)
running_loss += loss.item()
loss.backward()
optimizer.step()
snn.reset()
if (i + 1) % 100 == 0:
running_loss = 0
correct = 0
total = 0
optimizer = lr_scheduler(optimizer, epoch, learning_rate, 40)
for batch_idx, (inputs, targets) in enumerate(test_loader):
inputs = inputs.float().to(device)
snn.zero_grad()
optimizer.zero_grad()
outputs = snn(inputs)
targets=targets.to(device)
loss = criterion(outputs, targets)
_, predicted = outputs.max(1)
total += float(targets.size(0))
correct += float(predicted.eq(targets).sum().item())
snn.reset()
if batch_idx % 100 == 0:
acc = 100. * float(correct) / float(total)
print(batch_idx, len(test_loader), ' Acc: %.5f' % acc)
print('Test Accuracy: %.3f' % (100 * correct / total))
acc = 100. * float(correct) / float(total)
if best_acc < acc:
best_acc = acc
print(best_acc)
l.append(best_acc)
================================================
FILE: examples/Structure_Evolution/ELSM/model.py
================================================
from functools import partial
from torch.nn import functional as F
from torch import nn as nn
import torchvision, pprint
from copy import deepcopy
from timm.models import register_model
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.encoder.encoder import *
from braincog.model_zoo.base_module import BaseModule, BaseConvModule, BaseLinearModule
from braincog.base.brainarea.BrainArea import BrainArea
from braincog.base.connection.CustomLinear import *
from braincog.base.learningrule.STDP import *
import matplotlib.pyplot as plt
@register_model
class nSNN(BaseModule):
def __init__(self,
batchsize,
liquid_size,
device,
connectivity_matrix,
num_classes=10,
step=1,
node_type=LIFNode,
encode_type='direct',
lsm_th=0.3,
fc_th=0.3,
lsm_tau=3,
fc_tau=3,
ins=1156,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.batchsize=batchsize
self.ins=ins
self.node_lsm=partial(node_type, **kwargs, step=step,tau=lsm_tau,threshold=lsm_th)
self.node_fc = partial(node_type, **kwargs, step=step,tau=fc_tau,threshold=fc_th)
self.liquid_size=liquid_size
self.device=device
self.con=[]
self.learning_rule=[]
self.connectivity_matrix=connectivity_matrix
w1tmp=nn.Linear(ins,liquid_size,bias=False).to(device)
self.con.append(w1tmp)
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False).to(device)
self.liquid_weight=w2tmp.weight.data
w2tmp.weight.data=w2tmp.weight.data*self.connectivity_matrix
self.con.append(w2tmp)
self.learning_rule.append(MutliInputSTDP(self.node_lsm(), [self.con[0], self.con[1]])) # pm
self.fc = nn.Sequential(
nn.Linear(liquid_size,num_classes),
self.node_fc()
)
def forward(self, x):
sum_spike=0
self.out = torch.zeros(x.shape[0], self.liquid_size).to(self.device)
tw=x.shape[1]
self.tw=tw
self.firing_tw=torch.zeros(tw, self.batchsize, self.liquid_size).to(self.device)
for t in range(tw):
self.out, self.dw = self.learning_rule[0](x[:,t,:], self.out)
out_liquid=self.out[:,0:self.liquid_size]
xout = self.fc(out_liquid)
sum_spike=sum_spike+xout
self.firing_tw[t]=out_liquid
outputs = sum_spike / tw
return outputs
@register_model
class mSNN(BaseModule):
def __init__(self,
batchsize,
liquid_size,
device,
connectivity_matrix,
num_classes=10,
step=1,
node_type=LIFNode,
encode_type='direct',
lsm_th=0.3,
fc_th=0.3,
lsm_tau=3,
fc_tau=3,
tw=100,
*args,
**kwargs):
super().__init__(step, encode_type, *args, **kwargs)
self.batchsize=batchsize
self.node_lsm=partial(node_type, **kwargs, step=step,tau=lsm_tau,threshold=lsm_th)
self.node_fc = partial(node_type, **kwargs, step=step,tau=fc_tau,threshold=fc_th)
self.liquid_size=liquid_size
self.out = torch.zeros(self.batchsize, liquid_size).to(device)
self.device=device
self.con=[]
self.learning_rule=[]
self.connectivity_matrix=connectivity_matrix
w1tmp=nn.Linear(784,liquid_size,bias=False).to(device)
self.con.append(w1tmp)
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False).to(device)
self.liquid_weight=w2tmp.weight.data
w2tmp.weight.data=w2tmp.weight.data*self.connectivity_matrix
self.con.append(w2tmp)
self.learning_rule.append(MutliInputSTDP(self.node_lsm(), [self.con[0], self.con[1]])) # pm
self.fc = nn.Sequential(
nn.Linear(liquid_size,num_classes),
self.node_fc()
)
def forward(self, x):
x = x.reshape(x.shape[0], -1)
sum_spike=0
time_window=20
self.tw=time_window
self.firing_tw=torch.zeros(time_window, self.batchsize, self.liquid_size).to(self.device)
self.out = torch.zeros(self.batchsize, self.liquid_size).to(self.device)
for t in range(time_window):
self.out, self.dw = self.learning_rule[0](x, self.out)
out_liquid=self.out[:,0:self.liquid_size]
xout = self.fc(out_liquid)
sum_spike=sum_spike+xout
self.firing_tw[t]=out_liquid
# print(out_liquid.sum())
# print(xout.sum())
outputs = sum_spike / time_window
return outputs
================================================
FILE: examples/Structure_Evolution/ELSM/nsganet.py
================================================
import numpy as np
from pymoo.algorithms.genetic_algorithm import GeneticAlgorithm
from pymoo.docs import parse_doc_string
from pymoo.model.individual import Individual
from pymoo.model.survival import Survival
from pymoo.operators.crossover.point_crossover import PointCrossover
from pymoo.operators.mutation.polynomial_mutation import PolynomialMutation
from pymoo.operators.mutation.bitflip_mutation import BinaryBitflipMutation
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.selection.tournament_selection import compare, TournamentSelection
from pymoo.util.display import disp_multi_objective
from pymoo.util.dominator import Dominator
from pymoo.util.non_dominated_sorting import NonDominatedSorting
from pymoo.util.randomized_argsort import randomized_argsort
# =========================================================================================================
# Implementation
# based on nsga2 from https://github.com/msu-coinlab/pymoo
# =========================================================================================================
class NSGANet(GeneticAlgorithm):
def __init__(self, **kwargs):
kwargs['individual'] = Individual(rank=np.inf, crowding=-1)
super().__init__(**kwargs)
self.tournament_type = 'comp_by_dom_and_crowding'
self.func_display_attrs = disp_multi_objective
# ---------------------------------------------------------------------------------------------------------
# Binary Tournament Selection Function
# ---------------------------------------------------------------------------------------------------------
def binary_tournament(pop, P, algorithm, **kwargs):
if P.shape[1] != 2:
raise ValueError("Only implemented for binary tournament!")
tournament_type = algorithm.tournament_type
S = np.full(P.shape[0], np.nan)
for i in range(P.shape[0]):
a, b = P[i, 0], P[i, 1]
# if at least one solution is infeasible
if pop[a].CV > 0.0 or pop[b].CV > 0.0:
S[i] = compare(a, pop[a].CV, b, pop[b].CV, method='smaller_is_better', return_random_if_equal=True)
# both solutions are feasible
else:
if tournament_type == 'comp_by_dom_and_crowding':
rel = Dominator.get_relation(pop[a].F, pop[b].F)
if rel == 1:
S[i] = a
elif rel == -1:
S[i] = b
elif tournament_type == 'comp_by_rank_and_crowding':
S[i] = compare(a, pop[a].rank, b, pop[b].rank,
method='smaller_is_better')
else:
raise Exception("Unknown tournament type.")
# if rank or domination relation didn't make a decision compare by crowding
if np.isnan(S[i]):
S[i] = compare(a, pop[a].get("crowding"), b, pop[b].get("crowding"),
method='larger_is_better', return_random_if_equal=True)
return S[:, None].astype(np.int)
# ---------------------------------------------------------------------------------------------------------
# Survival Selection
# ---------------------------------------------------------------------------------------------------------
class RankAndCrowdingSurvival(Survival):
def __init__(self) -> None:
super().__init__(True)
def _do(self, pop, n_survive, D=None, **kwargs):
# get the objective space values and objects
F = pop.get("F")
# the final indices of surviving individuals
survivors = []
# do the non-dominated sorting until splitting front
fronts = NonDominatedSorting().do(F, n_stop_if_ranked=n_survive)
for k, front in enumerate(fronts):
# calculate the crowding distance of the front
crowding_of_front = calc_crowding_distance(F[front, :])
# save rank and crowding in the individual class
for j, i in enumerate(front):
pop[i].set("rank", k)
pop[i].set("crowding", crowding_of_front[j])
# current front sorted by crowding distance if splitting
if len(survivors) + len(front) > n_survive:
I = randomized_argsort(crowding_of_front, order='descending', method='numpy')
I = I[:(n_survive - len(survivors))]
# otherwise take the whole front unsorted
else:
I = np.arange(len(front))
# extend the survivors by all or selected individuals
survivors.extend(front[I])
return pop[survivors]
def calc_crowding_distance(F):
infinity = 1e+14
n_points = F.shape[0]
n_obj = F.shape[1]
if n_points <= 2:
return np.full(n_points, infinity)
else:
# sort each column and get index
I = np.argsort(F, axis=0, kind='mergesort')
# now really sort the whole array
F = F[I, np.arange(n_obj)]
# get the distance to the last element in sorted list and replace zeros with actual values
dist = np.concatenate([F, np.full((1, n_obj), np.inf)]) \
- np.concatenate([np.full((1, n_obj), -np.inf), F])
index_dist_is_zero = np.where(dist == 0)
dist_to_last = np.copy(dist)
for i, j in zip(*index_dist_is_zero):
dist_to_last[i, j] = dist_to_last[i - 1, j]
dist_to_next = np.copy(dist)
for i, j in reversed(list(zip(*index_dist_is_zero))):
dist_to_next[i, j] = dist_to_next[i + 1, j]
# normalize all the distances
norm = np.max(F, axis=0) - np.min(F, axis=0)
norm[norm == 0] = np.nan
dist_to_last, dist_to_next = dist_to_last[:-1] / norm, dist_to_next[1:] / norm
# if we divided by zero because all values in one columns are equal replace by none
dist_to_last[np.isnan(dist_to_last)] = 0.0
dist_to_next[np.isnan(dist_to_next)] = 0.0
# sum up the distance to next and last and norm by objectives - also reorder from sorted list
J = np.argsort(I, axis=0)
crowding = np.sum(dist_to_last[J, np.arange(n_obj)] + dist_to_next[J, np.arange(n_obj)], axis=1) / n_obj
# replace infinity with a large number
crowding[np.isinf(crowding)] = infinity
return crowding
# =========================================================================================================
# Interface
# =========================================================================================================
def nsganet(
pop_size=100,
sampling=RandomSampling(var_type=np.int),
selection=TournamentSelection(func_comp=binary_tournament),
crossover=PointCrossover(n_points=2),
mutation=PolynomialMutation(eta=3, var_type=np.int),
eliminate_duplicates=True,
n_offsprings=None,
**kwargs):
"""
Parameters
----------
pop_size : {pop_size}
sampling : {sampling}
selection : {selection}
crossover : {crossover}
mutation : {mutation}
eliminate_duplicates : {eliminate_duplicates}
n_offsprings : {n_offsprings}
Returns
-------
nsganet : :class:`~pymoo.model.algorithm.Algorithm`
Returns an NSGANet algorithm object.
"""
return NSGANet(pop_size=pop_size,
sampling=sampling,
selection=selection,
crossover=crossover,
mutation=mutation,
survival=RankAndCrowdingSurvival(),
eliminate_duplicates=eliminate_duplicates,
n_offsprings=n_offsprings,
**kwargs)
parse_doc_string(nsganet)
================================================
FILE: examples/Structure_Evolution/ELSM/spikes.py
================================================
from __future__ import print_function
import torchvision
import torchvision.transforms as transforms
import os
import numpy as np
import torch
from torch import nn as nn
from model import *
from tqdm import tqdm
import argparse
from datetime import datetime
import logging
from timm.utils import *
from spikingjelly.datasets.n_mnist import NMNIST
from timm.loss import LabelSmoothingCrossEntropy
from braincog.base.utils.criterions import *
import networkx as nx
import time
from braincog.base.learningrule.STDP import *
def randbool(size, p=0.5):
return torch.rand(*size) < p
def calc_f2(con,device):
batch_size=1
liquid_size=8000
images=torch.load('/1000images.pt')
labels=torch.load('/1000labels.pt')
load_path='970.t7'
snn = nSNN(ins=2312,
batchsize=batch_size,
device=device,
liquid_size=liquid_size,
lsm_tau=2.0,
lsm_th=0.20,
connectivity_matrix=randbool([liquid_size, liquid_size],p=0.01).to(device).int())
snn.load_state_dict(torch.load(load_path,map_location={'cuda:2':device})['fc'])
snn.con[0].load_state_dict(torch.load(load_path,map_location={'cuda:2':device})['lsm0'])
snn.to(device)
criterion = UnilateralMse(1.)
optimizer = torch.optim.AdamW(snn.fc.parameters(),lr=0.001, weight_decay=1e-4)
k=0
sbr=0
snn.connectivity_matrix=con
snn.learning_rule=[]
w2tmp=nn.Linear(liquid_size,liquid_size,bias=False,device=device)
w2tmp.weight.data=(torch.load(load_path,map_location={'cuda:2':device})['liquid_weight'])*snn.connectivity_matrix
snn.learning_rule.append(MutliInputSTDP(snn.node_lsm(), [snn.con[0], w2tmp]))
snn.eval()
for label,data in zip(labels,images):
running_loss = 0
snn.zero_grad()
optimizer.zero_grad()
data = data.to(device)
label = label.to(device)
data=data.reshape(batch_size,data.shape[0],-1)
output = snn(data)
# print(torch.argmax(output)==label)
out_liquid=snn.firing_tw.squeeze(-2)
mupost=torch.matmul(con,out_liquid.unsqueeze(-1))
mupre=torch.matmul(con.t(),out_liquid.unsqueeze(-1))
for t in range(snn.tw):
if t>5 and t 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
s = h1 + h2
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = torch.cat([states[i]
for i in self._concat], dim=1) # N,C,H, W
return outputs
# return self.node(outputs)
class EvoCell3(nn.Module):
def __init__(self,motif, C_prev_prev_prev, C_prev_prev, C_prev, C, reduction, reduction_prev, reduction_prev_prev, act_fun):
# print(C_prev_prev_prev,C_prev_prev, C_prev, C, reduction,reduction_prev, reduction_prev_prev)
super(EvoCell3, self).__init__()
self.act_fun = act_fun
self.reduction = reduction
self.motif=motif
self.back_connection=False
if reduction:
self.fun = FactorizedReduce(C_prev, C * 3, act_fun=act_fun)
self.multiplier = 3
else:
if reduction_prev:
self.preprocess1 = FactorizedReduce(C_prev_prev, C, act_fun=act_fun)
else:
self.preprocess1 = ReLUConvBN(C_prev_prev, C, 1, 1, 0, act_fun=act_fun)
if int(reduction_prev_prev)+int(reduction_prev)==1:
self.preprocess0 = FactorizedReduce(C_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev)+int(reduction_prev)==2:
self.preprocess0 = F0(C_prev_prev_prev, C, act_fun=act_fun)
else:
self.preprocess0 = ReLUConvBN(C_prev_prev_prev, C, 1, 1, 0, act_fun=act_fun)
self.preprocess2 = ReLUConvBN(C_prev, C, 1, 1, 0, act_fun=act_fun)
op_names, indices = zip(*motif.normal)
concat = motif.normal_concat
self._compile(C, op_names, indices, concat, reduction)
def _compile(self, C, op_names, indices, concat, reduction):
assert len(op_names) == len(indices)
# self._steps = len(op_names) // 2
self._concat = concat
self.multiplier = len(concat)
self._ops = nn.ModuleList()
self._ops_back = nn.ModuleList()
back_begin_index = 0
for i, (name, index) in enumerate(zip(op_names, indices)):
# print(name, index)
if '_back' in name:
self.back_connection=True
back_begin_index = i
break
stride = 2 if reduction and index < 2 else 1
op = OPS[name](C, stride, True, act_fun=self.act_fun)
self._ops += [op]
if self.back_connection:
for name, index in zip(op_names[back_begin_index:], indices[back_begin_index:]):
op = OPS[name.replace('_back', '')](
C, 1, True, act_fun=self.act_fun)
self._ops_back += [op]
if self.back_connection:
self._indices_forward = indices[:back_begin_index]
self._indices_backward = indices[back_begin_index:]
else:
self._indices_backward = []
self._indices_forward = indices
self._steps = len(self._indices_forward) // 3
def forward(self, s0, s1, s2, drop_prob):
if self.reduction:
return self.fun(s2)
s0 = self.preprocess0(s0)
s1 = self.preprocess1(s1)
s2 = self.preprocess2(s2)
states = [s0, s1, s2]
for i in range(self._steps):
i1=self._indices_forward[3 * i]
i2=self._indices_forward[3 * i + 1]
i3=self._indices_forward[3 * i + 2]
h1 = states[i1]
h2 = states[i2]
h3 = states[i3]
op1 = self._ops[3 * i]
op2 = self._ops[3 * i + 1]
op3 = self._ops[3 * i + 2]
h1 = op1(h1)
h2 = op2(h2)
h3 = op3(h3)
if self.training and drop_prob > 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
if not isinstance(op3, Identity):
h3 = drop_path(h3, drop_prob)
s = h1 + h2 + h3
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = torch.cat([states[i] for i in self._concat], dim=1) # N,C,H, W
return outputs
# return self.node(outputs)
class EvoCell4(nn.Module):
def __init__(self,motif, C_prev_prev_prev_prev,C_prev_prev_prev, C_prev_prev, C_prev, C, reduction, reduction_prev, reduction_prev_prev,reduction_prev_prev_prev, act_fun):
# print(C_prev_prev_prev_prev,C_prev_prev_prev,C_prev_prev, C_prev, C, reduction,reduction_prev, reduction_prev_prev,reduction_prev_prev_prev)
super(EvoCell4, self).__init__()
self.act_fun = act_fun
self.reduction = reduction
self.motif=motif
self.back_connection=False
if reduction:
self.fun = FactorizedReduce(C_prev, C * 3, act_fun=act_fun)
self.multiplier = 3
else:
if reduction_prev:
self.preprocess2 = FactorizedReduce(C_prev_prev, C, act_fun=act_fun)
else:
self.preprocess2 = ReLUConvBN(C_prev_prev, C, 1, 1, 0, act_fun=act_fun)
if int(reduction_prev_prev)+int(reduction_prev)==1:
self.preprocess1 = FactorizedReduce(C_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev)+int(reduction_prev)==2:
self.preprocess1 = F0(C_prev_prev_prev, C, act_fun=act_fun)
else:
self.preprocess1 = ReLUConvBN(C_prev_prev_prev, C, 1, 1, 0, act_fun=act_fun)
if int(reduction_prev_prev_prev)+int(reduction_prev_prev)+int(reduction_prev)==1:
self.preprocess0 = FactorizedReduce(C_prev_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev_prev)+int(reduction_prev_prev)+int(reduction_prev)==2:
self.preprocess0 = F0(C_prev_prev_prev_prev, C, act_fun=act_fun)
elif int(reduction_prev_prev_prev)+int(reduction_prev_prev)+int(reduction_prev)==3:
self.preprocess0 = F1(C_prev_prev_prev_prev, C, act_fun=act_fun)
else:
self.preprocess0 = ReLUConvBN(C_prev_prev_prev_prev, C, 1, 1, 0, act_fun=act_fun)
self.preprocess3 = ReLUConvBN(C_prev, C, 1, 1, 0, act_fun=act_fun)
op_names, indices = zip(*motif.normal)
# print(self.preprocess0)
# print(self.preprocess1)
# print(self.preprocess2)
# print(self.preprocess3)
concat = motif.normal_concat
self._compile(C, op_names, indices, concat, reduction)
def _compile(self, C, op_names, indices, concat, reduction):
assert len(op_names) == len(indices)
# self._steps = len(op_names) // 2
self._concat = concat
self.multiplier = len(concat)
self._ops = nn.ModuleList()
self._ops_back = nn.ModuleList()
back_begin_index = 0
for i, (name, index) in enumerate(zip(op_names, indices)):
# print(name, index)
if '_back' in name:
self.back_connection=True
back_begin_index = i
break
stride = 2 if reduction and index < 2 else 1
op = OPS[name](C, stride, True, act_fun=self.act_fun)
self._ops += [op]
if self.back_connection:
for name, index in zip(op_names[back_begin_index:], indices[back_begin_index:]):
op = OPS[name.replace('_back', '')](
C, 1, True, act_fun=self.act_fun)
self._ops_back += [op]
if self.back_connection:
self._indices_forward = indices[:back_begin_index]
self._indices_backward = indices[back_begin_index:]
else:
self._indices_backward = []
self._indices_forward = indices
self._steps = len(self._indices_forward) // 4
def forward(self, s0, s1, s2, s3, drop_prob):
if self.reduction:
return self.fun(s3)
s0 = self.preprocess0(s0)
s3 = self.preprocess3(s3)
s1 = self.preprocess1(s1)
s2 = self.preprocess2(s2)
# if s1.shape[1]!=s3.shape[1]:
# s1 = nn.Conv2d(s1.shape[1], s3.shape[1], 3, stride=2, padding=1, bias=False)
states = [s0, s1, s2,s3]
for i in range(self._steps):
i1=self._indices_forward[4 * i]
i2=self._indices_forward[4 * i + 1]
i3=self._indices_forward[4 * i + 2]
i4=self._indices_forward[4 * i + 3]
h1 = states[i1]
h2 = states[i2]
h3 = states[i3]
h4 = states[i4]
op1 = self._ops[4 * i]
op2 = self._ops[4 * i + 1]
op3 = self._ops[4 * i + 2]
op4 = self._ops[4 * i + 3]
h1 = op1(h1)
h2 = op2(h2)
h3 = op3(h3)
h4 = op4(h4)
if self.training and drop_prob > 0.:
if not isinstance(op1, Identity):
h1 = drop_path(h1, drop_prob)
if not isinstance(op2, Identity):
h2 = drop_path(h2, drop_prob)
if not isinstance(op3, Identity):
h3 = drop_path(h3, drop_prob)
if not isinstance(op4, Identity):
h4= drop_path(h4, drop_prob)
s = h1 + h2 + h3 + h4
if self.back_connection:
if i != 0:
s_back = self._ops_back[i - 1](s)
states[self._indices_backward[i - 1]] = states[self._indices_backward[i - 1]] + s_back
states += [s]
outputs = torch.cat([states[i] for i in self._concat], dim=1) # N,C,H, W
return outputs
# return self.node(outputs)
@register_model
class NetworkCIFAR(BaseModule):
def __init__(self,
C,
num_classes,
layers,
auxiliary,
motif,
cell_type,
parse_method='darts',
step=5,
node_type='ReLUNode',
**kwargs):
super(NetworkCIFAR, self).__init__(
step=step,
num_classes=num_classes,
**kwargs
)
self.node_type=node_type
if isinstance(node_type, str):
self.act_fun = eval(node_type)
else:
self.act_fun = node_type
self.act_fun = partial(self.act_fun, **kwargs)
self.spike_output = kwargs['spike_output'] if 'spike_output' in kwargs else True
self.dataset = kwargs['dataset']
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
self._layers = layers
self.cell_type = cell_type
self._auxiliary = auxiliary
self.drop_path_prob = 0
stem_multiplier = 3
C_curr = stem_multiplier * C
if self.dataset == 'dvsg' or self.dataset == 'dvsc10' or self.dataset == 'NCALTECH101':
self.stem = nn.Sequential(
nn.Conv2d(2 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
# self.reduce_idx = [
# layers // 4,
# layers // 2,
# 3 * layers // 4
# ]
self.reduce_idx = [1, 3, 5, 7]
else:
self.stem = nn.Sequential(
nn.Conv2d(1, 3 * self.init_channel_mul, 3, padding=1, bias=False),
nn.Conv2d(3 * self.init_channel_mul, C_curr, 3, padding=1, bias=False),
nn.BatchNorm2d(C_curr),
)
self.reduce_idx = [layers // 4,
layers // 2,
3 * layers // 4]
C_prev_prev_prev = C_curr
C_prev_prev_prev_prev = C_curr
C_prev_prev, C_prev, C_curr = C_curr, C_curr, C
self.cells = nn.ModuleList()
reduction_prev = False
reduction_prev_prev = False
reduction_prev_prev_prev = False
for i in range(layers):
if i in self.reduce_idx:
C_curr *= 2
reduction = True
else:
reduction = False
if cell_type==2:
# print(C_prev_prev, C_prev, C_curr)
cell = EvoCell2(motif[i], C_prev_prev, C_prev, C_curr,reduction, reduction_prev,act_fun=self.act_fun)
self.cells += [cell]
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
if cell_type==3:
cell = EvoCell3(motif[i], C_prev_prev_prev, C_prev_prev, C_prev, C_curr,reduction, reduction_prev,reduction_prev_prev,act_fun=self.act_fun)
self.cells += [cell]
C_prev_prev_prev = C_prev_prev
reduction_prev_prev = reduction_prev
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
if cell_type==4:
cell = EvoCell4(motif[i], C_prev_prev_prev_prev,C_prev_prev_prev, C_prev_prev, C_prev, C_curr,reduction, reduction_prev,reduction_prev_prev,reduction_prev_prev_prev,act_fun=self.act_fun)
self.cells += [cell]
C_prev_prev_prev_prev = C_prev_prev_prev
C_prev_prev_prev = C_prev_prev
reduction_prev_prev_prev = reduction_prev_prev
reduction_prev_prev = reduction_prev
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
reduction_prev = reduction
self.global_pooling = nn.Sequential(
self.act_fun(), nn.AdaptiveAvgPool2d(1))
if self.spike_output:
self.classifier = nn.Sequential(
nn.Linear(C_prev, 10 * num_classes),
self.act_fun())
self.vote = VotingLayer(10)
else:
self.classifier = nn.Linear(C_prev, num_classes)
self.vote = nn.Identity()
# self.classifier = nn.Linear(C_prev, num_classes)
# self.vote = nn.Identity()
def forward(self, inputs):
logits_aux = None
inputs = self.encoder(inputs)
if not self.layer_by_layer:
outputs = []
output_aux = []
self.reset()
if self.cell_type==2:
for t in range(self.step):
x = inputs[t]
s0 = s1 = self.stem(x)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
out = self.global_pooling(s1)
out = self.classifier(self.flatten(out))
logits = self.vote(out)
outputs.append(logits)
output_aux.append(logits_aux)
return sum(outputs) / len(outputs)
if self.cell_type==3:
for t in range(self.step):
x = inputs[t]
s0 = s1 = s2= self.stem(x)
for i, cell in enumerate(self.cells):
s0, s1, s2 = s1, s2, cell(s0, s1, s2, self.drop_path_prob)
out = self.global_pooling(s2)
out = self.classifier(self.flatten(out))
logits = self.vote(out)
outputs.append(logits)
output_aux.append(logits_aux)
return sum(outputs) / len(outputs)
if self.cell_type==4:
for t in range(self.step):
x = inputs[t]
s0 = s1 = s2= s3=self.stem(x)
for i, cell in enumerate(self.cells):
s0, s1, s2,s3= s1, s2, s3,cell(s0, s1, s2,s3 ,self.drop_path_prob)
out = self.global_pooling(s3)
out = self.classifier(self.flatten(out))
logits = self.vote(out)
outputs.append(logits)
output_aux.append(logits_aux)
return sum(outputs) / len(outputs)
# logits_aux if logits_aux is None else (sum(output_aux) / len(output_aux))
else:
self.reset()
if self.cell_type==2:
s0 = s1 = self.stem(inputs)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
if i == 2 * self._layers // 3:
if self._auxiliary and self.training:
logits_aux = self.auxiliary_head(s1)
out = self.global_pooling(s1)
out = self.classifier(self.flatten(out))
out = rearrange(out, '(t b) c -> t b c', t=self.step).mean(0)
logits = self.vote(out)
return logits
if self.cell_type==3:
s0 = s1 = s2= self.stem(inputs)
for i, cell in enumerate(self.cells):
s0, s1, s2 = s1, s2, cell(s0, s1, s2, self.drop_path_prob)
if i == 2 * self._layers // 3:
if self._auxiliary and self.training:
logits_aux = self.auxiliary_head(s1)
out = self.global_pooling(s2)
out = self.classifier(self.flatten(out))
out = rearrange(out, '(t b) c -> t b c', t=self.step).mean(0)
logits = self.vote(out)
return logits
if self.cell_type==4:
s0 = s1 = s2=s3= self.stem(inputs)
for i, cell in enumerate(self.cells):
s0, s1, s2,s3= s1, s2, s3,cell(s0, s1, s2,s3 ,self.drop_path_prob)
if i == 2 * self._layers // 3:
if self._auxiliary and self.training:
logits_aux = self.auxiliary_head(s1)
out = self.global_pooling(s3)
out = self.classifier(self.flatten(out))
out = rearrange(out, '(t b) c -> t b c', t=self.step).mean(0)
logits = self.vote(out)
return logits
@register_model
class NetworkImageNet(BaseModule):
def __init__(self,
C,
num_classes,
layers,
auxiliary,
motif,
step=1,
node_type='ReLUNode',
**kwargs):
super(NetworkImageNet, self).__init__(
step=step,
num_classes=num_classes,
**kwargs)
if isinstance(node_type, str):
self.act_fun = eval(node_type)
else:
self.act_fun = node_type
self.act_fun = partial(self.act_fun, **kwargs)
if 'back_connection' in kwargs.keys():
self.back_connection = kwargs['back_connection']
else:
self.back_connection = False
self.spike_output = kwargs['spike_output'] if 'spike_output' in kwargs else True
if self.layer_by_layer:
self.flatten = nn.Flatten(start_dim=1)
else:
self.flatten = nn.Flatten()
self._layers = layers
self._auxiliary = auxiliary
self.drop_path_prob = 0
self.stem0 = nn.Sequential(
nn.Conv2d(3, C // 2, kernel_size=3,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(C // 2),
# nn.ReLU(inplace=True),
self.act_fun(),
nn.Conv2d(C // 2, C, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(C),
)
self.stem1 = nn.Sequential(
# nn.ReLU(inplace=True),
self.act_fun(),
nn.Conv2d(C, C, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(C),
)
C_prev_prev, C_prev, C_curr = C, C, C
self.cells = nn.ModuleList()
reduction_prev = True
for i in range(layers):
if i in [layers // 3, 2 * layers // 3]:
C_curr *= 2
reduction = True
else:
reduction = False
cell = EvoCell2(motif[i], C_prev_prev, C_prev,C_curr, reduction, reduction_prev,act_fun=self.act_fun)
reduction_prev = reduction
self.cells += [cell]
C_prev_prev, C_prev = C_prev, cell.multiplier * C_curr
self.global_pooling = nn.AvgPool2d(7)
self.classifier = nn.Linear(C_prev, num_classes)
def forward(self, inputs):
outputs = []
self.reset()
for t in range(self.step):
s0 = self.stem0(inputs)
s1 = self.stem1(s0)
for i, cell in enumerate(self.cells):
s0, s1 = s1, cell(s0, s1, self.drop_path_prob)
out = self.global_pooling(s1)
logits = self.classifier(self.flatten(out))
outputs.append(logits)
return sum(outputs) / len(outputs)
if __name__ == '__main__':
x = torch.rand(128, 36, 32, 32)
extra_edge=np.array([[3,5],[4,1]])
# sort based on head
extra_edge = extra_edge[extra_edge[:,0].argsort()]
# motifs=[mm1,mm2,mm3,mm1,mm5,mm4]
# motifs=[m1,m2,m3,m1,m5,m4,m1,m2,m3,m1,m5,m4,m5,m4,m1]
motifs=[t2,t3,t4,t5,t5,t4,t3,t4]
net=NetworkCIFAR(C=12,num_classes=10,motif=motifs,layers=len(motifs),auxiliary=True,dataset='cifar10',cell_type=4)
out=net(torch.rand(128, 3, 32, 32))
print(out.shape)
================================================
FILE: examples/Structure_Evolution/MSE-NAS/evolution.py
================================================
import sys
import numpy as np
import argparse
import time
import obj
import timm.models
import yaml
import os
import logging
from random import choice
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from micro_encoding import ops
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import micro_encoding
import nsganet as engine
from pymop.problem import Problem
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from pymoo.optimize import minimize
from utils import data_transforms
from tm import train_motifs
from timm.data import create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
# os.environ['CUDA_VISIBLE_DEVICES']='3'
bits=20
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('')
# The first arg parser parses out only thei --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
devices=[1]
max_gen = 100
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--seed', type=int, default=99, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--eval_epochs', type=int, default=10)
parser.add_argument('--bns', action='store_true', default=True)
parser.add_argument('--mid', type=int, default=3)
parser.add_argument('--trainning_epochs', type=int, default=600, metavar='N',help='number of epochs to train (default: 2)')
parser.add_argument('--cooldown-epochs', type=int, default=0, metavar='N',help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--init-channels', type=int, default=48)
parser.add_argument('--layers', type=int, default=6)
parser.add_argument('--pop_size', type=int, default=50, help='population size of networks')
parser.add_argument('--output', default='', type=str, metavar='PATH')
parser.add_argument('--spike-rate', action='store_true', default=False)
parser.add_argument('--n_gens', type=int, default=max_gen, help='population size')
parser.add_argument('--bs', type=int, default=100)
parser.add_argument('--n_offspring', type=int, default=50, help='number of offspring created per generation')
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser.add_argument('--dataset', default='dvsg', type=str)
parser.add_argument('--num-classes', type=int, default=11, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--model', default='NetworkCIFAR', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
parser.add_argument('--strgenome', default='4,0,0,1,1,1,0,1,0,1,0,0,0,1,0,1,0,1,0,0,4,1,1,1,1,1,0,1,1,0,1,1,0,1,1,1,0,1,0,0,4,1,1,0,1,0,0,1,0,1,1,0,1,1,0,0,1,0,1,2,4,1,0,0,1,1,1,0,0,1,0,0,1,0,0,1,0,0,1,1,4,0,1,1,0,1,0,0,1,0,1,0,1,1,1,0,1,0,1,3,4,1,0,1,0,0,1,1,1,0,0,1,0,1,0,0,0,1,0,0,3', type=str)
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=0.01,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR, if scheduler supports')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.8,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=1.0,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=1.0,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=len(devices),
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=devices[0])
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='QGateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=1.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
parser.add_argument('--node-trainable', action='store_true')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
# DARTS parameters
parser.add_argument('--auxiliary', action='store_true', default=False, help='use auxiliary tower')
# parser.add_argument('--arch', default='dvsc10_new_skip19', type=str)
# parser.add_argument('--motif', default='m1', type=str)
parser.add_argument('--parse_method', default='darts', type=str)
parser.add_argument('--drop_path_prob', type=float, default=0.2, help='drop path probability')
# parser.add_argument('--back-connection', action='store_true',default=True)
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def check_mem(cuda_device):
devices_info = os.popen('"/usr/bin/nvidia-smi" --query-gpu=memory.total,memory.used --format=csv,nounits,noheader').read().strip().split("\n")
total, used = devices_info[int(cuda_device)].split(',')
return total,used
def occumpy_mem(cuda_device):
total, used = check_mem(cuda_device)
total = int(total)
used = int(used)
max_mem = int(total * 1)
block_mem = int((max_mem - used)*0.3)
x = torch.cuda.FloatTensor(256,1024,block_mem)
del x
class NAS(Problem):
# first define the NAS problem (inherit from pymop)
def __init__(self, args,n_var=20, n_obj=1, n_constr=0, lb=None, ub=None,
init_channels=24, layers=8):
super().__init__(n_var=n_var, n_obj=n_obj, n_constr=n_constr, type_var=np.int64)
self.xl = lb
self.xu = ub
self._lr =args.lr
self._n_evaluated = 0 # keep track of how many architectures are sampled
self.args=args
def _evaluate(self, x, out, *args, **kwargs):
objs = np.full((x.shape[0], self.n_obj), np.nan)
train_data, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % self.args.dataset)(
batch_size=self.args.batch_size,
step=self.args.step,
args=self.args,
_logge=_logger,
size=self.args.event_size,
mix_up=self.args.mix_up,
cut_mix=self.args.cut_mix,
event_mix=self.args.event_mix,
beta=self.args.cutmix_beta,
prob=self.args.cutmix_prob,
num=self.args.cutmix_num,
noise=self.args.cutmix_noise,
num_classes=self.args.num_classes,
rand_aug=self.args.rand_aug,
randaug_n=self.args.randaug_n,
randaug_m=self.args.randaug_m,
temporal_flatten=self.args.temporal_flatten,
portion=self.args.train_portion,
_logger=_logger)
for i in range(x.shape[0]):
arch_id = self._n_evaluated + 1
print('\n')
_logger.info('Network= {}'.format(arch_id))
genome = x[i, :]
arch_dir=os.path.join(self.args.output_dir)
if os.path.exists(arch_dir) is False:
os.makedirs(arch_dir,exist_ok = True)
self.args.lr=self._lr
performance,acc=train_motifs(args=self.args,gen=0,arch_dir=arch_dir,genome=genome,_logger=_logger,args_text=args_text,devices=devices,bits=bits)
objs[i, 0] = 1000 - performance
# sJ,J,Cm,Ccosine,Cpe,K = obj.LSP(self.args,genome,train_data)
# objs[i, 0] = 1000 - Cm
_logger.info('performance= {}'.format(objs[i, 0]))
self._n_evaluated += 1
out["F"] = objs
# if your NAS problem has constraints, use the following line to set constraints
# out["G"] = np.column_stack([g1, g2, g3, g4, g5, g6]) in case 6 constraints
def do_every_generations(algorithm):
# this function will be call every generation
# it has access to the whole algorithm class
gen = algorithm.n_gen
pop_var = algorithm.pop.get("X")
pop_obj = algorithm.pop.get("F")
# report generation info to files
_logger.info("generation = {}".format(gen))
_logger.info("population error: best = {}, mean = {}, "
"median = {}, worst = {}".format(np.min(pop_obj[:, 0]), np.mean(pop_obj[:, 0]),
np.median(pop_obj[:, 0]), np.max(pop_obj[:, 0])))
_logger.info('Best Genome= {}'.format(pop_var[np.argmin(pop_obj[:, 0])]))
def _parse_args():
args_config, remaining = config_parser.parse_known_args()
args = parser.parse_args(remaining)
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
if __name__ == '__main__':
args, args_text = _parse_args()
args.no_spike_output = True
output_dir = ''
if args.bns:
from cellmodel import NetworkCIFAR
else:
from cell123model import NetworkCIFAR
if args.local_rank == 0:
output_base = args.output if args.output else './output'
exp_name = '-'.join([
datetime.now().strftime("%Y%m%d-%H%M%S"),
# args.model,
# args.dataset,
str(args.layers)+'layers',
str(args.init_channels)+'channels',
'motif'+str(args.mid),
str(args.step)+'steps',
# args.suffix
# str(args.img_size)
])
output_dir = get_outdir(output_base,str(args.dataset),exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
else:
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
defalut_lr = args.lr
occumpy_mem(str(args.device))
train_data, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
temporal_flatten=args.temporal_flatten,
portion=args.train_portion,
_logger=_logger,
)
len_motifs=args.layers*bits+1
low = np.zeros(len_motifs)
low[-1] = 2
up=[]
for i in range(0,args.layers*bits,bits):
t=[args.mid]
t=t+[(ops-1) for j in range(bits-1)]
t[-1]=2*(ops-1)
up.extend(t)
up.append(3)
up=np.array(up).reshape(-1,)
kkk = NAS(args,n_var=len_motifs,
n_obj=2, n_constr=0, lb=low, ub=up,
init_channels=args.init_channels, layers=args.layers)
method = engine.nsganet(pop_size=args.pop_size,
n_offsprings=args.n_offspring,
eliminate_duplicates=True)
kres=minimize(kkk,
method,
callback=do_every_generations,
termination=('n_gen', args.n_gens))
================================================
FILE: examples/Structure_Evolution/MSE-NAS/loss_f.py
================================================
import torch
import torch.nn.functional as f
def psp(inputs, n_steps,tau_s):
shape = inputs.shape
n_steps = n_steps
tau_s = tau_s
syn = torch.zeros(shape[0], shape[1], shape[2], shape[3]).cuda()
syns = torch.zeros(shape[0], shape[1], shape[2], shape[3], n_steps).cuda()
for t in range(n_steps):
syn = syn - syn / tau_s + inputs[..., t]
syns[..., t] = syn / tau_s
return syns
class SpikeLoss(torch.nn.Module):
"""
This class defines different spike based loss modules that can be used to optimize the SNN.
