Showing preview only (1,904K chars total). Download the full file or copy to clipboard to get everything.
Repository: DataTalksClub/data-engineering-zoomcamp
Branch: main
Commit: ef44b885b9bb
Files: 381
Total size: 12.5 MB
Directory structure:
gitextract_ffam8vtv/
├── .github/
│ └── FUNDING.yml
├── .gitignore
├── 01-docker-terraform/
│ ├── README.md
│ ├── docker-sql/
│ │ ├── 01-introduction.md
│ │ ├── 02-virtual-environment.md
│ │ ├── 03-dockerizing-pipeline.md
│ │ ├── 04-postgres-docker.md
│ │ ├── 05-data-ingestion.md
│ │ ├── 06-ingestion-script.md
│ │ ├── 07-pgadmin.md
│ │ ├── 08-dockerizing-ingestion.md
│ │ ├── 09-docker-compose.md
│ │ ├── 10-sql-refresher.md
│ │ ├── 11-cleanup.md
│ │ ├── README.md
│ │ └── pipeline/
│ │ ├── .python-version
│ │ ├── Dockerfile
│ │ ├── docker-compose.yaml
│ │ ├── docker-helper-scripts/
│ │ │ ├── docker-ingest.sh
│ │ │ ├── docker-pgadmin.sh
│ │ │ └── docker-postgres.sh
│ │ ├── ingest_data.py
│ │ └── pyproject.toml
│ └── terraform/
│ ├── 1_terraform_overview.md
│ ├── 2_gcp_overview.md
│ ├── README.md
│ ├── terraform/
│ │ ├── README.md
│ │ ├── terraform_basic/
│ │ │ └── main.tf
│ │ ├── terraform_with_variable_AWS/
│ │ │ ├── README.md
│ │ │ ├── main.tf
│ │ │ ├── terraform.tfvars
│ │ │ └── variables.tf
│ │ └── terraform_with_variables/
│ │ ├── main.tf
│ │ └── variables.tf
│ └── windows.md
├── 02-workflow-orchestration/
│ ├── README.md
│ ├── docker-compose.yml
│ └── flows/
│ ├── 01_hello_world.yaml
│ ├── 02_python.yaml
│ ├── 03_getting_started_data_pipeline.yaml
│ ├── 04_postgres_taxi.yaml
│ ├── 05_postgres_taxi_scheduled.yaml
│ ├── 06_gcp_kv.yaml
│ ├── 07_gcp_setup.yaml
│ ├── 08_gcp_taxi.yaml
│ ├── 09_gcp_taxi_scheduled.yaml
│ ├── 10_chat_without_rag.yaml
│ └── 11_chat_with_rag.yaml
├── 03-data-warehouse/
│ ├── README.md
│ ├── big_query.sql
│ ├── big_query_hw.sql
│ ├── big_query_ml.sql
│ ├── extract_model.md
│ └── extras/
│ ├── .env-example
│ ├── .gitignore
│ ├── README.md
│ ├── pyproject.toml
│ ├── web_to_gcs.py
│ └── web_to_gcs_with_progress_bar.py
├── 04-analytics-engineering/
│ ├── README.md
│ ├── class_notes/
│ │ ├── 4_1_1_analytics_engineering_basics.md
│ │ ├── 4_1_2_what_is_dbt.md
│ │ ├── 4_2_1_dbt_core_vs_dbt_cloud.md
│ │ ├── 4_3_1_dbt_project_structure.md
│ │ ├── 4_3_2_dbt_sources.md
│ │ ├── 4_4_1_dbt_models.md
│ │ ├── 4_4_2_dbt_seeds_and_macros.md
│ │ ├── 4_5_1_documentation.md
│ │ ├── 4_5_2_dbt_tests.md
│ │ ├── 4_5_3_dbt_packages.md
│ │ └── 4_6_1_dbt_commands.md
│ ├── refreshers/
│ │ └── SQL.md
│ ├── setup/
│ │ ├── cloud_setup.md
│ │ ├── duckdb_troubleshooting.md
│ │ └── local_setup.md
│ └── taxi_rides_ny/
│ ├── .gitignore
│ ├── dbt_project.yml
│ ├── macros/
│ │ ├── get_trip_duration_minutes.sql
│ │ ├── get_vendor_data.sql
│ │ ├── macros_properties.yml
│ │ └── safe_cast.sql
│ ├── models/
│ │ ├── intermediate/
│ │ │ ├── int_trips.sql
│ │ │ ├── int_trips_unioned.sql
│ │ │ └── schema.yml
│ │ ├── marts/
│ │ │ ├── dim_vendors.sql
│ │ │ ├── dim_zones.sql
│ │ │ ├── fct_trips.sql
│ │ │ ├── reporting/
│ │ │ │ ├── fct_monthly_zone_revenue.sql
│ │ │ │ └── schema.yml
│ │ │ └── schema.yml
│ │ └── staging/
│ │ ├── schema.yml
│ │ ├── sources.yml
│ │ ├── stg_green_tripdata.sql
│ │ └── stg_yellow_tripdata.sql
│ ├── package-lock.yml
│ ├── packages.yml
│ ├── seeds/
│ │ └── seeds_properties.yml
│ ├── snapshots/
│ │ └── .gitkeep
│ └── tests/
│ └── .gitkeep
├── 05-data-platforms/
│ ├── README.md
│ └── notes/
│ ├── 01-introduction.md
│ ├── 02-getting-started.md
│ ├── 03-nyc-taxi-pipeline.md
│ ├── 04-bruin-mcp.md
│ ├── 05-bruin-cloud.md
│ ├── 06-core-01-projects.md
│ ├── 06-core-02-pipelines.md
│ ├── 06-core-03-assets.md
│ ├── 06-core-04-variables.md
│ └── 06-core-05-commands.md
├── 06-batch/
│ ├── .gitignore
│ ├── README.md
│ ├── code/
│ │ ├── 03_test.ipynb
│ │ ├── 04_pyspark.ipynb
│ │ ├── 05_taxi_schema.ipynb
│ │ ├── 06_spark_sql.ipynb
│ │ ├── 06_spark_sql.py
│ │ ├── 06_spark_sql_big_query.py
│ │ ├── 07_groupby_join.ipynb
│ │ ├── 08_rdds.ipynb
│ │ ├── 09_spark_gcs.ipynb
│ │ ├── cloud.md
│ │ ├── download_data.sh
│ │ └── homework.ipynb
│ └── setup/
│ ├── config/
│ │ ├── core-site.xml
│ │ ├── spark-defaults.conf
│ │ └── spark.dockerfile
│ ├── hadoop-yarn.md
│ ├── linux.md
│ ├── macos.md
│ └── windows.md
├── 07-streaming/
│ ├── .gitignore
│ ├── README.md
│ ├── extras/
│ │ ├── README.md
│ │ ├── ksqldb/
│ │ │ └── commands.md
│ │ ├── pyflink/
│ │ │ ├── .gitignore
│ │ │ ├── Dockerfile.flink
│ │ │ ├── LICENSE
│ │ │ ├── Makefile
│ │ │ ├── README.md
│ │ │ ├── docker-compose.yml
│ │ │ ├── homework.md
│ │ │ ├── requirements.txt
│ │ │ └── src/
│ │ │ ├── job/
│ │ │ │ ├── aggregation_job.py
│ │ │ │ ├── start_job.py
│ │ │ │ └── taxi_job.py
│ │ │ └── producers/
│ │ │ ├── load_taxi_data.py
│ │ │ └── producer.py
│ │ └── python/
│ │ ├── README.md
│ │ ├── avro_example/
│ │ │ ├── consumer.py
│ │ │ ├── producer.py
│ │ │ ├── ride_record.py
│ │ │ ├── ride_record_key.py
│ │ │ └── settings.py
│ │ ├── docker/
│ │ │ ├── README.md
│ │ │ ├── docker-compose.yml
│ │ │ ├── kafka/
│ │ │ │ └── docker-compose.yml
│ │ │ └── spark/
│ │ │ ├── build.sh
│ │ │ ├── cluster-base.Dockerfile
│ │ │ ├── docker-compose.yml
│ │ │ ├── jupyterlab.Dockerfile
│ │ │ ├── spark-base.Dockerfile
│ │ │ ├── spark-master.Dockerfile
│ │ │ └── spark-worker.Dockerfile
│ │ ├── json_example/
│ │ │ ├── consumer.py
│ │ │ ├── producer.py
│ │ │ ├── ride.py
│ │ │ └── settings.py
│ │ ├── redpanda_example/
│ │ │ ├── README.md
│ │ │ ├── consumer.py
│ │ │ ├── docker-compose.yaml
│ │ │ ├── producer.py
│ │ │ ├── ride.py
│ │ │ └── settings.py
│ │ ├── requirements.txt
│ │ ├── resources/
│ │ │ └── schemas/
│ │ │ ├── taxi_ride_key.avsc
│ │ │ └── taxi_ride_value.avsc
│ │ └── streams-example/
│ │ ├── faust/
│ │ │ ├── branch_price.py
│ │ │ ├── producer_taxi_json.py
│ │ │ ├── stream.py
│ │ │ ├── stream_count_vendor_trips.py
│ │ │ ├── taxi_rides.py
│ │ │ └── windowing.py
│ │ ├── pyspark/
│ │ │ ├── README.md
│ │ │ ├── consumer.py
│ │ │ ├── producer.py
│ │ │ ├── settings.py
│ │ │ ├── spark-submit.sh
│ │ │ ├── streaming-notebook.ipynb
│ │ │ └── streaming.py
│ │ └── redpanda/
│ │ ├── README.md
│ │ ├── consumer.py
│ │ ├── docker-compose.yaml
│ │ ├── producer.py
│ │ ├── settings.py
│ │ ├── spark-submit.sh
│ │ ├── streaming-notebook.ipynb
│ │ └── streaming.py
│ ├── theory/
│ │ ├── README.md
│ │ └── java/
│ │ └── kafka_examples/
│ │ ├── .gitignore
│ │ ├── build/
│ │ │ └── generated-main-avro-java/
│ │ │ └── schemaregistry/
│ │ │ ├── RideRecord.java
│ │ │ ├── RideRecordCompatible.java
│ │ │ └── RideRecordNoneCompatible.java
│ │ ├── build.gradle
│ │ ├── gradle/
│ │ │ └── wrapper/
│ │ │ ├── gradle-wrapper.jar
│ │ │ └── gradle-wrapper.properties
│ │ ├── gradlew
│ │ ├── gradlew.bat
│ │ ├── settings.gradle
│ │ └── src/
│ │ ├── main/
│ │ │ ├── avro/
│ │ │ │ ├── rides.avsc
│ │ │ │ ├── rides_compatible.avsc
│ │ │ │ └── rides_non_compatible.avsc
│ │ │ └── java/
│ │ │ └── org/
│ │ │ └── example/
│ │ │ ├── AvroProducer.java
│ │ │ ├── JsonConsumer.java
│ │ │ ├── JsonKStream.java
│ │ │ ├── JsonKStreamJoins.java
│ │ │ ├── JsonKStreamWindow.java
│ │ │ ├── JsonProducer.java
│ │ │ ├── JsonProducerPickupLocation.java
│ │ │ ├── Secrets.java
│ │ │ ├── Topics.java
│ │ │ ├── customserdes/
│ │ │ │ └── CustomSerdes.java
│ │ │ └── data/
│ │ │ ├── PickupLocation.java
│ │ │ ├── Ride.java
│ │ │ └── VendorInfo.java
│ │ └── test/
│ │ └── java/
│ │ └── org/
│ │ └── example/
│ │ ├── JsonKStreamJoinsTest.java
│ │ ├── JsonKStreamTest.java
│ │ └── helper/
│ │ └── DataGeneratorHelper.java
│ └── workshop/
│ ├── .python-version
│ ├── Dockerfile.flink
│ ├── Dockerfile_ARM64.flink
│ ├── Makefile
│ ├── README.md
│ ├── docker-compose.yml
│ ├── flink-config.yaml
│ ├── live/
│ │ ├── .gitignore
│ │ ├── .python-version
│ │ ├── Dockerfile.flink
│ │ ├── README.md
│ │ ├── docker-compose.yaml
│ │ ├── flink-config.yaml
│ │ ├── main.py
│ │ ├── notebooks/
│ │ │ ├── consumer_db.ipynb
│ │ │ ├── models.py
│ │ │ └── producer.ipynb
│ │ ├── pyproject.flink.toml
│ │ ├── pyproject.toml
│ │ └── src/
│ │ ├── job/
│ │ │ ├── aggregation_job.py
│ │ │ └── pass_through_job.py
│ │ └── producers/
│ │ ├── models.py
│ │ └── producer_realtime.py
│ ├── pyproject.flink.toml
│ ├── pyproject.toml
│ └── src/
│ ├── consumers/
│ │ ├── consumer.py
│ │ └── consumer_postgres.py
│ ├── job/
│ │ ├── aggregation_job.py
│ │ ├── aggregation_job_demo.py
│ │ └── pass_through_job.py
│ ├── models.py
│ └── producers/
│ ├── producer.py
│ └── producer_realtime.py
├── README.md
├── after-sign-up.md
├── asking-questions.md
├── awesome-data-engineering.md
├── certificates.md
├── cohorts/
│ ├── 2022/
│ │ ├── README.md
│ │ ├── project.md
│ │ ├── week_1_basics_n_setup/
│ │ │ └── homework.md
│ │ ├── week_2_data_ingestion/
│ │ │ ├── README.md
│ │ │ ├── airflow/
│ │ │ │ ├── .env_example
│ │ │ │ ├── 1_setup_official.md
│ │ │ │ ├── 2_setup_nofrills.md
│ │ │ │ ├── Dockerfile
│ │ │ │ ├── README.md
│ │ │ │ ├── dags/
│ │ │ │ │ └── data_ingestion_gcs_dag.py
│ │ │ │ ├── dags_local/
│ │ │ │ │ ├── data_ingestion_local.py
│ │ │ │ │ └── ingest_script.py
│ │ │ │ ├── docker-compose-nofrills.yml
│ │ │ │ ├── docker-compose.yaml
│ │ │ │ ├── docker-compose_2.3.4.yaml
│ │ │ │ ├── docs/
│ │ │ │ │ └── 1_concepts.md
│ │ │ │ ├── extras/
│ │ │ │ │ ├── data_ingestion_gcs_dag_ex2.py
│ │ │ │ │ └── web_to_gcs.sh
│ │ │ │ ├── requirements.txt
│ │ │ │ └── scripts/
│ │ │ │ └── entrypoint.sh
│ │ │ ├── homework/
│ │ │ │ ├── homework.md
│ │ │ │ └── solution.py
│ │ │ └── transfer_service/
│ │ │ └── README.md
│ │ ├── week_3_data_warehouse/
│ │ │ └── airflow/
│ │ │ ├── .env_example
│ │ │ ├── 1_setup_official.md
│ │ │ ├── 2_setup_nofrills.md
│ │ │ ├── README.md
│ │ │ ├── dags/
│ │ │ │ └── gcs_to_bq_dag.py
│ │ │ ├── docker-compose-nofrills.yml
│ │ │ ├── docker-compose.yaml
│ │ │ └── scripts/
│ │ │ └── entrypoint.sh
│ │ ├── week_5_batch_processing/
│ │ │ └── homework.md
│ │ └── week_6_stream_processing/
│ │ └── homework.md
│ ├── 2023/
│ │ ├── README.md
│ │ ├── leaderboard.md
│ │ ├── project.md
│ │ ├── week_1_docker_sql/
│ │ │ └── homework.md
│ │ ├── week_1_terraform/
│ │ │ └── homework.md
│ │ ├── week_2_workflow_orchestration/
│ │ │ ├── README.md
│ │ │ └── homework.md
│ │ ├── week_3_data_warehouse/
│ │ │ └── homework.md
│ │ ├── week_4_analytics_engineering/
│ │ │ └── homework.md
│ │ ├── week_5_batch_processing/
│ │ │ └── homework.md
│ │ ├── week_6_stream_processing/
│ │ │ ├── client.properties
│ │ │ ├── homework.md
│ │ │ ├── producer_confluent.py
│ │ │ ├── settings.py
│ │ │ ├── spark-submit.sh
│ │ │ └── streaming_confluent.py
│ │ └── workshops/
│ │ └── piperider.md
│ ├── 2024/
│ │ ├── 01-docker-terraform/
│ │ │ ├── homework.md
│ │ │ └── solutions.md
│ │ ├── 02-workflow-orchestration/
│ │ │ ├── README.md
│ │ │ └── homework.md
│ │ ├── 03-data-warehouse/
│ │ │ └── homework.md
│ │ ├── 04-analytics-engineering/
│ │ │ └── homework.md
│ │ ├── 05-batch/
│ │ │ └── homework.md
│ │ ├── 06-streaming/
│ │ │ ├── docker-compose.yml
│ │ │ └── homework.md
│ │ ├── README.md
│ │ ├── leaderboard.md
│ │ ├── project.md
│ │ └── workshops/
│ │ ├── dlt.md
│ │ ├── dlt_resources/
│ │ │ ├── data_ingestion_workshop.md
│ │ │ ├── homework_solution.ipynb
│ │ │ ├── homework_starter.ipynb
│ │ │ └── workshop.ipynb
│ │ └── rising-wave.md
│ ├── 2025/
│ │ ├── 01-docker-terraform/
│ │ │ └── homework.md
│ │ ├── 02-workflow-orchestration/
│ │ │ ├── README.md
│ │ │ ├── flows/
│ │ │ │ ├── 01_getting_started_data_pipeline.yaml
│ │ │ │ ├── 02_postgres_taxi.yaml
│ │ │ │ ├── 02_postgres_taxi_scheduled.yaml
│ │ │ │ ├── 03_postgres_dbt.yaml
│ │ │ │ ├── 04_gcp_kv.yaml
│ │ │ │ ├── 05_gcp_setup.yaml
│ │ │ │ ├── 06_gcp_taxi.yaml
│ │ │ │ ├── 06_gcp_taxi_scheduled.yaml
│ │ │ │ └── 07_gcp_dbt.yaml
│ │ │ └── homework.md
│ │ ├── 03-data-warehouse/
│ │ │ ├── DLT_upload_to_GCP.ipynb
│ │ │ ├── homework.md
│ │ │ └── load_yellow_taxi_data.py
│ │ ├── 04-analytics-engineering/
│ │ │ └── homework.md
│ │ ├── 05-batch/
│ │ │ └── homework.md
│ │ ├── 06-streaming/
│ │ │ ├── homework/
│ │ │ │ └── homework.ipynb
│ │ │ └── homework.md
│ │ ├── README.md
│ │ ├── project.md
│ │ └── workshops/
│ │ ├── dlt/
│ │ │ ├── README.md
│ │ │ ├── data_ingestion_workshop.md
│ │ │ └── dlt_homework.md
│ │ └── dynamic_load_dlt.py
│ └── 2026/
│ ├── 01-docker-terraform/
│ │ └── homework.md
│ ├── 02-workflow-orchestration/
│ │ └── homework.md
│ ├── 03-data-warehouse/
│ │ ├── DLT_upload_to_GCP.ipynb
│ │ ├── homework.md
│ │ └── load_yellow_taxi_data.py
│ ├── 04-analytics-engineering/
│ │ └── homework.md
│ ├── 05-data-platforms/
│ │ └── homework.md
│ ├── 06-batch/
│ │ └── homework.md
│ ├── 07-streaming/
│ │ └── homework.md
│ ├── README.md
│ ├── project.md
│ └── workshops/
│ ├── dlt/
│ │ ├── README.md
│ │ ├── analysis.py
│ │ ├── dlt_Pipeline_Overview.ipynb
│ │ ├── dlt_homework.md
│ │ ├── open_library_pipeline.py
│ │ └── pyproject.toml
│ └── dlt.md
├── learning-in-public.md
├── projects/
│ ├── README.md
│ └── datasets.md
└── workshop-best-practices.md
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/FUNDING.yml
================================================
github: alexeygrigorev
================================================
FILE: .gitignore
================================================
.DS_Store
.idea
*.tfstate
*.tfstate.*
**.terraform
**.terraform.lock.*
**google_credentials.json
**logs/
**.env
**__pycache__/
.history
**/ny_taxi_postgres_data/*
serving_dir
.ipynb_checkpoints/
!week_6_stream_processing/avro_example/data/rides.csv
*.parquet
*.csv
*.duckdb
================================================
FILE: 01-docker-terraform/README.md
================================================
# Introduction
[](https://www.youtube.com/watch?v=JgspdlKXS-w)
We suggest watching videos in the same order as in this document.
# Docker + Postgres
## Workshop
[](https://youtu.be/lP8xXebHmuE&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=10)
* Video: https://www.youtube.com/watch?v=lP8xXebHmuE
* Follow the instructions here: [docker-sql/](docker-sql/)
## :movie_camera: SQL refresher
[](https://youtu.be/QEcps_iskgg&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=10)
* Video: https://www.youtube.com/watch?v=QEcps_iskgg
* SQL queries: [10-sql-refresher.md](docker-sql/10-sql-refresher.md)
# GCP
## :movie_camera: Introduction to GCP (Google Cloud Platform)
[](https://youtu.be/18jIzE41fJ4&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=3)
# Terraform
[Code and notes](terraform/)
## :movie_camera: Introduction Terraform: Concepts and Overview, a primer
[](https://youtu.be/s2bOYDCKl_M&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=11)
## :movie_camera: Terraform Basics: Simple one file Terraform Deployment
[](https://youtu.be/Y2ux7gq3Z0o&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=12)
## :movie_camera: Deployment with a Variables File
[](https://youtu.be/PBi0hHjLftk&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=13)
## Configuring terraform and GCP SDK on Windows
* [Instructions](terraform/windows.md)
# Homework
* [Homework](../cohorts/2026/01-docker-terraform/homework.md)
# Community notes
<details>
<summary>Did you take notes? You can share them here</summary>
* [Notes from Alvaro Navas](https://github.com/ziritrion/dataeng-zoomcamp/blob/main/notes/1_intro.md)
* [Notes from Abd](https://itnadigital.notion.site/Week-1-Introduction-f18de7e69eb4453594175d0b1334b2f4)
* [Notes from Aaron](https://github.com/ABZ-Aaron/DataEngineerZoomCamp/blob/master/week_1_basics_n_setup/README.md)
* [Notes from Faisal](https://github.com/FaisalMohd/data-engineering-zoomcamp/blob/main/week_1_basics_n_setup/Notes/DE%20Zoomcamp%20Week-1.pdf)
* [Michael Harty's Notes](https://github.com/mharty3/data_engineering_zoomcamp_2022/tree/main/week01)
* [Blog post from Isaac Kargar](https://kargarisaac.github.io/blog/data%20engineering/jupyter/2022/01/18/data-engineering-w1.html)
* [Handwritten Notes By Mahmoud Zaher](https://github.com/zaherweb/DataEngineering/blob/master/week%201.pdf)
* [Notes from Candace Williams](https://teacherc.github.io/data-engineering/2023/01/18/zoomcamp1.html)
* [Notes from Marcos Torregrosa](https://www.n4gash.com/2023/data-engineering-zoomcamp-semana-1/)
* [Notes from Vincenzo Galante](https://binchentso.notion.site/Data-Talks-Club-Data-Engineering-Zoomcamp-8699af8e7ff94ec49e6f9bdec8eb69fd)
* [Notes from Victor Padilha](https://github.com/padilha/de-zoomcamp/tree/master/week1)
* [Notes from froukje](https://github.com/froukje/de-zoomcamp/blob/main/week_1_basics_n_setup/notes/notes_week_01.md)
* [Notes from adamiaonr](https://github.com/adamiaonr/data-engineering-zoomcamp/blob/main/week_1_basics_n_setup/2_docker_sql/NOTES.md)
* [Notes from Xia He-Bleinagel](https://xiahe-bleinagel.com/2023/01/week-1-data-engineering-zoomcamp-notes/)
* [Notes from Balaji](https://github.com/Balajirvp/DE-Zoomcamp/blob/main/Week%201/Detailed%20Week%201%20Notes.ipynb)
* [Notes from Erik](https://twitter.com/ehub96/status/1621351266281730049)
* [Notes by Alain Boisvert](https://github.com/boisalai/de-zoomcamp-2023/blob/main/week1.md)
* Notes on [Docker, Docker Compose, and setting up a proper Python environment](https://medium.com/@verazabeida/zoomcamp-2023-week-1-f4f94cb360ae), by Vera
* [Setting up the development environment on Google Virtual Machine](https://itsadityagupta.hashnode.dev/setting-up-the-development-environment-on-google-virtual-machine), blog post by Aditya Gupta
* [Notes from Zharko Cekovski](https://www.zharconsulting.com/contents/data/data-engineering-bootcamp-2024/week-1-postgres-docker-and-ingestion-scripts/)
* [2024 Module-01 Walkthough video by ellacharmed on youtube](https://youtu.be/VUZshlVAnk4)
* [2024 Companion Module Walkthough slides by ellacharmed](https://github.com/ellacharmed/data-engineering-zoomcamp/blob/ella2024/cohorts/2024/01-docker-terraform/walkthrough-01.pdf)
* [2024 Module-01 Environment setup video by ellacharmed on youtube](https://youtu.be/Zce_Hd37NGs)
* [Docker Notes by Linda](https://github.com/inner-outer-space/de-zoomcamp-2024/blob/main/1a-docker_sql/readme.md) • [Terraform Notes by Linda](https://github.com/inner-outer-space/de-zoomcamp-2024/blob/main/1b-terraform_gcp/readme.md)
* [Notes from Hammad Tariq](https://github.com/hamad-tariq/HammadTariq-ZoomCamp2024/blob/9c8b4908416eb8cade3d7ec220e7664c003e9b11/week_1_basics_n_setup/README.md)
* [Hung's Notes](https://hung.bearblog.dev/docker/) & [Docker Cheatsheet](https://github.com/HangenYuu/docker-cheatsheet)
* [Kemal's Notes](https://github.com/kemaldahha/data-engineering-course/blob/main/week_1_notes.md)
* [Notes from Manuel Guerra (Windows+WSL2 Environment)](https://github.com/ManuelGuerra1987/data-engineering-zoomcamp-notes/blob/main/1_Containerization-and-Infrastructure-as-Code/README.md)
* [Notes from Horeb SEIDOU](https://spotted-hardhat-eea.notion.site/Week-1-Containerization-and-Infrastructure-as-Code-15729780dc4a80a08288e497ba937a37)
* [2025 Gitbook Notes from Tinker0425](https://data-engineering-zoomcamp-2025-t.gitbook.io/tinker0425/introduction/introduction-and-set-up)
* [Alex's Docker Notes](https://github.com/alexg9010/2025_data_engineering_zoomcamp/blob/master/01_docker/README.md) | [Alex's Terraform Notes](https://github.com/alexg9010/2025_data_engineering_zoomcamp/blob/master/01_3_terraform/README.md)
* [2025 SQL Refresher - Notes by Gabi Fonseca](https://github.com/fonsecagabriella/data_engineering/blob/main/01_docker_postgress/0_sql_refresh.ipynb)
* [2025 Setting up the Environment - Notes by Gabi Fonseca](https://github.com/fonsecagabriella/data_engineering/blob/main/01_docker_postgress/_setting_up.md)
* [Notes from Mercy Markus: Linux/Fedora Tweaks and Tips](https://mercymarkus.com/posts/2025/series/dtc-dez-jan-2025/dtc-dez-2025-module-1/)
* [[2026 tutorial video - Khanh Nguyen] Setting up the environment for homework-w1](https://youtu.be/_iqCWi_UoOc)
* Add your notes above this line
</details>
================================================
FILE: 01-docker-terraform/docker-sql/01-introduction.md
================================================
# Introduction to Docker
**[↑ Up](README.md)** | **[← Previous](README.md)** | **[Next →](02-virtual-environment.md)**
Docker is a _containerization software_ that allows us to isolate software in a similar way to virtual machines but in a much leaner way.
A Docker image is a _snapshot_ of a container that we can define to run our software, or in this case our data pipelines. By exporting our Docker images to Cloud providers such as Amazon Web Services or Google Cloud Platform we can run our containers there.
## Why Docker?
Docker provides the following advantages:
- Reproducibility: Same environment everywhere
- Isolation: Applications run independently
- Portability: Run anywhere Docker is installed
They are used in many situations:
- Integration tests: CI/CD pipelines
- Running pipelines on the cloud: AWS Batch, Kubernetes jobs
- Spark: Analytics engine for large-scale data processing
- Serverless: AWS Lambda, Google Functions
## Basic Docker Commands
Check Docker version:
```bash
docker --version
```
Run a simple container:
```bash
docker run hello-world
```
Run something more complex:
```bash
docker run ubuntu
```
Nothing happens. Need to run it in `-it` mode:
```bash
docker run -it ubuntu
```
We don't have `python` there so let's install it:
```bash
apt update && apt install python3
python3 -V
```
## Stateless Containers
Important: Docker containers are stateless - any changes done inside a container will NOT be saved when the container is killed and started again.
When you exit the container and use it again, the changes are gone:
```bash
docker run -it ubuntu
python3 -V
```
This is good, because it doesn't affect your host system. Let's say you do something crazy like this:
```bash
docker run -it ubuntu
rm -rf / # don't run it on your computer!
```
Next time we run it, all the files are back.
## Managing Containers
But, this is not _completely_ correct. The state is saved somewhere. We can see stopped containers:
```bash
docker ps -a
```
We can restart one of them, but we won't do it, because it's not a good practice. They take space, so let's delete them:
```bash
docker rm $(docker ps -aq)
```
Next time we run something, we add `--rm`:
```bash
docker run -it --rm ubuntu
```
## Different Base Images
There are other base images besides `hello-world` and `ubuntu`. For example, Python:
```bash
docker run -it --rm python:3.9.16
# add -slim to get a smaller version
```
This one starts `python`. If we want bash, we need to overwrite `entrypoint`:
```bash
docker run -it \
--rm \
--entrypoint=bash \
python:3.9.16-slim
```
## Volumes
So, we know that with docker we can restore any container to its initial state in a reproducible manner. But what about data? A common way to do so is with _volumes_.
Let's create some data in `test`:
```bash
mkdir test
cd test
touch file1.txt file2.txt file3.txt
echo "Hello from host" > file1.txt
cd ..
```
Now let's create a simple script `test/list_files.py` that shows the files in the folder:
```python
from pathlib import Path
current_dir = Path.cwd()
current_file = Path(__file__).name
print(f"Files in {current_dir}:")
for filepath in current_dir.iterdir():
if filepath.name == current_file:
continue
print(f" - {filepath.name}")
if filepath.is_file():
content = filepath.read_text(encoding='utf-8')
print(f" Content: {content}")
```
Now let's map this to a Python container:
```bash
docker run -it \
--rm \
-v $(pwd)/test:/app/test \
--entrypoint=bash \
python:3.9.16-slim
```
Inside the container, run:
```bash
cd /app/test
ls -la
cat file1.txt
python list_files.py
```
You'll see the files from your host machine are accessible in the container!
**[↑ Up](README.md)** | **[← Previous](README.md)** | **[Next →](02-virtual-environment.md)**
================================================
FILE: 01-docker-terraform/docker-sql/02-virtual-environment.md
================================================
# Virtual Environments and Data Pipelines
**[↑ Up](README.md)** | **[← Previous](01-introduction.md)** | **[Next →](03-dockerizing-pipeline.md)**
A **data pipeline** is a service that receives data as input and outputs more data. For example, reading a CSV file, transforming the data somehow and storing it as a table in a PostgreSQL database.
```mermaid
graph LR
A[CSV File] --> B[Data Pipeline]
B --> C[Parquet File]
B --> D[PostgreSQL Database]
B --> E[Data Warehouse]
style B fill:#4CAF50,stroke:#333,stroke-width:2px,color:#fff
```
In this workshop, we'll build pipelines that:
- Download CSV data from the web
- Transform and clean the data with pandas
- Load it into PostgreSQL for querying
- Process data in chunks to handle large files
## Creating a Simple Pipeline
Let's create an example pipeline. First, create a directory `pipeline` and inside, create a file `pipeline.py`:
```python
import sys
print("arguments", sys.argv)
day = int(sys.argv[1])
print(f"Running pipeline for day {day}")
```
Now let's add pandas:
```python
import pandas as pd
df = pd.DataFrame({"A": [1, 2], "B": [3, 4]})
print(df.head())
df.to_parquet(f"output_day_{sys.argv[1]}.parquet")
```
## Why Virtual Environments?
We need pandas, but we don't have it. We want to test it before we run things in a container.
We can install it with `pip`:
```bash
pip install pandas pyarrow
```
But this installs it globally on your system. This can cause conflicts if different projects need different versions of the same package.
Instead, we want to use a **virtual environment** - an isolated Python environment that keeps dependencies for this project separate from other projects and from your system Python.
## Using uv - Modern Python Package Manager
We'll use `uv` - a modern, fast Python package and project manager written in Rust. It's much faster than pip and handles virtual environments automatically.
```bash
pip install uv
```
Now initialize a Python project with uv:
```bash
uv init --python=3.13
```
This creates a `pyproject.toml` file for managing dependencies and a `.python-version` file.
### Comparing Python Versions
```bash
uv run which python # Python in the virtual environment
uv run python -V
which python # System Python
python -V
```
You'll see they're different - `uv run` uses the isolated environment.
### Adding Dependencies
Now let's add pandas:
```bash
uv add pandas pyarrow
```
This adds pandas to your `pyproject.toml` and installs it in the virtual environment.
### Running the Pipeline
Now we can execute the file:
```bash
uv run python pipeline.py 10
```
We will see:
* `['pipeline.py', '10']`
* `job finished successfully for day = 10`
## Git Configuration
This script produces a binary (parquet) file, so let's make sure we don't accidentally commit it to git by adding parquet extensions to `.gitignore`:
```
*.parquet
```
**[↑ Up](README.md)** | **[← Previous](01-introduction.md)** | **[Next →](03-dockerizing-pipeline.md)**
================================================
FILE: 01-docker-terraform/docker-sql/03-dockerizing-pipeline.md
================================================
# Dockerizing the Pipeline
**[↑ Up](README.md)** | **[← Previous](02-virtual-environment.md)** | **[Next →](04-postgres-docker.md)**
Now let's containerize the script. Create the following `Dockerfile` file:
## Simple Dockerfile with pip
```dockerfile
# base Docker image that we will build on
FROM python:3.13.11-slim
# set up our image by installing prerequisites; pandas in this case
RUN pip install pandas pyarrow
# set up the working directory inside the container
WORKDIR /app
# copy the script to the container. 1st name is source file, 2nd is destination
COPY pipeline.py pipeline.py
# define what to do first when the container runs
# in this example, we will just run the script
ENTRYPOINT ["python", "pipeline.py"]
```
**Explanation:**
- `FROM`: Base image (Python 3.13)
- `RUN`: Execute commands during build
- `WORKDIR`: Set working directory
- `COPY`: Copy files into the image
- `ENTRYPOINT`: Default command to run
### Build and Run
Let's build the image:
```bash
docker build -t test:pandas .
```
* The image name will be `test` and its tag will be `pandas`. If the tag isn't specified it will default to `latest`.
We can now run the container and pass an argument to it, so that our pipeline will receive it:
```bash
docker run -it test:pandas some_number
```
You should get the same output you did when you ran the pipeline script by itself.
> Note: these instructions assume that `pipeline.py` and `Dockerfile` are in the same directory. The Docker commands should also be run from the same directory as these files.
## Dockerfile with uv
What about uv? Let's use it instead of using pip:
```dockerfile
# Start with slim Python 3.13 image
FROM python:3.13.10-slim
# Copy uv binary from official uv image (multi-stage build pattern)
COPY --from=ghcr.io/astral-sh/uv:latest /uv /bin/
# Set working directory
WORKDIR /app
# Add virtual environment to PATH so we can use installed packages
ENV PATH="/app/.venv/bin:$PATH"
# Copy dependency files first (better layer caching)
COPY "pyproject.toml" "uv.lock" ".python-version" ./
# Install dependencies from lock file (ensures reproducible builds)
RUN uv sync --locked
# Copy application code
COPY pipeline.py pipeline.py
# Set entry point
ENTRYPOINT ["uv", "run", "python", "pipeline.py"]
```
**[↑ Up](README.md)** | **[← Previous](02-virtual-environment.md)** | **[Next →](04-postgres-docker.md)**
================================================
FILE: 01-docker-terraform/docker-sql/04-postgres-docker.md
================================================
# Running PostgreSQL with Docker
**[↑ Up](README.md)** | **[← Previous](03-dockerizing-pipeline.md)** | **[Next →](05-data-ingestion.md)**
Now we want to do real data engineering. Let's use a Postgres database for that.
You can run a containerized version of Postgres that doesn't require any installation steps. You only need to provide a few _environment variables_ to it as well as a _volume_ for storing data.
## Running PostgreSQL in a Container
Create a folder anywhere you'd like for Postgres to store data in. We will use the example folder `ny_taxi_postgres_data`. Here's how to run the container:
```bash
docker run -it --rm \
-e POSTGRES_USER="root" \
-e POSTGRES_PASSWORD="root" \
-e POSTGRES_DB="ny_taxi" \
-v ny_taxi_postgres_data:/var/lib/postgresql \
-p 5432:5432 \
postgres:18
```
### Explanation of Parameters
* `-e` sets environment variables (user, password, database name)
* `-v ny_taxi_postgres_data:/var/lib/postgresql` creates a **named volume**
* Docker manages this volume automatically
* Data persists even after container is removed
* Volume is stored in Docker's internal storage
* `-p 5432:5432` maps port 5432 from container to host
* `postgres:18` uses PostgreSQL version 18 (latest as of Dec 2025)
### Alternative Approach - Bind Mount
First create the directory, then map it:
```bash
mkdir ny_taxi_postgres_data
docker run -it \
-e POSTGRES_USER="root" \
-e POSTGRES_PASSWORD="root" \
-e POSTGRES_DB="ny_taxi" \
-v $(pwd)/ny_taxi_postgres_data:/var/lib/postgresql \
-p 5432:5432 \
postgres:18
```
### Named Volume vs Bind Mount
* **Named volume** (`name:/path`): Managed by Docker, easier
* **Bind mount** (`/host/path:/container/path`): Direct mapping to host filesystem, more control
## Connecting to PostgreSQL
Once the container is running, we can log into our database with [pgcli](https://www.pgcli.com/).
