Repository: DingHanyang/chatLog
Branch: master
Commit: 2ac503faa3fd
Files: 18
Total size: 22.6 MB
Directory structure:
gitextract_tluzrh7n/
├── .gitignore
├── README.md
├── chatlog/
│ ├── analysis/
│ │ ├── collectivity.py
│ │ ├── content.py
│ │ ├── individual.py
│ │ └── interesting.py
│ ├── base/
│ │ ├── constant.py
│ │ ├── read_chatlog.py
│ │ ├── seg_word.py
│ │ └── user_profile.py
│ ├── model/
│ │ ├── message.py
│ │ └── user.py
│ ├── run.py
│ └── visualization/
│ ├── charts.py
│ ├── msyh.ttc
│ └── word_img.py
├── license
└── photos/
└── README.md
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
*.txt
/TEST/
.idea/
/.idea
/.idea/
.idea
================================================
FILE: README.md
================================================
# ChatLog
通过QQ导出的QQ群聊天记录进行一定的分析。
just a toy
## 开发日志
2020-08-27 完成数据处理部分代码清洗,优化部分代码。
## 基本功能
* QQ群聊天记录的数据清洗
* 构建简单用户画像
* 简单分析与统计
* 部分数据可视化
## 安装说明
python版本:`3.6.x`
系统平台:`windows`
需要的第三方库:`pymongo,pandas,jieba,seaborn,numpy`
以上均可通过`pip install `安装
需要的软件:`MongoDB`
## 说明
### 1.base
- read_chatlog.py
对导出的.txt聊天记录文件进行数据清洗。
`注意:腾讯导出的聊天记录是UTF-8+bom的 需改成 -bom`
清洗后的数据存入mongo数据库中,具体数据如下:
| 数据项 | 说明 |
| ---- | :----------- |
| time | 消息发送时间 |
| ID | QQ号或邮箱 |
| name | 发送该消息时所使用的马甲 |
| text | 发送消息的内容 |
- user_profile.py
通过清洗好的数据构建用户画像,并保存到mongo数据库中。
用户基本画像数据如下:
| 数据项 | 说明 |
| ----------- | ------------------ |
| ID | QQ号或邮箱 |
| name_list | 可统计得到的所有马甲 |
| speak_num | 发言次数 |
| word_num | 发言字数 |
| photos_num | 发送图片数 |
| week_online | 记录着周一到周日每天每小时的活跃数据 |
| ban_time | 被禁言时间(有待改进) |
- seg_word.py
通过[jieba](https://github.com/fxsjy/jieba)分词工具将文本进行分析,统计词频并去停用词后保存。
- chinese_stopword.txt
停用词典。
### 2.analysis
- individual.py
个人数据统计,分析发言次数最多,发送字数最多,发送图片最多,被禁言时长最长的用户。
- collecticity.py
总体数据分析,分析群活跃时间。
- interesting.py
因吹斯听的分析。
- 马甲最长的聚聚
- 改名次数最多的聚聚
- 群内队形(+1)次数最多的内容,即使局部打断也可统计。
- content.py
开发中
### 3.visualization
- charts.py
将部分数据可视化。如下:
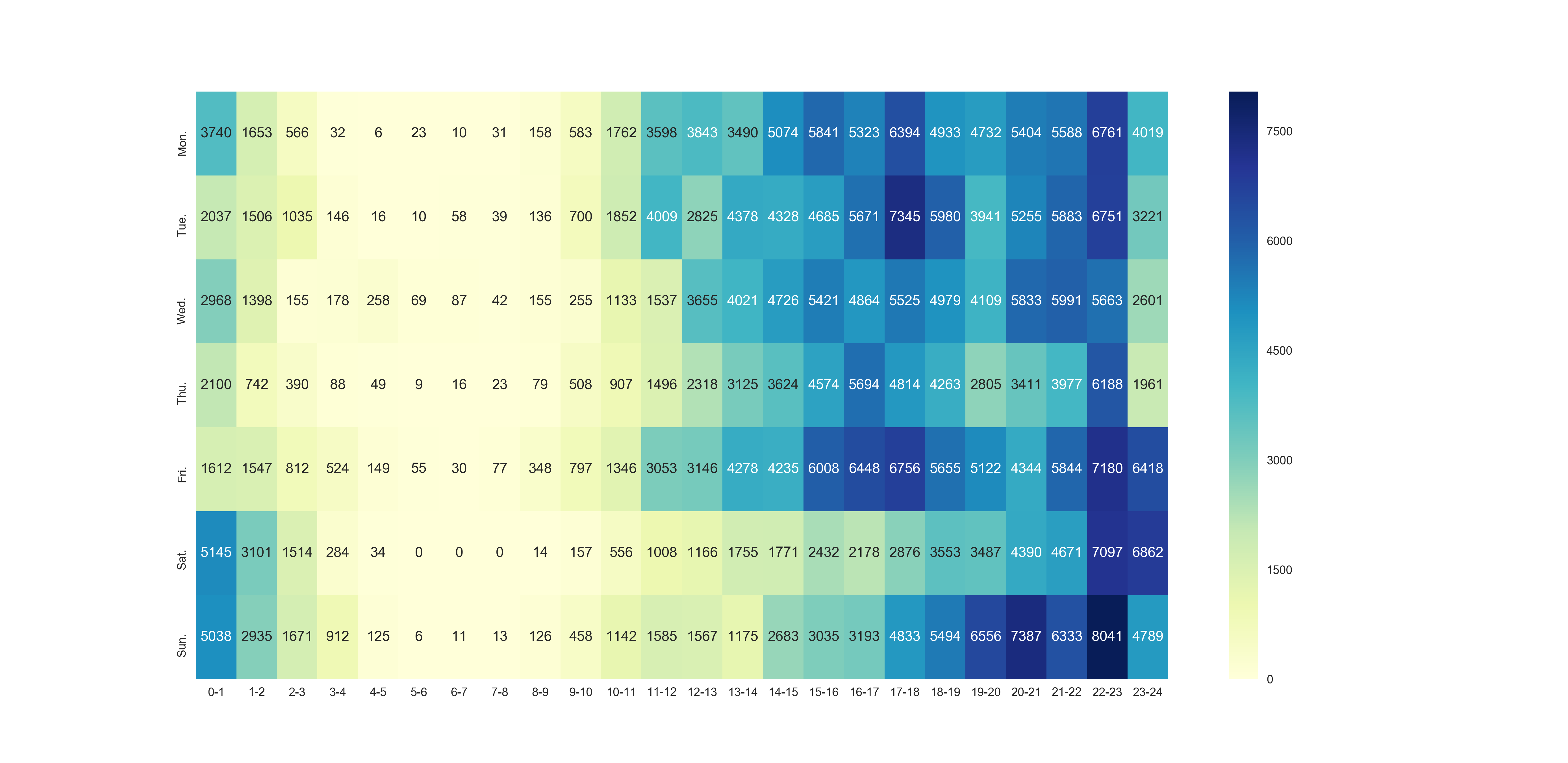
用户活跃时间heatmap,横轴为一天0-24时,纵轴为周一到周日。颜色越深的方块活跃程度越高。
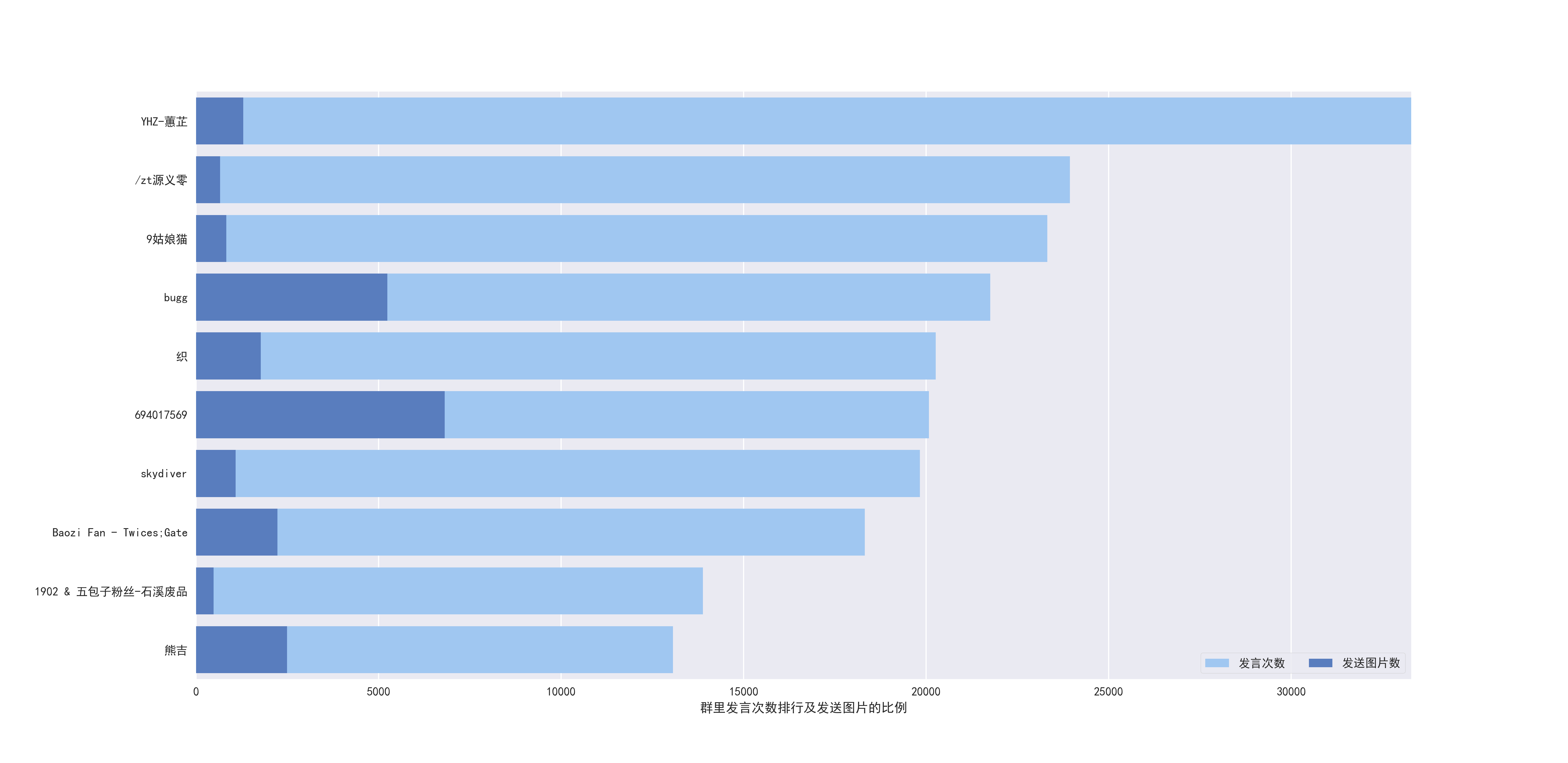
用户发言数TOP10及发表图片所占比例。
- word_img.py
构建词云。分析群内常用词及部分话题,如下:
针对所有信息进行词云
- 构建词长度大于0:

- 词长度大于1:

- 词长度大于3:

针对群聊天记录构建的词云:
因为测试数据为技(zhuang)术(bi)群,所以本项不具有通用性。具体实现在[此处](https://github.com/DingHanyang/chatLog/blob/master/visualization/Wordcloud.py)
- 针对经常谈论的公司:

- 针对谈论的编程语言:

## 运行
0.clone本项目到本地。
1.手动从QQ消息管理器中导出消息,注意改为UTF-8-BOM。并将其命名为chatlog.txt放置于run.py同级目录下。
2.开启mongodb服务,运行run.py
3.易于修改的参数有:
- 群等级标签:[DataClean.py](https://github.com/DingHanyang/chatLog/blob/master/base/DataClean.py) line83:根据不同群等级标签修改。不改无妨,影响用户名称显示
- 词云样式及背景图片:[Wordcloud](https://github.com/DingHanyang/chatLog/blob/master/visualization/Wordcloud.py)
- 词云屏蔽词:[Wordcloud](https://github.com/DingHanyang/chatLog/blob/master/visualization/Wordcloud.py) line45:此处已经屏蔽‘图片’,‘表情’,‘说’
## 最后
填坑中,希望收到改进意见。