"""
def __init__(self, desired_count,undesired_count):
super(SpikeLoss, self).__init__()
self.desired_count = desired_count
self.desired_count = undesired_count
self.criterion = torch.nn.CrossEntropyLoss()
def spike_count(self, outputs, target, desired_count,undesired_count):
delta = loss_count.apply(outputs, target, desired_count,undesired_count)
return 1 / 2 * torch.sum(delta ** 2)
def spike_kernel(self, outputs, target, desired_count,undesired_count):
delta = loss_kernel.apply(outputs, target, desired_count,undesired_count)
return 1 / 2 * torch.sum(delta ** 2)
def spike_soft_max(self, outputs, target):
delta = f.log_softmax(outputs.sum(dim=4).squeeze(-1).squeeze(-1), dim = 1)
return self.criterion(delta, target)
class loss_count(torch.autograd.Function): # a and u is the incremnet of each time steps
@staticmethod
def forward(ctx, outputs, target, desired_count,undesired_count):
desired_count = desired_count
undesired_count = undesired_count
shape = outputs.shape
n_steps = shape[4]
out_count = torch.sum(outputs, dim=4)
delta = (out_count - target) / n_steps
mask = torch.ones_like(out_count)
mask[target == undesired_count] = 0
mask[delta < 0] = 0
delta[mask == 1] = 0
mask = torch.ones_like(out_count)
mask[target == desired_count] = 0
mask[delta > 0] = 0
delta[mask == 1] = 0
delta = delta.unsqueeze_(-1).repeat(1, 1, 1, 1, n_steps)
return delta
@staticmethod
def backward(ctx, grad):
return grad, None, None, None
class loss_kernel(torch.autograd.Function): # a and u is the incremnet of each time steps
@staticmethod
def forward(ctx, outputs, target, n_steps,tau_s):
# out_psp = psp(outputs, network_config)
target_psp = psp(target, n_steps,tau_s)
delta = outputs - target_psp
return delta
@staticmethod
def backward(ctx, grad):
return grad, None, None
================================================
FILE: examples/Structure_Evolution/MSE-NAS/micro_encoding.py
================================================
# NASNet Search Space https://arxiv.org/pdf/1707.07012.pdf
# code modified from DARTS https://github.com/quark0/darts
import numpy as np
from collections import namedtuple
import torch
# from models.micro_models import NetworkCIFAR as Network
import motifs
# Genotype = namedtuple('Genotype', 'normal normal_concat reduce reduce_concat')
# Genotype_norm = namedtuple('Genotype', 'normal normal_concat')
# Genotype_redu = namedtuple('Genotype', 'reduce reduce_concat')
Genotype = namedtuple('Genotype', 'normal normal_concat')
# what you want to search should be defined here and in micro_operations
PRIMITIVES = [
'max_pool_3x3',
'avg_pool_3x3',
'skip_connect',
'sep_conv_3x3',
'sep_conv_5x5',
'dil_conv_3x3',
'dil_conv_5x5',
'sep_conv_7x7',
'conv_7x1_1x7',
]
OPERATIONS_back = [
# 'max_pool_3x3_p_back',
# 'avg_pool_3x3_p_back',
'conv_3x3_p_back',
'conv_5x5_p_back',
# 'avg_pool_3x3_n_back',
'conv_3x3_n_back',
'conv_5x5_n_back',
# 'sep_conv_3x3_p_back',
# 'sep_conv_5x5_p_back',
# 'dil_conv_3x3_p_back',
# 'dil_conv_5x5_p_back',
# 'def_conv_3x3_p_back',
# 'def_conv_5x5_p_back',
]
OPERATIONS_p = [
# 'max_pool_3x3_p',
# 'avg_pool_3x3_p',
'conv_3x3_p',
'conv_5x5_p',
# 'sep_conv_3x3_p',
# 'sep_conv_5x5_p',
# 'dil_conv_3x3_p',
# 'dil_conv_5x5_p',
# 'def_conv_3x3_p',
# 'def_conv_5x5_p',
]
ops=len(OPERATIONS_p)
OPERATIONS_n = [
# 'max_pool_3x3_n',
# 'avg_pool_3x3_n',
'conv_3x3_n',
'conv_5x5_n',
# 'sep_conv_3x3_n',
# 'sep_conv_5x5_n',
# 'dil_conv_3x3_n',
# 'dil_conv_5x5_n',
# 'def_conv_3x3_n',
# 'def_conv_5x5_n',
# 'transformer',
]
def convert_cell(cell_bit_string):
# convert cell bit-string to genome
tmp = [cell_bit_string[i:i + 2] for i in range(0, len(cell_bit_string), 2)]
return [tmp[i:i + 2] for i in range(0, len(tmp), 2)]
def convert(bit_string):
# convert network bit-string (norm_cell + redu_cell) to genome
norm_gene = convert_cell(bit_string[:len(bit_string)//2])
redu_gene = convert_cell(bit_string[len(bit_string)//2:])
return [norm_gene, redu_gene]
# def decode_cell(genome, norm=True):
# cell, cell_concat = [], list(range(2, len(genome)+2))
# for block in genome:
# for unit in block:
# cell.append((PRIMITIVES[unit[0]], unit[1]))
# if unit[1] in cell_concat:
# cell_concat.remove(unit[1])
# if norm:
# return Genotype_norm(normal=cell, normal_concat=cell_concat)
# else:
# return Genotype_redu(reduce=cell, reduce_concat=cell_concat)
def decode(genome):
# decodes genome to architecture
normal_cell = genome[0]
reduce_cell = genome[1]
normal, normal_concat = [], list(range(2, len(normal_cell)+2))
reduce, reduce_concat = [], list(range(2, len(reduce_cell)+2))
for block in normal_cell:
for unit in block:
normal.append((PRIMITIVES[unit[0]], unit[1]))
if unit[1] in normal_concat:
normal_concat.remove(unit[1])
for block in reduce_cell:
for unit in block:
reduce.append((PRIMITIVES[unit[0]], unit[1]))
if unit[1] in reduce_concat:
reduce_concat.remove(unit[1])
return Genotype(
normal=normal, normal_concat=normal_concat,
reduce=reduce, reduce_concat=reduce_concat
)
def decode_motif(layers,bits,genome):
# decodes genome to architecture
motif_list=[]
motif_ids=[]
for b in range(0,layers*bits,bits):
if genome[-1]==2:
motif_id='mm'+str(genome[b])
elif genome[-1]==3:
motif_id='m'+str(genome[b])
else:
motif_id='t'+str(genome[b])
motif_ids.append(genome[b])
normalcell=eval('motifs.%s' % motif_id)
newnormal=[]
for i in range(0,len(normalcell.normal)):
op=normalcell.normal[i]
if 'skip' in op[0]:
newnormal.append(op)
continue
elif 'back' in op[0]:
newnormal.append((OPERATIONS_back[genome[b+1+len(normalcell.normal)-1]],op[1]))
continue
elif '_n' in op[0]:
newnormal.append((OPERATIONS_n[genome[b+1+i]],op[1]))
continue
elif '_p' in op[0]:
newnormal.append((OPERATIONS_p[genome[b+1+i]],op[1]))
continue
m=Genotype(normal=newnormal, normal_concat=normalcell.normal_concat,)
motif_list.append(m)
return motif_list,motif_ids
def compare_cell(cell_string1, cell_string2):
cell_genome1 = convert_cell(cell_string1)
cell_genome2 = convert_cell(cell_string2)
cell1, cell2 = cell_genome1[:], cell_genome2[:]
for block1 in cell1:
for block2 in cell2:
if block1 == block2 or block1 == block2[::-1]:
cell2.remove(block2)
break
if len(cell2) > 0:
return False
else:
return True
def compare(string1, string2):
if compare_cell(string1[:len(string1)//2],
string2[:len(string2)//2]):
if compare_cell(string1[len(string1)//2:],
string2[len(string2)//2:]):
return True
return False
# def debug():
# # design to debug the encoding scheme
# seed = 0
# np.random.seed(seed)
# budget = 2000
# B, n_ops, n_cell = 5, 7, 2
# networks = []
# design_id = 1
# while len(networks) < budget:
# bit_string = []
# for c in range(n_cell):
# for b in range(B):
# bit_string += [np.random.randint(n_ops),
# np.random.randint(b + 2),
# np.random.randint(n_ops),
# np.random.randint(b + 2)
# ]
# genome = convert(bit_string)
# # check against evaluated networks in case of duplicates
# doTrain = True
# for network in networks:
# if compare(genome, network):
# doTrain = False
# break
# if doTrain:
# genotype = decode(genome)
# model = Network(16, 10, 8, False, genotype)
# model.drop_path_prob = 0.0
# data = torch.randn(1, 3, 32, 32)
# output, output_aux = model(torch.autograd.Variable(data))
# networks.append(genome)
# design_id += 1
# print(design_id)
if __name__ == "__main__":
# debug()
# genome1 = [[[[3, 0], [3, 1]], [[3, 0], [3, 1]],
# [[3, 1], [2, 0]], [[2, 0], [5, 2]]],
# [[[0, 0], [0, 1]], [[2, 2], [0, 1]],
# [[0, 0], [2, 2]], [[2, 2], [0, 1]]]]
# genome2 = [[[[3, 1], [3, 0]], [[3, 1], [3, 0]],
# [[3, 1], [2, 0]], [[2, 0], [5, 2]]],
# [[[0, 1], [0, 0]], [[2, 2], [0, 1]],
# [[0, 0], [2, 2]], [[2, 2], [0, 0]]]]
#
# print(compare(genome1, genome2))
# print(genome1)
# print(genome2)
# bit_string1 = [3,1,3,0,3,1,3,0,3,1,2,0,2,0,5,2,0,0,0,1,2,2,0,1,0,0,2,2,2,2,0,1]
# bit_string2 = [3, 0, 3, 1, 3, 0, 3, 1, 3, 1, 2, 0, 2, 0, 5, 2,
# 0, 0, 0, 1, 2, 2, 0, 1, 0, 0, 2, 2, 2, 2, 0, 1]
# # print(convert(bit_string1))
# print(compare(bit_string1, bit_string2))
# print(decode(convert(bit_string)))
cell_bit_string = [3, 0, 3, 1, 3, 0, 3, 1, 3, 1, 2, 0, 2, 0, 5, 2]
# print(decode_cell(convert_cell(cell_bit_string), norm=False))
================================================
FILE: examples/Structure_Evolution/MSE-NAS/motifs.py
================================================
from collections import namedtuple
import torch
Genotype = namedtuple('Genotype', 'normal normal_concat')
m0=Genotype(
normal=[
('skip', 0), ('skip', 1),('skip', 2),
],
normal_concat=range(3, 4)
)
mm0=Genotype(
normal=[
('skip', 0), ('skip', 1),('skip', 2),
],
normal_concat=range(2, 3)
)
mm1=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),
('skip_connect', 0), ('conv_5x5_p', 2),
],
normal_concat=range(2, 4)
)
mm2=Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),
('skip_connect', 0), ('conv_5x5_n', 2),
('conv_5x5_p', 2), ('conv_3x3_n', 3),
],
normal_concat=range(2, 5)
)
mm4=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),#2
('conv_3x3_p', 0), ('conv_3x3_p', 1),#3
('conv_5x5_p', 2), ('conv_5x5_p', 3),#4
('skip_connect', 0), ('conv_3x3_p', 4),#5
('skip_connect', 0), ('conv_3x3_p', 4),#6
],
normal_concat=range(2, 7)
)
mm3=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),#2
('skip_connect', 0), ('conv_5x5_n', 2),#3
('skip_connect', 0), ('conv_5x5_p', 3),#4
('skip_connect_back', 2),#3
('conv_3x3_p_back', 3),#4
],
normal_concat=range(2, 5)
)
mm5=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),#2
('skip_connect', 0), ('conv_5x5_p', 2),#3
('skip_connect_back', 2),#3
],
normal_concat=range(2, 4)
)
m1=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2), #B3
('skip', 0), ('conv_5x5_p', 3), ('skip', 1), #C4
],
normal_concat=range(3, 5)
)
m2=Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), #B3
('skip', 0), ('conv_5x5_n', 3), ('skip', 1),#C4
('conv_5x5_p', 3), ('conv_3x3_n', 4), ('skip', 1), #D5
],
normal_concat=range(3, 6)
)
m4=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), #3
('conv_3x3_p', 0), ('conv_3x3_p', 1),('conv_5x5_p', 2), #4
('skip', 0), ('conv_5x5_p', 3), ('conv_5x5_p', 4), #5
('skip', 0), ('conv_3x3_p', 3),('conv_3x3_n', 5),#6
('skip', 0), ('conv_3x3_p', 4),('conv_3x3_n', 5),#7
],
normal_concat=range(3, 8)
)
m3=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_3x3_p', 2), #3
('skip', 0), ('conv_5x5_p', 3),('skip', 1), #4
('skip', 0), ('conv_5x5_p', 3), ('skip', 1), #5
('conv_3x3_n_back', 3),#4
('skip_back', 2),#5
],
normal_concat=range(3, 6)
)
m5=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2),#3
('skip', 0),('skip', 1), ('conv_5x5_n', 3), #4
('skip_connect_back', 3),#4
],
normal_concat=range(3, 5)
)
t1=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2), ('conv_5x5_p', 3), #4
('skip', 0), ('conv_5x5_p', 4), ('skip', 1), ('skip', 2), #5
('skip', 0), ('conv_5x5_p', 5), ('skip', 1), ('skip', 2), #6
('skip', 0), ('conv_5x5_p', 5), ('skip', 1), ('skip', 2), #7
],
normal_concat=range(4, 8)
)
t2=Genotype(
normal=[
('conv_5x5_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), ('conv_5x5_p', 3), #4
('skip', 0), ('conv_5x5_n', 4), ('skip', 1),('skip', 2),#5
('conv_5x5_p', 4), ('conv_3x3_n', 5), ('skip', 1),('skip', 2), #6
],
normal_concat=range(4, 7)
)
t4=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1),('conv_5x5_p', 2), ('conv_5x5_p', 3), #4
('conv_5x5_p', 0), ('skip', 1),('conv_5x5_n', 4), ('skip', 3), #5
('skip', 0), ('conv_5x5_p', 3), ('conv_5x5_n', 4), ('skip', 2),#6
],
normal_concat=range(4, 7)
)
t3=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_3x3_p', 2), ('conv_3x3_p', 3),#4
('skip', 0), ('skip', 2),('skip', 1), ('skip', 3),('conv_3x3_p', 4),#5
('skip', 0), ('conv_5x5_p', 4), ('skip', 1),('skip', 2), #6
('conv_3x3_n_back', 4),#5
('skip_back', 4),#6
],
normal_concat=range(4, 7)
)
t5=Genotype(
normal=[
('conv_3x3_p', 0), ('conv_5x5_p', 1), ('conv_5x5_p', 2),('conv_5x5_p', 3),#4
('skip', 0),('skip', 1), ('skip', 2), ('conv_5x5_n', 4), #5
('skip', 0),('skip', 1), ('conv_5x5_n', 4),('conv_5x5_n', 5), #6
('skip', 0),('skip', 1), ('conv_5x5_n', 4),('conv_5x5_n', 5), #7
('conv_3x3_n_back', 4),#5
('skip_back', 4),#6
('skip_back', 5),#7
],
normal_concat=range(4, 8)
)
================================================
FILE: examples/Structure_Evolution/MSE-NAS/nsganet.py
================================================
import numpy as np
from pymoo.algorithms.genetic_algorithm import GeneticAlgorithm
from pymoo.docs import parse_doc_string
from pymoo.model.individual import Individual
from pymoo.model.survival import Survival
from pymoo.operators.crossover.point_crossover import PointCrossover
from pymoo.operators.mutation.polynomial_mutation import PolynomialMutation
from pymoo.operators.sampling.random_sampling import RandomSampling
from pymoo.operators.selection.tournament_selection import compare, TournamentSelection
from pymoo.util.display import disp_multi_objective
from pymoo.util.dominator import Dominator
from pymoo.util.non_dominated_sorting import NonDominatedSorting
from pymoo.util.randomized_argsort import randomized_argsort
# =========================================================================================================
# Implementation
# based on nsga2 from https://github.com/msu-coinlab/pymoo
# =========================================================================================================
class NSGANet(GeneticAlgorithm):
def __init__(self, **kwargs):
kwargs['individual'] = Individual(rank=np.inf, crowding=-1)
super().__init__(**kwargs)
self.tournament_type = 'comp_by_dom_and_crowding'
self.func_display_attrs = disp_multi_objective
# ---------------------------------------------------------------------------------------------------------
# Binary Tournament Selection Function
# ---------------------------------------------------------------------------------------------------------
def binary_tournament(pop, P, algorithm, **kwargs):
if P.shape[1] != 2:
raise ValueError("Only implemented for binary tournament!")
tournament_type = algorithm.tournament_type
S = np.full(P.shape[0], np.nan)
for i in range(P.shape[0]):
a, b = P[i, 0], P[i, 1]
# if at least one solution is infeasible
if pop[a].CV > 0.0 or pop[b].CV > 0.0:
S[i] = compare(a, pop[a].CV, b, pop[b].CV, method='smaller_is_better', return_random_if_equal=True)
# both solutions are feasible
else:
if tournament_type == 'comp_by_dom_and_crowding':
rel = Dominator.get_relation(pop[a].F, pop[b].F)
if rel == 1:
S[i] = a
elif rel == -1:
S[i] = b
elif tournament_type == 'comp_by_rank_and_crowding':
S[i] = compare(a, pop[a].rank, b, pop[b].rank,
method='smaller_is_better')
else:
raise Exception("Unknown tournament type.")
# if rank or domination relation didn't make a decision compare by crowding
if np.isnan(S[i]):
S[i] = compare(a, pop[a].get("crowding"), b, pop[b].get("crowding"),
method='larger_is_better', return_random_if_equal=True)
return S[:, None].astype(np.int)
# ---------------------------------------------------------------------------------------------------------
# Survival Selection
# ---------------------------------------------------------------------------------------------------------
class RankAndCrowdingSurvival(Survival):
def __init__(self) -> None:
super().__init__(True)
def _do(self, pop, n_survive, D=None, **kwargs):
# get the objective space values and objects
F = pop.get("F")
# the final indices of surviving individuals
survivors = []
# do the non-dominated sorting until splitting front
fronts = NonDominatedSorting().do(F, n_stop_if_ranked=n_survive)
for k, front in enumerate(fronts):
# calculate the crowding distance of the front
crowding_of_front = calc_crowding_distance(F[front, :])
# save rank and crowding in the individual class
for j, i in enumerate(front):
pop[i].set("rank", k)
pop[i].set("crowding", crowding_of_front[j])
# current front sorted by crowding distance if splitting
if len(survivors) + len(front) > n_survive:
I = randomized_argsort(crowding_of_front, order='descending', method='numpy')
I = I[:(n_survive - len(survivors))]
# otherwise take the whole front unsorted
else:
I = np.arange(len(front))
# extend the survivors by all or selected individuals
survivors.extend(front[I])
return pop[survivors]
def calc_crowding_distance(F):
infinity = 1e+14
n_points = F.shape[0]
n_obj = F.shape[1]
if n_points <= 2:
return np.full(n_points, infinity)
else:
# sort each column and get index
I = np.argsort(F, axis=0, kind='mergesort')
# now really sort the whole array
F = F[I, np.arange(n_obj)]
# get the distance to the last element in sorted list and replace zeros with actual values
dist = np.concatenate([F, np.full((1, n_obj), np.inf)]) \
- np.concatenate([np.full((1, n_obj), -np.inf), F])
index_dist_is_zero = np.where(dist == 0)
dist_to_last = np.copy(dist)
for i, j in zip(*index_dist_is_zero):
dist_to_last[i, j] = dist_to_last[i - 1, j]
dist_to_next = np.copy(dist)
for i, j in reversed(list(zip(*index_dist_is_zero))):
dist_to_next[i, j] = dist_to_next[i + 1, j]
# normalize all the distances
norm = np.max(F, axis=0) - np.min(F, axis=0)
norm[norm == 0] = np.nan
dist_to_last, dist_to_next = dist_to_last[:-1] / norm, dist_to_next[1:] / norm
# if we divided by zero because all values in one columns are equal replace by none
dist_to_last[np.isnan(dist_to_last)] = 0.0
dist_to_next[np.isnan(dist_to_next)] = 0.0
# sum up the distance to next and last and norm by objectives - also reorder from sorted list
J = np.argsort(I, axis=0)
crowding = np.sum(dist_to_last[J, np.arange(n_obj)] + dist_to_next[J, np.arange(n_obj)], axis=1) / n_obj
# replace infinity with a large number
crowding[np.isinf(crowding)] = infinity
return crowding
# =========================================================================================================
# Interface
# =========================================================================================================
def nsganet(
pop_size=100,
sampling=RandomSampling(var_type=np.int),
selection=TournamentSelection(func_comp=binary_tournament),
crossover=PointCrossover(n_points=2),
mutation=PolynomialMutation(eta=3, var_type=np.int),
eliminate_duplicates=True,
n_offsprings=None,
**kwargs):
"""
Parameters
----------
pop_size : {pop_size}
sampling : {sampling}
selection : {selection}
crossover : {crossover}
mutation : {mutation}
eliminate_duplicates : {eliminate_duplicates}
n_offsprings : {n_offsprings}
Returns
-------
nsganet : :class:`~pymoo.model.algorithm.Algorithm`
Returns an NSGANet algorithm object.
"""
return NSGANet(pop_size=pop_size,
sampling=sampling,
selection=selection,
crossover=crossover,
mutation=mutation,
survival=RankAndCrowdingSurvival(),
eliminate_duplicates=eliminate_duplicates,
n_offsprings=n_offsprings,
**kwargs)
parse_doc_string(nsganet)
================================================
FILE: examples/Structure_Evolution/MSE-NAS/obj.py
================================================
import sys
import os
import numpy as np
import torch
import logging
import argparse
import torch.nn as nn
import torch.utils
# import torchvision.datasets as dset
import torch.backends.cudnn as cudnn
import torchvision.transforms as transforms
from timm.models import create_model
from cell123model import NetworkCIFAR
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.reactnet import *
from braincog.model_zoo.convxnet import *
from scipy.stats import kendalltau
from misc import utils
import micro_encoding
from misc.flops_counter import add_flops_counting_methods
from utils import data_transforms
from datetime import datetime
bits=20
def logdet(K):
s, ld = torch.linalg.slogdet(K)
return ld
def LSP(args,genome,train_data):
with torch.no_grad():
test_motifs,ids = micro_encoding.decode_motif(layers=args.layers,bits=bits,genome=genome)
pmodel = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
C=args.init_channels,
layers=args.layers,
auxiliary=args.auxiliary,
motif=test_motifs,
parse_method=args.parse_method,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
cell_type=genome[-1]
)
pmodel.to(args.device)
pmodel.K = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.J = torch.zeros(args.batch_size, args.batch_size,device=args.device)
# pmodel.Cou = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.Ccosine = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.Cm = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.Cpe = torch.zeros(args.batch_size, args.batch_size,device=args.device)
# pmodel.Cou = torch.zeros(args.batch_size,device=args.device)
# pmodel.Ccosine = torch.zeros(args.batch_size, device=args.device)
# pmodel.Cm = torch.zeros(args.batch_size,device=args.device)
pmodel.num_actfun_C = 0
pmodel.num_actfun_K = 0
def computing_LSP(module, inp, out):
if isinstance(out, tuple):
out = out[0]
#
out = out.view(out.size(0), -1)
batch_num , neuron_num = out.size()
x = (out > 0).float()
full_matrix = torch.ones((args.batch_size, args.batch_size)).cuda() * neuron_num
sparsity = (x.sum(1)/neuron_num).unsqueeze(1)
norm_K = ((sparsity @ (1-sparsity.t())) + ((1-sparsity) @ sparsity.t())) * neuron_num
rescale_factor = torch.div(0.5* torch.ones((args.batch_size, args.batch_size)).cuda(), norm_K+1e-3)
K1_0 = (x @ (1 - x.t()))
K0_1 = ((1-x) @ x.t())
K0_0 = (1-x) @ (1-x).t()
K1_1 = (1-x) @ (1-x).t()
K_total = (full_matrix - rescale_factor * (K0_1 + K1_0))
J_total = (K1_1+K0_0)/(K0_1+K1_0+K1_1)
pmodel.K = pmodel.K + K_total
pmodel.J = pmodel.J + J_total
pmodel.num_actfun_K += 1
# x = x / torch.norm(x, dim=-1, keepdim=True)
# similarity = torch.mm(x, x.T)
# dis_ou=torch.zeros_like(pmodel.Cou)
dis_man=torch.zeros_like(pmodel.Cm)
dis_cosine=torch.zeros_like(pmodel.Ccosine)
ou_dist = nn.PairwiseDistance(p=2)
m_dist = nn.PairwiseDistance(p=1)
cos = nn.CosineSimilarity(dim=1, eps=1e-6)
# cos = nn.CosineSimilarity(dim=0, eps=1e-6)
# for i in range(args.batch_size):
# for j in range(i,args.batch_size):
# input1 = x[i]
# input2 = x[j]
# dis_ou[i][j] = ou_dist(input1,input2)
# dis_man[i][j] = m_dist(input1,input2)
# dis_cosine[i][j] = cos(input1,input2)
# pmodel.Cou = pmodel.Cou + dis_ou
for i in range(args.batch_size):
temp = x[i].repeat(args.batch_size,1)
dis_cosine[i] = cos(x,temp)
dis_man[i] = m_dist(x,temp)
# pmodel.Cou = pmodel.Cou + ou_dist(x,x.flip(dims=[0]))
# pmodel.Cm = pmodel.Cou + m_dist(x,x.flip(dims=[0]))
pmodel.Ccosine = pmodel.Ccosine + dis_cosine
pmodel.Cm = pmodel.Cm + dis_man
pmodel.Cpe = pmodel.Cpe + torch.corrcoef(x / torch.norm(x, dim=-1, keepdim=True))
pmodel.num_actfun_C += 1
pmodel.num_actfun_K += 1
s_ou = []
s_m = []
s_pe = []
s_cos = []
s_k = []
s_jac=[]
s_sum_j=[]
repeat=2
for name,module in pmodel.named_modules():
if args.node_type in str(type(module)):
handle = module.register_forward_hook(computing_LSP)
for j in range(repeat):
pmodel.K = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.J = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.Ccosine = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.Cm = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.Cpe = torch.zeros(args.batch_size, args.batch_size,device=args.device)
pmodel.num_actfun_C = 0
pmodel.num_actfun_K = 0
data_iterator = iter(train_data)
inputs, targets = next(data_iterator)
inputs, targets = inputs.cuda(), targets.cuda()
outputs = pmodel(inputs)
tc=pmodel.Ccosine/pmodel.num_actfun_C
tp=pmodel.Cpe/pmodel.num_actfun_C
tm=pmodel.Cm/pmodel.num_actfun_C
tj=pmodel.J/ (pmodel.num_actfun_K)
Ccos = torch.where(torch.isnan(tc), torch.full_like(tc, 0), tc)
Cpe = torch.where(torch.isnan(tp), torch.full_like(tp, 0), tp)
Cm = torch.where(torch.isnan(tm), torch.full_like(tm, 0), tm)
s_k.append(float(logdet(pmodel.K/ (pmodel.num_actfun_K))))
s_jac.append(float(logdet(tj)))
s_sum_j.append(float(tj.sum()))
s_m.append(float(Cm.sum()))
s_cos.append(float(Ccos.sum()))
s_pe.append(float(Cpe.sum()))
return np.mean(np.array(s_sum_j)),np.mean(np.array(s_jac)), np.mean(np.array(s_m)),np.mean(np.array(s_cos)),np.mean(np.array(s_pe)),np.mean(np.array(s_k))
================================================
FILE: examples/Structure_Evolution/MSE-NAS/operations.py
================================================
import numpy as np
import torch
import torch.nn as nn
from torch.nn import *
import torch.nn.functional as F
from torch import einsum
from einops import rearrange
# from braincog.model_zoo.base_module import DeformConvPack
from braincog.model_zoo.base_module import BaseLinearModule
# from mmcv.ops import ModulatedDeformConv2dPack
def si_relu(x, positive):
if positive == 1:
return torch.where(x > 0., x, torch.zeros_like(x))
elif positive == 0:
return x
elif positive == -1:
return torch.where(x < 0., x, torch.zeros_like(x))
else:
raise ValueError
class SiReLU(nn.Module):
def __init__(self, positive=0):
super().__init__()
self.positive = positive
def forward(self, x):
return si_relu(x, self.positive)
def weight_init(m):
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal(m.weight.data, gain=0.1)
torch.nn.init.constant(m.bias.data, 0.)
OPS_Mlp = {
'mlp': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=0),
'mlp_p': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=1),
'mlp_n': lambda C, act_fun:
SiMLP(C, C, act_fun=act_fun, positive=-1),
'skip_connect': lambda C, act_fun:
Identity(positive=0),
'skip_connect_p': lambda C, act_fun:
Identity(positive=1),
'skip_connect_n': lambda C, act_fun:
Identity(positive=-1),
}
OPS = {
'avg_pool_3x3': lambda C, stride, affine, act_fun: nn.AvgPool2d(3, stride=stride, padding=1,
count_include_pad=False),
'conv_3x3': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=0),
'conv_5x5': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=0),
'max_pool_3x3': lambda C, stride, affine, act_fun: nn.MaxPool2d(3, stride=stride, padding=1),
'skip_connect': lambda C, stride, affine, act_fun:
Identity(positive=0) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun),
'sep_conv_3x3': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=0),
'sep_conv_5x5': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=0),
'sep_conv_7x7': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=0),
'dil_conv_3x3': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=0),
'dil_conv_5x5': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=0),
'def_conv_3x3': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=0),
'def_conv_5x5': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=0),
'avg_pool_3x3_p': lambda C, stride, affine, act_fun: nn.Sequential(
nn.AvgPool2d(3, stride=stride, padding=1, count_include_pad=False),
SiReLU(positive=1)
),
'max_pool_3x3_p': lambda C, stride, affine, act_fun: nn.Sequential(
nn.MaxPool2d(3, stride=stride, padding=1),
SiReLU(positive=1)
),
'conv_3x3_p': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=1),
'conv_5x5_p': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=1),
'skip_connect_p': lambda C, stride, affine, act_fun:
Identity(positive=1) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_3x3_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_5x5_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=1),
'sep_conv_7x7_p': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=1),
'dil_conv_3x3_p': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=1),
'dil_conv_5x5_p': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=1),
'def_conv_3x3_p': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=1),
'def_conv_5x5_p': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=1),
'avg_pool_3x3_n': lambda C, stride, affine, act_fun: nn.Sequential(
nn.AvgPool2d(3, stride=stride, padding=1, count_include_pad=False),
SiReLU(positive=-1)
),
'max_pool_3x3_n': lambda C, stride, affine, act_fun: nn.Sequential(
nn.MaxPool2d(3, stride=stride, padding=1),
SiReLU(positive=-1)
),
'conv_3x3_n': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=3, padding=1, stride=stride, affine=affine, act_fun=act_fun, positive=-1),
'conv_5x5_n': lambda C, stride, affine, act_fun:
ReLUConvBN(C_in=C, C_out=C, kernel_size=5, padding=2, stride=stride, affine=affine, act_fun=act_fun, positive=-1),
'skip_connect_n': lambda C, stride, affine, act_fun:
Identity(positive=-1) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_3x3_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_5x5_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=-1),
'sep_conv_7x7_n': lambda C, stride, affine, act_fun:
SepConv(C, C, 7, stride, 3, affine=affine, act_fun=act_fun, positive=-1),
'dil_conv_3x3_n': lambda C, stride, affine, act_fun:
DilConv(C, C, 3, stride, 2, 2, affine=affine, act_fun=act_fun, positive=-1),
'dil_conv_5x5_n': lambda C, stride, affine, act_fun:
DilConv(C, C, 5, stride, 4, 2, affine=affine, act_fun=act_fun, positive=-1),
'def_conv_3x3_n': lambda C, stride, affine, act_fun:
DeformConv(C, C, 3, stride, 1, affine=affine, act_fun=act_fun, positive=-1),
'def_conv_5x5_n': lambda C, stride, affine, act_fun:
DeformConv(C, C, 5, stride, 2, affine=affine, act_fun=act_fun, positive=-1),
'conv_7x1_1x7': lambda C, stride, affine, act_fun: nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C, C, (1, 7), stride=(1, stride),
padding=(0, 3), bias=False),
nn.Conv2d(C, C, (7, 1), stride=(stride, 1),
padding=(3, 0), bias=False),
nn.BatchNorm2d(C, affine=affine)
),
'skip': lambda C, stride, affine, act_fun:
Zero(stride) if stride == 1 else FactorizedReduce(C, C, affine=affine, act_fun=act_fun, positive=1),
'transformer': lambda C, stride, affine, act_fun:
FactorizedReduce(
C, C, affine=affine, act_fun=act_fun) if stride != 1 else TransformerEncoderLayer(C),
}
class SiMLP(nn.Module):
def __init__(self, c_in, c_out, act_fun=nn.ReLU, positive=0, *args, **kwargs):
super(SiMLP, self).__init__()
self.op = nn.Sequential(
nn.Linear(c_in, c_out, bias=True),
act_fun()
)
self.positive = positive
def forward(self, x):
out = self.op(si_relu(x, self.positive))
return out
class DilConv(nn.Module):
"""
Dilation Convolution : ReLU -> DilConv -> Conv2d -> BatchNorm2d
"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, dilation, affine=True, act_fun=nn.ReLU, positive=0):
super(DilConv, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation,
groups=C_in, bias=False),
nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=affine),
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class SepConv(nn.Module):
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
super(SepConv, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size,
stride=stride, padding=padding, groups=C_in, bias=False),
nn.Conv2d(C_in, C_in, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_in, affine=affine),
nn.ReLU(inplace=False),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size,
stride=1, padding=padding, groups=C_in, bias=False),
nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=affine),
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
class Identity(nn.Module):
def __init__(self, positive=0):
super(Identity, self).__init__()
self.positive = positive
def forward(self, x):
return si_relu(x, self.positive)
class Zero(nn.Module):
def __init__(self, stride):
super(Zero, self).__init__()
self.stride = stride
def forward(self, x):
if self.stride == 1:
return x.mul(0.)
return x[:, :, ::self.stride, ::self.stride].mul(0.) # N * C * W * H
class FactorizedReduce(nn.Module):
def __init__(self, C_in, C_out, affine=True, act_fun=nn.ReLU, positive=0):
super(FactorizedReduce, self).__init__()
assert C_out % 2 == 0
# self.relu = nn.ReLU(inplace=False)
self.activation = act_fun()
self.conv_1 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.conv_2 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.bn = nn.BatchNorm2d(C_out, affine=affine)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
# x = self.relu(x)
x = self.activation(x)
out = torch.cat([self.conv_1(x), self.conv_2(x[:, :, 1:, 1:])], dim=1)
out = self.bn(out)
out = si_relu(out, self.positive)
return out
class F0(nn.Module):
def __init__(self, C_in, C_out, affine=True, act_fun=nn.ReLU, positive=0):
super(F0, self).__init__()
assert C_out % 2 == 0
# self.relu = nn.ReLU(inplace=False)
self.activation = act_fun()
self.op=nn.Conv2d(C_out, C_out, 3, stride=2, padding=1, bias=False)
self.conv_1 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.conv_2 = nn.Conv2d(C_in, C_out // 2, 3,stride=2, padding=1, bias=False)
self.bn = nn.BatchNorm2d(C_out, affine=affine)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
# x = self.relu(x)
x = self.activation(x)
out = torch.cat([self.conv_1(x), self.conv_2(x[:, :, 1:, 1:])], dim=1)
out = self.bn(out)
out = si_relu(out, self.positive)
out=self.op(out)
return out
class ReLUConvBN(nn.Module):
"""
ReLu -> Conv2d -> BatchNorm2d
"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
super(ReLUConvBN, self).__init__()
self.op = nn.Sequential(
# nn.ReLU(inplace=False),
act_fun(),
nn.Conv2d(C_in, C_out, kernel_size, stride=stride,
padding=padding, bias=False),
nn.BatchNorm2d(C_out, affine=affine)
)
self.positive = positive
# if positive == -1:
# weight_init(self.op)
def forward(self, x):
out = self.op(x)
return si_relu(out, self.positive)
# class DeformConv(nn.Module):
# def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True, act_fun=nn.ReLU, positive=0):
# super(DeformConv, self).__init__()
# self.op = nn.Sequential(
# # nn.ReLU(inplace=False),
# act_fun(),
# DeformConvPack(C_in, C_out, kernel_size=kernel_size,
# stride=stride, padding=padding, bias=True),
# nn.BatchNorm2d(C_out, affine=affine)
# )
# self.positive = positive
# # if positive == -1:
# # weight_init(self.op)
# def forward(self, x):
# out = self.op(x)
# return si_relu(out, self.positive)
class Attention(Module):
"""
Obtained from: github.com:rwightman/pytorch-image-models
"""
def __init__(self, dim, num_heads=4, attention_dropout=0.1, projection_dropout=0.1):
super().__init__()
self.num_heads = num_heads
head_dim = dim // self.num_heads
self.scale = head_dim ** -0.5
self.qkv = Linear(dim, dim * 3, bias=False)
self.attn_drop = Dropout(attention_dropout)
self.proj = Linear(dim, dim)
self.proj_drop = Dropout(projection_dropout)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C //
self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class TransformerEncoderLayer(Module):
"""
Inspired by torch.nn.TransformerEncoderLayer and
rwightman's timm package.
