Showing preview only (2,471K chars total). Download the full file or copy to clipboard to get everything.
Repository: Cinnamon/kotaemon
Branch: main
Commit: 155e590720f9
Files: 363
Total size: 2.3 MB
Directory structure:
gitextract_waa09c9u/
├── .commitlintrc
├── .dockerignore
├── .gitattributes
├── .github/
│ ├── ISSUE_TEMPLATE/
│ │ ├── bug_report.yml
│ │ ├── config.yml
│ │ └── feature_request.yml
│ ├── PULL_REQUEST_TEMPLATE.md
│ └── workflows/
│ ├── auto-bump-and-release.yaml
│ ├── build-push-docker.yaml
│ ├── pr-lint.yaml
│ ├── style-check.yaml
│ └── unit-test.yaml
├── .gitignore
├── .pre-commit-config.yaml
├── .python-version
├── CODE_OF_CONDUCT.md
├── CONTRIBUTING.md
├── Dockerfile
├── LICENSE.txt
├── README.md
├── app.py
├── doc_env_reqs.txt
├── docs/
│ ├── about.md
│ ├── development/
│ │ ├── contributing.md
│ │ ├── create-a-component.md
│ │ ├── data-components.md
│ │ ├── index.md
│ │ └── utilities.md
│ ├── extra/
│ │ └── css/
│ │ └── code_select.css
│ ├── index.md
│ ├── local_model.md
│ ├── online_install.md
│ ├── pages/
│ │ └── app/
│ │ ├── customize-flows.md
│ │ ├── ext/
│ │ │ └── user-management.md
│ │ ├── features.md
│ │ ├── functional-description.md
│ │ ├── index/
│ │ │ └── file.md
│ │ └── settings/
│ │ ├── overview.md
│ │ └── user-settings.md
│ ├── scripts/
│ │ ├── generate_examples_docs.py
│ │ └── generate_reference_docs.py
│ ├── theme/
│ │ ├── assets/
│ │ │ └── pymdownx-extras/
│ │ │ ├── extra-fb5a2a1c86.css
│ │ │ ├── extra-loader-MCFnu0Wd.js
│ │ │ ├── material-extra-3rdparty-E-i8w1WA.js
│ │ │ └── material-extra-theme-TVq-kNRT.js
│ │ ├── main.html
│ │ └── partials/
│ │ ├── footer.html
│ │ ├── header.html
│ │ └── libs.html
│ └── usage.md
├── flowsettings.py
├── fly.toml
├── launch.sh
├── libs/
│ ├── kotaemon/
│ │ ├── README.md
│ │ ├── kotaemon/
│ │ │ ├── __init__.py
│ │ │ ├── agents/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── io/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── base.py
│ │ │ │ ├── langchain_based.py
│ │ │ │ ├── react/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── agent.py
│ │ │ │ │ └── prompt.py
│ │ │ │ ├── rewoo/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── agent.py
│ │ │ │ │ ├── planner.py
│ │ │ │ │ ├── prompt.py
│ │ │ │ │ └── solver.py
│ │ │ │ ├── tools/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── base.py
│ │ │ │ │ ├── google.py
│ │ │ │ │ ├── llm.py
│ │ │ │ │ ├── mcp.py
│ │ │ │ │ └── wikipedia.py
│ │ │ │ └── utils.py
│ │ │ ├── base/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── component.py
│ │ │ │ └── schema.py
│ │ │ ├── chatbot/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ └── simple_respondent.py
│ │ │ ├── cli.py
│ │ │ ├── contribs/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── docs.py
│ │ │ │ └── promptui/
│ │ │ │ ├── .gitignore
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── cli.py
│ │ │ │ ├── config.py
│ │ │ │ ├── export.py
│ │ │ │ ├── logs.py
│ │ │ │ ├── themes.py
│ │ │ │ ├── tunnel.py
│ │ │ │ └── ui/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── blocks.py
│ │ │ │ ├── chat.py
│ │ │ │ └── pipeline.py
│ │ │ ├── embeddings/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── endpoint_based.py
│ │ │ │ ├── fastembed.py
│ │ │ │ ├── langchain_based.py
│ │ │ │ ├── openai.py
│ │ │ │ ├── tei_endpoint_embed.py
│ │ │ │ └── voyageai.py
│ │ │ ├── indices/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── extractors/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── doc_parsers.py
│ │ │ │ ├── ingests/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── files.py
│ │ │ │ ├── qa/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── citation.py
│ │ │ │ │ ├── citation_qa.py
│ │ │ │ │ ├── citation_qa_inline.py
│ │ │ │ │ ├── format_context.py
│ │ │ │ │ └── utils.py
│ │ │ │ ├── rankings/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── base.py
│ │ │ │ │ ├── cohere.py
│ │ │ │ │ ├── llm.py
│ │ │ │ │ ├── llm_scoring.py
│ │ │ │ │ └── llm_trulens.py
│ │ │ │ ├── retrievers/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── jina_web_search.py
│ │ │ │ │ └── tavily_web_search.py
│ │ │ │ ├── splitters/
│ │ │ │ │ └── __init__.py
│ │ │ │ └── vectorindex.py
│ │ │ ├── llms/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── branching.py
│ │ │ │ ├── chats/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── base.py
│ │ │ │ │ ├── endpoint_based.py
│ │ │ │ │ ├── langchain_based.py
│ │ │ │ │ ├── llamacpp.py
│ │ │ │ │ └── openai.py
│ │ │ │ ├── completions/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── base.py
│ │ │ │ │ └── langchain_based.py
│ │ │ │ ├── cot.py
│ │ │ │ ├── linear.py
│ │ │ │ └── prompts/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ └── template.py
│ │ │ ├── loaders/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── adobe_loader.py
│ │ │ │ ├── azureai_document_intelligence_loader.py
│ │ │ │ ├── base.py
│ │ │ │ ├── composite_loader.py
│ │ │ │ ├── docling_loader.py
│ │ │ │ ├── docx_loader.py
│ │ │ │ ├── excel_loader.py
│ │ │ │ ├── html_loader.py
│ │ │ │ ├── mathpix_loader.py
│ │ │ │ ├── ocr_loader.py
│ │ │ │ ├── pdf_loader.py
│ │ │ │ ├── txt_loader.py
│ │ │ │ ├── unstructured_loader.py
│ │ │ │ ├── utils/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── adobe.py
│ │ │ │ │ ├── box.py
│ │ │ │ │ ├── gpt4v.py
│ │ │ │ │ ├── pdf_ocr.py
│ │ │ │ │ └── table.py
│ │ │ │ └── web_loader.py
│ │ │ ├── parsers/
│ │ │ │ ├── __init__.py
│ │ │ │ └── regex_extractor.py
│ │ │ ├── rerankings/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── cohere.py
│ │ │ │ ├── tei_fast_rerank.py
│ │ │ │ └── voyageai.py
│ │ │ └── storages/
│ │ │ ├── __init__.py
│ │ │ ├── docstores/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── elasticsearch.py
│ │ │ │ ├── in_memory.py
│ │ │ │ ├── lancedb.py
│ │ │ │ └── simple_file.py
│ │ │ └── vectorstores/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── chroma.py
│ │ │ ├── in_memory.py
│ │ │ ├── lancedb.py
│ │ │ ├── milvus.py
│ │ │ ├── qdrant.py
│ │ │ └── simple_file.py
│ │ ├── pyproject.toml
│ │ ├── pytest.ini
│ │ └── tests/
│ │ ├── __init__.py
│ │ ├── _test_multimodal_reader.py
│ │ ├── conftest.py
│ │ ├── resources/
│ │ │ ├── dummy.docx
│ │ │ ├── dummy.mhtml
│ │ │ ├── dummy.xlsx
│ │ │ ├── embedding_openai.json
│ │ │ ├── embedding_openai_batch.json
│ │ │ ├── fullocr_sample_output.json
│ │ │ ├── ggml-vocab-llama.gguf
│ │ │ ├── html/
│ │ │ │ └── dummy.html
│ │ │ └── policy.md
│ │ ├── simple_pipeline.py
│ │ ├── test_agent.py
│ │ ├── test_composite.py
│ │ ├── test_cot.py
│ │ ├── test_docstores.py
│ │ ├── test_documents.py
│ │ ├── test_embedding_models.py
│ │ ├── test_indexing_retrieval.py
│ │ ├── test_ingestor.py
│ │ ├── test_llms_chat_models.py
│ │ ├── test_llms_completion_models.py
│ │ ├── test_mcp_manager.py
│ │ ├── test_mcp_tools.py
│ │ ├── test_post_processing.py
│ │ ├── test_prompt.py
│ │ ├── test_promptui.py
│ │ ├── test_reader.py
│ │ ├── test_reranking.py
│ │ ├── test_splitter.py
│ │ ├── test_table_reader.py
│ │ ├── test_telemetry.py
│ │ ├── test_template.py
│ │ ├── test_tools.py
│ │ └── test_vectorstore.py
│ └── ktem/
│ ├── .gitignore
│ ├── MANIFEST.in
│ ├── alembic.ini
│ ├── ktem/
│ │ ├── __init__.py
│ │ ├── app.py
│ │ ├── assets/
│ │ │ ├── __init__.py
│ │ │ ├── css/
│ │ │ │ └── main.css
│ │ │ ├── js/
│ │ │ │ ├── main.js
│ │ │ │ └── pdf_viewer.js
│ │ │ ├── md/
│ │ │ │ ├── about.md
│ │ │ │ ├── changelogs.md
│ │ │ │ └── usage.md
│ │ │ └── theme.py
│ │ ├── components.py
│ │ ├── db/
│ │ │ ├── __init__.py
│ │ │ ├── base_models.py
│ │ │ ├── engine.py
│ │ │ └── models.py
│ │ ├── embeddings/
│ │ │ ├── __init__.py
│ │ │ ├── db.py
│ │ │ ├── manager.py
│ │ │ └── ui.py
│ │ ├── exceptions.py
│ │ ├── extension_protocol.py
│ │ ├── index/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── file/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── exceptions.py
│ │ │ │ ├── graph/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── graph_index.py
│ │ │ │ │ ├── light_graph_index.py
│ │ │ │ │ ├── lightrag_pipelines.py
│ │ │ │ │ ├── nano_graph_index.py
│ │ │ │ │ ├── nano_pipelines.py
│ │ │ │ │ ├── pipelines.py
│ │ │ │ │ └── visualize.py
│ │ │ │ ├── index.py
│ │ │ │ ├── knet/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── knet_index.py
│ │ │ │ │ └── pipelines.py
│ │ │ │ ├── pipelines.py
│ │ │ │ ├── ui.py
│ │ │ │ └── utils.py
│ │ │ ├── manager.py
│ │ │ ├── models.py
│ │ │ └── ui.py
│ │ ├── llms/
│ │ │ ├── __init__.py
│ │ │ ├── db.py
│ │ │ ├── manager.py
│ │ │ └── ui.py
│ │ ├── main.py
│ │ ├── mcp/
│ │ │ ├── __init__.py
│ │ │ ├── db.py
│ │ │ ├── manager.py
│ │ │ └── ui.py
│ │ ├── pages/
│ │ │ ├── __init__.py
│ │ │ ├── chat/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── chat_panel.py
│ │ │ │ ├── chat_suggestion.py
│ │ │ │ ├── common.py
│ │ │ │ ├── control.py
│ │ │ │ ├── demo_hint.py
│ │ │ │ ├── paper_list.py
│ │ │ │ └── report.py
│ │ │ ├── help.py
│ │ │ ├── login.py
│ │ │ ├── resources/
│ │ │ │ ├── __init__.py
│ │ │ │ └── user.py
│ │ │ ├── settings.py
│ │ │ └── setup.py
│ │ ├── reasoning/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── prompt_optimization/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── decompose_question.py
│ │ │ │ ├── fewshot_rewrite_question.py
│ │ │ │ ├── mindmap.py
│ │ │ │ ├── rephrase_question_train.json
│ │ │ │ ├── rewrite_question.py
│ │ │ │ ├── suggest_conversation_name.py
│ │ │ │ └── suggest_followup_chat.py
│ │ │ ├── react.py
│ │ │ ├── rewoo.py
│ │ │ └── simple.py
│ │ ├── rerankings/
│ │ │ ├── __init__.py
│ │ │ ├── db.py
│ │ │ ├── manager.py
│ │ │ └── ui.py
│ │ ├── settings.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ ├── commands.py
│ │ ├── conversation.py
│ │ ├── file.py
│ │ ├── generator.py
│ │ ├── hf_papers.py
│ │ ├── lang.py
│ │ ├── plantuml.py
│ │ ├── rate_limit.py
│ │ ├── render.py
│ │ └── visualize_cited.py
│ ├── ktem_tests/
│ │ ├── __init__.py
│ │ ├── resources/
│ │ │ └── embedding_openai.json
│ │ └── test_qa.py
│ ├── migrations/
│ │ ├── README
│ │ ├── env.py
│ │ ├── script.py.mako
│ │ └── versions/
│ │ └── .keep
│ ├── pyproject.toml
│ └── requirements.txt
├── mkdocs.yml
├── pyproject.toml
├── scripts/
│ ├── download_pdfjs.sh
│ ├── migrate/
│ │ ├── __init__.py
│ │ └── migrate_chroma_db.py
│ ├── run_linux.sh
│ ├── run_macos.sh
│ ├── run_windows.bat
│ ├── serve_local.py
│ ├── server_llamacpp_linux.sh
│ ├── server_llamacpp_macos.sh
│ ├── server_llamacpp_windows.bat
│ ├── update_linux.sh
│ ├── update_macos.sh
│ └── update_windows.bat
├── settings.yaml.example
├── sso_app.py
├── sso_app_demo.py
└── templates/
├── component-default/
│ └── README.md
└── project-default/
├── cookiecutter.json
└── {{cookiecutter.project_name}}/
├── .gitattributes
├── .gitignore
├── .pre-commit-config.yaml
├── README.md
├── setup.py
├── tests/
│ └── __init__.py
└── {{cookiecutter.project_name}}/
├── __init__.py
└── pipeline.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .commitlintrc
================================================
{
"extends": ["@commitlint/config-conventional"],
"defaultIgnores": true,
"rules": {
"body-leading-blank": [1, "always"],
"body-max-line-length": [2, "always", 100],
"footer-leading-blank": [1, "always"],
"footer-max-line-length": [2, "always", 10000],
"header-max-length": [2, "always", 200],
"subject-case": [
2,
"never",
[]
],
"subject-empty": [2, "never"],
"subject-full-stop": [2, "never", "."],
"type-case": [2, "always", "lower-case"],
"type-empty": [2, "never"],
"type-enum": [
2,
"always",
[
"build",
"chore",
"ci",
"docs",
"feat",
"fix",
"perf",
"refactor",
"revert",
"style",
"test"
]
]
}
}
================================================
FILE: .dockerignore
================================================
.github/
.git/
.mypy_cache/
__pycache__/
ktem_app_data/
env/
.pre-commit-config.yaml
.commitlintrc
.gitignore
.gitattributes
README.md
*.zip
*.sh
!/launch.sh
================================================
FILE: .gitattributes
================================================
*.bat text eol=crlf
================================================
FILE: .github/ISSUE_TEMPLATE/bug_report.yml
================================================
name: "Bug Report"
description: Report something that is not working as expected
title: "[BUG] "
labels: ["bug"]
body:
- type: markdown
attributes:
value: |
*Please fill this form with as much information as possible.*
- type: textarea
id: description
attributes:
label: "Description"
description: Please enter an explicit description of your issue
placeholder: Short and explicit description of your incident...
validations:
required: true
- type: textarea
id: reprod
attributes:
label: "Reproduction steps"
description: Please enter an explicit description of your issue
value: |
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
render: bash
validations:
required: true
- type: textarea
id: screenshot
attributes:
label: "Screenshots"
description: If applicable, add screenshots to help explain your problem.
value: |

render: bash
validations:
required: false
- type: textarea
id: logs
attributes:
label: "Logs"
description: Please copy and paste any relevant log output. This will be automatically formatted into code, so no need for backticks.
render: bash
validations:
required: false
- type: dropdown
id: browsers
attributes:
label: "Browsers"
description: What browsers are you seeing the problem on ?
multiple: true
options:
- Firefox
- Chrome
- Safari
- Microsoft Edge
- Opera
- Brave
- Other
validations:
required: false
- type: dropdown
id: os
attributes:
label: "OS"
description: What is the impacted environment ?
multiple: true
options:
- Windows
- MacOS
- Linux
- Other
validations:
required: false
- type: textarea
id: additional_information
attributes:
label: "Additional information"
description: Add any relevant information or context.
placeholder:
validations:
required: false
================================================
FILE: .github/ISSUE_TEMPLATE/config.yml
================================================
blank_issues_enabled: false
================================================
FILE: .github/ISSUE_TEMPLATE/feature_request.yml
================================================
name: "Feature Request"
description: Brainstorm and propose new features for the project
title: "[REQUEST] "
labels: ["enhancement"]
body:
- type: markdown
attributes:
value: |
*Please fill this form with as much information as possible.*
- type: textarea
id: reference_issues
attributes:
label: "Reference Issues"
description: Common issues
placeholder: "#Issues IDs"
validations:
required: false
- type: textarea
id: summary
attributes:
label: "Summary"
description: Provide a brief explanation of the feature
placeholder: Describe in a few lines your feature request
validations:
required: true
- type: textarea
id: basic_example
attributes:
label: "Basic Example"
description: Indicate here some basic examples of your feature.
placeholder: A few specific words about your feature request.
validations:
required: true
- type: textarea
id: drawbacks
attributes:
label: "Drawbacks"
description: What are the drawbacks/impacts of your feature request ?
placeholder: Identify the drawbacks and impacts while being neutral on your feature request
validations:
required: true
- type: textarea
id: additional_information
attributes:
label: "Additional information"
description: Add any additional information that you think is important for your feature request
placeholder:
validations:
required: false
================================================
FILE: .github/PULL_REQUEST_TEMPLATE.md
================================================
## Description
- Please include a summary of the changes and the related issue.
- Fixes # (issue)
## Type of change
- [ ] New features (non-breaking change).
- [ ] Bug fix (non-breaking change).
- [ ] Breaking change (fix or feature that would cause existing functionality not to work as expected).
## Checklist
- [ ] I have performed a self-review of my code.
- [ ] I have added thorough tests if it is a core feature.
- [ ] There is a reference to the original bug report and related work.
- [ ] I have commented on my code, particularly in hard-to-understand areas.
- [ ] The feature is well documented.
================================================
FILE: .github/workflows/auto-bump-and-release.yaml
================================================
name: Auto Bump and Release
on:
push:
branches:
- main
jobs:
auto-bump-and-release:
runs-on: ubuntu-latest
steps:
- name: Clone the repo
uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Update Application Version
id: update-version
uses: anothrNick/github-tag-action@v1
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
WITH_V: true
DEFAULT_BUMP: patch
MAJOR_STRING_TOKEN: "bump:major"
MINOR_STRING_TOKEN: "bump:minor"
PATCH_STRING_TOKEN: "bump:patch"
- name: Create release for ${{ steps.update-version.outputs.new_tag }}
# need to repeat this if statement because Github Action doesn't support early
# stopping for steps
if: ${{ steps.update-version.outputs.new_tag != steps.update-version.outputs.old_tag }}
run: |
echo Create release folder
mkdir kotaemon-app
echo ${{ steps.update-version.outputs.new_tag }} > kotaemon-app/VERSION
cp LICENSE.txt kotaemon-app/
cp flowsettings.py kotaemon-app/
cp app.py kotaemon-app/
cp .env.example kotaemon-app/.env
cp -r scripts kotaemon-app/
mkdir -p kotaemon-app/libs/ktem/ktem/
cp -r libs/ktem/ktem/assets kotaemon-app/libs/ktem/ktem/
tree kotaemon-app
zip -r kotaemon-app.zip kotaemon-app
- name: Release ${{ steps.update-version.outputs.new_tag }}
if: ${{ steps.update-version.outputs.new_tag != steps.update-version.outputs.old_tag }}
uses: softprops/action-gh-release@v2
with:
files: kotaemon-app.zip
fail_on_unmatched_files: true
token: ${{ secrets.GITHUB_TOKEN }}
generate_release_notes: true
tag_name: ${{ steps.update-version.outputs.new_tag }}
make_latest: true
- name: Setup latest branch locally without switching current branch
if: ${{ steps.update-version.outputs.new_tag != steps.update-version.outputs.old_tag }}
run: git fetch origin latest:latest
- name: Update latest branch
if: ${{ steps.update-version.outputs.new_tag != steps.update-version.outputs.old_tag }}
run: |
git branch -f latest tags/${{ steps.update-version.outputs.new_tag }}
git checkout latest
git push -f -u origin latest
================================================
FILE: .github/workflows/build-push-docker.yaml
================================================
name: Build and Push Docker Image
on:
release:
types:
- created
push:
tags:
- "v[0-9]+.[0-9]+.[0-9]+"
workflow_dispatch:
env:
REGISTRY: ghcr.io
jobs:
build:
name: Build and push container
runs-on: ubuntu-latest
permissions:
contents: read
packages: write
attestations: write
id-token: write
strategy:
matrix:
target:
- lite
- full
- ollama
# The maximum number of jobs that can run simultaneously
max-parallel: 1
steps:
- name: Free Disk Space (Ubuntu)
uses: jlumbroso/free-disk-space@main
with:
# this might remove tools that are actually needed,
# if set to "true" but frees about 6 GB
tool-cache: true
# all of these default to true, but feel free to set to
# "false" if necessary for your workflow
android: true
dotnet: true
haskell: true
large-packages: true
docker-images: true
swap-storage: true
- name: Set repository and image name
run: |
echo "FULL_IMAGE_NAME=${{ env.REGISTRY }}/${IMAGE_NAME,,}" >>${GITHUB_ENV}
env:
IMAGE_NAME: "${{ github.repository }}"
- name: Checkout
uses: actions/checkout@v4
- name: Set up QEMU
uses: docker/setup-qemu-action@v3
with:
image: tonistiigi/binfmt:latest
platforms: arm64,arm
- name: Set up Docker Buildx
id: buildx
uses: docker/setup-buildx-action@v3
- name: Set up Docker meta
id: meta
uses: docker/metadata-action@v5
with:
images: ${{ env.FULL_IMAGE_NAME }}
tags: |
# branch
type=ref,event=branch,suffix=-${{ matrix.target }}
# semver with suffix for lite/full targets
type=semver,pattern={{version}},suffix=-${{ matrix.target }}
# latest tag with suffix for lite/full targets
type=raw,value=latest,enable=${{ startsWith(github.ref, 'refs/tags/') && !contains(github.ref, 'pre') }},suffix=-${{ matrix.target }}
flavor: |
# This is disabled here so we can use the raw form above
latest=false
# Suffix is not used here since there's no way to disable it above
- name: Log in to the Container registry
uses: docker/login-action@v3
with:
registry: ${{ env.REGISTRY }}
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Build docker image
uses: docker/build-push-action@v6
with:
file: Dockerfile
context: .
push: true
platforms: linux/amd64, linux/arm64
tags: |
${{ steps.meta.outputs.tags }}
labels: ${{ steps.meta.outputs.labels }}
target: ${{ matrix.target }}
cache-from: type=gha
cache-to: type=gha,mode=max
================================================
FILE: .github/workflows/pr-lint.yaml
================================================
name: "Lint PR"
on:
pull_request:
types:
- opened
- edited
- synchronize
permissions:
pull-requests: write
jobs:
pr-title:
name: Validate PR title
runs-on: ubuntu-latest
permissions: write-all
steps:
- uses: amannn/action-semantic-pull-request@v5
id: lint_pr_title
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
- uses: marocchino/sticky-pull-request-comment@v2
# When the previous steps fails, the workflow would stop. By adding this
# condition you can continue the execution with the populated error message.
if: always() && (steps.lint_pr_title.outputs.error_message != null)
with:
header: pr-title-lint-error
message: |
Hey there and thank you for opening this pull request! 👋🏼
We require pull request titles to follow the [Conventional Commits specification](https://www.conventionalcommits.org/en/v1.0.0/) and it looks like your proposed title needs to be adjusted.
Details:
```
${{ steps.lint_pr_title.outputs.error_message }}
```
# Delete a previous comment when the issue has been resolved
- if: ${{ steps.lint_pr_title.outputs.error_message == null }}
uses: marocchino/sticky-pull-request-comment@v2
with:
header: pr-title-lint-error
delete: true
commitlint:
if: false # Disable this job for now
name: Validate commit messages
runs-on: ubuntu-latest
permissions: write-all
steps:
- uses: actions/checkout@v4
- uses: wagoid/commitlint-github-action@v6
id: commitlint
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
with:
configFile: ./.commitlintrc
- uses: buildingcash/json-to-markdown-table-action@v1
if: always() && (steps.commitlint.outcome != 'success')
id: table
with:
json: ${{ steps.commitlint.outputs.results }}
- uses: marocchino/sticky-pull-request-comment@v2
if: always() && (steps.commitlint.outcome != 'success')
with:
header: commitlint-error
message: |
**All commits** in this PR need to follow the [Conventional Commits specification](https://www.conventionalcommits.org/en/v1.0.0/) and [.commitlintrc](${{ github.server_url }}/${{ github.repository }}/blob/${{ github.head_ref || github.ref_name }}/.commitlintrc).
Details:
${{ steps.table.outputs.table }}
- if: ${{ steps.commitlint.outcome == 'success' }}
uses: marocchino/sticky-pull-request-comment@v2
with:
header: commitlint-error
delete: true
================================================
FILE: .github/workflows/style-check.yaml
================================================
name: style-check
on:
pull_request:
branches: [main, develop]
push:
branches: [main, develop]
jobs:
pre-commit:
runs-on: ubuntu-latest
steps:
- name: Clone the repo
uses: actions/checkout@v4
- name: Setup python
uses: actions/setup-python@v4
with:
python-version: "3.10"
- name: run pre-commit
uses: pre-commit/action@v3.0.0
================================================
FILE: .github/workflows/unit-test.yaml
================================================
name: unit-test
on:
pull_request:
branches: [main]
push:
branches: [main]
env:
THEFLOW_TEMP_PATH: ./tmp
jobs:
unit-test:
# if: false # temporary disable this job due to legacy interface
#TODO: enable this job after the new interface is ready
if: ${{ !cancelled() }}
runs-on: ${{ matrix.os }}
timeout-minutes: 20
defaults:
run:
shell: ${{ matrix.shell }}
strategy:
matrix:
python-version: ["3.10", "3.11"]
include:
- os: ubuntu-latest
shell: bash
ACTIVATE_ENV: ". env/bin/activate"
GITHUB_OUTPUT: "$GITHUB_OUTPUT"
# - os: windows-latest
# shell: pwsh
# ACTIVATE_ENV: env/Scripts/activate.ps1
# GITHUB_OUTPUT: "$env:GITHUB_OUTPUT"
name: unit testing with python ${{ matrix.python-version }}
steps:
- name: Clone the repo
uses: actions/checkout@v4
with:
ref: ${{ github.event.pull_request.head.sha }}
- name: Get Head Commit Message
id: get-head-commit-message
run: echo "message=$(git show -s --format=%s)" | tee -a ${{ matrix.GITHUB_OUTPUT }}
- name: Check ignore caching
id: check-ignore-cache
run: |
ignore_cache=${{ contains(steps.get-head-commit-message.outputs.message, '[ignore cache]') }}
echo "check=$ignore_cache" | tee -a ${{ matrix.GITHUB_OUTPUT }}
- name: Set up Python ${{ matrix.python-version }} on ${{ runner.os }}
uses: actions/setup-python@v4
id: setup_python
with:
python-version: ${{ matrix.python-version }}
architecture: x64
- name: Install uv
uses: astral-sh/setup-uv@v5
with:
python-version: ${{ matrix.python-version }}
enable-cache: true
- name: Get cache key
id: get-cache-key
run: |
pip install "setuptools-git-versioning>=2.0,<3"
package_version=$(setuptools-git-versioning)
cache_key="${{ runner.os }}-py${{ matrix.python-version }}-v${package_version}"
echo "key=$cache_key" | tee -a ${{ matrix.GITHUB_OUTPUT }}
- name: Try to restore dependencies from ${{ steps.get-cache-key.outputs.key }}
id: restore-dependencies
if: steps.check-ignore-cache.outputs.check != 'true'
uses: actions/cache/restore@v3
with:
path: ${{ env.pythonLocation }}
key: ${{ steps.get-cache-key.outputs.key }}
# could using cache of previous ver to reuse unchanged packages
restore-keys: ${{ runner.os }}-py${{ matrix.python-version }}
- name: Check cache hit
id: check-cache-hit
run: |
echo "cache-hit=${{ steps.restore-dependencies.outputs.cache-hit }}"
echo "cache-matched-key=${{ steps.restore-dependencies.outputs.cache-matched-key }}"
cache_hit=${{ steps.restore-dependencies.outputs.cache-primary-key == steps.restore-dependencies.outputs.cache-matched-key }}
echo "check=$cache_hit" | tee -a ${{ matrix.GITHUB_OUTPUT }}
- name: Install additional dependencies (if any)
run: |
uv sync --frozen --no-cache
- name: New dependencies cache for key ${{ steps.restore-dependencies.outputs.cache-primary-key }}
if: |
steps.check-ignore-cache.outputs.check != 'true' &&
steps.check-cache-hit.outputs.check != 'true'
uses: actions/cache/save@v3
with:
path: ${{ env.pythonLocation }}
key: ${{ steps.restore-dependencies.outputs.cache-primary-key }}
- name: Install OS-based packages
run: |
sudo apt update -qqy
sudo apt install -y poppler-utils libpoppler-dev tesseract-ocr
- name: Test kotaemon with pytest
run: |
source .venv/bin/activate
uv pip show pytest
cd libs/kotaemon
pytest
================================================
FILE: .gitignore
================================================
# Created by https://www.toptal.com/developers/gitignore/api/python,linux,macos,windows,vim,emacs,visualstudiocode,pycharm
# Edit at https://www.toptal.com/developers/gitignore?templates=python,linux,macos,windows,vim,emacs,visualstudiocode,pycharm
activate*
activate/*
kotaemon-env*
.env
### Emacs ###
# -*- mode: gitignore; -*-
*~
\#*\#
/.emacs.desktop
/.emacs.desktop.lock
*.elc
auto-save-list
tramp
.\#*
# Org-mode
.org-id-locations
*_archive
# flymake-mode
*_flymake.*
# eshell files
/eshell/history
/eshell/lastdir
# elpa packages
/elpa/
# reftex files
*.rel
# AUCTeX auto folder
/auto/
# cask packages
.cask/
dist/
# Flycheck
flycheck_*.el
# server auth directory
/server/
# projectiles files
.projectile
# directory configuration
.dir-locals.el
# network security
/network-security.data
### Linux ###
# temporary files which can be created if a process still has a handle open of a deleted file
.fuse_hidden*
# KDE directory preferences
.directory
# Linux trash folder which might appear on any partition or disk
.Trash-*
# .nfs files are created when an open file is removed but is still being accessed
.nfs*
### macOS ###
# General
.DS_Store
.AppleDouble
.LSOverride
# Icon must end with two \r
Icon
# Thumbnails
._*
# Files that might appear in the root of a volume
.DocumentRevisions-V100
.fseventsd
.Spotlight-V100
.TemporaryItems
.Trashes
.VolumeIcon.icns
.com.apple.timemachine.donotpresent
# Directories potentially created on remote AFP share
.AppleDB
.AppleDesktop
Network Trash Folder
Temporary Items
.apdisk
### macOS Patch ###
# iCloud generated files
*.icloud
### PyCharm ###
# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio, WebStorm and Rider
# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
# User-specific stuff
.idea/**/workspace.xml
.idea/**/tasks.xml
.idea/**/usage.statistics.xml
.idea/**/dictionaries
.idea/**/shelf
# AWS User-specific
.idea/**/aws.xml
# Generated files
.idea/**/contentModel.xml
# Sensitive or high-churn files
.idea/**/dataSources/
.idea/**/dataSources.ids
.idea/**/dataSources.local.xml
.idea/**/sqlDataSources.xml
.idea/**/dynamic.xml
.idea/**/uiDesigner.xml
.idea/**/dbnavigator.xml
# Gradle
.idea/**/gradle.xml
.idea/**/libraries
# Gradle and Maven with auto-import
# When using Gradle or Maven with auto-import, you should exclude module files,
# since they will be recreated, and may cause churn. Uncomment if using
# auto-import.
# .idea/artifacts
# .idea/compiler.xml
# .idea/jarRepositories.xml
# .idea/modules.xml
# .idea/*.iml
# .idea/modules
# *.iml
# *.ipr
# CMake
cmake-build-*/
# Mongo Explorer plugin
.idea/**/mongoSettings.xml
# File-based project format
*.iws
# IntelliJ
out/
# mpeltonen/sbt-idea plugin
.idea_modules/
# JIRA plugin
atlassian-ide-plugin.xml
# Cursive Clojure plugin
.idea/replstate.xml
# SonarLint plugin
.idea/sonarlint/
# Crashlytics plugin (for Android Studio and IntelliJ)
com_crashlytics_export_strings.xml
crashlytics.properties
crashlytics-build.properties
fabric.properties
# Editor-based Rest Client
.idea/httpRequests
# Android studio 3.1+ serialized cache file
.idea/caches/build_file_checksums.ser
### PyCharm Patch ###
# Comment Reason: https://github.com/joeblau/gitignore.io/issues/186#issuecomment-215987721
# *.iml
# modules.xml
# .idea/misc.xml
# *.ipr
# Sonarlint plugin
# https://plugins.jetbrains.com/plugin/7973-sonarlint
.idea/**/sonarlint/
# SonarQube Plugin
# https://plugins.jetbrains.com/plugin/7238-sonarqube-community-plugin
.idea/**/sonarIssues.xml
# Markdown Navigator plugin
# https://plugins.jetbrains.com/plugin/7896-markdown-navigator-enhanced
.idea/**/markdown-navigator.xml
.idea/**/markdown-navigator-enh.xml
.idea/**/markdown-navigator/
# Cache file creation bug
# See https://youtrack.jetbrains.com/issue/JBR-2257
.idea/$CACHE_FILE$
# CodeStream plugin
# https://plugins.jetbrains.com/plugin/12206-codestream
.idea/codestream.xml
# Azure Toolkit for IntelliJ plugin
# https://plugins.jetbrains.com/plugin/8053-azure-toolkit-for-intellij
.idea/**/azureSettings.xml
### Python ###
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
cover/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
.pybuilder/
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
# For a library or package, you might want to ignore these files since the code is
# intended to run in multiple environments; otherwise, check them in:
# .python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# poetry
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
# This is especially recommended for binary packages to ensure reproducibility, and is more
# commonly ignored for libraries.
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
#poetry.lock
# pdm
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
#pdm.lock
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
# in version control.
# https://pdm.fming.dev/#use-with-ide
.pdm.toml
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# pytype static type analyzer
.pytype/
# Cython debug symbols
cython_debug/
# PyCharm
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
# and can be added to the global gitignore or merged into this file. For a more nuclear
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
#.idea/
### Python Patch ###
# Poetry local configuration file - https://python-poetry.org/docs/configuration/#local-configuration
poetry.toml
# ruff
.ruff_cache/
# LSP config files
pyrightconfig.json
### Vim ###
# Swap
[._]*.s[a-v][a-z]
!*.svg # comment out if you don't need vector files
[._]*.sw[a-p]
[._]s[a-rt-v][a-z]
[._]ss[a-gi-z]
[._]sw[a-p]
# Session
Session.vim
Sessionx.vim
# Temporary
.netrwhist
# Auto-generated tag files
tags
# Persistent undo
[._]*.un~
### VisualStudioCode ###
.vscode/*
!.vscode/settings.json
!.vscode/tasks.json
!.vscode/launch.json
!.vscode/extensions.json
!.vscode/*.code-snippets
# Local History for Visual Studio Code
.history/
# Built Visual Studio Code Extensions
*.vsix
### VisualStudioCode Patch ###
# Ignore all local history of files
.history
.ionide
### Windows ###
# Windows thumbnail cache files
Thumbs.db
Thumbs.db:encryptable
ehthumbs.db
ehthumbs_vista.db
# Dump file
*.stackdump
# Folder config file
[Dd]esktop.ini
# Recycle Bin used on file shares
$RECYCLE.BIN/
# Windows Installer files
*.cab
*.msi
*.msix
*.msm
*.msp
# Windows shortcuts
*.lnk
# PDF files
*.pdf
!libs/kotaemon/tests/resources/*.pdf
.theflow/
# End of https://www.toptal.com/developers/gitignore/api/python,linux,macos,windows,vim,emacs,visualstudiocode,pycharm
*.py[coid]
logs/
.gitsecret/keys/random_seed
!*.secret
.envrc
.env
S.gpg-agent*
.vscode/settings.json
examples/example1/assets
storage/*
# Conda and env storages
*install_dir/
doc_env/
# application data
ktem_app_data/
gradio_tmp/
================================================
FILE: .pre-commit-config.yaml
================================================
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v4.3.0
hooks:
- id: check-yaml
args: ["--unsafe"]
- id: check-toml
- id: end-of-file-fixer
- id: trailing-whitespace
- id: mixed-line-ending
- id: detect-aws-credentials
args: ["--allow-missing-credentials"]
- id: detect-private-key
- id: check-added-large-files
args: ["--maxkb=750"]
- id: debug-statements
- repo: https://github.com/ambv/black
rev: 22.3.0
hooks:
- id: black
language_version: python3
- repo: https://github.com/pycqa/isort
rev: 5.12.0
hooks:
- id: isort
args: ["--profile", "black"]
language_version: python3.10
- repo: https://github.com/pycqa/flake8
rev: 4.0.1
hooks:
- id: flake8
args: ["--max-line-length", "88", "--extend-ignore", "E203"]
- repo: https://github.com/myint/autoflake
rev: v1.4
hooks:
- id: autoflake
args:
[
"--in-place",
"--remove-unused-variables",
"--remove-all-unused-imports",
"--ignore-init-module-imports",
"--exclude=tests/*",
]
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v2.7.1
hooks:
- id: prettier
types_or: [markdown, yaml]
- repo: https://github.com/pre-commit/mirrors-mypy
rev: "v1.7.1"
hooks:
- id: mypy
additional_dependencies:
[
types-PyYAML==6.0.12.11,
"types-requests",
"sqlmodel",
"types-Markdown",
"types-cachetools",
types-tzlocal,
]
args: ["--check-untyped-defs", "--ignore-missing-imports"]
exclude: "^templates/"
- repo: https://github.com/codespell-project/codespell
rev: v2.2.4
hooks:
- id: codespell
additional_dependencies:
- tomli
================================================
FILE: .python-version
================================================
3.10
================================================
FILE: CODE_OF_CONDUCT.md
================================================
# Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our
community a harassment-free experience for everyone, regardless of age, body
size, visible or invisible disability, ethnicity, sex characteristics, gender
identity and expression, level of experience, education, socio-economic status,
nationality, personal appearance, race, religion, or sexual identity
and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming,
diverse, inclusive, and healthy community.
## Our Standards
Examples of behavior that contributes to a positive environment for our
community include:
- Demonstrating empathy and kindness toward other people
- Being respectful of differing opinions, viewpoints, and experiences
- Giving and gracefully accepting constructive feedback
- Accepting responsibility and apologizing to those affected by our mistakes,
and learning from the experience
- Focusing on what is best not just for us as individuals, but for the
overall community
Examples of unacceptable behavior include:
- The use of sexualized language or imagery, and sexual attention or
advances of any kind
- Trolling, insulting or derogatory comments, and personal or political attacks
- Public or private harassment
- Publishing others' private information, such as a physical or email
address, without their explicit permission
- Other conduct which could reasonably be considered inappropriate in a
professional setting
## Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of
acceptable behavior and will take appropriate and fair corrective action in
response to any behavior that they deem inappropriate, threatening, offensive,
or harmful.
Community leaders have the right and responsibility to remove, edit, or reject
comments, commits, code, wiki edits, issues, and other contributions that are
not aligned to this Code of Conduct, and will communicate reasons for moderation
decisions when appropriate.
## Scope
This Code of Conduct applies within all community spaces, and also applies when
an individual is officially representing the community in public spaces.
Examples of representing our community include using an official e-mail address,
posting via an official social media account, or acting as an appointed
representative at an online or offline event.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported to the community leaders responsible for enforcement at
.
All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the
reporter of any incident.
## Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining
the consequences for any action they deem in violation of this Code of Conduct:
### 1. Correction
**Community Impact**: Use of inappropriate language or other behavior deemed
unprofessional or unwelcome in the community.
**Consequence**: A private, written warning from community leaders, providing
clarity around the nature of the violation and an explanation of why the
behavior was inappropriate. A public apology may be requested.
### 2. Warning
**Community Impact**: A violation through a single incident or series
of actions.
**Consequence**: A warning with consequences for continued behavior. No
interaction with the people involved, including unsolicited interaction with
those enforcing the Code of Conduct, for a specified period of time. This
includes avoiding interactions in community spaces as well as external channels
like social media. Violating these terms may lead to a temporary or
permanent ban.
### 3. Temporary Ban
**Community Impact**: A serious violation of community standards, including
sustained inappropriate behavior.
**Consequence**: A temporary ban from any sort of interaction or public
communication with the community for a specified period of time. No public or
private interaction with the people involved, including unsolicited interaction
with those enforcing the Code of Conduct, is allowed during this period.
Violating these terms may lead to a permanent ban.
### 4. Permanent Ban
**Community Impact**: Demonstrating a pattern of violation of community
standards, including sustained inappropriate behavior, harassment of an
individual, or aggression toward or disparagement of classes of individuals.
**Consequence**: A permanent ban from any sort of public interaction within
the community.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
version 2.0, available at
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
Community Impact Guidelines were inspired by [Mozilla's code of conduct
enforcement ladder](https://github.com/mozilla/diversity).
[homepage]: https://www.contributor-covenant.org
For answers to common questions about this code of conduct, see the FAQ at
https://www.contributor-covenant.org/faq. Translations are available at
https://www.contributor-covenant.org/translations.
================================================
FILE: CONTRIBUTING.md
================================================
# Contributing to Kotaemon
Welcome 👋 to the Kotaemon project! We're thrilled that you're interested in contributing. Whether you're fixing bugs, adding new features, or improving documentation, your efforts are highly appreciated. This guide aims to help you get started with contributing to Kotaemon.
<a href="https://github.com/Cinnamon/kotaemon/graphs/contributors">
<img src="https://contrib.rocks/image?repo=Cinnamon/kotaemon" />
</a>
### Table of Contents
1. [📖 Code of Conduct](#code-of-conduct)
2. [🔁 Contributing via Pull Requests](#contributing-via-pull-requests)
3. [📥 Opening an Issue](#-opening-an-issue)
4. [📝 Commit Messages](#-commit-messages)
5. [🧾 License](#-license)
## 📖 Code of Conduct
Please review our [code of conduct](./CODE_OF_CONDUCT.md), which is in effect at all times. We expect everyone who contributes to this project to honor it.
## 🔁 Contributing via Pull Requests
1. [**Fork the repository**](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/working-with-forks/fork-a-repo): Click on the [Fork](https://github.com/Cinnamon/kotaemon/fork) button on the repository's page to create a copy of Kotaemon under your GitHub account.
2. [**Clone your code**](https://docs.github.com/en/repositories/creating-and-managing-repositories/cloning-a-repository): Clone your forked repository to your local machine.
3. [**Create new branch**](https://docs.github.com/en/desktop/making-changes-in-a-branch/managing-branches-in-github-desktop): Create a new branch in your forked repo with a descriptive name that reflects your changes.
```sh
git checkout -b descriptive-name-for-your-changes
```
4. **Setup the development environment**: If you are working on the code, make sure to install the necessary dependencies for development
```sh
pip install -e "libs/kotaemon[dev]"
```
5. **Make your changes**: Ensure your code follows the project's coding style and passes all test cases.
- Check the coding style
```sh
pre-commit run --all-files
```
- Run the tests
```sh
pytest libs/kotaemon/tests/
```
6. [**Commit your changes**](https://docs.github.com/en/desktop/making-changes-in-a-branch/committing-and-reviewing-changes-to-your-project-in-github-desktop): Once you are done with your changes, add and commit them with clear messages.
```sh
git add your_changes.py
git commit -m "clear message described your changes."
git push -u origin descriptive-name-for-your-changes
```
7. [**Create a pull request**](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request): When you are satisfied with your changes, [submit a pull request](https://github.com/Cinnamon/kotaemon/compare) from your forked repository to Kotaemon repository. In the pull request, provide a clear description of your changes and any related issues. For the title of the pull request, please refer to our [commit messages convention](#-commit-messages).
8. **Wait for reviews**: Wait for the maintainers to review your pull request. If everything is okay, your changes will be merged into the Kotaemon project.
### GitHub Actions CI Tests
All pull requests must pass the [GitHub Actions Continuous Integration (CI)](https://docs.github.com/en/actions/about-github-actions/about-continuous-integration-with-github-actions) tests before they can be merged. These tests include coding-style checks, PR title validation, unit tests, etc. to ensure that your changes meet the project's quality standards. Please review and fix any CI failures that arise.
## 📥 Opening an Issue
Before [creating an issues](https://github.com/Cinnamon/kotaemon/issues/new/choose), search through existing issues to ensure you are not opening a duplicate. If you are reporting a bug or issue, please provide a reproducible example to help us quickly identify the problem.
## 📝 Commit Messages
### Overview
We use [Angular convention](https://www.conventionalcommits.org/en/) for commit messages to maintain consistency and clarity in our project history. Please take a moment to familiarize yourself with this convention before making your first commit.
_For the sake of simplicity, we use [squashing merge](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/incorporating-changes-from-a-pull-request/about-pull-request-merges#squash-and-merge-your-commits) with pull requests. Therefore, if you contribute via a pull request, just make sure your PR's title, instead of the whole commits, follows this convention._
Commit format:
```sh
<gitmoji> <type>(<scope>): <subject>
<BLANK LINE>
<body>
<BLANK LINE>
<footer>
```
Examples:
```sh
docs(api): update api doc
```
### Commit types
| Types | Description |
| :--------- | :------------------------------------------------------------ |
| `feat` | New features |
| `fix` | Bug fix |
| `docs` | Documentation only changes |
| `build` | Changes that affect the build system or external dependencies |
| `chore` | Something that doesn’t fit the other types |
| `ci` | Changes to our CI configuration files and scripts |
| `perf` | Improve performance |
| `refactor` | Refactor code |
| `revert` | Revert a previous commit |
| `style` | Improve structure/format of the code |
| `test` | Add, update or pass tests |
## 🧾 License
All contributions will be licensed under the project's license: [Apache License 2.0](https://github.com/Cinnamon/kotaemon/blob/main/LICENSE.txt).
================================================
FILE: Dockerfile
================================================
# Lite version
FROM python:3.10-slim AS lite
# Common dependencies
RUN apt-get update -qqy && \
apt-get install -y --no-install-recommends \
ssh \
git \
gcc \
g++ \
poppler-utils \
libpoppler-dev \
unzip \
curl \
cargo \
&& \
apt-get autoremove && apt-get clean && rm -rf /var/lib/apt/lists/*
# Setup args
ARG TARGETPLATFORM
ARG TARGETARCH
# Set environment variables
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
ENV PYTHONIOENCODING=UTF-8
ENV TARGETARCH=${TARGETARCH}
# Create working directory
WORKDIR /app
# Download pdfjs
COPY scripts/download_pdfjs.sh /app/scripts/download_pdfjs.sh
RUN chmod +x /app/scripts/download_pdfjs.sh
ENV PDFJS_PREBUILT_DIR="/app/libs/ktem/ktem/assets/prebuilt/pdfjs-dist"
RUN bash scripts/download_pdfjs.sh $PDFJS_PREBUILT_DIR
# Install uv dependencies
RUN pip install --no-cache-dir "uv"
# Copy contents
COPY . /app
COPY launch.sh /app/launch.sh
COPY .env.example /app/.env
# Install pip packages
RUN --mount=type=ssh \
--mount=type=cache,target=/root/.cache/uv \
uv sync --frozen --no-cache \
&& uv pip install --python .venv "pdfservices-sdk@git+https://github.com/niallcm/pdfservices-python-sdk.git@bump-and-unfreeze-requirements"
RUN --mount=type=ssh \
--mount=type=cache,target=/root/.cache/uv \
if [ "$TARGETARCH" = "amd64" ]; then uv pip install --python .venv "graphrag<=0.3.6" future; fi
ENTRYPOINT ["sh", "/app/launch.sh"]
# Full version
FROM lite AS full
# Additional dependencies for full version
RUN apt-get update -qqy && \
apt-get install -y --no-install-recommends \
tesseract-ocr \
tesseract-ocr-jpn \
libsm6 \
libxext6 \
libreoffice \
ffmpeg \
libmagic-dev \
&& \
apt-get autoremove && apt-get clean && rm -rf /var/lib/apt/lists/*
# Install torch and torchvision for unstructured
RUN --mount=type=ssh \
--mount=type=cache,target=/root/.cache/uv \
uv pip install --python .venv torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
# Install additional pip packages
RUN --mount=type=ssh \
--mount=type=cache,target=/root/.cache/uv \
uv pip install --python .venv "libs/kotaemon[adv]" \
&& uv pip install --python .venv unstructured[all-docs]
# Install lightRAG
ENV USE_LIGHTRAG=true
RUN --mount=type=ssh \
--mount=type=cache,target=/root/.cache/uv \
uv pip install --python .venv aioboto3 nano-vectordb ollama xxhash "lightrag-hku<=1.3.0"
RUN --mount=type=ssh \
--mount=type=cache,target=/root/.cache/uv \
uv pip install --python .venv "docling<=2.5.2"
# Download NLTK data from LlamaIndex
RUN /app/.venv/bin/python -c "from llama_index.core.readers.base import BaseReader"
ENTRYPOINT ["sh", "/app/launch.sh"]
# Ollama-bundled version
FROM full AS ollama
# Install ollama
RUN curl -fsSL https://ollama.com/install.sh | sh
# RUN nohup bash -c "ollama serve &" && sleep 4 && ollama pull qwen2.5:7b
RUN nohup bash -c "ollama serve &" && sleep 4 && ollama pull nomic-embed-text
ENTRYPOINT ["sh", "/app/launch.sh"]
================================================
FILE: LICENSE.txt
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: README.md
================================================
<div align="center">
# kotaemon
An open-source clean & customizable RAG UI for chatting with your documents. Built with both end users and
developers in mind.

