[
{
"path": "Pytorch/B站-Pytorch与深度学习-代码/minist.py",
"content": "import pandas as pd\nimport numpy as np\nfrom PIL import Image\nimport torch \nfrom torch.utils.data import Dataset\nfrom torchvision import transforms\nimport torch.nn as nn\nimport torchvision\n\n\nclass MnistDataset(Dataset):\n\n def __init__(self, image_path, image_label, transform=None):\n super(MnistDataset, self).__init__()\n self.image_path = image_path # 初始化图像路径列表\n self.image_label = image_label # 初始化图像标签列表\n self.transform = transform # 初始化数据增强方法\n\n def __getitem__(self, index):\n \"\"\"\n 获取对应index的图像,并视情况进行数据增强\n \"\"\"\n image = Image.open(self.image_path[index])\n image = np.array(image)\n label = int(self.image_label[index])\n\n if self.transform is not None:\n image = self.transform(image)\n\n return image, torch.tensor(label)\n\n def __len__(self):\n return len(self.image_path)\n\n \ndef get_path_label(img_root, label_file_path):\n \"\"\"\n 获取数字图像的路径和标签并返回对应列表\n @para: img_root: 保存图像的根目录\n @para:label_file_path: 保存图像标签数据的文件路径 .csv 或 .txt 分隔符为','\n @return: 图像的路径列表和对应标签列表\n \"\"\"\n data = pd.read_csv(label_file_path, names=['img', 'label'])\n data['img'] = data['img'].apply(lambda x: img_root + x)\n return data['img'].tolist(), data['label'].tolist()\n\n\n# 获取训练集路径列表和标签列表\ntrain_data_root = './mnist_data/train/'\ntrain_label = './mnist_data/train.txt'\ntrain_img_list, train_label_list = get_path_label(train_data_root, train_label) \n# 训练集dataset\ntrain_dataset = MnistDataset(train_img_list,\n train_label_list,\n transform=transforms.Compose([transforms.ToTensor()]))\n\n# 获取测试集路径列表和标签列表\ntest_data_root = './mnist_data/test/'\ntest_label = './mnist_data/test.txt'\ntest_img_list, test_label_list = get_path_label(test_data_root, test_label)\n# 测试集sdataset\ntest_dataset = MnistDataset(test_img_list,\n test_label_list,\n transform=transforms.Compose([transforms.ToTensor()]))\n\nnum_epochs = 5\nnum_classes = 10\nbatch_size = 100\nlearning_rate = 0.001\n\n\ntrain_loader = torch.utils.data.DataLoader(dataset=train_dataset,\n batch_size=batch_size, \n shuffle=True)\n\ntest_loader = torch.utils.data.DataLoader(dataset=test_dataset,\n batch_size=batch_size, \n shuffle=False)\n\nclass ConvNet(nn.Module):\n def __init__(self, num_classes=10):\n super(ConvNet, self).__init__()\n ## 池化+batchnorm+relu激活+池化\n self.layer1 = nn.Sequential(\n nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),\n nn.BatchNorm2d(16),\n nn.ReLU(),\n nn.MaxPool2d(kernel_size=2, stride=2)) \n self.layer2 = nn.Sequential(\n nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),\n nn.BatchNorm2d(32),\n nn.ReLU(),\n nn.MaxPool2d(kernel_size=2, stride=2))\n self.fc = nn.Linear(7*7*32, num_classes) ## 全链接\n \n def forward(self, x):\n out = self.layer1(x)\n out = self.layer2(out)\n out = out.reshape(out.size(0), -1)\n out = self.fc(out)\n return out\n\nmodel = ConvNet(num_classes).to(device)\n\n# Loss and optimizer\ncriterion = nn.CrossEntropyLoss()\noptimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)\n\n# Train the model\ntotal_step = len(train_loader)\nfor epoch in range(num_epochs):\n for i, (images, labels) in enumerate(train_loader):\n images = images.to(device)\n labels = labels.to(device)\n \n # Forward pass\n outputs = model(images)\n loss = criterion(outputs, labels)\n \n # Backward and optimize\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n \n if (i+1) % 100 == 0:\n print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' \n .format(epoch+1, num_epochs, i+1, total_step, loss.item()))\n"
},
{
"path": "Pytorch/B站-Pytorch与深度学习-代码/mnist_data/test.txt",
"content": "0.jpg,7\n1.jpg,2\n2.jpg,1\n3.jpg,0\n4.jpg,4\n5.jpg,1\n6.jpg,4\n7.jpg,9\n8.jpg,5\n9.jpg,9\n10.jpg,0"
},
{
"path": "Pytorch/B站-Pytorch与深度学习-代码/mnist_data/train.txt",
"content": "0.jpg,5\n1.jpg,0\n2.jpg,4\n3.jpg,1\n4.jpg,9\n5.jpg,2\n6.jpg,1\n7.jpg,3\n8.jpg,1\n9.jpg,4\n10.jpg,3\n11.jpg,5\n12.jpg,3\n13.jpg,6\n14.jpg,1\n15.jpg,7\n16.jpg,2\n17.jpg,8\n18.jpg,6\n19.jpg,9\n20.jpg,4"
},
{
"path": "Pytorch/B站-Pytorch与深度学习-代码/线性回归/.idea/inspectionProfiles/profiles_settings.xml",
"content": "\n \n \n \n \n"
},
{
"path": "Pytorch/B站-Pytorch与深度学习-代码/线性回归/.idea/misc.xml",
"content": "\n\n \n"
},
{
"path": "Pytorch/B站-Pytorch与深度学习-代码/线性回归/.idea/modules.xml",
"content": "\n\n \n \n \n \n \n"
},
{
"path": "Pytorch/B站-Pytorch与深度学习-代码/线性回归/.idea/workspace.xml",
"content": "\n\n \n
\n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n 1617886772769\n \n \n 1617886772769\n \n \n \n \n \n \n \n file://$PROJECT_DIR$/sigmoid.py\n 22\n \n \n \n file://$PROJECT_DIR$/sigmoid.py\n 23\n \n \n \n \n \n"
},
{
"path": "Pytorch/B站-Pytorch与深度学习-代码/线性回归/.idea/线性回归.iml",
"content": "\n\n \n \n \n \n \n \n \n \n \n \n \n \n"
},
{
"path": "Pytorch/B站-Pytorch与深度学习-代码/线性回归/.ipynb_checkpoints/house_price_predict-checkpoint.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"# 3.16 实战Kaggle比赛:房价预测\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"1.3.1\\n\"\n ]\n }\n ],\n \"source\": [\n \"# 如果没有安装pandas,则反注释下面一行\\n\",\n \"# !pip install pandas\\n\",\n \"\\n\",\n \"%matplotlib inline\\n\",\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"import numpy as np\\n\",\n \"import pandas as pd\\n\",\n \"import sys\\n\",\n \"\\n\",\n \"import utils as d2l\\n\",\n \"\\n\",\n \"print(torch.__version__)\\n\",\n \"torch.set_default_tensor_type(torch.FloatTensor)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## 3.16.2 获取和读取数据集\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"metadata\": {\n \"collapsed\": true\n },\n \"outputs\": [],\n \"source\": [\n \"train_data = pd.read_csv('./kaggle_house/train.csv')\\n\",\n \"test_data = pd.read_csv('./kaggle_house/test.csv')\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"(1460, 81)\"\n ]\n },\n \"execution_count\": 3,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"train_data.shape\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"(1459, 80)\"\n ]\n },\n \"execution_count\": 4,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"test_data.shape\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/html\": [\n \"\\n\",\n \"\\n\",\n \"
\\n\",\n \" \\n\",\n \" \\n\",\n \" | \\n\",\n \" Id | \\n\",\n \" MSSubClass | \\n\",\n \" MSZoning | \\n\",\n \" LotFrontage | \\n\",\n \" SaleType | \\n\",\n \" SaleCondition | \\n\",\n \" SalePrice | \\n\",\n \"
\\n\",\n \" \\n\",\n \" \\n\",\n \" \\n\",\n \" | 0 | \\n\",\n \" 1 | \\n\",\n \" 60 | \\n\",\n \" RL | \\n\",\n \" 65.0 | \\n\",\n \" WD | \\n\",\n \" Normal | \\n\",\n \" 208500 | \\n\",\n \"
\\n\",\n \" \\n\",\n \" | 1 | \\n\",\n \" 2 | \\n\",\n \" 20 | \\n\",\n \" RL | \\n\",\n \" 80.0 | \\n\",\n \" WD | \\n\",\n \" Normal | \\n\",\n \" 181500 | \\n\",\n \"
\\n\",\n \" \\n\",\n \" | 2 | \\n\",\n \" 3 | \\n\",\n \" 60 | \\n\",\n \" RL | \\n\",\n \" 68.0 | \\n\",\n \" WD | \\n\",\n \" Normal | \\n\",\n \" 223500 | \\n\",\n \"
\\n\",\n \" \\n\",\n \" | 3 | \\n\",\n \" 4 | \\n\",\n \" 70 | \\n\",\n \" RL | \\n\",\n \" 60.0 | \\n\",\n \" WD | \\n\",\n \" Abnorml | \\n\",\n \" 140000 | \\n\",\n \"
\\n\",\n \" \\n\",\n \"
\\n\",\n \"
\n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n 1608022213982\n \n \n 1608022213982\n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n file://$PROJECT_DIR$/process.py\n 167\n \n \n \n \n \n"
},
{
"path": "深度学习自然语言处理/文本匹配和文本相似度/src/ESIM-attention/ESIM代码解读.md",
"content": "ESIM\n\n1. 导入数据\n\n1.1 train_data = LCQMC_Dataset(train_file, vocab_file, max_length)\n\n通过LCQMC_Dataset 导入数据,在LCQMC_Dataset 中,做了这几件事情:\n\n1.1.1 p, h, self.label = load_sentences(LCQMC_file)\n\n读取数据文件,切分数据\n\n1.1.2 word2idx, _, _ = load_vocab(vocab_file)\n\n读取字典文件,从而获得 word2idx, idx2word, vocab\n\n1.1.3 self.p_list, self.p_lengths, self.h_list, self.h_lengths = word_index(p, h, word2idx, max_char_len)\n\n将数据转化为对应的数值,并且根据max_char_len进行切分或者截断\n\n1.1.4 \nself.p_list = torch.from_numpy(self.p_list).type(torch.long)\nself.h_list = torch.from_numpy(self.h_list).type(torch.long)\n\n转化为对应的torch tensor\n\n1.2 数据batch化\ntrain_loader = DataLoader(train_data, shuffle=True, batch_size=batch_size)\n按照batch进行读取。是torch的代码,我就不看了\n\n1.3 读取embedding文件\nembeddings = load_embeddings(embeddings_file)\n注意pad全为零\n\n2. model构建\nmodel = ESIM(hidden_size, embeddings=embeddings, dropout=dropout, num_classes=num_classes, device=device).to(device)\n\n3. 为了方便,我把ESIM整体流程重点是attention的部分抽离了出来\n"
},
{
"path": "深度学习自然语言处理/文本匹配和文本相似度/src/ESIM-attention/process.py",
"content": "import numpy as np\nimport torch\nimport torch.nn as nn\n\nq1_numpy = np.load(\"q1_numpy.npy\")\nq1_lengths_numpy = np.load(\"q1_lengths_numpy.npy\")\nq2_numpy = np.load(\"q2_numpy.npy\")\nq2_lengths_numpy = np.load(\"q2_lengths_numpy.npy\")\n\n\nq1= torch.from_numpy(q1_numpy)\nq1_lengths= torch.from_numpy(q1_lengths_numpy)\nq2= torch.from_numpy(q2_numpy)\nq2_lengths= torch.from_numpy(q2_lengths_numpy)\n\n\ndef get_mask(sequences_batch, sequences_lengths):\n batch_size = sequences_batch.size()[0]\n max_length = torch.max(sequences_lengths)\n mask = torch.ones(batch_size, max_length, dtype=torch.float)\n mask[sequences_batch[:, :max_length] == 0] = 0.0\n return mask\t\t\n\nq1_mask = get_mask(q1, q1_lengths)\nq2_mask = get_mask(q2, q2_lengths)\n\n\nq1_embed_numpy = np.load(\"q1_embed.npy\")\nq2_embed_numpy = np.load(\"q2_embed.npy\")\n\nq1_embed= torch.from_numpy(q1_embed_numpy)\nq2_embed= torch.from_numpy(q2_embed_numpy)\n\n\ndef sort_by_seq_lens(batch, sequences_lengths, descending=True):\n sorted_seq_lens, sorting_index = sequences_lengths.sort(0, descending=descending)\n sorted_batch = batch.index_select(0, sorting_index)\n idx_range = torch.arange(0, len(sequences_lengths)).type_as(sequences_lengths)\n #idx_range = sequences_lengths.new_tensor(torch.arange(0, len(sequences_lengths)))\n _, revese_mapping = sorting_index.sort(0, descending=False)\n restoration_index = idx_range.index_select(0, revese_mapping)\n return sorted_batch, sorted_seq_lens, sorting_index, restoration_index\n\n\n\nclass Seq2SeqEncoder(nn.Module):\n def __init__(self, rnn_type, input_size, hidden_size, num_layers=1, bias=True, dropout=0.0, bidirectional=False):\n \"rnn_type must be a class inheriting from torch.nn.RNNBase\"\n assert issubclass(rnn_type, nn.RNNBase)\n super(Seq2SeqEncoder, self).__init__()\n self.rnn_type = rnn_type\n self.input_size = input_size\n self.hidden_size = hidden_size\n self.num_layers = num_layers\n self.bias = bias\n self.dropout = dropout\n self.bidirectional = bidirectional\n self.encoder = rnn_type(input_size, hidden_size, num_layers, bias=bias, \n batch_first=True, dropout=dropout, bidirectional=bidirectional)\n \n def forward(self, sequences_batch, sequences_lengths):\n sorted_batch, sorted_lengths, _, restoration_idx = sort_by_seq_lens(sequences_batch, sequences_lengths)\n packed_batch = nn.utils.rnn.pack_padded_sequence(sorted_batch, sorted_lengths, batch_first=True)\n outputs, _ = self.encoder(packed_batch, None)\n outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs, batch_first=True)\n \n \n reordered_outputs = outputs.index_select(0, restoration_idx.long())\n return reordered_outputs\n\n\nfirst_rnn = Seq2SeqEncoder(nn.LSTM, 300, 300, bidirectional=True)\n\n\nq1_encoded = first_rnn(q1_embed, q1_lengths)\n#torch.Size([256, 29, 600])\nq2_encoded = first_rnn(q2_embed, q2_lengths)\n#torch.Size([256, 32, 600])\n\n\n\"\"\"\nimport numpy as np\nq1_encoded_numpy=q1_encoded.detach().numpy()\nq2_encoded_numpy = q2_encoded.detach().numpy()\n\nnp.save(\"q1_encoded.npy\", q1_encoded_numpy)\nnp.save(\"q2_encoded.npy\", q2_encoded_numpy)\n\n\n\nq1_encoded_numpy = np.load(\"q1_encoded.npy\")\nq2_encoded_numpy = np.load(\"q2_encoded.npy\")\n\nq1_encoded= torch.from_numpy(q1_encoded_numpy)\nq2_encoded= torch.from_numpy(q2_encoded_numpy)\n\"\"\"\n## 计算attention\n\ndef masked_softmax(tensor, mask):\n tensor_shape = tensor.size()\n reshaped_tensor = tensor.view(-1, tensor_shape[-1])\n # Reshape the mask so it matches the size of the input tensor.\n while mask.dim() < tensor.dim():\n mask = mask.unsqueeze(1)\n mask = mask.expand_as(tensor).contiguous().float()\n reshaped_mask = mask.view(-1, mask.size()[-1])\n\n result = nn.functional.softmax(reshaped_tensor * reshaped_mask, dim=-1)\n result = result * reshaped_mask\n # 1e-13 is added to avoid divisions by zero.\n result = result / (result.sum(dim=-1, keepdim=True) + 1e-13)\n return result.view(*tensor_shape)\n\n\ndef weighted_sum(tensor, weights, mask):\n\n weighted_sum = weights.bmm(tensor)\n\n while mask.dim() < weighted_sum.dim():\n mask = mask.unsqueeze(1)\n mask = mask.transpose(-1, -2)\n mask = mask.expand_as(weighted_sum).contiguous().float()\n\n return weighted_sum * mask\n\n\nclass SoftmaxAttention(nn.Module):\n\n def forward(self, premise_batch, premise_mask, hypothesis_batch, hypothesis_mask):\n similarity_matrix = premise_batch.bmm(hypothesis_batch.transpose(2, 1).contiguous())\n # Softmax attention weights.\n prem_hyp_attn = masked_softmax(similarity_matrix, hypothesis_mask)#prem_hyp_attn=[256,28,32]\n hyp_prem_attn = masked_softmax(similarity_matrix.transpose(1, 2).contiguous(), premise_mask)##prem_hyp_attn=[256,32,28]\n # Weighted sums of the hypotheses for the the premises attention,\n # and vice-versa for the attention of the hypotheses.\n attended_premises = weighted_sum(hypothesis_batch, prem_hyp_attn, premise_mask)\n attended_hypotheses = weighted_sum(premise_batch, hyp_prem_attn, hypothesis_mask)\n return attended_premises, attended_hypotheses \n\nSoftmaxAttention=SoftmaxAttention()\nq1_aligned, q2_aligned = SoftmaxAttention(q1_encoded, q1_mask, q2_encoded, q2_mask)\n\n\nprojection = nn.Sequential(nn.Linear(4*2*300, 300), nn.ReLU())\n\n\nq1_combined = torch.cat([q1_encoded, q1_aligned, q1_encoded - q1_aligned, q1_encoded * q1_aligned], dim=-1)\nq2_combined = torch.cat([q2_encoded, q2_aligned, q2_encoded - q2_aligned, q2_encoded * q2_aligned], dim=-1)\n\n\nprojected_q1 = projection(q1_combined)\nprojected_q2 = projection(q2_combined)\n\nsecond_rnn = Seq2SeqEncoder(nn.LSTM, 300, 300, bidirectional=True)\n\nq1_compare = second_rnn(projected_q1, q1_lengths)\nq2_compare = second_rnn(projected_q2, q2_lengths)\n\n\ndef replace_masked(tensor, mask, value):\n mask = mask.unsqueeze(1).transpose(2, 1)\n reverse_mask = 1.0 - mask\n values_to_add = value * reverse_mask\n return tensor * mask + values_to_add\n \n\n\nq1_avg_pool = torch.sum(q1_compare * q1_mask.unsqueeze(1).transpose(2, 1), dim=1)/torch.sum(q1_mask, dim=1, keepdim=True)\nq2_avg_pool = torch.sum(q2_compare * q2_mask.unsqueeze(1).transpose(2, 1), dim=1)/torch.sum(q2_mask, dim=1, keepdim=True)\nq1_max_pool, _ = replace_masked(q1_compare, q1_mask, -1e7).max(dim=1)\nq2_max_pool, _ = replace_masked(q2_compare, q2_mask, -1e7).max(dim=1)\n\nmerged = torch.cat([q1_avg_pool, q1_max_pool, q2_avg_pool, q2_max_pool], dim=1)\nprint(merged.shape)"
},
{
"path": "深度学习自然语言处理/文本匹配和文本相似度/src/models.py",
"content": "class ESIM(nn.Module):\n def __init__(self, config_base):\n super(ESIM, self).__init__()\n self.device = config_base.device\n self.dropout=config_base.dropout\n if config_base.embedding_pretrained is not None:\n self.word_emb = nn.Embedding.from_pretrained(config_base.embedding_pretrained, freeze=False)\n else:\n self.word_emb = nn.Embedding(config_base.vord_size, config_base.embeds_dim)\n self.word_emb.float()\n self.word_emb.weight.requires_grad = True\n self.word_emb.to(self.device)\n if self.dropout:\n self.rnn_dropout = RNNDropout(p=config_base.dropout)\n self.first_rnn = Seq2SeqEncoder(nn.LSTM, config_base.embeds_dim, config_base.hidden_size, bidirectional=True)\n self.projection = nn.Sequential(nn.Linear(4*2*config_base.hidden_size, config_base.hidden_size),\n nn.ReLU())\n self.attention = SoftmaxAttention()\n self.second_rnn = Seq2SeqEncoder(nn.LSTM, config_base.hidden_size, config_base.hidden_size, bidirectional=True)\n self.classification = nn.Sequential(nn.Linear(2*4*config_base.hidden_size, config_base.hidden_size),\n nn.ReLU(),\n nn.Dropout(p=config_base.dropout),\n nn.Linear(config_base.hidden_size, config_base.hidden_size//2),\n nn.ReLU(),\n nn.Dropout(p=config_base.dropout),\n nn.Linear(config_base.hidden_size//2, config_base.num_classes))\n \n def forward(self, q1, q1_lengths, q2, q2_lengths):\n q1_mask = get_mask(q1, q1_lengths).to(self.device)\n q2_mask = get_mask(q2, q2_lengths).to(self.device)\n q1_embed = self.word_emb(q1) ## 这里输入的不是q1_mask (维度是[256,32] 32是按照这个batch中中的最大长度来的,输入的是q1[256,50])\n q2_embed = self.word_emb(q2)\n if self.dropout:\n q1_embed = self.rnn_dropout(q1_embed)\n q2_embed = self.rnn_dropout(q2_embed)\n # 双向lstm编码\n q1_encoded = self.first_rnn(q1_embed, q1_lengths) ## 这里我们输入的是q1_embed 和q1_lengths\n q2_encoded = self.first_rnn(q2_embed, q2_lengths)\n # atention\n q1_aligned, q2_aligned = self.attention(q1_encoded, q1_mask, q2_encoded, q2_mask)\n # concat\n q1_combined = torch.cat([q1_encoded, q1_aligned, q1_encoded - q1_aligned, q1_encoded * q1_aligned], dim=-1)\n q2_combined = torch.cat([q2_encoded, q2_aligned, q2_encoded - q2_aligned, q2_encoded * q2_aligned], dim=-1)\n # 映射一下\n projected_q1 = self.projection(q1_combined)\n projected_q2 = self.projection(q2_combined)\n if self.dropout:\n projected_q1 = self.rnn_dropout(projected_q1)\n projected_q2 = self.rnn_dropout(projected_q2)\n # 再次经过双向RNN\n q1_compare = self.second_rnn(projected_q1, q1_lengths)\n q2_compare = self.second_rnn(projected_q2, q2_lengths)\n # 平均池化 + 最大池化\n q1_avg_pool = torch.sum(q1_compare * q1_mask.unsqueeze(1).transpose(2, 1), dim=1)/torch.sum(q1_mask, dim=1, keepdim=True)\n q2_avg_pool = torch.sum(q2_compare * q2_mask.unsqueeze(1).transpose(2, 1), dim=1)/torch.sum(q2_mask, dim=1, keepdim=True)\n q1_max_pool, _ = replace_masked(q1_compare, q1_mask, -1e7).max(dim=1)\n q2_max_pool, _ = replace_masked(q2_compare, q2_mask, -1e7).max(dim=1)\n # 拼接成最后的特征向量\n merged = torch.cat([q1_avg_pool, q1_max_pool, q2_avg_pool, q2_max_pool], dim=1)\n # 分类\n logits = self.classification(merged)\n probabilities = nn.functional.softmax(logits, dim=-1)\n return logits, probabilities\n\n\n\n\n\nclass SiaGRU(nn.Module):\n def __init__(self, config_base):\n super(SiaGRU, self).__init__()\n self.device = config_base.device\n if config_base.embedding_pretrained is not None:\n self.word_emb = nn.Embedding.from_pretrained(config_base.embedding_pretrained, freeze=False)\n else:\n self.word_emb = nn.Embedding(config_base.vord_size, config_base.embeds_dim)\n self.word_emb.float()\n self.word_emb.weight.requires_grad = True\n self.word_emb.to(self.device)\n self.gru = nn.LSTM(config_base.embeds_dim, config_base.hidden_size, batch_first=True, bidirectional=True, num_layers=2)\n self.h0 = self.init_hidden((2 * config_base.num_layer, 1, config_base.hidden_size))\n self.h0.to(self.device )\n self.pred_fc = nn.Linear(config_base.pad_size, 2)\n\n def init_hidden(self, size):\n h0 = nn.Parameter(torch.randn(size))\n nn.init.xavier_normal_(h0)\n return h0\n\n def forward_once(self, x):\n output, hidden = self.gru(x)\n return output\n \n def dropout(self, v):\n return F.dropout(v, p=0.2, training=self.training)\n\n def forward(self, q1, q1_lengths, q2, q2_lengths):\n p_encode = self.word_emb(q1)\n h_endoce = self.word_emb(q2)\n p_encode = self.dropout(p_encode)\n h_endoce = self.dropout(h_endoce)\n \n encoding1 = self.forward_once(p_encode)\n encoding2 = self.forward_once(h_endoce)\n sim = torch.exp(-torch.norm(encoding1 - encoding2, p=2, dim=-1, keepdim=True))\n x = self.pred_fc(sim.squeeze(dim=-1))\n probabilities = nn.functional.softmax(x, dim=-1)\n return x, probabilities"
},
{
"path": "深度学习自然语言处理/文本匹配和文本相似度/五千字全面梳理文本相似度和文本匹配模型.md",
"content": "[TOC]\n\n### 五千字梳理文本相似度判定(无监督+有监督)\n\n#### 1. 为什么需要文本匹配/文本相似度判定使用场景\n\n先问一个核心问题,为啥需要文本相似度/文本匹配?换句话说,文本匹配的应用场景有哪些?\n\n举个例子,比如说海量文本去重。\n\n在一些社交媒体,某个话题之下,存在大量的营销号的文本,这些文本存在一个特点,内容大同小异,都在说同一个事情。\n\n我在对这些文本进行处理的时候,本质上只需要处理其中的一条就可以,这样可以极大提高我的处理速度。\n\n那么问题来了,我如何判定句子a和句子b/c/d/e等等是在说同一个事情?\n\n再举个例子,老生常谈,搜索场景,你在某度搜索“深度学习如何入门?”,某度如何返回和你这个问题最接近的问题/文章/博客等等内容网页?\n\n这些本质上都是在做文本相似度的判定或者说文本匹配,只是在不同场景下,有着不同办法不同的特色。\n\n文本匹配,并不是简简单单的词汇层次的匹配:比如“深度学习如何入门”和“如何入门深度学习”。\n\n还会有语义方面的匹配考虑,比如说“我想撒尿去哪里啊?”和“我想去卫生间”。这两句话在问答系统中,匹配到标准问题都是“卫生间在哪里”这个问题。\n\n对文本匹配方法来说,我们一般可以使用两种:无监督和有监督。\n\n#### 2.无监督文本匹配\n\n首先我们来谈一下无监督的方法。\n\n对于无监督的文本匹配,我们需要实时把握两个重点:文本表征和相似函数的度量。\n\n文本表征指的是我们将文本表示为计算机可以处理的形式,更准确了来说是数字化文本。而这个数字化文本,必须能够表征文本信息,这样才说的通。\n\n相似函数的度量就是你选择何种函数对文本相似度进行一个判定,比如欧氏距离,余弦距离,Jacard相似度,海明距离等等\n\n\n我大概梳理了一下无监督的几种比较典型的方法,,如下所示:\n\n1. TF-IDF/IDF+词向量(word2vec/fasttext/glove)\n\n2. BM25(提前计算IDF矩阵,无需使用词向量)\n\n3. WMD\n\n4. SIF\n\nTF-IDF/IDF+词向量比较简单,我就不多说了。我们先来看一下BM25。\n\n##### 2.1 BM25\n\n对于BM25,有搜索Query q,分词之后单词 w,候选文档 d。\n\n掌握BM25,核心要点有三个:分词之后w的权重,w和q的相似性,w和d的相似性。\n\n对于搜索场景,显而易见的一个问题就是,我们的搜索query和候选文档的长度是不一样甚至差距很大,所以BM25在计算相似性的时候需要对文档长度做一定的处理。\n\n##### 2.2 WMD\n\n话说回来,其次我们谈一谈WMD,项目中并没有用到 WMD 这个获取句子向量的方法,所以这里只是对它有一个简单的了解即可,在这里做一个记录,等以后需要用到的时候, 会在这里继续更新,深挖进入。文章末尾会列出相关参考资源,感兴趣的可以看一看。\n\nWMD Word Mover's Distance的缩写,翻译为词移距离,WMD距离越大相似度越小,WMD距离越小文本相似度越大。\n\n理解这个概念,分为两个步骤。\n\n首先第一步,有两个文档A和B,A中的每个词遍历和B中每个词的距离,挑出A中每个词和B中每个词中最小的距离,最后相加,得到A到B的WMD。\n\n这个时候,需要明白第一步是存在巨大问题的。什么问题呢?A,B,C三个文档。A全部词和音乐相关。B中一个词和音乐相关,C中一个词和音乐相关,其余词和音乐有点关系,而且定义B和C中和音乐相关的词是同一个词。\n\n根据我们的直觉,A和B相关性肯定小于A和C的相关性,但是如果按照第一步的算法去做,会得到相关性相等的结果,这是不对的。\n\n这是因为A中的所有词匹配到的B中的那个和音乐相关的词(遍历取最小),A中所有的词匹配到C中和音乐相关的词(遍历取最小),B和C中和音乐相关的词一样,就导致相关性相等。\n\n怎么解决这个问题,这就是第二步,让A中的所有词在匹配的时候,不是遍历取最小,而是让每个词匹配到C中的所有词,只不过匹配的权重不同。\n\n这个权重从两个部分去看:一个是从A看,要符合分配出去的权重等于自身这个词在本文档的权重,一个是从B看,分配到B的某个词的权重要等于这个词在B文档的权重。\n\n大概理解到这里。之后关于WMD加速(因为复杂度比较高)的内容就没有进一步的去了解\n\n##### 2.3 SIF\n\n这个时候,我想到了一个比较有意思的点。我们知道有监督,比如说SiaGRU 这个方法,也是对句子进行编码,只不过这里的编码我们使用的是基于损失函数和标注语料训练出来的编码。\n\n注意,这句话里我认为是有个重点的,就是句子编码是基于损失函数训练出来的。\n\n换句话说,不同的损失函数我们训练出来的句子编码肯定是不一样的,效果也就有好有坏。\n\n换句话说,我们使用不同的损失函数,比如调整正样本对应的损失权重和正常损失函数训练出来的文本编码肯定是不一样的。\n\n为什么说这么呢?我们想一下,如果我使用SiaGRU训练出来的句子对的编码,我们直接使用cosine进行相似度的度量,效果会怎么样?\n\n对于这个问题,大家可以自己实践一下。我想提到的一点就是,我们的句子对的编码并不是基于我们的cosine这种相似度量训练出来的,所以不存在完全匹配,所以效果肯定是比不上有监督的。\n\n我们更近一步的想一个问题。通过实践,我们在使用bert做句子对的相似度的时候会发现一个问题,就是效果可能还没有使用word2vec的效果好。\n\n我自己猜测这个原因可能就是因为cosine这个函数没有办法表征出bert训练的句子编码信息,因为bert训练过程复杂,不是consien这种简单函数就可以表达的。这是我自己的一个理解。\n\n然后,我们详细聊一下SIF这个方法。\n\n我先说一下这个方法最容易出问题的一个地方:数据预处理的时候不要去除停用词等高频词汇\n\n掌握SIF,就抓住两个核心要点:\n\n1. 词向量加权求和\n\n2. 句子词向量矩阵减去主成分投影\n\n我们先说核心要点1。其实词向量加权求和这个方法并不是特别的陌生,比如等权求和,IDF权重求和,TF-IDF权重求和等等,这些我们平时都会用到。至于用哪一个就看你的数据集上的效果了。\n\n我们知道word2vec这种词向量是含有语义信息的(在我看来其实它本质上是一种位置信息,相同句子结构下不同词的词向量可能很相似)。所以等权求和或者加权求和更像是在做Pooling(最大池化,平均池化,加权池化)等等,就是从我们各个词语信息中提取中有用的部分。\n\n因为我们是无监督,这个权重的设定我们没有办法像在CNN处理图片一样,把参数学出来,所以只能人工的去定这个参数。\n\n说到这里,想要插一句话,上面说到因为无监督我们无法将权重参数学出来。换句话说,如果是有监督,这个参数是可以学出来的,那怎么学呢?\n\n最简单的一个方法就是全连接,或者说逻辑回归啊,只要有数据,我们就可以使用机器学习,复杂就使用神经网络基于标注数据把这个参数学出来。\n\n现在没有标注数据,这个参数我们需要人工去定。这个参数需要含有一定的意义,不是我们一拍脑袋就定个参数,它需要加权求和之后使句子编码含有的语义信息可以对下游任务有帮助或者说在下游任务中效果好才可以。\n\nSIF这里使用的权重函数是这样的:a/a+p(w) p(w)代表的是词在句子中的频次或者频率。用大白话去描述这个公式就是词在语料中出现的越多,对应的权重越小。这么做就减少了高频词的作用。也是我们不需要在数据处理的时候去除高频词的原因。\n\n想一下这个公式的作用,其实本质上和IDF是很类似的。它并没有涉及到IF这个概念,也就是词在本句话出现的情况。\n\n我们再来看核心要点2。什么叫主成分?具体的原理不多说,PCA本质上是找到原始数据存在最大方差的那个方向,让原始数据的投影尽可能的分散,从而可以起到降维的作用。\n\n核心要点2就是减去了矩阵中共有的一部分信息,比如都含有的高频词汇信息等等。比如原始句子是”我爱吃红烧肉“和”我超不爱吃红烧肉“。减去共有信息之后,剩下的词向量矩阵就回对不相似的信息比较敏感。\n\n总体来说。SIF这个算法还是很不错,很适合做个基线初期上线的。\n\n\n\n#### 3.有监督文本相似度方法\n\n我主要是讲两个模型:SiamGRU和ESIM模型\n\n##### 3.1 SiamGRU\n\n主要是参考了论文:Siamese Recurrent Architectures for Learning Sentence Similarity.\n\n从三个核心要点来掌握这个模型:\n\n1.使用神经网络对句子进行编码;\n\n2.两个句子共享一个神经网络;\n\n3.对句子编码进行相似性的度量进行训练。\n\n首先我们来看核心要点1。\n\n对于这个我觉得应该这么去想。首先,我们考虑一个使用神经网络进行文本分类的场景。我们使用交叉熵损失函数,基于此,训练神经网络。\n\n在这个过程中,神经网络可以认为依赖了两个东西,一个是标注数据,\n比如属于娱乐领域或者音乐领域等等,我们通过更新神经网络的参数让我们的模型预测结果不停的逼近这个标注数据。\n\n其次,我们使用损失函数来度量预测结果和真实数据的差距。损失函数在我看来更像是一种解题方法,\n\n不同的解题方法可能对应不同的结果,有的解题方法得到的结果既高效又准确,有的方法就很差。\n\n为什么讲上面这些话?神经网络在上面这个过程中究竟起到了什么作用?在上面这个例子中,神经网络就是一个载体,接受文本数据,输出一个文本编码,从而判定属于哪个类别。所以神经网络的输出是带有语义信息。\n\nSiamGRU的损失函数应该是什么?数据格式是输入一个句子对,标注结果是两个句子是不是表达同一个含义。这个属于0/1的二分类问题,也就是损失函数和二分类问题的损失函数是一样的,基于此损失函数,我们对模型进行训练。\n\n对于核心要点2,两个句子共享一个神经网络。最大的好处是可以减少参数量。对于这个,我们可以想一下,能不能不共享参数,而是每个句子对应一个自己的Bilstm/GRU等编码器。\n\n当然可以,我们的神经网络只是对句子进行编码,每个句子对应自己的编码器也可以做到这样的效果,所以没问题。我们再想一下,有没有必要这么做?关于这一点,我并没有去具体的做实验。我只是说一下自己的理解。\n\n我觉得是没有必要的。首先,如果每个句子都对应自己的编码器,我想到的一个问题是需不需要对训练数据进行一个翻转重新输入的问题。换句话说,作为输入,分别对应。\n\n那么我需不需要作为一次输入再训练一次增加泛化性,我认为这个步骤是需要,这样就增加了训练来量。\n\n简单来说,我们的句子对的输入不应该对句子对的输入顺序敏感,所以共享编码反而很好的解决了这个问题。\n\n最后,我们来看核心要点3,我觉得这里还是值得注意的。\n\n这里我认为有两个细节点需要注意。首先,这里做了一个两个句子编码的交互。对的,SiaGRU在我看来是对两个句子编码进行了交互的,只不过是在后期做的交互。\n\n为什么这么说呢?这里的相似性的度量使用的是曼哈顿距离,也就是对应坐标差值。注意,这里涉及到了对应坐标位置的操作,所以可以看做是一种交互,而且这种差值在模型训练过程中是会随着模型参数的变化而变化的。\n\n其次一个细节点,还是曼哈顿距离,这里不是一个标量,也就是不是一个和。简单来说就是对应位置相减之后,每个位置对应一个神经元,然后直接接全连接层就可以。\n\n如果你认为这里是一个标量,就是很大的问题,标量如何接全连接层最终做二分类呢?\n\n代码实现部分参考:\nhttps://github.com/DA-southampton/NLP_ability/blob/master/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86/%E6%96%87%E6%9C%AC%E5%8C%B9%E9%85%8D_%E6%96%87%E6%9C%AC%E7%9B%B8%E4%BC%BC%E5%BA%A6/src/models.py\n\n##### 3.2 ESIM\n\n理解ESIM模型最核心的要点就在于两个句子word层次的attentino就可以了。\n\n区别于SiamGRU 在后期进行两个句子之间的交互,ESIM在模型中期进行了word层级的两个句子之间的交互。这种交互在我看来是一种attention。\n\n最近在做多模态的东西,其中一部分的attention和这里的很类似,更准确的说attention形式很类似。\n\n整个ESIM可以分为三个部分。\n\n首先第一部分是对两个句子的初期编码,这里和SiamGRU没有什么区别,都是使用神经网络对句子进行信息的提取。\n\n需要注意的一点是在这里,我们编码之后,比如说LSTM,我们是可以得到每一个时刻或者说每一个单词的输出的,这就为交互中用到的Q/K/V提供了基础。\n\n这里,我们使用LSTM作为编码器,然后得到编码向量,得到的维度是这样的[batch_size,seq_len,embedding_dim]。\n\n为了下面解释的更加的方便,我们举个简单的例子,句子a,长度为10,句子b,长度为20.\n\n现在经过初期编码,句子a:[1,10,300],句子b: [1,20,300]\n\n随后,我们的操作就是进行交互操作,为了简单,我们省略掉第一个维度。它的交互就是矩阵相乘,得到[10,20]一个矩阵。\n\n这个矩阵需要根据针对a句子横向做概率归一化,针对b句子纵向做概率归一化。\n\n上面这句话其实就是ESIM的核心要点。它是一个两个item之间互相做attention,简单称之为both attention。\n\n这样针对句子a我们就获得了attention之后的语境向量,针对句子b我们也获得了attention之后的语境向量,然后各自在做差和点击,然后结果拼接。\n\n最后我们用获得的向量拼接输入到另一个编码器,输出pool接全连接就可以了,这块没有什么好说的。\n\n代码参考链接:\nhttps://github.com/DA-southampton/NLP_ability/blob/master/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86/%E6%96%87%E6%9C%AC%E5%8C%B9%E9%85%8D_%E6%96%87%E6%9C%AC%E7%9B%B8%E4%BC%BC%E5%BA%A6/src/models.py\n\n#### 总结\n\n针对不同的业务场景挑选不同的匹配模型很考验一个工程师的能力,所以需要掌握每个模型的特点和优缺点。\n\n\n\n参考链接:\n\n参考链接:常见文本相似度计算方法简介 - 李鹏宇的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/88938220\n\n短文本相似度算法研究 - 刘聪NLP的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/111414376\n\n现在工业界有哪些比较实用的计算短文本相似度的算法或者模型? - vincent的回答 - 知乎\nhttps://www.zhihu.com/question/342548427/answer/806986596\n\n推荐系统中的深度匹配模型 - 辛俊波的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/101136699\n\n四种计算文本相似度的方法对比 - 论智的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/37104535\n\n深度文本匹配发展总结 - xiayto的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/40741576\n\n常见文本相似度计算方法简介 - 李鹏宇的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/88938220\n\n参考链接:\nhttps://zhuanlan.zhihu.com/p/48188731"
},
{
"path": "深度学习自然语言处理/文本匹配和文本相似度/聊一下孪生网络和DSSM的混淆点以及向量召回的一个细节.md",
"content": "在学习DSSM的时候,很容易和孪生网络搞混,我这里稍微总结一下自己的思考;\n\n\n\n对于孪生网络,并不是一个网络的名称,而是一种网络的名称;\n\n它的特点就是encoder参数共享,也就是在对句子或者图像编码的网络权重共享;\n\n它的网络的输入形式是这样的::(X1,X2,Y);X1,X2是两个输入文本,Y是我们的标签数据;\n\n对于孪生网络来说,一般的损失函数是对比损失函数:Contrastive Loss\n\n什么是对比损失函数呢?公式如下:\n\n\n\n这个公式需要注意两个细节点,一个是d,代表的是距离度量,一个是margin,代表的是一个超参;\n\n那么我感兴趣的是孪生网路可以不可以使用其他的损失函数?如果可以,又是哪些呢?\n\n首先当然是可以,只要能够优化都可以;\n\n\n\n参考自这里:\n\nSiamese network 孪生神经网络--一个简单神奇的结构 - mountain blue的文章 - 知乎 https://zhuanlan.zhihu.com/p/35040994\n\n# 三种损失函数形式\n\n我把自己思考的三种损失函数形式总结在这里,之后有问题再回来修改:\n\n两个向量做consine相似度或者欧氏距离度量函数,然后归一化到0-1,然后做二分类交叉熵损失函数;\n\n两个向量做cosine相似度或者欧氏距离,带入到对应的对比损失函数\n\n两个向量做拼接或者其他操作,然后接单个或者多个全连接,然后可以做逻辑回归或者做softmax;\n\n# fassi做向量召回-样本重复和consine度量疑惑点\n\n我其实一直有一个疑问,在做向量召回的时候,一般的操作就是双塔模型,然后存储对应的样本的向量,存储到fassi中,然后搜索的时候使用找最近的向量就够了;\n\n这里面我最开始理解的时候有两个疑惑点,一个是如果做到同一个样本不会有多个向量;\n\n我的误解原因是没有对向量的是如何落地有很好的理解;我开始的理解是模型训练好了之后,进入一个pair(query,d),分别计算向量,然后存储,这样当然会出现同一个d,出现在不同的pair;\n\n但是,由于之间没有交互,右边这个塔模型参数不变,得到的向量当然也不变,也就是同一个d不会出现多个向量;\n\n而且在计算的时候,不用输入一个pair对,只需要对右边这个单塔输入去重之后的d就可以;\n\n第二个问题,为什么在faiss中使用最近的向量可以(先不用计较度量方式)得到相似的向量,而在模型中,我们在得到cosine或者其他度量结果之后,还会再接一个sigmoid;\n\n优化sigmoid的输出的时候,cosine的值或者其他度量的值也会同等趋势变化,所以可以起到作用;\n\n然后多说一下,如果用到向量召回,中间还是需要一个度量的值的,需要和faiss对应上,如果接一个MLP,感觉就够呛。\n\n"
},
{
"path": "深度学习自然语言处理/文本匹配和文本相似度/阿里RE2-将残差连接和文本匹配模型融合.md",
"content": "[RE2](https://www.aclweb.org/anthology/P19-1465/, \"Simple and Effective Text Matching with Richer Alignment Features\") 这个名称来源于该网络三个重要部分的合体:**R**esidual vectors;**E**mbedding vectors;**E**ncoded vectors;\n\n掌握这个论文,最重要的一个细节点就是**了解如何将增强残差连接融入到模型之中**。\n\n# 1.架构图\n\n先来看架构图,如下:\n\n\n\n这个架构图很精简,所以不太容易理解。\n\n大体上区分可以分为三层。第一层就是输入层,第二个就是中间处理层,第三个就是输出层。\n\n中间处理层我们可以称之为block,就是画虚线的部分,可以被循环为n次,但是需要注意的是每个block不是共享的,参数是不同的,是独立的,这点需要注意。\n\n# 2.增强残差连接\n\n其实这个论文比较有意思的点就是增强残差连接这里。架构图在这里其实很精简,容易看糊涂,要理解还是要看代码和公式。\n\n## 2.1 第一个残差\n\n首先假设我们的句子长度为$l$,然后对于第n个block(就是第n个虚线框的部分)。\n\n它的输入和输出分别是:$x^{(n)}=(x_{1}^{(n)},x_{2}^{(n)},...,x_{l}^{(n)})$ 和$o^{(n)}=(o_{1}^{(n)},o_{2}^{(n)},...,o_{l}^{(n)})$;\n\n首先对一第一个block,也就是$x^{(1)}$,它的输入是embedding层,注意这里仅仅是embedding层;\n\n对于第二个block,也就是$x^{(2)}$,它的输入是embedding层(就是初始的embedding层)和第一个block的输出$o^{(1)}$拼接在一起;\n\n紧接着对于n大于2的情况下,也就是对于第三个,第四个等等的block,它的输入形式是这样的;\n\n\n\n理解的重点在这里:在每个block的输入,大体可以分为两个部分,第一部分就是初始的embedding层,这个永远不变,第二个部分就是此时block之前的两层的blocks的输出和;这两个部分进行拼接。\n\n这是第一个体现残差的部分。\n\n## 2.2第二个残差\n\n第二个残差的部分在block内部:\n\nalignment层之前的输入就有三个部分:第一部分就是embedding,第二部分就是前两层的输出,第三部分就是encoder的输出。\n\n这点结合着图就很好理解了。\n\n# 3.Alignment Layer\n\nattention这里其实操作比较常规,和ESIM很类似,大家可以去看之前这个文章。\n\n公式大概如下:\n\n\n\n\n\n这里有一个细节点需要注意,在源码中计算softmax之前,也是做了类似TRM中的缩放,也就是参数,放个代码:\n\n```python\n#核心代码\ndef __init__(self, args, __):\n super().__init__()\n self.temperature = nn.Parameter(torch.tensor(1 / math.sqrt(args.hidden_size)))\n\ndef _attention(self, a, b):\n return torch.matmul(a, b.transpose(1, 2)) * self.temperature\n```\n\n# 4.Fusion Layer\n\n融合层,就是对attentino之前和之后的特征进行一个融合,具体如下:\n\n\n\n三种融合方式分别是直接拼接,算了对位减法然后拼接,算了对位乘法然后拼接。最后是对三个融合结果进行拼接。\n\n有一个很有意思的点,作者说到减法强调了两句话的不同,而乘法强调了两句话相同的地方。\n\n# 5.Prediction Layer\n\nPooling层之后两个句子分别得到向量表达:$v_{1}$和$v_{2}$\n\n三个表达方式,各取所需就可以:\n\n\n\n\n\n\n\n# 6. 总结\n\n简单总结一下,这个论文最主要就是掌握残差连接。\n\n残差体现在模型两个地方,一个是block外,一个是block内;\n\n对于block,需要了解的是,每一个block的输入是有两部分拼接而成,一个是最初始的embeddding,一个是之前两层的输出和。\n\n对于block内,需要注意的是Alignment之前,有三个部分的输入一个是最初始的embeddding,一个是之前两层的输出和,还有一个是encoder的输出。"
},
{
"path": "深度学习自然语言处理/文本纠错/文本纠错资源总结.md",
"content": "文本纠错\n医疗健康领域的短文本解析探索(三) ----文本纠错\nhttps://mp.weixin.qq.com/s/p9UMvy_VSW5g9IqDDjK6GA"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/.gitignore",
"content": "# repo-specific stuff\npred.txt\nmulti-bleu.perl\n*.pt\n\\#*#\n.idea\n*.sublime-*\n.DS_Store\ndata/\n\n# Byte-compiled / optimized / DLL files\n__pycache__/\n*.py[cod]\n*$py.class\n\n# C extensions\n*.so\n\n# Distribution / packaging\n.Python\nbuild/\ndevelop-eggs/\ndist/\ndownloads/\neggs/\n.eggs/\nlib/\nlib64/\nparts/\nsdist/\nvar/\nwheels/\n*.egg-info/\n.installed.cfg\n*.egg\n\n# PyInstaller\n# Usually these files are written by a python script from a template\n# before PyInstaller builds the exe, so as to inject date/other infos into it.\n*.manifest\n*.spec\n\n# Installer logs\npip-log.txt\npip-delete-this-directory.txt\n\n# Unit test / coverage reports\nhtmlcov/\n.tox/\n.coverage\n.coverage.*\n.cache\nnosetests.xml\ncoverage.xml\n*.cover\n.hypothesis/\n\n# Translations\n*.mo\n*.pot\n\n# Django stuff:\n*.log\nlocal_settings.py\n\n# Flask stuff:\ninstance/\n.webassets-cache\n\n# Scrapy stuff:\n.scrapy\n\n# Sphinx documentation\ndocs/_build/\n\n# PyBuilder\ntarget/\n\n# Jupyter Notebook\n.ipynb_checkpoints\n\n# pyenv\n.python-version\n\n# celery beat schedule file\ncelerybeat-schedule\n\n# SageMath parsed files\n*.sage.py\n\n# Environments\n.env\n.venv\nenv/\nvenv/\nENV/\n\n# Spyder project settings\n.spyderproject\n.spyproject\n\n# Rope project settings\n.ropeproject\n\n# mkdocs documentation\n/site\n\n# mypy\n.mypy_cache/\n\n# Tensorboard\nruns/\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/.travis.yml",
"content": "dist: xenial\nlanguage: python\npython:\n - \"3.5\"\ngit:\n depth: false\naddons:\n apt:\n packages:\n # Additional dependencies for im2text and speech2text\n - libsox-dev\n - libsox-fmt-all\n - sox\nbefore_install:\n # Install CPU version of PyTorch.\n - if [[ $TRAVIS_PYTHON_VERSION == 3.5 ]]; then pip install torch==1.2.0 -f https://download.pytorch.org/whl/cpu/torch_stable.html; fi\n - pip install -r requirements.opt.txt\n - python setup.py install \nenv:\n global:\n # Doctr deploy key for OpenNMT/OpenNMT-py\n - secure: \"gL0Soefo1cQgAqwiHUrlNyZd/+SI1eJAAjLD3BEDQWXW160eXyjQAAujGgJoCirjOM7cPHVwLzwmK3S7Y3PVM3JOZguOX5Yl4uxMh/mhiEM+RG77SZyv4OGoLFsEQ8RTvIdYdtP6AwyjlkRDXvZql88TqFNYjpXDu8NG+JwEfiIoGIDYxxZ5SlbrZN0IqmQSZ4/CsV6VQiuq99Jn5kqi4MnUZBTcmhqjaztCP1omvsMRdbrG2IVhDKQOCDIO0kaPJrMy2SGzP4GV7ar52bdBtpeP3Xbm6ZOuhDNfds7M/OMHp1wGdl7XwKtolw9MeXhnGBC4gcrqhhMfcQ6XtfVLMLnsB09Ezl3FXX5zWgTB5Pm0X6TgnGrMA25MAdVqKGJpfqZxOKTh4EMb04b6OXrVbxZ88mp+V0NopuxwlTPD8PMfYLWlTe9chh1BnT0iQlLqeA4Hv3+NdpiFb4aq3V3cWTTgMqOoWSGq4t318pqIZ3qbBXBq12DLFgO5n6+M6ZrdxbDUGQvgh8nAiZcIEdodKJ4ABHi1SNCeWOzCoedUdegcbjShHfkMVmNKrncB18aRWwQ3GQJ5qdkjgJmC++uZmkS6+GPM8UmmAy1ZIkRW0aWiitjG6teqtvUHOofNd/TCxX4bhnxAj+mtVIrARCE/ci8topJ6uG4wVJ1TrIkUlAY=\"\n\njobs:\n include:\n - name: \"Flake8 Lint Check\"\n env: LINT_CHECK\n install: pip install flake8 pep8-naming==0.7.0\n script: flake8\n - name: \"Build Docs\"\n install:\n - pip install doctr\n script:\n - pip install -r docs/requirements.txt\n - set -e\n - cd docs/ && make html && cd ..\n - doctr deploy --built-docs docs/build/html/ .\n - name: \"Unit tests\"\n # Please also add tests to `test/pull_request_chk.sh`.\n script:\n - wget -O /tmp/im2text.tgz http://lstm.seas.harvard.edu/latex/im2text_small.tgz; tar zxf /tmp/im2text.tgz -C /tmp/; head /tmp/im2text/src-train.txt > /tmp/im2text/src-train-head.txt; head /tmp/im2text/tgt-train.txt > /tmp/im2text/tgt-train-head.txt; head /tmp/im2text/src-val.txt > /tmp/im2text/src-val-head.txt; head /tmp/im2text/tgt-val.txt > /tmp/im2text/tgt-val-head.txt\n - wget -O /tmp/speech.tgz http://lstm.seas.harvard.edu/latex/speech.tgz; tar zxf /tmp/speech.tgz -C /tmp/; head /tmp/speech/src-train.txt > /tmp/speech/src-train-head.txt; head /tmp/speech/tgt-train.txt > /tmp/speech/tgt-train-head.txt; head /tmp/speech/src-val.txt > /tmp/speech/src-val-head.txt; head /tmp/speech/tgt-val.txt > /tmp/speech/tgt-val-head.txt\n - wget -O /tmp/test_model_speech.pt http://lstm.seas.harvard.edu/latex/model_step_2760.pt\n - wget -O /tmp/test_model_im2text.pt http://lstm.seas.harvard.edu/latex/test_model_im2text.pt\n - python -m unittest discover\n # test nmt preprocessing\n - python preprocess.py -train_src data/src-train.txt -train_tgt data/tgt-train.txt -valid_src data/src-val.txt -valid_tgt data/tgt-val.txt -save_data /tmp/data -src_vocab_size 1000 -tgt_vocab_size 1000 && rm -rf /tmp/data*.pt\n # test im2text preprocessing\n - python preprocess.py -data_type img -shard_size 100 -src_dir /tmp/im2text/images -train_src /tmp/im2text/src-train.txt -train_tgt /tmp/im2text/tgt-train.txt -valid_src /tmp/im2text/src-val.txt -valid_tgt /tmp/im2text/tgt-val.txt -save_data /tmp/im2text/data && rm -rf /tmp/im2text/data*.pt\n # test speech2text preprocessing\n - python preprocess.py -data_type audio -shard_size 300 -src_dir /tmp/speech/an4_dataset -train_src /tmp/speech/src-train.txt -train_tgt /tmp/speech/tgt-train.txt -valid_src /tmp/speech/src-val.txt -valid_tgt /tmp/speech/tgt-val.txt -save_data /tmp/speech/data && rm -rf /tmp/speech/data*.pt\n # test nmt translation\n - head data/src-test.txt > /tmp/src-test.txt; python translate.py -model onmt/tests/test_model.pt -src /tmp/src-test.txt -verbose\n # test nmt ensemble translation\n - head data/src-test.txt > /tmp/src-test.txt; python translate.py -model onmt/tests/test_model.pt onmt/tests/test_model.pt -src /tmp/src-test.txt -verbose\n # test im2text translation\n - head /tmp/im2text/src-val.txt > /tmp/im2text/src-val-head.txt; head /tmp/im2text/tgt-val.txt > /tmp/im2text/tgt-val-head.txt; python translate.py -data_type img -src_dir /tmp/im2text/images -model /tmp/test_model_im2text.pt -src /tmp/im2text/src-val-head.txt -tgt /tmp/im2text/tgt-val-head.txt -verbose -out /tmp/im2text/trans\n # test speech2text translation\n - head /tmp/speech/src-val.txt > /tmp/speech/src-val-head.txt; head /tmp/speech/tgt-val.txt > /tmp/speech/tgt-val-head.txt; python translate.py -data_type audio -src_dir /tmp/speech/an4_dataset -model /tmp/test_model_speech.pt -src /tmp/speech/src-val-head.txt -tgt /tmp/speech/tgt-val-head.txt -verbose -out /tmp/speech/trans; diff /tmp/speech/tgt-val-head.txt /tmp/speech/trans\n # test nmt preprocessing and training\n - head -500 data/src-val.txt > /tmp/src-val.txt; head -500 data/tgt-val.txt > /tmp/tgt-val.txt; python preprocess.py -train_src /tmp/src-val.txt -train_tgt /tmp/tgt-val.txt -valid_src /tmp/src-val.txt -valid_tgt /tmp/tgt-val.txt -save_data /tmp/q -src_vocab_size 1000 -tgt_vocab_size 1000; python train.py -data /tmp/q -rnn_size 2 -batch_size 2 -word_vec_size 5 -report_every 5 -rnn_size 10 -train_steps 10 && rm -rf /tmp/q*.pt\n # test nmt preprocessing w/ sharding and training w/copy\n - head -50 data/src-val.txt > /tmp/src-val.txt; head -50 data/tgt-val.txt > /tmp/tgt-val.txt; python preprocess.py -train_src /tmp/src-val.txt -train_tgt /tmp/tgt-val.txt -valid_src /tmp/src-val.txt -valid_tgt /tmp/tgt-val.txt -shard_size 25 -dynamic_dict -save_data /tmp/q -src_vocab_size 1000 -tgt_vocab_size 1000; python train.py -data /tmp/q -rnn_size 2 -batch_size 2 -word_vec_size 5 -report_every 5 -rnn_size 10 -copy_attn -train_steps 10 -pool_factor 10 && rm -rf /tmp/q*.pt\n\n # test im2text preprocessing and training\n - head -50 /tmp/im2text/src-val.txt > /tmp/im2text/src-val-head.txt; head -50 /tmp/im2text/tgt-val.txt > /tmp/im2text/tgt-val-head.txt; python preprocess.py -data_type img -src_dir /tmp/im2text/images -train_src /tmp/im2text/src-val-head.txt -train_tgt /tmp/im2text/tgt-val-head.txt -valid_src /tmp/im2text/src-val-head.txt -valid_tgt /tmp/im2text/tgt-val-head.txt -save_data /tmp/im2text/q -tgt_seq_length 100; python train.py -model_type img -data /tmp/im2text/q -rnn_size 2 -batch_size 2 -word_vec_size 5 -report_every 5 -rnn_size 10 -train_steps 10 -pool_factor 10 && rm -rf /tmp/im2text/q*.pt\n # test speech2text preprocessing and training\n - head -100 /tmp/speech/src-val.txt > /tmp/speech/src-val-head.txt; head -100 /tmp/speech/tgt-val.txt > /tmp/speech/tgt-val-head.txt; python preprocess.py -data_type audio -src_dir /tmp/speech/an4_dataset -train_src /tmp/speech/src-val-head.txt -train_tgt /tmp/speech/tgt-val-head.txt -valid_src /tmp/speech/src-val-head.txt -valid_tgt /tmp/speech/tgt-val-head.txt -save_data /tmp/speech/q; python train.py -model_type audio -data /tmp/speech/q -rnn_size 2 -batch_size 2 -word_vec_size 5 -report_every 5 -rnn_size 10 -train_steps 10 -pool_factor 10 && rm -rf /tmp/speech/q*.pt\n # test nmt translation\n - python translate.py -model onmt/tests/test_model2.pt -src data/morph/src.valid -verbose -batch_size 10 -beam_size 10 -tgt data/morph/tgt.valid -out /tmp/trans; diff data/morph/tgt.valid /tmp/trans\n # test nmt translation with random sampling\n - python translate.py -model onmt/tests/test_model2.pt -src data/morph/src.valid -verbose -batch_size 10 -beam_size 1 -seed 1 -random_sampling_topk \"-1\" -random_sampling_temp 0.0001 -tgt data/morph/tgt.valid -out /tmp/trans; diff data/morph/tgt.valid /tmp/trans\n # test tool\n - PYTHONPATH=$PYTHONPATH:. python tools/extract_embeddings.py -model onmt/tests/test_model.pt\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/CHANGELOG.md",
"content": "\n**Notes on versioning**\n\n\n## [Unreleased]\n### Fixes and improvements\n\n## [1.0.0.rc1](https://github.com/OpenNMT/OpenNMT-py/tree/1.0.0.rc1) (2019-10-01)\n* Fix Apex / FP16 training (Apex new API is buggy)\n* Multithread preprocessing way faster (Thanks François Hernandez)\n* Pip Installation v1.0.0.rc1 (thanks Paul Tardy)\n\n## [0.9.2](https://github.com/OpenNMT/OpenNMT-py/tree/0.9.2) (2019-09-04)\n* Switch to Pytorch 1.2\n* Pre/post processing on the translation server\n* option to remove the FFN layer in AAN + AAN optimization (faster)\n* Coverage loss (per Abisee paper 2017) implementation\n* Video Captioning task: Thanks Dylan Flaute!\n* Token batch at inference\n* Small fixes and add-ons\n\n\n## [0.9.1](https://github.com/OpenNMT/OpenNMT-py/tree/0.9.1) (2019-06-13)\n* New mechanism for MultiGPU training \"1 batch producer / multi batch consumers\"\n resulting in big memory saving when handling huge datasets\n* New APEX AMP (mixed precision) API\n* Option to overwrite shards when preprocessing\n* Small fixes and add-ons\n\n## [0.9.0](https://github.com/OpenNMT/OpenNMT-py/tree/0.9.0) (2019-05-16)\n* Faster vocab building when processing shards (no reloading)\n* New dataweighting feature\n* New dropout scheduler.\n* Small fixes and add-ons\n\n## [0.8.2](https://github.com/OpenNMT/OpenNMT-py/tree/0.8.2) (2019-02-16)\n* Update documentation and Library example\n* Revamp args\n* Bug fixes, save moving average in FP32\n* Allow FP32 inference for FP16 models\n\n## [0.8.1](https://github.com/OpenNMT/OpenNMT-py/tree/0.8.1) (2019-02-12)\n* Update documentation\n* Random sampling scores fixes\n* Bug fixes\n\n## [0.8.0](https://github.com/OpenNMT/OpenNMT-py/tree/0.8.0) (2019-02-09)\n* Many fixes and code cleaning thanks @flauted, @guillaumekln\n* Datasets code refactor (thanks @flauted) you need to r-preeprocess datasets\n\n### New features\n* FP16 Support: Experimental, using Apex, Checkpoints may break in future version.\n* Continuous exponential moving average (thanks @francoishernandez, and Marian)\n* Relative positions encoding (thanks @francoishernanndez, and Google T2T)\n* Deprecate the old beam search, fast batched beam search supports all options\n\n\n## [0.7.2](https://github.com/OpenNMT/OpenNMT-py/tree/0.7.2) (2019-01-31)\n* Many fixes and code cleaning thanks @bpopeters, @flauted, @guillaumekln\n\n### New features\n* Multilevel fields for better handling of text featuer embeddinggs. \n\n\n## [0.7.1](https://github.com/OpenNMT/OpenNMT-py/tree/0.7.1) (2019-01-24)\n* Many fixes and code refactoring thanks @bpopeters, @flauted, @guillaumekln\n\n### New features\n* Random sampling thanks @daphnei\n* Enable sharding for huge files at translation\n\n## [0.7.0](https://github.com/OpenNMT/OpenNMT-py/tree/0.7.0) (2019-01-02)\n* Many fixes and code refactoring thanks @benopeters\n* Migrated to Pytorch 1.0\n\n## [0.6.0](https://github.com/OpenNMT/OpenNMT-py/tree/0.6.0) (2018-11-28)\n* Many fixes and code improvements\n* New: Ability to load a yml config file. See examples in config folder.\n\n## [0.5.0](https://github.com/OpenNMT/OpenNMT-py/tree/0.5.0) (2018-10-24)\n* Fixed advance n_best beam in translate_batch_fast\n* Fixed remove valid set vocab from total vocab\n* New: Ability to reset optimizer when using train_from\n* New: create_vocabulary tool + fix when loading existing vocab.\n\n## [0.4.1](https://github.com/OpenNMT/OpenNMT-py/tree/0.4.1) (2018-10-11)\n* Fixed preprocessing files names, cleaning intermediary files.\n\n## [0.4.0](https://github.com/OpenNMT/OpenNMT-py/tree/0.4.0) (2018-10-08)\n* Fixed Speech2Text training (thanks Yuntian)\n\n* Removed -max_shard_size, replaced by -shard_size = number of examples in a shard.\n Default value = 1M which works fine in most Text dataset cases. (will avoid Ram OOM in most cases)\n\n\n## [0.3.0](https://github.com/OpenNMT/OpenNMT-py/tree/0.3.0) (2018-09-27)\n* Now requires Pytorch 0.4.1\n\n* Multi-node Multi-GPU with Torch Distributed\n\n New options are:\n -master_ip: ip address of the master node\n -master_port: port number of th emaster node\n -world_size = total number of processes to be run (total GPUs accross all nodes)\n -gpu_ranks = list of indices of processes accross all nodes\n\n* gpuid is deprecated\nSee examples in https://github.com/OpenNMT/OpenNMT-py/blob/master/docs/source/FAQ.md\n\n* Fixes to img2text now working\n\n* New sharding based on number of examples\n\n* Fixes to avoid 0.4.1 deprecated functions.\n\n\n## [0.2.1](https://github.com/OpenNMT/OpenNMT-py/tree/0.2.1) (2018-08-31)\n\n### Fixes and improvements\n\n* First compatibility steps with Pytorch 0.4.1 (non breaking)\n* Fix TranslationServer (when various request try to load the same model at the same time)\n* Fix StopIteration error (python 3.7)\n\n### New features\n* Ensemble at inference (thanks @Waino)\n\n## [0.2](https://github.com/OpenNMT/OpenNMT-py/tree/v0.2) (2018-08-28)\n\n### improvements\n\n* Compatibility fixes with Pytorch 0.4 / Torchtext 0.3\n* Multi-GPU based on Torch Distributed\n* Average Attention Network (AAN) for the Transformer (thanks @francoishernandez )\n* New fast beam search (see -fast in translate.py) (thanks @guillaumekln)\n* Sparse attention / sparsemax (thanks to @bpopeters)\n* Refactoring of many parts of the code base:\n - change from -epoch to -train_steps -valid_steps (see opts.py)\n - reorg of the logic train => train_multi / train_single => trainer\n* Many fixes / improvements in the translationserver (thanks @pltrdy @francoishernandez)\n* fix BPTT\n\n## [0.1](https://github.com/OpenNMT/OpenNMT-py/tree/v0.1) (2018-06-08)\n\n### First and Last Release using Pytorch 0.3.x\n\n\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/CONTRIBUTING.md",
"content": "# Contributors\n\nOpenNMT-py is a community developed project and we love developer contributions.\n\n## Guidelines\nBefore sending a PR, please do this checklist first:\n\n- Please run `onmt/tests/pull_request_chk.sh` and fix any errors. When adding new functionality, also add tests to this script. Included checks:\n 1. flake8 check for coding style;\n 2. unittest;\n 3. continuous integration tests listed in `.travis.yml`.\n- When adding/modifying class constructor, please make the arguments as same naming style as its superclass in PyTorch.\n- If your change is based on a paper, please include a clear comment and reference in the code (more on that below).\n\n### Docstrings\nAbove all, try to follow the Google docstring format\n([Napoleon example](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html),\n[Google styleguide](http://google.github.io/styleguide/pyguide.html)).\nThis makes it easy to include your contributions in the Sphinx documentation. And, do feel free\nto autodoc your contributions in the API ``.rst`` files in the `docs/source` folder! If you do, check that\nyour additions look right.\n\n```bash\ncd docs\n# install some dependencies if necessary:\n# recommonmark, sphinx_rtd_theme, sphinxcontrib-bibtex\nmake html\nfirefox build/html/main.html # or your browser of choice\n```\n\nSome particular advice:\n- Try to follow Python 3 [``typing`` module](https://docs.python.org/3/library/typing.html) conventions when documenting types.\n - Exception: use \"or\" instead of unions for more readability\n - For external types, use the full \"import name\". Common abbreviations (e.g. ``np``) are acceptable.\n For ``torch.Tensor`` types, the ``torch.`` is optional.\n - Please don't use tics like `` (`str`) `` or rst directives like `` (:obj:`str`) ``. Napoleon handles types\n very well without additional help, so avoid the clutter.\n- [Google docstrings don't support multiple returns](https://stackoverflow.com/questions/29221551/can-sphinx-napoleon-document-function-returning-multiple-arguments).\nFor multiple returns, the following works well with Sphinx and is still very readable.\n ```python\n def foo(a, b):\n \"\"\"This is my docstring.\n\n Args:\n a (object): Something.\n b (class): Another thing.\n\n Returns:\n (object, class):\n\n * a: Something or rather with a long\n description that spills over.\n * b: And another thing.\n \"\"\"\n\n return a, b\n ```\n- When citing a paper, avoid directly linking in the docstring! Add a Bibtex entry to `docs/source/refs.bib`.\nE.g., to cite \"Attention Is All You Need\", visit [arXiv](https://arxiv.org/abs/1706.03762), choose the\n[bibtext](https://dblp.uni-trier.de/rec/bibtex/journals/corr/VaswaniSPUJGKP17) link, search `docs/source/refs.bib`\nusing `CTRL-F` for `DBLP:journals/corr/VaswaniSPUJGKP17`, and if you do not find it then copy-paste the\ncitation into `refs.bib`. Then, in your docstring, use ``:cite:`DBLP:journals/corr/VaswaniSPUJGKP17` ``.\n - However, a link is better than nothing.\n- Please document tensor shapes. Prefer the format\n ``` ``(a, b, c)`` ```. This style is easy to read, allows using ``x`` for multplication, and is common\n (PyTorch uses a few variations on the parentheses format, AllenNLP uses exactly this format, Fairseq uses\n the parentheses format with single ticks).\n - Again, a different style is better than no shape documentation.\n- Please avoid unnecessary space characters, try to capitalize, and try to punctuate.\n\n For multi-line docstrings, add a blank line after the closing ``\"\"\"``.\n Don't use a blank line before the closing quotes.\n\n ``\"\"\" not this \"\"\"`` ``\"\"\"This.\"\"\"``\n\n ```python\n \"\"\"\n Not this.\n \"\"\"\n ```\n ```python\n \"\"\"This.\"\"\"\n ```\n\n This note is the least important. Focus on content first, but remember that consistent docs look good.\n- Be sensible about the first line. Generally, one stand-alone summary line (per the Google guidelines) is good.\n Sometimes, it's better to cut directly to the args or an extended description. It's always acceptable to have a\n \"trailing\" citation.\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/LICENSE.md",
"content": "MIT License\n\nCopyright (c) 2017-Present OpenNMT\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof this software and associated documentation files (the \"Software\"), to deal\nin the Software without restriction, including without limitation the rights\nto use, copy, modify, merge, publish, distribute, sublicense, and/or sell\ncopies of the Software, and to permit persons to whom the Software is\nfurnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in all\ncopies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\nIMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\nFITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\nAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\nLIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\nOUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\nSOFTWARE.\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/README.md",
"content": "# 机器翻译竞赛-唱园杯-Pytorch代码-Baseline\n\n几天前看到一个机器翻译竞赛-唱园杯,奖金60万,真是吓了一跳。\n\n不过我不是冲奖金,因为这么高奖金可以想一下竞争程度。我本意想要积累一下中英文翻译数据,后来发现是编码之后的数据...\n\n有点失望,就没有然后了。所以就没有花太多时间去做这个东西,简单跑了一个baselines。\n\n官方评测指标简单粗暴,一个句子有一个单词翻译错了就pass。这个比赛数据量不小,迭代20万步,目测需要一周。所以现在排行榜的分数都很低,大佬们估计在等后期发力吧。\n\n没时间打比赛,一些相关代码也不想浪费掉,就分享给大家,希望对您有所帮助。\n\nBaseline代码很简单,就是用 OpenNMT-py 这个库做的机器翻译,不过中文关于这个库的资料很少,当初啃这个库也是一点点看的源代码,细节还挺多的。\n\n默默吐槽一句代码组织架构有点乱,有些地方真的是让人摸不到头脑......\n\n我也用这个文章做一个简单的 OpenNMT-py 的教程。如果是参加竞赛的话,后期可能需要修改源代码,所以建议大家不用安装 OpenNMT-py 库,而是直接下载源代码,方便修改。\n\n首先,使用环境如下,大家照此下载就可以:\n\ntorchtext==0.4\nOpenNMT-py==1.0\npython==3.5\ncuda==9.0\n\n如果 OpenNMT-py==1.0 这个版本大家找不到,直接来我github上下载下来用就可以。\n\n## 数据预处理\n\n在 /data 目录下,需要包含四个文件,分别是 src-train.txt src-val.txt tgt-train.txt tgt-val.txt\n\n假如我们是中文翻译成英文,那么我们的 src-train.txt 和 src-val.txt 就是中文文件, tgt-train.txt 和 tgt-val.txt 就是英文文件。\n\n其中文件内容格式为每行为一句文本,以空格进行分割。\n\n对于唱园杯的数据,我们需要对其进行一些简单的修改,以满足上面的要求,我这边给出一个简单的处理代码,以字为单位,代码文件名称为「process_ori_data.py」:\n\n```pyth9on\nfile=open('train_data.csv','r')\nlines=file.readlines()\n\nsrc_train=open('src-train.txt','w')\ntgt_train=open('tgt-train.txt','w')\nsrc_val=open('src-val.txt','w')\ntgt_val=open('tgt-val.txt','w')\n\nchinese_lists=[]\nenglish_lists=[]\nindex=0\nfor line in lines:\n if index ==0:\n index+=1\n continue\n line=line.strip().split(',')\n chinese=line[1].strip().split('_')\n english=line[2].strip().split('_')\n chinese_lists.append(' '.join(chinese))\n english_lists.append(' '.join(english))\n index+=1\nassert len(chinese_lists)==len(english_lists)\nsplit_num=int(0.85*index)\n\nfor num in range(len(english_lists)):\n if num<=split_num:\n src_train.write(chinese_lists[num]+'\\n')\n tgt_train.write(english_lists[num]+'\\n')\n else:\n src_val.write(chinese_lists[num]+'\\n')\n tgt_val.write(english_lists[num]+'\\n')\n\nsrc_train.close()\ntgt_train.close()\nsrc_val.close()\ntgt_val.close()\n\n```\n\n在对原始数据进行处理之后,我们还需要进一步处理,代码如下:\n\n```python\nnohup python preprocess.py -train_src data/src-train.txt -train_tgt data/tgt-train.txt -valid_src data/src-val.txt -valid_tgt data/tgt-val.txt -save_data data/data -src_seq_length 500 -tgt_seq_length 500 >preposs_datalog &\n```\n\n在这里需要提一个很重要的小细节,就是 src_seq_length 参数 和tgt_seq_length 参数的设定问题。默认这里是50。它的含义是如果句子长度小于50,不会被读入dataset!!!因为唱园杯的数据普遍比较长,所以你如果这里保持默认的话,会出现你只处理了一小部分原始数据的问题。\n\n具体这个数值你设定为多少,看你自己具体情况。因为唱园杯在数据说明中说到已经去掉了特殊字符等,所以我就全部保留了。\n\n## 模型进行预测\n\n直接使用 Transformer 进行训练。Opennmt使用特定参数复现了 Transformer 的效果,这里我们直接套用就可以。\n\n\n```python\nnohup python train.py -data data/data -save_model data-model \\\n -layers 6 -rnn_size 512 -word_vec_size 512 -transformer_ff 2048 -heads 8 \\\n -encoder_type transformer -decoder_type transformer -position_encoding \\\n -train_steps 200000 -max_generator_batches 2 -dropout 0.1 \\\n -batch_size 4096 -batch_type tokens -normalization tokens -accum_count 2 \\\n -optim adam -adam_beta2 0.998 -decay_method noam -warmup_steps 8000 -learning_rate 2 \\\n -max_grad_norm 0 -param_init 0 -param_init_glorot \\\n -label_smoothing 0.1 -valid_steps 10000 -save_checkpoint_steps 10000 \\\n -world_size 4 -gpu_ranks 0 1 2 3 &\n```\n\n## 预测\n\n在预测之前,我们需要看一下测试数据,发现是双向预测,所以我们需要将上面的数据颠倒过来再来一次,训练另一个模型即可。\n\n按道理也可以使用全部数据(颠倒混合),这样训练一个模型就可以,不过我没试过,不知道效果如何,感兴趣的可以试一试。\n\n预测代码如下:\n\n```python\npython translate.py -model demo-model_200000.pt -src data/src-test.txt -output pred.txt \n```\n\n## 优化思路\n\n因为是编码之后的数据,所有常规的优化没啥用,这里简单提两个:\n\n1. 使用全部数据(训练数据和测试数据)训练Word2vec/Glove/Bert 等,然后作为输入,从而加入先验信息\n\n2. 如果不想自己训练,可以使用词频对应到编码之后的数据,得到一个大致的结果,从而可以使用我们正常的word2vec/glove/bert\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/README_old.md",
"content": "# OpenNMT-py: Open-Source Neural Machine Translation\n\n[](https://travis-ci.org/OpenNMT/OpenNMT-py)\n[](https://floydhub.com/run?template=https://github.com/OpenNMT/OpenNMT-py)\n\nThis is a [Pytorch](https://github.com/pytorch/pytorch)\nport of [OpenNMT](https://github.com/OpenNMT/OpenNMT),\nan open-source (MIT) neural machine translation system. It is designed to be research friendly to try out new ideas in translation, summary, image-to-text, morphology, and many other domains. Some companies have proven the code to be production ready.\n\nWe love contributions. Please consult the Issues page for any [Contributions Welcome](https://github.com/OpenNMT/OpenNMT-py/issues?q=is%3Aissue+is%3Aopen+label%3A%22contributions+welcome%22) tagged post. \n\n \n\nBefore raising an issue, make sure you read the requirements and the documentation examples.\n\nUnless there is a bug, please use the [Forum](http://forum.opennmt.net) or [Gitter](https://gitter.im/OpenNMT/OpenNMT-py) to ask questions.\n\n\nTable of Contents\n=================\n * [Full Documentation](http://opennmt.net/OpenNMT-py/)\n * [Requirements](#requirements)\n * [Features](#features)\n * [Quickstart](#quickstart)\n * [Run on FloydHub](#run-on-floydhub)\n * [Acknowledgements](#acknowledgements)\n * [Citation](#citation)\n\n## Requirements\n\nInstall `OpenNMT-py` from `pip`:\n```bash\npip install OpenNMT-py\n```\n\nor from the sources:\n```bash\ngit clone https://github.com/OpenNMT/OpenNMT-py.git\ncd OpenNMT-py\npython setup.py install\n```\n\nNote: If you have MemoryError in the install try to use `pip` with `--no-cache-dir`.\n\n*(Optionnal)* some advanced features (e.g. working audio, image or pretrained models) requires extra packages, you can install it with:\n```bash\npip install -r requirements.opt.txt\n```\n\nNote:\n\n- some features require Python 3.5 and after (eg: Distributed multigpu, entmax)\n- we currently only support PyTorch 1.2 (should work with 1.1)\n\n## Features\n\n- [Seq2Seq models (encoder-decoder) with multiple RNN cells (lstm/gru) and attention (dotprod/mlp) types](http://opennmt.net/OpenNMT-py/options/train.html#model-encoder-decoder)\n- [Transformer models](http://opennmt.net/OpenNMT-py/FAQ.html#how-do-i-use-the-transformer-model)\n- [Copy and Coverage Attention](http://opennmt.net/OpenNMT-py/options/train.html#model-attention)\n- [Pretrained Embeddings](http://opennmt.net/OpenNMT-py/FAQ.html#how-do-i-use-pretrained-embeddings-e-g-glove)\n- [Source word features](http://opennmt.net/OpenNMT-py/options/train.html#model-embeddings)\n- [Image-to-text processing](http://opennmt.net/OpenNMT-py/im2text.html)\n- [Speech-to-text processing](http://opennmt.net/OpenNMT-py/speech2text.html)\n- [TensorBoard logging](http://opennmt.net/OpenNMT-py/options/train.html#logging)\n- [Multi-GPU training](http://opennmt.net/OpenNMT-py/FAQ.html##do-you-support-multi-gpu)\n- [Data preprocessing](http://opennmt.net/OpenNMT-py/options/preprocess.html)\n- [Inference (translation) with batching and beam search](http://opennmt.net/OpenNMT-py/options/translate.html)\n- Inference time loss functions.\n- [Conv2Conv convolution model]\n- SRU \"RNNs faster than CNN\" paper\n- Mixed-precision training with [APEX](https://github.com/NVIDIA/apex), optimized on [Tensor Cores](https://developer.nvidia.com/tensor-cores)\n\n## Quickstart\n\n[Full Documentation](http://opennmt.net/OpenNMT-py/)\n\n\n### Step 1: Preprocess the data\n\n```bash\nonmt_preprocess -train_src data/src-train.txt -train_tgt data/tgt-train.txt -valid_src data/src-val.txt -valid_tgt data/tgt-val.txt -save_data data/demo\n```\n\nWe will be working with some example data in `data/` folder.\n\nThe data consists of parallel source (`src`) and target (`tgt`) data containing one sentence per line with tokens separated by a space:\n\n* `src-train.txt`\n* `tgt-train.txt`\n* `src-val.txt`\n* `tgt-val.txt`\n\nValidation files are required and used to evaluate the convergence of the training. It usually contains no more than 5000 sentences.\n\n\nAfter running the preprocessing, the following files are generated:\n\n* `demo.train.pt`: serialized PyTorch file containing training data\n* `demo.valid.pt`: serialized PyTorch file containing validation data\n* `demo.vocab.pt`: serialized PyTorch file containing vocabulary data\n\n\nInternally the system never touches the words themselves, but uses these indices.\n\n### Step 2: Train the model\n\n```bash\nonmt_train -data data/demo -save_model demo-model\n```\n\nThe main train command is quite simple. Minimally it takes a data file\nand a save file. This will run the default model, which consists of a\n2-layer LSTM with 500 hidden units on both the encoder/decoder.\nIf you want to train on GPU, you need to set, as an example:\nCUDA_VISIBLE_DEVICES=1,3\n`-world_size 2 -gpu_ranks 0 1` to use (say) GPU 1 and 3 on this node only.\nTo know more about distributed training on single or multi nodes, read the FAQ section.\n\n### Step 3: Translate\n\n```bash\nonmt_translate -model demo-model_acc_XX.XX_ppl_XXX.XX_eX.pt -src data/src-test.txt -output pred.txt -replace_unk -verbose\n```\n\nNow you have a model which you can use to predict on new data. We do this by running beam search. This will output predictions into `pred.txt`.\n\n!!! note \"Note\"\n The predictions are going to be quite terrible, as the demo dataset is small. Try running on some larger datasets! For example you can download millions of parallel sentences for [translation](http://www.statmt.org/wmt16/translation-task.html) or [summarization](https://github.com/harvardnlp/sent-summary).\n\n## Alternative: Run on FloydHub\n\n[](https://floydhub.com/run?template=https://github.com/OpenNMT/OpenNMT-py)\n\nClick this button to open a Workspace on [FloydHub](https://www.floydhub.com/?utm_medium=readme&utm_source=opennmt-py&utm_campaign=jul_2018) for training/testing your code.\n\n\n## Pretrained embeddings (e.g. GloVe)\n\nPlease see the FAQ: [How to use GloVe pre-trained embeddings in OpenNMT-py](http://opennmt.net/OpenNMT-py/FAQ.html#how-do-i-use-pretrained-embeddings-e-g-glove)\n\n## Pretrained Models\n\nThe following pretrained models can be downloaded and used with translate.py.\n\nhttp://opennmt.net/Models-py/\n\n## Acknowledgements\n\nOpenNMT-py is run as a collaborative open-source project.\nThe original code was written by [Adam Lerer](http://github.com/adamlerer) (NYC) to reproduce OpenNMT-Lua using Pytorch.\n\nMajor contributors are:\n[Sasha Rush](https://github.com/srush) (Cambridge, MA)\n[Vincent Nguyen](https://github.com/vince62s) (Ubiqus)\n[Ben Peters](http://github.com/bpopeters) (Lisbon)\n[Sebastian Gehrmann](https://github.com/sebastianGehrmann) (Harvard NLP)\n[Yuntian Deng](https://github.com/da03) (Harvard NLP)\n[Guillaume Klein](https://github.com/guillaumekln) (Systran)\n[Paul Tardy](https://github.com/pltrdy) (Ubiqus / Lium)\n[François Hernandez](https://github.com/francoishernandez) (Ubiqus)\n[Jianyu Zhan](http://github.com/jianyuzhan) (Shanghai)\n[Dylan Flaute](http://github.com/flauted (University of Dayton)\nand more !\n\nOpentNMT-py belongs to the OpenNMT project along with OpenNMT-Lua and OpenNMT-tf.\n\n## Citation\n\n[OpenNMT: Neural Machine Translation Toolkit](https://arxiv.org/pdf/1805.11462)\n\n[OpenNMT technical report](https://doi.org/10.18653/v1/P17-4012)\n\n```\n@inproceedings{opennmt,\n author = {Guillaume Klein and\n Yoon Kim and\n Yuntian Deng and\n Jean Senellart and\n Alexander M. Rush},\n title = {Open{NMT}: Open-Source Toolkit for Neural Machine Translation},\n booktitle = {Proc. ACL},\n year = {2017},\n url = {https://doi.org/10.18653/v1/P17-4012},\n doi = {10.18653/v1/P17-4012}\n}\n```\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/available_models/example.conf.json",
"content": "{\n \"models_root\": \"./available_models\",\n \"models\": [\n {\n \"id\": 100,\n \"model\": \"model_0.pt\",\n \"timeout\": 600,\n \"on_timeout\": \"to_cpu\",\n \"load\": true,\n \"opt\": {\n \"gpu\": 0,\n \"beam_size\": 5\n },\n \"tokenizer\": {\n \"type\": \"sentencepiece\",\n \"model\": \"wmtenfr.model\"\n }\n },{\n \"model\": \"model_0.light.pt\",\n \"timeout\": -1,\n \"on_timeout\": \"unload\",\n \"model_root\": \"../other_models\",\n \"opt\": {\n \"batch_size\": 1,\n \"beam_size\": 10\n }\n }\n ]\n}\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/config/config-rnn-summarization.yml",
"content": "data: data/cnndm/CNNDM\nsave_model: models/cnndm\nsave_checkpoint_steps: 10000\nkeep_checkpoint: 10\nseed: 3435\ntrain_steps: 100000\nvalid_steps: 10000\nreport_every: 100\n\nencoder_type: brnn\nword_vec_size: 128\nrnn_size: 512\nlayers: 1\n\noptim: adagrad\nlearning_rate: 0.15\nadagrad_accumulator_init: 0.1\nmax_grad_norm: 2\n\nbatch_size: 16\ndropout: 0.0\n\ncopy_attn: 'true'\nglobal_attention: mlp\nreuse_copy_attn: 'true'\nbridge: 'true'\n\nworld_size: 2\ngpu_ranks:\n- 0\n- 1\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/config/config-transformer-base-1GPU.yml",
"content": "data: exp/dataset.de-en\nsave_model: exp/model.de-en\nsave_checkpoint_steps: 10000\nkeep_checkpoint: 10\nseed: 3435\ntrain_steps: 500000\nvalid_steps: 10000\nwarmup_steps: 8000\nreport_every: 100\n\ndecoder_type: transformer\nencoder_type: transformer\nword_vec_size: 512\nrnn_size: 512\nlayers: 6\ntransformer_ff: 2048\nheads: 8\n\naccum_count: 8\noptim: adam\nadam_beta1: 0.9\nadam_beta2: 0.998\ndecay_method: noam\nlearning_rate: 2.0\nmax_grad_norm: 0.0\n\nbatch_size: 4096\nbatch_type: tokens\nnormalization: tokens\ndropout: 0.1\nlabel_smoothing: 0.1\n\nmax_generator_batches: 2\n\nparam_init: 0.0\nparam_init_glorot: 'true'\nposition_encoding: 'true'\n\nworld_size: 1\ngpu_ranks:\n- 0\n\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/config/config-transformer-base-4GPU.yml",
"content": "data: exp/dataset.de-en\nsave_model: exp/model.de-en\nsave_checkpoint_steps: 10000\nkeep_checkpoint: 10\nseed: 3435\ntrain_steps: 200000\nvalid_steps: 10000\nwarmup_steps: 8000\nreport_every: 100\n\ndecoder_type: transformer\nencoder_type: transformer\nword_vec_size: 512\nrnn_size: 512\nlayers: 6\ntransformer_ff: 2048\nheads: 8\n\naccum_count: 2\noptim: adam\nadam_beta1: 0.9\nadam_beta2: 0.998\ndecay_method: noam\nlearning_rate: 2.0\nmax_grad_norm: 0.0\n\nbatch_size: 4096\nbatch_type: tokens\nnormalization: tokens\ndropout: 0.1\nlabel_smoothing: 0.1\n\nmax_generator_batches: 2\n\nparam_init: 0.0\nparam_init_glorot: 'true'\nposition_encoding: 'true'\n\nworld_size: 4\ngpu_ranks:\n- 0\n- 1\n- 2\n- 3\n\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/Makefile",
"content": "# Minimal makefile for Sphinx documentation\n#\n\n# You can set these variables from the command line.\nSPHINXOPTS =\nSPHINXBUILD = python3 -msphinx\nSPHINXPROJ = OpenNMT-py\nSOURCEDIR = source\nBUILDDIR = build\n\n# Put it first so that \"make\" without argument is like \"make help\".\nhelp:\n\t@$(SPHINXBUILD) -M help \"$(SOURCEDIR)\" \"$(BUILDDIR)\" $(SPHINXOPTS) $(O)\n\n.PHONY: help Makefile\n\n# Catch-all target: route all unknown targets to Sphinx using the new\n# \"make mode\" option. $(O) is meant as a shortcut for $(SPHINXOPTS).\n%: Makefile\n\t@$(SPHINXBUILD) -M $@ \"$(SOURCEDIR)\" \"$(BUILDDIR)\" $(SPHINXOPTS) $(O)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/requirements.txt",
"content": "sphinx\nsphinxcontrib.bibtex\nsphinxcontrib.mermaid\nsphinx-rtd-theme\nrecommonmark\nsphinx-argparse\nsphinx_markdown_tables\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/CONTRIBUTING.md",
"content": "# Contributors\n\nOpenNMT-py is a community developed project and we love developer contributions.\n\n## Guidelines\nBefore sending a PR, please do this checklist first:\n\n- Please run `tools/pull_request_chk.sh` and fix any errors. When adding new functionality, also add tests to this script. Included checks:\n 1. flake8 check for coding style;\n 2. unittest;\n 3. continuous integration tests listed in `.travis.yml`.\n- When adding/modifying class constructor, please make the arguments as same naming style as its superclass in PyTorch.\n- If your change is based on a paper, please include a clear comment and reference in the code (more on that below). \n\n### Docstrings\nAbove all, try to follow the Google docstring format\n([Napoleon example](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html),\n[Google styleguide](http://google.github.io/styleguide/pyguide.html)).\nThis makes it easy to include your contributions in the Sphinx documentation. And, do feel free\nto autodoc your contributions in the API ``.rst`` files in the `docs/source` folder! If you do, check that\nyour additions look right.\n\n```bash\ncd docs\n# install some dependencies if necessary:\n# recommonmark, sphinx_rtd_theme, sphinxcontrib-bibtex\nmake html\nfirefox build/html/main.html # or your browser of choice\n```\n\nSome particular advice:\n- Try to follow Python 3 [``typing`` module](https://docs.python.org/3/library/typing.html) conventions when documenting types.\n - Exception: use \"or\" instead of unions for more readability\n - For external types, use the full \"import name\". Common abbreviations (e.g. ``np``) are acceptable.\n For ``torch.Tensor`` types, the ``torch.`` is optional.\n - Please don't use tics like `` (`str`) `` or rst directives like `` (:obj:`str`) ``. Napoleon handles types\n very well without additional help, so avoid the clutter.\n- [Google docstrings don't support multiple returns](https://stackoverflow.com/questions/29221551/can-sphinx-napoleon-document-function-returning-multiple-arguments).\nFor multiple returns, the following works well with Sphinx and is still very readable.\n ```python\n def foo(a, b):\n \"\"\"This is my docstring.\n \n Args:\n a (object): Something.\n b (class): Another thing.\n \n Returns:\n (object, class):\n \n * a: Something or rather with a long\n description that spills over.\n * b: And another thing.\n \"\"\"\n \n return a, b\n ```\n- When citing a paper, avoid directly linking in the docstring! Add a Bibtex entry to `docs/source/refs.bib`.\nE.g., to cite \"Attention Is All You Need\", visit [arXiv](https://arxiv.org/abs/1706.03762), choose the\n[bibtext](https://dblp.uni-trier.de/rec/bibtex/journals/corr/VaswaniSPUJGKP17) link, search `docs/source/refs.bib`\nusing `CTRL-F` for `DBLP:journals/corr/VaswaniSPUJGKP17`, and if you do not find it then copy-paste the\ncitation into `refs.bib`. Then, in your docstring, use ``:cite:`DBLP:journals/corr/VaswaniSPUJGKP17` ``.\n - However, a link is better than nothing.\n- Please document tensor shapes. Prefer the format\n ``` ``(a, b, c)`` ```. This style is easy to read, allows using ``x`` for multplication, and is common\n (PyTorch uses a few variations on the parentheses format, AllenNLP uses exactly this format, Fairseq uses\n the parentheses format with single ticks).\n - Again, a different style is better than no shape documentation.\n- Please avoid unnecessary space characters, try to capitalize, and try to punctuate.\n \n For multi-line docstrings, add a blank line after the closing ``\"\"\"``.\n Don't use a blank line before the closing quotes.\n \n ``\"\"\" not this \"\"\"`` ``\"\"\"This.\"\"\"``\n \n ```python\n \"\"\"\n Not this.\n \"\"\"\n ```\n ```python\n \"\"\"This.\"\"\"\n ```\n\n This note is the least important. Focus on content first, but remember that consistent docs look good.\n- Be sensible about the first line. Generally, one stand-alone summary line (per the Google guidelines) is good.\n Sometimes, it's better to cut directly to the args or an extended description. It's always acceptable to have a\n \"trailing\" citation."
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/FAQ.md",
"content": "# FAQ\n\n## How do I use Pretrained embeddings (e.g. GloVe)?\n\nUsing vocabularies from OpenNMT-py preprocessing outputs, `embeddings_to_torch.py` to generate encoder and decoder embeddings initialized with GloVe's values.\n\nthe script is a slightly modified version of ylhsieh's one2.\n\nUsage:\n\n```shell\nembeddings_to_torch.py [-h] [-emb_file_both EMB_FILE_BOTH]\n [-emb_file_enc EMB_FILE_ENC]\n [-emb_file_dec EMB_FILE_DEC] -output_file\n OUTPUT_FILE -dict_file DICT_FILE [-verbose]\n [-skip_lines SKIP_LINES]\n [-type {GloVe,word2vec}]\n```\n\nRun embeddings_to_torch.py -h for more usagecomplete info.\n\nExample\n\n1) get GloVe files:\n\n```shell\nmkdir \"glove_dir\"\nwget http://nlp.stanford.edu/data/glove.6B.zip\nunzip glove.6B.zip -d \"glove_dir\"\n```\n\n2) prepare data:\n\n```shell\nonmt_preprocess \\\n-train_src data/train.src.txt \\\n-train_tgt data/train.tgt.txt \\\n-valid_src data/valid.src.txt \\\n-valid_tgt data/valid.tgt.txt \\\n-save_data data/data\n```\n\n3) prepare embeddings:\n\n```shell\n./tools/embeddings_to_torch.py -emb_file_both \"glove_dir/glove.6B.100d.txt\" \\\n-dict_file \"data/data.vocab.pt\" \\\n-output_file \"data/embeddings\"\n```\n\n4) train using pre-trained embeddings:\n\n```shell\nonmt_train -save_model data/model \\\n -batch_size 64 \\\n -layers 2 \\\n -rnn_size 200 \\\n -word_vec_size 100 \\\n -pre_word_vecs_enc \"data/embeddings.enc.pt\" \\\n -pre_word_vecs_dec \"data/embeddings.dec.pt\" \\\n -data data/data\n```\n\n## How do I use the Transformer model?\n\nThe transformer model is very sensitive to hyperparameters. To run it\neffectively you need to set a bunch of different options that mimic the Google\nsetup. We have confirmed the following command can replicate their WMT results.\n\n```shell\npython train.py -data /tmp/de2/data -save_model /tmp/extra \\\n -layers 6 -rnn_size 512 -word_vec_size 512 -transformer_ff 2048 -heads 8 \\\n -encoder_type transformer -decoder_type transformer -position_encoding \\\n -train_steps 200000 -max_generator_batches 2 -dropout 0.1 \\\n -batch_size 4096 -batch_type tokens -normalization tokens -accum_count 2 \\\n -optim adam -adam_beta2 0.998 -decay_method noam -warmup_steps 8000 -learning_rate 2 \\\n -max_grad_norm 0 -param_init 0 -param_init_glorot \\\n -label_smoothing 0.1 -valid_steps 10000 -save_checkpoint_steps 10000 \\\n -world_size 4 -gpu_ranks 0 1 2 3\n```\n\nHere are what each of the parameters mean:\n\n* `param_init_glorot` `-param_init 0`: correct initialization of parameters\n* `position_encoding`: add sinusoidal position encoding to each embedding\n* `optim adam`, `decay_method noam`, `warmup_steps 8000`: use special learning rate.\n* `batch_type tokens`, `normalization tokens`, `accum_count 4`: batch and normalize based on number of tokens and not sentences. Compute gradients based on four batches.\n* `label_smoothing 0.1`: use label smoothing loss.\n\n## Do you support multi-gpu?\n\nFirst you need to make sure you `export CUDA_VISIBLE_DEVICES=0,1,2,3`.\n\nIf you want to use GPU id 1 and 3 of your OS, you will need to `export CUDA_VISIBLE_DEVICES=1,3`\n\nBoth `-world_size` and `-gpu_ranks` need to be set. E.g. `-world_size 4 -gpu_ranks 0 1 2 3` will use 4 GPU on this node only.\n\nIf you want to use 2 nodes with 2 GPU each, you need to set `-master_ip` and `-master_port`, and\n\n* `-world_size 4 -gpu_ranks 0 1`: on the first node\n* `-world_size 4 -gpu_ranks 2 3`: on the second node\n* `-accum_count 2`: This will accumulate over 2 batches before updating parameters.\n\nif you use a regular network card (1 Gbps) then we suggest to use a higher `-accum_count` to minimize the inter-node communication.\n\n**Note:**\n\nWhen training on several GPUs, you can't have them in 'Exclusive' compute mode (`nvidia-smi -c 3`).\n\nThe multi-gpu setup relies on a Producer/Consumer setup. This setup means there will be `2 + 1` processes spawned, with 2 processes per GPU, one for model training and one (Consumer) that hosts a `Queue` of batches that will be processed next. The additional process is the Producer, creating batches and sending them to the Consumers. This setup is beneficial for both wall time and memory, since it loads data shards 'in advance', and does not require to load it for each GPU process.\n\n## How can I ensemble Models at inference?\n\nYou can specify several models in the translate.py command line: -model model1_seed1 model2_seed2\nBear in mind that your models must share the same target vocabulary.\n\n## How can I weight different corpora at training?\n\n### Preprocessing\n\nWe introduced `-train_ids` which is a list of IDs that will be given to the preprocessed shards.\n\nE.g. we have two corpora : `parallel.en` and `parallel.de` + `from_backtranslation.en` `from_backtranslation.de`, we can pass the following in the `preprocess.py` command:\n\n```shell\n...\n-train_src parallel.en from_backtranslation.en \\\n-train_tgt parallel.de from_backtranslation.de \\\n-train_ids A B \\\n-save_data my_data \\\n...\n```\n\nand it will dump `my_data.train_A.X.pt` based on `parallel.en`//`parallel.de` and `my_data.train_B.X.pt` based on `from_backtranslation.en`//`from_backtranslation.de`.\n\n### Training\n\nWe introduced `-data_ids` based on the same principle as above, as well as `-data_weights`, which is the list of the weight each corpus should have.\nE.g.\n\n```shell\n...\n-data my_data \\\n-data_ids A B \\\n-data_weights 1 7 \\\n...\n```\n\nwill mean that we'll look for `my_data.train_A.*.pt` and `my_data.train_B.*.pt`, and that when building batches, we'll take 1 example from corpus A, then 7 examples from corpus B, and so on.\n\n**Warning**: This means that we'll load as many shards as we have `-data_ids`, in order to produce batches containing data from every corpus. It may be a good idea to reduce the `-shard_size` at preprocessing.\n\n## Can I get word alignment while translating?\n\n### Raw alignments from averaging Transformer attention heads\n\nCurrently, we support producing word alignment while translating for Transformer based models. Using `-report_align` when calling `translate.py` will output the inferred alignments in Pharaoh format. Those alignments are computed from an argmax on the average of the attention heads of the *second to last* decoder layer. The resulting alignment src-tgt (Pharaoh) will be pasted to the translation sentence, separated by ` ||| `.\nNote: The *second to last* default behaviour was empirically determined. It is not the same as the paper (they take the *penultimate* layer), probably because of light differences in the architecture.\n\n* alignments use the standard \"Pharaoh format\", where a pair `i-j` indicates the ith word of source language is aligned to jth word of target language.\n* Example: {'src': 'das stimmt nicht !'; 'output': 'that is not true ! ||| 0-0 0-1 1-2 2-3 1-4 1-5 3-6'}\n* Using the`-tgt` option when calling `translate.py`, we output alignments between the source and the gold target rather than the inferred target, assuming we're doing evaluation.\n* To convert subword alignments to word alignments, or symetrize bidirectional alignments, please refer to the [lilt scripts](https://github.com/lilt/alignment-scripts).\n\n### Supervised learning on a specific head\n\nThe quality of output alignments can be further improved by providing reference alignments while training. This will invoke multi-task learning on translation and alignment. This is an implementation based on the paper [Jointly Learning to Align and Translate with Transformer Models](https://arxiv.org/abs/1909.02074).\n\nThe data need to be preprocessed with the reference alignments in order to learn the supervised task.\n\nWhen calling `preprocess.py`, add:\n\n* `--train_align `: path(s) to the training alignments in Pharaoh format\n* `--valid_align `: path to the validation set alignments in Pharaoh format (optional).\nThe reference alignment file(s) could be generated by [GIZA++](https://github.com/moses-smt/mgiza/) or [fast_align](https://github.com/clab/fast_align).\n\nNote: There should be no blank lines in the alignment files provided.\n\nOptions to learn such alignments are:\n\n* `-lambda_align`: set the value > 0.0 to enable joint align training, the paper suggests 0.05;\n* `-alignment_layer`: indicate the index of the decoder layer;\n* `-alignment_heads`: number of alignment heads for the alignment task - should be set to 1 for the supervised task, and preferably kept to default (or same as `num_heads`) for the average task;\n* `-full_context_alignment`: do full context decoder pass (no future mask) when computing alignments. This will slow down the training (~12% in terms of tok/s) but will be beneficial to generate better alignment.\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/Library.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"metadata\": {\n \"collapsed\": true\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"import onmt\\n\",\n \"import onmt.inputters\\n\",\n \"import onmt.modules\\n\",\n \"import onmt.utils\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"We begin by loading in the vocabulary for the model of interest. This will let us check vocab size and to get the special ids for padding.\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"vocab = dict(torch.load(\\\"../../data/data.vocab.pt\\\"))\\n\",\n \"src_padding = vocab[\\\"src\\\"].stoi[onmt.inputters.PAD_WORD]\\n\",\n \"tgt_padding = vocab[\\\"tgt\\\"].stoi[onmt.inputters.PAD_WORD]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"Next we specify the core model itself. Here we will build a small model with an encoder and an attention based input feeding decoder. Both models will be RNNs and the encoder will be bidirectional\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"emb_size = 10\\n\",\n \"rnn_size = 6\\n\",\n \"# Specify the core model. \\n\",\n \"encoder_embeddings = onmt.modules.Embeddings(emb_size, len(vocab[\\\"src\\\"]),\\n\",\n \" word_padding_idx=src_padding)\\n\",\n \"\\n\",\n \"encoder = onmt.encoders.RNNEncoder(hidden_size=rnn_size, num_layers=1, \\n\",\n \" rnn_type=\\\"LSTM\\\", bidirectional=True,\\n\",\n \" embeddings=encoder_embeddings)\\n\",\n \"\\n\",\n \"decoder_embeddings = onmt.modules.Embeddings(emb_size, len(vocab[\\\"tgt\\\"]),\\n\",\n \" word_padding_idx=tgt_padding)\\n\",\n \"decoder = onmt.decoders.decoder.InputFeedRNNDecoder(hidden_size=rnn_size, num_layers=1, \\n\",\n \" bidirectional_encoder=True,\\n\",\n \" rnn_type=\\\"LSTM\\\", embeddings=decoder_embeddings)\\n\",\n \"model = onmt.models.model.NMTModel(encoder, decoder)\\n\",\n \"\\n\",\n \"# Specify the tgt word generator and loss computation module\\n\",\n \"model.generator = nn.Sequential( \\n\",\n \" nn.Linear(rnn_size, len(vocab[\\\"tgt\\\"])), \\n\",\n \" nn.LogSoftmax())\\n\",\n \"loss = onmt.utils.loss.NMTLossCompute(model.generator, vocab[\\\"tgt\\\"]) \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"Now we set up the optimizer. This could be a core torch optim class, or our wrapper which handles learning rate updates and gradient normalization automatically.\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"optim = onmt.utils.optimizers.Optimizer(method=\\\"sgd\\\", lr=1, max_grad_norm=2)\\n\",\n \"optim.set_parameters(model.named_parameters())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"Now we load the data from disk. Currently will need to call a function to load the fields into the data as well. \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Load some data\\n\",\n \"data = torch.load(\\\"../../data/data.train.1.pt\\\")\\n\",\n \"valid_data = torch.load(\\\"../../data/data.valid.1.pt\\\")\\n\",\n \"data.load_fields(vocab)\\n\",\n \"valid_data.load_fields(vocab)\\n\",\n \"data.examples = data.examples[:100] \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"To iterate through the data itself we use a torchtext iterator class. We specify one for both the training and test data. \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"train_iter = onmt.inputters.OrderedIterator( \\n\",\n \" dataset=data, batch_size=10, \\n\",\n \" device=-1, \\n\",\n \" repeat=False)\\n\",\n \"valid_iter = onmt.inputters.OrderedIterator( \\n\",\n \" dataset=valid_data, batch_size=10, \\n\",\n \" device=-1,\\n\",\n \" train=False) \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"Finally we train.\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Epoch 0, 0/ 10; acc: 0.00; ppl: 1225.23; 1320 src tok/s; 1320 tgt tok/s; 1514090454 s elapsed\\n\",\n \"Epoch 0, 1/ 10; acc: 9.50; ppl: 996.33; 1188 src tok/s; 1194 tgt tok/s; 1514090454 s elapsed\\n\",\n \"Epoch 0, 2/ 10; acc: 16.51; ppl: 694.48; 1265 src tok/s; 1267 tgt tok/s; 1514090454 s elapsed\\n\",\n \"Epoch 0, 3/ 10; acc: 20.49; ppl: 470.39; 1459 src tok/s; 1420 tgt tok/s; 1514090454 s elapsed\\n\",\n \"Epoch 0, 4/ 10; acc: 22.68; ppl: 387.03; 1511 src tok/s; 1462 tgt tok/s; 1514090454 s elapsed\\n\",\n \"Epoch 0, 5/ 10; acc: 24.58; ppl: 345.44; 1625 src tok/s; 1509 tgt tok/s; 1514090454 s elapsed\\n\",\n \"Epoch 0, 6/ 10; acc: 25.37; ppl: 314.39; 1586 src tok/s; 1493 tgt tok/s; 1514090454 s elapsed\\n\",\n \"Epoch 0, 7/ 10; acc: 26.14; ppl: 291.15; 1593 src tok/s; 1520 tgt tok/s; 1514090455 s elapsed\\n\",\n \"Epoch 0, 8/ 10; acc: 26.32; ppl: 274.79; 1606 src tok/s; 1545 tgt tok/s; 1514090455 s elapsed\\n\",\n \"Epoch 0, 9/ 10; acc: 26.83; ppl: 247.32; 1669 src tok/s; 1614 tgt tok/s; 1514090455 s elapsed\\n\",\n \"Validation\\n\",\n \"Epoch 0, 11/ 10; acc: 13.41; ppl: 111.94; 0 src tok/s; 7329 tgt tok/s; 1514090464 s elapsed\\n\",\n \"Epoch 1, 0/ 10; acc: 6.59; ppl: 147.05; 1849 src tok/s; 1743 tgt tok/s; 1514090464 s elapsed\\n\",\n \"Epoch 1, 1/ 10; acc: 22.10; ppl: 130.66; 2002 src tok/s; 1957 tgt tok/s; 1514090464 s elapsed\\n\",\n \"Epoch 1, 2/ 10; acc: 20.16; ppl: 122.49; 1748 src tok/s; 1760 tgt tok/s; 1514090464 s elapsed\\n\",\n \"Epoch 1, 3/ 10; acc: 23.52; ppl: 117.41; 1690 src tok/s; 1698 tgt tok/s; 1514090464 s elapsed\\n\",\n \"Epoch 1, 4/ 10; acc: 24.16; ppl: 119.42; 1647 src tok/s; 1662 tgt tok/s; 1514090464 s elapsed\\n\",\n \"Epoch 1, 5/ 10; acc: 25.44; ppl: 115.31; 1775 src tok/s; 1709 tgt tok/s; 1514090465 s elapsed\\n\",\n \"Epoch 1, 6/ 10; acc: 24.05; ppl: 115.11; 1780 src tok/s; 1718 tgt tok/s; 1514090465 s elapsed\\n\",\n \"Epoch 1, 7/ 10; acc: 25.32; ppl: 109.59; 1799 src tok/s; 1765 tgt tok/s; 1514090465 s elapsed\\n\",\n \"Epoch 1, 8/ 10; acc: 25.14; ppl: 108.16; 1771 src tok/s; 1734 tgt tok/s; 1514090465 s elapsed\\n\",\n \"Epoch 1, 9/ 10; acc: 25.58; ppl: 107.13; 1817 src tok/s; 1757 tgt tok/s; 1514090465 s elapsed\\n\",\n \"Validation\\n\",\n \"Epoch 1, 11/ 10; acc: 19.58; ppl: 88.09; 0 src tok/s; 7371 tgt tok/s; 1514090474 s elapsed\\n\"\n ]\n }\n ],\n \"source\": [\n \"trainer = onmt.Trainer(model, loss, loss, optim)\\n\",\n \"\\n\",\n \"def report_func(*args):\\n\",\n \" stats = args[-1]\\n\",\n \" stats.output(args[0], args[1], 10, 0)\\n\",\n \" return stats\\n\",\n \"\\n\",\n \"for epoch in range(2):\\n\",\n \" trainer.train(epoch, report_func)\\n\",\n \" val_stats = trainer.validate()\\n\",\n \"\\n\",\n \" print(\\\"Validation\\\")\\n\",\n \" val_stats.output(epoch, 11, 10, 0)\\n\",\n \" trainer.epoch_step(val_stats.ppl(), epoch)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"To use the model, we need to load up the translation functions \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"metadata\": {\n \"collapsed\": true\n },\n \"outputs\": [],\n \"source\": [\n \"import onmt.translate\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"PRED SCORE: -4.0690\\n\",\n \"\\n\",\n \"SENT 0: ('The', 'competitors', 'have', 'other', 'advantages', ',', 'too', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -4.2736\\n\",\n \"\\n\",\n \"SENT 0: ('The', 'company', ''s', 'durability', 'goes', 'back', 'to', 'its', 'first', 'boss', ',', 'a', 'visionary', ',', 'Thomas', 'J.', 'Watson', 'Sr.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -4.0144\\n\",\n \"\\n\",\n \"SENT 0: ('"', 'From', 'what', 'we', 'know', 'today', ',', 'you', 'have', 'to', 'ask', 'how', 'I', 'could', 'be', 'so', 'wrong', '.', '"')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -4.1361\\n\",\n \"\\n\",\n \"SENT 0: ('Boeing', 'Co', 'shares', 'rose', '1.5%', 'to', '$', '67.94', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -4.1382\\n\",\n \"\\n\",\n \"SENT 0: ('Some', 'did', 'not', 'believe', 'him', ',', 'they', 'said', 'that', 'he', 'got', 'dizzy', 'even', 'in', 'the', 'truck', ',', 'but', 'always', 'wanted', 'to', 'fulfill', 'his', 'dream', ',', 'that', 'of', 'becoming', 'a', 'pilot', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -3.8881\\n\",\n \"\\n\",\n \"SENT 0: ('In', 'your', 'opinion', ',', 'the', 'council', 'should', 'ensure', 'that', 'the', 'band', 'immediately', 'above', 'the', 'Ronda', 'de', 'Dalt', 'should', 'provide', 'in', 'its', 'entirety', ',', 'an', 'area', 'of', 'equipment', 'to', 'conduct', 'a', 'smooth', 'transition', 'between', 'the', 'city', 'and', 'the', 'green', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -4.0778\\n\",\n \"\\n\",\n \"SENT 0: ('The', 'clerk', 'of', 'the', 'court', ',', 'Jorge', 'Yanez', ',', 'went', 'to', 'the', 'jail', 'of', 'the', 'municipality', 'of', 'San', 'Nicolas', 'of', 'Garza', 'to', 'notify', 'Jonah', 'that', 'he', 'has', 'been', 'legally', 'pardoned', 'and', 'his', 'record', 'will', 'be', 'filed', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -4.2479\\n\",\n \"\\n\",\n \"SENT 0: ('"', 'In', 'a', 'research', 'it', 'is', 'reported', 'that', 'there', 'are', 'no', 'parts', 'or', 'components', 'of', 'the', 'ship', 'in', 'another', 'place', ',', 'the', 'impact', 'is', 'presented', 'in', 'a', 'structural', 'way', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -3.8585\\n\",\n \"\\n\",\n \"SENT 0: ('On', 'the', 'asphalt', 'covering', ',', 'he', 'added', ',', 'is', 'placed', 'a', 'final', 'layer', 'called', 'rolling', 'covering', ',', 'which', 'is', 'made', '\\\\u200b', '\\\\u200b', 'of', 'a', 'fine', 'stone', 'material', ',', 'meaning', 'sand', 'also', 'dipped', 'into', 'the', 'asphalt', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -4.2298\\n\",\n \"\\n\",\n \"SENT 0: ('This', 'is', '200', 'bar', 'on', 'leaving', 'and', '100', 'bar', 'on', 'arrival', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\"\n ]\n },\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"/usr/local/lib/python3.5/dist-packages/torch/tensor.py:297: UserWarning: other is not broadcastable to self, but they have the same number of elements. Falling back to deprecated pointwise behavior.\\n\",\n \" return self.add_(other)\\n\"\n ]\n }\n ],\n \"source\": [\n \"translator = onmt.translate.Translator(beam_size=10, fields=data.fields, model=model)\\n\",\n \"builder = onmt.translate.TranslationBuilder(data=valid_data, fields=data.fields)\\n\",\n \"\\n\",\n \"valid_data.src_vocabs\\n\",\n \"for batch in valid_iter:\\n\",\n \" trans_batch = translator.translate_batch(batch=batch, data=valid_data)\\n\",\n \" translations = builder.from_batch(trans_batch)\\n\",\n \" for trans in translations:\\n\",\n \" print(trans.log(0))\\n\",\n \" break\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.5.2\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 2\n}\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/Library.md",
"content": "# Library\n\nFor this example, we will assume that we have run preprocess to\ncreate our datasets. For instance\n\n> onmt_preprocess -train_src data/src-train.txt -train_tgt data/tgt-train.txt -valid_src data/src-val.txt -valid_tgt data/tgt-val.txt -save_data data/data -src_vocab_size 10000 -tgt_vocab_size 10000\n\n\n\n```python\nimport torch\nimport torch.nn as nn\n\nimport onmt\nimport onmt.inputters\nimport onmt.modules\nimport onmt.utils\n```\n\nWe begin by loading in the vocabulary for the model of interest. This will let us check vocab size and to get the special ids for padding.\n\n\n```python\nvocab_fields = torch.load(\"data/data.vocab.pt\")\n\nsrc_text_field = vocab_fields[\"src\"].base_field\nsrc_vocab = src_text_field.vocab\nsrc_padding = src_vocab.stoi[src_text_field.pad_token]\n\ntgt_text_field = vocab_fields['tgt'].base_field\ntgt_vocab = tgt_text_field.vocab\ntgt_padding = tgt_vocab.stoi[tgt_text_field.pad_token]\n```\n\nNext we specify the core model itself. Here we will build a small model with an encoder and an attention based input feeding decoder. Both models will be RNNs and the encoder will be bidirectional\n\n\n```python\nemb_size = 100\nrnn_size = 500\n# Specify the core model.\n\nencoder_embeddings = onmt.modules.Embeddings(emb_size, len(src_vocab),\n word_padding_idx=src_padding)\n\nencoder = onmt.encoders.RNNEncoder(hidden_size=rnn_size, num_layers=1,\n rnn_type=\"LSTM\", bidirectional=True,\n embeddings=encoder_embeddings)\n\ndecoder_embeddings = onmt.modules.Embeddings(emb_size, len(tgt_vocab),\n word_padding_idx=tgt_padding)\ndecoder = onmt.decoders.decoder.InputFeedRNNDecoder(\n hidden_size=rnn_size, num_layers=1, bidirectional_encoder=True, \n rnn_type=\"LSTM\", embeddings=decoder_embeddings)\n\ndevice = \"cuda\" if torch.cuda.is_available() else \"cpu\"\nmodel = onmt.models.model.NMTModel(encoder, decoder)\nmodel.to(device)\n\n# Specify the tgt word generator and loss computation module\nmodel.generator = nn.Sequential(\n nn.Linear(rnn_size, len(tgt_vocab)),\n nn.LogSoftmax(dim=-1)).to(device)\n\nloss = onmt.utils.loss.NMTLossCompute(\n criterion=nn.NLLLoss(ignore_index=tgt_padding, reduction=\"sum\"),\n generator=model.generator)\n```\n\nNow we set up the optimizer. Our wrapper around a core torch optim class handles learning rate updates and gradient normalization automatically.\n\n\n```python\nlr = 1\ntorch_optimizer = torch.optim.SGD(model.parameters(), lr=lr)\noptim = onmt.utils.optimizers.Optimizer(\n torch_optimizer, learning_rate=lr, max_grad_norm=2)\n```\n\nNow we load the data from disk with the associated vocab fields. To iterate through the data itself we use a wrapper around a torchtext iterator class. We specify one for both the training and test data.\n\n\n```python\n# Load some data\nfrom itertools import chain\ntrain_data_file = \"data/data.train.0.pt\"\nvalid_data_file = \"data/data.valid.0.pt\"\ntrain_iter = onmt.inputters.inputter.DatasetLazyIter(dataset_paths=[train_data_file],\n fields=vocab_fields,\n batch_size=50,\n batch_size_multiple=1,\n batch_size_fn=None,\n device=device,\n is_train=True,\n repeat=True)\n\nvalid_iter = onmt.inputters.inputter.DatasetLazyIter(dataset_paths=[valid_data_file],\n fields=vocab_fields,\n batch_size=10,\n batch_size_multiple=1,\n batch_size_fn=None,\n device=device,\n is_train=False,\n repeat=False)\n```\n\nFinally we train. Keeping track of the output requires a report manager.\n\n\n```python\nreport_manager = onmt.utils.ReportMgr(\n report_every=50, start_time=None, tensorboard_writer=None)\ntrainer = onmt.Trainer(model=model,\n train_loss=loss,\n valid_loss=loss,\n optim=optim,\n report_manager=report_manager)\ntrainer.train(train_iter=train_iter,\n train_steps=400,\n valid_iter=valid_iter,\n valid_steps=200)\n```\n\n```\n[2019-02-15 16:34:17,475 INFO] Start training loop and validate every 200 steps...\n[2019-02-15 16:34:17,601 INFO] Loading dataset from data/data.train.0.pt, number of examples: 10000\n[2019-02-15 16:35:43,873 INFO] Step 50/ 400; acc: 11.54; ppl: 1714.07; xent: 7.45; lr: 1.00000; 662/656 tok/s; 86 sec\n[2019-02-15 16:37:05,965 INFO] Step 100/ 400; acc: 13.75; ppl: 534.80; xent: 6.28; lr: 1.00000; 675/671 tok/s; 168 sec\n[2019-02-15 16:38:31,289 INFO] Step 150/ 400; acc: 15.02; ppl: 439.96; xent: 6.09; lr: 1.00000; 675/668 tok/s; 254 sec\n[2019-02-15 16:39:56,715 INFO] Step 200/ 400; acc: 16.08; ppl: 357.62; xent: 5.88; lr: 1.00000; 642/647 tok/s; 339 sec\n[2019-02-15 16:39:56,811 INFO] Loading dataset from data/data.valid.0.pt, number of examples: 3000\n[2019-02-15 16:41:13,415 INFO] Validation perplexity: 208.73\n[2019-02-15 16:41:13,415 INFO] Validation accuracy: 23.3507\n[2019-02-15 16:41:13,567 INFO] Loading dataset from data/data.train.0.pt, number of examples: 10000\n[2019-02-15 16:42:41,562 INFO] Step 250/ 400; acc: 17.07; ppl: 310.41; xent: 5.74; lr: 1.00000; 347/344 tok/s; 504 sec\n[2019-02-15 16:44:04,899 INFO] Step 300/ 400; acc: 19.17; ppl: 262.81; xent: 5.57; lr: 1.00000; 665/661 tok/s; 587 sec\n[2019-02-15 16:45:33,653 INFO] Step 350/ 400; acc: 19.38; ppl: 244.81; xent: 5.50; lr: 1.00000; 649/642 tok/s; 676 sec\n[2019-02-15 16:47:06,141 INFO] Step 400/ 400; acc: 20.44; ppl: 214.75; xent: 5.37; lr: 1.00000; 593/598 tok/s; 769 sec\n[2019-02-15 16:47:06,265 INFO] Loading dataset from data/data.valid.0.pt, number of examples: 3000\n[2019-02-15 16:48:27,328 INFO] Validation perplexity: 150.277\n[2019-02-15 16:48:27,328 INFO] Validation accuracy: 24.2132\n```\n\nTo use the model, we need to load up the translation functions. A Translator object requires the vocab fields, readers for source and target and a global scorer.\n\n\n```python\nimport onmt.translate\n\nsrc_reader = onmt.inputters.str2reader[\"text\"]\ntgt_reader = onmt.inputters.str2reader[\"text\"]\nscorer = onmt.translate.GNMTGlobalScorer(alpha=0.7, \n beta=0., \n length_penalty=\"avg\", \n coverage_penalty=\"none\")\ngpu = 0 if torch.cuda.is_available() else -1\ntranslator = onmt.translate.Translator(model=model, \n fields=vocab_fields, \n src_reader=src_reader, \n tgt_reader=tgt_reader, \n global_scorer=scorer,\n gpu=gpu)\nbuilder = onmt.translate.TranslationBuilder(data=torch.load(valid_data_file), \n fields=vocab_fields)\n\n\nfor batch in valid_iter:\n trans_batch = translator.translate_batch(\n batch=batch, src_vocabs=[src_vocab],\n attn_debug=False)\n translations = builder.from_batch(trans_batch)\n for trans in translations:\n print(trans.log(0))\n```\n```\n[2019-02-15 16:48:27,419 INFO] Loading dataset from data/data.valid.0.pt, number of examples: 3000\n\n\nSENT 0: ['Parliament', 'Does', 'Not', 'Support', 'Amendment', 'Freeing', 'Tymoshenko']\nPRED 0: ist ein .\nPRED SCORE: -1.0983\n\n\nSENT 0: ['Today', ',', 'the', 'Ukraine', 'parliament', 'dismissed', ',', 'within', 'the', 'Code', 'of', 'Criminal', 'Procedure', 'amendment', ',', 'the', 'motion', 'to', 'revoke', 'an', 'article', 'based', 'on', 'which', 'the', 'opposition', 'leader', ',', 'Yulia', 'Tymoshenko', ',', 'was', 'sentenced', '.']\nPRED 0: ist das .\nPRED SCORE: -1.5950\n\n\nSENT 0: ['The', 'amendment', 'that', 'would', 'lead', 'to', 'freeing', 'the', 'imprisoned', 'former', 'Prime', 'Minister', 'was', 'revoked', 'during', 'second', 'reading', 'of', 'the', 'proposal', 'for', 'mitigation', 'of', 'sentences', 'for', 'economic', 'offences', '.']\nPRED 0: Es gibt es das der für .\nPRED SCORE: -1.5128\n\n\nSENT 0: ['In', 'October', ',', 'Tymoshenko', 'was', 'sentenced', 'to', 'seven', 'years', 'in', 'prison', 'for', 'entering', 'into', 'what', 'was', 'reported', 'to', 'be', 'a', 'disadvantageous', 'gas', 'deal', 'with', 'Russia', '.']\nPRED 0: ist ein .\nPRED SCORE: -1.5578\n\n\nSENT 0: ['The', 'verdict', 'is', 'not', 'yet', 'final;', 'the', 'court', 'will', 'hear', 'Tymoshenko', ''s', 'appeal', 'in', 'December', '.']\nPRED 0: ist nicht .\nPRED SCORE: -0.9623\n\n\nSENT 0: ['Tymoshenko', 'claims', 'the', 'verdict', 'is', 'a', 'political', 'revenge', 'of', 'the', 'regime;', 'in', 'the', 'West', ',', 'the', 'trial', 'has', 'also', 'evoked', 'suspicion', 'of', 'being', 'biased', '.']\nPRED 0: ist ein .\nPRED SCORE: -0.8703\n\n\nSENT 0: ['The', 'proposal', 'to', 'remove', 'Article', '365', 'from', 'the', 'Code', 'of', 'Criminal', 'Procedure', ',', 'upon', 'which', 'the', 'former', 'Prime', 'Minister', 'was', 'sentenced', ',', 'was', 'supported', 'by', '147', 'members', 'of', 'parliament', '.']\nPRED 0: Sie sich mit .\nPRED SCORE: -1.4778\n\n\nSENT 0: ['Its', 'ratification', 'would', 'require', '226', 'votes', '.']\nPRED 0: Sie sich .\nPRED SCORE: -1.3341\n\n\nSENT 0: ['Libya', ''s', 'Victory']\nPRED 0: Sie die .\nPRED SCORE: -1.5192\n\n\nSENT 0: ['The', 'story', 'of', 'Libya', ''s', 'liberation', ',', 'or', 'rebellion', ',', 'already', 'has', 'its', 'defeated', '.']\nPRED 0: ist ein .\nPRED SCORE: -1.2772\n\n...\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/Summarization.md",
"content": "# Summarization\n\nNote: The process and results below are presented in our paper `Bottom-Up Abstractive Summarization`. Please consider citing it if you follow these instructions. \n\n```\n@inproceedings{gehrmann2018bottom,\n title={Bottom-Up Abstractive Summarization},\n author={Gehrmann, Sebastian and Deng, Yuntian and Rush, Alexander},\n booktitle={Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing},\n pages={4098--4109},\n year={2018}\n}\n```\n\n\nThis document describes how to replicate summarization experiments on the CNN-DM and gigaword datasets using OpenNMT-py.\nIn the following, we assume access to a tokenized form of the corpus split into train/valid/test set. You can find the data [here](https://github.com/harvardnlp/sent-summary).\n\nAn example article-title pair from Gigaword should look like this:\n\n**Input**\n*australia 's current account deficit shrunk by a record #.## billion dollars -lrb- #.## billion us -rrb- in the june quarter due to soaring commodity prices , figures released monday showed .*\n\n**Output**\n*australian current account deficit narrows sharply*\n\n\n### Preprocessing the data\n\nSince we are using copy-attention [1] in the model, we need to preprocess the dataset such that source and target are aligned and use the same dictionary. This is achieved by using the options `dynamic_dict` and `share_vocab`.\nWe additionally turn off truncation of the source to ensure that inputs longer than 50 words are not truncated.\nFor CNN-DM we follow See et al. [2] and additionally truncate the source length at 400 tokens and the target at 100. We also note that in CNN-DM, we found models to work better if the target surrounds sentences with tags such that a sentence looks like ` w1 w2 w3 . `. If you use this formatting, you can remove the tags after the inference step with the commands `sed -i 's/ <\\/t>//g' FILE.txt` and `sed -i 's/ //g' FILE.txt`.\n\n**Command used**:\n\n(1) CNN-DM\n\n```bash\nonmt_preprocess -train_src data/cnndm/train.txt.src \\\n -train_tgt data/cnndm/train.txt.tgt.tagged \\\n -valid_src data/cnndm/val.txt.src \\\n -valid_tgt data/cnndm/val.txt.tgt.tagged \\\n -save_data data/cnndm/CNNDM \\\n -src_seq_length 10000 \\\n -tgt_seq_length 10000 \\\n -src_seq_length_trunc 400 \\\n -tgt_seq_length_trunc 100 \\\n -dynamic_dict \\\n -share_vocab \\\n -shard_size 100000\n```\n\n(2) Gigaword\n\n```bash\nonmt_preprocess -train_src data/giga/train.article.txt \\\n -train_tgt data/giga/train.title.txt \\\n -valid_src data/giga/valid.article.txt \\\n -valid_tgt data/giga/valid.title.txt \\\n -save_data data/giga/GIGA \\\n -src_seq_length 10000 \\\n -dynamic_dict \\\n -share_vocab \\\n -shard_size 100000\n```\n\n\n### Training\n\nThe training procedure described in this section for the most part follows parameter choices and implementation similar to that of See et al. [2]. We describe notable options in the following list:\n\n- `copy_attn`: This is the most important option, since it allows the model to copy words from the source.\n- `global_attention mlp`: This makes the model use the attention mechanism introduced by Bahdanau et al. [3] instead of that by Luong et al. [4] (`global_attention dot`).\n- `share_embeddings`: This shares the word embeddings between encoder and decoder. This option drastically decreases the number of parameters a model has to learn. We did not find this option to helpful, but you can try it out by adding it to the command below.\n- `reuse_copy_attn`: This option reuses the standard attention as copy attention. Without this, the model learns an additional attention that is only used for copying.\n- `copy_loss_by_seqlength`: This modifies the loss to divide the loss of a sequence by the number of tokens in it. In practice, we found this to generate longer sequences during inference. However, this effect can also be achieved by using penalties during decoding.\n- `bridge`: This is an additional layer that uses the final hidden state of the encoder as input and computes an initial hidden state for the decoder. Without this, the decoder is initialized with the final hidden state of the encoder directly.\n- `optim adagrad`: Adagrad outperforms SGD when coupled with the following option.\n- `adagrad_accumulator_init 0.1`: PyTorch does not initialize the accumulator in adagrad with any values. To match the optimization algorithm with the Tensorflow version, this option needs to be added.\n\n\nWe are using using a 128-dimensional word-embedding, and 512-dimensional 1 layer LSTM. On the encoder side, we use a bidirectional LSTM (`brnn`), which means that the 512 dimensions are split into 256 dimensions per direction.\n\nWe additionally set the maximum norm of the gradient to 2, and renormalize if the gradient norm exceeds this value and do not use any dropout.\n\n**commands used**:\n\n(1) CNN-DM\n\n```bash\nonmt_train -save_model models/cnndm \\\n -data data/cnndm/CNNDM \\\n -copy_attn \\\n -global_attention mlp \\\n -word_vec_size 128 \\\n -rnn_size 512 \\\n -layers 1 \\\n -encoder_type brnn \\\n -train_steps 200000 \\\n -max_grad_norm 2 \\\n -dropout 0. \\\n -batch_size 16 \\\n -valid_batch_size 16 \\\n -optim adagrad \\\n -learning_rate 0.15 \\\n -adagrad_accumulator_init 0.1 \\\n -reuse_copy_attn \\\n -copy_loss_by_seqlength \\\n -bridge \\\n -seed 777 \\\n -world_size 2 \\\n -gpu_ranks 0 1\n```\n\n(2) CNN-DM Transformer\n\nThe following script trains the transformer model on CNN-DM\n\n```bash\nonmt_train -data data/cnndm/CNNDM \\\n -save_model models/cnndm \\\n -layers 4 \\\n -rnn_size 512 \\\n -word_vec_size 512 \\\n -max_grad_norm 0 \\\n -optim adam \\\n -encoder_type transformer \\\n -decoder_type transformer \\\n -position_encoding \\\n -dropout 0\\.2 \\\n -param_init 0 \\\n -warmup_steps 8000 \\\n -learning_rate 2 \\\n -decay_method noam \\\n -label_smoothing 0.1 \\\n -adam_beta2 0.998 \\\n -batch_size 4096 \\\n -batch_type tokens \\\n -normalization tokens \\\n -max_generator_batches 2 \\\n -train_steps 200000 \\\n -accum_count 4 \\\n -share_embeddings \\\n -copy_attn \\\n -param_init_glorot \\\n -world_size 2 \\\n -gpu_ranks 0 1\n```\n\n(3) Gigaword\n\nGigaword can be trained equivalently. As a baseline, we show a model trained with the following command:\n\n```\nonmt_train -data data/giga/GIGA \\\n -save_model models/giga \\\n -copy_attn \\\n -reuse_copy_attn \\\n -train_steps 200000\n```\n\n\n### Inference\n\nDuring inference, we use beam-search with a beam-size of 10. We also added specific penalties that we can use during decoding, described in the following.\n\n- `stepwise_penalty`: Applies penalty at every step\n- `coverage_penalty summary`: Uses a penalty that prevents repeated attention to the same source word\n- `beta 5`: Parameter for the Coverage Penalty\n- `length_penalty wu`: Uses the Length Penalty by Wu et al.\n- `alpha 0.8`: Parameter for the Length Penalty.\n- `block_ngram_repeat 3`: Prevent the model from repeating trigrams.\n- `ignore_when_blocking \".\" \"\" \"\"`: Allow the model to repeat trigrams with the sentence boundary tokens.\n\n**commands used**:\n\n(1) CNN-DM\n\n```\nonmt_translate -gpu X \\\n -batch_size 20 \\\n -beam_size 10 \\\n -model models/cnndm... \\\n -src data/cnndm/test.txt.src \\\n -output testout/cnndm.out \\\n -min_length 35 \\\n -verbose \\\n -stepwise_penalty \\\n -coverage_penalty summary \\\n -beta 5 \\\n -length_penalty wu \\\n -alpha 0.9 \\\n -verbose \\\n -block_ngram_repeat 3 \\\n -ignore_when_blocking \".\" \"\" \"\"\n```\n\n\n\n### Evaluation\n\n#### CNN-DM\n\nTo evaluate the ROUGE scores on CNN-DM, we extended the pyrouge wrapper with additional evaluations such as the amount of repeated n-grams (typically found in models with copy attention), found [here](https://github.com/sebastianGehrmann/rouge-baselines). The repository includes a sub-repo called pyrouge. Make sure to clone the code with the `git clone --recurse-submodules https://github.com/sebastianGehrmann/rouge-baselines` command to check this out as well and follow the installation instructions on the pyrouge repository before calling this script.\nThe installation instructions can be found [here](https://github.com/falcondai/pyrouge/tree/9cdbfbda8b8d96e7c2646ffd048743ddcf417ed9#installation). Note that on MacOS, we found that the pointer to your perl installation in line 1 of `pyrouge/RELEASE-1.5.5/ROUGE-1.5.5.pl` might be different from the one you have installed. A simple fix is to change this line to `#!/usr/local/bin/perl -w` if it fails.\n\nIt can be run with the following command:\n\n```\npython baseline.py -s testout/cnndm.out -t data/cnndm/test.txt.tgt.tagged -m sent_tag_verbatim -r\n```\n\nThe `sent_tag_verbatim` option strips `` and `` tags around sentences - when a sentence previously was ` w w w w . `, it becomes `w w w w .`.\n\n#### Gigaword\n\nFor evaluation of large test sets such as Gigaword, we use the a parallel python wrapper around ROUGE, found [here](https://github.com/pltrdy/files2rouge).\n\n**command used**:\n`files2rouge giga.out test.title.txt --verbose`\n\n### Scores and Models\n\n#### CNN-DM\n\n| Model Type | Model | R1 R | R1 P | R1 F | R2 R | R2 P | R2 F | RL R | RL P | RL F |\n| ------------- | -------- | -----:| -----:| -----:|------:| -----:| -----:|-----: | -----:| -----:|\n| Pointer-Generator + Coverage [2] | [link](https://github.com/abisee/pointer-generator) | 39.05 |\t43.02 |\t39.53 |\t17.16 | 18.77 | 17.28 | 35.98 | 39.56 | 36.38 |\n| Pointer-Generator [2] | [link](https://github.com/abisee/pointer-generator) | 37.76 | 37.60| 36.44| 16.31| 16.12| 15.66| 34.66| 34.46| 33.42 |\n| OpenNMT BRNN (1 layer, emb 128, hid 512) | [link](https://s3.amazonaws.com/opennmt-models/Summary/ada6_bridge_oldcopy_tagged_acc_54.17_ppl_11.17_e20.pt) | 40.90| 40.20| \t39.02| \t17.91| \t17.99| \t17.25| \t37.76\t| 37.18| \t36.05 |\n| OpenNMT BRNN (1 layer, emb 128, hid 512, shared embeddings) | [link](https://s3.amazonaws.com/opennmt-models/Summary/ada6_bridge_oldcopy_tagged_share_acc_54.50_ppl_10.89_e20.pt) | 38.59\t| 40.60\t| 37.97\t| 16.75\t| 17.93\t| 16.59\t| 35.67\t| 37.60\t| 35.13 |\n| OpenNMT BRNN (2 layer, emb 256, hid 1024) | [link](https://s3.amazonaws.com/opennmt-models/Summary/ada6_bridge_oldcopy_tagged_larger_acc_54.84_ppl_10.58_e17.pt) | 40.41\t| 40.94 | 39.12 | 17.76 | 18.38 | 17.35 | 37.27 | 37.83 | 36.12 |\n| OpenNMT Transformer | [link](https://s3.amazonaws.com/opennmt-models/sum_transformer_model_acc_57.25_ppl_9.22_e16.pt) | 40.31\t| 41.09\t| 39.25\t| 17.97\t| 18.46\t| 17.54\t| 37.41\t| 38.18\t| 36.45 |\n\n\n#### Gigaword\n\n| Model Type | Model | R1 R | R1 P | R1 F | R2 R | R2 P | R2 F | RL R | RL P | RL F |\n| ------------- | -------- | -----:| -----:| -----:|------:| -----:| -----:|-----: | -----:| -----:|\n| OpenNMT, no penalties | [link](https://s3.amazonaws.com/opennmt-models/gigaword_copy_acc_51.78_ppl_11.71_e20.pt) | ? |\t? |\t35.51 |\t? | ? | 17.35 | ? | ? | 33.17 |\n\n\n\n### References\n\n[1] Vinyals, O., Fortunato, M. and Jaitly, N., 2015. Pointer Network. NIPS\n\n[2] See, A., Liu, P.J. and Manning, C.D., 2017. Get To The Point: Summarization with Pointer-Generator Networks. ACL\n\n[3] Bahdanau, D., Cho, K. and Bengio, Y., 2014. Neural machine translation by jointly learning to align and translate. ICLR\n\n[4] Luong, M.T., Pham, H. and Manning, C.D., 2015. Effective approaches to attention-based neural machine translation. EMNLP\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/_static/theme_overrides.css",
"content": "/* override table width restrictions */\n@media screen and (min-width: 767px) {\n\n .wy-table-responsive table td {\n /* !important prevents the common CSS stylesheets from overriding\n this as on RTD they are loaded after this stylesheet */\n white-space: normal !important;\n }\n\n .wy-table-responsive {\n overflow: visible !important;\n }\n}"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/conf.py",
"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n#\n# OpenNMT-py documentation build configuration file, created by\n# sphinx-quickstart on Sun Dec 17 12:07:14 2017.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n# import os\n# import sys\n# sys.path.insert(0, os.path.abspath('.'))\n\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\n\nfrom recommonmark.parser import CommonMarkParser\nimport sphinx_rtd_theme\nfrom recommonmark.transform import AutoStructify\n\nsource_parsers = {\n '.md': CommonMarkParser,\n}\n\nsource_suffix = ['.rst', '.md']\nextensions = ['sphinx.ext.autodoc',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.viewcode',\n 'sphinx.ext.coverage',\n 'sphinx.ext.githubpages',\n 'sphinx.ext.napoleon',\n 'sphinxcontrib.mermaid',\n 'sphinxcontrib.bibtex',\n 'sphinxarg.ext',\n 'sphinx_markdown_tables']\n\n# Show base classes\nautodoc_default_options = {\n 'show-inheritance': True\n}\n\n# Use \"variables\" section for Attributes instead of weird block things\n# mimicking the function style.\nnapoleon_use_ivar = True\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['.templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = 'OpenNMT-py'\ncopyright = '2017, srush'\nauthor = 'srush'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = ''\n# The full version, including alpha/beta/rc tags.\nrelease = ''\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = []\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\n\n\n# html_theme = 'sphinx_materialdesign_theme'\n# html_theme_path = [sphinx_materialdesign_theme.get_path()]\nhtml_theme = \"sphinx_rtd_theme\"\nhtml_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\nhtml_context = {\n 'css_files': [\n '_static/theme_overrides.css', # override wide tables in RTD theme\n ],\n }\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# This is required for the alabaster theme\n# refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars\nhtml_sidebars = {\n '**': [\n 'relations.html', # needs 'show_related': True theme option to display\n 'searchbox.html',\n ]\n}\n\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'OpenNMT-pydoc'\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'OpenNMT-py.tex', 'OpenNMT-py Documentation',\n 'srush', 'manual'),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'opennmt-py', 'OpenNMT-py Documentation',\n [author], 1)\n]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'OpenNMT-py', 'OpenNMT-py Documentation',\n author, 'OpenNMT-py', 'One line description of project.',\n 'Miscellaneous'),\n]\n\ngithub_doc_root = 'https://github.com/opennmt/opennmt-py/tree/master/doc/'\n\n\ndef setup(app):\n print(\"hello\")\n app.add_config_value('recommonmark_config', {\n 'enable_eval_rst': True\n }, True)\n app.add_transform(AutoStructify)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/examples.rst",
"content": "== Examples ==\n\n\n.. include:: quickstart.md\n.. include:: extended.md\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/extended.md",
"content": "\n# Translation\n\nThe example below uses the Moses tokenizer (http://www.statmt.org/moses/) to prepare the data and the moses BLEU script for evaluation. This example if for training for the WMT'16 Multimodal Translation task (http://www.statmt.org/wmt16/multimodal-task.html).\n\nStep 0. Download the data.\n\n```bash\nmkdir -p data/multi30k\nwget http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz && tar -xf training.tar.gz -C data/multi30k && rm training.tar.gz\nwget http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz && tar -xf validation.tar.gz -C data/multi30k && rm validation.tar.gz\nwget http://www.quest.dcs.shef.ac.uk/wmt17_files_mmt/mmt_task1_test2016.tar.gz && tar -xf mmt_task1_test2016.tar.gz -C data/multi30k && rm mmt_task1_test2016.tar.gz\n```\n\nStep 1. Preprocess the data.\n\n```bash\nfor l in en de; do for f in data/multi30k/*.$l; do if [[ \"$f\" != *\"test\"* ]]; then sed -i \"$ d\" $f; fi; done; done\nfor l in en de; do for f in data/multi30k/*.$l; do perl tools/tokenizer.perl -a -no-escape -l $l -q < $f > $f.atok; done; done\nonmt_preprocess -train_src data/multi30k/train.en.atok -train_tgt data/multi30k/train.de.atok -valid_src data/multi30k/val.en.atok -valid_tgt data/multi30k/val.de.atok -save_data data/multi30k.atok.low -lower\n```\n\nStep 2. Train the model.\n\n```bash\nonmt_train -data data/multi30k.atok.low -save_model multi30k_model -gpu_ranks 0\n```\n\nStep 3. Translate sentences.\n\n```bash\nonmt_translate -gpu 0 -model multi30k_model_*_e13.pt -src data/multi30k/test2016.en.atok -tgt data/multi30k/test2016.de.atok -replace_unk -verbose -output multi30k.test.pred.atok\n```\n\nAnd evaluate\n\n```bash\nperl tools/multi-bleu.perl data/multi30k/test2016.de.atok < multi30k.test.pred.atok\n```\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/im2text.md",
"content": "# Image to Text\n\nA deep learning-based approach to learning the image-to-text conversion, built on top of the OpenNMT system. It is completely data-driven, hence can be used for a variety of image-to-text problems, such as image captioning, optical character recognition and LaTeX decompilation. \n\nTake LaTeX decompilation as an example, given a formula image:\n\n
\n\nBefore raising an issue, make sure you read the requirements and the documentation examples.\n\nUnless there is a bug, please use the [Forum](http://forum.opennmt.net) or [Gitter](https://gitter.im/OpenNMT/OpenNMT-py) to ask questions.\n\n\nTable of Contents\n=================\n * [Full Documentation](http://opennmt.net/OpenNMT-py/)\n * [Requirements](#requirements)\n * [Features](#features)\n * [Quickstart](#quickstart)\n * [Run on FloydHub](#run-on-floydhub)\n * [Acknowledgements](#acknowledgements)\n * [Citation](#citation)\n\n## Requirements\n\nInstall `OpenNMT-py` from `pip`:\n```bash\npip install OpenNMT-py\n```\n\nor from the sources:\n```bash\ngit clone https://github.com/OpenNMT/OpenNMT-py.git\ncd OpenNMT-py\npython setup.py install\n```\n\nNote: If you have MemoryError in the install try to use `pip` with `--no-cache-dir`.\n\n*(Optionnal)* some advanced features (e.g. working audio, image or pretrained models) requires extra packages, you can install it with:\n```bash\npip install -r requirements.opt.txt\n```\n\nNote:\n\n- some features require Python 3.5 and after (eg: Distributed multigpu, entmax)\n- we currently only support PyTorch 1.2 (should work with 1.1)\n\n## Features\n\n- [Seq2Seq models (encoder-decoder) with multiple RNN cells (lstm/gru) and attention (dotprod/mlp) types](http://opennmt.net/OpenNMT-py/options/train.html#model-encoder-decoder)\n- [Transformer models](http://opennmt.net/OpenNMT-py/FAQ.html#how-do-i-use-the-transformer-model)\n- [Copy and Coverage Attention](http://opennmt.net/OpenNMT-py/options/train.html#model-attention)\n- [Pretrained Embeddings](http://opennmt.net/OpenNMT-py/FAQ.html#how-do-i-use-pretrained-embeddings-e-g-glove)\n- [Source word features](http://opennmt.net/OpenNMT-py/options/train.html#model-embeddings)\n- [Image-to-text processing](http://opennmt.net/OpenNMT-py/im2text.html)\n- [Speech-to-text processing](http://opennmt.net/OpenNMT-py/speech2text.html)\n- [TensorBoard logging](http://opennmt.net/OpenNMT-py/options/train.html#logging)\n- [Multi-GPU training](http://opennmt.net/OpenNMT-py/FAQ.html##do-you-support-multi-gpu)\n- [Data preprocessing](http://opennmt.net/OpenNMT-py/options/preprocess.html)\n- [Inference (translation) with batching and beam search](http://opennmt.net/OpenNMT-py/options/translate.html)\n- Inference time loss functions.\n- [Conv2Conv convolution model]\n- SRU \"RNNs faster than CNN\" paper\n- Mixed-precision training with [APEX](https://github.com/NVIDIA/apex), optimized on [Tensor Cores](https://developer.nvidia.com/tensor-cores)\n\n## Quickstart\n\n[Full Documentation](http://opennmt.net/OpenNMT-py/)\n\n\n### Step 1: Preprocess the data\n\n```bash\nonmt_preprocess -train_src data/src-train.txt -train_tgt data/tgt-train.txt -valid_src data/src-val.txt -valid_tgt data/tgt-val.txt -save_data data/demo\n```\n\nWe will be working with some example data in `data/` folder.\n\nThe data consists of parallel source (`src`) and target (`tgt`) data containing one sentence per line with tokens separated by a space:\n\n* `src-train.txt`\n* `tgt-train.txt`\n* `src-val.txt`\n* `tgt-val.txt`\n\nValidation files are required and used to evaluate the convergence of the training. It usually contains no more than 5000 sentences.\n\n\nAfter running the preprocessing, the following files are generated:\n\n* `demo.train.pt`: serialized PyTorch file containing training data\n* `demo.valid.pt`: serialized PyTorch file containing validation data\n* `demo.vocab.pt`: serialized PyTorch file containing vocabulary data\n\n\nInternally the system never touches the words themselves, but uses these indices.\n\n### Step 2: Train the model\n\n```bash\nonmt_train -data data/demo -save_model demo-model\n```\n\nThe main train command is quite simple. Minimally it takes a data file\nand a save file. This will run the default model, which consists of a\n2-layer LSTM with 500 hidden units on both the encoder/decoder.\nIf you want to train on GPU, you need to set, as an example:\nCUDA_VISIBLE_DEVICES=1,3\n`-world_size 2 -gpu_ranks 0 1` to use (say) GPU 1 and 3 on this node only.\nTo know more about distributed training on single or multi nodes, read the FAQ section.\n\n### Step 3: Translate\n\n```bash\nonmt_translate -model demo-model_acc_XX.XX_ppl_XXX.XX_eX.pt -src data/src-test.txt -output pred.txt -replace_unk -verbose\n```\n\nNow you have a model which you can use to predict on new data. We do this by running beam search. This will output predictions into `pred.txt`.\n\n!!! note \"Note\"\n The predictions are going to be quite terrible, as the demo dataset is small. Try running on some larger datasets! For example you can download millions of parallel sentences for [translation](http://www.statmt.org/wmt16/translation-task.html) or [summarization](https://github.com/harvardnlp/sent-summary).\n\n## Alternative: Run on FloydHub\n\n[](https://floydhub.com/run?template=https://github.com/OpenNMT/OpenNMT-py)\n\nClick this button to open a Workspace on [FloydHub](https://www.floydhub.com/?utm_medium=readme&utm_source=opennmt-py&utm_campaign=jul_2018) for training/testing your code.\n\n\n## Pretrained embeddings (e.g. GloVe)\n\nPlease see the FAQ: [How to use GloVe pre-trained embeddings in OpenNMT-py](http://opennmt.net/OpenNMT-py/FAQ.html#how-do-i-use-pretrained-embeddings-e-g-glove)\n\n## Pretrained Models\n\nThe following pretrained models can be downloaded and used with translate.py.\n\nhttp://opennmt.net/Models-py/\n\n## Acknowledgements\n\nOpenNMT-py is run as a collaborative open-source project.\nThe original code was written by [Adam Lerer](http://github.com/adamlerer) (NYC) to reproduce OpenNMT-Lua using Pytorch.\n\nMajor contributors are:\n[Sasha Rush](https://github.com/srush) (Cambridge, MA)\n[Vincent Nguyen](https://github.com/vince62s) (Ubiqus)\n[Ben Peters](http://github.com/bpopeters) (Lisbon)\n[Sebastian Gehrmann](https://github.com/sebastianGehrmann) (Harvard NLP)\n[Yuntian Deng](https://github.com/da03) (Harvard NLP)\n[Guillaume Klein](https://github.com/guillaumekln) (Systran)\n[Paul Tardy](https://github.com/pltrdy) (Ubiqus / Lium)\n[François Hernandez](https://github.com/francoishernandez) (Ubiqus)\n[Jianyu Zhan](http://github.com/jianyuzhan) (Shanghai)\n[Dylan Flaute](http://github.com/flauted (University of Dayton)\nand more !\n\nOpentNMT-py belongs to the OpenNMT project along with OpenNMT-Lua and OpenNMT-tf.\n\n## Citation\n\n[OpenNMT: Neural Machine Translation Toolkit](https://arxiv.org/pdf/1805.11462)\n\n[OpenNMT technical report](https://doi.org/10.18653/v1/P17-4012)\n\n```\n@inproceedings{opennmt,\n author = {Guillaume Klein and\n Yoon Kim and\n Yuntian Deng and\n Jean Senellart and\n Alexander M. Rush},\n title = {Open{NMT}: Open-Source Toolkit for Neural Machine Translation},\n booktitle = {Proc. ACL},\n year = {2017},\n url = {https://doi.org/10.18653/v1/P17-4012},\n doi = {10.18653/v1/P17-4012}\n}\n```\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/available_models/example.conf.json",
"content": "{\n \"models_root\": \"./available_models\",\n \"models\": [\n {\n \"id\": 100,\n \"model\": \"model_0.pt\",\n \"timeout\": 600,\n \"on_timeout\": \"to_cpu\",\n \"load\": true,\n \"opt\": {\n \"gpu\": 0,\n \"beam_size\": 5\n },\n \"tokenizer\": {\n \"type\": \"sentencepiece\",\n \"model\": \"wmtenfr.model\"\n }\n },{\n \"model\": \"model_0.light.pt\",\n \"timeout\": -1,\n \"on_timeout\": \"unload\",\n \"model_root\": \"../other_models\",\n \"opt\": {\n \"batch_size\": 1,\n \"beam_size\": 10\n }\n }\n ]\n}\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/config/config-rnn-summarization.yml",
"content": "data: data/cnndm/CNNDM\nsave_model: models/cnndm\nsave_checkpoint_steps: 10000\nkeep_checkpoint: 10\nseed: 3435\ntrain_steps: 100000\nvalid_steps: 10000\nreport_every: 100\n\nencoder_type: brnn\nword_vec_size: 128\nrnn_size: 512\nlayers: 1\n\noptim: adagrad\nlearning_rate: 0.15\nadagrad_accumulator_init: 0.1\nmax_grad_norm: 2\n\nbatch_size: 16\ndropout: 0.0\n\ncopy_attn: 'true'\nglobal_attention: mlp\nreuse_copy_attn: 'true'\nbridge: 'true'\n\nworld_size: 2\ngpu_ranks:\n- 0\n- 1\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/config/config-transformer-base-1GPU.yml",
"content": "data: exp/dataset.de-en\nsave_model: exp/model.de-en\nsave_checkpoint_steps: 10000\nkeep_checkpoint: 10\nseed: 3435\ntrain_steps: 500000\nvalid_steps: 10000\nwarmup_steps: 8000\nreport_every: 100\n\ndecoder_type: transformer\nencoder_type: transformer\nword_vec_size: 512\nrnn_size: 512\nlayers: 6\ntransformer_ff: 2048\nheads: 8\n\naccum_count: 8\noptim: adam\nadam_beta1: 0.9\nadam_beta2: 0.998\ndecay_method: noam\nlearning_rate: 2.0\nmax_grad_norm: 0.0\n\nbatch_size: 4096\nbatch_type: tokens\nnormalization: tokens\ndropout: 0.1\nlabel_smoothing: 0.1\n\nmax_generator_batches: 2\n\nparam_init: 0.0\nparam_init_glorot: 'true'\nposition_encoding: 'true'\n\nworld_size: 1\ngpu_ranks:\n- 0\n\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/config/config-transformer-base-4GPU.yml",
"content": "data: exp/dataset.de-en\nsave_model: exp/model.de-en\nsave_checkpoint_steps: 10000\nkeep_checkpoint: 10\nseed: 3435\ntrain_steps: 200000\nvalid_steps: 10000\nwarmup_steps: 8000\nreport_every: 100\n\ndecoder_type: transformer\nencoder_type: transformer\nword_vec_size: 512\nrnn_size: 512\nlayers: 6\ntransformer_ff: 2048\nheads: 8\n\naccum_count: 2\noptim: adam\nadam_beta1: 0.9\nadam_beta2: 0.998\ndecay_method: noam\nlearning_rate: 2.0\nmax_grad_norm: 0.0\n\nbatch_size: 4096\nbatch_type: tokens\nnormalization: tokens\ndropout: 0.1\nlabel_smoothing: 0.1\n\nmax_generator_batches: 2\n\nparam_init: 0.0\nparam_init_glorot: 'true'\nposition_encoding: 'true'\n\nworld_size: 4\ngpu_ranks:\n- 0\n- 1\n- 2\n- 3\n\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/Makefile",
"content": "# Minimal makefile for Sphinx documentation\n#\n\n# You can set these variables from the command line.\nSPHINXOPTS =\nSPHINXBUILD = python3 -msphinx\nSPHINXPROJ = OpenNMT-py\nSOURCEDIR = source\nBUILDDIR = build\n\n# Put it first so that \"make\" without argument is like \"make help\".\nhelp:\n\t@$(SPHINXBUILD) -M help \"$(SOURCEDIR)\" \"$(BUILDDIR)\" $(SPHINXOPTS) $(O)\n\n.PHONY: help Makefile\n\n# Catch-all target: route all unknown targets to Sphinx using the new\n# \"make mode\" option. $(O) is meant as a shortcut for $(SPHINXOPTS).\n%: Makefile\n\t@$(SPHINXBUILD) -M $@ \"$(SOURCEDIR)\" \"$(BUILDDIR)\" $(SPHINXOPTS) $(O)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/requirements.txt",
"content": "sphinx\nsphinxcontrib.bibtex\nsphinxcontrib.mermaid\nsphinx-rtd-theme\nrecommonmark\nsphinx-argparse\nsphinx_markdown_tables\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/CONTRIBUTING.md",
"content": "# Contributors\n\nOpenNMT-py is a community developed project and we love developer contributions.\n\n## Guidelines\nBefore sending a PR, please do this checklist first:\n\n- Please run `tools/pull_request_chk.sh` and fix any errors. When adding new functionality, also add tests to this script. Included checks:\n 1. flake8 check for coding style;\n 2. unittest;\n 3. continuous integration tests listed in `.travis.yml`.\n- When adding/modifying class constructor, please make the arguments as same naming style as its superclass in PyTorch.\n- If your change is based on a paper, please include a clear comment and reference in the code (more on that below). \n\n### Docstrings\nAbove all, try to follow the Google docstring format\n([Napoleon example](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html),\n[Google styleguide](http://google.github.io/styleguide/pyguide.html)).\nThis makes it easy to include your contributions in the Sphinx documentation. And, do feel free\nto autodoc your contributions in the API ``.rst`` files in the `docs/source` folder! If you do, check that\nyour additions look right.\n\n```bash\ncd docs\n# install some dependencies if necessary:\n# recommonmark, sphinx_rtd_theme, sphinxcontrib-bibtex\nmake html\nfirefox build/html/main.html # or your browser of choice\n```\n\nSome particular advice:\n- Try to follow Python 3 [``typing`` module](https://docs.python.org/3/library/typing.html) conventions when documenting types.\n - Exception: use \"or\" instead of unions for more readability\n - For external types, use the full \"import name\". Common abbreviations (e.g. ``np``) are acceptable.\n For ``torch.Tensor`` types, the ``torch.`` is optional.\n - Please don't use tics like `` (`str`) `` or rst directives like `` (:obj:`str`) ``. Napoleon handles types\n very well without additional help, so avoid the clutter.\n- [Google docstrings don't support multiple returns](https://stackoverflow.com/questions/29221551/can-sphinx-napoleon-document-function-returning-multiple-arguments).\nFor multiple returns, the following works well with Sphinx and is still very readable.\n ```python\n def foo(a, b):\n \"\"\"This is my docstring.\n \n Args:\n a (object): Something.\n b (class): Another thing.\n \n Returns:\n (object, class):\n \n * a: Something or rather with a long\n description that spills over.\n * b: And another thing.\n \"\"\"\n \n return a, b\n ```\n- When citing a paper, avoid directly linking in the docstring! Add a Bibtex entry to `docs/source/refs.bib`.\nE.g., to cite \"Attention Is All You Need\", visit [arXiv](https://arxiv.org/abs/1706.03762), choose the\n[bibtext](https://dblp.uni-trier.de/rec/bibtex/journals/corr/VaswaniSPUJGKP17) link, search `docs/source/refs.bib`\nusing `CTRL-F` for `DBLP:journals/corr/VaswaniSPUJGKP17`, and if you do not find it then copy-paste the\ncitation into `refs.bib`. Then, in your docstring, use ``:cite:`DBLP:journals/corr/VaswaniSPUJGKP17` ``.\n - However, a link is better than nothing.\n- Please document tensor shapes. Prefer the format\n ``` ``(a, b, c)`` ```. This style is easy to read, allows using ``x`` for multplication, and is common\n (PyTorch uses a few variations on the parentheses format, AllenNLP uses exactly this format, Fairseq uses\n the parentheses format with single ticks).\n - Again, a different style is better than no shape documentation.\n- Please avoid unnecessary space characters, try to capitalize, and try to punctuate.\n \n For multi-line docstrings, add a blank line after the closing ``\"\"\"``.\n Don't use a blank line before the closing quotes.\n \n ``\"\"\" not this \"\"\"`` ``\"\"\"This.\"\"\"``\n \n ```python\n \"\"\"\n Not this.\n \"\"\"\n ```\n ```python\n \"\"\"This.\"\"\"\n ```\n\n This note is the least important. Focus on content first, but remember that consistent docs look good.\n- Be sensible about the first line. Generally, one stand-alone summary line (per the Google guidelines) is good.\n Sometimes, it's better to cut directly to the args or an extended description. It's always acceptable to have a\n \"trailing\" citation."
