Showing preview only (307K chars total). Download the full file or copy to clipboard to get everything.
Repository: CoderLeixiaoshuai/java-eight-part
Branch: master
Commit: 77620444e663
Files: 39
Total size: 292.3 KB
Directory structure:
gitextract_hyqgw0oi/
├── .gitattributes
├── .gitignore
├── .nojekyll
├── README.md
├── _sidebar.md
├── docs/
│ ├── distributed/
│ │ ├── 13张图彻底搞懂分布式系统服务注册与发现原理.md
│ │ ├── 原来10张图就可以搞懂分布式链路追踪系统原理.md
│ │ └── 用大白话给你解释Zookeeper的选举机制.md
│ ├── it-hot/
│ │ └── 鸿蒙OS尖刀武器之分布式软总线技术.md
│ ├── java/
│ │ ├── annotation/
│ │ │ └── 想自己写框架不会写Java注解可不行.md
│ │ ├── base/
│ │ │ └── Java基础入门80问.md
│ │ ├── java8/
│ │ │ ├── Java8函数式接口和Lambda表达式你真的会了吗.md
│ │ │ ├── 使用Java8 Optional类优雅解决空指针问题.md
│ │ │ ├── 包学会,教你用Java函数式编程重构烂代码.md
│ │ │ └── 请避开Stream流式编程常见的坑.md
│ │ ├── juc/
│ │ │ ├── 倒计时计数CountDownLatch.md
│ │ │ ├── 内存泄露的原因找到了,罪魁祸首居然是Java TheadLocal.md
│ │ │ ├── 十张图告诉你多线程那些破事.md
│ │ │ ├── 图解Java中那18 把锁.md
│ │ │ ├── 面试官:说说Atomic原子类的实现原理.md
│ │ │ ├── 面试官:说说什么是Java内存模型?.md
│ │ │ └── 面试必问的CAS原理你会了吗.md
│ │ └── roadmap/
│ │ └── 2021 版最新Java 学习路线图(持续刷新).md
│ ├── mq/
│ │ ├── Kafka支持百万级TPS的秘密都藏在这里.md
│ │ └── 刨根问底,kafka到底会不会丢消息.md
│ ├── redis/
│ │ ├── Redis 数据结构和常用命令速记.md
│ │ ├── Redis核心技术知识点全集.md
│ │ ├── 一张图搞懂Redis缓存雪崩、缓存穿透、缓存击穿.md
│ │ ├── 一次性将Redis RDB持久化和AOF持久化讲透.md
│ │ ├── 看完这20道Redis面试题,阿里面试可以约起来了.md
│ │ ├── 经理让我复盘上次Redis缓存雪崩事故.md
│ │ ├── 记一次由Redis分布式锁造成的重大事故,避免以后踩坑!.md
│ │ ├── 还在用单机版?教你用Docker+Redis搭建主从复制多实例.md
│ │ ├── 面试官再问Redis事务把这篇文章扔给他.md
│ │ └── 高并发场景下,到底先更新缓存还是先更新数据库?.md
│ └── tools/
│ ├── git/
│ │ └── 保姆级Git教程,10000字详解.md
│ ├── 推荐十款精选IntelliJIdea插件.md
│ └── 高效学习资源网站汇总.md
└── index.html
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitattributes
================================================
*.js linguist-language=java
*.css linguist-language=java
*.html linguist-language=java
================================================
FILE: .gitignore
================================================
.DS_Store
================================================
FILE: .nojekyll
================================================
================================================
FILE: README.md
================================================
:star: 点右上角给一个 `Star`,鼓励技术人输出更多干货,爱了 !
:gift::gift::gift: 号外号外,学习资料免费下载!
- [进BAT大厂前必读的经典编程书籍,吐血整理共6G一次打包带走](http://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=502841590&idx=1&sn=938f0a4c45d2843aa7545c1f78fcffc6&chksm=0f09beec387e37faede87b50c31e37ee384093f1bd3363304054b7919f9b6266368954b4cbd8#rd)
- [阿里师兄总结的JAVA核心知识点整理(283页,超级详细,高清带目录)](http://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=502841004&idx=1&sn=059dab6b76cbbc50eabd39566ee5ce28&chksm=0f09c0b6387e49a099b9c55d37e112f2049309f2a895a314f0a362e9ce5fb248ad4caafd50e8#rd)
- [Github 疯传!阿里大佬「LeetCode刷题手册」开放下载了!史上最强悍!](http://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=502841057&idx=1&sn=97576b1a66502b75a6770265515b4a57&chksm=0f09c0fb387e49ed543d3fec9b3ff6ae9da6efbcf8ff52e07c15a05de9d2b90dcee1152a1b28#rd)
<img src="https://cdn.jsdelivr.net/gh/smileArchitect/assets/202102/Java-eight-part-logo-2021-04-28-23-07-56.png" alt="Java八股文">
<div align="center">
<a href="http://coderleixiaoshuai.gitee.io/java-eight-part/" target="_blank"> <img src="https://img.shields.io/badge/GitPages-%E5%9C%A8%E7%BA%BF%E9%98%85%E8%AF%BB-ef8b00"></a>
<a href="https://space.bilibili.com/1997769079" target="_blank"> <img src="https://img.shields.io/badge/B%E7%AB%99-%E7%A8%8B%E5%BA%8F%E5%91%98%E9%9B%B7%E5%B0%8F%E5%B8%85-ef8b00"></a>
<a href="#boy-%E5%85%B3%E4%BA%8E%E6%88%91" target="_blank"> <img src="https://img.shields.io/badge/%E5%BE%AE%E4%BF%A1%E5%85%AC%E4%BC%97%E5%8F%B7-%E7%88%B1%E7%AC%91%E7%9A%84%E6%9E%B6%E6%9E%84%E5%B8%88-ef8b00"></a>
<a href="https://www.zhihu.com/people/smileArchitect" target="_blank"> <img src="https://img.shields.io/badge/%E7%9F%A5%E4%B9%8E-%E6%BD%9C%E5%8A%9B%E7%AD%94%E4%B8%BB-ef8b00"></a>
<a href="https://juejin.im/user/3500462825546958/posts" target="_blank"> <img src="https://img.shields.io/badge/%E6%8E%98%E9%87%91-%E4%BA%BA%E6%B0%94%E4%BD%9C%E8%80%85-ef8b00"></a>
<a href="https://blog.csdn.net/guoguo527" target="_blank"> <img src="https://img.shields.io/badge/CSDN-%E5%8D%9A%E5%AE%A2%E4%B8%93%E5%AE%B6-ef8b00"></a>
</div>
<br />
> 什么是 Java 八股文?Java 面试中经常会问的一些知识点或者套路被大家戏称为『八股文』。希望读完本开源项目可以帮助你熟悉面试套路、拿大厂 offer。
>
> 勘误:如果文章内容有误欢迎[联系我](#iphone-联系我)修改,或者提交 [`PR`](https://github.com/CoderLeixiaoshuai/java-eight-part/pulls) or [`Issue`](https://github.com/CoderLeixiaoshuai/java-eight-part/issues),开源靠大家共同的努力!
>
> 版权说明:所有文章都已首发我的微信公众号,如果需要转载可以[联系我](#iphone-联系我)授权,恶意抄袭我会不惜一切代价维护权益,希望同行一起维护良好的创作环境。
# :coffee: Java
[『必看』2021 版最新Java 学习路线图(持续刷新):+1::+1::+1:](docs/java/roadmap/2021%20版最新Java%20学习路线图(持续刷新).md)
## Java入门面试题
[Java基础入门80问,适合新手,老鸟直接跳过](docs/java/base/Java基础入门80问.md)
## Java并发编程(J.U.C) :+1:
- [『死磕Java并发编程系列』 01 十张图告诉你多线程那些破事](docs/java/juc/十张图告诉你多线程那些破事.md)
- [『死磕Java并发编程系列』 02 面试官:说说什么是Java内存模型?](docs/java/juc/面试官:说说什么是Java内存模型?.md)
- [『死磕Java并发编程系列』 03 面试必问的CAS原理你会了吗?](docs/java/juc/面试必问的CAS原理你会了吗.md)
- [『死磕Java并发编程系列』 04 面试官:说说Atomic原子类的实现原理?](docs/java/juc/面试官:说说Atomic原子类的实现原理.md)
- [『死磕Java并发编程系列』 05 图解Java中那18 把锁.md](docs/java/juc/图解Java中那18%20把锁.md)
- [『死磕Java并发编程系列』06 倒计时计数CountDownLatch](docs/java/juc/倒计时计数CountDownLatch.md)
- 『死磕Java并发编程系列』07 人齐了一起干CyclicBarrier
- 『死磕Java并发编程系列』08 限量供应Semaphore
- 『死磕Java并发编程系列』09 一手交钱一手交货Exchange
- [内存泄露的原因找到了,罪魁祸首居然是Java TheadLocal](docs/java/juc/内存泄露的原因找到了,罪魁祸首居然是Java%20TheadLocal.md)
*疯狂更新中……*
## Java8实战
- [『Java8实战系列』01 Java8函数式接口和Lambda表达式你真的会了吗?](docs/java/java8/Java8函数式接口和Lambda表达式你真的会了吗.md)
- [『Java8实战系列』02 包学会,教你用Java函数式编程重构烂代码](docs/java/java8/包学会,教你用Java函数式编程重构烂代码.md)
- [『Java8实战系列』03 请避开Stream流式编程常见的坑](docs/java/java8/请避开Stream流式编程常见的坑.md)
- [『Java8实战系列』04 详解Lambda表达式中Predicate Function Consumer Supplier函数式接口](docs/java/java8/%E8%AF%A6%E8%A7%A3Lambda%E8%A1%A8%E8%BE%BE%E5%BC%8F%E4%B8%ADPredicate%20Function%20Consumer%20Supplier%E5%87%BD%E6%95%B0%E5%BC%8F%E6%8E%A5%E5%8F%A3.md)
- [『Java8实战系列』05 使用Java8 Optional类优雅解决空指针问题](docs/java/java8/使用Java8%20Optional类优雅解决空指针问题.md)
## Java注解
- [想自己写框架?不会写Java注解可不行!](docs/advanced/java-annotation/想自己写框架不会写Java注解可不行.md)
# :baby_chick: Redis
**面试八股文**
- [『玩转Redis面试篇』看完这20道Redis面试题,阿里面试可以约起来了](docs/redis/看完这20道Redis面试题,阿里面试可以约起来了.md)
**知识点详解**
- [『玩转Redis基础篇』Redis数据结构和常用命令速记](docs/redis/Redis%20数据结构和常用命令速记.md)
- [『玩转Redis基础篇』面试官再问Redis事务把这篇文章扔给他](docs/redis/面试官再问Redis事务把这篇文章扔给他.md)
- [『玩转Redis基础篇』一次性将Redis RDB持久化和AOF持久化讲透](docs/redis/一次性将Redis%20RDB持久化和AOF持久化讲透.md)
- [『玩转Redis基础篇』一张图搞懂Redis缓存雪崩、缓存穿透、缓存击穿](docs/redis/一张图搞懂Redis缓存雪崩、缓存穿透、缓存击穿.md)
- [『玩转Redis实战篇』高并发场景下,到底先更新缓存还是先更新数据库?:+1::+1:](docs/redis/高并发场景下,到底先更新缓存还是先更新数据库?.md)
- [『玩转Redis实战篇』经理让我复盘上次Redis缓存雪崩事故](docs/redis/经理让我复盘上次Redis缓存雪崩事故.md)
- [『玩转Redis实战篇』还在用单机版?教你用Docker+Redis搭建主从复制多实例](docs/redis/还在用单机版?教你用Docker%2BRedis搭建主从复制多实例.md)
- [『玩转Redis实战篇』记一次由Redis分布式锁造成的重大事故,避免以后踩坑!](docs/redis/记一次由Redis分布式锁造成的重大事故,避免以后踩坑!.md)
# :tiger: 消息队列(kafka)
- [Kafka支持百万级TPS的秘密都藏在这里:+1::+1::+1:](docs/mq/Kafka支持百万级TPS的秘密都藏在这里.md)
- [刨根问底,kafka到底会不会丢消息:+1::+1::+1:](docs/mq/刨根问底,kafka到底会不会丢消息.md)
# :cow: 分布式
- [13张图彻底搞懂分布式系统服务注册与发现原理:+1::+1::+1:](docs/distributed/13张图彻底搞懂分布式系统服务注册与发现原理.md)
- [原来10张图就可以搞懂分布式链路追踪系统原理:+1::+1::+1:](docs/distributed/原来10张图就可以搞懂分布式链路追踪系统原理.md)
- [用大白话给你解释Zookeeper的选举机制:+1::+1:](docs/distributed/用大白话给你解释Zookeeper的选举机制.md)
# :sheep: 关系数据库
[我们为什么要分库分表?](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322981&idx=1&sn=644537003c300db69934aa7acee80c8c&chksm=8f09c63fb87e4f29b5bebeca1c03e102898fcbd663b6f189a78dba8cec646f875cc01832a221&token=1553501157&lang=zh_CN#rd)
# :frog: 五分钟入门系列
- [5分钟带你快速了解ServiceMesh的前世今生](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322518&idx=1&sn=c6e23e98a838e7960e72623326c99360&chksm=8f09c84cb87e415a91f3a898918f45aa32ab17ed784cd68ce07945ecbb3a78b54429a38c9941&token=1553501157&lang=zh_CN#rd)
- [Docker不香吗?为什么还要用k8s](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322467&idx=1&sn=30ab39d4f59135ecf6eb322fb0712189&chksm=8f09c839b87e412fdae1c39072ebdbbdcc3420b46fb66a324f5f81d8ebe621fe0ac3ef003a7d&token=1553501157&lang=zh_CN#rd)
# :horse: 设计模式
[说完观察者和发布订阅模式的区别,面试官不留我吃饭了](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322141&idx=1&sn=ccece65719b5693ecdc6893642caefc3&chksm=8f09cac7b87e43d1efb3fcd2ba4b59159c7fa833b777fbdffaf0e739d3530c6834f80eaffbdd&token=1553501157&lang=zh_CN#rd)
# :bulb: 工具&效率提升
## Git
基础教程:
- [保姆级Git教程,10000字详解,必看:+1:](docs/tools/git/保姆级Git教程,10000字详解.md)
进阶实战:
- [牛逼!简单的代码提交能玩出这么多花样](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322730&idx=1&sn=6b7593e2cd29747ba424b9ca987ac86c&chksm=8f09c930b87e40269c52f2156d1ed08ce87509f4eca25aeb49f4977e97164622f614d3b93dd0&token=1553501157&lang=zh_CN#rd)
- [吵疯了,Pull Request到底是个啥?](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650323040&idx=1&sn=12b5f1342661c7964f8908eb1e14f590&chksm=8f09c67ab87e4f6ce6aa04b9a12ab95700089455b682eea6007e90172ec2d92f705277da34f6&token=1553501157&lang=zh_CN#rd)
## IntelliJ IDEA - Java开发利器
- [开发效率不高?推荐这十款精选IntelliJ Idea插件](docs/tools/推荐十款精选IntelliJIdea插件.md)
## 代码重构
- [讲点码德!避免这些代码坏味道,努力做一名优秀的程序员](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322056&idx=1&sn=ab5552ffdc868d3ea004ed0782bd80d3&chksm=8f09ca92b87e4384881ec3ab1d1b20f61c0f77e1185d5f0ad60c7b96d3420cf7f101e88492c6&token=1553501157&lang=zh_CN#rd)
## 学习资源
- [高效学习资源网站汇总](docs/tools/高效学习资源网站汇总.md)
# :dart: 我要进大厂系列
- [两年半完成逆袭,室友终于拿到字节跳动的Offer:+1:](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321727&idx=1&sn=2e530651ba6176415cacc91f065d333c&chksm=8f09cd25b87e4433f5a7a248bf91ee64f3e1b025a3096873f543a5cf8f03f31433b6d31c0ddc&token=1941065265&lang=zh_CN#rd)
- [找工作前这四个坑不要重复踩了](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321540&idx=1&sn=c17e195ec6fa7d40a6327a456f9fd4b2&chksm=8f09cc9eb87e45889fed564e4c1e461cf53863930323c9a5aa86169e94b25092bdd9097c81fc&token=1553501157&lang=zh_CN#rd)
- [网易面试干货之HR解密网易招聘(上篇)](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321320&idx=1&sn=d0c73f80b6ee92aebc12dbdbcb41d8ec&chksm=8f09cfb2b87e46a4afa541bb198c0bca3acdb9067c269406447587c3c8cfd135bea0ec701bd8&scene=178&cur_album_id=1531431564587417601#rd)
- [网易面试干货之HR解密网易招聘(下篇)](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321320&idx=2&sn=21940f268890e43032434b628fc08819&chksm=8f09cfb2b87e46a4e6c94b8b94667f036be9e8a3e6780e7ca8b714d18b53e0f1b96c67d07781&scene=178&cur_album_id=1531431564587417601#rd)
# :see_no_evil: 程序人生
- [我也是从寒门走出来的:+1::+1::+1: ](https://mp.weixin.qq.com/s/pejkW9F1QsH2toEfoNPe1g)
- [逃离百度](https://mp.weixin.qq.com/s/0Sobo5R4GLE3QmEK_gbksg)
- [寒门难出贵子,我当程序员让爸妈在老家长脸了:+1::+1::+1: ](https://mp.weixin.qq.com/s/GOKberslgcxN7Jl5cTrmyw)
- [摊牌了,这半个月我拍"电影"去了](https://mp.weixin.qq.com/s/ihTIFUqM0z7V1zmgPvT0yA)
- [谈谈拼夕夕事件!为什么我们拼尽全力却还要996](https://mp.weixin.qq.com/s/3WVde2dAKfqKv0DBt5dGLw)
- [IT双职工赢在起跑线,还怕未来吗?](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321489&idx=1&sn=c31f56cc06fd21e889be51e189ffed23&chksm=8f09cc4bb87e455d09e5ceda718c27cbf5df113cbe0336faf947b1bce3d28d40cc454ebf872d&token=1553501157&lang=zh_CN#rd)
- [程序员版《我和我的家乡》,拼搏奋斗的IT人是家乡的骄傲!](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321444&idx=1&sn=17f3ce6c05b40afc3c18bdb23ee2f6d7&chksm=8f09cc3eb87e45289fd1e51055a4acb7d9689a8e3d4ffc598fc7fd1ca1e918f1628ee67d55c6&scene=178&cur_album_id=1531431564587417601#rd)
- [女程序员在互联网界到底有没有被歧视?](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321297&idx=1&sn=d547a2c54e99e6a69723e39ec955d24e&chksm=8f09cf8bb87e469d560ef47c47e59d814a224a31ccfefe12efe9e62a20abbc0f870e14660648&scene=178&cur_album_id=1531431564587417601#rd)
- [离开华为换种生活,它不香吗?](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321143&idx=1&sn=85a794588811541a8e920a60a0edcf4e&chksm=8f09ceedb87e47fb0b9301b6d268b4c68f5a213f47f5a1286fc800a2707b6a9bf57958bd301b&scene=178&cur_album_id=1531431564587417601#rd)
- [如果可以选择,我再也不想在国企当程序员了](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321085&idx=1&sn=12a7cc5c910d547cc696c325826295e1&chksm=8f09cea7b87e47b13256c15a631506fc18fd2d8a25a4546b202f268f84347723f59a9e2e86ac&scene=178&cur_album_id=1531431564587417601#rd)
- [30岁的程序员出路在哪里?](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321044&idx=1&sn=30b10126e477876229f77cd604540b57&chksm=8f09ce8eb87e47981c945363f9601bf8bd524d220fe1b1397f01a18420c8e1cc8f7c76ba94cb&scene=178&cur_album_id=1531431564587417601#rd)
# :cloud: 侃天侃地侃互联网
- [求伯君,一个你必须知道的程序员
](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321596&idx=1&sn=c64858e4f5ed07d53feb00b1aeec2974&chksm=8f09cca6b87e45b09eb7ddc6c35be06d1be7514330e9ac9ef144cd3a5ae61b14e1a6e22bf295&token=1553501157&lang=zh_CN#rd)
- [华为鸿蒙OS尖刀武器之分布式软总线技术全解析](/docs/it-hot/鸿蒙OS尖刀武器之分布式软总线技术.md)
- [汇聚开发者星星之火,华为鸿蒙系统有希望成为国产之光](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321645&idx=1&sn=c263f8db73cdbffee96c2f511ff7ae74&chksm=8f09ccf7b87e45e18eb684d620073d256f95fa25217b8d5c81116600df9a137d33fa93c92961&token=1941065265&lang=zh_CN#rd)
# :boy: 关于我
大家好,我是『雷小帅』,也是微信公众号『爱笑的架构师』的作者。
- :coffee:读过几年书:华中科技大学硕士毕业;
- :star2:浪过几个大厂:华为、网易、百度……
- :kissing:一直坚信技术能改变生活,愿保持初心,加油技术人!
`我有技术和故事,等你来!`
**Github 上所有的文章我都会首发在微信公众号『爱笑的架构师』,大家可以关注一下。定时推送技术干货~**
<div align="center">
<img src="https://cdn.jsdelivr.net/gh/smileArchitect/assets@main/202012/20201205221844.png"></img>
</div>
# :iphone: 联系我
- 如果你迷茫了,欢迎找雷小帅咨询、交流、聊天,尽最大能力为你解答;
- 如果你想找到一群志同道合的小伙伴,也欢迎加我,拉你进技术交流群,群里有 BAT 大佬,不说话看他们聊天也能学到东西。
个人微信二维码如下,添加时一定要备注一下来意。
<div align="center">
<img src="https://cdn.jsdelivr.net/gh/smileArchitect/assets@main/202012/20201205222851.png"></img>
</div>
================================================
FILE: _sidebar.md
================================================
- [:coffee: Java](#coffee-java)
- [Java入门面试题](#java入门面试题)
- [Java并发编程(J.U.C) :+1:](#java并发编程juc-1)
- [Java8实战](#java8实战)
- [Java注解](#java注解)
- [:baby_chick: Redis](#baby_chick-redis)
- [:tiger: 消息队列(kafka)](#tiger-消息队列kafka)
- [:cow: 分布式](#cow-分布式)
- [:sheep: 关系数据库](#sheep-关系数据库)
- [:frog: 五分钟入门系列](#frog-五分钟入门系列)
- [:horse: 设计模式](#horse-设计模式)
- [:bulb: 工具&效率提升](#bulb-工具效率提升)
- [Git](#git)
- [IntelliJ IDEA - Java开发利器](#intellij-idea---java开发利器)
- [代码重构](#代码重构)
- [学习资源](#学习资源)
- [:dart: 我要进大厂系列](#dart-我要进大厂系列)
- [:see_no_evil: 程序人生](#see_no_evil-程序人生)
- [:cloud: 侃天侃地侃互联网](#cloud-侃天侃地侃互联网)
- [:boy: 关于我](#boy-关于我)
- [:iphone: 联系我](#iphone-联系我)
================================================
FILE: docs/distributed/13张图彻底搞懂分布式系统服务注册与发现原理.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321879&idx=1&sn=8b786ec4c6ef90e30834516f62feace7&chksm=8f09cdcdb87e44db1b3643dfbc89e5501b2289fd024586eda36e1236c8fe5eda18dd6b4adab6&token=1553501157&lang=zh_CN#rd)』,欢迎大家关注。
<!-- TOC -->
- [引入服务注册与发现组件的原因](#引入服务注册与发现组件的原因)
- [**单体架构**](#单体架构)
- [应用与数据分离](#应用与数据分离)
- [集群部署](#集群部署)
- [微服务架构](#微服务架构)
- [架构演进总结](#架构演进总结)
- [服务注册与发现基本原理](#服务注册与发现基本原理)
- [服务注册](#服务注册)
- [服务发现](#服务发现)
- [心跳机制](#心跳机制)
- [业界常用的服务注册与发现组件对比](#业界常用的服务注册与发现组件对比)
- [Consul——值得推荐的服务注册与发现开源组件](#consul值得推荐的服务注册与发现开源组件)
- [简单认识一下Consul](#简单认识一下consul)
- [Consul有哪些优势?](#consul有哪些优势)
- [Consul的架构图](#consul的架构图)
- [Consul的使用场景](#consul的使用场景)
<!-- /TOC -->
在微服务架构或分布式环境下,服务注册与发现技术不可或缺,这也是程序员进阶之路必须要掌握的核心技术之一,本文通过图解的方式带领大家轻轻松松掌握。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504231822-2021-05-04-23-18-22.png" alt="20210504231822-2021-05-04-23-18-22">
# 引入服务注册与发现组件的原因
先来看一个问题,假如现在我们要做一个商城项目,作为架构师的你应该怎样设计系统的架构?你心里肯定在想:这还不容易直接照搬淘宝的架构不就行了。但在现实的创业环境中一个项目可能是九死一生,如果一开始投入巨大的人力和财力,一旦项目失败损失就很大。
作为一位有经验的架构师需要结合公司财力、人力投入预算等现状选择最适合眼下的架构才是王道。大型网站都是从小型网站发展而来,架构也是一样。
任何一个大型网站的架构都不是从一开始就一层不变的,而是随着用户量和数据量的不断增加不断迭代演进的结果。
在架构不断迭代演进的过程中我们会遇到很多问题,**技术发展的本质就是不断发现问题再解决问题,解决问题又发现问题**。
## **单体架构**
在系统建立之初可能不会有特别多的用户,将所有的业务打成一个应用包放在tomcat容器中运行,与数据库共用一台服务器,这种架构一般称之为单体架构。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/-2021-05-04-23-18-38.png" alt="-2021-05-04-23-18-38">
在初期这种架构的效率非常高,根据用户的反馈可以快速迭代上线。但是随着用户量增加,一台服务的内存和CPU吃紧,很容易造成瓶颈,新的问题来了怎么解决呢?
## 应用与数据分离
随着用户请求量增加,一台服务器的内存和CPU持续飙升,用户请求响应时间变慢。这时候可以考虑将应用与数据库拆开,各自使用一台服务器,你看问题又解决了吧。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504231902-2021-05-04-23-19-02.png" alt="20210504231902-2021-05-04-23-19-02">
突然有一天扫地阿姨不小心碰了电线,其中一台服务器掉电了,用户所有的请求都报错,随之而来的是一系列投诉电话。
## 集群部署
单实例很容易造成单点问题,比如遇到服务器故障或者服务能力瓶颈,那怎么办?聪明的你肯定想到了,用集群呀。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232036-2021-05-04-23-20-37.png" alt="20210504232036-2021-05-04-23-20-37">
集群部署是指将应用部署在多个服务器或者虚机上,用户通过服务均衡随机访问其中的一个实例,从而使多个实例的流量均衡,如果一个实例出现故障可以将其下线,其他实例不受影响仍然可以对外提供服务。
随着用户数量快速增加,老板决定增加投入扩大团队规模。开发团队壮大后效率并没有得到显著的提高,以前小团队可以一周迭代上线一次,现在至少需要两到三周时间。
业务逻辑越来越复杂,代码间耦合很严重,修改一行代码可能引入几个线上问题。架构师意识到需要进行架构重构。
## 微服务架构
当单体架构演进到一定阶段后开发测试的复杂性都会成本增加,团队规模的扩大也会使得各自工作耦合性更严重,牵一发而动全身就是这种场景。
单体架构遇到瓶颈了,微服务架构就横空出世了。微服务就是将之前的单体服务按照业务维度进行拆分,拆分粒度可大可小,拆分时机可以分节奏进行。最佳实践是先将一些独立的功能从单体中剥离出来抽成一个或多个微服务,这样可以保障业务的连续性和稳定性。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232049-2021-05-04-23-20-51.png" alt="20210504232049-2021-05-04-23-20-51">
如上图将一个商用应用拆分为六个独立微服务。六个微服务可以使用Docker容器化进行多实例部署。
架构演化到这里遇到了一个难题,如果要查询用户所有的订单,用户服务可能会依赖订单服务,用户服务如何与订单服务交互呢?订单服务有多个实例该访问哪一个?
通常有几种解决办法:
**(1)服务地址硬编码**
服务的地址写死在数据库或者配置文件,通过访问DNS域名进行寻址路由。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232109-2021-05-04-23-21-10.png" alt="20210504232109-2021-05-04-23-21-10">
服务B的地址硬编码在数据库或者配置文件中,服务A首先需要拿到服务B的地址,然后通过DNS服务器解析获取其中一实例的真实地址,最后可以向服务B发起请求。
如果遇到大促活动需要对服务实例扩容,大促完需要对服务实例进行下线,运维人员要做大量的手工操作,非常容易误操作。
**(2)服务动态注册与发现**
服务地址硬编码还有一个非常致命的问题,如果一台实例挂了,运维人员可能不能及时感知到,导致一部分用户的请求会异常。
引入服务注册与发现组件可以很好解决上面遇到的问题,避免过多的人工操作。
## 架构演进总结
在单体架构中一个应用程序就是一个服务包,包内的模块通过函数方法相互调用,模型足够简单,根本没有服务注册和发现一说。
在微服务架构中会将一个应用程序拆分为多个微服务,微服务会部署在不同的服务器、不同的容器、甚至多数据中心,微服务间要相互调用,服务注册和发现成为了一个不可或缺的组件。
# 服务注册与发现基本原理
服务注册与发现是分为注册和发现两个关键的步骤。
**服务注册**:服务进程在注册中心注册自己的元数据信息。通常包括主机和端口号,有时还有身份验证信息,协议,版本号,以及运行环境的信息。
**服务发现**:客户端服务进程向注册中心发起查询,来获取服务的信息。服务发现的一个重要作用就是提供给客户端一个可用的服务列表。
## 服务注册
服务注册有两种形式:客户端注册和代理注册。
**客户端注册**
客户端注册是服务自己要负责注册与注销的工作。当服务启动后注册线程向注册中心注册,当服务下线时注销自己。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232139-2021-05-04-23-21-40.png" alt="20210504232139-2021-05-04-23-21-40">
这种方式的缺点是注册注销逻辑与服务的业务逻辑耦合在一起,如果服务使用不同语言开发,那需要适配多套服务注册逻辑。
**代理注册**
代理注册由一个单独的代理服务负责注册与注销。当服务提供者启动后以某种方式通知代理服务,然后代理服务负责向注册中心发起注册工作。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232151-2021-05-04-23-21-52.png" alt="20210504232151-2021-05-04-23-21-52">
这种方式的缺点是多引用了一个代理服务,并且代理服务要保持高可用状态。
## 服务发现
服务发现也分为客户端发现和代理发现。
**客户端发现**
客户端发现是指客户端负责向注册中心查询可用服务地址,获取到所有的可用实例地址列表后客户端根据负载均衡算法选择一个实例发起请求调用。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232203-2021-05-04-23-22-04.png" alt="20210504232203-2021-05-04-23-22-04">
这种方式非常直接,客户端可以控制负载均衡算法。但是缺点也很明显,获取实例地址、负载均衡等逻辑与服务的业务逻辑耦合在一起,如果服务发现或者负载平衡有变化,那么所有的服务都要修改重新上线。
**代理发现**
代理发现是指新增一个路由服务负责服务发现获取可用的实例列表,服务消费者如果需要调用服务A的一个实例可以直接将请求发往路由服务,路由服务根据配置好的负载均衡算法从可用的实例列表中选择一个实例将请求转发过去即可,如果发现实例不可用,路由服务还可以自行重试,服务消费者完全不用感知。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232217-2021-05-04-23-22-17.png" alt="20210504232217-2021-05-04-23-22-17">
## 心跳机制
如果服务有多个实例,其中一个实例出现宕机,注册中心是可以实时感知到,并且将该实例信息从列表中移出,也称为摘机。
如何实现摘机?业界比较常用的方式是通过心跳检测的方式实现,心跳检测有**主动**和**被动**两种方式。
**被动检测**是指服务主动向注册中心发送心跳消息,时间间隔可自定义,比如配置5秒发送一次,注册中心如果在三个周期内比如说15秒内没有收到实例的心跳消息,就会将该实例从列表中移除。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232235-2021-05-04-23-22-35.png" alt="20210504232235-2021-05-04-23-22-35">
上图中服务A的实例2已经宕机不能主动给注册中心发送心跳消息,15秒之后注册就会将实例2移除掉。
**主动检测**是注册中心主动发起,每隔几秒中会给所有列表中的服务实例发送心跳检测消息,如果多个周期内未发送成功或未收到回复就会主动移除该实例。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232247-2021-05-04-23-22-48.png" alt="20210504232247-2021-05-04-23-22-48">
# 业界常用的服务注册与发现组件对比
了解服务注册与发现的基本原理后,如果你要在项目中使用服务注册与发现组件,当面对众多的开源组件该如何进行技术选型?
在互联网公司里,有研发实力的大公司一般会选择自研或者基于开源组件进行二次开发,但是对于中小型公司来说直接选用一款开源软件会是一个不错的选择。
常用的注册与发现组件有eureka,zookeeper,consul,etcd等,由于eureka在2018年已经宣布放弃维护,这里就不再推荐使用了。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232300-2021-05-04-23-23-00.png" alt="20210504232300-2021-05-04-23-23-00">
下面结合各个维度对比一下各组件。
|**组件**|**优点**|**缺点**|**接口类型**|**一致性算法**|
|:----|:----|:----|:----|:----|:----|:----|
|zookeeper|1.功能强大,不仅仅只是服务发现;<br>2.提供watcher机制可以实时获取服务提供者的状态;<br>3.广泛使用,dubbo等微服务框架已支持;|1.没有健康检查;<br>2.需要在服务中引入sdk,集成复杂度高;<br>3.不支持多数据中心;|sdk|Paxos|
|consul|1.开箱即用,方便集成;<br>2.带健康检查;<br>3.支持多数据中心;<br>4.提供web管理界面;|不能实时获取服务变换通知|restful/dns|Raft|
|etcd|1.开箱即用,方便集成;<br>2.可配置性强|1.没有健康检查;<br>2.需配合三方工具完成服务发现功能;<br>3.不支持多数据中心;|restful|Raft|
从整体上看consul的功能更加完备和均衡。接下来以consul为例详细介绍一下。
# Consul——值得推荐的服务注册与发现开源组件
## 简单认识一下Consul
Consul是HashiCorp公司推出的开源工,使用Go语言开发,具有开箱即可部署方便的特点。Consul是分布式的、高可用的、 可横向扩展的用于实现分布式系统的服务发现与配置。
## Consul有哪些优势?
* 服务注册发现:Consul提供了通过DNS或者restful接口的方式来注册服务和发现服务。服务可根据实际情况自行选择。
* 健康检查:Consul的Client可以提供任意数量的健康检查,既可以与给定的服务相关联,也可以与本地节点相关联。
* 多数据中心:Consul支持多数据中心,这意味着用户不需要担心Consul自身的高可用性问题以及多数据中心带来的扩展接入等问题。
## Consul的架构图
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232315-2021-05-04-23-23-15.png" alt="20210504232315-2021-05-04-23-23-15">
Consul 实现多数据中心依赖于gossip protocol协议。这样做的目的:
* 不需要使用服务器的地址来配置客户端;服务发现是自动完成的。
* 健康检查故障的工作不是放在服务器上,而是分布式的。
## Consul的使用场景
Consul的应用场景包括**服务注册发现**、**服务隔离**、**服务配置**等。
**服务注册发现场景**中consul作为注册中心,服务地址被注册到consul中以后,可以使用consul提供的dns、http接口查询,consul支持health check。
**服务隔离场景**中consul支持以服务为单位设置访问策略,能同时支持经典的平台和新兴的平台,支持tls证书分发,service-to-service加密。
**服务配置场景**中consul提供key-value数据存储功能,并且能将变动迅速地通知出去,借助Consul可以实现配置共享,需要读取配置的服务可以从Consul中读取到准确的配置信息。
================================================
FILE: docs/distributed/原来10张图就可以搞懂分布式链路追踪系统原理.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321924&idx=1&sn=d8572df23b47409ab997029cb34c6c07&chksm=8f09ca1eb87e4308d81d322814fdc56acf1e3c4ff9d8655c239ad1468af512719d01b03027c8&token=1553501157&lang=zh_CN#rd)』,欢迎大家关注。
<!-- TOC -->
- [分布式系统为什么需要链路追踪?](#分布式系统为什么需要链路追踪)
- [什么是链路追踪?](#什么是链路追踪)
- [链路追踪基本原理](#链路追踪基本原理)
- [Trace](#trace)
- [Span](#span)
- [Annotations](#annotations)
- [带内数据与带外数据](#带内数据与带外数据)
- [采样](#采样)
- [存储](#存储)
- [业界常用链路追踪系统](#业界常用链路追踪系统)
- [分布式链路追踪系统Zipkin实现](#分布式链路追踪系统zipkin实现)
- [**Zipkin基本架构**](#zipkin基本架构)
- [**Zipkin核心组件**](#zipkin核心组件)
- [总结](#总结)
<!-- /TOC -->
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232415-2021-05-04-23-24-15.png" alt="20210504232415-2021-05-04-23-24-15">
# 分布式系统为什么需要链路追踪?
随着互联网业务快速扩展,软件架构也日益变得复杂,为了适应海量用户高并发请求,系统中越来越多的组件开始走向分布式化,如单体架构拆分为微服务、服务内缓存变为分布式缓存、服务组件通信变为分布式消息,这些组件共同构成了繁杂的分布式网络。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232426-2021-05-04-23-24-27.png" alt="20210504232426-2021-05-04-23-24-27">
假如现在有一个系统部署了成千上万个服务,用户通过浏览器在主界面上下单一箱茅台酒,结果系统给用户提示:系统内部错误,相信用户是很崩溃的。
运营人员将问题抛给开发人员定位,开发人员只知道有异常,但是这个异常具体是由哪个微服务引起的就需要逐个服务排查了。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232438-2021-05-04-23-24-39.png" alt="20210504232438-2021-05-04-23-24-39">
开发人员借助日志逐个排查的效率是非常低的,那有没有更好的解决方案了?**答案是引入链路追踪系统。**
# 什么是链路追踪?
分布式链路追踪就是将一次分布式请求还原成调用链路,将一次分布式请求的调用情况集中展示,比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
**链路跟踪主要功能:**
* **故障快速定位**:可以通过调用链结合业务日志快速定位错误信息。
* **链路性能可视化**:各个阶段链路耗时、服务依赖关系可以通过可视化界面展现出来。
* **链路分析**:通过分析链路耗时、服务依赖关系可以得到用户的行为路径,汇总分析应用在很多业务场景。
# 链路追踪基本原理
链路追踪系统(可能)最早是由Goggle公开发布的一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》被大家广泛熟悉,所以各位技术大牛们如果有黑武器不要藏起来赶紧去发表论文吧。
在这篇著名的论文中主要讲述了Dapper链路追踪系统的基本原理和关键技术点。接下来挑几个重点的技术点详细给大家介绍一下。
## Trace
Trace的含义比较直观,就是链路,指一个请求经过所有服务的路径,可以用下面树状的图形表示。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232454-2021-05-04-23-24-55.png" alt="20210504232454-2021-05-04-23-24-55">
图中一条完整的链路是:chrome -> 服务A -> 服务B -> 服务C -> 服务D -> 服务E -> 服务C -> 服务A -> chrome。服务间经过的局部链路构成了一条完整的链路,其中每一条局部链路都用一个全局唯一的traceid来标识。
## Span
在上图中可以看出来请求经过了服务A,同时服务A又调用了服务B和服务C,但是先调的服务B还是服务C呢?从图中很难看出来,只有通过查看源码才知道顺序。
为了表达这种父子关系引入了Span的概念。
同一层级parent id相同,span id不同,span id从小到大表示请求的顺序,从下图中可以很明显看出服务A是先调了服务B然后再调用了C。
上下层级代表调用关系,如下图服务C的span id为2,服务D的parent id为2,这就表示服务C和服务D形成了父子关系,很明显是服务C调用了服务D。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232515-2021-05-04-23-25-16.png" alt="20210504232515-2021-05-04-23-25-16">
**总结:通过事先在日志中埋点,找出相同traceId的日志,再加上parent id和span id就可以将一条完整的请求调用链串联起来。**
## Annotations
Dapper中还定义了annotation的概念,用于用户自定义事件,用来辅助定位问题。
**通****常****包含四个注解信息**:
cs:Client Start,表示客户端发起请求;
sr:ServerReceived,表示服务端收到请求;
ss: Server Send,表示服务端完成处理,并将结果发送给客户端;
cr:ClientReceived,表示客户端获取到服务端返回信息;
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232532-2021-05-04-23-25-33.png" alt="20210504232532-2021-05-04-23-25-33">
上图中描述了一次请求和响应的过程,四个点也就是对应四个Annotation事件。
如下面的图表示从客户端调用服务端的一次完整过程。如果要计算一次调用的耗时,只需要将客户端接收的时间点减去客户端开始的时间点,也就是图中时间线上的T4 - T1。如果要计算客户端发送网络耗时,也就是图中时间线上的T2 - T1,其他类似可计算。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232544-2021-05-04-23-25-45.png" alt="20210504232544-2021-05-04-23-25-45">
## 带内数据与带外数据
链路信息的还原依赖于**带内**和**带外**两种数据。
带外数据是各个节点产生的事件,如cs,ss,这些数据可以由节点独立生成,并且需要集中上报到存储端。通过带外数据,可以在存储端分析更多链路的细节。
带内数据如traceid,spanid,parentid,用来标识trace,span,以及span在一个trace中的位置,这些数据需要从链路的起点一直传递到终点。 通过带内数据的传递,可以将一个链路的所有过程串起来。
## 采样
由于每一个请求都会生成一个链路,为了减少性能消耗,避免存储资源的浪费,dapper并不会上报所有的span数据,而是使用采样的方式。举个例子,每秒有1000个请求访问系统,如果设置采样率为1/1000,那么只会上报一个请求到存储端。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232557-2021-05-04-23-25-58.png" alt="20210504232557-2021-05-04-23-25-58">
通过采集端自适应地调整采样率,控制span上报的数量,可以在发现性能瓶颈的同时,有效减少性能损耗。
## 存储
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232609-2021-05-04-23-26-10.png" alt="20210504232609-2021-05-04-23-26-10">
链路中的span数据经过收集和上报后会集中存储在一个地方,Dapper使用了BigTable数据仓库,常用的存储还有ElasticSearch, HBase, In-memory DB等。
# 业界常用链路追踪系统
Google Dapper论文发出来之后,很多公司基于链路追踪的基本原理给出了各自的解决方案,如Twitter的Zipkin,Uber的Jaeger,pinpoint,Apache开源的skywalking,还有国产如阿里的鹰眼,美团的Mtrace,滴滴Trace,新浪的Watchman,京东的Hydra,不过国内的这些基本都没有开源。
为了便于各系统间能彼此兼容互通,OpenTracing组织制定了一系列标准,旨在让各系统提供统一的接口。
下面对比一下几个开源组件,方便日后大家做技术选型。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232625-2021-05-04-23-26-26.png" alt="20210504232625-2021-05-04-23-26-26">
附各大开源组件的地址:
* zipkin[https://zipkin.io/](https://zipkin.io/?fileGuid=Q8RQjVxpcvdvtC6q)
* Jaeger[www.](http://www.baidu.com/link?url=BktsXcEs4Z1Ci_M7bV8PsKC3PZLoGVDS-omdih46FUB5HP4XXSbzSQRJW-Z0cqps&fileGuid=Q8RQjVxpcvdvtC6q)[jaeger](http://www.baidu.com/link?url=BktsXcEs4Z1Ci_M7bV8PsKC3PZLoGVDS-omdih46FUB5HP4XXSbzSQRJW-Z0cqps&fileGuid=Q8RQjVxpcvdvtC6q)[tracing.io/](http://www.baidu.com/link?url=BktsXcEs4Z1Ci_M7bV8PsKC3PZLoGVDS-omdih46FUB5HP4XXSbzSQRJW-Z0cqps&fileGuid=Q8RQjVxpcvdvtC6q)
* Pinpoint[https://github.com/pinpoint-apm/pinpoint](https://github.com/pinpoint-apm/pinpoint?fileGuid=Q8RQjVxpcvdvtC6q)
* SkyWalking[http://skywalking.apache.org/](http://skywalking.apache.org/?fileGuid=Q8RQjVxpcvdvtC6q)
接下来介绍一下Zipkin基本实现。
# 分布式链路追踪系统Zipkin实现
Zipkin 是 Twitter 的一个开源项目,它基于 Google Dapper 实现,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
## **Zipkin基本架构**
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232640-2021-05-04-23-26-40.png" alt="20210504232640-2021-05-04-23-26-40">
在服务运行的过程中会产生很多链路信息,产生数据的地方可以称之为Reporter。将链路信息通过多种传输方式如HTTP,RPC,kafka消息队列等发送到Zipkin的采集器,Zipkin处理后最终将链路信息保存到存储器中。运维人员通过UI界面调用接口即可查询调用链信息。
## **Zipkin核心组件**
Zipkin有四大核心组件
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504232652-2021-05-04-23-26-52.png" alt="20210504232652-2021-05-04-23-26-52">
**(1)Collector**
一旦Collector采集线程获取到链路追踪数据,Zipkin就会对其进行验证、存储和索引,并调用存储接口保存数据,以便进行查找。
**(2)Storage**
Zipkin Storage最初是为了在Cassandra上存储数据而构建的,因为Cassandra是可伸缩的,具有灵活的模式,并且在Twitter中大量使用。除了Cassandra,还支持支持ElasticSearch和MySQL存储,后续可能会提供第三方扩展。
**(3)Query Service**
链路追踪数据被存储和索引之后,webui 可以调用query service查询任意数据帮助运维人员快速定位线上问题。query service提供了简单的json api来查找和检索数据。
**(4)Web UI**
Zipkin 提供了基本查询、搜索的web界面,运维人员可以根据具体的调用链信息快速识别线上问题。
# 总结
1. 分布式链路追踪就是将每一次分布式请求还原成调用链路。
2. 链路追踪的核心概念:Trace、Span、Annotation、带内和带外数据、采样、存储。
3. 业界常用的开源组件都是基于谷歌Dapper论文演变而来;
4. Zipkin核心组件有:Collector、Storage、Query Service、Web UI。
================================================
FILE: docs/distributed/用大白话给你解释Zookeeper的选举机制.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322098&idx=1&sn=100089ec2d8c49b85f4acc5ff2af8ca5&chksm=8f09caa8b87e43be0454c4583a914779a5d78d2ae0493e2ec54fd2337d3be9ae99b391a1a35c&token=1553501157&lang=zh_CN#rd)』,欢迎大家关注。
<!-- TOC -->
- [人类选举的基本原理](#人类选举的基本原理)
- [Zookeeper选举的基本原理](#zookeeper选举的基本原理)
- [什么场景下 Zookeeper 需要选举?](#什么场景下-zookeeper-需要选举)
- [启动时期的 Leader 选举](#启动时期的-leader-选举)
- [运行时期的Leader选举](#运行时期的leader选举)
- [选举机制中涉及到的核心概念](#选举机制中涉及到的核心概念)
- [总结](#总结)
<!-- /TOC -->
`Zookeeper` 是一个分布式服务框架,主要是用来解决分布式应用中遇到的一些数据管理问题如:`统一命名服务`、`状态同步服务`、`集群管理`、`分布式应用配置项的管理`等。
我们可以简单把 `Zookeeper` 理解为分布式家庭的大管家,那么管家团队是如何选出`Leader`的呢?好奇吗,接下来带领大家一探究竟。
# 人类选举的基本原理
讲解 `Zookeeper` 选举过程前先来介绍一下人类的选举。
我们每个人或多或少都经历过几次选举,在投票的过程中可能会遇到这样几种情况:
**情况1**:自己与几个候选人都比较熟,你会将票投给你认为`能力比较强的人`;
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504231519-2021-05-04-23-15-20.png" alt="20210504231519-2021-05-04-23-15-20">
**情况2**:自己也是候选人,并且与其他几个候选人都不熟,这个时候你肯定想着要去拉票,因为觉得自己才是最厉害的人呀,所有人都应该把票投给我。但是遗憾的是在拉票的过程中,你`发现别人比你强`,你开始自卑了,最终还是把票投给了自己认为最强的人。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504231548-2021-05-04-23-15-49.png" alt="20210504231548-2021-05-04-23-15-49">
所有人都投完票之后,最后从投票箱中进行统计,获得票数最多的人当选。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504231603-2021-05-04-23-16-04.png" alt="20210504231603-2021-05-04-23-16-04">
在整个投票过程中我们可以提炼出四个最核心的概念:
* `候选人能力`:投票的基本原则是选最强的人。
* `遇强改投`:如果后面发现更强的人可以改投票。
* `投票箱`:所有人的票都会放在投票箱。
* `领导者`:得票最多的人即为领导者。
从人类选举的原理我们来简单推导一下Zookeeper的选举原理。
# Zookeeper选举的基本原理
>注意如果 Zookeeper 是单机部署是不需要选举的,集群模式下才需要选举。
Zookeeper 的选举原理和人类选举的逻辑类似,套用一下人类选举的四个基本概念详细解释一下Zookeeper。
* **个人能力**
如何衡量 Zookeeper 节点个人能力?答案是靠`数据是否够新`,如果节点的数据越新就代表这个节点的个人能力越强,是不是感觉很奇怪,就是这么定的!