<a href="https://trendshift.io/repositories/11607" target="_blank"><img src="https://trendshift.io/api/badge/repositories/11607" alt="Cinnamon%2Fkotaemon | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/></a>
[Live Demo #1](https://huggingface.co/spaces/cin-model/kotaemon) |
[Live Demo #2](https://huggingface.co/spaces/cin-model/kotaemon-demo) |
[Online Install](https://cinnamon.github.io/kotaemon/online_install/) |
[Colab Notebook (Local RAG)](https://colab.research.google.com/drive/1eTfieec_UOowNizTJA1NjawBJH9y_1nn)
[User Guide](https://cinnamon.github.io/kotaemon/) |
[Developer Guide](https://cinnamon.github.io/kotaemon/development/) |
[Feedback](https://github.com/Cinnamon/kotaemon/issues) |
[Contact](mailto:kotaemon.support@cinnamon.is)
[](https://www.python.org/downloads/release/python-31013/)
[](https://github.com/psf/black)
<a href="https://github.com/Cinnamon/kotaemon/pkgs/container/kotaemon" target="_blank">
<img src="https://img.shields.io/badge/docker_pull-kotaemon:latest-brightgreen" alt="docker pull ghcr.io/cinnamon/kotaemon:latest"></a>

<a href='https://huggingface.co/spaces/cin-model/kotaemon-demo'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue'></a>
<a href="https://hellogithub.com/en/repository/d3141471a0244d5798bc654982b263eb" target="_blank"><img src="https://abroad.hellogithub.com/v1/widgets/recommend.svg?rid=d3141471a0244d5798bc654982b263eb&claim_uid=RLiD9UZ1rEHNaMf&theme=small" alt="Featured|HelloGitHub" /></a>
</div>
<!-- start-intro -->
## Introduction
This project serves as a functional RAG UI for both end users who want to do QA on their
documents and developers who want to build their own RAG pipeline.
<br>
```yml
+----------------------------------------------------------------------------+
| End users: Those who use apps built with `kotaemon`. |
| (You use an app like the one in the demo above) |
| +----------------------------------------------------------------+ |
| | Developers: Those who built with `kotaemon`. | |
| | (You have `import kotaemon` somewhere in your project) | |
| | +----------------------------------------------------+ | |
| | | Contributors: Those who make `kotaemon` better. | | |
| | | (You make PR to this repo) | | |
| | +----------------------------------------------------+ | |
| +----------------------------------------------------------------+ |
+----------------------------------------------------------------------------+
```
### For end users
- **Clean & Minimalistic UI**: A user-friendly interface for RAG-based QA.
- **Support for Various LLMs**: Compatible with LLM API providers (OpenAI, AzureOpenAI, Cohere, etc.) and local LLMs (via `ollama` and `llama-cpp-python`).
- **Easy Installation**: Simple scripts to get you started quickly.
### For developers
- **Framework for RAG Pipelines**: Tools to build your own RAG-based document QA pipeline.
- **Customizable UI**: See your RAG pipeline in action with the provided UI, built with <a href='https://github.com/gradio-app/gradio'>Gradio <img src='https://img.shields.io/github/stars/gradio-app/gradio'></a>.
- **Gradio Theme**: If you use Gradio for development, check out our theme here: [kotaemon-gradio-theme](https://github.com/lone17/kotaemon-gradio-theme).
## Key Features
- **Host your own document QA (RAG) web-UI**: Support multi-user login, organize your files in private/public collections, collaborate and share your favorite chat with others.
- **Organize your LLM & Embedding models**: Support both local LLMs & popular API providers (OpenAI, Azure, Ollama, Groq).
- **Hybrid RAG pipeline**: Sane default RAG pipeline with hybrid (full-text & vector) retriever and re-ranking to ensure best retrieval quality.
- **Multi-modal QA support**: Perform Question Answering on multiple documents with figures and tables support. Support multi-modal document parsing (selectable options on UI).
- **Advanced citations with document preview**: By default the system will provide detailed citations to ensure the correctness of LLM answers. View your citations (incl. relevant score) directly in the _in-browser PDF viewer_ with highlights. Warning when retrieval pipeline return low relevant articles.
- **Support complex reasoning methods**: Use question decomposition to answer your complex/multi-hop question. Support agent-based reasoning with `ReAct`, `ReWOO` and other agents.
- **Configurable settings UI**: You can adjust most important aspects of retrieval & generation process on the UI (incl. prompts).
- **Extensible**: Being built on Gradio, you are free to customize or add any UI elements as you like. Also, we aim to support multiple strategies for document indexing & retrieval. `GraphRAG` indexing pipeline is provided as an example.

## Installation
> If you are not a developer and just want to use the app, please check out our easy-to-follow [User Guide](https://cinnamon.github.io/kotaemon/). Download the `.zip` file from the [latest release](https://github.com/Cinnamon/kotaemon/releases/latest) to get all the newest features and bug fixes.
### System requirements
1. [Python](https://www.python.org/downloads/) >= 3.10
2. [Docker](https://www.docker.com/): optional, if you [install with Docker](#with-docker-recommended)
3. [Unstructured](https://docs.unstructured.io/open-source/installation/full-installation#full-installation) if you want to process files other than `.pdf`, `.html`, `.mhtml`, and `.xlsx` documents. Installation steps differ depending on your operating system. Please visit the link and follow the specific instructions provided there.
### With Docker (recommended)
1. We support both `lite` & `full` version of Docker images. With `full` version, the extra packages of `unstructured` will be installed, which can support additional file types (`.doc`, `.docx`, ...) but the cost is larger docker image size. For most users, the `lite` image should work well in most cases.
- To use the `full` version.
```bash
docker run \
-e GRADIO_SERVER_NAME=0.0.0.0 \
-e GRADIO_SERVER_PORT=7860 \
-v ./ktem_app_data:/app/ktem_app_data \
-p 7860:7860 -it --rm \
ghcr.io/cinnamon/kotaemon:main-full
```
- To use the `full` version with bundled **Ollama** for _local / private RAG_.
```bash
# change image name to
docker run <...> ghcr.io/cinnamon/kotaemon:main-ollama
```
- To use the `lite` version.
```bash
# change image name to
docker run <...> ghcr.io/cinnamon/kotaemon:main-lite
```
2. We currently support and test two platforms: `linux/amd64` and `linux/arm64` (for newer Mac). You can specify the platform by passing `--platform` in the `docker run` command. For example:
```bash
# To run docker with platform linux/arm64
docker run \
-e GRADIO_SERVER_NAME=0.0.0.0 \
-e GRADIO_SERVER_PORT=7860 \
-v ./ktem_app_data:/app/ktem_app_data \
-p 7860:7860 -it --rm \
--platform linux/arm64 \
ghcr.io/cinnamon/kotaemon:main-lite
```
3. Once everything is set up correctly, you can go to `http://localhost:7860/` to access the WebUI.
4. We use [GHCR](https://docs.github.com/en/packages/working-with-a-github-packages-registry/working-with-the-container-registry) to store docker images, all images can be found [here.](https://github.com/Cinnamon/kotaemon/pkgs/container/kotaemon)
### Without Docker
#### Option 1: Using uv (Recommended for faster installation)
1. Clone the repository and run the uv installation script:
```shell
# clone this repo
git clone https://github.com/Cinnamon/kotaemon
cd kotaemon
# run the uv installation script (installs uv automatically if not present)
bash scripts/run_uv.sh
```
This script will:
- Install uv package manager if not present
- Create a virtual environment with Python 3.10
- Install all dependencies using uv (significantly faster than conda/pip)
- Set up PDF.js viewer
- Launch the application
#### Option 2: Using conda (Traditional method)
1. Clone and install required packages on a fresh python environment.
```shell
# optional (setup env)
conda create -n kotaemon python=3.10
conda activate kotaemon
# clone this repo
git clone https://github.com/Cinnamon/kotaemon
cd kotaemon
pip install -e "libs/kotaemon[all]"
pip install -e "libs/ktem"
```
2. Create a `.env` file in the root of this project. Use `.env.example` as a template
The `.env` file is there to serve use cases where users want to pre-config the models before starting up the app (e.g. deploy the app on HF hub). The file will only be used to populate the db once upon the first run, it will no longer be used in consequent runs.
3. (Optional) To enable in-browser `PDF_JS` viewer, download [PDF_JS_DIST](https://github.com/mozilla/pdf.js/releases/download/v4.0.379/pdfjs-4.0.379-dist.zip) then extract it to `libs/ktem/ktem/assets/prebuilt`
<img src="https://raw.githubusercontent.com/Cinnamon/kotaemon/main/docs/images/pdf-viewer-setup.png" alt="pdf-setup" width="300">
4. Start the web server:
```shell
python app.py
```
- The app will be automatically launched in your browser.
- Default username and password are both `admin`. You can set up additional users directly through the UI.

5. Check the `Resources` tab and `LLMs and Embeddings` and ensure that your `api_key` value is set correctly from your `.env` file. If it is not set, you can set it there.
### Setup GraphRAG
> [!NOTE]
> Official MS GraphRAG indexing only works with OpenAI or Ollama API.
> We recommend most users to use NanoGraphRAG implementation for straightforward integration with Kotaemon.
<details>
<summary>Setup Nano GRAPHRAG</summary>
- Install nano-GraphRAG: `pip install nano-graphrag`
- `nano-graphrag` install might introduce version conflicts, see [this issue](https://github.com/Cinnamon/kotaemon/issues/440)
- To quickly fix: `pip uninstall hnswlib chroma-hnswlib && pip install chroma-hnswlib`
- Launch Kotaemon with `USE_NANO_GRAPHRAG=true` environment variable.
- Set your default LLM & Embedding models in Resources setting and it will be recognized automatically from NanoGraphRAG.
</details>
<details>
<summary>Setup LIGHTRAG</summary>
- Install LightRAG: `pip install git+https://github.com/HKUDS/LightRAG.git`
- `LightRAG` install might introduce version conflicts, see [this issue](https://github.com/Cinnamon/kotaemon/issues/440)
- To quickly fix: `pip uninstall hnswlib chroma-hnswlib && pip install chroma-hnswlib`
- Launch Kotaemon with `USE_LIGHTRAG=true` environment variable.
- Set your default LLM & Embedding models in Resources setting and it will be recognized automatically from LightRAG.
</details>
<details>
<summary>Setup MS GRAPHRAG</summary>
- **Non-Docker Installation**: If you are not using Docker, install GraphRAG with the following command:
```shell
pip install "graphrag<=0.3.6" future
```
- **Setting Up API KEY**: To use the GraphRAG retriever feature, ensure you set the `GRAPHRAG_API_KEY` environment variable. You can do this directly in your environment or by adding it to a `.env` file.
- **Using Local Models and Custom Settings**: If you want to use GraphRAG with local models (like `Ollama`) or customize the default LLM and other configurations, set the `USE_CUSTOMIZED_GRAPHRAG_SETTING` environment variable to true. Then, adjust your settings in the `settings.yaml.example` file.
</details>
### Setup Local Models (for local/private RAG)
See [Local model setup](docs/local_model.md).
### Setup multimodal document parsing (OCR, table parsing, figure extraction)
These options are available:
- [Azure Document Intelligence (API)](https://azure.microsoft.com/en-us/products/ai-services/ai-document-intelligence)
- [Adobe PDF Extract (API)](https://developer.adobe.com/document-services/docs/overview/pdf-extract-api/)
- [Docling (local, open-source)](https://github.com/DS4SD/docling)
- To use Docling, first install required dependencies: `pip install docling`
Select corresponding loaders in `Settings -> Retrieval Settings -> File loader`
### Customize your application
- By default, all application data is stored in the `./ktem_app_data` folder. You can back up or copy this folder to transfer your installation to a new machine.
- For advanced users or specific use cases, you can customize these files:
- `flowsettings.py`
- `.env`
#### `flowsettings.py`
This file contains the configuration of your application. You can use the example
[here](flowsettings.py) as the starting point.
<details>
<summary>Notable settings</summary>
```python
# setup your preferred document store (with full-text search capabilities)
KH_DOCSTORE=(Elasticsearch | LanceDB | SimpleFileDocumentStore)
# setup your preferred vectorstore (for vector-based search)
KH_VECTORSTORE=(ChromaDB | LanceDB | InMemory | Milvus | Qdrant)
# Enable / disable multimodal QA
KH_REASONINGS_USE_MULTIMODAL=True
# Setup your new reasoning pipeline or modify existing one.
KH_REASONINGS = [
"ktem.reasoning.simple.FullQAPipeline",
"ktem.reasoning.simple.FullDecomposeQAPipeline",
"ktem.reasoning.react.ReactAgentPipeline",
"ktem.reasoning.rewoo.RewooAgentPipeline",
]
```
</details>
#### `.env`
This file provides another way to configure your models and credentials.
<details>
<summary>Configure model via the .env file</summary>
- Alternatively, you can configure the models via the `.env` file with the information needed to connect to the LLMs. This file is located in the folder of the application. If you don't see it, you can create one.
- Currently, the following providers are supported:
- **OpenAI**
In the `.env` file, set the `OPENAI_API_KEY` variable with your OpenAI API key in order
to enable access to OpenAI's models. There are other variables that can be modified,
please feel free to edit them to fit your case. Otherwise, the default parameter should
work for most people.
```shell
OPENAI_API_BASE=https://api.openai.com/v1
OPENAI_API_KEY=<your OpenAI API key here>
OPENAI_CHAT_MODEL=gpt-3.5-turbo
OPENAI_EMBEDDINGS_MODEL=text-embedding-ada-002
```
- **Azure OpenAI**
For OpenAI models via Azure platform, you need to provide your Azure endpoint and API
key. Your might also need to provide your developments' name for the chat model and the
embedding model depending on how you set up Azure development.
```shell
AZURE_OPENAI_ENDPOINT=
AZURE_OPENAI_API_KEY=
OPENAI_API_VERSION=2024-02-15-preview
AZURE_OPENAI_CHAT_DEPLOYMENT=gpt-35-turbo
AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=text-embedding-ada-002
```
- **Local Models**
- Using `ollama` OpenAI compatible server:
- Install [ollama](https://github.com/ollama/ollama) and start the application.
- Pull your model, for example:
```shell
ollama pull llama3.1:8b
ollama pull nomic-embed-text
```
- Set the model names on web UI and make it as default:

- Using `GGUF` with `llama-cpp-python`
You can search and download a LLM to be ran locally from the [Hugging Face Hub](https://huggingface.co/models). Currently, these model formats are supported:
- GGUF
You should choose a model whose size is less than your device's memory and should leave
about 2 GB. For example, if you have 16 GB of RAM in total, of which 12 GB is available,
then you should choose a model that takes up at most 10 GB of RAM. Bigger models tend to
give better generation but also take more processing time.
Here are some recommendations and their size in memory:
- [Qwen1.5-1.8B-Chat-GGUF](https://huggingface.co/Qwen/Qwen1.5-1.8B-Chat-GGUF/resolve/main/qwen1_5-1_8b-chat-q8_0.gguf?download=true): around 2 GB
Add a new LlamaCpp model with the provided model name on the web UI.
</details>
### Adding your own RAG pipeline
#### Custom Reasoning Pipeline
1. Check the default pipeline implementation in [here](libs/ktem/ktem/reasoning/simple.py). You can make quick adjustment to how the default QA pipeline work.
2. Add new `.py` implementation in `libs/ktem/ktem/reasoning/` and later include it in `flowssettings` to enable it on the UI.
#### Custom Indexing Pipeline
- Check sample implementation in `libs/ktem/ktem/index/file/graph`
> (more instruction WIP).
<!-- end-intro -->
## Citation
Please cite this project as
```BibTeX
@misc{kotaemon2024,
title = {Kotaemon - An open-source RAG-based tool for chatting with any content.},
author = {The Kotaemon Team},
year = {2024},
howpublished = {\url{https://github.com/Cinnamon/kotaemon}},
}
```
## Star History
<a href="https://star-history.com/#Cinnamon/kotaemon&Date">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=Cinnamon/kotaemon&type=Date&theme=dark" />
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=Cinnamon/kotaemon&type=Date" />
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=Cinnamon/kotaemon&type=Date" />
</picture>
</a>
## Contribution
Since our project is actively being developed, we greatly value your feedback and contributions. Please see our [Contributing Guide](https://github.com/Cinnamon/kotaemon/blob/main/CONTRIBUTING.md) to get started. Thank you to all our contributors!
<a href="https://github.com/Cinnamon/kotaemon/graphs/contributors">
<img src="https://contrib.rocks/image?repo=Cinnamon/kotaemon" />
</a>
================================================
FILE: app.py
================================================
import os
from theflow.settings import settings as flowsettings
KH_APP_DATA_DIR = getattr(flowsettings, "KH_APP_DATA_DIR", ".")
KH_GRADIO_SHARE = getattr(flowsettings, "KH_GRADIO_SHARE", False)
GRADIO_TEMP_DIR = os.getenv("GRADIO_TEMP_DIR", None)
# override GRADIO_TEMP_DIR if it's not set
if GRADIO_TEMP_DIR is None:
GRADIO_TEMP_DIR = os.path.join(KH_APP_DATA_DIR, "gradio_tmp")
os.environ["GRADIO_TEMP_DIR"] = GRADIO_TEMP_DIR
from ktem.main import App # noqa
app = App()
demo = app.make()
demo.queue().launch(
favicon_path=app._favicon,
inbrowser=True,
allowed_paths=[
"libs/ktem/ktem/assets",
GRADIO_TEMP_DIR,
],
share=KH_GRADIO_SHARE,
)
================================================
FILE: doc_env_reqs.txt
================================================
mkdocs
mkdocstrings[python]
mkdocs-material
mkdocs-gen-files
mkdocs-literate-nav
mkdocs-git-revision-date-localized-plugin
mkdocs-section-index
mkdocs-include-markdown-plugin[cache]
mdx_truly_sane_lists
================================================
FILE: docs/about.md
================================================
# About Kotaemon
An open-source tool for chatting with your documents. Built with both end users and
developers in mind.
[Source Code](https://github.com/Cinnamon/kotaemon) |
[HF Space](https://huggingface.co/spaces/cin-model/kotaemon-demo)
[Installation Guide](https://cinnamon.github.io/kotaemon/) |
[Developer Guide](https://cinnamon.github.io/kotaemon/development/) |
[Feedback](https://github.com/Cinnamon/kotaemon/issues)
================================================
FILE: docs/development/contributing.md
================================================
# Contributing
## Setting up
- Clone the repo
```shell
git clone git@github.com:Cinnamon/kotaemon.git
cd kotaemon
```
- Install the environment
- Create a conda environment (python >= 3.10 is recommended)
```shell
conda create -n kotaemon python=3.10
conda activate kotaemon
# install dependencies
cd libs/kotaemon
pip install -e ".[all]"
```
- Or run the installer (one of the `scripts/run_*` scripts depends on your OS), then
you will have all the dependencies installed as a conda environment at
`install_dir/env`.
```shell
conda activate install_dir/env
```
- Pre-commit
```shell
pre-commit install
```
- Test
```shell
pytest tests
```
## Package overview
`kotaemon` library focuses on the AI building blocks to implement a RAG-based QA application. It consists of base interfaces, core components and a list of utilities:
- Base interfaces: `kotaemon` defines the base interface of a component in a pipeline. A pipeline is also a component. By clearly define this interface, a pipeline of steps can be easily constructed and orchestrated.
- Core components: `kotaemon` implements (or wraps 3rd-party libraries
like Langchain, llama-index,... when possible) commonly used components in
kotaemon use cases. Some of these components are: LLM, vector store,
document store, retriever... For a detailed list and description of these
components, please refer to the [API Reference](../reference/Summary.md) section.
- List of utilities: `kotaemon` provides utilities and tools that are
usually needed in client project. For example, it provides a prompt
engineering UI for AI developers in a project to quickly create a prompt
engineering tool for DMs and QALs. It also provides a command to quickly spin
up a project code base. For a full list and description of these utilities,
please refer to the [Utilities](utilities.md) section.
```mermaid
mindmap
root((kotaemon))
Base Interfaces
Document
LLMInterface
RetrievedDocument
BaseEmbeddings
BaseChat
BaseCompletion
...
Core Components
LLMs
AzureOpenAI
OpenAI
Embeddings
AzureOpenAI
OpenAI
HuggingFaceEmbedding
VectorStore
InMemoryVectorstore
ChromaVectorstore
Agent
Tool
DocumentStore
...
Utilities
Scaffold project
PromptUI
Documentation Support
```
## Common conventions
- PR title: One-line description (example: Feat: Declare BaseComponent and decide LLM call interface).
- [Encouraged] Provide a quick description in the PR, so that:
- Reviewers can quickly understand the direction of the PR.
- It will be included in the commit message when the PR is merged.
## Environment caching on PR
- To speed up CI, environments are cached based on the version specified in `__init__.py`.
- Since dependencies versions in `setup.py` are not pinned, you need to pump the version in order to use a new environment. That environment will then be cached and used by your subsequence commits within the PR, until you pump the version again
- The new environment created during your PR is cached and will be available to others once the PR is merged.
- If you are experimenting with new dependencies and want a fresh environment every time, add `[ignore cache]` in your commit message. The CI will create a fresh environment to run your commit and then discard it.
- If your PR include updated dependencies, the recommended workflow would be:
- Doing development as usual.
- When you want to run the CI, push a commit with the message containing `[ignore cache]`.
- Once the PR is final, pump the version in `__init__.py` and push a final commit not containing `[ignore cache]`.
## Merge PR guideline
- Use squash and merge option
- 1st line message is the PR title.
- The text area is the PR description.
================================================
FILE: docs/development/create-a-component.md
================================================
# Creating a component
A fundamental concept in kotaemon is "component".
Anything that isn't data or data structure is a "component". A component can be
thought of as a step within a pipeline. It takes in some input, processes it,
and returns an output, just the same as a Python function! The output will then
become an input for the next component in a pipeline. In fact, a pipeline is just
a component. More appropriately, a nested component: a component that makes use of one or more other components in
the processing step. So in reality, there isn't a difference between a pipeline
and a component! Because of that, in kotaemon, we will consider them the
same as "component".
To define a component, you will:
1. Create a class that subclasses from `kotaemon.base.BaseComponent`
2. Declare init params with type annotation
3. Declare nodes (nodes are just other components!) with type annotation
4. Implement the processing logic in `run`.
The syntax of a component is as follow:
```python
from kotaemon.base import BaseComponent
from kotaemon.llms import LCAzureChatOpenAI
from kotaemon.parsers import RegexExtractor
class FancyPipeline(BaseComponent):
param1: str = "This is param1"
param2: int = 10
param3: float
node1: BaseComponent # this is a node because of BaseComponent type annotation
node2: LCAzureChatOpenAI # this is also a node because LCAzureChatOpenAI subclasses BaseComponent
node3: RegexExtractor # this is also a node bceause RegexExtractor subclasses BaseComponent
def run(self, some_text: str):
prompt = (self.param1 + some_text) * int(self.param2 + self.param3)
llm_pred = self.node2(prompt).text
matches = self.node3(llm_pred)
return matches
```
Then this component can be used as follow:
```python
llm = LCAzureChatOpenAI(endpoint="some-endpont")
extractor = RegexExtractor(pattern=["yes", "Yes"])
component = FancyPipeline(
param1="Hello"
param3=1.5
node1=llm,
node2=llm,
node3=extractor
)
component("goodbye")
```
This way, we can define each operation as a reusable component, and use them to
compose larger reusable components!
## Benefits of component
By defining a component as above, we formally encapsulate all the necessary
information inside a single class. This introduces several benefits:
1. Allow tools like promptui to inspect the inner working of a component in
order to automatically generate the promptui.
2. Allow visualizing a pipeline for debugging purpose.
================================================
FILE: docs/development/data-components.md
================================================
# Data & Data Structure Components
The data & data structure components include:
- The `Document` class.
- The document store.
- The vector store.
## Data Loader
- PdfLoader
- Layout-aware with table parsing PdfLoader
- MathPixLoader: To use this loader, you need MathPix API key, refer to [mathpix docs](https://docs.mathpix.com/#introduction) for more information
- OCRLoader: This loader uses lib-table and Flax pipeline to perform OCR and read table structure from PDF file (TODO: add more info about deployment of this module).
- Output:
- Document: text + metadata to identify whether it is table or not
```
- "source": source file name
- "type": "table" or "text"
- "table_origin": original table in markdown format (to be feed to LLM or visualize using external tools)
- "page_label": page number in the original PDF document
```
## Document Store
- InMemoryDocumentStore
## Vector Store
- ChromaVectorStore
- InMemoryVectorStore
================================================
FILE: docs/development/index.md
================================================
{%
include-markdown "../../README.md"
start="<!-- start-intro -->"
end="<!-- end-intro -->"
%}
================================================
FILE: docs/development/utilities.md
================================================
# Utilities
## Prompt engineering UI

**_Important:_** despite the name prompt engineering UI, this tool allows testers to test any kind of parameters that are exposed by developers. Prompt is one kind of param. There can be other type of params that testers can tweak (e.g. top_k, temperature...).
In the development process, developers typically build the pipeline. However, for use
cases requiring expertise in prompt creation, non-technical members (testers, domain experts) can be more
effective. To facilitate this, `kotaemon` offers a user-friendly prompt engineering UI
that developers integrate into their pipelines. This enables non-technical members to
adjust prompts and parameters, run experiments, and export results for optimization.
As of Sept 2023, there are 2 kinds of prompt engineering UI:
- Simple pipeline: run one-way from start to finish.
- Chat pipeline: interactive back-and-forth.
### Simple pipeline
For simple pipeline, the supported client project workflow looks as follow:
1. [tech] Build pipeline
2. [tech] Export pipeline to config: `$ kotaemon promptui export <module.path.piplineclass> --output <path/to/config/file.yml>`
3. [tech] Customize the config
4. [tech] Spin up prompt engineering UI: `$ kotaemon promptui run <path/to/config/file.yml>`
5. [non-tech] Change params, run inference
6. [non-tech] Export to Excel
7. [non-tech] Select the set of params that achieve the best output
The prompt engineering UI prominently involves from step 2 to step 7 (step 1 is normally
done by the developers, while step 7 happens exclusively in Excel file).
#### Step 2 - Export pipeline to config
Command:
```shell
$ kotaemon promptui export <module.path.piplineclass> --output <path/to/config/file.yml>
```
where:
- `<module.path.pipelineclass>` is a dot-separated path to the pipeline. For example, if your pipeline can be accessed with `from projectA.pipelines import AnsweringPipeline`, then this value is `projectA.pipelines.AnswerPipeline`.
- `<path/to/config/file.yml>` is the target file path that the config will be exported to. If the config file already exists, and contains information of other pipelines, the config of current pipeline will additionally be added. If it contains information of the current pipeline (in the past), the old information will be replaced.
By default, all params in a pipeline (including nested params) will be export to the configuration file. For params that you do not wish to expose to the UI, you can directly remove them from the config YAML file. You can also annotate those param with `ignore_ui=True`, and they will be ignored in the config generation process. Example:
```python
class Pipeline(BaseComponent):
param1: str = Param(default="hello")
param2: str = Param(default="goodbye", ignore_ui=True)
```
Declared as above, and `param1` will show up in the config YAML file, while `param2` will not.
#### Step 3 - Customize the config
developers can further edit the config file in this step to get the most suitable UI (step 4) with their tasks. The exported config will have this overall schema:
```yml
<module.path.pipelineclass1>:
params: ... (Detail param information to initiate a pipeline. This corresponds to the pipeline init parameters.)
inputs: ... (Detail the input of the pipeline e.g. a text prompt. This corresponds to the params of `run(...)` method.)
outputs: ... (Detail the output of the pipeline e.g. prediction, accuracy... This is the output information we wish to see in the UI.)
logs: ... (Detail what information should show up in the log.)
```
##### Input and params
The inputs section have the overall schema as follow:
```yml
inputs:
<input-variable-name-1>:
component: <supported-UI-component>
params: # this section is optional)
value: <default-value>
<input-variable-name-2>: ... # similar to above
params:
<param-variable-name-1>: ... # similar to those in the inputs
```
The list of supported prompt UI and their corresponding gradio UI components:
```python
COMPONENTS_CLASS = {
"text": gr.components.Textbox,
"checkbox": gr.components.CheckboxGroup,
"dropdown": gr.components.Dropdown,
"file": gr.components.File,
"image": gr.components.Image,
"number": gr.components.Number,
"radio": gr.components.Radio,
"slider": gr.components.Slider,
}
```
##### Outputs
The outputs are a list of variables that we wish to show in the UI. Since in Python, the function output doesn't have variable name, so output declaration is a little bit different than input and param declaration:
```yml
outputs:
- component: <supported-UI-component>
step: <name-of-pipeline-step>
item: <jsonpath way to retrieve the info>
- ... # similar to above
```
where:
- component: the same text string and corresponding Gradio UI as in inputs & params
- step: the pipeline step that we wish to look fetch and show output on the UI
- item: the jsonpath mechanism to get the targeted variable from the step above
##### Logs
The logs show a list of sheetname and how to retrieve the desired information.
```yml
logs:
<logname>:
inputs:
- name: <column name>
step: <the pipeline step that we would wish to see the input>
variable: <the variable in the step>
- ...
outputs:
- name: <column name>
step: <the pipeline step that we would wish to see the output>
item: <how to retrieve the output of that step>
```
#### Step 4 + 5 - Spin up prompt engineering UI + Perform prompt engineering
Command:
```shell
$ kotaemon promptui run <path/to/config/file.yml>
```
This will generate an UI as follow:

where:
- The tabs at the top of the UI corresponds to the pipeline to do prompt engineering.
- The inputs and params tabs allow users to edit (these corresponds to the inputs and params in the config file).
- The outputs panel holds the UI elements to show the outputs defined in config file.
- The Run button: will execute pipeline with the supplied inputs and params, and render result in the outputs panel.
- The Export button: will export the logs of all the run to an Excel files users to inspect for best set of params.
#### Step 6 - Export to Excel
Upon clicking export, the users can download Excel file.
### Chat pipeline
Chat pipeline workflow is different from simple pipeline workflow. In simple pipeline, each Run creates a set of output, input and params for users to compare. In chat pipeline, each Run is not a one-off run, but a long interactive session. Hence, the workflow is as follow:
1. Set the desired parameters.
2. Click "New chat" to start a chat session with the supplied parameters. This set of parameters will persist until the end of the chat session. During an ongoing chat session, changing the parameters will not take any effect.
3. Chat and interact with the chat bot on the right panel. You can add any additional input (if any), and they will be supplied to the chatbot.
4. During chat, the log of the chat will show up in the "Output" tabs. This is empty by default, so if you want to show the log here, tell the AI developers to configure the UI settings.
5. When finishing chat, select your preference in the radio box. Click "End chat". This will save the chat log and the preference to disk.
6. To compare the result of different run, click "Export" to get an Excel spreadsheet summary of different run.
================================================
FILE: docs/extra/css/code_select.css
================================================
.language-pycon .gp,
.language-pycon .go {
/* Generic.Prompt, Generic.Output */
user-select: none;
}
================================================
FILE: docs/index.md
================================================
# Getting Started with Kotaemon

This page is intended for **end users** who want to use the `kotaemon` tool for Question
Answering on local documents. If you are a **developer** who wants contribute to the project, please visit the [development](development/index.md) page.
## Installation (Online HuggingFace Space) - easy (10 mins)
Visit this [guide](online_install.md).
## Installation (Offline) - intermediate (20 mins)
### Download
Download the `kotaemon-app.zip` file from the [latest release](https://github.com/Cinnamon/kotaemon/releases/latest/).
### Run setup script
0. Unzip the downloaded file.
1. Navigate to the `scripts` folder and start an installer that matches your OS:
- Windows: `run_windows.bat`. Just double click the file.
- macOS: `run_macos.sh`
1. Right click on your file and select Open with and Other.
2. Enable All Applications and choose Terminal.
3. NOTE: If you always want to open that file with Terminal, then check Always Open With.
4. From now on, double click on your file and it should work.
- Linux: `run_linux.sh`. Please run the script using `bash run_linux.sh` in your terminal.
2. After the installation, the installer will ask to launch the ktem's UI, answer to continue.
3. If launched, the application will be open automatically in your browser.
4. Default login information is: `username: admin / password: admin`. You should change this credential right after the first login on the UI.
## Launch
To launch the app after initial setup or any change, simply run the `run_*` script again.
A browser window will be opened and greets you with this screen:

## Usage
For how to use the application, see [Usage](usage.md). This page will also be available to
you within the application.
## Feedback
Feel free to create a bug report or a feature request on our [repo](https://github.com/Cinnamon/kotaemon/issues).
================================================
FILE: docs/local_model.md
================================================
# Setup local LLMs & Embedding models
## Prepare local models
#### NOTE
In the case of using Docker image, please replace `http://localhost` with `http://host.docker.internal` to correctly communicate with service on the host machine. See [more detail](https://stackoverflow.com/questions/31324981/how-to-access-host-port-from-docker-container).
### Ollama OpenAI compatible server (recommended)
Install [ollama](https://github.com/ollama/ollama) and start the application.
Pull your model (e.g):
```
ollama pull llama3.1:8b
ollama pull nomic-embed-text
```
Setup LLM and Embedding model on Resources tab with type OpenAI. Set these model parameters to connect to Ollama:
```
api_key: ollama
base_url: http://localhost:11434/v1/
model: gemma2:2b (for llm) | nomic-embed-text (for embedding)
```

### oobabooga/text-generation-webui OpenAI compatible server
Install [oobabooga/text-generation-webui](https://github.com/oobabooga/text-generation-webui/).
Follow the setup guide to download your models (GGUF, HF).
Also take a look at [OpenAI compatible server](https://github.com/oobabooga/text-generation-webui/wiki/12-%E2%80%90-OpenAI-API) for detail instructions.
Here is a short version
```
# install sentence-transformer for embeddings creation
pip install sentence_transformers
# change to text-generation-webui src dir
python server.py --api
```
Use the `Models` tab to download new model and press Load.
Setup LLM and Embedding model on Resources tab with type OpenAI. Set these model parameters to connect to `text-generation-webui`:
```
api_key: dummy
base_url: http://localhost:5000/v1/
model: any
```
### llama-cpp-python server (LLM only)
See [llama-cpp-python OpenAI server](https://llama-cpp-python.readthedocs.io/en/latest/server/).
Download any GGUF model weight on HuggingFace or other source. Place it somewhere on your local machine.
Run
```
LOCAL_MODEL=<path/to/GGUF> python scripts/serve_local.py
```
Setup LLM model on Resources tab with type OpenAI. Set these model parameters to connect to `llama-cpp-python`:
```
api_key: dummy
base_url: http://localhost:8000/v1/
model: model_name
```
## Use local models for RAG
- Set default LLM and Embedding model to a local variant.
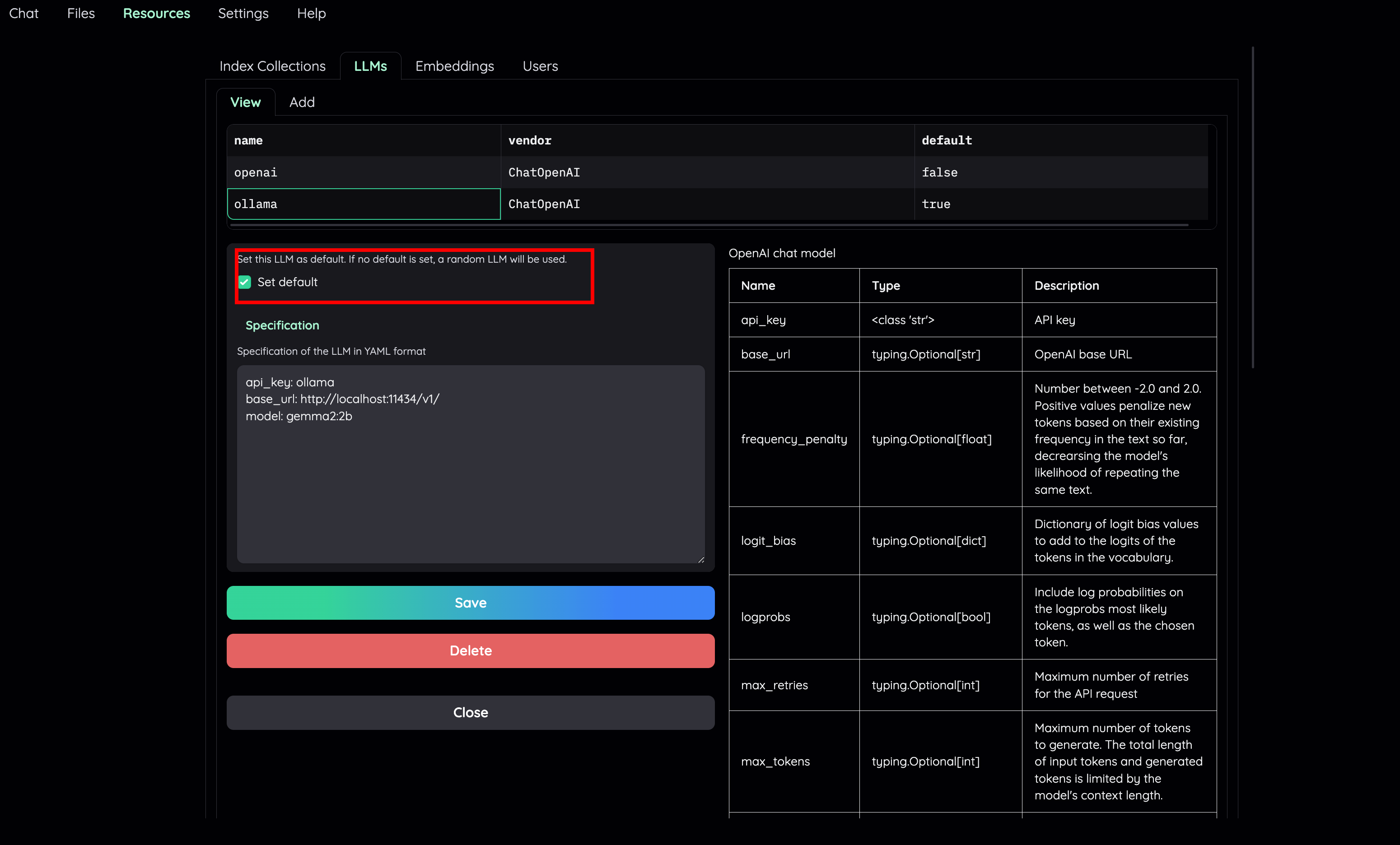
- Set embedding model for the File Collection to a local model (e.g: `ollama`)
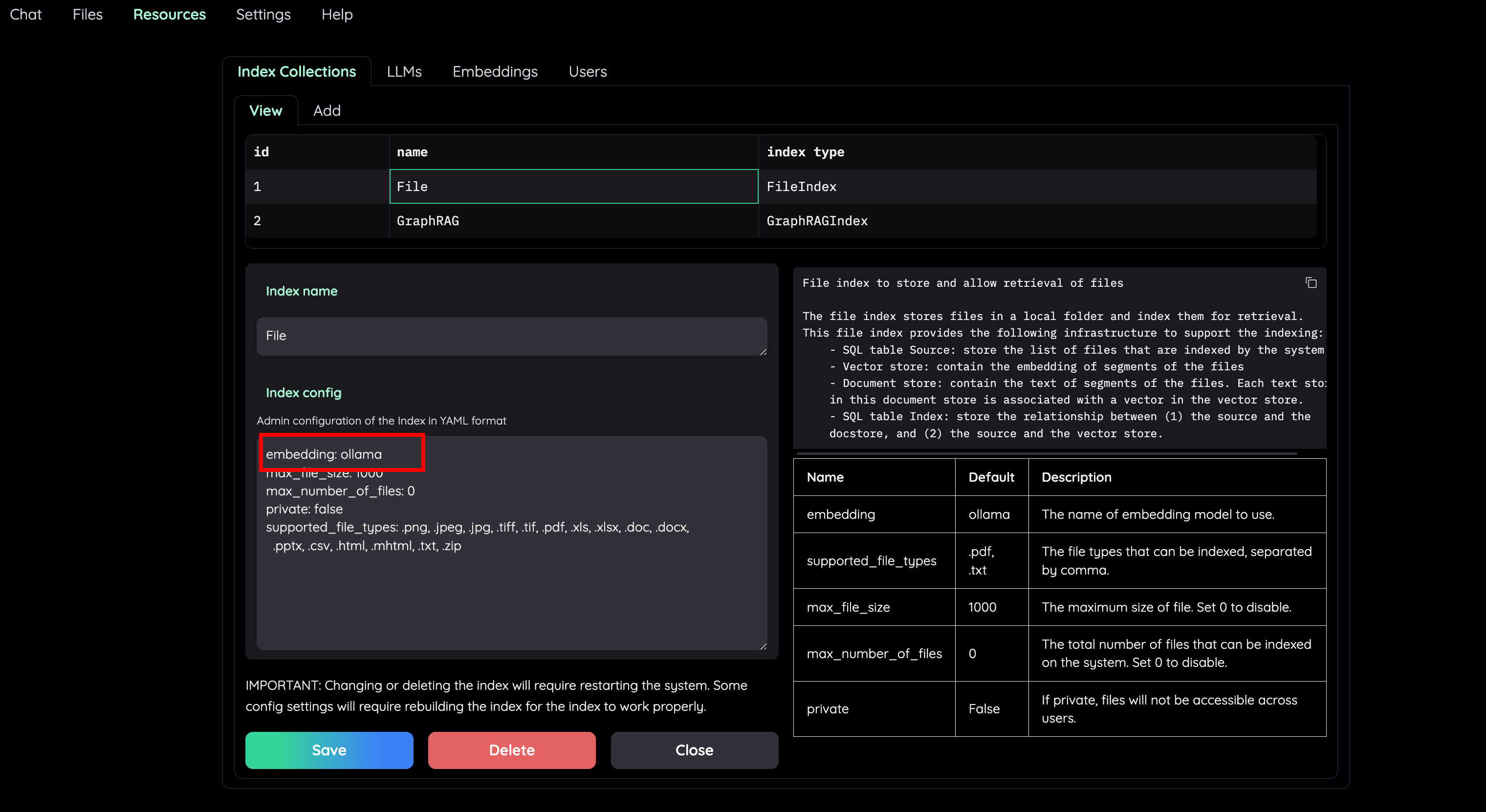
- Go to Retrieval settings and choose LLM relevant scoring model as a local model (e.g: `ollama`). Or, you can choose to disable this feature if your machine cannot handle a lot of parallel LLM requests at the same time.
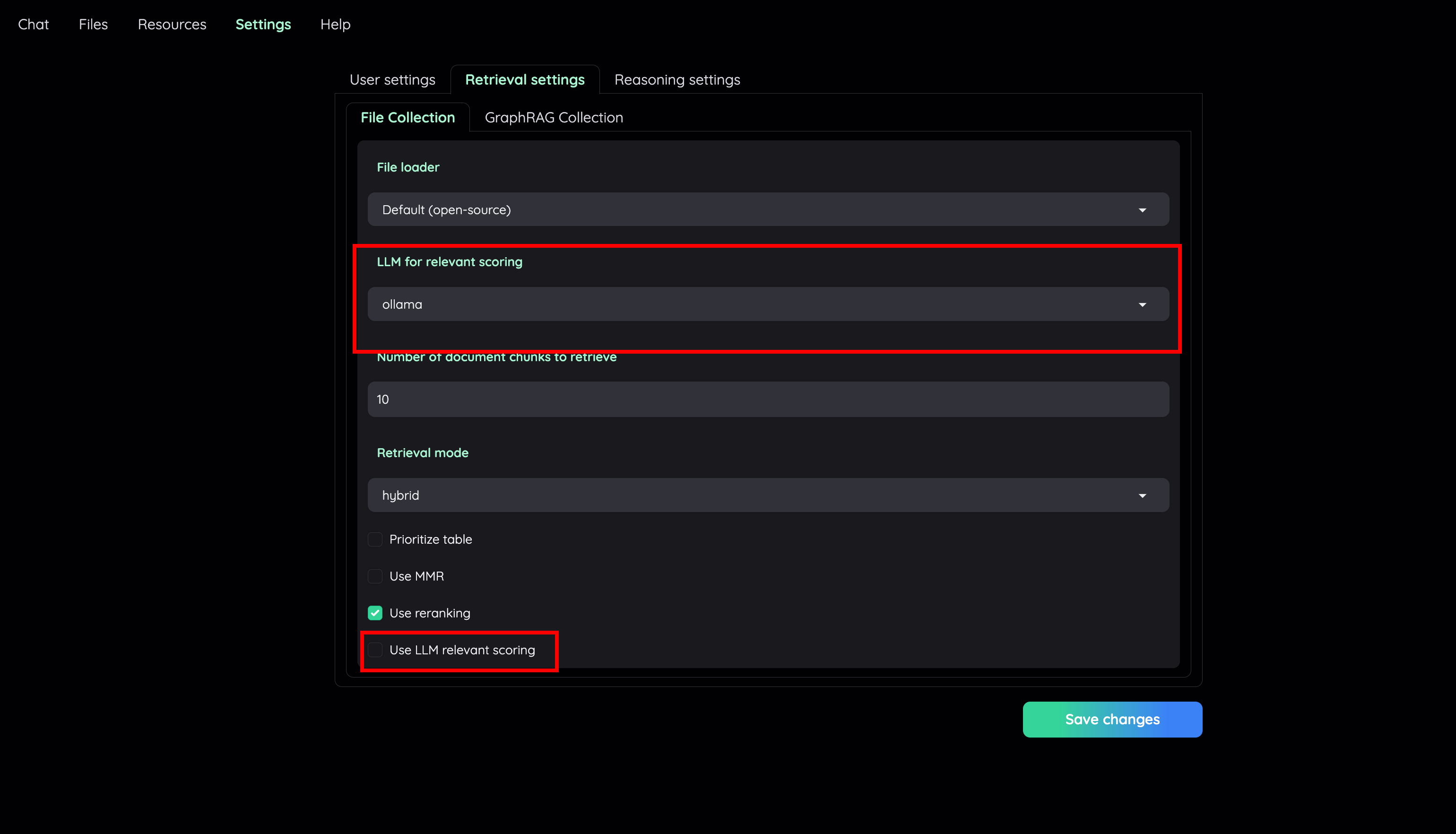
You are set! Start a new conversation to test your local RAG pipeline.
================================================
FILE: docs/online_install.md
================================================
## Installation (Online HuggingFace Space)
1. Go to [HF kotaemon_template](https://huggingface.co/spaces/cin-model/kotaemon_template).
2. Use Duplicate function to create your own space. Or use this [direct link](https://huggingface.co/spaces/cin-model/kotaemon_template?duplicate=true).