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/FAQ.md",
"content": "# FAQ\n\n## How do I use Pretrained embeddings (e.g. GloVe)?\n\nUsing vocabularies from OpenNMT-py preprocessing outputs, `embeddings_to_torch.py` to generate encoder and decoder embeddings initialized with GloVe's values.\n\nthe script is a slightly modified version of ylhsieh's one2.\n\nUsage:\n\n```shell\nembeddings_to_torch.py [-h] [-emb_file_both EMB_FILE_BOTH]\n [-emb_file_enc EMB_FILE_ENC]\n [-emb_file_dec EMB_FILE_DEC] -output_file\n OUTPUT_FILE -dict_file DICT_FILE [-verbose]\n [-skip_lines SKIP_LINES]\n [-type {GloVe,word2vec}]\n```\n\nRun embeddings_to_torch.py -h for more usagecomplete info.\n\nExample\n\n1) get GloVe files:\n\n```shell\nmkdir \"glove_dir\"\nwget http://nlp.stanford.edu/data/glove.6B.zip\nunzip glove.6B.zip -d \"glove_dir\"\n```\n\n2) prepare data:\n\n```shell\nonmt_preprocess \\\n-train_src data/train.src.txt \\\n-train_tgt data/train.tgt.txt \\\n-valid_src data/valid.src.txt \\\n-valid_tgt data/valid.tgt.txt \\\n-save_data data/data\n```\n\n3) prepare embeddings:\n\n```shell\n./tools/embeddings_to_torch.py -emb_file_both \"glove_dir/glove.6B.100d.txt\" \\\n-dict_file \"data/data.vocab.pt\" \\\n-output_file \"data/embeddings\"\n```\n\n4) train using pre-trained embeddings:\n\n```shell\nonmt_train -save_model data/model \\\n -batch_size 64 \\\n -layers 2 \\\n -rnn_size 200 \\\n -word_vec_size 100 \\\n -pre_word_vecs_enc \"data/embeddings.enc.pt\" \\\n -pre_word_vecs_dec \"data/embeddings.dec.pt\" \\\n -data data/data\n```\n\n## How do I use the Transformer model?\n\nThe transformer model is very sensitive to hyperparameters. To run it\neffectively you need to set a bunch of different options that mimic the Google\nsetup. We have confirmed the following command can replicate their WMT results.\n\n```shell\npython train.py -data /tmp/de2/data -save_model /tmp/extra \\\n -layers 6 -rnn_size 512 -word_vec_size 512 -transformer_ff 2048 -heads 8 \\\n -encoder_type transformer -decoder_type transformer -position_encoding \\\n -train_steps 200000 -max_generator_batches 2 -dropout 0.1 \\\n -batch_size 4096 -batch_type tokens -normalization tokens -accum_count 2 \\\n -optim adam -adam_beta2 0.998 -decay_method noam -warmup_steps 8000 -learning_rate 2 \\\n -max_grad_norm 0 -param_init 0 -param_init_glorot \\\n -label_smoothing 0.1 -valid_steps 10000 -save_checkpoint_steps 10000 \\\n -world_size 4 -gpu_ranks 0 1 2 3\n```\n\nHere are what each of the parameters mean:\n\n* `param_init_glorot` `-param_init 0`: correct initialization of parameters\n* `position_encoding`: add sinusoidal position encoding to each embedding\n* `optim adam`, `decay_method noam`, `warmup_steps 8000`: use special learning rate.\n* `batch_type tokens`, `normalization tokens`, `accum_count 4`: batch and normalize based on number of tokens and not sentences. Compute gradients based on four batches.\n* `label_smoothing 0.1`: use label smoothing loss.\n\n## Do you support multi-gpu?\n\nFirst you need to make sure you `export CUDA_VISIBLE_DEVICES=0,1,2,3`.\n\nIf you want to use GPU id 1 and 3 of your OS, you will need to `export CUDA_VISIBLE_DEVICES=1,3`\n\nBoth `-world_size` and `-gpu_ranks` need to be set. E.g. `-world_size 4 -gpu_ranks 0 1 2 3` will use 4 GPU on this node only.\n\nIf you want to use 2 nodes with 2 GPU each, you need to set `-master_ip` and `-master_port`, and\n\n* `-world_size 4 -gpu_ranks 0 1`: on the first node\n* `-world_size 4 -gpu_ranks 2 3`: on the second node\n* `-accum_count 2`: This will accumulate over 2 batches before updating parameters.\n\nif you use a regular network card (1 Gbps) then we suggest to use a higher `-accum_count` to minimize the inter-node communication.\n\n**Note:**\n\nWhen training on several GPUs, you can't have them in 'Exclusive' compute mode (`nvidia-smi -c 3`).\n\nThe multi-gpu setup relies on a Producer/Consumer setup. This setup means there will be `2 + 1` processes spawned, with 2 processes per GPU, one for model training and one (Consumer) that hosts a `Queue` of batches that will be processed next. The additional process is the Producer, creating batches and sending them to the Consumers. This setup is beneficial for both wall time and memory, since it loads data shards 'in advance', and does not require to load it for each GPU process.\n\n## How can I ensemble Models at inference?\n\nYou can specify several models in the translate.py command line: -model model1_seed1 model2_seed2\nBear in mind that your models must share the same target vocabulary.\n\n## How can I weight different corpora at training?\n\n### Preprocessing\n\nWe introduced `-train_ids` which is a list of IDs that will be given to the preprocessed shards.\n\nE.g. we have two corpora : `parallel.en` and `parallel.de` + `from_backtranslation.en` `from_backtranslation.de`, we can pass the following in the `preprocess.py` command:\n\n```shell\n...\n-train_src parallel.en from_backtranslation.en \\\n-train_tgt parallel.de from_backtranslation.de \\\n-train_ids A B \\\n-save_data my_data \\\n...\n```\n\nand it will dump `my_data.train_A.X.pt` based on `parallel.en`//`parallel.de` and `my_data.train_B.X.pt` based on `from_backtranslation.en`//`from_backtranslation.de`.\n\n### Training\n\nWe introduced `-data_ids` based on the same principle as above, as well as `-data_weights`, which is the list of the weight each corpus should have.\nE.g.\n\n```shell\n...\n-data my_data \\\n-data_ids A B \\\n-data_weights 1 7 \\\n...\n```\n\nwill mean that we'll look for `my_data.train_A.*.pt` and `my_data.train_B.*.pt`, and that when building batches, we'll take 1 example from corpus A, then 7 examples from corpus B, and so on.\n\n**Warning**: This means that we'll load as many shards as we have `-data_ids`, in order to produce batches containing data from every corpus. It may be a good idea to reduce the `-shard_size` at preprocessing.\n\n## Can I get word alignment while translating?\n\n### Raw alignments from averaging Transformer attention heads\n\nCurrently, we support producing word alignment while translating for Transformer based models. Using `-report_align` when calling `translate.py` will output the inferred alignments in Pharaoh format. Those alignments are computed from an argmax on the average of the attention heads of the *second to last* decoder layer. The resulting alignment src-tgt (Pharaoh) will be pasted to the translation sentence, separated by ` ||| `.\nNote: The *second to last* default behaviour was empirically determined. It is not the same as the paper (they take the *penultimate* layer), probably because of light differences in the architecture.\n\n* alignments use the standard \"Pharaoh format\", where a pair `i-j` indicates the ith word of source language is aligned to jth word of target language.\n* Example: {'src': 'das stimmt nicht !'; 'output': 'that is not true ! ||| 0-0 0-1 1-2 2-3 1-4 1-5 3-6'}\n* Using the`-tgt` option when calling `translate.py`, we output alignments between the source and the gold target rather than the inferred target, assuming we're doing evaluation.\n* To convert subword alignments to word alignments, or symetrize bidirectional alignments, please refer to the [lilt scripts](https://github.com/lilt/alignment-scripts).\n\n### Supervised learning on a specific head\n\nThe quality of output alignments can be further improved by providing reference alignments while training. This will invoke multi-task learning on translation and alignment. This is an implementation based on the paper [Jointly Learning to Align and Translate with Transformer Models](https://arxiv.org/abs/1909.02074).\n\nThe data need to be preprocessed with the reference alignments in order to learn the supervised task.\n\nWhen calling `preprocess.py`, add:\n\n* `--train_align `: path(s) to the training alignments in Pharaoh format\n* `--valid_align `: path to the validation set alignments in Pharaoh format (optional).\nThe reference alignment file(s) could be generated by [GIZA++](https://github.com/moses-smt/mgiza/) or [fast_align](https://github.com/clab/fast_align).\n\nNote: There should be no blank lines in the alignment files provided.\n\nOptions to learn such alignments are:\n\n* `-lambda_align`: set the value > 0.0 to enable joint align training, the paper suggests 0.05;\n* `-alignment_layer`: indicate the index of the decoder layer;\n* `-alignment_heads`: number of alignment heads for the alignment task - should be set to 1 for the supervised task, and preferably kept to default (or same as `num_heads`) for the average task;\n* `-full_context_alignment`: do full context decoder pass (no future mask) when computing alignments. This will slow down the training (~12% in terms of tok/s) but will be beneficial to generate better alignment.\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/Library.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"metadata\": {\n \"collapsed\": true\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"import onmt\\n\",\n \"import onmt.inputters\\n\",\n \"import onmt.modules\\n\",\n \"import onmt.utils\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"We begin by loading in the vocabulary for the model of interest. This will let us check vocab size and to get the special ids for padding.\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"vocab = dict(torch.load(\\\"../../data/data.vocab.pt\\\"))\\n\",\n \"src_padding = vocab[\\\"src\\\"].stoi[onmt.inputters.PAD_WORD]\\n\",\n \"tgt_padding = vocab[\\\"tgt\\\"].stoi[onmt.inputters.PAD_WORD]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"Next we specify the core model itself. Here we will build a small model with an encoder and an attention based input feeding decoder. Both models will be RNNs and the encoder will be bidirectional\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"emb_size = 10\\n\",\n \"rnn_size = 6\\n\",\n \"# Specify the core model. \\n\",\n \"encoder_embeddings = onmt.modules.Embeddings(emb_size, len(vocab[\\\"src\\\"]),\\n\",\n \" word_padding_idx=src_padding)\\n\",\n \"\\n\",\n \"encoder = onmt.encoders.RNNEncoder(hidden_size=rnn_size, num_layers=1, \\n\",\n \" rnn_type=\\\"LSTM\\\", bidirectional=True,\\n\",\n \" embeddings=encoder_embeddings)\\n\",\n \"\\n\",\n \"decoder_embeddings = onmt.modules.Embeddings(emb_size, len(vocab[\\\"tgt\\\"]),\\n\",\n \" word_padding_idx=tgt_padding)\\n\",\n \"decoder = onmt.decoders.decoder.InputFeedRNNDecoder(hidden_size=rnn_size, num_layers=1, \\n\",\n \" bidirectional_encoder=True,\\n\",\n \" rnn_type=\\\"LSTM\\\", embeddings=decoder_embeddings)\\n\",\n \"model = onmt.models.model.NMTModel(encoder, decoder)\\n\",\n \"\\n\",\n \"# Specify the tgt word generator and loss computation module\\n\",\n \"model.generator = nn.Sequential( \\n\",\n \" nn.Linear(rnn_size, len(vocab[\\\"tgt\\\"])), \\n\",\n \" nn.LogSoftmax())\\n\",\n \"loss = onmt.utils.loss.NMTLossCompute(model.generator, vocab[\\\"tgt\\\"]) \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"Now we set up the optimizer. This could be a core torch optim class, or our wrapper which handles learning rate updates and gradient normalization automatically.\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"optim = onmt.utils.optimizers.Optimizer(method=\\\"sgd\\\", lr=1, max_grad_norm=2)\\n\",\n \"optim.set_parameters(model.named_parameters())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"Now we load the data from disk. Currently will need to call a function to load the fields into the data as well. \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Load some data\\n\",\n \"data = torch.load(\\\"../../data/data.train.1.pt\\\")\\n\",\n \"valid_data = torch.load(\\\"../../data/data.valid.1.pt\\\")\\n\",\n \"data.load_fields(vocab)\\n\",\n \"valid_data.load_fields(vocab)\\n\",\n \"data.examples = data.examples[:100] \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"To iterate through the data itself we use a torchtext iterator class. We specify one for both the training and test data. \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"train_iter = onmt.inputters.OrderedIterator( \\n\",\n \" dataset=data, batch_size=10, \\n\",\n \" device=-1, \\n\",\n \" repeat=False)\\n\",\n \"valid_iter = onmt.inputters.OrderedIterator( \\n\",\n \" dataset=valid_data, batch_size=10, \\n\",\n \" device=-1,\\n\",\n \" train=False) \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"Finally we train.\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Epoch 0, 0/ 10; acc: 0.00; ppl: 1225.23; 1320 src tok/s; 1320 tgt tok/s; 1514090454 s elapsed\\n\",\n \"Epoch 0, 1/ 10; acc: 9.50; ppl: 996.33; 1188 src tok/s; 1194 tgt tok/s; 1514090454 s elapsed\\n\",\n \"Epoch 0, 2/ 10; acc: 16.51; ppl: 694.48; 1265 src tok/s; 1267 tgt tok/s; 1514090454 s elapsed\\n\",\n \"Epoch 0, 3/ 10; acc: 20.49; ppl: 470.39; 1459 src tok/s; 1420 tgt tok/s; 1514090454 s elapsed\\n\",\n \"Epoch 0, 4/ 10; acc: 22.68; ppl: 387.03; 1511 src tok/s; 1462 tgt tok/s; 1514090454 s elapsed\\n\",\n \"Epoch 0, 5/ 10; acc: 24.58; ppl: 345.44; 1625 src tok/s; 1509 tgt tok/s; 1514090454 s elapsed\\n\",\n \"Epoch 0, 6/ 10; acc: 25.37; ppl: 314.39; 1586 src tok/s; 1493 tgt tok/s; 1514090454 s elapsed\\n\",\n \"Epoch 0, 7/ 10; acc: 26.14; ppl: 291.15; 1593 src tok/s; 1520 tgt tok/s; 1514090455 s elapsed\\n\",\n \"Epoch 0, 8/ 10; acc: 26.32; ppl: 274.79; 1606 src tok/s; 1545 tgt tok/s; 1514090455 s elapsed\\n\",\n \"Epoch 0, 9/ 10; acc: 26.83; ppl: 247.32; 1669 src tok/s; 1614 tgt tok/s; 1514090455 s elapsed\\n\",\n \"Validation\\n\",\n \"Epoch 0, 11/ 10; acc: 13.41; ppl: 111.94; 0 src tok/s; 7329 tgt tok/s; 1514090464 s elapsed\\n\",\n \"Epoch 1, 0/ 10; acc: 6.59; ppl: 147.05; 1849 src tok/s; 1743 tgt tok/s; 1514090464 s elapsed\\n\",\n \"Epoch 1, 1/ 10; acc: 22.10; ppl: 130.66; 2002 src tok/s; 1957 tgt tok/s; 1514090464 s elapsed\\n\",\n \"Epoch 1, 2/ 10; acc: 20.16; ppl: 122.49; 1748 src tok/s; 1760 tgt tok/s; 1514090464 s elapsed\\n\",\n \"Epoch 1, 3/ 10; acc: 23.52; ppl: 117.41; 1690 src tok/s; 1698 tgt tok/s; 1514090464 s elapsed\\n\",\n \"Epoch 1, 4/ 10; acc: 24.16; ppl: 119.42; 1647 src tok/s; 1662 tgt tok/s; 1514090464 s elapsed\\n\",\n \"Epoch 1, 5/ 10; acc: 25.44; ppl: 115.31; 1775 src tok/s; 1709 tgt tok/s; 1514090465 s elapsed\\n\",\n \"Epoch 1, 6/ 10; acc: 24.05; ppl: 115.11; 1780 src tok/s; 1718 tgt tok/s; 1514090465 s elapsed\\n\",\n \"Epoch 1, 7/ 10; acc: 25.32; ppl: 109.59; 1799 src tok/s; 1765 tgt tok/s; 1514090465 s elapsed\\n\",\n \"Epoch 1, 8/ 10; acc: 25.14; ppl: 108.16; 1771 src tok/s; 1734 tgt tok/s; 1514090465 s elapsed\\n\",\n \"Epoch 1, 9/ 10; acc: 25.58; ppl: 107.13; 1817 src tok/s; 1757 tgt tok/s; 1514090465 s elapsed\\n\",\n \"Validation\\n\",\n \"Epoch 1, 11/ 10; acc: 19.58; ppl: 88.09; 0 src tok/s; 7371 tgt tok/s; 1514090474 s elapsed\\n\"\n ]\n }\n ],\n \"source\": [\n \"trainer = onmt.Trainer(model, loss, loss, optim)\\n\",\n \"\\n\",\n \"def report_func(*args):\\n\",\n \" stats = args[-1]\\n\",\n \" stats.output(args[0], args[1], 10, 0)\\n\",\n \" return stats\\n\",\n \"\\n\",\n \"for epoch in range(2):\\n\",\n \" trainer.train(epoch, report_func)\\n\",\n \" val_stats = trainer.validate()\\n\",\n \"\\n\",\n \" print(\\\"Validation\\\")\\n\",\n \" val_stats.output(epoch, 11, 10, 0)\\n\",\n \" trainer.epoch_step(val_stats.ppl(), epoch)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"To use the model, we need to load up the translation functions \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"metadata\": {\n \"collapsed\": true\n },\n \"outputs\": [],\n \"source\": [\n \"import onmt.translate\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"PRED SCORE: -4.0690\\n\",\n \"\\n\",\n \"SENT 0: ('The', 'competitors', 'have', 'other', 'advantages', ',', 'too', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -4.2736\\n\",\n \"\\n\",\n \"SENT 0: ('The', 'company', ''s', 'durability', 'goes', 'back', 'to', 'its', 'first', 'boss', ',', 'a', 'visionary', ',', 'Thomas', 'J.', 'Watson', 'Sr.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -4.0144\\n\",\n \"\\n\",\n \"SENT 0: ('"', 'From', 'what', 'we', 'know', 'today', ',', 'you', 'have', 'to', 'ask', 'how', 'I', 'could', 'be', 'so', 'wrong', '.', '"')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -4.1361\\n\",\n \"\\n\",\n \"SENT 0: ('Boeing', 'Co', 'shares', 'rose', '1.5%', 'to', '$', '67.94', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -4.1382\\n\",\n \"\\n\",\n \"SENT 0: ('Some', 'did', 'not', 'believe', 'him', ',', 'they', 'said', 'that', 'he', 'got', 'dizzy', 'even', 'in', 'the', 'truck', ',', 'but', 'always', 'wanted', 'to', 'fulfill', 'his', 'dream', ',', 'that', 'of', 'becoming', 'a', 'pilot', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -3.8881\\n\",\n \"\\n\",\n \"SENT 0: ('In', 'your', 'opinion', ',', 'the', 'council', 'should', 'ensure', 'that', 'the', 'band', 'immediately', 'above', 'the', 'Ronda', 'de', 'Dalt', 'should', 'provide', 'in', 'its', 'entirety', ',', 'an', 'area', 'of', 'equipment', 'to', 'conduct', 'a', 'smooth', 'transition', 'between', 'the', 'city', 'and', 'the', 'green', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -4.0778\\n\",\n \"\\n\",\n \"SENT 0: ('The', 'clerk', 'of', 'the', 'court', ',', 'Jorge', 'Yanez', ',', 'went', 'to', 'the', 'jail', 'of', 'the', 'municipality', 'of', 'San', 'Nicolas', 'of', 'Garza', 'to', 'notify', 'Jonah', 'that', 'he', 'has', 'been', 'legally', 'pardoned', 'and', 'his', 'record', 'will', 'be', 'filed', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -4.2479\\n\",\n \"\\n\",\n \"SENT 0: ('"', 'In', 'a', 'research', 'it', 'is', 'reported', 'that', 'there', 'are', 'no', 'parts', 'or', 'components', 'of', 'the', 'ship', 'in', 'another', 'place', ',', 'the', 'impact', 'is', 'presented', 'in', 'a', 'structural', 'way', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -3.8585\\n\",\n \"\\n\",\n \"SENT 0: ('On', 'the', 'asphalt', 'covering', ',', 'he', 'added', ',', 'is', 'placed', 'a', 'final', 'layer', 'called', 'rolling', 'covering', ',', 'which', 'is', 'made', '\\\\u200b', '\\\\u200b', 'of', 'a', 'fine', 'stone', 'material', ',', 'meaning', 'sand', 'also', 'dipped', 'into', 'the', 'asphalt', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\",\n \"PRED SCORE: -4.2298\\n\",\n \"\\n\",\n \"SENT 0: ('This', 'is', '200', 'bar', 'on', 'leaving', 'and', '100', 'bar', 'on', 'arrival', '.')\\n\",\n \"PRED 0: .\\n\",\n \"\\n\"\n ]\n },\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"/usr/local/lib/python3.5/dist-packages/torch/tensor.py:297: UserWarning: other is not broadcastable to self, but they have the same number of elements. Falling back to deprecated pointwise behavior.\\n\",\n \" return self.add_(other)\\n\"\n ]\n }\n ],\n \"source\": [\n \"translator = onmt.translate.Translator(beam_size=10, fields=data.fields, model=model)\\n\",\n \"builder = onmt.translate.TranslationBuilder(data=valid_data, fields=data.fields)\\n\",\n \"\\n\",\n \"valid_data.src_vocabs\\n\",\n \"for batch in valid_iter:\\n\",\n \" trans_batch = translator.translate_batch(batch=batch, data=valid_data)\\n\",\n \" translations = builder.from_batch(trans_batch)\\n\",\n \" for trans in translations:\\n\",\n \" print(trans.log(0))\\n\",\n \" break\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.5.2\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 2\n}\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/Library.md",
"content": "# Library\n\nFor this example, we will assume that we have run preprocess to\ncreate our datasets. For instance\n\n> onmt_preprocess -train_src data/src-train.txt -train_tgt data/tgt-train.txt -valid_src data/src-val.txt -valid_tgt data/tgt-val.txt -save_data data/data -src_vocab_size 10000 -tgt_vocab_size 10000\n\n\n\n```python\nimport torch\nimport torch.nn as nn\n\nimport onmt\nimport onmt.inputters\nimport onmt.modules\nimport onmt.utils\n```\n\nWe begin by loading in the vocabulary for the model of interest. This will let us check vocab size and to get the special ids for padding.\n\n\n```python\nvocab_fields = torch.load(\"data/data.vocab.pt\")\n\nsrc_text_field = vocab_fields[\"src\"].base_field\nsrc_vocab = src_text_field.vocab\nsrc_padding = src_vocab.stoi[src_text_field.pad_token]\n\ntgt_text_field = vocab_fields['tgt'].base_field\ntgt_vocab = tgt_text_field.vocab\ntgt_padding = tgt_vocab.stoi[tgt_text_field.pad_token]\n```\n\nNext we specify the core model itself. Here we will build a small model with an encoder and an attention based input feeding decoder. Both models will be RNNs and the encoder will be bidirectional\n\n\n```python\nemb_size = 100\nrnn_size = 500\n# Specify the core model.\n\nencoder_embeddings = onmt.modules.Embeddings(emb_size, len(src_vocab),\n word_padding_idx=src_padding)\n\nencoder = onmt.encoders.RNNEncoder(hidden_size=rnn_size, num_layers=1,\n rnn_type=\"LSTM\", bidirectional=True,\n embeddings=encoder_embeddings)\n\ndecoder_embeddings = onmt.modules.Embeddings(emb_size, len(tgt_vocab),\n word_padding_idx=tgt_padding)\ndecoder = onmt.decoders.decoder.InputFeedRNNDecoder(\n hidden_size=rnn_size, num_layers=1, bidirectional_encoder=True, \n rnn_type=\"LSTM\", embeddings=decoder_embeddings)\n\ndevice = \"cuda\" if torch.cuda.is_available() else \"cpu\"\nmodel = onmt.models.model.NMTModel(encoder, decoder)\nmodel.to(device)\n\n# Specify the tgt word generator and loss computation module\nmodel.generator = nn.Sequential(\n nn.Linear(rnn_size, len(tgt_vocab)),\n nn.LogSoftmax(dim=-1)).to(device)\n\nloss = onmt.utils.loss.NMTLossCompute(\n criterion=nn.NLLLoss(ignore_index=tgt_padding, reduction=\"sum\"),\n generator=model.generator)\n```\n\nNow we set up the optimizer. Our wrapper around a core torch optim class handles learning rate updates and gradient normalization automatically.\n\n\n```python\nlr = 1\ntorch_optimizer = torch.optim.SGD(model.parameters(), lr=lr)\noptim = onmt.utils.optimizers.Optimizer(\n torch_optimizer, learning_rate=lr, max_grad_norm=2)\n```\n\nNow we load the data from disk with the associated vocab fields. To iterate through the data itself we use a wrapper around a torchtext iterator class. We specify one for both the training and test data.\n\n\n```python\n# Load some data\nfrom itertools import chain\ntrain_data_file = \"data/data.train.0.pt\"\nvalid_data_file = \"data/data.valid.0.pt\"\ntrain_iter = onmt.inputters.inputter.DatasetLazyIter(dataset_paths=[train_data_file],\n fields=vocab_fields,\n batch_size=50,\n batch_size_multiple=1,\n batch_size_fn=None,\n device=device,\n is_train=True,\n repeat=True)\n\nvalid_iter = onmt.inputters.inputter.DatasetLazyIter(dataset_paths=[valid_data_file],\n fields=vocab_fields,\n batch_size=10,\n batch_size_multiple=1,\n batch_size_fn=None,\n device=device,\n is_train=False,\n repeat=False)\n```\n\nFinally we train. Keeping track of the output requires a report manager.\n\n\n```python\nreport_manager = onmt.utils.ReportMgr(\n report_every=50, start_time=None, tensorboard_writer=None)\ntrainer = onmt.Trainer(model=model,\n train_loss=loss,\n valid_loss=loss,\n optim=optim,\n report_manager=report_manager)\ntrainer.train(train_iter=train_iter,\n train_steps=400,\n valid_iter=valid_iter,\n valid_steps=200)\n```\n\n```\n[2019-02-15 16:34:17,475 INFO] Start training loop and validate every 200 steps...\n[2019-02-15 16:34:17,601 INFO] Loading dataset from data/data.train.0.pt, number of examples: 10000\n[2019-02-15 16:35:43,873 INFO] Step 50/ 400; acc: 11.54; ppl: 1714.07; xent: 7.45; lr: 1.00000; 662/656 tok/s; 86 sec\n[2019-02-15 16:37:05,965 INFO] Step 100/ 400; acc: 13.75; ppl: 534.80; xent: 6.28; lr: 1.00000; 675/671 tok/s; 168 sec\n[2019-02-15 16:38:31,289 INFO] Step 150/ 400; acc: 15.02; ppl: 439.96; xent: 6.09; lr: 1.00000; 675/668 tok/s; 254 sec\n[2019-02-15 16:39:56,715 INFO] Step 200/ 400; acc: 16.08; ppl: 357.62; xent: 5.88; lr: 1.00000; 642/647 tok/s; 339 sec\n[2019-02-15 16:39:56,811 INFO] Loading dataset from data/data.valid.0.pt, number of examples: 3000\n[2019-02-15 16:41:13,415 INFO] Validation perplexity: 208.73\n[2019-02-15 16:41:13,415 INFO] Validation accuracy: 23.3507\n[2019-02-15 16:41:13,567 INFO] Loading dataset from data/data.train.0.pt, number of examples: 10000\n[2019-02-15 16:42:41,562 INFO] Step 250/ 400; acc: 17.07; ppl: 310.41; xent: 5.74; lr: 1.00000; 347/344 tok/s; 504 sec\n[2019-02-15 16:44:04,899 INFO] Step 300/ 400; acc: 19.17; ppl: 262.81; xent: 5.57; lr: 1.00000; 665/661 tok/s; 587 sec\n[2019-02-15 16:45:33,653 INFO] Step 350/ 400; acc: 19.38; ppl: 244.81; xent: 5.50; lr: 1.00000; 649/642 tok/s; 676 sec\n[2019-02-15 16:47:06,141 INFO] Step 400/ 400; acc: 20.44; ppl: 214.75; xent: 5.37; lr: 1.00000; 593/598 tok/s; 769 sec\n[2019-02-15 16:47:06,265 INFO] Loading dataset from data/data.valid.0.pt, number of examples: 3000\n[2019-02-15 16:48:27,328 INFO] Validation perplexity: 150.277\n[2019-02-15 16:48:27,328 INFO] Validation accuracy: 24.2132\n```\n\nTo use the model, we need to load up the translation functions. A Translator object requires the vocab fields, readers for source and target and a global scorer.\n\n\n```python\nimport onmt.translate\n\nsrc_reader = onmt.inputters.str2reader[\"text\"]\ntgt_reader = onmt.inputters.str2reader[\"text\"]\nscorer = onmt.translate.GNMTGlobalScorer(alpha=0.7, \n beta=0., \n length_penalty=\"avg\", \n coverage_penalty=\"none\")\ngpu = 0 if torch.cuda.is_available() else -1\ntranslator = onmt.translate.Translator(model=model, \n fields=vocab_fields, \n src_reader=src_reader, \n tgt_reader=tgt_reader, \n global_scorer=scorer,\n gpu=gpu)\nbuilder = onmt.translate.TranslationBuilder(data=torch.load(valid_data_file), \n fields=vocab_fields)\n\n\nfor batch in valid_iter:\n trans_batch = translator.translate_batch(\n batch=batch, src_vocabs=[src_vocab],\n attn_debug=False)\n translations = builder.from_batch(trans_batch)\n for trans in translations:\n print(trans.log(0))\n```\n```\n[2019-02-15 16:48:27,419 INFO] Loading dataset from data/data.valid.0.pt, number of examples: 3000\n\n\nSENT 0: ['Parliament', 'Does', 'Not', 'Support', 'Amendment', 'Freeing', 'Tymoshenko']\nPRED 0: ist ein .\nPRED SCORE: -1.0983\n\n\nSENT 0: ['Today', ',', 'the', 'Ukraine', 'parliament', 'dismissed', ',', 'within', 'the', 'Code', 'of', 'Criminal', 'Procedure', 'amendment', ',', 'the', 'motion', 'to', 'revoke', 'an', 'article', 'based', 'on', 'which', 'the', 'opposition', 'leader', ',', 'Yulia', 'Tymoshenko', ',', 'was', 'sentenced', '.']\nPRED 0: ist das .\nPRED SCORE: -1.5950\n\n\nSENT 0: ['The', 'amendment', 'that', 'would', 'lead', 'to', 'freeing', 'the', 'imprisoned', 'former', 'Prime', 'Minister', 'was', 'revoked', 'during', 'second', 'reading', 'of', 'the', 'proposal', 'for', 'mitigation', 'of', 'sentences', 'for', 'economic', 'offences', '.']\nPRED 0: Es gibt es das der für .\nPRED SCORE: -1.5128\n\n\nSENT 0: ['In', 'October', ',', 'Tymoshenko', 'was', 'sentenced', 'to', 'seven', 'years', 'in', 'prison', 'for', 'entering', 'into', 'what', 'was', 'reported', 'to', 'be', 'a', 'disadvantageous', 'gas', 'deal', 'with', 'Russia', '.']\nPRED 0: ist ein .\nPRED SCORE: -1.5578\n\n\nSENT 0: ['The', 'verdict', 'is', 'not', 'yet', 'final;', 'the', 'court', 'will', 'hear', 'Tymoshenko', ''s', 'appeal', 'in', 'December', '.']\nPRED 0: ist nicht .\nPRED SCORE: -0.9623\n\n\nSENT 0: ['Tymoshenko', 'claims', 'the', 'verdict', 'is', 'a', 'political', 'revenge', 'of', 'the', 'regime;', 'in', 'the', 'West', ',', 'the', 'trial', 'has', 'also', 'evoked', 'suspicion', 'of', 'being', 'biased', '.']\nPRED 0: ist ein .\nPRED SCORE: -0.8703\n\n\nSENT 0: ['The', 'proposal', 'to', 'remove', 'Article', '365', 'from', 'the', 'Code', 'of', 'Criminal', 'Procedure', ',', 'upon', 'which', 'the', 'former', 'Prime', 'Minister', 'was', 'sentenced', ',', 'was', 'supported', 'by', '147', 'members', 'of', 'parliament', '.']\nPRED 0: Sie sich mit .\nPRED SCORE: -1.4778\n\n\nSENT 0: ['Its', 'ratification', 'would', 'require', '226', 'votes', '.']\nPRED 0: Sie sich .\nPRED SCORE: -1.3341\n\n\nSENT 0: ['Libya', ''s', 'Victory']\nPRED 0: Sie die .\nPRED SCORE: -1.5192\n\n\nSENT 0: ['The', 'story', 'of', 'Libya', ''s', 'liberation', ',', 'or', 'rebellion', ',', 'already', 'has', 'its', 'defeated', '.']\nPRED 0: ist ein .\nPRED SCORE: -1.2772\n\n...\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/Summarization.md",
"content": "# Summarization\n\nNote: The process and results below are presented in our paper `Bottom-Up Abstractive Summarization`. Please consider citing it if you follow these instructions. \n\n```\n@inproceedings{gehrmann2018bottom,\n title={Bottom-Up Abstractive Summarization},\n author={Gehrmann, Sebastian and Deng, Yuntian and Rush, Alexander},\n booktitle={Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing},\n pages={4098--4109},\n year={2018}\n}\n```\n\n\nThis document describes how to replicate summarization experiments on the CNN-DM and gigaword datasets using OpenNMT-py.\nIn the following, we assume access to a tokenized form of the corpus split into train/valid/test set. You can find the data [here](https://github.com/harvardnlp/sent-summary).\n\nAn example article-title pair from Gigaword should look like this:\n\n**Input**\n*australia 's current account deficit shrunk by a record #.## billion dollars -lrb- #.## billion us -rrb- in the june quarter due to soaring commodity prices , figures released monday showed .*\n\n**Output**\n*australian current account deficit narrows sharply*\n\n\n### Preprocessing the data\n\nSince we are using copy-attention [1] in the model, we need to preprocess the dataset such that source and target are aligned and use the same dictionary. This is achieved by using the options `dynamic_dict` and `share_vocab`.\nWe additionally turn off truncation of the source to ensure that inputs longer than 50 words are not truncated.\nFor CNN-DM we follow See et al. [2] and additionally truncate the source length at 400 tokens and the target at 100. We also note that in CNN-DM, we found models to work better if the target surrounds sentences with tags such that a sentence looks like ` w1 w2 w3 . `. If you use this formatting, you can remove the tags after the inference step with the commands `sed -i 's/ <\\/t>//g' FILE.txt` and `sed -i 's/ //g' FILE.txt`.\n\n**Command used**:\n\n(1) CNN-DM\n\n```bash\nonmt_preprocess -train_src data/cnndm/train.txt.src \\\n -train_tgt data/cnndm/train.txt.tgt.tagged \\\n -valid_src data/cnndm/val.txt.src \\\n -valid_tgt data/cnndm/val.txt.tgt.tagged \\\n -save_data data/cnndm/CNNDM \\\n -src_seq_length 10000 \\\n -tgt_seq_length 10000 \\\n -src_seq_length_trunc 400 \\\n -tgt_seq_length_trunc 100 \\\n -dynamic_dict \\\n -share_vocab \\\n -shard_size 100000\n```\n\n(2) Gigaword\n\n```bash\nonmt_preprocess -train_src data/giga/train.article.txt \\\n -train_tgt data/giga/train.title.txt \\\n -valid_src data/giga/valid.article.txt \\\n -valid_tgt data/giga/valid.title.txt \\\n -save_data data/giga/GIGA \\\n -src_seq_length 10000 \\\n -dynamic_dict \\\n -share_vocab \\\n -shard_size 100000\n```\n\n\n### Training\n\nThe training procedure described in this section for the most part follows parameter choices and implementation similar to that of See et al. [2]. We describe notable options in the following list:\n\n- `copy_attn`: This is the most important option, since it allows the model to copy words from the source.\n- `global_attention mlp`: This makes the model use the attention mechanism introduced by Bahdanau et al. [3] instead of that by Luong et al. [4] (`global_attention dot`).\n- `share_embeddings`: This shares the word embeddings between encoder and decoder. This option drastically decreases the number of parameters a model has to learn. We did not find this option to helpful, but you can try it out by adding it to the command below.\n- `reuse_copy_attn`: This option reuses the standard attention as copy attention. Without this, the model learns an additional attention that is only used for copying.\n- `copy_loss_by_seqlength`: This modifies the loss to divide the loss of a sequence by the number of tokens in it. In practice, we found this to generate longer sequences during inference. However, this effect can also be achieved by using penalties during decoding.\n- `bridge`: This is an additional layer that uses the final hidden state of the encoder as input and computes an initial hidden state for the decoder. Without this, the decoder is initialized with the final hidden state of the encoder directly.\n- `optim adagrad`: Adagrad outperforms SGD when coupled with the following option.\n- `adagrad_accumulator_init 0.1`: PyTorch does not initialize the accumulator in adagrad with any values. To match the optimization algorithm with the Tensorflow version, this option needs to be added.\n\n\nWe are using using a 128-dimensional word-embedding, and 512-dimensional 1 layer LSTM. On the encoder side, we use a bidirectional LSTM (`brnn`), which means that the 512 dimensions are split into 256 dimensions per direction.\n\nWe additionally set the maximum norm of the gradient to 2, and renormalize if the gradient norm exceeds this value and do not use any dropout.\n\n**commands used**:\n\n(1) CNN-DM\n\n```bash\nonmt_train -save_model models/cnndm \\\n -data data/cnndm/CNNDM \\\n -copy_attn \\\n -global_attention mlp \\\n -word_vec_size 128 \\\n -rnn_size 512 \\\n -layers 1 \\\n -encoder_type brnn \\\n -train_steps 200000 \\\n -max_grad_norm 2 \\\n -dropout 0. \\\n -batch_size 16 \\\n -valid_batch_size 16 \\\n -optim adagrad \\\n -learning_rate 0.15 \\\n -adagrad_accumulator_init 0.1 \\\n -reuse_copy_attn \\\n -copy_loss_by_seqlength \\\n -bridge \\\n -seed 777 \\\n -world_size 2 \\\n -gpu_ranks 0 1\n```\n\n(2) CNN-DM Transformer\n\nThe following script trains the transformer model on CNN-DM\n\n```bash\nonmt_train -data data/cnndm/CNNDM \\\n -save_model models/cnndm \\\n -layers 4 \\\n -rnn_size 512 \\\n -word_vec_size 512 \\\n -max_grad_norm 0 \\\n -optim adam \\\n -encoder_type transformer \\\n -decoder_type transformer \\\n -position_encoding \\\n -dropout 0\\.2 \\\n -param_init 0 \\\n -warmup_steps 8000 \\\n -learning_rate 2 \\\n -decay_method noam \\\n -label_smoothing 0.1 \\\n -adam_beta2 0.998 \\\n -batch_size 4096 \\\n -batch_type tokens \\\n -normalization tokens \\\n -max_generator_batches 2 \\\n -train_steps 200000 \\\n -accum_count 4 \\\n -share_embeddings \\\n -copy_attn \\\n -param_init_glorot \\\n -world_size 2 \\\n -gpu_ranks 0 1\n```\n\n(3) Gigaword\n\nGigaword can be trained equivalently. As a baseline, we show a model trained with the following command:\n\n```\nonmt_train -data data/giga/GIGA \\\n -save_model models/giga \\\n -copy_attn \\\n -reuse_copy_attn \\\n -train_steps 200000\n```\n\n\n### Inference\n\nDuring inference, we use beam-search with a beam-size of 10. We also added specific penalties that we can use during decoding, described in the following.\n\n- `stepwise_penalty`: Applies penalty at every step\n- `coverage_penalty summary`: Uses a penalty that prevents repeated attention to the same source word\n- `beta 5`: Parameter for the Coverage Penalty\n- `length_penalty wu`: Uses the Length Penalty by Wu et al.\n- `alpha 0.8`: Parameter for the Length Penalty.\n- `block_ngram_repeat 3`: Prevent the model from repeating trigrams.\n- `ignore_when_blocking \".\" \"\" \"\"`: Allow the model to repeat trigrams with the sentence boundary tokens.\n\n**commands used**:\n\n(1) CNN-DM\n\n```\nonmt_translate -gpu X \\\n -batch_size 20 \\\n -beam_size 10 \\\n -model models/cnndm... \\\n -src data/cnndm/test.txt.src \\\n -output testout/cnndm.out \\\n -min_length 35 \\\n -verbose \\\n -stepwise_penalty \\\n -coverage_penalty summary \\\n -beta 5 \\\n -length_penalty wu \\\n -alpha 0.9 \\\n -verbose \\\n -block_ngram_repeat 3 \\\n -ignore_when_blocking \".\" \"\" \"\"\n```\n\n\n\n### Evaluation\n\n#### CNN-DM\n\nTo evaluate the ROUGE scores on CNN-DM, we extended the pyrouge wrapper with additional evaluations such as the amount of repeated n-grams (typically found in models with copy attention), found [here](https://github.com/sebastianGehrmann/rouge-baselines). The repository includes a sub-repo called pyrouge. Make sure to clone the code with the `git clone --recurse-submodules https://github.com/sebastianGehrmann/rouge-baselines` command to check this out as well and follow the installation instructions on the pyrouge repository before calling this script.\nThe installation instructions can be found [here](https://github.com/falcondai/pyrouge/tree/9cdbfbda8b8d96e7c2646ffd048743ddcf417ed9#installation). Note that on MacOS, we found that the pointer to your perl installation in line 1 of `pyrouge/RELEASE-1.5.5/ROUGE-1.5.5.pl` might be different from the one you have installed. A simple fix is to change this line to `#!/usr/local/bin/perl -w` if it fails.\n\nIt can be run with the following command:\n\n```\npython baseline.py -s testout/cnndm.out -t data/cnndm/test.txt.tgt.tagged -m sent_tag_verbatim -r\n```\n\nThe `sent_tag_verbatim` option strips `` and `` tags around sentences - when a sentence previously was ` w w w w . `, it becomes `w w w w .`.\n\n#### Gigaword\n\nFor evaluation of large test sets such as Gigaword, we use the a parallel python wrapper around ROUGE, found [here](https://github.com/pltrdy/files2rouge).\n\n**command used**:\n`files2rouge giga.out test.title.txt --verbose`\n\n### Scores and Models\n\n#### CNN-DM\n\n| Model Type | Model | R1 R | R1 P | R1 F | R2 R | R2 P | R2 F | RL R | RL P | RL F |\n| ------------- | -------- | -----:| -----:| -----:|------:| -----:| -----:|-----: | -----:| -----:|\n| Pointer-Generator + Coverage [2] | [link](https://github.com/abisee/pointer-generator) | 39.05 |\t43.02 |\t39.53 |\t17.16 | 18.77 | 17.28 | 35.98 | 39.56 | 36.38 |\n| Pointer-Generator [2] | [link](https://github.com/abisee/pointer-generator) | 37.76 | 37.60| 36.44| 16.31| 16.12| 15.66| 34.66| 34.46| 33.42 |\n| OpenNMT BRNN (1 layer, emb 128, hid 512) | [link](https://s3.amazonaws.com/opennmt-models/Summary/ada6_bridge_oldcopy_tagged_acc_54.17_ppl_11.17_e20.pt) | 40.90| 40.20| \t39.02| \t17.91| \t17.99| \t17.25| \t37.76\t| 37.18| \t36.05 |\n| OpenNMT BRNN (1 layer, emb 128, hid 512, shared embeddings) | [link](https://s3.amazonaws.com/opennmt-models/Summary/ada6_bridge_oldcopy_tagged_share_acc_54.50_ppl_10.89_e20.pt) | 38.59\t| 40.60\t| 37.97\t| 16.75\t| 17.93\t| 16.59\t| 35.67\t| 37.60\t| 35.13 |\n| OpenNMT BRNN (2 layer, emb 256, hid 1024) | [link](https://s3.amazonaws.com/opennmt-models/Summary/ada6_bridge_oldcopy_tagged_larger_acc_54.84_ppl_10.58_e17.pt) | 40.41\t| 40.94 | 39.12 | 17.76 | 18.38 | 17.35 | 37.27 | 37.83 | 36.12 |\n| OpenNMT Transformer | [link](https://s3.amazonaws.com/opennmt-models/sum_transformer_model_acc_57.25_ppl_9.22_e16.pt) | 40.31\t| 41.09\t| 39.25\t| 17.97\t| 18.46\t| 17.54\t| 37.41\t| 38.18\t| 36.45 |\n\n\n#### Gigaword\n\n| Model Type | Model | R1 R | R1 P | R1 F | R2 R | R2 P | R2 F | RL R | RL P | RL F |\n| ------------- | -------- | -----:| -----:| -----:|------:| -----:| -----:|-----: | -----:| -----:|\n| OpenNMT, no penalties | [link](https://s3.amazonaws.com/opennmt-models/gigaword_copy_acc_51.78_ppl_11.71_e20.pt) | ? |\t? |\t35.51 |\t? | ? | 17.35 | ? | ? | 33.17 |\n\n\n\n### References\n\n[1] Vinyals, O., Fortunato, M. and Jaitly, N., 2015. Pointer Network. NIPS\n\n[2] See, A., Liu, P.J. and Manning, C.D., 2017. Get To The Point: Summarization with Pointer-Generator Networks. ACL\n\n[3] Bahdanau, D., Cho, K. and Bengio, Y., 2014. Neural machine translation by jointly learning to align and translate. ICLR\n\n[4] Luong, M.T., Pham, H. and Manning, C.D., 2015. Effective approaches to attention-based neural machine translation. EMNLP\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/_static/theme_overrides.css",
"content": "/* override table width restrictions */\n@media screen and (min-width: 767px) {\n\n .wy-table-responsive table td {\n /* !important prevents the common CSS stylesheets from overriding\n this as on RTD they are loaded after this stylesheet */\n white-space: normal !important;\n }\n\n .wy-table-responsive {\n overflow: visible !important;\n }\n}"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/conf.py",
"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n#\n# OpenNMT-py documentation build configuration file, created by\n# sphinx-quickstart on Sun Dec 17 12:07:14 2017.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n# import os\n# import sys\n# sys.path.insert(0, os.path.abspath('.'))\n\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\n\nfrom recommonmark.parser import CommonMarkParser\nimport sphinx_rtd_theme\nfrom recommonmark.transform import AutoStructify\n\nsource_parsers = {\n '.md': CommonMarkParser,\n}\n\nsource_suffix = ['.rst', '.md']\nextensions = ['sphinx.ext.autodoc',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.viewcode',\n 'sphinx.ext.coverage',\n 'sphinx.ext.githubpages',\n 'sphinx.ext.napoleon',\n 'sphinxcontrib.mermaid',\n 'sphinxcontrib.bibtex',\n 'sphinxarg.ext',\n 'sphinx_markdown_tables']\n\n# Show base classes\nautodoc_default_options = {\n 'show-inheritance': True\n}\n\n# Use \"variables\" section for Attributes instead of weird block things\n# mimicking the function style.\nnapoleon_use_ivar = True\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['.templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = 'OpenNMT-py'\ncopyright = '2017, srush'\nauthor = 'srush'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = ''\n# The full version, including alpha/beta/rc tags.\nrelease = ''\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = []\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\n\n\n# html_theme = 'sphinx_materialdesign_theme'\n# html_theme_path = [sphinx_materialdesign_theme.get_path()]\nhtml_theme = \"sphinx_rtd_theme\"\nhtml_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\nhtml_context = {\n 'css_files': [\n '_static/theme_overrides.css', # override wide tables in RTD theme\n ],\n }\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# This is required for the alabaster theme\n# refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars\nhtml_sidebars = {\n '**': [\n 'relations.html', # needs 'show_related': True theme option to display\n 'searchbox.html',\n ]\n}\n\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'OpenNMT-pydoc'\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'OpenNMT-py.tex', 'OpenNMT-py Documentation',\n 'srush', 'manual'),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'opennmt-py', 'OpenNMT-py Documentation',\n [author], 1)\n]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'OpenNMT-py', 'OpenNMT-py Documentation',\n author, 'OpenNMT-py', 'One line description of project.',\n 'Miscellaneous'),\n]\n\ngithub_doc_root = 'https://github.com/opennmt/opennmt-py/tree/master/doc/'\n\n\ndef setup(app):\n print(\"hello\")\n app.add_config_value('recommonmark_config', {\n 'enable_eval_rst': True\n }, True)\n app.add_transform(AutoStructify)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/examples.rst",
"content": "== Examples ==\n\n\n.. include:: quickstart.md\n.. include:: extended.md\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/extended.md",
"content": "\n# Translation\n\nThe example below uses the Moses tokenizer (http://www.statmt.org/moses/) to prepare the data and the moses BLEU script for evaluation. This example if for training for the WMT'16 Multimodal Translation task (http://www.statmt.org/wmt16/multimodal-task.html).\n\nStep 0. Download the data.\n\n```bash\nmkdir -p data/multi30k\nwget http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz && tar -xf training.tar.gz -C data/multi30k && rm training.tar.gz\nwget http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz && tar -xf validation.tar.gz -C data/multi30k && rm validation.tar.gz\nwget http://www.quest.dcs.shef.ac.uk/wmt17_files_mmt/mmt_task1_test2016.tar.gz && tar -xf mmt_task1_test2016.tar.gz -C data/multi30k && rm mmt_task1_test2016.tar.gz\n```\n\nStep 1. Preprocess the data.\n\n```bash\nfor l in en de; do for f in data/multi30k/*.$l; do if [[ \"$f\" != *\"test\"* ]]; then sed -i \"$ d\" $f; fi; done; done\nfor l in en de; do for f in data/multi30k/*.$l; do perl tools/tokenizer.perl -a -no-escape -l $l -q < $f > $f.atok; done; done\nonmt_preprocess -train_src data/multi30k/train.en.atok -train_tgt data/multi30k/train.de.atok -valid_src data/multi30k/val.en.atok -valid_tgt data/multi30k/val.de.atok -save_data data/multi30k.atok.low -lower\n```\n\nStep 2. Train the model.\n\n```bash\nonmt_train -data data/multi30k.atok.low -save_model multi30k_model -gpu_ranks 0\n```\n\nStep 3. Translate sentences.\n\n```bash\nonmt_translate -gpu 0 -model multi30k_model_*_e13.pt -src data/multi30k/test2016.en.atok -tgt data/multi30k/test2016.de.atok -replace_unk -verbose -output multi30k.test.pred.atok\n```\n\nAnd evaluate\n\n```bash\nperl tools/multi-bleu.perl data/multi30k/test2016.de.atok < multi30k.test.pred.atok\n```\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/im2text.md",
"content": "# Image to Text\n\nA deep learning-based approach to learning the image-to-text conversion, built on top of the OpenNMT system. It is completely data-driven, hence can be used for a variety of image-to-text problems, such as image captioning, optical character recognition and LaTeX decompilation. \n\nTake LaTeX decompilation as an example, given a formula image:\n\n
\n\nThe goal is to infer the LaTeX source that can be compiled to such an image:\n\n```\n d s _ { 1 1 } ^ { 2 } = d x ^ { + } d x ^ { - } + l _ { p } ^ { 9 } \\frac { p _ { - } } { r ^ { 7 } } \\delta ( x ^ { - } ) d x ^ { - } d x ^ { - } + d x _ { 1 } ^ { 2 } + \\; \\cdots \\; + d x _ { 9 } ^ { 2 } \n```\n\nThe paper [[What You Get Is What You See: A Visual Markup Decompiler]](https://arxiv.org/pdf/1609.04938.pdf) provides more technical details of this model.\n\n### Dependencies\n\n* `torchvision`: `conda install torchvision`\n* `Pillow`: `pip install Pillow`\n\n### Quick Start\n\nTo get started, we provide a toy Math-to-LaTex example. We assume that the working directory is `OpenNMT-py` throughout this document.\n\nIm2Text consists of four commands:\n\n0) Download the data.\n\n```bash\nwget -O data/im2text.tgz http://lstm.seas.harvard.edu/latex/im2text_small.tgz; tar zxf data/im2text.tgz -C data/\n```\n\n1) Preprocess the data.\n\n```bash\nonmt_preprocess -data_type img \\\n -src_dir data/im2text/images/ \\\n -train_src data/im2text/src-train.txt \\\n -train_tgt data/im2text/tgt-train.txt -valid_src data/im2text/src-val.txt \\\n -valid_tgt data/im2text/tgt-val.txt -save_data data/im2text/demo \\\n -tgt_seq_length 150 \\\n -tgt_words_min_frequency 2 \\\n -shard_size 500 \\\n -image_channel_size 1\n```\n\n2) Train the model.\n\n```bash\nonmt_train -model_type img \\\n -data data/im2text/demo \\\n -save_model demo-model \\\n -gpu_ranks 0 \\\n -batch_size 20 \\\n -max_grad_norm 20 \\\n -learning_rate 0.1 \\\n -word_vec_size 80 \\\n -encoder_type brnn \\\n -image_channel_size 1\n```\n\n3) Translate the images.\n\n```bash\nonmt_translate -data_type img \\\n -model demo-model_acc_x_ppl_x_e13.pt \\\n -src_dir data/im2text/images \\\n -src data/im2text/src-test.txt \\\n -output pred.txt \\\n -max_length 150 \\\n -beam_size 5 \\\n -gpu 0 \\\n -verbose\n```\n\nThe above dataset is sampled from the [im2latex-100k-dataset](http://lstm.seas.harvard.edu/latex/im2text.tgz). We provide a trained model [[link]](http://lstm.seas.harvard.edu/latex/py-model.pt) on this dataset.\n\n### Options\n\n* `-src_dir`: The directory containing the images.\n\n* `-train_tgt`: The file storing the tokenized labels, one label per line. It shall look like:\n```\n ... \n ... \n ... \n...\n```\n\n* `-train_src`: The file storing the paths of the images (relative to `src_dir`).\n```\n\n\n\n...\n```\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/index.md",
"content": "\n.. toctree::\n:maxdepth: 2\n\nindex.md\nquickstart.md\nextended.md\n\n\nThis portal provides a detailled documentation of the OpenNMT toolkit. It describes how to use the PyTorch project and how it works.\n\n\n\n## Installation\n\n1\\. [Install PyTorch](http://pytorch.org/)\n\n2\\. Clone the OpenNMT-py repository:\n\n```bash\ngit clone https://github.com/OpenNMT/OpenNMT-py\ncd OpenNMT-py\n```\n\n3\\. Install required libraries\n\n```bash\npip install -r requirements.txt\n```\n\nAnd you are ready to go! Take a look at the [quickstart](quickstart.md) to familiarize yourself with the main training workflow.\n\nAlternatively you can use Docker to install with `nvidia-docker`. The main Dockerfile is included\nin the root directory.\n\n## Citation\n\nWhen using OpenNMT for research please cite our\n[OpenNMT technical report](https://doi.org/10.18653/v1/P17-4012)\n\n```\n@inproceedings{opennmt,\n author = {Guillaume Klein and\n Yoon Kim and\n Yuntian Deng and\n Jean Senellart and\n Alexander M. Rush},\n title = {OpenNMT: Open-Source Toolkit for Neural Machine Translation},\n booktitle = {Proc. ACL},\n year = {2017},\n url = {https://doi.org/10.18653/v1/P17-4012},\n doi = {10.18653/v1/P17-4012}\n}\n```\n\n## Additional resources\n\nYou can find additional help or tutorials in the following resources:\n\n* [Gitter channel](https://gitter.im/OpenNMT/openmt-py)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/index.rst",
"content": "Contents\n--------\n\n.. toctree::\n :caption: Getting Started\n :maxdepth: 2\n\n main.md\n quickstart.md\n FAQ.md\n CONTRIBUTING.md\n ref.rst\n\n\n.. toctree::\n :caption: Examples\n :maxdepth: 2\n\n Library.md\n extended.md\n Summarization.md\n im2text.md\n speech2text.md\n vid2text.rst\n\n\n.. toctree::\n :caption: Scripts\n :maxdepth: 2\n\n options/preprocess.rst\n options/train.rst\n options/translate.rst\n options/server.rst\n\n\n.. toctree::\n :caption: API\n :maxdepth: 2\n\n onmt.rst\n onmt.modules.rst\n onmt.translation.rst\n onmt.translate.translation_server.rst\n onmt.inputters.rst"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/main.md",
"content": "# Overview\n\n\nThis portal provides a detailed documentation of the OpenNMT toolkit. It describes how to use the PyTorch project and how it works.\n\n\n\n## Installation\nInstall from `pip`:\nInstall `OpenNMT-py` from `pip`:\n```bash\npip install OpenNMT-py\n```\n\nor from the sources:\n```bash\ngit clone https://github.com/OpenNMT/OpenNMT-py.git\ncd OpenNMT-py\npython setup.py install\n```\n\n*(Optionnal)* some advanced features (e.g. working audio, image or pretrained models) requires extra packages, you can install it with:\n```bash\npip install -r requirements.opt.txt\n```\n\nAnd you are ready to go! Take a look at the [quickstart](quickstart) to familiarize yourself with the main training workflow.\n\nAlternatively you can use Docker to install with `nvidia-docker`. The main Dockerfile is included\nin the root directory.\n\n## Citation\n\nWhen using OpenNMT for research please cite our\n[OpenNMT technical report](https://doi.org/10.18653/v1/P17-4012)\n\n```\n@inproceedings{opennmt,\n author = {Guillaume Klein and\n Yoon Kim and\n Yuntian Deng and\n Jean Senellart and\n Alexander M. Rush},\n title = {OpenNMT: Open-Source Toolkit for Neural Machine Translation},\n booktitle = {Proc. ACL},\n year = {2017},\n url = {https://doi.org/10.18653/v1/P17-4012},\n doi = {10.18653/v1/P17-4012}\n}\n```\n\n## Additional resources\n\nYou can find additional help or tutorials in the following resources:\n\n* [Gitter channel](https://gitter.im/OpenNMT/openmt-py)\n\n* [Forum](http://forum.opennmt.net/)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/modules.rst",
"content": "onmt\n====\n\n.. toctree::\n :maxdepth: 4\n\n onmt\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/onmt.inputters.rst",
"content": "Data Loaders\n=================\n\nData Readers\n-------------\n\n.. autoexception:: onmt.inputters.datareader_base.MissingDependencyException\n\n.. autoclass:: onmt.inputters.DataReaderBase\n :members:\n\n.. autoclass:: onmt.inputters.TextDataReader\n :members:\n\n.. autoclass:: onmt.inputters.ImageDataReader\n :members:\n\n.. autoclass:: onmt.inputters.AudioDataReader\n :members:\n\n\nDataset\n--------\n\n.. autoclass:: onmt.inputters.Dataset\n :members:\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/onmt.modules.rst",
"content": "Modules\n=============\n\nCore Modules\n------------\n\n.. autoclass:: onmt.modules.Embeddings\n :members:\n\n\nEncoders\n---------\n\n.. autoclass:: onmt.encoders.EncoderBase\n :members:\n\n.. autoclass:: onmt.encoders.MeanEncoder\n :members:\n\n.. autoclass:: onmt.encoders.RNNEncoder\n :members:\n\n\nDecoders\n---------\n\n\n.. autoclass:: onmt.decoders.DecoderBase\n :members:\n \n.. autoclass:: onmt.decoders.decoder.RNNDecoderBase\n :members:\n\n.. autoclass:: onmt.decoders.StdRNNDecoder\n :members:\n\n.. autoclass:: onmt.decoders.InputFeedRNNDecoder\n :members:\n\nAttention\n----------\n\n.. autoclass:: onmt.modules.AverageAttention\n :members:\n\n.. autoclass:: onmt.modules.GlobalAttention\n :members:\n\n\n\nArchitecture: Transformer\n----------------------------\n\n.. autoclass:: onmt.modules.PositionalEncoding\n :members:\n\n.. autoclass:: onmt.modules.position_ffn.PositionwiseFeedForward\n :members:\n\n.. autoclass:: onmt.encoders.TransformerEncoder\n :members:\n\n.. autoclass:: onmt.decoders.TransformerDecoder\n :members:\n\n.. autoclass:: onmt.modules.MultiHeadedAttention\n :members:\n :undoc-members:\n\n\nArchitecture: Conv2Conv\n----------------------------\n\n(These methods are from a user contribution\nand have not been thoroughly tested.)\n\n\n.. autoclass:: onmt.encoders.CNNEncoder\n :members:\n\n\n.. autoclass:: onmt.decoders.CNNDecoder\n :members:\n\n.. autoclass:: onmt.modules.ConvMultiStepAttention\n :members:\n\n.. autoclass:: onmt.modules.WeightNormConv2d\n :members:\n\nArchitecture: SRU\n----------------------------\n\n.. autoclass:: onmt.models.sru.SRU\n :members:\n\n\nAlternative Encoders\n--------------------\n\nonmt\\.modules\\.AudioEncoder\n\n.. autoclass:: onmt.encoders.AudioEncoder\n :members:\n\n\nonmt\\.modules\\.ImageEncoder\n\n.. autoclass:: onmt.encoders.ImageEncoder\n :members:\n\n\nCopy Attention\n--------------\n\n.. autoclass:: onmt.modules.CopyGenerator\n :members:\n\n\nStructured Attention\n-------------------------------------------\n\n.. autoclass:: onmt.modules.structured_attention.MatrixTree\n :members:\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/onmt.rst",
"content": "Framework\n=================\n\nModel\n-----\n\n.. autoclass:: onmt.models.NMTModel\n :members:\n\nTrainer\n-------\n\n.. autoclass:: onmt.Trainer\n :members:\n\n\n.. autoclass:: onmt.utils.Statistics\n :members:\n\nLoss\n----\n\n\n.. autoclass:: onmt.utils.loss.LossComputeBase\n :members:\n\n\nOptimizer\n-----\n\n.. autoclass:: onmt.utils.Optimizer\n :members:\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/onmt.translate.translation_server.rst",
"content": "Server\n======\n\n\nModels\n-------------\n\n.. autoclass:: onmt.translate.translation_server.ServerModel\n :members:\n\n\nCore Server\n------------\n\n.. autoexception:: onmt.translate.translation_server.ServerModelError\n\n.. autoclass:: onmt.translate.translation_server.Timer\n :members:\n\n.. autoclass:: onmt.translate.translation_server.TranslationServer\n :members:\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/onmt.translation.rst",
"content": "Translation\n==================\n\nTranslations\n-------------\n\n.. autoclass:: onmt.translate.Translation\n :members:\n\nTranslator Class\n-----------------\n\n.. autoclass:: onmt.translate.Translator\n :members:\n\n.. autoclass:: onmt.translate.TranslationBuilder\n :members:\n\n\nDecoding Strategies\n--------------------\n.. autoclass:: onmt.translate.DecodeStrategy\n :members:\n\n.. autoclass:: onmt.translate.BeamSearch\n :members:\n\n.. autofunction:: onmt.translate.greedy_search.sample_with_temperature\n\n.. autoclass:: onmt.translate.GreedySearch\n :members:\n\nScoring\n--------\n.. autoclass:: onmt.translate.penalties.PenaltyBuilder\n :members:\n\n.. autoclass:: onmt.translate.GNMTGlobalScorer\n :members:\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/options/preprocess.rst",
"content": "Preprocess\n==========\n\n.. argparse::\n :filename: ../onmt/bin/preprocess.py\n :func: _get_parser\n :prog: preprocess.py"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/options/server.rst",
"content": "Server\n=========\n\n.. argparse::\n :filename: ../onmt/bin/server.py\n :func: _get_parser\n :prog: server.py"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/options/train.rst",
"content": "Train\n=====\n\n.. argparse::\n :filename: ../onmt/bin/train.py\n :func: _get_parser\n :prog: train.py"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/options/translate.rst",
"content": "Translate\n=========\n\n.. argparse::\n :filename: ../onmt/bin/translate.py\n :func: _get_parser\n :prog: translate.py"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/quickstart.md",
"content": "\n\n# Quickstart\n\n\n### Step 1: Preprocess the data\n\n```bash\nonmt_preprocess -train_src data/src-train.txt -train_tgt data/tgt-train.txt -valid_src data/src-val.txt -valid_tgt data/tgt-val.txt -save_data data/demo\n```\n\nWe will be working with some example data in `data/` folder.\n\nThe data consists of parallel source (`src`) and target (`tgt`) data containing one sentence per line with tokens separated by a space:\n\n* `src-train.txt`\n* `tgt-train.txt`\n* `src-val.txt`\n* `tgt-val.txt`\n\nValidation files are required and used to evaluate the convergence of the training. It usually contains no more than 5000 sentences.\n\n```text\n$ head -n 3 data/src-train.txt\nIt is not acceptable that , with the help of the national bureaucracies , Parliament 's legislative prerogative should be made null and void by means of implementing provisions whose content , purpose and extent are not laid down in advance .\nFederal Master Trainer and Senior Instructor of the Italian Federation of Aerobic Fitness , Group Fitness , Postural Gym , Stretching and Pilates; from 2004 , he has been collaborating with Antiche Terme as personal Trainer and Instructor of Stretching , Pilates and Postural Gym .\n" Two soldiers came up to me and told me that if I refuse to sleep with them , they will kill me . They beat me and ripped my clothes .\n```\n\n### Step 2: Train the model\n\n```bash\nonmt_train -data data/demo -save_model demo-model\n```\n\nThe main train command is quite simple. Minimally it takes a data file\nand a save file. This will run the default model, which consists of a\n2-layer LSTM with 500 hidden units on both the encoder/decoder.\nIf you want to train on GPU, you need to set, as an example:\nCUDA_VISIBLE_DEVICES=1,3\n`-world_size 2 -gpu_ranks 0 1` to use (say) GPU 1 and 3 on this node only.\nTo know more about distributed training on single or multi nodes, read the FAQ section.\n\n### Step 3: Translate\n\n```bash\nonmt_translate -model demo-model_XYZ.pt -src data/src-test.txt -output pred.txt -replace_unk -verbose\n```\n\nNow you have a model which you can use to predict on new data. We do this by running beam search. This will output predictions into `pred.txt`.\n\nNote:\n\nThe predictions are going to be quite terrible, as the demo dataset is small. Try running on some larger datasets! For example you can download millions of parallel sentences for [translation](http://www.statmt.org/wmt16/translation-task.html) or [summarization](https://github.com/harvardnlp/sent-summary).\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/ref.rst",
"content": "==========\nReferences\n==========\n\n\n\nReferences\n \n.. bibliography:: refs.bib\n \n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/refs.bib",
"content": "@article{DBLP:journals/corr/LiuL17d,\n author = {Yang Liu and\n Mirella Lapata},\n title = {Learning Structured Text Representations},\n journal = {CoRR},\n volume = {abs/1705.09207},\n year = {2017},\n url = {http://arxiv.org/abs/1705.09207},\n archivePrefix = {arXiv},\n eprint = {1705.09207},\n timestamp = {Wed, 07 Jun 2017 14:41:46 +0200},\n biburl = {http://dblp.org/rec/bib/journals/corr/LiuL17d},\n bibsource = {dblp computer science bibliography, http://dblp.org}\n }\n\n@article{sennrich2016linguistic,\n title={Linguistic Input Features Improve Neural Machine Translation},\n author={Sennrich, Rico and Haddow, Barry},\n journal={arXiv preprint arXiv:1606.02892},\n year={2016}\n }\n\n@inproceedings{Bahdanau2015,\narchivePrefix = {arXiv},\narxivId = {1409.0473},\nauthor = {Bahdanau, Dzmitry and Cho, Kyunghyun and Bengio, Yoshua},\nbooktitle = {ICLR},\ndoi = {10.1146/annurev.neuro.26.041002.131047},\neprint = {1409.0473},\nisbn = {0147-006X (Print)},\nissn = {0147-006X},\nkeywords = {Neural machine translation is a recently proposed,Unlike the traditional statistical machine transla,a source sentence into a fixed-length vector from,and propose to extend this by allowing a model to,bottleneck in improving the performance of this ba,for parts of a source sentence that are relevant t,having to form these parts as a hard segment expli,machine translation often belong to a family of en,maximize the translation performance. The models p,phrase-based system on the task of English-to-Fren,qualitative analysis reveals that the (soft-)align,the neural machine,translation aims at building a single neural netwo,translation. In this paper,we achieve a translation performance comparable to,we conjecture that the use of a fixed-length vecto,well with our intuition,without},\npages = {1--15},\npmid = {14527267},\ntitle = {{Neural Machine Translation By Jointly Learning To Align and Translate}},\nurl = {http://arxiv.org/abs/1409.0473 http://arxiv.org/abs/1409.0473v3},\nyear = {2014}\n}\n\n@inproceedings{sutskever14sequence,\nabstract = {Deep Neural Networks (DNNs) are powerful models that have achieved excellent performance on difficult learning tasks. Although DNNs work well whenever large labeled training sets are available, they cannot be used to map sequences to sequences. In this paper, we present a general end-to-end approach to sequence learning that makes minimal assumptions on the sequence structure. Our method uses a multilayered Long Short-Term Memory (LSTM) to map the input sequence to a vector of a fixed dimensionality, and then another deep LSTM to decode the target sequence from the vector. Our main result is that on an English to French translation task from the WMT'14 dataset, the translations produced by the LSTM achieve a BLEU score of 34.8 on the entire test set, where the LSTM's BLEU score was penalized on out-of-vocabulary words. Additionally, the LSTM did not have difficulty on long sentences. For comparison, a phrase-based SMT system achieves a BLEU score of 33.3 on the same dataset. When we used the LSTM to rerank the 1000 hypotheses produced by the aforementioned SMT system, its BLEU score increases to 36.5, which is close to the previous best result on this task. The LSTM also learned sensible phrase and sentence representations that are sensitive to word order and are relatively invariant to the active and the passive voice. Finally, we found that reversing the order of the words in all source sentences (but not target sentences) improved the LSTM's performance markedly, because doing so introduced many short term dependencies between the source and the target sentence which made the optimization problem easier.},\narchivePrefix = {arXiv},\narxivId = {1409.3215},\nauthor = {Sutskever, Ilya and Vinyals, Oriol and Le, Quoc V.},\nbooktitle = {NIPS},\neprint = {1409.3215},\nisbn = {1409.3215},\npages = {9},\npmid = {2079951},\ntitle = {{Sequence to Sequence Learning with Neural Networks}},\nurl = {http://arxiv.org/abs/1409.3215},\nyear = {2014}\n}\n\n@article{Xu2015,\nabstract = {Inspired by recent work in machine translation and object detection, we introduce an attention based model that automatically learns to describe the content of images. We describe how we can train this model in a deterministic manner using standard backpropagation techniques and stochastically by maximizing a variational lower bound. We also show through visualization how the model is able to automatically learn to fix its gaze on salient objects while generating the corresponding words in the output sequence. We validate the use of attention with state-of-the-art performance on three benchmark datasets: Flickr8k, Flickr30k and MS COCO.},\narchivePrefix = {arXiv},\narxivId = {1502.03044},\nauthor = {Xu, Kelvin and Ba, Jimmy and Kiros, Ryan and Cho, Kyunghyun and Courville, Aaron and Salakhutdinov, Ruslan and Zemel, Richard and Bengio, Yoshua},\neprint = {1502.03044},\nfile = {:home/srush/.local/share/data/Mendeley Ltd./Mendeley Desktop/Downloaded/Xu et al. - 2015 - Show, Attend and Tell Neural Image Caption Generation with Visual Attention(2).pdf:pdf},\njournal = {ICML},\nmonth = {feb},\ntitle = {{Show, Attend and Tell: Neural Image Caption Generation with Visual Attention}},\nurl = {http://arxiv.org/abs/1502.03044},\nyear = {2015}\n}\n@article{systran,\n title={SYSTRAN's Pure Neural Machine Translation System},\n author={Josep Crego and Jungi Kim and Jean Senellart},\n journal={arXiv preprint arXiv:1602.06023},\n year={2016}\n }\n@InProceedings{Cho2014,\n title = {{L}earning {P}hrase {R}epresentations using {RNN} {E}ncoder-{D}ecoder for {S}tatistical {M}achine {T}ranslation},\n author = {Kyunghyun Cho and Bart van Merrienboer and Caglar Gulcehre and Dzmitry Bahdanau and Fethi Bougares and Holger Schwenk and Yoshua Bengio},\n booktitle = {Proc of EMNLP},\n year = {2014}\n}\n\n@InProceedings{Luong2015,\n title = {{E}ffective {A}pproaches to {A}ttention-based {N}eural {M}achine {T}ranslation},\n author = {Minh-Thang Luong and Hieu Pham and Christopher D. Manning},\n booktitle = {Proc of EMNLP},\n year = {2015}\n}\n\n@InProceedings{Luong2015b,\n title = {{A}ddressing the {R}are {W}ord {P}roblem in {N}eural {M}achine {T}ranslation},\n author = {Minh-Thang Luong and Ilya Sutskever and Quoc Le and Oriol Vinyals and Wojciech Zaremba},\n booktitle = {Proc of ACL},\n year = {2015}\n}\n\n@article{wu2016google,\n title={Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation},\n author={Wu, Yonghui and Schuster, Mike and Chen, Zhifeng and Le, Quoc V and Norouzi, Mohammad and Macherey, Wolfgang and Krikun, Maxim and Cao, Yuan and Gao, Qin and Macherey, Klaus and others},\n journal={arXiv preprint arXiv:1609.08144},\n year={2016}\n }\n\n\n@inproceedings{dean2012large,\n title={Large scale distributed deep networks},\n author={Dean, Jeffrey and Corrado, Greg and Monga, Rajat and Chen, Kai and Devin, Matthieu and Mao, Mark and Senior, Andrew and Tucker, Paul and Yang, Ke and Le, Quoc V and others},\n booktitle={Advances in neural information processing systems},\n pages={1223--1231},\n year={2012}\n}\n@inproceedings{koehn2007moses,\n title={Moses: Open source toolkit for statistical machine translation},\n author={Koehn, Philipp and Hoang, Hieu and Birch, Alexandra and Callison-Burch, Chris and Federico, Marcello and Bertoldi, Nicola and Cowan, Brooke and Shen, Wade and Moran, Christine and Zens, Richard and others},\n booktitle={Proc ACL},\n pages={177--180},\n year={2007},\n organization={Association for Computational Linguistics}\n }\n\n@inproceedings{dyer2010cdec,\n title={cdec: A decoder, alignment, and learning framework for finite-state and context-free translation models},\n author={Dyer, Chris and Weese, Jonathan and Setiawan, Hendra and Lopez, Adam and Ture, Ferhan and Eidelman, Vladimir and Ganitkevitch, Juri and Blunsom, Phil and Resnik, Philip},\n booktitle={Proc ACL},\n pages={7--12},\n year={2010},\n organization={Association for Computational Linguistics}\n }\n\n@article{hochreiter1997long,\n title={Long short-term memory},\n author={Hochreiter, Sepp and Schmidhuber, J{\\\"u}rgen},\n journal={Neural computation},\n volume={9},\n number={8},\n pages={1735--1780},\n year={1997},\n publisher={MIT Press}\n}\n\n\n@article{chung2014empirical,\n title={Empirical evaluation of gated recurrent neural networks on sequence modeling},\n author={Chung, Junyoung and Gulcehre, Caglar and Cho, KyungHyun and Bengio, Yoshua},\n journal={arXiv preprint arXiv:1412.3555},\n year={2014}\n }\n\n\n@inproceedings{yang2016hierarchical,\n title={Hierarchical attention networks for document classification},\n author={Yang, Zichao and Yang, Diyi and Dyer, Chris and He, Xiaodong and Smola, Alex and Hovy, Eduard},\n booktitle={Proc ACL},\n year={2016}\n }\n\n@article{martins2016softmax,\n title={From Softmax to Sparsemax: A Sparse Model of Attention and Multi-Label Classification},\n author={Martins, Andr{\\'e} FT and Astudillo, Ram{\\'o}n Fernandez},\n journal={arXiv preprint arXiv:1602.02068},\n year={2016}\n }\n\n@article{DBLP:journals/corr/LeonardWW15,\n author = {Nicholas L{\\'{e}}onard and\n Sagar Waghmare and\n Yang Wang and\n Jin{-}Hwa Kim},\n title = {rnn : Recurrent Library for Torch},\n journal = {CoRR},\n volume = {abs/1511.07889},\n year = {2015},\n url = {http://arxiv.org/abs/1511.07889},\n timestamp = {Wed, 23 Dec 2015 08:46:28 +0100},\n biburl = {http://dblp.uni-trier.de/rec/bib/journals/corr/LeonardWW15},\n bibsource = {dblp computer science bibliography, http://dblp.org}\n }\n\n\n@inproceedings{DBLP:conf/conll/BowmanVVDJB16,\n author = {Samuel R. Bowman and\n Luke Vilnis and\n Oriol Vinyals and\n Andrew M. Dai and\n Rafal J{\\'{o}}zefowicz and\n Samy Bengio},\n title = {Generating Sentences from a Continuous Space},\n booktitle = {Proceedings of the 20th {SIGNLL} Conference on Computational Natural\n Language Learning, CoNLL 2016, Berlin, Germany, August 11-12, 2016},\n pages = {10--21},\n year = {2016},\n crossref = {DBLP:conf/conll/2016},\n url = {http://aclweb.org/anthology/K/K16/K16-1002.pdf},\n timestamp = {Sun, 04 Sep 2016 10:01:12 +0200},\n biburl = {http://dblp.uni-trier.de/rec/bib/conf/conll/BowmanVVDJB16},\n bibsource = {dblp computer science bibliography, http://dblp.org}\n }\n\n@inproceedings{DBLP:conf/nips/VinyalsBLKW16,\n author = {Oriol Vinyals and\n Charles Blundell and\n Tim Lillicrap and\n Koray Kavukcuoglu and\n Daan Wierstra},\n title = {Matching Networks for One Shot Learning},\n booktitle = {Advances in Neural Information Processing Systems 29: Annual Conference\n on Neural Information Processing Systems 2016, December 5-10, 2016,\n Barcelona, Spain},\n pages = {3630--3638},\n year = {2016},\n crossref = {DBLP:conf/nips/2016},\n url = {http://papers.nips.cc/paper/6385-matching-networks-for-one-shot-learning},\n timestamp = {Fri, 16 Dec 2016 19:45:58 +0100},\n biburl = {http://dblp.uni-trier.de/rec/bib/conf/nips/VinyalsBLKW16},\n bibsource = {dblp computer science bibliography, http://dblp.org}\n }\n\n\n@article{DBLP:journals/corr/WestonCB14,\n author = {Jason Weston and\n Sumit Chopra and\n Antoine Bordes},\n title = {Memory Networks},\n journal = {CoRR},\n volume = {abs/1410.3916},\n year = {2014},\n url = {http://arxiv.org/abs/1410.3916},\n timestamp = {Sun, 02 Nov 2014 11:25:59 +0100},\n biburl = {http://dblp.uni-trier.de/rec/bib/journals/corr/WestonCB14},\n bibsource = {dblp computer science bibliography, http://dblp.org}\n }\n\n@article{DBLP:journals/corr/XuBKCCSZB15,\n author = {Kelvin Xu and\n Jimmy Ba and\n Ryan Kiros and\n Kyunghyun Cho and\n Aaron C. Courville and\n Ruslan Salakhutdinov and\n Richard S. Zemel and\n Yoshua Bengio},\n title = {Show, Attend and Tell: Neural Image Caption Generation with Visual\n Attention},\n journal = {CoRR},\n volume = {abs/1502.03044},\n year = {2015},\n url = {http://arxiv.org/abs/1502.03044},\n timestamp = {Mon, 02 Mar 2015 14:17:34 +0100},\n biburl = {http://dblp.uni-trier.de/rec/bib/journals/corr/XuBKCCSZB15},\n bibsource = {dblp computer science bibliography, http://dblp.org}\n }\n\n\n\n@article{DBLP:journals/corr/DengKR16,\n author = {Yuntian Deng and\n Anssi Kanervisto and\n Alexander M. Rush},\n title = {What You Get Is What You See: {A} Visual Markup Decompiler},\n journal = {CoRR},\n volume = {abs/1609.04938},\n year = {2016},\n url = {http://arxiv.org/abs/1609.04938},\n timestamp = {Mon, 03 Oct 2016 17:51:10 +0200},\n biburl = {http://dblp.uni-trier.de/rec/bib/journals/corr/DengKR16},\n bibsource = {dblp computer science bibliography, http://dblp.org}\n }\n\n\n@article{DBLP:journals/corr/ChanJLV15,\n author = {William Chan and\n Navdeep Jaitly and\n Quoc V. Le and\n Oriol Vinyals},\n title = {Listen, Attend and Spell},\n journal = {CoRR},\n volume = {abs/1508.01211},\n year = {2015},\n url = {http://arxiv.org/abs/1508.01211},\n timestamp = {Tue, 01 Sep 2015 14:42:40 +0200},\n biburl = {http://dblp.uni-trier.de/rec/bib/journals/corr/ChanJLV15},\n bibsource = {dblp computer science bibliography, http://dblp.org}\n }\n\n@article{DBLP:journals/corr/SennrichHB15,\n author = {Rico Sennrich and\n Barry Haddow and\n Alexandra Birch},\n title = {Neural Machine Translation of Rare Words with Subword Units},\n journal = {CoRR},\n volume = {abs/1508.07909},\n year = {2015},\n url = {http://arxiv.org/abs/1508.07909},\n timestamp = {Tue, 01 Sep 2015 14:42:40 +0200},\n biburl = {http://dblp.uni-trier.de/rec/bib/journals/corr/SennrichHB15},\n bibsource = {dblp computer science bibliography, http://dblp.org}\n }\n\n\n@article{chopra2016abstractive,\n title={Abstractive sentence summarization with attentive recurrent neural networks},\n author={Chopra, Sumit and Auli, Michael and Rush, Alexander M and Harvard, SEAS},\n journal={Proceedings of NAACL-HLT16},\n pages={93--98},\n year={2016}\n }\n\n@article{vinyals2015neural,\n title={A neural conversational model},\n author={Vinyals, Oriol and Le, Quoc},\n journal={arXiv preprint arXiv:1506.05869},\n year={2015}\n }\n\n@inproceedings{neubig13travatar,\n title = {Travatar: A Forest-to-String Machine Translation Engine based on Tree Transducers},\n author = {Graham Neubig},\n booktitle = {Proc ACL },\n address = {Sofia, Bulgaria},\n month = {August},\n year = {2013}\n }\n\n@ARTICLE{2017arXiv170301619N,\n author = {{Neubig}, G.},\n title = \"{Neural Machine Translation and Sequence-to-sequence Models: A Tutorial}\",\n journal = {ArXiv e-prints},\n archivePrefix = \"arXiv\",\n eprint = {1703.01619},\n primaryClass = \"cs.CL\",\n keywords = {Computer Science - Computation and Language, Computer Science - Learning, Statistics - Machine Learning},\n year = 2017,\n month = mar,\n adsurl = {http://adsabs.harvard.edu/abs/2017arXiv170301619N},\n adsnote = {Provided by the SAO/NASA Astrophysics Data System}\n }\n\n@article{DBLP:journals/corr/VaswaniSPUJGKP17,\n author = {Ashish Vaswani and\n Noam Shazeer and\n Niki Parmar and\n Jakob Uszkoreit and\n Llion Jones and\n Aidan N. Gomez and\n Lukasz Kaiser and\n Illia Polosukhin},\n title = {Attention Is All You Need},\n journal = {CoRR},\n volume = {abs/1706.03762},\n year = {2017},\n url = {http://arxiv.org/abs/1706.03762},\n archivePrefix = {arXiv},\n eprint = {1706.03762},\n timestamp = {Mon, 13 Aug 2018 16:48:37 +0200},\n biburl = {https://dblp.org/rec/bib/journals/corr/VaswaniSPUJGKP17},\n bibsource = {dblp computer science bibliography, https://dblp.org}\n}\n\n@article{DBLP:journals/corr/GehringAGYD17,\n author = {Jonas Gehring and\n Michael Auli and\n David Grangier and\n Denis Yarats and\n Yann N. Dauphin},\n title = {Convolutional Sequence to Sequence Learning},\n journal = {CoRR},\n volume = {abs/1705.03122},\n year = {2017},\n url = {http://arxiv.org/abs/1705.03122},\n archivePrefix = {arXiv},\n eprint = {1705.03122},\n timestamp = {Mon, 13 Aug 2018 16:48:03 +0200},\n biburl = {https://dblp.org/rec/bib/journals/corr/GehringAGYD17},\n bibsource = {dblp computer science bibliography, https://dblp.org}\n}\n\n@article{DBLP:journals/corr/abs-1709-02755,\n author = {Tao Lei and\n Yu Zhang and\n Yoav Artzi},\n title = {Training RNNs as Fast as CNNs},\n journal = {CoRR},\n volume = {abs/1709.02755},\n year = {2017},\n url = {http://arxiv.org/abs/1709.02755},\n archivePrefix = {arXiv},\n eprint = {1709.02755},\n timestamp = {Mon, 13 Aug 2018 16:46:29 +0200},\n biburl = {https://dblp.org/rec/bib/journals/corr/abs-1709-02755},\n bibsource = {dblp computer science bibliography, https://dblp.org}\n}\n\n@article{DBLP:journals/corr/SeeLM17,\n author = {Abigail See and\n Peter J. Liu and\n Christopher D. Manning},\n title = {Get To The Point: Summarization with Pointer-Generator Networks},\n journal = {CoRR},\n volume = {abs/1704.04368},\n year = {2017},\n url = {http://arxiv.org/abs/1704.04368},\n archivePrefix = {arXiv},\n eprint = {1704.04368},\n timestamp = {Mon, 13 Aug 2018 16:46:08 +0200},\n biburl = {https://dblp.org/rec/bib/journals/corr/SeeLM17},\n bibsource = {dblp computer science bibliography, https://dblp.org}\n}\n\n@article{DBLP:journals/corr/abs-1805-00631,\n author = {Biao Zhang and\n Deyi Xiong and\n Jinsong Su},\n title = {Accelerating Neural Transformer via an Average Attention Network},\n journal = {CoRR},\n volume = {abs/1805.00631},\n year = {2018},\n url = {http://arxiv.org/abs/1805.00631},\n archivePrefix = {arXiv},\n eprint = {1805.00631},\n timestamp = {Mon, 13 Aug 2018 16:46:01 +0200},\n biburl = {https://dblp.org/rec/bib/journals/corr/abs-1805-00631},\n bibsource = {dblp computer science bibliography, https://dblp.org}\n}\n\n@article{DBLP:journals/corr/MartinsA16,\n author = {Andr{\\'{e}} F. T. Martins and\n Ram{\\'{o}}n Fern{\\'{a}}ndez Astudillo},\n title = {From Softmax to Sparsemax: {A} Sparse Model of Attention and Multi-Label\n Classification},\n journal = {CoRR},\n volume = {abs/1602.02068},\n year = {2016},\n url = {http://arxiv.org/abs/1602.02068},\n archivePrefix = {arXiv},\n eprint = {1602.02068},\n timestamp = {Mon, 13 Aug 2018 16:49:13 +0200},\n biburl = {https://dblp.org/rec/bib/journals/corr/MartinsA16},\n bibsource = {dblp computer science bibliography, https://dblp.org}\n}\n\n@inproceedings{garg2019jointly,\n title = {Jointly Learning to Align and Translate with Transformer Models},\n author = {Garg, Sarthak and Peitz, Stephan and Nallasamy, Udhyakumar and Paulik, Matthias},\n booktitle = {Conference on Empirical Methods in Natural Language Processing (EMNLP)},\n address = {Hong Kong},\n month = {November},\n url = {https://arxiv.org/abs/1909.02074},\n year = {2019},\n}\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/speech2text.md",
"content": "# Speech to Text\n\nA deep learning-based approach to learning the speech-to-text conversion, built on top of the OpenNMT system.\n\nGiven raw audio, we first apply short-time Fourier transform (STFT), then apply Convolutional Neural Networks to get the source features. Based on this source representation, we use an LSTM decoder with attention to produce the text character by character.\n\n### Dependencies\n\n* `torchaudio`: `sudo apt-get install -y sox libsox-dev libsox-fmt-all; pip install git+https://github.com/pytorch/audio`\n* `librosa`: `pip install librosa`\n\n### Quick Start\n\nTo get started, we provide a toy speech-to-text example. We assume that the working directory is `OpenNMT-py` throughout this document.\n\n0) Download the data.\n\n```\nwget -O data/speech.tgz http://lstm.seas.harvard.edu/latex/speech.tgz; tar zxf data/speech.tgz -C data/\n```\n\n\n1) Preprocess the data.\n\n```\nonmt_preprocess -data_type audio -src_dir data/speech/an4_dataset -train_src data/speech/src-train.txt -train_tgt data/speech/tgt-train.txt -valid_src data/speech/src-val.txt -valid_tgt data/speech/tgt-val.txt -shard_size 300 -save_data data/speech/demo\n```\n\n2) Train the model.\n\n```\nonmt_train -model_type audio -enc_rnn_size 512 -dec_rnn_size 512 -audio_enc_pooling 1,1,2,2 -dropout 0 -enc_layers 4 -dec_layers 1 -rnn_type LSTM -data data/speech/demo -save_model demo-model -global_attention mlp -gpu_ranks 0 -batch_size 8 -optim adam -max_grad_norm 100 -learning_rate 0.0003 -learning_rate_decay 0.8 -train_steps 100000\n```\n\n3) Translate the speechs.\n\n```\nonmt_translate -data_type audio -model demo-model_acc_x_ppl_x_e13.pt -src_dir data/speech/an4_dataset -src data/speech/src-val.txt -output pred.txt -gpu 0 -verbose\n```\n\n\n### Options\n\n* `-src_dir`: The directory containing the audio files.\n\n* `-train_tgt`: The file storing the tokenized labels, one label per line. It shall look like:\n```\n ... \n ... \n ... \n...\n```\n\n* `-train_src`: The file storing the paths of the audio files (relative to `src_dir`).\n```\n\n\n\n...\n```\n\n* `sample_rate`: Sample rate. Default: 16000.\n* `window_size`: Window size for spectrogram in seconds. Default: 0.02.\n* `window_stride`: Window stride for spectrogram in seconds. Default: 0.01.\n* `window`: Window type for spectrogram generation. Default: hamming.\n\n### Acknowledgement\n\nOur preprocessing and CNN encoder is adapted from [deepspeech.pytorch](https://github.com/SeanNaren/deepspeech.pytorch).\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/docs/source/vid2text.rst",
"content": "Video to Text\n=============\n\nRecurrent\n---------\n\nThis tutorial shows how to replicate the results from\n`\"Describing Videos by Exploiting Temporal Structure\" `_\n[`code `_]\nusing OpenNMT-py.\n\nGet `YouTubeClips.tar` from `here `_.\nUse ``tar -xvf YouTubeClips.tar`` to decompress the archive.\n\nNow, visit `this repo `_.\nFollow the \"preprocessed YouTube2Text download link.\"\nWe'll be throwing away the Googlenet features. We just need the captions.\nUse ``unzip youtube2text_iccv15.zip`` to decompress the files.\n\nGet to the following directory structure: ::\n\n yt2t\n |-YouTubeClips\n |-youtube2text_iccv15\n\nChange directories to `yt2t`. We'll rename the videos to follow the \"vid#.avi\" format:\n\n.. code-block:: python\n\n import pickle\n import os\n\n\n YT = \"youtube2text_iccv15\"\n YTC = \"YouTubeClips\"\n\n # load the YouTube hash -> vid### map.\n with open(os.path.join(YT, \"dict_youtube_mapping.pkl\"), \"rb\") as f:\n yt2vid = pickle.load(f, encoding=\"latin-1\")\n\n for f in os.listdir(YTC):\n hashy, ext = os.path.splitext(f)\n vid = yt2vid[hashy]\n fpath_old = os.path.join(YTC, f)\n f_new = vid + ext\n fpath_new = os.path.join(YTC, f_new)\n os.rename(fpath_old, fpath_new)\n\nMake sure all the videos have the same (low) framerate by changing to the YouTubeClips directory and using\n\n.. code-block:: bash\n\n for fi in $( ls ); do ffmpeg -y -i $fi -r 2 $fi; done\n\nNow we want to convert the frames into sequences of CNN feature vectors.\n(We'll use the environment variable ``Y2T2`` to refer to the `yt2t` directory, so change directories back and use)\n\n.. code-block:: bash\n\n export YT2T=`pwd`\n\nThen change directories back to the `OpenNMT-py` directory.\nUse `tools/img_feature_extractor.py`.\nSet the ``--world_size`` argument to the number of GPUs you have available\n(You can use the environment variable ``CUDA_VISIBLE_DEVICES`` to restrict the GPUs used).\n\n.. code-block:: bash\n\n PYTHONPATH=$PWD:$PYTHONPATH python tools/vid_feature_extractor.py --root_dir $YT2T/YouTubeClips --out_dir $YT2T/r152\n\nEnsure the count is equal to 1970.\nYou can use ``ls -1 $YT2T/r152 | wc -l``.\nIf not, rerun the script. It will only process on the missing feature vectors.\n(Note this is unexpected behavior and consider opening an issue.)\n\nNow we turn our attention to the annotations. Each video has multiple associated captions. We want to\ntrain the model on each video + single caption pair. We'll collect all the captions per video, then we'll\nflatten them into files listing the feature vector sequence filenames (repeating for each caption) and the\nannotations. We skip the test videos since they are handled separately at translation time.\n\nChange directories back to ``YT2T``:\n\n.. code-block:: bash\n\n cd $YT2T\n\n.. code-block:: python\n\n import pickle\n import os\n from random import shuffle\n\n\n YT = \"youtube2text_iccv15\"\n SHUFFLE = True\n\n with open(os.path.join(YT, \"CAP.pkl\"), \"rb\") as f:\n ann = pickle.load(f, encoding=\"latin-1\")\n\n vid2anns = {}\n for vid_name, data in ann.items():\n for d in data:\n try:\n vid2anns[vid_name].append(d[\"tokenized\"])\n except KeyError:\n vid2anns[vid_name] = [d[\"tokenized\"]]\n\n with open(os.path.join(YT, \"train.pkl\"), \"rb\") as f:\n train = pickle.load(f, encoding=\"latin-1\")\n\n with open(os.path.join(YT, \"valid.pkl\"), \"rb\") as f:\n val = pickle.load(f, encoding=\"latin-1\")\n\n with open(os.path.join(YT, \"test.pkl\"), \"rb\") as f:\n test = pickle.load(f, encoding=\"latin-1\")\n\n train_files = open(\"yt2t_train_files.txt\", \"w\")\n val_files = open(\"yt2t_val_files.txt\", \"w\")\n val_folded = open(\"yt2t_val_folded_files.txt\", \"w\")\n test_files = open(\"yt2t_test_files.txt\", \"w\")\n\n train_cap = open(\"yt2t_train_cap.txt\", \"w\")\n val_cap = open(\"yt2t_val_cap.txt\", \"w\")\n\n vid_names = vid2anns.keys()\n if SHUFFLE:\n vid_names = list(vid_names)\n shuffle(vid_names)\n\n\n for vid_name in vid_names:\n anns = vid2anns[vid_name]\n vid_path = vid_name + \".npy\"\n for i, an in enumerate(anns):\n an = an.replace(\"\\n\", \" \") # some caps have newlines\n split_name = vid_name + \"_\" + str(i)\n if split_name in train:\n train_files.write(vid_path + \"\\n\")\n train_cap.write(an + \"\\n\")\n elif split_name in val:\n if i == 0:\n val_folded.write(vid_path + \"\\n\")\n val_files.write(vid_path + \"\\n\")\n val_cap.write(an + \"\\n\")\n else:\n # Don't need to save out the test captions,\n # just the files. And, don't need to repeat\n # it for each caption\n assert split_name in test\n if i == 0:\n test_files.write(vid_path + \"\\n\")\n\nReturn to the `OpenNMT-py` directory. Now we preprocess the data for training.\nWe preprocess with a small shard size of 1000. This keeps the amount of data in memory (RAM) to a\nmanageable 10 G. If you have more RAM, you can increase the shard size.\n\nPreprocess the data with\n\n.. code-block:: bash\n\n onmt_preprocess -data_type vec -train_src $YT2T/yt2t_train_files.txt -src_dir $YT2T/r152/ -train_tgt $YT2T/yt2t_train_cap.txt -valid_src $YT2T/yt2t_val_files.txt -valid_tgt $YT2T/yt2t_val_cap.txt -save_data data/yt2t --shard_size 1000\n\nTrain with\n\n.. code-block:: bash\n\n onmt_train -data data/yt2t -save_model yt2t-model -world_size 2 -gpu_ranks 0 1 -model_type vec -batch_size 64 -train_steps 10000 -valid_steps 500 -save_checkpoint_steps 500 -encoder_type brnn -optim adam -learning_rate .0001 -feat_vec_size 2048\n\nTranslate with\n\n.. code-block::\n\n onmt_translate -model yt2t-model_step_7200.pt -src $YT2T/yt2t_test_files.txt -output pred.txt -verbose -data_type vec -src_dir $YT2T/r152 -gpu 0 -batch_size 10\n\n.. note::\n\n Generally, you want to keep the model that has the lowest validation perplexity. That turned out to be\n at step 7200, but choosing a different validation frequency or random seed could result in different results.\n\n\nThen you can use `coco-caption `_ to evaluate the predictions.\n(Note that the fork `flauted `_ can be used for Python 3 compatibility).\nInstall the git repository with pip using\n\n\n.. code-block:: bash\n\n pip install git+\n\nThen use the following Python code to evaluate:\n\n.. code-block:: python\n\n import os\n from pprint import pprint\n from pycocoevalcap.bleu.bleu import Bleu\n from pycocoevalcap.meteor.meteor import Meteor\n from pycocoevalcap.rouge.rouge import Rouge\n from pycocoevalcap.cider.cider import Cider\n from pycocoevalcap.spice.spice import Spice\n\n\n if __name__ == \"__main__\":\n pred = open(\"pred.txt\")\n\n import pickle\n import os\n\n YT = os.path.join(os.environ[\"YT2T\"], \"youtube2text_iccv15\")\n\n with open(os.path.join(YT, \"CAP.pkl\"), \"rb\") as f:\n ann = pickle.load(f, encoding=\"latin-1\")\n\n vid2anns = {}\n for vid_name, data in ann.items():\n for d in data:\n try:\n vid2anns[vid_name].append(d[\"tokenized\"])\n except KeyError:\n vid2anns[vid_name] = [d[\"tokenized\"]]\n\n test_files = open(os.path.join(os.environ[\"YT2T\"], \"yt2t_test_files.txt\"))\n\n scorers = {\n \"Bleu\": Bleu(4),\n \"Meteor\": Meteor(),\n \"Rouge\": Rouge(),\n \"Cider\": Cider(),\n \"Spice\": Spice()\n }\n\n gts = {}\n res = {}\n for outp, filename in zip(pred, test_files):\n filename = filename.strip(\"\\n\")\n outp = outp.strip(\"\\n\")\n vid_id = os.path.splitext(filename)[0]\n anns = vid2anns[vid_id]\n gts[vid_id] = anns\n res[vid_id] = [outp]\n\n scores = {}\n for name, scorer in scorers.items():\n score, all_scores = scorer.compute_score(gts, res)\n if isinstance(score, list):\n for i, sc in enumerate(score, 1):\n scores[name + str(i)] = sc\n else:\n scores[name] = score\n pprint(scores)\n\nHere are our results ::\n\n {'Bleu1': 0.7888553878084233,\n 'Bleu2': 0.6729376621109295,\n 'Bleu3': 0.5778428507344473,\n 'Bleu4': 0.47633625833397897,\n 'Cider': 0.7122415518428051,\n 'Meteor': 0.31829562714082704,\n 'Rouge': 0.6811305229481235,\n 'Spice': 0.044147089472463576}\n\n\nSo how does this stack up against the paper? These results should be compared to the \"Global (Temporal Attention)\"\nrow in Table 1. The authors report BLEU4 0.4028, METEOR 0.2900, and CIDEr 0.4801. So, our results are a significant\nimprovement. Our architecture follows the general encoder + attentional decoder described in the paper, but the\nactual attention implementation is slightly different. The paper downsamples by choosing 26 equally spaced frames from\nthe first 240, while we downsample the video to 2 fps. Also, we use ResNet features instead of GoogLeNet, and we\nlowercase while the paper does not, so some improvement is expected.\n\nTransformer\n-----------\n\nNow we will try to replicate the baseline transformer results from\n`\"TVT: Two-View Transformer Network for Video Captioning\" `_\non the MSVD (YouTube2Text) dataset. See Table 3, Base model(R).\n\nIn Section 4.3, the authors report most of their preprocessing and hyperparameters.\n\nCreate a folder called *yt2t_2*. Copy *youtube2text_iccv15* directory and *YouTubeClips.tar* into\nthe new directory and untar *YouTubeClips*. Rerun the renaming code. Subssample at 5 FPS using\n\n.. code-block:: bash\n\n for fi in $( ls ); do ffmpeg -y -i $fi -r 5 $fi; done\n\nSet the environment variable ``$YT2T`` to this new directory and change to the repo directory.\nRun the feature extraction command again to extract ResNet features on the frames.\nThen use this reprocessing code. Note that it shuffles the data differently, and it performs\ntokenization similar to what the authors report.\n\n.. code-block:: python\n\n import pickle\n import os\n import random\n import string\n\n seed = 2345\n random.seed(seed)\n\n\n YT = \"youtube2text_iccv15\"\n SHUFFLE = True\n\n with open(os.path.join(YT, \"CAP.pkl\"), \"rb\") as f:\n ann = pickle.load(f, encoding=\"latin-1\")\n\n def clean(caption):\n caption = caption.lower()\n caption = caption.replace(\"\\n\", \" \").replace(\"\\t\", \" \").replace(\"\\r\", \" \")\n # remove punctuation\n caption = caption.translate(str.maketrans(\"\", \"\", string.punctuation))\n # multiple whitespace\n caption = \" \".join(caption.split())\n return caption\n\n\n with open(os.path.join(YT, \"train.pkl\"), \"rb\") as f:\n train = pickle.load(f, encoding=\"latin-1\")\n\n with open(os.path.join(YT, \"valid.pkl\"), \"rb\") as f:\n val = pickle.load(f, encoding=\"latin-1\")\n\n with open(os.path.join(YT, \"test.pkl\"), \"rb\") as f:\n test = pickle.load(f, encoding=\"latin-1\")\n\n train_data = []\n val_data = []\n test_data = []\n for vid_name, data in ann.items():\n vid_path = vid_name + \".npy\"\n for i, d in enumerate(data):\n split_name = vid_name + \"_\" + str(i)\n datum = (vid_path, i, clean(d[\"caption\"]))\n if split_name in train:\n train_data.append(datum)\n elif split_name in val:\n val_data.append(datum)\n elif split_name in test:\n test_data.append(datum)\n else:\n assert False\n\n if SHUFFLE:\n random.shuffle(train_data)\n\n train_files = open(\"yt2t_train_files.txt\", \"w\")\n train_cap = open(\"yt2t_train_cap.txt\", \"w\")\n\n for vid_path, _, an in train_data:\n train_files.write(vid_path + \"\\n\")\n train_cap.write(an + \"\\n\")\n\n train_files.close()\n train_cap.close()\n\n val_files = open(\"yt2t_val_files.txt\", \"w\")\n val_folded = open(\"yt2t_val_folded_files.txt\", \"w\")\n val_cap = open(\"yt2t_val_cap.txt\", \"w\")\n\n for vid_path, i, an in val_data:\n if i == 0:\n val_folded.write(vid_path + \"\\n\")\n val_files.write(vid_path + \"\\n\")\n val_cap.write(an + \"\\n\")\n\n val_files.close()\n val_folded.close()\n val_cap.close()\n\n test_files = open(\"yt2t_test_files.txt\", \"w\")\n\n for vid_path, i, an in test_data:\n # Don't need to save out the test captions,\n # just the files. And, don't need to repeat\n # it for each caption\n if i == 0:\n test_files.write(vid_path + \"\\n\")\n\n test_files.close()\n\nThen preprocess the data with max-length filtering. (Note you will be prompted to remove the\nold data. Do this, i.e. ``rm data/yt2t.*.pt.``)\n\n.. code-block:: bash\n\n onmt_preprocess -data_type vec -train_src $YT2T/yt2t_train_files.txt -src_dir $YT2T/r152/ -train_tgt $YT2T/yt2t_train_cap.txt -valid_src $YT2T/yt2t_val_files.txt -valid_tgt $YT2T/yt2t_val_cap.txt -save_data data/yt2t --shard_size 1000 --src_seq_length 50 --tgt_seq_length 20\n\nDelete the old checkpoints and train a transformer model on this data.\n\n.. code-block:: bash\n\n rm -r yt2t-model_step_*.pt; onmt_train -data data/yt2t -save_model yt2t-model -world_size 2 -gpu_ranks 0 1 -model_type vec -batch_size 64 -train_steps 8000 -valid_steps 400 -save_checkpoint_steps 400 -optim adam -learning_rate .0001 -feat_vec_size 2048 -layers 4 -rnn_size 512 -word_vec_size 512 -transformer_ff 2048 -heads 8 -encoder_type transformer -decoder_type transformer -position_encoding -dropout 0.3 -param_init 0 -param_init_glorot -report_every 400 --share_decoder_embedding --seed 7000\n\nNote we use the hyperparameters described in the paper.\nWe estimate the length of 20 epochs with ``-train_steps``. Note that this depends on\nusing a world size of 2. If you use a different world size, scale the ``-train_steps`` (and\n``-save_checkpoint_steps``, along with other parameters) accordingly.\n\nThe batch size is not specified in the paper, so we assume one checkpoint\nper our estimated epoch. And, sharing\nthe decoder embeddings is not mentioned, although we find this helps performance. Like the paper, we perform\n\"early-stopping\" with the COCO scores. We use beam search on the early stopping,\nalthough this too is not mentioned. You can reproduce our early-stops with these scripts\n(namely, running `find_val_stops.sh` and then `test_early_stops.sh` -\n`process_results.py` is a dependency of `find_val_stops.sh`):\n\n.. code-block:: python\n :caption: `process_results.py`\n\n import argparse\n\n from collections import defaultdict\n import pandas as pd\n\n\n def load_results(fname=\"results.txt\"):\n index = []\n data = []\n with open(fname, \"r\") as f:\n while True:\n try:\n filename = next(f).strip()\n except:\n break\n step = int(filename.split(\"_\")[-1].split(\".\")[0])\n next(f) # blank\n next(f) # spice junk\n next(f) # length stats\n next(f) # ratios\n scores = {}\n while True:\n score_line = next(f).strip().strip(\"{\").strip(\",\")\n metric, score = score_line.split(\": \")\n metric = metric.strip(\"'\")\n score_num = float(score.strip(\"}\").strip(\",\"))\n scores[metric] = float(score_num)\n if score.endswith(\"}\"):\n break\n next(f) # blank\n next(f) # blank\n next(f) # blank\n index.append(step)\n data.append(scores)\n df = pd.DataFrame(data, index=index)\n return df\n\n\n def find_absolute_stops(df):\n return df.idxmax()\n\n\n def find_early_stops(df, stop_count):\n maxes = defaultdict(lambda: 0)\n argmaxes = {}\n count_since_max = {}\n ended_metrics = set()\n for index, row in df.iterrows():\n for metric, score in row.items():\n if metric in ended_metrics:\n continue\n if score >= maxes[metric]:\n maxes[metric] = score\n argmaxes[metric] = index\n count_since_max[metric] = 0\n else:\n count_since_max[metric] += 1\n if count_since_max[metric] == stop_count:\n ended_metrics.add(metric)\n if len(ended_metrics) == len(row):\n break\n return pd.Series(argmaxes)\n\n\n def find_stops(df, stop_count):\n if stop_count > 0:\n return find_early_stops(df, stop_count)\n else:\n return find_absolute_stops(df)\n\n\n if __name__ == \"__main__\":\n parser = argparse.ArgumentParser(\"Find locations of best scores\")\n parser.add_argument(\n \"-s\", \"--stop_count\", type=int, default=0,\n help=\"Stop after this many scores worse than running max (0 to disable).\")\n args = parser.parse_args()\n df = load_results()\n maxes = find_stops(df, args.stop_count)\n for metric, idx in maxes.iteritems():\n print(f\"{metric} maxed @ {idx}\")\n print(df.loc[idx])\n print()\n\n\n.. code-block:: bash\n :caption: `find_val_stops.sh`\n\n rm results.txt\n touch results.txt\n for file in $( ls -1v yt2t-model_step*.pt )\n do\n echo $file\n onmt_translate -model $file -src $YT2T/yt2t_val_folded_files.txt -output pred.txt -verbose -data_type vec -src_dir $YT2T/r152 -gpu 0 -batch_size 16 -max_length 20 >/dev/null 2>/dev/null\n echo -e \"$file\\n\" >> results.txt\n python coco.py -s val >> results.txt\n echo -e \"\\n\\n\" >> results.txt\n done\n python process_results.py -s 10 > val_stops.txt\n\n.. code-block:: bash\n :caption: `test_early_stops.sh`\n\n rm test_results.txt\n touch test_results.txt\n while IFS='' read -r line || [[ -n \"$line\" ]]; do\n if [[ $line == *\"maxed\"* ]]; then\n metric=$(echo $line | awk '{print $1}')\n step=$(echo $line | awk '{print $NF}')\n echo $metric early stopped @ $step | tee -a test_results.txt\n onmt_translate -model \"yt2t-model_step_${step}.pt\" -src $YT2T/yt2t_test_files.txt -output pred.txt -data_type vec -src_dir $YT2T/r152 -gpu 0 -batch_size 16 -max_length 20 >/dev/null 2>/dev/null\n python coco.py -s 'test' >> test_results.txt\n echo -e \"\\n\\n\" >> test_results.txt\n fi\n done < val_stops.txt\n cat test_results.txt\n\nThus we test the checkpoint at step 2000 and find the following scores::\n\n Meteor early stopped @ 2000\n SPICE evaluation took: 2.522 s\n {'testlen': 3410, 'reflen': 3417, 'guess': [3410, 2740, 2070, 1400], 'correct': [2664, 1562, 887, 386]}\n ratio: 0.9979514193734276\n {'Bleu1': 0.7796296150773093,\n 'Bleu2': 0.6659837622637965,\n 'Bleu3': 0.5745524496015597,\n 'Bleu4': 0.4779574102543823,\n 'Cider': 0.7541600090591118,\n 'Meteor': 0.3259497476899707,\n 'Rouge': 0.6800279518634998,\n 'Spice': 0.046435637924854}\n\n\nNote our scores are an improvement over the recurrent approach.\n\nThe paper reports\nBLEU4 50.25, CIDEr 72.11, METEOR 33.41, ROUGE 70.16.\n\nThe CIDEr score is higher than the paper (but, considering the sensitivity of this\nmetric, not by much), while the other metrics are slightly lower.\nThis could be indicative of an implementation difference. Note that Table 5 reports\n24M parameters for a 2-layer transformer with ResNet inputs, while we find a few M less. This\ncould be due to generator or embedding differences, or perhaps linear layers on the\nresidual connections. Alternatively, the difference could be the initial tokenization.\nThe paper reports 9861 tokens, while we find fewer.\n\nPart of this could be due to using\nthe annotations from the other repository, where perhaps some annotations have been\nstripped. We also do not know the batch size or checkpoint frequency from the original\nwork.\n\nDifferent random initializations could account for some of the difference, although\nour random seed gives good results.\n\nOverall, however, the scores are nearly reproduced\nand the scores are favorable.\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/floyd.yml",
"content": "env: pytorch-0.4\nmachine: cpu\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/floyd_requirements.txt",
"content": "git+https://github.com/pytorch/text\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/github_deploy_key_opennmt_opennmt_py.enc",