================================================
FILE: chatlog/analysis/collectivity.py
================================================
"""
总体数据统计分析
@author:DingHanyang
"""
import numpy
from pymongo import MongoClient
class Collectivity(object):
def __init__(self):
self.client = MongoClient() # 默认连接 localhost 27017
self.db = self.client.chatlog
self.post = self.db.vczh
def get_all_speak_info(self):
"""
群总体在线时间分布
:return:
"""
post = self.db.profile
week_online = numpy.zeros((7, 24), dtype=numpy.int)
for doc in post.find({}, {'week_online': 1}):
week_online += numpy.array(doc['week_online'])
return week_online.tolist()
def close(self):
self.client.close()
================================================
FILE: chatlog/analysis/content.py
================================================
"""
聊天内容分析
@author:DingHanyang
"""
from pymongo import MongoClient
class ChatText(object):
def __init__(self):
self.client = MongoClient() # 默认连接 localhost 27017
self.db = self.client.chatlog
self.post = self.db.vczh
# TODO:一个大坑未填
================================================
FILE: chatlog/analysis/individual.py
================================================
"""
个体数据统计分析
@author:DingHanyang
"""
from pymongo import MongoClient
class Individual(object):
def __init__(self):
self.client = MongoClient() # 默认连接 localhost 27017
self.db = self.client.chatlog
self.post = self.db.profile
def most_speak(self, send_class='speak_num'):
"""
发言次数最多、发送字数最多、发送图片最多的用户排行
:param send_class:选择 speak_num,word_num,photo_num
:return:[(ID1,name1,num),(ID1,name2,num),...]
"""
top_list = []
for doc in self.post.find({}, {send_class: 1, 'name_list': 1, 'ID': 1}):
top_list.append((doc['ID'], doc['name_list'][len(doc['name_list']) - 1], doc[send_class]))
return sorted(top_list, key=lambda x: x[2], reverse=True)
def longest_ban(self):
"""
被禁言时间最长的人榜单
:return:[(name1,time),(name2,time),...]
"""
self.post = self.db.profile
top_list = []
for doc in self.post.find({}, {'ID': 1, 'ban_time': 1, 'name_list': 1}):
top_list.append((doc['ID'], doc['name_list'][len(doc['name_list']) - 1], doc['ban_time']))
return sorted(top_list, key=lambda x: x[2], reverse=True)
def close(self):
self.client.close()
================================================
FILE: chatlog/analysis/interesting.py
================================================
"""
因吹斯听 分析及统计
@author:DingHanyang
"""
from pymongo import MongoClient
class Interesting(object):
def __init__(self):
self.client = MongoClient() # 默认连接 localhost 27017
self.db = self.client.chatlog
self.post = self.db.vczh
def longest_name(self):
"""
取出所有用户的name,并排序。
..note::由于聊天记录时间跨度大,有的聚聚改名频繁,而有些名字由于QQ保存的原因保存成了QQ号而丢失
:return:top_list[('name',len(name)),(...,...),...] 按长度从大到小排序
"""
res_list = []
for doc in self.post.find({}, {'name': 1}):
res_list.append(doc['name'])