在 Zookeeper 中通常是以事务id(后面简称`zxid`)来标识数据的新旧程度(版本),节点最新的zxid越大代表这个节点的数据越新,也就代表这个节点能力越强。
>zxid 的全称是 `ZooKeeper Transaction Id`,即 Zookeeper 事务id。
* **遇强改投**
在集群选举开始时,节点首先认为自己时最强的(即数据是最新的),然后在选票上写上自己的名字(包括`zxid`和`sid`),zxid 是事务id,sid 唯一标识自己。
紧接着会将选票传递给其他节点,同时自己也会接收其他节点传过来的选票。每个节点接收到选票后会做比较,这个人是不是比我强(zxid比我大),如果比较强,那我就需要`改票`,明明别人比我强,我也不能厚着脸皮对吧。
* **投票箱**
与人类选举投票箱稍微有点不一样,Zookeeper 集群会在每个节点的内存中维护一个投票箱。节点会将自己的选票以及其他节点的选票都放在这个投票箱中。由于选票时互相传阅的,所以最终每个节点投票箱中的选票会是一样的。
* **领导者**
在投票的过程中会去统计是否有超过一半的选票和自己选择的是同一个节点,即都认为某个节点是最强的。一旦集群中有`超过半数`的节点都认为某个节点最强,那该节点就是领导者了,投票也宣告结束。
# 什么场景下 Zookeeper 需要选举?
当 Zookeeper 集群中的一台服务器出现以下两种情况之一时,需要进入 `Leader 选举`。
(1)服务器初始化启动。
(2)服务器运行期间 Leader 故障。
## 启动时期的 Leader 选举
假设一个 Zookeeper 集群中有5台服务器,id从1到5编号,并且它们都是最新启动的,没有历史数据。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504231624-2021-05-04-23-16-25.png" alt="20210504231624-2021-05-04-23-16-25">
假设服务器依次启动,我们来分析一下选举过程:
**(1)服务器1启动**
发起一次选举,服务器1投自己一票,此时服务器1票数一票,不够半数以上(3票),选举无法完成。
投票结果:服务器1为1票。
服务器1状态保持为`LOOKING`。
**(2)服务器2启动**
发起一次选举,服务器1和2分别投自己一票,此时服务器1发现服务器2的id比自己大,更改选票投给服务器2。
投票结果:服务器1为0票,服务器2为2票。
服务器1,2状态保持`LOOKING`
**(3)服务器3启动**
发起一次选举,服务器1、2、3先投自己一票,然后因为服务器3的id最大,两者更改选票投给为服务器3;
投票结果:服务器1为0票,服务器2为0票,服务器3为3票。 此时服务器3的票数已经超过半数(3票),**服务器3当选`Leader`**。
服务器1,2更改状态为`FOLLOWING`,服务器3更改状态为`LEADING`。
**(4)服务器4启动**
发起一次选举,此时服务器1,2,3已经不是LOOKING 状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3。
服务器4并更改状态为`FOLLOWING`。
**(5)服务器5启动**
与服务器4一样投票给3,此时服务器3一共5票,服务器5为0票。
服务器5并更改状态为`FOLLOWING`。
**最终的结果**:
服务器3是 `Leader`,状态为 `LEADING`;其余服务器是 `Follower`,状态为 `FOLLOWING`。
## 运行时期的Leader选举
在 Zookeeper运行期间 `Leader` 和 `非 Leader` 各司其职,当有非 Leader 服务器宕机或加入不会影响 Leader,但是一旦 Leader 服务器挂了,那么整个 Zookeeper 集群将暂停对外服务,会触发新一轮的选举。
初始状态下服务器3当选为`Leader`,假设现在服务器3故障宕机了,此时每个服务器上zxid可能都不一样,server1为99,server2为102,server4为100,server5为101
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504231642-2021-05-04-23-16-43.png" alt="20210504231642-2021-05-04-23-16-43">
运行期选举与初始状态投票过程基本类似,大致可以分为以下几个步骤:
(1)状态变更。Leader 故障后,余下的`非 Observer` 服务器都会将自己的服务器状态变更为`LOOKING`,然后开始进入`Leader选举过程`。
(2)每个Server会发出投票。
(3)接收来自各个服务器的投票,如果其他服务器的数据比自己的新会改投票。
(4)处理和统计投票,没一轮投票结束后都会统计投票,超过半数即可当选。
(5)改变服务器的状态,宣布当选。
话不多说先来一张图:
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504231659-2021-05-04-23-17-00.png" alt="20210504231659-2021-05-04-23-17-00">
(1)第一次投票,每台机器都会将票投给自己。
(2)接着每台机器都会将自己的投票发给其他机器,如果发现其他机器的zxid比自己大,那么就需要改投票重新投一次。比如server1 收到了三张票,发现server2的xzid为102,pk一下发现自己输了,后面果断改投票选server2为老大。
# 选举机制中涉及到的核心概念
敲黑板了,这些概念是面试必考的。
**(1)Server id(或sid):服务器ID**
比如有三台服务器,编号分别是1,2,3。编号越大在选择算法中的权重越大,比如初始化启动时就是根据服务器ID进行比较。
**(2)Zxid:事务ID**
服务器中存放的数据的事务ID,值越大说明数据越新,在选举算法中数据越新权重越大。
**(3)Epoch:逻辑时钟**
也叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的,每投完一次票这个数据就会增加。
**(4)Server状态:选举状态**
`LOOKING`,竞选状态。
`FOLLOWING`,随从状态,同步leader状态,参与投票。
`OBSERVING`,观察状态,同步leader状态,不参与投票。
`LEADING`,领导者状态。
# 总结
(1)Zookeeper 选举会发生在服务器初始状态和运行状态下。
(2)初始状态下会根据服务器sid的编号对比,编号越大权值越大,投票过半数即可选出Leader。
(3)Leader 故障会触发新一轮选举,`zxid` 代表数据越新,权值也就越大。
> 没有什么比每天有成长进步更高兴的事情
================================================
FILE: docs/it-hot/鸿蒙OS尖刀武器之分布式软总线技术.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s/AM3C5z1QulG0wEKBFCyH6g)』,欢迎大家关注。
<!-- MarkdownTOC -->
- [1 没有人能够熄灭满天星光](#1-没有人能够熄灭满天星光)
- [2 必须得补的传统总线知识](#2-必须得补的传统总线知识)
- [3 什么是分布式软总线?](#3-什么是分布式软总线)
- [4 分布式软总线功能和原理](#4-分布式软总线功能和原理)
- [4.1 分布式软总线的架构](#41-分布式软总线的架构)
- [4.2 软总线之发现连接:从手动发现,进化成自发现](#42-软总线之发现连接:从手动发现进化成自发现)
- [4.3 软总线组网关键技术-异构网络组网](#43-软总线组网关键技术-异构网络组网)
- [4.4 软总线之传输](#44-软总线之传输)
- [5 畅享未来,鸿蒙系统使能智慧生活](#5-畅享未来鸿蒙系统使能智慧生活)
- [公众号](#公众号)
<!-- /MarkdownTOC -->
# 1 没有人能够熄灭满天星光
华为开发者大会2020在广东东莞松山湖欧洲小镇举办,在主题演讲环节中,华为消费者业务总裁余承东宣布“鸿蒙”系统升级到2.0版本(HarmonyOS 2.0),余总表示,“鸿蒙”系统将在12月份推出手机版本,明年华为的手机将全面支持“鸿蒙”系统。
“没有人能够熄灭满天星光,每一位开发者,都是华为要汇聚的星星之火”,华为消费者业务CEO余承东说,华为将全面开放核心技术、软硬件能力,与开发者们共同驱动全场景智慧生态的蓬勃发展。
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201018212847.jpeg" width="500"/> </div><br>
在这场发布会上也详细讲解了分布式软总线的概念,下面我们来看一下分布式软总线是不是真的硬核,会给我们以后的生活带来什么影响?
# 2 必须得补的传统总线知识
总线英文名叫Bus,你猜的没错也是公共汽车的意思。总线是一个非常广泛的概念,在传统计算机硬件体系中应用的非常广泛。
总线是一种内部结构,它是cpu、内存、输入、输出设备传递信息的公用通道,主机的各个部件通过总线相连接,外部设备通过相应的接口电路再与总线相连接,从而形成了计算机硬件系统。
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201018213203.png" width="500"/> </div><br>
在计算机系统中,各个部件之间传送信息的公共通路叫总线,微型计算机是以总线结构来连接各个功能部件的。按照计算机所传输的信息种类,计算机的总线可以划分为数据总线、地址总线和控制总线,分别用来传输数据、数据地址和控制信号。
传统总线的典型特征:
* 即插即用
* 高带宽
* 低时延
* 高可靠
* 标准
# 3 什么是分布式软总线?
分布式软总线技术是基于华为多年的通信技术积累,参考计算机硬件总线,在1+8+N设备间搭建一条“无形”的总线,具备自发现、自组网、高带宽低时延的特点。
>简单解释一下什么是1+8+N:
>1指的是手机
>8代表车机、音箱、耳机、手表/手环、平板、大屏、PC、AR/VR
>N泛指其他IOT设备
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201018213514.png" width="500"/> </div><br>
HarmonyOS分布式软总线
全场景设备间可以基于软总线完成设备虚拟化、跨设备服务调用、多屏协同、文件分享等分布式业务。
分布式软总线的典型特征:
* 自动发现/即连即用
* 高带宽
* 低时延
* 高可靠
* 开放/标准
# 4 分布式软总线功能和原理
## 4.1 分布式软总线的架构
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201018213358.jpg" width="500"/> </div><br>
通过协议货架和软硬协同层屏蔽各种设备的协议差别,总线中枢模块负责解析命令完成设备间发现和连接,通过任务和数据两条总线实现设备间文件传输、消息传输等功能。
分布式总线的总体目标是实现设备间无感发现,零等待传输。实现这个目标需要解决三个问题:
(1)设备间如何发现和连接?
(2)多设备互联后如何组网?
(3)多设备多协议间如何实现传输?
下面带着这三个问题我们一探究竟。
## 4.2 软总线之发现连接:从手动发现,进化成自发现
传统的设备发现是手动的,需要人干预,以生活中常见的一个例子讲解:
比如手机上有很多照片需要传到个人PC上,我们可以采用蓝牙传输,首先要打开手机和PC的蓝牙发现功能,手机或者PC点击搜索设备,然后互相配对授权即可连接上,成功连上后就可以肆无忌惮的发送照片啦。
在分享照片这个场景中有很多人为的动作:开启蓝牙发现功能、搜索设备、配对授权,这确实有点麻烦,耗费了很多时间,可能会降低分享的意愿。
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201018213613.png" width="500"/> </div><br>
软总线提出了自动发现的概念,实现用户零等待的自发现体验,附近同账号的设备自动发现无需等待。
## 4.3 软总线组网关键技术-异构网络组网
上面的例子中手机传照片是通过蓝牙,假如PC没有蓝牙功能只有WIFI,在传统的场景中这种可能就不能实现分享传输了。
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201018213638.png" width="300"/> </div><br>
软总线能否做到手机通过蓝牙传输,PC通过WIFI接收照片呢?
答案是:当然可以。软总线提出了异构网络组网可以很好解决设备间不同协议如何交互的问题。
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201018213727.png" width="500"/> </div><br>
设备上线后会向网络层注册,同时网络层会与设备建立通道连接,实时检测设备的变换。网络层负责管理设备的上线下线变换,设备间可以监听自己感兴趣的设备,设备上线后可以立即与其建立连接,实现零等待体验。
软总线可以自动构建一个逻辑全连接网络,用户或者业务开发者无需关心组网方式与物理协议。
对于软件开发者来说软总线异构组网可以大大降低其开发成本。
传统开发模式:
在传统开发模式中开发者需要适配不同网络协议和标准规范。
分布式开发模式:
在HarmonyOS分布式开发模式中开发不再需要关心网络协议差异,业务开发与设备组网解耦,业务仅需监听设备上下线,开发成本大大降低。
## 4.4 软总线之传输
传统协议的传输速率差异非常大,时延也难以得到保证。
软总线传输要实现的目标:
高带宽(High Speed)
低时延(Low Latency)
高可靠(High Reliability)
软总线要实现的这三大目标的尖刀武器是:极简协议。
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201018213758.png" width="500"/> </div><br>
将中间的四层协议栈精简为一层提升有效载荷,有效传输带宽提升20%
极简协议在传统网络协议的基础上进行增强:
* 流式传输:基于UDP实现数据的保序和可靠传输;
* 双轮驱动:颠覆传统TCP每包确认机制;
* 不惧网损:摒弃传统滑动窗口机制,丢包快速恢复,避免阻塞;
* 不惧抖动:智能感知网络变化,自适应流量控制和拥塞控制;
# 5 畅享未来,鸿蒙系统使能智慧生活
鸿蒙系统的使命和目标是将不同设备的串联起来,成为设备的“万能语言”,实现万物互联的终极目标。
**变化一:软件开发从业者的福音**
以前开发一款APP不仅需要为手机、手表、平板、电视等不同终端专门设计APP版本,而且还要为同类终端的不同品牌(华为、小米、OV)设计不同的APP版本。
而有了鸿蒙分布式系统架构,只需要开发一个版本,鸿蒙可以帮你“翻译”成不同终端的对应版本,真正实现一次开发就能在不同的终端上运行。
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201018213817.png" width="150"/> </div><br>
看到这估计很多程序员们会仰天长叹:终于可以早点下班了!
**变换二:可以活得更懒**
鸿蒙系统分布式架构能让你在使用某个APP软件的时候,比如看视频,可以把屏幕随意切换到电视、电脑、手机、平板、投影仪等任何一个设备的界面上。
你也不必满桌子找各种遥控器了,一个手表一个手机就可以控制家里的空调、电饭煲、汽车空调、音响、电视、电脑、门口的摄像头以及所有能联网的所有东西。
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201018213829.png" width="150"/> </div><br>
这就是鸿蒙所构想的“万物互联”,让一个系统连接起所有上网的智能设备。大家期待吗,让我们拭目以待吧。
# 公众号
公众号比Github早一到两天更新,如果大家想要实时关注我更新的文章以及分享的干货,可以关注我的公众号。
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/wechat-01.jpg" width=""/> </div><br>
================================================
FILE: docs/java/annotation/想自己写框架不会写Java注解可不行.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s/JqrJGwyU0oKdWYtHe_W31w)』,欢迎大家关注。
<!-- MarkdownTOC -->
- [用注解一时爽,一直用一直爽](#用注解一时爽一直用一直爽)
- [原来注解不神秘](#原来注解不神秘)
- [造火箭啦,自己动手写一个注解](#造火箭啦自己动手写一个注解)
- [第一步定义一个注解](#第一步定义一个注解)
- [第二步实现注解的业务逻辑](#第二步实现注解的业务逻辑)
- [第三步在业务代码中尽情的使用注解](#第三步在业务代码中尽情的使用注解)
- [公众号](#公众号)
<!-- /MarkdownTOC -->
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201023232517.png" width=""/> </div><br>
# 用注解一时爽,一直用一直爽
Java后端开发进入spring全家桶时代后,开发一个微服务提供简单的增删改查接口跟玩泥巴似的非常简单,一顿操作猛如虎,回头一看代码加了一堆注解:@Controller @Autowired @Value,面向注解编程变成了大家不可缺少的操作。
想象一下如果没有注解Java程序员可以要哭瞎😭
既然注解(annotation)这么重要,用的这么爽,那注解的实现原理你知道么?我猜你只会用注解不会自己写注解(手动滑稽)。
好了,下面的内容带大家从零开始写一个注解,揭开注解神秘的面纱。
# 原来注解不神秘
注解用大白话来说就是一个标记或者说是特殊的注释,如果没有解析这些标记的操作那它啥也不是。
注解的格式如同类或者方法一样有自己特殊的语法,这个语法下文会详细介绍。
那如何去解析注解呢?这就要用到Java强大的反射功能了。反射大家应该都用过,可以通过类对象获取到这个类的各种信息比如成员变量、方法等,那注解标记能不能通过反射获取呢?当然可以了。
所以注解的原理其实很简单,本质上是通过反射功能动态获取注解标记,然后按照不同的注解执行不同的操作,比如@Autowired可以注入一个对象给变量赋值。
看到这里是不是很躁动啊,来吧自己也撸一个注解。
# 造火箭啦,自己动手写一个注解
便于大家理解,这里先引入一个场景:在线教育火了,经理让我写一个模块实现学生信息管理功能,考虑到分布式并发问题,经理让我务必加上分布式锁。
经理问我几天能搞定?我说至少3天。如是脑补了以下代码:
```java
/**
* 更新学生信息
* @param student 学生对象
* @return true 更新成功,false 更新失败
*/
public boolean updateStudentInfo(Student student) {
// 尝试获取分布式锁
String lockKey = "student:" + student.getId();
if (RedisTool.tryLock(lockKey, 10,
TimeUnit.SECONDS, 5)) {
try {
// 这里写业务逻辑
} finally {
RedisTool.releaseLock(lockKey);
}
}
// 获取锁失败
return false;
}
```
经理走后我在思考,我能不能只花一天时间写完,剩下两天时间用来写博客划水呢?突然灵感来了,我可以把重复的代码逻辑抽出来用注解实现不就节省代码了,哈哈,赶紧写。
使用注解之后整个方法清爽了很多,HR小姐姐都夸我写的好呢。
```java
@EnableRedisLock(lockKey = "student", expireTime = 10, timeUnit = TimeUnit.SECONDS, retryTimes = 5)
public boolean updateStudentInfo(Student student) {
// 这里写业务逻辑
// studentDao.update(student);
return true;
}
```
代码已经写完上库了,现在我在划水写博客呢。是不是很简洁很优雅很牛逼,怎么做到的呢,主要分为三步:1打开冰箱门,2把大象放进去,3把冰箱门关好。好了,扯远了,大家接着往下看。
## 第一步定义一个注解
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201023233716.png" width="70%"/> </div><br>
一个注解可以简单拆解为三个部分:
第一部分:注解体
注解的定义有点类似于接口(interface),只不过前面一个加了一个@符号,这个千万不能省。
第二部分:注解变量
注解变量的语法有点类似于接口里面定义的方法,变量名后面带一对括号,不同的是注解变量后面可以有默认值。另外返回值只能是Java基本类型、String类型或者枚举类,不可以是对象类型。
第三部分:元注解
元注解(meta-annotation)说白了就是给注解加注解的注解,是不是有点晕了,这种注解是JDK提前内置好的,可以直接拿来用的。不太懂也没有关系反正数量也不多,总共就4个,我们背下来吧:@Target @Retention @Documented @Inherited
* Target注解
用来描述注解的使用范围,即被修饰的注解可以用在什么地方 。
注解可以用于修饰 packages、types(类、接口、枚举、注解类)、类成员(方法、构造方法、成员变量、枚举值)、方法参数和本地变量(如循环变量、catch参数),在定义注解类时使用了@Target 能够更加清晰的知道它能够被用来修饰哪些对象,具体的取值范围定义在ElementType.java 枚举类中。
比如上面我们写的Redis锁的注解就只能用于方法上了。
* Retention注解
用来描述注解保留的时间范围,即注解的生命周期。在 RetentionPolicy 枚举类中定义了三个周期:
```java
public enum RetentionPolicy {
SOURCE, // 源文件保留
CLASS, // 编译期保留,默认值
RUNTIME // 运行期保留,可通过反射去获取注解信息
}
```
像我们熟知的@Override注解就只能保留在源文件中,代码编译后注解就消失了。
比如上面我们写的Redis锁的注解就保留到了运行期,运行的时候可以通过反射获取信息。
* Documented注解
用来描述在使用 javadoc 工具为类生成帮助文档时是否要保留其注解信息,很简单不多解释了。
* Inherited注解
被Inherited注解修饰的注解具有继承性,如果父类使用了被@Inherited修饰的注解,则其子类将自动继承该注解。
好了,这一步我们已经将注解定义好了,但是这个注解如何工作呢?接着看。
## 第二步实现注解的业务逻辑
在第一步中我们发现定义的注解(@EnableRedisLock)中没有业务逻辑,只有一些变量,别忘了我们的注解是要使能Redis分布式锁的功能,那这个注解到底是怎么实现加锁和释放锁的功能呢?这个就需要我们借助反射的强大功能了。
```java
@Aspect
public class RedisLockAspect {
@Around(value = "@annotation(com.smilelioncoder.EnableRedisLock)")
public void handleRedisLock(ProceedingJoinPoint joinPoint)
throws Throwable {
// 通过反射获取到注解对象,可见反射非常重要的
EnableRedisLock redisLock = ((MethodSignature) joinPoint.getSignature())
.getMethod()
.getAnnotation(EnableRedisLock.class);
// 获取注解对象的变量值
String lockKey = redisLock.lockKey();
long expireTime = redisLock.expireTime();
TimeUnit timeUnit = redisLock.timeUnit();
int retryTimes = redisLock.retryTimes();
// 获取锁
if (tryLock(lockKey, expireTime, timeUnit, retryTimes)) {
try {
// 获取锁成功继续执行业务逻辑
joinPoint.proceed();
} finally {
releseLock();
}
}
}
}
```
这里借助了切面的功能,将EnableRedisLock注解作为一个切点,只要方法上标注了这个注解就会自动执行这里的代码逻辑。
通过反射机制拿到注解对象后就可以执行加锁解锁的常用逻辑啦。Redis实现分布式锁相信大家已经很熟悉了,这里就不在啰嗦了。
## 第三步在业务代码中尽情的使用注解
```java
@EnableRedisLock(lockKey = "student", expireTime = 10, timeUnit = TimeUnit.SECONDS, retryTimes = 5)
public void method1(Student student) {
// 这里写业务逻辑
}
```
在需要加锁的方法上直接加上注解就可以啦,怎么样是不是很简单呀,赶紧在你的项目中运用起来吧。
好了,自己写一个注解的内容就介绍到这里了,学会了吗?
# 公众号
公众号比Github早一到两天更新,如果大家想要实时关注我更新的文章以及分享的干货,可以关注我的公众号。
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/wechat-01.jpg" width=""/> </div><br>
================================================
FILE: docs/java/base/Java基础入门80问.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](#公众号)』,欢迎大家关注。
<!-- TOC -->
- [1.一个".java"源文件中是否可以包括多个类(不是内部类)?有什么限制?](#1一个java源文件中是否可以包括多个类不是内部类有什么限制)
- [2.Java有没有goto?](#2java有没有goto)
- [3.说说&和&&的区别](#3说说和的区别)
- [4.在JAVA中如何跳出当前的多重嵌套循环?](#4在java中如何跳出当前的多重嵌套循环)
- [5.switch语句能否作用在byte上,能否作用在long上,能否作用在String上?](#5switch语句能否作用在byte上能否作用在long上能否作用在string上)
- [6.short s1 = 1; s1 = s1 + 1;有什么错? short s1 = 1; s1 += 1;有什么错?](#6short-s1--1-s1--s1--1有什么错-short-s1--1-s1--1有什么错)
- [7.char型变量中能不能存贮一个中文汉字?为什么?](#7char型变量中能不能存贮一个中文汉字为什么)
- [8.用最有效率的方法算出2乘以8等于几?](#8用最有效率的方法算出2乘以8等于几)
- [9.请设计一个一百亿的计算器](#9请设计一个一百亿的计算器)
- [10.使用final关键字修饰一个变量时,是引用不能变,还是引用的对象不能变?](#10使用final关键字修饰一个变量时是引用不能变还是引用的对象不能变)
- [11."=="和equals方法究竟有什么区别?](#11和equals方法究竟有什么区别)
- [12.静态变量和实例变量的区别?](#12静态变量和实例变量的区别)
- [13.是否可以从一个static方法内部发出对非static方法的调用?](#13是否可以从一个static方法内部发出对非static方法的调用)
- [14.Integer与int的区别](#14integer与int的区别)
- [15.Math.round(11.5)等于多少? Math.round(-11.5)等于多少?](#15mathround115等于多少-mathround-115等于多少)
- [16.请说出作用域public,private,protected,以及不写时的区别](#16请说出作用域publicprivateprotected以及不写时的区别)
- [17.Overload和Override的区别。Overloaded的方法是否可以改变返回值的类型?](#17overload和override的区别overloaded的方法是否可以改变返回值的类型)
- [18.构造器Constructor是否可被override?](#18构造器constructor是否可被override)
- [19.接口是否可继承接口? 抽象类是否可实现(implements)接口? 抽象类是否可继承具体类(concrete class)? 抽象类中是否可以有静态的main方法?](#19接口是否可继承接口-抽象类是否可实现implements接口-抽象类是否可继承具体类concrete-class-抽象类中是否可以有静态的main方法)
- [20.写clone()方法时,通常都有一行代码,是什么?](#20写clone方法时通常都有一行代码是什么)
- [21.面向对象的特征有哪些方面](#21面向对象的特征有哪些方面)
- [22.java中实现多态的机制是什么?](#22java中实现多态的机制是什么)
- [23.abstract class和interface有什么区别?](#23abstract-class和interface有什么区别)
- [24.abstract的method是否可同时是static,是否可同时是native,是否可同时是synchronized?](#24abstract的method是否可同时是static是否可同时是native是否可同时是synchronized)
- [25.什么是内部类?Static Nested Class 和 Inner Class的不同。](#25什么是内部类static-nested-class-和-inner-class的不同)
- [26.内部类可以引用它的包含类的成员吗?有没有什么限制?](#26内部类可以引用它的包含类的成员吗有没有什么限制)
- [27.Anonymous Inner Class (匿名内部类) 是否可以extends(继承)其它类,是否可以implements(实现)interface(接口)?](#27anonymous-inner-class-匿名内部类-是否可以extends继承其它类是否可以implements实现interface接口)
- [28.super.getClass()方法调用](#28supergetclass方法调用)
- [29.String是最基本的数据类型吗?](#29string是最基本的数据类型吗)
- [30.String s = "Hello";s = s + " world!";这两行代码执行后,原始的String对象中的内容到底变了没有?](#30string-s--hellos--s---world这两行代码执行后原始的string对象中的内容到底变了没有)
- [31.是否可以继承String类?](#31是否可以继承string类)
- [32.String s = new String("xyz");创建了几个String Object? 二者之间有什么区别?](#32string-s--new-stringxyz创建了几个string-object-二者之间有什么区别)
- [33.String 和StringBuffer的区别](#33string-和stringbuffer的区别)
- [34.如何把一段逗号分割的字符串转换成一个数组?](#34如何把一段逗号分割的字符串转换成一个数组)
- [35.数组有没有length()这个方法? String有没有length()这个方法?](#35数组有没有length这个方法-string有没有length这个方法)
- [36.下面这条语句一共创建了多少个对象? String s="a"+"b"+"c"+"d";](#36下面这条语句一共创建了多少个对象-string-sabcd)
- [37.try {}里有一个return语句,那么紧跟在这个try后的finally {}里的code会不会被执行,什么时候被执行,在return前还是后?](#37try-里有一个return语句那么紧跟在这个try后的finally-里的code会不会被执行什么时候被执行在return前还是后)
- [38.下面的程序代码输出的结果是多少?](#38下面的程序代码输出的结果是多少)
- [39.final, finally, finalize的区别。](#39final-finally-finalize的区别)
- [40.运行时异常与一般异常有何异同?](#40运行时异常与一般异常有何异同)
- [41.error和exception有什么区别?](#41error和exception有什么区别)
- [42.Java中的异常处理机制的简单原理和应用。](#42java中的异常处理机制的简单原理和应用)
- [43.请写出你最常见到的5个runtime exception。](#43请写出你最常见到的5个runtime-exception)
- [44.java中有几种方法可以实现一个线程?用什么关键字修饰同步方法? stop()和suspend()方法为何不推荐使用?](#44java中有几种方法可以实现一个线程用什么关键字修饰同步方法-stop和suspend方法为何不推荐使用)
- [45.sleep() 和 wait() 有什么区别?](#45sleep-和-wait-有什么区别)
- [46.同步和异步有何异同,在什么情况下分别使用他们?举例说明。](#46同步和异步有何异同在什么情况下分别使用他们举例说明)
- [47.多线程有几种实现方法?同步有几种实现方法?](#47多线程有几种实现方法同步有几种实现方法)
- [48.启动一个线程是用run()还是start()?](#48启动一个线程是用run还是start)
- [49.当一个线程进入一个对象的一个synchronized方法后,其它线程是否可进入此对象的其它方法?](#49当一个线程进入一个对象的一个synchronized方法后其它线程是否可进入此对象的其它方法)
- [50.线程的基本概念、线程的基本状态以及状态之间的关系。](#50线程的基本概念线程的基本状态以及状态之间的关系)
- [51.简述synchronized和java.util.concurrent.locks.Lock的异同 ?](#51简述synchronized和javautilconcurrentlockslock的异同-)
- [52.设计4个线程,其中两个线程每次对j增加1,另外两个线程对j每次减少1。写出程序。](#52设计4个线程其中两个线程每次对j增加1另外两个线程对j每次减少1写出程序)
- [53.子线程循环10次,接着主线程循环100,接着又回到子线程循环10次,接着再回到主线程又循环100,如此循环50次,请写出程序。](#53子线程循环10次接着主线程循环100接着又回到子线程循环10次接着再回到主线程又循环100如此循环50次请写出程序)
- [54.Collection框架中实现比较要实现什么接口](#54collection框架中实现比较要实现什么接口)
- [55.ArrayList和Vector的区别](#55arraylist和vector的区别)
- [56.HashMap和Hashtable的区别](#56hashmap和hashtable的区别)
- [57.List 和 Map 区别?](#57list-和-map-区别)
- [58.List, Set, Map是否继承自Collection接口?](#58list-set-map是否继承自collection接口)
- [59.List、Map、Set三个接口,存取元素时,各有什么特点?](#59listmapset三个接口存取元素时各有什么特点)
- [60.说出ArrayList,Vector, LinkedList的存储性能和特性](#60说出arraylistvector-linkedlist的存储性能和特性)
- [61.去掉一个Vector集合中重复的元素](#61去掉一个vector集合中重复的元素)
- [62.Collection 和 Collections的区别。](#62collection-和-collections的区别)
- [63.Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别?](#63set里的元素是不能重复的那么用什么方法来区分重复与否呢-是用还是equals-它们有何区别)
- [64.你所知道的集合类都有哪些?主要方法?](#64你所知道的集合类都有哪些主要方法)
- [65.两个对象值相同(x.equals(y) == true),但却可有不同的hash code,这句话对不对?](#65两个对象值相同xequalsy--true但却可有不同的hash-code这句话对不对)
- [66.TreeSet里面放对象,如果同时放入了父类和子类的实例对象,那比较时使用的是父类的compareTo方法,还是使用的子类的compareTo方法,还是抛异常!](#66treeset里面放对象如果同时放入了父类和子类的实例对象那比较时使用的是父类的compareto方法还是使用的子类的compareto方法还是抛异常)
- [67.说出一些常用的类,包,接口,请各举5个。](#67说出一些常用的类包接口请各举5个)
- [68.java中有几种类型的流?JDK为每种类型的流提供了一些抽象类以供继承,请说出他们分别是哪些类?](#68java中有几种类型的流jdk为每种类型的流提供了一些抽象类以供继承请说出他们分别是哪些类)
- [69.字节流与字符流的区别](#69字节流与字符流的区别)
- [70.什么是java序列化,如何实现java序列化?或者请解释Serializable接口的作用。](#70什么是java序列化如何实现java序列化或者请解释serializable接口的作用)
- [71.描述一下JVM加载class文件的原理机制?](#71描述一下jvm加载class文件的原理机制)
- [72.heap和stack有什么区别。](#72heap和stack有什么区别)
- [73.GC是什么? 为什么要有GC?](#73gc是什么-为什么要有gc)
- [74.垃圾回收的优点和原理。并考虑2种回收机制。](#74垃圾回收的优点和原理并考虑2种回收机制)
- [75.垃圾回收器的基本原理是什么?垃圾回收器可以马上回收内存吗?有什么办法主动通知虚拟机进行垃圾回收?](#75垃圾回收器的基本原理是什么垃圾回收器可以马上回收内存吗有什么办法主动通知虚拟机进行垃圾回收)
- [76.什么时候用assert。](#76什么时候用assert)
- [77.java中会存在内存泄漏吗,请简单描述。](#77java中会存在内存泄漏吗请简单描述)
- [78.能不能自己写个类,也叫java.lang.String?](#78能不能自己写个类也叫javalangstring)
- [79.获得一个类的类对象有哪些方式?](#79获得一个类的类对象有哪些方式)
- [80.Java代码查错](#80java代码查错)
- [公众号](#公众号)
<!-- /TOC -->
# 1.一个".java"源文件中是否可以包括多个类(不是内部类)?有什么限制?
可以有多个类,但只能有一个public的类,并且public的类名必须与文件名相一致。
# 2.Java有没有goto?
没有,但是 goto 是 java 中的保留字。
# 3.说说&和&&的区别
&和&&都可以用作逻辑与的运算符,表示逻辑与(and),当运算符两边的表达式的结果都为true时,整个运算结果才为true,否则,只要有一方为false,则结果为false。
&&还具有短路的功能,即如果第一个表达式为false,则不再计算第二个表达式,例如,对于if(str != null && !str.equals(“”))表达式,当str为null时,后面的表达式不会执行,所以不会出现NullPointerException如果将&&改为&,则会抛出NullPointerException异常。If(x==33 & ++y>0) y会增长,If(x==33 && ++y>0)不会增长
&还可以用作位运算符,当&操作符两边的表达式不是boolean类型时,&表示按位与操作,我们通常使用0x0f来与一个整数进行&运算,来获取该整数的最低4个bit位,例如,0x31 & 0x0f的结果为0x01。
# 4.在JAVA中如何跳出当前的多重嵌套循环?
在Java中,要想跳出多重循环,可以在外面的循环语句前定义一个标号,然后在里层循环体的代码中使用带有标号的break 语句,即可跳出外层循环。例如,
```java
ok:
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
System.out.println("i=" + i + ",j=" + j);
if (j == 5) break ok;
}
}
```
另外,可以不使用标号这种方式,而是让外层的循环条件表达式的结果可以受到里层循环体代码的控制,例如,要在二维数组中查找到某个数字。
```java
int[][] arr = {{1, 2, 3}, {4, 5, 6, 7}, {9}};
boolean found = false;
for (int i = 0; i < arr.length && !found; i++) {
for (int j = 0; j < arr[i].length; j++) {
System.out.println("i = " + i + ", j = " + j);
if (arr[i][j] == 5) {
found = true;
break;
}
}
}
```
敲黑板:建议使用第二种,第一种已经被业界淘汰了。
# 5.switch语句能否作用在byte上,能否作用在long上,能否作用在String上?
在switch(expr1)中,expr1只能是一个整数表达式或者枚举常量(更大字体),整数表达式可以是int基本类型或Integer包装类型,由于,byte,short,char都可以隐含转换为int,所以,这些类型以及这些类型的包装类型也是可以的。
switch 不支持 long 类型;从 java1.7开始 switch 开始支持 String,这是 Java 的语法糖。
# 6.short s1 = 1; s1 = s1 + 1;有什么错? short s1 = 1; s1 += 1;有什么错?
对于short s1 = 1; s1 = s1 + 1; 由于s1+1运算时会自动提升表达式的类型,所以结果是int型,再赋值给short类型s1时,编译器将报告需要强制转换类型的错误。
对于short s1 = 1; s1 += 1;由于 += 是java语言规定的运算符,java编译器会对它进行特殊处理,因此可以正确编译。
# 7.char型变量中能不能存贮一个中文汉字?为什么?
char型变量是用来存储Unicode编码的字符的,unicode编码字符集中包含了汉字,所以,char型变量中当然可以存储汉字啦。不过,如果某个特殊的汉字没有被包含在unicode编码字符集中,那么,这个char型变量中就不能存储这个特殊汉字。补充说明:unicode编码占用两个字节,所以,char类型的变量也是占用两个字节。
# 8.用最有效率的方法算出2乘以8等于几?
2 << 3。因为将一个数左移n位,就相当于乘以了2的n次方,那么,一个数乘以8只要将其左移3位即可,而位运算cpu直接支持的,效率最高,所以,2乘以8等於几的最效率的方法是2 << 3。
# 9.请设计一个一百亿的计算器
首先要明白这道题目的考查点是什么,一是要对计算机原理的底层细节要清楚,要知道加减法的位运算原理和计算机中的算术运算会发生越界的情况;二是要具备一定的面向对象的设计思想。
首先,计算机中用固定数量的几个字节来存储的数值,所以计算机中能够表示的数值是有一定的范围的,先以byte 类型的整数为例,它用1个字节进行存储,表示的最大数值范围为-128到+127。-1在内存中对应的二进制数据为11111111,如果两个-1相加,不考虑Java运算时的类型提升,运算后会产生进位,二进制结果为1,11111110,由于进位后超过了byte类型的存储空间,所以进位部分被舍弃,即最终的结果为11111110,也就是-2,这正好利用溢位的方式实现了负数的运算。-128在内存中对应的二进制数据为10000000,如果两个-128相加,不考虑Java运算时的类型提升,运算后会产生进位,二进制结果为1,00000000,由于进位后超过了byte类型的存储空间,所以进位部分被舍弃,即最终的结果为00000000,也就是0,这样的结果显然不符合期望,这说明计算机中的算术运算是会发生越界情况的,两个数值的运算结果不能超过计算机中的该类型的数值范围。由于Java中涉及表达式运算时的类型自动提升,无法用byte类型来做演示这种问题和现象的实验,可以用下面一个使用整数做实验的例子程序体验一下:
```java
int a = Integer.MAX_VALUE;
int b = Integer.MAX_VALUE;
int sum = a + b;
System.out.println(“a=”+a+”,b=”+b+”,sum=”+sum);
```
先不考虑long类型,由于int的正数范围为2的31次方,表示的最大数值约等于2*1000*1000*1000,也就是20亿的大小,所以,要实现一个一百亿的计算器,我们得自己设计一个类可以用于表示很大的整数,并且提供了与另外一个整数进行加减乘除的功能,大概功能如下:
1)这个类内部有两个成员变量,一个表示符号,另一个用字节数组表示数值的二进制数;
2)有一个构造方法,把一个包含有多位数值的字符串转换到内部的符号和字节数组中;
3)提供加减乘除的功能;
```java
public class BigInteger{
int sign;
byte[] val;
public Biginteger(String val) {
sign = ;
val = ;
}
public BigInteger add(BigInteger other) {
}
public BigInteger subtract(BigInteger other) {
}
public BigInteger multiply(BigInteger other){
}
public BigInteger divide(BigInteger other){
}
}
```
备注:要想写出这个类的完整代码,是非常复杂的,如果有兴趣的话,可以参看jdk中自带的java.math.BigInteger类的源码。面试的人也知道谁都不可能在短时间内写出这个类的完整代码的,他要的是你是否有这方面的概念和意识,他最重要的还是考查你的能力,所以,不要因为自己无法写出完整的最终结果就放弃答这道题,能做的就是你比别人写得多,证明你比别人强,有这方面的思想意识就可以了,毕竟别人可能连题目的意思都看不懂,什么都没写,要敢于答这道题,即使只答了一部分,那也与那些什么都不懂的人区别出来,拉开了距离,算是矮子中的高个,机会当然就得到了。另外,答案中的框架代码也很重要,体现了一些面向对象设计的功底,特别是其中的方法命名很专业,用的英文单词很精准,这也是能力、经验、专业性、英语水平等多个方面的体现,会给人留下很好的印象,在编程能力和其他方面条件差不多的情况下,英语好除了可以获得更多机会外,薪水可以高出一千元。
# 10.使用final关键字修饰一个变量时,是引用不能变,还是引用的对象不能变?
使用final关键字修饰一个变量时,是指引用变量不能变,引用变量所指向的对象中的内容还是可以改变的。例如,对于如下语句:
```java
final StringBuffer a=new StringBuffer("immutable");
```
执行如下语句将报告编译期错误:
```java
a=new StringBuffer("");
```
但是,执行如下语句则可以通过编译:
```java
a.append(" broken!");
```
有人在定义方法的参数时,可能想采用如下形式来阻止方法内部修改传进来的参数对象:
```java
public void method(final StringBuffer param){}
```
实际上,这是办不到的,在该方法内部仍然可以增加如下代码来修改参数对象:
```java
param.append("a");
```
# 11."=="和equals方法究竟有什么区别?
==操作符专门用来比较两个变量的值是否相等,也就是用于比较变量所对应的内存中所存储的数值是否相同,要比较两个基本类型的数据或两个引用变量是否相等,只能用==操作符。
如果一个变量指向的数据是对象类型的,那么,这时候涉及了两块内存,对象本身占用一块内存(堆内存),变量也占用一块内存,例如Objet obj = new Object();变量obj是一个内存,new Object()是另一个内存,此时,变量obj所对应的内存中存储的数值就是对象占用的那块内存的首地址。对于指向对象类型的变量,如果要比较两个变量是否指向同一个对象,即要看这两个变量所对应的内存中的数值是否相等,这时候就需要用==操作符进行比较。
equals方法是用于比较两个独立对象的内容是否相同,就好比去比较两个人的长相是否相同,它比较的两个对象是独立的。例如,对于下面的代码:
```java
String a=new String("foo");
String b=new String("foo");
```
两条new语句创建了两个对象,然后用a,b这两个变量分别指向了其中一个对象,这是两个不同的对象,它们的首地址是不同的,即a和b中存储的数值是不相同的,所以,表达式a==b将返回false,而这两个对象中的内容是相同的,所以,表达式a.equals(b)将返回true。
在实际开发中,我们经常要比较传递进行来的字符串内容是否等,例如,String input = input.equals(“quit”),许多人稍不注意就使用==进行比较了,这是错误的,随便从网上找几个项目实战的教学视频看看,里面就有大量这样的错误。记住,字符串的比较基本上都是使用equals方法。
如果一个类没有自己定义equals方法,那么它将继承Object类的equals方法,Object类的equals方法的实现代码如下:
```java
boolean equals(Object o){
return this==o;
}
```
这说明,如果一个类没有自己定义equals方法,它默认的equals方法(从Object 类继承的)就是使用==操作符,也是在比较两个变量指向的对象是否是同一对象,这时候使用equals和使用==会得到同样的结果,如果比较的是两个独立的对象则总返回false。如果你编写的类希望能够比较该类创建的两个实例对象的内容是否相同,那么你必须覆盖equals方法,由你自己写代码来决定在什么情况即可认为两个对象的内容是相同的。
# 12.静态变量和实例变量的区别?
在语法定义上的区别:静态变量前要加static关键字,而实例变量前则不加。
在程序运行时的区别:实例变量属于某个对象的属性,必须创建了实例对象,其中的实例变量才会被分配空间,才能使用这个实例变量。静态变量不属于某个实例对象,而是属于类,所以也称为类变量,只要程序加载了类的字节码,不用创建任何实例对象,静态变量就会被分配空间,静态变量就可以被使用了。总之,实例变量必须创建对象后才可以通过这个对象来使用,静态变量则可以直接使用类名来引用。
例如,对于下面的程序,无论创建多少个实例对象,永远都只分配了一个staticVar变量,并且每创建一个实例对象,这个staticVar就会加1;但是,每创建一个实例对象,就会分配一个instanceVar,即可能分配多个instanceVar,并且每个instanceVar的值都只自加了1次。
```java
public class VariantTest {
public static int staticVar = 0;
public int instanceVar = 0;
public VariantTest() {
staticVar++;
instanceVar++;
System.out.println("staticVar=" + staticVar + ",instanceVar=" + instanceVar);
}
}
```
# 13.是否可以从一个static方法内部发出对非static方法的调用?
不可以。
因为非static方法是要与对象关联在一起的,必须创建一个对象后,才可以在该对象上进行方法调用,而static方法调用时不需要创建对象,可以直接调用。也就是说,当一个static方法被调用时,可能还没有创建任何实例对象,如果从一个static方法中发出对非static方法的调用,那个非static方法是关联到哪个对象上的呢?这个逻辑无法成立,所以,一个static方法内部发出对非static方法的调用。
# 14.Integer与int的区别
int是java提供的8种原始数据类型之一。Java为每个原始类型提供了封装类,Integer是java为int提供的封装类。int的默认值为0,而Integer的默认值为null,即Integer可以区分出未赋值和值为0的区别,int则无法表达出未赋值的情况,例如,要想表达出没有参加考试和考试成绩为0的区别,则只能使用Integer。在JSP开发中,Integer的默认为null,所以用el表达式在文本框中显示时,值为空白字符串,而int默认的默认值为0,所以用el表达式在文本框中显示时,结果为0,所以,int不适合作为web层的表单数据的类型。
在Hibernate中,如果将OID定义为Integer类型,那么Hibernate就可以根据其值是否为null而判断一个对象是否是临时的,如果将OID定义为了int类型,还需要在hbm映射文件中设置其unsaved-value属性为0。
另外,Integer提供了多个与整数相关的操作方法,例如,将一个字符串转换成整数,Integer中还定义了表示整数的最大值和最小值的常量。
# 15.Math.round(11.5)等于多少? Math.round(-11.5)等于多少?
Math类中提供了三个与取整有关的方法:ceil、floor、round,这些方法的作用与它们的英文名称的含义相对应,例如,ceil的英文意义是天花板,该方法就表示向上取整,Math.ceil(11.3)的结果为12,Math.ceil(-11.3)的结果是-11;floor的英文意义是地板,该方法就表示向下取整,Math.floor(11.6)的结果为11,Math.floor(-11.6)的结果是-12;最难掌握的是round方法,它表示“四舍五入”,算法为Math.floor(x+0.5),即将原来的数字加上0.5后再向下取整,所以,Math.round(11.5)的结果为12,Math.round(-11.5)的结果为-11。
# 16.请说出作用域public,private,protected,以及不写时的区别
这四个作用域的可见范围如下表所示。
说明:如果在修饰的元素上面没有写任何访问修饰符,则表示friendly。
| 作用域 | 当前类 | 同一package | 子孙类 | 其他package |
|:----------|:------|:-----------|:------|:-----------|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| friendly | √ | √ | × | × |