"""
def __init__(self, d_model, nhead=4, dim_feedforward=256, dropout=0.1,
attention_dropout=0.1, drop_path_rate=0.1):
super(TransformerEncoderLayer, self).__init__()
self.pre_norm = LayerNorm(d_model)
self.self_attn = Attention(dim=d_model, num_heads=nhead,
attention_dropout=attention_dropout, projection_dropout=dropout)
dim_feedforward = d_model
self.linear1 = Linear(d_model, dim_feedforward)
self.dropout1 = Dropout(dropout)
self.norm1 = LayerNorm(d_model)
self.linear2 = Linear(dim_feedforward, d_model)
self.dropout2 = Dropout(dropout)
self.drop_path = DropPath(
drop_path_rate) if drop_path_rate > 0 else Identity()
self.activation = F.gelu
def forward(self, src: torch.Tensor, *args, **kwargs) -> torch.Tensor:
# print(src.shape)
c = src.shape[-1]
src = rearrange(src, 'b d r c -> b (r c) d')
# print(src.shape)
src = src + self.drop_path(self.self_attn(self.pre_norm(src)))
src = self.norm1(src)
src2 = self.linear2(self.dropout1(self.activation(self.linear1(src))))
src = src + self.drop_path(self.dropout2(src2))
src = rearrange(src, 'b (r c) d -> b d r c', c=c)
return src
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""
Obtained from: github.com:rwightman/pytorch-image-models
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
# work with diff dim tensors, not just 2D ConvNets
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + \
torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(Module):
"""
Obtained from: github.com:rwightman/pytorch-image-models
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
================================================
FILE: examples/Structure_Evolution/MSE-NAS/readme.md
================================================
# Brain-Inspired Multi-scale Evolutionary Architectures for Spiking Neural Networks —— Based on BrainCog #
## Requirments ##
* numpy
* pytorch >= 1.12.0
* pymoo = 0.4.0
* BrainCog
## Run ##
```python evolution.py```
## Citation ##
If you find the code and dataset useful in your research, please consider citing:
```
@article{pan2024brain,
title={Brain-Inspired Multi-Scale Evolutionary Neural Architecture Search for Deep Spiking Neural Networks},
author={Pan, Wenxuan and Zhao, Feifei and Shen, Guobin and Han, Bing and Zeng, Yi},
journal={IEEE Transactions on Evolutionary Computation},
year={2024},
publisher={IEEE}
}
@article{zeng2023braincog,
title={BrainCog: A spiking neural network based, brain-inspired cognitive intelligence engine for brain-inspired AI and brain simulation},
author={Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and others},
journal={Patterns},
volume={4},
number={8},
year={2023},
publisher={Elsevier}
}
```
================================================
FILE: examples/Structure_Evolution/MSE-NAS/tm.py
================================================
import sys
sys.path.insert(0, '/home/panwenxuan/back')
import numpy as np
import argparse
import time
import obj
import timm.models
import yaml
import os
import logging
from random import choice
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from micro_encoding import ops
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
from braincog.datasets.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix
import micro_encoding
from pymop.problem import Problem
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from pymoo.optimize import minimize
from utils import data_transforms
from timm.data import create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
# from tn import TinyImageNet
import copy
from sklearn.metrics import confusion_matrix,roc_auc_score
from sklearn.preprocessing import label_binarize
def train_motifs(args,gen,arch_dir,genome,_logger,args_text,devices,bits):
if args.bns:
from cellmodel import NetworkCIFAR
else:
from cell123model import NetworkCIFAR
test_motifs,ids = micro_encoding.decode_motif(args.layers,bits,genome)
if gen==-1:
args.epochs=args.trainning_epochs
else:
args.epochs=args.eval_epochs
all_best=[]
try:
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
dataset=args.dataset,
step=args.step,
encode_type=args.encode,
node_type=eval(args.node_type),
threshold=args.threshold,
tau=args.tau,
sigmoid_thres=args.sigmoid_thres,
requires_thres_grad=args.requires_thres_grad,
spike_output=not args.no_spike_output,
C=args.init_channels,
layers=args.layers,
auxiliary=args.auxiliary,
motif=test_motifs,
parse_method=args.parse_method,
act_fun=args.act_fun,
temporal_flatten=args.temporal_flatten,
layer_by_layer=args.layer_by_layer,
n_groups=args.n_groups,
cell_type=genome[-1],
)
if 'dvs' in args.dataset:
args.channels = 2
# elif 'mnist' in args.dataset:
# args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
# _logger.info(model)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
sumpram=sum([m.numel() for m in model.parameters()])
_logger.info('Model %s created, param count: %d' %
(args.model, sumpram))
# return
# if sumpram > 15000000:
# return 0,0
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
optimizer = create_optimizer(args, model)
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
checkpoint = torch.load(args.resume, map_location='cpu')
model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
# print(model.get_attr('mu'))
# print(model.get_attr('sigma'))
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=devices).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
if args.critical_loss or args.spike_rate:
if args.num_gpu>1:
model.module.set_requires_fp(True)
else:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model, device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
temporal_flatten=args.temporal_flatten,
portion=args.train_portion,
_logger=_logger,
)
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
if args.distributed:
state_dict = torch.load(args.eval_checkpoint)['state_dict_ema']
new_state_dict = OrderedDict()
# add module prefix for DDP
for k, v in state_dict.items():
k = 'module.' + k
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
# else:
# load_checkpoint(model, args.eval_checkpoint, args.model_ema)
for i in range(1):
val_metrics = validate(start_epoch, model, loader_eval, validate_loss_fn, args,_logger,arch_dir,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
print(f"Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
# return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=arch_dir, recovery_dir=arch_dir, decreasing=decreasing)
with open(os.path.join(arch_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
# if epoch == 3 and best_metric<5:
# return 0,0
if args.distributed:
loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,_logger=_logger,
lr_scheduler=lr_scheduler, saver=saver, output_dir=arch_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler, model_ema=model_ema, mixup_fn=mixup_fn)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics = validate(epoch, model, loader_eval, validate_loss_fn, args,_logger, arch_dir,amp_autocast=amp_autocast,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics = validate(
epoch, model_ema.ema, loader_eval, validate_loss_fn, args, _logger,arch_dir,amp_autocast=amp_autocast, log_suffix=' (EMA)',
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(arch_dir, 'summary.csv'),
write_header=best_metric is None)
best_metric, best_epoch = eval_metrics[eval_metric],epoch
_logger.info('Test: {0} '.format(best_metric))
all_best.append(best_metric)
f=open(os.path.join(arch_dir, 'direct.txt'), 'a')
f.write(str(best_metric))
f.write('\n')
f.close()
f=open(os.path.join(arch_dir, 'direct_genome.txt'), 'a')
f.write(",".join(str(k) for k in genome))
f.write('\n')
f.close()
except KeyboardInterrupt:
pass
except MemoryError:
return -10000, all_best
except RuntimeError:
return -10000, all_best
return best_metric,all_best
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,_logger,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and loader.mixup_enabled:
loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
model.drop_path_prob = args.drop_path_prob * epoch / args.epochs
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
data_time_m.update(time.time() - end)
if not args.prefetcher or args.dataset != 'imnet':
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
if mixup_fn is not None:
inputs, target = mixup_fn(inputs, target)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
with amp_autocast():
output = model(inputs)
loss = loss_fn(output, target)
if not (args.cut_mix | args.mix_up | args.event_mix) and args.dataset != 'imnet':
# print(output.shape, target.shape)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
closs = torch.tensor([0.], device=loss.device)
if args.critical_loss:
closs = calc_critical_loss(model)
loss = loss + .1 * closs
spike_rate_avg_layer_str = ''
threshold_str = ''
if not args.distributed:
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), inputs.size(0))
top5_m.update(acc5.item(), inputs.size(0))
closses_m.update(closs.item(), inputs.size(0))
if args.num_gpu>1:
spike_rate_avg_layer = model.module.get_fire_rate().tolist()
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
threshold = model.module.get_threshold()
else:
spike_rate_avg_layer = model.get_fire_rate().tolist()
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
if args.opt == 'lamb':
optimizer.step(epoch=epoch)
else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
losses_m.update(reduced_loss.item(), inputs.size(0))
closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
if args.distributed:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
else:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>9.6f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})\n'
# 'Fire_rate: {spike_rate}\n'
# 'Thres: {threshold}\n'
# 'Mu: {mu_str}\n'
# 'Sigma: {sigma_str}\n'
.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m,
# spike_rate=spike_rate_avg_layer_str,
# threshold=threshold_str,
# mu_str=mu_str,
# sigma_str=sigma_str
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
return OrderedDict([('loss', losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args,_logger, arch_dir,amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
end = time.time()
last_idx = len(loader) - 1
all_probs = np.array([]).reshape(0, args.num_classes)
all_targets = np.array([])
attack=False
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if attack:
data2 = copy.deepcopy(inputs)
inputs = pgd_attack(model, data2, target, target.device, nn.CrossEntropyLoss())
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat) and not args.critical_loss:
if args.num_gpu>1:
model.module.set_requires_fp(True)
else:
model.set_requires_fp(True)
# if not args.critical_loss:
# model.set_requires_fp(False)
with amp_autocast():
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
if not args.distributed:
if visualize:
x = model.get_fp()
feature_path = os.path.join(arch_dir, 'feature_map')
if os.path.exists(feature_path) is False:
os.mkdir(feature_path)
save_feature_map(x, feature_path)
# if not args.critical_loss:
# model_config.set_requires_fp(False)
if tsne:
x = model.get_fp(temporal_info=False)[-1]
x = torch.nn.AdaptiveAvgPool2d((1, 1))(x)
x = x.reshape(x.shape[0], -1)
feature_vec.append(x)
feature_cls.append(target)
if conf_mat:
logits_vec.append(output)
labels_vec.append(target)
if spike_rate:
if args.num_gpu>1:
avg, var, spike, avg_per_step = model.module.get_spike_info()
else:
avg, var, spike, avg_per_step = model.get_spike_info()
save_spike_info(
os.path.join(arch_dir, 'spike_info.csv'),
epoch, batch_idx,
args.step, avg, var,
spike, avg_per_step)
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
loss = loss_fn(output, target)
probs = output.softmax(dim=1) #
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
all_probs = np.vstack([all_probs, probs.detach().cpu().numpy()])
all_targets = np.concatenate([all_targets, target.detach().cpu().numpy()])
closs = torch.tensor([0.], device=loss.device)
if not args.distributed:
if args.num_gpu>1:
spike_rate_avg_layer = model.module.get_fire_rate().tolist()
threshold = model.module.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
tot_spike = model.module.get_tot_spike()
else:
spike_rate_avg_layer = model.get_fire_rate().tolist()
threshold = model.get_threshold()
threshold_str = ['{:.3f}'.format(i) for i in threshold]
spike_rate_avg_layer_str = ['{:.3f}'.format(i) for i in spike_rate_avg_layer]
tot_spike = model.get_tot_spike()
if args.critical_loss:
closs = calc_critical_loss(model)
loss = loss + .1 * closs
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
closses_m.update(closs.item(), inputs.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
mu_str = ''
sigma_str = ''
if not args.distributed:
if 'Noise' in args.node_type:
mu, sigma = model.get_noise_param()
mu_str = ['{:.3f}'.format(i.detach()) for i in mu]
sigma_str = ['{:.3f}'.format(i.detach()) for i in sigma]
if args.distributed:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
))
else:
_logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'cLoss: {closs.val:>7.4f} ({closs.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})\n'
'Fire_rate: {spike_rate}\n'
'Tot_spike: {tot_spike}\n'
'Thres: {threshold}\n'
'Mu: {mu_str}\n'
'Sigma: {sigma_str}\n'.format(
log_name,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
closs=closses_m,
top1=top1_m,
top5=top5_m,
spike_rate=spike_rate_avg_layer_str,
tot_spike=tot_spike,
threshold=threshold_str,
mu_str=mu_str,
sigma_str=sigma_str
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
if not args.distributed:
if tsne:
feature_vec = torch.cat(feature_vec)
feature_cls = torch.cat(feature_cls)
plot_tsne(feature_vec, feature_cls, os.path.join(arch_dir, 't-sne-2d.eps'))
plot_tsne_3d(feature_vec, feature_cls, os.path.join(arch_dir, 't-sne-3d.eps'))
if conf_mat:
logits_vec = torch.cat(logits_vec)
labels_vec = torch.cat(labels_vec)
plot_confusion_matrix(logits_vec, labels_vec, os.path.join(arch_dir, 'confusion_matrix.eps'))
# 将真实标签二值化,为每个类别创建一个二进制标签
all_targets_binarized = label_binarize(all_targets, classes=range(args.num_classes))
# 使用roc_auc_score的multi_class和average参数来计算平均AUC
auc = roc_auc_score(all_targets_binarized, all_probs, multi_class='ovr', average='macro')
# print("Mean AUC: {:.2f}".format(auc))
return OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('auc', auc)])
================================================
FILE: examples/Structure_Evolution/MSE-NAS/utils.py
================================================
import json
import matplotlib.pyplot as plt
import os
import numpy as np
import torch
import shutil
import torchvision.transforms as transforms
from torch.autograd import Variable
from auto_augment import CIFAR10Policy
from braincog.model_zoo.darts.genotypes import PRIMITIVES
forward_edge_num = sum(1 for i in range(3) for n in range(2 + i))
backward_edge_num = sum(1 for i in range(3) for n in range(i))
num_ops = len(PRIMITIVES)
type_num = len(PRIMITIVES) // 2
# edge_num = [2, 3, 4]
edge_num = [2, 3, 4, 1, 2]
def drop_path(x, drop_prob):
if drop_prob > 0.:
keep_prob = 1. - drop_prob
mask = Variable(torch.cuda.FloatTensor(
x.size(0), 1, 1, 1).bernoulli_(keep_prob))
x.div_(keep_prob)
x.mul_(mask)
return x
class AvgrageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.avg = 0
self.sum = 0
self.cnt = 0
def update(self, val, n=1):
self.sum += val * n
self.cnt += n
self.avg = self.sum / self.cnt
def accuracy(output, target, topk=(1,)):
"""Compute the top1 and top5 accuracy
"""
maxk = max(topk)
batch_size = target.size(0)
# Return the k largest elements of the given input tensor
# along a given dimension -> N * k
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0)
res.append(correct_k.mul_(100.0 / batch_size))
return res
class Cutout(object):
def __init__(self, length):
self.length = length
def __call__(self, img):
h, w = img.size(1), img.size(2)
mask = np.ones((h, w), np.float32)
y = np.random.randint(h)
x = np.random.randint(w)
y1 = np.clip(y - self.length // 2, 0, h)
y2 = np.clip(y + self.length // 2, 0, h)
x1 = np.clip(x - self.length // 2, 0, w)
x2 = np.clip(x + self.length // 2, 0, w)
mask[y1: y2, x1: x2] = 0.
mask = torch.from_numpy(mask)
mask = mask.expand_as(img)
img *= mask
return img
def _data_transforms_cifar(args):
CIFAR_MEAN = [0.49139968, 0.48215827, 0.44653124] if args.dataset == 'cifar10' else [0.50707519, 0.48654887,
0.44091785]
CIFAR_STD = [0.24703233, 0.24348505, 0.26158768] if args.dataset == 'cifar10' else [0.26733428, 0.25643846,
0.27615049]
normalize_transform = [
transforms.ToTensor(),
transforms.Normalize(CIFAR_MEAN, CIFAR_STD)]
random_transform = [
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip()]
if args.auto_aug:
random_transform += [CIFAR10Policy()]
if args.cutout:
cutout_transform = [Cutout(args.cutout_length)]
else:
cutout_transform = []
train_transform = transforms.Compose(
random_transform + normalize_transform + cutout_transform
)
valid_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(CIFAR_MEAN, CIFAR_STD),
])
return train_transform, valid_transform
def count_parameters_in_MB(model):
return np.sum(np.prod(v.size()) for v in model.parameters()) / 1e6
def save_checkpoint(state, is_best, save):
filename = os.path.join(save, 'checkpoint.pth.tar')
torch.save(state, filename)
if is_best:
best_filename = os.path.join(save, 'model_best.pth.tar')
shutil.copyfile(filename, best_filename)
def save(model, model_path):
torch.save(model.state_dict(), model_path)
def load(model, model_path):
model.load_state_dict(torch.load(model_path))
def drop_path(x, drop_prob):
if drop_prob > 0.:
keep_prob = 1. - drop_prob
mask = Variable(torch.cuda.FloatTensor(
x.size(0), 1, 1, 1).bernoulli_(keep_prob))
x.div_(keep_prob)
x.mul_(mask)
return x
def create_exp_dir(path, scripts_to_save=None):
if not os.path.exists(path):
os.makedirs(path)
print('Experiment dir : {}'.format(path))
if scripts_to_save is not None:
os.makedirs(os.path.join(path, 'scripts'))
for script in scripts_to_save:
dst_file = os.path.join(path, 'scripts', os.path.basename(script))
shutil.copyfile(script, dst_file)
def calc_time(seconds):
m, s = divmod(seconds, 60)
h, m = divmod(m, 60)
t, h = divmod(h, 24)
return {'day': t, 'hour': h, 'minute': m, 'second': int(s)}
def save_file(recoder, path='./', back_connection=False):
size = (forward_edge_num +
backward_edge_num if back_connection else forward_edge_num, num_ops)
fig, axs = plt.subplots(*size, figsize=(36, 98))
row = 0
col = 0
for (k, v) in recoder.items():
axs[row, col].set_title(k)
axs[row, col].plot(v, 'r+')
if col == num_ops - 1:
col = 0
row += 1
else:
col += 1
if not os.path.exists(path):
os.makedirs(path)
fig.savefig(os.path.join(path, 'output.png'), bbox_inches='tight')
plt.tight_layout()
print('save history weight in {}'.format(os.path.join(path, 'output.png')))
with open(os.path.join(path, 'history_weight.json'), 'w') as outf:
json.dump(recoder, outf)
print('save history weight in {}'.format(
os.path.join(path, 'history_weight.json')))
def data_transforms(args):
if args.dataset == 'cifar10':
MEAN = [0.4913, 0.4821, 0.4465]
STD = [0.2470, 0.2434, 0.2615]
elif args.dataset == 'cifar100':
MEAN = [0.5071, 0.4867, 0.4408]
STD = [0.2673, 0.2564, 0.2762]
elif args.dataset == 'tinyimagenet':
MEAN = [0.485, 0.456, 0.406]
STD = [0.229, 0.224, 0.225]
if (args.dataset== 'tinyimagenet'):
train_transform = transforms.Compose([
transforms.RandomCrop(64, padding=8),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(MEAN, STD)
])
valid_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(MEAN, STD)
])
else: # cifar10 or cifar100
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(MEAN, STD)
])
valid_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(MEAN, STD)
])
return train_transform, valid_transform
================================================
FILE: examples/TIM/README.md
================================================
# TIM: An Efficient Temporal Interaction Module for Spiking Transformer, [IJCAI2024](https://arxiv.org/abs/2401.11687)

## Reference
```
@misc{shen2024tim,
title={TIM: An Efficient Temporal Interaction Module for Spiking Transformer},
author={Sicheng Shen and Dongcheng Zhao and Guobin Shen and Yi Zeng},
year={2024},
eprint={2401.11687},
archivePrefix={arXiv},
primaryClass={cs.NE}
}
```
Here is the official implemented code of TIM. The code is based on Pytorch and [Braincog](https://github.com/BrainCog-X/Brain-Cog)
## Requirements
### Create Braincog Virtual Environment
```
conda create -n braincog python=3.8
conda activate braincog
pip install braincog
```
### Dataset Preparation
**Datasets Needed**: CIFAR10-DVS, N-CALTECH101, UCF101DVS, NCARS, HMDB51DVS, SHD
Please unzip data to ```/data/datasets``` so that dataset.py may directly load corresponding dataset for training
## Model Training
For most DVS data, we prefer using the event-frame size of 64 but not 128 here.
Please adjust your hyper parameters here. 10 is set as the default value of time step numbers.
```
@register_model
def spikformer_dvs(pretrained=False, **kwargs):
model = Spikformer(TIM_alpha=0.5,step=10,if_UCF=False,num_classes=10,
# img_size_h=64, img_size_w=64,
# patch_size=16, embed_dims=256, num_heads=16, mlp_ratios=4,
# in_channels=2, qkv_bias=False,
# depths=2, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
```
### Training on CIFAR10-DVS
```
python main.py --model spikformer_dvs --dataset dvsc10 --epoch 500 --batch-size 16 --event-size 64
```
### Training on N-CALTECH101
```num_classes``` should be set to 101
```
python main.py --model spikformer_dvs --dataset NCALTECH101 --epoch 500 --batch-size 16 --event-size 64 --num_classes 101
```
### Training on NCARS
```num_classes``` should be set to 2
```
python main.py --model spikformer_dvs --dataset NCARS --epoch 500 --batch-size 16 --event-size 64 --num_classes 2
```
### Training on UCF101DVS
```num_classes``` should be set to 101,```if_UCF``` should be set to ```True```
```
python main.py --model spikformer_dvs --dataset UCF101DVS --epoch 500 --batch-size 16 --event-size 64 --num_classes 101
```
### Training on HMDB51DVS
```
python main.py --model spikformer_dvs --dataset HMDBDVS --epoch 500 --batch-size 16 --event-size 64 --num_classes 51
```
### Training on SHD
```num_classes``` should be set to 20
```
python main.py --model spikformer_shd --dataset SHD --epoch 500 --batch-size 16 --num_classes 20
```
================================================
FILE: examples/TIM/main.py
================================================
import argparse
import time
import timm.models
import yaml
import os
import random as buildin_random
import logging
from collections import OrderedDict
from contextlib import suppress
from datetime import datetime
from braincog.base.node.node import *
from braincog.utils import *
from braincog.base.utils.criterions import *
# from braincog.datasets.datasets import *
from utils.datasets import *
from braincog.model_zoo.resnet import *
from braincog.model_zoo.convnet import *
from braincog.model_zoo.vgg_snn import VGG_SNN, SNN5
from braincog.model_zoo.resnet19_snn import resnet19
from braincog.utils import save_feature_map, setup_seed
from braincog.base.utils.visualization import plot_tsne_3d, plot_tsne, plot_confusion_matrix, plot_mem_distribution
import torch
import torch.nn as nn
import torchvision.utils
from torch.nn.parallel import DistributedDataParallel as NativeDDP
from timm.data import ImageDataset, create_loader, resolve_data_config, Mixup, FastCollateMixup, AugMixDataset
from timm.models import load_checkpoint, create_model, resume_checkpoint, convert_splitbn_model, register_model
from timm.utils import *
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy, JsdCrossEntropy
from timm.optim import create_optimizer
from timm.scheduler import create_scheduler
from timm.utils import ApexScaler, NativeScaler
from torch.utils.tensorboard import SummaryWriter
from models.spikformer_braincog_DVS import spikformer_dvs
from models.spikformer_braincog_DVS import spikformer_shd
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
torch.backends.cudnn.benchmark = True
_logger = logging.getLogger('train')
# The first arg parser parses out only the --config argument, this argument is used to
# load a yaml file containing key-values that override the defaults for the main parser below
config_parser = parser = argparse.ArgumentParser(description='Training Config', add_help=False)
parser.add_argument('-c', '--config', default='', type=str, metavar='FILE',
help='YAML config file specifying default arguments')
parser = argparse.ArgumentParser(description='SNN Training and Evaluating')
# Model parameters
parser.add_argument('--dataset', default='dvsc10', type=str)
parser.add_argument('--model', default='spikformer', type=str, metavar='MODEL',
help='Name of model to train (default: "countception"')
parser.add_argument('--pretrained', action='store_true', default=False,
help='Start with pretrained version of specified network (if avail)')
parser.add_argument('--initial-checkpoint', default='', type=str, metavar='PATH',
help='Initialize model from this checkpoint (default: none)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='Resume full model and optimizer state from checkpoint (default: none)')
parser.add_argument('--eval_checkpoint', default='', type=str, metavar='PATH',
help='path to eval checkpoint (default: none)')
parser.add_argument('--no-resume-opt', action='store_true', default=False,
help='prevent resume of optimizer state when resuming model')
parser.add_argument('--num-classes', type=int, default=10, metavar='N',
help='number of label classes (default: 1000)')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
# Dataset parameters for static datasets
parser.add_argument('--img-size', type=int, default=224, metavar='N',
help='Image patch size (default: None => model default)')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='inputs image center crop percent (for validation only)')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
# Dataloader parameters
parser.add_argument('-b', '--batch-size', type=int, default=128, metavar='N',
help='inputs batch size for training (default: 128)')
parser.add_argument('-vb', '--validation-batch-size-multiplier', type=int, default=1, metavar='N',
help='ratio of validation batch size to training batch size (default: 1)')
# Optimizer parameters
parser.add_argument('--opt', default='adamw', type=str, metavar='OPTIMIZER',
help='Optimizer (default: "adamw"')
parser.add_argument('--opt-eps', default=1e-8, type=float, metavar='EPSILON',
help='Optimizer Epsilon (default: None, use opt default)')
parser.add_argument('--opt-betas', default=None, type=float, nargs='+', metavar='BETA',
help='Optimizer Betas (default: None, use opt default)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='Optimizer momentum (default: 0.9)')
parser.add_argument('--weight-decay', type=float, default=1e-4,
help='weight decay (default: 0.01 for adamw)')
parser.add_argument('--clip-grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--adam-epoch', type=int, default=1000, help='lamb switch to adamw')
# Learning rate schedule parameters
parser.add_argument('--sched', default='cosine', type=str, metavar='SCHEDULER',
help='LR scheduler (default: "cosine"')
parser.add_argument('--lr', type=float, default=5e-3, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--lr-noise', type=float, nargs='+', default=None, metavar='pct, pct',
help='learning rate noise on/off epoch percentages')
parser.add_argument('--lr-noise-pct', type=float, default=0.67, metavar='PERCENT',
help='learning rate noise limit percent (default: 0.67)')
parser.add_argument('--lr-noise-std', type=float, default=1.0, metavar='STDDEV',
help='learning rate noise std-dev (default: 1.0)')
parser.add_argument('--lr-cycle-mul', type=float, default=1.0, metavar='MULT',
help='learning rate cycle len multiplier (default: 1.0)')
parser.add_argument('--lr-cycle-limit', type=int, default=1, metavar='N',
help='learning rate cycle limit')
parser.add_argument('--warmup-lr', type=float, default=1e-6, metavar='LR',
help='warmup learning rate (default: 0.0001)')
parser.add_argument('--min-lr', type=float, default=1e-5, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0 (1e-5)')
parser.add_argument('--epochs', type=int, default=400, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--start-epoch', default=None, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--decay-epochs', type=float, default=30, metavar='N',
help='epoch interval to decay LR')
parser.add_argument('--warmup-epochs', type=int, default=5, metavar='N',
help='epochss to warmup LR, if scheduler supports')
parser.add_argument('--cooldown-epochs', type=int, default=10, metavar='N',
help='epochs to cooldown LR at min_lr, after cyclic schedule ends')
parser.add_argument('--patience-epochs', type=int, default=10, metavar='N',
help='patience epochs for Plateau LR scheduler (default: 10')
parser.add_argument('--decay-rate', '--dr', type=float, default=0.1, metavar='RATE',
help='LR decay rate (default: 0.1)')
parser.add_argument('--power', type=int, default=1, help='power')
# Augmentation & regularization parameters ONLY FOR IMAGE NET
parser.add_argument('--no-aug', action='store_true', default=False,
help='Disable all training augmentation, override other train aug args')
parser.add_argument('--scale', type=float, nargs='+', default=[0.08, 1.0], metavar='PCT',
help='Random resize scale (default: 0.08 1.0)')
parser.add_argument('--ratio', type=float, nargs='+', default=[3. / 4., 4. / 3.], metavar='RATIO',
help='Random resize aspect ratio (default: 0.75 1.33)')
parser.add_argument('--hflip', type=float, default=0.5,
help='Horizontal flip training aug probability')
parser.add_argument('--vflip', type=float, default=0.,
help='Vertical flip training aug probability')
parser.add_argument('--color-jitter', type=float, default=0.4, metavar='PCT',
help='Color jitter factor (default: 0.4)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". (default: None)'),
parser.add_argument('--aug-splits', type=int, default=0,
help='Number of augmentation splits (default: 0, valid: 0 or >=2)')
parser.add_argument('--jsd', action='store_true', default=False,
help='Enable Jensen-Shannon Divergence + CE loss. Use with `--aug-splits`.')
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "const")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
parser.add_argument('--mixup', type=float, default=0.,
help='mixup alpha, mixup enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix', type=float, default=0.,
help='cutmix alpha, cutmix enabled if > 0. (default: 0.)')
parser.add_argument('--cutmix-minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup-prob', type=float, default=0.,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup-switch-prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup-mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
parser.add_argument('--mixup-off-epoch', default=0, type=int, metavar='N',
help='Turn off mixup after this epoch, disabled if 0 (default: 0)')
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
parser.add_argument('--train-interpolation', type=str, default='random',
help='Training interpolation (random, bilinear, bicubic default: "random")')
parser.add_argument('--drop', type=float, default=0.0, metavar='PCT',
help='Dropout rate (default: 0.0)')
parser.add_argument('--drop-connect', type=float, default=None, metavar='PCT',
help='Drop connect rate, DEPRECATED, use drop-path (default: None)')
parser.add_argument('--drop-path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: None)')
parser.add_argument('--drop-block', type=float, default=None, metavar='PCT',
help='Drop block rate (default: None)')
parser.add_argument('--newton-maxiter', default=20, type=int,
help='max iterration in newton method')
parser.add_argument('--reset-drop', action='store_true', default=False,
help='whether to reset drop')
parser.add_argument('--kernel-method', type=str, default='cuda', choices=['torch', 'cuda'],
help='The implementation way of gaussian kernel method, choose from "cuda" and "torch"')
# Batch norm parameters (only works with gen_efficientnet based models currently)
parser.add_argument('--bn-tf', action='store_true', default=False,
help='Use Tensorflow BatchNorm defaults for models that support it (default: False)')
parser.add_argument('--bn-momentum', type=float, default=None,
help='BatchNorm momentum override (if not None)')
parser.add_argument('--bn-eps', type=float, default=None,
help='BatchNorm epsilon override (if not None)')
parser.add_argument('--sync-bn', action='store_true',
help='Enable NVIDIA Apex or Torch synchronized BatchNorm.')
parser.add_argument('--dist-bn', type=str, default='',
help='Distribute BatchNorm stats between node after each epoch ("broadcast", "reduce", or "")')
parser.add_argument('--split-bn', action='store_true',
help='Enable separate BN layers per augmentation split.')
# Model Exponential Moving Average
parser.add_argument('--model-ema', action='store_true', default=False,
help='Enable tracking moving average of model weights')
parser.add_argument('--model-ema-force-cpu', action='store_true', default=False,
help='Force ema to be tracked on CPU, rank=0 node only. Disables EMA validation.')
parser.add_argument('--model-ema-decay', type=float, default=0.99996,
help='decay factor for model weights moving average (default: 0.9998)')
# Misc
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=50, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--recovery-interval', type=int, default=0, metavar='N',
help='how many batches to wait before writing recovery checkpoint')
parser.add_argument('-j', '--workers', type=int, default=8, metavar='N',
help='how many training processes to use (default: 1)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
parser.add_argument('--save-images', action='store_true', default=False,
help='save images of inputs bathes every log interval for debugging')
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--apex-amp', action='store_true', default=False,
help='Use NVIDIA Apex AMP mixed precision')
parser.add_argument('--native-amp', action='store_true', default=False,
help='Use Native Torch AMP mixed precision')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--output', default='/home/shensicheng/code/TIM/logs', type=str, metavar='PATH',
help='path to output folder (default: none, current dir)')
parser.add_argument('--tensorboard-dir', default='./runs', type=str)
parser.add_argument('--eval-metric', default='top1', type=str, metavar='EVAL_METRIC',
help='Best metric (default: "top1"')
parser.add_argument('--tta', type=int, default=0, metavar='N',
help='Test/inference time augmentation (oversampling) factor. 0=None (default: 0)')
parser.add_argument('--local_rank', default=0, type=int)
parser.add_argument('--use-multi-epochs-loader', action='store_true', default=False,
help='use the multi-epochs-loader to save time at the beginning of every epoch')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--device', type=int, default=0)
# Spike parameters
parser.add_argument('--step', type=int, default=10, help='Simulation time step (default: 10)')
parser.add_argument('--encode', type=str, default='direct', help='Input encode method (default: direct)')
parser.add_argument('--temporal-flatten', action='store_true',
help='Temporal flatten to channels. ONLY FOR EVENT DATA TRAINING BY ANN')
parser.add_argument('--adaptive-node', action='store_true')
parser.add_argument('--critical-loss', action='store_true')
parser.add_argument('--conv-type', type=str, default='normal')
parser.add_argument('--sew-cnf', type=str, default='ADD')
parser.add_argument('--rand-step', action='store_true')
# neuron type
parser.add_argument('--node-type', type=str, default='LIFNode', help='Node type in network (default: PLIF)')
parser.add_argument('--act-fun', type=str, default='QGateGrad',
help='Surogate Function in node. Only for Surrogate nodes (default: AtanGrad)')
parser.add_argument('--threshold', type=float, default=.5, help='Firing threshold (default: 0.5)')
parser.add_argument('--tau', type=float, default=2., help='Attenuation coefficient (default: 2.)')
parser.add_argument('--requires-thres-grad', action='store_true')
parser.add_argument('--sigmoid-thres', action='store_true')
parser.add_argument('--loss-fn', type=str, default='ce', help='loss function (default: ce)')
parser.add_argument('--noisy-grad', type=float, default=0.,
help='Add noise to backward, sometime will make higher accuracy (default: 0.)')
parser.add_argument('--spike-output', action='store_true', default=False,
help='Using mem output or spike output (default: False)')
parser.add_argument('--n_groups', type=int, default=1)
parser.add_argument('--n-encode-type', type=str, default='linear')
parser.add_argument('--n-preact', action='store_true')
parser.add_argument('--layer-by-layer', action='store_true',
help='forward step-by-step or layer-by-layer. '
'Larger Model with layer-by-layer will be faster (default: False)')
parser.add_argument('--tet-loss', action='store_true')
# EventData Augmentation
parser.add_argument('--mix-up', action='store_true', help='Mix-up for event data (default: False)')
parser.add_argument('--cut-mix', action='store_true', help='CutMix for event data (default: False)')
parser.add_argument('--event-mix', action='store_true', help='EventMix for event data (default: False)')
parser.add_argument('--cutmix_beta', type=float, default=2.0, help='cutmix_beta (default: 1.)')
parser.add_argument('--cutmix_prob', type=float, default=0.5, help='cutmix_prib for event data (default: .5)')
parser.add_argument('--cutmix_num', type=int, default=1, help='cutmix_num for event data (default: 1)')
parser.add_argument('--cutmix_noise', type=float, default=0.,
help='Add Pepper noise after mix, sometimes work (default: 0.)')
parser.add_argument('--gaussian-n', type=int, default=3)
parser.add_argument('--rand-aug', action='store_true',
help='Rand Augment for Event data (default: False)')
parser.add_argument('--randaug_n', type=int, default=3,
help='Rand Augment times n (default: 3)')
parser.add_argument('--randaug_m', type=int, default=15,
help='Rand Augment times n (default: 15) (0-30)')
parser.add_argument('--train-portion', type=float, default=0.9,
help='Dataset portion, only for datasets which do not have validation set (default: 0.9)')
parser.add_argument('--event-size', default=48, type=int,
help='Event size. Resize event data before process (default: 48)')
parser.add_argument('--node-resume', type=str, default='',
help='resume weights in node for adaptive node. (default: False)')
# visualize
parser.add_argument('--visualize', action='store_true',
help='Visualize spiking map for each layer, only for validate (default: False)')
parser.add_argument('--spike-rate', action='store_true',
help='Print spiking rate for each layer, only for validate(default: False)')
parser.add_argument('--tsne', action='store_true')
parser.add_argument('--conf-mat', action='store_true')
parser.add_argument('--mem-dist', action='store_true')
parser.add_argument('--adaptation-info', action='store_true')
parser.add_argument('--suffix', type=str, default='',
help='Add an additional suffix to the save path (default: \'\')')
try:
from apex import amp
from apex.parallel import DistributedDataParallel as ApexDDP
from apex.parallel import convert_syncbn_model
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
def _parse_args():
# Do we have a config file to parse?
args_config, remaining = config_parser.parse_known_args()
if args_config.config:
with open(args_config.config, 'r') as f:
cfg = yaml.safe_load(f)
parser.set_defaults(**cfg)
# The main arg parser parses the rest of the args, the usual
# defaults will have been overridden if config file specified.
args = parser.parse_args(remaining)
# Cache the args as a text string to save them in the output dir later
args_text = yaml.safe_dump(args.__dict__, default_flow_style=False)
return args, args_text
def main():
args, args_text = _parse_args()
# args.no_spike_output = args.no_spike_output | args.cut_mix
args.no_spike_output = True
output_dir = ''
if args.local_rank == 0:
output_base = args.output if args.output else './output'
exp_name = '-'.join([
args.model,
args.dataset,
args.node_type,
str(args.step),
args.suffix,
datetime.now().strftime("%Y%m%d-%H%M%S"),
# str(args.img_size)
])
output_dir = get_outdir(output_base, 'train', exp_name)
args.output_dir = output_dir
setup_default_logging(log_path=os.path.join(output_dir, 'log.txt'))
summary_writer = SummaryWriter(log_dir=os.path.join(args.tensorboard_dir, exp_name))
args.tensorboard_prefix = os.path.join(args.dataset, args.model)
else:
summary_writer = None
setup_default_logging()
args.prefetcher = not args.no_prefetcher
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed and args.num_gpu > 1:
_logger.warning(
'Using more than one GPU per process in distributed mode is not allowed.Setting num_gpu to 1.')
args.num_gpu = 1
# args.device = 'cuda:0'
args.world_size = 1
args.rank = 0 # global rank
if args.distributed:
args.num_gpu = 1
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
else:
torch.cuda.set_device('cuda:%d' % args.device)
assert args.rank >= 0
if args.distributed:
_logger.info('Training in distributed mode with multiple processes, 1 GPU per process. Process %d, total %d.'
% (args.rank, args.world_size))
else:
_logger.info('Training with a single process on %d GPUs.' % args.num_gpu)
# torch.manual_seed(args.seed + args.rank)
setup_seed(args.seed + args.rank)
model = create_model(
args.model,
# pretrained=args.pretrained,
# num_classes=args.num_classes,
# dataset=args.dataset,
# step=args.step,
# encode_type=args.encode,
# node_type=eval(args.node_type),
# threshold=args.threshold,
# tau=args.tau,
# sigmoid_thres=args.sigmoid_thres,
# requires_thres_grad=args.requires_thres_grad,
# spike_output=not args.no_spike_output,
# act_fun=args.act_fun,
# temporal_flatten=args.temporal_flatten,
# layer_by_layer=args.layer_by_layer,
# n_groups=args.n_groups,
# n_encode_type=args.n_encode_type,
# n_preact=args.n_preact,
# tet_loss=args.tet_loss,
# sew_cnf=args.sew_cnf,
# conv_type=args.conv_type,
)
_logger.info('[MODEL ARCH]\n{}'.format(model))
if 'dvs' in args.dataset:
args.channels = 2
elif 'mnist' in args.dataset:
args.channels = 1
else:
args.channels = 3
# flops, params = profile(model, inputs=(torch.randn(1, args.channels, args.event_size, args.event_size),), verbose=False)
# _logger.info('flops = %fM', flops / 1e6)
# _logger.info('param size = %fM', params / 1e6)
linear_scaled_lr = args.lr * args.batch_size * args.world_size / 1024.0
args.lr = linear_scaled_lr
_logger.info("learning rate is %f" % linear_scaled_lr)
if args.local_rank == 0:
_logger.info('Model %s created, param count: %d' %
(args.model, sum([m.numel() for m in model.parameters()])))
num_aug_splits = 0
if args.aug_splits > 0:
assert args.aug_splits > 1, 'A split of 1 makes no sense'
num_aug_splits = args.aug_splits
if args.split_bn:
assert num_aug_splits > 1 or args.resplit
model = convert_splitbn_model(model, max(num_aug_splits, 2))
use_amp = None
if args.amp:
# for backwards compat, `--amp` arg tries apex before native amp
if has_apex:
args.apex_amp = True
elif has_native_amp:
args.native_amp = True
if args.apex_amp and has_apex:
use_amp = 'apex'
elif args.native_amp and has_native_amp:
use_amp = 'native'
elif args.apex_amp or args.native_amp:
_logger.warning("Neither APEX or native Torch AMP is available, using float32. "
"Install NVIDA apex or upgrade to PyTorch 1.6")
if args.num_gpu > 1:
if use_amp == 'apex':
_logger.warning(
'Apex AMP does not work well with nn.DataParallel, disabling. Use DDP or Torch AMP.')
use_amp = None
model = nn.DataParallel(model, device_ids=list(range(args.num_gpu))).cuda()
assert not args.channels_last, "Channels last not supported with DP, use DDP."
else:
model = model.cuda()
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
optimizer = create_optimizer(args, model)
_logger.info('[OPTIMIZER]\n{}'.format(optimizer))
amp_autocast = suppress # do nothing
loss_scaler = None
if use_amp == 'apex':
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
loss_scaler = ApexScaler()
if args.local_rank == 0:
_logger.info('Using NVIDIA APEX AMP. Training in mixed precision.')
elif use_amp == 'native':
amp_autocast = torch.cuda.amp.autocast
loss_scaler = NativeScaler()
if args.local_rank == 0:
_logger.info('Using native Torch AMP. Training in mixed precision.')
else:
if args.local_rank == 0:
_logger.info('AMP not enabled. Training in float32.')