"content": "gAAAAABaPWC5LTHR5xMoviRbhWsMCxo0FPMTXwcm4DBbG2jYaTxuqdjT78PXu1XxcEfbRuZ-xX8723WjgJMaOVFRuB6k1Oow7Qw8YlO6CV5fyjU8jJFy0D4fSEE40P6A0GbvtMwj2uVKyhrCK341_8roVVegN96S40muebu0oi3cY0sDwLybAOBQYdf_J6gQgWIxf289hPMzmV4iy332V9gRN-cNbmpUYaVxINrxv0Ce6pw3NV99mNNK5izq-g4hlpErnF7LG60Jar7Vh7bw52C0PpEVJmUXWIJOtDGy6d_SuvR4SIj64J4IEDO78s7PyI8jAyP5Nu5emcH_eOV8z7C2nszkNbx6RwtDPh5qK0HILCgGmF4nzOTVK8mE9_8gD-tlWpS7jj7y_IJwNPJB3Gnqt383sg5NIQpgQqJMzmKtacXPF-sDvczsyf4t6GEURhPYobNociBQa3ZZBtJU0O_moUtwdSRsjkk1RdUbIgG3tcX73T_SYJqMLGtMKywmyDzv1CVqFCdCAhlVAcSnLLvP2xlJ1uJSKa46dtSDoUXleWCGMR9SoLz2UpPvtnJ1zZ8YKW7UD9iQfAsznBMSG4wKGEdZdFymvCuLnZQYWmJK9UFSyoYnrW1Jy1pmOJ8a25kfyI6_LiK52iC1zr9DZcn5MP2FGgrJnz0RfuvPtcgKFtvs731LzVycUT-u1I4WftPh_6b6fPxYuSnRPdJ39m7OnaGb5VOobleElaZMkh8niXM4K654i1dQA_ItuYeWjU3HPhwN86aOif6GeZSlq_Xjp3Z2DACSmYqyxKccVBWYBdZO8WSdSt07TEeWUboDDQTu_xCPEh-E8Z-Bb-xjTjVM99jkvZSrbqJn6TeY__nH2thfl9cVMj73o7wIp0EJgSpUuKEnJqPwenPwm-VEj_ODB8qbNYC3y4QkfHBL6nbdUt8Qx6P59i8C54st2v5OdZ31bF6bqbJxE5UElJRyuASmE92vu8QqQqPGjZqLhIE9Tl6EC4JFdwJMZI53gztzfKTYMAQLkbV0zYtSoBYavbBCTwQTlG49qDeZk6r5K4DPwZh9xM-M9j32Yr3NYE6QvS4sPaikPkAGoLqTAWVrfdLDc7IdIgAmZNt1D5E3Wm2n7wlQflrdLu6VgiGT1rZgsax_C1bTvsi7InkjuQuNphzXEn3_9FlWmnatDK0Nb0MFqGtEAd0S5SDGI2cf7drLVOtJzvNw9GUgdMoqn-hutvJNS1vpIZK2KektVoFMB-gBJj4oPp4gx8WDbvmkd88Jbitk3xuQp8JmoxPcVkZhPJYYMouMHnO982N9HiJ7AsvFmML_AEe72_qQCh5jcGpsbMq_U5Cu8S2L6MpaMmcn1Piup9ClCricSNEtJD-QS9EEyn-mCHnXnQ1_z6AQ-An5wwm2eNrsEN1F1DjqLcyO3ziE5pHKNXh5W1H3Ec1_ETpInJRBoZ7DEvPpI1KFyxSnwCCrONAIZwrZzMDHPsXgJbXZZfX8_bah36380_eecZOmeCVE1UsimA2MLE3K-ziv0YhXiyHkdzROSmXruXSmzr1NW1bn26Fwy3M3L3GDmHI4Wd62eiYlPAdiOOGO2rA1H37q47X-65BBdh9XXz0k_5YRPLtQeDUavLKzd9MIHc8Ef4g2PkHJTRp9jdkertDy1NkKg3rV-QZ12fCCce97ftcMJ4BSXLgEx_jvxISTo4mB8R0fAAWYJAYCd0vFc7Q4PRFHhyJsm_5BtrwEC5JFQF6sNQllkIRbixJ-kGaieAwRZ-JKzR7gzQ3MJVjArZKcZJV6N8YYRQvKcR8sEcgLv_lr_1hQNLjmGyFeZ1RYxagaddVLAxwp8W5_vofhnKCc5JpnVcAm4W-h_l7uZd42raso-7HeRYIacW9tuFhmUi7iZBHzsNz9G0XFdsdeD2FKJb2yt30Ze4VA1crIOWwVkHsfXid2tjV4wEkR1GGQXYJ2HSHeiH5W4_9vxyYlpum8swrEWY_vLywnv92Bqerk2pfBi6kJqE1ZyZR-8NQuZMxQO_l8pTurirI-nCeHY5Im-jhs4MmA4-zwthY6RKQqbijYCbEd3HeHHMS0k8c84NlMiVAlEd7cAQZYSvlrAxNsaUWmBazE6HAGhXlB0X5pYDYV0LDalIU4guqpVLx-B4iwvnQ7nA3EzsXSBSJDsYbtVQaOHabG_jTL-SDKpkMEdb1Fh0UAeflB02fSenwj1DmsZysiJDD16IxKq22XjGslQZKNvZqk2XivzbL7JfVkCDU6N8XgyOpImZmh28Cq5iyN0GfgzYBvUscrspXQd7QJmiatoGLA-nkCZae4XRfeEh9l0qj_jiLnDzDXxF8pz9A-2GMTUUiUFwehSw2haTZJ4Ndqj3ekItvVJZxwVPYs_Voim3orgFUKmT1SUWXy5lKWPuqpWpbhBs0W5EJ2gt5EzV_ejsnnMqyDoxS-R03-ZATHRaFtvf96Zz0qo7xP__UONT1c5l8FX4Tf_kBF5JlTFe3FbSk9fa38QJGqH3RiF1mx91VXOwXR4fw-vGy5CuZoCND3QVzrdwmYE3jqxClBo7AnAjLTXD-lUCf7gqFqHFU-on1zypAZaXhwMVmfuKeolQhPsuybzUWTlRQW5OT2rxnwI-xO_6s78sRIyBwtbQba6lcOUnNH5PF9TbGj4Z2ErzA7eBS6ZBlnEE_fx8QrHoF32x2KLbyX6ELgEG4pt6aWfroWTWWC2T1CjUrswmMEfF5F0aA0uvr-vikxFl62Ob2yIuyF39ytmr8mb_o4JBpd3Etj4m_T-5HwmrsNnAf8bUqf0hTHuQlS9ek5jJK-_pNWWL1Q3yQ7x-4eiJkppero7UYyOKXGLRqgWchry26edqEETCybJMvgjmN2kHqcrg3XBM4ItjOPw0s4XklG7YZzEVmq8O3hgp-fVozpX_RAaaFSGmDzuZcQl2R_-Yo13KzjLj8wu3KjBCfVhJoAjc4T2VZMGVL3T4AOZOEN_GXEKjT5rbrEo1E7eQUoKE_PKKxmyDeNZN3W3hULAS_FMKAURyCLT_nfQ-cKU7pg113AyV6juAS_DFnBPZkcwM-PJBKz69QsrN_D3s3M53rART78zbUAab-La7Q803g-eaSgxpGJgCZKqHHafE4OpMnhKJl1eXaO_YekbtNR-JNXxdMS5wMEA_BOpqu_ixwuw_vJx-tZxKJ1p_o75OVFK9YH9ZFT5_--ngM8G-kHZrV6u5XKc5Jymrq9m6nZaH__HdAMvQmRfMWbOsSXl3HrlyEoPK5nyBcKtlHLwANc_1WeMJp3HjpHi5HelTnqNDxi5I5Z0RWP1mU0f8mUMkTvGb5U1wW0pL0Aq_5vSfn5LQhH0QAt2JcHrFasMe_7dABIzMLb8_ph0yQQ57IAIfXUYleOwyD1ZpAFgysnh9V9duxPmg3yswRlJ9MZK9tYkwWcj_nOjq2407qR42aThqWYL4702HVycoQgErx6K4XSkF5mmJdfsZ515IIpqHJt-7Q5n_gzIPQa4Wq5ANgS5-2y97uN61NkoE9eIiLHZMY6OvuORvSdMeL6_84MuLBsKS_3OgXrOQFOgdK5mCn9Iv53UZiMkR0rLGHOLnb2hnTZGq4ao3yiNsauBqf0O4r6ecarYxGty4yWZBxB8aHLFcK-FAlFuoEL8PlRLChOEUqvUoaFs3jzyQY_iRZRyCMszPi0xPrvdiILk4VDaa0NR0XtCC-kA3tdcb_Xbdfv_Djw-wVLf7Dx6iBlPNwtjE4OzweqBaAkNkk5Ij35vk-6QQryHhAgiAHdXDGZoegdHZdKUeC_GSCMud0wpXloEPxDREskWu1VN310OXaa6VvpG0VB1B2CrUlFNvwzmal3PYCrb7XPAT1Lu5C4oSH3bTr6Hk9wtIEv0sAgt4B9RPhZ0Kq-lP85raW748Pkc0PDK1C4g4SzAxl_x7JTSTYUk_fjMnc7yEN0iBRJCMfmUq-ILtj2zOI7f3dazGCp9dXBOTVTYMVNRpcka7vWjlGHMMuVvid3Oz6GgBZl_I3csNzGXTZEvJurp3qXSaXL_THxHmDBDn7T_uY58uPaTC-qjdvkKNDUzg2kRtzejmO7TPEGIRAQghEkVK-ruZU5llxjMg1NOTeXfhXZlRK2Ri8F9QPs6FSFuiqLgOzgbl_rlecf3E6iJ9fgTsdE8OGgekAwmF5hi7Tp5DsGNlKXpWvc4TftLO7len-b9Tqa7XYPU5NKv1hVIIobSRjYuFuW1yDSWtXY0zzzqPsdhtrv97JoM71QL8fZ3tUDBDWhvlBmpXSSfjf4qYQ0PmP7pQWLjb_DuVBDO5EDV0xblgz_stLcNvxRIYChm0ytxN8B2jCaH1n_CLEWTvFloWBP72ovnRWcd1gqbZ4bD4KrI_Tb7VcepWqUg1CO-yTRHR4zQUSBBfM="
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/__init__.py",
"content": "\"\"\" Main entry point of the ONMT library \"\"\"\nfrom __future__ import division, print_function\n\nimport onmt.inputters\nimport onmt.encoders\nimport onmt.decoders\nimport onmt.models\nimport onmt.utils\nimport onmt.modules\nfrom onmt.trainer import Trainer\nimport sys\nimport onmt.utils.optimizers\nonmt.utils.optimizers.Optim = onmt.utils.optimizers.Optimizer\nsys.modules[\"onmt.Optim\"] = onmt.utils.optimizers\n\n# For Flake\n__all__ = [onmt.inputters, onmt.encoders, onmt.decoders, onmt.models,\n onmt.utils, onmt.modules, \"Trainer\"]\n\n__version__ = \"1.0.0.rc2\"\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/bin/__init__.py",
"content": ""
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/bin/average_models.py",
"content": "#!/usr/bin/env python\nimport argparse\nimport torch\n\n\ndef average_models(model_files, fp32=False):\n vocab = None\n opt = None\n avg_model = None\n avg_generator = None\n\n for i, model_file in enumerate(model_files):\n m = torch.load(model_file, map_location='cpu')\n model_weights = m['model']\n generator_weights = m['generator']\n\n if fp32:\n for k, v in model_weights.items():\n model_weights[k] = v.float()\n for k, v in generator_weights.items():\n generator_weights[k] = v.float()\n\n if i == 0:\n vocab, opt = m['vocab'], m['opt']\n avg_model = model_weights\n avg_generator = generator_weights\n else:\n for (k, v) in avg_model.items():\n avg_model[k].mul_(i).add_(model_weights[k]).div_(i + 1)\n\n for (k, v) in avg_generator.items():\n avg_generator[k].mul_(i).add_(generator_weights[k]).div_(i + 1)\n\n final = {\"vocab\": vocab, \"opt\": opt, \"optim\": None,\n \"generator\": avg_generator, \"model\": avg_model}\n return final\n\n\ndef main():\n parser = argparse.ArgumentParser(description=\"\")\n parser.add_argument(\"-models\", \"-m\", nargs=\"+\", required=True,\n help=\"List of models\")\n parser.add_argument(\"-output\", \"-o\", required=True,\n help=\"Output file\")\n parser.add_argument(\"-fp32\", \"-f\", action=\"store_true\",\n help=\"Cast params to float32\")\n opt = parser.parse_args()\n\n final = average_models(opt.models, opt.fp32)\n torch.save(final, opt.output)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/bin/preprocess.py",
"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\n Pre-process Data / features files and build vocabulary\n\"\"\"\nimport codecs\nimport glob\nimport gc\nimport torch\nfrom collections import Counter, defaultdict\n\nfrom onmt.utils.logging import init_logger, logger\nfrom onmt.utils.misc import split_corpus\nimport onmt.inputters as inputters\nimport onmt.opts as opts\nfrom onmt.utils.parse import ArgumentParser\nfrom onmt.inputters.inputter import _build_fields_vocab,\\\n _load_vocab\n\nfrom functools import partial\nfrom multiprocessing import Pool\n\n\ndef check_existing_pt_files(opt, corpus_type, ids, existing_fields):\n \"\"\" Check if there are existing .pt files to avoid overwriting them \"\"\"\n existing_shards = []\n for maybe_id in ids:\n if maybe_id:\n shard_base = corpus_type + \"_\" + maybe_id\n else:\n shard_base = corpus_type\n pattern = opt.save_data + '.{}.*.pt'.format(shard_base)\n if glob.glob(pattern):\n if opt.overwrite:\n maybe_overwrite = (\"will be overwritten because \"\n \"`-overwrite` option is set.\")\n else:\n maybe_overwrite = (\"won't be overwritten, pass the \"\n \"`-overwrite` option if you want to.\")\n logger.warning(\"Shards for corpus {} already exist, {}\"\n .format(shard_base, maybe_overwrite))\n existing_shards += [maybe_id]\n return existing_shards\n\n\ndef process_one_shard(corpus_params, params):\n corpus_type, fields, src_reader, tgt_reader, align_reader, opt,\\\n existing_fields, src_vocab, tgt_vocab = corpus_params\n i, (src_shard, tgt_shard, align_shard, maybe_id, filter_pred) = params\n # create one counter per shard\n sub_sub_counter = defaultdict(Counter)\n assert len(src_shard) == len(tgt_shard)\n logger.info(\"Building shard %d.\" % i)\n\n src_data = {\"reader\": src_reader, \"data\": src_shard, \"dir\": opt.src_dir}\n tgt_data = {\"reader\": tgt_reader, \"data\": tgt_shard, \"dir\": None}\n align_data = {\"reader\": align_reader, \"data\": align_shard, \"dir\": None}\n _readers, _data, _dir = inputters.Dataset.config(\n [('src', src_data), ('tgt', tgt_data), ('align', align_data)])\n\n dataset = inputters.Dataset(\n fields, readers=_readers, data=_data, dirs=_dir,\n sort_key=inputters.str2sortkey[opt.data_type],\n filter_pred=filter_pred\n )\n if corpus_type == \"train\" and existing_fields is None:\n for ex in dataset.examples:\n for name, field in fields.items():\n if ((opt.data_type == \"audio\") and (name == \"src\")):\n continue\n try:\n f_iter = iter(field)\n except TypeError:\n f_iter = [(name, field)]\n all_data = [getattr(ex, name, None)]\n else:\n all_data = getattr(ex, name)\n for (sub_n, sub_f), fd in zip(\n f_iter, all_data):\n has_vocab = (sub_n == 'src' and\n src_vocab is not None) or \\\n (sub_n == 'tgt' and\n tgt_vocab is not None)\n if (hasattr(sub_f, 'sequential')\n and sub_f.sequential and not has_vocab):\n val = fd\n sub_sub_counter[sub_n].update(val)\n if maybe_id:\n shard_base = corpus_type + \"_\" + maybe_id\n else:\n shard_base = corpus_type\n data_path = \"{:s}.{:s}.{:d}.pt\".\\\n format(opt.save_data, shard_base, i)\n\n logger.info(\" * saving %sth %s data shard to %s.\"\n % (i, shard_base, data_path))\n\n dataset.save(data_path)\n\n del dataset.examples\n gc.collect()\n del dataset\n gc.collect()\n\n return sub_sub_counter\n\n\ndef maybe_load_vocab(corpus_type, counters, opt):\n src_vocab = None\n tgt_vocab = None\n existing_fields = None\n if corpus_type == \"train\":\n if opt.src_vocab != \"\":\n try:\n logger.info(\"Using existing vocabulary...\")\n existing_fields = torch.load(opt.src_vocab)\n except torch.serialization.pickle.UnpicklingError:\n logger.info(\"Building vocab from text file...\")\n src_vocab, src_vocab_size = _load_vocab(\n opt.src_vocab, \"src\", counters,\n opt.src_words_min_frequency)\n if opt.tgt_vocab != \"\":\n tgt_vocab, tgt_vocab_size = _load_vocab(\n opt.tgt_vocab, \"tgt\", counters,\n opt.tgt_words_min_frequency)\n return src_vocab, tgt_vocab, existing_fields\n\n\ndef build_save_dataset(corpus_type, fields, src_reader, tgt_reader,\n align_reader, opt):\n assert corpus_type in ['train', 'valid']\n\n if corpus_type == 'train':\n counters = defaultdict(Counter)\n srcs = opt.train_src\n tgts = opt.train_tgt\n ids = opt.train_ids\n aligns = opt.train_align\n elif corpus_type == 'valid':\n counters = None\n srcs = [opt.valid_src]\n tgts = [opt.valid_tgt]\n ids = [None]\n aligns = [opt.valid_align]\n\n src_vocab, tgt_vocab, existing_fields = maybe_load_vocab(\n corpus_type, counters, opt)\n\n existing_shards = check_existing_pt_files(\n opt, corpus_type, ids, existing_fields)\n\n # every corpus has shards, no new one\n if existing_shards == ids and not opt.overwrite:\n return\n\n def shard_iterator(srcs, tgts, ids, aligns, existing_shards,\n existing_fields, corpus_type, opt):\n \"\"\"\n Builds a single iterator yielding every shard of every corpus.\n \"\"\"\n for src, tgt, maybe_id, maybe_align in zip(srcs, tgts, ids, aligns):\n if maybe_id in existing_shards:\n if opt.overwrite:\n logger.warning(\"Overwrite shards for corpus {}\"\n .format(maybe_id))\n else:\n if corpus_type == \"train\":\n assert existing_fields is not None,\\\n (\"A 'vocab.pt' file should be passed to \"\n \"`-src_vocab` when adding a corpus to \"\n \"a set of already existing shards.\")\n logger.warning(\"Ignore corpus {} because \"\n \"shards already exist\"\n .format(maybe_id))\n continue\n if ((corpus_type == \"train\" or opt.filter_valid)\n and tgt is not None):\n filter_pred = partial(\n inputters.filter_example,\n use_src_len=opt.data_type == \"text\",\n max_src_len=opt.src_seq_length,\n max_tgt_len=opt.tgt_seq_length)\n else:\n filter_pred = None\n src_shards = split_corpus(src, opt.shard_size)\n tgt_shards = split_corpus(tgt, opt.shard_size)\n align_shards = split_corpus(maybe_align, opt.shard_size)\n for i, (ss, ts, a_s) in enumerate(\n zip(src_shards, tgt_shards, align_shards)):\n yield (i, (ss, ts, a_s, maybe_id, filter_pred))\n\n shard_iter = shard_iterator(srcs, tgts, ids, aligns, existing_shards,\n existing_fields, corpus_type, opt)\n\n with Pool(opt.num_threads) as p:\n dataset_params = (corpus_type, fields, src_reader, tgt_reader,\n align_reader, opt, existing_fields,\n src_vocab, tgt_vocab)\n func = partial(process_one_shard, dataset_params)\n for sub_counter in p.imap(func, shard_iter):\n if sub_counter is not None:\n for key, value in sub_counter.items():\n counters[key].update(value)\n\n if corpus_type == \"train\":\n vocab_path = opt.save_data + '.vocab.pt'\n if existing_fields is None:\n fields = _build_fields_vocab(\n fields, counters, opt.data_type,\n opt.share_vocab, opt.vocab_size_multiple,\n opt.src_vocab_size, opt.src_words_min_frequency,\n opt.tgt_vocab_size, opt.tgt_words_min_frequency)\n else:\n fields = existing_fields\n torch.save(fields, vocab_path)\n\n\ndef build_save_vocab(train_dataset, fields, opt):\n fields = inputters.build_vocab(\n train_dataset, fields, opt.data_type, opt.share_vocab,\n opt.src_vocab, opt.src_vocab_size, opt.src_words_min_frequency,\n opt.tgt_vocab, opt.tgt_vocab_size, opt.tgt_words_min_frequency,\n vocab_size_multiple=opt.vocab_size_multiple\n )\n vocab_path = opt.save_data + '.vocab.pt'\n torch.save(fields, vocab_path)\n\n\ndef count_features(path):\n \"\"\"\n path: location of a corpus file with whitespace-delimited tokens and\n │-delimited features within the token\n returns: the number of features in the dataset\n \"\"\"\n with codecs.open(path, \"r\", \"utf-8\") as f:\n first_tok = f.readline().split(None, 1)[0]\n return len(first_tok.split(u\"│\")) - 1\n\n\ndef preprocess(opt):\n ArgumentParser.validate_preprocess_args(opt)\n torch.manual_seed(opt.seed)\n\n init_logger(opt.log_file)\n\n logger.info(\"Extracting features...\")\n\n src_nfeats = 0\n tgt_nfeats = 0\n for src, tgt in zip(opt.train_src, opt.train_tgt):\n src_nfeats += count_features(src) if opt.data_type == 'text' \\\n else 0\n tgt_nfeats += count_features(tgt) # tgt always text so far\n logger.info(\" * number of source features: %d.\" % src_nfeats)\n logger.info(\" * number of target features: %d.\" % tgt_nfeats)\n\n logger.info(\"Building `Fields` object...\")\n fields = inputters.get_fields(\n opt.data_type,\n src_nfeats,\n tgt_nfeats,\n dynamic_dict=opt.dynamic_dict,\n with_align=opt.train_align[0] is not None,\n src_truncate=opt.src_seq_length_trunc,\n tgt_truncate=opt.tgt_seq_length_trunc)\n\n src_reader = inputters.str2reader[opt.data_type].from_opt(opt)\n tgt_reader = inputters.str2reader[\"text\"].from_opt(opt)\n align_reader = inputters.str2reader[\"text\"].from_opt(opt)\n\n logger.info(\"Building & saving training data...\")\n build_save_dataset(\n 'train', fields, src_reader, tgt_reader, align_reader, opt)\n\n if opt.valid_src and opt.valid_tgt:\n logger.info(\"Building & saving validation data...\")\n build_save_dataset(\n 'valid', fields, src_reader, tgt_reader, align_reader, opt)\n\n\ndef _get_parser():\n parser = ArgumentParser(description='preprocess.py')\n\n opts.config_opts(parser)\n opts.preprocess_opts(parser)\n return parser\n\n\ndef main():\n parser = _get_parser()\n\n opt = parser.parse_args()\n preprocess(opt)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/bin/server.py",
"content": "#!/usr/bin/env python\nimport configargparse\n\nfrom flask import Flask, jsonify, request\nfrom onmt.translate import TranslationServer, ServerModelError\n\nSTATUS_OK = \"ok\"\nSTATUS_ERROR = \"error\"\n\n\ndef start(config_file,\n url_root=\"./translator\",\n host=\"0.0.0.0\",\n port=5000,\n debug=True):\n def prefix_route(route_function, prefix='', mask='{0}{1}'):\n def newroute(route, *args, **kwargs):\n return route_function(mask.format(prefix, route), *args, **kwargs)\n return newroute\n\n app = Flask(__name__)\n app.route = prefix_route(app.route, url_root)\n translation_server = TranslationServer()\n translation_server.start(config_file)\n\n @app.route('/models', methods=['GET'])\n def get_models():\n out = translation_server.list_models()\n return jsonify(out)\n\n @app.route('/health', methods=['GET'])\n def health():\n out = {}\n out['status'] = STATUS_OK\n return jsonify(out)\n\n @app.route('/clone_model/', methods=['POST'])\n def clone_model(model_id):\n out = {}\n data = request.get_json(force=True)\n timeout = -1\n if 'timeout' in data:\n timeout = data['timeout']\n del data['timeout']\n\n opt = data.get('opt', None)\n try:\n model_id, load_time = translation_server.clone_model(\n model_id, opt, timeout)\n except ServerModelError as e:\n out['status'] = STATUS_ERROR\n out['error'] = str(e)\n else:\n out['status'] = STATUS_OK\n out['model_id'] = model_id\n out['load_time'] = load_time\n\n return jsonify(out)\n\n @app.route('/unload_model/', methods=['GET'])\n def unload_model(model_id):\n out = {\"model_id\": model_id}\n\n try:\n translation_server.unload_model(model_id)\n out['status'] = STATUS_OK\n except Exception as e:\n out['status'] = STATUS_ERROR\n out['error'] = str(e)\n\n return jsonify(out)\n\n @app.route('/translate', methods=['POST'])\n def translate():\n inputs = request.get_json(force=True)\n out = {}\n try:\n trans, scores, n_best, _, aligns = translation_server.run(inputs)\n assert len(trans) == len(inputs) * n_best\n assert len(scores) == len(inputs) * n_best\n assert len(aligns) == len(inputs) * n_best\n\n out = [[] for _ in range(n_best)]\n for i in range(len(trans)):\n response = {\"src\": inputs[i // n_best]['src'], \"tgt\": trans[i],\n \"n_best\": n_best, \"pred_score\": scores[i]}\n if aligns[i] is not None:\n response[\"align\"] = aligns[i]\n out[i % n_best].append(response)\n except ServerModelError as e:\n out['error'] = str(e)\n out['status'] = STATUS_ERROR\n\n return jsonify(out)\n\n @app.route('/to_cpu/', methods=['GET'])\n def to_cpu(model_id):\n out = {'model_id': model_id}\n translation_server.models[model_id].to_cpu()\n\n out['status'] = STATUS_OK\n return jsonify(out)\n\n @app.route('/to_gpu/', methods=['GET'])\n def to_gpu(model_id):\n out = {'model_id': model_id}\n translation_server.models[model_id].to_gpu()\n\n out['status'] = STATUS_OK\n return jsonify(out)\n\n app.run(debug=debug, host=host, port=port, use_reloader=False,\n threaded=True)\n\n\ndef _get_parser():\n parser = configargparse.ArgumentParser(\n config_file_parser_class=configargparse.YAMLConfigFileParser,\n description=\"OpenNMT-py REST Server\")\n parser.add_argument(\"--ip\", type=str, default=\"0.0.0.0\")\n parser.add_argument(\"--port\", type=int, default=\"5000\")\n parser.add_argument(\"--url_root\", type=str, default=\"/translator\")\n parser.add_argument(\"--debug\", \"-d\", action=\"store_true\")\n parser.add_argument(\"--config\", \"-c\", type=str,\n default=\"./available_models/conf.json\")\n return parser\n\n\ndef main():\n parser = _get_parser()\n args = parser.parse_args()\n start(args.config, url_root=args.url_root, host=args.ip, port=args.port,\n debug=args.debug)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/bin/train.py",
"content": "#!/usr/bin/env python\n\"\"\"Train models.\"\"\"\nimport os\nimport signal\nimport torch\n\nimport onmt.opts as opts\nimport onmt.utils.distributed\n\nfrom onmt.utils.misc import set_random_seed\nfrom onmt.utils.logging import init_logger, logger\nfrom onmt.train_single import main as single_main\nfrom onmt.utils.parse import ArgumentParser\nfrom onmt.inputters.inputter import build_dataset_iter, \\\n load_old_vocab, old_style_vocab, build_dataset_iter_multiple\n\nfrom itertools import cycle\n\n\ndef train(opt):\n ArgumentParser.validate_train_opts(opt)\n ArgumentParser.update_model_opts(opt)\n ArgumentParser.validate_model_opts(opt)\n\n set_random_seed(opt.seed, False)\n\n # Load checkpoint if we resume from a previous training.\n if opt.train_from:\n logger.info('Loading checkpoint from %s' % opt.train_from)\n checkpoint = torch.load(opt.train_from,\n map_location=lambda storage, loc: storage)\n logger.info('Loading vocab from checkpoint at %s.' % opt.train_from)\n vocab = checkpoint['vocab']\n else:\n vocab = torch.load(opt.data + '.vocab.pt')\n\n # check for code where vocab is saved instead of fields\n # (in the future this will be done in a smarter way)\n if old_style_vocab(vocab):\n fields = load_old_vocab(\n vocab, opt.model_type, dynamic_dict=opt.copy_attn)\n else:\n fields = vocab\n\n if len(opt.data_ids) > 1: ##zida In case there are several corpora.\n train_shards = []\n for train_id in opt.data_ids:\n shard_base = \"train_\" + train_id\n train_shards.append(shard_base)\n train_iter = build_dataset_iter_multiple(train_shards, fields, opt)\n else:\n if opt.data_ids[0] is not None:\n shard_base = \"train_\" + opt.data_ids[0]\n else:\n shard_base = \"train\"\n train_iter = build_dataset_iter(shard_base, fields, opt)\n\n nb_gpu = len(opt.gpu_ranks)\n\n if opt.world_size > 1:\n queues = []\n mp = torch.multiprocessing.get_context('spawn')\n semaphore = mp.Semaphore(opt.world_size * opt.queue_size)\n # Create a thread to listen for errors in the child processes.\n error_queue = mp.SimpleQueue()\n error_handler = ErrorHandler(error_queue)\n # Train with multiprocessing.\n procs = []\n for device_id in range(nb_gpu):\n q = mp.Queue(opt.queue_size)\n queues += [q]\n procs.append(mp.Process(target=run, args=(\n opt, device_id, error_queue, q, semaphore), daemon=True))\n procs[device_id].start()\n logger.info(\" Starting process pid: %d \" % procs[device_id].pid)\n error_handler.add_child(procs[device_id].pid)\n producer = mp.Process(target=batch_producer,\n args=(train_iter, queues, semaphore, opt,),\n daemon=True)\n producer.start()\n error_handler.add_child(producer.pid)\n\n for p in procs:\n p.join()\n producer.terminate()\n\n elif nb_gpu == 1: # case 1 GPU only\n single_main(opt, 0)\n else: # case only CPU\n single_main(opt, -1)\n\n\ndef batch_producer(generator_to_serve, queues, semaphore, opt):\n init_logger(opt.log_file)\n set_random_seed(opt.seed, False)\n # generator_to_serve = iter(generator_to_serve)\n\n def pred(x):\n \"\"\"\n Filters batches that belong only\n to gpu_ranks of current node\n \"\"\"\n for rank in opt.gpu_ranks:\n if x[0] % opt.world_size == rank:\n return True\n\n generator_to_serve = filter(\n pred, enumerate(generator_to_serve))\n\n def next_batch(device_id):\n new_batch = next(generator_to_serve)\n semaphore.acquire()\n return new_batch[1]\n\n b = next_batch(0)\n\n for device_id, q in cycle(enumerate(queues)):\n b.dataset = None\n if isinstance(b.src, tuple):\n b.src = tuple([_.to(torch.device(device_id))\n for _ in b.src])\n else:\n b.src = b.src.to(torch.device(device_id))\n b.tgt = b.tgt.to(torch.device(device_id))\n b.indices = b.indices.to(torch.device(device_id))\n b.alignment = b.alignment.to(torch.device(device_id)) \\\n if hasattr(b, 'alignment') else None\n b.src_map = b.src_map.to(torch.device(device_id)) \\\n if hasattr(b, 'src_map') else None\n b.align = b.align.to(torch.device(device_id)) \\\n if hasattr(b, 'align') else None\n\n # hack to dodge unpicklable `dict_keys`\n b.fields = list(b.fields)\n q.put(b)\n b = next_batch(device_id)\n\n\ndef run(opt, device_id, error_queue, batch_queue, semaphore):\n \"\"\" run process \"\"\"\n try:\n gpu_rank = onmt.utils.distributed.multi_init(opt, device_id)\n if gpu_rank != opt.gpu_ranks[device_id]:\n raise AssertionError(\"An error occurred in \\\n Distributed initialization\")\n single_main(opt, device_id, batch_queue, semaphore)\n except KeyboardInterrupt:\n pass # killed by parent, do nothing\n except Exception:\n # propagate exception to parent process, keeping original traceback\n import traceback\n error_queue.put((opt.gpu_ranks[device_id], traceback.format_exc()))\n\n\nclass ErrorHandler(object):\n \"\"\"A class that listens for exceptions in children processes and propagates\n the tracebacks to the parent process.\"\"\"\n\n def __init__(self, error_queue):\n \"\"\" init error handler \"\"\"\n import signal\n import threading\n self.error_queue = error_queue\n self.children_pids = []\n self.error_thread = threading.Thread(\n target=self.error_listener, daemon=True)\n self.error_thread.start()\n signal.signal(signal.SIGUSR1, self.signal_handler)\n\n def add_child(self, pid):\n \"\"\" error handler \"\"\"\n self.children_pids.append(pid)\n\n def error_listener(self):\n \"\"\" error listener \"\"\"\n (rank, original_trace) = self.error_queue.get()\n self.error_queue.put((rank, original_trace))\n os.kill(os.getpid(), signal.SIGUSR1)\n\n def signal_handler(self, signalnum, stackframe):\n \"\"\" signal handler \"\"\"\n for pid in self.children_pids:\n os.kill(pid, signal.SIGINT) # kill children processes\n (rank, original_trace) = self.error_queue.get()\n msg = \"\"\"\\n\\n-- Tracebacks above this line can probably\n be ignored --\\n\\n\"\"\"\n msg += original_trace\n raise Exception(msg)\n\n\ndef _get_parser():\n parser = ArgumentParser(description='train.py')\n\n opts.config_opts(parser)\n opts.model_opts(parser)\n opts.train_opts(parser)\n return parser\n\n\ndef main():\n parser = _get_parser()\n\n opt = parser.parse_args()\n train(opt)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/bin/translate.py",
"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nfrom onmt.utils.logging import init_logger\nfrom onmt.utils.misc import split_corpus\nfrom onmt.translate.translator import build_translator\n\nimport onmt.opts as opts\nfrom onmt.utils.parse import ArgumentParser\n\n\ndef translate(opt):\n ArgumentParser.validate_translate_opts(opt)\n logger = init_logger(opt.log_file)\n\n translator = build_translator(opt, report_score=True)\n src_shards = split_corpus(opt.src, opt.shard_size)\n tgt_shards = split_corpus(opt.tgt, opt.shard_size)\n shard_pairs = zip(src_shards, tgt_shards)\n\n for i, (src_shard, tgt_shard) in enumerate(shard_pairs):\n logger.info(\"Translating shard %d.\" % i)\n translator.translate(\n src=src_shard,\n tgt=tgt_shard,\n src_dir=opt.src_dir,\n batch_size=opt.batch_size,\n batch_type=opt.batch_type,\n attn_debug=opt.attn_debug,\n align_debug=opt.align_debug\n )\n\n\ndef _get_parser():\n parser = ArgumentParser(description='translate.py')\n\n opts.config_opts(parser)\n opts.translate_opts(parser)\n return parser\n\n\ndef main():\n parser = _get_parser()\n\n opt = parser.parse_args()\n translate(opt)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/decoders/__init__.py",
"content": "\"\"\"Module defining decoders.\"\"\"\nfrom onmt.decoders.decoder import DecoderBase, InputFeedRNNDecoder, \\\n StdRNNDecoder\nfrom onmt.decoders.transformer import TransformerDecoder\nfrom onmt.decoders.cnn_decoder import CNNDecoder\n\n\nstr2dec = {\"rnn\": StdRNNDecoder, \"ifrnn\": InputFeedRNNDecoder,\n \"cnn\": CNNDecoder, \"transformer\": TransformerDecoder}\n\n__all__ = [\"DecoderBase\", \"TransformerDecoder\", \"StdRNNDecoder\", \"CNNDecoder\",\n \"InputFeedRNNDecoder\", \"str2dec\"]\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/decoders/cnn_decoder.py",
"content": "\"\"\"Implementation of the CNN Decoder part of\n\"Convolutional Sequence to Sequence Learning\"\n\"\"\"\nimport torch\nimport torch.nn as nn\n\nfrom onmt.modules import ConvMultiStepAttention, GlobalAttention\nfrom onmt.utils.cnn_factory import shape_transform, GatedConv\nfrom onmt.decoders.decoder import DecoderBase\n\nSCALE_WEIGHT = 0.5 ** 0.5\n\n\nclass CNNDecoder(DecoderBase):\n \"\"\"Decoder based on \"Convolutional Sequence to Sequence Learning\"\n :cite:`DBLP:journals/corr/GehringAGYD17`.\n\n Consists of residual convolutional layers, with ConvMultiStepAttention.\n \"\"\"\n\n def __init__(self, num_layers, hidden_size, attn_type,\n copy_attn, cnn_kernel_width, dropout, embeddings,\n copy_attn_type):\n super(CNNDecoder, self).__init__()\n\n self.cnn_kernel_width = cnn_kernel_width\n self.embeddings = embeddings\n\n # Decoder State\n self.state = {}\n\n input_size = self.embeddings.embedding_size\n self.linear = nn.Linear(input_size, hidden_size)\n self.conv_layers = nn.ModuleList(\n [GatedConv(hidden_size, cnn_kernel_width, dropout, True)\n for i in range(num_layers)]\n )\n self.attn_layers = nn.ModuleList(\n [ConvMultiStepAttention(hidden_size) for i in range(num_layers)]\n )\n\n # CNNDecoder has its own attention mechanism.\n # Set up a separate copy attention layer if needed.\n assert not copy_attn, \"Copy mechanism not yet tested in conv2conv\"\n if copy_attn:\n self.copy_attn = GlobalAttention(\n hidden_size, attn_type=copy_attn_type)\n else:\n self.copy_attn = None\n\n @classmethod\n def from_opt(cls, opt, embeddings):\n \"\"\"Alternate constructor.\"\"\"\n return cls(\n opt.dec_layers,\n opt.dec_rnn_size,\n opt.global_attention,\n opt.copy_attn,\n opt.cnn_kernel_width,\n opt.dropout[0] if type(opt.dropout) is list else opt.dropout,\n embeddings,\n opt.copy_attn_type)\n\n def init_state(self, _, memory_bank, enc_hidden):\n \"\"\"Init decoder state.\"\"\"\n self.state[\"src\"] = (memory_bank + enc_hidden) * SCALE_WEIGHT\n self.state[\"previous_input\"] = None\n\n def map_state(self, fn):\n self.state[\"src\"] = fn(self.state[\"src\"], 1)\n if self.state[\"previous_input\"] is not None:\n self.state[\"previous_input\"] = fn(self.state[\"previous_input\"], 1)\n\n def detach_state(self):\n self.state[\"previous_input\"] = self.state[\"previous_input\"].detach()\n\n def forward(self, tgt, memory_bank, step=None, **kwargs):\n \"\"\" See :obj:`onmt.modules.RNNDecoderBase.forward()`\"\"\"\n\n if self.state[\"previous_input\"] is not None:\n tgt = torch.cat([self.state[\"previous_input\"], tgt], 0)\n\n dec_outs = []\n attns = {\"std\": []}\n if self.copy_attn is not None:\n attns[\"copy\"] = []\n\n emb = self.embeddings(tgt)\n assert emb.dim() == 3 # len x batch x embedding_dim\n\n tgt_emb = emb.transpose(0, 1).contiguous()\n # The output of CNNEncoder.\n src_memory_bank_t = memory_bank.transpose(0, 1).contiguous()\n # The combination of output of CNNEncoder and source embeddings.\n src_memory_bank_c = self.state[\"src\"].transpose(0, 1).contiguous()\n\n emb_reshape = tgt_emb.contiguous().view(\n tgt_emb.size(0) * tgt_emb.size(1), -1)\n linear_out = self.linear(emb_reshape)\n x = linear_out.view(tgt_emb.size(0), tgt_emb.size(1), -1)\n x = shape_transform(x)\n\n pad = torch.zeros(x.size(0), x.size(1), self.cnn_kernel_width - 1, 1)\n\n pad = pad.type_as(x)\n base_target_emb = x\n\n for conv, attention in zip(self.conv_layers, self.attn_layers):\n new_target_input = torch.cat([pad, x], 2)\n out = conv(new_target_input)\n c, attn = attention(base_target_emb, out,\n src_memory_bank_t, src_memory_bank_c)\n x = (x + (c + out) * SCALE_WEIGHT) * SCALE_WEIGHT\n output = x.squeeze(3).transpose(1, 2)\n\n # Process the result and update the attentions.\n dec_outs = output.transpose(0, 1).contiguous()\n if self.state[\"previous_input\"] is not None:\n dec_outs = dec_outs[self.state[\"previous_input\"].size(0):]\n attn = attn[:, self.state[\"previous_input\"].size(0):].squeeze()\n attn = torch.stack([attn])\n attns[\"std\"] = attn\n if self.copy_attn is not None:\n attns[\"copy\"] = attn\n\n # Update the state.\n self.state[\"previous_input\"] = tgt\n # TODO change the way attns is returned dict => list or tuple (onnx)\n return dec_outs, attns\n\n def update_dropout(self, dropout):\n for layer in self.conv_layers:\n layer.dropout.p = dropout\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/decoders/decoder.py",
"content": "import torch\nimport torch.nn as nn\n\nfrom onmt.models.stacked_rnn import StackedLSTM, StackedGRU\nfrom onmt.modules import context_gate_factory, GlobalAttention\nfrom onmt.utils.rnn_factory import rnn_factory\n\nfrom onmt.utils.misc import aeq\n\n\nclass DecoderBase(nn.Module):\n \"\"\"Abstract class for decoders.\n\n Args:\n attentional (bool): The decoder returns non-empty attention.\n \"\"\"\n\n def __init__(self, attentional=True):\n super(DecoderBase, self).__init__()\n self.attentional = attentional\n\n @classmethod\n def from_opt(cls, opt, embeddings):\n \"\"\"Alternate constructor.\n\n Subclasses should override this method.\n \"\"\"\n\n raise NotImplementedError\n\n\nclass RNNDecoderBase(DecoderBase):\n \"\"\"Base recurrent attention-based decoder class.\n\n Specifies the interface used by different decoder types\n and required by :class:`~onmt.models.NMTModel`.\n\n\n .. mermaid::\n\n graph BT\n A[Input]\n subgraph RNN\n C[Pos 1]\n D[Pos 2]\n E[Pos N]\n end\n G[Decoder State]\n H[Decoder State]\n I[Outputs]\n F[memory_bank]\n A--emb-->C\n A--emb-->D\n A--emb-->E\n H-->C\n C-- attn --- F\n D-- attn --- F\n E-- attn --- F\n C-->I\n D-->I\n E-->I\n E-->G\n F---I\n\n Args:\n rnn_type (str):\n style of recurrent unit to use, one of [RNN, LSTM, GRU, SRU]\n bidirectional_encoder (bool) : use with a bidirectional encoder\n num_layers (int) : number of stacked layers\n hidden_size (int) : hidden size of each layer\n attn_type (str) : see :class:`~onmt.modules.GlobalAttention`\n attn_func (str) : see :class:`~onmt.modules.GlobalAttention`\n coverage_attn (str): see :class:`~onmt.modules.GlobalAttention`\n context_gate (str): see :class:`~onmt.modules.ContextGate`\n copy_attn (bool): setup a separate copy attention mechanism\n dropout (float) : dropout value for :class:`torch.nn.Dropout`\n embeddings (onmt.modules.Embeddings): embedding module to use\n reuse_copy_attn (bool): reuse the attention for copying\n copy_attn_type (str): The copy attention style. See\n :class:`~onmt.modules.GlobalAttention`.\n \"\"\"\n\n def __init__(self, rnn_type, bidirectional_encoder, num_layers,\n hidden_size, attn_type=\"general\", attn_func=\"softmax\",\n coverage_attn=False, context_gate=None,\n copy_attn=False, dropout=0.0, embeddings=None,\n reuse_copy_attn=False, copy_attn_type=\"general\"):\n super(RNNDecoderBase, self).__init__(\n attentional=attn_type != \"none\" and attn_type is not None)\n\n self.bidirectional_encoder = bidirectional_encoder\n self.num_layers = num_layers\n self.hidden_size = hidden_size\n self.embeddings = embeddings\n self.dropout = nn.Dropout(dropout)\n\n # Decoder state\n self.state = {}\n\n # Build the RNN.\n self.rnn = self._build_rnn(rnn_type,\n input_size=self._input_size,\n hidden_size=hidden_size,\n num_layers=num_layers,\n dropout=dropout)\n\n # Set up the context gate.\n self.context_gate = None\n if context_gate is not None:\n self.context_gate = context_gate_factory(\n context_gate, self._input_size,\n hidden_size, hidden_size, hidden_size\n )\n\n # Set up the standard attention.\n self._coverage = coverage_attn\n if not self.attentional:\n if self._coverage:\n raise ValueError(\"Cannot use coverage term with no attention.\")\n self.attn = None\n else:\n self.attn = GlobalAttention(\n hidden_size, coverage=coverage_attn,\n attn_type=attn_type, attn_func=attn_func\n )\n\n if copy_attn and not reuse_copy_attn:\n if copy_attn_type == \"none\" or copy_attn_type is None:\n raise ValueError(\n \"Cannot use copy_attn with copy_attn_type none\")\n self.copy_attn = GlobalAttention(\n hidden_size, attn_type=copy_attn_type, attn_func=attn_func\n )\n else:\n self.copy_attn = None\n\n self._reuse_copy_attn = reuse_copy_attn and copy_attn\n if self._reuse_copy_attn and not self.attentional:\n raise ValueError(\"Cannot reuse copy attention with no attention.\")\n\n @classmethod\n def from_opt(cls, opt, embeddings):\n \"\"\"Alternate constructor.\"\"\"\n return cls(\n opt.rnn_type,\n opt.brnn,\n opt.dec_layers,\n opt.dec_rnn_size,\n opt.global_attention,\n opt.global_attention_function,\n opt.coverage_attn,\n opt.context_gate,\n opt.copy_attn,\n opt.dropout[0] if type(opt.dropout) is list\n else opt.dropout,\n embeddings,\n opt.reuse_copy_attn,\n opt.copy_attn_type)\n\n def init_state(self, src, memory_bank, encoder_final):\n \"\"\"Initialize decoder state with last state of the encoder.\"\"\"\n def _fix_enc_hidden(hidden):\n # The encoder hidden is (layers*directions) x batch x dim.\n # We need to convert it to layers x batch x (directions*dim).\n if self.bidirectional_encoder:\n hidden = torch.cat([hidden[0:hidden.size(0):2],\n hidden[1:hidden.size(0):2]], 2)\n return hidden\n\n if isinstance(encoder_final, tuple): # LSTM\n self.state[\"hidden\"] = tuple(_fix_enc_hidden(enc_hid)\n for enc_hid in encoder_final)\n else: # GRU\n self.state[\"hidden\"] = (_fix_enc_hidden(encoder_final), )\n\n # Init the input feed.\n batch_size = self.state[\"hidden\"][0].size(1)\n h_size = (batch_size, self.hidden_size)\n self.state[\"input_feed\"] = \\\n self.state[\"hidden\"][0].data.new(*h_size).zero_().unsqueeze(0)\n self.state[\"coverage\"] = None\n\n def map_state(self, fn):\n self.state[\"hidden\"] = tuple(fn(h, 1) for h in self.state[\"hidden\"])\n self.state[\"input_feed\"] = fn(self.state[\"input_feed\"], 1)\n if self._coverage and self.state[\"coverage\"] is not None:\n self.state[\"coverage\"] = fn(self.state[\"coverage\"], 1)\n\n def detach_state(self):\n self.state[\"hidden\"] = tuple(h.detach() for h in self.state[\"hidden\"])\n self.state[\"input_feed\"] = self.state[\"input_feed\"].detach()\n\n def forward(self, tgt, memory_bank, memory_lengths=None, step=None,\n **kwargs):\n \"\"\"\n Args:\n tgt (LongTensor): sequences of padded tokens\n ``(tgt_len, batch, nfeats)``.\n memory_bank (FloatTensor): vectors from the encoder\n ``(src_len, batch, hidden)``.\n memory_lengths (LongTensor): the padded source lengths\n ``(batch,)``.\n\n Returns:\n (FloatTensor, dict[str, FloatTensor]):\n\n * dec_outs: output from the decoder (after attn)\n ``(tgt_len, batch, hidden)``.\n * attns: distribution over src at each tgt\n ``(tgt_len, batch, src_len)``.\n \"\"\"\n\n dec_state, dec_outs, attns = self._run_forward_pass(\n tgt, memory_bank, memory_lengths=memory_lengths)\n\n # Update the state with the result.\n if not isinstance(dec_state, tuple):\n dec_state = (dec_state,)\n self.state[\"hidden\"] = dec_state\n self.state[\"input_feed\"] = dec_outs[-1].unsqueeze(0)\n self.state[\"coverage\"] = None\n if \"coverage\" in attns:\n self.state[\"coverage\"] = attns[\"coverage\"][-1].unsqueeze(0)\n\n # Concatenates sequence of tensors along a new dimension.\n # NOTE: v0.3 to 0.4: dec_outs / attns[*] may not be list\n # (in particular in case of SRU) it was not raising error in 0.3\n # since stack(Variable) was allowed.\n # In 0.4, SRU returns a tensor that shouldn't be stacke\n if type(dec_outs) == list:\n dec_outs = torch.stack(dec_outs)\n\n for k in attns:\n if type(attns[k]) == list:\n attns[k] = torch.stack(attns[k])\n return dec_outs, attns\n\n def update_dropout(self, dropout):\n self.dropout.p = dropout\n self.embeddings.update_dropout(dropout)\n\n\nclass StdRNNDecoder(RNNDecoderBase):\n \"\"\"Standard fully batched RNN decoder with attention.\n\n Faster implementation, uses CuDNN for implementation.\n See :class:`~onmt.decoders.decoder.RNNDecoderBase` for options.\n\n\n Based around the approach from\n \"Neural Machine Translation By Jointly Learning To Align and Translate\"\n :cite:`Bahdanau2015`\n\n\n Implemented without input_feeding and currently with no `coverage_attn`\n or `copy_attn` support.\n \"\"\"\n\n def _run_forward_pass(self, tgt, memory_bank, memory_lengths=None):\n \"\"\"\n Private helper for running the specific RNN forward pass.\n Must be overriden by all subclasses.\n\n Args:\n tgt (LongTensor): a sequence of input tokens tensors\n ``(len, batch, nfeats)``.\n memory_bank (FloatTensor): output(tensor sequence) from the\n encoder RNN of size ``(src_len, batch, hidden_size)``.\n memory_lengths (LongTensor): the source memory_bank lengths.\n\n Returns:\n (Tensor, List[FloatTensor], Dict[str, List[FloatTensor]):\n\n * dec_state: final hidden state from the decoder.\n * dec_outs: an array of output of every time\n step from the decoder.\n * attns: a dictionary of different\n type of attention Tensor array of every time\n step from the decoder.\n \"\"\"\n\n assert self.copy_attn is None # TODO, no support yet.\n assert not self._coverage # TODO, no support yet.\n\n attns = {}\n emb = self.embeddings(tgt)\n\n if isinstance(self.rnn, nn.GRU):\n rnn_output, dec_state = self.rnn(emb, self.state[\"hidden\"][0])\n else:\n rnn_output, dec_state = self.rnn(emb, self.state[\"hidden\"])\n\n # Check\n tgt_len, tgt_batch, _ = tgt.size()\n output_len, output_batch, _ = rnn_output.size()\n aeq(tgt_len, output_len)\n aeq(tgt_batch, output_batch)\n\n # Calculate the attention.\n if not self.attentional:\n dec_outs = rnn_output\n else:\n dec_outs, p_attn = self.attn(\n rnn_output.transpose(0, 1).contiguous(),\n memory_bank.transpose(0, 1),\n memory_lengths=memory_lengths\n )\n attns[\"std\"] = p_attn\n\n # Calculate the context gate.\n if self.context_gate is not None:\n dec_outs = self.context_gate(\n emb.view(-1, emb.size(2)),\n rnn_output.view(-1, rnn_output.size(2)),\n dec_outs.view(-1, dec_outs.size(2))\n )\n dec_outs = dec_outs.view(tgt_len, tgt_batch, self.hidden_size)\n\n dec_outs = self.dropout(dec_outs)\n return dec_state, dec_outs, attns\n\n def _build_rnn(self, rnn_type, **kwargs):\n rnn, _ = rnn_factory(rnn_type, **kwargs)\n return rnn\n\n @property\n def _input_size(self):\n return self.embeddings.embedding_size\n\n\nclass InputFeedRNNDecoder(RNNDecoderBase):\n \"\"\"Input feeding based decoder.\n\n See :class:`~onmt.decoders.decoder.RNNDecoderBase` for options.\n\n Based around the input feeding approach from\n \"Effective Approaches to Attention-based Neural Machine Translation\"\n :cite:`Luong2015`\n\n\n .. mermaid::\n\n graph BT\n A[Input n-1]\n AB[Input n]\n subgraph RNN\n E[Pos n-1]\n F[Pos n]\n E --> F\n end\n G[Encoder]\n H[memory_bank n-1]\n A --> E\n AB --> F\n E --> H\n G --> H\n \"\"\"\n\n def _run_forward_pass(self, tgt, memory_bank, memory_lengths=None):\n \"\"\"\n See StdRNNDecoder._run_forward_pass() for description\n of arguments and return values.\n \"\"\"\n # Additional args check.\n input_feed = self.state[\"input_feed\"].squeeze(0)\n input_feed_batch, _ = input_feed.size()\n _, tgt_batch, _ = tgt.size()\n aeq(tgt_batch, input_feed_batch)\n # END Additional args check.\n\n dec_outs = []\n attns = {}\n if self.attn is not None:\n attns[\"std\"] = []\n if self.copy_attn is not None or self._reuse_copy_attn:\n attns[\"copy\"] = []\n if self._coverage:\n attns[\"coverage\"] = []\n\n emb = self.embeddings(tgt)\n assert emb.dim() == 3 # len x batch x embedding_dim\n\n dec_state = self.state[\"hidden\"]\n coverage = self.state[\"coverage\"].squeeze(0) \\\n if self.state[\"coverage\"] is not None else None\n\n # Input feed concatenates hidden state with\n # input at every time step.\n for emb_t in emb.split(1):\n decoder_input = torch.cat([emb_t.squeeze(0), input_feed], 1)\n rnn_output, dec_state = self.rnn(decoder_input, dec_state)\n if self.attentional:\n decoder_output, p_attn = self.attn(\n rnn_output,\n memory_bank.transpose(0, 1),\n memory_lengths=memory_lengths)\n attns[\"std\"].append(p_attn)\n else:\n decoder_output = rnn_output\n if self.context_gate is not None:\n # TODO: context gate should be employed\n # instead of second RNN transform.\n decoder_output = self.context_gate(\n decoder_input, rnn_output, decoder_output\n )\n decoder_output = self.dropout(decoder_output)\n input_feed = decoder_output\n\n dec_outs += [decoder_output]\n\n # Update the coverage attention.\n if self._coverage:\n coverage = p_attn if coverage is None else p_attn + coverage\n attns[\"coverage\"] += [coverage]\n\n if self.copy_attn is not None:\n _, copy_attn = self.copy_attn(\n decoder_output, memory_bank.transpose(0, 1))\n attns[\"copy\"] += [copy_attn]\n elif self._reuse_copy_attn:\n attns[\"copy\"] = attns[\"std\"]\n\n return dec_state, dec_outs, attns\n\n def _build_rnn(self, rnn_type, input_size,\n hidden_size, num_layers, dropout):\n assert rnn_type != \"SRU\", \"SRU doesn't support input feed! \" \\\n \"Please set -input_feed 0!\"\n stacked_cell = StackedLSTM if rnn_type == \"LSTM\" else StackedGRU\n return stacked_cell(num_layers, input_size, hidden_size, dropout)\n\n @property\n def _input_size(self):\n \"\"\"Using input feed by concatenating input with attention vectors.\"\"\"\n return self.embeddings.embedding_size + self.hidden_size\n\n def update_dropout(self, dropout):\n self.dropout.p = dropout\n self.rnn.dropout.p = dropout\n self.embeddings.update_dropout(dropout)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/decoders/ensemble.py",
"content": "\"\"\"Ensemble decoding.\n\nDecodes using multiple models simultaneously,\ncombining their prediction distributions by averaging.\nAll models in the ensemble must share a target vocabulary.\n\"\"\"\n\nimport torch\nimport torch.nn as nn\n\nfrom onmt.encoders.encoder import EncoderBase\nfrom onmt.decoders.decoder import DecoderBase\nfrom onmt.models import NMTModel\nimport onmt.model_builder\n\n\nclass EnsembleDecoderOutput(object):\n \"\"\"Wrapper around multiple decoder final hidden states.\"\"\"\n def __init__(self, model_dec_outs):\n self.model_dec_outs = tuple(model_dec_outs)\n\n def squeeze(self, dim=None):\n \"\"\"Delegate squeeze to avoid modifying\n :func:`onmt.translate.translator.Translator.translate_batch()`\n \"\"\"\n return EnsembleDecoderOutput([\n x.squeeze(dim) for x in self.model_dec_outs])\n\n def __getitem__(self, index):\n return self.model_dec_outs[index]\n\n\nclass EnsembleEncoder(EncoderBase):\n \"\"\"Dummy Encoder that delegates to individual real Encoders.\"\"\"\n def __init__(self, model_encoders):\n super(EnsembleEncoder, self).__init__()\n self.model_encoders = nn.ModuleList(model_encoders)\n\n def forward(self, src, lengths=None):\n enc_hidden, memory_bank, _ = zip(*[\n model_encoder(src, lengths)\n for model_encoder in self.model_encoders])\n return enc_hidden, memory_bank, lengths\n\n\nclass EnsembleDecoder(DecoderBase):\n \"\"\"Dummy Decoder that delegates to individual real Decoders.\"\"\"\n def __init__(self, model_decoders):\n model_decoders = nn.ModuleList(model_decoders)\n attentional = any([dec.attentional for dec in model_decoders])\n super(EnsembleDecoder, self).__init__(attentional)\n self.model_decoders = model_decoders\n\n def forward(self, tgt, memory_bank, memory_lengths=None, step=None,\n **kwargs):\n \"\"\"See :func:`onmt.decoders.decoder.DecoderBase.forward()`.\"\"\"\n # Memory_lengths is a single tensor shared between all models.\n # This assumption will not hold if Translator is modified\n # to calculate memory_lengths as something other than the length\n # of the input.\n dec_outs, attns = zip(*[\n model_decoder(\n tgt, memory_bank[i],\n memory_lengths=memory_lengths, step=step)\n for i, model_decoder in enumerate(self.model_decoders)])\n mean_attns = self.combine_attns(attns)\n return EnsembleDecoderOutput(dec_outs), mean_attns\n\n def combine_attns(self, attns):\n result = {}\n for key in attns[0].keys():\n result[key] = torch.stack(\n [attn[key] for attn in attns if attn[key] is not None]).mean(0)\n return result\n\n def init_state(self, src, memory_bank, enc_hidden):\n \"\"\" See :obj:`RNNDecoderBase.init_state()` \"\"\"\n for i, model_decoder in enumerate(self.model_decoders):\n model_decoder.init_state(src, memory_bank[i], enc_hidden[i])\n\n def map_state(self, fn):\n for model_decoder in self.model_decoders:\n model_decoder.map_state(fn)\n\n\nclass EnsembleGenerator(nn.Module):\n \"\"\"\n Dummy Generator that delegates to individual real Generators,\n and then averages the resulting target distributions.\n \"\"\"\n def __init__(self, model_generators, raw_probs=False):\n super(EnsembleGenerator, self).__init__()\n self.model_generators = nn.ModuleList(model_generators)\n self._raw_probs = raw_probs\n\n def forward(self, hidden, attn=None, src_map=None):\n \"\"\"\n Compute a distribution over the target dictionary\n by averaging distributions from models in the ensemble.\n All models in the ensemble must share a target vocabulary.\n \"\"\"\n distributions = torch.stack(\n [mg(h) if attn is None else mg(h, attn, src_map)\n for h, mg in zip(hidden, self.model_generators)]\n )\n if self._raw_probs:\n return torch.log(torch.exp(distributions).mean(0))\n else:\n return distributions.mean(0)\n\n\nclass EnsembleModel(NMTModel):\n \"\"\"Dummy NMTModel wrapping individual real NMTModels.\"\"\"\n def __init__(self, models, raw_probs=False):\n encoder = EnsembleEncoder(model.encoder for model in models)\n decoder = EnsembleDecoder(model.decoder for model in models)\n super(EnsembleModel, self).__init__(encoder, decoder)\n self.generator = EnsembleGenerator(\n [model.generator for model in models], raw_probs)\n self.models = nn.ModuleList(models)\n\n\ndef load_test_model(opt):\n \"\"\"Read in multiple models for ensemble.\"\"\"\n shared_fields = None\n shared_model_opt = None\n models = []\n for model_path in opt.models:\n fields, model, model_opt = \\\n onmt.model_builder.load_test_model(opt, model_path=model_path)\n if shared_fields is None:\n shared_fields = fields\n else:\n for key, field in fields.items():\n try:\n f_iter = iter(field)\n except TypeError:\n f_iter = [(key, field)]\n for sn, sf in f_iter:\n if sf is not None and 'vocab' in sf.__dict__:\n sh_field = shared_fields[key]\n try:\n sh_f_iter = iter(sh_field)\n except TypeError:\n sh_f_iter = [(key, sh_field)]\n sh_f_dict = dict(sh_f_iter)\n assert sf.vocab.stoi == sh_f_dict[sn].vocab.stoi, \\\n \"Ensemble models must use the same \" \\\n \"preprocessed data\"\n models.append(model)\n if shared_model_opt is None:\n shared_model_opt = model_opt\n ensemble_model = EnsembleModel(models, opt.avg_raw_probs)\n return shared_fields, ensemble_model, shared_model_opt\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/decoders/transformer.py",
"content": "\"\"\"\nImplementation of \"Attention is All You Need\"\n\"\"\"\n\nimport torch\nimport torch.nn as nn\n\nfrom onmt.decoders.decoder import DecoderBase\nfrom onmt.modules import MultiHeadedAttention, AverageAttention\nfrom onmt.modules.position_ffn import PositionwiseFeedForward\nfrom onmt.utils.misc import sequence_mask\n\n\nclass TransformerDecoderLayer(nn.Module):\n \"\"\"\n Args:\n d_model (int): the dimension of keys/values/queries in\n :class:`MultiHeadedAttention`, also the input size of\n the first-layer of the :class:`PositionwiseFeedForward`.\n heads (int): the number of heads for MultiHeadedAttention.\n d_ff (int): the second-layer of the :class:`PositionwiseFeedForward`.\n dropout (float): dropout probability.\n self_attn_type (string): type of self-attention scaled-dot, average\n \"\"\"\n\n def __init__(self, d_model, heads, d_ff, dropout, attention_dropout,\n self_attn_type=\"scaled-dot\", max_relative_positions=0,\n aan_useffn=False, full_context_alignment=False,\n alignment_heads=None):\n super(TransformerDecoderLayer, self).__init__()\n\n if self_attn_type == \"scaled-dot\":\n self.self_attn = MultiHeadedAttention(\n heads, d_model, dropout=dropout,\n max_relative_positions=max_relative_positions)\n elif self_attn_type == \"average\":\n self.self_attn = AverageAttention(d_model,\n dropout=attention_dropout,\n aan_useffn=aan_useffn)\n\n self.context_attn = MultiHeadedAttention(\n heads, d_model, dropout=attention_dropout)\n self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)\n self.layer_norm_1 = nn.LayerNorm(d_model, eps=1e-6)\n self.layer_norm_2 = nn.LayerNorm(d_model, eps=1e-6)\n self.drop = nn.Dropout(dropout)\n self.full_context_alignment = full_context_alignment\n self.alignment_heads = alignment_heads\n\n def forward(self, *args, **kwargs):\n \"\"\" Extend _forward for (possibly) multiple decoder pass:\n 1. Always a default (future masked) decoder forward pass,\n 2. Possibly a second future aware decoder pass for joint learn\n full context alignement.\n\n Args:\n * All arguments of _forward.\n with_align (bool): whether return alignment attention.\n\n Returns:\n (FloatTensor, FloatTensor, FloatTensor or None):\n\n * output ``(batch_size, 1, model_dim)``\n * top_attn ``(batch_size, 1, src_len)``\n * attn_align ``(batch_size, 1, src_len)`` or None\n \"\"\"\n with_align = kwargs.pop('with_align', False)\n output, attns = self._forward(*args, **kwargs)\n top_attn = attns[:, 0, :, :].contiguous()\n attn_align = None\n if with_align:\n if self.full_context_alignment:\n # return _, (B, Q_len, K_len)\n _, attns = self._forward(*args, **kwargs, future=True)\n\n if self.alignment_heads is not None:\n attns = attns[:, :self.alignment_heads, :, :].contiguous()\n # layer average attention across heads, get ``(B, Q, K)``\n # Case 1: no full_context, no align heads -> layer avg baseline\n # Case 2: no full_context, 1 align heads -> guided align\n # Case 3: full_context, 1 align heads -> full cte guided align\n attn_align = attns.mean(dim=1)\n return output, top_attn, attn_align\n\n def _forward(self, inputs, memory_bank, src_pad_mask, tgt_pad_mask,\n layer_cache=None, step=None, future=False):\n \"\"\" A naive forward pass for transformer decoder.\n # TODO: change 1 to T as T could be 1 or tgt_len\n Args:\n inputs (FloatTensor): ``(batch_size, 1, model_dim)``\n memory_bank (FloatTensor): ``(batch_size, src_len, model_dim)``\n src_pad_mask (LongTensor): ``(batch_size, 1, src_len)``\n tgt_pad_mask (LongTensor): ``(batch_size, 1, 1)``\n\n Returns:\n (FloatTensor, FloatTensor):\n\n * output ``(batch_size, 1, model_dim)``\n * attns ``(batch_size, head, 1, src_len)``\n\n \"\"\"\n dec_mask = None\n\n if step is None:\n tgt_len = tgt_pad_mask.size(-1)\n if not future: # apply future_mask, result mask in (B, T, T)\n future_mask = torch.ones(\n [tgt_len, tgt_len],\n device=tgt_pad_mask.device,\n dtype=torch.uint8)\n future_mask = future_mask.triu_(1).view(1, tgt_len, tgt_len)\n # BoolTensor was introduced in pytorch 1.2\n try:\n future_mask = future_mask.bool()\n except AttributeError:\n pass\n dec_mask = torch.gt(tgt_pad_mask + future_mask, 0)\n else: # only mask padding, result mask in (B, 1, T)\n dec_mask = tgt_pad_mask\n\n input_norm = self.layer_norm_1(inputs)\n\n if isinstance(self.self_attn, MultiHeadedAttention):\n query, _ = self.self_attn(input_norm, input_norm, input_norm,\n mask=dec_mask,\n layer_cache=layer_cache,\n attn_type=\"self\")\n elif isinstance(self.self_attn, AverageAttention):\n query, _ = self.self_attn(input_norm, mask=dec_mask,\n layer_cache=layer_cache, step=step)\n\n query = self.drop(query) + inputs\n\n query_norm = self.layer_norm_2(query)\n mid, attns = self.context_attn(memory_bank, memory_bank, query_norm,\n mask=src_pad_mask,\n layer_cache=layer_cache,\n attn_type=\"context\")\n output = self.feed_forward(self.drop(mid) + query)\n\n return output, attns\n\n def update_dropout(self, dropout, attention_dropout):\n self.self_attn.update_dropout(attention_dropout)\n self.context_attn.update_dropout(attention_dropout)\n self.feed_forward.update_dropout(dropout)\n self.drop.p = dropout\n\n\nclass TransformerDecoder(DecoderBase):\n \"\"\"The Transformer decoder from \"Attention is All You Need\".\n :cite:`DBLP:journals/corr/VaswaniSPUJGKP17`\n\n .. mermaid::\n\n graph BT\n A[input]\n B[multi-head self-attn]\n BB[multi-head src-attn]\n C[feed forward]\n O[output]\n A --> B\n B --> BB\n BB --> C\n C --> O\n\n\n Args:\n num_layers (int): number of encoder layers.\n d_model (int): size of the model\n heads (int): number of heads\n d_ff (int): size of the inner FF layer\n copy_attn (bool): if using a separate copy attention\n self_attn_type (str): type of self-attention scaled-dot, average\n dropout (float): dropout parameters\n embeddings (onmt.modules.Embeddings):\n embeddings to use, should have positional encodings\n \"\"\"\n\n def __init__(self, num_layers, d_model, heads, d_ff,\n copy_attn, self_attn_type, dropout, attention_dropout,\n embeddings, max_relative_positions, aan_useffn,\n full_context_alignment, alignment_layer,\n alignment_heads=None):\n super(TransformerDecoder, self).__init__()\n\n self.embeddings = embeddings\n\n # Decoder State\n self.state = {}\n\n self.transformer_layers = nn.ModuleList(\n [TransformerDecoderLayer(d_model, heads, d_ff, dropout,\n attention_dropout, self_attn_type=self_attn_type,\n max_relative_positions=max_relative_positions,\n aan_useffn=aan_useffn,\n full_context_alignment=full_context_alignment,\n alignment_heads=alignment_heads)\n for i in range(num_layers)])\n\n # previously, there was a GlobalAttention module here for copy\n # attention. But it was never actually used -- the \"copy\" attention\n # just reuses the context attention.\n self._copy = copy_attn\n self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)\n\n self.alignment_layer = alignment_layer\n\n @classmethod\n def from_opt(cls, opt, embeddings):\n \"\"\"Alternate constructor.\"\"\"\n return cls(\n opt.dec_layers,\n opt.dec_rnn_size,\n opt.heads,\n opt.transformer_ff,\n opt.copy_attn,\n opt.self_attn_type,\n opt.dropout[0] if type(opt.dropout) is list else opt.dropout,\n opt.attention_dropout[0] if type(opt.attention_dropout)\n is list else opt.dropout,\n embeddings,\n opt.max_relative_positions,\n opt.aan_useffn,\n opt.full_context_alignment,\n opt.alignment_layer,\n alignment_heads=opt.alignment_heads)\n\n def init_state(self, src, memory_bank, enc_hidden):\n \"\"\"Initialize decoder state.\"\"\"\n self.state[\"src\"] = src\n self.state[\"cache\"] = None\n\n def map_state(self, fn):\n def _recursive_map(struct, batch_dim=0):\n for k, v in struct.items():\n if v is not None:\n if isinstance(v, dict):\n _recursive_map(v)\n else:\n struct[k] = fn(v, batch_dim)\n\n self.state[\"src\"] = fn(self.state[\"src\"], 1)\n if self.state[\"cache\"] is not None:\n _recursive_map(self.state[\"cache\"])\n\n def detach_state(self):\n self.state[\"src\"] = self.state[\"src\"].detach()\n\n def forward(self, tgt, memory_bank, step=None, **kwargs):\n \"\"\"Decode, possibly stepwise.\"\"\"\n if step == 0:\n self._init_cache(memory_bank)\n\n tgt_words = tgt[:, :, 0].transpose(0, 1)\n\n emb = self.embeddings(tgt, step=step)\n assert emb.dim() == 3 # len x batch x embedding_dim\n\n output = emb.transpose(0, 1).contiguous()\n src_memory_bank = memory_bank.transpose(0, 1).contiguous()\n\n pad_idx = self.embeddings.word_padding_idx\n src_lens = kwargs[\"memory_lengths\"]\n src_max_len = self.state[\"src\"].shape[0]\n src_pad_mask = ~sequence_mask(src_lens, src_max_len).unsqueeze(1)\n tgt_pad_mask = tgt_words.data.eq(pad_idx).unsqueeze(1) # [B, 1, T_tgt]\n\n with_align = kwargs.pop('with_align', False)\n attn_aligns = []\n\n for i, layer in enumerate(self.transformer_layers):\n layer_cache = self.state[\"cache\"][\"layer_{}\".format(i)] \\\n if step is not None else None\n output, attn, attn_align = layer(\n output,\n src_memory_bank,\n src_pad_mask,\n tgt_pad_mask,\n layer_cache=layer_cache,\n step=step,\n with_align=with_align)\n if attn_align is not None:\n attn_aligns.append(attn_align)\n\n output = self.layer_norm(output)\n dec_outs = output.transpose(0, 1).contiguous()\n attn = attn.transpose(0, 1).contiguous()\n\n attns = {\"std\": attn}\n if self._copy:\n attns[\"copy\"] = attn\n if with_align:\n attns[\"align\"] = attn_aligns[self.alignment_layer] # `(B, Q, K)`\n # attns[\"align\"] = torch.stack(attn_aligns, 0).mean(0) # All avg\n\n # TODO change the way attns is returned dict => list or tuple (onnx)\n return dec_outs, attns\n\n def _init_cache(self, memory_bank):\n self.state[\"cache\"] = {}\n batch_size = memory_bank.size(1)\n depth = memory_bank.size(-1)\n\n for i, layer in enumerate(self.transformer_layers):\n layer_cache = {\"memory_keys\": None, \"memory_values\": None}\n if isinstance(layer.self_attn, AverageAttention):\n layer_cache[\"prev_g\"] = torch.zeros((batch_size, 1, depth),\n device=memory_bank.device)\n else:\n layer_cache[\"self_keys\"] = None\n layer_cache[\"self_values\"] = None\n self.state[\"cache\"][\"layer_{}\".format(i)] = layer_cache\n\n def update_dropout(self, dropout, attention_dropout):\n self.embeddings.update_dropout(dropout)\n for layer in self.transformer_layers:\n layer.update_dropout(dropout, attention_dropout)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/encoders/__init__.py",
"content": "\"\"\"Module defining encoders.\"\"\"\nfrom onmt.encoders.encoder import EncoderBase\nfrom onmt.encoders.transformer import TransformerEncoder\nfrom onmt.encoders.rnn_encoder import RNNEncoder\nfrom onmt.encoders.cnn_encoder import CNNEncoder\nfrom onmt.encoders.mean_encoder import MeanEncoder\nfrom onmt.encoders.audio_encoder import AudioEncoder\nfrom onmt.encoders.image_encoder import ImageEncoder\n\n\nstr2enc = {\"rnn\": RNNEncoder, \"brnn\": RNNEncoder, \"cnn\": CNNEncoder,\n \"transformer\": TransformerEncoder, \"img\": ImageEncoder,\n \"audio\": AudioEncoder, \"mean\": MeanEncoder}\n\n__all__ = [\"EncoderBase\", \"TransformerEncoder\", \"RNNEncoder\", \"CNNEncoder\",\n \"MeanEncoder\", \"str2enc\"]\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/encoders/audio_encoder.py",
"content": "\"\"\"Audio encoder\"\"\"\nimport math\n\nimport torch.nn as nn\n\nfrom torch.nn.utils.rnn import pack_padded_sequence as pack\nfrom torch.nn.utils.rnn import pad_packed_sequence as unpack\n\nfrom onmt.utils.rnn_factory import rnn_factory\nfrom onmt.encoders.encoder import EncoderBase\n\n\nclass AudioEncoder(EncoderBase):\n \"\"\"A simple encoder CNN -> RNN for audio input.\n\n Args:\n rnn_type (str): Type of RNN (e.g. GRU, LSTM, etc).\n enc_layers (int): Number of encoder layers.\n dec_layers (int): Number of decoder layers.\n brnn (bool): Bidirectional encoder.\n enc_rnn_size (int): Size of hidden states of the rnn.\n dec_rnn_size (int): Size of the decoder hidden states.\n enc_pooling (str): A comma separated list either of length 1\n or of length ``enc_layers`` specifying the pooling amount.\n dropout (float): dropout probablity.\n sample_rate (float): input spec\n window_size (int): input spec\n \"\"\"\n\n def __init__(self, rnn_type, enc_layers, dec_layers, brnn,\n enc_rnn_size, dec_rnn_size, enc_pooling, dropout,\n sample_rate, window_size):\n super(AudioEncoder, self).__init__()\n self.enc_layers = enc_layers\n self.rnn_type = rnn_type\n self.dec_layers = dec_layers\n num_directions = 2 if brnn else 1\n self.num_directions = num_directions\n assert enc_rnn_size % num_directions == 0\n enc_rnn_size_real = enc_rnn_size // num_directions\n assert dec_rnn_size % num_directions == 0\n self.dec_rnn_size = dec_rnn_size\n dec_rnn_size_real = dec_rnn_size // num_directions\n self.dec_rnn_size_real = dec_rnn_size_real\n self.dec_rnn_size = dec_rnn_size\n input_size = int(math.floor((sample_rate * window_size) / 2) + 1)\n enc_pooling = enc_pooling.split(',')\n assert len(enc_pooling) == enc_layers or len(enc_pooling) == 1\n if len(enc_pooling) == 1:\n enc_pooling = enc_pooling * enc_layers\n enc_pooling = [int(p) for p in enc_pooling]\n self.enc_pooling = enc_pooling\n\n if type(dropout) is not list:\n dropout = [dropout]\n if max(dropout) > 0:\n self.dropout = nn.Dropout(dropout[0])\n else:\n self.dropout = None\n self.W = nn.Linear(enc_rnn_size, dec_rnn_size, bias=False)\n self.batchnorm_0 = nn.BatchNorm1d(enc_rnn_size, affine=True)\n self.rnn_0, self.no_pack_padded_seq = \\\n rnn_factory(rnn_type,\n input_size=input_size,\n hidden_size=enc_rnn_size_real,\n num_layers=1,\n dropout=dropout[0],\n bidirectional=brnn)\n self.pool_0 = nn.MaxPool1d(enc_pooling[0])\n for l in range(enc_layers - 1):\n batchnorm = nn.BatchNorm1d(enc_rnn_size, affine=True)\n rnn, _ = \\\n rnn_factory(rnn_type,\n input_size=enc_rnn_size,\n hidden_size=enc_rnn_size_real,\n num_layers=1,\n dropout=dropout[0],\n bidirectional=brnn)\n setattr(self, 'rnn_%d' % (l + 1), rnn)\n setattr(self, 'pool_%d' % (l + 1),\n nn.MaxPool1d(enc_pooling[l + 1]))\n setattr(self, 'batchnorm_%d' % (l + 1), batchnorm)\n\n @classmethod\n def from_opt(cls, opt, embeddings=None):\n \"\"\"Alternate constructor.\"\"\"\n if embeddings is not None:\n raise ValueError(\"Cannot use embeddings with AudioEncoder.\")\n return cls(\n opt.rnn_type,\n opt.enc_layers,\n opt.dec_layers,\n opt.brnn,\n opt.enc_rnn_size,\n opt.dec_rnn_size,\n opt.audio_enc_pooling,\n opt.dropout,\n opt.sample_rate,\n opt.window_size)\n\n def forward(self, src, lengths=None):\n \"\"\"See :func:`onmt.encoders.encoder.EncoderBase.forward()`\"\"\"\n batch_size, _, nfft, t = src.size()\n src = src.transpose(0, 1).transpose(0, 3).contiguous() \\\n .view(t, batch_size, nfft)\n orig_lengths = lengths\n lengths = lengths.view(-1).tolist()\n\n for l in range(self.enc_layers):\n rnn = getattr(self, 'rnn_%d' % l)\n pool = getattr(self, 'pool_%d' % l)\n batchnorm = getattr(self, 'batchnorm_%d' % l)\n stride = self.enc_pooling[l]\n packed_emb = pack(src, lengths)\n memory_bank, tmp = rnn(packed_emb)\n memory_bank = unpack(memory_bank)[0]\n t, _, _ = memory_bank.size()\n memory_bank = memory_bank.transpose(0, 2)\n memory_bank = pool(memory_bank)\n lengths = [int(math.floor((length - stride) / stride + 1))\n for length in lengths]\n memory_bank = memory_bank.transpose(0, 2)\n src = memory_bank\n t, _, num_feat = src.size()\n src = batchnorm(src.contiguous().view(-1, num_feat))\n src = src.view(t, -1, num_feat)\n if self.dropout and l + 1 != self.enc_layers:\n src = self.dropout(src)\n\n memory_bank = memory_bank.contiguous().view(-1, memory_bank.size(2))\n memory_bank = self.W(memory_bank).view(-1, batch_size,\n self.dec_rnn_size)\n\n state = memory_bank.new_full((self.dec_layers * self.num_directions,\n batch_size, self.dec_rnn_size_real), 0)\n if self.rnn_type == 'LSTM':\n # The encoder hidden is (layers*directions) x batch x dim.\n encoder_final = (state, state)\n else:\n encoder_final = state\n return encoder_final, memory_bank, orig_lengths.new_tensor(lengths)\n\n def update_dropout(self, dropout):\n self.dropout.p = dropout\n for i in range(self.enc_layers - 1):\n getattr(self, 'rnn_%d' % i).dropout = dropout\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/encoders/cnn_encoder.py",
"content": "\"\"\"\nImplementation of \"Convolutional Sequence to Sequence Learning\"\n\"\"\"\nimport torch.nn as nn\n\nfrom onmt.encoders.encoder import EncoderBase\nfrom onmt.utils.cnn_factory import shape_transform, StackedCNN\n\nSCALE_WEIGHT = 0.5 ** 0.5\n\n\nclass CNNEncoder(EncoderBase):\n \"\"\"Encoder based on \"Convolutional Sequence to Sequence Learning\"\n :cite:`DBLP:journals/corr/GehringAGYD17`.\n \"\"\"\n\n def __init__(self, num_layers, hidden_size,\n cnn_kernel_width, dropout, embeddings):\n super(CNNEncoder, self).__init__()\n\n self.embeddings = embeddings\n input_size = embeddings.embedding_size\n self.linear = nn.Linear(input_size, hidden_size)\n self.cnn = StackedCNN(num_layers, hidden_size,\n cnn_kernel_width, dropout)\n\n @classmethod\n def from_opt(cls, opt, embeddings):\n \"\"\"Alternate constructor.\"\"\"\n return cls(\n opt.enc_layers,\n opt.enc_rnn_size,\n opt.cnn_kernel_width,\n opt.dropout[0] if type(opt.dropout) is list else opt.dropout,\n embeddings)\n\n def forward(self, input, lengths=None, hidden=None):\n \"\"\"See :class:`onmt.modules.EncoderBase.forward()`\"\"\"\n self._check_args(input, lengths, hidden)\n\n emb = self.embeddings(input)\n # s_len, batch, emb_dim = emb.size()\n\n emb = emb.transpose(0, 1).contiguous()\n emb_reshape = emb.view(emb.size(0) * emb.size(1), -1)\n emb_remap = self.linear(emb_reshape)\n emb_remap = emb_remap.view(emb.size(0), emb.size(1), -1)\n emb_remap = shape_transform(emb_remap)\n out = self.cnn(emb_remap)\n\n return emb_remap.squeeze(3).transpose(0, 1).contiguous(), \\\n out.squeeze(3).transpose(0, 1).contiguous(), lengths\n\n def update_dropout(self, dropout):\n self.cnn.dropout.p = dropout\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/encoders/encoder.py",
"content": "\"\"\"Base class for encoders and generic multi encoders.\"\"\"\n\nimport torch.nn as nn\n\nfrom onmt.utils.misc import aeq\n\n\nclass EncoderBase(nn.Module):\n \"\"\"\n Base encoder class. Specifies the interface used by different encoder types\n and required by :class:`onmt.Models.NMTModel`.\n\n .. mermaid::\n\n graph BT\n A[Input]\n subgraph RNN\n C[Pos 1]\n D[Pos 2]\n E[Pos N]\n end\n F[Memory_Bank]\n G[Final]\n A-->C\n A-->D\n A-->E\n C-->F\n D-->F\n E-->F\n E-->G\n \"\"\"\n\n @classmethod\n def from_opt(cls, opt, embeddings=None):\n raise NotImplementedError\n\n def _check_args(self, src, lengths=None, hidden=None):\n n_batch = src.size(1)\n if lengths is not None:\n n_batch_, = lengths.size()\n aeq(n_batch, n_batch_)\n\n def forward(self, src, lengths=None):\n \"\"\"\n Args:\n src (LongTensor):\n padded sequences of sparse indices ``(src_len, batch, nfeat)``\n lengths (LongTensor): length of each sequence ``(batch,)``\n\n\n Returns:\n (FloatTensor, FloatTensor):\n\n * final encoder state, used to initialize decoder\n * memory bank for attention, ``(src_len, batch, hidden)``\n \"\"\"\n\n raise NotImplementedError\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/encoders/image_encoder.py",
"content": "\"\"\"Image Encoder.\"\"\"\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch\n\nfrom onmt.encoders.encoder import EncoderBase\n\n\nclass ImageEncoder(EncoderBase):\n \"\"\"A simple encoder CNN -> RNN for image src.\n\n Args:\n num_layers (int): number of encoder layers.\n bidirectional (bool): bidirectional encoder.\n rnn_size (int): size of hidden states of the rnn.\n dropout (float): dropout probablity.\n \"\"\"\n\n def __init__(self, num_layers, bidirectional, rnn_size, dropout,\n image_chanel_size=3):\n super(ImageEncoder, self).__init__()\n self.num_layers = num_layers\n self.num_directions = 2 if bidirectional else 1\n self.hidden_size = rnn_size\n\n self.layer1 = nn.Conv2d(image_chanel_size, 64, kernel_size=(3, 3),\n padding=(1, 1), stride=(1, 1))\n self.layer2 = nn.Conv2d(64, 128, kernel_size=(3, 3),\n padding=(1, 1), stride=(1, 1))\n self.layer3 = nn.Conv2d(128, 256, kernel_size=(3, 3),\n padding=(1, 1), stride=(1, 1))\n self.layer4 = nn.Conv2d(256, 256, kernel_size=(3, 3),\n padding=(1, 1), stride=(1, 1))\n self.layer5 = nn.Conv2d(256, 512, kernel_size=(3, 3),\n padding=(1, 1), stride=(1, 1))\n self.layer6 = nn.Conv2d(512, 512, kernel_size=(3, 3),\n padding=(1, 1), stride=(1, 1))\n\n self.batch_norm1 = nn.BatchNorm2d(256)\n self.batch_norm2 = nn.BatchNorm2d(512)\n self.batch_norm3 = nn.BatchNorm2d(512)\n\n src_size = 512\n dropout = dropout[0] if type(dropout) is list else dropout\n self.rnn = nn.LSTM(src_size, int(rnn_size / self.num_directions),\n num_layers=num_layers,\n dropout=dropout,\n bidirectional=bidirectional)\n self.pos_lut = nn.Embedding(1000, src_size)\n\n @classmethod\n def from_opt(cls, opt, embeddings=None):\n \"\"\"Alternate constructor.\"\"\"\n if embeddings is not None:\n raise ValueError(\"Cannot use embeddings with ImageEncoder.\")\n # why is the model_opt.__dict__ check necessary?\n if \"image_channel_size\" not in opt.__dict__:\n image_channel_size = 3\n else:\n image_channel_size = opt.image_channel_size\n return cls(\n opt.enc_layers,\n opt.brnn,\n opt.enc_rnn_size,\n opt.dropout[0] if type(opt.dropout) is list else opt.dropout,\n image_channel_size\n )\n\n def load_pretrained_vectors(self, opt):\n \"\"\"Pass in needed options only when modify function definition.\"\"\"\n pass\n\n def forward(self, src, lengths=None):\n \"\"\"See :func:`onmt.encoders.encoder.EncoderBase.forward()`\"\"\"\n\n batch_size = src.size(0)\n # (batch_size, 64, imgH, imgW)\n # layer 1\n src = F.relu(self.layer1(src[:, :, :, :] - 0.5), True)\n\n # (batch_size, 64, imgH/2, imgW/2)\n src = F.max_pool2d(src, kernel_size=(2, 2), stride=(2, 2))\n\n # (batch_size, 128, imgH/2, imgW/2)\n # layer 2\n src = F.relu(self.layer2(src), True)\n\n # (batch_size, 128, imgH/2/2, imgW/2/2)\n src = F.max_pool2d(src, kernel_size=(2, 2), stride=(2, 2))\n\n # (batch_size, 256, imgH/2/2, imgW/2/2)\n # layer 3\n # batch norm 1\n src = F.relu(self.batch_norm1(self.layer3(src)), True)\n\n # (batch_size, 256, imgH/2/2, imgW/2/2)\n # layer4\n src = F.relu(self.layer4(src), True)\n\n # (batch_size, 256, imgH/2/2/2, imgW/2/2)\n src = F.max_pool2d(src, kernel_size=(1, 2), stride=(1, 2))\n\n # (batch_size, 512, imgH/2/2/2, imgW/2/2)\n # layer 5\n # batch norm 2\n src = F.relu(self.batch_norm2(self.layer5(src)), True)\n\n # (batch_size, 512, imgH/2/2/2, imgW/2/2/2)\n src = F.max_pool2d(src, kernel_size=(2, 1), stride=(2, 1))\n\n # (batch_size, 512, imgH/2/2/2, imgW/2/2/2)\n src = F.relu(self.batch_norm3(self.layer6(src)), True)\n\n # # (batch_size, 512, H, W)\n all_outputs = []\n for row in range(src.size(2)):\n inp = src[:, :, row, :].transpose(0, 2) \\\n .transpose(1, 2)\n row_vec = torch.Tensor(batch_size).type_as(inp.data) \\\n .long().fill_(row)\n pos_emb = self.pos_lut(row_vec)\n with_pos = torch.cat(\n (pos_emb.view(1, pos_emb.size(0), pos_emb.size(1)), inp), 0)\n outputs, hidden_t = self.rnn(with_pos)\n all_outputs.append(outputs)\n out = torch.cat(all_outputs, 0)\n\n return hidden_t, out, lengths\n\n def update_dropout(self, dropout):\n self.rnn.dropout = dropout\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/encoders/mean_encoder.py",
"content": "\"\"\"Define a minimal encoder.\"\"\"\nfrom onmt.encoders.encoder import EncoderBase\nfrom onmt.utils.misc import sequence_mask\nimport torch\n\n\nclass MeanEncoder(EncoderBase):\n \"\"\"A trivial non-recurrent encoder. Simply applies mean pooling.\n\n Args:\n num_layers (int): number of replicated layers\n embeddings (onmt.modules.Embeddings): embedding module to use\n \"\"\"\n\n def __init__(self, num_layers, embeddings):\n super(MeanEncoder, self).__init__()\n self.num_layers = num_layers\n self.embeddings = embeddings\n\n @classmethod\n def from_opt(cls, opt, embeddings):\n \"\"\"Alternate constructor.\"\"\"\n return cls(\n opt.enc_layers,\n embeddings)\n\n def forward(self, src, lengths=None):\n \"\"\"See :func:`EncoderBase.forward()`\"\"\"\n self._check_args(src, lengths)\n\n emb = self.embeddings(src)\n _, batch, emb_dim = emb.size()\n\n if lengths is not None:\n # we avoid padding while mean pooling\n mask = sequence_mask(lengths).float()\n mask = mask / lengths.unsqueeze(1).float()\n mean = torch.bmm(mask.unsqueeze(1), emb.transpose(0, 1)).squeeze(1)\n else:\n mean = emb.mean(0)\n\n mean = mean.expand(self.num_layers, batch, emb_dim)\n memory_bank = emb\n encoder_final = (mean, mean)\n return encoder_final, memory_bank, lengths\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/encoders/rnn_encoder.py",
"content": "\"\"\"Define RNN-based encoders.\"\"\"\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nfrom torch.nn.utils.rnn import pack_padded_sequence as pack\nfrom torch.nn.utils.rnn import pad_packed_sequence as unpack\n\nfrom onmt.encoders.encoder import EncoderBase\nfrom onmt.utils.rnn_factory import rnn_factory\n\n\nclass RNNEncoder(EncoderBase):\n \"\"\" A generic recurrent neural network encoder.\n\n Args:\n rnn_type (str):\n style of recurrent unit to use, one of [RNN, LSTM, GRU, SRU]\n bidirectional (bool) : use a bidirectional RNN\n num_layers (int) : number of stacked layers\n hidden_size (int) : hidden size of each layer\n dropout (float) : dropout value for :class:`torch.nn.Dropout`\n embeddings (onmt.modules.Embeddings): embedding module to use\n \"\"\"\n\n def __init__(self, rnn_type, bidirectional, num_layers,\n hidden_size, dropout=0.0, embeddings=None,\n use_bridge=False):\n super(RNNEncoder, self).__init__()\n assert embeddings is not None\n\n num_directions = 2 if bidirectional else 1\n assert hidden_size % num_directions == 0\n hidden_size = hidden_size // num_directions\n self.embeddings = embeddings\n\n self.rnn, self.no_pack_padded_seq = \\\n rnn_factory(rnn_type,\n input_size=embeddings.embedding_size,\n hidden_size=hidden_size,\n num_layers=num_layers,\n dropout=dropout,\n bidirectional=bidirectional)\n\n # Initialize the bridge layer\n self.use_bridge = use_bridge\n if self.use_bridge:\n self._initialize_bridge(rnn_type,\n hidden_size,\n num_layers)\n\n @classmethod\n def from_opt(cls, opt, embeddings):\n \"\"\"Alternate constructor.\"\"\"\n return cls(\n opt.rnn_type,\n opt.brnn,\n opt.enc_layers,\n opt.enc_rnn_size,\n opt.dropout[0] if type(opt.dropout) is list else opt.dropout,\n embeddings,\n opt.bridge)\n\n def forward(self, src, lengths=None):\n \"\"\"See :func:`EncoderBase.forward()`\"\"\"\n self._check_args(src, lengths)\n\n emb = self.embeddings(src)\n # s_len, batch, emb_dim = emb.size()\n\n packed_emb = emb\n if lengths is not None and not self.no_pack_padded_seq:\n # Lengths data is wrapped inside a Tensor.\n lengths_list = lengths.view(-1).tolist()\n packed_emb = pack(emb, lengths_list)\n\n memory_bank, encoder_final = self.rnn(packed_emb)\n\n if lengths is not None and not self.no_pack_padded_seq:\n memory_bank = unpack(memory_bank)[0]\n\n if self.use_bridge:\n encoder_final = self._bridge(encoder_final)\n return encoder_final, memory_bank, lengths\n\n def _initialize_bridge(self, rnn_type,\n hidden_size,\n num_layers):\n\n # LSTM has hidden and cell state, other only one\n number_of_states = 2 if rnn_type == \"LSTM\" else 1\n # Total number of states\n self.total_hidden_dim = hidden_size * num_layers\n\n # Build a linear layer for each\n self.bridge = nn.ModuleList([nn.Linear(self.total_hidden_dim,\n self.total_hidden_dim,\n bias=True)\n for _ in range(number_of_states)])\n\n def _bridge(self, hidden):\n \"\"\"Forward hidden state through bridge.\"\"\"\n def bottle_hidden(linear, states):\n \"\"\"\n Transform from 3D to 2D, apply linear and return initial size\n \"\"\"\n size = states.size()\n result = linear(states.view(-1, self.total_hidden_dim))\n return F.relu(result).view(size)\n\n if isinstance(hidden, tuple): # LSTM\n outs = tuple([bottle_hidden(layer, hidden[ix])\n for ix, layer in enumerate(self.bridge)])\n else:\n outs = bottle_hidden(self.bridge[0], hidden)\n return outs\n\n def update_dropout(self, dropout):\n self.rnn.dropout = dropout\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/encoders/transformer.py",
"content": "\"\"\"\nImplementation of \"Attention is All You Need\"\n\"\"\"\n\nimport torch.nn as nn\n\nfrom onmt.encoders.encoder import EncoderBase\nfrom onmt.modules import MultiHeadedAttention\nfrom onmt.modules.position_ffn import PositionwiseFeedForward\nfrom onmt.utils.misc import sequence_mask\n\n\nclass TransformerEncoderLayer(nn.Module):\n \"\"\"\n A single layer of the transformer encoder.\n\n Args:\n d_model (int): the dimension of keys/values/queries in\n MultiHeadedAttention, also the input size of\n the first-layer of the PositionwiseFeedForward.\n heads (int): the number of head for MultiHeadedAttention.\n d_ff (int): the second-layer of the PositionwiseFeedForward.\n dropout (float): dropout probability(0-1.0).\n \"\"\"\n\n def __init__(self, d_model, heads, d_ff, dropout, attention_dropout,\n max_relative_positions=0):\n super(TransformerEncoderLayer, self).__init__()\n\n self.self_attn = MultiHeadedAttention(\n heads, d_model, dropout=attention_dropout,\n max_relative_positions=max_relative_positions)\n self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)\n self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)\n self.dropout = nn.Dropout(dropout)\n\n def forward(self, inputs, mask):\n \"\"\"\n Args:\n inputs (FloatTensor): ``(batch_size, src_len, model_dim)``\n mask (LongTensor): ``(batch_size, 1, src_len)``\n\n Returns:\n (FloatTensor):\n\n * outputs ``(batch_size, src_len, model_dim)``\n \"\"\"\n input_norm = self.layer_norm(inputs)\n context, _ = self.self_attn(input_norm, input_norm, input_norm,\n mask=mask, attn_type=\"self\")\n out = self.dropout(context) + inputs\n return self.feed_forward(out)\n\n def update_dropout(self, dropout, attention_dropout):\n self.self_attn.update_dropout(attention_dropout)\n self.feed_forward.update_dropout(dropout)\n self.dropout.p = dropout\n\n\nclass TransformerEncoder(EncoderBase):\n \"\"\"The Transformer encoder from \"Attention is All You Need\"\n :cite:`DBLP:journals/corr/VaswaniSPUJGKP17`\n\n .. mermaid::\n\n graph BT\n A[input]\n B[multi-head self-attn]\n C[feed forward]\n O[output]\n A --> B\n B --> C\n C --> O\n\n Args:\n num_layers (int): number of encoder layers\n d_model (int): size of the model\n heads (int): number of heads\n d_ff (int): size of the inner FF layer\n dropout (float): dropout parameters\n embeddings (onmt.modules.Embeddings):\n embeddings to use, should have positional encodings\n\n Returns:\n (torch.FloatTensor, torch.FloatTensor):\n\n * embeddings ``(src_len, batch_size, model_dim)``\n * memory_bank ``(src_len, batch_size, model_dim)``\n \"\"\"\n\n def __init__(self, num_layers, d_model, heads, d_ff, dropout,\n attention_dropout, embeddings, max_relative_positions):\n super(TransformerEncoder, self).__init__()\n\n self.embeddings = embeddings\n self.transformer = nn.ModuleList(\n [TransformerEncoderLayer(\n d_model, heads, d_ff, dropout, attention_dropout,\n max_relative_positions=max_relative_positions)\n for i in range(num_layers)])\n self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)\n\n @classmethod\n def from_opt(cls, opt, embeddings):\n \"\"\"Alternate constructor.\"\"\"\n return cls(\n opt.enc_layers,\n opt.enc_rnn_size,\n opt.heads,\n opt.transformer_ff,\n opt.dropout[0] if type(opt.dropout) is list else opt.dropout,\n opt.attention_dropout[0] if type(opt.attention_dropout)\n is list else opt.attention_dropout,\n embeddings,\n opt.max_relative_positions)\n\n def forward(self, src, lengths=None):\n \"\"\"See :func:`EncoderBase.forward()`\"\"\"\n self._check_args(src, lengths)\n\n emb = self.embeddings(src)\n\n out = emb.transpose(0, 1).contiguous()\n mask = ~sequence_mask(lengths).unsqueeze(1)\n # Run the forward pass of every layer of the tranformer.\n for layer in self.transformer:\n out = layer(out, mask)\n out = self.layer_norm(out)\n\n return emb, out.transpose(0, 1).contiguous(), lengths\n\n def update_dropout(self, dropout, attention_dropout):\n self.embeddings.update_dropout(dropout)\n for layer in self.transformer:\n layer.update_dropout(dropout, attention_dropout)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/inputters/__init__.py",
"content": "\"\"\"Module defining inputters.\n\nInputters implement the logic of transforming raw data to vectorized inputs,\ne.g., from a line of text to a sequence of embeddings.\n\"\"\"\nfrom onmt.inputters.inputter import \\\n load_old_vocab, get_fields, OrderedIterator, \\\n build_vocab, old_style_vocab, filter_example\nfrom onmt.inputters.dataset_base import Dataset\nfrom onmt.inputters.text_dataset import text_sort_key, TextDataReader\nfrom onmt.inputters.image_dataset import img_sort_key, ImageDataReader\nfrom onmt.inputters.audio_dataset import audio_sort_key, AudioDataReader\nfrom onmt.inputters.vec_dataset import vec_sort_key, VecDataReader\nfrom onmt.inputters.datareader_base import DataReaderBase\n\n\nstr2reader = {\n \"text\": TextDataReader, \"img\": ImageDataReader, \"audio\": AudioDataReader,\n \"vec\": VecDataReader}\nstr2sortkey = {\n 'text': text_sort_key, 'img': img_sort_key, 'audio': audio_sort_key,\n 'vec': vec_sort_key}\n\n\n__all__ = ['Dataset', 'load_old_vocab', 'get_fields', 'DataReaderBase',\n 'filter_example', 'old_style_vocab',\n 'build_vocab', 'OrderedIterator',\n 'text_sort_key', 'img_sort_key', 'audio_sort_key', 'vec_sort_key',\n 'TextDataReader', 'ImageDataReader', 'AudioDataReader',\n 'VecDataReader']\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/inputters/audio_dataset.py",
"content": "# -*- coding: utf-8 -*-\nimport os\nfrom tqdm import tqdm\n\nimport torch\nfrom torchtext.data import Field\n\nfrom onmt.inputters.datareader_base import DataReaderBase\n\n# imports of datatype-specific dependencies\ntry:\n import torchaudio\n import librosa\n import numpy as np\nexcept ImportError:\n torchaudio, librosa, np = None, None, None\n\n\nclass AudioDataReader(DataReaderBase):\n \"\"\"Read audio data from disk.\n\n Args:\n sample_rate (int): sample_rate.\n window_size (float) : window size for spectrogram in seconds.\n window_stride (float): window stride for spectrogram in seconds.\n window (str): window type for spectrogram generation. See\n :func:`librosa.stft()` ``window`` for more details.\n normalize_audio (bool): subtract spectrogram by mean and divide\n by std or not.\n truncate (int or NoneType): maximum audio length\n (0 or None for unlimited).\n\n Raises:\n onmt.inputters.datareader_base.MissingDependencyException: If\n importing any of ``torchaudio``, ``librosa``, or ``numpy`` fail.\n \"\"\"\n\n def __init__(self, sample_rate=0, window_size=0, window_stride=0,\n window=None, normalize_audio=True, truncate=None):\n self._check_deps()\n self.sample_rate = sample_rate\n self.window_size = window_size\n self.window_stride = window_stride\n self.window = window\n self.normalize_audio = normalize_audio\n self.truncate = truncate\n\n @classmethod\n def from_opt(cls, opt):\n return cls(sample_rate=opt.sample_rate, window_size=opt.window_size,\n window_stride=opt.window_stride, window=opt.window)\n\n @classmethod\n def _check_deps(cls):\n if any([torchaudio is None, librosa is None, np is None]):\n cls._raise_missing_dep(\n \"torchaudio\", \"librosa\", \"numpy\")\n\n def extract_features(self, audio_path):\n # torchaudio loading options recently changed. It's probably\n # straightforward to rewrite the audio handling to make use of\n # up-to-date torchaudio, but in the meantime there is a legacy\n # method which uses the old defaults\n sound, sample_rate_ = torchaudio.legacy.load(audio_path)\n if self.truncate and self.truncate > 0:\n if sound.size(0) > self.truncate:\n sound = sound[:self.truncate]\n\n assert sample_rate_ == self.sample_rate, \\\n 'Sample rate of %s != -sample_rate (%d vs %d)' \\\n % (audio_path, sample_rate_, self.sample_rate)\n\n sound = sound.numpy()\n if len(sound.shape) > 1:\n if sound.shape[1] == 1:\n sound = sound.squeeze()\n else:\n sound = sound.mean(axis=1) # average multiple channels\n\n n_fft = int(self.sample_rate * self.window_size)\n win_length = n_fft\n hop_length = int(self.sample_rate * self.window_stride)\n # STFT\n d = librosa.stft(sound, n_fft=n_fft, hop_length=hop_length,\n win_length=win_length, window=self.window)\n spect, _ = librosa.magphase(d)\n spect = np.log1p(spect)\n spect = torch.FloatTensor(spect)\n if self.normalize_audio:\n mean = spect.mean()\n std = spect.std()\n spect.add_(-mean)\n spect.div_(std)\n return spect\n\n def read(self, data, side, src_dir=None):\n \"\"\"Read data into dicts.\n\n Args:\n data (str or Iterable[str]): Sequence of audio paths or\n path to file containing audio paths.\n In either case, the filenames may be relative to ``src_dir``\n (default behavior) or absolute.\n side (str): Prefix used in return dict. Usually\n ``\"src\"`` or ``\"tgt\"``.\n src_dir (str): Location of source audio files. See ``data``.\n\n Yields:\n A dictionary containing audio data for each line.\n \"\"\"\n\n assert src_dir is not None and os.path.exists(src_dir),\\\n \"src_dir must be a valid directory if data_type is audio\"\n\n if isinstance(data, str):\n data = DataReaderBase._read_file(data)\n\n for i, line in enumerate(tqdm(data)):\n line = line.decode(\"utf-8\").strip()\n audio_path = os.path.join(src_dir, line)\n if not os.path.exists(audio_path):\n audio_path = line\n\n assert os.path.exists(audio_path), \\\n 'audio path %s not found' % line\n\n spect = self.extract_features(audio_path)\n yield {side: spect, side + '_path': line, 'indices': i}\n\n\ndef audio_sort_key(ex):\n \"\"\"Sort using duration time of the sound spectrogram.\"\"\"\n return ex.src.size(1)\n\n\nclass AudioSeqField(Field):\n \"\"\"Defines an audio datatype and instructions for converting to Tensor.\n\n See :class:`Fields` for attribute descriptions.\n \"\"\"\n\n def __init__(self, preprocessing=None, postprocessing=None,\n include_lengths=False, batch_first=False, pad_index=0,\n is_target=False):\n super(AudioSeqField, self).__init__(\n sequential=True, use_vocab=False, init_token=None,\n eos_token=None, fix_length=False, dtype=torch.float,\n preprocessing=preprocessing, postprocessing=postprocessing,\n lower=False, tokenize=None, include_lengths=include_lengths,\n batch_first=batch_first, pad_token=pad_index, unk_token=None,\n pad_first=False, truncate_first=False, stop_words=None,\n is_target=is_target\n )\n\n def pad(self, minibatch):\n \"\"\"Pad a batch of examples to the length of the longest example.\n\n Args:\n minibatch (List[torch.FloatTensor]): A list of audio data,\n each having shape 1 x n_feats x len where len is variable.\n\n Returns:\n torch.FloatTensor or Tuple[torch.FloatTensor, List[int]]: The\n padded tensor of shape ``(batch_size, 1, n_feats, max_len)``.\n and a list of the lengths if `self.include_lengths` is `True`\n else just returns the padded tensor.\n \"\"\"\n\n assert not self.pad_first and not self.truncate_first \\\n and not self.fix_length and self.sequential\n minibatch = list(minibatch)\n lengths = [x.size(1) for x in minibatch]\n max_len = max(lengths)\n nfft = minibatch[0].size(0)\n sounds = torch.full((len(minibatch), 1, nfft, max_len), self.pad_token)\n for i, (spect, len_) in enumerate(zip(minibatch, lengths)):\n sounds[i, :, :, 0:len_] = spect\n if self.include_lengths:\n return (sounds, lengths)\n return sounds\n\n def numericalize(self, arr, device=None):\n \"\"\"Turn a batch of examples that use this field into a Variable.\n\n If the field has ``include_lengths=True``, a tensor of lengths will be\n included in the return value.\n\n Args:\n arr (torch.FloatTensor or Tuple(torch.FloatTensor, List[int])):\n List of tokenized and padded examples, or tuple of List of\n tokenized and padded examples and List of lengths of each\n example if self.include_lengths is True. Examples have shape\n ``(batch_size, 1, n_feats, max_len)`` if `self.batch_first`\n else ``(max_len, batch_size, 1, n_feats)``.\n device (str or torch.device): See `Field.numericalize`.\n \"\"\"\n\n assert self.use_vocab is False\n if self.include_lengths and not isinstance(arr, tuple):\n raise ValueError(\"Field has include_lengths set to True, but \"\n \"input data is not a tuple of \"\n \"(data batch, batch lengths).\")\n if isinstance(arr, tuple):\n arr, lengths = arr\n lengths = torch.tensor(lengths, dtype=torch.int, device=device)\n\n if self.postprocessing is not None:\n arr = self.postprocessing(arr, None)\n\n if self.sequential and not self.batch_first:\n arr = arr.permute(3, 0, 1, 2)\n if self.sequential:\n arr = arr.contiguous()\n arr = arr.to(device)\n if self.include_lengths:\n return arr, lengths\n return arr\n\n\ndef audio_fields(**kwargs):\n audio = AudioSeqField(pad_index=0, batch_first=True, include_lengths=True)\n return audio\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/inputters/datareader_base.py",
"content": "# coding: utf-8\n\n\n# several data readers need optional dependencies. There's no\n# appropriate builtin exception\nclass MissingDependencyException(Exception):\n pass\n\n\nclass DataReaderBase(object):\n \"\"\"Read data from file system and yield as dicts.\n\n Raises:\n onmt.inputters.datareader_base.MissingDependencyException: A number\n of DataReaders need specific additional packages.\n If any are missing, this will be raised.\n \"\"\"\n\n @classmethod\n def from_opt(cls, opt):\n \"\"\"Alternative constructor.\n\n Args:\n opt (argparse.Namespace): The parsed arguments.\n \"\"\"\n\n return cls()\n\n @classmethod\n def _read_file(cls, path):\n \"\"\"Line-by-line read a file as bytes.\"\"\"\n with open(path, \"rb\") as f:\n for line in f:\n yield line\n\n @staticmethod\n def _raise_missing_dep(*missing_deps):\n \"\"\"Raise missing dep exception with standard error message.\"\"\"\n raise MissingDependencyException(\n \"Could not create reader. Be sure to install \"\n \"the following dependencies: \" + \", \".join(missing_deps))\n\n def read(self, data, side, src_dir):\n \"\"\"Read data from file system and yield as dicts.\"\"\"\n raise NotImplementedError()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/inputters/dataset_base.py",
"content": "# coding: utf-8\n\nfrom itertools import chain, starmap\nfrom collections import Counter\n\nimport torch\nfrom torchtext.data import Dataset as TorchtextDataset\nfrom torchtext.data import Example\nfrom torchtext.vocab import Vocab\n\n\ndef _join_dicts(*args):\n \"\"\"\n Args:\n dictionaries with disjoint keys.\n\n Returns:\n a single dictionary that has the union of these keys.\n \"\"\"\n\n return dict(chain(*[d.items() for d in args]))\n\n\ndef _dynamic_dict(example, src_field, tgt_field):\n \"\"\"Create copy-vocab and numericalize with it.\n\n In-place adds ``\"src_map\"`` to ``example``. That is the copy-vocab\n numericalization of the tokenized ``example[\"src\"]``. If ``example``\n has a ``\"tgt\"`` key, adds ``\"alignment\"`` to example. That is the\n copy-vocab numericalization of the tokenized ``example[\"tgt\"]``. The\n alignment has an initial and final UNK token to match the BOS and EOS\n tokens.\n\n Args:\n example (dict): An example dictionary with a ``\"src\"`` key and\n maybe a ``\"tgt\"`` key. (This argument changes in place!)\n src_field (torchtext.data.Field): Field object.\n tgt_field (torchtext.data.Field): Field object.\n\n Returns:\n torchtext.data.Vocab and ``example``, changed as described.\n \"\"\"\n\n src = src_field.tokenize(example[\"src\"])\n # make a small vocab containing just the tokens in the source sequence\n unk = src_field.unk_token\n pad = src_field.pad_token\n src_ex_vocab = Vocab(Counter(src), specials=[unk, pad])\n unk_idx = src_ex_vocab.stoi[unk]\n # Map source tokens to indices in the dynamic dict.\n src_map = torch.LongTensor([src_ex_vocab.stoi[w] for w in src])\n example[\"src_map\"] = src_map\n example[\"src_ex_vocab\"] = src_ex_vocab\n\n if \"tgt\" in example:\n tgt = tgt_field.tokenize(example[\"tgt\"])\n mask = torch.LongTensor(\n [unk_idx] + [src_ex_vocab.stoi[w] for w in tgt] + [unk_idx])\n example[\"alignment\"] = mask\n return src_ex_vocab, example\n\n\nclass Dataset(TorchtextDataset):\n \"\"\"Contain data and process it.\n\n A dataset is an object that accepts sequences of raw data (sentence pairs\n in the case of machine translation) and fields which describe how this\n raw data should be processed to produce tensors. When a dataset is\n instantiated, it applies the fields' preprocessing pipeline (but not\n the bit that numericalizes it or turns it into batch tensors) to the raw\n data, producing a list of :class:`torchtext.data.Example` objects.\n torchtext's iterators then know how to use these examples to make batches.\n\n Args:\n fields (dict[str, Field]): a dict with the structure\n returned by :func:`onmt.inputters.get_fields()`. Usually\n that means the dataset side, ``\"src\"`` or ``\"tgt\"``. Keys match\n the keys of items yielded by the ``readers``, while values\n are lists of (name, Field) pairs. An attribute with this\n name will be created for each :class:`torchtext.data.Example`\n object and its value will be the result of applying the Field\n to the data that matches the key. The advantage of having\n sequences of fields for each piece of raw input is that it allows\n the dataset to store multiple \"views\" of each input, which allows\n for easy implementation of token-level features, mixed word-\n and character-level models, and so on. (See also\n :class:`onmt.inputters.TextMultiField`.)\n readers (Iterable[onmt.inputters.DataReaderBase]): Reader objects\n for disk-to-dict. The yielded dicts are then processed\n according to ``fields``.\n data (Iterable[Tuple[str, Any]]): (name, ``data_arg``) pairs\n where ``data_arg`` is passed to the ``read()`` method of the\n reader in ``readers`` at that position. (See the reader object for\n details on the ``Any`` type.)\n dirs (Iterable[str or NoneType]): A list of directories where\n data is contained. See the reader object for more details.\n sort_key (Callable[[torchtext.data.Example], Any]): A function\n for determining the value on which data is sorted (i.e. length).\n filter_pred (Callable[[torchtext.data.Example], bool]): A function\n that accepts Example objects and returns a boolean value\n indicating whether to include that example in the dataset.\n\n Attributes:\n src_vocabs (List[torchtext.data.Vocab]): Used with dynamic dict/copy\n attention. There is a very short vocab for each src example.\n It contains just the source words, e.g. so that the generator can\n predict to copy them.\n \"\"\"\n\n def __init__(self, fields, readers, data, dirs, sort_key,\n filter_pred=None):\n self.sort_key = sort_key\n can_copy = 'src_map' in fields and 'alignment' in fields\n\n read_iters = [r.read(dat[1], dat[0], dir_) for r, dat, dir_\n in zip(readers, data, dirs)]\n\n # self.src_vocabs is used in collapse_copy_scores and Translator.py\n self.src_vocabs = []\n examples = []\n for ex_dict in starmap(_join_dicts, zip(*read_iters)):\n if can_copy:\n src_field = fields['src']\n tgt_field = fields['tgt']\n # this assumes src_field and tgt_field are both text\n src_ex_vocab, ex_dict = _dynamic_dict(\n ex_dict, src_field.base_field, tgt_field.base_field)\n self.src_vocabs.append(src_ex_vocab)\n ex_fields = {k: [(k, v)] for k, v in fields.items() if\n k in ex_dict}\n ex = Example.fromdict(ex_dict, ex_fields)\n examples.append(ex)\n\n # fields needs to have only keys that examples have as attrs\n fields = []\n for _, nf_list in ex_fields.items():\n assert len(nf_list) == 1\n fields.append(nf_list[0])\n\n super(Dataset, self).__init__(examples, fields, filter_pred)\n\n def __getattr__(self, attr):\n # avoid infinite recursion when fields isn't defined\n if 'fields' not in vars(self):\n raise AttributeError\n if attr in self.fields:\n return (getattr(x, attr) for x in self.examples)\n else:\n raise AttributeError\n\n def save(self, path, remove_fields=True):\n if remove_fields:\n self.fields = []\n torch.save(self, path)\n\n @staticmethod\n def config(fields):\n readers, data, dirs = [], [], []\n for name, field in fields:\n if field[\"data\"] is not None:\n readers.append(field[\"reader\"])\n data.append((name, field[\"data\"]))\n dirs.append(field[\"dir\"])\n return readers, data, dirs\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/inputters/image_dataset.py",
"content": "# -*- coding: utf-8 -*-\n\nimport os\n\nimport torch\nfrom torchtext.data import Field\n\nfrom onmt.inputters.datareader_base import DataReaderBase\n\n# domain specific dependencies\ntry:\n from PIL import Image\n from torchvision import transforms\n import cv2\nexcept ImportError:\n Image, transforms, cv2 = None, None, None\n\n\nclass ImageDataReader(DataReaderBase):\n \"\"\"Read image data from disk.\n\n Args:\n truncate (tuple[int] or NoneType): maximum img size. Use\n ``(0,0)`` or ``None`` for unlimited.\n channel_size (int): Number of channels per image.\n\n Raises:\n onmt.inputters.datareader_base.MissingDependencyException: If\n importing any of ``PIL``, ``torchvision``, or ``cv2`` fail.\n \"\"\"\n\n def __init__(self, truncate=None, channel_size=3):\n self._check_deps()\n self.truncate = truncate\n self.channel_size = channel_size\n\n @classmethod\n def from_opt(cls, opt):\n return cls(channel_size=opt.image_channel_size)\n\n @classmethod\n def _check_deps(cls):\n if any([Image is None, transforms is None, cv2 is None]):\n cls._raise_missing_dep(\n \"PIL\", \"torchvision\", \"cv2\")\n\n def read(self, images, side, img_dir=None):\n \"\"\"Read data into dicts.\n\n Args:\n images (str or Iterable[str]): Sequence of image paths or\n path to file containing audio paths.\n In either case, the filenames may be relative to ``src_dir``\n (default behavior) or absolute.\n side (str): Prefix used in return dict. Usually\n ``\"src\"`` or ``\"tgt\"``.\n img_dir (str): Location of source image files. See ``images``.\n\n Yields:\n a dictionary containing image data, path and index for each line.\n \"\"\"\n if isinstance(images, str):\n images = DataReaderBase._read_file(images)\n\n for i, filename in enumerate(images):\n filename = filename.decode(\"utf-8\").strip()\n img_path = os.path.join(img_dir, filename)\n if not os.path.exists(img_path):\n img_path = filename\n\n assert os.path.exists(img_path), \\\n 'img path %s not found' % filename\n\n if self.channel_size == 1:\n img = transforms.ToTensor()(\n Image.fromarray(cv2.imread(img_path, 0)))\n else:\n img = transforms.ToTensor()(Image.open(img_path))\n if self.truncate and self.truncate != (0, 0):\n if not (img.size(1) <= self.truncate[0]\n and img.size(2) <= self.truncate[1]):\n continue\n yield {side: img, side + '_path': filename, 'indices': i}\n\n\ndef img_sort_key(ex):\n \"\"\"Sort using the size of the image: (width, height).\"\"\"\n return ex.src.size(2), ex.src.size(1)\n\n\ndef batch_img(data, vocab):\n \"\"\"Pad and batch a sequence of images.\"\"\"\n c = data[0].size(0)\n h = max([t.size(1) for t in data])\n w = max([t.size(2) for t in data])\n imgs = torch.zeros(len(data), c, h, w).fill_(1)\n for i, img in enumerate(data):\n imgs[i, :, 0:img.size(1), 0:img.size(2)] = img\n return imgs\n\n\ndef image_fields(**kwargs):\n img = Field(\n use_vocab=False, dtype=torch.float,\n postprocessing=batch_img, sequential=False)\n return img\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/inputters/inputter.py",