| private | √ | × | × | × |
备注:只要记住了有4种访问权限,4个访问范围,然后将全选和范围在水平和垂直方向上分别按排从小到大或从大到小的顺序排列,就很容易画出上面的图了。
# 17.Overload和Override的区别。Overloaded的方法是否可以改变返回值的类型?
Overload是重载的意思,Override是覆盖的意思,也就是重写。
重载Overload表示同一个类中可以有多个名称相同的方法,但这些方法的参数列表各不相同(即参数个数或类型不同)。
重写Override表示子类中的方法可以与父类中的某个方法的名称和参数完全相同,通过子类创建的实例对象调用这个方法时,将调用子类中的定义方法,这相当于把父类中定义的那个完全相同的方法给覆盖了,这也是面向对象编程的多态性的一种表现。子类覆盖父类的方法时,只能比父类抛出更少的异常,或者是抛出父类抛出的异常的子异常,因为子类可以解决父类的一些问题,不能比父类有更多的问题。子类方法的访问权限只能比父类的更大,不能更小。如果父类的方法是private类型,那么,子类则不存在覆盖的限制,相当于子类中增加了一个全新的方法。
至于Overloaded的方法是否可以改变返回值的类型这个问题,要看你倒底想问什么呢?这个题目很模糊。如果几个Overloaded的方法的参数列表不一样,它们的返回者类型当然也可以不一样。但我估计你想问的问题是:如果两个方法的参数列表完全一样,是否可以让它们的返回值不同来实现重载Overload。这是不行的,我们可以用反证法来说明这个问题,因为我们有时候调用一个方法时也可以不定义返回结果变量,即不要关心其返回结果,例如,我们调用map.remove(key)方法时,虽然remove方法有返回值,但是我们通常都不会定义接收返回结果的变量,这时候假设该类中有两个名称和参数列表完全相同的方法,仅仅是返回类型不同,java就无法确定编程者倒底是想调用哪个方法了,因为它无法通过返回结果类型来判断。
override可以翻译为覆盖,从字面就可以知道,它是覆盖了一个方法并且对其重写,以求达到不同的作用。对我们来说最熟悉的覆盖就是对接口方法的实现,在接口中一般只是对方法进行了声明,而我们在实现时,就需要实现接口声明的所有方法。除了这个典型的用法以外,我们在继承中也可能会在子类覆盖父类中的方法。在覆盖要注意以下的几点:
1)覆盖的方法的标志必须要和被覆盖的方法的标志完全匹配,才能达到覆盖的效果;
2)覆盖的方法的返回值必须和被覆盖的方法的返回一致;
3)覆盖的方法所抛出的异常必须和被覆盖方法的所抛出的异常一致,或者是其子类;
4)被覆盖的方法不能为private,否则在其子类中只是新定义了一个方法,并没有对其进行覆盖。
overload对我们来说可能比较熟悉,可以翻译为重载,它是指我们可以定义一些名称相同的方法,通过定义不同的输入参数来区分这些方法,然后再调用时,JVM就会根据不同的参数样式,来选择合适的方法执行。在使用重载要注意以下的几点:
1)在使用重载时只能通过不同的参数样式。例如,不同的参数类型,不同的参数个数,不同的参数顺序(当然,同一方法内的几个参数类型必须不一样,例如可以是fun(int,float),但是不能为fun(int,int));
2)不能通过访问权限、返回类型、抛出的异常进行重载;
3)方法的异常类型和数目不会对重载造成影响;
4)对于继承来说,如果某一方法在父类中是访问权限是priavte,那么就不能在子类对其进行重载,如果定义的话,也只是定义了一个新方法,而不会达到重载的效果。
# 18.构造器Constructor是否可被override?
构造器Constructor不能被继承,因此不能重写Override,但可以被重载Overload。
# 19.接口是否可继承接口? 抽象类是否可实现(implements)接口? 抽象类是否可继承具体类(concrete class)? 抽象类中是否可以有静态的main方法?
接口可以继承接口。抽象类可以实现(implements)接口,抽象类可以继承具体类。抽象类中可以有静态的main方法。
备注:只要明白了接口和抽象类的本质和作用,这些问题都很好回答,想想看,如果自己作为是java语言的设计者,是否会提供这样的支持,如果不提供的话,有什么理由吗?如果没有道理不提供,那答案就是肯定的了。
只有记住抽象类与普通类的唯一区别就是不能创建实例对象和允许有abstract方法。
# 20.写clone()方法时,通常都有一行代码,是什么?
clone 有缺省行为,super.clone();因为首先要把父类中的成员复制到位,然后才是复制自己的成员。
# 21.面向对象的特征有哪些方面
计算机软件系统是现实生活中的业务在计算机中的映射,而现实生活中的业务其实就是一个个对象协作的过程。面向对象编程就是按现实业务一样的方式将程序代码按一个个对象进行组织和编写,让计算机系统能够识别和理解用对象方式组织和编写的程序代码,这样就可以把现实生活中的业务对象映射到计算机系统中。
面向对象的编程语言有封装、继承 、抽象、多态等4个主要的特征。
1)封装:
封装是保证软件部件具有优良的模块性的基础,封装的目标就是要实现软件部件的“高内聚、低耦合”,防止程序相互依赖性而带来的变动影响。在面向对象的编程语言中,对象是封装的最基本单位,面向对象的封装比传统语言的封装更为清晰、更为有力。面向对象的封装就是把描述一个对象的属性和行为的代码封装在一个“模块”中,也就是一个类中,属性用变量定义,行为用方法进行定义,方法可以直接访问同一个对象中的属性。通常情况下,只要记住让变量和访问这个变量的方法放在一起,将一个类中的成员变量全部定义成私有的,只有这个类自己的方法才可以访问到这些成员变量,这就基本上实现对象的封装,就很容易找出要分配到这个类上的方法了,就基本上算是会面向对象的编程了。把握一个原则:把对同一事物进行操作的方法和相关的方法放在同一个类中,把方法和它操作的数据放在同一个类中。
例如,人要在黑板上画圆,这一共涉及三个对象:人、黑板、圆,画圆的方法要分配给哪个对象呢?由于画圆需要使用到圆心和半径,圆心和半径显然是圆的属性,如果将它们在类中定义成了私有的成员变量,那么,画圆的方法必须分配给圆,它才能访问到圆心和半径这两个属性,人以后只是调用圆的画圆方法、表示给圆发给消息而已,画圆这个方法不应该分配在人这个对象上,这就是面向对象的封装性,即将对象封装成一个高度自治和相对封闭的个体,对象状态(属性)由这个对象自己的行为(方法)来读取和改变。一个更便于理解的例子就是,司机将火车刹住了,刹车的动作是分配给司机,还是分配给火车,显然,应该分配给火车,因为司机自身是不可能有那么大的力气将一个火车给停下来的,只有火车自己才能完成这一动作,火车需要调用内部的离合器和刹车片等多个器件协作才能完成刹车这个动作,司机刹车的过程只是给火车发了一个消息,通知火车要执行刹车动作而已。
2)继承:
在定义和实现一个类的时候,可以在一个已经存在的类的基础之上来进行,把这个已经存在的类所定义的内容作为自己的内容,并可以加入若干新的内容,或修改原来的方法使之更适合特殊的需要,这就是继承。继承是子类自动共享父类数据和方法的机制,这是类之间的一种关系,提高了软件的可重用性和可扩展性。
3)抽象:
抽象就是找出一些事物的相似和共性之处,然后将这些事物归为一个类,这个类只考虑这些事物的相似和共性之处,并且会忽略与当前主题和目标无关的那些方面,将注意力集中在与当前目标有关的方面。例如,看到一只蚂蚁和大象,你能够想象出它们的相同之处,那就是抽象。抽象包括行为抽象和状态抽象两个方面。例如,定义一个Person类,如下:
class Person{
String name;
int age;
}
人本来是很复杂的事物,有很多方面,但因为当前系统只需要了解人的姓名和年龄,所以上面定义的类中只包含姓名和年龄这两个属性,这就是一种抽像,使用抽象可以避免考虑一些与目标无关的细节。我对抽象的理解就是不要用显微镜去看一个事物的所有方面,这样涉及的内容就太多了,而是要善于划分问题的边界,当前系统需要什么,就只考虑什么。
4)多态:
多态是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量倒底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。因为在程序运行时才确定具体的类,这样,不用修改源程序代码,就可以让引用变量绑定到各种不同的类实现上,从而导致该引用调用的具体方法随之改变,即不修改程序代码就可以改变程序运行时所绑定的具体代码,让程序可以选择多个运行状态,这就是多态性。多态性增强了软件的灵活性和扩展性。例如,下面代码中的UserDao是一个接口,它定义引用变量userDao指向的实例对象由daofactory.getDao()在执行的时候返回,有时候指向的是UserJdbcDao这个实现,有时候指向的是UserHibernateDao这个实现,这样,不用修改源代码,就可以改变userDao指向的具体类实现,从而导致userDao.insertUser()方法调用的具体代码也随之改变,即有时候调用的是UserJdbcDao的insertUser方法,有时候调用的是UserHibernateDao的insertUser方法:
UserDao userDao = daofactory.getDao();
userDao.insertUser(user);
比喻:人吃饭,你看到的是左手,还是右手?
# 22.java中实现多态的机制是什么?
靠的是父类或接口定义的引用变量可以指向子类或具体实现类的实例对象,而程序调用的方法在运行期才动态绑定,就是引用变量所指向的具体实例对象的方法,也就是内存里正在运行的那个对象的方法,而不是引用变量的类型中定义的方法。
# 23.abstract class和interface有什么区别?
含有abstract修饰符的class即为抽象类,abstract 类不能创建的实例对象。含有abstract方法的类必须定义为abstract class,abstract class类中的方法不必是抽象的。abstract class类中定义抽象方法必须在具体(Concrete)子类中实现,所以,不能有抽象构造方法或抽象静态方法。如果的子类没有实现抽象父类中的所有抽象方法,那么子类也必须定义为abstract类型。
接口(interface)可以说成是抽象类的一种特例,接口中的所有方法都必须是抽象的。接口中的方法定义默认为public abstract类型,接口中的成员变量类型默认为public static final。
下面比较一下两者的语法区别:
1)抽象类可以有构造方法,接口中不能有构造方法。
2)抽象类中可以有普通成员变量,接口中没有普通成员变量
3)抽象类中可以包含非抽象的普通方法,接口中的所有方法必须都是抽象的,不能有非抽象的普通方法。
4) 抽象类中的抽象方法的访问类型可以是public,protected和(默认类型,虽然
eclipse下不报错,但应该也不行),但接口中的抽象方法只能是public类型的,并且默认即为public abstract类型。
5)抽象类中可以包含静态方法,接口中不能包含静态方法
6)抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任意,但接口中定义的变量只能是public static final类型,并且默认即为public static final类型。
7)一个类可以实现多个接口,但只能继承一个抽象类。
下面接着再说说两者在应用上的区别:
接口更多的是在系统架构设计方法发挥作用,主要用于定义模块之间的通信契约。而抽象类在代码实现方面发挥作用,可以实现代码的重用,例如,模板方法设计模式是抽象类的一个典型应用,假设某个项目的所有Servlet类都要用相同的方式进行权限判断、记录访问日志和处理异常,那么就可以定义一个抽象的基类,让所有的Servlet都继承这个抽象基类,在抽象基类的service方法中完成权限判断、记录访问日志和处理异常的代码,在各个子类中只是完成各自的业务逻辑代码,伪代码如下:
```java
public abstract class BaseServlet extends HttpServlet {
public final void service(HttpServletRequest request, HttpServletResponse response) throws IOException, ServletException {
// 记录访问日志, 进行权限判断
if (具有权限) {
try {
doService(request, response);
} catch (Exception e) {
// todo:记录异常信息
}
}
}
protected abstract void doService(HttpServletRequest request, HttpServletResponse response) throws IOException, ServletException {
//注意访问权限定义成protected,显得既专业,又严谨,因为它是专门给子类用的
}
}
```
```java
public class MyServlet1 extends BaseServlet {
protected void doService(HttpServletRequest request, HttpServletResponse response) throws IOExcetion, ServletException {
// 本Servlet只处理的具体业务逻辑代码
}
}
```
父类方法中间的某段代码不确定,留给子类干,就用模板方法设计模式。
备注:这道题的思路是先从总体解释抽象类和接口的基本概念,然后再比较两者的语法细节,最后再说两者的应用区别。比较两者语法细节区别的条理是:先从一个类中的构造方法、普通成员变量和方法(包括抽象方法),静态变量和方法,继承性等6个方面逐一去比较回答,接着从第三者继承的角度的回答,特别是最后用了一个典型的例子来展现自己深厚的技术功底。
# 24.abstract的method是否可同时是static,是否可同时是native,是否可同时是synchronized?
abstract的method 不可以是static的,因为抽象的方法是要被子类实现的,而static与子类扯不上关系!
native方法表示该方法要用另外一种依赖平台的编程语言实现的,不存在着被子类实现的问题,所以,它也不能是抽象的,不能与abstract混用。例如,FileOutputSteam类要硬件打交道,底层的实现用的是操作系统相关的api实现,例如,在windows用c语言实现的,所以,查看jdk 的源代码,可以发现FileOutputStream的open方法的定义如下:
private native void open(String name) throws FileNotFoundException;
如果我们要用java调用别人写的c语言函数,我们是无法直接调用的,我们需要按照java的要求写一个c语言的函数,又我们的这个c语言函数去调用别人的c语言函数。由于我们的c语言函数是按java的要求来写的,我们这个c语言函数就可以与java对接上,java那边的对接方式就是定义出与我们这个c函数相对应的方法,java中对应的方法不需要写具体的代码,但需要在前面声明native。
关于synchronized与abstract合用的问题,我觉得也不行,因为在我几年的学习和开发中,从来没见到过这种情况,并且我觉得synchronized应该是作用在一个具体的方法上才有意义。而且,方法上的synchronized同步所使用的同步锁对象是this,而抽象方法上无法确定this是什么。
# 25.什么是内部类?Static Nested Class 和 Inner Class的不同。
内部类就是在一个类的内部定义的类,内部类中不能定义静态成员(静态成员不是对象的特性,只是为了找一个容身之处,所以需要放到一个类中而已,这么一点小事,你还要把它放到类内部的一个类中,过分了啊!提供内部类,不是为让你干这种事情,无聊,不让你干。我想可能是既然静态成员类似c语言的全局变量,而内部类通常是用于创建内部对象用的,所以,把“全局变量”放在内部类中就是毫无意义的事情,既然是毫无意义的事情,就应该被禁止),内部类可以直接访问外部类中的成员变量,内部类可以定义在外部类的方法外面,也可以定义在外部类的方法体中,如下所示:
```java
public class Outer {
int out_x = 0;
public void method() {
//在方法体内部定义的内部类
class Inner2 {
public void method() {
out_x = 3;
}
}
Inner2 inner2 = new Inner2();
}
//在方法体外面定义的内部类
public class Inner1 {
}
}
```
在方法体外面定义的内部类的访问类型可以是public,protecte,默认的,private等4种类型,这就好像类中定义的成员变量有4种访问类型一样,它们决定这个内部类的定义对其他类是否可见;对于这种情况,我们也可以在外面创建内部类的实例对象,创建内部类的实例对象时,一定要先创建外部类的实例对象,然后用这个外部类的实例对象去创建内部类的实例对象,代码如下:
```java
Outer outer = new Outer();
Outer.Inner1 inner1 = outer.new Innner1();
```
在方法内部定义的内部类前面不能有访问类型修饰符,就好像方法中定义的局部变量一样,但这种内部类的前面可以使用final或abstract修饰符。这种内部类对其他类是不可见的其他类无法引用这种内部类,但是这种内部类创建的实例对象可以传递给其他类访问。这种内部类必须是先定义,后使用,即内部类的定义代码必须出现在使用该类之前,这与方法中的局部变量必须先定义后使用的道理也是一样的。这种内部类可以访问方法体中的局部变量,但是,该局部变量前必须加final修饰符。
对于这些细节,只要在eclipse写代码试试,根据开发工具提示的各类错误信息就可以马上了解到。
在方法体内部还可以采用如下语法来创建一种匿名内部类,即定义某一接口或类的子类的同时,还创建了该子类的实例对象,无需为该子类定义名称:
```java
public class Outer {
public void start() {
new Thread(new Runnable() {
public void run() {
}
}).start();
}
}
```
最后,在方法外部定义的内部类前面可以加上static关键字,从而成为Static Nested Class,它不再具有内部类的特性,所有,从狭义上讲,它不是内部类。Static Nested Class与普通类在运行时的行为和功能上没有什么区别,只是在编程引用时的语法上有一些差别,它可以定义成public、protected、默认的、private等多种类型,而普通类只能定义成public和默认的这两种类型。在外面引用Static Nested Class类的名称为“外部类名.内部类名”。在外面不需要创建外部类的实例对象,就可以直接创建Static Nested Class,例如,假设Inner是定义在Outer类中的Static Nested Class,那么可以使用如下语句创建Inner类:
```java
Outer.Inner inner = new Outer.Inner();
```
由于static Nested Class不依赖于外部类的实例对象,所以,static Nested Class能访问外部类的非static成员变量。当在外部类中访问Static Nested Class时,可以直接使用Static Nested Class的名字,而不需要加上外部类的名字了,在Static Nested Class中也可以直接引用外部类的static的成员变量,不需要加上外部类的名字。
在静态方法中定义的内部类也是Static Nested Class,这时候不能在类前面加static关键字,静态方法中的Static Nested Class与普通方法中的内部类的应用方式很相似,它除了可以直接访问外部类中的static的成员变量,还可以访问静态方法中的局部变量,但是,该局部变量前必须加final修饰符。
备注:首先根据印象说出自己对内部类的总体方面的特点。例如,在两个地方可以定义,可以访问外部类的成员变量,不能定义静态成员,这是大的特点。然后再说一些细节方面的知识,例如,几种定义方式的语法区别,静态内部类,以及匿名内部类。
# 26.内部类可以引用它的包含类的成员吗?有没有什么限制?
完全可以。如果不是静态内部类,那没有什么限制!
如果把静态嵌套类当作内部类的一种特例,那在这种情况下不可以访问外部类的普通成员变量,而只能访问外部类中的静态成员,例如,下面的代码:
```java
class Outer {
static int x;
static class Inner {
void test() {
syso(x);
}
}
}
```
答题时,也要能察言观色,揣摩提问者的心思,显然面试官想知道的是静态内部类不能访问外部类的成员,但如果一上来就顶牛,这不好,要先顺着人家,让人家满意,然后再说特殊情况,让人家吃惊。
# 27.Anonymous Inner Class (匿名内部类) 是否可以extends(继承)其它类,是否可以implements(实现)interface(接口)?
可以继承其他类或实现其他接口。不仅是可以,而是必须!
# 28.super.getClass()方法调用
下面程序的输出结果是多少?
```java
import java.util.Date;
public class Test extends Date {
public static void main(String[] args) {
new Test().test();
}
public void test() {
System.out.println(super.getClass().getName());
}
}
```
很奇怪,结果是Test。
在test方法中,直接调用getClass().getName()方法,返回的是Test类名。由于getClass()在Object类中定义成了final,子类不能覆盖该方法,所以,在test方法中调用getClass().getName()方法,其实就是在调用从父类继承的getClass()方法,等效于调用super.getClass().getName()方法,所以,super.getClass().getName()方法返回的也应该是Test。
如果想得到父类的名称,应该用如下代码:
```java
getClass().getSuperClass().getName();
```
# 29.String是最基本的数据类型吗?
基本数据类型包括byte、int、char、long、float、double、boolean和short。
java.lang.String类是final类型的,因此不可以继承这个类、不能修改这个类。为了提高效率节省空间,我们应该用StringBuffer类
# 30.String s = "Hello";s = s + " world!";这两行代码执行后,原始的String对象中的内容到底变了没有?
没有。
因为String被设计成不可变(immutable)类,所以它的所有对象都是不可变对象。在这段代码中,s原先指向一个String对象,内容是 "Hello",然后我们对s进行了+操作,那么s所指向的那个对象是否发生了改变呢?答案是没有。这时,s不指向原来那个对象了,而指向了另一个 String对象,内容为"Hello world!",原来那个对象还存在于内存之中,只是s这个引用变量不再指向它了。
通过上面的说明,我们很容易导出另一个结论,如果经常对字符串进行各种各样的修改,或者说,不可预见的修改,那么使用String来代表字符串的话会引起很大的内存开销。因为 String对象建立之后不能再改变,所以对于每一个不同的字符串,都需要一个String对象来表示。这时,应该考虑使用StringBuffer类,它允许修改,而不是每个不同的字符串都要生成一个新的对象。并且,这两种类的对象转换十分容易。
同时,我们还可以知道,如果要使用内容相同的字符串,不必每次都new一个String。例如我们要在构造器中对一个名叫s的String引用变量进行初始化,把它设置为初始值,应当这样做:
```java
public class Demo {
private String s;
...
public Demo {
s = "Initial Value";
}
...
}
```
而非
```java
s = new String("Initial Value");
```
后者每次都会调用构造器,生成新对象,性能低下且内存开销大,并且没有意义,因为String对象不可改变,所以对于内容相同的字符串,只要一个String对象来表示就可以了。也就说,多次调用上面的构造器创建多个对象,他们的String类型属性s都指向同一个对象。
上面的结论还基于这样一个事实:对于字符串常量,如果内容相同,Java认为它们代表同一个String对象。而用关键字new调用构造器,总是会创建一个新的对象,无论内容是否相同。
至于为什么要把String类设计成不可变类,是它的用途决定的。其实不只String,很多Java标准类库中的类都是不可变的。在开发一个系统的时候,我们有时候也需要设计不可变类,来传递一组相关的值,这也是面向对象思想的体现。不可变类有一些优点,比如因为它的对象是只读的,所以多线程并发访问也不会有任何问题。当然也有一些缺点,比如每个不同的状态都要一个对象来代表,可能造成性能上的问题。所以Java标准类库还提供了一个可变版本,即StringBuffer。
# 31.是否可以继承String类?
String类是final类故不可以继承。
# 32.String s = new String("xyz");创建了几个String Object? 二者之间有什么区别?
两个或一个,”xyz”对应一个对象,这个对象放在字符串常量缓冲区,常量”xyz”不管出现多少遍,都是缓冲区中的那一个。New String每写一遍,就创建一个新的对象,它一句那个常量”xyz”对象的内容来创建出一个新String对象。如果以前就用过’xyz’,这句代表就不会创建”xyz”自己了,直接从缓冲区拿。
# 33.String 和StringBuffer的区别
JAVA平台提供了两个类:String和StringBuffer,它们可以储存和操作字符串,即包含多个字符的字符数据。这个String类提供了数值不可改变的字符串。而这个StringBuffer类提供的字符串进行修改。当你知道字符数据要改变的时候你就可以使用StringBuffer。典型地,你可以使用StringBuffers来动态构造字符数据。另外,String实现了equals方法,new String(“abc”).equals(new String(“abc”)的结果为true,而StringBuffer没有实现equals方法,所以,new StringBuffer(“abc”).equals(new StringBuffer(“abc”)的结果为false。
接着要举一个具体的例子来说明,我们要把1到100的所有数字拼起来,组成一个串。
```java
StringBuffer sbf = new StringBuffer();
for(int i=0;i<100;i++)
{
sbf.append(i);
}
```
上面的代码效率很高,因为只创建了一个StringBuffer对象,而下面的代码效率很低,因为创建了101个对象。
```java
String str = new String();
for(int i=0;i<100;i++)
{
str = str + i;
}
```
在讲两者区别时,应把循环的次数搞成10000,然后用endTime-beginTime来比较两者执行的时间差异,最后还要讲讲StringBuilder与StringBuffer的区别。
String覆盖了equals方法和hashCode方法,而StringBuffer没有覆盖equals方法和hashCode方法,所以,将StringBuffer对象存储进Java集合类中时会出现问题。
# 34.如何把一段逗号分割的字符串转换成一个数组?
1)用正则表达式,代码大概为:
```java
String [] result = orgStr.split(",");
```
2)用 StringTokenizer ,代码为:
```java
StringTokenizer tokener = StringTokenizer(orgStr,",");
String [] result = new String[tokener .countTokens()];
Int i=0;
while(tokener.hasNext(){result[i++]=toker.nextToken();}
```
# 35.数组有没有length()这个方法? String有没有length()这个方法?
数组没有length()这个方法,有length的属性。String有有length()这个方法。
# 36.下面这条语句一共创建了多少个对象? String s="a"+"b"+"c"+"d";
对于如下代码:
```java
String s1 = "a";
String s2 = s1 + "b";
String s3 = "a" + "b";
System.out.println(s2 == "ab");
System.out.println(s3 == "ab");
```
第一条语句打印的结果为false,第二条语句打印的结果为true,这说明javac编译可以对字符串常量直接相加的表达式进行优化,不必要等到运行期去进行加法运算处理,而是在编译时去掉其中的加号,直接将其编译成一个这些常量相连的结果。
题目中的第一行代码被编译器在编译时优化后,相当于直接定义了一个”abcd”的字符串,所以,上面的代码应该只创建了一个String对象。写如下两行代码,
```java
String s = "a" + "b" + "c" + "d";
System.out.println(s == "abcd");
```
最终打印的结果应该为true。
# 37.try {}里有一个return语句,那么紧跟在这个try后的finally {}里的code会不会被执行,什么时候被执行,在return前还是后?
也许你的答案是在return之前,但往更细地说,我的答案是在return中间执行,请看下面程序代码的运行结果:
```java
public class Test {
public static void main(String[] args) {
System.out.println(Test.test());
}
static int test() {
int x = 1;
try {
return x;
} finally {
++x;
}
}
}
```
---------执行结果 ---------
1
运行结果是1,为什么呢?主函数调用子函数并得到结果的过程,好比主函数准备一个空罐子,当子函数要返回结果时,先把结果放在罐子里,然后再将程序逻辑返回到主函数。所谓返回,就是子函数说,我不运行了,你主函数继续运行吧,这没什么结果可言,结果是在说这话之前放进罐子里的。
# 38.下面的程序代码输出的结果是多少?
```java
public class SmallT {
public static void main(String args[]) {
SmallT t = new SmallT();
int b = t.get();
System.out.println(b);
}
public int get() {
try {
return 1;
} finally {
return 2;
}
}
}
```
返回的结果是2。
从下面例子的运行结果中可以发现,try中的return语句调用的函数先于finally中调用的函数执行,也就是说return语句先执行,finally语句后执行,所以,返回的结果是2。Return并不是让函数马上返回,而是return语句执行后,将把返回结果放置进函数栈中,此时函数并不是马上返回,它要执行finally语句后才真正开始返回。
在讲解答案时可以用下面的程序来帮助分析:
```java
public class Test {
/**
* @param args add by leixiaoshuai 爱笑的架构师
*/
public static void main(String[] args) {
System.out.println(new Test().test());
}
int test() {
try {
return func1();
} finally {
return func2();
}
}
int func1() {
System.out.println("func1");
return 1;
}
int func2() {
System.out.println("func2");
return 2;
}
}
```
-----------执行结果-----------------
func1
func2
2
结论:finally中的代码比return 和break语句后执行。
# 39.final, finally, finalize的区别。
final 用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。
内部类要访问局部变量,局部变量必须定义成final类型。
finally是异常处理语句结构的一部分,表示总是执行。
finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等。JVM不保证此方法总被调用
# 40.运行时异常与一般异常有何异同?
异常表示程序运行过程中可能出现的非正常状态,运行时异常表示虚拟机的通常操作中可能遇到的异常,是一种常见运行错误。java编译器要求方法必须声明抛出可能发生的非运行时异常,但是并不要求必须声明抛出未被捕获的运行时异常。
# 41.error和exception有什么区别?
error 表示恢复不是不可能但很困难的情况下的一种严重问题。比如说内存溢出。不可能指望程序能处理这样的情况。 exception 表示一种设计或实现问题。也就是说,它表示如果程序运行正常,从不会发生的情况。
# 42.Java中的异常处理机制的简单原理和应用。
异常是指java程序运行时(非编译)所发生的非正常情况或错误,与现实生活中的事件很相似,现实生活中的事件可以包含事件发生的时间、地点、人物、情节等信息,可以用一个对象来表示,Java使用面向对象的方式来处理异常,它把程序中发生的每个异常也都分别封装到一个对象来表示的,该对象中包含有异常的信息。
Java对异常进行了分类,不同类型的异常分别用不同的Java类表示,所有异常的根类为java.lang.Throwable,Throwable下面又派生了两个子类:Error和Exception,Error 表示应用程序本身无法克服和恢复的一种严重问题,程序只有死的份了,例如,说内存溢出和线程死锁等系统问题。Exception表示程序还能够克服和恢复的问题,其中又分为系统异常和普通异常,系统异常是软件本身缺陷所导致的问题,也就是软件开发人员考虑不周所导致的问题,软件使用者无法克服和恢复这种问题,但在这种问题下还可以让软件系统继续运行或者让软件死掉,例如数组脚本越界(ArrayIndexOutOfBoundsException),空指针异常(NullPointerException)、类转换异常(ClassCastException);普通异常是运行环境的变化或异常所导致的问题,是用户能够克服的问题,例如,网络断线,硬盘空间不够,发生这样的异常后,程序不应该死掉。
java为系统异常和普通异常提供了不同的解决方案,编译器强制普通异常必须try..catch处理或用throws声明继续抛给上层调用方法处理,所以普通异常也称为checked异常,而系统异常可以处理也可以不处理,所以,编译器不强制用try..catch处理或用throws声明,所以系统异常也称为unchecked异常。
提示答题者:就按照三个级别去思考:虚拟机必须宕机的错误,程序可以死掉也可以不死掉的错误,程序不应该死掉的错误;
# 43.请写出你最常见到的5个runtime exception。
这道题主要考你的代码量到底多大,如果你长期写代码的,应该经常都看到过一些系统方面的异常,你不一定真要回答出5个具体的系统异常,但你要能够说出什么是系统异常,以及几个系统异常就可以了,当然,这些异常完全用其英文名称来写是最好的,如果实在写不出,那就用中文吧,有总比没有强!
所谓系统异常,就是…..,它们都是RuntimeException的子类,在jdk doc中查RuntimeException类,就可以看到其所有的子类列表,也就是看到了所有的系统异常。我比较有印象的系统异常有:NullPointerException、ArrayIndexOutOfBoundsException、ClassCastException。
# 44.java中有几种方法可以实现一个线程?用什么关键字修饰同步方法? stop()和suspend()方法为何不推荐使用?
java5以前,有如下两种:
第一种:new Thread(){}.start();这表示调用Thread子类对象的run方法,new Thread(){}表示一个Thread的匿名子类的实例对象,子类加上run方法后的代码如下:
```java
new Thread(){
public void run(){
}
}.start();
```
第二种:
new Thread(new Runnable(){}).start();这表示调用Thread对象接受的Runnable对象的run方法,new Runnable(){}表示一个Runnable的匿名子类的实例对象,runnable的子类加上run方法后的代码如下:
```java
new Thread(new Runnable(){
public void run(){
}
}
).start();
```
从java5开始,还有如下一些线程池创建多线程的方式:
```java
ExecutorService pool = Executors.newFixedThreadPool(3)
for(int i=0;i<10;i++)
{
pool.execute(new Runable(){public void run(){}});
}
Executors.newCachedThreadPool().execute(new Runable(){public void run(){}});
Executors.newSingleThreadExecutor().execute(new Runable(){public void run(){}});
```
有两种实现方法,分别使用new Thread()和new Thread(runnable)形式,第一种直接调用thread的run方法,所以,我们往往使用Thread子类,即new SubThread()。第二种调用runnable的run方法。
有两种实现方法,分别是继承Thread类与实现Runnable接口,用synchronized关键字修饰同步方法。反对使用stop(),是因为它不安全。它会解除由线程获取的所有锁定,而且如果对象处于一种不连贯状态,那么其他线程能在那种状态下检查和修改它们。结果很难检查出真正的问题所在。suspend()方法容易发生死锁。调用suspend()的时候,目标线程会停下来,但却仍然持有在这之前获得的锁定。此时,其他任何线程都不能访问锁定的资源,除非被"挂起"的线程恢复运行。对任何线程来说,如果它们想恢复目标线程,同时又试图使用任何一个锁定的资源,就会造成死锁。所以不应该使用suspend(),而应在自己的Thread类中置入一个标志,指出线程应该活动还是挂起。若标志指出线程应该挂起,便用wait()命其进入等待状态。若标志指出线程应当恢复,则用一个notify()重新启动线程。
# 45.sleep() 和 wait() 有什么区别?
sleep是线程类(Thread)的方法,导致此线程暂停执行指定时间,给执行机会给其他线程,但是监控状态依然保持,到时后会自动恢复。调用sleep不会释放对象锁。 wait是Object类的方法,对此对象调用wait方法导致本线程放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象发出notify方法(或notifyAll)后本线程才进入对象锁定池准备获得对象锁进入运行状态。
sleep就是正在执行的线程主动让出cpu,cpu去执行其他线程,在sleep指定的时间过后,cpu才会回到这个线程上继续往下执行,如果当前线程进入了同步锁,sleep方法并不会释放锁,即使当前线程使用sleep方法让出了cpu,但其他被同步锁挡住了的线程也无法得到执行。wait是指在一个已经进入了同步锁的线程内,让自己暂时让出同步锁,以便其他正在等待此锁的线程可以得到同步锁并运行,只有其他线程调用了notify方法(notify并不释放锁,只是告诉调用过wait方法的线程可以去参与获得锁的竞争了,但不是马上得到锁,因为锁还在别人手里,别人还没释放。如果notify方法后面的代码还有很多,需要这些代码执行完后才会释放锁,可以在notfiy方法后增加一个等待和一些代码,看看效果),调用wait方法的线程就会解除wait状态和程序可以再次得到锁后继续向下运行。对于wait的讲解一定要配合例子代码来说明,才显得自己真明白。
```java
public class MultiThread {
public static void main(String[] args) {
new Thread(new Thread1()).start();
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(new Thread2()).start();
}
private static class Thread1 implements Runnable {
@Override
public void run() {
//由于这里的Thread1和下面的Thread2内部run方法要用同一对象作为监视器,我们这里不能用this,因为在Thread2里面的this和这个Thread1的this不是同一个对象。我们用MultiThread.class这个字节码对象,当前虚拟机里引用这个变量时,指向的都是同一个对象。
synchronized (MultiThread.class) {
System.out.println("enter thread1...");
System.out.println("thread1 is waiting");
try {
//释放锁有两种方式,第一种方式是程序自然离开监视器的范围,也就是离开了synchronized关键字管辖的代码范围,另一种方式就是在synchronized关键字管辖的代码内部调用监视器对象的wait方法。这里,使用wait方法释放锁。
MultiThread.class.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("thread1 is going on...");
System.out.println("thread1 is being over!");
}
}
}
private static class Thread2 implements Runnable {
@Override
public void run() {
synchronized (MultiThread.class) {
System.out.println("enter thread2...");
System.out.println("thread2 notify other thread can release wait status..");
//由于notify方法并不释放锁, 即使thread2调用下面的sleep方法休息了10毫秒,但thread1仍然不会执行,因为thread2没有释放锁,所以Thread1无法得不到锁。
MultiThread.class.notify();
System.out.println("thread2 is sleeping ten millisecond...");
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("thread2 is going on...");
System.out.println("thread2 is being over!");
}
}
}
}
```
# 46.同步和异步有何异同,在什么情况下分别使用他们?举例说明。
如果数据将在线程间共享。例如正在写的数据以后可能被另一个线程读到,或者正在读的数据可能已经被另一个线程写过了,那么这些数据就是共享数据,必须进行同步存取。
当应用程序在对象上调用了一个需要花费很长时间来执行的方法,并且不希望让程序等待方法的返回时,就应该使用异步编程,在很多情况下采用异步途径往往更有效率。
# 47.多线程有几种实现方法?同步有几种实现方法?
多线程有两种实现方法,分别是继承Thread类与实现Runnable接口。
同步的实现方面有两种,分别是synchronized,wait与notify。
wait():使一个线程处于等待状态,并且释放所持有的对象的lock。
sleep():使一个正在运行的线程处于睡眠状态,是一个静态方法,调用此方法要捕捉InterruptedException异常。
notify():唤醒一个处于等待状态的线程,注意的是在调用此方法的时候,并不能确切的唤醒某一个等待状态的线程,而是由JVM确定唤醒哪个线程,而且不是按优先级。
Allnotity():唤醒所有处入等待状态的线程,注意并不是给所有唤醒线程一个对象的锁,而是让它们竞争。
# 48.启动一个线程是用run()还是start()?
启动一个线程是调用start()方法,使线程就绪状态,以后可以被调度为运行状态,一个线程必须关联一些具体的执行代码,run()方法是该线程所关联的执行代码。
# 49.当一个线程进入一个对象的一个synchronized方法后,其它线程是否可进入此对象的其它方法?
分几种情况:
1)其他方法前是否加了synchronized关键字,如果没加,则能。
2)如果这个方法内部调用了wait,则可以进入其他synchronized方法。
3)如果其他个方法都加了synchronized关键字,并且内部没有调用wait,则不能。
4)如果其他方法是static,它用的同步锁是当前类的字节码,与非静态的方法不能同步,因为非静态的方法用的是this。
# 50.线程的基本概念、线程的基本状态以及状态之间的关系。
一个程序中可以有多条执行线索同时执行,一个线程就是程序中的一条执行线索,每个线程上都关联有要执行的代码,即可以有多段程序代码同时运行,每个程序至少都有一个线程,即main方法执行的那个线程。如果只是一个cpu,它怎么能够同时执行多段程序呢?这是从宏观上来看的,cpu一会执行a线索,一会执行b线索,切换时间很快,给人的感觉是a,b在同时执行,好比大家在同一个办公室上网,只有一条链接到外部网线,其实,这条网线一会为a传数据,一会为b传数据,由于切换时间很短暂,所以,大家感觉都在同时上网。
状态:就绪,运行,synchronize阻塞,wait和sleep挂起,结束。wait必须在synchronized内部调用。
调用线程的start方法后线程进入就绪状态,线程调度系统将就绪状态的线程转为运行状态,遇到synchronized语句时,由运行状态转为阻塞,当synchronized获得锁后,由阻塞转为运行,在这种情况可以调用wait方法转为挂起状态,当线程关联的代码执行完后,线程变为结束状态。
# 51.简述synchronized和java.util.concurrent.locks.Lock的异同 ?
主要相同点:Lock能完成synchronized所实现的所有功能。
主要不同点:Lock有比synchronized更精确的线程语义和更好的性能。synchronized会自动释放锁,而Lock一定要求程序员手工释放,并且必须在finally从句中释放。Lock还有更强大的功能,例如,它的tryLock方法可以非阻塞方式去拿锁。
举例说明(对下面的题用lock进行了改写):
```java
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class ThreadTest {
private int j;
private Lock lock = new ReentrantLock();
public static void main(String[] args) {
ThreadTest tt = new ThreadTest();
for (int i = 0; i < 2; i++) {
new Thread(tt.new Adder()).start();
new Thread(tt.new Subtractor()).start();
}
}
private class Subtractor implements Runnable {
@Override
public void run() {
while (true) {
/*synchronized (ThreadTest.this) {
System.out.println("j--=" + j--);
//这里抛异常了,锁能释放吗?
}*/
lock.lock();
try {
System.out.println("j--=" + j--);
} finally {
lock.unlock();
}
}
}
}
private class Adder implements Runnable {
@Override
public void run() {
while (true) {
/*synchronized (ThreadTest.this) {
System.out.println("j++=" + j++);
}*/
lock.lock();
try {
System.out.println("j++=" + j++);
} finally {
lock.unlock();
}
}
}
}
}
```
# 52.设计4个线程,其中两个线程每次对j增加1,另外两个线程对j每次减少1。写出程序。
以下程序使用内部类实现线程,对j增减的时候没有考虑顺序问题。
```java
public class ThreadTest1
{
private int j;
public static void main(String[] args){
ThreadTest1 tt=new ThreadTest1();
Inc inc=tt.new Inc();
Dec dec=tt.new Dec();
for(int i=0;i<2;i++){
Thread t=new Thread(inc);
t.start();
t=new Thread(dec);
t.start();
}
}
private synchronized void inc(){
j++;
System.out.println(Thread.currentThread().getName()+"-inc:"+j);
}
private synchronized void dec(){
j--;
System.out.println(Thread.currentThread().getName()+"-dec:"+j);
}
class Inc implements Runnable{
public void run(){
for(int i=0;i<100;i++){
inc();
}
}
}
class Dec implements Runnable{
public void run(){
for(int i=0;i<100;i++){
dec();
}
}
}
}
```
----------随手再写的一个-------------
```java
class A
{
JManger j =new JManager();
main()
{
new A().call();
}
void call()
{
for(int i=0;i<2;i++)
{
new Thread(
new Runnable(){ public void run(){while(true){j.accumulate();}}}
).start();
new Thread(new Runnable(){ public void run(){while(true){j.sub();}}}).start();
}
}
}
class JManager
{
private int j = 0;
public synchronized void subtract()
{
j--;
}
public synchronized void accumulate()
{
j++;
}
}
```
# 53.子线程循环10次,接着主线程循环100,接着又回到子线程循环10次,接着再回到主线程又循环100,如此循环50次,请写出程序。
最终的程序代码如下:
```java
public class ThreadTest {
public static void main(String[] args) {
new ThreadTest().init();
}
public void init()
{
final Business business = new Business();
new Thread(
new Runnable()
{
public void run() {
for(int i=0;i<50;i++)
{
business.SubThread(i);
}
}
}
).start();
for(int i=0;i<50;i++)
{
business.MainThread(i);
}
}
private class Business
{
boolean bShouldSub = true;//这里相当于定义了控制该谁执行的一个信号灯
public synchronized void MainThread(int i)
{
if(bShouldSub)
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
for(int j=0;j<5;j++)
{
System.out.println(Thread.currentThread().getName() + ":i=" + i +",j=" + j);
}
bShouldSub = true;
this.notify();
}
public synchronized void SubThread(int i)
{
if(!bShouldSub)
try {
this.wait();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
for(int j=0;j<10;j++)
{
System.out.println(Thread.currentThread().getName() + ":i=" + i +",j=" + j);
}
bShouldSub = false;
this.notify();
}
}
}
```
备注:不可能一上来就写出上面的完整代码,最初写出来的代码如下,问题在于两个线程的代码要参照同一个变量,即这两个线程的代码要共享数据,所以,把这两个线程的执行代码搬到同一个类中去:
```java
package com.huawei.interview.lym;
public class ThreadTest {
private static boolean bShouldMain = false;
public static void main(String[] args) {
// TODO Auto-generated method stub
/*new Thread(){
public void run()
{
for(int i=0;i<50;i++)
{
for(int j=0;j<10;j++)
{
System.out.println("i=" + i + ",j=" + j);
}
}
}
}.start();*/
//final String str = new String("");
new Thread(
new Runnable()
{
public void run()
{
for(int i=0;i<50;i++)
{
synchronized (ThreadTest.class) {
if(bShouldMain)
{
try {
ThreadTest.class.wait();}
catch (InterruptedException e) {
e.printStackTrace();
}
}
for(int j=0;j<10;j++)
{
System.out.println(
Thread.currentThread().getName() +
"i=" + i + ",j=" + j);
}
bShouldMain = true;
ThreadTest.class.notify();
}
}
}
}
).start();
for(int i=0;i<50;i++)
{
synchronized (ThreadTest.class) {
if(!bShouldMain)
{
try {
ThreadTest.class.wait();}
catch (InterruptedException e) {
e.printStackTrace();
}
}
for(int j=0;j<5;j++)
{
System.out.println(
Thread.currentThread().getName() +
"i=" + i + ",j=" + j);
}
bShouldMain = false;
ThreadTest.class.notify();
}
}
}
}
```
下面使用jdk5中的并发库来实现的:
```java
import java.util.concurrent.Executors;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.concurrent.locks.Condition;
public class ThreadTest
{
private static Lock lock = new ReentrantLock();
private static Condition subThreadCondition = lock.newCondition();
private static boolean bBhouldSubThread = false;
public static void main(String [] args)
{
ExecutorService threadPool = Executors.newFixedThreadPool(3);
threadPool.execute(new Runnable(){
public void run()
{
for(int i=0;i<50;i++)
{
lock.lock();
try
{
if(!bBhouldSubThread)
subThreadCondition.await();
for(int j=0;j<10;j++)
{
System.out.println(Thread.currentThread().getName() + ",j=" + j);
}
bBhouldSubThread = false;
subThreadCondition.signal();
}catch(Exception e)
{
}
finally
{
lock.unlock();
}
}
}
});
threadPool.shutdown();
for(int i=0;i<50;i++)
{
lock.lock();
try
{
if(bBhouldSubThread)
subThreadCondition.await();
for(int j=0;j<10;j++)
{
System.out.println(Thread.currentThread().getName() + ",j=" + j);
}
bBhouldSubThread = true;
subThreadCondition.signal();
}catch(Exception e)
{
}
finally
{
lock.unlock();
}
}
}
}
```
# 54.Collection框架中实现比较要实现什么接口
comparable/comparator
# 55.ArrayList和Vector的区别
这两个类都实现了List接口(List接口继承了Collection接口),他们都是有序集合,即存储在这两个集合中的元素的位置都是有顺序的,相当于一种动态的数组,我们以后可以按位置索引号取出某个元素,,并且其中的数据是允许重复的,这是HashSet之类的集合的最大不同处,HashSet之类的集合不可以按索引号去检索其中的元素,也不允许有重复的元素(本来题目问的与hashset没有任何关系,但为了说清楚ArrayList与Vector的功能,我们使用对比方式,更有利于说明问题)。
接着才说ArrayList与Vector的区别,这主要包括两个方面:.
