Repository: BuilderIO/gpt-crawler
Branch: main
Commit: d2245d66a5ad
Files: 22
Total size: 32.6 KB
Directory structure:
gitextract_xsmjy0d3/
├── .dockerignore
├── .github/
│ └── workflows/
│ ├── pr.yml
│ └── release.yml
├── .gitignore
├── .husky/
│ └── pre-commit
├── .releaserc
├── CHANGELOG.md
├── Dockerfile
├── License
├── README.md
├── config.ts
├── containerapp/
│ ├── Dockerfile
│ ├── README.md
│ ├── data/
│ │ ├── config.ts
│ │ └── init.sh
│ └── run.sh
├── src/
│ ├── cli.ts
│ ├── config.ts
│ ├── core.ts
│ ├── main.ts
│ └── server.ts
└── swagger.js
================================================
FILE CONTENTS
================================================
================================================
FILE: .dockerignore
================================================
# configurations
.idea
# crawlee and apify storage folders
apify_storage
crawlee_storage
storage
# installed files
node_modules
# ignore base image 'main.js'
main.js
================================================
FILE: .github/workflows/pr.yml
================================================
name: Pull request workflow
on:
pull_request:
types: [opened, reopened, synchronize, edited]
permissions:
pull-requests: read
jobs:
build:
name: Build and test
runs-on: ubuntu-latest
env:
CI_JOB_NUMBER: 1
steps:
- uses: actions/checkout@v2
- uses: actions/setup-node@v2
with:
cache: npm
node-version: 18
- run: npm i
- run: npm run build
- run: npm run test
- uses: preactjs/compressed-size-action@v2
with:
pattern: ".dist/**/*.{js,ts,json}"
static-tests:
name: Static tests
runs-on: ubuntu-latest
needs: build
steps:
- uses: actions/checkout@v2
- uses: actions/setup-node@v2
with:
cache: npm
node-version: 18
- run: npm i
- run: npm run prettier:check
build-docker:
name: Build Docker image
runs-on: ubuntu-latest
needs: build
steps:
- uses: actions/checkout@v2
- uses: docker/build-push-action@v2
with:
context: .
file: ./Dockerfile
push: false
semantic-pr:
name: Validate PR title for semantic versioning
runs-on: ubuntu-latest
steps:
- uses: amannn/action-semantic-pull-request@v5
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
================================================
FILE: .github/workflows/release.yml
================================================
name: Release workflow
on:
push:
branches:
- main
jobs:
release:
name: release
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: actions/setup-node@v2
with:
cache: npm
node-version: 18
- run: npm i
- run: npm run build
- run: npm run semantic-release
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
NPM_TOKEN: ${{ secrets.NPM_TOKEN }}
================================================
FILE: .gitignore
================================================
# This file tells Git which files shouldn't be added to source control
.idea
dist
node_modules
apify_storage
crawlee_storage
storage
.DS_Store
!package.json
!package-lock.json
!tsconfig.json
# any output from the crawler
*.json
.env
pnpm-lock.yaml
================================================
FILE: .husky/pre-commit
================================================
#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
npm run fmt
================================================
FILE: .releaserc
================================================
{
"branches": [
"main"
],
"plugins": [
"@semantic-release/commit-analyzer",
"@semantic-release/release-notes-generator",
"@semantic-release/changelog",
"@semantic-release/npm",
"@semantic-release/git",
"@semantic-release/github"
]
}
================================================
FILE: CHANGELOG.md
================================================
## [1.5.1](https://github.com/BuilderIO/gpt-crawler/compare/v1.5.0...v1.5.1) (2025-01-23)
### Bug Fixes
* correctly set cookies ([567ab0b](https://github.com/BuilderIO/gpt-crawler/commit/567ab0b0a538032d02743ae3ecc51dfdc0fdb5c6))
# [1.5.0](https://github.com/BuilderIO/gpt-crawler/compare/v1.4.0...v1.5.0) (2024-07-05)
### Features
- git clone depth limit in docker ([87767db](https://github.com/BuilderIO/gpt-crawler/commit/87767dbda99b3259d44ec2c02dceb3a59bb2ca3c))
# [1.4.0](https://github.com/BuilderIO/gpt-crawler/compare/v1.3.0...v1.4.0) (2024-01-15)
### Bug Fixes
- linting ([0f4e58b](https://github.com/BuilderIO/gpt-crawler/commit/0f4e58b400eab312e7b595d7a2472bae93055415))
### Features
- add server api readme docs ([717e625](https://github.com/BuilderIO/gpt-crawler/commit/717e625f47257bdbd96437acb7242bcd28c233ba))
# [1.3.0](https://github.com/BuilderIO/gpt-crawler/compare/v1.2.1...v1.3.0) (2024-01-06)
### Features
- add exclude pattern for links in config ([16443ed](https://github.com/BuilderIO/gpt-crawler/commit/16443ed9501624de40d921b8e47e4c35f15bf6b4))
================================================
FILE: Dockerfile
================================================
# Specify the base Docker image. You can read more about
# the available images at https://crawlee.dev/docs/guides/docker-images
# You can also use any other image from Docker Hub.
FROM apify/actor-node-playwright-chrome:18 AS builder
# Copy just package.json and package-lock.json
# to speed up the build using Docker layer cache.
COPY --chown=myuser package*.json ./
# Delete the prepare script. It's not needed in the final image.
RUN npm pkg delete scripts.prepare
# Install all dependencies. Don't audit to speed up the installation.
RUN npm install --include=dev --audit=false
# Next, copy the source files using the user set
# in the base image.
COPY --chown=myuser . ./
# Install all dependencies and build the project.
# Don't audit to speed up the installation.
RUN npm run build
# Create final image
FROM apify/actor-node-playwright-chrome:18
# Copy only built JS files from builder image
COPY --from=builder --chown=myuser /home/myuser/dist ./dist
# Copy just package.json and package-lock.json
# to speed up the build using Docker layer cache.
COPY --chown=myuser package*.json ./
# Install NPM packages, skip optional and development dependencies to
# keep the image small. Avoid logging too much and print the dependency
# tree for debugging
RUN npm pkg delete scripts.prepare \
&& npm --quiet set progress=false \
&& npm install --omit=dev --omit=optional \
&& echo "Installed NPM packages:" \
&& (npm list --omit=dev --all || true) \
&& echo "Node.js version:" \
&& node --version \
&& echo "NPM version:" \
&& npm --version
# Next, copy the remaining files and directories with the source code.
# Since we do this after NPM install, quick build will be really fast
# for most source file changes.
COPY --chown=myuser . ./
# Run the image. If you know you won't need headful browsers,
# you can remove the XVFB start script for a micro perf gain.
CMD ./start_xvfb_and_run_cmd.sh && npm run start:prod --silent
================================================
FILE: License
================================================
ISC License
Copyright (c) 2023 BuilderIO
Permission to use, copy, modify, and/or distribute this software for any purpose
with or without fee is hereby granted, provided that the above copyright notice
and this permission notice appear in all copies.
THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES WITH
REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND
FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR ANY SPECIAL, DIRECT,
INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS
OF USE, DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER
TORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF
THIS SOFTWARE.