res_list = {}.fromkeys(res_list).keys()
top_list = []
for li in res_list:
top_list.append((li, len(li)))
return sorted(top_list, key=lambda x: x[1], reverse=True)
def longest_formation(self):
"""
所有记录中,跟队形最长的聊天记录。
:return:top_list[('text',len(text)),(...,...),...] 按长度从大到小排序
"""
res_list = []
for doc in self.post.find({}, {'text': 1}):
res_list.append(doc['text'])
top_list = []
# text 数据存储形式 [[sentences1],[sentences2],...] 队形大多只有一句 所以只考虑text长度为1的
i = 0
while i < len(res_list) - 1:
if res_list[i][0] == '[图片]':
i += 1
elif res_list[i][0] == res_list[i + 1][0]:
pos = i + 1
while pos < len(res_list) - 1:
if res_list[pos][0] == res_list[pos + 1][0]:
pos += 1
else:
if pos - i + 1 > 2:
top_list.append((res_list[i][0], pos - i + 1))
i = pos + 1
break
else:
i += 1
# 例如中间有人插话一句将队形打断的话,整合队形
k = 0
while k < len(top_list) - 1:
if top_list[k][0] == top_list[k + 1][0]:
top_list.append((top_list[k][0], top_list[k][1] + top_list[k + 1][1]))
top_list.pop(k - 1)
top_list.pop(k)
else:
k += 1
return sorted(top_list, key=lambda x: x[1], reverse=True)
def close(self):
self.client.close()
================================================
FILE: chatlog/base/constant.py
================================================
# re
JUDGE_TIME_RE = '^(((20[0-3][0-9]-(0[13578]|1[02])-(0[1-9]|[12][0-9]|3[01]))|(20[0-3][0-9]-(0[2469]|11)-(0[1-9]|[12][' \
'0-9]|30))) (20|21|22|23|[0-9]|[0-1][0-9]):[0-5][0-9]:[0-5][0-9])'
JUDGE_ID_RE = '[(][1-9]\d{4,}[)]$|[<][A-Za-z\d]+([-_.][A-Za-z\d]+)*@([A-Za-z\d]+[-.])+[A-Za-z\d]{2,4}[>]$'
================================================
FILE: chatlog/base/read_chatlog.py
================================================
import re
from pymongo import MongoClient
from chatlog.base import constant
class ReadChatlog(object):
def __init__(self, file_path, db_name='chatlog', collection_name='vczh'):
self.file_path = file_path
self.client = MongoClient() # 默认连接 localhost 27017
self.db = self.client[db_name]
self.post = self.db[collection_name]
# 初始化两个常用正则
self.time_pattern = re.compile(constant.JUDGE_TIME_RE)
self.ID_pattern = re.compile(constant.JUDGE_ID_RE)
def _judge_start_line(self, message):
"""
判断某行是不是起始行
条件1:YYYY-MM-DD HH-MM-SS开头(长度大于19)
条件2::(XXXXXXXXX)或者<xxx@xxx.xxx>结尾
:return: False or (time,ID)
"""
if len(message) > 19 and (self.time_pattern.match(message)) and (self.ID_pattern.search(message)):
return self.time_pattern.search(message).group(), self.ID_pattern.search(message).group()
return False
def work(self):
"""
腾讯导出的聊天记录是UTF-8+bom的 手动改成-bom
进行数据清洗,将原始数据划分成块保存进mongodb中
..note::例子
time:YYYY-MM-DD HH-MM-SS
ID:(XXXXXXXXX)或者<xxx@xxx.xxx>
name:username
text:['sentence1','sentence2',...]
"""
print('----------正在进行数据清洗-------------')
with open(self.file_path, 'r', encoding='utf-8') as chatlog_file:
chatlog_list = [line.strip() for line in chatlog_file if line.strip() != ""]