(1)同步性:
Vector是线程安全的,也就是说是它的方法之间是线程同步的,而ArrayList是线程序不安全的,它的方法之间是线程不同步的。如果只有一个线程会访问到集合,那最好是使用ArrayList,因为它不考虑线程安全,效率会高些;如果有多个线程会访问到集合,那最好是使用Vector,因为不需要我们自己再去考虑和编写线程安全的代码。
备注:对于Vector&ArrayList、Hashtable&HashMap,要记住线程安全的问题,记住Vector与Hashtable是旧的,是java一诞生就提供了的,它们是线程安全的,ArrayList与HashMap是java2时才提供的,它们是线程不安全的。所以,我们讲课时先讲老的。
(2)数据增长:
ArrayList与Vector都有一个初始的容量大小,当存储进它们里面的元素的个数超过了容量时,就需要增加ArrayList与Vector的存储空间,每次要增加存储空间时,不是只增加一个存储单元,而是增加多个存储单元,每次增加的存储单元的个数在内存空间利用与程序效率之间要取得一定的平衡。Vector默认增长为原来两倍,而ArrayList的增长策略在文档中没有明确规定(从源代码看到的是增长为原来的1.5倍)。ArrayList与Vector都可以设置初始的空间大小,Vector还可以设置增长的空间大小,而ArrayList没有提供设置增长空间的方法。
总结:即Vector增长原来的一倍,ArrayList增加原来的0.5倍。
# 56.HashMap和Hashtable的区别
HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,在只有一个线程访问的情况下,效率要高于Hashtable。
HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。
Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现。
最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。
Hashtable和HashMap采用的hash/rehash算法都大概一样,所以性能不会有很大的差异。
就HashMap与HashTable主要从三方面来说:
1)历史原因:Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现;
2)同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的;
3)值:只有HashMap可以让你将空值作为一个表的条目的key或value
# 57.List 和 Map 区别?
一个是存储单列数据的集合,另一个是存储键和值这样的双列数据的集合,List中存储的数据是有顺序,并且允许重复;Map中存储的数据是没有顺序的,其键是不能重复的,它的值是可以有重复的。
# 58.List, Set, Map是否继承自Collection接口?
List,Set是,Map不是
# 59.List、Map、Set三个接口,存取元素时,各有什么特点?
这样的题属于随意发挥题:这样的题比较考水平,两个方面的水平:一是要真正明白这些内容,二是要有较强的总结和表述能力。如果你明白,但表述不清楚,在别人那里则等同于不明白。
首先,List与Set具有相似性,它们都是单列元素的集合,所以,它们有一个功共同的父接口,叫Collection。Set里面不允许有重复的元素,所谓重复,即不能有两个相等(注意,不是仅仅是相同)的对象 ,即假设Set集合中有了一个A对象,现在我要向Set集合再存入一个B对象,但B对象与A对象equals相等,则B对象存储不进去,所以,Set集合的add方法有一个boolean的返回值,当集合中没有某个元素,此时add方法可成功加入该元素时,则返回true,当集合含有与某个元素equals相等的元素时,此时add方法无法加入该元素,返回结果为false。Set取元素时,没法说取第几个,只能以Iterator接口取得所有的元素,再逐一遍历各个元素。
List表示有先后顺序的集合, 注意,不是那种按年龄、按大小、按价格之类的排序。当我们多次调用add(Obj e)方法时,每次加入的对象就像火车站买票有排队顺序一样,按先来后到的顺序排序。有时候,也可以插队,即调用add(int index,Obj e)方法,就可以指定当前对象在集合中的存放位置。一个对象可以被反复存储进List中,每调用一次add方法,这个对象就被插入进集合中一次,其实,并不是把这个对象本身存储进了集合中,而是在集合中用一个索引变量指向这个对象,当这个对象被add多次时,即相当于集合中有多个索引指向了这个对象,如图x所示。List除了可以以Iterator接口取得所有的元素,再逐一遍历各个元素之外,还可以调用get(index i)来明确说明取第几个。
Map与List和Set不同,它是双列的集合,其中有put方法,定义如下:put(obj key,obj value),每次存储时,要存储一对key/value,不能存储重复的key,这个重复的规则也是按equals比较相等。取则可以根据key获得相应的value,即get(Object key)返回值为key 所对应的value。另外,也可以获得所有的key的结合,还可以获得所有的value的结合,还可以获得key和value组合成的Map.Entry对象的集合。
List 以特定次序来持有元素,可有重复元素。Set 无法拥有重复元素,内部排序。Map 保存key-value值,value可多值。
HashSet按照hashcode值的某种运算方式进行存储,而不是直接按hashCode值的大小进行存储。例如,"abc" ---> 78,"def" ---> 62,"xyz" ---> 65在hashSet中的存储顺序不是62,65,78。LinkedHashSet按插入的顺序存储,那被存储对象的hashcode方法还有什么作用呢?hashset集合比较两个对象是否相等,首先看hashcode方法是否相等,然后看equals方法是否相等。new 两个Student插入到HashSet中,看HashSet的size,实现hashcode和equals方法后再看size。
同一个对象可以在Vector中加入多次。往集合里面加元素,相当于集合里用一根绳子连接到了目标对象。往HashSet中却加不了多次的。
# 60.说出ArrayList,Vector, LinkedList的存储性能和特性
ArrayList和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢,Vector由于使用了synchronized方法(线程安全),通常性能上较ArrayList差,而LinkedList使用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
LinkedList也是线程不安全的,LinkedList提供了一些方法,使得LinkedList可以被当作堆栈和队列来使用。
# 61.去掉一个Vector集合中重复的元素
```java
Vector newVector = new Vector();
For (int i=0;i<vector.size();i++)
{
Object obj = vector.get(i);
if(!newVector.contains(obj);
newVector.add(obj);
}
```
还有一种简单的方式
```java
HashSet set = new HashSet(vector);
```
# 62.Collection 和 Collections的区别。
Collection是集合类的上级接口,继承与他的接口主要有Set 和List。
Collections是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作。
# 63.Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别?
Set里的元素是不能重复的,元素重复与否是使用equals()方法进行判断的。
equals()和==方法决定引用值是否指向同一对象equals()在类中被覆盖,为的是当两个分离的对象的内容和类型相配的话,返回真值。
# 64.你所知道的集合类都有哪些?主要方法?
最常用的集合类是 List 和 Map。 List 的具体实现包括 ArrayList 和 Vector,它们是可变大小的列表,比较适合构建、存储和操作任何类型对象的元素列表。 List 适用于按数值索引访问元素的情形。
Map 提供了一个更通用的元素存储方法。 Map 集合类用于存储元素对(称作"键"和"值"),其中每个键映射到一个值。
记的不是方法名,而是思想,知道它们都有增删改查的方法,。因为只要在eclispe下按点操作符,很自然的这些方法就出来了。记住的一些思想就是List类会有get(int index)这样的方法,因为它可以按顺序取元素,而set类中没有get(int index)这样的方法。List和set都可以迭代出所有元素,迭代时先要得到一个iterator对象,所以,set和list类都有一个iterator方法,用于返回那个iterator对象。map可以返回三个集合,一个是返回所有的key的集合,另外一个返回的是所有value的集合,再一个返回的key和value组合成的EntrySet对象的集合,map也有get方法,参数是key,返回值是key对应的value。
# 65.两个对象值相同(x.equals(y) == true),但却可有不同的hash code,这句话对不对?
对。
如果对象要保存在HashSet或HashMap中,它们的equals相等,那么,它们的hashcode值就必须相等。
如果不是要保存在HashSet或HashMap,则与hashcode没有什么关系了,这时候hashcode不等是可以的,例如arrayList存储的对象就不用实现hashcode,当然,我们没有理由不实现,通常都会去实现的。
# 66.TreeSet里面放对象,如果同时放入了父类和子类的实例对象,那比较时使用的是父类的compareTo方法,还是使用的子类的compareTo方法,还是抛异常!
当前的add方法放入的是哪个对象,就调用哪个对象的compareTo方法,至于这个compareTo方法怎么做,就看当前这个对象的类中是如何编写这个方法的。
代码:
```java
public class Parent implements Comparable {
private int age = 0;
public Parent(int age){
this.age = age;
}
public int compareTo(Object o) {
// TODO Auto-generated method stub
System.out.println("method of parent");
Parent o1 = (Parent)o;
return age>o1.age?1:age<o1.age?-1:0;
}
}
public class Child extends Parent {
public Child(){
super(3);
}
public int compareTo(Object o) {
// TODO Auto-generated method stub
System.out.println("method of child");
// Child o1 = (Child)o;
return 1;
}
}
public class TreeSetTest {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
TreeSet set = new TreeSet();
set.add(new Parent(3));
set.add(new Child());
set.add(new Parent(4));
System.out.println(set.size());
}
}
```
# 67.说出一些常用的类,包,接口,请各举5个。
要让人家感觉你对java ee开发很熟,所以,不能仅仅只列core java中的那些东西,要多列你在做ssh项目中涉及的那些东西,就写你最近写的那些程序中涉及的那些类。
常用的类:BufferedReader BufferedWriter FileReader FileWirter String Integer
java.util.Date,System,Class,List,HashMap
常用的包:java.lang java.io java.util java.sql ,javax.servlet,org.apache.strtuts.action,org.hibernate
常用的接口:Remote List Map Document NodeList,Servlet,HttpServletRequest,HttpServletResponse,Transaction(Hibernate)、Session(Hibernate),HttpSession
# 68.java中有几种类型的流?JDK为每种类型的流提供了一些抽象类以供继承,请说出他们分别是哪些类?
字节流,字符流。
字节流继承于InputStream OutputStream,字符流继承于InputStreamReader OutputStreamWriter。在java.io包中还有许多其他的流,主要是为了提高性能和使用方便。
# 69.字节流与字符流的区别
要把一片二进制数据数据逐一输出到某个设备中,或者从某个设备中逐一读取一片二进制数据,不管输入输出设备是什么,我们要用统一的方式来完成这些操作,用一种抽象的方式进行描述,这个抽象描述方式起名为IO流,对应的抽象类为OutputStream和InputStream ,不同的实现类就代表不同的输入和输出设备,它们都是针对字节进行操作的。
在应用中,经常要完全是字符的一段文本输出去或读进来,用字节流可以吗?计算机中的一切最终都是二进制的字节形式存在。对于“中国”这些字符,首先要得到其对应的字节,然后将字节写入到输出流。读取时,首先读到的是字节,可是我们要把它显示为字符,我们需要将字节转换成字符。由于这样的需求很广泛,人家专门提供了字符流的包装类。
底层设备永远只接受字节数据,有时候要写字符串到底层设备,需要将字符串转成字节再进行写入。字符流是字节流的包装,字符流则是直接接受字符串,它内部将串转成字节,再写入底层设备,这为我们向IO设别写入或读取字符串提供了一点点方便。
字符向字节转换时,要注意编码的问题,因为字符串转成字节数组,其实是转成该字符的某种编码的字节形式,读取也是反之的道理。
```java
字节流与字符流关系的代码案例:
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.InputStreamReader;
import java.io.PrintWriter;
public class IOTest {
public static void main(String[] args) throws Exception {
String str = "中国人";
/*FileOutputStream fos = new FileOutputStream("1.txt");
fos.write(str.getBytes("UTF-8"));
fos.close();*/
/*FileWriter fw = new FileWriter("1.txt");
fw.write(str);
fw.close();*/
PrintWriter pw = new PrintWriter("1.txt","utf-8");
pw.write(str);
pw.close();
/*FileReader fr = new FileReader("1.txt");
char[] buf = new char[1024];
int len = fr.read(buf);
String myStr = new String(buf,0,len);
System.out.println(myStr);*/
/*FileInputStream fr = new FileInputStream("1.txt");
byte[] buf = new byte[1024];
int len = fr.read(buf);
String myStr = new String(buf,0,len,"UTF-8");
System.out.println(myStr);*/
BufferedReader br = new BufferedReader(
new InputStreamReader(
new FileInputStream("1.txt"),"UTF-8"
)
);
String myStr = br.readLine();
br.close();
System.out.println(myStr);
}
}
```
# 70.什么是java序列化,如何实现java序列化?或者请解释Serializable接口的作用。
我们有时候将一个java对象变成字节流的形式传出去或者从一个字节流中恢复成一个java对象,例如,要将java对象存储到硬盘或者传送给网络上的其他计算机,这个过程我们可以自己写代码去把一个java对象变成某个格式的字节流再传输,但是,jre本身就提供了这种支持,我们可以调用OutputStream的writeObject方法来做,如果要让java 帮我们做,要被传输的对象必须实现serializable接口,这样,javac编译时就会进行特殊处理,编译的类才可以被writeObject方法操作,这就是所谓的序列化。需要被序列化的类必须实现Serializable接口,该接口是一个mini接口,其中没有需要实现的方法,implements Serializable只是为了标注该对象是可被序列化的。
例如,在web开发中,如果对象被保存在了Session中,tomcat在重启时要把Session对象序列化到硬盘,这个对象就必须实现Serializable接口。如果对象要经过分布式系统进行网络传输或通过rmi等远程调用,这就需要在网络上传输对象,被传输的对象就必须实现Serializable接口。
# 71.描述一下JVM加载class文件的原理机制?
JVM中类的装载是由ClassLoader和它的子类来实现的,Java ClassLoader 是一个重要的Java运行时系统组件。它负责在运行时查找和装入类文件的类。
# 72.heap和stack有什么区别。
Java的内存分为两类,一类是栈内存,一类是堆内存。栈内存是指程序进入一个方法时,会为这个方法单独分配一块私属存储空间,用于存储这个方法内部的局部变量,当这个方法结束时,分配给这个方法的栈会释放,这个栈中的变量也将随之释放。
堆是与栈作用不同的内存,一般用于存放不放在当前方法栈中的那些数据,例如,使用new创建的对象都放在堆里,所以,它不会随方法的结束而消失。方法中的局部变量使用final修饰后,放在堆中,而不是栈中。
# 73.GC是什么? 为什么要有GC?
GC是垃圾收集的意思(Gabage Collection),内存处理是编程人员容易出现问题的地方,忘记或者错误的内存回收会导致程序或系统的不稳定甚至崩溃,Java提供的GC功能可以自动监测对象是否超过作用域从而达到自动回收内存的目的,Java语言没有提供释放已分配内存的显示操作方法。
# 74.垃圾回收的优点和原理。并考虑2种回收机制。
Java语言中一个显著的特点就是引入了垃圾回收机制,使c++程序员最头疼的内存管理的问题迎刃而解,它使得Java程序员在编写程序的时候不再需要考虑内存管理。由于有个垃圾回收机制,Java中的对象不再有"作用域"的概念,只有对象的引用才有"作用域"。垃圾回收可以有效的防止内存泄露,有效的使用可以使用的内存。垃圾回收器通常是作为一个单独的低级别的线程运行,不可预知的情况下对内存堆中已经死亡的或者长时间没有使用的对象进行清楚和回收,程序员不能实时的调用垃圾回收器对某个对象或所有对象进行垃圾回收。回收机制有分代复制垃圾回收和标记垃圾回收,增量垃圾回收。
# 75.垃圾回收器的基本原理是什么?垃圾回收器可以马上回收内存吗?有什么办法主动通知虚拟机进行垃圾回收?
对于GC来说,当程序员创建对象时,GC就开始监控这个对象的地址、大小以及使用情况。通常,GC采用有向图的方式记录和管理堆(heap)中的所有对象。通过这种方式确定哪些对象是“可达的”,哪些对象是“不可达的”。当GC确定一些对象为“不可达”时,GC就有责任回收这些内存空间。可以。程序员可以手动执行System.gc(),通知GC运行,但是Java语言规范并不保证GC一定会执行。
# 76.什么时候用assert。
assertion(断言)在软件开发中是一种常用的调试方式,很多开发语言中都支持这种机制。在实现中,assertion就是在程序中的一条语句,它对一个boolean表达式进行检查,一个正确程序必须保证这个boolean表达式的值为true;如果该值为false,说明程序已经处于不正确的状态下,assert将给出警告或退出。一般来说,assertion用于保证程序最基本、关键的正确性。
assertion检查通常在开发和测试时开启。为了提高性能,在软件发布后,assertion检查通常是关闭的。
```java
package com.huawei.interview;
public class AssertTest {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
int i = 0;
for(i=0;i<5;i++)
{
System.out.println(i);
}
//假设程序不小心多了一句--i;
--i;
assert i==5;
}
}
```
# 77.java中会存在内存泄漏吗,请简单描述。
所谓内存泄露就是指一个不再被程序使用的对象或变量一直被占据在内存中。java中有垃圾回收机制,它可以保证一对象不再被引用的时候,即对象编程了孤儿的时候,对象将自动被垃圾回收器从内存中清除掉。由于Java 使用有向图的方式进行垃圾回收管理,可以消除引用循环的问题,例如有两个对象,相互引用,只要它们和根进程不可达的,那么GC也是可以回收它们的,例如下面的代码可以看到这种情况的内存回收:
```java
package com.huawei.interview;
import java.io.IOException;
public class GarbageTest {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
try {
gcTest();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("has exited gcTest!");
System.in.read();
System.in.read();
System.out.println("out begin gc!");
for(int i=0;i<100;i++)
{
System.gc();
System.in.read();
System.in.read();
}
}
private static void gcTest() throws IOException {
System.in.read();
System.in.read();
Person p1 = new Person();
System.in.read();
System.in.read();
Person p2 = new Person();
p1.setMate(p2);
p2.setMate(p1);
System.out.println("before exit gctest!");
System.in.read();
System.in.read();
System.gc();
System.out.println("exit gctest!");
}
private static class Person
{
byte[] data = new byte[20000000];
Person mate = null;
public void setMate(Person other)
{
mate = other;
}
}
}
```
Java中的内存泄露的情况:长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄露,尽管短生命周期对象已经不再需要,但是因为长生命周期对象持有它的引用而导致不能被回收,这就是Java中内存泄露的发生场景,通俗地说,就是程序员可能创建了一个对象,以后一直不再使用这个对象,这个对象却一直被引用,即这个对象无用但是却无法被垃圾回收器回收的,这就是Java中可能出现内存泄露的情况,例如,缓存系统,我们加载了一个对象放在缓存中(例如放在一个全局map对象中),然后一直不再使用它,这个对象一直被缓存引用,但却不再被使用。
检查Java中的内存泄露,一定要让程序将各种分支情况都完整执行到程序结束,然后看某个对象是否被使用过,如果没有,则才能判定这个对象属于内存泄露。
如果一个外部类的实例对象的方法返回了一个内部类的实例对象,这个内部类对象被长期引用了,即使那个外部类实例对象不再被使用,但由于内部类持久外部类的实例对象,这个外部类对象将不会被垃圾回收,这也会造成内存泄露。
主要特点就是清空堆栈中的某个元素,并不是彻底把它从数组中拿掉,而是把存储的总数减少,在拿掉某个元素时,顺便也让它从数组中消失,将那个元素所在的位置的值设置为null即可:
```java
public class Stack {
private Object[] elements=new Object[10];
private int size = 0;
public void push(Object e){
ensureCapacity();
elements[size++] = e;
}
public Object pop(){
if( size == 0)
throw new EmptyStackException();
return elements[--size];
}
private void ensureCapacity(){
if(elements.length == size){
Object[] oldElements = elements;
elements = new Object[2 * elements.length+1];
System.arraycopy(oldElements,0, elements, 0, size);
}
}
}
```
上面的原理应该很简单,假如堆栈加了10个元素,然后全部弹出来,虽然堆栈是空的,没有我们要的东西,但是这是个对象是无法回收的,这个才符合了内存泄露的两个条件:无用,无法回收。
但是就是存在这样的东西也不一定会导致什么样的后果,如果这个堆栈用的比较少,也就浪费了几个K内存而已,反正我们的内存都上G了,哪里会有什么影响,再说这个东西很快就会被回收的,有什么关系。
例:
```java
public class Bad{
public static Stack s=Stack();
static{
s.push(new Object());
s.pop(); //这里有一个对象发生内存泄露
s.push(new Object()); //上面的对象可以被回收了,等于是自愈了
}
}
```
因为是static,就一直存在到程序退出,但是我们也可以看到它有自愈功能,就是说如果你的Stack最多有100个对象,那么最多也就只有100个对象无法被回收其实这个应该很容易理解,Stack内部持有100个引用,最坏的情况就是他们都是无用的,因为我们一旦放新的进取,以前的引用自然消失!
内存泄露的另外一种情况:当一个对象被存储进HashSet集合中以后,就不能修改这个对象中的那些参与计算哈希值的字段了,否则,对象修改后的哈希值与最初存储进HashSet集合中时的哈希值就不同了,在这种情况下,即使在contains方法使用该对象的当前引用作为的参数去HashSet集合中检索对象,也将返回找不到对象的结果,这也会导致无法从HashSet集合中单独删除当前对象,造成内存泄露。
# 78.能不能自己写个类,也叫java.lang.String?
可以,但在应用的时候,需要用自己的类加载器去加载,否则,系统的类加载器永远只是去加载jre.jar包中的那个java.lang.String。由于在tomcat的web应用程序中,都是由webapp自己的类加载器先自己加载WEB-INF/classess目录中的类,然后才委托上级的类加载器加载,如果我们在tomcat的web应用程序中写一个java.lang.String,这时候Servlet程序加载的就是我们自己写的java.lang.String,但是这么干就会出很多潜在的问题,原来所有用了java.lang.String类的都将出现问题。
虽然java提供了endorsed技术,可以覆盖jdk中的某些类,具体做法是….。但是,能够被覆盖的类是有限制范围,反正不包括java.lang这样的包中的类。例如,运行下面的程序:
```java
package java.lang;
public class String {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
System.out.println("string");
}
}
```
报告的错误如下:
java.lang.NoSuchMethodError: main
Exception in thread "main"
这是因为加载了jre自带的java.lang.String,而该类中没有main方法。
# 79.获得一个类的类对象有哪些方式?
答:
方法1:类型.class,例如:String.class
方法2:对象.getClass(),例如:”hello”.getClass()
方法3:Class.forName(),例如:Class.forName(“java.lang.String”)
# 80.Java代码查错
1)
```java
abstract class Name {
private String name;
public abstract boolean isStupidName(String name) {}
}
```
这有何错误?
答案: 错。abstract method必须以分号结尾,且不带花括号。
2)
```java
public class Something {
void doSomething () {
private String s = "";
int l = s.length();
}
}
```
有错吗?
答案: 错。局部变量前不能放置任何访问修饰符 (private,public,和protected)。final可以用来修饰局部变量(final如同abstract和strictfp,都是非访问修饰符,strictfp只能修饰class和method而非variable)。
3)
```java
abstract class Something {
private abstract String doSomething ();
}
```
这好像没什么错吧?
答案: 错。abstract的methods不能以private修饰。abstract的methods就是让子类implement(实现)具体细节的,怎么可以用private把abstract method封锁起来呢? (同理,abstract method前不能加final)。
4)
```java
public class Something {
public int addOne(final int x) {
return ++x;
}
}
```
这个比较明显。
答案: 错。int x被修饰成final,意味着x不能在addOne method中被修改。
5)
```java
public class Something {
public static void main(String[] args) {
Other o = new Other();
new Something().addOne(o);
}
public void addOne(final Other o) {
o.i++;
}
}
class Other {
public int i;
}
```
和上面的很相似,都是关于final的问题,这有错吗?
答案: 正确。在addOne method中,参数o被修饰成final。如果在addOne method里我们修改了o的reference(比如: o = new Other();),那么如同上例这题也是错的。但这里修改的是o的member vairable(成员变量),而o的reference并没有改变。
6)
```java
class Something {
int i;
public void doSomething() {
System.out.println("i = " + i);
}
}
```
有什么错呢? 看不出来啊。
答案: 正确。输出的是"i = 0"。int i属於instant variable (实例变量,或叫成员变量)。instant variable有default value。int的default value是0。
7)
```java
class Something {
final int i;
public void doSomething() {
System.out.println("i = " + i);
}
}
```
和上面一题只有一个地方不同,就是多了一个final。这难道就错了吗?
答案: 错。final int i是个final的instant variable (实例变量,或叫成员变量)。final的instant variable没有default value,必须在constructor (构造器)结束之前被赋予一个明确的值。可以修改为“final int i = 0;”。
8)
```java
public class Something {
public static void main(String[] args) {
Something s = new Something();
System.out.println("s.doSomething() returns " + doSomething());
}
public String doSomething() {
return "Do something ...";
}
}
```
看上去很完美。
答案: 错。看上去在main里call doSomething没有什么问题,毕竟两个methods都在同一个class里。但仔细看,main是static的。static method不能直接call non-static methods。可改成"System.out.println("s.doSomething() returns " + s.doSomething());"。同理,static method不能访问non-static instant variable。
9)
此处,Something类的文件名叫OtherThing.java
```java
class Something {
private static void main(String[] something_to_do) {
System.out.println("Do something ...");
}
}
```
这个好像很明显。
答案: 正确。从来没有人说过Java的Class名字必须和其文件名相同。但public class的名字必须和文件名相同。
10)
```java
interface A{
int x = 0;
}
class B{
int x =1;
}
class C extends B implements A {
public void pX(){
System.out.println(x);
}
public static void main(String[] args) {
new C().pX();
}
}
```
答案:错误。在编译时会发生错误(错误描述不同的JVM有不同的信息,意思就是未明确的x调用,两个x都匹配(就象在同时import java.util和java.sql两个包时直接声明Date一样)。对于父类的变量,可以用super.x来明确,而接口的属性默认隐含为 public static final.所以可以通过A.x来明确。
11)
```java
interface Playable {
void play();
}
interface Bounceable {
void play();
}
interface Rollable extends Playable, Bounceable {
Ball ball = new Ball("PingPang");
}
class Ball implements Rollable {
private String name;
public String getName() {
return name;
}
public Ball(String name) {
this.name = name;
}
public void play() {
ball = new Ball("Football");
System.out.println(ball.getName());
}
}
```
这个错误不容易发现。
答案: 错。
"interface Rollable extends Playable, Bounceable"没有问题。interface可继承多个interfaces,所以这里没错。问题出在interface Rollable里的"Ball ball = new Ball("PingPang");"。任何在interface里声明的interface variable (接口变量,也可称成员变量),默认为public static final。也就是说"Ball ball = new Ball("PingPang");"实际上是"public static final Ball ball = new Ball("PingPang");"。在Ball类的Play()方法中,"ball = new Ball("Football");"改变了ball的reference,而这里的ball来自Rollable interface,Rollable interface里的ball是public static final的,final的object是不能被改变reference的。
因此编译器将在"ball = new Ball("Football");"这里显示有错。
# 公众号
**`Github` 上所有的文章我都会首发在微信公众号『爱笑的架构师』,大家可以关注一下,定时推送技术干货~**
<div align="center">
<img src="https://cdn.jsdelivr.net/gh/smileArchitect/assets@main/202012/20201205221844.png"></img>
</div>
================================================
FILE: docs/java/java8/Java8函数式接口和Lambda表达式你真的会了吗.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321342&idx=1&sn=2d87b7fe6709a8513eb0abf58b48521d&chksm=8f09cfa4b87e46b29378661f72c832ec5bef782c362eba8cee25527a455c12239e067a80bed9&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
<!-- MarkdownTOC -->
- [1. Lambda表达式小试牛刀](#1-lambda表达式小试牛刀)
- [2. Lambda高阶用法](#2-lambda高阶用法)
- [(1)函数式接口](#1函数式接口)
- [(2)函数式接口可以干什么?](#2函数式接口可以干什么)
- [(3)函数描述符](#3函数描述符)
- [(4)常用函数式接口](#4常用函数式接口)
- [(5)将lambda表达式重构为方法引用](#5将lambda表达式重构为方法引用)
- [公众号](#公众号)
<!-- /MarkdownTOC -->
>Java8 由Oracle在2014年发布,是继Java5之后最具革命性的版本了。
>Java8吸收其他语言的精髓带来了函数式编程,lambda表达式,Stream流等一系列新特性,学会了这些新特性,可以让你实现高效编码优雅编码。
# 1. Lambda表达式小试牛刀
Lambada表达式可以理解为:可传递的匿名函数的一种简洁表达方式。Lambda表达式没有名称,同普通方法一样有参数列表、函数主体、返回类型等;
下面简单看一个例子,new一个线程打印字符串,采用lambda表达式非常简洁:
```java
new Thread(() -> System.out.println("hello java8 lambda")).start()
```
<div align="center"> <img src="https://uploader.shimo.im/f/hjYkgyopFIjojyVV.gif" width=""/> </div><br>
Thread类接受一个Runnable类型实例,查看Jdk源码发现Runnable接口是一个函数式接口,可以直接用lambda表达式替代。
```java
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
```
<div align="center"> <img src="https://uploader.shimo.im/f/ZoU2dZ1ONJyGxQkg.gif" width=""/> </div><br>
Lambda表达式语法非常简单:
```java
() -> System.out.println("hello java8 lambda")
```
<div align="center"> <img src="https://uploader.shimo.im/f/deWXjbQMLw9Ldugr.gif" width=""/> </div><br>
* ()括号里面是参数列表,如果只有一个参数还可以写为: a -> System.out.println(a)
* -> 箭头为固定写法;
* System.out.println("hello java8 lambda") 为函数主体,如果有多条语句要用花括号包裹起来, 比如下面这样:
```java
(a, b) -> {int sum = a + b; return sum;}
```
<div align="center"> <img src="https://uploader.shimo.im/f/zrUVHrJsHdT5yPqh.gif" width=""/> </div><br>
综上,Lambda表达式模块可以固化为:
```java
(parameter) -> {expression} 或者 (parameter) -> {statements; statements; }
```
<div align="center"> <img src="https://uploader.shimo.im/f/57XJo3HwFiwfGb1f.gif" width=""/> </div><br>
参数只有一个可以省略括号
如果不用Lambda表达式,使用匿名内部类的方式,写法就不是那么优雅了。
```java
// before Java8
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("hello java8 without lambda");
}
}).start();
```
<div align="center"> <img src="https://uploader.shimo.im/f/T3lD8Nay00sSFa1v.gif" width=""/> </div><br>
# 2. Lambda高阶用法
## (1)函数式接口
函数式接口是只定义了一个抽象方法的接口。注意Java8中允许存在默认方法(default),哪怕有很多默认方法,只要有且仅有一个抽象方法,那么这个接口仍然是函数式接口。
函数式接口通常在类上有一个注解@FunctionalInterface,如:
```java
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
```
<div align="center"> <img src="https://uploader.shimo.im/f/Sh6RZmw074ke8fN6.gif" width=""/> </div><br>
## (2)函数式接口可以干什么?
通常lambda表达式与函数式接口结合一起用,lambda表达式以内联的形式为函数式接口的抽象方法提供实现,把整个表达式作为函数式接口的实例。在没有lambda表达式之前,我们通常会使用匿名内部类的方式实现,详细对比见第一小节的实例代码。
## (3)函数描述符
函数式接口抽象方法的签名基本上就是lambda表达式的签名,我们可以将这种对应关系称为函数描述符。由一个函数式接口的抽象方法抽象为一个函数描述符,这个过程非常重要,知道了函数描述符去写lambda表达式也就非常容易了。举个例子:
Runnable接口有一个抽象方法 void run(), 接受空参数返回void,那么函数描述符可以推导为: () -> void
lambda表达式可以写为 () -> System.out.println("hello java8 lambda")
## (4)常用函数式接口
java8 中常用函数式接口,针对基本类型java还定义了IntPredicate, LongPredicate等类型,详细可以参考jdk源码。
|函数式接口|函数描述符|
|:----|:----|
|Predicate<T>|T->boolean|
|Consumer<T>|T->void|
|Function<T,R>|T->R|
|Supplier<T>|() -> T|
|UnaryOperator<T>|T -> T|
|BinaryOperator<T>|(T,T)->T|
|BiPredicate<L,R>|(L,R)->boolean|
|BiConsumer<T,U>|(T,U)->void|
|BiFunction<T,U,R>|(T,U)->R|
至于 Predicate, Consumer, Function这些函数式接口具体作用,在后面的文章中笔者会详细介绍,这里只需有个大体印象即可。
## (5)将lambda表达式重构为方法引用
方法引用可以看作是lambda表达式的一种快捷写法,它可以调用特性的方法作为参数传递。你也可以将方法引用看作是lambda表达式的语法糖,让lambda表达式写起来更加简介。举个栗子,按学生年龄排序:
```java
// before
students.sort((s1, s2) -> s1.getAge.compareTo(s2.getAge()))));
// after 使用方法引用
students.sort(Comparator.comparing(Student::getAge()))));
```
<div align="center"> <img src="https://uploader.shimo.im/f/HKcf2sHykH2JPa2m.gif" width=""/> </div><br>
方法引用主要有三类:
* **静态方法的方法引用**
valueOf是String类的静态方法,方法引用写为 String::valueOf, 对应lambda表达式:a -> String.valueOf(a)
* **任意类型实例方法的方法引用**
length是String类的实例方法,方法引用写为 String::length,对应lambda表达式: (str) -> str.length()
* **现有对象的实例方法的方法引用**
第三种容易与第二种混淆,现有对象指的是在lambda表达式中调用外部对象(不是入参对象)的实例方法,比如:
String str = "hello java8";
() -> str.length();
对应方法引用写为 str::length, 注意不是 String::length
最后我们将三类方法引用归纳如下:
|lambda表达式|方法引用| |
|:----|:----|:----|
|(args) -> ClassName.staticMethod(args)|ClassName::staticMethod|静态方法方法引用|
|(arg0, params) -> arg0.instanceMethod(params)|ClassName::instanceMethod|内部实例方法引用|
|arg0<br>(params) -> arg0.instanceMethod(params)|arg0.instanceMethod|外部实例方法引用|
================================================
FILE: docs/java/java8/使用Java8 Optional类优雅解决空指针问题.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321295&idx=1&sn=2fdb1d4c7e44177a7b08393114e55f16&chksm=8f09cf95b87e4683e521502b33319f957a038b5ecc095171de9d287b337411f2ffb2bf1e01d5&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
<!-- MarkdownTOC -->
- [1. 不受待见的空指针异常](#1-不受待见的空指针异常)
- [2. 糟糕的代码](#2-糟糕的代码)
- [3. 解决空指针的"银弹"](#3-解决空指针的银弹)
- [4. Optional使用入门](#4-optional使用入门)
- [5. 使用Optional重构代码](#5-使用optional重构代码)
- [总结](#总结)
- [公众号](#公众号)
<!-- /MarkdownTOC -->
>Java8 由Oracle在2014年发布,是继Java5之后最具革命性的版本。
>Java8吸收其他语言的精髓带来了函数式编程,lambda表达式,Stream流等一系列新特性,学会了这些新特性,可以让你实现高效编码优雅编码。
# 1. 不受待见的空指针异常
有个小故事:null引用最早是由英国科学家Tony Hoare提出的,多年后Hoare为自己的这个想法感到后悔莫及,并认为这是"价值百万的重大失误"。可见空指针是多么不受待见。
NullPointerException是Java开发中最常遇见的异常,遇到这种异常我们通常的解决方法是在调用的地方加一个if判空。
if判空越多会造成过多的代码分支,后续代码维护也就越来越复杂。
# 2. 糟糕的代码
比如看下面这个例子,使用过多的if判空。
Person对象里定义了House对象,House对象里定义了Address对象:
```java
public class Person {
private String name;
private int age;
private House house;
public House getHouse() {
return house;
}
}
class House {
private long price;
private Address address;
public Address getAddress() {
return address;
}
}
class Address {
private String country;
private String city;
public String getCity() {
return city;
}
}
```
现在获取这个人买房的城市,那么通常会这样写:
```java
public String getCity() {
String city = new Person().getHouse().getAddress().getCity();
return city;
}
```
但是这样写容易出现空指针的问题,比如这个人没有房,House对象为null。接着你会改造这段代码,加上很多判断条件:
```java
public String getCity2(Person person) {
if (person != null) {
House house = person.getHouse();
if (house != null) {
Address address = house.getAddress();
if (address != null) {
String city = address.getCity();
return city;
}
}
}
return "unknown";
}
```
为了避免空指针异常,每一层都加上判断,但是这样会造成代码嵌套太深,不易维护。
你可能想到如何改造上面的代码,比如加上提前判空退出:
```java
public String getCity3(Person person) {
String city = "unknown";
if (person == null) {
return city;
}
House house = person.getHouse();
if (house == null) {
return city;
}
Address address = house.getAddress();
if (address == null) {
return city;
}
return address.getCity();
}
```
但是这样简单的代码已经加入了三个退出条件,非常不利于后面代码维护。那怎样才能将代码写的优雅一点呢,下面引入今天的主角"Optional"。
# 3. 解决空指针的"银弹"
从Java8开始引入了一个新类 java.util.Optional,这是一个对象的容器,意味着可能包含或者没有包含一个非空的值。下面重点看一下Optional的常用方法:
```java
public final class Optional<T> {
// 通过指定非空值创建Optional对象
// 如果指定的值为null,会抛空指针异常
public static <T> Optional<T> of(T value) {
return new Optional<>(value);
}
// 通过指定可能为空的值创建Optional对象
public static <T> Optional<T> ofNullable(T value) {
return value == null ? empty() : of(value);
}
// 返回值,不存在抛异常
public T get() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
// 如果值存在,根据consumer实现类消费该值
public void ifPresent(Consumer<? super T> consumer) {
if (value != null)
consumer.accept(value);
}
// 如果值存在则返回,如果值为空则返回指定的默认值
public T orElse(T other) {
return value != null ? value : other;
}
// map flatmap等方法与Stream使用方法类似,这里不再赘述,读者可以参考之前的Stream系列。
}
```
以上就是Optional类常用的方法,使用起来非常简单。
# 4. Optional使用入门
**(1)创建Optional实例**
* 创建空的Optional对象。可以通过静态工厂方法Optional.Empty() 创建一个空的对象,例如:
```java
Optional<Person> optionalPerson = Optional.Empty();
```
* 指定非空值创建Optional对象。
```java
Person person = new Person();
Optional<Person> optionalPerson = Optional.of(person);
```
* 指定可能为空的值创建Optional对象。
```java
Person person = null; // 可能为空
Optional<Person> optionalPerson = Optional.of(person);
```
**(2)常用方法**
**ifPresent**
如果值存在,则调用consumer实例消费该值,否则什么都不执行。举个栗子:
```java
String str = "hello java8";
// output: hello java8
Optional.ofNullable(str).ifPresent(System.out::println);
String str2 = null;
// output: nothing
Optional.ofNullable(str2).ifPresent(System.out::println);
```
**filter, map, flatMap**
在三个方法在前面讲Stream的时候已经详细讲解过,读者可以翻看之前写的文章,这里不再赘述。
**orElse**
如果value为空,则返回默认值,举个栗子:
```java
public void test(String city) {
String defaultCity = Optional.ofNullable(city).orElse("unknown");
}
```
**orElseGet**
如果value为空,则调用Supplier实例返回一个默认值。举个例子:
```java
public void test2(String city) {
// 如果city为空,则调用generateDefaultCity方法
String defaultCity = Optional.of(city).orElseGet(this::generateDefaultCity);
}
private String generateDefaultCity() {
return "beijing";
}
```
**orElseThrow**
如果value为空,则抛出自定义异常。举个栗子:
```java
public void test3(String city) {
// 如果city为空,则抛出空指针异常。
String defaultCity = Optional.of(city).orElseThrow(NullPointerException::new);
}
```
# 5. 使用Optional重构代码
**再看一遍重构之前的代码,使用了三个if使代码嵌套层次变得很深。**
```java
// before refactor
public String getCity2(Person person) {
if (person != null) {
House house = person.getHouse();
if (house != null) {
Address address = house.getAddress();
if (address != null) {
String city = address.getCity();
return city;
}
}
}
return "unknown";
}
```
**使用Optional重构**
```java
public String getCityUsingOptional(Person person) {
String city = Optional.ofNullable(person)
.map(Person::getHouse)
.map(House::getAddress)
.map(Address::getCity).orElse("Unknown city");
return city;
}
```
只使用了一行代码就获取到city值,不用再去不断的判断是否为空,这样写代码是不是很优雅呀。
# 总结
使用optional类可以很优雅的解决项目中空指针的问题,但是optional也不是万能的哦,小伙伴们要适度使用。赶紧用Optional重构之前写的项目吧~**
================================================
FILE: docs/java/java8/包学会,教你用Java函数式编程重构烂代码.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321467&idx=1&sn=62376145a601f4470532ccb62deaddf3&chksm=8f09cc21b87e4537a7961f8eaf751f2b4282d02f784e10cbd6b69ef01346ca23f48ff3dc260e&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
<!-- MarkdownTOC -->
- [烂代码登场](#烂代码登场)
- [开始重构烂代码](#开始重构烂代码)
- [**第一步:定义函数式接口**](#第一步:定义函数式接口)
- [**第二步:定义模板方法**](#第二步:定义模板方法)
- [**第三步:传递lambda表达式**](#第三步:传递lambda表达式)
- [总结](#总结)
- [公众号](#公众号)
<!-- /MarkdownTOC -->
>Java8 由Oracle在2014年发布,是继Java5之后最具革命性的版本。
>Java8吸收其他语言的精髓带来了函数式编程,lambda表达式,Stream流等一系列新特性,学会了这些新特性,可以让你实现高效编码优雅编码。
# 烂代码登场
首先引入一个实际的例子,我们常常会写一个dao类来操作数据库,比如查询记录,插入记录等。
下面的代码中实现了查询和插入功能(引入Mybatis三方件):
```java
public class StudentDao {
/**
* 根据学生id查询记录
* @param id 学生id
* @return 返回学生对象
*/
public Student queryOne(int id) {
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
SqlSession session = null;
try {
session = sqlSessionFactory.openSession();
// 根据id查询指定的student对象
return session.selectOne("com.coderspace.mapper.student.queryOne", id);
} finally {
if (session != null) {
session.close();
}
}
}
/**
* 插入一条学生记录
* @param student 待插入对象
* @return true if success, else return false
*/
public boolean insert(Student student) {
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
SqlSession session = null;
try {
session = sqlSessionFactory.openSession();
// 向数据库插入student对象
int rows = session.insert("com.coderspace.mapper.student.insert", student);
return rows > 0;
} finally {
if (session != null) {
session.close();
}
}
}
}
```
<div align="center"> <img src="https://uploader.shimo.im/f/MN7BiaxSuGpyBMFe.gif" width=""/> </div><br>
睁大眼睛观察上面的代码可以发现,这两个方法有很多重复的代码。
除了下面这两行,其他的代码都是一样的,都是先获取session,然后执行核心操作,最后关闭session。
```java
// 方法1中核心代码
return session.selectOne("com.coderspace.mapper.student.queryOne", id);
```
```java
// 方法2中核心代码
int rows = session.insert("com.coderspace.mapper.student.insert", student);
```
作为一个有追求的程序员,不,应该叫代码艺术家,是不是应该考虑重构一下。
获取session和关闭session这段代码围绕着具体的核心操作代码,我们可以称这段代码为模板代码。
假如又来了一个需求,需要实现删除student方法,那么你肯定会copy上面的获取session和关闭session代码,这样做有太多重复的代码,作为一名优秀的工程师肯定不会容忍这种事情的发生。
# 开始重构烂代码
怎么重构呢?现在请出我们的主角登场:**环绕执行模式使行为参数化**。
名字是不是很高大上,啥叫行为参数化?上面例子中我们已经观察到了,除了核心操作代码其他代码都是一模一样,那我们是不是可以**将核心操作代码作为入参传入模板方法中**,根据不同的行为分别执行。
变量对象很容易作为参数传入,行为可以作为参数传入吗?
答案是:当然可以,可以采用lambda表达式传入。
下面开始重构之前的例子,主要可以分为三步:
(1)定义函数式接口;
(2)定义模板方法;
(3)传递lambda表达式
所有的环绕执行模式都可以套用上面这三步公式。
## **第一步:定义函数式接口**
```java
@FunctionalInterface
public interface DbOperation<R> {
/**
* 通用操作数据库接口
* @param session 数据库连接session
* @param mapperId 关联mapper文件id操作
* @param params 操作参数
* @return 返回值,R泛型
*/
R operate(SqlSession session, String mapperId, Object params);
}
```
<div align="center"> <img src="https://uploader.shimo.im/f/gTcrLM9D9DjJVsqJ.gif" width=""/> </div><br>
定义了一个operate抽象方法,接收三个参数,返回泛型R。
## **第二步:定义模板方法**
DbOperation是一个函数式接口,作为入参传入:
```java
public class CommonDao<R> {
public R proccess(DbOperation<R> dbOperation, String mappperId, Object params) {
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
SqlSession session = null;
try {
session = sqlSessionFactory.openSession();
// 核心操作
return dbOperation.operate(session, mappperId, params);
} finally {
if (session != null) {
session.close();
}
}
}
}
```
<div align="center"> <img src="https://uploader.shimo.im/f/UttKDAdGSmrEt8Iv.gif" width=""/> </div><br>
## **第三步:传递lambda表达式**
```java
// 根据id查询学生
String mapperId = "com.coderspace.mapper.student.queryOne";
int studentNo = 123;
CommonDao<Student> commonDao = new CommonDao<>();
// 使用lambda传递具体的行为
Student studentObj = commonDao.proccess(
(session, mappperId, params) -> session.selectOne(mappperId, params),
mapperId, studentNo);
// 插入学生记录
String mapperId2 = "com.coderspace.mapper.student.insert";
Student student = new Student("coderspace", 1, 100);
CommonDao<Boolean> commonDao2 = new CommonDao<>();
// 使用lambda传递具体的行为
Boolean successInsert = commonDao2.proccess(
(session, mappperId, params) -> session.selectOne(mappperId, params),
mapperId2, student);
```
<div align="center"> <img src="https://uploader.shimo.im/f/YUqcPAZ0GfF0Di5G.gif" width=""/> </div><br>
实现了上面三步,假如要实现删除方法,CommonDao里面一行代码都不用改,只用在调用方传入不同的参数即可实现。
# 总结
环绕执行模式在项目实战中大有用途,如果你发现几行易变的代码外面围绕着一堆固定的代码,这个时候你应该考虑使用lambda环绕执行模式了。
环绕执行模式固有套路请跟我一起大声读三遍:
第一步:定义函数式接口
第二步:定义模板方法
第三步:传递lambda表达式
絮叨:
是不是太太太方便了,要是被经理看到了肯定又要给涨薪,NO,拒绝!