================================================
FILE: README.md
================================================
# GPT Crawler <!-- omit from toc -->
<!-- Keep these links. Translations will automatically update with the README. -->
[Deutsch](https://www.readme-i18n.com/BuilderIO/gpt-crawler?lang=de) |
[Español](https://www.readme-i18n.com/BuilderIO/gpt-crawler?lang=es) |
[français](https://www.readme-i18n.com/BuilderIO/gpt-crawler?lang=fr) |
[日本語](https://www.readme-i18n.com/BuilderIO/gpt-crawler?lang=ja) |
[한국어](https://www.readme-i18n.com/BuilderIO/gpt-crawler?lang=ko) |
[Português](https://www.readme-i18n.com/BuilderIO/gpt-crawler?lang=pt) |
[Русский](https://www.readme-i18n.com/BuilderIO/gpt-crawler?lang=ru) |
[中文](https://www.readme-i18n.com/BuilderIO/gpt-crawler?lang=zh)
Crawl a site to generate knowledge files to create your own custom GPT from one or multiple URLs
- [Example](#example)
- [Get started](#get-started)
- [Running locally](#running-locally)
- [Clone the repository](#clone-the-repository)
- [Install dependencies](#install-dependencies)
- [Configure the crawler](#configure-the-crawler)
- [Run your crawler](#run-your-crawler)
- [Alternative methods](#alternative-methods)
- [Running in a container with Docker](#running-in-a-container-with-docker)
- [Running as an API](#running-as-an-api)
- [Upload your data to OpenAI](#upload-your-data-to-openai)
- [Create a custom GPT](#create-a-custom-gpt)
- [Create a custom assistant](#create-a-custom-assistant)
- [Contributing](#contributing)
## Example
[Here is a custom GPT](https://chat.openai.com/g/g-kywiqipmR-builder-io-assistant) that I quickly made to help answer questions about how to use and integrate [Builder.io](https://www.builder.io) by simply providing the URL to the Builder docs.
This project crawled the docs and generated the file that I uploaded as the basis for the custom GPT.
[Try it out yourself](https://chat.openai.com/g/g-kywiqipmR-builder-io-assistant) by asking questions about how to integrate Builder.io into a site.
> Note that you may need a paid ChatGPT plan to access this feature
## Get started
### Running locally
#### Clone the repository
Be sure you have Node.js >= 16 installed.
```sh
git clone https://github.com/builderio/gpt-crawler
```
#### Install dependencies
```sh
npm i
```
#### Configure the crawler
Open [config.ts](config.ts) and edit the `url` and `selector` properties to match your needs.
E.g. to crawl the Builder.io docs to make our custom GPT you can use:
```ts
export const defaultConfig: Config = {
url: "https://www.builder.io/c/docs/developers",
match: "https://www.builder.io/c/docs/**",
selector: `.docs-builder-container`,
maxPagesToCrawl: 50,
outputFileName: "output.json",
};
```
See [config.ts](src/config.ts) for all available options. Here is a sample of the common configuration options:
```ts
type Config = {
/** URL to start the crawl, if sitemap is provided then it will be used instead and download all pages in the sitemap */
url: string;
/** Pattern to match against for links on a page to subsequently crawl */
match: string;
/** Selector to grab the inner text from */
selector: string;
/** Don't crawl more than this many pages */
maxPagesToCrawl: number;
/** File name for the finished data */
outputFileName: string;
/** Optional resources to exclude
*
* @example
* ['png','jpg','jpeg','gif','svg','css','js','ico','woff','woff2','ttf','eot','otf','mp4','mp3','webm','ogg','wav','flac','aac','zip','tar','gz','rar','7z','exe','dmg','apk','csv','xls','xlsx','doc','docx','pdf','epub','iso','dmg','bin','ppt','pptx','odt','avi','mkv','xml','json','yml','yaml','rss','atom','swf','txt','dart','webp','bmp','tif','psd','ai','indd','eps','ps','zipx','srt','wasm','m4v','m4a','webp','weba','m4b','opus','ogv','ogm','oga','spx','ogx','flv','3gp','3g2','jxr','wdp','jng','hief','avif','apng','avifs','heif','heic','cur','ico','ani','jp2','jpm','jpx','mj2','wmv','wma','aac','tif','tiff','mpg','mpeg','mov','avi','wmv','flv','swf','mkv','m4v','m4p','m4b','m4r','m4a','mp3','wav','wma','ogg','oga','webm','3gp','3g2','flac','spx','amr','mid','midi','mka','dts','ac3','eac3','weba','m3u','m3u8','ts','wpl','pls','vob','ifo','bup','svcd','drc','dsm','dsv','dsa','dss','vivo','ivf','dvd','fli','flc','flic','flic','mng','asf','m2v','asx','ram','ra','rm','rpm','roq','smi','smil','wmf','wmz','wmd','wvx','wmx','movie','wri','ins','isp','acsm','djvu','fb2','xps','oxps','ps','eps','ai','prn','svg','dwg','dxf','ttf','fnt','fon','otf','cab']
*/
resourceExclusions?: string[];
/** Optional maximum file size in megabytes to include in the output file */
maxFileSize?: number;
/** Optional maximum number tokens to include in the output file */
maxTokens?: number;
};
```
#### Run your crawler
```sh
npm start
```
### Alternative methods
#### [Running in a container with Docker](./containerapp/README.md)
To obtain the `output.json` with a containerized execution, go into the `containerapp` directory and modify the `config.ts` as shown above. The `output.json`file should be generated in the data folder. Note: the `outputFileName` property in the `config.ts` file in the `containerapp` directory is configured to work with the container.
#### Running as an API
To run the app as an API server you will need to do an `npm install` to install the dependencies. The server is written in Express JS.
To run the server.
`npm run start:server` to start the server. The server runs by default on port 3000.
You can use the endpoint `/crawl` with the post request body of config json to run the crawler. The api docs are served on the endpoint `/api-docs` and are served using swagger.
To modify the environment you can copy over the `.env.example` to `.env` and set your values like port, etc. to override the variables for the server.
### Upload your data to OpenAI
The crawl will generate a file called `output.json` at the root of this project. Upload that [to OpenAI](https://platform.openai.com/docs/assistants/overview) to create your custom assistant or custom GPT.