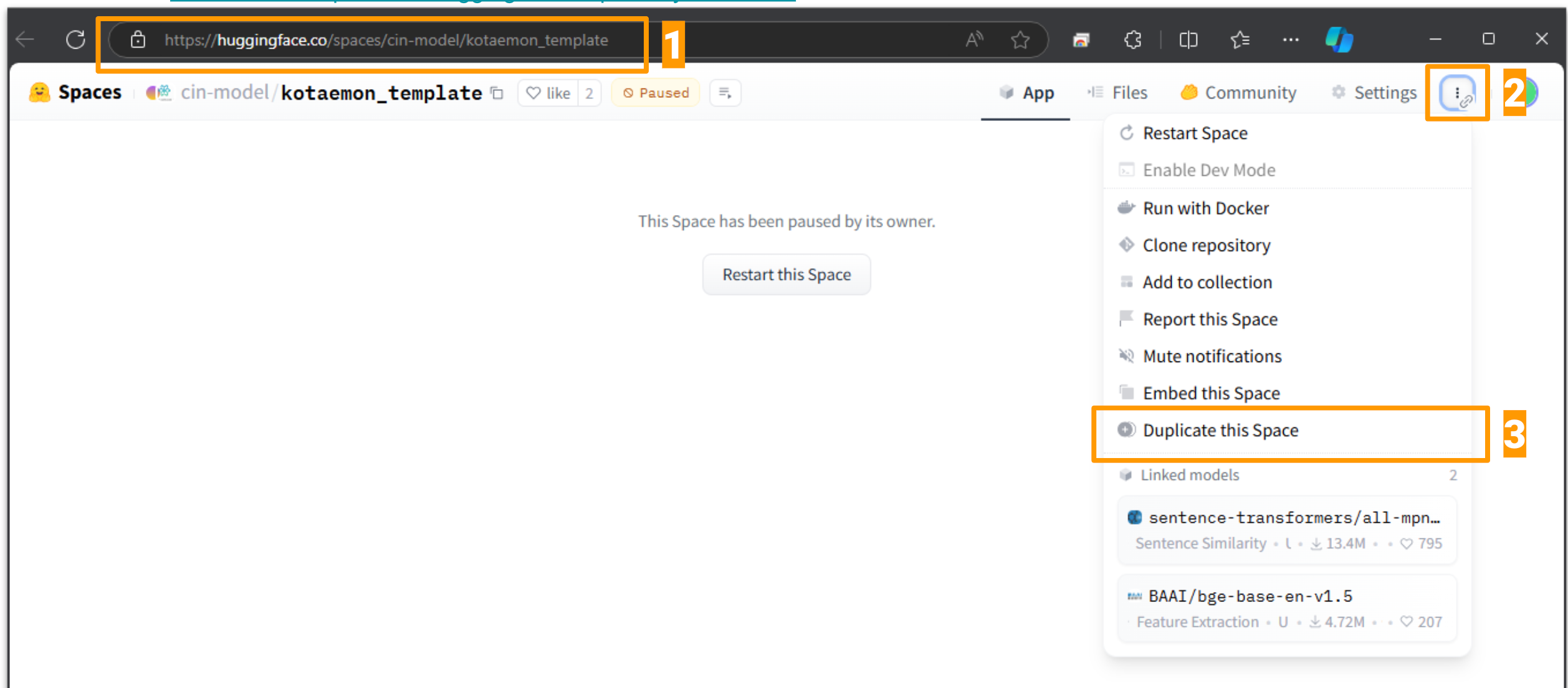
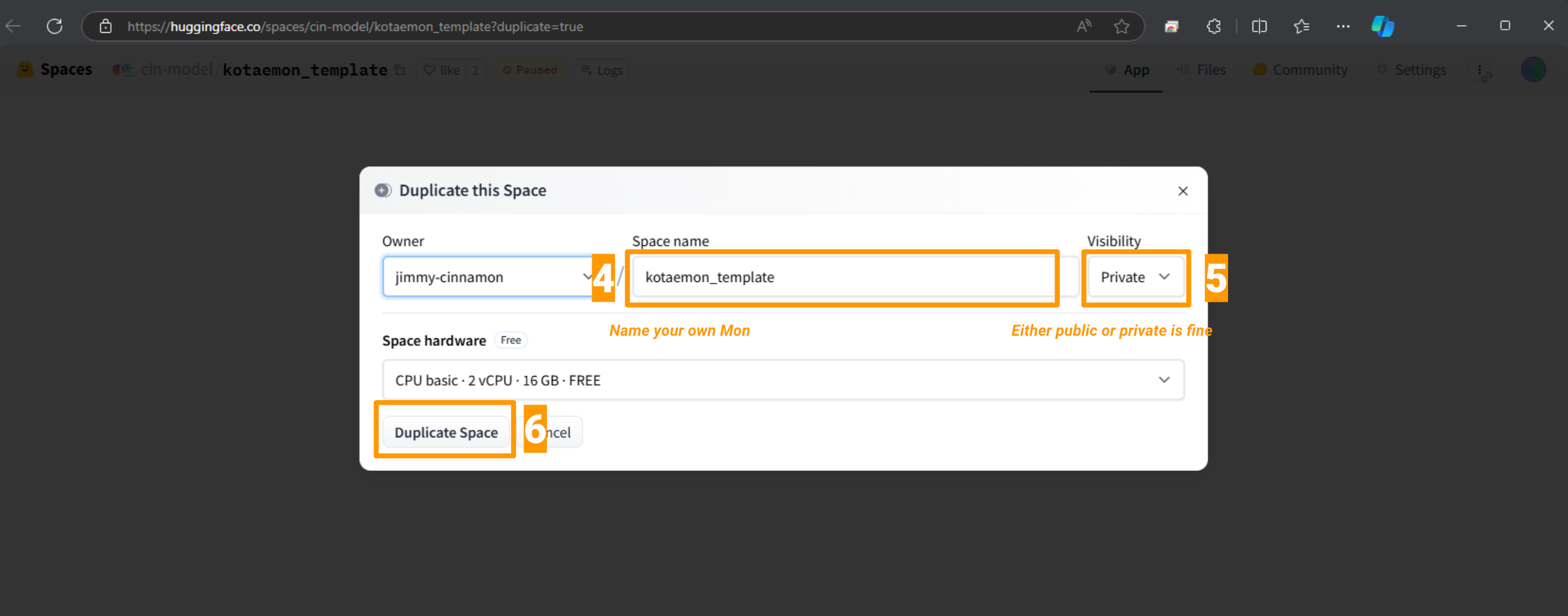
3. Wait for the build to complete and start up (apprx 10 mins).
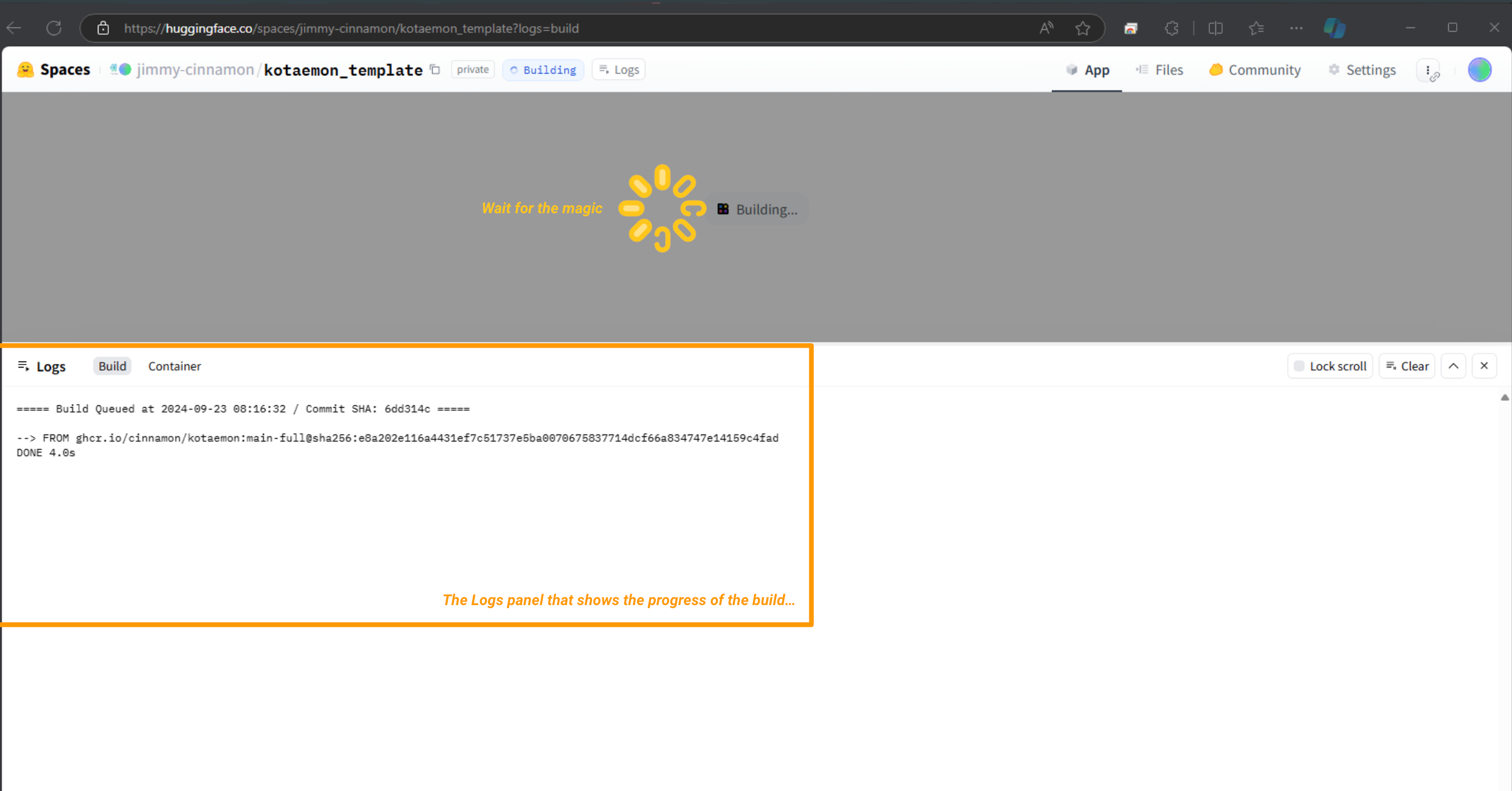
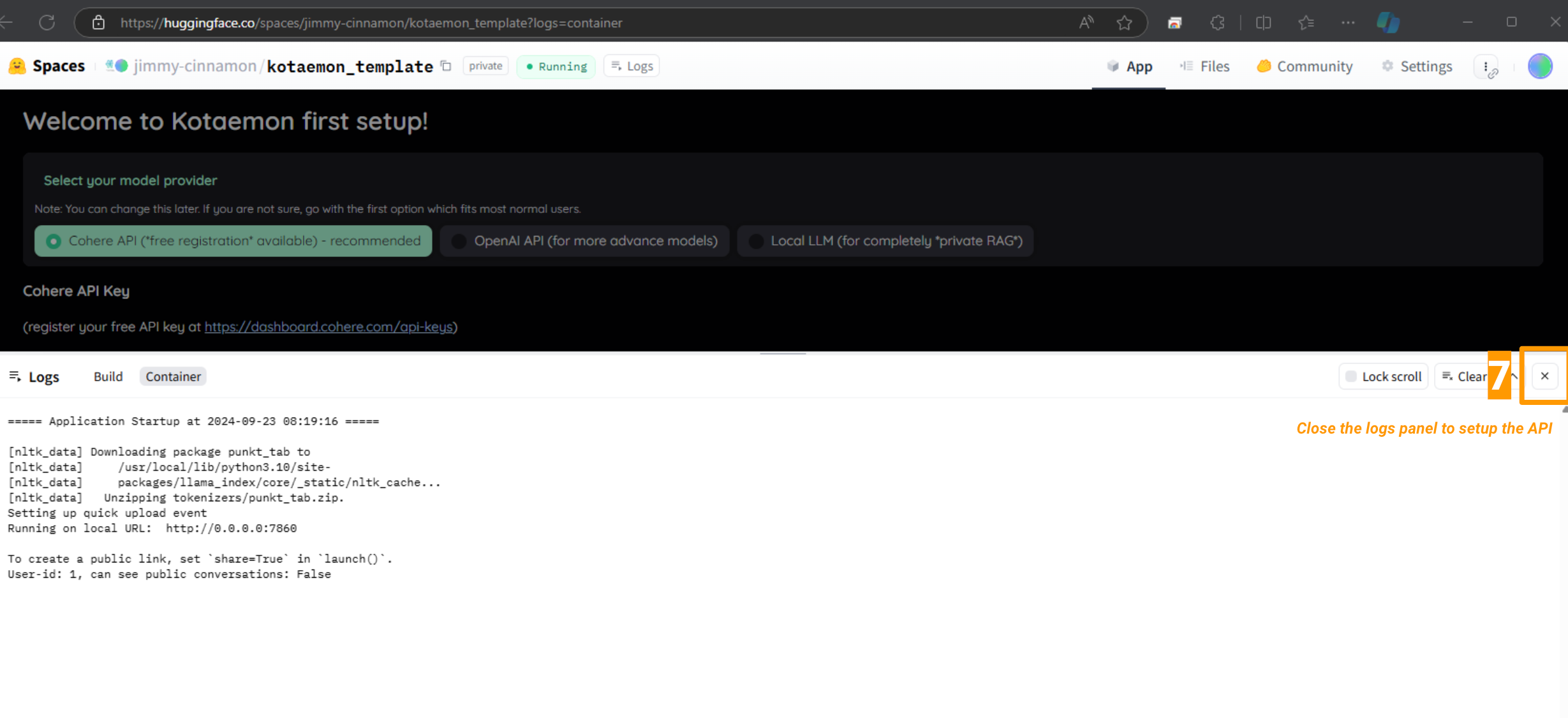
4. Follow the first setup instructions (and register for Cohere API key if needed).
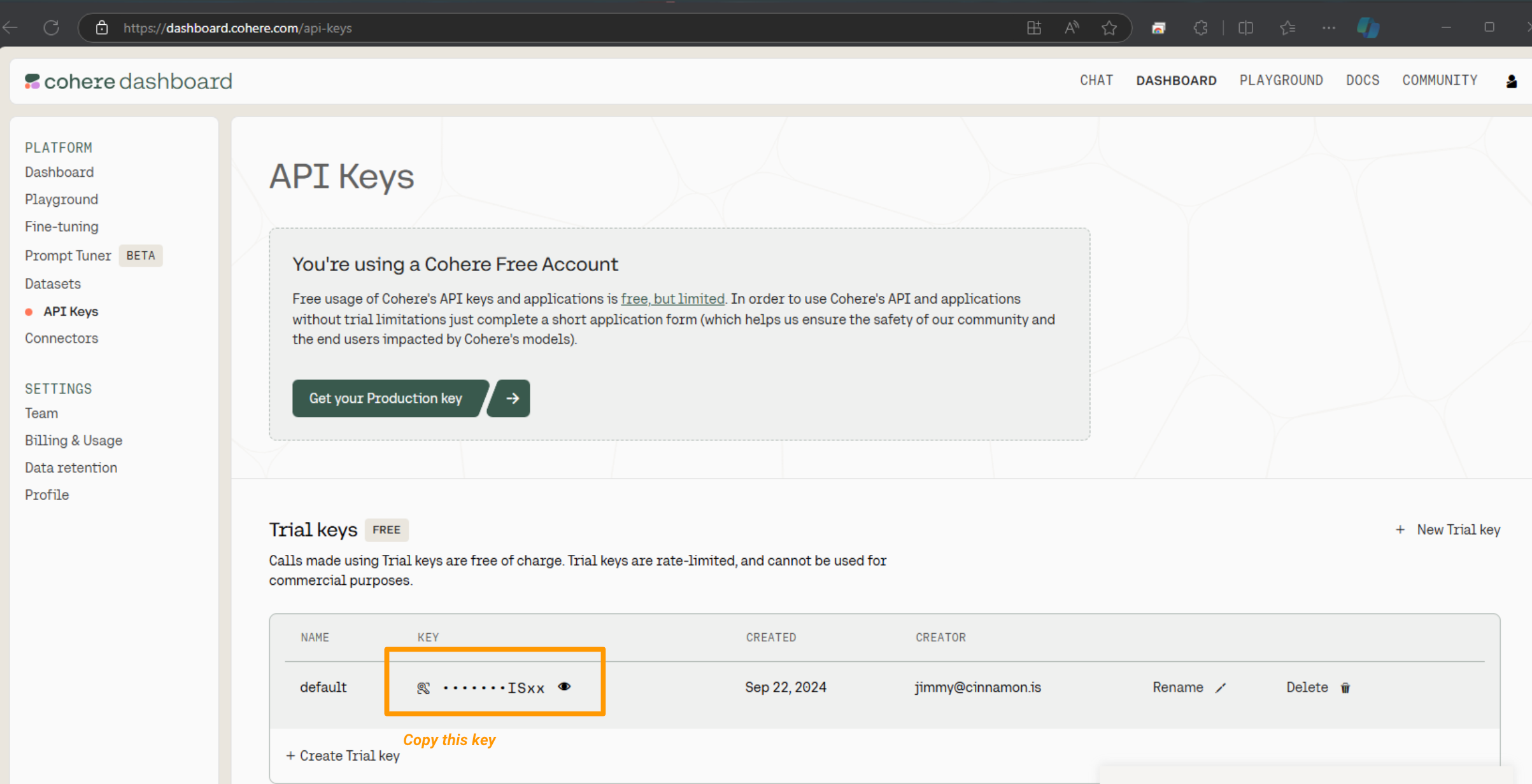
5. Complete the setup and use your own private space!
================================================
FILE: docs/pages/app/customize-flows.md
================================================
# Add new indexing and reasoning pipeline to the application
@trducng
At high level, to add new indexing and reasoning pipeline:
1. You define your indexing or reasoning pipeline as a class from
`BaseComponent`.
2. You declare that class in the setting files `flowsettings.py`.
Then when `python app.py`, the application will dynamically load those
pipelines.
The below sections talk in more detail about how the pipelines should be
constructed.
## Define a pipeline as a class
In essence, a pipeline will subclass from `kotaemon.base.BaseComponent`.
Each pipeline has 2 main parts:
- All declared arguments and sub-pipelines.
- The logic inside the pipeline.
An example pipeline:
```python
from kotaemon.base import BaseComponent
class SoSimple(BaseComponent):
arg1: int
arg2: str
def run(self, arg3: str):
return self.arg1 * self.arg2 + arg3
```
This pipeline is simple for demonstration purpose, but we can imagine pipelines
with much more arguments, that can take other pipelines as arguments, and have
more complicated logic in the `run` method.
**_An indexing or reasoning pipeline is just a class subclass from
`BaseComponent` like above._**
For more detail on this topic, please refer to [Creating a
Component](/create-a-component/)
## Run signatures
**Note**: this section is tentative at the moment. We will finalize `def run`
function signature by latest early April.
The indexing pipeline:
```python
def run(
self,
file_paths: str | Path | list[str | Path],
reindex: bool = False,
**kwargs,
):
"""Index files to intermediate representation (e.g. vector, database...)
Args:
file_paths: the list of paths to files
reindex: if True, files in `file_paths` that already exists in database
should be reindex.
"""
```
The reasoning pipeline:
```python
def run(self, question: str, history: list, **kwargs) -> Document:
"""Answer the question
Args:
question: the user input
history: the chat history [(user_msg1, bot_msg1), (user_msg2, bot_msg2)...]
Returns:
kotaemon.base.Document: the final answer
"""
```
## Register your pipeline to ktem
To register your pipelines to ktem, you declare it in the `flowsettings.py`
file. This file locates at the current working directory where you start the
ktem. In most use cases, it is this
[one](https://github.com/Cinnamon/kotaemon/blob/main/flowsettings.py).
```python
KH_REASONING = ["<python.module.path.to.the.reasoning.class>"]
KH_INDEX = "<python.module.path.to.the.indexing.class>"
```
You can register multiple reasoning pipelines to ktem by populating the
`KH_REASONING` list. The user can select which reasoning pipeline to use
in their Settings page.
For now, there's only one supported index option for `KH_INDEX`.
Make sure that your class is discoverable by Python.
## Allow users to customize your pipeline in the app settings
To allow the users to configure your pipeline, you need to declare what you
allow the users to configure as a dictionary. `ktem` will include them into the
application settings.
In your pipeline class, add a classmethod `get_user_settings` that returns a
setting dictionary, add a classmethod `get_info` that returns an info
dictionary. Example:
```python
class SoSimple(BaseComponent):
... # as above
@classmethod
def get_user_settings(cls) -> dict:
"""The settings to the user"""
return {
"setting_1": {
"name": "Human-friendly name",
"value": "Default value",
"choices": [("Human-friendly Choice 1", "choice1-id"), ("HFC 2", "choice2-id")], # optional
"component": "Which Gradio UI component to render, can be: text, number, checkbox, dropdown, radio, checkboxgroup"
},
"setting_2": {
# follow the same rule as above
}
}
@classmethod
def get_info(cls) -> dict:
"""Pipeline information for bookkeeping purpose"""
return {
"id": "a unique id to differentiate this pipeline from other pipeline",
"name": "Human-friendly name of the pipeline",
"description": "Can be a short description of this pipeline"
}
```
Once adding these methods to your pipeline class, `ktem` will automatically
extract and add them to the settings.
## Construct to pipeline object
Once `ktem` runs your pipeline, it will call your classmethod `get_pipeline`
with the full user settings and expect to obtain the pipeline object. Within
this `get_pipeline` method, you implement all the necessary logics to initiate
the pipeline object. Example:
```python
class SoSimple(BaseComponent):
... # as above
@classmethod
def get_pipeline(self, setting):
obj = cls(arg1=setting["reasoning.id.setting1"])
return obj
```
## Reasoning: Stream output to UI
For fast user experience, you can stream the output directly to UI. This way,
user can start observing the output as soon as the LLM model generates the 1st
token, rather than having to wait the pipeline finishes to read the whole message.
To stream the output, you need to;
1. Turn the `run` function to async.
2. Pass in the output to a special queue with `self.report_output`.
```python
async def run(self, question: str, history: list, **kwargs) -> Document:
for char in "This is a long messages":
self.report_output({"output": text.text})
```
The argument to `self.report_output` is a dictionary, that contains either or
all of these 2 keys: "output", "evidence". The "output" string will be streamed
to the chat message, and the "evidence" string will be streamed to the
information panel.
## Access application LLMs, Embeddings
You can access users' collections of LLMs and embedding models with:
```python
from ktem.embeddings.manager import embeddings
from ktem.llms.manager import llms
llm = llms.get_default()
embedding_model = embeddings.get_default()
```
You can also allow the users to specifically select which llms or embedding
models they want to use through the settings.
```python
@classmethod
def get_user_settings(cls) -> dict:
from ktem.llms.manager import llms
return {
"citation_llm": {
"name": "LLM for citation",
"value": llms.get_default(),
"component: "dropdown",
"choices": list(llms.options().keys()),
},
...
}
```
## Optional: Access application data
You can access the user's application database, vector store as follow:
```python
# get the database that contains the source files
from ktem.db.models import Source, Index, Conversation, User
# get the vector store
```
================================================
FILE: docs/pages/app/ext/user-management.md
================================================
`ktem` provides user management as an extension. To enable user management, in
your `flowsettings.py`, set the following variables:
- `KH_FEATURE_USER_MANAGEMENT`: True to enable.
- `KH_FEATURE_USER_MANAGEMENT_ADMIN`: the admin username. This user will be
created when the app 1st start.
- `KH_FEATURE_USER_MANAGEMENT_PASSWORD`: the admin password. This value
accompanies the admin username.
Once enabled, you have access to the following features:
- User login/logout (located in Settings Tab)
- User changing password (located in Settings Tab)
- Create / List / Edit / Delete user (located in Resources > Users Tab)
================================================
FILE: docs/pages/app/features.md
================================================
## Chat
The kotaemon focuses on question and answering over a corpus of data. Below
is the gentle introduction about the chat functionality.
- Users can upload corpus of files.
- Users can converse to the chatbot to ask questions about the corpus of files.
- Users can view the reference in the files.
================================================
FILE: docs/pages/app/functional-description.md
================================================
## User group / tenant management
### Create new user group
(6 man-days)
**Description**: each client has a dedicated user group. Each user group has an
admin user who can do administrative tasks (e.g. creating user account in that
user group...). The workflow for creating new user group is as follow:
1. Cinnamon accesses the user group management UI.
2. On "Create user group" panel, we supply:
a. Client name: e.g. Apple.
b. Sub-domain name: e.g. apple.
c. Admin email, username & password.
3. The system will:
a. An Aurora Platform deployment with the specified sub-domain.
b. Send an email to the admin, with the username & password.
**Expectation**:
- The admin can go to the deployed Aurora Platform.
- The admin can login with the specified username & password.
**Condition**:
- When sub-domain name already exists, raise error.
- If error sending email to the client, raise the error, and delete the
newly-created user-group.
- Password rule:
- Have at least 8 characters.
- Must contain uppercase, lowercase, number and symbols.
---
### Delete user group
(2 man-days)
**Description**: in the tenant management page, we can delete the selected user
group. The user flow is as follow:
1. Cinnamon accesses the user group management UI,
2. View list of user groups.
3. Next to target user group, click delete.
4. Confirm whether to delete.
5. If Yes, delete the user group. If No, cancel the operation.
**Expectation**: when a user group is deleted, we expect to delete everything
related to the user groups: domain, files, databases, caches, deployments.
## User management
---
### Create user account (for admin user)
(1 man-day)
**Description**: the admin user in the client's account can create user account
for that user group. To create the new user, the client admin do:
1. Navigate to "Admin" > "Users"
2. In the "Create user" panel, supply:
- Username
- Password
- Confirm password
3. Click "Create"
**Expectation**:
- The user can create the account.
- The username:
- Is case-insensitive (e.g. Moon and moon will be the same)
- Can only contains these characters: a-z A-Z 0-9 \_ + - .
- Has maximum length of 32 characters
- The password is subjected to the following rule:
- 8-character minimum length
- Contains at least 1 number
- Contains at least 1 lowercase letter
- Contains at least 1 uppercase letter
- Contains at least 1 special character from the following set, or a
non-leading, non-trailing space character: `^ $ * . [ ] { } ( ) ? - " ! @ # % & / \ , > < ' : ; | _ ~ ` + =
---
### Delete user account (for admin user)
**Description**: the admin user in the client's account can delete user account.
Once an user account is deleted, he/she cannot login to Aurora Platform.
1. The admin user navigates to "Admin" > "Users".
2. In the user list panel, next to the username, the admin click on the "Delete"
button. The Confirmation dialog appears.
3. If "Delete", the user account is deleted. If "Cancel", do nothing. The
Confirmation dialog disappears.
**Expectation**:
- Once the user is deleted, the following information relating to the user will
be deleted:
- His/her personal setting.
- His/her conversations.
- The following information relating to the user will still be retained:
- His/her uploaded files.
---
### Edit user account (for admin user)
**Description**: the admin user can change any information about the user
account, including password. To change user information:
1. The admin user navigates to "Admin" > "Users".
2. In the user list panel, next to the username, the admin click on the "Edit"
button.
3. The user list disappears, the user detail appears, with the following
information show up:
- Username: (prefilled the username)
- Password: (blank)
- Confirm password: (blank)
4. The admin can edit any of the information, and click "Save" or "Cancel".
- If "Save": the information will be updated to the database, or show
error per Expectation below.
- If "Cancel": skip.
5. If Save success or Cancel, transfer back to the user list UI, where the user
information is updated accordingly.
**Expectation**:
- If the "Password" & "Confirm password" are different from each other, show
error: "Password mismatch".
- If both "Password" & \*"Confirm password" are blank, don't change the user
password.
- If changing password, the password rule is subjected to the same rule when
creating user.
- It's possible to change username. If changing username, the target user has to
use the new username.
---
### Sign-in
(3 man-days)
**Description**: the users can sign-in to Aurora Platform as follow:
1. User navigates to the URL.
2. If the user is not logged in, the UI just shows the login screen.
3. User types username & password.
4. If correct, the user will proceed to normal working UI.
5. If incorrect, the login screen shows text error.
---
### Sign-out
(1 man-day)
**Description**: the user can sign-out of Aurora Platform as follow:
1. User navigates to the Settings > User page.
2. User click on logout.
3. The user is signed out to the UI login screen.
**Expectation**: the user is completely signed out. Next time he/she uses the
Aurora Platform, he/she has to login again.
---
### Change password
**Description**: the user can change their password as follow:
1. User navigates to the Settings > User page.
2. In the change password section, the user provides these info and click
Change:
- Current password
- New password
- Confirm new password
3. If changing successfully, then the password is changed. Otherwise, show the
error on the UI.
**Expectation**:
- If changing password succeeds, next time they logout/login to the system, they
can use the new password.
- Password rule (Same as normal password rule when creating user)
- Errors:
- Password does not match.
- Violated password rules.
---
## Chat
### Chat to the bot
**Description**: the Aurora Platform focuses on question and answering over the
uploaded data. Each chat has the following components:
- Chat message: show the exchange between bots and humans.
- Text input + send button: for the user to input the message.
- Data source panel: for selecting the files that will scope the context for the
bot.
- Information panel: showing evidence as the bot answers user's questions.
The chat workflow looks as follow:
1. [Optional] User select files that they want to scope the context for the bot.
If the user doesn't select any files, then all files on Aurora Platform will
be the context for the bot.
- The user can type multi-line messages, using "Shift + Enter" for
line-break.
2. User sends the message (either clicking the Send button or hitting the Enter
key).
3. The bot in the chat conversation will return "Thinking..." while it
processes.
4. The information panel on the right begin to show data related to the user
message.
5. The bot begins to generate answer. The "Thinking..." placeholder disappears..
**Expecatation**:
- Messages:
- User can send multi-line messages, using "Shift + Enter" for line-break.
- User can thumbs up, thumbs down the AI response. This information is
recorded in the database.
- User can click on a copy button on the chat message to copy the content to
clipboard.
- Information panel:
- The information panel shows the latest evidence.
- The user can click on the message, and the reference for that message will
show up on the "Reference panel" (feature in-planning).
- The user can click on the title to show/hide the content.
- The whole information panel can be collapsed.
- Chatbot quality:
- The user can converse with the bot. The bot answer the user's requests in a
natural manner.
- The bot message should be streamed to the UI. The bot don't wait to gather
alll the text response, then dump all of them at once.
### Conversation - switch
**Description**: users can jump around between different conversations. They can
see the list of all conversations, can select an old converation, and continue
the chat under the context of the old conversation. The switching workflow is
like this:
1. Users click on the conversation dropdown. It will show a list of
conversations.
2. Within that dropdown, the user selects one conversation.
3. The chat messages, information panel, and selected data will show the content
in that old chat.
4. The user can continue chatting as normal under the context of this old chat.
**Expectation**:
- In the conversation drop down list, the conversations are ordered in created
date order.
- When there is no conversation, the conversation list is empty.
- When there is no conversation, the user can still converse with the chat bot.
When doing so, it automatically create new conversation.
### Conversation - create
**Description**: the user can explicitly start a new conversation with the
chatbot:
1. User click on the "New" button.
2. The new conversation is automatically created.
**Expectation**:
- The default conversation name is the current datetime.
- It become selected.
- It is added to the conversation list.
### Conversation - rename
**Description**: user can rename the chatbot by typing the name, and click on
the Rename button next to it.
- If rename succeeds: the name shown in the 1st dropdown will change accordingly
- If rename doesn't succeed: show error message in red color below the rename section
**Condition**:
- Name constraint:
- Min characters: 1
- Max characters: 40
- Could not having the same name with an existing conversation of the same
user.
### Conversation - delete
**Description**: user can delete the existing conversation as follow:
1. Click on Delete button.
2. The UI show confirmation with 2 buttons:
- Delete
- Cancel.
3. If Delete, delete the conversation, switch to the next oldest conversation,
close the confirmation panel.
4. If cancel, just close the confirmation panel.
## File management
The file management allows users to upload, list and delete files that they
upload to the Aurora Platform
### Upload file
**Description**: the user can upload files to the Aurora Platform. The uploaded
files will be served as context for our chatbot to refer to when it converses
with the user. To upload file, the user:
1. Navigate to the File tab.
2. Within the File tab, there is an Upload section.
3. User can add files to the Upload section through drag & drop, and or by click
on the file browser.
4. User can select some options relating to uploading and indexing. Depending on
the project, these options can be different. Nevertheless, they will discuss
below.
5. User click on "Upload and Index" button.
6. The app show notifications when indexing starts and finishes, and when errors
happen on the top right corner.
**Options**:
- Force re-index file. When user tries to upload files that already exists on
the system:
- If this option is True: will re-index those files.
- If this option is False: will skip indexing those files.
**Condition**:
- Max number of files: 100 files.
- Max number of pages per file: 500 pages
- Max file size: 10 MB
### List all files
**Description**: the user can know which files are on the system by:
1. Navigate to the File tab.
2. By default, it will show all the uploaded files, each with the following
information: file name, file size, number of pages, uploaded date
3. The UI also shows total number of pages, and total number of sizes in MB.
### Delete file
**Description**: users can delete files from this UI to free up the space, or to
remove outdated information. To remove the files:
1. User navigate to the File tab.
2. In the list of file, next to each file, there is a Delete button.
3. The user clicks on the Delete button. Confirmation dialog appear.
4. If Delete, delete the file. If Cancel, close the confirmation dialog.
**Expectation**: once the file is deleted:
- The database entry of that file is deleted.
- The file is removed from "Chat - Data source".
- The total number of pages and MB sizes are reduced accordingly.
- The reference to the file in the information panel is still retained.
================================================
FILE: docs/pages/app/index/file.md
================================================
The file index stores files in a local folder and index them for retrieval.
This file index provides the following infrastructure to support the indexing:
- SQL table Source: store the list of files that are indexed by the system
- Vector store: contain the embedding of segments of the files
- Document store: contain the text of segments of the files. Each text stored
in this document store is associated with a vector in the vector store.
- SQL table Index: store the relationship between (1) the source and the
docstore, and (2) the source and the vector store.
The indexing and retrieval pipelines are encouraged to use the above software
infrastructure.
## Indexing pipeline
The ktem has default indexing pipeline: `ktem.index.file.pipelines.IndexDocumentPipeline`.
This default pipeline works as follow:
- **Input**: list of file paths
- **Output**: list of nodes that are indexed into database
- **Process**:
- Read files into texts. Different file types has different ways to read texts.
- Split text files into smaller segments
- Run each segments into embeddings.
- Store the embeddings into vector store. Store the texts of each segment
into docstore. Store the list of files in Source. Store the linking
between Sources and docstore + vectorstore in Index table.
You can customize this default pipeline if your indexing process is close to the
default pipeline. You can create your own indexing pipeline if there are too
much different logic.
### Customize the default pipeline
The default pipeline provides the contact points in `flowsettings.py`.
1. `FILE_INDEX_PIPELINE_FILE_EXTRACTORS`. Supply overriding file extractor,
based on file extension. Example: `{".pdf": "path.to.PDFReader", ".xlsx": "path.to.ExcelReader"}`
2. `FILE_INDEX_PIPELINE_SPLITTER_CHUNK_SIZE`. The expected number of characters
of each text segment. Example: 1024.
3. `FILE_INDEX_PIPELINE_SPLITTER_CHUNK_OVERLAP`. The expected number of
characters that consecutive text segments should overlap with each other.
Example: 256.
### Create your own indexing pipeline
Your indexing pipeline will subclass `BaseFileIndexIndexing`.
You should define the following methods:
- `run(self, file_paths)`: run the indexing given the pipeline
- `get_pipeline(cls, user_settings, index_settings)`: return the
fully-initialized pipeline, ready to be used by ktem.
- `user_settings`: is a dictionary contains user settings (e.g. `{"pdf_mode": True, "num_retrieval": 5}`). You can declare these settings in the `get_user_settings` classmethod. ktem will collect these settings into the app Settings page, and will supply these user settings to your `get_pipeline` method.
- `index_settings`: is a dictionary. Currently it's empty for File Index.
- `get_user_settings`: to declare user settings, return a dictionary.
By subclassing `BaseFileIndexIndexing`, You will have access to the following resources:
- `self._Source`: the source table
- `self._Index`: the index table
- `self._VS`: the vector store
- `self._DS`: the docstore
Once you have prepared your pipeline, register it in `flowsettings.py`: `FILE_INDEX_PIPELINE = "<python.path.to.your.pipeline>"`.
## Retrieval pipeline
The ktem has default retrieval pipeline:
`ktem.index.file.pipelines.DocumentRetrievalPipeline`. This pipeline works as
follow:
- Input: user text query & optionally a list of source file ids
- Output: the output segments that match the user text query
- Process:
- If a list of source file ids is given, get the list of vector ids that
associate with those file ids.
- Embed the user text query.
- Query the vector store. Provide a list of vector ids to limit query scope
if the user restrict.
- Return the matched text segments
### Create your own retrieval pipeline
Your retrieval pipeline will subclass `BaseFileIndexRetriever`. The retriever
has the same database, vectorstore and docstore accesses like the indexing
pipeline.
You should define the following methods:
- `run(self, query, file_ids)`: retrieve relevant documents relating to the
query. If `file_ids` is given, you should restrict your search within these
`file_ids`.
- `get_pipeline(cls, user_settings, index_settings, selected)`: return the
fully-initialized pipeline, ready to be used by ktem.
- `user_settings`: is a dictionary contains user settings (e.g. `{"pdf_mode": True, "num_retrieval": 5}`). You can declare these settings in the `get_user_settings` classmethod. ktem will collect these settings into the app Settings page, and will supply these user settings to your `get_pipeline` method.
- `index_settings`: is a dictionary. Currently it's empty for File Index.
- `selected`: a list of file ids selected by user. If user doesn't select
anything, this variable will be None.
- `get_user_settings`: to declare user settings, return a dictionary.
Once you build the retrieval pipeline class, you can register it in
`flowsettings.py`: `FILE_INDEXING_RETRIEVER_PIPELIENS = ["path.to.retrieval.pipelie"]`. Because there can be
multiple parallel pipelines within an index, this variable takes a list of
string rather than a string.
## Software infrastructure
| Infra | Access | Schema | Ref |
| ---------------- | ------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------- |
| SQL table Source | self.\_Source | - id (int): id of the source (auto)<br>- name (str): the name of the file<br>- path (str): the path of the file<br>- size (int): the file size in bytes<br>- note (dict): allow extra optional information about the file<br>- date_created (datetime): the time the file is created (auto) | This is SQLALchemy ORM class. Can consult |
| SQL table Index | self.\_Index | - id (int): id of the index entry (auto)<br>- source_id (int): the id of a file in the Source table<br>- target_id: the id of the segment in docstore or vector store<br>- relation_type (str): if the link is "document" or "vector" | This is SQLAlchemy ORM class |
| Vector store | self.\_VS | - self.\_VS.add: add the list of embeddings to the vector store (optionally associate metadata and ids)<br>- self.\_VS.delete: delete vector entries based on ids<br>- self.\_VS.query: get embeddings based on embeddings. | kotaemon > storages > vectorstores > BaseVectorStore |
| Doc store | self.\_DS | - self.\_DS.add: add the segments to document stores<br>- self.\_DS.get: get the segments based on id<br>- self.\_DS.get_all: get all segments<br>- self.\_DS.delete: delete segments based on id | kotaemon > storages > docstores > base > BaseDocumentStore |
================================================
FILE: docs/pages/app/settings/overview.md
================================================
# Overview
There are 3 kinds of settings in `ktem`, geared towards different stakeholders
for different use cases:
- Developer settings. These settings are meant for very basic app customization, such as database URL, cloud config, logging config, which features to enable... You will be interested in the developer settings if you deploy `ktem` to your customers, or if you build extension for `ktem` for developers. These settings are declared inside `flowsettings.py`.
- Admin settings. These settings show up in the Admin page, and are meant to allow admin-level user to customize low level features, such as which credentials to connect to data sources, which keys to use for LLM...
- [User settings](/pages/app/settings/user-settings/). These settings are meant for run-time users to tweak ktem to their personal needs, such as which output languages the chatbot should generate, which reasoning type to use...
================================================
FILE: docs/pages/app/settings/user-settings.md
================================================
# User settings
`ktem` allows developers to extend the index and the reasoning pipeline. In
many cases, these components can have settings that should be modified by
users at run-time, (e.g. `topk`, `chunksize`...). These are the user settings.
`ktem` allows developers to declare such user settings in their code. Once
declared, `ktem` will render them in a Settings page.
There are 2 places that `ktem` looks for declared user settings. You can
refer to the respective pages.
- In the index.
- In the reasoning pipeline.
## Syntax of a settings
A collection of settings is a dictionary of type `dict[str, dict]`, where the
key is a setting id, and the value is the description of the setting.
```python
settings = {
"topk": {
"name": "Top-k chunks",
"value": 10,
"component": "number",
},
"lang": {
"name": "Languages",
"value": "en",
"component": "dropdown",
"choices": [("en", "English"), ("cn", "Chinese")],
}
}
```
Each setting description must have:
- name: the human-understandable name of the settings.
- value: the default value of the settings.
- component: the UI component to render such setting on the UI. Available:
- "text": single-value
- "number": single-value
- "checkbox": single-value
- "dropdown": choices
- "radio": choices
- "checkboxgroup": choices
- choices: the list of choices, if the component type allows.
## Settings page structure
================================================
FILE: docs/scripts/generate_examples_docs.py
================================================
# import shutil
from pathlib import Path
from typing import Any, Iterable
import mkdocs_gen_files
# get the root source code directory
doc_dir_name = "docs"
doc_dir = Path(__file__)
while doc_dir.name != doc_dir_name and doc_dir != doc_dir.parent:
doc_dir = doc_dir.parent
if doc_dir == doc_dir.parent:
raise ValueError(f"root_name ({doc_dir_name}) not in path ({str(Path(__file__))}).")
def generate_docs_for_examples_readme(
examples_dir: Path, target_doc_folder: str, ignored_modules: Iterable[Any] = []
):
if not examples_dir.is_dir():
raise ModuleNotFoundError(str(examples_dir))
nav = mkdocs_gen_files.Nav()
for path in sorted(examples_dir.rglob("*README.md")):
# ignore modules with name starts with underscore (i.e. __init__)
if path.name.startswith("_") or path.name.startswith("test"):
continue
module_path = path.parent.relative_to(examples_dir).with_suffix("")
doc_path = path.parent.relative_to(examples_dir).with_suffix(".md")
full_doc_path = Path(target_doc_folder, doc_path)
parts = list(module_path.parts)
identifier = ".".join(parts)
if "tests" in parts:
continue
ignore = False
for each_module in ignored_modules:
if identifier.startswith(each_module):
ignore = True
break
if ignore:
continue
nav_titles = [name.replace("_", " ").title() for name in parts]
nav[nav_titles] = doc_path.as_posix()
with mkdocs_gen_files.open(full_doc_path, "w") as f:
f.write(f'--8<-- "{path.relative_to(examples_dir.parent)}"')
mkdocs_gen_files.set_edit_path(
full_doc_path, Path("..") / path.relative_to(examples_dir.parent)
)
with mkdocs_gen_files.open(f"{target_doc_folder}/NAV.md", "w") as nav_file:
nav_file.writelines(nav.build_literate_nav())
generate_docs_for_examples_readme(
examples_dir=doc_dir.parent / "examples",
target_doc_folder="examples",
)
================================================
FILE: docs/scripts/generate_reference_docs.py
================================================
# import shutil
from pathlib import Path
from typing import Any, Iterable
import mkdocs_gen_files
# get the root source code directory
doc_dir_name = "docs"
doc_dir = Path(__file__)
while doc_dir.name != doc_dir_name and doc_dir != doc_dir.parent:
doc_dir = doc_dir.parent
if doc_dir == doc_dir.parent:
raise ValueError(f"root_name ({doc_dir_name}) not in path ({str(Path(__file__))}).")