# 公众号
公众号比Github早一到两天更新,如果大家想要实时关注我更新的文章以及分享的干货,可以关注我的公众号。
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/wechat-01.jpg" width=""/> </div><br>
================================================
FILE: docs/java/java8/请避开Stream流式编程常见的坑.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321100&idx=1&sn=d566cdd805d14e121dfef498d30f2b20&chksm=8f09ced6b87e47c013288565f930a83a493cad48d545024ec842c17cda3d82939c5c29307287&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
<!-- MarkdownTOC -->
- [1. Stream是什么?](#1-stream是什么)
- [2. Stream的特点](#2-stream的特点)
- [3. 创建Stream实例的方法](#3-创建stream实例的方法)
- [4. Stream常用操作](#4-stream常用操作)
- [5. 实战:使用Stream重构老代码](#5-实战:使用stream重构老代码)
- [6. 使用Stream常见的误区](#6-使用stream常见的误区)
- [公众号](#公众号)
<!-- /MarkdownTOC -->
>Java8 由Oracle在2014年发布,是继Java5之后最具革命性的版本了。
>Java8吸收其他语言的精髓带来了函数式编程,lambda表达式,Stream流等一系列新特性,学会了这些新特性,可以让你实现高效编码优雅编码。
# 1. Stream是什么?
Stream是Java8新增的一个接口,允许以声明性方式处理数据集合。Stream不是一个集合类型不保存数据,可以把它看作是遍历数据集合的高级迭代器(Iterator)。
Stream操作可以像Builder一样逐步叠加,形成一条流水线。流水线一般由数据源+零或者多个中间操作+一个终端操作所构成。中间操作可以将流转换成另外一个流,比如使用filter过滤元素,使用map映射提取值。
Stream与lambda表达式密不可分,本文默认你已经掌握了lambda基础知识。
# 2. Stream的特点
* 只能遍历(消费)一次。Stream实例只能遍历一次,终端操作后一次遍历就结束,再次遍历需要重新生成实例,这一点类似于Iterator迭代器。
* 保护数据源。对Stream中任何元素的修改都不会导致数据源被修改,比如过滤删除流中的一个元素,再次遍历该数据源依然可以获取该元素。
* 懒。filter, map 操作串联起来形成一系列中间运算,如果没有一个终端操作(如collect)这些中间运算永远也不会被执行。
# 3. 创建Stream实例的方法
(1)使用指定值创建Stream实例
```java
// of为Stream的静态方法
Stream<String> strStream = Stream.of("hello", "java8", "stream");
// 或者使用基本类型流
IntStream intStream = IntStream.of(1, 2, 3);
```
(2)使用集合创建Stream实例(常用方式)
```java
// 使用guava库,初始化一个不可变的list对象
ImmutableList<Integer> integers = ImmutableList.of(1, 2, 3);
// List接口继承Collection接口,java8在Collection接口中添加了stream方法
Stream<Integer> stream = integers.stream();
```
(3)使用数组创建Stream实例
```java
// 初始化一个数组
Integer[] array = {1, 2, 3};
// 使用Arrays的静态方法stream
Stream<Integer> stream = Arrays.stream(array);
```
(4)使用生成器创建Stream实例
```java
// 随机生成100个整数
Random random = new Random();
// 加上limit否则就是无限流了
Stream<Integer> stream = Stream.generate(random::nextInt).limit(100);
```
(5)使用迭代器创建Stream实例
```java
// 生成100个奇数,加上limit否则就是无限流了
Stream<Integer> stream = Stream.iterate(1, n -> n + 2).limit(100);
stream.forEach(System.out::println);
```
(6)使用IO接口创建Stream实例
```java
// 获取指定路径下文件信息,list方法返回Stream类型
Stream<Path> pathStream = Files.list(Paths.get("/"));
```
# 4. Stream常用操作
Stream接口中定义了很多操作,大致可以分为两大类,一类是中间操作,另一类是终端操作;
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201018221358.png" width="500"/> </div><br>
**(1)中间操作**
中间操作会返回另外一个流,多个中间操作可以连接起来形成一个查询。
中间操作有惰性,如果流上没有一个终端操作,那么中间操作是不会做任何处理的。
下面介绍常用的中间操作:
**map操作**
map是将输入流中每一个元素映射为另一个元素形成输出流。
```java
// 初始化一个不可变字符串
List<String> words = ImmutableList.of("hello", "java8", "stream");
// 计算列表中每个单词的长度
List<Integer> list = words.stream()
.map(String::length)
.collect(Collectors.toList());
// output: 5 5 6
list.forEach(System.out::println);
```
**flatMap操作**
```java
List<String[]> list1 = words.stream()
.map(word -> word.split("-"))
.collect(Collectors.toList());
// output: [Ljava.lang.String;@59f95c5d,
// [Ljava.lang.String;@5ccd43c2
list1.forEach(System.out::println);
```
纳里?你预期是List<String>, 返回却是List<String[]>, 这是因为split方法返回的是String[]
这个时候你可以想到要将数组转成stream, 于是有了第二个版本
```java
Stream<Stream<String>> arrStream = words.stream()
.map(word -> word.split("-"))
.map(Arrays::stream);
// output: java.util.stream.ReferencePipeline$Head@2c13da15,
// java.util.stream.ReferencePipeline$Head@77556fd
arrStream.forEach(System.out::println);
```
还是不对,这个问题使用flatMap扁平流可以解决,flatMap将流中每个元素取出来转成另外一个输出流
```java
Stream<String> strStream = words.stream()
.map(word -> word.split("-"))
.flatMap(Arrays::stream)
.distinct();
// output: hello java8 stream
strStream.forEach(System.out::println);
```
**filter操作**
filter接收Predicate对象,按条件过滤,符合条件的元素生成另外一个流。
```java
// 过滤出单词长度大于5的单词,并打印出来
List<String> words = ImmutableList.of("hello", "java8", "hello", "stream");
words.stream()
.filter(word -> word.length() > 5)
.collect(Collectors.toList())
.forEach(System.out::println);
// output: stream
```
**(2)终端操作**
终端操作将stream流转成具体的返回值,比如List,Integer等。常见的终端操作有:foreach, min, max, count等。
foreach很常见了,下面举一个max的例子。
```java
// 找出最大的值
List<Integer> integers = Arrays.asList(6, 20, 19);
integers.stream()
.max(Integer::compareTo)
.ifPresent(System.out::println);
// output: 20
```
# 5. 实战:使用Stream重构老代码
假如有一个需求:过滤出年龄大于20岁并且分数大于95的学生。
使用for循环写法:
```java
private List<Student> getStudents() {
Student s1 = new Student("xiaoli", 18, 95);
Student s2 = new Student("xiaoming", 21, 100);
Student s3 = new Student("xiaohua", 19, 98);
List<Student> studentList = Lists.newArrayList();
studentList.add(s1);
studentList.add(s2);
studentList.add(s3);
return studentList;
}
public void refactorBefore() {
List<Student> studentList = getStudents();
// 使用临时list
List<Student> resultList = Lists.newArrayList();
for (Student s : studentList) {
if (s.getAge() > 20 && s.getScore() > 95) {
resultList.add(s);
}
}
// output: Student{name=xiaoming, age=21, score=100}
resultList.forEach(System.out::println);
}
```
使用for循环会初始化一个临时list用来存放最终的结果,整体看起来不够优雅和简洁。
使用lambda和stream重构后:
```java
public void refactorAfter() {
List<Student> studentLists = getStudents();
// output: Student{name=xiaoming, age=21, score=100}
studentLists.stream().filter(this::filterStudents).forEach(System.out::println);
}
private boolean filterStudents(Student student) {
// 过滤出年龄大于20岁并且分数大于95的学生
return student.getAge() > 20 && student.getScore() > 95;
}
```
使用filter和方法引用使代码清晰明了,也不用声明一个临时list,非常方便。
# 6. 使用Stream常见的误区
(1)误区一:重复消费stream对象
stream对象一旦被消费,不能再次重复消费。
```java
List<String> strings = Arrays.asList("hello", "java8", "stream");
Stream<String> stream = strings.stream();
stream.forEach(System.out::println); // ok
stream.forEach(System.out::println); // IllegalStateException
```
上述代码执行后报错:
java.lang.IllegalStateException: stream has already been operated upon or closed
(2)误区二:修改数据源
在流操作的过程中尝试添加新的string对象,结果报错:
```java
List<String> strings = Arrays.asList("hello", "java8", "stream");
// expect: HELLO JAVA8 STREAM WORLD, but throw UnsupportedOperationException
strings.stream()
.map(s -> {
strings.add("world");
return s.toUpperCase();
}).forEach(System.out::println);
```
注意:一定不要在操作流的过程中修改数据源。
# 总结
java8 流式编程在一定程度上可以使代码变得优美,不过也要避开常见的坑,如:不要重复消费对象、不要修改数据源。
================================================
FILE: docs/java/juc/倒计时计数CountDownLatch.md
================================================
在日常编码中,Java 并发编程可是少不了,试试下面这些并发编程工具类:
今天先带领大家一起重温学习 CountDownLatch 这个牛叉的工具类。
# 认识 CountDownLatch
`CountDownLatch`是一个同步工具类,用来协调多个线程之间的同步,或者说起到线程之间通信的作用(非互斥)。
CountDownLatch 能够使一个线程在等待另外一些线程完成各自工作之后,再继续执行。使用一个计数器进行实现。计数器初始值为线程的数量。当每一个线程完成自己任务后,计数器的值就会减一。当计数器的值为0时,表示所有的线程都已经完成一些任务,然后在CountDownLatch上等待的线程就可以恢复执行接下来的任务。
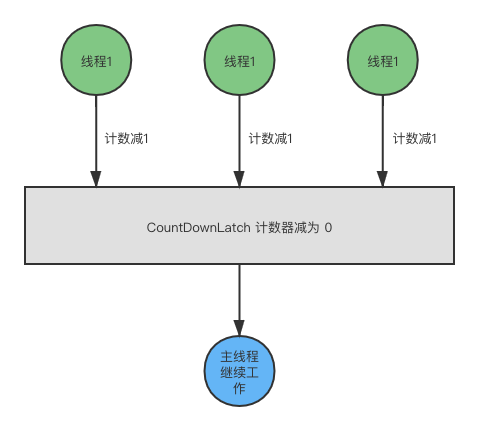
# CountDownLatch 的使用
CountDownLatch类使用起来非常简单。
Class 位于:`java.util.concurrent.CountDownLatch`
下面简单介绍它的构造方法和常用方法。
## 构造方法
CountDownLatch只提供了一个构造方法:
```java
// count 为初始计数值
public CountDownLatch(int count) {
// ……
}
```
## 常用方法
```java
//常用方法1:调用await()方法的线程会被挂起,它会等待直到count值为0才继续执行
public void await() throws InterruptedException {
// ……
}
// 常用方法2:和await()类似,只不过等待超时后count值还没变为0的话就会继续执行
public boolean await(long timeout, TimeUnit unit) throws InterruptedException {
// ……
}
// 常用方法3:将count值减1
public void countDown() {
// ……
}
```
# CountDownLatch 的应用场景
我们考虑一个场景:用户购买一个商品下单成功后,我们会给用户发送各种消息提示用户『购买成功』,比如发送邮件、微信消息、短信等。所有的消息都发送成功后,我们在后台记录一条消息表示成功。
当然我们可以使用单线程去完成,逐个完成每个操作,如下图所示:
但是这样效率就会非常低。如何解决单线程效率低的问题?当然是通过多线程啦。
使用多线程也会遇到一个问题,子线程消息还没发送完,主线程可能就已经打出『所有的消息都已经发送完毕啦』,这在逻辑上肯定是不对的。我们期望所有子线程发完消息主线程才会打印消息,怎么实现呢?CountDownLatch就可以解决这一类问题。
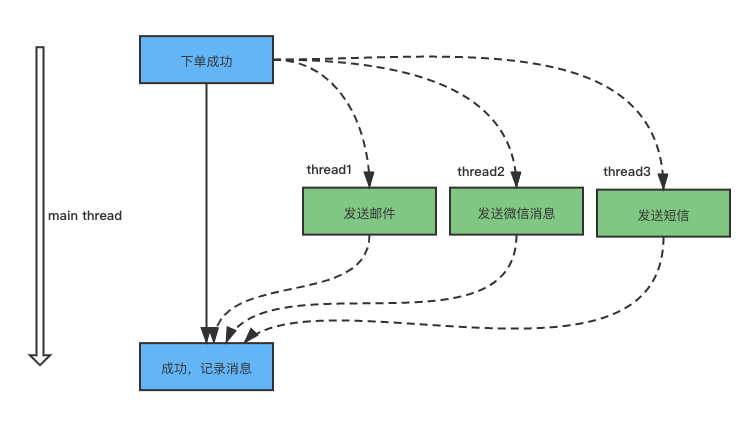
我们使用代码实现上面的需求。
```java
import java.util.concurrent.*;
public class OrderServiceDemo {
public static void main(String[] args) throws InterruptedException {
System.out.println("main thread: Success to place an order");
int count = 3;
CountDownLatch countDownLatch = new CountDownLatch(count);
Executor executor = Executors.newFixedThreadPool(count);
executor.execute(new MessageTask("email", countDownLatch));
executor.execute(new MessageTask("wechat", countDownLatch));
executor.execute(new MessageTask("sms", countDownLatch));
// 主线程阻塞,等待所有子线程发完消息
countDownLatch.await();
// 所有子线程已经发完消息,计数器为0,主线程恢复
System.out.println("main thread: all message has been sent");
}
static class MessageTask implements Runnable {
private String messageName;
private CountDownLatch countDownLatch;
public MessageTask(String messageName, CountDownLatch countDownLatch) {
this.messageName = messageName;
this.countDownLatch = countDownLatch;
}
@Override
public void run() {
try {
// 线程发送消息
System.out.println("Send " + messageName);
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
} finally {
// 发完消息计数器减 1
countDownLatch.countDown();
}
}
}
}
```
程序运行结果:
```text
main thread: Success to place an order
Send email
Send wechat
Send sms
main thread: all message has been sent
```
从运行结果可以看到主线程是在所有的子线程发送完消息后才打印,这符合我们的预期。
# CountDownLatch 的限制
CountDownLatch是一次性的,计算器的值只能在构造方法中初始化一次,之后没有任何机制再次对其设置值,当CountDownLatch使用完毕后,它不能再次被使用。
================================================
FILE: docs/java/juc/内存泄露的原因找到了,罪魁祸首居然是Java TheadLocal.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321684&idx=1&sn=c3f63443f7e6fb4f373a30699f51e55f&chksm=8f09cd0eb87e44185016b022fdf24e735684e91e5d1ae390b861098c18e3fb26925053b2fd50&token=1553501157&lang=zh_CN#rd)』,欢迎大家关注。
<!-- TOC -->
- [ThreadLocal的value值存在哪里?](#threadlocal的value值存在哪里)
- [ThreadLocal类set方法](#threadlocal类set方法)
- [ThreadLocal类get方法](#threadlocal类get方法)
- [ThreadLocal相关类的关系总结](#threadlocal相关类的关系总结)
- [ThreadLocal内存模型原理](#threadlocal内存模型原理)
- [强引用弱引用的概念](#强引用弱引用的概念)
- [强引用](#强引用)
- [弱引用](#弱引用)
- [软引用](#软引用)
- [虚引用](#虚引用)
- [内存泄露是不是弱引用的锅?](#内存泄露是不是弱引用的锅)
- [ThreadLocal最佳实践](#threadlocal最佳实践)
<!-- /TOC -->
组内来了一个实习生,看这小伙子春光满面、精神抖擞、头发微少,我心头一喜:绝对是个潜力股。于是我找经理申请亲自来带他,为了帮助小伙子快速成长,我给他分了一个需求,这不需求刚上线几天就出网上问题了😭后台监控服务发现内存一直在缓慢上升,初步怀疑是内存泄露。
把实习生的PR都找出来仔细review,果然发现问题了。由于公司内部代码是保密的,这里简单写一个demo还原场景(忽略代码风格问题)。
```java
public class ThreadPoolDemo {
private static final ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(5, 5, 1, TimeUnit.MINUTES, new LinkedBlockingQueue<>());
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 100; ++i) {
poolExecutor.execute(new Runnable() {
@Override
public void run() {
ThreadLocal<BigObject> threadLocal = new ThreadLocal<>();
threadLocal.set(new BigObject());
// 其他业务代码
}
});
Thread.sleep(1000);
}
}
static class BigObject {
// 100M
private byte[] bytes = new byte[100 * 1024 * 1024];
}
}
```
代码分析:
* 创建一个核心线程数和最大线程数都为10的线程池,保证线程池里一直会有10个线程在运行。
* 使用for循环向线程池中提交了100个任务。
* 定义了一个ThreadLocal类型的变量,Value类型是大对象。
* 每个任务会向threadLocal变量里塞一个大对象,然后执行其他业务逻辑。
* 由于没有调用线程池的shutdown方法,线程池里的线程还是会在运行。
乍一看这代码好像没有什么问题,那为什么会导致服务GC后内存还高居不下呢?
代码中给threadLocal赋值了一个大的对象,但是执行完业务逻辑后没有调用remove方法,最后导致线程池中10个线程的threadLocals变量中包含的大对象没有被释放掉,出现了内存泄露。
大家说说这样的实习生还能留不?
# ThreadLocal的value值存在哪里?
实习生说他以为线程任务结束了threadLocal赋值的对象会被JVM垃圾回收,很疑惑为什么会出现内存泄露。作为师傅我肯定要给他把原理讲透呀。
ThreadLocal类提供set/get方法存储和获取value值,但实际上ThreadLocal类并不存储value值,真正存储是靠ThreadLocalMap这个类,ThreadLocalMap是ThreadLocal的一个静态内部类,它的key是ThreadLocal实例对象,value是任意Object对象。
ThreadLocalMap类的定义
```java
static class ThreadLocalMap {
// 定义一个table数组,存储多个threadLocal对象及其value值
private Entry[] table;
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
// 定义一个Entry类,key是一个弱引用的ThreadLocal对象
// value是任意对象
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
// 省略其他
}
```
进一步分析ThreadLocal类的代码,看set和get方法如何与ThreadLocalMap静态内部类关联上。
## ThreadLocal类set方法
```java
public class ThreadLocal<T> {
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
// 省略其他方法
}
```
set的逻辑比较简单,就是获取当前线程的ThreadLocalMap,然后往map里添加KV,K是当前ThreadLocal实例,V是我们传入的value。
这里需要注意一下,map的获取是需要从Thread类对象里面取,看一下Thread类的定义。
```java
public class Thread implements Runnable {
ThreadLocal.ThreadLocalMap threadLocals = null;
//省略其他
}
```
Thread类维护了一个ThreadLocalMap的变量引用。
## ThreadLocal类get方法
get获取当前线程的对应的私有变量,是之前set或者通过initialValue的值,代码如下:
```java
class ThreadLocal<T> {
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null)
return (T)e.value;
}
return setInitialValue();
}
}
```
代码逻辑分析:
* 获取当前线程的ThreadLocalMap实例;
* 如果不为空,以当前ThreadLocal实例为key获取value;
* 如果ThreadLocalMap为空或者根据当前ThreadLocal实例获取的value为空,则执行setInitialValue();
# ThreadLocal相关类的关系总结
看了上面的分析是不是对Thread,ThreadLocal,ThreadLocalMap,Entry这几个类之间的关系有点晕了,没关系我专门画了一个UML类图来总结(忽略UML标准语法)。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504233932-2021-05-04-23-39-33.png" alt="20210504233932-2021-05-04-23-39-33">
* 每个线程是一个Thread实例,其内部维护一个threadLocals的实例成员,其类型是ThreadLocal.ThreadLocalMap。
* 通过实例化ThreadLocal实例,我们可以对当前运行的线程设置一些线程私有的变量,通过调用ThreadLocal的set和get方法存取。
* ThreadLocal本身并不是一个容器,我们存取的value实际上存储在ThreadLocalMap中,ThreadLocal只是作为TheadLocalMap的key。
* 每个线程实例都对应一个TheadLocalMap实例,我们可以在同一个线程里实例化很多个ThreadLocal来存储很多种类型的值,这些ThreadLocal实例分别作为key,对应各自的value,最终存储在Entry table数组中。
* 当调用ThreadLocal的set/get进行赋值/取值操作时,首先获取当前线程的ThreadLocalMap实例,然后就像操作一个普通的map一样,进行put和get。
# ThreadLocal内存模型原理
经过上面的分析我们对ThreadLocal相关的类设计已经非常清楚了,下面通过一张图更加深入理解一下ThreadLocal的内存存储。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210504233947-2021-05-04-23-39-48.png" alt="20210504233947-2021-05-04-23-39-48">
图中左边是栈,右边是堆。线程的一些局部变量和引用使用的内存属于Stack(栈)区,而普通的对象是存储在Heap(堆)区。
* 线程运行时,我们定义的TheadLocal对象被初始化,存储在Heap,同时线程运行的栈区保存了指向该实例的引用,也就是图中的ThreadLocalRef。
* 当ThreadLocal的set/get被调用时,虚拟机会根据当前线程的引用也就是CurrentThreadRef找到其对应在堆区的实例,然后查看其对用的TheadLocalMap实例是否被创建,如果没有,则创建并初始化。
* Map实例化之后,也就拿到了该ThreadLocalMap的句柄,那么就可以将当前ThreadLocal对象作为key,进行存取操作。
* 图中的虚线,表示key对应ThreadLocal实例的引用是个弱引用。
# 强引用弱引用的概念
ThreadLocalMap的key是一个弱引用类型,源代码如下:
```java
static class ThreadLocalMap {
// 定义一个Entry类,key是一个弱引用的ThreadLocal对象
// value是任意对象
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
// 省略其他
}
```
下面解释一下常见的几种引用概念。
## 强引用
**一直活着**:类似“Object obj=new Object()”这类的引用,只要强引用还存在,垃圾收集器永远不会回收掉被引用的对象实例。
## 弱引用
**回收就会死亡**:被弱引用关联的对象实例只能生存到下一次垃圾收集发生之前。当垃圾收集器工作时,无论当前内存是否足够,都会回收掉只被弱引用关联的对象实例。在JDK 1.2之后,提供了WeakReference类来实现弱引用。
## 软引用
**有一次活的机会**:软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象实例列进回收范围之中进行第二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常。在JDK 1.2之后,提供了SoftReference类来实现软引用。
## 虚引用
**也称为幽灵引用或者幻影引用**,它是最弱的一种引用关系。一个对象实例是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的就是能在这个对象实例被收集器回收时收到一个系统通知。在JDK 1.2之后,提供了PhantomReference类来实现虚引用。
# 内存泄露是不是弱引用的锅?
从表面上看内存泄漏的根源在于使用了弱引用,但是另一个问题也同样值得思考:为什么ThreadLocalMap使用弱引用而不是强引用?
翻看官网文档的说法:
>To help deal with very large and long-lived usages, the hash table entries use WeakReferences for keys.
>>为了处理非常大和长期的用途,哈希表条目使用weakreference作为键。
分两种情况讨论:
**(1)key 使用强引用**
引用ThreadLocal的对象被回收了,但是ThreadLocalMap还持有ThreadLocal的强引用,如果没有手动删除,ThreadLocal不会被回收,导致Entry内存泄漏。
**(2)key 使用弱引**
引用ThreadLocal的对象被回收了,由于ThreadLocalMap持有ThreadLocal的弱引用,即使没有手动删除,ThreadLocal也会被回收。value在下一次ThreadLocalMap调用set、get、remove的时候会被清除。
比较两种情况,我们可以发现:由于ThreadLocalMap的生命周期跟Thread一样长,如果都没有手动删除对应key,都会导致内存泄漏,但是使用弱引用可以多一层保障:弱引用ThreadLocal被清理后key为null,对应的value在下一次ThreadLocalMap调用set、get、remove的时候可能会被清除。
因此,ThreadLocal内存泄漏的根源是:由于ThreadLocalMap的生命周期跟Thread一样长,如果没有手动删除对应key就会导致内存泄漏,而不是因为弱引用。
# ThreadLocal最佳实践
通过前面几小节我们分析了ThreadLocal的类设计以及内存模型,同时也重点分析了发生内存泄露的条件和特定场景。最后结合项目中的经验给出建议使用ThreadLocal的场景:
* 当需要存储线程私有变量的时候。
* 当需要实现线程安全的变量时。
* 当需要减少线程资源竞争的时候。
综合上面的分析,我们可以理解ThreadLocal内存泄漏的前因后果,那么怎么避免内存泄漏呢?
答案就是:每次使用完ThreadLocal,建议调用它的remove()方法,清除数据。
另外需要强调的是并不是所有使用ThreadLocal的地方,都要在最后remove(),因为他们的生命周期可能是需要和项目的生存周期一样长的,所以要进行恰当的选择,以免出现业务逻辑错误!
================================================
FILE: docs/java/juc/十张图告诉你多线程那些破事.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650324639&idx=1&sn=3079f422a81ff29549df968d67961a18&chksm=8f09c085b87e4993c30975e0e7e422865c8e92d314bc01042f139d6e57365e15e17f22451f4d&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
<!-- TOC -->
- [线程安全问题](#线程安全问题)
- [活跃性问题](#活跃性问题)
- [性能问题](#性能问题)
- [有态度的总结](#有态度的总结)
<!-- /TOC -->
```
头发很多的程序员:『师父,这个批量处理接口太慢了,有什么办法可以优化?』
架构师:『试试使用多线程优化』
第二天
头发很多的程序员:『师父,我已经使用了多线程,为什么接口还变慢了?』
架构师:『去给我买杯咖啡,我写篇文章告诉你』
……吭哧吭哧买咖啡去了
```
在实际工作中,错误使用多线程非但不能提高效率还可能使程序崩溃。以在路上开车为例:
在一个单向行驶的道路上,每辆汽车都遵守交通规则,这时候整体通行是正常的。『单向车道』意味着『一个线程』,『多辆车』意味着『多个job任务』。
如果需要提升车辆的同行效率,一般的做法就是扩展车道,对应程序来说就是『加线程池』,增加线程数。这样在同一时间内,通行的车辆数远远大于单车道。
然而成年人的世界没有那么完美,车道一旦多起来『加塞』的场景就会越来越多,出现碰撞后也会影响整条马路的通行效率。这么一对比下来『多车道』确实可能比『单车道』要慢。
防止汽车频繁变道加塞可以采取在车道间增加『护栏』,那在程序的世界该怎么做呢?
程序世界中多线程遇到的问题归纳起来就是三类:`『线程安全问题』`、`『活跃性问题』`、`『性能问题』`,接下来会讲解这些问题,以及问题对应的解决手段。
## 线程安全问题
有时候我们会发现,明明在单线程环境中正常运行的代码,在多线程环境中可能会出现意料之外的结果,其实这就是大家常说的『线程不安全』。那到底什么是线程不安全呢?往下看。
**原子性**
举一个银行转账的例子,比如从账户A向账户B转1000元,那么必然包括2个操作:从账户A减去1000元,往账户B加上1000元,两个操作都成功才意味着一次转账最终成功。
试想一下,如果这两个操作不具备原子性,从A的账户扣减了1000元之后,操作突然终止了,账户B没有增加1000元,那问题就大了。
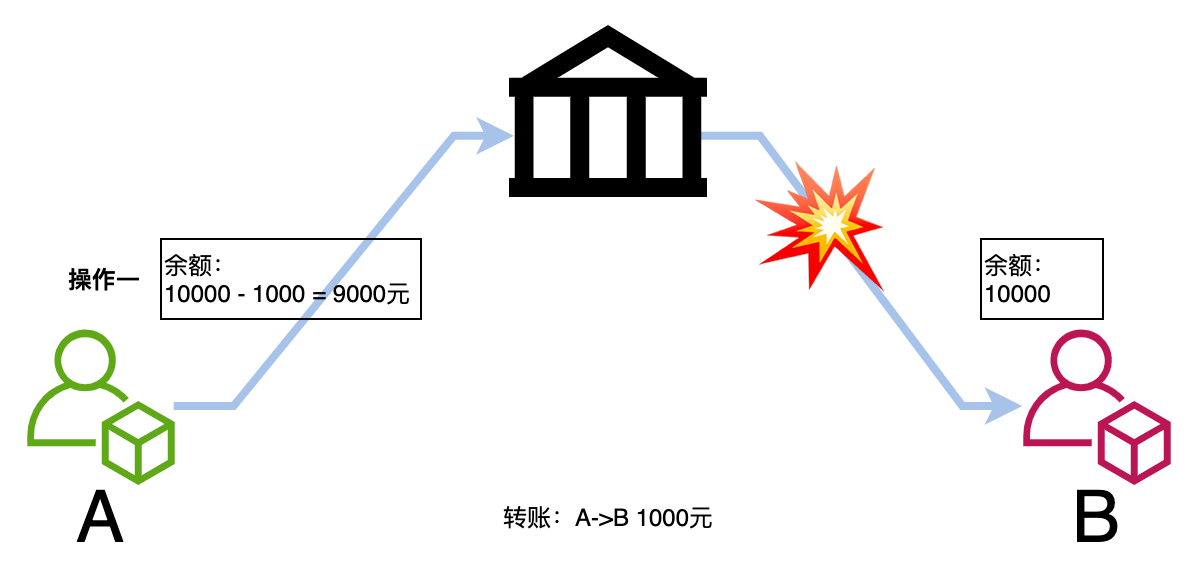
银行转账这个例子有两个步骤,出现了意外后导致转账失败,说明没有原子性。
> 原子性:即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
>
> 原子操作:即不会被线程调度机制打断的操作,没有上下文切换。
在并发编程中很多操作都不是原子操作,出个小题目:
```java
i = 0; // 操作1
i++; // 操作2
i = j; // 操作3
i = i + 1; // 操作4
```
上面这四个操作中有哪些是原子操作,哪些不是的?不熟悉的人可能认为这些都是原子操作,其实只有操作1是原子操作。
- 操作1:对基本数据类型变量的赋值是原子操作;
- 操作2:包含三个操作,读取i的值,将i加1,将值赋给i;
- 操作3:读取j的值,将j的值赋给i;
- 操作4:包含三个操作,读取i的值,将i加1,将值赋给i;
在单线程环境下上述四个操作都不会出现问题,但是在多线程环境下,如果不通过加锁操作,往往可能得到意料之外的值。
在Java语言中通过可以使用synchronize或者lock来保证原子性。
**可见性**
talk is cheap,先show一段代码:
```java
/**
* Author: leixiaoshuai
*/
class Test {
int i = 50;
int j = 0;
public void update() {
// 线程1执行
i = 100;
}
public int get() {
// 线程2执行
j = i;
return j;
}
}
```
线程1执行update方法将 i 赋值为100,一般情况下线程1会在自己的工作内存中完成赋值操作,却没有及时将新值刷新到主内存中。
这个时候线程2执行get方法,首先会从主内存中读取i的值,然后加载到自己的工作内存中,这个时候读取到i的值是50,再将50赋值给j,最后返回j的值就是50了。原本期望返回100,结果返回50,这就是可见性问题,线程1对变量i进行了修改,线程2没有立即看到i的新值。
> 可见性:指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
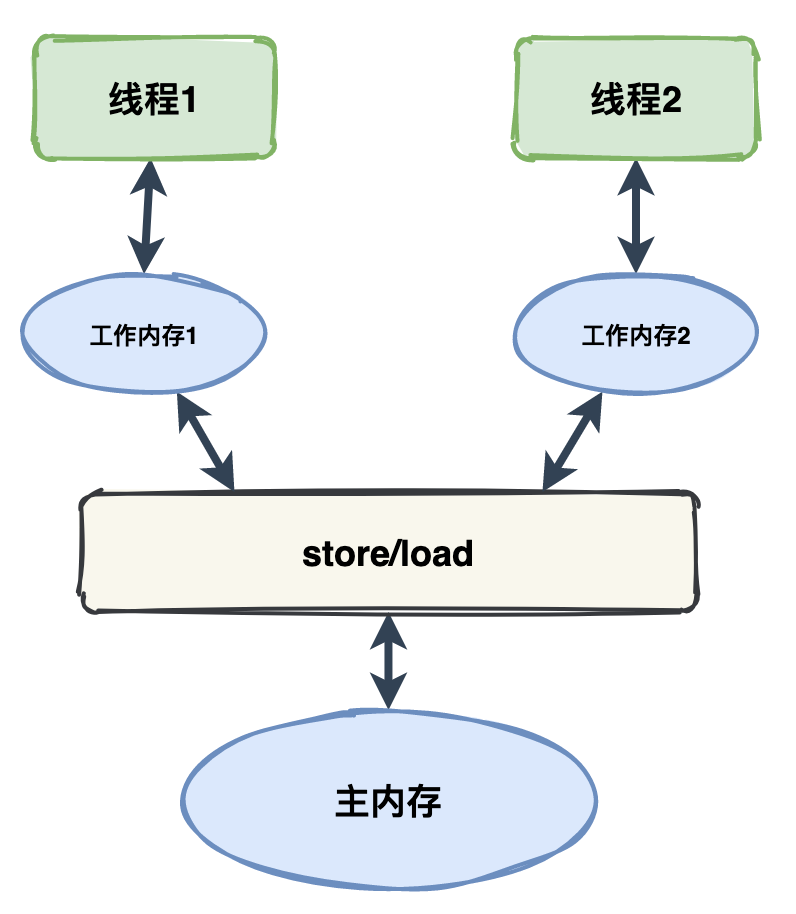
如上图每个线程都有属于自己的工作内存,工作内存和主内存间需要通过store和load等进行交互。
为了解决多线程可见性问题,Java语言提供了`volatile`这个关键字。当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。而普通共享变量不能保证可见性,因为变量被修改后什么时候刷回到主存是不确定的,另外一个线程读的可能就是旧值。
当然Java的锁机制如synchronize和lock也是可以保证可见性的,加锁可以保证在同一时刻只有一个线程在执行同步代码块,释放锁之前会将变量刷回至主存,这样也就保证了可见性。
关于线程不安全的表现还有『有序性』,这个问题会在后面的文章中深入讲解。
## 活跃性问题
上面讲到为了解决`可见性`问题,我们可以采取加锁方式解决,但是如果加锁使用不当也容易引入其他问题,比如『死锁』。
在说『死锁』前我们先引入另外一个概念:`活跃性问题`。
> 活跃性是指某件正确的事情最终会发生,当某个操作无法继续下去的时候,就会发生活跃性问题。
概念是不是有点拗口,如果看不懂也没关系,你可以记住活跃性问题一般有这样几类:`死锁`,`活锁`,`饥饿问题`。
**(1)死锁**
死锁是指多个线程因为环形的等待锁的关系而永远的阻塞下去。一图胜千语,不多解释。
**(2)活锁**
死锁是两个线程都在等待对方释放锁导致阻塞。而`活锁`的意思是线程没有阻塞,还活着呢。
当多个线程都在运行并且修改各自的状态,而其他线程彼此依赖这个状态,导致任何一个线程都无法继续执行,只能重复着自身的动作和修改自身的状态,这种场景就是发生了活锁。

如果大家还有疑惑,那我再举一个生活中的例子,大家平时在走路的时候,迎面走来一个人,两个人互相让路,但是又同时走到了一个方向,如果一直这样重复着避让,这俩人就是发生了活锁,学到了吧,嘿嘿。
**(3)饥饿**
如果一个线程无其他异常却迟迟不能继续运行,那基本是处于饥饿状态了。
常见有几种场景:
- 高优先级的线程一直在运行消耗CPU,所有的低优先级线程一直处于等待;
- 一些线程被永久堵塞在一个等待进入同步块的状态,而其他线程总是能在它之前持续地对该同步块进行访问;
有一个非常经典的饥饿问题就是`哲学家用餐问题`,如下图所示,有五个哲学家在用餐,每个人必须要同时拿两把叉子才可以开始就餐,如果哲学家1和哲学家3同时开始就餐,那哲学家2、4、5就得饿肚子等待了。
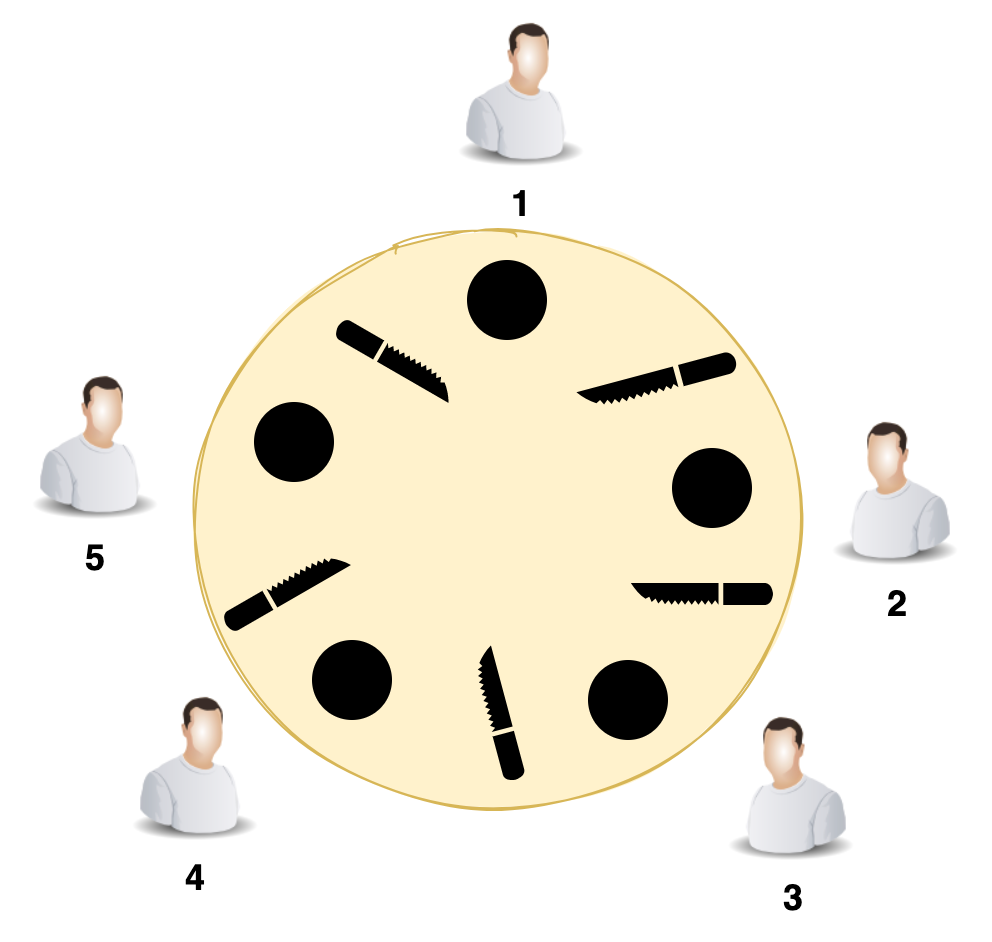
## 性能问题
前面讲到了线程安全和死锁、活锁这些问题会影响多线程执行过程,如果这些都没有发生,多线程并发一定比单线程串行执行快吗,答案是不一定,因为多线程有`创建线程`和`线程上下文切换`的开销。
创建线程是直接向系统申请资源的,对操作系统来说创建一个线程的代价是十分昂贵的,需要给它分配内存、列入调度等。
线程创建完之后,还会遇到线程`上下文切换`。
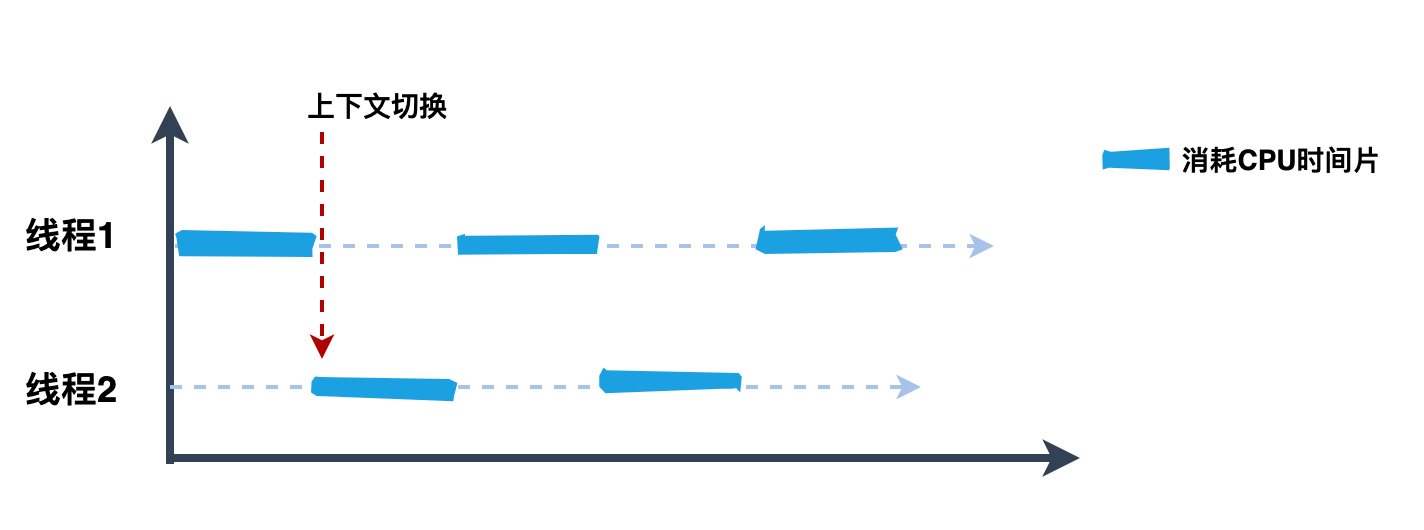
CPU是很宝贵的资源速度也非常快,为了保证雨露均沾,通常为给不同的线程分配`时间片`,当CPU从执行一个线程切换到执行另一个线程时,CPU 需要保存当前线程的本地数据,程序指针等状态,并加载下一个要执行的线程的本地数据,程序指针等,这个开关被称为『上下文切换』。
一般减少上下文切换的方法有:`无锁并发编程`、`CAS 算法`、`使用协程`等。
## 有态度的总结
多线程用好了可以让程序的效率成倍提升,用不好可能比单线程还要慢。
用一张图总结一下上面讲的:
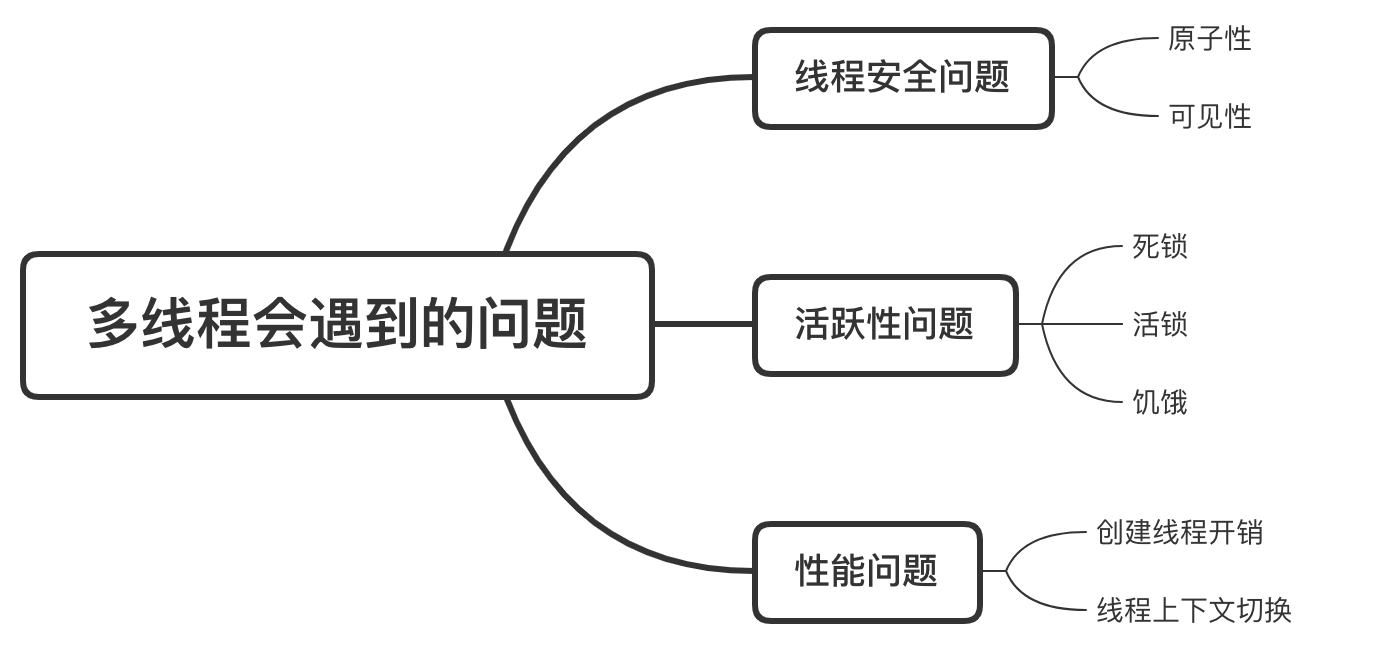
-- END --
文章讲了多线程并发会遇到的问题,你可能也发现了,文章中并没有给出具体的解决方案,因为这些问题在Java语言设计过程中大神都已经为你考虑过了。
Java并发编程学起来有一定难度,但这也是从`初级程序员`迈向`中高级程序员`的必经道路,接下来的文章会带领大家逐个击破!
================================================
FILE: docs/java/juc/图解Java中那18 把锁.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650325236&idx=1&sn=95a3d9aa64d5c0757bc46a46ff266832&chksm=8f09beeeb87e37f899aabc307a47488fe81b974a3e328b9f48d97cf6f03f92285398022814be&token=1565452340&lang=zh_CN#rd)』,欢迎大家关注。
- [乐观锁和悲观锁](#乐观锁和悲观锁)
- [独占锁和共享锁](#独占锁和共享锁)
- [互斥锁和读写锁](#互斥锁和读写锁)
- [公平锁和非公平锁](#公平锁和非公平锁)
- [可重入锁](#可重入锁)
- [自旋锁](#自旋锁)
- [分段锁](#分段锁)
- [锁升级(无锁|偏向锁|轻量级锁|重量级锁)](#锁升级无锁偏向锁轻量级锁重量级锁)
- [锁优化技术(锁粗化、锁消除)](#锁优化技术锁粗化锁消除)
# 乐观锁和悲观锁
**悲观锁**
`悲观锁`对应于生活中悲观的人,悲观的人总是想着事情往坏的方向发展。
举个生活中的例子,假设厕所只有一个坑位了,悲观锁上厕所会第一时间把门反锁上,这样其他人上厕所只能在门外等候,这种状态就是「阻塞」了。
回到代码世界中,一个共享数据加了悲观锁,那线程每次想操作这个数据前都会假设其他线程也可能会操作这个数据,所以每次操作前都会上锁,这样其他线程想操作这个数据拿不到锁只能阻塞了。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210606232504-2021-06-06-23-25-04.png" alt="20210606232504-2021-06-06-23-25-04">
在 Java 语言中 `synchronized` 和 `ReentrantLock`等就是典型的悲观锁,还有一些使用了 synchronized 关键字的容器类如 `HashTable` 等也是悲观锁的应用。
**乐观锁**
`乐观锁` 对应于生活中乐观的人,乐观的人总是想着事情往好的方向发展。
举个生活中的例子,假设厕所只有一个坑位了,乐观锁认为:这荒郊野外的,又没有什么人,不会有人抢我坑位的,每次关门上锁多浪费时间,还是不加锁好了。你看乐观锁就是天生乐观!