Install pgcli:
```bash
uv add --dev pgcli
```
The `--dev` flag marks this as a development dependency (not needed in production). It will be added to the `[dependency-groups]` section of `pyproject.toml` instead of the main `dependencies` section.
Now use it to connect to Postgres:
```bash
uv run pgcli -h localhost -p 5432 -u root -d ny_taxi
```
* `uv run` executes a command in the context of the virtual environment
* `-h` is the host. Since we're running locally we can use `localhost`.
* `-p` is the port.
* `-u` is the username.
* `-d` is the database name.
* The password is not provided; it will be requested after running the command.
When prompted, enter the password: `root`
## Basic SQL Commands
Try some SQL commands:
```sql
-- List tables
\dt
-- Create a test table
CREATE TABLE test (id INTEGER, name VARCHAR(50));
-- Insert data
INSERT INTO test VALUES (1, 'Hello Docker');
-- Query data
SELECT * FROM test;
-- Exit
\q
```
**[↑ Up](README.md)** | **[← Previous](03-dockerizing-pipeline.md)** | **[Next →](05-data-ingestion.md)**
================================================
FILE: 01-docker-terraform/docker-sql/05-data-ingestion.md
================================================
# NY Taxi Dataset and Data Ingestion
**[↑ Up](README.md)** | **[← Previous](04-postgres-docker.md)** | **[Next →](06-ingestion-script.md)**
We will now create a Jupyter Notebook `notebook.ipynb` file which we will use to read a CSV file and export it to Postgres.
## Setting up Jupyter
Install Jupyter:
```bash
uv add --dev jupyter
```
Let's create a Jupyter notebook to explore the data:
```bash
uv run jupyter notebook
```
## The NYC Taxi Dataset
We will use data from the [NYC TLC Trip Record Data website](https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page).
Specifically, we will use the [Yellow taxi trip records CSV file for January 2021](https://github.com/DataTalksClub/nyc-tlc-data/releases/download/yellow/yellow_tripdata_2021-01.csv.gz).
This data used to be csv, but later they switched to parquet. We want to keep using CSV because we need to do a bit of extra pre-processing (for the purposes of learning it).
A dictionary to understand each field is available [here](https://www1.nyc.gov/assets/tlc/downloads/pdf/data_dictionary_trip_records_yellow.pdf).
> Note: The CSV data is stored as gzipped files. Pandas can read them directly.
## Explore the Data
Create a new notebook and run:
```python
import pandas as pd
# Read a sample of the data
prefix = 'https://github.com/DataTalksClub/nyc-tlc-data/releases/download/yellow/'
df = pd.read_csv(prefix + 'yellow_tripdata_2021-01.csv.gz', nrows=100)
# Display first rows
df.head()
# Check data types
df.dtypes
# Check data shape
df.shape
```
### Handling Data Types
We have a warning: (Note that this warning might pop up later for some users, so it's best to follow the instructions below)
```
/tmp/ipykernel_25483/2933316018.py:1: DtypeWarning: Columns (6) have mixed types. Specify dtype option on import or set low_memory=False.
```
So we need to specify the types:
```python
dtype = {
"VendorID": "Int64",
"passenger_count": "Int64",
"trip_distance": "float64",
"RatecodeID": "Int64",
"store_and_fwd_flag": "string",
"PULocationID": "Int64",
"DOLocationID": "Int64",
"payment_type": "Int64",
"fare_amount": "float64",
"extra": "float64",
"mta_tax": "float64",
"tip_amount": "float64",
"tolls_amount": "float64",
"improvement_surcharge": "float64",
"total_amount": "float64",
"congestion_surcharge": "float64"
}
parse_dates = [
"tpep_pickup_datetime",
"tpep_dropoff_datetime"
]
df = pd.read_csv(
prefix + 'yellow_tripdata_2021-01.csv.gz',
nrows=100,
dtype=dtype,
parse_dates=parse_dates
)
```
## Ingesting Data into Postgres
In the Jupyter notebook, we create code to:
1. Download the CSV file
2. Read it in chunks with pandas
3. Convert datetime columns
4. Insert data into PostgreSQL using SQLAlchemy
### Install SQLAlchemy
```bash
uv add sqlalchemy "psycopg[binary,pool]"
```
### Create Database Connection
```python
from sqlalchemy import create_engine
engine = create_engine('postgresql+psycopg://root:root@localhost:5432/ny_taxi')
```
### Get DDL Schema
```python
print(pd.io.sql.get_schema(df, name='yellow_taxi_data', con=engine))
```
Output:
```sql
CREATE TABLE yellow_taxi_data (
"VendorID" BIGINT,
tpep_pickup_datetime TIMESTAMP WITHOUT TIME ZONE,
tpep_dropoff_datetime TIMESTAMP WITHOUT TIME ZONE,
passenger_count BIGINT,
trip_distance FLOAT(53),
"RatecodeID" BIGINT,
store_and_fwd_flag TEXT,
"PULocationID" BIGINT,
"DOLocationID" BIGINT,
payment_type BIGINT,
fare_amount FLOAT(53),
extra FLOAT(53),
mta_tax FLOAT(53),
tip_amount FLOAT(53),
tolls_amount FLOAT(53),
improvement_surcharge FLOAT(53),
total_amount FLOAT(53),
congestion_surcharge FLOAT(53)
)
```
### Create the Table
```python
df.head(n=0).to_sql(name='yellow_taxi_data', con=engine, if_exists='replace')
```
`head(n=0)` makes sure we only create the table, we don't add any data yet.
## Ingesting Data in Chunks
We don't want to insert all the data at once. Let's do it in batches and use an iterator for that:
```python
df_iter = pd.read_csv(
prefix + 'yellow_tripdata_2021-01.csv.gz',
dtype=dtype,
parse_dates=parse_dates,
iterator=True,
chunksize=100000
)
```
### Iterate Over Chunks
```python
for df_chunk in df_iter:
print(len(df_chunk))
```
### Inserting Data
```python
df_chunk.to_sql(name='yellow_taxi_data', con=engine, if_exists='append')
```
### Complete Ingestion Loop
```python
first = True
for df_chunk in df_iter:
if first:
# Create table schema (no data)
df_chunk.head(0).to_sql(
name="yellow_taxi_data",
con=engine,
if_exists="replace"
)
first = False
print("Table created")
# Insert chunk
df_chunk.to_sql(
name="yellow_taxi_data",
con=engine,
if_exists="append"
)
print("Inserted:", len(df_chunk))
```
### Alternative Approach (Without First Flag)
```python
first_chunk = next(df_iter)
first_chunk.head(0).to_sql(
name="yellow_taxi_data",
con=engine,
if_exists="replace"
)
print("Table created")
first_chunk.to_sql(
name="yellow_taxi_data",
con=engine,
if_exists="append"
)
print("Inserted first chunk:", len(first_chunk))
for df_chunk in df_iter:
df_chunk.to_sql(
name="yellow_taxi_data",
con=engine,
if_exists="append"
)
print("Inserted chunk:", len(df_chunk))
```
## Adding Progress Bar
Add `tqdm` to see progress:
```bash
uv add tqdm
```
Put it around the iterable:
```python
from tqdm.auto import tqdm
for df_chunk in tqdm(df_iter):
...
```
To see progress in terms of total chunks, you would have to add the `total` argument to `tqdm(df_iter)`. In our scenario, the pragmatic way is
to hardcode a value based on the number of entries in the table.
## Verify the Data
Connect to it using pgcli:
```bash
uv run pgcli -h localhost -p 5432 -u root -d ny_taxi
```
And explore the data.
**[↑ Up](README.md)** | **[← Previous](04-postgres-docker.md)** | **[Next →](06-ingestion-script.md)**
================================================
FILE: 01-docker-terraform/docker-sql/06-ingestion-script.md
================================================
# Creating the Data Ingestion Script
**[↑ Up](README.md)** | **[← Previous](05-data-ingestion.md)** | **[Next →](07-pgadmin.md)**
Now let's convert the notebook to a Python script.
## Convert Notebook to Script
```bash
uv run jupyter nbconvert --to=script notebook.ipynb
mv notebook.py ingest_data.py
```
## The Complete Ingestion Script
See the `pipeline/` directory for the complete script with click integration. Here's the core structure:
```python
import pandas as pd
from sqlalchemy import create_engine
from tqdm.auto import tqdm
dtype = {
"VendorID": "Int64",
"passenger_count": "Int64",
"trip_distance": "float64",
"RatecodeID": "Int64",
"store_and_fwd_flag": "string",
"PULocationID": "Int64",
"DOLocationID": "Int64",
"payment_type": "Int64",
"fare_amount": "float64",
"extra": "float64",
"mta_tax": "float64",
"tip_amount": "float64",
"tolls_amount": "float64",
"improvement_surcharge": "float64",
"total_amount": "float64",
"congestion_surcharge": "float64"
}
parse_dates = [
"tpep_pickup_datetime",
"tpep_dropoff_datetime"
]
```
## Click Integration
The script uses `click` for command-line argument parsing:
```python
import click
@click.command()
@click.option('--pg-user', default='root', help='PostgreSQL user')
@click.option('--pg-pass', default='root', help='PostgreSQL password')
@click.option('--pg-host', default='localhost', help='PostgreSQL host')
@click.option('--pg-port', default=5432, type=int, help='PostgreSQL port')
@click.option('--pg-db', default='ny_taxi', help='PostgreSQL database name')
@click.option('--target-table', default='yellow_taxi_data', help='Target table name')
def run(pg_user, pg_pass, pg_host, pg_port, pg_db, target_table):
# Ingestion logic here
pass
```
## Running the Script
The script reads data in chunks (100,000 rows at a time) to handle large files efficiently without running out of memory.
Example usage:
```bash
uv run python ingest_data.py \
--pg-user=root \
--pg-pass=root \
--pg-host=localhost \
--pg-port=5432 \
--pg-db=ny_taxi \
--target-table=yellow_taxi_trips
```
**[↑ Up](README.md)** | **[← Previous](05-data-ingestion.md)** | **[Next →](07-pgadmin.md)**
================================================
FILE: 01-docker-terraform/docker-sql/07-pgadmin.md
================================================
# pgAdmin - Database Management Tool
**[↑ Up](README.md)** | **[← Previous](06-ingestion-script.md)** | **[Next →](08-dockerizing-ingestion.md)**
`pgcli` is a handy tool but it's cumbersome to use for complex queries and database management. [`pgAdmin` is a web-based tool](https://www.pgadmin.org/) that makes it more convenient to access and manage our databases.
It's possible to run pgAdmin as a container along with the Postgres container, but both containers will have to be in the same _virtual network_ so that they can find each other.
## Run pgAdmin Container
```bash
docker run -it \
-e PGADMIN_DEFAULT_EMAIL="admin@admin.com" \
-e PGADMIN_DEFAULT_PASSWORD="root" \
-v pgadmin_data:/var/lib/pgadmin \
-p 8085:80 \
dpage/pgadmin4
```
The `-v pgadmin_data:/var/lib/pgadmin` volume mapping saves pgAdmin settings (server connections, preferences) so you don't have to reconfigure it every time you restart the container.
### Parameters Explained
* The container needs 2 environment variables: a login email and a password. We use `admin@admin.com` and `root` in this example.
* pgAdmin is a web app and its default port is 80; we map it to 8085 in our localhost to avoid any possible conflicts.
* The actual image name is `dpage/pgadmin4`.
**Note:** This won't work yet because pgAdmin can't see the PostgreSQL container. They need to be on the same Docker network!
## Docker Networks
Let's create a virtual Docker network called `pg-network`:
```bash
docker network create pg-network
```
> You can remove the network later with the command `docker network rm pg-network`. You can look at the existing networks with `docker network ls`.
### Run Containers on the Same Network
Stop both containers and re-run them with the network configuration:
```bash
# Run PostgreSQL on the network
docker run -it \
-e POSTGRES_USER="root" \
-e POSTGRES_PASSWORD="root" \
-e POSTGRES_DB="ny_taxi" \
-v ny_taxi_postgres_data:/var/lib/postgresql \
-p 5432:5432 \
--network=pg-network \
--name pgdatabase \
postgres:18
# In another terminal, run pgAdmin on the same network
docker run -it \
-e PGADMIN_DEFAULT_EMAIL="admin@admin.com" \
-e PGADMIN_DEFAULT_PASSWORD="root" \
-v pgadmin_data:/var/lib/pgadmin \
-p 8085:80 \
--network=pg-network \
--name pgadmin \
dpage/pgadmin4
```
* Just like with the Postgres container, we specify a network and a name for pgAdmin.
* The container names (`pgdatabase` and `pgadmin`) allow the containers to find each other within the network.
## Connect pgAdmin to PostgreSQL
You should now be able to load pgAdmin on a web browser by browsing to `http://localhost:8085`. Use the same email and password you used for running the container to log in.
1. Open browser and go to `http://localhost:8085`
2. Login with email: `admin@admin.com`, password: `root`
3. Right-click "Servers" → Register → Server
4. Configure:
- **General tab**: Name: `Local Docker`
- **Connection tab**:
- Host: `pgdatabase` (the container name)
- Port: `5432`
- Username: `root`
- Password: `root`
5. Save
Now you can explore the database using the pgAdmin interface!
**[↑ Up](README.md)** | **[← Previous](06-ingestion-script.md)** | **[Next →](08-dockerizing-ingestion.md)**
================================================
FILE: 01-docker-terraform/docker-sql/08-dockerizing-ingestion.md
================================================
# Dockerizing the Ingestion Script
**[↑ Up](README.md)** | **[← Previous](07-pgadmin.md)** | **[Next →](09-docker-compose.md)**
Now let's containerize the ingestion script so we can run it in Docker.
## The Dockerfile
The `pipeline/Dockerfile` shows how to containerize the ingestion script:
```dockerfile
FROM python:3.13.11-slim
COPY --from=ghcr.io/astral-sh/uv:latest /uv /bin/
WORKDIR /code
ENV PATH="/code/.venv/bin:$PATH"
COPY pyproject.toml .python-version uv.lock ./
RUN uv sync --locked
COPY ingest_data.py .
ENTRYPOINT ["uv", "run", "python", "ingest_data.py"]
```
### Explanation
- `FROM python:3.13.11-slim`: Start with slim Python 3.13 image for smaller size
- `COPY --from=ghcr.io/astral-sh/uv:latest /uv /bin/`: Copy uv binary from official uv image
- `WORKDIR /code`: Set working directory inside container
- `ENV PATH="/code/.venv/bin:$PATH"`: Add virtual environment to PATH
- `COPY pyproject.toml .python-version uv.lock ./`: Copy dependency files first (better caching)
- `RUN uv sync --locked`: Install all dependencies from lock file (ensures reproducible builds)
- `COPY ingest_data.py .`: Copy ingestion script
- `ENTRYPOINT ["uv", "run", "python", "ingest_data.py"]`: Set entry point to run the ingestion script
## Build the Docker Image
```bash
cd pipeline
docker build -t taxi_ingest:v001 .
```
## Run the Containerized Ingestion
```bash
docker run -it \
--network=pg-network \
taxi_ingest:v001 \
--pg-user=root \
--pg-pass=root \
--pg-host=pgdatabase \
--pg-port=5432 \
--pg-db=ny_taxi \
--target-table=yellow_taxi_trips
```
### Important Notes
* We need to provide the network for Docker to find the Postgres container. It goes before the name of the image.
* Since Postgres is running on a separate container, the host argument will have to point to the container name of Postgres (`pgdatabase`).
* You can drop the table in pgAdmin beforehand if you want, but the script will automatically replace the pre-existing table.
**[↑ Up](README.md)** | **[← Previous](07-pgadmin.md)** | **[Next →](09-docker-compose.md)**
================================================
FILE: 01-docker-terraform/docker-sql/09-docker-compose.md
================================================
# Docker Compose
**[↑ Up](README.md)** | **[← Previous](08-dockerizing-ingestion.md)** | **[Next →](10-sql-refresher.md)**
`docker-compose` allows us to launch multiple containers using a single configuration file, so that we don't have to run multiple complex `docker run` commands separately.
Docker compose makes use of YAML files. Here's the `docker-compose.yaml` file:
```yaml
services:
pgdatabase:
image: postgres:18
environment:
POSTGRES_USER: "root"
POSTGRES_PASSWORD: "root"
POSTGRES_DB: "ny_taxi"
volumes:
- "ny_taxi_postgres_data:/var/lib/postgresql"
ports:
- "5432:5432"
pgadmin:
image: dpage/pgadmin4
environment:
PGADMIN_DEFAULT_EMAIL: "admin@admin.com"
PGADMIN_DEFAULT_PASSWORD: "root"
volumes:
- "pgadmin_data:/var/lib/pgadmin"
ports:
- "8085:80"
volumes:
ny_taxi_postgres_data:
pgadmin_data:
```
### Explanation
* We don't have to specify a network because `docker compose` takes care of it: every single container (or "service", as the file states) will run within the same network and will be able to find each other according to their names (`pgdatabase` and `pgadmin` in this example).
* All other details from the `docker run` commands (environment variables, volumes and ports) are mentioned accordingly in the file following YAML syntax.
## Start Services with Docker Compose
We can now run Docker compose by running the following command from the same directory where `docker-compose.yaml` is found. Make sure that all previous containers aren't running anymore:
```bash
docker-compose up
```
### Detached Mode
If you want to run the containers again in the background rather than in the foreground (thus freeing up your terminal), you can run them in detached mode:
```bash
docker-compose up -d
```
## Stop Services
You will have to press `Ctrl+C` in order to shut down the containers when running in foreground mode. The proper way of shutting them down is with this command:
```bash
docker-compose down
```
## Other Useful Commands
```bash
# View logs
docker-compose logs
# Stop and remove volumes
docker-compose down -v
```
## Benefits of Docker Compose
- Single command to start all services
- Automatic network creation
- Easy configuration management
- Declarative infrastructure
## Running the Ingestion Script with Docker Compose
If you want to re-run the dockerized ingest script when you run Postgres and pgAdmin with `docker compose`, you will have to find the name of the virtual network that Docker compose created for the containers.
```bash
# check the network link:
docker network ls
# it's pipeline_default (or similar based on directory name)
# now run the script:
docker run -it --rm\
--network=pipeline_default \
taxi_ingest:v001 \
--pg-user=root \
--pg-pass=root \
--pg-host=pgdatabase \
--pg-port=5432 \
--pg-db=ny_taxi \
--target-table=yellow_taxi_trips
```
**[↑ Up](README.md)** | **[← Previous](08-dockerizing-ingestion.md)** | **[Next →](10-sql-refresher.md)**
================================================
FILE: 01-docker-terraform/docker-sql/10-sql-refresher.md
================================================
# SQL Refresher
**[↑ Up](README.md)** | **[← Previous](09-docker-compose.md)** | **[Next →](11-cleanup.md)**
[](https://youtu.be/QEcps_iskgg&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=10)
Pre-Requisites: If you followed the course in the given order, Docker Compose should already be running with pgdatabase and pgAdmin.
Once done, you can go to http://localhost:8085/browser/ to access pgAdmin.
Don't forget to Right Click on the server or database to refresh it in case you don't see the new table.
Now start querying!
## Inner Joins
### Implicit INNER JOIN
Joining Yellow Taxi table with Zones Lookup table (implicit INNER JOIN):
```sql
SELECT
tpep_pickup_datetime,
tpep_dropoff_datetime,
total_amount,
CONCAT(zpu."Borough", ' | ', zpu."Zone") AS "pickup_loc",
CONCAT(zdo."Borough", ' | ', zdo."Zone") AS "dropoff_loc"
FROM
yellow_taxi_trips t,
zones zpu,
zones zdo
WHERE
t."PULocationID" = zpu."LocationID"
AND t."DOLocationID" = zdo."LocationID"
LIMIT 100;
```
### Explicit INNER JOIN
```sql
SELECT
tpep_pickup_datetime,
tpep_dropoff_datetime,
total_amount,
CONCAT(zpu."Borough", ' | ', zpu."Zone") AS "pickup_loc",
CONCAT(zdo."Borough", ' | ', zdo."Zone") AS "dropoff_loc"
FROM
yellow_taxi_trips t
JOIN
-- or INNER JOIN but it's less used, when writing JOIN, postgreSQL understands implicitly that we want to use an INNER JOIN
zones zpu ON t."PULocationID" = zpu."LocationID"
JOIN
zones zdo ON t."DOLocationID" = zdo."LocationID"
LIMIT 100;
```
## Data Quality Checks
### Checking for NULL Location IDs
```sql
SELECT
tpep_pickup_datetime,
tpep_dropoff_datetime,
total_amount,
"PULocationID",
"DOLocationID"
FROM
yellow_taxi_trips
WHERE
"PULocationID" IS NULL
OR "DOLocationID" IS NULL
LIMIT 100;
```
### Checking for Location IDs NOT IN Zones Table
```sql
SELECT
tpep_pickup_datetime,
tpep_dropoff_datetime,
total_amount,
"PULocationID",
"DOLocationID"
FROM
yellow_taxi_trips
WHERE
"DOLocationID" NOT IN (SELECT "LocationID" from zones)
OR "PULocationID" NOT IN (SELECT "LocationID" from zones)
LIMIT 100;
```
## LEFT, RIGHT, and OUTER JOINS
Using LEFT, RIGHT, and OUTER JOINS when some Location IDs are not in either Tables:
```sql
DELETE FROM zones WHERE "LocationID" = 142;
SELECT
tpep_pickup_datetime,
tpep_dropoff_datetime,
total_amount,
CONCAT(zpu."Borough", ' | ', zpu."Zone") AS "pickup_loc",
CONCAT(zdo."Borough", ' | ', zdo."Zone") AS "dropoff_loc"
FROM
yellow_taxi_trips t
LEFT JOIN
zones zpu ON t."PULocationID" = zpu."LocationID"
JOIN
zones zdo ON t."DOLocationID" = zdo."LocationID"
LIMIT 100;
```
```sql
SELECT
tpep_pickup_datetime,
tpep_dropoff_datetime,
total_amount,
CONCAT(zpu."Borough", ' | ', zpu."Zone") AS "pickup_loc",
CONCAT(zdo."Borough", ' | ', zdo."Zone") AS "dropoff_loc"
FROM
yellow_taxi_trips t
RIGHT JOIN
zones zpu ON t."PULocationID" = zpu."LocationID"
JOIN
zones zdo ON t."DOLocationID" = zdo."LocationID"
LIMIT 100;
```
```sql
SELECT
tpep_pickup_datetime,
tpep_dropoff_datetime,
total_amount,
CONCAT(zpu."Borough", ' | ', zpu."Zone") AS "pickup_loc",
CONCAT(zdo."Borough", ' | ', zdo."Zone") AS "dropoff_loc"
FROM
yellow_taxi_trips t
OUTER JOIN
zones zpu ON t."PULocationID" = zpu."LocationID"
JOIN
zones zdo ON t."DOLocationID" = zdo."LocationID"
LIMIT 100;
```
## GROUP BY
### Calculate Number of Trips Per Day
```sql
SELECT
CAST(tpep_dropoff_datetime AS DATE) AS "day",
COUNT(1)
FROM
yellow_taxi_trips
GROUP BY
CAST(tpep_dropoff_datetime AS DATE)
LIMIT 100;
```
## ORDER BY
### Ordering by Day
```sql
SELECT
CAST(tpep_dropoff_datetime AS DATE) AS "day",
COUNT(1)
FROM
yellow_taxi_trips
GROUP BY
CAST(tpep_dropoff_datetime AS DATE)
ORDER BY
"day" ASC
LIMIT 100;
```
### Ordering by Count
```sql
SELECT
CAST(tpep_dropoff_datetime AS DATE) AS "day",
COUNT(1) AS "count"
FROM
yellow_taxi_trips
GROUP BY
CAST(tpep_dropoff_datetime AS DATE)
ORDER BY
"count" DESC
LIMIT 100;
```
## Other Aggregations
```sql
SELECT
CAST(tpep_dropoff_datetime AS DATE) AS "day",
COUNT(1) AS "count",
MAX(total_amount) AS "total_amount",
MAX(passenger_count) AS "passenger_count"
FROM
yellow_taxi_trips
GROUP BY
CAST(tpep_dropoff_datetime AS DATE)
ORDER BY
"count" DESC
LIMIT 100;
```
## Grouping by Multiple Fields
```sql
SELECT
CAST(tpep_dropoff_datetime AS DATE) AS "day",
"DOLocationID",
COUNT(1) AS "count",
MAX(total_amount) AS "total_amount",
MAX(passenger_count) AS "passenger_count"
FROM
yellow_taxi_trips
GROUP BY
1, 2
ORDER BY
"day" ASC,
"DOLocationID" ASC
LIMIT 100;
```
**[↑ Up](README.md)** | **[← Previous](09-docker-compose.md)** | **[Next →](11-cleanup.md)**
================================================
FILE: 01-docker-terraform/docker-sql/11-cleanup.md
================================================
# Cleanup
**[↑ Up](README.md)** | **[← Previous](10-sql-refresher.md)** | **[Next →](../README.md)**
When you're done with the workshop, clean up Docker resources to free up disk space.
## Stop All Running Containers
```bash
docker-compose down
```
## Remove Specific Containers
```bash
# List all containers
docker ps -a
# Remove specific container
docker rm <container_id>
# Remove all stopped containers
docker container prune
```
## Remove Docker Images
```bash
# List all images
docker images
# Remove specific image
docker rmi taxi_ingest:v001
# Remove all unused images
docker image prune -a
```
## Remove Docker Volumes
```bash
# List volumes
docker volume ls
# Remove specific volumes
docker volume rm ny_taxi_postgres_data
docker volume rm pgadmin_data
# Remove all unused volumes
docker volume prune
```
## Remove Docker Networks
```bash
# List networks
docker network ls
# Remove specific network
docker network rm pg-network
# Remove all unused networks
docker network prune
```
## Complete Cleanup
Removes ALL Docker resources - use with caution!
```bash
# ⚠️ Warning: This removes ALL Docker resources!
docker system prune -a --volumes
```
## Clean Up Local Files
```bash
# Remove parquet files
rm *.parquet
# Remove Python cache
rm -rf __pycache__ .pytest_cache
# Remove virtual environment (if using venv)
rm -rf .venv
```
---
That's all for today. Happy learning! 🐳📊
**[↑ Up](README.md)** | **[← Previous](10-sql-refresher.md)** | **[Next →](../README.md)**
================================================
FILE: 01-docker-terraform/docker-sql/README.md
================================================
# Docker and PostgreSQL: Data Engineering Workshop
* Video: [link](https://www.youtube.com/watch?v=lP8xXebHmuE)
* Slides: [link](https://docs.google.com/presentation/d/19pXcInDwBnlvKWCukP5sDoCAb69SPqgIoxJ_0Bikr00/edit?usp=sharing)
* Code: [pipeline/](pipeline/)
In this workshop, we will explore Docker fundamentals and data engineering workflows using Docker containers. This workshop is part of Module 1 of the [Data Engineering Zoomcamp](https://github.com/DataTalksClub/data-engineering-zoomcamp).
**Data Engineering** is the design and development of systems for collecting, storing and analyzing data at scale.
## Prerequisites
- Basic understanding of Python
- Basic SQL knowledge (helpful but not required)
- Docker and Python installed on your machine
- Git (optional)
## Workshop Contents
1. [Introduction to Docker](01-introduction.md) - What is Docker, why use it, basic commands
2. [Virtual Environments and Data Pipelines](02-virtual-environment.md) - Setting up Python environments with uv
3. [Dockerizing the Pipeline](03-dockerizing-pipeline.md) - Creating a Dockerfile for a simple pipeline
4. [Running PostgreSQL with Docker](04-postgres-docker.md) - Dockerizing PostgreSQL database
5. [NY Taxi Dataset and Data Ingestion](05-data-ingestion.md) - Working with real data, pandas, SQLAlchemy
6. [Creating the Data Ingestion Script](06-ingestion-script.md) - Converting notebook to Python script
7. [pgAdmin - Database Management Tool](07-pgadmin.md) - Web-based database management
8. [Dockerizing the Ingestion Script](08-dockerizing-ingestion.md) - Containerizing the pipeline
9. [Docker Compose](09-docker-compose.md) - Multi-container orchestration
10. [SQL Refresher](10-sql-refresher.md) - SQL joins, aggregations, and queries
11. [Cleanup](11-cleanup.md) - Cleaning up Docker resources
================================================
FILE: 01-docker-terraform/docker-sql/pipeline/.python-version
================================================
3.13
================================================
FILE: 01-docker-terraform/docker-sql/pipeline/Dockerfile
================================================
FROM python:3.13.11-slim
COPY --from=ghcr.io/astral-sh/uv:latest /uv /bin/
WORKDIR /code
ENV PATH="/code/.venv/bin:$PATH"
COPY pyproject.toml .python-version uv.lock ./
RUN uv sync --locked
COPY ingest_data.py .
ENTRYPOINT ["python", "ingest_data.py"]
================================================
FILE: 01-docker-terraform/docker-sql/pipeline/docker-compose.yaml
================================================
services:
pgdatabase:
image: postgres:18
environment:
POSTGRES_USER: "root"
POSTGRES_PASSWORD: "root"
POSTGRES_DB: "ny_taxi"
volumes:
- ny_taxi_postgres_data:/var/lib/postgresql
ports:
- "5432:5432"
pgadmin:
image: dpage/pgadmin4
environment:
PGADMIN_DEFAULT_EMAIL: "admin@admin.com"
PGADMIN_DEFAULT_PASSWORD: "root"
volumes:
- pgadmin_data:/var/lib/pgadmin
ports:
- "8085:80"
volumes:
ny_taxi_postgres_data:
pgadmin_data:
================================================
FILE: 01-docker-terraform/docker-sql/pipeline/docker-helper-scripts/docker-ingest.sh
================================================
#!/usr/bin/env bash
## bash script to run the ingestion container
echo "Running data ingestion for January 2021..."
docker run -it --rm \
--network=pg-network \
taxi_ingest:v001 \
--year=2021 \
--month=1 \
--pg-user=root \
--pg-pass=root \
--pg-host=pgdatabase \
--pg-port=5432 \
--pg-db=ny_taxi \
--chunksize=100000 \
--target-table=yellow_taxi_trips
================================================
FILE: 01-docker-terraform/docker-sql/pipeline/docker-helper-scripts/docker-pgadmin.sh
================================================
#!/usr/bin/env bash
## bash script to start pgadmin
echo "Starting pgAdmin container..."
mkdir -p ../pgadmin_data
docker run -it \
-e PGADMIN_DEFAULT_EMAIL="admin@admin.com" \
-e PGADMIN_DEFAULT_PASSWORD="root" \
-v ../pgadmin_data:/var/lib/pgadmin \
-p 8085:80 \
--network=pg-network \
--name pgadmin \
dpage/pgadmin4
================================================
FILE: 01-docker-terraform/docker-sql/pipeline/docker-helper-scripts/docker-postgres.sh
================================================
#!/usr/bin/env bash
## bash script to start the Postgres container
mkdir -p ../ny_taxi_postgres_data
echo "Starting PostgreSQL container..."
docker run -it \
-e POSTGRES_USER="root" \
-e POSTGRES_PASSWORD="root" \
-e POSTGRES_DB="ny_taxi" \
-v ../ny_taxi_postgres_data:/var/lib/postgresql \
-p 5432:5432 \
--network=pg-network \
--name pgdatabase \
postgres:18
# to use the pgcli
# pgcli -h localhost -p 5432 -u root -d ny_taxi
================================================
FILE: 01-docker-terraform/docker-sql/pipeline/ingest_data.py
================================================
#!/usr/bin/env python
# coding: utf-8
import click
import pandas as pd
from sqlalchemy import create_engine
from tqdm.auto import tqdm
dtype = {
"VendorID": "Int64",
"passenger_count": "Int64",
"trip_distance": "float64",
"RatecodeID": "Int64",
"store_and_fwd_flag": "string",
"PULocationID": "Int64",
"DOLocationID": "Int64",
"payment_type": "Int64",
"fare_amount": "float64",
"extra": "float64",
"mta_tax": "float64",
"tip_amount": "float64",
"tolls_amount": "float64",
"improvement_surcharge": "float64",
"total_amount": "float64",
"congestion_surcharge": "float64"
}
parse_dates = [
"tpep_pickup_datetime",
"tpep_dropoff_datetime"
]
@click.command()
@click.option('--pg-user', default='root', help='PostgreSQL user')
@click.option('--pg-pass', default='root', help='PostgreSQL password')
@click.option('--pg-host', default='localhost', help='PostgreSQL host')
@click.option('--pg-port', default=5432, type=int, help='PostgreSQL port')
@click.option('--pg-db', default='ny_taxi', help='PostgreSQL database name')
@click.option('--year', default=2021, type=int, help='Year of the data')
@click.option('--month', default=1, type=int, help='Month of the data')
@click.option('--target-table', default='yellow_taxi_data', help='Target table name')
@click.option('--chunksize', default=100000, type=int, help='Chunk size for reading CSV')
def run(pg_user, pg_pass, pg_host, pg_port, pg_db, year, month, target_table, chunksize):
"""Ingest NYC taxi data into PostgreSQL database."""
prefix = 'https://github.com/DataTalksClub/nyc-tlc-data/releases/download/yellow'
url = f'{prefix}/yellow_tripdata_{year}-{month:02d}.csv.gz'
engine = create_engine(f'postgresql+psycopg://{pg_user}:{pg_pass}@{pg_host}:{pg_port}/{pg_db}')
df_iter = pd.read_csv(
url,
dtype=dtype,
parse_dates=parse_dates,
iterator=True,
chunksize=chunksize,
)
first = True
for df_chunk in tqdm(df_iter):
if first:
df_chunk.head(0).to_sql(
name=target_table,
con=engine,
if_exists='replace'
)
first = False
df_chunk.to_sql(
name=target_table,
con=engine,
if_exists='append'
)
if __name__ == '__main__':
run()
================================================
FILE: 01-docker-terraform/docker-sql/pipeline/pyproject.toml
================================================
[project]
name = "pipeline"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.13"
dependencies = [
"click>=8.3.1",
"pandas>=2.3.3",
"psycopg2-binary>=2.9.11",
"pyarrow>=22.0.0",
"sqlalchemy>=2.0.44",
"tqdm>=4.67.1",
]
[dependency-groups]
dev = [
"jupyter>=1.1.1",
"pgcli>=4.3.0",
]
================================================
FILE: 01-docker-terraform/terraform/1_terraform_overview.md
================================================
## Terraform Overview
[Video](https://www.youtube.com/watch?v=18jIzE41fJ4&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=2)
### Concepts
#### Introduction
1. What is [Terraform](https://www.terraform.io)?
* open-source tool by [HashiCorp](https://www.hashicorp.com), used for provisioning infrastructure resources
* supports DevOps best practices for change management
* Managing configuration files in source control to maintain an ideal provisioning state
for testing and production environments
2. What is IaC?
* Infrastructure-as-Code
* build, change, and manage your infrastructure in a safe, consistent, and repeatable way
by defining resource configurations that you can version, reuse, and share.
3. Some advantages
* Infrastructure lifecycle management
* Version control commits
* Very useful for stack-based deployments, and with cloud providers such as AWS, GCP, Azure, K8S…
* State-based approach to track resource changes throughout deployments
#### Files
* `main.tf`
* `variables.tf`
* Optional: `resources.tf`, `output.tf`
* `.tfstate`
#### Declarations
* `terraform`: configure basic Terraform settings to provision your infrastructure
* `required_version`: minimum Terraform version to apply to your configuration
* `backend`: stores Terraform's "state" snapshots, to map real-world resources to your configuration.
* `local`: stores state file locally as `terraform.tfstate`
* `required_providers`: specifies the providers required by the current module
* `provider`:
* adds a set of resource types and/or data sources that Terraform can manage
* The Terraform Registry is the main directory of publicly available providers from most major infrastructure platforms.
* `resource`
* blocks to define components of your infrastructure
* Project modules/resources: google_storage_bucket, google_bigquery_dataset, google_bigquery_table
* `variable` & `locals`
* runtime arguments and constants
#### Execution steps
1. `terraform init`:
* Initializes & configures the backend, installs plugins/providers, & checks out an existing configuration from a version control
2. `terraform plan`:
* Matches/previews local changes against a remote state, and proposes an Execution Plan.
3. `terraform apply`:
* Asks for approval to the proposed plan, and applies changes to cloud
4. `terraform destroy`
* Removes your stack from the Cloud
### Terraform Workshop to create GCP Infra
Continue [here](./terraform): `week_1_basics_n_setup/1_terraform_gcp/terraform`
### References
https://learn.hashicorp.com/collections/terraform/gcp-get-started
================================================
FILE: 01-docker-terraform/terraform/2_gcp_overview.md
================================================
## GCP Overview
[Video](https://www.youtube.com/watch?v=18jIzE41fJ4&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=2)
### Project infrastructure modules in GCP:
* Google Cloud Storage (GCS): Data Lake
* BigQuery: Data Warehouse
(Concepts explained in Week 2 - Data Ingestion)
### Initial Setup
For this course, we'll use a free version (upto EUR 300 credits).
1. Create an account with your Google email ID
2. Setup your first [project](https://console.cloud.google.com/) if you haven't already
* eg. "DTC DE Course", and note down the "Project ID" (we'll use this later when deploying infra with TF)
3. Setup [service account & authentication](https://cloud.google.com/docs/authentication/getting-started) for this project
* Grant `Viewer` role to begin with.
* Download service-account-keys (.json) for auth.
4. Download [SDK](https://cloud.google.com/sdk/docs/quickstart) for local setup
5. Set environment variable to point to your downloaded GCP keys:
```shell
export GOOGLE_APPLICATION_CREDENTIALS="<path/to/your/service-account-authkeys>.json"
# Refresh token/session, and verify authentication
gcloud auth application-default login
```
### Setup for Access
1. [IAM Roles](https://cloud.google.com/storage/docs/access-control/iam-roles) for Service account:
* Go to the *IAM* section of *IAM & Admin* https://console.cloud.google.com/iam-admin/iam
* Click the *Edit principal* icon for your service account.