#### Create a custom GPT
Use this option for UI access to your generated knowledge that you can easily share with others
> Note: you may need a paid ChatGPT plan to create and use custom GPTs right now
1. Go to [https://chat.openai.com/](https://chat.openai.com/)
2. Click your name in the bottom left corner
3. Choose "My GPTs" in the menu
4. Choose "Create a GPT"
5. Choose "Configure"
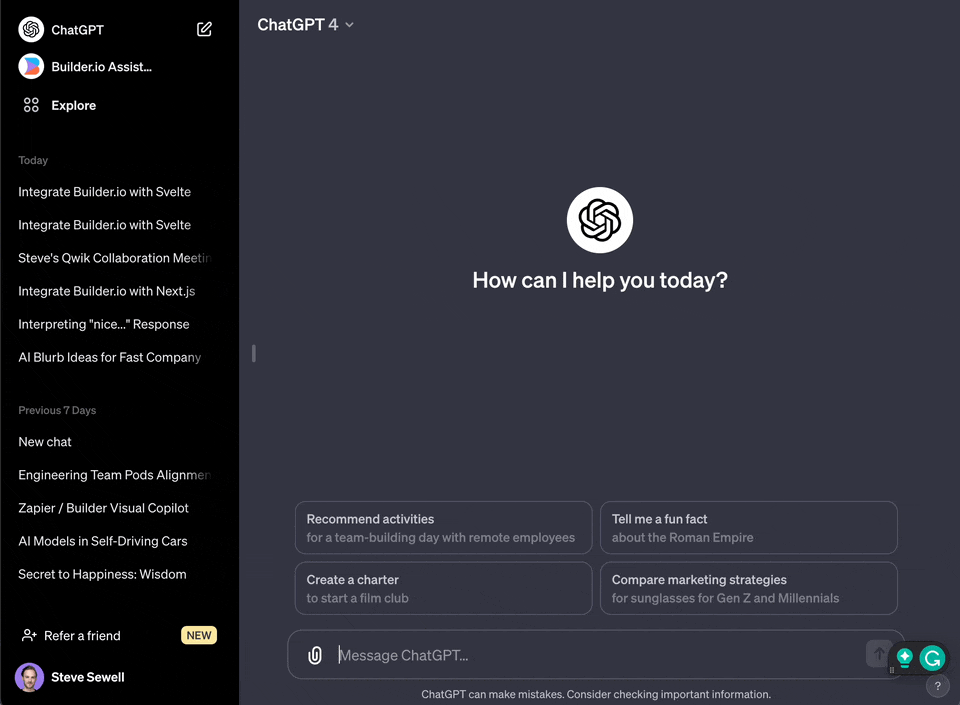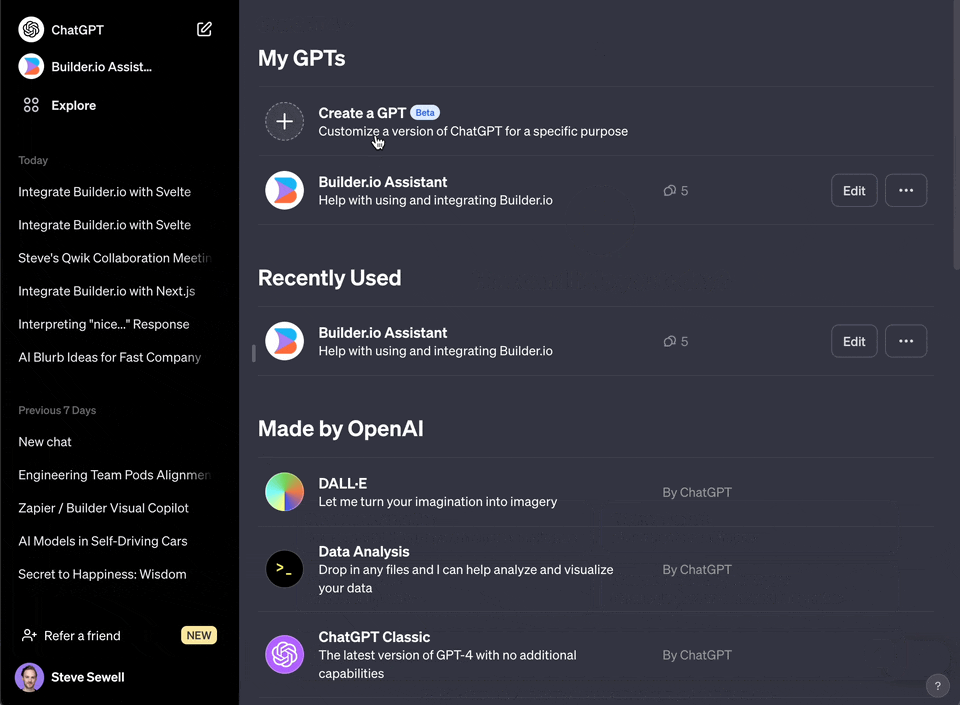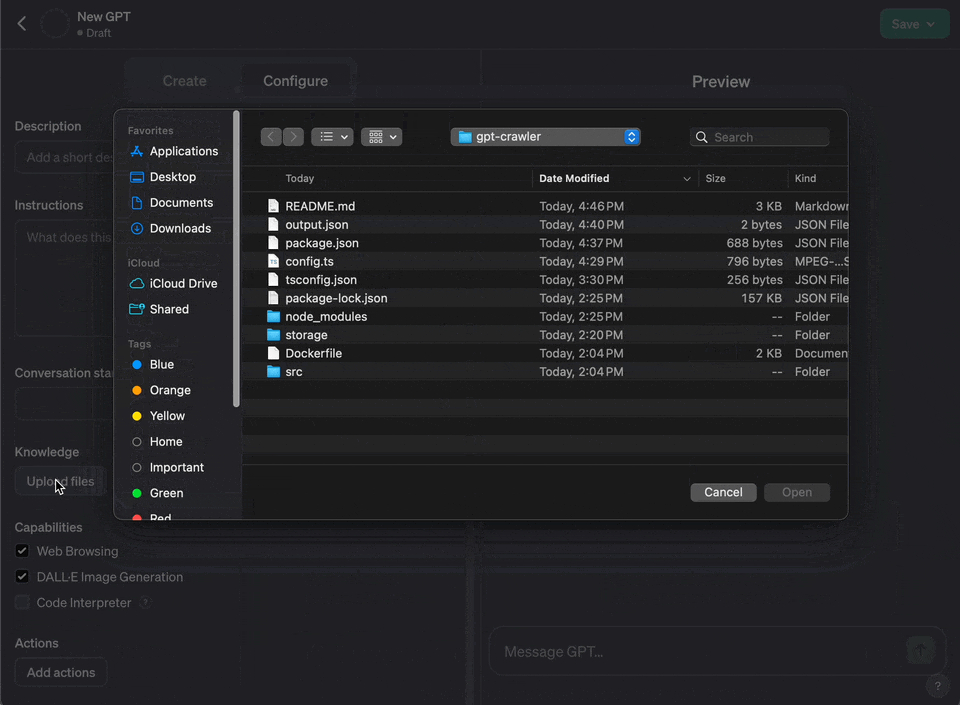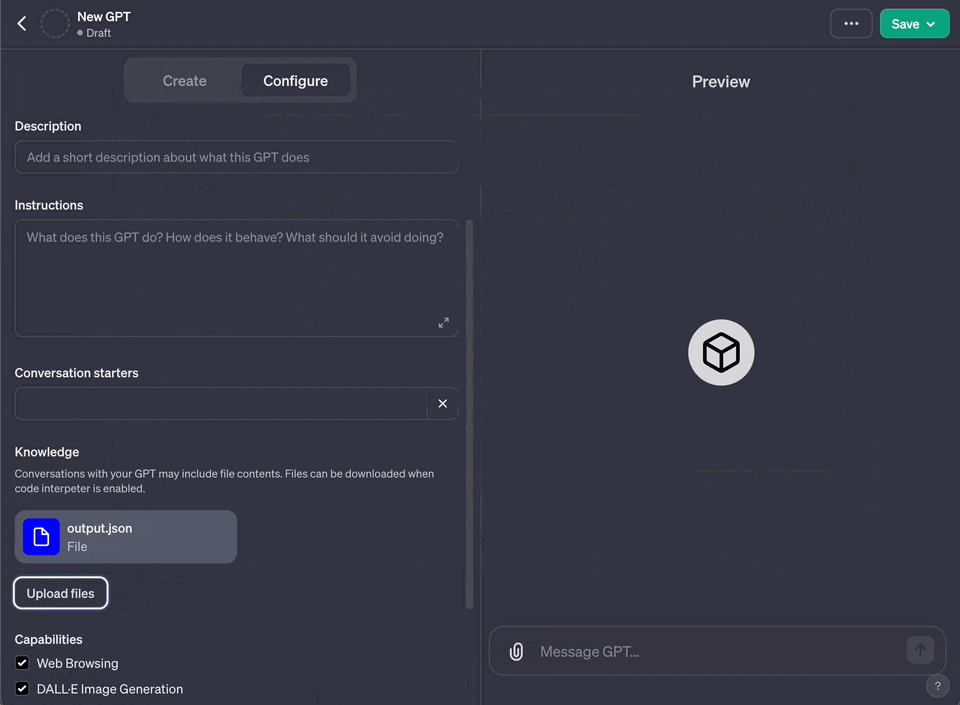
6. Under "Knowledge" choose "Upload a file" and upload the file you generated
7. if you get an error about the file being too large, you can try to split it into multiple files and upload them separately using the option maxFileSize in the config.ts file or also use tokenization to reduce the size of the file with the option maxTokens in the config.ts file
#### Create a custom assistant
Use this option for API access to your generated knowledge that you can integrate into your product.