回到代码世界中,乐观锁操作数据时不会上锁,在更新的时候会判断一下在此期间是否有其他线程去更新这个数据。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210606232434-2021-06-06-23-24-35.png" alt="20210606232434-2021-06-06-23-24-35">
乐观锁可以使用`版本号机制`和`CAS算法`实现。在 Java 语言中 `java.util.concurrent.atomic`包下的原子类就是使用CAS 乐观锁实现的。
**两种锁的使用场景**
悲观锁和乐观锁没有孰优孰劣,有其各自适应的场景。
乐观锁适用于写比较少(冲突比较小)的场景,因为不用上锁、释放锁,省去了锁的开销,从而提升了吞吐量。
如果是写多读少的场景,即冲突比较严重,线程间竞争激励,使用乐观锁就是导致线程不断进行重试,这样可能还降低了性能,这种场景下使用悲观锁就比较合适。
# 独占锁和共享锁
**独占锁**
`独占锁`是指锁一次只能被一个线程所持有。如果一个线程对数据加上排他锁后,那么其他线程不能再对该数据加任何类型的锁。获得独占锁的线程即能读数据又能修改数据。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210606232544-2021-06-06-23-25-45.png" alt="20210606232544-2021-06-06-23-25-45">
JDK中的`synchronized`和`java.util.concurrent(JUC)`包中Lock的实现类就是独占锁。
**共享锁**
`共享锁`是指锁可被多个线程所持有。如果一个线程对数据加上共享锁后,那么其他线程只能对数据再加共享锁,不能加独占锁。获得共享锁的线程只能读数据,不能修改数据。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210606232612-2021-06-06-23-26-13.png" alt="20210606232612-2021-06-06-23-26-13">
在 JDK 中 `ReentrantReadWriteLock` 就是一种共享锁。
# 互斥锁和读写锁
**互斥锁**
`互斥锁`是独占锁的一种常规实现,是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210606232634-2021-06-06-23-26-35.png" alt="20210606232634-2021-06-06-23-26-35">
互斥锁一次只能一个线程拥有互斥锁,其他线程只有等待。
**读写锁**
`读写锁`是共享锁的一种具体实现。读写锁管理一组锁,一个是只读的锁,一个是写锁。
读锁可以在没有写锁的时候被多个线程同时持有,而写锁是独占的。写锁的优先级要高于读锁,一个获得了读锁的线程必须能看到前一个释放的写锁所更新的内容。
读写锁相比于互斥锁并发程度更高,每次只有一个写线程,但是同时可以有多个线程并发读。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210606232658-2021-06-06-23-26-59.png" alt="20210606232658-2021-06-06-23-26-59">
在 JDK 中定义了一个读写锁的接口:`ReadWriteLock`
```java
public interface ReadWriteLock {
/**
* 获取读锁
*/
Lock readLock();
/**
* 获取写锁
*/
Lock writeLock();
}
```
`ReentrantReadWriteLock` 实现了`ReadWriteLock`接口,具体实现这里不展开,后续会深入源码解析。
# 公平锁和非公平锁
**公平锁**
`公平锁`是指多个线程按照申请锁的顺序来获取锁,这里类似排队买票,先来的人先买,后来的人在队尾排着,这是公平的。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210606232716-2021-06-06-23-27-17.png" alt="20210606232716-2021-06-06-23-27-17">
在 java 中可以通过构造函数初始化公平锁
```java
/**
* 创建一个可重入锁,true 表示公平锁,false 表示非公平锁。默认非公平锁
*/
Lock lock = new ReentrantLock(true);
```
**非公平锁**
`非公平锁`是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁,在高并发环境下,有可能造成优先级翻转,或者饥饿的状态(某个线程一直得不到锁)。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210606232737-2021-06-06-23-27-38.png" alt="20210606232737-2021-06-06-23-27-38">
在 java 中 synchronized 关键字是非公平锁,ReentrantLock默认也是非公平锁。
```java
/**
* 创建一个可重入锁,true 表示公平锁,false 表示非公平锁。默认非公平锁
*/
Lock lock = new ReentrantLock(false);
```
# 可重入锁
`可重入锁`又称之为`递归锁`,是指同一个线程在外层方法获取了锁,在进入内层方法会自动获取锁。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210606232755-2021-06-06-23-27-56.png" alt="20210606232755-2021-06-06-23-27-56">
对于Java ReentrantLock而言, 他的名字就可以看出是一个可重入锁。对于Synchronized而言,也是一个可重入锁。
敲黑板:可重入锁的一个好处是可一定程度避免死锁。
以 synchronized 为例,看一下下面的代码:
```java
public synchronized void mehtodA() throws Exception{
// Do some magic tings
mehtodB();
}
public synchronized void mehtodB() throws Exception{
// Do some magic tings
}
```
上面的代码中 methodA 调用 methodB,如果一个线程调用methodA 已经获取了锁再去调用 methodB 就不需要再次获取锁了,这就是可重入锁的特性。如果不是可重入锁的话,mehtodB 可能不会被当前线程执行,可能造成死锁。
# 自旋锁
`自旋锁`是指线程在没有获得锁时不是被直接挂起,而是执行一个忙循环,这个忙循环就是所谓的自旋。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210606232809-2021-06-06-23-28-09.png" alt="20210606232809-2021-06-06-23-28-09">
自旋锁的目的是为了减少线程被挂起的几率,因为线程的挂起和唤醒也都是耗资源的操作。
如果锁被另一个线程占用的时间比较长,即使自旋了之后当前线程还是会被挂起,忙循环就会变成浪费系统资源的操作,反而降低了整体性能。因此自旋锁是不适应锁占用时间长的并发情况的。
在 Java 中,`AtomicInteger` 类有自旋的操作,我们看一下代码:
```java
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);
} while (!compareAndSwapInt(o, offset, v, v + delta));
return v;
}
```
CAS 操作如果失败就会一直循环获取当前 value 值然后重试。
另外自适应自旋锁也需要了解一下。
在JDK1.6又引入了自适应自旋,这个就比较智能了,自旋时间不再固定,由前一次在同一个锁上的自旋时间以及锁的拥有者的状态来决定。如果虚拟机认为这次自旋也很有可能再次成功那就会次序较多的时间,如果自旋很少成功,那以后可能就直接省略掉自旋过程,避免浪费处理器资源。
# 分段锁
`分段锁` 是一种锁的设计,并不是具体的一种锁。
分段锁设计目的是将锁的粒度进一步细化,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210606232830-2021-06-06-23-28-31.png" alt="20210606232830-2021-06-06-23-28-31">
在 Java 语言中 CurrentHashMap 底层就用了分段锁,使用Segment,就可以进行并发使用了。
# 锁升级(无锁|偏向锁|轻量级锁|重量级锁)
JDK1.6 为了提升性能减少获得锁和释放锁所带来的消耗,引入了4种锁的状态:`无锁`、`偏向锁`、`轻量级锁`和`重量级锁`,它会随着多线程的竞争情况逐渐升级,但不能降级。
**无锁**
`无锁`状态其实就是上面讲的乐观锁,这里不再赘述。
**偏向锁**
Java偏向锁(Biased Locking)是指它会偏向于第一个访问锁的线程,如果在运行过程中,只有一个线程访问加锁的资源,不存在多线程竞争的情况,那么线程是不需要重复获取锁的,这种情况下,就会给线程加一个偏向锁。
偏向锁的实现是通过控制对象`Mark Word`的标志位来实现的,如果当前是`可偏向状态`,需要进一步判断对象头存储的线程 ID 是否与当前线程 ID 一致,如果一致直接进入。
**轻量级锁**
当线程竞争变得比较激烈时,偏向锁就会升级为`轻量级锁`,轻量级锁认为虽然竞争是存在的,但是理想情况下竞争的程度很低,通过`自旋方式`等待上一个线程释放锁。
**重量级锁**
如果线程并发进一步加剧,线程的自旋超过了一定次数,或者一个线程持有锁,一个线程在自旋,又来了第三个线程访问时(反正就是竞争继续加大了),轻量级锁就会膨胀为`重量级锁`,重量级锁会使除了此时拥有锁的线程以外的线程都阻塞。
升级到重量级锁其实就是互斥锁了,一个线程拿到锁,其余线程都会处于阻塞等待状态。
在 Java 中,synchronized 关键字内部实现原理就是锁升级的过程:无锁 --> 偏向锁 --> 轻量级锁 --> 重量级锁。这一过程在后续讲解 synchronized 关键字的原理时会详细介绍。
# 锁优化技术(锁粗化、锁消除)
**锁粗化**
`锁粗化`就是将多个同步块的数量减少,并将单个同步块的作用范围扩大,本质上就是将多次上锁、解锁的请求合并为一次同步请求。
举个例子,一个循环体中有一个代码同步块,每次循环都会执行加锁解锁操作。
```java
private static final Object LOCK = new Object();
for(int i = 0;i < 100; i++) {
synchronized(LOCK){
// do some magic things
}
}
```
经过`锁粗化`后就变成下面这个样子了:
```java
synchronized(LOCK){
for(int i = 0;i < 100; i++) {
// do some magic things
}
}
```
**锁消除**
`锁消除`是指虚拟机编译器在运行时检测到了共享数据没有竞争的锁,从而将这些锁进行消除。
举个例子让大家更好理解。
```java
public String test(String s1, String s2){
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(s1);
stringBuffer.append(s2);
return stringBuffer.toString();
}
```
上面代码中有一个 test 方法,主要作用是将字符串 s1 和字符串 s2 串联起来。
test 方法中三个变量s1, s2, stringBuffer, 它们都是局部变量,局部变量是在栈上的,栈是线程私有的,所以就算有多个线程访问 test 方法也是线程安全的。
我们都知道 StringBuffer 是线程安全的类,append 方法是同步方法,但是 test 方法本来就是线程安全的,为了提升效率,虚拟机帮我们消除了这些同步锁,这个过程就被称为`锁消除`。
```java
StringBuffer.class
// append 是同步方法
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
```
一张图总结:
前面讲了 Java 语言中各种各种的锁,最后再通过六个问题统一总结一下:
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/Java中那些眼花缭乱的锁-2021-06-16-23-19-40.png" alt="Java中那些眼花缭乱的锁-2021-06-16-23-19-40">
================================================
FILE: docs/java/juc/面试官:说说Atomic原子类的实现原理.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650325167&idx=1&sn=b71f86a9e25deb9a01721142fbc13902&chksm=8f09beb5b87e37a3efe9b41b2392aafdcf4ee126d4d9c4a5ecc7a39ab876f3498e2296a7e01d&token=1052638001&lang=zh_CN&scene=21#wechat_redirect)』,欢迎大家关注。
<!-- TOC -->
- [线程安全真的是线程的安全吗?](#线程安全真的是线程的安全吗)
- [什么是 Atomic?](#什么是-atomic)
- [实现一个计数器](#实现一个计数器)
- [AtomicInteger 源码分析](#atomicinteger-源码分析)
- [AtomicLong 和 LongAdder 谁更牛?](#atomiclong-和-longadder-谁更牛)
- [总结](#总结)
<!-- /TOC -->
当我们谈论『线程安全』的时候,肯定都会想到 Atomic 类。不错,Atomic 相关类都是线程安全的,在讲 Atomic 类之前我想再聊聊『线程安全』这个概念。
# 线程安全真的是线程的安全吗?
初看『线程安全』这几个字,很容易望文生义,这不就是线程的安全吗?其实不是,线程本身没有好坏,没有『安全的线程』和『不安全的线程』之分,俗话说:人之初性本善,线程天生也是纯洁善良的,真正让线程变坏是因为访问的变量的原因,变量对于操作系统来说其实就是内存块,所以绕了这么一大圈,线程安全称为『内存的安全』可能更为贴切。
简而言之,线程访问的内存决定了这个线程是否是安全的。
变量大致可以分为**局部变量**和**共享变量**,局部变量对于 JVM 来说是栈空间,大家都背过八股文,栈是线程私有的是非共享的,那自然也是内存安全的;共享变量对于 JVM 来说一般是存在于堆上,堆上的东西是所有线程共享的,如果不加任何限制自然是不安全的。
因为线程安全这个概念已经深入人心了,所以后面我们还是用线程安全来表达内存安全的含义。
那如何解决这种`不安全`呢?方法有很多,比如:加锁、Atomic 原子类等。
好了,咱们今天先来看看`Atomic类`。
# 什么是 Atomic?
`Java`从`JDK1.5`开始提供`java.util.concurrent.atomic`包,这里包含了多个原子操作类。原子操作类提供了一个简单、高效、安全的方式去更新一个变量。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210602205949-2021-06-02-20-59-50.png" alt="20210602205949-2021-06-02-20-59-50" height="300">
Atomic 包下的原子操作类有很多,可以大致分为四种类型:
- 原子操作基本类型
- 原子操作数组类型
- 原子操作引用类型
- 原子操作更新属性
Atomic原子操作类在源码中都使用了`Unsafe类`,`Unsafe类`提供了硬件级别的原子操作,可以安全地直接操作内存变量。后面讲解源码时再详细介绍。
# 实现一个计数器
假如在业务代码中需要实现一个计数器的功能,啪地一下,很快我们就写出了以下的代码:
```java
/**
* Author: leixiaoshuai
*/
public class Counter {
private int count;
public void increase() {
count++;
}
}
```
`increase`方法对 count 变量进行递增。
当代码提交上库进行`code review`时,啪地一下,很快收到了检视意见(严重级别):
> 如果在多线程场景下,你的计数器可能有问题。
上大一的时候老师就讲过 `count++` 是非原子性的,它实际上包含了三个操作:读数据,加一,写回数据。
再次修改代码,多线访问`increase方法`会有问题,那就给它加个锁吧,count变量修改了其他线程可能不能即时看到,那就给变量加个 `volatile` 吧。
吭哧吭哧,代码如下:
```java
/**
* Author: leixiaoshuai
*/
public class LockCounter {
private volatile int count;
public synchronized void increase() {
count++;
}
}
```
一顿操作猛如虎,再次提交代码后,依然收到了检视意见(建议级别):
> 加锁会影响效率,可以考虑使用原子操作类。
原子操作类?「黑人问号脸」,莫不是大佬知道我晚上有约会故意整我,不想合入代码吧。带着将信将疑的态度,打开百度谷歌,原来 AtomicInteger 可以轻松解决这个问题,手忙脚乱一顿复制粘贴代码搞定了,终于可以下班了。
```java
/**
* Author: leixiaoshuai
*/
public class AtomicCounter {
private AtomicInteger count = new AtomicInteger(0);
public void increase() {
count.incrementAndGet();
}
}
```
# AtomicInteger 源码分析
调用`AtomicInteger类`的`incrementAndGet方法`不用加锁可以实现安全的递增,这个好神奇,下面带领大家分析一下源码是这么实现的,等不及了等不及了。
打开源码,可以看到定义的incrementAndGet方法:
```java
/**
* 在当前值的基础上自动加 1
*
* @return 更新后的值
*/
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
```
通过源码可以看到实际上是调用了 unsafe 的一个方法,unsafe 是什么待会再说。
我们再看看getAndAddInt方法的参数:第一个参数 this 是当前对象的引用;第二个参数valueOffset是用来记录value值在内存中的偏移地址,第三个参数是一个常量 1;
在 AtomicInteger 中定义了一个常量`valueOffset`和一个可变的成员变量 `value`:
```java
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
```
`value` 变量保存当前对象的值,`valueOffset` 是变量的内存偏移地址,也是通过调用unsafe的方法获取。
```java
public final class Unsafe {
// ……省略其他方法
public native long objectFieldOffset(Field f);
}
```
这里再说说 `Unsafe` 这个类,人如其名:不安全的类。打开 Unsafe 类会看到大部分方法都标识了 `native`,也就是说这些都是本地方法,本地方法强依赖于操作系统平台,一般都是采用`C/C++`语言编写,在调用 Unsafe 类的本地方法实际会执行这些方法,熟悉 C/C++的小伙伴可自行下载源码研究。
好了,我们再回到最开始,调用了 Unsafe 类的getAndAddInt方法:
```java
public final class Unsafe {
// ……省略其他方法
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);
// 循环 CAS 操作
} while (!compareAndSwapInt(o, offset, v, v + delta));
return v;
}
// 根据内存偏移地址获取当前值
public native int getIntVolatile(Object o, long offset);
// CAS 操作
public final native boolean compareAndSwapInt(Object o, long offset,
int expected,
int x);
}
```
通过getIntVolatile方法获取当前 AtomicInteger 对象的value值,这是一个本地方法。
然后调用compareAndSwapInt进行 CAS 原子操作,尝试在当前值的基础上加 1,如果 CAS 失败会循环进行重试。
因此compareAndSwapInt方法是最核心的,详细实现大家可以自行找源码看。这里我们看看方法的参数,一共有四个参数:o 是指当前对象;offset 是指当前对象值的内存偏移地址;expected是期望值;x是修改后的值;
compareAndSwapInt方法的思路是拿到对象 o 和 offset 后会再去取对象实际的值,如果当前值与之前取的期望值是一致的就认为 value 没有被修改过,直接将 value 的值更新为 x,这样就完成了一次 CAS 操作,CAS 操作是通过操作系统保证原子性的。
如果当前值与期望值不一致,说明 value 值被修改过,那么就会重试 CAS 操作直到成功。
<img src="https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/20210602232044-2021-06-02-23-20-44.png" alt="20210602232044-2021-06-02-23-20-44">
AtomicInteger类中还有很多其他的方法,如:
```java
decrementAndGet()
getAndDecrement()
getAndIncrement()
accumulateAndGet()
// …… 省略
```
这些方法实现原理都是大同小异,希望大家可以举一反三理解其他的方法。
另外还有一些其他的类,如:`AtomicLong`,`AtomicReference`,`AtomicIntegerArray`等,这里也不再赘述,原理都是大同小异。
# AtomicLong 和 LongAdder 谁更牛?
Java 在 `jdk1.8版本` 引入了 `LongAdder` 类,与 `AtomicLong` 一样可以实现加、减、递增、递减等线程安全操作,但是在高并发竞争非常激烈的场景下 `LongAdder` 的效率更胜一筹,后续单独用一篇文章进行介绍。
# 总结
讲了半天,可能有的小伙伴还是比较懵,Atomic 类到底是如何实现线程安全的?
在语言层面上,Atomic 类是没有做任何同步操作的,翻看源代码方法没有任何加锁,其实最大功劳还是在 CAS 身上。CAS 利用操作系统的硬件特性实现了原子性,利用 CPU 多核能力实现了硬件层面的阻塞。
只有 CAS 的原子性保证就一定是线程安全的吗?当然不是的,通过源码发现 value 变量还用了 volatile 修饰了,保证了线程可见性。
那有些小伙伴可能要问了,那是不是加锁就没有用了,非也,虽然基于 CAS 的线程安全机制很好很高效,但是这适合一些粒度比较小的需求才有效,如果遇到非常复杂的业务逻辑还是需要加锁操作的。
大家学会了吗?
================================================
FILE: docs/java/juc/面试官:说说什么是Java内存模型?.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650324686&idx=1&sn=0f177ea0b3cbe6da00a4e8b0a46ee22c&chksm=8f09c0d4b87e49c2d98b428b3b42e70550905f36dfcf63a304743d3df88ddcd518501df60b65&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
<!-- TOC -->
- [1. 为什么要有内存模型?](#1-为什么要有内存模型)
- [1.1. 硬件内存架构](#11-硬件内存架构)
- [1.2. 缓存一致性问题](#12-缓存一致性问题)
- [1.3. 处理器优化和指令重排序](#13-处理器优化和指令重排序)
- [2. 并发编程的问题](#2-并发编程的问题)
- [3. Java 内存模型](#3-java-内存模型)
- [3.1. Java 运行时内存区域与硬件内存的关系](#31-java-运行时内存区域与硬件内存的关系)
- [3.2. Java 线程与主内存的关系](#32-java-线程与主内存的关系)
- [3.3. 线程间通信](#33-线程间通信)
- [4. 有态度的总结](#4-有态度的总结)
<!-- /TOC -->
在面试中,面试官经常喜欢问:『说说什么是Java内存模型(JMM)?』
面试者内心狂喜,这题刚背过:『Java内存主要分为五大块:堆、方法区、虚拟机栈、本地方法栈、PC寄存器,balabala……』
面试官会心一笑,露出一道光芒:『好了,今天的面试先到这里了,回去等通知吧』
一般听到等通知这句话,这场面试大概率就是凉凉了。为什么呢?因为面试者弄错了概念,面试官是想考察JMM,但是面试者一听到`Java内存`这几个关键字就开始背诵八股文了。Java内存模型(JMM)和Java运行时内存区域区别可大了呢,不要走开接着往下看,答应我要看完。
# 1. 为什么要有内存模型?
要想回答这个问题,我们需要先弄懂传统计算机硬件内存架构。好了,我要开始画图了。
## 1.1. 硬件内存架构
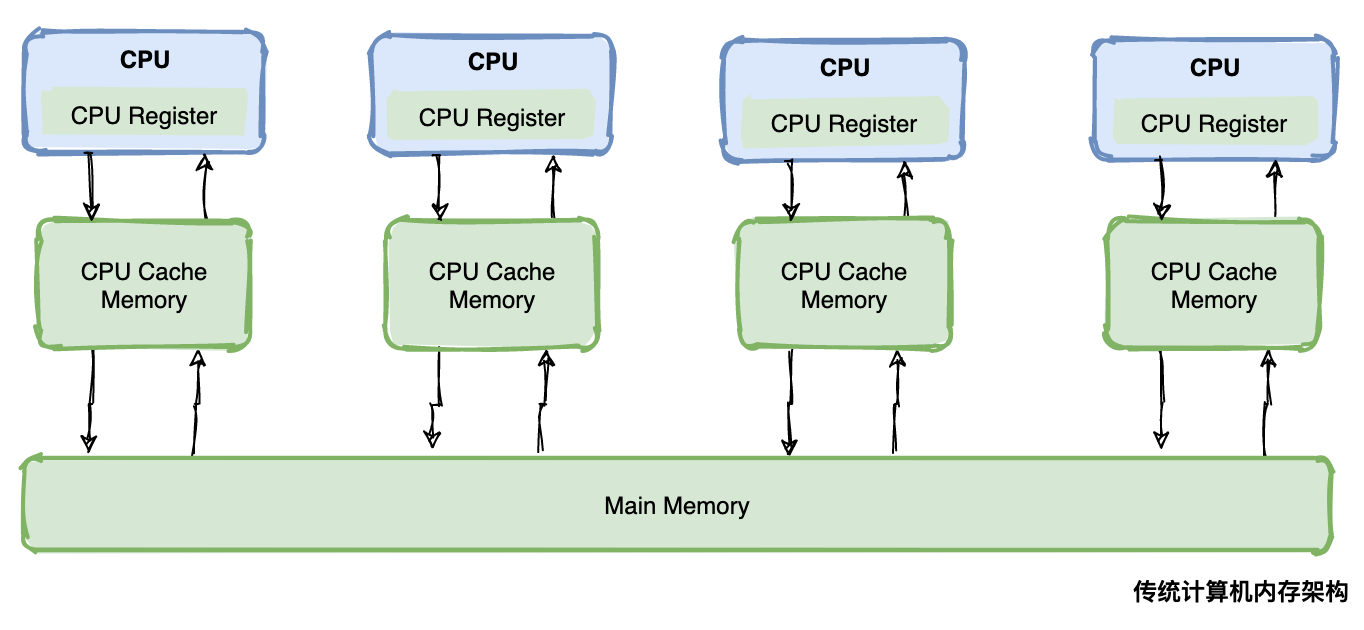
(1)CPU
去过机房的同学都知道,一般在大型服务器上会配置多个CPU,每个CPU还会有多个`核`,这就意味着多个CPU或者多个核可以同时(并发)工作。如果使用Java 起了一个多线程的任务,很有可能每个 CPU 都会跑一个线程,那么你的任务在某一刻就是真正并发执行了。
(2)CPU Register
CPU Register也就是 CPU 寄存器。CPU 寄存器是 CPU 内部集成的,在寄存器上执行操作的效率要比在主存上高出几个数量级。
(3)CPU Cache Memory
CPU Cache Memory也就是 CPU 高速缓存,相对于寄存器来说,通常也可以成为 L2 二级缓存。相对于硬盘读取速度来说内存读取的效率非常高,但是与 CPU 还是相差数量级,所以在 CPU 和主存间引入了多级缓存,目的是为了做一下缓冲。
(4)Main Memory
Main Memory 就是主存,主存比 L1、L2 缓存要大很多。
注意:部分高端机器还有 L3 三级缓存。
## 1.2. 缓存一致性问题
由于主存与 CPU 处理器的运算能力之间有数量级的差距,所以在传统计算机内存架构中会引入高速缓存来作为主存和处理器之间的缓冲,CPU 将常用的数据放在高速缓存中,运算结束后 CPU 再讲运算结果同步到主存中。
使用高速缓存解决了 CPU 和主存速率不匹配的问题,但同时又引入另外一个新问题:缓存一致性问题。
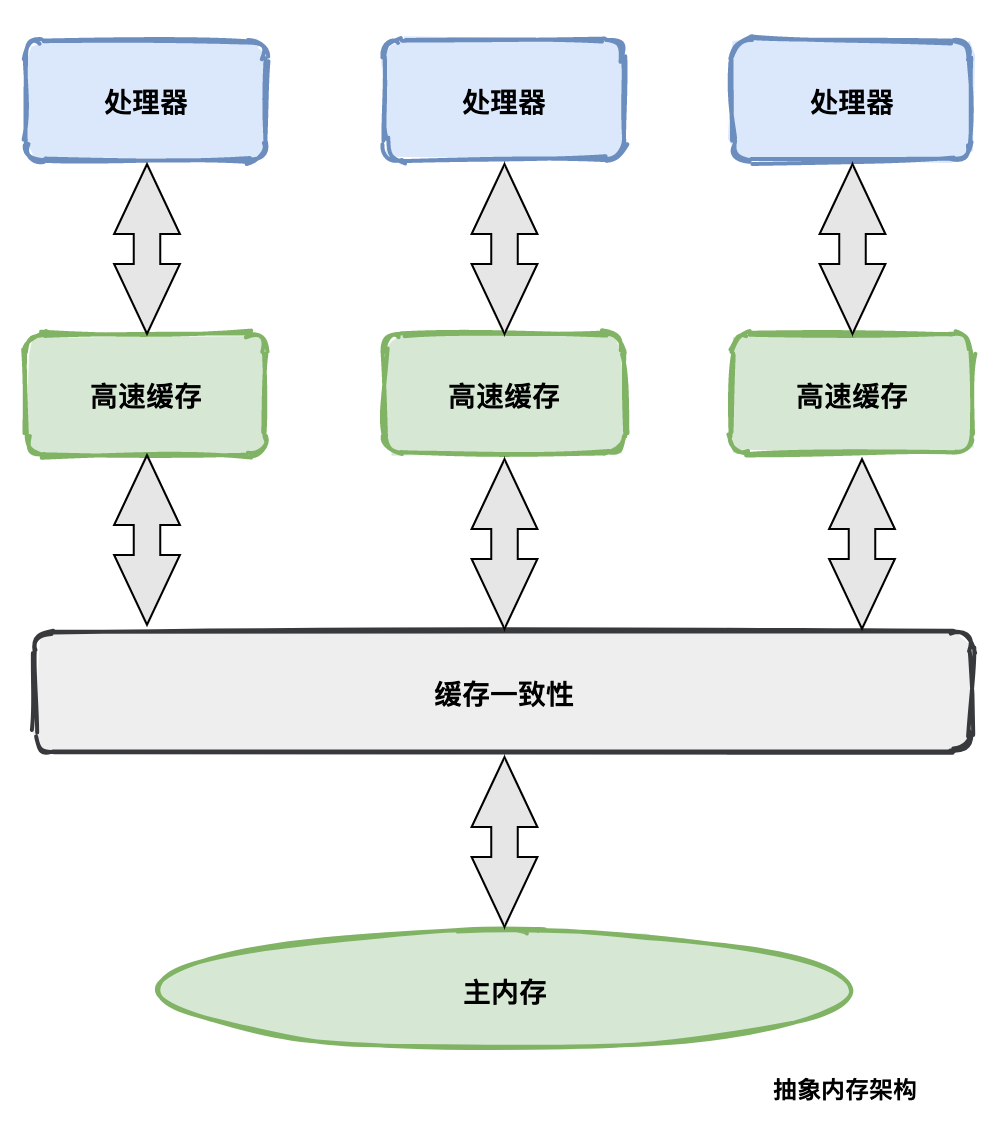
在多CPU的系统中(或者单CPU多核的系统),每个CPU内核都有自己的高速缓存,它们共享同一主内存(Main Memory)。当多个CPU的运算任务都涉及同一块主内存区域时,CPU 会将数据读取到缓存中进行运算,这可能会导致各自的缓存数据不一致。
因此需要每个 CPU 访问缓存时遵循一定的协议,在读写数据时根据协议进行操作,共同来维护缓存的一致性。这类协议有 MSI、MESI、MOSI、和 Dragon Protocol 等。
## 1.3. 处理器优化和指令重排序
为了提升性能在 CPU 和主内存之间增加了高速缓存,但在多线程并发场景可能会遇到`缓存一致性问题`。那还有没有办法进一步提升 CPU 的执行效率呢?答案是:处理器优化。
> 为了使处理器内部的运算单元能够最大化被充分利用,处理器会对输入代码进行乱序执行处理,这就是处理器优化。
除了处理器会对代码进行优化处理,很多现代编程语言的编译器也会做类似的优化,比如像 Java 的即时编译器(JIT)会做指令重排序。

> 处理器优化其实也是重排序的一种类型,这里总结一下,重排序可以分为三种类型:
>
> - 编译器优化的重排序。编译器在不改变单线程程序语义放入前提下,可以重新安排语句的执行顺序。
> - 指令级并行的重排序。现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
> - 内存系统的重排序。由于处理器使用缓存和读写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
# 2. 并发编程的问题
上面讲了一堆硬件相关的东西,有些同学可能会有点懵,绕了这么大圈,这些东西跟 Java 内存模型有啥关系吗?不要急咱们慢慢往下看。
熟悉 Java 并发的同学肯定对这三个问题很熟悉:『可见性问题』、『原子性问题』、『有序性问题』。如果从更深层次看这三个问题,其实就是上面讲的『缓存一致性』、『处理器优化』、『指令重排序』造成的。
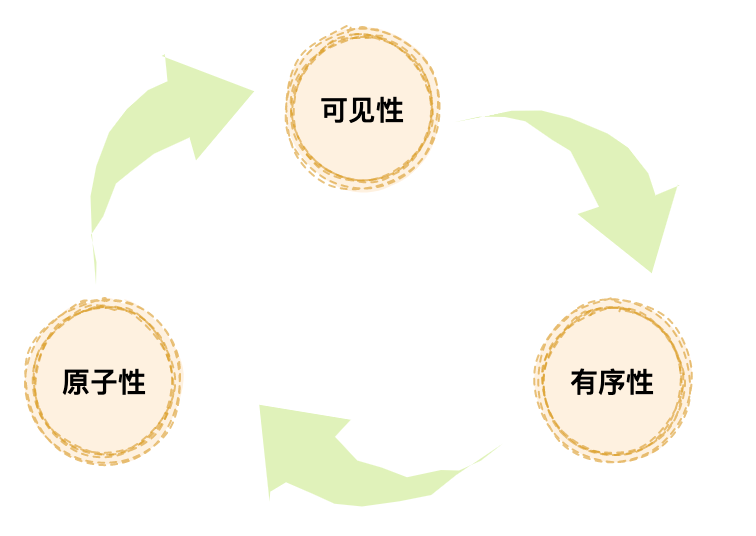
缓存一致性问题其实就是可见性问题,处理器优化可能会造成原子性问题,指令重排序会造成有序性问题,你看是不是都联系上了。
出了问题总是要解决的,那有什么办法呢?首先想到简单粗暴的办法,干掉缓存让 CPU 直接与主内存交互就解决了可见性问题,禁止处理器优化和指令重排序就解决了原子性和有序性问题,但这样一夜回到解放前了,显然不可取。
所以技术前辈们想到了在物理机器上定义出一套内存模型, 规范内存的读写操作。内存模型解决并发问题主要采用两种方式:`限制处理器优化`和`使用内存屏障`。
# 3. Java 内存模型
同一套内存模型规范,不同语言在实现上可能会有些差别。接下来着重讲一下 Java 内存模型实现原理。
## 3.1. Java 运行时内存区域与硬件内存的关系
了解过 JVM 的同学都知道,JVM 运行时内存区域是分片的,分为栈、堆等,其实这些都是 JVM 定义的逻辑概念。在传统的硬件内存架构中是没有栈和堆这种概念。
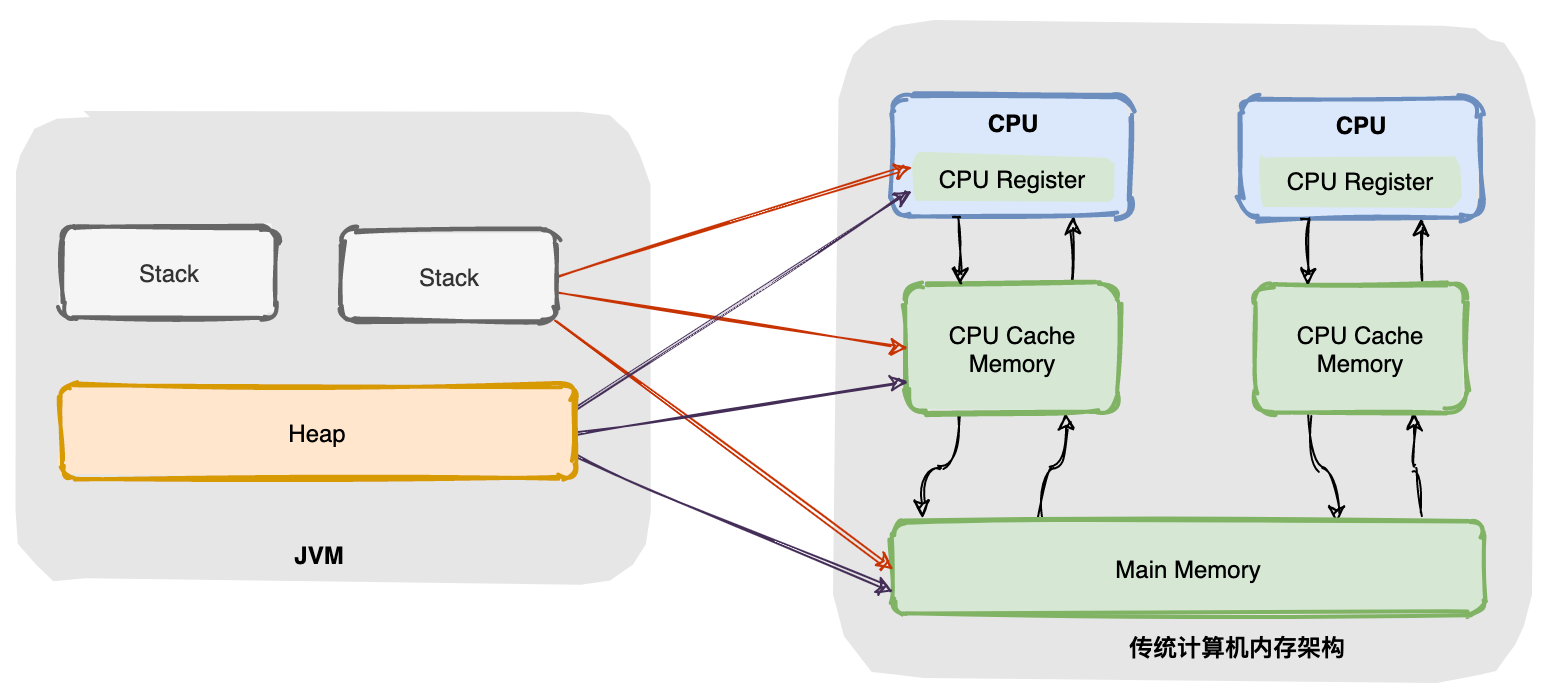
从图中可以看出栈和堆既存在于高速缓存中又存在于主内存中,所以两者并没有很直接的关系。
## 3.2. Java 线程与主内存的关系
Java 内存模型是一种规范,定义了很多东西:
- 所有的变量都存储在主内存(Main Memory)中。
- 每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的拷贝副本。
- 线程对变量的所有操作都必须在本地内存中进行,而不能直接读写主内存。
- 不同的线程之间无法直接访问对方本地内存中的变量。
看文字太枯燥了,我又画了一张图:
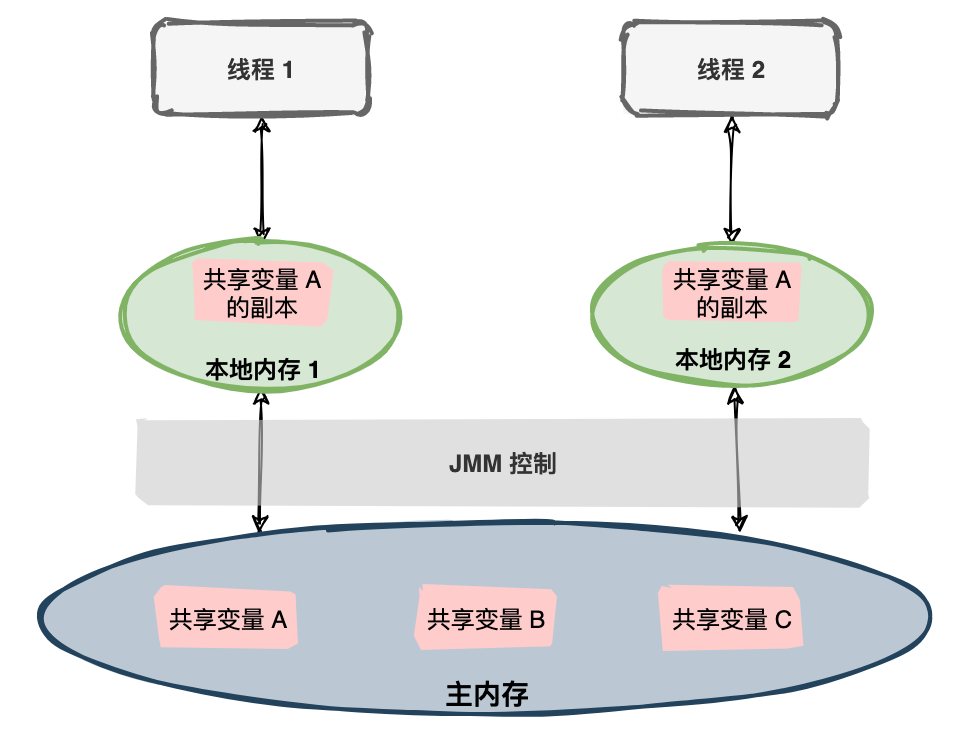
## 3.3. 线程间通信
如果两个线程都对一个共享变量进行操作,共享变量初始值为 1,每个线程都变量进行加 1,预期共享变量的值为 3。在 JMM 规范下会有一系列的操作。
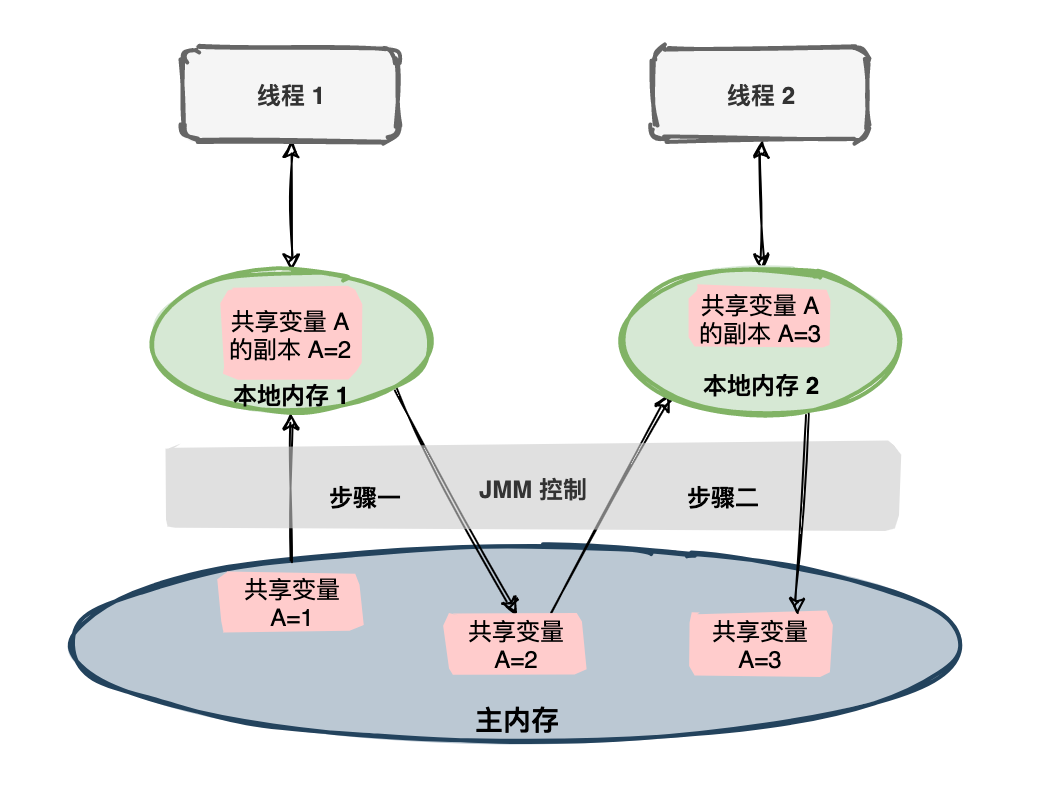
为了更好的控制主内存和本地内存的交互,Java 内存模型定义了八种操作来实现:
- lock:锁定。作用于主内存的变量,把一个变量标识为一条线程独占状态。
- unlock:解锁。作用于主内存变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
- read:读取。作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用
- load:载入。作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
- use:使用。作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
- assign:赋值。作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
- store:存储。作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作。
- write:写入。作用于主内存的变量,它把store操作从工作内存中一个变量的值传送到主内存的变量中。
> 注意:工作内存也就是本地内存的意思。
# 4. 有态度的总结
由于CPU 和主内存间存在数量级的速率差,想到了引入了多级高速缓存的传统硬件内存架构来解决,多级高速缓存作为 CPU 和主内间的缓冲提升了整体性能。解决了速率差的问题,却又带来了缓存一致性问题。
数据同时存在于高速缓存和主内存中,如果不加以规范势必造成灾难,因此在传统机器上又抽象出了内存模型。
Java 语言在遵循内存模型的基础上推出了 JMM 规范,目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。
为了更精准控制工作内存和主内存间的交互,JMM 还定义了八种操作:`lock`, `unlock`, `read`, `load`,` use`,` assign`, `store`, `write`。
-- End --
关于Java 内存模型还有很多东西没有展开讲,比如说:`内存屏障`、`happens-before`、`锁机制`、`CAS`等等。要肝一个系列了,加油!
我是雷小帅,大家有任何疑问、建议、想法欢迎在留言区套路,最后『求在看』、『求赞』、『求转发』,下期见~
================================================
FILE: docs/java/juc/面试必问的CAS原理你会了吗.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650324759&idx=1&sn=11908655d1388b44a61904a175a3a09a&chksm=8f09c10db87e481b025e620ecf86bd14ce4ab8b979264a12ac1e63de2e10eaae95eff2e3bf32&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
<!-- TOC -->
- [1. 什么是 CAS?](#1-什么是-cas)
- [2. CAS 基本原理](#2-cas-基本原理)
- [3. CAS 在 Java 语言中的应用](#3-cas-在-java-语言中的应用)
- [4. CAS 的问题](#4-cas-的问题)
- [4.1. 典型 ABA 问题](#41-典型-aba-问题)
- [4.2. 自旋开销问题](#42-自旋开销问题)
- [4.3. 只能保证单个变量的原子性](#43-只能保证单个变量的原子性)
- [5. 有态度的总结](#5-有态度的总结)
<!-- /TOC -->
在并发编程中我们都知道`i++`操作是非线程安全的,这是因为 `i++`操作不是原子操作。
如何保证原子性呢?常用的方法就是`加锁`。在Java语言中可以使用 `Synchronized`和`CAS`实现加锁效果。
`Synchronized`是悲观锁,线程开始执行第一步就是获取锁,一旦获得锁,其他的线程进入后就会阻塞等待锁。如果不好理解,举个生活中的例子:一个人进入厕所后首先把门锁上(获取锁),然后开始上厕所,这个时候有其他人来了只能在外面等(阻塞),就算再急也没用。上完厕所完事后把门打开(解锁),其他人就可以进入了。