nav_title_map = {"cli": "CLI", "llms": "LLMs"}
def generate_docs_for_src_code(
code_dir: Path, target_doc_folder: str, ignored_modules: Iterable[Any] = []
):
if not code_dir.is_dir():
raise ModuleNotFoundError(str(code_dir))
nav = mkdocs_gen_files.Nav()
for path in sorted(code_dir.rglob("*.py")):
# ignore modules with name starts with underscore (i.e. __init__)
# if path.name.startswith("_") or path.name.startswith("test"):
# continue
module_path = path.relative_to(code_dir).with_suffix("")
doc_path = path.relative_to(code_dir).with_suffix(".md")
full_doc_path = Path(target_doc_folder, doc_path)
parts = list(module_path.parts)
if parts[-1] == "__init__":
doc_path = doc_path.with_name("index.md")
full_doc_path = full_doc_path.with_name("index.md")
parts.pop()
if not parts:
continue
if "tests" in parts:
continue
identifier = ".".join(parts)
ignore = False
for each_module in ignored_modules:
if identifier.startswith(each_module):
ignore = True
break
if ignore:
continue
nav_titles = [
nav_title_map.get(name, name.replace("_", " ").title()) for name in parts
]
nav[nav_titles] = doc_path.as_posix()
with mkdocs_gen_files.open(full_doc_path, "w") as f:
f.write(f"::: {identifier}")
# this method works in docs folder
mkdocs_gen_files.set_edit_path(
full_doc_path, Path("..") / path.relative_to(code_dir.parent)
)
with mkdocs_gen_files.open(f"{target_doc_folder}/Summary.md", "w") as nav_file:
nav_file.writelines(nav.build_literate_nav())
generate_docs_for_src_code(
code_dir=doc_dir.parent / "libs" / "kotaemon" / "kotaemon",
target_doc_folder="reference",
ignored_modules={"contribs"},
)
================================================
FILE: docs/theme/assets/pymdownx-extras/extra-fb5a2a1c86.css
================================================
@charset "UTF-8";:root>*{--md-code-link-bg-color:hsla(0, 0%, 96%, 1);--md-code-link-accent-bg-color:var(--md-code-link-bg-color);--md-default-bg-color--trans:rgb(100%, 100%, 100%, 0);--md-code-title-bg-color:var(--md-code-bg-color);--md-code-inline-bg-color:var(--md-code-bg-color);--md-code-special-bg-color:#e8e8e8;--md-code-alternate-bg-color:var(--md-code-bg-color);--md-code-hl-punctuation-color:var(--md-code-fg-color);--md-code-hl-namespace-color:var(--md-code-fg-color);--md-code-hl-entity-color:var(--md-code-hl-keyword-color);--md-code-hl-tag-color:var(--md-code-hl-keyword-color);--md-code-hl-builtin-color:var(--md-code-hl-constant-color);--md-code-hl-class-color:var(--md-code-hl-function-color);--md-typeset-a-color:#00bcd4;--md-progress-stripe:var(--md-default-bg-color--lighter);--md-progress-100:#00e676;--md-progress-80:#00e676;--md-progress-60:#fbc02d;--md-progress-40:#ff9100;--md-progress-20:#ff5252;--md-progress-0:#ff1744;--md-typeset-kbd-color:#ebebeb;--md-typeset-kbd-border-color:#b8b8b8;--md-typeset-kbd-accent-color:hsla(0, 100%, 100%, 1)}:root>[data-md-color-scheme=slate]{--md-code-link-bg-color:hsla(232, 15%, 15%, 1);--md-code-link-accent-bg-color:var(--md-code-link-bg-color);--md-code-special-bg-color:#2b2d3b;--md-default-bg-color--trans:hsla(232,15%,15%, 0);--md-typeset-kbd-color:var(--md-default-fg-color--lightest);--md-typeset-kbd-border-color:#1a1c24;--md-typeset-kbd-accent-color:var(--md-default-fg-color--lighter)}:root>[data-md-color-scheme=dracula]{--md-default-fg-color:rgba(248, 248, 242, 0.87);--md-default-fg-color--light:rgba(248, 248, 242, 0.54);--md-default-fg-color--lighter:rgba(248, 248, 242, 0.16);--md-default-fg-color--lightest:rgba(248, 248, 242, 0.07);--md-default-autocomplete-fg-color:rgba(248, 248, 242, 0.4);--md-shadow-z2:0 0.2rem 0.5rem hsla(0, 0%, 0%, 0.3),0 0 0.05rem hsla(0, 0%, 0%, 0.2);--md-default-bg-color:var(--md-default-bg-color--darkest);--md-default-bg-color--light:rgba(50, 52, 67, 0.7);--md-default-bg-color--lighter:rgba(50, 52, 67, 0.3);--md-default-bg-color--lightest:rgba(50, 52, 67, 0.12);--md-default-bg-color--trans:rgba(50, 52, 67, 0);--md-default-bg-color--dark:#2b2e3b;--md-default-bg-color--darker:#252732;--md-default-bg-color--darkest:#1e2029;--md-default-bg-color--ultra-dark:#111217;--md-text-color:var(--md-default-fg-color);--md-typeset-color:var(--md-default-fg-color);--md-admonition-fg-color:var(--md-default-fg-color);--md-code-fg-color:hsl(60, 30%, 96%);--md-code-bg-color:hsl(231, 15%, 18%);--md-code-title-bg-color:var(--md-default-bg-color--ultra-dark);--md-code-inline-bg-color:#323443;--md-code-hl-operator-color:hsl(326, 100%, 74%);--md-code-hl-punctuation-color:hsl(60, 30%, 96%);--md-code-hl-string-color:hsl(65, 92%, 76%);--md-code-hl-special-color:hsl(265, 89%, 78%);--md-code-hl-number-color:hsl(265, 89%, 78%);--md-code-hl-keyword-color:hsl(326, 100%, 74%);--md-code-hl-name-color:hsl(60, 30%, 96%);--md-code-hl-constant-color:hsl(265, 89%, 78%);--md-code-hl-function-color:hsl(135, 94%, 65%);--md-code-hl-comment-color:hsl(225, 27%, 51%);--md-code-hl-variable-color:hsl(31, 100%, 71%);--md-code-hl-generic-color:hsl(225, 27%, 51%);--md-code-hl-color:hsl(231, 25%, 25%);--md-code-hl-entity-color:hsl(135, 94%, 65%);--md-code-hl-tag-color:hsl(326, 100%, 74%);--md-code-hl-namespace-color:hsl(60, 30%, 96%);--md-code-hl-builtin-color:hsl(191, 97%, 77%);--md-code-hl-class-color:hsl(191, 97%, 77%);--md-code-special-bg-color:#1c1e26;--md-code-alternate-bg-color:#3d3e49;--md-code-link-bg-color:#364653;--md-typeset-a-color:hsl(191, 97%, 77%);--md-typeset-mark-color:#6e7252;--md-typeset-del-color:#734568;--md-typeset-ins-color:#36724e;--md-progress-stripe:var(--md-default-bg-color--lightest);--md-progress-100:hsl(135, 94%, 65%);--md-progress-80:hsl(135, 92%, 79%);--md-progress-60:hsl(65, 92%, 76%);--md-progress-40:hsl(31, 100%, 71%);--md-progress-20:hsl(326, 100%, 74%);--md-progress-0:hsl(0, 100%, 67%);--md-typeset-kbd-color:var(--md-default-fg-color--lightest);--md-typeset-kbd-border-color:var(--md-default-bg-color--ultra-dark);--md-typeset-kbd-accent-color:var(--md-default-fg-color--lighter)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=red],[data-md-color-scheme=dracula][data-md-color-primary=red]{--md-primary-code-bg-color:#47303a;--md-primary-fg-color:hsla(0deg, 100%, 67%, 1);--md-primary-fg-color--transparent:hsla(0deg, 100%, 67%, 0.1);--md-primary-fg-color--light:hsla(0deg, 100%, 72%, 1);--md-primary-fg-color--dark:hsla(0deg, 100%, 62%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=pink],[data-md-color-scheme=dracula][data-md-color-primary=pink]{--md-primary-code-bg-color:#47354b;--md-primary-fg-color:hsla(326deg, 100%, 74%, 1);--md-primary-fg-color--transparent:hsla(326deg, 100%, 74%, 0.1);--md-primary-fg-color--light:hsla(326deg, 100%, 79%, 1);--md-primary-fg-color--dark:hsla(326deg, 100%, 69%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=purple],[data-md-color-scheme=dracula][data-md-color-primary=purple]{--md-primary-code-bg-color:#3e3952;--md-primary-fg-color:hsla(265deg, 89%, 78%, 1);--md-primary-fg-color--transparent:hsla(265deg, 89%, 78%, 0.1);--md-primary-fg-color--light:hsla(265deg, 89%, 83%, 1);--md-primary-fg-color--dark:hsla(265deg, 89%, 73%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=deep-purple],[data-md-color-scheme=dracula][data-md-color-primary=deep-purple]{--md-primary-code-bg-color:#3e3952;--md-primary-fg-color:hsla(265deg, 89%, 78%, 1);--md-primary-fg-color--transparent:hsla(265deg, 89%, 78%, 0.1);--md-primary-fg-color--light:hsla(265deg, 89%, 83%, 1);--md-primary-fg-color--dark:hsla(265deg, 89%, 73%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=blue],[data-md-color-scheme=dracula][data-md-color-primary=blue]{--md-primary-code-bg-color:#303446;--md-primary-fg-color:hsla(225deg, 27%, 51%, 1);--md-primary-fg-color--transparent:hsla(225deg, 27%, 51%, 0.1);--md-primary-fg-color--light:hsla(225deg, 27%, 56%, 1);--md-primary-fg-color--dark:hsla(225deg, 27%, 46%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=indigo],[data-md-color-scheme=dracula][data-md-color-primary=indigo]{--md-primary-code-bg-color:#303446;--md-primary-fg-color:hsla(225deg, 27%, 51%, 1);--md-primary-fg-color--transparent:hsla(225deg, 27%, 51%, 0.1);--md-primary-fg-color--light:hsla(225deg, 27%, 56%, 1);--md-primary-fg-color--dark:hsla(225deg, 27%, 46%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=light-blue],[data-md-color-scheme=dracula][data-md-color-primary=light-blue]{--md-primary-code-bg-color:#303446;--md-primary-fg-color:hsla(225deg, 27%, 51%, 1);--md-primary-fg-color--transparent:hsla(225deg, 27%, 51%, 0.1);--md-primary-fg-color--light:hsla(225deg, 27%, 56%, 1);--md-primary-fg-color--dark:hsla(225deg, 27%, 46%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=cyan],[data-md-color-scheme=dracula][data-md-color-primary=cyan]{--md-primary-code-bg-color:#364653;--md-primary-fg-color:hsla(191deg, 97%, 77%, 1);--md-primary-fg-color--transparent:hsla(191deg, 97%, 77%, 0.1);--md-primary-fg-color--light:hsla(191deg, 97%, 82%, 1);--md-primary-fg-color--dark:hsla(191deg, 97%, 72%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=teal],[data-md-color-scheme=dracula][data-md-color-primary=teal]{--md-primary-code-bg-color:#364653;--md-primary-fg-color:hsla(191deg, 97%, 77%, 1);--md-primary-fg-color--transparent:hsla(191deg, 97%, 77%, 0.1);--md-primary-fg-color--light:hsla(191deg, 97%, 82%, 1);--md-primary-fg-color--dark:hsla(191deg, 97%, 72%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=green],[data-md-color-scheme=dracula][data-md-color-primary=green]{--md-primary-code-bg-color:#2d4840;--md-primary-fg-color:hsla(135deg, 94%, 65%, 1);--md-primary-fg-color--transparent:hsla(135deg, 94%, 65%, 0.1);--md-primary-fg-color--light:hsla(135deg, 94%, 70%, 1);--md-primary-fg-color--dark:hsla(135deg, 94%, 60%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=light-green],[data-md-color-scheme=dracula][data-md-color-primary=light-green]{--md-primary-code-bg-color:#2d4840;--md-primary-fg-color:hsla(135deg, 94%, 65%, 1);--md-primary-fg-color--transparent:hsla(135deg, 94%, 65%, 0.1);--md-primary-fg-color--light:hsla(135deg, 94%, 70%, 1);--md-primary-fg-color--dark:hsla(135deg, 94%, 60%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=lime],[data-md-color-scheme=dracula][data-md-color-primary=lime]{--md-primary-code-bg-color:#2d4840;--md-primary-fg-color:hsla(135deg, 94%, 65%, 1);--md-primary-fg-color--transparent:hsla(135deg, 94%, 65%, 0.1);--md-primary-fg-color--light:hsla(135deg, 94%, 70%, 1);--md-primary-fg-color--dark:hsla(135deg, 94%, 60%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=yellow],[data-md-color-scheme=dracula][data-md-color-primary=yellow]{--md-primary-code-bg-color:#454842;--md-primary-fg-color:hsla(65deg, 92%, 76%, 1);--md-primary-fg-color--transparent:hsla(65deg, 92%, 76%, 0.1);--md-primary-fg-color--light:hsla(65deg, 92%, 81%, 1);--md-primary-fg-color--dark:hsla(65deg, 92%, 71%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=amber],[data-md-color-scheme=dracula][data-md-color-primary=amber]{--md-primary-code-bg-color:#454842;--md-primary-fg-color:hsla(65deg, 92%, 76%, 1);--md-primary-fg-color--transparent:hsla(65deg, 92%, 76%, 0.1);--md-primary-fg-color--light:hsla(65deg, 92%, 81%, 1);--md-primary-fg-color--dark:hsla(65deg, 92%, 71%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=orange],[data-md-color-scheme=dracula][data-md-color-primary=orange]{--md-primary-code-bg-color:#473e3d;--md-primary-fg-color:hsla(31deg, 100%, 71%, 1);--md-primary-fg-color--transparent:hsla(31deg, 100%, 71%, 0.1);--md-primary-fg-color--light:hsla(31deg, 100%, 76%, 1);--md-primary-fg-color--dark:hsla(31deg, 100%, 66%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=deep-orange],[data-md-color-scheme=dracula][data-md-color-primary=deep-orange]{--md-primary-code-bg-color:#473e3d;--md-primary-fg-color:hsla(31deg, 100%, 71%, 1);--md-primary-fg-color--transparent:hsla(31deg, 100%, 71%, 0.1);--md-primary-fg-color--light:hsla(31deg, 100%, 76%, 1);--md-primary-fg-color--dark:hsla(31deg, 100%, 66%, 1);--md-primary-bg-color:var(--md-default-bg-color);--md-primary-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=red],[data-md-color-scheme=dracula][data-md-color-accent=red]{--md-code-link-accent-bg-color:#472c36;--md-accent-fg-color:hsla(0deg, 100%, 62%, 1);--md-accent-fg-color--transparent:hsla(0deg, 100%, 62%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=pink],[data-md-color-scheme=dracula][data-md-color-accent=pink]{--md-code-link-accent-bg-color:#473149;--md-accent-fg-color:hsla(326deg, 100%, 69%, 1);--md-accent-fg-color--transparent:hsla(326deg, 100%, 69%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=purple],[data-md-color-scheme=dracula][data-md-color-accent=purple]{--md-code-link-accent-bg-color:#3c3652;--md-accent-fg-color:hsla(265deg, 89%, 73%, 1);--md-accent-fg-color--transparent:hsla(265deg, 89%, 73%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=deep-purple],[data-md-color-scheme=dracula][data-md-color-accent=deep-purple]{--md-code-link-accent-bg-color:#3c3652;--md-accent-fg-color:hsla(265deg, 89%, 73%, 1);--md-accent-fg-color--transparent:hsla(265deg, 89%, 73%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=blue],[data-md-color-scheme=dracula][data-md-color-accent=blue]{--md-code-link-accent-bg-color:#2e3243;--md-accent-fg-color:hsla(225deg, 27%, 46%, 1);--md-accent-fg-color--transparent:hsla(225deg, 27%, 46%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=indigo],[data-md-color-scheme=dracula][data-md-color-accent=indigo]{--md-code-link-accent-bg-color:#2e3243;--md-accent-fg-color:hsla(225deg, 27%, 46%, 1);--md-accent-fg-color--transparent:hsla(225deg, 27%, 46%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=light-blue],[data-md-color-scheme=dracula][data-md-color-accent=light-blue]{--md-code-link-accent-bg-color:#2e3243;--md-accent-fg-color:hsla(225deg, 27%, 46%, 1);--md-accent-fg-color--transparent:hsla(225deg, 27%, 46%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=cyan],[data-md-color-scheme=dracula][data-md-color-accent=cyan]{--md-code-link-accent-bg-color:#324553;--md-accent-fg-color:hsla(191deg, 97%, 72%, 1);--md-accent-fg-color--transparent:hsla(191deg, 97%, 72%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=teal],[data-md-color-scheme=dracula][data-md-color-accent=teal]{--md-code-link-accent-bg-color:#324553;--md-accent-fg-color:hsla(191deg, 97%, 72%, 1);--md-accent-fg-color--transparent:hsla(191deg, 97%, 72%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=green],[data-md-color-scheme=dracula][data-md-color-accent=green]{--md-code-link-accent-bg-color:#2a483d;--md-accent-fg-color:hsla(135deg, 94%, 60%, 1);--md-accent-fg-color--transparent:hsla(135deg, 94%, 60%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=light-green],[data-md-color-scheme=dracula][data-md-color-accent=light-green]{--md-code-link-accent-bg-color:#2a483d;--md-accent-fg-color:hsla(135deg, 94%, 60%, 1);--md-accent-fg-color--transparent:hsla(135deg, 94%, 60%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=lime],[data-md-color-scheme=dracula][data-md-color-accent=lime]{--md-code-link-accent-bg-color:#2a483d;--md-accent-fg-color:hsla(135deg, 94%, 60%, 1);--md-accent-fg-color--transparent:hsla(135deg, 94%, 60%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=yellow],[data-md-color-scheme=dracula][data-md-color-accent=yellow]{--md-code-link-accent-bg-color:#45483e;--md-accent-fg-color:hsla(65deg, 92%, 71%, 1);--md-accent-fg-color--transparent:hsla(65deg, 92%, 71%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=amber],[data-md-color-scheme=dracula][data-md-color-accent=amber]{--md-code-link-accent-bg-color:#45483e;--md-accent-fg-color:hsla(65deg, 92%, 71%, 1);--md-accent-fg-color--transparent:hsla(65deg, 92%, 71%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=orange],[data-md-color-scheme=dracula][data-md-color-accent=orange]{--md-code-link-accent-bg-color:#473d39;--md-accent-fg-color:hsla(31deg, 100%, 66%, 1);--md-accent-fg-color--transparent:hsla(31deg, 100%, 66%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}[data-md-color-scheme=dracula] :not([data-md-color-scheme])[data-md-color-primary=deep-orange],[data-md-color-scheme=dracula][data-md-color-accent=deep-orange]{--md-code-link-accent-bg-color:#473d39;--md-accent-fg-color:hsla(31deg, 100%, 66%, 1);--md-accent-fg-color--transparent:hsla(31deg, 100%, 66%, 0.1);--md-accent-bg-color:var(--md-default-bg-color);--md-accent-bg-color--light:var(--md-default-bg-color--light)}:root{--md-heart:#ff5252;--md-heart-big:#ff1744}:root :focus-visible{outline-style:solid}:root [data-md-color-scheme=dracula]{--md-heart:hsl(326, 100%, 74%);--md-heart-big:hsl(0, 100%, 67%)}.md-typeset h4{margin:2em 0 1em}.md-typeset a.source-link{position:relative;top:-.6rem;float:right;color:var(--md-default-fg-color--lighter);transition:color 125ms}.md-typeset a.source-link:hover{color:var(--md-accent-fg-color)}.md-typeset a.source-link .twemoji{height:1.2rem}.md-typeset a.source-link .twemoji svg{width:1.2rem;height:1.2rem}.md-typeset div.highlight.md-max-height pre>code{max-height:15rem}.twemoji.heart-throb svg,.twemoji.heart-throb-hover svg{position:relative;color:var(--md-heart);animation:pulse 1.5s ease infinite}@keyframes pulse{0%{transform:scale(1)}40%{color:var(--md-heart-big);transform:scale(1.3)}50%{transform:scale(1.2)}60%{color:var(--md-heart-big);transform:scale(1.3)}100%{transform:scale(1)}}footer.sponsorship{text-align:center}footer.sponsorship hr{display:inline-block;width:1.6rem;margin:0 .7rem;vertical-align:middle;border-bottom:2px solid var(--md-default-fg-color--lighter)}footer.sponsorship:hover hr{border-color:var(--md-accent-fg-color)}footer.sponsorship:not(:hover) .twemoji.heart-throb-hover svg{color:var(--md-default-fg-color--lighter)!important}body:not([data-md-prefers-color-scheme=true])[data-md-color-scheme=dracula] .md-icon .light-mode,body:not([data-md-prefers-color-scheme=true])[data-md-color-scheme=dracula] .md-icon .system-mode,body:not([data-md-prefers-color-scheme=true])[data-md-color-scheme=dracula] .md-icon .unknown-mode{display:none}body:not([data-md-prefers-color-scheme=true])[data-md-color-scheme=default] .md-icon .dark-mode,body:not([data-md-prefers-color-scheme=true])[data-md-color-scheme=default] .md-icon .system-mode,body:not([data-md-prefers-color-scheme=true])[data-md-color-scheme=default] .md-icon .unknown-mode{display:none}body:not([data-md-prefers-color-scheme=true]):not([data-md-color-scheme=default]):not([data-md-color-scheme=dracula]) .md-icon .dark-mode,body:not([data-md-prefers-color-scheme=true]):not([data-md-color-scheme=default]):not([data-md-color-scheme=dracula]) .md-icon .light-mode,body:not([data-md-prefers-color-scheme=true]):not([data-md-color-scheme=default]):not([data-md-color-scheme=dracula]) .md-icon .system-mode{display:none}body[data-md-prefers-color-scheme=true] .md-icon .dark-mode,body[data-md-prefers-color-scheme=true] .md-icon .light-mode,body[data-md-prefers-color-scheme=true] .md-icon .unknown-mode{display:none}.md-header-nav__scheme{z-index:0}[data-md-toggle=search]:checked~.md-header .md-header-nav__scheme{display:none}.md-typeset .admonition,.md-typeset details{border-width:0;border-left-width:4px}:root>*{--md-admonition-bg-color:transparent;--md-admonition-icon--settings:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M12 15.5A3.5 3.5 0 0 1 8.5 12 3.5 3.5 0 0 1 12 8.5a3.5 3.5 0 0 1 3.5 3.5 3.5 3.5 0 0 1-3.5 3.5m7.43-2.53c.04-.32.07-.64.07-.97 0-.33-.03-.66-.07-1l2.11-1.63c.19-.15.24-.42.12-.64l-2-3.46c-.12-.22-.39-.31-.61-.22l-2.49 1c-.52-.39-1.06-.73-1.69-.98l-.37-2.65A.506.506 0 0 0 14 2h-4c-.25 0-.46.18-.5.42l-.37 2.65c-.63.25-1.17.59-1.69.98l-2.49-1c-.22-.09-.49 0-.61.22l-2 3.46c-.13.22-.07.49.12.64L4.57 11c-.04.34-.07.67-.07 1 0 .33.03.65.07.97l-2.11 1.66c-.19.15-.25.42-.12.64l2 3.46c.12.22.39.3.61.22l2.49-1.01c.52.4 1.06.74 1.69.99l.37 2.65c.04.24.25.42.5.42h4c.25 0 .46-.18.5-.42l.37-2.65c.63-.26 1.17-.59 1.69-.99l2.49 1.01c.22.08.49 0 .61-.22l2-3.46c.12-.22.07-.49-.12-.64l-2.11-1.66Z"/></svg>');--md-admonition-bg-color--settings:rgba(170, 0, 255, 0.1);--md-admonition-icon-color--settings:#aa00ff;--md-admonition-shadow-color--settings:rgba(170, 0, 255, 0.1);--md-admonition-icon--new:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="m23 12-2.44-2.78.34-3.68-3.61-.82-1.89-3.18L12 3 8.6 1.54 6.71 4.72l-3.61.81.34 3.68L1 12l2.44 2.78-.34 3.69 3.61.82 1.89 3.18L12 21l3.4 1.46 1.89-3.18 3.61-.82-.34-3.68L23 12m-10 5h-2v-2h2v2m0-4h-2V7h2v6Z"/></svg>');--md-admonition-bg-color--new:rgba(255, 214, 0, 0.1);--md-admonition-icon-color--new:#ffd600;--md-admonition-shadow-color--new:rgba(255, 214, 0, 0.1);--md-admonition-bg-color--note:var(--md-default-bg-color--ultra-dark);--md-admonition-icon-color--note:hsl(51, 94%, 73%);--md-admonition-shadow-color--note:rgba(251, 231, 121, 0.1);--md-admonition-bg-color--abstract:var(--md-default-bg-color--ultra-dark);--md-admonition-icon-color--abstract:hsl(191, 97%, 77%);--md-admonition-shadow-color--abstract:rgba(139, 232, 253, 0.1);--md-admonition-bg-color--info:var(--md-default-bg-color--ultra-dark);--md-admonition-icon-color--info:hsl(190, 94%, 87%);--md-admonition-shadow-color--info:rgba(191, 243, 253, 0.1);--md-admonition-bg-color--tip:var(--md-default-bg-color--ultra-dark);--md-admonition-icon-color--tip:hsl(161, 97%, 77%);--md-admonition-shadow-color--tip:rgba(139, 253, 217, 0.1);--md-admonition-bg-color--success:var(--md-default-bg-color--ultra-dark);--md-admonition-icon-color--success:hsl(135, 94%, 65%);--md-admonition-shadow-color--success:rgba(82, 250, 124, 0.1);--md-admonition-bg-color--question:var(--md-default-bg-color--ultra-dark);--md-admonition-icon-color--question:hsl(135, 92%, 79%);--md-admonition-shadow-color--question:rgba(152, 251, 177, 0.1);--md-admonition-bg-color--warning:var(--md-default-bg-color--ultra-dark);--md-admonition-icon-color--warning:hsl(31, 100%, 71%);--md-admonition-shadow-color--warning:rgba(255, 184, 107, 0.1);--md-admonition-bg-color--failure:var(--md-default-bg-color--ultra-dark);--md-admonition-icon-color--failure:hsl(0, 100%, 59%);--md-admonition-shadow-color--failure:rgba(255, 46, 46, 0.1);--md-admonition-bg-color--danger:var(--md-default-bg-color--ultra-dark);--md-admonition-icon-color--danger:hsl(0, 100%, 67%);--md-admonition-shadow-color--danger:rgba(255, 87, 87, 0.1);--md-admonition-bg-color--bug:var(--md-default-bg-color--ultra-dark);--md-admonition-icon-color--bug:hsl(325, 100%, 64%);--md-admonition-shadow-color--bug:rgba(255, 71, 179, 0.1);--md-admonition-bg-color--example:var(--md-default-bg-color--ultra-dark);--md-admonition-icon-color--example:hsl(265, 89%, 78%);--md-admonition-shadow-color--example:rgba(191, 149, 249, 0.1);--md-admonition-bg-color--quote:var(--md-default-bg-color--ultra-dark);--md-admonition-icon-color--quote:hsl(225, 8%, 51%);--md-admonition-shadow-color--quote:rgba(120, 125, 140, 0.1)}:root>[data-md-color-scheme=dracula]{--md-admonition-icon-color:$drac-dark-yellow}:root>[data-md-color-scheme=dracula]{--md-admonition-bg-color--settings:var(--md-default-bg-color--ultra-dark);--md-admonition-icon-color--settings:hsl(326, 100%, 74%);--md-admonition-shadow-color--settings:rgba(255, 122, 198, 0.1)}:root>[data-md-color-scheme=dracula]{--md-admonition-bg-color--new:var(--md-default-bg-color--ultra-dark);--md-admonition-icon-color--new:hsl(65, 92%, 76%);--md-admonition-shadow-color--new:rgba(241, 250, 137, 0.1)}[data-md-color-scheme=dracula] .md-typeset .admonition,[data-md-color-scheme=dracula] .md-typeset details{border-color:var(--md-admonition-icon-color--note);box-shadow:var(--md-shadow-z2)}[data-md-color-scheme=dracula] .md-typeset .admonition:focus-within,[data-md-color-scheme=dracula] .md-typeset details:focus-within{box-shadow:0 0 0 .2rem var(--md-admonition-shadow-color--note)}[data-md-color-scheme=dracula] .md-typeset .admonition>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details>summary{background-color:var(--md-admonition-bg-color--note)}[data-md-color-scheme=dracula] .md-typeset .admonition>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details>summary::before{background-color:var(--md-admonition-icon-color--note)}[data-md-color-scheme=dracula] .md-typeset .admonition>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details>summary::after{color:var(--md-admonition-icon-color--note)}[data-md-color-scheme=dracula] .md-typeset .admonition.note,[data-md-color-scheme=dracula] .md-typeset details.note{border-color:var(--md-admonition-icon-color--note)}[data-md-color-scheme=dracula] .md-typeset .admonition.note:focus-within,[data-md-color-scheme=dracula] .md-typeset details.note:focus-within{box-shadow:0 0 0 .2rem var(--md-admonition-shadow-color--note)}[data-md-color-scheme=dracula] .md-typeset .admonition.note>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.note>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.note>summary{background-color:var(--md-admonition-bg-color--note);border-color:var(--md-admonition-icon-color--note)}[data-md-color-scheme=dracula] .md-typeset .admonition.note>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.note>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.note>summary::before{background-color:var(--md-admonition-icon-color--note)}[data-md-color-scheme=dracula] .md-typeset .admonition.note>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.note>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.note>summary::after{color:var(--md-admonition-icon-color--note)}[data-md-color-scheme=dracula] .md-typeset .admonition.abstract,[data-md-color-scheme=dracula] .md-typeset details.abstract{border-color:var(--md-admonition-icon-color--abstract)}[data-md-color-scheme=dracula] .md-typeset .admonition.abstract:focus-within,[data-md-color-scheme=dracula] .md-typeset details.abstract:focus-within{box-shadow:0 0 0 .2rem var(--md-admonition-shadow-color--abstract)}[data-md-color-scheme=dracula] .md-typeset .admonition.abstract>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.abstract>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.abstract>summary{background-color:var(--md-admonition-bg-color--abstract);border-color:var(--md-admonition-icon-color--abstract)}[data-md-color-scheme=dracula] .md-typeset .admonition.abstract>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.abstract>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.abstract>summary::before{background-color:var(--md-admonition-icon-color--abstract)}[data-md-color-scheme=dracula] .md-typeset .admonition.abstract>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.abstract>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.abstract>summary::after{color:var(--md-admonition-icon-color--abstract)}[data-md-color-scheme=dracula] .md-typeset .admonition.info,[data-md-color-scheme=dracula] .md-typeset details.info{border-color:var(--md-admonition-icon-color--info)}[data-md-color-scheme=dracula] .md-typeset .admonition.info:focus-within,[data-md-color-scheme=dracula] .md-typeset details.info:focus-within{box-shadow:0 0 0 .2rem var(--md-admonition-shadow-color--info)}[data-md-color-scheme=dracula] .md-typeset .admonition.info>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.info>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.info>summary{background-color:var(--md-admonition-bg-color--info);border-color:var(--md-admonition-icon-color--info)}[data-md-color-scheme=dracula] .md-typeset .admonition.info>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.info>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.info>summary::before{background-color:var(--md-admonition-icon-color--info)}[data-md-color-scheme=dracula] .md-typeset .admonition.info>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.info>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.info>summary::after{color:var(--md-admonition-icon-color--info)}[data-md-color-scheme=dracula] .md-typeset .admonition.tip,[data-md-color-scheme=dracula] .md-typeset details.tip{border-color:var(--md-admonition-icon-color--tip)}[data-md-color-scheme=dracula] .md-typeset .admonition.tip:focus-within,[data-md-color-scheme=dracula] .md-typeset details.tip:focus-within{box-shadow:0 0 0 .2rem var(--md-admonition-shadow-color--tip)}[data-md-color-scheme=dracula] .md-typeset .admonition.tip>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.tip>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.tip>summary{background-color:var(--md-admonition-bg-color--tip);border-color:var(--md-admonition-icon-color--tip)}[data-md-color-scheme=dracula] .md-typeset .admonition.tip>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.tip>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.tip>summary::before{background-color:var(--md-admonition-icon-color--tip)}[data-md-color-scheme=dracula] .md-typeset .admonition.tip>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.tip>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.tip>summary::after{color:var(--md-admonition-icon-color--tip)}[data-md-color-scheme=dracula] .md-typeset .admonition.success,[data-md-color-scheme=dracula] .md-typeset details.success{border-color:var(--md-admonition-icon-color--success)}[data-md-color-scheme=dracula] .md-typeset .admonition.success:focus-within,[data-md-color-scheme=dracula] .md-typeset details.success:focus-within{box-shadow:0 0 0 .2rem var(--md-admonition-shadow-color--success)}[data-md-color-scheme=dracula] .md-typeset .admonition.success>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.success>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.success>summary{background-color:var(--md-admonition-bg-color--success);border-color:var(--md-admonition-icon-color--success)}[data-md-color-scheme=dracula] .md-typeset .admonition.success>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.success>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.success>summary::before{background-color:var(--md-admonition-icon-color--success)}[data-md-color-scheme=dracula] .md-typeset .admonition.success>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.success>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.success>summary::after{color:var(--md-admonition-icon-color--success)}[data-md-color-scheme=dracula] .md-typeset .admonition.question,[data-md-color-scheme=dracula] .md-typeset details.question{border-color:var(--md-admonition-icon-color--question)}[data-md-color-scheme=dracula] .md-typeset .admonition.question:focus-within,[data-md-color-scheme=dracula] .md-typeset details.question:focus-within{box-shadow:0 0 0 .2rem var(--md-admonition-shadow-color--question)}[data-md-color-scheme=dracula] .md-typeset .admonition.question>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.question>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.question>summary{background-color:var(--md-admonition-bg-color--question);border-color:var(--md-admonition-icon-color--question)}[data-md-color-scheme=dracula] .md-typeset .admonition.question>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.question>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.question>summary::before{background-color:var(--md-admonition-icon-color--question)}[data-md-color-scheme=dracula] .md-typeset .admonition.question>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.question>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.question>summary::after{color:var(--md-admonition-icon-color--question)}[data-md-color-scheme=dracula] .md-typeset .admonition.warning,[data-md-color-scheme=dracula] .md-typeset details.warning{border-color:var(--md-admonition-icon-color--warning)}[data-md-color-scheme=dracula] .md-typeset .admonition.warning:focus-within,[data-md-color-scheme=dracula] .md-typeset details.warning:focus-within{box-shadow:0 0 0 .2rem var(--md-admonition-shadow-color--warning)}[data-md-color-scheme=dracula] .md-typeset .admonition.warning>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.warning>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.warning>summary{background-color:var(--md-admonition-bg-color--warning);border-color:var(--md-admonition-icon-color--warning)}[data-md-color-scheme=dracula] .md-typeset .admonition.warning>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.warning>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.warning>summary::before{background-color:var(--md-admonition-icon-color--warning)}[data-md-color-scheme=dracula] .md-typeset .admonition.warning>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.warning>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.warning>summary::after{color:var(--md-admonition-icon-color--warning)}[data-md-color-scheme=dracula] .md-typeset .admonition.failure,[data-md-color-scheme=dracula] .md-typeset details.failure{border-color:var(--md-admonition-icon-color--failure)}[data-md-color-scheme=dracula] .md-typeset .admonition.failure:focus-within,[data-md-color-scheme=dracula] .md-typeset details.failure:focus-within{box-shadow:0 0 0 .2rem var(--md-admonition-shadow-color--failure)}[data-md-color-scheme=dracula] .md-typeset .admonition.failure>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.failure>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.failure>summary{background-color:var(--md-admonition-bg-color--failure);border-color:var(--md-admonition-icon-color--failure)}[data-md-color-scheme=dracula] .md-typeset .admonition.failure>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.failure>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.failure>summary::before{background-color:var(--md-admonition-icon-color--failure)}[data-md-color-scheme=dracula] .md-typeset .admonition.failure>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.failure>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.failure>summary::after{color:var(--md-admonition-icon-color--failure)}[data-md-color-scheme=dracula] .md-typeset .admonition.danger,[data-md-color-scheme=dracula] .md-typeset details.danger{border-color:var(--md-admonition-icon-color--danger)}[data-md-color-scheme=dracula] .md-typeset .admonition.danger:focus-within,[data-md-color-scheme=dracula] .md-typeset details.danger:focus-within{box-shadow:0 0 0 .2rem var(--md-admonition-shadow-color--danger)}[data-md-color-scheme=dracula] .md-typeset .admonition.danger>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.danger>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.danger>summary{background-color:var(--md-admonition-bg-color--danger);border-color:var(--md-admonition-icon-color--danger)}[data-md-color-scheme=dracula] .md-typeset .admonition.danger>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.danger>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.danger>summary::before{background-color:var(--md-admonition-icon-color--danger)}[data-md-color-scheme=dracula] .md-typeset .admonition.danger>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.danger>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.danger>summary::after{color:var(--md-admonition-icon-color--danger)}[data-md-color-scheme=dracula] .md-typeset .admonition.bug,[data-md-color-scheme=dracula] .md-typeset details.bug{border-color:var(--md-admonition-icon-color--bug)}[data-md-color-scheme=dracula] .md-typeset .admonition.bug:focus-within,[data-md-color-scheme=dracula] .md-typeset details.bug:focus-within{box-shadow:0 0 0 .2rem var(--md-admonition-shadow-color--bug)}[data-md-color-scheme=dracula] .md-typeset .admonition.bug>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.bug>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.bug>summary{background-color:var(--md-admonition-bg-color--bug);border-color:var(--md-admonition-icon-color--bug)}[data-md-color-scheme=dracula] .md-typeset .admonition.bug>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.bug>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.bug>summary::before{background-color:var(--md-admonition-icon-color--bug)}[data-md-color-scheme=dracula] .md-typeset .admonition.bug>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.bug>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.bug>summary::after{color:var(--md-admonition-icon-color--bug)}[data-md-color-scheme=dracula] .md-typeset .admonition.example,[data-md-color-scheme=dracula] .md-typeset details.example{border-color:var(--md-admonition-icon-color--example)}[data-md-color-scheme=dracula] .md-typeset .admonition.example:focus-within,[data-md-color-scheme=dracula] .md-typeset details.example:focus-within{box-shadow:0 0 0 .2rem var(--md-admonition-shadow-color--example)}[data-md-color-scheme=dracula] .md-typeset .admonition.example>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.example>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.example>summary{background-color:var(--md-admonition-bg-color--example);border-color:var(--md-admonition-icon-color--example)}[data-md-color-scheme=dracula] .md-typeset .admonition.example>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.example>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.example>summary::before{background-color:var(--md-admonition-icon-color--example)}[data-md-color-scheme=dracula] .md-typeset .admonition.example>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.example>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.example>summary::after{color:var(--md-admonition-icon-color--example)}[data-md-color-scheme=dracula] .md-typeset .admonition.quote,[data-md-color-scheme=dracula] .md-typeset details.quote{border-color:var(--md-admonition-icon-color--quote)}[data-md-color-scheme=dracula] .md-typeset .admonition.quote:focus-within,[data-md-color-scheme=dracula] .md-typeset details.quote:focus-within{box-shadow:0 0 0 .2rem var(--md-admonition-shadow-color--quote)}[data-md-color-scheme=dracula] .md-typeset .admonition.quote>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.quote>.admonition-title,[data-md-color-scheme=dracula] .md-typeset details.quote>summary{background-color:var(--md-admonition-bg-color--quote);border-color:var(--md-admonition-icon-color--quote)}[data-md-color-scheme=dracula] .md-typeset .admonition.quote>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.quote>.admonition-title::before,[data-md-color-scheme=dracula] .md-typeset details.quote>summary::before{background-color:var(--md-admonition-icon-color--quote)}[data-md-color-scheme=dracula] .md-typeset .admonition.quote>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.quote>.admonition-title::after,[data-md-color-scheme=dracula] .md-typeset details.quote>summary::after{color:var(--md-admonition-icon-color--quote)}.md-typeset .admonition.config,.md-typeset .admonition.settings,.md-typeset details.config,.md-typeset details.settings{border-color:var(--md-admonition-icon-color--settings)}.md-typeset .admonition.config:focus-within,.md-typeset .admonition.settings:focus-within,.md-typeset details.config:focus-within,.md-typeset details.settings:focus-within{box-shadow:0 0 0 .2rem var(--md-admonition-shadow-color--settings)}.md-typeset .admonition.config>.admonition-title,.md-typeset .admonition.settings>.admonition-title,.md-typeset details.config>.admonition-title,.md-typeset details.config>summary,.md-typeset details.settings>.admonition-title,.md-typeset details.settings>summary{background-color:var(--md-admonition-bg-color--settings);border-color:var(--md-admonition-icon-color--settings)}.md-typeset .admonition.config>.admonition-title::before,.md-typeset .admonition.settings>.admonition-title::before,.md-typeset details.config>.admonition-title::before,.md-typeset details.config>summary::before,.md-typeset details.settings>.admonition-title::before,.md-typeset details.settings>summary::before{width:1rem;height:1rem;background-color:var(--md-admonition-icon-color--settings);background-size:1rem;-webkit-mask-image:var(--md-admonition-icon--settings);mask-image:var(--md-admonition-icon--settings);content:" "}.md-typeset .admonition.config>.admonition-title::after,.md-typeset .admonition.settings>.admonition-title::after,.md-typeset details.config>.admonition-title::after,.md-typeset details.config>summary::after,.md-typeset details.settings>.admonition-title::after,.md-typeset details.settings>summary::after{color:var(--md-admonition-icon-color--settings)}.md-typeset .admonition.new,.md-typeset details.new{border-color:var(--md-admonition-icon-color--new)}.md-typeset .admonition.new:focus-within,.md-typeset details.new:focus-within{box-shadow:0 0 0 .2rem var(--md-admonition-shadow-color--new)}.md-typeset .admonition.new>.admonition-title,.md-typeset details.new>.admonition-title,.md-typeset details.new>summary{background-color:var(--md-admonition-bg-color--new);border-color:var(--md-admonition-icon-color--new)}.md-typeset .admonition.new>.admonition-title::before,.md-typeset details.new>.admonition-title::before,.md-typeset details.new>summary::before{width:1rem;height:1rem;background-color:var(--md-admonition-icon-color--new);background-size:1rem;-webkit-mask-image:var(--md-admonition-icon--new);mask-image:var(--md-admonition-icon--new);content:" "}.md-typeset .admonition.new>.admonition-title::after,.md-typeset details.new>.admonition-title::after,.md-typeset details.new>summary::after{color:var(--md-admonition-icon-color--new)}mjx-container[display=true]{font-size:120%!important}mjx-container:not([display]){font-size:100%!important}[data-md-color-scheme=dracula] .CtxtMenu_InfoContent pre,[data-md-color-scheme=dracula] .CtxtMenu_InfoSignature input,[data-md-color-scheme=slate] .CtxtMenu_InfoContent pre,[data-md-color-scheme=slate] .CtxtMenu_InfoSignature input{color:#000}[data-md-color-scheme=dracula] .CtxtMenu_Info,[data-md-color-scheme=dracula] .CtxtMenu_Menu,[data-md-color-scheme=slate] .CtxtMenu_Info,[data-md-color-scheme=slate] .CtxtMenu_Menu{box-shadow:0 10px 20px rgba(0,0,0,.5)}.md-typeset .arithmatex{overflow-x:auto!important;overflow-y:hidden!important}.katex-display .katex-html{display:flex!important;flex-direction:row;flex-wrap:nowrap;align-items:baseline;justify-content:space-between}.katex-display .katex-html .base{display:inline!important}.katex-display .katex-html .tag{position:relative!important;display:inline!important;margin-left:var(--margin-small)}.md-typeset del.critic,.md-typeset ins.critic,.md-typeset mark.critic{padding:0 .25em;color:unset;box-shadow:none}.md-typeset .critic.break{margin:0}.md-typeset details{overflow:hidden}.md-typeset details>summary:focus{outline-style:none}.highlight .kc{color:var(--md-code-hl-constant-color)}.highlight .nc,.highlight .ne{color:var(--md-code-hl-class-color)}.highlight .mb{color:var(--md-code-hl-number-color)}.highlight .bp,.highlight .nb{color:var(--md-code-hl-builtin-color)}.highlight .nn{color:var(--md-code-hl-namespace-color)}.highlight .na,.highlight .nd,.highlight .ni{color:var(--md-code-hl-entity-color)}.highlight .nl,.highlight .nt{color:var(--md-code-hl-tag-color)}.md-typeset :not(pre)>code{margin:0;padding:0 .2941176471em;color:var(--md-code-fg-color);background-color:var(--md-code-inline-bg-color);border-radius:.1rem;box-shadow:none}.md-typeset a>code{color:inherit!important;background-color:var(--md-code-link-bg-color)!important;transition:color 125ms;transition:background-color 125ms}.md-typeset a>code *{color:var(--md-typeset-a-color)!important}.md-typeset a>code:hover{background-color:var(--md-code-link-accent-bg-color)!important}.md-typeset a>code:hover *{color:var(--md-accent-fg-color)!important}.md-typeset pre>code{outline:0}.md-typeset td code{word-break:normal}.md-typeset .highlight{-moz-tab-size:8;-o-tab-size:8;tab-size:8}.md-typeset .highlight+.result{border-width:.1rem}.md-typeset .highlight [data-linenos].special::before{background-color:var(--md-code-special-bg-color)}.md-typeset .highlighttable .linenodiv .special{margin-right:-.5882352941em;margin-left:-1.1764705882em;padding-right:.5882352941em;padding-left:1.1764705882em;background-color:var(--md-code-special-bg-color)}.md-typeset .highlight span.filename{position:relative;display:block;margin-top:1em;padding:.5em 1.1764705882em .5em 2.9411764706em;font-weight:700;font-size:.68rem;background-color:var(--md-code-title-bg-color);border-top-left-radius:.1rem;border-top-right-radius:.1rem}.md-typeset .highlight span.filename+pre{margin-top:0}.md-typeset .highlight span.filename+pre code{border-top-left-radius:0;border-top-right-radius:0}.md-typeset .highlight span.filename::before{position:absolute;left:.8823529412em;width:1.4705882353em;height:1.4705882353em;background-color:var(--md-default-fg-color);-webkit-mask-image:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M20 19V7H4v12h16m0-16a2 2 0 0 1 2 2v14a2 2 0 0 1-2 2H4a2 2 0 0 1-2-2V5a2 2 0 0 1 2-2h16m-7 14v-2h5v2h-5m-3.42-4L5.57 9H8.4l3.3 3.3c.39.39.39 1.03 0 1.42L8.42 17H5.59l3.99-4Z"/></svg>');mask-image:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M20 19V7H4v12h16m0-16a2 2 0 0 1 2 2v14a2 2 0 0 1-2 2H4a2 2 0 0 1-2-2V5a2 2 0 0 1 2-2h16m-7 14v-2h5v2h-5m-3.42-4L5.57 9H8.4l3.3 3.3c.39.39.39 1.03 0 1.42L8.42 17H5.59l3.99-4Z"/></svg>');-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;content:""}.md-typeset .collapse-code{position:relative;margin-top:1em;margin-bottom:1em}.md-typeset .collapse-code pre{margin-top:0;margin-bottom:0}.md-typeset .collapse-code input{display:none}.md-typeset .collapse-code input~.code-footer{width:100%;margin:0;padding:.25em .5em .25em 0}.md-typeset .collapse-code input~.code-footer label{position:relative;margin:.05em;padding:.15em .8em;color:var(--md-primary-bg-color);font-size:90%;background-color:var(--md-primary-fg-color);-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;border-radius:.1rem;cursor:pointer;content:""}.md-typeset .collapse-code input~.code-footer label:hover{background-color:var(--md-accent-fg-color)}.md-typeset .collapse-code input~.code-footer label::before{position:absolute;top:.15em;left:.15em;display:block;box-sizing:border-box;width:1.25em;height:1.25em;background-color:var(--md-primary-bg-color);background-size:1.25em;content:""}.md-typeset .collapse-code input~.code-footer label.expand{display:none}.md-typeset .collapse-code input~.code-footer label.expand::before{-webkit-mask-image:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M10 21v-2H6.41l4.5-4.5-1.41-1.41-4.5 4.5V14H3v7h7m4.5-10.09 4.5-4.5V10h2V3h-7v2h3.59l-4.5 4.5 1.41 1.41Z"/></svg>');mask-image:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M10 21v-2H6.41l4.5-4.5-1.41-1.41-4.5 4.5V14H3v7h7m4.5-10.09 4.5-4.5V10h2V3h-7v2h3.59l-4.5 4.5 1.41 1.41Z"/></svg>')}.md-typeset .collapse-code input~.code-footer label.collapse::before{-webkit-mask-image:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M19.5 3.09 15 7.59V4h-2v7h7V9h-3.59l4.5-4.5-1.41-1.41M4 13v2h3.59l-4.5 4.5 1.41 1.41 4.5-4.5V20h2v-7H4Z"/></svg>');mask-image:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M19.5 3.09 15 7.59V4h-2v7h7V9h-3.59l4.5-4.5-1.41-1.41M4 13v2h3.59l-4.5 4.5 1.41 1.41 4.5-4.5V20h2v-7H4Z"/></svg>')}.md-typeset .collapse-code input:checked~.code-footer label.expand{display:inline}.md-typeset .collapse-code input:checked~.code-footer label.collapse{display:none}.md-typeset .collapse-code input:checked+div.highlight code{max-height:9.375em;overflow:hidden}.md-typeset .collapse-code input:checked~.code-footer{position:absolute;bottom:0;left:0;padding:2em .5em .5em .8rem;background-image:linear-gradient(to bottom,transparent,var(--md-default-bg-color) 80% 100%)}.md-typeset .keys .key-power::before{padding-right:.4em;content:"⏻"}.md-typeset .keys .key-fingerprint::before{padding-right:.4em;content:"☝"}:root>*{--magiclink-email-icon:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M20 4H4c-1.11 0-2 .89-2 2v12a2 2 0 0 0 2 2h16a2 2 0 0 0 2-2V6a2 2 0 0 0-2-2m-3 13H7v-2h10m0-2H7v-2h10m3-2h-3V6h3"/></svg>');--magiclink-github-icon:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M12 2A10 10 0 0 0 2 12c0 4.42 2.87 8.17 6.84 9.5.5.08.66-.23.66-.5v-1.69c-2.77.6-3.36-1.34-3.36-1.34-.46-1.16-1.11-1.47-1.11-1.47-.91-.62.07-.6.07-.6 1 .07 1.53 1.03 1.53 1.03.87 1.52 2.34 1.07 2.91.83.09-.65.35-1.09.63-1.34-2.22-.25-4.55-1.11-4.55-4.92 0-1.11.38-2 1.03-2.71-.1-.25-.45-1.29.1-2.64 0 0 .84-.27 2.75 1.02.79-.22 1.65-.33 2.5-.33.85 0 1.71.11 2.5.33 1.91-1.29 2.75-1.02 2.75-1.02.55 1.35.2 2.39.1 2.64.65.71 1.03 1.6 1.03 2.71 0 3.82-2.34 4.66-4.57 4.91.36.31.69.92.69 1.85V21c0 .27.16.59.67.5C19.14 20.16 22 16.42 22 12A10 10 0 0 0 12 2Z"/></svg>');--magiclink-bitbucket-icon:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M2.65 3C2.3 3 2 3.3 2 3.65v.12l2.73 16.5c.07.42.43.73.85.73h13.05c.31 0 .59-.22.64-.54L22 3.77a.643.643 0 0 0-.54-.73c-.03-.01-.07-.01-.11-.01L2.65 3M14.1 14.95H9.94L8.81 9.07h6.3l-1.01 