"content": "# -*- coding: utf-8 -*-\nimport glob\nimport os\nimport codecs\nimport math\n\nfrom collections import Counter, defaultdict\nfrom itertools import chain, cycle\n\nimport torch\nimport torchtext.data\nfrom torchtext.data import Field, RawField, LabelField\nfrom torchtext.vocab import Vocab\nfrom torchtext.data.utils import RandomShuffler\n\nfrom onmt.inputters.text_dataset import text_fields, TextMultiField\nfrom onmt.inputters.image_dataset import image_fields\nfrom onmt.inputters.audio_dataset import audio_fields\nfrom onmt.inputters.vec_dataset import vec_fields\nfrom onmt.utils.logging import logger\n# backwards compatibility\nfrom onmt.inputters.text_dataset import _feature_tokenize # noqa: F401\nfrom onmt.inputters.image_dataset import ( # noqa: F401\n batch_img as make_img)\n\nimport gc\n\n\n# monkey-patch to make torchtext Vocab's pickleable\ndef _getstate(self):\n return dict(self.__dict__, stoi=dict(self.stoi))\n\n\ndef _setstate(self, state):\n self.__dict__.update(state)\n self.stoi = defaultdict(lambda: 0, self.stoi)\n\n\nVocab.__getstate__ = _getstate\nVocab.__setstate__ = _setstate\n\n\ndef make_src(data, vocab):\n src_size = max([t.size(0) for t in data])\n src_vocab_size = max([t.max() for t in data]) + 1\n alignment = torch.zeros(src_size, len(data), src_vocab_size)\n for i, sent in enumerate(data):\n for j, t in enumerate(sent):\n alignment[j, i, t] = 1\n return alignment\n\n\ndef make_tgt(data, vocab):\n tgt_size = max([t.size(0) for t in data])\n alignment = torch.zeros(tgt_size, len(data)).long()\n for i, sent in enumerate(data):\n alignment[:sent.size(0), i] = sent\n return alignment\n\n\nclass AlignField(LabelField):\n \"\"\"\n Parse ['-', ...] into ['','', ...]\n \"\"\"\n def __init__(self, **kwargs):\n kwargs['use_vocab'] = False\n kwargs['preprocessing'] = parse_align_idx\n super(AlignField, self).__init__(**kwargs)\n\n def process(self, batch, device=None):\n \"\"\" Turn a batch of align-idx to a sparse align idx Tensor\"\"\"\n sparse_idx = []\n for i, example in enumerate(batch):\n for src, tgt in example:\n # +1 for tgt side to keep coherent after \"bos\" padding,\n # register ['N°_in_batch', 'tgt_id+1', 'src_id']\n sparse_idx.append([i, tgt + 1, src])\n\n align_idx = torch.tensor(sparse_idx, dtype=self.dtype, device=device)\n\n return align_idx\n\n\ndef parse_align_idx(align_pharaoh):\n \"\"\"\n Parse Pharaoh alignment into [[, ], ...]\n \"\"\"\n align_list = align_pharaoh.strip().split(' ')\n flatten_align_idx = []\n for align in align_list:\n try:\n src_idx, tgt_idx = align.split('-')\n except ValueError:\n logger.warning(\"{} in `{}`\".format(align, align_pharaoh))\n logger.warning(\"Bad alignement line exists. Please check file!\")\n raise\n flatten_align_idx.append([int(src_idx), int(tgt_idx)])\n return flatten_align_idx\n\n\ndef get_fields(\n src_data_type,\n n_src_feats,\n n_tgt_feats,\n pad='',\n bos='',\n eos='',\n dynamic_dict=False,\n with_align=False,\n src_truncate=None,\n tgt_truncate=None\n):\n \"\"\"\n Args:\n src_data_type: type of the source input. Options are [text|img|audio].\n n_src_feats (int): the number of source features (not counting tokens)\n to create a :class:`torchtext.data.Field` for. (If\n ``src_data_type==\"text\"``, these fields are stored together\n as a ``TextMultiField``).\n n_tgt_feats (int): See above.\n pad (str): Special pad symbol. Used on src and tgt side.\n bos (str): Special beginning of sequence symbol. Only relevant\n for tgt.\n eos (str): Special end of sequence symbol. Only relevant\n for tgt.\n dynamic_dict (bool): Whether or not to include source map and\n alignment fields.\n with_align (bool): Whether or not to include word align.\n src_truncate: Cut off src sequences beyond this (passed to\n ``src_data_type``'s data reader - see there for more details).\n tgt_truncate: Cut off tgt sequences beyond this (passed to\n :class:`TextDataReader` - see there for more details).\n\n Returns:\n A dict mapping names to fields. These names need to match\n the dataset example attributes.\n \"\"\"\n\n assert src_data_type in ['text', 'img', 'audio', 'vec'], \\\n \"Data type not implemented\"\n assert not dynamic_dict or src_data_type == 'text', \\\n 'it is not possible to use dynamic_dict with non-text input'\n fields = {}\n\n fields_getters = {\"text\": text_fields,\n \"img\": image_fields,\n \"audio\": audio_fields,\n \"vec\": vec_fields}\n\n src_field_kwargs = {\"n_feats\": n_src_feats,\n \"include_lengths\": True,\n \"pad\": pad, \"bos\": None, \"eos\": None,\n \"truncate\": src_truncate,\n \"base_name\": \"src\"}\n fields[\"src\"] = fields_getters[src_data_type](**src_field_kwargs)\n\n tgt_field_kwargs = {\"n_feats\": n_tgt_feats,\n \"include_lengths\": False,\n \"pad\": pad, \"bos\": bos, \"eos\": eos,\n \"truncate\": tgt_truncate,\n \"base_name\": \"tgt\"}\n fields[\"tgt\"] = fields_getters[\"text\"](**tgt_field_kwargs)\n\n indices = Field(use_vocab=False, dtype=torch.long, sequential=False)\n fields[\"indices\"] = indices\n\n if dynamic_dict:\n src_map = Field(\n use_vocab=False, dtype=torch.float,\n postprocessing=make_src, sequential=False)\n fields[\"src_map\"] = src_map\n\n src_ex_vocab = RawField()\n fields[\"src_ex_vocab\"] = src_ex_vocab\n\n align = Field(\n use_vocab=False, dtype=torch.long,\n postprocessing=make_tgt, sequential=False)\n fields[\"alignment\"] = align\n\n if with_align:\n word_align = AlignField()\n fields[\"align\"] = word_align\n\n return fields\n\n\ndef load_old_vocab(vocab, data_type=\"text\", dynamic_dict=False):\n \"\"\"Update a legacy vocab/field format.\n\n Args:\n vocab: a list of (field name, torchtext.vocab.Vocab) pairs. This is the\n format formerly saved in *.vocab.pt files. Or, text data\n not using a :class:`TextMultiField`.\n data_type (str): text, img, or audio\n dynamic_dict (bool): Used for copy attention.\n\n Returns:\n a dictionary whose keys are the field names and whose values Fields.\n \"\"\"\n\n if _old_style_vocab(vocab):\n # List[Tuple[str, Vocab]] -> List[Tuple[str, Field]]\n # -> dict[str, Field]\n vocab = dict(vocab)\n n_src_features = sum('src_feat_' in k for k in vocab)\n n_tgt_features = sum('tgt_feat_' in k for k in vocab)\n fields = get_fields(\n data_type, n_src_features, n_tgt_features,\n dynamic_dict=dynamic_dict)\n for n, f in fields.items():\n try:\n f_iter = iter(f)\n except TypeError:\n f_iter = [(n, f)]\n for sub_n, sub_f in f_iter:\n if sub_n in vocab:\n sub_f.vocab = vocab[sub_n]\n return fields\n\n if _old_style_field_list(vocab): # upgrade to multifield\n # Dict[str, List[Tuple[str, Field]]]\n # doesn't change structure - don't return early.\n fields = vocab\n for base_name, vals in fields.items():\n if ((base_name == 'src' and data_type == 'text') or\n base_name == 'tgt'):\n assert not isinstance(vals[0][1], TextMultiField)\n fields[base_name] = [(base_name, TextMultiField(\n vals[0][0], vals[0][1], vals[1:]))]\n\n if _old_style_nesting(vocab):\n # Dict[str, List[Tuple[str, Field]]] -> List[Tuple[str, Field]]\n # -> dict[str, Field]\n fields = dict(list(chain.from_iterable(vocab.values())))\n\n return fields\n\n\ndef _old_style_vocab(vocab):\n \"\"\"Detect old-style vocabs (``List[Tuple[str, torchtext.data.Vocab]]``).\n\n Args:\n vocab: some object loaded from a *.vocab.pt file\n\n Returns:\n Whether ``vocab`` is a list of pairs where the second object\n is a :class:`torchtext.vocab.Vocab` object.\n\n This exists because previously only the vocab objects from the fields\n were saved directly, not the fields themselves, and the fields needed to\n be reconstructed at training and translation time.\n \"\"\"\n\n return isinstance(vocab, list) and \\\n any(isinstance(v[1], Vocab) for v in vocab)\n\n\ndef _old_style_nesting(vocab):\n \"\"\"Detect old-style nesting (``dict[str, List[Tuple[str, Field]]]``).\"\"\"\n return isinstance(vocab, dict) and \\\n any(isinstance(v, list) for v in vocab.values())\n\n\ndef _old_style_field_list(vocab):\n \"\"\"Detect old-style text fields.\n\n Not old style vocab, old nesting, and text-type fields not using\n ``TextMultiField``.\n\n Args:\n vocab: some object loaded from a *.vocab.pt file\n\n Returns:\n Whether ``vocab`` is not an :func:`_old_style_vocab` and not\n a :class:`TextMultiField` (using an old-style text representation).\n \"\"\"\n\n # if tgt isn't using TextMultiField, then no text field is.\n return (not _old_style_vocab(vocab)) and _old_style_nesting(vocab) and \\\n (not isinstance(vocab['tgt'][0][1], TextMultiField))\n\n\ndef old_style_vocab(vocab):\n \"\"\"The vocab/fields need updated.\"\"\"\n return _old_style_vocab(vocab) or _old_style_field_list(vocab) or \\\n _old_style_nesting(vocab)\n\n\ndef filter_example(ex, use_src_len=True, use_tgt_len=True,\n min_src_len=1, max_src_len=float('inf'),\n min_tgt_len=1, max_tgt_len=float('inf')):\n \"\"\"Return whether an example is an acceptable length.\n\n If used with a dataset as ``filter_pred``, use :func:`partial()`\n for all keyword arguments.\n\n Args:\n ex (torchtext.data.Example): An object with a ``src`` and ``tgt``\n property.\n use_src_len (bool): Filter based on the length of ``ex.src``.\n use_tgt_len (bool): Similar to above.\n min_src_len (int): A non-negative minimally acceptable length\n (examples of exactly this length will be included).\n min_tgt_len (int): Similar to above.\n max_src_len (int or float): A non-negative (possibly infinite)\n maximally acceptable length (examples of exactly this length\n will be included).\n max_tgt_len (int or float): Similar to above.\n \"\"\"\n\n src_len = len(ex.src[0])\n tgt_len = len(ex.tgt[0])\n return (not use_src_len or min_src_len <= src_len <= max_src_len) and \\\n (not use_tgt_len or min_tgt_len <= tgt_len <= max_tgt_len)\n\n\ndef _pad_vocab_to_multiple(vocab, multiple):\n vocab_size = len(vocab)\n if vocab_size % multiple == 0:\n return\n target_size = int(math.ceil(vocab_size / multiple)) * multiple\n padding_tokens = [\n \"averyunlikelytoken%d\" % i for i in range(target_size - vocab_size)]\n vocab.extend(Vocab(Counter(), specials=padding_tokens))\n return vocab\n\n\ndef _build_field_vocab(field, counter, size_multiple=1, **kwargs):\n # this is basically copy-pasted from torchtext.\n all_specials = [\n field.unk_token, field.pad_token, field.init_token, field.eos_token\n ]\n specials = [tok for tok in all_specials if tok is not None]\n field.vocab = field.vocab_cls(counter, specials=specials, **kwargs)\n if size_multiple > 1:\n _pad_vocab_to_multiple(field.vocab, size_multiple)\n\n\ndef _load_vocab(vocab_path, name, counters, min_freq):\n # counters changes in place\n vocab = _read_vocab_file(vocab_path, name)\n vocab_size = len(vocab)\n logger.info('Loaded %s vocab has %d tokens.' % (name, vocab_size))\n for i, token in enumerate(vocab):\n # keep the order of tokens specified in the vocab file by\n # adding them to the counter with decreasing counting values\n counters[name][token] = vocab_size - i + min_freq\n return vocab, vocab_size\n\n\ndef _build_fv_from_multifield(multifield, counters, build_fv_args,\n size_multiple=1):\n for name, field in multifield:\n _build_field_vocab(\n field,\n counters[name],\n size_multiple=size_multiple,\n **build_fv_args[name])\n logger.info(\" * %s vocab size: %d.\" % (name, len(field.vocab)))\n\n\ndef _build_fields_vocab(fields, counters, data_type, share_vocab,\n vocab_size_multiple,\n src_vocab_size, src_words_min_frequency,\n tgt_vocab_size, tgt_words_min_frequency):\n build_fv_args = defaultdict(dict)\n build_fv_args[\"src\"] = dict(\n max_size=src_vocab_size, min_freq=src_words_min_frequency)\n build_fv_args[\"tgt\"] = dict(\n max_size=tgt_vocab_size, min_freq=tgt_words_min_frequency)\n tgt_multifield = fields[\"tgt\"]\n _build_fv_from_multifield(\n tgt_multifield,\n counters,\n build_fv_args,\n size_multiple=vocab_size_multiple if not share_vocab else 1)\n if data_type == 'text':\n src_multifield = fields[\"src\"]\n _build_fv_from_multifield(\n src_multifield,\n counters,\n build_fv_args,\n size_multiple=vocab_size_multiple if not share_vocab else 1)\n if share_vocab:\n # `tgt_vocab_size` is ignored when sharing vocabularies\n logger.info(\" * merging src and tgt vocab...\")\n src_field = src_multifield.base_field\n tgt_field = tgt_multifield.base_field\n _merge_field_vocabs(\n src_field, tgt_field, vocab_size=src_vocab_size,\n min_freq=src_words_min_frequency,\n vocab_size_multiple=vocab_size_multiple)\n logger.info(\" * merged vocab size: %d.\" % len(src_field.vocab))\n\n return fields\n\n\ndef build_vocab(train_dataset_files, fields, data_type, share_vocab,\n src_vocab_path, src_vocab_size, src_words_min_frequency,\n tgt_vocab_path, tgt_vocab_size, tgt_words_min_frequency,\n vocab_size_multiple=1):\n \"\"\"Build the fields for all data sides.\n\n Args:\n train_dataset_files: a list of train dataset pt file.\n fields (dict[str, Field]): fields to build vocab for.\n data_type (str): A supported data type string.\n share_vocab (bool): share source and target vocabulary?\n src_vocab_path (str): Path to src vocabulary file.\n src_vocab_size (int): size of the source vocabulary.\n src_words_min_frequency (int): the minimum frequency needed to\n include a source word in the vocabulary.\n tgt_vocab_path (str): Path to tgt vocabulary file.\n tgt_vocab_size (int): size of the target vocabulary.\n tgt_words_min_frequency (int): the minimum frequency needed to\n include a target word in the vocabulary.\n vocab_size_multiple (int): ensure that the vocabulary size is a\n multiple of this value.\n\n Returns:\n Dict of Fields\n \"\"\"\n\n counters = defaultdict(Counter)\n\n if src_vocab_path:\n try:\n logger.info(\"Using existing vocabulary...\")\n vocab = torch.load(src_vocab_path)\n # return vocab to dump with standard name\n return vocab\n except torch.serialization.pickle.UnpicklingError:\n logger.info(\"Building vocab from text file...\")\n # empty train_dataset_files so that vocab is only loaded from\n # given paths in src_vocab_path, tgt_vocab_path\n train_dataset_files = []\n\n # Load vocabulary\n if src_vocab_path:\n src_vocab, src_vocab_size = _load_vocab(\n src_vocab_path, \"src\", counters,\n src_words_min_frequency)\n else:\n src_vocab = None\n\n if tgt_vocab_path:\n tgt_vocab, tgt_vocab_size = _load_vocab(\n tgt_vocab_path, \"tgt\", counters,\n tgt_words_min_frequency)\n else:\n tgt_vocab = None\n\n for i, path in enumerate(train_dataset_files):\n dataset = torch.load(path)\n logger.info(\" * reloading %s.\" % path)\n for ex in dataset.examples:\n for name, field in fields.items():\n try:\n f_iter = iter(field)\n except TypeError:\n f_iter = [(name, field)]\n all_data = [getattr(ex, name, None)]\n else:\n all_data = getattr(ex, name)\n for (sub_n, sub_f), fd in zip(\n f_iter, all_data):\n has_vocab = (sub_n == 'src' and src_vocab) or \\\n (sub_n == 'tgt' and tgt_vocab)\n if sub_f.sequential and not has_vocab:\n val = fd\n counters[sub_n].update(val)\n\n # Drop the none-using from memory but keep the last\n if i < len(train_dataset_files) - 1:\n dataset.examples = None\n gc.collect()\n del dataset.examples\n gc.collect()\n del dataset\n gc.collect()\n\n fields = _build_fields_vocab(\n fields, counters, data_type,\n share_vocab, vocab_size_multiple,\n src_vocab_size, src_words_min_frequency,\n tgt_vocab_size, tgt_words_min_frequency)\n\n return fields # is the return necessary?\n\n\ndef _merge_field_vocabs(src_field, tgt_field, vocab_size, min_freq,\n vocab_size_multiple):\n # in the long run, shouldn't it be possible to do this by calling\n # build_vocab with both the src and tgt data?\n specials = [tgt_field.unk_token, tgt_field.pad_token,\n tgt_field.init_token, tgt_field.eos_token]\n merged = sum(\n [src_field.vocab.freqs, tgt_field.vocab.freqs], Counter()\n )\n merged_vocab = Vocab(\n merged, specials=specials,\n max_size=vocab_size, min_freq=min_freq\n )\n if vocab_size_multiple > 1:\n _pad_vocab_to_multiple(merged_vocab, vocab_size_multiple)\n src_field.vocab = merged_vocab\n tgt_field.vocab = merged_vocab\n assert len(src_field.vocab) == len(tgt_field.vocab)\n\n\ndef _read_vocab_file(vocab_path, tag):\n \"\"\"Loads a vocabulary from the given path.\n\n Args:\n vocab_path (str): Path to utf-8 text file containing vocabulary.\n Each token should be on a line by itself. Tokens must not\n contain whitespace (else only before the whitespace\n is considered).\n tag (str): Used for logging which vocab is being read.\n \"\"\"\n\n logger.info(\"Loading {} vocabulary from {}\".format(tag, vocab_path))\n\n if not os.path.exists(vocab_path):\n raise RuntimeError(\n \"{} vocabulary not found at {}\".format(tag, vocab_path))\n else:\n with codecs.open(vocab_path, 'r', 'utf-8') as f:\n return [line.strip().split()[0] for line in f if line.strip()]\n\n\ndef batch_iter(data, batch_size, batch_size_fn=None, batch_size_multiple=1):\n \"\"\"Yield elements from data in chunks of batch_size, where each chunk size\n is a multiple of batch_size_multiple.\n\n This is an extended version of torchtext.data.batch.\n \"\"\"\n if batch_size_fn is None:\n def batch_size_fn(new, count, sofar):\n return count\n minibatch, size_so_far = [], 0\n for ex in data:\n minibatch.append(ex)\n size_so_far = batch_size_fn(ex, len(minibatch), size_so_far)\n if size_so_far >= batch_size:\n overflowed = 0\n if size_so_far > batch_size:\n overflowed += 1\n if batch_size_multiple > 1:\n overflowed += (\n (len(minibatch) - overflowed) % batch_size_multiple)\n if overflowed == 0:\n yield minibatch\n minibatch, size_so_far = [], 0\n else:\n if overflowed == len(minibatch):\n logger.warning(\n \"An example was ignored, more tokens\"\n \" than allowed by tokens batch_size\")\n else:\n yield minibatch[:-overflowed]\n minibatch = minibatch[-overflowed:]\n size_so_far = 0\n for i, ex in enumerate(minibatch):\n size_so_far = batch_size_fn(ex, i + 1, size_so_far)\n if minibatch:\n yield minibatch\n\n\ndef _pool(data, batch_size, batch_size_fn, batch_size_multiple,\n sort_key, random_shuffler, pool_factor):\n for p in torchtext.data.batch(\n data, batch_size * pool_factor,\n batch_size_fn=batch_size_fn):\n p_batch = list(batch_iter(\n sorted(p, key=sort_key),\n batch_size,\n batch_size_fn=batch_size_fn,\n batch_size_multiple=batch_size_multiple))\n for b in random_shuffler(p_batch):\n yield b\n\n\nclass OrderedIterator(torchtext.data.Iterator):\n\n def __init__(self,\n dataset,\n batch_size,\n pool_factor=1,\n batch_size_multiple=1,\n yield_raw_example=False,\n **kwargs):\n super(OrderedIterator, self).__init__(dataset, batch_size, **kwargs)\n self.batch_size_multiple = batch_size_multiple\n self.yield_raw_example = yield_raw_example\n self.dataset = dataset\n self.pool_factor = pool_factor\n\n def create_batches(self):\n if self.train:\n if self.yield_raw_example:\n self.batches = batch_iter(\n self.data(),\n 1,\n batch_size_fn=None,\n batch_size_multiple=1)\n else:\n self.batches = _pool(\n self.data(),\n self.batch_size,\n self.batch_size_fn,\n self.batch_size_multiple,\n self.sort_key,\n self.random_shuffler,\n self.pool_factor)\n else:\n self.batches = []\n for b in batch_iter(\n self.data(),\n self.batch_size,\n batch_size_fn=self.batch_size_fn,\n batch_size_multiple=self.batch_size_multiple):\n self.batches.append(sorted(b, key=self.sort_key))\n\n def __iter__(self):\n \"\"\"\n Extended version of the definition in torchtext.data.Iterator.\n Added yield_raw_example behaviour to yield a torchtext.data.Example\n instead of a torchtext.data.Batch object.\n \"\"\"\n while True:\n self.init_epoch()\n for idx, minibatch in enumerate(self.batches):\n # fast-forward if loaded from state\n if self._iterations_this_epoch > idx:\n continue\n self.iterations += 1\n self._iterations_this_epoch += 1\n if self.sort_within_batch:\n # NOTE: `rnn.pack_padded_sequence` requires that a\n # minibatch be sorted by decreasing order, which\n # requires reversing relative to typical sort keys\n if self.sort:\n minibatch.reverse()\n else:\n minibatch.sort(key=self.sort_key, reverse=True)\n if self.yield_raw_example:\n yield minibatch[0]\n else:\n yield torchtext.data.Batch(\n minibatch,\n self.dataset,\n self.device)\n if not self.repeat:\n return\n\n\nclass MultipleDatasetIterator(object):\n \"\"\"\n This takes a list of iterable objects (DatasetLazyIter) and their\n respective weights, and yields a batch in the wanted proportions.\n \"\"\"\n def __init__(self,\n train_shards,\n fields,\n device,\n opt):\n self.index = -1\n self.iterables = []\n for shard in train_shards:\n self.iterables.append(\n build_dataset_iter(shard, fields, opt, multi=True))\n self.init_iterators = True\n self.weights = opt.data_weights\n self.batch_size = opt.batch_size\n self.batch_size_fn = max_tok_len \\\n if opt.batch_type == \"tokens\" else None\n self.batch_size_multiple = 8 if opt.model_dtype == \"fp16\" else 1\n self.device = device\n # Temporarily load one shard to retrieve sort_key for data_type\n temp_dataset = torch.load(self.iterables[0]._paths[0])\n self.sort_key = temp_dataset.sort_key\n self.random_shuffler = RandomShuffler()\n self.pool_factor = opt.pool_factor\n del temp_dataset\n\n def _iter_datasets(self):\n if self.init_iterators:\n self.iterators = [iter(iterable) for iterable in self.iterables]\n self.init_iterators = False\n for weight in self.weights:\n self.index = (self.index + 1) % len(self.iterators)\n for i in range(weight):\n yield self.iterators[self.index]\n\n def _iter_examples(self):\n for iterator in cycle(self._iter_datasets()):\n yield next(iterator)\n\n def __iter__(self):\n while True:\n for minibatch in _pool(\n self._iter_examples(),\n self.batch_size,\n self.batch_size_fn,\n self.batch_size_multiple,\n self.sort_key,\n self.random_shuffler,\n self.pool_factor):\n minibatch = sorted(minibatch, key=self.sort_key, reverse=True)\n yield torchtext.data.Batch(minibatch,\n self.iterables[0].dataset,\n self.device)\n\n\nclass DatasetLazyIter(object):\n \"\"\"Yield data from sharded dataset files.\n\n Args:\n dataset_paths: a list containing the locations of dataset files.\n fields (dict[str, Field]): fields dict for the\n datasets.\n batch_size (int): batch size.\n batch_size_fn: custom batch process function.\n device: See :class:`OrderedIterator` ``device``.\n is_train (bool): train or valid?\n \"\"\"\n\n def __init__(self, dataset_paths, fields, batch_size, batch_size_fn,\n batch_size_multiple, device, is_train, pool_factor,\n repeat=True, num_batches_multiple=1, yield_raw_example=False):\n self._paths = dataset_paths\n self.fields = fields\n self.batch_size = batch_size\n self.batch_size_fn = batch_size_fn\n self.batch_size_multiple = batch_size_multiple\n self.device = device\n self.is_train = is_train\n self.repeat = repeat\n self.num_batches_multiple = num_batches_multiple\n self.yield_raw_example = yield_raw_example\n self.pool_factor = pool_factor\n\n def _iter_dataset(self, path):\n logger.info('Loading dataset from %s' % path)\n cur_dataset = torch.load(path)\n logger.info('number of examples: %d' % len(cur_dataset))\n cur_dataset.fields = self.fields\n cur_iter = OrderedIterator(\n dataset=cur_dataset,\n batch_size=self.batch_size,\n pool_factor=self.pool_factor,\n batch_size_multiple=self.batch_size_multiple,\n batch_size_fn=self.batch_size_fn,\n device=self.device,\n train=self.is_train,\n sort=False,\n sort_within_batch=True,\n repeat=False,\n yield_raw_example=self.yield_raw_example\n )\n for batch in cur_iter:\n self.dataset = cur_iter.dataset\n yield batch\n\n # NOTE: This is causing some issues for consumer/producer,\n # as we may still have some of those examples in some queue\n # cur_dataset.examples = None\n # gc.collect()\n # del cur_dataset\n # gc.collect()\n\n def __iter__(self):\n num_batches = 0\n paths = self._paths\n if self.is_train and self.repeat:\n # Cycle through the shards indefinitely.\n paths = cycle(paths)\n for path in paths:\n for batch in self._iter_dataset(path):\n yield batch\n num_batches += 1\n if self.is_train and not self.repeat and \\\n num_batches % self.num_batches_multiple != 0:\n # When the dataset is not repeated, we might need to ensure that\n # the number of returned batches is the multiple of a given value.\n # This is important for multi GPU training to ensure that all\n # workers have the same number of batches to process.\n for path in paths:\n for batch in self._iter_dataset(path):\n yield batch\n num_batches += 1\n if num_batches % self.num_batches_multiple == 0:\n return\n\n\ndef max_tok_len(new, count, sofar):\n \"\"\"\n In token batching scheme, the number of sequences is limited\n such that the total number of src/tgt tokens (including padding)\n in a batch <= batch_size\n \"\"\"\n # Maintains the longest src and tgt length in the current batch\n global max_src_in_batch, max_tgt_in_batch # this is a hack\n # Reset current longest length at a new batch (count=1)\n if count == 1:\n max_src_in_batch = 0\n max_tgt_in_batch = 0\n # Src: [ w1 ... wN ]\n max_src_in_batch = max(max_src_in_batch, len(new.src[0]) + 2)\n # Tgt: [w1 ... wM ]\n max_tgt_in_batch = max(max_tgt_in_batch, len(new.tgt[0]) + 1)\n src_elements = count * max_src_in_batch\n tgt_elements = count * max_tgt_in_batch\n return max(src_elements, tgt_elements)\n\n\ndef build_dataset_iter(corpus_type, fields, opt, is_train=True, multi=False):\n \"\"\"\n This returns user-defined train/validate data iterator for the trainer\n to iterate over. We implement simple ordered iterator strategy here,\n but more sophisticated strategy like curriculum learning is ok too.\n \"\"\"\n dataset_paths = list(sorted(\n glob.glob(opt.data + '.' + corpus_type + '.[0-9]*.pt')))\n if not dataset_paths:\n if is_train:\n raise ValueError('Training data %s not found' % opt.data)\n else:\n return None\n if multi:\n batch_size = 1\n batch_fn = None\n batch_size_multiple = 1\n else:\n batch_size = opt.batch_size if is_train else opt.valid_batch_size\n batch_fn = max_tok_len \\\n if is_train and opt.batch_type == \"tokens\" else None\n batch_size_multiple = 8 if opt.model_dtype == \"fp16\" else 1\n\n device = \"cuda\" if opt.gpu_ranks else \"cpu\"\n\n return DatasetLazyIter(\n dataset_paths,\n fields,\n batch_size,\n batch_fn,\n batch_size_multiple,\n device,\n is_train,\n opt.pool_factor,\n repeat=not opt.single_pass,\n num_batches_multiple=max(opt.accum_count) * opt.world_size,\n yield_raw_example=multi)\n\n\ndef build_dataset_iter_multiple(train_shards, fields, opt):\n return MultipleDatasetIterator(\n train_shards, fields, \"cuda\" if opt.gpu_ranks else \"cpu\", opt)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/inputters/text_dataset.py",
"content": "# -*- coding: utf-8 -*-\nfrom functools import partial\n\nimport six\nimport torch\nfrom torchtext.data import Field, RawField\n\nfrom onmt.inputters.datareader_base import DataReaderBase\n\n\nclass TextDataReader(DataReaderBase):\n def read(self, sequences, side, _dir=None):\n \"\"\"Read text data from disk.\n\n Args:\n sequences (str or Iterable[str]):\n path to text file or iterable of the actual text data.\n side (str): Prefix used in return dict. Usually\n ``\"src\"`` or ``\"tgt\"``.\n _dir (NoneType): Leave as ``None``. This parameter exists to\n conform with the :func:`DataReaderBase.read()` signature.\n\n Yields:\n dictionaries whose keys are the names of fields and whose\n values are more or less the result of tokenizing with those\n fields.\n \"\"\"\n assert _dir is None or _dir == \"\", \\\n \"Cannot use _dir with TextDataReader.\"\n if isinstance(sequences, str):\n sequences = DataReaderBase._read_file(sequences)\n for i, seq in enumerate(sequences):\n if isinstance(seq, six.binary_type):\n seq = seq.decode(\"utf-8\")\n yield {side: seq, \"indices\": i}\n\n\ndef text_sort_key(ex):\n \"\"\"Sort using the number of tokens in the sequence.\"\"\"\n if hasattr(ex, \"tgt\"):\n return len(ex.src[0]), len(ex.tgt[0])\n return len(ex.src[0])\n\n\n# mix this with partial\ndef _feature_tokenize(\n string, layer=0, tok_delim=None, feat_delim=None, truncate=None):\n \"\"\"Split apart word features (like POS/NER tags) from the tokens.\n\n Args:\n string (str): A string with ``tok_delim`` joining tokens and\n features joined by ``feat_delim``. For example,\n ``\"hello|NOUN|'' Earth|NOUN|PLANET\"``.\n layer (int): Which feature to extract. (Not used if there are no\n features, indicated by ``feat_delim is None``). In the\n example above, layer 2 is ``'' PLANET``.\n truncate (int or NoneType): Restrict sequences to this length of\n tokens.\n\n Returns:\n List[str] of tokens.\n \"\"\"\n\n tokens = string.split(tok_delim)\n if truncate is not None:\n tokens = tokens[:truncate]\n if feat_delim is not None:\n tokens = [t.split(feat_delim)[layer] for t in tokens]\n return tokens\n\n\nclass TextMultiField(RawField):\n \"\"\"Container for subfields.\n\n Text data might use POS/NER/etc labels in addition to tokens.\n This class associates the \"base\" :class:`Field` with any subfields.\n It also handles padding the data and stacking it.\n\n Args:\n base_name (str): Name for the base field.\n base_field (Field): The token field.\n feats_fields (Iterable[Tuple[str, Field]]): A list of name-field\n pairs.\n\n Attributes:\n fields (Iterable[Tuple[str, Field]]): A list of name-field pairs.\n The order is defined as the base field first, then\n ``feats_fields`` in alphabetical order.\n \"\"\"\n\n def __init__(self, base_name, base_field, feats_fields):\n super(TextMultiField, self).__init__()\n self.fields = [(base_name, base_field)]\n for name, ff in sorted(feats_fields, key=lambda kv: kv[0]):\n self.fields.append((name, ff))\n\n @property\n def base_field(self):\n return self.fields[0][1]\n\n def process(self, batch, device=None):\n \"\"\"Convert outputs of preprocess into Tensors.\n\n Args:\n batch (List[List[List[str]]]): A list of length batch size.\n Each element is a list of the preprocess results for each\n field (which are lists of str \"words\" or feature tags.\n device (torch.device or str): The device on which the tensor(s)\n are built.\n\n Returns:\n torch.LongTensor or Tuple[LongTensor, LongTensor]:\n A tensor of shape ``(seq_len, batch_size, len(self.fields))``\n where the field features are ordered like ``self.fields``.\n If the base field returns lengths, these are also returned\n and have shape ``(batch_size,)``.\n \"\"\"\n\n # batch (list(list(list))): batch_size x len(self.fields) x seq_len\n batch_by_feat = list(zip(*batch))\n base_data = self.base_field.process(batch_by_feat[0], device=device)\n if self.base_field.include_lengths:\n # lengths: batch_size\n base_data, lengths = base_data\n\n feats = [ff.process(batch_by_feat[i], device=device)\n for i, (_, ff) in enumerate(self.fields[1:], 1)]\n levels = [base_data] + feats\n # data: seq_len x batch_size x len(self.fields)\n data = torch.stack(levels, 2)\n if self.base_field.include_lengths:\n return data, lengths\n else:\n return data\n\n def preprocess(self, x):\n \"\"\"Preprocess data.\n\n Args:\n x (str): A sentence string (words joined by whitespace).\n\n Returns:\n List[List[str]]: A list of length ``len(self.fields)`` containing\n lists of tokens/feature tags for the sentence. The output\n is ordered like ``self.fields``.\n \"\"\"\n\n return [f.preprocess(x) for _, f in self.fields]\n\n def __getitem__(self, item):\n return self.fields[item]\n\n\ndef text_fields(**kwargs):\n \"\"\"Create text fields.\n\n Args:\n base_name (str): Name associated with the field.\n n_feats (int): Number of word level feats (not counting the tokens)\n include_lengths (bool): Optionally return the sequence lengths.\n pad (str, optional): Defaults to ``\"\"``.\n bos (str or NoneType, optional): Defaults to ``\"\"``.\n eos (str or NoneType, optional): Defaults to ``\"\"``.\n truncate (bool or NoneType, optional): Defaults to ``None``.\n\n Returns:\n TextMultiField\n \"\"\"\n\n n_feats = kwargs[\"n_feats\"]\n include_lengths = kwargs[\"include_lengths\"]\n base_name = kwargs[\"base_name\"]\n pad = kwargs.get(\"pad\", \"\")\n bos = kwargs.get(\"bos\", \"\")\n eos = kwargs.get(\"eos\", \"\")\n truncate = kwargs.get(\"truncate\", None)\n fields_ = []\n feat_delim = u\"│\" if n_feats > 0 else None\n for i in range(n_feats + 1):\n name = base_name + \"_feat_\" + str(i - 1) if i > 0 else base_name\n tokenize = partial(\n _feature_tokenize,\n layer=i,\n truncate=truncate,\n feat_delim=feat_delim)\n use_len = i == 0 and include_lengths\n feat = Field(\n init_token=bos, eos_token=eos,\n pad_token=pad, tokenize=tokenize,\n include_lengths=use_len)\n fields_.append((name, feat))\n assert fields_[0][0] == base_name # sanity check\n field = TextMultiField(fields_[0][0], fields_[0][1], fields_[1:])\n return field\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/inputters/vec_dataset.py",
"content": "import os\n\nimport torch\nfrom torchtext.data import Field\n\nfrom onmt.inputters.datareader_base import DataReaderBase\n\ntry:\n import numpy as np\nexcept ImportError:\n np = None\n\n\nclass VecDataReader(DataReaderBase):\n \"\"\"Read feature vector data from disk.\n Raises:\n onmt.inputters.datareader_base.MissingDependencyException: If\n importing ``np`` fails.\n \"\"\"\n\n def __init__(self):\n self._check_deps()\n\n @classmethod\n def _check_deps(cls):\n if np is None:\n cls._raise_missing_dep(\"np\")\n\n def read(self, vecs, side, vec_dir=None):\n \"\"\"Read data into dicts.\n Args:\n vecs (str or Iterable[str]): Sequence of feature vector paths or\n path to file containing feature vector paths.\n In either case, the filenames may be relative to ``vec_dir``\n (default behavior) or absolute.\n side (str): Prefix used in return dict. Usually\n ``\"src\"`` or ``\"tgt\"``.\n vec_dir (str): Location of source vectors. See ``vecs``.\n Yields:\n A dictionary containing feature vector data.\n \"\"\"\n\n if isinstance(vecs, str):\n vecs = DataReaderBase._read_file(vecs)\n\n for i, filename in enumerate(vecs):\n filename = filename.decode(\"utf-8\").strip()\n vec_path = os.path.join(vec_dir, filename)\n if not os.path.exists(vec_path):\n vec_path = filename\n\n assert os.path.exists(vec_path), \\\n 'vec path %s not found' % filename\n\n vec = np.load(vec_path)\n yield {side: torch.from_numpy(vec),\n side + \"_path\": filename, \"indices\": i}\n\n\ndef vec_sort_key(ex):\n \"\"\"Sort using the length of the vector sequence.\"\"\"\n return ex.src.shape[0]\n\n\nclass VecSeqField(Field):\n \"\"\"Defines an vector datatype and instructions for converting to Tensor.\n See :class:`Fields` for attribute descriptions.\n \"\"\"\n\n def __init__(self, preprocessing=None, postprocessing=None,\n include_lengths=False, batch_first=False, pad_index=0,\n is_target=False):\n super(VecSeqField, self).__init__(\n sequential=True, use_vocab=False, init_token=None,\n eos_token=None, fix_length=False, dtype=torch.float,\n preprocessing=preprocessing, postprocessing=postprocessing,\n lower=False, tokenize=None, include_lengths=include_lengths,\n batch_first=batch_first, pad_token=pad_index, unk_token=None,\n pad_first=False, truncate_first=False, stop_words=None,\n is_target=is_target\n )\n\n def pad(self, minibatch):\n \"\"\"Pad a batch of examples to the length of the longest example.\n Args:\n minibatch (List[torch.FloatTensor]): A list of audio data,\n each having shape ``(len, n_feats, feat_dim)``\n where len is variable.\n Returns:\n torch.FloatTensor or Tuple[torch.FloatTensor, List[int]]: The\n padded tensor of shape\n ``(batch_size, max_len, n_feats, feat_dim)``.\n and a list of the lengths if `self.include_lengths` is `True`\n else just returns the padded tensor.\n \"\"\"\n\n assert not self.pad_first and not self.truncate_first \\\n and not self.fix_length and self.sequential\n minibatch = list(minibatch)\n lengths = [x.size(0) for x in minibatch]\n max_len = max(lengths)\n nfeats = minibatch[0].size(1)\n feat_dim = minibatch[0].size(2)\n feats = torch.full((len(minibatch), max_len, nfeats, feat_dim),\n self.pad_token)\n for i, (feat, len_) in enumerate(zip(minibatch, lengths)):\n feats[i, 0:len_, :, :] = feat\n if self.include_lengths:\n return (feats, lengths)\n return feats\n\n def numericalize(self, arr, device=None):\n \"\"\"Turn a batch of examples that use this field into a Variable.\n If the field has ``include_lengths=True``, a tensor of lengths will be\n included in the return value.\n Args:\n arr (torch.FloatTensor or Tuple(torch.FloatTensor, List[int])):\n List of tokenized and padded examples, or tuple of List of\n tokenized and padded examples and List of lengths of each\n example if self.include_lengths is True.\n device (str or torch.device): See `Field.numericalize`.\n \"\"\"\n\n assert self.use_vocab is False\n if self.include_lengths and not isinstance(arr, tuple):\n raise ValueError(\"Field has include_lengths set to True, but \"\n \"input data is not a tuple of \"\n \"(data batch, batch lengths).\")\n if isinstance(arr, tuple):\n arr, lengths = arr\n lengths = torch.tensor(lengths, dtype=torch.int, device=device)\n arr = arr.to(device)\n\n if self.postprocessing is not None:\n arr = self.postprocessing(arr, None)\n\n if self.sequential and not self.batch_first:\n arr = arr.permute(1, 0, 2, 3)\n if self.sequential:\n arr = arr.contiguous()\n\n if self.include_lengths:\n return arr, lengths\n return arr\n\n\ndef vec_fields(**kwargs):\n vec = VecSeqField(pad_index=0, include_lengths=True)\n return vec\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/model_builder.py",
"content": "\"\"\"\nThis file is for models creation, which consults options\nand creates each encoder and decoder accordingly.\n\"\"\"\nimport re\nimport torch\nimport torch.nn as nn\nfrom torch.nn.init import xavier_uniform_\n\nimport onmt.inputters as inputters\nimport onmt.modules\nfrom onmt.encoders import str2enc\n\nfrom onmt.decoders import str2dec\n\nfrom onmt.modules import Embeddings, VecEmbedding, CopyGenerator\nfrom onmt.modules.util_class import Cast\nfrom onmt.utils.misc import use_gpu\nfrom onmt.utils.logging import logger\nfrom onmt.utils.parse import ArgumentParser\n\n\ndef build_embeddings(opt, text_field, for_encoder=True):\n \"\"\"\n Args:\n opt: the option in current environment.\n text_field(TextMultiField): word and feats field.\n for_encoder(bool): build Embeddings for encoder or decoder?\n \"\"\"\n emb_dim = opt.src_word_vec_size if for_encoder else opt.tgt_word_vec_size\n\n if opt.model_type == \"vec\" and for_encoder:\n return VecEmbedding(\n opt.feat_vec_size,\n emb_dim,\n position_encoding=opt.position_encoding,\n dropout=(opt.dropout[0] if type(opt.dropout) is list\n else opt.dropout),\n )\n\n pad_indices = [f.vocab.stoi[f.pad_token] for _, f in text_field]\n word_padding_idx, feat_pad_indices = pad_indices[0], pad_indices[1:]\n\n num_embs = [len(f.vocab) for _, f in text_field]\n num_word_embeddings, num_feat_embeddings = num_embs[0], num_embs[1:]\n\n fix_word_vecs = opt.fix_word_vecs_enc if for_encoder \\\n else opt.fix_word_vecs_dec\n\n emb = Embeddings(\n word_vec_size=emb_dim,\n position_encoding=opt.position_encoding,\n feat_merge=opt.feat_merge,\n feat_vec_exponent=opt.feat_vec_exponent,\n feat_vec_size=opt.feat_vec_size,\n dropout=opt.dropout[0] if type(opt.dropout) is list else opt.dropout,\n word_padding_idx=word_padding_idx,\n feat_padding_idx=feat_pad_indices,\n word_vocab_size=num_word_embeddings,\n feat_vocab_sizes=num_feat_embeddings,\n sparse=opt.optim == \"sparseadam\",\n fix_word_vecs=fix_word_vecs\n )\n return emb\n\n\ndef build_encoder(opt, embeddings):\n \"\"\"\n Various encoder dispatcher function.\n Args:\n opt: the option in current environment.\n embeddings (Embeddings): vocab embeddings for this encoder.\n \"\"\"\n enc_type = opt.encoder_type if opt.model_type == \"text\" \\\n or opt.model_type == \"vec\" else opt.model_type\n return str2enc[enc_type].from_opt(opt, embeddings)\n\n\ndef build_decoder(opt, embeddings):\n \"\"\"\n Various decoder dispatcher function.\n Args:\n opt: the option in current environment.\n embeddings (Embeddings): vocab embeddings for this decoder.\n \"\"\"\n dec_type = \"ifrnn\" if opt.decoder_type == \"rnn\" and opt.input_feed \\\n else opt.decoder_type\n return str2dec[dec_type].from_opt(opt, embeddings)\n\n\ndef load_test_model(opt, model_path=None):\n if model_path is None:\n model_path = opt.models[0]\n checkpoint = torch.load(model_path,\n map_location=lambda storage, loc: storage)\n\n model_opt = ArgumentParser.ckpt_model_opts(checkpoint['opt'])\n ArgumentParser.update_model_opts(model_opt)\n ArgumentParser.validate_model_opts(model_opt)\n vocab = checkpoint['vocab']\n if inputters.old_style_vocab(vocab):\n fields = inputters.load_old_vocab(\n vocab, opt.data_type, dynamic_dict=model_opt.copy_attn\n )\n else:\n fields = vocab\n\n model = build_base_model(model_opt, fields, use_gpu(opt), checkpoint,\n opt.gpu)\n if opt.fp32:\n model.float()\n model.eval()\n model.generator.eval()\n return fields, model, model_opt\n\n\ndef build_base_model(model_opt, fields, gpu, checkpoint=None, gpu_id=None):\n \"\"\"Build a model from opts.\n\n Args:\n model_opt: the option loaded from checkpoint. It's important that\n the opts have been updated and validated. See\n :class:`onmt.utils.parse.ArgumentParser`.\n fields (dict[str, torchtext.data.Field]):\n `Field` objects for the model.\n gpu (bool): whether to use gpu.\n checkpoint: the model gnerated by train phase, or a resumed snapshot\n model from a stopped training.\n gpu_id (int or NoneType): Which GPU to use.\n\n Returns:\n the NMTModel.\n \"\"\"\n\n # for back compat when attention_dropout was not defined\n try:\n model_opt.attention_dropout\n except AttributeError:\n model_opt.attention_dropout = model_opt.dropout\n\n # Build embeddings.\n if model_opt.model_type == \"text\" or model_opt.model_type == \"vec\":\n src_field = fields[\"src\"]\n src_emb = build_embeddings(model_opt, src_field)\n else:\n src_emb = None\n\n # Build encoder.\n encoder = build_encoder(model_opt, src_emb)\n\n # Build decoder.\n tgt_field = fields[\"tgt\"]\n tgt_emb = build_embeddings(model_opt, tgt_field, for_encoder=False)\n\n # Share the embedding matrix - preprocess with share_vocab required.\n if model_opt.share_embeddings:\n # src/tgt vocab should be the same if `-share_vocab` is specified.\n assert src_field.base_field.vocab == tgt_field.base_field.vocab, \\\n \"preprocess with -share_vocab if you use share_embeddings\"\n\n tgt_emb.word_lut.weight = src_emb.word_lut.weight\n\n decoder = build_decoder(model_opt, tgt_emb)\n\n # Build NMTModel(= encoder + decoder).\n if gpu and gpu_id is not None:\n device = torch.device(\"cuda\", gpu_id)\n elif gpu and not gpu_id:\n device = torch.device(\"cuda\")\n elif not gpu:\n device = torch.device(\"cpu\")\n model = onmt.models.NMTModel(encoder, decoder)\n\n # Build Generator.\n if not model_opt.copy_attn:\n if model_opt.generator_function == \"sparsemax\":\n gen_func = onmt.modules.sparse_activations.LogSparsemax(dim=-1)\n else:\n gen_func = nn.LogSoftmax(dim=-1)\n generator = nn.Sequential(\n nn.Linear(model_opt.dec_rnn_size,\n len(fields[\"tgt\"].base_field.vocab)),\n Cast(torch.float32),\n gen_func\n )\n if model_opt.share_decoder_embeddings:\n generator[0].weight = decoder.embeddings.word_lut.weight\n else:\n tgt_base_field = fields[\"tgt\"].base_field\n vocab_size = len(tgt_base_field.vocab)\n pad_idx = tgt_base_field.vocab.stoi[tgt_base_field.pad_token]\n generator = CopyGenerator(model_opt.dec_rnn_size, vocab_size, pad_idx)\n\n # Load the model states from checkpoint or initialize them.\n if checkpoint is not None:\n # This preserves backward-compat for models using customed layernorm\n def fix_key(s):\n s = re.sub(r'(.*)\\.layer_norm((_\\d+)?)\\.b_2',\n r'\\1.layer_norm\\2.bias', s)\n s = re.sub(r'(.*)\\.layer_norm((_\\d+)?)\\.a_2',\n r'\\1.layer_norm\\2.weight', s)\n return s\n\n checkpoint['model'] = {fix_key(k): v\n for k, v in checkpoint['model'].items()}\n # end of patch for backward compatibility\n\n model.load_state_dict(checkpoint['model'], strict=False)\n generator.load_state_dict(checkpoint['generator'], strict=False)\n else:\n if model_opt.param_init != 0.0:\n for p in model.parameters():\n p.data.uniform_(-model_opt.param_init, model_opt.param_init)\n for p in generator.parameters():\n p.data.uniform_(-model_opt.param_init, model_opt.param_init)\n if model_opt.param_init_glorot:\n for p in model.parameters():\n if p.dim() > 1:\n xavier_uniform_(p)\n for p in generator.parameters():\n if p.dim() > 1:\n xavier_uniform_(p)\n\n if hasattr(model.encoder, 'embeddings'):\n model.encoder.embeddings.load_pretrained_vectors(\n model_opt.pre_word_vecs_enc)\n if hasattr(model.decoder, 'embeddings'):\n model.decoder.embeddings.load_pretrained_vectors(\n model_opt.pre_word_vecs_dec)\n\n model.generator = generator\n model.to(device)\n if model_opt.model_dtype == 'fp16' and model_opt.optim == 'fusedadam':\n model.half()\n return model\n\n\ndef build_model(model_opt, opt, fields, checkpoint):\n logger.info('Building model...')\n model = build_base_model(model_opt, fields, use_gpu(opt), checkpoint)\n logger.info(model)\n return model\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/models/__init__.py",
"content": "\"\"\"Module defining models.\"\"\"\nfrom onmt.models.model_saver import build_model_saver, ModelSaver\nfrom onmt.models.model import NMTModel\n\n__all__ = [\"build_model_saver\", \"ModelSaver\", \"NMTModel\"]\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/models/model.py",
"content": "\"\"\" Onmt NMT Model base class definition \"\"\"\nimport torch.nn as nn\n\n\nclass NMTModel(nn.Module):\n \"\"\"\n Core trainable object in OpenNMT. Implements a trainable interface\n for a simple, generic encoder + decoder model.\n\n Args:\n encoder (onmt.encoders.EncoderBase): an encoder object\n decoder (onmt.decoders.DecoderBase): a decoder object\n \"\"\"\n\n def __init__(self, encoder, decoder):\n super(NMTModel, self).__init__()\n self.encoder = encoder\n self.decoder = decoder\n\n def forward(self, src, tgt, lengths, bptt=False, with_align=False):\n \"\"\"Forward propagate a `src` and `tgt` pair for training.\n Possible initialized with a beginning decoder state.\n\n Args:\n src (Tensor): A source sequence passed to encoder.\n typically for inputs this will be a padded `LongTensor`\n of size ``(len, batch, features)``. However, may be an\n image or other generic input depending on encoder.\n tgt (LongTensor): A target sequence passed to decoder.\n Size ``(tgt_len, batch, features)``.\n lengths(LongTensor): The src lengths, pre-padding ``(batch,)``.\n bptt (Boolean): A flag indicating if truncated bptt is set.\n If reset then init_state\n with_align (Boolean): A flag indicating whether output alignment,\n Only valid for transformer decoder.\n\n Returns:\n (FloatTensor, dict[str, FloatTensor]):\n\n * decoder output ``(tgt_len, batch, hidden)``\n * dictionary attention dists of ``(tgt_len, batch, src_len)``\n \"\"\"\n dec_in = tgt[:-1] # exclude last target from inputs\n\n enc_state, memory_bank, lengths = self.encoder(src, lengths)\n\n if bptt is False:\n self.decoder.init_state(src, memory_bank, enc_state)\n dec_out, attns = self.decoder(dec_in, memory_bank,\n memory_lengths=lengths,\n with_align=with_align)\n return dec_out, attns\n\n def update_dropout(self, dropout):\n self.encoder.update_dropout(dropout)\n self.decoder.update_dropout(dropout)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/models/model_saver.py",
"content": "import os\nimport torch\n\nfrom collections import deque\nfrom onmt.utils.logging import logger\n\nfrom copy import deepcopy\n\n\ndef build_model_saver(model_opt, opt, model, fields, optim):\n model_saver = ModelSaver(opt.save_model,\n model,\n model_opt,\n fields,\n optim,\n opt.keep_checkpoint)\n return model_saver\n\n\nclass ModelSaverBase(object):\n \"\"\"Base class for model saving operations\n\n Inherited classes must implement private methods:\n * `_save`\n * `_rm_checkpoint\n \"\"\"\n\n def __init__(self, base_path, model, model_opt, fields, optim,\n keep_checkpoint=-1):\n self.base_path = base_path\n self.model = model\n self.model_opt = model_opt\n self.fields = fields\n self.optim = optim\n self.last_saved_step = None\n self.keep_checkpoint = keep_checkpoint\n if keep_checkpoint > 0:\n self.checkpoint_queue = deque([], maxlen=keep_checkpoint)\n\n def save(self, step, moving_average=None):\n \"\"\"Main entry point for model saver\n\n It wraps the `_save` method with checks and apply `keep_checkpoint`\n related logic\n \"\"\"\n\n if self.keep_checkpoint == 0 or step == self.last_saved_step:\n return\n\n save_model = self.model\n if moving_average:\n model_params_data = []\n for avg, param in zip(moving_average, save_model.parameters()):\n model_params_data.append(param.data)\n param.data = avg.data\n\n chkpt, chkpt_name = self._save(step, save_model)\n self.last_saved_step = step\n\n if moving_average:\n for param_data, param in zip(model_params_data,\n save_model.parameters()):\n param.data = param_data\n\n if self.keep_checkpoint > 0:\n if len(self.checkpoint_queue) == self.checkpoint_queue.maxlen:\n todel = self.checkpoint_queue.popleft()\n self._rm_checkpoint(todel)\n self.checkpoint_queue.append(chkpt_name)\n\n def _save(self, step):\n \"\"\"Save a resumable checkpoint.\n\n Args:\n step (int): step number\n\n Returns:\n (object, str):\n\n * checkpoint: the saved object\n * checkpoint_name: name (or path) of the saved checkpoint\n \"\"\"\n\n raise NotImplementedError()\n\n def _rm_checkpoint(self, name):\n \"\"\"Remove a checkpoint\n\n Args:\n name(str): name that indentifies the checkpoint\n (it may be a filepath)\n \"\"\"\n\n raise NotImplementedError()\n\n\nclass ModelSaver(ModelSaverBase):\n \"\"\"Simple model saver to filesystem\"\"\"\n\n def _save(self, step, model):\n model_state_dict = model.state_dict()\n model_state_dict = {k: v for k, v in model_state_dict.items()\n if 'generator' not in k}\n generator_state_dict = model.generator.state_dict()\n\n # NOTE: We need to trim the vocab to remove any unk tokens that\n # were not originally here.\n\n vocab = deepcopy(self.fields)\n for side in [\"src\", \"tgt\"]:\n keys_to_pop = []\n if hasattr(vocab[side], \"fields\"):\n unk_token = vocab[side].fields[0][1].vocab.itos[0]\n for key, value in vocab[side].fields[0][1].vocab.stoi.items():\n if value == 0 and key != unk_token:\n keys_to_pop.append(key)\n for key in keys_to_pop:\n vocab[side].fields[0][1].vocab.stoi.pop(key, None)\n\n checkpoint = {\n 'model': model_state_dict,\n 'generator': generator_state_dict,\n 'vocab': vocab,\n 'opt': self.model_opt,\n 'optim': self.optim.state_dict(),\n }\n\n logger.info(\"Saving checkpoint %s_step_%d.pt\" % (self.base_path, step))\n checkpoint_path = '%s_step_%d.pt' % (self.base_path, step)\n torch.save(checkpoint, checkpoint_path)\n return checkpoint, checkpoint_path\n\n def _rm_checkpoint(self, name):\n os.remove(name)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/models/sru.py",
"content": "\"\"\" SRU Implementation \"\"\"\n# flake8: noqa\n\nimport subprocess\nimport platform\nimport os\nimport re\nimport configargparse\nimport torch\nimport torch.nn as nn\nfrom torch.autograd import Function\nfrom collections import namedtuple\n\n\n# For command-line option parsing\nclass CheckSRU(configargparse.Action):\n def __init__(self, option_strings, dest, **kwargs):\n super(CheckSRU, self).__init__(option_strings, dest, **kwargs)\n\n def __call__(self, parser, namespace, values, option_string=None):\n if values == 'SRU':\n check_sru_requirement(abort=True)\n # Check pass, set the args.\n setattr(namespace, self.dest, values)\n\n\n# This SRU version implements its own cuda-level optimization,\n# so it requires that:\n# 1. `cupy` and `pynvrtc` python package installed.\n# 2. pytorch is built with cuda support.\n# 3. library path set: export LD_LIBRARY_PATH=.\ndef check_sru_requirement(abort=False):\n \"\"\"\n Return True if check pass; if check fails and abort is True,\n raise an Exception, othereise return False.\n \"\"\"\n\n # Check 1.\n try:\n if platform.system() == 'Windows':\n subprocess.check_output('pip freeze | findstr cupy', shell=True)\n subprocess.check_output('pip freeze | findstr pynvrtc',\n shell=True)\n else: # Unix-like systems\n subprocess.check_output('pip freeze | grep -w cupy', shell=True)\n subprocess.check_output('pip freeze | grep -w pynvrtc',\n shell=True)\n except subprocess.CalledProcessError:\n if not abort:\n return False\n raise AssertionError(\"Using SRU requires 'cupy' and 'pynvrtc' \"\n \"python packages installed.\")\n\n # Check 2.\n if torch.cuda.is_available() is False:\n if not abort:\n return False\n raise AssertionError(\"Using SRU requires pytorch built with cuda.\")\n\n # Check 3.\n pattern = re.compile(\".*cuda/lib.*\")\n ld_path = os.getenv('LD_LIBRARY_PATH', \"\")\n if re.match(pattern, ld_path) is None:\n if not abort:\n return False\n raise AssertionError(\"Using SRU requires setting cuda lib path, e.g. \"\n \"export LD_LIBRARY_PATH=/usr/local/cuda/lib64.\")\n\n return True\n\n\nSRU_CODE = \"\"\"\nextern \"C\" {\n __forceinline__ __device__ float sigmoidf(float x)\n {\n return 1.f / (1.f + expf(-x));\n }\n __forceinline__ __device__ float reluf(float x)\n {\n return (x > 0.f) ? x : 0.f;\n }\n __global__ void sru_fwd(const float * __restrict__ u,\n const float * __restrict__ x,\n const float * __restrict__ bias,\n const float * __restrict__ init,\n const float * __restrict__ mask_h,\n const int len, const int batch,\n const int d, const int k,\n float * __restrict__ h,\n float * __restrict__ c,\n const int activation_type)\n {\n assert ((k == 3) || (x == NULL));\n int ncols = batch*d;\n int col = blockIdx.x * blockDim.x + threadIdx.x;\n if (col >= ncols) return;\n int ncols_u = ncols*k;\n int ncols_x = (k == 3) ? ncols : ncols_u;\n const float bias1 = *(bias + (col%d));\n const float bias2 = *(bias + (col%d) + d);\n const float mask = (mask_h == NULL) ? 1.0 : (*(mask_h + col));\n float cur = *(init + col);\n const float *up = u + (col*k);\n const float *xp = (k == 3) ? (x + col) : (up + 3);\n float *cp = c + col;\n float *hp = h + col;\n for (int row = 0; row < len; ++row)\n {\n float g1 = sigmoidf((*(up+1))+bias1);\n float g2 = sigmoidf((*(up+2))+bias2);\n cur = (cur-(*up))*g1 + (*up);\n *cp = cur;\n float val = (activation_type == 1) ? tanh(cur) : (\n (activation_type == 2) ? reluf(cur) : cur\n );\n *hp = (val*mask-(*xp))*g2 + (*xp);\n up += ncols_u;\n xp += ncols_x;\n cp += ncols;\n hp += ncols;\n }\n }\n __global__ void sru_bwd(const float * __restrict__ u,\n const float * __restrict__ x,\n const float * __restrict__ bias,\n const float * __restrict__ init,\n const float * __restrict__ mask_h,\n const float * __restrict__ c,\n const float * __restrict__ grad_h,\n const float * __restrict__ grad_last,\n const int len,\n const int batch, const int d, const int k,\n float * __restrict__ grad_u,\n float * __restrict__ grad_x,\n float * __restrict__ grad_bias,\n float * __restrict__ grad_init,\n int activation_type)\n {\n assert((k == 3) || (x == NULL));\n assert((k == 3) || (grad_x == NULL));\n int ncols = batch*d;\n int col = blockIdx.x * blockDim.x + threadIdx.x;\n if (col >= ncols) return;\n int ncols_u = ncols*k;\n int ncols_x = (k == 3) ? ncols : ncols_u;\n const float bias1 = *(bias + (col%d));\n const float bias2 = *(bias + (col%d) + d);\n const float mask = (mask_h == NULL) ? 1.0 : (*(mask_h + col));\n float gbias1 = 0;\n float gbias2 = 0;\n float cur = *(grad_last + col);\n const float *up = u + (col*k) + (len-1)*ncols_u;\n const float *xp = (k == 3) ? (x + col + (len-1)*ncols) : (up + 3);\n const float *cp = c + col + (len-1)*ncols;\n const float *ghp = grad_h + col + (len-1)*ncols;\n float *gup = grad_u + (col*k) + (len-1)*ncols_u;\n float *gxp = (k == 3) ? (grad_x + col + (len-1)*ncols) : (gup + 3);\n for (int row = len-1; row >= 0; --row)\n {\n const float g1 = sigmoidf((*(up+1))+bias1);\n const float g2 = sigmoidf((*(up+2))+bias2);\n const float c_val = (activation_type == 1) ? tanh(*cp) : (\n (activation_type == 2) ? reluf(*cp) : (*cp)\n );\n const float x_val = *xp;\n const float u_val = *up;\n const float prev_c_val = (row>0) ? (*(cp-ncols)) : (*(init+col));\n const float gh_val = *ghp;\n // h = c*g2 + x*(1-g2) = (c-x)*g2 + x\n // c = c'*g1 + g0*(1-g1) = (c'-g0)*g1 + g0\n // grad wrt x\n *gxp = gh_val*(1-g2);\n // grad wrt g2, u2 and bias2\n float gg2 = gh_val*(c_val*mask-x_val)*(g2*(1-g2));\n *(gup+2) = gg2;\n gbias2 += gg2;\n // grad wrt c\n const float tmp = (activation_type == 1) ? (g2*(1-c_val*c_val)) : (\n ((activation_type == 0) || (c_val > 0)) ? g2 : 0.f\n );\n const float gc = gh_val*mask*tmp + cur;\n // grad wrt u0\n *gup = gc*(1-g1);\n // grad wrt g1, u1, and bias1\n float gg1 = gc*(prev_c_val-u_val)*(g1*(1-g1));\n *(gup+1) = gg1;\n gbias1 += gg1;\n // grad wrt c'\n cur = gc*g1;\n up -= ncols_u;\n xp -= ncols_x;\n cp -= ncols;\n gup -= ncols_u;\n gxp -= ncols_x;\n ghp -= ncols;\n }\n *(grad_bias + col) = gbias1;\n *(grad_bias + col + ncols) = gbias2;\n *(grad_init +col) = cur;\n }\n __global__ void sru_bi_fwd(const float * __restrict__ u,\n const float * __restrict__ x,\n const float * __restrict__ bias,\n const float * __restrict__ init,\n const float * __restrict__ mask_h,\n const int len, const int batch,\n const int d, const int k,\n float * __restrict__ h,\n float * __restrict__ c,\n const int activation_type)\n {\n assert ((k == 3) || (x == NULL));\n assert ((k == 3) || (k == 4));\n int ncols = batch*d*2;\n int col = blockIdx.x * blockDim.x + threadIdx.x;\n if (col >= ncols) return;\n int ncols_u = ncols*k;\n int ncols_x = (k == 3) ? ncols : ncols_u;\n const float mask = (mask_h == NULL) ? 1.0 : (*(mask_h + col));\n float cur = *(init + col);\n const int d2 = d*2;\n const bool flip = (col%d2) >= d;\n const float bias1 = *(bias + (col%d2));\n const float bias2 = *(bias + (col%d2) + d2);\n const float *up = u + (col*k);\n const float *xp = (k == 3) ? (x + col) : (up + 3);\n float *cp = c + col;\n float *hp = h + col;\n if (flip) {\n up += (len-1)*ncols_u;\n xp += (len-1)*ncols_x;\n cp += (len-1)*ncols;\n hp += (len-1)*ncols;\n }\n int ncols_u_ = flip ? -ncols_u : ncols_u;\n int ncols_x_ = flip ? -ncols_x : ncols_x;\n int ncols_ = flip ? -ncols : ncols;\n for (int cnt = 0; cnt < len; ++cnt)\n {\n float g1 = sigmoidf((*(up+1))+bias1);\n float g2 = sigmoidf((*(up+2))+bias2);\n cur = (cur-(*up))*g1 + (*up);\n *cp = cur;\n float val = (activation_type == 1) ? tanh(cur) : (\n (activation_type == 2) ? reluf(cur) : cur\n );\n *hp = (val*mask-(*xp))*g2 + (*xp);\n up += ncols_u_;\n xp += ncols_x_;\n cp += ncols_;\n hp += ncols_;\n }\n }\n __global__ void sru_bi_bwd(const float * __restrict__ u,\n const float * __restrict__ x,\n const float * __restrict__ bias,\n const float * __restrict__ init,\n const float * __restrict__ mask_h,\n const float * __restrict__ c,\n const float * __restrict__ grad_h,\n const float * __restrict__ grad_last,\n const int len, const int batch,\n const int d, const int k,\n float * __restrict__ grad_u,\n float * __restrict__ grad_x,\n float * __restrict__ grad_bias,\n float * __restrict__ grad_init,\n int activation_type)\n {\n assert((k == 3) || (x == NULL));\n assert((k == 3) || (grad_x == NULL));\n assert((k == 3) || (k == 4));\n int ncols = batch*d*2;\n int col = blockIdx.x * blockDim.x + threadIdx.x;\n if (col >= ncols) return;\n int ncols_u = ncols*k;\n int ncols_x = (k == 3) ? ncols : ncols_u;\n const float mask = (mask_h == NULL) ? 1.0 : (*(mask_h + col));\n float gbias1 = 0;\n float gbias2 = 0;\n float cur = *(grad_last + col);\n const int d2 = d*2;\n const bool flip = ((col%d2) >= d);\n const float bias1 = *(bias + (col%d2));\n const float bias2 = *(bias + (col%d2) + d2);\n const float *up = u + (col*k);\n const float *xp = (k == 3) ? (x + col) : (up + 3);\n const float *cp = c + col;\n const float *ghp = grad_h + col;\n float *gup = grad_u + (col*k);\n float *gxp = (k == 3) ? (grad_x + col) : (gup + 3);\n if (!flip) {\n up += (len-1)*ncols_u;\n xp += (len-1)*ncols_x;\n cp += (len-1)*ncols;\n ghp += (len-1)*ncols;\n gup += (len-1)*ncols_u;\n gxp += (len-1)*ncols_x;\n }\n int ncols_u_ = flip ? -ncols_u : ncols_u;\n int ncols_x_ = flip ? -ncols_x : ncols_x;\n int ncols_ = flip ? -ncols : ncols;\n for (int cnt = 0; cnt < len; ++cnt)\n {\n const float g1 = sigmoidf((*(up+1))+bias1);\n const float g2 = sigmoidf((*(up+2))+bias2);\n const float c_val = (activation_type == 1) ? tanh(*cp) : (\n (activation_type == 2) ? reluf(*cp) : (*cp)\n );\n const float x_val = *xp;\n const float u_val = *up;\n const float prev_c_val = (cnt 0)) ? g2 : 0.f\n );\n const float gc = gh_val*mask*tmp + cur;\n // grad wrt u0\n *gup = gc*(1-g1);\n // grad wrt g1, u1, and bias1\n float gg1 = gc*(prev_c_val-u_val)*(g1*(1-g1));\n *(gup+1) = gg1;\n gbias1 += gg1;\n // grad wrt c'\n cur = gc*g1;\n up -= ncols_u_;\n xp -= ncols_x_;\n cp -= ncols_;\n gup -= ncols_u_;\n gxp -= ncols_x_;\n ghp -= ncols_;\n }\n *(grad_bias + col) = gbias1;\n *(grad_bias + col + ncols) = gbias2;\n *(grad_init +col) = cur;\n }\n}\n\"\"\"\nSRU_FWD_FUNC, SRU_BWD_FUNC = None, None\nSRU_BiFWD_FUNC, SRU_BiBWD_FUNC = None, None\nSRU_STREAM = None\n\n\ndef load_sru_mod():\n global SRU_FWD_FUNC, SRU_BWD_FUNC, SRU_BiFWD_FUNC, SRU_BiBWD_FUNC\n global SRU_STREAM\n if check_sru_requirement():\n from cupy.cuda import function\n from pynvrtc.compiler import Program\n\n # This sets up device to use.\n device = torch.device(\"cuda\")\n tmp_ = torch.rand(1, 1).to(device)\n\n sru_prog = Program(SRU_CODE.encode('utf-8'),\n 'sru_prog.cu'.encode('utf-8'))\n sru_ptx = sru_prog.compile()\n sru_mod = function.Module()\n sru_mod.load(bytes(sru_ptx.encode()))\n\n SRU_FWD_FUNC = sru_mod.get_function('sru_fwd')\n SRU_BWD_FUNC = sru_mod.get_function('sru_bwd')\n SRU_BiFWD_FUNC = sru_mod.get_function('sru_bi_fwd')\n SRU_BiBWD_FUNC = sru_mod.get_function('sru_bi_bwd')\n\n stream = namedtuple('Stream', ['ptr'])\n SRU_STREAM = stream(ptr=torch.cuda.current_stream().cuda_stream)\n\n\nclass SRU_Compute(Function):\n\n def __init__(self, activation_type, d_out, bidirectional=False):\n SRU_Compute.maybe_load_sru_mod()\n super(SRU_Compute, self).__init__()\n self.activation_type = activation_type\n self.d_out = d_out\n self.bidirectional = bidirectional\n\n @staticmethod\n def maybe_load_sru_mod():\n global SRU_FWD_FUNC\n\n if SRU_FWD_FUNC is None:\n load_sru_mod()\n\n def forward(self, u, x, bias, init=None, mask_h=None):\n bidir = 2 if self.bidirectional else 1\n length = x.size(0) if x.dim() == 3 else 1\n batch = x.size(-2)\n d = self.d_out\n k = u.size(-1) // d\n k_ = k // 2 if self.bidirectional else k\n ncols = batch * d * bidir\n thread_per_block = min(512, ncols)\n num_block = (ncols - 1) // thread_per_block + 1\n\n init_ = x.new(ncols).zero_() if init is None else init\n size = (length, batch, d * bidir) if x.dim() == 3 else (batch, d * bidir)\n c = x.new(*size)\n h = x.new(*size)\n\n FUNC = SRU_FWD_FUNC if not self.bidirectional else SRU_BiFWD_FUNC\n FUNC(args=[\n u.contiguous().data_ptr(),\n x.contiguous().data_ptr() if k_ == 3 else 0,\n bias.data_ptr(),\n init_.contiguous().data_ptr(),\n mask_h.data_ptr() if mask_h is not None else 0,\n length,\n batch,\n d,\n k_,\n h.data_ptr(),\n c.data_ptr(),\n self.activation_type],\n block=(thread_per_block, 1, 1), grid=(num_block, 1, 1),\n stream=SRU_STREAM\n )\n\n self.save_for_backward(u, x, bias, init, mask_h)\n self.intermediate = c\n if x.dim() == 2:\n last_hidden = c\n elif self.bidirectional:\n # -> directions x batch x dim\n last_hidden = torch.stack((c[-1, :, :d], c[0, :, d:]))\n else:\n last_hidden = c[-1]\n return h, last_hidden\n\n def backward(self, grad_h, grad_last):\n if self.bidirectional:\n grad_last = torch.cat((grad_last[0], grad_last[1]), 1)\n bidir = 2 if self.bidirectional else 1\n u, x, bias, init, mask_h = self.saved_tensors\n c = self.intermediate\n length = x.size(0) if x.dim() == 3 else 1\n batch = x.size(-2)\n d = self.d_out\n k = u.size(-1) // d\n k_ = k // 2 if self.bidirectional else k\n ncols = batch * d * bidir\n thread_per_block = min(512, ncols)\n num_block = (ncols - 1) // thread_per_block + 1\n\n init_ = x.new(ncols).zero_() if init is None else init\n grad_u = u.new(*u.size())\n grad_bias = x.new(2, batch, d * bidir)\n grad_init = x.new(batch, d * bidir)\n\n # For DEBUG\n # size = (length, batch, x.size(-1)) \\\n # if x.dim() == 3 else (batch, x.size(-1))\n # grad_x = x.new(*x.size()) if k_ == 3 else x.new(*size).zero_()\n\n # Normal use\n grad_x = x.new(*x.size()) if k_ == 3 else None\n\n FUNC = SRU_BWD_FUNC if not self.bidirectional else SRU_BiBWD_FUNC\n FUNC(args=[\n u.contiguous().data_ptr(),\n x.contiguous().data_ptr() if k_ == 3 else 0,\n bias.data_ptr(),\n init_.contiguous().data_ptr(),\n mask_h.data_ptr() if mask_h is not None else 0,\n c.data_ptr(),\n grad_h.contiguous().data_ptr(),\n grad_last.contiguous().data_ptr(),\n length,\n batch,\n d,\n k_,\n grad_u.data_ptr(),\n grad_x.data_ptr() if k_ == 3 else 0,\n grad_bias.data_ptr(),\n grad_init.data_ptr(),\n self.activation_type],\n block=(thread_per_block, 1, 1), grid=(num_block, 1, 1),\n stream=SRU_STREAM\n )\n return grad_u, grad_x, grad_bias.sum(1).view(-1), grad_init, None\n\n\nclass SRUCell(nn.Module):\n def __init__(self, n_in, n_out, dropout=0, rnn_dropout=0,\n bidirectional=False, use_tanh=1, use_relu=0):\n super(SRUCell, self).__init__()\n self.n_in = n_in\n self.n_out = n_out\n self.rnn_dropout = rnn_dropout\n self.dropout = dropout\n self.bidirectional = bidirectional\n self.activation_type = 2 if use_relu else (1 if use_tanh else 0)\n\n out_size = n_out * 2 if bidirectional else n_out\n k = 4 if n_in != out_size else 3\n self.size_per_dir = n_out * k\n self.weight = nn.Parameter(torch.Tensor(\n n_in,\n self.size_per_dir * 2 if bidirectional else self.size_per_dir\n ))\n self.bias = nn.Parameter(torch.Tensor(\n n_out * 4 if bidirectional else n_out * 2\n ))\n self.init_weight()\n\n def init_weight(self):\n val_range = (3.0 / self.n_in)**0.5\n self.weight.data.uniform_(-val_range, val_range)\n self.bias.data.zero_()\n\n def set_bias(self, bias_val=0):\n n_out = self.n_out\n if self.bidirectional:\n self.bias.data[n_out * 2:].zero_().add_(bias_val)\n else:\n self.bias.data[n_out:].zero_().add_(bias_val)\n\n def forward(self, input, c0=None):\n assert input.dim() == 2 or input.dim() == 3\n n_in, n_out = self.n_in, self.n_out\n batch = input.size(-2)\n if c0 is None:\n c0 = input.data.new(\n batch, n_out if not self.bidirectional else n_out * 2\n ).zero_()\n\n if self.training and (self.rnn_dropout > 0):\n mask = self.get_dropout_mask_((batch, n_in), self.rnn_dropout)\n x = input * mask.expand_as(input)\n else:\n x = input\n\n x_2d = x if x.dim() == 2 else x.contiguous().view(-1, n_in)\n u = x_2d.mm(self.weight)\n\n if self.training and (self.dropout > 0):\n bidir = 2 if self.bidirectional else 1\n mask_h = self.get_dropout_mask_(\n (batch, n_out * bidir), self.dropout)\n h, c = SRU_Compute(self.activation_type, n_out,\n self.bidirectional)(\n u, input, self.bias, c0, mask_h\n )\n else:\n h, c = SRU_Compute(self.activation_type, n_out,\n self.bidirectional)(\n u, input, self.bias, c0\n )\n\n return h, c\n\n def get_dropout_mask_(self, size, p):\n w = self.weight.data\n return w.new(*size).bernoulli_(1 - p).div_(1 - p)\n\n\nclass SRU(nn.Module):\n \"\"\"\n Implementation of \"Training RNNs as Fast as CNNs\"\n :cite:`DBLP:journals/corr/abs-1709-02755`\n\n TODO: turn to pytorch's implementation when it is available.\n\n This implementation is adpoted from the author of the paper:\n https://github.com/taolei87/sru/blob/master/cuda_functional.py.\n\n Args:\n input_size (int): input to model\n hidden_size (int): hidden dimension\n num_layers (int): number of layers\n dropout (float): dropout to use (stacked)\n rnn_dropout (float): dropout to use (recurrent)\n bidirectional (bool): bidirectional\n use_tanh (bool): activation\n use_relu (bool): activation\n \"\"\"\n\n def __init__(self, input_size, hidden_size,\n num_layers=2, dropout=0, rnn_dropout=0,\n bidirectional=False, use_tanh=1, use_relu=0):\n # An entry check here, will catch on train side and translate side\n # if requirements are not satisfied.\n check_sru_requirement(abort=True)\n super(SRU, self).__init__()\n self.n_in = input_size\n self.n_out = hidden_size\n self.depth = num_layers\n self.dropout = dropout\n self.rnn_dropout = rnn_dropout\n self.rnn_lst = nn.ModuleList()\n self.bidirectional = bidirectional\n self.out_size = hidden_size * 2 if bidirectional else hidden_size\n\n for i in range(num_layers):\n sru_cell = SRUCell(\n n_in=self.n_in if i == 0 else self.out_size,\n n_out=self.n_out,\n dropout=dropout if i + 1 != num_layers else 0,\n rnn_dropout=rnn_dropout,\n bidirectional=bidirectional,\n use_tanh=use_tanh,\n use_relu=use_relu,\n )\n self.rnn_lst.append(sru_cell)\n\n def set_bias(self, bias_val=0):\n for l in self.rnn_lst:\n l.set_bias(bias_val)\n\n def forward(self, input, c0=None, return_hidden=True):\n assert input.dim() == 3 # (len, batch, n_in)\n dir_ = 2 if self.bidirectional else 1\n if c0 is None:\n zeros = input.data.new(\n input.size(1), self.n_out * dir_\n ).zero_()\n c0 = [zeros for i in range(self.depth)]\n else:\n if isinstance(c0, tuple):\n # RNNDecoderState wraps hidden as a tuple.\n c0 = c0[0]\n assert c0.dim() == 3 # (depth, batch, dir_*n_out)\n c0 = [h.squeeze(0) for h in c0.chunk(self.depth, 0)]\n\n prevx = input\n lstc = []\n for i, rnn in enumerate(self.rnn_lst):\n h, c = rnn(prevx, c0[i])\n prevx = h\n lstc.append(c)\n\n if self.bidirectional:\n # fh -> (layers*directions) x batch x dim\n fh = torch.cat(lstc)\n else:\n fh = torch.stack(lstc)\n\n if return_hidden:\n return prevx, fh\n else:\n return prevx\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/models/stacked_rnn.py",
"content": "\"\"\" Implementation of ONMT RNN for Input Feeding Decoding \"\"\"\nimport torch\nimport torch.nn as nn\n\n\nclass StackedLSTM(nn.Module):\n \"\"\"\n Our own implementation of stacked LSTM.\n Needed for the decoder, because we do input feeding.\n \"\"\"\n\n def __init__(self, num_layers, input_size, rnn_size, dropout):\n super(StackedLSTM, self).__init__()\n self.dropout = nn.Dropout(dropout)\n self.num_layers = num_layers\n self.layers = nn.ModuleList()\n\n for _ in range(num_layers):\n self.layers.append(nn.LSTMCell(input_size, rnn_size))\n input_size = rnn_size\n\n def forward(self, input_feed, hidden):\n h_0, c_0 = hidden\n h_1, c_1 = [], []\n for i, layer in enumerate(self.layers):\n h_1_i, c_1_i = layer(input_feed, (h_0[i], c_0[i]))\n input_feed = h_1_i\n if i + 1 != self.num_layers:\n input_feed = self.dropout(input_feed)\n h_1 += [h_1_i]\n c_1 += [c_1_i]\n\n h_1 = torch.stack(h_1)\n c_1 = torch.stack(c_1)\n\n return input_feed, (h_1, c_1)\n\n\nclass StackedGRU(nn.Module):\n \"\"\"\n Our own implementation of stacked GRU.\n Needed for the decoder, because we do input feeding.\n \"\"\"\n\n def __init__(self, num_layers, input_size, rnn_size, dropout):\n super(StackedGRU, self).__init__()\n self.dropout = nn.Dropout(dropout)\n self.num_layers = num_layers\n self.layers = nn.ModuleList()\n\n for _ in range(num_layers):\n self.layers.append(nn.GRUCell(input_size, rnn_size))\n input_size = rnn_size\n\n def forward(self, input_feed, hidden):\n h_1 = []\n for i, layer in enumerate(self.layers):\n h_1_i = layer(input_feed, hidden[0][i])\n input_feed = h_1_i\n if i + 1 != self.num_layers:\n input_feed = self.dropout(input_feed)\n h_1 += [h_1_i]\n\n h_1 = torch.stack(h_1)\n return input_feed, (h_1,)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/modules/__init__.py",
"content": "\"\"\" Attention and normalization modules \"\"\"\nfrom onmt.modules.util_class import Elementwise\nfrom onmt.modules.gate import context_gate_factory, ContextGate\nfrom onmt.modules.global_attention import GlobalAttention\nfrom onmt.modules.conv_multi_step_attention import ConvMultiStepAttention\nfrom onmt.modules.copy_generator import CopyGenerator, CopyGeneratorLoss, \\\n CopyGeneratorLossCompute\nfrom onmt.modules.multi_headed_attn import MultiHeadedAttention\nfrom onmt.modules.embeddings import Embeddings, PositionalEncoding, \\\n VecEmbedding\nfrom onmt.modules.weight_norm import WeightNormConv2d\nfrom onmt.modules.average_attn import AverageAttention\n\n__all__ = [\"Elementwise\", \"context_gate_factory\", \"ContextGate\",\n \"GlobalAttention\", \"ConvMultiStepAttention\", \"CopyGenerator\",\n \"CopyGeneratorLoss\", \"CopyGeneratorLossCompute\",\n \"MultiHeadedAttention\", \"Embeddings\", \"PositionalEncoding\",\n \"WeightNormConv2d\", \"AverageAttention\", \"VecEmbedding\"]\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/modules/average_attn.py",
"content": "# -*- coding: utf-8 -*-\n\"\"\"Average Attention module.\"\"\"\n\nimport torch\nimport torch.nn as nn\n\nfrom onmt.modules.position_ffn import PositionwiseFeedForward\n\n\nclass AverageAttention(nn.Module):\n \"\"\"\n Average Attention module from\n \"Accelerating Neural Transformer via an Average Attention Network\"\n :cite:`DBLP:journals/corr/abs-1805-00631`.\n\n Args:\n model_dim (int): the dimension of keys/values/queries,\n must be divisible by head_count\n dropout (float): dropout parameter\n \"\"\"\n\n def __init__(self, model_dim, dropout=0.1, aan_useffn=False):\n self.model_dim = model_dim\n self.aan_useffn = aan_useffn\n super(AverageAttention, self).__init__()\n if aan_useffn:\n self.average_layer = PositionwiseFeedForward(model_dim, model_dim,\n dropout)\n self.gating_layer = nn.Linear(model_dim * 2, model_dim * 2)\n\n def cumulative_average_mask(self, batch_size, inputs_len, device):\n \"\"\"\n Builds the mask to compute the cumulative average as described in\n :cite:`DBLP:journals/corr/abs-1805-00631` -- Figure 3\n\n Args:\n batch_size (int): batch size\n inputs_len (int): length of the inputs\n\n Returns:\n (FloatTensor):\n\n * A Tensor of shape ``(batch_size, input_len, input_len)``\n \"\"\"\n\n triangle = torch.tril(torch.ones(inputs_len, inputs_len,\n dtype=torch.float, device=device))\n weights = torch.ones(1, inputs_len, dtype=torch.float, device=device) \\\n / torch.arange(1, inputs_len + 1, dtype=torch.float, device=device)\n mask = triangle * weights.transpose(0, 1)\n\n return mask.unsqueeze(0).expand(batch_size, inputs_len, inputs_len)\n\n def cumulative_average(self, inputs, mask_or_step,\n layer_cache=None, step=None):\n \"\"\"\n Computes the cumulative average as described in\n :cite:`DBLP:journals/corr/abs-1805-00631` -- Equations (1) (5) (6)\n\n Args:\n inputs (FloatTensor): sequence to average\n ``(batch_size, input_len, dimension)``\n mask_or_step: if cache is set, this is assumed\n to be the current step of the\n dynamic decoding. Otherwise, it is the mask matrix\n used to compute the cumulative average.\n layer_cache: a dictionary containing the cumulative average\n of the previous step.\n\n Returns:\n a tensor of the same shape and type as ``inputs``.\n \"\"\"\n\n if layer_cache is not None:\n step = mask_or_step\n average_attention = (inputs + step *\n layer_cache[\"prev_g\"]) / (step + 1)\n layer_cache[\"prev_g\"] = average_attention\n return average_attention\n else:\n mask = mask_or_step\n return torch.matmul(mask.to(inputs.dtype), inputs)\n\n def forward(self, inputs, mask=None, layer_cache=None, step=None):\n \"\"\"\n Args:\n inputs (FloatTensor): ``(batch_size, input_len, model_dim)``\n\n Returns:\n (FloatTensor, FloatTensor):\n\n * gating_outputs ``(batch_size, input_len, model_dim)``\n * average_outputs average attention\n ``(batch_size, input_len, model_dim)``\n \"\"\"\n\n batch_size = inputs.size(0)\n inputs_len = inputs.size(1)\n average_outputs = self.cumulative_average(\n inputs, self.cumulative_average_mask(batch_size,\n inputs_len, inputs.device)\n if layer_cache is None else step, layer_cache=layer_cache)\n if self.aan_useffn:\n average_outputs = self.average_layer(average_outputs)\n gating_outputs = self.gating_layer(torch.cat((inputs,\n average_outputs), -1))\n input_gate, forget_gate = torch.chunk(gating_outputs, 2, dim=2)\n gating_outputs = torch.sigmoid(input_gate) * inputs + \\\n torch.sigmoid(forget_gate) * average_outputs\n\n return gating_outputs, average_outputs\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/modules/conv_multi_step_attention.py",
"content": "\"\"\" Multi Step Attention for CNN \"\"\"\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nfrom onmt.utils.misc import aeq\n\n\nSCALE_WEIGHT = 0.5 ** 0.5\n\n\ndef seq_linear(linear, x):\n \"\"\" linear transform for 3-d tensor \"\"\"\n batch, hidden_size, length, _ = x.size()\n h = linear(torch.transpose(x, 1, 2).contiguous().view(\n batch * length, hidden_size))\n return torch.transpose(h.view(batch, length, hidden_size, 1), 1, 2)\n\n\nclass ConvMultiStepAttention(nn.Module):\n \"\"\"\n Conv attention takes a key matrix, a value matrix and a query vector.\n Attention weight is calculated by key matrix with the query vector\n and sum on the value matrix. And the same operation is applied\n in each decode conv layer.\n \"\"\"\n\n def __init__(self, input_size):\n super(ConvMultiStepAttention, self).__init__()\n self.linear_in = nn.Linear(input_size, input_size)\n self.mask = None\n\n def apply_mask(self, mask):\n \"\"\" Apply mask \"\"\"\n self.mask = mask\n\n def forward(self, base_target_emb, input_from_dec, encoder_out_top,\n encoder_out_combine):\n \"\"\"\n Args:\n base_target_emb: target emb tensor\n input_from_dec: output of decode conv\n encoder_out_top: the key matrix for calculation of attetion weight,\n which is the top output of encode conv\n encoder_out_combine:\n the value matrix for the attention-weighted sum,\n which is the combination of base emb and top output of encode\n \"\"\"\n\n # checks\n # batch, channel, height, width = base_target_emb.size()\n batch, _, height, _ = base_target_emb.size()\n # batch_, channel_, height_, width_ = input_from_dec.size()\n batch_, _, height_, _ = input_from_dec.size()\n aeq(batch, batch_)\n aeq(height, height_)\n\n # enc_batch, enc_channel, enc_height = encoder_out_top.size()\n enc_batch, _, enc_height = encoder_out_top.size()\n # enc_batch_, enc_channel_, enc_height_ = encoder_out_combine.size()\n enc_batch_, _, enc_height_ = encoder_out_combine.size()\n\n aeq(enc_batch, enc_batch_)\n aeq(enc_height, enc_height_)\n\n preatt = seq_linear(self.linear_in, input_from_dec)\n target = (base_target_emb + preatt) * SCALE_WEIGHT\n target = torch.squeeze(target, 3)\n target = torch.transpose(target, 1, 2)\n pre_attn = torch.bmm(target, encoder_out_top)\n\n if self.mask is not None:\n pre_attn.data.masked_fill_(self.mask, -float('inf'))\n\n attn = F.softmax(pre_attn, dim=2)\n\n context_output = torch.bmm(\n attn, torch.transpose(encoder_out_combine, 1, 2))\n context_output = torch.transpose(\n torch.unsqueeze(context_output, 3), 1, 2)\n return context_output, attn\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/modules/copy_generator.py",
"content": "import torch\nimport torch.nn as nn\n\nfrom onmt.utils.misc import aeq\nfrom onmt.utils.loss import NMTLossCompute\n\n\ndef collapse_copy_scores(scores, batch, tgt_vocab, src_vocabs=None,\n batch_dim=1, batch_offset=None):\n \"\"\"\n Given scores from an expanded dictionary\n corresponeding to a batch, sums together copies,\n with a dictionary word when it is ambiguous.\n \"\"\"\n offset = len(tgt_vocab)\n for b in range(scores.size(batch_dim)):\n blank = []\n fill = []\n\n if src_vocabs is None:\n src_vocab = batch.src_ex_vocab[b]\n else:\n batch_id = batch_offset[b] if batch_offset is not None else b\n index = batch.indices.data[batch_id]\n src_vocab = src_vocabs[index]\n\n for i in range(1, len(src_vocab)):\n sw = src_vocab.itos[i]\n ti = tgt_vocab.stoi[sw]\n if ti != 0:\n blank.append(offset + i)\n fill.append(ti)\n if blank:\n blank = torch.Tensor(blank).type_as(batch.indices.data)\n fill = torch.Tensor(fill).type_as(batch.indices.data)\n score = scores[:, b] if batch_dim == 1 else scores[b]\n score.index_add_(1, fill, score.index_select(1, blank))\n score.index_fill_(1, blank, 1e-10)\n return scores\n\n\nclass CopyGenerator(nn.Module):\n \"\"\"An implementation of pointer-generator networks\n :cite:`DBLP:journals/corr/SeeLM17`.\n\n These networks consider copying words\n directly from the source sequence.\n\n The copy generator is an extended version of the standard\n generator that computes three values.\n\n * :math:`p_{softmax}` the standard softmax over `tgt_dict`\n * :math:`p(z)` the probability of copying a word from\n the source\n * :math:`p_{copy}` the probility of copying a particular word.\n taken from the attention distribution directly.\n\n The model returns a distribution over the extend dictionary,\n computed as\n\n :math:`p(w) = p(z=1) p_{copy}(w) + p(z=0) p_{softmax}(w)`\n\n\n .. mermaid::\n\n graph BT\n A[input]\n S[src_map]\n B[softmax]\n BB[switch]\n C[attn]\n D[copy]\n O[output]\n A --> B\n A --> BB\n S --> D\n C --> D\n D --> O\n B --> O\n BB --> O\n\n\n Args:\n input_size (int): size of input representation\n output_size (int): size of output vocabulary\n pad_idx (int)\n \"\"\"\n\n def __init__(self, input_size, output_size, pad_idx):\n super(CopyGenerator, self).__init__()\n self.linear = nn.Linear(input_size, output_size)\n self.linear_copy = nn.Linear(input_size, 1)\n self.pad_idx = pad_idx\n\n def forward(self, hidden, attn, src_map):\n \"\"\"\n Compute a distribution over the target dictionary\n extended by the dynamic dictionary implied by copying\n source words.\n\n Args:\n hidden (FloatTensor): hidden outputs ``(batch x tlen, input_size)``\n attn (FloatTensor): attn for each ``(batch x tlen, input_size)``\n src_map (FloatTensor):\n A sparse indicator matrix mapping each source word to\n its index in the \"extended\" vocab containing.\n ``(src_len, batch, extra_words)``\n \"\"\"\n\n # CHECKS\n batch_by_tlen, _ = hidden.size()\n batch_by_tlen_, slen = attn.size()\n slen_, batch, cvocab = src_map.size()\n aeq(batch_by_tlen, batch_by_tlen_)\n aeq(slen, slen_)\n\n # Original probabilities.\n logits = self.linear(hidden)\n logits[:, self.pad_idx] = -float('inf')\n prob = torch.softmax(logits, 1)\n\n # Probability of copying p(z=1) batch.\n p_copy = torch.sigmoid(self.linear_copy(hidden))\n # Probability of not copying: p_{word}(w) * (1 - p(z))\n out_prob = torch.mul(prob, 1 - p_copy)\n mul_attn = torch.mul(attn, p_copy)\n copy_prob = torch.bmm(\n mul_attn.view(-1, batch, slen).transpose(0, 1),\n src_map.transpose(0, 1)\n ).transpose(0, 1)\n copy_prob = copy_prob.contiguous().view(-1, cvocab)\n return torch.cat([out_prob, copy_prob], 1)\n\n\nclass CopyGeneratorLoss(nn.Module):\n \"\"\"Copy generator criterion.\"\"\"\n def __init__(self, vocab_size, force_copy, unk_index=0,\n ignore_index=-100, eps=1e-20):\n super(CopyGeneratorLoss, self).__init__()\n self.force_copy = force_copy\n self.eps = eps\n self.vocab_size = vocab_size\n self.ignore_index = ignore_index\n self.unk_index = unk_index\n\n def forward(self, scores, align, target):\n \"\"\"\n Args:\n scores (FloatTensor): ``(batch_size*tgt_len)`` x dynamic vocab size\n whose sum along dim 1 is less than or equal to 1, i.e. cols\n softmaxed.\n align (LongTensor): ``(batch_size x tgt_len)``\n target (LongTensor): ``(batch_size x tgt_len)``\n \"\"\"\n # probabilities assigned by the model to the gold targets\n vocab_probs = scores.gather(1, target.unsqueeze(1)).squeeze(1)\n\n # probability of tokens copied from source\n copy_ix = align.unsqueeze(1) + self.vocab_size\n copy_tok_probs = scores.gather(1, copy_ix).squeeze(1)\n # Set scores for unk to 0 and add eps\n copy_tok_probs[align == self.unk_index] = 0\n copy_tok_probs += self.eps # to avoid -inf logs\n\n # find the indices in which you do not use the copy mechanism\n non_copy = align == self.unk_index\n if not self.force_copy:\n non_copy = non_copy | (target != self.unk_index)\n\n probs = torch.where(\n non_copy, copy_tok_probs + vocab_probs, copy_tok_probs\n )\n\n loss = -probs.log() # just NLLLoss; can the module be incorporated?\n # Drop padding.\n loss[target == self.ignore_index] = 0\n return loss\n\n\nclass CopyGeneratorLossCompute(NMTLossCompute):\n \"\"\"Copy Generator Loss Computation.\"\"\"\n def __init__(self, criterion, generator, tgt_vocab, normalize_by_length,\n lambda_coverage=0.0):\n super(CopyGeneratorLossCompute, self).__init__(\n criterion, generator, lambda_coverage=lambda_coverage)\n self.tgt_vocab = tgt_vocab\n self.normalize_by_length = normalize_by_length\n\n def _make_shard_state(self, batch, output, range_, attns):\n \"\"\"See base class for args description.\"\"\"\n if getattr(batch, \"alignment\", None) is None:\n raise AssertionError(\"using -copy_attn you need to pass in \"\n \"-dynamic_dict during preprocess stage.\")\n\n shard_state = super(CopyGeneratorLossCompute, self)._make_shard_state(\n batch, output, range_, attns)\n\n shard_state.update({\n \"copy_attn\": attns.get(\"copy\"),\n \"align\": batch.alignment[range_[0] + 1: range_[1]]\n })\n return shard_state\n\n def _compute_loss(self, batch, output, target, copy_attn, align,\n std_attn=None, coverage_attn=None):\n \"\"\"Compute the loss.\n\n The args must match :func:`self._make_shard_state()`.\n\n Args:\n batch: the current batch.\n output: the predict output from the model.\n target: the validate target to compare output with.\n copy_attn: the copy attention value.\n align: the align info.\n \"\"\"\n target = target.view(-1)\n align = align.view(-1)\n scores = self.generator(\n self._bottle(output), self._bottle(copy_attn), batch.src_map\n )\n loss = self.criterion(scores, align, target)\n\n if self.lambda_coverage != 0.0:\n coverage_loss = self._compute_coverage_loss(std_attn,\n coverage_attn)\n loss += coverage_loss\n\n # this block does not depend on the loss value computed above\n # and is used only for stats\n scores_data = collapse_copy_scores(\n self._unbottle(scores.clone(), batch.batch_size),\n batch, self.tgt_vocab, None)\n scores_data = self._bottle(scores_data)\n\n # this block does not depend on the loss value computed above\n # and is used only for stats\n # Correct target copy token instead of \n # tgt[i] = align[i] + len(tgt_vocab)\n # for i such that tgt[i] == 0 and align[i] != 0\n target_data = target.clone()\n unk = self.criterion.unk_index\n correct_mask = (target_data == unk) & (align != unk)\n offset_align = align[correct_mask] + len(self.tgt_vocab)\n target_data[correct_mask] += offset_align\n\n # Compute sum of perplexities for stats\n stats = self._stats(loss.sum().clone(), scores_data, target_data)\n\n # this part looks like it belongs in CopyGeneratorLoss\n if self.normalize_by_length:\n # Compute Loss as NLL divided by seq length\n tgt_lens = batch.tgt[:, :, 0].ne(self.padding_idx).sum(0).float()\n # Compute Total Loss per sequence in batch\n loss = loss.view(-1, batch.batch_size).sum(0)\n # Divide by length of each sequence and sum\n loss = torch.div(loss, tgt_lens).sum()\n else:\n loss = loss.sum()\n\n return loss, stats\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/modules/embeddings.py",
"content": "\"\"\" Embeddings module \"\"\"\nimport math\nimport warnings\n\nimport torch\nimport torch.nn as nn\n\nfrom onmt.modules.util_class import Elementwise\n\n\nclass PositionalEncoding(nn.Module):\n \"\"\"Sinusoidal positional encoding for non-recurrent neural networks.\n\n Implementation based on \"Attention Is All You Need\"\n :cite:`DBLP:journals/corr/VaswaniSPUJGKP17`\n\n Args:\n dropout (float): dropout parameter\n dim (int): embedding size\n \"\"\"\n\n def __init__(self, dropout, dim, max_len=5000):\n if dim % 2 != 0:\n raise ValueError(\"Cannot use sin/cos positional encoding with \"\n \"odd dim (got dim={:d})\".format(dim))\n pe = torch.zeros(max_len, dim)\n position = torch.arange(0, max_len).unsqueeze(1)\n div_term = torch.exp((torch.arange(0, dim, 2, dtype=torch.float) *\n -(math.log(10000.0) / dim)))\n pe[:, 0::2] = torch.sin(position.float() * div_term)\n pe[:, 1::2] = torch.cos(position.float() * div_term)\n pe = pe.unsqueeze(1)\n super(PositionalEncoding, self).__init__()\n self.register_buffer('pe', pe)\n self.dropout = nn.Dropout(p=dropout)\n self.dim = dim\n\n def forward(self, emb, step=None):\n \"\"\"Embed inputs.\n\n Args:\n emb (FloatTensor): Sequence of word vectors\n ``(seq_len, batch_size, self.dim)``\n step (int or NoneType): If stepwise (``seq_len = 1``), use\n the encoding for this position.\n \"\"\"\n\n emb = emb * math.sqrt(self.dim)\n if step is None:\n emb = emb + self.pe[:emb.size(0)]\n else:\n emb = emb + self.pe[step]\n emb = self.dropout(emb)\n return emb\n\n\nclass VecEmbedding(nn.Module):\n def __init__(self, vec_size,\n emb_dim,\n position_encoding=False,\n dropout=0):\n super(VecEmbedding, self).__init__()\n self.embedding_size = emb_dim\n self.proj = nn.Linear(vec_size, emb_dim, bias=False)\n self.word_padding_idx = 0 # vector seqs are zero-padded\n self.position_encoding = position_encoding\n\n if self.position_encoding:\n self.pe = PositionalEncoding(dropout, self.embedding_size)\n\n def forward(self, x, step=None):\n \"\"\"\n Args:\n x (FloatTensor): input, ``(len, batch, 1, vec_feats)``.\n\n Returns:\n FloatTensor: embedded vecs ``(len, batch, embedding_size)``.\n \"\"\"\n x = self.proj(x).squeeze(2)\n if self.position_encoding:\n x = self.pe(x, step=step)\n\n return x\n\n def load_pretrained_vectors(self, file):\n assert not file\n\n\nclass Embeddings(nn.Module):\n \"\"\"Words embeddings for encoder/decoder.\n\n Additionally includes ability to add sparse input features\n based on \"Linguistic Input Features Improve Neural Machine Translation\"\n :cite:`sennrich2016linguistic`.\n\n\n .. mermaid::\n\n graph LR\n A[Input]\n C[Feature 1 Lookup]\n A-->B[Word Lookup]\n A-->C\n A-->D[Feature N Lookup]\n B-->E[MLP/Concat]\n C-->E\n D-->E\n E-->F[Output]\n\n Args:\n word_vec_size (int): size of the dictionary of embeddings.\n word_padding_idx (int): padding index for words in the embeddings.\n feat_padding_idx (List[int]): padding index for a list of features\n in the embeddings.\n word_vocab_size (int): size of dictionary of embeddings for words.\n feat_vocab_sizes (List[int], optional): list of size of dictionary\n of embeddings for each feature.\n position_encoding (bool): see :class:`~onmt.modules.PositionalEncoding`\n feat_merge (string): merge action for the features embeddings:\n concat, sum or mlp.\n feat_vec_exponent (float): when using `-feat_merge concat`, feature\n embedding size is N^feat_dim_exponent, where N is the\n number of values the feature takes.\n feat_vec_size (int): embedding dimension for features when using\n `-feat_merge mlp`\n dropout (float): dropout probability.\n \"\"\"\n\n def __init__(self, word_vec_size,\n word_vocab_size,\n word_padding_idx,\n position_encoding=False,\n feat_merge=\"concat\",\n feat_vec_exponent=0.7,\n feat_vec_size=-1,\n feat_padding_idx=[],\n feat_vocab_sizes=[],\n dropout=0,\n sparse=False,\n fix_word_vecs=False):\n self._validate_args(feat_merge, feat_vocab_sizes, feat_vec_exponent,\n feat_vec_size, feat_padding_idx)\n\n if feat_padding_idx is None:\n feat_padding_idx = []\n self.word_padding_idx = word_padding_idx\n\n self.word_vec_size = word_vec_size\n\n # Dimensions and padding for constructing the word embedding matrix\n vocab_sizes = [word_vocab_size]\n emb_dims = [word_vec_size]\n pad_indices = [word_padding_idx]\n\n # Dimensions and padding for feature embedding matrices\n # (these have no effect if feat_vocab_sizes is empty)\n if feat_merge == 'sum':\n feat_dims = [word_vec_size] * len(feat_vocab_sizes)\n elif feat_vec_size > 0:\n feat_dims = [feat_vec_size] * len(feat_vocab_sizes)\n else:\n feat_dims = [int(vocab ** feat_vec_exponent)\n for vocab in feat_vocab_sizes]\n vocab_sizes.extend(feat_vocab_sizes)\n emb_dims.extend(feat_dims)\n pad_indices.extend(feat_padding_idx)\n\n # The embedding matrix look-up tables. The first look-up table\n # is for words. Subsequent ones are for features, if any exist.\n emb_params = zip(vocab_sizes, emb_dims, pad_indices)\n embeddings = [nn.Embedding(vocab, dim, padding_idx=pad, sparse=sparse)\n for vocab, dim, pad in emb_params]\n emb_luts = Elementwise(feat_merge, embeddings)\n\n # The final output size of word + feature vectors. This can vary\n # from the word vector size if and only if features are defined.\n # This is the attribute you should access if you need to know\n # how big your embeddings are going to be.\n self.embedding_size = (sum(emb_dims) if feat_merge == 'concat'\n else word_vec_size)\n\n # The sequence of operations that converts the input sequence\n # into a sequence of embeddings. At minimum this consists of\n # looking up the embeddings for each word and feature in the\n # input. Model parameters may require the sequence to contain\n # additional operations as well.\n super(Embeddings, self).__init__()\n self.make_embedding = nn.Sequential()\n self.make_embedding.add_module('emb_luts', emb_luts)\n\n if feat_merge == 'mlp' and len(feat_vocab_sizes) > 0:\n in_dim = sum(emb_dims)\n mlp = nn.Sequential(nn.Linear(in_dim, word_vec_size), nn.ReLU())\n self.make_embedding.add_module('mlp', mlp)\n\n self.position_encoding = position_encoding\n\n if self.position_encoding:\n pe = PositionalEncoding(dropout, self.embedding_size)\n self.make_embedding.add_module('pe', pe)\n\n if fix_word_vecs:\n self.word_lut.weight.requires_grad = False\n\n def _validate_args(self, feat_merge, feat_vocab_sizes, feat_vec_exponent,\n feat_vec_size, feat_padding_idx):\n if feat_merge == \"sum\":\n # features must use word_vec_size\n if feat_vec_exponent != 0.7:\n warnings.warn(\"Merging with sum, but got non-default \"\n \"feat_vec_exponent. It will be unused.\")\n if feat_vec_size != -1:\n warnings.warn(\"Merging with sum, but got non-default \"\n \"feat_vec_size. It will be unused.\")\n elif feat_vec_size > 0:\n # features will use feat_vec_size\n if feat_vec_exponent != -1:\n warnings.warn(\"Not merging with sum and positive \"\n \"feat_vec_size, but got non-default \"\n \"feat_vec_exponent. It will be unused.\")\n else:\n if feat_vec_exponent <= 0:\n raise ValueError(\"Using feat_vec_exponent to determine \"\n \"feature vec size, but got feat_vec_exponent \"\n \"less than or equal to 0.\")\n n_feats = len(feat_vocab_sizes)\n if n_feats != len(feat_padding_idx):\n raise ValueError(\"Got unequal number of feat_vocab_sizes and \"\n \"feat_padding_idx ({:d} != {:d})\".format(\n n_feats, len(feat_padding_idx)))\n\n @property\n def word_lut(self):\n \"\"\"Word look-up table.\"\"\"\n return self.make_embedding[0][0]\n\n @property\n def emb_luts(self):\n \"\"\"Embedding look-up table.\"\"\"\n return self.make_embedding[0]\n\n def load_pretrained_vectors(self, emb_file):\n \"\"\"Load in pretrained embeddings.\n\n Args:\n emb_file (str) : path to torch serialized embeddings\n \"\"\"\n\n if emb_file:\n pretrained = torch.load(emb_file)\n pretrained_vec_size = pretrained.size(1)\n if self.word_vec_size > pretrained_vec_size:\n self.word_lut.weight.data[:, :pretrained_vec_size] = pretrained\n elif self.word_vec_size < pretrained_vec_size:\n self.word_lut.weight.data \\\n .copy_(pretrained[:, :self.word_vec_size])\n else:\n self.word_lut.weight.data.copy_(pretrained)\n\n def forward(self, source, step=None):\n \"\"\"Computes the embeddings for words and features.\n\n Args:\n source (LongTensor): index tensor ``(len, batch, nfeat)``\n\n Returns:\n FloatTensor: Word embeddings ``(len, batch, embedding_size)``\n \"\"\"\n\n if self.position_encoding:\n for i, module in enumerate(self.make_embedding._modules.values()):\n if i == len(self.make_embedding._modules.values()) - 1:\n source = module(source, step=step)\n else:\n source = module(source)\n else:\n source = self.make_embedding(source)\n\n return source\n\n def update_dropout(self, dropout):\n if self.position_encoding:\n self._modules['make_embedding'][1].dropout.p = dropout\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/modules/gate.py",
"content": "\"\"\" ContextGate module \"\"\"\nimport torch\nimport torch.nn as nn\n\n\ndef context_gate_factory(gate_type, embeddings_size, decoder_size,\n attention_size, output_size):\n \"\"\"Returns the correct ContextGate class\"\"\"\n\n gate_types = {'source': SourceContextGate,\n 'target': TargetContextGate,\n 'both': BothContextGate}\n\n assert gate_type in gate_types, \"Not valid ContextGate type: {0}\".format(\n gate_type)\n return gate_types[gate_type](embeddings_size, decoder_size, attention_size,\n output_size)\n\n\nclass ContextGate(nn.Module):\n \"\"\"\n Context gate is a decoder module that takes as input the previous word\n embedding, the current decoder state and the attention state, and\n produces a gate.\n The gate can be used to select the input from the target side context\n (decoder state), from the source context (attention state) or both.\n \"\"\"\n\n def __init__(self, embeddings_size, decoder_size,\n attention_size, output_size):\n super(ContextGate, self).__init__()\n input_size = embeddings_size + decoder_size + attention_size\n self.gate = nn.Linear(input_size, output_size, bias=True)\n self.sig = nn.Sigmoid()\n self.source_proj = nn.Linear(attention_size, output_size)\n self.target_proj = nn.Linear(embeddings_size + decoder_size,\n output_size)\n\n def forward(self, prev_emb, dec_state, attn_state):\n input_tensor = torch.cat((prev_emb, dec_state, attn_state), dim=1)\n z = self.sig(self.gate(input_tensor))\n proj_source = self.source_proj(attn_state)\n proj_target = self.target_proj(\n torch.cat((prev_emb, dec_state), dim=1))\n return z, proj_source, proj_target\n\n\nclass SourceContextGate(nn.Module):\n \"\"\"Apply the context gate only to the source context\"\"\"\n\n def __init__(self, embeddings_size, decoder_size,\n attention_size, output_size):\n super(SourceContextGate, self).__init__()\n self.context_gate = ContextGate(embeddings_size, decoder_size,\n attention_size, output_size)\n self.tanh = nn.Tanh()\n\n def forward(self, prev_emb, dec_state, attn_state):\n z, source, target = self.context_gate(\n prev_emb, dec_state, attn_state)\n return self.tanh(target + z * source)\n\n\nclass TargetContextGate(nn.Module):\n \"\"\"Apply the context gate only to the target context\"\"\"\n\n def __init__(self, embeddings_size, decoder_size,\n attention_size, output_size):\n super(TargetContextGate, self).__init__()\n self.context_gate = ContextGate(embeddings_size, decoder_size,\n attention_size, output_size)\n self.tanh = nn.Tanh()\n\n def forward(self, prev_emb, dec_state, attn_state):\n z, source, target = self.context_gate(prev_emb, dec_state, attn_state)\n return self.tanh(z * target + source)\n\n\nclass BothContextGate(nn.Module):\n \"\"\"Apply the context gate to both contexts\"\"\"\n\n def __init__(self, embeddings_size, decoder_size,\n attention_size, output_size):\n super(BothContextGate, self).__init__()\n self.context_gate = ContextGate(embeddings_size, decoder_size,\n attention_size, output_size)\n self.tanh = nn.Tanh()\n\n def forward(self, prev_emb, dec_state, attn_state):\n z, source, target = self.context_gate(prev_emb, dec_state, attn_state)\n return self.tanh((1. - z) * target + z * source)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/modules/global_attention.py",