`CAS`是乐观锁,线程执行的时候不会加锁,假设没有冲突去完成某项操作,如果因为冲突失败了就重试,最后直到成功为止。
# 1. 什么是 CAS?
CAS(Compare-And-Swap)是`比较并交换`的意思,它是一条 CPU 并发原语,用于判断内存中某个值是否为预期值,如果是则更改为新的值,这个过程是`原子`的。下面用一个小示例解释一下。
CAS机制当中使用了3个基本操作数:内存地址V,旧的预期值A,计算后要修改后的新值B。
(1)初始状态:在内存地址V中存储着变量值为 1。

(2)线程1想要把内存地址为 V 的变量值增加1。这个时候对线程1来说,旧的预期值A=1,要修改的新值B=2。
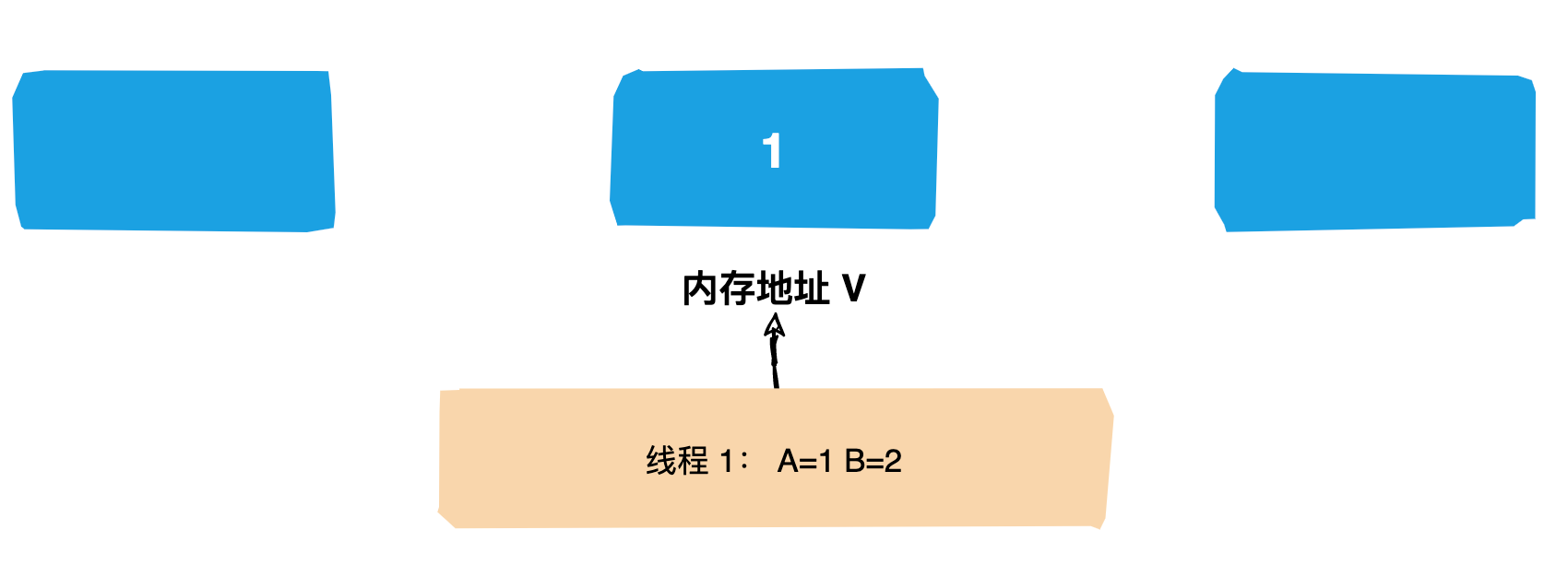
(3)在线程1要提交更新之前,线程2捷足先登了,已经把内存地址V中的变量值率先更新成了2。
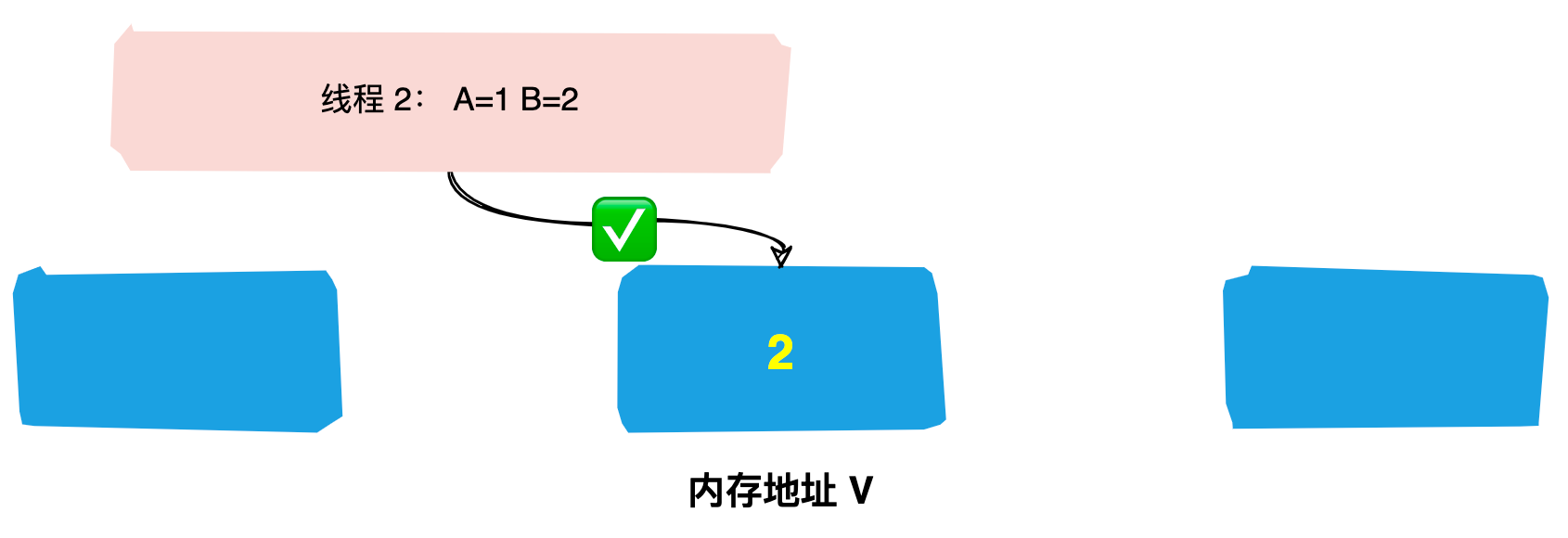
(4)线程1开始提交更新,首先将预期值A和内存地址V的实际值比较(Compare),发现A不等于V的实际值,提交失败。
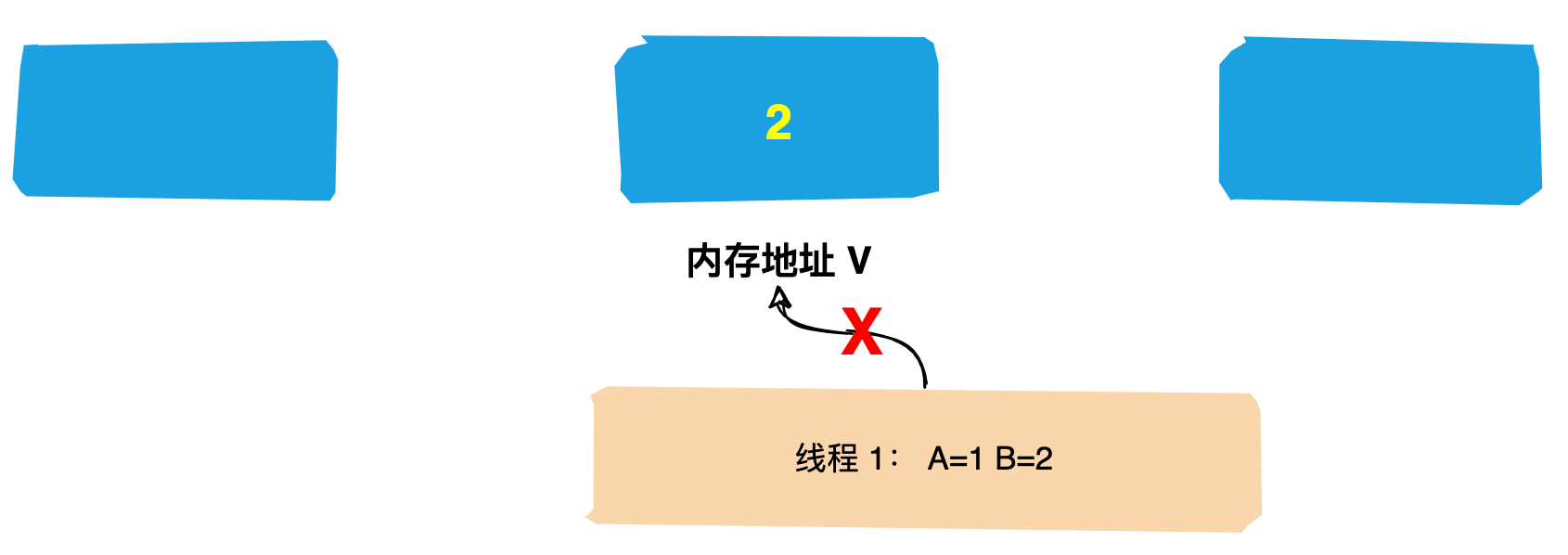
(5)线程1重新获取内存地址 V 的当前值,并重新计算想要修改的新值。此时对线程1来说,A=2,B=3。这个重新尝试的过程被称为`自旋`。如果多次失败会有多次自旋。
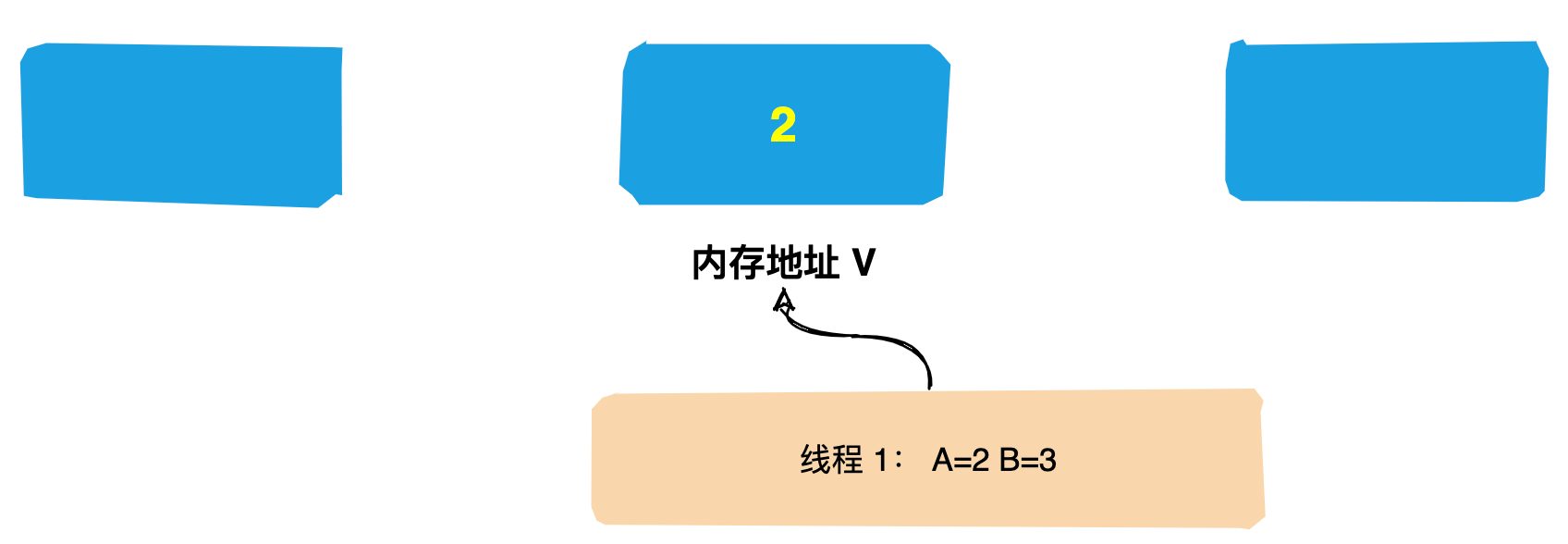
(6)线程 1 再次提交更新,这一次没有其他线程改变地址 V 的值。线程1进行Compare,发现预期值 A 和内存地址 V的实际值是相等的,进行 Swap 操作,将内存地址 V 的实际值修改为 B。
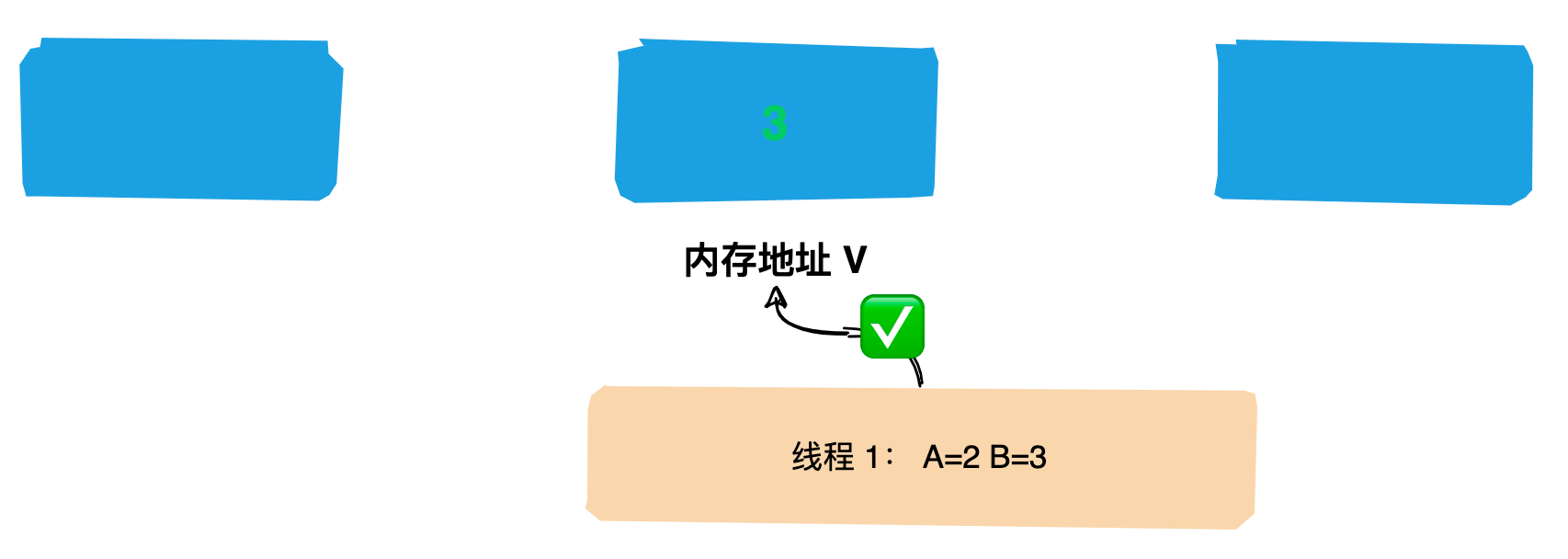
总结:更新一个变量的时候,只有当变量的预期值 A 和内存地址 V 中的实际值相同时,才会将内存地址 V 对应的值修改为 B,这整个操作就是`CAS`。
# 2. CAS 基本原理
CAS 主要包括两个操作:`Compare`和`Swap`,有人可能要问了:两个操作能保证是原子性吗?可以的。
CAS 是一种`系统原语`,原语属于操作系统用语,原语由若干指令组成,用于完成某个功能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许被中断,也就是说 CAS 是一条 CPU 的原子指令,由操作系统硬件来保证。
> 在 Intel 的 CPU 中,使用 cmpxchg 指令。
回到 Java 语言,JDK 是在 1.5 版本后才引入 CAS 操作,在`sun.misc.Unsafe`这个类中定义了 CAS 相关的方法。
```java
public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object x);
public final native boolean compareAndSwapInt(Object o, long offset, int expected, int x);
public final native boolean compareAndSwapLong(Object o, long offset, long expected, long x);
```
可以看到方法被声明为`native`,如果对 C++ 比较熟悉可以自行下载 OpenJDK 的源码查看 unsafe.cpp,这里不再展开分析。
# 3. CAS 在 Java 语言中的应用
在 Java 编程中我们通常不会直接使用到 CAS,都是通过 JDK 封装好的并发工具类来间接使用的,这些并发工具类都在`java.util.concurrent`包中。
> J.U.C 是`java.util.concurrent`的简称,也就是大家常说的 Java 并发编程工具包,面试常考,非常非常重要。
目前 CAS 在 JDK 中主要应用在 J.U.C 包下的 Atomic 相关类中。
比如说 AtomicInteger 类就可以解决 i++ 非原子性问题,通过查看源码可以发现主要是靠 volatile 关键字和 CAS 操作来实现,具体原理和源码分析后面的文章会展开分析。
# 4. CAS 的问题
CAS 不是万能的,也有很多问题。
`敲黑板:CAS有哪些问题,这是面试高频考点,需要重点掌握`。
## 4.1. 典型 ABA 问题
ABA 是 CAS 操作的一个经典问题,假设有一个变量初始值为 A,修改为 B,然后又修改为 A,这个变量实际被修改过了,但是 CAS 操作可能无法感知到。
如果是整形还好,不会影响最终结果,但如果是对象的引用类型包含了多个变量,引用没有变实际上包含的变量已经被修改,这就会造成大问题。
如何解决?思路其实很简单,在变量前加版本号,每次变量更新了就把版本号加一,结果如下:
最终结果都是 A 但是版本号改变了。
从 JDK 1.5 开始提供了`AtomicStampedReference`类,这个类的 `compareAndSe `方法首先检查`当前引用`是否等于`预期引用`,并且`当前标志`是否等于`预期标志`,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
## 4.2. 自旋开销问题
CAS 出现冲突后就会开始`自旋`操作,如果资源竞争非常激烈,自旋长时间不能成功就会给 CPU 带来非常大的开销。
解决方案:可以考虑限制自旋的次数,避免过度消耗 CPU;另外还可以考虑延迟执行。
## 4.3. 只能保证单个变量的原子性
当对一个共享变量执行操作时,可以使用 CAS 来保证原子性,但是如果要对多个共享变量进行操作时,CAS 是无法保证原子性的,比如需要将 i 和 j 同时加 1:
i++;j++;
这个时候可以使用 synchronized 进行加锁,有没有其他办法呢?有,将多个变量操作合成一个变量操作。从 JDK1.5 开始提供了`AtomicReference` 类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作。
# 5. 有态度的总结
CAS 是 Compare And Swap,是一条 CPU 原语,由操作系统保证原子性。
Java语言从 JDK1.5 版本开始引入 CAS , 并且是 Java 并发编程J.U.C 包的基石,应用非常广泛。
当然 CAS 也不是万能的,也有很多问题:典型 ABA 问题、自旋开销问题、只能保证单个变量的原子性。
================================================
FILE: docs/java/roadmap/2021 版最新Java 学习路线图(持续刷新).md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s/vc7rzYwfRC05bUR6eaUJcw)』,欢迎大家关注。
<!-- TOC -->
- [学Java有哪些就业方向?](#学java有哪些就业方向)
- [数据结构和算法](#数据结构和算法)
- [设计模式](#设计模式)
- [计算机基础](#计算机基础)
- [Java 入门](#java-入门)
- [Java 高手进阶](#java-高手进阶)
- [基础框架(SSM)](#基础框架ssm)
- [微服务框架](#微服务框架)
- [常用中间件](#常用中间件)
- [数据库](#数据库)
- [分布式架构](#分布式架构)
- [必须掌握的工具软件](#必须掌握的工具软件)
- [学习常见问题(FAQ)](#学习常见问题faq)
<!-- /TOC -->
**最近很多读者在问:Java 怎么学习啊?有没有什么学习路线?**
我相信这些读者或多或少都有一些 Java 基础,但由于看不到全貌,学了一段时间很容易迷失。所以我在寻思着能不能写一个学习的地图或者路线,让读者能知道下一步该学什么,自己离大厂的 offer还有多远的距离。
一个人最怕的不是路途遥远,而是看不到胜利曙光。我希望下面这篇文章能给你的学习之路带来一丝曙光,大家不妨试着读一下吧,如果有收获给我点个赞哟。
> 温馨提醒:这篇文章写着写着就一万字了,建议大家关注后再收藏,以防走丢。
这篇文章主要内容包括(干货满满):
- 学Java有哪些就业方向?
- 数据结构和算法
- 设计模式
- 计算机基础
- Java 入门
- Java 高手进阶
- 基础框架(SSM)
- 微服务框架
- 常用中间件
- 数据库
- 分布式架构
- 必须掌握的工具软件
- 学习资源网站列表汇总
- 学习常见问题(FAQ)
买一瓶可乐,泡一杯咖啡,lets go 学习~
## 学Java有哪些就业方向?
在介绍 Java 怎么学之前我给大家介绍一下学完了能干什么,因为有目标的学习才是最高效的。
很多 Java 入门学习者对岗位或者方向的概念非常模糊,今天学安卓、后天学大数据,三心二意的学习势必造成技术不精,这就是面试官通常说的:这位面试者基础比较差。
学习技术首先要认准一个方向专注下去,有了一定积累后再将自己的知识面扩宽,找到自己感兴趣的方向再沉下去学习,周而复始你就成为这个行业的专家了。
Java 这门语言,在公司里根据分工不同衍生出了众多的岗位或者技术方向。
我在 boss 直聘上搜索了 BAT 等大厂的岗位,目前有以下三类岗位非常热门:
(1)安卓开发
> 技能要求:
> - 熟悉 Android UI 开发非常熟悉,对 UI 架构有理解,并了解基础的 UI 交互知识;
> - 熟悉 Android 调试工具和方法,可以应付各种 Android 复杂问题;
> - 熟悉 Android Framework 层,有通过 Android 源码阅读定位问题的经验;
(2)Java 后端开发
> 技能要求:
> - 具备扎实的Java基础,对JVM原理有扎实的理解;对Spring、MyBatis、Dubbo等开源框架熟悉,并能了解它的原理和机制,具有大型分布式系统设计研发经验;
> - 熟悉基于Mysql关系数据库设计和开发、对数据库性能优化有丰富的经验;
> - 熟悉底层中间件、分布式技术(如RPC框架、缓存、消息系统等);
(3)大数据/数据仓库
> 技能要求:
> - 熟悉Hadoop/Spark/sqoop/hive/impala/azkaban/kylin等大数据相关组件;
> - 精通sql及性能调优,熟练使用java、python、scala其中一种编程语言;
> - 掌握数据仓库 (DW) / OLAP /商业智能 (BI) /数据统计理论,并灵活的应用,具备大型数据仓库设计经验;
这里只列举了三类比较热门的技术岗位,希望大家结合自己的经验思考一下方向。
`敲黑板:认清自己,找准方向,越早确定方向越容易成功!`
## 数据结构和算法
**学什么?**
有些同学可能要问了:我学 Java 的有必要学习算法吗?答案是:`别无选择`!
国内互联网面试的流程逐渐在向国外靠拢,像字节跳动、BAT 等大厂,`手撕算法题`已经成为了必选动作。
确实, Java 相对于 C、C++有着丰富的类库和三方框架,进入工作后大部分人都是在写业务代码,俗称 API boy 或者 Crud boy,算法看起来并不是那么重要,但是考算法真的是公司面试筛选人的低成本办法,如果你写出了算法并且通过了,要么你聪明要么你勤奋(刷题了)。
所以不管你是学什么语言:C、C++、python、Java、GO,算法这一关你必须得过。数据结构和算法的面试核心知识点我已经列出来了,大家可以参考学习,逐个击破。
- 栈与队列:先进先出、后进先出
- 线性链表
- 查找:顺序查找、二分查找
- 排序:交换类、插入类、选择类
- 树、二叉树、图:深度优先(DFS)、广度优先(BFS)
- 递归
- 分治
- 滑窗
- 三大牛逼算法:回溯、贪心、动态规划(DP)
**怎么学?**
最好或者最笨的方法就是刷题,强烈推荐力扣:[https://leetcode-cn.com](https://leetcode-cn.com)
建议刷300题以上,要覆盖简单、中等、困难的题目。面试前要训练手感,不要生疏了,可以选保持每日或几日一题。
在刷题之前我建议你看一些书:
《漫画算法-小灰的算法之旅》
> 如果你之前没有任何算法基础,这边书很适合你,可以补充数据结构和算法的基础知识,像什么是时间复杂度空间复杂度、查找、排序等。
> 如果你有了一定基础了,建议你直接跳到最后面的算法实战部分。
《剑指 offer》
> 非常经典的一本书,学算法的人必刷。但是要注意了,这边书里面的题目是用 C++写的,如果你是 Java 开发人员可能会有点影响。但是要记住学习算法最关键的还是解题思路和方法,用什么语言实现是其次的,如果你时间比较多我是建议你用 Java 语言再实现一遍。
《labuladong的算法小抄》
> 非常推荐!这是一本很新的书,写书前作者在 Github 开源了一个项目,主要讲解 LeetCode 解题套路,Start 总数排名前40。在书的开头讲解了学习算法的基本思维和套路,建议看这边书的同时再配合 leetcode 刷题,疗效非常棒!
《算法导论》
> 要是不推荐这本书是不是显得我有点 low 了,这是一本科班出身的同学必看必学的经典大部头。国外大佬写的,国内翻译的经典之作,虽然是经典但是不建议刚入门算法的同学看,因为看了这本书你可能要放弃算法了,比较难看懂。建议有了一定基础再入手这边书。
如果你觉得看书比较枯燥,可以推荐你看一些极客时间的专栏,不过是收费,但是质量非常高。
《数据结构与算法之美》
> 这个专栏是文字+语音,作者是王争,前 Google 工程师。他采用最适合工程师的学习方式,不拘泥于某一特定编程语言,从实际开发场景出发,由浅入深教你学习数据结构与算法的方法,帮你搞懂基本概念和核心理论,深入理解算法精髓,帮你提升使用数据结构和算法思维解决问题的能力。
《算法面试通关40讲》
> 这个专栏是视频,作者是覃超,前Facebook工程师。作者会用白板带你一步一步解题,层层深入一环扣一环,每一题还会用多种解题方法。我基本看完了,收获颇多。
leetcode、书和极客专栏可以并行,学练结合,不要光看不练哦。
## 设计模式
**学什么?**
金庸小说中牛叉的武功太多了,综合性最强的还是`九阳真经`,九阴真经分为上、下两卷,`上卷为内功基础,下卷为武功招式`,这些都是极负盛名的`武学秘籍`。
那大家思考一下什么是武学秘籍?其实打开来开就是一些固定的招式,牢记这些招式并运用好就是绝顶高手了。
回到编程上来,除了要写干净的代码(clean code),还要运用各种`设计模式`使代码可读性强、扩展性好、松耦合,这便是大家经常说的编码大牛。
所以不管是学武功还是学编码,都是有一些固定的招式,也就是设计模式。
说到`设计模式`很多同学可能会跳出来:这个我知道,就是单例模式、工厂模式……
巴拉巴拉说了一堆,但是真正在写代码的时候又是一脸蒙:为什么我写的代码用不到设计模式?究其原因是你的代码经验不够。
想一下设计模式是怎么来的?上个世纪四个大男人搞了一个组合叫 GoF,并出版了一本书,这本书共收录了23种设计模式,后面逐渐被人熟知。这四个人从大量的代码实践中总结了一套方法论(写代码的套路),而我们作为一个在学校的学生或者刚工作的新人,可能连代码都写的少,怎么可能轻松快速地掌握这么多设计模式。
所以说你学完了设计模式,但是还不会运用到日常的代码实践中,这个是很正常的,因为代码经验还不够。
那还学不学?当然要学,因为面试的时候有可能会问到。设计模式的理论知识我们还是要打好基础,需要掌握这些知识点:
- 设计模式的六大原则:单一职责、里氏替换、依赖倒置、接口隔离、迪米特法则、开闭原则
- UML 基础知识
- 设计模式三大分类:创建型、结构型、行为型
- 常用设计模式基本原理
经典设计模式总共有23种(现在远不止23种了,还有一些变种),全部掌握难度太大了,我们只需要掌握一些常用的就好了,必须要掌握的我用小红旗已经标出来了。
**怎么学?**
网上关于设计模式的学习资料非常多,质量也是参差不齐,大家找的时候可要擦亮眼睛。
在看书之前我还是推荐你熟悉一下 UML 的理论知识,因为你如果不懂 UML 那任何一本设计模式的书你都可能读不下去, UML 是设计模式的前提。
UML 学习网站:
https://www.w3cschool.cn/uml_tutorial/
不要花太多时间学习 UML,简单理解入门即可。
假设你已经入门 UML 了,那下面的这些书你可以考虑学习一下了:
《Head First 设计模式》
> Head First 是一个比较经典的系列丛书,有些人非常喜欢这种风格。这本书讲枯燥的设计概念讲解的生动有趣,作为一本入手书非常值得推荐。
《大话设计模式》
> 大话系列是国内非常经典的系列丛书,有众多粉丝。这本大话设计模式以对话的形式讲解知识,在当时可开创了先河。虽然书中有些例子比较牵强,但任然不失为一本入门的好书。
《图解设计模式》
> 图解系列是日本的一位作者写的,有一本图解 HTTP 非常经典,这本图解设计模式也是类似的风格。由于是翻译过来的,书中有些例子可能听起来比较奇怪,貌似翻译过来的技术书都有这个问题。
《设计模式-可复用面向对象软件的基础》
> 又是一本黑色大部头书,书的作者就是 GoF,大家都说经典。但是呢,经典归经典,读起来真的是晦涩难懂,对新人非常不优化,如果你想入门学习设计模式,这本书就不推荐了。不推荐为什么要说出来?经典的书如果不提,你们又要说我菜。(害)
这几本书都要看吗?当然不是,如果你是在准备面试,我个人建议是读其中一本就够了。至于说看哪一本,你可以找对应的电子书,挑一个章节试读一下,符合你的胃口就选择这一本继续读下去。
如果你已经有几年的编码经验,又想把代码写好,建议你多挑基本读读,吸收每本书的精华。
## 计算机基础
科班出身的同学对《计算机网络》和《操作系统》这两门课应该不会陌生,至于掌握了多少,你懂得,都是在考前一两周突击学习的,哈哈。
现在大公司对于应届生的要求越来越高,计网和操作系统这两门课是必考的。那些拿了 SSSP Offer 的大牛计算机基础都非常扎实。
**(1)计算机网络**
**学什么?**
计算网络的协议非常非常多,很多同学学完都一头雾水,或者仅仅懂一点 HTTP,但是真正要掌握的东西可不少:
- OSI 七层模型、TCP/IP五层模型
- 常见网络协议:HTTP、TCP/IP、UDP
- 网络安全:非对称加密、数字签名、数字证书
- 网络攻击:DDOS、XSS、CSRF 跨域攻击
**怎么学?**
计算机网络面试有一道非常经典的面试题:说说你从URL输入到最终页面展现的过程。这一题可以覆盖大部分计网的知识点,可以从 DNS 解析到 HTTP、TCP/IP协议、物理层协议,一直到浏览器渲染页面,你技术功底有多深你就可以聊多深。希望大家学完了也能试着回答一下这个问题。
推荐几本倍受好评的书:
《网络是怎么连接的》
> 这本书是一本日本作者写的。文章围绕着在浏览器中输入网址开始,一路追踪了到显示出网页内容为止的整个过程,图文并茂生动有趣,非常推荐!
《图解 HTTP》
> 也是一名日本作者写的。这本书对 HTTP 协议进行了全面系统的介绍,列举了很多常见通信场景及实战案例,相信读完会有恍然大悟的感觉。书很薄,几天就可以读完,强烈推荐!
《TCP/IP详解卷1:协议》
> 计算机网络的经典教材, 大部头书籍,很难啃。建议挑重点看。
最后安利一款工具,学习网络必备的抓包神奇:wireshark,如果你学网络没抓过包,那基本等于白学了(有点严重)。
**(2)操作系统**
**学什么?**
作为一名 Javaer 在平时的工作中可能不会直接跟操作系统打交道,因为 JVM 帮我们屏蔽了众多差异。但是要想学好 JVM,懂一点操作系统更有助于你深刻理解 JVM 工作原理。
Java 学习者这部分的要求可以稍微放低,但是你如果是搞 C++的,那这部分可是你的重点。
- 进程和线程的区别
- 进程间的通信方式:共享内存、管道、消息
- 内存管理、虚拟内存
- 死锁检测和避免
**怎么学?**
想要精通操作系统难度非常大,但是在面试中你要能讲出一些具体的操作系统知识,面试官会对你刮目相看。
推荐一些视频学习资料:
B 站:
麻省理工 MIT 6.828(无字幕):https://www.bilibili.com/video/BV1px411E7ST
操作系统(哈工大李治军老师)32讲(全)超清:https://www.bilibili.com/video/BV1d4411v7u7
推荐书籍资料:
《深入理解计算机系统 CSAPP》
> 赫赫有名的 CSAPP,全称:Computer Systems:A Programmer‘s Perspective。科班同学的圣经,哈哈,黑色大部头书籍,难啃。
《现代操作系统 (第3版)》
> 操作系统领域的经典之作,因为是翻译过来的,遇到比较晦涩的先跳过,多读几遍才能消化。
## Java 入门
**学什么?**
Java 语言从诞生到现在已经有20多年了,从Tiobe排行榜上来看,Java 语言常年霸榜经久不衰,所以不要怕学完 Java 后突然不流行了,至少这几年Java 就业机会非常多。
如果你有其他语言的基础,比如之前学过 C、C++等,那学起 Java 应该是非常容易的,也容易上手。如果你没有语言基础,又不想了解太底层的东西,那学 Java 还是不错的。至于说 python,光从语言层面上看,python 确实非常简单,估计你一周内就可以学会并且代码写的还不错,但是 Java 不一样,一周你只能简单了解一下语法,想写好代码几乎不可能。另外 Go 语言势头很猛,大家也可以关注一下。
一般来说 Java 入门你需要掌握下面这些知识点:
- 面向过程 VS 面向对象
- 面向对象基本特征:封装、继承、多态
- 访问控制符:private、default、protected、public
- 数据类型:基本类型、引用类型
- 控制流程:for、while、switch 等
- 序列化
- 异常处理(有点难度)
- 泛型(有点难度)
**怎么学?**
如果你是零基础,建议你可以找一些 Java 入门的视频看一下,网上视频鱼龙混杂,大家注意甄别。推荐一个比较好的平台:B 站(https://www.bilibili.com/)
不是让你去看二次元的,里面有很多学习资源。(嘿哈)
`敲黑板啦:视频不要贪多,因为没有一个大牛是看视频看出来的。` 看视频是别人将知识点往你脑袋里灌,最大的好处是能让你快速入门,如果你想学到更多,你需要的是`自我学习`,带有思考的自我学习。
看书是一种高效的自我学习方式,推荐基本比较好的书:
《Java 核心技术卷I》
> 这本书建议作为Java 之旅的第一本书,涵盖的内容非常全,比起那些30天学会 Java 之类的书,这边书更加务实。书中有些章节其实不用看,比如Swing GUI 的直接略过,因为用 Java 写桌面端应用已经过时了。
《阿里巴巴 Java 开发手册》
> 大厂阿里巴巴出品的,这其实是一本 Java 编码规范,编码习惯从一开始就要养好。
《Java 编程思想(Thinking In Java)》
> 这是一本非常非常经典的书,你要问搞 Java 的人如果没听过这本书那算是白学了,哈哈。其实说实话这本书我试图看过几次,最终都没有看完,一个原因是它太厚了,另外我觉得讲得太啰嗦了,所以我现在拿来垫桌子,高度合适挺好的。所以呢,建议新人不要一开始看这边书,不然你会怀疑人生还没入门就放弃了,就把它当做编程圣经,等你后面有经验了拿起来再翻翻吧。
敲黑板了:学习编程要有耐心,不要急于求成,要打好基础。也许你一个月两个月还在运行一些简单示例,这是正常的,多学习多思考。
## Java 高手进阶
**学什么?**
恭喜你终于Java 入门了,大牛和菜鸟的区别在于菜鸟永远止步于入门水平,而大牛已经找到新大陆了,翻过这几座山你离高手就不远了。
Java 高手进阶需要掌握的东西非常非常多,这里列举一些核心知识点,必须全部掌握的。这是 Java 面试高频考点,也是传说中 Java 八股文的一部分,面好了进入下一面,面不好回家等消息。
- Java 集合类源码
- 线程池
- Java 代理
- IO 模型
- JVM
- Java 并发编程(JUC)
**怎么学?**
Java 已经入门了,你都想进阶了,建议你不要再找视频看了,一边看书一边思考吧。
《Effective Java》
> 书中列举了很多编程建议,其实就是告诉怎样去写好代码,你需要从`能写代码`(入门)过渡到`会写代码`,这本书值得一看。如果你的编码经验比较少,那这边书你可以稍微往后延,因为看完了你可能没有感同身受。
《Java8 实战》
> Java15 都出来了为什么还要学 Java8 ?因为现在很多公司都还停留在 Java8, Java8是继Java5之后改动很大的一个版本,得好好学。Java8之后的版本非常不给力,换一个 JDK 版本费时费力,收益也不明显,公司肯定不愿意动了。这边书将 Java8所有的新特性都详细讲解了,非常推荐。
《深入理解 Java 虚拟机 第3版》
> 周志明大神写的,非常非常经典,已经更新到第三版了。Java 虚拟机也就是 JVM,JVM 是Java 面试必考的知识,不懂这个直接回家等消息吧。这边书我看了很多遍,每次看完都有新的收获,墙裂建议大家看完。
《Java 并发编程的艺术》
> 这是一本专门讲解Java并发的书,涉及到各种锁、常见安全的集合类,基本就是将 JUC(java.util.concurrent包的简称)里所有的内容覆盖了一遍,看完你一定有收获。强烈推荐!
上面推荐的几本书可能不太容易读懂,建议多读几遍。书中看不懂的地方可以在网上搜,多找一些优质的博客或者公众号看。
至此 Java 语言特性基本学习完了,就算达不到高手的水平,你也在正轨上了。
## 基础框架(SSM)
**学什么?**
学习 Java 语言特性可能比较枯燥,接下来可以学习基础框架动手做一些项目,比如 Java 领域非常流行的 Spring 框架,这就是为 Java 后端量身定做的,非常好用。
在 spring 流行之前,还出现 Struts 这样流行的框架,后面由于种种原因还是被 Spring 打败了。
大家在网上应该可以经常看到 SSM 的缩写,其实就是Spring+SpringMVC+MyBatis的缩写了。
你需要掌握以下这些:
- Spring 全家桶(Spring、Spring MVC、Spring Boot)使用
- ORM 框架(MyBatis、Hibernate)使用
- Spring 原理
- ORM 框架原理
**怎么学?**
学习 SSM 框架最好是动手完成一个简单的项目,建议跟着视频并且把代码敲出来,一来熟悉项目的开发流程,也可以给自己带来成就感。
敲黑板:阶段性成就感非常重要,没有这个很容易放弃学习,所以要不定时给自己定个小目标,加加鸡腿啥的。
有很多新手在做项目的时候非常纠结界面,作为一个 Java 后端程序员,你又不是全栈开发,纠结这个干什么,我的建议:要么不要界面只写接口,要么自己动手写点 html,不需要美观,实现功能即可。
跟着视频做完项目之后需要干什么?答案是:`深入理解框架原理`。会用框架并不代表你懂框架,作为一个有追求的程序员,懂原理是永远的必修课,谁让这一行太卷了呢,人无你有你最棒。
推荐几本书:
《Spring 基础内幕》
> 首先声明一下这是一本讲解Spring 源码的书,不是教你做项目的书。如果需要深入理解 Spring 的技术原理,这是一本非常推荐的书。有点难啃,多读几遍。
《MyBatis 技术内幕》
> MyBatis 是 ORM 框架的一种,在国内使用比较多,据说在国外喜欢用 Hibernate。这本书对 MyBatis 的使用和基本原理都介绍比较清楚了。
敲黑板:技术更新迭代很快,抓住技术的本质才能与时俱进。
关于基础框架这部分,大神们的学习方法是:使用框架 -> 懂框架 -> 造轮子。
## 微服务框架
**学什么?**
近些年微服务架构非常火,究其原因是因为传统的单体架构和面向服务的架构逐渐不能满足互联网快速迭代的需求。微服务可以更容易提供持续继承和持续部署的能力,让产品更快速交付推向市场。
面向服务的架构其实在五六年前就已经提出,期间经过了一段低潮期,泡沫散去后逐渐浮现了一些好用的框架,国外以 SpringCloud 为代表,国内以 Dubbo 为代表。
springCloud 和 Dubbo 有区别但是很多基本原理也是类似,大家学习的时候需要掌握技术的本质。下面列举一些核心知识点:
- Dubbo框架
- SpringCloud框架
- 服务注册与发现
- 分布式服务链路追踪
- 服务隔离、熔断、降级
- 服务网关
**怎么学?**
springCloud 和 Dubbo 在官网都有很详细的介绍文档:
- Dubbo官网 http://dubbo.apache.org/ 可以切到中文版
- SpringCloud 官网 https://spring.io/projects/spring-cloud
看官网技术文档大家可能会很懵,但这些确实是最权威的资料,也是一手的。
SpringCloud 和 Dubbo 是这几年刚刚流行的技术,从目前看来相关书籍还是比较少,也缺少一些经典的书,我还是列几本,大家按需获取。
《深入理解Apache Dubbo与实战》
> Dubbo 最开始是阿里巴巴开源的,后面捐赠给Apache 了。建议大家读这本配合源码一起看。
《Spring Cloud微服务实战》
> 读这本书之前你最好先学习 spring 和 spring boot,不然会很懵。另外这本书是2017年出版的,稍微显旧,大家注意分辨新旧特性。
如果技术网站和书籍还不能满足你,建议你去搜一些视频学习,这里不做推荐以免认为是广告。推荐搜索平台:B 站、慕课网、网易云课堂。
`敲黑板:微服务框架涵盖的内容非常多,也是有难点的技术,大家戒躁保持耐心。`
## 常用中间件
**学什么?**
最终用户并不直接使用`中间件`,换言之`中间件`不是大众消费类软件产品。但是在大公司里中间件是不可或缺的,它是支撑大型网站架构的一些基础的组件和服务,所以非常非常有必要学。
> 小百科
> 中间件(Middleware)通常是指在一个大型分布式的系统中,负责各个不同组件(Component)/服务(Service)之间管理以及交互数据的。
业界开源的优秀中间件非常多,通常会根据业务的需要在系统中引入若干,下面列举了一些常见的,都是必学的,非可选哈。
- 缓存:Redis、Memcached( 推荐 Redis)
- 消息队列:Kafka、RocketMQ、RabbitMQ、ActiveMQ、ZeroMQ(推荐 Kafka)
- 数据库中间件:ShardingSpere、Mycat
**怎么学?**
每个中间件涵盖的内容都非常多,要想学精需要大量时间。
Redis 中文官方网站:
[http://www.redis.cn/](http://www.redis.cn/)
当做字典学习 redis 常见命令
Kafka 官网:
[http://kafka.apache.org/](http://kafka.apache.org/)
ShardingSpere 官网:
[http://shardingsphere.apache.org/index_zh.html](http://shardingsphere.apache.org/index_zh.html)
Mycat 权威指南在线 PDF 版:
[http://www.mycat.org.cn/document/mycat-definitive-guide.pdf](http://www.mycat.org.cn/document/mycat-definitive-guide.pdf)
推荐几本相关的书:
《Redis 设计与实现》
> 这时Redis 口碑比较好的一本书,书中详细讲解了 Redis 实现原理,如果你只是想学会怎么用,可以跳过一些章节。
《深入理解Kafka:核心设计与实践原理》
> 这本书既适合新手入门扫盲也适合高手进阶,想知道怎么用看前四章即可,想深入学习可以从第五章开始看,写的非常好,推荐学习!
《分布式数据库架构及企业实践——基于Mycat中间件》
> Mycat 相关的书非常少,这本书是16年写的,有些陈旧了,如果对 Mycat 非常感兴趣可以简单翻一翻,但是不是特别推荐。
书看完了你还想深入学习,建议大家关注一下极客时间的两门课:
胡夕:《Kafka核心技术与实战》,老师是Apache Kafka Committer,很专业。
蒋德钧:《Redis核心技术与实战》
不过课程是付费的,手头紧的建议慎重哈。免费资源网上也有,靠大家搜索了~
中间件的学习是一个漫长的过程,不仅需要很多理论知识还需要实践经验。
比如你学 Redis 的时候,要思考五种基本数据类型各自使用场景、布隆过滤器是什么原理、用 Redis 怎么实现分布式锁,带着问题去学习效率非常高。
比如你学 Kafka 消息队列,要对比常见消息队列的优缺点、Kafka 为什么吞吐量高、Kafka 会不会丢消息以及怎么解决。
比如你学数据库中间件,要想数据库为什么要分库分表、分库分表 ID 如果处理等等。
## 数据库
**学什么?**
数据库非常重要,面试也是必考的,可以考的点非常多,可以考得很浅:问一下 SQL 使用,也可以考的很深:问索引和锁的实现原理。下面列了一些常见的知识点。
- 数据库基本理论:范式、索引原理、数据库引擎
- SQL 基本语法
- SQL 调优,explain 执行计划
- 数据库事务(ACID)
- 数据库锁:乐观锁、悲观锁、表锁、行锁等
**怎么学?**
建议数据库零基础的同学还是要先学习一下数据库的基本理论,因为我看到很多人都是一上来就学 SQL ,最终也只是会用而已,到后面 SQL 调优的时候就很迷茫了。如果你只是想用一用数据库,这部分也可以跳过。
关于原理部分有一本非常经典的教材《数据库系统概念》以供学习,经典书籍一般都比较难啃坑也比较厚,建议大家先看目录,挑重点看。大学学过这本书的可以直接跳过了。
有了一些理论后就可以开始学习 SQL 语法了,这里推荐一本《MySQL 必知必会》,一边看书一边对着电脑敲。
当然面试大厂肯定会问一下比较难的东西,你需要搞懂索引的原理、事务 ACID、锁,问数据库这些东西必考哦!
MySQL 学习书籍清单:
《数据库系统概念》
> 经典数据库教材,理解一些基本原理,可略看。
《MySQL必知必会》
> SQL 语法入门好书,推荐!
《MySQL技术内幕 : InnoDB存储引擎》
> 数据库进阶必看,理解存储引擎以及事务、锁、索引等原理。
## 分布式架构
**学什么?**
分布式这一部分就是面试的加分项了,答好了面试官会觉得你技术功底深厚,答不好,只要你前面的基础还不错也能过。所以呢,作为一个有追求的技术人,千万不要放过加分的机会。
分布式相关的内容非常多,下面列举几个在项目中或者面试中经常会遇到的知识点:
- 分布式事务:两阶段提交(2PC)、补偿事务(TCC)
- 分布式锁:基于关系型数据库(MySQL)、基于 Redis、基于Zookeeper
- 分布式 ID:雪花算法(Snowflake)、美团 Leaf
**怎么学?**
这部分内容学好非常难,在很多书中都是轻轻带过,没有深入讲解原理,所以就不推荐书了。
那怎么学呢?大家可以针对每个知识点到网上搜索优质的博客,后面我也会逐步更文讲解这些知识点,敬请期待,欢迎催更哟。
## 必须掌握的工具软件
工欲善其事,必先利其器。作为一个 Java 开发人员,你需要学习业界常用的软件,软件工具用得越熟你的编码效率越高,下班的时间可能越早(打工人太难了)。
- Java 最聪明的 IDE:IntelliJ IDEA (请放弃使用 Eclipse,我有一堆理由睡服你)
- 地球上最好用的版本管理工具:Git
- 经久不衰的依赖管理工具:Maven
- Docker
这些软件你要是用不好,那只能说明…… 你再多学学吧。
## 学习常见问题(FAQ)
**1. 学了容易忘怎么办?**
这是大家学习会遇到的头号大问题,怎么解决?重复学习。
打个比方,假如你正在学习 spring 注解,突然发现了一个注解@Aspect,不知道干什么用的,你可能会去查看源码或者通过博客学习,花了半小时终于弄懂了,下次又看到@Aspect 了,你有点郁闷了,上次好像在哪哪哪学习,你快速打开网页花了五分钟又学会了。
从半小时和五分钟的对比中可以发现多学一次就离真正掌握知识又近了一步。
人的本性就是容易遗忘,只有不断加深印象、重复学习才能真正掌握,所以很多书我都是推荐大家多看几遍。哪有那么多天才,他只是比你多看了几遍书。
**2. 推荐这么多书都要看完吗?**
当然不是!有一些书都是同类型的,作者写书的侧重点不一样,大家要学会挑重点看。
拿到一本书,首先要把目录多看一遍,一般而言书的前几章都是介绍型的内容,如果你已经有了基础,可以直接跳到后面原理解析或者实战部分。
**3. 需要学多久才能成为技术大牛?**
`学习无止境!`
业界说法,通过不断努力学习,一到两年可以达到初级水平,三到四年达到中级水平,五年可以达到高级水平。
实际上每个人的学习能力和精力不一样,时间参考意义不大。
只要你在一个方向或领域有自己的建树,就可以叫你大牛;如果你在公司是技术骨干、技术专家、架构师,也可以称之为大牛。
`敲黑板:技术学习千万不要浮躁,谦卑一点多学一点,天外有天。`
**4. 现在 python、Go 语言很火,要不要直接学它们?**
不要纠结语言,语言只是工具。今天 Go 很火,明天会有其他语言。
我有一个同学毕业去阿里写 Java,后面跳槽到深圳腾讯写 C++,现在又跳到字节跳动写 Go,在大佬面前这些语言只是语法不一样而已。所以建议大家打好基础,答应我一定打好基础。
『持续刷新……』
================================================
FILE: docs/mq/Kafka支持百万级TPS的秘密都藏在这里.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322018&idx=1&sn=ff1d7be13158a9d1cbc02a6d9123e503&chksm=8f09ca78b87e436e023de69301b326a9541d51b94a0d57393cc766da9dfef40c9ccaf0fdbc0c&token=1553501157&lang=zh_CN#rd)』,欢迎大家关注。
<!-- MarkdownTOC -->
- [Kafka 如何做到支持百万级 TPS ?](#kafka-如何做到支持百万级-tps-)
- [顺序读写磁盘](#顺序读写磁盘)
- [Memory Mapped Files\(MMAP\)](#memory-mapped-filesmmap)
- [Zero Copy(零拷贝)](#zero-copy零拷贝)
- [Batch Data(数据批量处理)](#batch-data数据批量处理)
- [总结](#总结)
- [公众号](#公众号)
<!-- /MarkdownTOC -->
谈到大数据传输都会想到 Kafka,Kafka 号称大数据的杀手锏,在业界有很多成熟的应用场景并且被主流公司认可。这款为大数据而生的消息中间件,以其百万级TPS的吞吐量名声大噪,迅速成为大数据领域的宠儿,在数据采集、传输、存储的过程中发挥着举足轻重的作用。
在业界已经有很多成熟的消息中间件如:RabbitMQ, RocketMQ, ActiveMQ, ZeroMQ,为什么 Kafka 在众多的敌手中依然能有一席之地,当然靠的是其强悍的吞吐量。下面带领大家来揭秘。