now_cursor = 0 # 当前分析位置
last = 0 # 上一个行首位置
flag = 0
first_line_info = self._judge_start_line(str(chatlog_list[now_cursor]))
while now_cursor < len(chatlog_list):
if self._judge_start_line(str(chatlog_list[now_cursor])):
if not flag:
first_line_info = self._judge_start_line(str(chatlog_list[now_cursor]))
last = now_cursor
flag = 1
else:
flag = 0
send_time = first_line_info[0]
send_id = first_line_info[1]
# 如果什么消息都没发直接不插入
if not chatlog_list[last + 1:now_cursor]:
continue
# 发送该消息时用户的马甲
name = chatlog_list[last].replace(send_id, "").replace(send_time, "").lstrip()
for extra_char in '()<>':
send_id = send_id.replace(extra_char, "")
# 由于等级标签有极大部分缺失,所以直接去除
# TODO:消息中大频率出现的标签应该就是等级标签,应自检测
for i in ['【实习】', '【能写代码】', '【专属骚头衔】', '【群地位倒数】', '【实习】', '【管理员】']:
if name[:len(i)] == i:
name = name.replace(i, "")
# 将时间格式统一
for li in '0123456789':
send_time = send_time.replace(' ' + li + ':', ' 0' + li + ':')
self.post.insert_one({'time': send_time, 'ID': send_id, 'name': name,
'text': chatlog_list[last + 1:now_cursor]})
print('time:', send_time, 'ID:', send_id, 'name:', name)
print(chatlog_list[last + 1:now_cursor])
print("------------------------------------------------")
continue
now_cursor += 1
self.client.close()
print('----------数据清洗完成-------------')
================================================
FILE: chatlog/base/seg_word.py
================================================
from collections import Counter
import jieba
from pymongo import MongoClient
class SegWord(object):
def __init__(self):
self.client = MongoClient() # 默认连接 localhost 27017
self.db = self.client.chatlog
self.post = self.db.vczh
def work(self):
stopword_list = []
fp = open('../base/chinese_stopword.txt', 'r', encoding='utf-8')
for line in fp.readlines():
stopword_list.append(line.replace('\n', ''))
fp.close()
word_list = []
for doc in self.post.find({}, {'text': 1}):
print(len(word_list))
word_list.extend(jieba.lcut(doc['text'][0]))
word_dict = Counter(word_list)
self.post = self.db.word
for key in word_dict.keys():
if str(key) in stopword_list:
print(key)
continue
self.post.insert({'word': key, 'item': word_dict[key]})
self.close()
def close(self):
self.client.close()
================================================
FILE: chatlog/base/user_profile.py
================================================
"""
构建用户基本画像
@author:DingHanyang
"""
from datetime import datetime
from pymongo import MongoClient
class UserProfile:
def __init__(self, db_name='chatlog', collection_name='vczh'):
print("正在初始化用户画像模块")
self.client = MongoClient() # 默认连接 localhost 27017
self.db = self.client[db_name]
self.post = self.db[collection_name]
self.res_list = [doc for doc in self.post.find({}, {'_id': 0})]
def close(self):
self.client.close()
def _get_user_id_list(self):
"""
获取记录中所有ID的列表
:return:[id1,id2,id3,...]