"content": "\"\"\"Global attention modules (Luong / Bahdanau)\"\"\"\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nfrom onmt.modules.sparse_activations import sparsemax\nfrom onmt.utils.misc import aeq, sequence_mask\n\n# This class is mainly used by decoder.py for RNNs but also\n# by the CNN / transformer decoder when copy attention is used\n# CNN has its own attention mechanism ConvMultiStepAttention\n# Transformer has its own MultiHeadedAttention\n\n\nclass GlobalAttention(nn.Module):\n r\"\"\"\n Global attention takes a matrix and a query vector. It\n then computes a parameterized convex combination of the matrix\n based on the input query.\n\n Constructs a unit mapping a query `q` of size `dim`\n and a source matrix `H` of size `n x dim`, to an output\n of size `dim`.\n\n\n .. mermaid::\n\n graph BT\n A[Query]\n subgraph RNN\n C[H 1]\n D[H 2]\n E[H N]\n end\n F[Attn]\n G[Output]\n A --> F\n C --> F\n D --> F\n E --> F\n C -.-> G\n D -.-> G\n E -.-> G\n F --> G\n\n All models compute the output as\n :math:`c = \\sum_{j=1}^{\\text{SeqLength}} a_j H_j` where\n :math:`a_j` is the softmax of a score function.\n Then then apply a projection layer to [q, c].\n\n However they\n differ on how they compute the attention score.\n\n * Luong Attention (dot, general):\n * dot: :math:`\\text{score}(H_j,q) = H_j^T q`\n * general: :math:`\\text{score}(H_j, q) = H_j^T W_a q`\n\n\n * Bahdanau Attention (mlp):\n * :math:`\\text{score}(H_j, q) = v_a^T \\text{tanh}(W_a q + U_a h_j)`\n\n\n Args:\n dim (int): dimensionality of query and key\n coverage (bool): use coverage term\n attn_type (str): type of attention to use, options [dot,general,mlp]\n attn_func (str): attention function to use, options [softmax,sparsemax]\n\n \"\"\"\n\n def __init__(self, dim, coverage=False, attn_type=\"dot\",\n attn_func=\"softmax\"):\n super(GlobalAttention, self).__init__()\n\n self.dim = dim\n assert attn_type in [\"dot\", \"general\", \"mlp\"], (\n \"Please select a valid attention type (got {:s}).\".format(\n attn_type))\n self.attn_type = attn_type\n assert attn_func in [\"softmax\", \"sparsemax\"], (\n \"Please select a valid attention function.\")\n self.attn_func = attn_func\n\n if self.attn_type == \"general\":\n self.linear_in = nn.Linear(dim, dim, bias=False)\n elif self.attn_type == \"mlp\":\n self.linear_context = nn.Linear(dim, dim, bias=False)\n self.linear_query = nn.Linear(dim, dim, bias=True)\n self.v = nn.Linear(dim, 1, bias=False)\n # mlp wants it with bias\n out_bias = self.attn_type == \"mlp\"\n self.linear_out = nn.Linear(dim * 2, dim, bias=out_bias)\n\n if coverage:\n self.linear_cover = nn.Linear(1, dim, bias=False)\n\n def score(self, h_t, h_s):\n \"\"\"\n Args:\n h_t (FloatTensor): sequence of queries ``(batch, tgt_len, dim)``\n h_s (FloatTensor): sequence of sources ``(batch, src_len, dim``\n\n Returns:\n FloatTensor: raw attention scores (unnormalized) for each src index\n ``(batch, tgt_len, src_len)``\n \"\"\"\n\n # Check input sizes\n src_batch, src_len, src_dim = h_s.size()\n tgt_batch, tgt_len, tgt_dim = h_t.size()\n aeq(src_batch, tgt_batch)\n aeq(src_dim, tgt_dim)\n aeq(self.dim, src_dim)\n\n if self.attn_type in [\"general\", \"dot\"]:\n if self.attn_type == \"general\":\n h_t_ = h_t.view(tgt_batch * tgt_len, tgt_dim)\n h_t_ = self.linear_in(h_t_)\n h_t = h_t_.view(tgt_batch, tgt_len, tgt_dim)\n h_s_ = h_s.transpose(1, 2)\n # (batch, t_len, d) x (batch, d, s_len) --> (batch, t_len, s_len)\n return torch.bmm(h_t, h_s_)\n else:\n dim = self.dim\n wq = self.linear_query(h_t.view(-1, dim))\n wq = wq.view(tgt_batch, tgt_len, 1, dim)\n wq = wq.expand(tgt_batch, tgt_len, src_len, dim)\n\n uh = self.linear_context(h_s.contiguous().view(-1, dim))\n uh = uh.view(src_batch, 1, src_len, dim)\n uh = uh.expand(src_batch, tgt_len, src_len, dim)\n\n # (batch, t_len, s_len, d)\n wquh = torch.tanh(wq + uh)\n\n return self.v(wquh.view(-1, dim)).view(tgt_batch, tgt_len, src_len)\n\n def forward(self, source, memory_bank, memory_lengths=None, coverage=None):\n \"\"\"\n\n Args:\n source (FloatTensor): query vectors ``(batch, tgt_len, dim)``\n memory_bank (FloatTensor): source vectors ``(batch, src_len, dim)``\n memory_lengths (LongTensor): the source context lengths ``(batch,)``\n coverage (FloatTensor): None (not supported yet)\n\n Returns:\n (FloatTensor, FloatTensor):\n\n * Computed vector ``(tgt_len, batch, dim)``\n * Attention distribtutions for each query\n ``(tgt_len, batch, src_len)``\n \"\"\"\n\n # one step input\n if source.dim() == 2:\n one_step = True\n source = source.unsqueeze(1)\n else:\n one_step = False\n\n batch, source_l, dim = memory_bank.size()\n batch_, target_l, dim_ = source.size()\n aeq(batch, batch_)\n aeq(dim, dim_)\n aeq(self.dim, dim)\n if coverage is not None:\n batch_, source_l_ = coverage.size()\n aeq(batch, batch_)\n aeq(source_l, source_l_)\n\n if coverage is not None:\n cover = coverage.view(-1).unsqueeze(1)\n memory_bank += self.linear_cover(cover).view_as(memory_bank)\n memory_bank = torch.tanh(memory_bank)\n\n # compute attention scores, as in Luong et al.\n align = self.score(source, memory_bank)\n\n if memory_lengths is not None:\n mask = sequence_mask(memory_lengths, max_len=align.size(-1))\n mask = mask.unsqueeze(1) # Make it broadcastable.\n align.masked_fill_(~mask, -float('inf'))\n\n # Softmax or sparsemax to normalize attention weights\n if self.attn_func == \"softmax\":\n align_vectors = F.softmax(align.view(batch*target_l, source_l), -1)\n else:\n align_vectors = sparsemax(align.view(batch*target_l, source_l), -1)\n align_vectors = align_vectors.view(batch, target_l, source_l)\n\n # each context vector c_t is the weighted average\n # over all the source hidden states\n c = torch.bmm(align_vectors, memory_bank)\n\n # concatenate\n concat_c = torch.cat([c, source], 2).view(batch*target_l, dim*2)\n attn_h = self.linear_out(concat_c).view(batch, target_l, dim)\n if self.attn_type in [\"general\", \"dot\"]:\n attn_h = torch.tanh(attn_h)\n\n if one_step:\n attn_h = attn_h.squeeze(1)\n align_vectors = align_vectors.squeeze(1)\n\n # Check output sizes\n batch_, dim_ = attn_h.size()\n aeq(batch, batch_)\n aeq(dim, dim_)\n batch_, source_l_ = align_vectors.size()\n aeq(batch, batch_)\n aeq(source_l, source_l_)\n\n else:\n attn_h = attn_h.transpose(0, 1).contiguous()\n align_vectors = align_vectors.transpose(0, 1).contiguous()\n # Check output sizes\n target_l_, batch_, dim_ = attn_h.size()\n aeq(target_l, target_l_)\n aeq(batch, batch_)\n aeq(dim, dim_)\n target_l_, batch_, source_l_ = align_vectors.size()\n aeq(target_l, target_l_)\n aeq(batch, batch_)\n aeq(source_l, source_l_)\n\n return attn_h, align_vectors\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/modules/multi_headed_attn.py",
"content": "\"\"\" Multi-Head Attention module \"\"\"\nimport math\nimport torch\nimport torch.nn as nn\n\nfrom onmt.utils.misc import generate_relative_positions_matrix,\\\n relative_matmul\n# from onmt.utils.misc import aeq\n\n\nclass MultiHeadedAttention(nn.Module):\n \"\"\"Multi-Head Attention module from \"Attention is All You Need\"\n :cite:`DBLP:journals/corr/VaswaniSPUJGKP17`.\n\n Similar to standard `dot` attention but uses\n multiple attention distributions simulataneously\n to select relevant items.\n\n .. mermaid::\n\n graph BT\n A[key]\n B[value]\n C[query]\n O[output]\n subgraph Attn\n D[Attn 1]\n E[Attn 2]\n F[Attn N]\n end\n A --> D\n C --> D\n A --> E\n C --> E\n A --> F\n C --> F\n D --> O\n E --> O\n F --> O\n B --> O\n\n Also includes several additional tricks.\n\n Args:\n head_count (int): number of parallel heads\n model_dim (int): the dimension of keys/values/queries,\n must be divisible by head_count\n dropout (float): dropout parameter\n \"\"\"\n\n def __init__(self, head_count, model_dim, dropout=0.1,\n max_relative_positions=0):\n assert model_dim % head_count == 0\n self.dim_per_head = model_dim // head_count\n self.model_dim = model_dim\n\n super(MultiHeadedAttention, self).__init__()\n self.head_count = head_count\n\n self.linear_keys = nn.Linear(model_dim,\n head_count * self.dim_per_head)\n self.linear_values = nn.Linear(model_dim,\n head_count * self.dim_per_head)\n self.linear_query = nn.Linear(model_dim,\n head_count * self.dim_per_head)\n self.softmax = nn.Softmax(dim=-1)\n self.dropout = nn.Dropout(dropout)\n self.final_linear = nn.Linear(model_dim, model_dim)\n\n self.max_relative_positions = max_relative_positions\n\n if max_relative_positions > 0:\n vocab_size = max_relative_positions * 2 + 1\n self.relative_positions_embeddings = nn.Embedding(\n vocab_size, self.dim_per_head)\n\n def forward(self, key, value, query, mask=None,\n layer_cache=None, attn_type=None):\n \"\"\"\n Compute the context vector and the attention vectors.\n\n Args:\n key (FloatTensor): set of `key_len`\n key vectors ``(batch, key_len, dim)``\n value (FloatTensor): set of `key_len`\n value vectors ``(batch, key_len, dim)``\n query (FloatTensor): set of `query_len`\n query vectors ``(batch, query_len, dim)``\n mask: binary mask 1/0 indicating which keys have\n zero / non-zero attention ``(batch, query_len, key_len)``\n Returns:\n (FloatTensor, FloatTensor):\n\n * output context vectors ``(batch, query_len, dim)``\n * Attention vector in heads ``(batch, head, query_len, key_len)``.\n \"\"\"\n\n # CHECKS\n # batch, k_len, d = key.size()\n # batch_, k_len_, d_ = value.size()\n # aeq(batch, batch_)\n # aeq(k_len, k_len_)\n # aeq(d, d_)\n # batch_, q_len, d_ = query.size()\n # aeq(batch, batch_)\n # aeq(d, d_)\n # aeq(self.model_dim % 8, 0)\n # if mask is not None:\n # batch_, q_len_, k_len_ = mask.size()\n # aeq(batch_, batch)\n # aeq(k_len_, k_len)\n # aeq(q_len_ == q_len)\n # END CHECKS\n\n batch_size = key.size(0)\n dim_per_head = self.dim_per_head\n head_count = self.head_count\n key_len = key.size(1)\n query_len = query.size(1)\n\n def shape(x):\n \"\"\"Projection.\"\"\"\n return x.view(batch_size, -1, head_count, dim_per_head) \\\n .transpose(1, 2)\n\n def unshape(x):\n \"\"\"Compute context.\"\"\"\n return x.transpose(1, 2).contiguous() \\\n .view(batch_size, -1, head_count * dim_per_head)\n\n # 1) Project key, value, and query.\n if layer_cache is not None:\n if attn_type == \"self\":\n query, key, value = self.linear_query(query),\\\n self.linear_keys(query),\\\n self.linear_values(query)\n key = shape(key)\n value = shape(value)\n if layer_cache[\"self_keys\"] is not None:\n key = torch.cat(\n (layer_cache[\"self_keys\"], key),\n dim=2)\n if layer_cache[\"self_values\"] is not None:\n value = torch.cat(\n (layer_cache[\"self_values\"], value),\n dim=2)\n layer_cache[\"self_keys\"] = key\n layer_cache[\"self_values\"] = value\n elif attn_type == \"context\":\n query = self.linear_query(query)\n if layer_cache[\"memory_keys\"] is None:\n key, value = self.linear_keys(key),\\\n self.linear_values(value)\n key = shape(key)\n value = shape(value)\n else:\n key, value = layer_cache[\"memory_keys\"],\\\n layer_cache[\"memory_values\"]\n layer_cache[\"memory_keys\"] = key\n layer_cache[\"memory_values\"] = value\n else:\n key = self.linear_keys(key)\n value = self.linear_values(value)\n query = self.linear_query(query)\n key = shape(key)\n value = shape(value)\n\n if self.max_relative_positions > 0 and attn_type == \"self\":\n key_len = key.size(2)\n # 1 or key_len x key_len\n relative_positions_matrix = generate_relative_positions_matrix(\n key_len, self.max_relative_positions,\n cache=True if layer_cache is not None else False)\n # 1 or key_len x key_len x dim_per_head\n relations_keys = self.relative_positions_embeddings(\n relative_positions_matrix.to(key.device))\n # 1 or key_len x key_len x dim_per_head\n relations_values = self.relative_positions_embeddings(\n relative_positions_matrix.to(key.device))\n\n query = shape(query)\n\n key_len = key.size(2)\n query_len = query.size(2)\n\n # 2) Calculate and scale scores.\n query = query / math.sqrt(dim_per_head)\n # batch x num_heads x query_len x key_len\n query_key = torch.matmul(query, key.transpose(2, 3))\n\n if self.max_relative_positions > 0 and attn_type == \"self\":\n scores = query_key + relative_matmul(query, relations_keys, True)\n else:\n scores = query_key\n scores = scores.float()\n\n if mask is not None:\n mask = mask.unsqueeze(1) # [B, 1, 1, T_values]\n scores = scores.masked_fill(mask, -1e18)\n\n # 3) Apply attention dropout and compute context vectors.\n attn = self.softmax(scores).to(query.dtype)\n drop_attn = self.dropout(attn)\n\n context_original = torch.matmul(drop_attn, value)\n\n if self.max_relative_positions > 0 and attn_type == \"self\":\n context = unshape(context_original\n + relative_matmul(drop_attn,\n relations_values,\n False))\n else:\n context = unshape(context_original)\n\n output = self.final_linear(context)\n # CHECK\n # batch_, q_len_, d_ = output.size()\n # aeq(q_len, q_len_)\n # aeq(batch, batch_)\n # aeq(d, d_)\n\n # Return multi-head attn\n attns = attn \\\n .view(batch_size, head_count,\n query_len, key_len)\n\n return output, attns\n\n def update_dropout(self, dropout):\n self.dropout.p = dropout\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/modules/position_ffn.py",
"content": "\"\"\"Position feed-forward network from \"Attention is All You Need\".\"\"\"\n\nimport torch.nn as nn\n\n\nclass PositionwiseFeedForward(nn.Module):\n \"\"\" A two-layer Feed-Forward-Network with residual layer norm.\n\n Args:\n d_model (int): the size of input for the first-layer of the FFN.\n d_ff (int): the hidden layer size of the second-layer\n of the FNN.\n dropout (float): dropout probability in :math:`[0, 1)`.\n \"\"\"\n\n def __init__(self, d_model, d_ff, dropout=0.1):\n super(PositionwiseFeedForward, self).__init__()\n self.w_1 = nn.Linear(d_model, d_ff)\n self.w_2 = nn.Linear(d_ff, d_model)\n self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)\n self.dropout_1 = nn.Dropout(dropout)\n self.relu = nn.ReLU()\n self.dropout_2 = nn.Dropout(dropout)\n\n def forward(self, x):\n \"\"\"Layer definition.\n\n Args:\n x: ``(batch_size, input_len, model_dim)``\n\n Returns:\n (FloatTensor): Output ``(batch_size, input_len, model_dim)``.\n \"\"\"\n\n inter = self.dropout_1(self.relu(self.w_1(self.layer_norm(x))))\n output = self.dropout_2(self.w_2(inter))\n return output + x\n\n def update_dropout(self, dropout):\n self.dropout_1.p = dropout\n self.dropout_2.p = dropout\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/modules/sparse_activations.py",
"content": "\"\"\"\nAn implementation of sparsemax (Martins & Astudillo, 2016). See\n:cite:`DBLP:journals/corr/MartinsA16` for detailed description.\n\nBy Ben Peters and Vlad Niculae\n\"\"\"\n\nimport torch\nfrom torch.autograd import Function\nimport torch.nn as nn\n\n\ndef _make_ix_like(input, dim=0):\n d = input.size(dim)\n rho = torch.arange(1, d + 1, device=input.device, dtype=input.dtype)\n view = [1] * input.dim()\n view[0] = -1\n return rho.view(view).transpose(0, dim)\n\n\ndef _threshold_and_support(input, dim=0):\n \"\"\"Sparsemax building block: compute the threshold\n\n Args:\n input: any dimension\n dim: dimension along which to apply the sparsemax\n\n Returns:\n the threshold value\n \"\"\"\n\n input_srt, _ = torch.sort(input, descending=True, dim=dim)\n input_cumsum = input_srt.cumsum(dim) - 1\n rhos = _make_ix_like(input, dim)\n support = rhos * input_srt > input_cumsum\n\n support_size = support.sum(dim=dim).unsqueeze(dim)\n tau = input_cumsum.gather(dim, support_size - 1)\n tau /= support_size.to(input.dtype)\n return tau, support_size\n\n\nclass SparsemaxFunction(Function):\n\n @staticmethod\n def forward(ctx, input, dim=0):\n \"\"\"sparsemax: normalizing sparse transform (a la softmax)\n\n Parameters:\n input (Tensor): any shape\n dim: dimension along which to apply sparsemax\n\n Returns:\n output (Tensor): same shape as input\n \"\"\"\n ctx.dim = dim\n max_val, _ = input.max(dim=dim, keepdim=True)\n input -= max_val # same numerical stability trick as for softmax\n tau, supp_size = _threshold_and_support(input, dim=dim)\n output = torch.clamp(input - tau, min=0)\n ctx.save_for_backward(supp_size, output)\n return output\n\n @staticmethod\n def backward(ctx, grad_output):\n supp_size, output = ctx.saved_tensors\n dim = ctx.dim\n grad_input = grad_output.clone()\n grad_input[output == 0] = 0\n\n v_hat = grad_input.sum(dim=dim) / supp_size.to(output.dtype).squeeze()\n v_hat = v_hat.unsqueeze(dim)\n grad_input = torch.where(output != 0, grad_input - v_hat, grad_input)\n return grad_input, None\n\n\nsparsemax = SparsemaxFunction.apply\n\n\nclass Sparsemax(nn.Module):\n\n def __init__(self, dim=0):\n self.dim = dim\n super(Sparsemax, self).__init__()\n\n def forward(self, input):\n return sparsemax(input, self.dim)\n\n\nclass LogSparsemax(nn.Module):\n\n def __init__(self, dim=0):\n self.dim = dim\n super(LogSparsemax, self).__init__()\n\n def forward(self, input):\n return torch.log(sparsemax(input, self.dim))\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/modules/sparse_losses.py",
"content": "import torch\nimport torch.nn as nn\nfrom torch.autograd import Function\nfrom onmt.modules.sparse_activations import _threshold_and_support\nfrom onmt.utils.misc import aeq\n\n\nclass SparsemaxLossFunction(Function):\n\n @staticmethod\n def forward(ctx, input, target):\n \"\"\"\n input (FloatTensor): ``(n, num_classes)``.\n target (LongTensor): ``(n,)``, the indices of the target classes\n \"\"\"\n input_batch, classes = input.size()\n target_batch = target.size(0)\n aeq(input_batch, target_batch)\n\n z_k = input.gather(1, target.unsqueeze(1)).squeeze()\n tau_z, support_size = _threshold_and_support(input, dim=1)\n support = input > tau_z\n x = torch.where(\n support, input**2 - tau_z**2,\n torch.tensor(0.0, device=input.device)\n ).sum(dim=1)\n ctx.save_for_backward(input, target, tau_z)\n # clamping necessary because of numerical errors: loss should be lower\n # bounded by zero, but negative values near zero are possible without\n # the clamp\n return torch.clamp(x / 2 - z_k + 0.5, min=0.0)\n\n @staticmethod\n def backward(ctx, grad_output):\n input, target, tau_z = ctx.saved_tensors\n sparsemax_out = torch.clamp(input - tau_z, min=0)\n delta = torch.zeros_like(sparsemax_out)\n delta.scatter_(1, target.unsqueeze(1), 1)\n return sparsemax_out - delta, None\n\n\nsparsemax_loss = SparsemaxLossFunction.apply\n\n\nclass SparsemaxLoss(nn.Module):\n \"\"\"\n An implementation of sparsemax loss, first proposed in\n :cite:`DBLP:journals/corr/MartinsA16`. If using\n a sparse output layer, it is not possible to use negative log likelihood\n because the loss is infinite in the case the target is assigned zero\n probability. Inputs to SparsemaxLoss are arbitrary dense real-valued\n vectors (like in nn.CrossEntropyLoss), not probability vectors (like in\n nn.NLLLoss).\n \"\"\"\n\n def __init__(self, weight=None, ignore_index=-100,\n reduction='elementwise_mean'):\n assert reduction in ['elementwise_mean', 'sum', 'none']\n self.reduction = reduction\n self.weight = weight\n self.ignore_index = ignore_index\n super(SparsemaxLoss, self).__init__()\n\n def forward(self, input, target):\n loss = sparsemax_loss(input, target)\n if self.ignore_index >= 0:\n ignored_positions = target == self.ignore_index\n size = float((target.size(0) - ignored_positions.sum()).item())\n loss.masked_fill_(ignored_positions, 0.0)\n else:\n size = float(target.size(0))\n if self.reduction == 'sum':\n loss = loss.sum()\n elif self.reduction == 'elementwise_mean':\n loss = loss.sum() / size\n return loss\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/modules/structured_attention.py",
"content": "import torch.nn as nn\nimport torch\nimport torch.cuda\n\n\nclass MatrixTree(nn.Module):\n \"\"\"Implementation of the matrix-tree theorem for computing marginals\n of non-projective dependency parsing. This attention layer is used\n in the paper \"Learning Structured Text Representations\"\n :cite:`DBLP:journals/corr/LiuL17d`.\n \"\"\"\n\n def __init__(self, eps=1e-5):\n self.eps = eps\n super(MatrixTree, self).__init__()\n\n def forward(self, input):\n laplacian = input.exp() + self.eps\n output = input.clone()\n for b in range(input.size(0)):\n lap = laplacian[b].masked_fill(\n torch.eye(input.size(1), device=input.device).ne(0), 0)\n lap = -lap + torch.diag(lap.sum(0))\n # store roots on diagonal\n lap[0] = input[b].diag().exp()\n inv_laplacian = lap.inverse()\n\n factor = inv_laplacian.diag().unsqueeze(1)\\\n .expand_as(input[b]).transpose(0, 1)\n term1 = input[b].exp().mul(factor).clone()\n term2 = input[b].exp().mul(inv_laplacian.transpose(0, 1)).clone()\n term1[:, 0] = 0\n term2[0] = 0\n output[b] = term1 - term2\n roots_output = input[b].diag().exp().mul(\n inv_laplacian.transpose(0, 1)[0])\n output[b] = output[b] + torch.diag(roots_output)\n return output\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/modules/util_class.py",
"content": "\"\"\" Misc classes \"\"\"\nimport torch\nimport torch.nn as nn\n\n\n# At the moment this class is only used by embeddings.Embeddings look-up tables\nclass Elementwise(nn.ModuleList):\n \"\"\"\n A simple network container.\n Parameters are a list of modules.\n Inputs are a 3d Tensor whose last dimension is the same length\n as the list.\n Outputs are the result of applying modules to inputs elementwise.\n An optional merge parameter allows the outputs to be reduced to a\n single Tensor.\n \"\"\"\n\n def __init__(self, merge=None, *args):\n assert merge in [None, 'first', 'concat', 'sum', 'mlp']\n self.merge = merge\n super(Elementwise, self).__init__(*args)\n\n def forward(self, inputs):\n inputs_ = [feat.squeeze(2) for feat in inputs.split(1, dim=2)]\n assert len(self) == len(inputs_)\n outputs = [f(x) for f, x in zip(self, inputs_)]\n if self.merge == 'first':\n return outputs[0]\n elif self.merge == 'concat' or self.merge == 'mlp':\n return torch.cat(outputs, 2)\n elif self.merge == 'sum':\n return sum(outputs)\n else:\n return outputs\n\n\nclass Cast(nn.Module):\n \"\"\"\n Basic layer that casts its input to a specific data type. The same tensor\n is returned if the data type is already correct.\n \"\"\"\n\n def __init__(self, dtype):\n super(Cast, self).__init__()\n self._dtype = dtype\n\n def forward(self, x):\n return x.to(self._dtype)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/modules/weight_norm.py",
"content": "\"\"\" Weights normalization modules \"\"\"\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nfrom torch.nn import Parameter\n\n\ndef get_var_maybe_avg(namespace, var_name, training, polyak_decay):\n \"\"\" utility for retrieving polyak averaged params\n Update average\n \"\"\"\n v = getattr(namespace, var_name)\n v_avg = getattr(namespace, var_name + '_avg')\n v_avg -= (1 - polyak_decay) * (v_avg - v.data)\n\n if training:\n return v\n else:\n return v_avg\n\n\ndef get_vars_maybe_avg(namespace, var_names, training, polyak_decay):\n \"\"\" utility for retrieving polyak averaged params \"\"\"\n vars = []\n for vn in var_names:\n vars.append(get_var_maybe_avg(\n namespace, vn, training, polyak_decay))\n return vars\n\n\nclass WeightNormLinear(nn.Linear):\n \"\"\"\n Implementation of \"Weight Normalization: A Simple Reparameterization\n to Accelerate Training of Deep Neural Networks\"\n :cite:`DBLP:journals/corr/SalimansK16`\n\n As a reparameterization method, weight normalization is same\n as BatchNormalization, but it doesn't depend on minibatch.\n\n NOTE: This is used nowhere in the code at this stage\n Vincent Nguyen 05/18/2018\n \"\"\"\n\n def __init__(self, in_features, out_features,\n init_scale=1., polyak_decay=0.9995):\n super(WeightNormLinear, self).__init__(\n in_features, out_features, bias=True)\n\n self.V = self.weight\n self.g = Parameter(torch.Tensor(out_features))\n self.b = self.bias\n\n self.register_buffer(\n 'V_avg', torch.zeros(out_features, in_features))\n self.register_buffer('g_avg', torch.zeros(out_features))\n self.register_buffer('b_avg', torch.zeros(out_features))\n\n self.init_scale = init_scale\n self.polyak_decay = polyak_decay\n self.reset_parameters()\n\n def reset_parameters(self):\n return\n\n def forward(self, x, init=False):\n if init is True:\n # out_features * in_features\n self.V.data.copy_(torch.randn(self.V.data.size()).type_as(\n self.V.data) * 0.05)\n # norm is out_features * 1\n v_norm = self.V.data / \\\n self.V.data.norm(2, 1).expand_as(self.V.data)\n # batch_size * out_features\n x_init = F.linear(x, v_norm).data\n # out_features\n m_init, v_init = x_init.mean(0).squeeze(\n 0), x_init.var(0).squeeze(0)\n # out_features\n scale_init = self.init_scale / \\\n torch.sqrt(v_init + 1e-10)\n self.g.data.copy_(scale_init)\n self.b.data.copy_(-m_init * scale_init)\n x_init = scale_init.view(1, -1).expand_as(x_init) \\\n * (x_init - m_init.view(1, -1).expand_as(x_init))\n self.V_avg.copy_(self.V.data)\n self.g_avg.copy_(self.g.data)\n self.b_avg.copy_(self.b.data)\n return x_init\n else:\n v, g, b = get_vars_maybe_avg(self, ['V', 'g', 'b'],\n self.training,\n polyak_decay=self.polyak_decay)\n # batch_size * out_features\n x = F.linear(x, v)\n scalar = g / torch.norm(v, 2, 1).squeeze(1)\n x = scalar.view(1, -1).expand_as(x) * x + \\\n b.view(1, -1).expand_as(x)\n return x\n\n\nclass WeightNormConv2d(nn.Conv2d):\n def __init__(self, in_channels, out_channels, kernel_size, stride=1,\n padding=0, dilation=1, groups=1, init_scale=1.,\n polyak_decay=0.9995):\n super(WeightNormConv2d, self).__init__(in_channels, out_channels,\n kernel_size, stride, padding,\n dilation, groups)\n\n self.V = self.weight\n self.g = Parameter(torch.Tensor(out_channels))\n self.b = self.bias\n\n self.register_buffer('V_avg', torch.zeros(self.V.size()))\n self.register_buffer('g_avg', torch.zeros(out_channels))\n self.register_buffer('b_avg', torch.zeros(out_channels))\n\n self.init_scale = init_scale\n self.polyak_decay = polyak_decay\n self.reset_parameters()\n\n def reset_parameters(self):\n return\n\n def forward(self, x, init=False):\n if init is True:\n # out_channels, in_channels // groups, * kernel_size\n self.V.data.copy_(torch.randn(self.V.data.size()\n ).type_as(self.V.data) * 0.05)\n v_norm = self.V.data / self.V.data.view(self.out_channels, -1)\\\n .norm(2, 1).view(self.out_channels, *(\n [1] * (len(self.kernel_size) + 1))).expand_as(self.V.data)\n x_init = F.conv2d(x, v_norm, None, self.stride,\n self.padding, self.dilation, self.groups).data\n t_x_init = x_init.transpose(0, 1).contiguous().view(\n self.out_channels, -1)\n m_init, v_init = t_x_init.mean(1).squeeze(\n 1), t_x_init.var(1).squeeze(1)\n # out_features\n scale_init = self.init_scale / \\\n torch.sqrt(v_init + 1e-10)\n self.g.data.copy_(scale_init)\n self.b.data.copy_(-m_init * scale_init)\n scale_init_shape = scale_init.view(\n 1, self.out_channels, *([1] * (len(x_init.size()) - 2)))\n m_init_shape = m_init.view(\n 1, self.out_channels, *([1] * (len(x_init.size()) - 2)))\n x_init = scale_init_shape.expand_as(\n x_init) * (x_init - m_init_shape.expand_as(x_init))\n self.V_avg.copy_(self.V.data)\n self.g_avg.copy_(self.g.data)\n self.b_avg.copy_(self.b.data)\n return x_init\n else:\n v, g, b = get_vars_maybe_avg(\n self, ['V', 'g', 'b'], self.training,\n polyak_decay=self.polyak_decay)\n\n scalar = torch.norm(v.view(self.out_channels, -1), 2, 1)\n if len(scalar.size()) == 2:\n scalar = g / scalar.squeeze(1)\n else:\n scalar = g / scalar\n\n w = scalar.view(self.out_channels, *\n ([1] * (len(v.size()) - 1))).expand_as(v) * v\n\n x = F.conv2d(x, w, b, self.stride,\n self.padding, self.dilation, self.groups)\n return x\n\n# This is used nowhere in the code at the moment (Vincent Nguyen 05/18/2018)\n\n\nclass WeightNormConvTranspose2d(nn.ConvTranspose2d):\n def __init__(self, in_channels, out_channels, kernel_size, stride=1,\n padding=0, output_padding=0, groups=1, init_scale=1.,\n polyak_decay=0.9995):\n super(WeightNormConvTranspose2d, self).__init__(\n in_channels, out_channels,\n kernel_size, stride,\n padding, output_padding,\n groups)\n # in_channels, out_channels, *kernel_size\n self.V = self.weight\n self.g = Parameter(torch.Tensor(out_channels))\n self.b = self.bias\n\n self.register_buffer('V_avg', torch.zeros(self.V.size()))\n self.register_buffer('g_avg', torch.zeros(out_channels))\n self.register_buffer('b_avg', torch.zeros(out_channels))\n\n self.init_scale = init_scale\n self.polyak_decay = polyak_decay\n self.reset_parameters()\n\n def reset_parameters(self):\n return\n\n def forward(self, x, init=False):\n if init is True:\n # in_channels, out_channels, *kernel_size\n self.V.data.copy_(torch.randn(self.V.data.size()).type_as(\n self.V.data) * 0.05)\n v_norm = self.V.data / self.V.data.transpose(0, 1).contiguous() \\\n .view(self.out_channels, -1).norm(2, 1).view(\n self.in_channels, self.out_channels,\n *([1] * len(self.kernel_size))).expand_as(self.V.data)\n x_init = F.conv_transpose2d(\n x, v_norm, None, self.stride,\n self.padding, self.output_padding, self.groups).data\n # self.out_channels, 1\n t_x_init = x_init.tranpose(0, 1).contiguous().view(\n self.out_channels, -1)\n # out_features\n m_init, v_init = t_x_init.mean(1).squeeze(\n 1), t_x_init.var(1).squeeze(1)\n # out_features\n scale_init = self.init_scale / \\\n torch.sqrt(v_init + 1e-10)\n self.g.data.copy_(scale_init)\n self.b.data.copy_(-m_init * scale_init)\n scale_init_shape = scale_init.view(\n 1, self.out_channels, *([1] * (len(x_init.size()) - 2)))\n m_init_shape = m_init.view(\n 1, self.out_channels, *([1] * (len(x_init.size()) - 2)))\n\n x_init = scale_init_shape.expand_as(x_init)\\\n * (x_init - m_init_shape.expand_as(x_init))\n self.V_avg.copy_(self.V.data)\n self.g_avg.copy_(self.g.data)\n self.b_avg.copy_(self.b.data)\n return x_init\n else:\n v, g, b = get_vars_maybe_avg(\n self, ['V', 'g', 'b'], self.training,\n polyak_decay=self.polyak_decay)\n scalar = g / \\\n torch.norm(v.transpose(0, 1).contiguous().view(\n self.out_channels, -1), 2, 1).squeeze(1)\n w = scalar.view(self.in_channels, self.out_channels,\n *([1] * (len(v.size()) - 2))).expand_as(v) * v\n\n x = F.conv_transpose2d(x, w, b, self.stride,\n self.padding, self.output_padding,\n self.groups)\n return x\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/opts.py",
"content": "\"\"\" Implementation of all available options \"\"\"\nfrom __future__ import print_function\n\nimport configargparse\nfrom onmt.models.sru import CheckSRU\n\n\ndef config_opts(parser):\n parser.add('-config', '--config', required=False,\n is_config_file_arg=True, help='config file path')\n parser.add('-save_config', '--save_config', required=False,\n is_write_out_config_file_arg=True,\n help='config file save path')\n\n\ndef model_opts(parser):\n \"\"\"\n These options are passed to the construction of the model.\n Be careful with these as they will be used during translation.\n \"\"\"\n\n # Embedding Options\n group = parser.add_argument_group('Model-Embeddings')\n group.add('--src_word_vec_size', '-src_word_vec_size',\n type=int, default=500,\n help='Word embedding size for src.')\n group.add('--tgt_word_vec_size', '-tgt_word_vec_size',\n type=int, default=500,\n help='Word embedding size for tgt.')\n group.add('--word_vec_size', '-word_vec_size', type=int, default=-1,\n help='Word embedding size for src and tgt.')\n\n group.add('--share_decoder_embeddings', '-share_decoder_embeddings',\n action='store_true',\n help=\"Use a shared weight matrix for the input and \"\n \"output word embeddings in the decoder.\")\n group.add('--share_embeddings', '-share_embeddings', action='store_true',\n help=\"Share the word embeddings between encoder \"\n \"and decoder. Need to use shared dictionary for this \"\n \"option.\")\n group.add('--position_encoding', '-position_encoding', action='store_true',\n help=\"Use a sin to mark relative words positions. \"\n \"Necessary for non-RNN style models.\")\n\n group = parser.add_argument_group('Model-Embedding Features')\n group.add('--feat_merge', '-feat_merge', type=str, default='concat',\n choices=['concat', 'sum', 'mlp'],\n help=\"Merge action for incorporating features embeddings. \"\n \"Options [concat|sum|mlp].\")\n group.add('--feat_vec_size', '-feat_vec_size', type=int, default=-1,\n help=\"If specified, feature embedding sizes \"\n \"will be set to this. Otherwise, feat_vec_exponent \"\n \"will be used.\")\n group.add('--feat_vec_exponent', '-feat_vec_exponent',\n type=float, default=0.7,\n help=\"If -feat_merge_size is not set, feature \"\n \"embedding sizes will be set to N^feat_vec_exponent \"\n \"where N is the number of values the feature takes.\")\n\n # Encoder-Decoder Options\n group = parser.add_argument_group('Model- Encoder-Decoder')\n group.add('--model_type', '-model_type', default='text',\n choices=['text', 'img', 'audio', 'vec'],\n help=\"Type of source model to use. Allows \"\n \"the system to incorporate non-text inputs. \"\n \"Options are [text|img|audio|vec].\")\n group.add('--model_dtype', '-model_dtype', default='fp32',\n choices=['fp32', 'fp16'],\n help='Data type of the model.')\n\n group.add('--encoder_type', '-encoder_type', type=str, default='rnn',\n choices=['rnn', 'brnn', 'mean', 'transformer', 'cnn'],\n help=\"Type of encoder layer to use. Non-RNN layers \"\n \"are experimental. Options are \"\n \"[rnn|brnn|mean|transformer|cnn].\")\n group.add('--decoder_type', '-decoder_type', type=str, default='rnn',\n choices=['rnn', 'transformer', 'cnn'],\n help=\"Type of decoder layer to use. Non-RNN layers \"\n \"are experimental. Options are \"\n \"[rnn|transformer|cnn].\")\n\n group.add('--layers', '-layers', type=int, default=-1,\n help='Number of layers in enc/dec.')\n group.add('--enc_layers', '-enc_layers', type=int, default=2,\n help='Number of layers in the encoder')\n group.add('--dec_layers', '-dec_layers', type=int, default=2,\n help='Number of layers in the decoder')\n group.add('--rnn_size', '-rnn_size', type=int, default=-1,\n help=\"Size of rnn hidden states. Overwrites \"\n \"enc_rnn_size and dec_rnn_size\")\n group.add('--enc_rnn_size', '-enc_rnn_size', type=int, default=500,\n help=\"Size of encoder rnn hidden states. \"\n \"Must be equal to dec_rnn_size except for \"\n \"speech-to-text.\")\n group.add('--dec_rnn_size', '-dec_rnn_size', type=int, default=500,\n help=\"Size of decoder rnn hidden states. \"\n \"Must be equal to enc_rnn_size except for \"\n \"speech-to-text.\")\n group.add('--audio_enc_pooling', '-audio_enc_pooling',\n type=str, default='1',\n help=\"The amount of pooling of audio encoder, \"\n \"either the same amount of pooling across all layers \"\n \"indicated by a single number, or different amounts of \"\n \"pooling per layer separated by comma.\")\n group.add('--cnn_kernel_width', '-cnn_kernel_width', type=int, default=3,\n help=\"Size of windows in the cnn, the kernel_size is \"\n \"(cnn_kernel_width, 1) in conv layer\")\n\n group.add('--input_feed', '-input_feed', type=int, default=1,\n help=\"Feed the context vector at each time step as \"\n \"additional input (via concatenation with the word \"\n \"embeddings) to the decoder.\")\n group.add('--bridge', '-bridge', action=\"store_true\",\n help=\"Have an additional layer between the last encoder \"\n \"state and the first decoder state\")\n group.add('--rnn_type', '-rnn_type', type=str, default='LSTM',\n choices=['LSTM', 'GRU', 'SRU'],\n action=CheckSRU,\n help=\"The gate type to use in the RNNs\")\n # group.add('--residual', '-residual', action=\"store_true\",\n # help=\"Add residual connections between RNN layers.\")\n\n group.add('--brnn', '-brnn', action=DeprecateAction,\n help=\"Deprecated, use `encoder_type`.\")\n\n group.add('--context_gate', '-context_gate', type=str, default=None,\n choices=['source', 'target', 'both'],\n help=\"Type of context gate to use. \"\n \"Do not select for no context gate.\")\n\n # Attention options\n group = parser.add_argument_group('Model- Attention')\n group.add('--global_attention', '-global_attention',\n type=str, default='general',\n choices=['dot', 'general', 'mlp', 'none'],\n help=\"The attention type to use: \"\n \"dotprod or general (Luong) or MLP (Bahdanau)\")\n group.add('--global_attention_function', '-global_attention_function',\n type=str, default=\"softmax\", choices=[\"softmax\", \"sparsemax\"])\n group.add('--self_attn_type', '-self_attn_type',\n type=str, default=\"scaled-dot\",\n help='Self attention type in Transformer decoder '\n 'layer -- currently \"scaled-dot\" or \"average\" ')\n group.add('--max_relative_positions', '-max_relative_positions',\n type=int, default=0,\n help=\"Maximum distance between inputs in relative \"\n \"positions representations. \"\n \"For more detailed information, see: \"\n \"https://arxiv.org/pdf/1803.02155.pdf\")\n group.add('--heads', '-heads', type=int, default=8,\n help='Number of heads for transformer self-attention')\n group.add('--transformer_ff', '-transformer_ff', type=int, default=2048,\n help='Size of hidden transformer feed-forward')\n group.add('--aan_useffn', '-aan_useffn', action=\"store_true\",\n help='Turn on the FFN layer in the AAN decoder')\n\n # Alignement options\n group = parser.add_argument_group('Model - Alignement')\n group.add('--lambda_align', '-lambda_align', type=float, default=0.0,\n help=\"Lambda value for alignement loss of Garg et al (2019)\"\n \"For more detailed information, see: \"\n \"https://arxiv.org/abs/1909.02074\")\n group.add('--alignment_layer', '-alignment_layer', type=int, default=-3,\n help='Layer number which has to be supervised.')\n group.add('--alignment_heads', '-alignment_heads', type=int, default=None,\n help='N. of cross attention heads per layer to supervised with')\n group.add('--full_context_alignment', '-full_context_alignment',\n action=\"store_true\",\n help='Whether alignment is conditioned on full target context.')\n\n # Generator and loss options.\n group = parser.add_argument_group('Generator')\n group.add('--copy_attn', '-copy_attn', action=\"store_true\",\n help='Train copy attention layer.')\n group.add('--copy_attn_type', '-copy_attn_type',\n type=str, default=None,\n choices=['dot', 'general', 'mlp', 'none'],\n help=\"The copy attention type to use. Leave as None to use \"\n \"the same as -global_attention.\")\n group.add('--generator_function', '-generator_function', default=\"softmax\",\n choices=[\"softmax\", \"sparsemax\"],\n help=\"Which function to use for generating \"\n \"probabilities over the target vocabulary (choices: \"\n \"softmax, sparsemax)\")\n group.add('--copy_attn_force', '-copy_attn_force', action=\"store_true\",\n help='When available, train to copy.')\n group.add('--reuse_copy_attn', '-reuse_copy_attn', action=\"store_true\",\n help=\"Reuse standard attention for copy\")\n group.add('--copy_loss_by_seqlength', '-copy_loss_by_seqlength',\n action=\"store_true\",\n help=\"Divide copy loss by length of sequence\")\n group.add('--coverage_attn', '-coverage_attn', action=\"store_true\",\n help='Train a coverage attention layer.')\n group.add('--lambda_coverage', '-lambda_coverage', type=float, default=0.0,\n help='Lambda value for coverage loss of See et al (2017)')\n group.add('--loss_scale', '-loss_scale', type=float, default=0,\n help=\"For FP16 training, the static loss scale to use. If not \"\n \"set, the loss scale is dynamically computed.\")\n group.add('--apex_opt_level', '-apex_opt_level', type=str, default=\"O1\",\n choices=[\"O0\", \"O1\", \"O2\", \"O3\"],\n help=\"For FP16 training, the opt_level to use.\"\n \"See https://nvidia.github.io/apex/amp.html#opt-levels.\")\n\n\ndef preprocess_opts(parser):\n \"\"\" Pre-procesing options \"\"\"\n # Data options\n group = parser.add_argument_group('Data')\n group.add('--data_type', '-data_type', default=\"text\",\n help=\"Type of the source input. \"\n \"Options are [text|img|audio|vec].\")\n\n group.add('--train_src', '-train_src', required=True, nargs='+',\n help=\"Path(s) to the training source data\")\n group.add('--train_tgt', '-train_tgt', required=True, nargs='+',\n help=\"Path(s) to the training target data\")\n group.add('--train_align', '-train_align', nargs='+', default=[None],\n help=\"Path(s) to the training src-tgt alignment\")\n group.add('--train_ids', '-train_ids', nargs='+', default=[None],\n help=\"ids to name training shards, used for corpus weighting\")\n\n group.add('--valid_src', '-valid_src',\n help=\"Path to the validation source data\")\n group.add('--valid_tgt', '-valid_tgt',\n help=\"Path to the validation target data\")\n group.add('--valid_align', '-valid_align', default=None,\n help=\"Path(s) to the validation src-tgt alignment\")\n\n group.add('--src_dir', '-src_dir', default=\"\",\n help=\"Source directory for image or audio files.\")\n\n group.add('--save_data', '-save_data', required=True,\n help=\"Output file for the prepared data\")\n\n group.add('--max_shard_size', '-max_shard_size', type=int, default=0,\n help=\"\"\"Deprecated use shard_size instead\"\"\")\n\n group.add('--shard_size', '-shard_size', type=int, default=1000000,\n help=\"Divide src_corpus and tgt_corpus into \"\n \"smaller multiple src_copus and tgt corpus files, then \"\n \"build shards, each shard will have \"\n \"opt.shard_size samples except last shard. \"\n \"shard_size=0 means no segmentation \"\n \"shard_size>0 means segment dataset into multiple shards, \"\n \"each shard has shard_size samples\")\n\n group.add('--num_threads', '-num_threads', type=int, default=1,\n help=\"Number of shards to build in parallel.\")\n\n group.add('--overwrite', '-overwrite', action=\"store_true\",\n help=\"Overwrite existing shards if any.\")\n\n # Dictionary options, for text corpus\n\n group = parser.add_argument_group('Vocab')\n # if you want to pass an existing vocab.pt file, pass it to\n # -src_vocab alone as it already contains tgt vocab.\n group.add('--src_vocab', '-src_vocab', default=\"\",\n help=\"Path to an existing source vocabulary. Format: \"\n \"one word per line.\")\n group.add('--tgt_vocab', '-tgt_vocab', default=\"\",\n help=\"Path to an existing target vocabulary. Format: \"\n \"one word per line.\")\n group.add('--features_vocabs_prefix', '-features_vocabs_prefix',\n type=str, default='',\n help=\"Path prefix to existing features vocabularies\")\n group.add('--src_vocab_size', '-src_vocab_size', type=int, default=50000,\n help=\"Size of the source vocabulary\")\n group.add('--tgt_vocab_size', '-tgt_vocab_size', type=int, default=50000,\n help=\"Size of the target vocabulary\")\n group.add('--vocab_size_multiple', '-vocab_size_multiple',\n type=int, default=1,\n help=\"Make the vocabulary size a multiple of this value\")\n\n group.add('--src_words_min_frequency',\n '-src_words_min_frequency', type=int, default=0)\n group.add('--tgt_words_min_frequency',\n '-tgt_words_min_frequency', type=int, default=0)\n\n group.add('--dynamic_dict', '-dynamic_dict', action='store_true',\n help=\"Create dynamic dictionaries\")\n group.add('--share_vocab', '-share_vocab', action='store_true',\n help=\"Share source and target vocabulary\")\n\n # Truncation options, for text corpus\n group = parser.add_argument_group('Pruning')\n group.add('--src_seq_length', '-src_seq_length', type=int, default=50,\n help=\"Maximum source sequence length\")\n group.add('--src_seq_length_trunc', '-src_seq_length_trunc',\n type=int, default=None,\n help=\"Truncate source sequence length.\")\n group.add('--tgt_seq_length', '-tgt_seq_length', type=int, default=50,\n help=\"Maximum target sequence length to keep.\")\n group.add('--tgt_seq_length_trunc', '-tgt_seq_length_trunc',\n type=int, default=None,\n help=\"Truncate target sequence length.\")\n group.add('--lower', '-lower', action='store_true', help='lowercase data')\n group.add('--filter_valid', '-filter_valid', action='store_true',\n help='Filter validation data by src and/or tgt length')\n\n # Data processing options\n group = parser.add_argument_group('Random')\n group.add('--shuffle', '-shuffle', type=int, default=0,\n help=\"Shuffle data\")\n group.add('--seed', '-seed', type=int, default=3435,\n help=\"Random seed\")\n\n group = parser.add_argument_group('Logging')\n group.add('--report_every', '-report_every', type=int, default=100000,\n help=\"Report status every this many sentences\")\n group.add('--log_file', '-log_file', type=str, default=\"\",\n help=\"Output logs to a file under this path.\")\n group.add('--log_file_level', '-log_file_level', type=str,\n action=StoreLoggingLevelAction,\n choices=StoreLoggingLevelAction.CHOICES,\n default=\"0\")\n\n # Options most relevant to speech\n group = parser.add_argument_group('Speech')\n group.add('--sample_rate', '-sample_rate', type=int, default=16000,\n help=\"Sample rate.\")\n group.add('--window_size', '-window_size', type=float, default=.02,\n help=\"Window size for spectrogram in seconds.\")\n group.add('--window_stride', '-window_stride', type=float, default=.01,\n help=\"Window stride for spectrogram in seconds.\")\n group.add('--window', '-window', default='hamming',\n help=\"Window type for spectrogram generation.\")\n\n # Option most relevant to image input\n group.add('--image_channel_size', '-image_channel_size',\n type=int, default=3,\n choices=[3, 1],\n help=\"Using grayscale image can training \"\n \"model faster and smaller\")\n\n\ndef train_opts(parser):\n \"\"\" Training and saving options \"\"\"\n\n group = parser.add_argument_group('General')\n group.add('--data', '-data', required=True,\n help='Path prefix to the \".train.pt\" and '\n '\".valid.pt\" file path from preprocess.py')\n\n group.add('--data_ids', '-data_ids', nargs='+', default=[None],\n help=\"In case there are several corpora.\")\n group.add('--data_weights', '-data_weights', type=int, nargs='+',\n default=[1], help=\"\"\"Weights of different corpora,\n should follow the same order as in -data_ids.\"\"\")\n\n group.add('--save_model', '-save_model', default='model',\n help=\"Model filename (the model will be saved as \"\n \"_N.pt where N is the number \"\n \"of steps\")\n\n group.add('--save_checkpoint_steps', '-save_checkpoint_steps',\n type=int, default=5000,\n help=\"\"\"Save a checkpoint every X steps\"\"\")\n group.add('--keep_checkpoint', '-keep_checkpoint', type=int, default=-1,\n help=\"Keep X checkpoints (negative: keep all)\")\n\n # GPU\n group.add('--gpuid', '-gpuid', default=[], nargs='*', type=int,\n help=\"Deprecated see world_size and gpu_ranks.\")\n group.add('--gpu_ranks', '-gpu_ranks', default=[], nargs='*', type=int,\n help=\"list of ranks of each process.\")\n group.add('--world_size', '-world_size', default=1, type=int,\n help=\"total number of distributed processes.\")\n group.add('--gpu_backend', '-gpu_backend',\n default=\"nccl\", type=str,\n help=\"Type of torch distributed backend\")\n group.add('--gpu_verbose_level', '-gpu_verbose_level', default=0, type=int,\n help=\"Gives more info on each process per GPU.\")\n group.add('--master_ip', '-master_ip', default=\"localhost\", type=str,\n help=\"IP of master for torch.distributed training.\")\n group.add('--master_port', '-master_port', default=10000, type=int,\n help=\"Port of master for torch.distributed training.\")\n group.add('--queue_size', '-queue_size', default=400, type=int,\n help=\"Size of queue for each process in producer/consumer\")\n\n group.add('--seed', '-seed', type=int, default=-1,\n help=\"Random seed used for the experiments \"\n \"reproducibility.\")\n\n # Init options\n group = parser.add_argument_group('Initialization')\n group.add('--param_init', '-param_init', type=float, default=0.1,\n help=\"Parameters are initialized over uniform distribution \"\n \"with support (-param_init, param_init). \"\n \"Use 0 to not use initialization\")\n group.add('--param_init_glorot', '-param_init_glorot', action='store_true',\n help=\"Init parameters with xavier_uniform. \"\n \"Required for transformer.\")\n\n group.add('--train_from', '-train_from', default='', type=str,\n help=\"If training from a checkpoint then this is the \"\n \"path to the pretrained model's state_dict.\")\n group.add('--reset_optim', '-reset_optim', default='none',\n choices=['none', 'all', 'states', 'keep_states'],\n help=\"Optimization resetter when train_from.\")\n\n # Pretrained word vectors\n group.add('--pre_word_vecs_enc', '-pre_word_vecs_enc',\n help=\"If a valid path is specified, then this will load \"\n \"pretrained word embeddings on the encoder side. \"\n \"See README for specific formatting instructions.\")\n group.add('--pre_word_vecs_dec', '-pre_word_vecs_dec',\n help=\"If a valid path is specified, then this will load \"\n \"pretrained word embeddings on the decoder side. \"\n \"See README for specific formatting instructions.\")\n # Fixed word vectors\n group.add('--fix_word_vecs_enc', '-fix_word_vecs_enc',\n action='store_true',\n help=\"Fix word embeddings on the encoder side.\")\n group.add('--fix_word_vecs_dec', '-fix_word_vecs_dec',\n action='store_true',\n help=\"Fix word embeddings on the decoder side.\")\n\n # Optimization options\n group = parser.add_argument_group('Optimization- Type')\n group.add('--batch_size', '-batch_size', type=int, default=64,\n help='Maximum batch size for training')\n group.add('--batch_type', '-batch_type', default='sents',\n choices=[\"sents\", \"tokens\"],\n help=\"Batch grouping for batch_size. Standard \"\n \"is sents. Tokens will do dynamic batching\")\n group.add('--pool_factor', '-pool_factor', type=int, default=8192,\n help=\"\"\"Factor used in data loading and batch creations.\n It will load the equivalent of `pool_factor` batches,\n sort them by the according `sort_key` to produce\n homogeneous batches and reduce padding, and yield\n the produced batches in a shuffled way.\n Inspired by torchtext's pool mechanism.\"\"\")\n group.add('--normalization', '-normalization', default='sents',\n choices=[\"sents\", \"tokens\"],\n help='Normalization method of the gradient.')\n group.add('--accum_count', '-accum_count', type=int, nargs='+',\n default=[1],\n help=\"Accumulate gradient this many times. \"\n \"Approximately equivalent to updating \"\n \"batch_size * accum_count batches at once. \"\n \"Recommended for Transformer.\")\n group.add('--accum_steps', '-accum_steps', type=int, nargs='+',\n default=[0], help=\"Steps at which accum_count values change\")\n group.add('--valid_steps', '-valid_steps', type=int, default=10000,\n help='Perfom validation every X steps')\n group.add('--valid_batch_size', '-valid_batch_size', type=int, default=32,\n help='Maximum batch size for validation')\n group.add('--max_generator_batches', '-max_generator_batches',\n type=int, default=32,\n help=\"Maximum batches of words in a sequence to run \"\n \"the generator on in parallel. Higher is faster, but \"\n \"uses more memory. Set to 0 to disable.\")\n group.add('--train_steps', '-train_steps', type=int, default=100000,\n help='Number of training steps')\n group.add('--single_pass', '-single_pass', action='store_true',\n help=\"Make a single pass over the training dataset.\")\n group.add('--epochs', '-epochs', type=int, default=0,\n help='Deprecated epochs see train_steps')\n group.add('--early_stopping', '-early_stopping', type=int, default=0,\n help='Number of validation steps without improving.')\n group.add('--early_stopping_criteria', '-early_stopping_criteria',\n nargs=\"*\", default=None,\n help='Criteria to use for early stopping.')\n group.add('--optim', '-optim', default='sgd',\n choices=['sgd', 'adagrad', 'adadelta', 'adam',\n 'sparseadam', 'adafactor', 'fusedadam'],\n help=\"Optimization method.\")\n group.add('--adagrad_accumulator_init', '-adagrad_accumulator_init',\n type=float, default=0,\n help=\"Initializes the accumulator values in adagrad. \"\n \"Mirrors the initial_accumulator_value option \"\n \"in the tensorflow adagrad (use 0.1 for their default).\")\n group.add('--max_grad_norm', '-max_grad_norm', type=float, default=5,\n help=\"If the norm of the gradient vector exceeds this, \"\n \"renormalize it to have the norm equal to \"\n \"max_grad_norm\")\n group.add('--dropout', '-dropout', type=float, default=[0.3], nargs='+',\n help=\"Dropout probability; applied in LSTM stacks.\")\n group.add('--attention_dropout', '-attention_dropout', type=float,\n default=[0.1], nargs='+',\n help=\"Attention Dropout probability.\")\n group.add('--dropout_steps', '-dropout_steps', type=int, nargs='+',\n default=[0], help=\"Steps at which dropout changes.\")\n group.add('--truncated_decoder', '-truncated_decoder', type=int, default=0,\n help=\"\"\"Truncated bptt.\"\"\")\n group.add('--adam_beta1', '-adam_beta1', type=float, default=0.9,\n help=\"The beta1 parameter used by Adam. \"\n \"Almost without exception a value of 0.9 is used in \"\n \"the literature, seemingly giving good results, \"\n \"so we would discourage changing this value from \"\n \"the default without due consideration.\")\n group.add('--adam_beta2', '-adam_beta2', type=float, default=0.999,\n help='The beta2 parameter used by Adam. '\n 'Typically a value of 0.999 is recommended, as this is '\n 'the value suggested by the original paper describing '\n 'Adam, and is also the value adopted in other frameworks '\n 'such as Tensorflow and Keras, i.e. see: '\n 'https://www.tensorflow.org/api_docs/python/tf/train/Adam'\n 'Optimizer or https://keras.io/optimizers/ . '\n 'Whereas recently the paper \"Attention is All You Need\" '\n 'suggested a value of 0.98 for beta2, this parameter may '\n 'not work well for normal models / default '\n 'baselines.')\n group.add('--label_smoothing', '-label_smoothing', type=float, default=0.0,\n help=\"Label smoothing value epsilon. \"\n \"Probabilities of all non-true labels \"\n \"will be smoothed by epsilon / (vocab_size - 1). \"\n \"Set to zero to turn off label smoothing. \"\n \"For more detailed information, see: \"\n \"https://arxiv.org/abs/1512.00567\")\n group.add('--average_decay', '-average_decay', type=float, default=0,\n help=\"Moving average decay. \"\n \"Set to other than 0 (e.g. 1e-4) to activate. \"\n \"Similar to Marian NMT implementation: \"\n \"http://www.aclweb.org/anthology/P18-4020 \"\n \"For more detail on Exponential Moving Average: \"\n \"https://en.wikipedia.org/wiki/Moving_average\")\n group.add('--average_every', '-average_every', type=int, default=1,\n help=\"Step for moving average. \"\n \"Default is every update, \"\n \"if -average_decay is set.\")\n\n # learning rate\n group = parser.add_argument_group('Optimization- Rate')\n group.add('--learning_rate', '-learning_rate', type=float, default=1.0,\n help=\"Starting learning rate. \"\n \"Recommended settings: sgd = 1, adagrad = 0.1, \"\n \"adadelta = 1, adam = 0.001\")\n group.add('--learning_rate_decay', '-learning_rate_decay',\n type=float, default=0.5,\n help=\"If update_learning_rate, decay learning rate by \"\n \"this much if steps have gone past \"\n \"start_decay_steps\")\n group.add('--start_decay_steps', '-start_decay_steps',\n type=int, default=50000,\n help=\"Start decaying every decay_steps after \"\n \"start_decay_steps\")\n group.add('--decay_steps', '-decay_steps', type=int, default=10000,\n help=\"Decay every decay_steps\")\n\n group.add('--decay_method', '-decay_method', type=str, default=\"none\",\n choices=['noam', 'noamwd', 'rsqrt', 'none'],\n help=\"Use a custom decay rate.\")\n group.add('--warmup_steps', '-warmup_steps', type=int, default=4000,\n help=\"Number of warmup steps for custom decay.\")\n\n group = parser.add_argument_group('Logging')\n group.add('--report_every', '-report_every', type=int, default=50,\n help=\"Print stats at this interval.\")\n group.add('--log_file', '-log_file', type=str, default=\"\",\n help=\"Output logs to a file under this path.\")\n group.add('--log_file_level', '-log_file_level', type=str,\n action=StoreLoggingLevelAction,\n choices=StoreLoggingLevelAction.CHOICES,\n default=\"0\")\n group.add('--exp_host', '-exp_host', type=str, default=\"\",\n help=\"Send logs to this crayon server.\")\n group.add('--exp', '-exp', type=str, default=\"\",\n help=\"Name of the experiment for logging.\")\n # Use Tensorboard for visualization during training\n group.add('--tensorboard', '-tensorboard', action=\"store_true\",\n help=\"Use tensorboard for visualization during training. \"\n \"Must have the library tensorboard >= 1.14.\")\n group.add(\"--tensorboard_log_dir\", \"-tensorboard_log_dir\",\n type=str, default=\"runs/onmt\",\n help=\"Log directory for Tensorboard. \"\n \"This is also the name of the run.\")\n\n group = parser.add_argument_group('Speech')\n # Options most relevant to speech\n group.add('--sample_rate', '-sample_rate', type=int, default=16000,\n help=\"Sample rate.\")\n group.add('--window_size', '-window_size', type=float, default=.02,\n help=\"Window size for spectrogram in seconds.\")\n\n # Option most relevant to image input\n group.add('--image_channel_size', '-image_channel_size',\n type=int, default=3, choices=[3, 1],\n help=\"Using grayscale image can training \"\n \"model faster and smaller\")\n\n\ndef translate_opts(parser):\n \"\"\" Translation / inference options \"\"\"\n group = parser.add_argument_group('Model')\n group.add('--model', '-model', dest='models', metavar='MODEL',\n nargs='+', type=str, default=[], required=True,\n help=\"Path to model .pt file(s). \"\n \"Multiple models can be specified, \"\n \"for ensemble decoding.\")\n group.add('--fp32', '-fp32', action='store_true',\n help=\"Force the model to be in FP32 \"\n \"because FP16 is very slow on GTX1080(ti).\")\n group.add('--avg_raw_probs', '-avg_raw_probs', action='store_true',\n help=\"If this is set, during ensembling scores from \"\n \"different models will be combined by averaging their \"\n \"raw probabilities and then taking the log. Otherwise, \"\n \"the log probabilities will be averaged directly. \"\n \"Necessary for models whose output layers can assign \"\n \"zero probability.\")\n\n group = parser.add_argument_group('Data')\n group.add('--data_type', '-data_type', default=\"text\",\n help=\"Type of the source input. Options: [text|img].\")\n\n group.add('--src', '-src', required=True,\n help=\"Source sequence to decode (one line per \"\n \"sequence)\")\n group.add('--src_dir', '-src_dir', default=\"\",\n help='Source directory for image or audio files')\n group.add('--tgt', '-tgt',\n help='True target sequence (optional)')\n group.add('--shard_size', '-shard_size', type=int, default=10000,\n help=\"Divide src and tgt (if applicable) into \"\n \"smaller multiple src and tgt files, then \"\n \"build shards, each shard will have \"\n \"opt.shard_size samples except last shard. \"\n \"shard_size=0 means no segmentation \"\n \"shard_size>0 means segment dataset into multiple shards, \"\n \"each shard has shard_size samples\")\n group.add('--output', '-output', default='pred.txt',\n help=\"Path to output the predictions (each line will \"\n \"be the decoded sequence\")\n group.add('--report_align', '-report_align', action='store_true',\n help=\"Report alignment for each translation.\")\n group.add('--report_bleu', '-report_bleu', action='store_true',\n help=\"Report bleu score after translation, \"\n \"call tools/multi-bleu.perl on command line\")\n group.add('--report_rouge', '-report_rouge', action='store_true',\n help=\"Report rouge 1/2/3/L/SU4 score after translation \"\n \"call tools/test_rouge.py on command line\")\n group.add('--report_time', '-report_time', action='store_true',\n help=\"Report some translation time metrics\")\n\n # Options most relevant to summarization.\n group.add('--dynamic_dict', '-dynamic_dict', action='store_true',\n help=\"Create dynamic dictionaries\")\n group.add('--share_vocab', '-share_vocab', action='store_true',\n help=\"Share source and target vocabulary\")\n\n group = parser.add_argument_group('Random Sampling')\n group.add('--random_sampling_topk', '-random_sampling_topk',\n default=1, type=int,\n help=\"Set this to -1 to do random sampling from full \"\n \"distribution. Set this to value k>1 to do random \"\n \"sampling restricted to the k most likely next tokens. \"\n \"Set this to 1 to use argmax or for doing beam \"\n \"search.\")\n group.add('--random_sampling_temp', '-random_sampling_temp',\n default=1., type=float,\n help=\"If doing random sampling, divide the logits by \"\n \"this before computing softmax during decoding.\")\n group.add('--seed', '-seed', type=int, default=829,\n help=\"Random seed\")\n\n group = parser.add_argument_group('Beam')\n group.add('--beam_size', '-beam_size', type=int, default=5,\n help='Beam size')\n group.add('--min_length', '-min_length', type=int, default=0,\n help='Minimum prediction length')\n group.add('--max_length', '-max_length', type=int, default=100,\n help='Maximum prediction length.')\n group.add('--max_sent_length', '-max_sent_length', action=DeprecateAction,\n help=\"Deprecated, use `-max_length` instead\")\n\n # Alpha and Beta values for Google Length + Coverage penalty\n # Described here: https://arxiv.org/pdf/1609.08144.pdf, Section 7\n group.add('--stepwise_penalty', '-stepwise_penalty', action='store_true',\n help=\"Apply penalty at every decoding step. \"\n \"Helpful for summary penalty.\")\n group.add('--length_penalty', '-length_penalty', default='none',\n choices=['none', 'wu', 'avg'],\n help=\"Length Penalty to use.\")\n group.add('--ratio', '-ratio', type=float, default=-0.,\n help=\"Ratio based beam stop condition\")\n group.add('--coverage_penalty', '-coverage_penalty', default='none',\n choices=['none', 'wu', 'summary'],\n help=\"Coverage Penalty to use.\")\n group.add('--alpha', '-alpha', type=float, default=0.,\n help=\"Google NMT length penalty parameter \"\n \"(higher = longer generation)\")\n group.add('--beta', '-beta', type=float, default=-0.,\n help=\"Coverage penalty parameter\")\n group.add('--block_ngram_repeat', '-block_ngram_repeat',\n type=int, default=0,\n help='Block repetition of ngrams during decoding.')\n group.add('--ignore_when_blocking', '-ignore_when_blocking',\n nargs='+', type=str, default=[],\n help=\"Ignore these strings when blocking repeats. \"\n \"You want to block sentence delimiters.\")\n group.add('--replace_unk', '-replace_unk', action=\"store_true\",\n help=\"Replace the generated UNK tokens with the \"\n \"source token that had highest attention weight. If \"\n \"phrase_table is provided, it will look up the \"\n \"identified source token and give the corresponding \"\n \"target token. If it is not provided (or the identified \"\n \"source token does not exist in the table), then it \"\n \"will copy the source token.\")\n group.add('--phrase_table', '-phrase_table', type=str, default=\"\",\n help=\"If phrase_table is provided (with replace_unk), it will \"\n \"look up the identified source token and give the \"\n \"corresponding target token. If it is not provided \"\n \"(or the identified source token does not exist in \"\n \"the table), then it will copy the source token.\")\n group = parser.add_argument_group('Logging')\n group.add('--verbose', '-verbose', action=\"store_true\",\n help='Print scores and predictions for each sentence')\n group.add('--log_file', '-log_file', type=str, default=\"\",\n help=\"Output logs to a file under this path.\")\n group.add('--log_file_level', '-log_file_level', type=str,\n action=StoreLoggingLevelAction,\n choices=StoreLoggingLevelAction.CHOICES,\n default=\"0\")\n group.add('--attn_debug', '-attn_debug', action=\"store_true\",\n help='Print best attn for each word')\n group.add('--align_debug', '-align_debug', action=\"store_true\",\n help='Print best align for each word')\n group.add('--dump_beam', '-dump_beam', type=str, default=\"\",\n help='File to dump beam information to.')\n group.add('--n_best', '-n_best', type=int, default=1,\n help=\"If verbose is set, will output the n_best \"\n \"decoded sentences\")\n\n group = parser.add_argument_group('Efficiency')\n group.add('--batch_size', '-batch_size', type=int, default=30,\n help='Batch size')\n group.add('--batch_type', '-batch_type', default='sents',\n choices=[\"sents\", \"tokens\"],\n help=\"Batch grouping for batch_size. Standard \"\n \"is sents. Tokens will do dynamic batching\")\n group.add('--gpu', '-gpu', type=int, default=-1,\n help=\"Device to run on\")\n\n # Options most relevant to speech.\n group = parser.add_argument_group('Speech')\n group.add('--sample_rate', '-sample_rate', type=int, default=16000,\n help=\"Sample rate.\")\n group.add('--window_size', '-window_size', type=float, default=.02,\n help='Window size for spectrogram in seconds')\n group.add('--window_stride', '-window_stride', type=float, default=.01,\n help='Window stride for spectrogram in seconds')\n group.add('--window', '-window', default='hamming',\n help='Window type for spectrogram generation')\n\n # Option most relevant to image input\n group.add('--image_channel_size', '-image_channel_size',\n type=int, default=3, choices=[3, 1],\n help=\"Using grayscale image can training \"\n \"model faster and smaller\")\n\n\n# Copyright 2016 The Chromium Authors. All rights reserved.\n# Use of this source code is governed by a BSD-style license that can be\n# found in the LICENSE file.\n\n\nclass StoreLoggingLevelAction(configargparse.Action):\n \"\"\" Convert string to logging level \"\"\"\n import logging\n LEVELS = {\n \"CRITICAL\": logging.CRITICAL,\n \"ERROR\": logging.ERROR,\n \"WARNING\": logging.WARNING,\n \"INFO\": logging.INFO,\n \"DEBUG\": logging.DEBUG,\n \"NOTSET\": logging.NOTSET\n }\n\n CHOICES = list(LEVELS.keys()) + [str(_) for _ in LEVELS.values()]\n\n def __init__(self, option_strings, dest, help=None, **kwargs):\n super(StoreLoggingLevelAction, self).__init__(\n option_strings, dest, help=help, **kwargs)\n\n def __call__(self, parser, namespace, value, option_string=None):\n # Get the key 'value' in the dict, or just use 'value'\n level = StoreLoggingLevelAction.LEVELS.get(value, value)\n setattr(namespace, self.dest, level)\n\n\nclass DeprecateAction(configargparse.Action):\n \"\"\" Deprecate action \"\"\"\n\n def __init__(self, option_strings, dest, help=None, **kwargs):\n super(DeprecateAction, self).__init__(option_strings, dest, nargs=0,\n help=help, **kwargs)\n\n def __call__(self, parser, namespace, values, flag_name):\n help = self.help if self.help is not None else \"\"\n msg = \"Flag '%s' is deprecated. %s\" % (flag_name, help)\n raise configargparse.ArgumentTypeError(msg)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/train_single.py",
"content": "#!/usr/bin/env python\n\"\"\"Training on a single process.\"\"\"\nimport os\n\nimport torch\n\nfrom onmt.inputters.inputter import build_dataset_iter, \\\n load_old_vocab, old_style_vocab, build_dataset_iter_multiple\nfrom onmt.model_builder import build_model\nfrom onmt.utils.optimizers import Optimizer\nfrom onmt.utils.misc import set_random_seed\nfrom onmt.trainer import build_trainer\nfrom onmt.models import build_model_saver\nfrom onmt.utils.logging import init_logger, logger\nfrom onmt.utils.parse import ArgumentParser\n\n\ndef _check_save_model_path(opt):\n save_model_path = os.path.abspath(opt.save_model)\n model_dirname = os.path.dirname(save_model_path)\n if not os.path.exists(model_dirname):\n os.makedirs(model_dirname)\n\n\ndef _tally_parameters(model):\n enc = 0\n dec = 0\n for name, param in model.named_parameters():\n if 'encoder' in name:\n enc += param.nelement()\n else:\n dec += param.nelement()\n return enc + dec, enc, dec\n\n\ndef configure_process(opt, device_id):\n if device_id >= 0:\n torch.cuda.set_device(device_id)\n set_random_seed(opt.seed, device_id >= 0)\n\n\ndef main(opt, device_id, batch_queue=None, semaphore=None):\n # NOTE: It's important that ``opt`` has been validated and updated\n # at this point.\n configure_process(opt, device_id)\n init_logger(opt.log_file)\n assert len(opt.accum_count) == len(opt.accum_steps), \\\n 'Number of accum_count values must match number of accum_steps'\n # Load checkpoint if we resume from a previous training.\n if opt.train_from:\n logger.info('Loading checkpoint from %s' % opt.train_from)\n checkpoint = torch.load(opt.train_from,\n map_location=lambda storage, loc: storage)\n model_opt = ArgumentParser.ckpt_model_opts(checkpoint[\"opt\"])\n ArgumentParser.update_model_opts(model_opt)\n ArgumentParser.validate_model_opts(model_opt)\n logger.info('Loading vocab from checkpoint at %s.' % opt.train_from)\n vocab = checkpoint['vocab']\n else:\n checkpoint = None\n model_opt = opt\n vocab = torch.load(opt.data + '.vocab.pt')\n\n # check for code where vocab is saved instead of fields\n # (in the future this will be done in a smarter way)\n if old_style_vocab(vocab):\n fields = load_old_vocab(\n vocab, opt.model_type, dynamic_dict=opt.copy_attn)\n else:\n fields = vocab\n\n # Report src and tgt vocab sizes, including for features\n for side in ['src', 'tgt']:\n f = fields[side]\n try:\n f_iter = iter(f)\n except TypeError:\n f_iter = [(side, f)]\n for sn, sf in f_iter:\n if sf.use_vocab:\n logger.info(' * %s vocab size = %d' % (sn, len(sf.vocab)))\n\n # Build model.\n model = build_model(model_opt, opt, fields, checkpoint)\n n_params, enc, dec = _tally_parameters(model)\n logger.info('encoder: %d' % enc)\n logger.info('decoder: %d' % dec)\n logger.info('* number of parameters: %d' % n_params)\n _check_save_model_path(opt)\n\n # Build optimizer.\n optim = Optimizer.from_opt(model, opt, checkpoint=checkpoint)\n\n # Build model saver\n model_saver = build_model_saver(model_opt, opt, model, fields, optim)\n\n trainer = build_trainer(\n opt, device_id, model, fields, optim, model_saver=model_saver)\n\n if batch_queue is None:\n if len(opt.data_ids) > 1:\n train_shards = []\n for train_id in opt.data_ids:\n shard_base = \"train_\" + train_id\n train_shards.append(shard_base)\n train_iter = build_dataset_iter_multiple(train_shards, fields, opt)\n else:\n if opt.data_ids[0] is not None:\n shard_base = \"train_\" + opt.data_ids[0]\n else:\n shard_base = \"train\"\n train_iter = build_dataset_iter(shard_base, fields, opt)\n\n else:\n assert semaphore is not None, \\\n \"Using batch_queue requires semaphore as well\"\n\n def _train_iter():\n while True:\n batch = batch_queue.get()\n semaphore.release()\n yield batch\n\n train_iter = _train_iter()\n\n valid_iter = build_dataset_iter(\n \"valid\", fields, opt, is_train=False)\n\n if len(opt.gpu_ranks):\n logger.info('Starting training on GPU: %s' % opt.gpu_ranks)\n else:\n logger.info('Starting training on CPU, could be very slow')\n train_steps = opt.train_steps\n if opt.single_pass and train_steps > 0:\n logger.warning(\"Option single_pass is enabled, ignoring train_steps.\")\n train_steps = 0\n\n trainer.train(\n train_iter,\n train_steps,\n save_checkpoint_steps=opt.save_checkpoint_steps,\n valid_iter=valid_iter,\n valid_steps=opt.valid_steps)\n\n if trainer.report_manager.tensorboard_writer is not None:\n trainer.report_manager.tensorboard_writer.close()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/trainer.py",
"content": "\"\"\"\n This is the loadable seq2seq trainer library that is\n in charge of training details, loss compute, and statistics.\n See train.py for a use case of this library.\n\n Note: To make this a general library, we implement *only*\n mechanism things here(i.e. what to do), and leave the strategy\n things to users(i.e. how to do it). Also see train.py(one of the\n users of this library) for the strategy things we do.\n\"\"\"\n\nimport torch\nimport traceback\n\nimport onmt.utils\nfrom onmt.utils.logging import logger\n\n\ndef build_trainer(opt, device_id, model, fields, optim, model_saver=None):\n \"\"\"\n Simplify `Trainer` creation based on user `opt`s*\n\n Args:\n opt (:obj:`Namespace`): user options (usually from argument parsing)\n model (:obj:`onmt.models.NMTModel`): the model to train\n fields (dict): dict of fields\n optim (:obj:`onmt.utils.Optimizer`): optimizer used during training\n data_type (str): string describing the type of data\n e.g. \"text\", \"img\", \"audio\"\n model_saver(:obj:`onmt.models.ModelSaverBase`): the utility object\n used to save the model\n \"\"\"\n\n tgt_field = dict(fields)[\"tgt\"].base_field\n train_loss = onmt.utils.loss.build_loss_compute(model, tgt_field, opt)\n valid_loss = onmt.utils.loss.build_loss_compute(\n model, tgt_field, opt, train=False)\n\n trunc_size = opt.truncated_decoder # Badly named...\n shard_size = opt.max_generator_batches if opt.model_dtype == 'fp32' else 0\n norm_method = opt.normalization\n accum_count = opt.accum_count\n accum_steps = opt.accum_steps\n n_gpu = opt.world_size\n average_decay = opt.average_decay\n average_every = opt.average_every\n dropout = opt.dropout\n dropout_steps = opt.dropout_steps\n if device_id >= 0:\n gpu_rank = opt.gpu_ranks[device_id]\n else:\n gpu_rank = 0\n n_gpu = 0\n gpu_verbose_level = opt.gpu_verbose_level\n\n earlystopper = onmt.utils.EarlyStopping(\n opt.early_stopping, scorers=onmt.utils.scorers_from_opts(opt)) \\\n if opt.early_stopping > 0 else None\n\n report_manager = onmt.utils.build_report_manager(opt, gpu_rank)\n trainer = onmt.Trainer(model, train_loss, valid_loss, optim, trunc_size,\n shard_size, norm_method,\n accum_count, accum_steps,\n n_gpu, gpu_rank,\n gpu_verbose_level, report_manager,\n with_align=True if opt.lambda_align > 0 else False,\n model_saver=model_saver if gpu_rank == 0 else None,\n average_decay=average_decay,\n average_every=average_every,\n model_dtype=opt.model_dtype,\n earlystopper=earlystopper,\n dropout=dropout,\n dropout_steps=dropout_steps)\n return trainer\n\n\nclass Trainer(object):\n \"\"\"\n Class that controls the training process.\n\n Args:\n model(:py:class:`onmt.models.model.NMTModel`): translation model\n to train\n train_loss(:obj:`onmt.utils.loss.LossComputeBase`):\n training loss computation\n valid_loss(:obj:`onmt.utils.loss.LossComputeBase`):\n training loss computation\n optim(:obj:`onmt.utils.optimizers.Optimizer`):\n the optimizer responsible for update\n trunc_size(int): length of truncated back propagation through time\n shard_size(int): compute loss in shards of this size for efficiency\n data_type(string): type of the source input: [text|img|audio]\n norm_method(string): normalization methods: [sents|tokens]\n accum_count(list): accumulate gradients this many times.\n accum_steps(list): steps for accum gradients changes.\n report_manager(:obj:`onmt.utils.ReportMgrBase`):\n the object that creates reports, or None\n model_saver(:obj:`onmt.models.ModelSaverBase`): the saver is\n used to save a checkpoint.\n Thus nothing will be saved if this parameter is None\n \"\"\"\n\n def __init__(self, model, train_loss, valid_loss, optim,\n trunc_size=0, shard_size=32,\n norm_method=\"sents\", accum_count=[1],\n accum_steps=[0],\n n_gpu=1, gpu_rank=1, gpu_verbose_level=0,\n report_manager=None, with_align=False, model_saver=None,\n average_decay=0, average_every=1, model_dtype='fp32',\n earlystopper=None, dropout=[0.3], dropout_steps=[0]):\n # Basic attributes.\n self.model = model\n self.train_loss = train_loss\n self.valid_loss = valid_loss\n self.optim = optim\n self.trunc_size = trunc_size\n self.shard_size = shard_size\n self.norm_method = norm_method\n self.accum_count_l = accum_count\n self.accum_count = accum_count[0]\n self.accum_steps = accum_steps\n self.n_gpu = n_gpu\n self.gpu_rank = gpu_rank\n self.gpu_verbose_level = gpu_verbose_level\n self.report_manager = report_manager\n self.with_align = with_align\n self.model_saver = model_saver\n self.average_decay = average_decay\n self.moving_average = None\n self.average_every = average_every\n self.model_dtype = model_dtype\n self.earlystopper = earlystopper\n self.dropout = dropout\n self.dropout_steps = dropout_steps\n\n for i in range(len(self.accum_count_l)):\n assert self.accum_count_l[i] > 0\n if self.accum_count_l[i] > 1:\n assert self.trunc_size == 0, \\\n \"\"\"To enable accumulated gradients,\n you must disable target sequence truncating.\"\"\"\n\n # Set model in training mode.\n self.model.train()\n\n def _accum_count(self, step):\n for i in range(len(self.accum_steps)):\n if step > self.accum_steps[i]:\n _accum = self.accum_count_l[i]\n return _accum\n\n def _maybe_update_dropout(self, step):\n for i in range(len(self.dropout_steps)):\n if step > 1 and step == self.dropout_steps[i] + 1:\n self.model.update_dropout(self.dropout[i])\n logger.info(\"Updated dropout to %f from step %d\"\n % (self.dropout[i], step))\n\n def _accum_batches(self, iterator):\n batches = []\n normalization = 0\n self.accum_count = self._accum_count(self.optim.training_step)\n for batch in iterator:\n batches.append(batch)\n if self.norm_method == \"tokens\":\n num_tokens = batch.tgt[1:, :, 0].ne(\n self.train_loss.padding_idx).sum()\n normalization += num_tokens.item()\n else:\n normalization += batch.batch_size\n if len(batches) == self.accum_count:\n yield batches, normalization\n self.accum_count = self._accum_count(self.optim.training_step)\n batches = []\n normalization = 0\n if batches:\n yield batches, normalization\n\n def _update_average(self, step):\n if self.moving_average is None:\n copy_params = [params.detach().float()\n for params in self.model.parameters()]\n self.moving_average = copy_params\n else:\n average_decay = max(self.average_decay,\n 1 - (step + 1)/(step + 10))\n for (i, avg), cpt in zip(enumerate(self.moving_average),\n self.model.parameters()):\n self.moving_average[i] = \\\n (1 - average_decay) * avg + \\\n cpt.detach().float() * average_decay\n\n def train(self,\n train_iter,\n train_steps,\n save_checkpoint_steps=5000,\n valid_iter=None,\n valid_steps=10000):\n \"\"\"\n The main training loop by iterating over `train_iter` and possibly\n running validation on `valid_iter`.\n\n Args:\n train_iter: A generator that returns the next training batch.\n train_steps: Run training for this many iterations.\n save_checkpoint_steps: Save a checkpoint every this many\n iterations.\n valid_iter: A generator that returns the next validation batch.\n valid_steps: Run evaluation every this many iterations.\n\n Returns:\n The gathered statistics.\n \"\"\"\n if valid_iter is None:\n logger.info('Start training loop without validation...')\n else:\n logger.info('Start training loop and validate every %d steps...',\n valid_steps)\n\n total_stats = onmt.utils.Statistics()\n report_stats = onmt.utils.Statistics()\n self._start_report_manager(start_time=total_stats.start_time)\n\n for i, (batches, normalization) in enumerate(\n self._accum_batches(train_iter)):\n step = self.optim.training_step\n # UPDATE DROPOUT\n self._maybe_update_dropout(step)\n\n if self.gpu_verbose_level > 1:\n logger.info(\"GpuRank %d: index: %d\", self.gpu_rank, i)\n if self.gpu_verbose_level > 0:\n logger.info(\"GpuRank %d: reduce_counter: %d \\\n n_minibatch %d\"\n % (self.gpu_rank, i + 1, len(batches)))\n\n if self.n_gpu > 1:\n normalization = sum(onmt.utils.distributed\n .all_gather_list\n (normalization))\n\n self._gradient_accumulation(\n batches, normalization, total_stats,\n report_stats)\n\n if self.average_decay > 0 and i % self.average_every == 0:\n self._update_average(step)\n\n report_stats = self._maybe_report_training(\n step, train_steps,\n self.optim.learning_rate(),\n report_stats)\n\n if valid_iter is not None and step % valid_steps == 0:\n if self.gpu_verbose_level > 0:\n logger.info('GpuRank %d: validate step %d'\n % (self.gpu_rank, step))\n valid_stats = self.validate(\n valid_iter, moving_average=self.moving_average)\n if self.gpu_verbose_level > 0:\n logger.info('GpuRank %d: gather valid stat \\\n step %d' % (self.gpu_rank, step))\n valid_stats = self._maybe_gather_stats(valid_stats)\n if self.gpu_verbose_level > 0:\n logger.info('GpuRank %d: report stat step %d'\n % (self.gpu_rank, step))\n self._report_step(self.optim.learning_rate(),\n step, valid_stats=valid_stats)\n # Run patience mechanism\n if self.earlystopper is not None:\n self.earlystopper(valid_stats, step)\n # If the patience has reached the limit, stop training\n if self.earlystopper.has_stopped():\n break\n\n if (self.model_saver is not None\n and (save_checkpoint_steps != 0\n and step % save_checkpoint_steps == 0)):\n self.model_saver.save(step, moving_average=self.moving_average)\n\n if train_steps > 0 and step >= train_steps:\n break\n\n if self.model_saver is not None:\n self.model_saver.save(step, moving_average=self.moving_average)\n return total_stats\n\n def validate(self, valid_iter, moving_average=None):\n \"\"\" Validate model.\n valid_iter: validate data iterator\n Returns:\n :obj:`nmt.Statistics`: validation loss statistics\n \"\"\"\n valid_model = self.model\n if moving_average:\n # swap model params w/ moving average\n # (and keep the original parameters)\n model_params_data = []\n for avg, param in zip(self.moving_average,\n valid_model.parameters()):\n model_params_data.append(param.data)\n param.data = avg.data.half() if self.optim._fp16 == \"legacy\" \\\n else avg.data\n\n # Set model in validating mode.\n valid_model.eval()\n\n with torch.no_grad():\n stats = onmt.utils.Statistics()\n\n for batch in valid_iter:\n src, src_lengths = batch.src if isinstance(batch.src, tuple) \\\n else (batch.src, None)\n tgt = batch.tgt\n\n # F-prop through the model.\n outputs, attns = valid_model(src, tgt, src_lengths,\n with_align=self.with_align)\n\n # Compute loss.\n _, batch_stats = self.valid_loss(batch, outputs, attns)\n\n # Update statistics.\n stats.update(batch_stats)\n if moving_average:\n for param_data, param in zip(model_params_data,\n self.model.parameters()):\n param.data = param_data\n\n # Set model back to training mode.\n valid_model.train()\n\n return stats\n\n def _gradient_accumulation(self, true_batches, normalization, total_stats,\n report_stats):\n if self.accum_count > 1:\n self.optim.zero_grad()\n\n for k, batch in enumerate(true_batches):\n target_size = batch.tgt.size(0)\n # Truncated BPTT: reminder not compatible with accum > 1\n if self.trunc_size:\n trunc_size = self.trunc_size\n else:\n trunc_size = target_size\n\n src, src_lengths = batch.src if isinstance(batch.src, tuple) \\\n else (batch.src, None)\n if src_lengths is not None:\n report_stats.n_src_words += src_lengths.sum().item()\n\n tgt_outer = batch.tgt\n\n bptt = False\n for j in range(0, target_size-1, trunc_size):\n # 1. Create truncated target.\n tgt = tgt_outer[j: j + trunc_size]\n\n # 2. F-prop all but generator.\n if self.accum_count == 1:\n self.optim.zero_grad()\n\n outputs, attns = self.model(src, tgt, src_lengths, bptt=bptt,\n with_align=self.with_align)\n bptt = True\n\n # 3. Compute loss.\n try:\n loss, batch_stats = self.train_loss(\n batch,\n outputs,\n attns,\n normalization=normalization,\n shard_size=self.shard_size,\n trunc_start=j,\n trunc_size=trunc_size)\n\n if loss is not None:\n self.optim.backward(loss)\n\n total_stats.update(batch_stats)\n report_stats.update(batch_stats)\n\n except Exception:\n traceback.print_exc()\n logger.info(\"At step %d, we removed a batch - accum %d\",\n self.optim.training_step, k)\n\n # 4. Update the parameters and statistics.\n if self.accum_count == 1:\n # Multi GPU gradient gather\n if self.n_gpu > 1:\n grads = [p.grad.data for p in self.model.parameters()\n if p.requires_grad\n and p.grad is not None]\n onmt.utils.distributed.all_reduce_and_rescale_tensors(\n grads, float(1))\n self.optim.step()\n\n # If truncated, don't backprop fully.\n # TO CHECK\n # if dec_state is not None:\n # dec_state.detach()\n if self.model.decoder.state is not None:\n self.model.decoder.detach_state()\n\n # in case of multi step gradient accumulation,\n # update only after accum batches\n if self.accum_count > 1:\n if self.n_gpu > 1:\n grads = [p.grad.data for p in self.model.parameters()\n if p.requires_grad\n and p.grad is not None]\n onmt.utils.distributed.all_reduce_and_rescale_tensors(\n grads, float(1))\n self.optim.step()\n\n def _start_report_manager(self, start_time=None):\n \"\"\"\n Simple function to start report manager (if any)\n \"\"\"\n if self.report_manager is not None:\n if start_time is None:\n self.report_manager.start()\n else:\n self.report_manager.start_time = start_time\n\n def _maybe_gather_stats(self, stat):\n \"\"\"\n Gather statistics in multi-processes cases\n\n Args:\n stat(:obj:onmt.utils.Statistics): a Statistics object to gather\n or None (it returns None in this case)\n\n Returns:\n stat: the updated (or unchanged) stat object\n \"\"\"\n if stat is not None and self.n_gpu > 1:\n return onmt.utils.Statistics.all_gather_stats(stat)\n return stat\n\n def _maybe_report_training(self, step, num_steps, learning_rate,\n report_stats):\n \"\"\"\n Simple function to report training stats (if report_manager is set)\n see `onmt.utils.ReportManagerBase.report_training` for doc\n \"\"\"\n if self.report_manager is not None:\n return self.report_manager.report_training(\n step, num_steps, learning_rate, report_stats,\n multigpu=self.n_gpu > 1)\n\n def _report_step(self, learning_rate, step, train_stats=None,\n valid_stats=None):\n \"\"\"\n Simple function to report stats (if report_manager is set)\n see `onmt.utils.ReportManagerBase.report_step` for doc\n \"\"\"\n if self.report_manager is not None:\n return self.report_manager.report_step(\n learning_rate, step, train_stats=train_stats,\n valid_stats=valid_stats)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/translate/__init__.py",
"content": "\"\"\" Modules for translation \"\"\"\nfrom onmt.translate.translator import Translator\nfrom onmt.translate.translation import Translation, TranslationBuilder\nfrom onmt.translate.beam_search import BeamSearch, GNMTGlobalScorer\nfrom onmt.translate.decode_strategy import DecodeStrategy\nfrom onmt.translate.greedy_search import GreedySearch\nfrom onmt.translate.penalties import PenaltyBuilder\nfrom onmt.translate.translation_server import TranslationServer, \\\n ServerModelError\n\n__all__ = ['Translator', 'Translation', 'BeamSearch',\n 'GNMTGlobalScorer', 'TranslationBuilder',\n 'PenaltyBuilder', 'TranslationServer', 'ServerModelError',\n \"DecodeStrategy\", \"GreedySearch\"]\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/translate/beam_search.py",
"content": "import torch\nfrom onmt.translate import penalties\nfrom onmt.translate.decode_strategy import DecodeStrategy\nfrom onmt.utils.misc import tile\n\nimport warnings\n\n\nclass BeamSearch(DecodeStrategy):\n \"\"\"Generation beam search.\n\n Note that the attributes list is not exhaustive. Rather, it highlights\n tensors to document their shape. (Since the state variables' \"batch\"\n size decreases as beams finish, we denote this axis with a B rather than\n ``batch_size``).\n\n Args:\n beam_size (int): Number of beams to use (see base ``parallel_paths``).\n batch_size (int): See base.\n pad (int): See base.\n bos (int): See base.\n eos (int): See base.\n n_best (int): Don't stop until at least this many beams have\n reached EOS.\n global_scorer (onmt.translate.GNMTGlobalScorer): Scorer instance.\n min_length (int): See base.\n max_length (int): See base.\n return_attention (bool): See base.\n block_ngram_repeat (int): See base.\n exclusion_tokens (set[int]): See base.\n\n Attributes:\n top_beam_finished (ByteTensor): Shape ``(B,)``.\n _batch_offset (LongTensor): Shape ``(B,)``.\n _beam_offset (LongTensor): Shape ``(batch_size x beam_size,)``.\n alive_seq (LongTensor): See base.\n topk_log_probs (FloatTensor): Shape ``(B x beam_size,)``. These\n are the scores used for the topk operation.\n memory_lengths (LongTensor): Lengths of encodings. Used for\n masking attentions.\n select_indices (LongTensor or NoneType): Shape\n ``(B x beam_size,)``. This is just a flat view of the\n ``_batch_index``.\n topk_scores (FloatTensor): Shape\n ``(B, beam_size)``. These are the\n scores a sequence will receive if it finishes.\n topk_ids (LongTensor): Shape ``(B, beam_size)``. These are the\n word indices of the topk predictions.\n _batch_index (LongTensor): Shape ``(B, beam_size)``.\n _prev_penalty (FloatTensor or NoneType): Shape\n ``(B, beam_size)``. Initialized to ``None``.\n _coverage (FloatTensor or NoneType): Shape\n ``(1, B x beam_size, inp_seq_len)``.\n hypotheses (list[list[Tuple[Tensor]]]): Contains a tuple\n of score (float), sequence (long), and attention (float or None).\n \"\"\"\n\n def __init__(self, beam_size, batch_size, pad, bos, eos, n_best,\n global_scorer, min_length, max_length, return_attention,\n block_ngram_repeat, exclusion_tokens,\n stepwise_penalty, ratio):\n super(BeamSearch, self).__init__(\n pad, bos, eos, batch_size, beam_size, min_length,\n block_ngram_repeat, exclusion_tokens, return_attention,\n max_length)\n # beam parameters\n self.global_scorer = global_scorer\n self.beam_size = beam_size\n self.n_best = n_best\n self.ratio = ratio\n\n # result caching\n self.hypotheses = [[] for _ in range(batch_size)]\n\n # beam state\n self.top_beam_finished = torch.zeros([batch_size], dtype=torch.uint8)\n # BoolTensor was introduced in pytorch 1.2\n try:\n self.top_beam_finished = self.top_beam_finished.bool()\n except AttributeError:\n pass\n self._batch_offset = torch.arange(batch_size, dtype=torch.long)\n\n self.select_indices = None\n self.done = False\n # \"global state\" of the old beam\n self._prev_penalty = None\n self._coverage = None\n\n self._stepwise_cov_pen = (\n stepwise_penalty and self.global_scorer.has_cov_pen)\n self._vanilla_cov_pen = (\n not stepwise_penalty and self.global_scorer.has_cov_pen)\n self._cov_pen = self.global_scorer.has_cov_pen\n\n def initialize(self, memory_bank, src_lengths, src_map=None, device=None):\n \"\"\"Initialize for decoding.\n Repeat src objects `beam_size` times.\n \"\"\"\n\n def fn_map_state(state, dim):\n return tile(state, self.beam_size, dim=dim)\n\n if isinstance(memory_bank, tuple):\n memory_bank = tuple(tile(x, self.beam_size, dim=1)\n for x in memory_bank)\n mb_device = memory_bank[0].device\n else:\n memory_bank = tile(memory_bank, self.beam_size, dim=1)\n mb_device = memory_bank.device\n if src_map is not None:\n src_map = tile(src_map, self.beam_size, dim=1)\n if device is None:\n device = mb_device\n\n self.memory_lengths = tile(src_lengths, self.beam_size)\n super(BeamSearch, self).initialize(\n memory_bank, self.memory_lengths, src_map, device)\n self.best_scores = torch.full(\n [self.batch_size], -1e10, dtype=torch.float, device=device)\n self._beam_offset = torch.arange(\n 0, self.batch_size * self.beam_size, step=self.beam_size,\n dtype=torch.long, device=device)\n self.topk_log_probs = torch.tensor(\n [0.0] + [float(\"-inf\")] * (self.beam_size - 1), device=device\n ).repeat(self.batch_size)\n # buffers for the topk scores and 'backpointer'\n self.topk_scores = torch.empty((self.batch_size, self.beam_size),\n dtype=torch.float, device=device)\n self.topk_ids = torch.empty((self.batch_size, self.beam_size),\n dtype=torch.long, device=device)\n self._batch_index = torch.empty([self.batch_size, self.beam_size],\n dtype=torch.long, device=device)\n return fn_map_state, memory_bank, self.memory_lengths, src_map\n\n @property\n def current_predictions(self):\n return self.alive_seq[:, -1]\n\n @property\n def current_backptr(self):\n # for testing\n return self.select_indices.view(self.batch_size, self.beam_size)\\\n .fmod(self.beam_size)\n\n @property\n def batch_offset(self):\n return self._batch_offset\n\n def advance(self, log_probs, attn):\n vocab_size = log_probs.size(-1)\n\n # using integer division to get an integer _B without casting\n _B = log_probs.shape[0] // self.beam_size\n\n if self._stepwise_cov_pen and self._prev_penalty is not None:\n self.topk_log_probs += self._prev_penalty\n self.topk_log_probs -= self.global_scorer.cov_penalty(\n self._coverage + attn, self.global_scorer.beta).view(\n _B, self.beam_size)\n\n # force the output to be longer than self.min_length\n step = len(self)\n self.ensure_min_length(log_probs)\n\n # Multiply probs by the beam probability.\n log_probs += self.topk_log_probs.view(_B * self.beam_size, 1)\n\n self.block_ngram_repeats(log_probs)\n\n # if the sequence ends now, then the penalty is the current\n # length + 1, to include the EOS token\n length_penalty = self.global_scorer.length_penalty(\n step + 1, alpha=self.global_scorer.alpha)\n\n # Flatten probs into a list of possibilities.\n curr_scores = log_probs / length_penalty\n curr_scores = curr_scores.reshape(_B, self.beam_size * vocab_size)\n torch.topk(curr_scores, self.beam_size, dim=-1,\n out=(self.topk_scores, self.topk_ids))\n\n # Recover log probs.\n # Length penalty is just a scalar. It doesn't matter if it's applied\n # before or after the topk.\n torch.mul(self.topk_scores, length_penalty, out=self.topk_log_probs)\n\n # Resolve beam origin and map to batch index flat representation.\n torch.div(self.topk_ids, vocab_size, out=self._batch_index)\n self._batch_index += self._beam_offset[:_B].unsqueeze(1)\n self.select_indices = self._batch_index.view(_B * self.beam_size)\n self.topk_ids.fmod_(vocab_size) # resolve true word ids\n\n # Append last prediction.\n self.alive_seq = torch.cat(\n [self.alive_seq.index_select(0, self.select_indices),\n self.topk_ids.view(_B * self.beam_size, 1)], -1)\n if self.return_attention or self._cov_pen:\n current_attn = attn.index_select(1, self.select_indices)\n if step == 1:\n self.alive_attn = current_attn\n # update global state (step == 1)\n if self._cov_pen: # coverage penalty\n self._prev_penalty = torch.zeros_like(self.topk_log_probs)\n self._coverage = current_attn\n else:\n self.alive_attn = self.alive_attn.index_select(\n 1, self.select_indices)\n self.alive_attn = torch.cat([self.alive_attn, current_attn], 0)\n # update global state (step > 1)\n if self._cov_pen:\n self._coverage = self._coverage.index_select(\n 1, self.select_indices)\n self._coverage += current_attn\n self._prev_penalty = self.global_scorer.cov_penalty(\n self._coverage, beta=self.global_scorer.beta).view(\n _B, self.beam_size)\n\n if self._vanilla_cov_pen:\n # shape: (batch_size x beam_size, 1)\n cov_penalty = self.global_scorer.cov_penalty(\n self._coverage,\n beta=self.global_scorer.beta)\n self.topk_scores -= cov_penalty.view(_B, self.beam_size).float()\n\n self.is_finished = self.topk_ids.eq(self.eos)\n self.ensure_max_length()\n\n def update_finished(self):\n # Penalize beams that finished.\n _B_old = self.topk_log_probs.shape[0]\n step = self.alive_seq.shape[-1] # 1 greater than the step in advance\n self.topk_log_probs.masked_fill_(self.is_finished, -1e10)\n # on real data (newstest2017) with the pretrained transformer,\n # it's faster to not move this back to the original device\n self.is_finished = self.is_finished.to('cpu')\n self.top_beam_finished |= self.is_finished[:, 0].eq(1)\n predictions = self.alive_seq.view(_B_old, self.beam_size, step)\n attention = (\n self.alive_attn.view(\n step - 1, _B_old, self.beam_size, self.alive_attn.size(-1))\n if self.alive_attn is not None else None)\n non_finished_batch = []\n for i in range(self.is_finished.size(0)): # Batch level\n b = self._batch_offset[i]\n finished_hyp = self.is_finished[i].nonzero().view(-1)\n # Store finished hypotheses for this batch.\n for j in finished_hyp: # Beam level: finished beam j in batch i\n if self.ratio > 0:\n s = self.topk_scores[i, j] / (step + 1)\n if self.best_scores[b] < s:\n self.best_scores[b] = s\n self.hypotheses[b].append((\n self.topk_scores[i, j],\n predictions[i, j, 1:], # Ignore start_token.\n attention[:, i, j, :self.memory_lengths[i]]\n if attention is not None else None))\n # End condition is the top beam finished and we can return\n # n_best hypotheses.\n if self.ratio > 0:\n pred_len = self.memory_lengths[i] * self.ratio\n finish_flag = ((self.topk_scores[i, 0] / pred_len)\n <= self.best_scores[b]) or \\\n self.is_finished[i].all()\n else:\n finish_flag = self.top_beam_finished[i] != 0\n if finish_flag and len(self.hypotheses[b]) >= self.n_best:\n best_hyp = sorted(\n self.hypotheses[b], key=lambda x: x[0], reverse=True)\n for n, (score, pred, attn) in enumerate(best_hyp):\n if n >= self.n_best:\n break\n self.scores[b].append(score)\n self.predictions[b].append(pred) # ``(batch, n_best,)``\n self.attention[b].append(\n attn if attn is not None else [])\n else:\n non_finished_batch.append(i)\n non_finished = torch.tensor(non_finished_batch)\n # If all sentences are translated, no need to go further.\n if len(non_finished) == 0:\n self.done = True\n return\n\n _B_new = non_finished.shape[0]\n # Remove finished batches for the next step.\n self.top_beam_finished = self.top_beam_finished.index_select(\n 0, non_finished)\n self._batch_offset = self._batch_offset.index_select(0, non_finished)\n non_finished = non_finished.to(self.topk_ids.device)\n self.topk_log_probs = self.topk_log_probs.index_select(0,\n non_finished)\n self._batch_index = self._batch_index.index_select(0, non_finished)\n self.select_indices = self._batch_index.view(_B_new * self.beam_size)\n self.alive_seq = predictions.index_select(0, non_finished) \\\n .view(-1, self.alive_seq.size(-1))\n self.topk_scores = self.topk_scores.index_select(0, non_finished)\n self.topk_ids = self.topk_ids.index_select(0, non_finished)\n if self.alive_attn is not None:\n inp_seq_len = self.alive_attn.size(-1)\n self.alive_attn = attention.index_select(1, non_finished) \\\n .view(step - 1, _B_new * self.beam_size, inp_seq_len)\n if self._cov_pen:\n self._coverage = self._coverage \\\n .view(1, _B_old, self.beam_size, inp_seq_len) \\\n .index_select(1, non_finished) \\\n .view(1, _B_new * self.beam_size, inp_seq_len)\n if self._stepwise_cov_pen:\n self._prev_penalty = self._prev_penalty.index_select(\n 0, non_finished)\n\n\nclass GNMTGlobalScorer(object):\n \"\"\"NMT re-ranking.\n\n Args:\n alpha (float): Length parameter.\n beta (float): Coverage parameter.\n length_penalty (str): Length penalty strategy.\n coverage_penalty (str): Coverage penalty strategy.\n\n Attributes:\n alpha (float): See above.\n beta (float): See above.\n length_penalty (callable): See :class:`penalties.PenaltyBuilder`.\n coverage_penalty (callable): See :class:`penalties.PenaltyBuilder`.\n has_cov_pen (bool): See :class:`penalties.PenaltyBuilder`.\n has_len_pen (bool): See :class:`penalties.PenaltyBuilder`.\n \"\"\"\n\n @classmethod\n def from_opt(cls, opt):\n return cls(\n opt.alpha,\n opt.beta,\n opt.length_penalty,\n opt.coverage_penalty)\n\n def __init__(self, alpha, beta, length_penalty, coverage_penalty):\n self._validate(alpha, beta, length_penalty, coverage_penalty)\n self.alpha = alpha\n self.beta = beta\n penalty_builder = penalties.PenaltyBuilder(coverage_penalty,\n length_penalty)\n self.has_cov_pen = penalty_builder.has_cov_pen\n # Term will be subtracted from probability\n self.cov_penalty = penalty_builder.coverage_penalty\n\n self.has_len_pen = penalty_builder.has_len_pen\n # Probability will be divided by this\n self.length_penalty = penalty_builder.length_penalty\n\n @classmethod\n def _validate(cls, alpha, beta, length_penalty, coverage_penalty):\n # these warnings indicate that either the alpha/beta\n # forces a penalty to be a no-op, or a penalty is a no-op but\n # the alpha/beta would suggest otherwise.\n if length_penalty is None or length_penalty == \"none\":\n if alpha != 0:\n warnings.warn(\"Non-default `alpha` with no length penalty. \"\n \"`alpha` has no effect.\")\n else:\n # using some length penalty\n if length_penalty == \"wu\" and alpha == 0.:\n warnings.warn(\"Using length penalty Wu with alpha==0 \"\n \"is equivalent to using length penalty none.\")\n if coverage_penalty is None or coverage_penalty == \"none\":\n if beta != 0:\n warnings.warn(\"Non-default `beta` with no coverage penalty. \"\n \"`beta` has no effect.\")\n else:\n # using some coverage penalty\n if beta == 0.:\n warnings.warn(\"Non-default coverage penalty with beta==0 \"\n \"is equivalent to using coverage penalty none.\")\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/translate/decode_strategy.py",
"content": "import torch\n\n\nclass DecodeStrategy(object):\n \"\"\"Base class for generation strategies.\n\n Args:\n pad (int): Magic integer in output vocab.\n bos (int): Magic integer in output vocab.\n eos (int): Magic integer in output vocab.\n batch_size (int): Current batch size.\n parallel_paths (int): Decoding strategies like beam search\n use parallel paths. Each batch is repeated ``parallel_paths``\n times in relevant state tensors.\n min_length (int): Shortest acceptable generation, not counting\n begin-of-sentence or end-of-sentence.\n max_length (int): Longest acceptable sequence, not counting\n begin-of-sentence (presumably there has been no EOS\n yet if max_length is used as a cutoff).\n block_ngram_repeat (int): Block beams where\n ``block_ngram_repeat``-grams repeat.\n exclusion_tokens (set[int]): If a gram contains any of these\n tokens, it may repeat.\n return_attention (bool): Whether to work with attention too. If this\n is true, it is assumed that the decoder is attentional.\n\n Attributes:\n pad (int): See above.\n bos (int): See above.\n eos (int): See above.\n predictions (list[list[LongTensor]]): For each batch, holds a\n list of beam prediction sequences.\n scores (list[list[FloatTensor]]): For each batch, holds a\n list of scores.\n attention (list[list[FloatTensor or list[]]]): For each\n batch, holds a list of attention sequence tensors\n (or empty lists) having shape ``(step, inp_seq_len)`` where\n ``inp_seq_len`` is the length of the sample (not the max\n length of all inp seqs).\n alive_seq (LongTensor): Shape ``(B x parallel_paths, step)``.\n This sequence grows in the ``step`` axis on each call to\n :func:`advance()`.\n is_finished (ByteTensor or NoneType): Shape\n ``(B, parallel_paths)``. Initialized to ``None``.\n alive_attn (FloatTensor or NoneType): If tensor, shape is\n ``(step, B x parallel_paths, inp_seq_len)``, where ``inp_seq_len``\n is the (max) length of the input sequence.\n min_length (int): See above.\n max_length (int): See above.\n block_ngram_repeat (int): See above.\n exclusion_tokens (set[int]): See above.\n return_attention (bool): See above.\n done (bool): See above.\n \"\"\"\n\n def __init__(self, pad, bos, eos, batch_size, parallel_paths,\n min_length, block_ngram_repeat, exclusion_tokens,\n return_attention, max_length):\n\n # magic indices\n self.pad = pad\n self.bos = bos\n self.eos = eos\n\n self.batch_size = batch_size\n self.parallel_paths = parallel_paths\n # result caching\n self.predictions = [[] for _ in range(batch_size)]\n self.scores = [[] for _ in range(batch_size)]\n self.attention = [[] for _ in range(batch_size)]\n\n self.alive_attn = None\n\n self.min_length = min_length\n self.max_length = max_length\n self.block_ngram_repeat = block_ngram_repeat\n self.exclusion_tokens = exclusion_tokens\n self.return_attention = return_attention\n\n self.done = False\n\n def initialize(self, memory_bank, src_lengths, src_map=None, device=None):\n \"\"\"DecodeStrategy subclasses should override :func:`initialize()`.\n\n `initialize` should be called before all actions.\n used to prepare necessary ingredients for decode.\n \"\"\"\n if device is None:\n device = torch.device('cpu')\n self.alive_seq = torch.full(\n [self.batch_size * self.parallel_paths, 1], self.bos,\n dtype=torch.long, device=device)\n self.is_finished = torch.zeros(\n [self.batch_size, self.parallel_paths],\n dtype=torch.uint8, device=device)\n return None, memory_bank, src_lengths, src_map\n\n def __len__(self):\n return self.alive_seq.shape[1]\n\n def ensure_min_length(self, log_probs):\n if len(self) <= self.min_length:\n log_probs[:, self.eos] = -1e20\n\n def ensure_max_length(self):\n # add one to account for BOS. Don't account for EOS because hitting\n # this implies it hasn't been found.\n if len(self) == self.max_length + 1:\n self.is_finished.fill_(1)\n\n def block_ngram_repeats(self, log_probs):\n cur_len = len(self)\n if self.block_ngram_repeat > 0 and cur_len > 1:\n for path_idx in range(self.alive_seq.shape[0]):\n # skip BOS\n hyp = self.alive_seq[path_idx, 1:]\n ngrams = set()\n fail = False\n gram = []\n for i in range(cur_len - 1):\n # Last n tokens, n = block_ngram_repeat\n gram = (gram + [hyp[i].item()])[-self.block_ngram_repeat:]\n # skip the blocking if any token in gram is excluded\n if set(gram) & self.exclusion_tokens:\n continue\n if tuple(gram) in ngrams:\n fail = True\n ngrams.add(tuple(gram))\n if fail:\n log_probs[path_idx] = -10e20\n\n def advance(self, log_probs, attn):\n \"\"\"DecodeStrategy subclasses should override :func:`advance()`.\n\n Advance is used to update ``self.alive_seq``, ``self.is_finished``,\n and, when appropriate, ``self.alive_attn``.\n \"\"\"\n\n raise NotImplementedError()\n\n def update_finished(self):\n \"\"\"DecodeStrategy subclasses should override :func:`update_finished()`.\n\n ``update_finished`` is used to update ``self.predictions``,\n ``self.scores``, and other \"output\" attributes.\n \"\"\"\n\n raise NotImplementedError()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/translate/greedy_search.py",