* Add these roles in addition to *Viewer* : **Storage Admin** + **Storage Object Admin** + **BigQuery Admin**
2. Enable these APIs for your project:
* https://console.cloud.google.com/apis/library/iam.googleapis.com
* https://console.cloud.google.com/apis/library/iamcredentials.googleapis.com
3. Please ensure `GOOGLE_APPLICATION_CREDENTIALS` env-var is set.
```shell
export GOOGLE_APPLICATION_CREDENTIALS="<path/to/your/service-account-authkeys>.json"
```
### Terraform Workshop to create GCP Infra
Continue [here](./terraform): `week_1_basics_n_setup/1_terraform_gcp/terraform`
================================================
FILE: 01-docker-terraform/terraform/README.md
================================================
## Local Setup for Terraform and GCP
### Pre-Requisites
1. Terraform client installation: https://www.terraform.io/downloads
2. Cloud Provider account: https://console.cloud.google.com/
### Terraform Concepts
[Terraform Overview](1_terraform_overview.md)
### GCP setup
1. [Setup for First-time](2_gcp_overview.md#initial-setup)
* [Only for Windows](windows.md) - Steps 4 & 5
2. [IAM / Access specific to this course](2_gcp_overview.md#setup-for-access)
### Terraform Workshop for GCP Infra
Your setup is ready!
Now head to the [terraform](terraform) directory, and perform the execution steps to create your infrastructure.
================================================
FILE: 01-docker-terraform/terraform/terraform/README.md
================================================
### Concepts
* [Terraform_overview](../1_terraform_overview.md)
* If you were unable to generate a service account keyfile due to organizational policies, refer to the instructions [below](#fallback)
### Execution
```shell
# Refresh service-account's auth-token for this session
gcloud auth application-default login
# Initialize state file (.tfstate)
terraform init
# Check changes to new infra plan
terraform plan -var="project=<your-gcp-project-id>"
```
```shell
# Create new infra
terraform apply -var="project=<your-gcp-project-id>"
```
```shell
# Delete infra after your work, to avoid costs on any running services
terraform destroy
```
### Warning
Remember to use a [proper gitignore](https://github.com/github/gitignore/blob/main/Terraform.gitignore) file before publishing your code on GitHub
### Fallback
1. Give yourself the token creator role on the pertinent service account
```bash
gcloud iam service-accounts add-iam-policy-binding \
<SERVICE_ACCOUNT_EMAIL> \
--member="user:YOUR_EMAIL@gmail.com" \
--role="roles/iam.serviceAccountTokenCreator"
```
2. Add the sections below the first block to your main terraform configuration
```terraform
# Connect to gcp using ADC (identity verification)
provider "google" {
project = var.project
region = var.region
zone = var.zone
}
/* add these data blocks */
# This data source gets a temporary token for the service account
data "google_service_account_access_token" "default" {
provider = google
target_service_account = "<SERVICE_ACCOUNT_EMAIL>"
scopes = ["https://www.googleapis.com/auth/cloud-platform"]
lifetime = "3600s"
}
# This second provider block uses that temporary token and does the real work
provider "google" {
alias = "impersonated"
access_token = data.google_service_account_access_token.default.access_token
project = var.project
region = var.region
zone = var.zone
}
```
3. Now, you can follow the instructions [above](#execution)
================================================
FILE: 01-docker-terraform/terraform/terraform/terraform_basic/main.tf
================================================
terraform {
required_providers {
google = {
source = "hashicorp/google"
version = "4.51.0"
}
}
}
provider "google" {
# Credentials only needs to be set if you do not have the GOOGLE_APPLICATION_CREDENTIALS set
# credentials =
project = "<Your Project ID>"
region = "us-central1"
}
resource "google_storage_bucket" "data-lake-bucket" {
name = "<Your Unique Bucket Name>"
location = "US"
# Optional, but recommended settings:
storage_class = "STANDARD"
uniform_bucket_level_access = true
versioning {
enabled = true
}
lifecycle_rule {
action {
type = "Delete"
}
condition {
age = 30 // days
}
}
force_destroy = true
}
resource "google_bigquery_dataset" "dataset" {
dataset_id = "<The Dataset Name You Want to Use>"
project = "<Your Project ID>"
location = "US"
}
================================================
FILE: 01-docker-terraform/terraform/terraform/terraform_with_variable_AWS/README.md
================================================
# AWS Terraform Data Lake (GCP Equivalent)
## 📌 Overview
This repository contains an **AWS-based Terraform implementation** that mirrors the **Google Cloud Platform (GCP)** infrastructure used in the Data Engineering course (e.g. GCS + BigQuery), but implemented using **AWS services**.
The goal is to help learners who:
- Are enrolled in a **GCP-focused Data Engineering course**
- Prefer or need to work with **AWS**
- Want to understand **cloud-agnostic data engineering concepts**
This setup focuses on building a **basic data lake foundation** using:
- **Amazon S3** (equivalent to GCS)
- **AWS Glue Data Catalog** (equivalent to BigQuery datasets / metadata layer)
- **Terraform** as Infrastructure as Code (IaC)
---
## 🏗️ Architecture Mapping (GCP → AWS)
| GCP Service | AWS Equivalent | Purpose |
|------------|---------------|---------|
| Google Cloud Storage (GCS) | Amazon S3 | Data Lake storage |
| Uniform Bucket Level Access | S3 Public Access Block | Secure bucket access |
| Object Lifecycle Rules | S3 Lifecycle Configuration | Automatic data expiration |
| BigQuery Dataset | AWS Glue Catalog Database | Metadata & query layer |
| Terraform (GCP provider) | Terraform (AWS provider) | Infrastructure as Code |
---
## 📁 Project Structure
```text
.
├── main.tf # Core infrastructure resources
├── variables.tf # Input variable definitions
├── terraform.tfvars # Environment-specific values
└── README.md # Project documentation
================================================
FILE: 01-docker-terraform/terraform/terraform/terraform_with_variable_AWS/main.tf
================================================
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
provider "aws" {
region = var.aws_region
}
#S3 Bucket to store data equivalent to GCS Bucket in GCP
resource "aws_s3_bucket" "data_lake_bucket" {
bucket = var.bucket_name
force_destroy = true
}
#Bucket verisioning
resource "aws_s3_bucket_versioning" "versioning" {
bucket = aws_s3_bucket.data_lake_bucket.id # Reference the S3 bucket created above
versioning_configuration {
status = "Enabled" # Enable versioning
}
}
# "Uniform bucket level access" ~ control prin policy/ACL; recomandat: block public access
resource "aws_s3_bucket_public_access_block" "block_public_access" {
bucket = aws_s3_bucket.data_lake_bucket.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
# Lifecycle: delete objects older than 30 days (echivalent lifecycle_rule age=30)
resource "aws_s3_bucket_lifecycle_configuration" "lifecycle_rules" {
bucket = aws_s3_bucket.data_lake_bucket.id
rule {
id = "Delete_old_older_than_30_days"
status = "Enabled"
expiration {
days = 30
}
filter {
prefix = "" # Apply to all objects in the bucket
}
}
}
resource "aws_glue_catalog_database" "dataset" {
name = var.dataset_name
}
================================================
FILE: 01-docker-terraform/terraform/terraform/terraform_with_variable_AWS/terraform.tfvars
================================================
bucket_name = "my-unique-data-lake-bucket-12345"
dataset_name = "ny_taxi_dataset"
================================================
FILE: 01-docker-terraform/terraform/terraform/terraform_with_variable_AWS/variables.tf
================================================
# Specifies the geographic location for AWS resource deployment.
# Defaulting to Stockholm (eu-north-1) to keep latency low for European users.
variable "aws_region" {
description = "AWS region to deploy resources in"
type = string
default = "eu-north-1"
}
# The unique identifier for the S3 bucket where raw data will be stored.
# S3 bucket names must be globally unique across all AWS accounts.
variable "bucket_name" {
description = "Name of the S3 bucket"
type = string
default = "data-engineering-zoomcamp-1568692036"
}
# Defines the logical grouping for metadata in the AWS Glue Catalog.
# This allows tools like Athena to query the S3 data using SQL.
variable "dataset_name" {
description = "Glue Catalog database name (logical dataset for Athena/Glue)"
type = string
default = "ny_taxi_database"
}
================================================
FILE: 01-docker-terraform/terraform/terraform/terraform_with_variables/main.tf
================================================
terraform {
required_providers {
google = {
source = "hashicorp/google"
version = "5.6.0"
}
}
}
provider "google" {
credentials = file(var.credentials)
project = var.project
region = var.region
}
resource "google_storage_bucket" "demo-bucket" {
name = var.gcs_bucket_name
location = var.location
force_destroy = true
lifecycle_rule {
condition {
age = 1
}
action {
type = "AbortIncompleteMultipartUpload"
}
}
}
resource "google_bigquery_dataset" "demo_dataset" {
dataset_id = var.bq_dataset_name
location = var.location
}
================================================
FILE: 01-docker-terraform/terraform/terraform/terraform_with_variables/variables.tf
================================================
variable "credentials" {
description = "My Credentials"
default = "<Path to your Service Account json file>"
#ex: if you have a directory where this file is called keys with your service account json file
#saved there as my-creds.json you could use default = "./keys/my-creds.json"
}
variable "project" {
description = "Project"
default = "<Your Project ID>"
}
variable "region" {
description = "Region"
#Update the below to your desired region
default = "us-central1"
}
variable "location" {
description = "Project Location"
#Update the below to your desired location
default = "US"
}
variable "bq_dataset_name" {
description = "My BigQuery Dataset Name"
#Update the below to what you want your dataset to be called
default = "demo_dataset"
}
variable "gcs_bucket_name" {
description = "My Storage Bucket Name"
#Update the below to a unique bucket name
default = "terraform-demo-terra-bucket"
}
variable "gcs_storage_class" {
description = "Bucket Storage Class"
default = "STANDARD"
}
================================================
FILE: 01-docker-terraform/terraform/windows.md
================================================
## GCP and Terraform on Windows
You don't need these instructions if you use WSL. It's only for "plain Windows"
### Google Cloud SDK
* For this tutorial, you'll need a Linux-like environment, e.g. [GitBash](https://gitforwindows.org/), [MinGW](https://www.mingw-w64.org/) or [cygwin](https://www.cygwin.com/)
* Power Shell should also work, but will require adjustments
* Download SDK in zip: https://dl.google.com/dl/cloudsdk/channels/rapid/google-cloud-sdk.zip
* source: https://cloud.google.com/sdk/docs/downloads-interactive
* Unzip it and run the `install.sh` script
When installing it, you might see something like that:
```
The installer is unable to automatically update your system PATH. Please add
C:\tools\google-cloud-sdk\bin
```
* To fix that, adjust your `.bashrc` to include this in `PATH` ([instructions](https://unix.stackexchange.com/questions/26047/how-to-correctly-add-a-path-to-path))
* You can also do it system-wide ([instructions](https://gist.github.com/nex3/c395b2f8fd4b02068be37c961301caa7))
Now we need to point it to correct Python installation. Assuming you use [Anaconda](https://www.anaconda.com/products/individual):
```bash
export CLOUDSDK_PYTHON=~/Anaconda3/python
```
Now let's check that it works:
```bash
$ gcloud version
Google Cloud SDK 367.0.0
bq 2.0.72
core 2021.12.10
gsutil 5.5
```
### Google Cloud SDK Authentication
* Now create a service account and generate keys like shown in the videos
* Download the key and put it to some location, e.g. `.gc/ny-rides.json`
* Set `GOOGLE_APPLICATION_CREDENTIALS` to point to the file
```bash
export GOOGLE_APPLICATION_CREDENTIALS=~/.gc/ny-rides.json
```
Now authenticate:
```bash
gcloud auth activate-service-account --key-file $GOOGLE_APPLICATION_CREDENTIALS
```
Alternatively, you can authenticate using OAuth like shown in the video
```bash
gcloud auth application-default login
```
If you get a message like `quota exceeded`
> WARNING:
> Cannot find a quota project to add to ADC. You might receive a "quota exceeded" or "API not enabled" error.
> Run `$ gcloud auth application-default set-quota-project` to add a quota project.
Then run this:
```bash
PROJECT_NAME="ny-rides-alexey"
gcloud auth application-default set-quota-project ${PROJECT_NAME}
```
### Terraform
* [Download Terraform](https://www.terraform.io/downloads)
* Put it to a folder in [PATH](https://gist.github.com/nex3/c395b2f8fd4b02068be37c961301caa7)
* Go to the location with Terraform files and initialize it
```bash
terraform init
```
Optionally you can configure your terraform files (`variables.tf`) to include your project id:
```bash
variable "project" {
description = "Your GCP Project ID"
default = "ny-rides-alexey"
type = string
}
```
* Now [follow the instructions](1_terraform_overview.md#execution-steps)
* Run `terraform plan`
* Next, run `terraform apply`
If you get an error like that:
> Error: googleapi: Error 403: terraform@ny-rides-alexey.iam.gserviceaccount.com does not have
> storage.buckets.create access to the Google Cloud project., forbidden
Then you need to give your service account all the permissions. Make sure you follow the instructions in the videos
* You can also use [this file](https://docs.google.com/document/d/e/2PACX-1vSZapy7gIj0TP-EFzub2OpAlAkuifGEVJ4XpkA1RvxZ45NjiQi29b6OhLuetdXXHWAn2lbbKxnbzMdd/pub), but it doesn't list all the required permissions
================================================
FILE: 02-workflow-orchestration/README.md
================================================
# Workflow Orchestration
Welcome to Module 2 of the Data Engineering Zoomcamp! This week, we’ll dive into workflow orchestration using [Kestra](https://go.kestra.io/de-zoomcamp/github).
Kestra is an open-source, event-driven orchestration platform that simplifies building both scheduled and event-driven workflows. By adopting Infrastructure as Code practices for data and process orchestration, Kestra enables you to build reliable workflows with just a few lines of YAML.
> [!NOTE]
>You can find all videos for this week in this [YouTube Playlist](https://go.kestra.io/de-zoomcamp/yt-playlist).
---
## Course Structure
- [2.1 - Introduction to Workflow Orchestration](#21-introduction-to-workflow-orchestration)
- [2.2 - Getting Started With Kestra](#22-getting-started-with-kestra)
- [2.3 - Hands-On Coding Project: Build ETL Data Pipelines with Kestra](#23-hands-on-coding-project-build-data-pipelines-with-kestra)
- [2.4 - ELT Pipelines in Kestra: Google Cloud Platform](#24-elt-pipelines-in-kestra-google-cloud-platform)
- [2.5 - Using AI for Data Engineering in Kestra](#25-using-ai-for-data-engineering-in-kestra)
- [2.6 - Bonus](#26-bonus-deploy-to-the-cloud-optional)
## 2.1 Introduction to Workflow Orchestration
In this section, you’ll learn the foundations of workflow orchestration, its importance, and how Kestra fits into the orchestration landscape.
### 2.1.1 - What is Workflow Orchestration?
Think of a music orchestra. There's a variety of different instruments. Some more than others, all with different roles when it comes to playing music. To make sure they all come together at the right time, they follow a conductor who helps the orchestra to play together.
Now replace the instruments with tools and the conductor with an orchestrator. We often have multiple tools and platforms that we need to work together. Sometimes on a routine schedule, other times based on events that happen. That's where the orchestrator comes in to help all of these tools work together.
A workflow orchestrator might do the following tasks:
- Run workflows which contain a number of predefined steps
- Monitor and log errors, as well as taking a number of extra steps when they occur
- Automatically run workflows based on schedules and events
In data engineering, you often need to move data from one place, to another, sometimes with some modifications made to the data in the middle. This is where a workflow orchestrator can help out by managing these steps, while giving us visibility into it at the same time.
In this module, we're going to build our own data pipeline using ETL (Extract, Transform Load) with Kestra at the core of the operation, but first we need to understand a bit more about how Kestra works before we can get building!
#### Videos
- **2.1.1 - What is Workflow Orchestration?**
[](https://youtu.be/-JLnp-iLins)
### 2.1.2 - What is Kestra?
Kestra is an open-source, infinitely-scalable orchestration platform that enables all engineers to manage business-critical workflows.
Kestra is a great choice for workflow orchestration:
- Build with Flow code (YAML), No-code or with the AI Copilot - flexibility in how you build your workflows
- 1000+ Plugins - integrate with all the tools you use
- Support for any programming language - pick the right tool for the job
- Schedule or Event Based Triggers - have your workflows respond to data
#### Videos
- **2.1.2 - What is Kestra?**
[](https://youtu.be/ZvVN_NmB_1s)
### Resources
- [Quickstart Guide](https://go.kestra.io/de-zoomcamp/quickstart)
- [What is an Orchestrator?](https://go.kestra.io/de-zoomcamp/what-is-an-orchestrator)
---
## 2.2 Getting Started with Kestra
In this section, you'll learn how to install Kestra, as well as the key concepts required to build your first workflow. Once our first workflow is built, we can extend this further by executing a Python script inside of a workflow.
You will:
1. Install Kestra using Docker Compose
2. Learn the concepts of Kestra to build your first workflow
3. Execute a Python script inside of a Kestra Flow
### 2.2.1 - Installing Kestra
To install Kestra, we are going to use Docker Compose. We already have a Postgres database set up, along with pgAdmin from Module 1. We can continue to use these with Kestra but we'll need to make a few modifications to our Docker Compose file.
Use [this example Docker Compose file](docker-compose.yml) to correctly add the 2 new services and set up the volumes correctly.
Add information about setting a username and password.
We'll set up Kestra using Docker Compose containing one container for the Kestra server and another for the Postgres database:
```bash
cd 02-workflow-orchestration
docker compose up -d
```
**Note:** Check that `pgAdmin` isn't running on the same ports as Kestra. If so, check out the [FAQ](#troubleshooting-tips) at the bottom of the README.
Once the container starts, you can access the Kestra UI at [http://localhost:8080](http://localhost:8080).
To shut down Kestra, go to the same directory and run the following command:
```bash
docker compose down
```
#### Add Flows to Kestra
Flows can be added to Kestra by copying and pasting the YAML directly into the editor, or by adding via Kestra's API. See below for adding programmatically.
<details>
<summary>Add Flows to Kestra programmatically</summary>
If you prefer to add flows programmatically using Kestra's API, run the following commands:
```bash
# Import all flows: assuming username admin@kestra.io and password Admin1234! (adjust to match your username and password)
curl -X POST -u 'admin@kestra.io:Admin1234!' http://localhost:8080/api/v1/flows/import -F fileUpload=@flows/01_hello_world.yaml
curl -X POST -u 'admin@kestra.io:Admin1234!' http://localhost:8080/api/v1/flows/import -F fileUpload=@flows/02_python.yaml
curl -X POST -u 'admin@kestra.io:Admin1234!' http://localhost:8080/api/v1/flows/import -F fileUpload=@flows/03_getting_started_data_pipeline.yaml
curl -X POST -u 'admin@kestra.io:Admin1234!' http://localhost:8080/api/v1/flows/import -F fileUpload=@flows/04_postgres_taxi.yaml
curl -X POST -u 'admin@kestra.io:Admin1234!' http://localhost:8080/api/v1/flows/import -F fileUpload=@flows/05_postgres_taxi_scheduled.yaml
curl -X POST -u 'admin@kestra.io:Admin1234!' http://localhost:8080/api/v1/flows/import -F fileUpload=@flows/06_gcp_kv.yaml
curl -X POST -u 'admin@kestra.io:Admin1234!' http://localhost:8080/api/v1/flows/import -F fileUpload=@flows/07_gcp_setup.yaml
curl -X POST -u 'admin@kestra.io:Admin1234!' http://localhost:8080/api/v1/flows/import -F fileUpload=@flows/08_gcp_taxi.yaml
curl -X POST -u 'admin@kestra.io:Admin1234!' http://localhost:8080/api/v1/flows/import -F fileUpload=@flows/09_gcp_taxi_scheduled.yaml
curl -X POST -u 'admin@kestra.io:Admin1234!' http://localhost:8080/api/v1/flows/import -F fileUpload=@flows/10_chat_without_rag.yaml
curl -X POST -u 'admin@kestra.io:Admin1234!' http://localhost:8080/api/v1/flows/import -F fileUpload=@flows/11_chat_with_rag.yaml
```
</details>
#### Videos
- **2.2.1 - Installing Kestra**
[](https://youtu.be/wgPxC4UjoLM)
#### Resources
- [Install Kestra with Docker Compose](https://go.kestra.io/de-zoomcamp/docker-compose)
### 2.2.2 - Kestra Concepts
To start building workflows in Kestra, we need to understand a number of concepts.
- [Flow](https://go.kestra.io/de-zoomcamp/flow) - a container for tasks and their orchestration logic.
- [Tasks](https://go.kestra.io/de-zoomcamp/tasks) - the steps within a flow.
- [Inputs](https://go.kestra.io/de-zoomcamp/inputs) - dynamic values passed to the flow at runtime.
- [Outputs](https://go.kestra.io/de-zoomcamp/outputs) - pass data between tasks and flows.
- [Triggers](https://go.kestra.io/de-zoomcamp/triggers) - mechanism that automatically starts the execution of a flow.
- [Execution](https://go.kestra.io/de-zoomcamp/execution) - a single run of a flow with a specific state.
- [Variables](https://go.kestra.io/de-zoomcamp/variables) - key–value pairs that let you reuse values across tasks.
- [Plugin Defaults](https://go.kestra.io/de-zoomcamp/plugin-defaults) - default values applied to every task of a given type within one or more flows.
- [Concurrency](https://go.kestra.io/de-zoomcamp/concurrency) - control how many executions of a flow can run at the same time.
While there are more concepts used for building powerful workflows, these are the ones we're going to use to build our data pipelines.
The flow [`01_hello_world.yaml`](flows/01_hello_world.yaml) showcases all of these concepts inside of one workflow:
- The flow has 5 tasks: 3 log tasks and a sleep task
- The flow takes an input called `name`.
- There is a variable that takes the `name` input to generate a full welcome message.
- An output is generated from the return task and is logged in a later log task.
- There is a trigger to execute this flow every day at 10am.
- Plugin Defaults are used to make both log tasks send their messages as `ERROR` level.
- We have a concurrency limit of 2 executions. Any further ones made while 2 are running will fail.
#### Videos
- **2.2.2 - Kestra Concepts**
[](https://youtu.be/MNOKVx8780E)
#### Resources
- [Tutorial](https://go.kestra.io/de-zoomcamp/tutorial)
- [Workflow Components Documentation](https://go.kestra.io/de-zoomcamp/workflow-components)
### 2.2.3 - Orchestrate Python Code
Now that we've built our first workflow, we can take it a step further by adding Python code into our flow. In Kestra, we can run Python code from a dedicated file or write it directly inside of our workflow.
While Kestra has a huge variety of plugins available for building your workflows, you also have the option to write your own code and have Kestra execute that based on schedules or events. This means you can pick the right tools for your pipelines, rather than the ones you're limited to.
In our example Python workflow, [`02_python.yaml`](flows/02_python.yaml), our code fetches the number of Docker image pulls from DockerHub and returns it as an output to Kestra. This is useful as we can access this output with other tasks, even though it was generated inside of our Python script.
#### Videos
- **2.2.3 - Orchestrate Python Code**
[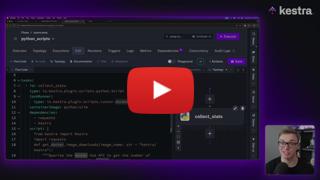](https://youtu.be/VAHm0R_XjqI)
#### Resources
- [How-to Guide: Python](https://go.kestra.io/de-zoomcamp/python)
## 2.3 Hands-On Coding Project: Build Data Pipelines with Kestra
Next, we're gonna build ETL pipelines for Yellow and Green Taxi data from NYC’s Taxi and Limousine Commission (TLC). You will:
1. Extract data from [CSV files](https://github.com/DataTalksClub/nyc-tlc-data/releases).
2. Load it into Postgres or Google Cloud (GCS + BigQuery).
3. Explore scheduling and backfilling workflows.
### 2.3.1 Getting Started Pipeline
This introductory flow is added just to demonstrate a simple data pipeline which extracts data via HTTP REST API, transforms that data in Python and then queries it using DuckDB. For this stage, a new separate Postgres database is created for the exercises.
```mermaid
graph LR
Extract[Extract Data via HTTP REST API] --> Transform[Transform Data in Python]
Transform --> Query[Query Data with DuckDB]
```
Add the flow [`03_getting_started_data_pipeline.yaml`](flows/03_getting_started_data_pipeline.yaml) from the UI if you haven't already and execute it to see the results. Inspect the Gantt and Logs tabs to understand the flow execution.
#### Videos
- **2.3.1 - Getting Started Pipeline**
[](https://youtu.be/-KmwrCqRhic)
#### Resources
- [ETL Tutorial Video](https://go.kestra.io/de-zoomcamp/etl-tutorial)
- [ETL in 3 Minutes](https://go.kestra.io/de-zoomcamp/etl-get-started)
### 2.3.2 Local DB: Load Taxi Data to Postgres
Before we start loading data to GCP, we'll first play with the Yellow and Green Taxi data using a local Postgres database running in a Docker container. We will use the same database from Module 1 which should be in the same Docker Compose file as Kestra.
The flow will extract CSV data partitioned by year and month, create tables, load data to the monthly table, and finally merge the data to the final destination table.
```mermaid
graph LR
Start[Select Year & Month] --> SetLabel[Set Labels]
SetLabel --> Extract[Extract CSV Data]
Extract -->|Taxi=Yellow| YellowFinalTable[Create Yellow Final Table]:::yellow
Extract -->|Taxi=Green| GreenFinalTable[Create Green Final Table]:::green
YellowFinalTable --> YellowMonthlyTable[Create Yellow Monthly Table]:::yellow
GreenFinalTable --> GreenMonthlyTable[Create Green Monthly Table]:::green
YellowMonthlyTable --> YellowCopyIn[Load Data to Monthly Table]:::yellow
GreenMonthlyTable --> GreenCopyIn[Load Data to Monthly Table]:::green
YellowCopyIn --> YellowMerge[Merge Yellow Data]:::yellow
GreenCopyIn --> GreenMerge[Merge Green Data]:::green
classDef yellow fill:#FFD700,stroke:#000,stroke-width:1px,color:#000;
classDef green fill:#32CD32,stroke:#000,stroke-width:1px,color:#000;
```
The flow code: [`04_postgres_taxi.yaml`](flows/04_postgres_taxi.yaml).
> [!NOTE]
> The NYC Taxi and Limousine Commission (TLC) Trip Record Data provided on the [nyc.gov](https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page) website is currently available only in a Parquet format, but this is NOT the dataset we're going to use in this course. For the purpose of this course, we'll use the **CSV files** available [here on GitHub](https://github.com/DataTalksClub/nyc-tlc-data/releases). This is because the Parquet format can be challenging to understand by newcomers, and we want to make the course as accessible as possible — the CSV format can be easily introspected using tools like Excel or Google Sheets, or even a simple text editor.
#### Videos
- **2.3.2 - Local DB: Load Taxi Data to Postgres**
[](https://youtu.be/Z9ZmmwtXDcU)
#### Resources
- [Docker Compose with Kestra, Postgres and pgAdmin](docker-compose.yml)
### 2.3.3 Local DB: Learn Scheduling and Backfills
We can now schedule the same pipeline shown above to run daily at 9 AM UTC. We'll also demonstrate how to backfill the data pipeline to run on historical data.
Note: given the large dataset, we'll backfill only data for the green taxi dataset for the year 2019.
The flow code: [`05_postgres_taxi_scheduled.yaml`](flows/05_postgres_taxi_scheduled.yaml).
#### Videos
- **2.3.3 - Scheduling and Backfills**
[](https://youtu.be/1pu_C_oOAMA)
---
## 2.4 ELT Pipelines in Kestra: Google Cloud Platform
Now that you've learned how to build ETL pipelines locally using Postgres, we are ready to move to the cloud. In this section, we'll load the same Yellow and Green Taxi data to Google Cloud Platform (GCP) using:
1. Google Cloud Storage (GCS) as a data lake
2. BigQuery as a data warehouse.
### 2.4.1 - ETL vs ELT
In 2.3, we made a ETL pipeline inside of Kestra:
- **Extract:** Firstly, we extract the dataset from GitHub
- **Transform:** Next, we transform it with Python
- **Load:** Finally, we load it into our Postgres database
While this is very standard across the industry, sometimes it makes sense to change the order when working with the cloud. If you're working with a large dataset, like the Yellow Taxi data, there can be benefits to extracting and loading straight into a data warehouse, and then performing transformations directly in the data warehouse. When working with BigQuery, we will use ELT:
- **Extract:** Firstly, we extract the dataset from GitHub
- **Load:** Next, we load this dataset (in this case, a csv file) into a data lake (Google Cloud Storage)
- **Transform:** Finally, we can create a table inside of our data warehouse (BigQuery) which uses the data from our data lake to perform our transformations.
The reason for loading into the data warehouse before transforming means we can utilize the cloud's performance benefits for transforming large datasets. What might take a lot longer for a local machine, can take a fraction of the time in the cloud.
Over the next few videos, we'll look at setting up BigQuery and transforming the Yellow Taxi dataset.
#### Videos
- **2.4.1 - ETL vs ELT**
[](https://youtu.be/E04yurp1tSU)
#### Resources
- [ETL vs ELT Video](https://go.kestra.io/de-zoomcamp/etl-vs-elt)
- [Data Warehouse 101 Video](https://go.kestra.io/de-zoomcamp/data-warehouse-101)
- [Data Lakes 101 Video](https://go.kestra.io/de-zoomcamp/data-lakes-101)
### 2.4.2 Setup Google Cloud Platform (GCP)
Before we start loading data to GCP, we need to set up the Google Cloud Platform.
First, adjust the following flow [`06_gcp_kv.yaml`](flows/06_gcp_kv.yaml) to include your service account, GCP project ID, BigQuery dataset and GCS bucket name (_along with their location_) as KV Store values:
- GCP_PROJECT_ID
- GCP_LOCATION
- GCP_BUCKET_NAME
- GCP_DATASET.
#### Create GCP Resources
If you haven't already created the GCS bucket and BigQuery dataset in the first week of the course, you can use this flow to create them: [`07_gcp_setup.yaml`](flows/07_gcp_setup.yaml).
> [!WARNING]
> The `GCP_CREDS` service account contains sensitive information. Ensure you keep it secure and do not commit it to Git. Keep it as secure as your passwords.
#### Videos
- **2.4.2 - Setup Google Cloud Platform**
[](https://youtu.be/TLGFAOHpOYM)
#### Resources
- [Set up Google Cloud Service Account in Kestra](https://go.kestra.io/de-zoomcamp/google-sa)
### 2.4.3 GCP Workflow: Load Taxi Data to BigQuery
Now that Google Cloud is set up with a storage bucket, we can start the ELT process.
```mermaid
graph LR
SetLabel[Set Labels] --> Extract[Extract CSV Data]
Extract --> UploadToGCS[Upload Data to GCS]
UploadToGCS -->|Taxi=Yellow| BQYellowTripdata[Main Yellow Tripdata Table]:::yellow
UploadToGCS -->|Taxi=Green| BQGreenTripdata[Main Green Tripdata Table]:::green
BQYellowTripdata --> BQYellowTableExt[External Table]:::yellow
BQGreenTripdata --> BQGreenTableExt[External Table]:::green
BQYellowTableExt --> BQYellowTableTmp[Monthly Table]:::yellow
BQGreenTableExt --> BQGreenTableTmp[Monthly Table]:::green
BQYellowTableTmp --> BQYellowMerge[Merge to Main Table]:::yellow
BQGreenTableTmp --> BQGreenMerge[Merge to Main Table]:::green
BQYellowMerge --> PurgeFiles[Purge Files]
BQGreenMerge --> PurgeFiles[Purge Files]
classDef yellow fill:#FFD700,stroke:#000,stroke-width:1px,color:#000
classDef green fill:#32CD32,stroke:#000,stroke-width:1px,color:#000
```
The flow code: [`08_gcp_taxi.yaml`](flows/08_gcp_taxi.yaml).
#### Videos
- **2.4.3 - Create an ETL Pipeline with GCS and BigQuery in Kestra**
[](https://youtu.be/52u9X_bfTAo)
### 2.4.4 GCP Workflow: Schedule and Backfill Full Dataset
We can now schedule the same pipeline shown above to run daily at 9 AM UTC for the green dataset and at 10 AM UTC for the yellow dataset. You can backfill historical data directly from the Kestra UI.
Since we now process data in a cloud environment with infinitely scalable storage and compute, we can backfill the entire dataset for both the yellow and green taxi data without the risk of running out of resources on our local machine.
The flow code: [`09_gcp_taxi_scheduled.yaml`](flows/09_gcp_taxi_scheduled.yaml).
#### Videos
- **2.4.4 - GCP Workflow: Schedule and Backfills**
[](https://youtu.be/b-6KhfWfk2M)
---
## 2.5 Using AI for Data Engineering in Kestra
This section builds on what you learned earlier in Module 2 to show you how AI can speed up workflow development.
By the end of this section, you will:
- Understand why context engineering matters when collaborating with LLMs
- Use AI Copilot to build Kestra flows faster
- Use Retrieval Augmented Generation (RAG) in data pipelines
### Prerequisites
- Completion of earlier sections in Module 2 (Workflow Orchestration with Kestra)
- Kestra running locally
- Google Cloud account with access to Gemini API (there's a generous free tier!)
---
### 2.5.1 Introduction: Why AI for Workflows?
As data engineers, we spend significant time writing boilerplate code, searching documentation, and structuring data pipelines. AI tools can help us:
- **Generate workflows faster**: Describe what you want to accomplish in natural language instead of writing YAML from scratch
- **Avoid errors**: Get syntax-correct, up-to-date workflow code that follows best practices
However, AI is only as good as the context we provide. This section teaches you how to engineer that context for reliable, production-ready data workflows.
#### Videos
- **2.5.1 - Using AI for Data Engineering**
[](https://youtu.be/GHPtRDAv044)
---
### 2.5.2 Context Engineering with ChatGPT
Let's start by seeing what happens when AI lacks proper context.
#### Experiment: ChatGPT Without Context
1. **Open ChatGPT in a private browser window** (to avoid any existing chat context): https://chatgpt.com
2. **Enter this prompt:**
```
Create a Kestra flow that loads NYC taxi data from a CSV file to BigQuery. The flow should extract data, upload to GCS, and load to BigQuery.
```
3. **Observe the results:**
- ChatGPT will generate a Kestra flow, but it likely contains:
- **Outdated plugin syntax** e.g., old task types that have been renamed
- **Incorrect property names** e.g., properties that don't exist in current versions
- **Hallucinated features** e.g., tasks, triggers or properties that never existed
#### Why Does This Happen?
Large Language Models (LLMs) like GPT models from OpenAI are trained on data up to a specific point in time (knowledge cutoff). They don't automatically know about:
- Software updates and new releases
- Renamed plugins or changed APIs
This is the fundamental challenge of using AI: **the model can only work with information it has access to.**
#### Key Learning: Context is Everything
Without proper context:
- ❌ Generic AI assistants hallucinate outdated or incorrect code
- ❌ You can't trust the output for production use
With proper context:
- ✅ AI generates accurate, current, production-ready code
- ✅ You can iterate faster by letting AI generate boilerplate workflow code
In the next section, we'll see how Kestra's AI Copilot solves this problem.
#### Videos
- **2.5.2 - Context Engineering with ChatGPT**
[](https://youtu.be/LmnfjGKwnVU)
---
### 2.5.3 AI Copilot in Kestra
Kestra's AI Copilot is specifically designed to generate and modify Kestra flows with full context about the latest plugins, workflow syntax, and best practices.
#### Setup AI Copilot
Before using AI Copilot, you need to configure Gemini API access in your Kestra instance.
**Step 1: Get Your Gemini API Key**
1. Visit Google AI Studio: https://aistudio.google.com/app/apikey
2. Sign in with your Google account
3. Click "Create API Key"
4. Copy the generated key (keep it secure!)
> [!WARNING]
> Never commit API keys to Git. Always use environment variables or Kestra's KV Store.
**Step 2: Configure Kestra AI Copilot**
Add the following to your Kestra configuration. You can do this by modifying your `docker-compose.yml` file from 2.2:
```yaml
services:
kestra:
environment:
KESTRA_CONFIGURATION: |
kestra:
ai:
type: gemini
gemini:
model-name: gemini-2.5-flash
api-key: ${GEMINI_API_KEY}
```
Then restart Kestra:
```bash
cd 02-workflow-orchestration/docker
export GEMINI_API_KEY="your-api-key-here"
docker compose up -d
```
#### Exercise: ChatGPT vs AI Copilot Comparison
**Objective:** Learn why context engineering matters.
1. **Open Kestra UI** at http://localhost:8080
2. **Create a new flow** and open the Code editor panel
3. **Click the AI Copilot button** (sparkle icon ✨) in the top-right corner
4. **Enter the same exact prompt** we used with ChatGPT:
```
Create a Kestra flow that loads NYC taxi data from a CSV file to BigQuery. The flow should extract data, upload to GCS, and load to BigQuery.
```
5. **Compare the outputs:**
- ✅ Copilot generates executable, working YAML
- ✅ Copilot uses correct plugin types and properties
- ✅ Copilot follows current Kestra best practices
**Key Learning:** Context matters! AI Copilot has access to current Kestra documentation, generating Kestra flows better than a generic ChatGPT assistant.
#### Videos
- **2.5.3 - AI Copilot in Kestra**
[](https://youtu.be/3IbjHfC8bMg)
### 2.5.4 Bonus: Retrieval Augmented Generation (RAG)
To further learn how to provide context to your prompts, this bonus section demonstrates how to use RAG.
#### What is RAG?
**RAG (Retrieval Augmented Generation)** is a technique that:
1. **Retrieves** relevant information from your data sources
2. **Augments** the AI prompt with this context
3. **Generates** a response grounded in real data
This solves the hallucination problem by ensuring the AI has access to current, accurate information at query time.