"""
user_id_list = [li['ID'] for li in self.res_list]
user_id_list = list(set(user_id_list))
print('记录中共有', len(user_id_list), '位聚聚发过言')
return user_id_list
def _get_all_name(self, user_id):
"""
根据ID返回一个用户所有曾用名
:param user_id:用户ID
:return:{'name1','name2',...}
"""
name_list = set()
for li in self.res_list:
if li['ID'] == user_id:
name_list.add(li['name'])
return list(name_list)
def _get_speak_infos(self, user_id):
"""
返回一个用户的发言次数,发言文字数,发言图片数
:param user_id:用户ID
:return:[speak_num,word_num,photo_num]
"""
speak_num = 0
word_num = 0
photo_num = 0
for li in self.res_list:
if li['ID'] == user_id:
speak_num += 1
for sp in li['text']:
word_num += len(sp)
photo_num += sp.count('[图片]')
return speak_num, word_num, photo_num
def _get_online_time(self, user_id):
"""
返回一个用户在那个时段发言数最多(0-24小时)(周1-7)
:param user_id:用户ID
:return:[[0,0,0,0],[],[],[],...] [周1-7]包含[0-24小时]
"""
time_list = []
for li in self.res_list:
if li['ID'] == user_id:
time_list.append(li['time'])
week_list = [[0 for _ in range(24)] for _ in range(7)]
for li in time_list:
week_list[int(datetime.strptime(li, "%Y-%m-%d %H:%M:%S").weekday())][int(li[11:13])] += 1
return week_list
def work(self):
"""
分析所有用户基本画像并存入数据库
..note::
ID:
name:[name1,name2,...]
speak_num:发言次数
word_num:发言字数
photo_num:发布图片数
week_online:周活跃分布
:return:None
"""
post = self.db.profile
user_id_list = self._get_user_id_list()
for li in user_id_list:
print('正在构建用户', li, '的用户画像')
name_list = self._get_all_name(li)
speak_num, word_num, photo_num = self._get_speak_infos(li)
week_online = self._get_online_time(li)
ban_time = self._ban_time(li)
post.insert_one({'ID': li, 'name_list': name_list, 'speak_num': speak_num,
'word_num': word_num, 'photo_num': photo_num,
'week_online': week_online, 'ban_time': ban_time})
self.close()
# TODO 管理员若解禁则扣除时间
def _ban_time(self, user_id):
"""
统计用户累计禁言时间
:return:
"""
def add_time(add_list):
time = 0
for times in add_list:
for info in [('天', 60 * 24), ('小时', 60), ('分钟', 1)]:
if info[0] in times:
index = times.find(info[0])
if times[index - 2].isdigit():
time += int(times[index - 2:index]) * info[1]
else:
time += int(times[index - 1:index]) * info[1]
return time
name_list = self._get_all_name(user_id)
res_list = []
for li in self.post.find({'ID': '10000'}, {'text': 1}):
if '被管理员禁言' in li['text'][0]:
res_list.append(li['text'][0].split(' 被管理员禁言'))
time_list = []
for li in res_list:
for name in name_list:
if li[0] == name:
time_list.append(li[1])
return add_time(time_list)
================================================
FILE: chatlog/model/message.py
================================================
from mongoengine import *
class Message(Document):
meta = {'db_alias': 'chatlog'}
name = StringField() # 发言用户昵称
ID = StringField() # 发言用户ID
time = DateTimeField() # 该消息发送时间
text = ListField() # 发送消息的列表
================================================
FILE: chatlog/model/user.py
================================================
from mongoengine import *
class User(Document):
meta = {'db_alias': 'chatlog'}
name_now = StringField() # 用户当前昵称
name_list = ListField(StringField) # 用户历史昵称列表
ID = StringField() # ID用户ID
speak_num = IntField() # 用户发言次数
word_num = IntField() # 用户发送文本分词后的词数
photo_num = IntField() # 用户发送图片的数量
ban_num = IntField() # 用户被禁言的次数
ban_time_sum = DateTimeField() # 用户被禁言时间总和
================================================
FILE: chatlog/run.py
================================================
from chatlog.analysis.collectivity import Collectivity
from chatlog.analysis.individual import Individual
from chatlog.analysis.interesting import Interesting
from chatlog.base.read_chatlog import ReadChatlog
from chatlog.base.user_profile import UserProfile
if __name__ == '__main__':
RC = ReadChatlog('./chatlog.txt')
RC.work() # 进行聊天记录的清洗并入库
UP = UserProfile()
UP.work() # 构建简单的用户画像
# Collectivity
# col = Collectivity()
# print(col.get_all_speak_info()) # 群聊天时间分布
# Individual
# ind = Individual()
# print(ind.longest_ban()) # 禁言时长的排名
# print(ind.most_speak('speak_num')) # 发言次数的排名
# Interesting
# interest = Interesting()
# print(interest.longest_formation()) # 最长队形的排名
# print(interest.longest_name()) # 最长的马甲排名
================================================
FILE: chatlog/visualization/charts.py
================================================
# -*- coding=utf-8 -*-
"""
数据可视化模块
"""
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from pymongo import MongoClient
from chatlog.analysis.individual import Individual
class Charts(object):
def __init__(self):
self.client = MongoClient() # 默认连接 localhost 27017
self.db = self.client.chatlog
self.post = self.db.profile
def ban_time(self):
ind = Individual()
res_list = ind.longest_ban()
res_list = res_list[0:10]
print(res_list)
name_list = [i[1] for i in res_list]
time_list = [i[2] for i in res_list]
sns.set(style="darkgrid")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
f, ax = plt.subplots(figsize=(18.5, 9))