5.88Z"/></svg>');--magiclink-gitlab-icon:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="m21.94 13.11-1.05-3.22c0-.03-.01-.06-.02-.09l-2.11-6.48a.859.859 0 0 0-.8-.57c-.36 0-.68.25-.79.58l-2 6.17H8.84L6.83 3.33a.851.851 0 0 0-.79-.58c-.37 0-.69.25-.8.58L3.13 9.82v.01l-1.07 3.28c-.16.5.01 1.04.44 1.34l9.22 6.71c.17.12.39.12.56-.01l9.22-6.7c.43-.3.6-.84.44-1.34M8.15 10.45l2.57 7.91-6.17-7.91m8.73 7.92 2.47-7.59.1-.33h3.61l-5.59 7.16m4.1-13.67 1.81 5.56h-3.62m-1.3.95-1.79 5.51L12 19.24l-2.86-8.79M6.03 3.94 7.84 9.5H4.23m-1.18 4.19c-.09-.07-.13-.19-.09-.29l.79-2.43 5.82 7.45m11.38-4.73-6.51 4.73.02-.03 5.79-7.42.79 2.43c.04.1 0 .22-.09.29"/></svg>');--magiclink-commit-icon:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M16.944 11h4.306a.75.75 0 0 1 0 1.5h-4.306a5.001 5.001 0 0 1-9.888 0H2.75a.75.75 0 0 1 0-1.5h4.306a5.001 5.001 0 0 1 9.888 0Zm-1.444.75a3.5 3.5 0 1 0-7 0 3.5 3.5 0 0 0 7 0Z"/></svg>');--magiclink-compare-icon:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M12.5 6.75a.75.75 0 0 0-1.5 0V9H8.75a.75.75 0 0 0 0 1.5H11v2.25a.75.75 0 0 0 1.5 0V10.5h2.25a.75.75 0 0 0 0-1.5H12.5V6.75ZM8.75 16a.75.75 0 0 0 0 1.5h6a.75.75 0 0 0 0-1.5h-6Z"/><path d="M5 1h9.982a2 2 0 0 1 1.414.586l4.018 4.018A2 2 0 0 1 21 7.018V21a2 2 0 0 1-2 2H5a2 2 0 0 1-2-2V3a2 2 0 0 1 2-2Zm-.5 2v18a.5.5 0 0 0 .5.5h14a.5.5 0 0 0 .5-.5V7.018a.5.5 0 0 0-.146-.354l-4.018-4.018a.5.5 0 0 0-.354-.146H5a.5.5 0 0 0-.5.5Z"/></svg>');--magiclink-pull-icon:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M16 19.25a3.25 3.25 0 1 1 6.5 0 3.25 3.25 0 0 1-6.5 0Zm-14.5 0a3.25 3.25 0 1 1 6.5 0 3.25 3.25 0 0 1-6.5 0Zm0-14.5a3.25 3.25 0 1 1 6.5 0 3.25 3.25 0 0 1-6.5 0ZM4.75 3a1.75 1.75 0 1 0 .001 3.501A1.75 1.75 0 0 0 4.75 3Zm0 14.5a1.75 1.75 0 1 0 .001 3.501A1.75 1.75 0 0 0 4.75 17.5Zm14.5 0a1.75 1.75 0 1 0 .001 3.501 1.75 1.75 0 0 0-.001-3.501Z"/><path d="M13.405 1.72a.75.75 0 0 1 0 1.06L12.185 4h4.065A3.75 3.75 0 0 1 20 7.75v8.75a.75.75 0 0 1-1.5 0V7.75a2.25 2.25 0 0 0-2.25-2.25h-4.064l1.22 1.22a.75.75 0 0 1-1.061 1.06l-2.5-2.5a.75.75 0 0 1 0-1.06l2.5-2.5a.75.75 0 0 1 1.06 0ZM4.75 7.25A.75.75 0 0 1 5.5 8v8A.75.75 0 0 1 4 16V8a.75.75 0 0 1 .75-.75Z"/></svg>');--magiclink-issue-icon:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M12 1c6.075 0 11 4.925 11 11s-4.925 11-11 11S1 18.075 1 12 5.925 1 12 1ZM2.5 12a9.5 9.5 0 0 0 9.5 9.5 9.5 9.5 0 0 0 9.5-9.5A9.5 9.5 0 0 0 12 2.5 9.5 9.5 0 0 0 2.5 12Zm9.5 2a2 2 0 1 1-.001-3.999A2 2 0 0 1 12 14Z"/></svg>');--magiclink-discussion-icon:url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M1.75 1h12.5c.966 0 1.75.784 1.75 1.75v9.5A1.75 1.75 0 0 1 14.25 14H8.061l-2.574 2.573A1.458 1.458 0 0 1 3 15.543V14H1.75A1.75 1.75 0 0 1 0 12.25v-9.5C0 1.784.784 1 1.75 1ZM1.5 2.75v9.5c0 .138.112.25.25.25h2a.75.75 0 0 1 .75.75v2.19l2.72-2.72a.749.749 0 0 1 .53-.22h6.5a.25.25 0 0 0 .25-.25v-9.5a.25.25 0 0 0-.25-.25H1.75a.25.25 0 0 0-.25.25Z"/><path d="M22.5 8.75a.25.25 0 0 0-.25-.25h-3.5a.75.75 0 0 1 0-1.5h3.5c.966 0 1.75.784 1.75 1.75v9.5A1.75 1.75 0 0 1 22.25 20H21v1.543a1.457 1.457 0 0 1-2.487 1.03L15.939 20H10.75A1.75 1.75 0 0 1 9 18.25v-1.465a.75.75 0 0 1 1.5 0v1.465c0 .138.112.25.25.25h5.5a.75.75 0 0 1 .53.22l2.72 2.72v-2.19a.75.75 0 0 1 .75-.75h2a.25.25 0 0 0 .25-.25v-9.5Z"/></svg>')}.md-typeset a[href^="mailto:"]:not(.magiclink-ignore)::before{-webkit-mask-image:var(--magiclink-email-icon);mask-image:var(--magiclink-email-icon)}.md-typeset .magiclink-commit:not(.magiclink-ignore),.md-typeset .magiclink-compare:not(.magiclink-ignore),.md-typeset .magiclink-discussion:not(.magiclink-ignore),.md-typeset .magiclink-issue:not(.magiclink-ignore),.md-typeset .magiclink-pull:not(.magiclink-ignore),.md-typeset .magiclink-repository:not(.magiclink-ignore),.md-typeset a[href^="mailto:"]:not(.magiclink-ignore){position:relative;padding-left:1.375em}.md-typeset .magiclink-commit:not(.magiclink-ignore)::before,.md-typeset .magiclink-compare:not(.magiclink-ignore)::before,.md-typeset .magiclink-discussion:not(.magiclink-ignore)::before,.md-typeset .magiclink-issue:not(.magiclink-ignore)::before,.md-typeset .magiclink-pull:not(.magiclink-ignore)::before,.md-typeset .magiclink-repository:not(.magiclink-ignore)::before,.md-typeset a[href^="mailto:"]:not(.magiclink-ignore)::before{position:absolute;top:0;left:0;display:block;box-sizing:border-box;width:1.25em;height:1.25em;background-color:var(--md-typeset-a-color);background-size:1.25em;transition:background-color 125ms;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;content:""}.md-typeset .magiclink-commit:not(.magiclink-ignore):hover::before,.md-typeset .magiclink-compare:not(.magiclink-ignore):hover::before,.md-typeset .magiclink-discussion:not(.magiclink-ignore):hover::before,.md-typeset .magiclink-issue:not(.magiclink-ignore):hover::before,.md-typeset .magiclink-pull:not(.magiclink-ignore):hover::before,.md-typeset .magiclink-repository:not(.magiclink-ignore):hover::before,.md-typeset a[href^="mailto:"]:not(.magiclink-ignore):hover::before{background-color:var(--md-accent-fg-color)}.md-typeset .magiclink-commit:not(.magiclink-ignore)::before{-webkit-mask-image:var(--magiclink-commit-icon);mask-image:var(--magiclink-commit-icon)}.md-typeset .magiclink-compare:not(.magiclink-ignore)::before{-webkit-mask-image:var(--magiclink-compare-icon);mask-image:var(--magiclink-compare-icon)}.md-typeset .magiclink-pull:not(.magiclink-ignore)::before{-webkit-mask-image:var(--magiclink-pull-icon);mask-image:var(--magiclink-pull-icon)}.md-typeset .magiclink-issue:not(.magiclink-ignore)::before{-webkit-mask-image:var(--magiclink-issue-icon);mask-image:var(--magiclink-issue-icon)}.md-typeset .magiclink-discussion:not(.magiclink-ignore)::before{-webkit-mask-image:var(--magiclink-discussion-icon);mask-image:var(--magiclink-discussion-icon)}.md-typeset .magiclink-repository.magiclink-github:not(.magiclink-ignore)::before{-webkit-mask-image:var(--magiclink-github-icon);mask-image:var(--magiclink-github-icon)}.md-typeset .magiclink-repository.magiclink-gitlab:not(.magiclink-ignore)::before{-webkit-mask-image:var(--magiclink-gitlab-icon);mask-image:var(--magiclink-gitlab-icon)}.md-typeset .magiclink-repository.magiclink-bitbucket:not(.magiclink-ignore)::before{-webkit-mask-image:var(--magiclink-bitbucket-icon);mask-image:var(--magiclink-bitbucket-icon)}.md-typeset mark:not(.critic){box-shadow:none}.md-typeset .progress-label{position:absolute;width:100%;margin:0;color:var(--md-text-color);font-weight:700;line-height:1.4rem;white-space:nowrap;text-align:center;text-shadow:-.0625em -.0625em .375em var(--md-default-bg-color--light),.0625em -.0625em .375em var(--md-default-bg-color--light),-.0625em .0625em .375em var(--md-default-bg-color--light),.0625em .0625em .375em var(--md-default-bg-color--light)}.md-typeset .progress-bar{float:left;height:1.2rem;background-color:#2979ff}.md-typeset .candystripe-animate .progress-bar{animation:animate-stripes 3s linear infinite}.md-typeset .progress{position:relative;display:block;width:100%;height:1.2rem;margin:.5rem 0;background-color:var(--md-default-fg-color--lightest)}.md-typeset .progress.thin{height:.4rem;margin-top:.9rem}.md-typeset .progress.thin .progress-label{margin-top:-.4rem}.md-typeset .progress.thin .progress-bar{height:.4rem}.md-typeset .progress.candystripe .progress-bar{background-image:linear-gradient(135deg,var(--md-progress-stripe) 27%,transparent 27%,transparent 52%,var(--md-progress-stripe) 52%,var(--md-progress-stripe) 77%,transparent 77%,transparent);background-size:2rem 2rem}.md-typeset .progress-100plus .progress-bar{background-color:var(--md-progress-100)}.md-typeset .progress-80plus .progress-bar{background-color:var(--md-progress-80)}.md-typeset .progress-60plus .progress-bar{background-color:var(--md-progress-60)}.md-typeset .progress-40plus .progress-bar{background-color:var(--md-progress-40)}.md-typeset .progress-20plus .progress-bar{background-color:var(--md-progress-20)}.md-typeset .progress-0plus .progress-bar{background-color:var(--md-progress-0)}@keyframes animate-stripes{0%{background-position:0 0}100%{background-position:6rem 0}}[data-md-color-scheme=dracula] .md-typeset .tabbed-set>.tabbed-labels{box-shadow:0 -.05rem var(--md-default-fg-color--lighter) inset}.md-typeset .tabbed-alternate.tabbed-set .tabbed-control{width:2rem}.md-typeset .tabbed-alternate.tabbed-set .tabbed-control[hidden]{width:1.2rem;opacity:0}.md-typeset .tabbed-alternate.tabbed-set>.tabbed-content>.tabbed-block{padding:0 .6rem}.md-typeset .tabbed-alternate.tabbed-set>.tabbed-content>.tabbed-block>.codehilite:only-child,.md-typeset .tabbed-alternate.tabbed-set>.tabbed-content>.tabbed-block>.codehilitetable:only-child,.md-typeset .tabbed-alternate.tabbed-set>.tabbed-content>.tabbed-block>.highlight:only-child,.md-typeset .tabbed-alternate.tabbed-set>.tabbed-content>.tabbed-block>.highlighttable:only-child,.md-typeset .tabbed-alternate.tabbed-set>.tabbed-content>.tabbed-block>pre:only-child{margin-right:-1.2rem;margin-left:-1.2rem;padding-right:.6rem;padding-left:.6rem}.md-typeset .tabbed-alternate.tabbed-set>.tabbed-content>.tabbed-block>.codehilite:only-child span.filename,.md-typeset .tabbed-alternate.tabbed-set>.tabbed-content>.tabbed-block>.codehilitetable:only-child span.filename,.md-typeset .tabbed-alternate.tabbed-set>.tabbed-content>.tabbed-block>.highlight:only-child span.filename,.md-typeset .tabbed-alternate.tabbed-set>.tabbed-content>.tabbed-block>.highlighttable:only-child span.filename,.md-typeset .tabbed-alternate.tabbed-set>.tabbed-content>.tabbed-block>pre:only-child span.filename{margin-top:0}.md-typeset .tabbed-alternate.tabbed-set>.tabbed-content>.tabbed-block>.collapse-code:only-child{margin-top:0;margin-right:-1.2rem;margin-left:-1.2rem;padding-right:.6rem;padding-left:.6rem}.md-typeset .tabbed-alternate.tabbed-set>.tabbed-content>.tabbed-block>.collapse-code:only-child>.code-footer{left:.6rem}.md-typeset .tabbed-alternate.tabbed-set>.tabbed-content>.tabbed-block>diagram-div:only-child{margin-right:-1.2rem;margin-left:-1.2rem;padding-right:.6rem;padding-left:.6rem}.js .md-typeset .tabbed-labels::before{background-color:var(--md-accent-fg-color)}[data-md-color-scheme=dracula] .md-typeset table:not([class]){box-shadow:var(--md-shadow-z2)}[data-md-color-scheme=dracula] .md-typeset table:not([class]) tr:hover{background-color:rgba(0,0,0,.08)}[data-md-color-scheme=dracula] .md-typeset table:not([class]) th{color:var(--md-text-color);background-color:var(--md-default-bg-color--ultra-dark);border-bottom:.05rem solid var(--md-primary-fg-color)}[data-md-color-scheme=dracula] .md-typeset table:not([class]) td{border-top:.05
gitextract_waa09c9u/
├── .commitlintrc
├── .dockerignore
├── .gitattributes
├── .github/
│ ├── ISSUE_TEMPLATE/
│ │ ├── bug_report.yml
│ │ ├── config.yml
│ │ └── feature_request.yml
│ ├── PULL_REQUEST_TEMPLATE.md
│ └── workflows/
│ ├── auto-bump-and-release.yaml
│ ├── build-push-docker.yaml
│ ├── pr-lint.yaml
│ ├── style-check.yaml
│ └── unit-test.yaml
├── .gitignore
├── .pre-commit-config.yaml
├── .python-version
├── CODE_OF_CONDUCT.md
├── CONTRIBUTING.md
├── Dockerfile
├── LICENSE.txt
├── README.md
├── app.py
├── doc_env_reqs.txt
├── docs/
│ ├── about.md
│ ├── development/
│ │ ├── contributing.md
│ │ ├── create-a-component.md
│ │ ├── data-components.md
│ │ ├── index.md
│ │ └── utilities.md
│ ├── extra/
│ │ └── css/
│ │ └── code_select.css
│ ├── index.md
│ ├── local_model.md
│ ├── online_install.md
│ ├── pages/
│ │ └── app/
│ │ ├── customize-flows.md
│ │ ├── ext/
│ │ │ └── user-management.md
│ │ ├── features.md
│ │ ├── functional-description.md
│ │ ├── index/
│ │ │ └── file.md
│ │ └── settings/
│ │ ├── overview.md
│ │ └── user-settings.md
│ ├── scripts/
│ │ ├── generate_examples_docs.py
│ │ └── generate_reference_docs.py
│ ├── theme/
│ │ ├── assets/
│ │ │ └── pymdownx-extras/
│ │ │ ├── extra-fb5a2a1c86.css
│ │ │ ├── extra-loader-MCFnu0Wd.js
│ │ │ ├── material-extra-3rdparty-E-i8w1WA.js
│ │ │ └── material-extra-theme-TVq-kNRT.js
│ │ ├── main.html
│ │ └── partials/
│ │ ├── footer.html
│ │ ├── header.html
│ │ └── libs.html
│ └── usage.md
├── flowsettings.py
├── fly.toml
├── launch.sh
├── libs/
│ ├── kotaemon/
│ │ ├── README.md
│ │ ├── kotaemon/
│ │ │ ├── __init__.py
│ │ │ ├── agents/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── io/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── base.py
│ │ │ │ ├── langchain_based.py
│ │ │ │ ├── react/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── agent.py
│ │ │ │ │ └── prompt.py
│ │ │ │ ├── rewoo/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── agent.py
│ │ │ │ │ ├── planner.py
│ │ │ │ │ ├── prompt.py
│ │ │ │ │ └── solver.py
│ │ │ │ ├── tools/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── base.py
│ │ │ │ │ ├── google.py
│ │ │ │ │ ├── llm.py
│ │ │ │ │ ├── mcp.py
│ │ │ │ │ └── wikipedia.py
│ │ │ │ └── utils.py
│ │ │ ├── base/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── component.py
│ │ │ │ └── schema.py
│ │ │ ├── chatbot/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ └── simple_respondent.py
│ │ │ ├── cli.py
│ │ │ ├── contribs/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── docs.py
│ │ │ │ └── promptui/
│ │ │ │ ├── .gitignore
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── cli.py
│ │ │ │ ├── config.py
│ │ │ │ ├── export.py
│ │ │ │ ├── logs.py
│ │ │ │ ├── themes.py
│ │ │ │ ├── tunnel.py
│ │ │ │ └── ui/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── blocks.py
│ │ │ │ ├── chat.py
│ │ │ │ └── pipeline.py
│ │ │ ├── embeddings/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── endpoint_based.py
│ │ │ │ ├── fastembed.py
│ │ │ │ ├── langchain_based.py
│ │ │ │ ├── openai.py
│ │ │ │ ├── tei_endpoint_embed.py
│ │ │ │ └── voyageai.py
│ │ │ ├── indices/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── extractors/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── doc_parsers.py
│ │ │ │ ├── ingests/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── files.py
│ │ │ │ ├── qa/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── citation.py
│ │ │ │ │ ├── citation_qa.py
│ │ │ │ │ ├── citation_qa_inline.py
│ │ │ │ │ ├── format_context.py
│ │ │ │ │ └── utils.py
│ │ │ │ ├── rankings/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── base.py
│ │ │ │ │ ├── cohere.py
│ │ │ │ │ ├── llm.py
│ │ │ │ │ ├── llm_scoring.py
│ │ │ │ │ └── llm_trulens.py
│ │ │ │ ├── retrievers/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── jina_web_search.py
│ │ │ │ │ └── tavily_web_search.py
│ │ │ │ ├── splitters/
│ │ │ │ │ └── __init__.py
│ │ │ │ └── vectorindex.py
│ │ │ ├── llms/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── branching.py
│ │ │ │ ├── chats/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── base.py
│ │ │ │ │ ├── endpoint_based.py
│ │ │ │ │ ├── langchain_based.py
│ │ │ │ │ ├── llamacpp.py
│ │ │ │ │ └── openai.py
│ │ │ │ ├── completions/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── base.py
│ │ │ │ │ └── langchain_based.py
│ │ │ │ ├── cot.py
│ │ │ │ ├── linear.py
│ │ │ │ └── prompts/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ └── template.py
│ │ │ ├── loaders/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── adobe_loader.py
│ │ │ │ ├── azureai_document_intelligence_loader.py
│ │ │ │ ├── base.py
│ │ │ │ ├── composite_loader.py
│ │ │ │ ├── docling_loader.py
│ │ │ │ ├── docx_loader.py
│ │ │ │ ├── excel_loader.py
│ │ │ │ ├── html_loader.py
│ │ │ │ ├── mathpix_loader.py
│ │ │ │ ├── ocr_loader.py
│ │ │ │ ├── pdf_loader.py
│ │ │ │ ├── txt_loader.py
│ │ │ │ ├── unstructured_loader.py
│ │ │ │ ├── utils/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── adobe.py
│ │ │ │ │ ├── box.py
│ │ │ │ │ ├── gpt4v.py
│ │ │ │ │ ├── pdf_ocr.py
│ │ │ │ │ └── table.py
│ │ │ │ └── web_loader.py
│ │ │ ├── parsers/
│ │ │ │ ├── __init__.py
│ │ │ │ └── regex_extractor.py
│ │ │ ├── rerankings/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── cohere.py
│ │ │ │ ├── tei_fast_rerank.py
│ │ │ │ └── voyageai.py
│ │ │ └── storages/
│ │ │ ├── __init__.py
│ │ │ ├── docstores/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── elasticsearch.py
│ │ │ │ ├── in_memory.py
│ │ │ │ ├── lancedb.py
│ │ │ │ └── simple_file.py
│ │ │ └── vectorstores/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── chroma.py
│ │ │ ├── in_memory.py
│ │ │ ├── lancedb.py
│ │ │ ├── milvus.py
│ │ │ ├── qdrant.py
│ │ │ └── simple_file.py
│ │ ├── pyproject.toml
│ │ ├── pytest.ini
│ │ └── tests/
│ │ ├── __init__.py
│ │ ├── _test_multimodal_reader.py
│ │ ├── conftest.py
│ │ ├── resources/
│ │ │ ├── dummy.docx
│ │ │ ├── dummy.mhtml
│ │ │ ├── dummy.xlsx
│ │ │ ├── embedding_openai.json
│ │ │ ├── embedding_openai_batch.json
│ │ │ ├── fullocr_sample_output.json
│ │ │ ├── ggml-vocab-llama.gguf
│ │ │ ├── html/
│ │ │ │ └── dummy.html
│ │ │ └── policy.md
│ │ ├── simple_pipeline.py
│ │ ├── test_agent.py
│ │ ├── test_composite.py
│ │ ├── test_cot.py
│ │ ├── test_docstores.py
│ │ ├── test_documents.py
│ │ ├── test_embedding_models.py
│ │ ├── test_indexing_retrieval.py
│ │ ├── test_ingestor.py
│ │ ├── test_llms_chat_models.py
│ │ ├── test_llms_completion_models.py
│ │ ├── test_mcp_manager.py
│ │ ├── test_mcp_tools.py
│ │ ├── test_post_processing.py
│ │ ├── test_prompt.py
│ │ ├── test_promptui.py
│ │ ├── test_reader.py
│ │ ├── test_reranking.py
│ │ ├── test_splitter.py
│ │ ├── test_table_reader.py
│ │ ├── test_telemetry.py
│ │ ├── test_template.py
│ │ ├── test_tools.py
│ │ └── test_vectorstore.py
│ └── ktem/
│ ├── .gitignore
│ ├── MANIFEST.in
│ ├── alembic.ini
│ ├── ktem/
│ │ ├── __init__.py
│ │ ├── app.py
│ │ ├── assets/
│ │ │ ├── __init__.py
│ │ │ ├── css/
│ │ │ │ └── main.css
│ │ │ ├── js/
│ │ │ │ ├── main.js
│ │ │ │ └── pdf_viewer.js
│ │ │ ├── md/
│ │ │ │ ├── about.md
│ │ │ │ ├── changelogs.md
│ │ │ │ └── usage.md
│ │ │ └── theme.py
│ │ ├── components.py
│ │ ├── db/
│ │ │ ├── __init__.py
│ │ │ ├── base_models.py
│ │ │ ├── engine.py
│ │ │ └── models.py
│ │ ├── embeddings/
│ │ │ ├── __init__.py
│ │ │ ├── db.py
│ │ │ ├── manager.py
│ │ │ └── ui.py
│ │ ├── exceptions.py
│ │ ├── extension_protocol.py
│ │ ├── index/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── file/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── exceptions.py
│ │ │ │ ├── graph/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── graph_index.py
│ │ │ │ │ ├── light_graph_index.py
│ │ │ │ │ ├── lightrag_pipelines.py
│ │ │ │ │ ├── nano_graph_index.py
│ │ │ │ │ ├── nano_pipelines.py
│ │ │ │ │ ├── pipelines.py
│ │ │ │ │ └── visualize.py
│ │ │ │ ├── index.py
│ │ │ │ ├── knet/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── knet_index.py
│ │ │ │ │ └── pipelines.py
│ │ │ │ ├── pipelines.py
│ │ │ │ ├── ui.py
│ │ │ │ └── utils.py
│ │ │ ├── manager.py
│ │ │ ├── models.py
│ │ │ └── ui.py
│ │ ├── llms/
│ │ │ ├── __init__.py
│ │ │ ├── db.py
│ │ │ ├── manager.py
│ │ │ └── ui.py
│ │ ├── main.py
│ │ ├── mcp/
│ │ │ ├── __init__.py
│ │ │ ├── db.py
│ │ │ ├── manager.py
│ │ │ └── ui.py
│ │ ├── pages/
│ │ │ ├── __init__.py
│ │ │ ├── chat/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── chat_panel.py
│ │ │ │ ├── chat_suggestion.py
│ │ │ │ ├── common.py
│ │ │ │ ├── control.py
│ │ │ │ ├── demo_hint.py
│ │ │ │ ├── paper_list.py
│ │ │ │ └── report.py
│ │ │ ├── help.py
│ │ │ ├── login.py
│ │ │ ├── resources/
│ │ │ │ ├── __init__.py
│ │ │ │ └── user.py
│ │ │ ├── settings.py
│ │ │ └── setup.py
│ │ ├── reasoning/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── prompt_optimization/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── decompose_question.py
│ │ │ │ ├── fewshot_rewrite_question.py
│ │ │ │ ├── mindmap.py
│ │ │ │ ├── rephrase_question_train.json
│ │ │ │ ├── rewrite_question.py
│ │ │ │ ├── suggest_conversation_name.py
│ │ │ │ └── suggest_followup_chat.py
│ │ │ ├── react.py
│ │ │ ├── rewoo.py
│ │ │ └── simple.py
│ │ ├── rerankings/
│ │ │ ├── __init__.py
│ │ │ ├── db.py
│ │ │ ├── manager.py
│ │ │ └── ui.py
│ │ ├── settings.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ ├── commands.py
│ │ ├── conversation.py
│ │ ├── file.py
│ │ ├── generator.py
│ │ ├── hf_papers.py
│ │ ├── lang.py
│ │ ├── plantuml.py
│ │ ├── rate_limit.py
│ │ ├── render.py
│ │ └── visualize_cited.py
│ ├── ktem_tests/
│ │ ├── __init__.py
│ │ ├── resources/
│ │ │ └── embedding_openai.json
│ │ └── test_qa.py
│ ├── migrations/
│ │ ├── README
│ │ ├── env.py
│ │ ├── script.py.mako
│ │ └── versions/
│ │ └── .keep
│ ├── pyproject.toml
│ └── requirements.txt
├── mkdocs.yml
├── pyproject.toml
├── scripts/
│ ├── download_pdfjs.sh
│ ├── migrate/
│ │ ├── __init__.py
│ │ └── migrate_chroma_db.py
│ ├── run_linux.sh
│ ├── run_macos.sh
│ ├── run_windows.bat
│ ├── serve_local.py
│ ├── server_llamacpp_linux.sh
│ ├── server_llamacpp_macos.sh
│ ├── server_llamacpp_windows.bat
│ ├── update_linux.sh
│ ├── update_macos.sh
│ └── update_windows.bat
├── settings.yaml.example
├── sso_app.py
├── sso_app_demo.py
└── templates/
├── component-default/
│ └── README.md
└── project-default/
├── cookiecutter.json
└── {{cookiecutter.project_name}}/
├── .gitattributes
├── .gitignore
├── .pre-commit-config.yaml
├── README.md
├── setup.py
├── tests/
│ └── __init__.py
└── {{cookiecutter.project_name}}/
├── __init__.py
└── pipeline.py
SYMBOL INDEX (1642 symbols across 212 files)
FILE: docs/scripts/generate_examples_docs.py
function generate_docs_for_examples_readme (line 17) | def generate_docs_for_examples_readme(
FILE: docs/scripts/generate_reference_docs.py
function generate_docs_for_src_code (line 19) | def generate_docs_for_src_code(
FILE: docs/theme/assets/pymdownx-extras/extra-loader-MCFnu0Wd.js
function _typeof (line 1) | function _typeof(t){return _typeof="function"==typeof Symbol&&"symbol"==...
function t (line 1) | function t(){t=function(){return r};var e,r={},n=Object.prototype,o=n.ha...
function e (line 1) | function e(t,e,r,n,o,i,a){try{var c=t[i](a),u=c.value}catch(t){return vo...
function r (line 1) | function r(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a ...
function n (line 1) | function n(t,e){for(var r=0;r<e.length;r++){var n=e[r];n.enumerable=n.en...
function o (line 1) | function o(t,e){if("function"!=typeof e&&null!==e)throw new TypeError("S...
function i (line 1) | function i(t){return i=Object.setPrototypeOf?Object.getPrototypeOf.bind(...
function a (line 1) | function a(t,e){return a=Object.setPrototypeOf?Object.setPrototypeOf.bin...
function c (line 1) | function c(){if("undefined"==typeof Reflect||!Reflect.construct)return!1...
function u (line 1) | function u(t,e,r){return u=c()?Reflect.construct.bind():function(t,e,r){...
function l (line 1) | function l(t){var e="function"==typeof Map?new Map:void 0;return l=funct...
function f (line 1) | function f(t,e){if(e&&("object"===_typeof(e)||"function"==typeof e))retu...
function d (line 1) | function d(){var t;r(this,d);var e=(t=h.call(this)).attachShadow({mode:"...
function c (line 1) | function c(t){e(i,n,o,c,u,"next",t)}
function u (line 1) | function u(t){e(i,n,o,c,u,"throw",t)}
FILE: libs/kotaemon/kotaemon/__init__.py
function capture (line 8) | def capture(*args, **kwargs):
FILE: libs/kotaemon/kotaemon/agents/base.py
class BaseAgent (line 10) | class BaseAgent(BaseComponent):
method safeguard_run (line 37) | def safeguard_run(run_func, *args, **kwargs):
method add_tools (line 51) | def add_tools(self, tools: list[BaseTool]) -> None:
method run (line 55) | def run(self, *args, **kwargs) -> AgentOutput | list[AgentOutput]:
FILE: libs/kotaemon/kotaemon/agents/io/base.py
function check_log (line 13) | def check_log():
class AgentType (line 22) | class AgentType(Enum):
class BaseScratchPad (line 36) | class BaseScratchPad:
method __init__ (line 93) | def __init__(self):
method stop (line 101) | def stop(self):
method update_status (line 106) | def update_status(self, output: str, **kwargs):
method thinking (line 113) | def thinking(self, name: str):
method done (line 120) | def done(self, _all=False):
method stream_print (line 128) | def stream_print(self, item: str):
method json_print (line 133) | def json_print(self, item: Dict[str, Any]):
method panel_print (line 140) | def panel_print(self, item: Any, title: str = "Output", stream: bool =...
method clear (line 158) | def clear(self):
method print (line 163) | def print(self, content: str, **kwargs):
method format_json (line 171) | def format_json(self, json_obj: str):
method debug (line 178) | def debug(self, content: str, **kwargs):
method info (line 185) | def info(self, content: str, **kwargs):
method warning (line 192) | def warning(self, content: str, **kwargs):
method error (line 199) | def error(self, content: str, **kwargs):
method critical (line 206) | def critical(self, content: str, **kwargs):
class AgentAction (line 215) | class AgentAction:
class AgentFinish (line 229) | class AgentFinish(NamedTuple):
class AgentOutput (line 241) | class AgentOutput(LLMInterface):
FILE: libs/kotaemon/kotaemon/agents/langchain_based.py
class LangchainAgent (line 14) | class LangchainAgent(BaseAgent):
method __init__ (line 28) | def __init__(self, *args, **kwargs):
method update_agent_tools (line 37) | def update_agent_tools(self):
method add_tools (line 62) | def add_tools(self, tools: List[BaseTool]) -> None:
method run (line 67) | def run(self, instruction: str) -> AgentOutput:
FILE: libs/kotaemon/kotaemon/agents/react/agent.py
class ReactAgent (line 18) | class ReactAgent(BaseAgent):
method _compose_plugin_description (line 48) | def _compose_plugin_description(self) -> str:
method _construct_scratchpad (line 64) | def _construct_scratchpad(
method _parse_output (line 74) | def _parse_output(self, text: str) -> Optional[AgentAction | AgentFini...
method _compose_prompt (line 116) | def _compose_prompt(self, instruction) -> str:
method _format_function_map (line 135) | def _format_function_map(self) -> dict[str, BaseTool]:
method _trim (line 147) | def _trim(self, text: str | Document) -> str:
method clear (line 175) | def clear(self):
method run (line 181) | def run(self, instruction, max_iterations=None) -> AgentOutput:
method stream (line 258) | def stream(self, instruction, max_iterations=None):
FILE: libs/kotaemon/kotaemon/agents/rewoo/agent.py
class RewooAgent (line 22) | class RewooAgent(BaseAgent):
method planner (line 49) | def planner(self):
method solver (line 58) | def solver(self):
method _parse_plan_map (line 66) | def _parse_plan_map(
method _parse_planner_evidences (line 108) | def _parse_planner_evidences(
method _run_plugin (line 153) | def _run_plugin(
method _get_worker_evidence (line 194) | def _get_worker_evidence(
method _find_plugin (line 240) | def _find_plugin(self, name: str):
method _trim_evidence (line 245) | def _trim_evidence(self, evidence: str):
method run (line 267) | def run(self, instruction: str, use_citation: bool = False) -> AgentOu...
method stream (line 312) | def stream(self, instruction: str, use_citation: bool = False):
FILE: libs/kotaemon/kotaemon/agents/rewoo/planner.py
class Planner (line 11) | class Planner(BaseComponent):
method _compose_worker_description (line 17) | def _compose_worker_description(self) -> str:
method _compose_fewshot_prompt (line 33) | def _compose_fewshot_prompt(self) -> str:
method _compose_prompt (line 41) | def _compose_prompt(self, instruction) -> str:
method run (line 70) | def run(self, instruction: str, output: BaseScratchPad = BaseScratchPa...
method stream (line 85) | def stream(self, instruction: str, output: BaseScratchPad = BaseScratc...
FILE: libs/kotaemon/kotaemon/agents/rewoo/solver.py
class Solver (line 10) | class Solver(BaseComponent):
method _compose_fewshot_prompt (line 16) | def _compose_fewshot_prompt(self) -> str:
method _compose_prompt (line 24) | def _compose_prompt(self, instruction, plan_evidence, output_lang) -> ...
method run (line 56) | def run(
method stream (line 76) | def stream(
FILE: libs/kotaemon/kotaemon/agents/tools/base.py
class ToolException (line 9) | class ToolException(Exception):
class BaseTool (line 19) | class BaseTool(BaseComponent):
method _parse_input (line 36) | def _parse_input(
method _run_tool (line 53) | def _run_tool(
method _to_args_and_kwargs (line 61) | def _to_args_and_kwargs(self, tool_input: Union[str, Dict]) -> Tuple[T...
method _handle_tool_error (line 69) | def _handle_tool_error(self, e: ToolException) -> Any:
method to_langchain_format (line 90) | def to_langchain_format(self) -> LCTool:
method run (line 94) | def run(
method from_langchain_format (line 114) | def from_langchain_format(cls, langchain_tool: LCTool) -> "BaseTool":
class ComponentTool (line 123) | class ComponentTool(BaseTool):
method _run_tool (line 134) | def _run_tool(self, *args: Any, **kwargs: Any) -> Any:
FILE: libs/kotaemon/kotaemon/agents/tools/google.py
class GoogleSearchArgs (line 10) | class GoogleSearchArgs(BaseModel):
class GoogleSearchTool (line 14) | class GoogleSearchTool(BaseTool):
method _run_tool (line 22) | def _run_tool(self, query: AnyStr) -> str:
class SerpTool (line 45) | class SerpTool(BaseTool):
method _run_tool (line 53) | def _run_tool(self, query: AnyStr) -> str:
FILE: libs/kotaemon/kotaemon/agents/tools/llm.py
class LLMArgs (line 11) | class LLMArgs(BaseModel):
class LLMTool (line 15) | class LLMTool(BaseTool):
method _run_tool (line 27) | def _run_tool(self, query: AnyStr) -> str:
FILE: libs/kotaemon/kotaemon/agents/tools/mcp.py
function _json_schema_type_to_python (line 30) | def _json_schema_type_to_python(json_type: str) -> type:
function build_args_model (line 43) | def build_args_model(tool_name: str, input_schema: dict) -> Type[BaseMod...
function parse_mcp_config (line 69) | def parse_mcp_config(config: dict) -> dict:
function _make_tool (line 102) | def _make_tool(parsed: dict, tool_info: Any) -> "MCPTool":
function _async_discover_tools (line 121) | async def _async_discover_tools(parsed: dict) -> list["MCPTool"]:
function _run_async (line 153) | def _run_async(coro: Any) -> Any:
function create_tools_from_config (line 168) | def create_tools_from_config(
function async_discover_tools_info (line 191) | async def async_discover_tools_info(config: dict) -> list[dict]:
function discover_tools_info (line 238) | def discover_tools_info(config: dict) -> list[dict]:
function format_tool_list (line 243) | def format_tool_list(
class MCPTool (line 282) | class MCPTool(BaseTool):
method _run_tool (line 314) | def _run_tool(self, *args: Any, **kwargs: Any) -> str:
method _arun_tool (line 318) | async def _arun_tool(self, *args: Any, **kwargs: Any) -> str:
method _format_result (line 367) | def _format_result(self, result: Any) -> str:
FILE: libs/kotaemon/kotaemon/agents/tools/wikipedia.py
class Wiki (line 10) | class Wiki:
method __init__ (line 13) | def __init__(self) -> None:
method search (line 23) | def search(self, search: str) -> Union[str, Document]:
class WikipediaArgs (line 44) | class WikipediaArgs(BaseModel):
class WikipediaTool (line 48) | class WikipediaTool(BaseTool):
method _run_tool (line 61) | def _run_tool(self, query: AnyStr) -> AnyStr:
FILE: libs/kotaemon/kotaemon/agents/utils.py
function get_plugin_response_content (line 4) | def get_plugin_response_content(output) -> str:
function calculate_cost (line 14) | def calculate_cost(model_name: str, prompt_token: int, completion_token:...
FILE: libs/kotaemon/kotaemon/base/component.py
class BaseComponent (line 9) | class BaseComponent(Function):
method flow (line 24) | def flow(self):
method set_output_queue (line 35) | def set_output_queue(self, queue):
method report_output (line 42) | def report_output(self, output: Optional[Document]):
method invoke (line 46) | def invoke(self, *args, **kwargs) -> Document | list[Document] | None:
method ainvoke (line 49) | async def ainvoke(self, *args, **kwargs) -> Document | list[Document] ...
method stream (line 52) | def stream(self, *args, **kwargs) -> Iterator[Document] | None:
method astream (line 55) | def astream(self, *args, **kwargs) -> AsyncGenerator[Document, None] |...
method run (line 59) | def run(
FILE: libs/kotaemon/kotaemon/base/schema.py
class Document (line 21) | class Document(BaseDocument):
method __init__ (line 43) | def __init__(self, content: Optional[Any] = None, *args, **kwargs):
method __bool__ (line 64) | def __bool__(self):
method example (line 68) | def example(cls) -> "Document":
method to_haystack_format (line 75) | def to_haystack_format(self) -> "HaystackDocument":
method __str__ (line 83) | def __str__(self):
class DocumentWithEmbedding (line 87) | class DocumentWithEmbedding(Document):
method __init__ (line 93) | def __init__(self, embedding: list[float], *args, **kwargs):
class BaseMessage (line 98) | class BaseMessage(Document):
method __add__ (line 99) | def __add__(self, other: Any):
method to_openai_format (line 102) | def to_openai_format(self) -> "ChatCompletionMessageParam":
class SystemMessage (line 106) | class SystemMessage(BaseMessage, LCSystemMessage):
method to_openai_format (line 107) | def to_openai_format(self) -> "ChatCompletionMessageParam":
class AIMessage (line 111) | class AIMessage(BaseMessage, LCAIMessage):
method to_openai_format (line 112) | def to_openai_format(self) -> "ChatCompletionMessageParam":
class HumanMessage (line 116) | class HumanMessage(BaseMessage, LCHumanMessage):
method to_openai_format (line 117) | def to_openai_format(self) -> "ChatCompletionMessageParam":
class RetrievedDocument (line 121) | class RetrievedDocument(Document):
class LLMInterface (line 135) | class LLMInterface(AIMessage):
class StructuredOutputLLMInterface (line 146) | class StructuredOutputLLMInterface(LLMInterface):
class ExtractorOutput (line 151) | class ExtractorOutput(Document):
FILE: libs/kotaemon/kotaemon/chatbot/base.py
class BaseChatBot (line 10) | class BaseChatBot(BaseComponent):
method run (line 12) | def run(self, messages: List[BaseMessage]) -> LLMInterface:
function session_chat_storage (line 16) | def session_chat_storage(obj):
class ChatConversation (line 21) | class ChatConversation(SessionFunction):
class Config (line 29) | class Config:
method __init__ (line 35) | def __init__(self, *args, **kwargs):
method run (line 42) | def run(self, message: HumanMessage) -> Optional[BaseMessage]:
method start_session (line 64) | def start_session(self):
method end_session (line 71) | def end_session(self):
method check_end (line 75) | def check_end(
method terminal_session (line 87) | def terminal_session(self):
method history (line 109) | def history(self):
method history (line 113) | def history(self, value):
FILE: libs/kotaemon/kotaemon/chatbot/simple_respondent.py
class SimpleRespondentChatbot (line 5) | class SimpleRespondentChatbot(BaseChatBot):
method _get_message (line 10) | def _get_message(self) -> str:
FILE: libs/kotaemon/kotaemon/cli.py
function check_config_format (line 9) | def check_config_format(config):
function main (line 20) | def main():
function promptui (line 25) | def promptui():
function export (line 35) | def export(export_path, output):
function run (line 81) | def run(run_path, share, username, password, appname, port):
function makedoc (line 150) | def makedoc(module, output, separation_level):
function start_project (line 173) | def start_project(template):
FILE: libs/kotaemon/kotaemon/contribs/docs.py
function from_definition_to_markdown (line 7) | def from_definition_to_markdown(definition: dict) -> str:
function make_doc (line 40) | def make_doc(module: str, output: str, separation_level: int):
FILE: libs/kotaemon/kotaemon/contribs/promptui/base.py
function get_component (line 23) | def get_component(component_def: dict) -> gr.components.Component:
FILE: libs/kotaemon/kotaemon/contribs/promptui/config.py
function config_from_value (line 14) | def config_from_value(value: Any) -> dict:
function handle_param (line 32) | def handle_param(param: dict) -> dict:
function handle_node (line 63) | def handle_node(node: dict) -> dict:
function handle_input (line 85) | def handle_input(pipeline: Union[BaseComponent, Type[BaseComponent]]) ->...
function export_pipeline_to_config (line 113) | def export_pipeline_to_config(
FILE: libs/kotaemon/kotaemon/contribs/promptui/export.py
function from_log_to_dict (line 17) | def from_log_to_dict(pipeline_cls: Type[BaseComponent], log_config: dict...
function export (line 80) | def export(config: dict, pipeline_def, output_path):
function export_from_dict (line 99) | def export_from_dict(
FILE: libs/kotaemon/kotaemon/contribs/promptui/logs.py
class ResultLog (line 1) | class ResultLog:
method _get_input (line 11) | def _get_input(obj):
method _get_output (line 15) | def _get_output(obj):
FILE: libs/kotaemon/kotaemon/contribs/promptui/themes.py
class John (line 9) | class John(Base):
method __init__ (line 10) | def __init__(
FILE: libs/kotaemon/kotaemon/contribs/promptui/tunnel.py
class Tunnel (line 31) | class Tunnel:
method __init__ (line 32) | def __init__(self, appname, username, local_port):
method download_binary (line 40) | def download_binary():
method run (line 68) | def run(self) -> str:
method kill (line 77) | def kill(self):
method _start_tunnel (line 83) | def _start_tunnel(self, binary: str) -> str:
FILE: libs/kotaemon/kotaemon/contribs/promptui/ui/__init__.py
function build_from_dict (line 12) | def build_from_dict(config: Union[str, dict]):
FILE: libs/kotaemon/kotaemon/contribs/promptui/ui/blocks.py
class ChatBlock (line 13) | class ChatBlock(ChatInterface):
method __init__ (line 20) | def __init__(
method _submit_fn (line 37) | async def _submit_fn(
method _stream_fn (line 71) | async def _stream_fn(
method _display_input (line 79) | def _display_input(
method _setup_events (line 87) | def _setup_events(self) -> None:
method _setup_api (line 173) | def _setup_api(self) -> None:
FILE: libs/kotaemon/kotaemon/contribs/promptui/ui/chat.py
function construct_chat_ui (line 46) | def construct_chat_ui(
function build_chat_ui (line 155) | def build_chat_ui(config, pipeline_def):
FILE: libs/kotaemon/kotaemon/contribs/promptui/ui/pipeline.py
function construct_pipeline_ui (line 41) | def construct_pipeline_ui(
function load_saved_params (line 129) | def load_saved_params(path: str) -> Dict:
function build_pipeline_ui (line 146) | def build_pipeline_ui(config: dict, pipeline_def):
FILE: libs/kotaemon/kotaemon/embeddings/base.py
class BaseEmbeddings (line 6) | class BaseEmbeddings(BaseComponent):
method run (line 7) | def run(
method invoke (line 12) | def invoke(
method ainvoke (line 17) | async def ainvoke(
method prepare_input (line 22) | def prepare_input(
FILE: libs/kotaemon/kotaemon/embeddings/endpoint_based.py
class EndpointEmbeddings (line 8) | class EndpointEmbeddings(BaseEmbeddings):
method run (line 18) | def run(
FILE: libs/kotaemon/kotaemon/embeddings/fastembed.py
class FastEmbedEmbeddings (line 11) | class FastEmbedEmbeddings(BaseEmbeddings):
method client_ (line 43) | def client_(self) -> "TextEmbedding":
method invoke (line 51) | def invoke(
method ainvoke (line 68) | async def ainvoke(
FILE: libs/kotaemon/kotaemon/embeddings/langchain_based.py
class LCEmbeddingMixin (line 8) | class LCEmbeddingMixin:
method _get_lc_class (line 9) | def _get_lc_class(self):
method __init__ (line 14) | def __init__(self, **params):
method run (line 21) | def run(self, text):
method __repr__ (line 32) | def __repr__(self):
method __str__ (line 40) | def __str__(self):
method __setattr__ (line 50) | def __setattr__(self, name, value):
method __getattr__ (line 60) | def __getattr__(self, name):
method dump (line 65) | def dump(self, *args, **kwargs):
method specs (line 74) | def specs(self, path: str):
class LCOpenAIEmbeddings (line 89) | class LCOpenAIEmbeddings(LCEmbeddingMixin, BaseEmbeddings):
method __init__ (line 92) | def __init__(
method _get_lc_class (line 112) | def _get_lc_class(self):
class LCAzureOpenAIEmbeddings (line 121) | class LCAzureOpenAIEmbeddings(LCEmbeddingMixin, BaseEmbeddings):
method __init__ (line 124) | def __init__(
method _get_lc_class (line 142) | def _get_lc_class(self):
class LCCohereEmbeddings (line 151) | class LCCohereEmbeddings(LCEmbeddingMixin, BaseEmbeddings):
method __init__ (line 168) | def __init__(
method _get_lc_class (line 184) | def _get_lc_class(self):
class LCHuggingFaceEmbeddings (line 193) | class LCHuggingFaceEmbeddings(LCEmbeddingMixin, BaseEmbeddings):
method __init__ (line 205) | def __init__(
method _get_lc_class (line 215) | def _get_lc_class(self):
class LCGoogleEmbeddings (line 224) | class LCGoogleEmbeddings(LCEmbeddingMixin, BaseEmbeddings):
method __init__ (line 238) | def __init__(
method _get_lc_class (line 250) | def _get_lc_class(self):
class LCMistralEmbeddings (line 259) | class LCMistralEmbeddings(LCEmbeddingMixin, BaseEmbeddings):
method __init__ (line 273) | def __init__(
method _get_lc_class (line 285) | def _get_lc_class(self):
FILE: libs/kotaemon/kotaemon/embeddings/openai.py
function split_text_by_chunk_size (line 20) | def split_text_by_chunk_size(text: str, chunk_size: int) -> list[list[in...
class BaseOpenAIEmbeddings (line 38) | class BaseOpenAIEmbeddings(BaseEmbeddings):
method max_retries_ (line 68) | def max_retries_(self):
method prepare_client (line 75) | def prepare_client(self, async_version: bool = False):
method openai_response (line 83) | def openai_response(self, client, **kwargs):
method invoke (line 87) | def invoke(
method ainvoke (line 127) | async def ainvoke(
class OpenAIEmbeddings (line 142) | class OpenAIEmbeddings(BaseOpenAIEmbeddings):
method prepare_client (line 156) | def prepare_client(self, async_version: bool = False):
method openai_response (line 185) | def openai_response(self, client, **kwargs):
class AzureOpenAIEmbeddings (line 197) | class AzureOpenAIEmbeddings(BaseOpenAIEmbeddings):
method azure_ad_token_provider_ (line 213) | def azure_ad_token_provider_(self):
method prepare_client (line 217) | def prepare_client(self, async_version: bool = False):
method openai_response (line 248) | def openai_response(self, client, **kwargs):
FILE: libs/kotaemon/kotaemon/embeddings/tei_endpoint_embed.py
class TeiEndpointEmbeddings (line 11) | class TeiEndpointEmbeddings(BaseEmbeddings):
method client_ (line 35) | async def client_(self, inputs: list[str]):
method ainvoke (line 48) | async def ainvoke(
method invoke (line 74) | def invoke(
FILE: libs/kotaemon/kotaemon/embeddings/voyageai.py
function _import_voyageai (line 13) | def _import_voyageai():
function _format_output (line 20) | def _format_output(texts: list[str], embeddings: list[list]):
class VoyageAIEmbeddings (line 32) | class VoyageAIEmbeddings(BaseEmbeddings):
method __init__ (line 46) | def __init__(self, *args, **kwargs):
method invoke (line 54) | def invoke(
method ainvoke (line 61) | async def ainvoke(
FILE: libs/kotaemon/kotaemon/indices/base.py
class DocTransformer (line 11) | class DocTransformer(BaseComponent):
method run (line 21) | def run(
class LlamaIndexDocTransformerMixin (line 29) | class LlamaIndexDocTransformerMixin:
method _get_li_class (line 44) | def _get_li_class(self) -> Type[NodeParser]:
method __init__ (line 49) | def __init__(self, **params):
method __repr__ (line 55) | def __repr__(self):
method __str__ (line 63) | def __str__(self):
method __setattr__ (line 73) | def __setattr__(self, name: str, value: Any) -> None:
method __getattr__ (line 80) | def __getattr__(self, name: str) -> Any:
method dump (line 85) | def dump(self, *args, **kwargs):
method run (line 94) | def run(
class BaseIndexing (line 106) | class BaseIndexing(BaseComponent):
method to_retrieval_pipeline (line 109) | def to_retrieval_pipeline(self, **kwargs):
method to_qa_pipeline (line 113) | def to_qa_pipeline(self, **kwargs):
class BaseRetrieval (line 118) | class BaseRetrieval(BaseComponent):
method run (line 122) | def run(self, *args, **kwargs) -> list[RetrievedDocument]:
FILE: libs/kotaemon/kotaemon/indices/extractors/doc_parsers.py
class BaseDocParser (line 4) | class BaseDocParser(DocTransformer):
class TitleExtractor (line 8) | class TitleExtractor(LlamaIndexDocTransformerMixin, BaseDocParser):
method __init__ (line 9) | def __init__(
method _get_li_class (line 17) | def _get_li_class(self):
class SummaryExtractor (line 23) | class SummaryExtractor(LlamaIndexDocTransformerMixin, BaseDocParser):
method __init__ (line 24) | def __init__(
method _get_li_class (line 32) | def _get_li_class(self):
FILE: libs/kotaemon/kotaemon/indices/ingests/files.py
class DocumentIngestor (line 61) | class DocumentIngestor(BaseComponent):
method _get_reader (line 90) | def _get_reader(self, input_files: list[str | Path]):
method run (line 114) | def run(self, file_paths: list[str | Path] | str | Path) -> list[Docum...
FILE: libs/kotaemon/kotaemon/indices/qa/citation.py
class CiteEvidence (line 10) | class CiteEvidence(BaseModel):
class CitationPipeline (line 22) | class CitationPipeline(BaseComponent):
method run (line 28) | def run(self, context: str, question: str):
method prepare_llm (line 31) | def prepare_llm(self, context: str, question: str):
method invoke (line 67) | def invoke(self, context: str, question: str):
method ainvoke (line 97) | async def ainvoke(self, context: str, question: str):
FILE: libs/kotaemon/kotaemon/indices/qa/citation_qa.py
class AnswerWithContextPipeline (line 83) | class AnswerWithContextPipeline(BaseComponent):
method get_prompt (line 121) | def get_prompt(self, question, evidence, evidence_mode: int):
method run (line 143) | def run(
method invoke (line 148) | def invoke(
method ainvoke (line 158) | async def ainvoke( # type: ignore
method stream (line 190) | def stream( # type: ignore
method match_evidence_with_context (line 296) | def match_evidence_with_context(self, answer, docs) -> dict[str, list[...
method prepare_citations (line 322) | def prepare_citations(self, answer, docs) -> tuple[list[Document], lis...
FILE: libs/kotaemon/kotaemon/indices/qa/citation_qa_inline.py
class InlineEvidence (line 78) | class InlineEvidence:
class AnswerWithInlineCitation (line 86) | class AnswerWithInlineCitation(AnswerWithContextPipeline):
method get_prompt (line 91) | def get_prompt(self, question, evidence, evidence_mode: int):
method answer_to_citations (line 103) | def answer_to_citations(self, answer) -> list[InlineEvidence]:
method replace_citation_with_link (line 152) | def replace_citation_with_link(self, answer: str):
method stream (line 193) | def stream( # type: ignore
method match_evidence_with_context (line 322) | def match_evidence_with_context(self, answer, docs) -> dict[str, list[...
FILE: libs/kotaemon/kotaemon/indices/qa/format_context.py
class PrepareEvidencePipeline (line 15) | class PrepareEvidencePipeline(BaseComponent):
method run (line 28) | def run(self, docs: list[RetrievedDocument]) -> Document:
FILE: libs/kotaemon/kotaemon/indices/qa/utils.py
function find_text (line 4) | def find_text(search_span, context, min_length=5):
function find_start_end_phrase (line 44) | def find_start_end_phrase(
function replace_think_tag_with_details (line 85) | def replace_think_tag_with_details(text):
function strip_think_tag (line 94) | def strip_think_tag(text):
FILE: libs/kotaemon/kotaemon/indices/rankings/base.py
class BaseReranking (line 8) | class BaseReranking(BaseComponent):
method run (line 10) | def run(self, documents: list[Document], query: str) -> list[Document]:
FILE: libs/kotaemon/kotaemon/indices/rankings/cohere.py
class CohereReranking (line 10) | class CohereReranking(BaseReranking):
method run (line 15) | def run(self, documents: list[Document], query: str) -> list[Document]:
FILE: libs/kotaemon/kotaemon/indices/rankings/llm.py
class LLMReranking (line 23) | class LLMReranking(BaseReranking):
method run (line 29) | def run(
FILE: libs/kotaemon/kotaemon/indices/rankings/llm_scoring.py
class LLMScoring (line 13) | class LLMScoring(LLMReranking):
method run (line 14) | def run(
FILE: libs/kotaemon/kotaemon/indices/rankings/llm_trulens.py
function validate_rating (line 52) | def validate_rating(rating) -> int:
function re_0_10_rating (line 61) | def re_0_10_rating(s: str) -> int:
class LLMTrulensScoring (line 96) | class LLMTrulensScoring(LLMReranking):
method run (line 113) | def run(
FILE: libs/kotaemon/kotaemon/indices/retrievers/jina_web_search.py
class WebSearch (line 10) | class WebSearch(BaseComponent):
method run (line 15) | def run(
method generate_relevant_scores (line 59) | def generate_relevant_scores(self, text, documents: list[RetrievedDocu...
FILE: libs/kotaemon/kotaemon/indices/retrievers/tavily_web_search.py
class WebSearch (line 8) | class WebSearch(BaseComponent):
method run (line 13) | def run(
method generate_relevant_scores (line 56) | def generate_relevant_scores(self, text, documents: list[RetrievedDocu...