# optionally resume from a checkpoint
resume_epoch = None
if args.resume and args.eval_checkpoint == '':
args.eval_checkpoint = args.resume
if args.resume:
args.eval = True
# checkpoint = torch.load(args.resume, map_location='cpu')
# model.load_state_dict(checkpoint['state_dict'], False)
resume_epoch = resume_checkpoint(
model, args.resume,
optimizer=None if args.no_resume_opt else optimizer,
loss_scaler=None if args.no_resume_opt else loss_scaler,
log_info=args.local_rank == 0)
# print(model.get_attr('mu'))
# print(model.get_attr('sigma'))
if hasattr(model, 'set_threshold'):
model.set_threshold(args.threshold)
if args.critical_loss or args.spike_rate:
model.set_requires_fp(True)
model_ema = None
if args.model_ema:
# Important to create EMA model after cuda(), DP wrapper, and AMP but before SyncBN and DDP wrapper
model_ema = ModelEma(
model,
decay=args.model_ema_decay,
device='cpu' if args.model_ema_force_cpu else '',
resume=args.resume)
if args.node_resume:
ckpt = torch.load(args.node_resume, map_location='cpu')
model.load_node_weight(ckpt, args.node_trainable)
model_without_ddp = model
if args.distributed:
if args.sync_bn:
assert not args.split_bn
try:
if has_apex and use_amp != 'native':
# Apex SyncBN preferred unless native amp is activated
model = convert_syncbn_model(model)
else:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
if args.local_rank == 0:
_logger.info(
'Converted model to use Synchronized BatchNorm. WARNING: You may have issues if using '
'zero initialized BN layers (enabled by default for ResNets) while sync-bn enabled.')
except Exception as e:
_logger.error('Failed to enable Synchronized BatchNorm. Install Apex or Torch >= 1.1')
if has_apex and use_amp != 'native':
# Apex DDP preferred unless native amp is activated
if args.local_rank == 0:
_logger.info("Using NVIDIA APEX DistributedDataParallel.")
model = ApexDDP(model, delay_allreduce=True)
else:
if args.local_rank == 0:
_logger.info("Using native Torch DistributedDataParallel.")
model = NativeDDP(model.cuda(), device_ids=[args.local_rank],
find_unused_parameters=True) # can use device str in Torch >= 1.1
model_without_ddp = model.module
# NOTE: EMA model does not need to be wrapped by DDP
lr_scheduler, num_epochs = create_scheduler(args, optimizer)
start_epoch = 0
if args.start_epoch is not None:
# a specified start_epoch will always override the resume epoch
start_epoch = args.start_epoch
elif resume_epoch is not None:
start_epoch = resume_epoch
if lr_scheduler is not None and start_epoch > 0:
lr_scheduler.step(start_epoch)
if args.local_rank == 0:
_logger.info('Scheduled epochs: {}'.format(num_epochs))
# now config only for imnet
data_config = resolve_data_config(vars(args), model=model, verbose=False)
loader_train, loader_eval, mixup_active, mixup_fn = eval('get_%s_data' % args.dataset)(
batch_size=args.batch_size,
step=args.step,
args=args,
_logge=_logger,
data_config=data_config,
num_aug_splits=num_aug_splits,
size=args.event_size,
mix_up=args.mix_up,
cut_mix=args.cut_mix,
event_mix=args.event_mix,
beta=args.cutmix_beta,
prob=args.cutmix_prob,
gaussian_n=args.gaussian_n,
num=args.cutmix_num,
noise=args.cutmix_noise,
num_classes=args.num_classes,
rand_aug=args.rand_aug,
randaug_n=args.randaug_n,
randaug_m=args.randaug_m,
portion=args.train_portion,
_logger=_logger,
)
# _logger.info('train_loader:\n{}\nval_loader:\n{}'.format(loader_train, loader_eval))
if args.loss_fn == 'mse':
train_loss_fn = UnilateralMse(1.)
validate_loss_fn = UnilateralMse(1.)
elif args.loss_fn == 'onehot-mse':
train_loss_fn = OnehotMse(args.num_classes)
validate_loss_fn = OnehotMse(args.num_classes)
else:
if args.jsd:
assert num_aug_splits > 1 # JSD only valid with aug splits set
train_loss_fn = JsdCrossEntropy(num_splits=num_aug_splits, smoothing=args.smoothing).cuda()
elif mixup_active:
# smoothing is handled with mixup target transform
train_loss_fn = SoftTargetCrossEntropy().cuda()
elif args.smoothing:
train_loss_fn = LabelSmoothingCrossEntropy(smoothing=args.smoothing).cuda()
else:
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
if args.loss_fn == 'mix':
train_loss_fn = MixLoss(train_loss_fn)
validate_loss_fn = MixLoss(validate_loss_fn)
if args.tet_loss:
train_loss_fn = TetLoss(train_loss_fn)
validate_loss_fn = TetLoss(validate_loss_fn)
eval_metric = args.eval_metric
best_metric = None
best_epoch = None
if args.eval: # evaluate the model
# if args.distributed:
# raise NotImplementedError('eval not has not been verified for distributed')
# else:
# load_checkpoint(model, args.eval_checkpoint, args.model_ema)
model.eval()
for t in range(1, args.step * 3):
# for t in range(args.step, args.step + 1):
model.set_attr('step', t)
val_metrics = validate(start_epoch, model, loader_eval, validate_loss_fn, args,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer)
print(f"[STEP:{t}], Top-1 accuracy of the model is: {val_metrics['top1']:.1f}%")
return
saver = None
if args.local_rank == 0:
decreasing = True if eval_metric == 'loss' else False
saver = CheckpointSaver(
model=model, optimizer=optimizer, args=args, model_ema=model_ema, amp_scaler=loss_scaler,
checkpoint_dir=output_dir, recovery_dir=output_dir, decreasing=decreasing, max_history=3)
with open(os.path.join(output_dir, 'args.yaml'), 'w') as f:
f.write(args_text)
try: # train the model
if args.reset_drop:
model_without_ddp.reset_drop_path(0.0)
for epoch in range(start_epoch, args.epochs):
if epoch == 0 and args.reset_drop:
model_without_ddp.reset_drop_path(args.drop_path)
if args.distributed:
loader_train.sampler.set_epoch(epoch)
train_metrics = train_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args,
lr_scheduler=lr_scheduler, saver=saver, output_dir=output_dir,
amp_autocast=amp_autocast, loss_scaler=loss_scaler,
model_ema=model_ema, mixup_fn=mixup_fn, summary_writer=summary_writer
)
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
if args.local_rank == 0:
_logger.info("Distributing BatchNorm running means and vars")
distribute_bn(model, args.world_size, args.dist_bn == 'reduce')
eval_metrics = validate(epoch, model, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast,
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer)
if model_ema is not None and not args.model_ema_force_cpu:
if args.distributed and args.dist_bn in ('broadcast', 'reduce'):
distribute_bn(model_ema, args.world_size, args.dist_bn == 'reduce')
ema_eval_metrics = validate(
epoch, model_ema.ema, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast, log_suffix=' (EMA)',
visualize=args.visualize, spike_rate=args.spike_rate,
tsne=args.tsne, conf_mat=args.conf_mat, summary_writer=summary_writer
)
eval_metrics = ema_eval_metrics
if lr_scheduler is not None:
# step LR for next epoch
lr_scheduler.step(epoch + 1, eval_metrics[eval_metric])
update_summary(
epoch, train_metrics, eval_metrics, os.path.join(output_dir, 'summary.csv'),
write_header=best_metric is None)
# if saver is not None and epoch >= args.n_warm_up:
if saver is not None:
# save proper checkpoint with eval metric
save_metric = eval_metrics[eval_metric]
best_metric, best_epoch = saver.save_checkpoint(epoch, metric=save_metric)
except KeyboardInterrupt:
pass
if best_metric is not None:
_logger.info('*** Best metric: {0} (epoch {1})'.format(best_metric, best_epoch))
def train_epoch(
epoch, model, loader, optimizer, loss_fn, args,
lr_scheduler=None, saver=None, output_dir='', amp_autocast=suppress,
loss_scaler=None, model_ema=None, mixup_fn=None, summary_writer=None):
if args.mixup_off_epoch and epoch >= args.mixup_off_epoch:
if args.prefetcher and loader.mixup_enabled:
loader.mixup_enabled = False
elif mixup_fn is not None:
mixup_fn.mixup_enabled = False
second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
# closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
model.train()
# t, k = adjust_surrogate_coeff(100, args.epochs)
# model.set_attr('t', t)
# model.set_attr('k', k)
end = time.time()
last_idx = len(loader) - 1
num_updates = epoch * len(loader)
iters_per_epoch = len(loader)
for batch_idx, (inputs, target) in enumerate(loader):
last_batch = batch_idx == last_idx
if args.rand_step:
step = buildin_random.randint(1, args.step + 2)
model.set_attr('step', step)
data_time_m.update(time.time() - end)
if not args.prefetcher or args.dataset != 'imnet':
inputs, target = inputs.type(torch.FloatTensor).cuda(), target.cuda()
if mixup_fn is not None:
inputs, target = mixup_fn(inputs, target)
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
with amp_autocast():
output = model(inputs)
loss = loss_fn(output, target)
if args.tet_loss:
output = output.mean(0)
if not (args.cut_mix | args.mix_up | args.event_mix | (args.cutmix != 0.) | (args.mixup != 0.)):
# print(output.shape, target.shape)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
# acc1, = accuracy(output, target)
else:
acc1, acc5 = torch.tensor([0.]), torch.tensor([0.])
optimizer.zero_grad()
if loss_scaler is not None:
loss_scaler(
loss, optimizer, clip_grad=args.clip_grad, parameters=model.parameters(), create_graph=second_order)
else:
loss.backward(create_graph=second_order)
if args.noisy_grad != 0.:
random_gradient(model, args.noisy_grad)
if args.clip_grad is not None:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_grad)
# if args.opt == 'lamb':
# optimizer.step(epoch=epoch)
# else:
optimizer.step()
torch.cuda.synchronize()
if model_ema is not None:
model_ema.update(model)
num_updates += 1
batch_time_m.update(time.time() - end)
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/top1'), acc1.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/top5'), acc5.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/train/loss'), loss.item(), epoch * iters_per_epoch + batch_idx)
if last_batch or batch_idx % args.log_interval == 0:
lrl = [param_group['lr'] for param_group in optimizer.param_groups]
lr = sum(lrl) / len(lrl)
if args.distributed:
loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
losses_m.update(loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
# closses_m.update(reduced_loss.item(), inputs.size(0))
if args.local_rank == 0:
# if args.distributed:
_logger.info(
'Train: {} [{:>4d}/{} ({:>3.0f}%)] '
'Loss: {loss.val:>9.6f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f}) '
'Time: {batch_time.val:.3f}s, {rate:>7.2f}/s '
'({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'LR: {lr:.3e} '
'Data: {data_time.val:.3f} ({data_time.avg:.3f})'.format(
epoch,
batch_idx, len(loader),
100. * batch_idx / last_idx,
loss=losses_m,
top1=top1_m,
top5=top5_m,
batch_time=batch_time_m,
rate=inputs.size(0) * args.world_size / batch_time_m.val,
rate_avg=inputs.size(0) * args.world_size / batch_time_m.avg,
lr=lr,
data_time=data_time_m
))
if args.save_images and output_dir:
torchvision.utils.save_image(
inputs,
os.path.join(output_dir, 'train-batch-%d.jpg' % batch_idx),
padding=0,
normalize=True)
if saver is not None and args.recovery_interval and (
last_batch or (batch_idx + 1) % args.recovery_interval == 0):
saver.save_recovery(epoch, batch_idx=batch_idx)
if lr_scheduler is not None:
lr_scheduler.step_update(num_updates=num_updates, metric=losses_m.avg)
end = time.time()
# end for
if hasattr(optimizer, 'sync_lookahead'):
optimizer.sync_lookahead()
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/top1'), top1_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/top5'), top5_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/train/loss'), losses_m.avg, epoch)
if args.rand_step:
model.set_attr('step', args.step)
return OrderedDict([('loss', losses_m.avg)])
def validate(epoch, model, loader, loss_fn, args, amp_autocast=suppress,
log_suffix='', visualize=False, spike_rate=False, tsne=False, conf_mat=False, summary_writer=None):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
# closses_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
spike_m = AverageMeter()
model.eval()
feature_vec = []
feature_cls = []
logits_vec = []
labels_vec = []
mem_vec = []
end = time.time()
last_idx = len(loader) - 1
iters_per_epoch = len(loader)
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(loader):
# inputs = inputs.type(torch.float64)
last_batch = batch_idx == last_idx
if not args.prefetcher or args.dataset != 'imnet':
inputs = inputs.type(torch.FloatTensor).cuda()
target = target.cuda()
if args.channels_last:
inputs = inputs.contiguous(memory_format=torch.channels_last)
if not args.distributed:
if (visualize or spike_rate or tsne or conf_mat or args.mem_dist) and not args.critical_loss:
model.set_requires_fp(True)
with amp_autocast():
output = model(inputs)
if isinstance(output, (tuple, list)):
output = output[0]
# augmentation reduction
reduce_factor = args.tta
if reduce_factor > 1:
output = output.unfold(0, reduce_factor, reduce_factor).mean(dim=2)
target = target[0:target.size(0):reduce_factor]
# print(args.rank, output.shape, target.shape, max(target))
loss = loss_fn(output, target)
if args.tet_loss:
output = output.mean(0)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
if args.distributed:
reduced_loss = reduce_tensor(loss.data, args.world_size)
acc1 = reduce_tensor(acc1, args.world_size)
acc5 = reduce_tensor(acc5, args.world_size)
else:
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), inputs.size(0))
top1_m.update(acc1.item(), output.size(0))
top5_m.update(acc5.item(), output.size(0))
# closses_m.update(closs, inputs.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/top1'), acc1.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/top5'), acc5.item(), epoch * iters_per_epoch + batch_idx)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'batch/val/loss'), loss.item(), epoch * iters_per_epoch + batch_idx)
if args.local_rank == 0 and (last_batch or batch_idx % args.log_interval == 0):
log_name = 'Test' + log_suffix
if not args.distributed and spike_rate:
spike_m.update(model.get_tot_spike() / output.size(0), output.size(0))
if not args.distributed and spike_rate:
_logger.info(
'[Spike Info]: {spike.val} ({spike.avg})'.format(
spike=spike_m
)
)
if last_batch or batch_idx % args.log_interval == 0:
_logger.info(
'Eval : {} '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f})'
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
epoch,
batch_idx,
last_idx,
batch_time=batch_time_m,
loss=losses_m,
top1=top1_m,
top5=top5_m,
))
# metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg), ('top5', top5_m.avg)])
metrics = OrderedDict([('loss', losses_m.avg), ('top1', top1_m.avg)])
if args.local_rank == 0:
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/top1'), top1_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/top5'), top5_m.avg, epoch)
summary_writer.add_scalar(os.path.join(args.tensorboard_prefix, 'epoch/val/loss'), losses_m.avg, epoch)
return metrics
if __name__ == '__main__':
main()
================================================
FILE: examples/TIM/models/TIM.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from utils.MyNode import *
class TIM(BaseModule):
def __init__(self,dim=256,encode_type='direct',in_channels=16,TIM_alpha=0.5):
super().__init__(step=1,encode_type=encode_type)
# channels may depends on the shape of input
self.interactor = nn.Conv1d(in_channels=in_channels,out_channels=in_channels,kernel_size=5, stride=1, padding=2, bias=True)
self.in_lif = MyNode(tau=2.0,v_threshold=0.3,layer_by_layer=False,step=1) #spike-driven
self.out_lif = MyNode(tau=2.0,v_threshold=0.5,layer_by_layer=False,step=1) #spike-driven
self.tim_alpha = TIM_alpha
# input [T, B, H, N, C/H]
def forward(self, x):
self.reset()
T, B, H, N, CoH = x.shape
output = []
x_tim = torch.empty_like(x[0])
#temporal interaction
for i in range(T):
#1st step
if i == 0 :
x_tim = x[i]
output.append(x_tim)
#other steps
else:
x_tim = self.interactor(x_tim.flatten(0,1)).reshape(B,H,N,CoH).contiguous()
x_tim = self.in_lif(x_tim) * self.tim_alpha + x[i] * (1-self.tim_alpha)
x_tim = self.out_lif(x_tim)
output.append(x_tim)
output = torch.stack(output) # T B H, N, C/H
return output # T B H, N, C/H
================================================
FILE: examples/TIM/models/spikformer_braincog_DVS.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from functools import partial
from torchvision import transforms
from utils.MyNode import *
from models.TIM import *
__all__ = ['spikformer']
class MLP(BaseModule):
def __init__(self,in_features,step=10,encode_type='direct',hidden_features=None, out_features=None, drop=0.):
super().__init__(step=10,encode_type='direct')
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_conv = nn.Conv1d(in_features, hidden_features, kernel_size=1, stride=1)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step,tau=2.0)
self.fc2_conv = nn.Conv1d(hidden_features, out_features, kernel_size=1, stride=1)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step,tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T,B,C,N = x.shape
x = self.fc1_conv(x.flatten(0,1))
x = self.fc1_bn(x).reshape(T, B, self.c_hidden, N ).contiguous() # T B C N
x = self.fc1_lif(x.flatten(0,1)).reshape(T, B, self.c_hidden, N).contiguous()
x = self.fc2_conv(x.flatten(0,1))
x = self.fc2_bn(x).reshape(T, B, C, N).contiguous()
x = self.fc2_lif(x.flatten(0,1)).reshape(T, B, C, N ).contiguous()
return x
class SSA(BaseModule):
def __init__(self,dim,step=10,encode_type='direct',num_heads=16,TIM_alpha=0.5,qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__(step=10,encode_type='direct')
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
self.in_channels = dim // num_heads
self.scale = 0.25
self.q_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.q_bn = nn.BatchNorm1d(dim)
self.q_lif = MyNode(step=step,tau=2.0)
self.k_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.k_bn = nn.BatchNorm1d(dim)
self.k_lif = MyNode(step=step,tau=2.0)
self.v_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.v_bn = nn.BatchNorm1d(dim)
self.v_lif = MyNode(step=step,tau=2.0)
self.attn_drop = nn.Dropout(0.2)
self.res_lif = MyNode(step=step, tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5,)
self.proj_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.proj_bn = nn.BatchNorm1d(dim)
self.proj_lif = MyNode(step=step, tau=2.0,)
self.TIM = TIM(TIM_alpha=TIM_alpha,in_channels=self.in_channels)
def forward(self, x):
self.reset()
T,B,C,N = x.shape
x_for_qkv = x.flatten(0, 1)
q_conv_out = self.q_conv(x_for_qkv)
q_conv_out = self.q_bn(q_conv_out).reshape(T, B, C, N).contiguous()
q_conv_out = self.q_lif(q_conv_out.flatten(0,1)).reshape(T, B, C ,N).transpose(-2,-1)
q = q_conv_out.reshape(T, B, N, self.num_heads, C//self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_conv_out = self.k_conv(x_for_qkv)
k_conv_out = self.k_bn(k_conv_out).reshape(T, B, C, N).contiguous()
k_conv_out= self.k_lif(k_conv_out.flatten(0,1)).reshape(T, B, C ,N).transpose(-2,-1)
k = k_conv_out.reshape(T, B, N, self.num_heads, C//self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_conv_out = self.v_conv(x_for_qkv)
v_conv_out = self.v_bn(v_conv_out).reshape(T, B, C, N).contiguous()
v_conv_out = self.v_lif(v_conv_out.flatten(0,1)).reshape(T, B, C ,N).transpose(-2,-1)
v = v_conv_out.reshape(T, B, N, self.num_heads, C//self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
#TIM on Q
q = self.TIM(q)
#SSA
attn = (q @ k.transpose(-2, -1))
x = (attn @ v) * self.scale
x = x.transpose(3,4).reshape(T, B, C, N).contiguous()
x = self.attn_lif(x.flatten(0,1))
x = self.proj_lif(self.proj_bn(self.proj_conv(x))).reshape(T, B, C, N)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, step=10,TIM_alpha=0.5, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = SSA(dim, step=step,TIM_alpha=TIM_alpha,num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(in_features=dim,step=step, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
x = x + self.attn(x)
x = x + self.mlp(x)
return x
class SPS(BaseModule):
def __init__(self, step=10, encode_type='direct', img_size_h=64, img_size_w=64, patch_size=4, in_channels=2,
embed_dims=256,if_UCF=False):
super().__init__(step=10, encode_type='direct')
self.image_size = [img_size_h, img_size_w]
patch_size = to_2tuple(patch_size)
self.patch_size = patch_size
self.C = in_channels
self.H, self.W = self.image_size[0] // patch_size[0], self.image_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.if_UCF = if_UCF
self.proj_conv = nn.Conv2d(in_channels, embed_dims // 8, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn = nn.BatchNorm2d(embed_dims // 8)
self.proj_lif = MyNode(step=step, tau=2.0)
self.maxpool = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv1 = nn.Conv2d(embed_dims // 8, embed_dims // 4, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn1 = nn.BatchNorm2d(embed_dims // 4)
self.proj_lif1 = MyNode(step=step, tau=2.0)
self.maxpool1 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv2 = nn.Conv2d(embed_dims // 4, embed_dims // 2, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn2 = nn.BatchNorm2d(embed_dims // 2)
self.proj_lif2 = MyNode(step=step, tau=2.0)
self.maxpool2 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv3 = nn.Conv2d(embed_dims // 2, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn3 = nn.BatchNorm2d(embed_dims)
self.proj_lif3 = MyNode(step=step, tau=2.0)
self.maxpool3 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.rpe_conv = nn.Conv2d(embed_dims, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.rpe_bn = nn.BatchNorm2d(embed_dims)
self.rpe_lif = MyNode(step=step, tau=2.0)
def forward(self, x):
self.reset()
T, B, C, H, W = x.shape
# UCF101DVS
if self.if_UCF:
x = F.adaptive_avg_pool2d(x.flatten(0,1), output_size=(64, 64)).reshape(T, B, C,64,64)
T, B, C, H, W = x.shape
x = self.proj_conv(x.flatten(0, 1)) # have some fire value
x = self.proj_bn(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif(x.flatten(0, 1)).contiguous()
x = self.maxpool(x)
x = self.proj_conv1(x)
x = self.proj_bn1(x).reshape(T, B, -1, H // 2, W // 2).contiguous()
x = self.proj_lif1(x.flatten(0, 1)).contiguous()
x = self.maxpool1(x)
x = self.proj_conv2(x)
x = self.proj_bn2(x).reshape(T, B, -1, H // 4, W // 4).contiguous()
x = self.proj_lif2(x.flatten(0, 1)).contiguous()
x = self.maxpool2(x)
x = self.proj_conv3(x)
x = self.proj_bn3(x).reshape(T, B, -1, H // 8, W // 8).contiguous()
x = self.proj_lif3(x.flatten(0, 1)).contiguous()
x = self.maxpool3(x)
x_rpe = self.rpe_bn(self.rpe_conv(x)).reshape(T, B, -1 , H // 16,W // 16).contiguous()
x_rpe = self.rpe_lif(x_rpe.flatten(0,1)).contiguous()
x = x + x_rpe
x = x.reshape(T, B, -1, (H//16)*(W//16)).contiguous()
return x # T B C N
class Spikformer(nn.Module):
def __init__(self, step=10,TIM_alpha=0.5,if_UCF=False,
img_size_h=64, img_size_w=64, patch_size=16, in_channels=2, num_classes=10,
embed_dims=256, num_heads=16, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=2, sr_ratios=4,
):
super().__init__()
self.T = step # time step
self.num_classes = num_classes
self.depths = depths
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
patch_embed = SPS( step=step,
if_UCF=if_UCF,
img_size_h=img_size_h,
img_size_w=img_size_w,
patch_size=patch_size,
in_channels=in_channels,
embed_dims=embed_dims)
block = nn.ModuleList([Block(step=step, TIM_alpha=TIM_alpha,
dim=embed_dims, num_heads=num_heads, mlp_ratio=mlp_ratios, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[j],
norm_layer=norm_layer, sr_ratio=sr_ratios)
for j in range(depths)])
setattr(self, f"patch_embed", patch_embed)
setattr(self, f"block", block)
# classification head
self.head = nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
block = getattr(self, f"block")
patch_embed = getattr(self, f"patch_embed")
x = patch_embed(x)
for blk in block:
x = blk(x)
return x.mean(3)
def forward(self, x):
x = x.permute(1, 0, 2, 3, 4)
x = self.forward_features(x)
x = self.head(x.mean(0))
return x
# Hyperparams could be adjust here
@register_model
def spikformer_dvs(pretrained=False, **kwargs):
model = Spikformer(TIM_alpha=0.5,step=10,if_UCF=False,num_classes=10,
# img_size_h=64, img_size_w=64,
# patch_size=16, embed_dims=256, num_heads=16, mlp_ratios=4,
# in_channels=2, qkv_bias=False,
# depths=2, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/TIM/models/spikformer_braincog_SHD.py
================================================
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch.nn.functional as F
from braincog.model_zoo.base_module import BaseModule
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from functools import partial
from torchvision import transforms
from utils.MyNode import *
from models.TIM import *
__all__ = ['spikformer']
class MLP(BaseModule):
def __init__(self,in_features,step=10,encode_type='direct',hidden_features=None, out_features=None, drop=0.):
super().__init__(step=10,encode_type='direct')
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1_conv = nn.Conv1d(in_features, hidden_features, kernel_size=1, stride=1)
self.fc1_bn = nn.BatchNorm1d(hidden_features)
self.fc1_lif = MyNode(step=step,tau=2.0)
self.fc2_conv = nn.Conv1d(hidden_features, out_features, kernel_size=1, stride=1)
self.fc2_bn = nn.BatchNorm1d(out_features)
self.fc2_lif = MyNode(step=step,tau=2.0)
self.c_hidden = hidden_features
self.c_output = out_features
def forward(self, x):
self.reset()
T,B,C,N = x.shape
x = self.fc1_conv(x.flatten(0,1))
x = self.fc1_bn(x).reshape(T, B, self.c_hidden, N ).contiguous() # T B C N
x = self.fc1_lif(x.flatten(0,1)).reshape(T, B, self.c_hidden, N).contiguous()
x = self.fc2_conv(x.flatten(0,1))
x = self.fc2_bn(x).reshape(T, B, C, N).contiguous()
x = self.fc2_lif(x.flatten(0,1)).reshape(T, B, C, N ).contiguous()
return x
class SSA(BaseModule):
def __init__(self,dim,step=10,encode_type='direct',num_heads=16,TIM_alpha=0.5,qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__(step=10,encode_type='direct')
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
self.in_channels = dim // num_heads
self.scale = 0.25
self.q_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.q_bn = nn.BatchNorm1d(dim)
self.q_lif = MyNode(step=step,tau=2.0)
self.k_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.k_bn = nn.BatchNorm1d(dim)
self.k_lif = MyNode(step=step,tau=2.0)
self.v_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.v_bn = nn.BatchNorm1d(dim)
self.v_lif = MyNode(step=step,tau=2.0)
self.attn_drop = nn.Dropout(0.2)
self.res_lif = MyNode(step=step, tau=2.0)
self.attn_lif = MyNode(step=step, tau=2.0, v_threshold=0.5,)
self.proj_conv = nn.Conv1d(dim, dim,kernel_size=1, stride=1,bias=False)
self.proj_bn = nn.BatchNorm1d(dim)
self.proj_lif = MyNode(step=step, tau=2.0,)
self.TIM = TIM(TIM_alpha=TIM_alpha,in_channels=self.in_channels)
def forward(self, x):
self.reset()
T,B,C,N = x.shape
x_for_qkv = x.flatten(0, 1)
q_conv_out = self.q_conv(x_for_qkv)
q_conv_out = self.q_bn(q_conv_out).reshape(T, B, C, N).contiguous()
q_conv_out = self.q_lif(q_conv_out.flatten(0,1)).reshape(T, B, C ,N).transpose(-2,-1)
q = q_conv_out.reshape(T, B, N, self.num_heads, C//self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
k_conv_out = self.k_conv(x_for_qkv)
k_conv_out = self.k_bn(k_conv_out).reshape(T, B, C, N).contiguous()
k_conv_out= self.k_lif(k_conv_out.flatten(0,1)).reshape(T, B, C ,N).transpose(-2,-1)
k = k_conv_out.reshape(T, B, N, self.num_heads, C//self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
v_conv_out = self.v_conv(x_for_qkv)
v_conv_out = self.v_bn(v_conv_out).reshape(T, B, C, N).contiguous()
v_conv_out = self.v_lif(v_conv_out.flatten(0,1)).reshape(T, B, C ,N).transpose(-2,-1)
v = v_conv_out.reshape(T, B, N, self.num_heads, C//self.num_heads).permute(0, 1, 3, 2, 4).contiguous()
#TIM on Q
q = self.TIM(q)
#SSA
attn = (q @ k.transpose(-2, -1))
x = (attn @ v) * self.scale
x = x.transpose(3,4).reshape(T, B, C, N).contiguous()
x = self.attn_lif(x.flatten(0,1))
x = self.proj_lif(self.proj_bn(self.proj_conv(x))).reshape(T, B, C, N)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, step=10,TIM_alpha=0.5, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = SSA(dim, step=step,TIM_alpha=TIM_alpha,num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(in_features=dim,step=step, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
x = x + self.attn(x)
x = x + self.mlp(x)
return x
class SPS(BaseModule):
def __init__(self, step=10, encode_type='direct', img_size_h=64, img_size_w=64, patch_size=4, in_channels=2,
embed_dims=256,if_UCF=False):
super().__init__(step=10, encode_type='direct')
self.image_size = [img_size_h, img_size_w]
patch_size = to_2tuple(patch_size)
self.patch_size = patch_size
self.C = in_channels
self.H, self.W = self.image_size[0] // patch_size[0], self.image_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.if_UCF = if_UCF
self.proj_conv = nn.Conv2d(in_channels, embed_dims // 8, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn = nn.BatchNorm2d(embed_dims // 8)
self.proj_lif = MyNode(step=step, tau=2.0)
self.maxpool = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv1 = nn.Conv2d(embed_dims // 8, embed_dims // 4, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn1 = nn.BatchNorm2d(embed_dims // 4)
self.proj_lif1 = MyNode(step=step, tau=2.0)
self.maxpool1 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv2 = nn.Conv2d(embed_dims // 4, embed_dims // 2, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn2 = nn.BatchNorm2d(embed_dims // 2)
self.proj_lif2 = MyNode(step=step, tau=2.0)
self.maxpool2 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.proj_conv3 = nn.Conv2d(embed_dims // 2, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.proj_bn3 = nn.BatchNorm2d(embed_dims)
self.proj_lif3 = MyNode(step=step, tau=2.0)
self.maxpool3 = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.rpe_conv = nn.Conv2d(embed_dims, embed_dims, kernel_size=3, stride=1, padding=1, bias=False)
self.rpe_bn = nn.BatchNorm2d(embed_dims)
self.rpe_lif = MyNode(step=step, tau=2.0)
def forward(self, x):
self.reset()
# SHD
T, B, _ = x.shape
x = x.reshape(T,B,2,-1) # T B 2 350
x = F.interpolate(x.flatten(0,1), size=256, mode='nearest').reshape(T,B,2,16,16)
T, B, C, H, W = x.shape
x = self.proj_conv(x.flatten(0, 1)) # have some fire value
x = self.proj_bn(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif(x.flatten(0, 1)).contiguous()
# x = self.maxpool(x)
x = self.proj_conv1(x)
x = self.proj_bn1(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif1(x.flatten(0, 1)).contiguous()
# x = self.maxpool1(x)
x = self.proj_conv2(x)
x = self.proj_bn2(x).reshape(T, B, -1, H, W).contiguous()
x = self.proj_lif2(x.flatten(0, 1)).contiguous()
x = self.maxpool2(x)
x = self.proj_conv3(x)
x = self.proj_bn3(x).reshape(T, B, -1, H // 2, W // 2).contiguous()
x = self.proj_lif3(x.flatten(0, 1)).contiguous()
x = self.maxpool3(x)
x_rpe = self.rpe_bn(self.rpe_conv(x)).reshape(T, B, -1 , H // 4,W // 4).contiguous()
x_rpe = self.rpe_lif(x_rpe.flatten(0,1)).contiguous()
x = x + x_rpe
x = x.reshape(T, B, -1, (H//4)*(W//4)).contiguous()
return x # T B C N
class Spikformer(nn.Module):
def __init__(self, step=10,TIM_alpha=0.5,if_UCF=False,
img_size_h=64, img_size_w=64, patch_size=16, in_channels=2, num_classes=10,
embed_dims=256, num_heads=16, mlp_ratios=4, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=2, sr_ratios=4,
):
super().__init__()
self.T = step # time step
self.num_classes = num_classes
self.depths = depths
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
patch_embed = SPS( step=step,
if_UCF=if_UCF,
img_size_h=img_size_h,
img_size_w=img_size_w,
patch_size=patch_size,
in_channels=in_channels,
embed_dims=embed_dims)
block = nn.ModuleList([Block(step=step, TIM_alpha=TIM_alpha,
dim=embed_dims, num_heads=num_heads, mlp_ratio=mlp_ratios, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[j],
norm_layer=norm_layer, sr_ratio=sr_ratios)
for j in range(depths)])
setattr(self, f"patch_embed", patch_embed)
setattr(self, f"block", block)
# classification head
self.head = nn.Linear(embed_dims, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
@torch.jit.ignore
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
block = getattr(self, f"block")
patch_embed = getattr(self, f"patch_embed")
x = patch_embed(x)
for blk in block:
x = blk(x)
return x.mean(3)
def forward(self, x):
x = x.permute(1, 0, 2)
x = self.forward_features(x)
x = self.head(x.mean(0))
return x
# Hyperparams could be adjust here
@register_model
def spikformer_shd(pretrained=False, **kwargs):
model = Spikformer(TIM_alpha=0.5,step=10,if_UCF=False,num_classes=20,
# img_size_h=64, img_size_w=64,
# patch_size=16, embed_dims=256, num_heads=16, mlp_ratios=4,
# in_channels=2, qkv_bias=False,
# depths=2, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return model
================================================
FILE: examples/TIM/utils/MyGrad.py
================================================
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
class MyGrad(SurrogateFunctionBase):
def __init__(self, alpha=4., requires_grad=False):
super().__init__(alpha, requires_grad)
@staticmethod
def act_fun(x, alpha):
return sigmoid.apply(x, alpha)
================================================
FILE: examples/TIM/utils/MyNode.py
================================================
from braincog.base.node.node import *
from braincog.base.connection.layer import *
from braincog.base.strategy.surrogate import *
from utils.MyGrad import MyGrad
class MyBaseNode(BaseNode):
def __init__(self,threshold=0.5,step=10,layer_by_layer=False,mem_detach=False):
super().__init__(threshold=threshold,step=step,layer_by_layer=layer_by_layer,mem_detach=mem_detach)
def rearrange2node(self, inputs):
if self.groups != 1:
if len(inputs.shape) == 4:
outputs = rearrange(inputs, 'b (c t) w h -> t b c w h', t=self.step)
elif len(inputs.shape) == 2:
outputs = rearrange(inputs, 'b (c t) -> t b c', t=self.step)
else:
raise NotImplementedError
elif self.layer_by_layer:
if len(inputs.shape) == 4:
outputs = rearrange(inputs, '(t b) c w h -> t b c w h', t=self.step)
#加入适配Transformer T B N C的rearange2node分支
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, '(t b) n c -> t b n c', t=self.step)
elif len(inputs.shape) == 2:
outputs = rearrange(inputs, '(t b) c -> t b c', t=self.step)
else:
raise NotImplementedError
else:
outputs = inputs
return outputs
def rearrange2op(self, inputs):
if self.groups != 1:
if len(inputs.shape) == 5:
outputs = rearrange(inputs, 't b c w h -> b (c t) w h')
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, ' t b c -> b (c t)')
else:
raise NotImplementedError
elif self.layer_by_layer:
if len(inputs.shape) == 5:
outputs = rearrange(inputs, 't b c w h -> (t b) c w h')
# 加入适配Transformer T B N C的rearange2op分支
elif len(inputs.shape) == 4:
outputs = rearrange(inputs, ' t b n c -> (t b) n c')
elif len(inputs.shape) == 3:
outputs = rearrange(inputs, ' t b c -> (t b) c')
else:
raise NotImplementedError
else:
outputs = inputs
return outputs
class MyNode(MyBaseNode):
def __init__(self, threshold=1.,step=10,layer_by_layer=True,tau=2., act_fun=MyGrad, mem_detach=True,*args, **kwargs):
super().__init__(threshold=threshold,step=step, layer_by_layer=layer_by_layer,mem_detach=mem_detach)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=4., requires_grad=False)
def integral(self, inputs):
self.mem = self.mem + (inputs - self.mem) / self.tau
def calc_spike(self):
self.spike = self.act_fun(self.mem - self.threshold)
self.mem = self.mem * (1 - self.spike.detach())
================================================
FILE: examples/TIM/utils/datasets.py
================================================
import os
import warnings
import random
import torchvision.datasets
import braincog.datasets.ucf101_dvs
try:
import tonic
from tonic import DiskCachedDataset
except:
warnings.warn("tonic should be installed, 'pip install git+https://github.com/FloyedShen/tonic.git'")
import torch
import torch.nn.functional as F
import torch.utils
import torchvision.datasets as datasets
from timm.data import ImageDataset, create_loader, Mixup, FastCollateMixup, AugMixDataset
from timm.data import create_transform, distributed_sampler
from timm.data.loader import PrefetchLoader
from tonic import DiskCachedDataset
from torchvision import transforms
from typing import Any, Dict, Optional, Sequence, Tuple, Union
from braincog.datasets.NOmniglot.nomniglot_full import NOmniglotfull
from braincog.datasets.NOmniglot.nomniglot_nw_ks import NOmniglotNWayKShot
from braincog.datasets.NOmniglot.nomniglot_pair import NOmniglotTrainSet, NOmniglotTestSet
# from braincog.base.conversion.conversion import CIFAR10Policy, Cutout
# from .cut_mix import CutMix, EventMix, MixUp
# from .rand_aug import *
# from .event_drop import event_drop
# from .utils import dvs_channel_check_expend, rescale
DVSCIFAR10_MEAN_16 = [0.3290, 0.4507]
DVSCIFAR10_STD_16 = [1.8398, 1.6549]
DATA_DIR = '/data/datasets'
DEFAULT_CROP_PCT = 0.875
IMAGENET_DEFAULT_MEAN = (0.485, 0.456, 0.406)
IMAGENET_DEFAULT_STD = (0.229, 0.224, 0.225)
IMAGENET_INCEPTION_MEAN = (0.5, 0.5, 0.5)
IMAGENET_INCEPTION_STD = (0.5, 0.5, 0.5)
IMAGENET_DPN_MEAN = (124 / 255, 117 / 255, 104 / 255)
IMAGENET_DPN_STD = tuple([1 / (.0167 * 255)] * 3)
CIFAR10_DEFAULT_MEAN = (0.4914, 0.4822, 0.4465)
CIFAR10_DEFAULT_STD = (0.2023, 0.1994, 0.2010)
CIFAR100_DEFAULT_MEAN = (0.5071, 0.4867, 0.4408)
CIFAR100_DEFAULT_STD = (0.2675, 0.2565, 0.2761)
def unpack_mix_param(args):
mix_up = args['mix_up'] if 'mix_up' in args else False
cut_mix = args['cut_mix'] if 'cut_mix' in args else False
event_mix = args['event_mix'] if 'event_mix' in args else False
beta = args['beta'] if 'beta' in args else 1.
prob = args['prob'] if 'prob' in args else .5
num = args['num'] if 'num' in args else 1
num_classes = args['num_classes'] if 'num_classes' in args else 10
noise = args['noise'] if 'noise' in args else 0.
gaussian_n = args['gaussian_n'] if 'gaussian_n' in args else None
return mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n
def build_transform(is_train, img_size):
"""
构建数据增强, 适用于static data
:param is_train: 是否训练集
:param img_size: 输出的图像尺寸
:return: 数据增强策略
"""
resize_im = img_size > 32
if is_train:
# this should always dispatch to transforms_imagenet_train
transform = create_transform(
input_size=img_size,
is_training=True,
color_jitter=0.4,
# auto_augment='rand-m9-mstd0.5-inc1',
interpolation='bicubic',
# re_prob=0.25,
# re_mode='pixel',
# re_count=1,
)
if not resize_im:
# replace RandomResizedCropAndInterpolation with
# RandomCrop
transform.transforms[0] = transforms.RandomCrop(
img_size, padding=4)
return transform
t = []
if resize_im:
size = int((256 / 224) * img_size)
t.append(
# to maintain same ratio w.r.t. 224 images
transforms.Resize(size, interpolation=3),
)
t.append(transforms.CenterCrop(img_size))
t.append(transforms.ToTensor())
if img_size > 32:
t.append(transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD))
else:
t.append(transforms.Normalize(CIFAR10_DEFAULT_MEAN, CIFAR10_DEFAULT_STD))
return transforms.Compose(t)
def build_dataset(is_train, img_size, dataset, path, same_da=False):
"""
构建带有增强策略的数据集
:param is_train: 是否训练集
:param img_size: 输出图像尺寸
:param dataset: 数据集名称
:param path: 数据集路径
:param same_da: 为训练集使用测试集的增广方法
:return: 增强后的数据集
"""
transform = build_transform(False, img_size) if same_da else build_transform(is_train, img_size)
if dataset == 'CIFAR10':
dataset = datasets.CIFAR10(
path, train=is_train, transform=transform, download=True)
nb_classes = 10
elif dataset == 'CIFAR100':
dataset = datasets.CIFAR100(
path, train=is_train, transform=transform, download=True)
nb_classes = 100
else:
raise NotImplementedError
return dataset, nb_classes
class MNISTData(object):
"""
Load MNIST datesets.