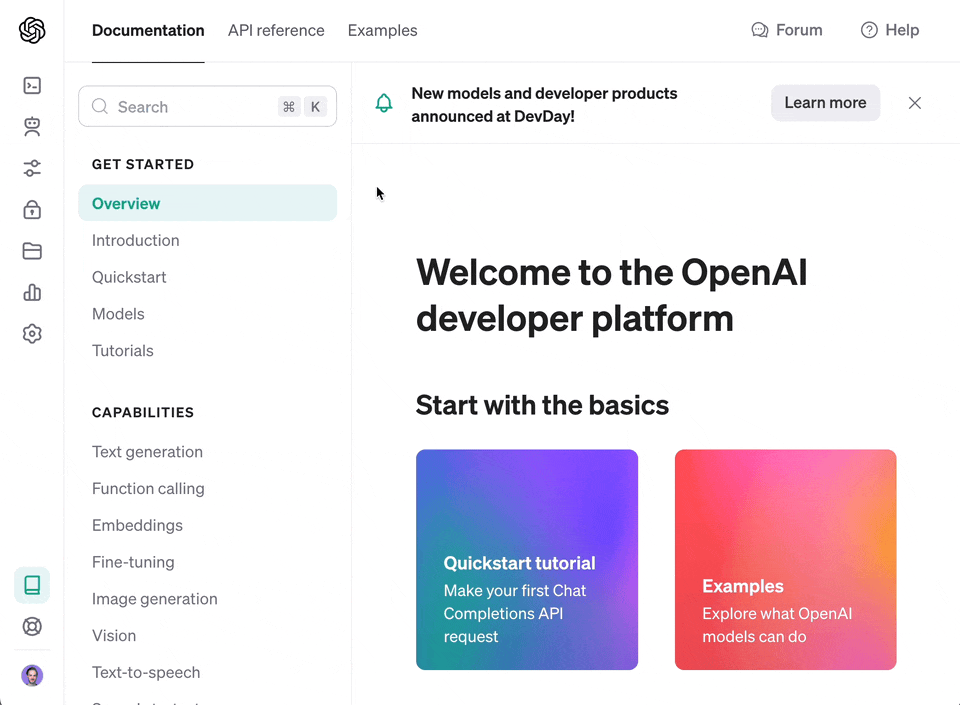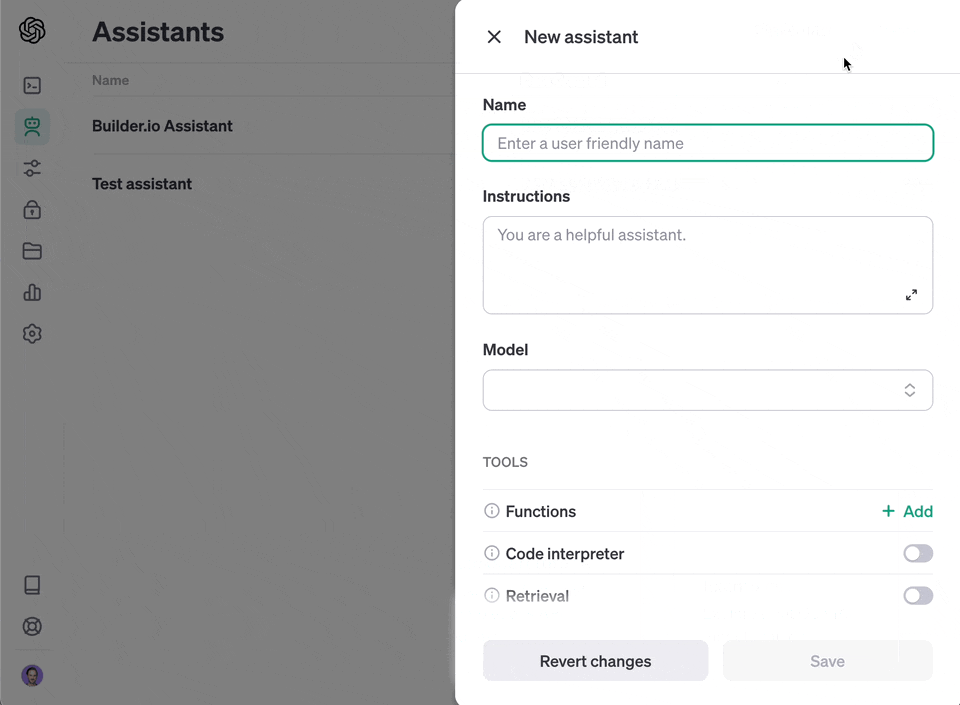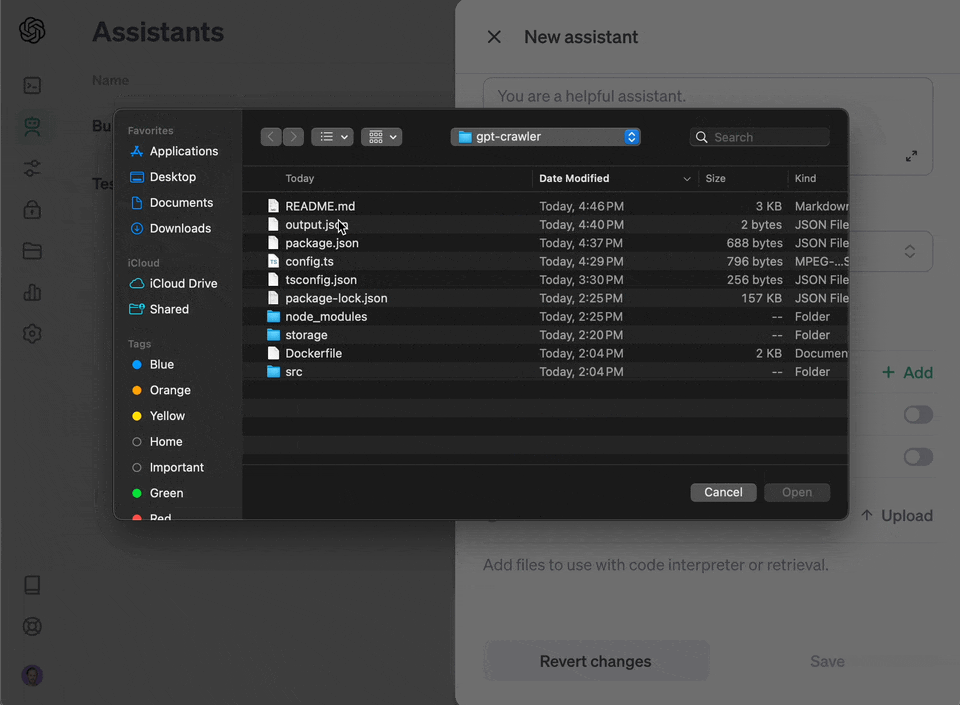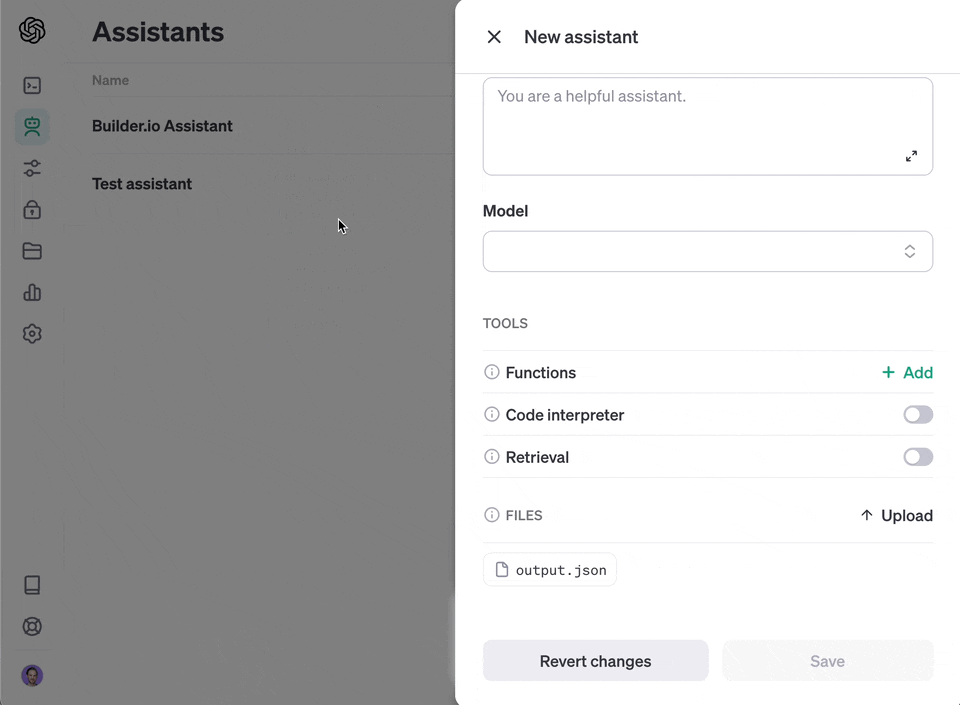
1. Go to [https://platform.openai.com/assistants](https://platform.openai.com/assistants)
2. Click "+ Create"
3. Choose "upload" and upload the file you generated
## Contributing
Know how to make this project better? Send a PR!
<br>
<br>
<p align="center">
<a href="https://www.builder.io/m/developers">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://user-images.githubusercontent.com/844291/230786554-eb225eeb-2f6b-4286-b8c2-535b1131744a.png">
<img width="250" alt="Made with love by Builder.io" src="https://user-images.githubusercontent.com/844291/230786555-a58479e4-75f3-4222-a6eb-74c5af953eac.png">
</picture>
</a>
</p>
================================================
FILE: config.ts
================================================
import { Config } from "./src/config";
export const defaultConfig: Config = {
url: "https://www.builder.io/c/docs/developers",
match: "https://www.builder.io/c/docs/**",
maxPagesToCrawl: 50,
outputFileName: "output.json",
maxTokens: 2000000,
};
================================================
FILE: containerapp/Dockerfile
================================================
FROM ubuntu:jammy
# Install Git
RUN apt-get update && \
apt-get install sudo -y && \
apt-get install git -y
# Install Docker
RUN apt-get install ca-certificates curl gnupg -y && \
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | gpg --dearmor -o /etc/apt/keyrings/docker.gpg && \
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | tee /etc/apt/sources.list.d/docker.list > /dev/null && \
apt-get update && \
apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin -y
# Install Nodejs v20 npm
RUN sudo apt-get update && \
sudo apt-get install -y ca-certificates curl gnupg && \
sudo mkdir -p /etc/apt/keyrings && \
curl -fsSL https://deb.nodesource.com/gpgkey/nodesource-repo.gpg.key | sudo gpg --dearmor -o /etc/apt/keyrings/nodesource.gpg