#### How RAG Works in Kestra
```mermaid
graph LR
A[Ask AI] --> B[Fetch Docs]
B --> C[Create Embeddings]
C --> D[Find Similar Content]
D --> E[Add Context to Prompt]
E --> F[LLM Answer]
```
**The Process:**
1. **Ingest documents**: Load documentation, release notes, or other data sources
2. **Create embeddings**: Convert text into vector representations using an LLM
3. **Store embeddings**: Save vectors in Kestra's KV Store (or a vector database)
4. **Query with context**: When you ask a question, retrieve relevant embeddings and include them in the prompt
5. **Generate response**: The LLM has real context and provides accurate answers
#### Exercise: Retrieval With vs Without Context
**Objective:** Understand how RAG eliminates hallucinations by grounding LLM responses in real data.
**Part A: Without RAG**
1. Navigate to the [`10_chat_without_rag.yaml`](flows/10_chat_without_rag.yaml) flow in your Kestra UI
2. Click **Execute**
3. Wait for the execution to complete
4. Open the **Logs** tab
5. Read the output - notice how the response about "Kestra 1.1 features" is:
- Vague or generic
- Potentially incorrect
- Missing specific details
- Based only on the model's training data (which may be outdated)
**Part B: With RAG**
1. Navigate to the [`11_chat_with_rag.yaml`](flows/11_chat_with_rag.yaml) flow
2. Click **Execute**
3. Watch the execution:
- First task: **Ingests** Kestra 1.1 release documentation, creates **embeddings** and stores them
- Second task: **Prompts LLM** with context retrieved from stored embeddings
4. Open the **Logs** tab
5. Compare this output with the previous one - notice how it's:
- ✅ Specific and detailed
- ✅ Accurate with real features from the release
- ✅ Grounded in actual documentation
**Key Learning:** RAG (Retrieval Augmented Generation) grounds AI responses in current documentation, eliminating hallucinations and providing accurate, context-aware answers.
#### RAG Best Practices
1. **Keep documents updated**: Regularly re-ingest to ensure current information
2. **Chunk appropriately**: Break large documents into meaningful chunks
3. **Test retrieval quality**: Verify that the right documents are retrieved
#### Additional AI Resources
Kestra Documentation:
- [AI Tools Overview](https://go.kestra.io/de-zoomcamp/ai-tools)
- [AI Copilot](https://go.kestra.io/de-zoomcamp/ai-copilot)
- [RAG Workflows](https://go.kestra.io/de-zoomcamp/rag-workflows)
- [AI Workflows](https://go.kestra.io/de-zoomcamp/ai-workflows)
- [Kestra Blueprints](https://go.kestra.io/de-zoomcamp/blueprints) - Pre-built workflow examples
Kestra Plugin Documentation:
- [AI Plugin](https://go.kestra.io/de-zoomcamp/ai-plugin)
- [RAG Tasks](https://go.kestra.io/de-zoomcamp/ai-rag-task)
External Documentation:
- [Google Gemini](https://go.kestra.io/de-zoomcamp/gemini-docs)
- [Google AI Studio](https://go.kestra.io/de-zoomcamp/ai-studio)
#### Videos
- **2.5.4 (Bonus) - Retrieval Augmented Generation**
[](https://youtu.be/XuPDQ1UcNyI)
## 2.6 Bonus: Deploy to the Cloud (Optional)
Now that we've got all our pipelines working and we know how to quickly create new flows with Kestra's AI Copilot, we can deploy Kestra to the cloud so it can continue to orchestrate our scheduled pipelines.
In this bonus section, we'll cover how you can deploy Kestra on Google Cloud and automatically sync your workflows from a Git repository.
Note: When committing your workflows to Kestra, make sure your workflow doesn't contain any sensitive information. You can use [Secrets](https://go.kestra.io/de-zoomcamp/secret) and the [KV Store](https://go.kestra.io/de-zoomcamp/kv-store) to keep sensitive data out of your workflow logic.
#### Resources
- [Install Kestra on Google Cloud](https://go.kestra.io/de-zoomcamp/gcp-install)
- [Moving from Development to Production](https://go.kestra.io/de-zoomcamp/dev-to-prod)
- [Using Git in Kestra](https://go.kestra.io/de-zoomcamp/git)
- [Deploy Flows with GitHub Actions](https://go.kestra.io/de-zoomcamp/deploy-github-actions)
## 2.7 Additional Resources 📚
- Check [Kestra Docs](https://go.kestra.io/de-zoomcamp/docs)
- Explore our [Blueprints](https://go.kestra.io/de-zoomcamp/blueprints) library
- Browse over 600 [plugins](https://go.kestra.io/de-zoomcamp/plugins) available in Kestra
- Give us a star on [GitHub](https://go.kestra.io/de-zoomcamp/github)
- Join our [Slack community](https://go.kestra.io/de-zoomcamp/slack) if you have any questions
- Find all the videos in this [YouTube Playlist](https://go.kestra.io/de-zoomcamp/yt-playlist)
### Troubleshooting tips
If you face any issues with Kestra flows in Module 2, make sure to use the following Docker images/ports:
- `image: kestra/kestra:v1.1` - pin your Kestra Docker image to this version so we can ensure reproducibility; do NOT use `kestra/kestra:develop` as this is a bleeding-edge development version that might contain bugs
- `postgres:18` — make sure to pin your Postgres image to version 18
- If you run `pgAdmin` or something else on port 8080, you can adjust Kestra `docker-compose` to use a different port, e.g. change port mapping to 18080 instead of 8080, and then access Kestra UI in your browser from http://localhost:18080/ instead of from http://localhost:8080/
If you are still facing any issues, stop and remove your existing Kestra + Postgres containers and start them again using `docker-compose up -d`. If this doesn't help, post your question on the DataTalksClub Slack or on Kestra's Slack http://kestra.io/slack.
If you encounter similar errors to:
```
BigQueryError{reason=invalid, location=null,
message=Error while reading table: kestra-sandbox.zooomcamp.yellow_tripdata_2020_01,
error message: CSV table references column position 17, but line contains only 14 columns.;
line_number: 2103925 byte_offset_to_start_of_line: 194863028
column_index: 17 column_name: "congestion_surcharge" column_type: NUMERIC
File: gs://anna-geller/yellow_tripdata_2020-01.csv}
```
It means that the CSV file you're trying to load into BigQuery has a mismatch in the number of columns between the external source table (i.e. file in GCS) and the destination table in BigQuery. This can happen when for due to network/transfer issues, the file is not fully downloaded from GitHub or not correctly uploaded to GCS. The error suggests schema issues but that's not the case. Simply rerun the entire execution including redownloading the CSV file and reuploading it to GCS. This should resolve the issue.
---
## Homework
See the [2026 cohort folder](../cohorts/2026/02-workflow-orchestration/homework.md)
---
# Community notes
Did you take notes? You can share them by creating a PR to this file!
* Add your notes above this line
---
# Previous Cohorts
* 2022: [notes](../cohorts/2022/week_2_data_ingestion#community-notes) and [videos](../cohorts/2022/week_2_data_ingestion)
* 2023: [notes](../cohorts/2023/week_2_workflow_orchestration#community-notes) and [videos](../cohorts/2023/week_2_workflow_orchestration)
* 2024: [notes](../cohorts/2024/02-workflow-orchestration#community-notes) and [videos](../cohorts/2024/02-workflow-orchestration)
* 2025: [notes](../cohorts/2025/02-workflow-orchestration/README.md#community-notes) and [videos](../cohorts/2025/02-workflow-orchestration)
================================================
FILE: 02-workflow-orchestration/docker-compose.yml
================================================
volumes:
ny_taxi_postgres_data:
driver: local
kestra_postgres_data:
driver: local
kestra_data:
driver: local
kestra_tmp:
driver: local
services:
pgdatabase:
image: postgres:18
environment:
POSTGRES_USER: root
POSTGRES_PASSWORD: root
POSTGRES_DB: ny_taxi
ports:
- "5432:5432"
volumes:
- ny_taxi_postgres_data:/var/lib/postgresql
depends_on:
kestra:
condition: service_started
pgadmin:
image: dpage/pgadmin4
environment:
- PGADMIN_DEFAULT_EMAIL=admin@admin.com
- PGADMIN_DEFAULT_PASSWORD=root
ports:
- "8085:80"
depends_on:
pgdatabase:
condition: service_started
kestra_postgres:
image: postgres:18
volumes:
- kestra_postgres_data:/var/lib/postgresql
environment:
POSTGRES_DB: kestra
POSTGRES_USER: kestra
POSTGRES_PASSWORD: k3str4
healthcheck:
test: ["CMD-SHELL", "pg_isready -d $${POSTGRES_DB} -U $${POSTGRES_USER}"]
interval: 30s
timeout: 10s
retries: 10
kestra:
image: kestra/kestra:v1.1
pull_policy: always
# Note that this setup with a root user is intended for development purpose.
# Our base image runs without root, but the Docker Compose implementation needs root to access the Docker socket
# To run Kestra in a rootless mode in production, see: https://kestra.io/docs/installation/podman-compose
user: "root"
command: server standalone
volumes:
- kestra_data:/app/storage
- /var/run/docker.sock:/var/run/docker.sock
- kestra_tmp:/tmp/kestra-wd
environment:
KESTRA_CONFIGURATION: |
datasources:
postgres:
url: jdbc:postgresql://kestra_postgres:5432/kestra
driverClassName: org.postgresql.Driver
username: kestra
password: k3str4
kestra:
server:
basicAuth:
username: "admin@kestra.io" # it must be a valid email address
password: Admin1234!
repository:
type: postgres
storage:
type: local
local:
basePath: "/app/storage"
queue:
type: postgres
tasks:
tmpDir:
path: /tmp/kestra-wd/tmp
url: http://localhost:8080/
ports:
- "8080:8080"
- "8081:8081"
depends_on:
kestra_postgres:
condition: service_started
================================================
FILE: 02-workflow-orchestration/flows/01_hello_world.yaml
================================================
id: 01_hello_world
namespace: zoomcamp
inputs:
- id: name
type: STRING
defaults: Will
concurrency:
behavior: FAIL
limit: 2
variables:
welcome_message: "Hello, {{ inputs.name }}!"
tasks:
- id: hello_message
type: io.kestra.plugin.core.log.Log
message: "{{ render(vars.welcome_message) }}"
- id: generate_output
type: io.kestra.plugin.core.debug.Return
format: I was generated during this workflow.
- id: sleep
type: io.kestra.plugin.core.flow.Sleep
duration: PT15S
- id: log_output
type: io.kestra.plugin.core.log.Log
message: "This is an output: {{ outputs.generate_output.value }}"
- id: goodbye_message
type: io.kestra.plugin.core.log.Log
message: "Goodbye, {{ inputs.name }}!"
pluginDefaults:
- type: io.kestra.plugin.core.log.Log
values:
level: ERROR
triggers:
- id: schedule
type: io.kestra.plugin.core.trigger.Schedule
cron: "0 10 * * *"
inputs:
name: Sarah
disabled: true
================================================
FILE: 02-workflow-orchestration/flows/02_python.yaml
================================================
id: 02_python
namespace: zoomcamp
description: This flow will install the pip package in a Docker container, and use kestra's Python library to generate outputs (number of downloads of the Kestra Docker image) and metrics (duration of the script).
tasks:
- id: collect_stats
type: io.kestra.plugin.scripts.python.Script
taskRunner:
type: io.kestra.plugin.scripts.runner.docker.Docker
containerImage: python:slim
dependencies:
- requests
- kestra
script: |
from kestra import Kestra
import requests
def get_docker_image_downloads(image_name: str = "kestra/kestra"):
"""Queries the Docker Hub API to get the number of downloads for a specific Docker image."""
url = f"https://hub.docker.com/v2/repositories/{image_name}/"
response = requests.get(url)
data = response.json()
downloads = data.get('pull_count', 'Not available')
return downloads
downloads = get_docker_image_downloads()
outputs = {
'downloads': downloads
}
Kestra.outputs(outputs)
================================================
FILE: 02-workflow-orchestration/flows/03_getting_started_data_pipeline.yaml
================================================
id: 03_getting_started_data_pipeline
namespace: zoomcamp
inputs:
- id: columns_to_keep
type: ARRAY
itemType: STRING
defaults:
- brand
- price
tasks:
- id: extract
type: io.kestra.plugin.core.http.Download
uri: https://dummyjson.com/products
- id: transform
type: io.kestra.plugin.scripts.python.Script
containerImage: python:3.11-alpine
inputFiles:
data.json: "{{outputs.extract.uri}}"
outputFiles:
- "*.json"
env:
COLUMNS_TO_KEEP: "{{inputs.columns_to_keep}}"
script: |
import json
import os
columns_to_keep_str = os.getenv("COLUMNS_TO_KEEP")
columns_to_keep = json.loads(columns_to_keep_str)
with open("data.json", "r") as file:
data = json.load(file)
filtered_data = [
{column: product.get(column, "N/A") for column in columns_to_keep}
for product in data["products"]
]
with open("products.json", "w") as file:
json.dump(filtered_data, file, indent=4)
- id: query
type: io.kestra.plugin.jdbc.duckdb.Queries
inputFiles:
products.json: "{{outputs.transform.outputFiles['products.json']}}"
sql: |
INSTALL json;
LOAD json;
SELECT brand, round(avg(price), 2) as avg_price
FROM read_json_auto('{{workingDir}}/products.json')
GROUP BY brand
ORDER BY avg_price DESC;
fetchType: STORE
================================================
FILE: 02-workflow-orchestration/flows/04_postgres_taxi.yaml
================================================
id: 04_postgres_taxi
namespace: zoomcamp
description: |
The CSV Data used in the course: https://github.com/DataTalksClub/nyc-tlc-data/releases
inputs:
- id: taxi
type: SELECT
displayName: Select taxi type
values: [yellow, green]
defaults: yellow
- id: year
type: SELECT
displayName: Select year
values: ["2019", "2020"]
defaults: "2019"
- id: month
type: SELECT
displayName: Select month
values: ["01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12"]
defaults: "01"
variables:
file: "{{inputs.taxi}}_tripdata_{{inputs.year}}-{{inputs.month}}.csv"
staging_table: "public.{{inputs.taxi}}_tripdata_staging"
table: "public.{{inputs.taxi}}_tripdata"
data: "{{outputs.extract.outputFiles[inputs.taxi ~ '_tripdata_' ~ inputs.year ~ '-' ~ inputs.month ~ '.csv']}}"
tasks:
- id: set_label
type: io.kestra.plugin.core.execution.Labels
labels:
file: "{{render(vars.file)}}"
taxi: "{{inputs.taxi}}"
- id: extract
type: io.kestra.plugin.scripts.shell.Commands
outputFiles:
- "*.csv"
taskRunner:
type: io.kestra.plugin.core.runner.Process
commands:
- wget -qO- https://github.com/DataTalksClub/nyc-tlc-data/releases/download/{{inputs.taxi}}/{{render(vars.file)}}.gz | gunzip > {{render(vars.file)}}
- id: if_yellow_taxi
type: io.kestra.plugin.core.flow.If
condition: "{{inputs.taxi == 'yellow'}}"
then:
- id: yellow_create_table
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
CREATE TABLE IF NOT EXISTS {{render(vars.table)}} (
unique_row_id text,
filename text,
VendorID text,
tpep_pickup_datetime timestamp,
tpep_dropoff_datetime timestamp,
passenger_count integer,
trip_distance double precision,
RatecodeID text,
store_and_fwd_flag text,
PULocationID text,
DOLocationID text,
payment_type integer,
fare_amount double precision,
extra double precision,
mta_tax double precision,
tip_amount double precision,
tolls_amount double precision,
improvement_surcharge double precision,
total_amount double precision,
congestion_surcharge double precision
);
- id: yellow_create_staging_table
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
CREATE TABLE IF NOT EXISTS {{render(vars.staging_table)}} (
unique_row_id text,
filename text,
VendorID text,
tpep_pickup_datetime timestamp,
tpep_dropoff_datetime timestamp,
passenger_count integer,
trip_distance double precision,
RatecodeID text,
store_and_fwd_flag text,
PULocationID text,
DOLocationID text,
payment_type integer,
fare_amount double precision,
extra double precision,
mta_tax double precision,
tip_amount double precision,
tolls_amount double precision,
improvement_surcharge double precision,
total_amount double precision,
congestion_surcharge double precision
);
- id: yellow_truncate_staging_table
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
TRUNCATE TABLE {{render(vars.staging_table)}};
- id: yellow_copy_in_to_staging_table
type: io.kestra.plugin.jdbc.postgresql.CopyIn
format: CSV
from: "{{render(vars.data)}}"
table: "{{render(vars.staging_table)}}"
header: true
columns: [VendorID,tpep_pickup_datetime,tpep_dropoff_datetime,passenger_count,trip_distance,RatecodeID,store_and_fwd_flag,PULocationID,DOLocationID,payment_type,fare_amount,extra,mta_tax,tip_amount,tolls_amount,improvement_surcharge,total_amount,congestion_surcharge]
- id: yellow_add_unique_id_and_filename
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
UPDATE {{render(vars.staging_table)}}
SET
unique_row_id = md5(
COALESCE(CAST(VendorID AS text), '') ||
COALESCE(CAST(tpep_pickup_datetime AS text), '') ||
COALESCE(CAST(tpep_dropoff_datetime AS text), '') ||
COALESCE(PULocationID, '') ||
COALESCE(DOLocationID, '') ||
COALESCE(CAST(fare_amount AS text), '') ||
COALESCE(CAST(trip_distance AS text), '')
),
filename = '{{render(vars.file)}}';
- id: yellow_merge_data
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
MERGE INTO {{render(vars.table)}} AS T
USING {{render(vars.staging_table)}} AS S
ON T.unique_row_id = S.unique_row_id
WHEN NOT MATCHED THEN
INSERT (
unique_row_id, filename, VendorID, tpep_pickup_datetime, tpep_dropoff_datetime,
passenger_count, trip_distance, RatecodeID, store_and_fwd_flag, PULocationID,
DOLocationID, payment_type, fare_amount, extra, mta_tax, tip_amount, tolls_amount,
improvement_surcharge, total_amount, congestion_surcharge
)
VALUES (
S.unique_row_id, S.filename, S.VendorID, S.tpep_pickup_datetime, S.tpep_dropoff_datetime,
S.passenger_count, S.trip_distance, S.RatecodeID, S.store_and_fwd_flag, S.PULocationID,
S.DOLocationID, S.payment_type, S.fare_amount, S.extra, S.mta_tax, S.tip_amount, S.tolls_amount,
S.improvement_surcharge, S.total_amount, S.congestion_surcharge
);
- id: if_green_taxi
type: io.kestra.plugin.core.flow.If
condition: "{{inputs.taxi == 'green'}}"
then:
- id: green_create_table
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
CREATE TABLE IF NOT EXISTS {{render(vars.table)}} (
unique_row_id text,
filename text,
VendorID text,
lpep_pickup_datetime timestamp,
lpep_dropoff_datetime timestamp,
store_and_fwd_flag text,
RatecodeID text,
PULocationID text,
DOLocationID text,
passenger_count integer,
trip_distance double precision,
fare_amount double precision,
extra double precision,
mta_tax double precision,
tip_amount double precision,
tolls_amount double precision,
ehail_fee double precision,
improvement_surcharge double precision,
total_amount double precision,
payment_type integer,
trip_type integer,
congestion_surcharge double precision
);
- id: green_create_staging_table
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
CREATE TABLE IF NOT EXISTS {{render(vars.staging_table)}} (
unique_row_id text,
filename text,
VendorID text,
lpep_pickup_datetime timestamp,
lpep_dropoff_datetime timestamp,
store_and_fwd_flag text,
RatecodeID text,
PULocationID text,
DOLocationID text,
passenger_count integer,
trip_distance double precision,
fare_amount double precision,
extra double precision,
mta_tax double precision,
tip_amount double precision,
tolls_amount double precision,
ehail_fee double precision,
improvement_surcharge double precision,
total_amount double precision,
payment_type integer,
trip_type integer,
congestion_surcharge double precision
);
- id: green_truncate_staging_table
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
TRUNCATE TABLE {{render(vars.staging_table)}};
- id: green_copy_in_to_staging_table
type: io.kestra.plugin.jdbc.postgresql.CopyIn
format: CSV
from: "{{render(vars.data)}}"
table: "{{render(vars.staging_table)}}"
header: true
columns: [VendorID,lpep_pickup_datetime,lpep_dropoff_datetime,store_and_fwd_flag,RatecodeID,PULocationID,DOLocationID,passenger_count,trip_distance,fare_amount,extra,mta_tax,tip_amount,tolls_amount,ehail_fee,improvement_surcharge,total_amount,payment_type,trip_type,congestion_surcharge]
- id: green_add_unique_id_and_filename
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
UPDATE {{render(vars.staging_table)}}
SET
unique_row_id = md5(
COALESCE(CAST(VendorID AS text), '') ||
COALESCE(CAST(lpep_pickup_datetime AS text), '') ||
COALESCE(CAST(lpep_dropoff_datetime AS text), '') ||
COALESCE(PULocationID, '') ||
COALESCE(DOLocationID, '') ||
COALESCE(CAST(fare_amount AS text), '') ||
COALESCE(CAST(trip_distance AS text), '')
),
filename = '{{render(vars.file)}}';
- id: green_merge_data
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
MERGE INTO {{render(vars.table)}} AS T
USING {{render(vars.staging_table)}} AS S
ON T.unique_row_id = S.unique_row_id
WHEN NOT MATCHED THEN
INSERT (
unique_row_id, filename, VendorID, lpep_pickup_datetime, lpep_dropoff_datetime,
store_and_fwd_flag, RatecodeID, PULocationID, DOLocationID, passenger_count,
trip_distance, fare_amount, extra, mta_tax, tip_amount, tolls_amount, ehail_fee,
improvement_surcharge, total_amount, payment_type, trip_type, congestion_surcharge
)
VALUES (
S.unique_row_id, S.filename, S.VendorID, S.lpep_pickup_datetime, S.lpep_dropoff_datetime,
S.store_and_fwd_flag, S.RatecodeID, S.PULocationID, S.DOLocationID, S.passenger_count,
S.trip_distance, S.fare_amount, S.extra, S.mta_tax, S.tip_amount, S.tolls_amount, S.ehail_fee,
S.improvement_surcharge, S.total_amount, S.payment_type, S.trip_type, S.congestion_surcharge
);
- id: purge_files
type: io.kestra.plugin.core.storage.PurgeCurrentExecutionFiles
description: This will remove output files. If you'd like to explore Kestra outputs, disable it.
pluginDefaults:
- type: io.kestra.plugin.jdbc.postgresql
values:
url: jdbc:postgresql://pgdatabase:5432/ny_taxi
username: root
password: root
================================================
FILE: 02-workflow-orchestration/flows/05_postgres_taxi_scheduled.yaml
================================================
id: 05_postgres_taxi_scheduled
namespace: zoomcamp
description: |
Best to add a label `backfill:true` from the UI to track executions created via a backfill.
CSV data used here comes from: https://github.com/DataTalksClub/nyc-tlc-data/releases
concurrency:
limit: 1
inputs:
- id: taxi
type: SELECT
displayName: Select taxi type
values: [yellow, green]
defaults: yellow
variables:
file: "{{inputs.taxi}}_tripdata_{{trigger.date | date('yyyy-MM')}}.csv"
staging_table: "public.{{inputs.taxi}}_tripdata_staging"
table: "public.{{inputs.taxi}}_tripdata"
data: "{{outputs.extract.outputFiles[inputs.taxi ~ '_tripdata_' ~ (trigger.date | date('yyyy-MM')) ~ '.csv']}}"
tasks:
- id: set_label
type: io.kestra.plugin.core.execution.Labels
labels:
file: "{{render(vars.file)}}"
taxi: "{{inputs.taxi}}"
- id: extract
type: io.kestra.plugin.scripts.shell.Commands
outputFiles:
- "*.csv"
taskRunner:
type: io.kestra.plugin.core.runner.Process
commands:
- wget -qO- https://github.com/DataTalksClub/nyc-tlc-data/releases/download/{{inputs.taxi}}/{{render(vars.file)}}.gz | gunzip > {{render(vars.file)}}
- id: if_yellow_taxi
type: io.kestra.plugin.core.flow.If
condition: "{{inputs.taxi == 'yellow'}}"
then:
- id: yellow_create_table
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
CREATE TABLE IF NOT EXISTS {{render(vars.table)}} (
unique_row_id text,
filename text,
VendorID text,
tpep_pickup_datetime timestamp,
tpep_dropoff_datetime timestamp,
passenger_count integer,
trip_distance double precision,
RatecodeID text,
store_and_fwd_flag text,
PULocationID text,
DOLocationID text,
payment_type integer,
fare_amount double precision,
extra double precision,
mta_tax double precision,
tip_amount double precision,
tolls_amount double precision,
improvement_surcharge double precision,
total_amount double precision,
congestion_surcharge double precision
);
- id: yellow_create_staging_table
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
CREATE TABLE IF NOT EXISTS {{render(vars.staging_table)}} (
unique_row_id text,
filename text,
VendorID text,
tpep_pickup_datetime timestamp,
tpep_dropoff_datetime timestamp,
passenger_count integer,
trip_distance double precision,
RatecodeID text,
store_and_fwd_flag text,
PULocationID text,
DOLocationID text,
payment_type integer,
fare_amount double precision,
extra double precision,
mta_tax double precision,
tip_amount double precision,
tolls_amount double precision,
improvement_surcharge double precision,
total_amount double precision,
congestion_surcharge double precision
);
- id: yellow_truncate_staging_table
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
TRUNCATE TABLE {{render(vars.staging_table)}};
- id: yellow_copy_in_to_staging_table
type: io.kestra.plugin.jdbc.postgresql.CopyIn
format: CSV
from: "{{render(vars.data)}}"
table: "{{render(vars.staging_table)}}"
header: true
columns: [VendorID,tpep_pickup_datetime,tpep_dropoff_datetime,passenger_count,trip_distance,RatecodeID,store_and_fwd_flag,PULocationID,DOLocationID,payment_type,fare_amount,extra,mta_tax,tip_amount,tolls_amount,improvement_surcharge,total_amount,congestion_surcharge]
- id: yellow_add_unique_id_and_filename
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
UPDATE {{render(vars.staging_table)}}
SET
unique_row_id = md5(
COALESCE(CAST(VendorID AS text), '') ||
COALESCE(CAST(tpep_pickup_datetime AS text), '') ||
COALESCE(CAST(tpep_dropoff_datetime AS text), '') ||
COALESCE(PULocationID, '') ||
COALESCE(DOLocationID, '') ||
COALESCE(CAST(fare_amount AS text), '') ||
COALESCE(CAST(trip_distance AS text), '')
),
filename = '{{render(vars.file)}}';
- id: yellow_merge_data
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
MERGE INTO {{render(vars.table)}} AS T
USING {{render(vars.staging_table)}} AS S
ON T.unique_row_id = S.unique_row_id
WHEN NOT MATCHED THEN
INSERT (
unique_row_id, filename, VendorID, tpep_pickup_datetime, tpep_dropoff_datetime,
passenger_count, trip_distance, RatecodeID, store_and_fwd_flag, PULocationID,
DOLocationID, payment_type, fare_amount, extra, mta_tax, tip_amount, tolls_amount,
improvement_surcharge, total_amount, congestion_surcharge
)
VALUES (
S.unique_row_id, S.filename, S.VendorID, S.tpep_pickup_datetime, S.tpep_dropoff_datetime,
S.passenger_count, S.trip_distance, S.RatecodeID, S.store_and_fwd_flag, S.PULocationID,
S.DOLocationID, S.payment_type, S.fare_amount, S.extra, S.mta_tax, S.tip_amount, S.tolls_amount,
S.improvement_surcharge, S.total_amount, S.congestion_surcharge
);
- id: if_green_taxi
type: io.kestra.plugin.core.flow.If
condition: "{{inputs.taxi == 'green'}}"
then:
- id: green_create_table
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
CREATE TABLE IF NOT EXISTS {{render(vars.table)}} (
unique_row_id text,
filename text,
VendorID text,
lpep_pickup_datetime timestamp,
lpep_dropoff_datetime timestamp,
store_and_fwd_flag text,
RatecodeID text,
PULocationID text,
DOLocationID text,
passenger_count integer,
trip_distance double precision,
fare_amount double precision,
extra double precision,
mta_tax double precision,
tip_amount double precision,
tolls_amount double precision,
ehail_fee double precision,
improvement_surcharge double precision,
total_amount double precision,
payment_type integer,
trip_type integer,
congestion_surcharge double precision
);
- id: green_create_staging_table
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
CREATE TABLE IF NOT EXISTS {{render(vars.staging_table)}} (
unique_row_id text,
filename text,
VendorID text,
lpep_pickup_datetime timestamp,
lpep_dropoff_datetime timestamp,
store_and_fwd_flag text,
RatecodeID text,
PULocationID text,
DOLocationID text,
passenger_count integer,
trip_distance double precision,
fare_amount double precision,
extra double precision,
mta_tax double precision,
tip_amount double precision,
tolls_amount double precision,
ehail_fee double precision,
improvement_surcharge double precision,
total_amount double precision,
payment_type integer,
trip_type integer,
congestion_surcharge double precision
);
- id: green_truncate_staging_table
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
TRUNCATE TABLE {{render(vars.staging_table)}};
- id: green_copy_in_to_staging_table
type: io.kestra.plugin.jdbc.postgresql.CopyIn
format: CSV
from: "{{render(vars.data)}}"
table: "{{render(vars.staging_table)}}"
header: true
columns: [VendorID,lpep_pickup_datetime,lpep_dropoff_datetime,store_and_fwd_flag,RatecodeID,PULocationID,DOLocationID,passenger_count,trip_distance,fare_amount,extra,mta_tax,tip_amount,tolls_amount,ehail_fee,improvement_surcharge,total_amount,payment_type,trip_type,congestion_surcharge]
- id: green_add_unique_id_and_filename
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
UPDATE {{render(vars.staging_table)}}
SET
unique_row_id = md5(
COALESCE(CAST(VendorID AS text), '') ||
COALESCE(CAST(lpep_pickup_datetime AS text), '') ||
COALESCE(CAST(lpep_dropoff_datetime AS text), '') ||
COALESCE(PULocationID, '') ||
COALESCE(DOLocationID, '') ||
COALESCE(CAST(fare_amount AS text), '') ||
COALESCE(CAST(trip_distance AS text), '')
),
filename = '{{render(vars.file)}}';
- id: green_merge_data
type: io.kestra.plugin.jdbc.postgresql.Queries
sql: |
MERGE INTO {{render(vars.table)}} AS T
USING {{render(vars.staging_table)}} AS S
ON T.unique_row_id = S.unique_row_id
WHEN NOT MATCHED THEN
INSERT (
unique_row_id, filename, VendorID, lpep_pickup_datetime, lpep_dropoff_datetime,
store_and_fwd_flag, RatecodeID, PULocationID, DOLocationID, passenger_count,
trip_distance, fare_amount, extra, mta_tax, tip_amount, tolls_amount, ehail_fee,
improvement_surcharge, total_amount, payment_type, trip_type, congestion_surcharge
)
VALUES (
S.unique_row_id, S.filename, S.VendorID, S.lpep_pickup_datetime, S.lpep_dropoff_datetime,
S.store_and_fwd_flag, S.RatecodeID, S.PULocationID, S.DOLocationID, S.passenger_count,
S.trip_distance, S.fare_amount, S.extra, S.mta_tax, S.tip_amount, S.tolls_amount, S.ehail_fee,
S.improvement_surcharge, S.total_amount, S.payment_type, S.trip_type, S.congestion_surcharge
);
- id: purge_files
type: io.kestra.plugin.core.storage.PurgeCurrentExecutionFiles
description: To avoid cluttering your storage, we will remove the downloaded files
pluginDefaults:
- type: io.kestra.plugin.jdbc.postgresql
values:
url: jdbc:postgresql://pgdatabase:5432/ny_taxi
username: root
password: root
triggers:
- id: green_schedule
type: io.kestra.plugin.core.trigger.Schedule
cron: "0 9 1 * *"
inputs:
taxi: green
- id: yellow_schedule
type: io.kestra.plugin.core.trigger.Schedule
cron: "0 10 1 * *"
inputs:
taxi: yellow
================================================
FILE: 02-workflow-orchestration/flows/06_gcp_kv.yaml
================================================
id: 06_gcp_kv
namespace: zoomcamp
tasks:
- id: gcp_project_id
type: io.kestra.plugin.core.kv.Set
key: GCP_PROJECT_ID
kvType: STRING
value: kestra-sandbox # TODO replace with your project id
- id: gcp_location
type: io.kestra.plugin.core.kv.Set
key: GCP_LOCATION
kvType: STRING
value: europe-west2
- id: gcp_bucket_name
type: io.kestra.plugin.core.kv.Set
key: GCP_BUCKET_NAME
kvType: STRING
value: your-name-kestra # TODO make sure it's globally unique!
- id: gcp_dataset
type: io.kestra.plugin.core.kv.Set
key: GCP_DATASET
kvType: STRING
value: zoomcamp
================================================
FILE: 02-workflow-orchestration/flows/07_gcp_setup.yaml
================================================
id: 07_gcp_setup
namespace: zoomcamp
tasks:
- id: create_gcs_bucket
type: io.kestra.plugin.gcp.gcs.CreateBucket
ifExists: SKIP
storageClass: REGIONAL
name: "{{kv('GCP_BUCKET_NAME')}}" # make sure it's globally unique!