# Plot the crashes where alcohol was involved
sns.set_color_codes("muted")
sns.barplot(x=time_list, y=name_list,
label="禁言时长", color="y")
# Add a legend and informative axis label
ax.legend(ncol=2, loc="lower right", frameon=True)
ax.set(xlim=(0, time_list[0]), ylabel="",
xlabel="禁言时间最长")
sns.despine(left=True, bottom=True)
plt.savefig('../photos/ban_time.png', format='png', dpi=400)
plt.close()
def speak_photo_in_total(self):
"""
发言次数前10的用户及发送图片的比例
:return:
"""
ind = Individual()
res_list = ind.most_speak('speak_num')
res_list = res_list[0:10]
print(res_list)
ID_list = [i[0] for i in res_list]
name_list = [i[1] for i in res_list]
speak_list = [i[2] for i in res_list]
photo_num = []
for id in ID_list:
for doc in self.post.find({'ID': id}, {'photo_num': 1}):
photo_num.append(doc['photo_num'])
sns.set(style="darkgrid")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
f, ax = plt.subplots(figsize=(18.5, 9))
sns.set_color_codes("pastel")
sns.barplot(x=speak_list, y=name_list,
label="发言次数", color="b")
# Plot the crashes where alcohol was involved
sns.set_color_codes("muted")
sns.barplot(x=photo_num, y=name_list,
label="发送图片数", color="b")
# Add a legend and informative axis label
ax.legend(ncol=2, loc="lower right", frameon=True)
ax.set(xlim=(0, speak_list[0]), ylabel="",
xlabel="群里发言次数排行及发送图片的比例")
sns.despine(left=True, bottom=True)
plt.savefig('../photos/speak_photo_in_total.png', format='png', dpi=300)
plt.close()
def user_online_time(self, user_ID=None):
"""
绘制(全体)用户活跃时间图像
:param user_ID:默认为空,指定全体用户,不为空时为指定ID用户
"""
res_list = []
if user_ID:
find_dict = {'ID': user_ID}
else:
find_dict = {}
week_online = [[0 for _ in range(24)] for _ in range(7)]
for doc in self.post.find(find_dict, {'week_online': 1}):
for i in range(0, 7):
for j in range(0, 24):
if user_ID:
week_online[i][j] = doc['week_online'][i][j]
else:
week_online[i][j] += doc['week_online'][i][j]
week_online = np.array([li for li in week_online])
columns = [str(i) + '-' + str(i + 1) for i in range(0, 24)]
index = ['Mon.', 'Tue.', 'Wed.', 'Thu.', 'Fri.', 'Sat.', 'Sun.']
week_online = pd.DataFrame(week_online, index=index, columns=columns)
plt.figure(figsize=(18.5, 9))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
sns.set()
# Draw a heatmap with the numeric values in each cell
sns.heatmap(week_online, annot=True, fmt="d", cmap="YlGnBu")
plt.savefig('../photos/user_time_online.png', format='png', dpi=300)
plt.close()
def close(self):
self.client.close()
def work(self):
self.speak_photo_in_total()
self.user_online_time()
self.close()
if __name__ == '__main__':
chart = Charts()
chart.user_online_time()
================================================
FILE: chatlog/visualization/msyh.ttc
================================================
[File too large to display: 22.6 MB]
================================================
FILE: chatlog/visualization/word_img.py
================================================
import sys
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from pymongo import MongoClient
from wordcloud import WordCloud, ImageColorGenerator
class WordImg(object):
def __init__(self):
self.client = MongoClient() # 默认连接 localhost 27017
self.db = self.client.chatlog
self.post = self.db.word
def close(self):
self.client.close()
def draw_wordcloud(self, word_dict, name):
cat_mask = np.array(Image.open('../visualization/cat.png'))
wc = WordCloud(font_path='../visualization/msyh.ttc',
width=800, height=400,
background_color="white", # 背景颜色
mask=cat_mask, # 设置背景图片
min_font_size=6
)
wc.fit_words(word_dict)
image_colors = ImageColorGenerator(cat_mask)
# recolor wordcloud and show
# we could also give color_func=image_colors directly in the constructor
plt.imshow(wc)
plt.axis("off")
plt.savefig('../photos/' + name + '.png', dpi=800)
plt.close()
def PL_wordcloud(self):
word_dict = {'JAVA': ['java', 'jawa'], 'C++': ['c++', 'c艹'], 'C': ['c', 'c语言'],
'PHP': ['php'], 'Python': ['py', 'python'], 'C#': ['c#']}
self.draw_wordcloud(self.word_fre(word_dict), sys._getframe().f_code.co_name)
def all_wordcloud(self, word_len=0):
word_dict = {}
stop_word = ['图片', '表情', '说']
for doc in self.post.find({}):
if len(doc['word']) > word_len and doc['word'] not in stop_word:
word_dict[doc['word']] = doc['item']
self.draw_wordcloud(word_dict, sys._getframe().f_code.co_name + str(word_len))
def company_wordcloud(self):
word_dict = {'Microsoft': ['微软', '巨硬', 'ms', 'microsoft'], 'Tencent': ['腾讯', 'tencent', '鹅厂'],
'360': ['360', '安全卫士', '奇虎'], 'Netease': ['netease', '网易', '猪场'],
'JD': ['jd', '京东', '某东', '狗东'], 'Taobao': ['淘宝', '天猫', 'taobao'],
'BaiDu': ['百度', '某度', 'baidu'], 'ZhiHu': ['zhihu', '知乎', '你乎', '某乎'],
'Sina': ['新浪', 'sina', '微博', 'weibo']}
self.draw_wordcloud(self.word_fre(word_dict), sys._getframe().f_code.co_name)
def word_fre(self, word_dict):
word_fre = {}
for key in word_dict.keys():
word_fre[key] = 0
res_dict = {}