RUN echo "deb [signed-by=/etc/apt/keyrings/nodesource.gpg] https://deb.nodesource.com/node_20.x nodistro main" | sudo tee /etc/apt/sources.list.d/nodesource.list && \
sudo apt-get update && \
sudo apt-get install nodejs -y
# Install gpt-crawler
RUN cd /home && git clone --depth=1 https://github.com/builderio/gpt-crawler && cd gpt-crawler && \
npm i && \
npx playwright install && \
npx playwright install-deps
# Directory to mount in the docker container to get the output.json data
RUN cd /home && mkdir data
WORKDIR /home
================================================
FILE: containerapp/README.md
================================================
# Containerized crawler
## Docker image with packaged crawler, with script for building and execution.
All dependencies set up and configured in the Dockerfile. Requires docker to be installed.
## Get started
### Prerequisites
Be sure you have docker installed
1. `cd gpt-crawler/containerapp `
2. `. ./run.sh `
================================================
FILE: containerapp/data/config.ts
================================================
import { Config } from "./src/config";
export const defaultConfig: Config = {
url: "https://www.builder.io/c/docs/developers",
match: "https://www.builder.io/c/docs/**",
maxPagesToCrawl: 50,
outputFileName: "../data/output.json",
};
================================================
FILE: containerapp/data/init.sh
================================================
#!/bin/bash
# copy the config when starting the container
cp /home/data/config.ts /home/gpt-crawler/
# start the crawler
cd /home/gpt-crawler && npm start
# Print message after crawling and exit
echo "Crawling complete.."
exit
================================================
FILE: containerapp/run.sh
================================================
#!/bin/bash
# Check if there is a Docker image named "crawler"
if ! sudo docker images | grep -w 'crawler' > /dev/null; then
echo "Docker repository 'crawler' not found. Building the image..."