"""
def __init__(self,
data_path: str,
batch_size: int,
train_trans: Sequence[torch.nn.Module] = None,
test_trans: Sequence[torch.nn.Module] = None,
pin_memory: bool = True,
drop_last: bool = True,
shuffle: bool = True,
) -> None:
self._data_path = data_path
self._batch_size = batch_size
self._pin_memory = pin_memory
self._drop_last = drop_last
self._shuffle = shuffle
self._train_transform = transforms.Compose(train_trans) if train_trans else None
self._test_transform = transforms.Compose(test_trans) if test_trans else None
def get_data_loaders(self):
print('Batch size: ', self._batch_size)
train_datasets = datasets.MNIST(root=self._data_path, train=True, transform=self._train_transform, download=True)
test_datasets = datasets.MNIST(root=self._data_path, train=False, transform=self._test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=self._drop_last, shuffle=self._shuffle
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=self._batch_size,
pin_memory=self._pin_memory, drop_last=False
)
return train_loader, test_loader
def get_standard_data(self):
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
self._train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
self._test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
return self.get_data_loaders()
def get_mnist_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取MNIST数据
http://data.pymvpa.org/datasets/mnist/
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
MNIST_MEAN = 0.1307
MNIST_STD = 0.3081
if 'skip_norm' in kwargs and kwargs['skip_norm'] is True:
train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(rescale)
])
else:
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
# transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((MNIST_MEAN,), (MNIST_STD,))])
train_datasets = datasets.MNIST(
root=DATA_DIR, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.MNIST(
root=DATA_DIR, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_fashion_data(batch_size, num_workers=8, same_da=False, **kwargs):
"""
获取fashion MNIST数据
http://arxiv.org/abs/1708.07747
:param batch_size: batch size
:param same_da: 为训练集使用测试集的增广方法
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_transform = transforms.Compose([transforms.RandomCrop(28, padding=4),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor()])
test_transform = transforms.Compose([transforms.ToTensor()])
train_datasets = datasets.FashionMNIST(
root=DATA_DIR, train=True, transform=test_transform if same_da else train_transform, download=True)
test_datasets = datasets.FashionMNIST(
root=DATA_DIR, train=False, transform=test_transform, download=True)
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size,
pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=num_workers
)
return train_loader, test_loader, False, None
def get_cifar10_data(batch_size, num_workers=8, same_da=False, **kwargs):
# """
# 获取CIFAR10数据
# https://www.cs.toronto.edu/~kriz/cifar.html
# :param batch_size: batch size
# :param kwargs:
# :return: (train loader, test loader, mixup_active, mixup_fn)
# """
# train_datasets, _ = build_dataset(True, 32, 'CIFAR10', DATA_DIR, same_da)
# test_datasets, _ = build_dataset(False, 32, 'CIFAR10', DATA_DIR, same_da)
#
# train_loader = torch.utils.data.DataLoader(
# train_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=True, shuffle=True,
# num_workers=num_workers
# )
#
# test_loader = torch.utils.data.DataLoader(
# test_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=False,
# num_workers=num_workers
# )
normalize = transforms.Normalize(CIFAR10_DEFAULT_MEAN, CIFAR10_DEFAULT_STD)
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(),
CIFAR10Policy(),
transforms.ToTensor(),
Cutout(n_holes=1, length=16),
normalize])
transform_test = transforms.Compose([transforms.ToTensor(), normalize])
train_dataset = datasets.CIFAR10(root=DATA_DIR, train=True, download=True, transform=transform_train)
test_dataset = datasets.CIFAR10(root=DATA_DIR, train=False, download=True, transform=transform_test)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
shuffle=True, num_workers=num_workers,
pin_memory=True
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
shuffle=False, num_workers=num_workers,
pin_memory=True
)
return train_loader, test_loader, None, None
def get_shd_data(batch_size, step, **kwargs):
"""
获取SHD数据
https://ieeexplore.ieee.org/abstract/document/9311226
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
:format: (b,t,c,len) 不同于vision, audio中c为1, 并且没有h,w; 只有len=700
"""
sensor_size = tonic.datasets.SHD.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
train_dataset = tonic.datasets.SHD(os.path.join(DATA_DIR, 'DVS/SHD'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.SHD(os.path.join(DATA_DIR, 'DVS/SHD'),
transform=test_transform, train=False)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, None, None
def get_cifar100_data(batch_size, num_workers=8, same_data=False, *args, **kwargs):
# """
# 获取CIFAR100数据
# https://www.cs.toronto.edu/~kriz/cifar.html
# :param batch_size: batch size
# :param kwargs:
# :return: (train loader, test loader, mixup_active, mixup_fn)
# """
# train_datasets, _ = build_dataset(True, 32, 'CIFAR100', DATA_DIR, same_data)
# test_datasets, _ = build_dataset(False, 32, 'CIFAR100', DATA_DIR, same_data)
#
# train_loader = torch.utils.data.DataLoader(
# train_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=True, shuffle=True, num_workers=num_workers
# )
#
# test_loader = torch.utils.data.DataLoader(
# test_datasets, batch_size=batch_size,
# pin_memory=True, drop_last=False, num_workers=num_workers
# )
# return train_loader, test_loader, False, None
normalize = transforms.Normalize(CIFAR100_DEFAULT_MEAN, CIFAR100_DEFAULT_STD)
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(),
CIFAR10Policy(),
transforms.ToTensor(),
Cutout(n_holes=1, length=16),
normalize])
transform_test = transforms.Compose([transforms.ToTensor(), normalize])
train_dataset = datasets.CIFAR100(root=DATA_DIR, train=True, download=True, transform=transform_train)
test_dataset = datasets.CIFAR100(root=DATA_DIR, train=False, download=True, transform=transform_test)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
shuffle=True, num_workers=num_workers,
pin_memory=True
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
shuffle=False, num_workers=num_workers,
pin_memory=True
)
return train_loader, test_loader, None, None
def get_imnet_data(args, _logger, data_config, num_aug_splits, **kwargs):
"""
获取ImageNet数据集
http://arxiv.org/abs/1409.0575
:param args: 其他的参数
:param _logger: 日志路径
:param data_config: 增强策略
:param num_aug_splits: 不同增强策略的数量
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
train_dir = os.path.join(DATA_DIR, 'ILSVRC2012/train')
if not os.path.exists(train_dir):
_logger.error(
'Training folder does not exist at: {}'.format(train_dir))
exit(1)
dataset_train = ImageDataset(train_dir)
# collate_fn = None
# mixup_fn = None
# mixup_active = args.mixup > 0 or args.cutmix > 0. or args.cutmix_minmax is not None
# if mixup_active:
# mixup_args = dict(
# mixup_alpha=args.mixup, cutmix_alpha=args.cutmix, cutmix_minmax=args.cutmix_minmax,
# prob=args.mixup_prob, switch_prob=args.mixup_switch_prob, mode=args.mixup_mode,
# label_smoothing=args.smoothing, num_classes=args.num_classes)
# if args.prefetcher:
# # collate conflict (need to support deinterleaving in collate mixup)
# assert not num_aug_splits
# collate_fn = FastCollateMixup(**mixup_args)
# else:
# mixup_fn = Mixup(**mixup_args)
# if num_aug_splits > 1:
# dataset_train = AugMixDataset(dataset_train, num_splits=num_aug_splits)
train_interpolation = args.train_interpolation
if args.no_aug or not train_interpolation:
train_interpolation = data_config['interpolation']
loader_train = create_loader(
dataset_train,
input_size=data_config['input_size'],
batch_size=args.batch_size,
is_training=True,
use_prefetcher=args.prefetcher,
no_aug=args.no_aug,
# re_prob=args.reprob,
# re_mode=args.remode,
# re_count=args.recount,
# re_split=args.resplit,
scale=args.scale,
ratio=args.ratio,
hflip=args.hflip,
# vflip=args.vflip,
# color_jitter=args.color_jitter,
# auto_augment=args.aa,
# num_aug_splits=num_aug_splits,
interpolation=train_interpolation,
mean=data_config['mean'],
std=data_config['std'],
num_workers=args.workers,
distributed=args.distributed,
# collate_fn=collate_fn,
pin_memory=args.pin_mem,
# use_multi_epochs_loader=args.use_multi_epochs_loader
)
eval_dir = os.path.join(DATA_DIR, 'ILSVRC2012/val')
if not os.path.isdir(eval_dir):
eval_dir = os.path.join(DATA_DIR, 'ILSVRC2012/validation')
if not os.path.isdir(eval_dir):
_logger.error(
'Validation folder does not exist at: {}'.format(eval_dir))
exit(1)
dataset_eval = ImageDataset(eval_dir)
loader_eval = create_loader(
dataset_eval,
input_size=data_config['input_size'],
batch_size=args.validation_batch_size_multiplier * args.batch_size,
is_training=False,
use_prefetcher=args.prefetcher,
interpolation=data_config['interpolation'],
mean=data_config['mean'],
std=data_config['std'],
num_workers=args.workers,
distributed=args.distributed,
crop_pct=data_config['crop_pct'],
pin_memory=args.pin_mem,
)
return loader_train, loader_eval, None, None
def get_dvsg_data(batch_size, step, **kwargs):
"""
获取DVS Gesture数据
DOI: 10.1109/CVPR.2017.781
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = tonic.datasets.DVSGesture.sensor_size
size = kwargs['size'] if 'size' in kwargs else 48
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step),
])
train_dataset = tonic.datasets.DVSGesture(os.path.join(DATA_DIR, 'DVS/DVSGesture'),
transform=train_transform, train=True)
test_dataset = tonic.datasets.DVSGesture(os.path.join(DATA_DIR, 'DVS/DVSGesture'),
transform=test_transform, train=False)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
transforms.RandomCrop(size, padding=size // 12),
# lambda x: event_drop(x),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
lambda x: dvs_channel_check_expend(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVSGesture/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVSGesture/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
pin_memory=True, drop_last=True, num_workers=8,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
pin_memory=True, drop_last=False, num_workers=2,
shuffle=False,
)
return train_loader, test_loader, mixup_active, None
def get_dvsc10_data(batch_size, step, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = tonic.datasets.CIFAR10DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=train_transform)
test_dataset = tonic.datasets.CIFAR10DVS(os.path.join(DATA_DIR, 'DVS/DVS_Cifar10'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
# lambda x: event_drop(x),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/DVS_Cifar10/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_train),
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_test),
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_nmnist_data(batch_size, step, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = tonic.datasets.NMNIST.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/NMNIST'), transform=train_transform)
test_dataset = tonic.datasets.NMNIST(os.path.join(DATA_DIR, 'DVS/NMNIST'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
# lambda x: event_drop(x),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NMNIST/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NMNIST/test_cache_{}'.format(step)),
transform=test_transform)
num_train = len(train_dataset)
num_per_cls = num_train // 10
indices_train, indices_test = [], []
portion = kwargs['portion'] if 'portion' in kwargs else .9
for i in range(10):
indices_train.extend(
list(range(i * num_per_cls, round(i * num_per_cls + num_per_cls * portion))))
indices_test.extend(
list(range(round(i * num_per_cls + num_per_cls * portion), (i + 1) * num_per_cls)))
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=indices_train,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_train),
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices_test),
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_NCALTECH101_data(batch_size, step, **kwargs):
"""
获取NCaltech101数据
http://journal.frontiersin.org/Article/10.3389/fnins.2015.00437/abstract
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
sensor_size = braincog.datasets.ncaltech101.NCALTECH101.sensor_size
cls_count = braincog.datasets.ncaltech101.NCALTECH101.cls_count
dataset_length = braincog.datasets.ncaltech101.NCALTECH101.length
portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += train_sample
train_sample_weight.extend(
[sample_weight] * train_sample
)
train_sample_weight.extend(
[0.] * test_sample
)
train_sample_index.extend(
list((range(idx_begin, idx_begin + train_sample)))
)
test_sample_index.extend(
list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.ncaltech101.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=train_transform)
test_dataset = braincog.datasets.ncaltech101.NCALTECH101(os.path.join(DATA_DIR, 'DVS/NCALTECH101'), transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: print(x.shape),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: temporal_flatten(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'DVS/NCALTECH101/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=train_sampler,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_UCF101DVS_data(batch_size, step, **kwargs):
"""
获取DVS CIFAR10数据
http://journal.frontiersin.org/article/10.3389/fnins.2017.00309/full
:param batch_size: batch size
:param step: 仿真步长
:param kwargs:
:return: (train loader, test loader, mixup_active, mixup_fn)
"""
size = kwargs['size'] if 'size' in kwargs else 48
sensor_size = braincog.datasets.ucf101_dvs.UCF101DVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.ucf101_dvs.UCF101DVS(os.path.join(DATA_DIR, 'DVS/UCF101DVS'), train=True, transform=train_transform)
test_dataset = braincog.datasets.ucf101_dvs.UCF101DVS(os.path.join(DATA_DIR, 'DVS/UCF101DVS'), train=False, transform=test_transform)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: TemporalShift(x, .01),
# lambda x: drop(x, 0.15),
# lambda x: ShearX(x, 15),
# lambda x: ShearY(x, 15),
# lambda x: TranslateX(x, 0.225),
# lambda x: TranslateY(x, 0.225),
# lambda x: Rotate(x, 15),
# lambda x: CutoutAbs(x, 0.25),
# lambda x: CutoutTemporal(x, 0.25),
# lambda x: GaussianBlur(x, 0.5),
# lambda x: SaltAndPepperNoise(x, 0.1),
# transforms.Normalize(DVSCIFAR10_MEAN_16, DVSCIFAR10_STD_16),
# transforms.RandomCrop(size, padding=size // 12),
transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
# print('randaug', m, n)
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'UCF101DVS/train_cache_{}'.format(step)),
transform=train_transform)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'UCF101DVS/test_cache_{}'.format(step)),
transform=test_transform)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
# print('cut_mix', beta, prob, num, num_classes)
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size, shuffle=False,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
def get_HMDBDVS_data(batch_size, step, **kwargs):
sensor_size = braincog.datasets.hmdb_dvs.HMDBDVS.sensor_size
train_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.DropEvent(p=0.1),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
test_transform = transforms.Compose([
# tonic.transforms.Denoise(filter_time=10000),
tonic.transforms.ToFrame(sensor_size=sensor_size, n_time_bins=step), ])
train_dataset = braincog.datasets.hmdb_dvs.HMDBDVS(os.path.join(DATA_DIR, 'HMDBDVS'), transform=train_transform)
test_dataset = braincog.datasets.hmdb_dvs.HMDBDVS(os.path.join(DATA_DIR, 'HMDBDVS'), transform=test_transform)
cls_count = train_dataset.cls_count
dataset_length = train_dataset.length
portion = .5
# portion = kwargs['portion'] if 'portion' in kwargs else .9
size = kwargs['size'] if 'size' in kwargs else 48
# print('portion', portion)
train_sample_weight = []
train_sample_index = []
train_count = 0
test_sample_index = []
idx_begin = 0
for count in cls_count:
sample_weight = dataset_length / count
train_sample = round(portion * count)
test_sample = count - train_sample
train_count += train_sample
train_sample_weight.extend(
[sample_weight] * train_sample
)
train_sample_weight.extend(
[0.] * test_sample
)
lst = list(range(idx_begin, idx_begin + train_sample + test_sample))
random.seed(0)
random.shuffle(lst)
train_sample_index.extend(
lst[:train_sample]
# list((range(idx_begin, idx_begin + train_sample)))
)
test_sample_index.extend(
lst[train_sample:train_sample + test_sample]
# list(range(idx_begin + train_sample, idx_begin + train_sample + test_sample))
)
idx_begin += count
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_sample_weight, train_count)
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_sample_index)
train_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: print(x.shape),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
])
test_transform = transforms.Compose([
lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: temporal_flatten(x),
])
if 'rand_aug' in kwargs.keys():
if kwargs['rand_aug'] is True:
n = kwargs['randaug_n']
m = kwargs['randaug_m']
train_transform.transforms.insert(2, RandAugment(m=m, n=n))
# if 'temporal_flatten' in kwargs.keys():
# if kwargs['temporal_flatten'] is True:
# train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
train_dataset = DiskCachedDataset(train_dataset,
cache_path=os.path.join(DATA_DIR, 'HMDBDVS/train_cache_{}'.format(step)),
transform=train_transform, num_copies=3)
test_dataset = DiskCachedDataset(test_dataset,
cache_path=os.path.join(DATA_DIR, 'HMDBDVS/test_cache_{}'.format(step)),
transform=test_transform, num_copies=3)
mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
mixup_active = cut_mix | event_mix | mix_up
if cut_mix:
train_dataset = CutMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
if event_mix:
train_dataset = EventMix(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise,
gaussian_n=gaussian_n)
if mix_up:
train_dataset = MixUp(train_dataset,
beta=beta,
prob=prob,
num_mix=num,
num_class=num_classes,
indices=train_sample_index,
noise=noise)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size,
sampler=train_sampler,
pin_memory=True, drop_last=True, num_workers=8
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size,
sampler=test_sampler,
pin_memory=True, drop_last=False, num_workers=2
)
return train_loader, test_loader, mixup_active, None
# def get_NCARS_data(batch_size, step, **kwargs):
# """
# 获取N-Cars数据
# https://ieeexplore.ieee.org/document/8578284/
# :param batch_size: batch size
# :param step: 仿真步长
# :param kwargs:
# :return: (train loader, test loader, mixup_active, mixup_fn)
# """
# sensor_size = tonic.datasets.NCARS.sensor_size
# size = kwargs['size'] if 'size' in kwargs else 48
#
# train_transform = transforms.Compose([
# # tonic.transforms.Denoise(filter_time=10000),
# # tonic.transforms.DropEvent(p=0.1),
# tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
# ])
# test_transform = transforms.Compose([
# # tonic.transforms.Denoise(filter_time=10000),
# tonic.transforms.ToFrame(sensor_size=None, n_time_bins=step),
# ])
#
# train_dataset = tonic.datasets.NCARS(os.path.join(DATA_DIR, 'DVS/NCARS'), transform=train_transform, train=True)
# test_dataset = tonic.datasets.NCARS(os.path.join(DATA_DIR, 'DVS/NCARS'), transform=test_transform, train=False)
#
# train_transform = transforms.Compose([
# lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: dvs_channel_check_expend(x),
# transforms.RandomCrop(size, padding=size // 12),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(15)
# ])
# test_transform = transforms.Compose([
# lambda x: torch.tensor(x, dtype=torch.float),
# lambda x: F.interpolate(x, size=[size, size], mode='bilinear', align_corners=True),
# lambda x: dvs_channel_check_expend(x),
# ])
# if 'rand_aug' in kwargs.keys():
# if kwargs['rand_aug'] is True:
# n = kwargs['randaug_n']
# m = kwargs['randaug_m']
# train_transform.transforms.insert(2, RandAugment(m=m, n=n))
#
# # if 'temporal_flatten' in kwargs.keys():
# # if kwargs['temporal_flatten'] is True:
# # train_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
# # test_transform.transforms.insert(-1, lambda x: temporal_flatten(x))
#
# train_dataset = DiskCachedDataset(train_dataset,
# cache_path=os.path.join(DATA_DIR, 'DVS/NCARS/train_cache_{}'.format(step)),
# transform=train_transform, num_copies=3)
# test_dataset = DiskCachedDataset(test_dataset,
# cache_path=os.path.join(DATA_DIR, 'DVS/NCARS/test_cache_{}'.format(step)),
# transform=test_transform, num_copies=3)
#
# mix_up, cut_mix, event_mix, beta, prob, num, num_classes, noise, gaussian_n = unpack_mix_param(kwargs)
# mixup_active = cut_mix | event_mix | mix_up
#
# if cut_mix:
# train_dataset = CutMix(train_dataset,
# beta=beta,
# prob=prob,
# num_mix=num,
# num_class=num_classes,
# noise=noise)
#
# if event_mix:
# train_dataset = EventMix(train_dataset,
# beta=beta,
# prob=prob,
# num_mix=num,
# num_class=num_classes,
# noise=noise,
# gaussian_n=gaussian_n)
# if mix_up:
# train_dataset = MixUp(train_dataset,
# beta=beta,
# prob=prob,
# num_mix=num,
# num_class=num_classes,
# noise=noise)
#
# train_loader = torch.utils.data.DataLoader(
# train_dataset, batch_size=batch_size,
# pin_memory=True, drop_last=True, num_workers=8,
# shuffle=True,
# )
#
# test_loader = torch.utils.data.DataLoader(
# test_dataset, batch_size=batch_size,
# pin_memory=True, drop_last=False, num_workers=2,
# shuffle=False,
# )
#
# return train_loader, test_loader, mixup_active, None
def get_nomni_data(batch_size, train_portion=1., **kwargs):
"""
获取N-Omniglot数据
:param batch_size:batch的大小
:param data_mode:一共full nkks pair三种模式
:param frames_num:一个样本帧的个数
:param data_type:event frequency两种模式
"""
data_mode = kwargs["data_mode"] if "data_mode" in kwargs else "full"
frames_num = kwargs["frames_num"] if "frames_num" in kwargs else 10
data_type = kwargs["data_type"] if "data_type" in kwargs else "event"
train_transform = transforms.Compose([
transforms.Resize((64, 64))])
test_transform = transforms.Compose([
transforms.Resize((64, 64))])
if data_mode == "full":
train_datasets = NOmniglotfull(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), train=True, frames_num=frames_num,
data_type=data_type,
transform=train_transform)
test_datasets = NOmniglotfull(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), train=False, frames_num=frames_num,
data_type=data_type,
transform=test_transform)
elif data_mode == "nkks":
train_datasets = NOmniglotNWayKShot(os.path.join(DATA_DIR, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=True,
frames_num=frames_num,
data_type=data_type,
transform=train_transform)
test_datasets = NOmniglotNWayKShot(os.path.join(DATA_DIR, 'DVS/NOmniglot'),
n_way=kwargs["n_way"],
k_shot=kwargs["k_shot"],
k_query=kwargs["k_query"],
train=False,
frames_num=frames_num,
data_type=data_type,
transform=test_transform)
elif data_mode == "pair":
train_datasets = NOmniglotTrainSet(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), use_frame=True,
frames_num=frames_num, data_type=data_type,
use_npz=False, resize=105)
test_datasets = NOmniglotTestSet(root=os.path.join(DATA_DIR, 'DVS/NOmniglot'), time=2000, way=kwargs["n_way"],
shot=kwargs["k_shot"], use_frame=True,
frames_num=frames_num, data_type=data_type, use_npz=False, resize=105)
else:
pass
train_loader = torch.utils.data.DataLoader(
train_datasets, batch_size=batch_size, num_workers=12,
pin_memory=True, drop_last=True, shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_datasets, batch_size=batch_size, num_workers=12,
pin_memory=True, drop_last=False
)
return train_loader, test_loader, None, None
================================================
FILE: examples/decision_making/BDM-SNN/BDM-SNN-UAV.py
================================================
import numpy as np
import torch,os,sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import torch.nn.functional as F
import matplotlib.pyplot as plt
#from braincog.base.strategy.surrogate import *
from braincog.base.node.node import IFNode
from braincog.base.learningrule.STDP import STDP,MutliInputSTDP
from braincog.base.connection.CustomLinear import CustomLinear
from braincog.base.brainarea.basalganglia import basalganglia
from braincog.model_zoo.bdmsnn import BDMSNN
from robomaster import robot
import time
def chooseAct(Net,input,weight_trace_d1,weight_trace_d2):
"""
根据输入选择行为
:param Net: 输入BDM-SNN网络
:param input: 输入电流 编码状态的脉冲
:param weight_trace_d1: 不断累积保存资格迹
:param weight_trace_d2: 不断累积保存资格迹
:return: 返回选择的行为、资格迹和网络
"""
for i_train in range(500):
out, dw = Net(input)
# rstdp
weight_trace_d1 *= trace_decay
weight_trace_d1 += dw[0][0]
weight_trace_d2 *= trace_decay
weight_trace_d2 += dw[1][0]
if torch.max(out) > 0:
return torch.argmax(out),weight_trace_d1,weight_trace_d2,Net
def updateNet(Net,reward, action, state,weight_trace_d1,weight_trace_d2):
"""
更新网络
:param Net: BDM-SNN网络
:param reward: 获得的奖励
:param action: 执行的行为
:param state: 执行行为前的状态
:param weight_trace_d1: 直接通路累积的资格迹
:param weight_trace_d2: 间接通路累积的资格迹
:return: 更新后的网络
"""
r = torch.ones((num_state, num_state * num_action), dtype=torch.float)
r[state, state * num_action + action] = reward
dw_d1 = r * weight_trace_d1
dw_d2 = -1 * r * weight_trace_d2
Net.UpdateWeight(0, state,num_action,dw_d1)
Net.UpdateWeight(1, state,num_action,dw_d2)
return Net
if __name__=="__main__":
"""
定义无人机 大疆Tello Talent
定义BDM-SNN网络
用户自定义状态空间、奖励函数,调用行为选择及网络更新
"""
#define UAV
tl_drone = robot.Drone()
tl_drone.initialize()
tl_flight = tl_drone.flight
tl_flight.takeoff().wait_for_completed()
#define Net
num_state=9
num_action=2
weight_exc=1
weight_inh=-0.5
trace_decay = 0.8
DM=BDMSNN(num_state,num_action,weight_exc,weight_inh,"lif")
con_matrix1 = torch.zeros((num_state, num_state * num_action), dtype=torch.float)
for i in range(num_state):
for j in range(num_action):
con_matrix1[i, i * num_action + j] = weight_exc
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
iteration=0
while iteration < 200:
input = torch.zeros((num_state), dtype=torch.float)
#users define the judgestate function
state=1
input[state]=2
action,weight_trace_d1,weight_trace_d2,DM = chooseAct(DM,input,weight_trace_d1,weight_trace_d2)
#uav do action
if action==0:
tl_flight.forward(distance=20).wait_for_completed()
if action == 1:
# flying left
tl_flight.rc(a=20, b=0, c=0, d=0)
time.sleep(4)
if action == 2:
# flying right
tl_flight.rc(a=-20, b=0, c=0, d=0)
time.sleep(3)
if action == 3:
tl_flight.backward(distance=20).wait_for_completed()
#users define the reward function
reward =1
DM=updateNet(DM,reward, action, state,weight_trace_d1,weight_trace_d2)
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
DM.reset()
iteration += 1
================================================
FILE: examples/decision_making/BDM-SNN/BDM-SNN-hh.py
================================================
import torch,os
from random import randint
import torch
from torch import nn
from braincog.base.strategy.surrogate import *
from braincog.model_zoo.bdmsnn import BDMSNN
import pygame
from pygame.locals import *
from collections import deque
from random import randint
import numpy as np
import matplotlib.pyplot as plt
import random
#os.environ["SDL_VIDEODRIVER"] = "dummy"
def load_images():
"""
Flappy Bird中load图像
:return:load的图像
"""
def load_image(img_file_name):
file_name = os.path.join('.', 'birdimages', img_file_name)
img = pygame.image.load(file_name)
# converting all images before use speeds up blitting
img.convert()
return img
return {'background': load_image('background.png'),
'pipe-end': load_image('pipe_end.png'),
'pipe-body': load_image('pipe_body.png'),
# images for animating the flapping bird -- animated GIFs are
# not supported in pygame
'bird-wingup': load_image('bird_wing_up.png'),
'bird-wingdown': load_image('bird_wing_down.png'),}
class Bird(pygame.sprite.Sprite):
"""
Flappy Bird类
"""
WIDTH = HEIGHT = 32
SINK_SPEED = 0.2
Fail_SINk_SPEED = 0.6
CLIMB_SPEED = 0.25
CLIMB_DURATION = 333.3
REGION = CLIMB_DURATION / 3
NEAR_COLLIDE = 30
NEAR_PIPE = 0
def __init__(self, x, y, msec_to_climb, images):
super(Bird, self).__init__()
self.x, self.y = x, y
self.msec_to_climb = msec_to_climb
self._img_wingup, self._img_wingdown = images
self._mask_wingup = pygame.mask.from_surface(self._img_wingup)
self._mask_wingdown = pygame.mask.from_surface(self._img_wingdown)
def update(self, action,state,delta_frames=1):
"""
更新小鸟的位置
:param action: 输入行为
:param state:输入状态
:param delta_frames:Fault
:return:None
"""
if self.msec_to_climb > 0 and action == 1:
if state==4 or state==5 or state == 2 or state == 3:
self.y -= (2*Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
self.y -= (Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
if state == 4 or state == 5 or state == 2 or state == 3:
self.y += 2*Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
else:
self.y += Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
def sink(self, delta_frames=1):
self.y += Bird.Fail_SINk_SPEED * (1000.0 * delta_frames / 60)
@property
def image(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._img_wingup
else:
return self._img_wingdown
@property
def mask(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._mask_wingup
else:
return self._mask_wingdown
@property
def rect(self):
return Rect(self.x, self.y, Bird.WIDTH, Bird.HEIGHT)
class PipePair(pygame.sprite.Sprite):
"""
Flappy Bird 中的管子类
"""
WIDTH = 80
PIECE_HEIGHT = 32
ADD_INTERVAL = 2000
ADD_EVENT = pygame.USEREVENT + 1
ROOM_HIGHT = 2 * Bird.HEIGHT + 2 * PIECE_HEIGHT
def __init__(self, pipe_end_img, pipe_body_img):
self.x = float(WIN_WIDTH - 1)
self.score_counted = False
self.isNewPipe = True
self.image = pygame.Surface((PipePair.WIDTH, WIN_HEIGHT), SRCALPHA)
self.image.convert() # speeds up blitting
self.image.fill((0, 0, 0, 0))
total_pipe_body_pieces = int(
(WIN_HEIGHT - # fill window from top to bottom
3 * Bird.HEIGHT - # make room for bird to fit through
3 * PipePair.PIECE_HEIGHT) / # 2 end pieces + 1 body piece
PipePair.PIECE_HEIGHT # to get number of pipe pieces
)
self.bottom_pieces = randint(1, total_pipe_body_pieces)
self.top_pieces = total_pipe_body_pieces - self.bottom_pieces
# bottom pipe
for i in range(1, self.bottom_pieces + 1):
piece_pos = (0, WIN_HEIGHT - i * PipePair.PIECE_HEIGHT)
self.image.blit(pipe_body_img, piece_pos)
bottom_pipe_end_y = WIN_HEIGHT - self.bottom_height_px
bottom_end_piece_pos = (0, bottom_pipe_end_y - PipePair.PIECE_HEIGHT)
self.image.blit(pipe_end_img, bottom_end_piece_pos)
# top pipe
for i in range(self.top_pieces):
self.image.blit(pipe_body_img, (0, i * PipePair.PIECE_HEIGHT))
top_pipe_end_y = self.top_height_px
self.image.blit(pipe_end_img, (0, top_pipe_end_y))
self.center = (top_pipe_end_y + bottom_pipe_end_y) / 2
# compensate for added end pieces
self.top_pieces += 1
self.bottom_pieces += 1
# for collision detection
self.mask = pygame.mask.from_surface(self.image)
self.top_y = top_pipe_end_y
self.bottom_y = bottom_pipe_end_y
@property
def top_height_px(self):
return self.top_pieces * PipePair.PIECE_HEIGHT
@property
def bottom_height_px(self):
return self.bottom_pieces * PipePair.PIECE_HEIGHT
@property
def visible(self):
return -PipePair.WIDTH < self.x < WIN_WIDTH
@property
def rect(self):
return Rect(self.x, 0, PipePair.WIDTH, PipePair.PIECE_HEIGHT)
def update(self, delta_frames=1):
self.x -= 0.18 * 1000.0 * delta_frames /60
def collides_with(self, bird):
return pygame.sprite.collide_mask(self, bird)
def chooseAct(Net,input,weight_trace_d1,weight_trace_d2):
"""
根据输入选择行为
:param Net: 输入BDM-SNN网络
:param input: 输入电流 编码状态的脉冲
:param weight_trace_d1: 不断累积保存资格迹
:param weight_trace_d2: 不断累积保存资格迹
:return: 返回选择的行为、资格迹和网络
"""
for i_train in range(500):
out, dw = Net(input)
# rstdp
weight_trace_d1 *= trace_decay
weight_trace_d1 += dw[0][0]
weight_trace_d2 *= trace_decay
weight_trace_d2 += dw[1][0]
if torch.max(out) > 0:
return torch.argmax(out),weight_trace_d1,weight_trace_d2,Net
def judgeState(bird, pipes, collide):
"""
根据小鸟和管子之间的位置关系判断当前状态
:param bird:传入小鸟的各项属性
:param pipes:传入管子的各项属性
:param collide:是否发生碰撞
:return:状态,距离,是否是新的管子
"""
# bird's x and y coordinate in the left top of the image
dist = bird.y + Bird.HEIGHT / 2 - WIN_HEIGHT / 2
isNew = False
index = -1
state = -1
if collide:
state = 8
return state
for p in pipes:
if p.x + PipePair.WIDTH - Bird.HEIGHT / 4 < bird.x and not p.score_counted:
continue
if p.x - Bird.NEAR_PIPE <= bird.x + Bird.HEIGHT and \
p.x + PipePair.WIDTH - Bird.HEIGHT / 4 >= bird.x:
p_top_y = p.top_y + PipePair.PIECE_HEIGHT
p_bottom_y = p.bottom_y - PipePair.PIECE_HEIGHT
if p.center - bird.y - Bird.HEIGHT / 2 >= 0 and bird.y >= p_top_y + Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - p.center + Bird.HEIGHT / 2 > 0 and bird.y + Bird.HEIGHT <= p_bottom_y - Bird.NEAR_COLLIDE / 2:
state = 1
elif bird.y < p_top_y + Bird.NEAR_COLLIDE / 2 and bird.y > p_top_y - 10:
state = 6
elif bird.y + Bird.HEIGHT > p_bottom_y - Bird.NEAR_COLLIDE / 2 and bird.y + Bird.HEIGHT < p_bottom_y + 10:
state = 7
if state > -0.5:
index = 1
elif p.x > bird.x + Bird.HEIGHT + Bird.NEAR_PIPE:
state = blankState(bird, p.center)
if p.isNewPipe:
isNew = True
p.isNewPipe = False
index = 1
if index > 0: # only judge the nearest and not passed pipe
dist = bird.y + Bird.HEIGHT / 2 - p.center
break
if index < -0.5: # no pipe left, key the bird in the middle
pos = WIN_HEIGHT / 2
dist = bird.y + Bird.HEIGHT / 2 - pos
state = blankState(bird, pos)
return state, dist, isNew
def blankState(bird, center):
"""
judgeState中调用的判断状态的函数 根据鸟的位置和管子中心的距离来判断
:param bird: 传入小鸟的各项属性
:param center:中心
:return:状态
"""
realHeight = (PipePair.ROOM_HIGHT - Bird.HEIGHT) / 2
if center - bird.y - Bird.HEIGHT / 2 >= 0 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - center + Bird.HEIGHT / 2 >= 0 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 1
elif center - bird.y - Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 2
elif bird.y - center + Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 3
elif bird.y + Bird.HEIGHT / 2 <= center - (realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION):
state = 4
elif bird.y + Bird.HEIGHT / 2 >= center + realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 5
return state
def getReward(state,lastState,smallerError,isNewPipe):
"""
根据状态和距离的变化获得奖励
:param state: 执行行为后的当前状态
:param lastState:执行行为之前的上一状态
:param smallerError:距离是否变小
:param isNewPipe:是否是新的管子
:return:奖励
"""
if state == 0 or state == 1:
reward = 6
elif state == 2 or state == 3:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -5
else:
reward = -3
elif state == 4 or state == 5:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -8
else:
reward = -5
elif state == 6 or state == 7:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -3
else:
reward = -3
elif state == 8: # collide
reward = -100
return reward
def updateNet(Net,reward, action, state,weight_trace_d1,weight_trace_d2):
"""
更新网络
:param Net: BDM-SNN网络
:param reward: 获得的奖励
:param action: 执行的行为
:param state: 执行行为前的状态
:param weight_trace_d1: 直接通路累积的资格迹
:param weight_trace_d2: 间接通路累积的资格迹
:return: 更新后的网络
"""
r = torch.ones((num_state, num_state * num_action), dtype=torch.float)
r[state, state * num_action + action] = reward
dw_d1 = r * weight_trace_d1
dw_d2 = -1 * r * weight_trace_d2
Net.UpdateWeight(0, state,num_action,dw_d1)
Net.UpdateWeight(1, state,num_action,dw_d2)
return Net
if __name__=="__main__":
"""
执行网络,运行Flappy Bird游戏
"""
num_state=9
num_action=2
weight_exc=50
weight_inh=-60
trace_decay = 0.8
DM=BDMSNN(num_state,num_action,weight_exc,weight_inh,"hh")
con_matrix1 = torch.zeros((num_state, num_state * num_action), dtype=torch.float)
for i in range(num_state):
for j in range(num_action):
con_matrix1[i, i * num_action + j] = weight_exc
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
pygame.init()
WIN_HEIGHT = 512
WIN_WIDTH = 284 * 2
heighest = 0
display_frame=0
display_surface = pygame.display.set_mode((WIN_WIDTH, WIN_HEIGHT))
pygame.display.set_caption('Flappy Bird')
images = load_images()
bird = Bird(250, int(WIN_HEIGHT / 2 - Bird.HEIGHT / 2), 2,
(images['bird-wingup'], images['bird-wingdown']))
clock = pygame.time.Clock()
score_font = pygame.font.SysFont(None, 25, bold=True)
info_font = pygame.font.SysFont(None, 50, bold=True)
collide = paused = False
frame_clock = 0
pipes = deque()
score = 0
lastDist = 0
lastState = 0 #init
state = lastState
num=0
num_reward=[]
num_score=[]
while not collide:
num=num+1
if num>30000:
break
input = torch.zeros((num_state), dtype=torch.float)
clock.tick(60)
if frame_clock %2==0 or frame_clock==1:
state, dist, isNewPipe = judgeState(bird, pipes, collide)
lastState = state
lastDist = dist
input[state]=2
print(input)
action,weight_trace_d1,weight_trace_d2,DM = chooseAct(DM,input,weight_trace_d1,weight_trace_d2)
print("state, dist:", state, dist)
print("state, action:",state,action)
if not (paused or frame_clock % (60 * PipePair.ADD_INTERVAL / 1000.0)):
pygame.event.post(pygame.event.Event(PipePair.ADD_EVENT))
for e in pygame.event.get():
if e.type == QUIT or (e.type == KEYUP and e.key == K_ESCAPE):
collide = True
elif e.type == KEYUP and e.key in (K_PAUSE, K_p):
paused = not paused
elif e.type == PipePair.ADD_EVENT:
pp = PipePair(images['pipe-end'], images['pipe-body'])
pipes.append(pp)
if paused:
continue # don't draw anything
pipe_collision = any(p.collides_with(bird) for p in pipes)