FILE: libs/kotaemon/kotaemon/indices/splitters/__init__.py
class BaseSplitter (line 4) | class BaseSplitter(DocTransformer):
class TokenSplitter (line 10) | class TokenSplitter(LlamaIndexDocTransformerMixin, BaseSplitter):
method __init__ (line 11) | def __init__(
method _get_li_class (line 25) | def _get_li_class(self):
class SentenceWindowSplitter (line 31) | class SentenceWindowSplitter(LlamaIndexDocTransformerMixin, BaseSplitter):
method __init__ (line 32) | def __init__(
method _get_li_class (line 46) | def _get_li_class(self):
FILE: libs/kotaemon/kotaemon/indices/vectorindex.py
class VectorIndexing (line 21) | class VectorIndexing(BaseIndexing):
method to_retrieval_pipeline (line 36) | def to_retrieval_pipeline(self, *args, **kwargs):
method write_chunk_to_file (line 45) | def write_chunk_to_file(self, docs: list[Document]):
method add_to_docstore (line 79) | def add_to_docstore(self, docs: list[Document]):
method add_to_vectorstore (line 84) | def add_to_vectorstore(self, docs: list[Document]):
method run (line 95) | def run(self, text: str | list[str] | Document | list[Document]):
class VectorRetrieval (line 116) | class VectorRetrieval(BaseRetrieval):
method _filter_docs (line 127) | def _filter_docs(
method run (line 134) | def run(
class TextVectorQA (line 306) | class TextVectorQA(BaseComponent):
method run (line 310) | def run(self, question, **kwargs):
FILE: libs/kotaemon/kotaemon/llms/base.py
class BaseLLM (line 8) | class BaseLLM(BaseComponent):
method to_langchain_format (line 9) | def to_langchain_format(self) -> BaseLanguageModel:
method invoke (line 12) | def invoke(self, *args, **kwargs) -> LLMInterface:
method ainvoke (line 15) | async def ainvoke(self, *args, **kwargs) -> LLMInterface:
method stream (line 18) | def stream(self, *args, **kwargs) -> Iterator[LLMInterface]:
method astream (line 21) | def astream(self, *args, **kwargs) -> AsyncGenerator[LLMInterface, None]:
method run (line 24) | def run(self, *args, **kwargs):
FILE: libs/kotaemon/kotaemon/llms/branching.py
class SimpleBranchingPipeline (line 8) | class SimpleBranchingPipeline(BaseComponent):
method add_branch (line 54) | def add_branch(self, component: BaseComponent):
method run (line 63) | def run(self, **prompt_kwargs):
class GatedBranchingPipeline (line 81) | class GatedBranchingPipeline(SimpleBranchingPipeline):
method run (line 128) | def run(self, *, condition_text: Optional[str] = None, **prompt_kwargs):
function identity (line 163) | def identity(x):
FILE: libs/kotaemon/kotaemon/llms/chats/base.py
class ChatLLM (line 11) | class ChatLLM(BaseLLM):
method flow (line 12) | def flow(self):
FILE: libs/kotaemon/kotaemon/llms/chats/endpoint_based.py
class EndpointChatLLM (line 15) | class EndpointChatLLM(ChatLLM):
method run (line 28) | def run(
method invoke (line 79) | def invoke(
method ainvoke (line 85) | async def ainvoke(
FILE: libs/kotaemon/kotaemon/llms/chats/langchain_based.py
class LCChatMixin (line 13) | class LCChatMixin:
method _get_lc_class (line 16) | def _get_lc_class(self):
method _get_tool_call_kwargs (line 21) | def _get_tool_call_kwargs(self):
method __init__ (line 24) | def __init__(self, stream: bool = False, **params):
method run (line 32) | def run(
method prepare_message (line 39) | def prepare_message(self, messages: str | BaseMessage | list[BaseMessa...
method prepare_response (line 51) | def prepare_response(self, pred):
method invoke (line 74) | def invoke(
method ainvoke (line 112) | async def ainvoke(
method stream (line 119) | def stream(
method astream (line 125) | async def astream(
method to_langchain_format (line 131) | def to_langchain_format(self):
method __repr__ (line 134) | def __repr__(self):
method __str__ (line 142) | def __str__(self):
method __setattr__ (line 152) | def __setattr__(self, name, value):
method __getattr__ (line 162) | def __getattr__(self, name):
method dump (line 167) | def dump(self, *args, **kwargs):
method specs (line 176) | def specs(self, path: str):
class LCChatOpenAI (line 191) | class LCChatOpenAI(LCChatMixin, ChatLLM): # type: ignore
method __init__ (line 192) | def __init__(
method _get_lc_class (line 210) | def _get_lc_class(self):
class LCAzureChatOpenAI (line 219) | class LCAzureChatOpenAI(LCChatMixin, ChatLLM): # type: ignore
method __init__ (line 220) | def __init__(
method _get_lc_class (line 240) | def _get_lc_class(self):
class LCAnthropicChat (line 249) | class LCAnthropicChat(LCChatMixin, ChatLLM): # type: ignore
method _get_tool_call_kwargs (line 261) | def _get_tool_call_kwargs(self):
method __init__ (line 264) | def __init__(
method _get_lc_class (line 278) | def _get_lc_class(self):
class LCGeminiChat (line 287) | class LCGeminiChat(LCChatMixin, ChatLLM): # type: ignore
method _get_tool_call_kwargs (line 299) | def _get_tool_call_kwargs(self):
method __init__ (line 308) | def __init__(
method _get_lc_class (line 322) | def _get_lc_class(self):
class LCCohereChat (line 331) | class LCCohereChat(LCChatMixin, ChatLLM): # type: ignore
method __init__ (line 340) | def __init__(
method _get_lc_class (line 354) | def _get_lc_class(self):
class LCOllamaChat (line 363) | class LCOllamaChat(LCChatMixin, ChatLLM): # type: ignore
method __init__ (line 377) | def __init__(
method _get_lc_class (line 391) | def _get_lc_class(self):
FILE: libs/kotaemon/kotaemon/llms/chats/llamacpp.py
class LlamaCppChat (line 12) | class LlamaCppChat(ChatLLM):
method client_object (line 54) | def client_object(self) -> "Llama":
method prepare_message (line 102) | def prepare_message(
method invoke (line 121) | def invoke(
method stream (line 142) | def stream(
FILE: libs/kotaemon/kotaemon/llms/chats/openai.py
class BaseChatOpenAI (line 23) | class BaseChatOpenAI(ChatLLM):
method max_retries_ (line 133) | def max_retries_(self):
method prepare_message (line 140) | def prepare_message(
method prepare_output (line 163) | def prepare_output(self, resp: dict) -> LLMInterface:
method prepare_client (line 195) | def prepare_client(self, async_version: bool = False):
method openai_response (line 203) | def openai_response(self, client, **kwargs):
method aopenai_response (line 207) | async def aopenai_response(self, client, **kwargs):
method invoke (line 211) | def invoke(
method ainvoke (line 221) | async def ainvoke(
method stream (line 234) | def stream(
method astream (line 262) | async def astream(
class ChatOpenAI (line 278) | class ChatOpenAI(BaseChatOpenAI):
method prepare_client (line 285) | def prepare_client(self, async_version: bool = False):
method prepare_params (line 307) | def prepare_params(self, **kwargs):
method openai_response (line 331) | def openai_response(self, client, **kwargs):
method aopenai_response (line 336) | async def aopenai_response(self, client, **kwargs):
class StructuredOutputChatOpenAI (line 341) | class StructuredOutputChatOpenAI(ChatOpenAI):
method prepare_output (line 348) | def prepare_output(self, resp: dict) -> StructuredOutputLLMInterface:
method prepare_params (line 382) | def prepare_params(self, **kwargs):
method openai_response (line 410) | def openai_response(self, client, **kwargs):
method aopenai_response (line 416) | async def aopenai_response(self, client, **kwargs):
class AzureChatOpenAI (line 423) | class AzureChatOpenAI(BaseChatOpenAI):
method azure_ad_token_provider_ (line 440) | def azure_ad_token_provider_(self):
method prepare_client (line 444) | def prepare_client(self, async_version: bool = False):
method prepare_params (line 468) | def prepare_params(self, **kwargs):
method openai_response (line 492) | def openai_response(self, client, **kwargs):
method aopenai_response (line 497) | async def aopenai_response(self, client, **kwargs):
FILE: libs/kotaemon/kotaemon/llms/completions/base.py
class LLM (line 4) | class LLM(BaseLLM):
FILE: libs/kotaemon/kotaemon/llms/completions/langchain_based.py
class LCCompletionMixin (line 11) | class LCCompletionMixin:
method _get_lc_class (line 12) | def _get_lc_class(self):
method __init__ (line 17) | def __init__(self, **params):
method run (line 24) | def run(self, text: str) -> LLMInterface:
method to_langchain_format (line 48) | def to_langchain_format(self):
method __repr__ (line 51) | def __repr__(self):
method __str__ (line 59) | def __str__(self):
method __setattr__ (line 69) | def __setattr__(self, name, value):
method __getattr__ (line 79) | def __getattr__(self, name):
method dump (line 84) | def dump(self, *args, **kwargs):
method specs (line 93) | def specs(self, path: str):
class OpenAI (line 108) | class OpenAI(LCCompletionMixin, LLM):
method __init__ (line 111) | def __init__(
method _get_lc_class (line 143) | def _get_lc_class(self):
class AzureOpenAI (line 152) | class AzureOpenAI(LCCompletionMixin, LLM):
method __init__ (line 155) | def __init__(
method _get_lc_class (line 191) | def _get_lc_class(self):
class LlamaCpp (line 200) | class LlamaCpp(LCCompletionMixin, LLM):
method __init__ (line 203) | def __init__(
method _get_lc_class (line 221) | def _get_lc_class(self):
FILE: libs/kotaemon/kotaemon/llms/cot.py
class Thought (line 13) | class Thought(BaseComponent):
method prompt_template (line 86) | def prompt_template(self):
method run (line 90) | def run(self, **kwargs) -> Document:
method get_variables (line 98) | def get_variables(self) -> List[str]:
method __add__ (line 101) | def __add__(self, next_thought: "Thought") -> "ManualSequentialChainOf...
class ManualSequentialChainOfThought (line 107) | class ManualSequentialChainOfThought(BaseComponent):
method run (line 156) | def run(self, **kwargs) -> Document:
method __add__ (line 172) | def __add__(self, next_thought: Thought) -> "ManualSequentialChainOfTh...
FILE: libs/kotaemon/kotaemon/llms/linear.py
class SimpleLinearPipeline (line 10) | class SimpleLinearPipeline(BaseComponent):
method run (line 52) | def run(
class GatedLinearPipeline (line 81) | class GatedLinearPipeline(SimpleLinearPipeline):
method run (line 120) | def run(
FILE: libs/kotaemon/kotaemon/llms/prompts/base.py
class BasePromptComponent (line 10) | class BasePromptComponent(BaseComponent):
class Config (line 20) | class Config:
method template__ (line 27) | def template__(self):
method __init__ (line 34) | def __init__(self, **kwargs):
method __check_redundant_kwargs (line 38) | def __check_redundant_kwargs(self, **kwargs):
method __check_unset_placeholders (line 53) | def __check_unset_placeholders(self):
method __validate_value_type (line 69) | def __validate_value_type(self, **kwargs):
method __set (line 96) | def __set(self, **kwargs):
method __prepare_value (line 113) | def __prepare_value(self):
method set_value (line 152) | def set_value(self, **kwargs):
method run (line 168) | def run(self, **kwargs):
method flow (line 186) | def flow(self):
FILE: libs/kotaemon/kotaemon/llms/prompts/template.py
class PromptTemplate (line 5) | class PromptTemplate:
method __init__ (line 10) | def __init__(self, template: str, ignore_invalid=True):
method check_missing_kwargs (line 34) | def check_missing_kwargs(self, **kwargs):
method check_redundant_kwargs (line 52) | def check_redundant_kwargs(self, **kwargs):
method populate (line 75) | def populate(self, safe=True, **kwargs) -> str:
method partial_populate (line 94) | def partial_populate(self, **kwargs):
method __add__ (line 130) | def __add__(self, other):
FILE: libs/kotaemon/kotaemon/loaders/adobe_loader.py
class AdobeReader (line 24) | class AdobeReader(BaseReader):
method __init__ (line 42) | def __init__(
method load_data (line 56) | def load_data(
FILE: libs/kotaemon/kotaemon/loaders/azureai_document_intelligence_loader.py
function crop_image (line 15) | def crop_image(file_path: Path, bbox: list[float], page_number: int = 0)...
class AzureAIDocumentIntelligenceLoader (line 59) | class AzureAIDocumentIntelligenceLoader(BaseReader):
method client_ (line 111) | def client_(self):
method run (line 122) | def run(
method load_data (line 127) | def load_data(
FILE: libs/kotaemon/kotaemon/loaders/base.py
class BaseReader (line 10) | class BaseReader(BaseComponent):
class AutoReader (line 16) | class AutoReader(BaseReader):
method __init__ (line 19) | def __init__(self, reader_type: Union[str, Type["LIBaseReader"]]) -> N...
method load_data (line 44) | def load_data(self, file: Union[Path, str], **kwargs: Any) -> List[Doc...
method run (line 51) | def run(self, file: Union[Path, str], **kwargs: Any) -> List[Document]:
class LIReaderMixin (line 55) | class LIReaderMixin(BaseComponent):
method _get_wrapped_class (line 72) | def _get_wrapped_class(self) -> Type["LIBaseReader"]:
method __init__ (line 77) | def __init__(self, *args, **kwargs):
method __setattr__ (line 82) | def __setattr__(self, name: str, value: Any) -> None:
method __getattr__ (line 88) | def __getattr__(self, name: str) -> Any:
method load_data (line 91) | def load_data(self, *args, **kwargs: Any) -> List[Document]:
method run (line 98) | def run(self, *args, **kwargs: Any) -> List[Document]:
FILE: libs/kotaemon/kotaemon/loaders/composite_loader.py
class DirectoryReader (line 8) | class DirectoryReader(LIReaderMixin, BaseReader):
method _get_wrapped_class (line 50) | def _get_wrapped_class(self) -> Type["LIBaseReader"]:
FILE: libs/kotaemon/kotaemon/loaders/docling_loader.py
class DoclingReader (line 14) | class DoclingReader(BaseReader):
method converter_ (line 45) | def converter_(self):
method run (line 53) | def run(
method load_data (line 58) | def load_data(
method _convert_bbox_bl_tl (line 211) | def _convert_bbox_bl_tl(
method _parse_table (line 223) | def _parse_table(self, table_obj: dict) -> str:
FILE: libs/kotaemon/kotaemon/loaders/docx_loader.py
class DocxReader (line 11) | class DocxReader(BaseReader):
method __init__ (line 21) | def __init__(self, *args, **kwargs):
method _load_single_table (line 30) | def _load_single_table(self, table) -> List[List[str]]:
method load_data (line 45) | def load_data(
FILE: libs/kotaemon/kotaemon/loaders/excel_loader.py
class PandasExcelReader (line 14) | class PandasExcelReader(BaseReader):
method __init__ (line 29) | def __init__(
method load_data (line 43) | def load_data(
class ExcelReader (line 107) | class ExcelReader(BaseReader):
method __init__ (line 122) | def __init__(
method load_data (line 136) | def load_data(
FILE: libs/kotaemon/kotaemon/loaders/html_loader.py
class HtmlReader (line 11) | class HtmlReader(BaseReader):
method __init__ (line 24) | def __init__(self, page_break_pattern: Optional[str] = None, *args, **...
method load_data (line 36) | def load_data(
class MhtmlReader (line 77) | class MhtmlReader(BaseReader):
method __init__ (line 80) | def __init__(
method load_data (line 115) | def load_data(
FILE: libs/kotaemon/kotaemon/loaders/mathpix_loader.py
class MathpixPDFReader (line 18) | class MathpixPDFReader(BaseReader):
method __init__ (line 21) | def __init__(
method _mathpix_headers (line 49) | def _mathpix_headers(self) -> Dict[str, str]:
method url (line 53) | def url(self) -> str:
method data (line 57) | def data(self) -> dict:
method send_pdf (line 64) | def send_pdf(self, file_path) -> str:
method wait_for_processing (line 77) | def wait_for_processing(self, pdf_id: str) -> None:
method get_processed_pdf (line 113) | def get_processed_pdf(self, pdf_id: str) -> str:
method clean_pdf (line 123) | def clean_pdf(self, contents: str) -> str:
method parse_markdown_text_to_tables (line 158) | def parse_markdown_text_to_tables(
method load_data (line 202) | def load_data(
method lazy_load_data (line 271) | def lazy_load_data(
FILE: libs/kotaemon/kotaemon/loaders/ocr_loader.py
function tenacious_api_post (line 26) | def tenacious_api_post(url, file_path, table_only, **kwargs):
class OCRReader (line 35) | class OCRReader(BaseReader):
method __init__ (line 54) | def __init__(self, endpoint: Optional[str] = None, use_ocr=True):
method load_data (line 62) | def load_data(
class ImageReader (line 131) | class ImageReader(BaseReader):
method __init__ (line 150) | def __init__(self, endpoint: Optional[str] = None):
method load_data (line 157) | def load_data(
FILE: libs/kotaemon/kotaemon/loaders/pdf_loader.py
function get_page_thumbnails (line 16) | def get_page_thumbnails(
function convert_image_to_base64 (line 49) | def convert_image_to_base64(img: Image.Image) -> str:
class PDFThumbnailReader (line 59) | class PDFThumbnailReader(PDFReader):
method __init__ (line 62) | def __init__(self) -> None:
method load_data (line 68) | def load_data(
FILE: libs/kotaemon/kotaemon/loaders/txt_loader.py
class TxtReader (line 9) | class TxtReader(BaseReader):
method run (line 10) | def run(
method load_data (line 15) | def load_data(
FILE: libs/kotaemon/kotaemon/loaders/unstructured_loader.py
class UnstructuredReader (line 20) | class UnstructuredReader(BaseReader):
method __init__ (line 23) | def __init__(self, *args: Any, **kwargs: Any) -> None:
method load_data (line 51) | def load_data(
FILE: libs/kotaemon/kotaemon/loaders/utils/adobe.py
function request_adobe_service (line 19) | def request_adobe_service(file_path: str, output_path: str = "") -> str:
function make_markdown_table (line 113) | def make_markdown_table(table_as_list: List[List[str]]) -> str:
function load_json (line 148) | def load_json(input_path: Union[str | Path]) -> dict:
function load_excel (line 156) | def load_excel(input_path: Union[str | Path]) -> str:
function encode_image_base64 (line 175) | def encode_image_base64(image_path: Union[str | Path]) -> Union[bytes, s...
function parse_table_paths (line 182) | def parse_table_paths(file_paths: List[Path]) -> str:
function parse_figure_paths (line 193) | def parse_figure_paths(file_paths: List[Path]) -> Union[bytes, str]:
function generate_single_figure_caption (line 205) | def generate_single_figure_caption(vlm_endpoint: str, figure: str) -> str:
function generate_figure_captions (line 224) | def generate_figure_captions(
FILE: libs/kotaemon/kotaemon/loaders/utils/box.py
function bbox_to_points (line 4) | def bbox_to_points(box: List[int]):
function points_to_bbox (line 10) | def points_to_bbox(points: List[Tuple[int, int]]):
function scale_points (line 17) | def scale_points(points: List[Tuple[int, int]], scale_factor: float = 1.0):
function union_points (line 22) | def union_points(points: List[Tuple[int, int]]):
function scale_box (line 30) | def scale_box(box: List[int], scale_factor: float = 1.0):
function box_h (line 35) | def box_h(box: List[int]):
function box_w (line 40) | def box_w(box: List[int]):
function box_area (line 45) | def box_area(box: List[int]):
function get_rect_iou (line 51) | def get_rect_iou(gt_box: List[tuple], pd_box: List[tuple], iou_type=0) -...
function sort_funsd_reading_order (line 106) | def sort_funsd_reading_order(lines: List[dict], box_key_name: str = "box"):
FILE: libs/kotaemon/kotaemon/loaders/utils/gpt4v.py
function generate_gpt4v (line 11) | def generate_gpt4v(
function stream_gpt4v (line 61) | def stream_gpt4v(
FILE: libs/kotaemon/kotaemon/loaders/utils/pdf_ocr.py
function read_pdf_unstructured (line 23) | def read_pdf_unstructured(input_path: Union[Path, str]):
function merge_ocr_and_pdf_texts (line 60) | def merge_ocr_and_pdf_texts(
function merge_table_cell_and_ocr (line 115) | def merge_table_cell_and_ocr(
function parse_ocr_output (line 227) | def parse_ocr_output(
FILE: libs/kotaemon/kotaemon/loaders/utils/table.py
function check_col_conflicts (line 8) | def check_col_conflicts(
function merge_cols (line 30) | def merge_cols(col_a: List[str], col_b: List[str]) -> List[str]:
function add_index_col (line 45) | def add_index_col(csv_rows: List[List[str]]) -> List[List[str]]:
function compress_csv (line 59) | def compress_csv(csv_rows: List[List[str]]) -> List[List[str]]:
function get_table_from_ocr (line 82) | def get_table_from_ocr(ocr_list: List[dict], table_list: List[dict]):
function make_markdown_table (line 106) | def make_markdown_table(array: List[List[str]]) -> str:
function parse_csv_string_to_list (line 143) | def parse_csv_string_to_list(csv_str: str) -> List[List[str]]:
function format_cell (line 158) | def format_cell(cell: str, length_limit: Optional[int] = None) -> str:
function extract_tables_from_csv_string (line 174) | def extract_tables_from_csv_string(
function strip_special_chars_markdown (line 217) | def strip_special_chars_markdown(text: str) -> str:
function parse_markdown_text_to_tables (line 222) | def parse_markdown_text_to_tables(text: str) -> Tuple[List[str], List[st...
function table_cells_to_markdown (line 258) | def table_cells_to_markdown(cells: List[dict]):
FILE: libs/kotaemon/kotaemon/loaders/web_loader.py
class WebReader (line 15) | class WebReader(BaseReader):
method run (line 16) | def run(
method fetch_url (line 21) | def fetch_url(self, url: str):
method load_data (line 36) | def load_data(
FILE: libs/kotaemon/kotaemon/parsers/regex_extractor.py
class RegexExtractor (line 9) | class RegexExtractor(BaseComponent):
class Config (line 19) | class Config:
method __init__ (line 27) | def __init__(self, pattern: str | list[str], **kwargs):
method run_raw_static (line 33) | def run_raw_static(pattern: str, text: str) -> list[str]:
method map_output (line 48) | def map_output(text, output_map) -> str:
method run_raw (line 69) | def run_raw(self, text: str) -> ExtractorOutput:
method run (line 91) | def run(
class FirstMatchRegexExtractor (line 134) | class FirstMatchRegexExtractor(RegexExtractor):
method run_raw (line 137) | def run_raw(self, text: str) -> ExtractorOutput:
FILE: libs/kotaemon/kotaemon/rerankings/base.py
class BaseReranking (line 8) | class BaseReranking(BaseComponent):
method run (line 10) | def run(self, documents: list[Document], query: str) -> list[Document]:
FILE: libs/kotaemon/kotaemon/rerankings/cohere.py
class CohereReranking (line 12) | class CohereReranking(BaseReranking):
method run (line 34) | def run(self, documents: list[Document], query: str) -> list[Document]:
FILE: libs/kotaemon/kotaemon/rerankings/tei_fast_rerank.py
class TeiFastReranking (line 14) | class TeiFastReranking(BaseReranking):
method client (line 40) | def client(self, query, texts):
method run (line 55) | def run(self, documents: list[Document], query: str) -> list[Document]:
FILE: libs/kotaemon/kotaemon/rerankings/voyageai.py
function _import_voyageai (line 14) | def _import_voyageai():
class VoyageAIReranking (line 21) | class VoyageAIReranking(BaseReranking):
method __init__ (line 38) | def __init__(self, *args, **kwargs):
method run (line 46) | def run(self, documents: list[Document], query: str) -> list[Document]:
FILE: libs/kotaemon/kotaemon/storages/docstores/base.py
class BaseDocumentStore (line 7) | class BaseDocumentStore(ABC):
method __init__ (line 11) | def __init__(self, *args, **kwargs):
method add (line 15) | def add(
method get (line 30) | def get(self, ids: Union[List[str], str]) -> List[Document]:
method get_all (line 35) | def get_all(self) -> List[Document]:
method count (line 40) | def count(self) -> int:
method query (line 45) | def query(
method delete (line 52) | def delete(self, ids: Union[List[str], str]):
method drop (line 57) | def drop(self):
FILE: libs/kotaemon/kotaemon/storages/docstores/elasticsearch.py
class ElasticsearchDocumentStore (line 10) | class ElasticsearchDocumentStore(BaseDocumentStore):
method __init__ (line 13) | def __init__(
method add (line 63) | def add(
method query_raw (line 103) | def query_raw(self, query: dict) -> List[Document]:
method query (line 124) | def query(
method get (line 143) | def get(self, ids: Union[List[str], str]) -> List[Document]:
method count (line 150) | def count(self) -> int:
method get_all (line 157) | def get_all(self) -> List[Document]:
method delete (line 162) | def delete(self, ids: Union[List[str], str]):
method drop (line 171) | def drop(self):
method __persist_flow__ (line 176) | def __persist_flow__(self):
FILE: libs/kotaemon/kotaemon/storages/docstores/in_memory.py
class InMemoryDocumentStore (line 10) | class InMemoryDocumentStore(BaseDocumentStore):
method __init__ (line 13) | def __init__(self):
method add (line 16) | def add(
method get (line 44) | def get(self, ids: Union[List[str], str]) -> List[Document]:
method get_all (line 51) | def get_all(self) -> List[Document]:
method count (line 55) | def count(self) -> int:
method delete (line 59) | def delete(self, ids: Union[List[str], str]):
method save (line 67) | def save(self, path: Union[str, Path]):
method load (line 73) | def load(self, path: Union[str, Path]):
method query (line 84) | def query(
method __persist_flow__ (line 90) | def __persist_flow__(self):
method drop (line 93) | def drop(self):
FILE: libs/kotaemon/kotaemon/storages/docstores/lancedb.py
class LanceDBDocumentStore (line 11) | class LanceDBDocumentStore(BaseDocumentStore):
method __init__ (line 14) | def __init__(self, path: str = "lancedb", collection_name: str = "docs...
method add (line 26) | def add(
method query (line 62) | def query(
method get (line 96) | def get(self, ids: Union[List[str], str]) -> List[Document]:
method delete (line 129) | def delete(self, ids: Union[List[str], str], refresh_indices: bool = T...
method drop (line 146) | def drop(self):
method count (line 150) | def count(self) -> int:
method get_all (line 153) | def get_all(self) -> List[Document]:
method __persist_flow__ (line 156) | def __persist_flow__(self):
FILE: libs/kotaemon/kotaemon/storages/docstores/simple_file.py
class SimpleFileDocumentStore (line 9) | class SimpleFileDocumentStore(InMemoryDocumentStore):
method __init__ (line 12) | def __init__(self, path: str | Path, collection_name: str = "default"):
method get (line 22) | def get(self, ids: Union[List[str], str]) -> List[Document]:
method add (line 34) | def add(
method delete (line 52) | def delete(self, ids: Union[List[str], str]):
method drop (line 57) | def drop(self):
method __persist_flow__ (line 62) | def __persist_flow__(self):
FILE: libs/kotaemon/kotaemon/storages/vectorstores/base.py
class BaseVectorStore (line 14) | class BaseVectorStore(ABC):
method __init__ (line 16) | def __init__(self, *args, **kwargs):
method add (line 20) | def add(
method delete (line 40) | def delete(self, ids: list[str], **kwargs):
method query (line 50) | def query(
method drop (line 70) | def drop(self):
class LlamaIndexVectorStore (line 75) | class LlamaIndexVectorStore(BaseVectorStore):
method _get_li_class (line 80) | def _get_li_class(self):
method __init__ (line 85) | def __init__(self, *args, **kwargs):
method __setattr__ (line 101) | def __setattr__(self, name: str, value: Any) -> None:
method __getattr__ (line 107) | def __getattr__(self, name: str) -> Any:
method add (line 113) | def add(
method delete (line 137) | def delete(self, ids: list[str], **kwargs):
method query (line 141) | def query(
FILE: libs/kotaemon/kotaemon/storages/vectorstores/chroma.py
class ChromaVectorStore (line 8) | class ChromaVectorStore(LlamaIndexVectorStore):
method __init__ (line 11) | def __init__(
method delete (line 60) | def delete(self, ids: List[str], **kwargs):
method drop (line 69) | def drop(self):
method count (line 73) | def count(self) -> int:
method __persist_flow__ (line 76) | def __persist_flow__(self):
FILE: libs/kotaemon/kotaemon/storages/vectorstores/in_memory.py
class InMemoryVectorStore (line 11) | class InMemoryVectorStore(LlamaIndexVectorStore):
method __init__ (line 15) | def __init__(
method save (line 31) | def save(
method load (line 46) | def load(self, load_path: str, fs: Optional[fsspec.AbstractFileSystem]...
method drop (line 56) | def drop(self):
method __persist_flow__ (line 60) | def __persist_flow__(self):
FILE: libs/kotaemon/kotaemon/storages/vectorstores/lancedb.py
function custom_to_lance_filter (line 13) | def custom_to_lance_filter(
class LanceDBVectorStore (line 30) | class LanceDBVectorStore(LlamaIndexVectorStore):
method __init__ (line 33) | def __init__(
method delete (line 67) | def delete(self, ids: List[str], **kwargs):
method drop (line 76) | def drop(self):
method count (line 80) | def count(self) -> int:
method __persist_flow__ (line 83) | def __persist_flow__(self):
FILE: libs/kotaemon/kotaemon/storages/vectorstores/milvus.py
class MilvusVectorStore (line 9) | class MilvusVectorStore(LlamaIndexVectorStore):
method _get_li_class (line 12) | def _get_li_class(self):
method __init__ (line 25) | def __init__(
method _lazy_init (line 39) | def _lazy_init(self, dim: Optional[int] = None):
method add (line 67) | def add(
method query (line 82) | def query(
method delete (line 93) | def delete(self, ids: list[str], **kwargs):
method drop (line 97) | def drop(self):
method count (line 100) | def count(self) -> int:
method __persist_flow__ (line 109) | def __persist_flow__(self):
FILE: libs/kotaemon/kotaemon/storages/vectorstores/qdrant.py
class QdrantVectorStore (line 6) | class QdrantVectorStore(LlamaIndexVectorStore):
method _get_li_class (line 9) | def _get_li_class(self):
method __init__ (line 22) | def __init__(
method delete (line 49) | def delete(self, ids: List[str], **kwargs):
method drop (line 66) | def drop(self):
method count (line 70) | def count(self) -> int:
method __persist_flow__ (line 75) | def __persist_flow__(self):
FILE: libs/kotaemon/kotaemon/storages/vectorstores/simple_file.py
class SimpleFileVectorStore (line 14) | class SimpleFileVectorStore(LlamaIndexVectorStore):
method __init__ (line 20) | def __init__(
method add (line 46) | def add(
method delete (line 56) | def delete(self, ids: list[str], **kwargs):
method drop (line 61) | def drop(self):
method __persist_flow__ (line 65) | def __persist_flow__(self):
FILE: libs/kotaemon/tests/_test_multimodal_reader.py
function test_adobe_reader (line 14) | def test_adobe_reader():
FILE: libs/kotaemon/tests/conftest.py
function mock_google_search (line 5) | def mock_google_search(monkeypatch):
function if_haystack_not_installed (line 18) | def if_haystack_not_installed():
function if_sentence_bert_not_installed (line 27) | def if_sentence_bert_not_installed():
function if_sentence_fastembed_not_installed (line 36) | def if_sentence_fastembed_not_installed():
function if_unstructured_pdf_not_installed (line 45) | def if_unstructured_pdf_not_installed():
function if_cohere_not_installed (line 55) | def if_cohere_not_installed():
function if_llama_cpp_not_installed (line 64) | def if_llama_cpp_not_installed():
function if_voyageai_not_installed (line 73) | def if_voyageai_not_installed():
FILE: libs/kotaemon/tests/simple_pipeline.py
class Pipeline (line 11) | class Pipeline(BaseComponent):
method run (line 31) | def run(self, text: str) -> LLMInterface:
FILE: libs/kotaemon/tests/test_agent.py
function generate_chat_completion_obj (line 34) | def generate_chat_completion_obj(text):
function llm (line 116) | def llm():
function test_agent_fail (line 129) | def test_agent_fail(openai_completion, llm, mock_google_search):
function test_rewoo_agent (line 148) | def test_rewoo_agent(openai_completion, llm, mock_google_search):
function test_react_agent (line 166) | def test_react_agent(openai_completion, llm, mock_google_search):
function test_react_agent_langchain (line 184) | def test_react_agent_langchain(openai_completion, llm, mock_google_search):
function test_wrapper_agent_langchain (line 209) | def test_wrapper_agent_langchain(openai_completion, llm, mock_google_sea...
function test_react_agent_with_langchain_tools (line 229) | def test_react_agent_with_langchain_tools(openai_completion, llm):
FILE: libs/kotaemon/tests/test_composite.py
function mock_llm (line 42) | def mock_llm():
function mock_post_processor (line 52) | def mock_post_processor():
function mock_prompt (line 57) | def mock_prompt():
function mock_simple_linear_pipeline (line 62) | def mock_simple_linear_pipeline(mock_prompt, mock_llm, mock_post_process...
function mock_gated_linear_pipeline_positive (line 69) | def mock_gated_linear_pipeline_positive(mock_prompt, mock_llm, mock_post...
function mock_gated_linear_pipeline_negative (line 79) | def mock_gated_linear_pipeline_negative(mock_prompt, mock_llm, mock_post...
function test_simple_linear_pipeline_run (line 88) | def test_simple_linear_pipeline_run(mocker, mock_simple_linear_pipeline):
function test_gated_linear_pipeline_run_positive (line 100) | def test_gated_linear_pipeline_run_positive(
function test_gated_linear_pipeline_run_negative (line 116) | def test_gated_linear_pipeline_run_negative(
function test_simple_branching_pipeline_run (line 132) | def test_simple_branching_pipeline_run(mocker, mock_simple_linear_pipeli...
function test_simple_gated_branching_pipeline_run (line 154) | def test_simple_gated_branching_pipeline_run(
FILE: libs/kotaemon/tests/test_cot.py
function test_cot_plus_operator (line 40) | def test_cot_plus_operator(openai_completion):
function test_cot_manual (line 71) | def test_cot_manual(openai_completion):
function test_cot_with_termination_callback (line 100) | def test_cot_with_termination_callback(openai_completion):
FILE: libs/kotaemon/tests/test_docstores.py
function test_inmemory_document_store_base_interfaces (line 215) | def test_inmemory_document_store_base_interfaces(tmp_path):
function test_simplefile_document_store_base_interfaces (line 271) | def test_simplefile_document_store_base_interfaces(tmp_path):
function test_elastic_document_store (line 329) | def test_elastic_document_store(elastic_api):
FILE: libs/kotaemon/tests/test_documents.py
function test_document_constructor_with_builtin_types (line 6) | def test_document_constructor_with_builtin_types():
function test_document_constructor_with_document (line 14) | def test_document_constructor_with_document():
function test_document_to_haystack_format (line 23) | def test_document_to_haystack_format():
function test_retrieved_document_default_values (line 35) | def test_retrieved_document_default_values():
function test_retrieved_document_attributes (line 43) | def test_retrieved_document_attributes():
FILE: libs/kotaemon/tests/test_embedding_models.py
function assert_embedding_result (line 31) | def assert_embedding_result(output):
function test_azureopenai_embeddings_raw (line 42) | def test_azureopenai_embeddings_raw(openai_embedding_call):
function test_lcazureopenai_embeddings_batch_raw (line 58) | def test_lcazureopenai_embeddings_batch_raw(openai_embedding_call):
function test_azureopenai_embeddings_batch_raw (line 74) | def test_azureopenai_embeddings_batch_raw(openai_embedding_call):
function test_openai_embeddings_raw (line 90) | def test_openai_embeddings_raw(openai_embedding_call):
function test_openai_embeddings_batch_raw (line 104) | def test_openai_embeddings_batch_raw(openai_embedding_call):
function test_lchuggingface_embeddings (line 123) | def test_lchuggingface_embeddings(
function test_lccohere_embeddings (line 143) | def test_lccohere_embeddings(langchain_cohere_embedding_call):
function test_fastembed_embeddings (line 156) | def test_fastembed_embeddings():
function test_voyageai_embeddings (line 169) | def test_voyageai_embeddings(sync_call, async_call):
FILE: libs/kotaemon/tests/test_indexing_retrieval.py
function test_indexing (line 21) | def test_indexing(tmp_path):
function test_retrieving (line 45) | def test_retrieving(tmp_path):
FILE: libs/kotaemon/tests/test_ingestor.py
function test_ingestor_include_src (line 7) | def test_ingestor_include_src():
FILE: libs/kotaemon/tests/test_llms_chat_models.py
function test_azureopenai_model (line 47) | def test_azureopenai_model(openai_completion):
function test_llamacpp_chat (line 77) | def test_llamacpp_chat():
FILE: libs/kotaemon/tests/test_llms_completion_models.py
function test_azureopenai_model (line 43) | def test_azureopenai_model(openai_completion):
function test_openai_model (line 66) | def test_openai_model(openai_completion):
function test_llamacpp_model (line 86) | def test_llamacpp_model():
FILE: libs/kotaemon/tests/test_mcp_manager.py
class _Base (line 16) | class _Base(DeclarativeBase):
class _MCPTable (line 20) | class _MCPTable(_Base):
function manager (line 32) | def manager():
class MCPManagerForTest (line 44) | class MCPManagerForTest:
method __init__ (line 47) | def __init__(self, engine):
method load (line 52) | def load(self):
method info (line 61) | def info(self) -> dict:
method get (line 64) | def get(self, name: str) -> dict | None:
method add (line 67) | def add(self, name: str, config: dict):
method update (line 76) | def update(self, name: str, config: dict):
method delete (line 87) | def delete(self, name: str):
method get_enabled_tools (line 95) | def get_enabled_tools(self) -> list[str]:
class TestMCPManagerAdd (line 108) | class TestMCPManagerAdd:
method test_add_and_retrieve (line 109) | def test_add_and_retrieve(self, manager):
method test_add_multiple (line 115) | def test_add_multiple(self, manager):
method test_empty_or_whitespace_name_raises (line 121) | def test_empty_or_whitespace_name_raises(self, manager, name):
method test_whitespace_name_is_stripped (line 125) | def test_whitespace_name_is_stripped(self, manager):
method test_complex_config_stored_correctly (line 129) | def test_complex_config_stored_correctly(self, manager):
class TestMCPManagerUpdateDelete (line 141) | class TestMCPManagerUpdateDelete:
method test_update_changes_config (line 142) | def test_update_changes_config(self, manager):
method test_update_nonexistent_raises (line 149) | def test_update_nonexistent_raises(self, manager):
method test_delete_removes_entry (line 153) | def test_delete_removes_entry(self, manager):
method test_delete_nonexistent_is_noop (line 160) | def test_delete_nonexistent_is_noop(self, manager):
class TestMCPManagerGetEnabledTools (line 165) | class TestMCPManagerGetEnabledTools:
method test_only_servers_with_enabled_tools_listed (line 166) | def test_only_servers_with_enabled_tools_listed(self, manager):
method test_empty_when_no_servers (line 173) | def test_empty_when_no_servers(self, manager):
class TestMCPManagerLoad (line 177) | class TestMCPManagerLoad:
method test_load_picks_up_external_db_changes (line 178) | def test_load_picks_up_external_db_changes(self, manager):
FILE: libs/kotaemon/tests/test_mcp_tools.py
function test_json_schema_type_to_python (line 39) | def test_json_schema_type_to_python(json_type, expected):
class TestBuildArgsModel (line 48) | class TestBuildArgsModel:
method test_model_fields_and_name (line 49) | def test_model_fields_and_name(self):
method test_optional_field_preserves_default (line 63) | def test_optional_field_preserves_default(self):
method test_empty_schema_produces_no_fields (line 76) | def test_empty_schema_produces_no_fields(self):
class TestParseMcpConfig (line 85) | class TestParseMcpConfig:
method test_full_stdio_config (line 86) | def test_full_stdio_config(self):
method test_defaults_for_empty_config (line 101) | def test_defaults_for_empty_config(self):
method test_auto_split_multi_word_command (line 108) | def test_auto_split_multi_word_command(self):
method test_no_split_when_args_already_provided (line 116) | def test_no_split_when_args_already_provided(self):
method test_sse_transport_uses_url_as_command (line 127) | def test_sse_transport_uses_url_as_command(self):
class TestMakeTool (line 145) | class TestMakeTool:
method test_creates_mcp_tool_with_schema (line 146) | def test_creates_mcp_tool_with_schema(self):
method test_missing_schema_and_description_uses_defaults (line 172) | def test_missing_schema_and_description_uses_defaults(self):
class TestFormatToolList (line 186) | class TestFormatToolList:
method test_all_tools_enabled_by_default (line 187) | def test_all_tools_enabled_by_default(self):
method test_partial_filter_shows_counts_and_icons (line 197) | def test_partial_filter_shows_counts_and_icons(self):
method test_long_description_is_truncated (line 207) | def test_long_description_is_truncated(self):
method test_none_description_shows_placeholder (line 211) | def test_none_description_shows_placeholder(self):
class TestCreateToolsFromConfig (line 221) | class TestCreateToolsFromConfig:
method _make_mock_tools (line 222) | def _make_mock_tools(self):
method test_no_filter_returns_all (line 241) | def test_no_filter_returns_all(self, mock_run_async):
method test_enabled_tools_filter (line 247) | def test_enabled_tools_filter(self, mock_run_async):
class TestMCPToolFormatResult (line 265) | class TestMCPToolFormatResult:
method _make_tool (line 266) | def _make_tool(self):
method test_text_content_joined (line 275) | def test_text_content_joined(self):
method test_error_flag (line 284) | def test_error_flag(self):
method test_binary_content (line 293) | def test_binary_content(self):
FILE: libs/kotaemon/tests/test_post_processing.py
function regex_extractor (line 8) | def regex_extractor():
function test_run_document (line 14) | def test_run_document(regex_extractor):
function test_run_raw (line 21) | def test_run_raw(regex_extractor):
function test_run_batch_raw (line 27) | def test_run_batch_raw(regex_extractor):
FILE: libs/kotaemon/tests/test_prompt.py
function test_set_attributes (line 8) | def test_set_attributes():
function test_check_redundant_kwargs (line 23) | def test_check_redundant_kwargs():
function test_check_unset_placeholders (line 30) | def test_check_unset_placeholders():
function test_validate_value_type (line 37) | def test_validate_value_type():
function test_run (line 44) | def test_run():
function test_set_method (line 59) | def test_set_method():
FILE: libs/kotaemon/tests/test_promptui.py
class TestPromptConfig (line 8) | class TestPromptConfig:
method test_export_prompt_config (line 9) | def test_export_prompt_config(self):
class TestPromptUI (line 27) | class TestPromptUI:
method test_uigeneration (line 28) | def test_uigeneration(self):
class TestExport (line 36) | class TestExport:
method test_export (line 37) | def test_export(self, tmp_path):
FILE: libs/kotaemon/tests/test_reader.py
function test_docx_reader (line 20) | def test_docx_reader():
function test_html_reader (line 27) | def test_html_reader():
function test_pdf_reader (line 36) | def test_pdf_reader():
function test_unstructured_pdf_reader (line 58) | def test_unstructured_pdf_reader():
function test_mhtml_reader (line 77) | def test_mhtml_reader():
function test_azureai_document_intelligence_reader (line 87) | def test_azureai_document_intelligence_reader(mock_client):
FILE: libs/kotaemon/tests/test_reranking.py
function llm (line 43) | def llm():
function test_reranking (line 56) | def test_reranking(openai_completion, llm):
FILE: libs/kotaemon/tests/test_splitter.py
function test_split_token (line 42) | def test_split_token():
FILE: libs/kotaemon/tests/test_table_reader.py
function fullocr_output (line 15) | def fullocr_output():
function mathpix_output (line 25) | def mathpix_output():
function test_ocr_reader (line 32) | def test_ocr_reader(fullocr_output):
function test_mathpix_reader (line 39) | def test_mathpix_reader(mathpix_output):
function test_excel_reader (line 46) | def test_excel_reader():
FILE: libs/kotaemon/tests/test_telemetry.py
function clean_artifacts_for_telemetry (line 10) | def clean_artifacts_for_telemetry():
function test_disable_telemetry_import_haystack_first (line 32) | def test_disable_telemetry_import_haystack_first():
function test_disable_telemetry_import_haystack_after_kotaemon (line 49) | def test_disable_telemetry_import_haystack_after_kotaemon():
FILE: libs/kotaemon/tests/test_template.py
function test_prompt_template_creation (line 6) | def test_prompt_template_creation():
function test_prompt_template_creation_invalid_placeholder (line 18) | def test_prompt_template_creation_invalid_placeholder():
function test_prompt_template_addition (line 32) | def test_prompt_template_addition():
function test_prompt_template_extract_placeholders (line 45) | def test_prompt_template_extract_placeholders():
function test_prompt_template_populate (line 52) | def test_prompt_template_populate():
function test_prompt_template_check_missing_kwargs (line 60) | def test_prompt_template_check_missing_kwargs():
function test_prompt_template_check_redundant_kwargs (line 74) | def test_prompt_template_check_redundant_kwargs():
function test_prompt_template_populate_complex_template (line 91) | def test_prompt_template_populate_complex_template():
function test_prompt_template_partial_populate (line 104) | def test_prompt_template_partial_populate():
FILE: libs/kotaemon/tests/test_tools.py
function test_google_tool (line 17) | def test_google_tool(mock_google_search):
function test_wikipedia_tool (line 25) | def test_wikipedia_tool():
function test_pipeline_tool (line 37) | def test_pipeline_tool(tmp_path):
FILE: libs/kotaemon/tests/test_vectorstore.py
class TestChromaVectorStore (line 16) | class TestChromaVectorStore:
method test_add (line 17) | def test_add(self, tmp_path):
method test_add_from_docs (line 30) | def test_add_from_docs(self, tmp_path):
method test_delete (line 44) | def test_delete(self, tmp_path):
method test_query (line 58) | def test_query(self, tmp_path):
method test_save_load_delete (line 74) | def test_save_load_delete(self, tmp_path):
class TestInMemoryVectorStore (line 96) | class TestInMemoryVectorStore:
method test_add (line 97) | def test_add(self):
method test_save_load_delete (line 108) | def test_save_load_delete(self, tmp_path):
class TestSimpleFileVectorStore (line 134) | class TestSimpleFileVectorStore:
method test_add_delete (line 135) | def test_add_delete(self, tmp_path):
class TestMilvusVectorStore (line 162) | class TestMilvusVectorStore:
method test_add (line 163) | def test_add(self, tmp_path):
method test_add_from_docs (line 179) | def test_add_from_docs(self, tmp_path):
method test_delete (line 196) | def test_delete(self, tmp_path):
method test_query (line 213) | def test_query(self, tmp_path):
method test_save_load_delete (line 238) | def test_save_load_delete(self, tmp_path):
class TestQdrantVectorStore (line 256) | class TestQdrantVectorStore:
method test_add (line 257) | def test_add(self):
method test_add_from_docs (line 273) | def test_add_from_docs(self, tmp_path):
method test_delete (line 289) | def test_delete(self, tmp_path):
method test_query (line 314) | def test_query(self, tmp_path):
method test_save_load_delete (line 336) | def test_save_load_delete(self, tmp_path):
FILE: libs/ktem/ktem/app.py
class BaseApp (line 19) | class BaseApp:
method __init__ (line 40) | def __init__(self):
method initialize_indices (line 84) | def initialize_indices(self):
method register_reasonings (line 95) | def register_reasonings(self):
method register_extensions (line 109) | def register_extensions(self):
method declare_event (line 136) | def declare_event(self, name: str):
method subscribe_event (line 146) | def subscribe_event(self, name: str, definition: dict):
method get_event (line 157) | def get_event(self, name) -> list[dict]:
method ui (line 163) | def ui(self):
method on_subscribe_public_events (line 166) | def on_subscribe_public_events(self):
method on_register_events (line 169) | def on_register_events(self):
method _on_app_created (line 172) | def _on_app_created(self):
method make (line 175) | def make(self):
method declare_public_events (line 222) | def declare_public_events(self):
method subscribe_public_events (line 231) | def subscribe_public_events(self):
method register_events (line 238) | def register_events(self):
method on_app_created (line 245) | def on_app_created(self):
class BasePage (line 253) | class BasePage:
method __init__ (line 258) | def __init__(self, app):
method on_building_ui (line 261) | def on_building_ui(self):
method on_subscribe_public_events (line 264) | def on_subscribe_public_events(self):
method on_register_events (line 267) | def on_register_events(self):
method _on_app_created (line 270) | def _on_app_created(self):
method as_gradio_component (line 273) | def as_gradio_component(
method render (line 282) | def render(self):
method unrender (line 289) | def unrender(self):
method declare_public_events (line 296) | def declare_public_events(self):
method subscribe_public_events (line 305) | def subscribe_public_events(self):
method register_events (line 312) | def register_events(self):
method on_app_created (line 319) | def on_app_created(self):
FILE: libs/ktem/ktem/assets/js/main.js
function run (line 1) | function run() {
FILE: libs/ktem/ktem/assets/js/pdf_viewer.js
function onBlockLoad (line 1) | function onBlockLoad() {
FILE: libs/ktem/ktem/assets/theme.py
class Kotaemon (line 146) | class Kotaemon(Soft):
method __init__ (line 152) | def __init__(
FILE: libs/ktem/ktem/components.py
function get_docstore (line 22) | def get_docstore(collection_name: str = "default") -> BaseDocumentStore:
function get_vectorstore (line 31) | def get_vectorstore(collection_name: str = "default") -> BaseVectorStore:
class ModelPool (line 39) | class ModelPool:
method __init__ (line 42) | def __init__(self, category: str, conf: dict):
method __getitem__ (line 61) | def __getitem__(self, key: str) -> BaseComponent:
method __setitem__ (line 65) | def __setitem__(self, key: str, value: BaseComponent):
method __delitem__ (line 69) | def __delitem__(self, key: str):
method __contains__ (line 73) | def __contains__(self, key: str) -> bool:
method get (line 77) | def get(
method settings (line 83) | def settings(self) -> dict:
method options (line 91) | def options(self) -> dict:
method get_random_name (line 95) | def get_random_name(self) -> str:
method get_default_name (line 108) | def get_default_name(self) -> str:
method get_random (line 127) | def get_random(self) -> BaseComponent:
method get_default (line 131) | def get_default(self) -> BaseComponent:
method get_highest_accuracy_name (line 142) | def get_highest_accuracy_name(self) -> str:
method get_highest_accuracy (line 152) | def get_highest_accuracy(self) -> BaseComponent:
method get_lowest_cost_name (line 163) | def get_lowest_cost_name(self) -> str:
method get_lowest_cost (line 173) | def get_lowest_cost(self) -> BaseComponent:
FILE: libs/ktem/ktem/db/base_models.py
class BaseConversation (line 10) | class BaseConversation(SQLModel):
class BaseUser (line 47) | class BaseUser(SQLModel):
class BaseSettings (line 67) | class BaseSettings(SQLModel):
class BaseIssueReport (line 85) | class BaseIssueReport(SQLModel):
FILE: libs/ktem/ktem/db/models.py
class Conversation (line 32) | class Conversation(_base_conv, table=True): # type: ignore
class User (line 36) | class User(_base_user, table=True): # type: ignore
class Settings (line 40) | class Settings(_base_settings, table=True): # type: ignore
class IssueReport (line 44) | class IssueReport(_base_issue_report, table=True): # type: ignore
FILE: libs/ktem/ktem/embeddings/db.py
class Base (line 10) | class Base(DeclarativeBase):
class BaseEmbeddingTable (line 14) | class BaseEmbeddingTable(Base):
class EmbeddingTable (line 31) | class EmbeddingTable(_base_llm): # type: ignore
FILE: libs/ktem/ktem/embeddings/manager.py
class EmbeddingManager (line 13) | class EmbeddingManager:
method __init__ (line 16) | def __init__(self):
method load (line 37) | def load(self):
method load_vendors (line 55) | def load_vendors(self):
method __getitem__ (line 80) | def __getitem__(self, key: str) -> BaseEmbeddings:
method __contains__ (line 84) | def __contains__(self, key: str) -> bool:
method get (line 88) | def get(
method settings (line 94) | def settings(self) -> dict:
method options (line 102) | def options(self) -> dict:
method get_random_name (line 106) | def get_random_name(self) -> str:
method get_default_name (line 119) | def get_default_name(self) -> str:
method get_random (line 136) | def get_random(self) -> BaseEmbeddings:
method get_default (line 140) | def get_default(self) -> BaseEmbeddings:
method info (line 151) | def info(self) -> dict:
method add (line 155) | def add(self, name: str, spec: dict, default: bool):
method delete (line 175) | def delete(self, name: str):
method update (line 187) | def update(self, name: str, spec: dict, default: bool, new_name: str =...