# Build the Docker image with the name 'crawler'
sudo docker build -t crawler .
else
echo "Docker image already built."
fi
# Ensure that init.sh script is executable
sudo chmod +x ./data/init.sh
# Starting docker, mount docker.sock to work with docker-in-docker function, mount data directory for input/output from container
sudo docker run --rm -it -v /var/run/docker.sock:/var/run/docker.sock -v ./data:/home/data crawler bash -c "/home/data/init.sh"
================================================
FILE: src/cli.ts
================================================
#!/usr/bin/env node
import { program } from "commander";
import { Config } from "./config.js";
import { crawl, write } from "./core.js";
import { createRequire } from "node:module";
import inquirer from "inquirer";
const require = createRequire(import.meta.url);
const { version, description } = require("../../package.json");
const messages = {
url: "What is the first URL of the website you want to crawl?",
match: "What is the URL pattern you want to match?",
selector: "What is the CSS selector you want to match?",
maxPagesToCrawl: "How many pages do you want to crawl?",
outputFileName: "What is the name of the output file?",
};
async function handler(options: Config) {
try {
const {
url,
match,
selector,
maxPagesToCrawl: maxPagesToCrawlStr,
outputFileName,
} = options;
// @ts-ignore
const maxPagesToCrawl = parseInt(maxPagesToCrawlStr, 10);
let config: Config = {
url,
match,
selector,
maxPagesToCrawl,
outputFileName,
};
if (!config.url || !config.match || !config.selector) {
const questions = [];
if (!config.url) {
questions.push({
type: "input",
name: "url",
message: messages.url,
});
}
if (!config.match) {
questions.push({
type: "input",
name: "match",
message: messages.match,
});
}
if (!config.selector) {
questions.push({
type: "input",
name: "selector",
message: messages.selector,
});
}
const answers = await inquirer.prompt(questions);
config = {
...config,
...answers,
};
}
await crawl(config);
await write(config);
} catch (error) {
console.log(error);
}
}
program.version(version).description(description);
program
.option("-u, --url <string>", messages.url, "")
.option("-m, --match <string>", messages.match, "")
.option("-s, --selector <string>", messages.selector, "")
.option("-m, --maxPagesToCrawl <number>", messages.maxPagesToCrawl, "50")
.option(
"-o, --outputFileName <string>",
messages.outputFileName,
"output.json",
)
.action(handler);
program.parse();
================================================
FILE: src/config.ts
================================================
import { z } from "zod";
import type { Page } from "playwright";
import { configDotenv } from "dotenv";
configDotenv();
const Page: z.ZodType<Page> = z.any();
export const configSchema = z.object({
/**
* URL to start the crawl, if url is a sitemap, it will crawl all pages in the sitemap
* @example "https://www.builder.io/c/docs/developers"
* @example "https://www.builder.io/sitemap.xml"
* @default ""
*/
url: z.string(),
/**
* Pattern to match against for links on a page to subsequently crawl
* @example "https://www.builder.io/c/docs/**"
* @default ""
*/
match: z.string().or(z.array(z.string())),
/**
* Pattern to match against for links on a page to exclude from crawling
* @example "https://www.builder.io/c/docs/**"
* @default ""
*/
exclude: z.string().or(z.array(z.string())).optional(),
/**
* Selector to grab the inner text from
* @example ".docs-builder-container"
* @default ""
*/
selector: z.string().optional(),
/**
* Don't crawl more than this many pages
* @default 50
*/
maxPagesToCrawl: z.number().int().positive(),
/**
* File name for the finished data
* @default "output.json"
*/
outputFileName: z.string(),
/** Optional cookie to be set. E.g. for Cookie Consent */
cookie: z
.union([
z.object({
name: z.string(),
value: z.string(),
}),
z.array(
z.object({
name: z.string(),
value: z.string(),
}),
),
])
.optional(),
/** Optional function to run for each page found */
onVisitPage: z
.function()
.args(
z.object({
page: Page,
pushData: z.function().args(z.any()).returns(z.promise(z.void())),
}),
)
.returns(z.promise(z.void()))
.optional(),
/** Optional timeout for waiting for a selector to appear */
waitForSelectorTimeout: z.number().int().nonnegative().optional(),
/** Optional resources to exclude
*
* @example
* ['png','jpg','jpeg','gif','svg','css','js','ico','woff','woff2','ttf','eot','otf','mp4','mp3','webm','ogg','wav','flac','aac','zip','tar','gz','rar','7z','exe','dmg','apk','csv','xls','xlsx','doc','docx','pdf','epub','iso','dmg','bin','ppt','pptx','odt','avi','mkv','xml','json','yml','yaml','rss','atom','swf','txt','dart','webp','bmp','tif','psd','ai','indd','eps','ps','zipx','srt','wasm','m4v','m4a','webp','weba','m4b','opus','ogv','ogm','oga','spx','ogx','flv','3gp','3g2','jxr','wdp','jng','hief','avif','apng','avifs','heif','heic','cur','ico','ani','jp2','jpm','jpx','mj2','wmv','wma','aac','tif','tiff','mpg','mpeg','mov','avi','wmv','flv','swf','mkv','m4v','m4p','m4b','m4r','m4a','mp3','wav','wma','ogg','oga','webm','3gp','3g2','flac','spx','amr','mid','midi','mka','dts','ac3','eac3','weba','m3u','m3u8','ts','wpl','pls','vob','ifo','bup','svcd','drc','dsm','dsv','dsa','dss','vivo','ivf','dvd','fli','flc','flic','flic','mng','asf','m2v','asx','ram','ra','rm','rpm','roq','smi','smil','wmf','wmz','wmd','wvx','wmx','movie','wri','ins','isp','acsm','djvu','fb2','xps','oxps','ps','eps','ai','prn','svg','dwg','dxf','ttf','fnt','fon','otf','cab']
*/
resourceExclusions: z.array(z.string()).optional(),
/** Optional maximum file size in megabytes to include in the output file
* @example 1
*/
maxFileSize: z.number().int().positive().optional(),
/** Optional maximum number tokens to include in the output file
* @example 5000
*/
maxTokens: z.number().int().positive().optional(),
});
export type Config = z.infer<typeof configSchema>;
================================================
FILE: src/core.ts
================================================
// For more information, see https://crawlee.dev/
import { Configuration, PlaywrightCrawler, downloadListOfUrls } from "crawlee";
import { readFile, writeFile } from "fs/promises";
import { glob } from "glob";
import { Config, configSchema } from "./config.js";
import { Page } from "playwright";
import { isWithinTokenLimit } from "gpt-tokenizer";
import { PathLike } from "fs";
let pageCounter = 0;
let crawler: PlaywrightCrawler;
export function getPageHtml(page: Page, selector = "body") {
return page.evaluate((selector) => {
// Check if the selector is an XPath
if (selector.startsWith("/")) {
const elements = document.evaluate(
selector,
document,
null,
XPathResult.ANY_TYPE,
null,
);
let result = elements.iterateNext();
return result ? result.textContent || "" : "";
} else {
// Handle as a CSS selector
const el = document.querySelector(selector) as HTMLElement | null;
return el?.innerText || "";
}
}, selector);
}
export async function waitForXPath(page: Page, xpath: string, timeout: number) {
await page.waitForFunction(
(xpath) => {
const elements = document.evaluate(
xpath,
document,
null,
XPathResult.ANY_TYPE,
null,
);
return elements.iterateNext() !== null;
},
xpath,
{ timeout },
);
}
export async function crawl(config: Config) {
configSchema.parse(config);
if (process.env.NO_CRAWL !== "true") {
// PlaywrightCrawler crawls the web using a headless
// browser controlled by the Playwright library.