## Kafka 如何做到支持百万级 TPS ?
先用一张思维导图直接告诉你答案:
<img src="https://cdn.jsdelivr.net/gh/smileArchitect/assets@main/202012/20201205225401.png" alt="图片" style="zoom: 50%;" />
## 顺序读写磁盘
生产者写入数据和消费者读取数据都是**顺序读写**的,先来一张图直观感受一下顺序读写和随机读写的速度:
<img src="https://cdn.jsdelivr.net/gh/smileArchitect/assets@main/202012/20201205225450.png" alt="图片" style="zoom: 33%;" />
从图中可以看出传统硬盘或者SSD的顺序读写甚至超过了内存的随机读写,当然与内存的顺序读写对比差距还是很大。
所以Kafka选择顺序读写磁盘也不足为奇了。
下面以传统机械磁盘为例详细介绍一下什么是顺序读写和随机读写。
**盘片**和**盘面:**一块硬盘一般有多块盘片,盘片分为上下两面,其中有效面称为盘面,一般上下都有效,也就是说:**盘面数 = 盘片数 * 2。**
**磁头**:磁头切换磁道读写数据时是通过机械设备实现的,一般速度较慢;而磁头切换盘面读写数据是通过电子设备实现的,一般速度较快,因此磁头一般是先读写完柱面后才开始寻道的(不用切换磁道),这样磁盘读写效率更快。
<img src="https://cdn.jsdelivr.net/gh/smileArchitect/assets@main/202012/20201205225538.png" alt="图片" style="zoom:50%;" />
**磁道**:磁道就是以中间轴为圆心的圆环,一个盘面有多个磁道,磁道之间有间隙,磁道也就是磁盘存储数据的介质。磁道上布有一层磁介质,通过磁头可以使磁介质的极性转换为数据信号,即磁盘的读,磁盘写刚好与之相反。
**柱面**:磁盘中不同盘面中半径相同的磁道组成的,也就是说柱面总数 = 某个盘面的磁道数。
**扇区:**单个磁道就是多个弧形扇区组成的,盘面上的每个磁道拥有的扇区数量是相等。扇区是最小存储单元,一般扇区大小为512bytes。
<img src="https://cdn.jsdelivr.net/gh/smileArchitect/assets@main/202012/20201205225609.png" alt="图片" style="zoom:50%;" />
如果系统每次只读取一个扇区,那恐怕效率太低了,所以出现了block(块)的概念。文件读取的最小单位是block,根据不同操作系统一个block一般由多个扇区组成。
有了磁盘的背景知识我们就可以很容易理解顺序读写和随机读写了。
>插播维基百科定义:
>>顺序读写:是一种按记录的逻辑顺序进行读、写操作的存取方法 ,即按照信息在存储器中的实际位置所决定的顺序使用信息。
>>随机读写:指的是当存储器中的消息被读取或写入时,所需要的时间与这段信息所在的位置无关。
当读取第一个block时,要经历寻道、旋转延迟、传输三个步骤才能读取完这个block的数据。而对于下一个block,如果它在磁盘的其他任意位置,访问它会同样经历寻道、旋转、延时、传输才能读取完这个block的数据,我们把这种方式叫做**随机读写**。但是如果这个block的起始扇区刚好在刚才访问的block的后面,磁头就能立刻遇到,不需等待直接传输,这种就叫**顺序读写**。
好,我们再回到 Kafka,详细介绍Kafka如何实现顺序读写入数据。
Kafka 写入数据是顺序的,下面每一个Partition 都可以当做一个文件,每次接收到新数据后Kafka会把数据插入到文件末尾,虚框部分代表文件尾。
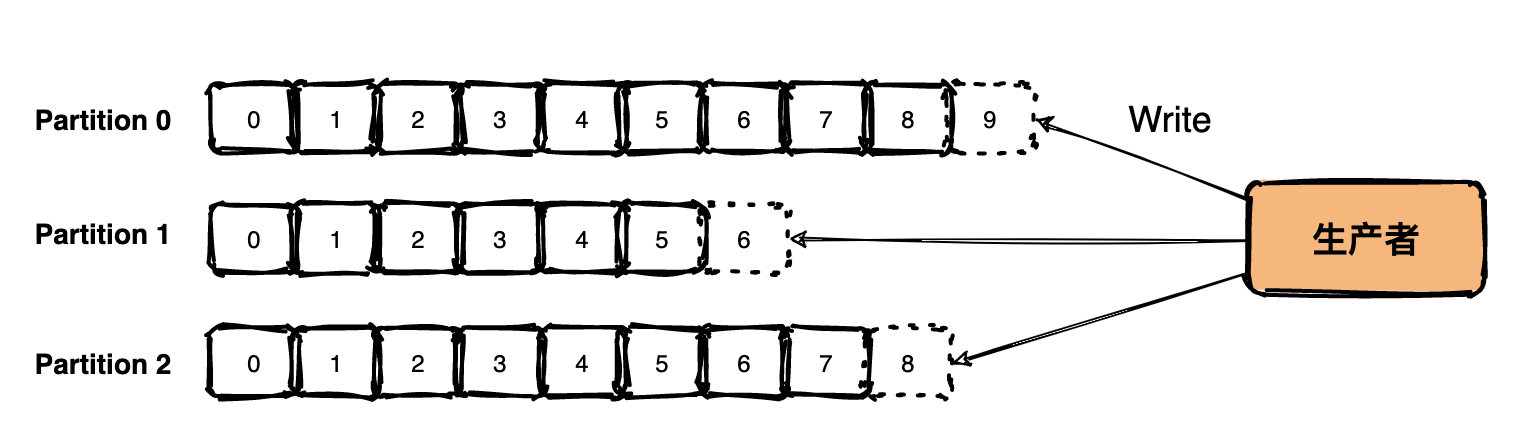
这种方法有一个问题就是删除数据不方便,所以 Kafka 一般会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个 offset 用来记录读取进度或者叫坐标。
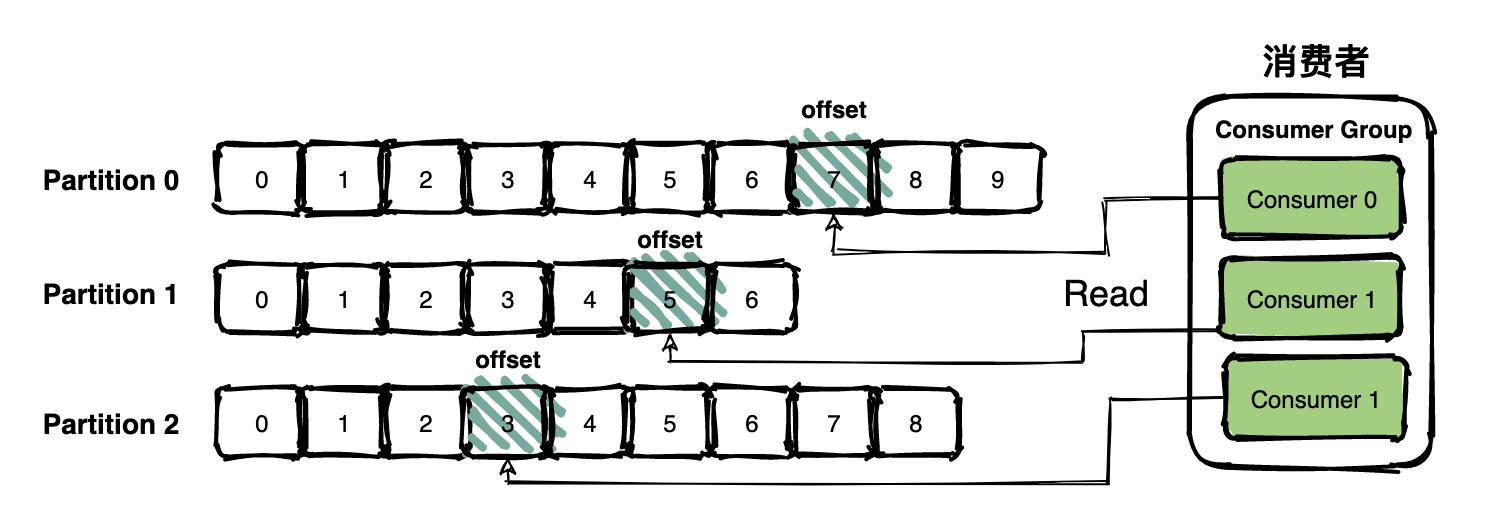
## Memory Mapped Files(MMAP)
在文章开头我们看到硬盘的顺序读写基本能与内存随机读写速度媲美,但是与内存顺序读写相比还是太慢了,那 Kafka 如果有追求想进一步提升效率怎么办?可以使用现代操作系统分页存储来充分利用内存提高I/O效率,这也是下面要介绍的 MMAP 技术。
**MMAP**也就是**内存映射文件**,在64位操作系统中一般可以表示 20G 的数据文件,它的工作原理是直接利用操作系统的 Page 来实现文件到物理内存的直接映射,完成映射之后对物理内存的操作会被同步到硬盘上。
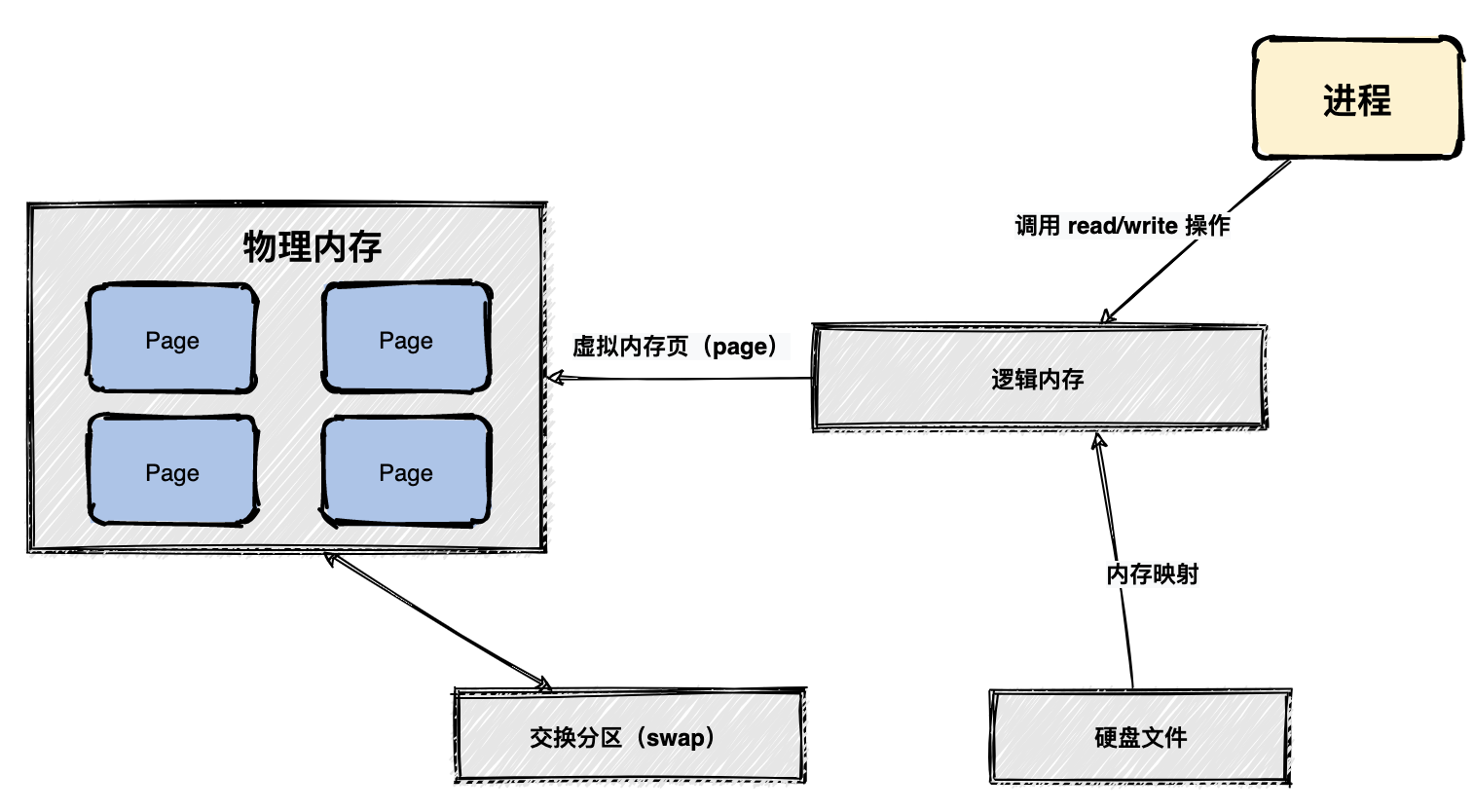
通过**MMAP**技术进程可以像读写硬盘一样读写内存(逻辑内存),不必关心内存的大小,因为有虚拟内存兜底。这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销。
也有一个很明显的缺陷,写到**MMAP**中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用 flush 的时候才把数据真正的写到硬盘。
Kafka提供了一个参数:producer.type 来控制是不是主动 flush,如果Kafka写入到MMAP之后就立即flush然后再返回Producer叫同步(sync);写入MMAP之后立即返回Producer不调用flush叫异步(async)。
## Zero Copy(零拷贝)
Kafka 另外一个黑技术就是使用了零拷贝,要想深刻理解零拷贝必须得知道什么是DMA。
**什么是DMA?**
众所周知 CPU 的速度与磁盘 IO 的速度比起来相差几个数量级,可以用乌龟和火箭做比喻。
一般来说 IO 操作都是由 CPU 发出指令,然后等待 IO 设备完成操作后返回,那CPU会有大量的时间都在等待IO操作。
但是CPU 的等待在很多时候并没有太多的实际意义,我们对于 I/O 设备的大量操作其实都只是把内存里面的数据传输到 I/O 设备而已。比如进行大文件复制,如果所有数据都要经过 CPU,实在是有点儿太浪费时间了。
基于此就有了DMA技术,翻译过来也就是直接内存访问(Direct Memory Access),有了这个可以减少 CPU 的等待时间。
**Kafka 零拷贝原理**
如果不使用零拷贝技术,消费者(consumer)从Kafka消费数据,Kafka从磁盘读数据然后发送到网络上去,数据一共发生了四次传输的过程。其中两次是 DMA 的传输,另外两次,则是通过 CPU 控制的传输。
<img src="https://cdn.jsdelivr.net/gh/smileArchitect/assets@main/202012/20201205225749.png" alt="图片" style="zoom:50%;" />
**第一次传输**:从硬盘上将数据读到操作系统内核的缓冲区里,这个传输是通过 DMA 搬运的。
**第二次传输**:从内核缓冲区里面的数据复制到分配的内存里面,这个传输是通过 CPU 搬运的。
**第三次传输**:从分配的内存里面再写到操作系统的 Socket 的缓冲区里面去,这个传输是由 CPU 搬运的。
**第四次传输**:从 Socket 的缓冲区里面写到网卡的缓冲区里面去,这个传输是通过 DMA 搬运的。
实际上在kafka中只进行了两次数据传输,如下图:
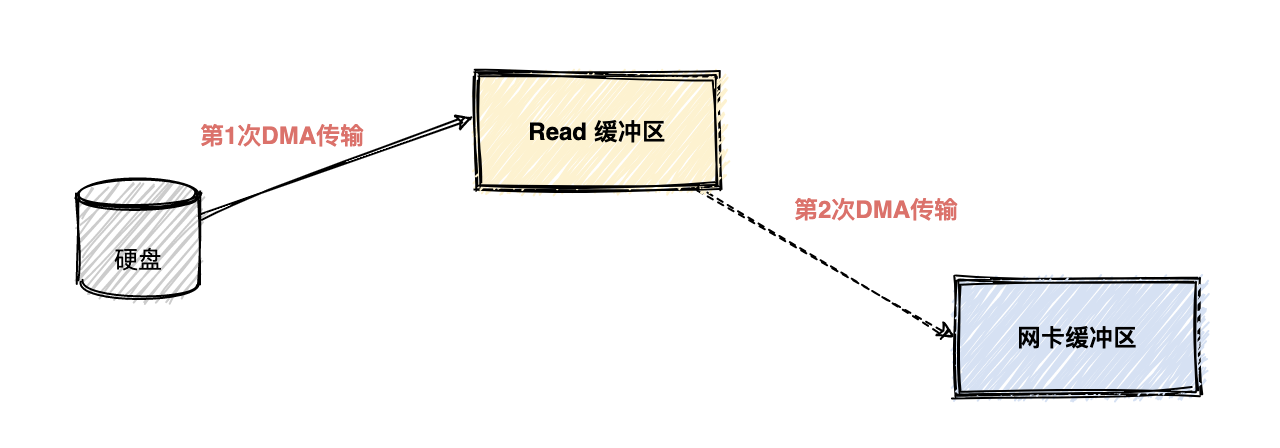
**第一次传输**:通过 DMA从硬盘直接读到操作系统内核的读缓冲区里面。
**第二次传输**:根据 Socket 的描述符信息直接从读缓冲区里面写入到网卡的缓冲区里面。
我们可以看到同一份数据的传输次数从四次变成了两次,并且没有通过 CPU 来进行数据搬运,所有的数据都是通过 DMA 来进行传输的。没有在内存层面去复制(Copy)数据,这个方法称之为**零拷贝(Zero-Copy)。**
无论传输数据量的大小,传输同样的数据使用了零拷贝能够缩短 65% 的时间,大幅度提升了机器传输数据的吞吐量,这也是Kafka能够支持百万TPS的一个重要原因。
## Batch Data(数据批量处理)
当消费者(consumer)需要消费数据时,首先想到的是消费者需要一条,kafka发送一条,消费者再要一条kafka再发送一条。但实际上 Kafka 不是这样做的,Kafka 耍小聪明了。
Kafka 把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候 Kafka 直接把文件发送给消费者。比如说100万条消息放在一个文件中可能是10M的数据量,如果消费者和Kafka之间网络良好,10MB大概1秒就能发送完,既100万TPS,Kafka每秒处理了10万条消息。
看到这里你可以有疑问了,消费者只需要一条消息啊,kafka把整个文件都发送过来了,文件里面剩余的消息怎么办?不要忘了消费者可以通过offset记录消费进度。
发送文件还有一个好处就是可以对文件进行批量压缩,减少网络IO损耗。
## 总结
最后再总结一下 Kafka 支持百万级 TPS 的秘密:
(1)顺序写入数据,在 Partition 末尾追加,所以速度最优。
(2)使用 MMAP 技术将磁盘文件与内存映射,Kafka 可以像操作磁盘一样操作内存。
(3)通过 DMA 技术实现零拷贝,减少数据传输次数。
(4)读取数据时配合sendfile直接暴力输出,批量压缩把所有消息变成一个批量文件,合理减少网络IO损耗。
# 公众号
公众号比Github早一到两天更新,如果大家想要实时关注我更新的文章以及分享的干货,可以关注我的公众号。
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/wechat-01.jpg" width=""/> </div><br>
================================================
FILE: docs/mq/刨根问底,kafka到底会不会丢消息.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321970&idx=1&sn=3a26ed6f0323c945c1eacb05c758cd62&chksm=8f09ca28b87e433e657fca2ffd9d45a74453ffeb17ee76a9bac8f2a7cfd3a0e6ac936396812c&token=1553501157&lang=zh_CN#rd)』,欢迎大家关注。
<!-- MarkdownTOC -->
- [认识Kafka](#认识kafka)
- [Kafka到底会不会丢失消息?](#kafka到底会不会丢失消息)
- [生产者丢失消息](#生产者丢失消息)
- [Kafka Broker丢失消息](#kafka-broker丢失消息)
- [消费者丢失消息](#消费者丢失消息)
- [总结](#总结)
- [公众号](#公众号)
<!-- /MarkdownTOC -->
大型互联网公司一般都会要求消息传递最大限度的不丢失,比如用户服务给代金券服务发送一个消息,如果消息丢失会造成用户未收到应得的代金券,最终用户会投诉。
??为避免上面类似情况的发生,除了做好补偿措施,更应该在系设计的时候充分考虑各种异常,设计一个稳定、高可用的消息系统。
# 认识Kafka
看一下维基百科的定义
>Kafka是分布式发布-订阅消息系统。
>它最初由LinkedIn公司开发,之后成为Apache项目的一部分。
>Kafka是一个分布式的,可划分的,冗余备份的持久性的日志服务。它主要用于处理活跃的流式数据。
**kafka架构**
Kafka的整体架构非常简单,是显式分布式架构,主要由producer、broker(kafka)和consumer组成。
<img src="https://cdn.jsdelivr.net/gh/smileArchitect/assets@main/202012/20201202235323.png" alt="img" style="zoom:67%;" />
**Producer**(生产者)可以将数据发布到所选择的topic(主题)中。生产者负责将记录分配到topic的哪一个 partition(分区)中。可以使用循环的方式来简单地实现负载均衡,也可以根据某些语义分区函数(如记录中的key)来完成。
**Consumer**(消费者)使用一个consumer group(消费组)名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例。消费者实例可以分布在多个进程中或者多个机器上。
# Kafka到底会不会丢失消息?
在讨论kafka是否丢消息前先来了解一下什么是**消息传递语义**。
<img src="https://cdn.jsdelivr.net/gh/smileArchitect/assets@main/202012/20201202235521.png" alt="图片" style="zoom:50%;" />
message delivery semantic 也就是消息传递语义,简单说就是消息传递过程中消息传递的保证性。主要分为三种:
* **at most once**:最多一次。消息可能丢失也可能被处理,但最多只会被处理一次。
* **at least once**:至少一次。消息不会丢失,但可能被处理多次。可能重复,不会丢失。
* **exactly once**:精确传递一次。消息被处理且只会被处理一次。不丢失不重复就一次。
理想情况下肯定是希望系统的消息传递是严格exactly once,也就是保证不丢失、只会被处理一次,但是很难做到。
回到主角Kafka,Kafka有三次消息传递的过程:
1. 生产者发消息给Kafka Broker。
2. Kafka Broker 消息同步和持久化
3. Kafka Broker 将消息传递给消费者。
在这三步中每一步都有可能会丢失消息,下面详细分析为什么会丢消息,如何最大限度避免丢失消息。
# 生产者丢失消息
先介绍一下生产者发送消息的一般流程(部分流程与具体配置项强相关,这里先忽略):
1. 生产者是与leader直接交互,所以先从集群获取topic对应分区的leader元数据;
2. 获取到leader分区元数据后直接将消息发给过去;
3. Kafka Broker对应的leader分区收到消息后写入文件持久化;
4. Follower拉取Leader消息与Leader的数据保持一致;
5. Follower消息拉取完毕需要给Leader回复ACK确认消息;
6. Kafka Leader和Follower分区同步完,Leader分区会给生产者回复ACK确认消息。
<img src="https://cdn.jsdelivr.net/gh/smileArchitect/assets@main/202012/20201202235556.png" alt="图片" style="zoom:80%;" />
生产者采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘。消息写入Leader后,Follower是主动与Leader进行同步。
Kafka消息发送有两种方式:同步(sync)和异步(async),默认是同步方式,可通过producer.type属性进行配置。
Kafka通过配置request.required.acks属性来确认消息的生产:
* 0表示不进行消息接收是否成功的确认;不能保证消息是否发送成功,生成环境基本不会用。
* 1表示当Leader接收成功时确认;只要Leader存活就可以保证不丢失,保证了吞吐量。
* -1或者all表示Leader和Follower都接收成功时确认;可以最大限度保证消息不丢失,但是吞吐量低。
kafka producer 的参数acks 的默认值为1,所以默认的producer级别是at least once,并不能exactly once。
**敲黑板了,这里可能会丢消息的!**
* 如果acks配置为0,发生网络抖动消息丢了,生产者不校验ACK自然就不知道丢了。
* 如果acks配置为1保证leader不丢,但是如果leader挂了,恰好选了一个没有ACK的follower,那也丢了。
* all:保证leader和follower不丢,但是如果网络拥塞,没有收到ACK,会有重复发的问题。
# Kafka Broker丢失消息
Kafka Broker 接收到数据后会将数据进行持久化存储,你以为是下面这样的:
<img src="https://cdn.jsdelivr.net/gh/smileArchitect/assets@main/202012/20201202235645.png" alt="图片" width="400" />
没想到是这样的:
<img src="https://cdn.jsdelivr.net/gh/smileArchitect/assets@main/202012/20201202235719.png" alt="图片" width="400" />
操作系统本身有一层缓存,叫做 Page Cache,当往磁盘文件写入的时候,系统会先将数据流写入缓存中,至于什么时候将缓存的数据写入文件中是由操作系统自行决定。
Kafka提供了一个参数 producer.type 来控制是不是主动flush,如果Kafka写入到mmap之后就立即 flush 然后再返回 Producer 叫同步 (sync);写入mmap之后立即返回 Producer 不调用 flush 叫异步 (async)。
**敲黑板了,这里可能会丢消息的!**
Kafka通过多分区多副本机制中已经能最大限度保证数据不会丢失,如果数据已经写入系统 cache 中但是还没来得及刷入磁盘,此时突然机器宕机或者掉电那就丢了,当然这种情况很极端。
# 消费者丢失消息
消费者通过pull模式主动的去 kafka 集群拉取消息,与producer相同的是,消费者在拉取消息的时候也是找leader分区去拉取。
多个消费者可以组成一个消费者组(consumer group),每个消费者组都有一个组id。同一个消费组者的消费者可以消费同一topic下不同分区的数据,但是不会出现多个消费者消费同一分区的数据。
<img src="https://cdn.jsdelivr.net/gh/smileArchitect/assets@main/202012/20201203000402.png" alt="图片" style="zoom: 80%;" />
消费者消费的进度通过offset保存在kafka集群的__consumer_offsets这个topic中。
消费消息的时候主要分为两个阶段:
1、标识消息已被消费,commit offset坐标;
2、处理消息。
**敲黑板了,这里可能会丢消息的!**
场景一:先commit再处理消息。如果在处理消息的时候异常了,但是offset 已经提交了,这条消息对于该消费者来说就是丢失了,再也不会消费到了。
场景二:先处理消息再commit。如果在commit之前发生异常,下次还会消费到该消息,重复消费的问题可以通过业务保证消息幂等性来解决。
# 总结
那么问题来了,kafka到底会不会丢消息?答案是:会!
Kafka可能会在三个阶段丢失消息:
(1)生产者发送数据;
(2)Kafka Broker 存储数据;
(3)消费者消费数据;
在生产环境中严格做到exactly once其实是难的,同时也会牺牲效率和吞吐量,最佳实践是业务侧做好补偿机制,万一出现消息丢失可以兜底。
# 公众号
公众号比Github早一到两天更新,如果大家想要实时关注我更新的文章以及分享的干货,可以关注我的公众号。
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/wechat-01.jpg" width=""/> </div><br>
================================================
FILE: docs/redis/Redis 数据结构和常用命令速记.md
================================================
> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650320964&idx=1&sn=c7c3435f8c9dc1b4657034dbc1f1510d&chksm=8f09ce5eb87e4748982d88402ab7d95c2770ed80813e634c42464cec671355b30a8dc53a5384&token=875646549&lang=zh_CN#rd)』,欢迎大家关注。
<!-- TOC -->
- [1. String字符串](#1--string字符串)
- [2. Hash哈希](#2-hash哈希)
- [3. List列表](#3-list列表)
- [4. Set集合](#4-set集合)
- [5. Sorted Set有序集合](#5-sorted-set有序集合)
- [6. Redis常用命令参考](#6-redis常用命令参考)
<!-- /TOC -->
Redis是key-value数据库,key的类型只能是String,但是value的数据类型就比较丰富了,主要包括五种:
* String
* Hash
* List
* Set
* Sorted Set
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201025211352.png" width="300"/> </div><br>
## 1. String字符串
**语法**
```plain
SET KEY_NAME VALUE
```
string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
string类型是Redis最基本的数据类型,一个键最大能存储512MB。
## 2. Hash哈希
**语法**
```plain
HSET KEY_NAME FIELD VALUE
```
Redis hash 是一个键值(key=>value)对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
## 3. List列表
**语法**
```plain
//在 key 对应 list 的头部添加字符串元素
LPUSH KEY_NAME VALUE1.. VALUEN
//在 key 对应 list 的尾部添加字符串元素
RPUSH KEY_NAME VALUE1..VALUEN
//对应 list 中删除 count 个和 value 相同的元素
LREM KEY_NAME COUNT VALUE
//返回 key 对应 list 的长度
LLEN KEY_NAME
```
Redis 列表是简单的字符串列表,按照插入顺序排序。
可以添加一个元素到列表的头部(左边)或者尾部(右边)
## 4. Set集合
**语法**
```plain
SADD KEY_NAME VALUE1...VALUEn
```
Redis的Set是string类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
## 5. Sorted Set有序集合
**语法**
```plain
ZADD KEY_NAME SCORE1 VALUE1.. SCOREN VALUEN
```
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。
redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
## 6. Redis常用命令参考
更多命令语法可以参考官网手册:
[https://www.redis.net.cn/order/](https://www.redis.net.cn/order/)
================================================
FILE: docs/redis/Redis核心技术知识点全集.md
================================================
<!-- MarkdownTOC -->
- [Redis数据结构和常用命令](#redis数据结构和常用命令)
- [1. String字符串](#1-string字符串)
- [2. Hash哈希](#2-hash哈希)
- [3. List列表](#3-list列表)
- [4. Set集合](#4-set集合)
- [5. Sorted Set有序集合](#5-sorted-set有序集合)
- [6. Redis常用命令参考](#6-redis常用命令参考)
- [Redis事务机制](#redis事务机制)
- [1. Redis事务生命周期](#1-redis事务生命周期)
- [2. Redis事务到底是不是原子性的?](#2-redis事务到底是不是原子性的)
- [3. Redis为什么不支持回滚(roll back)?](#3-redis为什么不支持回滚roll-back)
- [4. Redis事务失败场景](#4-redis事务失败场景)
- [5. Redis事务相关命令](#5-redis事务相关命令)
- [(1)WATCH](#1watch)
- [(2)MULTI](#2multi)
- [(3)UNWATCH](#3unwatch)
- [(4)DISCARD](#4discard)
- [(5)EXEC](#5exec)
- [Redis持久化策略](#redis持久化策略)
- [什么是持久化?](#什么是持久化)
- [Redis为什么要持久化?](#redis为什么要持久化)
- [Redis如何实现持久化?](#redis如何实现持久化)
- [RDB持久化](#rdb持久化)
- [AOF持久化](#aof持久化)
- [RDB和AOF的优缺点](#rdb和aof的优缺点)
- [Redis内存淘汰策略](#redis内存淘汰策略)
- [什么是淘汰策略?](#什么是淘汰策略)
- [如何配置最大内存?](#如何配置最大内存)
- [淘汰策略的分类](#淘汰策略的分类)
- [noeviction](#noeviction)
- [allkeys-lru](#allkeys-lru)
- [volatile-lru](#volatile-lru)
- [allkeys-random](#allkeys-random)
- [volatile-random](#volatile-random)
- [volatile-ttl](#volatile-ttl)
- [allkeys-lfu](#allkeys-lfu)
- [volatile-lfu](#volatile-lfu)
- [LRU算法](#lru算法)
- [LFU算法](#lfu算法)
- [Redis内存失效策略](#redis内存失效策略)
- [定时清除(主动)](#定时清除主动)
- [惰性清除(被动)](#惰性清除被动)
- [定期扫描清除(主动)](#定期扫描清除主动)
- [缓存更新策略](#缓存更新策略)
- [Cache aside(旁路缓存)](#cache-aside旁路缓存)
- [Cache aside踩坑](#cache-aside踩坑)
- [踩坑一:先更新数据库,再更新缓存](#踩坑一:先更新数据库再更新缓存)
- [踩坑二:先删缓存,再更新数据库](#踩坑二:先删缓存再更新数据库)
- [最佳实践:先更新数据库,再删除缓存](#最佳实践:先更新数据库再删除缓存)
- [Read through](#read-through)
- [Write through](#write-through)
- [Write behind](#write-behind)
- [缓存异常场景](#缓存异常场景)
- [缓存穿透](#缓存穿透)
- [什么是缓存穿透?](#什么是缓存穿透)
- [缓存穿透常用的解决方案](#缓存穿透常用的解决方案)
- [缓存击穿](#缓存击穿)
- [什么是缓存击穿?](#什么是缓存击穿)
- [缓存击穿危害](#缓存击穿危害)
- [如何解决](#如何解决)
- [缓存雪崩](#缓存雪崩)
- [什么是缓存雪崩?](#什么是缓存雪崩)
- [缓存雪崩解决方案](#缓存雪崩解决方案)
- [缓存预热](#缓存预热)
- [什么是缓存预热?](#什么是缓存预热)
- [缓存预热的操作方法](#缓存预热的操作方法)
- [缓存降级](#缓存降级)
- [高可用架构](#高可用架构)
- [Replication(主从复制)](#replication主从复制)
- [什么是主从复制?](#什么是主从复制)
- [主从复制的作用](#主从复制的作用)
- [主从复制实现原理](#主从复制实现原理)
- [连接建立阶段](#连接建立阶段)
- [数据同步阶段](#数据同步阶段)
- [命令传播阶段](#命令传播阶段)
- [Sentinel(哨兵模式)](#sentinel哨兵模式)
- [为什么要引入哨兵模式?](#为什么要引入哨兵模式)
- [什么是哨兵模式?](#什么是哨兵模式)
- [哨兵模式的原理](#哨兵模式的原理)
- [心跳机制](#心跳机制)
- [故障转移](#故障转移)
- [Cluster(集群)](#cluster集群)
- [为什么要引入Cluster模式?](#为什么要引入cluster模式)
- [什么是Cluster模式?](#什么是cluster模式)
- [Cluster模式的原理](#cluster模式的原理)
- [Redis集群TCP端口](#redis集群tcp端口)
- [Redis集群数据分片](#redis集群数据分片)
- [常见应用场景](#常见应用场景)
- [实战篇](#实战篇)
- [使用docker搭建redis主从复制集群](#使用docker搭建redis主从复制集群)
- [0. 目标](#0-目标)
- [1. 安装docker,运行docker](#1-安装docker运行docker)
- [2. 拉取redis镜像文件](#2-拉取redis镜像文件)
- [3. 准备好redis配置文件redis.conf](#3-准备好redis配置文件redisconf)
- [4. 启动redis实例](#4-启动redis实例)
- [5. 配置主从复制集群](#5-配置主从复制集群)
- [6. 测试主从复制效果](#6-测试主从复制效果)
- [使用docker搭建redis主从复制+哨兵模式](#使用docker搭建redis主从复制哨兵模式)
- [0. 哨兵作用](#0-哨兵作用)
- [1. 准备好哨兵配置文件sentinel.conf](#1-准备好哨兵配置文件sentinelconf)
- [2. 启动sentinel哨兵实例](#2-启动sentinel哨兵实例)
- [3. 测试哨兵模式](#3-测试哨兵模式)
- [公众号](#公众号)
<!-- /MarkdownTOC -->
# Redis数据结构和常用命令
Redis是key-value数据库,key的类型只能是String,但是value的数据类型就比较丰富了,主要包括五种:
* String
* Hash
* List
* Set
* Sorted Set
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201025211352.png" width="300"/> </div><br>
## 1. String字符串
**语法**
```plain
SET KEY_NAME VALUE
```
string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
string类型是Redis最基本的数据类型,一个键最大能存储512MB。
## 2. Hash哈希
**语法**
```plain
HSET KEY_NAME FIELD VALUE
```
Redis hash 是一个键值(key=>value)对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
## 3. List列表
**语法**
```plain
//在 key 对应 list 的头部添加字符串元素
LPUSH KEY_NAME VALUE1.. VALUEN
//在 key 对应 list 的尾部添加字符串元素
RPUSH KEY_NAME VALUE1..VALUEN
//对应 list 中删除 count 个和 value 相同的元素
LREM KEY_NAME COUNT VALUE
//返回 key 对应 list 的长度
LLEN KEY_NAME
```
Redis 列表是简单的字符串列表,按照插入顺序排序。
可以添加一个元素到列表的头部(左边)或者尾部(右边)
## 4. Set集合
**语法**
```plain
SADD KEY_NAME VALUE1...VALUEn
```
Redis的Set是string类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
## 5. Sorted Set有序集合
**语法**
```plain
ZADD KEY_NAME SCORE1 VALUE1.. SCOREN VALUEN
```
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。
redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
## 6. Redis常用命令参考
更多命令语法可以参考官网手册:
[https://www.redis.net.cn/order/](https://www.redis.net.cn/order/)
---完毕
# Redis事务机制
## 1. Redis事务生命周期
* 开启事务:使用MULTI开启一个事务
* 命令入队列:每次操作的命令都会加入到一个队列中,但命令此时不会真正被执行
* 提交事务:使用EXEC命令提交事务,开始顺序执行队列中的命令
## 2. Redis事务到底是不是原子性的?
先看关系型数据库ACID 中关于原子性的定义:
**原子性:**一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
官方文档对事务的定义:
* **事务是一个单独的隔离操作**:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
* **事务是一个原子操作**:事务中的命令要么全部被执行,要么全部都不执行。EXEC 命令负责触发并执行事务中的所有命令:如果客户端在使用 MULTI 开启了一个事务之后,却因为断线而没有成功执行 EXEC ,那么事务中的所有命令都不会被执行。另一方面,如果客户端成功在开启事务之后执行 EXEC ,那么事务中的所有命令都会被执行。
官方认为Redis事务是一个原子操作,这是站在执行与否的角度考虑的。但是从ACID原子性定义来看,**严格意义上讲Redis事务是非原子型的**,因为在命令顺序执行过程中,一旦发生命令执行错误Redis是不会停止执行然后回滚数据。
## 3. Redis为什么不支持回滚(roll back)?
在事务运行期间虽然Redis命令可能会执行失败,但是Redis依然会执行事务内剩余的命令而不会执行回滚操作。如果你熟悉mysql关系型数据库事务,你会对此非常疑惑,Redis官方的理由如下:
>只有当被调用的Redis命令有语法错误时,这条命令才会执行失败(在将这个命令放入事务队列期间,Redis能够发现此类问题),或者对某个键执行不符合其数据类型的操作:实际上,这就意味着只有程序错误才会导致Redis命令执行失败,这种错误很有可能在程序开发期间发现,一般很少在生产环境发现。
>支持事务回滚能力会导致设计复杂,这与Redis的初衷相违背,Redis的设计目标是功能简化及确保更快的运行速度。
>
对于官方的这种理由有一个普遍的反对观点:程序有bug怎么办?但其实回归不能解决程序的bug,比如某位粗心的程序员计划更新键A,实际上最后更新了键B,回滚机制是没法解决这种人为错误的。正因为这种人为的错误不太可能进入生产系统,所以官方在设计Redis时选用更加简单和快速的方法,没有实现回滚的机制。
## 4. Redis事务失败场景
有三种类型的失败场景:
(1)在事务提交之前,客户端执行的命令缓存(队列)失败,比如命令的语法错误(命令参数个数错误,不支持的命令等等)。如果发生这种类型的错误,Redis将向客户端返回包含错误提示信息的响应,同时Redis会清空队列中的命令并取消事务。
```plain
127.0.0.1:6379> set name xiaoming # 事务之前执行
OK
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set name zhangsan # 事务中执行,命令入队列
QUEUED
127.0.0.1:6379> setset name zhangsan2 # 错误的命令,模拟失败场景
(error) ERR unknown command `setset`, with args beginning with: `name`, `zhangsan2`,
127.0.0.1:6379> exec # 提交事务,发现由于上条命令的错误导致事务已经自动取消了
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get name # 查询name,发现未被修改
"xiaoming"
```
(2)事务提交后开始顺序执行命令,之前缓存在队列中的命令有可能执行失败。
```plain
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set name xiaoming # 设置名字
QUEUED
127.0.0.1:6379> set age 18 # 设置年龄
QUEUED
127.0.0.1:6379> lpush age 20 # 此处仅检查是否有语法错误,不会真正执行
QUEUED
127.0.0.1:6379> exec # 提交事务后开始顺序执行命令,第三条命令执行失败
1) OK
2) OK
3) (error) WRONGTYPE Operation against a key holding the wrong kind of value
127.0.0.1:6379> get name # 第三条命令失败没有将前两条命令回滚
"xiaoming"
```
(3)由于乐观锁失败,事务提交时将丢弃之前缓存的所有命令序列。
通过开启两个redis客户端并结合watch命令模拟这种失败场景。
```plain
# 客户端1
127.0.0.1:6379> set name xiaoming # 客户端1设置name
OK
127.0.0.1:6379> watch name # 客户端1通过watch命令给name加乐观锁
OK
# 客户端2
127.0.0.1:6379> get name # 客户端2查询name
"xiaoming"
127.0.0.1:6379> set name zhangsan # 客户端2修改name值
OK
# 客户端1
127.0.0.1:6379> multi # 客户端1开启事务
OK
127.0.0.1:6379> set name lisi # 客户端1修改name
QUEUED
127.0.0.1:6379> exec # 客户端1提交事务,返回空
(nil)
127.0.0.1:6379> get name # 客户端1查询name,发现name没有被修改为lisi
"zhangsan"
```
在事务过程中监控的key被其他客户端改变,则当前客户端的乐观锁失败,事务提交时将丢弃所有命令缓存队列。
## 5. Redis事务相关命令
### (1)WATCH
可以为Redis事务提供 check-and-set (CAS)行为。被WATCH的键会被监视,并会发觉这些键是否被改动过了。 如果有至少一个被监视的键在 EXEC 执行之前被修改了, 那么整个事务都会被取消, EXEC 返回nil-reply来表示事务已经失败。
### (2)MULTI
用于开启一个事务,它总是返回OK。MULTI执行之后,客户端可以继续向服务器发送任意多条命令, 这些命令不会立即被执行,而是被放到一个队列中,当 EXEC命令被调用时, 所有队列中的命令才会被执行。
### (3)UNWATCH
取消 WATCH 命令对所有 key 的监视,一般用于DISCARD和EXEC命令之前。如果在执行 WATCH 命令之后, EXEC 命令或 DISCARD 命令先被执行了的话,那么就不需要再执行 UNWATCH 了。因为 EXEC 命令会执行事务,因此 WATCH 命令的效果已经产生了;而 DISCARD 命令在取消事务的同时也会取消所有对 key 的监视,因此这两个命令执行之后,就没有必要执行 UNWATCH 了。
### (4)DISCARD
当执行 DISCARD 命令时, 事务会被放弃, 事务队列会被清空,并且客户端会从事务状态中退出。
### (5)EXEC
负责触发并执行事务中的所有命令:
如果客户端成功开启事务后执行EXEC,那么事务中的所有命令都会被执行。
如果客户端在使用MULTI开启了事务后,却因为断线而没有成功执行EXEC,那么事务中的所有命令都不会被执行。需要特别注意的是:即使事务中有某条/某些命令执行失败了,事务队列中的其他命令仍然会继续执行,Redis不会停止执行事务中的命令,而不会像我们通常使用的关系型数据库一样进行回滚。
# Redis持久化策略
## 什么是持久化?
持久化(Persistence),即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)。持久化的主要应用是将内存中的对象存储在数据库中,或者存储在磁盘文件中、XML数据文件中等等。
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/SmileLionCoder/assets@main/202010/20201025211500.png" width=""/> </div><br>
还可以从如下两个层面简单的理解持久化 :
* 应用层:如果关闭(shutdown)你的应用然后重新启动则先前的数据依然存在。
* 系统层:如果关闭(shutdown)你的系统(电脑)然后重新启动则先前的数据依然存在。
## Redis为什么要持久化?
Redis是内存数据库,为了保证效率所有的操作都是在内存中完成。数据都是缓存在内存中,当你重启系统或者关闭系统,之前缓存在内存中的数据都会丢失再也不能找回。因此为了避免这种情况,Redis需要实现持久化将内存中的数据存储起来。
## Redis如何实现持久化?
Redis官方提供了不同级别的持久化方式:
* RDB持久化:能够在指定的时间间隔能对你的数据进行快照存储。
* AOF持久化:记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾。Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
* 不使用持久化:如果你只希望你的数据在服务器运行的时候存在,你也可以选择不使用任何持久化方式。
* 同时开启RDB和AOF:你也可以同时开启两种持久化方式,在这种情况下当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
这么多持久化方式我们应该怎么选?在选择之前我们需要搞清楚每种持久化方式的区别以及各自的优劣势。
## RDB持久化
RDB(Redis Database)持久化是把当前内存数据生成快照保存到硬盘的过程,触发RDB持久化过程分为**手动触发**和**自动触发**。
(1)手动触发
手动触发对应save命令,会阻塞当前Redis服务器,直到RDB过程完成为止,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。
(2)自动触发
自动触发对应bgsave命令,Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
在redis.conf配置文件中可以配
gitextract_hyqgw0oi/ ├── .gitattributes ├── .gitignore ├── .nojekyll ├── README.md ├── _sidebar.md ├── docs/ │ ├── distributed/ │ │ ├── 13张图彻底搞懂分布式系统服务注册与发现原理.md │ │ ├── 原来10张图就可以搞懂分布式链路追踪系统原理.md │ │ └── 用大白话给你解释Zookeeper的选举机制.md │ ├── it-hot/ │ │ └── 鸿蒙OS尖刀武器之分布式软总线技术.md │ ├── java/ │ │ ├── annotation/ │ │ │ └── 想自己写框架不会写Java注解可不行.md │ │ ├── base/ │ │ │ └── Java基础入门80问.md │ │ ├── java8/ │ │ │ ├── Java8函数式接口和Lambda表达式你真的会了吗.md │ │ │ ├── 使用Java8 Optional类优雅解决空指针问题.md │ │ │ ├── 包学会,教你用Java函数式编程重构烂代码.md │ │ │ └── 请避开Stream流式编程常见的坑.md │ │ ├── juc/ │ │ │ ├── 倒计时计数CountDownLatch.md │ │ │ ├── 内存泄露的原因找到了,罪魁祸首居然是Java TheadLocal.md │ │ │ ├── 十张图告诉你多线程那些破事.md │ │ │ ├── 图解Java中那18 把锁.md │ │ │ ├── 面试官:说说Atomic原子类的实现原理.md │ │ │ ├── 面试官:说说什么是Java内存模型?.md │ │ │ └── 面试必问的CAS原理你会了吗.md │ │ └── roadmap/ │ │ └── 2021 版最新Java 学习路线图(持续刷新).md │ ├── mq/ │ │ ├── Kafka支持百万级TPS的秘密都藏在这里.md │ │ └── 刨根问底,kafka到底会不会丢消息.md │ ├── redis/ │ │ ├── Redis 数据结构和常用命令速记.md │ │ ├── Redis核心技术知识点全集.md │ │ ├── 一张图搞懂Redis缓存雪崩、缓存穿透、缓存击穿.md │ │ ├── 一次性将Redis RDB持久化和AOF持久化讲透.md │ │ ├── 看完这20道Redis面试题,阿里面试可以约起来了.md │ │ ├── 经理让我复盘上次Redis缓存雪崩事故.md │ │ ├── 记一次由Redis分布式锁造成的重大事故,避免以后踩坑!.md │ │ ├── 还在用单机版?教你用Docker+Redis搭建主从复制多实例.md │ │ ├── 面试官再问Redis事务把这篇文章扔给他.md │ │ └── 高并发场景下,到底先更新缓存还是先更新数据库?.md │ └── tools/ │ ├── git/ │ │ └── 保姆级Git教程,10000字详解.md │ ├── 推荐十款精选IntelliJIdea插件.md │ └── 高效学习资源网站汇总.md └── index.html
Condensed preview — 39 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (315K chars).
[
{
"path": ".gitattributes",
"chars": 86,
"preview": "*.js linguist-language=java\n*.css linguist-language=java\n*.html linguist-language=java"
},
{
"path": ".gitignore",
"chars": 10,
"preview": ".DS_Store\n"
},
{
"path": ".nojekyll",
"chars": 0,
"preview": ""
},
{
"path": "README.md",
"chars": 11414,
"preview": ":star: 点右上角给一个 `Star`,鼓励技术人输出更多干货,爱了 !\n\n:gift::gift::gift: 号外号外,学习资料免费下载!\n- [进BAT大厂前必读的经典编程书籍,吐血整理共6G一次打包带走](http://mp.w"
},
{
"path": "_sidebar.md",
"chars": 679,
"preview": "- [:coffee: Java](#coffee-java)\n - [Java入门面试题](#java入门面试题)\n - [Java并发编程(J.U.C) :+1:](#java并发编程juc-1)\n - [Java8实"
},
{
"path": "docs/distributed/13张图彻底搞懂分布式系统服务注册与发现原理.md",
"chars": 7452,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321879&idx=1&sn=8b786ec4c6ef90e30834516"
},
{
"path": "docs/distributed/原来10张图就可以搞懂分布式链路追踪系统原理.md",
"chars": 6577,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321924&idx=1&sn=d8572df23b47409ab997029"
},
{
"path": "docs/distributed/用大白话给你解释Zookeeper的选举机制.md",
"chars": 4886,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322098&idx=1&sn=100089ec2d8c49b85f4acc5"
},
{
"path": "docs/it-hot/鸿蒙OS尖刀武器之分布式软总线技术.md",
"chars": 4689,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s/AM3C5z1QulG0wEKBFCyH6g)』,欢迎大家关注。\n\n<!-- MarkdownTOC -->\n\n- [1 没有人能够熄灭满天"
},
{
"path": "docs/java/annotation/想自己写框架不会写Java注解可不行.md",
"chars": 4765,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s/JqrJGwyU0oKdWYtHe_W31w)』,欢迎大家关注。\n\n<!-- MarkdownTOC -->\n\n- [用注解一时爽,一直用一"
},
{
"path": "docs/java/base/Java基础入门80问.md",
"chars": 61990,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](#公众号)』,欢迎大家关注。\n\n<!-- TOC -->\n\n- [1.一个\".java\"源文件中是否可以包括多个类(不是内部类)?有什么限制?](#1一个java源文件中是否可以包括多个类不是内"
},
{
"path": "docs/java/java8/Java8函数式接口和Lambda表达式你真的会了吗.md",
"chars": 4525,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321342&idx=1&sn=2d87b7fe6709a8513eb0abf"
},
{
"path": "docs/java/java8/使用Java8 Optional类优雅解决空指针问题.md",
"chars": 5592,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321295&idx=1&sn=2fdb1d4c7e44177a7b08393"
},
{
"path": "docs/java/java8/包学会,教你用Java函数式编程重构烂代码.md",
"chars": 5051,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321467&idx=1&sn=62376145a601f4470532ccb"
},
{
"path": "docs/java/java8/请避开Stream流式编程常见的坑.md",
"chars": 6406,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321100&idx=1&sn=d566cdd805d14e121dfef49"
},
{
"path": "docs/java/juc/倒计时计数CountDownLatch.md",
"chars": 3455,
"preview": "在日常编码中,Java 并发编程可是少不了,试试下面这些并发编程工具类:\n\n.md",
"chars": 13532,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s/vc7rzYwfRC05bUR6eaUJcw)』,欢迎大家关注。\n\n<!-- TOC -->\n\n- [学Java有哪些就业方向?](#学ja"
},
{
"path": "docs/mq/Kafka支持百万级TPS的秘密都藏在这里.md",
"chars": 5330,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322018&idx=1&sn=ff1d7be13158a9d1cbc02a6"
},
{
"path": "docs/mq/刨根问底,kafka到底会不会丢消息.md",
"chars": 4392,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321970&idx=1&sn=3a26ed6f0323c945c1eacb0"
},
{
"path": "docs/redis/Redis 数据结构和常用命令速记.md",
"chars": 1769,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650320964&idx=1&sn=c7c3435f8c9dc1b4657034d"
},
{
"path": "docs/redis/Redis核心技术知识点全集.md",
"chars": 32291,
"preview": "<!-- MarkdownTOC -->\n\n- [Redis数据结构和常用命令](#redis数据结构和常用命令)\n\t- [1. String字符串](#1-string字符串)\n\t- [2. Hash哈希](#2-hash哈希)\n\t- "
},
{
"path": "docs/redis/一张图搞懂Redis缓存雪崩、缓存穿透、缓存击穿.md",
"chars": 4157,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321284&idx=1&sn=63f0143fd3a7ef408b9810d"
},
{
"path": "docs/redis/一次性将Redis RDB持久化和AOF持久化讲透.md",
"chars": 5858,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321014&idx=1&sn=ad594766b3973bbf5156567"
},
{
"path": "docs/redis/看完这20道Redis面试题,阿里面试可以约起来了.md",
"chars": 25231,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321227&idx=1&sn=d60883728b0c7479e1e5538"
},
{
"path": "docs/redis/经理让我复盘上次Redis缓存雪崩事故.md",
"chars": 2079,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321968&idx=1&sn=aaa3f84046651c5b2f57b7c"
},
{
"path": "docs/redis/记一次由Redis分布式锁造成的重大事故,避免以后踩坑!.md",
"chars": 6457,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321391&idx=2&sn=272aafc2c051e3b969efb92"
},
{
"path": "docs/redis/还在用单机版?教你用Docker+Redis搭建主从复制多实例.md",
"chars": 3420,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321391&idx=1&sn=0aea8b119ccee60a1366fff"
},
{
"path": "docs/redis/面试官再问Redis事务把这篇文章扔给他.md",
"chars": 3751,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321004&idx=1&sn=a8b058868390e133cfdf77b"
},
{
"path": "docs/redis/高并发场景下,到底先更新缓存还是先更新数据库?.md",
"chars": 3881,
"preview": "> 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322566&idx=1&sn=2142fe29c6a32e5a2100f4f"
},
{
"path": "docs/tools/git/保姆级Git教程,10000字详解.md",
"chars": 16854,
"preview": "大家好,我是雷小帅。\n\n最近群里有几位老哥私我,有没有好的 git 入门资料,想学一下。\n\n偶然看到这个很棒的教程推荐给大家,大家可以看一下,另外还有一个不错的 git 入门网站,也推荐给大家,可以搭配使用。\n\n[https://learn"
},
{
"path": "docs/tools/推荐十款精选IntelliJIdea插件.md",
"chars": 3630,
"preview": "<!-- MarkdownTOC -->\n\n- [1 Key Promoter X](#1-key-promoter-x)\n- [2 Alibaba Java Coding Guidelines](#2-alibaba-java-codin"
},
{
"path": "docs/tools/高效学习资源网站汇总.md",
"chars": 1929,
"preview": "\n<!-- TOC -->\n\n- [(1)视频网站](#1视频网站)\n- [(2)专栏](#2专栏)\n- [(3)Github](#3github)\n- [(4)技术博客:](#4技术博客)\n- [(5)搜索引擎:](#5搜索引擎)\n- ["
},
{
"path": "index.html",
"chars": 2686,
"preview": "<!DOCTYPE html>\r\n<html lang=\"en\">\r\n\r\n<head>\r\n <meta charset=\"UTF-8\">\r\n <title>Java八股文</title>\r\n <meta http-equiv=\"X-U"
}
]
About this extraction
This page contains the full source code of the CoderLeixiaoshuai/java-eight-part GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 39 files (292.3 KB), approximately 150.6k tokens. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.