method vendors (line 221) | def vendors(self) -> dict:
FILE: libs/ktem/ktem/embeddings/ui.py
function format_description (line 13) | def format_description(cls):
class EmbeddingManagement (line 23) | class EmbeddingManagement(BasePage):
method __init__ (line 24) | def __init__(self, app):
method on_building_ui (line 31) | def on_building_ui(self):
method _on_app_created (line 132) | def _on_app_created(self):
method on_emb_vendor_change (line 144) | def on_emb_vendor_change(self, vendor):
method on_register_events (line 155) | def on_register_events(self):
method create_emb (line 252) | def create_emb(self, name, choices, spec, default):
method list_embeddings (line 269) | def list_embeddings(self):
method select_emb (line 288) | def select_emb(self, emb_list, ev: gr.SelectData):
method on_selected_emb_change (line 298) | def on_selected_emb_change(self, selected_emb_name):
method on_btn_delete_click (line 337) | def on_btn_delete_click(self):
method check_connection (line 344) | def check_connection(self, selected_emb_name, selected_spec):
method save_emb (line 383) | def save_emb(self, selected_emb_name, edit_name, default, spec):
method delete_emb (line 403) | def delete_emb(self, selected_emb_name):
FILE: libs/ktem/ktem/exceptions.py
class KHException (line 1) | class KHException(Exception):
class HookNotDeclared (line 5) | class HookNotDeclared(KHException):
class HookAlreadyDeclared (line 9) | class HookAlreadyDeclared(KHException):
FILE: libs/ktem/ktem/extension_protocol.py
function ktem_declare_extensions (line 8) | def ktem_declare_extensions() -> dict: # type: ignore
FILE: libs/ktem/ktem/index/base.py
class BaseIndex (line 14) | class BaseIndex(abc.ABC):
method __init__ (line 56) | def __init__(self, app, id, name, config):
method on_create (line 62) | def on_create(self):
method on_delete (line 65) | def on_delete(self):
method on_start (line 68) | def on_start(self):
method get_selector_component_ui (line 77) | def get_selector_component_ui(self) -> Optional["BasePage"]:
method get_index_page_ui (line 81) | def get_index_page_ui(self) -> Optional["BasePage"]:
method get_user_settings (line 86) | def get_user_settings(cls) -> dict:
method get_admin_settings (line 99) | def get_admin_settings(cls) -> dict:
method get_indexing_pipeline (line 112) | def get_indexing_pipeline(
method get_retriever_pipelines (line 128) | def get_retriever_pipelines(
FILE: libs/ktem/ktem/index/file/base.py
class BaseFileIndexRetriever (line 7) | class BaseFileIndexRetriever(BaseComponent):
method get_user_settings (line 17) | def get_user_settings(cls) -> dict:
method get_pipeline (line 27) | def get_pipeline(
class BaseFileIndexIndexing (line 36) | class BaseFileIndexIndexing(BaseComponent):
method run (line 61) | def run(
method stream (line 77) | def stream(
method get_pipeline (line 100) | def get_pipeline(
method get_user_settings (line 106) | def get_user_settings(cls) -> dict:
method copy_to_filestorage (line 115) | def copy_to_filestorage(
method get_filestorage_path (line 140) | def get_filestorage_path(self, rel_paths: str | list[str]) -> list[str]:
method warning (line 151) | def warning(self, msg):
method rebuild_index (line 159) | def rebuild_index(self):
FILE: libs/ktem/ktem/index/file/exceptions.py
class FileExistsError (line 4) | class FileExistsError(KHException):
FILE: libs/ktem/ktem/index/file/graph/graph_index.py
class GraphRAGIndex (line 9) | class GraphRAGIndex(FileIndex):
method _setup_indexing_cls (line 10) | def _setup_indexing_cls(self):
method _setup_retriever_cls (line 13) | def _setup_retriever_cls(self):
method get_indexing_pipeline (line 16) | def get_indexing_pipeline(self, settings, user_id) -> BaseFileIndexInd...
method get_retriever_pipelines (line 25) | def get_retriever_pipelines(
FILE: libs/ktem/ktem/index/file/graph/light_graph_index.py
class LightRAGIndex (line 12) | class LightRAGIndex(GraphRAGIndex):
method __init__ (line 13) | def __init__(self, app, id: int, name: str, config: dict):
method _setup_indexing_cls (line 17) | def _setup_indexing_cls(self):
method _setup_retriever_cls (line 20) | def _setup_retriever_cls(self):
method _get_or_create_collection_graph_id (line 23) | def _get_or_create_collection_graph_id(self):
method get_indexing_pipeline (line 42) | def get_indexing_pipeline(self, settings, user_id) -> BaseFileIndexInd...
method get_retriever_pipelines (line 61) | def get_retriever_pipelines(
FILE: libs/ktem/ktem/index/file/graph/lightrag_pipelines.py
function get_llm_func (line 60) | def get_llm_func(model):
function get_embedding_func (line 110) | def get_embedding_func(model):
function get_default_models_wrapper (line 120) | def get_default_models_wrapper():
function prepare_graph_index_path (line 137) | def prepare_graph_index_path(graph_id: str):
function list_of_list_to_df (line 144) | def list_of_list_to_df(data: list[list]) -> pd.DataFrame:
function clean_quote (line 149) | def clean_quote(input: str) -> str:
function lightrag_build_local_query_context (line 153) | async def lightrag_build_local_query_context(
function build_graphrag (line 235) | def build_graphrag(working_dir, llm_func, embedding_func):
class LightRAGIndexingPipeline (line 249) | class LightRAGIndexingPipeline(GraphRAGIndexingPipeline):
method store_file_id_with_graph_id (line 256) | def store_file_id_with_graph_id(self, file_ids: list[str | None]):
method get_user_settings (line 290) | def get_user_settings(cls) -> dict:
method call_graphrag_index (line 324) | def call_graphrag_index(self, graph_id: str, docs: list[Document]):
method stream (line 404) | def stream(
class LightRAGRetrieverPipeline (line 416) | class LightRAGRetrieverPipeline(BaseFileIndexRetriever):
method get_user_settings (line 424) | def get_user_settings(cls) -> dict:
method _build_graph_search (line 435) | def _build_graph_search(self):
method _to_document (line 463) | def _to_document(self, header: str, context_text: str) -> RetrievedDoc...
method format_context_records (line 474) | def format_context_records(
method plot_graph (line 501) | def plot_graph(self, relationships):
method run (line 506) | def run(
FILE: libs/ktem/ktem/index/file/graph/nano_graph_index.py
class NanoGraphRAGIndex (line 12) | class NanoGraphRAGIndex(GraphRAGIndex):
method __init__ (line 13) | def __init__(self, app, id: int, name: str, config: dict):
method _setup_indexing_cls (line 17) | def _setup_indexing_cls(self):
method _setup_retriever_cls (line 20) | def _setup_retriever_cls(self):
method _get_or_create_collection_graph_id (line 23) | def _get_or_create_collection_graph_id(self):
method get_indexing_pipeline (line 42) | def get_indexing_pipeline(self, settings, user_id) -> BaseFileIndexInd...
method get_retriever_pipelines (line 61) | def get_retriever_pipelines(
FILE: libs/ktem/ktem/index/file/graph/nano_pipelines.py
function get_llm_func (line 58) | def get_llm_func(model):
function get_embedding_func (line 108) | def get_embedding_func(model):
function get_default_models_wrapper (line 118) | def get_default_models_wrapper():
function prepare_graph_index_path (line 135) | def prepare_graph_index_path(graph_id: str):
function list_of_list_to_df (line 142) | def list_of_list_to_df(data: list[list]) -> pd.DataFrame:
function clean_quote (line 147) | def clean_quote(input: str) -> str:
function nano_graph_rag_build_local_query_context (line 151) | async def nano_graph_rag_build_local_query_context(
function build_graphrag (line 227) | def build_graphrag(working_dir, llm_func, embedding_func):
class NanoGraphRAGIndexingPipeline (line 237) | class NanoGraphRAGIndexingPipeline(GraphRAGIndexingPipeline):
method store_file_id_with_graph_id (line 244) | def store_file_id_with_graph_id(self, file_ids: list[str | None]):
method get_user_settings (line 278) | def get_user_settings(cls) -> dict:
method call_graphrag_index (line 312) | def call_graphrag_index(self, graph_id: str, docs: list[Document]):
method stream (line 392) | def stream(
class NanoGraphRAGRetrieverPipeline (line 404) | class NanoGraphRAGRetrieverPipeline(BaseFileIndexRetriever):
method get_user_settings (line 412) | def get_user_settings(cls) -> dict:
method _build_graph_search (line 423) | def _build_graph_search(self):
method _to_document (line 451) | def _to_document(self, header: str, context_text: str) -> RetrievedDoc...
method format_context_records (line 462) | def format_context_records(
method plot_graph (line 497) | def plot_graph(self, relationships):
method run (line 502) | def run(
FILE: libs/ktem/ktem/index/file/graph/pipelines.py
function check_graphrag_api_key (line 55) | def check_graphrag_api_key():
function prepare_graph_index_path (line 59) | def prepare_graph_index_path(graph_id: str):
class GraphRAGIndexingPipeline (line 66) | class GraphRAGIndexingPipeline(IndexDocumentPipeline):
method route (line 69) | def route(self, file_path: str | Path) -> IndexPipeline:
method store_file_id_with_graph_id (line 76) | def store_file_id_with_graph_id(self, file_ids: list[str | None]):
method write_docs_to_files (line 98) | def write_docs_to_files(self, graph_id: str, docs: list[Document]):
method call_graphrag_index (line 109) | def call_graphrag_index(self, graph_id: str, all_docs: list[Document]):
method stream (line 154) | def stream(
class GraphRAGRetrieverPipeline (line 171) | class GraphRAGRetrieverPipeline(BaseFileIndexRetriever):
method get_user_settings (line 178) | def get_user_settings(cls) -> dict:
method _build_graph_search (line 189) | def _build_graph_search(self):
method _to_document (line 296) | def _to_document(self, header: str, context_text: str) -> RetrievedDoc...
method format_context_records (line 307) | def format_context_records(self, context_records) -> list[RetrievedDoc...
method plot_graph (line 345) | def plot_graph(self, context_records):
method generate_relevant_scores (line 351) | def generate_relevant_scores(self, text, documents: list[RetrievedDocu...
method run (line 354) | def run(
FILE: libs/ktem/ktem/index/file/graph/visualize.py
function create_knowledge_graph (line 6) | def create_knowledge_graph(df):
function visualize_graph (line 20) | def visualize_graph(G):
FILE: libs/ktem/ktem/index/file/index.py
function generate_uuid (line 20) | def generate_uuid():
class FileIndex (line 24) | class FileIndex(BaseIndex):
method __init__ (line 38) | def __init__(self, app, id: int, name: str, config: dict):
method _setup_resources (line 51) | def _setup_resources(self):
method _setup_indexing_cls (line 165) | def _setup_indexing_cls(self):
method _setup_retriever_cls (line 199) | def _setup_retriever_cls(self):
method _setup_file_selector_ui_cls (line 238) | def _setup_file_selector_ui_cls(self):
method _setup_file_index_ui_cls (line 273) | def _setup_file_index_ui_cls(self):
method on_create (line 308) | def on_create(self):
method on_delete (line 334) | def on_delete(self):
method on_start (line 346) | def on_start(self):
method get_selector_component_ui (line 354) | def get_selector_component_ui(self):
method get_index_page_ui (line 359) | def get_index_page_ui(self):
method get_user_settings (line 364) | def get_user_settings(self):
method get_admin_settings (line 377) | def get_admin_settings(cls):
method get_indexing_pipeline (line 440) | def get_indexing_pipeline(self, settings, user_id) -> BaseFileIndexInd...
method get_retriever_pipelines (line 462) | def get_retriever_pipelines(
FILE: libs/ktem/ktem/index/file/knet/knet_index.py
class KnowledgeNetworkFileIndex (line 9) | class KnowledgeNetworkFileIndex(FileIndex):
method get_admin_settings (line 11) | def get_admin_settings(cls):
method _setup_indexing_cls (line 19) | def _setup_indexing_cls(self):
method _setup_retriever_cls (line 22) | def _setup_retriever_cls(self):
method get_indexing_pipeline (line 25) | def get_indexing_pipeline(self, settings, user_id) -> BaseFileIndexInd...
method get_retriever_pipelines (line 36) | def get_retriever_pipelines(
FILE: libs/ktem/ktem/index/file/knet/pipelines.py
class KnetIndexingPipeline (line 16) | class KnetIndexingPipeline(IndexDocumentPipeline):
method get_user_settings (line 23) | def get_user_settings(cls):
method route (line 35) | def route(self, file_path: str | Path) -> IndexPipeline:
class KnetRetrievalPipeline (line 45) | class KnetRetrievalPipeline(BaseFileIndexRetriever):
method encode_image_base64 (line 51) | def encode_image_base64(self, image_path: str | Path) -> bytes | str:
method run (line 59) | def run(
method get_user_settings (line 119) | def get_user_settings(cls) -> dict:
method get_pipeline (line 146) | def get_pipeline(cls, user_settings, index_settings, selected):
FILE: libs/ktem/ktem/index/file/pipelines.py
function dev_settings (line 56) | def dev_settings():
class DocumentRetrievalPipeline (line 80) | class DocumentRetrievalPipeline(BaseFileIndexRetriever):
method vector_retrieval (line 104) | def vector_retrieval(self) -> VectorRetrieval:
method run (line 113) | def run(
method generate_relevant_scores (line 213) | def generate_relevant_scores(
method get_user_settings (line 224) | def get_user_settings(cls) -> dict:
method get_pipeline (line 281) | def get_pipeline(cls, user_settings, index_settings, selected):
class IndexPipeline (line 328) | class IndexPipeline(BaseComponent):
method vector_indexing (line 347) | def vector_indexing(self) -> VectorIndexing:
method handle_docs (line 352) | def handle_docs(self, docs, file_id, file_name) -> Generator[Document,...
method handle_chunks_docstore (line 424) | def handle_chunks_docstore(self, chunks, file_id):
method handle_chunks_vectorstore (line 443) | def handle_chunks_vectorstore(self, chunks, file_id):
method get_id_if_exists (line 464) | def get_id_if_exists(self, file_path: str | Path) -> Optional[str]:
method store_url (line 490) | def store_url(self, url: str) -> str:
method store_file (line 513) | def store_file(self, file_path: Path) -> str:
method finish (line 539) | def finish(self, file_id: str, file_path: str | Path) -> str:
method get_token_func (line 568) | def get_token_func(self):
method delete_file (line 572) | def delete_file(self, file_id: str):
method run (line 597) | def run(
method stream (line 602) | def stream(
class IndexDocumentPipeline (line 657) | class IndexDocumentPipeline(BaseFileIndexIndexing):
method readers (line 674) | def readers(self):
method get_user_settings (line 690) | def get_user_settings(cls):
method get_pipeline (line 709) | def get_pipeline(cls, user_settings, index_settings) -> BaseFileIndexI...
method is_url (line 723) | def is_url(self, file_path: str | Path) -> bool:
method route (line 728) | def route(self, file_path: str | Path) -> IndexPipeline:
method run (line 776) | def run(
method stream (line 781) | def stream(
FILE: libs/ktem/ktem/index/file/ui.py
class File (line 78) | class File(gr.File):
method _process_single_file (line 84) | def _process_single_file(self, f: FileData) -> NamedString | bytes:
class DirectoryUpload (line 104) | class DirectoryUpload(BasePage):
method __init__ (line 105) | def __init__(self, app, index):
method on_building_ui (line 116) | def on_building_ui(self):
class FileIndexPage (line 131) | class FileIndexPage(BasePage):
method __init__ (line 132) | def __init__(self, app, index):
method upload_instruction (line 150) | def upload_instruction(self) -> str:
method render_file_list (line 166) | def render_file_list(self):
method render_group_list (line 235) | def render_group_list(self):
method on_building_ui (line 286) | def on_building_ui(self):
method on_subscribe_public_events (line 342) | def on_subscribe_public_events(self):
method file_selected (line 395) | def file_selected(self, file_id):
method delete_event (line 447) | def delete_event(self, file_id):
method delete_no_event (line 481) | def delete_no_event(self):
method download_single_file (line 487) | def download_single_file(self, is_zipped_state, file_id):
method download_single_file_simple (line 523) | def download_single_file_simple(self, is_zipped_state, file_html, file...
method download_all_files (line 551) | def download_all_files(self):
method delete_all_files (line 569) | def delete_all_files(self, file_list):
method set_file_id_selector (line 573) | def set_file_id_selector(self, selected_file_id):
method show_delete_all_confirm (line 576) | def show_delete_all_confirm(self, file_list):
method on_register_quick_uploads (line 594) | def on_register_quick_uploads(self):
method on_register_events (line 726) | def on_register_events(self):
method _on_app_created (line 1039) | def _on_app_created(self):
method _may_extract_zip (line 1058) | def _may_extract_zip(self, files, zip_dir: str):
method index_fn (line 1092) | def index_fn(
method index_fn_file_with_default_loaders (line 1163) | def index_fn_file_with_default_loaders(
method index_fn_url_with_default_loaders (line 1203) | def index_fn_url_with_default_loaders(
method index_files_from_dir (line 1267) | def index_files_from_dir(
method format_size_human_readable (line 1340) | def format_size_human_readable(self, num: float | str, suffix="B"):
method list_file (line 1352) | def list_file(self, user_id, name_pattern=""):
method list_file_names (line 1407) | def list_file_names(self, file_list_state):
method list_group (line 1415) | def list_group(self, user_id, file_list):
method set_group_id_selector (line 1482) | def set_group_id_selector(self, selected_group_id):
method save_group (line 1494) | def save_group(self, group_id, group_name, group_files, user_id):
method delete_group (line 1531) | def delete_group(self, group_id):
method interact_file_list (line 1551) | def interact_file_list(self, list_files, ev: gr.SelectData):
method interact_group_list (line 1563) | def interact_group_list(self, list_groups, ev: gr.SelectData):
method validate_files (line 1577) | def validate_files(self, files: list[str]):
method validate_urls (line 1606) | def validate_urls(self, urls: list[str]):
class FileSelector (line 1615) | class FileSelector(BasePage):
method __init__ (line 1618) | def __init__(self, app, index):
method default (line 1623) | def default(self):
method on_building_ui (line 1628) | def on_building_ui(self):
method on_register_events (line 1654) | def on_register_events(self):
method as_gradio_component (line 1669) | def as_gradio_component(self):
method get_selected_ids (line 1672) | def get_selected_ids(self, components):
method load_files (line 1695) | def load_files(self, selected_files, user_id):
method _on_app_created (line 1739) | def _on_app_created(self):
method on_subscribe_public_events (line 1746) | def on_subscribe_public_events(self):
FILE: libs/ktem/ktem/index/file/utils.py
function clean_name (line 14) | def clean_name(name):
function is_arxiv_url (line 20) | def is_arxiv_url(url):
function download_arxiv_pdf (line 25) | def download_arxiv_pdf(url, output_path):
FILE: libs/ktem/ktem/index/manager.py
class IndexManager (line 12) | class IndexManager:
method __init__ (line 23) | def __init__(self, app):
method index_types (line 29) | def index_types(self) -> dict:
method build_index (line 33) | def build_index(self, name: str, config: dict, index_type: str):
method update_index (line 72) | def update_index(self, id: int, name: str, config: dict):
method start_index (line 95) | def start_index(self, id: int, name: str, config: dict, index_type: str):
method delete_index (line 111) | def delete_index(self, id: int):
method load_index_types (line 143) | def load_index_types(self):
method exists (line 158) | def exists(self, id: Optional[int] = None, name: Optional[str] = None)...
method on_application_startup (line 179) | def on_application_startup(self):
method indices (line 196) | def indices(self):
method info (line 199) | def info(self):
FILE: libs/ktem/ktem/index/models.py
class Index (line 9) | class Index(SQLModel, table=True):
FILE: libs/ktem/ktem/index/ui.py
function update_current_module_atime (line 11) | def update_current_module_atime():
function format_description (line 25) | def format_description(cls):
class IndexManagement (line 35) | class IndexManagement(BasePage):
method __init__ (line 36) | def __init__(self, app):
method on_building_ui (line 44) | def on_building_ui(self):
method _on_app_created (line 110) | def _on_app_created(self):
method on_register_events (line 126) | def on_register_events(self):
method on_index_type_change (line 224) | def on_index_type_change(self, index_type: str):
method create_index (line 241) | def create_index(self, name: str, index_type: str, config: str):
method list_indices (line 261) | def list_indices(self):
method select_index (line 280) | def select_index(self, index_list, ev: gr.SelectData) -> int:
method on_selected_index_change (line 291) | def on_selected_index_change(self, selected_index_id: int):
method update_index (line 316) | def update_index(self, selected_index_id: int, name: str, config: str):
method delete_index (line 337) | def delete_index(self, selected_index_id):
FILE: libs/ktem/ktem/llms/db.py
class Base (line 10) | class Base(DeclarativeBase):
class BaseLLMTable (line 14) | class BaseLLMTable(Base):
class LLMTable (line 31) | class LLMTable(_base_llm): # type: ignore
FILE: libs/ktem/ktem/llms/manager.py
class LLMManager (line 13) | class LLMManager:
method __init__ (line 16) | def __init__(self):
method load (line 39) | def load(self):
method load_vendors (line 56) | def load_vendors(self):
method __getitem__ (line 80) | def __getitem__(self, key: str) -> ChatLLM:
method __contains__ (line 84) | def __contains__(self, key: str) -> bool:
method get (line 89) | def get(self, key: str, default: None) -> Optional[ChatLLM]:
method get (line 93) | def get(self, key: str, default: ChatLLM) -> ChatLLM:
method get (line 96) | def get(self, key: str, default: Optional[ChatLLM] = None) -> Optional...
method settings (line 100) | def settings(self) -> dict:
method options (line 108) | def options(self) -> dict:
method get_random_name (line 112) | def get_random_name(self) -> str:
method get_default_name (line 125) | def get_default_name(self) -> str:
method get_random (line 142) | def get_random(self) -> ChatLLM:
method get_default (line 146) | def get_default(self) -> ChatLLM:
method info (line 157) | def info(self) -> dict:
method add (line 161) | def add(self, name: str, spec: dict, default: bool):
method delete (line 182) | def delete(self, name: str):
method update (line 194) | def update(self, name: str, spec: dict, default: bool, new_name: str =...
method vendors (line 228) | def vendors(self) -> dict:
FILE: libs/ktem/ktem/llms/ui.py
function format_description (line 13) | def format_description(cls):
class LLMManagement (line 23) | class LLMManagement(BasePage):
method __init__ (line 24) | def __init__(self, app):
method on_building_ui (line 31) | def on_building_ui(self):
method _on_app_created (line 131) | def _on_app_created(self):
method on_llm_vendor_change (line 143) | def on_llm_vendor_change(self, vendor):
method on_register_events (line 154) | def on_register_events(self):
method create_llm (line 251) | def create_llm(self, name, choices, spec, default):
method list_llms (line 268) | def list_llms(self):
method select_llm (line 287) | def select_llm(self, llm_list, ev: gr.SelectData):
method on_selected_llm_change (line 297) | def on_selected_llm_change(self, selected_llm_name):
method on_btn_delete_click (line 336) | def on_btn_delete_click(self):
method check_connection (line 343) | def check_connection(self, selected_llm_name: str, selected_spec):
method save_llm (line 382) | def save_llm(self, selected_llm_name, edit_name, default, spec):
method delete_llm (line 400) | def delete_llm(self, selected_llm_name):
FILE: libs/ktem/ktem/main.py
function toggle_first_setup_visibility (line 21) | def toggle_first_setup_visibility():
class App (line 28) | class App(BaseApp):
method ui (line 42) | def ui(self):
method on_subscribe_public_events (line 127) | def on_subscribe_public_events(self):
method _on_app_created (line 202) | def _on_app_created(self):
FILE: libs/ktem/ktem/mcp/db.py
class Base (line 7) | class Base(DeclarativeBase):
class BaseMCPTable (line 11) | class BaseMCPTable(Base):
class MCPTable (line 20) | class MCPTable(BaseMCPTable):
FILE: libs/ktem/ktem/mcp/manager.py
class MCPManager (line 17) | class MCPManager:
method __init__ (line 20) | def __init__(self):
method load (line 24) | def load(self):
method info (line 36) | def info(self) -> dict:
method get (line 40) | def get(self, name: str) -> dict | None:
method add (line 44) | def add(self, name: str, config: dict):
method update (line 57) | def update(self, name: str, config: dict):
method delete (line 71) | def delete(self, name: str):
method get_enabled_tools (line 81) | def get_enabled_tools(self) -> list[str]:
FILE: libs/ktem/ktem/mcp/ui.py
class MCPManagement (line 24) | class MCPManagement(BasePage):
method __init__ (line 25) | def __init__(self, app):
method on_building_ui (line 29) | def on_building_ui(self):
method _on_app_created (line 90) | def _on_app_created(self):
method on_register_events (line 98) | def on_register_events(self):
method _fetch_tools_markdown (line 180) | def _fetch_tools_markdown(self, config: dict) -> str:
method create_server (line 189) | def create_server(self, config_str):
method fetch_tools_for_add (line 239) | def fetch_tools_for_add(self, config_str):
method fetch_tools_for_view (line 262) | def fetch_tools_for_view(self, selected_name):
method list_servers (line 272) | def list_servers(self):
method select_server (line 286) | def select_server(self, mcp_list, ev: gr.SelectData):
method on_selected_server_change (line 294) | def on_selected_server_change(self, selected_name):
method on_btn_delete_click (line 320) | def on_btn_delete_click(self):
method delete_server (line 327) | def delete_server(self, selected_name):
method save_server (line 336) | def save_server(self, selected_name, config_str):
FILE: libs/ktem/ktem/pages/chat/__init__.py
class ChatPage (line 200) | class ChatPage(BasePage):
method __init__ (line 201) | def __init__(self, app):
method on_building_ui (line 217) | def on_building_ui(self):
method _json_to_plot (line 402) | def _json_to_plot(self, json_dict: dict | None):
method on_register_events (line 410) | def on_register_events(self):
method submit_msg (line 873) | def submit_msg(
method get_recommendations (line 980) | def get_recommendations(self, first_selector_choices, file_ids):
method toggle_delete (line 991) | def toggle_delete(self, conv_id):
method on_set_public_conversation (line 997) | def on_set_public_conversation(self, is_public, convo_id):
method on_subscribe_public_events (line 1019) | def on_subscribe_public_events(self):
method _on_app_created (line 1053) | def _on_app_created(self):
method persist_data_source (line 1075) | def persist_data_source(
method reasoning_changed (line 1136) | def reasoning_changed(self, reasoning_type):
method is_liked (line 1142) | def is_liked(self, convo_id, liked: gr.LikeData):
method message_selected (line 1156) | def message_selected(self, retrieval_history, plot_history, msg: gr.Se...
method create_pipeline (line 1168) | def create_pipeline(
method chat_fn (line 1266) | def chat_fn(
method check_and_suggest_name_conv (line 1370) | def check_and_suggest_name_conv(self, chat_history):
method suggest_chat_conv (line 1385) | def suggest_chat_conv(
FILE: libs/ktem/ktem/pages/chat/chat_panel.py
class ChatPanel (line 21) | class ChatPanel(BasePage):
method __init__ (line 22) | def __init__(self, app):
method on_building_ui (line 26) | def on_building_ui(self):
method submit_msg (line 49) | def submit_msg(self, chat_input, chat_history):
FILE: libs/ktem/ktem/pages/chat/chat_suggestion.py
class ChatSuggestion (line 6) | class ChatSuggestion(BasePage):
method __init__ (line 17) | def __init__(self, app):
method on_building_ui (line 21) | def on_building_ui(self):
method as_gradio_component (line 38) | def as_gradio_component(self):
method select_example (line 41) | def select_example(self, ev: gr.SelectData):
FILE: libs/ktem/ktem/pages/chat/control.py
function is_conv_name_valid (line 33) | def is_conv_name_valid(name):
class ConversationControl (line 44) | class ConversationControl(BasePage):
method __init__ (line 47) | def __init__(self, app):
method on_building_ui (line 52) | def on_building_ui(self):
method load_chat_history (line 201) | def load_chat_history(self, user_id):
method reload_conv (line 252) | def reload_conv(self, user_id):
method new_conv (line 259) | def new_conv(self, user_id):
method delete_conv (line 275) | def delete_conv(self, conversation_id, user_id):
method select_conv (line 299) | def select_conv(self, conversation_id, user_id):
method rename_conv (line 379) | def rename_conv(self, conversation_id, new_name, is_renamed, user_id):
method persist_chat_suggestions (line 412) | def persist_chat_suggestions(
method toggle_demo_login_visibility (line 442) | def toggle_demo_login_visibility(self, user_api_key, request: gr.Reque...
method _on_app_created (line 465) | def _on_app_created(self):
FILE: libs/ktem/ktem/pages/chat/demo_hint.py
class HintPage (line 7) | class HintPage(BasePage):
method __init__ (line 8) | def __init__(self, app):
method on_building_ui (line 12) | def on_building_ui(self):
FILE: libs/ktem/ktem/pages/chat/paper_list.py
class PaperListPage (line 8) | class PaperListPage(BasePage):
method __init__ (line 9) | def __init__(self, app):
method on_building_ui (line 13) | def on_building_ui(self):
method load (line 29) | def load(self):
method _on_app_created (line 34) | def _on_app_created(self):
method select_example (line 40) | def select_example(self, state, ev: gr.SelectData):
FILE: libs/ktem/ktem/pages/chat/report.py
class ReportIssue (line 9) | class ReportIssue(BasePage):
method __init__ (line 10) | def __init__(self, app):
method on_building_ui (line 14) | def on_building_ui(self):
method report (line 44) | def report(
FILE: libs/ktem/ktem/pages/help.py
function get_remote_doc (line 13) | def get_remote_doc(url: str) -> str:
function download_changelogs (line 23) | def download_changelogs(release_url: str) -> str:
class HelpPage (line 34) | class HelpPage:
method __init__ (line 35) | def __init__(
FILE: libs/ktem/ktem/pages/login.py
class LoginPage (line 26) | class LoginPage(BasePage):
method __init__ (line 30) | def __init__(self, app):
method on_building_ui (line 34) | def on_building_ui(self):
method on_register_events (line 40) | def on_register_events(self):
method toggle_login_visibility (line 56) | def toggle_login_visibility(self, user_id):
method _on_app_created (line 63) | def _on_app_created(self):
method on_subscribe_public_events (line 78) | def on_subscribe_public_events(self):
method login (line 89) | def login(self, usn, pwd, request: gr.Request):
FILE: libs/ktem/ktem/pages/resources/__init__.py
class ResourcesTab (line 14) | class ResourcesTab(BasePage):
method __init__ (line 15) | def __init__(self, app):
method on_building_ui (line 19) | def on_building_ui(self):
method on_subscribe_public_events (line 39) | def on_subscribe_public_events(self):
method toggle_user_management (line 61) | def toggle_user_management(self, user_id):
FILE: libs/ktem/ktem/pages/resources/user.py
function validate_username (line 30) | def validate_username(usn):
function validate_password (line 51) | def validate_password(pwd, pwd_cnf):
function create_user (line 97) | def create_user(usn, pwd, user_id=None, is_admin=True) -> bool:
class UserManagement (line 120) | class UserManagement(BasePage):
method __init__ (line 121) | def __init__(self, app):
method on_building_ui (line 135) | def on_building_ui(self):
method on_register_events (line 181) | def on_register_events(self):
method on_subscribe_public_events (line 262) | def on_subscribe_public_events(self):
method create_user (line 286) | def create_user(self, usn, pwd, pwd_cnf):
method list_users (line 315) | def list_users(self, user_id):
method select_user (line 343) | def select_user(self, user_list, ev: gr.SelectData):
method on_selected_user_change (line 353) | def on_selected_user_change(self, selected_user_id):
method on_btn_delete_click (line 392) | def on_btn_delete_click(self, selected_user_id):
method save_user (line 406) | def save_user(self, selected_user_id, usn, pwd, pwd_cnf, admin):
method delete_user (line 443) | def delete_user(self, current_user, selected_user_id):
FILE: libs/ktem/ktem/pages/settings.py
function render_setting_item (line 36) | def render_setting_item(setting_item, value):
class SettingsPage (line 59) | class SettingsPage(BasePage):
method __init__ (line 68) | def __init__(self, app):
method on_building_ui (line 117) | def on_building_ui(self):
method on_subscribe_public_events (line 133) | def on_subscribe_public_events(self):
method on_register_events (line 187) | def on_register_events(self):
method user_tab (line 234) | def user_tab(self):
method change_password (line 253) | def change_password(self, user_id, password, password_confirm):
method app_tab (line 277) | def app_tab(self):
method index_tab (line 287) | def index_tab(self):
method reasoning_tab (line 307) | def reasoning_tab(self):
method change_reasoning_mode (line 347) | def change_reasoning_mode(self, value):
method load_setting (line 356) | def load_setting(self, user_id=None):
method save_setting (line 368) | def save_setting(self, user_id: int, *args):
method components (line 394) | def components(self) -> list:
method component_names (line 401) | def component_names(self):
method _on_app_created (line 405) | def _on_app_created(self):
FILE: libs/ktem/ktem/pages/setup.py
function pull_model (line 25) | def pull_model(name: str, stream: bool = True):
class SetupPage (line 49) | class SetupPage(BasePage):
method __init__ (line 53) | def __init__(self, app):
method on_building_ui (line 57) | def on_building_ui(self):
method on_register_events (line 139) | def on_register_events(self):
method update_model (line 189) | def update_model(
method update_default_settings (line 393) | def update_default_settings(self, radio_model_value, default_settings):
method switch_options_view (line 402) | def switch_options_view(self, radio_model_value):
FILE: libs/ktem/ktem/reasoning/base.py
class BaseReasoning (line 6) | class BaseReasoning(BaseComponent):
method get_info (line 18) | def get_info(cls) -> dict:
method get_user_settings (line 31) | def get_user_settings(cls) -> dict:
method get_pipeline (line 36) | def get_pipeline(
method run (line 51) | def run(self, message: str, conv_id: str, history: list, **kwargs): #...
FILE: libs/ktem/ktem/reasoning/prompt_optimization/decompose_question.py
class SubQuery (line 13) | class SubQuery(BaseModel):
class DecomposeQuestionPipeline (line 22) | class DecomposeQuestionPipeline(RewriteQuestionPipeline):
method create_prompt (line 45) | def create_prompt(self, question):
method run (line 65) | def run(self, question: str) -> list: # type: ignore
FILE: libs/ktem/ktem/reasoning/prompt_optimization/fewshot_rewrite_question.py
class FewshotRewriteQuestionPipeline (line 19) | class FewshotRewriteQuestionPipeline(RewriteQuestionPipeline):
method add_documents (line 40) | def add_documents(self, examples, batch_size: int = 50):
method get_pipeline (line 59) | def get_pipeline(
method run (line 79) | def run(self, question: str) -> Document: # type: ignore
FILE: libs/ktem/ktem/reasoning/prompt_optimization/mindmap.py
class CreateMindmapPipeline (line 37) | class CreateMindmapPipeline(BaseComponent):
method convert_uml_to_markdown (line 67) | def convert_uml_to_markdown(cls, text: str) -> str:
method run (line 80) | def run(self, question: str, context: str) -> Document: # type: ignore
FILE: libs/ktem/ktem/reasoning/prompt_optimization/rewrite_question.py
class RewriteQuestionPipeline (line 17) | class RewriteQuestionPipeline(BaseComponent):
method run (line 31) | def run(self, question: str) -> Document: # type: ignore
FILE: libs/ktem/ktem/reasoning/prompt_optimization/suggest_conversation_name.py
class SuggestConvNamePipeline (line 11) | class SuggestConvNamePipeline(BaseComponent):
method run (line 25) | def run(self, chat_history: list[tuple[str, str]]) -> Document: # typ...
FILE: libs/ktem/ktem/reasoning/prompt_optimization/suggest_followup_chat.py
class SuggestFollowupQuesPipeline (line 11) | class SuggestFollowupQuesPipeline(BaseComponent):
method run (line 32) | def run(self, chat_history: list[tuple[str, str]]) -> Document:
FILE: libs/ktem/ktem/reasoning/react.py
class DocSearchArgs (line 30) | class DocSearchArgs(BaseModel):
class DocSearchTool (line 34) | class DocSearchTool(BaseTool):
method _run_tool (line 47) | def _run_tool(self, query: AnyStr) -> AnyStr:
method prepare_evidence (line 58) | def prepare_evidence(self, docs, trim_len: int = 4000):
class RewriteQuestionPipeline (line 157) | class RewriteQuestionPipeline(BaseComponent):
method run (line 171) | def run(self, question: str) -> Document: # type: ignore
class ReactAgentPipeline (line 181) | class ReactAgentPipeline(BaseReasoning):
class Config (line 184) | class Config:
method prepare_citation (line 192) | def prepare_citation(self, step_id, step, output, status) -> Document:
method ainvoke (line 212) | async def ainvoke( # type: ignore
method stream (line 229) | def stream(self, message, conv_id: str, history: list, **kwargs):
method get_pipeline (line 262) | def get_pipeline(
method get_user_settings (line 309) | def get_user_settings(cls) -> dict:
method get_info (line 353) | def get_info(cls) -> dict:
FILE: libs/ktem/ktem/reasoning/rewoo.py
class DocSearchArgs (line 67) | class DocSearchArgs(BaseModel):
class DocSearchTool (line 71) | class DocSearchTool(BaseTool):
method _run_tool (line 84) | def _run_tool(self, query: AnyStr) -> AnyStr:
method prepare_evidence (line 95) | def prepare_evidence(self, docs, trim_len: int = 3000):
class RewriteQuestionPipeline (line 176) | class RewriteQuestionPipeline(BaseComponent):
method run (line 190) | def run(self, question: str) -> Document: # type: ignore
function find_text (line 200) | def find_text(llm_output, context):
class RewooAgentPipeline (line 211) | class RewooAgentPipeline(BaseReasoning):
class Config (line 214) | class Config:
method format_info_panel_evidence (line 223) | def format_info_panel_evidence(self, worker_log):
method format_info_panel_planner (line 254) | def format_info_panel_planner(self, planner_output):
method prepare_citation (line 265) | def prepare_citation(self, answer) -> list[Document]:
method ainvoke (line 336) | async def ainvoke( # type: ignore
method stream (line 349) | def stream( # type: ignore
method get_pipeline (line 387) | def get_pipeline(
method get_user_settings (line 445) | def get_user_settings(cls) -> dict:
method get_info (line 507) | def get_info(cls) -> dict:
FILE: libs/ktem/ktem/reasoning/simple.py
class AddQueryContextPipeline (line 42) | class AddQueryContextPipeline(BaseComponent):
method run (line 47) | def run(self, question: str, history: list) -> Document:
class FullQAPipeline (line 86) | class FullQAPipeline(BaseReasoning):
class Config (line 89) | class Config:
method retrieve (line 108) | def retrieve(
method prepare_mindmap (line 166) | def prepare_mindmap(self, answer) -> Document | None:
method prepare_citation_viz (line 206) | def prepare_citation_viz(self, answer, question, docs) -> Document | N...
method show_citations_and_addons (line 223) | def show_citations_and_addons(self, answer, docs, question):
method ainvoke (line 276) | async def ainvoke( # type: ignore
method stream (line 281) | def stream( # type: ignore
method prepare_pipeline_instance (line 334) | def prepare_pipeline_instance(cls, settings, retrievers):
method get_pipeline (line 341) | def get_pipeline(cls, settings, states, retrievers):
method get_user_settings (line 398) | def get_user_settings(cls) -> dict:
method get_info (line 475) | def get_info(cls) -> dict:
class FullDecomposeQAPipeline (line 487) | class FullDecomposeQAPipeline(FullQAPipeline):
method answer_sub_questions (line 488) | def answer_sub_questions(
method stream (line 521) | def stream( # type: ignore
method get_user_settings (line 579) | def get_user_settings(cls) -> dict:
method prepare_pipeline_instance (line 588) | def prepare_pipeline_instance(cls, settings, retrievers):
method get_info (line 599) | def get_info(cls) -> dict:
FILE: libs/ktem/ktem/rerankings/db.py
class Base (line 10) | class Base(DeclarativeBase):
class BaseRerankingTable (line 14) | class BaseRerankingTable(Base):
class RerankingTable (line 31) | class RerankingTable(__base_reranking): # type: ignore
FILE: libs/ktem/ktem/rerankings/manager.py
class RerankingManager (line 13) | class RerankingManager:
method __init__ (line 16) | def __init__(self):
method load (line 37) | def load(self):
method load_vendors (line 54) | def load_vendors(self):
method __getitem__ (line 63) | def __getitem__(self, key: str) -> BaseReranking:
method __contains__ (line 67) | def __contains__(self, key: str) -> bool:
method get (line 71) | def get(
method settings (line 77) | def settings(self) -> dict:
method options (line 85) | def options(self) -> dict:
method get_random_name (line 89) | def get_random_name(self) -> str:
method get_default_name (line 102) | def get_default_name(self) -> str:
method get_random (line 119) | def get_random(self) -> BaseReranking:
method get_default (line 123) | def get_default(self) -> BaseReranking:
method info (line 134) | def info(self) -> dict:
method add (line 138) | def add(self, name: str, spec: dict, default: bool):
method delete (line 157) | def delete(self, name: str):
method update (line 169) | def update(self, name: str, spec: dict, default: bool, new_name: str =...
method vendors (line 202) | def vendors(self) -> dict:
FILE: libs/ktem/ktem/rerankings/ui.py
function format_description (line 15) | def format_description(cls):
class RerankingManagement (line 25) | class RerankingManagement(BasePage):
method __init__ (line 26) | def __init__(self, app):
method on_building_ui (line 33) | def on_building_ui(self):
method _on_app_created (line 134) | def _on_app_created(self):
method on_rerank_vendor_change (line 146) | def on_rerank_vendor_change(self, vendor):
method on_register_events (line 157) | def on_register_events(self):
method create_rerank (line 251) | def create_rerank(self, name, choices, spec, default):
method list_rerankings (line 268) | def list_rerankings(self):
method select_rerank (line 287) | def select_rerank(self, rerank_list, ev: gr.SelectData):
method on_selected_rerank_change (line 297) | def on_selected_rerank_change(self, selected_rerank_name):
method on_btn_delete_click (line 336) | def on_btn_delete_click(self):
method check_connection (line 343) | def check_connection(self, selected_rerank_name, selected_spec):
method save_rerank (line 382) | def save_rerank(self, selected_rerank_name, edit_name, default, spec):
method delete_rerank (line 404) | def delete_rerank(self, selected_rerank_name):
FILE: libs/ktem/ktem/settings.py
class SettingItem (line 6) | class SettingItem(BaseModel):
class BaseSettingGroup (line 25) | class BaseSettingGroup(BaseModel):
method _get_options (line 29) | def _get_options(self) -> dict:
method finalize (line 32) | def finalize(self):
method flatten (line 35) | def flatten(self) -> dict:
method get_setting_item (line 45) | def get_setting_item(self, path: str) -> SettingItem:
method __bool__ (line 59) | def __bool__(self):
class SettingReasoningGroup (line 63) | class SettingReasoningGroup(BaseSettingGroup):
method _get_options (line 64) | def _get_options(self) -> dict:
method finalize (line 72) | def finalize(self):
class SettingIndexOption (line 80) | class SettingIndexOption(BaseSettingGroup):
method flatten (line 88) | def flatten(self) -> dict:
method get_setting_item (line 99) | def get_setting_item(self, path: str) -> SettingItem:
class SettingIndexGroup (line 113) | class SettingIndexGroup(BaseSettingGroup):
method _get_options (line 114) | def _get_options(self) -> dict:
class SettingGroup (line 123) | class SettingGroup(BaseModel):
method flatten (line 128) | def flatten(self) -> dict:
method get_setting_item (line 142) | def get_setting_item(self, path: str) -> SettingItem:
FILE: libs/ktem/ktem/utils/conversation.py
function sync_retrieval_n_message (line 4) | def sync_retrieval_n_message(
function get_file_names_regex (line 22) | def get_file_names_regex(input_str: str) -> tuple[list[str], str]:
function get_urls (line 32) | def get_urls(input_str: str) -> tuple[list[str], str]:
FILE: libs/ktem/ktem/utils/file.py
class YAMLNoDateSafeLoader (line 4) | class YAMLNoDateSafeLoader(yaml.SafeLoader):
method remove_implicit_resolver (line 8) | def remove_implicit_resolver(cls, tag_to_remove):
FILE: libs/ktem/ktem/utils/generator.py
class Generator (line 1) | class Generator:
method __init__ (line 4) | def __init__(self, gen):
method __iter__ (line 7) | def __iter__(self):
FILE: libs/ktem/ktem/utils/hf_papers.py
function parse_date (line 16) | def parse_date(date_str):
function get_recommendations_from_semantic_scholar (line 21) | def get_recommendations_from_semantic_scholar(semantic_scholar_id: str):
function filter_recommendations (line 36) | def filter_recommendations(recommendations, max_paper_count=5):
function format_recommendation_into_markdown (line 46) | def format_recommendation_into_markdown(recommendations):
function get_paper_id_from_name (line 55) | def get_paper_id_from_name(paper_name):
function get_recommended_papers (line 70) | def get_recommended_papers(paper_name):
function fetch_papers (line 83) | def fetch_papers(top_n=5):
FILE: libs/ktem/ktem/utils/plantuml.py
class PlantUMLError (line 27) | class PlantUMLError(Exception):
class PlantUMLConnectionError (line 33) | class PlantUMLConnectionError(PlantUMLError):
class PlantUMLHTTPError (line 39) | class PlantUMLHTTPError(PlantUMLConnectionError):
method __init__ (line 44) | def __init__(self, response, content, *args, **kwdargs):
function deflate_and_encode (line 53) | def deflate_and_encode(plantuml_text):
class PlantUML (line 62) | class PlantUML(object):
method __init__ (line 73) | def __init__(self, url="http://www.plantuml.com/plantuml/svg/", reques...
method get_url (line 80) | def get_url(self, plantuml_text):
method process (line 89) | def process(self, plantuml_text):
FILE: libs/ktem/ktem/utils/rate_limit.py
function check_rate_limit (line 15) | def check_rate_limit(limit_type: str, request: gr.Request):
FILE: libs/ktem/ktem/utils/render.py
function is_close (line 11) | def is_close(val1, val2, tolerance=1e-9):
function replace_mardown_header (line 15) | def replace_mardown_header(text: str) -> str:
function get_header (line 28) | def get_header(doc: RetrievedDocument) -> str:
class Render (line 38) | class Render:
method collapsible (line 42) | def collapsible(header, content, open: bool = False) -> str:
method table (line 52) | def table(text: str) -> str:
method table_preserve_linebreaks (line 64) | def table_preserve_linebreaks(text: str) -> str:
method preview (line 75) | def preview(
method highlight (line 126) | def highlight(text: str, elem_id: str | None = None) -> str:
method image (line 132) | def image(url: str, text: str = "") -> str:
method collapsible_with_header (line 141) | def collapsible_with_header(
method collapsible_with_header_score (line 160) | def collapsible_with_header_score(
FILE: libs/ktem/ktem/utils/visualize_cited.py
class CreateCitationVizPipeline (line 27) | class CreateCitationVizPipeline(BaseComponent):
method _set_up_umap (line 33) | def _set_up_umap(self, embeddings: np.ndarray):
method _project_embeddings (line 37) | def _project_embeddings(self, embeddings, umap_transform) -> np.ndarray:
method _get_projections (line 43) | def _get_projections(self, embeddings, umap_transform):
method _prepare_projection_df (line 49) | def _prepare_projection_df(
method _plot_embeddings (line 71) | def _plot_embeddings(self, df: pd.DataFrame) -> go.Figure:
method run (line 113) | def run(self, context: List[str], question: str):
FILE: libs/ktem/ktem_tests/test_qa.py
function mock_openai_embedding (line 41) | def mock_openai_embedding(monkeypatch):
function test_ingest_pipeline (line 49) | def test_ingest_pipeline(patch, mock_openai_embedding, tmp_path):
FILE: libs/ktem/migrations/env.py
function run_migrations_offline (line 30) | def run_migrations_offline() -> None:
function run_migrations_online (line 53) | def run_migrations_online() -> None:
FILE: scripts/migrate/migrate_chroma_db.py
function _init_resource (line 22) | def _init_resource(private: bool = True, id: int = 1):
function get_chromadb_collection (line 95) | def get_chromadb_collection(
function update_metadata (line 106) | def update_metadata(metadata, file_id):
function migrate_chroma_db (line 112) | def migrate_chroma_db(
function main (line 165) | def main(chroma_db_dir: str, sqlite_path: str):
FILE: scripts/serve_local.py
function serve_llamacpp_python (line 17) | def serve_llamacpp_python(local_model_file: Path, **kwargs):
function main (line 53) | def main():
FILE: sso_app.py
function favicon (line 66) | async def favicon():
FILE: sso_app_demo.py
function add_session_middleware (line 27) | def add_session_middleware(app):
function public (line 56) | def public(request: Request):
function favicon (line 62) | async def favicon():
function logout (line 67) | async def logout(request: Request):
function login (line 73) | async def login(request: Request):
function auth (line 80) | async def auth(request: Request):
FILE: templates/project-default/{{cookiecutter.project_name}}/{{cookiecutter.project_name}}/pipeline.py
class QAResultLog (line 12) | class QAResultLog(ResultLog):
method _get_prompt (line 14) | def _get_prompt(obj):
class QuestionAnsweringPipeline (line 18) | class QuestionAnsweringPipeline(BaseComponent):
method run (line 60) | def run(self, text: str) -> LLMInterface:
class IndexingPipeline (line 75) | class IndexingPipeline(VectorIndexing):
method run (line 92) | def run(self, text: str) -> Document:
Condensed preview — 363 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (2,545K chars).