- id: create_bq_dataset
type: io.kestra.plugin.gcp.bigquery.CreateDataset
name: "{{kv('GCP_DATASET')}}"
ifExists: SKIP
pluginDefaults:
- type: io.kestra.plugin.gcp
values:
serviceAccount: "{{secret('GCP_CREDS')}}"
projectId: "{{kv('GCP_PROJECT_ID')}}"
location: "{{kv('GCP_LOCATION')}}"
bucket: "{{kv('GCP_BUCKET_NAME')}}"
================================================
FILE: 02-workflow-orchestration/flows/08_gcp_taxi.yaml
================================================
id: 08_gcp_taxi
namespace: zoomcamp
description: |
The CSV Data used in the course: https://github.com/DataTalksClub/nyc-tlc-data/releases
inputs:
- id: taxi
type: SELECT
displayName: Select taxi type
values: [yellow, green]
defaults: green
- id: year
type: SELECT
displayName: Select year
values: ["2019", "2020"]
defaults: "2019"
allowCustomValue: true # allows you to type 2021 from the UI for the homework 🤗
- id: month
type: SELECT
displayName: Select month
values: ["01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12"]
defaults: "01"
variables:
file: "{{inputs.taxi}}_tripdata_{{inputs.year}}-{{inputs.month}}.csv"
gcs_file: "gs://{{kv('GCP_BUCKET_NAME')}}/{{vars.file}}"
table: "{{kv('GCP_DATASET')}}.{{inputs.taxi}}_tripdata_{{inputs.year}}_{{inputs.month}}"
data: "{{outputs.extract.outputFiles[inputs.taxi ~ '_tripdata_' ~ inputs.year ~ '-' ~ inputs.month ~ '.csv']}}"
tasks:
- id: set_label
type: io.kestra.plugin.core.execution.Labels
labels:
file: "{{render(vars.file)}}"
taxi: "{{inputs.taxi}}"
- id: extract
type: io.kestra.plugin.scripts.shell.Commands
outputFiles:
- "*.csv"
taskRunner:
type: io.kestra.plugin.core.runner.Process
commands:
- wget -qO- https://github.com/DataTalksClub/nyc-tlc-data/releases/download/{{inputs.taxi}}/{{render(vars.file)}}.gz | gunzip > {{render(vars.file)}}
- id: upload_to_gcs
type: io.kestra.plugin.gcp.gcs.Upload
from: "{{render(vars.data)}}"
to: "{{render(vars.gcs_file)}}"
- id: if_yellow_taxi
type: io.kestra.plugin.core.flow.If
condition: "{{inputs.taxi == 'yellow'}}"
then:
- id: bq_yellow_tripdata
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
CREATE TABLE IF NOT EXISTS `{{kv('GCP_PROJECT_ID')}}.{{kv('GCP_DATASET')}}.yellow_tripdata`
(
unique_row_id BYTES OPTIONS (description = 'A unique identifier for the trip, generated by hashing key trip attributes.'),
filename STRING OPTIONS (description = 'The source filename from which the trip data was loaded.'),
VendorID STRING OPTIONS (description = 'A code indicating the LPEP provider that provided the record. 1= Creative Mobile Technologies, LLC; 2= VeriFone Inc.'),
tpep_pickup_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was engaged'),
tpep_dropoff_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was disengaged'),
passenger_count INTEGER OPTIONS (description = 'The number of passengers in the vehicle. This is a driver-entered value.'),
trip_distance NUMERIC OPTIONS (description = 'The elapsed trip distance in miles reported by the taximeter.'),
RatecodeID STRING OPTIONS (description = 'The final rate code in effect at the end of the trip. 1= Standard rate 2=JFK 3=Newark 4=Nassau or Westchester 5=Negotiated fare 6=Group ride'),
store_and_fwd_flag STRING OPTIONS (description = 'This flag indicates whether the trip record was held in vehicle memory before sending to the vendor, aka "store and forward," because the vehicle did not have a connection to the server. TRUE = store and forward trip, FALSE = not a store and forward trip'),
PULocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was engaged'),
DOLocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was disengaged'),
payment_type INTEGER OPTIONS (description = 'A numeric code signifying how the passenger paid for the trip. 1= Credit card 2= Cash 3= No charge 4= Dispute 5= Unknown 6= Voided trip'),
fare_amount NUMERIC OPTIONS (description = 'The time-and-distance fare calculated by the meter'),
extra NUMERIC OPTIONS (description = 'Miscellaneous extras and surcharges. Currently, this only includes the $0.50 and $1 rush hour and overnight charges'),
mta_tax NUMERIC OPTIONS (description = '$0.50 MTA tax that is automatically triggered based on the metered rate in use'),
tip_amount NUMERIC OPTIONS (description = 'Tip amount. This field is automatically populated for credit card tips. Cash tips are not included.'),
tolls_amount NUMERIC OPTIONS (description = 'Total amount of all tolls paid in trip.'),
improvement_surcharge NUMERIC OPTIONS (description = '$0.30 improvement surcharge assessed on hailed trips at the flag drop. The improvement surcharge began being levied in 2015.'),
total_amount NUMERIC OPTIONS (description = 'The total amount charged to passengers. Does not include cash tips.'),
congestion_surcharge NUMERIC OPTIONS (description = 'Congestion surcharge applied to trips in congested zones')
)
PARTITION BY DATE(tpep_pickup_datetime);
- id: bq_yellow_table_ext
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
CREATE OR REPLACE EXTERNAL TABLE `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}_ext`
(
VendorID STRING OPTIONS (description = 'A code indicating the LPEP provider that provided the record. 1= Creative Mobile Technologies, LLC; 2= VeriFone Inc.'),
tpep_pickup_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was engaged'),
tpep_dropoff_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was disengaged'),
passenger_count INTEGER OPTIONS (description = 'The number of passengers in the vehicle. This is a driver-entered value.'),
trip_distance NUMERIC OPTIONS (description = 'The elapsed trip distance in miles reported by the taximeter.'),
RatecodeID STRING OPTIONS (description = 'The final rate code in effect at the end of the trip. 1= Standard rate 2=JFK 3=Newark 4=Nassau or Westchester 5=Negotiated fare 6=Group ride'),
store_and_fwd_flag STRING OPTIONS (description = 'This flag indicates whether the trip record was held in vehicle memory before sending to the vendor, aka "store and forward," because the vehicle did not have a connection to the server. TRUE = store and forward trip, FALSE = not a store and forward trip'),
PULocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was engaged'),
DOLocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was disengaged'),
payment_type INTEGER OPTIONS (description = 'A numeric code signifying how the passenger paid for the trip. 1= Credit card 2= Cash 3= No charge 4= Dispute 5= Unknown 6= Voided trip'),
fare_amount NUMERIC OPTIONS (description = 'The time-and-distance fare calculated by the meter'),
extra NUMERIC OPTIONS (description = 'Miscellaneous extras and surcharges. Currently, this only includes the $0.50 and $1 rush hour and overnight charges'),
mta_tax NUMERIC OPTIONS (description = '$0.50 MTA tax that is automatically triggered based on the metered rate in use'),
tip_amount NUMERIC OPTIONS (description = 'Tip amount. This field is automatically populated for credit card tips. Cash tips are not included.'),
tolls_amount NUMERIC OPTIONS (description = 'Total amount of all tolls paid in trip.'),
improvement_surcharge NUMERIC OPTIONS (description = '$0.30 improvement surcharge assessed on hailed trips at the flag drop. The improvement surcharge began being levied in 2015.'),
total_amount NUMERIC OPTIONS (description = 'The total amount charged to passengers. Does not include cash tips.'),
congestion_surcharge NUMERIC OPTIONS (description = 'Congestion surcharge applied to trips in congested zones')
)
OPTIONS (
format = 'CSV',
uris = ['{{render(vars.gcs_file)}}'],
skip_leading_rows = 1,
ignore_unknown_values = TRUE
);
- id: bq_yellow_table_tmp
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
CREATE OR REPLACE TABLE `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}`
AS
SELECT
MD5(CONCAT(
COALESCE(CAST(VendorID AS STRING), ""),
COALESCE(CAST(tpep_pickup_datetime AS STRING), ""),
COALESCE(CAST(tpep_dropoff_datetime AS STRING), ""),
COALESCE(CAST(PULocationID AS STRING), ""),
COALESCE(CAST(DOLocationID AS STRING), "")
)) AS unique_row_id,
"{{render(vars.file)}}" AS filename,
*
FROM `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}_ext`;
- id: bq_yellow_merge
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
MERGE INTO `{{kv('GCP_PROJECT_ID')}}.{{kv('GCP_DATASET')}}.yellow_tripdata` T
USING `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}` S
ON T.unique_row_id = S.unique_row_id
WHEN NOT MATCHED THEN
INSERT (unique_row_id, filename, VendorID, tpep_pickup_datetime, tpep_dropoff_datetime, passenger_count, trip_distance, RatecodeID, store_and_fwd_flag, PULocationID, DOLocationID, payment_type, fare_amount, extra, mta_tax, tip_amount, tolls_amount, improvement_surcharge, total_amount, congestion_surcharge)
VALUES (S.unique_row_id, S.filename, S.VendorID, S.tpep_pickup_datetime, S.tpep_dropoff_datetime, S.passenger_count, S.trip_distance, S.RatecodeID, S.store_and_fwd_flag, S.PULocationID, S.DOLocationID, S.payment_type, S.fare_amount, S.extra, S.mta_tax, S.tip_amount, S.tolls_amount, S.improvement_surcharge, S.total_amount, S.congestion_surcharge);
- id: if_green_taxi
type: io.kestra.plugin.core.flow.If
condition: "{{inputs.taxi == 'green'}}"
then:
- id: bq_green_tripdata
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
CREATE TABLE IF NOT EXISTS `{{kv('GCP_PROJECT_ID')}}.{{kv('GCP_DATASET')}}.green_tripdata`
(
unique_row_id BYTES OPTIONS (description = 'A unique identifier for the trip, generated by hashing key trip attributes.'),
filename STRING OPTIONS (description = 'The source filename from which the trip data was loaded.'),
VendorID STRING OPTIONS (description = 'A code indicating the LPEP provider that provided the record. 1= Creative Mobile Technologies, LLC; 2= VeriFone Inc.'),
lpep_pickup_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was engaged'),
lpep_dropoff_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was disengaged'),
store_and_fwd_flag STRING OPTIONS (description = 'This flag indicates whether the trip record was held in vehicle memory before sending to the vendor, aka "store and forward," because the vehicle did not have a connection to the server. Y= store and forward trip N= not a store and forward trip'),
RatecodeID STRING OPTIONS (description = 'The final rate code in effect at the end of the trip. 1= Standard rate 2=JFK 3=Newark 4=Nassau or Westchester 5=Negotiated fare 6=Group ride'),
PULocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was engaged'),
DOLocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was disengaged'),
passenger_count INT64 OPTIONS (description = 'The number of passengers in the vehicle. This is a driver-entered value.'),
trip_distance NUMERIC OPTIONS (description = 'The elapsed trip distance in miles reported by the taximeter.'),
fare_amount NUMERIC OPTIONS (description = 'The time-and-distance fare calculated by the meter'),
extra NUMERIC OPTIONS (description = 'Miscellaneous extras and surcharges. Currently, this only includes the $0.50 and $1 rush hour and overnight charges'),
mta_tax NUMERIC OPTIONS (description = '$0.50 MTA tax that is automatically triggered based on the metered rate in use'),
tip_amount NUMERIC OPTIONS (description = 'Tip amount. This field is automatically populated for credit card tips. Cash tips are not included.'),
tolls_amount NUMERIC OPTIONS (description = 'Total amount of all tolls paid in trip.'),
ehail_fee NUMERIC,
improvement_surcharge NUMERIC OPTIONS (description = '$0.30 improvement surcharge assessed on hailed trips at the flag drop. The improvement surcharge began being levied in 2015.'),
total_amount NUMERIC OPTIONS (description = 'The total amount charged to passengers. Does not include cash tips.'),
payment_type INTEGER OPTIONS (description = 'A numeric code signifying how the passenger paid for the trip. 1= Credit card 2= Cash 3= No charge 4= Dispute 5= Unknown 6= Voided trip'),
trip_type STRING OPTIONS (description = 'A code indicating whether the trip was a street-hail or a dispatch that is automatically assigned based on the metered rate in use but can be altered by the driver. 1= Street-hail 2= Dispatch'),
congestion_surcharge NUMERIC OPTIONS (description = 'Congestion surcharge applied to trips in congested zones')
)
PARTITION BY DATE(lpep_pickup_datetime);
- id: bq_green_table_ext
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
CREATE OR REPLACE EXTERNAL TABLE `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}_ext`
(
VendorID STRING OPTIONS (description = 'A code indicating the LPEP provider that provided the record. 1= Creative Mobile Technologies, LLC; 2= VeriFone Inc.'),
lpep_pickup_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was engaged'),
lpep_dropoff_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was disengaged'),
store_and_fwd_flag STRING OPTIONS (description = 'This flag indicates whether the trip record was held in vehicle memory before sending to the vendor, aka "store and forward," because the vehicle did not have a connection to the server. Y= store and forward trip N= not a store and forward trip'),
RatecodeID STRING OPTIONS (description = 'The final rate code in effect at the end of the trip. 1= Standard rate 2=JFK 3=Newark 4=Nassau or Westchester 5=Negotiated fare 6=Group ride'),
PULocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was engaged'),
DOLocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was disengaged'),
passenger_count INT64 OPTIONS (description = 'The number of passengers in the vehicle. This is a driver-entered value.'),
trip_distance NUMERIC OPTIONS (description = 'The elapsed trip distance in miles reported by the taximeter.'),
fare_amount NUMERIC OPTIONS (description = 'The time-and-distance fare calculated by the meter'),
extra NUMERIC OPTIONS (description = 'Miscellaneous extras and surcharges. Currently, this only includes the $0.50 and $1 rush hour and overnight charges'),
mta_tax NUMERIC OPTIONS (description = '$0.50 MTA tax that is automatically triggered based on the metered rate in use'),
tip_amount NUMERIC OPTIONS (description = 'Tip amount. This field is automatically populated for credit card tips. Cash tips are not included.'),
tolls_amount NUMERIC OPTIONS (description = 'Total amount of all tolls paid in trip.'),
ehail_fee NUMERIC,
improvement_surcharge NUMERIC OPTIONS (description = '$0.30 improvement surcharge assessed on hailed trips at the flag drop. The improvement surcharge began being levied in 2015.'),
total_amount NUMERIC OPTIONS (description = 'The total amount charged to passengers. Does not include cash tips.'),
payment_type INTEGER OPTIONS (description = 'A numeric code signifying how the passenger paid for the trip. 1= Credit card 2= Cash 3= No charge 4= Dispute 5= Unknown 6= Voided trip'),
trip_type STRING OPTIONS (description = 'A code indicating whether the trip was a street-hail or a dispatch that is automatically assigned based on the metered rate in use but can be altered by the driver. 1= Street-hail 2= Dispatch'),
congestion_surcharge NUMERIC OPTIONS (description = 'Congestion surcharge applied to trips in congested zones')
)
OPTIONS (
format = 'CSV',
uris = ['{{render(vars.gcs_file)}}'],
skip_leading_rows = 1,
ignore_unknown_values = TRUE
);
- id: bq_green_table_tmp
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
CREATE OR REPLACE TABLE `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}`
AS
SELECT
MD5(CONCAT(
COALESCE(CAST(VendorID AS STRING), ""),
COALESCE(CAST(lpep_pickup_datetime AS STRING), ""),
COALESCE(CAST(lpep_dropoff_datetime AS STRING), ""),
COALESCE(CAST(PULocationID AS STRING), ""),
COALESCE(CAST(DOLocationID AS STRING), "")
)) AS unique_row_id,
"{{render(vars.file)}}" AS filename,
*
FROM `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}_ext`;
- id: bq_green_merge
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
MERGE INTO `{{kv('GCP_PROJECT_ID')}}.{{kv('GCP_DATASET')}}.green_tripdata` T
USING `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}` S
ON T.unique_row_id = S.unique_row_id
WHEN NOT MATCHED THEN
INSERT (unique_row_id, filename, VendorID, lpep_pickup_datetime, lpep_dropoff_datetime, store_and_fwd_flag, RatecodeID, PULocationID, DOLocationID, passenger_count, trip_distance, fare_amount, extra, mta_tax, tip_amount, tolls_amount, ehail_fee, improvement_surcharge, total_amount, payment_type, trip_type, congestion_surcharge)
VALUES (S.unique_row_id, S.filename, S.VendorID, S.lpep_pickup_datetime, S.lpep_dropoff_datetime, S.store_and_fwd_flag, S.RatecodeID, S.PULocationID, S.DOLocationID, S.passenger_count, S.trip_distance, S.fare_amount, S.extra, S.mta_tax, S.tip_amount, S.tolls_amount, S.ehail_fee, S.improvement_surcharge, S.total_amount, S.payment_type, S.trip_type, S.congestion_surcharge);
- id: purge_files
type: io.kestra.plugin.core.storage.PurgeCurrentExecutionFiles
description: If you'd like to explore Kestra outputs, disable it.
disabled: false
pluginDefaults:
- type: io.kestra.plugin.gcp
values:
serviceAccount: "{{secret('GCP_CREDS')}}"
projectId: "{{kv('GCP_PROJECT_ID')}}"
location: "{{kv('GCP_LOCATION')}}"
bucket: "{{kv('GCP_BUCKET_NAME')}}"
================================================
FILE: 02-workflow-orchestration/flows/09_gcp_taxi_scheduled.yaml
================================================
id: 09_gcp_taxi_scheduled
namespace: zoomcamp
description: |
Best to add a label `backfill:true` from the UI to track executions created via a backfill.
CSV data used here comes from: https://github.com/DataTalksClub/nyc-tlc-data/releases
inputs:
- id: taxi
type: SELECT
displayName: Select taxi type
values: [yellow, green]
defaults: green
variables:
file: "{{inputs.taxi}}_tripdata_{{trigger.date | date('yyyy-MM')}}.csv"
gcs_file: "gs://{{kv('GCP_BUCKET_NAME')}}/{{vars.file}}"
table: "{{kv('GCP_DATASET')}}.{{inputs.taxi}}_tripdata_{{trigger.date | date('yyyy_MM')}}"
data: "{{outputs.extract.outputFiles[inputs.taxi ~ '_tripdata_' ~ (trigger.date | date('yyyy-MM')) ~ '.csv']}}"
tasks:
- id: set_label
type: io.kestra.plugin.core.execution.Labels
labels:
file: "{{render(vars.file)}}"
taxi: "{{inputs.taxi}}"
- id: extract
type: io.kestra.plugin.scripts.shell.Commands
outputFiles:
- "*.csv"
taskRunner:
type: io.kestra.plugin.core.runner.Process
commands:
- wget -qO- https://github.com/DataTalksClub/nyc-tlc-data/releases/download/{{inputs.taxi}}/{{render(vars.file)}}.gz | gunzip > {{render(vars.file)}}
- id: upload_to_gcs
type: io.kestra.plugin.gcp.gcs.Upload
from: "{{render(vars.data)}}"
to: "{{render(vars.gcs_file)}}"
- id: if_yellow_taxi
type: io.kestra.plugin.core.flow.If
condition: "{{inputs.taxi == 'yellow'}}"
then:
- id: bq_yellow_tripdata
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
CREATE TABLE IF NOT EXISTS `{{kv('GCP_PROJECT_ID')}}.{{kv('GCP_DATASET')}}.yellow_tripdata`
(
unique_row_id BYTES OPTIONS (description = 'A unique identifier for the trip, generated by hashing key trip attributes.'),
filename STRING OPTIONS (description = 'The source filename from which the trip data was loaded.'),
VendorID STRING OPTIONS (description = 'A code indicating the LPEP provider that provided the record. 1= Creative Mobile Technologies, LLC; 2= VeriFone Inc.'),
tpep_pickup_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was engaged'),
tpep_dropoff_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was disengaged'),
passenger_count INTEGER OPTIONS (description = 'The number of passengers in the vehicle. This is a driver-entered value.'),
trip_distance NUMERIC OPTIONS (description = 'The elapsed trip distance in miles reported by the taximeter.'),
RatecodeID STRING OPTIONS (description = 'The final rate code in effect at the end of the trip. 1= Standard rate 2=JFK 3=Newark 4=Nassau or Westchester 5=Negotiated fare 6=Group ride'),
store_and_fwd_flag STRING OPTIONS (description = 'This flag indicates whether the trip record was held in vehicle memory before sending to the vendor, aka "store and forward," because the vehicle did not have a connection to the server. TRUE = store and forward trip, FALSE = not a store and forward trip'),
PULocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was engaged'),
DOLocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was disengaged'),
payment_type INTEGER OPTIONS (description = 'A numeric code signifying how the passenger paid for the trip. 1= Credit card 2= Cash 3= No charge 4= Dispute 5= Unknown 6= Voided trip'),
fare_amount NUMERIC OPTIONS (description = 'The time-and-distance fare calculated by the meter'),
extra NUMERIC OPTIONS (description = 'Miscellaneous extras and surcharges. Currently, this only includes the $0.50 and $1 rush hour and overnight charges'),
mta_tax NUMERIC OPTIONS (description = '$0.50 MTA tax that is automatically triggered based on the metered rate in use'),
tip_amount NUMERIC OPTIONS (description = 'Tip amount. This field is automatically populated for credit card tips. Cash tips are not included.'),
tolls_amount NUMERIC OPTIONS (description = 'Total amount of all tolls paid in trip.'),
improvement_surcharge NUMERIC OPTIONS (description = '$0.30 improvement surcharge assessed on hailed trips at the flag drop. The improvement surcharge began being levied in 2015.'),
total_amount NUMERIC OPTIONS (description = 'The total amount charged to passengers. Does not include cash tips.'),
congestion_surcharge NUMERIC OPTIONS (description = 'Congestion surcharge applied to trips in congested zones')
)
PARTITION BY DATE(tpep_pickup_datetime);
- id: bq_yellow_table_ext
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
CREATE OR REPLACE EXTERNAL TABLE `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}_ext`
(
VendorID STRING OPTIONS (description = 'A code indicating the LPEP provider that provided the record. 1= Creative Mobile Technologies, LLC; 2= VeriFone Inc.'),
tpep_pickup_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was engaged'),
tpep_dropoff_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was disengaged'),
passenger_count INTEGER OPTIONS (description = 'The number of passengers in the vehicle. This is a driver-entered value.'),
trip_distance NUMERIC OPTIONS (description = 'The elapsed trip distance in miles reported by the taximeter.'),
RatecodeID STRING OPTIONS (description = 'The final rate code in effect at the end of the trip. 1= Standard rate 2=JFK 3=Newark 4=Nassau or Westchester 5=Negotiated fare 6=Group ride'),
store_and_fwd_flag STRING OPTIONS (description = 'This flag indicates whether the trip record was held in vehicle memory before sending to the vendor, aka "store and forward," because the vehicle did not have a connection to the server. TRUE = store and forward trip, FALSE = not a store and forward trip'),
PULocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was engaged'),
DOLocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was disengaged'),
payment_type INTEGER OPTIONS (description = 'A numeric code signifying how the passenger paid for the trip. 1= Credit card 2= Cash 3= No charge 4= Dispute 5= Unknown 6= Voided trip'),
fare_amount NUMERIC OPTIONS (description = 'The time-and-distance fare calculated by the meter'),
extra NUMERIC OPTIONS (description = 'Miscellaneous extras and surcharges. Currently, this only includes the $0.50 and $1 rush hour and overnight charges'),
mta_tax NUMERIC OPTIONS (description = '$0.50 MTA tax that is automatically triggered based on the metered rate in use'),
tip_amount NUMERIC OPTIONS (description = 'Tip amount. This field is automatically populated for credit card tips. Cash tips are not included.'),
tolls_amount NUMERIC OPTIONS (description = 'Total amount of all tolls paid in trip.'),
improvement_surcharge NUMERIC OPTIONS (description = '$0.30 improvement surcharge assessed on hailed trips at the flag drop. The improvement surcharge began being levied in 2015.'),
total_amount NUMERIC OPTIONS (description = 'The total amount charged to passengers. Does not include cash tips.'),
congestion_surcharge NUMERIC OPTIONS (description = 'Congestion surcharge applied to trips in congested zones')
)
OPTIONS (
format = 'CSV',
uris = ['{{render(vars.gcs_file)}}'],
skip_leading_rows = 1,
ignore_unknown_values = TRUE
);
- id: bq_yellow_table_tmp
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
CREATE OR REPLACE TABLE `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}`
AS
SELECT
MD5(CONCAT(
COALESCE(CAST(VendorID AS STRING), ""),
COALESCE(CAST(tpep_pickup_datetime AS STRING), ""),
COALESCE(CAST(tpep_dropoff_datetime AS STRING), ""),
COALESCE(CAST(PULocationID AS STRING), ""),
COALESCE(CAST(DOLocationID AS STRING), "")
)) AS unique_row_id,
"{{render(vars.file)}}" AS filename,
*
FROM `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}_ext`;
- id: bq_yellow_merge
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
MERGE INTO `{{kv('GCP_PROJECT_ID')}}.{{kv('GCP_DATASET')}}.yellow_tripdata` T
USING `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}` S
ON T.unique_row_id = S.unique_row_id
WHEN NOT MATCHED THEN
INSERT (unique_row_id, filename, VendorID, tpep_pickup_datetime, tpep_dropoff_datetime, passenger_count, trip_distance, RatecodeID, store_and_fwd_flag, PULocationID, DOLocationID, payment_type, fare_amount, extra, mta_tax, tip_amount, tolls_amount, improvement_surcharge, total_amount, congestion_surcharge)
VALUES (S.unique_row_id, S.filename, S.VendorID, S.tpep_pickup_datetime, S.tpep_dropoff_datetime, S.passenger_count, S.trip_distance, S.RatecodeID, S.store_and_fwd_flag, S.PULocationID, S.DOLocationID, S.payment_type, S.fare_amount, S.extra, S.mta_tax, S.tip_amount, S.tolls_amount, S.improvement_surcharge, S.total_amount, S.congestion_surcharge);
- id: if_green_taxi
type: io.kestra.plugin.core.flow.If
condition: "{{inputs.taxi == 'green'}}"
then:
- id: bq_green_tripdata
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
CREATE TABLE IF NOT EXISTS `{{kv('GCP_PROJECT_ID')}}.{{kv('GCP_DATASET')}}.green_tripdata`
(
unique_row_id BYTES OPTIONS (description = 'A unique identifier for the trip, generated by hashing key trip attributes.'),
filename STRING OPTIONS (description = 'The source filename from which the trip data was loaded.'),
VendorID STRING OPTIONS (description = 'A code indicating the LPEP provider that provided the record. 1= Creative Mobile Technologies, LLC; 2= VeriFone Inc.'),
lpep_pickup_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was engaged'),
lpep_dropoff_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was disengaged'),
store_and_fwd_flag STRING OPTIONS (description = 'This flag indicates whether the trip record was held in vehicle memory before sending to the vendor, aka "store and forward," because the vehicle did not have a connection to the server. Y= store and forward trip N= not a store and forward trip'),
RatecodeID STRING OPTIONS (description = 'The final rate code in effect at the end of the trip. 1= Standard rate 2=JFK 3=Newark 4=Nassau or Westchester 5=Negotiated fare 6=Group ride'),
PULocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was engaged'),
DOLocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was disengaged'),
passenger_count INT64 OPTIONS (description = 'The number of passengers in the vehicle. This is a driver-entered value.'),
trip_distance NUMERIC OPTIONS (description = 'The elapsed trip distance in miles reported by the taximeter.'),
fare_amount NUMERIC OPTIONS (description = 'The time-and-distance fare calculated by the meter'),
extra NUMERIC OPTIONS (description = 'Miscellaneous extras and surcharges. Currently, this only includes the $0.50 and $1 rush hour and overnight charges'),
mta_tax NUMERIC OPTIONS (description = '$0.50 MTA tax that is automatically triggered based on the metered rate in use'),
tip_amount NUMERIC OPTIONS (description = 'Tip amount. This field is automatically populated for credit card tips. Cash tips are not included.'),
tolls_amount NUMERIC OPTIONS (description = 'Total amount of all tolls paid in trip.'),
ehail_fee NUMERIC,
improvement_surcharge NUMERIC OPTIONS (description = '$0.30 improvement surcharge assessed on hailed trips at the flag drop. The improvement surcharge began being levied in 2015.'),
total_amount NUMERIC OPTIONS (description = 'The total amount charged to passengers. Does not include cash tips.'),
payment_type INTEGER OPTIONS (description = 'A numeric code signifying how the passenger paid for the trip. 1= Credit card 2= Cash 3= No charge 4= Dispute 5= Unknown 6= Voided trip'),
trip_type STRING OPTIONS (description = 'A code indicating whether the trip was a street-hail or a dispatch that is automatically assigned based on the metered rate in use but can be altered by the driver. 1= Street-hail 2= Dispatch'),
congestion_surcharge NUMERIC OPTIONS (description = 'Congestion surcharge applied to trips in congested zones')
)
PARTITION BY DATE(lpep_pickup_datetime);
- id: bq_green_table_ext
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
CREATE OR REPLACE EXTERNAL TABLE `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}_ext`
(
VendorID STRING OPTIONS (description = 'A code indicating the LPEP provider that provided the record. 1= Creative Mobile Technologies, LLC; 2= VeriFone Inc.'),
lpep_pickup_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was engaged'),
lpep_dropoff_datetime TIMESTAMP OPTIONS (description = 'The date and time when the meter was disengaged'),
store_and_fwd_flag STRING OPTIONS (description = 'This flag indicates whether the trip record was held in vehicle memory before sending to the vendor, aka "store and forward," because the vehicle did not have a connection to the server. Y= store and forward trip N= not a store and forward trip'),
RatecodeID STRING OPTIONS (description = 'The final rate code in effect at the end of the trip. 1= Standard rate 2=JFK 3=Newark 4=Nassau or Westchester 5=Negotiated fare 6=Group ride'),
PULocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was engaged'),
DOLocationID STRING OPTIONS (description = 'TLC Taxi Zone in which the taximeter was disengaged'),
passenger_count INT64 OPTIONS (description = 'The number of passengers in the vehicle. This is a driver-entered value.'),
trip_distance NUMERIC OPTIONS (description = 'The elapsed trip distance in miles reported by the taximeter.'),
fare_amount NUMERIC OPTIONS (description = 'The time-and-distance fare calculated by the meter'),
extra NUMERIC OPTIONS (description = 'Miscellaneous extras and surcharges. Currently, this only includes the $0.50 and $1 rush hour and overnight charges'),
mta_tax NUMERIC OPTIONS (description = '$0.50 MTA tax that is automatically triggered based on the metered rate in use'),
tip_amount NUMERIC OPTIONS (description = 'Tip amount. This field is automatically populated for credit card tips. Cash tips are not included.'),
tolls_amount NUMERIC OPTIONS (description = 'Total amount of all tolls paid in trip.'),
ehail_fee NUMERIC,
improvement_surcharge NUMERIC OPTIONS (description = '$0.30 improvement surcharge assessed on hailed trips at the flag drop. The improvement surcharge began being levied in 2015.'),
total_amount NUMERIC OPTIONS (description = 'The total amount charged to passengers. Does not include cash tips.'),
payment_type INTEGER OPTIONS (description = 'A numeric code signifying how the passenger paid for the trip. 1= Credit card 2= Cash 3= No charge 4= Dispute 5= Unknown 6= Voided trip'),
trip_type STRING OPTIONS (description = 'A code indicating whether the trip was a street-hail or a dispatch that is automatically assigned based on the metered rate in use but can be altered by the driver. 1= Street-hail 2= Dispatch'),
congestion_surcharge NUMERIC OPTIONS (description = 'Congestion surcharge applied to trips in congested zones')
)
OPTIONS (
format = 'CSV',
uris = ['{{render(vars.gcs_file)}}'],
skip_leading_rows = 1,
ignore_unknown_values = TRUE
);
- id: bq_green_table_tmp
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
CREATE OR REPLACE TABLE `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}`
AS
SELECT
MD5(CONCAT(
COALESCE(CAST(VendorID AS STRING), ""),
COALESCE(CAST(lpep_pickup_datetime AS STRING), ""),
COALESCE(CAST(lpep_dropoff_datetime AS STRING), ""),
COALESCE(CAST(PULocationID AS STRING), ""),
COALESCE(CAST(DOLocationID AS STRING), "")
)) AS unique_row_id,
"{{render(vars.file)}}" AS filename,
*
FROM `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}_ext`;
- id: bq_green_merge
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
MERGE INTO `{{kv('GCP_PROJECT_ID')}}.{{kv('GCP_DATASET')}}.green_tripdata` T
USING `{{kv('GCP_PROJECT_ID')}}.{{render(vars.table)}}` S
ON T.unique_row_id = S.unique_row_id
WHEN NOT MATCHED THEN
INSERT (unique_row_id, filename, VendorID, lpep_pickup_datetime, lpep_dropoff_datetime, store_and_fwd_flag, RatecodeID, PULocationID, DOLocationID, passenger_count, trip_distance, fare_amount, extra, mta_tax, tip_amount, tolls_amount, ehail_fee, improvement_surcharge, total_amount, payment_type, trip_type, congestion_surcharge)
VALUES (S.unique_row_id, S.filename, S.VendorID, S.lpep_pickup_datetime, S.lpep_dropoff_datetime, S.store_and_fwd_flag, S.RatecodeID, S.PULocationID, S.DOLocationID, S.passenger_count, S.trip_distance, S.fare_amount, S.extra, S.mta_tax, S.tip_amount, S.tolls_amount, S.ehail_fee, S.improvement_surcharge, S.total_amount, S.payment_type, S.trip_type, S.congestion_surcharge);
- id: purge_files
type: io.kestra.plugin.core.storage.PurgeCurrentExecutionFiles
description: To avoid cluttering your storage, we will remove the downloaded files
pluginDefaults:
- type: io.kestra.plugin.gcp
values:
serviceAccount: "{{secret('GCP_CREDS')}}"
projectId: "{{kv('GCP_PROJECT_ID')}}"
location: "{{kv('GCP_LOCATION')}}"
bucket: "{{kv('GCP_BUCKET_NAME')}}"
triggers:
- id: green_schedule
type: io.kestra.plugin.core.trigger.Schedule
cron: "0 9 1 * *"
inputs:
taxi: green
- id: yellow_schedule
type: io.kestra.plugin.core.trigger.Schedule
cron: "0 10 1 * *"
inputs:
taxi: yellow
================================================
FILE: 02-workflow-orchestration/flows/10_chat_without_rag.yaml
================================================
id: 10_chat_without_rag
namespace: zoomcamp
description: |
This flow demonstrates what happens when you query an LLM WITHOUT RAG.
The model can only rely on its training data, which may be outdated or incomplete.
After running this, check out 11_chat_with_rag.yaml to see how RAG fixes these issues.
tasks:
- id: chat_without_rag
type: io.kestra.plugin.ai.completion.ChatCompletion
description: Query about Kestra 1.1 features WITHOUT RAG
provider:
type: io.kestra.plugin.ai.provider.GoogleGemini
modelName: gemini-2.5-flash
apiKey: "{{ kv('GEMINI_API_KEY') }}"
messages:
- type: USER
content: |
Which features were released in Kestra 1.1?
Please list at least 5 major features with brief descriptions.
- id: log_results
type: io.kestra.plugin.core.log.Log
message: |
❌ Response WITHOUT RAG (no retrieved context):
{{ outputs.chat_without_rag.textOutput }}
🤔 Did you notice that this response seems to be:
- Incorrect
- Vague/generic
- Listing features that haven't been added in exactly this version but rather a long time ago
👉 This is why context matters. Run `11_chat_with_rag.yaml` to see the accurate, context-grounded response.
================================================
FILE: 02-workflow-orchestration/flows/11_chat_with_rag.yaml
================================================
id: 11_chat_with_rag
namespace: zoomcamp
description: |
This flow demonstrates RAG (Retrieval Augmented Generation) by ingesting Kestra release documentation and using it to answer questions accurately.
Compare this with 10_chat_without_rag.yaml to see the difference RAG makes.
tasks:
- id: ingest_release_notes
type: io.kestra.plugin.ai.rag.IngestDocument
description: Ingest Kestra 1.1 release notes to create embeddings
provider:
type: io.kestra.plugin.ai.provider.GoogleGemini
modelName: gemini-embedding-001
apiKey: "{{ kv('GEMINI_API_KEY') }}"
embeddings:
type: io.kestra.plugin.ai.embeddings.KestraKVStore
drop: true
fromExternalURLs:
- https://raw.githubusercontent.com/kestra-io/docs/refs/heads/main/src/contents/blogs/release-1-1/index.md
- id: chat_with_rag
type: io.kestra.plugin.ai.rag.ChatCompletion
description: Query about Kestra 1.1 features with RAG context
chatProvider:
type: io.kestra.plugin.ai.provider.GoogleGemini
modelName: gemini-2.5-flash
apiKey: "{{ kv('GEMINI_API_KEY') }}"
embeddingProvider:
type: io.kestra.plugin.ai.provider.GoogleGemini
modelName: gemini-embedding-001
apiKey: "{{ kv('GEMINI_API_KEY') }}"
embeddings:
type: io.kestra.plugin.ai.embeddings.KestraKVStore
systemMessage: |
You are a helpful assistant that answers questions about Kestra.
Use the provided documentation to give accurate, specific answers.
If you don't find the information in the context, say so.
prompt: |
Which features were released in Kestra 1.1?
Please list at least 5 major features with brief descriptions.
- id: log_results
type: io.kestra.plugin.core.log.Log
message: |
✅ RAG Response (with retrieved context):
{{ outputs.chat_with_rag.textOutput }}
Note that this response is detailed, accurate, and grounded in the actual release documentation. Compare this with the output from 06_chat_without_rag.yaml.