if pipe_collision or 0 >= bird.y or bird.y >= WIN_HEIGHT - Bird.HEIGHT:
collide = True
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
p.update()
display_surface.blit(p.image, p.rect)
bird.update(action,state)
display_surface.blit(bird.image, bird.rect)
if frame_clock %2==0 or frame_clock==1 or collide:
dist = 0
if collide:
nextState = 8
isNewPipe = False
else:
nextState, dist, isNewPipe = judgeState(bird, pipes, collide) # judge the bird's state
print("next state:", nextState)
print("lastdist, dist:", lastDist,dist)
isSmallerError = False
if state == nextState:
isSmallerError = False
if lastDist <= 0:
if lastDist < dist:
isSmallerError = True
else:
if lastDist > dist:
isSmallerError = True
if frame_clock>0 and not collide:
reward = getReward(nextState, state, isSmallerError, isNewPipe)
print("reward:", reward)
num_reward.append(reward)
DM=updateNet(DM,reward, action, state,weight_trace_d1,weight_trace_d2)
state = nextState #going on the next state
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
DM.reset()
display_frame += 1
for p in pipes:
if p.x + PipePair.WIDTH < bird.x and not p.score_counted:
score += 1
p.score_counted = True
num_score.append(score)
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: 0', True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
frame_clock += 1
pygame.display.flip()
# if collide, display the fail information, for 2 frames
cct = 0
while (bird.y < WIN_HEIGHT - Bird.HEIGHT - 3):
clock.tick(60)
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
display_surface.blit(p.image, p.rect)
if cct >= 6:
bird.sink()
display_surface.blit(bird.image, bird.rect)
fail_infor = info_font.render('Game over !', True, (255, 60, 30)) # current score
pos_x = WIN_WIDTH / 2 - fail_infor.get_width() / 2
pos_y = WIN_HEIGHT / 2 - 100
display_surface.blit(fail_infor, (pos_x, pos_y))
# display the score
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: 0' , True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
pygame.display.flip()
cct += 1
if heighest < score:
heighest = score
num_reward_np=np.array(num_reward)
num_score_np=np.array(num_score)
print(num_reward_np,num_score_np)
np.save('hh_reward_l.npy', num_reward_np)
np.save('hh_score_l.npy', num_score_np)
print(score)
================================================
FILE: examples/decision_making/BDM-SNN/BDM-SNN.py
================================================
import torch
import os
from braincog.model_zoo.bdmsnn import BDMSNN
import pygame
from pygame.locals import *
from collections import deque
from random import randint
import numpy as np
try:
pygame.display.init()
except:
os.environ["SDL_VIDEODRIVER"] = "dummy"
def load_images():
"""
Flappy Bird中load图像
:return:load的图像
"""
def load_image(img_file_name):
file_name = os.path.join('.', 'birdimages', img_file_name)
img = pygame.image.load(file_name)
# converting all images before use speeds up blitting
img.convert()
return img
return {'background': load_image('background.png'),
'pipe-end': load_image('pipe_end.png'),
'pipe-body': load_image('pipe_body.png'),
# images for animating the flapping bird -- animated GIFs are
# not supported in pygame
'bird-wingup': load_image('bird_wing_up.png'),
'bird-wingdown': load_image('bird_wing_down.png'), }
class Bird(pygame.sprite.Sprite):
"""
Flappy Bird类
"""
WIDTH = HEIGHT = 32
SINK_SPEED = 0.2
Fail_SINk_SPEED = 0.6
CLIMB_SPEED = 0.25
CLIMB_DURATION = 333.3
REGION = CLIMB_DURATION / 3
NEAR_COLLIDE = 30
NEAR_PIPE = 0
def __init__(self, x, y, msec_to_climb, images):
super(Bird, self).__init__()
self.x, self.y = x, y
self.msec_to_climb = msec_to_climb
self._img_wingup, self._img_wingdown = images
self._mask_wingup = pygame.mask.from_surface(self._img_wingup)
self._mask_wingdown = pygame.mask.from_surface(self._img_wingdown)
def update(self, action, state, delta_frames=1):
"""
更新小鸟的位置
:param action: 输入行为
:param state:输入状态
:param delta_frames:Fault
:return:None
"""
if self.msec_to_climb > 0 and action == 1:
if state == 4 or state == 5 or state == 2 or state == 3:
self.y -= (2 * Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
self.y -= (Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
if state == 4 or state == 5 or state == 2 or state == 3:
self.y += 2 * Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
else:
self.y += Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
def sink(self, delta_frames=1):
self.y += Bird.Fail_SINk_SPEED * (1000.0 * delta_frames / 60)
@property
def image(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._img_wingup
else:
return self._img_wingdown
@property
def mask(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._mask_wingup
else:
return self._mask_wingdown
@property
def rect(self):
return Rect(self.x, self.y, Bird.WIDTH, Bird.HEIGHT)
class PipePair(pygame.sprite.Sprite):
"""
Flappy Bird 中的管子类
"""
WIDTH = 80
PIECE_HEIGHT = 32
ADD_INTERVAL = 2000
ADD_EVENT = pygame.USEREVENT + 1
ROOM_HIGHT = 2 * Bird.HEIGHT + 2 * PIECE_HEIGHT
def __init__(self, pipe_end_img, pipe_body_img):
self.x = float(WIN_WIDTH - 1)
self.score_counted = False
self.isNewPipe = True
self.image = pygame.Surface((PipePair.WIDTH, WIN_HEIGHT), SRCALPHA)
self.image.convert() # speeds up blitting
self.image.fill((0, 0, 0, 0))
total_pipe_body_pieces = int(
(WIN_HEIGHT - # fill window from top to bottom
3 * Bird.HEIGHT - # make room for bird to fit through
3 * PipePair.PIECE_HEIGHT) / # 2 end pieces + 1 body piece
PipePair.PIECE_HEIGHT # to get number of pipe pieces
)
self.bottom_pieces = randint(1, total_pipe_body_pieces)
self.top_pieces = total_pipe_body_pieces - self.bottom_pieces
# bottom pipe
for i in range(1, self.bottom_pieces + 1):
piece_pos = (0, WIN_HEIGHT - i * PipePair.PIECE_HEIGHT)
self.image.blit(pipe_body_img, piece_pos)
bottom_pipe_end_y = WIN_HEIGHT - self.bottom_height_px
bottom_end_piece_pos = (0, bottom_pipe_end_y - PipePair.PIECE_HEIGHT)
self.image.blit(pipe_end_img, bottom_end_piece_pos)
# top pipe
for i in range(self.top_pieces):
self.image.blit(pipe_body_img, (0, i * PipePair.PIECE_HEIGHT))
top_pipe_end_y = self.top_height_px
self.image.blit(pipe_end_img, (0, top_pipe_end_y))
self.center = (top_pipe_end_y + bottom_pipe_end_y) / 2
# compensate for added end pieces
self.top_pieces += 1
self.bottom_pieces += 1
# for collision detection
self.mask = pygame.mask.from_surface(self.image)
self.top_y = top_pipe_end_y
self.bottom_y = bottom_pipe_end_y
@property
def top_height_px(self):
return self.top_pieces * PipePair.PIECE_HEIGHT
@property
def bottom_height_px(self):
return self.bottom_pieces * PipePair.PIECE_HEIGHT
@property
def visible(self):
return -PipePair.WIDTH < self.x < WIN_WIDTH
@property
def rect(self):
return Rect(self.x, 0, PipePair.WIDTH, PipePair.PIECE_HEIGHT)
def update(self, delta_frames=1):
self.x -= 0.18 * 1000.0 * delta_frames / 60
def collides_with(self, bird):
return pygame.sprite.collide_mask(self, bird)
def chooseAct(Net, input, weight_trace_d1, weight_trace_d2):
"""
根据输入选择行为
:param Net: 输入BDM-SNN网络
:param input: 输入电流 编码状态的脉冲
:param weight_trace_d1: 不断累积保存资格迹
:param weight_trace_d2: 不断累积保存资格迹
:return: 返回选择的行为、资格迹和网络
"""
for i_train in range(500):
out, dw = Net(input)
# rstdp
weight_trace_d1 *= trace_decay
weight_trace_d1 += dw[0][0]
weight_trace_d2 *= trace_decay
weight_trace_d2 += dw[1][0]
if torch.max(out) > 0:
return torch.argmax(out), weight_trace_d1, weight_trace_d2, Net
def judgeState(bird, pipes, collide):
"""
根据小鸟和管子之间的位置关系判断当前状态
:param bird:传入小鸟的各项属性
:param pipes:传入管子的各项属性
:param collide:是否发生碰撞
:return:状态,距离,是否是新的管子
"""
# bird's x and y coordinate in the left top of the image
dist = bird.y + Bird.HEIGHT / 2 - WIN_HEIGHT / 2
isNew = False
index = -1
state = -1
if collide:
state = 8
return state
for p in pipes:
if p.x + PipePair.WIDTH - Bird.HEIGHT / 4 < bird.x and not p.score_counted:
continue
if p.x - Bird.NEAR_PIPE <= bird.x + Bird.HEIGHT and \
p.x + PipePair.WIDTH - Bird.HEIGHT / 4 >= bird.x:
p_top_y = p.top_y + PipePair.PIECE_HEIGHT
p_bottom_y = p.bottom_y - PipePair.PIECE_HEIGHT
if p.center - bird.y - Bird.HEIGHT / 2 >= 0 and bird.y >= p_top_y + Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - p.center + Bird.HEIGHT / 2 > 0 and bird.y + Bird.HEIGHT <= p_bottom_y - Bird.NEAR_COLLIDE / 2:
state = 1
elif bird.y < p_top_y + Bird.NEAR_COLLIDE / 2 and bird.y > p_top_y - 10:
state = 6
elif bird.y + Bird.HEIGHT > p_bottom_y - Bird.NEAR_COLLIDE / 2 and bird.y + Bird.HEIGHT < p_bottom_y + 10:
state = 7
if state > -0.5:
index = 1
elif p.x > bird.x + Bird.HEIGHT + Bird.NEAR_PIPE:
state = blankState(bird, p.center)
if p.isNewPipe:
isNew = True
p.isNewPipe = False
index = 1
if index > 0: # only judge the nearest and not passed pipe
dist = bird.y + Bird.HEIGHT / 2 - p.center
break
if index < -0.5: # no pipe left, key the bird in the middle
pos = WIN_HEIGHT / 2
dist = bird.y + Bird.HEIGHT / 2 - pos
state = blankState(bird, pos)
return state, dist, isNew
def blankState(bird, center):
"""
judgeState中调用的判断状态的函数 根据鸟的位置和管子中心的距离来判断
:param bird: 传入小鸟的各项属性
:param center:中心
:return:状态
"""
realHeight = (PipePair.ROOM_HIGHT - Bird.HEIGHT) / 2
if center - bird.y - Bird.HEIGHT / 2 >= 0 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - center + Bird.HEIGHT / 2 >= 0 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 1
elif center - bird.y - Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 2
elif bird.y - center + Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 3
elif bird.y + Bird.HEIGHT / 2 <= center - (realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION):
state = 4
elif bird.y + Bird.HEIGHT / 2 >= center + realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 5
return state
def getReward(state, lastState, smallerError, isNewPipe):
"""
根据状态和距离的变化获得奖励
:param state: 执行行为后的当前状态
:param lastState:执行行为之前的上一状态
:param smallerError:距离是否变小
:param isNewPipe:是否是新的管子
:return:奖励
"""
if state == 0 or state == 1:
reward = 6
elif state == 2 or state == 3:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -5
else:
reward = -3
elif state == 4 or state == 5:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -8
else:
reward = -5
elif state == 6 or state == 7:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -3
else:
reward = -3
elif state == 8: # collide
reward = -100
return reward
def updateNet(Net, reward, action, state, weight_trace_d1, weight_trace_d2):
"""
更新网络
:param Net: BDM-SNN网络
:param reward: 获得的奖励
:param action: 执行的行为
:param state: 执行行为前的状态
:param weight_trace_d1: 直接通路累积的资格迹
:param weight_trace_d2: 间接通路累积的资格迹
:return: 更新后的网络
"""
r = torch.ones((num_state, num_state * num_action), dtype=torch.float)
r[state, state * num_action + action] = reward
dw_d1 = r * weight_trace_d1
dw_d2 = -1 * r * weight_trace_d2
Net.UpdateWeight(0, state, num_action, dw_d1)
Net.UpdateWeight(1, state, num_action, dw_d2)
return Net
if __name__ == "__main__":
"""
执行网络,运行Flappy Bird游戏
"""
num_state = 9
num_action = 2
weight_exc = 1
weight_inh = -0.5
trace_decay = 0.8
DM = BDMSNN(num_state, num_action, weight_exc, weight_inh, "lif")
con_matrix1 = torch.zeros((num_state, num_state * num_action), dtype=torch.float)
for i in range(num_state):
for j in range(num_action):
con_matrix1[i, i * num_action + j] = weight_exc
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
pygame.init()
WIN_HEIGHT = 512
WIN_WIDTH = 284 * 2
heighest = 0
contTime = 0
display_frame = 0
display_surface = pygame.display.set_mode((WIN_WIDTH, WIN_HEIGHT))
pygame.display.set_caption('Flappy Bird')
images = load_images()
bird = Bird(250, int(WIN_HEIGHT / 2 - Bird.HEIGHT / 2), 2,
(images['bird-wingup'], images['bird-wingdown']))
clock = pygame.time.Clock()
score_font = pygame.font.SysFont(None, 25, bold=True)
info_font = pygame.font.SysFont(None, 50, bold=True)
collide = paused = False
frame_clock = 0
pipes = deque()
score = 0
lastDist = 0
lastState = 0 # init
state = lastState
num = 0
num_reward = []
num_score = []
while not collide:
num = num + 1
if num > 30000:
break
input = torch.zeros((num_state), dtype=torch.float)
clock.tick(60)
if frame_clock % 2 == 0 or frame_clock == 1:
state, dist, isNewPipe = judgeState(bird, pipes, collide)
lastState = state
lastDist = dist
input[state] = 2
action, weight_trace_d1, weight_trace_d2, DM = chooseAct(DM, input, weight_trace_d1, weight_trace_d2)
print("state, dist:", state, dist)
print("state, action:", state, action)
if not (paused or frame_clock % (60 * PipePair.ADD_INTERVAL / 1000.0)):
pygame.event.post(pygame.event.Event(PipePair.ADD_EVENT))
for e in pygame.event.get():
if e.type == QUIT or (e.type == KEYUP and e.key == K_ESCAPE):
collide = True
elif e.type == KEYUP and e.key in (K_PAUSE, K_p):
paused = not paused
elif e.type == PipePair.ADD_EVENT:
pp = PipePair(images['pipe-end'], images['pipe-body'])
pipes.append(pp)
if paused:
continue # don't draw anything
pipe_collision = any(p.collides_with(bird) for p in pipes)
if pipe_collision or 0 >= bird.y or bird.y >= WIN_HEIGHT - Bird.HEIGHT:
collide = True
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
p.update()
display_surface.blit(p.image, p.rect)
bird.update(action, state)
display_surface.blit(bird.image, bird.rect)
if frame_clock % 2 == 0 or frame_clock == 1 or collide:
dist = 0
if collide:
nextState = 8
isNewPipe = False
else:
nextState, dist, isNewPipe = judgeState(bird, pipes, collide) # judge the bird's state
print("next state:", nextState)
print("lastdist, dist:", lastDist, dist)
isSmallerError = False
if state == nextState:
isSmallerError = False
if lastDist <= 0:
if lastDist < dist:
isSmallerError = True
else:
if lastDist > dist:
isSmallerError = True
if frame_clock > 0 and not collide:
reward = getReward(nextState, state, isSmallerError, isNewPipe)
print("reward:", reward)
num_reward.append(reward)
DM = updateNet(DM, reward, action, state, weight_trace_d1, weight_trace_d2)
state = nextState # going on the next state
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
DM.reset()
display_frame += 1
for p in pipes:
if p.x + PipePair.WIDTH < bird.x and not p.score_counted:
score += 1
p.score_counted = True
num_score.append(score)
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: 0', True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
frame_clock += 1
pygame.display.flip()
# if collide, display the fail information, for 2 frames
cct = 0
while (bird.y < WIN_HEIGHT - Bird.HEIGHT - 3):
clock.tick(60)
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
display_surface.blit(p.image, p.rect)
if cct >= 6:
bird.sink()
display_surface.blit(bird.image, bird.rect)
fail_infor = info_font.render('Game over !', True, (255, 60, 30)) # current score
pos_x = WIN_WIDTH / 2 - fail_infor.get_width() / 2
pos_y = WIN_HEIGHT / 2 - 100
display_surface.blit(fail_infor, (pos_x, pos_y))
# display the score
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: 0', True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
pygame.display.flip()
cct += 1
if heighest < score:
heighest = score
contTime += 1
num_reward_np = np.array(num_reward)
num_score_np = np.array(num_score)
print(num_reward_np, num_score_np)
np.save('lif_reward_l.npy', num_reward_np)
np.save('lif_score_l.npy', num_score_np)
print(score)
================================================
FILE: examples/decision_making/BDM-SNN/README.md
================================================
# Brain-inspired Decision-Making SNN
## Requirements
"decisionmaking.py", "BDM-SNN.py","BDM-SNN-hh.py":pygame
"BDM-SNN-UAV.py":robomaster
## Run
The decisionmaking.py and BDM-SNN.py implements the core code of the brain-inspired decision-making spiking neural network in paper entitled "A brain-inspired decision-making spiking neural network and its application in unmanned aerial vehicle".
"decisionmaking.py, BDM-SNN.py" includes the multi-brain regions coordinated decision-making spiking neural network with LIF neurons.
"BDM-SNN-hh.py" includes the BDM-SNN with simplified HH neurons.
"BDM-SNN-UAV.py" includes the BDM-SNN applied to the UAV (DJI Tello talent), users need to define the reinforcement learning task.
```shell
python decisionmaking.py
python BDM-SNN.py
python BDM-SNN-hh.py
python BDM-SNN-UAV.py
```
## Results
"decisionmaking.py", "BDM-SNN.py" and "BDM-SNN-hh.py" have been verified on Flappy Bird game. BDM-SNN could stably pass the pipeline on the first try.

Differences from the original article: an improved reward-modulated STDP learning rule.
## Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@article{zhao2018brain,
title={A brain-inspired decision-making spiking neural network and its application in unmanned aerial vehicle},
author={Zhao, Feifei and Zeng, Yi and Xu, Bo},
journal={Frontiers in neurorobotics},
volume={12},
pages={56},
year={2018},
publisher={Frontiers Media SA}
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/decision_making/BDM-SNN/decisionmaking.py
================================================
import numpy as np
import torch,os,sys
from torch import nn
from torch.nn import Parameter
import abc
import math
from abc import ABC
import torch.nn.functional as F
import matplotlib.pyplot as plt
#from BrainCog.base.strategy.surrogate import *
from braincog.base.node.node import IFNode, SimHHNode
from braincog.base.learningrule.STDP import STDP, MutliInputSTDP
from braincog.base.connection.CustomLinear import CustomLinear
from braincog.base.brainarea.basalganglia import basalganglia
#from braincog.model_zoo.bdmsnn import BDMSNN
import pygame
from pygame.locals import *
from collections import deque
from random import randint
#os.environ["SDL_VIDEODRIVER"] = "dummy"
class BDMSNN(nn.Module):
def __init__(self, num_state, num_action, weight_exc, weight_inh, node_type):
"""
定义BDM-SNN网络
:param num_state: 状态个数
:param num_action: 动作个数
:param weight_exc: 兴奋性连接权重
:param weight_inh: 抑制性连接权重
"""
super().__init__()
# parameters
BG = basalganglia(num_state, num_action, weight_exc, weight_inh, node_type)
dm_connection = BG.getweight()
dm_mask = BG.getmask()
# input-dlpfc
con_matrix9 = torch.eye((num_state), dtype=torch.float)
dm_connection.append(CustomLinear(weight_exc * con_matrix9, con_matrix9))
dm_mask.append(con_matrix9)
# gpi-th
con_matrix10 = torch.eye((num_action), dtype=torch.float)
dm_mask.append(con_matrix10)
dm_connection.append(CustomLinear(weight_inh * con_matrix10, con_matrix10))
# th-pm
dm_mask.append(con_matrix10)
dm_connection.append(CustomLinear(weight_exc * con_matrix10, con_matrix10))
# dlpfc-th
con_matrix11 = torch.ones((num_state, num_action), dtype=torch.float)
dm_mask.append(con_matrix11)
dm_connection.append(CustomLinear(0.2 * weight_exc * con_matrix11, con_matrix11))
# pm-pm
con_matrix3 = torch.ones((num_action, num_action), dtype=torch.float)
con_matrix4 = torch.eye((num_action), dtype=torch.float)
con_matrix5 = con_matrix3 - con_matrix4
con_matrix5 = con_matrix5
dm_mask.append(con_matrix5)
dm_connection.append(CustomLinear(5 * weight_inh * con_matrix5, con_matrix5))
# dlpfc thalamus pm +bg
self.weight_exc = weight_exc
self.num_subDM = 8
self.connection = dm_connection
self.mask = dm_mask
self.node = BG.node
self.node_type = node_type
if self.node_type == "hh":
self.node.extend([SimHHNode() for i in range(self.num_subDM - BG.num_subBG)])
self.node[6].g_Na = torch.tensor(12)
self.node[6].g_K = torch.tensor(3.6)
self.node[6].g_L = torch.tensor(0.03)
if self.node_type == "lif":
self.node.extend([IFNode() for i in range(self.num_subDM - BG.num_subBG)])
self.learning_rule = BG.learning_rule
self.learning_rule.append(MutliInputSTDP(self.node[5], [self.connection[10], self.connection[12]])) # gpi-丘脑
self.learning_rule.append(MutliInputSTDP(self.node[6], [self.connection[11], self.connection[13]])) # pm
self.learning_rule.append(STDP(self.node[7], self.connection[9]))
out_shape=[self.connection[0].weight.shape[1],self.connection[1].weight.shape[1],self.connection[2].weight.shape[1],self.connection[4].weight.shape[1],self.connection[3].weight.shape[1],self.connection[10].weight.shape[1],self.connection[11].weight.shape[1],self.connection[9].weight.shape[1]]
self.out = []
self.dw = []
for i in range(self.num_subDM):
self.out.append(torch.zeros((out_shape[i]), dtype=torch.float))
self.dw.append(torch.zeros((out_shape[i]), dtype=torch.float))
def forward(self, input):
"""
根据输入得到网络的输出
:param input: 输入
:return: 网络的输出
"""
self.out[7] = self.node[7](self.connection[9](input))
self.out[0], self.dw[0] = self.learning_rule[0](self.out[7])
self.out[1], self.dw[1] = self.learning_rule[1](self.out[7])
self.out[2], self.dw[2] = self.learning_rule[2](self.out[7], self.out[3])
self.out[3], self.dw[3] = self.learning_rule[3](self.out[1], self.out[2])
self.out[4], self.dw[4] = self.learning_rule[4](self.out[0], self.out[3], self.out[2])
self.out[5], self.dw[5] = self.learning_rule[5](self.out[4], self.out[7])
self.out[6], self.dw[6] = self.learning_rule[6](self.out[5], self.out[6])
br = ["StrD1", "StrD2", "STN", "Gpe", "Gpi", "thalamus", "PM", "DLPFC"]
for i in range(self.num_subDM):
if torch.max(self.out[i]) > 0 and self.node_type == "hh":
self.node[i].n_reset()
print("every areas:", br[i], self.out[i])
return self.out[6], self.dw
def UpdateWeight(self, i, s, num_action, dw):
"""
更新网络中第i组连接的权重
:param i:要更新的连接组索引
:param s:传入状态
:param dw:更新权重的量
:return:
"""
if self.node_type == "hh":
self.connection[i].update(0.2 * self.weight_exc * dw)
self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]] /= (self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]].float().max() + 1e-12)
self.connection[i].weight.data[s, :] = self.connection[i].weight.data[s, :] * self.weight_exc
if self.node_type == "lif":
dw_mean = dw[s, [s * num_action, s * num_action + 1]].mean()
dw_std = dw[s, [s * num_action, s * num_action + 1]].std()
dw[s, [s * num_action, s * num_action + 1]] = (dw[s, [s * num_action,s * num_action + 1]] - dw_mean) / dw_std
dw[s, :] = dw[s, :] * self.mask[i][s, :]
self.connection[i].update(dw)
self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]] /= (self.connection[i].weight.data[s, [s * num_action, s * num_action + 1]].float().max() + 1e-12)
if i in [0, 1, 2, 6, 7, 11, 12]:
self.connection[i].weight.data = torch.clamp(self.connection[i].weight.data, 0, None)
if i in [3, 4, 5, 8, 10]:
self.connection[i].weight.data = torch.clamp(self.connection[i].weight.data, None, 0)
def reset(self):
"""
reset神经元或学习法则的中间量
:return: None
"""
for i in range(self.num_subDM):
self.node[i].n_reset()
for i in range(len(self.learning_rule)):
self.learning_rule[i].reset()
def getweight(self):
"""
获取网络的连接(包括权值等)
:return: 网络的连接
"""
return self.connection
def load_images():
"""Load all images required by the game and return a dict of them.
The returned dict has the following keys:
background: The game's background image.
bird-wingup: An image of the bird with its wing pointing upward.
Use this and bird-wingdown to create a flapping bird.
bird-wingdown: An image of the bird with its wing pointing downward.
Use this and bird-wingup to create a flapping bird.
pipe-end: An image of a pipe's end piece (the slightly wider bit).
Use this and pipe-body to make pipes.
pipe-body: An image of a slice of a pipe's body. Use this and
pipe-body to make pipes.
"""
def load_image(img_file_name):
"""Return the loaded pygame image with the specified file name.
This function looks for images in the game's images folder
(./images/). All images are converted before being returned to
speed up blitting.
Arguments:
img_file_name: The file name (including its extension, e.g.
'.png') of the required image, without a file path.
"""
file_name = os.path.join('.', 'birdimages', img_file_name)
img = pygame.image.load(file_name)
# converting all images before use speeds up blitting
img.convert()
return img
return {'background': load_image('background.png'),
'pipe-end': load_image('pipe_end.png'),
'pipe-body': load_image('pipe_body.png'),
# images for animating the flapping bird -- animated GIFs are
# not supported in pygame
'bird-wingup': load_image('bird_wing_up.png'),
'bird-wingdown': load_image('bird_wing_down.png'),}
class Bird(pygame.sprite.Sprite):
WIDTH = HEIGHT = 32
SINK_SPEED = 0.2
Fail_SINk_SPEED = 0.6
CLIMB_SPEED = 0.25
CLIMB_DURATION = 333.3
REGION = CLIMB_DURATION / 3 # when far from the pipe, the bird can fluctuate in a certain region,wgx
NEAR_COLLIDE = 30 # when inside the pipe, near collide distance, this define another state
NEAR_PIPE = 0 # at what distance does the bird near the pipe
def __init__(self, x, y, msec_to_climb, images):
super(Bird, self).__init__()
self.x, self.y = x, y
self.msec_to_climb = msec_to_climb
self._img_wingup, self._img_wingdown = images
self._mask_wingup = pygame.mask.from_surface(self._img_wingup)
self._mask_wingdown = pygame.mask.from_surface(self._img_wingdown)
def update(self, action,state,delta_frames=1):
if self.msec_to_climb > 0 and action == 1:
if state==4 or state==5 or state == 2 or state == 3:
self.y -= (2*Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
self.y -= (Bird.CLIMB_SPEED * (1000.0 * delta_frames / 60))
else:
if state == 4 or state == 5 or state == 2 or state == 3:
self.y += 2*Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
else:
self.y += Bird.SINK_SPEED * (1000.0 * delta_frames / 60)
# if the bird fails, sink the bird till it hit the bottom
def sink(self, delta_frames=1):
self.y += Bird.Fail_SINk_SPEED * (1000.0 * delta_frames / 60)
@property
def image(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._img_wingup
else:
return self._img_wingdown
@property
def mask(self):
if pygame.time.get_ticks() % 500 >= 250:
return self._mask_wingup
else:
return self._mask_wingdown
@property
def rect(self):
return Rect(self.x, self.y, Bird.WIDTH, Bird.HEIGHT)
class PipePair(pygame.sprite.Sprite):
WIDTH = 80
PIECE_HEIGHT = 32
ADD_INTERVAL = 2000
ADD_EVENT = pygame.USEREVENT + 1
ROOM_HIGHT = 2 * Bird.HEIGHT + 2 * PIECE_HEIGHT
def __init__(self, pipe_end_img, pipe_body_img):
"""Initialises a new random PipePair.
The new PipePair will automatically be assigned an x attribute of
float(WIN_WIDTH - 1).
Arguments:
pipe_end_img: The image to use to represent a pipe's end piece.
pipe_body_img: The image to use to represent one horizontal slice
of a pipe's body.
"""
self.x = float(WIN_WIDTH - 1)
self.score_counted = False
self.isNewPipe = True
self.image = pygame.Surface((PipePair.WIDTH, WIN_HEIGHT), SRCALPHA)
self.image.convert() # speeds up blitting
self.image.fill((0, 0, 0, 0))
total_pipe_body_pieces = int(
(WIN_HEIGHT - # fill window from top to bottom
3 * Bird.HEIGHT - # make room for bird to fit through
3 * PipePair.PIECE_HEIGHT) / # 2 end pieces + 1 body piece
PipePair.PIECE_HEIGHT # to get number of pipe pieces
)
self.bottom_pieces = randint(1, total_pipe_body_pieces)
self.top_pieces = total_pipe_body_pieces - self.bottom_pieces
# bottom pipe
for i in range(1, self.bottom_pieces + 1):
piece_pos = (0, WIN_HEIGHT - i * PipePair.PIECE_HEIGHT)
self.image.blit(pipe_body_img, piece_pos)
bottom_pipe_end_y = WIN_HEIGHT - self.bottom_height_px
bottom_end_piece_pos = (0, bottom_pipe_end_y - PipePair.PIECE_HEIGHT)
self.image.blit(pipe_end_img, bottom_end_piece_pos)
# top pipe
for i in range(self.top_pieces):
self.image.blit(pipe_body_img, (0, i * PipePair.PIECE_HEIGHT))
top_pipe_end_y = self.top_height_px
self.image.blit(pipe_end_img, (0, top_pipe_end_y))
self.center = (top_pipe_end_y + bottom_pipe_end_y) / 2 # center of pipe-room,wgx
# compensate for added end pieces
self.top_pieces += 1
self.bottom_pieces += 1
# for collision detection
self.mask = pygame.mask.from_surface(self.image)
self.top_y = top_pipe_end_y
self.bottom_y = bottom_pipe_end_y
@property
def top_height_px(self):
"""Get the top pipe's height, in pixels."""
return self.top_pieces * PipePair.PIECE_HEIGHT
@property
def bottom_height_px(self):
"""Get the bottom pipe's height, in pixels."""
return self.bottom_pieces * PipePair.PIECE_HEIGHT
@property
def visible(self):
"""Get whether this PipePair on screen, visible to the player."""
return -PipePair.WIDTH < self.x < WIN_WIDTH
@property
def rect(self):
"""Get the Rect which contains this PipePair."""
return Rect(self.x, 0, PipePair.WIDTH, PipePair.PIECE_HEIGHT)
def update(self, delta_frames=1):
"""Update the PipePair's position.
Attributes:
delta_frames: The number of frames elapsed since this method was
last called.
"""
self.x -= 0.18 * 1000.0 * delta_frames /60
def collides_with(self, bird):
"""Get whether the bird collides with a pipe in this PipePair.
Arguments:
bird: The Bird which should be tested for collision with this
PipePair.
"""
return pygame.sprite.collide_mask(self, bird)
def chooseAct(Net,s,input,weight_trace_d1,weight_trace_d2):
for i_train in range(500):
out, dw = Net(input)
# 更新权重
# Net.UpdateWeight(10, dw[5][0])
# Net.UpdateWeight(12, dw[5][1])
# Net.UpdateWeight(11, dw[6][0])
# rstdp
weight_trace_d1 *= trace_decay
weight_trace_d1 += dw[0][0]
weight_trace_d2 *= trace_decay
weight_trace_d2 += dw[1][0]
if torch.max(out) > 0:
return torch.argmax(out),weight_trace_d1,weight_trace_d2,Net
def judgeState(bird, pipes, collide):
# bird's x and y coordinate in the left top of the image
dist = bird.y + Bird.HEIGHT / 2 - WIN_HEIGHT / 2
isNew = False
index = -1
state = -1
if collide:
state = 8
return state
for p in pipes:
if p.x + PipePair.WIDTH - Bird.HEIGHT / 4 < bird.x and not p.score_counted:
continue
if p.x - Bird.NEAR_PIPE <= bird.x + Bird.HEIGHT and \
p.x + PipePair.WIDTH - Bird.HEIGHT / 4 >= bird.x:
p_top_y = p.top_y + PipePair.PIECE_HEIGHT
p_bottom_y = p.bottom_y - PipePair.PIECE_HEIGHT
if p.center - bird.y - Bird.HEIGHT / 2 >= 0 and bird.y >= p_top_y + Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - p.center + Bird.HEIGHT / 2 > 0 and bird.y + Bird.HEIGHT <= p_bottom_y - Bird.NEAR_COLLIDE / 2:
state = 1
elif bird.y < p_top_y + Bird.NEAR_COLLIDE / 2 and bird.y > p_top_y - 10:
state = 6
elif bird.y + Bird.HEIGHT > p_bottom_y - Bird.NEAR_COLLIDE / 2 and bird.y + Bird.HEIGHT < p_bottom_y + 10:
state = 7
if state > -0.5:
index = 1
elif p.x > bird.x + Bird.HEIGHT + Bird.NEAR_PIPE:
state = blankState(bird, p.center)
if p.isNewPipe:
isNew = True
p.isNewPipe = False
index = 1
if index > 0: # only judge the nearest and not passed pipe
dist = bird.y + Bird.HEIGHT / 2 - p.center
break
if index < -0.5: # no pipe left, key the bird in the middle
pos = WIN_HEIGHT / 2
dist = bird.y + Bird.HEIGHT / 2 - pos
state = blankState(bird, pos)
return state, dist, isNew
def blankState(bird, center): # judge the state before passing the pipe
realHeight = (PipePair.ROOM_HIGHT - Bird.HEIGHT) / 2
if center - bird.y - Bird.HEIGHT / 2 >= 0 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 0
elif bird.y - center + Bird.HEIGHT / 2 >= 0 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2:
state = 1
elif center - bird.y - Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
center - bird.y - Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 2
elif bird.y - center + Bird.HEIGHT / 2 >= realHeight - Bird.NEAR_COLLIDE / 2 and \
bird.y - center + Bird.HEIGHT / 2 < realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 3
elif bird.y + Bird.HEIGHT / 2 <= center - (realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION):
state = 4
elif bird.y + Bird.HEIGHT / 2 >= center + realHeight - Bird.NEAR_COLLIDE / 2 + Bird.REGION:
state = 5
return state
def getReward(state,lastState,smallerError,isNewPipe):
if state == 0 or state == 1:
reward = 6
elif state == 2 or state == 3:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -5
else:
reward = -3
elif state == 4 or state == 5:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -8
else:
reward = -5
elif state == 6 or state == 7:
if lastState == state and not isNewPipe:
if smallerError:
reward = 3
else:
reward = -3
else:
reward = -3
elif state == 8: # collide
reward = -100
return reward
def updateNet(Net,reward, action, state,weight_trace_d1,weight_trace_d2):
r = torch.ones((num_state, num_state * num_action), dtype=torch.float)
r[state, state * num_action + action] = reward
dw_d1 = r * weight_trace_d1
dw_d2 = -1 * r * weight_trace_d2
Net.UpdateWeight(0, state, num_action, dw_d1)
Net.UpdateWeight(1, state, num_action, dw_d2)
return Net
if __name__=="__main__":
#定义网络
num_state=9
num_action=2
weight_exc=1
weight_inh=-0.5
trace_decay = 0.8
DM = BDMSNN(num_state, num_action, weight_exc, weight_inh, "lif")
con_matrix1 = torch.zeros((num_state, num_state * num_action), dtype=torch.float)
for i in range(num_state):
for j in range(num_action):
con_matrix1[i, i * num_action + j] = weight_exc
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
#定义游戏场景
pygame.init()
WIN_HEIGHT = 512
WIN_WIDTH = 284 * 2 # image size: 284x512 px; tiled twice
heighest = 0
iteration=0
contTime = 0 # number of times to restart
display_frame=0
while iteration < 20: # restart the game for reinforcement learning, wgx
display_surface = pygame.display.set_mode((WIN_WIDTH, WIN_HEIGHT))
pygame.display.set_caption('Flappy Bird')
images = load_images()
bird = Bird(250, int(WIN_HEIGHT / 2 - Bird.HEIGHT / 2), 2,
(images['bird-wingup'], images['bird-wingdown']))
clock = pygame.time.Clock()
score_font = pygame.font.SysFont(None, 25, bold=True) # default font
info_font = pygame.font.SysFont(None, 50, bold=True)
collide = paused = False
frame_clock = 0
pipes = deque()
score = 0
lastDist = 0
lastState = 0 #init
state = lastState
while not collide:
# 输入
input = torch.zeros((num_state), dtype=torch.float)
clock.tick(60)
if frame_clock %2==0 or frame_clock==1:
state, dist, isNewPipe = judgeState(bird, pipes, collide) # judge the bird's state
lastState = state
lastDist = dist
input[state]=2
action,weight_trace_d1,weight_trace_d2,DM = chooseAct(DM,state,input,weight_trace_d1,weight_trace_d2)
print("state, dist:", state, dist)
print("state, action:",state,action)
if not (paused or frame_clock % (60 * PipePair.ADD_INTERVAL / 1000.0)):
pygame.event.post(pygame.event.Event(PipePair.ADD_EVENT))
for e in pygame.event.get():
if e.type == QUIT or (e.type == KEYUP and e.key == K_ESCAPE):
collide = True
elif e.type == KEYUP and e.key in (K_PAUSE, K_p):
paused = not paused
elif e.type == PipePair.ADD_EVENT:
pp = PipePair(images['pipe-end'], images['pipe-body'])
pipes.append(pp)
if paused:
continue # don't draw anything
# check for collisions
pipe_collision = any(p.collides_with(bird) for p in pipes)
if pipe_collision or 0 >= bird.y or bird.y >= WIN_HEIGHT - Bird.HEIGHT:
collide = True
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
p.update()
display_surface.blit(p.image, p.rect)
bird.update(action,state)
display_surface.blit(bird.image, bird.rect)
if frame_clock %2==0 or frame_clock==1 or collide:
# judge the state and update the value function
dist = 0
if collide:
nextState = 8
isNewPipe = False
else:
nextState, dist, isNewPipe = judgeState(bird, pipes, collide) # judge the bird's state
print("next state:", nextState)
print("lastdist, dist:", lastDist,dist)
isSmallerError = False
if state == nextState:
isSmallerError = False
if lastDist <= 0:
if lastDist < dist:
isSmallerError = True
else:
if lastDist > dist:
isSmallerError = True
if frame_clock>0 and not collide:
reward = getReward(nextState, state, isSmallerError, isNewPipe)
print("reward:", reward)
DM=updateNet(DM,reward, action, state,weight_trace_d1,weight_trace_d2)
state = nextState #going on the next state
weight_trace_d1 = torch.zeros(con_matrix1.shape, dtype=torch.float)
weight_trace_d2 = torch.zeros(con_matrix1.shape, dtype=torch.float)
DM.reset()
display_frame += 1
# update and display score
for p in pipes:
if p.x + PipePair.WIDTH < bird.x and not p.score_counted:
score += 1
p.score_counted = True
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: ' + str(iteration), True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
frame_clock += 1
pygame.display.flip()
# if collide, display the fail information, for 2 frames
cct = 0
while (bird.y < WIN_HEIGHT - Bird.HEIGHT - 3):
clock.tick(60)
for x in (0, WIN_WIDTH / 2):
display_surface.blit(images['background'], (x, 0))
while pipes and not pipes[0].visible:
pipes.popleft()
for p in pipes:
display_surface.blit(p.image, p.rect)
if cct >= 6:
bird.sink()
display_surface.blit(bird.image, bird.rect)
fail_infor = info_font.render('Game over !', True, (255, 60, 30)) # current score
pos_x = WIN_WIDTH / 2 - fail_infor.get_width() / 2
pos_y = WIN_HEIGHT / 2 - 100
display_surface.blit(fail_infor, (pos_x, pos_y))
# display the score
score_surface = score_font.render('Current score: ' + str(score), True, (0, 0, 0)) # current score
score_x = WIN_WIDTH / 2 - 3 * score_surface.get_width() / 4
display_surface.blit(score_surface, (score_x, PipePair.PIECE_HEIGHT))
if heighest < score:
heighest = score
score_surface_h = score_font.render('Highest score: ' + str(heighest), True,
(0, 0, 0)) # heighest score
score_x_h = 4 * WIN_WIDTH / 5 - 1.2 * score_surface.get_width() / 3
display_surface.blit(score_surface_h, (score_x_h, PipePair.PIECE_HEIGHT))
score_surface_i = score_font.render('Attempts: ' + str(iteration), True, (0, 0, 0)) # heighest score
score_x_i = 10
display_surface.blit(score_surface_i, (score_x_i, PipePair.PIECE_HEIGHT))
pygame.display.flip()
cct += 1
if heighest < score:
heighest = score
contTime += 1
iteration += 1
================================================
FILE: examples/decision_making/RL/README.md
================================================
# PL-SDQN
This repository contains code from our paper [**Solving the Spike Feature Information Vanishing Problem in Spiking Deep Q Network with Potential Based Normalization**]. If you use our code or refer to this project, please cite this paper.