[
{
"path": ".commitlintrc",
"chars": 792,
"preview": "{\n \"extends\": [\"@commitlint/config-conventional\"],\n \"defaultIgnores\": true,\n \"rules\": {\n \"body-leading-blank\": [1,"
},
{
"path": ".dockerignore",
"chars": 159,
"preview": ".github/\n.git/\n.mypy_cache/\n__pycache__/\nktem_app_data/\nenv/\n.pre-commit-config.yaml\n.commitlintrc\n.gitignore\n.gitattrib"
},
{
"path": ".gitattributes",
"chars": 22,
"preview": "*.bat text eol=crlf\n"
},
{
"path": ".github/ISSUE_TEMPLATE/bug_report.yml",
"chars": 2184,
"preview": "name: \"Bug Report\"\ndescription: Report something that is not working as expected\ntitle: \"[BUG] \"\nlabels: [\"bug\"]\nbody:\n "
},
{
"path": ".github/ISSUE_TEMPLATE/config.yml",
"chars": 28,
"preview": "blank_issues_enabled: false\n"
},
{
"path": ".github/ISSUE_TEMPLATE/feature_request.yml",
"chars": 1511,
"preview": "name: \"Feature Request\"\ndescription: Brainstorm and propose new features for the project\ntitle: \"[REQUEST] \"\nlabels: [\"e"
},
{
"path": ".github/PULL_REQUEST_TEMPLATE.md",
"chars": 612,
"preview": "## Description\n\n- Please include a summary of the changes and the related issue.\n- Fixes # (issue)\n\n## Type of change\n\n-"
},
{
"path": ".github/workflows/auto-bump-and-release.yaml",
"chars": 2423,
"preview": "name: Auto Bump and Release\n\non:\n push:\n branches:\n - main\n\njobs:\n auto-bump-and-release:\n runs-on: ubuntu-"
},
{
"path": ".github/workflows/build-push-docker.yaml",
"chars": 3021,
"preview": "name: Build and Push Docker Image\n\non:\n release:\n types:\n - created\n\n push:\n tags:\n - \"v[0-9]+.[0-9]+."
},
{
"path": ".github/workflows/pr-lint.yaml",
"chars": 2727,
"preview": "name: \"Lint PR\"\n\non:\n pull_request:\n types:\n - opened\n - edited\n - synchronize\n\npermissions:\n pull-r"
},
{
"path": ".github/workflows/style-check.yaml",
"chars": 409,
"preview": "name: style-check\n\non:\n pull_request:\n branches: [main, develop]\n push:\n branches: [main, develop]\n\njobs:\n pre-"
},
{
"path": ".github/workflows/unit-test.yaml",
"chars": 3951,
"preview": "name: unit-test\n\non:\n pull_request:\n branches: [main]\n push:\n branches: [main]\n\nenv:\n THEFLOW_TEMP_PATH: ./tmp\n"
},
{
"path": ".gitignore",
"chars": 8727,
"preview": "# Created by https://www.toptal.com/developers/gitignore/api/python,linux,macos,windows,vim,emacs,visualstudiocode,pycha"
},
{
"path": ".pre-commit-config.yaml",
"chars": 1946,
"preview": "repos:\n - repo: https://github.com/pre-commit/pre-commit-hooks\n rev: v4.3.0\n hooks:\n - id: check-yaml\n "
},
{
"path": ".python-version",
"chars": 5,
"preview": "3.10\n"
},
{
"path": "CODE_OF_CONDUCT.md",
"chars": 5201,
"preview": "# Contributor Covenant Code of Conduct\n\n## Our Pledge\n\nWe as members, contributors, and leaders pledge to make participa"
},
{
"path": "CONTRIBUTING.md",
"chars": 5938,
"preview": "# Contributing to Kotaemon\n\nWelcome 👋 to the Kotaemon project! We're thrilled that you're interested in contributing. Wh"
},
{
"path": "Dockerfile",
"chars": 3142,
"preview": "# Lite version\nFROM python:3.10-slim AS lite\n\n# Common dependencies\nRUN apt-get update -qqy && \\\n apt-get install -y "
},
{
"path": "LICENSE.txt",
"chars": 11357,
"preview": " Apache License\n Version 2.0, January 2004\n "
},
{
"path": "README.md",
"chars": 18641,
"preview": "<div align=\"center\">\n\n# kotaemon\n\nAn open-source clean & customizable RAG UI for chatting with your documents. Built wit"
},
{
"path": "app.py",
"chars": 691,
"preview": "import os\n\nfrom theflow.settings import settings as flowsettings\n\nKH_APP_DATA_DIR = getattr(flowsettings, \"KH_APP_DATA_D"
},
{
"path": "doc_env_reqs.txt",
"chars": 203,
"preview": "mkdocs\nmkdocstrings[python]\nmkdocs-material\nmkdocs-gen-files\nmkdocs-literate-nav\nmkdocs-git-revision-date-localized-plug"
},
{
"path": "docs/about.md",
"chars": 431,
"preview": "# About Kotaemon\n\nAn open-source tool for chatting with your documents. Built with both end users and\ndevelopers in mind"
},
{
"path": "docs/development/contributing.md",
"chars": 3943,
"preview": "# Contributing\n\n## Setting up\n\n- Clone the repo\n\n ```shell\n git clone git@github.com:Cinnamon/kotaemon.git\n cd kotaem"
},
{
"path": "docs/development/create-a-component.md",
"chars": 2514,
"preview": "# Creating a component\n\nA fundamental concept in kotaemon is \"component\".\n\nAnything that isn't data or data structure is"
},
{
"path": "docs/development/data-components.md",
"chars": 995,
"preview": "# Data & Data Structure Components\n\nThe data & data structure components include:\n\n- The `Document` class.\n- The documen"
},
{
"path": "docs/development/index.md",
"chars": 107,
"preview": "{%\n include-markdown \"../../README.md\"\n start=\"<!-- start-intro -->\"\n end=\"<!-- end-intro -->\"\n%}\n"
},
{
"path": "docs/development/utilities.md",
"chars": 7571,
"preview": "# Utilities\n\n## Prompt engineering UI\n\n\n\n**_Importa"
},
{
"path": "docs/extra/css/code_select.css",
"chars": 106,
"preview": ".language-pycon .gp,\n.language-pycon .go {\n /* Generic.Prompt, Generic.Output */\n user-select: none;\n}\n"
},
{
"path": "docs/index.md",
"chars": 2100,
"preview": "# Getting Started with Kotaemon\n\n\n\n1. Go to [HF kotaemon_template](https://huggingface.co/spaces/cin-model/kota"
},
{
"path": "docs/pages/app/customize-flows.md",
"chars": 6887,
"preview": "# Add new indexing and reasoning pipeline to the application\n\n@trducng\n\nAt high level, to add new indexing and reasoning"
},
{
"path": "docs/pages/app/ext/user-management.md",
"chars": 625,
"preview": "`ktem` provides user management as an extension. To enable user management, in\nyour `flowsettings.py`, set the following"
},
{
"path": "docs/pages/app/features.md",
"chars": 304,
"preview": "## Chat\n\nThe kotaemon focuses on question and answering over a corpus of data. Below\nis the gentle introduction about th"
},
{
"path": "docs/pages/app/functional-description.md",
"chars": 12238,
"preview": "## User group / tenant management\n\n### Create new user group\n\n(6 man-days)\n\n**Description**: each client has a dedicated"
},
{
"path": "docs/pages/app/index/file.md",
"chars": 7496,
"preview": "The file index stores files in a local folder and index them for retrieval.\nThis file index provides the following infra"
},
{
"path": "docs/pages/app/settings/overview.md",
"chars": 919,
"preview": "# Overview\n\nThere are 3 kinds of settings in `ktem`, geared towards different stakeholders\nfor different use cases:\n\n- D"
},
{
"path": "docs/pages/app/settings/user-settings.md",
"chars": 1459,
"preview": "# User settings\n\n`ktem` allows developers to extend the index and the reasoning pipeline. In\nmany cases, these component"
},
{
"path": "docs/scripts/generate_examples_docs.py",
"chars": 2060,
"preview": "# import shutil\nfrom pathlib import Path\nfrom typing import Any, Iterable\n\nimport mkdocs_gen_files\n\n# get the root sourc"
},
{
"path": "docs/scripts/generate_reference_docs.py",
"chars": 2388,
"preview": "# import shutil\nfrom pathlib import Path\nfrom typing import Any, Iterable\n\nimport mkdocs_gen_files\n\n# get the root sourc"
},
{
"path": "docs/theme/assets/pymdownx-extras/extra-fb5a2a1c86.css",
"chars": 73161,
"preview": "@charset \"UTF-8\";:root>*{--md-code-link-bg-color:hsla(0, 0%, 96%, 1);--md-code-link-accent-bg-color:var(--md-code-link-b"
},
{
"path": "docs/theme/assets/pymdownx-extras/extra-loader-MCFnu0Wd.js",
"chars": 13582,
"preview": "function _typeof(t){return _typeof=\"function\"==typeof Symbol&&\"symbol\"==typeof Symbol.iterator?function(t){return typeof"
},
{
"path": "docs/theme/assets/pymdownx-extras/material-extra-3rdparty-E-i8w1WA.js",
"chars": 6576,
"preview": "!function(){\"use strict\";\"mathjaxConfig\"in window||(window.MathJax={tex:{inlineMath:[[\"\\\\(\",\"\\\\)\"]],displayMath:[[\"\\\\[\","
},
{
"path": "docs/theme/assets/pymdownx-extras/material-extra-theme-TVq-kNRT.js",
"chars": 1644,
"preview": "!function(){\"use strict\";var e;e=function(e){\"true\"===localStorage.getItem(\"data-md-prefers-color-scheme\")&&document.que"
},
{
"path": "docs/theme/main.html",
"chars": 123,
"preview": "{% extends \"base.html\" %}\n\n{% block libs %}\n{{ super() }}\n{% include \"partials/libs.html\" ignore missing %}\n{% endblock "
},
{
"path": "docs/theme/partials/footer.html",
"chars": 1499,
"preview": "\n{% import \"partials/language.html\" as lang with context %}\n<footer class=\"md-footer\">\n {% if page.previous_page or pag"
},
{
"path": "docs/theme/partials/header.html",
"chars": 2859,
"preview": "\n{% set site_url = config.site_url | d(nav.homepage.url, true) | url %}\n{% if not config.use_directory_urls and site_url"
},
{
"path": "docs/theme/partials/libs.html",
"chars": 237,
"preview": "<script src=\"{{ 'assets/pymdownx-extras/material-extra-theme-TVq-kNRT.js' | url }}\" type=\"text/javascript\"></script>\n<sc"
},
{
"path": "docs/usage.md",
"chars": 6681,
"preview": "## 1. Add your AI models\n\n\ntry:\n import posthog\n\n "
},
{
"path": "libs/kotaemon/kotaemon/agents/__init__.py",
"chars": 646,
"preview": "from .base import BaseAgent\nfrom .io import AgentFinish, AgentOutput, AgentType, BaseScratchPad\nfrom .langchain_based im"
},
{
"path": "libs/kotaemon/kotaemon/agents/base.py",
"chars": 1935,
"preview": "from typing import Optional, Union\n\nfrom kotaemon.base import BaseComponent, Node, Param\nfrom kotaemon.llms import BaseL"
},
{
"path": "libs/kotaemon/kotaemon/agents/io/__init__.py",
"chars": 171,
"preview": "from .base import AgentAction, AgentFinish, AgentOutput, AgentType, BaseScratchPad\n\n__all__ = [\"AgentOutput\", \"AgentFini"
},
{
"path": "libs/kotaemon/kotaemon/agents/io/base.py",
"chars": 5751,
"preview": "import json\nimport logging\nimport os\nfrom dataclasses import dataclass\nfrom enum import Enum\nfrom typing import Any, Dic"
},
{
"path": "libs/kotaemon/kotaemon/agents/langchain_based.py",
"chars": 2738,
"preview": "from typing import List, Optional\n\nfrom langchain.agents import AgentType as LCAgentType\nfrom langchain.agents import in"
},
{
"path": "libs/kotaemon/kotaemon/agents/react/__init__.py",
"chars": 56,
"preview": "from .agent import ReactAgent\n\n__all__ = [\"ReactAgent\"]\n"
},
{
"path": "libs/kotaemon/kotaemon/agents/react/agent.py",
"chars": 13653,
"preview": "import logging\nimport re\nfrom functools import partial\nfrom typing import Optional\n\nimport tiktoken\n\nfrom kotaemon.agent"
},
{
"path": "libs/kotaemon/kotaemon/agents/react/prompt.py",
"chars": 853,
"preview": "# flake8: noqa\n\nfrom kotaemon.llms import PromptTemplate\n\nzero_shot_react_prompt = PromptTemplate(\n template=\"\"\"Answe"
},
{
"path": "libs/kotaemon/kotaemon/agents/rewoo/__init__.py",
"chars": 56,
"preview": "from .agent import RewooAgent\n\n__all__ = [\"RewooAgent\"]\n"
},
{
"path": "libs/kotaemon/kotaemon/agents/rewoo/agent.py",
"chars": 14065,
"preview": "import logging\nimport re\nfrom concurrent.futures import ThreadPoolExecutor\nfrom functools import partial\nfrom typing imp"
},
{
"path": "libs/kotaemon/kotaemon/agents/rewoo/planner.py",
"chars": 3954,
"preview": "from typing import Any, List, Optional, Union\n\nfrom kotaemon.agents.base import BaseLLM, BaseTool\nfrom kotaemon.agents.i"
},
{
"path": "libs/kotaemon/kotaemon/agents/rewoo/prompt.py",
"chars": 3509,
"preview": "# flake8: noqa\n\nfrom kotaemon.llms import PromptTemplate\n\nzero_shot_planner_prompt = PromptTemplate(\n template=\"\"\"You"
},
{
"path": "libs/kotaemon/kotaemon/agents/rewoo/solver.py",
"chars": 3520,
"preview": "from typing import Any, List, Optional, Union\n\nfrom kotaemon.agents.io import BaseScratchPad\nfrom kotaemon.base import B"
},
{
"path": "libs/kotaemon/kotaemon/agents/tools/__init__.py",
"chars": 554,
"preview": "from .base import BaseTool, ComponentTool\nfrom .google import GoogleSearchTool\nfrom .llm import LLMTool\nfrom .mcp import"
},
{
"path": "libs/kotaemon/kotaemon/agents/tools/base.py",
"chars": 4997,
"preview": "from typing import Any, Callable, Dict, Optional, Tuple, Type, Union\n\nfrom langchain.agents import Tool as LCTool\nfrom p"
},
{
"path": "libs/kotaemon/kotaemon/agents/tools/google.py",
"chars": 1717,
"preview": "from typing import AnyStr, Optional, Type\nfrom urllib.error import HTTPError\n\nfrom langchain_community.utilities import "
},
{
"path": "libs/kotaemon/kotaemon/agents/tools/llm.py",
"chars": 1095,
"preview": "from typing import AnyStr, Optional, Type\n\nfrom pydantic import BaseModel, Field\n\nfrom kotaemon.agents.tools.base import"
},
{
"path": "libs/kotaemon/kotaemon/agents/tools/mcp.py",
"chars": 13966,
"preview": "\"\"\"MCP Tool for kotaemon agents.\r\n\r\nBridges the MCP SDK's tool schema with kotaemon's BaseTool abstraction\r\nso MCP tools"
},
{
"path": "libs/kotaemon/kotaemon/agents/tools/wikipedia.py",
"chars": 2173,
"preview": "from typing import Any, AnyStr, Optional, Type, Union\n\nfrom pydantic import BaseModel, Field\n\nfrom kotaemon.base import "
},
{
"path": "libs/kotaemon/kotaemon/agents/utils.py",
"chars": 540,
"preview": "from kotaemon.base import Document\n\n\ndef get_plugin_response_content(output) -> str:\n \"\"\"\n Wrapper for AgentOutput"
},
{
"path": "libs/kotaemon/kotaemon/base/__init__.py",
"chars": 585,
"preview": "from .component import BaseComponent, Node, Param, lazy\nfrom .schema import (\n AIMessage,\n BaseMessage,\n Docume"
},
{
"path": "libs/kotaemon/kotaemon/base/component.py",
"chars": 1955,
"preview": "from abc import abstractmethod\nfrom typing import Any, AsyncGenerator, Iterator, Optional\n\nfrom theflow import Function,"
},
{
"path": "libs/kotaemon/kotaemon/base/schema.py",
"chars": 5140,
"preview": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Any, Literal, Optional, TypeVar\n\nfrom langchain.sc"
},
{
"path": "libs/kotaemon/kotaemon/chatbot/__init__.py",
"chars": 177,
"preview": "from .base import BaseChatBot, ChatConversation\nfrom .simple_respondent import SimpleRespondentChatbot\n\n__all__ = [\"Base"
},
{
"path": "libs/kotaemon/kotaemon/chatbot/base.py",
"chars": 3312,
"preview": "from abc import abstractmethod\nfrom typing import List, Optional\n\nfrom theflow import SessionFunction\n\nfrom kotaemon.bas"
},
{
"path": "libs/kotaemon/kotaemon/chatbot/simple_respondent.py",
"chars": 282,
"preview": "from ..llms import ChatLLM\nfrom .base import BaseChatBot\n\n\nclass SimpleRespondentChatbot(BaseChatBot):\n \"\"\"Simple tex"
},
{
"path": "libs/kotaemon/kotaemon/cli.py",
"chars": 4942,
"preview": "import os\n\nimport click\nimport yaml\nfrom trogon import tui\n\n\n# check if the output is not a .yml file -> raise error\ndef"
},
{
"path": "libs/kotaemon/kotaemon/contribs/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "libs/kotaemon/kotaemon/contribs/docs.py",
"chars": 2300,
"preview": "import inspect\nfrom collections import defaultdict\n\nfrom theflow.utils.documentation import get_function_documentation_f"
},
{
"path": "libs/kotaemon/kotaemon/contribs/promptui/.gitignore",
"chars": 8,
"preview": "/frpc_*\n"
},
{
"path": "libs/kotaemon/kotaemon/contribs/promptui/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "libs/kotaemon/kotaemon/contribs/promptui/base.py",
"chars": 1317,
"preview": "import gradio as gr\n\nCOMPONENTS_CLASS = {\n \"text\": gr.components.Textbox,\n \"checkbox\": gr.components.CheckboxGroup"
},
{
"path": "libs/kotaemon/kotaemon/contribs/promptui/cli.py",
"chars": 67,
"preview": "\"\"\"CLI commands that can be imported by the kotaemon.cli module\"\"\"\n"
},
{
"path": "libs/kotaemon/kotaemon/contribs/promptui/config.py",
"chars": 5771,
"preview": "\"\"\"Get config from Pipeline\"\"\"\nimport inspect\nfrom pathlib import Path\nfrom typing import Any, Dict, Optional, Type, Uni"
},
{
"path": "libs/kotaemon/kotaemon/contribs/promptui/export.py",
"chars": 4959,
"preview": "\"\"\"Export logs into Excel file\"\"\"\nimport os\nimport pickle\nfrom pathlib import Path\nfrom typing import Any, Dict, List, T"
},
{
"path": "libs/kotaemon/kotaemon/contribs/promptui/logs.py",
"chars": 367,
"preview": "class ResultLog:\n \"\"\"Callback getter to get the desired log result\n\n The callback resolution will be as follow:\n "
},
{
"path": "libs/kotaemon/kotaemon/contribs/promptui/themes.py",
"chars": 3700,
"preview": "from __future__ import annotations\n\nfrom typing import Iterable\n\nfrom gradio.themes.base import Base\nfrom gradio.themes."
},
{
"path": "libs/kotaemon/kotaemon/contribs/promptui/tunnel.py",
"chars": 3229,
"preview": "import atexit\nimport logging\nimport os\nimport platform\nimport stat\nimport subprocess\nfrom pathlib import Path\n\nimport re"
},
{
"path": "libs/kotaemon/kotaemon/contribs/promptui/ui/__init__.py",
"chars": 1240,
"preview": "from typing import Union\n\nimport gradio as gr\nimport yaml\nfrom theflow.utils.modules import import_dotted_string\n\nfrom ."
},
{
"path": "libs/kotaemon/kotaemon/contribs/promptui/ui/blocks.py",
"chars": 6003,
"preview": "from __future__ import annotations\n\nfrom typing import Any, AsyncGenerator\n\nimport anyio\nfrom gradio import ChatInterfac"
},
{
"path": "libs/kotaemon/kotaemon/contribs/promptui/ui/chat.py",
"chars": 10715,
"preview": "import pickle\nfrom datetime import datetime\nfrom pathlib import Path\n\nimport gradio as gr\nfrom theflow.storage import st"
},
{
"path": "libs/kotaemon/kotaemon/contribs/promptui/ui/pipeline.py",
"chars": 8935,
"preview": "import pickle\nimport time\nfrom datetime import datetime\nfrom pathlib import Path\nfrom typing import Any, Dict\n\nimport gr"
},
{
"path": "libs/kotaemon/kotaemon/embeddings/__init__.py",
"chars": 831,
"preview": "from .base import BaseEmbeddings\nfrom .endpoint_based import EndpointEmbeddings\nfrom .fastembed import FastEmbedEmbeddin"
},
{
"path": "libs/kotaemon/kotaemon/embeddings/base.py",
"chars": 992,
"preview": "from __future__ import annotations\n\nfrom kotaemon.base import BaseComponent, Document, DocumentWithEmbedding\n\n\nclass Bas"
},
{
"path": "libs/kotaemon/kotaemon/embeddings/endpoint_based.py",
"chars": 1313,
"preview": "import requests\n\nfrom kotaemon.base import Document, DocumentWithEmbedding\n\nfrom .base import BaseEmbeddings\n\n\nclass End"
},
{
"path": "libs/kotaemon/kotaemon/embeddings/fastembed.py",
"chars": 2320,
"preview": "from typing import TYPE_CHECKING, Optional\n\nfrom kotaemon.base import Document, DocumentWithEmbedding, Param\n\nfrom .base"
},
{
"path": "libs/kotaemon/kotaemon/embeddings/langchain_based.py",
"chars": 8742,
"preview": "from typing import Optional\n\nfrom kotaemon.base import DocumentWithEmbedding, Param\n\nfrom .base import BaseEmbeddings\n\n\n"
},
{
"path": "libs/kotaemon/kotaemon/embeddings/openai.py",
"chars": 8642,
"preview": "from itertools import islice\nfrom typing import Optional\n\nimport numpy as np\nimport openai\nimport tiktoken\nfrom tenacity"
},
{
"path": "libs/kotaemon/kotaemon/embeddings/tei_endpoint_embed.py",
"chars": 3496,
"preview": "import aiohttp\nimport requests\n\nfrom kotaemon.base import Document, DocumentWithEmbedding, Param\n\nfrom .base import Base"
},
{
"path": "libs/kotaemon/kotaemon/embeddings/voyageai.py",
"chars": 2165,
"preview": "\"\"\"Implements embeddings from [Voyage AI](https://voyageai.com).\n\"\"\"\n\nimport importlib\n\nfrom kotaemon.base import Docume"
},
{
"path": "libs/kotaemon/kotaemon/indices/__init__.py",
"chars": 106,
"preview": "from .vectorindex import VectorIndexing, VectorRetrieval\n\n__all__ = [\"VectorIndexing\", \"VectorRetrieval\"]\n"
},
{
"path": "libs/kotaemon/kotaemon/indices/base.py",
"chars": 4009,
"preview": "from __future__ import annotations\n\nfrom abc import abstractmethod\nfrom typing import Any, Type\n\nfrom llama_index.core.n"
},
{
"path": "libs/kotaemon/kotaemon/indices/extractors/__init__.py",
"chars": 155,
"preview": "from .doc_parsers import BaseDocParser, SummaryExtractor, TitleExtractor\n\n__all__ = [\n \"BaseDocParser\",\n \"TitleExt"
},
{
"path": "libs/kotaemon/kotaemon/indices/extractors/doc_parsers.py",
"chars": 843,
"preview": "from ..base import DocTransformer, LlamaIndexDocTransformerMixin\n\n\nclass BaseDocParser(DocTransformer):\n ...\n\n\nclass "
},
{
"path": "libs/kotaemon/kotaemon/indices/ingests/__init__.py",
"chars": 68,
"preview": "from .files import DocumentIngestor\n\n__all__ = [\"DocumentIngestor\"]\n"
},
{
"path": "libs/kotaemon/kotaemon/indices/ingests/files.py",
"chars": 4558,
"preview": "from pathlib import Path\nfrom typing import Type\n\nfrom decouple import config\nfrom llama_index.core.readers.base import "
},
{
"path": "libs/kotaemon/kotaemon/indices/qa/__init__.py",
"chars": 78,
"preview": "from .citation import CitationPipeline\n\n__all__ = [\n \"CitationPipeline\",\n]\n"
},
{
"path": "libs/kotaemon/kotaemon/indices/qa/citation.py",
"chars": 3241,
"preview": "from typing import List\n\nfrom pydantic import BaseModel, Field\n\nfrom kotaemon.base import BaseComponent\nfrom kotaemon.ba"
},
{
"path": "libs/kotaemon/kotaemon/indices/qa/citation_qa.py",
"chars": 14184,
"preview": "import threading\nfrom collections import defaultdict\nfrom typing import Generator\n\nimport numpy as np\nfrom decouple impo"
},
{
"path": "libs/kotaemon/kotaemon/indices/qa/citation_qa_inline.py",
"chars": 12066,
"preview": "import re\nimport threading\nfrom collections import defaultdict\nfrom dataclasses import dataclass\nfrom typing import Gene"
},
{
"path": "libs/kotaemon/kotaemon/indices/qa/format_context.py",
"chars": 4420,
"preview": "import html\nfrom functools import partial\n\nimport tiktoken\n\nfrom kotaemon.base import BaseComponent, Document, Retrieved"
},
{
"path": "libs/kotaemon/kotaemon/indices/qa/utils.py",
"chars": 3013,
"preview": "from difflib import SequenceMatcher\n\n\ndef find_text(search_span, context, min_length=5):\n search_span, context = sear"
},
{
"path": "libs/kotaemon/kotaemon/indices/rankings/__init__.py",
"chars": 299,
"preview": "from .base import BaseReranking\nfrom .cohere import CohereReranking\nfrom .llm import LLMReranking\nfrom .llm_scoring impo"
},
{
"path": "libs/kotaemon/kotaemon/indices/rankings/base.py",
"chars": 358,
"preview": "from __future__ import annotations\n\nfrom abc import abstractmethod\n\nfrom kotaemon.base import BaseComponent, Document\n\n\n"
},
{
"path": "libs/kotaemon/kotaemon/indices/rankings/cohere.py",
"chars": 2057,
"preview": "from __future__ import annotations\n\nfrom decouple import config\n\nfrom kotaemon.base import Document\n\nfrom .base import B"
},
{
"path": "libs/kotaemon/kotaemon/indices/rankings/llm.py",
"chars": 2074,
"preview": "from __future__ import annotations\n\nfrom concurrent.futures import ThreadPoolExecutor\n\nfrom langchain.output_parsers.boo"
},
{
"path": "libs/kotaemon/kotaemon/indices/rankings/llm_scoring.py",
"chars": 1781,
"preview": "from __future__ import annotations\n\nfrom concurrent.futures import ThreadPoolExecutor\n\nimport numpy as np\nfrom langchain"
},
{
"path": "libs/kotaemon/kotaemon/indices/rankings/llm_trulens.py",
"chars": 5843,
"preview": "from __future__ import annotations\n\nimport re\nfrom concurrent.futures import ThreadPoolExecutor\nfrom functools import pa"
},
{
"path": "libs/kotaemon/kotaemon/indices/retrievers/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "libs/kotaemon/kotaemon/indices/retrievers/jina_web_search.py",
"chars": 1822,
"preview": "import requests\nfrom decouple import config\n\nfrom kotaemon.base import BaseComponent, RetrievedDocument\n\nJINA_API_KEY = "
},
{
"path": "libs/kotaemon/kotaemon/indices/retrievers/tavily_web_search.py",
"chars": 1579,
"preview": "from decouple import config\n\nfrom kotaemon.base import BaseComponent, RetrievedDocument\n\nTAVILY_API_KEY = config(\"TAVILY"
},
{
"path": "libs/kotaemon/kotaemon/indices/splitters/__init__.py",
"chars": 1300,
"preview": "from ..base import DocTransformer, LlamaIndexDocTransformerMixin\n\n\nclass BaseSplitter(DocTransformer):\n \"\"\"Represent "
},
{
"path": "libs/kotaemon/kotaemon/indices/vectorindex.py",
"chars": 11543,
"preview": "from __future__ import annotations\n\nimport threading\nimport uuid\nfrom pathlib import Path\nfrom typing import Optional, S"
},
{
"path": "libs/kotaemon/kotaemon/llms/__init__.py",
"chars": 1467,
"preview": "from kotaemon.base.schema import AIMessage, BaseMessage, HumanMessage, SystemMessage\n\nfrom .base import BaseLLM\nfrom .br"
},
{
"path": "libs/kotaemon/kotaemon/llms/base.py",
"chars": 769,
"preview": "from typing import AsyncGenerator, Iterator\n\nfrom langchain_core.language_models.base import BaseLanguageModel\n\nfrom kot"
},
{
"path": "libs/kotaemon/kotaemon/llms/branching.py",
"chars": 5869,
"preview": "from typing import List, Optional\n\nfrom kotaemon.base import BaseComponent, Document, Param\n\nfrom .linear import GatedLi"
},
{
"path": "libs/kotaemon/kotaemon/llms/chats/__init__.py",
"chars": 660,
"preview": "from .base import ChatLLM\nfrom .endpoint_based import EndpointChatLLM\nfrom .langchain_based import (\n LCAnthropicChat"
},
{
"path": "libs/kotaemon/kotaemon/llms/chats/base.py",
"chars": 551,
"preview": "from __future__ import annotations\n\nimport logging\n\nfrom kotaemon.base import BaseComponent\nfrom kotaemon.llms.base impo"
},
{
"path": "libs/kotaemon/kotaemon/llms/chats/endpoint_based.py",
"chars": 2591,
"preview": "import requests\n\nfrom kotaemon.base import (\n AIMessage,\n BaseMessage,\n HumanMessage,\n LLMInterface,\n Par"
},
{
"path": "libs/kotaemon/kotaemon/llms/chats/langchain_based.py",
"chars": 11797,
"preview": "from __future__ import annotations\n\nimport logging\nfrom typing import AsyncGenerator, Iterator\n\nfrom kotaemon.base impor"
},
{
"path": "libs/kotaemon/kotaemon/llms/chats/llamacpp.py",
"chars": 5189,
"preview": "from typing import TYPE_CHECKING, Iterator, Optional, cast\n\nfrom kotaemon.base import BaseMessage, HumanMessage, LLMInte"
},
{
"path": "libs/kotaemon/kotaemon/llms/chats/openai.py",
"chars": 17328,
"preview": "from typing import TYPE_CHECKING, AsyncGenerator, Iterator, Optional, Type\n\nfrom pydantic import BaseModel\nfrom theflow."
},
{
"path": "libs/kotaemon/kotaemon/llms/completions/__init__.py",
"chars": 177,
"preview": "from .base import LLM\nfrom .langchain_based import AzureOpenAI, LCCompletionMixin, LlamaCpp, OpenAI\n\n__all__ = [\"LLM\", \""
},
{
"path": "libs/kotaemon/kotaemon/llms/completions/base.py",
"chars": 70,
"preview": "from kotaemon.llms.base import BaseLLM\n\n\nclass LLM(BaseLLM):\n pass\n"
},
{
"path": "libs/kotaemon/kotaemon/llms/completions/langchain_based.py",
"chars": 6866,
"preview": "import logging\nfrom typing import Optional\n\nfrom kotaemon.base import LLMInterface\n\nfrom .base import LLM\n\nlogger = logg"
},
{
"path": "libs/kotaemon/kotaemon/llms/cot.py",
"chars": 5930,
"preview": "from copy import deepcopy\nfrom typing import Callable, List\n\nfrom theflow import Function, Node, Param\n\nfrom kotaemon.ba"
},
{
"path": "libs/kotaemon/kotaemon/llms/linear.py",
"chars": 5091,
"preview": "from typing import Any, Callable, Optional, Union\n\nfrom ..base import BaseComponent\nfrom ..base.schema import Document, "
},
{
"path": "libs/kotaemon/kotaemon/llms/prompts/__init__.py",
"chars": 128,
"preview": "from .base import BasePromptComponent\nfrom .template import PromptTemplate\n\n__all__ = [\"BasePromptComponent\", \"PromptTem"
},
{
"path": "libs/kotaemon/kotaemon/llms/prompts/base.py",
"chars": 5417,
"preview": "from typing import Callable\n\nfrom theflow import Param\n\nfrom kotaemon.base import BaseComponent, Document\n\nfrom .templat"
},
{
"path": "libs/kotaemon/kotaemon/llms/prompts/template.py",
"chars": 4594,
"preview": "import warnings\nfrom string import Formatter\n\n\nclass PromptTemplate:\n \"\"\"\n Base class for prompt templates.\n \"\""
},
{
"path": "libs/kotaemon/kotaemon/loaders/__init__.py",
"chars": 1048,
"preview": "from .adobe_loader import AdobeReader\nfrom .azureai_document_intelligence_loader import AzureAIDocumentIntelligenceLoade"
},
{
"path": "libs/kotaemon/kotaemon/loaders/adobe_loader.py",
"chars": 6404,
"preview": "import logging\nimport os\nimport re\nfrom collections import defaultdict\nfrom pathlib import Path\nfrom typing import Any, "
},
{
"path": "libs/kotaemon/kotaemon/loaders/azureai_document_intelligence_loader.py",
"chars": 8517,
"preview": "import base64\nimport os\nfrom io import BytesIO\nfrom pathlib import Path\nfrom typing import Optional\n\nfrom PIL import Ima"
},
{
"path": "libs/kotaemon/kotaemon/loaders/base.py",
"chars": 3565,
"preview": "from pathlib import Path\nfrom typing import TYPE_CHECKING, Any, List, Type, Union\n\nfrom kotaemon.base import BaseCompone"
},
{
"path": "libs/kotaemon/kotaemon/loaders/composite_loader.py",
"chars": 2281,
"preview": "from typing import Callable, List, Optional, Type\n\nfrom llama_index.core.readers.base import BaseReader as LIBaseReader\n"
},
{
"path": "libs/kotaemon/kotaemon/loaders/docling_loader.py",
"chars": 8155,
"preview": "import base64\nfrom collections import defaultdict\nfrom io import BytesIO\nfrom pathlib import Path\nfrom typing import Lis"
},
{
"path": "libs/kotaemon/kotaemon/loaders/docx_loader.py",
"chars": 3081,
"preview": "import unicodedata\nfrom pathlib import Path\nfrom typing import List, Optional\n\nimport pandas as pd\nfrom llama_index.core"
},
{
"path": "libs/kotaemon/kotaemon/loaders/excel_loader.py",
"chars": 6324,
"preview": "\"\"\"Pandas Excel reader.\n\nPandas parser for .xlsx files.\n\n\"\"\"\nfrom pathlib import Path\nfrom typing import Any, List, Opti"
},
{
"path": "libs/kotaemon/kotaemon/loaders/html_loader.py",
"chars": 5289,
"preview": "import email\nfrom pathlib import Path\nfrom typing import Optional\n\nfrom llama_index.core.readers.base import BaseReader\n"
},
{
"path": "libs/kotaemon/kotaemon/loaders/mathpix_loader.py",
"chars": 11776,
"preview": "import json\nimport re\nimport time\nfrom pathlib import Path\nfrom typing import Any, Dict, Generator, List, Optional, Unio"
},
{
"path": "libs/kotaemon/kotaemon/loaders/ocr_loader.py",
"chars": 6574,
"preview": "import logging\nimport os\nfrom pathlib import Path\nfrom typing import List, Optional\nfrom uuid import uuid4\n\nimport reque"
},
{
"path": "libs/kotaemon/kotaemon/loaders/pdf_loader.py",
"chars": 3517,
"preview": "import base64\nfrom io import BytesIO\nfrom pathlib import Path\nfrom typing import Dict, List, Optional\n\nfrom decouple imp"
},
{
"path": "libs/kotaemon/kotaemon/loaders/txt_loader.py",
"chars": 648,
"preview": "from pathlib import Path\nfrom typing import Optional\n\nfrom kotaemon.base import Document\n\nfrom .base import BaseReader\n\n"
},
{
"path": "libs/kotaemon/kotaemon/loaders/unstructured_loader.py",
"chars": 3778,
"preview": "\"\"\"Unstructured file reader.\n\nA parser for unstructured text files using Unstructured.io.\nSupports .txt, .docx, .pptx, ."
},
{
"path": "libs/kotaemon/kotaemon/loaders/utils/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "libs/kotaemon/kotaemon/loaders/utils/adobe.py",
"chars": 8192,
"preview": "# need pip install pdfservices-sdk==2.3.0\n\nimport base64\nimport json\nimport logging\nimport os\nimport tempfile\nimport zip"
},
{
"path": "libs/kotaemon/kotaemon/loaders/utils/box.py",
"chars": 4597,
"preview": "from typing import List, Tuple\n\n\ndef bbox_to_points(box: List[int]):\n \"\"\"Convert bounding box to list of points\"\"\"\n "
},
{
"path": "libs/kotaemon/kotaemon/loaders/utils/gpt4v.py",
"chars": 3922,
"preview": "import json\nimport logging\nfrom typing import Any, List\n\nimport requests\nfrom decouple import config\n\nlogger = logging.g"
},
{
"path": "libs/kotaemon/kotaemon/loaders/utils/pdf_ocr.py",
"chars": 9869,
"preview": "from collections import defaultdict\nfrom pathlib import Path\nfrom typing import Dict, List, Optional, Union\n\nfrom .box i"
},
{
"path": "libs/kotaemon/kotaemon/loaders/utils/table.py",
"chars": 8694,
"preview": "import csv\nfrom io import StringIO\nfrom typing import List, Optional, Tuple\n\nfrom .box import get_rect_iou\n\n\ndef check_c"
},
{
"path": "libs/kotaemon/kotaemon/loaders/web_loader.py",
"chars": 1221,
"preview": "from pathlib import Path\nfrom typing import Optional\n\nimport requests\nfrom decouple import config\n\nfrom kotaemon.base im"
},
{
"path": "libs/kotaemon/kotaemon/parsers/__init__.py",
"chars": 128,
"preview": "from .regex_extractor import FirstMatchRegexExtractor, RegexExtractor\n\n__all__ = [\"RegexExtractor\", \"FirstMatchRegexExtr"
},
{
"path": "libs/kotaemon/kotaemon/parsers/regex_extractor.py",
"chars": 4776,
"preview": "from __future__ import annotations\n\nimport re\nfrom typing import Callable\n\nfrom kotaemon.base import BaseComponent, Docu"
},
{
"path": "libs/kotaemon/kotaemon/rerankings/__init__.py",
"chars": 243,
"preview": "from .base import BaseReranking\nfrom .cohere import CohereReranking\nfrom .tei_fast_rerank import TeiFastReranking\nfrom ."
},
{
"path": "libs/kotaemon/kotaemon/rerankings/base.py",
"chars": 358,
"preview": "from __future__ import annotations\n\nfrom abc import abstractmethod\n\nfrom kotaemon.base import BaseComponent, Document\n\n\n"
},
{
"path": "libs/kotaemon/kotaemon/rerankings/cohere.py",
"chars": 1960,
"preview": "from __future__ import annotations\n\nimport os\n\nfrom decouple import config\n\nfrom kotaemon.base import Document, Param\n\nf"
},
{
"path": "libs/kotaemon/kotaemon/rerankings/tei_fast_rerank.py",
"chars": 2888,
"preview": "from __future__ import annotations\n\nfrom typing import Optional\n\nimport requests\n\nfrom kotaemon.base import Document, Pa"
},
{
"path": "libs/kotaemon/kotaemon/rerankings/voyageai.py",
"chars": 1773,
"preview": "from __future__ import annotations\n\nimport importlib\n\nfrom decouple import config\n\nfrom kotaemon.base import Document, P"
},
{
"path": "libs/kotaemon/kotaemon/storages/__init__.py",
"chars": 744,
"preview": "from .docstores import (\n BaseDocumentStore,\n ElasticsearchDocumentStore,\n InMemoryDocumentStore,\n LanceDBDo"
},
{
"path": "libs/kotaemon/kotaemon/storages/docstores/__init__.py",
"chars": 388,
"preview": "from .base import BaseDocumentStore\nfrom .elasticsearch import ElasticsearchDocumentStore\nfrom .in_memory import InMemor"
},
{
"path": "libs/kotaemon/kotaemon/storages/docstores/base.py",
"chars": 1436,
"preview": "from abc import ABC, abstractmethod\nfrom typing import List, Optional, Union\n\nfrom kotaemon.base import Document\n\n\nclass"
},
{
"path": "libs/kotaemon/kotaemon/storages/docstores/elasticsearch.py",
"chars": 5933,
"preview": "from typing import List, Optional, Union\n\nfrom kotaemon.base import Document\n\nfrom .base import BaseDocumentStore\n\nMAX_D"
},
{
"path": "libs/kotaemon/kotaemon/storages/docstores/in_memory.py",
"chars": 3044,
"preview": "import json\nfrom pathlib import Path\nfrom typing import List, Optional, Union\n\nfrom kotaemon.base import Document\n\nfrom "
},
{
"path": "libs/kotaemon/kotaemon/storages/docstores/lancedb.py",
"chars": 5183,
"preview": "import json\nfrom typing import List, Optional, Union\n\nfrom kotaemon.base import Document\n\nfrom .base import BaseDocument"
},
{
"path": "libs/kotaemon/kotaemon/storages/docstores/simple_file.py",
"chars": 2072,
"preview": "from pathlib import Path\nfrom typing import List, Optional, Union\n\nfrom kotaemon.base import Document\n\nfrom .in_memory i"
},
{
"path": "libs/kotaemon/kotaemon/storages/vectorstores/__init__.py",
"chars": 473,
"preview": "from .base import BaseVectorStore\nfrom .chroma import ChromaVectorStore\nfrom .in_memory import InMemoryVectorStore\nfrom "
},
{
"path": "libs/kotaemon/kotaemon/storages/vectorstores/base.py",
"chars": 5895,
"preview": "from __future__ import annotations\n\nfrom abc import ABC, abstractmethod\nfrom typing import Any, Optional\n\nfrom llama_ind"
},
{
"path": "libs/kotaemon/kotaemon/storages/vectorstores/chroma.py",
"chars": 2837,
"preview": "from typing import Any, Dict, List, Optional, Type, cast\n\nfrom llama_index.vector_stores.chroma import ChromaVectorStore"
},
{
"path": "libs/kotaemon/kotaemon/storages/vectorstores/in_memory.py",
"chars": 1942,
"preview": "\"\"\"Simple vector store index.\"\"\"\nfrom typing import Any, Optional, Type\n\nimport fsspec\nfrom llama_index.core.vector_stor"
},
{
"path": "libs/kotaemon/kotaemon/storages/vectorstores/lancedb.py",
"chars": 2676,
"preview": "from typing import Any, List, Type, cast\n\nfrom llama_index.core.vector_stores.types import MetadataFilters\nfrom llama_in"
},
{
"path": "libs/kotaemon/kotaemon/storages/vectorstores/milvus.py",
"chars": 3481,
"preview": "import os\nfrom typing import Any, Optional, cast\n\nfrom kotaemon.base import DocumentWithEmbedding\n\nfrom .base import Lla"
},
{
"path": "libs/kotaemon/kotaemon/storages/vectorstores/qdrant.py",
"chars": 2384,
"preview": "from typing import Any, List, Optional, cast\n\nfrom .base import LlamaIndexVectorStore\n\n\nclass QdrantVectorStore(LlamaInd"
},
{
"path": "libs/kotaemon/kotaemon/storages/vectorstores/simple_file.py",
"chars": 2307,
"preview": "\"\"\"Simple file vector store index.\"\"\"\nfrom pathlib import Path\nfrom typing import Any, Optional, Type\n\nimport fsspec\nfro"
},
{
"path": "libs/kotaemon/pyproject.toml",
"chars": 2919,
"preview": "# build backand and build dependencies\n[build-system]\nrequires = [\"setuptools >= 61.0\", \"wheel\", \"setuptools-git-version"
},
{
"path": "libs/kotaemon/pytest.ini",
"chars": 213,
"preview": "[pytest]\nminversion = 7.4.0\ntestpaths = tests\naddopts = -ra -q\nlog_cli=true\nlog_level=WARNING\nlog_format = %(asctime)s %"
},
{
"path": "libs/kotaemon/tests/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "libs/kotaemon/tests/_test_multimodal_reader.py",
"chars": 580,
"preview": "# TODO: This test is broken and should be rewritten\nfrom pathlib import Path\n\nfrom kotaemon.loaders import AdobeReader\n\n"
},
{
"path": "libs/kotaemon/tests/conftest.py",
"chars": 2634,
"preview": "import pytest\n\n\n@pytest.fixture(scope=\"function\")\ndef mock_google_search(monkeypatch):\n import googlesearch\n\n def "
},
{
"path": "libs/kotaemon/tests/resources/dummy.mhtml",
"chars": 33080,
"preview": "MIME-Version: 1.0\nContent-Type: multipart/related; boundary=\"----=_NextPart_01CF5AE5.5C24CD00\"\n\nThis document is a Singl"
},
{
"path": "libs/kotaemon/tests/resources/embedding_openai.json",
"chars": 46914,
"preview": "{\n \"object\": \"list\",\n \"data\": [\n {\n \"object\": \"embedding\",\n \"index\": 0,\n \"embedding\": [\n 0.00"
},
{
"path": "libs/kotaemon/tests/resources/embedding_openai_batch.json",
"chars": 93731,
"preview": "{\n \"object\": \"list\",\n \"data\": [\n {\n \"object\": \"embedding\",\n \"index\": 0,\n \"embedding\": [\n 0.00"
},
{
"path": "libs/kotaemon/tests/resources/fullocr_sample_output.json",
"chars": 122542,
"preview": "[{\"csv_string\": \",,,\\u5358\\u4f4d,\\u5b9f\\u65bd\\u4f8b1,\\u5b9f\\u65bd\\u4f8b2,\\u5b9f\\u65bd\\u4f8b3,\\u6bd4\\u8f03\\u4f8b1,\\u6bd4\\"
},
{
"path": "libs/kotaemon/tests/resources/html/dummy.html",
"chars": 33682,
"preview": "<html><head><meta http-equiv=\"Content-Type\" content=\"text/html; charset=utf-8\" /><meta http-equiv=\"Content-Style-Type\" c"
},
{
"path": "libs/kotaemon/tests/resources/policy.md",
"chars": 13771,
"preview": "# 5 年ごと配当付特定状態保障定期保険特約条項 目次\n\n## 1. この特約の概要\n\n第 1 条 特約保険金の支払\n\n第 2 条 特約保険金の支払に関する補則\n\n第 3 条 特約保険金の免責事由に該当した場合の取扱\n\n第 4 条 特約保険"
},
{
"path": "libs/kotaemon/tests/simple_pipeline.py",
"chars": 1168,
"preview": "import tempfile\nfrom typing import List\n\nfrom kotaemon.base import BaseComponent, LLMInterface, lazy\nfrom kotaemon.embed"
}
]
// ... and 163 more files (download for full content)
About this extraction
This page contains the full source code of the Cinnamon/kotaemon GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 363 files (2.3 MB), approximately 620.0k tokens, and a symbol index with 1642 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.