for doc in self.post.find({}):
res_dict[doc['word']] = doc['item']
for res_key in res_dict.keys():
for word_key in word_dict.keys():
if str(res_key).lower() in word_dict[word_key]:
word_fre[word_key] = word_fre[word_key] + res_dict[res_key]
return word_fre
def longest_formation_wordcloud(self):
word_dict = {}
fp = open('../visualization/list.txt', 'r')
for line in fp.readlines():
li = line.split(' ')
print(li)
word_dict[li[0]] = int(li[1])
wc = WordCloud(font_path='../visualization/msyh.ttc',
width=1080, height=720,
background_color="white", # 背景颜色
min_font_size=6
)
wc.fit_words(word_dict)
plt.imshow(wc)
plt.axis("off")
plt.savefig('../photos/' + sys._getframe().f_code.co_name + '.png', dpi=800)
plt.show()
plt.close()
def work(self):
self.PL_wordcloud()
self.company_wordcloud()
self.all_wordcloud()
self.close()
================================================
FILE: license
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: photos/README.md
================================================
gitextract_tluzrh7n/
├── .gitignore
├── README.md
├── chatlog/
│ ├── analysis/
│ │ ├── collectivity.py
│ │ ├── content.py
│ │ ├── individual.py
│ │ └── interesting.py
│ ├── base/
│ │ ├── constant.py
│ │ ├── read_chatlog.py
│ │ ├── seg_word.py
│ │ └── user_profile.py
│ ├── model/
│ │ ├── message.py
│ │ └── user.py
│ ├── run.py
│ └── visualization/
│ ├── charts.py
│ ├── msyh.ttc
│ └── word_img.py
├── license
└── photos/
└── README.md
SYMBOL INDEX (52 symbols across 11 files)
FILE: chatlog/analysis/collectivity.py
class Collectivity (line 9) | class Collectivity(object):
method __init__ (line 10) | def __init__(self):
method get_all_speak_info (line 15) | def get_all_speak_info(self):
method close (line 27) | def close(self):
FILE: chatlog/analysis/content.py
class ChatText (line 8) | class ChatText(object):
method __init__ (line 9) | def __init__(self):
FILE: chatlog/analysis/individual.py
class Individual (line 8) | class Individual(object):
method __init__ (line 9) | def __init__(self):
method most_speak (line 14) | def most_speak(self, send_class='speak_num'):
method longest_ban (line 26) | def longest_ban(self):
method close (line 38) | def close(self):
FILE: chatlog/analysis/interesting.py
class Interesting (line 8) | class Interesting(object):
method __init__ (line 9) | def __init__(self):
method longest_name (line 14) | def longest_name(self):
method longest_formation (line 31) | def longest_formation(self):
method close (line 70) | def close(self):
FILE: chatlog/base/read_chatlog.py
class ReadChatlog (line 7) | class ReadChatlog(object):
method __init__ (line 8) | def __init__(self, file_path, db_name='chatlog', collection_name='vczh'):
method _judge_start_line (line 18) | def _judge_start_line(self, message):
method work (line 29) | def work(self):
FILE: chatlog/base/seg_word.py
class SegWord (line 6) | class SegWord(object):
method __init__ (line 7) | def __init__(self):
method work (line 12) | def work(self):
method close (line 32) | def close(self):
FILE: chatlog/base/user_profile.py
class UserProfile (line 9) | class UserProfile:
method __init__ (line 10) | def __init__(self, db_name='chatlog', collection_name='vczh'):
method close (line 18) | def close(self):
method _get_user_id_list (line 21) | def _get_user_id_list(self):
method _get_all_name (line 33) | def _get_all_name(self, user_id):
method _get_speak_infos (line 46) | def _get_speak_infos(self, user_id):
method _get_online_time (line 63) | def _get_online_time(self, user_id):
method work (line 81) | def work(self):
method _ban_time (line 107) | def _ban_time(self, user_id):
FILE: chatlog/model/message.py
class Message (line 4) | class Message(Document):
FILE: chatlog/model/user.py
class User (line 4) | class User(Document):
FILE: chatlog/visualization/charts.py
class Charts (line 14) | class Charts(object):
method __init__ (line 15) | def __init__(self):
method ban_time (line 20) | def ban_time(self):
method speak_photo_in_total (line 46) | def speak_photo_in_total(self):
method user_online_time (line 84) | def user_online_time(self, user_ID=None):
method close (line 118) | def close(self):
method work (line 121) | def work(self):
FILE: chatlog/visualization/word_img.py
class WordImg (line 10) | class WordImg(object):
method __init__ (line 11) | def __init__(self):
method close (line 16) | def close(self):
method draw_wordcloud (line 19) | def draw_wordcloud(self, word_dict, name):
method PL_wordcloud (line 37) | def PL_wordcloud(self):
method all_wordcloud (line 42) | def all_wordcloud(self, word_len=0):
method company_wordcloud (line 50) | def company_wordcloud(self):
method word_fre (line 59) | def word_fre(self, word_dict):
method longest_formation_wordcloud (line 75) | def longest_formation_wordcloud(self):
method work (line 101) | def work(self):
Condensed preview — 18 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (43K chars).