================================================
FILE: 03-data-warehouse/README.md
================================================
# Data Warehouse and BigQuery
- [Slides](https://docs.google.com/presentation/d/1a3ZoBAXFk8-EhUsd7rAZd-5p_HpltkzSeujjRGB2TAI/edit?usp=sharing)
- [Big Query basic SQL](big_query.sql)
# Videos
## Data Warehouse
- Data Warehouse and BigQuery
[](https://youtu.be/jrHljAoD6nM&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=34)
## :movie_camera: Partitioning and clustering
- Partitioning vs Clustering
[](https://youtu.be/-CqXf7vhhDs?si=p1sYQCAs8dAa7jIm&t=193&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=35)
## :movie_camera: Best practices
[](https://youtu.be/k81mLJVX08w&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=36)
## :movie_camera: Internals of BigQuery
[](https://youtu.be/eduHi1inM4s&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=37)
## Advanced topics
### :movie_camera: Machine Learning in Big Query
[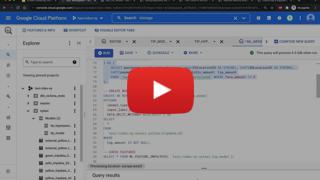](https://youtu.be/B-WtpB0PuG4&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=34)
* [SQL for ML in BigQuery](big_query_ml.sql)
**Important links**
- [BigQuery ML Tutorials](https://cloud.google.com/bigquery-ml/docs/tutorials)
- [BigQuery ML Reference Parameter](https://cloud.google.com/bigquery-ml/docs/analytics-reference-patterns)
- [Hyper Parameter tuning](https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-create-glm)
- [Feature preprocessing](https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-preprocess-overview)
### :movie_camera: Deploying Machine Learning model from BigQuery
[](https://youtu.be/BjARzEWaznU&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=39)
- [Steps to extract and deploy model with docker](extract_model.md)
# Homework
* [2026 Homework](../cohorts/2026/03-data-warehouse/homework.md)
# Community notes
<details>
<summary>Did you take notes? You can share them here</summary>
* [Notes by Alvaro Navas](https://github.com/ziritrion/dataeng-zoomcamp/blob/main/notes/3_data_warehouse.md)
* [Isaac Kargar's blog post](https://kargarisaac.github.io/blog/data%20engineering/jupyter/2022/01/30/data-engineering-w3.html)
* [Marcos Torregrosa's blog post](https://www.n4gash.com/2023/data-engineering-zoomcamp-semana-3/)
* [Notes by Victor Padilha](https://github.com/padilha/de-zoomcamp/tree/master/week3)
* [Notes from Xia He-Bleinagel](https://xiahe-bleinagel.com/2023/02/week-3-data-engineering-zoomcamp-notes-data-warehouse-and-bigquery/)
* [Bigger picture summary on Data Lakes, Data Warehouses, and tooling](https://medium.com/@verazabeida/zoomcamp-week-4-b8bde661bf98), by Vera
* [Notes by froukje](https://github.com/froukje/de-zoomcamp/blob/main/week_3_data_warehouse/notes/notes_week_03.md)
* [Notes by Alain Boisvert](https://github.com/boisalai/de-zoomcamp-2023/blob/main/week3.md)
* [Notes from Vincenzo Galante](https://binchentso.notion.site/Data-Talks-Club-Data-Engineering-Zoomcamp-8699af8e7ff94ec49e6f9bdec8eb69fd)
* [2024 videos transcript week3](https://drive.google.com/drive/folders/1quIiwWO-tJCruqvtlqe_Olw8nvYSmmDJ?usp=sharing) by Maria Fisher
* [Notes by Linda](https://github.com/inner-outer-space/de-zoomcamp-2024/blob/main/3a-data-warehouse/readme.md)
* [Jonah Oliver's blog post](https://www.jonahboliver.com/blog/de-zc-w3)
* [2024 - steps to send data from Mage to GCS + creating external table](https://drive.google.com/file/d/1GIi6xnS4070a8MUlIg-ozITt485_-ePB/view?usp=drive_link) by Maria Fisher
* [2024 - mage dataloader script to load the parquet files from a remote URL and push it to Google bucket as parquet file](https://github.com/amohan601/dataengineering-zoomcamp2024/blob/main/week_3_data_warehouse/mage_scripts/green_taxi_2022_v2.py) by Anju Mohan
* [2024 - steps to send data from Mage to GCS + creating external table](https://drive.google.com/file/d/1GIi6xnS4070a8MUlIg-ozITt485_-ePB/view?usp=drive_link) by Maria Fisher
* [Notes by HongWei](https://github.com/hwchua0209/data-engineering-zoomcamp-submission/blob/main/03-data-warehouse/README.md)
* [2025 Notes by Manuel Guerra](https://github.com/ManuelGuerra1987/data-engineering-zoomcamp-notes/blob/main/3_Data-Warehouse/README.md)
* [Notes from Horeb SEIDOU](https://spotted-hardhat-eea.notion.site/Week-3-Data-Warehouse-and-BigQuery-17c29780dc4a80c8a226f372543ae388)
* [2025 - Notes by Gabi Fonseca](https://github.com/fonsecagabriella/data_engineering/blob/main/03_data_warehouse/00_notes.md)
* [2025 Gitbook Notes Tinker0425](https://data-engineering-zoomcamp-2025-t.gitbook.io/tinker0425/module-3/introduction-to-module-3)
* [2025 Notes from Daniel Lachner](https://drive.google.com/file/d/105zjtLFi0sRqqFFgdMSCTzfcLPx2rfv4/view?usp=sharing)
* [2026 Notes from Catherine Frost](https://docs.google.com/document/d/1j3jeNnBI2fw1nq7JwEauPx2G8FybDfTqmMk7eRu0vSo/edit?tab=t.0)
* Add your notes here (above this line)
</details>
================================================
FILE: 03-data-warehouse/big_query.sql
================================================
-- Query public available table
SELECT station_id, name FROM
bigquery-public-data.new_york_citibike.citibike_stations
LIMIT 100;
-- Creating external table referring to gcs path
CREATE OR REPLACE EXTERNAL TABLE `taxi-rides-ny.nytaxi.external_yellow_tripdata`
OPTIONS (
format = 'CSV',
uris = ['gs://nyc-tl-data/trip data/yellow_tripdata_2019-*.csv', 'gs://nyc-tl-data/trip data/yellow_tripdata_2020-*.csv']
);
-- Check yellow trip data
SELECT * FROM taxi-rides-ny.nytaxi.external_yellow_tripdata limit 10;
-- Create a non partitioned table from external table
CREATE OR REPLACE TABLE taxi-rides-ny.nytaxi.yellow_tripdata_non_partitioned AS
SELECT * FROM taxi-rides-ny.nytaxi.external_yellow_tripdata;
-- Create a partitioned table from external table
CREATE OR REPLACE TABLE taxi-rides-ny.nytaxi.yellow_tripdata_partitioned
PARTITION BY
DATE(tpep_pickup_datetime) AS
SELECT * FROM taxi-rides-ny.nytaxi.external_yellow_tripdata;
-- Impact of partition
-- Scanning 1.6GB of data
SELECT DISTINCT(VendorID)
FROM taxi-rides-ny.nytaxi.yellow_tripdata_non_partitioned
WHERE DATE(tpep_pickup_datetime) BETWEEN '2019-06-01' AND '2019-06-30';
-- Scanning ~106 MB of DATA
SELECT DISTINCT(VendorID)
FROM taxi-rides-ny.nytaxi.yellow_tripdata_partitioned
WHERE DATE(tpep_pickup_datetime) BETWEEN '2019-06-01' AND '2019-06-30';
-- Let's look into the partitions
SELECT table_name, partition_id, total_rows
FROM `nytaxi.INFORMATION_SCHEMA.PARTITIONS`
WHERE table_name = 'yellow_tripdata_partitioned'
ORDER BY total_rows DESC;
-- Creating a partition and cluster table
CREATE OR REPLACE TABLE taxi-rides-ny.nytaxi.yellow_tripdata_partitioned_clustered
PARTITION BY DATE(tpep_pickup_datetime)
CLUSTER BY VendorID AS
SELECT * FROM taxi-rides-ny.nytaxi.external_yellow_tripdata;
-- Query scans 1.1 GB
SELECT count(*) as trips
FROM taxi-rides-ny.nytaxi.yellow_tripdata_partitioned
WHERE DATE(tpep_pickup_datetime) BETWEEN '2019-06-01' AND '2020-12-31'
AND VendorID=1;
-- Query scans 864.5 MB
SELECT count(*) as trips
FROM taxi-rides-ny.nytaxi.yellow_tripdata_partitioned_clustered
WHERE DATE(tpep_pickup_datetime) BETWEEN '2019-06-01' AND '2020-12-31'
AND VendorID=1;
================================================
FILE: 03-data-warehouse/big_query_hw.sql
================================================
CREATE OR REPLACE EXTERNAL TABLE `taxi-rides-ny.nytaxi.fhv_tripdata`
OPTIONS (
format = 'CSV',
uris = ['gs://nyc-tl-data/trip data/fhv_tripdata_2019-*.csv']
);
SELECT count(*) FROM `taxi-rides-ny.nytaxi.fhv_tripdata`;
SELECT COUNT(DISTINCT(dispatching_base_num)) FROM `taxi-rides-ny.nytaxi.fhv_tripdata`;
CREATE OR REPLACE TABLE `taxi-rides-ny.nytaxi.fhv_nonpartitioned_tripdata`
AS SELECT * FROM `taxi-rides-ny.nytaxi.fhv_tripdata`;
CREATE OR REPLACE TABLE `taxi-rides-ny.nytaxi.fhv_partitioned_tripdata`
PARTITION BY DATE(dropoff_datetime)
CLUSTER BY dispatching_base_num AS (
SELECT * FROM `taxi-rides-ny.nytaxi.fhv_tripdata`
);
SELECT count(*) FROM `taxi-rides-ny.nytaxi.fhv_nonpartitioned_tripdata`
WHERE DATE(dropoff_datetime) BETWEEN '2019-01-01' AND '2019-03-31'
AND dispatching_base_num IN ('B00987', 'B02279', 'B02060');
SELECT count(*) FROM `taxi-rides-ny.nytaxi.fhv_partitioned_tripdata`
WHERE DATE(dropoff_datetime) BETWEEN '2019-01-01' AND '2019-03-31'
AND dispatching_base_num IN ('B00987', 'B02279', 'B02060');
================================================
FILE: 03-data-warehouse/big_query_ml.sql
================================================
-- SELECT THE COLUMNS INTERESTED FOR YOU
SELECT passenger_count, trip_distance, PULocationID, DOLocationID, payment_type, fare_amount, tolls_amount, tip_amount
FROM `taxi-rides-ny.nytaxi.yellow_tripdata_partitioned` WHERE fare_amount != 0;
-- CREATE A ML TABLE WITH APPROPRIATE TYPE
CREATE OR REPLACE TABLE `taxi-rides-ny.nytaxi.yellow_tripdata_ml` (
`passenger_count` INTEGER,
`trip_distance` FLOAT64,
`PULocationID` STRING,
`DOLocationID` STRING,
`payment_type` STRING,
`fare_amount` FLOAT64,
`tolls_amount` FLOAT64,
`tip_amount` FLOAT64
) AS (
SELECT passenger_count, trip_distance, cast(PULocationID AS STRING), CAST(DOLocationID AS STRING),
CAST(payment_type AS STRING), fare_amount, tolls_amount, tip_amount
FROM `taxi-rides-ny.nytaxi.yellow_tripdata_partitioned` WHERE fare_amount != 0
);
-- CREATE MODEL WITH DEFAULT SETTING
CREATE OR REPLACE MODEL `taxi-rides-ny.nytaxi.tip_model`
OPTIONS
(model_type='linear_reg',
input_label_cols=['tip_amount'],
DATA_SPLIT_METHOD='AUTO_SPLIT') AS
SELECT
*
FROM
`taxi-rides-ny.nytaxi.yellow_tripdata_ml`
WHERE
tip_amount IS NOT NULL;
-- CHECK FEATURES
SELECT * FROM ML.FEATURE_INFO(MODEL `taxi-rides-ny.nytaxi.tip_model`);
-- EVALUATE THE MODEL
SELECT
*
FROM
ML.EVALUATE(MODEL `taxi-rides-ny.nytaxi.tip_model`,
(
SELECT
*
FROM
`taxi-rides-ny.nytaxi.yellow_tripdata_ml`
WHERE
tip_amount IS NOT NULL
));
-- PREDICT THE MODEL
SELECT
*
FROM
ML.PREDICT(MODEL `taxi-rides-ny.nytaxi.tip_model`,
(
SELECT
*
FROM
`taxi-rides-ny.nytaxi.yellow_tripdata_ml`
WHERE
tip_amount IS NOT NULL
));
-- PREDICT AND EXPLAIN
SELECT
*
FROM
ML.EXPLAIN_PREDICT(MODEL `taxi-rides-ny.nytaxi.tip_model`,
(
SELECT
*
FROM
`taxi-rides-ny.nytaxi.yellow_tripdata_ml`
WHERE
tip_amount IS NOT NULL
), STRUCT(3 as top_k_features));
-- HYPER PARAM TUNNING
CREATE OR REPLACE MODEL `taxi-rides-ny.nytaxi.tip_hyperparam_model`
OPTIONS
(model_type='linear_reg',
input_label_cols=['tip_amount'],
DATA_SPLIT_METHOD='AUTO_SPLIT',
num_trials=5,
max_parallel_trials=2,
l1_reg=hparam_range(0, 20),
l2_reg=hparam_candidates([0, 0.1, 1, 10])) AS
SELECT
*
FROM
`taxi-rides-ny.nytaxi.yellow_tripdata_ml`
WHERE
tip_amount IS NOT NULL;
================================================
FILE: 03-data-warehouse/extract_model.md
================================================
## Model deployment
[Tutorial](https://cloud.google.com/bigquery-ml/docs/export-model-tutorial)
### Steps
- gcloud auth login
- bq --project_id taxi-rides-ny extract -m nytaxi.tip_model gs://taxi_ml_model/tip_model
- mkdir /tmp/model
- gsutil cp -r gs://taxi_ml_model/tip_model /tmp/model
- mkdir -p serving_dir/tip_model/1
- cp -r /tmp/model/tip_model/* serving_dir/tip_model/1
- docker pull tensorflow/serving
- docker run -p 8501:8501 --mount type=bind,source=`pwd`/serving_dir/tip_model,target=
/models/tip_model -e MODEL_NAME=tip_model -t tensorflow/serving &
- curl -d '{"instances": [{"passenger_count":1, "trip_distance":12.2, "PULocationID":"193", "DOLocationID":"264", "payment_type":"2","fare_amount":20.4,"tolls_amount":0.0}]}' -X POST http://localhost:8501/v1/models/tip_model:predict
- http://localhost:8501/v1/models/tip_model
================================================
FILE: 03-data-warehouse/extras/.env-example
================================================
GCP_GCS_BUCKET="your_bucket_name"
GOOGLE_APPLICATION_CREDENTIALS=Path/to/key/GCP_service_account_key.json
================================================
FILE: 03-data-warehouse/extras/.gitignore
================================================
*.env
*.parquet
*.csv*
================================================
FILE: 03-data-warehouse/extras/README.md
================================================
Quick hack to load files directly to GCS, without Airflow. Downloads csv files from https://nyc-tlc.s3.amazonaws.com/trip+data/ and uploads them to your Cloud Storage Account as parquet files.
1. Install pre-reqs with `uv sync`
2. Run: `uv run python web_to_gcs_with_progress_bar.py`
2. or Run: `uv run python web_to_gcs.py` for less verbose (if you have fast internet connection in upload)
================================================
FILE: 03-data-warehouse/extras/pyproject.toml
================================================
[project]
name = "extras"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.14"
dependencies = [
"google-cloud-storage>=3.8.0",
"pandas>=3.0.0",
"pyarrow>=23.0.0",
"python-dotenv>=1.2.1",
"requests>=2.32.5",
"tqdm>=4.67.1",
]
================================================
FILE: 03-data-warehouse/extras/web_to_gcs.py
================================================
import os
import requests
import pandas as pd
from google.cloud import storage
from dotenv import load_dotenv
"""
Pre-reqs:
1. run `uv sync` from this 'extra' folder (create venv and install dependencies from pyproject.toml)
2. rename .env-example to .env (not commited thanks to .gitignore)
3. in .env,
- set GCP_GCS_BUCKET as your bucket or change default value of BUCKET
- Set GOOGLE_APPLICATION_CREDENTIALS to your project/service-account json key
(or don't set it if you use google ADC)
"""
# load env vars from .env
load_dotenv()
# services = ['fhv','green','yellow']
init_url = "https://github.com/DataTalksClub/nyc-tlc-data/releases/download/"
# if not done in .env, switch out the default bucketname
BUCKET = os.environ.get("GCP_GCS_BUCKET", "dtc-data-lake-bucketname")
def upload_to_gcs(bucket, object_name, local_file):
"""
Ref: https://cloud.google.com/storage/docs/uploading-objects#storage-upload-object-python
"""
# # WORKAROUND to prevent timeout for files > 6 MB on 800 kbps upload speed.
# # (Ref: https://github.com/googleapis/python-storage/issues/74)
# storage.blob._MAX_MULTIPART_SIZE = 5 * 1024 * 1024 # 5 MB
# storage.blob._DEFAULT_CHUNKSIZE = 5 * 1024 * 1024 # 5 MB
client = storage.Client()
bucket = client.bucket(bucket)
blob = bucket.blob(object_name)
blob.upload_from_filename(local_file)
def web_to_gcs(year, service):
for i in range(12):
# sets the month part of the file_name string
month = "0" + str(i + 1)
month = month[-2:]
# csv file_name
file_name = f"{service}_tripdata_{year}-{month}.csv.gz"
# download it using requests via a pandas df
request_url = f"{init_url}{service}/{file_name}"
r = requests.get(request_url)
open(file_name, "wb").write(r.content)
print(f"Local: {file_name}")
# read it back into a parquet file
# enforce types so parquet columns will directly have good types
# (as we did in module 1 in ingest.py script)
dtypes = {
"VendorID": "Int64",
"RatecodeID": "Int64",
"PULocationID": "Int64",
"DOLocationID": "Int64",
"passenger_count": "Int64",
"payment_type": "Int64",
"trip_type": "Int64", # only in green but ignored if missing column
"store_and_fwd_flag": "string",
"trip_distance": "float64",
"fare_amount": "float64",
"extra": "float64",
"mta_tax": "float64",
"tip_amount": "float64",
"tolls_amount": "float64",
"ehailfee": "float64", # only in green but ignored if missing column
"improvement_surcharge": "float64",
"total_amount": "float64",
"congestion_surcharge": "float64",
}
if service == "yellow":
parse_dates = ["tpep_pickup_datetime", "tpep_dropoff_datetime"]
else:
parse_dates = ["lpep_pickup_datetime", "lpep_dropoff_datetime"]
df = pd.read_csv(
file_name, dtype=dtypes, parse_dates=parse_dates, compression="gzip"
)
file_name = file_name.replace(".csv.gz", ".parquet")
df.to_parquet(file_name, engine="pyarrow")
print(f"Parquet: {file_name}")
# upload it to gcs
upload_to_gcs(BUCKET, f"{service}/{file_name}", file_name)
print(f"GCS: {service}/{file_name}")
web_to_gcs("2019", "green")
web_to_gcs("2020", "green")
web_to_gcs("2021", "green") # fail when reach 08 (normal, file not in github :)
# web_to_gcs("2019", "yellow")
# web_to_gcs("2020", "yellow")
# web_to_gcs("2021", "yellow") # fail when reach 08 (normal, file not in github :)
================================================
FILE: 03-data-warehouse/extras/web_to_gcs_with_progress_bar.py
================================================
import os
import requests
import pandas as pd
from google.cloud import storage
from dotenv import load_dotenv
from tqdm import tqdm
import gzip
import pyarrow as pa
import pyarrow.parquet as pq
"""
Pre-reqs:
1. run `uv sync` from this 'extra' folder (create venv and install dependencies from pyproject.toml)
2. rename .env-example to .env (not commited thanks to .gitignore)
3. in .env,
- set GCP_GCS_BUCKET as your bucket or change default value of BUCKET
- Set GOOGLE_APPLICATION_CREDENTIALS to your project/service-account json key
(or don't set it if you use google ADC)
"""
# load env vars from .env
load_dotenv()
# services = ['fhv','green','yellow']
init_url = "https://github.com/DataTalksClub/nyc-tlc-data/releases/download/"
# if not done in .env, switch out the default bucketname
BUCKET = os.environ.get("GCP_GCS_BUCKET", "dtc-data-lake-bucketname")
def download_with_progress(url: str, local_path: str, desc: str = "Downloading"):
with requests.get(url, stream=True) as r:
r.raise_for_status()
total = int(r.headers.get("content-length", 0))
# Configure tqdm for bytes
with (
open(local_path, "wb") as f,
tqdm(
total=total,
unit="B",
unit_scale=True,
unit_divisor=1024,
desc=desc,
) as bar,
):
for chunk in r.iter_content(chunk_size=1024 * 1024): # 1 MB
if not chunk:
continue
size = f.write(chunk)
bar.update(size)
def csv_to_parquet_with_progress(
csv_path: str, parquet_path: str, service_color: str, chunksize: int = 100_000
):
# 1) Count rows (gzip-aware)
with gzip.open(csv_path, mode="rt") as f:
total_rows = sum(1 for _ in f) - 1 # minus header
if total_rows <= 0:
raise ValueError("CSV appears to be empty")
# 2) Read in chunks with fixed dtypes so parquet
gitextract_ffam8vtv/ ├── .github/ │ └── FUNDING.yml ├── .gitignore ├── 01-docker-terraform/ │ ├── README.md │ ├── docker-sql/ │ │ ├── 01-introduction.md │ │ ├── 02-virtual-environment.md │ │ ├── 03-dockerizing-pipeline.md │ │ ├── 04-postgres-docker.md │ │ ├── 05-data-ingestion.md │ │ ├── 06-ingestion-script.md │ │ ├── 07-pgadmin.md │ │ ├── 08-dockerizing-ingestion.md │ │ ├── 09-docker-compose.md │ │ ├── 10-sql-refresher.md │ │ ├── 11-cleanup.md │ │ ├── README.md │ │ └── pipeline/ │ │ ├── .python-version │ │ ├── Dockerfile │ │ ├── docker-compose.yaml │ │ ├── docker-helper-scripts/ │ │ │ ├── docker-ingest.sh │ │ │ ├── docker-pgadmin.sh │ │ │ └── docker-postgres.sh │ │ ├── ingest_data.py │ │ └── pyproject.toml │ └── terraform/ │ ├── 1_terraform_overview.md │ ├── 2_gcp_overview.md │ ├── README.md │ ├── terraform/ │ │ ├── README.md │ │ ├── terraform_basic/ │ │ │ └── main.tf │ │ ├── terraform_with_variable_AWS/ │ │ │ ├── README.md │ │ │ ├── main.tf │ │ │ ├── terraform.tfvars │ │ │ └── variables.tf │ │ └── terraform_with_variables/ │ │ ├── main.tf │ │ └── variables.tf │ └── windows.md ├── 02-workflow-orchestration/ │ ├── README.md │ ├── docker-compose.yml │ └── flows/ │ ├── 01_hello_world.yaml │ ├── 02_python.yaml │ ├── 03_getting_started_data_pipeline.yaml │ ├── 04_postgres_taxi.yaml │ ├── 05_postgres_taxi_scheduled.yaml │ ├── 06_gcp_kv.yaml │ ├── 07_gcp_setup.yaml │ ├── 08_gcp_taxi.yaml │ ├── 09_gcp_taxi_scheduled.yaml │ ├── 10_chat_without_rag.yaml │ └── 11_chat_with_rag.yaml ├── 03-data-warehouse/ │ ├── README.md │ ├── big_query.sql │ ├── big_query_hw.sql │ ├── big_query_ml.sql │ ├── extract_model.md │ └── extras/ │ ├── .env-example │ ├── .gitignore │ ├── README.md │ ├── pyproject.toml │ ├── web_to_gcs.py │ └── web_to_gcs_with_progress_bar.py ├── 04-analytics-engineering/ │ ├── README.md │ ├── class_notes/ │ │ ├── 4_1_1_analytics_engineering_basics.md │ │ ├── 4_1_2_what_is_dbt.md │ │ ├── 4_2_1_dbt_core_vs_dbt_cloud.md │ │ ├── 4_3_1_dbt_project_structure.md │ │ ├── 4_3_2_dbt_sources.md │ │ ├── 4_4_1_dbt_models.md │ │ ├── 4_4_2_dbt_seeds_and_macros.md │ │ ├── 4_5_1_documentation.md │ │ ├── 4_5_2_dbt_tests.md │ │ ├── 4_5_3_dbt_packages.md │ │ └── 4_6_1_dbt_commands.md │ ├── refreshers/ │ │ └── SQL.md │ ├── setup/ │ │ ├── cloud_setup.md │ │ ├── duckdb_troubleshooting.md │ │ └── local_setup.md │ └── taxi_rides_ny/ │ ├── .gitignore │ ├── dbt_project.yml │ ├── macros/ │ │ ├── get_trip_duration_minutes.sql │ │ ├── get_vendor_data.sql │ │ ├── macros_properties.yml │ │ └── safe_cast.sql │ ├── models/ │ │ ├── intermediate/ │ │ │ ├── int_trips.sql │ │ │ ├── int_trips_unioned.sql │ │ │ └── schema.yml │ │ ├── marts/ │ │ │ ├── dim_vendors.sql │ │ │ ├── dim_zones.sql │ │ │ ├── fct_trips.sql │ │ │ ├── reporting/ │ │ │ │ ├── fct_monthly_zone_revenue.sql │ │ │ │ └── schema.yml │ │ │ └── schema.yml │ │ └── staging/ │ │ ├── schema.yml │ │ ├── sources.yml │ │ ├── stg_green_tripdata.sql │ │ └── stg_yellow_tripdata.sql │ ├── package-lock.yml │ ├── packages.yml │ ├── seeds/ │ │ └── seeds_properties.yml │ ├── snapshots/ │ │ └── .gitkeep │ └── tests/ │ └── .gitkeep ├── 05-data-platforms/ │ ├── README.md │ └── notes/ │ ├── 01-introduction.md │ ├── 02-getting-started.md │ ├── 03-nyc-taxi-pipeline.md │ ├── 04-bruin-mcp.md │ ├── 05-bruin-cloud.md │ ├── 06-core-01-projects.md │ ├── 06-core-02-pipelines.md │ ├── 06-core-03-assets.md │ ├── 06-core-04-variables.md │ └── 06-core-05-commands.md ├── 06-batch/ │ ├── .gitignore │ ├── README.md │ ├── code/ │ │ ├── 03_test.ipynb │ │ ├── 04_pyspark.ipynb │ │ ├── 05_taxi_schema.ipynb │ │ ├── 06_spark_sql.ipynb │ │ ├── 06_spark_sql.py │ │ ├── 06_spark_sql_big_query.py │ │ ├── 07_groupby_join.ipynb │ │ ├── 08_rdds.ipynb │ │ ├── 09_spark_gcs.ipynb │ │ ├── cloud.md │ │ ├── download_data.sh │ │ └── homework.ipynb │ └── setup/ │ ├── config/ │ │ ├── core-site.xml │ │ ├── spark-defaults.conf │ │ └── spark.dockerfile │ ├── hadoop-yarn.md │ ├── linux.md │ ├── macos.md │ └── windows.md ├── 07-streaming/ │ ├── .gitignore │ ├── README.md │ ├── extras/ │ │ ├── README.md │ │ ├── ksqldb/ │ │ │ └── commands.md │ │ ├── pyflink/ │ │ │ ├── .gitignore │ │ │ ├── Dockerfile.flink │ │ │ ├── LICENSE │ │ │ ├── Makefile │ │ │ ├── README.md │ │ │ ├── docker-compose.yml │ │ │ ├── homework.md │ │ │ ├── requirements.txt │ │ │ └── src/ │ │ │ ├── job/ │ │ │ │ ├── aggregation_job.py │ │ │ │ ├── start_job.py │ │ │ │ └── taxi_job.py │ │ │ └── producers/ │ │ │ ├── load_taxi_data.py │ │ │ └── producer.py │ │ └── python/ │ │ ├── README.md │ │ ├── avro_example/ │ │ │ ├── consumer.py │ │ │ ├── producer.py │ │ │ ├── ride_record.py │ │ │ ├── ride_record_key.py │ │ │ └── settings.py │ │ ├── docker/ │ │ │ ├── README.md │ │ │ ├── docker-compose.yml │ │ │ ├── kafka/ │ │ │ │ └── docker-compose.yml │ │ │ └── spark/ │ │ │ ├── build.sh │ │ │ ├── cluster-base.Dockerfile │ │ │ ├── docker-compose.yml │ │ │ ├── jupyterlab.Dockerfile │ │ │ ├── spark-base.Dockerfile │ │ │ ├── spark-master.Dockerfile │ │ │ └── spark-worker.Dockerfile │ │ ├── json_example/ │ │ │ ├── consumer.py │ │ │ ├── producer.py │ │ │ ├── ride.py │ │ │ └── settings.py │ │ ├── redpanda_example/ │ │ │ ├── README.md │ │ │ ├── consumer.py │ │ │ ├── docker-compose.yaml │ │ │ ├── producer.py │ │ │ ├── ride.py │ │ │ └── settings.py │ │ ├── requirements.txt │ │ ├── resources/ │ │ │ └── schemas/ │ │ │ ├── taxi_ride_key.avsc │ │ │ └── taxi_ride_value.avsc │ │ └── streams-example/ │ │ ├── faust/ │ │ │ ├── branch_price.py │ │ │ ├── producer_taxi_json.py │ │ │ ├── stream.py │ │ │ ├── stream_count_vendor_trips.py │ │ │ ├── taxi_rides.py │ │ │ └── windowing.py │ │ ├── pyspark/ │ │ │ ├── README.md │ │ │ ├── consumer.py │ │ │ ├── producer.py │ │ │ ├── settings.py │ │ │ ├── spark-submit.sh │ │ │ ├── streaming-notebook.ipynb │ │ │ └── streaming.py │ │ └── redpanda/ │ │ ├── README.md │ │ ├── consumer.py │ │ ├── docker-compose.yaml │ │ ├── producer.py │ │ ├── settings.py │ │ ├── spark-submit.sh │ │ ├── streaming-notebook.ipynb │ │ └── streaming.py │ ├── theory/ │ │ ├── README.md │ │ └── java/ │ │ └── kafka_examples/ │ │ ├── .gitignore │ │ ├── build/ │ │ │ └── generated-main-avro-java/ │ │ │ └── schemaregistry/ │ │ │ ├── RideRecord.java │ │ │ ├── RideRecordCompatible.java │ │ │ └── RideRecordNoneCompatible.java │ │ ├── build.gradle │ │ ├── gradle/ │ │ │ └── wrapper/ │ │ │ ├── gradle-wrapper.jar │ │ │ └── gradle-wrapper.properties │ │ ├── gradlew │ │ ├── gradlew.bat │ │ ├── settings.gradle │ │ └── src/ │ │ ├── main/ │ │ │ ├── avro/ │ │ │ │ ├── rides.avsc │ │ │ │ ├── rides_compatible.avsc │ │ │ │ └── rides_non_compatible.avsc │ │ │ └── java/ │ │ │ └── org/ │ │ │ └── example/ │ │ │ ├── AvroProducer.java │ │ │ ├── JsonConsumer.java │ │ │ ├── JsonKStream.java │ │ │ ├── JsonKStreamJoins.java │ │ │ ├── JsonKStreamWindow.java │ │ │ ├── JsonProducer.java │ │ │ ├── JsonProducerPickupLocation.java │ │ │ ├── Secrets.java │ │ │ ├── Topics.java │ │ │ ├── customserdes/ │ │ │ │ └── CustomSerdes.java │ │ │ └── data/ │ │ │ ├── PickupLocation.java │ │ │ ├── Ride.java │ │ │ └── VendorInfo.java │ │ └── test/ │ │ └── java/ │ │ └── org/ │ │ └── example/ │ │ ├── JsonKStreamJoinsTest.java │ │ ├── JsonKStreamTest.java │ │ └── helper/ │ │ └── DataGeneratorHelper.java │ └── workshop/ │ ├── .python-version │ ├── Dockerfile.flink │ ├── Dockerfile_ARM64.flink │ ├── Makefile │ ├── README.md │ ├── docker-compose.yml │ ├── flink-config.yaml │ ├── live/ │ │ ├── .gitignore │ │ ├── .python-version │ │ ├── Dockerfile.flink │ │ ├── README.md │ │ ├── docker-compose.yaml │ │ ├── flink-config.yaml │ │ ├── main.py │ │ ├── notebooks/ │ │ │ ├── consumer_db.ipynb │ │ │ ├── models.py │ │ │ └── producer.ipynb │ │ ├── pyproject.flink.toml │ │ ├── pyproject.toml │ │ └── src/ │ │ ├── job/ │ │ │ ├── aggregation_job.py │ │ │ └── pass_through_job.py │ │ └── producers/ │ │ ├── models.py │ │ └── producer_realtime.py │ ├── pyproject.flink.toml │ ├── pyproject.toml │ └── src/ │ ├── consumers/ │ │ ├── consumer.py │ │ └── consumer_postgres.py │ ├── job/ │ │ ├── aggregation_job.py │ │ ├── aggregation_job_demo.py │ │ └── pass_through_job.py │ ├── models.py │ └── producers/ │ ├── producer.py │ └── producer_realtime.py ├── README.md ├── after-sign-up.md ├── asking-questions.md ├── awesome-data-engineering.md ├── certificates.md ├── cohorts/ │ ├── 2022/ │ │ ├── README.md │ │ ├── project.md │ │ ├── week_1_basics_n_setup/ │ │ │ └── homework.md │ │ ├── week_2_data_ingestion/ │ │ │ ├── README.md │ │ │ ├── airflow/ │ │ │ │ ├── .env_example │ │ │ │ ├── 1_setup_official.md │ │ │ │ ├── 2_setup_nofrills.md │ │ │ │ ├── Dockerfile │ │ │ │ ├── README.md │ │ │ │ ├── dags/ │ │ │ │ │ └── data_ingestion_gcs_dag.py │ │ │ │ ├── dags_local/ │ │ │ │ │ ├── data_ingestion_local.py │ │ │ │ │ └── ingest_script.py │ │ │ │ ├── docker-compose-nofrills.yml │ │ │ │ ├── docker-compose.yaml │ │ │ │ ├── docker-compose_2.3.4.yaml │ │ │ │ ├── docs/ │ │ │ │ │ └── 1_concepts.md │ │ │ │ ├── extras/ │ │ │ │ │ ├── data_ingestion_gcs_dag_ex2.py │ │ │ │ │ └── web_to_gcs.sh │ │ │ │ ├── requirements.txt │ │ │ │ └── scripts/ │ │ │ │ └── entrypoint.sh │ │ │ ├── homework/ │ │ │ │ ├── homework.md │ │ │ │ └── solution.py │ │ │ └── transfer_service/ │ │ │ └── README.md │ │ ├── week_3_data_warehouse/ │ │ │ └── airflow/ │ │ │ ├── .env_example │ │ │ ├── 1_setup_official.md │ │ │ ├── 2_setup_nofrills.md │ │ │ ├── README.md │ │ │ ├── dags/ │ │ │ │ └── gcs_to_bq_dag.py │ │ │ ├── docker-compose-nofrills.yml │ │ │ ├── docker-compose.yaml │ │ │ └── scripts/ │ │ │ └── entrypoint.sh │ │ ├── week_5_batch_processing/ │ │ │ └── homework.md │ │ └── week_6_stream_processing/ │ │ └── homework.md │ ├── 2023/ │ │ ├── README.md │ │ ├── leaderboard.md │ │ ├── project.md │ │ ├── week_1_docker_sql/ │ │ │ └── homework.md │ │ ├── week_1_terraform/ │ │ │ └── homework.md │ │ ├── week_2_workflow_orchestration/ │ │ │ ├── README.md │ │ │ └── homework.md │ │ ├── week_3_data_warehouse/ │ │ │ └── homework.md │ │ ├── week_4_analytics_engineering/ │ │ │ └── homework.md │ │ ├── week_5_batch_processing/ │ │ │ └── homework.md │ │ ├── week_6_stream_processing/ │ │ │ ├── client.properties │ │ │ ├── homework.md │ │ │ ├── producer_confluent.py │ │ │ ├── settings.py │ │ │ ├── spark-submit.sh │ │ │ └── streaming_confluent.py │ │ └── workshops/ │ │ └── piperider.md │ ├── 2024/ │ │ ├── 01-docker-terraform/ │ │ │ ├── homework.md │ │ │ └── solutions.md │ │ ├── 02-workflow-orchestration/ │ │ │ ├── README.md │ │ │ └── homework.md │ │ ├── 03-data-warehouse/ │ │ │ └── homework.md │ │ ├── 04-analytics-engineering/ │ │ │ └── homework.md │ │ ├── 05-batch/ │ │ │ └── homework.md │ │ ├── 06-streaming/ │ │ │ ├── docker-compose.yml │ │ │ └── homework.md │ │ ├── README.md │ │ ├── leaderboard.md │ │ ├── project.md │ │ └── workshops/ │ │ ├── dlt.md │ │ ├── dlt_resources/ │ │ │ ├── data_ingestion_workshop.md │ │ │ ├── homework_solution.ipynb │ │ │ ├── homework_starter.ipynb │ │ │ └── workshop.ipynb │ │ └── rising-wave.md │ ├── 2025/ │ │ ├── 01-docker-terraform/ │ │ │ └── homework.md │ │ ├── 02-workflow-orchestration/ │ │ │ ├── README.md │ │ │ ├── flows/ │ │ │ │ ├── 01_getting_started_data_pipeline.yaml │ │ │ │ ├── 02_postgres_taxi.yaml │ │ │ │ ├── 02_postgres_taxi_scheduled.yaml │ │ │ │ ├── 03_postgres_dbt.yaml │ │ │ │ ├── 04_gcp_kv.yaml │ │ │ │ ├── 05_gcp_setup.yaml │ │ │ │ ├── 06_gcp_taxi.yaml │ │ │ │ ├── 06_gcp_taxi_scheduled.yaml │ │ │ │ └── 07_gcp_dbt.yaml │ │ │ └── homework.md │ │ ├── 03-data-warehouse/ │ │ │ ├── DLT_upload_to_GCP.ipynb │ │ │ ├── homework.md │ │ │ └── load_yellow_taxi_data.py │ │ ├── 04-analytics-engineering/ │ │ │ └── homework.md │ │ ├── 05-batch/ │ │ │ └── homework.md │ │ ├── 06-streaming/ │ │ │ ├── homework/ │ │ │ │ └── homework.ipynb │ │ │ └── homework.md │ │ ├── README.md │ │ ├── project.md │ │ └── workshops/ │ │ ├── dlt/ │ │ │ ├── README.md │ │ │ ├── data_ingestion_workshop.md │ │ │ └── dlt_homework.md │ │ └── dynamic_load_dlt.py │ └── 2026/ │ ├── 01-docker-terraform/ │ │ └── homework.md │ ├── 02-workflow-orchestration/ │ │ └── homework.md │ ├── 03-data-warehouse/ │ │ ├── DLT_upload_to_GCP.ipynb │ │ ├── homework.md │ │ └── load_yellow_taxi_data.py │ ├── 04-analytics-engineering/ │ │ └── homework.md │ ├── 05-data-platforms/ │ │ └── homework.md │ ├── 06-batch/ │ │ └── homework.md │ ├── 07-streaming/ │ │ └── homework.md │ ├── README.md │ ├── project.md │ └── workshops/ │ ├── dlt/ │ │ ├── README.md │ │ ├── analysis.py │ │ ├── dlt_Pipeline_Overview.ipynb │ │ ├── dlt_homework.md │ │ ├── open_library_pipeline.py │ │ └── pyproject.toml │ └── dlt.md ├── learning-in-public.md ├── projects/ │ ├── README.md │ └── datasets.md └── workshop-best-practices.md
SYMBOL INDEX (375 symbols across 73 files)
FILE: 01-docker-terraform/docker-sql/pipeline/ingest_data.py
function run (line 44) | def run(pg_user, pg_pass, pg_host, pg_port, pg_db, year, month, target_t...
FILE: 03-data-warehouse/big_query.sql
type `taxi-rides-ny (line 8) | CREATE OR REPLACE EXTERNAL TABLE `taxi-rides-ny.nytaxi.external_yellow_t...