"content": "import torch\n\nfrom onmt.translate.decode_strategy import DecodeStrategy\n\n\ndef sample_with_temperature(logits, sampling_temp, keep_topk):\n \"\"\"Select next tokens randomly from the top k possible next tokens.\n\n Samples from a categorical distribution over the ``keep_topk`` words using\n the category probabilities ``logits / sampling_temp``.\n\n Args:\n logits (FloatTensor): Shaped ``(batch_size, vocab_size)``.\n These can be logits (``(-inf, inf)``) or log-probs (``(-inf, 0]``).\n (The distribution actually uses the log-probabilities\n ``logits - logits.logsumexp(-1)``, which equals the logits if\n they are log-probabilities summing to 1.)\n sampling_temp (float): Used to scale down logits. The higher the\n value, the more likely it is that a non-max word will be\n sampled.\n keep_topk (int): This many words could potentially be chosen. The\n other logits are set to have probability 0.\n\n Returns:\n (LongTensor, FloatTensor):\n\n * topk_ids: Shaped ``(batch_size, 1)``. These are\n the sampled word indices in the output vocab.\n * topk_scores: Shaped ``(batch_size, 1)``. These\n are essentially ``(logits / sampling_temp)[topk_ids]``.\n \"\"\"\n\n if sampling_temp == 0.0 or keep_topk == 1:\n # For temp=0.0, take the argmax to avoid divide-by-zero errors.\n # keep_topk=1 is also equivalent to argmax.\n topk_scores, topk_ids = logits.topk(1, dim=-1)\n if sampling_temp > 0:\n topk_scores /= sampling_temp\n else:\n logits = torch.div(logits, sampling_temp)\n\n if keep_topk > 0:\n top_values, top_indices = torch.topk(logits, keep_topk, dim=1)\n kth_best = top_values[:, -1].view([-1, 1])\n kth_best = kth_best.repeat([1, logits.shape[1]]).float()\n\n # Set all logits that are not in the top-k to -10000.\n # This puts the probabilities close to 0.\n ignore = torch.lt(logits, kth_best)\n logits = logits.masked_fill(ignore, -10000)\n\n dist = torch.distributions.Multinomial(\n logits=logits, total_count=1)\n topk_ids = torch.argmax(dist.sample(), dim=1, keepdim=True)\n topk_scores = logits.gather(dim=1, index=topk_ids)\n return topk_ids, topk_scores\n\n\nclass GreedySearch(DecodeStrategy):\n \"\"\"Select next tokens randomly from the top k possible next tokens.\n\n The ``scores`` attribute's lists are the score, after applying temperature,\n of the final prediction (either EOS or the final token in the event\n that ``max_length`` is reached)\n\n Args:\n pad (int): See base.\n bos (int): See base.\n eos (int): See base.\n batch_size (int): See base.\n min_length (int): See base.\n max_length (int): See base.\n block_ngram_repeat (int): See base.\n exclusion_tokens (set[int]): See base.\n return_attention (bool): See base.\n max_length (int): See base.\n sampling_temp (float): See\n :func:`~onmt.translate.greedy_search.sample_with_temperature()`.\n keep_topk (int): See\n :func:`~onmt.translate.greedy_search.sample_with_temperature()`.\n \"\"\"\n\n def __init__(self, pad, bos, eos, batch_size, min_length,\n block_ngram_repeat, exclusion_tokens, return_attention,\n max_length, sampling_temp, keep_topk):\n assert block_ngram_repeat == 0\n super(GreedySearch, self).__init__(\n pad, bos, eos, batch_size, 1, min_length, block_ngram_repeat,\n exclusion_tokens, return_attention, max_length)\n self.sampling_temp = sampling_temp\n self.keep_topk = keep_topk\n self.topk_scores = None\n\n def initialize(self, memory_bank, src_lengths, src_map=None, device=None):\n \"\"\"Initialize for decoding.\"\"\"\n fn_map_state = None\n\n if isinstance(memory_bank, tuple):\n mb_device = memory_bank[0].device\n else:\n mb_device = memory_bank.device\n if device is None:\n device = mb_device\n\n self.memory_lengths = src_lengths\n super(GreedySearch, self).initialize(\n memory_bank, src_lengths, src_map, device)\n self.select_indices = torch.arange(\n self.batch_size, dtype=torch.long, device=device)\n self.original_batch_idx = torch.arange(\n self.batch_size, dtype=torch.long, device=device)\n return fn_map_state, memory_bank, self.memory_lengths, src_map\n\n @property\n def current_predictions(self):\n return self.alive_seq[:, -1]\n\n @property\n def batch_offset(self):\n return self.select_indices\n\n def advance(self, log_probs, attn):\n \"\"\"Select next tokens randomly from the top k possible next tokens.\n\n Args:\n log_probs (FloatTensor): Shaped ``(batch_size, vocab_size)``.\n These can be logits (``(-inf, inf)``) or log-probs\n (``(-inf, 0]``). (The distribution actually uses the\n log-probabilities ``logits - logits.logsumexp(-1)``,\n which equals the logits if they are log-probabilities summing\n to 1.)\n attn (FloatTensor): Shaped ``(1, B, inp_seq_len)``.\n \"\"\"\n\n self.ensure_min_length(log_probs)\n self.block_ngram_repeats(log_probs)\n topk_ids, self.topk_scores = sample_with_temperature(\n log_probs, self.sampling_temp, self.keep_topk)\n\n self.is_finished = topk_ids.eq(self.eos)\n\n self.alive_seq = torch.cat([self.alive_seq, topk_ids], -1)\n if self.return_attention:\n if self.alive_attn is None:\n self.alive_attn = attn\n else:\n self.alive_attn = torch.cat([self.alive_attn, attn], 0)\n self.ensure_max_length()\n\n def update_finished(self):\n \"\"\"Finalize scores and predictions.\"\"\"\n # shape: (sum(~ self.is_finished), 1)\n finished_batches = self.is_finished.view(-1).nonzero()\n for b in finished_batches.view(-1):\n b_orig = self.original_batch_idx[b]\n self.scores[b_orig].append(self.topk_scores[b, 0])\n self.predictions[b_orig].append(self.alive_seq[b, 1:])\n self.attention[b_orig].append(\n self.alive_attn[:, b, :self.memory_lengths[b]]\n if self.alive_attn is not None else [])\n self.done = self.is_finished.all()\n if self.done:\n return\n is_alive = ~self.is_finished.view(-1)\n self.alive_seq = self.alive_seq[is_alive]\n if self.alive_attn is not None:\n self.alive_attn = self.alive_attn[:, is_alive]\n self.select_indices = is_alive.nonzero().view(-1)\n self.original_batch_idx = self.original_batch_idx[is_alive]\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/translate/penalties.py",
"content": "from __future__ import division\nimport torch\n\n\nclass PenaltyBuilder(object):\n \"\"\"Returns the Length and Coverage Penalty function for Beam Search.\n\n Args:\n length_pen (str): option name of length pen\n cov_pen (str): option name of cov pen\n\n Attributes:\n has_cov_pen (bool): Whether coverage penalty is None (applying it\n is a no-op). Note that the converse isn't true. Setting beta\n to 0 should force coverage length to be a no-op.\n has_len_pen (bool): Whether length penalty is None (applying it\n is a no-op). Note that the converse isn't true. Setting alpha\n to 1 should force length penalty to be a no-op.\n coverage_penalty (callable[[FloatTensor, float], FloatTensor]):\n Calculates the coverage penalty.\n length_penalty (callable[[int, float], float]): Calculates\n the length penalty.\n \"\"\"\n\n def __init__(self, cov_pen, length_pen):\n self.has_cov_pen = not self._pen_is_none(cov_pen)\n self.coverage_penalty = self._coverage_penalty(cov_pen)\n self.has_len_pen = not self._pen_is_none(length_pen)\n self.length_penalty = self._length_penalty(length_pen)\n\n @staticmethod\n def _pen_is_none(pen):\n return pen == \"none\" or pen is None\n\n def _coverage_penalty(self, cov_pen):\n if cov_pen == \"wu\":\n return self.coverage_wu\n elif cov_pen == \"summary\":\n return self.coverage_summary\n elif self._pen_is_none(cov_pen):\n return self.coverage_none\n else:\n raise NotImplementedError(\"No '{:s}' coverage penalty.\".format(\n cov_pen))\n\n def _length_penalty(self, length_pen):\n if length_pen == \"wu\":\n return self.length_wu\n elif length_pen == \"avg\":\n return self.length_average\n elif self._pen_is_none(length_pen):\n return self.length_none\n else:\n raise NotImplementedError(\"No '{:s}' length penalty.\".format(\n length_pen))\n\n # Below are all the different penalty terms implemented so far.\n # Subtract coverage penalty from topk log probs.\n # Divide topk log probs by length penalty.\n\n def coverage_wu(self, cov, beta=0.):\n \"\"\"GNMT coverage re-ranking score.\n\n See \"Google's Neural Machine Translation System\" :cite:`wu2016google`.\n ``cov`` is expected to be sized ``(*, seq_len)``, where ``*`` is\n probably ``batch_size x beam_size`` but could be several\n dimensions like ``(batch_size, beam_size)``. If ``cov`` is attention,\n then the ``seq_len`` axis probably sums to (almost) 1.\n \"\"\"\n\n penalty = -torch.min(cov, cov.clone().fill_(1.0)).log().sum(-1)\n return beta * penalty\n\n def coverage_summary(self, cov, beta=0.):\n \"\"\"Our summary penalty.\"\"\"\n penalty = torch.max(cov, cov.clone().fill_(1.0)).sum(-1)\n penalty -= cov.size(-1)\n return beta * penalty\n\n def coverage_none(self, cov, beta=0.):\n \"\"\"Returns zero as penalty\"\"\"\n none = torch.zeros((1,), device=cov.device,\n dtype=torch.float)\n if cov.dim() == 3:\n none = none.unsqueeze(0)\n return none\n\n def length_wu(self, cur_len, alpha=0.):\n \"\"\"GNMT length re-ranking score.\n\n See \"Google's Neural Machine Translation System\" :cite:`wu2016google`.\n \"\"\"\n\n return ((5 + cur_len) / 6.0) ** alpha\n\n def length_average(self, cur_len, alpha=0.):\n \"\"\"Returns the current sequence length.\"\"\"\n return cur_len\n\n def length_none(self, cur_len, alpha=0.):\n \"\"\"Returns unmodified scores.\"\"\"\n return 1.0\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/translate/process_zh.py",
"content": "from pyhanlp import HanLP\nfrom snownlp import SnowNLP\nimport pkuseg\n\n\n# Chinese segmentation\ndef zh_segmentator(line):\n return \" \".join(pkuseg.pkuseg().cut(line))\n\n\n# Chinese simplify -> Chinese traditional standard\ndef zh_traditional_standard(line):\n return HanLP.convertToTraditionalChinese(line)\n\n\n# Chinese simplify -> Chinese traditional (HongKong)\ndef zh_traditional_hk(line):\n return HanLP.s2hk(line)\n\n\n# Chinese simplify -> Chinese traditional (Taiwan)\ndef zh_traditional_tw(line):\n return HanLP.s2tw(line)\n\n\n# Chinese traditional -> Chinese simplify (v1)\ndef zh_simplify(line):\n return HanLP.convertToSimplifiedChinese(line)\n\n\n# Chinese traditional -> Chinese simplify (v2)\ndef zh_simplify_v2(line):\n return SnowNLP(line).han\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/translate/translation.py",
"content": "\"\"\" Translation main class \"\"\"\nfrom __future__ import unicode_literals, print_function\n\nimport torch\nfrom onmt.inputters.text_dataset import TextMultiField\nfrom onmt.utils.alignment import build_align_pharaoh\n\n\nclass TranslationBuilder(object):\n \"\"\"\n Build a word-based translation from the batch output\n of translator and the underlying dictionaries.\n\n Replacement based on \"Addressing the Rare Word\n Problem in Neural Machine Translation\" :cite:`Luong2015b`\n\n Args:\n data (onmt.inputters.Dataset): Data.\n fields (List[Tuple[str, torchtext.data.Field]]): data fields\n n_best (int): number of translations produced\n replace_unk (bool): replace unknown words using attention\n has_tgt (bool): will the batch have gold targets\n \"\"\"\n\n def __init__(self, data, fields, n_best=1, replace_unk=False,\n has_tgt=False, phrase_table=\"\"):\n self.data = data\n self.fields = fields\n self._has_text_src = isinstance(\n dict(self.fields)[\"src\"], TextMultiField)\n self.n_best = n_best\n self.replace_unk = replace_unk\n self.phrase_table = phrase_table\n self.has_tgt = has_tgt\n\n def _build_target_tokens(self, src, src_vocab, src_raw, pred, attn):\n tgt_field = dict(self.fields)[\"tgt\"].base_field\n vocab = tgt_field.vocab\n tokens = []\n for tok in pred:\n if tok < len(vocab):\n tokens.append(vocab.itos[tok])\n else:\n tokens.append(src_vocab.itos[tok - len(vocab)])\n if tokens[-1] == tgt_field.eos_token:\n tokens = tokens[:-1]\n break\n if self.replace_unk and attn is not None and src is not None:\n for i in range(len(tokens)):\n if tokens[i] == tgt_field.unk_token:\n _, max_index = attn[i][:len(src_raw)].max(0)\n tokens[i] = src_raw[max_index.item()]\n if self.phrase_table != \"\":\n with open(self.phrase_table, \"r\") as f:\n for line in f:\n if line.startswith(src_raw[max_index.item()]):\n tokens[i] = line.split('|||')[1].strip()\n return tokens\n\n def from_batch(self, translation_batch):\n batch = translation_batch[\"batch\"]\n assert(len(translation_batch[\"gold_score\"]) ==\n len(translation_batch[\"predictions\"]))\n batch_size = batch.batch_size\n\n preds, pred_score, attn, align, gold_score, indices = list(zip(\n *sorted(zip(translation_batch[\"predictions\"],\n translation_batch[\"scores\"],\n translation_batch[\"attention\"],\n translation_batch[\"alignment\"],\n translation_batch[\"gold_score\"],\n batch.indices.data),\n key=lambda x: x[-1])))\n\n if not any(align): # when align is a empty nested list\n align = [None] * batch_size\n\n # Sorting\n inds, perm = torch.sort(batch.indices)\n if self._has_text_src:\n src = batch.src[0][:, :, 0].index_select(1, perm)\n else:\n src = None\n tgt = batch.tgt[:, :, 0].index_select(1, perm) \\\n if self.has_tgt else None\n\n translations = []\n for b in range(batch_size):\n if self._has_text_src:\n src_vocab = self.data.src_vocabs[inds[b]] \\\n if self.data.src_vocabs else None\n src_raw = self.data.examples[inds[b]].src[0]\n else:\n src_vocab = None\n src_raw = None\n pred_sents = [self._build_target_tokens(\n src[:, b] if src is not None else None,\n src_vocab, src_raw,\n preds[b][n], attn[b][n])\n for n in range(self.n_best)]\n gold_sent = None\n if tgt is not None:\n gold_sent = self._build_target_tokens(\n src[:, b] if src is not None else None,\n src_vocab, src_raw,\n tgt[1:, b] if tgt is not None else None, None)\n\n translation = Translation(\n src[:, b] if src is not None else None,\n src_raw, pred_sents, attn[b], pred_score[b],\n gold_sent, gold_score[b], align[b]\n )\n translations.append(translation)\n\n return translations\n\n\nclass Translation(object):\n \"\"\"Container for a translated sentence.\n\n Attributes:\n src (LongTensor): Source word IDs.\n src_raw (List[str]): Raw source words.\n pred_sents (List[List[str]]): Words from the n-best translations.\n pred_scores (List[List[float]]): Log-probs of n-best translations.\n attns (List[FloatTensor]) : Attention distribution for each\n translation.\n gold_sent (List[str]): Words from gold translation.\n gold_score (List[float]): Log-prob of gold translation.\n word_aligns (List[FloatTensor]): Words Alignment distribution for\n each translation.\n \"\"\"\n\n __slots__ = [\"src\", \"src_raw\", \"pred_sents\", \"attns\", \"pred_scores\",\n \"gold_sent\", \"gold_score\", \"word_aligns\"]\n\n def __init__(self, src, src_raw, pred_sents,\n attn, pred_scores, tgt_sent, gold_score, word_aligns):\n self.src = src\n self.src_raw = src_raw\n self.pred_sents = pred_sents\n self.attns = attn\n self.pred_scores = pred_scores\n self.gold_sent = tgt_sent\n self.gold_score = gold_score\n self.word_aligns = word_aligns\n\n def log(self, sent_number):\n \"\"\"\n Log translation.\n \"\"\"\n\n msg = ['\\nSENT {}: {}\\n'.format(sent_number, self.src_raw)]\n\n best_pred = self.pred_sents[0]\n best_score = self.pred_scores[0]\n pred_sent = ' '.join(best_pred)\n msg.append('PRED {}: {}\\n'.format(sent_number, pred_sent))\n msg.append(\"PRED SCORE: {:.4f}\\n\".format(best_score))\n\n if self.word_aligns is not None:\n pred_align = self.word_aligns[0]\n pred_align_pharaoh = build_align_pharaoh(pred_align)\n pred_align_sent = ' '.join(pred_align_pharaoh)\n msg.append(\"ALIGN: {}\\n\".format(pred_align_sent))\n\n if self.gold_sent is not None:\n tgt_sent = ' '.join(self.gold_sent)\n msg.append('GOLD {}: {}\\n'.format(sent_number, tgt_sent))\n msg.append((\"GOLD SCORE: {:.4f}\\n\".format(self.gold_score)))\n if len(self.pred_sents) > 1:\n msg.append('\\nBEST HYP:\\n')\n for score, sent in zip(self.pred_scores, self.pred_sents):\n msg.append(\"[{:.4f}] {}\\n\".format(score, sent))\n\n return \"\".join(msg)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/translate/translation_server.py",
"content": "#!/usr/bin/env python\n\"\"\"REST Translation server.\"\"\"\nfrom __future__ import print_function\nimport codecs\nimport sys\nimport os\nimport time\nimport json\nimport threading\nimport re\nimport traceback\nimport importlib\nimport torch\nimport onmt.opts\n\nfrom onmt.utils.logging import init_logger\nfrom onmt.utils.misc import set_random_seed\nfrom onmt.utils.misc import check_model_config\nfrom onmt.utils.alignment import to_word_align\nfrom onmt.utils.parse import ArgumentParser\nfrom onmt.translate.translator import build_translator\n\n\ndef critical(func):\n \"\"\"Decorator for critical section (mutually exclusive code)\"\"\"\n def wrapper(server_model, *args, **kwargs):\n if sys.version_info[0] == 3:\n if not server_model.running_lock.acquire(True, 120):\n raise ServerModelError(\"Model %d running lock timeout\"\n % server_model.model_id)\n else:\n # semaphore doesn't have a timeout arg in Python 2.7\n server_model.running_lock.acquire(True)\n try:\n o = func(server_model, *args, **kwargs)\n except (Exception, RuntimeError):\n server_model.running_lock.release()\n raise\n server_model.running_lock.release()\n return o\n return wrapper\n\n\nclass Timer:\n def __init__(self, start=False):\n self.stime = -1\n self.prev = -1\n self.times = {}\n if start:\n self.start()\n\n def start(self):\n self.stime = time.time()\n self.prev = self.stime\n self.times = {}\n\n def tick(self, name=None, tot=False):\n t = time.time()\n if not tot:\n elapsed = t - self.prev\n else:\n elapsed = t - self.stime\n self.prev = t\n\n if name is not None:\n self.times[name] = elapsed\n return elapsed\n\n\nclass ServerModelError(Exception):\n pass\n\n\nclass TranslationServer(object):\n def __init__(self):\n self.models = {}\n self.next_id = 0\n\n def start(self, config_file):\n \"\"\"Read the config file and pre-/load the models.\"\"\"\n self.config_file = config_file\n with open(self.config_file) as f:\n self.confs = json.load(f)\n\n self.models_root = self.confs.get('models_root', './available_models')\n for i, conf in enumerate(self.confs[\"models\"]):\n if \"models\" not in conf:\n if \"model\" in conf:\n # backwards compatibility for confs\n conf[\"models\"] = [conf[\"model\"]]\n else:\n raise ValueError(\"\"\"Incorrect config file: missing 'models'\n parameter for model #%d\"\"\" % i)\n check_model_config(conf, self.models_root)\n kwargs = {'timeout': conf.get('timeout', None),\n 'load': conf.get('load', None),\n 'preprocess_opt': conf.get('preprocess', None),\n 'tokenizer_opt': conf.get('tokenizer', None),\n 'postprocess_opt': conf.get('postprocess', None),\n 'on_timeout': conf.get('on_timeout', None),\n 'model_root': conf.get('model_root', self.models_root)\n }\n kwargs = {k: v for (k, v) in kwargs.items() if v is not None}\n model_id = conf.get(\"id\", None)\n opt = conf[\"opt\"]\n opt[\"models\"] = conf[\"models\"]\n self.preload_model(opt, model_id=model_id, **kwargs)\n\n def clone_model(self, model_id, opt, timeout=-1):\n \"\"\"Clone a model `model_id`.\n\n Different options may be passed. If `opt` is None, it will use the\n same set of options\n \"\"\"\n if model_id in self.models:\n if opt is None:\n opt = self.models[model_id].user_opt\n opt[\"models\"] = self.models[model_id].opt.models\n return self.load_model(opt, timeout)\n else:\n raise ServerModelError(\"No such model '%s'\" % str(model_id))\n\n def load_model(self, opt, model_id=None, **model_kwargs):\n \"\"\"Load a model given a set of options\n \"\"\"\n model_id = self.preload_model(opt, model_id=model_id, **model_kwargs)\n load_time = self.models[model_id].load_time\n\n return model_id, load_time\n\n def preload_model(self, opt, model_id=None, **model_kwargs):\n \"\"\"Preloading the model: updating internal datastructure\n\n It will effectively load the model if `load` is set\n \"\"\"\n if model_id is not None:\n if model_id in self.models.keys():\n raise ValueError(\"Model ID %d already exists\" % model_id)\n else:\n model_id = self.next_id\n while model_id in self.models.keys():\n model_id += 1\n self.next_id = model_id + 1\n print(\"Pre-loading model %d\" % model_id)\n model = ServerModel(opt, model_id, **model_kwargs)\n self.models[model_id] = model\n\n return model_id\n\n def run(self, inputs):\n \"\"\"Translate `inputs`\n\n We keep the same format as the Lua version i.e.\n ``[{\"id\": model_id, \"src\": \"sequence to translate\"},{ ...}]``\n\n We use inputs[0][\"id\"] as the model id\n \"\"\"\n\n model_id = inputs[0].get(\"id\", 0)\n if model_id in self.models and self.models[model_id] is not None:\n return self.models[model_id].run(inputs)\n else:\n print(\"Error No such model '%s'\" % str(model_id))\n raise ServerModelError(\"No such model '%s'\" % str(model_id))\n\n def unload_model(self, model_id):\n \"\"\"Manually unload a model.\n\n It will free the memory and cancel the timer\n \"\"\"\n\n if model_id in self.models and self.models[model_id] is not None:\n self.models[model_id].unload()\n else:\n raise ServerModelError(\"No such model '%s'\" % str(model_id))\n\n def list_models(self):\n \"\"\"Return the list of available models\n \"\"\"\n models = []\n for _, model in self.models.items():\n models += [model.to_dict()]\n return models\n\n\nclass ServerModel(object):\n \"\"\"Wrap a model with server functionality.\n\n Args:\n opt (dict): Options for the Translator\n model_id (int): Model ID\n preprocess_opt (list): Options for preprocess processus or None\n (extend for CJK)\n tokenizer_opt (dict): Options for the tokenizer or None\n postprocess_opt (list): Options for postprocess processus or None\n (extend for CJK)\n load (bool): whether to load the model during :func:`__init__()`\n timeout (int): Seconds before running :func:`do_timeout()`\n Negative values means no timeout\n on_timeout (str): Options are [\"to_cpu\", \"unload\"]. Set what to do on\n timeout (see :func:`do_timeout()`.)\n model_root (str): Path to the model directory\n it must contain the model and tokenizer file\n \"\"\"\n\n def __init__(self, opt, model_id, preprocess_opt=None, tokenizer_opt=None,\n postprocess_opt=None, load=False, timeout=-1,\n on_timeout=\"to_cpu\", model_root=\"./\"):\n self.model_root = model_root\n self.opt = self.parse_opt(opt)\n\n self.model_id = model_id\n self.preprocess_opt = preprocess_opt\n self.tokenizer_opt = tokenizer_opt\n self.postprocess_opt = postprocess_opt\n self.timeout = timeout\n self.on_timeout = on_timeout\n\n self.unload_timer = None\n self.user_opt = opt\n self.tokenizer = None\n\n if len(self.opt.log_file) > 0:\n log_file = os.path.join(model_root, self.opt.log_file)\n else:\n log_file = None\n self.logger = init_logger(log_file=log_file,\n log_file_level=self.opt.log_file_level)\n\n self.loading_lock = threading.Event()\n self.loading_lock.set()\n self.running_lock = threading.Semaphore(value=1)\n\n set_random_seed(self.opt.seed, self.opt.cuda)\n\n if load:\n self.load()\n\n def parse_opt(self, opt):\n \"\"\"Parse the option set passed by the user using `onmt.opts`\n\n Args:\n opt (dict): Options passed by the user\n\n Returns:\n opt (argparse.Namespace): full set of options for the Translator\n \"\"\"\n\n prec_argv = sys.argv\n sys.argv = sys.argv[:1]\n parser = ArgumentParser()\n onmt.opts.translate_opts(parser)\n\n models = opt['models']\n if not isinstance(models, (list, tuple)):\n models = [models]\n opt['models'] = [os.path.join(self.model_root, model)\n for model in models]\n opt['src'] = \"dummy_src\"\n\n for (k, v) in opt.items():\n if k == 'models':\n sys.argv += ['-model']\n sys.argv += [str(model) for model in v]\n elif type(v) == bool:\n sys.argv += ['-%s' % k]\n else:\n sys.argv += ['-%s' % k, str(v)]\n\n opt = parser.parse_args()\n ArgumentParser.validate_translate_opts(opt)\n opt.cuda = opt.gpu > -1\n\n sys.argv = prec_argv\n return opt\n\n @property\n def loaded(self):\n return hasattr(self, 'translator')\n\n def load(self):\n self.loading_lock.clear()\n\n timer = Timer()\n self.logger.info(\"Loading model %d\" % self.model_id)\n timer.start()\n\n try:\n self.translator = build_translator(self.opt,\n report_score=False,\n out_file=codecs.open(\n os.devnull, \"w\", \"utf-8\"))\n except RuntimeError as e:\n raise ServerModelError(\"Runtime Error: %s\" % str(e))\n\n timer.tick(\"model_loading\")\n if self.preprocess_opt is not None:\n self.logger.info(\"Loading preprocessor\")\n self.preprocessor = []\n\n for function_path in self.preprocess_opt:\n function = get_function_by_path(function_path)\n self.preprocessor.append(function)\n\n if self.tokenizer_opt is not None:\n self.logger.info(\"Loading tokenizer\")\n\n if \"type\" not in self.tokenizer_opt:\n raise ValueError(\n \"Missing mandatory tokenizer option 'type'\")\n\n if self.tokenizer_opt['type'] == 'sentencepiece':\n if \"model\" not in self.tokenizer_opt:\n raise ValueError(\n \"Missing mandatory tokenizer option 'model'\")\n import sentencepiece as spm\n sp = spm.SentencePieceProcessor()\n model_path = os.path.join(self.model_root,\n self.tokenizer_opt['model'])\n sp.Load(model_path)\n self.tokenizer = sp\n elif self.tokenizer_opt['type'] == 'pyonmttok':\n if \"params\" not in self.tokenizer_opt:\n raise ValueError(\n \"Missing mandatory tokenizer option 'params'\")\n import pyonmttok\n if self.tokenizer_opt[\"mode\"] is not None:\n mode = self.tokenizer_opt[\"mode\"]\n else:\n mode = None\n # load can be called multiple times: modify copy\n tokenizer_params = dict(self.tokenizer_opt[\"params\"])\n for key, value in self.tokenizer_opt[\"params\"].items():\n if key.endswith(\"path\"):\n tokenizer_params[key] = os.path.join(\n self.model_root, value)\n tokenizer = pyonmttok.Tokenizer(mode,\n **tokenizer_params)\n self.tokenizer = tokenizer\n else:\n raise ValueError(\"Invalid value for tokenizer type\")\n\n if self.postprocess_opt is not None:\n self.logger.info(\"Loading postprocessor\")\n self.postprocessor = []\n\n for function_path in self.postprocess_opt:\n function = get_function_by_path(function_path)\n self.postprocessor.append(function)\n\n self.load_time = timer.tick()\n self.reset_unload_timer()\n self.loading_lock.set()\n\n @critical\n def run(self, inputs):\n \"\"\"Translate `inputs` using this model\n\n Args:\n inputs (List[dict[str, str]]): [{\"src\": \"...\"},{\"src\": ...}]\n\n Returns:\n result (list): translations\n times (dict): containing times\n \"\"\"\n\n self.stop_unload_timer()\n\n timer = Timer()\n timer.start()\n\n self.logger.info(\"Running translation using %d\" % self.model_id)\n\n if not self.loading_lock.is_set():\n self.logger.info(\n \"Model #%d is being loaded by another thread, waiting\"\n % self.model_id)\n if not self.loading_lock.wait(timeout=30):\n raise ServerModelError(\"Model %d loading timeout\"\n % self.model_id)\n\n else:\n if not self.loaded:\n self.load()\n timer.tick(name=\"load\")\n elif self.opt.cuda:\n self.to_gpu()\n timer.tick(name=\"to_gpu\")\n\n texts = []\n head_spaces = []\n tail_spaces = []\n sslength = []\n for i, inp in enumerate(inputs):\n src = inp['src']\n if src.strip() == \"\":\n head_spaces.append(src)\n texts.append(\"\")\n tail_spaces.append(\"\")\n else:\n whitespaces_before, whitespaces_after = \"\", \"\"\n match_before = re.search(r'^\\s+', src)\n match_after = re.search(r'\\s+$', src)\n if match_before is not None:\n whitespaces_before = match_before.group(0)\n if match_after is not None:\n whitespaces_after = match_after.group(0)\n head_spaces.append(whitespaces_before)\n preprocessed_src = self.maybe_preprocess(src.strip())\n tok = self.maybe_tokenize(preprocessed_src)\n texts.append(tok)\n sslength.append(len(tok.split()))\n tail_spaces.append(whitespaces_after)\n\n empty_indices = [i for i, x in enumerate(texts) if x == \"\"]\n texts_to_translate = [x for x in texts if x != \"\"]\n\n scores = []\n predictions = []\n if len(texts_to_translate) > 0:\n try:\n scores, predictions = self.translator.translate(\n texts_to_translate,\n batch_size=len(texts_to_translate)\n if self.opt.batch_size == 0\n else self.opt.batch_size)\n except (RuntimeError, Exception) as e:\n err = \"Error: %s\" % str(e)\n self.logger.error(err)\n self.logger.error(\"repr(text_to_translate): \"\n + repr(texts_to_translate))\n self.logger.error(\"model: #%s\" % self.model_id)\n self.logger.error(\"model opt: \" + str(self.opt.__dict__))\n self.logger.error(traceback.format_exc())\n\n raise ServerModelError(err)\n\n timer.tick(name=\"translation\")\n self.logger.info(\"\"\"Using model #%d\\t%d inputs\n \\ttranslation time: %f\"\"\" % (self.model_id, len(texts),\n timer.times['translation']))\n self.reset_unload_timer()\n\n # NOTE: translator returns lists of `n_best` list\n def flatten_list(_list): return sum(_list, [])\n tiled_texts = [t for t in texts_to_translate\n for _ in range(self.opt.n_best)]\n results = flatten_list(predictions)\n scores = [score_tensor.item()\n for score_tensor in flatten_list(scores)]\n\n results = [self.maybe_detokenize_with_align(result, src)\n for result, src in zip(results, tiled_texts)]\n\n aligns = [align for _, align in results]\n results = [self.maybe_postprocess(seq) for seq, _ in results]\n\n # build back results with empty texts\n for i in empty_indices:\n j = i * self.opt.n_best\n results = results[:j] + [\"\"] * self.opt.n_best + results[j:]\n aligns = aligns[:j] + [None] * self.opt.n_best + aligns[j:]\n scores = scores[:j] + [0] * self.opt.n_best + scores[j:]\n\n head_spaces = [h for h in head_spaces for i in range(self.opt.n_best)]\n tail_spaces = [h for h in tail_spaces for i in range(self.opt.n_best)]\n results = [\"\".join(items)\n for items in zip(head_spaces, results, tail_spaces)]\n\n self.logger.info(\"Translation Results: %d\", len(results))\n return results, scores, self.opt.n_best, timer.times, aligns\n\n def do_timeout(self):\n \"\"\"Timeout function that frees GPU memory.\n\n Moves the model to CPU or unloads it; depending on\n attr`self.on_timemout` value\n \"\"\"\n\n if self.on_timeout == \"unload\":\n self.logger.info(\"Timeout: unloading model %d\" % self.model_id)\n self.unload()\n if self.on_timeout == \"to_cpu\":\n self.logger.info(\"Timeout: sending model %d to CPU\"\n % self.model_id)\n self.to_cpu()\n\n @critical\n def unload(self):\n self.logger.info(\"Unloading model %d\" % self.model_id)\n del self.translator\n if self.opt.cuda:\n torch.cuda.empty_cache()\n self.unload_timer = None\n\n def stop_unload_timer(self):\n if self.unload_timer is not None:\n self.unload_timer.cancel()\n\n def reset_unload_timer(self):\n if self.timeout < 0:\n return\n\n self.stop_unload_timer()\n self.unload_timer = threading.Timer(self.timeout, self.do_timeout)\n self.unload_timer.start()\n\n def to_dict(self):\n hide_opt = [\"models\", \"src\"]\n d = {\"model_id\": self.model_id,\n \"opt\": {k: self.user_opt[k] for k in self.user_opt.keys()\n if k not in hide_opt},\n \"models\": self.user_opt[\"models\"],\n \"loaded\": self.loaded,\n \"timeout\": self.timeout,\n }\n if self.tokenizer_opt is not None:\n d[\"tokenizer\"] = self.tokenizer_opt\n return d\n\n @critical\n def to_cpu(self):\n \"\"\"Move the model to CPU and clear CUDA cache.\"\"\"\n self.translator.model.cpu()\n if self.opt.cuda:\n torch.cuda.empty_cache()\n\n def to_gpu(self):\n \"\"\"Move the model to GPU.\"\"\"\n torch.cuda.set_device(self.opt.gpu)\n self.translator.model.cuda()\n\n def maybe_preprocess(self, sequence):\n \"\"\"Preprocess the sequence (or not)\n\n \"\"\"\n\n if self.preprocess_opt is not None:\n return self.preprocess(sequence)\n return sequence\n\n def preprocess(self, sequence):\n \"\"\"Preprocess a single sequence.\n\n Args:\n sequence (str): The sequence to preprocess.\n\n Returns:\n sequence (str): The preprocessed sequence.\n \"\"\"\n if self.preprocessor is None:\n raise ValueError(\"No preprocessor loaded\")\n for function in self.preprocessor:\n sequence = function(sequence)\n return sequence\n\n def maybe_tokenize(self, sequence):\n \"\"\"Tokenize the sequence (or not).\n\n Same args/returns as `tokenize`\n \"\"\"\n\n if self.tokenizer_opt is not None:\n return self.tokenize(sequence)\n return sequence\n\n def tokenize(self, sequence):\n \"\"\"Tokenize a single sequence.\n\n Args:\n sequence (str): The sequence to tokenize.\n\n Returns:\n tok (str): The tokenized sequence.\n \"\"\"\n\n if self.tokenizer is None:\n raise ValueError(\"No tokenizer loaded\")\n\n if self.tokenizer_opt[\"type\"] == \"sentencepiece\":\n tok = self.tokenizer.EncodeAsPieces(sequence)\n tok = \" \".join(tok)\n elif self.tokenizer_opt[\"type\"] == \"pyonmttok\":\n tok, _ = self.tokenizer.tokenize(sequence)\n tok = \" \".join(tok)\n return tok\n\n @property\n def tokenizer_marker(self):\n marker = None\n tokenizer_type = self.tokenizer_opt.get('type', None)\n if tokenizer_type == \"pyonmttok\":\n params = self.tokenizer_opt.get('params', None)\n if params is not None:\n if params.get(\"joiner_annotate\", None) is not None:\n marker = 'joiner'\n elif params.get(\"spacer_annotate\", None) is not None:\n marker = 'spacer'\n elif tokenizer_type == \"sentencepiece\":\n marker = 'spacer'\n return marker\n\n def maybe_detokenize_with_align(self, sequence, src):\n \"\"\"De-tokenize (or not) the sequence (with alignment).\n\n Args:\n sequence (str): The sequence to detokenize, possible with\n alignment seperate by ` ||| `.\n\n Returns:\n sequence (str): The detokenized sequence.\n align (str): The alignment correspand to detokenized src/tgt\n sorted or None if no alignment in output.\n \"\"\"\n align = None\n if self.opt.report_align:\n # output contain alignment\n sequence, align = sequence.split(' ||| ')\n align = self.maybe_convert_align(src, sequence, align)\n sequence = self.maybe_detokenize(sequence)\n return (sequence, align)\n\n def maybe_detokenize(self, sequence):\n \"\"\"De-tokenize the sequence (or not)\n\n Same args/returns as :func:`tokenize()`\n \"\"\"\n\n if self.tokenizer_opt is not None and ''.join(sequence.split()) != '':\n return self.detokenize(sequence)\n return sequence\n\n def detokenize(self, sequence):\n \"\"\"Detokenize a single sequence\n\n Same args/returns as :func:`tokenize()`\n \"\"\"\n\n if self.tokenizer is None:\n raise ValueError(\"No tokenizer loaded\")\n\n if self.tokenizer_opt[\"type\"] == \"sentencepiece\":\n detok = self.tokenizer.DecodePieces(sequence.split())\n elif self.tokenizer_opt[\"type\"] == \"pyonmttok\":\n detok = self.tokenizer.detokenize(sequence.split())\n\n return detok\n\n def maybe_convert_align(self, src, tgt, align):\n \"\"\"Convert alignment to match detokenized src/tgt (or not).\n\n Args:\n src (str): The tokenized source sequence.\n tgt (str): The tokenized target sequence.\n align (str): The alignment correspand to src/tgt pair.\n\n Returns:\n align (str): The alignment correspand to detokenized src/tgt.\n \"\"\"\n if self.tokenizer_marker is not None and ''.join(tgt.split()) != '':\n return to_word_align(src, tgt, align, mode=self.tokenizer_marker)\n return align\n\n def maybe_postprocess(self, sequence):\n \"\"\"Postprocess the sequence (or not)\n\n \"\"\"\n\n if self.postprocess_opt is not None:\n return self.postprocess(sequence)\n return sequence\n\n def postprocess(self, sequence):\n \"\"\"Preprocess a single sequence.\n\n Args:\n sequence (str): The sequence to process.\n\n Returns:\n sequence (str): The postprocessed sequence.\n \"\"\"\n if self.postprocessor is None:\n raise ValueError(\"No postprocessor loaded\")\n for function in self.postprocessor:\n sequence = function(sequence)\n return sequence\n\n\ndef get_function_by_path(path, args=[], kwargs={}):\n module_name = \".\".join(path.split(\".\")[:-1])\n function_name = path.split(\".\")[-1]\n try:\n module = importlib.import_module(module_name)\n except ValueError as e:\n print(\"Cannot import module '%s'\" % module_name)\n raise e\n function = getattr(module, function_name)\n return function\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/translate/translator.py",
"content": "#!/usr/bin/env python\n\"\"\" Translator Class and builder \"\"\"\nfrom __future__ import print_function\nimport codecs\nimport os\nimport math\nimport time\nfrom itertools import count, zip_longest\n\nimport torch\n\nimport onmt.model_builder\nimport onmt.inputters as inputters\nimport onmt.decoders.ensemble\nfrom onmt.translate.beam_search import BeamSearch\nfrom onmt.translate.greedy_search import GreedySearch\nfrom onmt.utils.misc import tile, set_random_seed, report_matrix\nfrom onmt.utils.alignment import extract_alignment, build_align_pharaoh\nfrom onmt.modules.copy_generator import collapse_copy_scores\n\n\ndef build_translator(opt, report_score=True, logger=None, out_file=None):\n if out_file is None:\n out_file = codecs.open(opt.output, 'w+', 'utf-8')\n\n load_test_model = onmt.decoders.ensemble.load_test_model \\\n if len(opt.models) > 1 else onmt.model_builder.load_test_model\n fields, model, model_opt = load_test_model(opt)\n\n scorer = onmt.translate.GNMTGlobalScorer.from_opt(opt)\n\n translator = Translator.from_opt(\n model,\n fields,\n opt,\n model_opt,\n global_scorer=scorer,\n out_file=out_file,\n report_align=opt.report_align,\n report_score=report_score,\n logger=logger\n )\n return translator\n\n\ndef max_tok_len(new, count, sofar):\n \"\"\"\n In token batching scheme, the number of sequences is limited\n such that the total number of src/tgt tokens (including padding)\n in a batch <= batch_size\n \"\"\"\n # Maintains the longest src and tgt length in the current batch\n global max_src_in_batch # this is a hack\n # Reset current longest length at a new batch (count=1)\n if count == 1:\n max_src_in_batch = 0\n # max_tgt_in_batch = 0\n # Src: [ w1 ... wN ]\n max_src_in_batch = max(max_src_in_batch, len(new.src[0]) + 2)\n # Tgt: [w1 ... wM ]\n src_elements = count * max_src_in_batch\n return src_elements\n\n\nclass Translator(object):\n \"\"\"Translate a batch of sentences with a saved model.\n\n Args:\n model (onmt.modules.NMTModel): NMT model to use for translation\n fields (dict[str, torchtext.data.Field]): A dict\n mapping each side to its list of name-Field pairs.\n src_reader (onmt.inputters.DataReaderBase): Source reader.\n tgt_reader (onmt.inputters.TextDataReader): Target reader.\n gpu (int): GPU device. Set to negative for no GPU.\n n_best (int): How many beams to wait for.\n min_length (int): See\n :class:`onmt.translate.decode_strategy.DecodeStrategy`.\n max_length (int): See\n :class:`onmt.translate.decode_strategy.DecodeStrategy`.\n beam_size (int): Number of beams.\n random_sampling_topk (int): See\n :class:`onmt.translate.greedy_search.GreedySearch`.\n random_sampling_temp (int): See\n :class:`onmt.translate.greedy_search.GreedySearch`.\n stepwise_penalty (bool): Whether coverage penalty is applied every step\n or not.\n dump_beam (bool): Debugging option.\n block_ngram_repeat (int): See\n :class:`onmt.translate.decode_strategy.DecodeStrategy`.\n ignore_when_blocking (set or frozenset): See\n :class:`onmt.translate.decode_strategy.DecodeStrategy`.\n replace_unk (bool): Replace unknown token.\n data_type (str): Source data type.\n verbose (bool): Print/log every translation.\n report_bleu (bool): Print/log Bleu metric.\n report_rouge (bool): Print/log Rouge metric.\n report_time (bool): Print/log total time/frequency.\n copy_attn (bool): Use copy attention.\n global_scorer (onmt.translate.GNMTGlobalScorer): Translation\n scoring/reranking object.\n out_file (TextIO or codecs.StreamReaderWriter): Output file.\n report_score (bool) : Whether to report scores\n logger (logging.Logger or NoneType): Logger.\n \"\"\"\n\n def __init__(\n self,\n model,\n fields,\n src_reader,\n tgt_reader,\n gpu=-1,\n n_best=1,\n min_length=0,\n max_length=100,\n ratio=0.,\n beam_size=30,\n random_sampling_topk=1,\n random_sampling_temp=1,\n stepwise_penalty=None,\n dump_beam=False,\n block_ngram_repeat=0,\n ignore_when_blocking=frozenset(),\n replace_unk=False,\n phrase_table=\"\",\n data_type=\"text\",\n verbose=False,\n report_bleu=False,\n report_rouge=False,\n report_time=False,\n copy_attn=False,\n global_scorer=None,\n out_file=None,\n report_align=False,\n report_score=True,\n logger=None,\n seed=-1):\n self.model = model\n self.fields = fields\n tgt_field = dict(self.fields)[\"tgt\"].base_field\n self._tgt_vocab = tgt_field.vocab\n self._tgt_eos_idx = self._tgt_vocab.stoi[tgt_field.eos_token]\n self._tgt_pad_idx = self._tgt_vocab.stoi[tgt_field.pad_token]\n self._tgt_bos_idx = self._tgt_vocab.stoi[tgt_field.init_token]\n self._tgt_unk_idx = self._tgt_vocab.stoi[tgt_field.unk_token]\n self._tgt_vocab_len = len(self._tgt_vocab)\n\n self._gpu = gpu\n self._use_cuda = gpu > -1\n self._dev = torch.device(\"cuda\", self._gpu) \\\n if self._use_cuda else torch.device(\"cpu\")\n\n self.n_best = n_best\n self.max_length = max_length\n\n self.beam_size = beam_size\n self.random_sampling_temp = random_sampling_temp\n self.sample_from_topk = random_sampling_topk\n\n self.min_length = min_length\n self.ratio = ratio\n self.stepwise_penalty = stepwise_penalty\n self.dump_beam = dump_beam\n self.block_ngram_repeat = block_ngram_repeat\n self.ignore_when_blocking = ignore_when_blocking\n self._exclusion_idxs = {\n self._tgt_vocab.stoi[t] for t in self.ignore_when_blocking}\n self.src_reader = src_reader\n self.tgt_reader = tgt_reader\n self.replace_unk = replace_unk\n if self.replace_unk and not self.model.decoder.attentional:\n raise ValueError(\n \"replace_unk requires an attentional decoder.\")\n self.phrase_table = phrase_table\n self.data_type = data_type\n self.verbose = verbose\n self.report_bleu = report_bleu\n self.report_rouge = report_rouge\n self.report_time = report_time\n\n self.copy_attn = copy_attn\n\n self.global_scorer = global_scorer\n if self.global_scorer.has_cov_pen and \\\n not self.model.decoder.attentional:\n raise ValueError(\n \"Coverage penalty requires an attentional decoder.\")\n self.out_file = out_file\n self.report_align = report_align\n self.report_score = report_score\n self.logger = logger\n\n self.use_filter_pred = False\n self._filter_pred = None\n\n # for debugging\n self.beam_trace = self.dump_beam != \"\"\n self.beam_accum = None\n if self.beam_trace:\n self.beam_accum = {\n \"predicted_ids\": [],\n \"beam_parent_ids\": [],\n \"scores\": [],\n \"log_probs\": []}\n\n set_random_seed(seed, self._use_cuda)\n\n @classmethod\n def from_opt(\n cls,\n model,\n fields,\n opt,\n model_opt,\n global_scorer=None,\n out_file=None,\n report_align=False,\n report_score=True,\n logger=None):\n \"\"\"Alternate constructor.\n\n Args:\n model (onmt.modules.NMTModel): See :func:`__init__()`.\n fields (dict[str, torchtext.data.Field]): See\n :func:`__init__()`.\n opt (argparse.Namespace): Command line options\n model_opt (argparse.Namespace): Command line options saved with\n the model checkpoint.\n global_scorer (onmt.translate.GNMTGlobalScorer): See\n :func:`__init__()`..\n out_file (TextIO or codecs.StreamReaderWriter): See\n :func:`__init__()`.\n report_align (bool) : See :func:`__init__()`.\n report_score (bool) : See :func:`__init__()`.\n logger (logging.Logger or NoneType): See :func:`__init__()`.\n \"\"\"\n\n src_reader = inputters.str2reader[opt.data_type].from_opt(opt)\n tgt_reader = inputters.str2reader[\"text\"].from_opt(opt)\n return cls(\n model,\n fields,\n src_reader,\n tgt_reader,\n gpu=opt.gpu,\n n_best=opt.n_best,\n min_length=opt.min_length,\n max_length=opt.max_length,\n ratio=opt.ratio,\n beam_size=opt.beam_size,\n random_sampling_topk=opt.random_sampling_topk,\n random_sampling_temp=opt.random_sampling_temp,\n stepwise_penalty=opt.stepwise_penalty,\n dump_beam=opt.dump_beam,\n block_ngram_repeat=opt.block_ngram_repeat,\n ignore_when_blocking=set(opt.ignore_when_blocking),\n replace_unk=opt.replace_unk,\n phrase_table=opt.phrase_table,\n data_type=opt.data_type,\n verbose=opt.verbose,\n report_bleu=opt.report_bleu,\n report_rouge=opt.report_rouge,\n report_time=opt.report_time,\n copy_attn=model_opt.copy_attn,\n global_scorer=global_scorer,\n out_file=out_file,\n report_align=report_align,\n report_score=report_score,\n logger=logger,\n seed=opt.seed)\n\n def _log(self, msg):\n if self.logger:\n self.logger.info(msg)\n else:\n print(msg)\n\n def _gold_score(self, batch, memory_bank, src_lengths, src_vocabs,\n use_src_map, enc_states, batch_size, src):\n if \"tgt\" in batch.__dict__:\n gs = self._score_target(\n batch, memory_bank, src_lengths, src_vocabs,\n batch.src_map if use_src_map else None)\n self.model.decoder.init_state(src, memory_bank, enc_states)\n else:\n gs = [0] * batch_size\n return gs\n\n def translate(\n self,\n src,\n tgt=None,\n src_dir=None,\n batch_size=None,\n batch_type=\"sents\",\n attn_debug=False,\n align_debug=False,\n phrase_table=\"\"):\n \"\"\"Translate content of ``src`` and get gold scores from ``tgt``.\n\n Args:\n src: See :func:`self.src_reader.read()`.\n tgt: See :func:`self.tgt_reader.read()`.\n src_dir: See :func:`self.src_reader.read()` (only relevant\n for certain types of data).\n batch_size (int): size of examples per mini-batch\n attn_debug (bool): enables the attention logging\n align_debug (bool): enables the word alignment logging\n\n Returns:\n (`list`, `list`)\n\n * all_scores is a list of `batch_size` lists of `n_best` scores\n * all_predictions is a list of `batch_size` lists\n of `n_best` predictions\n \"\"\"\n\n if batch_size is None:\n raise ValueError(\"batch_size must be set\")\n\n src_data = {\"reader\": self.src_reader, \"data\": src, \"dir\": src_dir}\n tgt_data = {\"reader\": self.tgt_reader, \"data\": tgt, \"dir\": None}\n _readers, _data, _dir = inputters.Dataset.config(\n [('src', src_data), ('tgt', tgt_data)])\n\n data = inputters.Dataset(\n self.fields, readers=_readers, data=_data, dirs=_dir,\n sort_key=inputters.str2sortkey[self.data_type],\n filter_pred=self._filter_pred\n )\n\n data_iter = inputters.OrderedIterator(\n dataset=data,\n device=self._dev,\n batch_size=batch_size,\n batch_size_fn=max_tok_len if batch_type == \"tokens\" else None,\n train=False,\n sort=False,\n sort_within_batch=True,\n shuffle=False\n )\n\n xlation_builder = onmt.translate.TranslationBuilder(\n data, self.fields, self.n_best, self.replace_unk, tgt,\n self.phrase_table\n )\n\n # Statistics\n counter = count(1)\n pred_score_total, pred_words_total = 0, 0\n gold_score_total, gold_words_total = 0, 0\n\n all_scores = []\n all_predictions = []\n\n start_time = time.time()\n\n for batch in data_iter:\n batch_data = self.translate_batch(\n batch, data.src_vocabs, attn_debug\n )\n translations = xlation_builder.from_batch(batch_data)\n\n for trans in translations:\n all_scores += [trans.pred_scores[:self.n_best]]\n pred_score_total += trans.pred_scores[0]\n pred_words_total += len(trans.pred_sents[0])\n if tgt is not None:\n gold_score_total += trans.gold_score\n gold_words_total += len(trans.gold_sent) + 1\n\n n_best_preds = [\" \".join(pred)\n for pred in trans.pred_sents[:self.n_best]]\n if self.report_align:\n align_pharaohs = [build_align_pharaoh(align) for align\n in trans.word_aligns[:self.n_best]]\n n_best_preds_align = [\" \".join(align) for align\n in align_pharaohs]\n n_best_preds = [pred + \" ||| \" + align\n for pred, align in zip(\n n_best_preds, n_best_preds_align)]\n all_predictions += [n_best_preds]\n self.out_file.write('\\n'.join(n_best_preds) + '\\n')\n self.out_file.flush()\n\n if self.verbose:\n sent_number = next(counter)\n output = trans.log(sent_number)\n if self.logger:\n self.logger.info(output)\n else:\n os.write(1, output.encode('utf-8'))\n\n if attn_debug:\n preds = trans.pred_sents[0]\n preds.append('')\n attns = trans.attns[0].tolist()\n if self.data_type == 'text':\n srcs = trans.src_raw\n else:\n srcs = [str(item) for item in range(len(attns[0]))]\n output = report_matrix(srcs, preds, attns)\n if self.logger:\n self.logger.info(output)\n else:\n os.write(1, output.encode('utf-8'))\n\n if align_debug:\n if trans.gold_sent is not None:\n tgts = trans.gold_sent\n else:\n tgts = trans.pred_sents[0]\n align = trans.word_aligns[0].tolist()\n if self.data_type == 'text':\n srcs = trans.src_raw\n else:\n srcs = [str(item) for item in range(len(align[0]))]\n output = report_matrix(srcs, tgts, align)\n if self.logger:\n self.logger.info(output)\n else:\n os.write(1, output.encode('utf-8'))\n\n end_time = time.time()\n\n if self.report_score:\n msg = self._report_score('PRED', pred_score_total,\n pred_words_total)\n self._log(msg)\n if tgt is not None:\n msg = self._report_score('GOLD', gold_score_total,\n gold_words_total)\n self._log(msg)\n if self.report_bleu:\n msg = self._report_bleu(tgt)\n self._log(msg)\n if self.report_rouge:\n msg = self._report_rouge(tgt)\n self._log(msg)\n\n if self.report_time:\n total_time = end_time - start_time\n self._log(\"Total translation time (s): %f\" % total_time)\n self._log(\"Average translation time (s): %f\" % (\n total_time / len(all_predictions)))\n self._log(\"Tokens per second: %f\" % (\n pred_words_total / total_time))\n\n if self.dump_beam:\n import json\n json.dump(self.translator.beam_accum,\n codecs.open(self.dump_beam, 'w', 'utf-8'))\n return all_scores, all_predictions\n\n def _align_pad_prediction(self, predictions, bos, pad):\n \"\"\"\n Padding predictions in batch and add BOS.\n\n Args:\n predictions (List[List[Tensor]]): `(batch, n_best,)`, for each src\n sequence contain n_best tgt predictions all of which ended with\n eos id.\n bos (int): bos index to be used.\n pad (int): pad index to be used.\n\n Return:\n batched_nbest_predict (torch.LongTensor): `(batch, n_best, tgt_l)`\n \"\"\"\n dtype, device = predictions[0][0].dtype, predictions[0][0].device\n flatten_tgt = [best.tolist() for bests in predictions\n for best in bests]\n paded_tgt = torch.tensor(\n list(zip_longest(*flatten_tgt, fillvalue=pad)),\n dtype=dtype, device=device).T\n bos_tensor = torch.full([paded_tgt.size(0), 1], bos,\n dtype=dtype, device=device)\n full_tgt = torch.cat((bos_tensor, paded_tgt), dim=-1)\n batched_nbest_predict = full_tgt.view(\n len(predictions), -1, full_tgt.size(-1)) # (batch, n_best, tgt_l)\n return batched_nbest_predict\n\n def _align_forward(self, batch, predictions):\n \"\"\"\n For a batch of input and its prediction, return a list of batch predict\n alignment src indice Tensor in size ``(batch, n_best,)``.\n \"\"\"\n # (0) add BOS and padding to tgt prediction\n if hasattr(batch, 'tgt'):\n batch_tgt_idxs = batch.tgt.transpose(1, 2).transpose(0, 2)\n else:\n batch_tgt_idxs = self._align_pad_prediction(\n predictions, bos=self._tgt_bos_idx, pad=self._tgt_pad_idx)\n tgt_mask = (batch_tgt_idxs.eq(self._tgt_pad_idx) |\n batch_tgt_idxs.eq(self._tgt_eos_idx) |\n batch_tgt_idxs.eq(self._tgt_bos_idx))\n\n n_best = batch_tgt_idxs.size(1)\n # (1) Encoder forward.\n src, enc_states, memory_bank, src_lengths = self._run_encoder(batch)\n\n # (2) Repeat src objects `n_best` times.\n # We use batch_size x n_best, get ``(src_len, batch * n_best, nfeat)``\n src = tile(src, n_best, dim=1)\n enc_states = tile(enc_states, n_best, dim=1)\n if isinstance(memory_bank, tuple):\n memory_bank = tuple(tile(x, n_best, dim=1) for x in memory_bank)\n else:\n memory_bank = tile(memory_bank, n_best, dim=1)\n src_lengths = tile(src_lengths, n_best) # ``(batch * n_best,)``\n\n # (3) Init decoder with n_best src,\n self.model.decoder.init_state(src, memory_bank, enc_states)\n # reshape tgt to ``(len, batch * n_best, nfeat)``\n tgt = batch_tgt_idxs.view(-1, batch_tgt_idxs.size(-1)).T.unsqueeze(-1)\n dec_in = tgt[:-1] # exclude last target from inputs\n _, attns = self.model.decoder(\n dec_in, memory_bank, memory_lengths=src_lengths, with_align=True)\n\n alignment_attn = attns[\"align\"] # ``(B, tgt_len-1, src_len)``\n # masked_select\n align_tgt_mask = tgt_mask.view(-1, tgt_mask.size(-1))\n prediction_mask = align_tgt_mask[:, 1:] # exclude bos to match pred\n # get aligned src id for each prediction's valid tgt tokens\n alignement = extract_alignment(\n alignment_attn, prediction_mask, src_lengths, n_best)\n return alignement\n\n def translate_batch(self, batch, src_vocabs, attn_debug):\n \"\"\"Translate a batch of sentences.\"\"\"\n with torch.no_grad():\n if self.beam_size == 1:\n decode_strategy = GreedySearch(\n pad=self._tgt_pad_idx,\n bos=self._tgt_bos_idx,\n eos=self._tgt_eos_idx,\n batch_size=batch.batch_size,\n min_length=self.min_length, max_length=self.max_length,\n block_ngram_repeat=self.block_ngram_repeat,\n exclusion_tokens=self._exclusion_idxs,\n return_attention=attn_debug or self.replace_unk,\n sampling_temp=self.random_sampling_temp,\n keep_topk=self.sample_from_topk)\n else:\n # TODO: support these blacklisted features\n assert not self.dump_beam\n decode_strategy = BeamSearch(\n self.beam_size,\n batch_size=batch.batch_size,\n pad=self._tgt_pad_idx,\n bos=self._tgt_bos_idx,\n eos=self._tgt_eos_idx,\n n_best=self.n_best,\n global_scorer=self.global_scorer,\n min_length=self.min_length, max_length=self.max_length,\n return_attention=attn_debug or self.replace_unk,\n block_ngram_repeat=self.block_ngram_repeat,\n exclusion_tokens=self._exclusion_idxs,\n stepwise_penalty=self.stepwise_penalty,\n ratio=self.ratio)\n return self._translate_batch_with_strategy(batch, src_vocabs,\n decode_strategy)\n\n def _run_encoder(self, batch):\n src, src_lengths = batch.src if isinstance(batch.src, tuple) \\\n else (batch.src, None)\n\n enc_states, memory_bank, src_lengths = self.model.encoder(\n src, src_lengths)\n if src_lengths is None:\n assert not isinstance(memory_bank, tuple), \\\n 'Ensemble decoding only supported for text data'\n src_lengths = torch.Tensor(batch.batch_size) \\\n .type_as(memory_bank) \\\n .long() \\\n .fill_(memory_bank.size(0))\n return src, enc_states, memory_bank, src_lengths\n\n def _decode_and_generate(\n self,\n decoder_in,\n memory_bank,\n batch,\n src_vocabs,\n memory_lengths,\n src_map=None,\n step=None,\n batch_offset=None):\n if self.copy_attn:\n # Turn any copied words into UNKs.\n decoder_in = decoder_in.masked_fill(\n decoder_in.gt(self._tgt_vocab_len - 1), self._tgt_unk_idx\n )\n\n # Decoder forward, takes [tgt_len, batch, nfeats] as input\n # and [src_len, batch, hidden] as memory_bank\n # in case of inference tgt_len = 1, batch = beam times batch_size\n # in case of Gold Scoring tgt_len = actual length, batch = 1 batch\n dec_out, dec_attn = self.model.decoder(\n decoder_in, memory_bank, memory_lengths=memory_lengths, step=step\n )\n\n # Generator forward.\n if not self.copy_attn:\n if \"std\" in dec_attn:\n attn = dec_attn[\"std\"]\n else:\n attn = None\n log_probs = self.model.generator(dec_out.squeeze(0))\n # returns [(batch_size x beam_size) , vocab ] when 1 step\n # or [ tgt_len, batch_size, vocab ] when full sentence\n else:\n attn = dec_attn[\"copy\"]\n scores = self.model.generator(dec_out.view(-1, dec_out.size(2)),\n attn.view(-1, attn.size(2)),\n src_map)\n # here we have scores [tgt_lenxbatch, vocab] or [beamxbatch, vocab]\n if batch_offset is None:\n scores = scores.view(-1, batch.batch_size, scores.size(-1))\n scores = scores.transpose(0, 1).contiguous()\n else:\n scores = scores.view(-1, self.beam_size, scores.size(-1))\n scores = collapse_copy_scores(\n scores,\n batch,\n self._tgt_vocab,\n src_vocabs,\n batch_dim=0,\n batch_offset=batch_offset\n )\n scores = scores.view(decoder_in.size(0), -1, scores.size(-1))\n log_probs = scores.squeeze(0).log()\n # returns [(batch_size x beam_size) , vocab ] when 1 step\n # or [ tgt_len, batch_size, vocab ] when full sentence\n return log_probs, attn\n\n def _translate_batch_with_strategy(\n self,\n batch,\n src_vocabs,\n decode_strategy):\n \"\"\"Translate a batch of sentences step by step using cache.\n\n Args:\n batch: a batch of sentences, yield by data iterator.\n src_vocabs (list): list of torchtext.data.Vocab if can_copy.\n decode_strategy (DecodeStrategy): A decode strategy to use for\n generate translation step by step.\n\n Returns:\n results (dict): The translation results.\n \"\"\"\n # (0) Prep the components of the search.\n use_src_map = self.copy_attn\n parallel_paths = decode_strategy.parallel_paths # beam_size\n batch_size = batch.batch_size\n\n # (1) Run the encoder on the src.\n src, enc_states, memory_bank, src_lengths = self._run_encoder(batch)\n self.model.decoder.init_state(src, memory_bank, enc_states)\n\n results = {\n \"predictions\": None,\n \"scores\": None,\n \"attention\": None,\n \"batch\": batch,\n \"gold_score\": self._gold_score(\n batch, memory_bank, src_lengths, src_vocabs, use_src_map,\n enc_states, batch_size, src)}\n\n # (2) prep decode_strategy. Possibly repeat src objects.\n src_map = batch.src_map if use_src_map else None\n fn_map_state, memory_bank, memory_lengths, src_map = \\\n decode_strategy.initialize(memory_bank, src_lengths, src_map)\n if fn_map_state is not None:\n self.model.decoder.map_state(fn_map_state)\n\n # (3) Begin decoding step by step:\n for step in range(decode_strategy.max_length):\n decoder_input = decode_strategy.current_predictions.view(1, -1, 1)\n\n log_probs, attn = self._decode_and_generate(\n decoder_input,\n memory_bank,\n batch,\n src_vocabs,\n memory_lengths=memory_lengths,\n src_map=src_map,\n step=step,\n batch_offset=decode_strategy.batch_offset)\n\n decode_strategy.advance(log_probs, attn)\n any_finished = decode_strategy.is_finished.any()\n if any_finished:\n decode_strategy.update_finished()\n if decode_strategy.done:\n break\n\n select_indices = decode_strategy.select_indices\n\n if any_finished:\n # Reorder states.\n if isinstance(memory_bank, tuple):\n memory_bank = tuple(x.index_select(1, select_indices)\n for x in memory_bank)\n else:\n memory_bank = memory_bank.index_select(1, select_indices)\n\n memory_lengths = memory_lengths.index_select(0, select_indices)\n\n if src_map is not None:\n src_map = src_map.index_select(1, select_indices)\n\n if parallel_paths > 1 or any_finished:\n self.model.decoder.map_state(\n lambda state, dim: state.index_select(dim, select_indices))\n\n results[\"scores\"] = decode_strategy.scores\n results[\"predictions\"] = decode_strategy.predictions\n results[\"attention\"] = decode_strategy.attention\n if self.report_align:\n results[\"alignment\"] = self._align_forward(\n batch, decode_strategy.predictions)\n else:\n results[\"alignment\"] = [[] for _ in range(batch_size)]\n return results\n\n def _score_target(self, batch, memory_bank, src_lengths,\n src_vocabs, src_map):\n tgt = batch.tgt\n tgt_in = tgt[:-1]\n\n log_probs, attn = self._decode_and_generate(\n tgt_in, memory_bank, batch, src_vocabs,\n memory_lengths=src_lengths, src_map=src_map)\n\n log_probs[:, :, self._tgt_pad_idx] = 0\n gold = tgt[1:]\n gold_scores = log_probs.gather(2, gold)\n gold_scores = gold_scores.sum(dim=0).view(-1)\n\n return gold_scores\n\n def _report_score(self, name, score_total, words_total):\n if words_total == 0:\n msg = \"%s No words predicted\" % (name,)\n else:\n msg = (\"%s AVG SCORE: %.4f, %s PPL: %.4f\" % (\n name, score_total / words_total,\n name, math.exp(-score_total / words_total)))\n return msg\n\n def _report_bleu(self, tgt_path):\n import subprocess\n base_dir = os.path.abspath(__file__ + \"/../../..\")\n # Rollback pointer to the beginning.\n self.out_file.seek(0)\n print()\n\n res = subprocess.check_output(\n \"perl %s/tools/multi-bleu.perl %s\" % (base_dir, tgt_path),\n stdin=self.out_file, shell=True\n ).decode(\"utf-8\")\n\n msg = \">> \" + res.strip()\n return msg\n\n def _report_rouge(self, tgt_path):\n import subprocess\n path = os.path.split(os.path.realpath(__file__))[0]\n msg = subprocess.check_output(\n \"python %s/tools/test_rouge.py -r %s -c STDIN\" % (path, tgt_path),\n shell=True, stdin=self.out_file\n ).decode(\"utf-8\").strip()\n return msg\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/utils/__init__.py",
"content": "\"\"\"Module defining various utilities.\"\"\"\nfrom onmt.utils.misc import split_corpus, aeq, use_gpu, set_random_seed\nfrom onmt.utils.alignment import make_batch_align_matrix\nfrom onmt.utils.report_manager import ReportMgr, build_report_manager\nfrom onmt.utils.statistics import Statistics\nfrom onmt.utils.optimizers import MultipleOptimizer, \\\n Optimizer, AdaFactor\nfrom onmt.utils.earlystopping import EarlyStopping, scorers_from_opts\n\n__all__ = [\"split_corpus\", \"aeq\", \"use_gpu\", \"set_random_seed\", \"ReportMgr\",\n \"build_report_manager\", \"Statistics\",\n \"MultipleOptimizer\", \"Optimizer\", \"AdaFactor\", \"EarlyStopping\",\n \"scorers_from_opts\", \"make_batch_align_matrix\"]\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/utils/alignment.py",
"content": "# -*- coding: utf-8 -*-\n\nimport torch\nfrom itertools import accumulate\n\n\ndef make_batch_align_matrix(index_tensor, size=None, normalize=False):\n \"\"\"\n Convert a sparse index_tensor into a batch of alignment matrix,\n with row normalize to the sum of 1 if set normalize.\n\n Args:\n index_tensor (LongTensor): ``(N, 3)`` of [batch_id, tgt_id, src_id]\n size (List[int]): Size of the sparse tensor.\n normalize (bool): if normalize the 2nd dim of resulting tensor.\n \"\"\"\n n_fill, device = index_tensor.size(0), index_tensor.device\n value_tensor = torch.ones([n_fill], dtype=torch.float)\n dense_tensor = torch.sparse_coo_tensor(\n index_tensor.t(), value_tensor, size=size, device=device).to_dense()\n if normalize:\n row_sum = dense_tensor.sum(-1, keepdim=True) # sum by row(tgt)\n # threshold on 1 to avoid div by 0\n torch.nn.functional.threshold(row_sum, 1, 1, inplace=True)\n dense_tensor.div_(row_sum)\n return dense_tensor\n\n\ndef extract_alignment(align_matrix, tgt_mask, src_lens, n_best):\n \"\"\"\n Extract a batched align_matrix into its src indice alignment lists,\n with tgt_mask to filter out invalid tgt position as EOS/PAD.\n BOS already excluded from tgt_mask in order to match prediction.\n\n Args:\n align_matrix (Tensor): ``(B, tgt_len, src_len)``,\n attention head normalized by Softmax(dim=-1)\n tgt_mask (BoolTensor): ``(B, tgt_len)``, True for EOS, PAD.\n src_lens (LongTensor): ``(B,)``, containing valid src length\n n_best (int): a value indicating number of parallel translation.\n * B: denote flattened batch as B = batch_size * n_best.\n\n Returns:\n alignments (List[List[FloatTensor]]): ``(batch_size, n_best,)``,\n containing valid alignment matrix for each translation.\n \"\"\"\n batch_size_n_best = align_matrix.size(0)\n assert batch_size_n_best % n_best == 0\n\n alignments = [[] for _ in range(batch_size_n_best // n_best)]\n\n # treat alignment matrix one by one as each have different lengths\n for i, (am_b, tgt_mask_b, src_len) in enumerate(\n zip(align_matrix, tgt_mask, src_lens)):\n valid_tgt = ~tgt_mask_b\n valid_tgt_len = valid_tgt.sum()\n # get valid alignment (sub-matrix from full paded aligment matrix)\n am_valid_tgt = am_b.masked_select(valid_tgt.unsqueeze(-1)) \\\n .view(valid_tgt_len, -1)\n valid_alignment = am_valid_tgt[:, :src_len] # only keep valid src\n alignments[i // n_best].append(valid_alignment)\n\n return alignments\n\n\ndef build_align_pharaoh(valid_alignment):\n \"\"\"Convert valid alignment matrix to i-j Pharaoh format.(0 indexed)\"\"\"\n align_pairs = []\n tgt_align_src_id = valid_alignment.argmax(dim=-1)\n\n for tgt_id, src_id in enumerate(tgt_align_src_id.tolist()):\n align_pairs.append(str(src_id) + \"-\" + str(tgt_id))\n align_pairs.sort(key=lambda x: int(x.split('-')[-1])) # sort by tgt_id\n align_pairs.sort(key=lambda x: int(x.split('-')[0])) # sort by src_id\n return align_pairs\n\n\ndef to_word_align(src, tgt, subword_align, mode):\n \"\"\"Convert subword alignment to word alignment.\n\n Args:\n src (string): tokenized sentence in source language.\n tgt (string): tokenized sentence in target language.\n subword_align (string): align_pharaoh correspond to src-tgt.\n mode (string): tokenization mode used by src and tgt,\n choose from [\"joiner\", \"spacer\"].\n\n Returns:\n word_align (string): converted alignments correspand to\n detokenized src-tgt.\n \"\"\"\n src, tgt = src.strip().split(), tgt.strip().split()\n subword_align = {(int(a), int(b)) for a, b in (x.split(\"-\")\n for x in subword_align.split())}\n if mode == 'joiner':\n src_map = subword_map_by_joiner(src, marker='■')\n tgt_map = subword_map_by_joiner(tgt, marker='■')\n elif mode == 'spacer':\n src_map = subword_map_by_spacer(src, marker='▁')\n tgt_map = subword_map_by_spacer(tgt, marker='▁')\n else:\n raise ValueError(\"Invalid value for argument mode!\")\n word_align = list({\"{}-{}\".format(src_map[a], tgt_map[b])\n for a, b in subword_align})\n word_align.sort(key=lambda x: int(x.split('-')[-1])) # sort by tgt_id\n word_align.sort(key=lambda x: int(x.split('-')[0])) # sort by src_id\n return \" \".join(word_align)\n\n\ndef subword_map_by_joiner(subwords, marker='■'):\n \"\"\"Return word id for each subword token (annotate by joiner).\"\"\"\n flags = [0] * len(subwords)\n for i, tok in enumerate(subwords):\n if tok.endswith(marker):\n flags[i] = 1\n if tok.startswith(marker):\n assert i >= 1 and flags[i-1] != 1, \\\n \"Sentence `{}` not correct!\".format(\" \".join(subwords))\n flags[i-1] = 1\n marker_acc = list(accumulate([0] + flags[:-1]))\n word_group = [(i - maker_sofar) for i, maker_sofar\n in enumerate(marker_acc)]\n return word_group\n\n\ndef subword_map_by_spacer(subwords, marker='▁'):\n \"\"\"Return word id for each subword token (annotate by spacer).\"\"\"\n word_group = list(accumulate([int(marker in x) for x in subwords]))\n if word_group[0] == 1: # when dummy prefix is set\n word_group = [item - 1 for item in word_group]\n return word_group\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/utils/cnn_factory.py",
"content": "\"\"\"\nImplementation of \"Convolutional Sequence to Sequence Learning\"\n\"\"\"\nimport torch\nimport torch.nn as nn\nimport torch.nn.init as init\n\nimport onmt.modules\n\nSCALE_WEIGHT = 0.5 ** 0.5\n\n\ndef shape_transform(x):\n \"\"\" Tranform the size of the tensors to fit for conv input. \"\"\"\n return torch.unsqueeze(torch.transpose(x, 1, 2), 3)\n\n\nclass GatedConv(nn.Module):\n \"\"\" Gated convolution for CNN class \"\"\"\n\n def __init__(self, input_size, width=3, dropout=0.2, nopad=False):\n super(GatedConv, self).__init__()\n self.conv = onmt.modules.WeightNormConv2d(\n input_size, 2 * input_size, kernel_size=(width, 1), stride=(1, 1),\n padding=(width // 2 * (1 - nopad), 0))\n init.xavier_uniform_(self.conv.weight, gain=(4 * (1 - dropout))**0.5)\n self.dropout = nn.Dropout(dropout)\n\n def forward(self, x_var):\n x_var = self.dropout(x_var)\n x_var = self.conv(x_var)\n out, gate = x_var.split(int(x_var.size(1) / 2), 1)\n out = out * torch.sigmoid(gate)\n return out\n\n\nclass StackedCNN(nn.Module):\n \"\"\" Stacked CNN class \"\"\"\n\n def __init__(self, num_layers, input_size, cnn_kernel_width=3,\n dropout=0.2):\n super(StackedCNN, self).__init__()\n self.dropout = dropout\n self.num_layers = num_layers\n self.layers = nn.ModuleList()\n for _ in range(num_layers):\n self.layers.append(\n GatedConv(input_size, cnn_kernel_width, dropout))\n\n def forward(self, x):\n for conv in self.layers:\n x = x + conv(x)\n x *= SCALE_WEIGHT\n return x\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/utils/distributed.py",
"content": "\"\"\" Pytorch Distributed utils\n This piece of code was heavily inspired by the equivalent of Fairseq-py\n https://github.com/pytorch/fairseq\n\"\"\"\n\n\nfrom __future__ import print_function\n\nimport math\nimport pickle\nimport torch.distributed\n\nfrom onmt.utils.logging import logger\n\n\ndef is_master(opt, device_id):\n return opt.gpu_ranks[device_id] == 0\n\n\ndef multi_init(opt, device_id):\n dist_init_method = 'tcp://{master_ip}:{master_port}'.format(\n master_ip=opt.master_ip,\n master_port=opt.master_port)\n dist_world_size = opt.world_size\n torch.distributed.init_process_group(\n backend=opt.gpu_backend, init_method=dist_init_method,\n world_size=dist_world_size, rank=opt.gpu_ranks[device_id])\n gpu_rank = torch.distributed.get_rank()\n if not is_master(opt, device_id):\n logger.disabled = True\n\n return gpu_rank\n\n\ndef all_reduce_and_rescale_tensors(tensors, rescale_denom,\n buffer_size=10485760):\n \"\"\"All-reduce and rescale tensors in chunks of the specified size.\n\n Args:\n tensors: list of Tensors to all-reduce\n rescale_denom: denominator for rescaling summed Tensors\n buffer_size: all-reduce chunk size in bytes\n \"\"\"\n # buffer size in bytes, determine equiv. # of elements based on data type\n buffer_t = tensors[0].new(\n math.ceil(buffer_size / tensors[0].element_size())).zero_()\n buffer = []\n\n def all_reduce_buffer():\n # copy tensors into buffer_t\n offset = 0\n for t in buffer:\n numel = t.numel()\n buffer_t[offset:offset+numel].copy_(t.view(-1))\n offset += numel\n\n # all-reduce and rescale\n torch.distributed.all_reduce(buffer_t[:offset])\n buffer_t.div_(rescale_denom)\n\n # copy all-reduced buffer back into tensors\n offset = 0\n for t in buffer:\n numel = t.numel()\n t.view(-1).copy_(buffer_t[offset:offset+numel])\n offset += numel\n\n filled = 0\n for t in tensors:\n sz = t.numel() * t.element_size()\n if sz > buffer_size:\n # tensor is bigger than buffer, all-reduce and rescale directly\n torch.distributed.all_reduce(t)\n t.div_(rescale_denom)\n elif filled + sz > buffer_size:\n # buffer is full, all-reduce and replace buffer with grad\n all_reduce_buffer()\n buffer = [t]\n filled = sz\n else:\n # add tensor to buffer\n buffer.append(t)\n filled += sz\n\n if len(buffer) > 0:\n all_reduce_buffer()\n\n\ndef all_gather_list(data, max_size=4096):\n \"\"\"Gathers arbitrary data from all nodes into a list.\"\"\"\n world_size = torch.distributed.get_world_size()\n if not hasattr(all_gather_list, '_in_buffer') or \\\n max_size != all_gather_list._in_buffer.size():\n all_gather_list._in_buffer = torch.cuda.ByteTensor(max_size)\n all_gather_list._out_buffers = [\n torch.cuda.ByteTensor(max_size)\n for i in range(world_size)\n ]\n in_buffer = all_gather_list._in_buffer\n out_buffers = all_gather_list._out_buffers\n\n enc = pickle.dumps(data)\n enc_size = len(enc)\n if enc_size + 2 > max_size:\n raise ValueError(\n 'encoded data exceeds max_size: {}'.format(enc_size + 2))\n assert max_size < 255*256\n in_buffer[0] = enc_size // 255 # this encoding works for max_size < 65k\n in_buffer[1] = enc_size % 255\n in_buffer[2:enc_size+2] = torch.ByteTensor(list(enc))\n\n torch.distributed.all_gather(out_buffers, in_buffer.cuda())\n\n results = []\n for i in range(world_size):\n out_buffer = out_buffers[i]\n size = (255 * out_buffer[0].item()) + out_buffer[1].item()\n\n bytes_list = bytes(out_buffer[2:size+2].tolist())\n result = pickle.loads(bytes_list)\n results.append(result)\n return results\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/utils/earlystopping.py",
"content": "\nfrom enum import Enum\nfrom onmt.utils.logging import logger\n\n\nclass PatienceEnum(Enum):\n IMPROVING = 0\n DECREASING = 1\n STOPPED = 2\n\n\nclass Scorer(object):\n def __init__(self, best_score, name):\n self.best_score = best_score\n self.name = name\n\n def is_improving(self, stats):\n raise NotImplementedError()\n\n def is_decreasing(self, stats):\n raise NotImplementedError()\n\n def update(self, stats):\n self.best_score = self._caller(stats)\n\n def __call__(self, stats, **kwargs):\n return self._caller(stats)\n\n def _caller(self, stats):\n raise NotImplementedError()\n\n\nclass PPLScorer(Scorer):\n\n def __init__(self):\n super(PPLScorer, self).__init__(float(\"inf\"), \"ppl\")\n\n def is_improving(self, stats):\n return stats.ppl() < self.best_score\n\n def is_decreasing(self, stats):\n return stats.ppl() > self.best_score\n\n def _caller(self, stats):\n return stats.ppl()\n\n\nclass AccuracyScorer(Scorer):\n\n def __init__(self):\n super(AccuracyScorer, self).__init__(float(\"-inf\"), \"acc\")\n\n def is_improving(self, stats):\n return stats.accuracy() > self.best_score\n\n def is_decreasing(self, stats):\n return stats.accuracy() < self.best_score\n\n def _caller(self, stats):\n return stats.accuracy()\n\n\nDEFAULT_SCORERS = [PPLScorer(), AccuracyScorer()]\n\n\nSCORER_BUILDER = {\n \"ppl\": PPLScorer,\n \"accuracy\": AccuracyScorer\n}\n\n\ndef scorers_from_opts(opt):\n if opt.early_stopping_criteria is None:\n return DEFAULT_SCORERS\n else:\n scorers = []\n for criterion in set(opt.early_stopping_criteria):\n assert criterion in SCORER_BUILDER.keys(), \\\n \"Criterion {} not found\".format(criterion)\n scorers.append(SCORER_BUILDER[criterion]())\n return scorers\n\n\nclass EarlyStopping(object):\n\n def __init__(self, tolerance, scorers=DEFAULT_SCORERS):\n \"\"\"\n Callable class to keep track of early stopping.\n\n Args:\n tolerance(int): number of validation steps without improving\n scorer(fn): list of scorers to validate performance on dev\n \"\"\"\n\n self.tolerance = tolerance\n self.stalled_tolerance = self.tolerance\n self.current_tolerance = self.tolerance\n self.early_stopping_scorers = scorers\n self.status = PatienceEnum.IMPROVING\n self.current_step_best = 0\n\n def __call__(self, valid_stats, step):\n \"\"\"\n Update the internal state of early stopping mechanism, whether to\n continue training or stop the train procedure.\n\n Checks whether the scores from all pre-chosen scorers improved. If\n every metric improve, then the status is switched to improving and the\n tolerance is reset. If every metric deteriorate, then the status is\n switched to decreasing and the tolerance is also decreased; if the\n tolerance reaches 0, then the status is changed to stopped.\n Finally, if some improved and others not, then it's considered stalled;\n after tolerance number of stalled, the status is switched to stopped.\n\n :param valid_stats: Statistics of dev set\n \"\"\"\n\n if self.status == PatienceEnum.STOPPED:\n # Don't do anything\n return\n\n if all([scorer.is_improving(valid_stats) for scorer\n in self.early_stopping_scorers]):\n self._update_increasing(valid_stats, step)\n\n elif all([scorer.is_decreasing(valid_stats) for scorer\n in self.early_stopping_scorers]):\n self._update_decreasing()\n\n else:\n self._update_stalled()\n\n def _update_stalled(self):\n self.stalled_tolerance -= 1\n\n logger.info(\n \"Stalled patience: {}/{}\".format(self.stalled_tolerance,\n self.tolerance))\n\n if self.stalled_tolerance == 0:\n logger.info(\n \"Training finished after stalled validations. Early Stop!\"\n )\n self._log_best_step()\n\n self._decreasing_or_stopped_status_update(self.stalled_tolerance)\n\n def _update_increasing(self, valid_stats, step):\n self.current_step_best = step\n for scorer in self.early_stopping_scorers:\n logger.info(\n \"Model is improving {}: {:g} --> {:g}.\".format(\n scorer.name, scorer.best_score, scorer(valid_stats))\n )\n # Update best score of each criteria\n scorer.update(valid_stats)\n\n # Reset tolerance\n self.current_tolerance = self.tolerance\n self.stalled_tolerance = self.tolerance\n\n # Update current status\n self.status = PatienceEnum.IMPROVING\n\n def _update_decreasing(self):\n # Decrease tolerance\n self.current_tolerance -= 1\n\n # Log\n logger.info(\n \"Decreasing patience: {}/{}\".format(self.current_tolerance,\n self.tolerance)\n )\n # Log\n if self.current_tolerance == 0:\n logger.info(\"Training finished after not improving. Early Stop!\")\n self._log_best_step()\n\n self._decreasing_or_stopped_status_update(self.current_tolerance)\n\n def _log_best_step(self):\n logger.info(\"Best model found at step {}\".format(\n self.current_step_best))\n\n def _decreasing_or_stopped_status_update(self, tolerance):\n self.status = PatienceEnum.DECREASING \\\n if tolerance > 0 \\\n else PatienceEnum.STOPPED\n\n def is_improving(self):\n return self.status == PatienceEnum.IMPROVING\n\n def has_stopped(self):\n return self.status == PatienceEnum.STOPPED\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/utils/logging.py",
"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import\n\nimport logging\nfrom logging.handlers import RotatingFileHandler\nlogger = logging.getLogger()\n\n\ndef init_logger(log_file=None, log_file_level=logging.NOTSET):\n log_format = logging.Formatter(\"[%(asctime)s %(levelname)s] %(message)s\")\n logger = logging.getLogger()\n logger.setLevel(logging.INFO)\n\n console_handler = logging.StreamHandler()\n console_handler.setFormatter(log_format)\n logger.handlers = [console_handler]\n\n if log_file and log_file != '':\n file_handler = RotatingFileHandler(\n log_file, maxBytes=1000, backupCount=10)\n file_handler.setLevel(log_file_level)\n file_handler.setFormatter(log_format)\n logger.addHandler(file_handler)\n\n return logger\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/utils/loss.py",
"content": "\"\"\"\nThis includes: LossComputeBase and the standard NMTLossCompute, and\n sharded loss compute stuff.\n\"\"\"\nfrom __future__ import division\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nimport onmt\nfrom onmt.modules.sparse_losses import SparsemaxLoss\nfrom onmt.modules.sparse_activations import LogSparsemax\n\n\ndef build_loss_compute(model, tgt_field, opt, train=True):\n \"\"\"\n Returns a LossCompute subclass which wraps around an nn.Module subclass\n (such as nn.NLLLoss) which defines the loss criterion. The LossCompute\n object allows this loss to be computed in shards and passes the relevant\n data to a Statistics object which handles training/validation logging.\n Currently, the NMTLossCompute class handles all loss computation except\n for when using a copy mechanism.\n \"\"\"\n device = torch.device(\"cuda\" if onmt.utils.misc.use_gpu(opt) else \"cpu\")\n\n padding_idx = tgt_field.vocab.stoi[tgt_field.pad_token]\n unk_idx = tgt_field.vocab.stoi[tgt_field.unk_token]\n\n if opt.lambda_coverage != 0:\n assert opt.coverage_attn, \"--coverage_attn needs to be set in \" \\\n \"order to use --lambda_coverage != 0\"\n\n if opt.copy_attn:\n criterion = onmt.modules.CopyGeneratorLoss(\n len(tgt_field.vocab), opt.copy_attn_force,\n unk_index=unk_idx, ignore_index=padding_idx\n )\n elif opt.label_smoothing > 0 and train:\n criterion = LabelSmoothingLoss(\n opt.label_smoothing, len(tgt_field.vocab), ignore_index=padding_idx\n )\n elif isinstance(model.generator[-1], LogSparsemax):\n criterion = SparsemaxLoss(ignore_index=padding_idx, reduction='sum')\n else:\n criterion = nn.NLLLoss(ignore_index=padding_idx, reduction='sum')\n\n # if the loss function operates on vectors of raw logits instead of\n # probabilities, only the first part of the generator needs to be\n # passed to the NMTLossCompute. At the moment, the only supported\n # loss function of this kind is the sparsemax loss.\n use_raw_logits = isinstance(criterion, SparsemaxLoss)\n loss_gen = model.generator[0] if use_raw_logits else model.generator\n if opt.copy_attn:\n compute = onmt.modules.CopyGeneratorLossCompute(\n criterion, loss_gen, tgt_field.vocab, opt.copy_loss_by_seqlength,\n lambda_coverage=opt.lambda_coverage\n )\n else:\n compute = NMTLossCompute(\n criterion, loss_gen, lambda_coverage=opt.lambda_coverage,\n lambda_align=opt.lambda_align)\n compute.to(device)\n\n return compute\n\n\nclass LossComputeBase(nn.Module):\n \"\"\"\n Class for managing efficient loss computation. Handles\n sharding next step predictions and accumulating multiple\n loss computations\n\n Users can implement their own loss computation strategy by making\n subclass of this one. Users need to implement the _compute_loss()\n and make_shard_state() methods.\n\n Args:\n generator (:obj:`nn.Module`) :\n module that maps the output of the decoder to a\n distribution over the target vocabulary.\n tgt_vocab (:obj:`Vocab`) :\n torchtext vocab object representing the target output\n normalzation (str): normalize by \"sents\" or \"tokens\"\n \"\"\"\n\n def __init__(self, criterion, generator):\n super(LossComputeBase, self).__init__()\n self.criterion = criterion\n self.generator = generator\n\n @property\n def padding_idx(self):\n return self.criterion.ignore_index\n\n def _make_shard_state(self, batch, output, range_, attns=None):\n \"\"\"\n Make shard state dictionary for shards() to return iterable\n shards for efficient loss computation. Subclass must define\n this method to match its own _compute_loss() interface.\n Args:\n batch: the current batch.\n output: the predict output from the model.\n range_: the range of examples for computing, the whole\n batch or a trunc of it?\n attns: the attns dictionary returned from the model.\n \"\"\"\n return NotImplementedError\n\n def _compute_loss(self, batch, output, target, **kwargs):\n \"\"\"\n Compute the loss. Subclass must define this method.\n\n Args:\n\n batch: the current batch.\n output: the predict output from the model.\n target: the validate target to compare output with.\n **kwargs(optional): additional info for computing loss.\n \"\"\"\n return NotImplementedError\n\n def __call__(self,\n batch,\n output,\n attns,\n normalization=1.0,\n shard_size=0,\n trunc_start=0,\n trunc_size=None):\n \"\"\"Compute the forward loss, possibly in shards in which case this\n method also runs the backward pass and returns ``None`` as the loss\n value.\n\n Also supports truncated BPTT for long sequences by taking a\n range in the decoder output sequence to back propagate in.\n Range is from `(trunc_start, trunc_start + trunc_size)`.\n\n Note sharding is an exact efficiency trick to relieve memory\n required for the generation buffers. Truncation is an\n approximate efficiency trick to relieve the memory required\n in the RNN buffers.\n\n Args:\n batch (batch) : batch of labeled examples\n output (:obj:`FloatTensor`) :\n output of decoder model `[tgt_len x batch x hidden]`\n attns (dict) : dictionary of attention distributions\n `[tgt_len x batch x src_len]`\n normalization: Optional normalization factor.\n shard_size (int) : maximum number of examples in a shard\n trunc_start (int) : starting position of truncation window\n trunc_size (int) : length of truncation window\n\n Returns:\n A tuple with the loss and a :obj:`onmt.utils.Statistics` instance.\n \"\"\"\n if trunc_size is None:\n trunc_size = batch.tgt.size(0) - trunc_start\n trunc_range = (trunc_start, trunc_start + trunc_size)\n shard_state = self._make_shard_state(batch, output, trunc_range, attns)\n if shard_size == 0:\n loss, stats = self._compute_loss(batch, **shard_state)\n return loss / float(normalization), stats\n batch_stats = onmt.utils.Statistics()\n for shard in shards(shard_state, shard_size):\n loss, stats = self._compute_loss(batch, **shard)\n loss.div(float(normalization)).backward()\n batch_stats.update(stats)\n return None, batch_stats\n\n def _stats(self, loss, scores, target):\n \"\"\"\n Args:\n loss (:obj:`FloatTensor`): the loss computed by the loss criterion.\n scores (:obj:`FloatTensor`): a score for each possible output\n target (:obj:`FloatTensor`): true targets\n\n Returns:\n :obj:`onmt.utils.Statistics` : statistics for this batch.\n \"\"\"\n pred = scores.max(1)[1]\n non_padding = target.ne(self.padding_idx)\n num_correct = pred.eq(target).masked_select(non_padding).sum().item()\n num_non_padding = non_padding.sum().item()\n return onmt.utils.Statistics(loss.item(), num_non_padding, num_correct)\n\n def _bottle(self, _v):\n return _v.view(-1, _v.size(2))\n\n def _unbottle(self, _v, batch_size):\n return _v.view(-1, batch_size, _v.size(1))\n\n\nclass LabelSmoothingLoss(nn.Module):\n \"\"\"\n With label smoothing,\n KL-divergence between q_{smoothed ground truth prob.}(w)\n and p_{prob. computed by model}(w) is minimized.\n \"\"\"\n def __init__(self, label_smoothing, tgt_vocab_size, ignore_index=-100):\n assert 0.0 < label_smoothing <= 1.0\n self.ignore_index = ignore_index\n super(LabelSmoothingLoss, self).__init__()\n\n smoothing_value = label_smoothing / (tgt_vocab_size - 2)\n one_hot = torch.full((tgt_vocab_size,), smoothing_value)\n one_hot[self.ignore_index] = 0\n self.register_buffer('one_hot', one_hot.unsqueeze(0))\n\n self.confidence = 1.0 - label_smoothing\n\n def forward(self, output, target):\n \"\"\"\n output (FloatTensor): batch_size x n_classes\n target (LongTensor): batch_size\n \"\"\"\n model_prob = self.one_hot.repeat(target.size(0), 1)\n model_prob.scatter_(1, target.unsqueeze(1), self.confidence)\n model_prob.masked_fill_((target == self.ignore_index).unsqueeze(1), 0)\n\n return F.kl_div(output, model_prob, reduction='sum')\n\n\nclass NMTLossCompute(LossComputeBase):\n \"\"\"\n Standard NMT Loss Computation.\n \"\"\"\n\n def __init__(self, criterion, generator, normalization=\"sents\",\n lambda_coverage=0.0, lambda_align=0.0):\n super(NMTLossCompute, self).__init__(criterion, generator)\n self.lambda_coverage = lambda_coverage\n self.lambda_align = lambda_align\n\n def _make_shard_state(self, batch, output, range_, attns=None):\n shard_state = {\n \"output\": output,\n \"target\": batch.tgt[range_[0] + 1: range_[1], :, 0],\n }\n if self.lambda_coverage != 0.0:\n coverage = attns.get(\"coverage\", None)\n std = attns.get(\"std\", None)\n assert attns is not None\n assert std is not None, \"lambda_coverage != 0.0 requires \" \\\n \"attention mechanism\"\n assert coverage is not None, \"lambda_coverage != 0.0 requires \" \\\n \"coverage attention\"\n\n shard_state.update({\n \"std_attn\": attns.get(\"std\"),\n \"coverage_attn\": coverage\n })\n if self.lambda_align != 0.0:\n # attn_align should be in (batch_size, pad_tgt_size, pad_src_size)\n attn_align = attns.get(\"align\", None)\n # align_idx should be a Tensor in size([N, 3]), N is total number\n # of align src-tgt pair in current batch, each as\n # ['sent_N°_in_batch', 'tgt_id+1', 'src_id'] (check AlignField)\n align_idx = batch.align\n assert attns is not None\n assert attn_align is not None, \"lambda_align != 0.0 requires \" \\\n \"alignement attention head\"\n assert align_idx is not None, \"lambda_align != 0.0 requires \" \\\n \"provide guided alignement\"\n pad_tgt_size, batch_size, _ = batch.tgt.size()\n pad_src_size = batch.src[0].size(0)\n align_matrix_size = [batch_size, pad_tgt_size, pad_src_size]\n ref_align = onmt.utils.make_batch_align_matrix(\n align_idx, align_matrix_size, normalize=True)\n # NOTE: tgt-src ref alignement that in range_ of shard\n # (coherent with batch.tgt)\n shard_state.update({\n \"align_head\": attn_align,\n \"ref_align\": ref_align[:, range_[0] + 1: range_[1], :]\n })\n return shard_state\n\n def _compute_loss(self, batch, output, target, std_attn=None,\n coverage_attn=None, align_head=None, ref_align=None):\n\n bottled_output = self._bottle(output)\n\n scores = self.generator(bottled_output)\n gtruth = target.view(-1)\n\n loss = self.criterion(scores, gtruth)\n if self.lambda_coverage != 0.0:\n coverage_loss = self._compute_coverage_loss(\n std_attn=std_attn, coverage_attn=coverage_attn)\n loss += coverage_loss\n if self.lambda_align != 0.0:\n if align_head.dtype != loss.dtype: # Fix FP16\n align_head = align_head.to(loss.dtype)\n if ref_align.dtype != loss.dtype:\n ref_align = ref_align.to(loss.dtype)\n align_loss = self._compute_alignement_loss(\n align_head=align_head, ref_align=ref_align)\n loss += align_loss\n stats = self._stats(loss.clone(), scores, gtruth)\n\n return loss, stats\n\n def _compute_coverage_loss(self, std_attn, coverage_attn):\n covloss = torch.min(std_attn, coverage_attn).sum()\n covloss *= self.lambda_coverage\n return covloss\n\n def _compute_alignement_loss(self, align_head, ref_align):\n \"\"\"Compute loss between 2 partial alignment matrix.\"\"\"\n # align_head contains value in [0, 1) presenting attn prob,\n # 0 was resulted by the context attention src_pad_mask\n # So, the correspand position in ref_align should also be 0\n # Therefore, clip align_head to > 1e-18 should be bias free.\n align_loss = -align_head.clamp(min=1e-18).log().mul(ref_align).sum()\n align_loss *= self.lambda_align\n return align_loss\n\n\ndef filter_shard_state(state, shard_size=None):\n for k, v in state.items():\n if shard_size is None:\n yield k, v\n\n if v is not None:\n v_split = []\n if isinstance(v, torch.Tensor):\n for v_chunk in torch.split(v, shard_size):\n v_chunk = v_chunk.data.clone()\n v_chunk.requires_grad = v.requires_grad\n v_split.append(v_chunk)\n yield k, (v, v_split)\n\n\ndef shards(state, shard_size, eval_only=False):\n \"\"\"\n Args:\n state: A dictionary which corresponds to the output of\n *LossCompute._make_shard_state(). The values for\n those keys are Tensor-like or None.\n shard_size: The maximum size of the shards yielded by the model.\n eval_only: If True, only yield the state, nothing else.\n Otherwise, yield shards.\n\n Yields:\n Each yielded shard is a dict.\n\n Side effect:\n After the last shard, this function does back-propagation.\n \"\"\"\n if eval_only:\n yield filter_shard_state(state)\n else:\n # non_none: the subdict of the state dictionary where the values\n # are not None.\n non_none = dict(filter_shard_state(state, shard_size))\n\n # Now, the iteration:\n # state is a dictionary of sequences of tensor-like but we\n # want a sequence of dictionaries of tensors.\n # First, unzip the dictionary into a sequence of keys and a\n # sequence of tensor-like sequences.\n keys, values = zip(*((k, [v_chunk for v_chunk in v_split])\n for k, (_, v_split) in non_none.items()))\n\n # Now, yield a dictionary for each shard. The keys are always\n # the same. values is a sequence of length #keys where each\n # element is a sequence of length #shards. We want to iterate\n # over the shards, not over the keys: therefore, the values need\n # to be re-zipped by shard and then each shard can be paired\n # with the keys.\n for shard_tensors in zip(*values):\n yield dict(zip(keys, shard_tensors))\n\n # Assumed backprop'd\n variables = []\n for k, (v, v_split) in non_none.items():\n if isinstance(v, torch.Tensor) and state[k].requires_grad:\n variables.extend(zip(torch.split(state[k], shard_size),\n [v_chunk.grad for v_chunk in v_split]))\n inputs, grads = zip(*variables)\n torch.autograd.backward(inputs, grads)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/utils/misc.py",
"content": "# -*- coding: utf-8 -*-\n\nimport torch\nimport random\nimport inspect\nfrom itertools import islice, repeat\nimport os\n\n\ndef split_corpus(path, shard_size, default=None):\n \"\"\"yield a `list` containing `shard_size` line of `path`,\n or repeatly generate `default` if `path` is None.\n \"\"\"\n if path is not None:\n return _split_corpus(path, shard_size)\n else:\n return repeat(default)\n\n\ndef _split_corpus(path, shard_size):\n \"\"\"Yield a `list` containing `shard_size` line of `path`.\n \"\"\"\n with open(path, \"rb\") as f:\n if shard_size <= 0:\n yield f.readlines()\n else:\n while True:\n shard = list(islice(f, shard_size))\n if not shard:\n break\n yield shard\n\n\ndef aeq(*args):\n \"\"\"\n Assert all arguments have the same value\n \"\"\"\n arguments = (arg for arg in args)\n first = next(arguments)\n assert all(arg == first for arg in arguments), \\\n \"Not all arguments have the same value: \" + str(args)\n\n\ndef sequence_mask(lengths, max_len=None):\n \"\"\"\n Creates a boolean mask from sequence lengths.\n \"\"\"\n batch_size = lengths.numel()\n max_len = max_len or lengths.max()\n return (torch.arange(0, max_len, device=lengths.device)\n .type_as(lengths)\n .repeat(batch_size, 1)\n .lt(lengths.unsqueeze(1)))\n\n\ndef tile(x, count, dim=0):\n \"\"\"\n Tiles x on dimension dim count times.\n \"\"\"\n perm = list(range(len(x.size())))\n if dim != 0:\n perm[0], perm[dim] = perm[dim], perm[0]\n x = x.permute(perm).contiguous()\n out_size = list(x.size())\n out_size[0] *= count\n batch = x.size(0)\n x = x.view(batch, -1) \\\n .transpose(0, 1) \\\n .repeat(count, 1) \\\n .transpose(0, 1) \\\n .contiguous() \\\n .view(*out_size)\n if dim != 0:\n x = x.permute(perm).contiguous()\n return x\n\n\ndef use_gpu(opt):\n \"\"\"\n Creates a boolean if gpu used\n \"\"\"\n return (hasattr(opt, 'gpu_ranks') and len(opt.gpu_ranks) > 0) or \\\n (hasattr(opt, 'gpu') and opt.gpu > -1)\n\n\ndef set_random_seed(seed, is_cuda):\n \"\"\"Sets the random seed.\"\"\"\n if seed > 0:\n torch.manual_seed(seed)\n # this one is needed for torchtext random call (shuffled iterator)\n # in multi gpu it ensures datasets are read in the same order\n random.seed(seed)\n # some cudnn methods can be random even after fixing the seed\n # unless you tell it to be deterministic\n torch.backends.cudnn.deterministic = True\n\n if is_cuda and seed > 0:\n # These ensure same initialization in multi gpu mode\n torch.cuda.manual_seed(seed)\n\n\ndef generate_relative_positions_matrix(length, max_relative_positions,\n cache=False):\n \"\"\"Generate the clipped relative positions matrix\n for a given length and maximum relative positions\"\"\"\n if cache:\n distance_mat = torch.arange(-length+1, 1, 1).unsqueeze(0)\n else:\n range_vec = torch.arange(length)\n range_mat = range_vec.unsqueeze(-1).expand(-1, length).transpose(0, 1)\n distance_mat = range_mat - range_mat.transpose(0, 1)\n distance_mat_clipped = torch.clamp(distance_mat,\n min=-max_relative_positions,\n max=max_relative_positions)\n # Shift values to be >= 0\n final_mat = distance_mat_clipped + max_relative_positions\n return final_mat\n\n\ndef relative_matmul(x, z, transpose):\n \"\"\"Helper function for relative positions attention.\"\"\"\n batch_size = x.shape[0]\n heads = x.shape[1]\n length = x.shape[2]\n x_t = x.permute(2, 0, 1, 3)\n x_t_r = x_t.reshape(length, heads * batch_size, -1)\n if transpose:\n z_t = z.transpose(1, 2)\n x_tz_matmul = torch.matmul(x_t_r, z_t)\n else:\n x_tz_matmul = torch.matmul(x_t_r, z)\n x_tz_matmul_r = x_tz_matmul.reshape(length, batch_size, heads, -1)\n x_tz_matmul_r_t = x_tz_matmul_r.permute(1, 2, 0, 3)\n return x_tz_matmul_r_t\n\n\ndef fn_args(fun):\n \"\"\"Returns the list of function arguments name.\"\"\"\n return inspect.getfullargspec(fun).args\n\n\ndef report_matrix(row_label, column_label, matrix):\n header_format = \"{:>10.10} \" + \"{:>10.7} \" * len(row_label)\n row_format = \"{:>10.10} \" + \"{:>10.7f} \" * len(row_label)\n output = header_format.format(\"\", *row_label) + '\\n'\n for word, row in zip(column_label, matrix):\n max_index = row.index(max(row))\n row_format = row_format.replace(\n \"{:>10.7f} \", \"{:*>10.7f} \", max_index + 1)\n row_format = row_format.replace(\n \"{:*>10.7f} \", \"{:>10.7f} \", max_index)\n output += row_format.format(word, *row) + '\\n'\n row_format = \"{:>10.10} \" + \"{:>10.7f} \" * len(row_label)\n return output\n\n\ndef check_model_config(model_config, root):\n # we need to check the model path + any tokenizer path\n for model in model_config[\"models\"]:\n model_path = os.path.join(root, model)\n if not os.path.exists(model_path):\n raise FileNotFoundError(\n \"{} from model {} does not exist\".format(\n model_path, model_config[\"id\"]))\n if \"tokenizer\" in model_config.keys():\n if \"params\" in model_config[\"tokenizer\"].keys():\n for k, v in model_config[\"tokenizer\"][\"params\"].items():\n if k.endswith(\"path\"):\n tok_path = os.path.join(root, v)\n if not os.path.exists(tok_path):\n raise FileNotFoundError(\n \"{} from model {} does not exist\".format(\n tok_path, model_config[\"id\"]))\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/utils/optimizers.py",