To run the PL-SDQN model, please install 'tianshou' framework first https://github.com/thu-ml/tianshou
## Requirments
* numpy
* scipy
* pytorch >= 1.7.0
* torchvision
* gym
* atari-py
* opencv-python
* tianshou
## Train
```shell
python ./sdqn/main.py
```
## Citation
If you find this package helpful, please consider citing the following papers:
```BibTex
@ARTICLE{sun2022,
AUTHOR={Sun, Yinqian and Zeng, Yi and Li, Yang},
TITLE={Solving the spike feature information vanishing problem in spiking deep Q network with potential based normalization},
JOURNAL={Frontiers in Neuroscience},
VOLUME={16},
YEAR={2022},
URL={https://www.frontiersin.org/articles/10.3389/fnins.2022.953368},
DOI={10.3389/fnins.2022.953368},
ISSN={1662-453X},
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}
```
================================================
FILE: examples/decision_making/RL/atari/__init__.py
================================================
================================================
FILE: examples/decision_making/RL/atari/atari_wrapper.py
================================================
# Borrow a lot from openai baselines:
# https://github.com/openai/baselines/blob/master/baselines/common/atari_wrappers.py
from collections import deque
import cv2
import gym
import numpy as np
class NoopResetEnv(gym.Wrapper):
"""Sample initial states by taking random number of no-ops on reset.
No-op is assumed to be action 0.
:param gym.Env env: the environment to wrap.
:param int noop_max: the maximum value of no-ops to run.
"""
def __init__(self, env, noop_max=30):
super().__init__(env)
self.noop_max = noop_max
self.noop_action = 0
assert env.unwrapped.get_action_meanings()[0] == 'NOOP'
def reset(self):
self.env.reset()
noops = self.unwrapped.np_random.randint(1, self.noop_max + 1)
for _ in range(noops):
obs, _, done, _ = self.env.step(self.noop_action)
if done:
obs = self.env.reset()
return obs
class MaxAndSkipEnv(gym.Wrapper):
"""Return only every `skip`-th frame (frameskipping) using most recent raw
observations (for max pooling across time steps)
:param gym.Env env: the environment to wrap.
:param int skip: number of `skip`-th frame.
"""
def __init__(self, env, skip=4):
super().__init__(env)
self._skip = skip
def step(self, action):
"""Step the environment with the given action. Repeat action, sum
reward, and max over last observations.
"""
obs_list, total_reward, done = [], 0., False
for _ in range(self._skip):
obs, reward, done, info = self.env.step(action)
obs_list.append(obs)
total_reward += reward
if done:
break
max_frame = np.max(obs_list[-2:], axis=0)
return max_frame, total_reward, done, info
class EpisodicLifeEnv(gym.Wrapper):
"""Make end-of-life == end-of-episode, but only reset on true game over. It
helps the value estimation.
:param gym.Env env: the environment to wrap.
"""
def __init__(self, env):
super().__init__(env)
self.lives = 0
self.was_real_done = True
def step(self, action):
obs, reward, done, info = self.env.step(action)
self.was_real_done = done
# check current lives, make loss of life terminal, then update lives to
# handle bonus lives
lives = self.env.unwrapped.ale.lives()
if 0 < lives < self.lives:
# for Qbert sometimes we stay in lives == 0 condition for a few
# frames, so its important to keep lives > 0, so that we only reset
# once the environment is actually done.
done = True
self.lives = lives
return obs, reward, done, info
def reset(self):
"""Calls the Gym environment reset, only when lives are exhausted. This
way all states are still reachable even though lives are episodic, and
the learner need not know about any of this behind-the-scenes.
"""
if self.was_real_done:
obs = self.env.reset()
else:
# no-op step to advance from terminal/lost life state
obs = self.env.step(0)[0]
self.lives = self.env.unwrapped.ale.lives()
return obs
class FireResetEnv(gym.Wrapper):
"""Take action on reset for environments that are fixed until firing.
Related discussion: https://github.com/openai/baselines/issues/240
:param gym.Env env: the environment to wrap.
"""
def __init__(self, env):
super().__init__(env)
assert env.unwrapped.get_action_meanings()[1] == 'FIRE'
assert len(env.unwrapped.get_action_meanings()) >= 3
def reset(self):
self.env.reset()
return self.env.step(1)[0]
class WarpFrame(gym.ObservationWrapper):
"""Warp frames to 84x84 as done in the Nature paper and later work.
:param gym.Env env: the environment to wrap.
"""
def __init__(self, env):
super().__init__(env)
self.size = 84
self.observation_space = gym.spaces.Box(
low=np.min(env.observation_space.low),
high=np.max(env.observation_space.high),
shape=(self.size, self.size),
dtype=env.observation_space.dtype
)
def observation(self, frame):
"""returns the current observation from a frame"""
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
return cv2.resize(frame, (self.size, self.size), interpolation=cv2.INTER_AREA)
class ScaledFloatFrame(gym.ObservationWrapper):
"""Normalize observations to 0~1.
:param gym.Env env: the environment to wrap.
"""
def __init__(self, env):
super().__init__(env)
low = np.min(env.observation_space.low)
high = np.max(env.observation_space.high)
self.bias = low
self.scale = high - low
self.observation_space = gym.spaces.Box(
low=0., high=1., shape=env.observation_space.shape, dtype=np.float32
)
def observation(self, observation):
return (observation - self.bias) / self.scale
class ClipRewardEnv(gym.RewardWrapper):
"""clips the reward to {+1, 0, -1} by its sign.
:param gym.Env env: the environment to wrap.
"""
def __init__(self, env):
super().__init__(env)
self.reward_range = (-1, 1)
def reward(self, reward):
"""Bin reward to {+1, 0, -1} by its sign. Note: np.sign(0) == 0."""
return np.sign(reward)
class FrameStack(gym.Wrapper):
"""Stack n_frames last frames.
:param gym.Env env: the environment to wrap.
:param int n_frames: the number of frames to stack.
"""
def __init__(self, env, n_frames):
super().__init__(env)
self.n_frames = n_frames
self.frames = deque([], maxlen=n_frames)
shape = (n_frames, ) + env.observation_space.shape
self.observation_space = gym.spaces.Box(
low=np.min(env.observation_space.low),
high=np.max(env.observation_space.high),
shape=shape,
dtype=env.observation_space.dtype
)
def reset(self):
obs = self.env.reset()
for _ in range(self.n_frames):
self.frames.append(obs)
return self._get_ob()
def step(self, action):
obs, reward, done, info = self.env.step(action)
self.frames.append(obs)
return self._get_ob(), reward, done, info
def _get_ob(self):
# the original wrapper use `LazyFrames` but since we use np buffer,
# it has no effect
return np.stack(self.frames, axis=0)
def wrap_deepmind(
env_id,
episode_life=True,
clip_rewards=True,
frame_stack=4,
scale=False,
warp_frame=True
):
"""Configure environment for DeepMind-style Atari. The observation is
channel-first: (c, h, w) instead of (h, w, c).
:param str env_id: the atari environment id.
:param bool episode_life: wrap the episode life wrapper.
:param bool clip_rewards: wrap the reward clipping wrapper.
:param int frame_stack: wrap the frame stacking wrapper.
:param bool scale: wrap the scaling observation wrapper.
:param bool warp_frame: wrap the grayscale + resize observation wrapper.
:return: the wrapped atari environment.
"""
assert 'NoFrameskip' in env_id
env = gym.make(env_id)
env = NoopResetEnv(env, noop_max=30)
env = MaxAndSkipEnv(env, skip=4)
if episode_life:
env = EpisodicLifeEnv(env)
if 'FIRE' in env.unwrapped.get_action_meanings():
env = FireResetEnv(env)
if warp_frame:
env = WarpFrame(env)
if scale:
env = ScaledFloatFrame(env)
if clip_rewards:
env = ClipRewardEnv(env)
if frame_stack:
env = FrameStack(env, frame_stack)
return env
================================================
FILE: examples/decision_making/RL/mcs-fqf/discrete.py
================================================
from audioop import bias
from time import time
from typing import Any, Optional, Sequence, Tuple, Union
import numpy as np
import torch
import torch.nn.functional as F
from torch import nn
from tianshou.data import Batch
from braincog.base.node.node import LIFNode, ThreeCompNode
class SpikePopEncodingNetwork(nn.Module):
"""Cosine embedding network for IQN. Convert a scalar in [0, 1] to a list \
of n-dim vectors.
:param num_cosines: the number of cosines used for the embedding.
:param embedding_dim: the dimension of the embedding/output.
.. note::
From https://github.com/ku2482/fqf-iqn-qrdqn.pytorch/blob/master
/fqf_iqn_qrdqn/network.py .
"""
def __init__(self, num_cosines: int, embedding_dim: int, device, time_window: int=8) -> None:
super().__init__()
self._threshold = 0.5
# self._decay = 0.2
self._decay = 0.5
self.r_max = 0.5
# self.mus = torch.from_numpy(np.arange(num_cosines) / num_cosines)
self.sigma = 0.05
# self.sigma = 0.01
self._node = LIFNode
self.net = nn.Sequential(
nn.Linear(num_cosines, embedding_dim),
self._node()
# self._node(threshold=self._threshold, decay=self._decay)
)
self.num_cosines = num_cosines
self.embedding_dim = embedding_dim
self.mus = torch.arange(0, num_cosines, device=device).view(1, 1, self.num_cosines) / num_cosines
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def forward(self, taus: torch.Tensor, time_window: int) -> torch.Tensor:
batch_size = taus.shape[0]
N = taus.shape[1]
self.reset()
taus_lam = self.r_max * torch.exp(-(taus.unsqueeze(-1) - self.mus)**2/2/self.sigma**2).view(batch_size*N, self.num_cosines)
taus_repeat = taus_lam.unsqueeze(0).repeat(time_window, 1, 1)
taus_emb = torch.poisson(taus_repeat)
tau_embeddings = []
for i in range(time_window):
t_e = self.net(taus_emb[i])
tau_embeddings.append(t_e)
return tau_embeddings
class SpikeFractionProposalNetwork(nn.Module):
"""Fraction proposal network for FQF.
:param num_fractions: the number of factions to propose.
:param embedding_dim: the dimension of the embedding/input.
.. note::
Adapted from https://github.com/ku2482/fqf-iqn-qrdqn.pytorch/blob/master
/fqf_iqn_qrdqn/network.py .
"""
def __init__(self, num_fractions: int, embedding_dim: int) -> None:
super().__init__()
self.net = nn.Linear(embedding_dim, num_fractions)
torch.nn.init.xavier_uniform_(self.net.weight, gain=0.01)
torch.nn.init.constant_(self.net.bias, 0)
self.num_fractions = num_fractions
self.embedding_dim = embedding_dim
def forward(
self, state_embeddings: list
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
state_embeddings = torch.stack(state_embeddings).detach()
time_window = state_embeddings.shape[0]
batch_size = state_embeddings.shape[1]
logits = self.net(state_embeddings.view(time_window*batch_size, -1))
logits = logits.view(time_window, batch_size, -1)
m = torch.distributions.Categorical(logits=logits.mean(0))
taus_1_N = torch.cumsum(m.probs, dim=1)
taus = F.pad(taus_1_N, (1, 0))
tau_hats = (taus[:, :-1] + taus[:, 1:]).detach() / 2.0
entropies = m.entropy()
return taus, tau_hats, entropies
class MCQuantiles(nn.Module):
def __init__(self,
state_embedings_shape: int,
tau_embeddings_shape: int,
hidden_size: int,
last_size: int,
fusion_size : int=512,
tau_s : int = 2.0):
super().__init__()
self.basal_w = nn.Linear(state_embedings_shape, fusion_size, bias=False)
self.apical_w = nn.Linear(tau_embeddings_shape, fusion_size, bias=False)
self._node = LIFNode
self.mc_node = ThreeCompNode()
self._last = nn.Sequential(
nn.Linear(fusion_size, hidden_size),
self._node(),
nn.Linear(hidden_size, last_size),
)
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def forward(self, state_embedding, tau_embedding):
"""
state_embedding: list
tau_embedding: torch.Tensor
"""
self.reset()
assert isinstance(state_embedding, type(tau_embedding))
if isinstance(state_embedding, list):
time_window = len(state_embedding)
elif isinstance(state_embedding, torch.Tensor):
time_window = state_embedding.shape[0]
else:
raise TypeError('Not support data type.')
batch_size = state_embedding[0].shape[0]
sample_size = tau_embedding[0].shape[0] // batch_size
quantiles = []
for step in range(time_window):
basal_psp = self.basal_w(state_embedding[step]).unsqueeze(1)
apical_psp = self.apical_w(tau_embedding[step]).view(batch_size, sample_size, -1)
embeddings = self.mc_node({'basal_inputs': basal_psp, 'apical_inputs': apical_psp}).view(batch_size*sample_size, -1)
out = self._last(embeddings)
quantiles.append(out)
quantiles = sum(quantiles) / time_window
return quantiles.view(batch_size, sample_size, -1).transpose(1, 2)
class SpikeFullQuantileFunction(nn.Module):
"""Full(y parameterized) Quantile Function.
:param preprocess_net: a self-defined preprocess_net which output a
flattened hidden state.
:param int action_dim: the dimension of action space.
:param hidden_sizes: a sequence of int for constructing the MLP after
preprocess_net. Default to empty sequence (where the MLP now contains
only a single linear layer).
:param int num_cosines: the number of cosines to use for cosine embedding.
Default to 64.
:param int preprocess_net_output_dim: the output dimension of
preprocess_net.
.. note::
The first return value is a tuple of (quantiles, fractions, quantiles_tau),
where fractions is a Batch(taus, tau_hats, entropies).
"""
def __init__(
self,
preprocess_net: nn.Module,
action_shape: Sequence[int],
hidden_sizes: Sequence[int] = (),
num_cosines: int = 64,
preprocess_net_output_dim: Optional[int] = None,
device: Union[str, int, torch.device] = "cpu",
) -> None:
super().__init__()
self.device = device
self.last_size = np.prod(action_shape)
self.preprocess = preprocess_net
self.input_dim = getattr(
self.preprocess, "output_dim", preprocess_net_output_dim
)
self.embed_model = SpikePopEncodingNetwork(num_cosines,
self.input_dim, device=device).to(device)
self.mcquantiles = MCQuantiles(self.input_dim, self.input_dim, hidden_size=np.prod(hidden_sizes),
last_size=action_shape).to(device)
def forward( # type: ignore
self, s: Union[np.ndarray, torch.Tensor],
propose_model: SpikeFractionProposalNetwork,
fractions: Optional[Batch] = None,
**kwargs: Any
) -> Tuple[Any, torch.Tensor]:
r"""Mapping: s -> Q(s, \*)."""
logits, h = self.preprocess(s, state=kwargs.get("state", None))
# Propose fractions
if fractions is None:
taus, tau_hats, entropies = propose_model(logits)
fractions = Batch(taus=taus, tau_hats=tau_hats, entropies=entropies)
else:
taus, tau_hats = fractions.taus, fractions.tau_hats
time_window = len(logits)
tau_hats_emb = self.embed_model(tau_hats, time_window)
quantiles = self.mcquantiles(logits, tau_hats_emb)
quantiles_tau = None
if self.training:
with torch.no_grad():
tau_emb = self.embed_model(taus[:, 1:-1], time_window)
quantiles_tau = self.mcquantiles(logits, tau_emb)
return (quantiles, fractions, quantiles_tau), h
================================================
FILE: examples/decision_making/RL/mcs-fqf/main.py
================================================
import argparse
import os
import pprint
import numpy as np
import torch
from network import SpikingDQN
from ..atari.atari_wrapper import wrap_deepmind
from torch.utils.tensorboard import SummaryWriter
from tianshou.data import Collector, VectorReplayBuffer
from tianshou.env import ShmemVectorEnv
from tianshou.trainer import offpolicy_trainer
from tianshou.utils import TensorboardLogger, SequenceLogger
from discrete import SpikeFractionProposalNetwork, SpikeFullQuantileFunction
from policy import FQFPolicy
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--task', type=str, default='MsPacmanNoFrameskip-v4')
parser.add_argument('--seed', type=int, default=3128)
parser.add_argument('--eps-test', type=float, default=0.005)
parser.add_argument('--eps-train', type=float, default=1.)
parser.add_argument('--eps-train-final', type=float, default=0.05)
parser.add_argument('--buffer-size', type=int, default=100000)
parser.add_argument('--lr', type=float, default=1e-4)
parser.add_argument('--fraction-lr', type=float, default=2.5e-9)
parser.add_argument('--gamma', type=float, default=0.99)
parser.add_argument('--num-fractions', type=int, default=32)
parser.add_argument('--num-cosines', type=int, default=64)
parser.add_argument('--ent-coef', type=float, default=10.)
parser.add_argument('--hidden-sizes', type=int, nargs='*', default=[512])
parser.add_argument('--n-step', type=int, default=3)
parser.add_argument('--target-update-freq', type=int, default=500)
parser.add_argument('--epoch', type=int, default=200)
parser.add_argument('--step-per-epoch', type=int, default=100000)
parser.add_argument('--step-per-collect', type=int, default=10)
# parser.add_argument('--update-per-step', type=float, default=0.1)
parser.add_argument('--update-per-step', type=float, default=0.1)
parser.add_argument('--batch-size', type=int, default=32)
parser.add_argument('--training-num', type=int, default=10)
parser.add_argument('--test-num', type=int, default=10)
parser.add_argument('--logdir', type=str, default='log')
parser.add_argument('--render', type=float, default=0.)
parser.add_argument(
'--device', type=str, default='cuda' if torch.cuda.is_available() else 'cpu'
)
parser.add_argument('--frames-stack', type=int, default=4)
parser.add_argument('--resume-path', type=str, default=None)
parser.add_argument('--resume-id', type=str, default=None)
parser.add_argument(
'--watch',
default=False,
action='store_true',
help='watch the play of pre-trained policy only'
)
parser.add_argument('--save-buffer-name', type=str, default=None)
parser.add_argument('--time-window', type=int, default=8)
parser.add_argument('--prefix', type=str, default='')
parser.add_argument('--save-interval', type=int, default=10)
return parser.parse_args()
def make_atari_env(args):
return wrap_deepmind(args.task, frame_stack=args.frames_stack)
def make_atari_env_watch(args):
return wrap_deepmind(
args.task,
frame_stack=args.frames_stack,
episode_life=False,
clip_rewards=False
)
def main(args=get_args()):
print('Setting: ', args)
env = make_atari_env(args)
args.state_shape = env.observation_space.shape or env.observation_space.n
args.action_shape = env.action_space.shape or env.action_space.n
# should be N_FRAMES x H x W
print("Observations shape:", args.state_shape)
print("Actions shape:", args.action_shape)
print('update_per_step: ', args.update_per_step)
print('lr: ', args.lr)
# make environments
train_envs = ShmemVectorEnv(
[lambda: make_atari_env(args) for _ in range(args.training_num)]
)
test_envs = ShmemVectorEnv(
[lambda: make_atari_env_watch(args) for _ in range(args.test_num)]
)
# define model
feature_net = SpikingDQN(
*args.state_shape, args.action_shape, args.device, time_window=args.time_window, features_only=True
)
net = SpikeFullQuantileFunction(
feature_net,
args.action_shape,
args.hidden_sizes,
args.num_cosines,
device=args.device,
).to(args.device)
optim = torch.optim.Adam(net.parameters(), lr=args.lr)
fraction_net = SpikeFractionProposalNetwork(args.num_fractions, net.input_dim)
fraction_optim = torch.optim.RMSprop(
fraction_net.parameters(), lr=args.fraction_lr
)
# define policy
policy = FQFPolicy(
net,
optim,
fraction_net,
fraction_optim,
args.gamma,
args.num_fractions,
args.ent_coef,
args.n_step,
target_update_freq=args.target_update_freq
).to(args.device)
# load a previous policy
if args.resume_path:
policy.load_state_dict(torch.load(args.resume_path, map_location=args.device))
print("Loaded agent from: ", args.resume_path)
# replay buffer: `save_last_obs` and `stack_num` can be removed together
# when you have enough RAM
buffer = VectorReplayBuffer(
args.buffer_size,
buffer_num=len(train_envs),
ignore_obs_next=True,
save_only_last_obs=True,
stack_num=args.frames_stack
)
# collector
train_collector = Collector(policy, train_envs, buffer, exploration_noise=True)
test_collector = Collector(policy, test_envs, exploration_noise=True)
# log
log_path = os.path.join(args.logdir, args.task, 'spike_fqf', args.prefix)
model_log_path = os.path.join(log_path, 'models')
if not os.path.exists(model_log_path):
os.makedirs(model_log_path)
print('log_path: ', log_path)
writer = SummaryWriter(log_path)
writer.add_text("args", str(args))
logger = TensorboardLogger(writer, save_interval=args.save_interval)
result_logger = SequenceLogger(log_path)
def save_checkpoint_fn(epoch, env_step, gradient_step, epoch_round=True):
# see also: https://pytorch.org/tutorials/beginner/saving_loading_models.html
if epoch_round:
ckpt_path = os.path.join(model_log_path, 'checkpoint_epoch{}.pth'.format(epoch))
else:
ckpt_path = os.path.join(model_log_path, 'checkpoint.pth')
ckpt = {
'epoch': epoch,
'env_step': env_step,
'gradient_step': gradient_step,
'model': policy.state_dict()
}
torch.save(ckpt, ckpt_path)
return ckpt_path
setting_path = os.path.join(log_path, 'settings.txt')
argsDict = args.__dict__
with open(setting_path, 'w') as f:
f.writelines('------------------ start ------------------' + '\n')
for eachArg, value in argsDict.items():
f.writelines(eachArg + ' : ' + str(value) + '\n')
f.writelines('------------------- end -------------------')
def save_fn(policy, is_best=False):
if is_best:
torch.save(policy.state_dict(), os.path.join(log_path, 'best_policy.pth'))
else:
torch.save(policy.state_dict(), os.path.join(log_path, 'policy.pth'))
def stop_fn(mean_rewards):
if env.spec.reward_threshold:
return mean_rewards >= env.spec.reward_threshold
elif 'Pong' in args.task:
return mean_rewards >= 20
else:
return False
def train_fn(epoch, env_step):
# nature DQN setting, linear decay in the first 1M steps
if env_step <= 1e6:
eps = args.eps_train - env_step / 1e6 * \
(args.eps_train - args.eps_train_final)
else:
eps = args.eps_train_final
policy.set_eps(eps)
if env_step % 1000 == 0:
logger.write("train/env_step", env_step, {"train/eps": eps})
def test_fn(epoch, env_step):
policy.set_eps(args.eps_test)
# watch agent's performance
def watch():
print("Setup test envs ...")
policy.eval()
policy.set_eps(args.eps_test)
test_envs.seed(args.seed)
if args.save_buffer_name:
print(f"Generate buffer with size {args.buffer_size}")
buffer = VectorReplayBuffer(
args.buffer_size,
buffer_num=len(test_envs),
ignore_obs_next=True,
save_only_last_obs=True,
stack_num=args.frames_stack
)
collector = Collector(policy, test_envs, buffer, exploration_noise=True)
result = collector.collect(n_step=args.buffer_size)
print(f"Save buffer into {args.save_buffer_name}")
buffer.save_hdf5(args.save_buffer_name)
else:
print("Testing agent ...")
test_collector.reset()
result = test_collector.collect(
n_episode=args.test_num, render=args.render
)
rew = result["rews"].mean()
print(f'Mean reward (over {result["n/ep"]} episodes): {rew}')
if args.watch:
watch()
exit(0)
# test train_collector and start filling replay buffer
train_collector.collect(n_step=args.batch_size * args.training_num)
# trainer
result = offpolicy_trainer(
policy,
train_collector,
test_collector,
args.epoch,
args.step_per_epoch,
args.step_per_collect,
args.test_num,
args.batch_size,
train_fn=train_fn,
test_fn=test_fn,
stop_fn=stop_fn,
save_fn=save_fn,
logger=logger,
update_per_step=args.update_per_step,
test_in_train=False,
resume_from_log=args.resume_id is not None,
save_checkpoint_fn=save_checkpoint_fn,
result_logger=result_logger
)
pprint.pprint(result)
watch()
if __name__ == '__main__':
main(get_args())
================================================
FILE: examples/decision_making/RL/mcs-fqf/network.py
================================================
from typing import Any, Dict, Optional, Sequence, Tuple, Union
import numpy as np
import torch
from torch import nn
from braincog.base.node.node import LIFNode
from ..utils.normalization import PopNorm
class SpikingDQN(nn.Module):
"""Reference: Human-level control through deep reinforcement learning.
For advanced usage (how to customize the network), please refer to
:ref:`build_the_network`.
"""
def __init__(
self,
c: int,
h: int,
w: int,
action_shape: Sequence[int],
device: Union[str, int, torch.device] = "cpu",
time_window: int = 16,
features_only: bool = False,
) -> None:
super().__init__()
self._node = LIFNode
# self._node = ReLUNode
self.features_only = features_only
self.device = device
# self._threshold = 0.5
self._threshold = 1.0
self.v_reset = 0.0
# self._decay = 0.2
self._decay = 0.5
self._time_window = time_window
init_layer = lambda m: init(m, nn.init.orthogonal_, lambda x: nn.init.constant_(x, 0), gain=1)
self.p_count = 0
self.net = nn.Sequential(
# nn.utils.weight_norm(nn.Conv2d(c, 32, kernel_size=8, stride=4)),
nn.Conv2d(c, 32, kernel_size=8, stride=4),
# nn.BatchNorm2d(32),
# self._node(threshold=self._threshold, decay=self._decay),
PopNorm([32, 20, 20], threshold=self._threshold, v_reset=self.v_reset),
self._node(threshold=self._threshold, v_reset=self.v_reset),
# nn.utils.weight_norm(nn.Conv2d(32, 64, kernel_size=4, stride=2)),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
# nn.BatchNorm2d(64),
# self._node(threshold=self._threshold, decay=self._decay),
PopNorm([64, 9, 9], threshold=self._threshold, v_reset=self.v_reset),
self._node(threshold=self._threshold, v_reset=self.v_reset),
# nn.utils.weight_norm(nn.Conv2d(64, 64, kernel_size=3, stride=1)),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
# nn.BatchNorm2d(64),
PopNorm([64, 7, 7], threshold=self._threshold, v_reset=self.v_reset),
# self._node(threshold=self._threshold, decay=self._decay),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Flatten()
)
with torch.no_grad():
self.output_dim = np.prod(self.net(torch.zeros(1, c, h, w)).shape[1:])
if not features_only:
self.net = nn.Sequential(
self.net, nn.Linear(self.output_dim, 512),
# self.net, nn.Linear(self.output_dim, 512),
# self._node(threshold=self._threshold, decay=self._decay),
self._node(threshold=self._threshold, v_reset=self.v_reset),
# nn.Linear(512, np.prod(action_shape))
nn.Linear(512, np.prod(action_shape), bias=False)
)
self.output_dim = np.prod(action_shape)
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def forward(
self,
x: Union[np.ndarray, torch.Tensor],
state: Optional[Any] = None,
info: Dict[str, Any] = {},
) -> Tuple[torch.Tensor, Any]:
r"""Mapping: x -> Q(x, \*)."""
self.reset()
# obs = torch.as_tensor(x, device=self.device, dtype=torch.float32)
x = torch.as_tensor(x, device=self.device, dtype=torch.float32) / 255.0
qs = []
for i in range(self._time_window):
value = self.net(x)
qs.append(value)
if self.features_only:
return qs, state
else:
q_values = sum(qs) / self._time_window
return q_values, state
================================================
FILE: examples/decision_making/RL/mcs-fqf/policy.py
================================================
from typing import Any, Dict, Optional, Union
import numpy as np
import torch
import torch.nn.functional as F
from tianshou.data import Batch, ReplayBuffer, to_numpy
from tianshou.policy import DQNPolicy, QRDQNPolicy
from discrete import SpikeFractionProposalNetwork, SpikeFullQuantileFunction
class FQFPolicy(QRDQNPolicy):
"""Implementation of Fully-parameterized Quantile Function. arXiv:1911.02140.
:param torch.nn.Module model: a model following the rules in
:class:`~tianshou.policy.BasePolicy`. (s -> logits)
:param torch.optim.Optimizer optim: a torch.optim for optimizing the model.
:param FractionProposalNetwork fraction_model: a FractionProposalNetwork for
proposing fractions/quantiles given state.
:param torch.optim.Optimizer fraction_optim: a torch.optim for optimizing
the fraction model above.
:param float discount_factor: in [0, 1].
:param int num_fractions: the number of fractions to use. Default to 32.
:param float ent_coef: the coefficient for entropy loss. Default to 0.
:param int estimation_step: the number of steps to look ahead. Default to 1.
:param int target_update_freq: the target network update frequency (0 if
you do not use the target network).
:param bool reward_normalization: normalize the reward to Normal(0, 1).
Default to False.
.. seealso::
Please refer to :class:`~tianshou.policy.QRDQNPolicy` for more detailed
explanation.
"""
def __init__(
self,
model: SpikeFullQuantileFunction,
optim: torch.optim.Optimizer,
fraction_model: SpikeFractionProposalNetwork,
fraction_optim: torch.optim.Optimizer,
discount_factor: float = 0.99,
num_fractions: int = 32,
ent_coef: float = 0.0,
estimation_step: int = 1,
target_update_freq: int = 0,
reward_normalization: bool = False,
**kwargs: Any,
) -> None:
super().__init__(
model, optim, discount_factor, num_fractions, estimation_step,
target_update_freq, reward_normalization, **kwargs
)
self.propose_model = fraction_model
self._ent_coef = ent_coef
self._fraction_optim = fraction_optim
def _target_q(self, buffer: ReplayBuffer, indices: np.ndarray) -> torch.Tensor:
batch = buffer[indices] # batch.obs_next: s_{t+n}
if self._target:
result = self(batch, input="obs_next")
a, fractions = result.act, result.fractions
next_dist = self(
batch, model="model_old", input="obs_next", fractions=fractions
).logits
else:
next_b = self(batch, input="obs_next")
a = next_b.act
next_dist = next_b.logits
next_dist = next_dist[np.arange(len(a)), a, :]
return next_dist # shape: [bsz, num_quantiles]
def forward(
self,
batch: Batch,
state: Optional[Union[dict, Batch, np.ndarray]] = None,
model: str = "model",
input: str = "obs",
fractions: Optional[Batch] = None,
**kwargs: Any,
) -> Batch:
model = getattr(self, model)
obs = batch[input]
obs_ = obs.obs if hasattr(obs, "obs") else obs
# print('fractions: ', fractions)
if fractions is None:
(logits, fractions, quantiles_tau), h = model(
obs_, propose_model=self.propose_model, state=state, info=batch.info
)
else:
(logits, _, quantiles_tau), h = model(
obs_,
propose_model=self.propose_model,
fractions=fractions,
state=state,
info=batch.info
)
# print('fractions.taus shape : ', fractions.taus.shape)
# print('logits shape: ', logits.shape)
weighted_logits = (fractions.taus[:, 1:] -
fractions.taus[:, :-1]).unsqueeze(1) * logits
# print('weighted_logits shape: ', weighted_logits.shape)
q = DQNPolicy.compute_q_value(
self, weighted_logits.sum(2), getattr(obs, "mask", None)
)
if not hasattr(self, "max_action_num"):
self.max_action_num = q.shape[1]
act = to_numpy(q.max(dim=1)[1])
return Batch(
logits=logits,
act=act,
state=h,
fractions=fractions,
quantiles_tau=quantiles_tau
)
def learn(self, batch: Batch, **kwargs: Any) -> Dict[str, float]:
if self._target and self._iter % self._freq == 0:
self.sync_weight()
weight = batch.pop("weight", 1.0)
out = self(batch)
curr_dist_orig = out.logits
taus, tau_hats = out.fractions.taus, out.fractions.tau_hats
act = batch.act
curr_dist = curr_dist_orig[np.arange(len(act)), act, :].unsqueeze(2)
target_dist = batch.returns.unsqueeze(1)
# calculate each element's difference between curr_dist and target_dist
u = F.smooth_l1_loss(target_dist, curr_dist, reduction="none")
huber_loss = (
u * (
tau_hats.unsqueeze(2) -
(target_dist - curr_dist).detach().le(0.).float()
).abs()
).sum(-1).mean(1)
quantile_loss = (huber_loss * weight).mean()
# ref: https://github.com/ku2482/fqf-iqn-qrdqn.pytorch/
# blob/master/fqf_iqn_qrdqn/agent/qrdqn_agent.py L130
batch.weight = u.detach().abs().sum(-1).mean(1) # prio-buffer
# calculate fraction loss
with torch.no_grad():
sa_quantile_hats = curr_dist_orig[np.arange(len(act)), act, :]
sa_quantiles = out.quantiles_tau[np.arange(len(act)), act, :]
# ref: https://github.com/ku2482/fqf-iqn-qrdqn.pytorch/
# blob/master/fqf_iqn_qrdqn/agent/fqf_agent.py L169
values_1 = sa_quantiles - sa_quantile_hats[:, :-1]
signs_1 = sa_quantiles > torch.cat(
[sa_quantile_hats[:, :1], sa_quantiles[:, :-1]], dim=1
)
values_2 = sa_quantiles - sa_quantile_hats[:, 1:]
signs_2 = sa_quantiles < torch.cat(
[sa_quantiles[:, 1:], sa_quantile_hats[:, -1:]], dim=1
)
gradient_of_taus = (
torch.where(signs_1, values_1, -values_1) +
torch.where(signs_2, values_2, -values_2)
)
fraction_loss = (gradient_of_taus * taus[:, 1:-1]).sum(1).mean()
# calculate entropy loss
entropy_loss = out.fractions.entropies.mean()
fraction_entropy_loss = fraction_loss - self._ent_coef * entropy_loss
self._fraction_optim.zero_grad()
fraction_entropy_loss.backward(retain_graph=True)
self._fraction_optim.step()
self.optim.zero_grad()
quantile_loss.backward()
self.optim.step()
self._iter += 1
return {
"loss": quantile_loss.item() + fraction_entropy_loss.item(),
"loss/quantile": quantile_loss.item(),
"loss/fraction": fraction_loss.item(),
"loss/entropy": entropy_loss.item()
}
================================================
FILE: examples/decision_making/RL/requirements.txt
================================================
gym
atari-py
opencv-python
tianshou
================================================
FILE: examples/decision_making/RL/sdqn/main.py
================================================
import argparse
import os
import pprint
import numpy as np
import torch
try:
import tianshou
except:
raise ImportError('Need install "tianshou" lib at https://github.com/thu-ml/tianshou !')
from tianshou.data import Collector, VectorReplayBuffer
from tianshou.env import ShmemVectorEnv
from tianshou.policy import DQNPolicy
from tianshou.trainer import offpolicy_trainer
from tianshou.utils import TensorboardLogger, WandbLogger
import random
from network import SpikingDQN
from ..atari.atari_wrapper import wrap_deepmind
from torch.utils.tensorboard import SummaryWriter
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--task', type=str, default='PongNoFrameskip-v4')
parser.add_argument('--seed', type=int, default=40)
parser.add_argument('--eps-test', type=float, default=0.005)
parser.add_argument('--eps-train', type=float, default=1.)
parser.add_argument('--eps-train-final', type=float, default=0.05)
parser.add_argument('--buffer-size', type=int, default=100000)
parser.add_argument('--lr', type=float, default=0.0001)
parser.add_argument('--gamma', type=float, default=0.99)
parser.add_argument('--n-step', type=int, default=3)
parser.add_argument('--target-update-freq', type=int, default=500)
parser.add_argument('--epoch', type=int, default=100)
parser.add_argument('--step-per-epoch', type=int, default=100000)
parser.add_argument('--step-per-collect', type=int, default=10)
parser.add_argument('--update-per-step', type=float, default=0.1)
parser.add_argument('--batch-size', type=int, default=32)
parser.add_argument('--training-num', type=int, default=10)
parser.add_argument('--test-num', type=int, default=10)
parser.add_argument('--logdir', type=str, default='log')
parser.add_argument('--render', type=float, default=0.)