FILE: 03-data-warehouse/big_query_hw.sql
type `taxi-rides-ny (line 1) | CREATE OR REPLACE EXTERNAL TABLE `taxi-rides-ny.nytaxi.fhv_tripdata`
FILE: 03-data-warehouse/extras/web_to_gcs.py
function upload_to_gcs (line 26) | def upload_to_gcs(bucket, object_name, local_file):
function web_to_gcs (line 41) | def web_to_gcs(year, service):
FILE: 03-data-warehouse/extras/web_to_gcs_with_progress_bar.py
function download_with_progress (line 30) | def download_with_progress(url: str, local_path: str, desc: str = "Downl...
function csv_to_parquet_with_progress (line 52) | def csv_to_parquet_with_progress(
function upload_to_gcs_with_progress (line 115) | def upload_to_gcs_with_progress(bucket: str, object_name: str, local_fil...
function web_to_gcs (line 151) | def web_to_gcs(year, service):
FILE: 07-streaming/extras/pyflink/src/job/aggregation_job.py
function create_events_aggregated_sink (line 6) | def create_events_aggregated_sink(t_env):
function create_events_source_kafka (line 26) | def create_events_source_kafka(t_env):
function log_aggregation (line 47) | def log_aggregation():
FILE: 07-streaming/extras/pyflink/src/job/start_job.py
function create_processed_events_sink_postgres (line 5) | def create_processed_events_sink_postgres(t_env):
function create_events_source_kafka (line 24) | def create_events_source_kafka(t_env):
function log_processing (line 45) | def log_processing():
FILE: 07-streaming/extras/pyflink/src/job/taxi_job.py
function create_taxi_events_sink_postgres (line 5) | def create_taxi_events_sink_postgres(t_env):
function create_events_source_kafka (line 42) | def create_events_source_kafka(t_env):
function log_processing (line 81) | def log_processing():
FILE: 07-streaming/extras/pyflink/src/producers/load_taxi_data.py
function main (line 5) | def main():
FILE: 07-streaming/extras/pyflink/src/producers/producer.py
function json_serializer (line 5) | def json_serializer(data):
FILE: 07-streaming/extras/python/avro_example/consumer.py
class RideAvroConsumer (line 15) | class RideAvroConsumer:
method __init__ (line 16) | def __init__(self, props: Dict):
method load_schema (line 36) | def load_schema(schema_path: str):
method consume_from_kafka (line 42) | def consume_from_kafka(self, topics: List[str]):
FILE: 07-streaming/extras/python/avro_example/producer.py
function delivery_report (line 17) | def delivery_report(err, msg):
class RideAvroProducer (line 25) | class RideAvroProducer:
method __init__ (line 26) | def __init__(self, props: Dict):
method load_schema (line 40) | def load_schema(schema_path: str):
method delivery_report (line 47) | def delivery_report(err, msg):
method read_records (line 55) | def read_records(resource_path: str):
method publish (line 65) | def publish(self, topic: str, records: [RideRecordKey, RideRecord]):
FILE: 07-streaming/extras/python/avro_example/ride_record.py
class RideRecord (line 4) | class RideRecord:
method __init__ (line 6) | def __init__(self, arr: List[str]):
method from_dict (line 14) | def from_dict(cls, d: Dict):
method __repr__ (line 24) | def __repr__(self):
function dict_to_ride_record (line 28) | def dict_to_ride_record(obj, ctx):
function ride_record_to_dict (line 35) | def ride_record_to_dict(ride_record: RideRecord, ctx):
FILE: 07-streaming/extras/python/avro_example/ride_record_key.py
class RideRecordKey (line 4) | class RideRecordKey:
method __init__ (line 5) | def __init__(self, vendor_id):
method from_dict (line 9) | def from_dict(cls, d: Dict):
method __repr__ (line 12) | def __repr__(self):
function dict_to_ride_record_key (line 16) | def dict_to_ride_record_key(obj, ctx):
function ride_record_key_to_dict (line 23) | def ride_record_key_to_dict(ride_record_key: RideRecordKey, ctx):
FILE: 07-streaming/extras/python/json_example/consumer.py
class JsonConsumer (line 9) | class JsonConsumer:
method __init__ (line 10) | def __init__(self, props: Dict):
method consume_from_kafka (line 13) | def consume_from_kafka(self, topics: List[str]):
FILE: 07-streaming/extras/python/json_example/producer.py
class JsonProducer (line 11) | class JsonProducer(KafkaProducer):
method __init__ (line 12) | def __init__(self, props: Dict):
method read_records (line 16) | def read_records(resource_path: str):
method publish_rides (line 25) | def publish_rides(self, topic: str, messages: List[Ride]):
FILE: 07-streaming/extras/python/json_example/ride.py
class Ride (line 6) | class Ride:
method __init__ (line 7) | def __init__(self, arr: List[str]):
method from_dict (line 28) | def from_dict(cls, d: Dict):
method __repr__ (line 51) | def __repr__(self):
FILE: 07-streaming/extras/python/redpanda_example/consumer.py
class JsonConsumer (line 10) | class JsonConsumer:
method __init__ (line 11) | def __init__(self, props: Dict):
method consume_from_kafka (line 14) | def consume_from_kafka(self, topics: List[str]):
FILE: 07-streaming/extras/python/redpanda_example/producer.py
class JsonProducer (line 11) | class JsonProducer(KafkaProducer):
method __init__ (line 12) | def __init__(self, props: Dict):
method read_records (line 16) | def read_records(resource_path: str):
method publish_rides (line 25) | def publish_rides(self, topic: str, messages: List[Ride]):
FILE: 07-streaming/extras/python/redpanda_example/ride.py
class Ride (line 6) | class Ride:
method __init__ (line 7) | def __init__(self, arr: List[str]):
method from_dict (line 28) | def from_dict(cls, d: Dict):
method __repr__ (line 51) | def __repr__(self):
FILE: 07-streaming/extras/python/streams-example/faust/branch_price.py
function process (line 13) | async def process(stream):
FILE: 07-streaming/extras/python/streams-example/faust/stream.py
function start_reading (line 10) | async def start_reading(records):
FILE: 07-streaming/extras/python/streams-example/faust/stream_count_vendor_trips.py
function process (line 12) | async def process(stream):
FILE: 07-streaming/extras/python/streams-example/faust/taxi_rides.py
class TaxiRide (line 4) | class TaxiRide(faust.Record, validation=True):
FILE: 07-streaming/extras/python/streams-example/faust/windowing.py
function process (line 16) | async def process(stream):
FILE: 07-streaming/extras/python/streams-example/pyspark/consumer.py
class RideCSVConsumer (line 8) | class RideCSVConsumer:
method __init__ (line 9) | def __init__(self, props: Dict):
method consume_from_kafka (line 12) | def consume_from_kafka(self, topics: List[str]):
FILE: 07-streaming/extras/python/streams-example/pyspark/producer.py
function delivery_report (line 9) | def delivery_report(err, msg):
class RideCSVProducer (line 17) | class RideCSVProducer:
method __init__ (line 18) | def __init__(self, props: Dict):
method read_records (line 23) | def read_records(resource_path: str):
method publish (line 38) | def publish(self, topic: str, records: [str, str]):
FILE: 07-streaming/extras/python/streams-example/pyspark/streaming.py
function read_from_kafka (line 7) | def read_from_kafka(consume_topic: str):
function parse_ride_from_kafka_message (line 20) | def parse_ride_from_kafka_message(df, schema):
function sink_console (line 35) | def sink_console(df, output_mode: str = 'complete', processing_time: str...
function sink_memory (line 45) | def sink_memory(df, query_name, query_template):
function sink_kafka (line 56) | def sink_kafka(df, topic):
function prepare_df_to_kafka_sink (line 67) | def prepare_df_to_kafka_sink(df, value_columns, key_column=None):
function op_groupby (line 77) | def op_groupby(df, column_names):
function op_windowed_groupby (line 82) | def op_windowed_groupby(df, window_duration, slide_duration):
FILE: 07-streaming/extras/python/streams-example/redpanda/consumer.py
class RideCSVConsumer (line 8) | class RideCSVConsumer:
method __init__ (line 9) | def __init__(self, props: Dict):
method consume_from_kafka (line 12) | def consume_from_kafka(self, topics: List[str]):
FILE: 07-streaming/extras/python/streams-example/redpanda/producer.py
function delivery_report (line 9) | def delivery_report(err, msg):
class RideCSVProducer (line 17) | class RideCSVProducer:
method __init__ (line 18) | def __init__(self, props: Dict):
method read_records (line 23) | def read_records(resource_path: str):
method publish (line 38) | def publish(self, topic: str, records: [str, str]):
FILE: 07-streaming/extras/python/streams-example/redpanda/streaming.py
function read_from_kafka (line 7) | def read_from_kafka(consume_topic: str):
function parse_ride_from_kafka_message (line 20) | def parse_ride_from_kafka_message(df, schema):
function sink_console (line 35) | def sink_console(df, output_mode: str = 'complete', processing_time: str...
function sink_memory (line 45) | def sink_memory(df, query_name, query_template):
function sink_kafka (line 56) | def sink_kafka(df, topic):
function prepare_df_to_kafka_sink (line 67) | def prepare_df_to_kafka_sink(df, value_columns, key_column=None):
function op_groupby (line 77) | def op_groupby(df, column_names):
function op_windowed_groupby (line 82) | def op_windowed_groupby(df, window_duration, slide_duration):
FILE: 07-streaming/theory/java/kafka_examples/build/generated-main-avro-java/schemaregistry/RideRecord.java
class RideRecord (line 15) | @org.apache.avro.specific.AvroGenerated
method getClassSchema (line 21) | public static org.apache.avro.Schema getClassSchema() { return SCHEMA$; }
method getEncoder (line 35) | public static BinaryMessageEncoder<RideRecord> getEncoder() {
method getDecoder (line 43) | public static BinaryMessageDecoder<RideRecord> getDecoder() {
method createDecoder (line 52) | public static BinaryMessageDecoder<RideRecord> createDecoder(SchemaSto...
method toByteBuffer (line 61) | public java.nio.ByteBuffer toByteBuffer() throws java.io.IOException {
method fromByteBuffer (line 71) | public static RideRecord fromByteBuffer(
method RideRecord (line 85) | public RideRecord() {}
method RideRecord (line 93) | public RideRecord(java.lang.String vendor_id, java.lang.Integer passen...
method getSpecificData (line 99) | @Override
method getSchema (line 102) | @Override
method get (line 106) | @Override
method put (line 117) | @Override
method getVendorId (line 132) | public java.lang.String getVendorId() {
method setVendorId (line 141) | public void setVendorId(java.lang.String value) {
method getPassengerCount (line 149) | public int getPassengerCount() {
method setPassengerCount (line 158) | public void setPassengerCount(int value) {
method getTripDistance (line 166) | public double getTripDistance() {
method setTripDistance (line 175) | public void setTripDistance(double value) {
method newBuilder (line 183) | public static schemaregistry.RideRecord.Builder newBuilder() {
method newBuilder (line 192) | public static schemaregistry.RideRecord.Builder newBuilder(schemaregis...
method newBuilder (line 205) | public static schemaregistry.RideRecord.Builder newBuilder(schemaregis...
class Builder (line 216) | @org.apache.avro.specific.AvroGenerated
method Builder (line 225) | private Builder() {
method Builder (line 233) | private Builder(schemaregistry.RideRecord.Builder other) {
method Builder (line 253) | private Builder(schemaregistry.RideRecord other) {
method getVendorId (line 273) | public java.lang.String getVendorId() {
method setVendorId (line 283) | public schemaregistry.RideRecord.Builder setVendorId(java.lang.Strin...
method hasVendorId (line 294) | public boolean hasVendorId() {
method clearVendorId (line 303) | public schemaregistry.RideRecord.Builder clearVendorId() {
method getPassengerCount (line 313) | public int getPassengerCount() {
method setPassengerCount (line 323) | public schemaregistry.RideRecord.Builder setPassengerCount(int value) {
method hasPassengerCount (line 334) | public boolean hasPassengerCount() {
method clearPassengerCount (line 343) | public schemaregistry.RideRecord.Builder clearPassengerCount() {
method getTripDistance (line 352) | public double getTripDistance() {
method setTripDistance (line 362) | public schemaregistry.RideRecord.Builder setTripDistance(double valu...
method hasTripDistance (line 373) | public boolean hasTripDistance() {
method clearTripDistance (line 382) | public schemaregistry.RideRecord.Builder clearTripDistance() {
method build (line 387) | @Override
method writeExternal (line 408) | @Override public void writeExternal(java.io.ObjectOutput out)
method readExternal (line 417) | @Override public void readExternal(java.io.ObjectInput in)
method hasCustomCoders (line 422) | @Override protected boolean hasCustomCoders() { return true; }
method customEncode (line 424) | @Override public void customEncode(org.apache.avro.io.Encoder out)
method customDecode (line 435) | @Override public void customDecode(org.apache.avro.io.ResolvingDecoder...
FILE: 07-streaming/theory/java/kafka_examples/build/generated-main-avro-java/schemaregistry/RideRecordCompatible.java
class RideRecordCompatible (line 15) | @org.apache.avro.specific.AvroGenerated
method getClassSchema (line 21) | public static org.apache.avro.Schema getClassSchema() { return SCHEMA$; }
method getEncoder (line 35) | public static BinaryMessageEncoder<RideRecordCompatible> getEncoder() {
method getDecoder (line 43) | public static BinaryMessageDecoder<RideRecordCompatible> getDecoder() {
method createDecoder (line 52) | public static BinaryMessageDecoder<RideRecordCompatible> createDecoder...
method toByteBuffer (line 61) | public java.nio.ByteBuffer toByteBuffer() throws java.io.IOException {
method fromByteBuffer (line 71) | public static RideRecordCompatible fromByteBuffer(
method RideRecordCompatible (line 86) | public RideRecordCompatible() {}
method RideRecordCompatible (line 95) | public RideRecordCompatible(java.lang.String vendorId, java.lang.Integ...
method getSpecificData (line 102) | @Override
method getSchema (line 105) | @Override
method get (line 109) | @Override
method put (line 121) | @Override
method getVendorId (line 137) | public java.lang.String getVendorId() {
method setVendorId (line 146) | public void setVendorId(java.lang.String value) {
method getPassengerCount (line 154) | public int getPassengerCount() {
method setPassengerCount (line 163) | public void setPassengerCount(int value) {
method getTripDistance (line 171) | public double getTripDistance() {
method setTripDistance (line 180) | public void setTripDistance(double value) {
method getPuLocationId (line 188) | public java.lang.Long getPuLocationId() {
method setPuLocationId (line 197) | public void setPuLocationId(java.lang.Long value) {
method newBuilder (line 205) | public static schemaregistry.RideRecordCompatible.Builder newBuilder() {
method newBuilder (line 214) | public static schemaregistry.RideRecordCompatible.Builder newBuilder(s...
method newBuilder (line 227) | public static schemaregistry.RideRecordCompatible.Builder newBuilder(s...
class Builder (line 238) | @org.apache.avro.specific.AvroGenerated
method Builder (line 248) | private Builder() {
method Builder (line 256) | private Builder(schemaregistry.RideRecordCompatible.Builder other) {
method Builder (line 280) | private Builder(schemaregistry.RideRecordCompatible other) {
method getVendorId (line 304) | public java.lang.String getVendorId() {
method setVendorId (line 314) | public schemaregistry.RideRecordCompatible.Builder setVendorId(java....
method hasVendorId (line 325) | public boolean hasVendorId() {
method clearVendorId (line 334) | public schemaregistry.RideRecordCompatible.Builder clearVendorId() {
method getPassengerCount (line 344) | public int getPassengerCount() {
method setPassengerCount (line 354) | public schemaregistry.RideRecordCompatible.Builder setPassengerCount...
method hasPassengerCount (line 365) | public boolean hasPassengerCount() {
method clearPassengerCount (line 374) | public schemaregistry.RideRecordCompatible.Builder clearPassengerCou...
method getTripDistance (line 383) | public double getTripDistance() {
method setTripDistance (line 393) | public schemaregistry.RideRecordCompatible.Builder setTripDistance(d...
method hasTripDistance (line 404) | public boolean hasTripDistance() {
method clearTripDistance (line 413) | public schemaregistry.RideRecordCompatible.Builder clearTripDistance...
method getPuLocationId (line 422) | public java.lang.Long getPuLocationId() {
method setPuLocationId (line 432) | public schemaregistry.RideRecordCompatible.Builder setPuLocationId(j...
method hasPuLocationId (line 443) | public boolean hasPuLocationId() {
method clearPuLocationId (line 452) | public schemaregistry.RideRecordCompatible.Builder clearPuLocationId...
method build (line 458) | @Override
method writeExternal (line 480) | @Override public void writeExternal(java.io.ObjectOutput out)
method readExternal (line 489) | @Override public void readExternal(java.io.ObjectInput in)
method hasCustomCoders (line 494) | @Override protected boolean hasCustomCoders() { return true; }
method customEncode (line 496) | @Override public void customEncode(org.apache.avro.io.Encoder out)
method customDecode (line 515) | @Override public void customDecode(org.apache.avro.io.ResolvingDecoder...
FILE: 07-streaming/theory/java/kafka_examples/build/generated-main-avro-java/schemaregistry/RideRecordNoneCompatible.java
class RideRecordNoneCompatible (line 15) | @org.apache.avro.specific.AvroGenerated
method getClassSchema (line 21) | public static org.apache.avro.Schema getClassSchema() { return SCHEMA$; }
method getEncoder (line 35) | public static BinaryMessageEncoder<RideRecordNoneCompatible> getEncode...
method getDecoder (line 43) | public static BinaryMessageDecoder<RideRecordNoneCompatible> getDecode...
method createDecoder (line 52) | public static BinaryMessageDecoder<RideRecordNoneCompatible> createDec...
method toByteBuffer (line 61) | public java.nio.ByteBuffer toByteBuffer() throws java.io.IOException {
method fromByteBuffer (line 71) | public static RideRecordNoneCompatible fromByteBuffer(
method RideRecordNoneCompatible (line 85) | public RideRecordNoneCompatible() {}
method RideRecordNoneCompatible (line 93) | public RideRecordNoneCompatible(java.lang.Integer vendorId, java.lang....
method getSpecificData (line 99) | @Override
method getSchema (line 102) | @Override
method get (line 106) | @Override
method put (line 117) | @Override
method getVendorId (line 132) | public int getVendorId() {
method setVendorId (line 141) | public void setVendorId(int value) {
method getPassengerCount (line 149) | public int getPassengerCount() {
method setPassengerCount (line 158) | public void setPassengerCount(int value) {
method getTripDistance (line 166) | public double getTripDistance() {
method setTripDistance (line 175) | public void setTripDistance(double value) {
method newBuilder (line 183) | public static schemaregistry.RideRecordNoneCompatible.Builder newBuild...
method newBuilder (line 192) | public static schemaregistry.RideRecordNoneCompatible.Builder newBuild...
method newBuilder (line 205) | public static schemaregistry.RideRecordNoneCompatible.Builder newBuild...
class Builder (line 216) | @org.apache.avro.specific.AvroGenerated
method Builder (line 225) | private Builder() {
method Builder (line 233) | private Builder(schemaregistry.RideRecordNoneCompatible.Builder othe...
method Builder (line 253) | private Builder(schemaregistry.RideRecordNoneCompatible other) {
method getVendorId (line 273) | public int getVendorId() {
method setVendorId (line 283) | public schemaregistry.RideRecordNoneCompatible.Builder setVendorId(i...
method hasVendorId (line 294) | public boolean hasVendorId() {
method clearVendorId (line 303) | public schemaregistry.RideRecordNoneCompatible.Builder clearVendorId...
method getPassengerCount (line 312) | public int getPassengerCount() {
method setPassengerCount (line 322) | public schemaregistry.RideRecordNoneCompatible.Builder setPassengerC...
method hasPassengerCount (line 333) | public boolean hasPassengerCount() {
method clearPassengerCount (line 342) | public schemaregistry.RideRecordNoneCompatible.Builder clearPassenge...
method getTripDistance (line 351) | public double getTripDistance() {
method setTripDistance (line 361) | public schemaregistry.RideRecordNoneCompatible.Builder setTripDistan...
method hasTripDistance (line 372) | public boolean hasTripDistance() {
method clearTripDistance (line 381) | public schemaregistry.RideRecordNoneCompatible.Builder clearTripDist...
method build (line 386) | @Override
method writeExternal (line 407) | @Override public void writeExternal(java.io.ObjectOutput out)
method readExternal (line 416) | @Override public void readExternal(java.io.ObjectInput in)
method hasCustomCoders (line 421) | @Override protected boolean hasCustomCoders() { return true; }
method customEncode (line 423) | @Override public void customEncode(org.apache.avro.io.Encoder out)
method customDecode (line 434) | @Override public void customDecode(org.apache.avro.io.ResolvingDecoder...
FILE: 07-streaming/theory/java/kafka_examples/src/main/java/org/example/AvroProducer.java
class AvroProducer (line 20) | public class AvroProducer {
method AvroProducer (line 24) | public AvroProducer() {
method getRides (line 40) | public List<RideRecord> getRides() throws IOException, CsvException {
method publishRides (line 54) | public void publishRides(List<RideRecord> rides) throws ExecutionExcep...
method main (line 67) | public static void main(String[] args) throws IOException, CsvExceptio...
FILE: 07-streaming/theory/java/kafka_examples/src/main/java/org/example/JsonConsumer.java
class JsonConsumer (line 15) | public class JsonConsumer {
method JsonConsumer (line 19) | public JsonConsumer() {
method consumeFromKafka (line 36) | public void consumeFromKafka() {
method main (line 52) | public static void main(String[] args) {
FILE: 07-streaming/theory/java/kafka_examples/src/main/java/org/example/JsonKStream.java
class JsonKStream (line 16) | public class JsonKStream {
method JsonKStream (line 19) | public JsonKStream() {
method createTopology (line 32) | public Topology createTopology() {
method countPLocation (line 40) | public void countPLocation() throws InterruptedException {
method main (line 52) | public static void main(String[] args) throws InterruptedException {
FILE: 07-streaming/theory/java/kafka_examples/src/main/java/org/example/JsonKStreamJoins.java
class JsonKStreamJoins (line 19) | public class JsonKStreamJoins {
method JsonKStreamJoins (line 22) | public JsonKStreamJoins() {
method createTopology (line 34) | public Topology createTopology() {
method joinRidesPickupLocation (line 54) | public void joinRidesPickupLocation() throws InterruptedException {
method main (line 72) | public static void main(String[] args) throws InterruptedException {
FILE: 07-streaming/theory/java/kafka_examples/src/main/java/org/example/JsonKStreamWindow.java
class JsonKStreamWindow (line 20) | public class JsonKStreamWindow {
method JsonKStreamWindow (line 23) | public JsonKStreamWindow() {
method createTopology (line 36) | public Topology createTopology() {
method countPLocationWindowed (line 48) | public void countPLocationWindowed() {
method main (line 56) | public static void main(String[] args) {
FILE: 07-streaming/theory/java/kafka_examples/src/main/java/org/example/JsonProducer.java
class JsonProducer (line 17) | public class JsonProducer {
method JsonProducer (line 19) | public JsonProducer() {
method getRides (line 31) | public List<Ride> getRides() throws IOException, CsvException {
method publishRides (line 40) | public void publishRides(List<Ride> rides) throws ExecutionException, ...
method main (line 56) | public static void main(String[] args) throws IOException, CsvExceptio...
FILE: 07-streaming/theory/java/kafka_examples/src/main/java/org/example/JsonProducerPickupLocation.java
class JsonProducerPickupLocation (line 14) | public class JsonProducerPickupLocation {
method JsonProducerPickupLocation (line 17) | public JsonProducerPickupLocation() {
method publish (line 29) | public void publish(PickupLocation pickupLocation) throws ExecutionExc...
method main (line 40) | public static void main(String[] args) throws IOException, CsvExceptio...
FILE: 07-streaming/theory/java/kafka_examples/src/main/java/org/example/Secrets.java
class Secrets (line 3) | public class Secrets {
FILE: 07-streaming/theory/java/kafka_examples/src/main/java/org/example/Topics.java
class Topics (line 3) | public class Topics {
FILE: 07-streaming/theory/java/kafka_examples/src/main/java/org/example/customserdes/CustomSerdes.java
class CustomSerdes (line 19) | public class CustomSerdes {
method getSerde (line 21) | public static <T> Serde<T> getSerde(Class<T> classOf) {
method getAvroSerde (line 32) | public static <T extends SpecificRecordBase> SpecificAvroSerde getAvro...
FILE: 07-streaming/theory/java/kafka_examples/src/main/java/org/example/data/PickupLocation.java
class PickupLocation (line 5) | public class PickupLocation {
method PickupLocation (line 6) | public PickupLocation(long PULocationID, LocalDateTime tpep_pickup_dat...
method PickupLocation (line 11) | public PickupLocation() {
FILE: 07-streaming/theory/java/kafka_examples/src/main/java/org/example/data/Ride.java
class Ride (line 8) | public class Ride {
method Ride (line 9) | public Ride(String[] arr) {
method Ride (line 29) | public Ride(){}
FILE: 07-streaming/theory/java/kafka_examples/src/main/java/org/example/data/VendorInfo.java
class VendorInfo (line 5) | public class VendorInfo {
method VendorInfo (line 7) | public VendorInfo(String vendorID, long PULocationID, LocalDateTime pi...
method VendorInfo (line 14) | public VendorInfo() {
FILE: 07-streaming/theory/java/kafka_examples/src/test/java/org/example/JsonKStreamJoinsTest.java
class JsonKStreamJoinsTest (line 21) | class JsonKStreamJoinsTest {
method setup (line 29) | @BeforeEach
method testIfJoinWorksOnSameDropOffPickupLocationId (line 43) | @Test
method shutdown (line 59) | @AfterAll
FILE: 07-streaming/theory/java/kafka_examples/src/test/java/org/example/JsonKStreamTest.java
class JsonKStreamTest (line 14) | class JsonKStreamTest {
method setup (line 21) | @BeforeEach
method testIfOneMessageIsPassedToInputTopicWeGetCountOfOne (line 34) | @Test
method testIfTwoMessageArePassedWithDifferentKey (line 43) | @Test
method testIfTwoMessageArePassedWithSameKey (line 58) | @Test
method tearDown (line 74) | @AfterAll
FILE: 07-streaming/theory/java/kafka_examples/src/test/java/org/example/helper/DataGeneratorHelper.java
class DataGeneratorHelper (line 11) | public class DataGeneratorHelper {
method generateRide (line 12) | public static Ride generateRide() {
method generatePickUpLocation (line 18) | public static PickupLocation generatePickUpLocation(long pickupLocatio...
FILE: 07-streaming/workshop/live/main.py
function main (line 1) | def main():
FILE: 07-streaming/workshop/live/notebooks/models.py
class Ride (line 8) | class Ride:
function ride_from_row (line 16) | def ride_from_row(row):
function ride_serializer (line 26) | def ride_serializer(ride):
function ride_deserializer (line 32) | def ride_deserializer(data):
FILE: 07-streaming/workshop/live/src/job/aggregation_job.py
function create_events_source_kafka (line 5) | def create_events_source_kafka(t_env):
function create_events_aggregated_sink (line 29) | def create_events_aggregated_sink(t_env):
function log_aggregation (line 51) | def log_aggregation():
FILE: 07-streaming/workshop/live/src/job/pass_through_job.py
function create_events_source_kafka (line 6) | def create_events_source_kafka(t_env):
function create_processed_events_sink_postgres (line 28) | def create_processed_events_sink_postgres(t_env):
function log_processing (line 50) | def log_processing():
FILE: 07-streaming/workshop/live/src/producers/models.py
class Ride (line 8) | class Ride:
function ride_from_row (line 16) | def ride_from_row(row):
function ride_serializer (line 26) | def ride_serializer(ride):
function ride_deserializer (line 32) | def ride_deserializer(data):
FILE: 07-streaming/workshop/live/src/producers/producer_realtime.py
function make_ride (line 43) | def make_ride(delay_seconds=0):
function ride_serializer (line 54) | def ride_serializer(ride):
FILE: 07-streaming/workshop/src/job/aggregation_job.py
function create_events_aggregated_sink (line 5) | def create_events_aggregated_sink(t_env):
function create_events_source_kafka (line 26) | def create_events_source_kafka(t_env):
function log_aggregation (line 50) | def log_aggregation():
FILE: 07-streaming/workshop/src/job/aggregation_job_demo.py
function create_events_source_kafka (line 14) | def create_events_source_kafka(t_env):
function create_events_aggregated_sink (line 38) | def create_events_aggregated_sink(t_env):
function log_aggregation (line 60) | def log_aggregation():
FILE: 07-streaming/workshop/src/job/pass_through_job.py
function create_processed_events_sink_postgres (line 5) | def create_processed_events_sink_postgres(t_env):
function create_events_source_kafka (line 27) | def create_events_source_kafka(t_env):
function log_processing (line 48) | def log_processing():
FILE: 07-streaming/workshop/src/models.py
class Ride (line 6) | class Ride:
function ride_from_row (line 14) | def ride_from_row(row):
function ride_deserializer (line 24) | def ride_deserializer(data):
FILE: 07-streaming/workshop/src/producers/producer.py
function ride_serializer (line 18) | def ride_serializer(ride):
FILE: 07-streaming/workshop/src/producers/producer_realtime.py
function make_ride (line 43) | def make_ride(delay_seconds=0):
function ride_serializer (line 54) | def ride_serializer(ride):
FILE: cohorts/2022/week_2_data_ingestion/airflow/dags/data_ingestion_gcs_dag.py
function format_to_parquet (line 24) | def format_to_parquet(src_file):
function upload_to_gcs (line 33) | def upload_to_gcs(bucket, object_name, local_file):
FILE: cohorts/2022/week_2_data_ingestion/airflow/dags_local/ingest_script.py
function ingest_callable (line 9) | def ingest_callable(user, password, host, port, db, table_name, csv_file...
FILE: cohorts/2022/week_2_data_ingestion/homework/solution.py
function format_to_parquet (line 22) | def format_to_parquet(src_file, dest_file):
function upload_to_gcs (line 30) | def upload_to_gcs(bucket, object_name, local_file):
function donwload_parquetize_upload_dag (line 45) | def donwload_parquetize_upload_dag(
FILE: cohorts/2023/week_6_stream_processing/producer_confluent.py
class RideCSVProducer (line 13) | class RideCSVProducer:
method __init__ (line 14) | def __init__(self, probs: Dict, ride_type: str):
method parse_row (line 19) | def parse_row(self, row):
method read_records (line 28) | def read_records(self, resource_path: str):
method publish (line 39) | def publish(self, records: [str, str], topic: str):
FILE: cohorts/2023/week_6_stream_processing/settings.py
function read_ccloud_config (line 17) | def read_ccloud_config(config_file):
FILE: cohorts/2023/week_6_stream_processing/streaming_confluent.py
function read_from_kafka (line 7) | def read_from_kafka(consume_topic: str):
function parse_rides (line 27) | def parse_rides(df, schema):
function sink_console (line 46) | def sink_console(df, output_mode: str = 'complete', processing_time: str...
function sink_kafka (line 57) | def sink_kafka(df, topic, output_mode: str = 'complete'):
function op_groupby (line 73) | def op_groupby(df, column_names):
FILE: cohorts/2025/03-data-warehouse/load_yellow_taxi_data.py
function download_file (line 31) | def download_file(month):
function create_bucket (line 45) | def create_bucket(bucket_name):
function verify_gcs_upload (line 74) | def verify_gcs_upload(blob_name):
function upload_to_gcs (line 78) | def upload_to_gcs(file_path, max_retries=3):
FILE: cohorts/2025/workshops/dynamic_load_dlt.py
function generate_urls (line 25) | def generate_urls(color, start_year, end_year, start_month, end_month):
function parquet_source (line 79) | def parquet_source():
function paginated_getter (line 94) | def paginated_getter():
FILE: cohorts/2026/03-data-warehouse/load_yellow_taxi_data.py
function download_file (line 31) | def download_file(month):
function create_bucket (line 45) | def create_bucket(bucket_name):
function verify_gcs_upload (line 74) | def verify_gcs_upload(blob_name):
function upload_to_gcs (line 78) | def upload_to_gcs(file_path, max_retries=3):
FILE: cohorts/2026/workshops/dlt/analysis.py
function _ (line 8) | def _():
function _ (line 19) | def _(mo):
function _ (line 29) | def _(dlt):
function _ (line 39) | async def _(load_package_viewer, render):
function _ (line 46) | def _(mo):
function _ (line 54) | def _(alt, ibis, ibis_con):
function _ (line 82) | def _(mo):
function _ (line 90) | def _(alt, ibis_con):
function _ (line 121) | def _(mo):
function _ (line 129) | def _(alt, ibis, ibis_con):
function _ (line 164) | def _(mo):
function _ (line 174) | def _(ibis_con, mo):
function _ (line 191) | def _():
function _ (line 196) | def _():
FILE: cohorts/2026/workshops/dlt/open_library_pipeline.py
function open_library_source (line 7) | def open_library_source(query: str = "harry potter"):
Condensed preview — 381 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (1,946K chars).