"content": "\"\"\" Optimizers class \"\"\"\nimport torch\nimport torch.optim as optim\nfrom torch.nn.utils import clip_grad_norm_\nimport operator\nimport functools\nfrom copy import copy\nfrom math import sqrt\nimport types\nimport importlib\nfrom onmt.utils.misc import fn_args\n\n\ndef build_torch_optimizer(model, opt):\n \"\"\"Builds the PyTorch optimizer.\n\n We use the default parameters for Adam that are suggested by\n the original paper https://arxiv.org/pdf/1412.6980.pdf\n These values are also used by other established implementations,\n e.g. https://www.tensorflow.org/api_docs/python/tf/train/AdamOptimizer\n https://keras.io/optimizers/\n Recently there are slightly different values used in the paper\n \"Attention is all you need\"\n https://arxiv.org/pdf/1706.03762.pdf, particularly the value beta2=0.98\n was used there however, beta2=0.999 is still arguably the more\n established value, so we use that here as well\n\n Args:\n model: The model to optimize.\n opt. The dictionary of options.\n\n Returns:\n A ``torch.optim.Optimizer`` instance.\n \"\"\"\n params = [p for p in model.parameters() if p.requires_grad]\n betas = [opt.adam_beta1, opt.adam_beta2]\n if opt.optim == 'sgd':\n optimizer = optim.SGD(params, lr=opt.learning_rate)\n elif opt.optim == 'adagrad':\n optimizer = optim.Adagrad(\n params,\n lr=opt.learning_rate,\n initial_accumulator_value=opt.adagrad_accumulator_init)\n elif opt.optim == 'adadelta':\n optimizer = optim.Adadelta(params, lr=opt.learning_rate)\n elif opt.optim == 'adafactor':\n optimizer = AdaFactor(\n params,\n non_constant_decay=True,\n enable_factorization=True,\n weight_decay=0)\n elif opt.optim == 'adam':\n optimizer = optim.Adam(\n params,\n lr=opt.learning_rate,\n betas=betas,\n eps=1e-9)\n elif opt.optim == 'sparseadam':\n dense = []\n sparse = []\n for name, param in model.named_parameters():\n if not param.requires_grad:\n continue\n # TODO: Find a better way to check for sparse gradients.\n if 'embed' in name:\n sparse.append(param)\n else:\n dense.append(param)\n optimizer = MultipleOptimizer(\n [optim.Adam(\n dense,\n lr=opt.learning_rate,\n betas=betas,\n eps=1e-8),\n optim.SparseAdam(\n sparse,\n lr=opt.learning_rate,\n betas=betas,\n eps=1e-8)])\n elif opt.optim == 'fusedadam':\n # we use here a FusedAdam() copy of an old Apex repo\n optimizer = FusedAdam(\n params,\n lr=opt.learning_rate,\n betas=betas)\n else:\n raise ValueError('Invalid optimizer type: ' + opt.optim)\n\n if opt.model_dtype == 'fp16':\n import apex\n if opt.optim != 'fusedadam':\n # In this case use the new AMP API from apex\n loss_scale = \"dynamic\" if opt.loss_scale == 0 else opt.loss_scale\n model, optimizer = apex.amp.initialize(\n [model, model.generator],\n optimizer,\n opt_level=opt.apex_opt_level,\n loss_scale=loss_scale,\n keep_batchnorm_fp32=None)\n else:\n # In this case use the old FusedAdam with FP16_optimizer wrapper\n static_loss_scale = opt.loss_scale\n dynamic_loss_scale = opt.loss_scale == 0\n optimizer = apex.optimizers.FP16_Optimizer(\n optimizer,\n static_loss_scale=static_loss_scale,\n dynamic_loss_scale=dynamic_loss_scale)\n return optimizer\n\n\ndef make_learning_rate_decay_fn(opt):\n \"\"\"Returns the learning decay function from options.\"\"\"\n if opt.decay_method == 'noam':\n return functools.partial(\n noam_decay,\n warmup_steps=opt.warmup_steps,\n model_size=opt.rnn_size)\n elif opt.decay_method == 'noamwd':\n return functools.partial(\n noamwd_decay,\n warmup_steps=opt.warmup_steps,\n model_size=opt.rnn_size,\n rate=opt.learning_rate_decay,\n decay_steps=opt.decay_steps,\n start_step=opt.start_decay_steps)\n elif opt.decay_method == 'rsqrt':\n return functools.partial(\n rsqrt_decay, warmup_steps=opt.warmup_steps)\n elif opt.start_decay_steps is not None:\n return functools.partial(\n exponential_decay,\n rate=opt.learning_rate_decay,\n decay_steps=opt.decay_steps,\n start_step=opt.start_decay_steps)\n\n\ndef noam_decay(step, warmup_steps, model_size):\n \"\"\"Learning rate schedule described in\n https://arxiv.org/pdf/1706.03762.pdf.\n \"\"\"\n return (\n model_size ** (-0.5) *\n min(step ** (-0.5), step * warmup_steps**(-1.5)))\n\n\ndef noamwd_decay(step, warmup_steps,\n model_size, rate, decay_steps, start_step=0):\n \"\"\"Learning rate schedule optimized for huge batches\n \"\"\"\n return (\n model_size ** (-0.5) *\n min(step ** (-0.5), step * warmup_steps**(-1.5)) *\n rate ** (max(step - start_step + decay_steps, 0) // decay_steps))\n\n\ndef exponential_decay(step, rate, decay_steps, start_step=0):\n \"\"\"A standard exponential decay, scaling the learning rate by :obj:`rate`\n every :obj:`decay_steps` steps.\n \"\"\"\n return rate ** (max(step - start_step + decay_steps, 0) // decay_steps)\n\n\ndef rsqrt_decay(step, warmup_steps):\n \"\"\"Decay based on the reciprocal of the step square root.\"\"\"\n return 1.0 / sqrt(max(step, warmup_steps))\n\n\nclass MultipleOptimizer(object):\n \"\"\" Implement multiple optimizers needed for sparse adam \"\"\"\n\n def __init__(self, op):\n \"\"\" ? \"\"\"\n self.optimizers = op\n\n @property\n def param_groups(self):\n param_groups = []\n for optimizer in self.optimizers:\n param_groups.extend(optimizer.param_groups)\n return param_groups\n\n def zero_grad(self):\n \"\"\" ? \"\"\"\n for op in self.optimizers:\n op.zero_grad()\n\n def step(self):\n \"\"\" ? \"\"\"\n for op in self.optimizers:\n op.step()\n\n @property\n def state(self):\n \"\"\" ? \"\"\"\n return {k: v for op in self.optimizers for k, v in op.state.items()}\n\n def state_dict(self):\n \"\"\" ? \"\"\"\n return [op.state_dict() for op in self.optimizers]\n\n def load_state_dict(self, state_dicts):\n \"\"\" ? \"\"\"\n assert len(state_dicts) == len(self.optimizers)\n for i in range(len(state_dicts)):\n self.optimizers[i].load_state_dict(state_dicts[i])\n\n\nclass Optimizer(object):\n \"\"\"\n Controller class for optimization. Mostly a thin\n wrapper for `optim`, but also useful for implementing\n rate scheduling beyond what is currently available.\n Also implements necessary methods for training RNNs such\n as grad manipulations.\n \"\"\"\n\n def __init__(self,\n optimizer,\n learning_rate,\n learning_rate_decay_fn=None,\n max_grad_norm=None):\n \"\"\"Initializes the controller.\n\n Args:\n optimizer: A ``torch.optim.Optimizer`` instance.\n learning_rate: The initial learning rate.\n learning_rate_decay_fn: An optional callable taking the current step\n as argument and return a learning rate scaling factor.\n max_grad_norm: Clip gradients to this global norm.\n \"\"\"\n self._optimizer = optimizer\n self._learning_rate = learning_rate\n self._learning_rate_decay_fn = learning_rate_decay_fn\n self._max_grad_norm = max_grad_norm or 0\n self._training_step = 1\n self._decay_step = 1\n self._fp16 = None\n\n @classmethod\n def from_opt(cls, model, opt, checkpoint=None):\n \"\"\"Builds the optimizer from options.\n\n Args:\n cls: The ``Optimizer`` class to instantiate.\n model: The model to optimize.\n opt: The dict of user options.\n checkpoint: An optional checkpoint to load states from.\n\n Returns:\n An ``Optimizer`` instance.\n \"\"\"\n optim_opt = opt\n optim_state_dict = None\n\n if opt.train_from and checkpoint is not None:\n optim = checkpoint['optim']\n ckpt_opt = checkpoint['opt']\n ckpt_state_dict = {}\n if isinstance(optim, Optimizer): # Backward compatibility.\n ckpt_state_dict['training_step'] = optim._step + 1\n ckpt_state_dict['decay_step'] = optim._step + 1\n ckpt_state_dict['optimizer'] = optim.optimizer.state_dict()\n else:\n ckpt_state_dict = optim\n\n if opt.reset_optim == 'none':\n # Load everything from the checkpoint.\n optim_opt = ckpt_opt\n optim_state_dict = ckpt_state_dict\n elif opt.reset_optim == 'all':\n # Build everything from scratch.\n pass\n elif opt.reset_optim == 'states':\n # Reset optimizer, keep options.\n optim_opt = ckpt_opt\n optim_state_dict = ckpt_state_dict\n del optim_state_dict['optimizer']\n elif opt.reset_optim == 'keep_states':\n # Reset options, keep optimizer.\n optim_state_dict = ckpt_state_dict\n\n optimizer = cls(\n build_torch_optimizer(model, optim_opt),\n optim_opt.learning_rate,\n learning_rate_decay_fn=make_learning_rate_decay_fn(optim_opt),\n max_grad_norm=optim_opt.max_grad_norm)\n if opt.model_dtype == \"fp16\":\n if opt.optim == \"fusedadam\":\n optimizer._fp16 = \"legacy\"\n else:\n optimizer._fp16 = \"amp\"\n if optim_state_dict:\n optimizer.load_state_dict(optim_state_dict)\n return optimizer\n\n @property\n def training_step(self):\n \"\"\"The current training step.\"\"\"\n return self._training_step\n\n def learning_rate(self):\n \"\"\"Returns the current learning rate.\"\"\"\n if self._learning_rate_decay_fn is None:\n return self._learning_rate\n scale = self._learning_rate_decay_fn(self._decay_step)\n return scale * self._learning_rate\n\n def state_dict(self):\n return {\n 'training_step': self._training_step,\n 'decay_step': self._decay_step,\n 'optimizer': self._optimizer.state_dict()\n }\n\n def load_state_dict(self, state_dict):\n self._training_step = state_dict['training_step']\n # State can be partially restored.\n if 'decay_step' in state_dict:\n self._decay_step = state_dict['decay_step']\n if 'optimizer' in state_dict:\n self._optimizer.load_state_dict(state_dict['optimizer'])\n\n def zero_grad(self):\n \"\"\"Zero the gradients of optimized parameters.\"\"\"\n self._optimizer.zero_grad()\n\n def backward(self, loss):\n \"\"\"Wrapper for backward pass. Some optimizer requires ownership of the\n backward pass.\"\"\"\n if self._fp16 == \"amp\":\n import apex\n with apex.amp.scale_loss(loss, self._optimizer) as scaled_loss:\n scaled_loss.backward()\n elif self._fp16 == \"legacy\":\n kwargs = {}\n if \"update_master_grads\" in fn_args(self._optimizer.backward):\n kwargs[\"update_master_grads\"] = True\n self._optimizer.backward(loss, **kwargs)\n else:\n loss.backward()\n\n def step(self):\n \"\"\"Update the model parameters based on current gradients.\n\n Optionally, will employ gradient modification or update learning\n rate.\n \"\"\"\n learning_rate = self.learning_rate()\n if self._fp16 == \"legacy\":\n if hasattr(self._optimizer, \"update_master_grads\"):\n self._optimizer.update_master_grads()\n if hasattr(self._optimizer, \"clip_master_grads\") and \\\n self._max_grad_norm > 0:\n self._optimizer.clip_master_grads(self._max_grad_norm)\n\n for group in self._optimizer.param_groups:\n group['lr'] = learning_rate\n if self._fp16 is None and self._max_grad_norm > 0:\n clip_grad_norm_(group['params'], self._max_grad_norm)\n self._optimizer.step()\n self._decay_step += 1\n self._training_step += 1\n\n# Code below is an implementation of https://arxiv.org/pdf/1804.04235.pdf\n# inspired but modified from https://github.com/DeadAt0m/adafactor-pytorch\n\n\nclass AdaFactor(torch.optim.Optimizer):\n\n def __init__(self, params, lr=None, beta1=0.9, beta2=0.999, eps1=1e-30,\n eps2=1e-3, cliping_threshold=1, non_constant_decay=True,\n enable_factorization=True, ams_grad=True, weight_decay=0):\n\n enable_momentum = beta1 != 0\n\n if non_constant_decay:\n ams_grad = False\n\n defaults = dict(lr=lr, beta1=beta1, beta2=beta2, eps1=eps1,\n eps2=eps2, cliping_threshold=cliping_threshold,\n weight_decay=weight_decay, ams_grad=ams_grad,\n enable_factorization=enable_factorization,\n enable_momentum=enable_momentum,\n non_constant_decay=non_constant_decay)\n\n super(AdaFactor, self).__init__(params, defaults)\n\n def __setstate__(self, state):\n super(AdaFactor, self).__setstate__(state)\n\n def _experimental_reshape(self, shape):\n temp_shape = shape[2:]\n if len(temp_shape) == 1:\n new_shape = (shape[0], shape[1]*shape[2])\n else:\n tmp_div = len(temp_shape) // 2 + len(temp_shape) % 2\n new_shape = (shape[0]*functools.reduce(operator.mul,\n temp_shape[tmp_div:], 1),\n shape[1]*functools.reduce(operator.mul,\n temp_shape[:tmp_div], 1))\n return new_shape, copy(shape)\n\n def _check_shape(self, shape):\n '''\n output1 - True - algorithm for matrix, False - vector;\n output2 - need reshape\n '''\n if len(shape) > 2:\n return True, True\n elif len(shape) == 2:\n return True, False\n elif len(shape) == 2 and (shape[0] == 1 or shape[1] == 1):\n return False, False\n else:\n return False, False\n\n def _rms(self, x):\n return sqrt(torch.mean(x.pow(2)))\n\n def step(self, closure=None):\n loss = None\n if closure is not None:\n loss = closure()\n for group in self.param_groups:\n for p in group['params']:\n if p.grad is None:\n continue\n grad = p.grad.data\n\n if grad.is_sparse:\n raise RuntimeError('Adam does not support sparse \\\n gradients, use SparseAdam instead')\n\n is_matrix, is_need_reshape = self._check_shape(grad.size())\n new_shape = p.data.size()\n if is_need_reshape and group['enable_factorization']:\n new_shape, old_shape = \\\n self._experimental_reshape(p.data.size())\n grad = grad.view(new_shape)\n\n state = self.state[p]\n if len(state) == 0:\n state['step'] = 0\n if group['enable_momentum']:\n state['exp_avg'] = torch.zeros(new_shape,\n dtype=torch.float32,\n device=p.grad.device)\n\n if is_matrix and group['enable_factorization']:\n state['exp_avg_sq_R'] = \\\n torch.zeros((1, new_shape[1]),\n dtype=torch.float32,\n device=p.grad.device)\n state['exp_avg_sq_C'] = \\\n torch.zeros((new_shape[0], 1),\n dtype=torch.float32,\n device=p.grad.device)\n else:\n state['exp_avg_sq'] = torch.zeros(new_shape,\n dtype=torch.float32,\n device=p.grad.device)\n if group['ams_grad']:\n state['exp_avg_sq_hat'] = \\\n torch.zeros(new_shape, dtype=torch.float32,\n device=p.grad.device)\n\n if group['enable_momentum']:\n exp_avg = state['exp_avg']\n\n if is_matrix and group['enable_factorization']:\n exp_avg_sq_r = state['exp_avg_sq_R']\n exp_avg_sq_c = state['exp_avg_sq_C']\n else:\n exp_avg_sq = state['exp_avg_sq']\n\n if group['ams_grad']:\n exp_avg_sq_hat = state['exp_avg_sq_hat']\n\n state['step'] += 1\n lr_t = group['lr']\n lr_t *= max(group['eps2'], self._rms(p.data))\n\n if group['enable_momentum']:\n if group['non_constant_decay']:\n beta1_t = group['beta1'] * \\\n (1 - group['beta1'] ** (state['step'] - 1)) \\\n / (1 - group['beta1'] ** state['step'])\n else:\n beta1_t = group['beta1']\n exp_avg.mul_(beta1_t).add_(1 - beta1_t, grad)\n\n if group['non_constant_decay']:\n beta2_t = group['beta2'] * \\\n (1 - group['beta2'] ** (state['step'] - 1)) / \\\n (1 - group['beta2'] ** state['step'])\n else:\n beta2_t = group['beta2']\n\n if is_matrix and group['enable_factorization']:\n exp_avg_sq_r.mul_(beta2_t). \\\n add_(1 - beta2_t, torch.sum(torch.mul(grad, grad).\n add_(group['eps1']),\n dim=0, keepdim=True))\n exp_avg_sq_c.mul_(beta2_t). \\\n add_(1 - beta2_t, torch.sum(torch.mul(grad, grad).\n add_(group['eps1']),\n dim=1, keepdim=True))\n v = torch.mul(exp_avg_sq_c,\n exp_avg_sq_r).div_(torch.sum(exp_avg_sq_r))\n else:\n exp_avg_sq.mul_(beta2_t). \\\n addcmul_(1 - beta2_t, grad, grad). \\\n add_((1 - beta2_t)*group['eps1'])\n v = exp_avg_sq\n\n g = grad\n if group['enable_momentum']:\n g = torch.div(exp_avg, 1 - beta1_t ** state['step'])\n\n if group['ams_grad']:\n torch.max(exp_avg_sq_hat, v, out=exp_avg_sq_hat)\n v = exp_avg_sq_hat\n u = torch.div(g, (torch.div(v, 1 - beta2_t **\n state['step'])).sqrt().add_(group['eps1']))\n else:\n u = torch.div(g, v.sqrt())\n\n u.div_(max(1, self._rms(u) / group['cliping_threshold']))\n p.data.add_(-lr_t * (u.view(old_shape) if is_need_reshape and\n group['enable_factorization'] else u))\n\n if group['weight_decay'] != 0:\n p.data.add_(-group['weight_decay'] * lr_t, p.data)\n\n return loss\n\n\nclass FusedAdam(torch.optim.Optimizer):\n\n \"\"\"Implements Adam algorithm. Currently GPU-only.\n Requires Apex to be installed via\n ``python setup.py install --cuda_ext --cpp_ext``.\n It has been proposed in `Adam: A Method for Stochastic Optimization`_.\n Arguments:\n params (iterable): iterable of parameters to optimize or dicts defining\n parameter groups.\n lr (float, optional): learning rate. (default: 1e-3)\n betas (Tuple[float, float], optional): coefficients used for computing\n running averages of gradient and its square.\n (default: (0.9, 0.999))\n eps (float, optional): term added to the denominator to improve\n numerical stability. (default: 1e-8)\n weight_decay (float, optional): weight decay (L2 penalty) (default: 0)\n amsgrad (boolean, optional): whether to use the AMSGrad variant of this\n algorithm from the paper `On the Convergence of Adam and Beyond`_\n (default: False) NOT SUPPORTED in FusedAdam!\n eps_inside_sqrt (boolean, optional): in the 'update parameters' step,\n adds eps to the bias-corrected second moment estimate before\n evaluating square root instead of adding it to the square root of\n second moment estimate as in the original paper. (default: False)\n .. _Adam: A Method for Stochastic Optimization:\n https://arxiv.org/abs/1412.6980\n .. _On the Convergence of Adam and Beyond:\n https://openreview.net/forum?id=ryQu7f-RZ\n \"\"\"\n\n def __init__(self, params,\n lr=1e-3, bias_correction=True,\n betas=(0.9, 0.999), eps=1e-8, eps_inside_sqrt=False,\n weight_decay=0., max_grad_norm=0., amsgrad=False):\n global fused_adam_cuda\n fused_adam_cuda = importlib.import_module(\"fused_adam_cuda\")\n\n if amsgrad:\n raise RuntimeError('AMSGrad variant not supported.')\n defaults = dict(lr=lr, bias_correction=bias_correction,\n betas=betas, eps=eps, weight_decay=weight_decay,\n max_grad_norm=max_grad_norm)\n super(FusedAdam, self).__init__(params, defaults)\n self.eps_mode = 0 if eps_inside_sqrt else 1\n\n def step(self, closure=None, grads=None, output_params=None,\n scale=1., grad_norms=None):\n \"\"\"Performs a single optimization step.\n Arguments:\n closure (callable, optional): A closure that reevaluates the model\n and returns the loss.\n grads (list of tensors, optional): weight gradient to use for the\n optimizer update. If gradients have type torch.half, parameters\n are expected to be in type torch.float. (default: None)\n output params (list of tensors, optional): A reduced precision copy\n of the updated weights written out in addition to the regular\n updated weights. Have to be of same type as gradients.\n (default: None)\n scale (float, optional): factor to divide gradient tensor values\n by before applying to weights. (default: 1)\n \"\"\"\n loss = None\n if closure is not None:\n loss = closure()\n\n if grads is None:\n grads_group = [None]*len(self.param_groups)\n # backward compatibility\n # assuming a list/generator of parameter means single group\n elif isinstance(grads, types.GeneratorType):\n grads_group = [grads]\n elif type(grads[0]) != list:\n grads_group = [grads]\n else:\n grads_group = grads\n\n if output_params is None:\n output_params_group = [None]*len(self.param_groups)\n elif isinstance(output_params, types.GeneratorType):\n output_params_group = [output_params]\n elif type(output_params[0]) != list:\n output_params_group = [output_params]\n else:\n output_params_group = output_params\n\n if grad_norms is None:\n grad_norms = [None]*len(self.param_groups)\n\n for group, grads_this_group, output_params_this_group, \\\n grad_norm in zip(self.param_groups, grads_group,\n output_params_group, grad_norms):\n if grads_this_group is None:\n grads_this_group = [None]*len(group['params'])\n if output_params_this_group is None:\n output_params_this_group = [None]*len(group['params'])\n\n # compute combined scale factor for this group\n combined_scale = scale\n if group['max_grad_norm'] > 0:\n # norm is in fact norm*scale\n clip = ((grad_norm / scale) + 1e-6) / group['max_grad_norm']\n if clip > 1:\n combined_scale = clip * scale\n\n bias_correction = 1 if group['bias_correction'] else 0\n\n for p, grad, output_param in zip(group['params'],\n grads_this_group,\n output_params_this_group):\n # note: p.grad should not ever be set for correct operation of\n # mixed precision optimizer that sometimes sends None gradients\n if p.grad is None and grad is None:\n continue\n if grad is None:\n grad = p.grad.data\n if grad.is_sparse:\n raise RuntimeError('FusedAdam does not support sparse \\\n gradients, please consider \\\n SparseAdam instead')\n\n state = self.state[p]\n\n # State initialization\n if len(state) == 0:\n state['step'] = 0\n # Exponential moving average of gradient values\n state['exp_avg'] = torch.zeros_like(p.data)\n # Exponential moving average of squared gradient values\n state['exp_avg_sq'] = torch.zeros_like(p.data)\n\n exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']\n beta1, beta2 = group['betas']\n\n state['step'] += 1\n\n out_p = torch.tensor([], dtype=torch.float) if output_param \\\n is None else output_param\n fused_adam_cuda.adam(p.data,\n out_p,\n exp_avg,\n exp_avg_sq,\n grad,\n group['lr'],\n beta1,\n beta2,\n group['eps'],\n combined_scale,\n state['step'],\n self.eps_mode,\n bias_correction,\n group['weight_decay'])\n return loss\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/utils/parse.py",
"content": "import configargparse as cfargparse\nimport os\n\nimport torch\n\nimport onmt.opts as opts\nfrom onmt.utils.logging import logger\n\n\nclass ArgumentParser(cfargparse.ArgumentParser):\n def __init__(\n self,\n config_file_parser_class=cfargparse.YAMLConfigFileParser,\n formatter_class=cfargparse.ArgumentDefaultsHelpFormatter,\n **kwargs):\n super(ArgumentParser, self).__init__(\n config_file_parser_class=config_file_parser_class,\n formatter_class=formatter_class,\n **kwargs)\n\n @classmethod\n def defaults(cls, *args):\n \"\"\"Get default arguments added to a parser by all ``*args``.\"\"\"\n dummy_parser = cls()\n for callback in args:\n callback(dummy_parser)\n defaults = dummy_parser.parse_known_args([])[0]\n return defaults\n\n @classmethod\n def update_model_opts(cls, model_opt):\n if model_opt.word_vec_size > 0:\n model_opt.src_word_vec_size = model_opt.word_vec_size\n model_opt.tgt_word_vec_size = model_opt.word_vec_size\n\n if model_opt.layers > 0:\n model_opt.enc_layers = model_opt.layers\n model_opt.dec_layers = model_opt.layers\n\n if model_opt.rnn_size > 0:\n model_opt.enc_rnn_size = model_opt.rnn_size\n model_opt.dec_rnn_size = model_opt.rnn_size\n\n model_opt.brnn = model_opt.encoder_type == \"brnn\"\n\n if model_opt.copy_attn_type is None:\n model_opt.copy_attn_type = model_opt.global_attention\n\n if model_opt.alignment_layer is None:\n model_opt.alignment_layer = -2\n model_opt.lambda_align = 0.0\n model_opt.full_context_alignment = False\n\n @classmethod\n def validate_model_opts(cls, model_opt):\n assert model_opt.model_type in [\"text\", \"img\", \"audio\", \"vec\"], \\\n \"Unsupported model type %s\" % model_opt.model_type\n\n # this check is here because audio allows the encoder and decoder to\n # be different sizes, but other model types do not yet\n same_size = model_opt.enc_rnn_size == model_opt.dec_rnn_size\n assert model_opt.model_type == 'audio' or same_size, \\\n \"The encoder and decoder rnns must be the same size for now\"\n\n assert model_opt.rnn_type != \"SRU\" or model_opt.gpu_ranks, \\\n \"Using SRU requires -gpu_ranks set.\"\n if model_opt.share_embeddings:\n if model_opt.model_type != \"text\":\n raise AssertionError(\n \"--share_embeddings requires --model_type text.\")\n if model_opt.lambda_align > 0.0:\n assert model_opt.decoder_type == 'transformer', \\\n \"Only transformer is supported to joint learn alignment.\"\n assert model_opt.alignment_layer < model_opt.dec_layers and \\\n model_opt.alignment_layer >= -model_opt.dec_layers, \\\n \"N° alignment_layer should be smaller than number of layers.\"\n logger.info(\"Joint learn alignment at layer [{}] \"\n \"with {} heads in full_context '{}'.\".format(\n model_opt.alignment_layer,\n model_opt.alignment_heads,\n model_opt.full_context_alignment))\n\n @classmethod\n def ckpt_model_opts(cls, ckpt_opt):\n # Load default opt values, then overwrite with the opts in\n # the checkpoint. That way, if there are new options added,\n # the defaults are used.\n opt = cls.defaults(opts.model_opts)\n opt.__dict__.update(ckpt_opt.__dict__)\n return opt\n\n @classmethod\n def validate_train_opts(cls, opt):\n if opt.epochs:\n raise AssertionError(\n \"-epochs is deprecated please use -train_steps.\")\n if opt.truncated_decoder > 0 and max(opt.accum_count) > 1:\n raise AssertionError(\"BPTT is not compatible with -accum > 1\")\n\n if opt.gpuid:\n raise AssertionError(\n \"gpuid is deprecated see world_size and gpu_ranks\")\n if torch.cuda.is_available() and not opt.gpu_ranks:\n logger.warn(\"You have a CUDA device, should run with -gpu_ranks\")\n if opt.world_size < len(opt.gpu_ranks):\n raise AssertionError(\n \"parameter counts of -gpu_ranks must be less or equal \"\n \"than -world_size.\")\n if opt.world_size == len(opt.gpu_ranks) and \\\n min(opt.gpu_ranks) > 0:\n raise AssertionError(\n \"-gpu_ranks should have master(=0) rank \"\n \"unless -world_size is greater than len(gpu_ranks).\")\n assert len(opt.data_ids) == len(opt.data_weights), \\\n \"Please check -data_ids and -data_weights options!\"\n\n assert len(opt.dropout) == len(opt.dropout_steps), \\\n \"Number of dropout values must match accum_steps values\"\n\n assert len(opt.attention_dropout) == len(opt.dropout_steps), \\\n \"Number of attention_dropout values must match accum_steps values\"\n\n @classmethod\n def validate_translate_opts(cls, opt):\n if opt.beam_size != 1 and opt.random_sampling_topk != 1:\n raise ValueError('Can either do beam search OR random sampling.')\n\n @classmethod\n def validate_preprocess_args(cls, opt):\n assert opt.max_shard_size == 0, \\\n \"-max_shard_size is deprecated. Please use \\\n -shard_size (number of examples) instead.\"\n assert opt.shuffle == 0, \\\n \"-shuffle is not implemented. Please shuffle \\\n your data before pre-processing.\"\n\n assert len(opt.train_src) == len(opt.train_tgt), \\\n \"Please provide same number of src and tgt train files!\"\n\n assert len(opt.train_src) == len(opt.train_ids), \\\n \"Please provide proper -train_ids for your data!\"\n\n for file in opt.train_src + opt.train_tgt:\n assert os.path.isfile(file), \"Please check path of %s\" % file\n\n if len(opt.train_align) == 1 and opt.train_align[0] is None:\n opt.train_align = [None] * len(opt.train_src)\n else:\n assert len(opt.train_align) == len(opt.train_src), \\\n \"Please provide same number of word alignment train \\\n files as src/tgt!\"\n for file in opt.train_align:\n assert os.path.isfile(file), \"Please check path of %s\" % file\n\n assert not opt.valid_align or os.path.isfile(opt.valid_align), \\\n \"Please check path of your valid alignment file!\"\n\n assert not opt.valid_src or os.path.isfile(opt.valid_src), \\\n \"Please check path of your valid src file!\"\n assert not opt.valid_tgt or os.path.isfile(opt.valid_tgt), \\\n \"Please check path of your valid tgt file!\"\n\n assert not opt.src_vocab or os.path.isfile(opt.src_vocab), \\\n \"Please check path of your src vocab!\"\n assert not opt.tgt_vocab or os.path.isfile(opt.tgt_vocab), \\\n \"Please check path of your tgt vocab!\"\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/utils/report_manager.py",
"content": "\"\"\" Report manager utility \"\"\"\nfrom __future__ import print_function\nimport time\nfrom datetime import datetime\n\nimport onmt\n\nfrom onmt.utils.logging import logger\n\n\ndef build_report_manager(opt, gpu_rank):\n if opt.tensorboard and gpu_rank == 0:\n from torch.utils.tensorboard import SummaryWriter\n tensorboard_log_dir = opt.tensorboard_log_dir\n\n if not opt.train_from:\n tensorboard_log_dir += datetime.now().strftime(\"/%b-%d_%H-%M-%S\")\n\n writer = SummaryWriter(tensorboard_log_dir, comment=\"Unmt\")\n else:\n writer = None\n\n report_mgr = ReportMgr(opt.report_every, start_time=-1,\n tensorboard_writer=writer)\n return report_mgr\n\n\nclass ReportMgrBase(object):\n \"\"\"\n Report Manager Base class\n Inherited classes should override:\n * `_report_training`\n * `_report_step`\n \"\"\"\n\n def __init__(self, report_every, start_time=-1.):\n \"\"\"\n Args:\n report_every(int): Report status every this many sentences\n start_time(float): manually set report start time. Negative values\n means that you will need to set it later or use `start()`\n \"\"\"\n self.report_every = report_every\n self.start_time = start_time\n\n def start(self):\n self.start_time = time.time()\n\n def log(self, *args, **kwargs):\n logger.info(*args, **kwargs)\n\n def report_training(self, step, num_steps, learning_rate,\n report_stats, multigpu=False):\n \"\"\"\n This is the user-defined batch-level traing progress\n report function.\n\n Args:\n step(int): current step count.\n num_steps(int): total number of batches.\n learning_rate(float): current learning rate.\n report_stats(Statistics): old Statistics instance.\n Returns:\n report_stats(Statistics): updated Statistics instance.\n \"\"\"\n if self.start_time < 0:\n raise ValueError(\"\"\"ReportMgr needs to be started\n (set 'start_time' or use 'start()'\"\"\")\n\n if step % self.report_every == 0:\n if multigpu:\n report_stats = \\\n onmt.utils.Statistics.all_gather_stats(report_stats)\n self._report_training(\n step, num_steps, learning_rate, report_stats)\n return onmt.utils.Statistics()\n else:\n return report_stats\n\n def _report_training(self, *args, **kwargs):\n \"\"\" To be overridden \"\"\"\n raise NotImplementedError()\n\n def report_step(self, lr, step, train_stats=None, valid_stats=None):\n \"\"\"\n Report stats of a step\n\n Args:\n train_stats(Statistics): training stats\n valid_stats(Statistics): validation stats\n lr(float): current learning rate\n \"\"\"\n self._report_step(\n lr, step, train_stats=train_stats, valid_stats=valid_stats)\n\n def _report_step(self, *args, **kwargs):\n raise NotImplementedError()\n\n\nclass ReportMgr(ReportMgrBase):\n def __init__(self, report_every, start_time=-1., tensorboard_writer=None):\n \"\"\"\n A report manager that writes statistics on standard output as well as\n (optionally) TensorBoard\n\n Args:\n report_every(int): Report status every this many sentences\n tensorboard_writer(:obj:`tensorboard.SummaryWriter`):\n The TensorBoard Summary writer to use or None\n \"\"\"\n super(ReportMgr, self).__init__(report_every, start_time)\n self.tensorboard_writer = tensorboard_writer\n\n def maybe_log_tensorboard(self, stats, prefix, learning_rate, step):\n if self.tensorboard_writer is not None:\n stats.log_tensorboard(\n prefix, self.tensorboard_writer, learning_rate, step)\n\n def _report_training(self, step, num_steps, learning_rate,\n report_stats):\n \"\"\"\n See base class method `ReportMgrBase.report_training`.\n \"\"\"\n report_stats.output(step, num_steps,\n learning_rate, self.start_time)\n\n self.maybe_log_tensorboard(report_stats,\n \"progress\",\n learning_rate,\n step)\n report_stats = onmt.utils.Statistics()\n\n return report_stats\n\n def _report_step(self, lr, step, train_stats=None, valid_stats=None):\n \"\"\"\n See base class method `ReportMgrBase.report_step`.\n \"\"\"\n if train_stats is not None:\n self.log('Train perplexity: %g' % train_stats.ppl())\n self.log('Train accuracy: %g' % train_stats.accuracy())\n\n self.maybe_log_tensorboard(train_stats,\n \"train\",\n lr,\n step)\n\n if valid_stats is not None:\n self.log('Validation perplexity: %g' % valid_stats.ppl())\n self.log('Validation accuracy: %g' % valid_stats.accuracy())\n\n self.maybe_log_tensorboard(valid_stats,\n \"valid\",\n lr,\n step)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/utils/rnn_factory.py",
"content": "\"\"\"\n RNN tools\n\"\"\"\nimport torch.nn as nn\nimport onmt.models\n\n\ndef rnn_factory(rnn_type, **kwargs):\n \"\"\" rnn factory, Use pytorch version when available. \"\"\"\n no_pack_padded_seq = False\n if rnn_type == \"SRU\":\n # SRU doesn't support PackedSequence.\n no_pack_padded_seq = True\n rnn = onmt.models.sru.SRU(**kwargs)\n else:\n rnn = getattr(nn, rnn_type)(**kwargs)\n return rnn, no_pack_padded_seq\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/onmt/utils/statistics.py",
"content": "\"\"\" Statistics calculation utility \"\"\"\nfrom __future__ import division\nimport time\nimport math\nimport sys\n\nfrom onmt.utils.logging import logger\n\n\nclass Statistics(object):\n \"\"\"\n Accumulator for loss statistics.\n Currently calculates:\n\n * accuracy\n * perplexity\n * elapsed time\n \"\"\"\n\n def __init__(self, loss=0, n_words=0, n_correct=0):\n self.loss = loss\n self.n_words = n_words\n self.n_correct = n_correct\n self.n_src_words = 0\n self.start_time = time.time()\n\n @staticmethod\n def all_gather_stats(stat, max_size=4096):\n \"\"\"\n Gather a `Statistics` object accross multiple process/nodes\n\n Args:\n stat(:obj:Statistics): the statistics object to gather\n accross all processes/nodes\n max_size(int): max buffer size to use\n\n Returns:\n `Statistics`, the update stats object\n \"\"\"\n stats = Statistics.all_gather_stats_list([stat], max_size=max_size)\n return stats[0]\n\n @staticmethod\n def all_gather_stats_list(stat_list, max_size=4096):\n \"\"\"\n Gather a `Statistics` list accross all processes/nodes\n\n Args:\n stat_list(list([`Statistics`])): list of statistics objects to\n gather accross all processes/nodes\n max_size(int): max buffer size to use\n\n Returns:\n our_stats(list([`Statistics`])): list of updated stats\n \"\"\"\n from torch.distributed import get_rank\n from onmt.utils.distributed import all_gather_list\n\n # Get a list of world_size lists with len(stat_list) Statistics objects\n all_stats = all_gather_list(stat_list, max_size=max_size)\n\n our_rank = get_rank()\n our_stats = all_stats[our_rank]\n for other_rank, stats in enumerate(all_stats):\n if other_rank == our_rank:\n continue\n for i, stat in enumerate(stats):\n our_stats[i].update(stat, update_n_src_words=True)\n return our_stats\n\n def update(self, stat, update_n_src_words=False):\n \"\"\"\n Update statistics by suming values with another `Statistics` object\n\n Args:\n stat: another statistic object\n update_n_src_words(bool): whether to update (sum) `n_src_words`\n or not\n\n \"\"\"\n self.loss += stat.loss\n self.n_words += stat.n_words\n self.n_correct += stat.n_correct\n\n if update_n_src_words:\n self.n_src_words += stat.n_src_words\n\n def accuracy(self):\n \"\"\" compute accuracy \"\"\"\n return 100 * (self.n_correct / self.n_words)\n\n def xent(self):\n \"\"\" compute cross entropy \"\"\"\n return self.loss / self.n_words\n\n def ppl(self):\n \"\"\" compute perplexity \"\"\"\n return math.exp(min(self.loss / self.n_words, 100))\n\n def elapsed_time(self):\n \"\"\" compute elapsed time \"\"\"\n return time.time() - self.start_time\n\n def output(self, step, num_steps, learning_rate, start):\n \"\"\"Write out statistics to stdout.\n\n Args:\n step (int): current step\n n_batch (int): total batches\n start (int): start time of step.\n \"\"\"\n t = self.elapsed_time()\n step_fmt = \"%2d\" % step\n if num_steps > 0:\n step_fmt = \"%s/%5d\" % (step_fmt, num_steps)\n logger.info(\n (\"Step %s; acc: %6.2f; ppl: %5.2f; xent: %4.2f; \" +\n \"lr: %7.5f; %3.0f/%3.0f tok/s; %6.0f sec\")\n % (step_fmt,\n self.accuracy(),\n self.ppl(),\n self.xent(),\n learning_rate,\n self.n_src_words / (t + 1e-5),\n self.n_words / (t + 1e-5),\n time.time() - start))\n sys.stdout.flush()\n\n def log_tensorboard(self, prefix, writer, learning_rate, step):\n \"\"\" display statistics to tensorboard \"\"\"\n t = self.elapsed_time()\n writer.add_scalar(prefix + \"/xent\", self.xent(), step)\n writer.add_scalar(prefix + \"/ppl\", self.ppl(), step)\n writer.add_scalar(prefix + \"/accuracy\", self.accuracy(), step)\n writer.add_scalar(prefix + \"/tgtper\", self.n_words / t, step)\n writer.add_scalar(prefix + \"/lr\", learning_rate, step)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/preprocess.py",
"content": "#!/usr/bin/env python\nfrom onmt.bin.preprocess import main\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/process_ori_data.py",
"content": "file=open('train_data.csv','r')\nlines=file.readlines()\n\nsrc_train=open('src-train.txt','w')\ntgt_train=open('tgt-train.txt','w')\n\nsrc_val=open('src-val.txt','w')\ntgt_val=open('tgt-val.txt','w')\n\nchinese_lists=[]\nenglish_lists=[]\nindex=0\nfor line in lines:\n if index ==0:\n index+=1\n continue\n line=line.strip().split(',')\n chinese=line[1].strip().split('_')\n english=line[2].strip().split('_')\n chinese_lists.append(' '.join(chinese))\n english_lists.append(' '.join(english))\n index+=1\n \n\nassert len(chinese_lists)==len(english_lists)\n\nsplit_num=int(0.85*index)\n\nfor num in range(len(english_lists)):\n if num<=split_num:\n src_train.write(chinese_lists[num]+'\\n')\n tgt_train.write(english_lists[num]+'\\n')\n else:\n src_val.write(chinese_lists[num]+'\\n')\n tgt_val.write(english_lists[num]+'\\n')\n\nsrc_train.close()\ntgt_train.close()\n\nsrc_val.close()\ntgt_val.close()\n\n\n\n\n\n\n\nfile=open('test_cs_a.csv','r')\nlines=file.readlines()\n\nsrc_test=open('src-test.txt','w')\n\nfor line in lines:\n line=line.strip().split(',')\n cont=line[2].split('_')\n cont=' '.join(cont)\n src_test.write(cont+'\\n')\nsrc_test.close()"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/requirements.opt.txt",
"content": "cffi\ntorchvision\njoblib\nlibrosa\nPillow\ngit+git://github.com/pytorch/audio.git@d92de5b97fc6204db4b1e3ed20c03ac06f5d53f0\npyrouge\nopencv-python\ngit+https://github.com/NVIDIA/apex\npretrainedmodels\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/server.py",
"content": "#!/usr/bin/env python\nfrom onmt.bin.server import main\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/setup.py",
"content": "#!/usr/bin/env python\nfrom setuptools import setup, find_packages\nfrom os import path\n\nthis_directory = path.abspath(path.dirname(__file__))\nwith open(path.join(this_directory, 'README.md'), encoding='utf-8') as f:\n long_description = f.read()\n\nsetup(\n name='OpenNMT-py',\n description='A python implementation of OpenNMT',\n long_description=long_description,\n long_description_content_type='text/markdown',\n version='1.0.0.rc2',\n packages=find_packages(),\n project_urls={\n \"Documentation\": \"http://opennmt.net/OpenNMT-py/\",\n \"Forum\": \"http://forum.opennmt.net/\",\n \"Gitter\": \"https://gitter.im/OpenNMT/OpenNMT-py\",\n \"Source\": \"https://github.com/OpenNMT/OpenNMT-py/\"\n },\n install_requires=[\n \"six\",\n \"tqdm~=4.30.0\",\n \"torch>=1.2\",\n \"torchtext==0.4.0\",\n \"future\",\n \"configargparse\",\n \"tensorboard>=1.14\",\n \"flask\",\n \"pyonmttok==1.*;platform_system=='Linux'\",\n ],\n entry_points={\n \"console_scripts\": [\n \"onmt_server=onmt.bin.server:main\",\n \"onmt_train=onmt.bin.train:main\",\n \"onmt_translate=onmt.bin.translate:main\",\n \"onmt_preprocess=onmt.bin.preprocess:main\",\n \"onmt_average_models=onmt.bin.average_models:main\"\n ],\n }\n)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/README.md",
"content": "This directly contains scripts and tools adopted from other open source projects such as Apache Joshua and Moses Decoder.\n\nTODO: credit the authors and resolve license issues (if any)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/apply_bpe.py",
"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n# Author: Rico Sennrich\n# flake8: noqa\n\n\"\"\"Use operations learned with learn_bpe.py to encode a new text.\nThe text will not be smaller, but use only a fixed vocabulary, with rare words\nencoded as variable-length sequences of subword units.\n\nReference:\nRico Sennrich, Barry Haddow and Alexandra Birch (2015). Neural Machine Translation of Rare Words with Subword Units.\nProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016). Berlin, Germany.\n\"\"\"\n# This file is retrieved from https://github.com/rsennrich/subword-nmt\n\nfrom __future__ import unicode_literals, division\n\nimport sys\nimport codecs\nimport io\nimport argparse\nimport json\nimport re\nfrom collections import defaultdict\n\n# hack for python2/3 compatibility\nfrom io import open\nargparse.open = open\n\n\nclass BPE(object):\n\n def __init__(self, codes, separator='@@', vocab=None, glossaries=None):\n\n # check version information\n firstline = codes.readline()\n if firstline.startswith('#version:'):\n self.version = tuple([int(x) for x in re.sub(\n r'(\\.0+)*$', '', firstline.split()[-1]).split(\".\")])\n else:\n self.version = (0, 1)\n codes.seek(0)\n\n self.bpe_codes = [tuple(item.split()) for item in codes]\n\n # some hacking to deal with duplicates (only consider first instance)\n self.bpe_codes = dict(\n [(code, i) for (i, code) in reversed(list(enumerate(self.bpe_codes)))])\n\n self.bpe_codes_reverse = dict(\n [(pair[0] + pair[1], pair) for pair, i in self.bpe_codes.items()])\n\n self.separator = separator\n\n self.vocab = vocab\n\n self.glossaries = glossaries if glossaries else []\n\n self.cache = {}\n\n def segment(self, sentence):\n \"\"\"segment single sentence (whitespace-tokenized string) with BPE encoding\"\"\"\n output = []\n for word in sentence.split():\n new_word = [out for segment in self._isolate_glossaries(word)\n for out in encode(segment,\n self.bpe_codes,\n self.bpe_codes_reverse,\n self.vocab,\n self.separator,\n self.version,\n self.cache,\n self.glossaries)]\n\n for item in new_word[:-1]:\n output.append(item + self.separator)\n output.append(new_word[-1])\n\n return ' '.join(output)\n\n def _isolate_glossaries(self, word):\n word_segments = [word]\n for gloss in self.glossaries:\n word_segments = [out_segments for segment in word_segments\n for out_segments in isolate_glossary(segment, gloss)]\n return word_segments\n\n\ndef create_parser():\n parser = argparse.ArgumentParser(\n formatter_class=argparse.RawDescriptionHelpFormatter,\n description=\"learn BPE-based word segmentation\")\n\n parser.add_argument(\n '--input', '-i', type=argparse.FileType('r'), default=sys.stdin,\n metavar='PATH',\n help=\"Input file (default: standard input).\")\n parser.add_argument(\n '--codes', '-c', type=argparse.FileType('r'), metavar='PATH',\n required=True,\n help=\"File with BPE codes (created by learn_bpe.py).\")\n parser.add_argument(\n '--output', '-o', type=argparse.FileType('w'), default=sys.stdout,\n metavar='PATH',\n help=\"Output file (default: standard output)\")\n parser.add_argument(\n '--separator', '-s', type=str, default='@@', metavar='STR',\n help=\"Separator between non-final subword units (default: '%(default)s'))\")\n parser.add_argument(\n '--vocabulary', type=argparse.FileType('r'), default=None,\n metavar=\"PATH\",\n help=\"Vocabulary file (built with get_vocab.py). If provided, this script reverts any merge operations that produce an OOV.\")\n parser.add_argument(\n '--vocabulary-threshold', type=int, default=None,\n metavar=\"INT\",\n help=\"Vocabulary threshold. If vocabulary is provided, any word with frequency < threshold will be treated as OOV\")\n parser.add_argument(\n '--glossaries', type=str, nargs='+', default=None,\n metavar=\"STR\",\n help=\"Glossaries. The strings provided in glossaries will not be affected\" +\n \"by the BPE (i.e. they will neither be broken into subwords, nor concatenated with other subwords\")\n\n return parser\n\n\ndef get_pairs(word):\n \"\"\"Return set of symbol pairs in a word.\n\n word is represented as tuple of symbols (symbols being variable-length strings)\n \"\"\"\n pairs = set()\n prev_char = word[0]\n for char in word[1:]:\n pairs.add((prev_char, char))\n prev_char = char\n return pairs\n\n\ndef encode(orig, bpe_codes, bpe_codes_reverse, vocab, separator, version, cache, glossaries=None):\n \"\"\"Encode word based on list of BPE merge operations, which are applied consecutively\n \"\"\"\n\n if orig in cache:\n return cache[orig]\n\n if orig in glossaries:\n cache[orig] = (orig,)\n return (orig,)\n\n if version == (0, 1):\n word = tuple(orig) + ('',)\n elif version == (0, 2): # more consistent handling of word-final segments\n word = tuple(orig[:-1]) + (orig[-1] + '',)\n else:\n raise NotImplementedError\n\n pairs = get_pairs(word)\n\n if not pairs:\n return orig\n\n while True:\n bigram = min(pairs, key=lambda pair: bpe_codes.get(pair, float('inf')))\n if bigram not in bpe_codes:\n break\n first, second = bigram\n new_word = []\n i = 0\n while i < len(word):\n try:\n j = word.index(first, i)\n new_word.extend(word[i:j])\n i = j\n except:\n new_word.extend(word[i:])\n break\n\n if word[i] == first and i < len(word) - 1 and word[i + 1] == second:\n new_word.append(first + second)\n i += 2\n else:\n new_word.append(word[i])\n i += 1\n new_word = tuple(new_word)\n word = new_word\n if len(word) == 1:\n break\n else:\n pairs = get_pairs(word)\n\n # don't print end-of-word symbols\n if word[-1] == '':\n word = word[:-1]\n elif word[-1].endswith(''):\n word = word[:-1] + (word[-1].replace('', ''),)\n\n if vocab:\n word = check_vocab_and_split(word, bpe_codes_reverse, vocab, separator)\n\n cache[orig] = word\n return word\n\n\ndef recursive_split(segment, bpe_codes, vocab, separator, final=False):\n \"\"\"Recursively split segment into smaller units (by reversing BPE merges)\n until all units are either in-vocabulary, or cannot be split futher.\"\"\"\n\n try:\n if final:\n left, right = bpe_codes[segment + '']\n right = right[:-4]\n else:\n left, right = bpe_codes[segment]\n except:\n #sys.stderr.write('cannot split {0} further.\\n'.format(segment))\n yield segment\n return\n\n if left + separator in vocab:\n yield left\n else:\n for item in recursive_split(left, bpe_codes, vocab, separator, False):\n yield item\n\n if (final and right in vocab) or (not final and right + separator in vocab):\n yield right\n else:\n for item in recursive_split(right, bpe_codes, vocab, separator, final):\n yield item\n\n\ndef check_vocab_and_split(orig, bpe_codes, vocab, separator):\n \"\"\"Check for each segment in word if it is in-vocabulary,\n and segment OOV segments into smaller units by reversing the BPE merge operations\"\"\"\n\n out = []\n\n for segment in orig[:-1]:\n if segment + separator in vocab:\n out.append(segment)\n else:\n #sys.stderr.write('OOV: {0}\\n'.format(segment))\n for item in recursive_split(segment, bpe_codes, vocab, separator, False):\n out.append(item)\n\n segment = orig[-1]\n if segment in vocab:\n out.append(segment)\n else:\n #sys.stderr.write('OOV: {0}\\n'.format(segment))\n for item in recursive_split(segment, bpe_codes, vocab, separator, True):\n out.append(item)\n\n return out\n\n\ndef read_vocabulary(vocab_file, threshold):\n \"\"\"read vocabulary file produced by get_vocab.py, and filter according to frequency threshold.\n \"\"\"\n\n vocabulary = set()\n\n for line in vocab_file:\n word, freq = line.split()\n freq = int(freq)\n if threshold == None or freq >= threshold:\n vocabulary.add(word)\n\n return vocabulary\n\n\ndef isolate_glossary(word, glossary):\n \"\"\"\n Isolate a glossary present inside a word.\n\n Returns a list of subwords. In which all 'glossary' glossaries are isolated \n\n For example, if 'USA' is the glossary and '1934USABUSA' the word, the return value is:\n ['1934', 'USA', 'B', 'USA']\n \"\"\"\n if word == glossary or glossary not in word:\n return [word]\n else:\n splits = word.split(glossary)\n segments = [segment.strip() for split in splits[:-1]\n for segment in [split, glossary] if segment != '']\n return segments + [splits[-1].strip()] if splits[-1] != '' else segments\n\n\nif __name__ == '__main__':\n\n # python 2/3 compatibility\n if sys.version_info < (3, 0):\n sys.stderr = codecs.getwriter('UTF-8')(sys.stderr)\n sys.stdout = codecs.getwriter('UTF-8')(sys.stdout)\n sys.stdin = codecs.getreader('UTF-8')(sys.stdin)\n else:\n sys.stdin = io.TextIOWrapper(sys.stdin.buffer, encoding='utf-8')\n sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')\n sys.stdout = io.TextIOWrapper(\n sys.stdout.buffer, encoding='utf-8', write_through=True, line_buffering=True)\n\n parser = create_parser()\n args = parser.parse_args()\n\n # read/write files as UTF-8\n args.codes = codecs.open(args.codes.name, encoding='utf-8')\n if args.input.name != '':\n args.input = codecs.open(args.input.name, encoding='utf-8')\n if args.output.name != '':\n args.output = codecs.open(args.output.name, 'w', encoding='utf-8')\n if args.vocabulary:\n args.vocabulary = codecs.open(args.vocabulary.name, encoding='utf-8')\n\n if args.vocabulary:\n vocabulary = read_vocabulary(\n args.vocabulary, args.vocabulary_threshold)\n else:\n vocabulary = None\n\n bpe = BPE(args.codes, args.separator, vocabulary, args.glossaries)\n\n for line in args.input:\n args.output.write(bpe.segment(line).strip())\n args.output.write('\\n')\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/average_models.py",
"content": "#!/usr/bin/env python\nfrom onmt.bin.average_models import main\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/bpe_pipeline.sh",
"content": "#!/usr/bin/env bash\n# Author : Thamme Gowda\n# Created : Nov 06, 2017\n\nONMT=\"$( cd \"$( dirname \"${BASH_SOURCE[0]}\" )/..\" && pwd )\"\n\n#======= EXPERIMENT SETUP ======\n# Activate python environment if needed\nsource ~/.bashrc\n# source activate py3\n\n# update these variables\nNAME=\"run1\"\nOUT=\"onmt-runs/$NAME\"\n\nDATA=\"$ONMT/onmt-runs/data\"\nTRAIN_SRC=$DATA/*train.src\nTRAIN_TGT=$DATA/*train.tgt\nVALID_SRC=$DATA/*dev.src\nVALID_TGT=$DATA/*dev.tgt\nTEST_SRC=$DATA/*test.src\nTEST_TGT=$DATA/*test.tgt\n\nBPE=\"\" # default\nBPE=\"src\" # src, tgt, src+tgt\n\n# applicable only when BPE=\"src\" or \"src+tgt\"\nBPE_SRC_OPS=10000\n\n# applicable only when BPE=\"tgt\" or \"src+tgt\"\nBPE_TGT_OPS=10000\n\nGPUARG=\"\" # default\nGPUARG=\"0\"\n\n\n#====== EXPERIMENT BEGIN ======\n\n# Check if input exists\nfor f in $TRAIN_SRC $TRAIN_TGT $VALID_SRC $VALID_TGT $TEST_SRC $TEST_TGT; do\n if [[ ! -f \"$f\" ]]; then\n echo \"Input File $f doesnt exist. Please fix the paths\"\n exit 1\n fi\ndone\n\nfunction lines_check {\n l1=`wc -l $1`\n l2=`wc -l $2`\n if [[ $l1 != $l2 ]]; then\n echo \"ERROR: Record counts doesnt match between: $1 and $2\"\n exit 2\n fi\n}\nlines_check $TRAIN_SRC $TRAIN_TGT\nlines_check $VALID_SRC $VALID_TGT\nlines_check $TEST_SRC $TEST_TGT\n\n\necho \"Output dir = $OUT\"\n[ -d $OUT ] || mkdir -p $OUT\n[ -d $OUT/data ] || mkdir -p $OUT/data\n[ -d $OUT/models ] || mkdir $OUT/models\n[ -d $OUT/test ] || mkdir -p $OUT/test\n\n\necho \"Step 1a: Preprocess inputs\"\nif [[ \"$BPE\" == *\"src\"* ]]; then\n echo \"BPE on source\"\n # Here we could use more monolingual data\n $ONMT/tools/learn_bpe.py -s $BPE_SRC_OPS < $TRAIN_SRC > $OUT/data/bpe-codes.src\n\n $ONMT/tools/apply_bpe.py -c $OUT/data/bpe-codes.src < $TRAIN_SRC > $OUT/data/train.src\n $ONMT/tools/apply_bpe.py -c $OUT/data/bpe-codes.src < $VALID_SRC > $OUT/data/valid.src\n $ONMT/tools/apply_bpe.py -c $OUT/data/bpe-codes.src < $TEST_SRC > $OUT/data/test.src\nelse\n ln -sf $TRAIN_SRC $OUT/data/train.src\n ln -sf $VALID_SRC $OUT/data/valid.src\n ln -sf $TEST_SRC $OUT/data/test.src\nfi\n\n\nif [[ \"$BPE\" == *\"tgt\"* ]]; then\n echo \"BPE on target\"\n # Here we could use more monolingual data\n $ONMT/tools/learn_bpe.py -s $BPE_SRC_OPS < $TRAIN_TGT > $OUT/data/bpe-codes.tgt\n\n $ONMT/tools/apply_bpe.py -c $OUT/data/bpe-codes.tgt < $TRAIN_TGT > $OUT/data/train.tgt\n $ONMT/tools/apply_bpe.py -c $OUT/data/bpe-codes.tgt < $VALID_TGT > $OUT/data/valid.tgt\n #$ONMT/tools/apply_bpe.py -c $OUT/data/bpe-codes.tgt < $TEST_TGT > $OUT/data/test.tgt\n # We dont touch the test References, No BPE on them!\n ln -sf $TEST_TGT $OUT/data/test.tgt\nelse\n ln -sf $TRAIN_TGT $OUT/data/train.tgt\n ln -sf $VALID_TGT $OUT/data/valid.tgt\n ln -sf $TEST_TGT $OUT/data/test.tgt\nfi\n\n\n#: < maxv) {maxv=score; max=$0}} END{ print max}'`\necho \"Chosen Model = $model\"\nif [[ -z \"$model\" ]]; then\n echo \"Model not found. Looked in $OUT/models/\"\n exit 1\nfi\n\nGPU_OPTS=\"\"\nif [ ! -z $GPUARG ]; then\n GPU_OPTS=\"-gpu $GPUARG\"\nfi\n\necho \"Step 3a: Translate Test\"\npython $ONMT/translate.py -model $model \\\n -src $OUT/data/test.src \\\n -output $OUT/test/test.out \\\n -replace_unk -verbose $GPU_OPTS > $OUT/test/test.log\n\necho \"Step 3b: Translate Dev\"\npython $ONMT/translate.py -model $model \\\n -src $OUT/data/valid.src \\\n -output $OUT/test/valid.out \\\n -replace_unk -verbose $GPU_OPTS > $OUT/test/valid.log\n\nif [[ \"$BPE\" == *\"tgt\"* ]]; then\n echo \"BPE decoding/detokenising target to match with references\"\n mv $OUT/test/test.out{,.bpe}\n mv $OUT/test/valid.out{,.bpe} \n cat $OUT/test/valid.out.bpe | sed -E 's/(@@ )|(@@ ?$)//g' > $OUT/test/valid.out\n cat $OUT/test/test.out.bpe | sed -E 's/(@@ )|(@@ ?$)//g' > $OUT/test/test.out\nfi\n\necho \"Step 4a: Evaluate Test\"\n$ONMT/tools/multi-bleu-detok.perl $OUT/data/test.tgt < $OUT/test/test.out > $OUT/test/test.tc.bleu\n$ONMT/tools/multi-bleu-detok.perl -lc $OUT/data/test.tgt < $OUT/test/test.out > $OUT/test/test.lc.bleu\n\necho \"Step 4b: Evaluate Dev\"\n$ONMT/tools/multi-bleu-detok.perl $OUT/data/valid.tgt < $OUT/test/valid.out > $OUT/test/valid.tc.bleu\n$ONMT/tools/multi-bleu-detok.perl -lc $OUT/data/valid.tgt < $OUT/test/valid.out > $OUT/test/valid.lc.bleu\n\n#===== EXPERIMENT END ======\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/create_vocabulary.py",
"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nimport argparse\nimport sys\nimport os\n\n\ndef read_files_batch(file_list):\n \"\"\"Reads the provided files in batches\"\"\"\n batch = [] # Keep batch for each file\n fd_list = [] # File descriptor list\n\n exit = False # Flag used for quitting the program in case of error\n try:\n for filename in file_list:\n fd_list.append(open(filename))\n\n for lines in zip(*fd_list):\n for i, line in enumerate(lines):\n line = line.rstrip(\"\\n\").split(\" \")\n batch.append(line)\n\n yield batch\n batch = [] # Reset batch\n\n except IOError:\n print(\"Error reading file \" + filename + \".\")\n exit = True # Flag to exit the program\n\n finally:\n for fd in fd_list:\n fd.close()\n\n if exit: # An error occurred, end execution\n sys.exit(-1)\n\n\ndef main():\n parser = argparse.ArgumentParser()\n parser.add_argument('-file_type', default='text',\n choices=['text', 'field'], required=True,\n help=\"\"\"Options for vocabulary creation.\n The default is 'text' where the user passes\n a corpus or a list of corpora files for which\n they want to create a vocabulary from.\n If choosing the option 'field', we assume\n the file passed is a torch file created during\n the preprocessing stage of an already\n preprocessed corpus. The vocabulary file created\n will just be the vocabulary inside the field\n corresponding to the argument 'side'.\"\"\")\n parser.add_argument(\"-file\", type=str, nargs=\"+\", required=True)\n parser.add_argument(\"-out_file\", type=str, required=True)\n parser.add_argument(\"-side\", choices=['src', 'tgt'], help=\"\"\"Specifies\n 'src' or 'tgt' side for 'field' file_type.\"\"\")\n\n opt = parser.parse_args()\n\n vocabulary = {}\n if opt.file_type == 'text':\n print(\"Reading input file...\")\n for batch in read_files_batch(opt.file):\n for sentence in batch:\n for w in sentence:\n if w in vocabulary:\n vocabulary[w] += 1\n else:\n vocabulary[w] = 1\n\n print(\"Writing vocabulary file...\")\n with open(opt.out_file, \"w\") as f:\n for w, count in sorted(vocabulary.items(), key=lambda x: x[1],\n reverse=True):\n f.write(\"{0}\\n\".format(w))\n else:\n if opt.side not in ['src', 'tgt']:\n raise ValueError(\"If using -file_type='field', specifies \"\n \"'src' or 'tgt' argument for -side.\")\n import torch\n try:\n from onmt.inputters.inputter import _old_style_vocab\n except ImportError:\n sys.path.insert(1, os.path.join(sys.path[0], '..'))\n from onmt.inputters.inputter import _old_style_vocab\n\n print(\"Reading input file...\")\n if not len(opt.file) == 1:\n raise ValueError(\"If using -file_type='field', only pass one \"\n \"argument for -file.\")\n vocabs = torch.load(opt.file[0])\n voc = dict(vocabs)[opt.side]\n if _old_style_vocab(voc):\n word_list = voc.itos\n else:\n try:\n word_list = voc[0][1].base_field.vocab.itos\n except AttributeError:\n word_list = voc[0][1].vocab.itos\n\n print(\"Writing vocabulary file...\")\n with open(opt.out_file, \"wb\") as f:\n for w in word_list:\n f.write(u\"{0}\\n\".format(w).encode(\"utf-8\"))\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/detokenize.perl",
"content": "#!/usr/bin/env perl\n\n# Note: retrieved from https://github.com/apache/incubator-joshua/blob/master/scripts/preparation/detokenize.pl\n\n# Licensed to the Apache Software Foundation (ASF) under one or more\n# contributor license agreements. See the NOTICE file distributed with\n# this work for additional information regarding copyright ownership.\n# The ASF licenses this file to You under the Apache License, Version 2.0\n# (the \"License\"); you may not use this file except in compliance with\n# the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nuse warnings;\nuse strict;\n\n# Sample De-Tokenizer\n# written by Josh Schroeder, based on code by Philipp Koehn\n# modified later by ByungGyu Ahn, bahn@cs.jhu.edu, Luke Orland\n\nbinmode(STDIN, \":utf8\");\nbinmode(STDOUT, \":utf8\");\n\nmy $language = \"en\";\nmy $QUIET = 1;\nmy $HELP = 0;\n\nwhile (@ARGV) {\n $_ = shift;\n /^-l$/ && ($language = shift, next);\n /^-v$/ && ($QUIET = 0, next);\n /^-h$/ && ($HELP = 1, next);\n}\n\nif ($HELP) {\n print \"Usage ./detokenizer.perl (-l [en|de|...]) < tokenizedfile > detokenizedfile\\n\";\n exit;\n}\nif (!$QUIET) {\n print STDERR \"Detokenizer Version 1.1\\n\";\n print STDERR \"Language: $language\\n\";\n}\n\nwhile() {\n if (/^<.+>$/ || /^\\s*$/) {\n #don't try to detokenize XML/HTML tag lines\n print $_;\n }\n else {\n print &detokenize($_);\n }\n}\n\nsub detokenize {\n my($text) = @_;\n chomp($text);\n $text = \" $text \";\n\n # convert curly quotes to ASCII e.g. ‘“”’\n $text =~ s/\\x{2018}/'/gs;\n $text =~ s/\\x{2019}/'/gs;\n $text =~ s/\\x{201c}/\"/gs;\n $text =~ s/\\x{201d}/\"/gs;\n $text =~ s/\\x{e2}\\x{80}\\x{98}/'/gs;\n $text =~ s/\\x{e2}\\x{80}\\x{99}/'/gs;\n $text =~ s/\\x{e2}\\x{80}\\x{9c}/\"/gs;\n $text =~ s/\\x{e2}\\x{80}\\x{9d}/\"/gs;\n\n $text =~ s/ '\\s+' / \" /g;\n $text =~ s/ ` / ' /g;\n $text =~ s/ ' / ' /g;\n $text =~ s/ `` / \" /g;\n $text =~ s/ '' / \" /g;\n\n # replace the pipe character, which is\n # a special reserved character in Moses\n $text =~ s/ -PIPE- / \\| /g;\n\n $text =~ s/ -LRB- / \\( /g;\n $text =~ s/ -RRB- / \\) /g;\n $text =~ s/ -LSB- / \\[ /g;\n $text =~ s/ -RSB- / \\] /g;\n $text =~ s/ -LCB- / \\{ /g;\n $text =~ s/ -RCB- / \\} /g;\n $text =~ s/ -lrb- / \\( /g;\n $text =~ s/ -rrb- / \\) /g;\n $text =~ s/ -lsb- / \\[ /g;\n $text =~ s/ -rsb- / \\] /g;\n $text =~ s/ -lcb- / \\{ /g;\n $text =~ s/ -rcb- / \\} /g;\n\n $text =~ s/ 'll /'ll /g;\n $text =~ s/ 're /'re /g;\n $text =~ s/ 've /'ve /g;\n $text =~ s/ n't /n't /g;\n $text =~ s/ 'LL /'LL /g;\n $text =~ s/ 'RE /'RE /g;\n $text =~ s/ 'VE /'VE /g;\n $text =~ s/ N'T /N'T /g;\n $text =~ s/ can not / cannot /g;\n $text =~ s/ Can not / Cannot /g;\n\n # just in case the contraction was not properly treated\n $text =~ s/ ' ll /'ll /g;\n $text =~ s/ ' re /'re /g;\n $text =~ s/ ' ve /'ve /g;\n $text =~ s/n ' t /n't /g;\n $text =~ s/ ' LL /'LL /g;\n $text =~ s/ ' RE /'RE /g;\n $text =~ s/ ' VE /'VE /g;\n $text =~ s/N ' T /N'T /g;\n\n my $word;\n my $i;\n my @words = split(/ /,$text);\n $text = \"\";\n my %quoteCount = (\"\\'\"=>0,\"\\\"\"=>0);\n my $prependSpace = \" \";\n for ($i=0;$i<(scalar(@words));$i++) {\n if ($words[$i] =~ /^[\\p{IsSc}]+$/) {\n #perform shift on currency\n if (($i<(scalar(@words)-1)) && ($words[$i+1] =~ /^[0-9]/)) {\n $text = $text.$prependSpace.$words[$i];\n $prependSpace = \"\";\n } else {\n $text=$text.$words[$i];\n $prependSpace = \" \";\n }\n } elsif ($words[$i] =~ /^[\\(\\[\\{\\¿\\¡]+$/) {\n #perform right shift on random punctuation items\n $text = $text.$prependSpace.$words[$i];\n $prependSpace = \"\";\n } elsif ($words[$i] =~ /^[\\,\\.\\?\\!\\:\\;\\\\\\%\\}\\]\\)]+$/){\n #perform left shift on punctuation items\n $text=$text.$words[$i];\n $prependSpace = \" \";\n } elsif (($language eq \"en\") && ($i>0) && ($words[$i] =~ /^[\\'][\\p{IsAlpha}]/) && ($words[$i-1] =~ /[\\p{IsAlnum}]$/)) {\n #left-shift the contraction for English\n $text=$text.$words[$i];\n $prependSpace = \" \";\n } elsif (($language eq \"en\") && ($i>0) && ($i<(scalar(@words)-1)) && ($words[$i] eq \"&\") && ($words[$i-1] =~ /^[A-Z]$/) && ($words[$i+1] =~ /^[A-Z]$/)) {\n #some contraction with an ampersand e.g. \"R&D\"\n $text .= $words[$i];\n $prependSpace = \"\";\n } elsif (($language eq \"fr\") && ($i<(scalar(@words)-1)) && ($words[$i] =~ /[\\p{IsAlpha}][\\']$/) && ($words[$i+1] =~ /^[\\p{IsAlpha}]/)) {\n #right-shift the contraction for French\n $text = $text.$prependSpace.$words[$i];\n $prependSpace = \"\";\n } elsif ($words[$i] =~ /^[\\'\\\"]+$/) {\n #combine punctuation smartly\n if (($quoteCount{$words[$i]} % 2) eq 0) {\n if(($language eq \"en\") && ($words[$i] eq \"'\") && ($i > 0) && ($words[$i-1] =~ /[s]$/)) {\n #single quote for posesssives ending in s... \"The Jones' house\"\n #left shift\n $text=$text.$words[$i];\n $prependSpace = \" \";\n } elsif (($language eq \"en\") && ($words[$i] eq \"'\") && ($i < (scalar(@words)-1)) && ($words[$i+1] eq \"s\")) {\n #single quote for possessive construction. \"John's\"\n $text .= $words[$i];\n $prependSpace = \"\";\n } elsif (($quoteCount{$words[$i]} == 0) &&\n ($language eq \"en\") && ($words[$i] eq '\"') && ($i>1) && ($words[$i-1] =~ /^[,.]$/) && ($words[$i-2] ne \"said\")) {\n #emergency case in which the opening quote is missing\n #ending double quote for direct quotes. e.g. Blah,\" he said. but not like he said, \"Blah.\n $text .= $words[$i];\n $prependSpace = \" \";\n } elsif (($language eq \"en\") && ($words[$i] eq '\"') && ($i < (scalar(@words)-1)) && ($words[$i+1] =~ /^[,.]$/)) {\n $text .= $words[$i];\n $prependSpace = \" \";\n } else {\n #right shift\n $text = $text.$prependSpace.$words[$i];\n $prependSpace = \"\";\n $quoteCount{$words[$i]} = $quoteCount{$words[$i]} + 1;\n\n }\n } else {\n #left shift\n $text=$text.$words[$i];\n $prependSpace = \" \";\n $quoteCount{$words[$i]} = $quoteCount{$words[$i]} + 1;\n\n }\n\n } else {\n $text=$text.$prependSpace.$words[$i];\n $prependSpace = \" \";\n }\n }\n\n #clean continuing spaces\n $text =~ s/ +/ /g;\n\n #delete spaces around double angle brackets «»\n # Uh-oh. not a good idea. it is not consistent.\n $text =~ s/(\\x{c2}\\x{ab}|\\x{ab}) /$1/g;\n $text =~ s/ (\\x{c2}\\x{bb}|\\x{bb})/$1/g;\n\n # delete spaces around all other special characters\n # Uh-oh. not a good idea. \"Men&Women\"\n #$text =~ s/ ([^\\p{IsAlnum}\\s\\.\\'\\`\\,\\-\\\"\\|]) /$1/g;\n $text =~ s/ \\/ /\\//g;\n\n # clean up spaces at head and tail of each line as well as any double-spacing\n $text =~ s/\\n /\\n/g;\n $text =~ s/ \\n/\\n/g;\n $text =~ s/^ //g;\n $text =~ s/ $//g;\n\n #add trailing break\n $text .= \"\\n\" unless $text =~ /\\n$/;\n\n return $text;\n}\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/embeddings_to_torch.py",
"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom __future__ import division\nimport six\nimport argparse\nimport torch\nfrom onmt.utils.logging import init_logger, logger\nfrom onmt.inputters.inputter import _old_style_vocab\n\n\ndef get_vocabs(dict_path):\n fields = torch.load(dict_path)\n\n vocs = []\n for side in ['src', 'tgt']:\n if _old_style_vocab(fields):\n vocab = next((v for n, v in fields if n == side), None)\n else:\n try:\n vocab = fields[side].base_field.vocab\n except AttributeError:\n vocab = fields[side].vocab\n vocs.append(vocab)\n enc_vocab, dec_vocab = vocs\n\n logger.info(\"From: %s\" % dict_path)\n logger.info(\"\\t* source vocab: %d words\" % len(enc_vocab))\n logger.info(\"\\t* target vocab: %d words\" % len(dec_vocab))\n\n return enc_vocab, dec_vocab\n\n\ndef read_embeddings(file_enc, skip_lines=0, filter_set=None):\n embs = dict()\n total_vectors_in_file = 0\n with open(file_enc, 'rb') as f:\n for i, line in enumerate(f):\n if i < skip_lines:\n continue\n if not line:\n break\n if len(line) == 0:\n # is this reachable?\n continue\n\n l_split = line.decode('utf8').strip().split(' ')\n if len(l_split) == 2:\n continue\n total_vectors_in_file += 1\n if filter_set is not None and l_split[0] not in filter_set:\n continue\n embs[l_split[0]] = [float(em) for em in l_split[1:]]\n return embs, total_vectors_in_file\n\n\ndef convert_to_torch_tensor(word_to_float_list_dict, vocab):\n dim = len(six.next(six.itervalues(word_to_float_list_dict)))\n tensor = torch.zeros((len(vocab), dim))\n for word, values in word_to_float_list_dict.items():\n tensor[vocab.stoi[word]] = torch.Tensor(values)\n return tensor\n\n\ndef calc_vocab_load_stats(vocab, loaded_embed_dict):\n matching_count = len(\n set(vocab.stoi.keys()) & set(loaded_embed_dict.keys()))\n missing_count = len(vocab) - matching_count\n percent_matching = matching_count / len(vocab) * 100\n return matching_count, missing_count, percent_matching\n\n\ndef main():\n parser = argparse.ArgumentParser(description='embeddings_to_torch.py')\n parser.add_argument('-emb_file_both', required=False,\n help=\"loads Embeddings for both source and target \"\n \"from this file.\")\n parser.add_argument('-emb_file_enc', required=False,\n help=\"source Embeddings from this file\")\n parser.add_argument('-emb_file_dec', required=False,\n help=\"target Embeddings from this file\")\n parser.add_argument('-output_file', required=True,\n help=\"Output file for the prepared data\")\n parser.add_argument('-dict_file', required=True,\n help=\"Dictionary file\")\n parser.add_argument('-verbose', action=\"store_true\", default=False)\n parser.add_argument('-skip_lines', type=int, default=0,\n help=\"Skip first lines of the embedding file\")\n parser.add_argument('-type', choices=[\"GloVe\", \"word2vec\"],\n default=\"GloVe\")\n opt = parser.parse_args()\n\n enc_vocab, dec_vocab = get_vocabs(opt.dict_file)\n\n # Read in embeddings\n skip_lines = 1 if opt.type == \"word2vec\" else opt.skip_lines\n if opt.emb_file_both is not None:\n if opt.emb_file_enc is not None:\n raise ValueError(\"If --emb_file_both is passed in, you should not\"\n \"set --emb_file_enc.\")\n if opt.emb_file_dec is not None:\n raise ValueError(\"If --emb_file_both is passed in, you should not\"\n \"set --emb_file_dec.\")\n set_of_src_and_tgt_vocab = \\\n set(enc_vocab.stoi.keys()) | set(dec_vocab.stoi.keys())\n logger.info(\"Reading encoder and decoder embeddings from {}\".format(\n opt.emb_file_both))\n src_vectors, total_vec_count = \\\n read_embeddings(opt.emb_file_both, skip_lines,\n set_of_src_and_tgt_vocab)\n tgt_vectors = src_vectors\n logger.info(\"\\tFound {} total vectors in file\".format(total_vec_count))\n else:\n if opt.emb_file_enc is None:\n raise ValueError(\"If --emb_file_enc not provided. Please specify \"\n \"the file with encoder embeddings, or pass in \"\n \"--emb_file_both\")\n if opt.emb_file_dec is None:\n raise ValueError(\"If --emb_file_dec not provided. Please specify \"\n \"the file with encoder embeddings, or pass in \"\n \"--emb_file_both\")\n logger.info(\"Reading encoder embeddings from {}\".format(\n opt.emb_file_enc))\n src_vectors, total_vec_count = read_embeddings(\n opt.emb_file_enc, skip_lines,\n filter_set=enc_vocab.stoi\n )\n logger.info(\"\\tFound {} total vectors in file.\".format(\n total_vec_count))\n logger.info(\"Reading decoder embeddings from {}\".format(\n opt.emb_file_dec))\n tgt_vectors, total_vec_count = read_embeddings(\n opt.emb_file_dec, skip_lines,\n filter_set=dec_vocab.stoi\n )\n logger.info(\"\\tFound {} total vectors in file\".format(total_vec_count))\n logger.info(\"After filtering to vectors in vocab:\")\n logger.info(\"\\t* enc: %d match, %d missing, (%.2f%%)\"\n % calc_vocab_load_stats(enc_vocab, src_vectors))\n logger.info(\"\\t* dec: %d match, %d missing, (%.2f%%)\"\n % calc_vocab_load_stats(dec_vocab, tgt_vectors))\n\n # Write to file\n enc_output_file = opt.output_file + \".enc.pt\"\n dec_output_file = opt.output_file + \".dec.pt\"\n logger.info(\"\\nSaving embedding as:\\n\\t* enc: %s\\n\\t* dec: %s\"\n % (enc_output_file, dec_output_file))\n torch.save(\n convert_to_torch_tensor(src_vectors, enc_vocab),\n enc_output_file\n )\n torch.save(\n convert_to_torch_tensor(tgt_vectors, dec_vocab),\n dec_output_file\n )\n logger.info(\"\\nDone.\")\n\n\nif __name__ == \"__main__\":\n init_logger('embeddings_to_torch.log')\n main()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/extract_embeddings.py",
"content": "import argparse\n\nimport torch\n\nimport onmt\nimport onmt.model_builder\nimport onmt.inputters as inputters\nimport onmt.opts\n\nfrom onmt.utils.misc import use_gpu\nfrom onmt.utils.logging import init_logger, logger\n\nparser = argparse.ArgumentParser(description='translate.py')\n\nparser.add_argument('-model', required=True,\n help='Path to model .pt file')\nparser.add_argument('-output_dir', default='.',\n help=\"\"\"Path to output the embeddings\"\"\")\nparser.add_argument('-gpu', type=int, default=-1,\n help=\"Device to run on\")\n\n\ndef write_embeddings(filename, dict, embeddings):\n with open(filename, 'wb') as file:\n for i in range(min(len(embeddings), len(dict.itos))):\n str = dict.itos[i].encode(\"utf-8\")\n for j in range(len(embeddings[0])):\n str = str + (\" %5f\" % (embeddings[i][j])).encode(\"utf-8\")\n file.write(str + b\"\\n\")\n\n\ndef main():\n dummy_parser = argparse.ArgumentParser(description='train.py')\n onmt.opts.model_opts(dummy_parser)\n dummy_opt = dummy_parser.parse_known_args([])[0]\n opt = parser.parse_args()\n opt.cuda = opt.gpu > -1\n if opt.cuda:\n torch.cuda.set_device(opt.gpu)\n\n # Add in default model arguments, possibly added since training.\n checkpoint = torch.load(opt.model,\n map_location=lambda storage, loc: storage)\n model_opt = checkpoint['opt']\n\n vocab = checkpoint['vocab']\n if inputters.old_style_vocab(vocab):\n fields = onmt.inputters.load_old_vocab(vocab)\n else:\n fields = vocab\n src_dict = fields['src'].base_field.vocab # assumes src is text\n tgt_dict = fields['tgt'].base_field.vocab\n\n model_opt = checkpoint['opt']\n for arg in dummy_opt.__dict__:\n if arg not in model_opt:\n model_opt.__dict__[arg] = dummy_opt.__dict__[arg]\n\n model = onmt.model_builder.build_base_model(\n model_opt, fields, use_gpu(opt), checkpoint)\n encoder = model.encoder\n decoder = model.decoder\n\n encoder_embeddings = encoder.embeddings.word_lut.weight.data.tolist()\n decoder_embeddings = decoder.embeddings.word_lut.weight.data.tolist()\n\n logger.info(\"Writing source embeddings\")\n write_embeddings(opt.output_dir + \"/src_embeddings.txt\", src_dict,\n encoder_embeddings)\n\n logger.info(\"Writing target embeddings\")\n write_embeddings(opt.output_dir + \"/tgt_embeddings.txt\", tgt_dict,\n decoder_embeddings)\n\n logger.info('... done.')\n logger.info('Converting model...')\n\n\nif __name__ == \"__main__\":\n init_logger('extract_embeddings.log')\n main()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/learn_bpe.py",
"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n# Author: Rico Sennrich\n# flake8: noqa\n\n\"\"\"Use byte pair encoding (BPE) to learn a variable-length encoding of the vocabulary in a text.\nUnlike the original BPE, it does not compress the plain text, but can be used to reduce the vocabulary\nof a text to a configurable number of symbols, with only a small increase in the number of tokens.\n\nReference:\nRico Sennrich, Barry Haddow and Alexandra Birch (2016). Neural Machine Translation of Rare Words with Subword Units.\nProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016). Berlin, Germany.\n\"\"\"\n# This file is retrieved from https://github.com/rsennrich/subword-nmt\n\nfrom __future__ import unicode_literals\n\nimport sys\nimport codecs\nimport re\nimport copy\nimport argparse\nfrom collections import defaultdict, Counter\n\n# hack for python2/3 compatibility\nfrom io import open\nargparse.open = open\n\n\ndef create_parser():\n parser = argparse.ArgumentParser(\n formatter_class=argparse.RawDescriptionHelpFormatter,\n description=\"learn BPE-based word segmentation\")\n\n parser.add_argument(\n '--input', '-i', type=argparse.FileType('r'), default=sys.stdin,\n metavar='PATH',\n help=\"Input text (default: standard input).\")\n\n parser.add_argument(\n '--output', '-o', type=argparse.FileType('w'), default=sys.stdout,\n metavar='PATH',\n help=\"Output file for BPE codes (default: standard output)\")\n parser.add_argument(\n '--symbols', '-s', type=int, default=10000,\n help=\"Create this many new symbols (each representing a character n-gram) (default: %(default)s))\")\n parser.add_argument(\n '--min-frequency', type=int, default=2, metavar='FREQ',\n help='Stop if no symbol pair has frequency >= FREQ (default: %(default)s))')\n parser.add_argument('--dict-input', action=\"store_true\",\n help=\"If set, input file is interpreted as a dictionary where each line contains a word-count pair\")\n parser.add_argument(\n '--verbose', '-v', action=\"store_true\",\n help=\"verbose mode.\")\n\n return parser\n\n\ndef get_vocabulary(fobj, is_dict=False):\n \"\"\"Read text and return dictionary that encodes vocabulary\n \"\"\"\n vocab = Counter()\n for line in fobj:\n if is_dict:\n word, count = line.strip().split()\n vocab[word] = int(count)\n else:\n for word in line.split():\n vocab[word] += 1\n return vocab\n\n\ndef update_pair_statistics(pair, changed, stats, indices):\n \"\"\"Minimally update the indices and frequency of symbol pairs\n\n if we merge a pair of symbols, only pairs that overlap with occurrences\n of this pair are affected, and need to be updated.\n \"\"\"\n stats[pair] = 0\n indices[pair] = defaultdict(int)\n first, second = pair\n new_pair = first + second\n for j, word, old_word, freq in changed:\n\n # find all instances of pair, and update frequency/indices around it\n i = 0\n while True:\n # find first symbol\n try:\n i = old_word.index(first, i)\n except ValueError:\n break\n # if first symbol is followed by second symbol, we've found an occurrence of pair (old_word[i:i+2])\n if i < len(old_word) - 1 and old_word[i + 1] == second:\n # assuming a symbol sequence \"A B C\", if \"B C\" is merged, reduce the frequency of \"A B\"\n if i:\n prev = old_word[i - 1:i + 1]\n stats[prev] -= freq\n indices[prev][j] -= 1\n if i < len(old_word) - 2:\n # assuming a symbol sequence \"A B C B\", if \"B C\" is merged, reduce the frequency of \"C B\".\n # however, skip this if the sequence is A B C B C, because the frequency of \"C B\" will be reduced by the previous code block\n if old_word[i + 2] != first or i >= len(old_word) - 3 or old_word[i + 3] != second:\n nex = old_word[i + 1:i + 3]\n stats[nex] -= freq\n indices[nex][j] -= 1\n i += 2\n else:\n i += 1\n\n i = 0\n while True:\n try:\n # find new pair\n i = word.index(new_pair, i)\n except ValueError:\n break\n # assuming a symbol sequence \"A BC D\", if \"B C\" is merged, increase the frequency of \"A BC\"\n if i:\n prev = word[i - 1:i + 1]\n stats[prev] += freq\n indices[prev][j] += 1\n # assuming a symbol sequence \"A BC B\", if \"B C\" is merged, increase the frequency of \"BC B\"\n # however, if the sequence is A BC BC, skip this step because the count of \"BC BC\" will be incremented by the previous code block\n if i < len(word) - 1 and word[i + 1] != new_pair:\n nex = word[i:i + 2]\n stats[nex] += freq\n indices[nex][j] += 1\n i += 1\n\n\ndef get_pair_statistics(vocab):\n \"\"\"Count frequency of all symbol pairs, and create index\"\"\"\n\n # data structure of pair frequencies\n stats = defaultdict(int)\n\n # index from pairs to words\n indices = defaultdict(lambda: defaultdict(int))\n\n for i, (word, freq) in enumerate(vocab):\n prev_char = word[0]\n for char in word[1:]:\n stats[prev_char, char] += freq\n indices[prev_char, char][i] += 1\n prev_char = char\n\n return stats, indices\n\n\ndef replace_pair(pair, vocab, indices):\n \"\"\"Replace all occurrences of a symbol pair ('A', 'B') with a new symbol 'AB'\"\"\"\n first, second = pair\n pair_str = ''.join(pair)\n pair_str = pair_str.replace('\\\\', '\\\\\\\\')\n changes = []\n pattern = re.compile(\n r'(?');\n # version numbering allows bckward compatibility\n outfile.write('#version: 0.2\\n')\n\n vocab = get_vocabulary(infile, is_dict)\n vocab = dict([(tuple(x[:-1]) + (x[-1] + '',), y)\n for (x, y) in vocab.items()])\n sorted_vocab = sorted(vocab.items(), key=lambda x: x[1], reverse=True)\n\n stats, indices = get_pair_statistics(sorted_vocab)\n big_stats = copy.deepcopy(stats)\n # threshold is inspired by Zipfian assumption, but should only affect speed\n threshold = max(stats.values()) / 10\n for i in range(num_symbols):\n if stats:\n most_frequent = max(stats, key=lambda x: (stats[x], x))\n\n # we probably missed the best pair because of pruning; go back to full statistics\n if not stats or (i and stats[most_frequent] < threshold):\n prune_stats(stats, big_stats, threshold)\n stats = copy.deepcopy(big_stats)\n most_frequent = max(stats, key=lambda x: (stats[x], x))\n # threshold is inspired by Zipfian assumption, but should only affect speed\n threshold = stats[most_frequent] * i / (i + 10000.0)\n prune_stats(stats, big_stats, threshold)\n\n if stats[most_frequent] < min_frequency:\n sys.stderr.write(\n 'no pair has frequency >= {0}. Stopping\\n'.format(min_frequency))\n break\n\n if verbose:\n sys.stderr.write('pair {0}: {1} {2} -> {1}{2} (frequency {3})\\n'.format(\n i, most_frequent[0], most_frequent[1], stats[most_frequent]))\n outfile.write('{0} {1}\\n'.format(*most_frequent))\n changes = replace_pair(most_frequent, sorted_vocab, indices)\n update_pair_statistics(most_frequent, changes, stats, indices)\n stats[most_frequent] = 0\n if not i % 100:\n prune_stats(stats, big_stats, threshold)\n\n\nif __name__ == '__main__':\n\n # python 2/3 compatibility\n if sys.version_info < (3, 0):\n sys.stderr = codecs.getwriter('UTF-8')(sys.stderr)\n sys.stdout = codecs.getwriter('UTF-8')(sys.stdout)\n sys.stdin = codecs.getreader('UTF-8')(sys.stdin)\n else:\n sys.stderr = codecs.getwriter('UTF-8')(sys.stderr.buffer)\n sys.stdout = codecs.getwriter('UTF-8')(sys.stdout.buffer)\n sys.stdin = codecs.getreader('UTF-8')(sys.stdin.buffer)\n\n parser = create_parser()\n args = parser.parse_args()\n\n # read/write files as UTF-8\n if args.input.name != '':\n args.input = codecs.open(args.input.name, encoding='utf-8')\n if args.output.name != '':\n args.output = codecs.open(args.output.name, 'w', encoding='utf-8')\n\n main(args.input, args.output, args.symbols,\n args.min_frequency, args.verbose, is_dict=args.dict_input)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/multi-bleu-detok.perl",
"content": "#!/usr/bin/env perl\n#\n# This file is part of moses. Its use is licensed under the GNU Lesser General\n# Public License version 2.1 or, at your option, any later version.\n\n# This file uses the internal tokenization of mteval-v13a.pl,\n# giving the exact same (case-sensitive) results on untokenized text.\n# Using this script with detokenized output and untokenized references is\n# preferrable over multi-bleu.perl, since scores aren't affected by tokenization differences.\n# \n# like multi-bleu.perl , it supports plain text input and multiple references.\n\n# This file is retrieved from Moses Decoder :: https://github.com/moses-smt/mosesdecoder\n# $Id$\nuse warnings;\nuse strict;\n\nmy $lowercase = 0;\nif ($ARGV[0] eq \"-lc\") {\n $lowercase = 1;\n shift;\n}\n\nmy $stem = $ARGV[0];\nif (!defined $stem) {\n print STDERR \"usage: multi-bleu-detok.pl [-lc] reference < hypothesis\\n\";\n print STDERR \"Reads the references from reference or reference0, reference1, ...\\n\";\n exit(1);\n}\n\n$stem .= \".ref\" if !-e $stem && !-e $stem.\"0\" && -e $stem.\".ref0\";\n\nmy @REF;\nmy $ref=0;\nwhile(-e \"$stem$ref\") {\n &add_to_ref(\"$stem$ref\",\\@REF);\n $ref++;\n}\n&add_to_ref($stem,\\@REF) if -e $stem;\ndie(\"ERROR: could not find reference file $stem\") unless scalar @REF;\n\n# add additional references explicitly specified on the command line\nshift;\nforeach my $stem (@ARGV) {\n &add_to_ref($stem,\\@REF) if -e $stem;\n}\n\n\n\nsub add_to_ref {\n my ($file,$REF) = @_;\n my $s=0;\n if ($file =~ /.gz$/) {\n\topen(REF,\"gzip -dc $file|\") or die \"Can't read $file\";\n } else { \n\topen(REF,$file) or die \"Can't read $file\";\n }\n while([) {\n\tchop;\n\t$_ = tokenization($_);\n\tpush @{$$REF[$s++]}, $_;\n }\n close(REF);\n}\n\nmy(@CORRECT,@TOTAL,$length_translation,$length_reference);\nmy $s=0;\nwhile() {\n chop;\n $_ = lc if $lowercase;\n $_ = tokenization($_);\n my @WORD = split;\n my %REF_NGRAM = ();\n my $length_translation_this_sentence = scalar(@WORD);\n my ($closest_diff,$closest_length) = (9999,9999);\n foreach my $reference (@{$REF[$s]}) {\n# print \"$s $_ <=> $reference\\n\";\n $reference = lc($reference) if $lowercase;\n\tmy @WORD = split(' ',$reference);\n\tmy $length = scalar(@WORD);\n my $diff = abs($length_translation_this_sentence-$length);\n\tif ($diff < $closest_diff) {\n\t $closest_diff = $diff;\n\t $closest_length = $length;\n\t # print STDERR \"$s: closest diff \".abs($length_translation_this_sentence-$length).\" = abs($length_translation_this_sentence-$length), setting len: $closest_length\\n\";\n\t} elsif ($diff == $closest_diff) {\n $closest_length = $length if $length < $closest_length;\n # from two references with the same closeness to me\n # take the *shorter* into account, not the \"first\" one.\n }\n\tfor(my $n=1;$n<=4;$n++) {\n\t my %REF_NGRAM_N = ();\n\t for(my $start=0;$start<=$#WORD-($n-1);$start++) {\n\t\tmy $ngram = \"$n\";\n\t\tfor(my $w=0;$w<$n;$w++) {\n\t\t $ngram .= \" \".$WORD[$start+$w];\n\t\t}\n\t\t$REF_NGRAM_N{$ngram}++;\n\t }\n\t foreach my $ngram (keys %REF_NGRAM_N) {\n\t\tif (!defined($REF_NGRAM{$ngram}) ||\n\t\t $REF_NGRAM{$ngram} < $REF_NGRAM_N{$ngram}) {\n\t\t $REF_NGRAM{$ngram} = $REF_NGRAM_N{$ngram};\n#\t print \"$i: REF_NGRAM{$ngram} = $REF_NGRAM{$ngram}]
\\n\";\n\t\t}\n\t }\n\t}\n }\n $length_translation += $length_translation_this_sentence;\n $length_reference += $closest_length;\n for(my $n=1;$n<=4;$n++) {\n\tmy %T_NGRAM = ();\n\tfor(my $start=0;$start<=$#WORD-($n-1);$start++) {\n\t my $ngram = \"$n\";\n\t for(my $w=0;$w<$n;$w++) {\n\t\t$ngram .= \" \".$WORD[$start+$w];\n\t }\n\t $T_NGRAM{$ngram}++;\n\t}\n\tforeach my $ngram (keys %T_NGRAM) {\n\t $ngram =~ /^(\\d+) /;\n\t my $n = $1;\n # my $corr = 0;\n#\tprint \"$i e $ngram $T_NGRAM{$ngram}
\\n\";\n\t $TOTAL[$n] += $T_NGRAM{$ngram};\n\t if (defined($REF_NGRAM{$ngram})) {\n\t\tif ($REF_NGRAM{$ngram} >= $T_NGRAM{$ngram}) {\n\t\t $CORRECT[$n] += $T_NGRAM{$ngram};\n # $corr = $T_NGRAM{$ngram};\n#\t print \"$i e correct1 $T_NGRAM{$ngram}
\\n\";\n\t\t}\n\t\telse {\n\t\t $CORRECT[$n] += $REF_NGRAM{$ngram};\n # $corr = $REF_NGRAM{$ngram};\n#\t print \"$i e correct2 $REF_NGRAM{$ngram}
\\n\";\n\t\t}\n\t }\n # $REF_NGRAM{$ngram} = 0 if !defined $REF_NGRAM{$ngram};\n # print STDERR \"$ngram: {$s, $REF_NGRAM{$ngram}, $T_NGRAM{$ngram}, $corr}\\n\"\n\t}\n }\n $s++;\n}\nmy $brevity_penalty = 1;\nmy $bleu = 0;\n\nmy @bleu=();\n\nfor(my $n=1;$n<=4;$n++) {\n if (defined ($TOTAL[$n])){\n $bleu[$n]=($TOTAL[$n])?$CORRECT[$n]/$TOTAL[$n]:0;\n # print STDERR \"CORRECT[$n]:$CORRECT[$n] TOTAL[$n]:$TOTAL[$n]\\n\";\n }else{\n $bleu[$n]=0;\n }\n}\n\nif ($length_reference==0){\n printf \"BLEU = 0, 0/0/0/0 (BP=0, ratio=0, hyp_len=0, ref_len=0)\\n\";\n exit(1);\n}\n\nif ($length_translation<$length_reference) {\n $brevity_penalty = exp(1-$length_reference/$length_translation);\n}\n$bleu = $brevity_penalty * exp((my_log( $bleu[1] ) +\n\t\t\t\tmy_log( $bleu[2] ) +\n\t\t\t\tmy_log( $bleu[3] ) +\n\t\t\t\tmy_log( $bleu[4] ) ) / 4) ;\nprintf \"BLEU = %.2f, %.1f/%.1f/%.1f/%.1f (BP=%.3f, ratio=%.3f, hyp_len=%d, ref_len=%d)\\n\",\n 100*$bleu,\n 100*$bleu[1],\n 100*$bleu[2],\n 100*$bleu[3],\n 100*$bleu[4],\n $brevity_penalty,\n $length_translation / $length_reference,\n $length_translation,\n $length_reference;\n\nsub my_log {\n return -9999999999 unless $_[0];\n return log($_[0]);\n}\n\n\n\nsub tokenization\n{\n\tmy ($norm_text) = @_;\n\n# language-independent part:\n\t$norm_text =~ s///g; # strip \"skipped\" tags\n\t$norm_text =~ s/-\\n//g; # strip end-of-line hyphenation and join lines\n\t$norm_text =~ s/\\n/ /g; # join lines\n\t$norm_text =~ s/"/\"/g; # convert SGML tag for quote to \"\n\t$norm_text =~ s/&/&/g; # convert SGML tag for ampersand to &\n\t$norm_text =~ s/</\n\t$norm_text =~ s/>/>/g; # convert SGML tag for greater-than to <\n\n# language-dependent part (assuming Western languages):\n\t$norm_text = \" $norm_text \";\n\t$norm_text =~ s/([\\{-\\~\\[-\\` -\\&\\(-\\+\\:-\\@\\/])/ $1 /g; # tokenize punctuation\n\t$norm_text =~ s/([^0-9])([\\.,])/$1 $2 /g; # tokenize period and comma unless preceded by a digit\n\t$norm_text =~ s/([\\.,])([^0-9])/ $1 $2/g; # tokenize period and comma unless followed by a digit\n\t$norm_text =~ s/([0-9])(-)/$1 $2 /g; # tokenize dash when preceded by a digit\n\t$norm_text =~ s/\\s+/ /g; # one space only between words\n\t$norm_text =~ s/^\\s+//; # no leading space\n\t$norm_text =~ s/\\s+$//; # no trailing space\n\n\treturn $norm_text;\n}\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/README.txt",
"content": "The language suffix can be found here:\n\nhttp://www.loc.gov/standards/iso639-2/php/code_list.php\n\nThis code includes data from Daniel Naber's Language Tools (czech abbreviations).\nThis code includes data from czech wiktionary (also czech abbreviations).\n\n\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.ca",
"content": "Dr\nDra\npàg\np\nc\nav\nSr\nSra\nadm\nesq\nProf\nS.A\nS.L\np.e\nptes\nSta\nSt\npl\nmàx\ncast\ndir\nnre\nfra\nadmdora\nEmm\nExcma\nespf\ndc\nadmdor\ntel\nangl\naprox\nca\ndept\ndj\ndl\ndt\nds\ndg\ndv\ned\nentl\nal\ni.e\nmaj\nsmin\nn\nnúm\npta\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.cs",
"content": "Bc\nBcA\nIng\nIng.arch\nMUDr\nMVDr\nMgA\nMgr\nJUDr\nPhDr\nRNDr\nPharmDr\nThLic\nThDr\nPh.D\nTh.D\nprof\ndoc\nCSc\nDrSc\ndr. h. c\nPaedDr\nDr\nPhMr\nDiS\nabt\nad\na.i\naj\nangl\nanon\napod\natd\natp\naut\nbd\nbiogr\nb.m\nb.p\nb.r\ncca\ncit\ncizojaz\nc.k\ncol\nčes\nčín\nčj\ned\nfacs\nfasc\nfol\nfot\nfranc\nh.c\nhist\nhl\nhrsg\nibid\nil\nind\ninv.č\njap\njhdt\njv\nkoed\nkol\nkorej\nkl\nkrit\nlat\nlit\nm.a\nmaď\nmj\nmp\nnásl\nnapř\nnepubl\nněm\nno\nnr\nn.s\nokr\nodd\nodp\nobr\nopr\norig\nphil\npl\npokrač\npol\nport\npozn\npř.kr\npř.n.l\npřel\npřeprac\npříl\npseud\npt\nred\nrepr\nresp\nrevid\nrkp\nroč\nroz\nrozš\nsamost\nsect\nsest\nseš\nsign\nsl\nsrv\nstol\nsv\nšk\nšk.ro\nšpan\ntab\nt.č\ntis\ntj\ntř\ntzv\nuniv\nuspoř\nvol\nvl.jm\nvs\nvyd\nvyobr\nzal\nzejm\nzkr\nzprac\nzvl\nn.p\nnapř\nnež\nMUDr\nabl\nabsol\nadj\nadv\nak\nak. sl\nakt\nalch\namer\nanat\nangl\nanglosas\narab\narch\narchit\narg\nastr\nastrol\natt\nbás\nbelg\nbibl\nbiol\nboh\nbot\nbulh\ncírk\ncsl\nč\nčas\nčes\ndat\nděj\ndep\ndět\ndial\ndór\ndopr\ndosl\nekon\nepic\netnonym\neufem\nf\nfam\nfem\nfil\nfilm\nform\nfot\nfr\nfut\nfyz\ngen\ngeogr\ngeol\ngeom\ngerm\ngram\nhebr\nherald\nhist\nhl\nhovor\nhud\nhut\nchcsl\nchem\nie\nimp\nimpf\nind\nindoevr\ninf\ninstr\ninterj\nión\niron\nit\nkanad\nkatalán\nklas\nkniž\nkomp\nkonj\n \nkonkr\nkř\nkuch\nlat\nlék\nles\nlid\nlit\nliturg\nlok\nlog\nm\nmat\nmeteor\nmetr\nmod\nms\nmysl\nn\nnáb\nnámoř\nneklas\nněm\nnesklon\nnom\nob\nobch\nobyč\nojed\nopt\npart\npas\npejor\npers\npf\npl\nplpf\n \npráv\nprep\npředl\npřivl\nr\nrcsl\nrefl\nreg\nrkp\nř\nřec\ns\nsamohl\nsg\nsl\nsouhl\nspec\nsrov\nstfr\nstřv\nstsl\nsubj\nsubst\nsuperl\nsv\nsz\ntáz\ntech\ntelev\nteol\ntrans\ntypogr\nvar\nvedl\nverb\nvl. jm\nvoj\nvok\nvůb\nvulg\nvýtv\nvztaž\nzahr\nzájm\nzast\nzejm\n \nzeměd\nzkr\nzř\nmj\ndl\natp\nsport\nMgr\nhorn\nMVDr\nJUDr\nRSDr\nBc\nPhDr\nThDr\nIng\naj\napod\nPharmDr\npomn\nev\nslang\nnprap\nodp\ndop\npol\nst\nstol\np. n. l\npřed n. l\nn. l\npř. Kr\npo Kr\npř. n. l\nodd\nRNDr\ntzv\natd\ntzn\nresp\ntj\np\nbr\nč. j\nčj\nč. p\nčp\na. s\ns. r. o\nspol. s r. o\np. o\ns. p\nv. o. s\nk. s\no. p. s\no. s\nv. r\nv z\nml\nvč\nkr\nmld\nhod\npopř\nap\nevent\nrus\nslov\nrum\nšvýc\nP. T\nzvl\nhor\ndol\nS.O.S"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.de",
"content": "#Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.\n#Special cases are included for prefixes that ONLY appear before 0-9 numbers.\n\n#any single upper case letter followed by a period is not a sentence ender (excluding I occasionally, but we leave it in)\n#usually upper case letters are initials in a name\n#no german words end in single lower-case letters, so we throw those in too.\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\na\nb\nc\nd\ne\nf\ng\nh\ni\nj\nk\nl\nm\nn\no\np\nq\nr\ns\nt\nu\nv\nw\nx\ny\nz\n\n\n#Roman Numerals. A dot after one of these is not a sentence break in German.\nI\nII\nIII\nIV\nV\nVI\nVII\nVIII\nIX\nX\nXI\nXII\nXIII\nXIV\nXV\nXVI\nXVII\nXVIII\nXIX\nXX\ni\nii\niii\niv\nv\nvi\nvii\nviii\nix\nx\nxi\nxii\nxiii\nxiv\nxv\nxvi\nxvii\nxviii\nxix\nxx\n\n#Titles and Honorifics\nAdj\nAdm\nAdv\nAsst\nBart\nBldg\nBrig\nBros\nCapt\nCmdr\nCol\nComdr\nCon\nCorp\nCpl\nDR\nDr\nEns\nGen\nGov\nHon\nHosp\nInsp\nLt\nMM\nMR\nMRS\nMS\nMaj\nMessrs\nMlle\nMme\nMr\nMrs\nMs\nMsgr\nOp\nOrd\nPfc\nPh\nProf\nPvt\nRep\nReps\nRes\nRev\nRt\nSen\nSens\nSfc\nSgt\nSr\nSt\nSupt\nSurg\n\n#Misc symbols\nMio\nMrd\nbzw\nv\nvs\nusw\nd.h\nz.B\nu.a\netc\nMrd\nMwSt\nggf\nd.J\nD.h\nm.E\nvgl\nI.F\nz.T\nsogen\nff\nu.E\ng.U\ng.g.A\nc.-à-d\nBuchst\nu.s.w\nsog\nu.ä\nStd\nevtl\nZt\nChr\nu.U\no.ä\nLtd\nb.A\nz.Zt\nspp\nsen\nSA\nk.o\njun\ni.H.v\ndgl\ndergl\nCo\nzzt\nusf\ns.p.a\nDkr\nCorp\nbzgl\nBSE\n\n#Number indicators\n# add #NUMERIC_ONLY# after the word if it should ONLY be non-breaking when a 0-9 digit follows it\nNo\nNos\nArt\nNr\npp\nca\nCa\n\n#Ordinals are done with . in German - \"1.\" = \"1st\" in English\n1\n2\n3\n4\n5\n6\n7\n8\n9\n10\n11\n12\n13\n14\n15\n16\n17\n18\n19\n20\n21\n22\n23\n24\n25\n26\n27\n28\n29\n30\n31\n32\n33\n34\n35\n36\n37\n38\n39\n40\n41\n42\n43\n44\n45\n46\n47\n48\n49\n50\n51\n52\n53\n54\n55\n56\n57\n58\n59\n60\n61\n62\n63\n64\n65\n66\n67\n68\n69\n70\n71\n72\n73\n74\n75\n76\n77\n78\n79\n80\n81\n82\n83\n84\n85\n86\n87\n88\n89\n90\n91\n92\n93\n94\n95\n96\n97\n98\n99\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.el",
"content": "# Sigle letters in upper-case are usually abbreviations of names\nΑ\nΒ\nΓ\nΔ\nΕ\nΖ\nΗ\nΘ\nΙ\nΚ\nΛ\nΜ\nΝ\nΞ\nΟ\nΠ\nΡ\nΣ\nΤ\nΥ\nΦ\nΧ\nΨ\nΩ\n\n# Includes abbreviations for the Greek language compiled from various sources (Greek grammar books, Greek language related web content).\nΆθαν\nΈγχρ\nΈκθ\nΈσδ\nΈφ\nΌμ\nΑ΄Έσδρ\nΑ΄Έσδ\nΑ΄Βασ\nΑ΄Θεσ\nΑ΄Ιω\nΑ΄Κορινθ\nΑ΄Κορ\nΑ΄Μακκ\nΑ΄Μακ\nΑ΄Πέτρ\nΑ΄Πέτ\nΑ΄Παραλ\nΑ΄Πε\nΑ΄Σαμ\nΑ΄Τιμ\nΑ΄Χρον\nΑ΄Χρ\nΑ.Β.Α\nΑ.Β\nΑ.Ε\nΑ.Κ.Τ.Ο\nΑέθλ\nΑέτ\nΑίλ.Δ\nΑίλ.Τακτ\nΑίσ\nΑββακ\nΑβυδ\nΑβ\nΑγάκλ\nΑγάπ\nΑγάπ.Αμαρτ.Σ\nΑγάπ.Γεωπ\nΑγαθάγγ\nΑγαθήμ\nΑγαθιν\nΑγαθοκλ\nΑγαθρχ\nΑγαθ\nΑγαθ.Ιστ\nΑγαλλ\nΑγαπητ\nΑγγ\nΑγησ\nΑγλ\nΑγορ.Κ\nΑγρο.Κωδ\nΑγρ.Εξ\nΑγρ.Κ\nΑγ.Γρ\nΑδριαν\nΑδρ\nΑετ\nΑθάν\nΑθήν\nΑθήν.Επιγρ\nΑθήν.Επιτ\nΑθήν.Ιατρ\nΑθήν.Μηχ\nΑθανάσ\nΑθαν\nΑθηνί\nΑθηναγ\nΑθηνόδ\nΑθ\nΑθ.Αρχ\nΑιλ\nΑιλ.Επιστ\nΑιλ.ΖΙ\nΑιλ.ΠΙ\nΑιλ.απ\nΑιμιλ\nΑιν.Γαζ\nΑιν.Τακτ\nΑισχίν\nΑισχίν.Επιστ\nΑισχ\nΑισχ.Αγαμ\nΑισχ.Αγ\nΑισχ.Αλ\nΑισχ.Ελεγ\nΑισχ.Επτ.Θ\nΑισχ.Ευμ\nΑισχ.Ικέτ\nΑισχ.Ικ\nΑισχ.Περσ\nΑισχ.Προμ.Δεσμ\nΑισχ.Πρ\nΑισχ.Χοηφ\nΑισχ.Χο\nΑισχ.απ\nΑιτΕ\nΑιτ\nΑλκ\nΑλχιας\nΑμ.Π.Ο\nΑμβ\nΑμμών\nΑμ.\nΑν.Πειθ.Συμβ.Δικ\nΑνακρ\nΑνακ\nΑναμν.Τόμ\nΑναπλ\nΑνδ\nΑνθλγος\nΑνθστης\nΑντισθ\nΑνχης\nΑν\nΑποκ\nΑπρ\nΑπόδ\nΑπόφ\nΑπόφ.Νομ\nΑπ\nΑπ.Δαπ\nΑπ.Διατ\nΑπ.Επιστ\nΑριθ\nΑριστοτ\nΑριστοφ\nΑριστοφ.Όρν\nΑριστοφ.Αχ\nΑριστοφ.Βάτρ\nΑριστοφ.Ειρ\nΑριστοφ.Εκκλ\nΑριστοφ.Θεσμ\nΑριστοφ.Ιππ\nΑριστοφ.Λυσ\nΑριστοφ.Νεφ\nΑριστοφ.Πλ\nΑριστοφ.Σφ\nΑριστ\nΑριστ.Αθ.Πολ\nΑριστ.Αισθ\nΑριστ.Αν.Πρ\nΑριστ.Ζ.Ι\nΑριστ.Ηθ.Ευδ\nΑριστ.Ηθ.Νικ\nΑριστ.Κατ\nΑριστ.Μετ\nΑριστ.Πολ\nΑριστ.Φυσιογν\nΑριστ.Φυσ\nΑριστ.Ψυχ\nΑριστ.Ρητ\nΑρμεν\nΑρμ\nΑρχ.Εκ.Καν.Δ\nΑρχ.Ευβ.Μελ\nΑρχ.Ιδ.Δ\nΑρχ.Νομ\nΑρχ.Ν\nΑρχ.Π.Ε\nΑρ\nΑρ.Φορ.Μητρ\nΑσμ\nΑσμ.ασμ\nΑστ.Δ\nΑστ.Χρον\nΑσ\nΑτομ.Γνωμ\nΑυγ\nΑφρ\nΑχ.Νομ\nΑ\nΑ.Εγχ.Π\nΑ.Κ.΄Υδρας\nΒ΄Έσδρ\nΒ΄Έσδ\nΒ΄Βασ\nΒ΄Θεσ\nΒ΄Ιω\nΒ΄Κορινθ\nΒ΄Κορ\nΒ΄Μακκ\nΒ΄Μακ\nΒ΄Πέτρ\nΒ΄Πέτ\nΒ΄Πέ\nΒ΄Παραλ\nΒ΄Σαμ\nΒ΄Τιμ\nΒ΄Χρον\nΒ΄Χρ\nΒ.Ι.Π.Ε\nΒ.Κ.Τ\nΒ.Κ.Ψ.Β\nΒ.Μ\nΒ.Ο.Α.Κ\nΒ.Ο.Α\nΒ.Ο.Δ\nΒίβλ\nΒαρ\nΒεΘ\nΒι.Περ\nΒιπερ\nΒιργ\nΒλγ\nΒούλ\nΒρ\nΓ΄Βασ\nΓ΄Μακκ\nΓΕΝμλ\nΓέν\nΓαλ\nΓεν\nΓλ\nΓν.Ν.Σ.Κρ\nΓνωμ\nΓν\nΓράμμ\nΓρηγ.Ναζ\nΓρηγ.Νύσ\nΓ Νοσ\nΓ' Ογκολ\nΓ.Ν\nΔ΄Βασ\nΔ.Β\nΔ.Δίκη\nΔ.Δίκ\nΔ.Ε.Σ\nΔ.Ε.Φ.Α\nΔ.Ε.Φ\nΔ.Εργ.Ν\nΔαμ\nΔαμ.μνημ.έργ\nΔαν\nΔασ.Κ\nΔεκ\nΔελτ.Δικ.Ε.Τ.Ε\nΔελτ.Νομ\nΔελτ.Συνδ.Α.Ε\nΔερμ\nΔευτ\nΔεύτ\nΔημοσθ\nΔημόκρ\nΔι.Δικ\nΔιάτ\nΔιαιτ.Απ\nΔιαιτ\nΔιαρκ.Στρατ\nΔικ\nΔιοίκ.Πρωτ\nΔιοικΔνη\nΔιοικ.Εφ\nΔιον.Αρ\nΔιόρθ.Λαθ\nΔ.κ.Π\nΔνη\nΔν\nΔογμ.Όρος\nΔρ\nΔ.τ.Α\nΔτ\nΔωδΝομ\nΔ.Περ\nΔ.Στρ\nΕΔΠολ\nΕΕυρΚ\nΕΙΣ\nΕΝαυτΔ\nΕΣΑμΕΑ\nΕΣΘ\nΕΣυγκΔ\nΕΤρΑξΧρΔ\nΕ.Φ.Ε.Τ\nΕ.Φ.Ι\nΕ.Φ.Ο.Επ.Α\nΕβδ\nΕβρ\nΕγκύκλ.Επιστ\nΕγκ\nΕε.Αιγ\nΕθν.Κ.Τ\nΕθν\nΕιδ.Δικ.Αγ.Κακ\nΕικ\nΕιρ.Αθ\nΕιρην.Αθ\nΕιρην\nΈλεγχ\nΕιρ\nΕισ.Α.Π\nΕισ.Ε\nΕισ.Ν.Α.Κ\nΕισ.Ν.Κ.Πολ.Δ\nΕισ.Πρωτ\nΕισηγ.Έκθ\nΕισ\nΕκκλ\nΕκκ\nΕκ\nΕλλ.Δνη\nΕν.Ε\nΕξ\nΕπ.Αν\nΕπ.Εργ.Δ\nΕπ.Εφ\nΕπ.Κυπ.Δ\nΕπ.Μεσ.Αρχ\nΕπ.Νομ\nΕπίκτ\nΕπίκ\nΕπι.Δ.Ε\nΕπιθ.Ναυτ.Δικ\nΕπικ\nΕπισκ.Ε.Δ\nΕπισκ.Εμπ.Δικ\nΕπιστ.Επετ.Αρμ\nΕπιστ.Επετ\nΕπιστ.Ιερ\nΕπιτρ.Προστ.Συνδ.Στελ\nΕπιφάν\nΕπτ.Εφ\nΕπ.Ιρ\nΕπ.Ι\nΕργ.Ασφ.Νομ\nΕρμ.Α.Κ\nΕρμη.Σ\nΕσθ\nΕσπερ\nΕτρ.Δ\nΕυκλ\nΕυρ.Δ.Δ.Α\nΕυρ.Σ.Δ.Α\nΕυρ.ΣτΕ\nΕυρατόμ\nΕυρ.Άλκ\nΕυρ.Ανδρομ\nΕυρ.Βάκχ\nΕυρ.Εκ\nΕυρ.Ελ\nΕυρ.Ηλ\nΕυρ.Ηρακ\nΕυρ.Ηρ\nΕυρ.Ηρ.Μαιν\nΕυρ.Ικέτ\nΕυρ.Ιππόλ\nΕυρ.Ιφ.Α\nΕυρ.Ιφ.Τ\nΕυρ.Ι.Τ\nΕυρ.Κύκλ\nΕυρ.Μήδ\nΕυρ.Ορ\nΕυρ.Ρήσ\nΕυρ.Τρωάδ\nΕυρ.Φοίν\nΕφ.Αθ\nΕφ.Εν\nΕφ.Επ\nΕφ.Θρ\nΕφ.Θ\nΕφ.Ι\nΕφ.Κερ\nΕφ.Κρ\nΕφ.Λ\nΕφ.Ν\nΕφ.Πατ\nΕφ.Πειρ\nΕφαρμ.Δ.Δ\nΕφαρμ\nΕφεσ\nΕφημ\nΕφ\nΖαχ\nΖιγ\nΖυ\nΖχ\nΗΕ.Δ\nΗμερ\nΗράκλ\nΗροδ\nΗσίοδ\nΗσ\nΗ.Ε.Γ\nΘΗΣ\nΘΡ\nΘαλ\nΘεοδ\nΘεοφ\nΘεσ\nΘεόδ.Μοψ\nΘεόκρ\nΘεόφιλ\nΘουκ\nΘρ\nΘρ.Ε\nΘρ.Ιερ\nΘρ.Ιρ\nΙακ\nΙαν\nΙβ\nΙδθ\nΙδ\nΙεζ\nΙερ\nΙζ\nΙησ\nΙησ.Ν\nΙκ\nΙλ\nΙν\nΙουδ\nΙουστ\nΙούδα\nΙούλ\nΙούν\nΙπποκρ\nΙππόλ\nΙρ\nΙσίδ.Πηλ\nΙσοκρ\nΙσ.Ν\nΙωβ\nΙωλ\nΙων\nΙω\nΚΟΣ\nΚΟ.ΜΕ.ΚΟΝ\nΚΠοινΔ\nΚΠολΔ\nΚαΒ\nΚαλ\nΚαλ.Τέχν\nΚανΒ\nΚαν.Διαδ\nΚατάργ\nΚλ\nΚοινΔ\nΚολσ\nΚολ\nΚον\nΚορ\nΚος\nΚριτΕπιθ\nΚριτΕ\nΚριτ\nΚρ\nΚτΒ\nΚτΕ\nΚτΠ\nΚυβ\nΚυπρ\nΚύριλ.Αλεξ\nΚύριλ.Ιερ\nΛεβ\nΛεξ.Σουίδα\nΛευϊτ\nΛευ\nΛκ\nΛογ\nΛουκΑμ\nΛουκιαν\nΛουκ.Έρωτ\nΛουκ.Ενάλ.Διάλ\nΛουκ.Ερμ\nΛουκ.Εταιρ.Διάλ\nΛουκ.Ε.Δ\nΛουκ.Θε.Δ\nΛουκ.Ικ.\nΛουκ.Ιππ\nΛουκ.Λεξιφ\nΛουκ.Μεν\nΛουκ.Μισθ.Συν\nΛουκ.Ορχ\nΛουκ.Περ\nΛουκ.Συρ\nΛουκ.Τοξ\nΛουκ.Τυρ\nΛουκ.Φιλοψ\nΛουκ.Φιλ\nΛουκ.Χάρ\nΛουκ.\nΛουκ.Αλ\nΛοχ\nΛυδ\nΛυκ\nΛυσ\nΛωζ\nΛ1\nΛ2\nΜΟΕφ\nΜάρκ\nΜέν\nΜαλ\nΜατθ\nΜα\nΜιχ\nΜκ\nΜλ\nΜμ\nΜον.Δ.Π\nΜον.Πρωτ\nΜον\nΜρ\nΜτ\nΜχ\nΜ.Βασ\nΜ.Πλ\nΝΑ\nΝαυτ.Χρον\nΝα\nΝδικ\nΝεεμ\nΝε\nΝικ\nΝκΦ\nΝμ\nΝοΒ\nΝομ.Δελτ.Τρ.Ελ\nΝομ.Δελτ\nΝομ.Σ.Κ\nΝομ.Χρ\nΝομ\nΝομ.Διεύθ\nΝοσ\nΝτ\nΝόσων\nΝ1\nΝ2\nΝ3\nΝ4\nΝtot\nΞενοφ\nΞεν\nΞεν.Ανάβ\nΞεν.Απολ\nΞεν.Απομν\nΞεν.Απομ\nΞεν.Ελλ\nΞεν.Ιέρ\nΞεν.Ιππαρχ\nΞεν.Ιππ\nΞεν.Κυρ.Αν\nΞεν.Κύρ.Παιδ\nΞεν.Κ.Π\nΞεν.Λακ.Πολ\nΞεν.Οικ\nΞεν.Προσ\nΞεν.Συμπόσ\nΞεν.Συμπ\nΟ΄\nΟβδ\nΟβ\nΟικΕ\nΟικ\nΟικ.Πατρ\nΟικ.Σύν.Βατ\nΟλομ\nΟλ\nΟλ.Α.Π\nΟμ.Ιλ\nΟμ.Οδ\nΟπΤοιχ\nΟράτ\nΟρθ\nΠΡΟ.ΠΟ\nΠίνδ\nΠίνδ.Ι\nΠίνδ.Νεμ\nΠίνδ.Ν\nΠίνδ.Ολ\nΠίνδ.Παθ\nΠίνδ.Πυθ\nΠίνδ.Π\nΠαγΝμλγ\nΠαν\nΠαρμ\nΠαροιμ\nΠαρ\nΠαυσ\nΠειθ.Συμβ\nΠειρΝ\nΠελ\nΠεντΣτρ\nΠεντ\nΠεντ.Εφ\nΠερΔικ\nΠερ.Γεν.Νοσ\nΠετ\nΠλάτ\nΠλάτ.Αλκ\nΠλάτ.Αντ\nΠλάτ.Αξίοχ\nΠλάτ.Απόλ\nΠλάτ.Γοργ\nΠλάτ.Ευθ\nΠλάτ.Θεαίτ\nΠλάτ.Κρατ\nΠλάτ.Κριτ\nΠλάτ.Λύσ\nΠλάτ.Μεν\nΠλάτ.Νόμ\nΠλάτ.Πολιτ\nΠλάτ.Πολ\nΠλάτ.Πρωτ\nΠλάτ.Σοφ.\nΠλάτ.Συμπ\nΠλάτ.Τίμ\nΠλάτ.Φαίδρ\nΠλάτ.Φιλ\nΠλημ\nΠλούτ\nΠλούτ.Άρατ\nΠλούτ.Αιμ\nΠλούτ.Αλέξ\nΠλούτ.Αλκ\nΠλούτ.Αντ\nΠλούτ.Αρτ\nΠλούτ.Ηθ\nΠλούτ.Θεμ\nΠλούτ.Κάμ\nΠλούτ.Καίσ\nΠλούτ.Κικ\nΠλούτ.Κράσ\nΠλούτ.Κ\nΠλούτ.Λυκ\nΠλούτ.Μάρκ\nΠλούτ.Μάρ\nΠλούτ.Περ\nΠλούτ.Ρωμ\nΠλούτ.Σύλλ\nΠλούτ.Φλαμ\nΠλ\nΠοιν.Δικ\nΠοιν.Δ\nΠοιν.Ν\nΠοιν.Χρον\nΠοιν.Χρ\nΠολ.Δ\nΠολ.Πρωτ\nΠολ\nΠολ.Μηχ\nΠολ.Μ\nΠρακτ.Αναθ\nΠρακτ.Ολ\nΠραξ\nΠρμ\nΠρξ\nΠρωτ\nΠρ\nΠρ.Αν\nΠρ.Λογ\nΠταισμ\nΠυρ.Καλ\nΠόλη\nΠ.Δ\nΠ.Δ.Άσμ\nΡΜ.Ε\nΡθ\nΡμ\nΡωμ\nΣΠλημ\nΣαπφ\nΣειρ\nΣολ\nΣοφ\nΣοφ.Αντιγ\nΣοφ.Αντ\nΣοφ.Αποσ\nΣοφ.Απ\nΣοφ.Ηλέκ\nΣοφ.Ηλ\nΣοφ.Οιδ.Κολ\nΣοφ.Οιδ.Τύρ\nΣοφ.Ο.Τ\nΣοφ.Σειρ\nΣοφ.Σολ\nΣοφ.Τραχ\nΣοφ.Φιλοκτ\nΣρ\nΣ.τ.Ε\nΣ.τ.Π\nΣτρ.Π.Κ\nΣτ.Ευρ\nΣυζήτ\nΣυλλ.Νομολ\nΣυλ.Νομ\nΣυμβΕπιθ\nΣυμπ.Ν\nΣυνθ.Αμ\nΣυνθ.Ε.Ε\nΣυνθ.Ε.Κ\nΣυνθ.Ν\nΣφν\nΣφ\nΣφ.Σλ\nΣχ.Πολ.Δ\nΣχ.Συντ.Ε\nΣωσ\nΣύντ\nΣ.Πληρ\nΤΘ\nΤΣ.Δ\nΤίτ\nΤβ\nΤελ.Ενημ\nΤελ.Κ\nΤερτυλ\nΤιμ\nΤοπ.Α\nΤρ.Ο\nΤριμ\nΤριμ.Πλ\nΤρ.Πλημ\nΤρ.Π.Δ\nΤ.τ.Ε\nΤτ\nΤωβ\nΥγ\nΥπερ\nΥπ\nΥ.Γ\nΦιλήμ\nΦιλιπ\nΦιλ\nΦλμ\nΦλ\nΦορ.Β\nΦορ.Δ.Ε\nΦορ.Δνη\nΦορ.Δ\nΦορ.Επ\nΦώτ\nΧρ.Ι.Δ\nΧρ.Ιδ.Δ\nΧρ.Ο\nΧρυσ\nΨήφ\nΨαλμ\nΨαλ\nΨλ\nΩριγ\nΩσ\nΩ.Ρ.Λ\nάγν\nάγν.ετυμολ\nάγ\nάκλ\nάνθρ\nάπ\nάρθρ\nάρν\nάρ\nάτ\nάψ\nά\nέκδ\nέκφρ\nέμψ\nένθ.αν\nέτ\nέ.α\nίδ\nαβεστ\nαβησσ\nαγγλ\nαγγ\nαδημ\nαεροναυτ\nαερον\nαεροπ\nαθλητ\nαθλ\nαθροιστ\nαιγυπτ\nαιγ\nαιτιολ\nαιτ\nαι\nακαδ\nακκαδ\nαλβ\nαλλ\nαλφαβητ\nαμα\nαμερικ\nαμερ\nαμετάβ\nαμτβ\nαμφιβ\nαμφισβ\nαμφ\nαμ\nανάλ\nανάπτ\nανάτ\nαναβ\nαναδαν\nαναδιπλασ\nαναδιπλ\nαναδρ\nαναλ\nαναν\nανασυλλ\nανατολ\nανατομ\nανατυπ\nανατ\nαναφορ\nαναφ\nανα.ε\nανδρων\nανθρωπολ\nανθρωπ\nανθ\nανομ\nαντίτ\nαντδ\nαντιγρ\nαντιθ\nαντικ\nαντιμετάθ\nαντων\nαντ\nανωτ\nανόργ\nανών\nαορ\nαπαρέμφ\nαπαρφ\nαπαρχ\nαπαρ\nαπλολ\nαπλοπ\nαποβ\nαποηχηροπ\nαποθ\nαποκρυφ\nαποφ\nαπρμφ\nαπρφ\nαπρόσ\nαπόδ\nαπόλ\nαπόσπ\nαπόφ\nαραβοτουρκ\nαραβ\nαραμ\nαρβαν\nαργκ\nαριθμτ\nαριθμ\nαριθ\nαρκτικόλ\nαρκ\nαρμεν\nαρμ\nαρνητ\nαρσ\nαρχαιολ\nαρχιτεκτ\nαρχιτ\nαρχκ\nαρχ\nαρωμουν\nαρωμ\nαρ\nαρ.μετρ\nαρ.φ\nασσυρ\nαστρολ\nαστροναυτ\nαστρον\nαττ\nαυστραλ\nαυτοπ\nαυτ\nαφγαν\nαφηρ\nαφομ\nαφρικ\nαχώρ\nαόρ\nα.α\nα/α\nα0\nβαθμ\nβαθ\nβαπτ\nβασκ\nβεβαιωτ\nβεβ\nβεδ\nβενετ\nβεν\nβερβερ\nβιβλγρ\nβιολ\nβιομ\nβιοχημ\nβιοχ\nβλάχ\nβλ\nβλ.λ\nβοταν\nβοτ\nβουλγαρ\nβουλγ\nβούλ\nβραζιλ\nβρετον\nβόρ\nγαλλ\nγενικότ\nγενοβ\nγεν\nγερμαν\nγερμ\nγεωγρ\nγεωλ\nγεωμετρ\nγεωμ\nγεωπ\nγεωργ\nγλυπτ\nγλωσσολ\nγλωσσ\nγλ\nγνμδ\nγνμ\nγνωμ\nγοτθ\nγραμμ\nγραμ\nγρμ\nγρ\nγυμν\nδίδες\nδίκ\nδίφθ\nδαν\nδεικτ\nδεκατ\nδηλ\nδημογρ\nδημοτ\nδημώδ\nδημ\nδιάγρ\nδιάκρ\nδιάλεξ\nδιάλ\nδιάσπ\nδιαλεκτ\nδιατρ\nδιαφ\nδιαχ\nδιδα\nδιεθν\nδιεθ\nδικον\nδιστ\nδισύλλ\nδισ\nδιφθογγοπ\nδογμ\nδολ\nδοτ\nδρμ\nδρχ\nδρ(α)\nδωρ\nδ\nεβρ\nεγκλπ\nεδ\nεθνολ\nεθν\nειδικότ\nειδ\nειδ.β\nεικ\nειρ\nεισ\nεκατοστμ\nεκατοστ\nεκατστ.2\nεκατστ.3\nεκατ\nεκδ\nεκκλησ\nεκκλ\nεκ\nελλην\nελλ\nελνστ\nελπ\nεμβ\nεμφ\nεναλλ\nενδ\nενεργ\nενεστ\nενικ\nενν\nεν\nεξέλ\nεξακολ\nεξομάλ\nεξ\nεο\nεπέκτ\nεπίδρ\nεπίθ\nεπίρρ\nεπίσ\nεπαγγελμ\nεπανάλ\nεπανέκδ\nεπιθ\nεπικ\nεπιμ\nεπιρρ\nεπιστ\nεπιτατ\nεπιφ\nεπών\nεπ\nεργ\nερμ\nερρινοπ\nερωτ\nετρουσκ\nετυμ\nετ\nευφ\nευχετ\nεφ\nεύχρ\nε.α\nε/υ\nε0\nζωγρ\nζωολ\nηθικ\nηθ\nηλεκτρολ\nηλεκτρον\nηλεκτρ\nημίτ\nημίφ\nημιφ\nηχηροπ\nηχηρ\nηχομιμ\nηχ\nη\nθέατρ\nθεολ\nθετ\nθηλ\nθρακ\nθρησκειολ\nθρησκ\nθ\nιαπων\nιατρ\nιδιωμ\nιδ\nινδ\nιραν\nισπαν\nιστορ\nιστ\nισχυροπ\nιταλ\nιχθυολ\nιων\nκάτ\nκαθ\nκακοσ\nκαν\nκαρ\nκατάλ\nκατατ\nκατωτ\nκατ\nκα\nκελτ\nκεφ\nκινεζ\nκινημ\nκλητ\nκλιτ\nκλπ\nκλ\nκν\nκοινωνιολ\nκοινων\nκοπτ\nκουτσοβλαχ\nκουτσοβλ\nκπ\nκρ.γν\nκτγ\nκτην\nκτητ\nκτλ\nκτ\nκυριολ\nκυρ\nκύρ\nκ\nκ.ά\nκ.ά.π\nκ.α\nκ.εξ\nκ.επ\nκ.ε\nκ.λπ\nκ.λ.π\nκ.ού.κ\nκ.ο.κ\nκ.τ.λ\nκ.τ.τ\nκ.τ.ό\nλέξ\nλαογρ\nλαπ\nλατιν\nλατ\nλαϊκότρ\nλαϊκ\nλετ\nλιθ\nλογιστ\nλογοτ\nλογ\nλουβ\nλυδ\nλόγ\nλ\nλ.χ\nμέλλ\nμέσ\nμαθημ\nμαθ\nμαιευτ\nμαλαισ\nμαλτ\nμαμμων\nμεγεθ\nμεε\nμειωτ\nμελ\nμεξ\nμεσν\nμεσογ\nμεσοπαθ\nμεσοφ\nμετάθ\nμεταβτ\nμεταβ\nμετακ\nμεταπλ\nμεταπτωτ\nμεταρ\nμεταφορ\nμετβ\nμετεπιθ\nμετεπιρρ\nμετεωρολ\nμετεωρ\nμετον\nμετουσ\nμετοχ\nμετρ\nμετ\nμητρων\nμηχανολ\nμηχ\nμικροβιολ\nμογγολ\nμορφολ\nμουσ\nμπενελούξ\nμσνλατ\nμσν\nμτβ\nμτγν\nμτγ\nμτφρδ\nμτφρ\nμτφ\nμτχ\nμυθ\nμυκην\nμυκ\nμφ\nμ\nμ.ε\nμ.μ\nμ.π.ε\nμ.π.π\nμ0\nναυτ\nνεοελλ\nνεολατιν\nνεολατ\nνεολ\nνεότ\nνλατ\nνομ\nνορβ\nνοσ\nνότ\nν\nξ.λ\nοικοδ\nοικολ\nοικον\nοικ\nολλανδ\nολλ\nομηρ\nομόρρ\nονομ\nον\nοπτ\nορθογρ\nορθ\nοριστ\nορυκτολ\nορυκτ\nορ\nοσετ\nοσκ\nουαλ\nουγγρ\nουδ\nουσιαστικοπ\nουσιαστ\nουσ\nπίν\nπαθητ\nπαθολ\nπαθ\nπαιδ\nπαλαιοντ\nπαλαιότ\nπαλ\nπαππων\nπαράγρ\nπαράγ\nπαράλλ\nπαράλ\nπαραγ\nπαρακ\nπαραλ\nπαραπ\nπαρατ\nπαρβ\nπαρετυμ\nπαροξ\nπαρων\nπαρωχ\nπαρ\nπαρ.φρ\nπατριδων\nπατρων\nπβ\nπεριθ\nπεριλ\nπεριφρ\nπερσ\nπερ\nπιθ\nπληθ\nπληροφ\nποδ\nποιητ\nπολιτ\nπολλαπλ\nπολ\nπορτογαλ\nπορτ\nποσ\nπρακριτ\nπρβλ\nπρβ\nπργ\nπρκμ\nπρκ\nπρλ\nπροέλ\nπροβηγκ\nπροελλ\nπροηγ\nπροθεμ\nπροπαραλ\nπροπαροξ\nπροπερισπ\nπροσαρμ\nπροσηγορ\nπροσταχτ\nπροστ\nπροσφών\nπροσ\nπροτακτ\nπροτ.Εισ\nπροφ\nπροχωρ\nπρτ\nπρόθ\nπρόσθ\nπρόσ\nπρότ\nπρ\nπρ.Εφ\nπτ\nπυ\nπ\nπ.Χ\nπ.μ\nπ.χ\nρήμ\nρίζ\nρηματ\nρητορ\nριν\nρουμ\nρωμ\nρωσ\nρ\nσανσκρ\nσαξ\nσελ\nσερβοκρ\nσερβ\nσημασιολ\nσημδ\nσημειολ\nσημερ\nσημιτ\nσημ\nσκανδ\nσκυθ\nσκωπτ\nσλαβ\nσλοβ\nσουηδ\nσουμερ\nσουπ\nσπάν\nσπανιότ\nσπ\nσσ\nστατ\nστερ\nστιγμ\nστιχ\nστρέμ\nστρατιωτ\nστρατ\nστ\nσυγγ\nσυγκρ\nσυγκ\nσυμπερ\nσυμπλεκτ\nσυμπλ\nσυμπροφ\nσυμφυρ\nσυμφ\nσυνήθ\nσυνίζ\nσυναίρ\nσυναισθ\nσυνδετ\nσυνδ\nσυνεκδ\nσυνηρ\nσυνθετ\nσυνθ\nσυνοπτ\nσυντελ\nσυντομογρ\nσυντ\nσυν\nσυρ\nσχημ\nσχ\nσύγκρ\nσύμπλ\nσύμφ\nσύνδ\nσύνθ\nσύντμ\nσύντ\nσ\nσ.π\nσ/β\nτακτ\nτελ\nτετρ\nτετρ.μ\nτεχνλ\nτεχνολ\nτεχν\nτεύχ\nτηλεπικ\nτηλεόρ\nτιμ\nτιμ.τομ\nτοΣ\nτον\nτοπογρ\nτοπων\nτοπ\nτοσκ\nτουρκ\nτοχ\nτριτοπρόσ\nτροποπ\nτροπ\nτσεχ\nτσιγγ\nττ\nτυπ\nτόμ\nτόνν\nτ\nτ.μ\nτ.χλμ\nυβρ\nυπερθ\nυπερσ\nυπερ\nυπεύθ\nυποθ\nυποκορ\nυποκ\nυποσημ\nυποτ\nυποφ\nυποχωρ\nυπόλ\nυπόχρ\nυπ\nυστλατ\nυψόμ\nυψ\nφάκ\nφαρμακολ\nφαρμ\nφιλολ\nφιλοσ\nφιλοτ\nφινλ\nφοινικ\nφράγκ\nφρανκον\nφριζ\nφρ\nφυλλ\nφυσιολ\nφυσ\nφωνηεντ\nφωνητ\nφωνολ\nφων\nφωτογρ\nφ\nφ.τ.μ\nχαμιτ\nχαρτόσ\nχαρτ\nχασμ\nχαϊδ\nχγφ\nχειλ\nχεττ\nχημ\nχιλ\nχλγρ\nχλγ\nχλμ\nχλμ.2\nχλμ.3\nχλσγρ\nχλστγρ\nχλστμ\nχλστμ.2\nχλστμ.3\nχλ\nχργρ\nχρημ\nχρον\nχρ\nχφ\nχ.ε\nχ.κ\nχ.ο\nχ.σ\nχ.τ\nχ.χ\nψευδ\nψυχαν\nψυχιατρ\nψυχολ\nψυχ\nωκεαν\nόμ\nόν\nόπ.παρ\nόπ.π\nό.π\nύψ\n1Βσ\n1Εσ\n1Θσ\n1Ιν\n1Κρ\n1Μκ\n1Πρ\n1Πτ\n1Τμ\n2Βσ\n2Εσ\n2Θσ\n2Ιν\n2Κρ\n2Μκ\n2Πρ\n2Πτ\n2Τμ\n3Βσ\n3Ιν\n3Μκ\n4Βσ\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.en",
"content": "#Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.\n#Special cases are included for prefixes that ONLY appear before 0-9 numbers.\n\n#any single upper case letter followed by a period is not a sentence ender (excluding I occasionally, but we leave it in)\n#usually upper case letters are initials in a name\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\n\n#List of titles. These are often followed by upper-case names, but do not indicate sentence breaks\nAdj\nAdm\nAdv\nAsst\nBart\nBldg\nBrig\nBros\nCapt\nCmdr\nCol\nComdr\nCon\nCorp\nCpl\nDR\nDr\nDrs\nEns\nGen\nGov\nHon\nHr\nHosp\nInsp\nLt\nMM\nMR\nMRS\nMS\nMaj\nMessrs\nMlle\nMme\nMr\nMrs\nMs\nMsgr\nOp\nOrd\nPfc\nPh\nProf\nPvt\nRep\nReps\nRes\nRev\nRt\nSen\nSens\nSfc\nSgt\nSr\nSt\nSupt\nSurg\n\n#misc - odd period-ending items that NEVER indicate breaks (p.m. does NOT fall into this category - it sometimes ends a sentence)\nv\nvs\ni.e\nrev\ne.g\n\n#Numbers only. These should only induce breaks when followed by a numeric sequence\n# add NUMERIC_ONLY after the word for this function\n#This case is mostly for the english \"No.\" which can either be a sentence of its own, or\n#if followed by a number, a non-breaking prefix\nNo #NUMERIC_ONLY# \nNos\nArt #NUMERIC_ONLY#\nNr\npp #NUMERIC_ONLY#\n\n#month abbreviations\nJan\nFeb\nMar\nApr\n#May is a full word\nJun\nJul\nAug\nSep\nOct\nNov\nDec\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.es",
"content": "#Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.\n#Special cases are included for prefixes that ONLY appear before 0-9 numbers.\n\n#any single upper case letter followed by a period is not a sentence ender\n#usually upper case letters are initials in a name\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\n\n# Period-final abbreviation list from http://www.ctspanish.com/words/abbreviations.htm\n\nA.C\nApdo\nAv\nBco\nCC.AA\nDa\nDep\nDn\nDr\nDra\nEE.UU\nExcmo\nFF.CC\nFil \nGral\nJ.C\nLet\nLic\nN.B\nP.D\nP.V.P\nProf\nPts\nRte\nS.A\nS.A.R\nS.E\nS.L\nS.R.C\nSr\nSra\nSrta\nSta\nSto\nT.V.E\nTel\nUd\nUds\nV.B\nV.E\nVd\nVds\na/c\nadj\nadmón\nafmo\napdo\nav\nc\nc.f\nc.g\ncap\ncm\ncta\ndcha\ndoc\nej\nentlo\nesq\netc\nf.c\ngr \ngrs\nizq\nkg\nkm\nmg\nmm\nnúm\nnúm\np\np.a\np.ej\nptas\npág \npágs\npág\npágs\nq.e.g.e\nq.e.s.m\ns\ns.s.s\nvid\nvol\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.fi",
"content": "#Anything in this file, followed by a period (and an upper-case word), does NOT\n#indicate an end-of-sentence marker. Special cases are included for prefixes\n#that ONLY appear before 0-9 numbers.\n\n#This list is compiled from omorfi database\n#by Tommi A Pirinen.\n\n\n#any single upper case letter followed by a period is not a sentence ender\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\nÅ\nÄ\nÖ\n\n#List of titles. These are often followed by upper-case names, but do not indicate sentence breaks\nalik\nalil\namir\napul\napul.prof\narkkit\nass\nassist\ndipl\ndipl.arkkit\ndipl.ekon\ndipl.ins\ndipl.kielenk\ndipl.kirjeenv\ndipl.kosm\ndipl.urk\ndos\nerikoiseläinl\nerikoishammasl\nerikoisl\nerikoist\nev.luutn\nevp\nfil\nft\nhallinton\nhallintot\nhammaslääket\njatk\njääk\nkansaned\nkapt\nkapt.luutn\nkenr\nkenr.luutn\nkenr.maj\nkers\nkirjeenv\nkom\nkom.kapt\nkomm\nkonst\nkorpr\nluutn\nmaist\nmaj\nMr\nMrs\nMs\nM.Sc\nneuv\nnimim\nPh.D\nprof\npuh.joht\npääll\nres\nsan\nsiht\nsuom\nsähköp\nsäv\ntoht\ntoim\ntoim.apul\ntoim.joht\ntoim.siht\ntuom\nups\nvänr\nvääp\nye.ups\nylik\nylil\nylim\nylimatr\nyliop\nyliopp\nylip\nyliv\n\n#misc - odd period-ending items that NEVER indicate breaks (p.m. does NOT fall\n#into this category - it sometimes ends a sentence)\ne.g\nent\nesim\nhuom\ni.e\nilm\nl\nmm\nmyöh\nnk\nnyk\npar\npo\nt\nv\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.fr",
"content": "#Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.\n#Special cases are included for prefixes that ONLY appear before 0-9 numbers.\n#\n#any single upper case letter followed by a period is not a sentence ender\n#usually upper case letters are initials in a name\n#no French words end in single lower-case letters, so we throw those in too?\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\n#a\nb\nc\nd\ne\nf\ng\nh\ni\nj\nk\nl\nm\nn\no\np\nq\nr\ns\nt\nu\nv\nw\nx\ny\nz\n\n# Period-final abbreviation list for French\nA.C.N\nA.M\nart\nann\napr\nav\nauj\nlib\nB.P\nboul\nca\nc.-à-d\ncf\nch.-l\nchap\ncontr\nC.P.I\nC.Q.F.D\nC.N\nC.N.S\nC.S\ndir\néd\ne.g\nenv\nal\netc\nE.V\nex\nfasc\nfém\nfig\nfr\nhab\nibid\nid\ni.e\ninf\nLL.AA\nLL.AA.II\nLL.AA.RR\nLL.AA.SS\nL.D\nLL.EE\nLL.MM\nLL.MM.II.RR\nloc.cit\nmasc\nMM\nms\nN.B\nN.D.A\nN.D.L.R\nN.D.T\nn/réf\nNN.SS\nN.S\nN.D\nN.P.A.I\np.c.c\npl\npp\np.ex\np.j\nP.S\nR.A.S\nR.-V\nR.P\nR.I.P\nSS\nS.S\nS.A\nS.A.I\nS.A.R\nS.A.S\nS.E\nsec\nsect\nsing\nS.M\nS.M.I.R\nsq\nsqq\nsuiv\nsup\nsuppl\ntél\nT.S.V.P\nvb\nvol\nvs\nX.O\nZ.I\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.ga",