[
{
"path": ".gitignore",
"chars": 40,
"preview": "*.txt\n/TEST/\n.idea/\n/.idea\n/.idea/\n.idea"
},
{
"path": "README.md",
"chars": 2990,
"preview": "# ChatLog\n\n通过QQ导出的QQ群聊天记录进行一定的分析。\n\njust a toy\n\n## 开发日志\n\n2020-08-27 完成数据处理部分代码清洗,优化部分代码。\n\n## 基本功能\n\n* QQ群聊天记录的数据清洗\n* 构建简单用"
},
{
"path": "chatlog/analysis/collectivity.py",
"chars": 660,
"preview": "\"\"\"\n 总体数据统计分析\n @author:DingHanyang\n\"\"\"\nimport numpy\nfrom pymongo import MongoClient\n\n\nclass Collectivity(object):\n"
},
{
"path": "chatlog/analysis/content.py",
"chars": 279,
"preview": "\"\"\"\n 聊天内容分析\n @author:DingHanyang\n\"\"\"\nfrom pymongo import MongoClient\n\n\nclass ChatText(object):\n def __init__(se"
},
{
"path": "chatlog/analysis/individual.py",
"chars": 1236,
"preview": "\"\"\"\n 个体数据统计分析\n @author:DingHanyang\n\"\"\"\nfrom pymongo import MongoClient\n\n\nclass Individual(object):\n def __init_"
},
{
"path": "chatlog/analysis/interesting.py",
"chars": 2210,
"preview": "\"\"\"\n 因吹斯听 分析及统计\n @author:DingHanyang\n\"\"\"\nfrom pymongo import MongoClient\n\n\nclass Interesting(object):\n def __in"
},
{
"path": "chatlog/base/constant.py",
"chars": 316,
"preview": "# re\nJUDGE_TIME_RE = '^(((20[0-3][0-9]-(0[13578]|1[02])-(0[1-9]|[12][0-9]|3[01]))|(20[0-3][0-9]-(0[2469]|11)-(0[1-9]|[12"
},
{
"path": "chatlog/base/read_chatlog.py",
"chars": 3410,
"preview": "import re\nfrom pymongo import MongoClient\n\nfrom chatlog.base import constant\n\n\nclass ReadChatlog(object):\n def __init"
},
{
"path": "chatlog/base/seg_word.py",
"chars": 1000,
"preview": "from collections import Counter\nimport jieba\nfrom pymongo import MongoClient\n\n\nclass SegWord(object):\n def __init__(s"
},
{
"path": "chatlog/base/user_profile.py",
"chars": 4140,
"preview": "\"\"\"\n 构建用户基本画像\n @author:DingHanyang\n\"\"\"\nfrom datetime import datetime\nfrom pymongo import MongoClient\n\n\nclass UserP"
},
{
"path": "chatlog/model/message.py",
"chars": 229,
"preview": "from mongoengine import *\n\n\nclass Message(Document):\n meta = {'db_alias': 'chatlog'}\n\n name = StringField() # 发言用"
},
{
"path": "chatlog/model/user.py",
"chars": 413,
"preview": "from mongoengine import *\n\n\nclass User(Document):\n meta = {'db_alias': 'chatlog'}\n\n name_now = StringField() # 用户"
},
{
"path": "chatlog/run.py",
"chars": 790,
"preview": "from chatlog.analysis.collectivity import Collectivity\nfrom chatlog.analysis.individual import Individual\nfrom chatlog.a"
},
{
"path": "chatlog/visualization/charts.py",
"chars": 4177,
"preview": "# -*- coding=utf-8 -*-\n\"\"\"\n 数据可视化模块\n\"\"\"\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nimport"
},
{
"path": "chatlog/visualization/word_img.py",
"chars": 3630,
"preview": "import sys\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom PIL import Image\nfrom pymongo import MongoClient\nfro"
},
{
"path": "license",
"chars": 11357,
"preview": " Apache License\n Version 2.0, January 2004\n "
},
{
"path": "photos/README.md",
"chars": 0,
"preview": ""
}
]
// ... and 1 more files (download for full content)
About this extraction
This page contains the full source code of the DingHanyang/chatLog GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 18 files (22.6 MB), approximately 10.1k tokens, and a symbol index with 52 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.