crawler = new PlaywrightCrawler(
{
// Use the requestHandler to process each of the crawled pages.
async requestHandler({ request, page, enqueueLinks, log, pushData }) {
const title = await page.title();
pageCounter++;
log.info(
`Crawling: Page ${pageCounter} / ${config.maxPagesToCrawl} - URL: ${request.loadedUrl}...`,
);
// Use custom handling for XPath selector
if (config.selector) {
if (config.selector.startsWith("/")) {
await waitForXPath(
page,
config.selector,
config.waitForSelectorTimeout ?? 1000,
);
} else {
await page.waitForSelector(config.selector, {
timeout: config.waitForSelectorTimeout ?? 1000,
});
}
}
const html = await getPageHtml(page, config.selector);
// Save results as JSON to ./storage/datasets/default
await pushData({ title, url: request.loadedUrl, html });
if (config.onVisitPage) {
await config.onVisitPage({ page, pushData });
}
// Extract links from the current page
// and add them to the crawling queue.
await enqueueLinks({
globs:
typeof config.match === "string" ? [config.match] : config.match,
exclude:
typeof config.exclude === "string"
? [config.exclude]
: config.exclude ?? [],
});
},
// Comment this option to scrape the full website.
maxRequestsPerCrawl: config.maxPagesToCrawl,
// Uncomment this option to see the browser window.
// headless: false,
preNavigationHooks: [
// Abort requests for certain resource types and add cookies
async (crawlingContext, _gotoOptions) => {
const { request, page, log } = crawlingContext;
// Add cookies to the page
// Because the crawler has not yet navigated to the page, so the loadedUrl is always undefined. Use the request url instead.
if (config.cookie) {
const cookies = (
Array.isArray(config.cookie) ? config.cookie : [config.cookie]
).map((cookie) => {
return {
name: cookie.name,
value: cookie.value,
url: request.url,
};
});
await page.context().addCookies(cookies);
}
const RESOURCE_EXCLUSTIONS = config.resourceExclusions ?? [];
// If there are no resource exclusions, return
if (RESOURCE_EXCLUSTIONS.length === 0) {
return;
}
await page.route(
`**\/*.{${RESOURCE_EXCLUSTIONS.join()}}`,
(route) => route.abort("aborted"),
);
log.info(
`Aborting requests for as this is a resource excluded route`,
);
},
],
},
new Configuration({
purgeOnStart: true,
}),
);
const isUrlASitemap = /sitemap.*\.xml$/.test(config.url);
if (isUrlASitemap) {
const listOfUrls = await downloadListOfUrls({ url: config.url });
// Add the initial URL to the crawling queue.
await crawler.addRequests(listOfUrls);
// Run the crawler
await crawler.run();
} else {
// Add first URL to the queue and start the crawl.
await crawler.run([config.url]);
}
}
}
export async function write(config: Config) {
let nextFileNameString: PathLike = "";
const jsonFiles = await glob("storage/datasets/default/*.json", {
absolute: true,
});
console.log(`Found ${jsonFiles.length} files to combine...`);
let currentResults: Record<string, any>[] = [];
let currentSize: number = 0;
let fileCounter: number = 1;
const maxBytes: number = config.maxFileSize
? config.maxFileSize * 1024 * 1024
: Infinity;
const getStringByteSize = (str: string): number =>
Buffer.byteLength(str, "utf-8");
const nextFileName = (): string =>
`${config.outputFileName.replace(/\.json$/, "")}-${fileCounter}.json`;
const writeBatchToFile = async (): Promise<void> => {
nextFileNameString = nextFileName();
await writeFile(
nextFileNameString,
JSON.stringify(currentResults, null, 2),
);
console.log(
`Wrote ${currentResults.length} items to ${nextFileNameString}`,
);
currentResults = [];
currentSize = 0;
fileCounter++;
};
let estimatedTokens: number = 0;
const addContentOrSplit = async (
data: Record<string, any>,
): Promise<void> => {
const contentString: string = JSON.stringify(data);
const tokenCount: number | false = isWithinTokenLimit(
contentString,
config.maxTokens || Infinity,
);
if (typeof tokenCount === "number") {
if (estimatedTokens + tokenCount > config.maxTokens!) {
// Only write the batch if it's not empty (something to write)
if (currentResults.length > 0) {
await writeBatchToFile();
}
// Since the addition of a single item exceeded the token limit, halve it.
estimatedTokens = Math.floor(tokenCount / 2);
currentResults.push(data);
} else {
currentResults.push(data);
estimatedTokens += tokenCount;
}
}
currentSize += getStringByteSize(contentString);
if (currentSize > maxBytes) {
await writeBatchToFile();
}
};
// Iterate over each JSON file and process its contents.
for (const file of jsonFiles) {
const fileContent = await readFile(file, "utf-8");
const data: Record<string, any> = JSON.parse(fileContent);
await addContentOrSplit(data);
}
// Check if any remaining data needs to be written to a file.