"content": "\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\nÁ\nÉ\nÍ\nÓ\nÚ\n\nUacht\nDr\nB.Arch\n\nm.sh\n.i\nCo\nCf\ncf\ni.e\nr\nChr\nlch #NUMERIC_ONLY#\nlgh #NUMERIC_ONLY#\nuimh #NUMERIC_ONLY#\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.hu",
"content": "#Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.\n#Special cases are included for prefixes that ONLY appear before 0-9 numbers.\n\n#any single upper case letter followed by a period is not a sentence ender (excluding I occasionally, but we leave it in)\n#usually upper case letters are initials in a name\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\nÁ\nÉ\nÍ\nÓ\nÖ\nŐ\nÚ\nÜ\nŰ\n\n#List of titles. These are often followed by upper-case names, but do not indicate sentence breaks\nDr\ndr\nkb\nKb\nvö\nVö\npl\nPl\nca\nCa\nmin\nMin\nmax\nMax\nún\nÚn\nprof\nProf\nde\nDe\ndu\nDu\nSzt\nSt\n\n#Numbers only. These should only induce breaks when followed by a numeric sequence\n# add NUMERIC_ONLY after the word for this function\n#This case is mostly for the english \"No.\" which can either be a sentence of its own, or\n#if followed by a number, a non-breaking prefix\n\n# Month name abbreviations\njan #NUMERIC_ONLY#\nJan #NUMERIC_ONLY#\nFeb #NUMERIC_ONLY#\nfeb #NUMERIC_ONLY#\nmárc #NUMERIC_ONLY#\nMárc #NUMERIC_ONLY#\nápr #NUMERIC_ONLY#\nÁpr #NUMERIC_ONLY#\nmáj #NUMERIC_ONLY#\nMáj #NUMERIC_ONLY#\njún #NUMERIC_ONLY#\nJún #NUMERIC_ONLY#\nJúl #NUMERIC_ONLY#\njúl #NUMERIC_ONLY#\naug #NUMERIC_ONLY#\nAug #NUMERIC_ONLY#\nSzept #NUMERIC_ONLY#\nszept #NUMERIC_ONLY#\nokt #NUMERIC_ONLY#\nOkt #NUMERIC_ONLY#\nnov #NUMERIC_ONLY#\nNov #NUMERIC_ONLY#\ndec #NUMERIC_ONLY#\nDec #NUMERIC_ONLY#\n\n# Other abbreviations\ntel #NUMERIC_ONLY#\nTel #NUMERIC_ONLY#\nFax #NUMERIC_ONLY#\nfax #NUMERIC_ONLY#\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.is",
"content": "no #NUMERIC_ONLY#\nNo #NUMERIC_ONLY#\nnr #NUMERIC_ONLY#\nNr #NUMERIC_ONLY#\nnR #NUMERIC_ONLY#\nNR #NUMERIC_ONLY#\na\nb\nc\nd\ne\nf\ng\nh\ni\nj\nk\nl\nm\nn\no\np\nq\nr\ns\nt\nu\nv\nw\nx\ny\nz\n^\ní\ná\nó\næ\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\nab.fn\na.fn\nafs\nal\nalm\nalg\nandh\nath\naths\natr\nao\nau\naukaf\náfn\náhrl.s\náhrs\nákv.gr\nákv\nbh\nbls\ndr\ne.Kr\net\nef\nefn\nennfr\neink\nend\ne.st\nerl\nfél\nfskj\nfh\nf.hl\nfísl\nfl\nfn\nfo\nforl\nfrb\nfrl\nfrh\nfrt\nfsl\nfsh\nfs\nfsk\nfst\nf.Kr\nft\nfv\nfyrrn\nfyrrv\ngerm\ngm\ngr\nhdl\nhdr\nhf\nhl\nhlsk\nhljsk\nhljv\nhljóðv\nhr\nhv\nhvk\nholl\nHos\nhöf\nhk\nhrl\nísl\nkaf\nkap\nKhöfn\nkk\nkg\nkk\nkm\nkl\nklst\nkr\nkt\nkgúrsk\nkvk\nleturbr\nlh\nlh.nt\nlh.þt\nlo\nltr\nmlja\nmljó\nmillj\nmm\nmms\nm.fl\nmiðm\nmgr\nmst\nmín\nnf\nnh\nnhm\nnl\nnk\nnmgr\nno\nnúv\nnt\no.áfr\no.m.fl\nohf\no.fl\no.s.frv\nófn\nób\nóákv.gr\nóákv\npfn\nPR\npr\nRitstj\nRvík\nRvk\nsamb\nsamhlj\nsamn\nsamn\nsbr\nsek\nsérn\nsf\nsfn\nsh\nsfn\nsh\ns.hl\nsk\nskv\nsl\nsn\nso\nss.us\ns.st\nsamþ\nsbr\nshlj\nsign\nskál\nst\nst.s\nstk\nsþ\nteg\ntbl\ntfn\ntl\ntvíhlj\ntvt\ntill\nto\numr\nuh\nus\nuppl\nútg\nvb\nVf\nvh\nvkf\nVl\nvl\nvlf\nvmf\n8vo\nvsk\nvth\nþt\nþf\nþjs\nþgf\nþlt\nþolm\nþm\nþml\nþýð\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.it",
"content": "#Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.\n#Special cases are included for prefixes that ONLY appear before 0-9 numbers.\n\n#any single upper case letter followed by a period is not a sentence ender (excluding I occasionally, but we leave it in)\n#usually upper case letters are initials in a name\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\n\n#List of titles. These are often followed by upper-case names, but do not indicate sentence breaks\nAdj\nAdm\nAdv\nAmn \nArch \nAsst\nAvv\nBart\nBcc\nBldg\nBrig\nBros\nC.A.P\nC.P\nCapt\nCc\nCmdr\nCo\nCol\nComdr\nCon\nCorp\nCpl\nDR\nDott\nDr\nDrs\nEgr\nEns\nGen\nGeom\nGov\nHon\nHosp\nHr\nId\nIng\nInsp\nLt\nMM\nMR\nMRS\nMS\nMaj\nMessrs\nMlle\nMme\nMo\nMons\nMr\nMrs\nMs\nMsgr\nN.B\nOp\nOrd\nP.S\nP.T\nPfc\nPh\nProf\nPvt\nRP\nRSVP\nRag\nRep\nReps\nRes\nRev\nRif\nRt\nS.A\nS.B.F\nS.P.M\nS.p.A\nS.r.l\nSen\nSens\nSfc\nSgt\nSig\nSigg\nSoc\nSpett\nSr\nSt\nSupt\nSurg\nV.P\n\n# other\na.c \nacc\nall \nbanc\nc.a\nc.c.p\nc.m\nc.p\nc.s\nc.v\ncorr\ndott\ne.p.c\necc\nes \nfatt\ngg\nint\nlett\nogg\non\np.c\np.c.c\np.es\np.f\np.r\np.v\npost\npp\nracc\nric\ns.n.c\nseg\nsgg\nss\ntel\nu.s\nv.r\nv.s\n\n#misc - odd period-ending items that NEVER indicate breaks (p.m. does NOT fall into this category - it sometimes ends a sentence)\nv\nvs\ni.e\nrev\ne.g\n\n#Numbers only. These should only induce breaks when followed by a numeric sequence\n# add NUMERIC_ONLY after the word for this function\n#This case is mostly for the english \"No.\" which can either be a sentence of its own, or\n#if followed by a number, a non-breaking prefix\nNo #NUMERIC_ONLY# \nNos\nArt #NUMERIC_ONLY#\nNr\npp #NUMERIC_ONLY#\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.lt",
"content": "# Anything in this file, followed by a period (and an upper-case word),\n# does NOT indicate an end-of-sentence marker.\n# Special cases are included for prefixes that ONLY appear before 0-9 numbers.\n\n# Any single upper case letter followed by a period is not a sentence ender\n# (excluding I occasionally, but we leave it in)\n# usually upper case letters are initials in a name\nA\nĀ\nB\nC\nČ\nD\nE\nĒ\nF\nG\nĢ\nH\nI\nĪ\nJ\nK\nĶ\nL\nĻ\nM\nN\nŅ\nO\nP\nQ\nR\nS\nŠ\nT\nU\nŪ\nV\nW\nX\nY\nZ\nŽ\n\n# Initialis -- Džonas\nDz\nDž\nJust\n\n# Day and month abbreviations\n# m. menesis d. diena g. gimes\nm\nmėn\nd\ng\ngim\n# Pirmadienis Penktadienis\nPr\nPn\nPirm\nAntr\nTreč\nKetv\nPenkt\nŠešt\nSekm\nSaus\nVas\nKov\nBal\nGeg\nBirž\nLiep\nRugpj\nRugs\nSpal\nLapkr\nGruod\n\n# Business, governmental, geographical terms\na\n# aikštė\nadv\n# advokatas\nakad\n# akademikas\naklg\n# akligatvis\nakt\n# aktorius\nal\n# alėja\nA.V\n# antspaudo vieta\naps\napskr\n# apskritis\napyg\n# apygarda\naps\napskr\n# apskritis\nasist\n# asistentas\nasmv\navd\n# asmenvardis\na.k\nasm\nasm.k\n# asmens kodas\natsak\n# atsakingasis\natsisk\nsąsk\n# atsiskaitomoji sąskaita\naut\n# autorius\nb\nk\nb.k\n# banko kodas\nbkl\n# bakalauras\nbt\n# butas\nbuv\n# buvęs, -usi\ndail\n# dailininkas\ndek\n# dekanas\ndėst\n# dėstytojas\ndir\n# direktorius\ndirig\n# dirigentas\ndoc\n# docentas\ndrp\n# durpynas\ndš\n# dešinysis\negz\n# egzempliorius\neil\n# eilutė\nekon\n# ekonomika\nel\n# elektroninis\netc\než\n# ežeras\nfaks\n# faksas\nfak\n# fakultetas\ngen\n# generolas\ngyd\n# gydytojas\ngv\n# gyvenvietė\nįl\n# įlanka\nĮn\n# įnagininkas\ninsp\n# inspektorius\npan\n# ir panašiai\nt.t\n# ir taip toliau\nk.a\n# kaip antai\nkand\n# kandidatas\nkat\n# katedra\nkyš\n# kyšulys\nkl\n# klasė\nkln\n# kalnas\nkn\n# knyga\nkoresp\n# korespondentas\nkpt\n# kapitonas\nkr\n# kairysis\nkt\n# kitas\nkun\n# kunigas\nl\ne\np\nl.e.p\n# laikinai einantis pareigas\nltn\n# leitenantas\nm\nmst\n# miestas\nm.e\n# mūsų eros\nm.m\n# mokslo metai\nmot\n# moteris\nmstl\n# miestelis\nmgr\n# magistras\nmgnt\n# magistrantas\nmjr\n# majoras\nmln\n# milijonas\nmlrd\n# milijardas\nmok\n# mokinys\nmokyt\n# mokytojas\nmoksl\n# mokslinis\nnkt\n# nekaitomas\nntk\n# neteiktinas\nNr\nnr\n# numeris\np\n# ponas\np.d\na.d\n# pašto dėžutė, abonentinė dėžutė\np.m.e\n# prieš mūsų erą\npan\n# ir panašiai\npav\n# paveikslas\npavad\n# pavaduotojas\npirm\n# pirmininkas\npl\n# plentas\nplg\n# palygink\nplk\n# pulkininkas; pelkė\npr\n# prospektas\nKr\npr.Kr\n# prieš Kristų\nprok\n# prokuroras\nprot\n# protokolas\npss\n# pusiasalis\npšt\n# paštas\npvz\n# pavyzdžiui\nr\n# rajonas\nred\n# redaktorius\nrš\n# raštų kalbos\nsąs\n# sąsiuvinis\nsaviv\nsav\n# savivaldybė\nsekr\n# sekretorius\nsen\n# seniūnija, seniūnas\nsk\n# skaityk; skyrius\nskg\n# skersgatvis\nskyr\nsk\n# skyrius\nskv\n# skveras\nsp\n# spauda; spaustuvė\nspec\n# specialistas\nsr\n# sritis\nst\n# stotis\nstr\n# straipsnis\nstud\n# studentas\nš\nš.m\n# šių metų\nšnek\n# šnekamosios\ntir\n# tiražas\ntūkst\n# tūkstantis\nup\n# upė\nupl\n# upelis\nvad\n# vadinamasis, -oji\nvlsč\n# valsčius\nved\n# vedėjas\nvet\n# veterinarija\nvirš\n# viršininkas, viršaitis\nvyr\n# vyriausiasis, -ioji; vyras\nvyresn\n# vyresnysis\nvlsč\n# valsčius\nvs\n# viensėdis\nVt\nvt\n# vietininkas\nvtv\nvv\n# vietovardis\nžml\n# žemėlapis\n\n# Technical terms, abbreviations used in guidebooks, advertisments, etc.\n# Generally lower-case.\nair\n# airiškai\namer\n# amerikanizmas\nanat\n# anatomija\nangl\n# angl. angliskai\narab\n# arabų\narcheol\narchit\nasm\n# asmuo\nastr\n# astronomija\naustral\n# australiškai\naut\n# automobilis\nav\n# aviacija\nbažn\nbdv\n# būdvardis\nbibl\n# Biblija\nbiol\n# biologija\nbot\n# botanika\nbrt\n# burtai, burtažodis.\nbrus\n# baltarusių\nbuh\n# buhalterija\nchem\n# chemija\ncol\n# collectivum\ncon\nconj\n# conjunctivus, jungtukas\ndab\n# dab. dabartine\ndgs\n# daugiskaita\ndial\n# dialektizmas\ndipl\ndktv\n# daiktavardis\ndžn\n# dažnai\nekon\nel\n# elektra\nesam\n# esamasis laikas\neuf\n# eufemizmas\nfam\n# familiariai\nfarm\n# farmacija\nfilol\n# filologija\nfilos\n# filosofija\nfin\n# finansai\nfiz\n# fizika\nfiziol\n# fiziologija\nflk\n# folkloras\nfon\n# fonetika\nfot\n# fotografija\ngeod\n# geodezija\ngeogr\ngeol\n# geologija\ngeom\n# geometrija\nglžk\ngr\n# graikų\ngram\nher\n# heraldika\nhidr\n# hidrotechnika\nind\n# Indų\niron\n# ironiškai\nisp\n# ispanų\nist\nistor\n# istorija\nit\n# italų\nįv\nreikšm\nįv.reikšm\n# įvairiomis reikšmėmis\njap\n# japonų\njuok\n# juokaujamai\njūr\n# jūrininkystė\nkalb\n# kalbotyra\nkar\n# karyba\nkas\n# kasyba\nkin\n# kinematografija\nklaus\n# klausiamasis\nknyg\n# knyginis\nkom\n# komercija\nkomp\n# kompiuteris\nkosm\n# kosmonautika\nkt\n# kitas\nkul\n# kulinarija\nkuop\n# kuopine\nl\n# laikas\nlit\n# literatūrinis\nlingv\n# lingvistika\nlog\n# logika\nlot\n# lotynų\nmat\n# matematika\nmaž\n# mažybinis\nmed\n# medicina\nmedž\n# medžioklė\nmen\n# menas\nmenk\n# menkinamai\nmetal\n# metalurgija\nmeteor\nmin\n# mineralogija\nmit\n# mitologija\nmok\n# mokyklinis\nms\n# mįslė\nmuz\n# muzikinis\nn\n# naujasis\nneig\n# neigiamasis\nneol\n# neologizmas\nniek\n# niekinamai\nofic\n# oficialus\nopt\n# optika\norig\n# original\np\n# pietūs\npan\n# panašiai\nparl\n# parlamentas\npat\n# patarlė\npaž\n# pažodžiui\nplg\n# palygink\npoet\n# poetizmas\npoez\n# poezija\npoligr\n# poligrafija\npolit\n# politika\nppr\n# paprastai\npranc\npr\n# prancūzų, prūsų\npriet\n# prietaras\nprek\n# prekyba\nprk\n# perkeltine\nprs\n# persona, asmuo\npsn\n# pasenęs žodis\npsich\n# psichologija\npvz\n# pavyzdžiui\nr\n# rytai\nrad\n# radiotechnika\nrel\n# religija\nret\n# retai\nrus\n# rusų\nsen\n# senasis\nsl\n# slengas, slavų\nsov\n# sovietinis\nspec\n# specialus\nsport\nstat\n# statyba\nsudurt\n# sudurtinis\nsutr\n# sutrumpintas\nsuv\n# suvalkiečių\nš\n# šiaurė\nšach\n# šachmatai\nšiaur\nškot\n# škotiškai\nšnek\n# šnekamoji\nteatr\ntech\ntechn\n# technika\nteig\n# teigiamas\nteis\n# teisė\ntekst\n# tekstilė\ntel\n# telefonas\nteol\n# teologija\nv\n# tik vyriškosios, vakarai\nt.p\nt\np\n# ir taip pat\nt.t\n# ir taip toliau\nt.y\n# tai yra\nvaik\n# vaikų\nvart\n# vartojama\nvet\n# veterinarija\nvid\n# vidurinis\nvksm\n# veiksmažodis\nvns\n# vienaskaita\nvok\n# vokiečių\nvulg\n# vulgariai\nzool\n# zoologija\nžr\n# žiūrėk\nž.ū\nž\nū\n# žemės ūkis\n\n# List of titles. These are often followed by upper-case names, but do\n# not indicate sentence breaks\n#\n# Jo Eminencija\nEm.\n# Gerbiamasis\nGerb\ngerb\n# malonus\nmalon\n# profesorius\nProf\nprof\n# daktaras (mokslų)\nDr\ndr\nhabil\nmed\n# inž inžinierius\ninž\nInž\n\n\n#Numbers only. These should only induce breaks when followed by a numeric sequence\n# add NUMERIC_ONLY after the word for this function\n#This case is mostly for the english \"No.\" which can either be a sentence of its own, or\n#if followed by a number, a non-breaking prefix\nNo #NUMERIC_ONLY#\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.lv",
"content": "#Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.\n#Special cases are included for prefixes that ONLY appear before 0-9 numbers.\n\n#any single upper case letter followed by a period is not a sentence ender (excluding I occasionally, but we leave it in)\n#usually upper case letters are initials in a name\nA\nĀ\nB\nC\nČ\nD\nE\nĒ\nF\nG\nĢ\nH\nI\nĪ\nJ\nK\nĶ\nL\nĻ\nM\nN\nŅ\nO\nP\nQ\nR\nS\nŠ\nT\nU\nŪ\nV\nW\nX\nY\nZ\nŽ\n\n#List of titles. These are often followed by upper-case names, but do not indicate sentence breaks\ndr\nDr\nmed\nprof\nProf\ninž\nInž\nist.loc\nIst.loc\nkor.loc\nKor.loc\nv.i\nvietn\nVietn\n\n#misc - odd period-ending items that NEVER indicate breaks (p.m. does NOT fall into this category - it sometimes ends a sentence)\na.l\nt.p\npārb\nPārb\nvec\nVec\ninv\nInv\nsk\nSk\nspec\nSpec\nvienk\nVienk\nvirz\nVirz\nmāksl\nMāksl\nmūz\nMūz\nakad\nAkad\nsoc\nSoc\ngalv\nGalv\nvad\nVad\nsertif\nSertif\nfolkl\nFolkl\nhum\nHum\n\n#Numbers only. These should only induce breaks when followed by a numeric sequence\n# add NUMERIC_ONLY after the word for this function\n#This case is mostly for the english \"No.\" which can either be a sentence of its own, or\n#if followed by a number, a non-breaking prefix\nNr #NUMERIC_ONLY# \n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.nl",
"content": "#Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.\n#Special cases are included for prefixes that ONLY appear before 0-9 numbers.\n#Sources: http://nl.wikipedia.org/wiki/Lijst_van_afkortingen \n# http://nl.wikipedia.org/wiki/Aanspreekvorm\n# http://nl.wikipedia.org/wiki/Titulatuur_in_het_Nederlands_hoger_onderwijs\n#any single upper case letter followed by a period is not a sentence ender (excluding I occasionally, but we leave it in)\n#usually upper case letters are initials in a name\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\n\n#List of titles. These are often followed by upper-case names, but do not indicate sentence breaks\nbacc\nbc\nbgen\nc.i\ndhr\ndr\ndr.h.c\ndrs\ndrs\nds\neint\nfa\nFa\nfam\ngen\ngenm\ning\nir\njhr\njkvr\njr\nkand\nkol\nlgen\nlkol\nLt\nmaj\nMej\nmevr\nMme\nmr\nmr\nMw\no.b.s\nplv\nprof\nritm\ntint\nVz\nZ.D\nZ.D.H\nZ.E\nZ.Em\nZ.H\nZ.K.H\nZ.K.M\nZ.M\nz.v\n\n#misc - odd period-ending items that NEVER indicate breaks (p.m. does NOT fall into this category - it sometimes ends a sentence)\n#we seem to have a lot of these in dutch i.e.: i.p.v - in plaats van (in stead of) never ends a sentence\na.g.v\nbijv\nbijz\nbv\nd.w.z\ne.c\ne.g\ne.k\nev\ni.p.v\ni.s.m\ni.t.t\ni.v.m\nm.a.w\nm.b.t\nm.b.v\nm.h.o\nm.i\nm.i.v\nv.w.t\n\n#Numbers only. These should only induce breaks when followed by a numeric sequence\n# add NUMERIC_ONLY after the word for this function\n#This case is mostly for the english \"No.\" which can either be a sentence of its own, or\n#if followed by a number, a non-breaking prefix\nNr #NUMERIC_ONLY# \nNrs \nnrs\nnr #NUMERIC_ONLY#\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.pl",
"content": "adw\nafr\nakad\nal\nAl\nam\namer\narch\nart\nArt\nartyst\nastr\naustr\nbałt\nbdb\nbł\nbm\nbr\nbryg\nbryt\ncentr\nces\nchem\nchiń\nchir\nc.k\nc.o\ncyg\ncyw\ncyt\nczes\nczw\ncd\nCd\nczyt\nćw\nćwicz\ndaw\ndcn\ndekl\ndemokr\ndet\ndiec\ndł\ndn\ndot\ndol\ndop\ndost\ndosł\nh.c\nds\ndst\nduszp\ndypl\negz\nekol\nekon\nelektr\nem\new\nfab\nfarm\nfot\nfr\ngat\ngastr\ngeogr\ngeol\ngimn\ngłęb\ngm\ngodz\ngórn\ngosp\ngr\ngram\nhist\nhiszp\nhr\nHr\nhot\nid\nin\nim\niron\njn\nkard\nkat\nkatol\nk.k\nkk\nkol\nkl\nk.p.a\nkpc\nk.p.c\nkpt\nkr\nk.r\nkrak\nk.r.o\nkryt\nkult\nlaic\nłac\nniem\nwoj\nnb\nnp\nNb\nNp\npol\npow\nm.in\npt\nps\nPt\nPs\ncdn\njw\nryc\nrys\nRyc\nRys\ntj\ntzw\nTzw\ntzn\nzob\nang\nub\nul\npw\npn\npl\nal\nk\nn\nnr #NUMERIC_ONLY#\nNr #NUMERIC_ONLY#\nww\nwł\nur\nzm\nżyd\nżarg\nżyw\nwył\nbp\nbp\nwyst\ntow\nTow\no\nsp\nSp\nst\nspółdz\nSpółdz\nspoł\nspółgł\nstoł\nstow\nStoł\nStow\nzn\nzew\nzewn\nzdr\nzazw\nzast\nzaw\nzał\nzal\nzam\nzak\nzakł\nzagr\nzach\nadw\nAdw\nlek\nLek\nmed\nmec\nMec\ndoc\nDoc\ndyw\ndyr\nDyw\nDyr\ninż\nInż\nmgr\nMgr\ndh\ndr\nDh\nDr\np\nP\nred\nRed\nprof\nprok\nProf\nProk\nhab\npłk\nPłk\nnadkom\nNadkom\npodkom\nPodkom\nks\nKs\ngen\nGen\npor\nPor\nreż\nReż\nprzyp\nPrzyp\nśp\nśw\nśW\nŚp\nŚw\nŚW\nszer\nSzer\npkt #NUMERIC_ONLY#\nstr #NUMERIC_ONLY#\ntab #NUMERIC_ONLY#\nTab #NUMERIC_ONLY#\ntel\nust #NUMERIC_ONLY#\npar #NUMERIC_ONLY#\npoz\npok\noo\noO\nOo\nOO\nr #NUMERIC_ONLY#\nl #NUMERIC_ONLY#\ns #NUMERIC_ONLY#\nnajśw\nNajśw\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\nŚ\nĆ\nŻ\nŹ\nDz\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.ro",
"content": "A\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\ndpdv\netc\nșamd\nM.Ap.N\ndl\nDl\nd-na\nD-na\ndvs\nDvs\npt\nPt\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.ru",
"content": "# added Cyrillic uppercase letters [А-Я]\n# removed 000D carriage return (this is not removed by chomp in tokenizer.perl, and prevents recognition of the prefixes)\n# edited by Kate Young (nspaceanalysis@earthlink.net) 21 May 2013\nА\nБ\nВ\nГ\nД\nЕ\nЖ\nЗ\nИ\nЙ\nК\nЛ\nМ\nН\nО\nП\nР\nС\nТ\nУ\nФ\nХ\nЦ\nЧ\nШ\nЩ\nЪ\nЫ\nЬ\nЭ\nЮ\nЯ\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\n0гг\n1гг\n2гг\n3гг\n4гг\n5гг\n6гг\n7гг\n8гг\n9гг\n0г\n1г\n2г\n3г\n4г\n5г\n6г\n7г\n8г\n9г\nXвв\nVвв\nIвв\nLвв\nMвв\nCвв\nXв\nVв\nIв\nLв\nMв\nCв\n0м\n1м\n2м\n3м\n4м\n5м\n6м\n7м\n8м\n9м\n0мм\n1мм\n2мм\n3мм\n4мм\n5мм\n6мм\n7мм\n8мм\n9мм\n0см\n1см\n2см\n3см\n4см\n5см\n6см\n7см\n8см\n9см\n0дм\n1дм\n2дм\n3дм\n4дм\n5дм\n6дм\n7дм\n8дм\n9дм\n0л\n1л\n2л\n3л\n4л\n5л\n6л\n7л\n8л\n9л\n0км\n1км\n2км\n3км\n4км\n5км\n6км\n7км\n8км\n9км\n0га\n1га\n2га\n3га\n4га\n5га\n6га\n7га\n8га\n9га\n0кг\n1кг\n2кг\n3кг\n4кг\n5кг\n6кг\n7кг\n8кг\n9кг\n0т\n1т\n2т\n3т\n4т\n5т\n6т\n7т\n8т\n9т\n0г\n1г\n2г\n3г\n4г\n5г\n6г\n7г\n8г\n9г\n0мг\n1мг\n2мг\n3мг\n4мг\n5мг\n6мг\n7мг\n8мг\n9мг\nбульв\nв\nвв\nг\nга\nгг\nгл\nгос\nд\nдм\nдоп\nдр\nе\nед\nед\nзам\nи\nинд\nисп\nИсп\nк\nкап\nкг\nкв\nкл\nкм\nкол\nкомн\nкоп\nкуб\nл\nлиц\nлл\nм\nмакс\nмг\nмин\nмл\nмлн\nмлрд\nмм\nн\nнаб\nнач\nнеуд\nном\nо\nобл\nобр\nобщ\nок\nост\nотл\nп\nпер\nперераб\nпл\nпос\nпр\nпросп\nпроф\nр\nред\nруб\nс\nсб\nсв\nсм\nсоч\nср\nст\nстр\nт\nтел\nТел\nтех\nтт\nтуп\nтыс\nуд\nул\nуч\nфиз\nх\nхор\nч\nчел\nшт\nэкз\nэ\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.sk",
"content": "Bc\nMgr\nRNDr\nPharmDr\nPhDr\nJUDr\nPaedDr\nThDr\nIng\nMUDr\nMDDr\nMVDr\nDr\nThLic\nPhD\nArtD\nThDr\nDr\nDrSc\nCSs\nprof\nobr\nObr\nČ\nč\nabsol\nadj\nadmin\nadr\nAdr\nadv\nadvok\nafr\nak\nakad\nakc\nakuz\net\nal\nalch\namer\nanat\nangl\nAngl\nanglosas\nanorg\nap\napod\narch\narcheol\narchit\narg\nart\nastr\nastrol\nastron\natp\natď\naustr\nAustr\naut\nbelg\nBelg\nbibl\nBibl\nbiol\nbot\nbud\nbás\nbýv\ncest\nchem\ncirk\ncsl\nčs\nČs\ndat\ndep\ndet\ndial\ndiaľ\ndipl\ndistrib\ndokl\ndosl\ndopr\ndram\nduš\ndv\ndvojčl\ndór\nekol\nekon\nel\nelektr\nelektrotech\nenerget\nepic\nest\netc\netonym\neufem\neuróp\nEuróp\nev\nevid\nexpr\nfa\nfam\nfarm\nfem\nfeud\nfil\nfilat\nfiloz\nfi\nfon\nform\nfot\nfr\nFr\nfranc\nFranc\nfraz\nfut\nfyz\nfyziol\ngarb\ngen\ngenet\ngenpor\ngeod\ngeogr\ngeol\ngeom\ngerm\ngr\nGr\ngréc\nGréc\ngréckokat\nhebr\nherald\nhist\nhlav\nhosp\nhromad\nhud\nhypok\nident\ni.e\nident\nimp\nimpf\nindoeur\ninf\ninform\ninstr\nint\ninterj\ninšt\ninštr\niron\njap\nJap\njaz\njedn\njuhoamer\njuhových\njuhozáp\njuž\nkanad\nKanad\nkanc\nkapit\nkpt\nkart\nkatastr\nknih\nkniž\nkomp\nkonj\nkonkr\nkozmet\nkrajč\nkresť\nkt\nkuch\nlat\nlatinskoamer\nlek\nlex\nlingv\nlit\nlitur\nlog\nlok\nmax\nMax\nmaď\nMaď\nmedzinár\nmest\nmetr\nmil\nMil\nmin\nMin\nminer\nml\nmld\nmn\nmod\nmytol\nnapr\nnar\nNar\nnasl\nnedok\nneg\nnegat\nneklas\nnem\nNem\nneodb\nneos\nneskl\nnesklon\nnespis\nnespráv\nneved\nnež\nniekt\nniž\nnom\nnáb\nnákl\nnámor\nnár\nobch\nobj\nobv\nobyč\nobč\nobčian\nodb\nodd\nods\nojed\nokr\nOkr\nopt\nopyt\norg\nos\nosob\not\novoc\npar\npart\npejor\npers\npf\nPf \nP.f\np.f\npl\nPlk\npod\npodst\npokl\npolit\npolitol\npolygr\npomn\npopl\npor\nporad\nporov\nposch\npotrav\npouž\npoz\npozit\npoľ\npoľno\npoľnohosp\npoľov\npošt\npož\nprac\npredl\npren\nprep\npreuk\npriezv\nPriezv\nprivl\nprof\npráv\npríd\npríj\nprík\npríp\nprír\nprísl\npríslov\npríč\npsych\npubl\npís\npísm\npôv\nrefl\nreg\nrep\nresp\nrozk\nrozlič\nrozpráv\nroč\nRoč\nryb\nrádiotech\nrím\nsamohl\nsemest\nsev\nseveroamer\nseverových\nseverozáp\nsg\nskr\nskup\nsl\nSloven\nsoc\nsoch\nsociol\nsp\nspol\nSpol\nspoloč\nspoluhl\nspráv\nspôs\nst\nstar\nstarogréc\nstarorím\ns.r.o\nstol\nstor\nstr\nstredoamer\nstredoškol\nsubj\nsubst\nsuperl\nsv\nsz\nsúkr\nsúp\nsúvzť\ntal\nTal\ntech\ntel\nTel\ntelef\nteles\ntelev\nteol\ntrans\nturist\ntuzem\ntypogr\ntzn\ntzv\nukaz\nul\nUl\numel\nuniv\nust\nved\nvedľ\nverb\nveter\nvin\nviď\nvl\nvod\nvodohosp\npnl\nvulg\nvyj\nvys\nvysokoškol\nvzťaž\nvôb\nvých\nvýd\nvýrob\nvýsk\nvýsl\nvýtv\nvýtvar\nvýzn\nvčel\nvš\nvšeob\nzahr\nzar\nzariad\nzast\nzastar\nzastaráv\nzb\nzdravot\nzdruž\nzjemn\nzlat\nzn\nZn\nzool\nzr\nzried\nzv\nzáhr\nzák\nzákl\nzám\nzáp\nzápadoeur\nzázn\núzem\núčt\nčast\nčes\nČes\nčl\nčísl\nživ\npr\nfak\nKr\np.n.l\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.sl",
"content": "dr\nDr\nitd\nitn\nšt #NUMERIC_ONLY#\nŠt #NUMERIC_ONLY#\nd\njan\nJan\nfeb\nFeb\nmar\nMar\napr\nApr\njun\nJun\njul\nJul\navg\nAvg\nsept\nSept\nsep\nSep\nokt\nOkt\nnov\nNov\ndec\nDec\ntj\nTj\nnpr\nNpr\nsl\nSl\nop\nOp\ngl\nGl\noz\nOz\nprev\ndipl\ning\nprim\nPrim\ncf\nCf\ngl\nGl\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.sv",
"content": "#single upper case letter are usually initials\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\n#misc abbreviations\nAB\nG\nVG\ndvs\netc\nfrom\niaf\njfr\nkl\nkr\nmao\nmfl\nmm\nosv\npga\ntex\ntom\nvs\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.ta",
"content": "#Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.\n#Special cases are included for prefixes that ONLY appear before 0-9 numbers.\n\n#any single upper case letter followed by a period is not a sentence ender (excluding I occasionally, but we leave it in)\n#usually upper case letters are initials in a name\nஅ\nஆ\nஇ\nஈ\nஉ\nஊ\nஎ\nஏ\nஐ\nஒ\nஓ\nஔ\nஃ\nக\nகா\nகி\nகீ\nகு\nகூ\nகெ\nகே\nகை\nகொ\nகோ\nகௌ\nக்\nச\nசா\nசி\nசீ\nசு\nசூ\nசெ\nசே\nசை\nசொ\nசோ\nசௌ\nச்\nட\nடா\nடி\nடீ\nடு\nடூ\nடெ\nடே\nடை\nடொ\nடோ\nடௌ\nட்\nத\nதா\nதி\nதீ\nது\nதூ\nதெ\nதே\nதை\nதொ\nதோ\nதௌ\nத்\nப\nபா\nபி\nபீ\nபு\nபூ\nபெ\nபே\nபை\nபொ\nபோ\nபௌ\nப்\nற\nறா\nறி\nறீ\nறு\nறூ\nறெ\nறே\nறை\nறொ\nறோ\nறௌ\nற்\nய\nயா\nயி\nயீ\nயு\nயூ\nயெ\nயே\nயை\nயொ\nயோ\nயௌ\nய்\nர\nரா\nரி\nரீ\nரு\nரூ\nரெ\nரே\nரை\nரொ\nரோ\nரௌ\nர்\nல\nலா\nலி\nலீ\nலு\nலூ\nலெ\nலே\nலை\nலொ\nலோ\nலௌ\nல்\nவ\nவா\nவி\nவீ\nவு\nவூ\nவெ\nவே\nவை\nவொ\nவோ\nவௌ\nவ்\nள\nளா\nளி\nளீ\nளு\nளூ\nளெ\nளே\nளை\nளொ\nளோ\nளௌ\nள்\nழ\nழா\nழி\nழீ\nழு\nழூ\nழெ\nழே\nழை\nழொ\nழோ\nழௌ\nழ்\nங\nஙா\nஙி\nஙீ\nஙு\nஙூ\nஙெ\nஙே\nஙை\nஙொ\nஙோ\nஙௌ\nங் \nஞ\nஞா\nஞி\nஞீ\nஞு\nஞூ\nஞெ\nஞே\nஞை\nஞொ\nஞோ\nஞௌ\nஞ் \nண\nணா\nணி\nணீ\nணு\nணூ\nணெ\nணே\nணை\nணொ\nணோ\nணௌ\nண்\nந\nநா\nநி\nநீ\nநு\nநூ\nநெ\nநே\nநை\nநொ\nநோ\nநௌ\nந் \t\nம\nமா\nமி\nமீ\nமு\nமூ\nமெ\nமே\nமை\nமொ\nமோ\nமௌ\nம் \t\nன\nனா\nனி\nனீ\nனு\nனூ\nனெ\nனே\nனை\nனொ\nனோ\nனௌ\nன்\n\n\n#List of titles. These are often followed by upper-case names, but do not indicate sentence breaks\nதிரு\nதிருமதி\nவண\nகௌரவ\n\n\n#misc - odd period-ending items that NEVER indicate breaks (p.m. does NOT fall into this category - it sometimes ends a sentence)\nஉ.ம்\n#கா.ம்\n#எ.ம்\n\n\n#Numbers only. These should only induce breaks when followed by a numeric sequence\n# add NUMERIC_ONLY after the word for this function\n#This case is mostly for the english \"No.\" which can either be a sentence of its own, or\n#if followed by a number, a non-breaking prefix\nNo #NUMERIC_ONLY# \nNos\nArt #NUMERIC_ONLY#\nNr\npp #NUMERIC_ONLY#\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.yue",
"content": "#\n# Cantonese (Chinese)\n#\n# Anything in this file, followed by a period, \n# does NOT indicate an end-of-sentence marker.\n#\n# English/Euro-language given-name initials (appearing in\n# news, periodicals, etc.)\nA\nĀ\nB\nC\nČ\nD\nE\nĒ\nF\nG\nĢ\nH\nI\nĪ\nJ\nK\nĶ\nL\nĻ\nM\nN\nŅ\nO\nP\nQ\nR\nS\nŠ\nT\nU\nŪ\nV\nW\nX\nY\nZ\nŽ\n\n# Numbers only. These should only induce breaks when followed by\n# a numeric sequence.\n# Add NUMERIC_ONLY after the word for this function. This case is\n# mostly for the english \"No.\" which can either be a sentence of its\n# own, or if followed by a number, a non-breaking prefix.\nNo #NUMERIC_ONLY#\nNr #NUMERIC_ONLY#\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/nonbreaking_prefixes/nonbreaking_prefix.zh",
"content": "#\n# Mandarin (Chinese)\n#\n# Anything in this file, followed by a period, \n# does NOT indicate an end-of-sentence marker.\n#\n# English/Euro-language given-name initials (appearing in\n# news, periodicals, etc.)\nA\nĀ\nB\nC\nČ\nD\nE\nĒ\nF\nG\nĢ\nH\nI\nĪ\nJ\nK\nĶ\nL\nĻ\nM\nN\nŅ\nO\nP\nQ\nR\nS\nŠ\nT\nU\nŪ\nV\nW\nX\nY\nZ\nŽ\n\n# Numbers only. These should only induce breaks when followed by\n# a numeric sequence.\n# Add NUMERIC_ONLY after the word for this function. This case is\n# mostly for the english \"No.\" which can either be a sentence of its\n# own, or if followed by a number, a non-breaking prefix.\nNo #NUMERIC_ONLY#\nNr #NUMERIC_ONLY#\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/release_model.py",
"content": "#!/usr/bin/env python\nimport argparse\nimport torch\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser(\n description=\"Removes the optim data of PyTorch models\")\n parser.add_argument(\"--model\", \"-m\",\n help=\"The model filename (*.pt)\", required=True)\n parser.add_argument(\"--output\", \"-o\",\n help=\"The output filename (*.pt)\", required=True)\n opt = parser.parse_args()\n\n model = torch.load(opt.model)\n model['optim'] = None\n torch.save(model, opt.output)\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/test_rouge.py",
"content": "# -*- encoding: utf-8 -*-\nimport argparse\nimport os\nimport time\nimport pyrouge\nimport shutil\nimport sys\nimport codecs\n\nfrom onmt.utils.logging import init_logger, logger\n\n\ndef test_rouge(cand, ref):\n \"\"\"Calculate ROUGE scores of sequences passed as an iterator\n e.g. a list of str, an open file, StringIO or even sys.stdin\n \"\"\"\n current_time = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime())\n tmp_dir = \".rouge-tmp-{}\".format(current_time)\n try:\n if not os.path.isdir(tmp_dir):\n os.mkdir(tmp_dir)\n os.mkdir(tmp_dir + \"/candidate\")\n os.mkdir(tmp_dir + \"/reference\")\n candidates = [line.strip() for line in cand]\n references = [line.strip() for line in ref]\n assert len(candidates) == len(references)\n cnt = len(candidates)\n for i in range(cnt):\n if len(references[i]) < 1:\n continue\n with open(tmp_dir + \"/candidate/cand.{}.txt\".format(i), \"w\",\n encoding=\"utf-8\") as f:\n f.write(candidates[i])\n with open(tmp_dir + \"/reference/ref.{}.txt\".format(i), \"w\",\n encoding=\"utf-8\") as f:\n f.write(references[i])\n r = pyrouge.Rouge155()\n r.model_dir = tmp_dir + \"/reference/\"\n r.system_dir = tmp_dir + \"/candidate/\"\n r.model_filename_pattern = 'ref.#ID#.txt'\n r.system_filename_pattern = r'cand.(\\d+).txt'\n rouge_results = r.convert_and_evaluate()\n results_dict = r.output_to_dict(rouge_results)\n return results_dict\n finally:\n pass\n if os.path.isdir(tmp_dir):\n shutil.rmtree(tmp_dir)\n\n\ndef rouge_results_to_str(results_dict):\n return \">> ROUGE(1/2/3/L/SU4): {:.2f}/{:.2f}/{:.2f}/{:.2f}/{:.2f}\".format(\n results_dict[\"rouge_1_f_score\"] * 100,\n results_dict[\"rouge_2_f_score\"] * 100,\n results_dict[\"rouge_3_f_score\"] * 100,\n results_dict[\"rouge_l_f_score\"] * 100,\n results_dict[\"rouge_su*_f_score\"] * 100)\n\n\nif __name__ == \"__main__\":\n init_logger('test_rouge.log')\n parser = argparse.ArgumentParser()\n parser.add_argument('-c', type=str, default=\"candidate.txt\",\n help='candidate file')\n parser.add_argument('-r', type=str, default=\"reference.txt\",\n help='reference file')\n args = parser.parse_args()\n if args.c.upper() == \"STDIN\":\n candidates = sys.stdin\n else:\n candidates = codecs.open(args.c, encoding=\"utf-8\")\n references = codecs.open(args.r, encoding=\"utf-8\")\n\n results_dict = test_rouge(candidates, references)\n logger.info(rouge_results_to_str(results_dict))\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/tokenizer.perl",
"content": "#!/usr/bin/env perl\n#\n# This file is part of moses. Its use is licensed under the GNU Lesser General\n# Public License version 2.1 or, at your option, any later version.\n\nuse warnings;\n\n# Sample Tokenizer\n### Version 1.1\n# written by Pidong Wang, based on the code written by Josh Schroeder and Philipp Koehn\n# Version 1.1 updates:\n# (1) add multithreading option \"-threads NUM_THREADS\" (default is 1);\n# (2) add a timing option \"-time\" to calculate the average speed of this tokenizer;\n# (3) add an option \"-lines NUM_SENTENCES_PER_THREAD\" to set the number of lines for each thread (default is 2000), and this option controls the memory amount needed: the larger this number is, the larger memory is required (the higher tokenization speed);\n### Version 1.0\n# $Id: tokenizer.perl 915 2009-08-10 08:15:49Z philipp $\n# written by Josh Schroeder, based on code by Philipp Koehn\n\nbinmode(STDIN, \":utf8\");\nbinmode(STDOUT, \":utf8\");\n\nuse warnings;\nuse FindBin qw($RealBin);\nuse strict;\nuse Time::HiRes;\n\nif (eval {require Thread;1;}) {\n #module loaded\n Thread->import();\n}\n\nmy $mydir = \"$RealBin/nonbreaking_prefixes\";\n\nmy %NONBREAKING_PREFIX = ();\nmy @protected_patterns = ();\nmy $protected_patterns_file = \"\";\nmy $language = \"en\";\nmy $QUIET = 0;\nmy $HELP = 0;\nmy $AGGRESSIVE = 0;\nmy $SKIP_XML = 0;\nmy $TIMING = 0;\nmy $NUM_THREADS = 1;\nmy $NUM_SENTENCES_PER_THREAD = 2000;\nmy $PENN = 0;\nmy $NO_ESCAPING = 0;\nwhile (@ARGV)\n{\n\t$_ = shift;\n\t/^-b$/ && ($| = 1, next);\n\t/^-l$/ && ($language = shift, next);\n\t/^-q$/ && ($QUIET = 1, next);\n\t/^-h$/ && ($HELP = 1, next);\n\t/^-x$/ && ($SKIP_XML = 1, next);\n\t/^-a$/ && ($AGGRESSIVE = 1, next);\n\t/^-time$/ && ($TIMING = 1, next);\n # Option to add list of regexps to be protected\n /^-protected/ && ($protected_patterns_file = shift, next);\n\t/^-threads$/ && ($NUM_THREADS = int(shift), next);\n\t/^-lines$/ && ($NUM_SENTENCES_PER_THREAD = int(shift), next);\n\t/^-penn$/ && ($PENN = 1, next);\n\t/^-no-escape/ && ($NO_ESCAPING = 1, next);\n}\n\n# for time calculation\nmy $start_time;\nif ($TIMING)\n{\n $start_time = [ Time::HiRes::gettimeofday( ) ];\n}\n\n# print help message\nif ($HELP)\n{\n\tprint \"Usage ./tokenizer.perl (-l [en|de|...]) (-threads 4) < textfile > tokenizedfile\\n\";\n print \"Options:\\n\";\n print \" -q ... quiet.\\n\";\n print \" -a ... aggressive hyphen splitting.\\n\";\n print \" -b ... disable Perl buffering.\\n\";\n print \" -time ... enable processing time calculation.\\n\";\n print \" -penn ... use Penn treebank-like tokenization.\\n\";\n print \" -protected FILE ... specify file with patters to be protected in tokenisation.\\n\";\n\tprint \" -no-escape ... don't perform HTML escaping on apostrophy, quotes, etc.\\n\";\n\texit;\n}\n\nif (!$QUIET)\n{\n\tprint STDERR \"Tokenizer Version 1.1\\n\";\n\tprint STDERR \"Language: $language\\n\";\n\tprint STDERR \"Number of threads: $NUM_THREADS\\n\";\n}\n\n# load the language-specific non-breaking prefix info from files in the directory nonbreaking_prefixes\nload_prefixes($language,\\%NONBREAKING_PREFIX);\n\nif (scalar(%NONBREAKING_PREFIX) eq 0)\n{\n\tprint STDERR \"Warning: No known abbreviations for language '$language'\\n\";\n}\n\n# Load protected patterns\nif ($protected_patterns_file)\n{\n open(PP,$protected_patterns_file) || die \"Unable to open $protected_patterns_file\";\n while() {\n chomp;\n push @protected_patterns, $_;\n }\n}\n\nmy @batch_sentences = ();\nmy @thread_list = ();\nmy $count_sentences = 0;\n\nif ($NUM_THREADS > 1)\n{# multi-threading tokenization\n while()\n {\n $count_sentences = $count_sentences + 1;\n push(@batch_sentences, $_);\n if (scalar(@batch_sentences)>=($NUM_SENTENCES_PER_THREAD*$NUM_THREADS))\n {\n # assign each thread work\n for (my $i=0; $i<$NUM_THREADS; $i++)\n {\n my $start_index = $i*$NUM_SENTENCES_PER_THREAD;\n my $end_index = $start_index+$NUM_SENTENCES_PER_THREAD-1;\n my @subbatch_sentences = @batch_sentences[$start_index..$end_index];\n my $new_thread = new Thread \\&tokenize_batch, @subbatch_sentences;\n push(@thread_list, $new_thread);\n }\n foreach (@thread_list)\n {\n my $tokenized_list = $_->join;\n foreach (@$tokenized_list)\n {\n print $_;\n }\n }\n # reset for the new run\n @thread_list = ();\n @batch_sentences = ();\n }\n }\n # the last batch\n if (scalar(@batch_sentences)>0)\n {\n # assign each thread work\n for (my $i=0; $i<$NUM_THREADS; $i++)\n {\n my $start_index = $i*$NUM_SENTENCES_PER_THREAD;\n if ($start_index >= scalar(@batch_sentences))\n {\n last;\n }\n my $end_index = $start_index+$NUM_SENTENCES_PER_THREAD-1;\n if ($end_index >= scalar(@batch_sentences))\n {\n $end_index = scalar(@batch_sentences)-1;\n }\n my @subbatch_sentences = @batch_sentences[$start_index..$end_index];\n my $new_thread = new Thread \\&tokenize_batch, @subbatch_sentences;\n push(@thread_list, $new_thread);\n }\n foreach (@thread_list)\n {\n my $tokenized_list = $_->join;\n foreach (@$tokenized_list)\n {\n print $_;\n }\n }\n }\n}\nelse\n{# single thread only\n while()\n {\n if (($SKIP_XML && /^<.+>$/) || /^\\s*$/)\n {\n #don't try to tokenize XML/HTML tag lines\n print $_;\n }\n else\n {\n print &tokenize($_);\n }\n }\n}\n\nif ($TIMING)\n{\n my $duration = Time::HiRes::tv_interval( $start_time );\n print STDERR (\"TOTAL EXECUTION TIME: \".$duration.\"\\n\");\n print STDERR (\"TOKENIZATION SPEED: \".($duration/$count_sentences*1000).\" milliseconds/line\\n\");\n}\n\n#####################################################################################\n# subroutines afterward\n\n# tokenize a batch of texts saved in an array\n# input: an array containing a batch of texts\n# return: another array containing a batch of tokenized texts for the input array\nsub tokenize_batch\n{\n my(@text_list) = @_;\n my(@tokenized_list) = ();\n foreach (@text_list)\n {\n if (($SKIP_XML && /^<.+>$/) || /^\\s*$/)\n {\n #don't try to tokenize XML/HTML tag lines\n push(@tokenized_list, $_);\n }\n else\n {\n push(@tokenized_list, &tokenize($_));\n }\n }\n return \\@tokenized_list;\n}\n\n# the actual tokenize function which tokenizes one input string\n# input: one string\n# return: the tokenized string for the input string\nsub tokenize\n{\n my($text) = @_;\n\n if ($PENN) {\n return tokenize_penn($text);\n }\n\n chomp($text);\n $text = \" $text \";\n\n # remove ASCII junk\n $text =~ s/\\s+/ /g;\n $text =~ s/[\\000-\\037]//g;\n\n # Find protected patterns\n my @protected = ();\n foreach my $protected_pattern (@protected_patterns) {\n my $t = $text;\n while ($t =~ /(?$protected_pattern)(?.*)$/) {\n push @protected, $+{PATTERN};\n $t = $+{TAIL};\n }\n }\n\n for (my $i = 0; $i < scalar(@protected); ++$i) {\n my $subst = sprintf(\"THISISPROTECTED%.3d\", $i);\n $text =~ s,\\Q$protected[$i], $subst ,g;\n }\n $text =~ s/ +/ /g;\n $text =~ s/^ //g;\n $text =~ s/ $//g;\n\n # seperate out all \"other\" special characters\n $text =~ s/([^\\p{IsAlnum}\\s\\.\\'\\`\\,\\-])/ $1 /g;\n\n # aggressive hyphen splitting\n if ($AGGRESSIVE)\n {\n $text =~ s/([\\p{IsAlnum}])\\-(?=[\\p{IsAlnum}])/$1 \\@-\\@ /g;\n }\n\n #multi-dots stay together\n $text =~ s/\\.([\\.]+)/ DOTMULTI$1/g;\n while($text =~ /DOTMULTI\\./)\n {\n $text =~ s/DOTMULTI\\.([^\\.])/DOTDOTMULTI $1/g;\n $text =~ s/DOTMULTI\\./DOTDOTMULTI/g;\n }\n\n # seperate out \",\" except if within numbers (5,300)\n #$text =~ s/([^\\p{IsN}])[,]([^\\p{IsN}])/$1 , $2/g;\n\n # separate out \",\" except if within numbers (5,300)\n # previous \"global\" application skips some: A,B,C,D,E > A , B,C , D,E\n # first application uses up B so rule can't see B,C\n # two-step version here may create extra spaces but these are removed later\n # will also space digit,letter or letter,digit forms (redundant with next section)\n $text =~ s/([^\\p{IsN}])[,]/$1 , /g;\n $text =~ s/[,]([^\\p{IsN}])/ , $1/g;\n \n # separate \",\" after a number if it's the end of a sentence\n $text =~ s/([\\p{IsN}])[,]$/$1 ,/g;\n\n # separate , pre and post number\n #$text =~ s/([\\p{IsN}])[,]([^\\p{IsN}])/$1 , $2/g;\n #$text =~ s/([^\\p{IsN}])[,]([\\p{IsN}])/$1 , $2/g;\n\n # turn `into '\n #$text =~ s/\\`/\\'/g;\n\n #turn '' into \"\n #$text =~ s/\\'\\'/ \\\" /g;\n\n if ($language eq \"en\")\n {\n #split contractions right\n $text =~ s/([^\\p{IsAlpha}])[']([^\\p{IsAlpha}])/$1 ' $2/g;\n $text =~ s/([^\\p{IsAlpha}\\p{IsN}])[']([\\p{IsAlpha}])/$1 ' $2/g;\n $text =~ s/([\\p{IsAlpha}])[']([^\\p{IsAlpha}])/$1 ' $2/g;\n $text =~ s/([\\p{IsAlpha}])[']([\\p{IsAlpha}])/$1 '$2/g;\n #special case for \"1990's\"\n $text =~ s/([\\p{IsN}])[']([s])/$1 '$2/g;\n }\n elsif (($language eq \"fr\") or ($language eq \"it\") or ($language eq \"ga\"))\n {\n #split contractions left\n $text =~ s/([^\\p{IsAlpha}])[']([^\\p{IsAlpha}])/$1 ' $2/g;\n $text =~ s/([^\\p{IsAlpha}])[']([\\p{IsAlpha}])/$1 ' $2/g;\n $text =~ s/([\\p{IsAlpha}])[']([^\\p{IsAlpha}])/$1 ' $2/g;\n $text =~ s/([\\p{IsAlpha}])[']([\\p{IsAlpha}])/$1' $2/g;\n }\n else\n {\n $text =~ s/\\'/ \\' /g;\n }\n\n #word token method\n my @words = split(/\\s/,$text);\n $text = \"\";\n for (my $i=0;$i<(scalar(@words));$i++)\n {\n my $word = $words[$i];\n if ( $word =~ /^(\\S+)\\.$/)\n {\n my $pre = $1;\n if (($pre =~ /\\./ && $pre =~ /\\p{IsAlpha}/) || ($NONBREAKING_PREFIX{$pre} && $NONBREAKING_PREFIX{$pre}==1) || ($i/\\>/g; # xml\n\t$text =~ s/\\'/\\'/g; # xml\n\t$text =~ s/\\\"/\\"/g; # xml\n\t$text =~ s/\\[/\\[/g; # syntax non-terminal\n\t$text =~ s/\\]/\\]/g; # syntax non-terminal\n }\n\n #ensure final line break\n $text .= \"\\n\" unless $text =~ /\\n$/;\n\n return $text;\n}\n\nsub tokenize_penn\n{\n # Improved compatibility with Penn Treebank tokenization. Useful if\n # the text is to later be parsed with a PTB-trained parser.\n #\n # Adapted from Robert MacIntyre's sed script:\n # http://www.cis.upenn.edu/~treebank/tokenizer.sed\n\n my($text) = @_;\n chomp($text);\n\n # remove ASCII junk\n $text =~ s/\\s+/ /g;\n $text =~ s/[\\000-\\037]//g;\n\n # attempt to get correct directional quotes\n $text =~ s/^``/`` /g;\n $text =~ s/^\"/`` /g;\n $text =~ s/^`([^`])/` $1/g;\n $text =~ s/^'/` /g;\n $text =~ s/([ ([{<])\"/$1 `` /g;\n $text =~ s/([ ([{<])``/$1 `` /g;\n $text =~ s/([ ([{<])`([^`])/$1 ` $2/g;\n $text =~ s/([ ([{<])'/$1 ` /g;\n # close quotes handled at end\n\n $text =~ s=\\.\\.\\.= _ELLIPSIS_ =g;\n\n # separate out \",\" except if within numbers (5,300)\n $text =~ s/([^\\p{IsN}])[,]([^\\p{IsN}])/$1 , $2/g;\n # separate , pre and post number\n $text =~ s/([\\p{IsN}])[,]([^\\p{IsN}])/$1 , $2/g;\n $text =~ s/([^\\p{IsN}])[,]([\\p{IsN}])/$1 , $2/g;\n\n #$text =~ s=([;:@#\\$%&\\p{IsSc}])= $1 =g;\n$text =~ s=([;:@#\\$%&\\p{IsSc}\\p{IsSo}])= $1 =g;\n\n # Separate out intra-token slashes. PTB tokenization doesn't do this, so\n # the tokens should be merged prior to parsing with a PTB-trained parser\n # (see syntax-hyphen-splitting.perl).\n $text =~ s/([\\p{IsAlnum}])\\/([\\p{IsAlnum}])/$1 \\@\\/\\@ $2/g;\n\n # Assume sentence tokenization has been done first, so split FINAL periods\n # only.\n $text =~ s=([^.])([.])([\\]\\)}>\"']*) ?$=$1 $2$3 =g;\n # however, we may as well split ALL question marks and exclamation points,\n # since they shouldn't have the abbrev.-marker ambiguity problem\n $text =~ s=([?!])= $1 =g;\n\n # parentheses, brackets, etc.\n $text =~ s=([\\]\\[\\(\\){}<>])= $1 =g;\n $text =~ s/\\(/-LRB-/g;\n $text =~ s/\\)/-RRB-/g;\n $text =~ s/\\[/-LSB-/g;\n $text =~ s/\\]/-RSB-/g;\n $text =~ s/{/-LCB-/g;\n $text =~ s/}/-RCB-/g;\n\n $text =~ s=--= -- =g;\n\n # First off, add a space to the beginning and end of each line, to reduce\n # necessary number of regexps.\n $text =~ s=$= =;\n $text =~ s=^= =;\n\n $text =~ s=\"= '' =g;\n # possessive or close-single-quote\n $text =~ s=([^'])' =$1 ' =g;\n # as in it's, I'm, we'd\n $text =~ s='([sSmMdD]) = '$1 =g;\n $text =~ s='ll = 'll =g;\n $text =~ s='re = 're =g;\n $text =~ s='ve = 've =g;\n $text =~ s=n't = n't =g;\n $text =~ s='LL = 'LL =g;\n $text =~ s='RE = 'RE =g;\n $text =~ s='VE = 'VE =g;\n $text =~ s=N'T = N'T =g;\n\n $text =~ s= ([Cc])annot = $1an not =g;\n $text =~ s= ([Dd])'ye = $1' ye =g;\n $text =~ s= ([Gg])imme = $1im me =g;\n $text =~ s= ([Gg])onna = $1on na =g;\n $text =~ s= ([Gg])otta = $1ot ta =g;\n $text =~ s= ([Ll])emme = $1em me =g;\n $text =~ s= ([Mm])ore'n = $1ore 'n =g;\n $text =~ s= '([Tt])is = '$1 is =g;\n $text =~ s= '([Tt])was = '$1 was =g;\n $text =~ s= ([Ww])anna = $1an na =g;\n\n #word token method\n my @words = split(/\\s/,$text);\n $text = \"\";\n for (my $i=0;$i<(scalar(@words));$i++)\n {\n my $word = $words[$i];\n if ( $word =~ /^(\\S+)\\.$/)\n {\n my $pre = $1;\n if (($pre =~ /\\./ && $pre =~ /\\p{IsAlpha}/) || ($NONBREAKING_PREFIX{$pre} && $NONBREAKING_PREFIX{$pre}==1) || ($i/\\>/g; # xml\n $text =~ s/\\'/\\'/g; # xml\n $text =~ s/\\\"/\\"/g; # xml\n $text =~ s/\\[/\\[/g; # syntax non-terminal\n $text =~ s/\\]/\\]/g; # syntax non-terminal\n\n #ensure final line break\n $text .= \"\\n\" unless $text =~ /\\n$/;\n\n return $text;\n}\n\nsub load_prefixes\n{\n my ($language, $PREFIX_REF) = @_;\n\n my $prefixfile = \"$mydir/nonbreaking_prefix.$language\";\n\n #default back to English if we don't have a language-specific prefix file\n if (!(-e $prefixfile))\n {\n $prefixfile = \"$mydir/nonbreaking_prefix.en\";\n print STDERR \"WARNING: No known abbreviations for language '$language', attempting fall-back to English version...\\n\";\n die (\"ERROR: No abbreviations files found in $mydir\\n\") unless (-e $prefixfile);\n }\n\n if (-e \"$prefixfile\")\n {\n open(PREFIX, \"<:utf8\", \"$prefixfile\");\n while ()\n {\n my $item = $_;\n chomp($item);\n if (($item) && (substr($item,0,1) ne \"#\"))\n {\n if ($item =~ /(.*)[\\s]+(\\#NUMERIC_ONLY\\#)/)\n {\n $PREFIX_REF->{$1} = 2;\n }\n else\n {\n $PREFIX_REF->{$item} = 1;\n }\n }\n }\n close(PREFIX);\n }\n}\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/tools/vid_feature_extractor.py",
"content": "import argparse\nimport os\n\nimport tqdm\nfrom multiprocessing import Manager\nimport numpy as np\nimport cv2\nimport torch\nimport torch.nn as nn\nfrom PIL import Image\nimport pretrainedmodels\nfrom pretrainedmodels.utils import TransformImage\n\n\nQ_FIN = \"finished\" # end-of-queue flag\n\n\ndef read_to_imgs(file):\n \"\"\"Yield images and their frame number from a video file.\"\"\"\n vidcap = cv2.VideoCapture(file)\n success, image = vidcap.read()\n idx = 0\n while success:\n image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)\n yield image, idx\n idx += 1\n success, image = vidcap.read()\n\n\ndef vid_len(path):\n \"\"\"Return the length of a video.\"\"\"\n return int(cv2.VideoCapture(path).get(cv2.CAP_PROP_FRAME_COUNT))\n\n\nclass VidDset(object):\n \"\"\"For each video, yield its frames.\"\"\"\n def __init__(self, model, root_dir, filenames):\n self.root_dir = root_dir\n self.filenames = filenames\n self.paths = [os.path.join(self.root_dir, f) for f in self.filenames]\n self.xform = TransformImage(model)\n\n self.current = 0\n\n def __len__(self):\n return len(self.filenames)\n\n def __getitem__(self, i):\n path = self.paths[i]\n return ((path, idx, self.xform(Image.fromarray(img)))\n for img, idx in read_to_imgs(path))\n\n def __iter__(self):\n return self\n\n def next(self):\n if self.current >= len(self):\n raise StopIteration\n else:\n self.current += 1\n return self[self.current - 1]\n\n def __next__(self):\n return self.next()\n\n\ndef collate_tensor(batch):\n batch[-1] = torch.stack(batch[-1], 0)\n\n\ndef batch(dset, batch_size):\n \"\"\"Collate frames into batches of equal length.\"\"\"\n batch = [[], [], []]\n batch_ct = 0\n for seq in dset:\n for path, idx, img in seq:\n if batch_ct == batch_size:\n collate_tensor(batch)\n yield batch\n batch = [[], [], []]\n batch_ct = 0\n batch[0].append(path)\n batch[1].append(idx)\n batch[2].append(img)\n batch_ct += 1\n if batch_ct != 0:\n collate_tensor(batch)\n yield batch\n\n\nclass FeatureExtractor(nn.Module):\n \"\"\"Extract feature vectors from a batch of frames.\"\"\"\n def __init__(self):\n super(FeatureExtractor, self).__init__()\n self.model = pretrainedmodels.resnet152()\n self.FEAT_SIZE = 2048\n\n def forward(self, x):\n return self.model.avgpool(\n self.model.features(x)).view(-1, 1, self.FEAT_SIZE)\n\n\nclass Reconstructor(object):\n \"\"\"Turn batches of feature vectors into sequences for each video.\n Assumes data is ordered (use one reconstructor per process).\n :func:`push()` batches in. When finished, :func:`flush()`\n the last sequence.\n \"\"\"\n\n def __init__(self, out_path, finished_queue):\n self.out_path = out_path\n self.feats = None\n self.finished_queue = finished_queue\n\n def save(self, path, feats):\n np.save(path, feats.numpy())\n\n @staticmethod\n def name_(path, out_path):\n vid_path = path\n vid_fname = os.path.basename(vid_path)\n vid_id = os.path.splitext(vid_fname)[0]\n\n save_fname = vid_id + \".npy\"\n save_path = os.path.join(out_path, save_fname)\n return save_path, vid_id\n\n def name(self, path):\n return self.name_(path, self.out_path)\n\n def push(self, paths, idxs, feats):\n start = 0\n for i, idx in enumerate(idxs):\n if idx == 0:\n if self.feats is None and i == 0:\n # degenerate case\n continue\n these_finished_seq_feats = feats[start:i]\n if self.feats is not None:\n all_last_seq_feats = torch.cat(\n [self.feats, these_finished_seq_feats], 0)\n else:\n all_last_seq_feats = these_finished_seq_feats\n if i - 1 < 0:\n name = self.path\n else:\n name = paths[i-1]\n save_path, vid_id = self.name(name)\n self.save(save_path, all_last_seq_feats)\n n_feats = all_last_seq_feats.shape[0]\n self.finished_queue.put((vid_id, n_feats))\n self.feats = None\n start = i\n # cache the features\n if self.feats is None:\n self.feats = feats[start:]\n else:\n self.feats = torch.cat([self.feats, feats[start:]], 0)\n self.path = paths[-1]\n\n def flush(self):\n if self.feats is not None: # shouldn't be\n save_path, vid_id = self.name(self.path)\n self.save(save_path, self.feats)\n self.finished_queue.put((vid_id, self.feats.shape[0]))\n\n\ndef finished_watcher(finished_queue, world_size, root_dir, files):\n \"\"\"Keep a progress bar of frames finished.\"\"\"\n n_frames = sum(vid_len(os.path.join(root_dir, f)) for f in files)\n n_finished_frames = 0\n with tqdm.tqdm(total=n_frames, unit=\"Fr\") as pbar:\n n_proc_finished = 0\n while True:\n item = finished_queue.get()\n if item == Q_FIN:\n n_proc_finished += 1\n if n_proc_finished == world_size:\n return\n else:\n vid_id, n_these_frames = item\n n_finished_frames += n_these_frames\n pbar.set_postfix(vid=vid_id)\n pbar.update(n_these_frames)\n\n\ndef run(device_id, world_size, root_dir, batch_size_per_device,\n feats_queue, files):\n \"\"\"Process a disjoint subset of the videos on each device.\"\"\"\n if world_size > 1:\n these_files = [f for i, f in enumerate(files)\n if i % world_size == device_id]\n else:\n these_files = files\n\n fe = FeatureExtractor()\n dset = VidDset(fe.model, root_dir, these_files)\n dev = torch.device(\"cuda\", device_id) \\\n if device_id >= 0 else torch.device(\"cpu\")\n fe.to(dev)\n fe = fe.eval()\n with torch.no_grad():\n for samp in batch(dset, batch_size_per_device):\n paths, idxs, images = samp\n images = images.to(dev)\n feats = fe(images)\n if torch.is_tensor(feats):\n feats = feats.to(\"cpu\")\n else:\n feats = [f.to(\"cpu\") for f in feats]\n feats_queue.put((paths, idxs, feats))\n feats_queue.put(Q_FIN)\n return\n\n\ndef saver(out_path, feats_queue, finished_queue):\n rc = Reconstructor(out_path, finished_queue)\n while True:\n item = feats_queue.get()\n if item == Q_FIN:\n rc.flush()\n finished_queue.put(Q_FIN)\n return\n else:\n paths, idxs, feats = item\n rc.push(paths, idxs, feats)\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--root_dir\", type=str, required=True,\n help=\"Directory of videos.\")\n parser.add_argument(\"--out_dir\", type=str, required=True,\n help=\"Directory for output features.\")\n parser.add_argument(\"--world_size\", type=int, default=1,\n help=\"Number of devices to run on.\")\n parser.add_argument(\"--batch_size_per_device\", type=int, default=512)\n opt = parser.parse_args()\n\n batch_size_per_device = opt.batch_size_per_device\n root_dir = opt.root_dir\n out_path = opt.out_dir\n if not os.path.exists(out_path):\n os.makedirs(out_path)\n\n # mp queues don't work well between procs unless they're from a manager\n manager = Manager()\n finished_queue = manager.Queue()\n\n world_size = opt.world_size if torch.cuda.is_available() else -1\n\n mp = torch.multiprocessing.get_context(\"spawn\")\n procs = []\n\n print(\"Starting processing. Progress bar startup can take some time, but \"\n \"processing will start in the meantime.\")\n\n files = list(sorted(list(os.listdir(root_dir))))\n files = [f for f in files\n if os.path.basename(Reconstructor.name_(f, out_path)[0])\n not in os.listdir(out_path)]\n\n procs.append(mp.Process(\n target=finished_watcher,\n args=(finished_queue, world_size, root_dir, files),\n daemon=False\n ))\n procs[0].start()\n\n if world_size >= 1:\n feat_queues = [manager.Queue(2) for _ in range(world_size)]\n for feats_queue, device_id in zip(feat_queues, range(world_size)):\n # each device has its own saver so that reconstructing is easier\n procs.append(mp.Process(\n target=run,\n args=(device_id, world_size, root_dir,\n batch_size_per_device, feats_queue, files),\n daemon=True))\n procs[-1].start()\n procs.append(mp.Process(\n target=saver,\n args=(out_path, feats_queue, finished_queue),\n daemon=True))\n procs[-1].start()\n else:\n feats_queue = manager.Queue()\n procs.append(mp.Process(\n target=run,\n args=(-1, 1, root_dir,\n batch_size_per_device, feats_queue, files),\n daemon=True))\n procs[-1].start()\n procs.append(mp.Process(\n target=saver,\n args=(out_path, feats_queue, finished_queue),\n daemon=True))\n procs[-1].start()\n\n for p in procs:\n p.join()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/train.py",
"content": "#!/usr/bin/env python\nfrom onmt.bin.train import main\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/OpenNMT-py/translate.py",
"content": "#!/usr/bin/env python\nfrom onmt.bin.translate import main\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "深度学习自然语言处理/机器翻译/README.md",
"content": "## 机器翻译\n\n"
},
{
"path": "深度学习自然语言处理/机器翻译/bpe-subword论文的我的阅读总结.md",
"content": "bpe论文的我的阅读感受\n\nNeural Machine Translation of Rare Words with Subword Units\n\n提出这个算法的直觉是这样的,作者发现翻译一个单词,有时候不需要这个单词的全部信息,可能只需要一部分信息就可以知道大致信息。还有一种可能是翻译这个单词与,可能通过组成\n这个单词的多个小单元信息来翻译就可以了。\n\n这个方法是为了解决稀少单词(也就是频率在人为规定下的单词)和未登录词没有办法有效翻译的问题。\n\n这里作者在摘要中提到了一个back-off 字典,就是说在之前翻译模型在处理未登录词汇的时候,处理办法是使用一个词典,把source-target中未登陆词汇一一对应起来,我们在翻译过程中\n如果出现了未登录词汇,直接使用字典中的对应关系进行替换就可以了。但是这样存在一个问题,就是说,最低频率是我们人为规定的,有些时候在调参的时候,这个频率是一个超参,,那么\n我们在准备词典的时候,就是一个动态的长度,这样很不方便,但是如果我们准备所有单词的back-off就得不偿失。还有一个问题是我们不确定source-target对应的关系是一一对应的,可能对应不上,可能对应\n是多种,在不同句子环境中,我们需要选择不同的单词翻译,这也是存在的一个问题。\n\n基于word-level的模型还存在一个问题,就是不能产生没有看见过的单词,也就是说在翻译端,没有出现在词汇表中的在翻译模型测试的时候是不会出现的。这其实是一个很重要的问题,就是我不能确定\n我的训练语料包含所有情况下的翻译。\n\n作者在摘要中说明,自己使用了字符级的n-gram和bpe方法,在WMT 15 英文德文翻译中提升1.1,在英文俄罗斯中提升1.3。\n\n\n\n翻译是一个开放词汇表的问题,我们在翻译模型中,一般把翻译模型词汇表限制在30000–50000(基于词)。\n\n作者通过实验发现,使用subeword模型,比使用大量词汇表的模型和使用back-off模型效果很好更简单。\n\n\n\n我在博客中看到了总结这个论文不错的博客,总结在下面\n通过BPE解决OOV问题----Neural machine Translation of Rare Words with Subword Units\nhttps://blog.csdn.net/weixin_38937984/article/details/101723700\n\n"
},
{
"path": "深度学习自然语言处理/模型蒸馏/BERT知识蒸馏代码解析-如何写好损失函数.md",
"content": "大家好,我是DASOU;\n\n今天从代码角度深入了解一下知识蒸馏,主要核心部分就是分析一下在知识蒸馏中损失函数是如何实现的;\n\n之前写过一个关于BERT知识蒸馏的理论的文章,感兴趣的朋友可以去看一下:[Bert知识蒸馏系列(一):什么是知识蒸馏](http://mp.weixin.qq.com/s?__biz=MzIyNTY1MDUwNQ==&mid=2247484225&idx=1&sn=b48cfea668bd5b91e1bb8c74e3ab1db3&chksm=e87d3167df0ab8713d045bf656291b0da9e4928f57c27d5ea4e4f537cf44f051dc0b6d6ec35a&scene=21#wechat_redirect)。\n\n知识蒸馏一个简单的脉络可以这么去梳理:**学什么,从哪里学,怎么学?**\n\n**学什么**:学的是老师的知识,体现在网络的参数上;\n\n**从哪里学**:输入层,中间层,输出层;\n\n**怎么学**:损失函数度量老师网络和学生网络的差异性;\n\n从架构上来说,BERT可以蒸馏到简单的TextCNN,LSTM等,也就可以蒸馏到TRM架构模型,比如12层BERT到4层BERT;\n\n之前工作中用到的是BERT蒸馏到TextCNN;\n\n最近在往TRM蒸馏靠近,使用的是 Textbrewer 这个库(这个库太强大了);\n\n接下来,我从代码的角度来梳理一下知识蒸馏的核心步骤,其实最主要的就是分析一下损失函数那块的代码形式。\n\n我以一个文本分类的任务为例子,在阅读理解的过程中,最需要注意的一点是数据的流入流出的Shape,这个很重要,在自己写代码的时候,最重要的其实就是这个;\n\n首先使用的是MNLI任务,也就是一个文本分类任务,三个标签;\n\n输入为Batch_data:[32,128]---[Batch_size,seq_len];\n\n老师网络:BERT_base:12层,Hidden_size为768;\n\n学生网络:BERT_base:4层,Hidden_size为312;\n\n首先第一个步骤是训练一个老师网络,这个没啥可说。\n\n其次是初始化学生网络,然后将输入Batch_data流经两个网络;\n\n在初始化学生网络的时候,之前有的同学问到是如何初始化的一个BERT模型的;\n\n关于这个,最主要的是修改Config文件那里的层数,由正常的12改为4,然后如果你不是从本地load参数到学生网络,BERT模型的类会自动调用初始化;\n\n关于代码实现,我之前写过一个文章,大家可以看这里的代码解析,更加的清洗一点:[Pytorch代码验证--如何让Bert在finetune小数据集时更“稳”一点](http://mp.weixin.qq.com/s?__biz=MzIyNTY1MDUwNQ==&mid=2247483696&idx=1&sn=cc79da01752c5e7588ef8686c1f95e1f&chksm=e87d3316df0aba00e23189158bfdb7a41e964f545422d97940a87d89571881a5ac1be4bb77f8&scene=21#wechat_redirect);\n\n然后我们来说数据首先流经学生网络,我们得到两个东西,一个是最后一层【CLS】的输出,此时未经softmax操作,所以是logits,维度为:[32,3]-[batch_size,label_size];\n\n第二个东西是中间隐层的输出,维度为:[5,32,128,312],也就是 [隐层数量,batch_size,seq_len,Hidden_size];\n\n需要注意的是这里的隐层数量是5,因为正常的隐层在模型定义的时候是4,然后这里是加上了embedding层;\n\n还有一点需要注意的是,在度量学生网络和老师网络隐层差异的时候,这里是度量的seq_len,也就是对每个token的输出都做了操作;\n\n如果在这里我们想做类似【CLS】的输出的时候,只需要提取最开始的一个[32,312]的向量就可以;不过,一般来说我们不这么做;\n\n其次流经老师网络,我们同样得到两个东西,一个是最后一层【CLS】的输出,此时未经softmax操作,所以是logits,维度为:[32,3]-[batch_size,label_size];\n\n第二个东西是中间隐层的输出,维度为:[5,32,128,768],也就是 [隐层数量,batch_size,seq_len,Hidden_size];\n\n这里需要注意的是老师网络和学生网络隐层数量不一样,一个是768,一个是312。\n\n这其实是一个很常见的现象;就是我们的学生网络在减少参数的时候,不仅会变矮,有时候我们也想让它变窄,也就是隐层的输出会发生变化,从768变为312;\n\n这个维度的变化需要注意两点,首先就是在学生模型初始化的时候,不能套用老师网络的对应层的参数,因为隐层Hidden_size发生了变化。所以一般调用的是BERT自带的初始化方式;\n\n其次就是在度量学生网络和老师网络差异性的时候,因为矩阵大小不一致,不能直接做MSE。在代码层面上,需要做一个线性映射,才能做MSE。\n\n而且还需要注意的一点是,由于老师网络已经固定不动了,所以在做映射的时候我们是要对学生网路的312加一个线性层转化到768层,也就是说这个线性层是加在了学生网络;\n\n整个架构的损失函数可以分为三种:首先对于【CLS】的输出,使用KL散度度量差异;对于隐层输出使用MSE和MMD损失函数进行度量;\n\n对于损失函数这块的选择,其实我觉得没啥经验可说,只能试一试;\n\n看了很多论文加上自己的经验,一般来说在最后面使用KL,中间层使用MSE会更好一点;当然有的实验也会在最后一层直接用MSE;玄学。\n\n在初看代码的时候,MMD这个之前我没接触过,还特意去看了一下,关于理论我就不多说了,一会看代码吧。\n\n首先对【CLS】的输出,代码如下:\n\n```\ndef kd_ce_loss(logits_S, logits_T, temperature=1):\n if isinstance(temperature, torch.Tensor) and temperature.dim() > 0:\n temperature = temperature.unsqueeze(-1)\n beta_logits_T = logits_T / temperature\n beta_logits_S = logits_S / temperature\n p_T = F.softmax(beta_logits_T, dim=-1)\n loss = -(p_T * F.log_softmax(beta_logits_S, dim=-1)).sum(dim=-1).mean()\n return loss\n```\n\n首先对于 logits_S,就是学生网络的【CLS】的输出,logits_T就是老师网络【CLS】的输出,temperature 在代码中默认参数是1,例子中设置为了8;\n\n整个代码其实很简单,就是先做Temp的一个转化,注意这里我们对学生网络的输出和老师网络的输出都做了转化,然后做loss计算;\n\n其次我们来看比较复杂的中间层的度量;\n\n首先需要掌握一点,就是学生网络和老师网络层之间的对应关系;\n\n学生网络是4层,老师网络12层,那么在对应的时候,简单的对应关系就是这样的:\n\n```\nlayer_T : 0, layer_S : 0,\nlayer_T : 3, layer_S : 1, \nlayer_T : 6, layer_S : 2, \nlayer_T : 9, layer_S : 3,\nlayer_T : 12, layer_S : 4,\n```\n\n这个对应关系是需要我们认为去设定的,将学生网络的1层对应到老师网络的12层可不可以?当然可以,但是效果不一定好;\n\n一般来说等间隔的对应上就好;\n\n这个对应关系其实还有一个用处,就是学生网络在初始化的时候【假如没有变窄,只是变矮,也就是层数变低了】,那么可以从依据这个对应关系把权重copy过来;\n\n学生网络的隐层输出为:[5,32,128,312],老师网络隐层输出为[5,32,128,768]\n\n那么在代码实现的时候,需要做一个zip函数把对应层映射过去,然后每一层计算MSE,然后加起来作为损失函数;\n\n我们来看代码:\n\n```\ninters_T = {feature: results_T.get(feature,[]) for feature in FEATURES}\ninters_S = {feature: results_S.get(feature,[]) for feature in FEATURES}\n\nfor ith,inter_match in enumerate(self.d_config.intermediate_matches):\n if type(layer_S) is list and type(layer_T) is list: ## MMD损失函数对应的情况\n inter_S = [inters_S[feature][s] for s in layer_S]\n inter_T = [inters_T[feature][t] for t in layer_T]\n name_S = '-'.join(map(str,layer_S))\n name_T = '-'.join(map(str,layer_T))\n if self.projs[ith]: ## 这里失去做学生网络隐层的映射\n #inter_T = [self.projs[ith](t) for t in inter_T]\n inter_S = [self.projs[ith](s) for s in inter_S]\n else:## MSE 损失函数\n inter_S = inters_S[feature][layer_S]\n inter_T = inters_T[feature][layer_T]\n name_S = str(layer_S)\n name_T = str(layer_T)\n if self.projs[ith]:\n inter_S = self.projs[ith](inter_S) # 需要注意的是隐层输出是312,但是老师网络是768,所以这里要做一个linear投影到更高维,方便计算损失函数\n \n intermediate_loss = match_loss(inter_S, inter_T, mask=inputs_mask_S) ## loss = F.mse_loss(state_S, state_T)\n total_loss += intermediate_loss * match_weight\n```\n\n这个代码里面比如迷糊的是【self.d_config.intermediate_matches】,打印出来发现是这个东西:\n\n```\nIntermediateMatch: layer_T : 0, layer_S : 0, feature : hidden, weight : 1, loss : hidden_mse, proj : ['linear', 312, 768, {}], \nIntermediateMatch: layer_T : 3, layer_S : 1, feature : hidden, weight : 1, loss : hidden_mse, proj : ['linear', 312, 768, {}], \nIntermediateMatch: layer_T : 6, layer_S : 2, feature : hidden, weight : 1, loss : hidden_mse, proj : ['linear', 312, 768, {}], \nIntermediateMatch: layer_T : 9, layer_S : 3, feature : hidden, weight : 1, loss : hidden_mse, proj : ['linear', 312, 768, {}], \nIntermediateMatch: layer_T : 12, layer_S : 4, feature : hidden, weight : 1, loss : hidden_mse, proj : ['linear', 312, 768, {}], \nIntermediateMatch: layer_T : [0, 0], layer_S : [0, 0], feature : hidden, weight : 1, loss : mmd, proj : None, \nIntermediateMatch: layer_T : [3, 3], layer_S : [1, 1], feature : hidden, weight : 1, loss : mmd, proj : None, \nIntermediateMatch: layer_T : [6, 6], layer_S : [2, 2], feature : hidden, weight : 1, loss : mmd, proj : None, \nIntermediateMatch: layer_T : [9, 9], layer_S : [3, 3], feature : hidden, weight : 1, loss : mmd, proj : None, \nIntermediateMatch: layer_T : [12, 12], layer_S : [4, 4], feature : hidden, weight : 1, loss : mmd, proj : None\n```\n\n简单说,这个变量存储的就是上面我们谈到的层与层之间的对应关系。前面5行就是MSE损失函数度量,后面那个注意看,层数对应的时候是一个列表,对应的是MMD损失函数;\n\n我们来看一下MMD损失的代码形式:\n\n```\ndef mmd_loss(state_S, state_T, mask=None):\n state_S_0 = state_S[0] # (batch_size , length, hidden_dim_S)\n state_S_1 = state_S[1] # (batch_size , length, hidden_dim_S)\n state_T_0 = state_T[0] # (batch_size , length, hidden_dim_T)\n state_T_1 = state_T[1] # (batch_size , length, hidden_dim_T)\n if mask isNone:\n gram_S = torch.bmm(state_S_0, state_S_1.transpose(1, 2)) / state_S_1.size(2) # (batch_size, length, length)\n gram_T = torch.bmm(state_T_0, state_T_1.transpose(1, 2)) / state_T_1.size(2)\n loss = F.mse_loss(gram_S, gram_T)\n else:\n mask = mask.to(state_S[0])\n valid_count = torch.pow(mask.sum(dim=1), 2).sum()\n gram_S = torch.bmm(state_S_0, state_S_1.transpose(1, 2)) / state_S_1.size(2) # (batch_size, length, length)\n gram_T = torch.bmm(state_T_0, state_T_1.transpose(1, 2)) / state_T_1.size(2)\n loss = (F.mse_loss(gram_S, gram_T, reduction='none') * mask.unsqueeze(-1) * mask.unsqueeze(1)).sum() / valid_count\n return loss\n```\n\n看最重要的代码就可以:\n\n```\nstate_S_0 = state_S[0]# 32 128 312 (batch_size , length, hidden_dim_S)\nstate_T_0 = state_T[0] # 32 128 768 (batch_size , length, hidden_dim_T)\ngram_S = torch.bmm(state_S_0, state_S_1.transpose(1, 2)) / state_S_1.size(2) \ngram_T = torch.bmm(state_T_0, state_T_1.transpose(1, 2)) / state_T_1.size(2)\n```\n\n简单说就是现在自己内部计算bmm,然后两个矩阵之间做mse;这里如果我没理解错使用的是一个线性核函数;\n\n损失函数代码大致就是这样,之后有时间我写个简单的repository,梳理一下整个流程;"
},
{
"path": "深度学习自然语言处理/模型蒸馏/Bert蒸馏到简单网络lstm.md",
"content": "假如手上有一个文本分类任务,我们在提升模型效果的时候一般有以下几个思路:\n\n1. 增大数据集,同时提升标注质量\n\n2. 寻找更多有效的文本特征,比如词性特征,词边界特征等等\n\n3. 更换模型,使用更加适合当前任务或者说更加复杂的模型,比如FastText-->TextCNN--Bert\n\n...\n\n之后接触到了知识蒸馏,学习到了简单的神经网络可以从复杂的网路中学习知识,进而提升模型效果。\n\n之前写个一个文章是TextCNN如何逼近Bert,当时写得比较粗糙,但是比较核心的点已经写出来。\n\n这个文章脱胎于这个论文:Distilling Task-Specific Knowledge from BERT into Simple Neural Networks\n\n整个训练过程是这样的:\n\n1. 在标签数据上微调Bert模型\n2. 使用三种方式对无标签数据进行数据增强\n3. Bert模型在无标签数据上进行推理,Lstm模型学习Bert模型的推理结果,使用MSE作为损失函数。\n\n#### 目标函数\n\n知识蒸馏的目标函数:\n\n\n\n一般来说,我们会使用两个部分,一个是硬目标损失函数,一个是软目标损失函数,两者都可以使用交叉熵进行度量。\n\n在原论文中,作者在计算损失函数的时候只是使用到了软目标,同时这个软目标并不是使用softmax之前的logits进行MSE度量损失,也就是并没有使用带有温度参数T的sotmax进行归一化。\n\n#### 数据增强\n\n为了促进有效的知识转移,我们经常需要一个庞大的,未标记的数据集。\n\n三种数据增强的方式:\n\n1. Masking:使用概率$P_{mask}$随机的替换一个单词为[MASK].\n\n 需要注意的是这里替换之后,Bert模型也会输入这个数据的。从直觉上来讲,这个规则可以阐明每个单词对标签的影响。\n\n2. POS-guided word replacement.使用概率$P_{pos}$随机替换一个单词为另一个相同POS的单词。这个规则有可能会改变句子的语义信息。\n\n3. n-gram sampling\n\n\n\n整个流程是这样的:对于每个单词,如果概率p<$p_{mask}$,我们使用第一条规则,如果p<$p_{mask}+p_{pos}$,我们使用第二条规则,两条规则互斥,也就是同一个单词只使用两者之间的一个。当对句子中的每个单词都过了一遍之后,我进行第三条规则,之后把整条句子补充道无标签数据集中。\n\n#### 知识蒸馏结果图\n\n效果图:\n\n"
},
{
"path": "深度学习自然语言处理/模型蒸馏/PKD-Bert基于多层的知识蒸馏方式.md",
"content": "[PKD](https://arxiv.org/pdf/1908.09355.pdf \"Patient Knowledge Distillation for BERT Model Compression\") 核心点就是不仅仅从Bert(老师网络)的最后一层学习知识去做蒸馏,它还另加了一部分,就是从**Bert的中间层去学习**。\n\n简单说,PKD的知识来源有两部分:**中间层+最后输出**。\n\n它缓解了之前只用最后softmax输出层的蒸馏方式出现的过拟合而导致泛化能力降低的问题。\n\n接下来,我们从PKD模型的两个策略说起:PKD-Last 和 PKD-Skip。\n\n# 1.PKD-Last and PKD-Skip\n\nPKD的本质是从中间层学习知识,但是这个中间层如何去定义,就各式各样了。\n\n比如说,我完全可以定位我只要**奇数层**,或者我只要**偶数层**,或者说我只要**最中间的两层**,等等,不一而足。\n\n那么作者,主要是使用了这么多想法中的看起来比较合理的两种。\n\n**PKD-Last,就是把中间层定义为老师网络的最后k层**。\n\n这样做是基于老师网络越靠后的层数含有更多更重要的信息。\n\n这样的想法其实和之前的蒸馏想法很类似,也就是只使用softmax层的输出去做蒸馏。但是从感官来看,有种尾大不掉的感觉,不均衡。\n\n另一个策略是 就是**PKD-Skip,顾名思义,就是每跳几层学习一层**。\n\n这么做是基于老师网络比较底层的层也含有一些重要性信息,这些信息不应该被错过。\n\n作者在后面的实验中,证明了,PKD-Skip 效果稍微好一点(slightly better);\n\n作者认为PKD-Skip抓住了老师网络不同层的多样性信息。而PKD-Last抓住的更多相对来说同质化信息,因为集中在了最后几层。\n\n# 2. PKD \n\n## 2.1架构图\n\n两种策略的PKD的架构图如下所示,**注意观察图,有个细节很容易忽视掉**:\n\n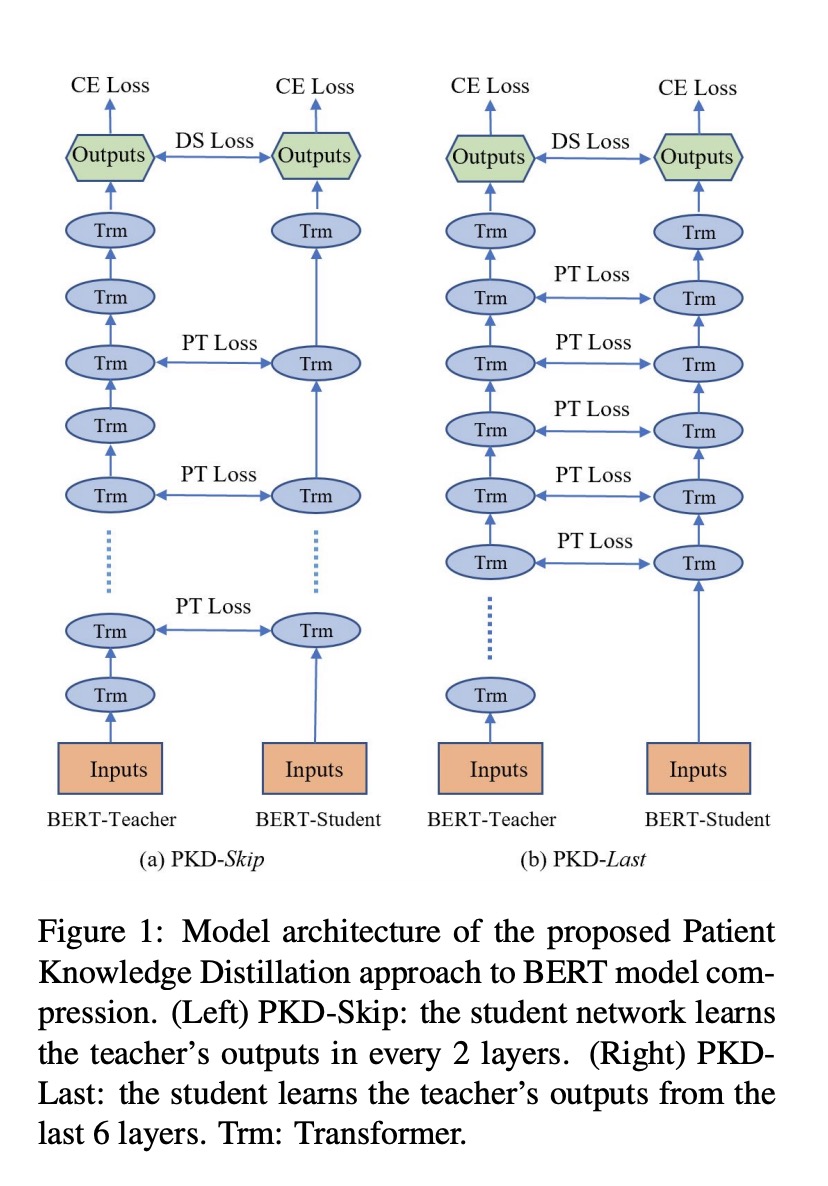\n\n我们注意看这个图,**Bert的最后一层(不是那个绿色的输出层)是没有被蒸馏的,这个细节一会会提到**。\n\n## 2.2 怎么蒸馏中间层\n\n这个时候,需要解决一个问题:我们怎么蒸馏中间层?\n\n仔细想一下Bert的架构,假设最大长度是128,那么我们每一层Transformer encoder的输出都应该是128个单元,每个单元是768维度。\n\n那么在对中间层进行蒸馏的时候,我们需要针对哪一个单元?是针对所有单元还是其中的部分单元?\n\n首先,我们想一下,正常KD进行蒸馏的时候,我们使用的是[CLS]单元Softmax的输出,进行蒸馏。\n\n我们可以把这个思想借鉴过来,一来,对所有单元进行蒸馏,计算量太大。二来,[CLS] 不严谨的说,可以看到整个句子的信息。\n\n为啥说是不严谨的说呢?因为[CLS]是不能代表整个句子的输出信息,这一点我记得Bert中有提到。\n\n## 2.3蒸馏层数和学生网络的初始化\n\n接下来,我想说一个很小的细节点,对比着看上面的模型架构图:\n\n**Bert(老师网络)的最后一层 (Layer 12 for BERT-Base) 在蒸馏的时候是不予考虑**;\n\n原因的话,其一可以这么理解,PKD创新点是从中间层学习知识,最后一层不属于中间层。当然这么说有点牵强附会。\n\n作者的解释是最后一层的隐层输出之后连接的就是Softmax层,而Softmax层的输出已经被KD Loss计算在内了。\n\n比如说,K=5,那么对于两种PKD的模式,被学习的中间层分别是:\n\nPKD-Skip: $I_{pt} = {2,4,6,8,10}$;\n\nPKD-Last: $I_{pt} = {7,8,9,10,11}$\n\n还有一个细节点需要注意,就是学生网络的初始化方式,直接使用老师网络的前几层去初始化学生网络的参数。\n\n## 2.4 损失函数\n\n首先需要注意的是中间层的损失,作者使用的是MSE损失。如下:\n\n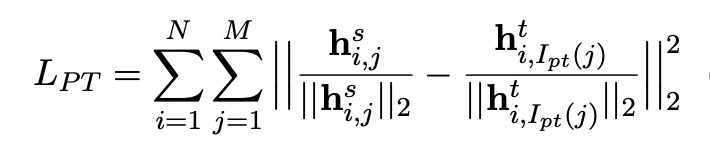\n\n整个模型的损失主要是分为两个部分:KD损失和中间层的损失,如下:\n\n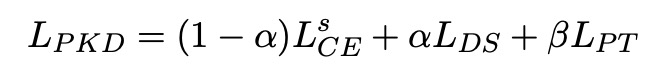\n\n超参数问题:\n\n1. $T:{5,10,20}$\n2. $\\alpha:{0.2,0.5,0.7}$\n3. $LR :{5e-5, 2e-5, 1e-5}$\n4. $\\beta :{10, 100, 500, 1000} $ \n\n# 3. 实验效果\n\n实验效果可以总结如下:\n\n1. PKD确实有效,而且Skip模型比Last效果稍微好一点。\n2. PKD模型减少了参数量,加快了推理速度,基本是线性关系,毕竟减少了层数\n\n除了这两点,作者还做了一个实验去验证:**如果老师网络更大,PKD模型得到的学生网络会表现更好吗**?\n\n这个实验我很感兴趣。\n\n直接上结果图:\n\n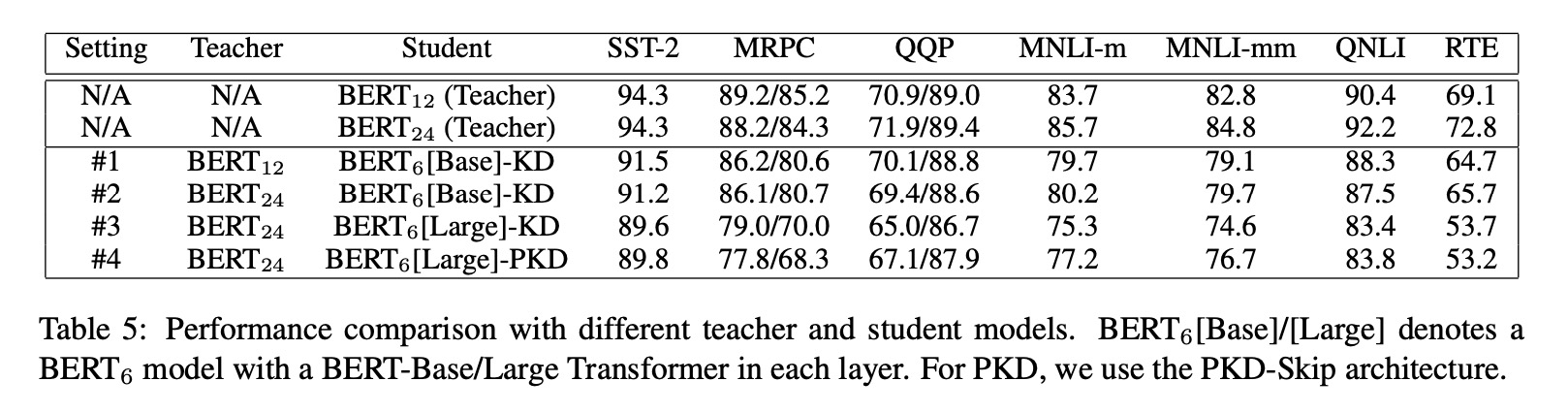\n\nKD情况下,注意不是PKD模型,看#1 和#2,在老师网络增加的情况下,效果有好有坏。这个和训练数据大小有关。\n\nKD情况下,看#1和#3,在老师网络增加的情况下,学生网络明显变差。\n\n作者分析是因为,压缩比高了,学生网络获取的信息变少了。\n\n也就是大网络和小网络本身效果没有差多少,但是学生网络在老师是大网络的情况下压缩比大,学到的信息就少了。\n\n更有意思的是对比#2和#3,老师是大网络的情况下,学生网络效果差。\n\n这里刚开始没理解,后来仔细看了一下,注意#2 的学生网络是$Bert_{6}[Base]-KD$,也就是它的初始化是从$Bert_{12}[Base]$来的,占了一半的信息。\n\n好的,写到这里\n\n\n\n"
},
{
"path": "深度学习自然语言处理/模型蒸馏/Theseus-模块压缩交替训练.md",
"content": "大家好,我是DASOU,今天介绍一下:BERT-of-Theseus\n\n这个论文我觉得还挺有意思,攒个思路。\n\n读完这个文章,BERT-of-Theseus 掌握以下两点就可以了:\n\n1. 基于模块替换进行压缩\n\n2. 除了具体任务的损失函数,没有其他多余损失函数。\n\n效果的话,与$Bert-base$相比,$BERT-of-Theseus$:推理速度 $1.94$;模型效果 98%;\n\n# 模块替换\n\n举个例子,比如有一个老师网络是12层的Bert,现在我每隔两层Transformer,替换为学生网络的一层Transformer。那么最后我的学生网络也就变成了6层的小Bert,训练的时候老师网络和学生网络的模块交替训练。\n\n直接看下面这个架构图:\n\n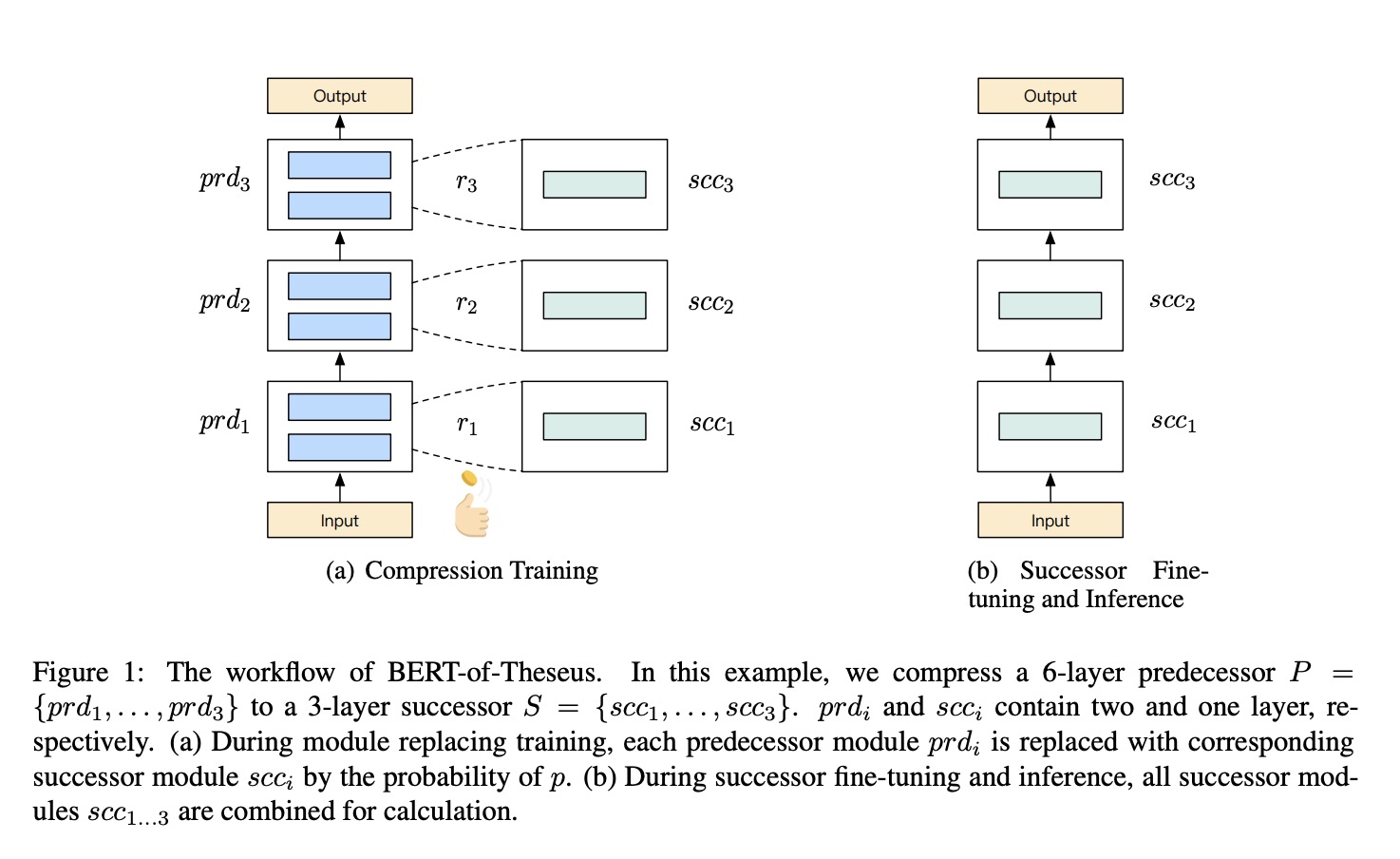\n\n作者说他是受 Dropout 的启发,仔细想了想还真的挺像的。\n\n我们来说一下这样做的好处。\n\n我刚才说每隔老师网络的两层替换为学生网络的一层。很容易就想到PKD里面,有一个是PKD-Skip策略。\n\n就是每隔几层,学生网络的层去学习老师网络对应层的输出,使用损失函数让两者输出接近,使用的是CLS的输出。\n\n在这里提一下蒸馏/压缩的基本思想,一个最朴素的想法就是让学生网络和老师网络通过损失函数在输出层尽可能的靠近。\n\n进一步的,为了提升效果,可以通过损失函数,让学生网络和老师网络在中间层尽可能的靠近,就像PKD这种。\n\n这个过程最重要的就是在训练的时候需要通过损失函数来让老师网络和学生网络尽可能的接近。\n\n如果是这样的话,问题就来了,损失函数的选取以及各自损失函数之前的权重就需要好好的选择,这是一个很麻烦的事情。\n\n然后我们再来看 BERT-of-Theseus,它就没有这个问题。\n\n它是在训练的时候以概率 $r$ 来从老师网络某一层和学生网络的某一层选择一个出来,放入到训练过程中。\n\n在这个论文里,老师网络叫做 $predecessor$, 学生网络叫做 $successor$ ;\n\n# 训练过程\n\n对着这个网络架构,我说一下整体训练的过程:\n\n1. 在具体任务数据上训练一个 BERT-base 网络作为 $predecessor$;\n2. 使用 $predecessor$ 前六层初始化一个 6层的Bert作为 $successor$ ;\n3. 在具体任务数据上,固定 $predecessor$ 相应权重,以概率$r$(随着steps,线性增加到1),对整个网络($predecessor$加上$successor$ )进行整体的训练。\n4. 为了让$successor$ 作为一个整体,单独抽离出来$successor$ (其实$r$设置为1就可以了),作为一个单独的个体,在训练数据上继续微调。直至效果不再增加。\n\n简单总结,在训练数据上,老师网络和学生网络共同训练,因为存在概率问题,有的时候是老师网络的部分层加入训练,有的时候是学生网络的部分层加入训练。在这一步训练完成之后,为了保证学生网络作为一个整体(因为在第一步训练的时候大部分情况下学生网络的层都是分开加入训练过程的),在具体任务数据上,对学生网络继续微调,直至效果不再增加。\n\n# 结果分析\n\n## 不同方法的损失函数\n\n论文提供了一个不同Bert蒸馏方法使用的损失函数的图,值得一看,见下图:\n\n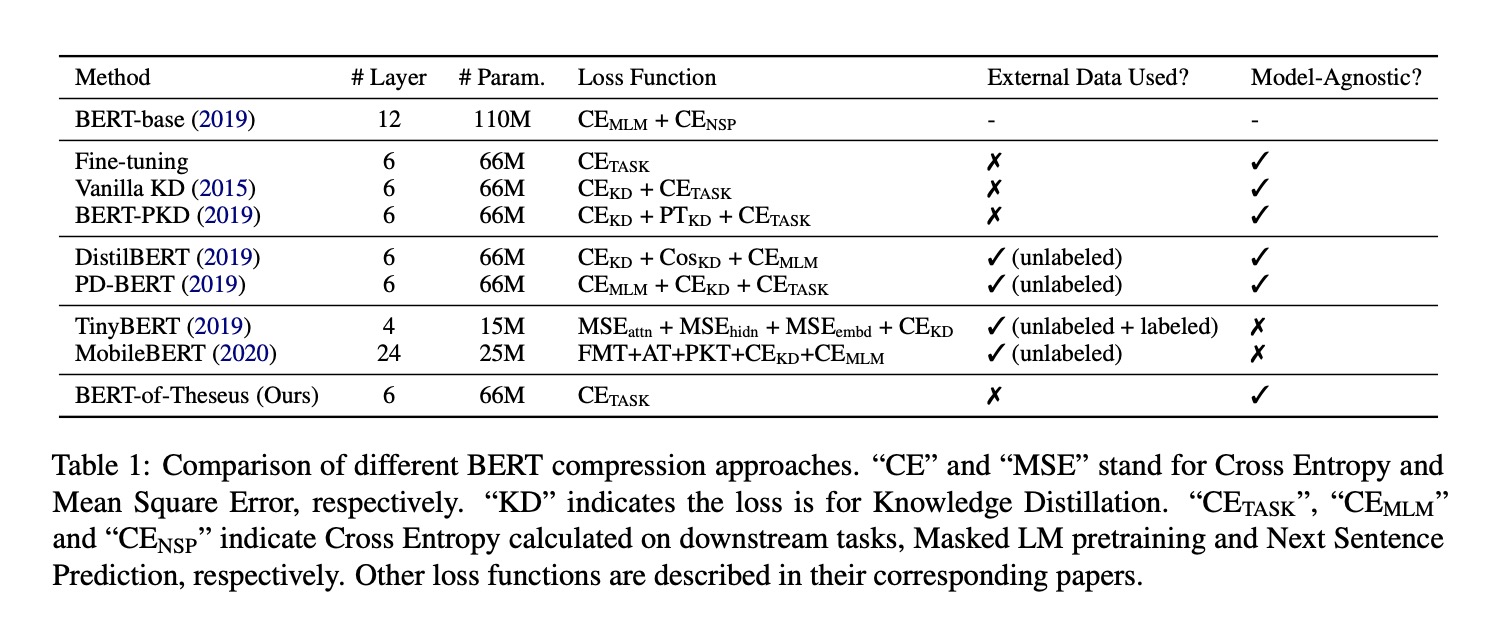\n\n值得注意的是,这里的 $Finetuning$应该是选取前六层,在具体任务微调的结果。\n\n## 效果\n\n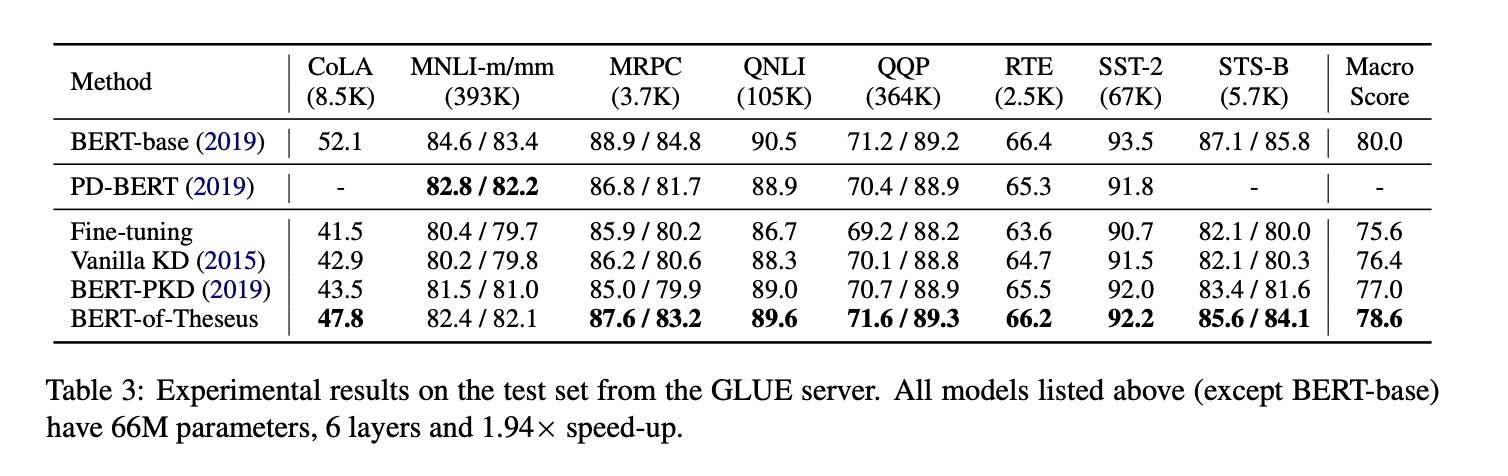\n\n整体来说,BERT-of-Theseus 思路很简单,效果也还不错。\n\n"
},
{
"path": "深度学习自然语言处理/模型蒸馏/bert2textcnn模型蒸馏.md",
"content": "为什么需要做模型蒸馏?\n\nBert类模型精读高,但是推理速度慢,模型蒸馏可以在速度和精读之间做一个平衡。\n\n1. 从蒸馏方法\n\n从蒸馏方法来看,一般可以分为三种:\n\n1. 参数的共享或者剪枝\n\n2. 低秩分解\n\n3. 知识蒸馏\n\n对于1和2,可以参考一下 Albert。\n\n而对于知识蒸馏来说,本质是通过一种映射关系,将老师学到的东西映射到或者说传递给学生网络。\n\n在最开始的时候,一般都会有一种疑问? 我有训练数据了,训练数据的准确度肯定比你大模型的输出结构准确度高,为什么还需要从老师网络来学习知识?\n\n我觉得对于这个问题,我在李如的文章看到这样一句话:”好模型的目标不是拟合训练数据,而是学习如何泛化到新的数据“\n\n我觉得写的很好。对于这个问题,我们这么去想,我们的大模型的输出对于logits不仅仅是类别属于哪一个,还有一个特点就是会给出不同类别之间的一个关系。\n\n比如说,在预测”今天天气真不错,现在就决定了,出去浪一波,来顿烧烤哦“。\n\n文本真实标签可能就直接给出了”旅游“这个标签,而我们的模型在概率输出的时候可能会发现”旅游“和”美食“两个标签都还行。\n\n这就是模型从数据中学习到的一种”暗知识“(好像是这么叫,忘了在哪里看到了)、\n\n而且还存在一个问题,有些时候是没有那么多训练数据的,需要的是大模型Bert这种给出无监督数据的伪标签作为冷启动也是不错的。\n\n2. 从蒸馏结构\n\n从蒸馏结构来说,我们可以分为两种:\n\n1. 从transformer到transformer结构\n\n2. 从transformer结构到别的模型(CNN或者lstm结构)\n\n我主要是想聊一下 Bert 到 TextCNN模型的蒸馏。\n\n为啥选择textcnn?最大的原因就是速度快精读还不错。\n\n论文参考 Distilling Task-Specific Knowledge from BERT into Simple Neural Networks\n\n对于这个蒸馏,对于我而言,最重要的掌握一个点就是损失函数的设定,别的地方我暂且不考虑。\n\n对于损失函数,分为两个部分,一个是我当前lstm输出结果和真实标签的交叉熵损失,一个是我的当前lstm输出结果和大模型bert的输出logits的平方损失。\n\n至于为啥一个是交叉熵一个是平方损失,是因为其实前面的看做分类问题,后面的看做回归问题。当然只是谁更合适的选择问题。\n\n因为是加权两个部分做损失,我这边选择为都是0.5。\n\n当然在李如的文章中谈到,可能真实标签这边的权重小一点会更好一点,因为蒸馏本质上还是想多关注bert的输出多一点。\n\n关于这个论文有一个很好的解释:\n\n知识蒸馏论文选读(二) - 小禅心的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/89420539\n\n\n\n\n关于模型蒸馏,我就简单了解到这里,可能之后会花费大量精力看看背的蒸馏方式,放上开源代码:\n\n[bert到lstm的蒸馏](https://github.com/DA-southampton/knowledge-distillation)\n\n[bert到textcnn/lstm/lkeras/torch](https://github.com/DA-southampton/bert_distill)\n\n[一个pytorch实现的模型蒸馏库](https://github.com/DA-southampton/KD_Lib)\n\n\n\n\n\n罗列一下关于Bert模型蒸馏的文章和博客:\n\n首先一个讲的比较好的文章就是下面这个文章,比较系统的讲了一遍\n\nBERT知识蒸馏综述 - 王三火的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/106810758\n\n还有一个文章讲的比较好的是:BERT 模型蒸馏 Distillation BERT\n\nhttps://www.jianshu.com/p/ed7942b5207a\n\n这个文章就是比较系统的对比了Bert的两个蒸馏操作:DistilBERT 和 Distilled BiLSTM 我觉得写得还不错\n\n从实战的角度来说,我觉得写得很好的就是:BERT 蒸馏在垃圾舆情识别中的探索\nhttps://blog.csdn.net/alitech2017/article/details/107412038\n\n这个文章是对bert的蒸馏,到textcnn,使用了多种方式并且比较了最终的结果。\n\n接下来是李如的这个文章,很概括,确实大佬,写得很好:\n【DL】模型蒸馏Distillation - 李如的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/71986772\n\n"
},
{
"path": "深度学习自然语言处理/模型蒸馏/tinybert-全方位蒸馏.md",
"content": "大家好,我是DASOU,今天说一下 TinyBert;\n\n[TinyBert](https://openreview.net/pdf?id=rJx0Q6EFPB \"TINYBERT: DISTILLING BERT FOR NATURAL LANGUAGE UNDERSTANDING\") 主要掌握两个核心点:\n\n1. 提出了对基于 transformer 的模型的蒸馏方式:Transformer distillation;\n\n2. 提出了两阶段学习框架:在预训练和具体任务微调阶段都进行了 Transformer distillation(两阶段有略微不同);\n\n下面对这两个核心点进行阐述。\n\n# 1. Transformer distillation\n\n## 1.1整体架构\n\n整体架构如下:\n\n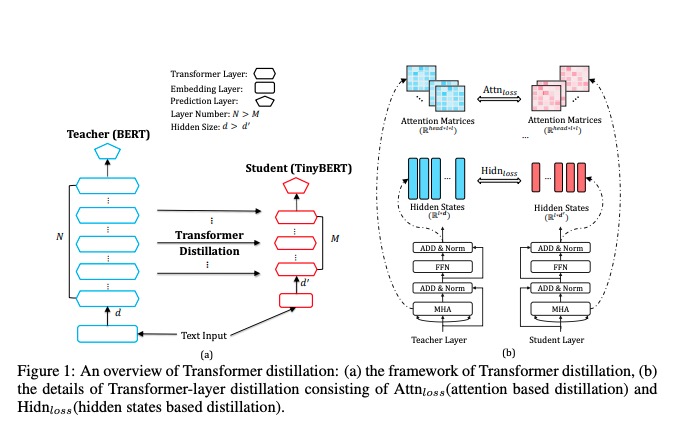\n\nBert不严谨的来划分,可以分为三个部分:词向量输入层,中间的TRM层,尾端的预测输出层。\n\n在这个论文里,作者把词向量输入层 和中间的TRM层统一称之为中间层,大家读的时候需要注意哈。\n\nBert的不同层代表了学习到了不同的知识,所以针对不同的层,设定不同的损失函数,让学生网络向老师网络靠近,如下:\n\n1. ebedding层的输出\n2. 多头注意力层的注意力矩阵和隐层的输出\n3. 预测层的输出\n\n## 1.2 Transformer 基础知识:\n\n注意力层:\n\n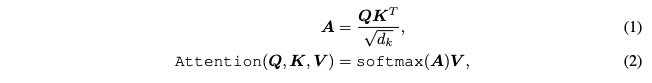\n\n多头注意力层:\n\n\n\n前馈神经网路:\n\n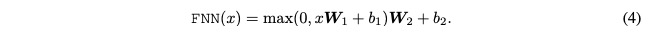\n\n\n\n## 1.3 Transformer 的蒸馏\n\n对 Transformer的蒸馏分为两个部分:一个是注意力层矩阵的蒸馏,一个是前馈神经网络输出的蒸馏。\n\n**注意力层矩阵蒸馏的损失函数**:\n\n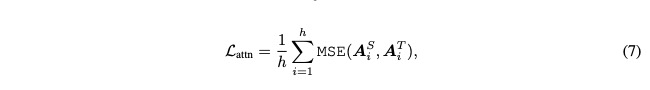\n\n这里注意两个细节点:\n\n一个是使用的是MSE;\n\n还有一个是,使用的没有归一化的注意力矩阵,见(1),而不是softmax之后的。**原因是实验证明这样能够更快的收敛而且效果会更好**。\n\n**前馈神经网络蒸馏的损失函数**\n\n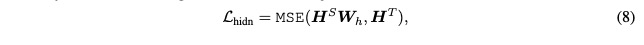\n\n两个细节点:\n\n第一仍然使用的是MSE.\n\n第二个细节点是注意,学生网路的隐层输出乘以了一个权重矩阵$w_{h}$,这样的原因是学生网络的隐层维度和老师网络的隐层维度不一定相同。\n\n所以如果直接计算MSE是不行的,这个权重矩阵也是在训练过程中学习的。\n\n写到这里提一点,其实这里也可以看出来为什么tinybert的初始化没有采用类似PKD这种,而是使用GD过程进行蒸馏学习。\n\n因为我们的tinybert 在减少层数的同时也减少了宽度(隐层的输出维度),如果采用PKD这种形式,学生网络的维度和老师网络的维度对不上,是不能初始化的。\n\n**词向量输入层的蒸馏**:\n\n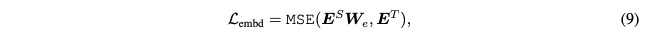\n\n**预测层输出蒸馏**:\n\n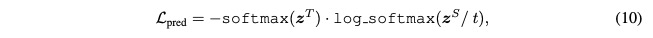\n\n\n\n## 1.4 总体蒸馏损失函数\n\n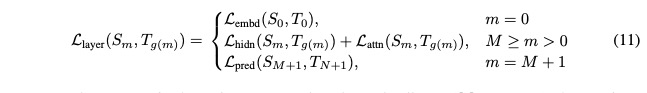\n\n# 2. 两阶段蒸馏\n\n## 2.1 整体架构\n\n整体架构如图:\n\n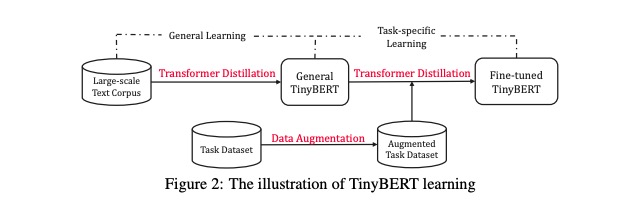\n\n## 2.2 为什么需要GD:\n\n说一下我自己的理解哈,我觉得有两个原因:\n\n首先,就是上文说到的,tinybert不仅降低了层数,也降低了维度,所以学生网络和老师网络的维度是不符的,所以PKD这种初始化方式不太行。\n\n其次,一般来说,比如PKD,学生网络会使用老师网络的部分层进行初始化。这个从直觉上来说,就不太对。\n\n老师网络12层,学到的是文本的全部信息。学生网络是6层,如果使用老师的12层的前6层进行初始化,这个操作相当于认为这前6层代表了文本的全部信息。\n\n当然,对于学生网络,还会在具体任务上微调。这里只是说这个初始化方式不太严谨。\n\nTiny bert的初始化方式很有意思,也是用了蒸馏的方式。\n\n老师网络是没有经过在具体任务进行过微调的Bert网络,然后在大规模无监督数据集上,进行Transformer distillation。当然这里的蒸馏就没有预测输出层的蒸馏,翻看附录,发现这里只是中间层的蒸馏。\n\n简单总结一下,这个阶段,使用一个预训练好的Bert( 尚未微调)进行了3epochs的 distillation;\n\n## 2.3 TD:\n\nTD就是针对具体任务进行蒸馏。\n\n核心点:先进行中间层(包含embedding层)的蒸馏,再去做输出层的蒸馏。\n\n老师网络是一个微调好的Bert,学生网络使用GD之后的tinybert,对老师网络进行TD蒸馏。\n\nTD过程是,先在数据增强之后的数据上进行中间层的蒸馏-10eopchs,learning rate 5e-5;然后预测层的蒸馏3epochs,learning rate 3e-5.\n\n# 3. 数据增强\n\n在具体任务数据上进行微调的时候,进行了数据增强。\n\n(感觉怪怪的)\n\n两个细节点:\n\n1. 对于 single-piece word 通过Bert找到当前mask词最相近的M个单词;对于 multiple sub-word pieces 使用Glove和Consine找到最相近的M个词\n\n2. 通过概率P来决定是否替换当前的词为替换词。\n3. 对任务数据集中的所有文本数据做上述操作,持续N次。\n\n伪代码如下:\n\n\n\n# 4. 实验效果\n\n其实我最关心的一个点就是,数据增强起到了多大的作用。\n\n作者确实也做了实验,如下,数据增强作用还是很大的:\n\n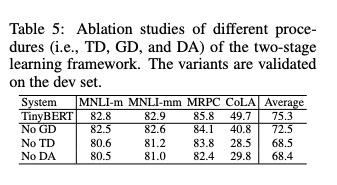\n\n我比较想知道的是,在和PKD同等模型架构下,两者的比较,很遗憾,作者好像并没有做类似的实验(或者我没发现)。\n\n这里的tinybert参数如下:\n\n> the number of layers M=4, the hidden size d 0=312, the feedforward/filter size d 0 i=1200 and the head number h=12.\n\n# 5. 简单总结\n\n先说一下,我读完论文学到的东西:\n\n首先是transformer层蒸馏是如何涉及到的损失函数:\n\n1. 注意力矩阵和前馈神经层使用mse;\n2. 蒸馏的时候注意力矩阵使用未归一化\n3. 维度不同使用权重矩阵进行转化\n\n其次,维度不同导致不能从老师Bert初始化。GD过程为了解决这个问题,直接使用学生网络的架构从老师网络蒸馏一个就可以,这里并不是重新学一个学生网络。\n\n还有就是数据增强,感觉tinyebert的数据增强还是比较简陋的,也比较牵强,而且是针对英文的方法。\n\nTD过程,对不同的层的蒸馏是分开进行的,先进行的中间层的蒸馏,然后是进行的输出层的蒸馏,输出层使用的是Soft没有使用hard。\n\n这个分过程蒸馏很有意思,之前没注意到这个细节点。\n\n在腾讯的文章中看到这样一句话:\n\n> 并且实验中,softmax cross-entropy loss 容易发生不收敛的情况,把 softmax 交叉熵改成 MSE, 收敛效果变好,但泛化效果变差。这是因为使用 softmax cross-entropy 需要学到整个概率分布,更难收敛,因为拟合了 teacher BERT 的概率分布,有更强的泛化性。MSE 对极值敏感,收敛的更快,但泛化效果不如前者。\n\n是有道理的,积累一下。\n\n值得看的一些资料:\n\n比 Bert 体积更小速度更快的 TinyBERT - 腾讯技术工程的文章 - 知乎 https://zhuanlan.zhihu.com/p/94359189"
},
{
"path": "深度学习自然语言处理/模型蒸馏/什么是知识蒸馏.md",
"content": "Bert知识蒸馏系列(一):什么是知识蒸馏\n\n全文参考的论文是:Distilling the Knowledge in a Neural Network\n\n参考的讲解的比较的博文是:\n\n《Distilling the Knowledge in a Neural Network》知识蒸馏 - musk星辰大海的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/75031938\n\n这个含有Hiton的PPT介绍\n\n【经典简读】知识蒸馏(Knowledge Distillation) 经典之作 - 潘小小的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/102038521\n\n这个把其中的公式推导写的比较明白\n\n如何理解soft target这一做法? - YJango的回答 - 知乎\nhttps://www.zhihu.com/question/50519680/answer/136406661\n\n\nBert 系列文章\n\n1. Bert 模型压缩\n\n 什么是知识蒸馏?知识蒸馏基础概念一览。\n\n2. Bert 的后续改进\n Albert\n Robert\n\n#### 什么是蒸馏\n\n一般来说,为了提高模型效果,我们可以使用两种方式。一种是直接使用复杂模型,比如你原来使用的TextCNN,现在使用Bert。一种是多个简单模型的集成,这种套路在竞赛中非常的常见。\n\n这两种方法在离线的时候是没有什么问题的,因为不涉及到实时性的要求。但是一旦涉及到到部署模型,线上实时推理,我们需要考虑时延和计算资源,一般需要对模型的复杂度和精度做一个平衡。\n\n这个时候,我们就可以将我们大模型学到的信息提取精华灌输到到小模型中去,这个过程就是蒸馏。\n\n#### 什么是知识\n\n对于一个模型,我们一般关注两个部分:模型架构和模型参数。\n\n简答的说,我们可以把这两个部分当做是我们模型从数据中学习到的信息或者说是知识(当然主要是参数,因为架构一般来说是训练之前就定下来的)\n\n但是这两个部分,对于我们来说,属于黑箱,就是我们不知道里面究竟发生了什么事情。\n\n那么什么东西是我们肉眼可见的呢?从输入向量到输出向量的一个映射关系是可以被我们观测到的。\n\n简单来说,我输入一个example,你输出是一个什么情况我是可以看到的。\n\n区别于标签数据格式 [0,0,1,0],模型的输出结果一般是这样的:[0.01,0.01,0.97,0.01]。\n\n举个比较具象的例子,就是如果我们在做一个图片分类的任务,你的输入图像是一辆宝马,那么模型在宝马这个类别上会有着最大的概率值,与此同时还会把剩余的概率值分给其他的类别。\n\n这些其他类别的概率值一般都很小,但是仍然存在着一些信息,比如垃圾车的概率就会比胡萝卜的概率更高一些。\n\n模型的输出结果含有的信息更丰富了,信息熵更大了,我们进一步的可以把这种当成是一种知识,也就是小模型需要从大模型中学习到的经验。\n\n这个时候我们一般把大模型也就是复杂模型称之为老师网络,小模型也就那我们需要的蒸馏模型称之为学生网络。学生网络通过学习老师网络的输出,进而训练模型,达到比较好的收敛效果。\n\n#### 为什么知识蒸馏可以获得比较好的效果\n\n在前面提到过,卡车和胡萝卜都会有概率值的输出,但是卡车的概率会比胡萝卜大,这种信息是很有用的,它定义了一种丰富的数据相似结构。\n\n上面谈到一个问题,就是不正确的类别概率都比较小,它对交叉熵损失函数的作用非常的低,因为这个概率太接近零了,也就是说,这种相似性存在,但是在损失函数中并没有充分的体现出来。\n\n\n第一种就是,使用sofmax之前的值,也就是logits,计算损失函数\n\n第二种是在计算损失函数的时候,使用温度参数T,温度参数越高,得到的概率值越平缓。通过升高温度T,我们获取“软目标”,进而训练小模型\n\n其实对于第一种其实是第二种蒸馏方式的的一种特例情况,论文后续有对此进行证明。\n\n这里的温度参数其实在一定程度上和蒸馏这个名词相呼应,通过升温,提取精华,进而灌输知识。\n\n#### 带温度参数T的Softmax函数\n\n软化公式如下:\n\n\n\n\n说一下为什么需要这么一个软化公式。上面我们谈到,通过升温T,我们得到的概率分布会变得比较平缓。\n\n用上面的例子说就是,宝马被识别为垃圾车的概率比较小,但是通过升温之后,仍然比较小,但是没有那么小(好绕口啊)。\n\n也就是说,数据中存在的相似性信息通过升温被放大了,这样在计算损失函数的时候,这个相似性才会被更大的注意到,才会对损失函数产生比较大的影响力。\n\n#### 损失函数\n\n\n\n损失函数是软目标损失函数和硬目标损失函数的结合,一般来说,软目标损失函数设置的权重需要大一些效果会更好一点。\n\n#### 如何训练\n\n整体的算法示意图如下:\n\n\n\n整体的算法示意图如上所示:\n\n1. 首先使用标签数据训练一个正常的大模型\n2. 使用训练好的模型,计算soft targets。\n3. 训练小模型,分为两个步骤,首先小模型使用相同的温度参数得到输出结果和软目标做交叉熵损失,其次小模型使用温度参数为1,和标签数据(也就是硬目标)做交叉损失函数。\n4. 预测的时候,温度参数设置为1,正常预测。"
},
{
"path": "深度学习自然语言处理/模型蒸馏/知识蒸馏综述万字长文.md",
"content": "本文首发公众号:**【DASOU】**\n\n涉及到的代码部分,可以去我仓库里找,已经**1.2k**了:\n\nDA-southampton/NLP_abilitygithub.com\n\n文中内容有不同见解大家及时沟通\n\n目录如下:\n\n1. 知识蒸馏简单介绍\n2. Bert 蒸馏到 BiLSTM\n3. PKD-BERT\n4. BERT-of-Theseus\n5. TinyBert\n\n## 1. 知识蒸馏简单介绍\n\n**1.1 什么是蒸馏**\n\n一般来说,为了提高模型效果,我们可以使用两种方式。一种是直接使用复杂模型,比如你原来使用的TextCNN,现在使用Bert。一种是多个简单模型的集成,这种套路在竞赛中非常的常见。\n\n这两种方法在离线的时候是没有什么问题的,因为不涉及到实时性的要求。但是一旦涉及到到部署模型,线上实时推理,我们需要考虑时延和计算资源,一般需要对模型的复杂度和精度做一个平衡。\n\n这个时候,我们就可以将我们大模型学到的信息提取精华灌输到到小模型中去,这个过程就是蒸馏。\n\n### **1.2 什么是知识**\n\n对于一个模型,我们一般关注两个部分:模型架构和模型参数。\n\n简答的说,我们可以把这两个部分当做是我们模型从数据中学习到的信息或者说是知识(当然主要是参数,因为架构一般来说是训练之前就定下来的)\n\n但是这两个部分,对于我们来说,属于黑箱,就是我们不知道里面究竟发生了什么事情。\n\n那么什么东西是我们肉眼可见的呢?从输入向量到输出向量的一个映射关系是可以被我们观测到的。\n\n简单来说,我输入一个example,你输出是一个什么情况我是可以看到的。\n\n区别于标签数据格式 [0,0,1,0],模型的输出结果一般是这样的:[0.01,0.01,0.97,0.01]。\n\n举个比较具象的例子,就是如果我们在做一个图片分类的任务,你的输入图像是一辆宝马,那么模型在宝马这个类别上会有着最大的概率值,与此同时还会把剩余的概率值分给其他的类别。\n\n这些其他类别的概率值一般都很小,但是仍然存在着一些信息,比如垃圾车的概率就会比胡萝卜的概率更高一些。\n\n模型的输出结果含有的信息更丰富了,信息熵更大了,我们进一步的可以把这种当成是一种知识,也就是小模型需要从大模型中学习到的经验。\n\n这个时候我们一般把大模型也就是复杂模型称之为老师网络,小模型也就那我们需要的蒸馏模型称之为学生网络。学生网络通过学习老师网络的输出,进而训练模型,达到比较好的收敛效果。\n\n### **1.3 为什么知识蒸馏可以获得比较好的效果**\n\n在前面提到过,卡车和胡萝卜都会有概率值的输出,但是卡车的概率会比胡萝卜大,这种信息是很有用的,它定义了一种丰富的数据相似结构。\n\n上面谈到一个问题,就是不正确的类别概率都比较小,它对交叉熵损失函数的作用非常的低,因为这个概率太接近零了,也就是说,这种相似性存在,但是在损失函数中并没有充分的体现出来。\n\n第一种就是,使用sofmax之前的值,也就是logits,计算损失函数\n\n第二种是在计算损失函数的时候,使用温度参数T,温度参数越高,得到的概率值越平缓。通过升高温度T,我们获取“软目标”,进而训练小模型\n\n其实对于第一种其实是第二种蒸馏方式的的一种特例情况,论文后续有对此进行证明。\n\n这里的温度参数其实在一定程度上和蒸馏这个名词相呼应,通过升温,提取精华,进而灌输知识。\n\n### **1.4 带温度参数T的Softmax函数**\n\n软化公式如下:\n\n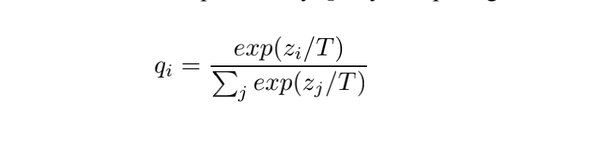\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n说一下为什么需要这么一个软化公式。上面我们谈到,通过升温T,我们得到的概率分布会变得比较平缓。\n\n用上面的例子说就是,宝马被识别为垃圾车的概率比较小,但是通过升温之后,仍然比较小,但是没有那么小(好绕口啊)。\n\n也就是说,数据中存在的相似性信息通过升温被放大了,这样在计算损失函数的时候,这个相似性才会被更大的注意到,才会对损失函数产生比较大的影响力。\n\n### **1.5 损失函数**\n\n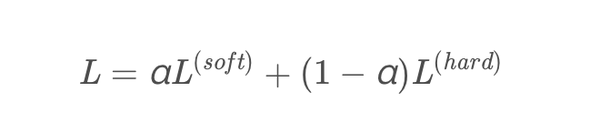\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n损失函数是软目标损失函数和硬目标损失函数的结合,一般来说,软目标损失函数设置的权重需要大一些效果会更好一点。\n\n### **1.6 如何训练**\n\n整体的算法示意图如下:\n\n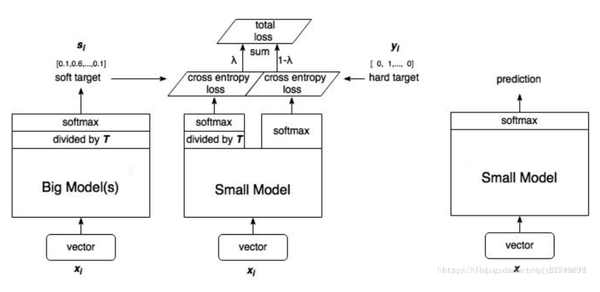\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n整体的算法示意图如上所示:\n\n1. 首先使用标签数据训练一个正常的大模型\n2. 使用训练好的模型,计算soft targets。\n3. 训练小模型,分为两个步骤,首先小模型使用相同的温度参数得到输出结果和软目标做交叉熵损失,其次小模型使用温度参数为1,和标签数据(也就是硬目标)做交叉损失函数。\n4. 预测的时候,温度参数设置为1,正常预测。\n\n## 2. Bert 蒸馏到 BiLSTM\n\n**2.1 简单介绍**\n\n假如手上有一个文本分类任务,我们在提升模型效果的时候一般有以下几个思路:\n\n1. 增大数据集,同时提升标注质量\n2. 寻找更多有效的文本特征,比如词性特征,词边界特征等等\n3. 更换模型,使用更加适合当前任务或者说更加复杂的模型,比如FastText-->TextCNN--Bert\n\n...\n\n之后接触到了知识蒸馏,学习到了简单的神经网络可以从复杂的网路中学习知识,进而提升模型效果。\n\n之前写个一个文章是TextCNN如何逼近Bert,当时写得比较粗糙,但是比较核心的点已经写出来。\n\n这个文章脱胎于这个论文:Distilling Task-Specific Knowledge from BERT into Simple Neural Networks\n\n整个训练过程是这样的:\n\n1. 在标签数据上微调Bert模型\n2. 使用三种方式对无标签数据进行数据增强\n3. Bert模型在无标签数据上进行推理,Lstm模型学习Bert模型的推理结果,使用MSE作为损失函数。\n\n### **2.2 目标函数**\n\n知识蒸馏的目标函数:\n\n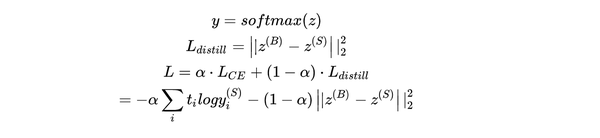\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n一般来说,我们会使用两个部分,一个是硬目标损失函数,一个是软目标损失函数,两者都可以使用交叉熵进行度量。\n\n在原论文中,作者在计算损失函数的时候只是使用到了软目标,同时这个软目标并不是使用softmax之前的logits进行MSE度量损失,也就是并没有使用带有温度参数T的sotmax进行归一化。\n\n### **2.3 数据增强**\n\n为了促进有效的知识转移,我们经常需要一个庞大的,未标记的数据集。\n\n三种数据增强的方式:\n\n1. Masking:使用概率随机的替换一个单词为[MASK]. 需要注意的是这里替换之后,Bert模型也会输入这个数据的。从直觉上来讲,这个规则可以阐明每个单词对标签的影响。\n2. POS-guided word replacement.使用概率随机替换一个单词为另一个相同POS的单词。这个规则有可能会改变句子的语义信息。\n3. n-gram sampling\n\n整个流程是这样的:对于每个单词,如果概率p<,我们使用第一条规则,如果p<,我们使用第二条规则,两条规则互斥,也就是同一个单词只使用两者之间的一个。当对句子中的每个单词都过了一遍之后,我进行第三条规则,之后把整条句子补充道无标签数据集中。\n\n### **2.4 知识蒸馏结果图**\n\n效果图:\n\n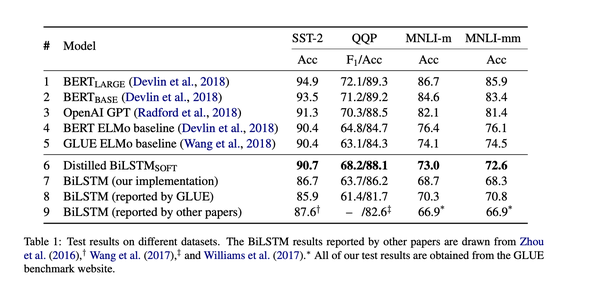\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n## 3. PKD-BERT\n\n[PKD](https://arxiv.org/pdf/1908.09355.pdf) 核心点就是不仅仅从Bert(老师网络)的最后一层学习知识去做蒸馏,它还另加了一部分,就是从**Bert的中间层去学习**。\n\n简单说,PKD的知识来源有两部分:**中间层+最后输出**。\n\n它缓解了之前只用最后softmax输出层的蒸馏方式出现的过拟合而导致泛化能力降低的问题。\n\n接下来,我们从PKD模型的两个策略说起:PKD-Last 和 PKD-Skip。\n\n## **3.1 PKD-Last and PKD-Skip**\n\nPKD的本质是从中间层学习知识,但是这个中间层如何去定义,就各式各样了。\n\n比如说,我完全可以定位我只要**奇数层**,或者我只要**偶数层**,或者说我只要**最中间的两层**,等等,不一而足。\n\n那么作者,主要是使用了这么多想法中的看起来比较合理的两种。\n\n**PKD-Last,就是把中间层定义为老师网络的最后k层**。\n\n这样做是基于老师网络越靠后的层数含有更多更重要的信息。\n\n这样的想法其实和之前的蒸馏想法很类似,也就是只使用softmax层的输出去做蒸馏。但是从感官来看,有种尾大不掉的感觉,不均衡。\n\n另一个策略是 就是**PKD-Skip,顾名思义,就是每跳几层学习一层**。\n\n这么做是基于老师网络比较底层的层也含有一些重要性信息,这些信息不应该被错过。\n\n作者在后面的实验中,证明了,PKD-Skip 效果稍微好一点(slightly better);\n\n作者认为PKD-Skip抓住了老师网络不同层的多样性信息。而PKD-Last抓住的更多相对来说同质化信息,因为集中在了最后几层。\n\n## **3.2. PKD** \n\n## **3. 2.1架构图**\n\n两种策略的PKD的架构图如下所示,**注意观察图,有个细节很容易忽视掉**:\n\n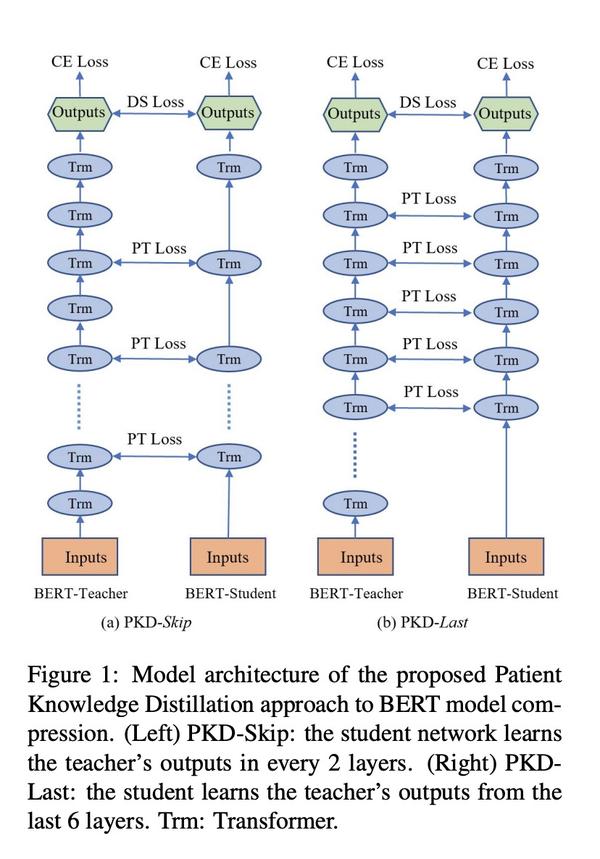\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n我们注意看这个图,**Bert的最后一层(不是那个绿色的输出层)是没有被蒸馏的,这个细节一会会提到**。\n\n## **3. 2.2 怎么蒸馏中间层**\n\n这个时候,需要解决一个问题:我们怎么蒸馏中间层?\n\n仔细想一下Bert的架构,假设最大长度是128,那么我们每一层Transformer encoder的输出都应该是128个单元,每个单元是768维度。\n\n那么在对中间层进行蒸馏的时候,我们需要针对哪一个单元?是针对所有单元还是其中的部分单元?\n\n首先,我们想一下,正常KD进行蒸馏的时候,我们使用的是[CLS]单元Softmax的输出,进行蒸馏。\n\n我们可以把这个思想借鉴过来,一来,对所有单元进行蒸馏,计算量太大。二来,[CLS] 不严谨的说,可以看到整个句子的信息。\n\n为啥说是不严谨的说呢?因为[CLS]是不能代表整个句子的输出信息,这一点我记得Bert中有提到。\n\n## **3.2.3蒸馏层数和学生网络的初始化**\n\n接下来,我想说一个很小的细节点,对比着看上面的模型架构图:\n\n**Bert(老师网络)的最后一层 (Layer 12 for BERT-Base) 在蒸馏的时候是不予考虑**;\n\n原因的话,其一可以这么理解,PKD创新点是从中间层学习知识,最后一层不属于中间层。当然这么说有点牵强附会。\n\n作者的解释是最后一层的隐层输出之后连接的就是Softmax层,而Softmax层的输出已经被KD Loss计算在内了。\n\n比如说,K=5,那么对于两种PKD的模式,被学习的中间层分别是:\n\nPKD-Skip: ;\n\nPKD-Last: \n\n还有一个细节点需要注意,就是学生网络的初始化方式,直接使用老师网络的前几层去初始化学生网络的参数。\n\n## **3.2.4 损失函数**\n\n首先需要注意的是中间层的损失,作者使用的是MSE损失。如下:\n\n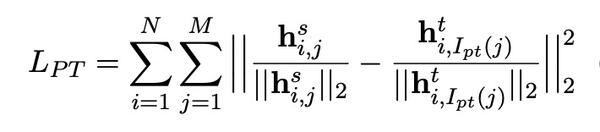\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n整个模型的损失主要是分为两个部分:KD损失和中间层的损失,如下:\n\n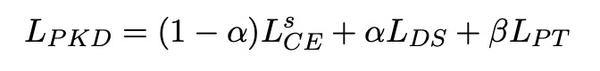\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n## **3.3. 实验效果**\n\n实验效果可以总结如下:\n\n1. PKD确实有效,而且Skip模型比Last效果稍微好一点。\n2. PKD模型减少了参数量,加快了推理速度,基本是线性关系,毕竟减少了层数\n\n除了这两点,作者还做了一个实验去验证:**如果老师网络更大,PKD模型得到的学生网络会表现更好吗**?\n\n这个实验我很感兴趣。\n\n直接上结果图:\n\n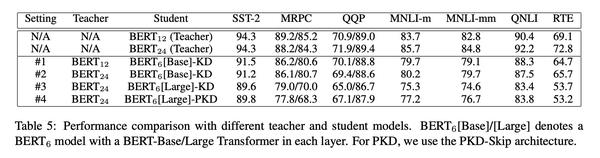\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\nKD情况下,注意不是PKD模型,看#1 和#2,在老师网络增加的情况下,效果有好有坏。这个和训练数据大小有关。\n\nKD情况下,看#1和#3,在老师网络增加的情况下,学生网络明显变差。\n\n作者分析是因为,压缩比高了,学生网络获取的信息变少了。\n\n也就是大网络和小网络本身效果没有差多少,但是学生网络在老师是大网络的情况下压缩比大,学到的信息就少了。\n\n更有意思的是对比#2和#3,老师是大网络的情况下,学生网络效果差。\n\n这里刚开始没理解,后来仔细看了一下,注意#2 的学生网络是,也就是它的初始化是从来的,占了一半的信息。\n\n好的,写到这里\n\n## 4. BERT-of-Theseus\n\n大家好,我是DASOU,今天介绍一下:BERT-of-Theseus\n\n这个论文我觉得还挺有意思,攒个思路。\n\n读完这个文章,BERT-of-Theseus 掌握以下两点就可以了:\n\n1. 基于模块替换进行压缩\n2. 除了具体任务的损失函数,没有其他多余损失函数。\n\n效果的话,与相比,:推理速度 ;模型效果 98%;\n\n## **4.1 模块替换**\n\n举个例子,比如有一个老师网络是12层的Bert,现在我每隔两层Transformer,替换为学生网络的一层Transformer。那么最后我的学生网络也就变成了6层的小Bert,训练的时候老师网络和学生网络的模块交替训练。\n\n直接看下面这个架构图:\n\n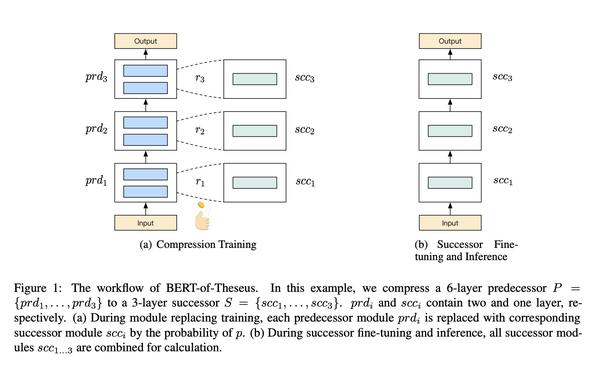\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n作者说他是受 Dropout 的启发,仔细想了想还真的挺像的。\n\n我们来说一下这样做的好处。\n\n我刚才说每隔老师网络的两层替换为学生网络的一层。很容易就想到PKD里面,有一个是PKD-Skip策略。\n\n就是每隔几层,学生网络的层去学习老师网络对应层的输出,使用损失函数让两者输出接近,使用的是CLS的输出。\n\n在这里提一下蒸馏/压缩的基本思想,一个最朴素的想法就是让学生网络和老师网络通过损失函数在输出层尽可能的靠近。\n\n进一步的,为了提升效果,可以通过损失函数,让学生网络和老师网络在中间层尽可能的靠近,就像PKD这种。\n\n这个过程最重要的就是在训练的时候需要通过损失函数来让老师网络和学生网络尽可能的接近。\n\n如果是这样的话,问题就来了,损失函数的选取以及各自损失函数之前的权重就需要好好的选择,这是一个很麻烦的事情。\n\n然后我们再来看 BERT-of-Theseus,它就没有这个问题。\n\n它是在训练的时候以概率 来从老师网络某一层和学生网络的某一层选择一个出来,放入到训练过程中。\n\n在这个论文里,老师网络叫做 , 学生网络叫做 ;\n\n## **4.2 训练过程**\n\n对着这个网络架构,我说一下整体训练的过程:\n\n1. 在具体任务数据上训练一个 BERT-base 网络作为 ;\n2. 使用 前六层初始化一个 6层的Bert作为 ;\n3. 在具体任务数据上,固定 相应权重,以概率(随着steps,线性增加到1),对整个网络(加上 )进行整体的训练。\n4. 为了让 作为一个整体,单独抽离出来 (其实设置为1就可以了),作为一个单独的个体,在训练数据上继续微调。直至效果不再增加。\n\n简单总结,在训练数据上,老师网络和学生网络共同训练,因为存在概率问题,有的时候是老师网络的部分层加入训练,有的时候是学生网络的部分层加入训练。在这一步训练完成之后,为了保证学生网络作为一个整体(因为在第一步训练的时候大部分情况下学生网络的层都是分开加入训练过程的),在具体任务数据上,对学生网络继续微调,直至效果不再增加。\n\n## **4.3 结果分析**\n\n## **不同方法的损失函数**\n\n论文提供了一个不同Bert蒸馏方法使用的损失函数的图,值得一看,见下图:\n\n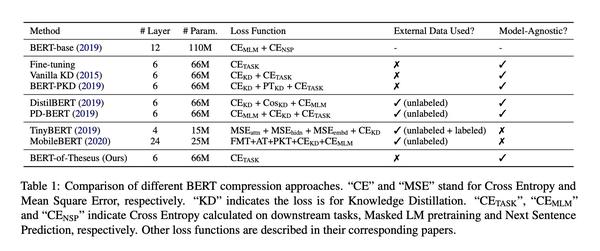\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n值得注意的是,这里的 应该是选取前六层,在具体任务微调的结果。\n\n## **效果**\n\n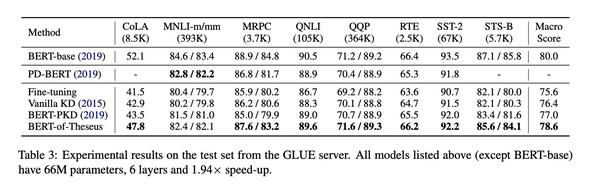\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n整体来说,BERT-of-Theseus 思路很简单,效果也还不错。\n\n## 5. Tiny-Bert\n\n大家好,我是DASOU,今天说一下 TinyBert;\n\n[TinyBert](https://openreview.net/pdf?id=rJx0Q6EFPB) 主要掌握两个核心点:\n\n1. 提出了对基于 transformer 的模型的蒸馏方式:Transformer distillation;\n2. 提出了两阶段学习框架:在预训练和具体任务微调阶段都进行了 Transformer distillation(两阶段有略微不同);\n\n下面对这两个核心点进行阐述。\n\n## **5.1. Transformer distillation**\n\n## **5.1.1整体架构**\n\n整体架构如下:\n\n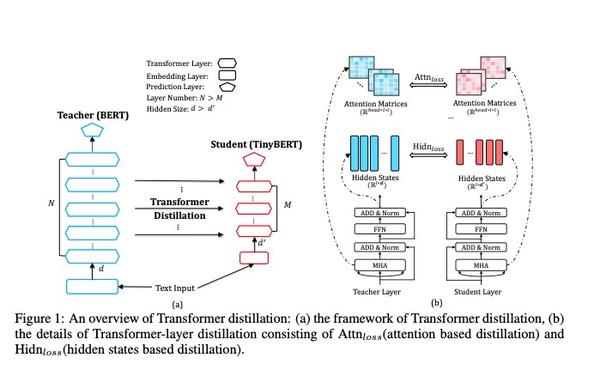\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\nBert不严谨的来划分,可以分为三个部分:词向量输入层,中间的TRM层,尾端的预测输出层。\n\n在这个论文里,作者把词向量输入层 和中间的TRM层统一称之为中间层,大家读的时候需要注意哈。\n\nBert的不同层代表了学习到了不同的知识,所以针对不同的层,设定不同的损失函数,让学生网络向老师网络靠近,如下:\n\n1. ebedding层的输出\n2. 多头注意力层的注意力矩阵和隐层的输出\n3. 预测层的输出\n\n## **5.1.2 Transformer 基础知识:**\n\n注意力层:\n\n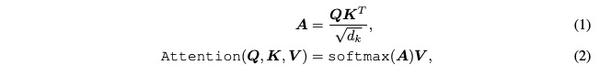\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n多头注意力层:\n\n\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n前馈神经网路:\n\n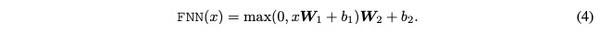\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n## **5.1.3 Transformer 的蒸馏**\n\n对 Transformer的蒸馏分为两个部分:一个是注意力层矩阵的蒸馏,一个是前馈神经网络输出的蒸馏。\n\n**注意力层矩阵蒸馏的损失函数**:\n\n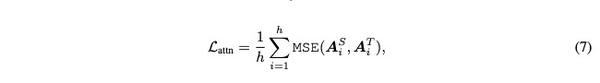\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n这里注意两个细节点:\n\n一个是使用的是MSE;\n\n还有一个是,使用的没有归一化的注意力矩阵,见(1),而不是softmax之后的。**原因是实验证明这样能够更快的收敛而且效果会更好**。\n\n**前馈神经网络蒸馏的损失函数**\n\n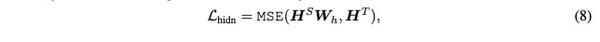\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n两个细节点:\n\n第一仍然使用的是MSE.\n\n第二个细节点是注意,学生网路的隐层输出乘以了一个权重矩阵,这样的原因是学生网络的隐层维度和老师网络的隐层维度不一定相同。\n\n所以如果直接计算MSE是不行的,这个权重矩阵也是在训练过程中学习的。\n\n写到这里提一点,其实这里也可以看出来为什么tinybert的初始化没有采用类似PKD这种,而是使用GD过程进行蒸馏学习。\n\n因为我们的tinybert 在减少层数的同时也减少了宽度(隐层的输出维度),如果采用PKD这种形式,学生网络的维度和老师网络的维度对不上,是不能初始化的。\n\n**词向量输入层的蒸馏**:\n\n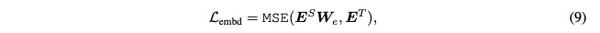\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n**预测层输出蒸馏**:\n\n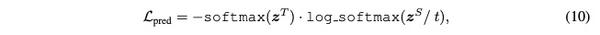\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n## **5.1.4 总体蒸馏损失函数**\n\n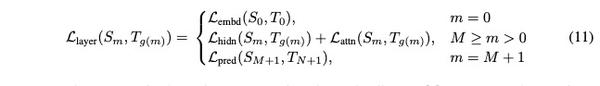\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n## **5.2. 两阶段蒸馏**\n\n## **5.2.1 整体架构**\n\n整体架构如图:\n\n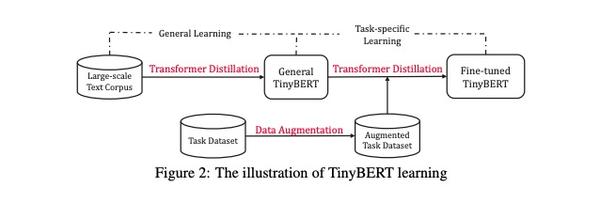\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n## **5.2.2 为什么需要GD:**\n\n说一下我自己的理解哈,我觉得有两个原因:\n\n首先,就是上文说到的,tinybert不仅降低了层数,也降低了维度,所以学生网络和老师网络的维度是不符的,所以PKD这种初始化方式不太行。\n\n其次,一般来说,比如PKD,学生网络会使用老师网络的部分层进行初始化。这个从直觉上来说,就不太对。\n\n老师网络12层,学到的是文本的全部信息。学生网络是6层,如果使用老师的12层的前6层进行初始化,这个操作相当于认为这前6层代表了文本的全部信息。\n\n当然,对于学生网络,还会在具体任务上微调。这里只是说这个初始化方式不太严谨。\n\nTiny bert的初始化方式很有意思,也是用了蒸馏的方式。\n\n老师网络是没有经过在具体任务进行过微调的Bert网络,然后在大规模无监督数据集上,进行Transformer distillation。当然这里的蒸馏就没有预测输出层的蒸馏,翻看附录,发现这里只是中间层的蒸馏。\n\n简单总结一下,这个阶段,使用一个预训练好的Bert( 尚未微调)进行了3epochs的 distillation;\n\n## **5.2.3 TD:**\n\nTD就是针对具体任务进行蒸馏。\n\n核心点:先进行中间层(包含embedding层)的蒸馏,再去做输出层的蒸馏。\n\n老师网络是一个微调好的Bert,学生网络使用GD之后的tinybert,对老师网络进行TD蒸馏。\n\nTD过程是,先在数据增强之后的数据上进行中间层的蒸馏-10eopchs,learning rate 5e-5;然后预测层的蒸馏3epochs,learning rate 3e-5.\n\n## **5.3. 数据增强**\n\n在具体任务数据上进行微调的时候,进行了数据增强。\n\n(感觉怪怪的)\n\n两个细节点:\n\n1. 对于 single-piece word 通过Bert找到当前mask词最相近的M个单词;对于 multiple sub-word pieces 使用Glove和Consine找到最相近的M个词\n2. 通过概率P来决定是否替换当前的词为替换词。\n3. 对任务数据集中的所有文本数据做上述操作,持续N次。\n\n伪代码如下:\n\n\n\n\n\n编辑切换为居中\n\n添加图片注释,不超过 140 字(可选)\n\n## **5.4. 实验效果**\n\n其实我最关心的一个点就是,数据增强起到了多大的作用。\n\n作者确实也做了实验,如下,数据增强作用还是很大的:\n\n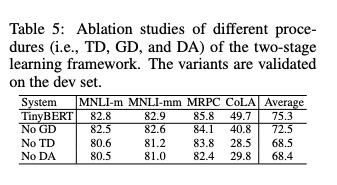\n\n\n\n编辑\n\n添加图片注释,不超过 140 字(可选)\n\n我比较想知道的是,在和PKD同等模型架构下,两者的比较,很遗憾,作者好像并没有做类似的实验(或者我没发现)。\n\n这里的tinybert参数如下:\n\n> the number of layers M=4, the hidden size d 0=312, the feedforward/filter size d 0 i=1200 and the head number h=12.\n\n## **5.5. 简单总结**\n\n先说一下,我读完论文学到的东西:\n\n首先是transformer层蒸馏是如何涉及到的损失函数:\n\n1. 注意力矩阵和前馈神经层使用mse;\n2. 蒸馏的时候注意力矩阵使用未归一化\n3. 维度不同使用权重矩阵进行转化\n\n其次,维度不同导致不能从老师Bert初始化。GD过程为了解决这个问题,直接使用学生网络的架构从老师网络蒸馏一个就可以,这里并不是重新学一个学生网络。\n\n还有就是数据增强,感觉tinyebert的数据增强还是比较简陋的,也比较牵强,而且是针对英文的方法。\n\nTD过程,对不同的层的蒸馏是分开进行的,先进行的中间层的蒸馏,然后是进行的输出层的蒸馏,输出层使用的是Soft没有使用hard。\n\n这个分过程蒸馏很有意思,之前没注意到这个细节点。\n\n在腾讯的文章中看到这样一句话:\n\n> 并且实验中,softmax cross-entropy loss 容易发生不收敛的情况,把 softmax 交叉熵改成 MSE, 收敛效果变好,但泛化效果变差。这是因为使用 softmax cross-entropy 需要学到整个概率分布,更难收敛,因为拟合了 teacher BERT 的概率分布,有更强的泛化性。MSE 对极值敏感,收敛的更快,但泛化效果不如前者。\n\n是有道理的,积累一下。\n\n值得看的一些资料:\n\n比 Bert 体积更小速度更快的 TinyBERT - 腾讯技术工程的文章 - 知乎 https://zhuanlan.zhihu.com/p/94359189"
},
{
"path": "深度学习自然语言处理/论文解读/模型训练需不需要将损失降低为零.md",
"content": "本文是对苏神文章的解读,主要是关于公式推导中省略的部分细节记录了自己的理解,希望能帮助大家更好的理解。\n\n模型训练的时候,我们会把数据分为训练数据和开发数据。\n\nLoss变化一般是这样的:训练集损失在不停的降低,开发集先降低随后上升。\n\n我们一般选择两条线的交叉点(其实也没有交叉),也就是开发数据集开始上升的那个点作为我们的最终模型的选择,这样既可以得到最好的结果,也可以避免过拟合。\n\n这个论文思路是这样的,当损失函数降低的一定程度(足够小)的时候,改变损失函数为:\n$$\n\\widetilde{J_{\\theta}} =|J_{\\theta}-b|+b\\tag{1}\n$$\n\n\n公式 $(1)$ 中 $J_{\\theta}$ 为原始的损失函数, $\\widetilde{J_{\\theta}}$ 改变之后的损失函数。\n\n观察这个公式,其实可以这样去描述:\n\n1. 当 $J_{\\theta} \\geq b$ 时,损失函数就是$J_{\\theta}$;\n\n2. 当$J_{\\theta} < b$ 的时候,损失函数就是$\\widetilde{J_{\\theta}}=2b - J_{\\theta}$。\n\n这个时候,我们想一下梯度下降算法公式,如下:\n$$\n\\theta_{n}=\\theta_{n-1}- \\alpha\\nabla J(\\theta_{n-1})\\tag{2}\n$$\n\n\n所以,当损失函数为 $\\widetilde{J_{\\theta}}$ 的时候,符号就会发生变化,这个时候我们就使用就不是梯度下降而是梯度上升算法。也就是说,以$b$ 为临界点,在交替的进行梯度上升和梯度下降算法。\n\n论文发现,在某些任务上,使用这个方法,开发集上的损失函数会发生二次下降。\n\n再次说一下,关于这一点,苏剑林给出来相关的数学推导(参考链接放在文章末尾)。不过有个关于泰勒公式的展开跳过了,我简单做了一个补充,帮助自己和大家理解。\n\n首先如果交替做梯度上升和梯度下降算法,参数更新公式如下所示:\n$$\n\\theta_{n}=\\theta_{n-1}- \\alpha\\nabla J(\\theta_{n-1})\n$$\n\n$$\n\\theta_{n+1}=\\theta_{n}+ \\alpha\\nabla J(\\theta_{n}) \\tag{3}\n$$\n\n\n\n对此公式上下消参 中,我们可以得到:\n$$\n\\theta_{n+1}= \\theta_{n-1}- \\alpha\\nabla J(\\theta_{n-1})+ \\alpha\\nabla J( \\theta_{n-1}- \\alpha\\nabla J(\\theta_{n-1}))\\tag{4}\n$$\n对于公式$(4)$ ,重点是对 **$ J(\\theta_{n-1}- \\alpha\\nabla J(\\theta_{n-1}))$** 这个损失函数进行一个剖析化简,这里用到了泰勒公式的展开。\n\n先回忆一下泰勒公式,这里直接给出一个一阶泰勒公式的展开:\n$$\nJ(\\omega) \\approx J(\\omega_{0}) + (\\omega - \\omega_{0})*J^{'}(\\omega_{0}) + \\epsilon \\qquad \\omega_{0} 和 \\omega 足够接近\\tag{5}\n$$\n注意,这个时候,我们仔细观察公式 **$ J(\\theta_{n-1}- \\alpha\\nabla J(\\theta_{n-1}))$** 和 公式$(5)$。\n\n首先,我们知道的是,$\\alpha\\nabla J(\\theta_{n-1}))$ 是每次参数更新时候的增量,在损失函数足够小的时候,我们每次参数更新的增量可以认定是一个极小值。\n\n换句话说,$\\theta_{n-1}- \\alpha\\nabla J(\\theta_{n-1})$可以对应到我们公式(5) 中的$\\omega_{0}$,$\\theta_{n-1}$ 对应的就是公式(5) 中的 $\\omega$\n\n也就是说,\n$$\nJ( \\theta_{n-1}) \\approx J( \\theta_{n-1}- \\alpha\\nabla J(\\theta_{n-1})) +\\alpha\\nabla J(\\theta_{n-1})*\\nabla J(\\theta_{n-1}) \\tag{6}\n$$\n这里需要注意的,公式最后面一个$\\nabla J(\\theta_{n-1})$ 的由来。按道理,这里应该是对$J^{'}(\\omega_{0})$进行求导 。但是这里因为$\\omega 和 \\omega_{0}$ 非常的相近,我们直接使用对$J(\\omega)$的求导结果就可以,这一点是个比较重要的细节点。\n\n基于此,我们可以继续往下推导:\n\n\n$$\n\\theta_{n+1}= \\theta_{n-1}- \\alpha\\nabla J(\\theta_{n-1})+ \\alpha\\nabla J( \\theta_{n-1}- \\alpha\\nabla J(\\theta_{n-1}))\n$$\n\n$$\n\\approx \\theta_{n-1}- \\alpha\\nabla J(\\theta_{n-1})+ \\alpha\\nabla (J (\\theta_{n-1})- \\alpha\\nabla J(\\theta_{n-1})*\\nabla J(\\theta_{n-1}))\n$$\n\n$$\n= \\theta_{n-1}- \\alpha\\nabla J(\\theta_{n-1})+ \\alpha\\nabla J (\\theta_{n-1})- \\alpha^{2}\\nabla (\\nabla J(\\theta_{n-1})*\\nabla J(\\theta_{n-1}))\n$$\n\n$$\n= \\theta_{n-1}- \\alpha^{2}\\nabla ||\\nabla J(\\theta_{n-1})||^{2} \\tag{7}\n$$\n\n\n\n这里,我还想提一点就是 $||\\nabla J(\\theta_{n-1})||^{2}$ ,它是两个求微分函数的乘积,所以结果是一个带参数的函数,也就是求得一个微分之后,做一个平方,得到的函数,这个时候在参数更新的时候,我们带入相应的值就可以了。\n\n我们针对这个公式(7),会发现一个很奇怪的现象,就是参数更新的模式没有发生变化,都是进行了梯度下降(注意开头我们单从损失函数看是认为梯度下降和梯度上升是交替进行的,两个理解其实都没有问题)。\n\n只是,当前步骤的参数更新不再是取决于上一个步骤,而是取决于上上一个步骤的参数。\n\n这一点,我是这么理解的。使用普通的损失函数,相当于此时我们站在上一个步骤往山下看。当损失函数非常小的时候,极有可能会陷入局部最小值,并不是全局最优点。此时寻找出来的更新的方向,还是局限于局部最优点。而使用新的损失函数,我们通过公式,最直观的感受就是,是站在了上上一个步骤,是脱离了当前的视线(虽然只是差了一个步骤),相当于视野变大了,有更大的可能跳出当前的局部最优点,从而寻找到全局最优点。\n\n我的理解就是这样的,当然苏神给出了另一个解释。大家可以去看一下。我这个文章主要是对他的公式推导中的跳过的泰勒公式的展开做了一个比较详细的阐述,记录下来,方便自己和大家理解。\n\n"
},
{
"path": "深度学习自然语言处理/词向量/CBOW和skip-gram相较而言,彼此相对适合哪些场景.md",
"content": "CBOW和skip-gram相较而言,彼此相对适合哪些场景\n\n先用一句话来个结论:CBOW比Skip-gram 训练速度快,但是Skip-gram可以得到更好的词向量表达。\n\n为什么这么说?\n\n因为我们知道两种优化方式只是对softmax的近似优化,不会影响最终结果,所以这里,我们讨论的时候,为了更加的清晰讲解,不考虑优化的情况。\n\n使用一句话作为一个例子: “我/永远/爱/中国/共产党”\n\n先说CBOW,我们想一下,它的情况是使用周围词预测中心词。如果“爱”是中心词,别的是背景词。对于“爱”这个中心词,只是被预测了一次。\n\n对于Skip-gram,同样,我们的中心词是“爱”,背景词是其他词,对于每一个背景词,我们都需要进行一次预测,每进行一次预测,我们都会更新一次词向量。也就是说,相比CBOW,我们的词向量更新了2k次(假设K为窗口,那么窗口内包含中心词就有2k+1个单词)\n\n想一下是不是这么回事?Skip-gram被训练的次数更多,那么词向量的表达就会越丰富。\n\n如果语料库中,我们的的低频词很多,那么使用Skip-gram就会得到更好的低频词的词向量的表达,相应的训练时长就会更多。\n\n简单来说,我们视线回到一个大小为K的训练窗口(窗口内全部单词为2k+1个),CBOW只是训练一次,Skip-gram 则是训练了2K次。当然是Skip-gram词向量会更加的准确一点,相应的会训练的慢一点。\n\n欢迎大佬拍砖"
},
{
"path": "深度学习自然语言处理/词向量/Fasttext解读(1).md",
"content": "我先说一个小问题,估计很多人也有疑惑。\n\n看了很多文章,有的说是fasttext是CBOW的简单变种,有的说是Skip-gram的变种。究竟哪个是对的?\n\n带着这个问题,我们来聊一聊Fasttext。首先Fasttext涉及到两个论文:\n\n1. 第一个是Bag of Tricks for Efficient TextClassification(201607)。它解决的问题是使用Fasttext进行文本分类\n2. 第二个是Enriching Word Vectors with Subword Information(201607) 。它解决的是使用Fasttext训练词向量。\n\n今天这个文章,主要谈一下Bag of Tricks for Efficient Text Classification 这个论文 ,主要涉及到的就是文本分类的问题。\n\nFasttext用作文本分类,做到了速度和精读的一个平衡:标准多核CPU情况下,不到十分钟,可以训练超过十亿个单词。不到一分钟,可以对50万个句子在312千个类别中进行分类。\n\n这么说,其实不太明显,简单算一下。假设每个句子含有20个单词,那么十亿个单词对应就是五千万个句子,换句话讲在多核CPU的条件下,一分钟左右可以训练500万个句子。\n\n和Bert比较一下,在GPU条件下,8个小时训练300万条数据左右。相比之下Fasttext的这个速度是真的太快了。\n\n在这个论文中,也就是使用做文本分类的Fasttext,使用的是CBOW的架构。\n\n注意哦,强调一遍,Fasttext用在文本分类,模型架构使用的是CBOW的变种。(我这句话的意思不是说使用Skip-gram不可以,而是CBOW在理解文本分类的时候更加的容易理解)\n\n这里和Word2vec的CBOW有两个区别:\n\n1. 第一,使用类别标签替换了中心词。\n2. 第二,使用句子中所有单词作为输入,而不再是单单的针对滑动窗口中的单词。\n\n这两个点如果我们自己考虑,也很容易想到。\n\n为什么这么说呢?先说第二点。我现在要做的是针对文本进行分类,所以对于我的输入需要转换到整体这个句子来看,才能使对一个句子的特征表达。\n\n再说第一点,我们知道在Wrod2vec中,我们使用的是中心词作为输出,而且使用了霍夫曼作为输出层。\n\n非叶子点上的向量为了我的二分类提供计算,叶子节点为整个词汇表中所有词汇的向量。两个向量都会随着模型而训练。\n\n如果要做分类,我们可以想一下叶子节点和非叶子节点的变化。\n\n首先叶子节点对应的是所有类别。如果说我们的类别有5000个,那么对应到Word2vec,我们就有着5000个词汇。想一下是不是这么对应。\n\n非叶子节点其实没什么变化,因为它没有什么实际含义,只是为二分类提供计算。\n\n在这里还想说一下,word2vec中的叶子节点也就是词向量更新之后我们最后是要的,但是对于fasttext其实不会用到这个,因为我们是对文本进行分类,只需要保存了模型权重在预测的时候可以预测就可以了。\n\n还想谈一下词向量初始化的问题,模型训练开始的时候,词向量随机初始化就可以,模型训练结束之后,我们在预测阶段直接使用这个词向量就可以(就是随着模型训练而更新的这个词向量)。\n\n对这个论文还有一个很有意思的点,就是N-gram就是fasttext的模型的输入不仅仅针对的是每个单词,为了加入词序信息,还加入了n-gram信息。\n\n需要注意的一个细节是,这里的n-gram针对的是word,而不是char。对应到中文,应该对应的是分词之后的词,而不是字。但是我自己认为这么对应过来不太好理解。\n\n中文的字做n-gram貌似也有词序信息。但是英文的char-level的n-gram很难说针对这个句子提供一个语序信息。大家理解一下就好。\n\n还有一个问题想说一下,使用了n-gram信息之后,词表肯定是变大了的。你需要的n的内容越多,比如你想要n=1orn=2orn=3等等吧,n的取值范围越大,你的词表越大。\n\n这就会出现一个问题训练非常缓慢。这点很容易理解,参数越多训练当然越慢。\n\n针对这个问题,怎么解决呢?使用哈希。\n\n我举个简单的例子,不一定准确,\"我/爱/中国/共产党\",我在更新的时候,把'我','爱','中国','共产党'我们都使用同一个参数来代表(这种情况很难遇见,理解一下就好),那么在更新训练参数的时候,我只需要更新一个参数就把这个四个词都更新了,当然会快一点。\n\n但是会出现一个问题,就是精度的问题。这个过程,不知道大家有咩有想到和albert很类似。哈希这个过程我自己感觉有点共享参数的意思。"
},
{
"path": "深度学习自然语言处理/词向量/Fasttext解读(2).md",
"content": "\n这个文章主要是谈一下Enriching Word Vectors with Subword Information 这个论文。\n\n有了上一个文章的打底,([上一个文章点击这里](https://mp.weixin.qq.com/s?__biz=MzIyNTY1MDUwNQ==&mid=2247483925&idx=1&sn=9b980a4fb55fd55f92684e403188f024&chksm=e87d3033df0ab925e1ebdc3c89637974645698f1680fd1ad25e23db05903e2061ef8242f16a1&token=509904673&lang=zh_CN#rd))这个论文理解起来就比较简单,所以我写的也比较短。\n\n 对于这个论文,我先给出它最核心的部分: 使用负采样的skip-gram的基础上,将每个中心词视为子词的集合,并学习子词的词向量。 \n\n这句话涉及到的一个最关键的部分就是子词subword,也是这个论文的核心。\n\n 举个例子,现在我们的中心词是\"where\",设定子词大小为3,那么子词集合分为两个部分,注意是两个部分。\n\n 第一部分形如这样:“”,第二部分就是特殊子词,也就是整词“”。 \n\n那么对应到模型是,原来我的输入是“where”的词向量,现在在Fasttext就是所有子词的词向量的和。\n\n 注意哦,这里是所有子词,是包含特殊子词,也就是整词的。\n\n对于背景词,直接使用整词就可以。\n\n 简单来说,就是输出层使用子词(普通子词加上整词),输出层使用整词。\n\n 如果遇到了OOV怎么办?使用普通子词的向量和来表示就可以。\n\n 其实这里的子词,在名字上和上一个文章的ngram很类似,不过,这里使用的是就char的n-gram,缓解的问题并不是语序,而是利用了词序形态的规律。\n\n对应到中文,其实就是偏旁部首。 我记得阿里好像有发一个关于fasttext的中文版本,训练的就是偏旁部首。大家有兴趣可以去看一看。\n\n写完了,我对两个文章做个小总结,顺便对文章开头的问题做个回答: fasttext 训练词向量的时候一般是使用Skip-gram模型的变种。在用作文本分类的时候,一般是使用CBOW的变种。\n\n在这里,我想要强调一下,上一段我说的是一般情况,是为了方便大家了解,并不代表说CBOW架构不能训练词向量,skip-gram不能用作文本分类,需要注意这一点哦。\n\n"
},
{
"path": "深度学习自然语言处理/词向量/README.md",
"content": "## 词向量\n\n### Word2vec\n\n### Fasttext\n\n### Glove\n\n"
},
{
"path": "深度学习自然语言处理/词向量/Word2vec为什么需要二次采样?.md",
"content": "Word2vec为什么需要二次采样?\n\n说到 Word2vec 的采样,首先会想起来的是负采样,属于对Word2vec的一个近似训练方法。\n\n其实它还涉及到一个采样方法,就是subsampling,中文叫做二次采样。\n用最简单的一句话描述二次采样就是,对文本中的每个单词会有一定概率删除掉,这个概率是和词频有关,越高频的词越有概率被删掉。\n二次采样的公式如下所示:\n\n\n\n注意: t为超参数,分母 f(w) 为单词w的词频与总词数之比\n\n首先说一下,我们需要对文本数据进行二次采样?\n举个简单例子,“他/是/个/优秀/的/学生”。如果此时中心词为\"学生\",背景词为\"的\"。\n\n那么,我们的背景词对于我们这个中心词其实是没有什么作用的,并没有什么语义信息上的补充。\n\n但是像“的”这种高频词,出现的机会还很大,所以对于这一句话信息是存在冗余的。\n也就是说,在一个背景窗口中,一个词和较低频词同时出现比和较高频词同时出现对训练词嵌入模型更有益。\n\n举个生活中的例子,现实生活中自律优秀的人比较少,堕落不努力人的人比较多,当然是优秀的人出现在我们身边会对我们自身的成长更加的有益。\n\n所以我们的想法就是减少和堕落的人出现的次数,远离他们,让优秀的人出现在我们生活中的概率上升。\n\n那么二次采样之后文本数据变成了什么样子?\n\n还是上面那句话,“他/是/个/优秀/的/学生”,在这个时候,就变成了“他/是/个/优秀/学生”。也就是说高频词“的”在我们的训练数据中消失了。\n\n当然这个消失正如上文所说,是一个概率,可能在之后的另一个句子中,它还是存在的,只不过它出现在文本中的词频肯定是降低了的。"
},
{
"path": "深度学习自然语言处理/词向量/Word2vec模型究竟是如何获得词向量的.md",
"content": "Word2vec模型究竟是如何获得词向量的?\n\n问大家一个问题:Word2vec模型是如何获得词向量的?\n\n很多文章在解释的时候,会说对一个词通过One-hot编码,然后通过隐层训练,得到的输入到隐层的矩阵就对应的词表词向量。\n\n我不能说这么解释是不对的,但是我认为是不准确的。\n\n在前面文章也说过了,Word2vec是不涉及到隐层的,CBOW有投影层,只是简单的求和平均,Skip-gram没有投影层,就是中心词接了一个霍夫曼树。\n\n所以,很多文章涉及到的隐层的权重矩阵也就无从谈起。\n\n在此情况下,词向量是怎么来的?\n\n从源码的角度来看,我们是对每个词都初始化了一个词向量作为输入,这个词向量是会随着模型训练而更新的,词向量的维度就是我们想要的维度,比如说200维。\n\n以Skip-gram为例,我们的输入的中心词的词向量其实不是One-hot编码,而是随机初始化的一个词向量,它会随着模型训练而更新。\n\n需要注意的一个细节点是,每个单词都会对应两个词向量,一个是作为中心词的时候的词向量,一个是作为背景词的时候的词向量。大家一般选择第一种。\n\n这一点需要注意区别Glove中的中心词向量和背景词向量。Glove中的中心词向量和背景词向量从理论上来说是等价的,只不过由于初始化的不同,最终结果会略有不同。"
},
{
"path": "深度学习自然语言处理/词向量/Word2vec的负采样.md",
"content": "Word2vec的负采样\n\n\n负采样的特点\n\n首先对基于负采样的技术,我们更新的权重只是采样集合,减少了训练量,同时效果上来说,中心词一般来说只和上下文有关,更新其他词的权重并不重要,所以在降低计算量的同时,效果并没有变差。\n\n负采样具体实施细节\n\n我自己的总结就是创建两个线段,第一个线段切开词表大小的份数,每个份数的长度和频率正比。\n\n第二个线段均分M个,然后随机取整数,整数落在第二个线段那里,然后取第一个线段对应的词,如果碰到是自己,那么就跳过。\n\n\n欢迎拍砖\n\n"
},
{
"path": "深度学习自然语言处理/词向量/Word2vec训练参数的选定.md",
"content": "Word2vec训练参数的选定?\n\n首先根据具体任务,选一个领域相似的语料,在这个条件下,语料越大越好。然后下载一个 word2vec 的新版(14年9月更新),语料小(小于一亿词,约 500MB 的文本文件)的时候用 Skip-gram 模型,语料大的时候用 CBOW 模型。最后记得设置迭代次数为三五十次,维度至少选 50,就可以了。(引自 《How to Generate a Good Word Embedding》)\n\n"
},
{
"path": "深度学习自然语言处理/词向量/word2vec两种优化方式的联系和区别.md",
"content": "**总结不易,请大力点赞,感谢**\n\n上一个文章,[Word2vec-负采样/霍夫曼之后模型是否等价-绝对干货](http://mp.weixin.qq.com/s?__biz=MzIyNTY1MDUwNQ==&mid=2247483837&idx=1&sn=9b334c5db352acc298aa6bb0e5e41ce9&chksm=e87d339bdf0aba8d1e79d7ef88461a6914d0a74330e744b501394d7ad9aa0c1d8a65382ce80b&scene=21#wechat_redirect)是字节的面试真题,建议朋友们多看几遍,有问题及时沟通。\n\n私下有几个朋友看完之后还是有点懵,又问了一下具体细节。基于此,我重新写了一个简短的文章,希望能让大家明白,大家可以结合上一个文章看。\n\n我们再看一下题目:W2V经过霍夫曼或者负采样之后,模型与原模型相比,是等价的还是相似的?\n\n首先,我们要明确,这里的原模型指的是什么?原模型就是我们的没有经过优化的W2V(当然我们也说过它是一个工具不是一个模型)。\n\n也就是只是使用Skip-gram模型或者CBOW模型而没有进行优化的原始版本。对于这个原始版本,是在最后一层进行了Softmax。\n\n我们的目标函数中,最核心的一个部分就是在给定中心词的条件下生成正确背景词的概率,我们要最大化这个东西,公式如下:\n\n\n\n仔细看,在分母涉及到了一个V,这里的V就是我们的词典大小。也就是说,为了计算这个条件概率,我们需要对整个词典进行操作,复杂度就是O(|V|)\n\n所以,负采样和霍夫曼就是针对这一个计算开销大的地方进行了优化。当然W2V为了减少计算量,还是去掉了隐层。比如CBOW直接是输入向量求和平均然后接霍夫曼树。比如Skip-gram直接是中心词的词向量接霍夫曼树。\n\n这不是我这个文章的重点,就不细细展开了。\n\n我们先说负采样。负采样的本质在于生成K个噪声。它的本质是基于中心词生成正确的背景词概率为1,生成噪声词概率为0,这个是我们的优化方向。公式如下:\n\n\n\n仔细看这个公式,V已经消失,取而代之的是K,也就是我们的噪声词的数量,换句话讲,我们的复杂度被K这个大小限制住了,降低为了O(|K|)\n\n然后我们再来看层序Softmax。它的核心本质是在一条路径上不停的做二分类,概率连乘就会得到我们的条件概率。公式如下:\n\n\n\n注意看,这个公式中,V也已经消失了,被霍夫曼树中到达背景词的路径限制住了,这也就是上个文章中说到的,复杂度变成了二叉树的高度: O(log|V|)\n\n既然只是针对的部分节点,那么与原始版本相比,当然是近似。\n\n简单的总结一下:\n\n其实可以这样理解,以跳字模型为例,条件概率是中心词生成背景词的概率,也就是我们优化函数中最核心的部分。没有使用优化的,分母涉及到全部词汇,训练开销大。负采样近似训练,把复杂度限制在了k个噪声词,层序softmax也属于近似训练,在它的条件概率中,不断的二分类,涉及到的是能够达到背景词的那个路径上的非叶子结点,也就是没涉及到其他节点,这一点和负采样很类似,都是从全部词汇降低复杂度,只不过负采样是被k限制,层序是被路径编码限制(0,1,1,1,0)这种限制住。\n\n**不知道大家有没有注意到,负采样和霍夫曼都是讲Softmax转化为二分类的问题从而降低了复杂度。负采样是针对是不是背景词做二分类,霍夫曼是在对是不是正确路径上的节点做二分类。这么说有点不严谨,但是意思就是这么个意思,大家理解一下。**\n\n**总结不易,请大力点赞,感谢**"
},
{
"path": "深度学习自然语言处理/词向量/史上最全词向量面试题梳理.md",
"content": "**微信公众号:NLP从入门到放弃**\n\n1. 有没有使用自己的数据训练过Word2vec,详细说一下过程。包括但是不限于:语料如何获取,清理以及语料的大小,超参数的选择及其原因,词表以及维度大小,训练时长等等细节点。\n2. Word2vec模型是如何获得词向量的?聊一聊你对词嵌入的理解?如何理解分布式假设?\n3. 如何评估训练出来的词向量的好坏 \n4. Word2vec模型如何做到增量训练\n5. 大致聊一下 word2vec这个模型的细节,包括但不限于:两种模型以及两种优化方法(大致聊一下就可以,下面会详细问)\n6. 解释一下 hierarchical softmax 的流程(CBOW and Skip-gram)\n7. 基于6,可以展开问一下模型如何获取输入层,有没有隐层,输出层是什么情况。\n8. 基于6,可以展开问输出层为何选择霍夫曼树,它有什么优点,为何不选择其他的二叉树\n9. 基于6,可以问该模型的复杂度是多少,目标函数分别是什么,如何做到更新梯度(尤其是如何更新输入向量的梯度)\n10. 基于6,可以展开问一下 hierarchical softmax 这个模型 有什么缺点\n11. 聊一下负采样模型优点(为什么使用负采样技术)\n12. 如何对输入进行负采样(负采样的具体实施细节是什么)\n13. 负采样模型对应的目标函数分别是什么(CBOW and Skip-gram)\n14. CBOW和skip-gram相较而言,彼此相对适合哪些场景\n15. 有没有使用Word2vec计算过句子的相似度,效果如何,有什么细节可以分享出来\n16. 详细聊一下Glove细节,它是如何进行训练的?有什么优点?什么场景下适合使用?与Word2vec相比,有什么区别(比如损失函数)?\n17. 详细聊一下Fasttext细节,每一层都代表了什么?它与Wod2vec的区别在哪里?什么情况下适合使用Fasttext这个模型?\n18. ELMO的原理是什么?以及它的两个阶段分别如何应用?(第一阶段如何预训练,第二阶段如何在下游任务使用)\n19. ELMO的损失函数是什么?它是一个双向语言模型吗?为什么?\n20. ELMO的优缺点分别是什么?为什么可以做到一词多义的效果?\n\n\n\n\n\n本面试题词向量资源参考:\n\nword2vec、glove、cove、fastext以及elmo对于知识表达有什么优劣? - 霍华德的回答 - 知乎\nhttps://www.zhihu.com/question/292482891/answer/492247284\n\n面试题:Word2Vec中为什么使用负采样? - 七月在线 七仔的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/66088781\n\n关于word2vec,我有话要说 - 张云的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/29364112\n\nword2vec(二):面试!考点!都在这里 - 我的土歪客的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/133025678\n\nnlp中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert - JayLou娄杰的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/56382372\n\n史上最全词向量讲解(LSA/word2vec/Glove/FastText/ELMo/BERT) - 韦伟的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/75391062\n\nword2vec详解(CBOW,skip-gram,负采样,分层Softmax) - 孙孙的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/53425736\n\nWord2Vec详解-公式推导以及代码 - link-web的文章 - 知乎\nhttps://zhuanlan.zhihu.com/p/86445394\n\n关于ELMo,面试官们都怎么问:https://cloud.tencent.com/developer/article/1594557"
},
{
"path": "深度学习自然语言处理/词向量/聊一下Glove.md",
"content": "本文大概需要阅读 4.75 分钟\n先问大家两个问题,看能不能解答\n\n1. Glove 中词向量的表达是使用的中心词向量还是背景词向量还是有其他方法?\n\n2. 能不能分别用一句话概括出Glove和Fasttext 的核心要点?\n\n先来谈Glove。中文全称 Global Vectors for Word Representation。它做的事情概括出来就是:基于全局语料,获得词频统计,学习词语表征。\n\n我们从语料之中,学习到X共现词频矩阵,词频矩阵中的每个元素$x_{ij}$,代表的是词\n\n$x_{j}$出现在$x_{i}$的环境中的次数。注意,对于共现词频矩阵来说,它是一个对称矩阵。\n\n\n这一点非常的重要,也很容易理解,词A出现在词B周围的次数肯定是等价于词B出现在词A周围的次数的。\n\n类比于Word2vec,对于词$x_{i}$,就是中心词,对于词$x_{j}$也就是背景词。\n\n理论上,一个词作为中心词向量和一个词作为背景学到的两种向量应该是完全相同的。\n\n但是现实中,由于我们初始化的不同,所以我们最终学习到的两种词向量是有些许不同。\n\n为了增加模型的鲁棒性,在Glove中,使用两个词向量的和作为我们一个词的词向量的表达。\n\n这一点是区别于Word2vec,对于Word2vec,中心词向量和背景词向量是不等价的,我们一般使用中心词向量代表一个词最终的语义表达。\n\nGlove 论文中的推导过程其实不是很严谨,大致流程就是从大语料中发现了一个规律,即条件概率的比值可以比较直观的表达出词与词之间的关系。\n\n随后可以构建词向量函数去拟合条件概率的比值。基于此一步步的进行延伸推导,在我看了就是在基于一些假设,寻找出一种可能性的存在。\n\n在这里就不细说,直接给出Glove的损失函数:\n\n$\\sum_{i \\in V} \\sum_{j \\in V} h(x_{ij})(u_{j}^Tv_{i}+b_{i}+b_{j}-log(x_{ij}))^2$\n\n详细讲一下这个损失函数,它是一个平方损失函数,很值得琢磨。\n\n我把它分为了三个部分,权重函数h(x),词向量表达是$u_{j}^Tv_{i}+b_{i}+b_{j}$,共现词频的对数 $log(x_{ij})$\n\n\n从这里,我插一句我的理解,就是GLove基于的是无标签的语料,属于无监督的训练过程,但是从损失函数看,我觉得可以认为它是一个有监督的过程。\n\n标签就是$log(x_{ij})$,这个是我们从语料之中计算出来的,换句话说,在模型训练之前,我们可以对语料的计算,得到相应的标签数据,所以我自己认为这个可以看做是一个有监督的过程。\n\n我们使用一句话去描述这个损失函数可以这么去说:随着模型不停的优化,词向量的表达在不断的拟合共现词频的对数。\n\nh(x)是权重函数,代表的含义是表达一个词对的重要性,在值域[0,1]上单调递增。直观上理解就是一对词语共现的词频越多,那么它的重要性也就越大。\n\n论文中给出的函数是这样的,在x”,第二部分就是特殊子词,也就是整词“”。\n\n那么对应到模型是,原来我的输入是“where”的词向量,现在在Fasttext就是所有子词的词向量的和。\n\n注意哦,这里是所有子词,是包含特殊子词,也就是整词的。\n\n对于背景词,直接使用整词就可以。\n\n简单来说,就是输出层使用子词(普通子词加上整词),输出层使用整词。\n\n如果遇到了OOV怎么办?使用普通子词的向量和来表示就可以。\n\n其实这里的子词,在名字上和上一个文章的ngram很类似,不过,这里使用的是就char的n-gram,缓解的问题并不是语序,而是利用了词序形态的规律。\n\n对应到中文,其实就是偏旁部首。 我记得阿里好像有发一个关于fasttext的中文版本,训练的就是偏旁部首。大家有兴趣可以去看一看。\n\n写完了,我对两个文章做个小总结,顺便对文章开头的问题做个回答: fasttext 训练词向量的时候一般是使用Skip-gram模型的变种。在用作文本分类的时候,一般是使用CBOW的变种。\n\n在这里,我想要强调一下,上一段我说的是一般情况,是为了方便大家了解,并不代表说CBOW架构不能训练词向量,skip-gram不能用作文本分类,需要注意这一点哦。\n\n\n\n### 12. Glove细节详解解读\n\n本文大概需要阅读 4.75 分钟 先问大家两个问题,看能不能解答\n\n1. Glove 中词向量的表达是使用的中心词向量还是背景词向量还是有其他方法?\n2. 能不能分别用一句话概括出Glove和Fasttext 的核心要点?\n\n先来谈Glove。中文全称 Global Vectors for Word Representation。它做的事情概括出来就是:基于全局语料,获得词频统计,学习词语表征。\n\n我们从语料之中,学习到X共现词频矩阵,词频矩阵中的每个元素$x_{ij}$,代表的是词\n\n$x_{j}$出现在$x_{i}$的环境中的次数。注意,对于共现词频矩阵来说,它是一个对称矩阵。\n\n这一点非常的重要,也很容易理解,词A出现在词B周围的次数肯定是等价于词B出现在词A周围的次数的。\n\n类比于Word2vec,对于词$x_{i}$,就是中心词,对于词$x_{j}$也就是背景词。\n\n理论上,一个词作为中心词向量和一个词作为背景学到的两种向量应该是完全相同的。\n\n但是现实中,由于我们初始化的不同,所以我们最终学习到的两种词向量是有些许不同。\n\n为了增加模型的鲁棒性,在Glove中,使用两个词向量的和作为我们一个词的词向量的表达。\n\n这一点是区别于Word2vec,对于Word2vec,中心词向量和背景词向量是不等价的,我们一般使用中心词向量代表一个词最终的语义表达。\n\nGlove 论文中的推导过程其实不是很严谨,大致流程就是从大语料中发现了一个规律,即条件概率的比值可以比较直观的表达出词与词之间的关系。\n\n随后可以构建词向量函数去拟合条件概率的比值。基于此一步步的进行延伸推导,在我看了就是在基于一些假设,寻找出一种可能性的存在。\n\n在这里就不细说,直接给出Glove的损失函数:\n\n$\\sum_{i \\in V} \\sum_{j \\in V} h(x_{ij})(u_{j}^Tv_{i}+b_{i}+b_{j}-log(x_{ij}))^2$\n\n详细讲一下这个损失函数,它是一个平方损失函数,很值得琢磨。\n\n我把它分为了三个部分,权重函数h(x),词向量表达是$u_{j}^Tv_{i}+b_{i}+b_{j}$,共现词频的对数 $log(x_{ij})$\n\n从这里,我插一句我的理解,就是GLove基于的是无标签的语料,属于无监督的训练过程,但是从损失函数看,我觉得可以认为它是一个有监督的过程。\n\n标签就是$log(x_{ij})$,这个是我们从语料之中计算出来的,换句话说,在模型训练之前,我们可以对语料的计算,得到相应的标签数据,所以我自己认为这个可以看做是一个有监督的过程。\n\n我们使用一句话去描述这个损失函数可以这么去说:随着模型不停的优化,词向量的表达在不断的拟合共现词频的对数。\n\nh(x)是权重函数,代表的含义是表达一个词对的重要性,在值域[0,1]上单调递增。直观上理解就是一对词语共现的词频越多,那么它的重要性也就越大。\n\n论文中给出的函数是这样的,在x