parser.add_argument(
'--device', type=str, default='cuda' if torch.cuda.is_available() else 'cpu'
)
parser.add_argument('--frames-stack', type=int, default=4)
parser.add_argument('--resume-path', type=str, default=None)
parser.add_argument('--resume-id', type=str, default=None)
parser.add_argument('--time-window', type=int, default=16)
parser.add_argument(
'--spike',
default=False,
action='store_true',
help='execute spike dqn'
)
parser.add_argument(
'--logger',
type=str,
default="tensorboard",
choices=["tensorboard", "wandb"],
)
parser.add_argument(
'--watch',
default=False,
action='store_true',
help='watch the play of pre-trained policy only'
)
parser.add_argument('--save-buffer-name', type=str, default=None)
return parser.parse_args()
def make_atari_env(args):
return wrap_deepmind(args.task, frame_stack=args.frames_stack)
def make_atari_env_watch(args):
return wrap_deepmind(
args.task,
frame_stack=args.frames_stack,
episode_life=False,
clip_rewards=False
)
def main(args=get_args()):
print('n_step: ', args.n_step)
env = make_atari_env(args)
args.state_shape = env.observation_space.shape or env.observation_space.n
args.action_shape = env.action_space.shape or env.action_space.n
# should be N_FRAMES x H x W
print("Observations shape:", args.state_shape)
print("Actions shape:", args.action_shape)
print('logdir', args.logdir)
print('Spiking', args.spike)
# make environments
train_envs = ShmemVectorEnv(
[lambda: make_atari_env(args) for _ in range(args.training_num)]
)
test_envs = ShmemVectorEnv(
[lambda: make_atari_env_watch(args) for _ in range(args.test_num)]
)
# seed
os.environ['PYTHONHASHSEED'] = str(args.seed)
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed_all(args.seed)
train_envs.seed(args.seed)
test_envs.seed(args.seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
net = SpikingDQN(*args.state_shape, args.action_shape, args.device, args.time_window).to(args.device)
# optim = torch.optim.Adam(net.parameters(), lr=args.lr)
optim = torch.optim.AdamW(net.parameters(), lr=args.lr)
# define policy
policy = DQNPolicy(
net,
optim,
args.gamma,
args.n_step,
target_update_freq=args.target_update_freq
)
# load a previous policy
if args.resume_path:
policy.load_state_dict(torch.load(args.resume_path, map_location=args.device))
print("Loaded agent from: ", args.resume_path)
# replay buffer: `save_last_obs` and `stack_num` can be removed together
# when you have enough RAM
buffer = VectorReplayBuffer(
args.buffer_size,
buffer_num=len(train_envs),
ignore_obs_next=True,
save_only_last_obs=True,
stack_num=args.frames_stack
)
# collector
train_collector = Collector(policy, train_envs, buffer, exploration_noise=True)
test_collector = Collector(policy, test_envs, exploration_noise=True)
# log
log_path = os.path.join(args.logdir, args.task, 'csdqn')
if args.logger == "tensorboard":
writer = SummaryWriter(log_path)
writer.add_text("args", str(args))
logger = TensorboardLogger(writer)
else:
logger = WandbLogger(
save_interval=1,
project=args.task,
name='dqn',
run_id=args.resume_id,
config=args,
)
def save_fn(policy):
torch.save(policy.state_dict(), os.path.join(log_path, 'policy.pth'))
def stop_fn(mean_rewards):
if env.spec.reward_threshold:
return mean_rewards >= env.spec.reward_threshold
elif 'Pong' in args.task:
return mean_rewards >= 20
else:
return False
def train_fn(epoch, env_step):
# nature DQN setting, linear decay in the first 1M steps
if env_step <= 1e6:
eps = args.eps_train - env_step / 1e6 * \
(args.eps_train - args.eps_train_final)
else:
eps = args.eps_train_final
policy.set_eps(eps)
if env_step % 1000 == 0:
logger.write("train/env_step", env_step, {"train/eps": eps})
def test_fn(epoch, env_step):
policy.set_eps(args.eps_test)
def save_checkpoint_fn(epoch, env_step, gradient_step):
# see also: https://pytorch.org/tutorials/beginner/saving_loading_models.html
ckpt_path = os.path.join(log_path, 'checkpoint.pth')
torch.save({'model': policy.state_dict()}, ckpt_path)
return ckpt_path
# watch agent's performance
def watch():
print("Setup test envs ...")
policy.eval()
policy.set_eps(args.eps_test)
test_envs.seed(args.seed)
if args.save_buffer_name:
print(f"Generate buffer with size {args.buffer_size}")
buffer = VectorReplayBuffer(
args.buffer_size,
buffer_num=len(test_envs),
ignore_obs_next=True,
save_only_last_obs=True,
stack_num=args.frames_stack
)
collector = Collector(policy, test_envs, buffer, exploration_noise=True)
result = collector.collect(n_step=args.buffer_size)
print(f"Save buffer into {args.save_buffer_name}")
# Unfortunately, pickle will cause oom with 1M buffer size
buffer.save_hdf5(args.save_buffer_name)
else:
print("Testing agent ...")
test_collector.reset()
result = test_collector.collect(
n_episode=args.test_num, render=args.render
)
rew = result["rews"].mean()
print(f'Mean reward (over {result["n/ep"]} episodes): {rew}')
if args.watch:
watch()
exit(0)
# test train_collector and start filling replay buffer
train_collector.collect(n_step=args.batch_size * args.training_num)
# trainer
result = offpolicy_trainer(
policy,
train_collector,
test_collector,
args.epoch,
args.step_per_epoch,
args.step_per_collect,
args.test_num,
args.batch_size,
train_fn=train_fn,
test_fn=test_fn,
stop_fn=stop_fn,
save_fn=save_fn,
logger=logger,
update_per_step=args.update_per_step,
test_in_train=False,
resume_from_log=args.resume_id is not None,
save_checkpoint_fn=save_checkpoint_fn,
)
pprint.pprint(result)
watch()
if __name__ == '__main__':
main(get_args())
================================================
FILE: examples/decision_making/RL/sdqn/network.py
================================================
from typing import Any, Dict, Optional, Sequence, Tuple, Union
import numpy as np
import torch
from torch import nn
from braincog.base.node.node import LIFNode
from ..utils.normalization import PopNorm
class SpikingDQN(nn.Module):
"""Reference: Human-level control through deep reinforcement learning.
For advanced usage (how to customize the network), please refer to
:ref:`build_the_network`.
"""
def __init__(
self,
c: int,
h: int,
w: int,
action_shape: Sequence[int],
device: Union[str, int, torch.device] = "cpu",
time_window: int = 16,
features_only: bool = False,
) -> None:
super().__init__()
self._node = LIFNode
self.features_only = features_only
self.device = device
self._threshold = 1.0
self.v_reset = 0.0
self._decay = 0.5
self._time_window = time_window
self.p_count = 0
self.net = nn.Sequential(
nn.Conv2d(c, 32, kernel_size=8, stride=4),
PopNorm([32, 20, 20], threshold=self._threshold, v_reset=self.v_reset),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
PopNorm([64, 9, 9], threshold=self._threshold, v_reset=self.v_reset),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
PopNorm([64, 7, 7], threshold=self._threshold, v_reset=self.v_reset),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Flatten()
)
with torch.no_grad():
self.output_dim = np.prod(self.net(torch.zeros(1, c, h, w)).shape[1:])
if not features_only:
self.net = nn.Sequential(
self.net, nn.Linear(self.output_dim, 512),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Linear(512, np.prod(action_shape), bias=False)
)
self.output_dim = np.prod(action_shape)
def reset(self):
for mod in self.modules():
if hasattr(mod, 'n_reset'):
mod.n_reset()
def forward(
self,
x: Union[np.ndarray, torch.Tensor],
state: Optional[Any] = None,
info: Dict[str, Any] = {},
) -> Tuple[torch.Tensor, Any]:
r"""Mapping: x -> Q(x, \*)."""
self.reset()
x = torch.as_tensor(x, device=self.device, dtype=torch.float32) / 255.0
qs = []
for i in range(self._time_window):
value = self.net(x)
qs.append(value)
if self.features_only:
return qs, state
else:
q_values = sum(qs) / self._time_window
return q_values, state
================================================
FILE: examples/decision_making/RL/utils/__init__.py
================================================
__all__ = ['normalization']
from . import (
normalization,
)
================================================
FILE: examples/decision_making/RL/utils/normalization.py
================================================
from typing import Optional, Any
import torch
import torch.nn as nn
from torch import Tensor
from torch.nn.parameter import Parameter, UninitializedParameter, UninitializedBuffer
import torch.nn.functional as F
from torch import Tensor, Size
from typing import Union, List
import numbers
from torch.nn import Module
_shape_t = Union[int, List[int], Size]
class PopNorm(Module):
r"""Applies Layer Normalization over a mini-batch of inputs as described in
the paper `Layer Normalization `__
.. math::
y = \frac{x - \mathrm{E}[x]}{ \sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta
The mean and standard-deviation are calculated separately over the last
certain number dimensions which have to be of the shape specified by
:attr:`normalized_shape`.
:math:`\gamma` and :math:`\beta` are learnable affine transform parameters of
:attr:`normalized_shape` if :attr:`elementwise_affine` is ``True``.
The standard-deviation is calculated via the biased estimator, equivalent to
`torch.var(input, unbiased=False)`.
.. note::
Unlike Batch Normalization and Instance Normalization, which applies
scalar scale and bias for each entire channel/plane with the
:attr:`affine` option, Layer Normalization applies per-element scale and
bias with :attr:`elementwise_affine`.
This layer uses statistics computed from input data in both training and
evaluation modes.
Args:
normalized_shape (int or list or torch.Size): input shape from an expected input
of size
.. math::
[* \times \text{normalized\_shape}[0] \times \text{normalized\_shape}[1]
\times \ldots \times \text{normalized\_shape}[-1]]
If a single integer is used, it is treated as a singleton list, and this module will
normalize over the last dimension which is expected to be of that specific size.
eps: a value added to the denominator for numerical stability. Default: 1e-5
elementwise_affine: a boolean value that when set to ``True``, this module
has learnable per-element affine parameters initialized to ones (for weights)
and zeros (for biases). Default: ``True``.
Shape:
- Input: :math:`(N, *)`
- Output: :math:`(N, *)` (same shape as input)
Examples::
>>> input = torch.randn(20, 5, 10, 10)
>>> # With Learnable Parameters
>>> m = nn.LayerNorm(input.size()[1:])
>>> # Without Learnable Parameters
>>> m = nn.LayerNorm(input.size()[1:], elementwise_affine=False)
>>> # Normalize over last two dimensions
>>> m = nn.LayerNorm([10, 10])
>>> # Normalize over last dimension of size 10
>>> m = nn.LayerNorm(10)
>>> # Activating the module
>>> output = m(input)
"""
__constants__ = ['normalized_shape', 'eps', 'elementwise_affine']
normalized_shape: _shape_t
eps: float
elementwise_affine: bool
def __init__(self, normalized_shape: _shape_t, threshold: float, v_reset: float, eps: float = 1e-5, affine: bool = True) -> None:
super().__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
self.normalized_shape = tuple(normalized_shape)
self.threshold = threshold
self.v_reset = v_reset
self.eps = eps
self.affine = affine
if self.affine:
# self.weight = Parameter(torch.Tensor(*normalized_shape))
self.weight = Parameter(torch.Tensor(*normalized_shape))
self.bias = Parameter(torch.Tensor(*normalized_shape))
else:
self.register_parameter('weight', None)
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self) -> None:
if self.affine:
# nn.init.ones_(self.weight)
# nn.init.zeros_(self.bias)
nn.init.constant_(self.weight, self.threshold-self.v_reset)
nn.init.constant_(self.bias, self.v_reset)
def forward(self, input: Tensor) -> Tensor:
out = F.layer_norm(
input, self.normalized_shape, self.weight, self.bias, self.eps)
# out = F.layer_norm(
# input, self.normalized_shape, None, None, self.eps)
# if self.affine:
# out = self.weight * out + self.bias
return out
def extra_repr(self) -> Tensor:
return '{normalized_shape}, eps={eps}, ' \
'elementwise_affine={elementwise_affine}'.format(**self.__dict__)
class _NormBase(nn.Module):
"""Common base of _InstanceNorm and _BatchNorm"""
_version = 2
__constants__ = ["track_running_stats", "momentum", "eps", "num_features", "affine"]
num_features: int
eps: float
momentum: float
affine: bool
track_running_stats: bool
# WARNING: weight and bias purposely not defined here.
# See https://github.com/pytorch/pytorch/issues/39670
def __init__(
self,
num_features: int,
eps: float = 1e-5,
momentum: float = 0.1,
affine: bool = True,
track_running_stats: bool = True,
mean: float = 0.2,
device=None,
dtype=None
) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(_NormBase, self).__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
self.affine = affine
self.track_running_stats = track_running_stats
self.mean = mean
if self.affine:
self.weight = Parameter(torch.empty(num_features, **factory_kwargs))
self.bias = Parameter(torch.empty(num_features, **factory_kwargs))
# self.bias = Parameter(torch.empty(num_features, **factory_kwargs), requires_grad=False)
else:
self.register_parameter("weight", None)
self.register_parameter("bias", None)
if self.track_running_stats:
self.register_buffer('running_mean', torch.zeros(num_features, **factory_kwargs))
self.register_buffer('running_var', torch.ones(num_features, **factory_kwargs))
self.running_mean: Optional[Tensor]
self.running_var: Optional[Tensor]
self.register_buffer('num_batches_tracked',
torch.tensor(0, dtype=torch.long,
**{k: v for k, v in factory_kwargs.items() if k != 'dtype'}))
else:
self.register_buffer("running_mean", None)
self.register_buffer("running_var", None)
self.register_buffer("num_batches_tracked", None)
self.reset_parameters()
def reset_running_stats(self) -> None:
if self.track_running_stats:
# running_mean/running_var/num_batches... are registered at runtime depending
# if self.track_running_stats is on
self.running_mean.zero_() # type: ignore[union-attr]
self.running_var.fill_(1) # type: ignore[union-attr]
self.num_batches_tracked.zero_() # type: ignore[union-attr,operator]
def reset_parameters(self) -> None:
self.reset_running_stats()
if self.affine:
nn.init.ones_(self.weight)
# nn.init.zeros_(self.bias)
nn.init.constant_(self.bias, self.mean)
def _check_input_dim(self, input):
raise NotImplementedError
def extra_repr(self):
return (
"{num_features}, eps={eps}, momentum={momentum}, affine={affine}, "
"track_running_stats={track_running_stats}".format(**self.__dict__)
)
def _load_from_state_dict(
self,
state_dict,
prefix,
local_metadata,
strict,
missing_keys,
unexpected_keys,
error_msgs,
):
version = local_metadata.get("version", None)
if (version is None or version < 2) and self.track_running_stats:
# at version 2: added num_batches_tracked buffer
# this should have a default value of 0
num_batches_tracked_key = prefix + "num_batches_tracked"
if num_batches_tracked_key not in state_dict:
state_dict[num_batches_tracked_key] = torch.tensor(0, dtype=torch.long)
super(_NormBase, self)._load_from_state_dict(
state_dict,
prefix,
local_metadata,
strict,
missing_keys,
unexpected_keys,
error_msgs,
)
class _BatchNorm(_NormBase):
def __init__(
self,
num_features,
eps=1e-5,
momentum=0.1,
affine=True,
track_running_stats=True,
mean=0.2,
device=None,
dtype=None
):
factory_kwargs = {'device': device, 'dtype': dtype}
super().__init__(
num_features, eps, momentum, affine, track_running_stats, mean, **factory_kwargs
)
def forward(self, input: Tensor) -> Tensor:
self._check_input_dim(input)
# exponential_average_factor is set to self.momentum
# (when it is available) only so that it gets updated
# in ONNX graph when this node is exported to ONNX.
if self.momentum is None:
exponential_average_factor = 0.0
else:
exponential_average_factor = self.momentum
if self.training and self.track_running_stats:
# TODO: if statement only here to tell the jit to skip emitting this when it is None
if self.num_batches_tracked is not None: # type: ignore[has-type]
self.num_batches_tracked = self.num_batches_tracked + 1 # type: ignore[has-type]
if self.momentum is None: # use cumulative moving average
exponential_average_factor = 1.0 / float(self.num_batches_tracked)
else: # use exponential moving average
exponential_average_factor = self.momentum
r"""
Decide whether the mini-batch stats should be used for normalization rather than the buffers.
Mini-batch stats are used in training mode, and in eval mode when buffers are None.
"""
if self.training:
bn_training = True
else:
bn_training = (self.running_mean is None) and (self.running_var is None)
r"""
Buffers are only updated if they are to be tracked and we are in training mode. Thus they only need to be
passed when the update should occur (i.e. in training mode when they are tracked), or when buffer stats are
used for normalization (i.e. in eval mode when buffers are not None).
"""
return F.batch_norm(
input,
# If buffers are not to be tracked, ensure that they won't be updated
self.running_mean
if not self.training or self.track_running_stats
else None,
self.running_var if not self.training or self.track_running_stats else None,
self.weight,
self.bias,
bn_training,
exponential_average_factor,
self.eps,
)
class PDBatchNorm2d(_BatchNorm):
r"""Applies Batch Normalization over a 4D input (a mini-batch of 2D inputs
with additional channel dimension) as described in the paper
`Batch Normalization: Accelerating Deep Network Training by Reducing
Internal Covariate Shift `__ .
.. math::
y = \frac{x - \mathrm{E}[x]}{ \sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta
The mean and standard-deviation are calculated per-dimension over
the mini-batches and :math:`\gamma` and :math:`\beta` are learnable parameter vectors
of size `C` (where `C` is the input size). By default, the elements of :math:`\gamma` are set
to 1 and the elements of :math:`\beta` are set to 0. The standard-deviation is calculated
via the biased estimator, equivalent to `torch.var(input, unbiased=False)`.
Also by default, during training this layer keeps running estimates of its
computed mean and variance, which are then used for normalization during
evaluation. The running estimates are kept with a default :attr:`momentum`
of 0.1.
If :attr:`track_running_stats` is set to ``False``, this layer then does not
keep running estimates, and batch statistics are instead used during
evaluation time as well.
.. note::
This :attr:`momentum` argument is different from one used in optimizer
classes and the conventional notion of momentum. Mathematically, the
update rule for running statistics here is
:math:`\hat{x}_\text{new} = (1 - \text{momentum}) \times \hat{x} + \text{momentum} \times x_t`,
where :math:`\hat{x}` is the estimated statistic and :math:`x_t` is the
new observed value.
Because the Batch Normalization is done over the `C` dimension, computing statistics
on `(N, H, W)` slices, it's common terminology to call this Spatial Batch Normalization.
Args:
num_features: :math:`C` from an expected input of size
:math:`(N, C, H, W)`
eps: a value added to the denominator for numerical stability.
Default: 1e-5
momentum: the value used for the running_mean and running_var
computation. Can be set to ``None`` for cumulative moving average
(i.e. simple average). Default: 0.1
affine: a boolean value that when set to ``True``, this module has
learnable affine parameters. Default: ``True``
track_running_stats: a boolean value that when set to ``True``, this
module tracks the running mean and variance, and when set to ``False``,
this module does not track such statistics, and initializes statistics
buffers :attr:`running_mean` and :attr:`running_var` as ``None``.
When these buffers are ``None``, this module always uses batch statistics.
in both training and eval modes. Default: ``True``
Shape:
- Input: :math:`(N, C, H, W)`
- Output: :math:`(N, C, H, W)` (same shape as input)
Examples::
>>> # With Learnable Parameters
>>> m = nn.BatchNorm2d(100)
>>> # Without Learnable Parameters
>>> m = nn.BatchNorm2d(100, affine=False)
>>> input = torch.randn(20, 100, 35, 45)
>>> output = m(input)
"""
def _check_input_dim(self, input):
if input.dim() != 4:
raise ValueError("expected 4D input (got {}D input)".format(input.dim()))
================================================
FILE: examples/decision_making/swarm/Collision-Avoidance.py
================================================
import torch,os
from braincog.model_zoo.rsnn import RSNN
from random import randint
import math
import random
import matplotlib
# matplotlib.use("TkAgg")
import numpy as np
import random
import matplotlib.pyplot as plt
import matplotlib.animation as animation
#os.environ["SDL_VIDEODRIVER"] = "dummy"
#parameters
N =10
WORLD_WIDTH = 500
COLLISION_THRE =25 #60 65 70
WALL_COLLISION_LIMIT=10
VISIBLE_THRE=75 #3=75/COLLISION_THRE #3*COLLISION_THRE
#eight velocity
vel_space=[[0,1],[1,0],[0,-1],[-1,0],[1,1],[1,-1],[-1,-1],[-1,1]]
vel_x_small=[[0,1],[1,0],[0,-1],[1,1],[1,-1]]
vel_x_large=[[0,1],[0,-1],[-1,0],[-1,-1],[-1,1]]
vel_y_small=[[0,1],[1,0],[-1,0],[1,1],[-1,1]]
vel_y_large=[[1,0],[0,-1],[-1,0],[1,-1],[-1,-1]]
N_action=len(vel_space)
col_robot=[i for i in range(N)]
# parameters for rl+snn
C = 50
runtime = 100 # Runtime in ms for choosing action
# parameters for snn
tau = 10 # time constant of STDP
stdpwin = 10 # STDP windows in ms
Apos = 0.925
Aneg = 0.1
vr = 0 # Reset Potential
vt = 0.1 # Judge if the neurons fire or not
tau_m = 20
Rm = 0.5
tau_e = 5
# inhibition weight between output population
s_in = np.random.rand(N_action * C, N_action * C)
for i in range(N_action):
for j in range(C):
for k in range(C):
s_in[i * C + j][i * C + k] = 0
#init boids with no collision
global boids
boids = np.zeros(N, dtype=[('pos', int, 2), ('vel', int, 2),('nn',RSNN)])
list_rand=[i for i in range(16)]
rand_int=random.sample(list_rand,N)
for i in range(len(rand_int)):
boids['pos'][i,0]=np.random.uniform(int(rand_int[i]%4)*125,(int(rand_int[i]%4)+1)*125+1,1)
boids['pos'][i,1] = np.random.uniform(int(rand_int[i]/4) * 125, (int(rand_int[i]/4) + 1) * 125 + 1, 1)
boids['vel'] = np.random.uniform(-1, 2, (N, 2))
for i_vel in range(len(boids['vel'])):
boids['nn'][i_vel] = RSNN(N_action*2,N_action*C).cuda()
while(boids['vel'][i_vel][0]==0 and boids['vel'][i_vel][1]==0):
boids['vel'][i_vel] = np.random.uniform(-1, 2, (1, 2))
#update boids parameters
do_update=np.zeros(N)
distance_pre=np.zeros((N,N))
tmp_min_robot=[i for i in range(N)]
tmp_input=[i for i in range(N)]
sum_deta_tmp=np.zeros(N)
sum_deta_new=np.zeros(N)
trace_decay = 0.8
def chooseAct(Net,input,explore):
count_group = np.zeros(N_action)
count_output = np.zeros(N_action * C)
if explore==-1:
pass
else:
pass
for i_train in range(runtime):
out, dw = Net(input[:,i_train])
# rstdp
Net.weight_trace *= trace_decay
Net.weight_trace += dw[0][0]
count_output=count_output+np.array(out)
for i in range(N_action):
count_group[i]=count_output[i*C:(i+1)*C].sum()
if count_group.max()>C/2:
action=count_group.argmax()
return action,Net
# if t==runtime-2 and len(np.where(self.count_group==0)[0])!=len(self.count_group):
# self.action=self.count_group.argmax()
def update_boids(xs, ys, xvs, yvs,frame):
global distance_pre,col_c
# Matrix off position difference and distance
xdiff = np.add.outer(xs, -xs)
ydiff = np.add.outer(ys, -ys)
distance = np.sqrt(xdiff ** 2 + ydiff ** 2)
# Calculate the boids that are visible to every other boid -pi/2 to pi/2
visible = np.zeros((N, N))
dir = np.zeros((N, N))
col_c = WORLD_WIDTH * np.ones((N, 4))
dir_c = np.zeros((N, 4))
angle_towards = np.arctan2(-ydiff, -xdiff)
angle_vel = np.arctan2(yvs, xvs)
for i in range(N):
for j in range(N):
if (xvs[i] == 1 and yvs[i] == 0) or (xvs[i] == 1 and yvs[i] == 1) or (xvs[i] == 0 and yvs[i] == 1) or (
xvs[i] == 0 and yvs[i] == -1) or (xvs[i] == 1 and yvs[i] == -1):
if angle_towards[i][j] < angle_vel[i] + np.pi / 2 and angle_towards[i][j] > angle_vel[i] - np.pi / 2:
visible[i][j] = True
if angle_towards[i][j] > angle_vel[i] - np.pi / 2 and angle_towards[i][j] < angle_vel[i]:
dir[i][j]=1#right
if angle_towards[i][j] < angle_vel[i] + np.pi / 2 and angle_towards[i][j] >= angle_vel[i]:
dir[i][j] = 2#left
if xvs[i] == -1 and yvs[i] == 1:
if (angle_towards[i][j] > angle_vel[i] - np.pi / 2 and angle_towards[i][j] < np.pi) or (
angle_towards[i][j] > -np.pi and angle_towards[i][j] < angle_vel[i] - 1.5 * np.pi):
visible[i][j] = True
if angle_towards[i][j] > angle_vel[i] - np.pi / 2 and angle_towards[i][j] < angle_vel[i]:
dir[i][j] = 1
if (angle_towards[i][j] < np.pi and angle_towards[i][j] >= angle_vel[i]) or (
angle_towards[i][j] > -np.pi and angle_towards[i][j] < angle_vel[i] - 1.5 * np.pi):
dir[i][j] = 2
if xvs[i] == -1 and yvs[i] == 0:
if (angle_towards[i][j] > np.pi / 2 and angle_towards[i][j] < np.pi) or (
angle_towards[i][j] > -np.pi and angle_towards[i][j] < -np.pi / 2):
visible[i][j] = True
if angle_towards[i][j] > np.pi / 2 and angle_towards[i][j] < np.pi:
dir[i][j] = 1
if angle_towards[i][j] >= -np.pi and angle_towards[i][j] < -np.pi / 2:
dir[i][j] = 2
if xvs[i] == -1 and yvs[i] == -1:
if (angle_towards[i][j] > -np.pi and angle_towards[i][j] < -np.pi / 4) or (
angle_towards[i][j] > 0.75 * np.pi and angle_towards[i][j] < np.pi):
visible[i][j] = True
if (angle_towards[i][j] > 0.75 * np.pi and angle_towards[i][j] < np.pi) or (
angle_towards[i][j] > -np.pi and angle_towards[i][j] < angle_vel[i]):
dir[i][j] = 1
if angle_towards[i][j] >= angle_vel[i] and angle_towards[i][j] < -np.pi / 4:
dir[i][j] = 2
v_tmp = np.diag(np.diag(visible))
visible = visible - v_tmp
# the danger of collision, considering dis=6*collision
collision = np.clip(VISIBLE_THRE/COLLISION_THRE - distance / COLLISION_THRE, 0,VISIBLE_THRE/COLLISION_THRE) * visible # visible and in some distance 3*collision_thre
c_tmp = np.diag(np.diag(collision))
collision = collision - c_tmp
if len(np.where(yvs[np.where(ys < (VISIBLE_THRE/COLLISION_THRE)*WALL_COLLISION_LIMIT)] == -1)[0])>0:
wall_tmp=np.where(ys < (VISIBLE_THRE/COLLISION_THRE)*WALL_COLLISION_LIMIT)[0]
for i_wall in range(len(wall_tmp)):
if yvs[wall_tmp[i_wall]] == -1:
col_c[wall_tmp[i_wall], 0] = ys[wall_tmp[i_wall]]
if xvs[wall_tmp[i_wall]] >= 0:
dir_c[wall_tmp[i_wall], 0] = 1
else:
dir_c[wall_tmp[i_wall], 1] = 2
if len(np.where(xvs[np.where(xs < (VISIBLE_THRE/COLLISION_THRE)*WALL_COLLISION_LIMIT)]==-1)[0])>0:
wall_tmp = np.where(xs < (VISIBLE_THRE/COLLISION_THRE)*WALL_COLLISION_LIMIT)[0]
for i_wall in range(len(wall_tmp)):
if xvs[wall_tmp[i_wall]] == -1:
col_c[wall_tmp[i_wall], 1] = xs[wall_tmp[i_wall]]
if yvs[wall_tmp[i_wall]] >= 0:
dir_c[wall_tmp[i_wall], 1] = 2
else:
dir_c[wall_tmp[i_wall], 1] = 1
if len(np.where(yvs[np.where((WORLD_WIDTH - ys) < (VISIBLE_THRE/COLLISION_THRE) * WALL_COLLISION_LIMIT)] == 1)[0]) > 0:
wall_tmp = np.where((WORLD_WIDTH - ys) < (VISIBLE_THRE/COLLISION_THRE) * WALL_COLLISION_LIMIT)[0]
for i_wall in range(len(wall_tmp)):
if yvs[wall_tmp[i_wall]]==1:
col_c[wall_tmp[i_wall],2] =WORLD_WIDTH - ys[wall_tmp[i_wall]]
if xvs[wall_tmp[i_wall]]>=0:
dir_c[wall_tmp[i_wall],2]=2
else:
dir_c[wall_tmp[i_wall], 2] = 1
if len(np.where(xvs[np.where((WORLD_WIDTH - xs) < (VISIBLE_THRE/COLLISION_THRE)*WALL_COLLISION_LIMIT)] ==1)[0])>0:
wall_tmp=np.where((WORLD_WIDTH - xs) < (VISIBLE_THRE/COLLISION_THRE) * WALL_COLLISION_LIMIT)[0]
for i_wall in range(len(wall_tmp)):
if xvs[wall_tmp[i_wall]]==1:
col_c[wall_tmp[i_wall],3] =WORLD_WIDTH - xs[wall_tmp[i_wall]]
if yvs[wall_tmp[i_wall]]>=0:
dir_c[wall_tmp[i_wall],3]=1
else:
dir_c[wall_tmp[i_wall], 3] = 2
# print(col_c)
col_c_tmp = np.clip(VISIBLE_THRE/COLLISION_THRE - col_c / WALL_COLLISION_LIMIT, 0, VISIBLE_THRE/COLLISION_THRE)
deta_dis_tmp = distance - distance_pre
deta_dis = deta_dis_tmp * collision # <0 and small is the obstacle
collision=np.c_[collision, col_c_tmp]
deta_dis=np.c_[deta_dis, -col_c_tmp]
dir=np.c_[dir,dir_c]
# print(collision,deta_dis)
#for every agent, choose the approaching agent as input
for i in range(N):
if frame>1 and do_update[i]>0:
sum_deta_new[i] = (tmp_input[i] * collision[i][tmp_min_robot[i]]).sum()
# print(sum_deta_new[i] ,sum_deta_tmp[i] )
if sum_deta_new[i] < sum_deta_tmp[i] :
r=10*(sum_deta_tmp[i]-sum_deta_new[i])
else:
r=-10*(sum_deta_new[i]-sum_deta_tmp[i])
boids['nn'][i].UpdateWeight(r)
if frame > 0:
do_update[i] =0
if len(np.where(deta_dis[i] < 0)[0]) > 0:
do_update[i] += 1
# then get the velocity direction of objects and the distance between them as the network input
appro_index = np.where(deta_dis[i] < 0)[0] # the input is the approching directions and distances
# print(appro_index)
input = []
for j in range(len(appro_index)):
if appro_index[j]<=N-1:
xvs_input = xvs[appro_index[j]]
yvs_input = yvs[appro_index[j]]
input.append(vel_space.index([xvs_input, yvs_input]))
else:
vel_tmp=int(appro_index[j]%N)
input.append(vel_tmp)
dis_tmp=np.c_[distance,col_c]
weight = -1 * dis_tmp[i][np.where(deta_dis[i] < 0)]
# input=input[np.argmin(weight)]
if weight.max() - weight.min() == 0:
weight = np.random.randint(1, 5, weight.shape)
weight[0] = 4
else:
k = (4 - 1) / (weight.max() - weight.min())
weight = 1 + k * (weight - weight.min())
# print(input,weight)
I = np.zeros((N_action*2, runtime))
for j in range(len(input)):
# print(appro_index,input,appro_index[j],dir[i][appro_index[j]],input[j]*dir[i][appro_index[j]])
I[int(input[j]+N_action*(dir[i][appro_index[j]]-1))][0:runtime] = max(I[int(input[j]+N_action*(dir[i][appro_index[j]]-1))][0], weight[j])
if random.random()<0.7:
action_index,boids['nn'][i] = chooseAct(boids['nn'][i],I,-1)#exploitation
else:
action_index,boids['nn'][i] = chooseAct(boids['nn'][i],I, 1) #exploration
xvs[i] = vel_space[action_index][0]
yvs[i] = vel_space[action_index][1]
tmp_min_robot[i] = np.where(deta_dis[i] < 0)[0]
tmp_input[i] = weight
sum_deta_tmp[i] = (tmp_input[i] * collision[i][tmp_min_robot[i]]).sum()
xs+=xvs
ys+=yvs
xs=np.clip(xs,0,WORLD_WIDTH)
ys = np.clip(ys, 0, WORLD_WIDTH)
distance_pre = distance
if frame>=10000:
for i in range(N):
for j in range(N_action*2):
I = np.zeros((N_action * 2, runtime))
I[j][0:runtime]=4
a=chooseAct(boids['nn'][i],I,-1)
# print(a)
aaa=1
def animate(frame):
update_boids(boids['pos'][:, 0], boids['pos'][:, 1], boids['vel'][:, 0], boids['vel'][:, 1],frame)
scatter.set_offsets(boids['pos'])
scatter1.set_offsets(boids['pos'])
#build background
fig = plt.figure(figsize=(8, 8))
ax1 = fig.add_subplot(111)
ax1.set_title('Scatter Plot')
plt.xlim(-20,520)
plt.ylim(-20,520)
plt.grid(ls='--',c='gray')
plt.xlabel('X')
plt.ylabel('Y')
# Use a scatter plot to visualize the boids
color_list=['r','b','g','y','m','c','deeppink','tomato','gold','crimson','cornsilk','darkred','greenyellow','lightcoral','mintcream',
'rosybrown']
colors=color_list[0:N]
#colors=random.sample(color_list,N)
lines=np.zeros(N)+5
scatter = ax1.scatter(boids['pos'][:, 0], boids['pos'][:, 1],s=500,alpha=0.5,linewidths=lines)
scatter1 = ax1.scatter(boids['pos'][:, 0], boids['pos'][:, 1],s=2500,c=colors,alpha=0.5)
boids_newp=boids['pos']+boids['vel']*10
for i in range(N):
boids_linex=np.hstack((boids['pos'][i, 0],boids_newp[i,0]))
boids_liney=np.hstack((boids['pos'][i, 1],boids_newp[i,1]))
#line,=plt.plot(boids_linex,boids_liney,linewidth=5)
#lines = [ax1.plot(np.hstack((boids['pos'][i, 0],boids_newp[i,0])), np.hstack((boids['pos'][i, 1],boids_newp[i,1])),linewidth=5) for i in range(N)]
animation = animation.FuncAnimation(fig, animate,interval=0.001)
plt.show()
================================================
FILE: examples/decision_making/swarm/README.md
================================================
# Reward-modulated Spiking Neural Network for Self-organizing Collision Avoidance of Drone Swarm
This repository contains code from our paper [*Nature-inspired Self-organizing Collision Avoidance for Drones Swarm Based on Reward-modulated Spiking Neural Network*] published in Cell Patterns.
https://www.cell.com/patterns/fulltext/S2666-3899(22)00236-7
We also provide the BrainCog-based version: https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/decision_making/swarm
If you use our code or refer to this project, please cite this paper:
Feifei Zhao,Yi Zeng, Bing Han, Hongjian Fang, and Zhuoya Zhao. Nature-inspired Self-organizing Collision Avoidance for Drones Swarm Based on Reward-modulated Spiking Neural Network. Patterns, DOI:https://doi.org/10.1016/j.patter.2022.100611
## Paper Introduction
The collaborative interaction mechanisms of biological swarms in nature are of great importance to inspire the study of swarm intelligence. This paper proposed a self-organizing obstacle avoidance model by drawing on the decentralized, self-organizing properties of intelligent behavior of biological swarms. Each individual independently adopts brain-inspired reward-modulated spiking neural network (RSNN) to achieve online learning and makes decentralized decisions based on local observations. The following picture shows the decision-making process of our model.
 We validated the proposed model on swarm collision avoidance tasks (a swarm of unmanned aerial vehicles without central control) in a bounded space, carrying out simulation and real-world experiments. The drone swarm emerges with safe flight behavior, as shown in the following videos. Compared with artificial neural network-based online learning methods, our proposed method exhibits superior performance and better stability.
We validated the proposed model on swarm collision avoidance tasks (a swarm of unmanned aerial vehicles without central control) in a bounded space, carrying out simulation and real-world experiments. The drone swarm emerges with safe flight behavior, as shown in the following videos. Compared with artificial neural network-based online learning methods, our proposed method exhibits superior performance and better stability.


 ## Run
* "reward-modulated snn on swarm collision avoidance.py" includes the self-organized collision avoidance implemented by RSNN for simulation scenarios.
* "flytestfive.py" includes five UAVs swarm collision avoidance validation in real bounded scenario.
## Requirments
* "reward-modulated snn on swarm collision avoidance.py": python==3.7, numpy>=1.21.6
* "flytestfive.py": multi_robomaster
================================================
FILE: requirements.txt
================================================
numpy
scipy
h5py
torch
torchvision
torchaudio
timm == 0.6.13
scikit-learn
einops
thop
pyyaml
matplotlib
seaborn
pygame
dv
tensorboard
tonic
================================================
FILE: setup.py
================================================
from setuptools import find_packages
from setuptools import setup
with open("./requirements.txt", "r", encoding="utf-8") as fh:
install_requires = fh.read()
with open("README.md", "r", encoding="utf-8") as fh:
long_description = fh.read()
setup(
install_requires=install_requires,
packages=find_packages(),
description="BrainCog is an open source spiking neural network based brain-inspired cognitive intelligence engine for Brain-inspired Artificial Intelligence and brain simulation. More information on braincog can be found on its homepage http://www.brain-cog.network/",
long_description=long_description,
long_description_content_type="text/markdown",
classifiers=[
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"License :: Other/Proprietary License",
"Operating System :: OS Independent",
],
name='braincog',
version='0.2.7.19',
author='braincog',
python_requires='>=3.6'
)
## Run
* "reward-modulated snn on swarm collision avoidance.py" includes the self-organized collision avoidance implemented by RSNN for simulation scenarios.
* "flytestfive.py" includes five UAVs swarm collision avoidance validation in real bounded scenario.
## Requirments
* "reward-modulated snn on swarm collision avoidance.py": python==3.7, numpy>=1.21.6
* "flytestfive.py": multi_robomaster
================================================
FILE: requirements.txt
================================================
numpy
scipy
h5py
torch
torchvision
torchaudio
timm == 0.6.13
scikit-learn
einops
thop
pyyaml
matplotlib
seaborn
pygame
dv
tensorboard
tonic
================================================
FILE: setup.py
================================================
from setuptools import find_packages
from setuptools import setup
with open("./requirements.txt", "r", encoding="utf-8") as fh:
install_requires = fh.read()
with open("README.md", "r", encoding="utf-8") as fh:
long_description = fh.read()
setup(
install_requires=install_requires,
packages=find_packages(),
description="BrainCog is an open source spiking neural network based brain-inspired cognitive intelligence engine for Brain-inspired Artificial Intelligence and brain simulation. More information on braincog can be found on its homepage http://www.brain-cog.network/",
long_description=long_description,
long_description_content_type="text/markdown",
classifiers=[
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"License :: Other/Proprietary License",
"Operating System :: OS Independent",
],
name='braincog',
version='0.2.7.19',
author='braincog',
python_requires='>=3.6'
)