if (currentResults.length > 0) {
await writeBatchToFile();
}
return nextFileNameString;
}
class GPTCrawlerCore {
config: Config;
constructor(config: Config) {
this.config = config;
}
async crawl() {
await crawl(this.config);
}
async write(): Promise<PathLike> {
// we need to wait for the file path as the path can change
return new Promise((resolve, reject) => {
write(this.config)
.then((outputFilePath) => {
resolve(outputFilePath);
})
.catch(reject);
});
}
}
export default GPTCrawlerCore;
================================================
FILE: src/main.ts
================================================
import { defaultConfig } from "../config.js";
import { crawl, write } from "./core.js";
await crawl(defaultConfig);
await write(defaultConfig);
================================================
FILE: src/server.ts
================================================
import express, { Express } from "express";
import cors from "cors";
import { readFile } from "fs/promises";
import { Config, configSchema } from "./config.js";
import { configDotenv } from "dotenv";
import swaggerUi from "swagger-ui-express";
// @ts-ignore
import swaggerDocument from "../swagger-output.json" assert { type: "json" };
import GPTCrawlerCore from "./core.js";
import { PathLike } from "fs";
configDotenv();
const app: Express = express();
const port = Number(process.env.API_PORT) || 3000;
const hostname = process.env.API_HOST || "localhost";
app.use(cors());
app.use(express.json());
app.use("/api-docs", swaggerUi.serve, swaggerUi.setup(swaggerDocument));
// Define a POST route to accept config and run the crawler
app.post("/crawl", async (req, res) => {
const config: Config = req.body;
try {
const validatedConfig = configSchema.parse(config);
const crawler = new GPTCrawlerCore(validatedConfig);
await crawler.crawl();
const outputFileName: PathLike = await crawler.write();
const outputFileContent = await readFile(outputFileName, "utf-8");
res.contentType("application/json");
return res.send(outputFileContent);
} catch (error) {
return res
.status(500)
.json({ message: "Error occurred during crawling", error });
}
});
app.listen(port, hostname, () => {
console.log(`API server listening at http://${hostname}:${port}`);
});
export default app;
================================================
FILE: swagger.js
================================================
import swaggerAutogen from "swagger-autogen";
const doc = {
info: {
title: "GPT Crawler API",
description: "GPT Crawler",
},
host: "localhost:5000",
};
const outputFile = "swagger-output.json";
const routes = ["./src/server.ts"];
swaggerAutogen()(outputFile, routes, doc);
gitextract_xsmjy0d3/ ├── .dockerignore ├── .github/ │ └── workflows/ │ ├── pr.yml │ └── release.yml ├── .gitignore ├── .husky/ │ └── pre-commit ├── .releaserc ├── CHANGELOG.md ├── Dockerfile ├── License ├── README.md ├── config.ts ├── containerapp/ │ ├── Dockerfile │ ├── README.md │ ├── data/ │ │ ├── config.ts │ │ └── init.sh │ └── run.sh ├── src/ │ ├── cli.ts │ ├── config.ts │ ├── core.ts │ ├── main.ts │ └── server.ts └── swagger.js
SYMBOL INDEX (10 symbols across 3 files)
FILE: src/cli.ts
function handler (line 20) | async function handler(options: Config) {
FILE: src/config.ts
type Config (line 90) | type Config = z.infer<typeof configSchema>;
FILE: src/core.ts
function getPageHtml (line 13) | function getPageHtml(page: Page, selector = "body") {
function waitForXPath (line 34) | async function waitForXPath(page: Page, xpath: string, timeout: number) {
function crawl (line 51) | async function crawl(config: Config) {
function write (line 161) | async function write(config: Config) {
class GPTCrawlerCore (line 243) | class GPTCrawlerCore {
method constructor (line 246) | constructor(config: Config) {
method crawl (line 250) | async crawl() {
method write (line 254) | async write(): Promise<PathLike> {
Condensed preview — 22 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (36K chars).
[
{
"path": ".dockerignore",
"chars": 168,
"preview": "# configurations\n.idea\n\n# crawlee and apify storage folders\napify_storage\ncrawlee_storage\nstorage\n\n# installed files\nnod"
},
{
"path": ".github/workflows/pr.yml",
"chars": 1325,
"preview": "name: Pull request workflow\n\non:\n pull_request:\n types: [opened, reopened, synchronize, edited]\n\npermissions:\n pull"
},
{
"path": ".github/workflows/release.yml",
"chars": 464,
"preview": "name: Release workflow\n\non:\n push:\n branches:\n - main\n\njobs:\n release:\n name: release\n runs-on: ubuntu-l"
},
{
"path": ".gitignore",
"chars": 251,
"preview": "# This file tells Git which files shouldn't be added to source control\n\n.idea\ndist\nnode_modules\napify_storage\ncrawlee_st"
},
{
"path": ".husky/pre-commit",
"chars": 65,
"preview": "#!/usr/bin/env sh\n. \"$(dirname -- \"$0\")/_/husky.sh\"\n\nnpm run fmt\n"
},
{
"path": ".releaserc",
"chars": 269,
"preview": "{\n \"branches\": [\n \"main\"\n ],\n \"plugins\": [\n \"@semantic-release/commit-analyzer\",\n \"@semantic-release/release"
},
{
"path": "CHANGELOG.md",
"chars": 1087,
"preview": "## [1.5.1](https://github.com/BuilderIO/gpt-crawler/compare/v1.5.0...v1.5.1) (2025-01-23)\n\n\n### Bug Fixes\n\n* correctly s"
},
{
"path": "Dockerfile",
"chars": 1970,
"preview": "# Specify the base Docker image. You can read more about\n# the available images at https://crawlee.dev/docs/guides/docke"
},
{
"path": "License",
"chars": 740,
"preview": "ISC License\n\nCopyright (c) 2023 BuilderIO\n\nPermission to use, copy, modify, and/or distribute this software for any purp"
},
{
"path": "README.md",
"chars": 7998,
"preview": "# GPT Crawler <!-- omit from toc -->\n\n<!-- Keep these links. Translations will automatically update with the README. -->"
},
{
"path": "config.ts",
"chars": 256,
"preview": "import { Config } from \"./src/config\";\n\nexport const defaultConfig: Config = {\n url: \"https://www.builder.io/c/docs/dev"
},
{
"path": "containerapp/Dockerfile",
"chars": 1515,
"preview": "FROM ubuntu:jammy\n\n# Install Git\nRUN apt-get update && \\\n apt-get install sudo -y && \\\n apt-get install git -y\n\n# "
},
{
"path": "containerapp/README.md",
"chars": 318,
"preview": "# Containerized crawler\n\n## Docker image with packaged crawler, with script for building and execution.\n\nAll dependencie"
},
{
"path": "containerapp/data/config.ts",
"chars": 242,
"preview": "import { Config } from \"./src/config\";\n\nexport const defaultConfig: Config = {\n url: \"https://www.builder.io/c/docs/dev"
},
{
"path": "containerapp/data/init.sh",
"chars": 229,
"preview": "#!/bin/bash\n\n# copy the config when starting the container\ncp /home/data/config.ts /home/gpt-crawler/\n\n# start the crawl"
},
{
"path": "containerapp/run.sh",
"chars": 665,
"preview": "#!/bin/bash\n\n# Check if there is a Docker image named \"crawler\"\nif ! sudo docker images | grep -w 'crawler' > /dev/null;"
},
{
"path": "src/cli.ts",
"chars": 2270,
"preview": "#!/usr/bin/env node\n\nimport { program } from \"commander\";\nimport { Config } from \"./config.js\";\nimport { crawl, write } "
},
{
"path": "src/config.ts",
"chars": 3570,
"preview": "import { z } from \"zod\";\nimport type { Page } from \"playwright\";\nimport { configDotenv } from \"dotenv\";\n\nconfigDotenv();"
},
{
"path": "src/core.ts",
"chars": 8151,
"preview": "// For more information, see https://crawlee.dev/\nimport { Configuration, PlaywrightCrawler, downloadListOfUrls } from \""
},
{
"path": "src/main.ts",
"chars": 145,
"preview": "import { defaultConfig } from \"../config.js\";\nimport { crawl, write } from \"./core.js\";\n\nawait crawl(defaultConfig);\nawa"
},
{
"path": "src/server.ts",
"chars": 1434,
"preview": "import express, { Express } from \"express\";\nimport cors from \"cors\";\nimport { readFile } from \"fs/promises\";\nimport { Co"
},
{
"path": "swagger.js",
"chars": 290,
"preview": "import swaggerAutogen from \"swagger-autogen\";\n\nconst doc = {\n info: {\n title: \"GPT Crawler API\",\n description: \"G"
}
]
About this extraction
This page contains the full source code of the BuilderIO/gpt-crawler GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 22 files (32.6 KB), approximately 9.3k tokens, and a symbol index with 10 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.