[
{
"path": ".github/FUNDING.yml",
"chars": 23,
"preview": "github: alexeygrigorev\n"
},
{
"path": ".gitignore",
"chars": 275,
"preview": "\n.DS_Store\n.idea\n*.tfstate\n*.tfstate.*\n**.terraform\n**.terraform.lock.*\n**google_credentials.json\n**logs/\n**.env\n**__pyc"
},
{
"path": "01-docker-terraform/README.md",
"chars": 6680,
"preview": "# Introduction\n\n[](https://www.youtube.com/watch?v=Jgspd"
},
{
"path": "01-docker-terraform/docker-sql/01-introduction.md",
"chars": 3854,
"preview": "# Introduction to Docker\n\n**[↑ Up](README.md)** | **[← Previous](README.md)** | **[Next →](02-virtual-environment.md)**\n"
},
{
"path": "01-docker-terraform/docker-sql/02-virtual-environment.md",
"chars": 3016,
"preview": "# Virtual Environments and Data Pipelines\n\n**[↑ Up](README.md)** | **[← Previous](01-introduction.md)** | **[Next →](03-"
},
{
"path": "01-docker-terraform/docker-sql/03-dockerizing-pipeline.md",
"chars": 2391,
"preview": "# Dockerizing the Pipeline\n\n**[↑ Up](README.md)** | **[← Previous](02-virtual-environment.md)** | **[Next →](04-postgres"
},
{
"path": "01-docker-terraform/docker-sql/04-postgres-docker.md",
"chars": 2953,
"preview": "# Running PostgreSQL with Docker\n\n**[↑ Up](README.md)** | **[← Previous](03-dockerizing-pipeline.md)** | **[Next →](05-d"
},
{
"path": "01-docker-terraform/docker-sql/05-data-ingestion.md",
"chars": 6104,
"preview": "# NY Taxi Dataset and Data Ingestion\n\n**[↑ Up](README.md)** | **[← Previous](04-postgres-docker.md)** | **[Next →](06-in"
},
{
"path": "01-docker-terraform/docker-sql/06-ingestion-script.md",
"chars": 2238,
"preview": "# Creating the Data Ingestion Script\n\n**[↑ Up](README.md)** | **[← Previous](05-data-ingestion.md)** | **[Next →](07-pga"
},
{
"path": "01-docker-terraform/docker-sql/07-pgadmin.md",
"chars": 3266,
"preview": "# pgAdmin - Database Management Tool\n\n**[↑ Up](README.md)** | **[← Previous](06-ingestion-script.md)** | **[Next →](08-d"
},
{
"path": "01-docker-terraform/docker-sql/08-dockerizing-ingestion.md",
"chars": 2092,
"preview": "# Dockerizing the Ingestion Script\n\n**[↑ Up](README.md)** | **[← Previous](07-pgadmin.md)** | **[Next →](09-docker-compo"
},
{
"path": "01-docker-terraform/docker-sql/09-docker-compose.md",
"chars": 3064,
"preview": "# Docker Compose\n\n**[↑ Up](README.md)** | **[← Previous](08-dockerizing-ingestion.md)** | **[Next →](10-sql-refresher.md"
},
{
"path": "01-docker-terraform/docker-sql/10-sql-refresher.md",
"chars": 4948,
"preview": "# SQL Refresher\n\n**[↑ Up](README.md)** | **[← Previous](09-docker-compose.md)** | **[Next →](11-cleanup.md)**\n\n[** | **[← Previous](10-sql-refresher.md)** | **[Next →](../README.md)**\n\nWhen you're done "
},
{
"path": "01-docker-terraform/docker-sql/README.md",
"chars": 1817,
"preview": "# Docker and PostgreSQL: Data Engineering Workshop\n\n* Video: [link](https://www.youtube.com/watch?v=lP8xXebHmuE)\n* Slide"
},
{
"path": "01-docker-terraform/docker-sql/pipeline/.python-version",
"chars": 5,
"preview": "3.13\n"
},
{
"path": "01-docker-terraform/docker-sql/pipeline/Dockerfile",
"chars": 255,
"preview": "FROM python:3.13.11-slim\nCOPY --from=ghcr.io/astral-sh/uv:latest /uv /bin/\n\nWORKDIR /code\nENV PATH=\"/code/.venv/bin:$PAT"
},
{
"path": "01-docker-terraform/docker-sql/pipeline/docker-compose.yaml",
"chars": 521,
"preview": "services:\n pgdatabase:\n image: postgres:18\n environment:\n POSTGRES_USER: \"root\"\n POSTGRES_PASSWORD: \"ro"
},
{
"path": "01-docker-terraform/docker-sql/pipeline/docker-helper-scripts/docker-ingest.sh",
"chars": 375,
"preview": "#!/usr/bin/env bash\n\n## bash script to run the ingestion container\necho \"Running data ingestion for January 2021...\"\n\ndo"
},
{
"path": "01-docker-terraform/docker-sql/pipeline/docker-helper-scripts/docker-pgadmin.sh",
"chars": 334,
"preview": "#!/usr/bin/env bash\n\n## bash script to start pgadmin\necho \"Starting pgAdmin container...\"\nmkdir -p ../pgadmin_data\n\ndock"
},
{
"path": "01-docker-terraform/docker-sql/pipeline/docker-helper-scripts/docker-postgres.sh",
"chars": 447,
"preview": "#!/usr/bin/env bash\n\n## bash script to start the Postgres container\nmkdir -p ../ny_taxi_postgres_data\n\necho \"Starting Po"
},
{
"path": "01-docker-terraform/docker-sql/pipeline/ingest_data.py",
"chars": 2373,
"preview": "#!/usr/bin/env python\n# coding: utf-8\n\nimport click\nimport pandas as pd\nfrom sqlalchemy import create_engine\nfrom tqdm.a"
},
{
"path": "01-docker-terraform/docker-sql/pipeline/pyproject.toml",
"chars": 369,
"preview": "[project]\nname = \"pipeline\"\nversion = \"0.1.0\"\ndescription = \"Add your description here\"\nreadme = \"README.md\"\nrequires-py"
},
{
"path": "01-docker-terraform/terraform/1_terraform_overview.md",
"chars": 2643,
"preview": "## Terraform Overview\n\n[Video](https://www.youtube.com/watch?v=18jIzE41fJ4&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index"
},
{
"path": "01-docker-terraform/terraform/2_gcp_overview.md",
"chars": 2075,
"preview": "## GCP Overview\n\n[Video](https://www.youtube.com/watch?v=18jIzE41fJ4&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=2)\n\n\n"
},
{
"path": "01-docker-terraform/terraform/README.md",
"chars": 634,
"preview": "## Local Setup for Terraform and GCP\n\n### Pre-Requisites\n1. Terraform client installation: https://www.terraform.io/down"
},
{
"path": "01-docker-terraform/terraform/terraform/README.md",
"chars": 2157,
"preview": "### Concepts\n* [Terraform_overview](../1_terraform_overview.md)\n* If you were unable to generate a service account keyfi"
},
{
"path": "01-docker-terraform/terraform/terraform/terraform_basic/main.tf",
"chars": 884,
"preview": "terraform {\n required_providers {\n google = {\n source = \"hashicorp/google\"\n version = \"4.51.0\"\n }\n }\n"
},
{
"path": "01-docker-terraform/terraform/terraform/terraform_with_variable_AWS/README.md",
"chars": 1482,
"preview": "# AWS Terraform Data Lake (GCP Equivalent)\n\n## 📌 Overview\n\nThis repository contains an **AWS-based Terraform implementat"
},
{
"path": "01-docker-terraform/terraform/terraform/terraform_with_variable_AWS/main.tf",
"chars": 1401,
"preview": "terraform {\n required_providers {\n aws = {\n source = \"hashicorp/aws\"\n version = \"~> 5.0"
},
{
"path": "01-docker-terraform/terraform/terraform/terraform_with_variable_AWS/terraform.tfvars",
"chars": 83,
"preview": "bucket_name = \"my-unique-data-lake-bucket-12345\"\ndataset_name = \"ny_taxi_dataset\"\n"
},
{
"path": "01-docker-terraform/terraform/terraform/terraform_with_variable_AWS/variables.tf",
"chars": 845,
"preview": "# Specifies the geographic location for AWS resource deployment.\n# Defaulting to Stockholm (eu-north-1) to keep latency "
},
{
"path": "01-docker-terraform/terraform/terraform/terraform_with_variables/main.tf",
"chars": 627,
"preview": "terraform {\n required_providers {\n google = {\n source = \"hashicorp/google\"\n version = \"5.6.0\"\n }\n }\n}"
},
{
"path": "01-docker-terraform/terraform/terraform/terraform_with_variables/variables.tf",
"chars": 1061,
"preview": "variable \"credentials\" {\n description = \"My Credentials\"\n default = \"<Path to your Service Account json file>\"\n #"
},
{
"path": "01-docker-terraform/terraform/windows.md",
"chars": 3411,
"preview": "## GCP and Terraform on Windows\n\nYou don't need these instructions if you use WSL. It's only for \"plain Windows\" \n\n### G"
},
{
"path": "02-workflow-orchestration/README.md",
"chars": 34109,
"preview": "# Workflow Orchestration\n\nWelcome to Module 2 of the Data Engineering Zoomcamp! This week, we’ll dive into workflow orch"
},
{
"path": "02-workflow-orchestration/docker-compose.yml",
"chars": 2482,
"preview": "volumes:\n ny_taxi_postgres_data:\n driver: local\n kestra_postgres_data:\n driver: local\n kestra_data:\n driver:"
},
{
"path": "02-workflow-orchestration/flows/01_hello_world.yaml",
"chars": 995,
"preview": "id: 01_hello_world\nnamespace: zoomcamp\n\ninputs:\n - id: name\n type: STRING\n defaults: Will\n\nconcurrency:\n behavio"
},
{
"path": "02-workflow-orchestration/flows/02_python.yaml",
"chars": 1096,
"preview": "id: 02_python\nnamespace: zoomcamp\n\ndescription: This flow will install the pip package in a Docker container, and use ke"
},
{
"path": "02-workflow-orchestration/flows/03_getting_started_data_pipeline.yaml",
"chars": 1415,
"preview": "id: 03_getting_started_data_pipeline\nnamespace: zoomcamp\n\ninputs:\n - id: columns_to_keep\n type: ARRAY\n itemType: "
},
{
"path": "02-workflow-orchestration/flows/04_postgres_taxi.yaml",
"chars": 11762,
"preview": "id: 04_postgres_taxi\nnamespace: zoomcamp\ndescription: |\n The CSV Data used in the course: https://github.com/DataTalksC"
},
{
"path": "02-workflow-orchestration/flows/05_postgres_taxi_scheduled.yaml",
"chars": 11864,
"preview": "id: 05_postgres_taxi_scheduled\nnamespace: zoomcamp\ndescription: |\n Best to add a label `backfill:true` from the UI to t"
},
{
"path": "02-workflow-orchestration/flows/06_gcp_kv.yaml",
"chars": 631,
"preview": "id: 06_gcp_kv\nnamespace: zoomcamp\n\ntasks:\n - id: gcp_project_id\n type: io.kestra.plugin.core.kv.Set\n key: GCP_PRO"
},
{
"path": "02-workflow-orchestration/flows/07_gcp_setup.yaml",
"chars": 607,
"preview": "id: 07_gcp_setup\nnamespace: zoomcamp\n\ntasks:\n - id: create_gcs_bucket\n type: io.kestra.plugin.gcp.gcs.CreateBucket\n "
},
{
"path": "02-workflow-orchestration/flows/08_gcp_taxi.yaml",
"chars": 19147,
"preview": "id: 08_gcp_taxi\nnamespace: zoomcamp\ndescription: |\n The CSV Data used in the course: https://github.com/DataTalksClub/n"
},
{
"path": "02-workflow-orchestration/flows/09_gcp_taxi_scheduled.yaml",
"chars": 19154,
"preview": "\nid: 09_gcp_taxi_scheduled\nnamespace: zoomcamp\ndescription: |\n Best to add a label `backfill:true` from the UI to track"
},
{
"path": "02-workflow-orchestration/flows/10_chat_without_rag.yaml",
"chars": 1286,
"preview": "id: 10_chat_without_rag\nnamespace: zoomcamp\n\ndescription: |\n This flow demonstrates what happens when you query an LLM "
},
{
"path": "02-workflow-orchestration/flows/11_chat_with_rag.yaml",
"chars": 2036,
"preview": "id: 11_chat_with_rag\nnamespace: zoomcamp\n\ndescription: |\n This flow demonstrates RAG (Retrieval Augmented Generation) b"
},
{
"path": "03-data-warehouse/README.md",
"chars": 5144,
"preview": "# Data Warehouse and BigQuery\n\n- [Slides](https://docs.google.com/presentation/d/1a3ZoBAXFk8-EhUsd7rAZd-5p_HpltkzSeujjRG"
},
{
"path": "03-data-warehouse/big_query.sql",
"chars": 2174,
"preview": "-- Query public available table\nSELECT station_id, name FROM\n bigquery-public-data.new_york_citibike.citibike_station"
},
{
"path": "03-data-warehouse/big_query_hw.sql",
"chars": 1048,
"preview": "CREATE OR REPLACE EXTERNAL TABLE `taxi-rides-ny.nytaxi.fhv_tripdata`\nOPTIONS (\n format = 'CSV',\n uris = ['gs://nyc-tl-"
},
{
"path": "03-data-warehouse/big_query_ml.sql",
"chars": 2134,
"preview": "-- SELECT THE COLUMNS INTERESTED FOR YOU\nSELECT passenger_count, trip_distance, PULocationID, DOLocationID, payment_type"
},
{
"path": "03-data-warehouse/extract_model.md",
"chars": 843,
"preview": "## Model deployment\n[Tutorial](https://cloud.google.com/bigquery-ml/docs/export-model-tutorial)\n### Steps\n- gcloud auth "
},
{
"path": "03-data-warehouse/extras/.env-example",
"chars": 105,
"preview": "GCP_GCS_BUCKET=\"your_bucket_name\"\nGOOGLE_APPLICATION_CREDENTIALS=Path/to/key/GCP_service_account_key.json"
},
{
"path": "03-data-warehouse/extras/.gitignore",
"chars": 22,
"preview": "*.env\n*.parquet\n*.csv*"
},
{
"path": "03-data-warehouse/extras/README.md",
"chars": 393,
"preview": "Quick hack to load files directly to GCS, without Airflow. Downloads csv files from https://nyc-tlc.s3.amazonaws.com/tri"
},
{
"path": "03-data-warehouse/extras/pyproject.toml",
"chars": 304,
"preview": "[project]\nname = \"extras\"\nversion = \"0.1.0\"\ndescription = \"Add your description here\"\nreadme = \"README.md\"\nrequires-pyth"
},
{
"path": "03-data-warehouse/extras/web_to_gcs.py",
"chars": 3750,
"preview": "import os\nimport requests\nimport pandas as pd\nfrom google.cloud import storage\nfrom dotenv import load_dotenv\n\n\n\"\"\"\nPre-"
},
{
"path": "03-data-warehouse/extras/web_to_gcs_with_progress_bar.py",
"chars": 6784,
"preview": "import os\nimport requests\nimport pandas as pd\nfrom google.cloud import storage\nfrom dotenv import load_dotenv\nfrom tqdm "
},
{
"path": "04-analytics-engineering/README.md",
"chars": 7270,
"preview": "# Module 4: Analytics Engineering\n\nGoal: Transforming the data loaded in DWH into Analytical Views developing a [dbt pro"
},
{
"path": "04-analytics-engineering/class_notes/4_1_1_analytics_engineering_basics.md",
"chars": 5838,
"preview": "# DE Zoomcamp 4.1.1 — Analytics Engineering Basics\n\n> 📄 Video: [Analytics Engineering Basics](https://www.youtube.com/wa"
},
{
"path": "04-analytics-engineering/class_notes/4_1_2_what_is_dbt.md",
"chars": 5476,
"preview": "# DE Zoomcamp 4.1.2 — What is dbt?\n\n> 📄 Video: [What is dbt?](https://www.youtube.com/watch?v=gsKuETFJr54) \n> 📄 Officia"
},
{
"path": "04-analytics-engineering/class_notes/4_2_1_dbt_core_vs_dbt_cloud.md",
"chars": 3590,
"preview": "# DE Zoomcamp 4.2.1 — dbt Core vs dbt Cloud\n\n> 📄 Official feature comparison: [dbt Core vs dbt Cloud](https://www.getdbt"
},
{
"path": "04-analytics-engineering/class_notes/4_3_1_dbt_project_structure.md",
"chars": 6412,
"preview": "# DE Zoomcamp 4.3.1 — dbt Project Structure\n\n> 📄 Video: [dbt Project Structure](https://www.youtube.com/watch?v=2dYDS4OQ"
},
{
"path": "04-analytics-engineering/class_notes/4_3_2_dbt_sources.md",
"chars": 6261,
"preview": "# DE Zoomcamp 4.3.2 — dbt Sources\n\n> 📄 Video: [dbt Sources](https://www.youtube.com/watch?v=7CrrXazV_8k) \n> 📄 Official "
},
{
"path": "04-analytics-engineering/class_notes/4_4_1_dbt_models.md",
"chars": 7537,
"preview": "# DE Zoomcamp 4.4.1 — dbt Models\n\n> 📄 Video: [dbt Models](https://www.youtube.com/watch?v=JQYz-8sl1aQ) \n> 📄 Official do"
},
{
"path": "04-analytics-engineering/class_notes/4_4_2_dbt_seeds_and_macros.md",
"chars": 5499,
"preview": "# DE Zoomcamp 4.4.2 — dbt Seeds and Macros\n\n> 📄 Video: [dbt Seeds and Macros](https://www.youtube.com/watch?v=lT4fmTDEqV"
},
{
"path": "04-analytics-engineering/class_notes/4_5_1_documentation.md",
"chars": 6096,
"preview": "# DE Zoomcamp 4.5.1 — Documentation\n\n> 📄 Video: [Documentation](https://www.youtube.com/watch?v=UqoWyMjcqrA) \n> 📄 Offic"
},
{
"path": "04-analytics-engineering/class_notes/4_5_2_dbt_tests.md",
"chars": 8223,
"preview": "# DE Zoomcamp 4.5.2 — dbt Tests\n\n> 📄 Video: [dbt Tests](https://www.youtube.com/watch?v=bvZ-rJm7uMU) \n> 📄 Official docs"
},
{
"path": "04-analytics-engineering/class_notes/4_5_3_dbt_packages.md",
"chars": 5028,
"preview": "# DE Zoomcamp 4.5.3 — dbt Packages\n\n> 📄 Video: [dbt Packages](https://www.youtube.com/watch?v=KfhUA9Kfp8Y) \n> 📄 Officia"
},
{
"path": "04-analytics-engineering/class_notes/4_6_1_dbt_commands.md",
"chars": 9535,
"preview": "# DE Zoomcamp 4.6.1 — dbt Commands\n\n> 📄 Video: [dbt Commands](https://www.youtube.com/watch?v=t4OeWHW3SsA) \n> 📄 Officia"
},
{
"path": "04-analytics-engineering/refreshers/SQL.md",
"chars": 11739,
"preview": "# SQL Refresher\n\n### Table of contents\n\n\n- [Window Functions](#window-funtions)\n - [Row Number](#row-number)\n - [R"
},
{
"path": "04-analytics-engineering/setup/cloud_setup.md",
"chars": 9311,
"preview": "# Cloud Setup Guide\n\nThis guide walks you through setting up dbt to work with the BigQuery data warehouse you created in"
},
{
"path": "04-analytics-engineering/setup/duckdb_troubleshooting.md",
"chars": 5834,
"preview": "# Troubleshooting DuckDB Out of Memory Errors\n\nIf you're getting `Out of Memory` errors while running dbt build commands"
},
{
"path": "04-analytics-engineering/setup/local_setup.md",
"chars": 7682,
"preview": "# Local Setup Guide\n\nThis guide walks you through setting up a local analytics engineering environment using DuckDB and "
},
{
"path": "04-analytics-engineering/taxi_rides_ny/.gitignore",
"chars": 1106,
"preview": "# you shouldn't commit these into source control\n# these are the default directory names, adjust/add to fit your needs\nt"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/dbt_project.yml",
"chars": 944,
"preview": "name: 'taxi_rides_ny'\nversion: '1.0.0'\n\n# Require a specific dbt version for reproducibility\nrequire-dbt-version: [\">=1."
},
{
"path": "04-analytics-engineering/taxi_rides_ny/macros/get_trip_duration_minutes.sql",
"chars": 440,
"preview": "{#\n Calculate trip duration in minutes from pickup and dropoff timestamps.\n\n Uses dbts built-in cross-database dat"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/macros/get_vendor_data.sql",
"chars": 645,
"preview": "{#\n Macro to generate vendor_name column using Jinja dictionary.\n\n This approach works seamlessly across BigQuery,"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/macros/macros_properties.yml",
"chars": 952,
"preview": "macros:\n - name: get_trip_duration_minutes\n description: >\n Calculates trip duration in minutes from pickup and"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/macros/safe_cast.sql",
"chars": 223,
"preview": "{% macro safe_cast(column, data_type) %}\n {% if target.type == 'bigquery' %}\n safe_cast({{ column }} as {{ dat"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/models/intermediate/int_trips.sql",
"chars": 1710,
"preview": "-- Enrich and deduplicate trip data\n-- Demonstrates enrichment and surrogate key generation\n-- Note: Data quality analys"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/models/intermediate/int_trips_unioned.sql",
"chars": 1423,
"preview": "-- Union green and yellow taxi data into a single dataset\n-- Demonstrates how to combine data from multiple sources with"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/models/intermediate/schema.yml",
"chars": 3922,
"preview": "models:\n - name: int_trips_unioned\n description: Union of green and yellow taxi trip data with normalized schema\n "
},
{
"path": "04-analytics-engineering/taxi_rides_ny/models/marts/dim_vendors.sql",
"chars": 331,
"preview": "-- Dimension table for taxi technology vendors\n-- Small static dimension defining vendor codes and their company names\n\n"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/models/marts/dim_zones.sql",
"chars": 307,
"preview": "-- Dimension table for NYC taxi zones\n-- This is a simple pass-through from the seed file, but having it as a model\n-- a"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/models/marts/fct_trips.sql",
"chars": 1820,
"preview": "{{\n config(\n materialized='incremental',\n unique_key='trip_id',\n incremental_strategy='merge',\n on_schema_c"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/models/marts/reporting/fct_monthly_zone_revenue.sql",
"chars": 1293,
"preview": "-- Data mart for monthly revenue analysis by pickup zone and service type\n-- This aggregation is optimized for business "
},
{
"path": "04-analytics-engineering/taxi_rides_ny/models/marts/reporting/schema.yml",
"chars": 1087,
"preview": "models:\n - name: fct_monthly_zone_revenue\n description: Monthly revenue aggregation by pickup zone and service type "
},
{
"path": "04-analytics-engineering/taxi_rides_ny/models/marts/schema.yml",
"chars": 4380,
"preview": "models:\n - name: dim_zones\n description: Taxi zone dimension table with location details\n columns:\n - name: "
},
{
"path": "04-analytics-engineering/taxi_rides_ny/models/staging/schema.yml",
"chars": 4528,
"preview": "models:\n - name: stg_green_tripdata\n description: >\n Staging model for green taxi trip data. This model standar"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/models/staging/sources.yml",
"chars": 4409,
"preview": "sources:\n - name: raw\n description: Raw taxi trip data from NYC TLC\n database: |\n {%- if target.type == 'big"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/models/staging/stg_green_tripdata.sql",
"chars": 1699,
"preview": "with source as (\n select * from {{ source('raw', 'green_tripdata') }}\n),\n\nrenamed as (\n select\n -- identifi"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/models/staging/stg_yellow_tripdata.sql",
"chars": 1644,
"preview": "with source as (\n select * from {{ source('raw', 'yellow_tripdata') }}\n),\n\nrenamed as (\n select\n -- identif"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/package-lock.yml",
"chars": 201,
"preview": "packages:\n - name: dbt_utils\n package: dbt-labs/dbt_utils\n version: 1.3.3\n - name: codegen\n package: dbt-labs"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/packages.yml",
"chars": 142,
"preview": "packages:\n - package: dbt-labs/dbt_utils\n version: [\">=1.3.0\", \"<2.0.0\"]\n - package: dbt-labs/codegen\n version: "
},
{
"path": "04-analytics-engineering/taxi_rides_ny/seeds/seeds_properties.yml",
"chars": 833,
"preview": "seeds:\n - name: taxi_zone_lookup\n description: >\n Taxi Zones roughly based on NYC Department of City Planning's"
},
{
"path": "04-analytics-engineering/taxi_rides_ny/snapshots/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "04-analytics-engineering/taxi_rides_ny/tests/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "05-data-platforms/README.md",
"chars": 5482,
"preview": "# Module 5: Data Platforms\n\n## Overview\n\nIn this module, you'll learn about data platforms - tools that help you manage "
},
{
"path": "05-data-platforms/notes/01-introduction.md",
"chars": 1396,
"preview": "# 5.1 - Introduction to Bruin\n\n## What is Bruin?\n\nBruin is an end-to-end data platform that combines ingestion, transfor"
},
{
"path": "05-data-platforms/notes/02-getting-started.md",
"chars": 4061,
"preview": "# 5.2 - Getting Started with Bruin\n\n## Installation\n\nInstall Bruin CLI:\n\n```bash\ncurl -LsSf https://getbruin.com/install"
},
{
"path": "05-data-platforms/notes/03-nyc-taxi-pipeline.md",
"chars": 7156,
"preview": "# 5.3 - Building an End-to-End Pipeline with NYC Taxi Data\n\n## Architecture\n\nThree-layered pipeline using DuckDB as a lo"
},
{
"path": "05-data-platforms/notes/04-bruin-mcp.md",
"chars": 3206,
"preview": "# 5.4 - Using Bruin MCP with AI Agents\n\n## What is Bruin MCP?\n\nMCP stands for **Model Context Protocol**. Bruin MCP is a"
},
{
"path": "05-data-platforms/notes/05-bruin-cloud.md",
"chars": 2420,
"preview": "# 5.5 - Deploying to Bruin Cloud\n\n## What is Bruin Cloud?\n\nBruin Cloud is a fully managed infrastructure for your data p"
},
{
"path": "05-data-platforms/notes/06-core-01-projects.md",
"chars": 2209,
"preview": "# 5.6 - Core Concepts: Projects\n\n🎥 [Bruin Core Concepts | Projects](https://www.youtube.com/watch?v=YWDjnSxbBtY) (3:03)\n"
},
{
"path": "05-data-platforms/notes/06-core-02-pipelines.md",
"chars": 2208,
"preview": "# 5.6 - Core Concepts: Pipelines\n\n🎥 [Bruin Core Concepts | Pipelines](https://www.youtube.com/watch?v=uzp_DiR4Sok) (3:13"
},
{
"path": "05-data-platforms/notes/06-core-03-assets.md",
"chars": 3470,
"preview": "# 5.6 - Core Concepts: Assets\n\n🎥 [Bruin Core Concepts | Assets](https://www.youtube.com/watch?v=ZElY5SoqrwI) (6:11)\n\n## "
},
{
"path": "05-data-platforms/notes/06-core-04-variables.md",
"chars": 3808,
"preview": "# 5.6 - Core Concepts: Variables\n\n🎥 [Bruin Core Concepts | Variables](https://www.youtube.com/watch?v=XCx0nDmhhxA) (6:03"
},
{
"path": "05-data-platforms/notes/06-core-05-commands.md",
"chars": 3775,
"preview": "# 5.6 - Core Concepts: Commands\n\n🎥 [Bruin Core Concepts | Commands](https://www.youtube.com/watch?v=3nykPEs_V7E) (6:46)\n"
},
{
"path": "06-batch/.gitignore",
"chars": 0,
"preview": ""
},
{
"path": "06-batch/README.md",
"chars": 6184,
"preview": "# Module 6: Batch Processing\n\n## 6.1 Introduction\n\n* :movie_camera: 6.1.1 Introduction to Batch Processing\n\n[, but it shoul"
},
{
"path": "06-batch/setup/macos.md",
"chars": 1914,
"preview": "\n## MacOS\n\nHere we'll show you how to install Spark 4.x for macOS.\nWe tested it on macOS 15 (Sequoia), but it should wor"
},
{
"path": "06-batch/setup/windows.md",
"chars": 2397,
"preview": "## Windows\n\nHere we'll show you how to install Spark 4.x for Windows.\nWe tested it on Windows 10 and 11, but it should w"
},
{
"path": "07-streaming/.gitignore",
"chars": 10,
"preview": "week6_venv"
},
{
"path": "07-streaming/README.md",
"chars": 1033,
"preview": "# Module 7: Stream Processing\n\nVideo: https://www.youtube.com/live/YDUgFeHQzJU\n\n- [PyFlink workshop](workshop/) - build "
},
{
"path": "07-streaming/extras/README.md",
"chars": 1928,
"preview": "# Supplementary streaming examples\n\nAdditional stream processing examples from previous course years. These are\nnot part"
},
{
"path": "07-streaming/extras/ksqldb/commands.md",
"chars": 1021,
"preview": "## KSQL DB Examples\n### Create streams\n```sql\nCREATE STREAM ride_streams (\n VendorId varchar, \n trip_distance doub"
},
{
"path": "07-streaming/extras/pyflink/.gitignore",
"chars": 1874,
"preview": "data/\npostgres-data\n# Byte-compiled / optimized / DLL files\n__pycache__/\n*.py[cod]\n*$py.class\n\n# C extensions\n*.so\n\n# Di"
},
{
"path": "07-streaming/extras/pyflink/Dockerfile.flink",
"chars": 1829,
"preview": "FROM --platform=linux/amd64 flink:1.16.0-scala_2.12-java8\n\n# install python3: it has updated Python to 3.9 in Debian 11 "
},
{
"path": "07-streaming/extras/pyflink/LICENSE",
"chars": 1095,
"preview": "MIT License\n\nCopyright (c) 2025 Sreela Das, Julie Scherer, Zach Wilson\n\nPermission is hereby granted, free of charge, to"
},
{
"path": "07-streaming/extras/pyflink/Makefile",
"chars": 1485,
"preview": "PLATFORM ?= linux/amd64\n\n# COLORS\nGREEN := $(shell tput -Txterm setaf 2)\nYELLOW := $(shell tput -Txterm setaf 3)\nWHITE "
},
{
"path": "07-streaming/extras/pyflink/README.md",
"chars": 4747,
"preview": "# Apache Flink Training\nApache Flink Streaming Pipelines\n\n## :pushpin: Getting started \n\n### :whale: Installations\n\nTo r"
},
{
"path": "07-streaming/extras/pyflink/docker-compose.yml",
"chars": 2903,
"preview": "version: \"3.9\"\nservices:\n redpanda-1:\n image: redpandadata/redpanda:v24.2.18\n container_name: redpanda-1\n comm"
},
{
"path": "07-streaming/extras/pyflink/homework.md",
"chars": 2662,
"preview": "# Homework\n\nFor this homework we will be using the Taxi data:\n- Green 2019-10 data from [here](https://github.com/DataTa"
},
{
"path": "07-streaming/extras/pyflink/requirements.txt",
"chars": 65,
"preview": "apache-flink==1.16.0\npsycopg2-binary==2.9.1\nrequests\nkafka-python"
},
{
"path": "07-streaming/extras/pyflink/src/job/aggregation_job.py",
"chars": 3145,
"preview": "from pyflink.datastream import StreamExecutionEnvironment\nfrom pyflink.table import EnvironmentSettings, DataTypes, Tabl"
},
{
"path": "07-streaming/extras/pyflink/src/job/start_job.py",
"chars": 2532,
"preview": "from pyflink.datastream import StreamExecutionEnvironment\nfrom pyflink.table import EnvironmentSettings, DataTypes, Tabl"
},
{
"path": "07-streaming/extras/pyflink/src/job/taxi_job.py",
"chars": 3698,
"preview": "from pyflink.datastream import StreamExecutionEnvironment\nfrom pyflink.table import EnvironmentSettings, DataTypes, Tabl"
},
{
"path": "07-streaming/extras/pyflink/src/producers/load_taxi_data.py",
"chars": 777,
"preview": "import csv\nimport json\nfrom kafka import KafkaProducer\n\ndef main():\n # Create a Kafka producer\n producer = KafkaPr"
},
{
"path": "07-streaming/extras/pyflink/src/producers/producer.py",
"chars": 564,
"preview": "import json\nimport time\nfrom kafka import KafkaProducer\n\ndef json_serializer(data):\n return json.dumps(data).encode('"
},
{
"path": "07-streaming/extras/python/README.md",
"chars": 1020,
"preview": "### Stream-Processing with Python\n\nIn this document, you will be finding information about stream processing \nusing diff"
},
{
"path": "07-streaming/extras/python/avro_example/consumer.py",
"chars": 3110,
"preview": "import os\nfrom typing import Dict, List\n\nfrom confluent_kafka import Consumer\nfrom confluent_kafka.schema_registry impor"
},
{
"path": "07-streaming/extras/python/avro_example/producer.py",
"chars": 4039,
"preview": "import os\nimport csv\nfrom time import sleep\nfrom typing import Dict\n\nfrom confluent_kafka import Producer\nfrom confluent"
},
{
"path": "07-streaming/extras/python/avro_example/ride_record.py",
"chars": 837,
"preview": "from typing import List, Dict\n\n\nclass RideRecord:\n\n def __init__(self, arr: List[str]):\n self.vendor_id = int("
},
{
"path": "07-streaming/extras/python/avro_example/ride_record_key.py",
"chars": 525,
"preview": "from typing import Dict\n\n\nclass RideRecordKey:\n def __init__(self, vendor_id):\n self.vendor_id = vendor_id\n\n "
},
{
"path": "07-streaming/extras/python/avro_example/settings.py",
"chars": 289,
"preview": "INPUT_DATA_PATH = '../resources/rides.csv'\n\nRIDE_KEY_SCHEMA_PATH = '../resources/schemas/taxi_ride_key.avsc'\nRIDE_VALUE_"
},
{
"path": "07-streaming/extras/python/docker/README.md",
"chars": 1201,
"preview": "\n# Running Spark and Kafka Clusters on Docker\n\n### 1. Build Required Images for running Spark\n\nThe details of how to spa"
},
{
"path": "07-streaming/extras/python/docker/docker-compose.yml",
"chars": 3464,
"preview": "version: \"3.6\"\nvolumes:\n shared-workspace:\n name: \"hadoop-distributed-file-system\"\n driver: local\nservices:\n jup"
},
{
"path": "07-streaming/extras/python/docker/kafka/docker-compose.yml",
"chars": 2688,
"preview": "version: '3.6'\nnetworks:\n default:\n name: kafka-spark-network\n external: true\nservices:\n broker:\n image: conf"
},
{
"path": "07-streaming/extras/python/docker/spark/build.sh",
"chars": 658,
"preview": "# -- Software Stack Version\n\nSPARK_VERSION=\"3.3.1\"\nHADOOP_VERSION=\"3\"\nJUPYTERLAB_VERSION=\"3.6.1\"\n\n# -- Building the Imag"
},
{
"path": "07-streaming/extras/python/docker/spark/cluster-base.Dockerfile",
"chars": 600,
"preview": "# Reference from offical Apache Spark repository Dockerfile for Kubernetes\n# https://github.com/apache/spark/blob/master"
},
{
"path": "07-streaming/extras/python/docker/spark/docker-compose.yml",
"chars": 1108,
"preview": "version: \"3.6\"\nvolumes:\n shared-workspace:\n name: \"hadoop-distributed-file-system\"\n driver: local\nnetworks:\n def"
},
{
"path": "07-streaming/extras/python/docker/spark/jupyterlab.Dockerfile",
"chars": 389,
"preview": "FROM cluster-base\n\n# -- Layer: JupyterLab\n\nARG spark_version=3.3.1\nARG jupyterlab_version=3.6.1\n\nRUN apt-get update -y &"
},
{
"path": "07-streaming/extras/python/docker/spark/spark-base.Dockerfile",
"chars": 692,
"preview": "FROM cluster-base\n\n# -- Layer: Apache Spark\n\nARG spark_version=3.3.1\nARG hadoop_version=3\n\nRUN apt-get update -y && \\\n "
},
{
"path": "07-streaming/extras/python/docker/spark/spark-master.Dockerfile",
"chars": 194,
"preview": "FROM spark-base\n\n# -- Runtime\n\nARG spark_master_web_ui=8080\n\nEXPOSE ${spark_master_web_ui} ${SPARK_MASTER_PORT}\nCMD bin/"
},
{
"path": "07-streaming/extras/python/docker/spark/spark-worker.Dockerfile",
"chars": 224,
"preview": "FROM spark-base\n\n# -- Runtime\n\nARG spark_worker_web_ui=8081\n\nEXPOSE ${spark_worker_web_ui}\nCMD bin/spark-class org.apach"
},
{
"path": "07-streaming/extras/python/json_example/consumer.py",
"chars": 1512,
"preview": "from typing import Dict, List\nfrom json import loads\nfrom kafka import KafkaConsumer\n\nfrom ride import Ride\nfrom setting"
},
{
"path": "07-streaming/extras/python/json_example/producer.py",
"chars": 1536,
"preview": "import csv\nimport json\nfrom typing import List, Dict\nfrom kafka import KafkaProducer\nfrom kafka.errors import KafkaTimeo"
},
{
"path": "07-streaming/extras/python/json_example/ride.py",
"chars": 1769,
"preview": "from typing import List, Dict\nfrom decimal import Decimal\nfrom datetime import datetime\n\n\nclass Ride:\n def __init__(s"
},
{
"path": "07-streaming/extras/python/json_example/settings.py",
"chars": 110,
"preview": "INPUT_DATA_PATH = '../resources/rides.csv'\n\nBOOTSTRAP_SERVERS = ['localhost:9092']\nKAFKA_TOPIC = 'rides_json'\n"
},
{
"path": "07-streaming/extras/python/redpanda_example/README.md",
"chars": 4098,
"preview": "# Basic PubSub example with Redpanda\n\nThe aim of this module is to have a good grasp on the foundation of these Kafka/Re"
},
{
"path": "07-streaming/extras/python/redpanda_example/consumer.py",
"chars": 1943,
"preview": "import os\nfrom typing import Dict, List\nfrom json import loads\nfrom kafka import KafkaConsumer\n\nfrom ride import Ride\nfr"
},
{
"path": "07-streaming/extras/python/redpanda_example/docker-compose.yaml",
"chars": 2443,
"preview": "version: '3.7'\nservices:\n # Redpanda cluster\n redpanda-1:\n image: docker.redpanda.com/redpandadata/redpanda:v23.2.2"
},
{
"path": "07-streaming/extras/python/redpanda_example/producer.py",
"chars": 1593,
"preview": "import csv\nimport json\nfrom typing import List, Dict\nfrom kafka import KafkaProducer\nfrom kafka.errors import KafkaTimeo"
},
{
"path": "07-streaming/extras/python/redpanda_example/ride.py",
"chars": 1769,
"preview": "from typing import List, Dict\nfrom decimal import Decimal\nfrom datetime import datetime\n\n\nclass Ride:\n def __init__(s"
},
{
"path": "07-streaming/extras/python/redpanda_example/settings.py",
"chars": 110,
"preview": "INPUT_DATA_PATH = '../resources/rides.csv'\n\nBOOTSTRAP_SERVERS = ['localhost:9092']\nKAFKA_TOPIC = 'rides_json'\n"
},
{
"path": "07-streaming/extras/python/requirements.txt",
"chars": 65,
"preview": "kafka-python==1.4.6\nconfluent_kafka\nrequests\navro\nfaust\nfastavro\n"
},
{
"path": "07-streaming/extras/python/resources/schemas/taxi_ride_key.avsc",
"chars": 168,
"preview": "{\n \"namespace\": \"com.datatalksclub.taxi\",\n \"type\": \"record\",\n \"name\": \"RideRecordKey\",\n \"fields\": [\n {\n \"nam"
},
{
"path": "07-streaming/extras/python/resources/schemas/taxi_ride_value.avsc",
"chars": 425,
"preview": "{\n \"namespace\": \"com.datatalksclub.taxi\",\n \"type\": \"record\",\n \"name\": \"RideRecord\",\n \"fields\": [\n {\n \"name\":"
},
{
"path": "07-streaming/extras/python/streams-example/faust/branch_price.py",
"chars": 710,
"preview": "import faust\nfrom taxi_rides import TaxiRide\nfrom faust import current_event\n\napp = faust.App('datatalksclub.stream.v3',"
},
{
"path": "07-streaming/extras/python/streams-example/faust/producer_taxi_json.py",
"chars": 739,
"preview": "import csv\nfrom json import dumps\nfrom kafka import KafkaProducer\nfrom time import sleep\n\n\nproducer = KafkaProducer(boot"
},
{
"path": "07-streaming/extras/python/streams-example/faust/stream.py",
"chars": 353,
"preview": "import faust\nfrom taxi_rides import TaxiRide\n\n\napp = faust.App('datatalksclub.stream.v2', broker='kafka://localhost:9092"
},
{
"path": "07-streaming/extras/python/streams-example/faust/stream_count_vendor_trips.py",
"chars": 446,
"preview": "import faust\nfrom taxi_rides import TaxiRide\n\n\napp = faust.App('datatalksclub.stream.v2', broker='kafka://localhost:9092"
},
{
"path": "07-streaming/extras/python/streams-example/faust/taxi_rides.py",
"chars": 176,
"preview": "import faust\n\n\nclass TaxiRide(faust.Record, validation=True):\n vendorId: str\n passenger_count: int\n trip_distan"
},
{
"path": "07-streaming/extras/python/streams-example/faust/windowing.py",
"chars": 557,
"preview": "from datetime import timedelta\nimport faust\nfrom taxi_rides import TaxiRide\n\n\napp = faust.App('datatalksclub.stream.v2',"
},
{
"path": "07-streaming/extras/python/streams-example/pyspark/README.md",
"chars": 1208,
"preview": "\n# Running PySpark Streaming \n\n#### Prerequisite\n\nEnsure your Kafka and Spark services up and running by following the ["
},
{
"path": "07-streaming/extras/python/streams-example/pyspark/consumer.py",
"chars": 1739,
"preview": "import argparse\nfrom typing import Dict, List\nfrom kafka import KafkaConsumer\n\nfrom settings import BOOTSTRAP_SERVERS, C"
},
{
"path": "07-streaming/extras/python/streams-example/pyspark/producer.py",
"chars": 2177,
"preview": "import csv\nfrom time import sleep\nfrom typing import Dict\nfrom kafka import KafkaProducer\n\nfrom settings import BOOTSTRA"
},
{
"path": "07-streaming/extras/python/streams-example/pyspark/settings.py",
"chars": 664,
"preview": "import pyspark.sql.types as T\n\nINPUT_DATA_PATH = '../../resources/rides.csv'\nBOOTSTRAP_SERVERS = 'localhost:9092'\n\nTOPIC"
},
{
"path": "07-streaming/extras/python/streams-example/pyspark/spark-submit.sh",
"chars": 581,
"preview": "# Submit Python code to SparkMaster\n\nif [ $# -lt 1 ]\nthen\n\techo \"Usage: $0 <pyspark-job.py> [ executor-memory ]\"\n\techo \""
},
{
"path": "07-streaming/extras/python/streams-example/pyspark/streaming-notebook.ipynb",
"chars": 26039,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c4419168-c0e6-4a65-b56e-8454c42060ac\",\n \"metadata\": {\n \"jp-"
},
{
"path": "07-streaming/extras/python/streams-example/pyspark/streaming.py",
"chars": 4243,
"preview": "from pyspark.sql import SparkSession\nimport pyspark.sql.functions as F\n\nfrom settings import RIDE_SCHEMA, CONSUME_TOPIC_"
},
{
"path": "07-streaming/extras/python/streams-example/redpanda/README.md",
"chars": 1389,
"preview": "\n# Running PySpark Streaming with Redpanda\n\n### 1. Prerequisite\n\nIt is important to create network and volume as describ"
},
{
"path": "07-streaming/extras/python/streams-example/redpanda/consumer.py",
"chars": 1739,
"preview": "import argparse\nfrom typing import Dict, List\nfrom kafka import KafkaConsumer\n\nfrom settings import BOOTSTRAP_SERVERS, C"
},
{
"path": "07-streaming/extras/python/streams-example/redpanda/docker-compose.yaml",
"chars": 2702,
"preview": "version: '3.7'\nvolumes:\n shared-workspace:\n name: \"hadoop-distributed-file-system\"\n driver: local\nnetworks:\n def"
},
{
"path": "07-streaming/extras/python/streams-example/redpanda/producer.py",
"chars": 2177,
"preview": "import csv\nfrom time import sleep\nfrom typing import Dict\nfrom kafka import KafkaProducer\n\nfrom settings import BOOTSTRA"
},
{
"path": "07-streaming/extras/python/streams-example/redpanda/settings.py",
"chars": 664,
"preview": "import pyspark.sql.types as T\n\nINPUT_DATA_PATH = '../../resources/rides.csv'\nBOOTSTRAP_SERVERS = 'localhost:9092'\n\nTOPIC"
},
{
"path": "07-streaming/extras/python/streams-example/redpanda/spark-submit.sh",
"chars": 582,
"preview": "# Submit Python code to SparkMaster\n\nif [ $# -lt 1 ]\nthen\n\techo \"Usage: $0 <pyspark-job.py> [ executor-memory ]\"\n\techo \""
},
{
"path": "07-streaming/extras/python/streams-example/redpanda/streaming-notebook.ipynb",
"chars": 86292,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c4419168-c0e6-4a65-b56e-8454c42060ac\",\n \"metadata\": {\n \"tag"
},
{
"path": "07-streaming/extras/python/streams-example/redpanda/streaming.py",
"chars": 4234,
"preview": "from pyspark.sql import SparkSession\nimport pyspark.sql.functions as F\n\nfrom settings import RIDE_SCHEMA, CONSUME_TOPIC_"
},
{
"path": "07-streaming/theory/README.md",
"chars": 1997,
"preview": "# Kafka theory (optional)\n\nVideo lectures covering Kafka concepts, with code examples in Java.\n\nCode: [java/kafka_exampl"
},
{
"path": "07-streaming/theory/java/kafka_examples/.gitignore",
"chars": 143,
"preview": ".gradle\nbin\n!src/main/resources/rides.csv\n\nbuild/classes\nbuild/generated\nbuild/libs\nbuild/reports\nbuild/resources\nbuild/"
}
]
// ... and 181 more files (download for full content)
About this extraction
This page contains the full source code of the DataTalksClub/data-engineering-zoomcamp GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 381 files (12.5 MB), approximately 523.0k tokens, and a symbol index with 375 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.